
text
stringlengths 100
500k
| subset
stringclasses 4
values |
|---|---|
Alan M. Frieze
Template:EngvarB {{ safesubst:#invoke:Unsubst||$N=Use dmy dates |date=__DATE__ |$B= }} Alan M. Frieze (born 25 October 1945 in London, England) is a professor in the Department of Mathematical Sciences at Carnegie Mellon University, Pittsburgh, United States. He graduated from the University of Oxford in 1966, and obtained his PhD from the University of London in 1975. His research interests lie in combinatorics, discrete optimisation and theoretical computer science. Currently, he focuses on the probabilistic aspects of these areas; in particular, the study of the asymptotic properties of random graphs, the average case analysis of algorithms, and randomised algorithms. His recent work has included approximate counting and volume computation via random walks; finding edge disjoint paths in expander graphs, and exploring anti-Ramsey theory and the stability of routing algorithms.
1 Key contributions
1.1 Polynomial time algorithm for approximating the volume of convex bodies
1.2 Algorithmic version for Szemerédi regularity partition
2 Awards and honours
3 References and external links
Two key contributions made by Alan Frieze are:
(1) polynomial time algorithm for approximating the volume of convex bodies
(2) algorithmic version for Szemerédi regularity lemma
Both these algorithms will be described briefly here.
Polynomial time algorithm for approximating the volume of convex bodies
The paper [1] is a joint work by Martin Dyer, Alan Frieze and Ravindran Kannan.
The main result of the paper is a randomised algorithm for finding an ϵ{\displaystyle \epsilon } approximation to the volume of a convex body K{\displaystyle K} in n{\displaystyle n} -dimensional Euclidean space by assume the existence of a membership oracle. The algorithm takes time bounded by a polynomial in n{\displaystyle n} , the dimension of K{\displaystyle K} and 1/ϵ{\displaystyle 1/\epsilon } .
The algorithm is a sophisticated usage of the so-called Markov Chain Monte Carlo (MCMC) method. The basic scheme of the algorithm is a nearly uniform sampling from within K{\displaystyle K} by placing a grid consisting n-dimensional cubes and doing a random walk over these cubes. By using the theory of rapidly mixing Markov chains, they show that it takes a polynomial time for the random walk to settle down to being a nearly uniform distribution.
Algorithmic version for Szemerédi regularity partition
This paper [2] is a combined work by Alan Frieze and Ravindran Kannan. They use two lemmas to derive the algorithmic version of the Szemerédi regularity lemma to find an ϵ{\displaystyle \epsilon } -regular partition.
Lemma 1:
Fix k and γ{\displaystyle \gamma } and let G=(V,E){\displaystyle G=(V,E)} be a graph with n{\displaystyle n} vertices. Let P{\displaystyle P} be an equitable partition of V{\displaystyle V} in classes V0,V1,…,Vk{\displaystyle V_{0},V_{1},\ldots ,V_{k}} . Assume | V 1 | > 4 2 k {\displaystyle |V_{1}|>4^{2k}} and 4k>600γ2{\displaystyle 4^{k}>600\gamma ^{2}} . Given proofs that more than γk2{\displaystyle \gamma k^{2}} pairs (Vr,Vs){\displaystyle (V_{r},V_{s})} are not γ{\displaystyle \gamma } -regular, it is possible to find in O(n) time an equitable partition P′{\displaystyle P'} (which is a refinement of P{\displaystyle P} ) into 1+k4k{\displaystyle 1+k4^{k}} classes, with an exceptional class of cardinality at most |V0|+n/4k{\displaystyle |V_{0}|+n/4^{k}} and such that ind(P′)≥ind(P)+γ5/20{\displaystyle \operatorname {ind} (P')\geq \operatorname {ind} (P)+\gamma ^{5}/20}
Let W{\displaystyle W} be a R×C{\displaystyle R\times C} matrix with |R|=p{\displaystyle |R|=p} , | C | = q {\displaystyle |C|=q} and ‖W‖inf≤1{\displaystyle \|W\|_{\inf }\leq 1} and γ{\displaystyle \gamma } be a positive real.
(a) If there exist S ⊆ R {\displaystyle S\subseteq R} , T⊆C{\displaystyle T\subseteq C} such that |S|≥γp{\displaystyle |S|\geq \gamma p} , | T | ≥ γ q {\displaystyle |T|\geq \gamma q} and |W(S,T)|≥γ|S||T|{\displaystyle |W(S,T)|\geq \gamma |S||T|} then σ1(W)≥γ3pq{\displaystyle \sigma _{1}(W)\geq \gamma ^{3}{\sqrt {pq}}}
(b) If σ1(W)≥γpq{\displaystyle \sigma _{1}(W)\geq \gamma {\sqrt {pq}}} , then there exist S⊆R{\displaystyle S\subseteq R} , T⊆C{\displaystyle T\subseteq C} such that |S|≥γ′p{\displaystyle |S|\geq \gamma 'p} , |T|≥γ′q{\displaystyle |T|\geq \gamma 'q} and W(S,T)≥γ′|S||T|{\displaystyle W(S,T)\geq \gamma '|S||T|} where γ′=γ3/108{\displaystyle \gamma '=\gamma ^{3}/108} . Furthermore S{\displaystyle S} , T{\displaystyle T} can be constructed in polynomial time.
These two lemmas are combined in the following algorithmic construction of the Szemerédi regularity lemma.
[Step 1] Arbitrarily divide the vertices of G{\displaystyle G} into an equitable partition P1{\displaystyle P_{1}} with classes V0,V1,…,Vb{\displaystyle V_{0},V_{1},\ldots ,V_{b}} where |Vi|⌊n/b⌋{\displaystyle |V_{i}|\lfloor n/b\rfloor } and hence | V 0 | < b {\displaystyle |V_{0}|<b} . denote k 1 = b {\displaystyle k_{1}=b} .
[Step 2] For every pair (Vr,Vs){\displaystyle (V_{r},V_{s})} of Pi{\displaystyle P_{i}} , compute σ 1 ( W r , s ) {\displaystyle \sigma _{1}(W_{r,s})} . If the pair (Vr,Vs){\displaystyle (V_{r},V_{s})} are not ϵ−{\displaystyle \epsilon -} regular then by Lemma 2 we obtain a proof that they are not γ=ϵ9/108−{\displaystyle \gamma =\epsilon ^{9}/108-} regular.
[Step 3] If there are at most ϵ(k12){\displaystyle \epsilon \left({\begin{array}{c}k_{1}\\2\\\end{array}}\right)} pairs that produce proofs of non γ − {\displaystyle \gamma -} regularity that halt. Pi{\displaystyle P_{i}} is ϵ−{\displaystyle \epsilon -} regular.
[Step 4] Apply Lemma 1 where P=Pi{\displaystyle P=P_{i}} , k=ki{\displaystyle k=k_{i}} , γ=ϵ9/108{\displaystyle \gamma =\epsilon ^{9}/108} and obtain P′{\displaystyle P'} with 1+ki4ki{\displaystyle 1+k_{i}4^{k_{i}}} classes
[Step 5] Let ki+1=ki4ki{\displaystyle k_{i}+1=k_{i}4^{k_{i}}} , Pi+1=P′{\displaystyle P_{i}+1=P'} , i=i+1{\displaystyle i=i+1} and go to Step 2.
In 1991, Frieze received (jointly with Martin Dyer and Ravi Kannan) the Fulkerson Prize in Discrete Mathematics awarded by the American Mathematical Society and the Mathematical Programming Society. The award was for the paper "A random polynomial time algorithm for approximating the volume of convex bodies" in the Journal of the ACM).
In 1997 he was a Guggenheim Fellow.
In 2000, he received the IBM Faculty Partnership Award.
In 2006 he jointly received (with Michael Krivelevich) the Professor Pazy Memorial Research Award from the United States-Israel Binational Science Foundation.
In 2011 he was selected as a SIAM Fellow.[3]
In 2012 he was selected as an AMS fellow.[4]
In 2014 he gave a plenary talk at the International Congress of Mathematicians in Seoul, South Korea.
References and external links
↑ Template:Cite news
↑ Siam Fellows Class of 2011
↑ List of Fellows of the American Mathematical Society, retrieved 29 December 2012.
Alan Frieze's web page
Fulkerson prize-winning paper
Carol Frieze's web page
Alan Frieze's publications at DBLP
Certain self-archived works are available here
Template:Persondata
Retrieved from "https://en.formulasearchengine.com/index.php?title=Alan_M._Frieze&oldid=263971"
Use dmy dates from September 2014
Alumni of the University of Oxford
Alumni of University College London
Carnegie Mellon University faculty
Theoretical computer scientists
Fellows of the American Mathematical Society
Guggenheim Fellows
English mathematicians
Fellows of the Society for Industrial and Applied Mathematics | CommonCrawl |
Earth Science Meta
Earth Science Stack Exchange is a question and answer site for those interested in the geology, meteorology, oceanography, and environmental sciences. It only takes a minute to sign up.
Why doesn't the 71% water of the earth dry or evaporate?
Perhaps a simple question, we know 71% of the earth's surface contains water as oceans. If Earth's age is 4.543 billion years, then I guess it should be decreased with drying or should have been dried so far. Why doesn't it dry or decrease?
If we put some water in sunlight, it evaporates. The oceans are the chief source of rain, but lakes and rivers also contribute to it. The sun's heat evaporates the water.
So I wonder why doesn't the 71% water coverage not evaporate, decreasing until gone? Why is it still 71% after billions of years? Does water keep coming from somewhere? Or, does moving water not evaporate? Why is it still here?
HarryHarry
$\begingroup$ Water evaporates, but comes down back as rain or other forms of precipitation. $\endgroup$
– Gimelist
$\begingroup$ Where do you think the water goes when it evaporates? $\endgroup$
$\begingroup$ tl,dr: Because earth's atmosphere can only hold so much evaporated water, far, far less than earth's oceans hold. $\endgroup$
– RBarryYoung
$\begingroup$ How would anyone know that it was 71% billions of years ago? $\endgroup$
– Tim
$\begingroup$ Who said it doesn't evaporate :O :D? It just also precipitates :D. $\endgroup$
– Teacher KSHuang
There are two ways this problem needs to be looked at. The first is more astronomy than Earth science. The Earth as an entire system is largely contained. Its gravity and magnetic field retains nearly all of its elements. Earth does lose hydrogen and helium and cosmic rays will split water molecules leading to a loss of an impressive amount of hydrogen and as an indirect result a loss of water, but this is loss irrelevant compared to the size of the oceans. More detail here. Space dust, comets and asteroids contain water so some water is returned from space too.
By the upper estimate in one article, 50,000 tons of hydrogen per year works out to about 450,000 tons of water lost every year. (and 400,000 tons of oxygen added as a result). Compared to the mass of Earth's oceans those numbers are small. 450,000 tons per year, or 450 trillion tons over a billion years is nothing compared to the 1.3 million trillion tons of water Earth has in its oceans. By the highest estimate, it will take 30 billion years at the current rate and at the Sun's current luminosity for Earth to lose just 1% of its oceans. (Will look to update with other estimates).
As for the rest of the question, once we recognize that loss into space is insignificant, then virtually all water is continuously cycled though the water cycle or hydrological cycle. Very little water gets destroyed or chemically transformed. Nearly all of it, even of millions or billions of years, evaporates, or, turns into ice, or gets absorbed by plants, or seeps underground, but it always returns. Evaporated water returns to Earth as rain. Water that gets frozen on the ice caps eventually melts back into the oceans. Water absorbed by plants or that seeps underground does eventually get returned to the surface by plate tectonics or volcanism. Plants that store water return it when the plant is eaten. Water is very hard to destroy, so it stays remarkably constant on Earth over time.
edited May 1, 2017 at 3:10
Nayuki
userLTKuserLTK
$\begingroup$ I think you have a typo in "gets absorbed by planets". $\endgroup$
– Dragomok
$\begingroup$ One problem with this answer is that 50000 tons per year is nowhere near the highest estimate. A fairly common estimate is 3 kg/sec, which is equivalent to twice your rate of 50000 tons per year. Some estimate even higher current mass loss rates. Another problem: Oxygen comprises 8/9 of the mass of a water molecule. Lose the 1/9 that is hydrogen and the water it's gone. One last problem: That ~3 kg/second is the current rate. It was arguably orders of magnitude higher in the distant past and will be orders of magnitude higher in the distant future. $\endgroup$
– David Hammen
$\begingroup$ @Dragomok Thank you. That should be gets absorbed by plants. Fixed. $\endgroup$
– userLTK
$\begingroup$ @DavidHammen I did the math for the 8/9ths. That's why 50 tons of hydrogen works out to 450 tons of water. Also, I know it was orders of magnitudes higher in the distant past, certainly higher when Earth was forming and very hot and higher during the late heavy bombardment and higher prior to the magnetic field. I didn't want to get into that, but I should probably add a notation. As to the estimate, that's a good point. I should adjust the estimate. $\endgroup$
Why doesn't 71% water of the earth dry or evaporate?
The simple answer: Because it rains.
The not so simple answer: By some estimates, the Earth has already lost about a quarter of its water, and it is predicted to lose almost all of its water in a billion or so years from now.
It rains because temperature decreases with altitude. This lapse rate means that moist air becomes saturated at some point in the atmosphere. You can see this point on somewhat cloudy days. While cumulus clouds have puffy tops, they have flat bottoms. Those flat bottoms reflect the point where the humidity level reaches 100%.
Currently, only an extremely small fraction of the moisture in the air makes its way to the top of the thermosphere. The tiny amount of moisture that does make its way to the stratosphere can migrate throughout the stratosphere. The top of the stratosphere is unprotected from the nastier parts of the Sun's output. Ultraviolet radiation dissociates water into hydrogen and oxygen. Some of that hydrogen escapes into space. That lost hydrogen represents lost water.
The Earth is currently losing about three kilograms of hydrogen into space every second. At that rate, it would take about a trillion (1012) years for the Earth to lose all of its waters. There are signs that the escape rate was significantly higher in the distant past. This is a byproduct of solutions to the Faint Young Sun problem. The signs of this early high escape rate are written in stone (serpentine, to be specific). Very old rocks have a different deuterium ratio that is currently observed.
The escape rate will inevitably become significantly higher in the distant future as the Sun gets warmer and warmer. The Earth will eventually lose all of its water.
David HammenDavid Hammen
$\begingroup$ A related question is how much of Earth's water that locked in the mantle will be locked in the mantle and not be lost to space. Might not relevant though because that water is not available for liquid water on the surface. $\endgroup$
$\begingroup$ is predicted to lose almost all of its water in a billion or so years from now.. Strange, considering the most upvoted answer suggests that the Earth will lose about 1% of its water after 30 billion years! $\endgroup$
$\begingroup$ @user1993 - That answer reflects the current loss rate. The Sun grows more luminous as it ages. It will be about 10% more luminous a billion years from now. That increase in luminosity will eventually trigger a runaway greenhouse effect. $\endgroup$
$\begingroup$ @Harry .. as Michael mentioned above there may be a very large amount of water locked in the Earth's mantle. See this article astrobio.net/news-exclusive/… (there are many others). However, contrary to what Michael said, the researchers think that this water may have been a buffer helping the Earth maintain a constant (even more than expected) volume of surface water. $\endgroup$
– Jack R. Woods
$\begingroup$ @DavidHammen, Hi, is it measured beyond doubt that the earth is currently losing kilograms of hydrogen into space every second? Or is it speculation that has its critics? $\endgroup$
– Pacerier
The bigger question is really: where would it go?
Because of course matter isn't created or destroyed. So it'd have to go elsewhere.
The only two places it could go are:
Into the Earth. But water is fairly light (1 g/mL versus Earth which appears to increase from 1.02 g/mL near the surface to 13.09 g/mL at the center). Plus, even if water could/did continue to transition into the Earth in large amounts, it'd just build up there until it reached a saturation level. And there's only so much room between the highly compressed rock.
Out to space. However gravity generally keeps the atmosphere here, just like it does for us. A very small percentage of gas does escape. However, it's predominantly lower mass gases like hydrogen and helium. The question on our site of What "g" would be needed to keep helium on Earth? is quite useful for information on this.
Or, alternatively,
Out to space as its constituent gases. (Monotonic) Oxygen and especially Hydrogen do escape somewhat more readily. Electrolysis and other water splitting methods do cause a small percentage of Earth's water to be broken down at any given time. However, based upon this estimate of 95,000 tons of hydrogen lost per year, and this estimate of $1.4 \times 10^{21}$ kg of water, it'd take 1.8 trillion years to lose all of Earth's water by hydrogen loss.
Otherwise, if it isn't leaving the system, it could only build up in the atmosphere... potentially until reaching a level where the air could hold no more. Theoretically that'd be at 100% relative humidity. Unfortunately the troposphere can only hold the equivalent of a layer of a couple inches\few cm of water. Additionally water tends to leaves the air when enough areas of it reach 100% RH, through processes like dew and precipitation.
And so over the long run, it can only reach an equilibrium, where the amount of water the air held was in balance with the amount it lost. And that seems in line with what we see. Moisture levels vary, but aren't rapidly changing in any direction. Considering that there's 96000 times more water in the oceans than there is in the air currently, the atmosphere surely couldn't hold it all anyways! If it can't leave, and the atmosphere cannot hold it all... well, it has to stay on the Earth. Certainly we see the equilibrium in practice too, as sea\lake levels aren't dropping consistently. Lake levels actually vary quite a bit, showing evaporation has the ability to drain at least the lakes fairly fast. Yet they aren't dropping consistently in any noticeable way. We're very dry in Florida right now, and lakes are way down... but in places like California and the Piedmont they've been seeing great flooding. But neither lasts in the long run.
Looks like studies do estimate that the Earth has lost 1/4 of its water in its estimated lifetime. So indeed it's not that nothing leaves. It's just that it's very slow. If it wasn't... well we'd be seeing it quickly change now! Over our lifetimes, over the past few thousand years. But there's no indications that general lake/ocean levels have drastically changed.
I do really get that there can be skepticism at billions of years. It's certainly something we can't verify too easily, visually, personally. And with Biblical\other religious sources casting potential dispute upon it, that increases the question.
Honestly, a reasonable scientist should welcome skepticism and try to address it with fairness and levelheadedness. Unfortunately there certainly are plenty who are dismissive and belittling, either openly, or in their attitudes.
But while questioning is a very worthwhile endeavor, this particular line of reasoning doesn't appear to hold much mustard. Be wary not to jump too quickly on any potential disagreements you see to accepted theories and thus run hard with them, or you're no different from those overly rigid scientists. Keep seeking for the truth as something of the greatest value. Regardless of what it is, and in the end it alone shall stand, and shall set you free!
JeopardyTempestJeopardyTempest
$\begingroup$ informative, your opinion is much appreciated. $\endgroup$
– Harry
$\begingroup$ There's one big problem with this answer, which is that almost all of the hydrogen that escapes from the Earth's atmosphere was originally in the form of water. Sunlight dissociates water in the middle atmosphere into hydrogen and oxygen. Hydrogen escaping into space means water is lost into space. $\endgroup$
$\begingroup$ @David Hammen: I'm confused, that's what I'm suggesting by option 3. I didn't know the water dissociation region was primarily the middle atmosphere, as you suggest, and can add that... but my calculation equated any hydrogen loss to be water loss, so wherever the water splitting occurs, the hydrogen loss is being counted as water loss. You sound like it's a bad answer! $\endgroup$
– JeopardyTempest
$\begingroup$ (I see my calculation used a poorly noted 9 to do the water to hydrogen mass conversion), perhaps I should've more explicitly used (2.02/18.02), as looking back I thought I'd misequated water mass to hydrogen mass too $\endgroup$
Sep 20, 2022 at 3:35
There are good answers for this question but Earth Science is one of the few sciences that lends itself really well to experiments around the house.
To see the effect you're talking about (water evaporating, but not going away) take a large rag, and soak it in water. Get it very, very wet. Place the large rag in a zip-lock bag and make sure to seal it tight. Now place the bag with the rag out in the sun.
You will notice how the water never leaves the bag. During the sunny part of the day the water evaporates into the air in the bag, and when there is enough in the air, the water condenses and drips (rains) back down onto the rag.
The rag is like the "ground". The bag is like the atmosphere.
Just like with the rag, after water evaporates it "condenses" in the atmosphere (on the bag) and rains (drips) back down to earth (the rag).
This is a over simplified example of the process, but it demonstrates it very well.
coteyrcoteyr
$\begingroup$ sounds logical, but don't you think reprocessing of water that evaporates and comes down in rain form should decrease in amount? we see when it rains there's puddles and some water amount in streets for 1 or 2 days then it evaporates but eventually it gets dried. $\endgroup$
$\begingroup$ It doesnt go anywhere just soaks into the ground or moves by evaporating and raining somewhere elae $\endgroup$
– coteyr
$\begingroup$ Barring some really really small amounts that "leak" into space via various amounts (very very small). All the water on earth stays on earth. It just moves around from place to place. Some times it's ice, some times it's water, some times clouds, but always here. $\endgroup$
$\begingroup$ as clouds travel, so evaporated water of oceans should fall as rain form somewhere on dry part of lands. still it's 71% after so many years as you mentioned some water soaks into the ground as well? $\endgroup$
$\begingroup$ Essentially yes. With out getting silly with numbers there is always the same amount of water on earth, it just moves around. $\endgroup$
"If we put some water in sunlight it evaporates." Really? If I take some water in a closed bottle and put it in the sunlight, then it will evaporate? Obviously not. Why not? Because the air (gas) in the bottle is saturated with water. The relative humidity of that air is 100%, or close to it. You probably know this already. So you should realize that your question is flawed. Not only does water not evaporate in the bottle, but water evaporates at night and inside houses without any sunlight. A better question, imho, is: "Why isn't the Earth's atmosphere saturated with water after 4 billion years?" The atmosphere has a mass of about 5E+18 kg (that is 5 followed by 18 0s, eg 5,000,000,000,000,000,000). The water in the oceans has a mass of about 1.3E+21 kg, meaning about 250 times more mass than the atmosphere. Simply put: there's not enough atmosphere to hold all that water. The reason why the atmosphere is not saturated, does not have 100% relative humidity, is that the temperature of the air varies a lot. Both day to night, and season to season. The air is frequently being cooled and the water lost via precipitation. When this air is reheated, both by direct sunlight and by contact with the surface which warms up even more in direct sunlight, it is low in relative humidity. This is the air that will allow water to evaporate. Because of these temperature cycles, air never has the time to reach saturation.
ableable
5111 bronze badge
Answer #43 above is absolutely correct. Unless water molecules are split (disintegrate) into hydrogen and oxygen, they almost never leave Earth into space. We have practically the same amount of water on Earth as it had when first created. After evaporation, it returns as rain. Every time. Every place. This is why I become crazy when government officials tell us that we are running out of water. This is absurd. We can't run out of water. But it certainly can be mismanaged -- but then, that's the government's job. Isn't it?
Paul MorrisPaul Morris
$\begingroup$ A little water vapor getting out to the upper atmosphere can escape due to solar winds, but it is small (making your post imho okay). Note, water as vapor is lesser dense than air (molecular weight is $\approx$ 18 to the $\approx$ 29 or the air), this increases its relative density in the higher atmosphere - but the effect is still small. Although water escaped from Mars and Venus probably by this process. $\endgroup$
– peterh
I don't want to post a super long answer so I'll keep it simple.
Pressure and gravity due to the mass of the earth keeps the water within the atmosphere and cycling through the 3 states of solid, liquid, and gas.
Our water is constantly being recycled, and some things create water, like humans (we create water in our lungs when we breathe.)
JoshJosh
Thanks for contributing an answer to Earth Science Stack Exchange!
What "g" would be needed to keep helium on Earth?
Why do the dry and moist adiabatic lapse rates converge with height?
Why is Venezuela so dry?
Water on Mars and Earth
Does the magnetic field really protect Earth from anything?
Why doesn't sea level show seasonality?
Why the Indian Monsoon doesn't start in the north?
At what latitudes does the precipitation water for Europe evaporate?
Why doesn't earth radiate at wavelengths where there is strong absorption?
How is centrifugal force identified in equations of fluid motion in the rotating reference system of earth? | CommonCrawl |
Unsupervised machine learning applied to scanning precession electron diffraction data
Ben H. Martineau1,
Duncan N. Johnstone1,
Antonius T. J. van Helvoort3,
Paul A. Midgley1 &
Alexander S. Eggeman ORCID: orcid.org/0000-0002-3447-43222
Advanced Structural and Chemical Imaging volume 5, Article number: 3 (2019) Cite this article
Scanning precession electron diffraction involves the acquisition of a two-dimensional precession electron diffraction pattern at every probe position in a two-dimensional scan. The data typically comprise many more diffraction patterns than the number of distinct microstructural volume elements (e.g. crystals) in the region sampled. A dimensionality reduction, ideally to one representative diffraction pattern per distinct element, may then be sought. Further, some diffraction patterns will contain contributions from multiple crystals sampled along the beam path, which may be unmixed by harnessing this oversampling. Here, we report on the application of unsupervised machine learning methods to achieve both dimensionality reduction and signal unmixing. Potential artefacts are discussed and precession electron diffraction is demonstrated to improve results by reducing the impact of bending and dynamical diffraction so that the data better approximate the case in which each crystal yields a given diffraction pattern.
Scanning transmission electron microscopy (STEM) investigations increasingly combine the measurement of multiple analytical signals as a function of probe position with post-facto computational analysis [1]. In a scan, the number of local signal measurements is usually much greater than the number of significantly distinct microstructural elements and this redundancy may be harnessed during analysis, for example by averaging signals over like regions to improve signal to noise. Unsupervised machine learning techniques automatically exploit data redundancy to find patterns with minimal prior constraints [2]. In analytical electron microscopy, such methods have been applied to learn representative signals corresponding to separate microstructural elements (e.g. crystal phases) and to unmix signals comprising contributions from multiple microstructural elements sampled along the beam path [3,4,5,6,7,8,9,10]. These studies have primarily applied linear matrix decompositions such as independent component analysis (ICA) and non-negative matrix factorisation (NMF).
Scanning precession electron diffraction (SPED) enables nanoscale investigation of local crystallography [11, 12] by recording electron diffraction patterns as the electron beam is scanned across the sample with a step size on the order of nanometres. The incorporation of double conical rocking of the beam, also known as precession [13], achieves integration through a reciprocal space volume for each reflection. Precession has been found to convey a number of advantages for interpretation and analysis of the resultant diffraction patterns, in particular the suppression of intensity variation due to dynamical scattering [14,15,16]. The resultant four-dimensional dataset, comprising two real and two reciprocal dimensions (4D-SPED), can be analysed in numerous ways. For example, the intensity of a sub-set of pixels in each diffraction pattern can be integrated (or summed) as a function of probe position, to form so-called virtual bright field (VBF) or virtual dark field (VDF) images [17, 18]. VBF/VDF analysis has been used to provide insight into local crystallographic variations such as phase [17], strain [19] and orientation [20]. In another approach, the collected diffraction patterns are compared against a library of precomputed templates, providing a visualisation of the microstructure and orientation information, a process known as template or pattern matching [11]. These analyses do not utilise the aforementioned redundancy present in data and may require significant effort on the part of the researcher. Here, we explore the application of unsupervised machine learning methods to achieve dimensionality reduction and signal unmixing.
GaAs (cubic, F43m) nanowires containing type I twin (\(\Sigma 3\)) [21] boundaries were taken as a model system for this work. The long axis of these nanowires is approximately parallel to the [111] crystallographic direction as a result of growth by molecular beam epitaxy [22] on (111). In cross section, these nanowires have an approximately hexagonal geometry with a vertex-to-vertex distance of 120–150 nm. Viewed near to the \([1{\overline{1}}0]\) zone axis, the twin boundary normal is approximately perpendicular to the incident beam direction.
SPED experiments
Scanning precession electron diffraction was performed on a Philips CM300 FEGTEM operating at 300 kV with the scan and simultaneous double rocking of the electron beam controlled using a NanoMegas Digistar external scan generator. A convergent probe with convergence semi-angle of \(\sim 1.5\hbox { mrad}\) and precession angles of 0, 9 and 35 mrad was used to perform scans with a step size of 10 nm using the ASTAR software package. The resolution was thus dominated by the step size. PED patterns were recorded using a Stingray CCD camera to capture the image on the fluorescent binocular viewing screen.
It is generally inappropriate to manipulate raw data before applying multivariate methods such as decomposition or clustering, which cannot be considered objective if subjective prior alterations have been made. In this work, the only data manipulation applied before machine learning is to align the central beams of each diffraction pattern. Geometric distortions introduced from the angle between the camera and the viewing screen were corrected by applying an opposite distortion to the data after the application of machine learning methods.
Multislice simulations
A twinned bi-crystal model was constructed with the normal to the [111] twin boundary inclined at an angle of \(55 ^{\circ }\) to the incident beam direction so that the two crystals overlapped in projection. In this geometry, both crystals are oriented close to \(\langle 511\rangle\) zone axes with coherent matching of the \(\{0{\bar{6}}6\}\) and \(\{2{\bar{8}}2\}\) planes in these zones. Three precession angles were simulated using the TurboSlice package [23]: 0, 10 and 20 mrad, with 200 distinct azimuthal positions about the optic axis to ensure appropriate integration in the resultant simulated patterns [24]. The crystal model used in the simulation comprised 9 unique layers each 0.404 nm thick. 15 layers were used leading to a total thickness of 54.6 nm. These \(512\times 512\)-pixel patterns with 16-bit dynamic range were convolved with a 4-pixel Gaussian kernel to approximate a point spread function.
Linear matrix decomposition
Latent linear models describe data by the linear combination of latent variables that are learned from the data rather than measured—more pragmatically, the repeated features in the data can be well approximated using a small number of basis vectors. With appropriate constraints, the basis vectors may be interpreted as physical signals. To achieve this, a data matrix, \(\mathbf X\), can be approximated as the matrix product of a matrix of basis vectors \(\mathbf W\) (components), and corresponding coefficients \(\mathbf Z\) (loadings). The error in the approximation, or reconstruction error, may be expressed as an objective function to be minimised in a least squares scheme:
$$\begin{aligned} \left| \left| \mathbf X -\mathbf WZ \right| \right| ^{2}_{\mathrm {F}} \end{aligned}$$
where \(||\mathbf A ||_{\mathrm {F}}\) is the Frobenius normFootnote 1 of matrix \(\mathbf A\). More complex objective functions, for example incorporating sparsity promoting weighting factors [25], may be defined. We note that the decomposition is not necessarily performed by directly computing this error minimisation.
Three linear decompositions were used here: singular value decomposition (SVD) [2, 26], independent component analysis (ICA) [27], and non-negative matrix factorisation (NMF) [25, 28]. These decompositions were used as implemented in HyperSpy [29], which itself draws on the algorithms implemented in the open-source package scikit-learn [30].
The singular value decomposition is closely related to the better-known principal component analysis, in which the vectors comprising \(\mathbf W\) are orthonormal. The optimal solution to rank L is then obtained when \(\mathbf W\) is estimated by eigenvectors (principal components) corresponding to the L largest eigenvalues of the empirical covariance matrixFootnote 2. The optimal low-dimensional representation of the data is given by \(\mathbf z _{i} = \mathbf W ^{T}{} \mathbf x _{i}\), which is an orthogonal projection of the data on to the corresponding subspace and maximises the statistical variance of the projected data. This optimal reconstruction may be obtained via truncated SVD of the data matrix—the factors for PCA and SVD are equivalent, though the loadings may differ by independent scaling factors [31].
Unmixing measured signals to determine source signals a priori is known as blind source separation (BSS) [32]. SVD typically yields components that do not correspond well with the original sources due to its orthogonality constraint. ICA solves this problem by maximising the independence of the components, instead of the variance, and is applied to data previously projected by SVD using the widespread FastICA algorithm [27]. NMF [25, 28] may also be used for BSS and imposes \(\mathbf W \ge \mathbf 0 , \mathbf Z \ge \mathbf 0\). To impose these constraints, the algorithm computes a coordinate descent numerical minimisation of Eq. 1. Such an approach does not guarantee convergence to a global minimum and the results are sensitive to initialisation. The implementation used here initialises the optimisation using a non-negative double singular value decomposition (NNDSVD), which is based on two SVD processes, one approximating the data matrix, the other approximating positive sections of the resulting partial SVD factors [33]. This algorithm gives a well-defined non-negative starting point suitable for obtaining a sparse factorisation. Finally, the product \(\mathbf WZ\) is invariant under the transformation \(\mathbf W \rightarrow\) \(\mathbf W \varvec{\lambda }\), \(\mathbf Z \rightarrow\) \(\varvec{\lambda }^{-1}{} \mathbf Z\), where \(\varvec{\lambda }\) is a diagonal matrix. This fact is used to scale the loadings to a maximum value of 1.
Data clustering
Clustering points in space may be achieved using numerous methods. One of the best known is k-means, in which the positions of several cluster prototypes (centroids) are iteratively updated according to the mean of the nearest data points [34]. The clusters thus found are considered to be "hard"—each datum can only belong to a single cluster. Here, we apply fuzzy c-means [35] clustering, which has the significant advantage that data points may be members of multiple clusters allowing for an interpretation based on mixing of multiple cluster centres. For example, a measured diffraction pattern that is an equal mixture of the two basis patterns lies precisely between the two cluster centres and will have a membership of 0.5 to each. We also employ the Gustafson–Kessel variation for c-means, which allows the clusters to adopt elliptical, rather than spherical, shapes [36].
Cluster analysis in spaces of dimension greater than about 10 is unreliable [37, 38] as with increasing dimension "long" distances become less distinct from "short". The relevant dimension of the collected diffraction patterns is the size of the image, on the order of \(10^4\). A dimensionality reduction is, therefore, performed first, using SVD, and clustering is applied in the space of loading coefficients [34]. The cluster centres found in this low-dimensional space can be re-projected into the data space of diffraction patterns to produce a result equivalent to a weighted mean of the measured patterns within the cluster. The spatial occurrence of each basis pattern may then be visualised by plotting the membership values associated with each cluster as a function of probe position to form a membership map.
SPED data were acquired with precession angles of 0, 9 and 35 mrad from a GaAs nanowire oriented near to a \([1{\overline{1}}0]\) zone axis such that the twin boundary normal was approximately perpendicular to the incident beam direction, as shown in Fig. 1. The bending of this nanowire is evident in the data acquired without precession (Fig. 1a) as at position iii the diffraction pattern is near the zone axis, whereas at position i a Laue circle is clearly visible. The radius of this Laue circle is \(\sim 24\hbox { mrad}\), which provides an estimate of the bending angle across the field of view. When a precession angle of 35 mrad (i.e. larger than the bending angle) was used, all measured patterns appear close to zone axis (Fig. 1b) due to the reciprocal space integration resulting from the double conical rocking geometry. The effect of this integration is also seen in the contrast of the virtual dark-field image, which shows numerous bend contours without precession and less complex variation in intensity with precession. We surmise that precession leads to the data better approximating the situation where there is a single diffraction pattern associated with each microstructural element, which here is essentially the two twinned crystal orientations and the vacuum surrounding the sample. The region of interest also contains a small portion of carbon support film, which is just visible in the virtual dark-field images as a small variation in intensity. The position of the carbon film has been indicated in the figure.
SPED data from a GaAs nanowire and virtual dark-field images formed by plotting the intensity within the disks marked around \(\lbrace 111\rbrace\) reflections, as a function of probe position. a Without precession and b with 35 mrad precession. Diffraction pattern and VDF image scale bars are common to all subfigures and measure 1 Å\(^{-1}\) and 150 nm respectively. The approximate position of the carbon film is indicated by the red dashed line
Using SVD, we can produce a scree plot showing the fraction of total variance in the data explained by each principal component pattern. Figure 2a shows the scree plot for the 0, 9 and 35 mrad data. A regime change, from relatively high variance components to relatively low variance components, may be identified [2, 39] after 3 components for the data acquired with 35 mrad precession, after 4 components with 9 mrad precession, and cannot clearly be identified without precession. While there is a small change in the line after 4 components in the curve for data recorded without precession, the variance described by the components on either side of this is relatively similar, particularly given the ordinate is on a log scale. This demonstrates that the use of precession reduces the number of components required to describe the data, consistent with the intuitive understanding of the effect of reciprocal space integration achieved using precession. The 4th component, significant in the 9 mrad data, arises because the top and bottom of the nanowire are sufficiently differently oriented, as a result of bending, to be distinguished by the algorithm. We, therefore, continue our analysis focusing attention on data acquired with relatively large precession angles.
SVD and ICA analysis of SPED data from a GaAs nanowire. a Scree plot of variance explained by each SVD component for 0, 9 and 35 mrad data. b First 3 SVD components for 35 mrad data. c ICA components for 35 mrad data. Intensities in red indicate positive values and those in blue indicate negative values. Pattern and loading scale bars are common to all subfigures and measure 1 Å\(^{-1}\) and 150 nm respectively
Component patterns and corresponding loading maps obtained by SVD and ICA analysis of 35 mrad SPED data are shown in Fig. 2b, c, respectively. In either analysis, each feature clearly describes some significant variation in the diffraction peak intensities, although it is worth noting that SVD requires two components to describe the two twins in the wire where ICA needs only one. Both descriptions of the data are mathematically sensible and physical insight can be obtained from the differences between diffraction patterns that are highlighted by negative values in the SVD and ICA component patterns, but neither method produces patterns that can be directly associated with crystal structure. To make use of more conventional diffraction pattern analysis, we seek decomposition constraints that yield learned components which more closely resemble physical diffraction patterns. To this end, we apply NMF and fuzzy clustering.
The data were decomposed to three component patterns using NMF, of which, by inspection, one corresponded to the background and two corresponded to the two twinned crystal orientations—the latter shown in Fig. 3a, b. The choice of three components was guided by the intrinsic dimensionality indicated by the SVD analysis and it was further verified that a plot of the NMF reconstruction error (Eq. 1) as a function of increasing number of components showed a similar regime change to the SVD scree plot (see "Availability of data and materials" section at the end of the main text). In the NMF component patterns, white spots are visible, representing intensity lower than background level. We describe these as a pseudo-subtractive contribution of intensity from those locations.
NMF and fuzzy clustering of SPED data from a GaAs nanowire. a, b NMF factors and corresponding loading maps. c Two-dimensional projection of 3 component SVD loadings onto the plane of the second and third loading with cluster membership as contours. d, e Weighted average cluster centre patterns. Pattern and loading scale bars are common to all subfigures and measure 1 Å\(^{-1}\) and 150 nm respectively
In Fig. 3c, SVD loadings for the scan data are shown as a scatter plot, where the axes correspond to the SVD factors. Because the SVD and PCA factors are equivalent, this projection represents the maximum possible variation in the data, and so the maximum discrimination. The loadings associated with each measured pattern are approximately distributed about a triangle in this space. Fuzzy clustering was applied to three SVD components, and the learned memberships are overlaid as contours. Three clusters describe the distribution of the loadings well, and the cluster centres correspond to the background and the twinned crystals as shown in Fig. 3d, e. Both the NMF factors and c-means centers represent the same orientations, but the pseudo-subtractive artefacts in the NMF factors are not present in the cluster centers.
The scatter plot in Fig. 3c also shows that two of the clusters comprise two smaller subclusters. Membership maps for these subclusters reveal that the splitting is due to the underlying carbon film with the subcluster nearer to the background cluster in each case corresponding to the region where the film is present. In the membership maps, there are bright lines along the boundaries between the nanowire and the vacuum, due to overlap between clusters.
The unmixing of diffraction signals from overlapping crystals was investigated. SPED data with a precession angle of 18 mrad were acquired from a nanowire tilted away from the \([1{\overline{1}}0]\) zone axis by \(\sim 30 ^{\circ }\), such that two microstructural elements overlapped in projection. The overlap of the two crystals was assessed using virtual dark-field imaging, NMF loading maps, and fuzzy clustering membership maps (Fig. 4). The region in which the crystals overlap can be identified by all these methods. The VDF result can be considered a reference and is obtained with minimal processing but requires manual specification of appropriate diffracting conditions for image formation. The NMF and fuzzy clustering approaches are semi-automatic. There is good agreement between the VDF images and NMF loading maps. The boundary appears slightly narrower in the clustering membership map. The NMF loading corresponding to the background component decreases along the profile, which may be related to the underlying carbon film, whilst the cluster membership for the background contains a spurious peak in the overlap region. Finally, the direct beam intensity is much lower in the NMF component patterns than in the true source signals. Our results indicate that either machine learning method is superior to conventional linear decomposition for the analysis of SPED datasets, but some unintuitive and potentially misleading features are present in the learning results.
SPED data from a GaAs nanowire with a twin boundary at an oblique angle to the beam. a Virtual dark-field images formed, using a virtual aperture 4 pixels in diameter, from the circled diffraction spots. b NMF decomposition results. c Clustering results. For b and c the profiles are taken from the line scans indicated, and the blue profile represents the intensity of the background component. Pattern and loading scale bars are common to all subfigures and measure 1 Å\(^{-1}\) and 70 nm respectively
Unsupervised learning methods (SVD, ICA, NMF, and fuzzy clustering) have been explored here in application to SPED data as applied to materials where the region of interest comprises a finite number of significantly different microstructrual elements, i.e. crystals of particular phase and/or orientation. In this case, NMF and clustering may yield a small number of component patterns and weighted average cluster centres that resemble physical electron diffraction patterns. These methods are, therefore, effective for both dimensionality reduction and signal unmixing although we note that neither approach is well suited to situations where there are continuous changes in crystal structure. By contrast, SVD and ICA provide effective means of dimensionality reduction but the components are not readily interpreted using analogous methods to conventional electron diffraction analysis, owing to the presence of many negative values. The SVD and ICA results do nevertheless tend to highlight physically important differences in the diffraction signal across the region of interest. The massive data reduction from many thousands of measured diffraction patterns to a handful of learned component patterns is very useful, as is the unmixing achieved. Artefacts in the learning results were however identified, particularly when applied to achieve signal unmixing, and these are explored further here.
To illustrate artefacts resulting from learning methods, model SPED datasets were constructed based on line scans across inclined boundaries in hypothetical bicrystals. Models (Figs. 5 and 6) were designed to highlight features of two-dimensional diffraction-like signals rather than to reflect the physics of diffraction. These were, therefore, constructed with the strength of the signal directly proportional to thickness of the hypothetical crystal at each point, with no noise, and Gaussian peak profiles.
Construction and decomposition of an idealised model SPED dataset system comprising non-overlapping two-dimensional signals. a Schematic representation of hypothetical bi-crystal. b Ground truth end-member patterns and relative thickness of the two crystals. c Factors and loadings obtained by 2-component NMF. d Cluster centre average patterns and membership maps obtained by fuzzy clustering
Non-independent components. a Expected result for an artificial dataset with two 'phases' with overlapping peaks. b NMF decomposition. c Cluster results. d SVD loadings of the dataset, used for clustering. Each point corresponds to a diffraction pattern in the scan—several are indicated with the dotted lines. Contours indicate the value of membership to the two clusters—refer to "Methods" section "Data clustering"
The model SPED dataset shown in Fig. 5 comprises the linear summation of two square arrays of Gaussians (to emulate diffraction patterns) with no overlap between the two patterns. NMF decomposition exactly recovers the signal profile in this simple case. In contrast, the membership profile obtained by fuzzy clustering, which varies smoothly owing to the use of a Euclidean distance metric, does not match the source signal. The boundary region instead appears qualitatively narrower than the true boundary. Further, the membership value for each of the pure phases is slightly below 100% because the cluster centre is a weighted average position that will only correspond to the end member if there are many more measurements near to it than away from it. A related effect is that the membership value rises at the edge of the boundary region where mixed patterns are closer to the weighted centre than the end members. We conclude that clustering should be used only if the data comprises a significant amount of unmixed signal. In the extreme, cluster analysis cannot separate the contribution from a microstructural feature which has no pure signal in the scan, for example a fully embedded particle. These observations are consistent with the results reported in association with Fig. 4.
A common challenge for signal separation arises when the source signals contain coincident peaks from distinct microstructural elements, as would be the case in SPED data when crystallographic orientation relationships exist between crystals. A model SPED dataset corresponding to this case was constructed and decomposed using NMF and fuzzy clustering (Fig. 6). In this case, the NMF decomposition yields a factor containing all the common reflections and a factor containing the reflections unique to only one end member. Whilst this is interpretable, it is not physical, although it should be noted that this is an extreme example where there is no unique information in one of the source patterns. Nevertheless, it should be expected that the intensity of shared peaks is likely to be unreliable in the learned factors and this was the case for the direct beam in learned component patterns shown in Fig. 4. As a result, components learned through NMF should not be analysed quantitativelyFootnote 3. The weighted average cluster centres resemble the true end members much more closely than the NMF components. The pure phases have a membership of around 99%, rather than 100%, due to the cluster centre being offset from the pure cluster by the mixed data, as shown in Fig. 6d. The observation that memberships extend across all the data (albeit sometimes with vanishingly small values) explains the rise in intensity of the background component in Fig. 4c in the interface region. Such interface regions do not evenly split their membership between their two true constituent clusters, meaning that some membership is attributed to the third cluster, causing a small increase in the membership locally. These issues may potentially be addressed using extensions to the algorithm developed by Rousseeuw et al. [41] or using alternative geometric decompositions such as vertex component analysis [42].
Precession was found empirically to improve machine learning decomposition as discussed above (Fig. 2), so long as the precession angle is large enough. This was attributed primarily to integration through bending of the nanowire. Precession may also result in a more monotonic variation of diffracted intensity with thickness [15] as a result of integration through the Bragg condition. It was, therefore, suggested that precession may improve the approximation that signals from two overlapping crystals may be considered to be combined linearly. To explore this, a multislice simulation of a line scan across a bi-crystal was performed and decomposed using both NMF and fuzzy clustering (Fig. 7). Without precession, both the NMF loadings and the cluster memberships do not increase monotonically with thickness but rather vary significantly in a manner reminiscent of diffracted intensity modulation with thickness due to dynamical scattering. Both the loading profile and the membership profile reach subsidiary minima when the corresponding component is just thicker than half the thickness of the simulation, which corresponds to a thickness of approximately 100 nm and is consistent with the \(2{\bar{2}}0\) extinction length for GaAs of 114 nm. This suggests that the decomposition of the diffraction patterns is highly influenced by a few strong reflections; hence, the variation of the \(2{\bar{2}}0\) reflections with thickness is overwhelming the other structural information encoded in the patterns. The removal of this effect, an essential function of applying precession, is seen: with 10 or 20 mrad precession this intensity modulation is suppressed and the loading or membership maps obtained show a monotonic increase across the inclined boundary. The cluster centres again show intensity corresponding to the opposite end member due to the weighted averaging. Precession is, therefore, beneficial for the application of unsupervised learning algorithms both in reducing signal variations arising from bending, which is a common artefact of specimen preparation, and reducing the impact of dynamical effects on signal mixing.
Unsupervised learning applied to SPED data simulated using dynamical multislice calculations a Original data with a 20 mrad precession angle. b NMF decomposition, in which the loadings have been re-scaled as in Fig. 5. The factors show pseudo-subtractive features, typical of NMF. c Cluster analysis. The high proportion of data points from the boundary means there is information shared between the cluster centres. Without precession, neither method can reproduce the original data structure
Noise and background are both significant in determining the performance of unsupervised learning algorithms. Extensive exploration of these parameters is beyond the scope of this work but we note that the various direct electron detectors that have recently been developed and that are likely to play a significant role in future SPED studies have very different noise properties. Therefore, understanding the optimal noise performance for unsupervised learning may become an important consideration. We also note that the pseudo-subtractive features evident in the NMF decomposition results of Fig. 3 may become more significant in this case and the robustness of fuzzy clustering to this may prove advantageous.
Unsupervised machine learning methods, particularly non-negative matrix factorisation and fuzzy clustering, have been demonstrated here to be capable of learning the significant microstructural features within SPED data. NMF may be considered a true linear unmixing whereas fuzzy clustering, when applied to learn representative patterns, is essentially an automated way of performing a weighted averaging with the weighting learned from the data. The former can struggle to separate coincident signals (including signal shared with a background or noise) whereas the latter implicitly leaves some mixing when a large fraction of measurements are mixed. In both cases, precession electron diffraction patterns are more amenable to unsupervised learning than the static beam equivalents. This is due to the integration through the Bragg condition, resulting from rocking the beam, causing diffracted beam intensities to vary more monotonically with thickness and the integration through small orientation changes due to out of plane bending. This work has, therefore, demonstrated that unsupervised machine learning methods, when applied to SPED data, are capable of reducing the data to the most salient structural features and unmixing signals. The scope for machine learning to reveal nanoscale crystallography will expand rapidly in the coming years with the application of more advanced methods.
The Frobenius norm is defined as \(||\mathbf A ||_{\mathrm {F}} = \sqrt{\sum \limits _{i=1}^{m} \sum \limits _{j=1}^{n} a_{ij}^{2}}\)
The empirical covariance matrix, \(\Sigma = \frac{1}{N}\sum _{i=1}^{N} \mathbf x _{i}{} \mathbf x _{i}^{T}\)
This problem may be mitigated by enforcing a sum-to-one constraint on the loadings learned through NMF during optimisation. See for example [40].
BSS:
blind source separation
FEGTEM:
field-emission gun transmission electron microscope
ICA:
independent component analysis
NNDSVD:
non-negative double singular value decomposition
NMF:
non-negative matrix factorisation
PED:
precession electron diffraction
SPED:
scanning precession electron diffraction
scanning transmission electron microscopy
SVD:
singular value decomposition
VBF:
virtual bright field
VDF:
virtual dark field
Thomas, J.M., Leary, R.K., Eggeman, A.S., Midgley, P.A.: The rapidly changing face of electron microscopy. Chem. Phys. Lett. 631, 103–113 (2015). https://doi.org/10.1016/j.cplett.2015.04.048
Murphy, K.P.: Machine Learning: A Probabilistic Perspective. Adaptive Computation and Machine Learning. MIT Press, Boston (2012)
de la Peña, F., Berger, M.H., Hochepied, J.F., Dynys, F., Stephan, O., Walls, M.: Mapping titanium and tin oxide phases using EELS: an application of independent component analysis. Ultramicroscopy 111(2), 169–176 (2011). https://doi.org/10.1016/J.ULTRAMIC.2010.10.001
Nicoletti, O., de la Peña, F., Leary, R.K., Holland, D.J., Ducati, C., Midgley, P.A.: Three-dimensional imaging of localized surface plasmon resonances of metal nanoparticles. Nature 502(7469), 80–84 (2013). https://doi.org/10.1038/nature12469
Rossouw, D., Burdet, P., de la Peña, F., Ducati, C., Knappett, B.R., Wheatley, A.E.H., Midgley, P.A.: Multicomponent signal unmixing from nanoheterostructures: overcoming the traditional challenges of nanoscale X-ray analysis via machine learning. Nano Lett. 15(4), 2716–2720 (2015). https://doi.org/10.1021/acs.nanolett.5b00449
Rossouw, D., Krakow, R., Saghi, Z., Yeoh, C.S., Burdet, P., Leary, R.K., de la Peña, F., Ducati, C., Rae, C.M., Midgley, P.A.: Blind source separation aided characterization of the \(\gamma\)' strengthening phase in an advanced nickel-based superalloy by spectroscopic 4D electron microscopy. Acta Mater. 107, 229–238 (2016). https://doi.org/10.1016/j.actamat.2016.01.042
Rossouw, D., Knappett, B.R., Wheatley, A.E.H., Midgley, P.A.: A new method for determining the composition of core-shell nanoparticles via dual-EDX+EELS spectrum imaging. Particle Particle Syst. Charact. 33(10), 749–755 (2016). https://doi.org/10.1002/ppsc.201600096
Shiga, M., Tatsumi, K., Muto, S., Tsuda, K., Yamamoto, Y., Mori, T., Tanji, T.: Sparse modeling of EELS and EDX spectral imaging data by nonnegative matrix factorization. Ultramicroscopy 170, 43–59 (2016). https://doi.org/10.1016/J.ULTRAMIC.2016.08.006
Eggeman, A.S., Krakow, R., Midgley, Pa: Scanning precession electron tomography for three-dimensional nanoscale orientation imaging and crystallographic analysis. Nat. Commun. 6, 7267 (2015). https://doi.org/10.1038/ncomms8267
Sunde, J.K., Marioara, C.D., Van Helvoort, A.T.J., Holmestad, R.: The evolution of precipitate crystal structures in an Al-Mg-Si(-Cu) alloy studied by a combined HAADF-STEM and SPED approach. Mater. Charact. 142, 458–469 (2018). https://doi.org/10.1016/j.matchar.2018.05.031
Rauch, E.F., Veron, M.: Coupled microstructural observations and local texture measurements with an automated crystallographic orientation mapping tool attached to a TEM. Materialwissenschaft und Werkstofftechnik 36(10), 552–556 (2005). https://doi.org/10.1002/mawe.200500923
Rauch, E.F., Portillo, J., Nicolopoulos, S., Bultreys, D., Rouvimov, S., Moeck, P.: Automated nanocrystal orientation and phase mapping in the transmission electron microscope on the basis of precession electron diffraction. Zeitschrift für Kristallographie 225(2–3), 103–109 (2010). https://doi.org/10.1524/zkri.2010.1205
Vincent, R., Midgley, P.: Double conical beam-rocking system for measurement of integrated electron diffraction intensities. Ultramicroscopy 53(3), 271–282 (1994). https://doi.org/10.1016/0304-3991(94)90039-6
White, T., Eggeman, A., Midgley, P.: Is precession electron diffraction kinematical? Part I: "Phase-scrambling" multislice simulations. Ultramicroscopy 110(7), 763–770 (2010). https://doi.org/10.1016/J.ULTRAMIC.2009.10.013
Eggeman, A.S., White, T.A., Midgley, P.A.: Is precession electron diffraction kinematical? Part II. A practical method to determine the optimum precession angle. Ultramicroscopy 110(7), 771–777 (2010). https://doi.org/10.1016/j.ultramic.2009.10.012
Sinkler, W., Marks, L.D.: Characteristics of precession electron diffraction intensities from dynamical simulations. Zeitschrift für Kristallographie 225(2–3), 47–55 (2010). https://doi.org/10.1524/zkri.2010.1199
Rauch, E.F., Véron, M.: Virtual dark-field images reconstructed from electron diffraction patterns. Eur. Phys. J. Appl. Phys. 66(1), 10,701 (2014). https://doi.org/10.1051/epjap/2014130556
Gammer, C., Burak Ozdol, V., Liebscher, C.H., Minor, A.M.: Diffraction contrast imaging using virtual apertures. Ultramicroscopy 155, 1–10 (2015). https://doi.org/10.1016/J.ULTRAMIC.2015.03.015
Rouviere, J.L., Béché, A., Martin, Y., Denneulin, T., Cooper, D.: Improved strain precision with high spatial resolution using nanobeam precession electron diffraction. Appl. Phys. Lett. 103(24), 241913 (2013). https://doi.org/10.1063/1.4829154
Moeck, P., Rouvimov, S., Rauch, E.F., Véron, M., Kirmse, H., Häusler, I., Neumann, W., Bultreys, D., Maniette, Y., Nicolopoulos, S.: High spatial resolution semi-automatic crystallite orientation and phase mapping of nanocrystals in transmission electron microscopes. Crys. Res. Technol. 46(6), 589–606 (2011). https://doi.org/10.1002/crat.201000676
Kelly, A., Groves, G., Kidd, P.: Crystallography and Crystal Defects. Wiley, Chichester (2000)
Munshi, A.M., Dheeraj, D.L., Fauske, V.T., Kim, D.C., Huh, J., Reinertsen, J.F., Ahtapodov, L., Lee, K.D., Heidari, B., van Helvoort, A.T.J., Fimland, B.O., Weman, H.: Position-controlled uniform GaAs nanowires on silicon using nanoimprint lithography. Nano Lett. 14(2), 960–966 (2014). https://doi.org/10.1021/nl404376m
Eggeman, A., London, A., Midgley, P.: Ultrafast electron diffraction pattern simulations using gpu technology. Applications to lattice vibrations. Ultramicroscopy 134, 44–47 (2013). https://doi.org/10.1016/j.ultramic.2013.05.013
Palatinus, L., Jacob, D., Cuvillier, P., Klementová, M., Sinkler, W., Marks, L.D.: IUCr: structure refinement from precession electron diffraction data. Acta Crystallogr. Sect. A Found. Crystallogr. 69(2), 171–188 (2013). https://doi.org/10.1107/S010876731204946X
Hoyer, P.O.: Non-negative matrix factorization with sparseness constraints. J. Mach. Learn. Res. 5, 1457–1469 (2004)
Jolliffe, I.: Principal component analysis. In: International Encyclopedia of Statistical Science, pp. 1094–1096. Springer , Berlin (2011)
Hyvärinen, A., Karhunen, J., Oja, E.: Independent Component Analysis. Wiley, New York (2001)
Lee, D.D., Seung, H.S.: Learning the parts of objects by non-negative matrix factorization. Nature 401(6755), 788–91 (1999). https://doi.org/10.1038/44565
de la Pena, F., Ostasevicius, T., Tonaas Fauske, V., Burdet, P., Jokubauskas, P., Nord, M., Sarahan, M., Prestat, E., Johnstone, D.N., Taillon, J., Jan Caron, J., Furnival, T., MacArthur, K.E., Eljarrat, A., Mazzucco, S., Migunov, V., Aarholt, T., Walls, M., Winkler, F., Donval, G., Martineau, B., Garmannslund, A., Zagonel, L.F., Iyengar, I.: Electron Microscopy (Big and Small) Data Analysis With the Open Source Software Package HyperSpy. Microsc. Microanal. 23(S1), 214–215 (2017). https://doi.org/10.1017/S1431927617001751
Pedregosa, F., Varoquaux, G., Gramfort, A., Michel, V., Thirion, B., Grisel, O., Blondel, M., Prettenhofer, P., Weiss, R., Dubourg, V., Vanderplas, J., Passos, A., Cournapeau, D., Brucher, M., Perrot, M., Duchesnay, É.: Scikit-learn: machine learning in python. J. Mach. Learn. Res. 12(Oct), 2825–2830 (2011)
Shlens, J.: A tutorial on principal component analysis. CoRR (2014). arXiv:abs/1404.1100
Bishop, C.: Pattern Recognition and Machine Learning. Information Science and Statistics. Springer, New York (2006)
Boutsidis, C., Gallopoulos, E.: Svd based initialization: a head start for nonnegative matrix factorization. Pattern Recogn. 41(4), 1350–1362 (2008). https://doi.org/10.1016/j.patcog.2007.09.010
Everitt, B., Landau, S., Leese, M.: Clust. Anal. Wiley, Chichester (2009)
Bezdek, J.C., Ehrlich, R., Full, W.: FCM: the fuzzy c-means clustering algorithm. Comput. Geosci. 10(2–3), 191–203 (1984). https://doi.org/10.1016/0098-3004(84)90020-7
Gustafson, D., Kessel, W.: Fuzzy clustering with a fuzzy covariance matrix. In: 1978 IEEE conference on decision and control including the 17th symposium on adaptive processes, pp. 761–766. IEEE, San Diego (1978). https://doi.org/10.1109/CDC.1978.268028
Marimont, R.B., Shapiro, M.B.: Nearest neighbour searches and the curse of dimensionality. IMA J. Appl. Math. 24(1), 59–70 (1979). https://doi.org/10.1093/imamat/24.1.59
Aggarwal, C.C., Hinneburg, A., Keim, D.A.: On the surprising behavior of distance metric in high-dimensional space (2002)
Rencher, A.: Methods of Multivariate Analysis. Wiley Series in Probability and Statistics. Wiley, Hoboken (2002)
Kannan, R., Ievlev, A.V., Laanait, N., Ziatdinov, M.A., Vasudevan, R.K., Jesse, S., Kalinin, S.V.: Deep data analysis via physically constrained linear unmixing: universal framework, domain examples, and a community-wide platform. Adv. Struct. Chem. Imaging 4(1), 6 (2018). https://doi.org/10.1186/s40679-018-0055-8
Rousseeuw, P.J., Trauwaertb, E., Kaufman, L.: Fuzzy clustering with high contrast. J. Comput. Appl. Math. 0427(95), 8–9 (1995)
Spiegelberg, J., Rusz, J., Thersleff, T., Pelckmans, K.: Analysis of electron energy loss spectroscopy data using geometric extraction methods. Ultramicroscopy 174, 14–26 (2017). https://doi.org/10.1016/J.ULTRAMIC.2016.12.014
BHM, DNJ, ASE, and PAM proposed the investigation. DNJ, ASE, and ATJvH performed the SPED experiments, ASE provided the multislice simulations, and BHM implemented the c-means algorithm. The data analysis was undertaken by BHM and DNJ who also prepared the manuscript, with oversight and critical contributions from ASE, ATJvH, and PAM. All authors read and approved the final manuscript.
Acknowlegements
Prof. Weman and Fimland of IES at NTNU are acknowledged for supplying the nanowire samples.
Data used in this work has been made freely available to download at https://doi.org/10.17863/CAM.26432.
The Python 3 code to perform the analysis has also been made available, at https://doi.org/10.17863/CAM.26444.
The authors acknowledge financial support from: The Royal Society (Grant RG140453; UF130286); the Seventh Framework Programme of the European Commission: ESTEEM2, contract number 312483; the European Research Council under the European Union's Seventh Framework Programme (FP7/2007-2013)/ERC grant agreement 291522-3DIMAGE; the University of Cambridge and the Cambridge NanoDTC; the EPSRC (Grant no. EP/R008779/1).
Department of Materials Science and Metallurgy, University of Cambridge, 27 Charles Babbage Road, Cambridge, CB3 0FS, UK
Ben H. Martineau, Duncan N. Johnstone & Paul A. Midgley
The School of Materials, The University of Manchester, Oxford Road, Manchester, M13 9PL, UK
Alexander S. Eggeman
Department of Physics, Norwegian University of Science and Technology, Hogskolering 5, 7491, Trondheim, Norway
Antonius T. J. van Helvoort
Ben H. Martineau
Duncan N. Johnstone
Paul A. Midgley
Correspondence to Ben H. Martineau.
Martineau, B.H., Johnstone, D.N., van Helvoort, A.T.J. et al. Unsupervised machine learning applied to scanning precession electron diffraction data. Adv Struct Chem Imag 5, 3 (2019). https://doi.org/10.1186/s40679-019-0063-3
Multivariate analysis
Scanning electron diffraction | CommonCrawl |
Criterion predicting the generation of microdamages in the filled elastomers
Alexander Konstantinovich Sokolov1,
Oleg Konstantinovich Garishin1 and
Alexander L'vovich Svistkov1Email author
Mechanics of Advanced Materials and Modern Processes20184:7
Received: 30 June 2018
Accepted: 6 December 2018
Incorporation of active fillers to rubber markedly improves the strength properties and deformation characteristics of such materials. One possible explanation of this phenomenon is suggested in this work. It is based on the fact that for large deformations the binder (high-elastic, cross-linked elastomer) in the gaps between the filler particles (carbon black) is in a state close to the uniaxial extension. The greater part of polymer molecular chains are oriented along the loading axis in this situation. Therefore it can be assumed that the material in this state has a higher strength compared to other ones at the same intensity of deformation. In this paper, a new strength criterion is proposed, and a few examples are given to illustrate its possible use. It is shown that microscopic ruptures that occur during materials deformation happen not in the space between filler particles but at some distance around from it without breaking particle "interactions" through these gaps. The verification of this approach in modeling the stretching of a sample from an unfilled elastomer showed that in this case it works in full accordance with the classical strength criteria, where the presence in the material of a small defect (microscopic incision) leads to the appearance and catastrophic growth of the macrocrack.
Damage generation
Nanocomposite
Finite deformations
Computational modeling
Fracture criterion
Elastomeric nanocomposites contains a highly elastic rubber matrix, where rigid grain nanoparticles or aggregates of nanoparticles are dispersed. Over the past years, a lot of practical experience has been gained in creating such materials for a variety of applications. Elastomers in which nanoparticles are used as filler are characterized by increased strength and ultimate deformation (strain at break). However, the reasons for such improvement of their mechanical characteristics are still the subject of discussions among materials experts. Since the beginning of the 20-th century, it has been well established that the reinforcement of rubbers with carbon black (20–30% by volume) significantly improves their operational characteristics. In particular, such materials possess enhanced rigidity; their tensile strength and ultimate strains increase by 5–15 times and 2–4 times, respectively. Intensive study of the mechanical properties of elastomeric nanocomposites in relation to the type of filler and its concentration and manufacturing technology is still in progress. An example are the works related to the study of the elastomers properties filled with carbon black, carbon nanotubes, nanodiamonds, various mineral particles (montmorillonite, palygorskite, schungite etc.) (Rodgers & Waddel, 2013; Jovanovic et al., 2013; Le et al., 2015; Lvov et al., 2016; Mokhireva et al., 2017; He et al., 2015; Huili et al., 2017; Stöckelhuber et al., 2011; Garishin et al., 2017). A part from numerous experimental investigations, there are many theoretical works devoted to structural modeling of the physical-mechanical properties of materials, which takes into account the characteristic features of the internal structure and processes at micro- and nanolevels (Garishin & Moshev, 2005; Reese, 2003; Österlöf et al., 2015; Ivaneiko et al., 2016; Raghunath et al., 2016; Plagge & Klüppel, 2017; Svistkov et al., 2016; Svistkov, 2010).
An important feature of elastomeric composites is the ability to change their mechanical properties (softening) as a result of preliminary deformation (the Mullins-Patrikeev effect) (Svistkov, 2010; Patrikeev, 1946; Mullins, 1947; Mullins & Tobin, 1965; Mullins, 1986; Diani et al., 2009). This feature can significantly influence the mechanical behavior of the products made of filled elastomer (Sokolov et al., 2016; Sokolov et al., 2018). To date, the Mullins effect is an object of intensive theoretical and experimental study. In the literature there is still no single settled opinion about its nature.
It has been found that, the anisotropic properties can also be formed in filled elastomers under softening (Govindjee & Simo, 1991; Machado et al., 2012). The anisotropy features are clearly seen in the samples the second loading of which is executed at some angle to the direction of the force applied during the first loading (Machado et al., 2014). Some authors try to describe these effects using purely phenomenological models (without specifying the physical meaning of the internal variables used) (Ragni et al., 2018; Itskov et al., 2010). A model based on the features of the interaction of polymer chains with filler particles is proposed in (Dorfmann & Pancheri, 2012). In particular, it is assumed that the anisotropic softening of the material during its cyclic loading is due to the peculiarities of interaction of polymer network with filler particles, including breaking and mutual slipping of macromolecules segments.
However, despite the undoubted progress in the analysis of possible mechanisms responsible for the formation of properties of nanofilled elastomers, there are still ambiguities to be clarified. An increase in strength and the appearance of anisotropic properties after the first deformation can be attributed to the existence of micro and nanostrands in its structure. Their existence is confirmed by experimental studies (Marckmann et al., 2016; Reichert et al., 1993; Le Cam et al., 2004; Watabe et al., 2005; Beurrot et al., 2010; Marco et al., 2010). In (Matos et al., 2012), based on the results of experimental studies of the carbon-filled rubber structure (using electron microtomography) and computer simulation, it was shown that the macrodeformation of about 15% can cause significant microdeformation of the matrix of 100 and more percent in the zones between the agglomerates of carbon black particles. Investigations of the nanostructure of filled rubbers in a stretched (up to pre-rupture) state by the atomic force microscopy methods (AFM) demonstrate the formation of a fibrous texture between filler particles (Morozov et al., 2012). Tomograms of the microstructure of rubber (electron microscopy), obtained in (Akutagava et al., 2008) also show strands and strand-linked aggregates of carbon black particles.
The results of experimental studies indicate that the fraction of polymer is not extractable from uncured filled rubber compounds by a good solvent of the gum elastomer. A polymer layer remains on the surface of the filler particles remains, called "bound rubber". The simplest and most obvious explanation for this fact is the phenomenon of adsorption of polymer chains on the surface of particles and the occurrence of a strong bond between the polymer and the particles. So, the basis of the Meissner theory and its further refinements (Meissner, 1974; Meissner, 1993; Karásek & Meissner, 1994; Karásek & Meissner, 1998) is the idea of random adsorption of portions of polymer chains on the reactive sites which are assumed to exist on the surface of filler particles. In this approach, the filler particles are considered as a polyfunctional crosslinking agent for the polymer chains. Carbon black particles are assembled into aggregates with a strong bond that is difficult to destroy. These aggregates have dimensions of 100 to 300 nm. Therefore, many authors, when constructing models of the behavior of filled elastomers, consider the state of the polymer around particle aggregates within the framework of continuum mechanics. It is reasonable to consider nanofiller not as multifunctional stitching of polymer chains, but as nanoinclusions of a composite material.
The appearance of the interfacial layer may be the result of a chemical reaction in the process of manufacturing the material (Kondyurin et al., 2018). The thicknesses of the layers near the filler particles and their properties can be specially selected to obtain a good agreement between the results of numerical calculations on relatively simple models with experimental data (Goudarzi et al., 2015). Numerical experiments allow us to find arguments in favor of the rationality of one or another hypothesis. A possible connection between the layers near the filler particles and the macroscopic properties of the material was considered in (Fukahori, 2003; Fukahori, 2005; Fukahori, 2007). An assumption was made about the existence of two layers with special properties, which the author of the hypothesis called Glassy Hard and Sticky Hard layers. The first layer is formed by a rigid material, in which molecular chain seem to be strongly adhered to the surface of the particle, whether physically or chemically. In contrast to it Sticky Hard layer is tightly entangled with the molecules extended from the Glassy Hard layer. Under large extension, themolecules in the Sticky Hard layer sandwiched between two adjacent carbon particles are stronglyextended by the separation of the carbon particles accompanied with molecular sliding and orientation. As a result the network of the strands of oriented molecules interconnected by carbon particles is formed. The hypothesis proposed explains the Mullins effect and the increase in the strength of the elastomer when the active filler is embedded into it.
In contrast to the Fukachori hypothesis, Wang used another illustration of the change in the properties of an elastomeric material with distance from the surface of the filler particles (Wang, 1998). The stiffness of the binder slowly decreases with removal until it becomes equal to the stiffness of the elastomer, which it has in the absence of filler. Work related to the study of bound rubber properties near the filler is currently underway. However, many things remain unclear as to the properties of the layers near the particles and the mechanism of their formation.
In our work, a new hypothesis is considered, which makes it possible to explain one of the possible mechanisms for the formation of the strength properties of a filled elastomeric material.
A new hypothesis that the elastomeric matrix in the gaps between adjacent filler particles is capable of withstanding very high loads is analyzed through computational modeling in this work. This is possible for the following reason. In an unloaded elastomer, molecular chains have a form of "polymer coils". When the material is stretched in one direction, polymer chains unfold and may orient along the loading axis. The elastomeric material is converted into a state in which most chains are oriented approximately identically. In the case of a semi-crystalline polymer, so-called crystallites will arise in such regions (zones of increased rigidity with densely and orderly stacked polymer chains, so that the intermolecular forces acting at a small distance reliably connect them). If the polymer is not capable of semi-crystallization (amorphous), then these similar supramolecular formations do not arise in it. But, nevertheless, there is every reason to believe that the preferential orientation of the polymer chains along one common axis contributes to the ability of the elastomer to withstand a higher load in the direction of orientation than in other loaded states.
In order to quantify the moment of appearance of damage in the elastomeric composite, taking into account this factor, an appropriate strength criterion is needed. Classical approaches, when structural microdamages should occur in the most stressed places, that is, in the gaps between closely spaced particles, in this case do not work. Therefore, we propose to use a new criterion of strength in the form of the following condition: the destruction of a given point of the material is impossible if inequality (1) is satisfied.
$$ f\left({\lambda}_1,{\lambda}_2,{\lambda}_3\right)=\alpha \left(\sum \limits_{i=1}^3{\lambda}_i^{-2}-3\right)+\beta \left|\ln \frac{\lambda_1}{\lambda_2}\ln \frac{\lambda_2}{\lambda_3}\ln \frac{\lambda_3}{\lambda_1}\right|+\gamma p<1, $$
where λi are the extension ratios, p is the average stress (the first invariant of the Cauchy stress tensor divided by three). The strain strength criterion includes two dimensionless α, β and one dimensional γ constants, which characterize the strength properties of the material. The values of theses constants can be determined experimentally. The first term yields a non-zero contribution to criterion (1) for the material in any deformation state. The second term is equal to zero for the material under uniaxial stretching. In the case of other types of the stress-strain state, it provides only an additional positive contribution to the function f. Note that this contribution can be very significant if the value of the parameter β is sufficiently large. The third term takes into account the fact that when the material is compressed comprehensively, the damage appears much more difficult. It was assumed that the value of γ is equal to zero in this investigation.
Thus, the main distinctive feature of the proposed criterion is that the value of function f under uniaxial stretching is minimal in comparison with other types of the stress-strain state at the same values of the strain invariant \( I={\lambda}_1^{-2}+{\lambda}_2^{-2}+{\lambda}_3^{-2} \) and the values of average stress p.
Figure 1 presents a map to illustrate the region of an incompressible medium (the inequality λ1λ2λ3 = 1 is always fulfilled) where no microdamages may occur. It is the domain of extension ratios where the condition f(λ1,λ2,λ3) < 1 is fulfilled. Three solid lines correspond to uniaxial stretching along each of the principal axes. The map is plotted for the following values of constants: α = 0.25; β = 0.05; γ=0. These values were used further as a basis for our computational modeling. The drawing illustrates the main peculiar features of the criterion applied. As one can see, the material under uniaxial stretching can be deformed along the loading axis up to significantly high extension ratios. In other states, the onset of damage is observed at a much lower deformations.
A map illustrating the states where no damages (shown in grey) occur and the states where microdamages should happen (shaded areas). Solid curves correspond to uniaxial tensile loading conditions
The use of the circuit shown in Fig. 2, when the filler particles are arranged in the form of a regular rectangular lattice is The simplest and most suitable for computer experiments on modeling structural changes in an elastomeric composite.
The simplest calculation scheme for modeling the structure of an elastomeric composite. The centers of spherical inclusions are located in the nodes of a regular rectangular lattice. Arrows show the direction of uniaxial loading of the material
If the filler particles are located close enough to each other, the stress-strain state of the binder in the gaps is close to the state obtained during the analysis of the pair interaction of hard inclusions in an "soft" elastic matrix (Fig. 3), when the axis passing through the centers of inclusions coincides with the direction of the medium stretching (Dohi et al., 2007; Moshev & Garishin, 2005). In this case the macroscopic extension ratios can be calculated as a relative change in the distance between particles centers. Again, we must say that we are dealing here with the uniaxial loading of the composite in the direction shown by arrows in Fig. 3. For the convenience of computational experiments, we investigate the generation of damages near the pair of inclusions loaded by forces applied to the centers of particles.
Calculation scheme of the problem of two rigid spherical inclusions in a nonlinear elastic matrix
The following geometric relationships are used in the problem under study. Finite elements methods (ANSYS) have been used for modeling elastic composite materials (license ANSYS Academic Research Mechanical and CFD). Isoparametric quadrilateral elements of the 2-nd order (8 nodes in elements) were used in the calculation. Finite elements mesh was used: 12600 elements, 26,600 nodes (filler particles — 1600 elements, 3600 nodes, elastic matrix — 11,000 elements, 23,000 nodes).
Simulations are performed for the cylindrical cell, in which two rigid spheres of radius R are located. The inclusions are placed on the symmetry axis at a distance δ0 from each other. The cylinder height Hc and its diameter Dc are assumed to be equal to 15R. Thus provides the condition under which the effects of remote boundaries on the stress-strain state around this pair are absent.. The external boundaries of the structural cells are considered to be free of stress. The system is loaded on moving apart the spheres along the center-to-center axis to a certain distance δ. As a measure to characterize macroscopic strains, we use the parameter λ = (δ + 2R) / (δ0 + 2R).
All calculations were performed for the case when the initial gap between filler particles, δ0, was equal to 0.4R. The choice of this value has been made reasoning from the fact that at this distance stress gradients in the gap are still not so high as to pose technical difficulties during the solution of the problem, and at the same time the "mutual influence" of particles is sufficient enough for our purposes (microstrand generation modeling) (Garishin & Moshev, 2002; Garishin, 2012).
The adhesion strength of the contact between the dispersed phase and the continuum is assumed to be much greater the matrix strength (no debonding), i.e. for the "matrix-inclusion" boundaries the condition for complete adhesion is specified. The rigidity of filler particles in reinforced elastomeric composites is, as rule, markedly higher compared to the matrix. Therefore, the elastic modulus of spherical inclusions Ep was given to be equal to 104Em (Em – initial Young's modulus of the matrix). That is, the inclusions considered in the numerical calculation are practically undeformable and undamageable. So damages could appear only in the elastomer. The matrix is assumed to be an incompressible nonlinear-elastic medium, the mechanical properties of which are set were using the neo-Hookean potential w:
$$ w=\frac{E_m}{6}\left({\lambda}_1^2+{\lambda}_2^2+{\lambda}_3^2-3\right). $$
The solutions of the above-described boundary-value problem using of various conventional strength criteria (destruction upon exceeding the limiting values of such invariants of the stress-strain state as stress or strain intensities, principal stresses or strains, hydrostatic stresses) showed that in all these cases the rupture of the binder should occur in the gaps between the inclusions. That is, no any strands or similar formations can appear there in principle. A different picture is observed when using the new criterion (1). Calculations showed that the initial damages of the matrix do not occur in the gap, but at some distance from it. In this case, the further growth of the resulting damage caused by the increasing external load also does not affect the central gap region, but occurs in the surrounding space. Computer modeling of this process was carried out as follows. The boundary nonlinear elastic problem was solved in an axisymmetric formulation using the finite element method. In the process of incremental loading of the cylindrical cell, each finite element was checked for the fulfillment of condition (1) and if the condition f(λ1,λ2,λ3) > 1 was satisfied, its modulus decreased to a value close to zero.
The isolines of parameter f values corresponding to the following moments of the formation of the nanostrand in the material are shown in Fig. 4: At λ = 2, the material is extended, but there are still no microdamages (Fig. 4a). At λ = 2.17, primary damages occur in the matrix (Fig. 4b). At λ = 2.34 the process of fracture region formation occurs in a direction parallel to the line connecting the centers of inclusions (Fig. 4c). If we continue modeling the loading process, then a uniaxially stretched "strand" which connects the surfaces of neighbor filler particles is formed. Around it is the area of the destroyed binder.
Fields of distribution of parameter f the values in the gap between the particles: a – λ = 2.00 (matrix without damage); b – λ = 2.17 (occurrence of primary damage); c – λ = 2.34 (development of damage)
Geometry of a homogeneous elastomeric sample with a lateral defect
Application of the strength criterion (1) for uniaxial stretching of a homogeneous in mechanical properties elastomeric sample with a small defect in the form of an elliptical cut on the lateral side, gave a completely different picture of damage development.
This boundary value problem was also solved by the finite element method, but already for the case of a plane deformed state. The model sample was in the form of a square with side H (Fig. 5). There was a microdefect on the lateral side. It has the form of a small notch shaped like an elongated half-ellipse The distance between the edges of the notch h1 is 0.05H, and its length h2 = 0.075H. The sample is stretched vertically due to the displacement of the upper and lower faces, and the side surfaces are free.
The mechanical properties of the matrix material and the constants of the strength criterion α, β and γ were set to the same as for a cylindrical cell with two inclusions. The calculation scheme for modeling the appearance and growth of damage was also taken without changes, that is, when the condition f > 1 was satisfied, the modulus of this finite element was changed to values close to zero.
The isolines of the strength parameter f distribution for an unfilled elastomer sample stretched 2.5 times are shown in Fig. 6. The map given in this figure corresponds to the instant of fracture initiation near the defect. Computer simulation has revealed that in this case, the destruction of a single finite element leads to a redistribution of its share of the load to "neighbors", that is, to their additional overload. The computational experiment has revealed that once the elastic modulus of the binder is specified for the elements where fracture should occur, the neighboring elements become immediately overloaded. Accordingly, the risk of their own destruction increases. A system with "positive feedback" is obtained, when the presence of a microdefect leads to an avalanche-like increase in damage and, ultimately, to macroscopic rupture of the whole sample. Such a behavior of the unfilled elastomer completely agrees with the known experiments (i.e. the proposed criterion is quite operational even in this case).
A map of the strength parameter f values distribution in model unfilled elastomer specimen with lateral notch which is uniaxially stretched in 2.5 times
The mechanism of damage development in elastomeric nanocomposites is of another character. Filler particles promote the appearance and formation of nanostrands in the matrix, which prevent the "germination" of the macroscopic crack. This circumstance can serve as one of the most plausible explanations of the well-known experimental fact that the strength and ultimate deformation of elastomeric composites can be substantially higher than that of a pure matrix.
It is the well known experimental fact that the input of active nanoparticles into an elastomer leads to a significant increase in tensile stresses and elongations of the material at the moment of sample rupture. To explain this fact, there are several hypotheses. Many researchers associate an increase in the strength of the material with either specific processes occurring near the filler particles or with the features of the movement of the macro-fracture in the filled elastomeric material. We drew attention to the fact that the increase in the strength of elastomers can be even in the case when the filler particles have micron dimensions (not only nanosize). In this case, this phenomenon cannot be explained with the help of hypotheses about the important role of the layers with special properties near the filler particles and specific processes in the polymer network near the surface of the filler particles.
The second fact, which we take into account, is forming of strong microfibers at the top of the macrorcrack that were observed in experiments with elastomers. These fibers connect the filler particles in the material and, apparently, inhibit the germination of the macro-fracture. To explain the features of the destruction of filled elastomers, we proposed to use a new strength criterion for an elastomeric material. According to this criterion, areas of a material whose state is close to a state of uniaxial tension have significantly greater strength compared to other states of a material with the same strain intensity. The examples given in the article show that it can be used to explain the formation of intact regions of the elastomeric binder in the gaps between the filler particles. These areas are able to change the process of the macro-fracture development in polymer sample.
This work is executed at a financial support of RFBR Grants 16-08-00756 and 16-08-00914.
This work is executed at a financial support of RFBR Grants 16–08-00756 and 16–08-00914.
The data and materials supporting this review are available online as per the cited journal publications and conference proceedings.
All the authors contributed to preparation of the paper. All authors read and approved the final manuscript.
Author agrees to publication.
Institute of Continuous Media Mechanics of the Ural Branch of Russian Academy of Science, Perm, Russia
Akutagava K, Yamaguchi K, Yamamoto A, Heguru H (2008) Mesoscopical mechanical analysis of filled elastomer with 3D-finite element analysis and transmission electron microtomography. Rubber Chem Technol 81:182–189View ArticleGoogle Scholar
Beurrot S, Huneau B, Verron E (2010) In situ SEM study of fatigue crack growth mechanism in carbon black-filled natural rubber. J Appl Polym Sci 117:1260–1269Google Scholar
Diani J, Fayolle B, Gilormini P (2009) A review on the Mullins effect. Eur Polym J 45:601–612View ArticleGoogle Scholar
Dohi H, Kimura H, Kotani M, Kaneko T, Kitaoka T, Nishi T, Jinnai H (2007) Three-dimensional imaging in polymer science: its application to block copolymer morphologies and rubber composites. Polym J 39(8):749–758View ArticleGoogle Scholar
Dorfmann A, Pancheri F (2012) A constitutive model for the Mullins effect with changes in material symmetry. Int J Non-Linear Mech 47(8):874–887View ArticleGoogle Scholar
Fukahori Y (2003) The mechanics and mechanism of the carbon black reinforcement of elastomers. Rubber Chem Technol 76:548–565View ArticleGoogle Scholar
Fukahori Y (2005) New Progress in the theory and model of carbon black reinforcement of elastomers. J Appl Polym Sci 95:60–67View ArticleGoogle Scholar
Fukahori Y (2007) Generalized concept of the reinforcement of elastomers. Part 1: carbon black reinforcement of rubbers. Rubber Chem Technol 80:701–725View ArticleGoogle Scholar
Garishin OK (2012) Mekhanicheskie svojstva i razrushenie dispersno napolnennyh ehlastomerov. Strukturnoe modelirovanie [Mechanical properties and destruction of dispersely filled elastomers. Structural modeling]. Palmarium Academic Publishing (LAP), Germany, Saarbrucken, p 286Google Scholar
Garishin OK, Moshev VV (2005) Structural rearrangement in dispersion-filled composites: influence on mechanical properties. Polymer Science 47:403–408Google Scholar
Garishin OK, Shadrin VV, Svistkov AL, Sokolov AK, Stockelhuber WK (2017) Visco-elastic-plastic properties of natural rubber filled with carbon black and layered clay nanoparticles. Experiment and simulation. Polym Test 63:133–140View ArticleGoogle Scholar
Garishin ОC, Moshev VV (2002) Damage model of elastic rubber particulate composites. Theor Appl Fract Mech 38:63–69View ArticleGoogle Scholar
Goudarzi T, Spring DW, Paulino GH, Lopez-Pamies O (2015) Filled elastomers: a theory of filler reinforcement based on hydrodynamic and interphasial effects. J Mech Phys Solids 80:37–67MathSciNetView ArticleGoogle Scholar
Govindjee S, Simo JC (1991) A micro-mechanically continuum damage model for carbon black filled rubbers incorporating Mullins's effect. Mech Phys Solids 39(1):87–112MathSciNetView ArticleGoogle Scholar
He Q, Runguo W, Hui Y, Xiaohui W, Weiwei L, Xinxin Z, Xiaoran H, Liqun Z (2015) Design and preparation of natural layered silicate/bio-based elastomer nanocomposites with improved dispersion and interfacial interaction. Polymer 79:1–11View ArticleGoogle Scholar
Huili L, Hongwei B, Dongyu B, Zhenwei L, Qin Z, Qiang F (2017) Design of high-performance poly(L-lactide)/elastomer blends through anchoring carbon nanotubes at the interface with the aid of stereo-complex crystallization. Polymer 108:38–49View ArticleGoogle Scholar
Itskov M, Ehret A, Kazakeviciute-Makovska R, Weinhold G (2010) A thermodynamically consistent phenomenological model of the anisotropic Mullins effect. J Appl Math Mech 90(5):370–386MATHGoogle Scholar
Ivaneiko I, Toshchevikov V, Saphiannikova M, Stöckelhuber KW, Petry F, Westermann S, Heinrich G (2016) Modeling of dynamic-mechanical behavior of reinforced elastomers using a multiscale approach. Polymer 82:356–365View ArticleGoogle Scholar
Jovanovic V, Samarzija-Jovanovic S, Budinski-Simendic J, Markovic G, Marinovic-Cincovic M (2013) Composites based on carbon black reinforced NBR/EPDM rubber blends. Compos Part B 45:333–340View ArticleGoogle Scholar
Karásek L, Meissner B (1994) Experimental testing of the polymer-filler. Gel formation theory. Part I. J Appl Polym Sci 52:1925–1931View ArticleGoogle Scholar
Karásek L, Meissner B (1998) Experimental testing of the polymer-filler gel formation theory. II. J Appl Polym Sci 69:95–107View ArticleGoogle Scholar
Kondyurin AV, Eliseeva AY, Svistkov AL (2018) Bound ("glassy") rubber as a free radical cross-linked rubber layer on a carbon black. Materials 11:1–20Google Scholar
Le Cam J-B, Huneau B, Verron E, Gornet L (2004) Mechanism of fatigue crack growth in carbon black filled natural rubber. Macromolecules 37:5011–5017View ArticleGoogle Scholar
Le HH, Pham T, Henning S, Klehm J, Wießner S, Stöckelhuber S, Das A, Hoang XT, Do QK, Wu M, Vennemann N, Heinrich G, Radusch G (2015) Formation and stability of carbon nanotube network in natural rubber: Effect of non-rubber components. Polymer 73:111–121View ArticleGoogle Scholar
Lvov Y, Fakhrullin R, Wang W, Zhang L (2016) Hallousite clay nanotubes for loading and sustained release of functional compounds. Adv Mater 28:1227–1250View ArticleGoogle Scholar
Machado G, Chagnon G, Favier D (2012) Induced anisotropy by the Mullins effect in filled silicone rubber. Mech Mater 50:70–80View ArticleGoogle Scholar
Machado G, Chagnon G, Favier D (2014) Theory and identification of a constitutive model of induced anisotropy by the Mullins effect. J Mech Phys Solids 63:29–39MathSciNetView ArticleGoogle Scholar
Marckmann G, Chagnon G, Le SM, Charrier P (2016) Experimental investigation and theoretical modelling of induced anisotropy during stress-softening of rubber. Int J Solids Struct 97:554–565View ArticleGoogle Scholar
Marco Y, Le Saux V, Calloch S, Charrier P (2010) X-ray computed μ-tomography: a tool for the characterization fatigue defect population in a polychloroprene. Procedia Engineering 2:2131–2140View ArticleGoogle Scholar
Matos CF, Galembeck F, Zarbin AJ (2012) Multifunctional materials based on iron/iron oxide-filled carbon nanotubes / natural rubber composites. Carbon 50:4685–4695View ArticleGoogle Scholar
Meissner B (1974) Theory of bound rubber. J Appl Polym Sci 18:2483–2491View ArticleGoogle Scholar
Meissner B (1993) Bound rubber theory and experiment. J Appl Polym Sci 50:285–292View ArticleGoogle Scholar
Mokhireva KA, Svistkov AL, Solod'ko VN, Komar LA, Stöckelhuber KW (2017) Experimental analysis of the effect of carbon nanoparticles with different geometry on the appearance of anisotropy of mechanical properties in elastomeric composites. Polym Test 59:46–54View ArticleGoogle Scholar
Morozov IA, Lauke B, Heinrich G (2012) Quantitative microstructural investigation of carbon-black-filled rubbers by AFM. Rubber Chem Technol 85:244–263View ArticleGoogle Scholar
Moshev VV, Garishin OK (2005) Structural mechanics of dispersed-filled elastomeric composites. Achiev Mech (Uspehi mehaniki) 2005(4):3–36 (in Russian)Google Scholar
Mullins L (1947) Effect of stretching in the properties of rubber. J Rubber Res 16:245–289Google Scholar
Mullins L (1986) Engineering with rubber. Rubber Chem Technol 59:G69–G83View ArticleGoogle Scholar
Mullins L, Tobin NR (1965) Stress softening in rubber vulcanizates. Part I. use of a strain amplification factor to prescribe the elastic behavior of filler reinforced vulcanized rubber. J Appl Polym Sci 9:2993–3005View ArticleGoogle Scholar
Österlöf R, Wentzel H, Kari L (2015) An efficient method for obtaining the hyperelastic properties of filled elastomers in finite strain applications. Polym Test 41:44–54View ArticleGoogle Scholar
Patrikeev G.A. (1946) Glava v kn. Obshhaja himicheskaja tehnologija [General Chemical Engineering]. Pod red. S.I. Vol'fkovicha – M.–L.: Gosudarstvennoe nauchno-tehnicheskoe izdatel'stvo himicheskoj literatury 407. (in Russian)Google Scholar
Plagge J, Klüppel M (2017) A physically based model of stress softening and hysteresis of filled rubber including rate- and temperature dependency. Int J Plast 89:173–196View ArticleGoogle Scholar
Raghunath R, Juhre D, Klüppel M (2016) A physically motivated model for filled elastomers including strain rate and amplitude dependency in finite viscoelasticity. Int J Plast 78:223–241View ArticleGoogle Scholar
Ragni L, Tubaldi E, Dall'Asta A, Ahmadi H, Muhr A (2018) Biaxial shear behavior of HDNR with Mullins effect and deformation-induced anisotropy. Eng Struct 154:78–92View ArticleGoogle Scholar
Reese SA (2003) Micromechanically motivated material model for the thermo-viscoelastic material behavior of rubber-like polymers. Int J Plast 19:909–940View ArticleGoogle Scholar
Reichert WF, Dietmar G, Duschl EJ (1993) The double network, a model describing filled elastomers. Polymer 34(6):1216–1221View ArticleGoogle Scholar
Rodgers B, Waddel W (2013) Chapter 9: the science of rubber compounding. Sci Technol Rubber 4:417–471Google Scholar
Sokolov AK, Svistkov AL, Komar LA, Shadrin VV, Terpugov VN (2016) Proyavlenie ehffekta razmyagcheniya materiala v izmenenii napryazhenno-deformirovannogo sostoyaniya shiny [stress softening effect on changes in the stress-strain state of a Tyre]. Vychislitel'naya mekhanika sploshnyh sred 9:358–365 (in Russian)Google Scholar
Sokolov AK, Svistkov AL, Shadrin VV, Terpugov VN (2018) Influence of the Mullins effect on the stress–strain state of design at the example of calculation of deformation field in Tyre. Int J Non-Linear Mech 104:67–74View ArticleGoogle Scholar
Stöckelhuber KW, Svistkov AL, Pelevin AG, Heinrich G (2011) Impact of filler surface modification on large scale mechanics of styrene butadiene/silica rubber composites. Macromolecules 44:4366–4381. https://doi.org/10.1021/ma1026077 View ArticleGoogle Scholar
Svistkov AL (2010) A continuum-molecular model of oriented polymer region formation in elastomer nanocomposite. Mechanics Solids 45:562–574View ArticleGoogle Scholar
Svistkov AL, Solod'ko VN, Kondyurin AV, Eliseeva AYU (2016) Gipoteza o roli svobodnyh radikalov na poverhnosti nanochastic tekhnicheskogo ugleroda v formirovanii mekhanicheskih svojstv napolnennogo kauchuka [hypothesis on the freedom of radicals on the validity of nanotechnological technological carbon in the formation of mechanical qualities of a filled rubber]. Fizicheskaya Mezomekhanika (Physical Mesomechanics) 19:84–93Google Scholar
Wang M-J (1998) Effect of polymer-filler and filler-filler interactions on dynamic properties of filled vulcanizates. Rubber Chem Technol 71:520–589View ArticleGoogle Scholar
Watabe H, Komura M, Nakajima K, Nishi T (2005) Atomic force microscopy of mechanical property of natural rubber. Jpn J Appl Phys 44(7B):5393–5396View ArticleGoogle Scholar
Advanced Composites: Microstructure, Mechanics, Manufacturing and Optimi... | CommonCrawl |
5.5.1 The "square banjo" model
In order to have a model for banjo synthesis with full control over the model parameters, a very simple model has been developed based on results for a rectangular membrane. It might seem odd to use the rectangular shape, when we have relatively easy expressions for the mode shapes and natural frequencies of a more realistic circular membrane (see section 3.6.1). However, it turns out that a model giving realistic sound needs to pay careful attention to damping, including the damping of the membrane due to sound radiation. There are no simple expressions for this radiation damping of a circular membrane, but Leppington et al. [1] have provided simple formulae for the rectangular case. These approximate expressions were calculated by an asymptotic method, but they give sufficiently accurate results for this application.
The datum membrane is chosen to have the same area, tension and mass per unit area as the head of the Deering banjo. Specifically, it has tension 5.33 kN/m, mass per unit area 308 g/m$^2$, and dimensions $249 \times 226$ mm in the directions normal and parallel to the strings, respectively. An allowance is made for the added mass resulting from the air in contact with the membrane, as we discussed briefly in section 3.6 in the context of the kettledrum. It is done using a result for an infinite membrane (see reference [2] for details).
Radiation damping of the membrane is modelled using the formulae of Leppington et al. [1], as explained above. These formulae are calculated using the Rayleigh integral, which we met in section 4.3.2. They assume an infinite baffle around the membrane, which is of course not physically accurate for a banjo. However, comparisons of admittance computed from the model with the measured admittance of the real banjo gives reasonably good agreement. A constant "background structural damping" with loss factor $4 \times 10^{-3}$ is added to suppress unrealistically high modal Q-factors. A final detail concerning damping of this datum case will be discussed in section 5.5.2.
The "bridge" is modelled as a concentrated mass of 1.5 g, with a footprint $10 \times 10$ mm centred at position (105,80) in mm relative to a corner of the rectangle. An additional stiffness 20 kN/m is applied to the bridge to represent the combined effect of the axial stiffness of the strings, a similar stiffness contributed by in-plane stretching of the head membrane, and also an effect associated with the string tension. All these stiffness components are sensitive to the break angle over the bridge. Finally, a "dashpot" (mechanical resistance) with impedance 1 Ns/m is added, to increase the damping of the strongest resonances to a level comparable with the measurements. Reference [2] gives a detailed discussion of the effect of these successive additions, and of the choice of parameter values.
[1] F. G. Leppington, E. G. Broadbent and K. H. Heron, "The acoustic radiation efficiency of rectangular panels". Proceedings of the Royal Society of London Series A-Mathematical Physical and Engineering Sciences, 382, 245–271 (1982).
[2] Jim Woodhouse, David Politzer and Hossein Mansour. "Acoustics of the banjo: theoretical and numerical modelling", Acta Acustica5, 16 (2021). The article is available here: https://doi.org/10.1051/aacus/2021008 | CommonCrawl |
Functional analyses of phosphatidylserine/PI(4)P exchangers with diverse lipid species and membrane contexts reveal unanticipated rules on lipid transfer
Souade Ikhlef1 na1,
Nicolas-Frédéric Lipp1,3 na1,
Vanessa Delfosse2,
Nicolas Fuggetta1,
William Bourguet2,
Maud Magdeleine1 &
Guillaume Drin ORCID: orcid.org/0000-0002-3484-45811
BMC Biology volume 19, Article number: 248 (2021) Cite this article
Lipid species are accurately distributed in the eukaryotic cell so that organelle and plasma membranes have an adequate lipid composition to support numerous cellular functions. In the plasma membrane, a precise regulation of the level of lipids such as phosphatidylserine, PI(4)P, and PI(4,5)P2, is critical for maintaining the signaling competence of the cell. Several lipid transfer proteins of the ORP/Osh family contribute to this fine-tuning by delivering PS, synthesized in the endoplasmic reticulum, to the plasma membrane in exchange for PI(4)P. To get insights into the role of these PS/PI(4)P exchangers in regulating plasma membrane features, we question how they selectively recognize and transfer lipid ligands with different acyl chains, whether these proteins exchange PS exclusively for PI(4)P or additionally for PI(4,5)P2, and how sterol abundance in the plasma membrane impacts their activity.
We measured in vitro how the yeast Osh6p and human ORP8 transported PS and PI(4)P subspecies of diverse length and unsaturation degree between membranes by fluorescence-based assays. We established that the exchange activity of Osh6p and ORP8 strongly depends on whether these ligands are saturated or not, and is high with representative cellular PS and PI(4)P subspecies. Unexpectedly, we found that the speed at which these proteins individually transfer lipid ligands between membranes is inversely related to their affinity for them and that high-affinity ligands must be exchanged to be transferred more rapidly. Next we determined that Osh6p and ORP8 cannot use PI(4,5)P2 for exchange processes, because it is a low-affinity ligand, and do not transfer more PS into sterol-rich membranes.
Our study provides new insights into PS/PI(4)P exchangers by indicating the degree to which they can regulate the acyl chain composition of the PM, and how they control PM phosphoinositide levels. Moreover, we establish general rules on how the activity of lipid transfer proteins relates to their affinity for ligands.
Lipid transfer proteins (LTPs) are cytosolic proteins that distribute diverse lipids between organelles, and along with metabolic pathways, regulate the features of cell membranes [1,2,3,4,5,6,7,8,9,10]. Some members of a major family of LTPs, the oxysterol-binding protein-related proteins (ORP)/oxysterol-binding homology (Osh) family, vectorially transfer lipids by exchange mechanisms [11]. In yeast, Osh6p and its closest homolog Osh7p transfer phosphatidylserine (PS), an anionic lipid made in the endoplasmic reticulum (ER), to the plasma membrane (PM) [12, 13], where this lipid must be abundant to support signaling pathways. Crystallographic data have revealed that Osh6p consists of one domain—called ORD (OSBP-related domain)—with a pocket that could alternately host one molecule of PS or PI(4)P, a lipid belonging to the class of polyphosphoinositides (PIPs) [12, 13]. The pocket is closed by a molecular lid once the lipid is loaded. These structural data along with in vitro analyses and cellular observations have revealed the following mechanism: Osh6/7p extract PS from the ER and exchange it for PI(4)P at the PM; then they deliver PI(4)P into the ER and take PS once again. This PS/PI(4)P exchange cycle is propelled by the synthesis of PI(4)P from phosphatidylinositol (PI) in the PM and its hydrolysis in the ER membrane, which maintains a PI(4)P concentration gradient between the two compartments.
The PS/PI(4)P exchange mechanism is evolutionarily conserved [14]. Human cells express ORP5 and ORP8 that tether the ER membrane to the PM and exchange PS and PI(4)P between these membranes. They include an N-terminal pleckstrin homology (PH) domain, an ORD resembling Osh6p, and a C-terminal transmembrane segment [15, 16]. They are anchored to the ER by this segment and associate with the PM via their PH domain that targets PI(4)P but also PI(4,5)P2 [17,18,19], which is another essential PIP of the PM [20, 21]. Recently, a complex relationship has been unveiled between the ORP/Osh-mediated PS transfer process and the PI(4,5)P2-dependent signaling competences of the cell [17, 19, 22]. It lies in the fact that PI(4)P is both used as a precursor for PI(4,5)P2 production and a fuel for PS/PI(4)P exchange. Moreover, as PI(4,5)P2, like PI(4)P, serves as anchoring point at the PM for ORP5/8, its level in the PM controls the recruitment and therefore the exchange activity of these LTPs [14, 19]. Consequently, PS/PI(4)P exchange allows for a reciprocal control of PS delivery and PI(4,5)P2 synthesis in the PM [19, 22].
Several functional aspects of PS/PI(4)P exchangers remain enigmatic. First, it is unclear whether they selectively transfer certain PS and PI(4)P subspecies at the ER/PM interface. Eukaryotic cells contain a repertoire of PS and PIP subspecies with acyl chains of different lengths and unsaturation degrees. The nature and proportion of each subspecies in these repertoires vary considerably between organisms (e.g., yeasts and mammals [23,24,25]) but also cell types and tissues in mammals [26, 27]. Moreover, inside the cell, the relative proportion of each PI(4)P and PS subspecies differs among organelles [28, 29]. Some of these subspecies are predominant and this might have functional reasons. For instance, certain unsaturated PS species seem to associate preferentially with sterol in the PM, which could control the transversal distribution of sterol and the lateral distribution of PS [30, 31], and thereby the asymmetry and remodeling propensity of this membrane. Also functional lipid nanodomains are formed by the association of 18:0/18:1-PS with very-long-chain sphingolipids [25]. A hallmark of mammal cells is the dominance of polyunsaturated PIPs with 18:0/20:4 acyl chains. This seems critical for the maintenance of a PI(4,5)P2 pool and of PI(4,5)P2-dependent signaling processes in the PM via the so-called PI cycle [32, 33]. Consequently, it is worth analyzing how precisely ORP/Osh proteins transfer PS and PI(4)P species with different acyl chains, in order to define how selective they can be and to what extent they can contribute to the tuning of lipid homeostasis in the PM.
A second issue concerns the links between the ORP/Osh-mediated PS transfer process and the regulation of PI(4,5)P2 levels. It has been reported recently that ORP5/8 use PI(4,5)P2 rather than PI(4)P as a counterligand for supplying the PM with PS [17]. This would mean that the PI(4,5)P2 level in the PM is directly lowered by the consumption of PI(4,5)P2 during exchange cycles. Yet, this conclusion is disputed [19] and remains surprising in view of the very first structural analyses that suggest that the polar head of PI(4,5)P2, unlike that of PI(4)P, cannot be accommodated by the ORD due to steric constraints [34]. The structures of the ORD of ORP1 and ORP2 in complex with PI(4,5)P2 have been solved [35, 36] but they revealed that the PI(4,5)P2 molecule is only partially buried in the binding pocket. All these observations raise doubts about the existence of functional PI(4,5)P2-bound forms of ORPs, including ORP5 and ORP8, in the cell.
Third, as mentioned above, unsaturated PS and sterol preferentially associate with each other in the PM [30, 31]. In parallel, it has been recently proposed that in the yeast PM, unsaturated PS and PI(4)P co-distribute in the presence of sterol to synergistically stimulate PI(4)P 5-kinase activity and promote a robust PI(4)P-to-PI(4,5)P2 conversion [22]. Osh proteins, such as Osh6/7p but also Osh4/5p which are sterol/PI(4)P exchangers, control the formation of these domains. Considering all these observations, one might wonder whether the tight association of sterol with PS acts as a thermodynamic trap that aids PS/PI(4)P exchangers to accumulate PS in the PM and thus contribute to the coupling between PS transfer and PI(4,5)P2 synthesis.
Here, we addressed these three interrelated questions by conducting in vitro functional analyses of Osh6p and ORP8, combined with simulations and cellular observations. Using a large set of PS subspecies, we found that these LTPs transfer unsaturated PS more slowly than saturated PS between liposomes. In contrast, in a situation of PS/PI(4)P exchange, only the transfer of unsaturated PS species is largely accelerated, and efficient exchange occurs with certain unsaturated PS and PI(4)P species that are prominent in cells. Unexpectedly, by measuring the affinity of Osh6p and ORP8 for PS and PI(4)P subspecies and correlating these data with transfer rates, we established that the simple transfer of high-affinity ligands is slower than that of low-affinity ligands. Next we found that high-affinity ligands are rapidly transferred only if they can be exchanged for ligands of equivalent affinity. Furthermore, we determined that, if PI(4)P and PI(4,5)P2 are both accessible to Osh6p and ORP8, PI(4,5)P2 cannot be transferred or exchanged for PS because PI(4,5)P2 is a low-affinity ligand. This suggests that PI(4,5)P2 cannot be transported by ORP/Osh proteins in cells. Finally, we found that the activity of PS/PI(4)P exchangers barely changes on sterol-rich membranes. Our study provides insights into PS/PI(4)P exchangers but also sets general rules on how the activity of LTPs relates to their affinity for lipids, which improves our knowledge of lipid transfer.
Osh6p and ORP8 transfer saturated and unsaturated PS species differently
We first measured in vitro the speed at which Osh6p and the ORD of ORP8 (ORP8 [370-809] [14], hereafter called ORD8) transferred PS subspecies with different acyl chains between two membranes (Fig. 1a). Our series comprised subspecies with saturated acyl chains of increasing length (12:0/12:0, 14:0/14:0, 16:0/16:0, 18:0/18:0), with two C18 acyl chains that are more or less unsaturated (18:0/18:1, 18:1/18:1, 18:2/18:2) and with one saturated C16 acyl chain at the sn-1 position and one C18 acyl chain, with a different unsaturation degree, at the sn-2 position (16:0/18:1, 16:0/18:2). Note that 16:0/18:1-PS is the dominant PS species in S. cerevisiae yeast [22, 24, 28, 37] (under standard growing conditions), whereas in humans, 18:0/18:1-PS and 16:0/18:1-PS are the two most abundant species [25, 38,39,40]. PS transfer was measured between LA liposomes, made of DOPC and containing 5% PS (mol/mol) and 2% Rhod-PE, and LB liposomes only made of DOPC, using the fluorescent sensor NBD-C2Lact. In each measurement, NBD-C2Lact was initially bound to LA liposomes and its fluorescence was quenched due to energy transfer to Rhod-PE; when LTP transferred PS to LB liposomes, NBD-C2Lact translocated onto these liposomes and the fluorescence increased (Fig. 1b). By normalizing the NBD signal, we established transfer kinetics (Additional file 1: Fig. S1a) and initial transfer rates (Fig. 1c). Osh6p transferred saturated PS rapidly, with rates between 7.6 ± 1 (mean ± s.e.m., 14:0/14:0-PS) and 35.2 ± 2 PS min−1 (18:0/18:0-PS). The transfer of unsaturated PS species was much slower (from 0.8 ± 0.1 to 3.1 ± 0.8 PS min−1 per Osh6p). A different picture was obtained when we measured PS transfer in a situation of PS/PI(4)P exchange using LB liposomes containing 5% 16:0/16:0-PI(4)P. The transfer rates measured with 14:0/14:0-PS and 16:0/16:0-PS were similar to those measured in non-exchange contexts, and significantly lower with 12:0/12:0-PS and 18:0/18:0-PS. In contrast, the transfer rate of unsaturated PS, with the exception of 18:2/18:2-PS, strongly increased (by a factor from 3.2 to 19.5).
PS transfer and PS/PI(4)P exchange activity of Osh6p and ORD8 measured with different PS subspecies. a Name and chemical structure of the different PS subspecies. b Description of FRET-based protocols to measure PS transfer from LA to LB liposomes using the NBD-C2Lact sensor, and PI(4)P transfer along the opposite direction using NBD-PHFAPP. c Initial transfer rates determined for each PS subspecies. Osh6p (200 nM) or ORD8 (240 nM) was added to LA liposomes (200 μM total lipid), made of DOPC and containing a given PS species at 5%, mixed with LB liposomes (200 μM) containing or not 5% 16:0/16:0-PI(4)P and 250 nM NBD-C2Lact. Data are represented as mean ± s.e.m. (Osh6p, non-exchange condition, n = 3–16; Osh6p, exchange condition, n = 3–8; ORD8, non-exchange condition, n = 3–11; ORD8, exchange condition, n = 3–7). Statistically significant differences between PS transfer rates measured under non-exchange and exchange conditions were determined using an unpaired Mann–Whitney U test; **** p < 0.0001, **p < 0.01, *p < 0.05, ns: not significant. d Initial PI(4)P transfer rate. LB liposomes containing 5% 16:0/16:0-PI(4)P were mixed with LA liposomes, containing or not a given PS species (at 5%), and with Osh6p (200 nM) or ORD8 (240 nM) in the presence of 250 nM NBD-PHFAPP. Data are represented as mean ± s.e.m. (Osh6p, non-exchange condition, n = 9; Osh6p, exchange condition, n = 3–9; ORD8, non-exchange condition, n = 9; ORD8, exchange condition, n = 3–10). An unpaired Mann–Whitney U test was used to determine the statistically significant differences between the PI(4)P transfer rates measured in non-exchange and exchange conditions; ****p < 0.0001 , **p < 0.01, *p < 0.05, ns: not significant. e Acceleration of PS transfer as a function of the acceleration of PI(4)P transfer determined from rates measured in non-exchange and exchange conditions with all PS subspecies
Overall, ORD8 transported PS more slowly than Osh6p in both exchange and non-exchange situations (Fig. 1c, Additional file 1: Fig. S1b). Nevertheless, the activity of ORD8 changed depending on the PS subspecies in a manner similar to that of Osh6p, as highlighted by the correlation of transfer rates measured for the two LTPs with each PS ligand (R2 ~ 0.75, Additional file 1: Fig. S1c). Like Osh6p, ORD8 transferred saturated PS species more rapidly than unsaturated ones when PI(4)P was absent. In a situation of PS/PI(4)P exchange, the transfer of unsaturated PS species (except for 18:2/18:2-PS) was much more rapid (up to 29-fold) whereas the transfer of saturated PS was slightly enhanced or inhibited. Collectively, these data did not point to a monotonic relationship between PS transfer rates and the length of PS acyl chains or the degree of unsaturation of these chains. However, they indicated that PS species were transported and exchanged with PI(4)P quite differently depending on whether or not they had at least one double bond.
Coupling between the transfer rate of PS species and PI(4)P under exchange conditions
Next, we determined whether the rate of 16:0/16:0-PI(4)P transfer was different depending on the nature of the PS species under the exchange conditions. Using a fluorescent PI(4)P sensor (NBD-PHFAPP) and a FRET-based strategy akin to that used to measure PS transfer, we measured the speed at which PI(4)P, at 5% in LB liposomes, was transported by Osh6p and ORD8 to LA liposomes devoid of PS or containing a given PS species (at 5%) (Fig. 1b, Additional file 1: Fig. S2). With PS-free LA liposomes, the initial PI(4)P transfer rate was 8.4 ± 1.3 PI(4)P min−1 for Osh6p and 4.2 ± 0.5 PI(4)P min−1 for ORD8 (Fig. 1d). In a situation of lipid exchange, these transfer rates increased to a different degree when LA liposomes contained a PS species other than 18:0/18:0-PS and, in experiments with ORD8, 16:0/16:0-PS (Fig. 1d). For each PS species, we calculated an acceleration factor corresponding to the ratio (expressed as a log value) of the PI(4)P transfer rate, measured in the presence of this PS species, to the PI(4)P transfer rate measured in the absence of counterligand. Also, acceleration factors based on PS transfer rates reported in Fig. 1c were determined. Then for each LTP, these two factors were plotted against each other, allowing saturated and unsaturated PS species to cluster in two groups (Fig. 1e). With Osh6p, the group including saturated PS species was characterized by null or negative acceleration factors for PS (down to − 0.49) associated with low or moderate acceleration factors for 16:0/16:0-PI(4)P (from 0.20 to 0.58). In contrast, the group corresponding to unsaturated PS species was characterized by higher acceleration factors for both PS (from 0.30 to 1.30) and PI(4)P (from 0.49 to 0.79). With ORD8, the acceleration factors for saturated PS were negative, null, or moderate (from − 0.15 to 0.47) and associated with null or moderate acceleration factors for PI(4)P (from 0 to 0.48). For unsaturated PS, the acceleration factors were higher, ranging from 0.44 to 1.47 for PS and from 0.40 to 0.55 for PI(4)P. The observation of high acceleration factors for both unsaturated PS and 16:0/16:0-PI(4)P, and much lower or even negative values for saturated PS species, suggests that the LTPs exchange unsaturated PS for PI(4)P much more efficiently than saturated PS.
Exchange activity with prominent cellular PS and PI(4)P species
We next measured how Osh6p and ORD8 exchanged PS and PI(4)P species that are dominant in the yeast and/or human repertoire. With Osh6p, we tested 16:0/18:1-PS and 18:0/18:1-PS with 16:0/18:1-PI(4)P, one of the two most abundant yeast PI(4)P species [22, 23]. As a comparison, we tested a non-yeast species, 18:0/20:4-PI(4)P, which is the main constituent of purified brain PI(4)P. With ORD8, we tested the two same PS species with 18:1/18:1-PI(4)P that resembles unsaturated PI(4)P species (36:1 and 36:2) found in transformed cells [41, 42] and 18:0/20:4-PI(4)P, which is prominent in primary cells and tissues [42]. As a comparison, we used 16:0/16:0-PI(4)P as in our previous assays.
Osh6p slowly transferred the two PS species from LA to LB liposomes in the absence of PI(4)P but ten times faster when LB liposomes contained 16:0/18:1-PI(4)P or 16:0/16:0-PI(4)P. Smaller accelerations of PS transfer were seen with 18:0/20:4-PI(4)P as counterligand. Conversely, in the absence of PS, Osh6p hardly transported any 16:0/18:1-PI(4)P and 18:0/20:4-PI(4)P (< 0.4 lipids min−1) compared to saturated PI(4)P (5.4 lipids min−1) (Fig. 2a, Additional file 1: Fig. S3a, b). When LA liposomes contained PS, the transfer rate of all PI(4)P species increased but with rates that were high for 16:0/16:0-PI(4)P (25.8–39.6 lipids min−1), intermediate for 16:0/18:1-PI(4)P (7–13.3 lipids min−1) and low for 18:0/20:4-PI(4)P (1.63–2.4 lipids min−1). Interestingly, the 16:0/18-1-PS and 16:0/18:1-PI(4)P transfer rates were both similar and high in a situation of lipid exchange, suggesting that Osh6p can execute an efficient one-for-one exchange of these major yeast PS and PI(4)P species.
Ability of Osh6p and ORP8 to transfer and exchange cellular PS and PI(4)P species. a Initial PS and PI(4)P transfer rates, measured along opposite directions, between LA and LB liposomes (200 μM total lipid each) with Osh6p (200 nM) at 30 °C, in the absence of counterligand or in a situation of lipid exchange, with diverse combinations of PS (16:0/18:1 or 18:0/18:1, 5% in LA liposomes) and PI(4)P species (16:0/16:0, 16:0/18:1 or 18:0/20:4, 5% in LB liposomes). Data are represented as mean ± s.e.m. (n = 3–4). b Similar experiments were conducted with ORD8 (240 nM) at 37 °C using 18:1/18:1-PI(4)P instead of 16:0/18:1-PI(4)P. Data are represented as mean ± s.e.m. (n = 3–4)
In the absence of PI(4)P, ORD8 slowly transferred 16:0/18:1-PS and 18:0/18:1-PS between membranes and much faster in a situation of exchange, by a factor of 4.8–6.8 and 11.5–16.6, respectively, depending on the PI(4)P species used as counterligand (Fig. 2b, Additional file 1: Fig. S3c, d). Like Osh6p, ORD8 barely transferred unsaturated PI(4)P under non-exchange conditions (< 0.26 lipids min−1), compared to 16:0/16:0-PI(4)P. Under exchange conditions, ORD8 transferred these PI(4)P species more rapidly but far less than PS in the opposite direction. This suggests that ORP8 cannot efficiently exchange unsaturated PS for PI(4)P. We conclude that the acyl chain composition of PI(4)P, and primarily its unsaturation degree, impacts how Osh6p and ORP8 transfer and use this PIP in exchange for PS.
Osh6p and ORP8 activities drastically change if the sn-1 or sn-2 chain of PS is monounsaturated
Striking differences were seen between 18:0/18:0-PS and unsaturated forms of this lipid in our transfer assays. In particular, data obtained with 18:0/18:0-PS and 18:0/18:1 PS suggested that only one double bond in PS was sufficient to drastically change LTP activity. Whether this depends on the location of this double bond in the sn-2 chain was unclear. Therefore, we compared how Osh6p transferred 18:0/18:1 PS and 18:1/18:0-PS, in which the saturated and monounsaturated acyl chains are permuted, between membranes (Fig. 3a). In mere transfer assays, 18:0/18:1-PS and 18:1/18:0-PS were transported at rates that were slightly different (4.7 vs 2.1 PS min−1) but ten-fold more slowly than 18:0/18:0-PS (Fig. 3b). In the presence of 16:0/18:1-PI(4)P, the transfer of the two unsaturated PS species was faster whereas the transfer of 18:0/18:0-PS was inhibited. The opposite transfer of 16:0/18:1-PI(4)P was inhibited if 18:0/18:0-PS was tested as counterligand but enhanced using the two unsaturated PS forms (Fig. 3b). Similar results were obtained with ORD8 except that the transfer of 18:0/18:0-PS was slightly more rapid (by 2.2-fold) in exchange conditions (here 18:1/18:1-PI(4)P was used as counterligand (Fig. 3c3c)). However, the rate of acceleration was low compared to that measured with 18:0/18:1-PS and 18:1/18:0-PS (by 24.0 and 8.4-fold, respectively). Jointly, these results indicate that only one double bond, in one or the other acyl chain of PS, is enough to dramatically change how the two LTPs transport and exchange this lipid for PI(4)P.
Transfer of 18:1/18:0-PS vs 18:0/18:1-PS by Osh6p and ORD8. a Chemical structure of 18:1/18:0-PS compared to that of 18:0/18:0-PS and 18:0/18:1-PS. b Initial rates of PS and PI(4)P transfer, measured along opposite directions, between LA and LB liposomes (200 μM total lipid each) with Osh6p (200 nM) at 30 °C, in non-exchange or exchange contexts with 18:0/18:0-PS, 18:0/18:1-PS, or 18:1/18:0-PS (5% in LA liposomes) and 16:0/18:1-PI(4)P (5% in LB liposomes). Data are represented as mean ± s.e.m. (n = 3–4). c Similar experiments were performed with ORD8 (240 nM) at 37 °C using 18:1/18:1-PI(4)P instead of 16:0/18:1-PI(4)P
Osh6p and ORD8 have a higher affinity for unsaturated than saturated PS and PI(4)P species
Our results suggest that Osh6p and ORD8 transport and exchange PS and PI(4)P at a different speed depending on the unsaturation degree of these lipids. To further analyze why, we devised assays to determine the relative affinity of these LTPs for each PS and PI(4)P species. We established that the intrinsic fluorescence of both proteins (from tryptophan, with a maximum intensity at λ = 335 and 340 nm, respectively) was quenched by ~ 25% when mixed with liposomes doped with 2% NBD-PS, a PS species whose C12:0 acyl chain at the sn-2 position bears an NBD moiety (Additional file 1: Fig. S4). Concomitantly, a higher NBD fluorescence was measured at λ = 540 nm. Adding each LTP to liposomes doped with 2% NBD-PC provoked a slighter decrease of tryptophan fluorescence, yet similar to the changes recorded with pure PC liposomes, and no change in NBD fluorescence. Likely, FRET exclusively occurs between these proteins and NBD-PS because this lipid is specifically trapped in their binding pocket and close to a number of tryptophan residues. Interestingly, we found subsequently that Osh6p and ORP8 fluorescence, pre-mixed with NBD-PS-containing liposomes, increased when adding incremental amounts of liposomes containing unlabelled PS. This allowed us to measure how each PS species competes with NBD-PS for occupation of the Osh6p and ORD8 pocket and thus determine the relative affinity of each ORD for different lipid ligands (Fig. 4a, b, Additional file 1: Fig. S5a and Additional file 2: Table S1 and Table S5). Remarkably, Osh6p had a very low affinity for 18:0/18:0-PS and 12:0/12:0-PS. It showed a higher affinity for 14:0/14:0-PS and 16:0/16:0-PS. Highest affinities were found with unsaturated PS and more particularly 16:0/18:1-PS, 18:1/18-1-PS and 18:0/18:1-PS. Interestingly, Osh6p had a higher affinity for 18:0/18:1-PS than its mirror 18:1/18:0-PS counterpart (Fig. 4b and Additional file 2: Table S1). Using this assay, we also found that Osh6p had a high affinity for 16:0/18:1-PI(4)P and 18:0/20:4-PI(4)P and less for 16:0/16:0-PI(4)P (Fig. 4c, Additional file 2: Table S2). With ORD8, competition assays revealed that it had a much lower affinity for saturated PS than for unsaturated PS (Additional file 1: Fig. S5a, Additional file 2: Table S5). ORD8 had a higher affinity for 18:1/18:1-PI(4)P and 18:0/20:4-PI(4)P than for 16:0/16:0-PI(4)P (Additional file 1: Fig. S5b, Additional file 2: Table S6). Collectively, our data indicated that Osh6p and ORD8 had a higher affinity for unsaturated than saturated lipid ligands.
Relationship between the affinity of Osh6p for PS and PI(4)P species and its capacity to transfer them. a Principle of the NBD-PS-based competition assays. The tryptophan (W) fluorescence of Osh6p and ORD8 is quenched when they host an NBD-PS molecule. The replacement of NBD-PS by unlabelled PS restores the fluorescence of these proteins. b Competition assays with different PS species. Liposomes (100 μM total lipid, final concentration), made of DOPC and doped with 2% NBD-PS, were added to Osh6p (240 nM) in HK buffer at 30 °C. The sample was excited at 280 nm and the emission was measured at 335 nm. Incremental amounts of liposome, containing a given PS species at 5%, were added to the sample. The fluorescence was normalized considering the initial Fmax fluorescence, prior to the addition of NBD-PS-containing liposomes, and the dilution effects due to liposome addition. Data are represented as mean ± s.e.m. (n = 3). c Competition assays with liposomes containing either 5% 16:0/16:0-PI(4)P, 16:0/18:1-PI(4)P, or 18:0/20:4-PI(4)P. Data are represented as mean ± s.e.m. (n = 4 for 16:0/18:1-PI(4)P, n = 3 for other PI(4)P species). d Melting curves of Osh6p loaded with different PS species or 16:0/16:0-PI(4)P. In a typical measurement, a sample containing 5 μM of protein and 5× SYPRO Orange in HK buffer was heated and fluorescence was measured at λem = 568 nm (λex = 545 nm). A control experiment with Osh6p incubated with DOPC liposomes devoid of lipid ligands is shown (DOPC only). Only a few curves corresponding to representative ligands are shown for clarity. e Melting temperatures (Tm) determined for Osh6p pre-incubated with pure DOPC liposome or loaded with diverse PS and PI(4)P subspecies. Data are represented as mean ± s.e.m (n = 3–5). Pairwise comparison by unpaired Mann–Whitney U test of Tm rate measured with Osh6p in apo form (DOPC only) and Osh6p loaded with saturated or unsaturated PS species, or a PI(4)P species; *p < 0.05, ns: not significant. f Initial transfer rates determined in non-exchange contexts for PS and PI(4)P subspecies with Osh6p (shown in Figs. 1b,c, 2, and 3) as a function of 1/[L]50 values determined for each lipid subspecies. g PS transfer rates in non-exchange conditions as a function of Tm values determined with Osh6p. h Acceleration factors determined for PS and PI(4)P from experiments shown in Fig. 1b and c1b and c, as a function of the 1/[L]50 values determined for each PS subspecies. The 1/[L]50 value determined with 16:0/16:0-PI(4)P is indicated
Alternatively, Osh6p was incubated with liposomes doped with a given PS or PI(4)P subspecies, isolated, and then subjected to thermal shift assays (TSAs) to evaluate to what extent it formed a stable complex with each ligand ((Fig. 4d,e and Additional file 2: Table S3). Low melting temperatures (Tm) were observed with Osh6p exposed to liposomes containing saturated PS species (from 45 to 47.4 °C), near the Tm value of Osh6p incubated with DOPC liposomes devoid of ligand (44.9 ± 0.7 °C). In contrast, significantly higher values were obtained with unsaturated PS (from 47.8 to 50.1 °C). The highest Tm values were found with Osh6p loaded with 16:0/18:1 and 18:0/20:4-PI(4)P species (56.1 and 62.1 °C, respectively), and a slightly lower Tm was found with 16:0/16:0-PI(4)P (52 °C). These results suggest that Osh6p is more prone to capture and hold unsaturated PS and PI(4)P than saturated PS, corroborating the results from competition assays.
The affinity of Osh6p and ORP8 for PS and PI(4)P species dictates how they transfer and exchange them
Next, we analyzed how the affinity of Osh6p and ORD8 for lipid ligands was related to their capacity to transfer them. To do so, we plotted the PS and PI(4)P transfer rates measured in non-exchange contexts (reported in Fig. 1c, d, Fig. 2, and Fig. 3) as a function of 1/[L]50, with [L]50 being the concentration of each species necessary to displace 50% NBD-PS from each LTP in the competition assays. Remarkably, this revealed an inverse relationship between the transfer rates and 1/[L]50 values (Fig. 4f and Additional file 1: Fig. S5c) for each LTP. For Osh6p, plotting the transfer rates as a function of Tm values uncovered a comparable relationship (Fig. 4 g). This suggested that the less affinity these LTPs have for a ligand, the faster they transfer it between membranes. We also plotted the acceleration factors established under exchange conditions with different PS species and 16:0/16:0-PI(4)P (showed in Fig. 1e) against 1/[L]50 values determined with each PS species and LTP (Fig. 4 h, Additional file 1: Fig. S5d). Interestingly, a positive relationship was found between the 1/[L]50 values and each of these factors. Moreover, we noted that PS and PI(4)P transfer rates measured under exchange conditions were overall higher when the LTPs had a higher affinity for PS than PI(4)P (1/[PS]50 > 1/[16:0/16:0-PI(4)P]50). Collectively, these analyses reveal an inverse correlation between the affinity of an LTP for a ligand and its ability to simply transfer it down its concentration gradient. Moreover, they indicate that in a situation of lipid exchange, the acceleration of the PS and PI(4)P transfer rate is more pronounced with high-affinity PS species.
Simulation of transfer and exchange activity of the ORD as a function of its affinity for PS and PI(4)P
To understand why the affinity of Osh6p and ORD8 for PS and PI(4)P species governed how they transferred and exchanged these lipids, we built a simplified kinetic model (Fig. 5a). It was assumed that the ORD interacts similarly with A and B membranes during a transfer process (kON-Mb= 10µM–1 s−1and kOFF-Mb = 0.1 s−1) with an equal ability to capture and release a given lipid (similar kON-lipid and kOFF-lipid). We simulated initial PS transfer rates for kON-PS values ranging from 10−2 to 104 μM−1 s−1 to evaluate how the affinity of the ORD for PS (proportional to kON-PS) governs how it transfers this lipid. The kON-PI4P values was set to 10 μM−1 s−1 and kOFF-PS and kOFF-PI4P values to 1 s−1; the ORD concentration was 200 nM, with an A membrane including 5 μM accessible PS and a B membrane devoid of ligand (as in our transfer assays). A bell-shaped curve (Fig. 5b, black dots) was obtained with a maximum at kON-PS = 3.7 μM−1 s−1 and minima near zero for very low and high kON-PS values. Remarkably, our simulations indicate that an LTP can transfer a low-affinity ligand more rapidly than a high-affinity one, as seen for instance when comparing rates at kON-PS = 10 and 100 μM−1 s−1, and as observed experimentally with saturated and unsaturated PS.
Analysis of the relationship between ORD's affinity for PS and PI(4)P and its ability to transfer these lipids between membranes. a Description of the kinetic model. Osh6p or ORD8 (ORD) interacts with the same affinity with two distinct membranes A and B, each harboring a PS and PI(4)P pool, and can extract and release PS and PI(4)P. ORD-PS and ORD-PI(4)P correspond to the ORD in 1:1 complex with PS and PI(4)P, respectively. All kON and kOFF rates were set to 10 μM−1 s−1, and 1 s−1, respectively, unless otherwise specified. b Initial PS transfer rate (gray dots) as a function of kON-PS values (ranging from 0.01 to 10,000 μM−1 s−1), under the condition where the A membrane initially contained 5% PS and B membrane was devoid of PI(4)P (non-exchange condition). Initial PS (pink dots) and PI(4)P transfer rates (orange dots) were also calculated as a function of kON-PS, considering that PS and PI(4)P were initially present at 5% in the A and B membranes, respectively (exchange condition). PI(4)P transfer rate simulated with A membrane devoid of PS (non-exchange condition) was indicated by a dashed line. The gray areas correspond to regimes where kON-PS > kON-PI(4)P, i.e., the ORD has more affinity for PS than PI(4)P. The acceleration factors, calculated for PS and PI(4)P, correspond to the ratio (in log value) between the transfer rates derived from simulations performed in exchange and non-exchange conditions. c Acceleration factors of PS and PI(4)P transfer in exchange conditions, established for Osh6p and ORD8 with different PS species and 16:0/16:0-PI(4)P, are plotted against each other as in the Fig. 1e. For comparison, theoretical acceleration factors of PS and PI(4)P transfer, considering kON-PS value ranging from 0.01 to 10,000 μM−1 s−1 and a kON-PI(4)P value of 75 μM−1 s−1 for Osh6p or 40 μM−1 s−1 for ORD8, are plotted against each other (Osh6p, green; ORD8, blue)
Next, using the same range of kON-PS values, we simulated PS and PI(4)P transfer rates in a situation of lipid exchange between A and B membranes that initially contained 5 μM PS and PI(4)P, respectively (Fig. 5b, pink dots for PS and orange dots for PI(4)P). Acceleration factors were determined from rates established for each lipid in exchange and non-exchange contexts. The PS transfer rate found to be maximal at kON-PS = 3.7 μM−1 s−1 when PI(4)P was absent, slightly increased in the presence of PI(4)P (acceleration factor = 0.13). If kON-PS > 3.7 μM−1 s−1, the PS transfer rates were lower in a non-exchange situation but considerably higher if PI(4)P was present as counterligand. In contrast, for kON-PS < 3.7 μM−1 s−1, the PS transfer rate decreased toward zero, even if PI(4)P was present, and acceleration factors were almost null. In parallel, the PI(4)P transfer rates were found to be systematically higher in the presence of PS yet to a degree that depended on kON-PS values (Fig. 5b). Finally, we noted that an ORD efficiently exchanges PS and PI(4)P if it has a higher affinity for PS than PI(4)P (kON-PS > kON-PI(4)P, Fig. 5b, gray area). These simulations again corroborated our experimental data. In non-exchange situations, saturated PS species, which are low-affinity ligands compared to 16:0/16:0-PI(4)P, are transferred at the fastest rates; yet these rates barely or marginally increase once PI(4)P is present. In contrast, unsaturated PS species, which are globally better ligands than 16:0/16:0-PI(4)P, are slowly transferred in non-exchange situations, but much faster when PI(4)P is present. In all cases, the PI(4)P transfer rate is unchanged or higher in the presence of PS.
To consolidate this analysis, we plotted the acceleration factors for PS and PI(4)P, simulated for different kON-PS and kON-PI(4)P values (Additional file 1: Fig. S6a), against each other and compared the curves obtained with experimental factors shown in Fig. 1e. By setting kON-PI(4)P at 40 or 75 μM−1 s−1, we obtained curves that follow the distribution of acceleration factors obtained with ORD8 and Osh6p, respectively (Fig. 5c).
Finally, simulations performed with variable kON-PI(4)P values (10, 40, 75, or 100 μM−1 s−1) indicated that, when the ORD had a higher affinity for PI(4)P, the PI(4)P transfer rate decreased in a non-exchange context (dashed lines, Additional file 1: Fig. S6a) but increased to a greater extent in a situation of PS/PI(4)P exchange. Interestingly, a different picture emerged if the affinity of the ORD for PI(4)P was increased by ten, by lowering the kOFF-PI(4)P value from 1 to 0.1 s−1 instead of increasing the kON-PI4P value from 10 to 100 μM−1 s−1 (Additional file 1: Fig. S6b): PI(4)P transfer rates were low in non-exchange conditions and only slightly higher in exchange conditions, for all tested kON-PS values. PS transfer was more rapid in exchange conditions with high kON-PS values. This resembled our data showing that unsaturated PI(4)P species were poorly transferred and exchanged for PS while PS transfer was enhanced by these PI(4)P species (Fig. 2). Overall, our model showed how variations in the capacity of the ORD to extract and deliver PS and PI(4)P could modify how it transfers and exchanges these lipids.
Osh6p and ORD8 cannot use PI(4,5)P2 if PI(4)P is present in membranes
ORP5/8 have been suggested, notably based on in vitro data, to use PI(4,5)P2 instead of PI(4)P as a counterligand to supply the PM with PS [17] but this conclusion is disputed [19]. To address this issue, we measured how ORD8 transferred PI(4)P and PI(4,5)P2 (with 16:0/16:0 acyl chains) from LB liposomes that contained only one kind of PIP or, like the PM, both PIPs, to LA liposomes. NBD-PHFAPP, which can detect PI(4,5)P2 in addition to PI(4)P [17], was used as sensor. ORD8 transported PI(4,5)P2 more swiftly than PI(4)P (Fig. 6a, b), as previously shown, but surprisingly, when both PIPs were in LB liposomes, the transfer kinetics was comparable to that measured with PI(4)P alone.
PIP selectivity of Osh6p and ORD8. a Intermembrane PI(4)P and PI(4,5)P2 transfer activity of ORD8 measured with donor LB liposomes containing either PI(4)P or PI(4,5)P2 or both PIPs. LB liposomes (200 μM total lipid concentration) made of DOPC and containing either 5% 16:0/16:0-PI(4)P or 5% 16:0/16:0-PI(4,5)P2 or both PIPs were mixed with NBD-PHFAPP (250 nM) in HK buffer at 37 °C. After 1 min, LA liposomes, made of DOPC and containing 2% Rhod-PE (200 μM), were added to the reaction mix. After 3 min, ORD8 was injected (240 nM). Similar experiments were conducted with NBD-PHPLCδ1 (250 nM) and LB liposomes containing only 5% 16:0/16:0-PI(4,5)P2 or also 5% 16:0/16:0-PI(4)P. PIP transport was followed by measurement of the quenching of the fluorescence signal of NBD-PHPLCδ1 or NBD-PHFAPP caused by the translocation of the lipid sensor from LB to LA liposomes and FRET with Rhod-PE. The signal was normalized in term of PI(4)P or PI(4,5)P2 amount delivered into LA liposomes. The injection of ORD8 set time to zero. Each trace is the mean ± s.e.m. of independent kinetics (n = 3). b Initial 16:0/16:0-PIP transfer rates determined with NBD-PHFAPP and NBD-PHPLCδ1. Data are represented as mean ± s.e.m. (error bars, n = 3). c Initial rates of 18:0/20:4-PIP transfer between membranes determined for ORD8 using NBD-PHFAPP and NBD-PHPLCδ1 sensors. Data are represented as mean ± s.e.m. (error bars, n = 3). d LA liposomes (200 μM total lipid), made of DOPC and 16:0/18:1-PS (95:5), were mixed with NBD-C2Lact in HK buffer at 37 °C. After 1 min, LB liposomes (200 μM), consisting of 93% DOPC, 2% Rhod-PE, and 5% 18:0/20:4-PI(4)P or 18:0/20:4-PI(4,5)P2, were injected. Two minutes later, a third population of liposomes (LC, 200 μM) made of DOPC, doped or not with 5% 18:0/20:4-PI(4)P or 18:0/20:4-PI(4,5)P2, was injected. ORD8 (240 nM final concentration) was injected 2 min later. PS delivery into LB liposomes was followed by measurement of the quenching of the fluorescence of NBD-C2Lact provoked by its translocation from LA to LB liposomes and FRET with Rhod-PE. The signal was normalized in term of PS amount transferred into LB liposomes. e Initial rates of ORD8-mediated PS transfer into acceptor LB liposomes, as a function of the presence of PI(4)P and PI(4,5)P2 in acceptor LB and/or LC liposomes. Data are represented as mean ± s.e.m. (error bars, n = 4). f Competition assay. DOPC/NBD-PS liposomes (98:2, 100 μM total lipid) were added to ORD8 or Osh6p (200 nM) in HK buffer at 30 °C. The sample was excited at 280 nm and the emission was measured at 335 nm. Incremental amounts of liposome, containing 5% PI(4)P or PI(4,5)P2, were injected to the reaction mix. The signal was normalized considering the initial Fmax fluorescence, prior to the addition of NBD-PS-containing liposomes, and the dilution effect due to liposome addition. Data are represented as mean ± s.e.m. (n = 3). g Accessibility assay. CPM (4 μM) was mixed with 400 nM Osh6p(noC/S190C) in the presence of pure DOPC liposomes or liposomes doped with 2% 18:0/20:4-PI(4)P or 18:0/20:4-PI(4,5)P2. Intensity bars correspond to the fluorescence measured 30 min after adding CPM (n = 3)
To understand why, we specifically measured the transfer of PI(4,5)P2 with a sensor based on the PH domain of the phospholipase C-δ1 (PHPLCδ1), which has a high affinity and specificity for the PI(4,5)P2 headgroup [43]. This domain was reengineered to include, near its PI(4,5)P2-binding site [44], a unique solvent-exposed cysteine (C61) to which a NBD group was attached (Additional file 1: Fig. S7a). In flotation assays this NBD-PHPLCδ1 construct associated with liposomes doped with PI(4,5)P2 but not with liposomes only made of DOPC or containing either PI or PI(4)P (Additional file 1: Fig. S7b). Fluorescence assays also indicated that NBD-PHPLCδ1 bound to PI(4,5)P2-containing liposomes, as its NBD signal underwent a blue-shift and a 2.2-fold increase in intensity (Additional file 1: Fig. S7c). A binding curve was established by measuring this change as a function of the incremental addition of these liposomes (Additional file 1: Fig. S7d, Additional file 2: Table S7). In contrast, no signal change occurred with PI(4)P-containing liposomes, indicative of an absence of binding (Additional file 1: Fig. S7c, d, Additional file 2: Table S7). NBD-PHPLCδ1 was thus suitable to detect PI(4,5)P2 but not PI(4)P. It was substituted for NBD-PHFAPP to measure to what extent ORD8 specifically transported PI(4,5)P2 from LB liposomes, containing or not PI(4)P, to LA liposomes. Remarkably, we found that ORD8 efficiently transferred PI(4,5)P2 but only if PI(4)P was absent (Fig. 6a,b). Similar conclusions were reached using each PIP sensor by assaying ORD8 with PI(4)P and PI(4,5)P2 ligands with 18:0/20:4 acyl chains (Fig. 6c, Additional file 1: Fig. S8a), and Osh6p using PIPs with a 16:0/16:0 composition (Additional file 1: Fig. S8b, c). These data indicate that ORP8 and Osh6p preferentially extract PI(4)P from a membrane that contains both PI(4)P and PI(4,5)P2, suggesting that they use PI(4)P rather than PI(4,5)P2 in exchange cycles with PS at the PM.
To address this possibility in vitro, we devised an assay with three liposome populations (Fig. 6d, e) to examine whether ORP8 delivers PS in a PI(4)P-containing membrane or in a PI(4,5)P2-containing membrane. First, LA liposomes doped with 5% PS were mixed with NBD-C2Lact. Then LB liposomes, containing 5% PI(4)P and 2% Rhod-PE, and LC liposomes, only made of PC, were successively added. Injecting ORD8 provoked a quenching of the NBD signal, indicating that the C2Lact domain moved onto the LB liposomes. The signal normalization indicated that ~ 1 μM of PS was transferred to LB liposomes. Equivalent data were obtained with LC liposomes doped with PI(4,5)P2, suggesting that this lipid has no influence on the PI(4)P-driven transfer of PS to LB liposomes mediated by ORD8. We performed mirror experiments with LB liposomes that contained PI(4,5)P2 and LC liposomes with or without PI(4)P. Remarkably, PS was transferred to LB liposomes but not if LC liposomes contained PI(4)P. We concluded that ORP8 selectively delivers PS in a compartment that harbors PI(4)P if PI(4,5)P2 is present in a second compartment. This suggests that PI(4)P, and not PI(4,5)P2, is used by ORP5/8 to transfer PS intracellularly.
These observations suggest that ORD8 and Osh6p have a lower affinity for PI(4,5)P2 than for PI(4)P. Confirming this, the NBD-PS-based competition assay showed that each protein barely bound to PI(4,5)P2 compared to PI(4)P (with 16:0/16:0 or 18:0/20:4 acyl chains, Fig. 6f and Additional file 2: Table S4). Likewise, TSAs indicated that Osh6p incubated with liposomes containing 16:0/16:0- and 18:0/20:4-PI(4)P or PI(4,5)P2 was loaded with and stabilized by PI(4)P but not PI(4,5)P2 (Additional file 1: Fig. S8d, e and Additional file 2: Table S8). Finally, we evaluated the conformational state of Osh6p in the presence of each PIP. To this end, we used a version of the protein, Osh6p(noC/S190C), which has a unique cysteine at position 190; this residue is solvent-exposed only if the molecular lid that controls the entrance of the binding pocket of the protein is open [45]. This construct was added to liposomes devoid of PIPs or containing 2% PI(4)P or PI(4,5)P2. Then, 7-diethylamino-3-(4′-maleimidylphenyl)-4-methylcoumarin (CPM), a molecule that becomes fluorescent only when forming a covalent bond with accessible thiol, was added to each sample. After a 30-min incubation, a high fluorescence signal was measured with Osh6p(noC/S190C) mixed with PC liposomes, indicating that the protein remained essentially open over time (Fig. 6g). In contrast, almost no fluorescence was recorded when the protein was incubated with PI(4)P-containing liposomes, indicating that it remained mostly closed, as previously shown [45]. Remarkably, a high signal was obtained with liposomes doped with 2% PI(4,5)P2, indicating that Osh6p remained open as observed with pure PC liposomes. Altogether, these data suggest that Osh6p/7p and ORP5/8 have a low affinity for PI(4,5)P2 compared to PI(4)P, likely as they cannot form stable and closed complexes with this lipid.
Sterol abundance in membrane does not enhance PS delivery and retention
Like PS, sterol is synthesized in the ER and enriched in the PM, where it constitutes 30–40% of all lipids [46]. PS is thought to associate laterally with sterol, thus retaining sterol in the inner leaflet of the PM and controlling its transbilayer distribution [30, 31]. However, it was not known whether sterol stabilizes PS and thereby aids ORP/Osh proteins to accumulate PS in the PM. To explore this possibility, we measured in vitro the speed at which Osh6p transported PS from LA liposomes to LB liposomes, containing or not 30% cholesterol or ergosterol, and doped or not with 5% PI(4)P. These assays were performed using 16:0/18:1-PS and 16:0/18:1-PI(4)P, as in yeast PM, these predominant PS and PI(4)P species are thought to co-distribute in the presence of sterol [22]. However, we observed that the transfer of PS was not markedly impacted by higher contents of sterol in LB liposomes in non-exchange and exchange conditions (Fig. 7a, Additional file 1: Fig. S9a). We then replaced 16:0/18:1-PS in our assays with 18:0/18:1-PS shown to segregate with cholesterol in vitro [31]. Yet, with LB liposomes containing 0, 30 or even 50% cholesterol, no change was seen in the 18:0/18:1-PS transfer rate in a non-exchange context. If PI(4)P was present in LB liposomes, PS was transferred more rapidly but at a slightly lesser extent when LB liposomes also contained 50% cholesterol (Fig. 7b,c). This suggests that sterols do not favor PS transfer, possibly as they are dispensable for PS retention. To examine more extensively how cholesterol controls the retention of PS in the complex context of the PM, we used a GFP-C2Lact probe to examine whether the steady-state accumulation of PS in the PM of HeLa cells was impacted when cholesterol was depleted from the PM. This depletion was achieved by treating the cells for 24 h with U18666A, a compound that blocks lysosomal-to-PM sterol movement through the inhibition of Niemann-Pick disease, type C1 (NPC1) protein [31, 47, 48]. Such a treatment lowers sterol levels without provoking the remodeling of the PM that occurs following a faster and acute sterol removal [30]. Using the sterol sensor mCherry-D4, we detected sterol in the PM of untreated cells but not in U18666A-treated cells (Fig. 7d). The same results were obtained with a mCherry-D4H construct (carrying the D434S mutation) even if it can detect lower sterol density [31], confirming that the PM was highly deprived in sterol (Additional file 1: Fig. S9b). However, no change was seen in the distribution of PS, which remained in the PM. This was ascertained by measuring the relative distribution of GFP-C2Lact between the PM and the cytosol, in treated and untreated cells, using Lyn11-FRB-mCherry as a stable PM marker and internal reference (Fig. 7e, Additional file 1: Fig. S9c). We conclude that a high, normal level of sterol in the PM is not critical for PS retention and for PS/PI(4)P exchange. However, because we primarily impacted a NPC1-regulated pool of sterol, and as D4 and D4H probes do not detect sterol below a certain threshold [49], we cannot rule out that a sterol pool, inaccessible to our depletion procedure, contributes to stabilizing PS in the PM.
Influence of the sterol content of acceptor membranes on PS delivery. a Initial rates of 16:0/18:1-PS transfer measured with Osh6p (200 nM) at 30 °C from LA (5% PS) to LB liposomes with different bulk lipid compositions and containing or not 5% 16:0/18:1-PI(4)P (at the expense of PC). Data are represented as mean ± s.e.m. (non-exchange condition, n = 4–5, exchange condition, n = 4). b Initial rates of 18:0/18:1-PS transfer from LA to LB liposomes without or with 30% or 50% cholesterol, and containing or not 5% 16:0/18:1-PI(4)P. Data are represented as mean ± s.e.m. (n = 3–6). c Experiments are similar to those shown in Fig. S9a except that 16:0/18:1-PS was replaced by 18:0/18:1-PS in LA liposomes. LB liposomes contained 0, 30, or 50% cholesterol. Each trace is the mean ± s.e.m. of kinetics recorded in independent experiments (n = 3–6). d Confocal images of live GFP-C2Lact-expressing HeLa cells (green) treated or not with U18666A for 24 h at 37 °C. Cholesterol in the PM was detected by incubating the cells for 10 min with mCherry-D4 (purple) at room temperature and then washed with medium prior to imaging. The overlay panel shows merged green and magenta images. The top-right image corresponds to a higher magnification (× 5.2) image of the area outlined in white. Scale bars: 10 μm. e Quantification of the ratio of GFP-C2Lact signal at the PM to the cytosolic GFP-C2Lact signal, as assessed by wide-field microscopy and line scan analysis. GFP-C2Lact-expressing HeLa cells with or without U18666A treatment (2.5 μg/mL for 24 h at 37 °C) as shown in d (mean ± s.e.m., n = 68 cells for non-treated cells and n = 51 cells for treated cells; data are pooled from four independent experiments for each condition). Control experiments were done with GFP-expressing HeLa cells (mean ± s.e.m., n = 37 cells for non-treated cells and n = 33 cells for treated cells; data are pooled from two independent experiments for each condition)
LTPs have been discovered and studied for more than 40 years, yet few studies have explored how their activity depends on the nature of the lipid acyl chains. A few kinetic studies have shown that a nonspecific-LTP transfers shorter PC more easily than long PC [50], that a glycolipid transfer protein (GLTP) preferentially transports short glucosylceramides [51] and that the ceramide transfer protein (CERT) is active with ceramide species whose length does not exceed the size of its binding pocket [52, 53]. Moreover, the link between the activity of LTPs and their affinity for lipid ligands remained largely obscure. Here, we measured how fast LTPs transfer saturated vs unsaturated lipids between membranes, both in a situation of simple transfer and in a situation of exchange with a second ligand, and we measured their relative affinity for these lipids. Our investigations used approaches that detect the transfer and binding capacities of LTPs with unmodified lipid ligands (i.e., without bulky fluorophores), thus with an unprecedented level of accuracy. This study offers novel insights into PS/PI(4)P exchangers and, by identifying how the activity of LTPs relates to their affinity for lipid ligands, provides general rules that serve to better analyze lipid transfer processes.
Our kinetic measurement indicated that overall ORD8 transfers PS and PI(4)P more slowly than Osh6p does. This might be due to structural differences between the two proteins or to the fact that the ORD of ORP8 only functions optimally in the context of the full-length protein or between closely apposed membranes. Apart from this, Osh6p and ORD8 responded similarly to the same changes in the PS and PI(4)P acyl chain structures. In particular, they transferred these lipids quite differently depending on whether they were saturated or not. This seems to be mainly because these LTPs have a lower affinity for saturated than unsaturated lipids. Remarkably, the presence of only one double bond in one of the acyl chains of the ligand is sufficient to significantly change their behavior. Our kinetic model suggests that the affinity of PS/PI(4)P exchangers for lipid ligands and their capacity to transfer them is governed by the extraction step (reflected by the kON values). An early study of large series of PE and PC species showed that increasing the degree of unsaturation in the acyl chains of phospholipids increases the rate at which they spontaneously desorb from the membrane [54]. One might therefore posit that the intrinsic propensity of PS species to move out of the membrane determines how they are captured and transferred by ORP/Osh proteins. However, several data suggest that the intrinsic tendency of PS species to leave the membrane cannot explain, or only very partially, why these lipids are more or less easily captured by Osh6p and ORD8.
First, considering the spontaneous desorption rates measured with other phospholipids [54], we should have obtained the exact same results with 18:0/18:1-PS as with 18:1/18:0-PS, which was not the case, notably in binding assays. Secondly, 16:0/16:0-PS should have been as good a ligand as an unsaturated species such as 16:0/18:1-PS and 18:1/18:1-PS whereas shorter saturated PS species (12:0/12:0 and 14:0/14:0) should have been better. Also, similar results should have been obtained with 16:0/16:0-PI(4)P and 16:0/18:1-PI(4)P. Structural analyses revealed that the sn-1 acyl chain of PS or PI(4)P is deeply inserted in the binding pocket, and that their sn-2 acyl chain is twisted, pointing its end to the lid that closes the pocket [12, 13]. These structural constraints along with other parameters, such as the intrinsic dynamics of lipid species in a bilayer, might govern how they are captured and stabilized by ORP/Osh proteins. In the future, studies addressing these hypotheses at the atomic level will be of great interest to understand what imparts these LTPs with such an enigmatic selectivity for unsaturated lipids. For instance, solving the structure of Osh6p or ORD8 in complex with various lipid species along with molecular dynamics (MD) simulations [55,56,57] might shed light on how lipid species are stabilized inside the binding pocket, released into or extracted from the membrane.
Kinetic data obtained with unsaturated lipids that correspond to or resemble PS and PI(4)P species that are prominent in yeast and human cells, provided hints on the activity of these LTPs in cellular context, which remains difficult to obtain in situ. Osh6p slowly transfers 16:0/18:1-PS and 16:0/18:1-PI(4)P, the most abundant yeast PS and PI(4)P species [22, 24, 28, 37], under non-exchange conditions and ten times faster under exchange condition, and with the same initial velocity (~ 14 lipid min−1). This suggests that, at the ER/PM interface, the transfer of PS by Osh6p/7p in yeast is highly dependent on the synthesis of PI(4)P in the PM and is tightly coupled with the transfer of PI(4)P in the opposite direction. Another PS species, 18:0/18:1-PS paired with 16:0/16:0-PI(4)P or 16:0/18:1-PI(4)P efficiently completes fast exchange, as does 18:1/18:1-PS with 16:0/16:0-PI(4)P. These PS species do not exist in yeast but resemble 16:0/18:1-PS and the few other major yeast PS species (16:0/16:1, 16:1/18:1, 16:1/16:1), which contain at least one monounsaturated acyl chain. In comparison, PS species with one or two di-unsaturated chains seemed less suitable for exchange processes. An equivalent analysis with PI(4)P remains difficult to conduct as much fewer PI(4)P species were assayed. The fact that polyunsaturated PI(4)P, the major brain PI(4)P species, exchanges poorly with 16:0/18:1-PS does not mean that Osh6p is specifically designed for yeast monounsaturated PI(4)P. Indeed, slow transfers were measured when assaying polyunsaturated PI(4)P with ORD8. Collectively, our data suggest that Osh6p can efficiently exchange unsaturated PS and PI(4)P species at the ER/PM interface. This supports the notion that Osh6p/7p regulate a pool of unsaturated PS and PI(4)P that together with ergosterol form functional lipid nanodomains [22]. Moreover, this is compatible with the observation that 34:1-PI(4)P (i.e., 16:0/18:1-PI(4)P) can be predominantly hydrolyzed by Sac1p [23]. However, our investigations suggest that the delivery of 16:0/18:1-PS in the PM, and its exchange for PI(4)P are likely not promoted by the presence of ergosterol. Finally, our data suggest that the massive increase in the proportion of 16:0/18:1-PS observed between the ER membrane and the PM [28] (from 30 to 60% compared to the other PS species) is not caused by a preferential transfer of this species by Osh6p/7p.
Analyzing the association of ORD8 with 16:0/18:1-PS and 18:0/18:1-PS, the prevalent PS species in human cells, and the speed at which it transfers these lipids, we can draw similar conclusions as those obtained with Osh6p. These PS species are recognized with high affinity by ORD8 and, interestingly, a substantial fraction of ORD8 can be purified as a stable complex with each of these two PS species from human cells [14]. Indeed, ORD8, purified from HEK293 cells, is bound to 34:1 and 36:1-PS that correspond to 16:0/18:1-PS and 18:0/18:1-PS, respectively, considering lipidomic analyses of this cell line [38]. The identification of these PS species as ligands is likely due to their cellular abundance but also their high affinity for ORD8. In vitro, these PS species are slowly transferred under non-exchange conditions and faster under exchange conditions to an extent that is however only slightly dependent on the PI(4)P species used as counterligand (16:0/16:0, 18:1/18:1 or 18:0/20:4-PI(4)P). This suggests that the capacity of ORP5/8 to efficiently transfer cellular PS species strongly depends on PI(4)P but is minimally influenced by the unsaturation degree of this latter. In line with this, when ORD8 is purified from cells, it is also found partially loaded with 36:1 and 36:2-PI(4)P [14] (likely 18:0/18:1-PI(4)P and 18:0/18.2-PI(4)P [38]), which might indicate that this domain can use unsaturated PI(4)P species other than those tested in our assays for PS/PI(4)P exchange. In parallel, we noted that, when exchange is possible, the transfer of 18:0/20:4-PI(4)P and 18:1/18:1-PI(4)P is faster but remains much slower than the PS transfer, suggesting a weak coupling between the two transfer processes. This presumably arises from the high affinity of the ORD for these PI(4)P species, as suggested by our kinetic model. It has been reported that the hydrolysis of PI(4)P by Sac1 is mandatory for OSBP-mediated sterol/PI(4)P exchange [58]. Indeed, OSBP has a much higher affinity for PI(4)P than for sterol and the hydrolysis of PI(4)P by Sac1, by mass action, promotes the exchange process. Possibly, Sac1 also enhances the transfer of PI(4)P from the PM to the ER by ORP5/8 while facilitating the extraction of PS from this organelle, and thus improves the coupling between PS and PI(4)P transfer at the ER/PM interface. This model would be valid whatever the nature of PI(4)P subspecies as Sac1 can hydrolyze mono-, di-, and polyunsaturated PI(4)P with a similar efficiency [41]. Collectively, these observations suggest that the degree of unsaturation of PI(4)P, a parameter that varies between cells in tissues and cultured transformed cells [32], should not strongly impact the PS/PI(4)P exchange capacity of ORP5/8. One can thus envision that ORP5/8-mediated exchange cycles are not linked with the preferential synthesis and consumption of certain PIP subspecies contrary to the PI cycle [33]. Finally, we measured in vitro that cholesterol does not promote the delivery of 18:0/18:1-PS in a membrane and that depleting sterol from the PM of human cells does not perturb the cellular distribution of PS. This suggests that a normal and high level of sterol in the PM does not seem critical for the accumulation of PS in that membrane. However, considering the existence of different sterol pools in the PM [59] and that the D4 and D4H probes do not detect sterol below a certain threshold concentration [49], we cannot exclude the possibility that a substantial amount of PS is retained by a small pool of sterol that cannot be removed by our depletion procedure. In the future, lipid transfer assays in primary and transformed cells coupled to lipidomic analyses will be of great value to more precisely define the dependency of ORP5/8 activity on the nature of PI(4)P and sterol.
It was unclear whether ORP5/8 could use PI(4,5)P2 instead of PI(4)P as a counterligand [14, 17, 19]. Corroborating previous observations [17], we measured that Osh6p and ORD8 transferred PI(4,5)P2 between liposomes more rapidly than PI(4)P. However, when PI(4)P and PI(4,5)P2 both resided in the same donor membrane, only PI(4)P was transferred to acceptor membranes, for all tested acyl chain compositions. Moreover, only PI(4)P was used as counterligand for the transfer of PS when both PIPs were present. In fact, Osh6p and ORD8 show a much lower affinity for PI(4,5)P2 than for PI(4)P. This likely relates to the fact that PI(4,5)P2, contrary to PI(4)P (or PS), cannot be entirely buried in the pocket and capped by the lid. This hypothesis was suggested by structural analyses of ORP1 and ORP2 in complex with PI(4,5)P2 [35, 36] and confirmed by our in vitro assays. Because PI(4)P and PI(4,5)P2 co-exist in the PM, this strongly suggests that only PI(4)P is used by ORP5 or ORP8 for the exchange with PS in the cell. Our data also suggest that ORP1, ORP2, and ORP4L [60] cannot trap PIPs other than PI(4)P in cells or only if they operate on organelle membranes devoid of PI(4)P.
Quite interestingly, the comparison between the transfer rates and affinity determined with Osh6p and ORD8 for various lipid species allows us to infer general rules that can serve to better understand the cellular activity of LTPs. A first lesson is that, in a simple transfer process between membranes, a low-affinity ligand can be transferred more rapidly down its concentration gradient than a high-affinity ligand. This was observed when comparing saturated PS with unsaturated PS or PI(4,5)P2 with PI(4)P. Presumably, as suggested by our kinetic model, it lies in the fact that a low-affinity recognition process can be detrimental when the ligand is extracted from a donor membrane but an advantage in the transfer process, notably by preventing any re-extraction of the ligand from the acceptor membrane.
The picture is different with a membrane system of higher complexity that reconstitutes a cellular context more faithfully. In exchange conditions, the ability of Osh6p and ORD8 to transport saturated PS was poorly enhanced or often inhibited when PI(4)P was present as a counterligand, because these LTPs have a higher affinity for the latter. When PI(4)P and PI(4,5)P2 were present in the same donor membrane, these LTPs preferentially transferred PI(4)P, for which they have the highest affinity, to acceptor membranes. In an even more complex system where PS, PI(4)P, and PI(4,5)P2 were present each in distinct liposome populations, mimicking three cellular compartments, ORD8 used PI(4)P as a counterligand to transfer PS between two membranes.
These observations have important implications. They suggest first that some caution must be exercised when analyzing in vitro data using membranes of low compositional complexity: measuring a fashe same results were obtainedt transfer rate for a given lipid ligand and an LTP does not necessarily mean that this ligand is the true cellular cargo of the LTP. When considering a cellular context, one can assume that a mere lipid transporter preferentially recognizes and transfers its high-affinity lipid ligand. This potentially implies, as suggested in vitro, a lower speed of transfer but at the benefit of a higher accuracy as no fortuitous ligand can be taken. However, this limitation in terms of speed is lifted if the LTP can exchange this high-affinity ligand for a second one, as measured with Osh6p and ORP8 using unsaturated PS and PI(4)P. This can primarily be explained by the fact that this second ligand prevents the re-extraction by the LTPs of the other ligand from its destination compartment, which improves its net delivery. These observations on Osh6p and ORP8 confirm very first data on the sterol/PI(4)P exchange capacity of Osh4p [34]. Of note, our experiments and models suggest that an optimal exchange occurs, i.e., with similar PS and PI(4)P transfer rates along opposite directions, when a lipid exchanger has a similar affinity for each ligand. Interestingly, the experiments with PS, PI(4)P and PI(4,5)P2 even suggest that this exchange process can channel a lipid flux between two membrane-bound compartments if there are more than two compartments, such as in a cell. Collectively, our study supports the notion that lipid exchange processes are mechanisms that ensure fast, accurate, and directional transfer of lipids between organelles.
Our study provides novel insights into PS/PI(4)P exchangers, by showing that their activity is highly dependent on whether their lipid ligands are saturated or not and indicating the extent to which they can regulate the acyl chain composition of the PM. Moreover, it establishes that these LTPs cannot control PM PI(4,5)P2 level by a direct PS/PI(4,5)P2 exchange mechanism and that, unexpectedly, their activity is not influenced by the sterol abundance in the PM. Importantly, by conducting both kinetics and binding measurements with a large set of lipids, we also determine how the activity of LTPs depends on their affinity for ligands and propose general mechanistic rules on intracellular lipid transport.
Protein expression, labelling, and purification
Osh6p, Osh6p(noC/S190C), NBD-PHFAPP, and NBD-C2Lact were purified as previously described [13, 45, 61].Their concentration was determined by UV spectrometry.
GST-ORD8 (GST-ORP8[370-809]) [14] was expressed in E. coli (BL21-GOLD(DE3)) competent cells (Stratagene) grown in Luria Bertani Broth (LB) medium at 18 °C overnight upon induction with 0.1 mM isopropyl β-D-1-thiogalactopyranoside (IPTG). When the optical density of the bacterial suspension, measured at 600 nm (OD600), reached a value of 0.6, bacteria cells were harvested and re-suspended in cold buffer (50 mM Tris, pH 8, 500 mM NaCl, 2 mM DTT) supplemented with 1 mM PMSF, 10 μM bestatin, 1 μM pepstatin A, and cOmplete EDTA-free protease inhibitor tablets (Roche). Cells were lysed in a Cell Disruptor TS SERIES (Constant Systems Ltd.) and the lysate was centrifuged at 186,000×g for 1 h. Then, the supernatant was applied to Glutathione Sepharose 4B (Cytiva) for 4 h at 4 °C. After three washing steps with the buffer devoid of protease inhibitors, the beads were incubated with PreScission Protease (Cytiva) overnight at 4 °C to cleave off the ORD8 from the GST domain. The protein was recovered in the supernatant after several cycles of centrifugation and washing of the beads, concentrated, and injected onto a XK-16/70 column packed with Sephacryl S-200 HR to be purified by size-exclusion chromatography. The fractions with ~ 100% pure ORD8 were pooled, concentrated, and supplemented with 10% (v/v) pure glycerol (Sigma). Aliquots were prepared, flash-frozen in liquid nitrogen and stored at − 80 °C. The concentration of the protein was determined by measuring its absorbance at λ = 280 nm (ε = 81,820 M−1 cm−1).
To prepare NBD-labelled PHPLCδ1, an endogenous, solvent-exposed cysteine at position 48 of a GST-PHPLCδ1 construct [62] (PH domain of 1-phosphatidylinositol 4,5-bisphosphate phosphodiesterase delta-1, R. norvegicus, Uniprot: P10688) was replaced by a serine, and a serine at position 61 was replaced by a cysteine using the Quikchange kit (Agilent). GST-PHPLCδ1 was expressed in E. coli BL21-GOLD(DE3) competent cells at 20 °C for 24 h upon induction with 0.1 mM IPTG (at OD600 = 0.6). Harvested bacteria cells were re-suspended in 50 mM Tris, pH 7.4, 120 mM NaCl buffer containing 2 mM DTT and supplemented with 1 mM PMSF, 10 μM bestatin, 1 μM pepstatin A, and EDTA-free protease inhibitor tablets. Cells were lysed and the lysate was centrifuged at 186,000×g for 1 h. Next, the supernatant was applied to Glutathione Sepharose 4B for 4 h at 4 °C. The beads were washed three times with protease inhibitor-free buffer and incubated with thrombin at 4 °C for 16 h to cleave off the protein from the GST domain. Then, the eluate obtained after thrombin treatment was concentrated and mixed (after DTT removal by gel filtration on illustra NAP-10 columns (Cytiva) with a 10-fold excess of N,N′-dimethyl-N-(iodoacetyl)-N′-(7-nitrobenz-2-oxa-1,3-diazol-4-yl) ethylenediamine (IANBD-amide, Molecular Probes). After 90 min on ice, the reaction was stopped by adding a 10-fold excess of L-cysteine over the probe. The free probe was removed by size-exclusion chromatography using a XK-16/70 column packed with Sephacryl S-200 HR. The fractions that contained NBD-PHPLCδ1 were pooled, concentrated, and supplemented with 10% (v/v) pure glycerol. Aliquots were stored at − 80 °C once flash-frozen in liquid nitrogen. The labelled protein was analyzed by SDS-PAGE and UV-visible spectroscopy. The gel was directly visualized in a fluorescence imaging system (FUSION FX fluorescence imaging system) to detect NBD-labelled protein excited in near-UV and then stained with SYPRO Orange to determine the purity of NBD-labelled protein. The labelling yield (~ 100%) was estimated from the ratio between the absorbance of the protein at λ = 280 nm (ε = 17,990 M−1 cm−1 for PHPLCδ1) and NBD at λ = 495 nm (ε = 25,000 M−1 cm−1). The concentration of the protein was determined by a BCA assay and UV spectrometry.
mCherry-D4-His6 and mCherry-D4H-His6 (carrying the D434S mutation) were each overexpressed overnight in E. coli (BL21-GOLD(DE3)) at 18 °C for 20 h upon induction by 0.4 mM IPTG at OD600 = 0.6. Bacteria cells were harvested and re-suspended in 50 mM NaH2PO4/Na2HPO4, pH 8, 300 mM NaCl, 10 mM imidazole buffer supplemented with 1 mM PMSF, 10 μM bestatine, 1 μM pepstatine, and EDTA-free protease inhibitor tablets. Cells were broken and the lysate was centrifuged at 186,000×g for 1 h. Then, the supernatant was applied to HisPur Cobalt Resin (Thermo Scientific) for 4 h at 4 °C. The beads were loaded into a column and washed four times with buffer devoid of protease inhibitors. Bound protein was eluted from the beads incubated for 10 min with 20 mM NaH2PO4/Na2HPO4, pH 7.4, 250 mM imidazole buffer. This step was repeated six times to collect a maximal amount of protein. Each protein was concentrated and stored at − 80 °C in the presence of 10% (v/v) glycerol. The concentration of protein was determined by measuring the absorbance at λ = 280 nm (ε = 77,810 M−1 cm−1).
18:1/18:1-PC (1,2-dioleoyl-sn-glycero-3-phosphocholine or DOPC), 12:0/12:0-PS (1,2-dilauroyl-sn-glycero-3-phospho-L-serine or DLPS), 14:0/14:0-PS (1,2-dimyristoyl-sn-glycero-3-phospho-L-serine or DMPS), 16:0/16:0-PS (1,2-dipalmitoyl-sn-glycero-3-phospho-L-serine or DPPS), 18:0/18:0-PS (1,2-distearoyl-sn-glycero-3-phospho-L-serine or DSPS), 16:0/18:1-PS (1-palmitoyl-2-oleoyl-sn-glycero-3 phospho-L-serine or POPS), 18:0/18:1-PS (1-stearoyl-2-oleoyl-sn-glycero-3-phospho-L-serine or SOPS), 18:1/18:0-PS (1-oleoyl-2-stearoyl-sn-glycero-3-phospho-L-serine or OSPS), 18:1/18:1-PS (1,2-dioleoyl-sn-glycero-3-phospho-L-serine or DOPS), 16:0/18:2-PS (1-palmitoyl-2-linoleoyl-sn-glycero-3-phospho-L-serine), 18:2/18:2-PS (1,2-dilinoleoyl-sn-glycero-3-phospho-L-serine), liver PI (L-α-phosphatidylinositol, bovine), 16:0/18:1-PI(4)P (1-palmitoyl-2-oleoyl-sn-glycero-3-phospho-(1'-myo-inositol-4'-phosphate)), 18:1/18:1-PI(4)P (1,2-dioleoyl-sn-glycero-3-phospho-(1'-myo-inositol-4'-phosphate)), brain PI(4)P (L-α-phosphatidylinositol 4-phosphate), brain PI(4,5)P2 (L-α-phosphatidylinositol 4,5-bisphosphate), Rhodamine-PE (1,2-dipalmitoyl-sn-glycero-3-phosphoethanolamine-N-(lissamine rhodamine B sulfonyl)), 16:0/12:0 NBD-PS (1-palmitoyl-2-(12-[(7-nitro-2-1,3-benzoxadiazol-4-yl)amino]dodecanoyl)-sn-glycero-3-phosphoserine), 16:0/12:0 NBD-PC (1-palmitoyl-2-(12-[(7-nitro-2-1,3-benzoxadiazol-4-yl)amino]dodecanoyl)-sn-glycero-3-phosphocholine), cholesterol, and ergosterol were purchased from Avanti Polar Lipids. Saturated PIPs, namely 16:0/16:0-PI(4)P (1,2-dipalmitoyl-sn-glycero-3-phospho-(1'-myo-inositol-4'-phosphate) and 16:0/16:0-PI(4,5)P2 (1,2-dipalmitoyl-sn-glycero-3-phospho-(1′-myo-inositol-4′,5′-bisphosphate)) were purchased from Echelon Biosciences.
Liposome preparation
Lipids stored in stock solutions in CHCl3 or CHCl3/methanol were mixed at the desired molar ratio. The solvent was removed in a rotary evaporator under vacuum. If the flask contained a mixture with PI(4)P and/or PI(4,5)P2, it was pre-warmed at 33 °C for 5 min prior to creating a vacuum. The lipid film was hydrated in 50 mM HEPES, pH 7.2, 120 mM K-Acetate (HK) buffer to obtain a suspension of multi-lamellar vesicles. The multi-lamellar vesicles suspensions were frozen and thawed five times and then extruded through polycarbonate filters of 0.2 μm pore size using a mini-extruder (Avanti Polar Lipids). Liposomes were stored at 4 °C and in the dark when containing fluorescent lipids and used within 2 days.
Lipid transfer assays with two liposome populations
Lipid transfer assays were carried out in a Shimadzu RF 5301-PC or a JASCO FP-8300 spectrofluorometer. Each sample (600 μL final volume) was placed in a cylindrical quartz cuvette, continuously stirred with a small magnetic bar and thermostated at 30 °C and 37 °C for experiments done with Osh6p and ORD8, respectively. At precise times, samples were injected from stock solutions with Hamilton syringes through a guide in the cover of the spectrofluorometer. The signal of fluorescent lipid sensors (NBD-C2Lact, NBD-PHFAPP and NBD-PHPLCδ1) was followed by measuring the NBD signal at λ = 530 nm (bandwidth 10 nm) upon excitation at λ = 460 nm (bandwidth 1.5 nm) with a time resolution of 0.5 s. To measure PS transfer, a suspension (540 μL) of LA liposomes (200 μM total lipid, final concentration), made of DOPC and containing 5% PS and 2% Rhod-PE, was mixed with 250 nM NBD-C2Lact in HK buffer. After 1 min, 30 μL of a suspension of LB liposomes (200 μM lipids, final concentration) containing or not 5% PI(4)P was added to the sample. Three minutes after, Osh6p (200 nM) or ORD8 (240 nM) was injected. The amount of PS ([PS], expressed in μM) transferred over time was determined from the raw NBD traces using the formula [PS] = 2.5 × FNorm with FNorm = (F − F0)/(FEq − F0-Eq). F corresponds to the data point recorded over time. F0 is equal to the average NBD signal measured between the injection of LB liposomes and LTP. FEq is the signal measured with the sensor in the presence of LA-Eq and LB-Eq liposomes, and F0-Eq is the signal of the suspension of LA-Eq only, prior to the addition of LB-Eq. The lipid composition of LA-Eq and LB-Eq liposomes were similar to that of LA and LB liposomes used in the transfer assays, except that both contained 2.5% PS (and additionally 2.5% PI(4)P in the experiments conducted in the context of the lipid exchange) to normalize the signal. The amount of PS transferred from LA to LB liposomes corresponds to 2.5 × FNorm, as one considers that at equilibrium one half of accessible PS molecules, contained in the outer leaflet of the LA liposomes (i.e., corresponding to 5% of 0.5 × 200 μM total lipids) have been delivered into LB liposomes.
To measure PI(4)P transfer, a suspension (540 μL) of LB liposomes (200 μM total lipid) containing 5% PI(4)P was mixed with 250 nM NBD-PHFAPP in HK buffer. After 1 min, 30 μL of a suspension of LA liposomes (200 μM lipids) containing 2% Rhod-PE and doped or not with 5% PS were injected. After 3 additional minutes, LTP was injected. The amount of PI(4)P transferred from LB to LA liposomes was determined considering that [PI(4)P] = 2.5 × FNorm with FNorm = (F − F0)/(FEq − F0). F corresponded to the data point recorded over time, F0 was the average signal measured before the addition of LTP, and FEq was the average signal measured in the presence of LA-Eq and LB-Eq liposomes that each contained 2.5% PI(4)P (and additionally 2.5% PS to normalize data obtained in exchange conditions). At equilibrium, it is considered that one half of accessible PI(4)P molecules, contained in the outer leaflet of LB liposomes, (i.e., corresponding to 5% of 0.5 × 200 μM total lipids) have been transferred into LA liposomes. The transfer of PI(4,5)P2 from LB to LA liposomes was determined using NBD-PHFAPP or NBD-PHPLCδ1 at 250 nM as described for PI(4)P transfer measurements except that FEq was determined using LA and LB liposomes that each contained 2.5% PI(4,5)P2. For all the measurements, the initial transport rates (or initial velocities) were determined from normalized curves by fitting the first eight data points (4 s) measured upon Osh6p/ORD8 injection with a linear function, divided by the amount of LTP and expressed in terms of lipid min−1 per protein.
PS transport assay with three liposome populations
At time zero, LA liposomes (200 μM total lipid, final concentration) containing 95% DOPC and 5% 16:0/18:1-PS were mixed with 250 nM NBD-C2Lact in 480 μL of HK buffer at 37 °C in a quartz cuvette. After 1 min, 60 μL of a suspension of LB liposomes (200 μM total lipid) made of 93% DOPC, 2% Rhod-PE, and 5% 18:0/20:4-PI(4)P or 18:0/20:4-PI(4,5)P2 were injected. After 2 additional minutes, 60 μL of a suspension of LC liposomes (200 μM total lipid) consisting only of DOPC or containing 5% 18:0/20:4-PI(4)P or 18:0/20:4-PI(4,5)P2. Finally, after 2 min, ORD8 (240 nM) was injected. PS transport was followed by measuring the NBD signal at λ = 525 nm (bandwidth 5 nm) upon excitation at λ = 460 nm (bandwidth 1 nm) under constant stirring. The quenching of the NBD signal was due to the translocation of the probe onto LB liposome doped with Rhod-PE and reflected how much PS was transferred from LA to LB liposomes. The amount of transferred PS (in μM) was determined by normalizing the NBD signal considering that [PS] = 2.5 × FNorm with FNorm = (F − F0)/(FEq − F0). F corresponded to data points measured over time, F0 corresponded to the NBD-C2Lact signal measured when PS was only in LA liposomes and FEq corresponded to the signal of the probe when PS was fully equilibrated between LA and LB liposomes. F0 value was obtained by averaging the fluorescence measured after the injection of LC liposomes and before the injection of ORD8. FEq was the fluorescence of NBD-C2Lact (250 nM) measured once it was sequentially mixed with LA-Eq liposomes consisting of 97.5% DOPC and 2.5% 16:0/18:1-PS and LB-Eq liposomes consisting of 95.5% DOPC, 2.5% 16:0/18:1-PS and 2% Rhod-PE, and LC liposomes only made of DOPC (the concentration of each liposome population was 200 μM). Its value corresponded to the average fluorescence measured 15 min after the addition of LC liposomes and for a 5-min period. FEq was also measured using only LA and LB liposomes and was found to be identical. A maximum of 2.5 μM of PS can be transferred from LA to LB liposomes as one half of accessible PS molecules, contained in the outer leaflet of the LA liposomes, (i.e., 5% of 0.5 × 200 μM total lipids), can be transferred to reach equilibrium.
NBD-PS-based competition assays
In a cylindrical quartz cuvette, Osh6p or ORD8 was diluted at 240 nM in a final volume of 555 μL of freshly degassed and filtered HK buffer at 30 °C under constant stirring. Two minutes after, 30 μL of a suspension of DOPC liposomes containing 2% NBD-PS was added (100 μM total lipid, 1 μM accessible NBD-PS). Five minutes after, successive injections of 3 μL of a suspension of DOPC liposomes enriched with a given PS or PI(4)P species (at 5%) were done every 3 min. Tryptophan fluorescence was measured at λ = 340 nm (bandwidth 5 nm) upon excitation at λ = 280 nm (bandwidth 1.5 nm). The signal was normalized by dividing F, the signal measured over time, by F0, the signal measured prior to the addition of the NBD-PS-containing liposome population, and corrected for dilution effects due to the successive injections of the second population of liposome. The signal between each liposome injection was averaged over 2 min to build the binding curve as a function of concentration of accessible non-fluorescent PS or PI(4)P species (from 0 to 1.25 μM).
Thermal shift assay
The relative melting temperatures (Tm) of Osh6p in an empty form or loaded with a lipid ligand were determined by measuring the unfolding of the protein as a function of increasing temperature through the detection of the denatured form of the protein by fluorescence. To prepare Osh6p-PS and Osh6p-PI(4)P complexes, the protein at 5 μM was incubated with heavy liposomes made of DOPC (800 μM total lipid), containing a given PS or PI(4)P subspecies (5%) and encapsulating 50 mM HEPES, pH 7.4, 210 mM sucrose buffer, in a volume of 250 μL of HK buffer. An apo form of the protein was prepared by incubating the protein with DOPC liposomes devoid of lipid ligands. Each sample was mixed by agitation for 30 min at 30 °C and then was centrifuged at 400,000×g for 20 min at 20 °C to pellet the liposomes using a fixed-angle rotor (Beckmann TLA 120.1). A fraction of each supernatant (200 μL) containing Osh6p loaded with lipid was collected and the concentration of each complex was assessed by measuring sample absorbance.
A volume of 15 μL of each Osh6p sample was mixed with 5× SYPRO Orange in an individual well of a 96-well PCR plate. The plates were sealed with an optical sealing tape (Bio-Rad) and heated in an Mx3005P Q-PCR system (Stratagene) from 25 to 95 °C with a step interval of 1 °C. The excitation and emission wavelengths were set at λ = 545 nm and λ = 568 nm, respectively (Cy3 signal). Fluorescence changes in the wells were measured with a photomultiplier tube. The melting temperatures (Tm) were obtained by fitting the fluorescence data from 3 to 5 independent experiments with a Boltzmann model using the GraphPad Prism software.
Flotation experiment
NBD-PHPLCδ1 protein (1 μM) was incubated with liposomes (1.5 mM total lipid) only made of DOPC, or additionally doped with 2% liver PI, 18:0/20:4-PI(4)P or 18:0/20:4-PI(4,5)P2, in 150 μL of HK buffer at room temperature for 10 min under agitation. The suspension was adjusted to 28% (w/w) sucrose by mixing 100 μL of a 60% (w/w) sucrose solution in HK buffer and overlaid with 200 μL of HK buffer containing 24% (w/w) sucrose and 50 μL of sucrose-free HK buffer. The sample was centrifuged at 240,000×g in a swing rotor (TLS 55 Beckmann) for 1 h. The bottom (250 μL), middle (150 μL), and top (100 μL) fractions were collected. The bottom and top fractions were analyzed by SDS-PAGE by direct fluorescence and after staining with SYPRO Orange, using a FUSION FX fluorescence imaging system.
Fluorescence-based membrane binding assay
Measurements were taken in a 96-well black plate (Microplate 96 Well PS F-Bottom Black Non-Binding, Greiner Bio-one) using a TECAN M1000 Pro. Incremental amounts of DOPC liposomes, containing either 2% 18:0/20:4-PI(4)P or 18:0/20:4-PI(4,5)P2, were mixed with NBD-PHPLCδ1 (250 nM) at 25 °C in individual wells (100 μL final volume). NBD spectra were recorded from 509 to 649 nm (bandwidth 5 nm) upon excitation at 460 nm (bandwidth 5 nm). The intensity at λ = 535 nm was plotted as a function of total lipid concentration (from 0 to 300 μM).
CPM accessibility assay
The day of the experiment, 100 μL from a stock solution of Osh6p(noC/S190C) construct was applied onto an illustra NAP-5 column (Cytiva) and eluted with freshly degassed HK buffer, according to the manufacturer's indications to remove DTT. The concentration of the eluted protein was determined by UV spectroscopy considering ε = 55,810 M−1 cm−1 at λ = 280 nm. A stock solution of CPM (7-diethylamino-3-(4-maleimidophenyl)-4-methylcoumarin, Sigma-Aldrich) at 4 mg/mL was freshly prepared as described in [63] by mixing 1 mg of CPM powder in 250 μL of DMSO. Thereafter, this solution was diluted in a final volume of 10 mL of HK buffer and incubated for 5 min at room temperature. The solution was protected from light and used immediately. In individual wells of a 96-well black plate (Greiner Bio-one), Osh6p(noC/S190C) at 400 nM was mixed either with DOPC liposomes (400 μM total lipid) or liposomes containing 2% 18:0/20:4-PI(4)P or 18:0/20:4-PI(4,5)P2 in 200 μL of HK buffer. A small volume of CPM stock solution was then added to obtain a final concentration of 4 μM. After a 30 min incubation at 30 °C, emission fluorescence spectra were measured from 400 to 550 nm (bandwidth 5 nm) upon excitation at λ = 387 nm (bandwidth 5 nm) using a fluorescence plate reader (TECAN M1000 Pro). The maximal intensity of the spectral peak was at 460 nm. Control spectra were recorded in the absence of protein for each condition.
Kinetic modeling
To analyze the experimental data, we considered that an ORD-mediated PS/PI(4)P exchange cycle can be described by the following sequence of reactions:
$$ O+{M}_A\ {\displaystyle \begin{array}{c}\overset{k_{\mathrm{ON}- Mb}}{\to}\\ {}\underset{k_{\mathrm{OFF}- Mb}}{\leftarrow}\end{array}}\ O-{M}_A $$
$$ O+{M}_B\ {\displaystyle \begin{array}{c}\overset{k_{\mathrm{ON}- Mb}}{\to}\\ {}\underset{k_{\mathrm{OFF}- Mb}}{\leftarrow}\end{array}}\ O-{M}_B $$
$$ O-{M}_A+{PS}_A\ {\displaystyle \begin{array}{c}\overset{k_{\mathrm{ON}- PS}}{\to}\\ {}\underset{k_{\mathrm{OFF}- PS}}{\leftarrow}\end{array}}\ O(PS) $$
$$ O-{M}_B+{PS}_B{\displaystyle \begin{array}{c}\overset{k_{\mathrm{ON}- PS}}{\to}\\ {}\underset{k_{\mathrm{OFF}- PS}}{\leftarrow}\end{array}}\ O(PS) $$
$$ O-{M}_A+ PI4{P}_A{\displaystyle \begin{array}{c}\overset{k_{\mathrm{ON}- PI4P}}{\to}\\ {}\underset{k_{\mathrm{OFF}- PI4P}}{\leftarrow}\end{array}}\ O(PI4P) $$
$$ O-{M}_B+ PI4{P}_B{\displaystyle \begin{array}{c}\overset{k_{\mathrm{ON}- PI4P}}{\to}\\ {}\underset{k_{\mathrm{OFF}- PI4P}}{\leftarrow}\end{array}}\ O(PI4P) $$
O corresponds to an empty form of the ORD in solution. O − MA and O − MB correspond to ORD in an empty state, bound to A and B membrane, respectively. O(PS) and O(PI4P) correspond to ORD in a soluble state in 1:1 complex with a PS and PI(4)P molecule, respectively. PSA and PSB correspond to the PS pool in the A and B membrane, respectively. PI4PA and PI4PB are the PI(4)P pools in the A and B membrane, respectively. The time evolution of the PS and PI(4)P concentrations in A and B membranes respectively was determined by integrating a system of ordinary differential equations corresponding to our model. PS transfer was simulated in non-exchange conditions by considering [PSA] = 5 μM, [PSB] = 0 μM, [PI4PA] = [PI4PB] = 0 μM, and [O] = 200 nM at t = 0. The concentrations of the other forms of the ORD were considered to be equal to 0. PS transfer in exchange conditions was calculated considering that [PI4PB] was initially equal to 5 μM. Inversely, PI(4)P transfer was simulated in non-exchange conditions considering [PI4PB] = 5 μM, [PI4PA] = 0 μM, and [PSA] = [PSB] = 0 μM. In exchange conditions, [PSA] value was set at 5 μM. All kON-Mb and kOFF-Mb rates were set to 10 µM-1 s−1 and 1 s−1, respectively. All kON-lipid and kOFF-lipid rates were set to 10 μM−1 s−1 and 1 s−1, respectively, unless otherwise specified. The implementation of the kinetic model and the simulations were carried out with the software GEPASI v3.3 [64].
Cell culture, transfection, and drug treatment
HeLa cells (Hela W.S, STRB7753, ATCC, tested for mycoplasma contamination) were grown in Dulbecco's modified Eagle's medium (DMEM) supplemented with 10% (v/v) fetal bovine serum (Eurobio) at 37 °C under 5% CO2. Cells were seeded (40,000 cells per condition) in an 8-well coverslip (Ibidi). The next day, the cells were transiently transfected with 125 ng of GFP-C2Lact (Addgene, #22852) plasmid only or additionally with 125 ng of Lyn11-FRB-mCherry plasmid (Addgene, #38004) using Lipofectamine 3000 (Thermo Fisher Scientific) according to the manufacturer's instructions. To deplete cholesterol from the PM, cells were treated for 24 h with 2.5 μg/mL of U18666A (Sigma) following the transfection step.
Microscopy and image analysis
One day after transfection, the cells were observed in live conditions using a wide-field microscope (Olympus IX83, × 60) or a confocal microscope (Zeiss LSM780, × 63). Prior to the observation, the medium was replaced by HEPES-containing DMEM devoid of red phenol. The depletion of cholesterol in the PM was assessed in cells that were only transfected by GFP-C2Lact using the fluorescent sterol sensor mCherry-D4-His6. These cells were incubated for 10 min at room temperature with the protein added at 1:500 in DMEM. Then the cells were rinsed twice with HEPES-containing DMEM devoid of red phenol and the cells were immediately observed. To quantify the recruitment of GFP-C2Lact to the PM, line scan analyses of a large set of cells were performed using Fiji ImageJ 2.1.0 [65]. A line was manually drawn across each individual cell and the peak intensity at the PM region was normalized with the intensity of the cytosolic region and then plotted for quantification. The localization of the PM was ascertained for each measurement by using Lyn11-FRB-mCherry as an internal reference.
Statistical analyses were performed using an unpaired Mann–Whitney non-parametric U tests (Prism, GraphPad). p values < 0.05, < 0.01, and < 0.0001 are identified with 1, 2, and 4 asterisks, respectively. ns: p ≥ 0.05. The number of replicates (n) used for calculating statistics is specified in the figure legends.
All data generated or analyzed during this study are included in this published article and its supplementary information files.
C2Lact :
C2 domain of lactadherin
DOPC:
1,2-Dioleoyl-sn-glycero-3-phosphocholine
FRB:
FKBP-rapamycin-binding
FRET:
Fluorescence Resonance Energy Transfer
LTPs:
Lipid transfer proteins
NBD:
Nitrobenzoxadiazole
OSBP-related domain
ORP:
Oxysterol-binding protein-related proteins
Osh:
Oxysterol-binding homology
Pleckstrin homology
PHFAPP :
PH domain of the four-phosphate-adaptor protein
PI:
Phosphatidylinositol
PI(4)P:
Phosphatidylinositol 4-phosphate
PI(4,5)P2 :
Phosphatidylinositol 4,5-bisphosphate
PIPs:
Polyphosphoinositides
Rhod-PE:
1,2-Dipalmitoyl-sn-glycero-3-phosphoethanolamine-N-(lissamine rhodamine B sulfonyl
TSA:
Wong LH, Gatta AT, Levine TP. Lipid transfer proteins: the lipid commute via shuttles, bridges and tubes. Nat Rev Mol Cell Biol. 2019;20(2):85–101.
Balla T, Kim YJ, Alvarez-Prats A, Pemberton J. Lipid dynamics at contact sites between the endoplasmic reticulum and other organelles. Annu Rev Cell Dev Biol. 2019;35:85–109.
Kumagai K, Hanada K. Structure, functions and regulation of CERT, a lipid-transfer protein for the delivery of ceramide at the ER-Golgi membrane contact sites. FEBS Lett. 2019;593(17):2366–77.
Osawa T, Noda NN. Atg2: A novel phospholipid transfer protein that mediates de novo autophagosome biogenesis. Protein Sci. 2019;28(6):1005–12.
Wong LH, Čopič A, Levine TP. Advances on the transfer of lipids by lipid transfer proteins. Trends Biochem Sci. 2017;42(7):516–30.
Jain A, Holthuis JCM. Membrane contact sites, ancient and central hubs of cellular lipid logistics. Biochim Biophys Acta, Mol Cell Res. 2017;1864(9):1450–8.
Saheki Y, De Camilli P. Endoplasmic reticulum-plasma membrane contact sites. Annu Rev Biochem. 2017;86:659–84.
Grabon A, Bankaitis VA, McDermott MI. The interface between phosphatidylinositol transfer protein function and phosphoinositide signaling in higher eukaryotes. J Lipid Res. 2019;60(2):242–68.
Cockcroft S, Raghu P. Phospholipid transport protein function at organelle contact sites. Curr Opin Cell Biol. 2018;53:52–60.
Chiapparino A, Maeda K, Turei D, Saez-Rodriguez J, Gavin AC. The orchestra of lipid-transfer proteins at the crossroads between metabolism and signaling. Prog Lipid Res. 2016;61:30–9.
Delfosse V, Bourguet W, Drin G. Structural and functional specialization of OSBP-related proteins. Contact. 2020;3:2515256420946627.
Maeda K, Anand K, Chiapparino A, Kumar A, Poletto M, Kaksonen M, et al. Interactome map uncovers phosphatidylserine transport by oxysterol-binding proteins. Nature. 2013;501(7466):257–61.
Moser von Filseck J, Copic A, Delfosse V, Vanni S, Jackson CL, Bourguet W, et al. INTRACELLULAR TRANSPORT. Phosphatidylserine transport by ORP/Osh proteins is driven by phosphatidylinositol 4-phosphate. Science. 2015;349(6246):432–6.
Chung J, Torta F, Masai K, Lucast L, Czapla H, Tanner LB, et al. INTRACELLULAR TRANSPORT. PI4P/phosphatidylserine countertransport at ORP5- and ORP8-mediated ER-plasma membrane contacts. Science. 2015;349(6246):428–32.
Yan D, Mayranpaa MI, Wong J, Perttila J, Lehto M, Jauhiainen M, et al. OSBP-related protein 8 (ORP8) suppresses ABCA1 expression and cholesterol efflux from macrophages. J Biol Chem. 2008;283(1):332–40.
Du X, Kumar J, Ferguson C, Schulz TA, Ong YS, Hong W, et al. A role for oxysterol-binding protein-related protein 5 in endosomal cholesterol trafficking. J Cell Biol. 2011;192(1):121–35.
Ghai R, Du X, Wang H, Dong J, Ferguson C, Brown AJ, et al. ORP5 and ORP8 bind phosphatidylinositol-4,5-biphosphate (PtdIns(4,5)P2) and regulate its level at the plasma membrane. Nat Commun. 2017;8(1):757.
Lee M, Fairn GD. Both the PH domain and N-terminal region of oxysterol-binding protein related protein 8S are required for localization to PM-ER contact sites. Biochem Biophys Res Commun. 2018;496(4):1088–94.
Sohn M, Korzeniowski M, Zewe JP, Wills RC, Hammond GRV, Humpolickova J, et al. PI(4,5)P2 controls plasma membrane PI4P and PS levels via ORP5/8 recruitment to ER-PM contact sites. J Cell Biol. 2018;217(5):1797–813.
Di Paolo G, De Camilli P. Phosphoinositides in cell regulation and membrane dynamics. Nature. 2006;443(7112):651–7.
Behnia R, Munro S. Organelle identity and the signposts for membrane traffic. Nature. 2005;438(7068):597–604.
Nishimura T, Gecht M, Covino R, Hummer G, Surma MA, Klose C, et al. Osh proteins control nanoscale lipid organization necessary for PI(4,5)P2 synthesis. Mol Cell. 2019;75(5):1043–57.e8.
Wenk MR, Lucast L, Di Paolo G, Romanelli AJ, Suchy SF, Nussbaum RL, et al. Phosphoinositide profiling in complex lipid mixtures using electrospray ionization mass spectrometry. Nat Biotechnol. 2003;21(7):813–7.
Klose C, Surma MA, Gerl MJ, Meyenhofer F, Shevchenko A, Simons K. Flexibility of a eukaryotic lipidome--insights from yeast lipidomics. PLoS One. 2012;7(4):e35063.
Skotland T, Sandvig K. The role of PS 18:0/18:1 in membrane function. Nat Commun. 2019;10(1):2752.
Symons JL, Cho K-J, Chang JT, Du G, Waxham MN, Hancock JF, et al. Lipidomic atlas of mammalian cell membranes reveals hierarchical variation induced by culture conditions, subcellular membranes, and cell lineages. Soft Matter. 2021;17(2):288–97.
Hicks AM, DeLong CJ, Thomas MJ, Samuel M, Cui Z. Unique molecular signatures of glycerophospholipid species in different rat tissues analyzed by tandem mass spectrometry. Biochim Biophys Acta. 2006;1761(9):1022–9.
Schneiter R, Brugger B, Sandhoff R, Zellnig G, Leber A, Lampl M, et al. Electrospray ionization tandem mass spectrometry (ESI-MS/MS) analysis of the lipid molecular species composition of yeast subcellular membranes reveals acyl chain-based sorting/remodeling of distinct molecular species en route to the plasma membrane. J Cell Biol. 1999;146(4):741–54.
Andreyev AY, Fahy E, Guan Z, Kelly S, Li X, McDonald JG, et al. Subcellular organelle lipidomics in TLR-4-activated macrophages. J Lipid Res. 2010;51(9):2785–97.
Hirama T, Lu SM, Kay JG, Maekawa M, Kozlov MM, Grinstein S, et al. Membrane curvature induced by proximity of anionic phospholipids can initiate endocytosis. Nat Commun. 2017;8(1):1393.
Maekawa M, Fairn GD. Complementary probes reveal that phosphatidylserine is required for the proper transbilayer distribution of cholesterol. J Cell Sci. 2015;128(7):1422.
Bozelli JC Jr, Epand RM. Specificity of acyl chain composition of phosphatidylinositols. Proteomics. 2019;19(18):e1900138.
Epand RM. Features of the phosphatidylinositol cycle and its role in signal transduction. J Membr Biol. 2017;250(4):353–66.
de Saint-Jean M, Delfosse V, Douguet D, Chicanne G, Payrastre B, Bourguet W, et al. Osh4p exchanges sterols for phosphatidylinositol 4-phosphate between lipid bilayers. J Cell Biol. 2011;195(6):965–78.
Dong J, Du X, Wang H, Wang J, Lu C, Chen X, et al. Allosteric enhancement of ORP1-mediated cholesterol transport by PI(4,5)P2/PI(3,4)P2. Nat Commun. 2019;10(1):829.
Wang H, Ma Q, Qi Y, Dong J, Du X, Rae J, et al. ORP2 Delivers Cholesterol to the Plasma Membrane in Exchange for Phosphatidylinositol 4,5-Bisphosphate (PI(4,5)P2). Mol Cell. 2019;73(3):458–73.e7.
D'Ambrosio JM, Albanese V, Lipp NF, Fleuriot L, Debayle D, Drin G, et al. Osh6 requires Ist2 for localization to ER-PM contacts and efficient phosphatidylserine transport in budding yeast. J Cell Sci. 2020;133(11).
Zhang Y, Baycin-Hizal D, Kumar A, Priola J, Bahri M, Heffner KM, et al. High-throughput lipidomic and transcriptomic analysis to compare SP2/0, CHO, and HEK-293 Mammalian Cell Lines. Anal Chem. 2017;89(3):1477–85.
Llorente A, Skotland T, Sylvänne T, Kauhanen D, Róg T, Orłowski A, et al. Molecular lipidomics of exosomes released by PC-3 prostate cancer cells. Biochim Biophys Acta. 2013;1831(7):1302–9.
Kavaliauskiene S, Nymark CM, Bergan J, Simm R, Sylvänne T, Simolin H, et al. Cell density-induced changes in lipid composition and intracellular trafficking. Cell Mol Life Sci. 2014;71(6):1097–116.
Dickson EJ, Jensen JB, Vivas O, Kruse M, Traynor-Kaplan AE, Hille B. Dynamic formation of ER-PM junctions presents a lipid phosphatase to regulate phosphoinositides. J Cell Biol. 2016;213(1):33–48.
Traynor-Kaplan A, Kruse M, Dickson EJ, Dai G, Vivas O, Yu H, et al. Fatty-acyl chain profiles of cellular phosphoinositides. Biochim Biophys Acta Mol Cell Biol Lipids. 2017;1862(5):513–22.
Lemmon MA, Ferguson KM, O'Brien R, Sigler PB, Schlessinger J. Specific and high-affinity binding of inositol phosphates to an isolated pleckstrin homology domain. Proc Natl Acad Sci U S A. 1995;92(23):10472–6.
Ferguson KM, Lemmon MA, Schlessinger J, Sigler PB. Structure of the high affinity complex of inositol trisphosphate with a phospholipase C pleckstrin homology domain. Cell. 1995;83(6):1037–46.
Lipp N-F, Gautier R, Magdeleine M, Renard M, Albanèse V, Čopič A, et al. An electrostatic switching mechanism to control the lipid transfer activity of Osh6p. Nat Commun. 2019;10(1):3926.
Drin G. Topological regulation of lipid balance in cells. Annu Rev Biochem. 2014;83:51–77.
Amblard I, Dupont E, Alves I, Miralves J, Queguiner I, Joliot A. Bidirectional transfer of homeoprotein EN2 across the plasma membrane requires PIP2. J Cell Sci. 2020;133(13).
Underwood KW, Jacobs NL, Howley A, Liscum L. Evidence for a cholesterol transport pathway from lysosomes to endoplasmic reticulum that is independent of the plasma membrane. J Biol Chem. 1998;273(7):4266–74.
Maekawa M. Domain 4 (D4) of Perfringolysin O to visualize cholesterol in cellular membranes-the update. Sensors. 2017;17(3).
Huuskonen J, Olkkonen VM, Jauhiainen M, Metso J, Somerharju P, Ehnholm C. Acyl chain and headgroup specificity of human plasma phospholipid transfer protein. Biochim Biophys Acta. 1996;1303(3):207–14.
Backman APE, Halin J, Nurmi H, Mouts A, Kjellberg MA, Mattjus P. Glucosylceramide acyl chain length is sensed by the glycolipid transfer protein. PLoS One. 2018;13(12):e0209230.
Kudo N, Kumagai K, Tomishige N, Yamaji T, Wakatsuki S, Nishijima M, et al. Structural basis for specific lipid recognition by CERT responsible for nonvesicular trafficking of ceramide. Proc Natl Acad Sci U S A. 2008;105(2):488–93.
Kumagai K, Yasuda S, Okemoto K, Nishijima M, Kobayashi S, Hanada K. CERT mediates intermembrane transfer of various molecular species of ceramides. J Biol Chem. 2005;280(8):6488–95.
Silvius JR, Leventis R. Spontaneous interbilayer transfer of phospholipids: dependence on acyl chain composition. Biochemistry. 1993;32(48):13318–26.
Singh RP, Brooks BR, Klauda JB. Binding and release of cholesterol in the Osh4 protein of yeast. Proteins. 2009;75(2):468–77.
Canagarajah BJ, Hummer G, Prinz WA, Hurley JH. Dynamics of cholesterol exchange in the oxysterol binding protein family. J Mol Biol. 2008;378(3):737–48.
Manni MM, Tiberti ML, Pagnotta S, Barelli H, Gautier R, Antonny B. Acyl chain asymmetry and polyunsaturation of brain phospholipids facilitate membrane vesiculation without leakage. Elife. 2018;7.
Mesmin B, Bigay J, Moser von Filseck J, Lacas-Gervais S, Drin G, Antonny B. A four-step cycle driven by PI(4)P hydrolysis directs sterol/PI(4)P exchange by the ER-Golgi tether OSBP. Cell. 2013;155(4):830–43.
Das A, Brown MS, Anderson DD, Goldstein JL, Radhakrishnan A. Three pools of plasma membrane cholesterol and their relation to cholesterol homeostasis. Elife. 2014;3.
Zhong W, Xu M, Li C, Zhu B, Cao X, Li D, et al. ORP4L extracts and presents PIP2 from plasma membrane for PLCβ3 catalysis: targeting it eradicates leukemia stem cells. Cell Rep. 2019;26(8):2166–77.e9.
Moser von Filseck J, Vanni S, Mesmin B, Antonny B, Drin G. A phosphatidylinositol-4-phosphate powered exchange mechanism to create a lipid gradient between membranes. Nat Commun. 2015;6:6671.
Morales J, Sobol M, Rodriguez-Zapata LC, Hozak P, Castano E. Aromatic amino acids and their relevance in the specificity of the PH domain. J Mol Recognit. 2017;30(12):e2649.
Alexandrov AI, Mileni M, Chien EY, Hanson MA, Stevens RC. Microscale fluorescent thermal stability assay for membrane proteins. Structure. 2008;16(3):351–9.
Mendes P. GEPASI: a software package for modelling the dynamics, steady states and control of biochemical and other systems. Comput Appl Biosci. 1993;9(5):563–71.
Schindelin J, Arganda-Carreras I, Frise E, Kaynig V, Longair M, Pietzsch T, et al. Fiji: an open-source platform for biological-image analysis. Nat Methods. 2012;9(7):676–82.
We wish to thank Pr. Pietro De Camilli for providing the plasmid coding for the GST-ORD8 construct, Dr. Enrique Castano for the plasmid coding for the GST-PHPLCδ1, and Dr. Fabien Alpy for the plasmid coding for the mCherry-D4-His6. We thank Dr. Frédéric Brau for his help in image analysis. We are grateful to Ms. Y. Van Der Does for her careful corrections and proofreading of the manuscript.
This work was supported by the CNRS and by a grant from the Agence Nationale de la Recherche (ANR-16-CE13-0006). NFL was supported by a fellowship from the Ministère de l'Enseignement Supérieur, de la Recherche et de l'Innovation.
Souade Ikhlef and Nicolas-Frédéric Lipp contributed equally to this work.
Université Côte d'Azur, Centre National de la Recherche Scientifique, Institut de Pharmacologie Moléculaire et Cellulaire, 660 route des lucioles, 06560, Valbonne, France
Souade Ikhlef, Nicolas-Frédéric Lipp, Nicolas Fuggetta, Maud Magdeleine & Guillaume Drin
Centre de Biologie Structurale, INSERM, CNRS, Université de Montpellier, Montpellier, France
Vanessa Delfosse & William Bourguet
Current position: Department of Chemistry and Biochemistry, University of California San Diego, La Jolla, CA, USA
Nicolas-Frédéric Lipp
Souade Ikhlef
Vanessa Delfosse
Nicolas Fuggetta
William Bourguet
Maud Magdeleine
Guillaume Drin
G.D. designed and supervised research. S.I., N-F. L., M.M., N.F., and G.D. carried out site-directed mutagenesis, produced, purified, and labelled all the recombinant proteins of this study. S.I., N-F.L., N.F. V.D., and G.D. performed the in vitro experiments. M.M performed the cellular experiments. G.D., S.I., N-F.L , W.B., V.D., and M.M. analyzed the data. G.D wrote the manuscript. All authors discussed the results and commented on the manuscript. All authors read and approved the final manuscript.
Correspondence to Guillaume Drin.
12915_2021_1183_MOESM1_ESM.pdf
Ikhlef, S., Lipp, NF., Delfosse, V. et al. Functional analyses of phosphatidylserine/PI(4)P exchangers with diverse lipid species and membrane contexts reveal unanticipated rules on lipid transfer. BMC Biol 19, 248 (2021). https://doi.org/10.1186/s12915-021-01183-1
Lipid transport
Phosphoinositide
Submission enquiries: [email protected] | CommonCrawl |
Inequality with five variables
Let $a$, $b$, $c$, $d$ and $e$ be positive numbers. Prove that:
$$\frac{a}{a+b}+\frac{b}{b+c}+\frac{c}{c+d}+\frac{d}{d+e}+\frac{e}{e+a}\geq\frac{a+b+c+d+e}{a+b+c+d+e-3\sqrt[5]{abcde}}$$
Easy to show that $$\frac{a}{a+b}+\frac{b}{b+c}+\frac{c}{c+a}\geq\frac{a+b+c}{a+b+c-\sqrt[3]{abc}}$$ is true
and for even $n$ and positives $a_i$ the following inequality is true.
$$\frac{a_1}{a_1+a_2}+\frac{a_2}{a_2+a_3}+...+\frac{a_n}{a_n+a_1}\geq\frac{a_1+a_2+...+a_n}{a_1+a_2+...+a_n-(n-2)\sqrt[n]{a_1a_2...a_n}}$$
inequality contest-math fractions a.m.-g.m.-inequality cauchy-schwarz-inequality
Michael Rozenberg
Michael RozenbergMichael Rozenberg
$\begingroup$ hello Michael nice to meet you here i think BW! $\endgroup$
– Dr. Sonnhard Graubner
$\begingroup$ Hello, Dr. Sonnhard Graubner! I think BW is not useable here. $\endgroup$
– Michael Rozenberg
$\begingroup$ The right side is never more than $n/2$. Can the left side be less than $n/2$? $\endgroup$
– Paul
$\begingroup$ @Paul: For $(a, b, c, d, e) = (1, k, k^2, k^3, k^4)$ and $k \to \infty$, the lhs comes arbitrarity close to one. $\endgroup$
– Martin R
$\begingroup$ @Michael: Can you share your "easy proof" for $n=3$ and $n$ even? $\endgroup$
Here is a full proof.
Let us start the discussion for general $n$. Denote $S = \sum_{i=1}^n a_i$.
Since by AM-GM, $S \geq n \sqrt[n]{a_1a_2...a_n}$, we have
$$1+\frac{n(n-2)\sqrt[n]{a_1a_2...a_n}}{2S} \geq \frac{S}{S - (n-2)\sqrt[n]{a_1a_2...a_n}}$$
Hence a tighter claim is (simultaneously defining $L$ and $R$):
$$L = \sum_{cyc}\frac{a_i}{a_i+a_{i+1}}\geq 1+\frac{n(n-2)\sqrt[n]{a_1a_2...a_n}}{2S} = R$$ and it suffices to show that one.
We write $2 L \geq 2 R$ or $L \geq 2 R- L$ and add on both sides a term $$\sum_{cyc}\frac{a_{i+1}}{a_i+a_{i+1}}$$ which leaves us to show
$$n = \sum_{cyc}\frac{a_i + a_{i+1}}{a_i+a_{i+1}}\geq 2+\frac{n(n-2)\sqrt[n]{a_1a_2...a_n}}{S} + \sum_{cyc}\frac{-a_i + a_{i+1}}{a_i+a_{i+1}}$$ or, in our final equivalent reformulation of the L-R claim above, $$ \sum_{cyc}\frac{-a_i + a_{i+1}}{a_i+a_{i+1}} \leq (n - 2) (1- \frac{n \sqrt[n]{a_1a_2...a_n}}{S} )$$
For general odd $n$ see the remark at the bottom. Here the task is to show $n=5$.
Before doing so, we will first prove the following Lemma (required below), which is the above L-R-inequality for 3 variables (which is tighter than the original formulation, hence we cannot apply the proof for $n=3$ given above by Michael Rozenberg for the original formulation):
$$ \frac{b-a}{b+a} + \frac{c-b}{c+b} + \frac{a-c}{a+c} \leq (1- \frac{3 \sqrt[3]{a\, b \, c}}{a + b+ c} )$$
This Lemma is, from the above discussion, just a re-formulation of the claim in $L$ and $R$ above, for 3 variables, i.e.
$$ \frac{a}{b+a} + \frac{b}{c+b} + \frac{c}{a+c} \geq 1+\frac{3\sqrt[3]{a \, b \ c}}{2(a+b+c)}$$
By homogeneity, we can demand $abc=1$ and prove, under that restriction, $$ \frac{a}{b+a} + \frac{b}{c+b} + \frac{c}{a+c} \geq 1+\frac{3}{2(a+b+c)}$$
This reformulates into $$ \frac{a\; c}{a +b} + \frac{b\; a}{b +c} + \frac{c\; b}{c +a} \geq \frac{3}{2}$$ or equivalently, due to $abc=1$, $$ \frac{1}{b(a +b)} + \frac{1}{c(b +c)} + \frac{1}{a(c +a)} \geq \frac{3}{2}$$
which is known (2008 International Zhautykov Olympiad), for some proofs see here: http://artofproblemsolving.com/community/c6h183916p1010959 Hence the Lemma holds.
For $n=5$, we rewrite the LHS of our above final reformulation by adding and subtracting terms:
$$ \frac{b-a}{b+a} + \frac{c-b}{c+b} + \frac{d-c}{d+c} + \frac{e-d}{e+d} + \frac{a-e}{a+e} = \\ (\frac{b-a}{b+a} + \frac{c-b}{c+b} + \frac{a-c}{a+c}) + (\frac{c-a}{c+a}+\frac{d-c}{d+c} + \frac{a-d}{a+d}) + (\frac{d-a}{d+a}+ \frac{e-d}{e+d} + \frac{a-e}{a+e}) $$ This also holds for any cyclic shift in (abcde), so we can write
$$ 5 (\frac{b-a}{b+a} + \frac{c-b}{c+b} + \frac{d-c}{d+c} + \frac{e-d}{e+d} + \frac{a-e}{a+e}) = \\ \sum_{cyc (abcde)} (\frac{b-a}{b+a} + \frac{c-b}{c+b} + \frac{a-c}{a+c}) + \sum_{cyc (abcde)}(\frac{c-a}{c+a}+\frac{d-c}{d+c} + \frac{a-d}{a+d}) + \sum_{cyc (abcde)} (\frac{d-a}{d+a}+ \frac{e-d}{e+d} + \frac{a-e}{a+e}) $$
Using our Lemma, it suffices to show (with $S = a +b+c+d+e$)
$$ \sum_{cyc (abcde)} (1- \frac{3 \sqrt[3]{a\, b \, c}}{a + b+ c} ) + \sum_{cyc (abcde)}(1- \frac{3 \sqrt[3]{a\, c \, d}}{a + c+ d} ) + \sum_{cyc (abcde)}(1- \frac{3 \sqrt[3]{a\, d \, e}}{a + d+ e} ) \leq 15 (1- \frac{5 \sqrt[5]{a b c d e }}{S} ) $$ which is $$ \sum_{cyc (abcde)} (\frac{\sqrt[3]{a\, b \, c}}{a + b+ c} + \frac{\sqrt[3]{a\, c \, d}}{a + c+ d} + \frac{\sqrt[3]{a\, d \, e}}{a + d+ e} ) \geq 25 \frac{\sqrt[5]{a b c d e }}{S} $$ Using Cauchy-Schwarz leaves us with showing $$ \frac {(\sum_{cyc (abcde)} \sqrt[6]{a\, b \, c})^2}{\sum_{cyc (abcde)}(a + b+ c)} + \frac {(\sum_{cyc (abcde)} \sqrt[6]{a\, c \, d})^2}{\sum_{cyc (abcde)}(a + c+ d)} + \frac {(\sum_{cyc (abcde)} \sqrt[6]{a\, d \, e})^2}{\sum_{cyc (abcde)}(a + d+ e)} \geq 25 \frac{\sqrt[5]{a b c d e }}{S} $$ The denominators all equal $3S$, so this becomes $$ (\sum_{cyc (abcde)} \sqrt[6]{a\, b \, c})^2 + (\sum_{cyc (abcde)} \sqrt[6]{a\, c \, d})^2 + (\sum_{cyc (abcde)} \sqrt[6]{a\, d \, e})^2 \geq 75 \sqrt[5]{a b c d e } $$ Using AM-GM gives for the first term
$$ (\sum_{cyc (abcde)} \sqrt[6]{a\, b \, c})^2 \geq ( 5 (\prod_{cyc (abcde)} \sqrt[6]{a\, b \, c} )^{1/5})^2 = 25 (\prod_{cyc (abcde)} ({a\, b \, c} ) )^{1/15} = 25 \sqrt[5]{a b c d e } $$
By the same procedure, the second and the third term on the LHS are likewise greater or equal than $25 \sqrt[5]{a b c d e }$. This concludes the proof.
the tighter $L-R$-claim used here is - for general $n$ - asked for in the problem given at Cyclic Inequality in n (at least 4) variables
For general odd $n$, the above reformulation can be used again. For odd $n>5$, take the method of adding and subtracting terms to form smaller sub-sums which are cyclically closed in a smaller number of variables, and apply previous results for smaller $n$ recursively.
AndreasAndreas
$\begingroup$ Beautiful proof. Thank you! $\endgroup$
$\begingroup$ @Michael Rozenberg. Thank you for the bounty! In the original question you wrote "for even n and positives $a_i$ the following inequality is true." Could you make that solution available? $\endgroup$
$\begingroup$ The proof for any $n$ (for the tighter L-R-claim stated above) is given here: math.stackexchange.com/questions/1711515 $\endgroup$
A proof for $n=3$.
We'll prove that $\frac{a}{a+b}+\frac{b}{b+c}+\frac{c}{c+a}\geq\frac{a+b+c}{a+b+c-\sqrt[3]{abc}}$ for all positives $a$, $b$ and $c$.
Indeed, let $ab+ac+bc\geq(a+b+c)\sqrt[3]{abc}$.
Hence, by C-S $\sum\limits_{cyc}\frac{a}{a+b}\geq\frac{(a+b+c)^2}{\sum\limits_{cyc}(a^2+ab)}=\frac{1}{1-\frac{ab+ac+bc}{(a+b+c)^2}}\geq\frac{a+b+c}{a+b+c-\sqrt[3]{abc}}$.
Let $ab+ac+bc\leq(a+b+c)\sqrt[3]{abc}$.
Hence, by C-S $\sum\limits_{cyc}\frac{a}{a+b}\geq\frac{(ab+ac+bc)^2}{\sum\limits_{cyc}(a^2c^2+a^2bc)}=\frac{1}{1-\frac{abc(a+b+c)}{(ab+ac+bc)^2}}\geq\frac{1}{1-\frac{\sqrt[3]{abc}}{a+b+c}}=\frac{a+b+c}{a+b+c-\sqrt[3]{abc}}$.
A proof for even $n$.
Let $a_i>0$, $a_{n+1}=a_1$ and $n$ is an even natural number. Prove that: $$\frac{a_1}{a_1+a_2}+\frac{a_2}{a_2+a_3}+...+\frac{a_n}{a_n+a_1}\geq\frac{a_1+a_2+...+a_n}{a_1+a_2+...+a_n-(n-2)\sqrt[n]{a_1a_2...a_n}}$$ Proof.
By C-S and AM-GM $\sum\limits_{i=1}^n\frac{a_i}{a_i+a_{i+1}}=\sum\limits_{k=1}^{\frac{n}{2}}\frac{a_{2k-1}}{a_{2k-1}+a_{2k}}+\sum\limits_{k=1}^{\frac{n}{2}}\frac{a_{2k}}{a_{2k}+a_{2k+1}}\geq\frac{\left(\sum\limits_{k=1}^{\frac{n}{2}}\sqrt{a_{2k-1}}\right)^2}{a_1+a_2+...+a_n}+\frac{\left(\sum\limits_{k=1}^{\frac{n}{2}}\sqrt{a_{2k}}\right)^2}{a_1+a_2+...+a_n}\geq$
$\geq\frac{a_1+a_2+...+a_n+\frac{n^2-2n}{2}\sqrt[n]{a_1a_2...a_n}}{a_1+a_2+...+a_n}\geq\frac{a_1+a_2+...+a_n}{a_1+a_2+...+a_n-(n-2)\sqrt[n]{a_1a_2...a_n}}$.
$\begingroup$ Thanks for the proof for even $n$ - very short and concise! $\endgroup$
I'm going to prove a different but similar inequality.
Let $x_1,x_2,\ldots,x_n>0$, $x_{n+1}=x_1$, $x_{n+2}=x_2$, $n$ be a positive integer such that either
$a)\ $ $n\le 12$; or
$b)\ $ $13\le n\le 23$, $n$ is odd.
Then this inequality is true:
$$\sum_{i=1}^n\frac{x_i}{x_{i+1}+x_{i+2}}\ge \frac{\sum_{i=1}^n x_i}{\sum_{i=1}^n x_i - (n-2)\sqrt[n]{\prod_{i=1}^n x_i}}$$
Proof: by AM-GM:
$$\frac{\sum_{i=1}^n x_i}{\sum_{i=1}^n x_i - (n-2)\sqrt[n]{\prod_{i=1}^n x_i}}\le $$
$$\le \frac{\sum_{i=1}^n x_i}{\sum_{i=1}^n x_i - (n-2)\frac{\sum_{i=1}^n x_i}{n}}=$$
$$=\frac{\sum_{i=1}^n x_i}{\frac{2}{n}\sum_{i=1}^n x_i}=\frac{n}{2}$$
By Shapiro inequality: $$\frac{n}{2}\le \sum_{i=1}^n\frac{x_i}{x_{i+1}+x_{i+2}}$$
Not the answer you're looking for? Browse other questions tagged inequality contest-math fractions a.m.-g.m.-inequality cauchy-schwarz-inequality or ask your own question.
Prove that $\sum\limits_{cyc}\frac{a}{a+b}\geq1+\frac{3\sqrt[3]{a^2b^2c^2}}{2(ab+ac+bc)}$
Geometric inequality $\frac{R_a}{2a+b}+\frac{R_b}{2b+c}+\frac{R_c}{2c+a}\geq\frac{1}{\sqrt3}$
Cyclic Inequality in n (at least 4) variables
Cauchy-Schwarz inequality in $\mathbb{R}^3$
Inequality with reciprocals of $n$-variable sums
Proof of this inequality
General inequality
Inequality : $ (a_1a_2+a_2a_3+\ldots+a_na_1)\left(\frac{a_1}{a^2_2+a_2}+\frac{a_2}{a^2_3+a_3}+ \ldots+\frac{a_n}{a^2_1+a_1}\right)\geq \frac{n}{n+1} $
Regarding AM-GM inequality
$\frac{a_1}{\sqrt{1-a_1}}+\frac{a_2}{\sqrt{1-a_2}}+..+ \frac{a_n}{\sqrt{1-a_n}} \geq \frac{1}{\sqrt{n-1}}(\sqrt{a_1}+\sqrt{a_2}+\dots+ \sqrt{a_n})$ | CommonCrawl |
Quantitative Aspects Of Chemical Change
Atomic mass and the mole
Amount of substance
19.2 Composition (ESAGB)
Knowing either the empirical or molecular formula of a compound, can help to determine its composition in more detail. The opposite is also true. Knowing the composition of a substance can help you to determine its formula. There are four different types of composition problems that you might come across:
Problems where you will be given the formula of the substance and asked to calculate the percentage by mass of each element in the substance.
Problems where you will be given the percentage composition and asked to calculate the formula.
Problems where you will be given the products of a chemical reaction and asked to calculate the formula of one of the reactants. These are often referred to as combustion analysis problems.
Problems where you will be asked to find number of moles of waters of crystallisation.
The following worked examples will show you how to do each of these.
Worked example 7: Calculating the percentage by mass of elements in a compound
Calculate the percentage that each element contributes to the overall mass of sulphuric acid (\(\text{H}_{2}\text{SO}_{4}\)).
Calculate the molar masses
\[\text{Hydrogen } = 2 \times \text{1,01} = \text{2,02}\text{ g·mol$^{-1}$} \\ \text{Sulfur } = \text{32,1}\text{ g·mol$^{-1}$} \\ \text{Oxygen } = 4 \times \text{16,0} = \text{64,0}\text{ g·mol$^{-1}$}\]
Use the calculations in the previous step to calculate the molecular mass of sulphuric acid.
\[\text{Mass } = \text{2,02}\text{ g·mol$^{-1}$} + \text{32,1}\text{ g·mol$^{-1}$} + \text{64,0}\text{ g·mol$^{-1}$} = \text{98,12}\text{ g·mol$^{-1}$}\]
Use the equation
\[\text{Percentage by mass } = \frac{\text{atomic mass}}{\text{molecular mass of H}_{2}\text{SO}_{4}} \times 100\]
\[\frac{\text{2,02}\text{ g·mol$^{-1}$}}{\text{98,12}\text{ g·mol$^{-1}$}} \times \text{100}\% = \text{2,0587}\%\]
\[\frac{\text{32,1}\text{ g·mol$^{-1}$}}{\text{98,12}\text{ g·mol$^{-1}$}} \times \text{100}\% = \text{32,7150}\%\]
(You should check at the end that these percentages add up to \(\text{100}\%\)!)
In other words, in one molecule of sulphuric acid, hydrogen makes up \(\text{2,06}\%\) of the mass of the compound, sulfur makes up \(\text{32,71}\%\) and oxygen makes up \(\text{65,23}\%\).
Worked example 8: Determining the empirical formula of a compound
A compound contains \(\text{52,2}\%\) carbon (C), \(\text{13,0}\%\) hydrogen (H) and \(\text{34,8}\%\) oxygen (O). Determine its empirical formula.
Give the masses
Carbon = \(\text{52,2}\) \(\text{g}\), hydrogen = \(\text{13,0}\) \(\text{g}\) and oxygen = \(\text{34,8}\) \(\text{g}\)
Calculate the number of moles
\[n = \frac{m}{M}\]
\begin{align*} n_{\text{carbon}} & = \frac{\text{52,2}\text{ g}}{\text{12,0}\text{ g·mol$^{-1}$}} \\ & = \text{4,35}\text{ mol} \\\\ n_{\text{hydrogen}} & = \frac{\text{13,0}\text{ g}}{\text{1,01}\text{ g·mol$^{-1}$}} \\ & = \text{12,871}\text{ mol} \\\\ n_{\text{oxygen}} & = \frac{\text{34,8}\text{ g}}{\text{16,0}\text{ g·mol$^{-1}$}} \\ & = \text{2,175}\text{ mol} \end{align*}
Find the smallest number of moles
Use the ratios of molar numbers calculated above to find the empirical formula.
\[\text{units in empirical formula } = \frac{\text{moles of this element}}{\text{smallest number of moles}}\]
In this case, the smallest number of moles is \(\text{2,175}\). Therefore:
\[\frac{\text{4,35}}{\text{2,175}} = \text{2}\]
\[\frac{\text{12,87}}{\text{2,175}} = \text{6}\]
\[\frac{\text{2,175}}{\text{2,175}} = \text{1}\]
Therefore the empirical formula of this substance is: \(\text{C}_{2}\text{H}_{6}\text{O}\).
Worked example 9: Determining the formula of a compound
\(\text{207}\) \(\text{g}\) of lead combines with oxygen to form \(\text{239}\) \(\text{g}\) of a lead oxide. Use this information to work out the formula of the lead oxide (Relative atomic masses: \(\text{Pb } = \text{202,7}\text{ u}\) and \(\text{O } = \text{16,0}\text{ u}\)).
Find the mass of oxygen
\[\text{239}\text{ g} - \text{207}\text{ g} = \text{32}\text{ g}\]
Find the moles of oxygen
\[n = \frac{\text{207}\text{ g}}{\text{207,2}\text{ g·mol$^{-1}$}} = \text{1}\text{ mol}\]
\[n = \frac{\text{32}\text{ g}}{\text{16,0}\text{ g·mol$^{-1}$}} = \text{2}\text{ mol}\]
Find the mole ratio
The mole ratio of \(\text{Pb }: \text{ O}\) in the product is \(1:2\), which means that for every atom of lead, there will be two atoms of oxygen. The formula of the compound is \(\text{PbO}_{2}\).
Worked example 10: Empirical and molecular formula
Vinegar, which is used in our homes, is a dilute form of acetic acid. A sample of acetic acid has the following percentage composition: \(\text{39,9}\%\) carbon, \(\text{6,7}\%\) hydrogen and \(\text{53,4}\%\) oxygen.
Determine the empirical formula of acetic acid.
Determine the molecular formula of acetic acid if the molar mass of acetic acid is \(\text{60,06}\) \(\text{g·mol$^{-1}$}\).
Find the mass
In \(\text{100}\) \(\text{g}\) of acetic acid, there is \(\text{39,9}\) \(\text{g}\) \(\text{C}\), \(\text{6,7}\) \(\text{g}\) \(\text{H}\) and \(\text{53,4}\) \(\text{g}\) \(\text{O}\).
Find the moles
\[n = \frac{m}{M}\] \begin{align*} n_{\text{C}} & = \frac{\text{39,9}\text{ g}}{\text{12,0}\text{ g·mol$^{-1}$}} \\ & = \text{3,325}\text{ mol} \\\\ n_{\text{H}} & = \frac{\text{6,7}\text{ g}}{\text{1,01}\text{ g·mol$^{-1}$}} \\ & = \text{6,637}\text{ mol} \\\\ n_{\text{O}} & = \frac{\text{53,4}\text{ g}}{\text{16,0}\text{ g·mol$^{-1}$}} \\ & = \text{3,375}\text{ mol} \end{align*}
Find the empirical formula
\(\text{C}\)
\(\text{H}\)
\(\text{O}\)
\(\text{3,325}\)
\(\text{6,6337}\)
Empirical formula is \(\text{CH}_{2}\text{O}\)
Find the molecular formula
The molar mass of acetic acid using the empirical formula is \(\text{30,02}\) \(\text{g·mol$^{-1}$}\). However the question gives the molar mass as \(\text{60,06}\) \(\text{g·mol$^{-1}$}\). Therefore the actual number of moles of each element must be double what it is in the empirical formula (\(\frac{\text{60,06}}{\text{30,02}} = 2\)). The molecular formula is therefore \(\text{C}_{2}\text{H}_{4}\text{O}_{2}\) or \(\text{CH}_{3}\text{COOH}\)
Worked example 11: Waters of crystallisation
Aluminium trichloride (\(\text{AlCl}_{3}\)) is an ionic substance that forms crystals in the solid phase. Water molecules may be trapped inside the crystal lattice. We represent this as: \(\text{AlCl}_{3}.\text{nH}_{2}\text{O}\). Carine heated some aluminium trichloride crystals until all the water had evaporated and found that the mass after heating was \(\text{2,8}\) \(\text{g}\). The mass before heating was \(\text{5}\) \(\text{g}\). What is the number of moles of water molecules in the aluminium trichloride before heating?
Find the number of water molecules
We first need to find n, the number of water molecules that are present in the crystal. To do this we first note that the mass of water lost is \(\text{5}\text{ g} - \text{2,8}\text{ g} = \text{2,2}\text{ g}\).
Find the mass ratio
The mass ratio is:
\(\text{AlCl}_{3}\)
\(\text{H}_{2}\text{O}\)
\(\text{2,8}\)
To work out the mole ratio we divide the mass ratio by the molecular mass of each species:
\(\frac{\text{2,8}\text{ g·mol$^{-1}$}}{\text{133,35}\text{ g}}\)
\(\frac{\text{2,2}\text{ g·mol$^{-1}$}}{\text{18,02}\text{ g}}\)
\(\text{0,02099...}\)
\(\text{0,12...}\)
Next we convert the ratio to whole numbers by dividing both sides by the smaller amount:
\(\text{0,020997375}\)
\(\text{0,12208657}\)
\(\frac{\text{0,021}}{\text{0,021}}\)
The mole ratio of aluminium trichloride to water is: \(1:6\)
Write the final answer
And now we know that there are 6 moles of water molecules in the crystal. The formula is \(\text{AlCl}_{3}.6\text{H}_{2}\text{O}\).
We can perform experiments to determine the composition of substances. For example, blue copper sulphate (\(\text{CuSO}_{4}\)) crystals contain water. On heating the waters of crystallisation evaporate and the blue crystals become white. By weighing the starting and ending products, we can determine the amount of water that is in copper sulphate. Another example is reducing copper oxide to copper.
Don't get left behind
Join thousands of learners improving their science marks online with Siyavula Practice.
Moles and empirical formulae
Exercise 19.5
Calcium chloride is produced as the product of a chemical reaction.
What is the formula of calcium chloride?
What is the percentage mass of each of the elements in a molecule of calcium chloride?
If the sample contains \(\text{5}\) \(\text{g}\) of calcium chloride, what is the mass of calcium in the sample?
How many moles of calcium chloride are in the sample?
Solution not yet available
\(\text{13}\) \(\text{g}\) of zinc combines with \(\text{6,4}\) \(\text{g}\) of sulphur.
What is the empirical formula of zinc sulphide?
What mass of zinc sulphide will be produced?
What is the percentage mass of each of the elements in zinc sulphide?
The molar mass of zinc sulphide is found to be \(\text{97,44}\) \(\text{g·mol$^{-1}$}\). Determine the molecular formula of zinc sulphide.
A calcium mineral consisted of \(\text{29,4}\%\) calcium, \(\text{23,5}\%\) sulphur and \(\text{47,1}\%\) oxygen by mass. Calculate the empirical formula of the mineral.
A chlorinated hydrocarbon compound was analysed and found to consist of \(\text{24,24}\%\) carbon, \(\text{4,04}\%\) hydrogen and \(\text{71,72}\%\) chlorine. From another experiment the molecular mass was found to be \(\text{99}\) \(\text{g·mol$^{-1}$}\). Deduce the empirical and molecular formula.
Magnesium sulphate has the formula \(\text{MgSO}_{4}.\text{nH}_{2}\text{O}\). A sample containing \(\text{5,0}\) \(\text{g}\) of magnesium sulphate was heated until all the water had evaporated. The final mass was found to be \(\text{2,6}\) \(\text{g}\). How many water molecules were in the original sample?
All Siyavula textbook content made available on this site is released under the terms of a Creative Commons Attribution License. Embedded videos, simulations and presentations from external sources are not necessarily covered by this license. | CommonCrawl |
Asian-Australasian Journal of Animal Sciences (아세아태평양축산학회지)
Pages.1445-1450
Asian Australasian Association of Animal Production Societies (아세아태평양축산학회)
Effect of Feed Withdrawal and Heat Acclimatization on Stress Responses of Male Broiler and Layer-type Chickens (Gallus gallus domesticus)
Mahmoud, Kamel Z. (Department of Animal production, Faculty of Agriculture Jordan University of Science and Technology) ;
Yaseen, A.M. (Department of Animal production, Faculty of Agriculture Jordan University of Science and Technology)
https://doi.org/10.5713/ajas.2005.1445
This experiment was conducted to evaluate the effect of feed withdrawal (F) and heat acclimatization (A) on malebroiler and -layer chickens responses to acute heat stress (AHS) at four weeks of age. Totals of ninety male chicks of broiler or layer type were randomly allocated into 30 pens of grower batteries with raised wire floors. Chicks were subjected to F and A three times a week through the first three weeks of age. At each time, feed withdrawal and heat acclimatization (T = $35^{\circ}C$) lasted for six and four hours, respectively. Feed consumption (FC), body weight (BW), and feed conversion ratio (FCR) were recorded weekly for broiler type chickens only. At four weeks of age, all groups of chickens were exposed to AHS (T = $39{\pm}1^{\circ}C$) for three hours. Before and after AHS challenge, body temperature (Tb), heterophil (H), and lymphocyte (L) counts were recorded, and H/L ratio was calculated. Antibody (Ab) response to sheep red blood cells (SRBC) was assessed from all treatments without being exposed to AHS. Group F of broiler-type chickens weighed less (p<0.05) compared to control group. Also, both A and F groups of broiler-type chickens consumed less (p<0.05) feed when compared to control group. Acute heat stress elevated Tb of all treatment groups, however the increase was more profound (p<0.001) in broiler chicks. Broiler chicks of both A and F groups showed a tendency to have higher (p = 0.08) Tb when compared to control group. Acute heat stress elevated (p<0.001) H/L ratio in both types of chickens. Broiler chicks maintained higher (p<0.001) H/L ratio. Both F and A groups reduced (p<0.01) the level of elevation in H/L ratio compared to control groups of both types of chickens. Neither A nor F group affected the Ab production in response to SRBC. However, there was a tendency towards higher Ab responses in F group when compared to other groups in both types of chickens. Results of the present study demonstrate that previous history of feed withdrawal or episodes of heat exposures improved chicks'physiological withstanding of AHS and a tendency to improved humoral immune response.
Feed Withdrawal;Acclimatization;Body Temperature;Chicken;H/L;Heat Stress
Arjona, A., D. Denbow and W. D. Weaver. 1990. Neonatally induced thermotolerance: physiological responses. Comp. Biochem. Physiol. 95:393-399.
El-Gendy, E. and K. W. Wahburn. 1995. Genetic variation in body temperature and its response to short-term acute heat stress in broilers. Poult. Sci. 74:1528-1530.
Maxwell, M. H. and G. W. Robertson. 1998. UK survey of broiler ascites and sudden death syndromes in 1993. Br. Poult. Sci. 39:203-315.
SAS Institute Inc. 1990. SAS/STAT User's guide: Version 6, fourth ed. SAS Institute Inc., Cary, NC, USA.
Shini, S. 2003. Physiological responses of laying hens to the alternative housing systems. Int. J. Poult. Sci. 2:357-360.
Zulkifli, I., M. T. Che Norma, D. A. Israf and A. R. Omar. 2000. The effect of early age feed restriction on subsequent response to high environmental temperatures in female broiler chickens. Poult. Sci. 79:1401-1407.
Ballay, M., E. A. Dunnington, W. B. Gross and P. B. Siegel. 1992. Restricted feeding and broiler performance: age at initiation and length of restriction. Poult. Sci. 71:440-447.
Henken, M., A. M. Scarrsberg and W. van der Hel. 1983. The effect of environmental temperature on immune response and metabolism of the young chicken. 4. Effect of environmental temperature on some aspects of energy and protein metabolism. Poult. Sci. 62:59-67.
Dale, N. M. and H. L. Fuller. 1980. Effect of diet composition on feed intake and growth of chicks under heat stress. II. Constant vs. cyclic temperatures. Poult. Sci. 59:1434-1441.
Wiernusz, C. J. and R. G. Teeter. 1996. Acclimation effects on fed and fasted broiler thermobalance during thermoneutral and high ambient temperature exposure. Br. Poult. Sci. 37:677-687.
Munns, P. L. and S. J. Lamont. 1991. Effects of age and immunization interval on the anamnestic response to T-celldependent and T-cell-independent antigens in chickens. Poult. Sci. 70:2371-2374.
Eberhart, D. E. and K. W. Washburn. 1993a. Variation in body temperature response of naked neck and normally feathered chickens to heat stress. Poult. Sci. 72:1385-1390.
National Research Council. 1994. Nutrient requirements of poultry. 9th rev. ed. National Academy Press, Washington, DC.
Marder, J. 1973. Temperature regulation in the Bedouin fowl (Gallus domesticus). Physiol. Zool. 47:180-189.
Bollengier-Lee, S., P. E. Williams and C. G. Whithead. 1999. Optimal dietary concentration of vitamin E for alleviating the effect of heat stress on egg production in laying hens. Br. Poult. Sci. 40:102-107.
Yahav, S., A. Shamay, G. Horev, D. Bar-Ilan, O. Genina and M. Friedman-Einat. 1997. Effect of acquisition of improved thermotolerance on the induction of heat shock proteins in broiler chickens. Poult. Sci. 76:1428-1434. https://doi.org/10.1093/ps/76.10.1428
Givisiez, P. E., J. A. Ferro, M. I. Ferro, S. N. Kronka, E. Decuypere and M. Macari. 1999. Hepatic concentration of heat shock protein 70 kD (Hsp70) in broilers subjected to different thermal treatments. Br. Poult. Sci. 40:292-296.
Arad, Z., E. Moskovitis and J. Marder. 1975. A preliminary study of egg productionand heat tolerance in a new breed of fowl (Leghorn${\times}$Bedouin). Poult. Sci. 54:780-783.
May, J. D., J. W. Deaton and S. L. Branton. 1987. Body temperature of acclimated broilers during exposure to high temperature. Poult. Sci. 66:378-380.
Zulkifli, I., E. A. Dunnington, W. B. Gross and P. B. Siegel. 1994. Food restriction early or later in life and its effect on adaptability, disease resistance, and immunocompetence of heat stressed dwarf and nondwarf chickens. Br. Poult. Sci. 35:203-214.
Cahaner, A. and F. R. Leenstra. 1992. Effects of high temperature on growth and efficiency of male and female broilers from lines selected for high weight gain, favourable feed conversion and high or low fat content. Poult. Sci. 71:1237-1250.
Eberhart, D. E. and K. W. Washburn. 1993b. Assessing the effects of the naked neck gene on chronic heat stress resistance in two genetic populations. Poult. Sci. 72:1391-1399.
Plavnik, I. and S. Yahav. 1998. Effect of environmental temperature on broiler chickens subjected to growth restriction at an early age. Poult. Sci. 77:870-872.
Teeter, R. G., M. O. Smith and C. J. Wiernusz. 1992. Research note: broiler acclimation to heat distress and feed intake effects on body temperature in birds exposed to thermoneutral and high ambient temperatures. Poult. Sci. 71:1101-1104.
Yalcin, S., S. Ozkan, L. Turkmut and P. B. Siegel. 2001. Responses to heat stress in commercial and local broiler stocks. 1. Performance traits. Br. Poult. Sci. 42:49-152. https://doi.org/10.1080/713655061
Gross, W. B. and P. B. Siegel. 1983. Evaluation of heterophil/lymphocyte ratio as a measure of stress in chickens. Avi. Dis. 27:972-979.
Davis, G. S., F. W. Edens and C. R. Parkhurst. 1991. Computeraided heat acclimation in broiler cockerels. Poult. Sci. 70:302-306.
Zulkifli, I., P. K. Liew, D. A. Israf, A. R. Omar and M. Hair-Bejo. 2003. Effects of early age feed restriction and heat conditioning on heterophil/lymphocyte ratios, heat shock protein 70 expression and body temperature of heat-stressed broiler chickens. J. Therm. Biol. 28:217-222.
Mahmoud, K. Z. and F. W. Edens. 2003. Influence of selenium sources on age-related and mild heat stress-related changes of blood and liver glutathione redox cycle in broiler chickens (Gallus domesticus). Comp. Biochem. Physiol. B 136:921-934.
Kubikova, L L., P. Vyboh and L. Kostal. 2001. Behavioural, endocrine and metabolic effects of food restriction in broiler breeder hens. Acta Vet. Brno. 70:247-257.
Teeter, R. G., M. O. Smith, F. N. Owens, S. C. Arp, S. Sangiah and J. E. Breazile. 1985. Chronic heat stress and relative humidity:Occurrence and treatment in broiler chicks. Poult. Sci. 64:1060-1064.
Zulkifli, I., S. A. Mysahra and L. Z. Jin. 2004. Dietary supplementation of Betaine ($Betafin^{\circledR} $) and response to high temperature stress in Male broiler chickens. Asian-Aust. J. Anim. Sci. 17:244-249.
The effect of supplemental L-threonine on laying performance, serum free amino acids, and immune function of laying hens under high-temperature and high-humidity environmental climates vol.20, pp.3, 2011, https://doi.org/10.3382/japr.2010-00308
The effects of chronic intermittent noise exposure on broiler chicken performance vol.82, pp.4, 2011, https://doi.org/10.1111/j.1740-0929.2011.00877.x
Evaluating the impact of excess dietary tryptophan on laying performance and immune function of laying hens reared under hot and humid summer conditions vol.53, pp.4, 2012, https://doi.org/10.1080/00071668.2012.719149
The effects of early-age thermal manipulation and daily short-term fasting on performance and body temperatures in broiler exposed to heat stress pp.09312439, 2012, https://doi.org/10.1111/j.1439-0396.2012.01330.x
Classificação de características produtivas fenotípicas de diferentes raças de poedeiras através da mineração de dados vol.43, pp.1, 2013, https://doi.org/10.1590/S0103-84782012005000139
The effects of supplemental threonine on performance, carcass characteristics, immune response and gut health of broilers in subtropics during pre-starter and starter period pp.09312439, 2018, https://doi.org/10.1111/jpn.12991 | CommonCrawl |
Bernasconi, Anna and Ciriani, Valentina and Drechsler, Rolf and Villa, Tiziano
Efficient Minimization of Fully Testable 2-SPP Networks
The paper presents a heuristic algorithm for the minimization of 2-SPP networks, i.e., three-level XOR-AND-OR forms with XOR gates restricted to fan-in 2. Previous works had presented exact algorithms for the minimization of unrestricted SPP networks and of 2-SPP networks. The exact minimization procedures were formulated as covering problems as in the minimization of SOP forms and had worst-case exponential complexity. Extending the expand-irredundant-reduce paradigm of ESPRESSO heuristic, we propose a minimization algorithm for 2-SPP networks that iterates local minimization and reshape of a solution until further improvement. We introduce also the notion of EXOR-irredundant to prove that OR-AND-EXOR irredundant networks are fully testable and guarantee that our algorithm yields OR-AND-EXOR irredundant solutions. We report a large set of experiments showing impressive high-quality results with affordable run times, handling also examples whose exact solutions could not be computed.
Aldinucci, Marco and Danelutto, Marco and Paternesi, Andrea and Ravazzolo, Roberto and Vanneschi, Marco
Building Interoperable Grid-aware ASSIST Applications via Web Services
The ASSIST environment provides a high-level programming toolkit for the grid. ASSIST applications are described by means of a coordination language, which can express arbitrary graphs of modules. These modules (or a graph of them) may be enclosed in components specifically designed for the grid (GRID.it components). In this paper we describe how ASSIST modules can be wired through standard Web Services, and how GRID.it components may be made available as standard Web Services.
Implicit and Explicit Representation of Approximated Motifs
Detecting repeated 3D protein substructures has become a new crucial frontier in motifs inference. In \cite{cpm} we have suggested a possible solution to this problem by means of a new framework in which the repeated pattern is required to be conserved also in terms of relations between its position pairs. In our application these relations are the distances between $\alpha$-carbons of amino acids in 3D proteins structures, thus leading to a \emph{structural consensus} as well. In this paper we motivate some complexity issues claimed (and assumed, but not proved) in \cite{cpm} concerning inclusion tests between occurrences of repeated motifs. These inclusion tests are performed during the motifs inference in \emph{KMRoverlapR} (presented in \cite{cpm}), but also within other motifs inference tools such as \emph{KMRC} (\cite{kmrc}). These involve alternative representations of motifs, for which we also prove here some interesting properties concerning pattern matching issues. We conclude this contribution with a few tests on cytochrome P450 protein structures.
Del Corso, Gianna M. and Gullì, Antonio and Romani, Francesco
Comparison of Krylov Subspace Methods on the PageRank Problem
PageRank algorithm plays a very important role in search engine technology and consists in the computation of the eigenvector corresponding to the eigenvalue one of a matrix whose size is now in the billions. The problem incorporates a parameter $\alpha$ that determines the difficulty of the problem. In this paper, the effectiveness of stationary and non stationary methods are compared on some portion of real web matrices for different choices of $\alpha$. We see that stationary methods are very reliable and more competitive when the problem is well conditioned, that is for small values of $\alpha$. However, for large value of the parameter $\alpha$ the problem becomes more difficult and methods such as preconditioned BiCGStab or restarted preconditioned GMRES become competitive with stationary methods in terms of Mflops count as well as in number of iterations necessary to reach convergence.
Aldinucci, Marco and Danelutto, Marco and Giaccherini, Gianni and Torquati, Massimo and Vanneschi, Marco
Towards a distributed scalable data service for the Grid
AdHoc (Adaptive Distributed Herd of Ob ject Caches) is a Grid-enabled, fast, scalable ob ject repository providing programmers with a general storage module. We present three different software tools based on AdHoc: A parallel cache for Apache, a DSM, a main-memory parallel file system. We also show that these tool exhibit a considerable performance and speedup both in absolute figures and w.r.t. other software tools exploiting the same features.
Gorlatch, Sergei and Danelutto, Marco
Proceedings of the CoreGRID Integration Workshop (CGIW'2005)
The workshop is organised by the Network of Excellence CoreGRID funded by the European Commission under the sixth framework programme IST-2003-2.3.2.8 starting September 1st, 2004. CoreGRID aims at strengthening and advancing scientific and technological excellence in the area of Grid and Peer-to-Peer technologies. To achieve this objective, the network brings together a critical mass of well-established researchers (119 permanent researchers and 165 PhD students) from forty-two institutions who have constructed an ambitious joint programme of activities. The goal of the workshop is to promote the integration of the CoreGRID network and of the European research community in the area of Grid technologies, in order to overcome the current fragmentation and duplication of efforts in this area. The list of topics of Grid research covered at the workshop includes but is not limited to: knowledge & data management; programming models; system architecture; Grid information, resource and workflow monitoring services; resource management and scheduling;systems, tools and environments;trust and security issues on the Grid.
Packet Delay Monitoring without a GPS
This paper illustrates a technique to characterize one-way packet delays. Such technique does not depend on external clock synchronization facilities: instead, it computes the relative skew of the two clocks, and uses this information to characterize one-way packet delays. We focus on the applicability of such technique to a network monitoring environment, and perform an extensive test that includes second order clock frequency variations. We conclude that the approach is especially suited to estimate jitter, and other characteristics of one-way delay variation. It can be helpful also to evaluate second order parameters of one-way delay, like standard deviation, when second order variations of clock frequency, usually due to temperature variations, are compensated by hardware. This result makes one-way delay variations measurement widely accessible to Internet hosts, at a cost which is overall comparable with that of a ping.
A Compositional Coalgebraic Model of Monadic Fusion Calculus
We propose a compositional coalgebraic semantics of the Fusion calculus of Parrow and Victor in the version with explicit fusions by Gardner and Wischik. We follow a recent approach developed by the same authors and previously applied to the pi-calculus for lifting calculi with structural axioms to bialgebraic models. In our model, the unique morphism to the final bialgebra induces a bisimilarity relation which coincides with hyperequivalence and which is a congruence with respect to the operations. Interesting enough, the explicit fusion approach allows to exploit for the Fusion calculus essentially the same algebraic structure used for the pi-calculus.
Ciriani, Valentina and Bernasconi, Anna and Drechsler, Rolf
Testability of SPP Three-Level Logic Networks in Static Fault Models
Recently introduced, three-level logic Sum of Pseudoproducts (SPP) forms allow the representation of Boolean functions with much shorter expressions than standard two-level Sum of Products (SOP) forms, or other three-level logic forms. In this paper the testability of circuits derived from SPPs is analyzed. We study testability under static Fault Models (FMs),i.e., the Stuck-At Fault Model (SAFM) and the Cellular Fault Model(CFM). For SPP networks several minimal forms can be considered. While full testability can be proved in the SAFM for some forms, SPP networks in the CFM are shown to contain redundancies. Finally, we propose a method for transforming non-testable networks into testable ones. Experimental results are given to demonstrate the efficiency of the approach.
Augusto, Ciuffoletti
The Wandering Token: Congestion Avoidance of a Shared Resource
In a distributed system where scalability is an issue, like in a GRID, the problem of enforcing mutual exclusion often arises in a soft form: the infrequent failure of the mutual exclusion predicate is tolerated, without compromising the consistent operation of the overall system. For instance this occurs when the operation subject to mutual exclusion requires massive use of a shared resource. We introduce a scalable soft mutual exclusion algorithm, based on token passing: one distinguished feature of our algorithm is that instead of introducing an overlay topology we adopt a random walk approach. The consistency of our proposal is evaluated by simulation, and we exemplify its use in the coordination of large data transfers in a backbone based network.
Danelutto, Marco and Migliore, Castrenze and Pantaleo, Cosimino
A dataflow-like implementation of ASSIST parmod
ASSIST is a structured parallel programming environment targeting networks/clusters of workstations and grids. It introduced the parmod parallel construct, supporting a variety of parallelism exploitation patterns, including classical ones. The original implementation of parmod relies on static assignment of parallel activities to the processing elements at hand. In this work we discuss an alternative implementation of the parmod construct that implements completely dynamic assignment of parallel activities to the processing elements. We show that the new implementation introduces very limited overhead in case of regular computations, whereas it performs much better than the original one in case of irregular applications. The whole implementation of parmod is available as a C++/MPI library.
Andreozzi, Sergio and Ciuffoletti, Augusto and Ghiselli, Antonia and Vistoli, Cristina
GlueDomains: Organization and Accessibility of Network Monitoring Data in a Grid
The availability of the outcome of network monitoring activities, while valuable for the operation of Grid applications, poses serious scalability problems: in principle, in a Grid composed of resources, we need to keep record of end-to-end paths. We introduce a scalable approach to network monitoring, that consists in partitioning the Grid into limiting monitoring activity to the measurement of domain-to-domain connectivity. Partitions must be consistent with network performance, since we expect that an observed network performance between domains is representative of the performance between the Grid Services included into such domains. We argue that partition design is a critical step: a consequence of an inconsistent partitioning is the production of invalid characteristics. The paper discusses such approach, also exploring its limits. We describe a fully functional prototype which is currently under test in the frame of the DATATAG project.
Bevilacqua, Roberto and Bozzo, Enrico and Del Corso, Gianna M. and Fasino, Dario
Rank structure of generalized inverses of rectangular banded matrices
We describe rank structures in generalized inverses of possibly rectangular banded matrices. In particular, we show that various kind of generalized inverses of rectangular banded matrices have submatrices whose rank depends on the bandwidth and on the nullity of the matrix. Moreover, we give an explicit representation formula for some generalized inverses of strictly banded matrices.
Bruni, Roberto and Montanari, Ugo and Lanese, Ivan
Normal Forms for Stateless Connectors
The conceptual separation between computation and coordination in distributed computing systems motivates the use of peculiar entities commonly called connectors, whose task is managing the interaction among distributed components. Different kinds of connectors exist in the literature at different levels of abstraction. We focus on a basic algebra of connectors which is expressive enough to model e.g. all the architectural connectors of CommUnity. We first define the operational, observational and denotational semantics of connectors, then we show that the observational and denotational semantics coincide and finally we give a complete normal-form axiomatization.
Gallo, Giorgio and Sodini, Claudia
Operations Research Methods and Models for Crisis Prevention and Early Warning
Security is one particular global challenge that has recently come to the fore due to world events and societal changes. Within this context, one of the areas in which Operations Research can give an important contribution is the area of early warning and crisis prevention. This is a challenging research area requiring a multidisciplinary approach, which has enjoyed an increased interest in recent years. Here, we will highlight some of the problems arising in this area in which O.R. techniques can find useful applications.
Scozzari, Francesca and Amato, Gianluca
In the context of abstract interpretation based static analysis, we cope with the problem of correctness and optimality for logic program analysis. We propose a new framework equipped with a denotational, goal-dependent semantics which refines many goal-driven frameworks appeared in the literature. The key point is the introduction of two specialized concrete operators for forward and backward unification. We prove that our goal-dependent semantics is correct w.r.t. computed answers and we provide the best correct approximations of all the operators involved in the semantics for set-sharing analysis. We show that the precision of the overall analysis is strictly improved and that, in some cases, we gain precision w.r.t. more complex domains involving linearity and freeness information.
Menconi, Giulia and Marangoni, Roberto
A compression-based approach for coding sequences identification in prokaryotic genomes
To identify coding regions in genomic sequences represents the first step toward further analysis of the biological function carried on by the different functional elements in a genome. The present paper presents a novel method for the classification of coding and non-coding regions in prokaryotic genomes, based on a suitable defined compression index of a DNA sequence. The proposed approach has been applied on some prokaryotic complete genomes, obtaining optimal scores of correctly recognized coding and non-coding regions. Several false-positive and false-negative cases have been investigated in detail, discovering that this approach can fail in the presence of highly-structured coding regions (e.g., genes coding for modular proteins) or quasi-random non-coding regions (regions hosting non-functional fragments of copies of functional genes; regions hosting promoters or other protein-binding sequences, etc.).
Danelutto, Marco and Vanneschi, Marco
A RISC approach to GRID
Current GRID technology provides users/programmers with extended and comprehensive middleware tools covering all the basic aspects a programmer must deal with when writing GRID aware applications. Programmers of GRID aware applications use such middleware systems to gather the needed resources, stage code and data to the selected computing resources, schedule computations on them and so on. Overall, a huge programming effort is required in order to come to a working, efficient GRID aware application code. Here we propose a different approach. By recognizing that most GRID applications share a common parallel/distributed structure, we propose to use application managers that take care of all the details involved in the implementation of well known GRID aware application schemas. Such application managers use the functionalities of a RISC GRID core run time system (RGC). The RGC may be built on top of existing GRID middleware. Programmers of GRID aware applications, therefore, do not directly use GRID middleware. Rather, they structure the application using the available application managers. The application managers, in turn, invoke the basic GRID services provided by RGC to accomplish both functional and performance user requirements.
Luccio, Fabrizio and Mesa Enriquez, Antonio and Pagli, Linda
k-Restricted Rotation with an Application to Search Tree Rebalancing
The restricted rotation distance d_{R}(S,T) between two binary trees S, T of n vertices is the minimum number of rotations by which S can be transformed into T, where rotations can only take place at the root of the tree, or at the right child of the root. A sharp upper bound d_{R}(S,T) \leq 4n-8 is known, based on the word metric of Thompson's group. We refine this bound to a sharp d_{R}(S,T) \leq 4n-8-\rho_{S}-\rho_{T}, where \rho_{S} and \rho_{T} are the numbers of vertices in the rightmost vertex chains of the two trees, by means of a very simple transformation algorithm based on elementary properties of trees. We then generalize the concept of restricted rotation to k-restricted rotation, by allowing rotations to take place at all the vertices of the highest k levels of the tree. For k=2 we show that not much is gained in the worst case, although the classical problem of rebalancing an AVL tree can be solved efficiently, in particular rebalancing after vertex deletion requires O(log n) rotations as in the standard algorithm. Finding significant bounds and applications for k \geq 3 is open.
Aldinucci, Marco and Petrocelli, Alessandro and Pistoletti, Edoardo and Torquati, Massimo and Vanneschi, Marco and Veraldi, Luca and Zoccolo, Corrado
Dynamic reconfiguration of Grid-aware applications in ASSIST
Current Grid-aware applications are developed on top of lowlevel libraries by developers who are experts on Grid software implementation. Although some applications have been produced this way, this approach can hardly support the additional complexity to QoS control in real applications. We describe the ASSIST programming environment, showing that it is a suitable basis to capture and cope with many of the desired features for QoS control for the Grid. Grid applications, built as compositions of ASSIST modules, are supported by a hierarchical Application Manager targeting application QoS control.
Amato, Gianluca and Coppola, Massimo and Gnesi, Stefania and Scozzari, Francesca and Semini, Laura
Modeling Web Applications by the Multiple Levels of Integrity Policy
We propose a formal method to validate the reliability of a web application, by modeling interactions among its constituent objects. Modeling exploits the recent "Multiple Levels of Integrity" mechanism which allows objects with dynamically changing reliability to cooperate within the application. The novelty of the method is the ability to describe systems where objects can modify their own integrity level, and react to such changes in other objects. The model is formalized with a process algebra, properties are expressed using the ACTL temporal logic, and can be verified by means of a model checker. Any instance of the above model inherits both the established properties and the proof techniques. To substantiate our proposal we consider several case-studies of web applications, showing how to express specific useful properties, and their validation schemata. Examples range from on-line travel agencies, inverted Turing test to detect malicious web-bots, to content cross-validation in peer to peer systems.
Geraci, Filippo and Grossi, Roberto
Distilling Router Data Analysis for Faster and Simpler Dynamic IP Lookup Algorithms
We consider the problem of fast IP address lookup in the forwarding engines of Internet routers. Many hardware and software solutions available in the literature solve a more general problem on strings, the longest prefix match. These solutions are then specialized on real IPv4/IPv6 addresses to work well on the specific IP lookup problem. We propose to go the other way around. We first analyze over 2400 public snapshots of routing tables collected over five years, discovering what we call the "middle-class effect" of those routes. We then exploit this effect for tailoring a simple solution to the IP lookup scheme, taking advantage of the skewed distribution of Internet addresses in routing tables. Our algorithmic solution is easy to implement in hardware or software as it is tantamount to performing an indirect memory access. Its performance can be bounded tightly in the worst case and has very low memory dependence (e.g., just one memory access to off-chip memory in the hardware implementation). It can quickly handle route announcements and withdrawals on the fly, with a small cost which scales well with the number of routes. Concurrent access is permitted during these updates. Our ideas may be helpful for attaining state-of-art link speed and may contribute to setting up a general framework for designing lookup methods by data analysis.
On abstract unification for variable aliasing
We face the problem of devising optimal unification operators for domains of abstract substitutions. In particular, we are interested in abstract domains for sharing and linerity properties, which are widely used in logic program analysis. We propose a new (infinite) domain ShLin which can be thought of as a general framework from which other domains can be easily derived by abstraction. The advantage is that abstract unification in ShLin is simple and elegant, and it is based on a new concept of sharing graph which plays the same role of alternating paths for pair sharing analysis. We also provide an alternative, purely algebraic description of sharing graphs. Starting from the results for ShLin, we derive optimal abstract operators for two well-known domains which combine sharing and linearity: a domain proposed by Andy King and the classic Sharing X Lin.
Generalized inverses of band matrices
In 1959 Edgar Asplund presented a geometric lemma that largely anticipated many results on the structure of inverses of band matrices. In this note we discuss an extension of Asplund's lemma that addresses the concept of generalized inverse,in particular the Moore-Penrose inverse. | CommonCrawl |
Invariant stable manifolds for partial neutral functional differential equations in admissible spaces on a half-line
DCDS-B Home
Kurzweil integral representation of interacting Prandtl-Ishlinskii operators
November 2015, 20(9): 2967-2992. doi: 10.3934/dcdsb.2015.20.2967
Shape stability of optimal control problems in coefficients for coupled system of Hammerstein type
Olha P. Kupenko 1, and Rosanna Manzo 2,
Dnipropetrovsk Mining University, Department of System Analysis and Control, Karl Marks av., 19, 49005 Dnipropetrovsk, Ukraine
Università degli Studi di Salerno, Dipartimento di Ingegneria dell'Informazione, Ingegneria Elettrica e Matematica Applicata, Via Giovanni Paolo II, 132, 84084 Fisciano (SA), Italy
Received April 2014 Revised October 2014 Published September 2015
In this paper we consider an optimal control problem (OCP) for the coupled system of a nonlinear monotone Dirichlet problem with matrix-valued $L^\infty(\Omega;\mathbb{R}^{N\times N} )$-controls in coefficients and a nonlinear equation of Hammerstein type. Since problems of this type have no solutions in general, we make a special assumption on the coefficients of the state equation and introduce the class of so-called solenoidal admissible controls. Using the direct method in calculus of variations, we prove the existence of an optimal control. We also study the stability of the optimal control problem with respect to the domain perturbation. In particular, we derive the sufficient conditions of the Mosco-stability for the given class of OCPs.
Keywords: control in coefficients, Nonlinear monotone Dirichlet problem, domain perturbation., equation of Hammerstein type.
Mathematics Subject Classification: Primary: 49J20, 35J57; Secondary: 49J45, 93C7.
Citation: Olha P. Kupenko, Rosanna Manzo. Shape stability of optimal control problems in coefficients for coupled system of Hammerstein type. Discrete & Continuous Dynamical Systems - B, 2015, 20 (9) : 2967-2992. doi: 10.3934/dcdsb.2015.20.2967
D. E. Akbarov, V. S. Melnik and V. V. Jasinskiy, Coupled Systems Control Methods,, Viriy, (1998). Google Scholar
G. Allaire, Shape Optimization by the Homogenization Method,, Applied Mathematical Sciences, (2002). doi: 10.1007/978-1-4684-9286-6. Google Scholar
T. Bagby, Quasi topologies and rational approximation,, J. Func. Anal., 10 (1972), 259. doi: 10.1016/0022-1236(72)90025-0. Google Scholar
D. Bucur and G. Buttazzo, Variational Methods in Shape Optimization Problems,, Birkhäuser, (2005). Google Scholar
D. Bucur and P. Trebeschi, Shape optimization problems governed by nonlinear state equations,, Proc. Roy. Soc. Edinburgh, 128 (1998), 943. doi: 10.1017/S0308210500030006. Google Scholar
D. Bucur and J. P. Zolésio, $N$-Dimensional Shape Optimization under Capacitary Constraints,, J. Differential Equations, 123 (1995), 504. doi: 10.1006/jdeq.1995.1171. Google Scholar
G. Buttazzo and G. Dal Maso, Shape optimization for Dirichlet problems. Relaxed SIS and optimally conditions,, Appl. Math. Optim., 23 (1991), 17. doi: 10.1007/BF01442391. Google Scholar
C. Calvo-Jurado and J. Casado-Diaz, Results on existence of solution for an optimal design problem,, Extracta Mathematicae, 18 (2003), 263. Google Scholar
G. Dal Maso and F. Murat, Asymptotic behaviour and correctors for Dirichlet problem in perforated domains with homogeneous monotone operators,, Ann. Scuola Norm. Sup. Pisa Cl.Sci., 24 (1997), 239. Google Scholar
G. Dal Maso, F. Ebobisse and M. Ponsiglione, A stability result for nonlinear Neumann problems under boundary variations,, J. Math. Pures Appl., 82 (2003), 503. doi: 10.1016/S0021-7824(03)00014-X. Google Scholar
E. N. Dancer, The effect of domains shape on the number of positive solutions of certain nonlinear equations,, J. Diff. Equations, 87 (1990), 316. doi: 10.1016/0022-0396(90)90005-A. Google Scholar
D. Daners, Domain perturbation for linear and nonlinear parabolic equations,, J. Diff. Equations, 129 (1996), 358. doi: 10.1006/jdeq.1996.0122. Google Scholar
C. D'Apice, U. De Maio and O. P. Kogut, On shape stability of Dirichlet optimal control problems in coefficients for nonlinear elliptic equations,, Advances in Differential Equations, 15 (2010), 689. Google Scholar
C. D'Apice, U. De Maio and O. P. Kogut, Optimal control problems in coefficients for degenerate equations of monotone type: shape stability and attainability problems,, SIAM Journal on Control and Optimization, 50 (2012), 1174. doi: 10.1137/100815761. Google Scholar
C. D'Apice, U. De Maio and P. I. Kogut, Suboptimal boundary control for elliptic equations in critically perforated domains,, Ann. Inst. H. Poincaré Anal. Non Line'aire, 25 (2008), 1073. doi: 10.1016/j.anihpc.2007.07.001. Google Scholar
L. C. Evans and R. F. Gariepy, Measure Theory and Fine Properties of Functions,, CRC Press, (1992). Google Scholar
K. J. Falconer, The Geometry of Fractal Sets,, Cambridge University Press, (1986). Google Scholar
H. Gajewski, K. Gröger and K. Zacharias, Nichtlineare Operatorgleichungen und Operatordifferentialgleichungen,, Academie-Varlar, (1974). Google Scholar
J. Haslinger and P. Neittaanmäki, Finite Element Approximation of Optimal Shape. Material and Topology Design,, John Wiley and Sons, (1996). Google Scholar
J. Heinonen, T. Kilpelainen and O. Martio, Nonlinear Potential Theory of Degenerate Elliptic Equations,, Unabridged republication of the 1993 original. Dover Publications, (1993). Google Scholar
V. I. Ivanenko and V. S. Mel'nik, Varational Metods in Control Problems for Systems with Distributed Parameters,, Naukova Dumka, (1988). Google Scholar
O. P. Kogut, Qualitative Analysis of one Class of Optimization Problems for Nonlinear Elliptic Operators,, PhD thesis at Gluskov Institute of Cyberentics NAS Kiev, (2010). Google Scholar
P. I. Kogut and G. Leugering, Optimal Control Problems for Partial Differential Equations on Reticulated Domains,, Series: Systems and Control, (2011). doi: 10.1007/978-0-8176-8149-4. Google Scholar
O. P. Kupenko, Optimal control problems in coefficients for degenerate variational inequalities of monotone type.I Existence of solutions,, Journal of Computational & Applied Mathematics, 106 (2011), 88. Google Scholar
I. Lasiecka, NSF-CMBS Lecture Notes: Mathematical Control Theory of Coupled Systems of Partial Differential Equations,, SIAM, (2002). Google Scholar
J.-L. Lions, Optimal Control of Systems Governed by Partial Differential Equations,, Springer Verlag, (1971). Google Scholar
K. A. Lurie, Applied Optimal Control Theory of Distributed Systems,, Plenum Press, (1993). doi: 10.1007/978-1-4757-9262-1. Google Scholar
U. Mosco, Convergence of convex sets and of solutions of variational inequalities,, Adv. Math., 3 (1969), 510. doi: 10.1016/0001-8708(69)90009-7. Google Scholar
F. Murat, Un contre-exemple pour le probleme du controle dans les coefficients,, C. R. Acad. Sci. Paris Ser. A-B, 273 (1971). Google Scholar
F. Murat and L. Tartar, H-convergence. Topics in the mathematical modelling of composite materials,, Progr. Nonlinear Differential Equations Appl., 31 (1997), 21. Google Scholar
O. Pironneau, Optimal Shape Design for Elliptic Systems,, Springer-Verlag, (1984). doi: 10.1007/978-3-642-87722-3. Google Scholar
U. Ë. Raytum, Optimal Control Problems for Elliptic Equations,, Zinatne, (1989). Google Scholar
J. Sokolowski and J. P. Zolesio, Introduction to Shape Optimization,, Springer-Verlag, (1992). doi: 10.1007/978-3-642-58106-9. Google Scholar
D. Tiba, Lectures on the Control of Elliptic Systems,, in: Lecture Notes, (1995). Google Scholar
M. M. Vainberg and I. M. Lavrentieff, Nonlinear equations of hammerstein type with potential and monotone operators in banach spaces,, Matematicheskij Sbornik, 87 (1972), 324. Google Scholar
M. Z. Zgurovski and V. S. Mel'nik, Nonlinear Analysis and Control of Physical Processes and Fields,, Springer-Verlag, (2004). doi: 10.1007/978-3-642-18770-4. Google Scholar
M. Z. Zgurovski, V. S. Mel'nik and A. N. Novikov, Applied Methods for Analysis and Control of Nonlinear Processes and Fields,, Naukova Dumka, (2004). Google Scholar
W. P. Ziemer, Weakly Differentiable Functions,, Springer-Verlag, (1989). doi: 10.1007/978-1-4612-1015-3. Google Scholar
Gabriella Zecca. An optimal control problem for some nonlinear elliptic equations with unbounded coefficients. Discrete & Continuous Dynamical Systems - B, 2019, 24 (3) : 1393-1409. doi: 10.3934/dcdsb.2019021
Peter I. Kogut. On approximation of an optimal boundary control problem for linear elliptic equation with unbounded coefficients. Discrete & Continuous Dynamical Systems - A, 2014, 34 (5) : 2105-2133. doi: 10.3934/dcds.2014.34.2105
Peter I. Kogut, Olha P. Kupenko. On optimal control problem for an ill-posed strongly nonlinear elliptic equation with $p$-Laplace operator and $L^1$-type of nonlinearity. Discrete & Continuous Dynamical Systems - B, 2019, 24 (3) : 1273-1295. doi: 10.3934/dcdsb.2019016
Khadijah Sharaf. A perturbation result for a critical elliptic equation with zero Dirichlet boundary condition. Discrete & Continuous Dynamical Systems - A, 2017, 37 (3) : 1691-1706. doi: 10.3934/dcds.2017070
Thierry Horsin, Peter I. Kogut, Olivier Wilk. Optimal $L^2$-control problem in coefficients for a linear elliptic equation. II. Approximation of solutions and optimality conditions. Mathematical Control & Related Fields, 2016, 6 (4) : 595-628. doi: 10.3934/mcrf.2016017
Haiyang Wang, Zhen Wu. Time-inconsistent optimal control problem with random coefficients and stochastic equilibrium HJB equation. Mathematical Control & Related Fields, 2015, 5 (3) : 651-678. doi: 10.3934/mcrf.2015.5.651
Thierry Horsin, Peter I. Kogut. Optimal $L^2$-control problem in coefficients for a linear elliptic equation. I. Existence result. Mathematical Control & Related Fields, 2015, 5 (1) : 73-96. doi: 10.3934/mcrf.2015.5.73
Isabeau Birindelli, Francoise Demengel. The dirichlet problem for singluar fully nonlinear operators. Conference Publications, 2007, 2007 (Special) : 110-121. doi: 10.3934/proc.2007.2007.110
Patrick Henning, Mario Ohlberger. Error control and adaptivity for heterogeneous multiscale approximations of nonlinear monotone problems. Discrete & Continuous Dynamical Systems - S, 2015, 8 (1) : 119-150. doi: 10.3934/dcdss.2015.8.119
A. Rodríguez-Bernal. Perturbation of the exponential type of linear nonautonomous parabolic equations and applications to nonlinear equations. Discrete & Continuous Dynamical Systems - A, 2009, 25 (3) : 1003-1032. doi: 10.3934/dcds.2009.25.1003
S.V. Zelik. The attractor for a nonlinear hyperbolic equation in the unbounded domain. Discrete & Continuous Dynamical Systems - A, 2001, 7 (3) : 593-641. doi: 10.3934/dcds.2001.7.593
Bo Guan, Heming Jiao. The Dirichlet problem for Hessian type elliptic equations on Riemannian manifolds. Discrete & Continuous Dynamical Systems - A, 2016, 36 (2) : 701-714. doi: 10.3934/dcds.2016.36.701
Piotr Kowalski. The existence of a solution for Dirichlet boundary value problem for a Duffing type differential inclusion. Discrete & Continuous Dynamical Systems - B, 2014, 19 (8) : 2569-2580. doi: 10.3934/dcdsb.2014.19.2569
Jan Andres, Luisa Malaguti, Martina Pavlačková. Hartman-type conditions for multivalued Dirichlet problem in abstract spaces. Conference Publications, 2015, 2015 (special) : 38-55. doi: 10.3934/proc.2015.0038
Xiaorui Wang, Genqi Xu. Uniform stabilization of a wave equation with partial Dirichlet delayed control. Evolution Equations & Control Theory, 2019, 0 (0) : 0-0. doi: 10.3934/eect.2020022
Takeshi Ohtsuka, Ken Shirakawa, Noriaki Yamazaki. Optimal control problem for Allen-Cahn type equation associated with total variation energy. Discrete & Continuous Dynamical Systems - S, 2012, 5 (1) : 159-181. doi: 10.3934/dcdss.2012.5.159
Minzilia A. Sagadeeva, Sophiya A. Zagrebina, Natalia A. Manakova. Optimal control of solutions of a multipoint initial-final problem for non-autonomous evolutionary Sobolev type equation. Evolution Equations & Control Theory, 2019, 8 (3) : 473-488. doi: 10.3934/eect.2019023
Kunquan Lan, Wei Lin. Lyapunov type inequalities for Hammerstein integral equations and applications to population dynamics. Discrete & Continuous Dynamical Systems - B, 2019, 24 (4) : 1943-1960. doi: 10.3934/dcdsb.2018256
Chunhui Qiu, Rirong Yuan. On the Dirichlet problem for fully nonlinear elliptic equations on annuli of metric cones. Discrete & Continuous Dynamical Systems - A, 2017, 37 (11) : 5707-5730. doi: 10.3934/dcds.2017247
Martino Bardi, Paola Mannucci. On the Dirichlet problem for non-totally degenerate fully nonlinear elliptic equations. Communications on Pure & Applied Analysis, 2006, 5 (4) : 709-731. doi: 10.3934/cpaa.2006.5.709
Olha P. Kupenko Rosanna Manzo | CommonCrawl |
Calibration of the Logarithmic-Periodic Dipole Antenna (LPDA) Radio Stations at the Pierre Auger Observatory using an Octocopter (1702.01392)
The Pierre Auger Collaboration: A. Aab, P. Abreu, M. Aglietta, I. Al Samarai, I.F.M. Albuquerque, I. Allekotte, A. Almela, J. Alvarez Castillo, J. Alvarez-Muñiz, G.A. Anastasi, L. Anchordoqui, B. Andrada, S. Andringa, C. Aramo, F. Arqueros, N. Arsene, H. Asorey, P. Assis, J. Aublin, G. Avila, A.M. Badescu, A. Balaceanu, F. Barbato, R.J. Barreira Luz, J.J. Beatty, K.H. Becker, J.A. Bellido, C. Berat, M.E. Bertaina, X. Bertou, P.L. Biermann, P. Billoir, J. Biteau, S.G. Blaess, A. Blanco, J. Blazek, C. Bleve, M. Boháčová, D. Boncioli, C. Bonifazi, N. Borodai, A.M. Botti, J. Brack, I. Brancus, T. Bretz, A. Bridgeman, F.L. Briechle, P. Buchholz, A. Bueno, S. Buitink, M. Buscemi, K.S. Caballero-Mora, L. Caccianiga, A. Cancio, F. Canfora, L. Caramete, R. Caruso, A. Castellina, G. Cataldi, L. Cazon, A.G. Chavez, J.A. Chinellato, J. Chudoba, R.W. Clay, A. Cobos, R. Colalillo, A. Coleman, L. Collica, M.R. Coluccia, R. Conceição, G. Consolati, F. Contreras, M.J. Cooper, S. Coutu, C.E. Covault, J. Cronin, S. D'Amico, B. Daniel, S. Dasso, K. Daumiller, B.R. Dawson, R.M. de Almeida, S.J. de Jong, G. De Mauro, J.R.T. de Mello Neto, I. De Mitri, J. de Oliveira, V. de Souza, J. Debatin, O. Deligny, C. Di Giulio, A. Di Matteo, M.L. Díaz Castro, F. Diogo, C. Dobrigkeit, J.C. D'Olivo, Q. Dorosti, R.C. dos Anjos, M.T. Dova, A. Dundovic, J. Ebr, R. Engel, M. Erdmann, M. Erfani, C.O. Escobar, J. Espadanal, A. Etchegoyen, H. Falcke, G. Farrar, A.C. Fauth, N. Fazzini, F. Fenu, B. Fick, J.M. Figueira, A. Filipčič, O. Fratu, M.M. Freire, T. Fujii, A. Fuster, R. Gaior, B. García, D. Garcia-Pinto, F. Gaté, H. Gemmeke, A. Gherghel-Lascu, P.L. Ghia, U. Giaccari, M. Giammarchi, M. Giller, D. Głas, C. Glaser, G. Golup, M. Gómez Berisso, P.F. Gómez Vitale, N. González, A. Gorgi, P. Gorham, A.F. Grillo, T.D. Grubb, F. Guarino, G.P. Guedes, M.R. Hampel, P. Hansen, D. Harari, T.A. Harrison, J.L. Harton, A. Haungs, T. Hebbeker, D. Heck, P. Heimann, A.E. Herve, G.C. Hill, C. Hojvat, E. Holt, P. Homola, J.R. Hörandel, P. Horvath, M. Hrabovský, T. Huege, J. Hulsman, A. Insolia, P.G. Isar, I. Jandt, S. Jansen, J.A. Johnsen, M. Josebachuili, A. Kääpä, O. Kambeitz, K.H. Kampert, I. Katkov, B. Keilhauer, N. Kemmerich, E. Kemp, J. Kemp, R.M. Kieckhafer, H.O. Klages, M. Kleifges, J. Kleinfeller, R. Krause, N. Krohm, D. Kuempel, G. Kukec Mezek, N. Kunka, A. Kuotb Awad, D. LaHurd, M. Lauscher, R. Legumina, M.A. Leigui de Oliveira, A. Letessier-Selvon, I. Lhenry-Yvon, K. Link, D. Lo Presti, L. Lopes, R. López, A. López Casado, Q. Luce, A. Lucero, M. Malacari, M. Mallamaci, D. Mandat, P. Mantsch, A.G. Mariazzi, I.C. Mariş, G. Marsella, D. Martello, H. Martinez, O. Martínez Bravo, J.J. Masías Meza, H.J. Mathes, S. Mathys, J. Matthews, J.A.J. Matthews, G. Matthiae, E. Mayotte, P.O. Mazur, C. Medina, G. Medina-Tanco, D. Melo, A. Menshikov, K.-D. Merenda, M.I. Micheletti, L. Middendorf, I.A. Minaya, L. Miramonti, B. Mitrica, D. Mockler, S. Mollerach, F. Montanet, C. Morello, M. Mostafá, A.L. Müller, G. Müller, M.A. Muller, S. Müller, R. Mussa, I. Naranjo, L. Nellen, P.H. Nguyen, M. Niculescu-Oglinzanu, M. Niechciol, L. Niemietz, T. Niggemann, D. Nitz, D. Nosek, V. Novotny, H. Nožka, L.A. Núñez, L. Ochilo, F. Oikonomou, A. Olinto, M. Palatka, J. Pallotta, P. Papenbreer, G. Parente, A. Parra, T. Paul, M. Pech, F. Pedreira, J. Pękala, R. Pelayo, J. Peña-Rodriguez, L. A. S. Pereira, M. Perlín, L. Perrone, C. Peters, S. Petrera, J. Phuntsok, R. Piegaia, T. Pierog, P. Pieroni, M. Pimenta, V. Pirronello, M. Platino, M. Plum, C. Porowski, R.R. Prado, P. Privitera, M. Prouza, E.J. Quel, S. Querchfeld, S. Quinn, R. Ramos-Pollan, J. Rautenberg, D. Ravignani, B. Revenu, J. Ridky, M. Risse, P. Ristori, V. Rizi, W. Rodrigues de Carvalho, G. Rodriguez Fernandez, J. Rodriguez Rojo, D. Rogozin, M.J. Roncoroni, M. Roth, E. Roulet, A.C. Rovero, P. Ruehl, S.J. Saffi, A. Saftoiu, F. Salamida, H. Salazar, A. Saleh, F. Salesa Greus, G. Salina, F. Sánchez, P. Sanchez-Lucas, E.M. Santos, E. Santos, F. Sarazin, R. Sarmento, C.A. Sarmiento, R. Sato, M. Schauer, V. Scherini, H. Schieler, M. Schimp, D. Schmidt, O. Scholten, P. Schovánek, F.G. Schröder, A. Schulz, J. Schumacher, S.J. Sciutto, A. Segreto, M. Settimo, A. Shadkam, R.C. Shellard, G. Sigl, G. Silli, O. Sima, A. Śmiałkowski, R. Šmída, G.R. Snow, P. Sommers, S. Sonntag, J. Sorokin, R. Squartini, D. Stanca, S. Stanič, J. Stasielak, P. Stassi, F. Strafella, F. Suarez, M. Suarez Durán, T. Sudholz, T. Suomijärvi, A.D. Supanitsky, J. Swain, Z. Szadkowski, A. Taboada, O.A. Taborda, A. Tapia, V.M. Theodoro, C. Timmermans, C.J. Todero Peixoto, L. Tomankova, B. Tomé, G. Torralba Elipe, P. Travnicek, M. Trini, R. Ulrich, M. Unger, M. Urban, J.F. Valdés Galicia, I. Valiño, L. Valore, G. van Aar, P. van Bodegom, A.M. van den Berg, A. van Vliet, E. Varela, B. Vargas Cárdenas, G. Varner, R.A. Vázquez, D. Veberič, I.D. Vergara Quispe, V. Verzi, J. Vicha, L. Villaseñor, S. Vorobiov, H. Wahlberg, O. Wainberg, D. Walz, A.A. Watson, M. Weber, A. Weindl, L. Wiencke, H. Wilczyński, T. Winchen, M. Wirtz, D. Wittkowski, B. Wundheiler, L. Yang, D. Yelos, A. Yushkov, E. Zas, D. Zavrtanik, M. Zavrtanik, A. Zepeda, B. Zimmermann, M. Ziolkowski, Z. Zong, F. Zuccarello
June 13, 2018 astro-ph.IM, astro-ph.HE
An in-situ calibration of a logarithmic periodic dipole antenna with a frequency coverage of 30 MHz to 80 MHz is performed. Such antennas are part of a radio station system used for detection of cosmic ray induced air showers at the Engineering Radio Array of the Pierre Auger Observatory, the so-called Auger Engineering Radio Array (AERA). The directional and frequency characteristics of the broadband antenna are investigated using a remotely piloted aircraft (RPA) carrying a small transmitting antenna. The antenna sensitivity is described by the vector effective length relating the measured voltage with the electric-field components perpendicular to the incoming signal direction. The horizontal and meridional components are determined with an overall uncertainty of 7.4^{+0.9}_{-0.3} % and 10.3^{+2.8}_{-1.7} % respectively. The measurement is used to correct a simulated response of the frequency and directional response of the antenna. In addition, the influence of the ground conductivity and permittivity on the antenna response is simulated. Both have a negligible influence given the ground conditions measured at the detector site. The overall uncertainties of the vector effective length components result in an uncertainty of 8.8^{+2.1}_{-1.3} % in the square root of the energy fluence for incoming signal directions with zenith angles smaller than 60{\deg}.
Observation of Anisotropy of TeV Cosmic Rays with Two Years of HAWC (1805.01847)
A.U. Abeysekara, R. Alfaro, C. Alvarez, J.D. Alvarez, R. Arceo, J.C. Arteaga-Velázquez, D. Avila Rojas, H.A. Ayala Solares, A. Becerril, E. Belmont-Moreno, S.Y. BenZvi, A. Bernal, J. Braun, K.S. Caballero-Mora, T. Capistrán, A. Carramiñana, S. Casanova, M. Castillo, U. Cotti, J. Cotzomi, C. De León, E. De la Fuente, R. Diaz Hernandez, S. Dichiara, B.L. Dingus, M.A. DuVernois, J.C. Díaz-Vélez, K. Engel, D.W. Fiorino, N. Fraija, J.A. García-González, F. Garfias, A. González Muñoz, M.M. González, J.A. Goodman, Z. Hampel-Arias, J.P. Harding, S. Hernandez, B. Hona, F. Hueyotl-Zahuantitla, C.M. Hui, P. Hüntemeyer, A. Iriarte, A. Jardin-Blicq, V. Joshi, S. Kaufmann, A. Lara, R.J. Lauer, W.H. Lee, H. León Vargas, A.L. Longinotti, G. Luis-Raya, R. Luna-García, D. López-Cámara, R. López-Coto, D. López-Cámara, R. López-Coto, K. Malone, S.S. Marinelli, O. Martinez, I. Martinez-Castellanos, J. Martínez-Castro, H. Martínez-Huerta, J.A. Matthews, P. Miranda-Romagnoli, E. Moreno, M. Mostafá, A. Nayerhoda, L. Nellen, M. Newbold, M.U. Nisa, R. Noriega-Papaqui, R. Pelayo, J. Pretz, E.G. Pérez-Pérez, Z. Ren, C.D. Rho, C. Rivière, D. Rosa-González, M. Rosenberg, E. Ruiz-Velasco, F. Salesa Greus, A. Sandoval, M. Schneider, H. Schoorlemmer, M. Seglar Arroyo, G. Sinnis, A.J. Smith, R.W. Springer, P. Surajbali, I. Taboada, O. Tibolla, K. Tollefson, I. Torres, G. Vianello, L. Villaseñor, T. Weisgarber, F. Werner, S. Westerhoff, J. Wood, T. Yapici, A. Zepeda, H. Zhou
May 7, 2018 astro-ph.HE
After two years of operation, the High-Altitude Water Cherenkov (HAWC) Observatory has analyzed the TeV cosmic-ray sky over an energy range between $2.0$ and $72.8$ TeV. The HAWC detector is a ground-based air-shower array located at high altitude in the state of Puebla, Mexico. Using 300 light-tight water tanks, it collects the Cherenkov light from the particles of extensive air showers from primary gamma rays and cosmic rays. This detection method allows for uninterrupted observation of the entire overhead sky (2~sr instantaneous, 8.5~sr integrated) in the energy range from a few TeV to hundreds of TeV. Like other detectors in the northern and southern hemisphere, HAWC observes an energy-dependent anisotropy in the arrival direction distribution of cosmic rays. The observed cosmic-ray anisotropy is dominated by a dipole moment with phase $\alpha\approx40^{\circ}$ and amplitude that slowly rises in relative intensity from $8\times10^{-4}$ at 2 TeV to $14\times10^{-4}$ around 30.3 TeV, above which the dipole decreases in strength. A significant large-scale ($>60^{\circ}$ in angular extent) signal is also observed in the quadrupole and octupole moments, and significant small-scale features are also present, with locations and shapes consistent with previous observations. Compared to previous measurements in this energy range, the HAWC cosmic-ray sky maps improve on the energy resolution and fit precision of the anisotropy. These data can be used in an effort to better constrain local cosmic-ray accelerators and the intervening magnetic fields.
Constraining the $\bar{p}/p$ Ratio in TeV Cosmic Rays with Observations of the Moon Shadow by HAWC (1802.08913)
A.U. Abeysekara, A. Albert, R. Alfaro, C. Alvarez, R. Arceo, J.C. Arteaga-Velázquez, D. Avila Rojas, H.A. Ayala Solares, E. Belmont-Moreno, S.Y. BenZvi, J. Braun, C. Brisbois, K.S. Caballero-Mora, T. Capistrán, A. Carramiñana, S. Casanova, M. Castillo, U. Cotti, J. Cotzomi, S. Coutiño de León, C. De León, E. D la Fuentem, R. Diaz Hernandez, S. Dichiara, B.L. Dingus, M.A. DuVernois, R.W. Ellsworth, K. Engels, O. Enríquez-Rivera, H. Fleischhack, N. Fraija, A. Galván-Gámez, J.A. García-González, A. González Muñoz, M.M. González, J.A. Goodman, Z. Hampel-Arias, J.P. Harding, S. Hernandez, B. Hona, F. Hueyotl-Zahuantitla, C.M. Hui, P. Hüntemeyer, A. Iriarte, A. Jardin-Blicq, V. Joshi, S. Kaufmann, A. Lara, W.H. Lee, H. León Vargas, J.T. Linnemann, A.L. Longinotti, G. Luis-Raya, R. Luna-García, R. López-Coto, K. Malone, S.S. Marinelli, O. Martinez, I. Martinez-Castellanos, J. Martínez-Castro, H. Martínez-Huerta, J.A. Matthews, P. Miranda-Romagnoli, E. Moreno, M. Mostafá, A. Nayerhoda, L. Nellena, M. Newbold, M.U. Nisa, R. Noriega-Papaqui, R. Pelayo, J. Pretz, E.G. Pérez-Pérez, Z. Ren, C.D. Rho, C. Riviére, D. Rosa-González, M. Rosenberg, E. Ruiz-Velasco, F. Salesa Greus, A. Sandoval, M. Schneider, H. Schoorlemmer, M. Seglar Arroyo, G. Sinnis, A.J. Smith, R.W. Springer, P. Surajbali, I. Taboada, O. Tibolla, K. Tollefson, I. Torres, L. Villaseñor, T. Weisgarber, S. Westerhoff, J. Wood, T. Yapici, G.B. Yodha, A. Zepeda, H. Zhou, J.D. Alvarez
April 22, 2018 astro-ph.IM, astro-ph.HE
An indirect measurement of the antiproton flux in cosmic rays is possible as the particles undergo deflection by the geomagnetic field. This effect can be measured by studying the deficit in the flux, or shadow, created by the Moon as it absorbs cosmic rays that are headed towards the Earth. The shadow is displaced from the actual position of the Moon due to geomagnetic deflection, which is a function of the energy and charge of the cosmic rays. The displacement provides a natural tool for momentum/charge discrimination that can be used to study the composition of cosmic rays. Using 33 months of data comprising more than 80 billion cosmic rays measured by the High Altitude Water Cherenkov (HAWC) observatory, we have analyzed the Moon shadow to search for TeV antiprotons in cosmic rays. We present our first upper limits on the $\bar{p}/p$ fraction, which in the absence of any direct measurements, provide the tightest available constraints of $\sim1\%$ on the antiproton fraction for energies between 1 and 10 TeV.
Search for Dark Matter Gamma-ray Emission from the Andromeda Galaxy with the High-Altitude Water Cherenkov Observatory (1804.00628)
A. Albert, R. Alfaro, C. Alvarez, J.D. Alvarez, R. Arceo, J.C. Arteaga-Velázquez, D. Avila Rojas, H.A. Ayala Solares, A. Becerril, E. Belmont-Moreno, S.Y. BenZvi, A. Bernal, C. Brisbois, K.S. Caballero-Mora, T. Capistrán, A. Carramiñana, S. Casanova, M. Castillo, U. Cotti, J. Cotzomi, S. Coutiño de León, C. De León, S. Dichiara, B.L. Dingus, M.A. DuVernois, J.C. Díaz-Vélez, C. Eckner, K. Engel, O. Enríquez-Rivera, C. Espinoza, D.W. Fiorino, N. Fraija, A. Galván-Gámez, J.A. García-González, F. Garfias, A. González Muñoz, M.M. González, J.A. Goodman, Z. Hampel-Arias, J.P. Harding, S. Hernandez, A. Hernandez-Almada, B. Hona, P. Hüntemeyer, A. Iriarte, A. Jardin-Blicq, V. Joshi, S. Kaufmann, G.J. Kunde, D. Lennarz, H. León Vargas, J.T. Linnemann, A.L. Longinotti, G. Luis Raya, R. Luna-García, K. Malone, S.S. Marinelli, O. Martinez, J. Martínez-Castro, H. Martínez-Huerta, J.A. Matthews, P. Miranda-Romagnoli, E. Moreno, M. Mostafá, A. Nayerhoda, L. Nellen, M. Newbold, M.U. Nisa, R. Noriega-Papaqui, R. Pelayo, J. Pretz, E.G. Pérez-Pérez, Z. Ren, C.D. Rho, C. Riviére, D. Rosa-González, M. Rosenberg, E. Ruiz-Velasco, E. Ruiz-Velasco, H. Salazar, F. Salesa Greus, A. Sandoval, M. Schneider, M. Seglar Arroyo, G. Sinnis, A.J. Smith, R.W. Springer, P. Surajbali, I. Taboada, O. Tibolla, K. Tollefson, I. Torres, T.N. Ukwatta, L. Villaseñor, T. Weisgarber, S. Westerhoff, J. Wood, T. Yapici, G. Zaharijas, A. Zepeda, , H. Zhou
April 3, 2018 astro-ph.HE
The Andromeda Galaxy (M31) is a nearby ($\sim$780 kpc) galaxy similar to our own Milky Way. Observational evidence suggests that it resides in a large halo of dark matter (DM), making it a good target for DM searches. We present a search for gamma rays from M31 using 1017 days of data from the High Altitude Water Cherenkov (HAWC) Observatory. With its wide field of view and constant monitoring, HAWC is well-suited to search for DM in extended targets like M31. No DM annihilation or decay signal was detected for DM masses from 1 to 100 TeV in the $b\bar{b}$, $t\bar{t}$, $\tau^{+}\tau^{-}$, $\mu^{+}\mu^{-}$, and $W^{+}W^{-}$ channels. Therefore we present limits on those processes. Our limits nicely complement the existing body of DM limits from other targets and instruments. Specifically the DM decay limits from our benchmark model are the most constraining for DM masses from 25 TeV to 100 TeV in the $b\bar{b}, t\bar{t}$ and $\mu^{+}\mu{-}$ channels. In addition to DM-specific limits, we also calculate general gamma-ray flux limits for M31 in 5 energy bins from 1 TeV to 100 TeV.
Combined fit of spectrum and composition data as measured by the Pierre Auger Observatory (1612.07155)
The Pierre Auger Collaboration: A. Aab, P. Abreu, M. Aglietta, I. Al Samarai, I.F.M. Albuquerque, I. Allekotte, A. Almela, J. Alvarez Castillo, J. Alvarez-Muñiz, G.A. Anastasi, L. Anchordoqui, B. Andrada, S. Andringa, C. Aramo, F. Arqueros, N. Arsene, H. Asorey, P. Assis, J. Aublin, G. Avila, A.M. Badescu, A. Balaceanu, R.J. Barreira Luz, J.J. Beatty, K.H. Becker, J.A. Bellido, C. Berat, M.E. Bertaina, X. Bertou, P.L. Biermann, P. Billoir, J. Biteau, S.G. Blaess, A. Blanco, J. Blazek, C. Bleve, M. Boháčová, D. Boncioli, C. Bonifazi, N. Borodai, A.M. Botti, J. Brack, I. Brancus, T. Bretz, A. Bridgeman, F.L. Briechle, P. Buchholz, A. Bueno, S. Buitink, M. Buscemi, K.S. Caballero-Mora, L. Caccianiga, A. Cancio, F. Canfora, L. Caramete, R. Caruso, A. Castellina, G. Cataldi, L. Cazon, A.G. Chavez, J.A. Chinellato, J. Chudoba, R.W. Clay, R. Colalillo, A. Coleman, L. Collica, M.R. Coluccia, R. Conceição, F. Contreras, M.J. Cooper, S. Coutu, C.E. Covault, J. Cronin, S. D'Amico, B. Daniel, S. Dasso, K. Daumiller, B.R. Dawson, R.M. de Almeida, S.J. de Jong, G. De Mauro, J.R.T. de Mello Neto, I. De Mitri, J. de Oliveira, V. de Souza, J. Debatin, O. Deligny, C. Di Giulio, A. Di Matteo, M.L. Díaz Castro, F. Diogo, C. Dobrigkeit, J.C. D'Olivo, Q. Dorosti, R.C. dos Anjos, M.T. Dova, A. Dundovic, J. Ebr, R. Engel, M. Erdmann, M. Erfani, C.O. Escobar, J. Espadanal, A. Etchegoyen, H. Falcke, G. Farrar, A.C. Fauth, N. Fazzini, B. Fick, J.M. Figueira, A. Filipčič, O. Fratu, M.M. Freire, T. Fujii, A. Fuster, R. Gaior, B. García, D. Garcia-Pinto, F. Gaté, H. Gemmeke, A. Gherghel-Lascu, P.L. Ghia, U. Giaccari, M. Giammarchi, M. Giller, D. Głas, C. Glaser, G. Golup, M. Gómez Berisso, P.F. Gómez Vitale, N. González, A. Gorgi, P. Gorham, A.F. Grillo, T.D. Grubb, F. Guarino, G.P. Guedes, M.R. Hampel, P. Hansen, D. Harari, T.A. Harrison, J.L. Harton, A. Haungs, T. Hebbeker, D. Heck, P. Heimann, A.E. Herve, G.C. Hill, C. Hojvat, E. Holt, P. Homola, J.R. Hörandel, P. Horvath, M. Hrabovský, T. Huege, J. Hulsman, A. Insolia, P.G. Isar, I. Jandt, S. Jansen, J.A. Johnsen, M. Josebachuili, A. Kääpä, O. Kambeitz, K.H. Kampert, I. Katkov, B. Keilhauer, E. Kemp, J. Kemp, R.M. Kieckhafer, H.O. Klages, M. Kleifges, J. Kleinfeller, R. Krause, N. Krohm, D. Kuempel, G. Kukec Mezek, N. Kunka, A. Kuotb Awad, D. LaHurd, M. Lauscher, R. Legumina, M.A. Leigui de Oliveira, A. Letessier-Selvon, I. Lhenry-Yvon, K. Link, L. Lopes, R. López, A. López Casado, Q. Luce, A. Lucero, M. Malacari, M. Mallamaci, D. Mandat, P. Mantsch, A.G. Mariazzi, I.C. Mariş, G. Marsella, D. Martello, H. Martinez, O. Martínez Bravo, J.J. Masías Meza, H.J. Mathes, S. Mathys, J. Matthews, J.A.J. Matthews, G. Matthiae, E. Mayotte, P.O. Mazur, C. Medina, G. Medina-Tanco, D. Melo, A. Menshikov, M.I. Micheletti, L. Middendorf, I.A. Minaya, L. Miramonti, B. Mitrica, D. Mockler, S. Mollerach, F. Montanet, C. Morello, M. Mostafá, A.L. Müller, G. Müller, M.A. Muller, S. Müller, R. Mussa, I. Naranjo, L. Nellen, P.H. Nguyen, M. Niculescu-Oglinzanu, M. Niechciol, L. Niemietz, T. Niggemann, D. Nitz, D. Nosek, V. Novotny, H. Nožka, L.A. Núñez, L. Ochilo, F. Oikonomou, A. Olinto, M. Palatka, J. Pallotta, P. Papenbreer, G. Parente, A. Parra, T. Paul, M. Pech, F. Pedreira, J. Pękala, R. Pelayo, J. Peña-Rodriguez, L. A. S. Pereira, M. Perlín, L. Perrone, C. Peters, S. Petrera, J. Phuntsok, R. Piegaia, T. Pierog, P. Pieroni, M. Pimenta, V. Pirronello, M. Platino, M. Plum, C. Porowski, R.R. Prado, P. Privitera, M. Prouza, E.J. Quel, S. Querchfeld, S. Quinn, R. Ramos-Pollan, J. Rautenberg, D. Ravignani, B. Revenu, J. Ridky, M. Risse, P. Ristori, V. Rizi, W. Rodrigues de Carvalho, G. Rodriguez Fernandez, J. Rodriguez Rojo, D. Rogozin, M.J. Roncoroni, M. Roth, E. Roulet, A.C. Rovero, P. Ruehl, S.J. Saffi, A. Saftoiu, F. Salamida, H. Salazar, A. Saleh, F. Salesa Greus, G. Salina, F. Sánchez, P. Sanchez-Lucas, E.M. Santos, E. Santos, F. Sarazin, R. Sarmento, C.A. Sarmiento, R. Sato, M. Schauer, V. Scherini, H. Schieler, M. Schimp, D. Schmidt, O. Scholten, P. Schovánek, F.G. Schröder, A. Schulz, J. Schulz, J. Schumacher, S.J. Sciutto, A. Segreto, M. Settimo, A. Shadkam, R.C. Shellard, G. Sigl, G. Silli, O. Sima, A. Śmiałkowski, R. Šmída, G.R. Snow, P. Sommers, S. Sonntag, J. Sorokin, R. Squartini, D. Stanca, S. Stanič, J. Stasielak, P. Stassi, F. Strafella, F. Suarez, M. Suarez Durán, T. Sudholz, T. Suomijärvi, A.D. Supanitsky, J. Swain, Z. Szadkowski, A. Taboada, O.A. Taborda, A. Tapia, V.M. Theodoro, C. Timmermans, C.J. Todero Peixoto, L. Tomankova, B. Tomé, G. Torralba Elipe, P. Travnicek, M. Trini, R. Ulrich, M. Unger, M. Urban, J.F. Valdés Galicia, I. Valiño, L. Valore, G. van Aar, P. van Bodegom, A.M. van den Berg, A. van Vliet, E. Varela, B. Vargas Cárdenas, G. Varner, J.R. Vázquez, R.A. Vázquez, D. Veberič, I.D. Vergara Quispe, V. Verzi, J. Vicha, L. Villaseñor, S. Vorobiov, H. Wahlberg, O. Wainberg, D. Walz, A.A. Watson, M. Weber, A. Weindl, L. Wiencke, H. Wilczyński, T. Winchen, M. Wirtz, D. Wittkowski, B. Wundheiler, L. Yang, D. Yelos, A. Yushkov, E. Zas, D. Zavrtanik, M. Zavrtanik, A. Zepeda, B. Zimmermann, M. Ziolkowski, Z. Zong, F. Zuccarello
Feb. 26, 2018 astro-ph.HE
We present a combined fit of a simple astrophysical model of UHECR sources to both the energy spectrum and mass composition data measured by the Pierre Auger Observatory. The fit has been performed for energies above $5 \cdot 10^{18}$ eV, i.e.~the region of the all-particle spectrum above the so-called "ankle" feature. The astrophysical model we adopted consists of identical sources uniformly distributed in a comoving volume, where nuclei are accelerated through a rigidity-dependent mechanism. The fit results suggest sources characterized by relatively low maximum injection energies, hard spectra and heavy chemical composition. We also show that uncertainties about physical quantities relevant to UHECR propagation and shower development have a non-negligible impact on the fit results.
Indication of anisotropy in arrival directions of ultra-high-energy cosmic rays through comparison to the flux pattern of extragalactic gamma-ray sources (1801.06160)
The Pierre Auger Collaboration: A. Aab, P. Abreu, M. Aglietta, I.F.M. Albuquerque, I. Allekotte, A. Almela, J. Alvarez Castillo, J. Alvarez-Muñiz, G.A. Anastasi, L. Anchordoqui, B. Andrada, S. Andringa, C. Aramo, N. Arsene, H. Asorey, P. Assis, G. Avila, A.M. Badescu, A. Balaceanu, F. Barbato, R.J. Barreira Luz, J.J. Beatty, K.H. Becker, J.A. Bellido, C. Berat, M.E. Bertaina, X. Bertou, P.L. Biermann, J. Biteau, S.G. Blaess, A. Blanco, J. Blazek, C. Bleve, M. Boháčová, C. Bonifazi, N. Borodai, A.M. Botti, J. Brack, I. Brancus, T. Bretz, A. Bridgeman, F.L. Briechle, P. Buchholz, A. Bueno, S. Buitink, M. Buscemi, K.S. Caballero-Mora, L. Caccianiga, A. Cancio, F. Canfora, R. Caruso, A. Castellina, F. Catalani, G. Cataldi, L. Cazon, A.G. Chavez, J.A. Chinellato, J. Chudoba, R.W. Clay, A.C. Cobos Cerutti, R. Colalillo, A. Coleman, L. Collica, M.R. Coluccia, R. Conceição, G. Consolati, F. Contreras, M.J. Cooper, S. Coutu, C.E. Covault, J. Cronin, S. D'Amico, B. Daniel, S. Dasso, K. Daumiller, B.R. Dawson, R.M. de Almeida, S.J. de Jong, G. De Mauro, J.R.T. de Mello Neto, I. De Mitri, J. de Oliveira, V. de Souza, J. Debatin, O. Deligny, M.L. Díaz Castro, F. Diogo, C. Dobrigkeit, J.C. D'Olivo, Q. Dorosti, R.C. dos Anjos, M.T. Dova, A. Dundovic, J. Ebr, R. Engel, M. Erdmann, M. Erfani, C.O. Escobar, J. Espadanal, A. Etchegoyen, H. Falcke, J. Farmer, G. Farrar, A.C. Fauth, N. Fazzini, F. Fenu, B. Fick, J.M. Figueira, A. Filipčič, M.M. Freire, T. Fujii, A. Fuster, R. Gaïor, B. García, F. Gaté, H. Gemmeke, A. Gherghel-Lascu, P.L. Ghia, U. Giaccari, M. Giammarchi, M. Giller, D. Głas, C. Glaser, G. Golup, M. Gómez Berisso, P.F. Gómez Vitale, N. González, A. Gorgi, A.F. Grillo, T.D. Grubb, F. Guarino, G.P. Guedes, R. Halliday, M.R. Hampel, P. Hansen, D. Harari, T.A. Harrison, A. Haungs, T. Hebbeker, D. Heck, P. Heimann, A.E. Herve, G.C. Hill, C. Hojvat, E. Holt, P. Homola, J.R. Hörandel, P. Horvath, M. Hrabovský, T. Huege, J. Hulsman, A. Insolia, P.G. Isar, I. Jandt, J.A. Johnsen, M. Josebachuili, J. Jurysek, A. Kääpä, O. Kambeitz, K.H. Kampert, B. Keilhauer, N. Kemmerich, E. Kemp, J. Kemp, R.M. Kieckhafer, H.O. Klages, M. Kleifges, J. Kleinfeller, R. Krause, N. Krohm, D. Kuempel, G. Kukec Mezek, N. Kunka, A. Kuotb Awad, B.L. Lago, D. LaHurd, R.G. Lang, M. Lauscher, R. Legumina, M.A. Leigui de Oliveira, A. Letessier-Selvon, I. Lhenry-Yvon, K. Link, D. Lo Presti, L. Lopes, R. López, A. López Casado, R. Lorek, Q. Luce, A. Lucero, M. Malacari, M. Mallamaci, D. Mandat, P. Mantsch, A.G. Mariazzi, I.C. Mariş, G. Marsella, D. Martello, H. Martinez, O. Martínez Bravo, J.J. Masías Meza, H.J. Mathes, S. Mathys, J. Matthews, G. Matthiae, E. Mayotte, P.O. Mazur, C. Medina, G. Medina-Tanco, D. Melo, A. Menshikov, K.-D. Merenda, S. Michal, M.I. Micheletti, L. Middendorf, L. Miramonti, B. Mitrica, D. Mockler, S. Mollerach, F. Montanet, C. Morello, G. Morlino, M. Mostafá, A.L. Müller, G. Müller, M.A. Muller, S. Müller, R. Mussa, I. Naranjo, L. Nellen, P.H. Nguyen, M. Niculescu-Oglinzanu, M. Niechciol, L. Niemietz, T. Niggemann, D. Nitz, D. Nosek, V. Novotny, L. Nožka, L.A. Núñez, F. Oikonomou, A. Olinto, M. Palatka, J. Pallotta, P. Papenbreer, G. Parente, A. Parra, T. Paul, M. Pech, F. Pedreira, J. Pękala, R. Pelayo, J. Peña-Rodriguez, L.A.S. Pereira, M. Perlin, L. Perrone, C. Peters, S. Petrera, J. Phuntsok, T. Pierog, M. Pimenta, V. Pirronello, M. Platino, M. Plum, J. Poh, C. Porowski, R.R. Prado, P. Privitera, M. Prouza, E.J. Quel, S. Querchfeld, S. Quinn, R. Ramos-Pollan, J. Rautenberg, D. Ravignani, J. Ridky, F. Riehn, M. Risse, P. Ristori, V. Rizi, W. Rodrigues de Carvalho, G. Rodriguez Fernandez, J. Rodriguez Rojo, M.J. Roncoroni, M. Roth, E. Roulet, A.C. Rovero, P. Ruehl, S.J. Saffi, A. Saftoiu, F. Salamida, H. Salazar, A. Saleh, G. Salina, F. Sánchez, P. Sanchez-Lucas, E.M. Santos, E. Santos, F. Sarazin, R. Sarmento, C. Sarmiento-Cano, R. Sato, M. Schauer, V. Scherini, H. Schieler, M. Schimp, D. Schmidt, O. Scholten, P. Schovánek, F.G. Schröder, S. Schröder, A. Schulz, J. Schumacher, S.J. Sciutto, A. Segreto, A. Shadkam, R.C. Shellard, G. Sigl, G. Silli, R. Šmída, G.R. Snow, P. Sommers, S. Sonntag, J. F. Soriano, R. Squartini, D. Stanca, S. Stanič, J. Stasielak, P. Stassi, M. Stolpovskiy, F. Strafella, A. Streich, F. Suarez, M. Suarez Durán, T. Sudholz, T. Suomijärvi, A.D. Supanitsky, J. Šupík, J. Swain, Z. Szadkowski, A. Taboada, O.A. Taborda, V.M. Theodoro, C. Timmermans, C.J. Todero Peixoto, L. Tomankova, B. Tomé, G. Torralba Elipe, P. Travnicek, M. Trini, R. Ulrich, M. Unger, M. Urban, J.F. Valdés Galicia, I. Valiño, L. Valore, G. van Aar, P. van Bodegom, A.M. van den Berg, A. van Vliet, E. Varela, B. Vargas Cárdenas, R.A. Vázquez, D. Veberič, C. Ventura, I.D. Vergara Quispe, V. Verzi, J. Vicha, L. Villaseñor, S. Vorobiov, H. Wahlberg, O. Wainberg, D. Walz, A.A. Watson, M. Weber, A. Weindl, M. Wiedeński, L. Wiencke, H. Wilczyński, M. Wirtz, D. Wittkowski, B. Wundheiler, L. Yang, A. Yushkov, E. Zas, D. Zavrtanik, M. Zavrtanik, A. Zepeda, B. Zimmermann, M. Ziolkowski, Z. Zong, F. Zuccarello
Feb. 6, 2018 astro-ph.CO, astro-ph.HE
A new analysis of the dataset from the Pierre Auger Observatory provides evidence for anisotropy in the arrival directions of ultra-high-energy cosmic rays on an intermediate angular scale, which is indicative of excess arrivals from strong, nearby sources. The data consist of 5514 events above 20 EeV with zenith angles up to 80 deg recorded before 2017 April 30. Sky models have been created for two distinct populations of extragalactic gamma-ray emitters: active galactic nuclei from the second catalog of hard Fermi-LAT sources (2FHL) and starburst galaxies from a sample that was examined with Fermi-LAT. Flux-limited samples, which include all types of galaxies from the Swift-BAT and 2MASS surveys, have been investigated for comparison. The sky model of cosmic-ray density constructed using each catalog has two free parameters, the fraction of events correlating with astrophysical objects and an angular scale characterizing the clustering of cosmic rays around extragalactic sources. A maximum-likelihood ratio test is used to evaluate the best values of these parameters and to quantify the strength of each model by contrast with isotropy. It is found that the starburst model fits the data better than the hypothesis of isotropy with a statistical significance of 4.0 sigma, the highest value of the test statistic being for energies above 39 EeV. The three alternative models are favored against isotropy with 2.7-3.2 sigma significance. The origin of the indicated deviation from isotropy is examined and prospects for more sensitive future studies are discussed.
A Search for Dark Matter in the Galactic Halo with HAWC (1710.10288)
A. U. Abeysekara, A. M. Albert, R. Alfaro, C. Alvarez, J. D. Álvarez, R. Arceo, J. C. Arteaga-Velázquez, D. Avila Rojas, H. A. Ayala Solares, A. Becerril, E. Belmont-Moreno, S. Y. BenZvi, A. Bernal, C. Brisbois, K. S. Caballero-Mora, T. Capistrán, A. Carramiñana, S. Casanova, M. Castillo, U. Cotti, J. Cotzomi, C. De León, E. De la Fuente, R. Diaz Hernandez, B. L. Dingus, M. A. DuVernois, J. C. Díaz-Vélez, K. Engel, O. Enríquez-Rivera, D. W. Fiorino, H. Fleischhack, N. Fraija, J. A. García-González, F. Garfias, A. González Muñoz, M. M. González, J. A. Goodman, Z. Hampel-Arias, J. P. Harding, S. Hernandez, A. Hernandez-Almada, F. Hueyotl-Zahuantitla, P. Hüntemeyer, A. Iriarte, A. Jardin-Blicq, V. Joshi, S. Kaufmann, R. J. Lauer, W. H. Lee, D. Lennarz, H. León Vargas, J. T. Linnemann, A. L. Longinotti, G. Luis-Raya, R. Luna-García, R. López-Coto, K. Malone, S. S. Marinelli, O. Martinez, I. Martinez-Castellanos, J. Martínez-Castro, J. A. Matthews, P. Miranda-Romagnoli, E. Moreno, M. Mostafá, L. Nellen, M. Newbold, M. U. Nisa, R. Noriega-Papaqui, R. Pelayo, J. Pretz, E. G. Pérez-Pérez, Z. Ren, C. D. Rho, N. L. Rodd, D. Rosa-González, M. Rosenberg, E. Ruiz-Velasco, B. R. Safdi, H. Salazar, F. Salesa Greus, A. Sandoval, M. Schneider, G. Sinnis, A. J. Smith, R. W. Springer, P. Surajbali, I. Taboada, O. Tibolla, K. Tollefson, I. Torres, T. N. Ukwatta, G. Vianello, L. Villaseñor, T. Weisgarber, S. Westerhoff, I. G. Wisher, J. Wood, T. Yapici, G. B. Yodh, P. W. Younk, A. Zepeda, H. Zhou
Nov. 3, 2017 hep-ph, astro-ph.CO, astro-ph.HE
The High Altitude Water Cherenkov (HAWC) gamma-ray observatory is a wide field-of-view observatory sensitive to 500 GeV - 100 TeV gamma rays and cosmic rays. With its observations over 2/3 of the sky every day, the HAWC observatory is sensitive to a wide variety of astrophysical sources, including possible gamma rays from dark matter. Dark matter annihilation and decay in the Milky Way Galaxy should produce gamma-ray signals across many degrees on the sky. The HAWC instantaneous field-of-view of 2 sr enables observations of extended regions on the sky, such as those from dark matter in the Galactic halo. Here we show limits on the dark matter annihilation cross-section and decay lifetime from HAWC observations of the Galactic halo with 15 months of data. These are some of the most robust limits on TeV and PeV dark matter, largely insensitive to the dark matter morphology. These limits begin to constrain models in which PeV IceCube neutrinos are explained by dark matter which primarily decays into hadrons.
Inferences on Mass Composition and Tests of Hadronic Interactions from 0.3 to 100 EeV using the water-Cherenkov Detectors of the Pierre Auger Observatory (1710.07249)
The Pierre Auger Collaboration: A. Aab, P. Abreu, M. Aglietta, I. Al Samarai, I.F.M. Albuquerque, I. Allekotte, A. Almela, J. Alvarez Castillo, J. Alvarez-Muñiz, G.A. Anastasi, L. Anchordoqui, B. Andrada, S. Andringa, C. Aramo, F. Arqueros, N. Arsene, H. Asorey, P. Assis, J. Aublin, G. Avila, A.M. Badescu, A. Balaceanu, F. Barbato, R.J. Barreira Luz, J.J. Beatty, K.H. Becker, J.A. Bellido, C. Berat, M.E. Bertaina, X. Bertou, P.L. Biermann, J. Biteau, S.G. Blaess, A. Blanco, J. Blazek, C. Bleve, M. Boháčová, D. Boncioli, C. Bonifazi, N. Borodai, A.M. Botti, J. Brack, I. Brancus, T. Bretz, A. Bridgeman, F.L. Briechle, P. Buchholz, A. Bueno, S. Buitink, M. Buscemi, K.S. Caballero-Mora, L. Caccianiga, A. Cancio, F. Canfora, L. Caramete, R. Caruso, A. Castellina, F. Catalani, G. Cataldi, L. Cazon, A.G. Chavez, J.A. Chinellato, J. Chudoba, R.W. Clay, A. Cobos, R. Colalillo, A. Coleman, L. Collica, M.R. Coluccia, R. Conceição, G. Consolati, F. Contreras, M.J. Cooper, S. Coutu, C.E. Covault, J. Cronin, S. D'Amico, B. Daniel, S. Dasso, K. Daumiller, B.R. Dawson, R.M. de Almeida, S.J. de Jong, G. De Mauro, J.R.T. de Mello Neto, I. De Mitri, J. de Oliveira, V. de Souza, J. Debatin, O. Deligny, M.L. Díaz Castro, F. Diogo, C. Dobrigkeit, J.C. D'Olivo, Q. Dorosti, R.C. dos Anjos, M.T. Dova, A. Dundovic, J. Ebr, R. Engel, M. Erdmann, M. Erfani, C.O. Escobar, J. Espadanal, A. Etchegoyen, H. Falcke, J. Farmer, G. Farrar, A.C. Fauth, N. Fazzini, F. Fenu, B. Fick, J.M. Figueira, A. Filipčič, O. Fratu, M.M. Freire, T. Fujii, A. Fuster, R. Gaior, B. García, D. Garcia-Pinto, F. Gaté, H. Gemmeke, A. Gherghel-Lascu, P.L. Ghia, U. Giaccari, M. Giammarchi, M. Giller, D. Głas, C. Glaser, G. Golup, M. Gómez Berisso, P.F. Gómez Vitale, N. González, A. Gorgi, P. Gorham, A.F. Grillo, T.D. Grubb, F. Guarino, G.P. Guedes, R. Halliday, M.R. Hampel, P. Hansen, D. Harari, T.A. Harrison, J.L. Harton, A. Haungs, T. Hebbeker, D. Heck, P. Heimann, A.E. Herve, G.C. Hill, C. Hojvat, E. Holt, P. Homola, J.R. Hörandel, P. Horvath, M. Hrabovský, T. Huege, J. Hulsman, A. Insolia, P.G. Isar, I. Jandt, J.A. Johnsen, M. Josebachuili, J. Jurysek, A. Kääpä, O. Kambeitz, K.H. Kampert, B. Keilhauer, N. Kemmerich, E. Kemp, J. Kemp, R.M. Kieckhafer, H.O. Klages, M. Kleifges, J. Kleinfeller, R. Krause, N. Krohm, D. Kuempel, G. Kukec Mezek, N. Kunka, A. Kuotb Awad, B.L. Lago, D. LaHurd, R.G. Lang, M. Lauscher, R. Legumina, M.A. Leigui de Oliveira, A. Letessier-Selvon, I. Lhenry-Yvon, K. Link, D. Lo Presti, L. Lopes, R. López, A. López Casado, R. Lorek, Q. Luce, A. Lucero, M. Malacari, M. Mallamaci, D. Mandat, P. Mantsch, A.G. Mariazzi, I.C. Mariş, G. Marsella, D. Martello, H. Martinez, O. Martínez Bravo, J.J. Masías Meza, H.J. Mathes, S. Mathys, J. Matthews, J.A.J. Matthews, G. Matthiae, E. Mayotte, P.O. Mazur, C. Medina, G. Medina-Tanco, D. Melo, A. Menshikov, K.-D. Merenda, S. Michal, M.I. Micheletti, L. Middendorf, L. Miramonti, B. Mitrica, D. Mockler, S. Mollerach, F. Montanet, C. Morello, M. Mostafá, A.L. Müller, G. Müller, M.A. Muller, S. Müller, R. Mussa, I. Naranjo, L. Nellen, P.H. Nguyen, M. Niculescu-Oglinzanu, M. Niechciol, L. Niemietz, T. Niggemann, D. Nitz, D. Nosek, V. Novotny, L. Nožka, L.A. Núñez, L. Ochilo, F. Oikonomou, A. Olinto, M. Palatka, J. Pallotta, P. Papenbreer, G. Parente, A. Parra, T. Paul, M. Pech, F. Pedreira, J. Pękala, R. Pelayo, J. Peña-Rodriguez, L. A. S. Pereira, M. Perlin, L. Perrone, C. Peters, S. Petrera, J. Phuntsok, R. Piegaia, T. Pierog, M. Pimenta, V. Pirronello, M. Platino, M. Plum, C. Porowski, R.R. Prado, P. Privitera, M. Prouza, E.J. Quel, S. Querchfeld, S. Quinn, R. Ramos-Pollan, J. Rautenberg, D. Ravignani, J. Ridky, F. Riehn, M. Risse, P. Ristori, V. Rizi, W. Rodrigues de Carvalho, G. Rodriguez Fernandez, J. Rodriguez Rojo, D. Rogozin, M.J. Roncoroni, M. Roth, E. Roulet, A.C. Rovero, P. Ruehl, S.J. Saffi, A. Saftoiu, F. Salamida, H. Salazar, A. Saleh, F. Salesa Greus, G. Salina, F. Sánchez, P. Sanchez-Lucas, E.M. Santos, E. Santos, F. Sarazin, R. Sarmento, C. Sarmiento-Cano, R. Sato, M. Schauer, V. Scherini, H. Schieler, M. Schimp, D. Schmidt, O. Scholten, P. Schovánek, F.G. Schröder, S. Schröder, A. Schulz, J. Schumacher, S.J. Sciutto, A. Segreto, A. Shadkam, R.C. Shellard, G. Sigl, G. Silli, O. Sima, A. Śmiałkowski, R. Šmída, G.R. Snow, P. Sommers, S. Sonntag, R. Squartini, D. Stanca, S. Stanič, J. Stasielak, P. Stassi, M. Stolpovskiy, F. Strafella, A. Streich, F. Suarez, M. Suarez Durán, T. Sudholz, T. Suomijärvi, A.D. Supanitsky, J. Šupík, J. Swain, Z. Szadkowski, A. Taboada, O.A. Taborda, V.M. Theodoro, C. Timmermans, C.J. Todero Peixoto, L. Tomankova, B. Tomé, G. Torralba Elipe, P. Travnicek, M. Trini, R. Ulrich, M. Unger, M. Urban, J.F. Valdés Galicia, I. Valiño, L. Valore, G. van Aar, P. van Bodegom, A.M. van den Berg, A. van Vliet, E. Varela, B. Vargas Cárdenas, G. Varner, R.A. Vázquez, D. Veberič, C. Ventura, I.D. Vergara Quispe, V. Verzi, J. Vicha, L. Villaseñor, S. Vorobiov, H. Wahlberg, O. Wainberg, D. Walz, A.A. Watson, M. Weber, A. Weindl, L. Wiencke, H. Wilczyński, M. Wirtz, D. Wittkowski, B. Wundheiler, L. Yang, A. Yushkov, E. Zas, D. Zavrtanik, M. Zavrtanik, A. Zepeda, B. Zimmermann, M. Ziolkowski, Z. Zong, F. Zuccarello
We present a new method for probing the hadronic interaction models at ultra-high energy and extracting details about mass composition. This is done using the time profiles of the signals recorded with the water-Cherenkov detectors of the Pierre Auger Observatory. The profiles arise from a mix of the muon and electromagnetic components of air-showers. Using the risetimes of the recorded signals we define a new parameter, which we use to compare our observations with predictions from simulations. We find, firstly, inconsistencies between our data and predictions over a greater energy range and with substantially more events than in previous studies. Secondly, by calibrating the new parameter with fluorescence measurements from observations made at the Auger Observatory, we can infer the depth of shower maximum for a sample of over 81,000 events extending from 0.3 EeV to over 100 EeV. Above 30 EeV, the sample is nearly fourteen times larger than currently available from fluorescence measurements and extending the covered energy range by half a decade. The energy dependence of the average depth of shower maximum is compared to simulations and interpreted in terms of the mean of the logarithmic mass. We find good agreement with previous work and extend the measurement of the mean depth of shower maximum to greater energies than before, reducing significantly the statistical uncertainty associated with the inferences about mass composition.
Muon Counting using Silicon Photomultipliers in the AMIGA detector of the Pierre Auger Observatory (1703.06193)
The Pierre Auger Collaboration: A. Aab, P. Abreu, M. Aglietta, E.J. Ahn, I. Al Samarai, I.F.M. Albuquerque, I. Allekotte, P. Allison, A. Almela, J. Alvarez Castillo, J. Alvarez-Muñiz, M. Ambrosio, G.A. Anastasi, L. Anchordoqui, B. Andrada, S. Andringa, C. Aramo, F. Arqueros, N. Arsene, H. Asorey, P. Assis, J. Aublin, G. Avila, A.M. Badescu, A. Balaceanu, C. Baus, J.J. Beatty, K.H. Becker, J.A. Bellido, C. Berat, M.E. Bertaina, X. Bertou, P.L. Biermann, P. Billoir, J. Biteau, S.G. Blaess, A. Blanco, J. Blazek, C. Bleve, M. Boháčová, D. Boncioli, C. Bonifazi, N. Borodai, A.M. Botti, J. Brack, I. Brancus, T. Bretz, A. Bridgeman, F.L. Briechle, P. Buchholz, A. Bueno, S. Buitink, M. Buscemi, K.S. Caballero-Mora, B. Caccianiga, L. Caccianiga, A. Cancio, F. Canfora, L. Caramete, R. Caruso, A. Castellina, G. Cataldi, L. Cazon, R. Cester, A.G. Chavez, A. Chiavassa, J.A. Chinellato, J. Chudoba, R.W. Clay, R. Colalillo, A. Coleman, L. Collica, M.R. Coluccia, R. Conceição, F. Contreras, M.J. Cooper, S. Coutu, C.E. Covault, J. Cronin, R. Dallier, S. D'Amico, B. Daniel, S. Dasso, K. Daumiller, B.R. Dawson, R.M. de Almeida, S.J. de Jong, G. De Mauro, J.R.T. de Mello Neto, I. De Mitri, J. de Oliveira, V. de Souza, J. Debatin, L. del Peral, O. Deligny, C. Di Giulio, A. Di Matteo, M.L. Díaz Castro, F. Diogo, C. Dobrigkeit, J.C. D'Olivo, A. Dorofeev, R.C. dos Anjos, M.T. Dova, A. Dundovic, J. Ebr, R. Engel, M. Erdmann, M. Erfani, C.O. Escobar, J. Espadanal, A. Etchegoyen, H. Falcke, K. Fang, G. Farrar, A.C. Fauth, N. Fazzini, B. Fick, J.M. Figueira, A. Filevich, A. Filipčič, O. Fratu, M.M. Freire, T. Fujii, A. Fuster, B. García, D. Garcia-Pinto, F. Gaté, H. Gemmeke, A. Gherghel-Lascu, P.L. Ghia, U. Giaccari, M. Giammarchi, M. Giller, D. Głas, C. Glaser, H. Glass, G. Golup, M. Gómez Berisso, P.F. Gómez Vitale, N. González, B. Gookin, J. Gordon, A. Gorgi, P. Gorham, P. Gouffon, A.F. Grillo, T.D. Grubb, F. Guarino, G.P. Guedes, M.R. Hampel, P. Hansen, D. Harari, T.A. Harrison, J.L. Harton, Q. Hasankiadeh, A. Haungs, T. Hebbeker, D. Heck, P. Heimann, A.E. Herve, G.C. Hill, C. Hojvat, E. Holt, P. Homola, J.R. Hörandel, P. Horvath, M. Hrabovský, T. Huege, J. Hulsman, A. Insolia, P.G. Isar, I. Jandt, S. Jansen, J.A. Johnsen, M. Josebachuili, A. Kääpä, O. Kambeitz, K.H. Kampert, P. Kasper, I. Katkov, B. Keilhauer, E. Kemp, R.M. Kieckhafer, H.O. Klages, M. Kleifges, J. Kleinfeller, R. Krause, N. Krohm, D. Kuempel, G. Kukec Mezek, N. Kunka, A. Kuotb Awad, D. LaHurd, L. Latronico, M. Lauscher, P. Lautridou, P. Lebrun, R. Legumina, M.A. Leigui de Oliveira, A. Letessier-Selvon, I. Lhenry-Yvon, K. Link, L. Lopes, R. López, A. López Casado, Q. Luce, A. Lucero, M. Malacari, M. Mallamaci, D. Mandat, P. Mantsch, A.G. Mariazzi, I.C. Mariş, G. Marsella, D. Martello, H. Martinez, O. Martínez Bravo, J.J. Masías Meza, H.J. Mathes, S. Mathys, J. Matthews, J.A.J. Matthews, G. Matthiae, E. Mayotte, P.O. Mazur, C. Medina, G. Medina-Tanco, D. Melo, A. Menshikov, S. Messina, M.I. Micheletti, L. Middendorf, I.A. Minaya, L. Miramonti, B. Mitrica, D. Mockler, L. Molina-Bueno, S. Mollerach, F. Montanet, C. Morello, M. Mostafá, G. Müller, M.A. Muller, S. Müller, I. Naranjo, S. Navas, L. Nellen, J. Neuser, P.H. Nguyen, M. Niculescu-Oglinzanu, M. Niechciol, L. Niemietz, T. Niggemann, D. Nitz, D. Nosek, V. Novotny, H. Nožka, L.A. Núñez, L. Ochilo, F. Oikonomou, A. Olinto, D. Pakk Selmi-Dei, M. Palatka, J. Pallotta, P. Papenbreer, G. Parente, A. Parra, T. Paul, M. Pech, F. Pedreira, J. Pękala, R. Pelayo, J. Peña-Rodriguez, L. A. S. Pereira, L. Perrone, C. Peters, S. Petrera, J. Phuntsok, R. Piegaia, T. Pierog, P. Pieroni, M. Pimenta, V. Pirronello, M. Platino, M. Plum, C. Porowski, R.R. Prado, P. Privitera, M. Prouza, E.J. Quel, S. Querchfeld, S. Quinn, R. Ramos-Pollant, J. Rautenberg, O. Ravel, D. Ravignani, D. Reinert, B. Revenu, J. Ridky, M. Risse, P. Ristori, V. Rizi, W. Rodrigues de Carvalho, G. Rodriguez Fernandez, J. Rodriguez Rojo, M.D. Rodríguez-Frías, D. Rogozin, J. Rosado, M. Roth, E. Roulet, A.C. Rovero, S.J. Saffi, A. Saftoiu, H. Salazar, A. Saleh, F. Salesa Greus, G. Salina, J.D. Sanabria Gomez, F. Sánchez, P. Sanchez-Lucas, E.M. Santos, E. Santos, F. Sarazin, B. Sarkar, R. Sarmento, C. Sarmiento-Cano, R. Sato, C. Scarso, M. Schauer, V. Scherini, H. Schieler, D. Schmidt, O. Scholten, P. Schovánek, F.G. Schröder, A. Schulz, J. Schulz, J. Schumacher, S.J. Sciutto, A. Segreto, M. Settimo, A. Shadkam, R.C. Shellard, G. Sigl, G. Silli, O. Sima, A. Śmiałkowski, R. Šmída, G.R. Snow, P. Sommers, S. Sonntag, J. Sorokin, R. Squartini, D. Stanca, S. Stanič, J. Stasielak, F. Strafella, F. Suarez, M. Suarez Durán, T. Sudholz, T. Suomijärvi, A.D. Supanitsky, M.S. Sutherland, J. Swain, Z. Szadkowski, O.A. Taborda, A. Tapia, A. Tepe, V.M. Theodoro, C. Timmermans, C.J. Todero Peixoto, L. Tomankova, B. Tomé, A. Tonachini, G. Torralba Elipe, D. Torres Machado, M. Torri, P. Travnicek, M. Trini, R. Ulrich, M. Unger, M. Urban, A. Valbuena-Delgado, J.F. Valdés Galicia, I. Valiño, L. Valore, G. van Aar, P. van Bodegom, A.M. van den Berg, A. van Vliet, E. Varela, B. Vargas Cárdenas, G. Varner, J.R. Vázquez, R.A. Vázquez, D. Veberič, V. Verzi, J. Vicha, L. Villaseñor, S. Vorobiov, H. Wahlberg, O. Wainberg, D. Walz, A.A. Watson, M. Weber, A. Weindl, L. Wiencke, H. Wilczyński, T. Winchen, D. Wittkowski, B. Wundheiler, S. Wykes, L. Yang, D. Yelos, A. Yushkov, E. Zas, D. Zavrtanik, M. Zavrtanik, A. Zepeda, B. Zimmermann, M. Ziolkowski, Z. Zong, F. Zuccarello
Oct. 4, 2017 physics.ins-det, astro-ph.IM
AMIGA (Auger Muons and Infill for the Ground Array) is an upgrade of the Pierre Auger Observatory designed to extend its energy range of detection and to directly measure the muon content of the cosmic ray primary particle showers. The array will be formed by an infill of surface water-Cherenkov detectors associated with buried scintillation counters employed for muon counting. Each counter is composed of three scintillation modules, with a 10 m$^2$ detection area per module. In this paper, a new generation of detectors, replacing the current multi-pixel photomultiplier tube (PMT) with silicon photo sensors (aka. SiPMs), is proposed. The selection of the new device and its front-end electronics is explained. A method to calibrate the counting system that ensures the performance of the detector is detailed. This method has the advantage of being able to be carried out in a remote place such as the one where the detectors are deployed. High efficiency results, i.e. 98 % efficiency for the highest tested overvoltage, combined with a low probability of accidental counting ($\sim$2 %), show a promising performance for this new system.
Spectral Calibration of the Fluorescence Telescopes of the Pierre Auger Observatory (1709.01537)
The Pierre Auger Collaboration: A. Aab, P. Abreu, M. Aglietta, I. Al Samarai, I.F.M. Albuquerque, I. Allekotte, A. Almela, J. Alvarez Castillo, J. Alvarez-Muñiz, G.A. Anastasi, L. Anchordoqui, B. Andrada, S. Andringa, C. Aramo, F. Arqueros, N. Arsene, H. Asorey, P. Assis, J. Aublin, G. Avila, A.M. Badescu, A. Balaceanu, F. Barbato, R.J. Barreira Luz, J.J. Beatty, K.H. Becker, J.A. Bellido, C. Berat, M.E. Bertaina, P.L. Biermann, J. Biteau, S.G. Blaess, A. Blanco, J. Blazek, C. Bleve, M. Boháčová, D. Boncioli, C. Bonifazi, N. Borodai, A.M. Botti, J. Brack, I. Brancus, T. Bretz, A. Bridgeman, F.L. Briechle, P. Buchholz, A. Bueno, S. Buitink, M. Buscemi, K.S. Caballero-Mora, L. Caccianiga, A. Cancio, F. Canfora, L. Caramete, R. Caruso, A. Castellina, F. Catalani, G. Cataldi, L. Cazon, A.G. Chavez, J.A. Chinellato, J. Chudoba, R.W. Clay, A. Cobos, R. Colalillo, A. Coleman, L. Collica, M.R. Coluccia, R. Conceição, G. Consolati, F. Contreras, M.J. Cooper, S. Coutu, C.E. Covault, J. Cronin, S. D'Amico, B. Daniel, S. Dasso, K. Daumiller, B.R. Dawson, R.M. de Almeida, S.J. de Jong, G. De Mauro, J.R.T. de Mello Neto, I. De Mitri, J. de Oliveira, V. de Souza, J. Debatin, O. Deligny, M.L. Díaz Castro, F. Diogo, C. Dobrigkeit, J.C. D'Olivo, Q. Dorosti, R.C. dos Anjos, M.T. Dova, A. Dundovic, J. Ebr, R. Engel, M. Erdmann, M. Erfani, C.O. Escobar, J. Espadanal, A. Etchegoyen, H. Falcke, J. Farmer, G. Farrar, A.C. Fauth, N. Fazzini, F. Fenu, B. Fick, J.M. Figueira, A. Filipčič, O. Fratu, M.M. Freire, T. Fujii, A. Fuster, R. Gaior, B. García, D. Garcia-Pinto, F. Gaté, H. Gemmeke, A. Gherghel-Lascu, P.L. Ghia, U. Giaccari, M. Giammarchi, M. Giller, D. Głas, C. Glaser, G. Golup, M. Gómez Berisso, P.F. Gómez Vitale, N. González, B. Gookin, A. Gorgi, P. Gorham, A.F. Grillo, T.D. Grubb, F. Guarino, G.P. Guedes, R. Halliday, M.R. Hampel, P. Hansen, D. Harari, T.A. Harrison, J.L. Harton, A. Haungs, T. Hebbeker, D. Heck, P. Heimann, A.E. Herve, G.C. Hill, C. Hojvat, E. Holt, P. Homola, J.R. Hörandel, P. Horvath, M. Hrabovský, T. Huege, J. Hulsman, A. Insolia, P.G. Isar, I. Jandt, J.A. Johnsen, M. Josebachuili, J. Jurysek, A. Kääpä, O. Kambeitz, K.H. Kampert, B. Keilhauer, N. Kemmerich, E. Kemp, J. Kemp, R.M. Kieckhafer, H.O. Klages, M. Kleifges, J. Kleinfeller, R. Krause, N. Krohm, D. Kuempel, G. Kukec Mezek, N. Kunka, A. Kuotb Awad, B.L. Lago, D. LaHurd, R.G. Lang, M. Lauscher, R. Legumina, M.A. Leigui de Oliveira, A. Letessier-Selvon, I. Lhenry-Yvon, K. Link, D. Lo Presti, L. Lopes, R. López, A. López Casado, R. Lorek, Q. Luce, A. Lucero, M. Malacari, M. Mallamaci, D. Mandat, P. Mantsch, A.G. Mariazzi, I.C. Mariş, G. Marsella, D. Martello, H. Martinez, O. Martínez Bravo, J.J. Masías Meza, H.J. Mathes, S. Mathys, J. Matthews, J.A.J. Matthews, G. Matthiae, E. Mayotte, P.O. Mazur, C. Medina, G. Medina-Tanco, D. Melo, A. Menshikov, K.-D. Merenda, S. Michal, M.I. Micheletti, L. Middendorf, L. Miramonti, B. Mitrica, D. Mockler, S. Mollerach, F. Montanet, C. Morello, M. Mostafá, A.L. Müller, G. Müller, M.A. Muller, S. Müller, R. Mussa, I. Naranjo, L. Nellen, P.H. Nguyen, M. Niculescu-Oglinzanu, M. Niechciol, L. Niemietz, T. Niggemann, D. Nitz, D. Nosek, V. Novotny, L. Nožka, L.A. Núñez, L. Ochilo, F. Oikonomou, A. Olinto, M. Palatka, J. Pallotta, P. Papenbreer, G. Parente, A. Parra, T. Paul, M. Pech, F. Pedreira, J. Pękala, R. Pelayo, J. Peña-Rodriguez, L. A. S. Pereira, M. Perlin, L. Perrone, C. Peters, S. Petrera, J. Phuntsok, R. Piegaia, T. Pierog, M. Pimenta, V. Pirronello, M. Platino, M. Plum, C. Porowski, R.R. Prado, P. Privitera, M. Prouza, E.J. Quel, S. Querchfeld, S. Quinn, R. Ramos-Pollan, J. Rautenberg, D. Ravignani, J. Ridky, F. Riehn, M. Risse, P. Ristori, V. Rizi, W. Rodrigues de Carvalho, G. Rodriguez Fernandez, J. Rodriguez Rojo, D. Rogozin, M.J. Roncoroni, M. Roth, E. Roulet, A.C. Rovero, P. Ruehl, S.J. Saffi, A. Saftoiu, F. Salamida, H. Salazar, A. Saleh, F. Salesa Greus, G. Salina, F. Sánchez, P. Sanchez-Lucas, E.M. Santos, E. Santos, F. Sarazin, R. Sarmento, C. Sarmiento-Cano, R. Sato, M. Schauer, V. Scherini, H. Schieler, M. Schimp, D. Schmidt, O. Scholten, P. Schovánek, F.G. Schröder, S. Schröder, A. Schulz, J. Schumacher, S.J. Sciutto, A. Segreto, A. Shadkam, R.C. Shellard, G. Sigl, G. Silli, O. Sima, A. Śmiałkowski, R. Šmída, G.R. Snow, P. Sommers, S. Sonntag, R. Squartini, D. Stanca, S. Stanič, J. Stasielak, P. Stassi, M. Stolpovskiy, F. Strafella, A. Streich, F. Suarez, M. Suarez Durán, T. Sudholz, T. Suomijärvi, A.D. Supanitsky, J. Šupík, J. Swain, Z. Szadkowski, A. Taboada, O.A. Taborda, V.M. Theodoro, C. Timmermans, C.J. Todero Peixoto, L. Tomankova, B. Tomé, G. Torralba Elipe, P. Travnicek, M. Trini, R. Ulrich, M. Unger, M. Urban, J.F. Valdés Galicia, I. Valiño, L. Valore, G. van Aar, P. van Bodegom, A.M. van den Berg, A. van Vliet, E. Varela, B. Vargas Cárdenas, G. Varner, R.A. Vázquez, D. Veberič, C. Ventura, I.D. Vergara Quispe, V. Verzi, J. Vicha, L. Villaseñor, S. Vorobiov, H. Wahlberg, O. Wainberg, D. Walz, A.A. Watson, M. Weber, A. Weindl, L. Wiencke, H. Wilczyński, M. Wirtz, D. Wittkowski, B. Wundheiler, L. Yang, A. Yushkov, E. Zas, D. Zavrtanik, M. Zavrtanik, A. Zepeda, B. Zimmermann, M. Ziolkowski, Z. Zong, F. Zuccarello
We present a novel method to measure precisely the relative spectral response of the fluorescence telescopes of the Pierre Auger Observatory. We used a portable light source based on a xenon flasher and a monochromator to measure the relative spectral efficiencies of eight telescopes in steps of 5 nm from 280 nm to 440 nm. Each point in a scan had approximately 2 nm FWHM out of the monochromator. Different sets of telescopes in the observatory have different optical components, and the eight telescopes measured represent two each of the four combinations of components represented in the observatory. We made an end-to-end measurement of the response from different combinations of optical components, and the monochromator setup allowed for more precise and complete measurements than our previous multi-wavelength calibrations. We find an overall uncertainty in the calibration of the spectral response of most of the telescopes of 1.5% for all wavelengths; the six oldest telescopes have larger overall uncertainties of about 2.2%. We also report changes in physics measureables due to the change in calibration, which are generally small.
The Pierre Auger Observatory: Contributions to the 35th International Cosmic Ray Conference (ICRC 2017) (1708.06592)
The Pierre Auger Collaboration: A. Aab, P. Abreu, M. Aglietta, I.F.M. Albuquerque, I. Allekotte, A. Almela, J. Alvarez Castillo, J. Alvarez-Muñiz, G.A. Anastasi, L. Anchordoqui, B. Andrada, S. Andringa, C. Aramo, N. Arsene, H. Asorey, P. Assis, J. Aublin, G. Avila, A.M. Badescu, A. Balaceanu, F. Barbato, R.J. Barreira Luz, K.H. Becker, J.A. Bellido, C. Berat, M.E. Bertaina, X. Bertou, P.L. Biermann, J. Biteau, S.G. Blaess, A. Blanco, J. Blazek, C. Bleve, M. Boháčová, D. Boncioli, C. Bonifazi, N. Borodai, A.M. Botti, J. Brack, I. Brancus, T. Bretz, A. Bridgeman, F.L. Briechle, P. Buchholz, A. Bueno, S. Buitink, M. Buscemi, K.S. Caballero-Mora, B. Caccianiga, L. Caccianiga, A. Cancio, F. Canfora, L. Caramete, R. Caruso, A. Castellina, F. Catalani, G. Cataldi, L. Cazon, A.G. Chavez, J.A. Chinellato, J. Chudoba, R.W. Clay, A. Cobos, R. Colalillo, A. Coleman, L. Collica, M.R. Coluccia, R. Conceição, G. Consolati, G. Consolati, F. Contreras, M.J. Cooper, S. Coutu, C.E. Covault, J. Cronin, S. D'Amico, B. Daniel, S. Dasso, K. Daumiller, B.R. Dawson, R.M. de Almeida, S.J. de Jong, G. De Mauro, J.R.T. de Mello Neto, I. De Mitri, J. de Oliveira, V. de Souza, J. Debatin, O. Deligny, M.L. Díaz Castro, F. Diogo, C. Dobrigkeit, J.C. D'Olivo, Q. Dorosti, R.C. dos Anjos, M.T. Dova, A. Dundovic, J. Ebr, R. Engel, M. Erdmann, M. Erfani, C.O. Escobar, J. Espadanal, A. Etchegoyen, H. Falcke, J. Farmer, G. Farrar, A.C. Fauth, N. Fazzini, F. Fenu, B. Fick, J.M. Figueira, A. Filipčič, M.M. Freire, T. Fujii, A. Fuster, R. Gaïor, B. García, F. Gaté, H. Gemmeke, A. Gherghel-Lascu, P.L. Ghia, U. Giaccari, M. Giammarchi, M. Giller, D. Głas, C. Glaser, G. Golup, M. Gómez Berisso, P.F. Gómez Vitale, N. González, A. Gorgi, A.F. Grillo, T.D. Grubb, F. Guarino, G.P. Guedes, R. Halliday, M.R. Hampel, P. Hansen, D. Harari, T.A. Harrison, A. Haungs, T. Hebbeker, D. Heck, P. Heimann, A.E. Herve, G.C. Hill, C. Hojvat, E. Holt, P. Homola, J.R. Hörandel, P. Horvath, M. Hrabovský, T. Huege, J. Hulsman, A. Insolia, P.G. Isar, I. Jandt, J.A. Johnsen, M. Josebachuili, J. Jurysek, A. Kääpä, O. Kambeitz, K.H. Kampert, B. Keilhauer, N. Kemmerich, E. Kemp, J. Kemp, R.M. Kieckhafer, H.O. Klages, M. Kleifges, J. Kleinfeller, R. Krause, N. Krohm, D. Kuempel, G. Kukec Mezek, N. Kunka, A. Kuotb Awad, B.L. Lago, D. LaHurd, R.G. Lang, M. Lauscher, R. Legumina, M.A. Leigui de Oliveira, A. Letessier-Selvon, I. Lhenry-Yvon, K. Link, D. Lo Presti, L. Lopes, R. López, A. López Casado, R. Lorek, Q. Luce, A. Lucero, M. Malacari, M. Mallamaci, D. Mandat, P. Mantsch, A.G. Mariazzi, I.C. Mariş, G. Marsella, D. Martello, H. Martinez, O. Martínez Bravo, J.J. Masías Meza, H.J. Mathes, S. Mathys, G. Matthiae, E. Mayotte, P.O. Mazur, C. Medina, G. Medina-Tanco, D. Melo, A. Menshikov, K.-D. Merenda, S. Michal, M.I. Micheletti, L. Middendorf, L. Miramonti, B. Mitrica, D. Mockler, S. Mollerach, F. Montanet, C. Morello, G. Morlino, M. Mostafá, A.L. Müller, G. Müller, M.A. Muller, S. Müller, R. Mussa, I. Naranjo, L. Nellen, P.H. Nguyen, M. Niculescu-Oglinzanu, M. Niechciol, L. Niemietz, T. Niggemann, D. Nitz, D. Nosek, V. Novotny, L. Nožka, L.A. Núñez, L. Ochilo, F. Oikonomou, A. Olinto, M. Palatka, J. Pallotta, P. Papenbreer, G. Parente, A. Parra, T. Paul, M. Pech, F. Pedreira, J. Pękala, R. Pelayo, J. Peña-Rodriguez, L. A. S. Pereira, M. Perlin, L. Perrone, C. Peters, S. Petrera, J. Phuntsok, R. Piegaia, T. Pierog, M. Pimenta, V. Pirronello, M. Platino, M. Plum, J. Poh, C. Porowski, R.R. Prado, P. Privitera, M. Prouza, E.J. Quel, S. Querchfeld, S. Quinn, R. Ramos-Pollan, J. Rautenberg, D. Ravignani, J. Ridky, F. Riehn, M. Risse, P. Ristori, V. Rizi, W. Rodrigues de Carvalho, G. Rodriguez Fernandez, J. Rodriguez Rojo, M.J. Roncoroni, M. Roth, E. Roulet, A.C. Rovero, P. Ruehl, S.J. Saffi, A. Saftoiu, F. Salamida, H. Salazar, A. Saleh, G. Salina, F. Sánchez, P. Sanchez-Lucas, E.M. Santos, E. Santos, F. Sarazin, R. Sarmento, C. Sarmiento-Cano, R. Sato, M. Schauer, V. Scherini, H. Schieler, M. Schimp, D. Schmidt, O. Scholten, P. Schovánek, F.G. Schröder, S. Schröder, A. Schulz, J. Schumacher, S.J. Sciutto, A. Segreto, R.C. Shellard, G. Sigl, G. Silli, R. Šmída, G.R. Snow, P. Sommers, S. Sonntag, J. F. Soriano, R. Squartini, D. Stanca, S. Stanič, J. Stasielak, P. Stassi, M. Stolpovskiy, F. Strafella, A. Streich, F. Suarez, M. Suarez Durán, T. Sudholz, T. Suomijärvi, A.D. Supanitsky, J. Šupík, J. Swain, Z. Szadkowski, A. Taboada, O.A. Taborda, V.M. Theodoro, C. Timmermans, C.J. Todero Peixoto, L. Tomankova, B. Tomé, G. Torralba Elipe, P. Travnicek, M. Trini, R. Ulrich, M. Unger, M. Urban, J.F. Valdés Galicia, I. Valiño, L. Valore, G. van Aar, P. van Bodegom, A.M. van den Berg, A. van Vliet, E. Varela, B. Vargas Cárdenas, R.A. Vázquez, D. Veberič, C. Ventura, I.D. Vergara Quispe, V. Verzi, J. Vicha, L. Villaseñor, S. Vorobiov, H. Wahlberg, O. Wainberg, D. Walz, A.A. Watson, M. Weber, A. Weindl, M. Wiedeński, L. Wiencke, H. Wilczyński, T. Winchen, M. Wirtz, D. Wittkowski, B. Wundheiler, L. Yang, A. Yushkov, E. Zas, D. Zavrtanik, M. Zavrtanik, A. Zepeda, B. Zimmermann, M. Ziolkowski, Z. Zong, F. Zuccarello
Oct. 2, 2017 astro-ph.CO, astro-ph.IM, astro-ph.HE
Contributions of the Pierre Auger Collaboration to the 35th International Cosmic Ray Conference (ICRC 2017), 12-20 July 2017, Bexco, Busan, Korea.
Observation of a Large-scale Anisotropy in the Arrival Directions of Cosmic Rays above $8 \times 10^{18}$ eV (1709.07321)
The Pierre Auger Collaboration: A. Aab, P. Abreu, M. Aglietta, I. Al Samarai, I.F.M. Albuquerque, I. Allekotte, A. Almela, J. Alvarez Castillo, J. Alvarez-Muñiz, G.A. Anastasi, L. Anchordoqui, B. Andrada, S. Andringa, C. Aramo, F. Arqueros, N. Arsene, H. Asorey, P. Assis, J. Aublin, G. Avila, A.M. Badescu, A. Balaceanu, F. Barbato, R.J. Barreira Luz, J.J. Beatty, K.H. Becker, J.A. Bellido, C. Berat, M.E. Bertaina, X. Bertou, P.L. Biermann, P. Billoir, J. Biteau, S.G. Blaess, A. Blanco, J. Blazek, C. Bleve, M. Boháčová, D. Boncioli, C. Bonifazi, N. Borodai, A.M. Botti, J. Brack, I. Brancus, T. Bretz, A. Bridgeman, F.L. Briechle, P. Buchholz, A. Bueno, S. Buitink, M. Buscemi, K.S. Caballero-Mora, L. Caccianiga, A. Cancio, F. Canfora, L. Caramete, R. Caruso, A. Castellina, G. Cataldi, L. Cazon, A.G. Chavez, J.A. Chinellato, J. Chudoba, R.W. Clay, A. Cobos, R. Colalillo, A. Coleman, L. Collica, M.R. Coluccia, R. Conceição, G. Consolati, F. Contreras, M.J. Cooper, S. Coutu, C.E. Covault, J. Cronin, S. D'Amico, B. Daniel, S. Dasso, K. Daumiller, B.R. Dawson, R.M. de Almeida, S.J. de Jong, G. De Mauro, J.R.T. de Mello Neto, I. De Mitri, J. de Oliveira, V. de Souza, J. Debatin, O. Deligny, C. Di Giulio, A. Di Matteo, M.L. Díaz Castro, F. Diogo, C. Dobrigkeit, J.C. D'Olivo, Q. Dorosti, R.C. dos Anjos, M.T. Dova, A. Dundovic, J. Ebr, R. Engel, M. Erdmann, M. Erfani, C.O. Escobar, J. Espadanal, A. Etchegoyen, H. Falcke, G. Farrar, A.C. Fauth, N. Fazzini, F. Fenu, B. Fick, J.M. Figueira, A. Filipčič, O. Fratu, M.M. Freire, T. Fujii, A. Fuster, R. Gaior, B. García, D. Garcia-Pinto, F. Gaté, H. Gemmeke, A. Gherghel-Lascu, P.L. Ghia, U. Giaccari, M. Giammarchi, M. Giller, D. Głas, C. Glaser, G. Golup, M. Gómez Berisso, P.F. Gómez Vitale, N. González, A. Gorgi, P. Gorham, A.F. Grillo, T.D. Grubb, F. Guarino, G.P. Guedes, M.R. Hampel, P. Hansen, D. Harari, T.A. Harrison, J.L. Harton, A. Haungs, T. Hebbeker, D. Heck, P. Heimann, A.E. Herve, G.C. Hill, C. Hojvat, E. Holt, P. Homola, J.R. Hörandel, P. Horvath, M. Hrabovský, T. Huege, J. Hulsman, A. Insolia, P.G. Isar, I. Jandt, S. Jansen, J.A. Johnsen, M. Josebachuili, J. Jurysek, A. Kääpä, O. Kambeitz, K.H. Kampert, I. Katkov, B. Keilhauer, N. Kemmerich, E. Kemp, J. Kemp, R.M. Kieckhafer, H.O. Klages, M. Kleifges, J. Kleinfeller, R. Krause, N. Krohm, D. Kuempel, G. Kukec Mezek, N. Kunka, A. Kuotb Awad, D. LaHurd, M. Lauscher, R. Legumina, M.A. Leigui de Oliveira, A. Letessier-Selvon, I. Lhenry-Yvon, K. Link, D. Lo Presti, L. Lopes, R. López, A. López Casado, Q. Luce, A. Lucero, M. Malacari, M. Mallamaci, D. Mandat, P. Mantsch, A.G. Mariazzi, I.C. Mariş, G. Marsella, D. Martello, H. Martinez, O. Martínez Bravo, J.J. Masías Meza, H.J. Mathes, S. Mathys, J. Matthews, J.A.J. Matthews, G. Matthiae, E. Mayotte, P.O. Mazur, C. Medina, G. Medina-Tanco, D. Melo, A. Menshikov, K.-D. Merenda, S. Michal, M.I. Micheletti, L. Middendorf, L. Miramonti, B. Mitrica, D. Mockler, S. Mollerach, F. Montanet, C. Morello, M. Mostafá, A.L. Müller, G. Müller, M.A. Muller, S. Müller, R. Mussa, I. Naranjo, L. Nellen, P.H. Nguyen, M. Niculescu-Oglinzanu, M. Niechciol, L. Niemietz, T. Niggemann, D. Nitz, D. Nosek, V. Novotny, L. Nožka, L.A. Núñez, L. Ochilo, F. Oikonomou, A. Olinto, M. Palatka, J. Pallotta, P. Papenbreer, G. Parente, A. Parra, T. Paul, M. Pech, F. Pedreira, J. Pękala, R. Pelayo, J. Peña-Rodriguez, L. A. S. Pereira, M. Perlín, L. Perrone, C. Peters, S. Petrera, J. Phuntsok, R. Piegaia, T. Pierog, P. Pieroni, M. Pimenta, V. Pirronello, M. Platino, M. Plum, C. Porowski, R.R. Prado, P. Privitera, M. Prouza, E.J. Quel, S. Querchfeld, S. Quinn, R. Ramos-Pollan, J. Rautenberg, D. Ravignani, B. Revenu, J. Ridky, F. Riehn, M. Risse, P. Ristori, V. Rizi, W. Rodrigues de Carvalho, G. Rodriguez Fernandez, J. Rodriguez Rojo, D. Rogozin, M.J. Roncoroni, M. Roth, E. Roulet, A.C. Rovero, P. Ruehl, S.J. Saffi, A. Saftoiu, F. Salamida, H. Salazar, A. Saleh, F. Salesa Greus, G. Salina, F. Sánchez, P. Sanchez-Lucas, E.M. Santos, E. Santos, F. Sarazin, R. Sarmento, C.A. Sarmiento, R. Sato, M. Schauer, V. Scherini, H. Schieler, M. Schimp, D. Schmidt, O. Scholten, P. Schovánek, F.G. Schröder, A. Schulz, J. Schumacher, S.J. Sciutto, A. Segreto, M. Settimo, A. Shadkam, R.C. Shellard, G. Sigl, G. Silli, O. Sima, A. Śmiałkowski, R. Šmída, G.R. Snow, P. Sommers, S. Sonntag, J. Sorokin, R. Squartini, D. Stanca, S. Stanič, J. Stasielak, P. Stassi, F. Strafella, F. Suarez, M. Suarez Durán, T. Sudholz, T. Suomijärvi, A.D. Supanitsky, J. Šupík, J. Swain, Z. Szadkowski, A. Taboada, O.A. Taborda, A. Tapia, V.M. Theodoro, C. Timmermans, C.J. Todero Peixoto, L. Tomankova, B. Tomé, G. Torralba Elipe, P. Travnicek, M. Trini, R. Ulrich, M. Unger, M. Urban, J.F. Valdés Galicia, I. Valiño, L. Valore, G. van Aar, P. van Bodegom, A.M. van den Berg, A. van Vliet, E. Varela, B. Vargas Cárdenas, G. Varner, R.A. Vázquez, D. Veberič, C. Ventura, I.D. Vergara Quispe, V. Verzi, J. Vicha, L. Villaseñor, S. Vorobiov, H. Wahlberg, O. Wainberg, D. Walz, A.A. Watson, M. Weber, A. Weindl, L. Wiencke, H. Wilczyński, M. Wirtz, D. Wittkowski, B. Wundheiler, L. Yang, A. Yushkov, E. Zas, D. Zavrtanik, M. Zavrtanik, A. Zepeda, B. Zimmermann, M. Ziolkowski, Z. Zong, F. Zuccarello
Sept. 21, 2017 astro-ph.HE
Cosmic rays are atomic nuclei arriving from outer space that reach the highest energies observed in nature. Clues to their origin come from studying the distribution of their arrival directions. Using $3 \times 10^4$ cosmic rays above $8 \times 10^{18}$ electron volts, recorded with the Pierre Auger Observatory from a total exposure of 76,800 square kilometers steradian year, we report an anisotropy in the arrival directions. The anisotropy, detected at more than the 5.2$\sigma$ level of significance, can be described by a dipole with an amplitude of $6.5_{-0.9}^{+1.3}$% towards right ascension $\alpha_{d} = 100 \pm 10$ degrees and declination $\delta_{d} = -24_{-13}^{+12}$ degrees. That direction indicates an extragalactic origin for these ultra-high energy particles.
Multi-resolution anisotropy studies of ultrahigh-energy cosmic rays detected at the Pierre Auger Observatory (1611.06812)
The Pierre Auger Collaboration: A. Aab, P. Abreu, M. Aglietta, I. Al Samarai, I.F.M. Albuquerque, I. Allekotte, A. Almela, J. Alvarez Castillo, J. Alvarez-Muñiz, G.A. Anastasi, L. Anchordoqui, B. Andrada, S. Andringa, C. Aramo, F. Arqueros, N. Arsene, H. Asorey, P. Assis, J. Aublin, G. Avila, A.M. Badescu, A. Balaceanu, R.J. Barreira Luz, C. Baus, J.J. Beatty, K.H. Becker, J.A. Bellido, C. Berat, M.E. Bertaina, X. Bertou, P.L. Biermann, P. Billoir, J. Biteau, S.G. Blaess, A. Blanco, J. Blazek, C. Bleve, M. Boháčová, D. Boncioli, C. Bonifazi, N. Borodai, A.M. Botti, J. Brack, I. Brancus, T. Bretz, A. Bridgeman, F.L. Briechle, P. Buchholz, A. Bueno, S. Buitink, M. Buscemi, K.S. Caballero-Mora, L. Caccianiga, A. Cancio, F. Canfora, L. Caramete, R. Caruso, A. Castellina, G. Cataldi, L. Cazon, A.G. Chavez, J.A. Chinellato, J. Chudoba, R.W. Clay, R. Colalillo, A. Coleman, L. Collica, M.R. Coluccia, R. Conceição, F. Contreras, M.J. Cooper, S. Coutu, C.E. Covault, J. Cronin, S. D'Amico, B. Daniel, S. Dasso, K. Daumiller, B.R. Dawson, R.M. de Almeida, S.J. de Jong, G. De Mauro, J.R.T. de Mello Neto, I. De Mitri, J. de Oliveira, V. de Souza, J. Debatin, O. Deligny, C. Di Giulio, A. Di Matteo, M.L. Díaz Castro, F. Diogo, C. Dobrigkeit, J.C. D'Olivo, R.C. dos Anjos, M.T. Dova, A. Dundovic, J. Ebr, R. Engel, M. Erdmann, M. Erfani, C.O. Escobar, J. Espadanal, A. Etchegoyen, H. Falcke, G. Farrar, A.C. Fauth, N. Fazzini, B. Fick, J.M. Figueira, A. Filipčič, O. Fratu, M.M. Freire, T. Fujii, A. Fuster, R. Gaior, B. García, D. Garcia-Pinto, F. Gaté, H. Gemmeke, A. Gherghel-Lascu, P.L. Ghia, U. Giaccari, M. Giammarchi, M. Giller, D. Głas, C. Glaser, G. Golup, M. Gómez Berisso, P.F. Gómez Vitale, N. González, A. Gorgi, P. Gorham, P. Gouffon, A.F. Grillo, T.D. Grubb, F. Guarino, G.P. Guedes, M.R. Hampel, P. Hansen, D. Harari, T.A. Harrison, J.L. Harton, Q. Hasankiadeh, A. Haungs, T. Hebbeker, D. Heck, P. Heimann, A.E. Herve, G.C. Hill, C. Hojvat, E. Holt, P. Homola, J.R. Hörandel, P. Horvath, M. Hrabovský, T. Huege, J. Hulsman, A. Insolia, P.G. Isar, I. Jandt, S. Jansen, J.A. Johnsen, M. Josebachuili, A. Kääpä, O. Kambeitz, K.H. Kampert, I. Katkov, B. Keilhauer, E. Kemp, J. Kemp, R.M. Kieckhafer, H.O. Klages, M. Kleifges, J. Kleinfeller, R. Krause, N. Krohm, D. Kuempel, G. Kukec Mezek, N. Kunka, A. Kuotb Awad, D. LaHurd, M. Lauscher, R. Legumina, M.A. Leigui de Oliveira, A. Letessier-Selvon, I. Lhenry-Yvon, K. Link, L. Lopes, R. López, A. López Casado, Q. Luce, A. Lucero, M. Malacari, M. Mallamaci, D. Mandat, P. Mantsch, A.G. Mariazzi, I.C. Mariş, G. Marsella, D. Martello, H. Martinez, O. Martínez Bravo, J.J. Masías Meza, H.J. Mathes, S. Mathys, J. Matthews, J.A.J. Matthews, G. Matthiae, E. Mayotte, P.O. Mazur, C. Medina, G. Medina-Tanco, D. Melo, A. Menshikov, S. Messina, M.I. Micheletti, L. Middendorf, I.A. Minaya, L. Miramonti, B. Mitrica, D. Mockler, S. Mollerach, F. Montanet, C. Morello, M. Mostafá, A.L. Müller, G. Müller, M.A. Muller, S. Müller, R. Mussa, I. Naranjo, L. Nellen, P.H. Nguyen, M. Niculescu-Oglinzanu, M. Niechciol, L. Niemietz, T. Niggemann, D. Nitz, D. Nosek, V. Novotny, H. Nožka, L.A. Núñez, L. Ochilo, F. Oikonomou, A. Olinto, D. Pakk Selmi-Dei, M. Palatka, J. Pallotta, P. Papenbreer, G. Parente, A. Parra, T. Paul, M. Pech, F. Pedreira, J. Pękala, R. Pelayo, J. Peña-Rodriguez, L. A. S. Pereira, M. Perlín, L. Perrone, C. Peters, S. Petrera, J. Phuntsok, R. Piegaia, T. Pierog, P. Pieroni, M. Pimenta, V. Pirronello, M. Platino, M. Plum, C. Porowski, R.R. Prado, P. Privitera, M. Prouza, E.J. Quel, S. Querchfeld, S. Quinn, R. Ramos-Pollan, J. Rautenberg, D. Ravignani, B. Revenu, J. Ridky, M. Risse, P. Ristori, V. Rizi, W. Rodrigues de Carvalho, G. Rodriguez Fernandez, J. Rodriguez Rojo, D. Rogozin, M.J. Roncoroni, M. Roth, E. Roulet, A.C. Rovero, P. Ruehl, S.J. Saffi, A. Saftoiu, H. Salazar, A. Saleh, F. Salesa Greus, G. Salina, F. Sánchez, P. Sanchez-Lucas, E.M. Santos, E. Santos, F. Sarazin, R. Sarmento, C.A. Sarmiento, R. Sato, M. Schauer, V. Scherini, H. Schieler, M. Schimp, D. Schmidt, O. Scholten, P. Schovánek, F.G. Schröder, A. Schulz, J. Schulz, J. Schumacher, S.J. Sciutto, A. Segreto, M. Settimo, A. Shadkam, R.C. Shellard, G. Sigl, G. Silli, O. Sima, A. Śmiałkowski, R. Šmída, G.R. Snow, P. Sommers, S. Sonntag, J. Sorokin, R. Squartini, D. Stanca, S. Stanič, J. Stasielak, P. Stassi, F. Strafella, F. Suarez, M. Suarez Durán, T. Sudholz, T. Suomijärvi, A.D. Supanitsky, J. Swain, Z. Szadkowski, A. Taboada, O.A. Taborda, A. Tapia, V.M. Theodoro, C. Timmermans, C.J. Todero Peixoto, L. Tomankova, B. Tomé, G. Torralba Elipe, M. Torri, P. Travnicek, M. Trini, R. Ulrich, M. Unger, M. Urban, J.F. Valdés Galicia, I. Valiño, L. Valore, G. van Aar, P. van Bodegom, A.M. van den Berg, A. van Vliet, E. Varela, B. Vargas Cárdenas, G. Varner, J.R. Vázquez, R.A. Vázquez, D. Veberič, I.D. Vergara Quispe, V. Verzi, J. Vicha, L. Villaseñor, S. Vorobiov, H. Wahlberg, O. Wainberg, D. Walz, A.A. Watson, M. Weber, A. Weindl, L. Wiencke, H. Wilczyński, T. Winchen, D. Wittkowski, B. Wundheiler, L. Yang, D. Yelos, A. Yushkov, E. Zas, D. Zavrtanik, M. Zavrtanik, A. Zepeda, B. Zimmermann, M. Ziolkowski, Z. Zong, F. Zuccarello
June 20, 2017 astro-ph.HE
We report a multi-resolution search for anisotropies in the arrival directions of cosmic rays detected at the Pierre Auger Observatory with local zenith angles up to $80^\circ$ and energies in excess of 4 EeV ($4 \times 10^{18}$ eV). This search is conducted by measuring the angular power spectrum and performing a needlet wavelet analysis in two independent energy ranges. Both analyses are complementary since the angular power spectrum achieves a better performance in identifying large-scale patterns while the needlet wavelet analysis, considering the parameters used in this work, presents a higher efficiency in detecting smaller-scale anisotropies, potentially providing directional information on any observed anisotropies. No deviation from isotropy is observed on any angular scale in the energy range between 4 and 8 EeV. Above 8 EeV, an indication for a dipole moment is captured; while no other deviation from isotropy is observed for moments beyond the dipole one. The corresponding $p$-values obtained after accounting for searches blindly performed at several angular scales, are $1.3 \times 10^{-5}$ in the case of the angular power spectrum, and $2.5 \times 10^{-3}$ in the case of the needlet analysis. While these results are consistent with previous reports making use of the same data set, they provide extensions of the previous works through the thorough scans of the angular scales.
The HAWC real-time flare monitor for rapid detection of transient events (1704.07411)
A.U. Abeysekara, R. Alfaro, C. Alvarez, J.D. Álvarez, R. Arceo, J.C. Arteaga-Velázquez, D. Avila Rojas, H.A. Ayala Solares, A.S. Barber, N. Bautista-Elivar, J. Becerra Gonzalez, A. Becerril, E. Belmont-Moreno, S.Y. BenZvi, A. Bernal, J. Braun, C. Brisbois, K.S. Caballero-Mora, T. Capistrán, A. Carramiñana, S. Casanova, M. Castillo, U. Cotti, J. Cotzomi, S. Coutiño de León, E. De la Fuente, C. De León, J.C. Díaz-Vélez, B.L. Dingus, M.A. DuVernois, R.W. Ellsworth, K. Engel, D.W. Fiorino, N. Fraija, J.A. García-González, F. Garfias, M. Gerhardt, M.M. González, A. González Muñoz, J.A. Goodman, Z. Hampel-Arias, J.P. Harding, S. Hernandez, A. Hernandez-Almada, B. Hona, C.M. Hui, P. Hüntemeyer, A. Iriarte, A. Jardin-Blicq, V. Joshi, S. Kaufmann, D. Kieda, R.J. Lauer, W.H. Lee, D. Lennarz, H. León Vargas, J.T. Linnemann, A.L. Longinotti, D. López-Cámara, R. López-Coto, G. Luis Raya, R. Luna-García, K. Malone, S.S. Marinelli, O. Martinez, I. Martinez-Castellanos, J. Martínez-Castro, H. Martínez-Huerta, J.A. Matthews, P. Miranda-Romagnoli, E. Moreno, M. Mostafá, L. Nellen, M. Newbold, M.U. Nisa, R. Noriega-Papaqui, R. Pelayo, E.G. Pérez-Pérez, J. Pretz, Z. Ren, C.D. Rho, C. Rivière, D. Rosa-González, M. Rosenberg, E. Ruiz-Velasco, H. Salazar, F. Salesa Greus, A. Sandoval, M. Schneider, H. Schoorlemmer, G. Sinnis, A.J. Smith, R.W. Springer, P. Surajbali, I. Taboada, O. Tibolla, K. Tollefson, I. Torres, T.N. Ukwatta, G. Vianello, T. Weisgarber, S. Westerhoff, I.G. Wisher, J. Wood, T. Yapici, P.W. Younk, A. Zepeda, H. Zhou
We present the development of a real-time flare monitor for the High Altitude Water Cherenkov (HAWC) observatory. The flare monitor has been fully operational since 2017 January and is designed to detect very high energy (VHE; $E\gtrsim100$ GeV) transient events from blazars on time scales lasting from 2 minutes to 10 hours in order to facilitate multiwavelength and multimessenger studies. These flares provide information for investigations into the mechanisms that power the blazars' relativistic jets and accelerate particles within them, and they may also serve as probes of the populations of particles and fields in intergalactic space. To date, the detection of blazar flares in the VHE range has relied primarily on pointed observations by imaging atmospheric Cherenkov telescopes. The recently completed HAWC observatory offers the opportunity to study VHE flares in survey mode, scanning 2/3 of the entire sky every day with a field of view of $\sim$1.8 steradians. In this work, we report on the sensitivity of the HAWC real-time flare monitor and demonstrate its capabilities via the detection of three high-confidence VHE events in the blazars Markarian 421 and Markarian 501.
Search for Very High Energy Gamma Rays from the Northern $\textit{Fermi}$ Bubble Region with HAWC (1703.01344)
A.U. Abeysekara, A. Albert, R. Alfaro, C. Alvarez, J.D. Álvarez, R. Arceo, J.C. Arteaga-Velázquez, H.A. Ayala Solares, A.S. Barber, N. Bautista-Elivar, A. Becerril, E. Belmont-Moreno, S.Y. BenZvi, D. Berley, J. Braun, C. Brisbois, K.S. Caballero-Mora, T. Capistrán, A. Carramiñana, S. Casanova, M. Castillo, U. Cotti, J. Cotzomi, S. Coutiño de León, C. De León, E. De la Fuente, R. Diaz Hernandez, B.L. Dingus, M.A. DuVernois, J.C. Díaz-Vélez, R.W. Ellsworth, K. Engel, B. Fick, D.W. Fiorino, H.Fleischhack, N. Fraija, J.A. García-González, F. Garfias, M. Gerhardt, A. González Muñoz, M.M. González, J.A. Goodman, Z. Hampel-Arias, J.P. Harding, S. Hernandez, A. Hernandez-Almada, J. Hinton, B. Hona, C.M. Hui, P. Hüntemeyer, A. Iriarte, A. Jardin-Blicq, V. Joshi, S. Kaufmann, D.Kieda, A. Lara, R.J. Lauer, W.H. Lee, D. Lennarz, H. León Vargas, J.T. Linnemann, A.L. Longinotti, G. Luis Raya, R. Luna-García, R. López-Coto, K. Malone, S.S. Marinelli, O. Martinez, I. Martinez-Castellanos, J. Martínez-Castro, H. Martínez-Huerta, J.A. Matthews, P. Miranda-Romagnoli, E. Moreno, M. Mostafá, L. Nellen, M. Newbold, M.U. Nisa, R. Noriega-Papaqui, R. Pelayo, J. Pretz, E.G. Pérez-Pérez, Z. Ren, C.D. Rho, C. Rivière, D. Rosa-González, M. Rosenberg, E. Ruiz-Velasco, H. Salazar, F. Salesa Greus, A. Sandoval, M. Schneider, H. Schoorlemmer, G. Sinnis, A.J. Smith, R.W. Springer, P. Surajbali, I. Taboada, O. Tibolla, K. Tollefson, I. Torres, T.N. Ukwatta, G. Vianello, T. Weisgarber, S. Westerhoff, I.G. Wisher, J. Wood, T. Yapici, G.B. Yodh, A. Zepeda, H. Zhou
May 24, 2017 astro-ph.HE
We present a search of very high energy gamma-ray emission from the Northern $\textit{Fermi}$ Bubble region using data collected with the High Altitude Water Cherenkov (HAWC) gamma-ray observatory. The size of the data set is 290 days. No significant excess is observed in the Northern $\textit{Fermi}$ Bubble region, hence upper limits above $1\,\text{TeV}$ are calculated. The upper limits are between $3\times 10^{-7}\,\text{GeV}\, \text{cm}^{-2}\, \text{s}^{-1}\,\text{sr}^{-1}$ and $4\times 10^{-8}\,\text{GeV}\,\text{cm}^{-2}\,\text{s}^{-1}\,\text{sr}^{-1}$. The upper limits disfavor a proton injection spectrum that extends beyond $100\,\text{TeV}$ without being suppressed. They also disfavor a hadronic injection spectrum derived from neutrino measurements.
Daily monitoring of TeV gamma-ray emission from Mrk 421, Mrk 501, and the Crab Nebula with HAWC (1703.06968)
A.U. Abeysekara, A. Albert, R. Alfaro, C. Alvarez, J.D. Álvarez, R. Arceo, J.C. Arteaga-Velázquez, D. Avila Rojas, H.A. Ayala Solares, A.S. Barber, N. Bautista-Elivar, J. Becerra Gonzalez, A. Becerril, E. Belmont-Moreno, S.Y. BenZvi, A. Bernal, J. Braun, C. Brisbois, K.S. Caballero-Mora, T. Capistrán, A. Carramiñana, S. Casanova, M. Castillo, U. Cotti, J. Cotzomi, S. Coutiño de León, C. De León, E. De la Fuente, R. Diaz Hernandez, B.L. Dingus, M.A. DuVernois, J.C. Díaz-Vélez, R.W. Ellsworth, K. Engel, D.W. Fiorino, N. Fraija, J.A. García-González, F. Garfias, M. Gerhardt, A. González Muñoz, M.M. González, J.A. Goodman, Z. Hampel-Arias, J.P. Harding, S. Hernandez, A. Hernandez-Almada, B. Hona, C.M. Hui, P. Hüntemeyer, A. Iriarte, A. Jardin-Blicq, V. Joshi, S. Kaufmann, D. Kieda, A. Lara, R.J. Lauer, W.H. Lee, D. Lennarz, H. León Vargas, J.T. Linnemann, A.L. Longinotti, G. Luis Raya, R. Luna-García, R. López-Coto, K. Malone, S.S. Marinelli, O. Martinez, I. Martinez-Castellanos, J. Martínez-Castro, J.A. Matthews, P. Miranda-Romagnoli, E. Moreno, M. Mostafá, L. Nellen, M. Newbold, M.U. Nisa, R. Noriega-Papaqui, J. Pretz, E.G. Pérez-Pérez, Z. Ren, C.D. Rho, C. Rivière, D. Rosa-González, M. Rosenberg, E. Ruiz-Velasco, F. Salesa Greus, A. Sandoval, M. Schneider, H. Schoorlemmer, G. Sinnis, A.J. Smith, R.W. Springer, P. Surajbali, I. Taboada, O. Tibolla, K. Tollefson, I. Torres, T.N. Ukwatta, G. Vianello, T. Weisgarber, S. Westerhoff, I.G. Wisher, J. Wood, T. Yapici, P.W. Younk, A. Zepeda, H. Zhou
We present results from daily monitoring of gamma rays in the energy range $\sim0.5$ to $\sim100$ TeV with the first 17 months of data from the High Altitude Water Cherenkov (HAWC) Observatory. Its wide field of view of 2 steradians and duty cycle of $>95$% are unique features compared to other TeV observatories that allow us to observe every source that transits over HAWC for up to $\sim6$ hours each sidereal day. This regular sampling yields unprecedented light curves from unbiased measurements that are independent of seasons or weather conditions. For the Crab Nebula as a reference source we find no variability in the TeV band. Our main focus is the study of the TeV blazars Markarian (Mrk) 421 and Mrk 501. A spectral fit for Mrk 421 yields a power law index $\Gamma=2.21 \pm0.14_{\mathrm{stat}}\pm0.20_{\mathrm{sys}}$ and an exponential cut-off $E_0=5.4 \pm 1.1_{\mathrm{stat}}\pm 1.0_{\mathrm{sys}}$ TeV. For Mrk 501, we find an index $\Gamma=1.60\pm 0.30_{\mathrm{stat}} \pm 0.20_{\mathrm{sys}}$ and exponential cut-off $E_0=5.7\pm 1.6_{\mathrm{stat}} \pm 1.0_{\mathrm{sys}}$ TeV. The light curves for both sources show clear variability and a Bayesian analysis is applied to identify changes between flux states. The highest per-transit fluxes observed from Mrk 421 exceed the Crab Nebula flux by a factor of approximately five. For Mrk 501, several transits show fluxes in excess of three times the Crab Nebula flux. In a comparison to lower energy gamma-ray and X-ray monitoring data with comparable sampling we cannot identify clear counterparts for the most significant flaring features observed by HAWC.
Search for gamma-rays from the unusually bright GRB 130427A with the HAWC Gamma-ray Observatory (1410.1536)
The HAWC collaboration: A.U. Abeysekara, R. Alfaro, C. Alvarez, J.D. Álvarez, R. Arceo, J.C. Arteaga-Velázquez, H.A. Ayala Solares, A.S. Barber, B.M. Baughman, N. Bautista-Elivar, S.Y. BenZvi, M. Bonilla Rosales, J. Braun, K.S. Caballero-Mora, A. Carramiñana, M. Castillo, U. Cotti, J. Cotzomi, E. de la Fuente, C. De León, T. DeYoung, R. Diaz Hernandez, B.L. Dingus, M.A. DuVernois, R.W. Ellsworth, D.W. Fiorino, N. Fraija, A. Galindo, F. Garfias, M.M. González, J.A. Goodman, M. Gussert, Z. Hampel-Arias, J.P. Harding, P. Hüntemeyer, C.M. Hui, A. Imran, A. Iriarte, P. Karn, D. Kieda, G.J. Kunde, A. Lara, R.J. Lauer, W.H. Lee, D. Lennarz, H. León Vargas, J.T. Linnemann, M. Longo, R. Luna-García, K. Malone, A. Marinelli, S.S. Marinelli, H. Martinez, O. Martinez, J. Martínez-Castro, J.A. Matthews, E. Mendoza Torres, P. Miranda-Romagnoli, E. Moreno, M. Mostafá, L. Nellen, M. Newbold, R. Noriega-Papaqui, T.O. Oceguera-Becerra, B. Patricelli, R. Pelayo, E.G. Pérez-Pérez, J. Pretz, C. Rivière, D. Rosa-González, H. Salazar, F. Salesa Greus, A. Sandoval, M. Schneider, G. Sinnis, A.J. Smith, K. Sparks Woodle, R.W. Springer, I. Taboada, K. Tollefson, I. Torres, T.N. Ukwatta, L. Villaseñor, T. Weisgarber, S. Westerhoff, I.G. Wisher, J. Wood, G.B. Yodh, P.W. Younk, D. Zaborov, A. Zepeda, H. Zhou
The first limits on the prompt emission from the long gamma-ray burst (GRB) 130427A in the $>100\nobreakspace\rm{GeV}$ energy band are reported. GRB 130427A was the most powerful burst ever detected with a redshift $z\lesssim0.5$ and featured the longest lasting emission above $100\nobreakspace\rm{MeV}$. The energy spectrum extends at least up to $95\nobreakspace\rm{GeV}$, clearly in the range observable by the High Altitude Water Cherenkov (HAWC) Gamma-ray Observatory, a new extensive air shower detector currently under construction in central Mexico. The burst occurred under unfavourable observation conditions, low in the sky and when HAWC was running 10% of the final detector. Based on the observed light curve at MeV-GeV energies, eight different time periods have been searched for prompt and delayed emission from this GRB. In all cases, no statistically significant excess of counts has been found and upper limits have been placed. It is shown that a similar GRB close to zenith would be easily detected by the full HAWC detector, which will be completed soon. The detection rate of the full HAWC detector may be as high as one to two GRBs per year. A detection could provide important information regarding the high energy processes at work and the observation of a possible cut-off beyond the $\mathit{Fermi}$-LAT energy range could be the signature of gamma-ray absorption, either in the GRB or along the line of sight due to the extragalactic background light.
Search for photons with energies above 10$^{18}$ eV using the hybrid detector of the Pierre Auger Observatory (1612.01517)
April 7, 2017 hep-ex, astro-ph.HE
A search for ultra-high energy photons with energies above 1 EeV is performed using nine years of data collected by the Pierre Auger Observatory in hybrid operation mode. An unprecedented separation power between photon and hadron primaries is achieved by combining measurements of the longitudinal air-shower development with the particle content at ground measured by the fluorescence and surface detectors, respectively. Only three photon candidates at energies 1 - 2 EeV are found, which is compatible with the expected hadron-induced background. Upper limits on the integral flux of ultra-high energy photons of 0.027, 0.009, 0.008, 0.008 and 0.007 km$^{-2}$ sr$^{-1}$ yr$^{-1}$ are derived at 95% C.L. for energy thresholds of 1, 2, 3, 5 and 10 EeV. These limits bound the fractions of photons in the all-particle integral flux below 0.1%, 0.15%, 0.33%, 0.85% and 2.7%. For the first time the photon fraction at EeV energies is constrained at the sub-percent level. The improved limits are below the flux of diffuse photons predicted by some astrophysical scenarios for cosmogenic photon production. The new results rule-out the early top-down models $-$ in which ultra-high energy cosmic rays are produced by, e.g., the decay of super-massive particles $-$ and challenge the most recent super-heavy dark matter models.
A targeted search for point sources of EeV photons with the Pierre Auger Observatory (1612.04155)
March 21, 2017 hep-ph, astro-ph.HE
Simultaneous measurements of air showers with the fluorescence and surface detectors of the Pierre Auger Observatory allow a sensitive search for EeV photon point sources. Several Galactic and extragalactic candidate objects are grouped in classes to reduce the statistical penalty of many trials from that of a blind search and are analyzed for a significant excess above the background expectation. The presented search does not find any evidence for photon emission at candidate sources, and combined $p$-values for every class are reported. Particle and energy flux upper limits are given for selected candidate sources. These limits significantly constrain predictions of EeV proton emission models from non-transient Galactic and nearby extragalactic sources, as illustrated for the particular case of the Galactic center region.
The 2HWC HAWC Observatory Gamma Ray Catalog (1702.02992)
A.U. Abeysekara, A. Albert, R. Alfaro, C. Alvarez, J.D. Álvarez, R. Arceo, J.C. Arteaga-Velázquez, H.A. Ayala Solares, A.S. Barber, N. Bautista-Elivar, J. Becerra Gonzalez, A. Becerril, E. Belmont-Moreno, S.Y. BenZvi, D. Berley, A. Bernal, J. Braun, C. Brisbois, K.S. Caballero-Mora, T. Capistrán, A. Carramiñana, S. Casanova, M. Castillo, U. Cotti, J. Cotzomi, S. Coutiño de León, E. de la Fuente, C. De León, R. Diaz Hernandez, B.L. Dingus, M.A. DuVernois, J.C. Díaz-Vélez, R.W. Ellsworth, K. Engel, D.W. Fiorino, N. Fraija, J.A. García-González, F. Garfias, M. Gerhardt, A. González Muñoz, M.M. González, J.A. Goodman, Z. Hampel-Arias, J.P. Harding, S. Hernandez, A. Hernandez-Almada, J. Hinton, C.M. Hui, P. Hüntemeyer, A. Iriarte, A. Jardin-Blicq, V. Joshi, S. Kaufmann, D. Kieda, A. Lara, R.J. Lauer, W.H. Lee, D. Lennarz, H. León Vargas, J.T. Linnemann, A.L. Longinotti, G. Luis Raya, R. Luna-García, R. López-Coto, K. Malone, S.S. Marinelli, O. Martinez, I. Martinez-Castellanos, J. Martínez-Castro, H. Martínez-Huerta, J.A. Matthews, P. Miranda-Romagnoli, E. Moreno, M. Mostafá, L. Nellen, M. Newbold, M.U. Nisa, R. Noriega-Papaqui, R. Pelayo, J. Pretz, E.G. Pérez-Pérez, Z. Ren, C.D. Rho, C. Rivière, D. Rosa-González, M. Rosenberg, E. Ruiz-Velasco, H. Salazar, F. Salesa Greus, A. Sandoval, M. Schneider, H. Schoorlemmer, G. Sinnis, A.J. Smith, R.W. Springer, P. Surajbali, I. Taboada, O. Tibolla, K. Tollefson, I. Torres, T.N. Ukwatta, G. Vianello, L. Villaseñor, T. Weisgarber, S. Westerhoff, I.G. Wisher, J. Wood, T. Yapici, P.W. Younk, A. Zepeda, H. Zhou
Feb. 9, 2017 astro-ph.HE
We present the first catalog of TeV gamma-ray sources realized with the recently completed High Altitude Water Cherenkov Observatory (HAWC). It is the most sensitive wide field-of-view TeV telescope currently in operation, with a 1-year survey sensitivity of ~5-10% of the flux of the Crab Nebula. With an instantaneous field of view >1.5 sr and >90% duty cycle, it continuously surveys and monitors the sky for gamma ray energies between hundreds GeV and tens of TeV. HAWC is located in Mexico at a latitude of 19 degree North and was completed in March 2015. Here, we present the 2HWC catalog, which is the result of the first source search realized with the complete HAWC detector. Realized with 507 days of data and represents the most sensitive TeV survey to date for such a large fraction of the sky. A total of 39 sources were detected, with an expected contamination of 0.5 due to background fluctuation. Out of these sources, 16 are more than one degree away from any previously reported TeV source. The source list, including the position measurement, spectrum measurement, and uncertainties, is reported. Seven of the detected sources may be associated with pulsar wind nebulae, two with supernova remnants, two with blazars, and the remaining 23 have no firm identification yet. | CommonCrawl |
All-----TitleAuthor(s)AbstractSubjectKeywordAll FieldsFull Text-----About
Duke Mathematical Journal
Duke Math. J.
Volume 162, Number 4 (2013), 767-823.
Flexible varieties and automorphism groups
I. Arzhantsev, H. Flenner, S. Kaliman, F. Kutzschebauch, and M. Zaidenberg
More by I. Arzhantsev
More by H. Flenner
More by S. Kaliman
More by F. Kutzschebauch
More by M. Zaidenberg
Full-text: Access denied (subscription has expired)
We're sorry, but we are unable to provide you with the full text of this article because we are not able to identify you as a subscriber. If you have a personal subscription to this journal, then please login. If you are already logged in, then you may need to update your profile to register your subscription. Read more about accessing full-text
Article info and citation
Given an irreducible affine algebraic variety X of dimension n≥2, we let SAut(X) denote the special automorphism group of X, that is, the subgroup of the full automorphism group Aut(X) generated by all one-parameter unipotent subgroups. We show that if SAut(X) is transitive on the smooth locus Xreg, then it is infinitely transitive on Xreg. In turn, the transitivity is equivalent to the flexibility of X. The latter means that for every smooth point x∈Xreg the tangent space TxX is spanned by the velocity vectors at x of one-parameter unipotent subgroups of Aut(X). We also provide various modifications and applications.
Duke Math. J., Volume 162, Number 4 (2013), 767-823.
First available in Project Euclid: 15 March 2013
Permanent link to this document
https://projecteuclid.org/euclid.dmj/1363355693
doi:10.1215/00127094-2080132
Mathematical Reviews number (MathSciNet)
MR3039680
Zentralblatt MATH identifier
Primary: 14R20: Group actions on affine varieties [See also 13A50, 14L30] 32M17: Automorphism groups of Cn and affine manifolds
Secondary: 14L30: Group actions on varieties or schemes (quotients) [See also 13A50, 14L24, 14M17]
Arzhantsev, I.; Flenner, H.; Kaliman, S.; Kutzschebauch, F.; Zaidenberg, M. Flexible varieties and automorphism groups. Duke Math. J. 162 (2013), no. 4, 767--823. doi:10.1215/00127094-2080132. https://projecteuclid.org/euclid.dmj/1363355693
[1] I. V. Arzhantsev, M. G. Zaidenberg, and K. G. Kuyumzhiyan, Flag varieties, toric varieties, and suspensions: Three instances of infinite transitivity, Sb. Math. 203 (2012), 923–949.
Mathematical Reviews (MathSciNet): MR2986429
Digital Object Identifier: doi:10.4213/sm7876
[2] V. Batyrev and F. Haddad, On the geometry of $\operatorname{SL}(2)$-equivariant flips, Mosc. Math. J. 8 (2008), 621–646, 846.
Zentralblatt MATH: 1221.14052
[3] A. Białynicki-Birula, G. Hochschild, and G. D. Mostow, Extensions of representations of algebraic linear groups, Amer. J. Math. 85 (1963), 131–144.
Mathematical Reviews (MathSciNet): MR155938
Digital Object Identifier: doi:10.2307/2373191
[4] F. Bogomolov, I. Karzhemanov, and K. Kuyumzhiyan, "Unirationality and existence of infinitely transitive models," to appear in Birational Geometry, Rational Curves, and Arithmetic, preprint, arXiv:1204.0862v3 [math.AG].
arXiv: 1204.0862v3
[5] A. Borel, Les bouts des espaces homogènes de groupes de Lie, Ann. of Math. (2) 58 (1953), 443–457.
Mathematical Reviews (MathSciNet): MR57263
[6] G. T. Buzzard and F. Forstneric, An interpolation theorem for holomorphic automorphisms of $\mathbf{C}^n$, J. Geom. Anal. 10 (2000), 101–108.
Digital Object Identifier: doi:10.1007/BF02921807
[7] V. I. Danilov, "Algebraic varieties and schemes" in Algebraic Geometry, I, Encyclopaedia Math. Sci. 23, Springer, Berlin, 1994, 167–297.
[8] F. Donzelli, Algebraic density property of Danilov–Gizatullin surfaces, Math. Z. 272 (2012), 1187–1194.
Zentralblatt MATH: 06116848
Digital Object Identifier: doi:10.1007/s00209-012-0982-3
[9] F. Donzelli, Makar-Limanov invariant, Derksen invariant, flexible points, preprint, arXiv:1107.3340v1 [math.AG].
[10] A. Dubouloz, Completions of normal affine surfaces with a trivial Makar-Limanov invariant, Michigan Math. J. 52 (2004), 289–308.
Digital Object Identifier: doi:10.1307/mmj/1091112077
Project Euclid: euclid.mmj/1091112077
[11] H. Flenner, S. Kaliman, and M. Zaidenberg, Smooth affine surfaces with nonunique $\mathbb{C}^*$-actions, J. Algebraic Geom. 20 (2011), 329–398.
Digital Object Identifier: doi:10.1090/S1056-3911-2010-00533-4
[12] F. Forstnerič, "The homotopy principle in complex analysis: a survey" in Explorations in Complex and Riemannian Geometry, Contemp. Math. 332, Amer. Math. Soc., Providence, 2003, 73–99.
Digital Object Identifier: doi:10.1090/conm/332/05930
[13] F. Forstnerič, Holomorphic flexibility properties of complex manifolds, Amer. J. Math. 128 (2006), 239–270.
Digital Object Identifier: doi:10.1353/ajm.2006.0005
[14] F. Forstnerič, Stein manifolds and holomorphic mappings, Ergeb. Math. Grenzgeb. (3) 56, Springer, Berlin, 2011.
[15] G. Freudenburg, Algebraic theory of locally nilpotent derivations, Encyclopaedia Math. Sci. 136, Springer, Berlin, 2006.
[16] G. Freudenburg and P. Russell, "Open problems in affine algebraic geometry: 11, Problems by V. Popov" in Affine Algebraic Geometry, Contemp. Math. 369, Amer. Math. Soc., Providence, 2005, 1–30.
[17] J.-P. Furter and S. Lamy, Normal subgroup generated by a plane polynomial automorphism, Transform. Groups 15 (2010), 577–610.
[18] S. A. Gaifullin, Affine toric $\operatorname{SL}(2)$-embeddings, Sb. Math. 199 (2008), 319–339.
[19] M. H. Gizatullin, Affine surfaces that can be augmented by a nonsingular rational curve, Izv. Akad. Nauk SSSR Ser. Mat. 34 (1970), 778–802.
[20] M. H. Gizatullin, Affine surfaces that are quasihomogeneous with respect to an algebraic group, Izv. Akad. Nauk SSSR Ser. Mat. 35 (1971), 738–753.
[21] M. H. Gizatullin, Quasihomogeneous affine surfaces, Izv. Akad. Nauk SSSR Ser. Mat. 35 (1971), 1047–1071.
[22] M. H. Gizatullin and V. I. Danilov, Examples of nonhomogeneous quasihomogeneous surfaces, Izv. Akad. Nauk SSSR Ser. Mat. 38 (1974), 42–58.
[23] M. Gromov, Oka's principle for holomorphic sections of elliptic bundles, J. Amer. Math. Soc. 2 (1989), 851–897.
[24] A. Grothendieck, Éléments de géométrie algébrique, II: Étude globale élémentaire de quelques classes de morphismes, Inst. Hautes Études Sci. Publ. Math. 8 (1961). IV: Étude locale des schémas et des morphismes de schémas III, 28 (1966).
[25] R. Hartshorne, Algebraic geometry, Grad. Texts in Math. 52, Springer, New York, 1977.
[26] Z. Jelonek, A hypersurface which has the Abhyankar-Moh property, Math. Ann. 308 (1997), 73–84.
Digital Object Identifier: doi:10.1007/s002080050065
[27] S. Kaliman and F. Kutzschebauch, Criteria for the density property of complex manifolds, Invent. Math. 172 (2008), 71–87.
[28] S. Kaliman and F. Kutzschebauch, Algebraic volume density property of affine algebraic manifolds, Invent. Math. 181 (2010), 605–647.
Digital Object Identifier: doi:10.1007/s00222-010-0255-x
[29] S. Kaliman and F. Kutzschebauch, "On the present state of the Andersen-Lempert theory" in Affine Algebraic Geometry, CRM Proc. Lecture Notes 54, Amer. Math. Soc., Providence, 2011, 85–122.
[30] S. Kaliman and M. Zaidenberg, Affine modifications and affine hypersurfaces with a very transitive automorphism group, Transform. Groups 4 (1999), 53–95.
[31] S. Kaliman, M. Zaidenberg, Miyanishi's characterization of the affine 3-space does not hold in higher dimensions, Ann. Inst. Fourier (Grenoble) 50 (2000), 1649–1669.
Digital Object Identifier: doi:10.5802/aif.1803
[32] S. L. Kleiman, The transversality of a general translate, Compos. Math. 28 (1974), 287–297.
[33] F. Knop, Mehrfach transitive Operationen algebraischer Gruppen, Arch. Math. (Basel) 41 (1983), 438–446.
[34] H. Kraft, Geometrische Methoden in der Invariantentheorie, Aspects Math. D1, Vieweg, Braunschweig, 1984.
[35] S. Kumar, Kac-Moody groups, their flag varieties, and representation theory, Progr. Math. 204, Birkhäuser, Boston, 2002.
[36] A. Liendo, Affine $\mathbb{T}$-varieties of complexity one and locally nilpotent derivations, Transform. Groups 15 (2010), 389–425.
[37] A. Liendo, $\mathbb{G}_a$-actions of fiber type on affine $\mathbb{T}$-varieties, J. Algebra 324 (2010), 3653–3665.
Digital Object Identifier: doi:10.1016/j.jalgebra.2010.09.008
[38] L. Makar-Limanov, On groups of automorphisms of a class of surfaces, Israel J. Math. 69 (1990), 250–256.
[39] L. Makar-Limanov, "Locally nilpotent derivations on the surface $xy=p(z)$" in Proceedings of the Third International Algebra Conference (Tainan, 2002), Kluwer, Dordrecht, 2003, 215–219.
[40] A. Perepechko, Flexibility of affine cones over del Pezzo surfaces of degree 4 and 5, to appear in Funct. Anal. Appl., preprint, arXiv:1108.5841v1 [math.AG].
[41] V. L. Popov, Classification of affine algebraic surfaces that are quasihomogeneous with respect to an algebraic group, Izv. Akad. Nauk SSSR Ser. Mat. 37 (1973), 1038–1055.
[42] V. L. Popov, Quasihomogeneous affine algebraic varieties of the group $\operatorname{SL}(2)$, Izv. Akad. Nauk SSSR Ser. Mat. 37 (1973), 792–832.
[43] V. L. Popov, Classification of three-dimensional affine algebraic varieties that are quasihomogeneous with respect to an algebraic group, Izv. Akad. Nauk SSSR Ser. Mat. 39 (1975), no. 3, 566–609, 703.
[44] V.L. Popov, "On actions of $\mathbf{G}_a$ on $\mathbf{A}^n$" in Algebraic Groups, Utrecht 1986, Lecture Notes in Math. 1271, Springer, Berlin, 1987, 237–242.
Digital Object Identifier: doi:10.1007/BFb0079241
[45] V.L. Popov, "Generically multiple transitive algebraic group actions" in Algebraic Groups and Homogeneous Spaces, Tata Inst. Fund. Res. Stud. Math., Tata Inst. Fund. Res., Mumbai, 2007, 481–523.
[46] V. L. Popov, "On the Makar-Limanov, Derksen invariants, and finite automorphism groups of algebraic varieties" in Affine Algebraic Geometry, CRM Proc. Lecture Notes 54, Amer. Math. Soc., Providence, 2011, 289–312.
[47] V. L. Popov and E. B. Vinberg, "Invariant theory" in Algebraic Geometry, IV, Encyclopaedia Math. Sci. 55, Springer, Berlin, 1994, 123–278.
[48] C. Procesi, Lie Groups: An Approach through Invariants and Representations, Universitext, Springer, New York, 2007.
[49] C. P. Ramanujam, A note on automorphism groups of algebraic varieties, Math. Ann. 156 (1964), 25–33.
[50] Z. Reichstein, On automorphisms of matrix invariants, Trans. Amer. Math. Soc. 340 (1993), no. 1, 353–371.
Digital Object Identifier: doi:10.1090/S0002-9947-1993-1124173-1
[51] Z. Reichstein, On automorphisms of matrix invariants induced from the trace ring, Linear Algebra Appl. 193 (1993), 51–74.
Digital Object Identifier: doi:10.1016/0024-3795(93)90271-O
[52] R. Rentschler, Opérations du groupe additif sur le plan affine, C. R. Acad. Sci. Paris Sér. A 267 (1968), 384–387.
[53] I. R. Shafarevich, On some infinite-dimensional groups, Rend. Mat. e Appl. (5) 25 (1966), 208–212.
[54] I. P. Shestakov and U. U. Umirbaev, The tame and the wild automorphisms of polynomial rings in three variables, J. Amer. Math. Soc. 17 (2004), 197–227.
Digital Object Identifier: doi:10.1090/S0894-0347-03-00440-5
[55] D. Varolin, A general notion of shears, and applications, Michigan Math. J. 46 (1999), 533–553.
[56] D. Varolin, The density property for complex manifolds and geometric structures, I, J. Geom. Anal. 11 (2001), 135–160. II, Internat. J. Math. 11 (2000), 837–847.
[57] J. Winkelmann, On automorphisms of complements of analytic subsets in $\mathbf{C}^n$, Math. Z. 204 (1990), 117–127.
Purchase print copies of recent issues
DMJ 100
Email RSS ToC RSS Article
Turn Off MathJax
What is MathJax?
Infinite transitivity and special automorphisms
Arzhantsev, Ivan, Arkiv för Matematik, 2018
Automorphisms of open surfaces with irreducible boundary
Dubouloz, Adrien and Lamy, Stéphane, Osaka Journal of Mathematics, 2015
Topologies on the group of Borel automorphisms of a standard Borel space
Bezuglyi, Sergey, Dooley, Anthony H., and Kwiatkowski, Jan, Topological Methods in Nonlinear Analysis, 2006
On commuting automorphisms of finite $p$-groups
Rai, Pradeep Kumar, Proceedings of the Japan Academy, Series A, Mathematical Sciences, 2015
On derived categories of K3 surfaces, symplectic automorphisms and the Conway group
Huybrechts, Daniel, , 2016
Automorphism groups of smooth cubic threefolds
WEI, Li and YU, Xun, Journal of the Mathematical Society of Japan, 2020
Group extensions and automorphism group rings
Martino, John and Priddy, Stewart, Homology, Homotopy and Applications, 2003
Euler characteristics and actions of automorphism groups of free groups
Ye, Shengkui, Algebraic & Geometric Topology, 2018
Complement to explicit description of Hopf surfaces and their automorphism groups
Matumoto, Takao and Nakagawa, Noriaki, Osaka Journal of Mathematics, 2011
Ordinary algebraic curves with many automorphisms in positive characteristic
Korchmáros, Gábor and Montanucci, Maria, Algebra & Number Theory, 2019
euclid.dmj/1363355693 | CommonCrawl |
Monday, July 16, 2012 ... / /
Poincaré disk
Almost everyone knows the sphere. However, the fame of a close cousin of the spherical geometry, the hyperbolic geometry, is much more limited. How many people know what is the Poincaré disk, for example?
Using the politically correct speech, people are discriminating against geometries of mixed signature. Let's try to fix it.
The ordinary two-dimensional sphere may be defined as the set of all points in the flat three-dimensional Euclidean space whose coordinates obey\[
x_1^2+x_2^2+x_3^2 = 1.
\] We have set the radius to one. One of the three coordinates may be expressed in terms of the other two – up to the sign. The remaining surface – e.g. the surface of the Earth – is two-dimensional which means that it can be parameterized by two real coordinates, e.g. the longitude and the latitude.
On the surface, one may measure distances. The right way to measure the length of a path is to cut the path to many infinitesimal (infinitely short) pieces and to add their lengths. The length of the infinitesimal piece is determined by the metric. The metric of the sphere is invariant under the \(SO(3)\) rotations. Locally, this group is isomorphic to \(SU(2)\) which is also the same thing as \(USp(2)\).
But what if we change a sign or two? The equation\[
x_1^2+x_2^2-x_3^2=-1
\] With \(-1\) on the right hand side, we get a two-sheeted hyperboloid. (We would get a one-sheeted one if there were a plus sign.)
Let's take one component of this manifold only. Does it have some symmetries similar to the \(SO(3)\) rotational symmetry of the two-sphere we started with? If we only allow rotations that are also symmetries of the three-dimensional "environment" and if we assume this environment to be a flat Euclidean space that uses the Pythagorean theorem to measure distances, the answer is that the two-sheeted hyperboloid only has an \(SO(2)\) symmetry: we may rotate it around the axis. That's a one-dimensional group isomorphic to \(U(1)\).
But we have only modified one sign. That's not a big change; in some sense, we have only changed a radius to an imaginary value. Doesn't the hyperboloid have a larger, three-dimensional group of symmetries that would be as large as the group \(SO(3)\)? The answer is Yes. But we must allow transformations that don't preserve the distances in the parent three-dimensional Euclidean spacetime. Even more accurately, we must imagine that the parent three-dimensional spacetime is not Euclidean but Lorentzian, like in general relativity, and its distances are given by\[
ds^2 = dx_1^2+dx_2^2 - dx_3^2.
\] The signs defining the hyperboloid respect the relative signs from the metric above so the symmetries of the actual hyperboloid will include the whole \(SO(2,1)\) Lorentz group of the original three-dimensional space – or spacetime, if you want to call it this way.
Such a two-sheeted hyperboloid may be thought of as the space of all allowed energy-momentum vectors of a massive particle in 2+1 dimensions, i.e. all vectors obeying\[
E^2 - p_x^2 - p_y^2 = m^2 \gt 0.
\] The Lorentz transformations, \(SO(2,1)\), act on the vectors' coordinates in the usual way. When we talk about the single component of the two-sheeted hyperboloid as about a "geometry", we call it a "hyperbolic geometry". This concept should be viewed as another example of a non-Euclidean geometry besides the spherical geometry. Non-Euclidean geometries are similar to geometries of the flat Euclidean plane/space but they reject Euclid's axiom about the parallel line: it is no longer true that "there is exactly one straight line going through a given point that doesn't intersect another given straight line". For the spherical geometries, there is usually none (pairs of maximal circles such as two meridians always intersect, e.g. at the poles); for the hyperbolic geometries, there are infinitely many (the lines diverge from each other so there are many ways to adjust their directions so that they still don't intersect).
Is there something we should know about the hyperbolic geometry? How can we visualize it? Much like the sphere, the hyperbolic geometry has an intrinsic curvature so it is not isometric to a piece of the flat plane. Much like in the case of maps of the sphere, i.e. the Earth's surface, we have to choose a method to depict it. Some geometric quantities will be inevitably distorted.
One cute "compact" way to visualize the hyperbolic geometry is the Poincaré disk. Here is an animation of the Poincaré disk equipped with a uniform collection of Escher's batmen.
The hyperboloid had an infinite area – even when you adopt the Lorentzian signature for the metric – because one may "Lorentz boost" vectors indefinitely. Another related fact is that the group \(SO(2,1)\) of the symmetries of the hyperbolic geometry is noncompact; if we define a group-invariant volume form on the group manifold, the volume of the group is infinite. It follows that there have to be infinitely many batmen living on the hyperbolic geometry.
As the name indicates, the Poincaré disk represents the hyperbolic geometry as a disk – it means the interior of a circle. But because there have to be infinitely many batmen, their density has to diverge in some regions. As you see in the animation above, the density of batmen diverges near the boundaries of the disk.
But much like in the case of angle-preserving maps (e.g. the stereographic projection), you see that all the internal angles of the batmen are preserved. The model of the hyperbolic geometry obviously doesn't preserve the areas (batmen near the boundary look smaller). And the Poincaré disk model doesn't make straight lines (geodesics) on the hyperboloid look straight here, either. (Another model, the Beltrami-Klein model or the Klein disk, does, but it doesn't preserve the angles.)
Can we reconstruct the metric on the original hyperboloid from the coordinates \(x_1,x_2\) parameterizing the unit Poincaré disk? Yes, we can.\[
ds^2= 4 \frac{dx_1^2+dx_2^2}{1-x_1^2-x_2^2}
\] It would be straightforward to add additional coordinates if you needed to do so.
Note that up to the factor of \(4\) (which is a convention, an overall scale of the metric, but it is actually helpful to make the curvature radius equal to one) and up to the denominator (a pure scalar), this is nothing else than the metric on the flat plane. Because the metric on the Poincaré disk only differs from the metric on the underlying paper by a scalar, Weyl rescaling, it preserves the angles. The denominator makes it clear that as \(x_1^2+x_2^2\to 1\), the proper distances (and areas) blow up.
The animation shows some transformations that don't change the internal geometry of the hyperbolic geometry. They are elements of \(SO(2,1)\). This group has three generators. The action of one of them is shown by the animation; the action of another one would look the same except that the batmen would be drifting in another, orthogonal direction; the action of the third generation is nothing else than the rotations of the disk which are isometries of the underlying paper, too.
In the case of the sphere, we noticed that \(SU(2)\sim SO(3)\); the groups are locally isomorphic. This fact is related to the existence of spinors which have 2 complex (pseudoreal) components if we deal with the three-dimensional Euclidean space. Are there similar groups isomorphic to \(SO(2,1)\)? Yes, there are. In fact, there are at least two very important additional ways to write \(SO(2,1)\).
Because we are talking about transformations preserving the angles, both of these alternative definitions of \(SO(2,1)\) may be obtained as subgroups of \(SL(2,\CC)\), the group of Möbius transformations. The cute old video below discusses the angle-preserving tranformations of the plane.
All one-to-one angle-preserving transformations of the plane may be written down in terms of a simple function of a complex variable \(z\in\CC\),\[
z\to z' = \frac{az+b}{cz+d}, \quad \{a,b,c,d\}\subseteq\CC.
\] For the transformation to be nonsingular, we require \(ad-bc\neq 0\). In fact, whenever this determinant is nonzero, we may rescale \(a,b,c,d\) by the same complex number to achieve \(ad-bc=1\) without changing the function. So we may assume \(ad-bc=1\) and the group of all transformations of this form is therefore \(SL(2,\CC)\). Just to be sure, if you're annoyed by the nonlinear character of the function \(z\to z'\), don't be annoyed. The variable \(z\) may be represented simply as \(u_1/u_2\), the ratio of two coordinates of a complex vector, and when the Möbius transformations are acting on \((u_1,u_2)\) in the ordinary linear way, they will be acting on \(z=u_1/u_2\) in the nonlinear way depicted by the formula above.
There are four complex parameters underlying the transformation, \(a,b,c,d\), but because we imposed one complex condition \(ad-bc=1\), there are effectively three free complex parameters i.e. six real parameters in the Möbius group. But we're interested in the Poincaré disk. It means that we would like to restrict our focus on the Möbius transformations that map the disk onto itself. If we deal with the boundary i.e. \(zz^*=1\), then we would like to have \(z' z^{\prime *}=1\), too. How does this condition constrain the parameters \(a,b,c,d\)?
One may prove that this restricts the matrix to be inside a smaller group, \(SU(1,1)\). That's a group of matrices \(M\) obeying\[
M\cdot \diag (1,-1)\cdot M^\dagger = \diag (1,-1), \quad {\rm det}\,M = 1.
\] Note that up to the insertion of the diagonal matrix with the \(\pm 1\) entries, this would be a condition for a unitary group. However, the extra diagonal matrix changes the signature so instead of a unitary group, we obtain a pseudounitary group. This group \(SU(1,1)\) is the group of all angle-preserving, one-to-one transformations of the unit disk onto itself, and because we've seen that the unit disk may be viewed as an angle-preserving depiction of the two-sheeted hyperboloid, i.e. the hyperbolic geometry, it follows that this group must be isomorphic to the group of symmetries of the hyperboloid,\[
SU(1,1)\sim SO(2,1).
\] The isomorphism is valid locally. Note that both groups have three real parameters. And I won't spend too much time with it but there's another isomorphism of this kind we may derive from the Poincaré disk model. The disk is conformally equivalent to a half-plane and the group of Möbius transformations that preserve the half-plane (and its boundary, let's say the real axis) is nothing else than the group of Möbius transformations with real parameters \(a,b,c,d\). So we also have\[
SU(1,1)\sim SO(2,1)\sim SL(2,\RR).
\] Both \(SU(1,1)\) and \(SL(2,\RR)\) may be easily visualized as the groups acting on the two-component spinors in 2+1 dimensions.
In the case of the spherical geometry, we may construct Platonic polyhedra and various cute discrete subgroups of \(SO(3)\), i.e. the group of isometries of an icosahedron (which is the same one as the group of isometries of a dodecahedron, the dual object to the icosahedron). Analogously, there are many interesting "polyhedra" and discrete subgroups of \(SO(2,1)\), too. These mathematical facts were essential for Escher to be able to draw his batmen into the Poincaré disk, of course.
There are many things to be said about the Poincaré disk and its higher-dimensional generalizations. And these objects play a very important role in theoretical physics – in some sense, they are as important as the spheres themselves. The importance of the hyperbolic geometry in relativity (on-shell conditions for the momentum vectors) has already been mentioned. But there are many other applications. The world sheet description of string theory depends on conformal transformations which makes the appearance of similar structures omnipresent, too. The geometry of the moduli spaces of Riemann surfaces – starting from the torus – depends on groups such as \(SL(2,\RR)\) which are also analyzed by tools similar to the mathematical games above.
Finally, the anti de Sitter space – the key geometric player of the AdS/CFT correspondence – may be considered as a higher-dimensional generalization of the hyperbolic geometry, too. (But in this case, there is a temporal dimension even "inside" the picture with the batmen.) That's why the Poincaré disk and various "cylinders" that generalize it are a faithful portrait of the AdS spaces. The regions near the boundary where the batmen get very dense become the usual "AdS boundary" which is where the conformal field theory, CFT, is defined.
But I didn't want to beyond the elementary mathematical observations so if you were intrigued by the previous two paragraphs, you will have to solve the mysteries yourself (or find the answers elsewhere in books or on the Internet).
Off-topic: Bad Universe
Tonight, I turned on my Czech Prima Cool TV half an hour too early, before the S05E17 episode of The Big Bang Theory. Whenever I do it, I can see things like the Simpsons, Futurama, Topgear, and others – in Czech dubbing. And they're often nice programs. But what I got tonight was... Phil Plait's Bad Universe ("Divoký vesmír" in Czech, meaning "Wild Universe"). Holy cow, this is an incredibly crappy would-be scientific program!
I have watched it for ten minutes or so but this period of time has saturated my adrenaline reservoir and depleted all my patience. First of all, it's sort of a crazy explosion of exhibitionism if someone looking like Phil Plait – the blogger behind Bad Astronomy – agrees to turn himself into a "TV star". But the content was much worse than that. He was showing some random combinations of scientific concepts – X-rays from outer space, global cooling, solar eruptions, random oxides etc. – as the culprits that have destroyed the trilobites. The program is meant to be catastrophic and in between the lines, the program clearly wants to fill the viewers' heads with many kinds of hypothetical catastrophes that may occur in a foreseeable future, too.
The unlimited combination of random "scientific ingredients" and contrived lab experiments pretending to emulate conditions in the past combined with a nearly complete absence of any explanation or argument or fair judgement or impartial and careful analysis or anything that actually makes any sense is what creates a program that decent people can't possibly like. I like to listen to scientific explanations about chemistry, biology, history, cosmology, geology, and other things – but this weird mixture of everything is just over the edge.
My rating for the program: pure shit.
Other texts on similar topics: mathematics
reader Curious George said...
Formulas are unreadable, both in Chrome and Firefox.
Jul 16, 2012, 7:36:00 PM ...
reader Dilaton said...
Hm, at the moment I still think a Poincare disk is some kind of a frisbee ... ;-P
From scrolling through this article looks very nice and accessible to me; so I look forward to read and enjoy it and learn better tomorrow during my lunch break :-)
Are they serious about what they are saying in the "Bad Universe" or is it meant to be a (bad) parody ...? If it is serious it seems really bad as I learn from your description ...
Jul 16, 2012, 11:49:00 PM ...
reader Honza said...
Pretty cool, I'm already familiar with quadrics and elementary topological terms from my calculus class but not with groups and symmetries, is there an article where you explain those?
Prof Matt Strassler and global warming
Nine physicists win $27 million in total
Have Muller or Watts transformed the AGW landscape...
Permutations join twistor minirevolution
Strings 2012, a few words
Olympic Czechs w/ wellies: climate in London hasn'...
Watts up with that Anthony's major announcement?
Greek triple jumper and political correctness
Euler characteristic
CO2 may lag temperature just by 400 years or so
Lisa Randall: Higgs discovery, e-book
Paul Frampton's Argentine sweetheart revealed: a C...
Czechia wins the European alcohol contest
Calabi-Yau tree of life and XY chromosomes cut by ...
James Weatherall's limitations
New York Times: We are all climate change idiots
Relative strength of HEP experiments, phenomenolog...
Mostly good news on the Fermi \(130\GeV\) line
Global spam dropped 50% in two days
Diphoton Higgs enhancement as a proof of naturalne...
Generation X not concerned about AGW
Comparisons of the Higgs boson and global warming
Why there had to be a Higgs boson
Why the Standard Model isn't the whole story
Diversity of observables in quantum mechanics
53rd IMO: Problem 2
Sheldon Glashow on apocalypse
ATLAS: a 2.5-sigma stop squark excess
Have we observed the Higgs imposter?
Land biosphere's absorption of CO2 skyrockets
Should experimenters bet on their own experiments?...
Knowledge and passions: why various physicists sta...
Brian Greene: The Hidden Reality (in Czech)
Texas nationalizes the atmosphere
Landscape wars: David Gross vs Brian Greene's PBS ...
Two papers: no bacteria use As to grow
Buckley, Hooper: Higgs decay deviations due to \(3...
Obama SSN: the question to which the answer is 042...
LHC Higgs: does it deviate from the Standard Model...
Higgs bets: I won $500, Gordy Kane won $100 from S...
Stephen Wolfram on Higgs, particle physics
Václav Havel's heart melted by global warming
CMS: tantalizing excess of top partners
Compact formula for all tree \(\NNN=8\) SUGRA ampl...
Higgs has been discovered: a chat box
Why a \(125\GeV\) Higgs boson isn't quite compatib...
François Englert: a hero of the Higgs mechanism, S...
Tevatron: DØ has made a lot of Higgs progress
CO2 will turn savannahs to forests
An interview with Arkani-Hamed on SUSY
U.K.: energy smart meters will monitor your sex ha... | CommonCrawl |
Novel correlation coefficients under the intuitionistic multiplicative environment and their applications to decision-making process
Parameter identification and numerical simulation for the exchange coefficient of dissolved oxygen concentration under ice in a boreal lake
Scheduling family jobs on an unbounded parallel-batch machine to minimize makespan and maximum flow time
Zhichao Geng and Jinjiang Yuan ,
School of Mathematics and Statistics, Zhengzhou University, Zhengzhou, Henan 450001, China
* Corresponding author: Jinjiang Yuan
Received February 2017 Revised August 2017 Published October 2018 Early access January 2018
Fund Project: The authors are supported by NSFC (11671368), NSFC (11571321), and NSFC (11771406).
This paper investigates the scheduling of family jobs with release dates on an unbounded parallel-batch machine. The involved objective functions are makespan and maximum flow time. It was reported in the literature that the single-criterion problem for minimizing makespan is strongly NP-hard when the number of families is arbitrary, and is polynomially solvable when the number of families is fixed. We first show in this paper that the single-criterion problem for minimizing maximum flow time is also strongly NP-hard when the number of families is arbitrary. We further show that the Pareto optimization problem (also called bicriteria problem) for minimizing makespan and maximum flow time is polynomially solvable when the number of families is fixed, by enumerating all Pareto optimal points in polynomial time. This implies that the single-criterion problem for minimizing maximum flow time is also polynomially solvable when the number of families is fixed.
Keywords: Parallel-batch, family jobs, maximum flow time, pareto optimization.
Citation: Zhichao Geng, Jinjiang Yuan. Scheduling family jobs on an unbounded parallel-batch machine to minimize makespan and maximum flow time. Journal of Industrial & Management Optimization, 2018, 14 (4) : 1479-1500. doi: 10.3934/jimo.2018017
A. Allahverdi, C. T. Ng, T. C. E. Cheng and M. Y. Kovalyov, A survey of scheduling problems with setup times or costs, European Journal of Operational Research, 187 (2008), 985-1032. doi: 10.1016/j.ejor.2006.06.060. Google Scholar
J. Bai, Z. R. Li and X. Huang, Single-machine group scheduling with general deterioration and learning effects, Applied Mathematical Modelling, 36 (2012), 1267-1274. doi: 10.1016/j.apm.2011.07.068. Google Scholar
P. Brucker, A. Gladky, H. Hoogeveen, M. Y. Kovalyov, C. N. Potts and T. Tautenhahn, Scheduling a batching machine, Journal of Scheduling, 1 (1998), 31-54. doi: 10.1002/(SICI)1099-1425(199806)1:1<31::AID-JOS4>3.0.CO;2-R. Google Scholar
K. Chakhlevitch, C. A. Glass and H. Kellerer, Batch machine production with perishability time windows and limited batch size, European Journal of Operational Research, 210 (2011), 39-47. doi: 10.1016/j.ejor.2010.10.033. Google Scholar
T. C. E. Cheng, Z. H. Liu and W. C. Yu, Scheduling jobs with release dates and deadlines on a batch processing machine, IIE Transactions, 33 (2001), 685-690. Google Scholar
Y. Gao and J. J. Yuan, A note on Pareto minimizing total completion time and maximum cost, Operational Research Letter, 43 (2015), 80-82. doi: 10.1016/j.orl.2014.12.001. Google Scholar
Z. C. Geng and J. J. Yuan, Pareto optimization scheduling of family jobs on a p-batch machine to minimize makespan and maximum lateness, Theoretical Computer Science, 570 (2015), 22-29. doi: 10.1016/j.tcs.2014.12.020. Google Scholar
Z. C. Geng and J. J. Yuan, A note on unbounded parallel-batch scheduling, Information Processing Letters, 115 (2015), 969-974. doi: 10.1016/j.ipl.2015.07.002. Google Scholar
C. He, Y. X. Lin and J. J. Yuan, Bicriteria scheduling on a batching machine to minimize maximum lateness and makespan, Theoretical Computer Science, 381 (2007), 234-240. doi: 10.1016/j.tcs.2007.04.034. Google Scholar
H. Hoogeveen, Multicriteria scheduling, European Journal of Operational Research, 167 (2005), 592-623. doi: 10.1016/j.ejor.2004.07.011. Google Scholar
J. A. Hoogeveen, Single-machine scheduling to minimize a function of two or three maximum cost criteria, Journal of Algorithms, 21 (1996), 415-433. doi: 10.1006/jagm.1996.0051. Google Scholar
J. A. Hoogeveen and S. L. van de Velde, Minimizing total completion time and maximum cost simultaneously is solvable in polynomial time, Operations Research Letters, 17 (1995), 205-208. doi: 10.1016/0167-6377(95)00023-D. Google Scholar
J. A. Hoogeveen and S. L. van de Velde, Scheduling with target start times, European Journal of Operational Research, 129 (2001), 87-94. doi: 10.1016/S0377-2217(99)00426-9. Google Scholar
Y. Ikura and M. Gimple, Efficient scheduling algorithms for a single batch processing machine, Operations Research Letters, 5 (1986), 61-65. doi: 10.1016/0167-6377(86)90104-5. Google Scholar
F. Jolai, Minimizing number of tardy jobs on a batch processing machine with incompatible job families, European Journal of Operational Research, 162 (2005), 184-190. doi: 10.1016/j.ejor.2003.10.011. Google Scholar
C. Y. Lee, R. Uzsoy and L. A. Martin-Vega, Efficient algorithms for scheduling semi-conductor burn-in operations, Operations Research, 40 (1992), 764-775. doi: 10.1287/opre.40.4.764. Google Scholar
S. S. Li and R. X. Chen, Single-machine parallel-batching scheduling with family jobs to minimize weighted number of tardy jobs, Computers and Industrial Engineering, 73 (2014), 5-10. doi: 10.1016/j.cie.2014.04.007. Google Scholar
S. S. Li, C. T. Ng, T. C. E. Cheng and J. J. Yuan, Parallel-batch scheduling of deteriorating jobs with release dates to minimize the makespan, European Journal of Operational Research, 210 (2011), 482-488. doi: 10.1016/j.ejor.2010.11.021. Google Scholar
S. S. Li and J. J. Yuan, Parallel-machine parallel-batching scheduling with family jobs and release dates to minimize makespan, Journal of Combinatorial Optimization, 19 (2010), 84-93. doi: 10.1007/s10878-008-9163-z. Google Scholar
Z. H. Liu and W. C. Yu, Scheduling one batch processor subject to job release dates, Discrete Applied Mathematics, 105 (2000), 129-136. doi: 10.1016/S0166-218X(00)00181-5. Google Scholar
L. L. Liu and F. Zhang, Minimizing the number of tardy jobs on a batch processing machine with incompatible job families, ISECS International Colloquium on Computing, Communication, Control, and Management, 3 (2008), 277-280. doi: 10.1109/CCCM.2008.107. Google Scholar
Z. H. Liu, J. J. Yuan and T. C. E. Cheng, On scheduling an unbounded batch machine, Operations Research Letters, 31 (2003), 42-48. doi: 10.1016/S0167-6377(02)00186-4. Google Scholar
S. Malve and R. Uzsoy, A genetic algorithm for minimizing maximum lateness on parallel identical batch processing machines with dynamic job arrivals and incompatible job families, Computers and Operations Research, 34 (2007), 3016-3028. doi: 10.1016/j.cor.2005.11.011. Google Scholar
C. X. Miao, Y. Z. Zhang and Z. G. Cao, Bounded parallel-batch scheduling on single and multi machines for deteriorating jobs, Information Processing Letters, 111 (2011), 798-803. doi: 10.1016/j.ipl.2011.05.018. Google Scholar
Q. Q. Nong, C. T. Ng and T. C. E. Cheng, The bounded single-machine parallel-batching scheduling problem with family jobs and release dates to minimize makespan, Operations Research Letters, 36 (2008), 61-66. doi: 10.1016/j.orl.2007.01.007. Google Scholar
E. S. Pan, G. N. Wang, L. F. Xi, L. Chen and X. L. Han, Single-machine group scheduling problem considering learning, forgetting effects and preventive maintenance, International Journal of Production Research, 52 (2014), 5690-5704. doi: 10.1080/00207543.2014.904967. Google Scholar
J. Pei, X. B. Liu, P. M. Pardalos, A. Migdalas and S. L. Yang, Serial-batching scheduling with time-dependent Setup time and effects of deterioration and learning on a single-machine, Journal of Global Optimization, 67 (2017), 251-262. doi: 10.1007/s10898-015-0320-5. Google Scholar
J. Pei, B. Y. Cheng, X. B. Liu, P. M. Pardalos and M. Kong, Single-machine and parallel-machine serial-batching scheduling problems with position-based learning effect and linear setup time, Annals of Operations Research, (2017), 1-25. doi: 10.1007/s10479-017-2481-8. Google Scholar
J. Pei, X. B. Liu, P. M. Pardalos, W. J. Fan and S. L. Yang, Single machine serial-batching scheduling with independent setup time and deteriorating job processing times, Optimization Letters, 9 (2015), 91-104. doi: 10.1007/s11590-014-0740-z. Google Scholar
J. Pei, X. B. Liu, P. M. Pardalos, W. J. Fan and S. L. Yang, Scheduling deteriorating jobs on a single serial-batching machine with multiple job types and sequence-dependent setup times, Annals of Operations Research, 249 (2017), 175-195. doi: 10.1007/s10479-015-1824-6. Google Scholar
J. Pei, P. M. Pardalos, X. B. Liu, W. J. Fan and S. L. Yang, Serial batching scheduling of deteriorating jobs in a two-stage supply chain to minimize the makespan, European Journal of Operational Research, 244 (2015), 13-25. doi: 10.1016/j.ejor.2014.11.034. Google Scholar
C. N. Potts and M. Y. Kovalyov, Scheduling with batching: a review, European Journal of Operational Research, 120 (2000), 228-249. doi: 10.1016/S0377-2217(99)00153-8. Google Scholar
X. L. Qi, S. G. Zhou and J. J. Yuan, Single machine parallel-batch scheduling with dete-riorating jobs, Theoretical Computer Science, 410 (2009), 830-836. doi: 10.1016/j.tcs.2008.11.009. Google Scholar
[34] V. T'kindt and J. C. Billaut, Multicriteria Scheduling: Theory, Models and Algorithms, 2$^{nd}$ edition, Springer, Berlin, 2006. doi: 10.1007/978-3-662-04986-0. Google Scholar
H. Xuan and L. X. Tang, Scheduling a hybrid flowshop with batch production at the last stage, Computers and Operations Research, 34 (2007), 2718-2733. doi: 10.1016/j.cor.2005.10.014. Google Scholar
J. J. Yuan, Z. H. Liu, C. T. Ng and T. C. E. Cheng, The unbounded single machine parallel batch scheduling problem with family jobs and release dates to minimize makespan, Theoretical Computer Science, 320 (2004), 199-212. doi: 10.1016/j.tcs.2004.01.038. Google Scholar
Figure 1. The structure of the scheduling problem
Figure 2. An intuitive interpretation of the proposed algorithm
Table 1. The definitions of the abbreviations/notations
Abbreviation/Notation Definition
ERD earliest release date first (rule)
PoP Pareto optimal point
PoS Pareto optimal schedule
ERD-family scheule a schedule of family jobs defined in the first paragraph in section 3.1
${\mathcal F}_f$ the $f$-th job family
$f$-job a job which belongs to family ${\mathcal F}_f$
$f$-batch a p-bath which only includes $f$-jobs
$J_{f, j}$ the $j$-th job in family ${\mathcal F}_f$
$J_{j}$ a general job
$p_{j}~(p_{f, j})$/$r_{j}~(r_{f, j})$ the processing time/the release dates of job $J_{j}~(J_{f, j})$
$n_f$ the number of jobs in family ${\mathcal F}_f$
$(b<n)/(b\geq n)$ the bounded/unbounded capacity of a p-batch
$p(B)$ the processing time of batch $B$
$\pi/\sigma$ a feasible schedule
$C_{j}(\pi)(C_{f, j}(\pi))$ the completion time of job $J_{j}$ ($J_{f, j}$) in $\pi$
$S_{j}(\pi)(S_{f, j}(\pi))$ the starting time of job $J_{j}$ ($J_{f, j}$) in $\pi$
$C_{B}(\pi)$ the completion time of batch $B$ in $\pi$
$S_{B}(\pi)$ the starting time of batch $B$ in $\pi$
$F_{j}(\pi)(F_{f, j}(\pi))$ the flow time of job $J_{j}$ ($J_{f, j}$) in $\pi$ which is $F_{j}(\pi)=C_{j}(\pi)-r_{j}(\pi)$
$C_{\max}(\pi)$ the maximum completion time of all jobs in $\pi$
$F_{\max}(\pi)$ the maximum flow time of all jobs in $\pi$
${\mathcal F}_f^{(i)}$ the set composed by the first $i$ jobs of family ${\mathcal F}_f$, i.e., $\{J_{f, 0}, J_{f, 1}, \cdots, J_{f, i}\}$
$(i_1, \cdots, i_K)$ the instance composed by the job set ${\mathcal F}_1^{(i_1)} \cup \cdots \cup {\mathcal F}_K^{(i_K)}$
$P(i_1, \cdots, i_K)$ the problem $1|\beta |^\#(C_{\max}, F_{\max})$ restricted on the instance $(i_1, \cdots, i_K)$
$P_{Y}(i_1, \cdots, i_K)$ the problem $1|\beta |C_{\max}: F_{\max}\leq Y$ restricted on the instance $(i_1, \cdots, i_K)$
$P_{Y}^{(f)}(i_1, \cdots, i_K)$ a restricted version of $P_{Y}(i_1, \cdots, i_K)$ with $i_f \geq 1$ for which it is required that feasible schedules end with an $f$-batch
$C_Y^{(f)}(i_1, \cdots, i_K)$ the optimal makespan of problem $P_{Y}^{(f)}(i_1, \cdots, i_K)$
$C_Y^{(f, k_f)}(i_1, \cdots, i_K)$ defined in equation (3)
$D_Y^{(f)}(i_1, \cdots, i_K)$ defined in equation (4)
${\mathcal X}_{Y}(i_1, \cdots, i_K)$ defined in equation (5), the set of family indices attaining the minimum in equation (1)
$\Psi^{(f)}_{Y}(i_1, \cdots, i_K)$ defined in equation (6), the set of the $f$-job indices attaining the minimum in equation (2)
$C_Y(i_1, \cdots, i_K)$ the optimal makespan of problem $P_{Y}(i_1, \cdots, i_K)$
Algorithm DP($Y$) the proposed dynamic programming algorithm for problem $1|\beta |C_{\max}: F_{\max}\leq Y$
Algorithm Family-CF the proposed algorithm for problem $1|\beta |^\#(C_{\max}, F_{\max})$
Table 2. The jobs in family ${\mathcal F}_1$
${\mathcal F}_1$ $J_{1, 1}$ $J_{1, 2}$ $J_{1, 3}$ $J_{1, 4}$ $J_{1, 5}$ $J_{1, 6}$ $J_{1, 7}$ $J_{1, 8}$ $J_{1, 9}$ $J_{1, 10}$
$r_{1, i}$ 0 2 3 4 6 7 9 11 14 17
$p_{1, i}$ 2 2 4 5 7 12 3 6 1 3
$r_{1, i}$ 1 2 4 6 8 10 11 14 16 19
$p_{1, i}$ 2 1 1 4 3 8 10 2 11 9
Table 4. The PoPs of the instances
jobs PoPs jobs PoPs jobs PoPs jobs PoPs jobs PoPs
${\mathcal J}(1, 1)$ $(4, 3)$ ${\mathcal J}(1, 2)$ $(4, 3)$ ${\mathcal J}(2, 1)$ $(6, 4)$ ${\mathcal J}(2, 2)$ $(6, 4)$ ${\mathcal J}(1, 3)$ $(5, 3)$
$(5, 5)$
$(7, 7)$ $(7, 7)$ $(8, 7)$
${\mathcal J}(4, 4)$ $(10, 4)$ ${\mathcal J}(1, 5)$ $(2, 2)$ ${\mathcal J}(2, 5)$ $(4, 2)$ ${\mathcal J}(3, 5)$ $(7, 5)$ ${\mathcal J}(4, 5)$ $(13, 5)$
$(9, 6)$ $(9, 6)$
${\mathcal J}(5, 1)$ $(3, 2)$ ${\mathcal J}(5, 2)$ $(4, 2)$ ${\mathcal J}(5, 3)$ $(5, 2)$ ${\mathcal J}(5, 4)$ $(10, 4)$ ${\mathcal J}(5, 5)$ $(13, 5)$
$(12, 6)$
${\mathcal J}(1, 6)$ $(2, 2)$ ${\mathcal J}(2, 6)$ $(4, 2)$ ${\mathcal J}(3, 6)$ $(7, 5)$ ${\mathcal J}(4, 6)$ $(9, 6)$ ${\mathcal J}(5, 6)$ $(13, 10)$
${\mathcal J}(6, 6)$ $(18, 10)$ ${\mathcal J}(1, 7)$ $(2, 2)$ ${\mathcal J}(2, 7)$ $(4, 2)$ ${\mathcal J}(3, 7)$ $(7, 5)$ ${\mathcal J}(4, 7)$ $(9, 6)$
${\mathcal J}(5, 7)$ $(13, 10)$ ${\mathcal J}(6, 7)$ $(22, 12)$ ${\mathcal J}(7, 1)$ $(3, 2)$ ${\mathcal J}(7, 2)$ $(4, 2)$ ${\mathcal J}(7, 3)$ $(5, 2)$
$(21, 13)$
${\mathcal J}(7, 4)$ $(10, 4)$ ${\mathcal J}(7, 5)$ $(13, 5)$ ${\mathcal J}(7, 6)$ $(18, 10)$ ${\mathcal J}(7, 7)$ $(22, 12)$ ${\mathcal J}(1, 8)$ $(2, 2)$
$(12, 6)$ $(21, 13)$
${\mathcal J}(2, 8)$ $(4, 2)$ ${\mathcal J}(3, 8)$ $(7, 5)$ ${\mathcal J}(4, 8)$ $(9, 6)$ ${\mathcal J}(5, 8)$ $(13, 10)$ ${\mathcal J}(6, 8)$ $(24, 12)$
${\mathcal J}(7, 8)$ $(24, 12)$ ${\mathcal J}(8, 1)$ $(3, 2)$ ${\mathcal J}(8, 2)$ $(4, 2)$ ${\mathcal J}(8, 3)$ $(5, 2)$ ${\mathcal J}(8, 4)$ $(10, 4)$
${\mathcal J}(8, 5)$ $(13, 5)$ ${\mathcal J}(8, 6)$ $(18, 10)$ ${\mathcal J}(8, 7)$ $(22, 12)$ ${\mathcal J}(8, 8)$ $(24, 12)$ ${\mathcal J}(1, 9)$ $(2, 2)$
$(12, 6)$ $(21, 13)$ $(23, 13)$
${\mathcal J}(9, 4)$ $(10, 4)$ ${\mathcal J}(9, 5)$ $(13, 5)$ ${\mathcal J}(9, 6)$ $(18, 10)$ ${\mathcal J}(9, 7)$ $(22, 12)$ ${\mathcal J}(9, 8)$ $(24, 12)$
${\mathcal J}(9, 9)$ $(25, 16)$ ${\mathcal J}(1, 10)$ $(2, 2)$ ${\mathcal J}(2, 10)$ $(4, 2)$ ${\mathcal J}(3, 10)$ $(7, 5)$ ${\mathcal J}(4, 10)$ $(9, 6)$
${\mathcal J}(5, 10)$ $(13, 10)$ ${\mathcal J}(6, 10)$ $(19, 15)$ ${\mathcal J}(7, 10)$ $(21, 15)$ ${\mathcal J}(8, 10)$ $(25, 16)$ ${\mathcal J}(9, 10)$ $(25, 16)$
$(23, 17)$ $(24, 17)$
${\mathcal J}(10, 1)$ $(3, 2)$ ${\mathcal J}(10, 2)$ $(4, 2)$ ${\mathcal J}(10, 3)$ $(5, 2)$ ${\mathcal J}(10, 4)$ $(13, 5)$ ${\mathcal J}(10, 5)$ $(18, 10)$
${\mathcal J}(10, 1)$ $(3, 2)$ ${\mathcal J}(10, 2)$ $(4, 2)$ ${\mathcal J}(10, 3)$ $(5, 2)$ ${\mathcal J}(10, 4)$ $(10, 4)$ ${\mathcal J}(10, 5)$ $(13, 5)$
${\mathcal J}(10, 6)$ $(18, 10)$ ${\mathcal J}(10, 7)$ $(22, 12)$ ${\mathcal J}(10, 8)$ $(24, 12)$ ${\mathcal J}(10, 9)$ $(25, 16)$ ${\mathcal J}(10, 10)$ $(25, 16)$
Le Thi Hoai An, Tran Duc Quynh, Kondo Hloindo Adjallah. A difference of convex functions algorithm for optimal scheduling and real-time assignment of preventive maintenance jobs on parallel processors. Journal of Industrial & Management Optimization, 2014, 10 (1) : 243-258. doi: 10.3934/jimo.2014.10.243
Leiyang Wang, Zhaohui Liu. Heuristics for parallel machine scheduling with batch delivery consideration. Journal of Industrial & Management Optimization, 2014, 10 (1) : 259-273. doi: 10.3934/jimo.2014.10.259
Chengwen Jiao, Qi Feng. Research on the parallel–batch scheduling with linearly lookahead model. Journal of Industrial & Management Optimization, 2021, 17 (6) : 3551-3558. doi: 10.3934/jimo.2020132
Qun Lin, Antoinette Tordesillas. Towards an optimization theory for deforming dense granular materials: Minimum cost maximum flow solutions. Journal of Industrial & Management Optimization, 2014, 10 (1) : 337-362. doi: 10.3934/jimo.2014.10.337
John Sheekey. A new family of linear maximum rank distance codes. Advances in Mathematics of Communications, 2016, 10 (3) : 475-488. doi: 10.3934/amc.2016019
Chengxin Luo. Single machine batch scheduling problem to minimize makespan with controllable setup and jobs processing times. Numerical Algebra, Control & Optimization, 2015, 5 (1) : 71-77. doi: 10.3934/naco.2015.5.71
R.L. Sheu, M.J. Ting, I.L. Wang. Maximum flow problem in the distribution network. Journal of Industrial & Management Optimization, 2006, 2 (3) : 237-254. doi: 10.3934/jimo.2006.2.237
Zhao-Hong Jia, Ting-Ting Wen, Joseph Y.-T. Leung, Kai Li. Effective heuristics for makespan minimization in parallel batch machines with non-identical capacities and job release times. Journal of Industrial & Management Optimization, 2017, 13 (2) : 977-993. doi: 10.3934/jimo.2016057
Mingshang Hu. Stochastic global maximum principle for optimization with recursive utilities. Probability, Uncertainty and Quantitative Risk, 2017, 2 (0) : 1-. doi: 10.1186/s41546-017-0014-7
Yan Gu, Nobuo Yamashita. A proximal ADMM with the Broyden family for convex optimization problems. Journal of Industrial & Management Optimization, 2021, 17 (5) : 2715-2732. doi: 10.3934/jimo.2020091
Radu C. Cascaval, Ciro D'Apice, Maria Pia D'Arienzo, Rosanna Manzo. Flow optimization in vascular networks. Mathematical Biosciences & Engineering, 2017, 14 (3) : 607-624. doi: 10.3934/mbe.2017035
Henri Bonnel, Ngoc Sang Pham. Nonsmooth optimization over the (weakly or properly) Pareto set of a linear-quadratic multi-objective control problem: Explicit optimality conditions. Journal of Industrial & Management Optimization, 2011, 7 (4) : 789-809. doi: 10.3934/jimo.2011.7.789
Yang Woo Shin, Dug Hee Moon. Throughput of flow lines with unreliable parallel-machine workstations and blocking. Journal of Industrial & Management Optimization, 2017, 13 (2) : 901-916. doi: 10.3934/jimo.2016052
Changli Yuan, Mojdeh Delshad, Mary F. Wheeler. Modeling multiphase non-Newtonian polymer flow in IPARS parallel framework. Networks & Heterogeneous Media, 2010, 5 (3) : 583-602. doi: 10.3934/nhm.2010.5.583
Kien Ming Ng, Trung Hieu Tran. A parallel water flow algorithm with local search for solving the quadratic assignment problem. Journal of Industrial & Management Optimization, 2019, 15 (1) : 235-259. doi: 10.3934/jimo.2018041
Tsuguhito Hirai, Hiroyuki Masuyama, Shoji Kasahara, Yutaka Takahashi. Performance optimization of parallel-distributed processing with checkpointing for cloud environment. Journal of Industrial & Management Optimization, 2018, 14 (4) : 1423-1442. doi: 10.3934/jimo.2018014
Mostafa Abouei Ardakan, A. Kourank Beheshti, S. Hamid Mirmohammadi, Hamed Davari Ardakani. A hybrid meta-heuristic algorithm to minimize the number of tardy jobs in a dynamic two-machine flow shop problem. Numerical Algebra, Control & Optimization, 2017, 7 (4) : 465-480. doi: 10.3934/naco.2017029
Ji-Bo Wang, Mengqi Liu, Na Yin, Ping Ji. Scheduling jobs with controllable processing time, truncated job-dependent learning and deterioration effects. Journal of Industrial & Management Optimization, 2017, 13 (2) : 1025-1039. doi: 10.3934/jimo.2016060
Hongtruong Pham, Xiwen Lu. The inverse parallel machine scheduling problem with minimum total completion time. Journal of Industrial & Management Optimization, 2014, 10 (2) : 613-620. doi: 10.3934/jimo.2014.10.613
Wenjuan Zhao, Shunfu Jin, Wuyi Yue. A stochastic model and social optimization of a blockchain system based on a general limited batch service queue. Journal of Industrial & Management Optimization, 2021, 17 (4) : 1845-1861. doi: 10.3934/jimo.2020049
Zhichao Geng Jinjiang Yuan | CommonCrawl |
Empirical article
Customer satisfaction of Vietnam Airline domestic service quality
Giao Ha Nam Khanh1
International Journal of Quality Innovation volume 3, Article number: 10 (2017) Cite this article
The paper examines the relation between Vietnam Airline domestic service quality and customer satisfaction by gathering opinions from 402 passengers employing the Skytrax scale with some modification along with Cronbach's alpha, exploratory factor analysis, and multiple regression analysis. Results show that Vietnam Airline domestic service quality can be measured by the following six determinants in order of decreasing importance: (1) boarding/deplaning/baggage, (2) check-in, (3) in-flight services, (4) reservation, (5) aircraft, and (6) flight crew. All of them have directly proportional effects to customer satisfaction. The paper also offers some suggestions to improve the service quality, thereby enhancing the customer satisfaction.
In the past few years, air transport has gained high growth rates. IATA reports showed that air transport of passengers in 2015 rose by 7.4%; this was the greatest increase since the rebound from the depth of the global financial crisis in 2010 and well above the long-run average of 5.5%.
According to the 2016 Report by Civil Aviation Authority of Vietnam, the air transport business served 52.2 million passengers, increasing by 29% in 2015, in which 28 million are domestic passengers, increasing by 30% in 2015. Additionally, 52 foreign airlines are operating 78 routes from 28 countries or territories to Vietnam. Domestic services offered by local airlines comprise 50 routes from three hubs—HaNoi, DaNang, and HoChiMinh City—to 17 local airports. The biggest market shares of this business are held by Vietnam Airline (VNA), VietJet Air, and Jetstar Pacific Airline. The data show that air transport is a potential and promising market. Local airlines and VNA in particular are facing great challenges and keen competition from foreign rivals.
According to Skytrax [18], VNA is only ranked as a three-star service on a five-star scale. This means that VNA service quality is at a medium level and it should make great effort to improve its service quality. When VNA joined Skyteam on June 10, 2010, use of the Skytrax ranking scale is necessary and also an objective of this research.
To retain its stability and competitiveness in such a global dynamic market, VNA should put a major emphasis on service quality in order to gain the highest level of passenger satisfaction. According to Aksoy et al. [1], passenger satisfaction is one of the most critical factors in the airline industry and regarded as playing a crucial part in guaranteeing the business success in today's competitive world. This research aimed at (1) identifying the key determinants that effect directly to local passenger satisfaction of VNA, (2) measuring the direct effects on local passenger satisfaction of VNA, and (3) recommending suggestions for the company to better off its field based on the results and findings of the research.
This paper includes five parts. Part 1 introduces the pivotal point of departure for the paper which is the problem that seeks to be solved. The problem statement is generated by the preceding problem identification which fits the purpose of identifying the specific research objective at hand. Subsequently, part 2 discusses the theoretical area and instruments applied to answer the problem at hand, which are founded in the nature of service quality and customer satisfaction, and rise to a research model. Part 3 encompasses the methodological considerations applied to answer the posed research questions. The analysis in part 4 covers the actual statistical data analysis which processes and examines the data gathered from the questionnaire and states out the findings. Part 5 summarizes the findings from the analysis in a comprehensive conclusion, raises suggested solutions, and recommends further studies.
Quality of aviation service
Nowadays, customer satisfaction is regarded as one of the most indispensable elements playing a vital part in determining the success and prosperity of a specific business in such a dynamic and fast-growing market. According to Rust and Oliver [16], customer satisfaction is defined as an emotional or affective response which surfaces and develops when meeting with any kind of service. After service is provided, a positive or negative reaction will emerge from customers getting that service. Also, Oliver [13] stated that "customer satisfaction is the outcome of the evaluative process between the impression during or after service is performed and the expectations before experiencing the service." In specific situations, what people assume before using the service may contradict what we actually encounter during and after the service is performed.
In transportation context, the fact that passengers are satisfied with the services provided has a crucial effect on determining the long-term continuance of a specific carrier [15]. Dissatisfied passengers may lose their trust and not consider choosing the same airline again due to the bad service provided. Therefore, it is absolutely imperative for airlines to assure what customers expect and experience with their desired service quality [7].
The Draft International Standard, ISO/DIS 9000:2000, defines quality as "ability of a set of inherit characteristics of product, system, or process to fulfill requirements of customers and the other interested parties." Parasuraman et al. [14] argue that service quality is considered as results of customers' comparison between their expectation of the service and their perception after using the service. Tiernan et al. [19] and Namukasa [11] used the model of SERVQUAL [14] and SERVPERF [2] to examine the impact of airline service quality on passenger satisfaction.
Morash and Ozment [10] note that service quality conditions influence an airline's competitive advantage and with this comes market share and ultimately profitability. However, air transport service, like many other services, has its own characteristics and standards, about safety for example. Some characteristics are (i) interactive effects between service provider and customer, (ii) personalization, and (iii) high labor content.
According to the Australian Bureau of Transport Economics, standards of air transport service quality include (1) safety, (2) customer information, (3) flight frequency, (4) smooth air services, (5) on-time operation, (6) ground services and equipment, and (7) in-flight amenity and services. Elliott and Roach [3] suggest the following standards for aviation service: (1) food and beverages, (2) time for baggage collection, (3) comfortable seat, (4) checking procedure, and (5) in-flight services. Groundin and Kloppenborg [4] suggest a scale for aviation service quality including (1) baggage handling, (2) compensation procedure, (3) operation and safety, (4) flight comfort, and (5) network and flight frequency.
The McGraw-Hill Company [8] measures the service quality and satisfaction of 12,300 passengers of 12 North American airlines using the Skytrax standard suggested by Skyteam and finds seven influential factors: (1) fee, (2) in-flight service, (3) reservation, (4) flight crew, (5) boarding/deplaning/baggage, (6) aircraft, and (7) check-in.
Relation between aviation service quality and customer satisfaction
Ha and Nguyen [5] give a simple conclusion of customer satisfaction as an intersection or overlap area between corporate ability and customer need or a feeling of a person coming from comparison of outcome produced by commodity/service with his/her expectations.
Zeithaml and Bitner [20] argue that customer satisfaction with service quality is assessment and comparison of their perception of value of the service they receive with their expectation. Huang [6] says that many researches on aviation verify the relation between aviation service quality and customer satisfaction.
This research combines the findings from the abovementioned researches and applies modified criteria for measuring customer satisfaction with aviation service quality offered by McGraw-Hill [8] to the case of VNA in which aviation service quality comprises six determinants: (1) reservation (RES), (2) check-in (CHE), (3) aircraft (AIR), (4) in-flight services (INF), (5) flight crew (FLI), and (6) boarding/deplaning/baggage (BDB) (Additional file 1). The suggested research model is based on aforementioned theoretical preconditions and presented in Fig. 1, and the research hypotheses are stated as follows:
H1: Reservation has the direct, positive impact on the VNA domestic passengers' satisfaction.
H2: Check-in has the direct, positive impact on the VNA domestic passengers' satisfaction.
H3: Aircraft has the direct, positive impact on the VNA domestic passengers' satisfaction.
H4: In-flight service has the direct, positive impact on the VNA domestic passengers' satisfaction.
H5: Flight crew has the direct, positive impact on the VNA domestic passengers' satisfaction.
H6: Boarding/deplaning/baggage has the direct, positive impact on the VNA domestic passengers' satisfaction.
Suggested research model
Population and sampling
The sample identified in this study was drawn from a population size of 28 million passengers in 2016. The intended sampling method is quota sampling. The sample size and sampling result are presented in Table 1. It has been found that sample sizes larger than 30 and less than 500 are appropriate for most research [17].
Table 1 Sample size and sampling result
In-depth interviews with three high-ranking VNA officials are conducted to identify determinants of service quality and evaluating criteria. Questions are devised beforehand. The interviewers are followed by a group discussion based on open questions with seven passengers who frequently use VNA domestic services in order to find their perception of determinants of service quality. Their opinions are used for improving and developing scales for aviation service quality.
A structured questionnaire with 5-point Likert scales with anchors "strongly disagree" to "strongly agree" was used in this study. Since 5-point Likert scales are widely used, especially in a business context, this research felt that it was appropriate to use the same tactic for this study. The questionnaire consisted of two parts. The first part was to examine the customer satisfaction through the variables of service quality. The second part was designed to collect respondents' demographic information. To validate the questionnaire, a pilot test was carried out on a convenient sample of 30 passengers and the collected data was used to refine the survey instrument.
A quantitative survey is conducted in Tan Son Nhat Airport. The target population includes Vietnamese passengers who are in the 18–60 age bracket and used VNA domestic services two times at least in the last 6 months. To motivate the respondents, along with each questionnaire, a ball pen was distributed as a takeaway souvenir.
After collecting the data, a statistical package for social sciences (SPSS, 22 versions) was used for analyzing the data. Cronbach's alpha and exploratory factor analysis (EFA) were employed to test the reliability and validity, and then multiple regression analysis was performed to test the hypotheses. Subsequently, the tests of regression assumptions and difference tests consolidated the findings.
Characteristics of sample
Data are gathered by 15-min direct interviews and questionnaires. The interviews are conducted at waiting lounges of airports. Out of 500 issued questionnaires, 437 (87.4%) responded and 35 of them considered as inappropriate because of many wrong answers or unfilled blanks. Thus, only 402 answered questionnaires can be used for the research. The characteristics are presented in Table 2.
Table 2 Sample characteristics
Results of scale test
Table 3 shows that Cronbach's alpha coefficients of all scales are greater than 0.6 and all item-total correlation coefficients are greater than 0.3. Thus, all scales are reliable and can be used for EFA [12].
Table 3 Cronbach's alpha coefficients for scales of determinants of quality service and customer satisfaction
In the EFA process, principal determinant analysis and Varimax are employed. EFA results show that KMO = 0.888 while chi-square statistic of Barlett's test reaches 7298.249 at Sig. = 0.000. All 31 determinants are reduced to seven factors with eigenvalue of 1.041 (greater than 1) with a variation of 66.42% (able to explain 66.42% of changes in dataset). Observed variables of seven factors all have factor loadings greater than 0.5, and they are used for analyzing the research model of multiple linear regression. Thus, resultant scales are acceptable. After conducting the factor rotation with all 31 aforementioned variables, seven factors are extracted (Table 4).
Table 4 EFA results
EFA results show that scales measuring customer satisfaction and determinants of service quality did obtain convergent validity. The results also imply that the research model remains stable, comprising six independent variables and one dependent variable.
Multiple linear regression analysis
Table 5 shows that the dependent variable has a close linear relation with six independent variables at α < 0.05. Because all absolute correlation coefficients between variables vary from 0.245 to 0.671, thus satisfying condition − 1 ≤ r ≤ + 1, all variables are qualified for multiple linear regression analysis. This demonstrates that the discriminant validity is achieved, or in other words, scales used in this research can measure various constructs. The correlation matrix also shows that the variable BDB has the greatest effect on the customer satisfaction while CHE produces the smallest effect.
Table 5 Correlation coefficients between determinants
Results of the MLR analysis of relations between factors of service quality and satisfaction using the Enter method are presented in Table 6. Relations between the aviation service quality reflected in six factors (INF, FLI, RES, CHE, BDB, and AIR) with satisfaction (SAT) all have Sig. greater than 0.05, and they are presented in the following:
$$ \mathrm{SAT}=0.3794\times \mathrm{BDB}+0.541\times \mathrm{INF}+0.275\times \mathrm{RES}+0.133\times \mathrm{FLI}+0.483\times \mathrm{CHE}+0.128\times \mathrm{AIR}+0.241 $$
Table 6 MLR analysis results
It turns out that all hypotheses are supported. Adjusted R 2 = 0.627, F = 113.414, and Sig. = 0.000. Table 6 shows that the greatest effect on SAT is produced by BDB (β = 0.536), followed by CHE (β = 0.419), INF (β = 0.329), RES (β = 0.164), AIR (β = 0.158), and FLI (β = 0.106). Additionally, all regression coefficients bear positive signs, implying that all factors in the model are directly proportional to customer satisfaction.
Table 7 shows that R 2 is 0.633 and adjusted R 2 is 0.627. This implies that the fitness of the model is 62.7%. In other words, 62.7% of customer satisfaction can be explained by the sic independent variables, and the remaining 37.3% is affected by other variables.
Table 7 Adjusted R 2 and F values
Results of analysis of variance show that the F value is 113.414 and Sig. = 0.000 < 0.01 (Table 8), implying that at least one independent variable has a linear relation with the dependent variable. Thus, independent variables in the model have linear relations with the dependent variable and explain its changes; that is, determinants of service quality can explain changes in satisfaction. This means that the regression model is fit for dataset and usable, and all variables are statistically significant at 5%.
Table 8 Results of analysis of variance
Table 6 shows that tolerance value is very small and all VIF coefficients are smaller than 10, implying that multi-collinearity does not exist. Scatter plot of residual and predicted value of the regression model reveals no relation between them, and thus, the linearity assumption of the model is acceptable. In the result of analysis of residual based on histogram approximates—the standard level, the residual has a mean value 3.32 × 10 ≈ 0 and std. dev. = 0.992 ≈ 1. P-P plot shows that distribution of the residual can be considered as standard, and assumption of normal distribution of residual is not violated. In short, results of model tests and tests for violation of necessary assumptions show that the regression model used in the research is suitable (Additional file 2).
Difference testing
All the difference tests can be found in Additional file 3. Independent samples T test was used to test the satisfaction by gender. The result shows that Levene's Test for Equality of Variances has Sig. = 0.037(< 0.05), so Sig. of T test at equal variances not assumed was used. T test of 0.561 > 0.05 shows that means of two samples are equal; it confers that there is no difference between male and female passengers of satisfaction.
Test of homogeneity of variances shows that the Levene statistic equals to 1.744 and Sig. = 0.160 (> 0.05), the variances between age groups are equal, and ANOVA could be used. ANOVA shows that F = 1.556 and Sig. = 0.202 (> 0.05); it confers that there is no difference among age groups of satisfaction.
Test of homogeneity of variances shows that the Levene statistic equals to 0.865 and Sig. = 0.461 (> 0.05), the variances between age groups are equal, and ANOVA could be used. ANOVA shows that F = 1.403 and Sig. = 0.244 (> 0.05); it confers that there is no difference among monthly income of satisfaction.
Test of homogeneity of variances shows that the Levene statistic equals to 5.474 and Sig. = 0.001 (< 0.05), the variances between age groups are unequal, and one-way ANOVA could not be used. Welch test [9] shows that F = 15.705 and Sig. = 0.000 (< 0.05); it confers that there is difference among purpose of passengers about satisfaction.
Test of homogeneity of variances shows that the Levene statistic equals to 3.102 and Sig. = 0.028 (< 0.05), the variances between age groups are unequal, and one-way ANOVA could not be used. Welch test shows that F = 1.288 and Sig. = 0.288 (> 0.05); it confers that there is no difference among education of passengers about satisfaction.
Suggested solutions
Results of estimation of determinants of aviation service according to statistic method describing the mean value in a 5-scale Likert show that scores given by passengers vary from "medium" to "pretty good" (Table 9). The highest scores are given to reservation (mean = 3.60), followed by in-flight services (3.56) and flight crew (3.51), while medium scores are given to aircraft (3.47) and boarding/deplaning/baggage (3.40) and the lowest one to check-in (3.31); SAT is given a pretty high score of 3.41. Based on those results, we can suggest some solutions to the management of VNA of how to enhance the customers' satisfaction.
Table 9 Passengers' estimates of determinants
For boarding/deplaning/baggage, flight schedule, especially for domestic services, should be preserved. Passengers should be informed timely of all changes or delays. Baggage delivery and collection should be done conveniently, and all damage to baggage should be handled and compensated properly. VNA must apply necessary services to passengers of delayed or canceled flights, such as some fee services in waiting lounges and hotel rooms at reasonable charges.
For check-in, VNA staff should service passengers with professionalism to avoid mistakes. More training courses in foreign languages and work ethics should be given to VNA staff to create a friendly atmosphere for passengers. For in-flight services, it can be improved by diversifying in-flight meals and entertainment programs and supplying more newspapers and magazines. Needed information about the flight should be given to the passengers. Air hostesses should be polite, considerate, and friendly towards passengers.
For reservation, VNA should respond properly when passengers want to change their reservation. Information about flight schedules should be available on the VNA website to spare customers from seeking information at travel agencies. VNA should supply online reservation services. For aircraft, VNA aircraft should have modern equipment to serve passengers better, especially children, pregnant women, and the disabled.
For flight crew, the pilot should have professional training and experience. The air crew should be friendly, considerate, and fluent in foreign languages. Knowledge of sign language also helps improve their communicative power.
Finally, VNA, as the national carrier with great financial and human potentials, along with support from local passengers, should make the best use of its advantages and favorable conditions to develop into an internationally acclaimed airline company.
It has been figured out that some adjustments could be done further to improve the quality of the research.
First of all, we should target a bigger sample size and more generalizable sampling method. This research is conducted based on a sample size of 402 passengers on the 03 domestic flights of SGN-HAN, SGN-NHA, and SGN-DAN, which certainly do not cover the whole population of passengers who traveled with VNA. Moreover, the majority of the targeted population was passengers who were waiting for their flights, so they somehow had been in a hurry or busy and not willing to fill in the questionnaire. Therefore, this can affect the reliability as well as the overall evaluation of the research.
Last but not least, many passengers would prefer to see VNA lower flight prices or discount programs to compete against competitors. Therefore, price should be considered as another important factor beside the current variables to increase the reliability and accuracy of the research.
The research identifies six determinants affecting the aviation service quality and customer satisfaction with VNA domestic services. The greatest effects are produced by BDB, followed by CHE, INF, RES, and AIR, and the weakest effect is caused by FLI. The six determinants can explain 62.7% of customer satisfaction. There is no difference of satisfaction between male and female passengers, among the age groups, among the monthly income groups, and among the education groups. The difference happens only among the passengers' purpose of travel, especially the high level of satisfaction appears with people who travel for business and conference; it may be rooted from the characteristics of on-time performance of VNA in comparison to the low-cost domestic airlines.
Statistics of mean values given by customers to those six determinants show that these values are not high. This implies that passengers are not really satisfied with VNA service. This research can be considered as a contribution to an empirical research on aviation service quality based on Skytrax standards.
Aksoy S., Atilgan E., & Akinci S. (2003). Airline services marketing by domestic and foreign firms: differences from the customers' "viewpoint". J Air Transport Manag, 9, pp. 343-351
Cronin JJ, Taylor SA (1992) Measuring service quality: a reexamination and extension. J Mark 56:55–68
Elliott KM, Roach DW (1993) Service quality in the airline industry: are carriers getting an unbiased evaluation from consumers? J Prof Serv Mark 9:71–82
Groundin KN, Kloppenborg TJ (1991) Identifying service gaps in commercial air travel: the first step toward quality improvement. Transp J 1(1):22–30
Ha NKG, Nguyen TV (2011) Customer satisfaction on the service quality of the of Vinatex-mart chain. Econ Dev Rev 253:9–16
Huang YK (2010) The effect of airline service quality on passengers' behavioral intentions using SERVQUAL score: a Taiwan case study. J Eastern Asia Society Transport Stud 8:2330–2343
Kossmann M (2006) Delivering excellent service quality in aviation: a practical guide for internal and external service providers. Ashgate Publishing Limited, England, p 2006
McGraw-Hill (2010) North American airline satisfaction. Manag Serv Qual 18(1):4–19
Moder, K. (2010). Alternatives to F-test in one way ANOVA in case of heterogeneity of variances (a simulation study). Psychol Test Assess Model, 52(4): 343-353
Morash WA, Ozment J (1994) Toward management of transportation service quality. Log Transport Review 30:115–140
Namukasa J (2013) The influence of airline service quality on passenger satisfaction and loyalty: the case of Uganda airline industry. TQM J 25(5):520–532
Nunnally J, Bernstein IH (1994) Pschychometric theory, 3rd edn. Irwin McGraw-Hill, New York
Oliver RL (1980) A cognitive model of the antecedents and consequences of satisfaction decisions. J Mark Res 49(Fall):41–50
Parasuraman A, Zeithaml VA, Berry LL (1985) A conceptual model of service quality and its implications for future research. J Mark 49:41–50
Rhea MJ, Shrock DL (1987) Measuring distribution effectiveness with key informant report. Log Transport Review 23(3):295–306
Rust TR, Oliver RL (1994) Service quality: insights and managerial implications from the frontier. Sage Publications, Thousand Oaks
Sekaran U (2003) Research methods for business: a skill-building approach, 4th edn. John Wiley & Sons, Inc, New York
Skytrax (2010). Vietnam Airlines: official 3-star ranking of product and service quality, retrieved from www.airlinequality.com/Airlines/VN.htm, July 22, 2016
Tiernan S, Rhoades DL, Waguespack B (2008) Airline service quality—exploratory analysis of customer perceptions and operational performance in the USA and EU. Manag Serv Qual 8(3):212–224
Zeithaml VA, Bitner MJ (2001) Services marketing: integrating customer focus across the firms. Tata McGraw Hill, Boston
University Finance Marketing, 2C Pho Quang Street, Ward 2, Tan Binh District, HoChiMinh City, Vietnam
Giao Ha Nam Khanh
Correspondence to Giao Ha Nam Khanh.
Variable measurement. (DOCX 12 kb)
Regression assumption test. (DOCX 170 kb)
Difference test. (DOCX 21 kb)
Ha Nam Khanh, G. Customer satisfaction of Vietnam Airline domestic service quality. Int J Qual Innov 3, 10 (2017). https://doi.org/10.1186/s40887-017-0019-4
Received: 09 May 2017
Domestic service | CommonCrawl |
Tag Archives: mario
SUPER game night 3: GAMES MADE QUICK??? 2.0
2018-01-24 Eevee
Post Syndicated from Eevee original https://eev.ee/blog/2018/01/23/super-game-night-3-games-made-quick-2-0/
Game night continues with a smorgasbord of games from my recent game jam, GAMES MADE QUICK??? 2.0!
The idea was to make a game in only a week while watching AGDQ, as an alternative to doing absolutely nothing for a week while watching AGDQ. (I didn't submit a game myself; I was chugging along on my Anise game, which isn't finished yet.)
I can't very well run a game jam and not play any of the games, so here's some of them in no particular order! Enjoy!
These are impressions, not reviews. I try to avoid major/ending spoilers, but big plot points do tend to leave impressions.
Weather Quest, by timlmul
short · rpg · jan 2017 · (lin)/mac/win · free on itch · jam entry
Weather Quest is its author's first shipped game, written completely from scratch (the only vendored code is a micro OO base). It's very short, but as someone who has also written LÖVE games completely from scratch, I can attest that producing something this game-like in a week is a fucking miracle. Bravo!
For reference, a week into my first foray, I think I was probably still writing my own Tiled importer like an idiot.
Only Mac and Windows builds are on itch, but it's a LÖVE game, so Linux folks can just grab a zip from GitHub and throw that at love.
FINAL SCORE: ⛅☔☀
Pancake Numbers Simulator, by AnorakThePrimordial
short · sim · jan 2017 · lin/mac/win · free on itch · jam entry
Given a stack of N pancakes (of all different sizes and in no particular order), the Nth pancake number is the most flips you could possibly need to sort the pancakes in order with the smallest on top. A "flip" is sticking a spatula under one of the pancakes and flipping the whole sub-stack over. There's, ah, a video embedded on the game page with some visuals.
Anyway, this game lets you simulate sorting a stack via pancake flipping, which is surprisingly satisfying! I enjoy cleaning up little simulated messes, such as… incorrectly-sorted pancakes, I guess?
This probably doesn't work too well as a simulator for solving the general problem — you'd have to find an optimal solution for every permutation of N pancakes to be sure you were right. But it's a nice interactive illustration of the problem, and if you know the pancake number for your stack size of choice (which I wish the game told you — for seven pancakes, it's 8), then trying to restore a stack in that many moves makes for a nice quick puzzle.
FINAL SCORE: \(\frac{18}{11}\)
Framed Animals, by chridd
short · metroidvania · jan 2017 · web/win · free on itch · jam entry
The concept here was to kill the frames, save the animals, which is a delightfully literal riff on a long-running AGDQ/SGDQ donation incentive — people vote with their dollars to decide whether Super Metroid speedrunners go out of their way to free the critters who show you how to walljump and shinespark. Super Metroid didn't have a showing at this year's AGDQ, and so we have this game instead.
It's rough, but clever, and I got really into it pretty quickly — each animal you save gives you a new ability (in true Metroid style), and you get to test that ability out by playing as the animal, with only that ability and no others, to get yourself back to the most recent save point.
I did, tragically, manage to get myself stuck near what I think was about to be the end of the game, so some of the animals will remain framed forever. What an unsatisfying conclusion.
Gravity feels a little high given the size of the screen, and like most tile-less platformers, there's not really any way to gauge how high or long your jump is before you leap. But I'm only even nitpicking because I think this is a great idea and I hope the author really does keep working on it.
FINAL SCORE: $136,596.69
Battle 4 Glory, by Storyteller Games
short · fighter · jan 2017 · win · free on itch · jam entry
This is a Smash Bros-style brawler, complete with the four players, the 2D play area in a 3D world, and the random stage obstacles showing up. I do like the Smash style, despite not otherwise being a fan of fighting games, so it's nice to see another game chase that aesthetic.
Alas, that's about as far as it got — which is pretty far for a week of work! I don't know what more to say, though. The environments are neat, but unless I'm missing something, the only actions at your disposal are jumping and very weak melee attacks. I did have a good few minutes of fun fruitlessly mashing myself against the bumbling bots, as you can see.
FINAL SCORE: 300%
Icnaluferu Guild, Year Sixteen, by CHz
short · adventure · jan 2017 · web · free on itch · jam entry
Here we have the first of several games made with bitsy, a micro game making tool that basically only supports walking around, talking to people, and picking up items.
I tell you this because I think half of my appreciation for this game is in the ways it wriggled against those limits to emulate a Zelda-like dungeon crawler. Everything in here is totally fake, and you can't really understand just how fake unless you've tried to make something complicated with bitsy.
It's pretty good. The dialogue is entertaining (the rest of your party develops distinct personalities solely through oneliners, somehow), the riffs on standard dungeon fare are charming, and the Link's Awakening-esque perspective walls around the edges of each room are fucking glorious.
FINAL SCORE: 2 bits
The Lonely Tapes, by JTHomeslice
short · rpg · jan 2017 · web · free on itch · jam entry
Another bitsy entry, this one sees you play as a Wal— sorry, a JogDawg, which has lost its cassette tapes and needs to go recover them!
(A cassette tape is like a VHS, but for music.)
(A VHS is—)
I have the sneaking suspicion that I missed out on some musical in-jokes, due to being uncultured swine. I still enjoyed the game — it's always clear when someone is passionate about the thing they're writing about, and I could tell I was awash in that aura even if some of it went over my head. You know you've done good if someone from way outside your sphere shows up and still has a good time.
FINAL SCORE: Nine… Inch Nails? They're a band, right? God I don't know write your own damn joke
Pirate Kitty-Quest, by TheKoolestKid
short · adventure · jan 2017 · win · free on itch · jam entry
I completely forgot I'd even given "my birthday" and "my cat" as mostly-joking jam themes until I stumbled upon this incredible gem. I don't think — let me just check here and — yeah no this person doesn't even follow me on Twitter. I have no idea who they are?
BUT THEY MADE A GAME ABOUT ANISE AS A PIRATE, LOOKING FOR TREASURE
PIRATE. ANISE
PIRATE ANISE!!!
This game wins the jam, hands down. 🏆
FINAL SCORE: Yarr, eight pieces o' eight
CHIPS Mario, by NovaSquirrel
short · platformer · jan 2017 · (lin/mac)/win · free on itch · jam entry
You see this? This is fucking witchcraft.
This game is made with MegaZeux. MegaZeux games look like THIS. Text-mode, bound to a grid, with two colors per cell. That's all you get.
Until now, apparently?? The game is a tech demo of "unbound" sprites, which can be drawn on top of the character grid without being aligned to it. And apparently have looser color restrictions.
The collision is a little glitchy, which isn't surprising for a MegaZeux platformer; I had some fun interactions with platforms a couple times. But hey, goddamn, it's free-moving Mario, in MegaZeux, what the hell.
(I'm looking at the most recently added games on DigitalMZX now, and I notice that not only is this game in the first slot, but NovaSquirrel's MegaZeux entry for Strawberry Jam last February is still in the seventh slot. RIP, MegaZeux. I'm surprised a major feature like this was even added if the community has largely evaporated?)
FINAL SCORE: n/a, disqualified for being probably summoned from the depths of Hell
d!¢< pic, by 573 Games
short · story · jan 2017 · web · free on itch · jam entry
This is a short story about not sending dick pics. It's very short, so I can't say much without spoiling it, but: you are generally prompted to either text something reasonable, or send a dick pic. You should not send a dick pic.
It's a fascinating artifact, not because of the work itself, but because it's so terse that I genuinely can't tell what the author was even going for. And this is the kind of subject where the author was, surely, going for something. Right? But was it genuinely intended to be educational, or was it tongue-in-cheek about how some dudes still don't get it? Or is it side-eying the player who clicks the obviously wrong option just for kicks, which is the same reason people do it for real? Or is it commentary on how "send a dick pic" is a literal option for every response in a real conversation, too, and it's not that hard to just not do it — unless you are one of the kinds of people who just feels a compulsion to try everything, anything, just because you can? Or is it just a quick Twine and I am way too deep in this? God, just play the thing, it's shorter than this paragraph.
I'm also left wondering when it is appropriate to send a dick pic. Presumably there is a correct time? Hopefully the author will enter Strawberry Jam 2 to expound upon this.
FINAL SCORE: 3½" 😉
Marble maze, by Shtille
short · arcade · jan 2017 · win · free on itch · jam entry
Ah, hm. So this is a maze navigated by rolling a marble around. You use WASD to move the marble, and you can also turn the camera with the arrow keys.
The trouble is… the marble's movement is always relative to the world, not the camera. That means if you turn the camera 30° and then try to move the marble, it'll move at a 30° angle from your point of view.
That makes navigating a maze, er, difficult.
Camera-relative movement is the kind of thing I take so much for granted that I wouldn't even think to do otherwise, and I think it's valuable to look at surprising choices that violate fundamental conventions, so I'm trying to take this as a nudge out of my comfort zone. What could you design in an interesting way that used world-relative movement? Probably not the player, but maybe something else in the world, as long as you had strong landmarks? Hmm.
FINAL SCORE: ᘔ
Refactor: flight, by fluffy
short · arcade · jan 2017 · lin/mac/win · free on itch · jam entry
Refactor is a game album, which is rather a lot what it sounds like, and Flight is one of the tracks. Which makes this a single, I suppose.
It's one of those games where you move down an oddly-shaped tunnel trying not to hit the walls, but with some cute twists. Coins and gems hop up from the bottom of the screen in time with the music, and collecting them gives you points. Hitting a wall costs you some points and kills your momentum, but I don't think outright losing is possible, which is great for me!
Also, the monk cycles through several animal faces. I don't know why, and it's very good. One of those odd but memorable details that sits squarely on the intersection of abstract, mysterious, and a bit weird, and refuses to budge from that spot.
The music is great too? Really chill all around.
FINAL SCORE: 🎵🎵🎵🎵
The Adventures of Klyde
Another bitsy game, this one starring a pig (humorously symbolized by a giant pig nose with ears) who must collect fruit and solve some puzzles.
This is charmingly nostalgic for me — it reminds me of some standard fare in engines like MegaZeux, where the obvious things to do when presented with tiles and pickups were to make mazes. I don't mean that in a bad way; the maze is the fundamental environmental obstacle.
A couple places in here felt like invisible teleport mazes I had to brute-force, but I might have been missing a hint somewhere. I did make it through with only a little trouble, but alas — I stepped in a bad warp somewhere and got sent to the upper left corner of the starting screen, which is surrounded by walls. So Klyde's new life is being trapped eternally in a nowhere space.
FINAL SCORE: 19/20 apples
That was only a third of the games, and I don't think even half of the ones I've played. I'll have to do a second post covering the rest of them? Maybe a third?
Or maybe this is a ludicrous format for commenting on several dozen games and I should try to narrow it down to the ones that resonated the most for Strawberry Jam 2? Maybe??
if (false) { align = (screen.width < 768) ? "left" : align; indent = (screen.width < 768) ? "0em" : indent; linebreak = (screen.width < 768) ? 'true' : linebreak; } var mathjaxscript = document.createElement('script'); mathjaxscript.id = 'mathjaxscript_pelican_#%@#$@#'; mathjaxscript.type = 'text/javascript'; mathjaxscript.src = 'https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.0/MathJax.js?config=TeX-AMS-MML_HTMLorMML'; mathjaxscript[(window.opera ? "innerHTML" : "text")] = "MathJax.Hub.Config({" + " config: ['MMLorHTML.js']," + " TeX: { extensions: ['AMSmath.js','AMSsymbols.js','noErrors.js','noUndefined.js'], equationNumbers: { autoNumber: 'AMS' } }," + " jax: ['input/TeX','input/MathML','output/HTML-CSS']," + " extensions: ['tex2jax.js','mml2jax.js','MathMenu.js','MathZoom.js']," + " displayAlign: '"+ align +"'," + " displayIndent: '"+ indent +"'," + " showMathMenu: true," + " messageStyle: 'normal'," + " tex2jax: { " + " inlineMath: [ ['\\\\(','\\\\)'] ], " + " displayMath: [ ['$$','$$'] ]," + " processEscapes: true," + " preview: 'TeX'," + " }, " + " 'HTML-CSS': { " + " styles: { '.MathJax_Display, .MathJax .mo, .MathJax .mi, .MathJax .mn': {color: 'inherit ! important'} }," + " linebreaks: { automatic: "+ linebreak +", width: '90% container' }," + " }, " + "}); " + "if ('default' !== 'default') {" + "MathJax.Hub.Register.StartupHook('HTML-CSS Jax Ready',function () {" + "var VARIANT = MathJax.OutputJax['HTML-CSS'].FONTDATA.VARIANT;" + "VARIANT['normal'].fonts.unshift('MathJax_default');" + "VARIANT['bold'].fonts.unshift('MathJax_default-bold');" + "VARIANT['italic'].fonts.unshift('MathJax_default-italic');" + "VARIANT['-tex-mathit'].fonts.unshift('MathJax_default-italic');" + "});" + "MathJax.Hub.Register.StartupHook('SVG Jax Ready',function () {" + "var VARIANT = MathJax.OutputJax.SVG.FONTDATA.VARIANT;" + "VARIANT['normal'].fonts.unshift('MathJax_default');" + "VARIANT['bold'].fonts.unshift('MathJax_default-bold');" + "VARIANT['italic'].fonts.unshift('MathJax_default-italic');" + "VARIANT['-tex-mathit'].fonts.unshift('MathJax_default-italic');" + "});" + "}"; (document.body || document.getElementsByTagName('head')[0]).appendChild(mathjaxscript); }
20173D90ACEactionsADaesAIajaxALAAllanimalsappApplearcadeARIAARMarpartArtifactASDATIauthBASICBECbirthdayBitsblebotsCCADcamcameracapCAScdCDNChoiceciciaclicloudCloudflarecodecommunitycontainerCorecssculturedamdatadeaDemodesigndetDigitaldisplaydocumentdownecedEdgeeducationembeddedenvironmenteteueventfactfakefanfinefirfontfontsformfruitFungamegame nightgamesGeneralGitGithubGogotGREHAThtmlhttphttpshumorICEIDEinteractionInteractiveIOTIPirsISPissISTEjavajavascriptkeyskitlightlimitlinuxLTEluaMacMakemakingmanamariomathMegaMetroidMiramitmovmovemusicNCRNESNSAnseoperaORGOSSOtherOUsPApartypeoplepersonalpiePINPIRpiratePlayPPLPresentproblempspthRratraterawrestROIrorrsaRTIrunningS.SAMscrscratchshedspaceSparkspotSSESSLstageStarstssupportTAGtalkteatechtedtestThethingsTICtimetortraptwitterUIunUnityUSUSTRUXvideowarwatchweatherwebwinwindowsWorkwritingZeldazip
Coaxing 2D platforming out of Unity
Post Syndicated from Eevee original https://eev.ee/blog/2017/10/13/coaxing-2d-platforming-out-of-unity/
An anonymous donor asked a question that I can't even begin to figure out how to answer, but they also said anything else is fine, so here's anything else.
I've been avoiding writing about game physics, since I want to save it for ✨ the book I'm writing ✨, but that book will almost certainly not touch on Unity. Here, then, is a brief run through some of the brick walls I ran into while trying to convince Unity to do 2D platforming.
This is fairly high-level — there are no blocks of code or helpful diagrams. I'm just getting this out of my head because it's interesting. If you want more gritty details, I guess you'll have to wait for ✨ the book ✨.
I hadn't used Unity before. I hadn't even used a "real" physics engine before. My games so far have mostly used LÖVE, a Lua-based engine. LÖVE includes box2d bindings, but for various reasons (not all of them good), I opted to avoid them and instead write my own physics completely from scratch. (How, you ask? ✨ Book ✨!)
I was invited to work on a Unity project, Chaos Composer, that someone else had already started. It had basic movement already implemented; I taught myself Unity's physics system by hacking on it. It's entirely possible that none of this is actually the best way to do anything, since I was really trying to reproduce my own homegrown stuff in Unity, but it's the best I've managed to come up with.
Two recurring snags were that you can't ask Unity to do multiple physics updates in a row, and sometimes getting the information I wanted was difficult. Working with my own code spoiled me a little, since I could invoke it at any time and ask it anything I wanted; Unity, on the other hand, is someone else's black box with a rigid interface on top.
Also, wow, Googling for a lot of this was not quite as helpful as expected. A lot of what's out there is just the first thing that works, and often that's pretty hacky and imposes severe limits on the game design (e.g., "this won't work with slopes"). Basic movement and collision are the first thing you do, which seems to me like the worst time to be locking yourself out of a lot of design options. I tried very (very, very, very) hard to minimize those kinds of constraints.
Problem 1: Movement
When I showed up, movement was already working. Problem solved!
Like any good programmer, I immediately set out to un-solve it. Given a "real" physics engine like Unity prominently features, you have two options: ⓐ treat the player as a physics object, or ⓑ don't. The existing code went with option ⓑ, like I'd done myself with LÖVE, and like I'd seen countless people advise. Using a physics sim makes for bad platforming.
But… why? I believed it, but I couldn't concretely defend it. I had to know for myself. So I started a blank project, drew some physics boxes, and wrote a dozen-line player controller.
Ah! Immediate enlightenment.
If the player was sliding down a wall, and I tried to move them into the wall, they would simply freeze in midair until I let go of the movement key. The trouble is that the physics sim works in terms of forces — moving the player involves giving them a nudge in some direction, like a giant invisible hand pushing them around the level. Surprise! If you press a real object against a real wall with your real hand, you'll see the same effect — friction will cancel out gravity, and the object will stay in midair..
Platformer movement, as it turns out, doesn't make any goddamn physical sense. What is air control? What are you pushing against? Nothing, really; we just have it because it's nice to play with, because not having it is a nightmare.
I looked to see if there were any common solutions to this, and I only really found one: make all your walls frictionless.
Game development is full of hacks like this, and I… don't like them. I can accept that minor hacks are necessary sometimes, but this one makes an early and widespread change to a fundamental system to "fix" something that was wrong in the first place. It also imposes an "invisible" requirement, something I try to avoid at all costs — if you forget to make a particular wall frictionless, you'll never know unless you happen to try sliding down it.
And so, I swiftly returned to the existing code. It wasn't too different from what I'd come up with for LÖVE: it applied gravity by hand, tracked the player's velocity, computed the intended movement each frame, and moved by that amount. The interesting thing was that it used MovePosition, which schedules a movement for the next physics update and stops the movement if the player hits something solid.
It's kind of a nice hybrid approach, actually; all the "physics" for conscious actors is done by hand, but the physics engine is still used for collision detection. It's also used for collision rejection — if the player manages to wedge themselves several pixels into a solid object, for example, the physics engine will try to gently nudge them back out of it with no extra effort required on my part. I still haven't figured out how to get that to work with my homegrown stuff, which is built to prevent overlap rather than to jiggle things out of it.
But wait, what about…
Our player is a dynamic body with rotation lock and no gravity. Why not just use a kinematic body?
I must be missing something, because I do not understand the point of kinematic bodies. I ran into this with Godot, too, which documented them the same way: as intended for use as players and other manually-moved objects. But by default, they don't even collide with other kinematic bodies or static geometry. What? There's a checkbox to turn this on, which I enabled, but then I found out that MovePosition doesn't stop kinematic bodies when they hit something, so I would've had to cast along the intended path of movement to figure out when to stop, thus duplicating the same work the physics engine was about to do.
But that's impossible anyway! Static geometry generally wants to be made of edge colliders, right? They don't care about concave/convex. Imagine the player is standing on the ground near a wall and tries to move towards the wall. Both the ground and the wall are different edges from the same edge collider.
If you try to cast the player's hitbox horizontally, parallel to the ground, you'll only get one collision: the existing collision with the ground. Casting doesn't distinguish between touching and hitting. And because Unity only reports one collision per collider, and because the ground will always show up first, you will never find out about the impending wall collision.
So you're forced to either use raycasts for collision detection or decomposed polygons for world geometry, both of which are slightly worse tools for no real gain.
I ended up sticking with a dynamic body.
Oh, one other thing that doesn't really fit anywhere else: keep track of units! If you're adding something called "velocity" directly to something called "position", something has gone very wrong. Acceleration is distance per time squared; velocity is distance per time; position is distance. You must multiply or divide by time to convert between them.
I never even, say, add a constant directly to position every frame; I always phrase it as velocity and multiply by Δt. It keeps the units consistent: time is always in seconds, not in tics.
Problem 2: Slopes
Ah, now we start to get off in the weeds.
A sort of pre-problem here was detecting whether we're on a slope, which means detecting the ground. The codebase originally used a manual physics query of the area around the player's feet to check for the ground, which seems to be somewhat common, but that can't tell me the angle of the detected ground. (It's also kind of error-prone, since "around the player's feet" has to be specified by hand and may not stay correct through animations or changes in the hitbox.)
I replaced that with what I'd eventually settled on in LÖVE: detect the ground by detecting collisions, and looking at the normal of the collision. A normal is a vector that points straight out from a surface, so if you're standing on the ground, the normal points straight up; if you're on a 10° incline, the normal points 10° away from straight up.
Not all collisions are with the ground, of course, so I assumed something is ground if the normal pointed away from gravity. (I like this definition more than "points upwards", because it avoids assuming anything about the direction of gravity, which leaves some interesting doors open for later on.) That's easily detected by taking the dot product — if it's negative, the collision was with the ground, and I now have the normal of the ground.
Actually doing this in practice was slightly tricky. With my LÖVE engine, I could cram this right into the middle of collision resolution. With Unity, not quite so much. I went through a couple iterations before I really grasped Unity's execution order, which I guess I will have to briefly recap for this to make sense.
Unity essentially has two update cycles. It performs physics updates at fixed intervals for consistency, and updates everything else just before rendering. Within a single frame, Unity does as many fixed physics updates as it has spare time for (which might be zero, one, or more), then does a regular update, then renders. User code can implement either or both of Update, which runs during a regular update, and FixedUpdate, which runs just before Unity does a physics pass.
So my solution was:
At the very end of FixedUpdate, clear the actor's "on ground" flag and ground normal.
During OnCollisionEnter2D and OnCollisionStay2D (which are called from within a physics pass), if there's a collision that looks like it's with the ground, set the "on ground" flag and ground normal. (If there are multiple ground collisions, well, good luck figuring out the best way to resolve that! At the moment I'm just taking the first and hoping for the best.)
That means there's a brief window between the end of FixedUpdate and Unity's physics pass during which a grounded actor might mistakenly believe it's not on the ground, which is a bit of a shame, but there are very few good reasons for anything to be happening in that window.
Okay! Now we can do slopes.
Just kidding! First we have to do sliding.
When I first looked at this code, it didn't apply gravity while the player was on the ground. I think I may have had some problems with detecting the ground as result, since the player was no longer pushing down against it? Either way, it seemed like a silly special case, so I made gravity always apply.
Lo! I was a fool. The player could no longer move.
Why? Because MovePosition does exactly what it promises. If the player collides with something, they'll stop moving. Applying gravity means that the player is trying to move diagonally downwards into the ground, and so MovePosition stops them immediately.
Hence, sliding. I don't want the player to actually try to move into the ground. I want them to move the unblocked part of that movement. For flat ground, that means the horizontal part, which is pretty much the same as discarding gravity. For sloped ground, it's a bit more complicated!
Okay but actually it's less complicated than you'd think. It can be done with some cross products fairly easily, but Unity makes it even easier with a couple casts. There's a Vector3.ProjectOnPlane function that projects an arbitrary vector on a plane given by its normal — exactly the thing I want! So I apply that to the attempted movement before passing it along to MovePosition. I do the same thing with the current velocity, to prevent the player from accelerating infinitely downwards while standing on flat ground.
One other thing: I don't actually use the detected ground normal for this. The player might be touching two ground surfaces at the same time, and I'd want to project on both of them. Instead, I use the player body's GetContacts method, which returns contact points (and normals!) for everything the player is currently touching. I believe those contact points are tracked by the physics engine anyway, so asking for them doesn't require any actual physics work.
(Looking at the code I have, I notice that I still only perform the slide for surfaces facing upwards — but I'd want to slide against sloped ceilings, too. Why did I do this? Maybe I should remove that.)
(Also, I'm pretty sure projecting a vector on a plane is non-commutative, which raises the question of which order the projections should happen in and what difference it makes. I don't have a good answer.)
(I note that my LÖVE setup does something slightly different: it just tries whatever the movement ought to be, and if there's a collision, then it projects — and tries again with the remaining movement. But I can't ask Unity to do multiple moves in one physics update, alas.)
Okay! Now, slopes. But actually, with the above work done, slopes are most of the way there already.
One obvious problem is that the player tries to move horizontally even when on a slope, and the easy fix is to change their movement from speed * Vector2.right to speed * new Vector2(ground.y, -ground.x) while on the ground. That's the ground normal rotated a quarter-turn clockwise, so for flat ground it still points to the right, and in general it points rightwards along the ground. (Note that it assumes the ground normal is a unit vector, but as far as I'm aware, that's true for all the normals Unity gives you.)
Another issue is that if the player stands motionless on a slope, gravity will cause them to slowly slide down it — because the movement from gravity will be projected onto the slope, and unlike flat ground, the result is no longer zero. For conscious actors only, I counter this by adding the opposite factor to the player's velocity as part of adding in their walking speed. This matches how the real world works, to some extent: when you're standing on a hill, you're exerting some small amount of effort just to stay in place.
(Note that slope resistance is not the same as friction. Okay, yes, in the real world, virtually all resistance to movement happens as a result of friction, but bracing yourself against the ground isn't the same as being passively resisted.)
From here there are a lot of things you can do, depending on how you think slopes should be handled. You could make the player unable to walk up slopes that are too steep. You could make walking down a slope faster than walking up it. You could make jumping go along the ground normal, rather than straight up. You could raise the player's max allowed speed while running downhill. Whatever you want, really. Armed with a normal and awareness of dot products, you can do whatever you want.
But first you might want to fix a few aggravating side effects.
Problem 3: Ground adherence
I don't know if there's a better name for this. I rarely even see anyone talk about it, which surprises me; it seems like it should be a very common problem.
The problem is: if the player runs up a slope which then abruptly changes to flat ground, their momentum will carry them into the air. For very fast players going off the top of very steep slopes, this makes sense, but it becomes visible even for relatively gentle slopes. It was a mild nightmare in the original release of our game Lunar Depot 38, which has very "rough" ground made up of lots of shallow slopes — so the player is very frequently slightly off the ground, which meant they couldn't jump, for seemingly no reason. (I even had code to fix this, but I disabled it because of a silly visual side effect that I never got around to fixing.)
Anyway! The reason this is a problem is that game protagonists are generally not boxes sliding around — they have legs. We don't go flying off the top of real-world hilltops because we put our foot down until it touches the ground.
Simulating this footfall is surprisingly fiddly to get right, especially with someone else's physics engine. It's made somewhat easier by Cast, which casts the entire hitbox — no matter what shape it is — in a particular direction, as if it had moved, and tells you all the hypothetical collisions in order.
So I cast the player in the direction of gravity by some distance. If the cast hits something solid with a ground-like collision normal, then the player must be close to the ground, and I move them down to touch it (and set that ground as the new ground normal).
There are some wrinkles.
Wrinkle 1: I only want to do this if the player is off the ground now, but was on the ground last frame, and is not deliberately moving upwards. That latter condition means I want to skip this logic if the player jumps, for example, but also if the player is thrust upwards by a spring or abducted by a UFO or whatever. As long as external code goes through some interface and doesn't mess with the player's velocity directly, that shouldn't be too hard to track.
Wrinkle 2: When does this logic run? It needs to happen after the player moves, which means after a Unity physics pass… but there's no callback for that point in time. I ended up running it at the beginning of FixedUpdate and the beginning of Update — since I definitely want to do it before rendering happens! That means it'll sometimes happen twice between physics updates. (I could carefully juggle a flag to skip the second run, but I… didn't do that. Yet?)
Wrinkle 3: I can't move the player with MovePosition! Remember, MovePosition schedules a movement, it doesn't actually perform one; that means if it's called twice before the physics pass, the first call is effectively ignored. I can't easily combine the drop with the player's regular movement, for various fiddly reasons. I ended up doing it "by hand" using transform.Translate, which I think was the "old way" to do manual movement before MovePosition existed. I'm not totally sure if it activates triggers? For that matter, I'm not sure it even notices collisions — but since I did a full-body Cast, there shouldn't be any anyway.
Wrinkle 4: What, exactly, is "some distance"? I've yet to find a satisfying answer for this. It seems like it ought to be based on the player's current speed and the slope of the ground they're moving along, but every time I've done that math, I've gotten totally ludicrous answers that sometimes exceed the size of a tile. But maybe that's not wrong? Play around, I guess, and think about when the effect should "break" and the player should go flying off the top of a hill.
Wrinkle 5: It's possible that the player will launch off a slope, hit something, and then be adhered to the ground where they wouldn't have hit it. I don't much like this edge case, but I don't see a way around it either.
This problem is surprisingly awkward for how simple it sounds, and the solution isn't entirely satisfying. Oh, well; the results are much nicer than the solution. As an added bonus, this also fixes occasional problems with running down a hill and becoming detached from the ground due to precision issues or whathaveyou.
Problem 4: One-way platforms
Ah, what a nightmare.
It took me ages just to figure out how to define one-way platforms. Only block when the player is moving downwards? Nope. Only block when the player is above the platform? Nuh-uh.
Well, okay, yes, those approaches might work for convex players and flat platforms. But what about… sloped, one-way platforms? There's no reason you shouldn't be able to have those. If Super Mario World can do it, surely Unity can do it almost 30 years later.
The trick is, again, to look at the collision normal. If it faces away from gravity, the player is hitting a ground-like surface, so the platform should block them. Otherwise (or if the player overlaps the platform), it shouldn't.
Here's the catch: Unity doesn't have conditional collision. I can't decide, on the fly, whether a collision should block or not. In fact, I think that by the time I get a callback like OnCollisionEnter2D, the physics pass is already over.
I could go the other way and use triggers (which are non-blocking), but then I have the opposite problem: I can't stop the player on the fly. I could move them back to where they hit the trigger, but I envision all kinds of problems as a result. What if they were moving fast enough to activate something on the other side of the platform? What if something else moved to where I'm trying to shove them back to in the meantime? How does this interact with ground detection and listing contacts, which would rightly ignore a trigger as non-blocking?
I beat my head against this for a while, but the inability to respond to collision conditionally was a huge roadblock. It's all the more infuriating a problem, because Unity ships with a one-way platform modifier thing. Unfortunately, it seems to have been implemented by someone who has never played a platformer. It's literally one-way — the player is only allowed to move straight upwards through it, not in from the sides. It also tries to block the player if they're moving downwards while inside the platform, which invokes clumsy rejection behavior. And this all seems to be built into the physics engine itself somehow, so I can't simply copy whatever they did.
Eventually, I settled on the following. After calculating attempted movement (including sliding), just at the end of FixedUpdate, I do a Cast along the movement vector. I'm not thrilled about having to duplicate the physics engine's own work, but I do filter to only things on a "one-way platform" physics layer, which should at least help. For each object the cast hits, I use Physics2D.IgnoreCollision to either ignore or un-ignore the collision between the player and the platform, depending on whether the collision was ground-like or not.
(A lot of people suggested turning off collision between layers, but that can't possibly work — the player might be standing on one platform while inside another, and anyway, this should work for all actors!)
Again, wrinkles! But fewer this time. Actually, maybe just one: handling the case where the player already overlaps the platform. I can't just check for that with e.g. OverlapCollider, because that doesn't distinguish between overlapping and merely touching.
I came up with a fairly simple fix: if I was going to un-ignore the collision (i.e. make the platform block), and the cast distance is reported as zero (either already touching or overlapping), I simply do nothing instead. If I'm standing on the platform, I must have already set it blocking when I was approaching it from the top anyway; if I'm overlapping it, I must have already set it non-blocking to get here in the first place.
I can imagine a few cases where this might go wrong. Moving platforms, especially, are going to cause some interesting issues. But this is the best I can do with what I know, and it seems to work well enough so far.
Oh, and our player can deliberately drop down through platforms, which was easy enough to implement; I just decide the platform is always passable while some button is held down.
Problem 5: Pushers and carriers
I haven't gotten to this yet! Oh boy, can't wait. I implemented it in LÖVE, but my way was hilariously invasive; I'm hoping that having a physics engine that supports a handwaved "this pushes that" will help. Of course, you also have to worry about sticking to platforms, for which the recommended solution is apparently to parent the cargo to the platform, which sounds goofy to me? I guess I'll find out when I throw myself at it later.
I ended up with a fairly pleasant-feeling system that supports slopes and one-way platforms and whatnot, with all the same pieces as I came up with for LÖVE. The code somehow ended up as less of a mess, too, but it probably helps that I've been down this rabbit hole once before and kinda knew what I was aiming for this time.
Sorry that I don't have a big block of code for you to copy-paste into your project. I don't think there are nearly enough narrative discussions of these fundamentals, though, so hopefully this is useful to someone. If not, well, look forward to ✨ my book, that I am writing ✨!
ADadblockAIALAAllanonymousappARMartASAATIBASICBECBehaviorBETTbleblockblockedblockingbookCcamcarCASCasecasesciciaCIScliclockcodeComputecontrollerdesigndetdevelopmentDISAdocumentdownDynEASTecedEdgeeffeteventfactfirFlyformFungamegame developmentgamedevgamesGeneralGogothackingHATICEInsideIPirsississueISTELAPSlaunchlightlimitLocksLTEluaMakemanamariomathmediamitMoUmovmoveNCRNECNESnistnoticesnseobjectsORGOSSOtherOUsPApcpeoplephysicspiePINpixelPlayPositionPPLproblemprojectProjectspsRracingratrateRDSReleasereportreportsrestrorRTIrunningRustS.SAMscratchsetupspringSSEStarstssupportSwiftTAGtalkteatechtedthingsTICToolstortouchUIunUnityUSUsefulwarwinWorkWOWwritingzero
Some memorable levels
Post Syndicated from Eevee original https://eev.ee/blog/2017/07/01/some-memorable-levels/
Another Patreon request from Nova Dasterin:
Maybe something about level design. In relation to a vertical shmup since I'm working on one of those.
I've been thinking about level design a lot lately, seeing as how I've started… designing levels. Shmups are probably the genre I'm the worst at, but perhaps some general principles will apply universally.
And speaking of general principles, that's something I've been thinking about too.
I've been struggling to create a more expansive tileset for a platformer, due to two general problems: figuring out what I want to show, and figuring out how to show it with a limited size and palette. I've been browsing through a lot of pixel art from games I remember fondly in the hopes of finding some inspiration, but so far all I've done is very nearly copy a dirt tile someone submitted to my potluck project.
Recently I realized that I might have been going about looking for inspiration all wrong. I've been sifting through stuff in the hopes of finding something that would create some flash of enlightenment, but so far that aimless tourism has only found me a thing or two to copy.
I don't want to copy a small chunk of the final product; I want to understand the underlying ideas that led the artist to create what they did in the first place. Or, no, that's not quite right either. I don't want someone else's ideas; I want to identify what I like, figure out why I like it, and turn that into some kinda of general design idea. Find the underlying themes that appeal to me and figure out some principles that I could apply. You know, examine stuff critically.
I haven't had time to take a deeper look at pixel art this way, so I'll try it right now with level design. Here, then, are some levels from various games that stand out to me for whatever reason; the feelings they evoke when I think about them; and my best effort at unearthing some design principles from those feelings.
Doom II: MAP10, Refueling Base
screenshots mine — map via doom wiki — see also textured perspective map (warning: large!) via ian albert — pistol start playthrough
I'm surprising myself by picking Refueling Base. I would've expected myself to pick MAP08, Tricks and Traps, for its collection of uniquely bizarre puzzles and mechanisms. Or MAP13, Downtown, the map that had me convinced (erroneously) that Doom levels supported multi-story structures. Or at least MAP08, The Pit, which stands out for the unique way it feels like a plunge into enemy territory.
(Curiously, those other three maps are all Sandy Petersen's sole work. Refueling Base was started by Tom Hall in the original Doom days, then finished by Sandy for Doom II.)
But Refueling Base is the level I have the most visceral reaction to: it terrifies me.
See, I got into Doom II through my dad, who played it on and off sometimes. My dad wasn't an expert gamer or anything, but as a ten-year-old, I assumed he was. I watched him play Refueling Base one night. He died. Again, and again, over and over. I don't even have very strong memories of his particular attempts, but watching my parent be swiftly and repeatedly defeated — at a time when I still somewhat revered parents — left enough of an impression that hearing the level music still makes my skin crawl.
This may seem strange to bring up as a first example in a post about level design, but I don't think it would have impressed on me quite so much if the level weren't designed the way it is. (It's just a video game, of course, and since then I've successfully beaten it from a pistol start myself. But wow, little kid fears sure do linger.)
The one thing that most defines the map has to be its interconnected layout. Almost every major area (of which there are at least half a dozen) has at least three exits. Not only are you rarely faced with a dead end, but you'll almost always have a choice of where to go next, and that choice will lead into more choices.
This hugely informs the early combat. Many areas near the beginning are simply adjacent with no doors between them, so it's easy for monsters to start swarming in from all directions. It's very easy to feel overwhelmed by an endless horde; no matter where you run, they just seem to keep coming. (In fact, Refueling Base has the most monsters of any map in the game by far: 279. The runner up is the preceding map at 238.) Compounding this effect is the relatively scant ammo and health in the early parts of the map; getting very far from a pistol start is an uphill battle.
The connections between rooms also yield numerous possible routes through the map, as well as several possible ways to approach any given room. Some of the connections are secrets, which usually connect the "backs" of two rooms. Clearing out one room thus rewards you with a sneaky way into another room that puts you behind all the monsters.
In fact, the map rewards you for exploring it in general.
Well, okay. It might be more accurate to say that that map punishes you for not exploring it. From a pistol start, the map is surprisingly difficult — the early areas offer rather little health and ammo, and your best chance of success is a very specific route that collects weapons as quickly as possible. Many of the most precious items are squirrelled away in (numerous!) secrets, and you'll have an especially tough time if you don't find any of them — though they tend to be telegraphed.
One particularly nasty surprise is in the area shown above, which has three small exits at the back. Entering or leaving via any of those exits will open one of the capsule-shaped pillars, revealing even more monsters. A couple of those are pain elementals, monsters which attack by spawning another monster and shooting it at you — not something you want to be facing with the starting pistol.
But nothing about the level indicates this, so you have to make the association the hard way, probably after making several mad dashes looking for cover. My successful attempt avoided this whole area entirely until I'd found some more impressive firepower. It's fascinating to me, because it's a fairly unique effect that doesn't make any kind of realistic sense, yet it's still built out of familiar level mechanics: walk through an area and something opens up. Almost like 2D sidescroller design logic applied to a 3D space. I really like it, and wish I saw more of it. So maybe that's a more interesting design idea: don't be afraid to do something weird only once, as long as it's built out of familiar pieces so the player has a chance to make sense of it.
A similarly oddball effect is hidden in a "barracks" area, visible on the far right of the map. A secret door leads to a short U-shaped hallway to a marble skull door, which is themed nothing like the rest of the room. Opening it seems to lead back into the room you were just in, but walking through the doorway teleports you to a back entrance to the boss fight at the end of the level.
It sounds so bizarre, but the telegraphing makes it seem very natural; if anything, the "oh, I get it!" moment overrides the weirdness. It stops being something random and becomes something consciously designed. I believe that this might have been built by someone, even if there's no sensible reason to have built it.
In fact, that single weird teleporter is exactly the kind of thing I'd like to be better at building. It could've been just a plain teleporter pad, but instead it's a strange thing that adds a lot of texture to the level and makes it much more memorable. I don't know how to even begin to have ideas like that. Maybe it's as simple as looking at mundane parts of a level and wondering: what could I do with this instead?
I think a big problem I have is limiting myself to the expected and sensible, to the point that I don't even consider more outlandish ideas. I can't shake that habit simply by bolding some text in a blog post, but maybe it would help to keep this in mind: you can probably get away with anything, as long as you justify it somehow. Even "justify" here is too strong a word; it takes only the slightest nod to make an arbitrary behavior feel like part of a world. Why does picking up a tiny glowing knight helmet give you 1% armor in Doom? Does anyone care? Have you even thought about it before? It's green and looks like armor; the bigger armor pickup is also green; yep, checks out.
On the other hand, the map as a whole ends up feeling very disorienting. There's no shortage of landmarks, but every space is distinct in both texture and shape, so everything feels like a landmark. No one part of the map feels particularly central; there are a few candidates, but they neighbor other equally grand areas with just as many exits. It's hard to get truly lost, but it's also hard to feel like you have a solid grasp of where everything is. The space itself doesn't make much sense, even though small chunks of it do. Of course, given that the Hellish parts of Doom were all just very weird overall, this is pretty fitting.
This sort of design fascinates me, because the way it feels to play is so different from the way it looks as a mapper with God Vision. Looking at the overhead map, I can identify all the familiar places easily enough, but I don't know how to feel the way the map feels to play; it just looks like some rooms with doors between them. Yet I can see screenshots and have a sense of how "deep" in the level they are, how difficult they are to reach, whether I want to visit or avoid them. The lesson here might be that most of the interesting flavor of the map isn't actually contained within the overhead view; it's in the use of height and texture and interaction.
I realize as I describe all of this that I'm really just describing different kinds of contrast. If I know one thing about creative work (and I do, I only know one thing), it's that effectively managing contrast is super duper important.
And it appears here in spades! A brightly-lit, outdoor, wide-open round room is only a short jog away from a dark, cramped room full of right angles and alcoves. A wide straight hallway near the beginning is directly across from a short, curvy, organic hallway. Most of the monsters in the map are small fry, but a couple stronger critters are sprinkled here and there, and then the exit is guarded by the toughest monster in the game. Some of the connections between rooms are simple doors; others are bizarre secret corridors or unnatural twisty passages.
You could even argue that the map has too much contrast, that it starts to lose cohesion. But if anything, I think this is one of the more cohesive maps in the first third of the game; many of the earlier maps aren't so much places as they are concepts. This one feels distinctly like it could be something. The theming is all over the place, but enough of the parts seem deliberate.
I hadn't even thought about it until I sat down to write this post, but since this is a "refueling base", I suppose those outdoor capsules (which contain green slime, inset into the floor) could be the fuel tanks! I already referred to that dark techy area as "barracks". Elsewhere is a rather large barren room, which might be where the vehicles in need of refueling are parked? Or is this just my imagination, and none of it was intended this way?
It doesn't really matter either way, because even in this abstract world of ambiguity and vague hints, all of those rooms still feel like a place. I don't have to know what the place is for it to look internally consistent.
I'm hesitant to say every game should have the loose design sense of Doom II, but it might be worth keeping in mind that anything can be a believable world as long as it looks consciously designed. And I'd say this applies even for natural spaces — we frequently treat real-world nature as though it were "designed", just with a different aesthetic sense.
Okay, okay. I'm sure I could clumsily ramble about Doom forever, but I do that enough as it is. Other people have plenty to say if you're interested.
I do want to stick in one final comment about MAP13, Downtown, while I'm talking about theming. I've seen a few people rag on it for being "just a box" with a lot of ideas sprinkled around — the map is basically a grid of skyscrapers, where each building has a different little mini encounter inside. And I think that's really cool, because those encounters are arranged in a way that very strongly reinforces the theme of the level, of what this place is supposed to be. It doesn't play quite like anything else in the game, simply because it was designed around a shape for flavor reasons. Weird physical constraints can do interesting things to level design.
Braid: World 4-7, Fickle Companion
screenshots via StrategyWiki — playthrough — playthrough of secret area
I love Braid. If you're not familiar (!), it's a platformer where you have the ability to rewind time — whenever you want, for as long as you want, all the way back to when you entered the level.
The game starts in world 2, where you do fairly standard platforming and use the rewind ability to do some finnicky jumps with minimal frustration. It gets more interesting in world 3 with the addition of glowing green objects, which aren't affected by the reversal of time.
And then there's world 4, "Time and Place". I love world 4, so much. It's unlike anything I've ever seen in any other game, and it's so simple yet so clever.
The premise is this: for everything except you, time moves forwards as you move right, and backwards as you move left.
This has some weird implications, which all come together in the final level of the world, Fickle Companion. It's so named because you have to use one (single-use) key to open three doors, but that key is very easy to lose.
Say you pick up the key and walk to the right with it. Time continues forwards for the key, so it stays with you as expected. Now you climb a ladder. Time is frozen since you aren't moving horizontally, but the key stays with you anyway. Now you walk to the left. Oops — the key follows its own path backwards in time, going down the ladder and back along the path you carried it in the first place. You can't fix this by walking to the right again, because that will simply advance time normally for the key; since you're no longer holding it, it will simply fall to the ground and stay there.
You can see how this might be a problem in the screenshot above (where you get the key earlier in the level, to the left). You can climb the first ladder, but to get to the door, you have to walk left to get to the second ladder, which will reverse the key back down to the ground.
The solution is in the cannon in the upper right, which spits out a Goomba-like critter. It has the timeproof green glow, so the critters it spits out have the same green glow — making them immune to both your time reversal power and to the effect your movement has on time. What you have to do is get one of the critters to pick up the key and carry it leftwards for you. Once you have the puzzle piece, you have to rewind time and do it again elsewhere. (Or, more likely, the other way around; this next section acts as a decent hint for how to do the earlier section.)
It's hard to convey how bizarre this is in just text. If you haven't played Braid, it's absolutely worth it just for this one world, this one level.
And it gets even better, slash more ridiculous: there's a super duper secret hidden very cleverly in this level. Reaching it involves bouncing twice off of critters; solving the puzzle hidden there involves bouncing the critters off of you. It's ludicrous and perhaps a bit too tricky, but very clever. Best of all, it's something that an enterprising player might just think to do on a whim — hey, this is possible here, I wonder what happens if I try it. And the game rewards the player for trying something creative! (Ironically, it's most rewarding to have a clever idea when it turns out the designer already had the same idea.)
What can I take away from this? Hm.
Well, the underlying idea of linking time with position is pretty novel, but getting to it may not be all that hard: just combine different concepts and see what happens.
A similar principle is to apply a general concept to everything and see what happens. This is the first sighting of a timeproof wandering critter; previously timeproofing had only been seen on keys, doors, puzzle pieces, and stationary monsters. Later it even applies to Tim himself in special circumstances.
The use of timeproofing on puzzle pieces is especially interesting, because the puzzle pieces — despite being collectibles that animate moving into the UI when you get them — are also affected by time. If the pieces in this level weren't timeproof, then as soon as you collected one and moved left to leave its alcove, time would move backwards and the puzzle piece would reverse out of the UI and right back into the world.
Along similar lines, the music and animated background are also subject to the flow of time. It's obvious enough that the music plays backwards when you rewind time, but in world 4, the music only plays at all while you're moving. It's a fantastic effect that makes the whole world feel as weird and jerky as it really is under these rules. It drives the concept home instantly, and it makes your weird influence over time feel all the more significant and far-reaching. I love when games weave all the elements of the game into the gameplaylike this, even (especially?) for the sake of a single oddball level.
Admittedly, this is all about gameplay or puzzle mechanics, not so much level design. What I like about the level itself is how simple and straightforward it is: it contains exactly as much as it needs to, yet still invites trying the wrong thing first, which immediately teaches the player why it won't work. And it's something that feels like it ought to work, except that the rules of the game get in the way just enough. This makes for my favorite kind of puzzle, the type where you feel like you've tried everything and it must be impossible — until you realize the creative combination of things you haven't tried yet. I'm talking about puzzles again, oops; I guess the general level design equivalent of this is that players tend to try the first thing they see first, so if you put required parts later, players will be more likely to see optional parts.
I think that's all I've got for this one puzzle room. I do want to say (again) that I love both endings of Braid. The normal ending weaves together the game mechanics and (admittedly loose) plot in a way that gave me chills when I first saw it; the secret ending completely changes both how the ending plays and how you might interpret the finale, all by making only the slightest changes to the level.
Portal: Testchamber 18 (advanced)
screenshot mine — playthrough of normal map — playthrough of advanced map
I love Portal. I blazed through the game in a couple hours the night it came out. I'd seen the trailer and instantly grasped the concept, so the very slow and gentle learning curve was actually a bit frustrating for me; I just wanted to portal around a big playground, and I finally got to do that in the six "serious" tests towards the end, 13 through 18.
Valve threw an interesting curveball with these six maps. As well as being more complete puzzles by themselves, Valve added "challenges" requiring that they be done with as few portals, time, or steps as possible. I only bothered with the portal challenges — time and steps seemed less about puzzle-solving and more about twitchy reflexes — and within them I found buried an extra layer of puzzles. All of the minimum portal requirements were only possible if you found an alternative solution to the map: skipping part of it, making do with only one cube instead of two, etc. But Valve offered no hints, only a target number. It was a clever way to make me think harder about familiar areas.
Alongside the challenges were "advanced" maps, and these blew me away. They were six maps identical in layout to the last six test chambers, but with a simple added twist that completely changed how you had to approach them. Test 13 has two buttons with two boxes to place on them; the advanced version removes a box and also changes the floor to lava. Test 14 is a live fire course with turrets you have to knock over; the advanced version puts them all in impenetrable cages. Test 17 is based around making extensive use of a single cube; the advanced version changes it to a ball.
But the one that sticks out the most to me is test 18, a potpourri of everything you've learned so far. The beginning part has you cross several large pits of toxic sludge by portaling from the ceilings; the advanced version simply changes the ceilings to unportalable metal. It seems you're completely stuck after only the first jump, unless you happen to catch a glimpse of the portalable floor you pass over in mid-flight. Or you might remember from the regular version of the map that the floor was portalable there, since you used it to progress further. Either way, you have to fire a portal in midair in a way you've never had to do before, and the result feels very cool, like you've defeated a puzzle that was intended to be unsolvable. All in a level that was fairly easy the first time around, and has been modified only slightly.
I'm not sure where I'm going with this. I could say it's good to make the player feel clever, but that feels wishy-washy. What I really appreciated about the advanced tests is that they exploited inklings of ideas I'd started to have when playing through the regular game; they encouraged me to take the spark of inspiration this game mechanic gave me and run with it.
So I suppose the better underlying principle here — the most important principle in level design, in any creative work — is to latch onto what gets you fired up and run with it. I am absolutely certain that the level designers for this game loved the portal concept as much as I do, they explored it thoroughly, and they felt compelled to fit their wilder puzzle ideas in somehow.
More of that. Find the stuff that feels like it's going to burst out of your head, and let it burst.
Chip's Challenge: Level 122, Totally Fair and Level 131, Totally Unfair
screenshots mine — full maps of both levels — playthrough of Totally Fair — playthrough of Totally Unfair
I mention this because Portal reminded me of it. The regular and advanced maps in Portal are reminiscent of parallel worlds or duality or whatever you want to call the theme. I extremely dig that theme, and it shows up in Chip's Challenge in an unexpected way.
Totally Fair is a wide open level with a little maze walled off in one corner. The maze contains a monster called a "teeth", which follows Chip at a slightly slower speed. (The second teeth, here shown facing upwards, starts outside the maze but followed me into it when I took this screenshot.)
The goal is to lure the teeth into standing on the brown button on the right side. If anything moves into a "trap" tile (the larger brown recesses at the bottom), it cannot move out of that tile until/unless something steps on the corresponding brown button. So there's not much room for error in maneuvering the teeth; if it falls in the water up top, it'll die, and if it touches the traps at the bottom, it'll be stuck permanently.
The reason you need the brown button pressed is to acquire the chips on the far right edge of the level.
The gray recesses turn into walls after being stepped on, so once you grab a chip, the only way out is through the force floors and ice that will send you onto the trap. If you haven't maneuvered the teeth onto the button beforehand, you'll be trapped there.
Doesn't seem like a huge deal, since you can go see exactly how the maze is shaped and move the teeth into position fairly easily. But you see, here is the beginning of Totally Fair.
The gray recess leads up into the maze area, so you can only enter it once. A force floor in the upper right lets you exit it.
Totally Unfair is exactly identical, except the second teeth has been removed, and the entrance to the maze looks like this.
You can't get into the maze area. You can't even see the maze; it's too far away from the wall. You have to position the teeth completely blind. In fact, if you take a single step to the left from here, you'll have already dumped the teeth into the water and rendered the level impossible.
The hint tile will tell you to "Remember sjum", where SJUM is the password to get back to Totally Fair. So you have to learn that level well enough to recreate the same effect without being able to see your progress.
It's not impossible, and it's not a "make a map" faux puzzle. A few scattered wall blocks near the chips, outside the maze area, are arranged exactly where the edges of the maze are. Once you notice that, all you have to do is walk up and down a few times, waiting a moment each time to make sure the teeth has caught up with you.
So in a sense, Totally Unfair is the advanced chamber version of Totally Fair. It makes a very minor change that force you to approach the whole level completely differently, using knowledge gleaned from your first attempt.
And crucially, it's an actual puzzle! A lot of later Chip's Challenge levels rely heavily on map-drawing, timing, tedium, or outright luck. (Consider, if you will, Blobdance.) The Totally Fair + Totally Unfair pairing requires a little ingenuity unlike anything else in the game, and the solution is something more than just combinations of existing game mechanics. There's something very interesting about that hint in the walls, a hint you'd have no reason to pick up on when playing through the first level. I wish I knew how to verbalize it better.
Anyway, enough puzzle games; let's get back to regular ol' level design.
Link's Awakening: Level 7, Eagle's Tower
maps via vgmaps and TCRF — playthrough with commentary
Link's Awakening was my first Zelda (and only Zelda for a long time), which made for a slightly confusing introduction to the series — what on earth is a Zelda and why doesn't it appear in the game?
The whole game is a blur of curiosities and interesting little special cases. It's fabulously well put together, especially for a Game Boy game, and the dungeons in particular are fascinating microcosms of design. I never really appreciated it before, but looking at the full maps, I'm struck by how each dungeon has several large areas neatly sliced into individual screens.
Much like with Doom II, I surprise myself by picking Eagle's Tower as the most notable part of the game. The dungeon isn't that interesting within the overall context of the game; it gives you only the mirror shield, possibly the least interesting item in the game, second only to the power bracelet upgrade from the previous dungeon. The dungeon itself is fairly long, full of traps, and overflowing with crystal switches and toggle blocks, making it possibly the most frustrating of the set. Getting to it involves spending some excellent quality time with a flying rooster, but you don't really do anything — mostly you just make your way through nondescript caves and mountaintops.
Having now thoroughly dunked on it, I'll tell you what makes it stand out: the player changes the shape of the dungeon.
That's something I like a lot about Doom, as well, but it's much more dramatic in Eagle's Tower. As you might expect, the dungeon is shaped like a tower, where each floor is on a 4×4 grid. The top floor, 4F, is a small 2×2 block of rooms in the middle — but one of those rooms is the boss door, and there's no way to get to that floor.
(Well, sort of. The "down" stairs in the upper-right of 3F actually lead up to 4F, but the connection is bogus and puts you in a wall, and both of the upper middle rooms are unreachable during normal gameplay.)
The primary objective of the dungeon is to smash four support columns on 2F by throwing a huge iron ball at them, which causes 4F to crash down into the middle of 3F.
Even the map on the pause screen updates to reflect this. In every meaningful sense, you, the player, have fundamentally reconfigured the shape of this dungeon.
I love this. It feels like I have some impact on the world, that I came along and did something much more significant than mere game mechanics ought to allow. I saw that the tower was unsolvable as designed, so I fixed it.
It's clear that the game engine supports rearranging screens arbitrarily — consider the Wind Fish's Egg — but this is s wonderfully clever and subtle use of that. Let the player feel like they have an impact on the world.
The cutting room floor
This is getting excessively long so I'm gonna cut it here. Some other things I thought of but don't know how to say more than a paragraph about:
Super Mario Land 2: Six Golden Coins has a lot of levels with completely unique themes, backed by very simple tilesets but enhanced by interesting one-off obstacles and enemies. I don't even know how to pick a most interesting one. Maybe just play the game, or at least peruse the maps.
This post about density of detail in Team Fortress 2 is really good so just read that I guess. It's really about careful balance of contrast again, but through the lens of using contrasting amounts of detail to draw the player's attention, while still carrying a simple theme through less detailed areas.
Metroid Prime is pretty interesting in a lot of ways, but I mostly laugh at how they spaced rooms out with long twisty hallways to improve load times — yet I never really thought about it because they all feel like they belong in the game.
One thing I really appreciate is level design that hints at a story, that shows me a world that exists persistently, that convinces me this space exists for some reason other than as a gauntlet for me as a player. But it seems what comes first to my mind is level design that's clever or quirky, which probably says a lot about me. Maybe the original Fallouts are a good place to look for that sort of detail.
Conversely, it sticks out like a sore thumb when a game tries to railroad me into experiencing the game As The Designer Intended. Games are interactive, so the more input the player can give, the better — and this can be as simple as deciding to avoid rather than confront enemies, or deciding to run rather than walk.
I think that's all I've got in me at the moment. Clearly I need to meditate on this a lot more, but I hope some of this was inspiring in some way!
3DADadsaesAIALAAllapparinARMartATIBASICBECBehaviorBETTbingbleblogBTCcagecamcarCASCasecasesChallengeChoiceciciacolumncontextcreativedeadesigndetdishdoomdownEASTecECRedEdgeeffeseteteuexploitfactfanfearfinesfirefishflashFlyformFrozenFungamegamesGeneralGogotGREHABHAThbohealthICEInsideinteractioniosIPiqIRCirskeyslieslightlimitlinkingLocksLTEMakemakingmanamapmariomediaMetroidmitMoUmovmoveMPAmusicnatureNECNESnseobjectsORGOSSOtherOUspatreonpeoplePHIpiePINPIRpixelPlayPositionpowerPPLproblemprojectpsRRAIDratraterawRDSReactrestRimerorROVrsaRTIS.SAMsecretsshedskysmsspaceSparkSSEStarstssupportSwiftTAGtalktargetTDOteateachteamtechtedtestthingstortouchtrapUIunUniversalUpgradeUSUSTRUXvideovideo gamewarwatchwaterweaponswinWorkWOWZelda
Teaching tech
Post Syndicated from Eevee original https://eev.ee/blog/2017/06/10/teaching-tech/
A sponsored post from Manishearth:
I would kinda like to hear about any thoughts you have on technical teaching or technical writing. Pedagogy is something I care about. But I don't know how much you do, so feel free to ignore this suggestion 🙂
Good news: I care enough that I'm trying to write a sorta-kinda-teaching book!
Ironically, one of the biggest problems I've had with writing the introduction to that book is that I keep accidentally rambling on for pages about problems and difficulties with teaching technical subjects. So maybe this is a good chance to get it out of my system.
I recently tried out a new thing. It was Phaser, but this isn't a dig on them in particular, just a convenient example fresh in my mind. If anything, they're better than most.
As you can see from Phaser's website, it appears to have tons of documentation. Two of the six headings are "LEARN" and "EXAMPLES", which seems very promising. And indeed, Phaser offers:
Several getting-started walkthroughs
Possibly hundreds of examples
A news feed that regularly links to third-party tutorials
Thorough API docs
Perfect. Beautiful. Surely, a dream.
Well, almost.
The examples are all microscopic, usually focused around a single tiny feature — many of them could be explained just as well with one line of code. There are a few example games, but they're short aimless demos. None of them are complete games, and there's no showcase either. Games sometimes pop up in the news feed, but most of them don't include source code, so they're not useful for learning from.
Likewise, the API docs are just API docs, leading to the sorts of problems you might imagine. For example, in a few places there's a mention of a preUpdate stage that (naturally) happens before update. You might rightfully wonder what kinds of things happen in preUpdate — and more importantly, what should you put there, and why?
Let's check the API docs for Phaser.Group.preUpdate:
The core preUpdate – as called by World.
Okay, that didn't help too much, but let's check what Phaser.World has to say:
Ah. Hm. It turns out World is a subclass of Group and inherits this method — and thus its unaltered docstring — from Group.
I did eventually find some brief docs attached to Phaser.Stage (but only by grepping the source code). It mentions what the framework uses preUpdate for, but not why, and not when I might want to use it too.
The trouble here is that there's no narrative documentation — nothing explaining how the library is put together and how I'm supposed to use it. I get handed some brief primers and a massive reference, but nothing in between. It's like buying an O'Reilly book and finding out it only has one chapter followed by a 500-page glossary.
API docs are great if you know specifically what you're looking for, but they don't explain the best way to approach higher-level problems, and they don't offer much guidance on how to mesh nicely with the design of a framework or big library. Phaser does a decent chunk of stuff for you, off in the background somewhere, so it gives the strong impression that it expects you to build around it in a particular way… but it never tells you what that way is.
Ah, but this is what tutorials are for, right?
I confess I recoil whenever I hear the word "tutorial". It conjures an image of a uniquely useless sort of post, which goes something like this:
Look at this cool thing I made! I'll teach you how to do it too.
Press all of these buttons in this order. Here's a screenshot, which looks nothing like what you have, because I've customized the hell out of everything.
The author is often less than forthcoming about why they made any of the decisions they did, where you might want to try something else, or what might go wrong (and how to fix it).
And this is to be expected! Writing out any of that stuff requires far more extensive knowledge than you need just to do the thing in the first place, and you need to do a good bit of introspection to sort out something coherent to say.
In other words, teaching is hard. It's a skill, and it takes practice, and most people blogging are not experts at it. Including me!
With Phaser, I noticed that several of the third-party tutorials I tried to look at were 404s — sometimes less than a year after they were linked on the site. Pretty major downside to relying on the community for teaching resources.
But I also notice that… um…
Okay, look. I really am not trying to rag on this author. I'm not. They tried to share their knowledge with the world, and that's a good thing, something worthy of praise. I'm glad they did it! I hope it helps someone.
But for the sake of example, here is the most recent entry in Phaser's list of community tutorials. I have to link it, because it's such a perfect example. Consider:
The post itself is a bulleted list of explanation followed by a single contiguous 250 lines of source code. (Not that there's anything wrong with bulleted lists, mind you.) That code contains zero comments and zero blank lines.
This is only part two in what I think is a series aimed at beginners, yet the title and much of the prose focus on object pooling, a performance hack that's easy to add later and that's almost certainly unnecessary for a game this simple. There is no explanation of why this is done; the prose only says you'll understand why it's critical once you add a lot more game objects.
It turns out I only have two things to say here so I don't know why I made this a bulleted list.
In short, it's not really a guided explanation; it's "look what I did".
And that's fine, and it can still be interesting. I'm not sure English is even this person's first language, so I'm hardly going to criticize them for not writing a novel about platforming.
The trouble is that I doubt a beginner would walk away from this feeling very enlightened. They might be closer to having the game they wanted, so there's still value in it, but it feels closer to having someone else do it for them. And an awful lot of tutorials I've seen — particularly of the "post on some blog" form (which I'm aware is the genre of thing I'm writing right now) — look similar.
This isn't some huge social problem; it's just people writing on their blog and contributing to the corpus of written knowledge. It does become a bit stickier when a large project relies on these community tutorials as its main set of teaching aids.
Again, I'm not ragging on Phaser here. I had a slightly frustrating experience with it, coming in knowing what I wanted but unable to find a description of the semantics anywhere, but I do sympathize. Teaching is hard, writing documentation is hard, and programmers would usually rather program than do either of those things. For free projects that run on volunteer work, and in an industry where anything other than programming is a little undervalued, getting good docs written can be tricky.
(Then again, Phaser sells books and plugins, so maybe they could hire a documentation writer. Or maybe the whole point is for you to buy the books?)
Some pretty good docs
Python has pretty good documentation. It introduces the language with a tutorial, then documents everything else in both a library and language reference.
This sounds an awful lot like Phaser's setup, but there's some considerable depth in the Python docs. The tutorial is highly narrative and walks through quite a few corners of the language, stopping to mention common pitfalls and possible use cases. I clicked an arbitrary heading and found a pleasant, informative read that somehow avoids being bewilderingly dense.
The API docs also take on a narrative tone — even something as humble as the collections module offers numerous examples, use cases, patterns, recipes, and hints of interesting ways you might extend the existing types.
I'm being a little vague and hand-wavey here, but it's hard to give specific examples without just quoting two pages of Python documentation. Hopefully you can see right away what I mean if you just take a look at them. They're good docs, Bront.
I've likewise always enjoyed the SQLAlchemy documentation, which follows much the same structure as the main Python documentation. SQLAlchemy is a database abstraction layer plus ORM, so it can do a lot of subtly intertwined stuff, and the complexity of the docs reflects this. Figuring out how to do very advanced things correctly, in particular, can be challenging. But for the most part it does a very thorough job of introducing you to a large library with a particular philosophy and how to best work alongside it.
I softly contrast this with, say, the Perl documentation.
It's gotten better since I first learned Perl, but Perl's docs are still a bit of a strange beast. They exist as a flat collection of manpage-like documents with terse names like perlootut. The documentation is certainly thorough, but much of it has a strange… allocation of detail.
For example, perllol — the explanation of how to make a list of lists, which somehow merits its own separate documentation — offers no fewer than nine similar variations of the same code for reading a file into a nested lists of words on each line. Where Python offers examples for a variety of different problems, Perl shows you a lot of subtly different ways to do the same basic thing.
A similar problem is that Perl's docs sometimes offer far too much context; consider the references tutorial, which starts by explaining that references are a powerful "new" feature in Perl 5 (first released in 1994). It then explains why you might want to nest data structures… from a Perl 4 perspective, thus explaining why Perl 5 is so much better.
Some stuff I've tried
I don't claim to be a great teacher. I like to talk about stuff I find interesting, and I try to do it in ways that are accessible to people who aren't lugging around the mountain of context I already have. This being just some blog, it's hard to tell how well that works, but I do my best.
I also know that I learn best when I can understand what's going on, rather than just seeing surface-level cause and effect. Of course, with complex subjects, it's hard to develop an understanding before you've seen the cause and effect a few times, so there's a balancing act between showing examples and trying to provide an explanation. Too many concrete examples feel like rote memorization; too much abstract theory feels disconnected from anything tangible.
The attempt I'm most pleased with is probably my post on Perlin noise. It covers a fairly specific subject, which made it much easier. It builds up one step at a time from scratch, with visualizations at every point. It offers some interpretations of what's going on. It clearly explains some possible extensions to the idea, but distinguishes those from the core concept.
It is a little math-heavy, I grant you, but that was hard to avoid with a fundamentally mathematical topic. I had to be economical with the background information, so I let the math be a little dense in places.
But the best part about it by far is that I learned a lot about Perlin noise in the process of writing it. In several places I realized I couldn't explain what was going on in a satisfying way, so I had to dig deeper into it before I could write about it. Perhaps there's a good guideline hidden in there: don't try to teach as much as you know?
I'm also fairly happy with my series on making Doom maps, though they meander into tangents a little more often. It's hard to talk about something like Doom without meandering, since it's a convoluted ecosystem that's grown organically over the course of 24 years and has at least three ways of doing anything.
And finally there's the book I'm trying to write, which is sort of about game development.
One of my biggest grievances with game development teaching in particular is how often it leaves out important touches. Very few guides will tell you how to make a title screen or menu, how to handle death, how to get a Mario-style variable jump height. They'll show you how to build a clearly unfinished demo game, then leave you to your own devices.
I realized that the only reliable way to show how to build a game is to build a real game, then write about it. So the book is laid out as a narrative of how I wrote my first few games, complete with stumbling blocks and dead ends and tiny bits of polish.
I have no idea how well this will work, or whether recapping my own mistakes will be interesting or distracting for a beginner, but it ought to be an interesting experiment.
ADADIAIALAAllappaptARIAartASAATIauthBASICBECbeginnersBETTBitsbleblogbloggingbookbooksBTCcarCASCasecasescciciciaCIScodecommunitycontextCoredatadatabasedeadeathDemodesigndetdevelopmentdocumentDocumentationdoomdownEASTebsecedEdgeeffEnglishertseteueventformFrameworkFungamegamesGogotGREguideGuidesHATICEindustryIPiqirslieslightlocationLocksloggingLTEMakemakingmapmariomathMICROSMoUMPANCRNECNESnewsnseobjectsORGOSSOtherOUspartypatreonpeoplePerformanceperlPHIphilosophyPINpluginpowerproblemprogrammingprojectProjectspspthpythonRratrateRDSReleaseResourceresourcesrestRimeROVRTIS.SAMscratchsetupshedsocialsource codesqlstageStarstsTAGtalkteateachteachingtechTechnicaltedthingstortouchTutorialTutorialsUIunUnityUSUSTRvolunteerwarwebwebsitewinWorkwritingzero
Inmates Secretly Build and Network Computers while in Prison
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2017/05/inmates_secretl.html
This is kind of amazing:
Inmates at a medium-security Ohio prison secretly assembled two functioning computers, hid them in the ceiling, and connected them to the Marion Correctional Institution's network. The hard drives were loaded with pornography, a Windows proxy server, VPN, VOIP and anti-virus software, the Tor browser, password hacking and e-mail spamming tools, and the open source packet analyzer Wireshark.
Another article.
Clearly there's a lot about prison security, or the lack thereof, that I don't know. This article reveals some of it.
ADAIartbleCComputersCurityecedetFunhackinghard driveHATIPmailmarioNECNetworkopen sourceOtherpornographyprisonproxyRRTIsearchessecurityserversoftwarespamSSEtedToolstorUIunUSVoIPvpnwarwinwindowsWork
Weekly roundup: Inktober 4: A New Hope
Post Syndicated from Eevee original https://eev.ee/dev/2016/11/01/weekly-roundup-inktober-4-a-new-hope/
Inktober is over! Oh my god.
art: Almost the last of the ink drawings of Pokémon, all of them done in fountain pen now. I filled up the sketchbook I'd been using and switched to a 9"×12" one. Much to my surprise, that made the inks take longer.
I did some final work on that loophole commission from a few weeks ago.
irl: I voted, and am quite cross that election news has continued in spite of this fact.
doom: I made a few speedmaps — maps based on random themes and made in an hour (or so). It was a fun and enlightening experience, and I'll definitely do some more of it.
blog: I wrote about game accessibility, which touched on those speedmaps.
mario maker: One of the level themes I got was "The Wreckage", and I didn't know how to speedmap that in Doom in only an hour, but it sounded like an interesting concept for a Mario level.
I managed to catch up on writing by the end of the month (by cheating slightly), so I'm starting fresh in November. The "three big things" obviously went out the window in favor of Inktober, but I'm okay with that. I've got something planned for this next month that should make up for it, anyway.
accessibilityAIAllartATIblogbookCcheatingdoomedfactFungameGogothboisslightMakemanamariomario makernewsOSSrawrestRTIS.StarstatusthingstouchUIUSwinWork
accessibilityAIAllartATIblogbookCcheatingdoomedelectionetfactFungameGogothboisslightMakemakermanamapmariomario makernewsOSSpsrawrestRTIS.StarstatustedthingstouchUIunUSwinWorkwriting
Mario Maker: The Wreck
Post Syndicated from Eevee original https://eev.ee/dev/2016/11/01/mario-maker-the-wreck/
33E8-0000-02B2-76DF
Quality: ★★★★☆
Secrets:
I was rolling a Doom random level theme generator for speedmapping purposes, and one of the prompts it gave was "The Wreckage". I didn't really know how to make that in Doom in only an hour, but I did know how to make it in Mario, so I did.
The additional rules were "no monsters" and "no stairs", so neither of those things appear in this level. It's quick and entirely atmospheric. I like it. Though it'd be slightly better if I'd correctly named it "The Wreckage". Oh well.
AIAllappBETTCdoomedirslightMakemappingmariomario makerPINratthingstorUI
Post Syndicated from Eevee original https://eev.ee/blog/2016/10/29/accessible-games/
I've now made a few small games. One of the trickiest and most interesting parts of designing them has been making them accessible.
I mean that in a very general and literal sense. I want as many people as possible to experience as much of my games as possible. Finding and clearing out unnecessary hurdles can be hard, but every one I leave risks losing a bunch of players who can't or won't clear it.
I've noticed three major categories of hurdle, all of them full of tradeoffs. Difficulty is what makes a game challenging, but if a player can't get past a certain point, they can never see the rest of the game. Depth is great, but not everyone has 80 hours to pour into a game, and it's tough to spend weeks of dev time on stuff most people won't see. Distribution is a question of who can even get your game in the first place.
Here are some thoughts.
Mario Maker
Mario Maker is most notable for how accessible it is to budding game designers, which is important but also a completely different sense of accessibility.
The really nice thing about Mario Maker is that its levels are also accessible to players. Virtually everyone who's heard of video games has heard of Mario. You don't need to know many rules to be able to play. Move to the right, jump over/on things, and get to the flag.
(The "distribution" model is a bit of a shame, though — you need to own a particular console and a $60 game. If I want people to play a single individual level I made, that's a lot of upfront investment to ask for. Ultimately Nintendo is in this to sell their own game more than to help people show off their own.)
But the emergent depth of Mario Maker's myriad objects — the very property that makes the platform more than a toy — also makes it less accessible. Everyone knows you move around and jump, but not everyone knows you can pick up an item with B, or that you can put on a hat you're carrying by pressing ↓, or that you can spinjump on certain hazards. And these are fairly basic controls — Mario Maker contains plenty of special interactions between more obscure objects, and no manual explaining them all.
I thought it was especially interesting that Nintendo's own comic series on building Mario Maker levels specifically points out that running jumps don't come naturally to everyone. It's hard to imagine too many people playing Mario Maker and not knowing how to jump while running.
And yet, imagine being one such person, and encountering a level that requires a running jump early on. You can't get past it. You might not even understand how to get past it; perhaps you don't even know Mario can run. Now what? That's it, you're stuck. You'll never see the rest of that level. It's a hurdle, in a somewhat more literal sense.
Why make the level that way in the first place, then? Does any seasoned Mario player jump over a moderate-width gap and come away feeling proud for having conquered it? Seems unlikely.
I've tried playing through 100 Mario Challenge on Expert a number of times (without once managing to complete it), and I've noticed three fuzzy categories. Some levels are an arbitrary mess of hazards right from the start, so I don't expect them to get any easier. Some levels are clearly designed as difficult obstacle courses, so again, I assume they'll be just as hard all the way through. In both cases, if I give up and skip to the next level, I don't feel like I'm missing out on anything — I'm not the intended audience.
But there are some Expert-ranked levels that seem pretty reasonable… until this one point where all hell breaks loose. I always wonder how deliberate those parts are, and I vaguely regret skipping them — would the rest of the level have calmed back down and been enjoyable?
That's the kind of hurdle I think about when I see conspicuous clusters of death markers in my own levels. How many people died there and gave up? I make levels intending for people to play them, to see them through, but how many players have I turned off with some needlessly tricky part?
One of my levels is a Boo house with a few cute tricks in it. Unfortunately, I also put a ring of Boos right at the beginning that's tricky to jump through, so it's very easy for a player to die several times right there and never see anything else.
I wanted my Boo house to be interesting rather than difficult, but I let difficulty creep in accidentally, and so I've reduced the number of people who can appreciate the interestingness. Every level I've made since then, I've struggled to keep the difficulty down, and still sometimes failed. It's easy to make a level that's very hard; it's surprisingly hard to make a level that's fairly easy. All it takes is a single unintended hurdle — a tricky jump, an awkwardly-placed enemy — to start losing players.
This isn't to say that games should never be difficult, but difficulty needs to be deliberately calibrated, and that's a hard thing to do. It's very easy to think only in terms of "can I beat this", and even that's not accurate, since you know every nook and cranny of your own level. Can you beat it blind, on the first few tries? Could someone else?
Those questions are especially important in Mario Maker, where the easiest way to encounter an assortment of levels is to play 100 Mario Challenge. You have 100 lives and need to beat 16 randomly-chosen levels. If you run out of lives, you're done, and you have to start over. If I encounter your level here, I can't afford to burn more than six or seven lives on it, or I'll game over and have wasted my time. So if your level looks ridiculously hard (and not even in a fun way), I'll just skip it and hope I get a better level next time.
I wonder if designers forget to calibrate for this. When you spend a lot of time working on something, it's easy to imagine it exists in a vacuum, to assume that other people will be as devoted to playing it as you were to making it.
Mario Maker is an extreme case: millions of levels are available, and any player can skip to another one with the push of a button. That might be why I feel like I've seen a huge schism in level difficulty: most Expert levels are impossible for me, whereas most Normal levels are fairly doable with one or two rough patches. I haven't seen much that's in the middle, that feels like a solid challenge. I suspect that people who are very good at Mario are looking for an extreme challenge, and everyone else just wants to play some Mario, so moderate-difficulty levels just aren't as common. The former group will be bored by them, and the latter group will skip them.
Or maybe that's a stretch. It's hard to generalize about the game's pool of levels when they number in the millions, and I can't have played more than a few hundred.
What Mario Maker has really taught me is what a hurdle looks like. The game keeps track of everywhere a player has ever died. I may not be able to watch people play my levels, but looking back at them later and seeing clumps of death markers is very powerful. Those are the places people failed. Did they stop playing after that? Did I intend for those places to be so difficult?
Doom is an interesting contrast to Mario Maker. A great many Doom maps have been produced over the past two decades, but nowhere near as many levels as Mario Maker has produced in a couple years. On the other hand, many people who still play Doom have been playing Doom this entire time, so a greater chunk of the community is really good at the game and enjoys a serious challenge.
I've only released a couple Doom maps of my own: Throughfare (the one I contributed to DUMP 2 earlier this year) and a few one-hour speedmaps I made earlier this week. I like building in Doom, with its interesting balance of restrictions — it's a fairly accessible way to build an interesting 3D world, and nothing else is quite like it.
I've had the privilege of watching a few people play through my maps live, and I have learned some things.
The first is that the community's love of difficulty is comically misleading. It's not wrong, but, well, that community isn't actually my target audience. So far I've "published" maps on this blog and Twitter, where my audience hasn't necessarily even played Doom in twenty years. If at all! Some of my followers are younger than Doom.
Most notably, this creates something of a distribution problem: to play my maps, you need to install a thing (ZDoom) and kinda figure out how to use it and also get a copy of Doom 2 which probably involves spending five bucks. Less of a hurdle than getting Mario Maker, yes, but still some upfront effort.
Also, ZDoom's default settings are… not optimal. Out of the box, it's similar to classic Doom: no WASD, no mouselook. I don't know who this is meant to appeal to. If you've never played Doom, the controls are goofy. If you've played other shooters, the controls are goofy. If you played Doom when it came out but not since, you probably don't remember the controls, so they're still goofy. Oof.
Not having mouselook is more of a problem than you'd think. If you as the designer play with mouselook, it's really easy to put important things off the top or bottom of the screen and never realize it'll be a problem. I watched someone play through Throughfare a few days ago and get completely stuck at what seemed to be a dead end — because he needed to drop down a hole in a small platform, and the hole was completely hidden by the status bar.
That's actually an interesting example for another reason. Here's the room where he got stuck.
When you press the switch, the metal plates on the ground rise up and become stairs, so you can get onto the platform. He did that, saw nowhere obvious to go, and immediately turned around and backtracked quite a ways looking for some other route.
This surprised me! The room makes no sense as a dead end. It's not an easter egg or interesting feature; it has no obvious reward; it has a button that appears to help you progress. If I were stuck here, I'd investigate the hell out of this room — yet this player gave up almost immediately.
Not to say that the player is wrong and the level is right. This room was supposed to be trivially simple, and I regret that it became a hurdle for someone. It's just a difference in playstyle I didn't account for. Besides the mouselook problem, this player tended to move very quickly in general, charging straight ahead in new areas without so much as looking around; I play more slowly, looking around for nooks and crannies. He ended up missing the plasma gun for much the same reason — it was on a ledge slightly below the default view angle, making it hard to see without mouselook.
Speaking of nooks and crannies: watching someone find or miss secrets in a world I built is utterly fascinating. I've watched several people play Throughfare now, and the secrets are the part I love watching the most. I've seen people charge directly into secrets on accident; I've seen people run straight to a very clever secret just because they had the same idea I did; I've seen people find a secret switch and then not press it. It's amazing how different just a handful of players have been.
I think the spread of secrets in Throughfare is pretty good, though I slightly regret using the same trick three times; either you get it right away and try it everywhere, or you don't get it at all and miss out on a lot of goodies. Of course, the whole point of secrets is that not everyone will find them on the first try (or at all), so it's probably okay to err on the trickier side.
As for the speedmaps, I've only watched one person play them live. The biggest hurdle was a room I made that required jumping.
Jumping wasn't in the original Doom games. People thus don't really expect to need to jump in Doom maps. Worse, ZDoom doesn't even have a key bound to jump out of the box, which I only discovered later.
See, when I made the room (very quickly), I was imagining a ZDoom veteran seeing it and immediately thinking, "oh, this is one of those maps where I need to jump". I've heard people say that about other maps before, so it felt like common knowledge. But it's only common knowledge if you're part of the community and have run into a few maps that require jumping.
The situation is made all the more complicated by the way ZDoom handles it. Maps can use a ZDoom-specific settings file to explicitly allow or forbid jumping, but the default is to allow it. The stock maps and most third-party vanilla maps won't have this ZDoom-specific file, so jumping will be allowed, even though they're not designed for it. Most mappers only use this file at all if they're making something specifically for ZDoom, in which case they might as well allow jumping anyway. It's opt-out, but the maps that don't want it are the ones least likely to use the opt-out, so in practice everyone has to assume jumping isn't allowed until they see some strong indication otherwise. It's a mess. Oh, and ZDoom also supports crouching, which is even more obscure.
I probably should've thought of all that at the time. In my defense, you know, speedmap.
One other minor thing was that, of course, ZDoom uses the traditional Doom HUD out of the box, and plenty of people play that way on purpose. I'm used to ZDoom's "alternative" HUD, which not only expands your field of view slightly, but also shows a permanent count of how many secrets are in the level and how many you've found. I love that, because it tells me how much secret-hunting I'll need to do from the beginning… but if you don't use that HUD (and don't look at the count on the automap), you won't even know whether there are secrets or not.
For a third-party example: a recent (well, late 2014) cool release was Going Down, a set of small and devilish maps presented as the floors of a building you're traversing from the roof downwards. I don't actually play a lot of Doom, but I liked this concept enough to actually play it, and I enjoyed the clever traps and interwoven architecture.
Then I reached MAP12, Dead End. An appropriate name, because I got stuck here. Permanently stuck. The climax of the map is too many monsters in not enough space, and it's cleverly rigged to remove the only remaining cover right when you need it. I couldn't beat it.
That was a year ago. I haven't seen any of the other 20 maps beyond this point. I'm sure they're very cool, but I can't get to them. This one is too high a hurdle.
Granted, hopping around levels is trivially easy in Doom games, but I don't want to cheat my way through — and anyway, if I can't beat MAP12, what hope do I have of beating MAP27?
I feel ambivalent about this. The author describes the gameplay as "chaotic evil", so it is meant to be very hard, and I appreciate the design of the traps… but I'm unable to appreciate any more of them.
This isn't the author's fault, anyway; it's baked into the design of Doom. If you can't beat one level, you don't get to see any future levels. In vanilla Doom it was particularly bad: if you die, you restart the level with no weapons or armor, probably making it even harder than it was before. You can save any time, and some modern source ports like ZDoom will autosave when you start a level, but the original game never saved automatically.
Isaac's Descent
Isaac's Descent is the little PICO-8 puzzle platformer I made for Ludum Dare 36 a couple months ago. It worked out surprisingly well; pretty much everyone who played it (and commented on it to me) got it, finished it, and enjoyed it. The PICO-8 exports to an HTML player, too, so anyone with a keyboard can play it with no further effort required.
I was really happy with the puzzle design, especially considering I hadn't really made a puzzle game before and was rushing to make some rooms in a very short span of time. Only two were perhaps unfair. One was the penultimate room, which involved a tricky timing puzzle, so I'm not too bothered about that. The other was this room:
Using the wheel raises all stone doors in the room. Stone doors open at a constant rate, wait for a fixed time, and then close again. The tricky part with this puzzle is that by the time the very tall door has opened, the short door has already closed again. The solution is simply to use the wheel again right after the short door has closed, while the tall door is still opening. The short door will reopen, while the tall door won't be affected since it's already busy.
This isn't particularly difficult to figure out, but it did catch a few people, and overall it doesn't sit particularly well with me. Using the wheel while a door is opening feels like a weird edge case, not something that a game would usually rely on, yet I based an entire puzzle around it. I don't know. I might be overthinking this. The problem might be that "ignore the message" is a very computery thing to do and doesn't match with how such a wheel would work in practice; perhaps I'd like the puzzle more if the wheel always interrupted whatever a door was doing and forced it to raise again.
Overall, though, the puzzles worked well.
The biggest snags I saw were control issues with the PICO-8 itself. The PICO-8 is a "fantasy console" — effectively an emulator for a console that never existed. One of the consequences of this is that the controls aren't defined in terms of keyboard keys, but in terms of the PICO-8's own "controller". Unfortunately, that controller is only defined indirectly, and the web player doesn't indicate in any way how it works.
The controller's main inputs — the only ones a game can actually read — are a directional pad and two buttons, ○ and ❌, which map to z and x on a keyboard. The PICO-8 font has glyphs for ○ and ❌, so I used those to indicate which button does what. Unfortunately, if you aren't familiar with the PICO-8, those won't make a lot of sense to you. It's nice that ❌ looks like the keyboard key it's bound to, but ○ looks like the wrong keyboard key. This caused a little confusion.
"Well," I hear you say, "why not just refer to the keys directly?" Ah, but there's a very good reason the PICO-8 is defined in terms of buttons: those aren't the only keys you can use! n and m also work, as do c and v. The PocketCHIP also allows… 0 and =, I think, which is good because z and x are directly under the arrow keys on the PocketCHIP keyboard. And of course you can play on a USB controller, or rebind the keys.
I could've mentioned that z and x are the defaults, but that's wrong for the PocketCHIP, and now I'm looking at a screenful of text explaining buttons that most people won't read anyway.
A similar problem is the pause menu, accessible with p or enter. I'd put an option on the pause menu for resetting the room you're in, just in case, but didn't bother to explain how to get to the pause menu.Or that a pause menu exists. Also, the ability to put custom things on the pause menu is new, so a lot of people might not even know about it. I'm sure you can see this coming: a few rooms (including the two-door one) had places you could get stuck, and without any obvious way to restart the room, a few people thought they had to start the whole game over. Whoops.
In my defense, the web player is actively working against me here: it has a "pause" link below the console, but all the link does is freeze the player, not bring up the pause menu.
This is a recurring problem, and perhaps a fundamental question of making games accessible: how much do you need to explain to people who aren't familiar with the platform or paradigm? Should every single game explain itself? Players who don't need the explanation can easily get irritated by it, and that's a bad way to start a game. The PICO-8 in particular has the extra wrinkle that its cartridge space is very limited, and any kind of explanation/tutorial costs space you could be using for gameplay. On the other hand, I've played more than one popular PICO-8 game that was completely opaque to me because it didn't explain its controls at all.
I'm reminded of Counterfeit Monkey, a very good interactive fiction game that goes out of its way to implement a hint system and a gentle tutorial. The tutorial knits perfectly with the story, and the hints are trivially turned off, so neither is a bother. The game also has a hard mode, which eliminates some of the more obvious solutions and gives a nod to seasoned IF players as well. The author is very interested in making interactive fiction more accessible in general, and it definitely shows. I think this game alone convinced me it's worth the effort — I'm putting many of the same touches in my own IF foray.
Under Construction is the PICO-8 game that Mel and I made early this year. It's a simple, slightly surreal, slightly obtuse platformer.
Traditional wisdom has it that you don't want games to be obtuse. That acts as a hurdle, and loses you players. Here, though, it's part of the experience, so the question becomes how to strike a good balance without losing the impact.
A valid complaint we heard was that the use of color is slightly inconsistent in places. For the most part, foreground objects (those you can stand on) are light and background decorations are gray, but a couple tiles break that pattern. A related problem that came up almost immediately in beta testing was that spikes were difficult to pick out. I addressed that — fairly effectively, I think — by adding a single dark red pixel to the tip of the spikes.
But the most common hurdle by far was act 3, which caught us completely by surprise. Spoilers!
From the very beginning, the world contains a lot of pillars containing eyeballs that look at you. They don't otherwise do anything, beyond act as platforms you can stand on.
In act 2, a number of little radios appear throughout the world. Mr. 5 complains that it's very noisy, so you need to break all the radios by jumping on them.
In act 3, the world seems largely the same… but the eyes in the pillars now turn to ❌'s when you touch them. If this happens before you make it to the end, Mr. 5 complains that he's in pain, and the act restarts.
The correct solution is to avoid touching any of the eye pillars. But because this comes immediately after act 2, where we taught the player to jump on things to defeat them — reinforcing a very common platforming mechanic — some players thought you were supposed to jump on all of them.
I don't know how we could've seen that coming. The acts were implemented one at a time and not in the order they appear in the game, so we were both pretty used to every individual mechanic before we started playing through the entire game at once. I suppose when a game is developed and tested in pieces (as most games are), the order and connection between those pieces is a weak point and needs some extra consideration.
We didn't change the game to address this, but the manual contains a strong hint.
Under Construction also contains a couple of easter eggs and different endings. All are fairly minor changes, but they added a lot of character to the game and gave its fans something else to delve into once they'd beaten it.
Crucially, these things worked as well as they did because they weren't accessible. Easily-accessed easter eggs aren't really easter eggs any more, after all. I don't think the game has any explicit indication that the ending can vary, which meant that players would only find out about it from us or other fans.
I don't yet know the right answer for balancing these kinds of extras, and perhaps there isn't one. If you spend a lot of time on easter eggs, multiple endings, or even just multiple paths through the game, you're putting a lot of effort into stuff that many players will never see. On the other hand, they add an incredible amount of depth and charm to a game and reward those players who do stick around to explore.
This is a lot like the balancing act with software interfaces. You want your thing to be accessible in the sense that a newcomer can sit down and get useful work done, but you also want to reward long-time users with shortcuts and more advanced features. You don't want to hide advanced features too much, but you also don't want to have an interface with a thousand buttons.
How larger and better-known games deal with this
I don't have the patience for Zelda I. I never even tried it until I got it for free on my 3DS, as part of a pack of Virtual Console games given to everyone who bought a 3DS early. I gave it a shot, but I got bored really quickly. The overworld was probably the most frustrating part: the connections between places are weird, everything looks pretty much the same, the map is not very helpful, and very little acts as a landmark. I could've drawn my own map, but, well, I usually can't be bothered to do that for games.
I contrast this with Skyward Sword, which I mostly enjoyed. Ironically, one of my complaints is that it doesn't quite have an overworld. It almost does, but they stopped most of the way, leaving us with three large chunks of world and a completely-open sky area reminiscent of Wind Waker's ocean.
Clearly, something about huge open spaces with no barriers whatsoever appeals to the Zelda team. I have to wonder if they're trying to avoid situations like my experience with Zelda I. If a player gets lost in an expansive overworld, either they'll figure out where to go eventually, or they'll give up and never see the rest of the game. Losing players that way, especially in a story-driven game, is a huge shame.
And this is kind of a problem with the medium in general. For all the lip service paid to nonlinearity and sandboxes, the vast majority of games require some core progression that's purely linear. You may be able to wander around a huge overworld, but you still must complete these dungeons and quests in this specific order. If something prevents you from doing one of them, you won't be able to experience the others. You have to do all of the first x parts of the game before you can see part x + 1.
This is really weird! No other media is like this. If you watch a movie or read a book or listen to a song and some part of it is inaccessible for whatever reason — the plot is poorly explained, a joke goes over your head, the lyrics are mumbled — you can still keep going and experience the rest. The stuff that comes later might even help you make sense of the part you didn't get.
In games, these little bumps in the road can become walls.
It's not even necessarily difficulty, or getting lost, or whatever. A lot of mobile puzzle games use the same kind of artificial progression where you can only do puzzles in sequential batches; solving enough of the available puzzles will unlock the next batch. But in the interest of padding out the length, many of these games will have dozens of trivially easy and nearly identical puzzles in the beginning, which you have to solve to get to the later interesting ones. Sometimes I've gotten so bored by this that I've given up on a game before reaching the interesting puzzles.
In a way, that's the same problem as getting lost in an overworld. Getting lost isn't a hard wall, after all — you can always do an exhaustive search and talk to every NPC twice. But that takes time, and it's not fun, much like the batches of required baby puzzles. People generally don't like playing games that waste their time.
I love the Picross "e" series on the 3DS, because over time they've largely figured out that this is pointless: in the latest game in the series, everything is available from the beginning. Want to do easy puzzles? Do easy puzzles. Want to skip right to the hard stuff? Sure, do that. Don't like being told when you made a wrong move? Turn it off.
(It's kinda funny that the same people then made Pokémon Picross, which has some of the most absurd progression I've ever seen. Progressing beyond the first half-dozen puzzles requires spending weeks doing a boring minigame every day to grind enough pseudocurrency to unlock more puzzles. Or you can just pay for pseudocurrency, and you'll have unlocked pretty much the whole game instantly. It might as well just be a demo; the non-paid progression is useless.)
Chip's Challenge also handled this pretty well. You couldn't skip around between levels arbitrarily, which was somewhat justified by the (very light) plot. Instead, if you died or restarted enough times, the game would offer to skip you to the next level, and that would be that. You weren't denied the rest of the game just because you couldn't figure out an ice maze or complete some horrible nightmare like Blobnet.
I wish this sort of mechanic were more common. Not so games could be more difficult, but so games wouldn't have to worry as much about erring on the side of ease. I don't know how it could work for a story-driven game where much of the story is told via experiencing the game itself, though — skipping parts of Portal would work poorly. On the other hand, Portal took the very clever step of offering "advanced" versions of several levels, which were altered very slightly to break all the obvious easy solutions.
Slapping on difficulty settings is nice for non-puzzle games (and even some puzzle games), but unless your game lets you change the difficulty partway through, someone who hits a wall still has to replay the entire game to change the difficulty. (Props to Doom 4, which looks to have taken difficulty levels very seriously — some have entirely different rules, and you can change whenever you want.)
I have a few wisps of ideas for how to deal with this in Isaac HD, but I can't really talk about them before the design of the game has solidified a little more. Ultimately, my goal is the same as with everything else I do: to make something that people have a chance to enjoy, even if they don't otherwise like the genre.
20143DaccessibilityADIAIALAAllappArchitecturearinartASDATIATSauthBASICBECbetaBETTblogbookCCADCalicarCASCasecasescciciacomiccommunityconsoleCoredeathDemodesigndoomdowndressEASTedEdgeeffeseteueventEventseyesfailfanfontformFungamegamedevgamesGeneralGogotGREhtmlICEinstallinteractioniosIPirsISPISPsississuekeyslightlimalimitLTEMakemaking thingsmanamariomario makermediamillionmitmobileMoUmovmovemovieMPANCRNECNESNintendonseOnlineORGOSSOtherpartypeoplePINPlaypowerproblemradioratraterawReleaserestrisksRTIrunningS.SearchshedskysoftwarespaceSSLStarstatusStrikestssupporttalktargetteamtechtestingthingstortouchtoytrapTutorialtwitterUIUnityUSusbUSTRvideowatchweaponswebwinWork
Five(ish) awesome RetroPie builds
Post Syndicated from Alex Bate original https://www.raspberrypi.org/blog/fiveish-awesome-retropie-builds/
If you've yet to hear about RetroPie, how's it going living under that rock?
RetroPie, for the few who are unfamiliar, allows users to play retro video games on their Raspberry Pi or PC. From Alex Kidd to Ecco the Dolphin, Streets of Rage 2 to Cool Spot, nostalgia junkies can get their fill by flashing the RetroPie image to their Pi and plugging in their TV and a couple of USB controllers.
But for many, this simple setup is not enough. Alongside the RetroPie unit, many makers are building incredible cases and modifications to make their creation stand out from the rest.
Here's five of what I believe to be some of the best RetroPie builds shared on social media:
1. Furniture Builds
If you don't have the space for an arcade machine, why not incorporate RetroPie into your coffee table or desk?
This 'Mid-century-ish Retro Games Table' by Reddit user GuzziGuy fits a screen and custom-made controllers beneath a folding surface, allowing full use of the table when you're not busy Space Raiding or Mario Karting.
2. Arcade Cabinets
While the arcade cabinet at Pi Towers has seen better days (we have #LukeTheIntern working on it as I type), many of you makers are putting us to shame with your own builds. Whether it be a tabletop version or full 7ft cabinet, more and more RetroPie arcades are popping up, their builders desperate to replicate the sights of our gaming pasts.
One maker, YouTuber Bob Clagett, built his own RetroPie Arcade Cabinet from scratch, documenting the entire process on his channel.
With sensors that start the machine upon your approach, LED backlighting, and cartoon vinyl artwork of his family, it's easy to see why this is a firm favourite.
Arcade Cabinet build – Part 3 // How-To
Check out how I made this fully custom arcade cabinet, powered by a Raspberry Pi, to play retro games! Subscribe to my channel: http://bit.ly/1k8msFr Get digital plans for this cabinet to build your own!
3. Handheld Gaming
If you're looking for a more personal gaming experience, or if you simply want to see just how small you can make your build, you can't go wrong with a handheld gaming console. With the release of the Raspberry Pi Zero, the ability to fit an entire RetroPie setup within the smallest of spaces has become somewhat of a social media maker challenge.
Chase Lambeth used an old Burger King toy and Pi Zero to create one of the smallest RetroPie Gameboys around… and it broke the internet in the process.
4. Console Recycling
What better way to play a retro game than via a retro game console? And while I don't condone pulling apart a working NES or MegaDrive, there's no harm in cannibalising a deceased unit for the greater good, or using one of many 3D-printable designs to recreate a classic.
Here's YouTuber DaftMike's entry into the RetroPie Hall of Fame: a mini-NES with NFC-enabled cartridges that autoplay when inserted.
Raspberry Pi Mini NES Classic Console
This is a demo of my Raspberry Pi 'NES Classic' build. You can see photos, more details and code here: http://www.daftmike.com/2016/07/NESPi.html Update video: https://youtu.be/M0hWhv1lw48 Update #2: https://youtu.be/hhYf5DPzLqg Electronics kits are now available for pre-order, details here: http://www.daftmike.com/p/nespi-electronics-kit.html Build Guide Update: https://youtu.be/8rFBWdRpufo Build Guide Part 1: https://youtu.be/8feZYk9HmYg Build Guide Part 2: https://youtu.be/vOz1-6GqTZc New case design files: http://www.thingiverse.com/thing:1727668 Better Snap Fit Cases!
5. Everything Else
I can't create a list of RetroPie builds without mentioning the unusual creations that appear on our social media feeds from time to time. And while you may consider putting more than one example in #5 cheating, I say… well, I say pfft.
Example 1 – Sean (from SimpleCove)'s Retro Arcade
It felt wrong to include this within Arcade Cabinets as it's not really a cabinet. Creating the entire thing from scratch using monitors, wood, and a lot of veneer, the end result could easily have travelled here from the 1940s.
Retro Arcade Cabinet Using A Raspberry Pi & RetroPie
I've wanted one of these raspberry pi/retro pi arcade systems for a while but wanted to make a special box to put it in that looked like an antique table top TV/radio. I feel the outcome of this project is exactly that.
Example 2 – the HackerHouse Portable Console… built-in controller… thing
The team at HackerHouse, along with many other makers, decided to incorporate the entire RetroPie build into the controller, allowing you to easily take your gaming system with you without the need for a separate console unit. Following on from the theme of their YouTube channel, they offer a complete tutorial on how to make the controller.
Make a Raspberry Pi Portable Arcade Console (with Retropie)
Find out how to make an easy portable arcade console (cabinet) using a Raspberry Pi. You can bring it anywhere, plug it into any tv, and play all your favorite classic ROMs. This arcade has 4 general buttons and a joystick, but you can also plug in any old usb enabled controller.
Example 3 – Zach's PiCart
RetroPie inside a NES game cartridge… need I say more?
Pi Cart: a Raspberry Pi Retro Gaming Rig in an NES Cartridge
I put a Raspberry Pi Zero (and 2,400 vintage games) into an NES cartridge and it's awesome. Powered by RetroPie. I also wrote a step-by-step guide on howchoo and a list of all the materials you'll need to build your own: https://howchoo.com/g/mti0oge5nzk/pi-cart-a-raspberry-pi-retro-gaming-rig-in-an-nes-cartridge
Here's a video to help you set up your own RetroPie. What games would you play first? And what other builds have caught your attention online?
The post Five(ish) awesome RetroPie builds appeared first on Raspberry Pi.
20163DADIAIAllapparcadeartATIBECBETTbit.lyCCADcarCASCasecasescheatingciacodeconsoleDemodesigndetDigitaldocumentdpedElectronicsfamilyflashfurnituregamegamesgamingGeneralGitGoGREHow-tohtmlhttphttpsInsideinternetIPiqirskitlightlightingMacMakemakersmariomediaMegaNCRNESNintendonseOnlineOtherpersonalPi ZeroPINPlaypowerprojectQtradioRAIDraspberry piRaspberry Pi ZeroratrateredditReleaserestretroretro gamingretropieRTIS.scratchsensorssetupsocialSocial MediaspaceStarstsTAGteamtortoyTutorialtvUIUKUncategorizedUSusbvideowdwinWorkwwwyoutubezero
Doom scale
Post Syndicated from Eevee original https://eev.ee/blog/2016/10/10/doom-scale/
I've been dipping my toes into Doom mapping again recently. Obviously I've done it successfully once before, but I'm having trouble doing it a second time.
I have three major problems: drawing everything too small, drawing everything too rectangular, and completely blanking on what to do next. Those last two are a bit tricky, but struggling with scale? That sounds like a problem I can easily solve with charts and diagrams and math.
Some fundamental metrics
Doom's mapping rules and built-in textures offer a few fixed reference points.
The z planes — floor and ceiling — are a 64×64 grid anchored at the origin. All "flat" textures are aligned to this grid. (ZDoom lets you rotate, scale, and offset flats, but in vanilla Doom, you sometimes have to design architecture around texture alignment.)
All actors (objects) are square and axis-aligned. Doomguy is 32×56. However, it's very difficult for an actor to move down a corridor of the same width, and the axis-alignment means a 32-unit square couldn't fit down a 32-unit diagonal hallway. (It's rare to see a hallway narrower than 64 or a room height shorter than 64.)
The viewport is 41 pixels above the ground. Doomguy's maximum step height is 24, which is actually fairly large, almost half his height. Doomguy can balance on a ledge of any width.
The vast majority of Doom's wall textures are 64×128. A few larger textures are 128×128, and a handful of very large outdoor textures are 256×128. A few "strut" textures and door borders are 8 or 16 wide. Some interesting exceptions:
DOOR3, the door you appear to have entered from in many Doom maps, is 64×72. So is DOOR1. EXITDOOR has some extra stuff on it, but the actual door part is also 64×72.
BIGDOOR1, the silver door with the UAC logo on it, is 128×96.
MIDBARS3 is a railing texture that's 64×72.
The Icon of Sin is built out of a 3×3 grid of textures. The full image is 768×384.
EXITSIGN is 64×16, though only half of it is the actual part that says "EXIT"; the rest is the sides of the sign.
The STEP textures are all 16 high.
Since Doom's textures tend to be 128 tall, we can conclude that a standard room tends to be no more than 128 tall. Any more and the texture would start to tile, which works poorly with a lot of textures.
Vertical distance is fine. Doom doesn't have a lot of vertical movement, so vertical distances tend not to get too outlandish in the first place.
The trouble is that I don't know how big spaces are. I draw rooms and they turn out, much later, to be far too cramped. I draw buildings and outdoor areas and they turn out to not really have enough space to fit everything I want.
An obvious approach is to find a conversion between Doom units and real-world units, then judge distances based on real-world units. That sounds great, but I don't have a good sense of real-world units, either. How big is the room I'm in now? Somewhere between ten and a hundred feet, I guess? Thirty? How much is thirty feet, is that a lot?
How long is my car, say? I guess two of me could lie down end-to-end beside it, so that's twelve feet? That sounds like I'm underestimating. Fifteen? Are these reasonable guesses? I don't know.
Hm, well. The answer turns out to be exactly halfway between at thirteen and a half feet, so I don't know what we've learned here exactly.
Okay, so let's consider in terms of architecture. How long is the quiet residential street in front of my house? I have no idea. The next biggest thing is a house, and I don't know how wide a house is, or how many houses there are on this street. I could estimate the street in terms of house lengths, and estimate a house in terms of car lengths, and estimate a car length in terms of my height, but that's enough wild guesses that the final answer could be a whole order of magnitude off.
I never have any reason to appreciate or internalize length measurements, especially moderately large ones. I have no reference point.
Also, Doom's grid and texture sizes mean that everything is done in multiples of powers of two. I know the powers of two, but I don't actually know every single multiple of 64 up to 32768, so I occasionally run into the problem that the numbers lose all meaning. How many 64s are in 768, again…?
Also, Doom doesn't make any sense
The other problem with relating to real-world sizes is that it assumes there's a way to convert between Doom and the real world. Alas, the universe of Doom has much more in common with the exaggerated and cartoony scale of platformers than with the hyper-realism in modern shooters.
Consider Doomguy. Here's his default forward-facing sprite, PLAYA1. The pink area is his 32×56 collision box, the red dot is where he fires from, and the yellow dot is the location of the viewport.
The collision box is the same height as the sprite itself, but it gets shifted upwards slightly because of the sprite offsets. (Every sprite has an offset indicating where its bottom center is, since that's where the game tracks an object's position. If Doomguy's sprite were just drawn from the bottom, he'd look like he were standing on his tiptoes.)
It is generally accepted — by which I mean "Doom Wiki says so" — that 32 units of height correspond to one meter (39"), which makes Doomguy about 5 feet 8 inches tall. It also makes him one meter wide, which seems rather extreme. The usual handwave is to say that vertical and horizontal scales are different (because pixels weren't square in the original game), so 32 units of width correspond to ¾ of a meter (just shy of 30").
That doesn't really make sense to me. If the architecture were truly distorted to compensate for the pixel size, then surely wall textures would be, too. They aren't. Switches are perfect 32×32 squares. Several floor textures also exist separately as wall textures, and they weren't distorted in any way. This is a cute explanation that neatly ties together several bits of Doom trivia, but I don't think it was a deliberate design decision.
Plus, according to this sprite, Doomguy's collision box is significantly wider than his actual appearance. I don't know why this is — perhaps the extra space is where he keeps his hundred rockets and half a dozen spare weapons. If we're interested in aesthetics, surely we should be going by Doomguy's sprite rather than his in-game dimensions.
More importantly… this weird ratio still doesn't jive with most architecture. Consider the fast skinny doors introduced in Doom II, which are 64×128. At 32u = 1m, those are two meters wide and four meters tall, or 78" × 157". The Internet tells me that an interior residential doorway is around 32" × 80" (2:5), and a human being is around 18" × 69" (~1:4).
Here are those measurements alongside the supposed sizes of Doomguy and a skinny door. Something seems slightly off.
The light blue boxes are the collision boxes; the dark blue boxes are Doomguy's apparent visible size. I'm using his waist rather than his shoulders, because most people's (or at least, my) shoulders are not too much wider than their hips — however Doomguy is a beefcake carved out of pure muscle and doors would not be designed for him.
It seems as though all the architecture in Doom is about twice the size it should be, for whatever reason. Look what happens if I shrink the door, but not Doomguy:
If I use some ZDoom shenanigans to shrink a door within the game, it looks rather more like a real door. (You'd have a hard time fitting through it without modifying the player's radius, though.)
It's not just architecture! Keycard sprites are 14×16, which would be about a foot and a half square. The shotgun is 63 pixels long, a whopping 77". A shotgun shell is 7 pixels long, almost 9". The candelabra is 61 pixels tall — taller than Doomguy! — which is just over six feet. This is ridiculous. Halving all of these lengths makes them closer to something reasonable.
It appears, for whatever reason, that the world of Doom is roughly twice the size of the world we're used to. (Or perhaps Doomguy has been shrunk by half.) That matches my attempts at replicating real-world places to scale — they turned out unusually cramped.
64 units equal 1 meter, then. Problem solved.
Ah, well, about that. The 64×128 doors make sense, but… real doorways don't span the full height of a room, yet many Doom rooms are 128 tall. Or less. The starting area in E1M1, the hallway in MAP01, and the DOOR1 "entrance" door are all 72 units tall, which converts to less than four feet.
Let's try something else. Tom Hall says in the Doom Bible that the 128-unit walls in Wolfenstein 3D were eight feet thick, i.e. 16 units equal 1 foot. The 64-unit grid is thus four feet, which seems reasonable. The maximum step height would be 18 inches, and shallow steps would be 6 inches, which also seem reasonable — the stairs in my house are 7" tall, and the most I can comfortably step up is 3 at a time.
But this still makes those 72-unit rooms be only four and a half feet tall.
This isn't a problem that can be solved with different height and width scaling, because we've come down to a conflict between door/room height and step height. If those 72-unit rooms are a more reasonable eight feet tall (the standard) then 9 units are 1 foot, and Doomguy's step height is over two and a half feet. Also, those 64×128 doors are over nine feet tall.
The fact is, Doomguy has goofy proportions, and the environment was designed around them. The textures have a gritty semi-realistic aesthetic, but comparing the levels to real-world architecture makes about as much sense as designing Mario levels around real places. Actual humans cannot jump several times their own height, so the design language doesn't translate at all.
Better reference points
If I can't use the real world to get a sense of scale, I might as well use Doom itself.
I've gone through some large areas that are particularly memorable to me, areas that I have a good sense of, and measured their dimensions.
However, I've tried using a new kind of unit: Doom grid cells. All of the numbers in parentheses are counts of 64-unit cells (for horizontal units only). It turns out to be much easier to grapple with 22 vs 24 than 1408 vs 1536.
E1M1: Hangar
The iconic starting room is 640×768 (10×12) and 72 tall. The recessed area in the middle is 448×320 (7×5) and 216 tall.
E3M8: Dis
The entire shuriken fits in a 3712×3584 (58×56) box. The sky is 256 units above the inner part of the ground.
MAP01: Entryway
The opening room is 640×448 (10×7) and 256 tall. The subsequent hallway is 128 (2) wide and 72 tall.
The large room before the exit is 960 (15) deep and 192 tall. Wow! I always think 1024 (16) sounds really huge, but this one humble room is almost that big.
MAP02: Underhalls
The entire area with the little brick "house" is 576×896 (9×14), measured from the water. The surrounding walkway is 88 tall; the grass is 216 below the sky.
The whole map fits in a 1920×1920 (30×30) box.
MAP03: The Gantlet
The main large outdoor area is carved from a 1664×832 (26×13) rectangle. The water is 264 below the sky.
The entire starting area just about fits in a 704×704 (11×11) box. The hallway is 128 tall; the center room is 160 tall.
MAP07: Dead Simple
The inner part, including the walkway, is 1536×1472 (24×23). The outdoor parts are 120 tall; the roof is 80 above the walkway.
MAP08: Tricks and Traps
The starting room is 448×448 (7×7) and 192 tall.
The cacodemon room is 448 (7) wide, 1792 (28) from the door to the far wall, and 288 tall.
The cyberdemon room is roughly 896×448 (14×7) and varies between 96 and 128 tall.
The room you teleport to with the pain elementals is 704×704 (11×11) and 144 tall.
MAP12: The Factory
The entire map is 3776×4288 (59×67). Outdoors is 208 tall. The outer wall is 96 tall, and the main raised outdoor part is 80 high, 128 below the sky.
The main "factory" interior is 2560×1536 (40×24).
MAP14: The Inmost Dens, the most detailed map in Doom II
Water to sky is 200, and the floor is 16 above the water. The brick wall surrounding everything is 32 high. The pillars between areas are 88 tall.
The entire map fits in a 3520×3904 (55×61) box.
MAP15: Industrial Zone
Ground to sky is 600.
The central structure — the one you jump off to reach the other side of the map — is 1600×1600 (25×25).
The entire map, excluding the purely aesthetic waterfront, fits in a particularly pleasing 4416×6144 (69×96) box.
MAP18: Courtyard
The grassy courtyard itself is, very roughly, 2112×1920 (33×30). Grass to sky is 192.
The surrounding area with the columns is 576 (9) at its deepest.
The separate cacodemon area with the blue key is 768×1216 (12×19) and 272 tall.
MAP23: Barrels o' Fun
The starting hallway is 2240 (35) long, 384 (6) wide, and 256 tall.
The blood pit is 960×1024 (15×16) and a whopping 384 tall. The hallways leading to it are 64×528 (1×8¼) and 80 tall.
MAP27: Monster Condo
The starting area plus library form a rough 2624×1728 (41×27) rectangle. The other main area plus pain elemental room form a rough 2432×1600 (38×25) rectangle. Both are 128 tall.
The twin marble rooms are about 576×1024 (9×16), not counting the 128 (2)-deep closets on the sides and backs. Total height is 256, and the walkway is 80 above the floor.
MAP29: The Living End
The huge central blood pit is 3072×2816 (48×44) and a whopping 696 tall, which is almost five and a half 128s. The platform you first see it from is 200 above the floor.
The central exit slab is 1216×1216 (19×19).
MAP30: Icon of Sin
The main area is 2688×1728 (42×27) and 768 tall. Each platform is 128 above the next. Pressing the switch up top raises the lift by 512, or four 128s.
MAP32: Grosse
The main room is a 2176×2944 (34×46) rectangle, plus a 1024 (16)-deep lead-in bit.
It might help to know that the player's maximum run speed is about 583 units per second… or just over 9 grid cells per second. With straferunning, it's about 11⅔ grid cells.
I also ran all of these maps through a slightly modified wad2svg and combined them into a single image, depicting all of them at the same scale. (If you like, I also have a large SVG version.)
One pixel is 16 Doom units; four pixels are 64 units or one grid cell; the grid lines mark 1024 units or 16 grid cells. The player can run across one grid cell in 1.8 seconds, or 1.4 seconds when straferunning.
I don't know if I've absorbed anything intuitively from this yet, but it'll give me something to refer back to the next time I try to map. Seeing that the entirety of Underhalls just about fits inside the Icon of Sin room, for example, is downright fascinating and says a lot about the importance of breaking space up.
Ah, you got me, this whole post was an excuse to list those dimensions and make a collage of Doom maps.
What if I fixed the player size?
Assuming Tom Hall is correct that 1 real-world foot is equal to 16 Doom units, a six-foot-tall Marine should be 96 units tall. With the magic of ZDoom, I can make that happen. I can also fix the heights of the humanoid enemies.
The results are pretty hilarious. Highly recommend running around for a bit with one of these. Hint: you may want to bind a key to "crouch".
Realistic proportions: player only
Realistic proportions: player, imps, and the three human enemies
ADIAIALAAllappAppleArchitecturearinartATIBECBETTBitsCCalicarCASciacodecolumnconversioncourtDemodesigndetdoomdownEASTedEdgeenvironmentertsfactFungamegamedevGeneralGogotGREICEindustrialInsideinternetIPirslightlocationMakemappingmariomathmovmoveMPANESNSAnseOSSOtherpeoplePINPlayPositionpowerproblemratrawrestrocketsRTIrunningS.S3skyspaceStarststortrapUIUSUSTRwaterweaponswinwolWorkWOW
Succeeding MegaZeux
Post Syndicated from Eevee original https://eev.ee/blog/2016/10/06/succeeding-megazeux/
In the beginning, there was ZZT. ZZT was a set of little shareware games for DOS that used VGA text mode for all the graphics, leading to such whimsical Rogue-like choices as ä for ammo pickups, Ω for lions, and ♀ for keys. It also came with an editor, including a small programming language for creating totally custom objects, which gave it the status of "game creation system" and a legacy that survives even today.
A little later on, there was MegaZeux. MegaZeux was something of a spiritual successor to ZZT, created by (as I understand it) someone well-known for her creative abuse of ZZT's limitations. It added quite a few bells and whistles, most significantly a built-in font editor, which let aspiring developers draw simple sprites rather than rely on whatever they could scrounge from the DOS font.
And then, nothing. MegaZeux was updated for quite a while, and (unlike ZZT) has even been ported to SDL so it can actually run on modern operating systems. But there was never a third entry in this series, another engine worthy of calling these its predecessors.
I think that's a shame.
Plenty of people have never heard of ZZT, and far more have never heard of MegaZeux, so here's a brief primer.
Both were released as "first-episode" shareware: they came with one game free, and you could pony up some cash to get the sequels. Those first games — Town of ZZT and Caverns of Zeux — have these moderately iconic opening scenes.
In the intervening decades, all of the sequels have been released online for free. If you want to try them yourself, ZZT 3.2 includes Town of ZZT and its sequels (but must be run in DOSBox), and you can get MegaZeux 2.84c, Caverns of Zeux, and the rest of the Zeux series separately.
Town of ZZT has you, the anonymous player, wandering around a loosely-themed "town" in search of five purple keys. It's very much a game of its time: the setting is very vague but manages to stay distinct and memorable with very light touches; the puzzles range from trivial to downright cruel; the interface itself fights against you, as you can't carry more than one purple key at a time; and the game can be softlocked in numerous ways, only some of which have advance warning in the form of "SAVE!!!" written carved directly into the environment.
Caverns of Zeux is a little more cohesive, with a (thin) plot that unfolds as you progress through the game. Your objectives are slightly vaguer; you start out only knowing you're trapped in a cave, and further information must be gleaned from NPCs. The gameplay is shaken up a couple times throughout — you discover spellbooks that give you new abilities, but later lose your primary weapon. The meat of the game is more about exploring and less about wacky Sokoban puzzles, though with many of the areas looking very similar and at least eight different-colored doors scattered throughout the game, the backtracking can get frustrating.
Those are obviously a bit retro-looking now, but they're not bad for VGA text made by individual hobbyists in 1991 and 1994. ZZT only even uses CGA's eight bright colors. MegaZeux takes a bit more advantage of VGA capabilities to let you edit the palette as well as the font, but games are still restricted to only using 16 colors at one time.
That's great, but who cares?
A fair question!
ZZT and MegaZeux both occupy a unique game development niche. It's the same niche as (Z)Doom, I think, and a niche that very few other tools fill.
I've mumbled about this on Twitter a couple times, and several people have suggested that the PICO-8 or Mario Maker might be in the same vein. I disagree wholeheartedly! ZZT, MegaZeux, and ZDoom all have two critical — and rare — things in common.
You can crack open the editor, draw a box, and have a game. On the PICO-8, you are a lonely god in an empty void; you must invent physics from scratch before you can do anything else. ZZT, MegaZeux, and Doom all have enough built-in gameplay to make a variety of interesting levels right out of the gate. You can treat them as nothing more than level editors, and you'll be hitting the ground running — no code required. And unlike most "no programming" GCSes, I mean that literally!
If and when you get tired of only using the built-in objects, you can extend the engine. ZZT and MegaZeux have programmable actors built right in. Even vanilla Doom was popular enough to gain a third-party tool, DEHACKED, which could edit the compiled doom.exe to customize actor behavior. Mario Maker might be a nice and accessible environment for making games, but at the end of the day, the only thing you can make with it is Mario.
Both of these properties together make for a very smooth learning curve. You can open the editor and immediately make something, rather than needing to absorb a massive pile of upfront stuff before you can even get a sprite on the screen. Once you need to make small tweaks, you can dip your toes into robots — a custom pickup that gives you two keys at once is four lines of fairly self-explanatory code. Want an NPC with a dialogue tree? That's a little more complex, but not much. And then suddenly you discover you're doing programming. At the same time, you get rendering, movement, combat, collision, health, death, pickups, map transitions, menus, dialogs, saving/loading… all for free.
MegaZeux has one more nice property, the art learning curve. The built-in font is perfectly usable, but a world built from monochrome 8×14 tiles is a very comfortable place to dabble in sprite editing. You can add eyebrows to the built-in player character or slightly reshape keys to fit your own tastes, and the result will still fit the "art style" of the built-in assets. Want to try making your own sprites from scratch? Go ahead! It's much easier to make something that looks nice when you don't have to worry about color or line weight or proportions or any of that stuff.
It's true that we're in an "indie" "boom" right now, and more game-making tools are available than ever before. A determined game developer can already choose from among dozens (hundreds?) of editors and engines and frameworks and toolkits and whatnot. But the operative word there is "determined". Not everyone has their heart set on this. The vast majority of people aren't interested in devoting themselves to making games, so the most they'd want to do (at first) is dabble.
But programming is a strange and complex art, where dabbling can be surprisingly difficult. If you want to try out art or writing or music or cooking or dance or whatever, you can usually get started with some very simple tools and a one-word Google search. If you want to try out game development, it usually requires programming, which in turn requires a mountain of upfront context and tool choices and explanations and mysterious incantations and forty-minute YouTube videos of some guy droning on in monotone.
To me, the magic of MegaZeux is that anyone with five minutes to spare can sit down, plop some objects around, and have made a thing.
MegaZeux has a lot of hidden features. It also has a lot of glass walls. Is that a phrase? It should be a phrase. I mean that it's easy to find yourself wanting to do something that seems common and obvious, yet find out quite abruptly that it's structurally impossible.
I'm not leading towards a conclusion here, only thinking out loud. I want to explain what makes MegaZeux interesting, but also explain what makes MegaZeux limiting, but also speculate on what might improve on it. So, you know, something for everyone.
MegaZeux is a top-down adventure-ish game engine. You can make platformers, if you fake your own gravity; you can make RPGs, if you want to build all the UI that implies.
MegaZeux games can only be played in, well, MegaZeux. Games that need instructions and multiple downloads to be played are fighting an uphill battle. It's a simple engine that seems reasonable to deploy to the web, and I've heard of a couple attempts at either reimplementing the engine in JavaScript or throwing the whole shebang at emscripten, but none are yet viable.
People have somewhat higher expectations from both games and tools nowadays. But approachability is often at odds with flexibility. The more things you explicitly support, the more complicated and intimidating the interface — or the more hidden features you have to scour the manual to even find out about.
I've looked through the advertising screenshots of Game Maker and RPG Maker, and I'm amazed how many things are all over the place at any given time. It's like trying to configure the old Mozilla Suite. Every new feature means a new checkbox somewhere, and eventually half of what new authors need to remember is the set of things they can safely ignore.
SLADE's Doom map editor manages to be much simpler, but I'm not particularly happy with that, either — it's not clever enough to save you from your mistakes (or necessarily detect them), and a lot of the jargon makes no sense unless you've already learned what it means somewhere else. Plus, making the most of ZDoom's extra features tends to involve navigating ten different text files that all have different syntax and different rules.
MegaZeux has your world, some menus with objects in them, and spacebar to place something. The UI is still very DOS-era, but once you get past that, it's pretty easy to build something.
How do you preserve that in something "modern"? I'm not sure. The only remotely-similar thing I can think of is Mario Maker, which cleverly hides a lot of customization options right in the world editor UI: placing wings on existing objects, dropping objects into blocks, feeding mushrooms to enemies to make them bigger. The downside is that Mario Maker has quite a lot of apocryphal knowledge that isn't written down anywhere. (That's not entirely a downside… but I could write a whole other post just exploring that one sentence.)
Graphics don't make the game, but they're a significant limiting factor for MegaZeux. Fixing everything to a grid means that even a projectile can only move one tile at a time. Only one character can be drawn per grid space, so objects can't usefully be drawn on top of each other. Animations are difficult, since they eat into your 255-character budget, which limits real-time visual feedback. Most individual objects are a single tile — creating anything larger requires either a lot of manual work to keep all the parts together, or the use of multi-tile sprites which don't quite exist on the board.
And yet! The same factors are what make MegaZeux very accessible. The tiles are small and simple enough that different art styles don't really clash. Using a grid means simple games don't have to think about collision detection at all. A monochromatic font can be palette-shifted, giving you colorful variants of the same objects for free.
How could you scale up the graphics but preserve the charm and approachability? Hmm.
I think the palette restrictions might be important here, but merely bumping from 2 to 8 colors isn't quite right. The palette-shifting in MegaZeux always makes me think of keys first, and multi-colored keys make me think of Chip's Challenge, where the key sprites were simple but lightly shaded.
The game has to contain all four sprites separately. If you wanted to have a single sprite and get all of those keys by drawing it in different colors, you'd have to specify three colors per key: the base color, a lighter color, and a darker color. In other words, a ramp — a short gradient, chosen from a palette, that can represent the same color under different lighting. Here are some PICO-8 ramps, for example. What about a sprite system that drew sprites in terms of ramps rather than individual colors?
I whipped up this crappy example to illustrate. All of the doors are fundamentally the same image, and all of them use only eight colors: black, transparent, and two ramps of three colors each. The top-left door could be expressed as just "light gray" and "blue" — those colors would be expanded into ramps automatically, and black would remain black.
I don't know how well this would work, but I'd love to see someone try it. It may not even be necessary to require all sprites be expressed this way — maybe you could import your own truecolor art if you wanted. ZDoom works kind of this way, though it's more of a historical accident: it does support arbitrary PNGs, but vanilla Doom sprites use a custom format that's in terms of a single global palette, and only that custom format can be subjected to palette manipulation.
Now, MegaZeux has the problem that small sprites make it difficult to draw bigger things like UI (or a non-microscopic player). The above sprites are 32×32 (scaled up 2× for ease of viewing here), which creates the opposite problem: you can't possibly draw text or other smaller details with them.
I wonder what could be done here. I know that the original Pokémon games have a concept of "metatiles": every map is defined in terms of 4×4 blocks of smaller tiles. You can see it pretty clearly on this map of Pallet Town. Each larger square is a metatile, and many of them repeat, even in areas that otherwise seem different.
I left the NPCs in because they highlight one of the things I found most surprising about this scheme. All the objects you interact with — NPCs, signs, doors, items, cuttable trees, even the player yourself — are 16×16 sprites. The map appears to be made out of 16×16 sprites, as well — but it's really built from 8×8 tiles arranged into bigger 32×32 tiles.
This isn't a particularly nice thing to expose directly to authors nowadays, but it demonstrates that there are other ways to compose tiles besides the obvious. Perhaps simple terrain like grass and dirt could be single large tiles, but you could also make a large tile by packing together several smaller tiles?
Text? Oh, text can just be a font.
MegaZeux has no HUD. To know how much health you have, you need to press Enter to bring up the pause menu, where your health is listed in a stack of other numbers like "gems" and "coins". I say "menu", but the pause menu is really a list of keyboard shortcuts, not something you can scroll through and choose items from.
To be fair, ZZT does reserve the right side of the screen for your stats, and it puts health at the top. I find myself scanning the MegaZeux pause menu for health every time, which seems a somewhat poor choice for the number that makes the game end when you run out of it.
Unlike most adventure games, your health is an integer starting at 100, not a small number of hearts or whatever. The only feedback when you take damage is a sound effect and an "Ouch!" at the bottom of the screen; you don't flinch, recoil, or blink. Health pickups might give you any amount of health, you can pick up health beyond 100, and nothing on the screen tells you how much you got when you pick one up. Keeping track of your health in your head is, ah, difficult.
MegaZeux also has a system of multiple lives, but those are also just a number, and the default behavior on "death" is for your health to reset to 100 and absolutely nothing else happens. Walking into lava (which hurts for 100 at a time) will thus kill you and strip you of all your lives quite rapidly.
It is possible to manually create a HUD in MegaZeux using the "overlay" layer, a layer that gets drawn on top of everything else in the world. The downside is that you then can't use the overlay for anything in-world, like roofs or buildings that can be walked behind. The overlay can be in multiple modes, one that's attached to the viewport (like a HUD) and one that's attached to the world (like a ceiling layer), so an obvious first step would be offering these as separate features.
An alternative is to use sprites, blocks of tiles created and drawn as a single unit by Robotic code. Sprites can be attached to the viewport and can even be drawn even above the overlay, though they aren't exposed in the editor and must be created entirely manually. Promising, if clumsy and a bit non-obvious — I only just now found out about this possibility by glancing at an obscure section of the manual.
Another looming problem is that text is the same size as everything else — but you generally want a HUD to be prominent enough to glance at very quickly.
This makes me wonder how more advanced drawing could work in general. Instead of writing code by hand to populate and redraw your UI, could you just drag and drop some obvious components (like "value of this number") onto a layer? Reuse the same concept for custom dialogs and menus, perhaps?
MegaZeux has no inventory. Or, okay, it has sort of an inventory, but it's all over the place.
The stuff in the pause menu is kind of like an inventory. It counts ammo, gems, coins, two kinds of bombs, and a variety of keys for you. The game also has multiple built-in objects that can give you specific numbers of gems and coins, which is neat, except that gems and coins don't do actually anything. I think they increase your score, but until now I'd forgotten that MegaZeux has a score.
A developer can also define six named "counters" (i.e., integers) that will show up on the pause menu when nonzero. Caverns of Zeux uses this to show you how many rainbow gems you've discovered… but it's just a number labeled RainbowGems, and there's no way to see which ones you have.
Other than that, you're on your own. All of the original Zeux games made use of an inventory, so this is a really weird oversight. Caverns of Zeux also had spellbooks, but you could only see which ones you'd found by trying to use them and seeing if it failed. Chronos Stasis has maybe a dozen items you can collect and no way to see which ones you have — though, to be fair, you use most of them in the same place. Forest of Ruin has a fairly standard inventory, but no way to view it. All three games have at least one usable item that they just bind to a key, which you'd better remember, because it's game-specific and thus not listed in the general help file.
To be fair, this is preposterously flexible in a way that a general inventory might not be. But it's also tedious for game authors and potentially confusing for players.
I don't think an inventory would be particularly difficult to support, and MegaZeux is already halfway there. Most likely, the support is missing because it would need to be based on some concept of a custom object, and MegaZeux doesn't have that either. I'll get to that in a bit.
Creating new objects
MegaZeux allows you to create "robots", objects that are controlled entirely through code you write in a simple programming language. You can copy and paste robots around as easily as any other object on the map. Cool.
What's less cool is that robots can't share code — when you place one, you make a separate copy of all of its code. If you create a small horde of custom monsters, then later want to make a change, you'll have to copy/paste all the existing ones. Hope you don't have them on other boards!
Some workarounds exist: you could make use of robots' ability to copy themselves at runtime, and it's possible to save or load code to/from an external file at runtime. More cumbersome than defining a template object and dropping it wherever you want, and definitely much less accessible.
This is really, really bad, because the only way to extend any of the builtin objects is to replace them with robots!
I'm a little spoiled by ZDoom, where you can create as many kinds of actor as you want. Actors can even inherit from one another, though the mechanism is a little limited and… idiosyncratic, so I wouldn't call it beginner-friendly. It's pretty nice to be able to define a type of monster or decoration and drop it all over a map, and I'm surprised such a thing doesn't exist in MegaZeux, where boards and the viewport both tend to be fairly large.
This is the core of how ZDoom's inventory works, too. I believe that inventories contain only kinds, not individual actors — that is, you can have 5 red keys, but the game only knows "5 of RedCard" rather than having five distinct RedCard objects. I'm sure part of the reason MegaZeux has no general-purpose inventory is that every custom object is completely distinct, with nothing fundamentally linking even identical copies of the same robot together.
By default, the player can shoot bullets by holding Space and pressing a direction. (Moving and shooting at the same time is… difficult.) Like everything else, bullets are fixed to the character grid, so they move an entire tile at a time.
Bullets can also destroy other projectiles, sometimes. A bullet hitting another bullet will annihilate both. A bullet hitting a fireball might either turn the fireball into a regular fire tile or simple be destroyed, depending on which animation frame the fireball is in when the bullet hits it. I didn't know this until someone told me only a couple weeks ago; I'd always just thought it was random and arbitrary and frustrating. Seekers can't be destroyed at all.
Most enemies charge directly at you; most are killed in one hit; most attack you by colliding with you; most are also destroyed by the collision.
The (built-in) combat is fairly primitive. It gives you something to do, but it's not particularly satisfting, which is unfortunate for an adventure game engine.
Several factors conspire here. Graphical limitations make it difficult to give much visual feedback when something (including the player) takes damage or is destroyed. The motion of small, fast-moving objects on a fixed grid can be hard to keep track of. No inventory means weapons aren't objects, either, so custom weapons need to be implemented separately in the global robot. No custom objects means new enemies and projectiles are difficult to create. No visual feedback means hitscan weapons are implausible.
I imagine some new and interesting directions would make themselves obvious in an engine with a higher resolution and custom objects.
Robotic is MegaZeux's programming language for defining the behavior of robots, and it's one of the most interesting parts of the engine. A robot that acts like an item giving you two keys might look like this:
: "touch"
* "You found two keys!"
givekey c04
die as an item
Robotic has no blocks, loops, locals, or functions — though recent versions can fake functions by using special jumps. All you get is a fixed list of a few hundred commands. It's effectively a form of bytecode assembly, with no manual assembling required.
And yet! For simple tasks, it works surprisingly well. Creating a state machine, as in the code above, is straightforward. end stops execution, since all robots start executing from their first line on start. : "touch" is a label (:"touch" is invalid syntax) — all external stimuli are received as jumps, and touch is a special label that a robot jumps to when the player pushes against it. * displays a message in the colorful status line at the bottom of the screen. givekey gives a key of a specific color — colors are a first-class argument type, complete with their own UI in the editor and an automatic preview of the particular colors. die as an item destroys the robot and simultaneously moves the player on top of it, as though the player had picked it up.
A couple other interesting quirks:
Most prepositions, articles, and other English glue words are semi-optional and shown in grey. The line die as an item above has as an greyed out, indicating that you could just type die item and MegaZeux would fill in the rest. You could also type die as item, die an item, or even die through item, because all of as, an, and through act like whitespace. Most commands sprinkle a few of these in to make themselves read a little more like English and clarify the order of arguments.
The same label may appear more than once. However, labels may be zapped, and a jump will always go to the first non-zapped occurrence of a label. This lets an author encode a robot's state within the state of its own labels, obviating the need for state-tracking variables in many cases. (Zapping labels predates per-robot variables — "local counters" — which are unhelpfully named local through local32.)
Of course, this can rapidly spiral out of control when state changes are more complicated or several labels start out zapped or different labels are zapped out of step with each other. Robotic offers no way to query how many of a label have been zapped and MegaZeux has no debugger for label states, so it's not hard to lose track of what's going on. Still, it's an interesting extension atop a simple label-based state machine.
The built-in types often have some very handy shortcuts. For example, GO [dir] # tells a robot to move in some direction, some number of spaces. The directions you'd expect all work: NORTH, SOUTH, EAST, WEST, and synonyms like N and UP. But there are some extras like RANDNB to choose a random direction that doesn't block the robot, or SEEK to move towards the player, or FLOW to continue moving in its current direction. Some of the extras only make sense in particular contexts, which complicates them a little, but the ability to tell an NPC to wander aimlessly with only RANDNB is incredible.
Robotic is more powerful than you might expect; it can change anything you can change in the editor, emulate the behavior of most other builtins, and make use of several features not exposed in the editor at all.
Nowadays, the obvious choice for an embedded language is Lua. It'd be much more flexible, to be sure, but it'd lose a little of the charm. One of the advantages of creating a totally custom language for a game is that you can add syntax for very common engine-specific features, like colors; in a general-purpose language, those are a little clumsier.
function myrobot:ontouch(toucher)
if not toucher.is_player then
world:showstatus("You found two keys!")
toucher.inventory:add(Key{color=world.colors.RED})
toucher.inventory:add(Key{color=world.colors.PURPLE})
self:die()
Changing the rules
MegaZeux has a couple kinds of built-in objects that are difficult to replicate — and thus difficult to customize.
One is projectiles, mentioned earlier. Several variants exist, and a handful of specific behaviors can be toggled with board or world settings, but otherwise that's all you get. It should be feasible to replicate them all with robots, but I suspect it'd involve a lot of subtleties.
Another is terrain. MegaZeux has a concept of a floor layer (though this is not explicitly exposed in the editor) and some floor tiles have different behavior. Ice is slippery; forest blocks almost everything but can be trampled by the player; lava hurts the player a lot; fire hurts the player and can spread, but burns out after a while. The trick with replicating these is that robots cannot be walked on. An alternative is to use sensors, which can be walked on and which can be controlled by a robot, but anything other than the player will push a sensor rather than stepping onto it. The only other approach I can think of is to keep track of all tiles that have a custom terrain, draw or animate them manually with custom floor tiles, and constantly check whether something's standing there.
Last are powerups, which are really effects that rings or potions can give you. Some of them are special cases of effects that Robotic can do more generally, such as giving 10 health or changing all of one object into another. Some are completely custom engine stuff, like "Slow Time", which makes everything on the board (even robots!) run at half speed. The latter are the ones you can't easily emulate. What if you want to run everything at a quarter speed, for whatever reason? Well, you can't, short of replacing everything with robots and doing a multiplication every time they wait.
ZDoom has a similar problem: it offers fixed sets of behaviors and powerups (which mostly derive from the commercial games it supports) and that's it. You can manually script other stuff and go quite far, but some surprisingly simple ideas are very difficult to implement, just because the engine doesn't offer the right kind of hook.
The tricky part of a generic engine is that a game creator will eventually want to change the rules, and they can only do that if the engine has rules for changing those rules. If the engine devs never thought of it, you're out of luck.
Someone else please carry on this legacy
MegaZeux still sees development activity, but it's very sporadic — the last release was in 2012. New features tend to be about making the impossible possible, rather than making the difficult easier. I think it's safe to call MegaZeux finished, in the sense that a novel is finished.
I would really like to see something pick up its torch. It's a very tricky problem, especially with the sprawling complexity of games, but surely it's worth giving non-developers a way to try out the field.
I suppose if ZZT and MegaZeux and ZDoom have taught us anything, it's that the best way to get started is to just write a game and give it very flexible editing tools. Maybe we should do that more. Maybe I'll try to do it with Isaac's Descent HD, and we'll see how it turns out.
ADIadsAdvertisingAIAllanonymousappARIAartArticlesATIauthBECBehaviorBETTbombsbookbooksbotsbugCCADcarCASCasecasescciChoicechromeciacodecommercialcontextCorecreativedeathDemodetDevelopersdevelopmentdisplaydoomdosdowndownloadsdrag and dropEASTedEdgeeffembeddedEnglishenvironmenteseteueventexpressfactfailfontFrameworkFungamegamedevgamesGeneralGogoogleGoogle searchgotGREHABhackedhealthICEiosIPiqirsISPissjavajavascriptkeyskitlieslightlightinglinkingLocksLTEMacMakemanamariomario makermediaMegaMICROSmitMoUmovmoveMozillamusicNCRNESnseOnlineoperaOperating SystemsORGOSSOtherpartypeoplephysicsPINPIRPlayPositionpowerproblemprogrammingprojectratrawReleaserestretrorobotrobotsROVRTIrunningS.scenescratchsensorsshedspaceSSLStarstatusstssupportSyncTAGtechthingsTodayToolstortouchtrackingtraptwitterUIupdatedUSUSTRUXvariablesvideovotingweaponswebwinWorkyoutubezero
AWS Week in Review – September 27, 2016
Post Syndicated from Jeff Barr original https://aws.amazon.com/blogs/aws/aws-week-in-review-september-27-2016/
Fourteen (14) external and internal contributors worked together to create this edition of the AWS Week in Review. If you would like to join the party (with the possibility of a free lunch at re:Invent), please visit the AWS Week in Review on GitHub.
The AWS Podcast released an episode interviewing Abby Fuller from Startup www.airtime.com.
The AWS Enterprise Blog talked about Getting Started with the Cloud.
The AWS Security Blog showed you How to Create a Custom AMI with Encrypted Amazon EBS Snapshots and Share It with Other Accounts and Regions.
The AWS Government, Education, & Nonprofits Blog wrote about Exatype: Cloud for HIV Drug Resistance Testing.
The Backspace Blog wrote about using CloudFront with next generation frameworks for dynamic data in Super Fast Dynamic Websites with CloudFront, EC2 and NodeJS – Part 1.
The A Cloud Guru blog wrote about AWS Certification: How many candidates will pass today?
Powerupcloud showed you how to Automate Multiple Domains Migration to Route53 using Nodejs.
Stelligent Blog wrote about One-Button Everything in AWS.
CloudCheckr wrote about Concrete Steps to Reduce Public Cloud IaaS Expenses.
Soenke Ruempler blogged about New AWS CloudFormation YAML syntax and variable substitution in action.
AWS Community Hero Eric Hammond provided a guide to deleting a Route 53 hosted zone and all DNS records using aws-cli.
The AWS Database Blog talked about Configuring the AWS Schema Conversion Tool (SCT).
Cloudadvisors wrote about Docker on AWS with ECS and ECR(Part 1).
Flux7 showed you How to Convert a CloudFormation Template from JSON to YAML.
We announced the M4.16xlarge Instance Type.
We announced that the Amazon Linux AMI 2016.09 is Now Available.
We shared the AWS Hot Startups for September 2016.
We announced the AWS Pop-up Loft and Innovation Lab in Munich.
Sander van de Graaf wrote about How to build a Serverless Screenshot Service with Lambda.
The AWS Startup Collection blog wrote about Serverless Architectures with Java 8, AWS Lambda, and Amazon DynamoDB in part 1 of their series.
The Batchly blog wrote about 4 points to consider in your spot bidding strategy.
The Concurrency Labs Blog wrote about How to Operate Reliable AWS Lambda Applications in Production.
Trainline Engineering wrote about Trainline Environment Manager.
The AWS Partner Network Blog wrote about The Evolution of Managed Services in Hyperscale Cloud Environments.
We announced the AWS Answers page for help architecting your solutions.
vBrownBag continues its AWS-SA Associate Certification Exam Study Webinar Series, this time covering Domain 4.0 with Zach Zeid of Ahead.
ParkMyCloud listed 5 Reasons to Turn Your Cloud Servers Off When You're Not Using Them.
Thinking Aloud discussed Securing SQL Server in EC2: Certificates, Ports, and Gotchas.
Parsec described The Technology Behind A Low Latency Cloud Gaming Service.
We announced that an AWS Region is Coming to France in 2017.
We launched the P2 Instance Type, with up to 16 GPUs.
We made an EC2 Reserved Instance Update, featuring Convertible RIs and a Regional Benefit.
We welcomed the Fall 2016 AWS Community Heroes.
We announced the First Annual Alexa Prize – $2.5 Million to Advance Conversational AI.
We announced that Amazon Cognito is Available in Asia Pacific (Seoul) and EU (Frankfurt) Regions.
Erik Meinders wrote a blog Serverless EC2 scheduler using Lambda and Cloudwatch events..
CloudHealth Technologies published a 2-part blog on the new RI types and features. This is Part 1.
Cloudadvisors wrote about Docker on AWS with ECS and ECR(Part 2)
The AWS Government, Education, & Nonprofits Blog wrote about Whiteboard with an SA: Tags.
We published The ISV Business Case for Building SaaS on Amazon Web Services (AWS), an August 2016 commissioned study conducted by Forrester Consulting on behalf of AWS.
Flux7 wrote A Review of AWS CloudFormation Cross-Stack References.
I advised you to Prepare for re:Invent 2016 by Attending our Upcoming Webinars.
We announced that Amazon Redshift has a New Data Type with Support for Time Zones in Time Stamps.
We announced that Amazon Elastic Transcoder is Now Available in the Asia Pacific (Mumbai) Region.
We enabled P2 instance support in CfnCluster. Details here.
The Customer Success Team at Cloudability explains how Amortizing Reserved Instance Costs Works, and why it can matter to your organization.
SingleStone Consulting wrote about secrets management in AWS with KMS and S3.
cloudonaut.io wrote about marbot, our submission to the AWS Serverless Chatbot Competition.
Andrej Kazakov wrote about Elasticsearch in AWS
Scott Johnson wrote a tutorial on how to use Ansible to automate installation of the CloudWatch Memory Monitoring scripts.
Colin Percival wrote about EC2-related improvements in the upcoming FreeBSD 11.0-RELEASE.
New & Notable Open Source
dynamodb-continuous-backup sets up continuous backup automation for DynamoDB.
lambda-billing uses NodeJS to automate billing to AWS tagged projects, producing PDF invoices.
vyos-based-vpc-wan is a complete Packer + CloudFormation + Troposphere powered setup of AMIs to run VyOS IPSec tunnels across multiple AWS VPCs, using BGP-4 for dynamic routing.
s3encrypt is a utility that encrypts and decrypts files in S3 with KMS keys.
lambda-uploader helps to package and upload Lambda functions to AWS.
AWS-Architect helps to deploy microservices to Lambda and API Gateway.
awsgi is an WSGI gateway for API Gateway and Lambda proxy integration.
rusoto is an AWS SDK for Rust.
EBS_Scripts contains some EBS tricks and triads.
landsat-on-aws is a web application that uses Amazon S3, Amazon API Gateway, and AWS Lambda to create an infinitely scalable interface to navigate Landsat satellite data.
New SlideShare Presentations
AWS Enterprise Summit Toronto:
Keynote – Future of Enterprise IT.
Getting Started with Amazon Aurora.
Getting Started with The Hybrid Cloud – Enterprise Backup and Recovery.
Cost Optimization at Scale.
Protecting Your Data in AWS.
Getting Started with Amazon Redshift.
DevOps on AWS – Deep Dive on Continuous Delivery.
DevOps on AWS – Deep Dive on Infrastructure as Code.
AWS Business Essentials.
Database Migration.
Getting Started with Amazon WorkSpaces.
Creating Your Virtual Data Center.
Breaking Down the Economics and TCO of Migrating to AWS.
Keeping Cloud Transformations on Track.
Getting Started with AWS Security.
Architecting Microservices on AWS.
Getting Started with Windows Workloads on EC2.
Another Day, Another Billion Packets.
AWS September 2016 Webinars:
AWS Services Overview.
Amazon Aurora New Features.
Building Real-Time Data Analytics Applications on AWS.
Getting Started with Managed Database Services on AWS.
Getting Started with AWS IoT.
Serverless Geospatial Mobile Apps with AWS.
Coding Apps in the Cloud to Reduce Costs up to 90%.
Addressing Amazon Inspector Assessment Findings.
Automating Compliance Defense in the Cloud.
Overview and Best Practices for Amazon Elastic Block Store.
AWS Infrastructure as Code.
Building a Recommendation Engine Using Amazon Machine Learning in Real-time.
Create Cloud Services on AWS.
Alexa IoT Skills Workshop.
Connecting to AWS IoT.
Best Practices of IoT in the Cloud.
Programming the Physical World with Device Shadows and Rules Engine.
Overview of IoT Infrastructure and Connectivity at AWS & Getting Started with AWS IoT.
Optimize Developer Agility & App Delivery on AWS.
The New Normal: Benefits of Cloud Computing and Defining your IT Strategy.
Security and Compliance.
New AWS Marketplace Listings
Application Development:
KloudGin Mobile and Web Cloud Platform, sold by KloudGin Inc
LAMP Stack With Virtualmin, sold by Aurora
SmartAMI SQLSplitter powered by MarioDB MaxScale, sold by AT-NET
WinDocks Community Edition with SQL Server 2014 Express (HVM), sold by Code Creator
Business Intelligence:
Simego Data Synchronisation Studio, sold by Simego Ltd
WebFOCUS Business User Edition, sold by Information Builders
Content Management:
Microsoft SharePoint Enterprise 2016 for AWS Business, sold by Data Resolution
CRM:
SuiteCRM powered by Symetricore, sold by Symetricore
FileMaker Cloud (5 users, 10 users, 25 users, 100 users, or BYOL), sold by Orbitera
Pivotal Greenplum Database (BYOL), sold by zData Inc.
HR:
Sentrifugo (HRMS), sold by Code Creator
Network Infrastructure:
FreePBX powered by Symetricore (Centos Edition), sold by Symetricore
Database Security and Compliance – On Demand, sold by HexaTier
October 6 (Hull, England) – AWS User Group Hull: Running Containerised Apps on AWS.
October 10 (Oslo, Norway) – AWS User Group Norway: Say Hello to Alexa!.
October 10 (Seoul, Korea) – AWS Partner-led Hands-on Labs.
October 11 (Redwood City, California, USA) – AWS Bay Area Meetup #21. A focus on Spinnaker from Netflix.
October 13 (Edinburgh, Scotland) – 7th AWS User Group Edinburgh Meetup.
October 13 (Seoul, Korea) – AWS Enterprise Summit.
October 13 (Warsaw, Poland) – Meetup of the Public Cloud User Group in Warsaw, Poland.
October 14 (Seoul, Korea) – AWS Lambda Zombie Workshop.
October 19 (Seoul, Korea) – AWS Korea User Group Monthly Seminar – Database Service.
October 26 (Cambridge, England) – Meetup #9 of the Cambridge AWS User Group: Everything Mobile.
October 26 (Dublin, Ireland) – Meetup #16 of the AWS User Group Network in Dublin.
November 23 (Cardiff, Wales) – Meetup #4 of the AWS South Wales User Group.
Linux Cloud Engineer at Red Wire Services (100% AWS Role, AWS Advanced Consulting Partner).
Teridion Sales Engineer (Cloud Optimized Routing for SaaS).
AWS Careers.
Stay tuned for next week! In the meantime, follow me on Twitter and subscribe to the RSS feed.
20142016about usadsAIALAAlexaAllamazonAmazon API GatewayAmazon AuroraAmazon CognitoAmazon DynamoDBAmazon Elastic Block StoreAmazon Elastic TranscoderAmazon InspectorAmazon Linux AMIAmazon RedshiftAmazon S3Amazon WorkSpacesAnalyticsapi gatewayappArchitectureARIAartasiaAsia PacificATIautomationAWSAWS CloudFormationAWS Community HeroesAWS IoTAWS LambdaAWS MarketplaceAWS Partner NetworkBest practicesblogBusinessCCaliCambridgecarCASCasecertificateschatciacloudcloud computingCloudWatchCloudWatch EventscodecodingcommunitycompetitionComplianceconversionCoreCurityCustomer SuccessdatadatabasedatabasesdetdevelopmentdevopsDNSDockerdomaindomainsdowndressdublinDynDynamoDBEC2ECSededucationejsEngineeringEnterpriseenvironmentEssentialseueventEventsFrameworkFrancefridaFungamingGatewayGitGithubGogotGovernmentGREhealthICEimprovementsinfrastructureinnovationinstallintelintelligenceinterviewIOTIPirelandirsissjavajsonkeyskorealambdalaunchlinuxMacmachine learningMakemanamarioMICROSmicrosoftmillionmitmobilemonitoringNCRNESNetflixNetworknodejsNorwayNPRnseopen sourceoperaORGOSSOtherpartyPINpowerprogrammingprojectProjectsproxyratReleaserestrorROVrsaRTIrunningS.S3securityseoserverserverssetupshedspacesqlStarstartupsstssupportSyncTAGtalkteamtechTechnologytestingTodaytorTutorialtwitterUIUnityUSutilityUXVPCwatchwebWeb appweb servicesWebinarswebsiteWeek in ReviewwinwindowsWorkwww
Monk Makes Puppet Kit
Post Syndicated from Alex Bate original https://www.raspberrypi.org/blog/monk-makes-puppet-kit/
A few weeks back, we were fortunate enough to be sent the Puppet Kit for Raspberry Pi, from our friend Simon Monk of Monk Makes. The kit shows you how to use your Raspberry Pi to take control of a traditional marionette, including controlling the puppet from your keyboard, recording stop-frame puppet movements, and setting the puppet up so that it waves when it detects movement.
Given my limited experience of physical computing with a Raspberry Pi, I decided to take on the challenge of completing the kit, and documented my journey through Snapchat.
Right out of the box, the kit feels as if it has been put together with care and thought. All wooden pieces have been laser cut, all components (apart from the Raspberry Pi itself) are provided, and the kit includes a step-by-step guide so foolproof that I felt confident I could complete the project.
The only issue?
My intense fear of clowns, which was instantly triggered when I opened the box and saw the puppet itself:
All the nope.
Despite my coulrophobia, I carried on with the build, because that's how much you all mean to me, dear readers. I do these things for you.
The guide walked me through the project, with clear instructions supported by photographs and diagrams. It was only when I reached Step 16, "Run the Test Code", that I realised I couldn't find a mouse. Fortunately I was able to enlist the aid of Ben Nuttall, who has become my Raspberry Pi hero in cases such as this.
Ben Nuttall is my hero
Ben helped me to set the Pi up on the Pi Towers local network, allowing me to feed Simon's code to the Pi via my MacBook. If you don't have access to Ben and his heroic abilities, you could use the recently mentioned PiBakery from the legendary David Ferguson to preset the network details into Raspbian before setting up your Raspberry Pi.
After this, setting up the walking functionality of the puppet, plus the additional sensor, was a breeze. With very little previous experience of using GPIO pins, servos, and nightmare-inducing clown puppets, I was somewhat taken aback by how easy I found the process. In fact, by the end, I had the clown dancing a merry jig and waving to anyone who passed. Cute, right?
Making a Waving Puppet – Snapchat Story
We recently got our hands on the Monk Makes Puppet Kit and decided to have Alex build it.. despite her complete lack of coding knowledge. Seriously… she knows nothing. She's the Jon Snow of Digital Making.
All in all, the kit was a wonderful experience and an interesting learning curve. Not only did it teach me the value of a well-executed and detailed maker kit, it also taught me the value of a Ben Nuttall, and helped me not to fear all clowns after having watched IT at a teenage slumber party like a fool!
*cries in a corner*
The post Monk Makes Puppet Kit appeared first on Raspberry Pi.
ADIAIAllappartBECbookCcarCASCasecaseschatcodecodingdaviddetDigitaldigital makingdocumentedEdgeesetfactFunGitGogotGPIOIPirsississuekitMacMakemariomitMoUmovmoveNetworknsepartypetsPINprojectraspberry piraspbianrestROVS.supportthingstorUIUncategorizedUSwatchwinWork
Graphical fidelity is ruining video games
Post Syndicated from Eevee original https://eev.ee/blog/2016/06/22/graphical-fidelity-is-ruining-video-games/
I'm almost 30, so I have to start practicing being crotchety.
Okay, maybe not all video games, but something curious has definitely happened here. Please bear with me for a moment.
Discovering Doom
Surprise! This is about Doom again.
Last month, I sat down and played through the first episode of Doom 1 for the first time. Yep, the first time. I've mentioned before that I was introduced to Doom a bit late, and mostly via Doom 2. I'm familiar with a decent bit of Doom 1, but I'd never gotten around to actually playing through any of it.
I might be almost unique in playing Doom 1 for the first time decades after it came out, while already being familiar with the series overall. I didn't experience Doom 1 only in contrast to modern games, but in contrast to later games using the same engine.
It was very interesting to experience Romero's design sense in one big chunk, rather than sprinkled around as it is in Doom 2. Come to think of it, Doom 1's first episode is the only contiguous block of official Doom maps to have any serious consistency: it sticks to a single dominant theme and expands gradually in complexity as you play through it. Episodes 2 and 3, as well of most of Doom 2, are dominated by Sandy Petersen's more haphazard and bizarre style. Episode 4 and Final Doom, if you care to count them, are effectively just map packs.
It was also painfully obvious just how new this kind of game was. I've heard Romero stress the importance of contrast in floor height (among other things) so many times, and yet Doom 1 is almost comically flat. There's the occasional lift or staircase, sure, but the spaces generally feel like they're focused around a single floor height with the occasional variation. Remember, floor height was a new thing — id had just finished making Wolfenstein 3D, where the floor and ceiling were completely flat and untextured.
The game was also clearly designed for people who had never played this kind of game. There was much more ammo than I could possibly carry; I left multiple shell boxes behind on every map. The levels were almost comically easy, even on UV, and I'm not particularly good at shooters. It was a very stark contrast to when I played partway through The Plutonia Experiment a few years ago and had to rely heavily on quicksaving.
Seeing Doom 1 from a Doom 2 perspective got me thinking about how design sensibilities in shooters have morphed over time. And then I realized something: I haven't enjoyed an FPS since Quake 2.
Or… hang on. That's not true. I enjoy Splatoon (except when I lose). I loved the Metroid Prime series. I played Team Fortress 2 for quite a while.
On the other hand, I found Half-Life 2 a little boring, I lost interest in Doom 3 before even reaching Hell, and I bailed on Quake 4 right around the extremely hammy spoiler plot thing. I loved Fallout, but I couldn't stand Fallout 3. Uncharted is pretty to watch, but looks incredibly tedious to play. I never cared about Halo. I don't understand the appeal of Counterstrike or Call of Duty.
If I made a collage of screenshots of these two sets of games, you'd probably spot the pattern pretty quickly. It seems I can't stand games with realistic graphics.
I have a theory about this.
The rise of realism
Quake introduced the world to "true" 3D — an environment made out of arbitrary shapes, not just floors and walls. (I'm sure there were other true-3D games before it, but I challenge you to name one off the top of your head.)
Before Quake, games couldn't even simulate a two-story building, which ruled out most realistic architecture. Walls that slid sideways were virtually unique to Hexen (and, for some reason, the much earlier Wolfenstein 3D). So level designers built slightly more abstract spaces instead. Consider this iconic room from the very beginning of Doom's E1M1.
What is this room? This is supposed to be a base of some kind, but who would build this room just to store a single armored vest? Up a flight of stairs, on a dedicated platform, and framed by glowing pillars? This is completely ridiculous.
But nobody thinks like that, and even the people who do, don't really care too much. It's a room with a clear design idea and a clear gameplay purpose: to house the green armor. It doesn't matter that this would never be a real part of a base. The game exists in its own universe, and it establishes early on that these are the rules of that universe. Sometimes a fancy room exists just to give the player a thing.
At the same time, the room still resembles a base. I can take for granted, in the back of my head, that someone deliberately placed this armor here for storage. It's off the critical path, too, so it doesn't quit feel like it was left specifically for me to pick up. The world is designed for the player, but it doesn't feel that way — the environment implies, however vaguely, that other stuff is going on here.
Fast forward twenty years. Graphics and physics technology have vastly improved, to the point that we can now roughly approximate a realistic aesthetic in real-time. A great many games thus strive to do exactly that.
And that… seems like a shame. The better a game emulates reality, the less of a style it has. I can't even tell Call of Duty and Battlefield apart.
That's fine, though, right? It's just an aesthetic thing. It doesn't really affect the game.
It totally affects the game
Everything looks the same
"Realism" generally means "ludicrous amounts of detail" — even moreso if the environments are already partially-destroyed, which is a fairly common trope I'll be touching on a lot here.
When everything is highly-detailed, screenshots may look very good, but gameplay suffers because the player can no longer tell what's important. The tendency for everything to have a thick coating of sepia certainly doesn't help.
Look at that Call of Duty screenshot again. What in this screenshot is actually important? What here matters to you as a player? As far as I can tell, the only critical objects are:
Your current weapon
That's it. The rocks and grass and billboards and vehicles and Hollywood sign might look very nice (by which I mean, "look like those things look"), but they aren't important to the game at all. This might as well be a completely empty hallway.
To be fair, I haven't played the game, so for all I know there's a compelling reason to collect traffic cones. Otherwise, this screenshot is 100% noise. Everything in it serves only to emphasize that you're in a realistic environment.
Don't get me wrong, setting the scene is important, but something has been missed here. Detail catches the eye, and this screenshot is nothing but detail. None of it is relevant. If there were ammo lying around, would you even be able to find it?
Ah, but then, modern realistic games either do away with ammo pickups entirely or make them glow so you can tell they're there. You know, for the realism.
(Speaking of glowing: something I always found ridiculous was how utterly bland the imp fireballs look in Doom 3 and 4. We have these amazing lighting engines, and the best we can do for a fireball is a solid pale orange circle? How do modern fireballs look less interesting than a Doom 1 fireball sprite?)
Even Fallout 2 bugged me a little with this; the world was full of shelves and containers, but it seemed almost all of them were completely empty. Fallout 1 had tons of loot waiting to be swiped from shelves, but someone must've decided that was a little silly and cut down on it in Fallout 2. So then, what's the point of having so many shelves? They encourage the player to explore, then offer no reward whatsoever most of the time.
Environments are boring and static
Fallout 3 went right off the rails, filling the world with tons of (gray) detail, none of which I could interact with. I was barely finished with the first settlement before I gave up on the game because of how empty it felt. Everywhere was detailed as though it were equally important, but most of it was static decorations. From what I've seen, Fallout 4 is even worse.
Our graphical capabilities have improved much faster than our ability to actually simulate all the junk we're putting on the screen. Hey, there's a car! Can I get in it? Can I drive it? No, I can only bump into an awkwardly-shaped collision box drawn around it. So what's the point of having a car, an object that — in the real world — I'm accustomed to being able to use?
And yet… a game that has nothing to do with driving a car doesn't need you to be able to drive a car. Games are games, not perfect simulations of reality. They have rules, a goal, and a set of things the player is able to do. There's no reason to make the player able to do everything if it has no bearing on what the game's about.
This puts "realistic" games in an awkward position. How do they solve it?
One good example that comes to mind is Portal, which was rendered realistically, but managed to develop a style from the limited palette it used in the actual play areas. It didn't matter that you couldn't interact with the world in any way other than portaling walls and lifting cubes, because for the vast majority of the game, you only encountered walls and cubes! Even the "behind the scenes" parts at the end were mostly architecture, not objects, and I'm not particularly bothered that I can't interact with a large rusty pipe.
The standouts were the handful of offices you managed to finagle your way into, which were of course full of files and computers and other desktop detritus. Everything in an office is — necessarily! — something a human can meaningfully interact with, but the most you can do in Portal is drop a coffee cup on the floor. It's all the more infuriating if you consider that the plot might have been explained by the information in those files or on those computers. Portal 2 was in fact a little worse about this, as you spent much more time outside of the controlled test areas.
I think Left 4 Dead may have also avoided this problem by forcing the players to be moving constantly — you don't notice that you can't get in a car if you're running for your life. The only time the players can really rest is in a safe house, which are generally full of objects the players can pick up and use.
Progression feels linear and prescripted
Ah, but the main draw of Portal is one of my favorite properties of games: you could manipulate the environment itself. It's the whole point of the game, even. And it seems to be conspicuously missing from many modern "realistic" games, partly because real environments are just static, but also in large part because… of the graphics!
Rendering a very complex scene is hard, so modern map formats do a whole lot of computing stuff ahead of time. (For similar reasons, albeit more primitive ones, vanilla Doom can't move walls sideways.) Having any of the environment actually move or change is thus harder, so it tends to be reserved for fancy cutscenes when you press the button that lets you progress. And because grandiose environmental changes aren't very realistic, that button often just opens a door or blows something up.
It feels hamfisted, like someone carefully set it all up just for me. Obviously someone did, but the last thing I want is to be reminded of that. I'm reminded very strongly of Half-Life 2, which felt like one very long corridor punctuated by the occasional overt physics puzzle. Contrast with Doom, where there are buttons all over the place and they just do things without drawing any particular attention to the results. Mystery switches are sometimes a problem, but for better or worse, Doom's switches always feel like something I'm doing to the game, rather than the game waiting for me to come along so it can do some preordained song and dance.
I miss switches. Real switches, not touchscreens. Big chunky switches that take up half a wall.
It's not just the switches, though. Several of Romero's maps from episode 1 are shaped like a "horseshoe", which more or less means that you can see the exit from the beginning (across some open plaza). More importantly, the enemies at the exit can see you, and will be shooting at you for much of the level.
That gives you choices, even within the limited vocabulary of Doom. Do you risk wasting ammo trying to take them out from a distance, or do you just dodge their shots all throughout the level? It's up to you! You get to decide how to play the game, naturally, without choosing from a How Do You Want To Play The Game menu. Hell, Doom has entire speedrun categories focused around combat — Tyson for only using the fist and pistol, pacifist for never attacking a monster at all.
You don't see a lot of that any more. Rendering an entire large area in a polygon-obsessed game is, of course, probably not going to happen — whereas the Doom engine can handle it just fine. I'll also hazard a guess and say that having too much enemy AI going at once and/or rendering too many highly-detailed enemies at once is too intensive. Or perhaps balancing and testing multiple paths is too complicated.
Or it might be the same tendency I see in modding scenes: the instinct to obsessively control the player's experience, to come up with a perfectly-crafted gameplay concept and then force the player to go through it exactly as it was conceived. Even Doom 4, from what I can see, has a shocking amount of "oh no the doors are locked, kill all the monsters to unlock them!" nonsense. Why do you feel the need to force the player to shoot the monsters? Isn't that the whole point of the game? Either the player wants to do it and the railroading is pointless, or the player doesn't want to do it and you're making the game actively worse for them!
Something that struck me in Doom's E1M7 was that, at a certain point, you run back across half the level and there are just straggler monsters all over the place. They all came out of closets when you picked up something, of course, but they also milled around while waiting for you to find them. They weren't carefully scripted to teleport around you in a fixed pattern when you showed up; they were allowed to behave however they want, following the rules of the game.
Whatever the cause, something has been lost. The entire point of games is that they're an interactive medium — the player has some input, too.
Exploration is discouraged
I haven't played through too many recent single-player shooters, but I get the feeling that branching paths (true nonlinearity) and sprawling secrets have become less popular too. I've seen a good few people specifically praise Doom 4 for having them, so I assume the status quo is to… not.
That's particularly sad off the back of Doom episode 1, which has sprawling secrets that often feel like an entire hidden part of the base. In several levels, merely getting outside qualifies as a secret. There are secrets within secrets. There are locked doors inside secrets. It's great.
And these are real secrets, not three hidden coins in a level and you need to find so many of them to unlock more levels. The rewards are heaps of resources, not a fixed list of easter eggs to collect. Sometimes they're not telegraphed at all; sometimes you need to do something strange to open them. Doom has a secret you open by walking up to one of two pillars with a heart on it. Doom 2 has a secret you open by run-jumping onto a light fixture, and another you open by "using" a torch and shooting some eyes in the wall.
I miss these, too. Finding one can be a serious advantage, and you can feel genuinely clever for figuring them out, yet at the same time you're not permanently missing out on anything if you don't find them all.
I can imagine why these might not be so common any more. If decorating an area is expensive and complicated, you're not going to want to build large areas off the critical path. In Doom, though, you can make a little closet containing a powerup in about twenty seconds.
More crucially, many of the Doom secrets require the player to notice a detail that's out of place — and that's much easier to set up in a simple world like Doom. In a realistic world where every square inch is filled with clutter, how could anyone possibly notice a detail out of place? How can a designer lay any subtle hints at all, when even the core gameplay elements have to glow for anyone to pick them out from background noise?
This might be the biggest drawback to extreme detail: it ultimately teaches the player to ignore the detail, because very little of it is ever worth exploring. After running into enough invisible walls, you're going to give up on straying from the beaten path.
We wind up with a world where players are trained to look for whatever glows, and completely ignore everything else. At which point… why are we even bothering?
There are no surprises
"Realistic" graphics mean a "realistic" world, and let's face it, the real world can be a little dull. That's why we invented video games, right?
Doom has a very clear design vocabulary. Here are some demons. They throw stuff at you; don't get hit by it. Here are some guns, which you can all hold at once, because those are the rules. Also here's a glowing floating sphere that gives you a lot of health.
What is a megasphere, anyway? Does it matter? It's a thing in the game with very clearly-defined rules. It's good; pick it up.
You can't do that in a "realistic" game. (Or maybe you can, but we seem to be trying to avoid it.) You can't just pick up a pair of stereoscopic glasses to inexplicably get night vision for 30 seconds; you need to have some night-vision goggles with batteries and it's a whole thing. You can't pick up health kits that heal you; you have to be wearing regenerative power armor and pick up energy cells. Even Doom 4 seems to be uncomfortable leaving brightly flashing keycards lying around — instead you retrieve them from the corpses of people wearing correspondingly-colored armor.
Everything needs an explanation, which vastly reduces the chances of finding anything too surprising or new.
I'm told that Call of Duty is the most popular vidya among the millenials, so I went to look at its weapons:
Fast gun
Long gun
Different gun
How exciting! If you click through each of those gun categories, you can even see the list of unintelligible gun model numbers, which are exactly what gets me excited about a game.
I wonder if those model numbers are real or not. I'm not sure which would be worse.
So my problem is that striving for realism is incredibly boring and counter-productive. I don't even understand the appeal; if I wanted reality, I could look out my window.
"Realism" actively sabotages games. I can judge Doom or Mario or Metroid or whatever as independent universes with their own rules, because that's what they are. A game that's trying to mirror reality, I can only compare to reality — and it'll be a very pale imitation.
It comes down to internal consistency. Doom and Team Fortress 2 and Portal and Splatoon and whatever else are pretty upfront about what they're offering: you have a gun, you can shoot it, also you can run around and maybe press some buttons if you're lucky. That's exactly what you get. It's right there on the box, even.
Then I load Fallout 3, and it tries to look like the real world, and it does a big song and dance asking me for my stats "in-world", and it tries to imply I can roam this world and do anything I want and forge my own destiny. Then I get into the game, and it turns out I can pretty much just shoot, pick from dialogue trees, and make the occasional hamfisted moral choice. The gameplay doesn't live up to what the environment tried to promise. The controls don't even live up to what the environment tried to promise.
The great irony is that "realism" is harshly limiting, even as it grows ever more expensive and elaborate. I'm reminded of the Fat Man in Fallout 3, the gun that launches "mini nukes". If that weapon had been in Fallout 1 or 2, I probably wouldn't think twice about it. But in the attempted "realistic" world of Fallout 3, I have to judge it as though it were trying to be a real thing — because it is! — and that makes it sound completely ridiculous.
(It may sound like I'm picking on Fallout 3 a lot here, but to its credit, it actually had enough stuff going on that it stands out to me. I barely remember anything about Doom 3 or Quake 4, and when I think of Half-Life 2 I mostly imagine indistinct crumbling hallways or a grungy river that never ends.)
I've never felt this way about series that ignored realism and went for their own art style. Pikmin 3 looks very nice, but I never once felt that I ought to be able to do anything other than direct Pikmin around. Metroid Prime looks great too and has some "realistic" touches, but it still has a very distinct aesthetic, and it manages to do everything important with a relatively small vocabulary — even plentiful secrets.
I just don't understand the game industry (and game culture)'s fanatical obsession with realistic graphics. They make games worse. It's entirely possible to have an art style other than "get a lot of unpaid interns to model photos of rocks", even for a mind-numbingly bland army man simulator. Please feel free to experiment a little more. I would love to see more weird and abstract worlds that follow their own rules and drag you down the rabbit hole with them.
ADIAIAllamfappArchitectureARIAartATIBECBETTbugCCADcarCASCaseChoiceciacomicComputersContainerscultureDemodesigndesktopdoomdownEASTedeffenvironmentfactflashgamedevgamesGeneralGogothealthhollyhollywoodICEindustryInsideintelIPiqirsisslaunchLawlieslightingMakemarioMegamitMoUmovmoveMPANCRNESnseofficeOnlineORGOSSOtherphysicsPlayPositionpowerproblemratrawresourcesrestrorROVrunningS.sabotagespacestatusstorageStrikestsTAGtechTechnologytestingthingstorUIUKUSUSTRvideowin
Post Syndicated from Eevee original https://eev.ee/blog/2016/06/12/one-year-later/
A year ago today was my last day working a tech job.
What I didn't do
I think I spent the first few months in a bit of a daze. I have a bad habit of expecting worst case scenarios, so I was in a constant state of mild panic over whether I could really earn enough to support myself. Not particularly conducive to doing things.
There was also a very striking change in… people scenery? Working for a tech company, even remotely, meant that I spent much of my time talking to a large group of tech-minded people who knew the context behind things I was working on. Even if they weren't the things I wanted to be working on, I could at least complain about an obscure problem and expect to find someone who understood it.
Suddenly, that was gone. I know some tech people, of course, and have some tech followers on Twitter, but those groups are much more heterogenous than a few dozen people all working on the same website. It was a little jarring.
And yet, looking back, I suspect that feeling had been fading for some time. I'd been working on increasingly obscure projects for Yelp, which limited how much I could really talk to anyone about them. Towards the end I was put on a particularly thorny problem just because I was the only person who knew anything about it at all. I spent a few weeks hammering away at this thing that zero other people understood, that I barely understood myself, that I didn't much enjoy doing, and that would ultimately just speed deployments up by a few minutes.
When I left, I had a lot of ideas for the kinds of things I wanted to do with all this newfound free time. Most of them were "pure" programming ideas: design and implement a programming language, build a new kind of parser, build a replacement for IRC, or at least build a little IRC bot framework.
I ended up doing… none of those! With more time to do things, rather than daydream restlessly about doing things, I discovered that building libraries and infrastructure is incredibly tedious and unrewarding. (For me, I mean. If that's your jam, well, I'm glad it's someone's.)
I drifted for a little while as I came to terms with this, trying to force myself to work on these grandiose dreams. Ultimately, I realized that I most enjoy programming when it's a means to an end, when there's a goal beyond "write some code to do this". Hence my recent tilt towards game development, where the code is just one part of a larger whole.
And, crucially, that larger whole is something that everyone can potentially enjoy. The difference has been night and day. I can tweet a screenshot of a text adventure and catch several people's interest. On the other hand, a Python library for resizing images? Who cares? It's not a complete thing; it's a building block, a tool. At worst, no one ever uses it, and I have nothing to show for the time. Even at best, well… let's just say the way programmers react to technical work is very different from the way everyone else reacts to creative work.
I do still like building libraries on occasion, but my sights are much smaller now. I may pick up sanpera or dywypi again, for instance, but I think that's largely because other people are already using them to do things. I don't have much interest in devoting months to designing and building a programming language that only a handful of PLT nerds will even look at, when I could instead spend a day and a half making a Twitter bot that posts random noise and immediately have multiple people tell me it's relaxing or interesting.
In short, I've learned a lot about what's important to me!
Ah, yes, I also thought I would've written a book by now. I, uh, haven't. Writing a book apparently takes a lot more long-term focus than I tend to have available. It also requires enough confidence in a single idea to write tens of thousands of words about it, and that doesn't come easily either. I've taken a lot of notes, written a couple short drafts, and picked up a bit of TeX, so it's still on the table, but I don't expect any particular timeframe.
What I did do
Argh, this is going to overlap with my birthday posts. But:
I wrote a whopping 43 blog posts, totalling just over 160,000 words. That's two or three novels! Along the way, my Patreon has more than tripled to a level that's, well, more reassuring. Thank you so much, everyone who's contributed — I can't imagine a better compliment than discovering that people are willing to directly pay me to keep writing and making whatever little strange things I want.
I drew a hell of a lot. My progress has been documented elsewhere, but suffice to say, I've come a long way. I also expanded into a few new media over this past year: watercolors, pixel art, and even a teeny bit of animation.
I made some games. The release of Mario Maker was a really nice start — I could play around with level design ideas inside a world with established gameplay and let other people play them fairly easily. Less seriously, I made Don't Eat the Cactus, which was microscopic but ended up entertaining a surprising number of people — that's made me rethink my notions of what a game even needs to be. I made a Doom level, and released it, for the first time. Most recently, of course, Mel and I made Under Construction, a fully-fledged little pixel game. I've really enjoyed this so far, and I have several more small things going at the moment.
The elephant in the room is perhaps Runed Awakening, the text adventure I started almost two years ago. It was supposed to be a small first game, but it's spiraled a little bit out of hand. Perhaps I underestimated text adventures. A year ago, I wasn't really sure where the game was going, and the ending was vague and unsatisfying; now there's a clear ending, a rough flow through the game, and most importantly enough ideas to see it through from here. I've rearchitected the entire world, added a few major NPCs, added core mechanics, added scoring, added a little reward for replaying, added several major areas, implemented some significant puzzles, and even made an effort to illustrate it. There's still quite a lot of work left, but I enjoy working on it and I'm excited about the prospect of releasing it.
I did more work on SLADE while messing around with Doom modding, most notably adding support for ZDoom's myriad kinds of slopes. I tracked down and fixed a lot of bugs with editing geometry, which is a really interesting exercise and a challenging problem, and I've fixed dozens of little papercuts. I've got a few major things in progress still: support for 3D floors is maybe 70% done, support for lock types is about 70% done. Oh, yes, and I started on a static analyzer for scripts, which is a fantastic intersection of "pure programming" and "something practical that people could make use of". That's maybe 10% done and will take a hell of a lot of work, but boy would it be great to see.
I improved spline (the software powering Floraverse) more than I'd realized: arbitrarily-nested folders, multiple media per "page", and the revamped archives were all done this past year. I used the same library to make Mel a simple site, too. It's still not something I would advise other people run, but I did put a modicum of effort into documenting it and cleaning up some general weirdness, and I made my own life easier by migrating everything to runit.
veekun has languished for a while, but fear not, I'm still working on it. I wrote brand new code to dump (most of) RBY from scratch, using a YAML schema instead of a relational database, which has grown increasingly awkward to fit all of Pokémon's special cases into. I still hope to revamp the site based on this idea in time for Sun and Moon. I also spent a little time modernizing the pokedex library itself, most notably making it work with Python 3.
I wrote some other code, too. Camel was an idea I'd had for a while, and I just sat down and wrote it over the course of a couple days, and I'm glad I did. I rewrote PARTYMODE. I did another round of heteroglot. I fixed some bugs in ZDoom. I sped Quixe (a JavaScript interpreter for some text adventures) up by 10% across the board. I wrote some weird Twitter bots. I wrote a lot of one-off stuff for various practical purposes, some of it abandoned, some of it used once and thrown away.
Is that a lot? It doesn't even feel like a lot. I want to do just as much again by the end of the year. I guess we'll see how that goes.
Some things people said
Not long after my original post made the rounds, I was contacted by a Vox editor who asked if I'd like to expand my post into an article. A paid article! I thought that sounded fantastic, and could even open the door to more paid writing. I spent most of a week on it.
It went up with the title "I'm 28, I just quit my tech job, and I never want another job again" and a hero image of fists slamming a keyboard. I hadn't been asked or told about either, and only found out by seeing the live page. I'd even given my own title; no idea what happened to that, or to the byline I wrote.
I can't imagine a more effective way to make me sound like a complete asshole. I barely remember how the article itself was phrased; I could swear I tried to adapt to a broader and less personal audience, but I guess I didn't do a very good job, and I'm too embarrassed to go look at it now.
I found out very quickly, via some heated Twitter responses, that it looks even worse without the context of "I wrote this in my blog and Vox approached me to publish it". It hadn't even occurred to me that people would assume writing an article for a news website had been my idea, but of course they would. Whoops. In the ensuing year, I've encountered one or two friends of friends who proactively blocked me just over that article. Hell, I'd block me too.
I don't think I want to do any more writing where I don't have final editorial control.
I bring this up because there have been some wildly differing reactions to what I wrote, and Vox had the most drastic divide. A lot of people were snarky or angry. But just as many people contacted me, often privately, to say they feel the same way and are hoping to quit their jobs in the future and wish me luck.
It's the money, right? You're not supposed to talk about money, but I'm an idiot and keep doing it anyway.
I don't want anyone to feel bad. I tried, actively, not to say anything wildly insensitive, in both the original post and the Vox article. I know a lot of people hate their jobs, and I know most people can't afford to quit. I wish everyone could. I'd love to see a world where everyone could do or learn or explore or make all the things they wanted. Unfortunately, my wishes have no bearing on how the system works.
I suspect… people have expectations. The American Dream™ is to get a bunch of money, at which point you win and can be happy forever.
I had a cushy well-paying job, and I wasn't happy. That's not how it's supposed to work. Yet if anything, the money made me more unhappy, by keeping me around longer.
People like to quip that money can't buy happiness. I think that's missing the point. Money can remove sadness, but only if that sadness is related to not having enough money. My problem was not having enough time.
I was tremendously lucky to have stock options and to be able to pay off the house, but those things cancelled each other out. The money was finite, and I spent it all at once. Now it's gone, and I still have bills, albeit fewer of them. I still need to earn income, or I'll run out of money for buying food and internets.
I make considerably less now. I'm also much, much happier.
I don't know why I feel the need to delve so deeply into this. The original post happened to hit lobste.rs a few days ago, and there were a couple "what a rich asshole" comments, which reminded me of all this. They were subtly weird to read, as though they were about an article from a slightly different parallel universe. I was reminded that many of the similar comments from a year ago had a similar feel to them.
If you think I'm an asshole because I've acted like an asshole, well, that's okay. I try not to, and I'll try to be better next time, but sometimes I fuck up.
If you think I'm an asshole because I pitched a whiny article to Vox about how one of the diamond lightbulbs in my Scrooge McDuck vault went out, damn. It bugs me a little to be judged as a carciature with little relation to what I've actually done.
To the people who ask me for advice
Here's a more good comment:
The first week was relaxing, productive, glorious. Then I passed the midpoint and saw the end of my freedom looming on the horizon. Gloom descended once more.
I thought I was the only one, who felt like this. I see myself in everything [they] describe. I just don't have the guts to try and sell my very own software as a full time thing.
I like to liberally license everything I do, and I fucking hate advertising and will never put it on anything I control
It's almost as if that [person] is me, with a different name, and cuter website graphics.
First of all, thank you! I have further increased the cuteness of my website graphics since this comment. I hope you enjoy.
I've heard a lot of this over the past year. A lot. There are a shocking number of people in tech who hate being in tech, even though we all get paid in chests full of gold doubloons.
A decent number of them also asked for my input. What should they do? Should they also quit? Should they switch careers?
I would like to answer everyone, once and for all, by stressing that I have no idea what I'm doing. I don't know anything. I'm not a renowned expert in job-quitting or anything.
I left because, ultimately, I had to. I was utterly, utterly exhausted. I'd been agonizing over it for almost a year prior, but had stayed because I didn't think I could pull it off. I was terrified of failure. Even after deciding to quit, I'd wanted to stay another six months and finish out the year. I left when I did because I was deteriorating.
I hoped I could make it work, Mel told me I could make it work, and I had some four layers of backup plans. I still might've failed, and every backup plan might've failed. I didn't. But I could've.
I can't tell you whether it's a good decision to quit your job to backpack through Europe or write that screenplay you've always wanted to write. I could barely tell myself whether this was a good idea. I'm not sure I'd admit to it even now. I can't decide your future for you.
On the other hand, if you're just looking for someone to tell you what you want to hear, what you've already decided…
Well, let's just say you'd know better than I would.
ADIAdvertisingAIAllappartATIBECBETTbirthdayblogbookbugCcarCASCasecasescodecontextcreativedatadatabasedesigndevelopmentdocumentdoomdowndpEASTedEdgeEditorialeffeuEuropefailfoodgamesGeneralGogotHABhiveICEinfrastructureInsideinternetIOTIPirsissjavajavascriptJobslibrariesMakemariomario makermediamitmovmoveMPANCRNESnewsNSAnseOSSOtherpartypatreonpersonalPIRPlaypowerproblemprogrammingpythonratReleaserestROVruned awakeningS.scratchsoftwaresshSSLstssupporttalktechTechnicalthingsTodaytortwitterUIUSUSTRveekunvotingwebwebsitewinWork
Weekly roundup: spring cleaning
Post Syndicated from Eevee original https://eev.ee/dev/2016/06/06/spring-cleaning/
June's theme is, ah, clearing my plate! Yes, we'll try that again; I have a lot of minor (and not-so-minor) todos that have been hanging over my head for a long time, and I'd like to clear some of them out. I also want to do DUMP 3 and make a significant dent in Runed Awakening, so, busy busy.
blog: I published a very fancy explanation of Perlin noise, using a lot of diagrams and interactive things I'd spent half the previous week making, but it came out pretty cool! I also wrote about how I extracted our game's soundtrack from the PICO-8. And I edited and published a two-year-old post about how I switched Yelp from tabs to spaces! I am on a roll and maybe won't have to write three posts in the same week at the end of the month this time.
I did a bit of work on the site itself, too. I linked my Mario Maker levels on the projects page. I fixed a PARTYMODE incompatibility with Edge, because I want my DHTML confetti to annoy as many people as possible. I fixed a silly slowdown with my build process. And at long last, I fixed the cruft in the titles of all my Disqus threads.
gamedev: I wrote a hecka bunch of notes for Mel for a… thing… that… we may or may not end up doing… but that would be pretty cool if we did.
patreon: I finally got my Pokémon Showdown adapter working well enough to write a very bad proof of concept battle bot for Sketch, which you can peruse if you really want to. I had some fun asking people to fight the bot, which just chooses moves at complete random and doesn't understand anything about the actual game. It hasn't won a single time. Except against me, when I was first writing it, and also choosing moves at complete random.
I rewrote my Patreon bio, too; now it's a bit more concrete and (ahem) better typeset.
doom: I started on three separate ideas for DUMP 3 maps, though I'm now leaning heavily in favor of just one of them. (I'd like to continue the other two some other time, though.) I did a few hours of work each day on it, and while I'm still in the creative quagmire of "what the heck do I do with all this space", it's coming along. I streamed some of the mapping, which I've never done before, and which the three people still awake at 3am seemed to enjoy.
SLADE: I can't do any Doom mapping without itching to add things to SLADE. I laid some groundwork for supporting multiple tags per sector, but that got kinda boring, so I rebased my old 3D floors branch and spruced that up a lot. Fixed a heckton of bugs in it and added support for some more features. Still a ways off, but it's definitely getting there.
art: I drew a June avatar! "Drew" might be a strong word, since I clearly modified it from my April/May avatar, but this time I put a lot of effort (and a lot of bugging Mel for advice) into redoing the colors from scratch, and I think it looks considerably better.
spring cleaning: Sorted through some photos (i.e. tagged which cats were in them), closed a few hundred browser tabs, and the like.
Wow, that's a lot of things! I'm pretty happy about that; here's to more things!
adsAIAllappartATIBECBETTblogbugCcatscreativedoomdownedEdgeeffFungamedevGogothtmlICEIPirsMakemappingmariomario makermovmoveMPANCROSSOtherpartypatreonperlratruned awakeningS.scratchspacestatusstssupportthingstorUIUSwdWorkWOW
Post Syndicated from Eevee original https://eev.ee/dev/2016/06/06/weekly-roundup-spring-cleaning/
adsAIAllapparinartATIBECBETTblogbugBugsCcatscreativedoomdownedEdgeeffFungamedevGogothtmlICEIPirsMakemappingmariomario makermovmoveMPANCROSSOtherpartypatreonperlratruned awakeningS.scratchspacestatusstssupportTAGthingstorUIUSwdWorkWOW
Biweekly roundup: doubling down
Post Syndicated from Eevee original https://eev.ee/dev/2016/03/20/weekly-roundup-doubling-down/
March's theme is video games, I guess?
It's actually been two weeks since the last roundup, but there's an excellent reason for that!
doom: As previously mentioned, someone started a "just get something done" ZDoom mapping project, so I made a map! I spent a solid seven days doing virtually nothing but working on it. And it came out pretty fantastically, I think. The final project is still in a bug-fixing phase, but I'll link it when it's done.
blog: I wrote about how maybe we could tone down the JavaScript, and it was phenomenally popular. People are still linking it anew on Twitter. That's pretty cool. I also wrote a ton of developer commentary for my Doom map, which I'll finish in the next few days and publish once the mapset is actually released. And I combed through my Doom series to edit a few things that are fixed in recent ZDoom and SLADE releases.
veekun: I managed to generate a YAML-based data file for Pokémon Red directly from game data. There's still a lot of work to do to capture moves and places and other data, but this is a great start.
SLADE: In my 3D floor preview branch, the sides of simple 3D floors now render. There is so much work left to do here but the basics are finally there. Also fixed about nine papercuts I encountered while making my map, though some others remain.
mario maker: I made a level but have neglected to write about it here yet. Oops.
art: I drew most of the next part of Pokémon Yellow but then got kinda distracted by Doom stuff. I redrew last year's Pi Day comic for the sake of comparison. I also started on Mel's birthday present, which involves something astoundingly difficult that I've never tried before.
irl: I replaced my case fans, and it was a nightmare. "Toolless" fasteners are awful.
Pouring a solid week into one thing is weird; I feel like I haven't drawn or touched Runed Awakening in ages, now. I'd like to get back to those.
I also still want to rig a category for posts about stuff I'm releasing, and also do something with that terrible "projects" page, so hopefully I'll get to those soon.
AllappartBASICbirthdayblogbugCCASCasecomicdatadoomdownedeNomgamesGogotIPjavajavascriptlinkingMakemappingmariomoveMPAOtherparisratrawReleaseruned awakeningS.statusststhingstwitterUSveekunvideoWork
Mario Maker: …
Post Syndicated from Eevee original https://eev.ee/dev/2016/03/08/mario-maker-dot-dot-dot/
14DC-0000-01ED-C104
Difficulty: fairly easy
Secrets: —
I removed the music and only used monochrome obstacles, with very few actual enemies. No pickups, no secrets. It's short, linear, pretty easy, entirely thematic.
The result is interesting.
ATICchromeedIPMakemariomario makermovemusicrestS.US | CommonCrawl |
Operational integration in primary health care: patient encounters and workflows
Dimitra Sifaki-Pistolla1,
Vasiliki-Eirini Chatzea1,
Adelais Markaki1,2,
Kyriakos Kritikos3,
Elena Petelos1 &
Christos Lionis1
Despite several countrywide attempts to strengthen and standardise the primary healthcare (PHC) system, Greece is still lacking a sustainable, policy-based model of integrated services. The aim of our study was to identify operational integration levels through existing patient care pathways and to recommend an alternative PHC model for optimum integration.
The study was part of a large state-funded project, which included 22 randomly selected PHC units located across two health regions of Greece. Dimensions of operational integration in PHC were selected based on the work of Kringos and colleagues. A five-point Likert-type scale, coupled with an algorithm, was used to capture and transform theoretical framework features into measurable attributes. PHC services were grouped under the main categories of chronic care, urgent/acute care, preventive care, and home care. A web-based platform was used to assess patient pathways, evaluate integration levels and propose improvement actions. Analysis relied on a comparison of actual pathways versus optimal, the latter ones having been identified through literature review.
Overall integration varied among units. The majority (57%) of units corresponded to a basic level. Integration by type of PHC service ranged as follows: basic (86%) or poor (14%) for chronic care units, poor (78%) or basic (22%) for urgent/acute care units, basic (50%) for preventive care units, and partial or basic (50%) for home care units. The actual pathways across all four categories of PHC services differed from those captured in the optimum integration model. Certain similarities were observed in the operational flows between chronic care management and urgent/acute care management. Such similarities were present at the highest level of abstraction, but also in common steps along the operational flows.
Existing patient care pathways were mapped and analysed, and recommendations for an optimum integration PHC model were made. The developed web platform, based on a strong theoretical framework, can serve as a robust integration evaluation tool. This could be a first step towards restructuring and improving PHC services within a financially restrained environment.
The concept of integration has received a lot of attention in the literature, although its definition and scope varies across settings [1,2,3]. The World Health Organization (WHO) has defined integrated care delivery as "[…] the management and delivery of health services so that clients receive a continuum of preventive and curative services, according to their needs over time and across different levels of the health system" [1]. Literature supports the premise that integration results in better health outcomes and minimises overall healthcare costs [2, 3]. Main benefits include patient orientation, equity, quality, accessibility, efficiency, continuity of care, and cost-effectiveness.
The first integrated care models were introduced during the 1980s in the USA [4]. Those models focused on chronic disease and care provision according to patient needs [5] and significantly influenced developments in other countries. The Netherlands and the United Kingdom (UK), both countries with strong primary healthcare (PHC) systems and gatekeeping, have adopted integrated approaches to link health promotion and disease prevention to disease management and self-management support [6]. Electronic prescribing, integration of pharmacies within healthcare units, comprehensive training of healthcare professionals (HCPs), use of community resources, and an accessible referral system with optimised patient flows in multidisciplinary centres, have all contributed towards reduced healthcare costs and more efficient reallocation of resources [7, 8]. In 2006, the last wave of healthcare reforms in the Netherlands focused on sustaining the successful innovations of previous decades. Strong emphasis was given on improving information technology (IT) services, coordinated and comprehensive chronic care and optimum utilisation of community resources [7]. In the UK, the "Quality and Outcomes Framework (QOF)" considered as best practice the adoption of electronic records and other measurable variables that facilitate quality monitoring and benchmarking data [8]. These best practices are crucial in ensuring sound resource allocation, especially in countries with highly burdened healthcare systems and less developed PHC, such as Greece [9]. Therefore, such experiences could guide countries with fragmented systems towards effective reforms in optimising unit and patient-level integration and introducing standardised processes. An added benefit could be the provision of valuable information for evidence-based policy in terms of allocating or reallocating resources at system level.
Having been subjected to a harsh austerity period, Southern European countries share similar healthcare system characteristics and challenges in PHC service delivery [9]. In 2000 and 2008, Greece and Spain exhibited a rapid expansion of public spending, while in Italy and Portugal the trend was moderate [9,10,11]. Despite restricted coverage of PHC services, Italy has achieved a high degree of system integration and an effective way of managing public funding and private healthcare expenditure [9]. Nevertheless, the lack of standardised processes and protocols for patient pathways, as well as for addressing the needs of patients with multiple morbidities, represents an important commonality for all these systems.
During the last thirty years, Greece has attempted to strengthen its national health system (NHS), by expanding and standardising PHC, initially in rural, and more recently in urban areas. Despite efforts and an intense debate lasting more than 15 years, Greece is still lacking a sustainable, evidence-based integrated model. As a result, integration still remains a largely neglected issue in the country's health policy agenda [12, 13]. The existing socio-economic hardships inflicted by the prolonged financial austerity, as well as the recent refugee and migrant crisis, render the need for healthcare reform urgent. Moreover, the country's rapidly aging population, along with the high incidence of mental health disorders [14] and the growing burden of chronic diseases, [15] necessitate immediate actions towards an integrated, multidisciplinary network of well-coordinated and cost-effective services. Lack of integration can result in fragmentation of care and poor health outcomes, [16] as well as in problems related to funding, planning, effectiveness and operation of the healthcare system[17]. Substantial healthcare budget cuts and prolonged delay of major reform are jeopardising the NHS, putting it at risk of becoming unsustainable and ultimately, obsolete [18]. Failing to achieve immediate policy and structural changes to this direction, could increase the risk of potential NHS collapse with numerous adverse consequences [13]. Thus, it is vital to develop and implement policy well-aligned to a strategic vision towards integrated PHC. This can be a challenging and arduous process, considering that it requires major NHS reform along with changes in organisational culture [12].
Having identified the above urgent need, the Clinic of Social and Family Medicine (CSFM) (School of Medicine, University of Crete) conducted a large nationally funded research project with a two-fold aim: 1) to assess the level of operational integration within PHC units by utilising standardised quality processes which included mapping and evaluation of both unit-level and patient-level integration and 2) to develop an optimum model of operational integration tailored to the Greek PHC system. This paper aims to present integration findings regarding existing patient care pathways and to suggest an alternative pathway model for optimum integration.
The project was funded by the Greek National Strategic Reference Framework (NSFR) 2007–2013 and was conducted from June 2012 to November 2015. The Health Region of Crete (Ref. #9674), the Health Region of the Aegean Islands (Ref. #1136) and the Ministry of Health and Solidarity (Ref. #38865) all granted ethics approval for the conduct of this study.
Primary health care is a broad term describing an approach to health policy and service provision that includes both services delivered to individuals (including patient pathways) and the general population. [19] Primary care (PC) refers to "family doctor-type" services delivered to individuals, whereas some frameworks [19, 20] use PC to assess PHC components.
The adopted operational integration model for this study was based on the Donabedian approach, [21] combining the basic PHC principles presented by Starfield [22] and the chronic care model [23]. Following a systematic literature review, the dimensions of PHC as reported in the work of Kringos and colleagues, [24] were selected as the most appropriate for the Greek healthcare system. According to Kringos and colleagues, [20] PHC is viewed as a complex system comprising three levels: (a) structures, (b) processes, and (c) outcomes. [20] Each level is composed of dimensions encompassing a range of key attributes/features (Fig. 1).
Adopted Primary Health Care System Framework (reproduced with permission) [20]
Setting and sample
The scope and range of PHC services in Greece tends to be broad, with services provided by entities that are not solely PHC oriented. For this project, the team adopted the PHC definition as established by legislation in effect at the time the study was designed (Laws 3235/2004, 3918/2011, and 4238/2014), classifying all of the following as PHC units:
NHS Rural Health Centres, along with their satellite Clinics
NHS Hospital Outpatient Clinics
Outpatient Units within the National Health Service Organization (EOPYY)
Private general practices affiliated with the EOPYY
Municipal agencies ("Care at Home", Senior Citizen Services, Outpatient Centres for Nursing Care of the Aged, Municipal Clinics)
Other facilities (outpatient mental health units, rehabilitation units, ambulatory/community care units)
Simple random sampling was performed to identify a representative sample of PHC units according to type of provided services. Study setting included parts of the 2nd Health Region (HR) of Piraeus and Aegean and the 7th HR of Crete, with a total of 12 and 27 eligible units, respectively. Approximately 50% of all eligible PHC units per setting were included in the study (N = 22 PHC units, 7 units from the 2nd HR and 15 units from the 7th HR). Sample units were grouped under the following six categories according to provider setting:
Rural Health Centres/Satellite Clinics
Emergency Departments / National Centre for Emergency Assistance (EKAB)
Outpatient Clinics/Private practices/Diagnostic Centres
Community-based agencies for vulnerable or at-risk groups/Home Care Programs
Prevention and Rehabilitation Centres
For the purpose of this study, patient encounters were defined as any physical contact between a patient and a PHC practitioner, during which an assessment or clinical activity was performed. Eligible patient encounters were grouped by type of PHC service sought for into 4 categories: chronic disease care, urgent/acute episodic care, preventive care, and home care. This encounter grouping was based on the approach of Starfield, [22] and the observed utilisation patterns for the most frequently sought services in Greek PHC settings. One of the following inclusion criteria had to be fulfilled: a) in need of chronic care (registered patient with a regular follow-up appointment for a chronic condition, based on attending physician orders); b) in need of urgent or acute care (registered patient seeking unplanned episodic care); c) in need of prevention [registered patient with routine appointment for primary prevention (e.g. vaccination, smoking cessation, etc.) or secondary prevention (e.g. Prostate-specific antigen (PSA) measurement, Papanicolaou (Pap) test); d) in need of home care [chronic patient with disability (physical, psychological or mental), who was registered in the home care program and had been followed by a public PHC unit physician (excluding private unit practitioners)]. All patients under the age of 18 years or not speaking Greek fluently were excluded.
Given the nature of the study, the selected methods of analysis, and the modelling processes using computerised techniques, no power analysis was conducted. A minimum of 12 patients per unit was set as a prerequisite for unit inclusion (convenience sampling), with higher patient flow units contributing more patients and with no upper limit. Out of 305 eligible patients attending the units during the 3-week study period (August – September, 2015), a total of 282 patients were enrolled in the study (92.5% response rate).
Tools and data collection process
A web-based platform entitled "Information system for operational integration assessment within PHC units" was developed to assess patient pathways, evaluate integration levels and propose improvement actions (http://ld.datacenter.uoc.gr/). This platform featured an online questionnaire consisting of four sub-scales, according to type of PHC service sought for, i.e., chronic disease care, urgent/acute episodic care, preventive care, and home care. Questions covered the following pathways: a) first contact, b) patient management/treatment, c) referral, and d) follow-up. Information regarding workflows, the role of each HCP, protocols/documents utilised and time required was collected. As a reminder, the definition of operational integration was clearly stated on the instruction page (first page), as well as on the lower part of each page of the questionnaire.
The questionnaires were completed by research associates (RAs) of the CSFM. The RAs used tablets to access the web-based platform. All RAs were extensively trained in theoretical and technical aspects of this project (i.e., integration conceptual framework, using the web-based platform, and resolving technical problems). Required qualifications for RAs included holding a health science degree, proven experience in health systems research, ability to use online platforms and having good communication skills. They visited the selected units for three weeks, identifying eligible patients at the reception (first contact). Upon establishing eligibility, RAs explained the purpose of the study in more detail. Upon receiving agreement for participation, they accompanied the patients, tracking pathway progress within the PHC unit and filling in the questionnaire directly into the web-based platform. At the end of data collection, one full-time HCP per unit was trained on the job to ensure continuous use of the platform and evaluation of the unit's integration level. This maximised the impact of the study through a continuous quality improvement tool that was made available to the units.
A five-point Likert-type scale, i.e., 1 "minimal", 2 "poor", 3 "basic", 4 "partial", and 5 "operational", coupled with an algorithm, was used to evaluate unit integration level. Based on the developed algorithm, different mathematical weights were used per PHC dimension in order to estimate the final scores. Weights ranged from 0.2 to 0.5 within each dimension's characteristics, leading to a final scoring ranging from 1 to 5 points (cut off = 2.5). Furthermore, a minimum integrated unit was defined as one that scored from 1 to 1.5 (1 ≥ x ≥ 1.5), while a poorly integrated unit scored from 1.5 to 2.5 (1.5 > x ≥ 2.5). Scores ranging from 2.5 to 3.5(2.5 > x ≥ 3.5) points characterised a basically integrated unit and scores from 3.5 to 4.5 point (3.5 > x ≥ 4.5) indicated a partial integration. A well-integrated unit (operational integration) ranged from 4.5 to 5.0 (4.5 > x ≥ 5.0).
Evaluation was computed in a hierarchical manner, starting from the lower level framework features, going through dimension levels, and reaching the top level for overall integration score. In each layer, the weighted sum of the respective elements (i.e., questionnaire field, feature, and dimension) was computed according to the Simple Additive Weighting (SAW) method [25]. Weight calculation was performed according to the Analytic Hierarchy Process (AHP) through input from highly qualified experts. Feature measurability was enforced via an expert-driven assignment of relevant questionnaire items. The following set of equations summarises, in a hierarchical manner, the evaluation of overall integration level:
$$ {score}_i^{feat}=\frac{\sum_q{f}_q\left({value}_q\right)}{\left|{Q}_{feat}\right|}- \mathrm{Level}\ 1\ \left(\mathrm{Bottom}\right) $$
$$ {score}_i^{\mathrm{dim}}=\sum \limits_{feat}{w}_{feat}\cdot {score}_{feat}^i- \mathrm{Level}\ 2 $$
$$ {score}_i=\sum \limits_{\dim }{w}_{\mathrm{dim}}\cdot {score}_{\mathrm{dim}}^i- \mathrm{Level}\ 3\ \left(\mathrm{Top}\right) $$
Where \( {score}_i^{feat} \) is the score of feature feat for unit i, value q is the value completed by unit professional for question q of the questionnaire where this question has been mapped to feature feat and belongs to the set |Q feat | of mapped questions of this feature, f q is the score function for question q, \( {score}_i^{\mathrm{dim}} \)is the score of dimension dim for unit i, w feat is the weight of feature feat, score i is the overall score for unit i and w dimis the weight of dimension "dim".
Ratings were exported for assessing operational integration in total for each unit, each type of patient, and each dimension and feature, respectively. Analysis was carried out via a stand-alone software, implemented in the Java programming language, which realised the Multi Criteria Decision Making (MCDM) method of quantitative process modelling. [26]
Quantitative process Modelling
While a great number of quantitative process modelling methodologies has been suggested in the literature, MCDM was selected for the current study. This approach allows data collection, analysis and modelling of information collected by interdisciplinary teams or individuals with PHC expertise, as demonstrated by this project team (physicians, nurses, social workers, health administrators, and computer engineers). In addition, it does not require large sample sizes; input from two participants is deemed sufficient to proceed with modelling processes. According to MCDM, two sequential steps were followed:
First step: modelling the four processes by monitoring current pathways, via the completed questionnaire parts, per type of PHC encounter, i.e., chronic conditions/diseases, urgent or acute problems/symptoms, prevention, and home care services. This was accomplished by: (a) collecting all pathway steps and mapping them to the four aforementioned processes, (b) matching steps with the same semantics, (c) abstracting multiple steps into an equivalent overall task or subprocess, (d) determining the control flow of the process (abstracted) tasks or subprocesses. Models of the four processes are available through the Additional files.
Second step: development of optimal processes. An interdisciplinary project team utilised the first step intermediate product for modelling the four PHC processes/pathways. The goal was to formulate a set of well-prescribed steps for each process and map them to particular roles that characterise each PHC unit. To this end, each process should be extended and cover all possible paths, involving all possible respective steps, regardless of whether they were mandatory or optional, or whether they were frequently or rarely executed. This allowed examination and determination as to which of the proposed modelled steps or paths were actually executed in practice and how these differed from the ones being followed at that time.
The second step comprised three main phases: a) mapping of generalised tasks/subprocesses into a set of steps with a particular logic sequence; b) validation of the derived processes according to literature, team experience, and outcomes from previous relevant projects; c) development of the final model for each process through simulation and error detection algorithms, with special focus on compact and hierarchical product models of high quality.
The above steps were visualised through diagrammatic modelling of the generalised processes (workflows) in the Microsoft Visio tool. This resulted in a simplified visual modelling for each process, comprehensive but readily understandable by non-experts in process modelling, and, thus, facilitating communication among interdisciplinary team members. An enriched dictionary of common steps (e.g., history taking) was used, while each step was also linked to an abstract/generalised task (e.g., patient reception). The overall (quantitative) assessment of current integration levels, as well as per type of patient and dimension, was estimated using the SAW algorithm according to a similar hierarchical manner as in the case of the qualitative evaluation. Results were then produced and illustrated in pie and bar charts. During the final phase (step 2), the Microsoft Visio diagrams were transformed into standard process models (according to the Business Process Model and Notation, BPMN) and were tested and simulated via the ADONIS (http://en.adonis-community.com/) business process management tool (Additional files).
The overall integration of current processes varied among units, with the majority (57%) scoring 3, basic integration, in the Likert-type scale. In addition, 29% and 14% of the units presented poor and partial integration, respectively. None of the units scored at the highest and lowest ends (operational or minimal integration).
Integration level by type of PHC services
Figure 2 shows integration levels by type of PHC services sought for by patients. Units for patients seeking care for chronic conditions presented basic (86%) and poor (14%) integration. For units offering urgent or acute care, the majority (78%) scored poor integration and only 22% basic. Integration among home care services was evenly split between partial (50%) and basic (50%). Last, all units providing prevention services scored at the basic level (100%).
Integration level by type of PHC services offered
The current patient processes are presented in two selective diagrams in Additional file 1: Figure S1; Additional file 2: Figure S2, while optimal processes are extensively presented in the following section.
Optimal processes by type of PHC services
The optimal workflow diagram for chronic care management is depicted in Additional file 3: Figure S3. This process comprises four subprocesses that are associated with: 1) patient reception/intake, 2) treatment, 3) referral, and 4) monitoring. These subprocesses are sequentially executed. Patient reception and intake are considered an independent step during which a non-physician HCP records patient demographics and medical history. Patient treatment is a subprocess that begins with assignment to a professional on the premise of a scheduled appointment. A scheduled appointment may involve more than one visit to different PHC professionals. Internal referrals can be made to either physicians or non-physician HCPs. A non-physician HCP can refer to a physician, while a physician can refer to a non-physician HCP or another physician of a different specialty, within the unit.
Patient treatment provided by an HCP involves the actual treatment, as well as consultation, including update of the health record. Actual treatment may include: behavioural change (lifestyle pattern) consultation, self-care management and training, medication prescription or psychological support. Treatment by a physician includes: update of patient health record and actual treatment, such as behavioural change (lifestyle pattern) consultation, self-care management and training, medication prescription, ordering laboratory or diagnostic tests. The physician can perform internal or external referrals to other physicians and other HCPs.
External referral is performed upon writing a referral note. The patient can be transferred either by own means or via the National Centre for Emergency Assistance (EKAB). External referral to a physician of a different specialty may be made to public and private PHC or secondary health care (SHC) units. Public PHC units include: the National Primary Healthcare Network (PEDY), mental health clinics, regular outpatient clinics or satellite clinics. Private PHC units include either private practices or private diagnostic centres. Public SHC units are regular outpatient clinics, emergency departments or hospital laboratories, while private SHC units can only be a private clinic.
External referral to an HCP involves either the public sector affiliated with PEDY, mental health clinics or satellite clinics or the private sector affiliated with private practices.
The last subprocess, patient progress monitoring, comprises three sequential steps: a) assessment of disease/symptom management, b) monitoring, and c) patient and family briefing/feedback.
Urgent or acute episodic care management
Optimal urgent or acute care management process is presented in Additional file 4: Figure S4. Overall, it follows the same pattern as the optimal chronic disease management process with main differences in treatment and referral making.
A nurse or a physician can administer patient treatment. Patient treatment by a nurse includes one or more of the following steps: a) medical history recording & triage, b) first aid or c) first aid provision, medication and/or psychological support. Patient treatment by physician involves: a) medical history recording & triage, b) first aid and medication treatment or c) first aid, medication treatment and laboratory or diagnostic exams.
Upon treatment, the nurse can only make an internal referral to a physician, while a physician can conduct both internal and external referrals to physicians of a different specialty or to non-physician HCPs. In case of an external referral, the physician should be affiliated either to the Primary National Health Network, Mental Health units, Outpatient Clinics or to Health Centres. On the other hand, an external HCP who receives a referral can be affiliated to the Primary National Health Network or the Mental Health units.
Preventive care management
The optimal prevention process (Additional file 5: Figure S5) is similar to the previous processes with patient reception/intake and monitoring of health outcome being the same. Incident treatment follows the same pattern with the main difference being the actual treatment.
Treatment by a non-physician HCP can involve primary or secondary prevention procedures. Treatment by a physician can include secondary prevention procedures, medication prescription, or ordering laboratory or diagnostic exams. The physician has the authority to conduct internal or external referral to both non-physician HCPs and other physicians. For external referrals, writing a referral note is necessary. Referral to an HCP can be made within the Primary National Health Network, mental health clinics, rehabilitation centres or private clinics. When referring to another specialty physician, an affiliation with outpatient clinics, private clinics or private diagnostic centres is required.
The optimal home care process model is depicted in Additional file 6: Figure S6. This process follows a different pattern due to the uniqueness of the setting, a patient's home rather than a formal PHC unit environment.
This process starts with two subprocesses, performed by nursing and social care professionals, which can be executed sequentially or interchangeably. The first step involves patient needs assessment, followed by one or more of the next steps: a) planning necessary care/interventions, b) implementation of care/interventions, and c) evaluation of care/interventions. Health needs assessment includes biological/physical as well as socio-economic and mental needs.
Care and intervention planning includes the conditional performance of four sub-steps, from the simplest to the most complex: a) lifestyle change, b) lifestyle change and self-management/training regarding medication regime, c) lifestyle change, self-management/training of medication regime and mental support, and d) lifestyle change, self-management/training of medication regime, mental support and laboratory tests.
Implementation of care and intervention includes: a) a personalised care plan, b) identifying resources, and c) connecting with community resources.
After each subprocess ends, a referral can be made to the patient's family physician. Such referral can involve a home visit by the family doctor or a patient visit to the PHC unit where the attending physician works. In the first case, once the physician visits the patient, he/she can be referred to a PHC unit for further examination or assessment. Referral can be made to the Outpatient Clinics, the Emergency Department or the Hospital Diagnostic Laboratories.
Finally, program or care evaluation includes one or more of the following sub-steps: a) patient/caregiver briefing, b) patient/caregiver training, and c) re-evaluation of care/intervention.
Main findings
This study met its objectives of assessing patient pathways within PHC units and proposing optimal integration processes. Integration per type of PHC service was measured for the first time in Greece and was found to greatly vary from poor to basic levels. Main limitations to achieving operational integration included: a) lack of an IT system that could support referral, patient history/EHR and prescribing within and across units, and most importantly across levels of care, b) absence of gatekeeping, c) incomplete or missing patient lists to facilitate monitoring, referral and prescribing patterns at practice/unit level and at district level, and d) absence of standardised patient pathways to facilitate virtual path and movement. To this end, optimal processes were developed in the form of diagrams that could facilitate evaluation of current process within the context of Greek PHC units. Members of the interdisciplinary research team developed detailed, comprehensive processes that covered different typical cases of patients within all possible PHC unit types and settings. These processes could be implemented by an execution runtime system to enable operational integration, tracking and overall monitoring. This runtime system is expected to enable modification of each process, as well as the dynamic management of computerised and human resources, according to each unit needs. It could also enable real-time analysis of stored data to assess levels of integration and provide optimisation guidelines.
Discussion in view of the literature
There is growing consensus that Greece should work towards operational integration by allocating resources in a cost-effective and quality-assured manner [27]. This is considered a challenging task due to the lack of data on current integration levels and the requirements of PHC units [28]. In addition, key performance indicators for processes should be developed and adopted in order to establish sustainable integrated care models [29]. The present study attempted to map the current integration levels and processes within the Greek PHC units, as well as to develop the optimum processes that should guide the national operational integration model.
Interestingly, despite the widespread budgetary and human resource problems, integration among home care provider units scored at higher levels. A recent SWOT analysis of home healthcare service operations identified a lack of an integrated institutional framework as a major deficit [30]. The pivotal role of nursing in case managing home care recipients and improving quality of life can be instrumental in integrating services and achieving seamless care [31, 32]. Yet, policy makers in Greece have failed to recognise existing evidence. Given the reported high level of operational integration, this study provides further support in the direction of expanding home care services led by nurses or social workers. Viewed as an action call to health policy makers, as well as healthcare institutions and professional organizations, to cover a larger proportion of the urban population in need of community-based and home-based skilled nursing care, the study tools can provide evidence and further guidance in that direction.
Existing literature has revealed a wide range of parameters that contribute to poor integration, including absence of an interoperable IT system with standardised flows, unequal distribution of equipment, staff and other resources [31,32,33]. Our study supports previous findings indicating that the lack of standardised processes and evidence-based guidelines widens the gap between theory and practice among PHC units.[7] Therefore, there is a negative impact on continuity, coordination, comprehensiveness and quality of PHC services for all patient categories [15, 17]. A systematic review by Van der Klauw and colleagues (2014) suggested that effective IT systems constitute a core element for operational integration within PHC [34]. This promotes patient-centeredness and facilitates communication between healthcare professionals and patients (e.g., follow-up, patient training and active self-management) [13, 28].
Reform of the Greek healthcare system during this intense austerity period, should be guided by best practices from other countries, adjusted according to current findings [35]. The theoretical model by Kringos and colleagues [20] coupled with the Chronic Care Model is strongly recommended by the authors and other researchers [36, 37]. Greece could become a case study for highly burdened healthcare systems aiming to streamline operations and achieve sustainability.
To our knowledge, this is the first study to capture the level of integration within PHC units by measuring specific indicators. The high response rate (92.5%) and the relatively large and representative sample strengthen the generalisability of our findings. The developed online tool could be utilised by both PHC units and the Ministry of Health to systematically monitor integration and take adequate steps towards reform and quality improvement. Another unique component is the project's interdisciplinary team that conceptualised the study design, mapped and interpreted data, and designed optimal processes. This is in line with experience from the UK that supports involvement of healthcare providers in the design of new operational integration models [38, 39].
Study limitations include the utilisation of a concrete operational definition of integration, which may not satisfy other definitions used in the literature. Participating PHC professionals and patients were not asked about their perception of integration, as this was not part of the study aim. Assessment of integration was based on the measurable indicators of our theoretical framework. This information was captured in real-time mode and based on the actual patient workflows within the PHC unit. Actual integration of patient flows within PHC units was monitored, but we did not assess patient perceptions regarding integration. Furthermore, assessment of operational integration was performed in only two health regions; therefore, results may differ at the national level. However, every effort was made to secure representation of all six types of PHC units, based on type of services offered. There is also potential for information bias due to the self-administered nature of the questionnaire, which might have resulted in an overestimation of unit integration level. Last, due to major structural changes in the healthcare sector at the time this study was carried out, mapping of PHC units was quite challenging, requiring frequent methodological adjustments.
Immediate actions towards patient-centred care are necessary in order to operationally integrate all provided services and existing functions of the PHC system. Health policymakers should adopt an evidence-based action plan that ensures and safeguards patient-centredness, comprehensiveness, sound coordination, and continuity. Linking the developed web-based platform with the existing healthcare information system is required in order to systematically evaluate efficiency (services, procedures, resources, manpower, and outputs). This could strengthen efforts to address new challenges such as poverty, an aging population, increasing healthcare expenditures, reduction of resources, rapidly changing epidemiological trends indicating mental disorders, and cardiovascular disease as leading causes of morbidity.
This national study revealed average or below average levels of patient-level integration within PHC units, with variations based on type of PHC services rendered. Indications for a fragmented and ineffective healthcare system in need of reform were evident, particularly when assessing the existing patient care pathways. Towards that end, this study generated new evidence from Greece that could offer valuable insights to other Southern European countries with similar characteristics. The web-based evaluation tool, along with the proposed patient-level operational integration model, could become the core elements for an overall sound and cost-effective primary healthcare system, a system where professionals, along with patients, are motivated and empowered to work collectively towards integrated patient-centred care.
BPMN:
Business Process Model and Notation
HCP:
MCDM:
Multi Criteria Decision Making
National Health System
NSFR:
National Strategic Reference Framework
SAW:
Simple Additive Weighting
Secondary Health Care
World Health Organization. Integrated health services - what and why? Technical brief no. 1. In: Geneva; 2008.
Glasby J, Dickinson H. Partnership working in health and social care: what is integrated care and how can we deliver it? Bristol: Policy Press; 2014.
Valentijn PP, Schepman SM, Opheij W, Bruijnzeels MA. Understanding integrated care: a comprehensive conceptual framework based on the integrative functions of primary care. International Journal of Integrated Care. 2013;13(1):655–79.
Nolte E, McKee M. Integration and chronic care: a review. In: Nolte E, McKee M, editors. Caring for people with chronic conditions. Geneva: Open University Press; 2008.
Kruis AL, Boland MR, Assendelft WJ, Gussekloo J, Tsiachristas A, Stijnen T, Blom C, Sont JK, Rutten-van Mölken MPHM, Chavannes NH. Effectiveness of integrated disease management for primary care chronic obstructive pulmonary disease patients: results of cluster randomised trial. BMJ. 2014;349:g5392.
Nolte E, McKee M. Caring for people with chronic conditions: a health systems perspective. European Observatory on Health Systems and Policies: WHO, Geneva; 2008.
Van Weel C, Schers H, Timmermans A. Health care in the Netherlands. The Journal of the American Board of Family Medicine. 2012;25(Suppl 1):12–7.
Van Loenen T, Van den Berg MJ, Heinemann S, Baker R, Faber MJ, Westert GP. Trends towards stronger primary care in three western European countries; 2006-2012. BMC Fam Pract. 2016;17(1):1.
Petmesidou M, Pavolini E, Guillén AM. South European healthcare systems under harsh austerity: a progress–regression mix? South European Society and Politics. 2014;19(3):331–52.
Petmesidou M. Southern Europe. In: Greve B, editor. International handbook of the welfare state. London: Routledge; 2013.
Boerma WG, Hutchinson A, Saltman RB. Building primary care in a changing Europe. D. S. Kringos (Ed.). World Health Organization, European Observatory on Health Systems and Policies. Denmark, 2015.
Lionis C, Symvoulakis EK, Markaki A, Vardavas C, Papadakaki M, Daniilidou N, Souliotis K, Kyriopoulos I. Integrated primary health care in Greece, a missing issue in the current health policy agenda: a systematic review. Int J Integr Care. 2009;9:e88.
Tsiachristas A, Lionis C, Yfantopoulos J. Bridging knowledge to develop an action plan for integrated care for chronic diseases in Greece. Int J Integr Care. 2015;15(4)
Karanikolos M, Mladovsky P, Cylus J, Thomson S, Basu S, Stuckler D, Mackenbach JP, McKee M. Financial crisis, austerity, and health in Europe. Lancet. 2013;381(9874):1323–31.
Zavras D, Tsiantou V, Pavi E, Mylona K, Kyriopoulos J. Impact of economic crisis and other demographic and socio-economic factors on self-rated health in Greece. Eur J Pub Health. 2013;23(2):206–10.
Bellali T, Kalafati M. Greek psychiatric care reform: new perspectives and challenges for community mental health nursing. J Psych Ment Health Nurs 2006;13(1):33–39.
DiClemente CC, Norwood AE, Gregory WH, Travaglini L, Graydon MM, Corno CM. Consumer-centered, collaborative, and comprehensive care: the core essentials of recovery-oriented system of care. J Addict Nurs. 2016;27(2):94–100.
Fragkoulis E. Economic crisis and primary healthcare in Greece: 'disaster' or 'blessing'? Clin Med (Lond). 2012;12(6):607.
White F. Primary health care and public health: foundations of universal health systems. Med Princ Pract. 2015;24(2):103–16.
Kringos DS, Boerma WG, Bourgueil Y, Cartier T, Hasvold T, Hutchinson A, Lember M, Oleszczyk M, Pavlic DR, Svab I, Tedeschi P, Wilson A, Windak A, Dedeu T, Wilm S. The European primary care monitor: structure, process and outcome indicators. BMC Fam Pract. 2010;11:81.
Donabedian A. Benefits in medical care programs, Cambridge: Harvard University press: 1976.
Starfield B. Primary care and equity in health: the importance of effectiveness and equity to people's needs. Humanity and. Society. 2009;33:56–73.
Boult C, Karm L, Groves C. Improving chronic care: the "guided care" model. Perm J. 2008;12:50–4.
Kringos DS, Boerma WG, Hutchinson A, van der Zee J, Groenewegen PP. The breadth of primary care: a systematic literature review of its core dimensions. BMC Health Serv Res. 2010;10:65.
Emrouznejad A, Kumar DP. Performance measurement in the health sector: uses of frontier efficiency methodologies and multi-criteria decision making. J Med Syst. 2011;35(5):977–9.
Thokala P, Duenas A. Multiple criteria decision analysis for health technology assessment. Value Health. 2012;15(8):1172–81.
Geitona M, Zavras D, Kyriopoulos J. Determinants of healthcare utilization in Greece: implications for decision-making. Eur J Gen Pract. 2007;13(3):144–50.
Kousoulis AA, Patelarou E, Shea S, Foss C, Ruud Knutsen IA, Todorova E, et al. Diabetes self-management arrangements in Europe: a realist review to facilitate a project implemented in six countries. BMC Health Serv Res. 2014;14:453.
Schäfer WLA, Boerma WGW, Murante AM, Sixma HJM, Schellevis FG, Groenewegen PP. Assessing the potential for improvement of primary care in 34 countries: a cross-sectional survey. Bull World Health Organ. 2015;93:161–8.
Adamakidou T, Kalokerinou-Anagnostopoulou A. Home health nursing care services in Greece during an economic crisis. Int Nurs Rev. 2016; doi:10.1111/inr.12329.
Genet N, Boerma W, Kroneman M, Hutchnson A. Conclusions and the way forward. In Homecare across Europe: current structure and future challenges (genet, N., et al. eds), WHO2012 UK; pp. 105–122.
Tarricone R, Tsouros AD. Home Care in Europe. The solid facts. The regional Office for Europe, WHO 2008; Milan. Italy.
Markaki A, Antonakis N, Philalithis A, Lionis C. Primary health care nursing staff in Crete: an emerging profile. Int Nurs Rev. 2006;53(1):16–8.
van der Klauw D, Molema H, Grooten L, Vrijhoef H. Identification of mechanisms enabling integrated care for patients with chronic diseases: a literature review. International Journal of Integrated Care 2014;14:e024.
Grol R, Grimshaw J. From best evidence to best practice: effective implementation of change in patients' care. Lancet. 2003;362(9391):1225–30.
Groenewegen PP, Jurgutis AA. Future for primary care for the Greek population. Qual Prim Care. 2013;21(6):369–78.
Nuno R, Coleman K, Bengoa R, Sauto R. Integrated care for chronic conditions: the contribution of the ICCC framework. Health Policy. 2012;105(1):55–64.
Lewis G, Vaithianathan R, Wright L, Brice MR, Lovell P, Rankin S, et al. Integrating care for high-risk patients in England using the virtual ward model: lessons in the process of care integration from three case sites. International Journal of Integrated Care. 2013;e046:13.
Kousoulis AA, Symvoulakis EK, Lionis C. What Greece can learn from UK primary care experience and empirical research. Br J Gen Pract. 2012;62(603):543.
We acknowledge the input from the members of the multidisciplinary team of the project: A. Aggelakis, A. Bertsias, A. Koutis, A. Philalithis, C. Gatzoudi, D. Plexousakis, E. Thireos, H. Van der Schaaf, M. Trigoni, M. Zampetaki, N. Elfadl Hag, N.Michalakis, P. Milaki, S. Kardasis, S. Kaukalakis, Y. Fragkiadakis, Y. Kalantzakis. Special thanks to Prof. D. Plexousakis and Y. Fragkiadakis for their significant contribution to the design of the project. In addition, we appreciate the contribution of the "Diadikasia SA" Business Consultants towards the successful implementation of this study. The authors would also like to thank all participating PHC units and regional authorities that facilitated data collection.
The current study was part of the nationally funded project: "Operational integration between bodies of PHC and other healthcare bodies using standardised quality processes". Funding agency: NSRF 2007–2013. MIS: 337,424. The project was carried out by the CSFM, School of Medicine, University of Crete from June 2012 to December 2015.
Data that support findings of this study are subject to restrictions as set by the funding agency. However, data can be available from the corresponding author, upon request, following approval by the CSFM of the School of Medicine at the University of Crete.
Clinic of Social and Family Medicine, School of Medicine, University of Crete, University Campus, Voutes, P.O. Box 2208, Heraklion, 71003, Crete, Crete, Greece
Dimitra Sifaki-Pistolla, Vasiliki-Eirini Chatzea, Adelais Markaki, Elena Petelos & Christos Lionis
School of Nursing, University of Alabama at Birmingham, Birmingham, USA
Adelais Markaki
Institute of Computer Science, FORTH, Vassilika Vouton, 70013, Crete, Greece
Kyriakos Kritikos
Dimitra Sifaki-Pistolla
Vasiliki-Eirini Chatzea
Elena Petelos
Christos Lionis
DSP, VEC, AM, EP, KK and CL participated in the study design, adaptation of the theoretical and methodological framework, and the development of the assessment tool. DSP and KK participated in the development of the mathematical algorithm and data analysis. DSP and VEC wrote the first manuscript draft. AM revised and edited subsequent versions. EP contributed to the discussion and data interpretation. CL conceived the idea and set the methodological framework. All authors reviewed and agreed on the final version of the manuscript.
Correspondence to Christos Lionis.
DSP, MPH, PhD(c), Epidemiology and Public Health Researcher in the Clinic of Social and Family Medicine, School of Medicine, University of Crete.
VEC, MPH, Welfare Management, Health Researcher in the Clinic of Social and Family Medicine, School of Medicine, University of Crete KK, PhD, Researcher in the Information Systems Laboratory (ISL), Institute of Computer Science (ICS) at the Foundation for Research and Technology, Hellas (FORTH).
AM, APRN-BC, PhD, Associate Professor, University of Alabama at Birmingham.
EP, Public Health Specialist, MPH, FRSPH, DrPHc, Senior Research Fellow, Clinic of Social and Family Medicine, School of Medicine, University of Crete.
CL, MD, PhD, FRCGP (Hon) Professor of General Practice and Primary Health Care,
Clinic of Social and Family Medicine, School of Medicine, University of Crete.
Ethics approval was obtained from the Health Region of Crete (Ref. #9674), the Health Region of Piraeus and Aegean (Ref. #38865) and the Ministry of Health and Solidarity (Ref. #38865). In addition, written consent was obtained from all participants, HCPs and patients, prior to the survey, following full disclosure about the study. No sensitive and personal data were recorded, while confidentiality of data was assured during data analysis and reporting. Data were saved in password protected electronic files, accessible by select members of the research team.
Current process workflows for managing patients with urgent or acute symptoms within PHC units. Illustrates the actual patient flows within the PHC units, as they were currently monitored and mapped by the project. It focuses on patients with urgent or acute symptoms seeking for PHC services. (JPEG 257 kb)
Current process workflows for managing patients with chronic conditions within PHC units. Illustrates the actual patient flows within the PHC units, as they were currently monitored and mapped by the project. It focuses on patients with chronic conditions seeking for PHC services. (JPEG 77 kb)
Optimal processes workflow for patients with chronic disease. Distributed the optimal patient flows within the PHC units, as they are proposed by the project. It depicts the processes workflows of patients with chronic conditions seeking for PHC services. (JPEG 150 kb)
Optimal processes workflows for patients with urgent or acute problems/symptoms. Distributed the optimal patient flows within the PHC units, as they are proposed by the project. It depicts the processes workflows of patients with urgent or acute problems/symptoms seeking for PHC services. (JPEG 182 kb)
Optimal processes workflows for patients in need of prevention services. Distributed the optimal patient flows within the PHC units, as they are proposed by the project. It depicts the processes workflows of patients seeking for prevention services in PHC units. (JPEG 5066 kb)
Optimal processes workflows for patients in need of home care services. Distributed the optimal patient flows within the PHC units (i.e. home care), as they are proposed by the project. It depicts the processes workflows of patients in need of home care service. (JPEG 4616 kb)
Sifaki-Pistolla, D., Chatzea, VE., Markaki, A. et al. Operational integration in primary health care: patient encounters and workflows. BMC Health Serv Res 17, 788 (2017). https://doi.org/10.1186/s12913-017-2702-5
Operational integration
Clinical pathways
Process assessment (healthcare)
Quality indicators (healthcare)
Organization, structure and delivery of healthcare | CommonCrawl |
Holomorphic quadratic differentials and the Bernstein problem in Heisenberg space
Authors: Isabel Fernández and Pablo Mira
Journal: Trans. Amer. Math. Soc. 361 (2009), 5737-5752
MSC (2000): Primary 53A10
DOI: https://doi.org/10.1090/S0002-9947-09-04645-5
Published electronically: June 22, 2009
Abstract | References | Similar Articles | Additional Information
Abstract: We classify the entire minimal vertical graphs in the Heisenberg group $\mathrm {Nil}_3$ endowed with a Riemannian left-invariant metric. This classification, which provides a solution to the Bernstein problem in $\mathrm {Nil}_3$, is given in terms of the Abresch-Rosenberg holomorphic differential for minimal surfaces in $\mathrm {Nil}_3$.
Uwe Abresch and Harold Rosenberg, A Hopf differential for constant mean curvature surfaces in ${\bf S}^2\times {\bf R}$ and ${\bf H}^2\times {\bf R}$, Acta Math. 193 (2004), no. 2, 141–174. MR 2134864, DOI https://doi.org/10.1007/BF02392562
Uwe Abresch and Harold Rosenberg, Generalized Hopf differentials, Mat. Contemp. 28 (2005), 1–28. MR 2195187
Luis J. Alías, Marcos Dajczer, and Harold Rosenberg, The Dirichlet problem for constant mean curvature surfaces in Heisenberg space, Calc. Var. Partial Differential Equations 30 (2007), no. 4, 513–522. MR 2332426, DOI https://doi.org/10.1007/s00526-007-0101-1
Vittorio Barone Adesi, Francesco Serra Cassano, and Davide Vittone, The Bernstein problem for intrinsic graphs in Heisenberg groups and calibrations, Calc. Var. Partial Differential Equations 30 (2007), no. 1, 17–49. MR 2333095, DOI https://doi.org/10.1007/s00526-006-0076-3
Robert L. Bryant, Surfaces of mean curvature one in hyperbolic space, Astérisque 154-155 (1987), 12, 321–347, 353 (1988) (English, with French summary). Théorie des variétés minimales et applications (Palaiseau, 1983–1984). MR 955072
Shiu Yuen Cheng and Shing Tung Yau, Maximal space-like hypersurfaces in the Lorentz-Minkowski spaces, Ann. of Math. (2) 104 (1976), no. 3, 407–419. MR 431061, DOI https://doi.org/10.2307/1970963
Jih-Hsin Cheng, Jenn-Fang Hwang, Andrea Malchiodi, and Paul Yang, Minimal surfaces in pseudohermitian geometry, Ann. Sc. Norm. Super. Pisa Cl. Sci. (5) 4 (2005), no. 1, 129–177. MR 2165405
P. Collin, H. Rosenberg, Construction of harmonic diffeomorphisms and minimal graphs, preprint, 2007.
Benoît Daniel, Isometric immersions into 3-dimensional homogeneous manifolds, Comment. Math. Helv. 82 (2007), no. 1, 87–131. MR 2296059, DOI https://doi.org/10.4171/CMH/86
B. Daniel, The Gauss map of minimal surfaces in the Heisenberg group, preprint, 2006.
B. Daniel, L. Hauswirth, Half-space theorem, embedded minimal annuli and minimal graphs in the Heisenberg space, preprint, 2007.
Isabel Fernández and Pablo Mira, Harmonic maps and constant mean curvature surfaces in $\Bbb H^2\times \Bbb R$, Amer. J. Math. 129 (2007), no. 4, 1145–1181. MR 2343386, DOI https://doi.org/10.1353/ajm.2007.0023
Isabel Fernández and Pablo Mira, A characterization of constant mean curvature surfaces in homogeneous 3-manifolds, Differential Geom. Appl. 25 (2007), no. 3, 281–289. MR 2330457, DOI https://doi.org/10.1016/j.difgeo.2006.11.006
Christiam B. Figueroa, Francesco Mercuri, and Renato H. L. Pedrosa, Invariant surfaces of the Heisenberg groups, Ann. Mat. Pura Appl. (4) 177 (1999), 173–194. MR 1747630, DOI https://doi.org/10.1007/BF02505908
José A. Gálvez and Pablo Mira, The Cauchy problem for the Liouville equation and Bryant surfaces, Adv. Math. 195 (2005), no. 2, 456–490. MR 2146351, DOI https://doi.org/10.1016/j.aim.2004.08.007
N. Garofalo, S. Pauls, The Bernstein problem in the Heisenberg group, preprint, 2003.
L. Hauswirth, H. Rosenberg, J. Spruck, On complete mean curvature $1/2$ surfaces in $\mathbb {H}^2\times \mathbb {R}$, preprint, 2007.
Wu-teh Hsiang and Wu-Yi Hsiang, On the uniqueness of isoperimetric solutions and imbedded soap bubbles in noncompact symmetric spaces. I, Invent. Math. 98 (1989), no. 1, 39–58. MR 1010154, DOI https://doi.org/10.1007/BF01388843
Jun-Ichi Inoguchi, Takatoshi Kumamoto, Nozomu Ohsugi, and Yoshihiko Suyama, Differential geometry of curves and surfaces in 3-dimensional homogeneous spaces. II, Fukuoka Univ. Sci. Rep. 30 (2000), no. 1, 17–47. MR 1763761
Francesco Mercuri, Stefano Montaldo, and Paola Piu, A Weierstrass representation formula for minimal surfaces in $\Bbb H_3$ and $\Bbb H^2\times \Bbb R$, Acta Math. Sin. (Engl. Ser.) 22 (2006), no. 6, 1603–1612. MR 2262416, DOI https://doi.org/10.1007/s10114-005-0637-y
M. Ritoré, C. Rosales, Area stationary surfaces in the Heisenberg group $\mathbb {H}^1$, preprint, 2005.
R. Sa Earp, Parabolic and hyperbolic screw motion surfaces in $\mathbb {H}^2\times \mathbb {R}$, to appear in J. Austr. Math. Soc., 2007.
Tom Yau-Heng Wan, Constant mean curvature surface, harmonic maps, and universal Teichmüller space, J. Differential Geom. 35 (1992), no. 3, 643–657. MR 1163452
Tom Yau-Heng Wan and Thomas Kwok-Keung Au, Parabolic constant mean curvature spacelike surfaces, Proc. Amer. Math. Soc. 120 (1994), no. 2, 559–564. MR 1169052, DOI https://doi.org/10.1090/S0002-9939-1994-1169052-5
U. Abresch, H. Rosenberg, A Hopf differential for constant mean curvature surfaces in $\mathbb {S}^2\times \mathbb {R}$ and $\mathbb {H}^2\times \mathbb {R}$, Acta Math. 193 (2004), 141–174.
U. Abresch, H. Rosenberg, Generalized Hopf differentials, Mat. Contemp. 28 (2005), 1–28.
L.J. Alías, M. Dajczer, H. Rosenberg, The Dirichlet problem for CMC surfaces in Heisenberg space, Calc. Var. Partial Diff. Equations, 30 (2007), 513–522.
V. Barone-Adesi, F. Serra-Cassano, D. Vittone, The Bernstein problem for intrinsic graphs in the Heisenberg group and calibrations, Calc. Var. Partial Diff. Equations, 30 (2007), 17–49.
R.L. Bryant, Surfaces of mean curvature one in hyperbolic space, Astérisque, 154-155 (1987), 321–347.
S.Y. Cheng, S.T. Yau, Maximal space-like hypersurfaces in the Lorentz-Minkowski spaces, Ann. of Math. (2) 104 (1976), 407–419.
J.H. Cheng, J.F Hwang, A. Malchiodi, P. Yang, Minimal surfaces in pseudohermitian geometry, Ann. Sc. Norm. Super. Pisa Cl. Sci. 4 (2005), 129–177.
B. Daniel, Isometric immersions into $3$-dimensional homogeneous manifolds, Comment. Math. Helv. 82 (2007), 87-131.
I. Fernández, P. Mira, Harmonic maps and constant mean curvature surfaces in $\mathbb {H}^2\times \mathbb {R}$, Amer. J. Math. 129 (2007), 1145–1181.
I. Fernández, P. Mira, A characterization of constant mean curvature surfaces in homogeneous $3$-manifolds, Diff. Geom. Appl., 25 (2007), 281–289.
C. Figueroa, F. Mercuri, R. Pedrosa, Invariant surfaces of the Heisenberg groups, Ann. Mat. Pura Appl. 177 (1999), 173–194.
J.A. Gálvez, P. Mira, The Cauchy problem for the Liouville equation and Bryant surfaces, Adv. Math., 195 (2005), 456–490.
W.Y. Hsiang, W.T. Hsiang, On the uniqueness of isoperimetric solutions and imbedded soap bubbles in noncompact symmetric spaces I, Invent. Math. 98 (1989), 39–58.
J. Inoguchi, T. Kumamoto, N. Ohsugi, Y. Suyama, Differential geometry of curves and surfaces in $3$-dimensional homogeneous spaces II, Fukuoka Univ. Sci. Reports 30 (2000), 17–47.
F. Mercuri, S. Montaldo, P. Piu, A Weierstrass representation formula for minimal surfaces in $\mathbb {H}_3$ and $\mathbb {H}^2\times \mathbb {R}$, Acta Math. Sinica, 22 (2006), 1603–1612.
T.Y. Wan, Constant mean curvature surface harmonic map and universal Teichmuller space, J. Differential Geom. 35 (1992), 643–657.
T.Y. Wan, T.K. Au, Parabolic constant mean curvature spacelike surfaces, Proc. Amer. Math. Soc. 120 (1994), 559-564.
Retrieve articles in Transactions of the American Mathematical Society with MSC (2000): 53A10
Retrieve articles in all journals with MSC (2000): 53A10
Isabel Fernández
Affiliation: Departamento de Matematica Aplicada I, Universidad de Sevilla, E-41012 Sevilla, Spain
Email: [email protected]
Pablo Mira
Affiliation: Departamento de Matemática Aplicada y Estadística, Universidad Politécnica de Cartagena, E-30203 Cartagena, Murcia, Spain
MR Author ID: 692410
Email: [email protected]
Keywords: Minimal graphs, Bernstein problem, holomorphic quadratic differential, Heisenberg group
Received by editor(s): May 15, 2007
Additional Notes: The first author was partially supported by MEC-FEDER Grant No. MTM2007-64504 and Regional J. Andalucia Grants P06-FQM-01642 and FQM 325
The second author was partially supported by MEC-FEDER, Grant No. MTM2007-65249 and the Programme in Support of Excellence Groups of Murcia, by Fund. Seneca, reference 04540/GERM/OG
Article copyright: © Copyright 2009 American Mathematical Society | CommonCrawl |
Multi-grade fuzzy assessment framework for software professionals in work-from-home mode during and post-COVID-19 era
M. Suresh ORCID: orcid.org/0000-0002-3796-36231 &
Kavya Gopakumar1
The pandemic novel Coronavirus disease and the resulting lockdowns have contributed to major economic disturbances around the world, forcing organisations to extend the work-from-home (WFH) option to their employees wherever feasible. The current major challenge of this option is maintaining the efficiency and productivity of the employees across the organisations. It is therefore important to understand the impact of this make-shift arrangement of WFH policy and their underlying effects that may affect the efficiency of employees and hence their output levels. This is a distinctive approach to develop a unique framework for efficiency index computation by evaluating the efficiency levels of WFH mode in software organisations using multi-grade fuzzy approach and importance–performance analysis. In turn, this would help to determine the crucial attributes that require improvement to increase the efficiency levels of employees concerned. In this study, a case project has been assessed and it was observed that the efficiency index of WFH accounts to 4.92, which is in between the range of (4.01–6) specified as 'Efficient'. The framework can be used on a periodic basis to help software organisations to continuously improve their WFH efficiency level.
The unprecedented COVID-19 pandemic has disrupted the business ecosystem in many ways. Many organisations across the globe have been left with a choice to have flexible working arrangements like working from home (WFH), especially the Information Technology (IT)-based organisations. During lockdown, the IT industry has shifted seamlessly to the work-from-home model, offering business continuity to customers without reducing efficiency or productivity. Several business leaders find WFH to be a permanent feature, and have started to analyse its advantages and drawbacks. Recent developments in the information and communication technologies have made it easier to perform tasks outside the work-environment. Good internet connectivity and user-friendly machines enable software professionals in the IT industry to work from home. But how this work-model transition has impacted the employees and the respective stakeholders is a concern to be studied upon. It is important to analyse the efficiency and performance of software professionals in the IT industry in order to evaluate the efficiency of WFH model. Only when efficiency improves, the performance improves. This results in an increase in productivity levels and performance, as these factors are interconnected and are essential to achieve the goals of a company.
This research is conducted to study the efficiency of software professionals who are working from home due to this COVID-19 pandemic. The attributes related to efficiency have been drawn from review of various literatures and also by taking note of expert opinions. The attributes were then rated according to its effect on efficiency, in order to find the weakest among them. An MGF assessment model is necessary to examine how the WFH model has affected a team's or project's efficiency and productivity. Through this study, the weaker attributes which are required to be improved in order to increase the efficiency will be assessed and proper suggestions will be provided to modify the same. Thus, a distinctive framework was developed which can be adopted by any organisation in the software industry, to evaluate the work-from-home efficiency levels of a particular team or a project.
A key policy implemented during the COVID-19 pandemic was 'social distancing' [19] in the absence of a vaccine or widespread testing which allows employees in many jobs to work from home wherever feasible. In addition to this, returning to work is likely to occur more slowly for those jobs which involves a large degree of personal closeness to others [22]. According to Felstead et al. [9], the option of working at home is more likely to be available in the public sector, in large establishments and also in those work environments where individuals are responsible for the quality of their own production.
As per Lakshmi et al. [18], work-from-home is one such activity that human resource managers should pursue to recruit and retain high-quality employees with benefits that go beyond the simple work–life balance. The organisations must consider the relevant perspectives and steps that will help both the organisations and their employees to plan and provide maximum value by providing an option to work from home. WFH provides temporary flexibility and flexibility to the worker when choosing working conditions [11].
Where occupational characteristics outweigh individual characteristics, shifting to work-from-home can depend on the average level of productivity at home versus at work, and does not require much selection, training and monitoring if workers choose to work from home [17]. From the perspective of work-from-home, most of the variable organisational and task characteristics were correlated with the outcome measures including productivity, while the individual and household variables were less closely related [3].
According to the study conducted by Duxbury et al. [8], computer-supported supplemental work-at-home (SWAH) provides advantages for organisations to promote the adoption of home technology for their employees. The organisations that provide computer equipment for their employees to work from home will be benefiting more in terms of employees' productivity and profit. If a company is not providing proper technical tools that fits the job that needs to be done in a virtual office, it can adversely affect the productivity of the employees [15]. There should be a well-designed training program for the employees and also for the leaders which includes detailed instructions on the usage of technology and also on the social and psychological changes to be made by the respective organisations in this regard.
The study conducted by Venkatesh and Vitalari [26] says that autonomy, flexibility and improved efficiency are the key reasons behind working from home. Another major defining factor is the portability. Hence, while designing jobs, the organisation must consider these factors to make the work-from-home facility more effective. The employers should be more conscious of the benefits that might be obtained from a sound and solid family lives of their employees, without dismissing these issues, if it were solely a personal problem of an individual employee alone [13].
Programmers consider telecommuting as an alternative to improve job satisfaction as they have a feeling that it would result in 'improved morale'. In a study conducted by DeSanctis [6], it was advised to carry out more research on how organisations can select the most appropriate alternative among the following options such as flexitime, working in a satellite facility and telecommuting so that it is favourable to enhance the productivity of their programmers.
The economic and psychological benefits gained from a family-friendly workplace include recruiting and retaining skilled-staff, high levels of physical and psychological well-being of employees, lower absenteeism, lesser sick-leave rates and increased productivity [4].
There are many theories related to how employees manage themselves based on the circumstances that they have to undergo, in order to achieve the targeted performance in their work. Also, in the face of high job demands, employees either adopt performance protection strategies (e.g. mobilisation of additional mental effort related with additional costs) or accept a decrease in insidious performance (with no cost increase). The former is termed active coping mode, and the latter the passive coping mode [5, 16].
According to the study conducted by Olson [23], the count of management and professional workers making use of information technology to stay in touch twenty-four hours a day, to extend the work day and the workplace, and to provide rapid responses is increasing day-by-day. This led to the usage of information technology to support remote collaboration, particularly in those companies which lack a traditional bureaucratic hierarchy structure.
The MGF assessment of efficiency of WFH model among software professionals is inevitably required at various stages of projects in software organisations. Adopting WFH strategy for all software professionals is a new research area, and since only a very little exploration has happened in this field, this has led to a motivation for our study. The current study attempts to apply multi-grade fuzzy to assess the efficiency of software professionals to achieve improvement in overall performance of software projects, during and post-COVID-19 era.
In this paper, WFH enablers, criteria and their attributes were identified and a conceptual framework was developed for the assessment of the efficiency level of WFH in COVID-19 era by using a multi-grade fuzzy approach. The major objectives are shown below:
To identify the WFH enablers, criteria and attributes of various software professionals.
To develop a multi-grade fuzzy based assessment framework for measuring the efficiency of WFH of software professionals.
To identify the weaker attributes of WFH of software professionals in the case of a software project organisation and to propose suggestions for improvement.
The aforementioned objectives were converted into the following research questions (RQ):
RQ1: How to measure the efficiency of WFH of software professionals?
RQ2: What are the attributes which affect efficiency of WFH mode in software projects?
RQ3: How to improve the weaker attributes to enhance the efficiency of WFH model?
In order to answer the questions listed above, an assessment study was conducted. The measure of efficiency so obtained would assist the project managers to achieve the scope of their project. Additionally, a periodical assessment on efficiency of WFH level of software professionals would notably enhance their continuous improvement in performance and services.
The rest of the paper is organised as follows. "Methods" section includes research methodology with a multi-grade fuzzy approach and an analysis on IPA. "Results and discussions" section is about the results and discussion with suggestions to improve weaker attributes of the case project. "Practical/Managerial implications" enlists the practical implications, while "Conclusion" section deals with the conclusion.
Case organisation
The case software organisation is located in India, and it encourages its share of employees to work from home, due to the dreaded COVID-19 situation. This particular organisation runs multiple projects parallelly. An assessment study was conducted on one among these case projects, where all members of the team were working from their home, from various locations across India and overseas. The objective of this framework was to assess the overall efficiency of their work through WFH mode in the respective case project.
Multi-grade fuzzy
The multi-grade fuzzy approach is extensively applied in manufacturing and service sectors for assessment of leanness, agility, marketing flexibility, safety practice level and service level [1, 12, 21, 24, 27,28,29,30,31,32]. The current study utilises multi-grade fuzzy to assess the efficiency of the work-from-home model among software professionals. The study begins with a review of literature on work-from-home policy and other related attributes across various domains. The new conceptual model was framed on the basis of COVID-19 situation to assess the efficiency levels with 3 enablers, 11 criteria and 27 attributes (Table 1). The enablers, criteria and attributes were finalised based on an interview with the experts' panel. A qualitative data collection was performed to amass weightage from a panel of five experts from various software organisations and ratings were procured from yet another set comprising five team members, working under the case project in software organisation across India. The respondents' profile is shown in Table 2. The interview lasted for 30–45 min, and a brief introduction was given to the respondents on enablers, criteria and attributes. The experts' opinion was captured in linguistic variables and was converted into an equivalent fuzzy scale using Table 3. While allocating weights, reverse ranking was performed for negative attributes, as their effect might tend to decrease the efficiency of software professionals (Table 3).
Table 1 Conceptual model for work-from-home for software professionals
Table 2 Respondents profile
Table 3 Rating and weight-scale for work-from-home for software professionals
Here, the efficiency assessment index of software projects is represented as I. It is the product of overall assessment level of ratings based on each driver (R) and the overall weights (W) given by the experts. The equation for efficiency index is
$$ I = W \times R $$
The assessment scale has been graded into five levels since every factor involves fuzzy determination. I = (10, 8, 6, 4, 2). 8–10 represents 'Extremely Efficient', 6–8 represents 'Highly Efficient', 4–6 represents 'Efficient', 2–4 represents 'Moderately Efficient' and less than 2 denotes 'Quite Inefficient'. Table 4 lists the assessment model weights and performance rating from the experts.
Table 4 Normalised weights and experts' rating of the case project
First-level calculation
The first-level calculation done for 'Work–life balance (O11)' criterion is given below. Weights concerning to 'Work–life balance' criterion is W11 = [0.238, 0.261, 0.215, 0.284]
$$ R_{11} = \left[ {\begin{array}{*{20}c} 9 \quad & 5 \quad & 4 \quad & 8 \quad & 3 \\ 5 \quad & 8 \quad & 1 \quad & 3 \quad & 2 \\ 7 \quad & 7 \quad & 4 \quad & 8 \quad & 9 \\ 4 \quad & \quad 3 \quad & 2 \quad & 8 \quad & 3 \\ \end{array} } \right] $$
'Work–life balance' calculation Index, I11 = W11 × R11
$$ I_{11} = \left[ {6.1, \, 5.65, \, 2.65, \, 6.69, \, 4.03} \right] $$
Using similar principle, remaining criterion indices were obtained as follows:
$$ \begin{aligned} I_{12} & = \, \left[ {4.51, \, 3.51, \, 2, \, 2, \, 1.51} \right] \\ I_{13} & = \, \left[ {4.86, \, 6.24, \, 7.26, \, 5.62, \, 6.24} \right] \\ I_{21} & = \, \left[ {6, \, 6.08, \, 6.18, \, 5.26, \, 6} \right] \\ I_{22} & = \, \left[ {6.57, \, 5.42, \, 5.57, \, 5.87, \, 6.45} \right] \\ I_{23} & = \, \left[ {3, \, 4.97, \, 4.97, \, 4.04, \, 4.97} \right] \\ I_{24} & = \, \left[ {3, \, 1, \, 2.97, \, 3.91, \, 8.48} \right] \\ I_{31} & = \, \left[ {5.97, \, 6.92, \, 5.95, \, 8.48, \, 8.48} \right] \\ I_{32} & = \, \left[ {3.15, \, 3.27, \, 4, \, 3.69, \, 3.29} \right] \\ I_{33} & = \, \left[ {5.25, \, 5.32, \, 6.9, \, 4.9, \, 6.33} \right] \\ I_{34} & = \, \left[ {5.55, \, 3.72, \, 5.11, \, 5, \, 4.32} \right] \\ \end{aligned} $$
Second-level calculation
The second-level calculation done for 'Human perspective (O1)' enabler is given below. Weights concerning to 'Human perspective' enabler is W1 = [0.343, 0.343, 0.312]
$$ R_{1} = \left[ {\begin{array}{*{20}c} {6.1} &\quad {5.65} &\quad {2.65} &\quad {6.69} &\quad {4.03} \\ {4.51} &\quad {3.51} &\quad 2 &\quad 2 &\quad {1.51} \\ {4.86} &\quad {6.24} &\quad {7.26} &\quad {5.62} &\quad {6.24} \\ \end{array} } \right] $$
'Human Perspective' calculation Index, I1 = W1 × R1
$$ I_{1} = \, \left[ {5.16, \, 5.10, \, 3.87, \, 4.74, \, 3.86} \right] $$
Using similar principle, remaining enabler indices were obtained as follows:
$$ \begin{gathered} I_{2} = \, \left[ {4.68, \, 4.46, \, 4.97, \, 4.8, \, 6.41} \right] \hfill \\ I_{3} = \, \left[ {4.99, \, 4.75, \, 5.47, \, 5.48, \, 5.53} \right] \hfill \\ \end{gathered} $$
Third-level calculation
The third-level calculation done for the 'Efficiency index' of WFH is given below. Weights concerning the overall 'efficiency' are W = [0.381, 0.309, 0.309]
$$ R_{1} = \left[ {\begin{array}{*{20}c} {5.16} &\quad {5.10} &\quad {3.87} &\quad {4.74} &\quad {3.86} \\ {4.68} &\quad {4.46} &\quad {4.97} &\quad {4.8} &\quad {6.41} \\ {4.99} &\quad {4.75} &\quad {5.47} &\quad {5.48} &\quad {5.53} \\ \end{array} } \right] $$
Overall efficiency calculation Index, I = W × R
$$ \begin{aligned} I & = \left[ {4.96, \, 4.79, \, 4.70, \, 4.99, \, 5.17} \right] \\ I & = \left( {4.96 \, + \, 4.79 \, + \, 4.70 \, + \, 4.99 \, + \, 5.17} \right)/5 \to 4.92 \\ I & = 4.92 \in \left( {4, \, 6} \right) \to {\text{'Efficient'}} \\ \end{aligned} $$
For the respective case project under study, the efficiency index accounts to 4.92, indicative of the fact that the project employees are 'efficient'. Up next, the IPA analysis was carried out for classifying the attributes based on their importance and performance.
Importance–performance analysis (IPA)
Importance–performance analysis (IPA) is widely used to classify attributes based on weaker attributes (attention required), good-performance attributes (keep it up), over-performance attributes (re-allocation of resources to reduce performance) and low-priority attributes (only less attention required), etc. It is extensively applied in manufacturing and service sectors to classify various attributes or to identify their priority [2, 7, 10, 14, 20, 25]. In IPA, the horizontal axis marks the performance of attributes and the vertical axis denotes their importance. In this case project, IPA of mean of x-axis is 4.89 and the mean of y-axis is 5.72 as per the perpendicular line given in Fig. 1.
IPA for efficiency assessment attributes of case project
Quadrant I (Weaker attributes): The attributes in this quadrant need immediate attention by the case project manager in order to improve the employees' efficiency. The attributes are stress, readiness to prioritise work and life, setting up of VPN and other network-related needs, unavailability of required hardware or incompatible hardware, and mismatch of intermission period among colleagues.
Quadrant II (Keep up the good work): The attributes in this quadrant are indeed necessary to keep up the efficacy of employees. They are motivation, more personal time, time lost in transportation, software knowledge, proper training and development, opportunities for personal/professional development, feeling of connectedness to the team and organisation.
Quadrant III (Possible overkill): The importance of these attributes is quite low since the performance rating is over the top. Those attributes include self-efficacy, 'Over the shoulder' supervision, supervisor's/manager's availability.
Quadrant IV (Low priority): The attributes in this quadrant are of low importance, and requires only lesser attention. It includes ergonomic issues, long screen time, long working hours, knowledge gap, unavailability of network at homes, network speed fluctuations, spending quality time discussing personal and professional life, peer-to-peer relationship, appreciation and other perks, miscommunication among the team, and team-building activities.
In an effort to measure the efficiency of employees working from home, the efficiency index was calculated as 4.92, which belongs to the range of (4.01–6) specified as 'Efficient'. The existing efficiency level requires further improvement on weaker attributes in order to achieve the level earmarked as 'Extremely Efficient'. This in turn, requires a detailed management of actions to be undertaken to improve the weaker attributes and thereby certain measures to enhance the efficiency of employees. According to the current study, the employees' feels motivated, enjoys their personal time and are equipped with proper knowledge about the software that they are using. They were getting the advantage of time that they tend to lose early, during their transport between home and the office. Provisions for proper training and development not only helps them to improve and enhance their efficiency but also provides good opportunities for their personal and professional development. Though miles apart, the members would still have the feeling of connectedness to their team and organisation, keeping them motivated to work cooperatively to achieve targets of the company.
The weaker attributes demand proper attention and strategies to improve them. Measures taken to improve these attributes not only helps to increase the efficiency of individual employees but also of the team as a whole. Engaging in stress-relieving activities, prioritising both work and life, proper rectification of network/software/hardware-related issues and coordination among team members demands major attention in accordance with IPA analysis performed as a part of this research. Suggestions to improve the weaker attributes are listed in Table 5.
Table 5 Identified weaker attributes and decisions suggested for their improvement
Practical/Managerial implications
The present study initially identifies the enablers, criteria and attributes which assists to measure the efficiency and productivity of employees from various software/Information Technology domains of an organisation, working from home during the COVID-19 period. Responses from various employees including a panel of experts from varied projects were recorded based on the attributes and were taken thereafter for a detailed IPA analysis. The output of IPA analysis identifies the weaker attributes as stress, readiness to prioritise both work and life, setting up of VPN and other network-related needs, unavailability of required hardware or incompatible hardware and mismatch of intermission period among colleagues, etc.
It is necessary for an organisation to take note of these weaker attributes in order to improve the efficiency of employees within a team and across teams to guarantee the achievement of maximum productivity. The suggestions for improvement should be taken into consideration to assist an organisation to achieve its goals through an efficient work-from-home policy for its employees during the COVID-19 situation. Both the team members and the panel of experts should be well-aware of these attributes which would encourage them to work more efficiently and effectively. The managers and the organisations must ensure that the stronger attributes and their related criteria are continuing as the way it is at present. Hence, with cooperation from the team as well as the organisation, one can succeed the challenges that hinder efficiency in a work-from-home model.
The unprecedented COVID-19 situation has forced many organisations to practise work-from-home policy for their employees wherever feasible. Through IPA analysis, the study identifies certain weaker attributes that demand immediate improvement. The enablers, criteria and attributes identified were manipulated and were used for IPA analysis. In order to evaluate the current efficiency level of employees working in an Information Technology (software) domain, this study can be considered as a base for further research on remaining domains as well. The suggested new approach would definitely improve the efficiency of employees within a team as well as across teams and would also help in attaining both personal and organisational goals. Management should be ready to accommodate these changes which would further help to improve the efficiency and in turn, the productivity of the employees both at team and organisational level.
The datasets used and/or analysed during the current study are presented in Table 3 of this paper.
O ijk :
Attributes rating
W ijk :
Attributes weightage
W ij :
Criteria weightage
W i :
Enabler weightage
Almutairi AM, Salonitis K, Al-Ashaab A (2019) Assessing the leanness of a supply chain using multi-grade fuzzy logic: a health-care case study. Int J Lean Six Sigma 10(1):81–105
Atalay KD, Atalay B, Isin FB (2019) FIPIA with information entropy: a new hybrid method to assess airline service quality. J Air Transp Manag 76:67–77
Baker E, Avery GC, Crawford JD (2007) Satisfaction and perceived productivity when professionals work from home. Res Pract Hum Resour Manag 15(1):37–62
Brough P, O'Driscoll MP (2010) Organizational interventions for balancing work and home demands: an overview. Work Stress 24(3):280–297
Demerouti E, Bakker AB, Bulters AJ (2004) The loss spiral of work pressure, work–home interference and exhaustion: reciprocal relations in a three-wave study. J Vocat Behav 64(1):131–149
DeSanctis G (1984) Attitudes toward telecommuting: implications for work-at-home programs. Inf Manag 7(3):133–139
Dickson D, Ford R, Deng WJ (2008) Fuzzy importance-performance analysis for determining critical service attributes. Int J Serv Ind Manag 19(2):252–270
Duxbury LE, Higgins CA, Thomas DR (1996) Work and family environments and the adoption of computer-supported supplemental work-at-home. J Vocat Behav 49(1):1–23
Felstead A, Jewson N, Phizacklea A, Walters S (2002) Opportunities to work at home in the context of work-life balance. Hum Resour Manag J 12(1):54–76
Feng M, Mangan J, Wong C, Xu M, Lalwani C (2014) Investigating the different approaches to importance–performance analysis. Serv Ind J 34(12):1021–1041
Gajendran RS, Harrison DA (2007) The good, the bad, and the unknown about telecommuting: meta-analysis of psychological mediators and individual consequences. J Appl Psychol 92(6):1524
Ganesh J, Suresh M (2016) Safety practice level assessment using multigrade fuzzy approach: a case of Indian manufacturing company. In: 2016 IEEE international conference on computational intelligence and computing research (ICCIC). IEEE, pp 1–5
Geurts S, Rutte C, Peeters M (1999) Antecedents and consequences of work–home interference among medical residents. Soc Sci Med 48(9):1135–1148
Hemmington N, Kim PB, Wang C (2018) Benchmarking hotel service quality using two-dimensional importance-performance benchmark vectors (IPBV). J Serv Theory Pract 28(1):2–25
Hill EJ, Miller BC, Weiner SP, Colihan J (1998) Influences of the virtual office on aspects of work and work/life balance. Pers Psychol 51(3):667–683
Hockey GRJ (1993) Cognitive-energetical control mechanisms in the management of work demands and psychological health. In: Baddely A, Weiskrantz L (eds) Attention: selection, awareness, and control. Clarendon Press, Oxford, pp 328–345
Kramer A, Kramer KZ (2020) The potential impact of the Covid-19 pandemic on occupational status, work from home, and occupational mobility. J Vocat Behav. https://doi.org/10.1016/j.jvb.2020.103442
Lakshmi V, Nigam R, Mishra S (2017) Telecommuting—a key driver to work-life balance and productivity. IOSR J Bus Manag 19(01):20–23. https://doi.org/10.9790/487X-1901032023
Lakshmi Priyadarsini S, Suresh M (2020) Factors influencing the epidemiological characteristics of pandemic COVID 19: a TISM approach. Int J Healthc Manag 13(2):89–98
Martín JC, Mendoza C, Román C (2018) Revising importance-performance analysis: a new synthetic service quality indicator applied to the tourist apartment industry. Tour Anal 23(3):337–350
Mishra R, Mishra ON (2018) A hybrid PCA-AHP-multi-grade fuzzy approach to assess marketing-based flexibility. Mark intell Plan 36(2):213–229
Mongey S, Weinberg A (2020) Characteristics of workers in low work-from-home and high personal-proximity occupations. Becker Friedman Institute for Economic White Paper, Chicago
Olson MH (1989) Work at home for computer professionals: current attitudes and future prospects. ACM Trans Inf Syst (TOIS) 7(4):317–338
Sridharan V, Suresh M (2016) Environmental sustainability assessment using multigrade fuzzy—a case of two Indian colleges. In 2016 IEEE international conference on computational intelligence and computing research (ICCIC). IEEE, pp 1–4
Tzeng GH, Chang HF (2011) Applying importance-performance analysis as a service quality measure in food service industry. J Technol Manag Innov 6(3):106–115
Venkatesh A, Vitalari NP (1992) An emerging distributed work arrangement: an investigation of computer-based supplemental work at home. Manag Sci 38(12):1687–1706
Vimal KEK, Vinodh S, Muralidharan R (2015) An approach for evaluation of process sustainability using multi-grade fuzzy method. Int J Sustain Eng 8(1):40–54
Vinodh S (2011) Assessment of sustainability using multi-grade fuzzy approach. Clean Technol Environ Policy 13(3):509–515
Vinodh S, Prasanna M (2011) Evaluation of agility in supply chains using multi-grade fuzzy approach. Int J Prod Res 49(17):5263–5276
Vinodh S, Chintha SK (2011) Leanness assessment using multi-grade fuzzy approach. Int J Prod Res 49(2):431–445
Vinodh S, Devadasan SR, Vasudeva Reddy B, Ravichand K (2010) Agility index measurement using multi-grade fuzzy approach integrated in a 20 criteria agile model. Int J Prod Res 48(23):7159–7176
Vinodh S, Madhyasta UR, Praveen T (2012) Scoring and multi-grade fuzzy assessment of agility in an Indian electric automotive car manufacturing organisation. Int J Prod Res 50(3):647–660
The study received no external funding.
Amrita School of Business, (AACSB Accredited Business School), Amrita Vishwa Vidyapeetham (University), Coimbatore, 641 112, India
M. Suresh & Kavya Gopakumar
M. Suresh
Kavya Gopakumar
SM analysed the data, and KG interpreted the data. All authors had contributed equally in other sections of the manuscript. All authors read and approved the final manuscript.
Correspondence to M. Suresh.
Suresh, M., Gopakumar, K. Multi-grade fuzzy assessment framework for software professionals in work-from-home mode during and post-COVID-19 era. Futur Bus J 7, 10 (2021). https://doi.org/10.1186/s43093-021-00057-w
Accepted: 10 February 2021
DOI: https://doi.org/10.1186/s43093-021-00057-w
Online work during COVID-19
Software professionals
Work effectiveness
Importance–performance analysis | CommonCrawl |
Coherent scattering
Coherent Scattering. Coherent scattering arising from the contrast between hydrogenous polymer and solvent can be avoided by arranging for the polymer and solvent to have the same scattering length density. From: Comprehensive Polymer Science and Supplements, 1989. Related terms: Wavelength; Neutron Scattering; Incoherent Scattering; Scattering Cross Sectio Coherent scattering (also known as unmodified, classical or elastic scattering) is one of three forms of photon interaction which occurs when the energy of the x-ray or gamma photon is small in relation to the ionisation energy of the atom Coherent scattering depends on Q and is therefore the part that contains information about scattering structures, whereas SANS incoherent scattering is featureless (Q independent) and contains information about the material scattering density only. Here only elastic scattering is considered. 1. COHERENT AND INCOHERENT CROSS SECTION Projec
Coherent scattering is then the case where the scattered particle or wave has a fixed phase relation relative to the initial wave, such that you can observe interference between the two. This coherence can be destroyed by fluctutations of the scattering medium or by quantum effects such as inversion of level systems the other hand, elastic or geometrical scattering simply converts the well-collimated coherent acoustic wave into diffusely propagating incoherent wave without reducing the total acoustic energy. Because of this fundamental difference between viscous and geometrical scattering, the two mechanisms can be best differentiated from the energ Coherent processes are typically associated with wave coherence, so coherent scattering means scattering of two waves. This is in opposition with scattering between a wave and something that is not a wave (or, by some interpretations, something that does not behave like a wave, like a macroscopic bunch of matter such as a bouncing ball)
Coherent Scattering - an overview ScienceDirect Topic
In physics, coherent backscattering is observed when coherent radiation (such as a laser beam) propagates through a medium which has a large number of scattering centers (such as milk or a thick cloud) of size comparable to the wavelength of the radiation
In coherent scattering, incident photon undergoes change in direction without change its frequency and obey conservation theorem of energy and momentum which is called coherent elastic scattering...
Something scattered, especially a small, irregularly occurring amount or quantity: a scattering of applause. 2. Physics The dispersal of a beam of particles or of radiation into a range of directions as a result of physical interactions
Scattering is a term used in physics to describe a wide range of physical processes where moving particles or radiation of some form, such as light or sound, are forced to deviate from a straight trajectory by localized non-uniformities in the medium through which they pass. In conventional use, this also includes deviation of reflected radiation from the angle predicted by the law of reflection. Reflections of radiation that undergo scattering are often called diffuse reflections and unscatter
Coherent Neutron Scattering. Neutron coherent scattering has its counterpart in small angle X-ray scattering (SAXS) and diffraction, for which the theory is very similar (19), although the possibilities afforded by contrast variation are unique to neutron scattering (18). From: Membrane Science and Technology, 2000. Download as PDF
(d) The modeling of dependent light scattering effects in dense media strongly depends on the value of the relative index of refraction of the system: (1) For low nr, the use of single coherent scattering approximation can lead to a fairly accurate modeling provided the particles' shape can be approximated by spheres and that their spatial correlation is mainly driven by a hard sphere potential
In a quasi-random array of scatterers, coherent scattering is predicted only for light waves with a wavelength of twice that of the largest components of the Fourier transform of the spatial. Coherent scattering occurs in one (or a few) directions, with coherent destructive scattering occurring in all others. A smooth surface scatters light coherently and constructively only in the direction whose angle of reflection equals the angle of incidence Also contains definition of: incoherent scattering https://doi.org/10.1351/goldbook.C01131 @S05487-1@ is coherent whenever the phases of the signals arising from different @S05487-2@ centres are correlated and incoherent whenever these phases are uncorrelated A Coherent Anti-Stokes Raman Scattering (CARS) signal was first recorded in the mid-1960s. At that time, it was called Three wave mixing experiment. After ten years, first applications on biological samples were shown. CARS spectroscopy is used to get detailed information of molecules or identification of components within a sample.
This video depicts the principle of Coherent scattering(one of three forms of photon interaction which occurs when the energy of the X-ray or gamma photon is.. scattering becomes coherent. The longitudinal density modulation is induced by beam echo [1]. Echo with a short laser pulse gives localized density modulation with wave length < O R [2]. Extreme short pulse can be emitted by the coherent T scattering. In this paper, radiation field emitted by T scattering is discussed for KEK-(c)ERL. The bea Coherent anti-Stokes Raman scattering (CARS) is a nonlinear four-wave mixing process that is used to enhance the weak (spontaneous) Raman signal. In the CARS process a pump laser beam (at frequency pump) and a Stokes laser beam (at Stokes) interact, producing an anti-Stokes signal at frequency CARS = 2 pump - Stokes Neutrino interactions. (A) Coherent Elastic Neutrino-Nucleus Scattering. For a sufficiently small momentum exchange (q) during neutral-current neutrino scattering (qR < 1, where R is the nuclear radius in natural units), a long-wavelength Z boson can probe the entire nucleus, and interact with it as a whole
A scattering medium is characterized by an unknown parameter θ. This parameter is estimated by illuminating the medium with coherent light and by measuring the outgoing field state via a homodyne. Define coherent scattering radiation. coherent scattering radiation synonyms, coherent scattering radiation pronunciation, coherent scattering radiation translation, English dictionary definition of coherent scattering radiation. n. 1. The act or process of radiating: the radiation of heat and light from a fire. 2. Physics a Despite the fact that coherent elastic neutrino-nucleus scattering (CEvNS) was proposed more than forty years ago , it was only recently that the COHERENT collaboration observed this process for the first time by using a CsI[Na] detector exposed to the neutrino flux generated at the Spallation Neutron Source (SNS) at Oak Ridge National Laboratory Coherent Raman scattering, including stimulated Raman scattering (SRS) and coherent anti-Stokes Raman scattering (CARS), are nonlinear alternatives that enhance the weak Raman signal by means of nonlinear excitation, enabling imaging speeds up to video-rate [1-3]. (a) SRS energy diagram with a Stokes and pump beam tuned to a sample's. Coherent microscopy: Radiation pattern is not symmetrical (CARS, SHG, THG) Small scatter radiates as a single dipole Bulk scatterers add constructively in the forward direction F-CARS detects large scatters, E-CARS detects small scatterers Volkmer et. al., Phys. Rev. Lett. V87, 0239011 (2001
The scattering of a partially coherent plane-wave pulse on a Gaussian-correlated, quasi-homogeneous random medium is investigated. The analytical expressions for the temporal coherence length and the pulse duration of the scattered field are derived. We demonstrate that the scattering-induced change coherent scattering 相干散射; 學術名詞 電工學名詞-兩岸電工學名詞 coherent scattering 相干散射; 學術名詞 地球科學名詞-天文 coherent scattering 相干散射;同調散射; 學術名詞 地球科學名詞-大氣 coherent scattering 相干散射; 學術名詞 地球科學名詞-太空 coherent scattering 同調. The strong light-matter optomechanical coupling offered by coherent scattering set-ups have allowed the experimental realization of quantum ground-state cavity cooling of the axial motion of a levitated nanoparticle [U. Delić et al., Science 367, 892 (2020)].An appealing milestone is now quantum two-dimensional (2D) cooling of the full in-plane motion, in any direction in the transverse plane coherent scattering. In radar, scattering produced when the incident wave encounters a point target that is either fixed or moving with a constant radial velocity, or a distributed target with individual scattering elements fixed or slowly moving relative to one another
Scattering for which reemission occurs at the same frequency as the incident radiation. See also: Incoherent Scattering
imal effect on the imaging process C) never affects the diagnostic image D) none of thes
Recently, a broad spectrum of exceptional scattering effects, including bound states in the continuum, exceptional points in PT-symmetrical non-Hermitian systems, and many others attainable in wisely suitably engineered structures have been predicted and demonstrated. Among these scattering effects, those that rely on coherence properties of light are of a particular interest today. Here, we.
Coherent Scattering - PowerPoint PPT Presentation. 1 / 7 } ?> Actions. Remove this presentation Flag as Inappropriate I Don't Like This I like this Remember as a Favorite. Download Share Share. View by Category Toggle navigation. Presentations. Tags: bounces | coherent.
Coherent scattering involves A) an x-ray photon with high energy B) an x-ray photon with low energy C) ionization D) all of thes
Coherent vs. Incoherent light scattering Coherent light scattering: scattered wavelets have nonrandom relative phases in the direction of interest. Incoherent light scattering: scattered wavelets have random relative phases in the direction of interest. Forward scattering is coherent— even if the scatterers are randomly arranged in the plane
Bound coherent neutron scattering lengths of hydrogen Z-Symb-A % or T1/2 I bc b+ b- b+-b- Meth Ref 1-H -3.7409 ± 0.0011 GR 75Koe1-3.74 ± 0.02 IN 81Ham
Coherent scattering - YouTub
Coherent (Classical) Scatter. Coherent Scattering, it is one of the 3 interactions that can take place with diagnostic X-rays and the body. It also has other names 'Elastic Scattering' and 'Rayleigh Scattering'. Coherent Scattering happens when an X-Ray photon comes in, interacts with electron cloud and goes out
We report the total (coherent + incoherent) scattering cross sections of some lead and sodium compounds measured at angles less than 10° for 241 Am (59.54 keV) gamma rays. The experimental cross sections so obtained are compared with the data interpolated from theoretical compilations based on nonrelativistic Hartree-Fock (NRHF) model for the samples of interest
The spin independent part of the quantity is referred to as the coherent scattering length [a.sub.c]. Measurement of the coherent neutron scattering length of [.sup.3]He. In the above equation, j denotes the atomic species, m is the neutron mass, [b.sub.j] is the coherent scattering length, [delta] is the delta function, r is the coordinate of.
translation and definition coherent scattering, Dictionary English-English online. coherent scattering. Example sentences with coherent scattering, translation memory. patents-wipo. X-ray inspection by coherent-scattering from variably disposed scatterers identified as suspect objects
The coherent nature of this process can make the CARS signal much greater than that of spontaneous Raman scattering. Since the first demonstration of CARS microscopy in 1982, and through its extensive development during the last decade, practically all methods have been based on scanning of tightly focused co-propagating pump and Stokes laser.
coherence - Difference between coherent scattering and
At low energies and small scattering angles, however, binding effects are very important, the Compton cross section is significantly reduced, and coherent scattering dominates (see Figs. 3-1 and 3-2). For details see Refs. 1 and 2. The scattered x-ray suffers an energy loss, which (ignoring binding effects) is given b The strong light-matter optomechanical coupling offered by coherent scattering set-ups have allowed the experimental realization of quantum ground-state cavity cooling of the axial motion of a. Here, we present a general framework to calculate and minimize this bound using coherent probe fields with tailored spatial distributions. As an example, we experimentally study a target located in between two disordered scattering media Coherent elastic scattering produces the effect of electron diffraction, which is used to analyze crystal structure (Spence and Zuo, 1992; Fuller et al., 2013). Inelastic scattering occurs when there is an interaction that causes loss of energy of the incident primary electron. Inelastically scattered electrons have a longer wavelength We investigated the statistical properties of partially coherent optical vortex beams scattered by a $\mathcal {PT}$ dipole, consisting of a pair of point particles having balanced gain and loss. The formalism of second-order classical coherence theory is adopted, together with the first Born approx
Coherent Scattering: lt;table class=vertical-navbox nowraplinks cellspacing=5 cellpadding=0 style=float:right;clea... World Heritage Encyclopedia, the. Coherent scatter radar is a volume scattering technique whereby the radar detects energy scattered from within a medium when there are regular spatial variations of the refractive index due to irregularities. This is the analogue of Bragg scattering of X-rays from crystals
Coherent and Incoherent Scattering Mechanisms Introductio
ID10 is a multi-purpose, high-brilliance undulator beamline. Endstation EH1 is for high-resolution X-ray scattering and surface diffraction on liquid and solid interfaces, combining multiple techniques in a single instrument. Endstation EH2 is for coherent small-angle X-ray scattering, X-ray photon correlation spectroscopy and coherent diffraction Coherent Raman scattering (CRS) techniques are recognized for their ability to induce and detect vibrational coherences in molecular samples. The generation of coherent light fields in CRS produces much stronger signals than what is common in incoherent Raman spectroscopy, while also enabling direct views of evolving molecular vibrations. Despite the attractive attributes of CRS spectroscopy.
Difference between coherent scattering and elastic
Electromagnetic scattering model from 3-D snowpack with arbitrary thickness is considered. A fully coherent model is presented through the usage of the Statistical S-Matrix Wave Propagation in Spectral Domain approach (SSWaP-SD). The computer-generated snow media is constructed using 3-D spatial exponential correlation function along with Lineal-Path function to preserve the connectivity of.
[en] It is known since the work of Freedman that neutran-current scattering of neutrinos from the nucleons in a nucleus can be coherent, leading, for sufficiently long wavelengths, to cross sections which are proportional to the square of the nuclear baryon number. When extended to macroscopic objects containing N nuclei, it has recently been reported, on the one hand, that coherent cross.
The purpose of this review is to introduce biologists to coherent anti-Stokes Raman scattering (CARS) microscopy, by introducing the concept, instrumentation, and progress in live cell and tissue imaging since its revival in 1999 . INTRODUCTION TO VIBRATIONAL SPECTROSCOPY AND RAMAN SCATTERING. Vibrational spectroscopy and Raman scattering are.
The setup of coherent-scattering cooling consists of an optical tweezer levitating a nanoparticle inside a high-finesse cavity. If the tweezer is slightly red detuned from the cavity resonance, the particle motion loses energy by scattering tweezer photons into the cavity mode Salzburger and Ritsch ; Gonzalez-Ballestero et al.
The concept of coherence in the scattering of neutrinos and antineutrinos off nuclei is discussed. Motivated by the results of the COHERENT experiment, a new approach to coherence in these processes is proposed, which allows a unified description of the elastic (coherent) and inelastic (incoherent) contributions to the total cross section for neutrino and antineutrino scattering off nuclei at.
coherent scattering setup is the simultaneous ground-state cooling of all three translational degrees of freedom. There is strong motivation, however, for investigating the cavity cooling of 2D motions in the tweezer transverse plane (x-y plane): The frequencies are similar ω x ≈ ω y and for suit-able experimental parameters, g x g y ≡ g. the coherence scattering process. In principle the nucleus could also be some higher spin particle but based on eq. (2.4) it is reasonable to deduce that the di erence should be suppressed for a large nucleus. 2.2 Detection Note that the recoil energy Tis the only measurable e ect of coherent neutrino scattering The scattering process is analogous to the coherent forward scattering of photons on atoms. This elastic scattering proceeds via the neutral weak current and benefits from a coherent enhancement to the cross-section. The enhancement, a purely quantum mechanical effect, is approximately proportional to the square of the number neutrons in the. Chemical imaging of calcifications was demonstrated in the depth of a tissue. Using long wavelength excitation, broadband coherent anti-Stokes Raman scattering and hierarchical cluster analysis, imaging and chemical analysis were performed 2 mm below the skin level in a model system. Applications to breast c Biomedical Raman Imagin Coherent anti-Stokes Raman scattering (CARS) microscopy is a label-free imaging technique that is capable of real-time, nonperturbative examination of living cells and organisms based on molecular vibrational spectroscopy. Recent advances in detection schemes, understanding of contrast mechanisms, and developments of laser sources have enabled superb sensitivity and high time resolution.
Video: Coherent backscattering - Wikipedi
By Kimberly K. Buhman. The First Book on CRS MicroscopyCompared to conventional Raman microscopy, coherent Raman scattering (CRS) allows label-free imaging of living cells and tissues at video rate by enhancing the weak Raman signal through nonlinear excitation. Edited by pioneers in the field and with contributions from a distinguished team of. Coherent Backscatter . Journal Contributor Gary Swearingen suggested the addition of a brief explanation of coherent backscattering. The following was found in a Wikipedia article on the general topic of scattering. (A) special type of EM (electromagnetic) scattering is coherent backscattering. This is a relatively obscure phenomenon that.
What is the difference between coherent, incoherent
Plasmon-enhanced coherent Raman scattering microscopy has reached single-molecule detection sensitivity. Due to the different driven fields, there are significant differences between a coherent Raman scattering process and its plasmon-enhanced derivative. The commonly accepted line shapes for coherent anti-Stokes Raman scattering and stimulated.
e the full coupled Hamiltonian for the nanoparticle, cavity, and free electromagnetic field. By tracing out the latter, we obtain a master equation for the cavity and the center-of-mass motion, where the decoherence rates.
Coherent scattering occurs when the momentum transfer from a neutrino to the nucleus is much smaller than the inverse size of the recoil nucleus. A detection of coherent neutrino-nucleus scattering would verify an unconfirmed Standard Model prediction [1], explore non-standard neutrino-quark interactions, confirm stellar collapse and supernova.
(A) Coherent elastic neutrino-nucleus scattering. For a sufficiently small momentum exchange (q) during neutral-current neutrino scattering (qR < 1, where R is the nuclear radius in natural units), a long-wavelength Z boson can probe the entire nucleus and interact with it as a whole. An inconspicuous low-energy nuclear recoil is the only.
Coherent Scattering - definition of Coherent Scattering by
A new technique for use in coherent anti‐Stokes Raman scattering experiments allows the simultaneous generation of an entire Q‐branch spectrum of the anti‐Stokes radiation from a molecular gas using a single laser pulse. With this technique the stringent requirements of the previous techniques concerning laser linewidth and frequency stability are significantly relaxed PHYSICAL REVIEW A 82, 043836 (2010) Coherent and spontaneous Rayleigh-Brillouin scattering in atomic and molecular gases and gas mixtures M. O. Vieitez, 1E. J. van Duijn, W. Ubachs, B. Witschas,2 A. Meijer,3 A. S. de Wijn, 3N. J. Dam, and W. van de Water4,* 1Laser Centre, Vrije Universiteit, De Boelelaan 1081, NL-1081 HV Amsterdam, The Netherlands 2Deutsches Zentrum fur Luft- und Raumfahrt DLR.
Scattering - Wikipedi
Coherence 2018 is a conference dedicated to the use of X-ray, electron and optical coherence for phase retrieval and coherent scattering, imaging matter as well as probing structure and dynamics. The conference first took place at Lawrence Berkeley Laboratory, in May 2001, and is now held every 2 years A promising technique is non-linear coherent anti-Stokes Raman scattering (CARS) microscopy, which has the ability to capture rich spatiotemporal structural and functional information at a high acquisition speed in a label-free manner from a biological system. Raman scattering is a process in which the distinctive spectral signatures associated. 2.3.1. Coherent scattering . The (coherent) scattering by a small crystal was first treated by von Laue (1936) and shortly after by Patterson (1939) and Ewald (1940). The electronic density of an infinite crystal can be expressed as the convolution of the electronic density of the unit cell, ρ 0 (r), and an infinite three-dimensional lattice The simulation-derived ζ coh (q,Δt) was estimated using the coherent intermediate scattering function, I coh (q,Δt), computed directly from the MD trajectories, and Δt is the instrument resolution ~1 ns. ζ coh (q,Δt) thus defined furnishes a quantitative measure of how much the intermediate scattering function decays at Δt and has the. The strong light-matter optomechanical coupling offered by coherent scattering set-ups have allowed the experimental realization of quantum ground-state cavity cooling of the axial motion of a.
where \(I\) is the identity matrix and \(\Tr{I}\) is basically the number of flavors, which we define as \(N\).. For antineutrinos, we have the freedom to put the signs in the equation or the Hamiltonian. Only the relative signs matter. If we think about antineutrinos as neutrinos going back in time, as interpreted in Feynman diagrams English examples for coherent scattering - This also means that in real space images, lattice planes edge-on are decorated not by diffuse scattering features but by contrast associated with coherent scattering. This structural coloration is the result of coherent scattering of light by the photonic crystal nature of the scales. The colour originates from coherent scattering and interference. Coherent Scattering-mediated correlations between levitated nanospheres. We explore entanglement generation between multiple optically levitated nanospheres interacting with a common optical cavity via the Coherent Scattering optomechanical interaction. We derive the many-particle Hamiltonian governing the unitary evolution of the system and. Coherence from Randomly Distributed Scatterers • A Virtual Dihedral exists within the random distribution of scatterers, for which there is coherent backscatter • All microwaves scattering from this diheral are coherent: they have same path length and thus the same phas
Coherent Neutron Scattering - an overview ScienceDirect
This page contains tables of bound coherent neutron scattering lengths. The tables can be downloaded in portable document format (pdf). The first column of the tables, Z-Symb-A, gives the nuclides´ charge number Z, the element symbol and the mass number A.The column %orT1/2 contains either natural abundance or half live, column I the nuclear spin Coherent scattering and matrix correction in bone-lead measurements. Todd AC (1). The technique of K shell x-ray fluorescence of lead in bone has been used in many studies of the health effects of lead. This paper addresses one aspect of the technique, namely the coherent conversion factor (CCF) which converts between the matrix of the. Coherent scatter (or Thompson scatter) There are three main steps in coherent scatter. 1. An incoming x ray photon with less than 10 keV (so a very low energy x ray photon) interacts with an outer orbital electron. 2. The incoming x ray photon transfers ALL of its energy to the outer orbital electron
• Coherent scattering has been proposed and schemed as a means of detecting neutrinos for many decades. • Relies on the principle of coherence, provides enhancement of cross-section that scales as A2. 2 by either resorting to targets with low mass numbers- considerably lowering the cross-section amplitude and re Scattering events in which such frequency redistribution occurs are said to be non-coherent. Hummer, Field, Spitzer, Mihalas, Avrett, and others have explored the physical causes for frequency noncoherence in the scattering of light by atoms and the effects of noncoherence arising from both the natural width of atomic levels and the thermal. Coherent elastic neutrino-nucleus scattering Grayson C. Rich 1. Introduction Soon after the experimental confirmation of the existence of the weak neutral current by the Gargamelle experiment, Freedman [1] and the duo of Kopeliovich & Frankfurt [2] recognized that such a force should allow for the coherent scattering of neutrinos off of nuclei Motivation. The International Conference on Phase Retrieval and Coherent Scattering is the top meeting on coherent scattering methodology. It focuses on the latest developments and prospects of coherent scattering methods and phase retrieval algorithms for X-ray, EUV, electron, laser and beyond, aiming at high-resolution structure determination and dynamic analysis of matters Under coherent scattering conditions, it is usually stated that the coherent signal component comes from an area equal to the first Fresnel zone. This letter analyzes in more detail the spatial resolution in this forward scattering configuration, showing that, when coherent scattering is nonnegligible, the spatial resolution is mostly.
Coherent Scattering definition of Coherent Scattering by
I. Phys.: Condens. Malta 7 (1995) 7589-7600. Printed in the UK Coherent scattering of a synchrotron radiation pulse by nuclei in vibrating crystals V G Kohnt and Yu V Shvyd'kot t Russian Research Centre 'Kurchatov Institute', Moscow 123182, Russia % lnstihlt fur Experimentalphysik, Universitit Hamburg, D-22761 Hamburg, Germany Received 20 Febrwry 1995, in final form 23 June 199 Compared to conventional Raman microscopy, coherent Raman scattering (CRS) allows label-free imaging of living cells and tissues at video rate by enhancing the weak Raman signal through nonlinear excitation. Edited by pioneers in the field and with contributions from a distinguished team of experts,. Scattering coherent soft x-rays off complex materials maps their complexity into an easily-measured far-field speckle diffraction pattern with atomic, structural, and magnetic contrast. These speckle patterns can be analyzed using various correlation functio Coherent light scattering by nanostructured collagen arrays in the caruncles of the Malagasy asities (Eurylaimidae: Aves). Development and evolutionary origin of feathers. 1998 . Coherent light scattering by blue feather barbs. Sexual selection and the evolution of mechanical sound production in manakins (Aves: Pipridae The CARS (coherent anti-Stokes Raman scattering) and SRS (stimulated Raman scattering) systems from Leica Microsystems found their way into principal-investigator (PI), government, and pharma-analytics-core labs, as well as imaging facilities, where they are being put to good use. Some of these applications are described below
Synonyms for coherent scattering radiation in Free Thesaurus. Antonyms for coherent scattering radiation. 10 synonyms for radiation: emission, rays, emanation, radiation sickness, radiation syndrome, radioactivity, actinotherapy, radiation therapy, radiotherapy.... What are synonyms for coherent scattering radiation It is shown that the Klein-Nishina-Tamm equation determines the total intensity of coherent and incoherent X-ray scattering. The change in the ratio of these components during the transition from scattering on a resting electron to scattering on the atomic electrons is estimated F Lu, W Zheng, and Z Huang*, Heterodyne polarization coherent anti-Stokes Raman scattering microscopy, Applied Physics Letters, 92 (12), 123901 (2008). F Lu, W Zheng, C Sheppard, Z Huang*, Interferometric polarization coherent anti-Stokes Raman scattering microscopy, Optics Letters, 33(6), 602-604 (2008) Coherent anti-Stokes Raman scattering (CARS) microscopy can provide high resolution, high speed, high sensitivity, and non-invasive imaging of specific biomolecules without labeling. In this review, we first introduce the principle of CARS microscopy, and then discuss its configuration, including that of the laser source and the multiplex CARS system bound coherent scattering cross section 6 barn bound incoherent scattering cross section 7 barn total bound scattering cross section 8 barn absorption cross section for 2200 m/s neutrons Note: 1fm=1E-15 m, 1barn=1E-24 cm^2, scattering lengths and cross sections in parenthesis are uncertainties
Coherent x-ray scattering We use coherent x-rays produced by 4th generation synchrotrons and free-electron lasers to study mesoscale structures and ultrafast dynamics in soft matter. The main focus is on fundamental problems in chemistry and physics with biological relevance that often require replenishable sample delivery using liquid. Coherent anti-Stokes Raman scattering (CARS) microscopy is employed to study cancer cell behaviours in excess lipid environments in vivo and in vitro. The impacts of a high fat diet on cancer development are evaluated in a Balb/c mice cancer model. Intravital flow cytometry and histology are employed to enumerate cancer cell escape to the. We measure the coherent scattering of light by a cloud of laser-cooled atoms with a size comparable to the wavelength of light. By interfering a laser beam tuned near an atomic resonance with the field scattered by the atoms, we observe a resonance with a redshift, a broadening, and a saturation of the extinction for increasing atom numbers. We attribute these features to enhanced light. Coherent scattering occurs when spatial variation in refractive index is periodic, resulting in predictable phase relationships among light waves scattered by different objects. Interference, reinforcement, diffraction,multilayer and thin-film reflection, and Bragg scattering are all forms of coherent scattering
It is shown that due to multichanneling coherent effects the scattering field intensity, measured directly at the emission point, exceeds the field intensity far from this point. The intensity difference between the joint and spaced method makes it possible to distinguish the contributions of single and multiple scattering (more precisely. Nope. I will try to explain via analogy to classical mechanics. Diffraction is the phenomenon where a wave that passes through a slit, the slit acts as a different emitter from the original wave. If the slit is very narrow, the new wave will dispe..
coherent scattering de traduction dans le dictionnaire anglais - français au Glosbe, dictionnaire en ligne, gratuitement. Parcourir mots et des phrases milions dans toutes les langues The generation of coherent and indistinguishable single photons is a critical step for photonic quantum technologies in information processing and metrology. A promising system is the resonant optical excitation of solid-state emitters embedded in wavelength-scale three-dimensional cavities. However, the challenge here is to reject the unwanted excitation to a level below the quantum signal [en] The angular distributions for coherent photon scattering from 4 He were measured at average laboratory bremsstrahlung energies of 187, 235, and 280 MeV. The experiment was performed at the Saskatchewan Accelerator Laboratory using the new high duty factor electron beam. The scattered photons were observed with a high-resolution NaI(Tl) total absorption scintillation detector Laser Photonics Rev. 9, No. 5, 435-451 (2015)/DOI 10.1002/lpor.201500023 LASER & PHOTONICS REVIEWS REVIEW ARTICLE Abstract During the past decade coherent anti-Stokes Raman scattering (CARS) microscopy has evolved to one of the most powerful imaging techniques in the biomedical sciences, en This is a well-recognized feature in tissue optics, which is widely used in optical diffusion tomography and optical coherence tomography to minimize the effect of light scattering. 15, 16 By using a longer wavelength of the incident radiation, light can penetrate deeper into a tissue without experiencing a significant scattering, which affects. Measurement of coherent plus incoherent scattering differential cross-section of γ-rays from gold. Journal of Quantitative Spectroscopy and Radiative Transfer, 2002. Orhan İçelli. Download PDF. Download Full PDF Package. This paper. A short summary of this paper
دولة من دول البلقان.
أفضل برنامج لاستعادة الملفات المحذوفة للاندرويد بدون روت.
قنفذ سام.
طريقة استخدام بذور الرجلة.
تحميل انشودة ماما جابت بيبي بدون موسيقى Mp3.
نوع السرعة التي يقرأها عداد السيارة.
تحميل شروح التعريفة الجمركية pdf.
Butox للبراغيث.
كم مرة ذكرت كلمة السبت في القرآن.
قانون التصوير في الأماكن العامة الجزائر.
جنيه استرليني لمصري.
تسديد ديون لوجه الله في مصر.
اتجاهات النقد المعاصر.
كرسبي كريم تاج مول.
مشروع فوتوسيشن.
المدينة الطبية الخدمات الطبية بوزارة الداخلية.
Pont Saint Michel.
الموقع الفلكي للجزائر.
استراتيجية الصراع.
Hamad bin Isa Al Khalifa.
كلمات بحرف شو.
موقع صيني ماركات.
انواع التصميم البنائي.
عام ٢٠١٧ كم يوافق هجري.
Oonoo free fire.
مرسيدس 84.
تحميل برنامج IPTV Smarters Player.
أسماء وفيات المدينة المنورة أمس.
لوحة مفاتيح اللغة العربية.
مسلسل العفريت ح5 Facebook.
هواوي 2020.
مقالب مضحكه2020.
فئات العلامات التجارية pdf.
فاكهة بحرف العين.
انمي spice Girl.
عمرو مكين تاريخ ميلاده.
الجلوتين والسمنة.
الدعسوقة والقط الاسود بالانجليزي.
اغنية حزينة عن الحب مكتوبه. | CommonCrawl |
#17445 new enhancement
Missing documentation of derivative operator/notation
schymans
sage-6.5
symbolics
kcrisman, eviatarbach
Description (last modified by kcrisman)
Taking the derivative of a symbolic function returns the D-notation: sage: var('x y z') sage: f(x) = function('f',x,y,z); sage: f(x).diff(x,y) D[0, 1](f)(x, y, z)
Unfortunately, the meaning of this notation is not documented anywhere, neither in diff(), nor in derivative() nor in function(). There is a ton of tickets about improving ambiguities and malfunctions related to this notation, but it would be very helpful to at least document how it is supposed to work and what it means if a user sees output as above.
See here for related tickets:
#6344 - allow typesetting in "diff" format (possibly only as non-default option)
#6756 - add input to Sage in "diff" format for derivatives (the most controversial)
#6480 - clarify or fix substituting functions inside of symbolic derivatives
#7401 - bug in our interaction with Maxima with evaluating derivative at a point (needs work due to multivariate derivatives not being there)
#12796 - allow evaluation at points
and this discussion: https://groups.google.com/forum/#!topic/sage-devel/_xD5lymnTuo
comment:1 Changed 5 years ago by nbruin
OK, I do not know where it should go in the documentation for best visibility (I'd think in "diff" somewhere), but the explanation should be along the lines of:
Partial derivatives are represented in sage using differential operators, referencing the position of the variable with respect to which the partial derivative is taken. This means that for a function f in $r+1$ variables we have
\[D[i_1,\ldots,i_n](f)(x_0,\ldots,x_r) = \left.\frac{\partial f(t_0,\ldots,t_r)}{\partial t_{i_1}\cdots \partial t_{i_n}} \right|_{t_0=x_0,\ldots,t_r=x_r}\]
An advantage of this notation is that it is clear which derivative is taken, regardless of the names of the variables. For instance, if we have
sage: var("x,y,t")
sage: f(x,y)=function('f',x,y)
sage: g=f(x,y).diff(x,y); g
D[0, 1](f)(x, y)
sage: g.subs(x=1,y=1)
D[0, 1](f)(1, 1)
sage: g.subs(x=t,y=t+1)
D[0, 1](f)(t, t+1)
Note that in the last two lines are completely unambiguous using operator notation, whereas Leibnitz notation would require the use of some arbitrary explicit choice of auxiliary variable names.
comment:2 follow-up: ↓ 3 Changed 5 years ago by kcrisman
Are there times where this notation is ambiguous, though? I seem to recall that being the case.
Also, I think something about this should show up at the top of the "sage/calculus/calculus.py" file as well. It's a constant source of questions I don't really know the answer to.
comment:3 in reply to: ↑ 2 Changed 5 years ago by nbruin
Replying to kcrisman:
I am not aware of any such cases. It's reflecting all information that sage has stored on the object, so an ambiguity would imply that sage is working with an ill-defined object.
If you rewrite it in Leibnitz notation using a set of auxiliary variables, you see that any expression has a clear interpretation.
Go ahead and put it in the docs!
Can you comment on some of the chain-rule type issues in #6480, then? I have to say that in particular the stuff at http://ask.sagemath.org/question/9932/how-to-substitute-a-function-within-derivatives/ and #6480 is massively confusing. Heck, let's add #7401 while we're at it.
I don't even know whether any of those things are "really" right or wrong at this point. I suppose you shouldn't be allowed to substitute in a function that "isn't there" in 6 and 7, but then why does 8 "work"? In any case, shouldn't there be an error raised if one attempts something like this when it's not "legitimate"?
# 6. Fails.
x = var('x')
f = function('f', x)
g = function('g', x)
p = f.diff()
print p.substitute_function(f, g) # Outputs "D[0](f)(x)"
print p.substitute_function(f(x), g(x)) # Outputs "D[0](f)(x)"
# 8. Works.
f = function('f')
g = function('g')
p = f(x).diff()
print p.substitute_function(f, g) # Outputs "D[0](g)(x)"
These are very subtle differences to anyone who is not in symbolic algebra/expressions, and part of the issue is the difference between expressions and functions, no doubt. So comment:1 is a good start, but definitely only a start.
comment:5 Changed 5 years ago by kcrisman
Okay, at least now I actually understand what the different tickets are about. Phew.
comment:6 in reply to: ↑ 4 ; follow-ups: ↓ 8 ↓ 11 Changed 5 years ago by nbruin
I don't even know whether any of those things are "really" right or wrong at this point.
There is an internal logic that explains the behaviour. I don't think this stuff can ever be made "intuitive" to the average calculus afficionado because the tradition in analysis notation is just to irredeemably confuse "function" and "function evaluated at...". Humans can handle this confusion to some extent, but I think it's just too incompatible with how computers represent math.
the problem: f is not a function, but a function evaluated at x, whatever x is. I'm not going to defend that function('f', x) doesn't return a function. THAT is the real source why this example seems confusing.
The fact that f.diff() doesn't fail is apparently a heuristic, because there's only one variable discernible in the expression. But then you see:
sage: p
D[0](f)(x)
as you can see, there's no f(x) appearing in that expression, so of course substituting f(x) for something else has no effect. Really,
p.substitute_function(f, g)
should give a TypeError, because the types of the arguments don't match. Indeed:
sage: p.substitute_function(f.operator(), g)
DeprecationWarning: Substitution using function-call syntax ...
Apparently sage does try to convert the argument g(x) (that is bound to g) to a function.
same problem, but even worse: f(x)(x) should have been deprecated already.
The fact that function('f') and function('f',x) return different types of arguments is really bad. It prevents any convincing explanation of the distinction that is essential here, because the interface itself confuses the two different issues. On top of that, we have a lot of documentation that was written by people who were equally confused, so the calculus doc makes a good effort to confuse any new user too.
It's an entirely different issue, though. Apparently the documentation never explains what D[0](f)(x) means. We can do that independent of whether we go out of our way to confuse users about the distinction between functions and functions evaluated at ...
comment:7 follow-up: ↓ 10 Changed 5 years ago by eviatarbach
Cc eviatarbach added
It would probably be good to add a note that D[0, 1](f)(x, y) does not in general equal D[1, 0](f)(x, y) (https://en.wikipedia.org/wiki/Symmetry_of_second_derivatives).
comment:8 in reply to: ↑ 6 Changed 5 years ago by schymans
Replying to nbruin:
Wow, the reason while I hesitated about adding documentation of the D-notation was that I thought it should go into the documentation of function() and then I found out that the documentation of function() itself is already incomplete and confusing. Should we open a ticket for that, too? For example, none of the methods described in http://www.sagemath.org/doc/reference/calculus/sage/symbolic/function_factory.html show up when I type:
function?
The distinction between
is also not documented. Only now I realised that function('f') returns a function, while function('f',x) returns an expression. Furthermore, differentiation of a function is not supported, it needs to be converted to an expression first:
fx = function('f', x)
print type(f)
print type(fx)
print type(f(x))
print fx.diff()
print f(x).diff()
print f.diff()
<class 'sage.symbolic.function_factory.NewSymbolicFunction'>
<type 'sage.symbolic.expression.Expression'>
Traceback (most recent call last): print f(x).diff()
File "", line 1, in <module>
File "/tmp/tmpMe44Jp/___code___.py", line 9, in <module>
exec compile(u'print f.diff()' + '\n', '', 'single')
AttributeError: 'NewSymbolicFunction' object has no attribute 'diff'
If we modify the documentation of diff(), though, we should explain why f(x).diff() works but f.diff() does not.
comment:9 follow-up: ↓ 14 Changed 5 years ago by schymans
Following on from the logic about function('f', x) being an expression, not a function, why does this fail, then?
# If all of f, g and p are expressions, why does this fail?
print type(g)
print type(p)
print p.subs_expr(f==g) # Outputs "D[0](f)(x)"
comment:10 in reply to: ↑ 7 ; follow-ups: ↓ 12 ↓ 13 ↓ 15 Changed 5 years ago by schymans
Replying to eviatarbach:
I just wanted to propose the following simple documentation:
Partial derivatives are represented in sage using differential operators, referencing the positions of the variables with respect to which consecutive partial derivatives are taken.
An advantage of this notation is that it is clear in which order derivatives are taken and on which variables they are performed, regardless of the names of the variables. For instance, if we have
(x, y, t)
sage: f=function('f',x,y)
sage: g=f.diff(x,y); g
sage: h=f.diff(y,x); g
I was expecting the second to give either D[0, 1](f)(y, x) or D[1, 0](f)(x, y). What is going on, is the order of differentiations not honoured in the notation?
Interestingly, the following does not return True but two visually indistinguishable expressions. To me, this looks like a bug.
sage: f.diff(x,y) == f.diff(y,x)
D[0, 1](f)(x, y) == D[0, 1](f)(x, y)
I would much prefer this behaviour:
f.diff(x,y) == f.diff(y,x)
It would be unambiguous and shorter. What is the advantage of the D-notation again?
Last edited 5 years ago by schymans (previous) (diff)
comment:11 in reply to: ↑ 6 Changed 5 years ago by schymans
I created a ticket to improve the documentation of function(): http://trac.sagemath.org/ticket/17447 I put you and kcrisman cc on that ticket, I hope you don't mind.
comment:12 in reply to: ↑ 10 ; follow-up: ↓ 16 Changed 5 years ago by kcrisman
In this case, it is not an example of Eviatar's (good) point. f always has the variables in the same order, so your first option is not possible. The second option would be legitimate but I guess Sage just assumes the Clairaut/Schwarz Theorem always holds for 'symbolic' functions.
I'm still not 100% sold on it, especially since it doesn't LaTeX with subscripts, but this would be a second issue.
Is it worth trying to distinguish D[0,1] and D[1,0]?
Would it be very hard to do so? (I have not looked at this code in a long time.)
Is it easy to have the LaTeX be subscripts?
Alternately (or with that), would it be possible to just "read off" the actual variable names and put those in, ala D[x,y] and D[y,x]? In principle it should be, since all such functions now have ordered variable names. I don't know how that would combine with the whole D[0,1](f)(x,x+1) thing, so maybe it's a bad idea.
comment:13 in reply to: ↑ 10 Changed 5 years ago by nbruin
Replying to schymans:
Please write f(x,y) there so that it's clear you're differentiating an expression, not a function:
sage: var('x,y')
(x, y)
sage: f=function('f')
sage: f.diff(x,y)
The advantage is that you can actually represent evaluations of the derivative:
sage: f(x,y).diff(x,y).subs(x=2,y=3)
Would you propose to print that as the (admittedly shorter) f.diff(2,3)? It's absolutely possible to print f(x,y).diff(x,y) for D[0,1](f)(x,y) because at some point we can see we have an expression with an operator that is an FDerivativeOperator, and where the arguments form a list of distinct symbolic variables. But we have to print D[0,1](f)(t,t^2). Printing f.diff(t,t^2) is just something else entirely.
comment:14 in reply to: ↑ 9 Changed 5 years ago by nbruin
Because you need subs_function there. These are two different routines that take different types of arguments and do different things with them. Objects of type SymbolicFunction cannot be used interchangeably with SymbolicExpression.
We could in principle extend subs to differentiate on type of passed argument and dispatch accordingly to subs_function or subs_expression (and raise an error if some impossible combination is tried).
Correct. Rewriting of differentials apparently assumes symmetry. That's not such a big issue, since in any reasonable application environment it holds anyway (if your functions aren't continuously differentiable you tend to have to use other things, such as distributions, anyway.
sage: D=sage.symbolic.operators.FDerivativeOperator
sage: D(f,[1,0])
D[1, 0](f)
sage: D(f,[0,1])(x,y)
As you can see, the reordering happens on evaluation. It's not an ambiguity in notation, it's an assumption that's been programmed into sage. Perhaps it's already in Pynac?
Last edited 5 years ago by nbruin (previous) (diff)
I think not, but it's not my field. When do you really work with non-continuously differentiable functions? Don't you use distributions then anyway? I think someone should point out a meaningful calculation where symmetry doesn't hold.
No. It's in the diff code somewhere. It's probably an explicit "sort" command you can just take out.
Alternately (or with that), would it be possible to just "read off" the actual variable names and put those in, ala D[x,y] and D[y,x]? In principle it should be, since all such functions now have ordered variable names.
Where would you get the names from in the following example?
sage: D(f,[0,1,0])
D[0, 1, 0](f)
sage: D(f,[0,1,0])(x,y)
D[0, 0, 1](f)(x, y)
If you're going to bother matching indices and variable names, you'd better go the whole way and recognize that in the last example the arguments are distinct symbolic variables that match up nicely with the differentiation indices, so we can print
diff(f(x,y),x,x,y)
I don't know how that would combine with the whole D[0,1](f)(x,x+1) thing, so maybe it's a bad idea.
comment:17 Changed 5 years ago by eviatarbach
I think it is worth distinguishing. The standard counterexample to equality of mixed partials is f(x, y) = x*y*(x^2 - y^2)/(x^2 + y^2), with f(0, 0) = 0, which is a continuous function but the second derivatives at (0, 0) are unequal. This may not come about often in practice (it doesn't seem like we can run this example without having multivariable piecewise functions), but especially if people are using the formal functions it should have correct mathematical properties.
comment:18 follow-up: ↓ 19 Changed 5 years ago by schymans
Wow, I think the description of this ticket should be changed. It is not any more about the documentation of the D[] notation, but about a meaningful way of using and displaying symbolic differentials.
One thing I learned from this post: http://trac.sagemath.org/ticket/17447#comment:3 is: The example I used in the description of the ticket, and most of the examples following, should not be used! If we avoid this, then we are stuck with the problem that the diff() method is not defined for symbolic functions:
sage: var('x')
sage: function('f', x)
sage: print type(g)
sage: p = f.diff()
Traceback (click to the left of this block for traceback)
What is the point of having a notation for differentials of symbolic functions, then? Should the first step not be to actually implement differentiation of symbolic functions and then explain the notation in the documentation of function?
It's already implemented, see 16. It's called FDerivativeOperator. It may be worthwhile having a nicer interface. Being able to write D[0,1](f) might be nice. See sage-devel:"D notation input for ODEs", which has a short and (I think) fully functional code snippet that implements it.
If you prefer inputting your derivatives with Leibnitz notation, you're going to need temporary variables, and in that case it's already about a efficient as you can get:
sage: f=sage.symbolic.function_factory.function('f')
sage: df=diff(f(x),x).operator()
sage: df
D[0](f)
Thanks, Nils, I didn't see that. However, I am still not able to achieve what I was hoping for. Let me give a pratical example. I define an expression for pressure following the ideal gas law:
sage: var('R t p n T V')
sage: eq_p = p == n*R*T/V
At some point, I would like to differentiate this equation for an open system, i.e. where p, n, T and V are functions of time. I re-defined the respective variables as functions of and time tried taking the derivative, but:
sage: function('p',t)
sage: function('n', t)
sage: function('T', t)
sage: function('V', t)
sage: diff(eq_p,t)
p == R*T*n/V
0 == 0
I also didn't find a way to get FderivativeOperator? to do the trick:
sage: D = sage.symbolic.operators.FDerivativeOperator
sage: D(eq_p,[0])
D[0](p == R*T*n/V)
The only way to get the desired outcome seems to be to re-write the whole equation:
sage: eq_p = p(t) == n(t)*R*T(t)/V(t)
D[0](p)(t) == R*n(t)*D[0](T)(t)/V(t) - R*T(t)*n(t)*D[0](V)(t)/V(t)^2 +
R*T(t)*D[0](n)(t)/V(t)
Alright, I thought, what about a system with constant volume?
sage: eq_p = p(t) == n(t)*R*T(t)/V
Pity, would have been too easy. Interestingly, this works instead:
sage: eq_p = p(t) == n(t)*R*T(t)/V(x)
D[0](p)(t) == R*n(t)*D[0](T)(t)/V(x) + R*T(t)*D[0](n)(t)/V(x)
I'm still confused. What I want to express by function('V', t) is that V is a function of t and hence needs to be treated as such when taking the derivative with respect to t. By writing V(t) above, I turn the function into an expression again, which does lead to the desired functionality, but you mentioned earlier that V(t) means "Function V evaluated at t", which to me means something different. I don't see the utility of defining function('V', t) in the above at all. I could have equally defined function('V', x), right?
What would be the correct way to do the above consistently?
comment:21 in reply to: ↑ 20 ; follow-up: ↓ 22 Changed 5 years ago by nbruin
Just by rebinding the names in the global scope, you do not change the identity of the consituents in eq_p. Those are still variables. Pointwise operations aren't supported for functions:
sage: function('f')
sage: function('g')
sage: f*g
TypeError: unsupported operand type(s) for *: 'NewSymbolicFunction' and 'NewSymbolicFunction'
This already fails for me, because V at this point is a function and dividing a symbolic expression by a function isn't supported.
I'm still confused. What I want to express by function('V', t) is that V is a function of t and hence needs to be treated as such when taking the derivative with respect to t.
I don't think you can, because in sage, symbolic functions have variable *positions*, not *names*.
By writing V(t) above, I turn the function into an expression again, which does lead to the desired functionality, but you mentioned earlier that V(t) means "Function V evaluated at t", which to me means something different. I don't see the utility of defining function('V', t) in the above at all. I could have equally defined function('V', x), right?
Or as function('V') for that matter. It seems misguided to me that function admits an argument list. It has no meaning other than that function('V',x) == function('V')(x). I think the RHS syntax is much clearer.
A "symbolic function" in sage is simply something that can occur in the "operator" slot of a symbolic expression. I don't think there is much support for algebra on such objects. Hence the need to talk about V(t) and V(x) (but better not in the same expression! Then you should use V(x,t) and be consistent about the order in which x,t occur). If you absolutely need to make the thing into a "function" again, you could turn it into a "callable symbolic expression":
sage: A = n(t)*R*T(t)/V(x)
sage: p=diff(A,t).function(t)
t |--> R*n(t)*D[0](T)(t)/V(x) + R*T(t)*D[0](n)(t)/V(x)
sage: parent(p)
Callable function ring with arguments (t,)
You do have to decide beforehand if V is going to be a function of x or of t or of both. Also, the expression above should probably be
sage: p=diff(A,t).function(x,t)
(x, t) |--> R*n(t)*D[0](T)(t)/V(x) + R*T(t)*D[0](n)(t)/V(x)
Callable function ring with arguments (x, t)
The root cause of this is the following: sin is a function, right? You know the meaning of sin(x) and of sin(y), right? So is sin a function of x or of y? What should diff(sin,x) and diff(sin,y) be?
The answer is of course that sin by itself isn't a function of x or y. It simply is a function. It depends on the context what you put into it. In any case D[0](sin) is its derivative,
You may wish that sage would treat V differently, but it doesn't. Otherwise, if you do function('V',t), what should it do if you call V(x)? raise an error? What about V(t+1)? It really has no choice other than to ignore the name of the parameter and only look at its position in the argument list. Indeed, going back to the topic of the ticket, I recommend that the whole function('f',x) syntax gets deprecated or at least gets advised against in the documentation. It pretends that sage can do something with it that it can't.
comment:22 in reply to: ↑ 21 Changed 5 years ago by schymans
A "symbolic function" in sage is simply something that can occur in the "operator" slot of a symbolic expression. I don't think there is much support for algebra on such objects. Hence the need to talk about V(t) and V(x) (but better not in the same expression! Then you should use V(x,t) and be consistent about the order in which x,t occur). Indeed, going back to the topic of the ticket, I recommend that the whole function('f',x) syntax gets deprecated or at least gets advised against in the documentation. It pretends that sage can do something with it that it can't.
Thanks, this clarifies a lot for me! I didn't realise I have to think of 'function' as of an operator. I have been thinking about using vars for independent variables and functions for dependent variables, but as you clarified, this was misguided. My thumbs up to deprecate the function('f',x) syntax, then. Is there another way to write an expression with dependent and independent variables and then transparently differentiate it according to assumptions which of the dependent variables are kept constant? | CommonCrawl |
Why is gadolinium specifically used in MRI contrast agents?
Gadolinium(III) chelate complexes are routinely used as contrast agents in magnetic resonance imaging (MRI);1 the usual explanation is that paramagnetic species contain unpaired electrons, which cause relaxation of nearby $\ce{^1H}$ nuclei.
Why gadolinium, and not any of the other lanthanides?
In particular, $\ce{Tb^3+/Dy^3+/Ho^3+/Er^3+}$ have magnetic moments that are larger than that of $\ce{Gd^3+}$ (due to orbital angular momentum). At first glance, these should possess even higher relaxivity, since the rate of relaxation due to random fields is proportional to $\langle B_\mathrm{loc}^2 \rangle$.2
I do vaguely recall reading one sentence, about the fact that ground states that aren't S terms are not spherically symmetric, and there's some problem associated with this. But I can't find the reference anymore and I don't remember any other detail.
Werner, E. J.; Datta, A.; Jocher, C. J.; Raymond, K. N. High-Relaxivity MRI Contrast Agents: Where Coordination Chemistry Meets Medical Imaging. Angew. Chem. Int. Ed. 2008, 47 (45), 8568–8580. DOI: 10.1002/anie.200800212.
Hore, P. J. Nuclear Magnetic Resonance, 2nd ed.; Oxford University Press: Oxford, U.K., 2015; pp 65, 71.
biochemistry nmr-spectroscopy magnetism rare-earth-elements
orthocresol♦orthocresol
$\begingroup$ Probably medical/economical reasons. $\endgroup$ – Mithoron Jul 31 '17 at 18:11
$\begingroup$ With very limited knowledge in this subject, I recommend reading a review 'Alternatives to Gadolinium-Based Metal Chelates for Magnetic Resonance Imaging' (Chem. Rev., $2010$, 110 (5), pp 2960–3018, DOI: 10.1021/cr900284a). It is also freely available as a manuscript here. Sections $3$ and $5$ should be especially pertinent. It specifically discusses $\ce{Gd^3+}$ vs other $\ce{Ln^3+}$ complexes. $\endgroup$ – Linear Christmas Jul 31 '17 at 18:12
$\begingroup$ You see a lot more variety in situations where people aren't bothered if the animal survives long term.. I think in human cases its simply that the Gd systems have been through trials and aren't horrendously toxic/can just about be gotten rid of by the body $\endgroup$ – NotEvans. Jul 31 '17 at 18:32
$\begingroup$ I found this section on Wikipedia after a short browse: "The maximum number of unpaired electrons is 7, in $\ce{Gd^{3+}}$, with a magnetic moment of 7.94 B.M., but the largest magnetic moments, at 10.4–10.7 B.M., are exhibited by $\ce{Dy^{3+}}$ and $\ce{Ho^{3+}}$. However, in $\ce{Gd^{3+}}$ all the electrons have parallel spin and this property is important for the use of gadolinium complexes as contrast reagent in MRI scans." $\endgroup$ – Nicolau Saker Neto Aug 1 '17 at 12:36
The reasons may possibly be:
T1shortening
Relatively less adverse reactions
Increased contrast enhancement
The most commonly used clinically approved contrast agents for MR imaging are gadolinium-based compounds that produce T1 shortening.
Tissue relaxation results from interactions between the unpaired electron of gadolinium and tissue hydrogen protons, which significantly decrease the T1 of the blood relative to the surrounding tissues.
Additionally, adverse reactions to this agent are far less frequent than those seen with iodinated compounds, with common reactions including nausea, vomiting, headache, paresthesias, or dizziness.
T1weighted sequences are part of almost all MRI protocols and are best thought of as the most 'anatomical' of images, resulting in images that most closely approximate the appearances of tissues macroscopically, although even this is a gross simplification.
Figure 1-10. MR enterography on a patient with Crohn disease. A. Coronal T2-weighted image shows wall thickening and stenotic ileum (arrow). B. Coronal gadolinium-enhanced fat suppressed T1-weighted image shows increased contrast enhancement of one thickened segment of ileum (arrow).
Credits Basic Radiology Chapter 1 page 11
Most of the answer above was based on Pharmacological/Medical aspects but some Chemistry aspects have been included below:
Also the article mentioned by@Linear Christmas contains valuable information on the subject
Contrast agents can be divided into two groups depending on whether they cause changes in either T1 (longitudinal relaxation – in simple terms, the time taken for the protons to realign with the external magnetic field) or T2 (transverse relaxation – in simple terms, the time taken for the protons to exchange energy with other nuclei) relaxation rates of the water protons, these being known as positive or negative agents respectively.
The ability of an agent to affect T1 and T2is characterised by the concentration-normalised relaxivities r1 and r2respectively. These parameters refer to the amount of increase in 1/T1 and 1/T2 respectively, per millimole of agent, and are normally quoted as a rate (mM21 s21).4 The values are used to determine the efficiency of a contrast agent, and they consist of contributions from both inner sphere and outer sphere relaxation mechanisms Negative contrast agents influence the signal intensity by shortening transverse relaxation (T2), thereby producing darker images as high T2 results in increased brightness of the images.
Gadolinium (III) vs other Lathanide (III) ions
Gadolinium(III) reagents are commonly focused on, due to the coupling of a large magnetic moment with a long electron spin relaxation time of $\ce10^{-9}$s at the magnetic field strengths used in MRI techniques.
Gadolinium (III) ion is unique in a number of respects:
It has the ability to shorten both the longitudinal and transverse relaxation times of water protons approximately to the same extent by relaxing all nearby protons. Other Ln(III) ions with large magnetic moments are less efficient in shortening T1.
The Gadolinium ion is also unique among other Ln(III) because its symmetric seven electron ground state results in an electronic relaxation rate that is six orders of magnitude slower than the other Ln(III) ions. This in turn results in a strong magnetic anisotropy and fast electronic relaxation states with very short T1, on the order of $\ce10^{-13}$s.
Other Ln (III) ions tend to undergo Curie relaxation enhancement arising from the interaction of the nuclear spin with the thermal average of the electron spin. (The Curie-spin relxation effect is significant at lower temperatures and higher magnetic fields and for ions with a large magnetic moment).
It has been observed that the Curie spin relaxation effect affects the transverse relaxation more than the longitudinal relaxation. Consequently paramagnetic Ln(III) other than Gd (III) are less efficient T1 relaxation agents.
Use of other Lanthanide (III) ions as MRI contrast agents
Dysprosium(III) is another lanthanide ion that has been used in MRI, being classed as a negative contrast agent. In the use of high magnetic fields,
Gd(III) based contrast agents exhibit poor water relaxivity. As a result, the interest in dysprosium-based complexes is increasing as they display slow water exchange, due to the need to lengthen the residence time in order to optimise the r2 relaxivity. Dy(III) has a large magnetic susceptibility which induces local field gradients resulting in a lowering of T2.
Generally, dysprosium complexes where the water molecules have a long residence time, possess potential application as negative contrast agents at high magnetic fields due to their efficient transverse relaxivity. However it has been demonstrated that lengthening the residence time of water can actually be detrimental, because the transverse relaxivity can then be limiting.
The overall conclusion from the use of dysprosium(III) complexes as contrast agents is that due to the balancing of factors required to optimise r2, design of a suitable molecular structure is crucial. Fine tuning these residence times of the water protons, and hence the relaxivity, may lead to promising contrast agents for high field magnetic resonance imaging.
Europium(II) analogues have been proposed as alternatives to Gd(III) because they are isoelectronic—each having seven unpaired electrons.
The only problem with this complex was that the stability of the Eu(II) chelate was 107 times higher than that of the Eu(III) chelate, which meant that the Eu(III) complex could be susceptible to dissociation, possibly releasing toxic Eu(III) into the body.
Other strongly paramagnetic ions e.g Tb(III), Ho(III), Er(III) can have significant effect on line widths and such line broadening usually makes it difficult or even impossible to detect nuclei that are located within a certain distance of the lanthanide ion.
There is still promising use of other Lanthanide (III) compounds as contrast agents as alternatives to using T1 shortening contrast agents as contrast can originate from altering proton density or the total water signal that is detected (using another technique called Magnetisation Transfer (MT).In this case Gadolinium(III)cannot be used in this technique because the T1 of water would be too short, but other lanthanides, such as Eu(III), can be used because they have smaller magnetic moments, relaxing bulk water much less efficiently.
Other potential candidates are still being tested under laboratory conditions, Contrast agents used in the body clearly should be biocompatible, but there are also other requisites need to be addressed as well. These include the requirements of rapid renal excretion, water solubility, stability in aqueous conditions, and a low osmotic potential when in solution for clinical work.
Basic Radiology Michael Y. M. Chen, MD
'Alternatives to Gadolinium-Based Metal Chelates for Magnetic Resonance Imaging' (Chem. Rev., 20102010, 110 (5), pp 2960–3018,
Lanthanides in magnetic resonance imaging. Melanie Bottrill, Lilian Kwok and Nicholas J. Long Chemistry Society Reviews, DOI: 10.1039/b516376p
xavier_fakeratxavier_fakerat
Not the answer you're looking for? Browse other questions tagged biochemistry nmr-spectroscopy magnetism rare-earth-elements or ask your own question.
Why is a squared cosine window function commonly used for 2D spectra?
Why is the Gaussian Window Function used to enhance resolution in 1D NMR spectra?
Mercury binding agents which cross the blood brain barrier
Why is iron used in the body?
Why is europium used in Euro bank notes?
why is molybdenum a much stronger magnet than chromium
Dinitrophenyl (DNP) derivatives of amino acids (specifically epsilon-DNP-lysine)
Why is tetramethylsilane (TMS) used as an internal standard in NMR spectroscopy?
Why can't diamagnetic, and paramagnetic magnetize?
What are contrast agents in MRI and how do they work? | CommonCrawl |
Revisiting the 1986 computer classic Number Munchers!
Belgin gets hooked on a classic maths game…in 16 bits! Here's her review…
©MECC 1990, reproduced for the purpose of review.
by Belgin Seymenoglu. Published on 11 December 2020.
Ready to play Number Munchers. Image: ©MECC 1990, reproduced for the purpose of review.
If you were a child in the eighties or nineties, you might have seen the educational game Number Munchers on your school PC. It was originally released by MECC in 1986, and was re-released several times (for MS-DOS, Apple, and more). Nearly three decades later, Number Munchers received a Readers' Choice Award in 2005 from Tech and Learning.
Believe it or not, I didn't play it as a kid—rather I just watched a classmate play the 1990s version on a Macintosh. It wasn't until two decades later (read: last winter) when I had a go at playing it. I couldn't find the Macintosh version of the game, but I did come across the older MS-DOS version, so I played that.
Yum, yum!
The controls are quite straightforward—just use the arrow keys to move your green muncher around, and the space bar when it's time to eat a number. Granted, most games I have played are for the PC, so I find keyboard controls easy to use.
Your green guy is sitting in a 5 by 6 grid, and each square on the grid contains a number. You get points by eating numbers that satisfy the rule given on the top of the screen. Meanwhile, if you eat a wrong number, you lose one life. The game ends when you run out of lives. Example rules include:
Multiples of 5: eat 5, 10, 15, etc
Factors of 14: only eat 1, 2, 7 and 14
Prime numbers: eat primes
Equals 6: you get expressions such as $6\times 1$, $3 + 0$, and need to pick the ones that equal 6
Less than 12: eat only the numbers 1–11
There's even a challenge mode that lets you mix and match the rules! Moreover, there are lots of difficulty levels to pick from. There are 11 levels in total; they start at 'third grade easy' (that's year 4 for Brits like me), and go all the way up to 'seventh grade easy/advanced', and finally eighth grade and above.
Number Munchers features five fearsome foes to fight or flee. Image: ©MECC 1990, reproduced for the purpose of review.
You will also want to avoid the Troggles—they are the monsters who want to eat your little muncher! It's another surefire way to lose a life. When I first saw the game as a child, I didn't notice that there were five types of Troggles, each coming in different colours and walking in specific patterns. I also forgot that when a Troggle walks over a square, it leaves a new number behind. If that's not challenging enough, things start to get more frantic in later levels. More Troggles will turn up on the same board, and they'll move faster, so you'd better be quick on your feet or have picked an easy maths mode! You're also more likely to see what happens when Troggles meet: one eats the other, then the surviving Troggle continues walking as if nothing happened.
The Troggles at it again in this cutscene. Image: ©MECC 1990, reproduced for the purpose of review.
When you've eaten all the numbers on the board that fit the rule, you get to move on to the next level! Also, every three or four levels you get treated to a funny cutscene featuring the muncher and the Troggles! In most of the cutscenes, the Troggles try to capture the muncher, only for the plan to backfire, so the muncher gets the last laugh! You can even hear the muncher a little jingle, as if they were singing "Nyah-nyah-nyah-nyah-nyah-nyah!" Apparently there are at least five more fun cutscenes out there. No, not all of them feature Troggles. Sorry Troggle fans!
My favourite mode
As a schoolgirl I watched my classmate play the level where you only eat prime numbers, and the moment he lost a life. No—he did not get eaten! The disaster was what he ate…the number 1. The game then said that 1 is not prime, but didn't explain why.
Late breaking news from Number Munchers: 1 is not prime! Image: ©MECC 1990, reproduced for the purpose of review.
Then the teacher's assistant was watching too. When the muncher lost a life, she turned to me and asked, "Why do you think the number 1 is not prime?". How was I supposed to know? I was only just starting to learn what a prime number is! I was aware that a prime is divisible only by 1 and itself, but didn't realise that these two divisors should be distinct. It only dawned on me years later, but I'd already moved into secondary school by then!
This is why the prime numbers round became my favourite level in the game. It showed me a something I didn't realise until then, and made me go "ooh". And now I'm older, I'm having no difficulties with the prime level…as long as there are no three-digit numbers!
Number Munchers is definitely one of those maths games that can be enjoyed by people of (almost) all ages. Just make sure you didn't pick the hardest difficulty setting! I did that, and I instantly regretted it—I found myself struggling to figure out which of the three-digit numbers I got were multiples of 19! It didn't help that I initially misread the question, and thought I was supposed to avoid said multiples! An easy way to throw a life away. And as if I didn't have enough to do already, I had to keep dodging the Troggles to make sure I didn't eaten! Unsurprisingly I gave up, and switched to an easier setting.
We do not recommend starting with this mode. Image: ©MECC 1990, reproduced for the purpose of review.
If you're after graphics, I recommend the 90s Apple version—the creatures are prettier in there (especially your little green muncher). The graphics on the DOS version are not as great, but the gameplay's the same and the Troggles still look quite nice in that version. If you want to try the game yourself, the original version is available to the public on the Internet Archive, all for free. Better still, no emulator is required. What's not to like?
Believe it or not, this is not the only maths-themed game in the Munchers series—there's another game called Fraction Munchers! It features fractions instead of whole numbers, but I've never seen it! If you've been lucky enough to have played that game, why not send your review of Fraction Munchers to Chalkdust? It might just become an online article in here, too!
Belgin Seymenoglu
Belgin is a data scientist having got her PhD in population genetics. When not working, you can usually find Belgin either playing the piano or playing Math Blaster. She is pictured here standing next to her copy of Zeeman's catastrophe machine.
www.ucl.ac.uk/~zcahge7/ + More articles by Belgin
Maths trumps review
A mathematically-themed version of the classic card game, with several new features
Significant figures: Sir Christopher Zeeman
Biography of Sir Christopher Zeeman
Math Blaster
Belgin plays a classic mathsy game from her childhood...in 16-bit graphics! Here's her review...
MathsJam 2017
Chalkdust descends upon the UK's largest pop maths gathering and tells you what you missed
Creating hot ice
We created hot ice from scratch, a solution that remains liquid even below its freezing point!
Cutting my birthday cake
How to make the most slices from just a few cuts of cake
← Flo-maps fractograms: the game
Christmas puzzle #1: Christmas tree sudoku → | CommonCrawl |
arXiv.org > cs > arXiv:1811.03717v1
cs.LG
stat.ML
DBLP - CS Bibliography
listing | bibtex
Michal Derezinski
Computer Science > Machine Learning
Title:Fast determinantal point processes via distortion-free intermediate sampling
Authors:Michał Dereziński
(Submitted on 8 Nov 2018 (this version), latest version 21 Feb 2019 (v2))
Abstract: Given a fixed $n\times d$ matrix $\mathbf{X}$, where $n\gg d$, we study the complexity of sampling from a distribution over all subsets of rows where the probability of a subset is proportional to the squared volume of the parallelopiped spanned by the rows (a.k.a. a determinantal point process). In this task, it is important to minimize the preprocessing cost of the procedure (performed once) as well as the sampling cost (performed repeatedly). To that end, we propose a new determinantal point process algorithm which has the following two properties, both of which are novel: (1) a preprocessing step which runs in time $O(\text{number-of-non-zeros}(\mathbf{X})\cdot\log n)+\text{poly}(d)$, and (2) a sampling step which runs in $\text{poly}(d)$ time, independent of the number of rows $n$. We achieve this by introducing a new regularized determinantal point process (R-DPP), which serves as an intermediate distribution in the sampling procedure by reducing the number of rows from $n$ to $\text{poly}(d)$. Crucially, this intermediate distribution does not distort the probabilities of the target sample. Our key novelty in defining the R-DPP is the use of a Poisson random variable for controlling the probabilities of different subset sizes, leading to new determinantal formulas such as the normalization constant for this distribution. Our algorithm has applications in many diverse areas where determinantal point processes have been used, such as machine learning, stochastic optimization, data summarization and low-rank matrix reconstruction.
Subjects: Machine Learning (cs.LG); Machine Learning (stat.ML)
Cite as: arXiv:1811.03717 [cs.LG]
(or arXiv:1811.03717v1 [cs.LG] for this version)
From: Michał Dereziński [view email]
[v1] Thu, 8 Nov 2018 23:35:29 UTC (30 KB) | CommonCrawl |
Du er her: Institut for Matematik Forskning The Mathematics Group Publications
Please use the English version of this page
Type og 1. forfatter
Årstal
Årstal og 1. forfatter
Årstal, type og 1. forfatter
Sortér i
Stigende orden
Faldende orden
Christandl, M., Cornean, H., Fournais, S., Müller, P. & Møller, J. S. (2021). Preface. Reviews in Mathematical Physics, 33(1), [2002001]. https://doi.org/10.1142/S0129055X20020018
Arkhipov, S. & Ørsted, S. (2018). Homotopy (co)limits via homotopy (co)ends in general combinatorial model categories. arXiv
Spotti, C., Angella, D. & Calamai, S. (2020). Remarks on Chern-Einstein Hermitian metrics. (s. 1707-1722). Mathematische Zeitschrift. https://doi.org/10.1007/s00209-019-02424-4
Dam, T. N. & Møller, J. S. (2018). Spin-Boson type models analysed through symmetries. https://arxiv.org/pdf/1803.05812.pdf
Thomsen, K. (2007). C*-algebras of homoclinic and heteroclinic structure in expansive dynamics. Department of Mathematical Sciences , University of Aarhus. http://www.imf.au.dk/publs?id=646
Brion, M. & Thomsen, J. F. (2004). F-regularity of large Schubert varieties. (s. A-59).
Fischler, S., Hussain, M., Kristensen, S. & Levesley, J. (2013). A converse to linear independence criteria, valid almost everywhere. Department of Mathematics, Aarhus University. Preprints Nr. 1 http://math.au.dk/publs?publid=975
Kock, A. (2003). A geometric theory of harmonic and semi-conformal maps. arXiv.org. http://front.math.ucdavis.edu/0306.5203
Thomsen, J. F. (2010). A proof of Wahl's conjecture in the symplectic case. arXiv.org. http://arxiv.org/abs/1009.0479
Neeb, K-H. & Ørsted, B. (2005). A topological Maslov index for 3-graded Lie groups.
Ito, K. & Skibsted, E. (2011). Absence of embedded eigenvalues for Riemannian Laplacians. Department of Mathematics, Aarhus University. Preprints Nr. 4
Ito, K. & Skibsted, E. (2012). Absence of positive eigenvalues for hard-core N-body systems. Department of Mathematics, Aarhus University. Preprints Nr. 6
Herbst, I. & Skibsted, E. (2003). Absence of quantum states corresponding to unstable classical channels: homogeneous potentials of degree zero. MaPhySto, Aarhus Universitet. http://www.maphysto.dk/cgi-bin/w3-msql/publications2/index.html
Kock, A. (2003). Algebra of Principal Fibre Bundles and Connections. Department of Mathematical Sciences , University of Aarhus.
Thomsen, K. (2008). All extensions by Cr* (Fn) are semi-invertible. (s. 1-6). Department of Mathematical Sciences, Aarhus University. http://www.imf.au.dk/publs?id=669
Bökstedt, M. & Ottosen, I. (2004). An Alternative Approach to Homotopy Operations. Department of Mathematical Sciences , University of Aarhus.
Herbst, I. & Skibsted, E. (2009). Analyticity estimates for the Navier-Stokes equations. Department of Mathematical Sciences, Aarhus University. http://www.imf.au.dk/publs?id=844
Gallardo, P., Martinez Garcia, J. & Spotti, C. (2018). Applications of the moduli continuity method to log K-stable pairs. ArXiv. https://arxiv.org/pdf/1811.00088.pdf
Hussain, M. & Kristensen, S. (2011). Badly approximable systems of linear forms in absolute value. Department of Mathematics, Aarhus University.
Salem, B. S. & Ørsted, B. (2004). Bessel Functions for Root Systems via the Trigonometric Setting. Department of Mathematical Sciences , University of Aarhus.
Kock, A. & Reyes, G. E. (2004). Categorical distribution theory; heat equation. Department of Mathematical Sciences , University of Aarhus.
Derezinski, J. & Skibsted, E. (2006). Classical scattering at low energies. http://www.imf.au.dk/publs?id=599
Madsen, T. B. & Swann, A. F. (2011). Closed forms and multi-moment maps. Department of Mathematics, Aarhus University.
Arkhipov, S. & Kanstrup, T. (2018). Colored DG-operads and homotopy adjunction for DG-categories. arXiv
Kock, A. (2006). Connections and path connections in groupoids. http://www.imf.au.dk/publs?id=619
Ebanks, B. & Stetkær, H. (2008). Continuous cocycles on locally compact groups. (s. 1-25). Department of Mathematical Sciences, Aarhus University. http://www.imf.au.dk/publs?id=675
Herbst, I. & Skibsted, E. (2013). Decay of eigenfunctions of elliptic PDE's. Department of Mathematics, Aarhus University. Preprints Nr. 3 http://math.au.dk/publs?publid=981
Bugeaud, Y. & Kristensen, S. (2007). Diophantine exponents for mildly restricted approximation. Department of Mathematical Sciences , University of Aarhus. http://www.imf.au.dk/publs?id=661
Bökstedt, M. & Romão, N. M. (2016). Divisor Braids.
Kock, A. (2003). Envelopes - notion and definiteness. Department of Mathematical Sciences , University of Aarhus.
Hansen, K. A., Koucky, M., Lauritzen, N., Miltersen, P. B. & Tsigaridas, E. (2012). Exact Algorithms for Solving Stochastic Games. http://arxiv.org/abs/1202.3898
Spotti, C. & Sun, S. (2017). Explicit Gromov-Hausdorff compactifications of moduli spaces of Kähler-Einstein Fano manifolds. ArXiv. https://arxiv.org/pdf/1705.00377.pdf
He, X. & Thomsen, J. F. (2007). Frobenius splitting and geometry of G-Schubert varieties. Department of Mathematical Sciences , University of Aarhus. http://www.imf.au.dk/publs?id=640
Thomsen, J. F. (2005). Frobenius splitting of equivariant closures of regular conjugacy classes.
He, X. & Thomsen, J. F. (2005). Geometry of BxB-orbit closures in equivariant embeddings.
Ørsted, B. & Wolf, J. A. (2009). Geometry of the Borel - de Siebenthal discrete series. Department of Mathematical Sciences, Aarhus University. http://www.imf.au.dk/publs?id=696
Lauritzen, N., Raben-Pedersen, U. & Thomsen, J. F. (2004). Global F-Regularity of Schubert Varieties with Applications to D-Modules. Department of Mathematical Sciences , University of Aarhus.
Cruz-Sampedro, J. & Skibsted, E. (2011). Global solutions to the eikonal equation. Aarhus University, Department of Mathematical Sciences.
Minuz, E. & Bökstedt, M. (2019). Graph cohomologies and rational homotopy type of configuration spaces. ArXiv. https://arxiv.org/abs/1904.01452
Kock, A. (2007). Group valued differential forms revisited. Department of Mathematical Sciences , University of Aarhus. http://www.imf.au.dk/publs?id=636
Arkhipov, S. & Ørsted, S. (2018). Homotopy limits in the category of dg-categories in terms of $\mathrm{A}_{\infty}$-comodules. arXiv
Plessis, A. D. & Wall, C. T. C. (2007). Hypersurfaces in pn with 1-parameter symmetry groups II. Department of Mathematical Sciences , University of Aarhus. http://www.imf.au.dk/publs?id=663
Andersen, J. E., Jantzen, J. C. & Pei, D. (2018). Identities for Poincaré polynomials via Kostant cascades. arXiv.org. https://arxiv.org/pdf/1810.05615.pdf
Lauritzen, N. & Thomsen, J. F. (2002). Line Bundles on Bott-Samelson varieties. Department of Mathematical Sciences , University of Aarhus.
Kashiwara, M. & Lauritzen, N. (2002). Local Cohomology and $D$-Affinity in Positive Characteristic. Department of Mathematical Sciences , University of Aarhus.
Thomsen, J. F. & Lauritzen, N. (2010). Maximal compatible splitting and diagonals of Kempf varieties. arXiv.org. http://arxiv.org/pdf/1004.2847v2
Jensen, A. N., Lauritzen, N. & Roune, B. H. (2007). Maximal lattice free bodies, test sets and the Frobenius problem. arXiv.org. http://arxiv.org/abs/0705.4439
Kristensen, S. (2009). Metric inhomogeneous Diophantine approximation in positive characteristic. Department of Mathematical Sciences, Aarhus University. http://www.imf.au.dk/publs?id=707
Haynes, A., Jensen, J. L. & Kristensen, S. (2012). Metrical musings on Littlewood and friends. Department of Mathematics, Aarhus University. Preprints Nr. 4
Hussain, M. & Kristensen, S. (2014). Metrical theorems on systems of small inhomogeneous linear forms. Department of Mathematics, Aarhus University. Preprints Nr. 1 http://math.au.dk/publs?publid=1009
Viser resultater 1 til 50 ud af 683
130912 / i31 | CommonCrawl |
<< Week of March 17 >>
African Film Festival 2019
Film - Series | March 2 – May 10, 2019 every day | Berkeley Art Museum and Pacific Film Archive
March 2–May 10, 2019
This year's edition of the African Film Festival highlights the best of both new African cinema and films of the black diaspora. We pay tribute to the great director Bill Gunn—also an actor, playwright, and novelist—with new restorations of two genre-benders, his radical horror film Ganja & Hess and his "meta–soap opera" Personal Problems. The latter was conceived by... More >
Winter at the Hall
Special Event | December 21, 2018 – March 20, 2019 every day | Lawrence Hall of Science
This winter, visit the Hall for interactive exhibits, special hands-on activities, intriguing Planetarium shows, and more!
Through the Learner's Lens: A Student Learning Center Photo Contest
Miscellaneous | February 25 – March 22, 2019 every day | César E. Chávez Student Center
Sponsor: Student Learning Center
The UC Berkeley Student Learning Center is excited to invite submissions for our first ever photo contest! We're calling on the creativity of our campus community to build a collection of images that showcase the diverse ways learning takes place in and through the Student Learning Center. We invite you to share moments in the learning process that excite you, challenge you, and encapsulate the... More >
41st California Celtic Conference
Conference/Symposium | March 15 – 17, 2019 every day | 370 Dwinelle Hall
Sponsors: Department of Linguistics, Celtic Studies Program, Arts & Humanities, Letters & Science Division of , Follan Fund
The conference is free and open to the public.
Papers will range through Celtic languages, cultures, literatures, histories, and linguistics (come hear about syntactic change in Gaulish!).
Symposium on Amazonian Languages 3
Conference/Symposium | March 17 | 9 a.m.-5 p.m. | 1226 Dwinelle Hall
Sponsor: Department of Linguistics
Exploration of Forms: Symbology of Orixá Dances Workshop
Workshop | March 17 | 1-3 p.m. | Bancroft Studio (2401 Bancroft)
Instructor: Rosangela Silvestre, Silvestre Dance Technique
This free workshop will explore the connections between the rhythms and the traditional movements, archetypes and stories of the Orixá dances, interpreted as an art form. It is a journey into the discovery of how the sacred symbolism of this tradition inspires the body to dance, making the connection between the traditional movements and rhythms of the Orixá, to our own human... More >
RSVP not required
SOLD OUT - Green Natural Dyes: The Seasonal Color Palette with Sasha Duerr
Workshop | March 17 | 1-4 p.m. | UC Botanical Garden
Green is one of the most elusive colors in the natural dye world. On this St. Patrick's Day, come and learn all about the plants that can yield this mysterious and gorgeous color, with dye whisperer and local color expert Sasha Duerr.
Registration required: $100 / $90 UCBG members
Registration info: SOLD OUT - email [email protected] to be added to the waitlist.
Stories of Migration: Dreamers Libretto reading with Nilo Cruz
Lecture | March 17 | 1:30 p.m. | Zellerbach Playhouse
Pulitzer Prize-winning playwright Nilo Cruz leads a read-through of his Dreamers libretto, with commentary and Q&A moderated by Sabrina Klein, Cal Performances' director of artistic literacy. Free and open to the public.
Tour/Open House | January 3 – December 29, 2019 every Sunday, Thursday, Friday & Saturday with exceptions | 1:30-2:45 p.m. | UC Botanical Garden
Join us for a free, docent-led tour of the Garden as we explore interesting plants from around the world, learn about the vast diversity in the collection, and see what is currently in bloom. Meet at the Entry Plaza.
Free with Garden admission. Advanced registration not required
Guided Tours: Hans Hofmann
Tour/Open House | March 17 | 2 p.m. | Berkeley Art Museum and Pacific Film Archive
Explore Hans Hofmann's dynamic and influential work with guided tours on selected Wednesdays, Sundays, and Free First Thursdays.
Film - Feature | March 17 | 2 p.m. | Berkeley Art Museum and Pacific Film Archive
Growing up, Chantal Akerman became aware that for women of her mother's generation the unending repetition of domestic duties became a proxy for emotion and self-expression. For Jeanne Dielman, Akerman chose Delphine Seyrig as the only actor who could make visible domestic tasks that normally go unnoticed. Watching Jeanne cook, mend, wash dishes, shine shoes, have sex for cash, bathe, and set the... More >
Beckett / Fornés / Pinter: Student-Directed One-Act Plays
Performing Arts - Theater | March 16 – 17, 2019 every day | 2-3:30 p.m. | Durham Studio Theater (Dwinelle Hall)
TDPS presents three one-act plays directed by TDPS students:
Silence (1969) by British playwright Harold Pinter, directed by Benjamin Arsenault
Springtime (1989) by Cuban American playwright María Irene Fornés, directed by Gabriela Pool
Footfalls (1976) by Irish playwright Samuel Beckett, directed by Marie Shelton
Tickets required: $10 for students/seniors and UC Berkeley faculty/staff, $15 for general admission
Ticket info: Buy tickets online
University Wind Ensemble
Performing Arts - Music | March 17 | 3 p.m. | Hertz Concert Hall
Matthew Sadowski, music director
The UC Berkeley Wind Ensemble is offered for the study and practice of traditional and contemporary wind band repertoire. The Wind Ensemble's long history at Cal dates back to before the 1930s, when the group was directed by Charles Cushing. In 1950, James Berdahl assumed the directorship and remained until the late 1970s. The Wind Ensemble's activities were... More >
Tickets: $16 General Admission, $12 non-UCB students, seniors, current/retired Berkeley staff & faculty, groups 10+, $5 UC Berkeley students
Rio, 100 Degrees
Five young peanut vendors head from the favelas to the tourist zones in search of easy money in dos Santos's first film, which was filmed in globally recognizable spots such as Copacabana Beach and Sugar Loaf but which revealed an entirely new side of Rio. Inspired by Italian neorealism but pulsing with a very Brazilian urban beat and attitude, Rio offers both tribute to and critique of its... More >
Philharmonia Orchestra, London: Esa-Pekka Salonen, conductor
Performing Arts - Music | March 17 | 3-5 p.m. | Zellerbach Hall
Speaker/Performer: Philharmonia Orchestra, London; Esa-Pekka Salonen, Cal Performances
Sibelius /The Oceanides, Op. 73
Esa-Pekka Salonen/Cello Concerto
Truls Mørk, cello
Bartók/Concerto for Orchestra, Sz. 116, BB 123
Schoenberg/Verklärte Nacht (Transfigured Night), Op. 4
Bruckner/Symphony No. 7 in E Major (WAB 107)
Jimmy López/Dreamers (World Premiere, Cal Performances Co-commission)
Libretto by Nilo... More >
Tickets: $40-125 (prices subject to change)
Ticket info: Tickets go on sale August 7. Buy tickets online or by calling 510-642-9988, or by emailing [email protected]
Esa-Pekka Salonen conducts the Philharmonia Orchestra, London Friday–Sunday, March 15–17, 2019 in Zellerbach Hall.
Chamisso's Shadow: A Journey to the Bering Sea in Three Chapters. Chapter 1: Alaska and the Aleutian Islands
Film - Documentary | March 17 | 3 p.m. | Berkeley Art Museum and Pacific Film Archive
In 2014, Ottinger journeyed to the distant regions of the Bering Sea—to Alaska, then Chukotka, and on to Kamchatka—following along the paths of historic expeditions and explorers, such as the naturalist Georg Willem Steller and Vitus Bering; later, Captain James Cook; and, still later, the poet and botanist Adelbert von Chamisso, who traveled with Otto von Kotzebue. Over a three-month period,... More >
Brunch with the Director and Senior Film Curator
Special Event | March 17 | 10 p.m. | Berkeley Art Museum and Pacific Film Archive
This event is part of March Member Appreciation Month, our month-long celebration of you—our extended BAMPFA family.
Members at the $500 level and above are invited to join Director and Chief Curator Lawrence Rinder and Senior Film Curator Susan Oxtoby for a delicious and intimate brunch at Babette, the cafe at BAMPFA. Learn about BAMPFA's recent successes and get an exclusive glimpse of our... More >
Civil and Environmental Engineering Department Seminar: Granular Mechanics: Soil, Additive Manufacturing, and Beyond
Seminar | March 18 | 10-11 a.m. | 542 Davis Hall
Speaker: Michelle Bernhardt-Barry
The advent of additive manufacturing (AM) has opened many new fields of study related to multi-scale granular material behavior and it has the potential to transform the way in which we design and construct geotechnical infrastructure. This talk will highlight several areas of ongoing research within Dr. Bernhardt-Barry's group and opportunities for expanding this research in the future. The... More >
Lecture | March 18 | 10:30 a.m.-12 p.m. | McEnerney Hall (1750 Arch St.)
Sponsor: Center for New Music and Audio Technologies (CNMAT)
The CNMAT Users Group presents: David Dunn
David Dunn is a composer and sound artist. He will be presenting on his recent work in large-scale meta-soundscape recording and invertebrate intervention research.
This Event is Free and Open to the Public
EH&S 403 Training Session
Course | March 18 | 10:30-11:30 a.m. | 370 University Hall | Note change in date
Speaker/Performer: Jason Smith, UC Berkeley Office of Environment, Health, & Safety
This session briefly covers the UC Berkeley specific radiation safety information you will need to start work. In addition, dosimeter will be issued, if required.
Workspace for Working on Your Human Subjects Protocol
Workshop | March 18 | 11 a.m.-1 p.m. | 2414 Dwinelle Hall
Speaker/Performer: Leah Carroll, UC Berkeley Office of Undergraduate Research and Scholarships
Sponsor: UC Berkeley Office of Undergraduate Research and Scholarships
Come work on your human subjects protocol in a space where others are doing the same, and one representative of the Haas Scholars or SURF program will be present to answer questions and guide you.
Adaptive changes in the adult visual system following visual deprivation
Seminar | March 18 | 11:10 a.m.-12:30 p.m. | 489 Minor Hall
Speaker/Performer: Dr. MiYoung Kwon, Department of Ophthalmology and Visual Sciences, University of Alabama at Birmingham
Sponsor: Neuroscience Institute, Helen Wills
As our population ages, a growing number of people must adapt to normal and pathological aging processes. Thus, understanding how the adult human brain deals with degraded sensory input is increasingly important. In this talk, I will present behavioral and brain-imaging evidence suggesting that visual deprivation results in compensatory changes in the adult human visual system. Here I will... More >
Leveraging Science to Improve the Lives of Children and Adolescents: IHD/Developmental Colloquium featuring a cross-disciplinary discussion
Colloquium | March 18 | 12-1 p.m. | 1102 Berkeley Way West
Sponsor: Institute of Human Development
There has been a great deal of progress in the scientific understanding of how children learn and develop—and the social contexts, conditions, and systems that can promote health, well-being, learning, and social success. There are many challenges to leveraging this science for real-world impact. Yet, there are also exciting opportunities—and compelling reasons for overcoming these
challenges.
STROBE Seminar: 3D Phase Contrast Tomography with Atomic Resolution
Seminar | March 18 | 12-1 p.m. | 775A Tan Hall
Featured Speaker: David Ren, Waller Group, UC Berkeley
Electron tomography is a technique used in both materials science and structural biology to image features well below optical resolution limit. In this work, we present a new algorithm for reconstructing the three-dimensional(3D) electrostatic potential of a sample at atomic resolution from phase contrast imaging using high-resolution transmission electron microscopy. Our method accounts for... More >
'Don't Fall off the Earth': The Armenian Communities in China from the 1880s to 1950s
Lecture | March 18 | 12-1:30 p.m. | 270 Stephens Hall
Speaker: Khatchig Mouradian, Lecturer in Middle Eastern, South Asian, and African Studies, Columbia University
Sponsors: Institute of Slavic, East European, and Eurasian Studies (ISEEES), Armenian Studies Program
Hundreds of Armenians journeyed eastward to China in the late 19th century in search of opportunity, anchoring themselves in major cities, as well as in Harbin, a town that rose to prominence with the construction of the Chinese Eastern Railway. A few thousand others arrived in the region escaping the Armenian Genocide and turmoil in the Caucasus in the years that followed. Many of these... More >
Maxwell, Rankine, Airy and Modern Structural Engineering Design
Lecture | March 18 | 12-1 p.m. | 502 Davis Hall
Speaker/Performer: Bill Baker, NAE, FREng, Partner, Skidmore, Owings & Merrill
Defining Roles. Representations of Lumumba and his Independence Speech in Congolese and Belgian Literature
Lecture | March 18 | 12-1 p.m. | 201 Moses Hall
Speaker/Performer: Lieselot De Taeye, Institute of European Studies, UC Berkeley
Sponsors: Institute of European Studies, Center for African Studies
On June 30th 1960, Congo declared its independence from Belgium. In his speech at the ceremony, the Belgian King Baudouin applauded the work of his countrymen during the colonial period, calling his great-granduncle Leopold II, who was responsible for the death of approximately ten million Congolese people, a 'genius'. Patrice Lumumba, the first Congolese Prime Minister, gave a now-famous speech... More >
Lieselot De Taeye
Leveraging Science to Improve the Lives of Children and Adolescents: A cross-disciplinary discussion
Panel Discussion | March 18 | 12-1 p.m. | 1102 Berkeley Way West
Panelist/Discussants: Prudence Carter, Dean, Graduate School of Education; Jill Duerr Berrick, Professor, School of Social Welfare; Lia Fernald, Professor, School of Public Health; Jason Okonofua, Professor, Department of Psychology
Moderator: Ron Dahl, Director, Institute of Human Development
There has been a great deal of progress in the scientific understanding of how children learn and develop—and the social contexts, conditions, and systems that can promote health, well-being, learning, and social success. There are many challenges to leveraging this science for real-world impact. Yet, there are also exciting opportunities—and compelling reasons for overcoming these challenges.
Edible Book Festival
Special Event | March 18 | 12-1:30 p.m. | Moffitt Undergraduate Library, 4th floor, Central Commons
What's an Edible Book Festival?
Edible Book Festivals feature creative food projects that draw their inspiration from books and stories. Edible books might physically resemble books, or they might refer to an aspect of a story, or they might incorporate text. Judges select winners for an array of light-hearted prize categories, such as "Best Literary Pun" or "Most Delicious Looking." The... More >
Attendance restrictions: Current UCB ID or gold UC Berkeley Library Card
Combinatorics Seminar: Cone valuations, Gram's relation, and combinatorics
Seminar | March 18 | 12:10-1 p.m. | 939 Evans Hall
Speaker: Raman Sanyal, Goethe Universitat-Frankfurt and Simons Institute
The Euler-Poincare formula is a cornerstone of the combinatorial theory of polytopes. It states that the number of faces of various dimensions of a convex polytope satisfy a linear relation and it is the only linear relation (up to scaling). Gram's relation generalizes the fact that the sum of (interior) angles at the vertices of a convex $n$-gon is $(n-2)\pi$. In dimensions $3$ and up, it is... More >
Political Economy Seminar: "Diversity in Schools: Immigrants and the Educational Performance of Natives"
Seminar | March 18 | 12:30-2 p.m. | 223 Moses Hall
Speaker: Paola Giuliano, UCLA
The Political Economy Seminar focuses on formal and quantitative work in the political economy field, including formal political theory.
Berkeley Statistics and Machine Learning Forum
Meeting | March 18 | 1:30-2:30 p.m. | 1011 Evans Hall
Sponsor: Berkeley Institute for Data Science
The Berkeley Statistics and Machine Learning Forum meets weekly to discuss current applications across a wide variety of research domains and software methodologies. All interested members of the UC Berkeley and LBL communities are welcome and encouraged to attend.
Seminar 231, Public Finance
Seminar | March 18 | 2-4 p.m. | 597 Evans Hall
Speakers: Johannes Kasinger; Dario Tortarolo
Johannes Kasinger - "Simplifying Information and Retirement Planning Disparities"
Dario Tortarolo - "Earnings responses to large income tax changes"
Seminar 211, Economic History: Governing the Computers: The London Stock Exchange, the Institute of Actuaries and the First Digital Revolution (1808-1875)
Seminar | March 18 | 2-3:30 p.m. | 639 Evans Hall
Featured Speaker: Marc Flandreau, University of Pennsylvania
String-Math Seminar: A Sheaf-Theoretic model for \(SL(2,\mathbb C)\) Floer homology
Seminar | March 18 | 2-3 p.m. | 402 LeConte Hall
Speaker: Mohammed Abouzaid, Columbia University
I will describe joint work with Ciprian Manolescu on constructing an analogue of instanton Floer homology replacing the group \(SU(2)\) by \(SL(2,\mathbb C)\). Having failed to do so using the standard Floer theoretic tools of gauge theory and symplectic topology, we turned to sheaf theory to produce an invariant. After describing our approach, I will discuss some features of this theory that are... More >
Special Quantum Geometry Seminar: Matrix algebras, geometry and particle physics
Seminar | March 18 | 2:10-4 p.m. | 736 Evans Hall
Speaker: Andrzej Sitarz, Jagiellonian University, Krakow
Starting from the description of the Standard Model of particle physics based on noncommutative geometry we study the properties of the matrix algebras in the model. We demonstrate that there exists a new previously unknown geometric feature of the model, which can be mathematically stated that the Hilbert space of particles is a self-Morita equivalence bimodule for the associated generalization... More >
Workshop | March 18 | 3-5 p.m. | 2414 Dwinelle Hall
Arithmetic Geometry and Number Theory RTG Seminar: Bounding 5-torsion in class groups using Elliptic Curves
Speaker: Jacob Tsimerman, University of Toronto
We discuss a new method to bound 5-torsion in class groups using elliptic curves. The most natural "trivial" bound on the n-torsion is to bound it by the size of the entire class group, for which one has a global class number formula. We explain how to make sense of the n-torsion of a class group intrinsically as a "dimension 0 selmer group", and by embedding it into an appropriate... More >
Evidence for the Suffixing Preference
Colloquium | March 18 | 3:10-5 p.m. | 370 Dwinelle Hall
Speaker/Performer: Matthew S. Dryer, Professor of Linguistics, University at Buffalo
It might be thought that there already exists overwhelming evidence for a preference for suffixes over prefixes. However, strictly speaking, most of the available evidence is evidence for an orthographic suffixing preference, i.e. a preference for suffixes over prefixes in the orthographic representations of words in grammatical descriptions. Haspelmath (2011), however, questions how reliable... More >
Differential Geometry Seminar: On the large time collapsing of Ricci flows
Speaker: Shaosai Huang, University of Wisconsin-Madison
In contrast to finite time singularities of Ricci flows, it is known that collapsing with bounded sectional curvature may occur as we approach time infinity along immortal Ricci flows. In this talk I will show that along an immortal Ricci flow with uniformly bounded diameter and sectional curvature, an unbounded sequence of time slices sub converges to a Ricci flat orbifold.
Jeffrey Linderoth – Perspectives on Integer Programming in Sparse Optimization
Seminar | March 18 | 3:30-4:30 p.m. | 1174 Etcheverry Hall
Speaker/Performer: Jeffrey Linderoth, University of Wisconsin - Madison
Abstract: Algorithms to solve mixed integer linear programs have made incredible progress in the past 20 years. Key to these advances has been a mathematical analysis of the structure of the set of feasible solutions. We argue that a similar analysis is required in the case of mixed integer quadratic programs, like those that arise in sparse optimization in machine learning. One such analysis... More >
Design Field Notes: Ben Allen
Lecture | March 18 | 4-5 p.m. | 220 Jacobs Hall
Ben Allen is a PhD candidate in Stanford University's interdisciplinary Modern Thought and Literature program, where he studies gender and the history of software. His current work focuses on the development of COBOL and other early business programming languages.
About Design Field Notes:
Each informal talk in this pop-up series brings a design practitioner to a Jacobs Hall teaching studio... More >
Quantitative analysis of energy metabolism: Dr. Sheng Hui, Lewis-Sigler Institute for Integrative Genomics, Princeton University
Seminar | March 18 | 4-5 p.m. | 101 Morgan Hall
Sponsors: Center for Computational Biology, Nutritional Sciences and Toxicology
Mammals generate energy by burning dietary carbon into CO2. The largest calorie source for most mammals is carbohydrate, which is broken down into glucose in the small intestinal lumen. Glucose is then absorbed and circulates in the blood stream. To acquire energy, tissues are generally assumed to take in glucose and break it down to CO2 through the concerted action of glycolysis and... More >
IB Finishing Talk: Tropical plant hydraulics in a changing world
Seminar | March 18 | 4-5 p.m. | 2040 Valley Life Sciences Building
Featured Speaker: Clarissa Fontes, UCB (Dawson Lab)
Behind the Curtain Translational Medicine Lecture
Lecture | March 18 | 4-5 p.m. | 410 Hearst Memorial Mining Building
Mar. 18 – Rajan Patel and Kate Stephenson
iO Design
These lectures highlight real-world experiences of leaders in the health technologies space. Looking beyond the initial excitement of a concept, industry veterans discuss the heavy lifting on many fronts that gets new ideas out of the lab and into the clinic.
Seminar 271, Development: "Consumption Insurance and Technology Adoption"
Speaker: Melanie Morten, Stanford University
Russian Nature Lyric, Short Forms: Tyutchev, Mandelstam, Glazova
Lecture | March 18 | 4-6 p.m. | B-4 Dwinelle Hall
Speaker: Luba Golburt, Associate Professor, Slavic Languages and Literatures, UC Berkeley
Sponsors: Institute of Slavic, East European, and Eurasian Studies (ISEEES), Department of Slavic Languages and Literatures
Slavic Graduate Colloquium Spring 2019 Series
Seminar 208, Microeconomic Theory: Secure Survey Design in Organizations: Theory and Experiments
Seminar | March 18 | 4:10-5:30 p.m. | 639 Evans Hall
Speaker/Performer: Sylvain Chassang, NYU
"Three-Dimensional Chess": Dissecting the Political, Economic, and Military Layers of US-PRC-ROC Relations in 2019
Colloquium | March 18 | 5-7 p.m. | 180 Doe Library
Speakers: Yukon Huang, Senior Fellow, Carnegie Endowment for International Peace Asia Program; T.J. Pempel, Jack M. Forcey Professor of Political Science, UC Berkeley
Moderator: Brian Tsui and Tim Smith, on behalf of Strait Talk at UC Berkeley
Sponsor: Institute of East Asian Studies (IEAS)
In the past six months, relations between the United States, the People's Republic of China, and the Republic of China have been subject to significant tensions. President Trump escalated US military ties with the ROC... More >
Perspectives on the Iranian Revolution: Commemorating 40 Years
Colloquium | March 18 | 5-8 p.m. | 340 Stephens Hall
Sponsor: Center for Middle Eastern Studies
Join Perspective Magazine, a student-run publication printed on a bi-annual basis, to celebrate the launch of their spring issue and commemorate the 40th anniversary of the Iranian Revolution.
Perspective offers the Iranian-American diaspora and anyone interested in Iran an outlet to explore the Iranian culture and key issues affecting the Iranian community.
Forty years later, we invite... More >
Spring 2019 Distinguished Guest Lecture: Renisa Mawani
Lecture | March 18 | 5:30-7:30 p.m. | Anthony Hall
Sponsors: Center for Race and Gender, Institute for South Asia Studies, Canadian Studies Program (CAN)), Townsend Center for the Humanities
The Center for Race & gender Presents its Spring 2019 Distinguished Guest Lecture:
Renisa Mawani
Across Oceans of Law
On Digital Colonialism and "Other" Futures with Morehshin Allahyari
Presentation | March 18 | 6:30 p.m. | Berkeley Art Museum and Pacific Film Archive
Media artist, activist, educator, and curator Morehshin Allahyari will discuss some of her projects focused on topics such as 3D fabrication, activism, digital colonialism, monstrosity, and fabulation. She will use this talk as a platform to show the possibilities of art making beyond aesthetics or visualization, positing and contextualizing a "position outside" that asks difficult questions and... More >
On Digital Colonialism and 'Other' Futures
Lecture | March 18 | 6:30-8 p.m. | Osher Theater, BAMPFA
Speaker/Performer: Morehshin Allahyari
Sponsors: Berkeley Center for New Media, Wiesenfeld Visiting Artist Lecture Series, Jacobs Institute for Design Innovation, Center for Middle Eastern Studies, Stanford University
For her talk Morehshin Allahyari will discuss some of her previous projects focused on topics such as 3D fabrication, activism, digital colonialism, monstrosity and fabulation. She will use this talk as a platform to show the possibilities of art-making beyond aesthetics or visualization. She will posit and contextualize "a position outside" that asks difficult questions and suggests alternative... More >
Lecture | March 18 | 6:30-8 p.m. | Berkeley Art Museum and Pacific Film Archive, Osher Theater
Speaker/Performer: Morehshin Allahyari, Artist, Activist, Educator
Sponsors: Berkeley Center for New Media, Art Practice Wiesenfeld Visiting Artist Lecture Series, Jacobs Institute for Design Innovation, Center for Middle Eastern Studies, Stanford University
Presented by Berkeley Center for New Media and co-sponsored with the Art Practice Wiesenfeld Visiting Artist Lecture Series, the Jacobs Institute for Design Innovation, the Center for Middle Eastern Studies, and Stanford University
For her talk Morehshin Allahyari will discuss some of her previous projects focused on topics such as 3D fabrication, activism, digital colonialism, monstrosity and... More >
2019 QBI/Institut Pasteur Symposium on Infectious Disease
Conference/Symposium | March 19 – 20, 2019 every day | Gladstone Institutes, Mahley Auditorium
Location: 1650 Owwens Street, San Francisco, CA
Jan AMBROSINI
Attachments10:21 AM (22 minutes ago)
to Jan, bcc: qb3facultyucb
Dear QB3-Berkeley researchers,
Please note this upcoming symposium on infectious disease, set for March 18-19 at the Gladstone Institutes. A flyer is attached.
The Quantitative Biosciences Institute (QBI), QB3 and Gladstone... More >
Novartis Chemical Sciences Lecture: Deciphering the human microbiota using chemistry
Seminar | March 19 | 11 a.m.-12 p.m. | 120 Latimer Hall
Featured Speaker: Emily Balskus, Department of Chemistry and Chemical Biology, Harvard University
The human body is colonized by trillions of microorganisms that exert a profound influence on human biology, in part by providing functional capabilities that extend beyond those of host cells. In particular, there is growing evidence linking chemical processes carried out by the microbial inhabitants of the gastrointestinal tract to both health and disease. However, we still do not understand... More >
Seminar 217, Risk Management: Asset Insurance Premium in the Cross-Section of Asset Synchronicity
Seminar | March 19 | 11 a.m.-12:30 p.m. | 1011 Evans Hall
Featured Speaker: Speaker: Raymond Leung, UC Berkeley
Sponsor: Consortium for Data Analytics in Risk
Any asset can use some portfolio of similar assets to insure against its own factor risks, even if the identities of the factors are unknown. A long position of an asset and a short position of this portfolio forms an asset insurance premium (AIP) that is different from the equity risk premium.
EECS Women's History Month: Lunch and Learn
Social Event | March 19 | 11 a.m.-2 p.m. | Soda Hall, Wozniak Lounge
Performer Group:
Canadian Language and Culture and Citizenship Development:: Academic Literacy Interventions using New Technologies for Immigrant and International Youth in Canadian Universities
Colloquium | March 19 | 11:30 a.m.-1 p.m. | 223 Moses Hall
Speaker: Jia Li, John A. Sproul Fellow, Canadian Studies
Sponsors: Canadian Studies Program (CAN)), Berkeley Language Center
Canada has a comparatively open immigration policy. On average the country has accepted about 200,000 immigrants and refugees a year over the past decade, one of the highest per capita admission rates in the world. In addition, Canada has been one of the top preferred countries for international students because of a wide selection of programs in top educational institutions, and great potential... More >
Camptown Races: Blackface Minstrelsy, Stephen Foster, and Americanization in Japanese Internment Camps
Lecture | March 19 | 12-1:30 p.m. | 3335 Dwinelle Hall
Speaker: Dr. Rhae Lynn Barnes, Assistant Professor of History, Princeton University
Sponsor: Department of History
This talk will contextualize the recent blackface scandals in Virginia by examining the central role amateur blackface minstrel shows played in the United States government. In the century spanning the end of the Civil War to the birth of the Civil Rights Movement (an era called "Jim Crow," after the first blackface character), the American government refocused domestic and foreign policy... More >
Dr. Rhae Lynn Barnes
The Uncivil Polity: Race, Poverty and Civil Legal Justice
Colloquium | March 19 | 12-1:30 p.m. | 2538 Channing (Inst. for the Study of Societal Issues), Wildavsky Conference Room
Speaker: Jamila Michener, Assistant Professor of Government, Cornell University
Sponsors: Center for Research on Social Change, Berkeley Institute for the Future of Young Americans, Institute of Governmental Studies, Department of Political Science
Civil legal institutions protect crucial economic, social, and political rights. The core functions of civil law include preventing evictions, averting deportations, advocating on behalf of public assistance beneficiaries, representing borrowers in disputes with lenders, safeguarding women from domestic violence, and resolving family disputes (e.g. child support, custody). Civil legal protections... More >
Sponsors: Center for Research on Social Change, Institute of Governmental Studies, Berkeley Institute for the Future of Young Americans
Lam Day at Berkeley
Panel Discussion | March 19 | 12-7 p.m. | Sutardja Dai Hall, Banatao Auditorium
Speaker/Performer: Vahid Vahedi, Senior Vice President, Etch Business Unit, Lam Research
On Tuesday, March 19, the College of Engineering and College of Chemistry will welcome Lam Research to campus for Lam Day @ Berkeley.
Headquartered in Fremont, California, Lam Research is a global supplier of innovative wafer fabrication equipment and services to the semiconductor industry. Lam's products and services are used to make virtually every leading-edge chip inside the electronic... More >
Student Faculty Macro Lunch - "Testing for Labor Rationing: Revealed Preference Estimates from Hiring Shocks"
Presentation | March 19 | 12-1 p.m. | 639 Evans Hall
Speaker: Supreet Kaur, Assistant Professor of Economics, UC Berkeley
Sponsor: Clausen Center
This workshop consists of one-hour informal presentations on topics related to macroeconomics and international finance, broadly defined. The presenters are UC Berkeley PhD students, faculty, and visitors.
** MUST RSVP**
RSVP info: RSVP by emailing [email protected] by March 15.
Rustic Meals for Camping, Cookouts, or Home (BEUHS641)
Workshop | March 19 | 12:10-1 p.m. | Tang Center, University Health Services, Section Club
Speaker: Kim Guess, RD
Sponsor: Be Well at Work - Wellness
Whether you're looking to spend more screen-free time outdoors (and participating in the Balancing Technology Challenge) or just looking for fun new recipes, this class will introduce you to healthy recipes that can be made outdoors or at home. Maybe you will even be inspired to go camping or host a cookout with friends or family! Demonstration, recipes, and samples provided.
Be Well at Work: Rustic Meals for Camping, Cookouts, or Home
Workshop | March 19 | 12:10-1 p.m. | Tang Center, University Health Services, Tang 1019b Section Club Room
Speaker/Performer: Kim Guess
Career Lab: CVs (for faculty positions or gov't research)
Career Fair | March 19 | 12:15-1:30 p.m. | 177 Stanley Hall
This interactive session will start with 15-20 minutes topic overview with advice and tips, then participants will have the opportunity to work on their own materials, with career advisor assistance. (You are encouraged to bring printed copies of your materials and/or a laptop.) You do not need to be currently on the job market to benefit from participating in this event. You will gain insights... More >
IB Seminar: How collective behavior can shape ecosystems
Seminar | March 19 | 12:30-1:30 p.m. | 2040 Valley Life Sciences Building
Featured Speaker: Michael Gil, University of California, Santa Cruz & NOAA Southwest Fisheries Science Center
BSAC Technology Seminar - Miniaturized Interfaces and Implants for Neural Applications and Bioelectronics Medicine
Seminar | March 19 | 12:30-1:30 p.m. | 521 Cory Hall
Speaker: Prof. Dr. Thomas Stieglitz, Dept. of Microsystems Engineering (IMTEK), Albert-Ludwig-University of Freiburg, Germany
Sponsor: Berkeley Sensor & Actuator Center
Neural implants need to establish stable and reliable interfaces to the target structure for chronic application in neurosciences as well as in clinical applications. They have to record electrical neural signals, excite neural cells or fibers by means of electrical stimulation. In case of optogenetic experiments, optical stimulation by integrated light sources or waveguides must be integrated on... More >
RSVP info: RSVP online by March 18.
AmpEquity Speaker Series with Jonathan McBride of BlackRock
Panel Discussion | March 19 | 12:30-1:30 p.m. | N470 Haas School of Business
Speakers/Performers: Jonathan McBride, BlackRock; Kellie McElhaney, Berkeley Haas
Sponsor: Center for Equity, Gender, and Leadership
Join Jonathan McBride (Managing Director and Global Head of Inclusion and Diversity, BlackRock) and Kellie McElhaney (Founding Executive Director, Center for Equity, Gender, and Leadership) as they discuss Jonathan's Equity Fluent Leadership journey.
This event will be held in N470, on the 4th floor of Chou Hall. Doors will open at 12:30pm. A light lunch will be served. This event will feature... More >
The discovery of Kisqali® (ribociclib), a CDK4/6 inhibitor for the treatment of breast cancer
Seminar | March 19 | 1:30-2:30 p.m. | 775 Tan Hall
Featured Speaker: Dr. Christopher Brain, Novartis
EndNote: Essentials and More
Workshop | March 19 | 2-3 p.m. | Valley Life Sciences Building, Bioscience Library Training Room, 2101 VLSB
Speaker/Performer: Debbie Jan, Optometry and Health Sciences Library
EndNote, a citation management program, helps you organize citations and easily insert these citations into your paper or report. Your citations can be converted by EndNote into thousands of different styles, saving you hours of time when you format your papers.
This hands-on workshop will give you practice using some of the EndNote features. This is a drop-in session; no sign up needed.
EndNote X9 Logo
Seminar 218, Psychology and Economics: Revealing temptation through menu choice: A field study
Featured Speaker: Severine Toussaert, University of Oxford
ABSTRACT: In a field study with participants in a weight loss challenge, I use the menu choice approach of Gul and Pesendorfer (2001) to explore the extent to which preference for smaller menus may "reveal" temptation. Focusing on the temptation to eat unhealthy, I elicit participants' preferences over a set of lunch reimbursement options ("the menus"), which differed in the
range of foods... More >
Seminar 237/281: Macro/International Seminar - "Labor Market Power"
Speaker: Kyle Herkenhoff, Assistant Professor of Economics, University of Minnesota
Abstract: We develop a quantitative general equilibrium oligopsony model of the U.S. labor market, calibrated to Census data. Parameters governing labor market power are identified using new measures of within-state-firm, across-market differences in the response of employment and wages to state corporate tax changes. After calibrating to match 2014 measures of labor market power, we find that... More >
RSVP info: RSVP by emailing Joseph G. Mendoza at [email protected]
Helke Sander's dffb Cinema, 1968 and West Germany's Feminist Movement
Lecture | March 19 | 2-3 p.m. | 201 Moses Hall
Speaker/Performer: Christina Gerhardt, University of Hawaiʻi at Mānoa
Sponsor: Institute of European Studies
Helke Sander was a key figure of the early dffb (Deutsche Film- und Fernsehakademie Berlin), where she studied between 1966 and 1969. Returning to her political organizing and her films of the era revises three crucial narratives:
1. it expands narratives about 1968 to include the establishment of feminism as part of it (The Tomatenwurf), which is often read as a 1970s phenomenon;
2. it... More >
Christina Gerhardt
The Energy Office presents: Sustainability Practices: A Panel on Sustainability in the Built Environment
Presentation | March 19 | 2-3 p.m. | 126 Barrows Hall
Speakers/Performers: David Lehrer, Center for the Built Environment; Housing & Dining Sustainability Advocates; Catherine Patton, UCB Energy Office
Sponsor: UCB Energy Office
The Energy Office presents: A brand new Sustainability Practices Panel! Do you know how much energy buildings use? This panel will be focused on sustainability in Cal's built environment, which represents almost 75% of carbon emissions from the University. Come hear about work the Energy Office is doing to reduce energy use and emissions, and cutting-edge technology and initiatives to inspire... More >
Librarian Office Hours at the SPH DREAM Office
Miscellaneous | February 5 – April 30, 2019 every Tuesday with exceptions | 3-5 p.m. | Berkeley Way West, 2220 (DREAM Office)
Speaker/Performer: Debbie Jan
Drop by during office hours if you need help with your literature reviews; setting up searches in PubMed, Embase, and other databases; using EndNote, RefWorks, or other citation management software; finding statistics or data; and answering any other questions you may have.
3-Manifold Seminar: Virtually special hyperbolic manifolds
We will discuss a theorem of Bergeron-Haglund-Wise that hyperbolic arithmetic groups of simplest type are virtually special. This implies that geometrically finite subgroups are separable.
Faculty Research Lecture: Life History and Learning: When (and Why) Children Are Better Learners than Both Adults and A.I.: Faculty Research Lecture by Alison Gopnik
Lecture | March 19 | 4-5 p.m. | International House, Chevron Auditorium
Speaker/Performer: Alison Gopnik, Professor of Psychology and Affiliate Professor of Philosophy
Sponsor: Academic Senate
Alison Gopnik received her B.A. from McGill University and her Ph.D. from Oxford University. She is an internationally recognized leader in the study of cognitive science and of children's learning and development and was one of the founders of the field of "theory of mind," an originator of the "theory theory" of children's development, and, more recently, introduced the idea that probabilistic... More >
Wai Wai Nu | On Rohingya Citizenship Rights: Talk followed by community updates by UC Berkeley's Rohingya Working Group
Lecture | March 19 | 4-6 p.m. | Stephens Hall, 10 (ISAS Conf. Room)
Speaker: Wai Wai Nu, Visiting Scholar, Human Rights Center, UC Berkeley
Moderator: Eric Stover, Faculty Director of the Human Rights Center and Adjunct Professor of Law and Public Health, UC Berkeley
Organizer: Yoshika Crider, PhD Student | Energy & Resources Group
Organizer: Samira Siddique, MS PhD Student | Energy & Resources Group
Sponsors: The Subir and Malini Chowdhury Center for Bangladesh Studies, Institute for South Asia Studies, Center for Southeast Asia Studies, Human Rights Center
A lecture on the Rohingya Crisis
The Specter Haunting Singapore: Why the People's Action Party Cannot Get Over Operation Coldstore
Lecture | March 19 | 4-5:30 p.m. | 180 Doe Library
Speaker: Dr. Thum Ping Tjin, Managing Director, New Naratif
Sponsor: Center for Southeast Asia Studies
This talk looks at the significance for Singapore's history of "Operation Coldstore" - the 1963 arrest and detention without trial of over 112 opposition politicians, trade unionists, and political activists on grounds of a communist conspiracy - including how it has shaped Singapore's governance, and why it matters to the ruling party today.
Thum Ping Tjin
Islamophobia Series, Episode 2: Islamophobia and Bullying in K-12
Lecture | March 19 | 4-5:30 p.m. | 691 Barrows Hall
Sponsor: Center for Race and Gender
Amna Salameh has a background in education, she serves on both the Positive Behavioral Intervention and Supports (PBIS) committee and the Office of Educational Equity (OEE) committee at the Elk Grove Unified School District. She completed her Bachelor of Arts in International Studies from Louisiana State University, and finished her Master of Arts in Education, with a concentration in Curriculum... More >
Kenneth Pitzer Lecture: Proton-Coupled Electron Transfer in Catalysis and Energy Conversion
Seminar | March 19 | 4-5 p.m. | 120 Latimer Hall
Featured Speaker: Sharon Hammes-Schiffer, Department of Chemistry, Yale University
Proton-coupled electron transfer (PCET) reactions play a vital role in a wide range of chemical and biological processes. This talk will focus on recent advances in the theory of PCET and applications to catalysis and energy conversion. The quantum mechanical effects of the active electrons and transferring proton, as well as the motions of the proton donor-acceptor mode and solvent or protein... More >
Citrin Center for Public Opinion
Lecture | March 19 | 4-5:30 p.m. | Barrows Hall, 8th floor Social Science Matrix Conference Room
Speakers: Morris Levy, Professor, University of Southern California; Cecilia Mo, Professor, UC Berkeley; Cara Wong, Professor, University of Illinois
Moderator: Laura Stoker, Professor, UC Berkeley
Sponsors: Department of Political Science, Social Science Matrix, Citrin Center for Public Opinion, Berkeley Law, Institute of International Studies, Insitute for the study of Societal Issues
American Opinion on Immigration: Implications for Policy
Seminar 221 - Industrial Organization: "Physician Behavior in the Presence of a Secondary Market: The Case of Prescription Opioids": Joint with Public Finance
Featured Speaker: Molly Schnell, Northwestern University
Joint with public seminar
Beyond Imperial Aesthetics: Theorizing Art and Politics in East Asia
Panel Discussion | March 19 | 5-7 p.m. | 3335 Dwinelle Hall
Panelist/Discussants: Naoki Sakai, Cornell University; Mayumo Inoue, Hitotsubashi University
Moderators: Miryam Sas, UC Berkeley; Steve Choe, San Francisco State University
Sponsors: Institute of East Asian Studies (IEAS), Center for Japanese Studies (CJS)
Observing that the division between theory and empiricism remains inextricably linked to imperial modernity, manifest at the most basic level in the binary between "the West" and "Asia," the authors in the forthcoming collection Beyond Imperial Aesthetics (co-edited by Mayumo Inoue and Steve Choe, Hong Kong University Press, 2019) reexamine art and aesthetics to challenge these oppositions... More >
Universal Coverage: Is "Medicare for All" the answer?
Lecture | March 19 | 5-7 p.m. | Berkeley Way West, Colloquia
Going Green iMix
Social Event | March 19 | 5-7 p.m. | International House, Sproul Rooms
Come join Berkeley International Office to celebrate St. Patrick's Day and the beginning of spring by planting flowers and herbs to take home, decorating flower pots, and meeting new people! We'll have free snacks, drinks, and fun games to celebrate the holiday—so come take a break, make some friends, and go green with BIO!
Space is limited, so <a... More >
Around Arthur Szyk: Berkeley Scholars on Art and History: Visual Judaica: Jewish Icons and Collecting Patterns in the early 20th century
Lecture | March 19 | 5:30-7 p.m. | Magnes Collection of Jewish Art and Life (2121 Allston Way)
The highly decorative works of Arthur Szyk contain key Jewish visual elements such as the Lion of Judah, the dove, and the seven spices mentioned in the bible as typical of the Land of Israel. These themes are repeated in Szyk's oeuvre throughout his life and can be found in his early pieces ("Book of Esther," 1925) as well as in later ones ("Pathways Through the Bible," 1946). In this talk, we... More >
RSVP info: RSVP online or by calling 5106432526
STEM PhD Leadership and Community Expo (SPLiCE)
Information Session | March 19 | 6-7:30 p.m. | Stanley Hall, First Floor Atrium
QB3-Berkeley, VSPA, and Grad Division invite you to participate in our first ever STEM PhD Leadership & Community Expo (SPLiCE), taking place on March 19, 2019, 6pm in Stanley Hall. SPLiCE is a new event with the aim of connecting Berkeley's graduate and postdoc scientists in an environment which will foster engagement and new opportunities.
Why should you attend SPLiCE? Because at this unique... More >
Free Member Screening: The Valiant Ones
A righteous husband-and-wife swordfighting duo are called to protect China from the machinations of Japanese pirates and corrupt officials in King Hu's masterly work, noted for its forest fight scene set to the moves of a Go match. "A muscleman is not enough; we need a schemer,"... More > | CommonCrawl |
CQE, CRE, Six Sigma, Statistics
One Sample Variance Test (Chi-square)
** Unlock Your Full Potential **
The Chi-Square Test for One Variance is a statistical test used to compare the variance of a sample to a known population variance. It is used to test a hypothesis about the population variance and is based on the assumption that the sample is drawn from a normally distributed population.
Steps in the Chi-Square Test for One Variance:
Specify the null and alternative hypotheses. The null hypothesis is usually that the population variance is equal to a specific value, while the alternative hypothesis is that the population variance is not equal to that value.
Select a sample from the population and calculate the sample variance and size.
Calculate the test statistic, which is the sample variance divided by the known population variance.
Determine the critical value of the test statistic based on the significance level (alpha) of the test and the degrees of freedom. The degrees of freedom are calculated as the sample size minus 1.
Compare the calculated test statistic to the critical value to determine whether to reject or fail to reject the null hypothesis. If the calculated test statistic exceeds the critical value, the null hypothesis is rejected, and the alternative hypothesis is accepted.
Conditions for the Chi-Square Test for One Variance:
To conduct a valid chi-square test for one variance, the following conditions must be met:
The sample must be drawn randomly from the population.
Each observation in the sample must be independent of the others.
The population distribution must approximate a normal distribution.
Typical Null and Alternate Hypotheses in the Chi-Square Test for One Variance:
The null hypothesis in a chi-square test for one variance is that the sample variance equals the known population variance. This can be expressed as:
H0: \(σ^2 = σ_0^2\)
Where \(σ^2\) is the sample variance and \(σ_0^2\) is the known population variance.
The alternate hypothesis is the opposite of the null hypothesis and is that the sample variance is not equal to the known population variance. This can be expressed as:
Ha: \(\sigma^2 \neq \sigma_0^2\)
Calculating Test Statistic:
The chi-square statistic in a chi-square test for one variance is calculated as the sample variance divided by the known population variance. It is used to determine whether the difference between the sample and population variance is statistically significant.
The formula for calculating the chi-square statistic is as follows:
$$\LARGE{\chi^2 = \frac{(n-1)s^2}{\sigma^2}}$$
Where \(n\) is the sample size, \(s^2\) is the sample variance, and \(\sigma^2\) is the known population variance.
Calculating Critical Values:
The critical values for the chi-square statistic in a chi-square test for one variance depend on the degrees of freedom and the significance level of the test.
The degrees of freedom are calculated as the sample size minus 1.
Using these two values (significance level and degrees of freedom), you can find out the value of the critical chi-square statistic using a Chi-square table.
In addition, you can use statistical software to find out the critical value. In Excel, you can use =CHISQ.INV.RT(probability, deg_freedom) for right tail values and =CHISQ.INV(probability, deg_freedom) for left tail values.
About the Author Quality Gurus
We provide Quality Management courses at an affordable price.
We offer Certified Manager of Quality/Organizational Excellence (CMQ/OE), Certified Six Sigma Green Belt (CSSGB), Certified Six Sigma Black Belt (CSSBB), Certified Quality Auditor (CQA), Certified Quality Engineer (CQE), Certified Supplier Quality Professional (CSQP), Certified Quality Improvement Associate (CQIA), and Certified Quality Process Analyst (CQPA) exam preparation courses.
Customers served! 1
Quality Management Course
FREE! Subscribe to get 52 weekly lessons. Every week you get an email that explains a quality concept, provides you with the study resources, test quizzes, tips and special discounts on our other e-learning courses.
I consent to having my information processed in order to receive personalized marketing material via email or phone in accordance with the Privacy policy
IASSC Lean Six Sigma Black Belt (LSSBB) Sample Questions
Six Sigma Certification – ASQ® or IASSC?
P-Value in Statistical Hypothesis Tests
Preventing Six Sigma Failure
Negative Team Dynamics
Affinity Diagram
Flowcharts: The Ultimate Tool for Visualizing Information
Free Certification (with Udemy Courses)
Prepare for the CSSBB Exam with …
Prepare for the CQE exam with …
Learn Statistics
32 Courses on SALE!
{({tcb_post_published_date type='published' date-format-select='F j, Y' date-format='F j, Y' show-time='0' time-format-select='g:i a' time-format='' link='0' target='1' rel='0' inline='1'})}
{({tcb_post_title link='1' target='0' rel='0' inline='1' static-link='{"className":"","href":"https://www.qualitygurus.com/abbreviations-in-the-field-of-quality-and-six-sigma/","title":"Abbreviations in the Field of Quality and Six Sigma","class":""}' css=''})} | CommonCrawl |
Are Newton's "laws" of motion laws or definitions of force and mass?
If you consider them as laws, then there must be independent definitions of force and mass but I don't think there's such definitions.
If you consider them as definitions, then why are they still called laws?
newtonian-mechanics forces mass definition
Qmechanic♦
ParacosmisteParacosmiste
$\begingroup$ there must be independent definitions of force and mass but I don't think there's such definitions. Suppose I define force as what I measure with a spring scale, and I define mass as what I measure with a balance (which has been calibrated in the same location with a standard mass). $\endgroup$ – Ben Crowell Jul 6 '13 at 20:47
$\begingroup$ @BenCrowell I wish life is that simple. $\endgroup$ – Paracosmiste Jul 6 '13 at 20:59
$\begingroup$ Just think of the laws as saying "one can assign a 'mass' to each object and a 'force' to each interaction so that ...". It is quite possible that with some laws of physics there would be no consistent assignments of 'masses' and 'forces' making Newton's laws hold. This means that Newton's laws are more than just definitions. For example, Newton's laws imply that an astronaut floating in space can't propel himself without throwing something. Can a definition imply anything? $\endgroup$ – Peter Shor Jul 6 '13 at 21:23
$\begingroup$ Conservative forces satisfy $m\ddot{\vec{x}}=-\vec{\nabla}V\left( x\right) $, so even in this special case an equation quantifying force isn't true by definition. A Lagrangian formulation makes this clearer with the on-shell concept. $\endgroup$ – J.G. Jun 22 '17 at 22:57
In my view, standard statements of Newton's laws are usually overly concise, and this lack of detail causes confusion about what is a definition, and what is an empirical fact. To avoid this confusion, let's proceed in a systematic way that makes the distinctions between these definitions and empirical statements clear.
What follows certainly is not the original statement of the laws made by Newton himself; it is a modern interpretation meant to clarify the foundations of Newtonian mechanics. As a result, the laws will be presented out of order in the interest of logical clarity.
To start off, we note that the definitions of mass and force given below will require the concept of a local inertial frame. These are frames of reference in which when an object is isolated from all other matter, it's local acceleration is zero. It is an empirical fact that such frames exist, and we'll take this as the first law:
First Law. Local inertial reference frames exist.
How is this in any way related to the first law we know and love? Well, the way it is often stated, it basically says "if an object isn't interacting with anything, then it won't accelerate." Of course, this is not entirely correct since there are reference frames (non-inertial ones) in which this statement breaks down. You could then say, all right, all we need to do then is to qualify this statement of the first law by saying "provided we are making observations in an inertial frame, an object that doesn't interact with anything won't accelerate," but one could then object that this merely follows from the definition of inertial frames, so it has no physical content. However, going one step further, we see that it's not at all clear a priori that inertial frames even exist, so the assertion that they do exist does have (deep) physical content. In fact, it seems to me that this existence statement is kind of the essence of how the first law should be thought because it basically is saying that there are these special frames in the real world, and if your are observing an isolated object in one of these frames, then it won't accelerate just as Newton says. This version of the first law also avoids the usual criticism that the first law trivially follows from the second law.
Equipped with the first law as stated above, we can now define mass. In doing so, we'll find it useful to have another physical fact.
Third Law. If two objects, sufficiently isolated from interactions with other objects, are observed in a local inertial frame, then their accelerations will be opposite in direction, and the ratio of their accelerations will be constant.
How is this related to the usual statement of the third law? Well, thinking a bit "meta" here to use terms that we haven't defined yet, note that the way the third law is usually stated is "when objects interact in an inertial frame, they exert forces on each other that are equal in magnitude, but opposite in direction." If you couple this with the second law, then you obtain that the product of their respective masses and accelerations are equal up to sign; $m_1\mathbf a_1 = -m_2\mathbf a_2$. The statement of the third law given in this treatment is equivalent to this, but it's just a way of saying it that avoids referring to the concepts of force and mass which we have not yet defined.
Now, we use the third law to define mass. Let two objects $O_0$ and $O_1$ be given, and suppose that they are being observed from a local inertial frame. By the third law above, the ratio of their accelerations is some constant $c_{01}$; \begin{align} \frac{a_0}{a_1} = c_{01} \end{align} We define object $O_0$ to have mass $m_0$ (whatever value we wish, like 1 for example if we want the reference object to be our unit mass), and we define the mass of $O_1$ to be \begin{align} m_1=-c_{01}m_0 \end{align} In this way, every object's mass is defined in terms of the reference mass.
We are now ready to define force. Suppose that we observe an object $O$ of mass $m$ from a local inertial frame, and suppose that it is not isolated; it is exposed to some interaction $I$ to which we would like to associate a "force." We observe that in the presence of only this interaction, the mass $m$ accelerates, and we define the force $\mathbf F_{I}$ exerted by $I$ on $O$ to be the product of the object's mass and its observed acceleration $\mathbf a$; \begin{align} \mathbf F_{I} \equiv m\mathbf a \end{align} In other words, we are defining the force exerted by a single interaction $I$ on some object of mass $m$ as the mass times acceleration that a given object would have if it were exposed only to that interaction in a local inertial frame.
Second Law. If an object $O$ of mass $m$ in a local inertial frame simultaneously experiences interactions $I_1, \dots, I_N$, and if $\mathbf F_{I_i}$ is the force that would be exerted on $O$ by $I_i$ if it were the only interaction, then the acceleration $\mathbf a$ of $O$ will satisfy the following equation: \begin{align} \mathbf F_{I_1} + \cdots \mathbf F_{I_N} = m \mathbf a \end{align}
joshphysicsjoshphysics
$\begingroup$ @sangstar Why so confident? All objects will gravitationally interact. $\endgroup$ – joshphysics Jun 15 '17 at 17:45
$\begingroup$ @joshphysics Wait, if there is never not an acceleration on an object since gravitational fields have infinite ranges, how can local inertial frames exist? $\endgroup$ – sangstar Jun 16 '17 at 7:35
$\begingroup$ This formulation has a loophole. Consider objects $O_0, O_1, O_2$ with given accelerations ratios $c_{01}, c_{02}, c_{21}$ and define mass as $m_1 = c_{01} m_0, \, m_2 = c_{02} m_0$. Now, however, there is no guarantee that $m_1 = c_{21} m_2$ and the definition of mass is thus non-unique. The definition of mass can be unique only if a transitivity postulate $c_{ij}/c_{ik} = c_{kj}$ holds for any three objects $O_i, O_j, O_k$. $\endgroup$ – Void Jun 25 '17 at 14:27
$\begingroup$ @Void That's an interesting observation, but I don't see how this is a problem if we all agree to use $O_0$ as our reference mass. If we want the ability to use another mass, say $O_1$, to measure masses after we have measured it against $O_0$, then I agree that the procedure outlined above would not guarantee that we would get consistent results, and we would need to add your transitivity postulate, but that seems unnecessary if we want a simple, predictive theory that works in principle, even if in practice it's hard to work with because we always have to use $O_0$ to measure all masses. $\endgroup$ – joshphysics Jun 25 '17 at 18:25
$\begingroup$ It's atrocious and totally unacceptable that this either isn't taught or isn't taught enough. How many go into physics and/or a discipline which features strong use of physics (e.g. engineering) and yet don't manage to get a rectified understanding of some of these most elementary principles of basic mechanics, or get it much later than they should? It makes one want to distrust a lot of what one gets out of the school/education system. If this is jixed up, what else might be as well? $\endgroup$ – The_Sympathizer Sep 2 '18 at 16:03
joshphysics's answer is excellent, and a perfectly good logical ordering of concepts, in which force is defined in terms of mass. I personally prefer a slightly different logical ordering (which of course ends up being equivalent), in which mass is defined in terms of force:
First law: Local inertial reference frames exist.
I can't improve on joshphysics's excellent explanation here.
Second law: Every object's mass exists, and is independent of the force applied to it.
We define a "force" $F_i$ to be a physical influence arising from a repeatable experimental setup. ($i$ is just a label, not a vector component.) For example, we could consider a single rubber band, stretched by a fixed amount, to which we connect a series of different "test objects." This defines a force $F_1$ which is not a vector quantity (hence the lack of bold script), but instead a label for a particular experimental setup. Or we could consider the gravitational pull $F_2$ from Jupiter on various "test objects" when it is at a particular location and distance relative to the test object. A given force $F_i$ acting on a given test object $o_j$ will impart on it a measurable acceleration vector ${\bf a}(F_i, o_j)$.
Now we find three nontrivial empirical results:
(i) If forces $F_1$ and $F_2$ induce accelerations ${\bf a}_1$ and ${\bf a}_2$ in an object when applied individually, then they induce acceleration ${\bf a}_1 + {\bf a}_2$ in the object when applied simultaneously.
(ii) A given force $F_i$ accelerates all test objects in the same direction (although with different magnitudes). In other words, $${\bf a}(F_i, o_j) \parallel {\bf a}(F_i, o_{j'})$$ for all $i$, $j$, and $j'$.
(iii) Suppose we have two different forces $F_1$ and $F_2$ (e.g. two rubber bands of different stiffness) and two different test objects $o_A$ and $o_B$. The following equality always holds:
$$\frac{|{\bf a}(F_1, o_A)|}{|{\bf a}(F_1, o_B)|} = \frac{|{\bf a}(F_2, o_A)|}{|{\bf a}(F_2, o_B)|}.$$
This suggests a natural way to systematically quantify the effects of the various forces. First take a particular test object $O$ and assign to it an arbitrary scalar quantity $m_O$ called its "mass." Don't worry about the physical significance of this quantity yet. Note that only this one particular object has a well-defined "mass" at this stage. Now apply all of your different forces to the object $O$. Each force $F_i$ will induce some acceleration ${\bf a}(F_i, O)$ on $O$. Now assign to each force $F_i$ a vector quantity $${\bf F}_i := m_O\, {\bf a}(F_i, O)$$ which "records" its action on the test object $O$. Note that Newton's second law is trivially true only for the particular test object $O$. Also note that changing the value of $m_O$ simply dilates all the force vectors by the same amount, so you might as well just choose mass units in which it has the numerical value of $1$. The empirical observation (ii) above can now be rephrased as
(ii') For all forces $F_i$ and test objects $o_j$, $${\bf F}_i \parallel {\bf a}(F_i, o_j).$$
We can therefore define a scalar quantity $m_{(i,j)}$, which depends both on the applied force and on the test object, such that $${\bf F}_i = m_{(i,j)} {\bf a}(F_i, o_j).$$
This justifies the first claim of the Second Law, that every object's mass exists. Recall from the definition of the force vector that $$m_O {\bf a}(F_i, O) = m_{(i,j)} {\bf a}(F_i, o_j),$$ so only the ratio $m_{(i,j)} / m_O$ is physically measurable, as mentioned above.
If we let $o_B$ be the test object $O$, then empirical observation (iii) above can be rearranged to $m_{(1,A)} = m_{(2,A)}$ for all test objects $o_A$, justifying the second claim of the Second Law that an object's mass does not depend on the external force applied to it.
Finally, the facts that (a) induced accelerations add as vectors and (b) an object's mass does not depend on the applied force, together imply that applied forces add as vectors as well.
Third law: When one object exerts a force on a second object, the second object simultaneously exerts a force equal in magnitude and opposite in direction on the first object.
We already defined the force vector ${\bf F}$ above, so this is clearly a nontrivial empirical observation rather than a definition.
tparkertparker
$\begingroup$ Truly fantastic answer! Maybe seems more so to me as this is exactly how I arrange the content of the Newton's laws for myself. It is frustrating how textbooks (or any other book) completely ignores all of this and turns towards applications. I would like to point out that this way of thinking is a bit advantageous over the otherwise excellent explanation by @joshphysics because of the fact that this way isolates the third law from the more fundamental definitions of mass and force. The third law is pretty much always violated and I would not like it to be the basis of my definitions ;-). $\endgroup$ – Feynmans Out for Grumpy Cat Jun 22 '17 at 22:58
$\begingroup$ There is a problem with this answer if one takes into account electrical charge. Consider the two experimental setups where $F_1$ corresponds to placing an object at a certain distance from Jupiter (assumed electrically neutral), and $F_2$ corresponds to placing an object at a certain distance from a positively charged object with the same mass as Jupiter. Then rule (iii) breaks down if you use objects $o_A$ and $o_B$ with the same mass but different charge. $\endgroup$ – Tob Ernack Feb 26 at 18:13
$\begingroup$ In fact, for gravitational forces the ratio $\frac{|\mathbf{a}(F_1, o_A)|}{|\mathbf{a}(F_1, o_B)|}$ is always equal to $1$ since the acceleration is independent of the mass of the object. This is not true for other forces in general. I think the problem is that the forces are not properties of the experimental setup only, but also depend on properties of the test objects themselves, and there is more than one degree of freedom because we have both mass and charge. $\endgroup$ – Tob Ernack Feb 26 at 18:16
$\begingroup$ What this means is that in your procedure for defining mass, you still have a good definition for $m_{(i, j)}$, but in fact this quantity depends on the applied force. $\endgroup$ – Tob Ernack Feb 26 at 18:42
$\begingroup$ @DvijMankad as for your comments about the Third Law being a definition rather than empirical in joshphysics' treatment, I am not completely sure, but perhaps one could change his treatment by refraining from claiming that accelerations are in opposite directions while defining mass. Instead of going straight to the Third Law, one could simply define mass using the empirical observation that ratio of magnitudes of the accelerations is constant. The Second Law is then defined as he did, and the Third Law (that forces have opposite directions) is an empirical fact. $\endgroup$ – Tob Ernack Feb 26 at 18:59
To understand what Newton's three Laws really are, one needs to consider the notion of momentum. Momentum $\vec{p}$ of a point particle is the product of its mass $m$ (which will be defined implicitly later) and its instantaneous velocity $\vec{V}$, so $\vec{p}:=m\vec{V}$. Also, $m \in \mathbb{R}_+$ mass units and $ m:=const $ (reasons are so that $ m$ characterises a particle and does not make vectors $\vec{V}$ and $\vec{p}$ point in a different directions). One also needs to consider the Law of Conservation of a Linear Momentum, which is the consequence of space translation symmetry (contrary to a pupular belief that it is the consequence of Newton's Laws).
Now, let's talk about the Newton's Laws:
Newton's first and third laws: consequence of the Law of Conservation of a Linear Momentum, nothing more.
Newton's second law: a definition of a force, $\sum \vec{F}:=\dot{\vec{p}}$ (which also yields the familiar $\sum \vec{F}=m\vec{a}$)
Remark: a question about measuring masses of point particles may arise, so here is the answer. Consider a system of two point particles moving along the $ x $-axis towards each other. Law of Conservation of Linear Momentum states:
\begin{align}m_1 \left |\vec{V}_{11} \right | - m_2 \left |\vec{V}_{21} \right | = m_2 \left |\vec{V}_{22} \right |-m_1 \left |\vec{V}_{12} \right |\end{align}
Defining $ m_1 $, for example, to be equal to one unit of mass, it is possible to calculate $ m_2 $ (measuring the values of the velocities of the particles before and after the collision is a standard procedure that can be carried out).
ConstantineConstantine
$\begingroup$ what's wrong in considering the conservation of linear momentum as a consequence of Newton Laws? If you assume $F= \dot p$, which is true in classical mechanics, 3rd law and conservation of linear momentum are completely equivalent. $\endgroup$ – pppqqq Jul 8 '13 at 16:36
$\begingroup$ Conservation of linear momentum is fundamentally the consequence of space translation symmetry, Newton's first and second laws are special cases. $\endgroup$ – Constantine Jul 8 '13 at 17:18
I think the answer by Joshphysics is very good. In particular the statement that asserting existence is a key element.
The idea is to restate the laws of motion in such a way that the question law versus definition issue becomes clearer.
In analogy with thermodynamics I will state a 'law zero'; a law that comes before the historical 'First law'.
As with Joshphysics's answer the following treatment is for the Newtonian domain.
Law zero:
(Assertion of existence)
There exists opposition to change of an object's velocity. This opposition to change of velocity is called 'inertia'.
First law:
(The uniformity law)
The opposition to change of velocity is uniform in all positions in space and in all spatial directions.
Second law:
(The acceleration law)
The change of velocity is proportional to the exerted force, and inversely proportional to the mass.
The above statements are not definitions.
For comparison, the zero point of the Celcius scale is a definition; it is interexchangeable with another definition of zero point of temperature scale. The laws of motion are not exchangeable for other statements.
The concept of force is also applicable in statics, hence Force can also be defined in the context of a static case (compression), and then we check for consistency with Force defined in terms of dynamics. As we know: we find consistency.
For mass things are more interesting. Mass is in fact defined by the laws of motion. Trivial example: if you would use the volume of an object as a measure of its mass the second law would not apply universally. It's the law of motion that singles out what an object's mass is: precisely that property for which the second law holds good.
The lesson is that if you would insist that any statement is either a physics law, or a definition, you would totally bog yourself down.
Our physics laws are both: they are statements about inherent properties of Nature, and they define the concepts that the laws are valid for.
Additional remarks:
The first and second law together are sufficient to imply the historical third law. This can be recognized in the following way:
Let object A and object B both be floating in space, not attached to any larger mass.
From an abstract point of view it might be argued: there is a difference between:
Case 1: object A exerting a force upon object B, but B not on A
Case 2: object A and object B exerting a force upon each other.
According to the laws of motion the above distinction is moot. Observationally the two cases are identical, making it meaningless to distinguish between them on an abstract level.
Assume for argument sake that object A exerts a attracting force upon object B, but B not upon A. Both A and B are floating in space. The leverage that object A has to pull object B towards itself is A's own inertia. A has no other leverage, A is not attached to any larger mass. A can pull B closer to itself if and only if A is itself in acceleration towards B. There is no scenario, no observation, where Case 1 and Case 2 are distinguishable, hence Case 1 and Case 2 must be regarded as one and the same case.
The first law and second law together are sufficient to imply the superposition of forces.
CleonisCleonis
$\begingroup$ How "The first law and second law together are sufficient to imply the superposition of forces"? You can't tell if a force will disrupt the source of another force. You have to assume the superposition of forces. $\endgroup$ – Shing Jun 23 '17 at 14:15
$\begingroup$ You forgot to add the only one very important thing of the Newton's laws: the above are only valid in inertial frames (and not elsewhere), where such frames are defined as existing by the first law (I don't really understand what you instead state the first law to be). $\endgroup$ – gented Jul 2 '17 at 17:06
First, I want to say I find your question excellent! It is very important, for anyone who wants to call himself a physicist, to know the answer on your question.
EVERY PHYSICAL QUANTITY must be defined through operation of measurement OR through mathematical relations to other physical quantities which are already defined through operations of measurements. Meaning, we must know how to measure a physical quantity (directly or indirectly).
For example, we define velocity as time derivative of position vector, and this makes sense only if we know how to measure time and length.
Time is "defined" as measurement of specific clock (which has some specific properties in every way independent of time - we cannot say our specific clock, which we want to use as instrument for measuring time, must have properties of ticking after same TIME interval). We call one tick of our specific clock one second. Then, duration of some process we are observing is measured by counting ticking of our clock. N ticking means process lasted N seconds. Of course, if that process did not occur at the same place, we must use more than one same (i.e. having same properties) specific clock. We must use two clocks, but then clocks must be synchronized (by some defined procedure e.g. using light signals). I just want to add that what I said does not mean that every laboratory should have same specific clocks. We just defined time that way. Once we have done it, we then use some other clock and compare it with our specific clock. If their ticking match we can also use other clock for measuring time and so on.
Length is defined similarly. We take some stick which we call one meter. That stick cannot have properties of being constant length (i.e. rigid) because we want to define length using that stick (we do not want circular definitions), so we want that our stick have some specific properties independent of length (we want it to be at the same pressure, temperature etc.). Then length of some object is how much our specific sticks we have between ending points of that object (we must know how we attach our sticks to each other i.e. what is straight line and we also must know simultaneously where ending points are, but I do not want to talk further about spacetime). Suppose we have N sticks we say length is N meter long. Once we defined procedure we can use some other sticks or methods for measuring length as long as they give same results as our specific stick (which we can check by comparison).
LAWS OF PHYSICS are mathematical relations between physical quantities and we discover them by method of observations (empirically). Law is correct if our experiment says so. If I cannot experimentally (I neglect here technology problems) check some mathematical statement, then that statement is nothing more than mathematical expression, it is not a physical law.
So, mass, as physical quantity, is defined through measurement. We have some specific weighing scale and some specific object which we call one kilogram. We put other object we want to measure on the one plate of scale and counting how much our specific objects we must put on the other plate so out weighing scale is balanced. We counted N, so our object has mass of N kilograms. We can check that mass is additive quantity i.e. if we put two same objects we see that mass is 2N kilograms etc. We can measure mass by using different apparatus as long as they give same result as our first device (which we used for definition of mass).
Same story is applied when we want to measure force. We define one Newton, procedure of measuring etc. We check that force is vector, find some other ways to measure force (they only need to match our first way).
Momentum is defined as product of mass and velocity and measured indirectly.
Now we know how mass and force are measured we can further explore properties of them i.e. we can now look for some law (mathematical relations) connecting quantities of mass and force. And we found through observations that F=ma and now we can interpret mass as measure of inertia of body and force as how much we would push or pull some body, but that is not definition of mass and force. If we defined force as F=ma, then this relation is not a physical law and we do not know nothing yet about force expect that it is calculated as product of mass and acceleration. Of course, we defined mass and force so they would be related somehow because we experience this Newton law on daily basis and we have already knew some properties which we want force and mass to have.
"The development of physics is progressive, and as the theories of external world become crystallised, we often tend to replace the elementary physical quantities defined through operations of measurement by theoretical quantities believed to have a more fundamental şignificance in the external world. Thus the vis viva mvv, which is immediately determinable by experiment, becomes replaced by a generalised energy, virtually defined by having a property of conservation; and our problem becomes inverted - we have not to discover the properties of thing which we have recognized in nature, but to discover how to recognize in nature a thing whose properties we have assigned." - Arthur Stanley Eddington - Mathematical theory of relativity
Conservation of momentum then becomes experimentally provable. If we defined mass through conservation of momentum (by measuring ratio of accelerations of two isolated body and calling one body 1kg), then we cannot to check if conservation of momentum is true, bacause it would not be a law, but a definition of mass.
NEWTON LAWS ARE LAWS!
The first Newton law is most complicated, because it is hard to know if our system really is inertial or not (general theory of relativity beautifully explains this problem). But we can, as Newton originally did, says that distant stars are inertial system and every system in uniform motion relative to them is also inertial and second and third laws are correct in them.
Answer of "joshphysics" is logically precise, but physically wrong.
Mihailo_SerbiaMihailo_Serbia
$\begingroup$ In my opinion, this answer is very close. I completely agree with the first part on measurement. Just needs more illustration on how we just knew that $F=ma$. $\endgroup$ – Khalid T. Salem Jun 22 '17 at 16:27
$\begingroup$ Important question is if there is something you do not agree with (Do you think I wrote something incorrect?). I did not say we JUST knew that F=ma, we discovered it experimentally, but you are maybe right that I should have written more about that. $\endgroup$ – Mihailo_Serbia Jul 2 '17 at 14:27
$\begingroup$ No I don't think there's something wrong with your answer, I liked it. $\endgroup$ – Khalid T. Salem Jul 2 '17 at 15:10
Newton's Law are in addition to laws of force and mass.
Newton's law of mass, changes in mass are caused in proportion to changes in density and changes in amount of matter (this might be paraphrased too badly).
Force Laws (there are many, ones for gravity, ones for springs, etc.)
Newton's third law of motion constrains what force laws you consider (effectively you only use/consider force laws that conserve momentum).
Newton's second law of motion turns these force laws into predictions about motion, thus allowing the force laws to be tested, not just eliminated for violating conservation of momentum. This works because he postulates that we can test force laws by using calculus and then looking at the prediction from solutions to second order differential equations.
Newton's first law of motion then excludes certain solutions that the second law allowed. I'm not saying that historically Newton knew this, but it is possible (see Nonuniqueness in the solutions of Newton's equation of motion by Abhishek Dhar Am. J. Phys. 61, 58 (1993); http://dx.doi.org/10.1119/1.17411 ) to have solutions to F=ma that violate Newton's first law. So adding the first law says to throw out those solutions.
In summary: the third law constrains the forces to consider, the second makes predictions so you can test the force laws, and the first constrains the (too many?) solutions that the second law allows. They all have a purpose, they all do something.
And you need to first have laws of mass and/or laws of forces before any of Newton's laws of motion mean anything.
TimaeusTimaeus
protected by Qmechanic♦ Jul 7 '13 at 17:30
Not the answer you're looking for? Browse other questions tagged newtonian-mechanics forces mass definition or ask your own question.
Is Newton's second law tautologous?
Is there a definition of force?
Definition of Newton's first law
What really is force?
Isn't Newton's Second "Law" merely a definition of force?
Is force really defined by the second axiom of Newtonian mechanics?
Is Force a fundamental concept just like position and time?
Is Newton's 2nd Law a definition?
Why does Newton's Third Law actually work?
Can Newton's laws of motion be proved (mathematically or analytically) or are they just axioms?
Can one of Newton's Laws of motion be derived from other Newton's Laws of motion?
Physics textbooks that distinguish between laws and definitions?
Mach's principle in empty universe, centripetal force and violation of Newton's laws of motion
Validity of point mass approximation in Newton's laws of motion
Are Newton's 1st and 3rd laws just consequences of the 2nd?
Operational definitions in Newtonian Physics
Just clearing doubts about the obviousness of newton's laws
Are the so called force balance drawings for motion systems "counterintuitive"?
Determining mass and force separately
Are there 2 laws of motion or only 1? | CommonCrawl |
Article | January 2021
Asymmetries in visual acuity around the visual field
Antoine Barbot; Shutian Xue; Marisa Carrasco
Antoine Barbot
Department of Psychology, New York University, New York, NY, USA
Center for Neural Science, New York University, New York, NY, USA
Spinoza Centre for Neuroimaging, Amsterdam, Netherlands
[email protected]
Shutian Xue
[email protected]
Marisa Carrasco
[email protected]
* AB and SX contributed equally to this work.
Journal of Vision January 2021, Vol.21, 2. doi:https://doi.org/10.1167/jov.21.1.2
Antoine Barbot, Shutian Xue, Marisa Carrasco; Asymmetries in visual acuity around the visual field. Journal of Vision 2021;21(1):2. doi: https://doi.org/10.1167/jov.21.1.2.
Human vision is heterogeneous around the visual field. At a fixed eccentricity, performance is better along the horizontal than the vertical meridian and along the lower than the upper vertical meridian. These asymmetric patterns, termed performance fields, have been found in numerous visual tasks, including those mediated by contrast sensitivity and spatial resolution. However, it is unknown whether spatial resolution asymmetries are confined to the cardinal meridians or whether and how far they extend into the upper and lower hemifields. Here, we measured visual acuity at isoeccentric peripheral locations (10 deg eccentricity), every 15° of polar angle. On each trial, observers judged the orientation (± 45°) of one of four equidistant, suprathreshold grating stimuli varying in spatial frequency (SF). On each block, we measured performance as a function of stimulus SF at 4 of 24 isoeccentric locations. We estimated the 75%-correct SF threshold, SF cutoff point (i.e., chance-level), and slope of the psychometric function for each location. We found higher SF estimates (i.e., better acuity) for the horizontal than the vertical meridian and for the lower than the upper vertical meridian. These asymmetries were most pronounced at the cardinal meridians and decreased gradually as the angular distance from the vertical meridian increased. This gradual change in acuity with polar angle reflected a shift of the psychometric function without changes in slope. The same pattern was found under binocular and monocular viewing conditions. These findings advance our understanding of visual processing around the visual field and help constrain models of visual perception.
Visual perception is not uniform across the visual field. Visual performance not only decreases as eccentricity increases (Cannon, 1985; Carrasco, Evert, Chang, & Katz, 1995; Rijsdijk, Kroon, & van der Wildt, 1980; Thibos, Cheney, & Walsh, 1987), but also varies across isoeccentric locations as a function of polar angle, a pattern referred to as visual performance fields (Altpeter, Mackeben, & Trauzettel-Klosinski, 2000; Cameron, Tai, & Carrasco, 2002; Carrasco, Talgar, & Cameron, 2001; Mackeben, 1999). Specifically, visual performance is better along the horizontal meridian (HM) than the vertical meridian (VM)—the horizontal-vertical anisotropy (HVA)—and better along the lower than the upper VM—the vertical-meridian asymmetry (VMA). Figure 1 illustrates the classic pattern of visual performance as a function of polar angle found in previous studies. Each dot represents performance at an isoeccentric location, with better performance indicated by points farther away from the center of the polar plot. The term performance fields was first introduced to describe performance asymmetries around the visual field (Altpeter et al., 2000; Mackeben, 1999), which were interpreted as differences in attentional performance. However, studies in which spatial attention has been manipulated, rather than inferred, have shown that attention modulates performance similarly across isoeccentric locations, without affecting the shape of performance fields (e.g., Carrasco et al., 2001, 2002; Purokayastha, Roberts, & Carrasco, 2020; Roberts, Ashinoff, Castellanos, & Carrasco, 2018; Roberts, Cymerman, Smith, Kiorpes, & Carrasco, 2016).
View OriginalDownload Slide
Graphic illustration of a canonical visual performance field (based on data from Carrasco et al., 2001). Each dot represents performance as a function of polar angle at a fixed eccentricity. The center of the polar plot corresponds to chance level, with highest performance typically observed along the horizontal meridian (HM; green), without differences between left and right hemifields. The horizontal-vertical anisotropy (HVA) depicts better performance in many tasks along the HM than the vertical meridian (VM). Moreover, performance is better at the lower VM (LVM; blue) than at the upper VM (UVM; purple), which is referred to as the vertical meridian asymmetry (VMA). Performance along the intercardinal (± 45°) meridians (gray) is usually similar, raising questions about the degree of visual performance fields as a function of polar angle.
Performance fields are ubiquitous in visual perception, having been observed in numerous tasks, including those mediated by contrast sensitivity (e.g., Abrams, Nizam, & Carrasco, 2012; Baldwin, Meese, & Baker, 2012; Cameron et al., 2002; Carrasco et al., 2001; Corbett & Carrasco, 2011; Fuller, Rodriguez, & Carrasco, 2008; Himmelberg, Winawer, & Carrasco, 2020; Pointer & Hess, 1989; Rosen, Lundstrom, Venkataraman, Winter, & Unsbo, 2014; Rovamo & Virsu, 1979), spatial resolution (Altpeter et al., 2000; Carrasco et al., 2002; De Lestrange-Anginieur & Kee, 2020; Greenwood, Szinte, Sayim, & Cavanagh, 2017; Montaser-Kouhsari & Carrasco, 2009; Nazir, 1992; Talgar & Carrasco, 2002), color hue (Levine & McAnany, 2005), motion (Fuller & Carrasco, 2009; Lakha & Humphreys, 2005; Levine & McAnany, 2005), spatial crowding (Greenwood, Szinte, Sayim, & Cavanagh, 2017; Petrov & Meleshkevich, 2011; Wallis & Bex, 2012), saccadic precision and spatial localization (Greenwood et al., 2017), saccade latency (Petrova & Wentura, 2012; Greene, Brown, & Dauphin 2014; Greenwood et al., 2017), peak saccade velocity (Greenwood et al., 2017), and speed of information accrual (Carrasco, Giordano, & McElree, 2004). Performance asymmetries are retinotopic, shifting in line with the retinal location of the stimulus rather than its location in space (Corbett & Carrasco, 2011), and pervasive, emerging regardless of stimulus orientation or display luminance (Carrasco et al., 2001). Furthermore, performance fields become more pronounced as eccentricity (Baldwin et al., 2012; Carrasco et al., 2001; Himmelberg et al., 2020; Rijsdijk et al., 1980), spatial frequency (Cameron et al., 2002; Carrasco et al., 2001; Himmelberg et al., 2020; Liu, Heeger, & Carrasco, 2006; Rijsdijk et al., 1980), and set size (Carrasco et al., 2001; Lakha & Humphreys, 2005; von Grunau & Dube, 1994) increase. Note that although performance fields usually become more pronounced as set size increases, visual asymmetries are present when target stimuli are presented alone (e.g., Baldwin et al., 2012; Cameron et al., 2002; Carrasco et al., 2001; Carrasco, Williams, & Yeshurun, 2002; Fuller & Carrasco, 2009; Rijsdijk et al., 1980). Performance asymmetries in perceived spatial frequency (SF) are also maintained in visual working memory (Montaser-Kouhsari & Carrasco, 2009).
Given the well-established asymmetries at the four cardinal locations, it is important to characterize whether and how the HVA and VMA extend away from the cardinal locations by measuring visual processing as a function of polar angle. The question is whether visual asymmetries are restricted to the cardinal meridians or whether (and how far) they extend into the upper and lower hemifields. In this context, the HVA corresponds to the HM-VM asymmetry observed at 0° angular distance from the VM. The angular extent of the HVA corresponds to the difference in performance between the HM and isoeccentric stimuli placed away from the VM, as a function of the angular distance from the VM (from 0° to 90° polar angle). Similarly, the VMA corresponds to the upper VM (UVM)–lower VM (LVM) asymmetry observed at 0° angular distance from the VM, and the angular extent of the VMA refers to the asymmetry between upper and lower isoeccentric locations measured as a function of the angular distance from the VM.
A previous study from our lab (Abrams et al., 2012) characterized the angular extent of these visual asymmetries for contrast sensitivity—a fundamental visual dimension—and showed that they are most pronounced at the VM and decrease gradually as the angular distance from the VM increases. This finding is consistent with previous findings showing similar performance at intercardinal (± 45° polar angle) locations (e.g., Altpeter et al., 2000; Baldwin et al., 2012; Cameron et al., 2002; Carrasco et al., 2001; Corbett & Carrasco, 2011; Fuller et al., 2008; Liu et al., 2006; Mackeben, 1999; Nazir, 1992; Talgar & Carrasco, 2002). The gray points representing equal performance at 45° polar angle in Figure 1 illustrate this finding. Given that the magnitude of performance fields becomes more pronounced for higher SFs and for further eccentricities (e.g., Baldwin et al., 2012; Cameron et al., 2002; Carrasco et al., 2001; Himmelberg et al., 2020; Liu et al., 2006), our primary goal here was to investigate whether and how far these visual asymmetries change away from the VM in terms of visual acuity.
Spatial resolution—our ability to discriminate fine patterns—is a fundamental dimension of visual perception. In the present study, we assessed performance fields in spatial resolution by measuring visual acuity as a function of polar angle. We hypothesized that the angular extent of asymmetries in visual acuity will be similar to that of contrast sensitivity—that is, most pronounced at the VM and decaying gradually as the angular distance from the VM toward the HM increases. Participants were asked to discriminate the orientation of high-contrast grating stimuli varying in SF, presented at 1 of 24 isoeccentric locations (at steps of 15° polar angle) at 10 deg eccentricity. We characterized performance fields in grating acuity in terms of 75%-correct SF thresholds (i.e., the SF at which observers can reliably discriminate stimulus orientation). In addition, we estimated SF cutoffs (i.e., the SF at which observers' performance drops to chance level) as a secondary measure (Figure 2a). Finally, by estimating the full SF psychometric function, we were also able to assess whether performance fields are characterized by a shift of the psychometric function without a change in its slope (Figure 2b) or whether performance fields also reflect changes in the slope of the psychometric function (Figures 2c,d). Differences in slope would differently affect SF threshold and SF cutoff estimates and indicate differences in the reliability of sensory SF estimates across isoeccentric locations.
Spatial frequency (SF) processing. (a) Performance in SF discrimination decreases as stimulus SF increases. For each polar angle location, we estimated the 75%-correct SF threshold (blue dot) and SF cutoff (red dot) corresponding to the SF at which participants were near chance level (i.e., 51% correct). We also estimated the slope (β) of the psychometric function, which was converted into the maximum slope estimate (β´) (see Methods). (b) Differences in SF processing between two locations (e.g., UVM and LVM) could reflect a shift of the psychometric function without a change in slope. Such change would result in a similar difference in SF threshold and SF cutoff. (c, d) Asymmetries in SF processing could also be characterized by a change in the slope of the psychometric function. Relative to a similar change in SF threshold in both panels, a (c) shallower or (d) steeper slope would result in the change in SF cutoff to be less or more pronounced, respectively.
Another goal of the present study was to assess whether variations in horizontal disparity—the difference in the azimuth between the images formed by the two eyes—across the visual field could be a potential source of visual performance fields. This hypothesis is based on two main findings: (1) Horizontal disparity is absent from the HM but varies along the VM: Stimuli presented above the fixation point have uncrossed disparity and are perceived as further away from fixation, whereas stimuli below fixation have crossed disparity and appear to be closer to fixation. This pattern has been shown both behaviorally in humans (Helmholtz, 1925; Hibbard & Bouzit, 2005; Sprague, Cooper, Reissier, Yellapragada, & Banks, 2016; Sprague, Cooper, Tosic, & Banks, 2015) and neurophysiologically in monkeys (Sprague et al., 2015). (2) Blur caused by disparity covers more area as stimulus eccentricity increases (Sprague et al., 2016). Given that these two factors increase with eccentricity, horizontal disparity could be a contributing source to the HVA and VMA and affect their magnitude. To investigate this possibility, we tested whether the HVA and VMA differ between binocular and monocular viewing conditions, as disparity is nonexistent for the latter.
Fourteen observers (10 females; age: 25.5 ± 5.5 years, age range: 23–35 years) with normal or corrected-to-normal vision participated in the binocular condition. All but one (author AB) were naive with respect to the purpose of this study. Eight were experienced psychophysical observers and the other six were not. Seven of them (6 females; age: 25.1 ± 4.1 years, age range: 23–35 years) also participated in the monocular experiment, in which only their dominant eye was tested (5/7 observers were right-eye dominant). Observers were paid $10/hour. The Institutional Review Board at New York University approved the experimental procedures, and all observers gave informed consent.
All stimuli were generated and presented using MATLAB (MathWorks, Natick, MA, USA) and the Psychophysics Toolbox (Kleiner, Brainard, & Pelli, 2007) on a CRT monitor (1,600 × 1,200 screen resolution; 60 Hz; 53 cd/m2 background luminance). Observers viewed the display at a distance of 57 cm with their head stabilized by a chinrest. An eye-tracker system (EyeLink 1000, SR Research, Ottawa, ON, Canada) was located in front of the observer to track eye position.
As illustrated in Figure 3a, the visual display consisted of four components: a black fixation cross (0.2 × 0.2 deg) presented at the center of the screen, four placeholders, four stimuli, and a response cue. The fixation cross and the four placeholders were always present across all frames of each trial to eliminate spatial uncertainty. The placeholders were centered at the four isoeccentric, equidistant stimulus locations (10 deg eccentricity), each separated by 90° polar angle. Each placeholder was composed of four corners (0.25 deg line length) delimiting a virtual square (3.5 × 3.5 deg). In a given block, the axes of the four placeholders were rotated clockwise from the vertical meridian by 0°, 15°, 30°, 45°, 60°, 75°, or 90° polar angle. This design enabled measuring orientation discrimination performance as a function of SF at 24 evenly spaced isoeccentric locations in the periphery, with only four locations tested simultaneously in a given block. Stimuli were suprathreshold (100% contrast) grating patches delimited by a raised-cosine envelope (2.5 deg diameter) and oriented ± 45° from vertical. Note that stimuli presented at adjacent isoeccentric locations, which were tested on different blocks, would have not overlapped with each other as the distance between the centers of two adjacent locations was 2.6 deg and the radius of each stimulus was 1.25 deg. In a given trial, the four stimuli had the same SF, which varied from trial to trial from 3 to 12 cpd, in 0.25-cpd steps. The response cue consisted of a white line presented next to one arm of the fixation cross to indicate which one of the four possible stimulus locations was the target location. The stimuli and the response cue were presented simultaneously to eliminate spatial uncertainty about the target location (e.g., Ling & Carrasco, 2006; Ling, Liu, & Carrasco, 2009; Lu & Dosher, 2000).
(a) Trial sequence. Observers were asked to maintain fixation at the center of the screen, which was ensured using online eye-tracking. In a given session, grating stimuli were presented at four isoeccentric (10 deg eccentricity) locations. Observers were asked to report the orientation of the target stimulus at the location indicated by the response cue. Spatial frequency (SF) varied across trials. A total of 24 isoeccentric locations were tested across separate blocks by rotating the angular position of the 4 stimulus locations by 15°. The size of the placeholders, fixation point, and response cue have been enlarged for illustration purposes. (b) Example observer. Psychometric functions for one observer at the four cardinal locations (LHM/RHM = left/right horizontal meridian; UVM/LVM = upper/lower vertical meridian). Vertical dashed lines indicate the 75%-correct SF thresholds, and the dotted lines indicate SF cutoff estimates. The SF range used for each observer and location was adjusted between sessions to capture the dynamic range of the psychometric function. The size of each data point varies with the number of trials collected at each SF level.
Figure 3a depicts the trial sequence. Each trial started with a 300-ms fixation period followed by the 50-ms presentation of four grating stimuli. Along with stimulus presentation, a response cue pointing to the target location was presented at fixation until a response was made. Observers were asked to report the orientation (± 45° counterclockwise or clockwise off vertical) of the stimulus presented at the target location by pressing either the left (counterclockwise) or down (clockwise) arrow keys. Auditory feedback was provided after each response, with either a high-pitched or low-pitched beep denoting a correct or incorrect response, respectively. The start of each trial was contingent on stable fixation (1.5 deg radius around the central fixation), which was ensured during the full trial sequence using online eye-tracking. Each block consisted of 300 trials, corresponding to 5 trials for each of 15 different SF values for each of the four tested locations within a block. The range of SF values always contained 2 and 12 cpd, to ensure a good estimation of the lower and upper asymptotes, in addition to 13 SF values centered on a given SF, with equal steps of 0.25 cpd. Based on pilot data, all observers were initially tested using a range of SF values centered at 7 cpd. The central SF value for each location was then adjusted in subsequent blocks, if needed, to ensure that the SF range was centered on the dynamic range for each observer and for each location.
Each observer completed five or six 1-hr sessions for a total of 9,107 ± 1,174 trials on average, consisting of 621 ± 85 trials on average at each of the four cardinal locations (two VM locations and two HM locations), and of 331 ± 48 trials on average at each of the 20 noncardinal locations. The four cardinal locations were tested twice more to increase power at these critical locations and to equate the number with the other locations, once we combined data at mirror locations on the left and right hemifields. Indeed, consistent with other studies (e.g., Abrams et al., 2012; Baldwin et al., 2012; Carrasco et al., 2001; Greene, Brown, & Dauphin, 2014; Petrov & Meleshkevich, 2011; Purokayastha et al., 2020), we did not find differences between the left and right hemifields. The same procedure was used in the monocular viewing condition (7,500 ± 917 trials collected, on average), except that the observer's nondominant eye was covered.
Psychometric functions were fit to the data using the Palamedes Toolbox (Prins & Kingdom, 2018). For each location, a cumulative normal distribution function was fit to the data using maximum likelihood estimation, with the function given as
\begin{eqnarray}\begin{array}{l}\!\!\!\!\!\!\!\!\!\!\!\!\! f\left( {SF} \right) = \displaystyle{\rm{\gamma }} + \left( {1 - {\rm{\gamma }} - {\rm{\lambda }}} \right){\rm{*\;}}\frac{{\rm{\beta }}}{{\sqrt {2{\rm{\pi }}} }}{\rm{*}}\mathop \int \nolimits_{ - \infty }^{SF} exp\left( { - \frac{{{{\rm{\beta }}^2}{{\left( {SF - {\rm{\alpha }}} \right)}^2}}}{2}} \right),{\rm{\;}}\end{array}\end{eqnarray}
in which f(SF) is the performance as a function of stimulus SF (in log cpd), α is the location parameter, β is the slope, and γ and λ are the lower and upper asymptotes, respectively. The lower asymptote γ was fixed to chance level (50% correct). The SF range was flipped in log-space when fitting the data to reflect the increasing psychometric function. For each location, we estimated the SF threshold (i.e., 75% correct), as well as the SF cutoff (i.e., 51% accuracy), and the slope of the psychometric function. As the slope value (β) depends on the psychometric function used to fit the data, the slope estimate (β) was converted into the maximum slope (β′) using the following equation (i.e., Equation 18 from Strasburger, 2001a):
\begin{equation}{\rm{\beta ^{\prime}}} = \left( {\frac{{1 - {\rm{\gamma }}}}{{\sqrt {2{\rm{\pi }}} }}} \right){\rm{*\;\beta }} \end{equation}
Figure 3b shows the psychometric functions at the cardinal locations for an example observer. After collecting data at 24 locations for all observers, we tested the left-right difference in performance and found it to be nonsignificant. Thus, we also collapsed the data in the right hemifield to the horizontally corresponding position in the left hemifield to increase the number of trials at each location and refit the new data using the method described above. Log-value estimates were used for statistical analysis. To assess the HVA and VMA, repeated-measures analyses of variance (ANOVAs) were used to assess differences in SF estimates at the four cardinal locations (left HM, right HM, upper VM, and lower VM), as well as differences between viewing conditions (monocular vs. binocular). In all cases in which Mauchly's test of sphericity indicated a violation of the sphericity assumption, Greenhouse-Geisser–corrected values were used. Partial eta-square (η2p) and Cohen's d are reported as an estimate of effect size for the ANOVAs and paired t-tests, respectively. To characterize asymmetries in acuity as a function of polar angle, we used linear mixed-effects models to predict SF estimates based on the angular distance from the VM (0°, 15°, 30°, 45°, 60°, 75°, and 90°), visual field (upper vs. lower), and viewing condition (monocular vs. binocular), whereas differences between participants were considered a random effect. Scatterplots of individual estimates, along with multiple linear regression equations and adjusted R2, are reported for the linear mixed-effects models. SF estimates are also reported in physical units (e.g., SF threshold in cpd). Note that there was no effect of participant's biological sex, with neither significant main effects nor interactions (all p values > 0.1) for any of the analyses reported below.
Visual asymmetries across cardinal locations: HVA and VMA
Figure 4 shows the performance at the four cardinal locations (left and right HM, upper and lower VM) averaged across observers, demonstrating a clear HVA and VMA in both SF threshold (Figure 4a) and SF cutoff (Figure 4b). One-way repeated-measures ANOVAs revealed significant differences between cardinal locations for both SF thresholds (F(3, 39) = 79.25, p < 0.001, η2p = .86) and SF cutoffs (F(3, 39) = 59.35, p < 0.001, η2p = .82). No difference in the slope estimates of the psychometric functions was observed (Figure 4c; F(3, 39) < 1). These results indicate that both the HVA and VMA reflect shifts of the psychometric functions without change in shape (Figure 2b). As expected, there was no difference between the left and right HM for both SF thresholds (LHM: 7.82 ± 1.23 cpd; RHM: 7.82 ± .99 cpd) and SF cutoffs (LHM: 10.06 ± 1.46 cpd; RHM: 10.09 ± 1.77 cpd). The HVA reflected higher acuity along the horizontal meridian (LHM and RHM) than along the vertical meridian (UVM and LVM) for both SF thresholds (HM: 7.82 ± 1.06 cpd; VM: 5.73 ± 0.75 cpd; t(13) = 13.73, p < 0.001, Cohen's d = 3.67) and SF cutoffs (HM: 10.07 ± 1.52 cpd; VM: 7.33 ± 1.06 cpd; t(13) = 11.53, p < 0.001, Cohen's d = 3.08). Moreover, characteristic of the VMA, performance at the LVM was significantly better than at the UVM, for both SF threshold (LVM: 6.22 ± 0.84 cpd; UVM: 5.28 ± 0.79 cpd; t(13) = 5.14, p < 0.001, Cohen's d = 1.37) and SF cutoffs (LVM: 7.93 ± 1.21 cpd; UVM: 6.77 ± 1.14 cpd; t(13) = 4.11, p < 0.001, Cohen's d = 1.10).
Horizontal vertical anisotropy (HVA) and vertical meridian asymmetry (VMA). Averaged binocular (a) SF threshold, (b) SF cutoff, and (c) slope estimates at each of the four cardinal locations (LHM = left horizontal meridian; RHM = right horizontal meridian; UVM = upper vertical meridian; LVM = lower vertical meridian). There was no difference between the LHM and RHM. The HVA corresponds to the difference between the HM (LHM and RHM combined) and VM (LVM and UVM combined). The VMA corresponds to the difference between the LVM and UVM. Error bars in panels a to c correspond to ± 1 SEM for each of the cardinal data points. Horizontal lines reflect comparisons between the LHM and RHM, between the HM and VM (i.e., HVA), and between the UVM and LVM (i.e., VMA), with error bars representing ± 1 SE of the mean difference. *p < 0.05, **p < 0.01, ***p < 0.001. (d–f) Scatterplots of individual participants' HVA for (d) threshold, (e) cutoff, and (f) slope estimates. (g–i) Scatterplots of individual participants' VMA for (g) threshold, (h) cutoff, and (i) slope estimates. Dots above the diagonal line indicate participants showing typical HVA and VMA patterns, which are observed for SF threshold and SF cutoff estimates but not for slope.
To examine group variability, we plotted individual estimates of the HVA and VMA for SF threshold (Figures 4d,g), SF cutoff (Figures 4e,h), and slope (Figures 4f,i) estimates. Each dot represents an individual estimate, with the dashed diagonal line indicating equal performance. All observers showed a clear HVA (Figures 4d–f) and VMA (Figures 4g–i) for SF threshold and SF cutoff estimates, with all individual estimates (except one for the VMA) being above the diagonal line. Slope estimates were distributed around the diagonal line, indicating no consistent changes in slope for either the HVA or VMA. Moreover, whereas all participants showed both HVA and VMA, there was no significant correlation between these two types of visual asymmetries (Figure 5; SF threshold: r = .085, p = 0.77; SF cutoff: r = –.22, p = 0.45).
Lack of correlation between the HVA and VMA. HVA and VMA ratios estimated from (a) SF threshold estimates or (b) SF cutoff estimates. Each data point corresponds to an individual participant's HVA and VMA ratios, with the solid black lines corresponding to Pearson correlations.
No difference between left and right hemifields
There was no significant left-right difference at the HM. We assessed whether this was also the case when comparing all tested locations. A two-factor repeated-measures ANOVA (2 hemifields × 11 non-VM locations) showed no significant difference between the left and right hemifields for either SF threshold (Figure 6a; F(1, 13) = 2.55, p = 0.134, η2p = .16), SF cutoff (Figure 6b; F(1, 13) < 1), or slope (F(1, 13) < 1). We found a substantial effect of polar angle on SF threshold (F(3.8, 49.2) = 53.72, p < 0.001, η2p = .81) and SF cutoff (F(10, 130) = 15.70, p < 0.001, η2p = .55) estimates but only a marginal effect on slope (F(3.7, 48.1) = 2.39, p = 0.068, η2p = .16). Importantly, there was no interaction between polar angle location and left-right hemifields (all p values > 0.1). Given the absence of left-right hemifield difference as a function of polar angle, we reanalyzed each polar angle location after collapsing the data across hemifields for simplicity of analysis and clarity of illustration.
No left-right hemifield difference. Changes in (a) SF threshold and (b) SF cutoff as a function of polar angle for the left and right hemifields. Polar plots of hemifields (left panels) show group-averaged SF estimates as a function of polar angle for the left and right hemifield locations separately (the data points corresponding to the UVM and LVM are color-coded as in Figure 1). Right panels show the same data with error bars corresponding to ± 1 SEM. No difference was observed between the left and right visual field (VF) locations. The asymmetry with polar angle between lower (−90° to 0°) and upper (0° to +90°) VF locations is characteristic of the VMA (HM = horizontal meridian; UVM/LVM = upper and lower vertical meridians).
Gradual decrease in visual asymmetries with increasing angular distance from the vertical meridian
First, we assessed whether and how the HVA extends from the VM. Figure 7 shows SF threshold (Figure 7a) and SF cutoff (Figure 7b) estimates, averaged over upper and lower hemifields, plotted as a function of the angular distance from the VM (from 0° to ± 90°, in 15° steps). We used linear mixed-effects models to predict SF estimates based on the angular distance from the VM, with participants as a random effect. We found that both SF threshold and SF cutoff estimates increased as the angular distance from the VM increased. Participants' SF threshold (in log cpd) was equal to .7503 + .00155 * angular distance (intercept: t(96) = 48.53, p < 0.001, CI [.7196, .7809]; angular distance: t(96) = 13.09, p < 0.001, CI [.0013, .0018]). Similarly, participants' SF cutoff (in log cpd) was equal to .8696 + .00155 * angular distance (intercept: t(96) = 60.32, p < 0.001, CI [.8410, .8983]; angular distance: t(96) = 13.02, p < 0.001, CI [.0013, .0018]). No difference in the slope of the psychometric functions was observed as a function of angular distance (intercept: t(96) = 26.53, p < 0.001, CI [.5352, .6218]; angular distance: t(96) = .39, p = 0.700, CI [–.0007, .0011]). In other words, SF estimates at isoeccentric locations were predicted to linearly increase from the VM to the HM, from 5.73 to 7.82 cpd for SF threshold and from 7.33 to 10.07 cpd for SF cutoff. The similar slope of the linear regression equations for SF threshold and SF cutoff estimates is consistent with the lack of change in the psychometric function slope with polar angle. In sum, the asymmetry observed between the HM and VM (i.e., HVA) is not restricted to the VM but rather reflects a linear change in visual acuity between the HM and VM, without differences in the slope of the psychometric function.
Angular extent of asymmetries in visual acuity. Group-averaged (a, c) SF threshold and (b, d) SF cutoff estimates plotted as a function of the angular distance from the vertical meridian (VM). Dashed line represents the value at the horizontal meridian (HM; green filled dot). (a, b) Horizontal vertical anisotropy (HVA). SF estimates were averaged across upper and lower hemifields, with the difference from the HM at 0° angular distance from the VM corresponding to the HVA. (c, d) Vertical meridian asymmetry (VMA). SF estimates plotted separately for the upper VF (open circles) and lower VF (filled circles), with the upper-lower difference at 0° angular distance from the VM corresponding to the VMA. VMA ratios plotted at the bottom of panels c and d were computed by dividing the lower by the upper visual field estimates. Adjusted R2 values indicate the goodness of fit of linear regression equations. Error bars correspond to ± 1 SEM.
Next, we assessed whether and how the VMA extends from the VM for both SF threshold (Figure 7c) and SF cutoff (Figure 7d) estimates. Specifically, we measured how the gradual change in SF estimates with angular distance from the VM differed between lower and upper visual field locations. We used linear mixed-effects models to predict both SF threshold and SF cutoff estimates, including the angular distance from the VM and visual field (i.e., upper vs. lower VF) as predictors and participants as a random effect. As expected, SF threshold estimates linearly increased with the angular distance from the VM (intercept: t(192) = 48.53, p < 0.001, CI [.7198, .7808]; angular distance: t(192) = 13.09, p < 0.001, CI [.0013, .0018]). Consistent with the presence of a VMA, SF threshold estimates were higher in the lower VF than in the upper VF at the VM (visual field: t(192) = 7.95, p < 0.001, CI [.0315, .0523]), but increased at a faster rate in the upper VF than in the lower VF with increasing angular distance from the VM (angular distance * visual field interaction: t(192) = 5.87, p < 0.001, CI [.0003, .0005]). Participants' SF threshold (in log cpd) was equal to .7083 + .00194 * angular distance in the upper VF and to .7922 + .00115 * angular distance in the lower VF. A similar pattern was observed for SF cutoff estimates, with participants' SF cutoff (in log cpd) being equal to .8326 + .00197 * angular distance in the upper VF and to .9067 + .00114 * angular distance in the lower VF (intercept: t(192) = 60.13, p < 0.001, CI [.8411, .8982]; angular distance: t(192) = 12.76, p < 0.001, CI [.0013, .0018]; visual field: t(192) = 5.61, p < 0.001, CI [.0240, .0501]; angular distance * visual field interaction: t(192) = 4.05, p < 0.001, CI [.0002, .0006]). Neither angular distance nor visual field had an effect on the psychometric slope estimates (p > 0.1 and CI includes 0 for angular distance, visual field, and the interaction). These results indicate that SF estimates linearly increase between the VM and HM but do so at a faster rate in the upper VF, resulting in a gradual decrease in the upper-lower asymmetry. This pattern was observed in all participants, with higher individual linear slope estimates as a function of the angular distance from the VM in the upper VF than in the lower VF for both SF threshold (Figure 8a) and SF cutoff (Figure 8b) estimates.
Individual linear slope estimates from the linear mixed-effects models. Scatterplots of individual linear slope estimates with angular distance from the VM show a steeper linear slope in the upper than lower visual field (VF) in all participants (n = 14), for both (a) SF threshold and (b) SF cutoff estimates. Filled circles correspond to individual participants and the open square symbol to the mean ± 1 SEM.
Performance fields become more pronounced with increasing stimulus SF
Our results provide additional evidence of how performance fields vary with stimulus SF. Both the HVA and VMA can be described by a shift of the psychometric function without change in slope (Figure 9a). We found that performance fields become more pronounced as stimulus SF increases (Figure 9b). At low SFs, performance is high and varies slightly with polar angle. As stimulus SF increases, performance decreases but does so faster for stimuli presented closer to the VM than near the HM, resulting in the HVA. Performance also decreases faster for stimuli presented at the lower VM than at the upper VM, resulting in the VMA. We estimated HVA and VMA accuracy ratios as a function of stimulus SF (Figure 9c). The SF range used was chosen to match the dynamic range of the psychometric functions where performance ratios can be estimated (i.e., where performance is neither at ceiling nor at chance level and where enough participants were tested). Both the HVA and VMA ratios increased with stimulus SF (Figure 9c). This pattern was attenuated when the angular distance from the VM increased.
Impact of stimulus SF on performance fields. (a) Group-averaged orientation discrimination performance plotted as a function of the stimulus SF at the four cardinal locations (LHM/RHM = left/right horizontal meridian; UVM/LVM = upper/lower vertical meridian). Performance decreases similarly with increasing SF at the LHM and RHM locations, resulting in similar psychometric functions along the HM. Relative to the HM, performance at the VM is worse (i.e., HVA). Moreover, performance at the UVM location is poorer than at the LVM location (i.e., VMA). These asymmetries in SF processing reflected shifts of the psychometric functions without change in slope. Marker size indicates the number of participants averaged for each data point, which was restricted to a minimum of 4 out of the 14 participants. (b) Polar plot showing group-averaged performance as a function of the stimulus polar angle and SF, with the center of the polar plot corresponding to chance level (50% accuracy). Asymmetries at isoeccentric locations become more pronounced as stimulus SF increases. (c) Both the HVA and VMA performance ratios increase with stimulus SF. Each data point is the average performance ratio (± 1 SEM) computed at different stimulus SF within the dynamic range of the psychometric functions. Marker size indicates the number of participants averaged for each data point (varying from 4 to 14 participants).
Similar performance fields under monocular and binocular viewing conditions
Figures 10 to 12 show monocular and binocular SF estimates for the seven observers tested under both monocular and binocular viewing conditions. Monocular performance was measured only for the observers' dominant eyes (i.e., right eye for five observers and left eye for the other two). We did not observe differences in SF estimates between the nasal and temporal retinal hemifields, which usually emerge further in the periphery, beyond 10 deg eccentricity (Harvey & Pöppel, 1972; Pöppel & Harvey, 1973). Similar to the results described above, here we conducted a series of analyses to examine the effect of viewing condition on the (1) HVA, (2) VMA, (3) HVA angular extent, and (4) VMA angular extent:
HVA and VMA under binocular and monocular viewing conditions. Averaged (a) SF threshold, (b) SF cutoff, and (c) slope estimates at each of the four cardinal locations (LHM/RHM = left/right horizontal meridian; UVM/LVM = upper/lower vertical meridian). Leftward and rightward triangles correspond to the monocular and binocular viewing condition, respectively. Filled circles correspond to average estimates across viewing conditions. Error bars correspond to ± 1 SEM. Horizontal lines reflect comparisons between the LHM and RHM, between the HM and VM (i.e., HVA), and between the UVM and LVM (i.e., VMA) for the combined binocular-monocular average data points, with error bars representing ± 1 SE of the mean difference. *p < 0.05, **p < 0.01, ***p < 0.001. (d–f) Scatterplots of individual participants' HVA ratios (HM/VM) for (a) SF threshold, (b) SF cutoff, and (c) slope estimates. (g–i) Scatterplots of individual participants' VMA ratios (LVM/UVM) for (g) SF threshold, (h) SF cutoff, and (i) slope estimates.
(1) To test the possible difference between monocular and binocular viewing conditions with respect to the HVA, we conducted a two-way repeated-measures ANOVA (HM vs. VM × 2 viewing conditions) on all three estimates. Figures 10a–c shows SF estimates at the cardinal locations averaged across observers for the monocular and binocular viewing conditions. As in Figure 4, we found a main effect of meridian, indicating a clear HVA for SF threshold (Figure 10a; F(1, 6) = 66.33, p < 0.001, η2p = .92) and SF cutoff (Figure 10b; F(1, 6) = 61.54, p < 0.001, η2p = .91) but not for slope (Figure 10c; F(1, 6) < 1). Performance at the HM (LHM and RHM combined) was significantly better than at the VM (UVM and LVM combined) for both SF threshold (HM: 7.33 ± 0.96 cpd; VM: 5.43 ± 0.83 cpd) and SF cutoff (HM: 9.33 ± 0.97 cpd; VM: 6.83 ± 0.81 cpd). Viewing condition had a marginal effect on SF threshold (F(1, 6) = 4.44, p = 0.080, η2p = .43), with higher SF threshold estimates at cardinal locations when tested under binocular (6.51 ± .83 cpd) than under monocular (6.11 ± .92 cpd) viewing condition. We found no significant difference at the cardinal locations between the binocular and monocular viewing conditions in SF cutoff (F(1, 6) = 3.14, p = 0.127, η2p = .34) or in slope (F(1, 6) < 1). Importantly, viewing condition did not interact with the effect of location (F(1, 6) < 1 for SF threshold, cutoff, and slope), indicating a similar HVA under monocular and binocular viewing conditions.
(2) To test the possible difference between monocular and binocular viewing conditions with respect to the VMA, we conducted a two-way repeated-measures ANOVA (UVM vs. LVM × 2 viewing conditions). As expected, there was a significant VMA for SF thresholds, with significantly higher SF thresholds at the LVM (5.82 ± 0.90 cpd) than at the UVM (5.07 ± 0.85 cpd) (Figure 10a; F(1, 6) = 9.23, p = 0.023, η2p = .61). No significant effect was found for SF cutoff estimates (Figure 10b; F(1, 6) = 3.29, p = 0.120, η2p = .35) or slope (Figure 10c; F(1, 6) < 1). When the stimuli were presented on the VM, there was a binocular advantage for SF thresholds (F(1, 6) = 9.56, p = 0.021, η2p = .61; binocular: 5.61 ± 0.84 cpd; monocular: 5.25 ± 0.84 cpd), but not for SF cutoff (F(1, 6) = 2.28, p = 0.182, η2p = .28) or slope (F(1, 6) < 1). Importantly, viewing condition did not interact with the effect of location (F(1, 6) < 1 for SF threshold, cutoff, and slope), indicating a similar VMA under monocular and binocular viewing conditions.
Figure 10 shows individual HVA ratios (Figures 10d–f; HM divided by VM) and VMA ratios (Figures 10g–i; LVM divided by UVM) as a function of viewing condition. Consistent with Figure 4, all seven observers showed a clear HVA and VMA for SF threshold and SF cutoff estimates (i.e., ratios are higher than 1), with no clear difference in slope (ratios distributed around 1). Importantly, HVA and VMA ratios were distributed along the diagonal line, indicating similar asymmetries under monocular and binocular viewing conditions.
(3) To examine a possible difference between monocular and binocular viewing conditions with respect to the angular extent of the HVA, we used linear mixed-effects models, with angular distance and viewing condition as predictors and participants as a random effect. Figure 11 shows SF threshold (Figure 11a) and SF cutoff (Figure 11b) averaged across lower and upper hemifields as a function of the angular distance from the VM. As in Figures 7a,b, both SF threshold and SF cutoff estimates increased linearly with angular distance (SF threshold—intercept: t(94) = 25.61, p < 0.001, CI [.6684, .7807]; angular distance: t(94) = 7.78, p < 0.001, CI [.0011, .0019]; SF cutoff—intercept: t(94) = 41.37, p < 0.001, CI [.7965, .8768]; angular distance: t(94) = 15.44, p < 0.001, CI [.0015, .0019]). Moreover, viewing condition had a significant effect on both SF estimates (SF threshold: t(94) = 3.01, p = 0.003, CI [.0055, .0266]; SF cutoff: t(94) = 3.06, p = 0.003, CI [.0063, .0295]), which were overall higher in the binocular (SF threshold: 6.35 ± 0.92 cpd; SF cutoff: 8.23 ± 1.06 cpd) than monocular viewing condition (SF threshold: 5.90 ± 1.05 cpd; SF cutoff: 7.89 ± 0.97 cpd). Importantly, viewing condition did not interact with the effect of angular distance for either SF estimates (all p values > 0.1 and CIs including 0). Participants' SF threshold (in log cpd) was equal to .7085 + .00151 * angular distance in the monocular viewing condition and to .7406 + .00150 * angular distance in the binocular viewing condition (Figure 11a). Participants' SF cutoff (in log cpd) was equal to .8188 + .00186 * angular distance in the monocular viewing condition and to .8545 + .00147 * angular distance in the binocular viewing condition (Figure 11b).
Angular extent of visual asymmetries under monocular and binocular viewing conditions. (a, b) SF threshold and (b, d) SF cutoff estimates plotted as a function of the angular distance from the vertical meridian (VM). (a, b) HVA extent. SF estimates were computed for monocular (leftward triangles; dashed lines) and binocular (rightward triangles; solid lines) viewing conditions by averaging values at upper and lower visual field locations. (c, d) VMA extent. SF estimates for monocular (leftward triangles; dashed lines) and binocular (rightward triangles; solid lines), plotted separately for upper (open triangles) and lower (filled triangles) visual field locations. VMA ratios at the bottom of panels c and d were computed by dividing the lower by the upper visual field estimates for monocular and binocular viewing conditions separately. Linear regression equations and adjusted R2 are provided for each linear fit. Error bars correspond to ± 1 SEM. Horizontal dashed lines represent values at the horizontal meridian.
(4) Finally, we assessed whether the angular extent of the VMA (i.e., upper vs. lower visual fields) differed under monocular and binocular viewing conditions. Linear mixed-effects models included angular distance, visual field (upper vs. lower), and viewing conditions (monocular vs. binocular) as predictors and participants as random effect. Figure 11 shows SF threshold (Figure 11c) and SF cutoff (Figure 11d) estimates plotted separately for upper and lower visual field locations as a function of the angular distance from the VM under either monocular or binocular viewing conditions. First, as expected, SF estimates linearly increased as the angular distance from the VM increased for both SF threshold (Figure 11c; intercept: t(188) = 25.61, p < 0.001, CI [.6688, .7804]; angular distance t(188) = 7.78, p < 0.001, CI [.0011, .0019]) and SF cutoff (Figure 11d; intercept: t(188) = 41.40, p < 0.001, CI [.7968, .8765]; angular distance: t(188) = 15.58, p < 0.001, CI [.0015, .0019]). As in Figures 7c,d, SF estimates were significantly higher in the lower than in the upper VF for both SF estimates (SF threshold: t(188) = 3.95, p < 0.001, CI [.0176, .0526]; SF cutoff: t(188) = 2.91, p = 0.004, CI [.0102, .0533]), with the effects of upper-lower VF interacting with angular distance (SF threshold: t(188) = 3.82, p < 0.001, CI [.0002, .0006]; SF cutoff: t(188) = 2.14, p = 0.034, CI [.00003, .0006]). All participants showed a steeper linear slope with angular distance in the upper VF than in the lower VF for both SF threshold (Figure 12a) and SF cutoff (Figure 12b) estimates. Finally, viewing condition was associated with a binocular advantage (SF threshold: t(188) = 3.14, p = 0.002, CI [.0060, .0261]; SF cutoff: t(188) = 2.95, p = 0.004, CI [.0059, .0298]) but did not interact with either visual field or angular distance (p values > 0.1 and CIs including 0). This binocular advantage in acuity was observed in all participants, for both SF threshold (Figure 12c) and SF cutoff (Figure 12d) estimates. Thus, although visual acuity was overall lower under monocular viewing condition, we observed a similar linear decrease in the upper-lower asymmetry (i.e., VMA) with angular distance under binocular and monocular viewing conditions (see Figures 11c,d for the corresponding linear equations).
Individual estimates from the linear mixed-effects models. (a, b) Scatterplots of individual linear slope estimates with angular distance from the VM show steeper linear slope in the upper than lower visual field (VF), for both (a) SF threshold and (b) SF cutoff estimates. (c, d) Scatterplots of individual intercept estimates show higher SF intercepts under binocular than monocular viewing condition, for both (c) SF threshold and (d) SF cutoff estimates. Filled symbols correspond to individual participants (n = 7) and the open square symbols to the mean ± 1 SEM.
Taken together, all of these analyses reveal that asymmetries in visual acuity across perifoveal locations (i.e., 10 deg eccentricity) are present regardless of whether participants are tested binocularly or monocularly.
In the present study, we investigated how visual acuity varies with polar angle. To do so, we measured orientation discrimination performance for ±45° oriented, suprathreshold gratings presented at isoeccentric (10 deg eccentricity) locations, every 15° of polar angle. The angular extent of visual asymmetries was characterized as variations in SF thresholds, SF cutoffs, and in the psychometric slope. In the following sections, we summarize and discuss the three main findings revealed by this study.
First, we found clear evidence of HVA and VMA in acuity, with better SF threshold and cutoff estimates at the HM than the VM—the HVA—as well as at the lower VM than the upper VM—the VMA: Observers were more sensitive to stimuli presented at the HM than at the VM and at the LVM than the UVM. These variations in sensory thresholds across cardinal locations are consistent with previous performance fields studies (e.g., Abrams et al., 2012; Altpeter et al., 2000; Baldwin et al., 2012; Cameron et al., 2002; Carrasco et al., 2001, 2002, 2004; Corbett & Carrasco, 2011; Fuller et al., 2008; Fuller & Carrasco, 2009; Greenwood et al., 2017; Himmelberg et al., 2020; Mackeben, 1999; Montaser-Kouhsari & Carrasco, 2009; Nazir, 1992; Petrov & Meleshkevich, 2011; Pointer & Hess, 1989; Rijsdijk et al., 1980; Traquair, 1938; Wallis & Bex, 2012). Moreover, we found that neither the HVA nor the VMA were associated with a consistent change in the slope of the psychometric function. The few studies on performance fields that have also assessed potential differences in psychometric slope across cardinal locations found inconsistent results: on the one hand, consistent with our findings, no difference in psychometric slopes between the upper and lower VM for perceived contrast (Fuller et al., 2008) and, on the other hand, steeper psychometric slopes for the VM than the HM and for the upper than the lower VM in contrast sensitivity (Cameron et al., 2002) but inversely steeper slopes for the HM than the VM and for the lower than the upper VM in illusory motion (Fuller & Carrasco, 2009).
Second, we showed that the angular extent of the HVA and of the VMA decreased gradually as stimuli were moved away from the VM. Thus, a consistent gradual change in visual processing as a function of polar angle not only exists for contrast sensitivity (Abrams et al., 2012; Baldwin et al., 2012) but also for spatial resolution–i.e., for two fundamental visual dimensions mediating performance in many perceptual tasks. This gradual change is consistent with behavioral findings showing similar performance levels at intercardinal (± 45° polar angle) locations (e.g., Abrams et al., 2012; Altpeter et al., 2000; Baldwin et al., 2012; Cameron et al., 2002; Carrasco et al., 2001; Corbett & Carrasco, 2011; Mackeben, 1999; Nazir, 1992; Talgar & Carrasco, 2002), as well as with functional MRI activity (Liu et al., 2006) and cortical magnification (Benson, Kupers, Barbot, Carrasco, & Winawer, 2020) in early visual cortex (i.e., V1/V2). Specifically, surface area in early visual cortex gradually decreases as a function of the angular distance from the HM, reflecting both the HVA and VMA. This gradual change in cortical magnification suggests a tight link between cortical topography and visual perception (Benson et al., 2020).
Third, we found similar performance fields regardless of whether observers were tested monocularly or binocularly. This result is consistent with reported (but unpublished) data from our lab showing no difference in performance fields for contrast sensitivity under binocular and monocular viewing conditions (Carrasco et al., 2001). Thus, we can rule out horizontal disparity as a potential source of performance heterogeneities across the visual field. We observed a binocular advantage consistent with studies reporting binocular enhancement for acuity tasks on the order of 5% to 10% for high-contrast acuity stimuli (e.g., Cagenello, Halpern, & Arditi, 1993; Campbell & Green, 1965; Home, 1978; Pardhan, 2003; Sabesan, Zheleznyak, & Yoon, 2012; Zlatkova, Anderson, & Ennis, 2001). For example, Campbell and Green (1965) reported a binocular advantage in visual acuity of ∼7% when comparing monocular (57 cpd) and binocular (61 cpd) acuity limit. Similarly, we observed a binocular advantage of ∼7% across isoeccentric locations when comparing SF threshold estimates under monocular (5.90 cpd) and binocular (6.35 cpd) viewing conditions. Note that binocular summation can vary substantially in magnitude depending on stimulus and task properties (Baker, Lygo, Meese, & Georgeson, 2018). For example, binocular summation in threshold contrast detection results in a larger binocular advantage than in acuity tasks, typically around √2 (∼40%) (e.g., Campbell & Green, 1965; Home, 1978; Sabesan et al., 2012). Moreover, the binocular advantage in acuity tasks is more pronounced in the periphery than the fovea (Zlatkova et al., 2001) and is reduced as stimulus contrast increases, which suggests that binocular enhancement in acuity can be largely explained by threshold contrast summation (Cagenello et al., 1993; Home, 1978). Importantly, whereas we observed the typical binocular advantage in visual acuity, viewing conditions did not influence the linear change in SF estimates and visual asymmetries with polar angle.
The present findings relate to evidence of performance inhomogeneities in spatial resolution tasks. For instance, the asymmetries in SF processing we observed could account for the finding that the magnitude of the HVA in a Landolt-square acuity task increases as gap size decreases (Carrasco et al., 2002), as it would rely on higher SFs. Similarly, both the HVA and VMA are observed in the detection of small acuity stimuli (De Lestrange-Anginieur & Kee, 2020) and Snellen E letters (Altpeter et al., 2000). The present results also relate to texture segmentation tasks, in which performance is constrained by the spatial resolution of the visual system and the scale of the texture target: Performance peaks at mid-eccentricity, where resolution is optimal for the scale of the texture target, and drops at more peripheral locations, where resolution is too low and at more foveal locations where resolution is too high, known as the central performance drop (CPD; Barbot & Carrasco, 2017; Carrasco, Loula, & Ho, 2006; Carrasco & Barbot, 2014; Gurnsey, Pearson, & Day, 1996; Jigo & Carrasco, 2018; Morikawa, 2000; Poirier & Gurnsey, 2005; Potechin & Gurnsey, 2003; Talgar & Carrasco, 2002; Yeshurun, Montagna, & Carrasco, 2008; Yeshurun & Carrasco, 1998, 2000, 2008). Selectively removing high SFs from the stimulus display eliminates the CPD (Morikawa, 2000). Likewise, selectively adapting to high SFs reduces the CPD and shifts the performance peak toward central locations (Barbot & Carrasco, 2017; Carrasco et al., 2006). Consistent with the asymmetries in SF processing we observed here, texture segmentation performance peaks at farther eccentricities in the lower than the upper VM (Talgar & Carrasco, 2002). Moreover, asymmetries in visual processing are not only present at the encoding stage of visual information, affecting SF discrimination and perceived SF, but also in visual short-term memory (Montaser-Kouhsari & Carrasco, 2009).
The gradual emergence of the HVA and VMA for visual acuity as we move from the HM toward the VM further challenges the idea of a constant upper versus lower visual field asymmetry. Changes in performance across isoeccentric locations have been described as an ellipse (Anderson, Cameron, & Levine, 2014; Engel, 1971; Harvey & Pöppel, 1972; Pöppel & Harvey, 1973; Pretorius & Hanekom, 2006; Wertheim, 1894). Although the horizontal elongation of the elliptical performance field can capture the HVA, an elliptical model cannot capture the robust VMA between upper and lower visual fields observed in the present study, as well as in many other studies (e.g., Abrams et al., 2012; Altpeter et al., 2000; Baldwin et al., 2012; Cameron et al., 2002; Carrasco et al., 2001; Corbett & Carrasco, 2011; Fuller et al., 2008; Himmelberg et al., 2020; Lakha & Humphreys, 2005; Mackeben, 1999; Montaser-Kouhsari & Carrasco, 2009; Nazir, 1992; Pointer & Hess, 1989; Rijsdijk et al., 1980; Talgar & Carrasco, 2002; von Grunau & Dube, 1994). Note that the ellipse model (Anderson et al., 2014) did not take into account important stimulus parameters (e.g., eccentricity, SF, stimulus size, and set size) that can determine whether a VMA is absent or present as well as its magnitude (e.g., Baldwin et al., 2012; Cameron et al., 2002; Carrasco et al., 2001; Himmelberg et al., 2020; Lakha & Humphreys, 2005; Liu et al., 2006; Rijsdijk et al., 1980). Therefore, the ellipse model does not suffice to capture asymmetries around the visual field.
The gradual emergence of the HVA and VMA also highlights the need to reexamine the conclusions of some studies reporting that the VMA reflects an overall upper versus lower visual field asymmetry, regardless of the angular position of the stimulus. Upon inspection, it is clear that such field asymmetries are driven by locations at the VM, as stimuli were only presented exactly at the VM (e.g., Danckert & Goodale, 2001; Edgar & Smith, 1990; Fortenbaugh, Silver, & Robertson, 2015; He et al., 1996; McAnany & Levine, 2007; Rubin, Nakayama, & Shapley, 1996; Schmidtmann, Logan, Kennedy, Gordon, & Loffler, 2015; Thomas & Elias, 2011) or near the VM (e.g., Levine & McAnany, 2005). Visual asymmetries between the upper and lower visual field could, to some degree, reflect ecological constraints. The lower visual field generally contains more visual information than the upper visual field and may be more important for survival. For instance, the sky would take up a significant portion of the upper visual field under most viewing conditions, at least in primates living outside the natural forest (Tootell, Switkes, Silverman, & Hamilton, 1988). It has been proposed that the upper and lower visual fields are functionally specialized for far and near vision, respectively, such that stimuli are processed more efficiently in the lower than in the upper visual field (Previc, 1990). Nevertheless, the present findings, along with those in contrast sensitivity (Abrams et al., 2012; Baldwin et al., 2012), indicate that the asymmetry between the upper and lower visual fields should be described in terms of the polar angular position of visual information.
Differences in visual processing at isoeccentric locations can be as pronounced as differences across eccentricities (Baldwin et al., 2012; Barbot, Abrams, & Carrasco, 2019; Carrasco et al., 2001; Himmelberg et al., 2020; Strasburger, Rentschler, & Juttner, 2011). For instance, contrast sensitivity nearly halves when stimuli are moved from 5 deg to 10 deg along the HM (Virsu & Rovamo, 1979) or when moving stimuli from the HM to the UVM at isoeccentric locations (Abrams et al., 2012). A recent study shows that contrast sensitivity decreases by a third when doubling eccentricity along the HM (4.5 deg vs. 9 deg) or when comparing HM and VM at 4.5 deg eccentricity (Himmelberg et al., 2020). Thus, to eliminate differences in sensory factors when assessing performance in visual tasks, it does not suffice to place stimuli at the same eccentricity. Moreover, the lack of significant differences along the intercardinal (± 45° polar angle) meridians (e.g., Abrams et al., 2012; Altpeter et al., 2000; Benson et al., 2020; Cameron et al., 2002; Carrasco et al., 2001; Corbett & Carrasco, 2011; Liu et al., 2006; Mackeben, 1999; Nazir, 1992; Talgar & Carrasco, 2002) has been used to collapse performance across intercardinal isoeccentric locations (e.g., Barbot & Carrasco, 2017; Guzman-Martinez, Grabowecky, Palafox, & Suzuki, 2011; Liu & Mance, 2011; Montagna, Pestilli, & Carrasco, 2009; Sawaki & Luck, 2013; Yashar, White, Fang, & Carrasco, 2017). It is worth noting that although visual field asymmetries linearly decrease with the angular distance from the vertical meridian and generally become negligible by the intercardinal (± 45° polar angle) meridians, they might still be present and may be worth checking for the specific task at hand. In addition, whereas the overall pattern in visual asymmetries is consistent across participants, the magnitude of visual asymmetries differs among individuals (e.g., Abrams et al., 2012; Baldwin et al., 2012; Carrasco et al., 2001; Himmelberg et al., 2020; Purokayastha et al., 2020; Strasburger et al., 2011; Wertheim, 1894).
Despite similarities in the magnitude of change in visual performance across eccentricity and polar angle, distinct mechanisms might mediate the HVA and the VMA. Whereas increased internal noise can account for the reduction in contrast sensitivity with eccentricity, differences across isoeccentric locations seem to reflect asymmetries in the efficiency of visual filters, particularly for high SFs (Barbot et al., 2019). Moreover, the HVA is present as early as at the retinal receptors (Kupers, Carrasco, & Winawer, 2019), but the VMA only emerges at the midget retinal ganglion cells (Kupers, Benson, Carrasco, & Winawer, 2020). Finally, we observed a lack of correlation between HVA and VMA ratios, consistent with a study that evaluated visual asymmetries in contrast sensitivity (Himmelberg et al., 2020).
What are the physiological substrates underlying performance fields? Starting at the level of the human eye, optical quality is not uniform across the retina (e.g., Curcio, Sloan, Kalina, & Hendrickson, 1990; Jaeken & Artal, 2012; Polans, Jaeken, McNabb, Artal, & Izatt, 2015; Song, Chui, Zhong, Elsner, & Burns, 2011; Thibos, Still, & Bradley, 1996; Zheleznyak, Barbot, Ghosh, & Yoon, 2016). Optical factors degrade retinal image quality, which can result in neural insensitivity to high-SF information (e.g., Barbot et al., 2020; Sabesan, Barbot, & Yoon, 2017; Sabesan & Yoon, 2009; Sawides, de Gracia, Dorronsoro, Webster, & Marcos, 2011). Both defocus and higher-order aberrations increase with eccentricity, with some differences as a function of polar angle (Atchison & Scott, 2002; Lundström, Mira-Agudelo, & Artal, 2009). At the level of the retina, cone density becomes sparser with eccentricity, due to increased size and larger gaps between cones, and decreases by ∼30% between the HM and VM at a fixed eccentricity (Curcio et al., 1990; Song et al., 2011).
A computational observer model has been used to evaluate the extent to which these optical and retinal factors can explain performance differences in contrast sensitivity with polar angle (Kupers et al., 2019). To account for the 30% increase in contrast sensitivity between the UVM and the HM for stimuli (4 cpd) presented at 4.5 deg eccentricity (Cameron et al., 2002), the model required an increase by ∼7 diopters of defocus or a reduction by 500% in cone density, which exceeds by far the variations observed in human eyes. Variations in retinal ganglion cell density also correlate with performance fields, with midget retinal ganglion cells density being 1.4 times greater along the HM than the VM (Curcio & Allen, 1990; Watson, 2014). However, including disparities in these cells still accounts from a small fraction of performance fields (Kupers et al., 2020).
At the level of the lateral geniculate nucleus (Connolly & Van Essen, 1984) and primary visual cortex (V1; Van Essen, Newsome, & Maunsell, 1984; but see Adams & Horton, 2003), there is a greater representation of the area around the HM than the VM. At the cortical level, there is 40% lower BOLD amplitude in V1 for visual stimuli presented on the UVM compared to the LVM (Liu et al., 2006). Consistent with behavioral findings, this asymmetry was observed only for high-SF stimuli, not for low-SF stimuli. Furthermore, performance fields could also reflect differences in the geometry of the visual cortex. For instance, more cortical area is devoted to representing the HM than the VM (Benson et al., 2012; Silva et al., 2018), which could account for the HVA. More cortical area is also devoted to representing the upper versus lower visual field within 1–6 deg eccentricity (Benson et al., 2020), which could account for the VMA. This difference decreases gradually with the angular distance from the VM and is no longer present by the intercardinal (± 45°) meridians, which could account for the present findings. In summary, whereas meridional effects are observed as early as the human eye, these front-end factors can account for only a small fraction of performance fields, which are likely due to asymmetries in visual processing across polar angle being amplified at cortical processing stages (Benson et al., 2020). Computational models are needed to quantify the degree to which these cortical factors account for many psychophysical findings of visual field asymmetries.
Our findings reveal that asymmetries in visual acuity emerge gradually with angular distance at isoeccentric, perifoveal (i.e., 10 deg eccentricity) locations. Although we did not test other eccentricities, performance fields have been reported over a wide range of eccentricities, from ∼2 deg to 60 deg (e.g., Abrams et al., 2012; Altpeter et al., 2000; Baldwin et al., 2012; Cameron et al., 2002; Carrasco et al., 2001, 2002; Corbett & Carrasco, 2011; Fuller et al., 2008; Himmelberg et al., 2020; Mackeben, 1999; Montaser-Kouhsari & Carrasco, 2009; Nazir, 1992; Pointer & Hess, 1989; Rijsdijk et al., 1980; Strasburger et al., 2011; Talgar & Carrasco, 2002; see also Table 1 in Baldwin et al., 2012). The magnitudes of both the HVA and the VMA vary with eccentricity. For instance, circular isoperformance lines are usually observed near the fovea and turn into horizontally elongated fields as stimuli are moved to the periphery (e.g., Baldwin et al., 2012; Harvey & Pöppel, 1972; Pointer & Hess, 1989; Pöppel & Harvey, 1973; Strasburger et al., 2011). Baldwin et al. (2012) measured contrast sensitivity as a function of eccentricity, SF, and polar angle and found that the decline in contrast sensitivity with eccentricity is bilinear within the central visual field. Specifically, they found that the attenuation in sensitivity as a function of eccentricity (0–4.5 deg) and polar angle (45° steps) had the form of a witch's hat, with a steep initial decline near the fovea followed by a shallower decline in sensitivity. This bilinear decline in sensitivity with eccentricity was steeper along the upper VM, with the slope of the lower VM being almost half that for the upper VM for the shallower part of the witch's hat. This finding is consistent with the VMA becoming more pronounced with eccentricity.
Measuring the conspicuity of visual stimuli across eccentricity as well as at isoeccentric locations provides a framework for how the visual system processes information across the visual field. Characterizing how visual performance varies at eccentric and isoeccentric locations has profound implications not only for our understanding of visual perception but also for ergonomic and human factors applications. For instance, when designing devices for drivers, pilots, radiologists, air traffic controllers, and many others, one should take into account perceptual asymmetries across the visual field and tailor displays for optimal speed and accuracy. Although visual performance measures, such as acuity and contrast sensitivity, are only marginally correlated (Poggel, Treutwein, Calmanti, & Strasburger, 2012a, 2012b), and the magnitude of visual field asymmetries varies with stimulus SF, stimulus eccentricity, set size (e.g., Baldwin et al., 2012; Cameron et al., 2002; Carrasco et al., 2001; Himmelberg et al., 2020), and across individuals (e.g., Abrams et al., 2012; Baldwin et al., 2012; Carrasco et al., 2001; Himmelberg et al., 2020; Purokayastha et al., 2020; Strasburger et al., 2011; Wertheim, 1894), it would be preferable to present critical information along the horizontal meridian rather than near the upper VM, given that it corresponds to the region of the visual field with the poorest contrast sensitivity and spatial resolution. Future studies are needed to fully characterize visual performance fields across different eccentricities, polar angle, and tasks.
Aiming to understand how limits in visual processing change around our visual field, we measured orientation discrimination performance of high-contrast gratings varying in SF at 24 isoeccentric and equidistant peripheral locations. The present results reveal that both the HVA and VMA in visual acuity are most pronounced at the vertical meridian and decrease gradually approaching the horizontal meridian. Furthermore, this pattern is the same for both monocular and binocular viewing, hence ruling out differences in horizontal disparity as a possible source of these performance fields. These results provide a more complete picture regarding how spatial resolution differs across our visual field, a fundamental dimension constraining visual performance in many tasks. These location-dependent asymmetries in visual acuity, as well as those in contrast sensitivity (e.g., Abrams et al., 2012; Baldwin et al., 2012), have important perceptual consequences that should be accounted for in current models of visual perception (e.g., Akbas & Eckstein, 2017; Bradley, Abrams, & Geisler, 2014; Kupers et al., 2019, 2020; Schira, Tyler, Spehar, & Breakspear, 2010; Schutt & Wichmann, 2017).
The authors thank Marc Himmelberg, Simran Purokayastha, and Mariel Roberts, as well as other members of the Carrasco lab for providing helpful comments on the manuscript.
Supported by a grant from the U.S. National Eye Institute (R01-EY027401 to MC).
Commercial relationships: none.
Corresponding author: Antoine Barbot.
Email: [email protected].
Address: NYU Department of Psychology, 6 Washington Place, Room 970, New York, NY 10003, USA.
Abrams, J., Nizam, A., & Carrasco, M. (2012). Isoeccentric locations are not equivalent: the extent of the vertical meridian asymmetry. Vision Research, 52(1), 70–78, https://doi.org/10.1016/j.visres.2011.10.016. [CrossRef]
Adams, D. L., & Horton, J. C. (2003). A precise retinotopic map of primate striate cortex generated from the representation of angioscotomas. Journal of Neuroscience, 23(9), 3771–3789, https://doi.org/10.1523/jneurosci.23-09-03771.2003. [CrossRef]
Akbas, E., & Eckstein, M. P. (2017). Object detection through search with a foveated visual system. PLoS Computational Biology, 13(10), e1005743, https://doi.org/10.1371/journal.pcbi.1005743. [CrossRef]
Altpeter, E., Mackeben, M., & Trauzettel-Klosinski, S. (2000). The importance of sustained attention for patients with maculopathies. Vision Research, 40(10–12), 1539–1547, https://doi.org/10.1016/s0042-6989(00)00059-6. [CrossRef]
Anderson, J. E., Cameron, E. L., & Levine, M. W. (2014). A method for quantifying visual field inhomogeneities. Vision Research, 105, 112–120, https://doi.org/10.1016/j.visres.2014.09.010. [CrossRef]
Atchison, D. A., & Scott, D. H. (2002). Monochromatic aberrations of human eyes in the horizontal visual field. Journal of the Optical Society of America A, Optics, Image Science, and Vision, 19(11), 2180–2184, https://doi.org/10.1364/josaa.19.002180. [CrossRef]
Baker, D. H., Lygo, F. A., Meese, T. S., & Georgeson, M. A. (2018). Binocular summation revisited: Beyond √2. Psychological Bulletin, 144(11), 1186–1199, https://doi.org/10.1037/bul0000163. [CrossRef]
Baldwin, A. S., Meese, T. S., & Baker, D. H. (2012). The attenuation surface for contrast sensitivity has the form of a witch's hat within the central visual field. Journal of Vision, 12(11):23, 1–17, https://doi.org/10.1167/12.11.23. [CrossRef]
Barbot, A., Abrams, J., & Carrasco, M. (2019). Distinct mechanisms limit contrast sensitivity across retinal eccentricity and polar angle. Journal of Vision, 19(10), 43, https://doi.org/10.1167/19.10.43. [CrossRef]
Barbot, A., & Carrasco, M. (2017). Attention modifies spatial resolution according to task demands. Psychological Science, 28(3), 285–296, https://doi.org/10.1177/0956797616679634. [CrossRef]
Barbot, A., Park, W. J., Zhang, R. Y., Huxlin, K. R., Tadin, D., & Yoon, G. (2020). Functional reorganization of sensory processing following long-term neural adaptation to optical defects. BioRxiv, 2020.02.19.956219, https://doi.org/10.1101/2020.02.19.956219.
Benson, N. C., Butt, O. H., Datta, R., Radoeva, P. D., Brainard, D. H., & Aguirre, G. K. (2012). The retinotopic organization of striate cortex is well predicted by surface topology. Current Biology, 22(21), 2081–2085, https://doi.org/10.1016/j.cub.2012.09.014. [CrossRef]
Benson, N. C., Kupers, E. R., Barbot, A., Carrasco, M., & Winawer, J. (2020). Cortical magnification in human visual cortex parallels task performance around the visual field. BioRxiv, 2020.08.26.268383, https://doi.org/10.1101/2020.08.26.268383.
Bradley, C., Abrams, J., & Geisler, W. S. (2014). Retina-V1 model of detectability across the visual field. Journal of Vision, 14(12):22, 1–22, https://doi.org/10.1167/14.12.22. [CrossRef]
Cagenello, R., Halpern, D. L., & Arditi, A. (1993). Binocular enhancement of visual acuity. Journal of the Optical Society of America A, Optics, Image Science, and Vision, 10(8), 1841–1848, https://doi.org/10.1364/josaa.10.001841. [CrossRef]
Cameron, E. L., Tai, J. C., & Carrasco, M. (2002). Covert attention affects the psychometric function of contrast sensitivity. Vision Research, 42, 949–967, https://doi.org/10.1016/S0042-6989(02)00039-1. [CrossRef]
Campbell, F. W., & Green, D. G. (1965). Monocular versus binocular visual acuity. Nature, 208(5006), 191–192, https://doi.org/10.1038/208191a0. [CrossRef]
Cannon, M. W., Jr. (1985). Perceived contrast in the fovea and periphery. Journal of the Optical Society of America A, 2(10), 1760–1768, https://doi.org/10.1364/josaa.2.001760. [CrossRef]
Carrasco, M., & Barbot, A. (2014). How attention affects spatial resolution. Cold Spring Harbor Symposia on Quantitative Biology, 79, 149–160, https://doi.org/10.1101/sqb.2014.79.024687. [CrossRef]
Carrasco, M., Evert, D. L., Chang, I., & Katz, S. M. (1995). The eccentricity effect: target eccentricity affects performance on conjunction searches. Perception & Psychophysics, 57(8), 1241–1261, https://doi.org/10.3758/bf03208380. [CrossRef]
Carrasco, M., Giordano, A. M., & McElree, B. (2004). Temporal performance fields: visual and attentional factors. Vision Research, 44(12), 1351–1365, https://doi.org/10.1016/j.visres.2003.11.026. [CrossRef]
Carrasco, M., Loula, F., & Ho, Y. X. (2006). How attention enhances spatial resolution: evidence from selective adaptation to spatial frequency. Perception & Psychophysics, 68, 1004–1012, https://doi.org/10.3758/BF03193361. [CrossRef]
Carrasco, M., Talgar, C. P., & Cameron, E. L. (2001). Characterizing visual performance fields: Effects of transient covert attention, spatial frequency, eccentricity, task and set size. Spatial Vision, 15(1), 61–75, https://doi.org/10.1163/15685680152692015.
Carrasco, M., Williams, P. E., & Yeshurun, Y. (2002). Covert attention increases spatial resolution with or without masks: support for signal enhancement. Journal of Vision, 2(6), 467–479, https://doi.org/10.1167/2.6.4.
Connolly, M., & Van Essen, D. (1984). The representation of the visual field in parvicellular and magnocellular layers of the lateral geniculate nucleus in the macaque monkey. Journal of Comparative Neurology, 226(4), 544–564, https://doi.org/10.1002/cne.902260408.
Corbett, J. E., & Carrasco, M. (2011). Visual performance fields: Frames of reference. PLoS One, 6(9), e24470, https://doi.org/10.1371/journal.pone.0024470.
Curcio, C. A., & Allen, K. A. (1990). Topography of ganglion cells in human retina. Journal of Comparative Neurology, 300(1), 5–25, https://doi.org/10.1002/cne.903000103.
Curcio, C. A., Sloan, K. R., Kalina, R. E., & Hendrickson, A. E. (1990). Human photoreceptor topography. Journal of Comparative Neurology, 292(4), 497–523, https://doi.org/10.1002/cne.902920402.
Danckert, J., & Goodale, M. A. (2001). Superior performance for visually guided pointing in the lower visual field. Experimental Brain Research, 137(3–4), 303–308, https://doi.org/10.1007/s002210000653.
De Lestrange-Anginieur, E., & Kee, C. S. (2020). Investigation of the impact of blur under mobile attentional orientation using a vision simulator. PLoS One, 15(6), e0234380, https://doi.org/10.1371/journal.pone.0234380.
Edgar, G. K., & Smith, A. T. (1990). Hemifield differences in perceived spatial frequency. Perception, 19(6), 759–766, https://doi.org/10.1068/p190759.
Engel, F. L. (1971). Visual conspicuity, directed attention and retinal locus. Vision Research, 11(6), 563–576, https://doi.org/10.1016/0042-6989(71)90077-0.
Fortenbaugh, F. C., Silver, M. A., & Robertson, L. C. (2015). Individual differences in visual field shape modulate the effects of attention on the lower visual field advantage in crowding. Journal of Vision, 15(2):19, 1–15, https://doi.org/10.1167/15.2.19.
Fuller, S., & Carrasco, M. (2009). Perceptual consequences of visual performance fields: the case of the line motion illusion. Journal of Vision, 9(4): 13, 1–17, https://doi.org/10.1167/9.4.13.
Fuller, S., Rodriguez, R. Z., & Carrasco, M. (2008). Apparent contrast differs across the vertical meridian: Visual and attentional factors. Journal of Vision, 8(1): 16, 1–16, https://doi.org/10.1167/8.1.16.
Greene, H. H., Brown, J. M., & Dauphin, B. (2014). When do you look where you look? A visual field asymmetry. Vision Research, 102, 33–40, https://doi.org/10.1016/j.visres.2014.07.012.
Greenwood, J. A., Szinte, M., Sayim, B., & Cavanagh, P. (2017). Variations in crowding, saccadic precision, and spatial localization reveal the shared topology of spatial vision. Proceedings of the National Academy of Sciences of the United States of America, 114(17), E3573–E3582, https://doi.org/10.1073/pnas.1615504114.
Gurnsey, R., Pearson, P., & Day, D. (1996). Texture segmentation along the horizontal meridian: Nonmonotonic changes in performance with eccentricity. Journal of Experimental Psychology: Human Perception & Performance, 22(3), 738–757, https://doi.org/10.1037//0096-1523.22.3.738.
Guzman-Martinez, E., Grabowecky, M., Palafox, G., & Suzuki, S. (2011). A unique role of endogenous visual-spatial attention in rapid processing of multiple targets. Journal of Experimental Psychology: Human Perception & Performance, 37(4), 1065–1073, https://doi.org/10.1037/a0023514.
Harvey, L. O., Jr, & Pöppel, E. (1972). Contrast sensitivity of the human retina. American Journal of Optometry and Archives of American Academy of Optometry, 49(9), 748–753, https://doi.org/10.1097/00006324-197209000-00007.
He, S., Cavanagh, P., & Intriligator, J. (1996). Attentional resolution and the locus of visual awareness. Nature, 383(6598), 334–337, https://doi.org/10.1038/383334a0.
Helmholtz, H. von . (1925). Treatise on physiological optics (Southall, J. P. C., Ed.). Rochester, NY: Optical Society of America.
Hibbard, P. B., & Bouzit, S. (2005). Stereoscopic correspondence for ambiguous targets is affected by elevation and fixation distance. Spatial Vision, 18(4), 399–411, https://doi.org/10.1163/1568568054389589.
Himmelberg, M. M., Winawer, J., & Carrasco, M. (2020). Stimulus-dependent contrast sensitivity asymmetries around the visual field. Journal of Vision, 20(9):18, 1–19, https://doi.org/10.1167/jov.20.9.18.
Home, R. (1978). Binocular summation: A study of contrast sensitivity, visual acuity and recognition. Vision Research, 8(5), 579–585, https://doi.org/10.1016/0042-6989(78)90206-7.
Jaeken, B., & Artal, P. (2012). Optical quality of emmetropic and myopic eyes in the periphery measured with high-angular resolution. Investigative Ophthalmology & Visual Science, 53(7), 3405–3413, https://doi.org/10.1167/iovs.11-8993.
Jigo, M., & Carrasco, M. (2018). Attention alters spatial resolution by modulating second-order processing. Journal of Vision, 18(7), 2, https://doi.org/10.1167/18.7.2.
Kleiner, M., Brainard, D. H., & Pelli, D. G. (2007). What's new in Psychtoolbox-3? Perception, 36(14), 1–16.
Kupers, E. R., Benson, N. C., Carrasco, M., & Winawer, J. (2020). Radial asymmetries around the visual field: From retina to cortex to behavior. BioRxiv, 2020.10.20.347492, https://doi.org/10.1101/2020.10.20.347492.
Kupers, E. R., Carrasco, M., & Winawer, J. (2019). Modeling visual performance differences "around" the visual field: A computational observer approach. PLoS Computational Biology, 15(5), e1007063, https://doi.org/10.1371/journal.pcbi.1007063.
Lakha, L., & Humphreys, G. (2005). Lower visual field advantage for motion segmentation during high competition for selection. Spatial Vision, 18(4), 447–460, https://doi.org/10.1163/1568568054389570.
Levine, M. W., & McAnany, J. J. (2005). The relative capabilities of the upper and lower visual hemifields. Vision Research, 45(21), 2820–2830, https://doi.org/10.1016/j.visres.2005.04.001.
Ling, S., & Carrasco, M. (2006). When sustained attention impairs perception. Nature Neuroscience, 9(10), 1243–1245, https://doi.org/10.1038/nn1761.
Ling, S., Liu, T., & Carrasco, M. (2009). How spatial and feature-based attention affect the gain and tuning of population responses. Vision Research, 49(10), 1194–1204, https://doi.org/10.1016/j.visres.2008.05.025.
Liu, T., Heeger, D. J., & Carrasco, M. (2006). Neural correlates of the visual vertical meridian asymmetry. Journal of Vision, 6(11), 1294–1306, https://doi.org/10.1167/5.1.1.
Liu, T., & Mance, I. (2011). Constant spread of feature-based attention across the visual field. Vision Research, 51(1), 26–33, https://doi.org/10.1016/j.visres.2010.09.023.
Lu, Z. L., & Dosher, B. A. (2000). Spatial attention: different mechanisms for central and peripheral temporal precues? Journal of Experimental Psychology: Human Perception & Performance, 26(5), 1534–1548, https://doi.org/10.1037//0096-1523.26.5.1534.
Lundström, L., Mira-Agudelo, A., & Artal, P. (2009). Peripheral optical errors and their change with accommodation differ between emmetropic and myopic eyes. Journal of Vision, 9(6):17, 1–11, https://doi.org/10.1167/9.6.17.
Mackeben, M. (1999). Sustained focal attention and peripheral letter recognition. Spatial Vision, 12(1), 51–72, https://doi.org/10.1163/156856899x00030.
McAnany, J. J., & Levine, M. W. (2007). Magnocellular and parvocellular visual pathway contributions to visual field anisotropies. Vision Research, 47(17), 2327–2336, https://doi.org/10.1016/j.visres.2007.05.013.
Montagna, B., Pestilli, F., & Carrasco, M. (2009). Attention trades off spatial acuity. Vision Research, 49(7), 735–745, https://doi.org/10.1016/j.visres.2009.02.001.
Montaser-Kouhsari, L., & Carrasco, M. (2009). Perceptual asymmetries are preserved in short-term memory tasks. Attention, Perception & Psychophysics, 71(8), 1782–1792, https://doi.org/10.3758/APP.71.8.1782.
Morikawa, K. (2000). Central performance drop in texture segmentation: the role of spatial and temporal factors. Vision Research, 40(25), 3517–3526, https://doi.org/10.1016/S0042-6989(00)00170-X.
Nazir, T. A. (1992). Effects of lateral masking and spatial precueing on gap-resolution in central and peripheral vision. Vision Research, 32(4), 771–777, https://doi.org/10.1016/0042-6989(92)90192-l.
Pardhan, S. (2003). Binocular recognition summation in the peripheral visual field: Contrast and orientation dependence. Vision Research, 43(11), 1249–1255, https://doi.org/10.1016/S0042-6989(03)00093-2.
Petrov, Y., & Meleshkevich, O. (2011). Asymmetries and idiosyncratic hot spots in crowding. Vision Research, 51(10), 1117–1123, https://doi.org/10.1016/j.visres.2011.03.001.
Petrova, K., & Wentura, D. (2012). Upper-lower visual field asymmetries in oculomotor inhibition of emotional distractors. Vision Research, 62, 209–219, https://doi.org/10.1016/j.visres.2012.04.010.
Poggel, D. A., Treutwein, B., Calmanti, C., & Strasburger, H. (2012a). The Tölz Temporal Topography Study: Mapping the visual field across the life span. Part I: The topography of light detection and temporal-information processing. Attention, Perception & Psychophysics, 74(6), 1114–1132, https://doi.org/10.3758/s13414-012-0278-z.
Poggel, D. A., Treutwein, B., Calmanti, C., & Strasburger, H. (2012b). The Tölz Temporal Topography Study: Mapping the visual field across the life span. Part II: Cognitive factors shaping visual field maps. Attention, Perception & Psychophysics, 74(6), 1133–1144, https://doi.org/10.3758/s13414-012-0279-y.
Pointer, J. S., & Hess, R. F. (1989). The contrast sensitivity gradient across the human visual field: with emphasis on the low spatial frequency range. Vision Research, 29(9), 1133–1151, https://doi.org/10.1016/0042-6989(89)90061-8.
Poirier, F. J., & Gurnsey, R. (2005). Non-monotonic changes in performance with eccentricity modeled by multiple eccentricity-dependent limitations. Vision Research, 45(18), 2436–2448, https://doi.org/S0042-6989(05)00170-7.
Polans, J., Jaeken, B., McNabb, R. P., Artal, P., & Izatt, J. A. (2015). Wide-field optical model of the human eye with asymmetrically tilted and decentered lens that reproduces measured ocular aberrations. Optica, 2(2), 124, https://doi.org/10.1364/OPTICA.2.000124.
Pöppel, E., & Harvey, L. O., Jr (1973). Light-difference threshold and subjective brightness in the periphery of the visual field. Psychologische Forschung, 36(2), 145–161, https://doi.org/10.1007/BF00424967.
Potechin, C., & Gurnsey, R. (2003). Backward masking is not required to elicit the central performance drop. Spatial Vision, 16(5), 393–406, https://doi.org/10.1163/156856803322552720.
Pretorius, L. L., & Hanekom, J. J. (2006). An accurate method for determining the conspicuity area associated with visual targets. Human Factors, 48(4), 774–784, https://doi.org/10.1518/001872006779166370.
Previc, F. H. (1990). Functional specialization in the lower and upper visual fields in humans: Its ecological origins and neurophysiological implications. Behavioral and Brain Sciences, 13(3), 519–542, https://doi.org/10.1017/S0140525X00080018.
Prins, N., & Kingdom, F. A. A. (2018). Applying the model-comparison approach to test specific research hypotheses in psychophysical research using the Palamedes Toolbox. Frontiers in Psychology, 9, 1250, https://doi.org/10.3389/fpsyg.2018.01250.
Purokayastha, S., Roberts, M., & Carrasco, M. (2020). Voluntary attention improves performance similarly around the visual field. PsyArXiv. https://doi.org/10.31234/osf.io/6fkys.
Rijsdijk, J. P., Kroon, J. N., & van der Wildt, G. J. (1980). Contrast sensitivity as a function of position on the retina. Vision Research, 20(3), 235–241, https://doi.org/10.1016/0042-6989(80)90108-x.
Roberts, M., Ashinoff, B. K., Castellanos, F. X., & Carrasco, M. (2018). When attention is intact in adults with ADHD. Psychonomic Bulletin & Review, 25(4), 1423–1434, https://doi.org/10.3758/s13423-017-1407-4.
Roberts, M., Cymerman, R., Smith, R. T., Kiorpes, L., & Carrasco, M. (2016). Covert spatial attention is functionally intact in amblyopic human adults. Journal of Vision, 16(15), 30, https://doi.org/10.1167/16.15.30.
Rosen, R., Lundstrom, L., Venkataraman, A. P., Winter, S., & Unsbo, P. (2014). Quick contrast sensitivity measurements in the periphery. Journal of Vision, 14(8), 3, https://doi.org/10.1167/14.8.3.
Rovamo, J., & Virsu, V. (1979). An estimation and application of the human cortical magnification factor. Experimental Brain Research, 37(3), 495–510, https://doi.org/10.1007/BF00236819.
Rubin, N., Nakayama, K., & Shapley, R. (1996). Enhanced perception of illusory contours in the lower versus upper visual hemifields. Science, 271(5249), 651–653, https://doi.org/10.1126/science.271.5249.651.
Sabesan, R., Barbot, A., & Yoon, G. (2017). Enhanced neural function in highly aberrated eyes following perceptual learning with adaptive optics. Vision Research, 132, 78–84, https://doi.org/10.1016/j.visres.2016.07.011.
Sabesan, R., & Yoon, G. (2009). Visual performance after correcting higher order aberrations in keratoconic eyes. Journal of Vision, 9(5):6,1–10, https://doi.org/10.1167/9.5.69/5/6.
Sabesan, R., Zheleznyak, L., & Yoon, G. (2012). Binocular visual performance and summation after correcting higher order aberrations. Biomedical Optics Express, 3(12), 3176–3189, https://doi.org/10.1364/BOE.3.003176.
Sawaki, R., & Luck, S. J. (2013). Active suppression after involuntary capture of attention. Psychonomic Bulletin & Review, 20(2), 296–301, https://doi.org/10.3758/s13423-012-0353-4.
Sawides, L., de Gracia, P., Dorronsoro, C., Webster, M. A., & Marcos, S. (2011). Vision is adapted to the natural level of blur present in the retinal image. PLoS One, 6(11), e27031, https://doi.org/10.1371/journal.pone.0027031.
Schira, M. M., Tyler, C. W., Spehar, B., & Breakspear, M. (2010). Modeling magnification and anisotropy in the primate foveal confluence. PLoS Computational Biology, https://doi.org/10.1371/journal.pcbi.1000651.
Schmidtmann, G., Logan, A. J., Kennedy, G. J., Gordon, G. E., & Loffler, G. (2015). Distinct lower visual field preference for object shape. Journal of Vision, 15(5), 18, https://doi.org/10.1167/15.5.18.
Schutt, H. H., & Wichmann, F. A. (2017). An image-computable psychophysical spatial vision model. Journal of Vision, 17(12), 12, https://doi.org/10.1167/17.12.12.
Silva, M. F., Brascamp, J. W., Ferreira, S., Castelo-Branco, M., Dumoulin, S. O., & Harvey, B. M. (2018). Radial asymmetries in population receptive field size and cortical magnification factor in early visual cortex. Neuroimage, 167, 41–52, https://doi.org/10.1016/j.neuroimage.2017.11.021.
Song, H., Chui, T. Y., Zhong, Z., Elsner, A. E., & Burns, S. A. (2011). Variation of cone photoreceptor packing density with retinal eccentricity and age. Investigative Ophthalmology & Visual Science, 52(10), 7376–7384, https://doi.org/10.1167/iovs.11-7199.
Sprague, W. W., Cooper, E. A., Reissier, S., Yellapragada, B., & Banks, M. S. (2016). The natural statistics of blur. Journal of Vision, 16(10), 23, https://doi.org/10.1167/16.10.23.
Sprague, W. W., Cooper, E. A., Tošić, I., & Banks, M. S. (2015). Stereopsis is adaptive for the natural environment. Science Advances, 1(4), 1–17, e1400254, https://doi.org/10.1126/sciadv.1400254.
Strasburger, H. (2001). Converting between measures of slope of the psychometric function. Perception & Psychophysics, 63(8), 1348–1355, https://doi.org/10.3758/bf03194547.
Strasburger, H., Rentschler, I., & Juttner, M. (2011). Peripheral vision and pattern recognition: a review. Journal of Vision, 11(5), 13, https://doi.org/10.1167/11.5.13.
Talgar, C. P., & Carrasco, M. (2002). Vertical meridian asymmetry in spatial resolution: Visual and attentional factors. Psychonomic Bulletin and Review, 9, 714–722, https://doi.org/10.3758/bf03196326.
Thibos, L. N., Cheney, F. E., & Walsh, D. J. (1987). Retinal limits to the detection and resolution of gratings. Journal of the Optical Society of America A, 4(8), 1524–1529, https://doi.org/10.1364/josaa.4.001524.
Thibos, L. N., Still, D. L., & Bradley, A. (1996). Characterization of spatial aliasing and contrast sensitivity in peripheral vision. Vision Research, 36(2), 249–258, https://doi.org/10.1016/0042-6989(95)00109-d.
Thomas, N. A., & Elias, L. J. (2011). Upper and lower visual field differences in perceptual asymmetries. Brain Research, 1387, 108–115, https://doi.org/10.1016/j.brainres.2011.02.063.
Tootell, R. B., Switkes, E., Silverman, M. S., & Hamilton, S. L. (1988). Functional anatomy of macaque striate cortex. II. Retinotopic organization. Journal of Neuroscience, 8(5), 1531–1568, https://doi.org/10.1523/jneurosci.08-05-01531.1988.
Traquair, H. M. (1938). An introduction to clinical perimetry (3rd ed.). London: H. Kimpton.
Van Essen, D. C., Newsome, W. T., & Maunsell, J. H. (1984). The visual field representation in striate cortex of the macaque monkey: asymmetries, anisotropies, and individual variability. Vision Research, 24(5), 429–448, https://doi.org/10.1016/0042-6989(84)90041-5.
Virsu, V., & Rovamo, J. (1979). Visual resolution, contrast sensitivity, and the cortical magnification factor. Experimental Brain Research, 37(3), 475–494, https://doi.org/10.1007/BF00236818.
von Grunau, M., & Dube, S. (1994). Visual search asymmetry for viewing direction. Perception & Psychophysics, 56(2), 211–220, https://doi.org/10.3758/bf03213899.
Wallis, T. S., & Bex, P. J. (2012). Image correlates of crowding in natural scenes. Journal of Vision, 12(7):6, 1–19, https://doi.org/10.1167/12.7.6.
Watson, A. B. (2014). A formula for human retinal ganglion cell receptive field density as a function of visual field location. Journal of Vision, 14(7):15, 1–17, https://doi.org/10.1167/14.7.15.
Wertheim, T. (1894). Über die indirekte Sehschärfe [On the indirect visual acuity]. Zeitschrift Für Psycholologie & Physiologie Der Sinnesorgane, 7, 172–187.
Yashar, A., White, A. L., Fang, W., & Carrasco, M. (2017). Feature singletons attract spatial attention independently of feature priming. Journal of Vision, 17(9), 7, https://doi.org/10.1167/17.9.7.
Yeshurun, Y., & Carrasco, M. (1998). Attention improves or impairs visual performance by enhancing spatial resolution. Nature, 396, 72–75, https://doi.org/10.1038/23936.
Yeshurun, Y., & Carrasco, M. (2000). The locus of attentional effects in texture segmentation. Nature Neuroscience, 3, 622–627, https://doi.org/10.1038/75804.
Yeshurun, Y., & Carrasco, M. (2008). The effects of transient attention on spatial resolution and the size of the attentional cue. Perception & Psychophysics, 70, 104–113, https://doi.org/10.1016/j.visres.2008.05.008.
Yeshurun, Y., Montagna, B., & Carrasco, M. (2008). On the flexibility of sustained attention and its effects on a texture segmentation task. Vision Research, 48, 80–95, https://doi.org/10.1016/j.visres.2007.10.015.
Zheleznyak, L., Barbot, A., Ghosh, A., & Yoon, G. (2016). Optical and neural anisotropy in peripheral vision. Journal of Vision, 16(5), 1, https://doi.org/10.1167/16.5.1.
Zlatkova, M. B., Anderson, R. S., & Ennis, F. A. (2001). Binocular summation for grating detection and resolution in foveal and peripheral vision. Vision Research, 41(24), 3093–3100, https://doi.org/10.1016/S0042-6989(01)00191-2.
Copyright 2021 The Authors | CommonCrawl |
Geographical Information System (GIS) and Analytical Hierarchy Process (AHP) based groundwater Potential Zones delineation in Chennai River Basin (CRB), India
Sajil Kumar PJ, Elnago L, Michael Schneider
posted 06 Aug, 2021
Groundwater depletion is one of the most important concerns for users and policy makers. Information on the locations where groundwater potential is high, or low is the key factor that helps them to do proper planning. Application of new technologies and methods are essential in this situation. This study has used the possibilities of Geographical Information System (GIS), Remote Sensing and, of course, field data to delineate the groundwater potential zones in the Chennai River Basin (CRB). To provide accurate results, 11 controlling factors- geology, water level, drainage, soil, lineament, rainfall, land use, slope, aspect, geomorphology, and depth to bed rock-- were brought into a digital GIS environment and appropriate weightage given to each layer depending on their effect on potential. The weightage is given based on Multi-Criteria Decision Making (MCDM), namely Analytical Hierarchal Process (AHP). Groundwater potential zones in the CRB were mapped as very poor, poor, moderate, good, very good using weighted overlay analysis. The results were compared with actual specific capacity from the borehole data. The accuracy of prediction was found to be 78.43%, indicating that in most of the locations, the predicted potential map agrees with the bore hole data. Thus, AHP aided GIS-RS mapping is a useful tool in groundwater prospecting in this region of the world.
Groundwater Potential
Thematic Layers
Chennai River Basin
According to availability and ease of access, surface water may be the most depended upon source of water for drinking and domestic purposes. However, with increased industrialization and urbanization, surface water faces serious threats in terms of quality. On a global scale, groundwater serves 50% of drinking and 43% of irrigation needs (FAO 2010). India is one the largest users of groundwater resources and the usage is increasing drastically (Postal 1999). As an agriculturally lead economy, 80% of the groundwater in India is used for irrigation (Dhavan 2017), and remaining is used for drinking, domestic and industrial purposes. Uncontrolled pumping has lowered the groundwater level severely and reported as overexploited in many parts of India (Dhavan 2017).
Chennai is the fourth largest metropolitan area in India and the biggest urban area in the Chennai River Basin (CRB). One of the earliest acts on the regulation of groundwater use and policy in India was The Chennai Metropolitan Area Groundwater (Regulation) Act in 1987, which banned the extraction of groundwater at 229 locations (Jenifer and Arul 2102). Further amendments to this restriction were made in 1995 and 2008. Rapid increase in population, industrialization, urbanization and irrigation have resulted in a huge demand of water from the Chennai Basin. Geographically, the eastern boundary of the basin is long coastline of the Bay of Bengal. Sea water intrusion into the freshwater zones and groundwater quality deterioration has been reported (Elango and Manickam 1986; Sajil Kumar et al., 2013; Nair et al., 2015). In this region, groundwater depletion and pollution affect the population and the economy, calling for sustainable water resources management. Previous studies suggests that most of the studies in this region focusing on groundwater quality, saline intrusions, hydrochemical investigations, managed aquifer recharge etc., (Elango et al., 1992; Senthik Kumar et al., 2001; Sathish et al., 2011; Parimala and Elango 2013; Raicy and Elango 2017). All these studies were performed at a watershed or sub-basin level. A more holistic approach is needed because the groundwater supply to the city also includes the well fields located north of Chennai. Thus, a study must be performed on the complete basin, with a special emphasis on the urban area.
Estimating groundwater reserve and the demarcation of prospective zones is the preliminary step of any water resources management project. Accurate calculation of inputs (recharge) and outputs (discharge) is essential at this stage. Systematic planning of groundwater exploitation using modern techniques is necessary for the proper utilization and management of this precious but shrinking natural resource (Chowdhury 2007). The use of conventional techniques like geological, geophysical, geostatistical and numerical modeling is expensive, laborious and time consuming (Elbeih 2014). The rapid growth of space technology has played a vital role in groundwater studies. Remote Sensing (Rs) and Geographic Information System (GIS) are promising tools for efficient planning and management of groundwater resources (Machiwal 2011). NRSA in India is one of the pioneers in using the integrated study of RS and GIS for delineating groundwater recharge potential in an area (NRSA 1987). Geospatial technologies provide cost-effective solutions for the aquifer management and integration of multi thematic data sets to a uniform scale.
The use of RS and GIS extensively used in India for the mapping and montoring of the groundwater potential zones and locating the suitable locations for the artificial groundwater recharge (Prasad et. al., 2008; Singh et al., 2013; Nagaraju et al., 2011 ; Magesh et al., 2012; Nag and Gosh 2013; Murthy et al., 2013 and many more). There are many studies found in many parts of India (Kurmapalli watershed Andharapradesh), (Bist Doab Basin, punjab), (Chamarajnagar District, Karnataka), (Bankura District, West Bengal), (Vamshadhara basin, Andhra Pradesh), (Theni district Tamil Nadu) and many more., on groundwater potential zone delineation using GIS techniques. The present study is concentrated mainly on the estimation of groundwater reserve and mapping groundwater potential zones in Chennai River Basin (CRB). We aim to create a basic platform for the sustainable groundwater management in future.
2. Study Area Settings
Chennai basin is located in the North-East region of Tamil Nadu State with latitudes 12° 40' N and 13° 40' N and longitudes 79° 10' E and 80° 25' E. The major portion of the basin is in Tamil Nadu and the remaining in the Andhra Pradesh state. The climate of the study area is semi-arid tropical, with temperature ranging from 13.9°C to 45°C (CGWB 2008). The highest temperature is recorded in Chennai in Summer season and the lowest in Tiruthani in Winter season. Variation in the availability of sunshine is mostly by the season. The location map of the study area is shown in Fig. 1. On an average the annual rainfall is 1156 mm/year. Relative humidity in the basin is varies from 53 to 84% and the wind velocity varies from 5.69 to 14.15 km/hr. Geomorphology of an area represents the origin, structure, development of landforms and alteration by human beings. Geomorphology can also hint to the underlying futures and also the processes that controls the evolution of the land forms. A wide range of geomorphological features are available in the study area. The major formations are beaches, Beach Ridges, Beach terraces, Buried Pediments, Wash Plains, Salt Pans, Swamps, Swale, Deltaic Plains, Deep Pediment, Pediment and Shallow Pediment, Buried Course & Channels, Tertiary Uplands, Flood Plains, Piedmont, and Inter Fluveo. Geologically Chennai basin is overlaid by the Precambrian gneisses and Charnockites and above which the marine and estuarine fluvial alluvium. The hard rocks include granite, gneissic complex, schist's and chamockites associated with basic and ultra-basic intrusive. The chamockites form the major rock types and constitute the residual hills around Pallavaram, Tambaram and Vandalur. Among the sedimentary formation's conglomerates, shale, and sandstone, and are covered by a thick cover of laterite. Tertiary sandstone is seen in small patches in the area around Perambur, and around northwest of Chennai city and up to Satyavedu, and is capped by lateritic soil. In the Chennai basin four different types of Soils were observed (i) Entisols, (ii) Inceptisols, (iii) Vertisols and (iv) Alfisols. The main aquifer system of the Chennai basin is formed by the river alluvium as well as Tertiary formations of the AK basin. The groundwater is mainly recharged by the rainfall recharge and river network. In the northern part, Minjur aquifer is already overexploited and facing threat from the seawater intrusion. South Chennai coastal aquifer is also not an exception. The present situation at the study area calling for immediate action to identify the groundwater potential zone and artificial recharge to protect the groundwater reserve.
Figure 1 Location map of the study area
3. Data And Methods
Factors influencing groundwater recharge are determined based on literature survey, field analysis and expert opinion. Based on this preliminary investigation geomorphology, geology, lineament, annual rainfall, pre-monsoon water level, depth to bed rock, soil, land use, aspect and slope were chosen as main factors. All these maps where digitized and integrated into a GIS platform using ArcGIS 10.2. The map layers used, and their hydrogeological significance are summarized in Table 1. Conventional data sets, such as topographical maps and field data, were used along with advanced data sets, such as satellite data. Corresponding topographic maps were collected from Survey of India (SOI), with a scale of 1:150,000. These maps were digitized in the GIS environment using ArcGIS 10.1. A geological and geomorphological map for the study were prepared from the SOI maps and soil map from the National Bureau of Soil Science and Land Use Planning (NBSS and LUP). SRTM -DEM were used to derive the slope maps. A flow chart of the adopted methodology is shown in Fig. 2
Phenomenon and need for the thematic layers
Map Layer
Geomorphology (GM)
Physical processes on the earth's surface that produce different landforms
A geomorphic unit is a composite unit that has specific characteristics
Geology (GEOL)
Different lithological formations
The aquifer characteristics of different geology is varied considerably
Lineament (including Fault & Shear zone) (Ln)
Planes/Zones of structural weakness in the rocks
Easy movement of water along weak planes
Rainfall (Rf)
Major source of water
Groundwater level (GWL)
Depth at which water occurs in the unconfined zone (top zone) below ground level
Accessible of water
Soil (Sl)
Result of physical surface processes and the lithology
Landuse (LU)
Purpose for which land has been put to use
Indicates the state of current use
Depth to Bed rock (DBR)
Massive rock below the soil and the weathered zone
Indication of the thickness of the unconfined aquifer
Slope (Sp)
Controls the movement of water (surface and ground)
Drainage (D)
Aspect (A)
Figure 2 Flow chart showing the methodology adopted in the study
Table 1: Phenomenon and need for the thematic layers
Data for the analysis was available in vector (from existing maps) and raster (interpolated from point data or classified from satellite images) formats. For rainfall, depth to bed rock, water level, and elevation, layers were created from the point data sources by the Inverse Distance Weighted (IDW) interpolation method. In the IDW method, the unknown data points are calculated from the four surrounding known data points. We opted for IDW over distance threshold methods, because the point data was sparse and distributed. The slope map was derived from the elevation contours from the Survey of India topographical maps of the study area.
Analytical Hierarchical Process (AHP), which was originally proposed by Saaty (1990), were used for assigning the weights for each thematic layer used in this study. AHP is one of the most commonly used multi criteria decision making technique in the field of environmental and groundwater studies (Das and Mukhopadhyay 2018; Rahmati et al. 2015).
In this method a pairwise comparison matrix is generated by comparing the assigned scores for each layer. The scores are generally assigned between 1 (equal importance) and 9 (extreme importance) (Table 2; Saaty 1990). In the AHP model, a pairwise comparison matrix for the 11 layers was created. And the normalized weights of the individual layers were created using the eigen vector method.
Saaty´s scale for assignment of weights and the pairwise comparison process (Saty 1980)
Equally important
More Important
Very Strongly
Strongly
Moderetely
Equally
Moderately
Strongely
Table 2: Saaty´s scale for assignment of weights and the pairwise comparison process (Saty 1980)
The weight of each thematic layer is derived from the maximum eigen value in the normalized eigen value in the pairwise comparison matrix. The reliability of the judgment is dependent on the Consistency Ratio (CR) and its value must be less than or equal to 0.1. In case it exceeds this limit, it is suggested to revise the process. CR is calculated as follows,
CR = CI/RI
Here RI is the Random Consistency Index (see Table 3) and CI is the Consistency Index, which is calculated as follows,
Random indices for matrices of various sizes
Matrix Size
\(\) \(CI=\frac{{\lambda }_{max}-\text{n}}{n-1}\)
In this equation, λ is the Principal eigen value of the matrix and n is the number factors used in the
estimation (Saty 1980).
Table 3: Random indices for matrices of various sizes
Groundwater potential zones were derived from 11 thematic layers integrated into the GIS environment to calculate the groundwater potential index (GWPI). This is done by Weighted Linear Combination (WLC), as suggested by Malczewski (1999).
$$GWPI=\sum _{w=1}^{m}\sum _{1}^{n} (Wj\times Xi)$$
Here GWPI is the Groundwater Potential Index, Xi is the normalized weight of the ith feature of the thematic layer, wj is the normalized weight of the jth thematic layer, m represents total number of themes, and n is the total number of classes in a theme.
4. Results And Discussion
4.1. Thematic Layers and Features in the CRB
Mapping and analysis of slope
Slope is an important geomorphological feature that affects the groundwater potential of a region and an important parameter in identifying groundwater recharge prospects (Fasche et al., 2014). Groundwater potential is greater in gentle slopes as more infiltration occurs due to the increased residence time. On the other hand, the increased runoff rate for steep slopes makes them less suitable for groundwater recharge. In this study, slope varies from 0 to 80.44%, the majority of the area having a slope between 0 to 4.73 %. The highest slopes were found mostly in the western region of the study area. Based on this, the slope range between 0-4.73% was given a weightage of 7 (very good) with 4 (moderate), 3(moderate) and 2 (poor)given to subsequent classes (see Fig. 3). Generally, steep slopes are given lower weights and gentle slope with higher weights (Agarwal and Garg 2016).
Figure 3 Slope Map
Mapping and analysis of aspect
Aspect is an important terrain characteristic that affects the groundwater recharge characteristics of a basin. It is the direction of slope usually measured clockwise from 0 to 360°. Zero means the aspect facing north, 90 ,180 is south-facing, and 270 is west-facing. In arid and semi-arid regions, microclimatic changes are dependent on slope exposure direction and drainage basin development. Thus, aspect has a direct influence on the microclimates (Hadley 1961; Al-Saady et al., 2016). An aspect map of the study area is shown in Fig. 4. The aspect of CRB is trending towards all the directions, however higher weightage is given to the flat terrains and the lowest to those areas trending north. terrains and the lowest to the north trending areas.
Figure 4 Aspect Map
Mapping and analysis of groundwater level
In Unsaturated conditions, the upper level of saturated underground surface in which water pressure equals the atmospheric pressure is known as groundwater table (Freeze and Cherry 1979). Depth to the water table is a measure of groundwater recharge or discharge. When the water table is deep, the flow is towards the water table via percolation and infiltration. On the other hand, when the water table meets the land surface, the flow is away from the water table. (Poehls and Smith 2009). So, for potential recharge zones, the higher depth to the water table is an essential factor. The groundwater level in the study area varies from 0 to 21m below ground level. Most of the region in the study area falls between 6 and 11m below ground level(mbgl) (Fig. 5). As the depth to the water table increases, the possibility of recharge increases because of the increased storage in aquifers. Greater weight is given to those regions where the depth to the water table is high and vice versa.
Figure 5 Groundwater Level Map
Mapping and analysis of rainfall
Rainfall data for the past 44 years has been collected by the India Meteorological Department (IMD). A spatial variation map of the rainfall was created with the IDW interpolation method. The minimum and maximum rainfall received in the Chennai Basin were 770 and 1570 mm, respectively. The coastal part of the basin is receiving a high amount of rainfall, compared to the western part. A spatial map of rainfall in the Chennai Basin is given in Fig. 6.
Figure 6 Rainfall map
Mapping and analysis of Lithology
The geology of an area is one of the key factors in groundwater potential zone delimitation. Various geological formations have different water bearing capacities and subsurface flow characteristics. A considerable variation in the water bearing capacities may be found between sedimentary to Igneous and metamorphic rocks of recent to Precambrian periods (see Fig. 7). The other principal factor is the weathering of the rocks, which increase the groundwater potential of the area. The Chennai basin exhibited a wide range (sedimentary-Metamorphic-Igneous) of geological formations. Starting from the eastern coastal region, a long stretch of coastal Alluvium is observed throughout the study area and charockites in the southern edge. From the middle to north alluvial formation begins and extend to greater areas towards the west. Laterites are found in the northern part of the basin and also spread in between the alluvial formations. In the southern part, just near to the charnockite, there are thick shale sandstone formations. The western end of the area is marked by biotite hornblende gneiss, with lengthy patch of hornblende-epidote. Geology of the area suggests that the possible high groundwater bearing formations are alluvium and sandstones Considering the geology of the area, alluviums, sandstone are promising locations for groundwater development. However, the degree of weathering, lineament and fractures determine the same for the hard rock formations.
Figure 7Geological of the study area
Mapping and analysis of Drainage
The drainage network map of the Chennai Basin is shown in Fig. 8. The Chennai Basin has many rivers, tanks and reservoirs. Since the basin has mostly permeable formations as well as built-up areas, the drainage density of the basin is very low. Thus, the main features are classified as rivers, tanks/reservoirs and others. Suitable ranking is given to each feature depending on their groundwater potentiality.
Figure 8 Drainage Map
Mapping and analysis of soils
Soils in the study area can be classified into Clay, clay loam, loamy sand, Sand, Sandy Clay, Sandy-clay- loam, Sandy loam, as shown in Fig. 9. Along the beeches sandy and sandy clay loam types are present, and these formations are permeable and can be a aquifer. These formations are extensively found along the East Coast Road (ECR), and holds good for agricultural activities.
Clayey soils are found in northern region, namely Gummidipoondi, Ponneri, Minjur, Madhavaram and Manali, and in the western portion of the East Coast Road around Thiruporur. These soils have much lower infiltration rates. Weights assigned for the soil layer are mainly based on the infiltration rate. As a result, clayey soils have been given the lowest weights, while sandy soil receives the highest.
Figure 9 Soil map
Mapping and analysis of land use
The rapid increase in population resulted in extensive changes in the land use pattern of the CRB. Groundwater recharge is largely controlled by the landuse. Hence, a proper understanding of land use is necessary for the sustainable groundwater development. Overexploitation of water resources for various purposes has a severe impact on the water system. Increased water exploitation has led to a reduction in water recharge and groundwater storage of the area. The various land use patterns of the study area are presented in Fig. 10. Cropland, mangroves, shrubs, and Casuarina cover a majority of the study area.
Figure.10 Land-use map of Chennai Basin
Mapping and analysis of Lineaments
Lineaments are rectilinear alignments observed on the surface of the earth, which are representations of geological or geomorphological events. They can be observed as straight lines in digital data, which represent a continuous series of pixels having similar terrain values. Large scale lineaments can be identified from remotely sensed images. Lineaments are the primary indicators of secondary porosity and also for potential sources of water supply. The presence of lineaments is observed in all directions in the study area. The lineament density seems to be very high in Takkolam, Cooum, Sriperumbudur, Thiruvallur, Thiruthani, etc (Fig. 11).
Figure 11: Lineaments Map
Mapping and analysis of geomorphology
The Chennai Basin has exceptionally versatile geomorphological features with beaches, Beach Ridges, Beach terraces, Buried Pediments, Wash Plains, Salt Pans, Swamps, Swale, Deltaic Plains, Deep Pediment, Pediment and Shallow Pediment, Buried Course & Channels, Tertiary Uplands, Flood Plains, Piedmont, Inter Fluveo. The presence of rivers, coastal regions, hills and plain land make this area an example of a complex geomorphological set up. It has a long coastal belt on the eastern boundary where the city of Chennai is located, with one of the thickest populated regions in southern India. The NE boundary of the study area has a long portion with Duricrust, a hard mineral layer on top of the sedimentary formations. Tertiary laterites are found as patches all along the basin. In the western part structural hills are visible. Lower Gondwana formations are seen in the southern and central parts. Upper Gondwana formations are Pediments seen in the Tambaam region pat of the city. At the northern part, along the state boundary of Andhra Pradesh, tertiary uplands form a larger area and the same is present in available north of the city. A detailed geomorphological map of the study area is shown in Fig. 12.
Figure12 Geomorphology map of the study area.
Mapping and analysis of Depth to bed Rock
Depth to bed rock is a representation of the thickness of unconsolidated or weathered formations in the area. The depth to bed rock of CRB varied from11 to 829m (Fig. 13). Southern coastal regions and western part of CRB has weathered thickness upto 45m. The deepest depth to bed rock is found in the extreme north region. Based on these values, three major categories such as poor, moderate and very good, with corresponding weights 5 ,6 and 8 were assigned for the layer.
Figure 13: depth to bed rock
4.2. Normalized weights for thematic maps
The pairwise comparison matrix of the groundwater prospecting thematic layers were derived based on the AHP method. The weights were normalized and the weights for individual thematic layers are calculated by Eigen vector method (Table 4).
Pairwise comparison matrix of 11 groundwater prospecting parameters for AHP
Thematic Layer
GWL
Ground Water level (GWL)
Drainage(D)
Lineament (Ln)
Table 5 shows the normalized weights of each layer and their corresponding total weightage. The maximum weightage shows the most influential parameter, and the minimum weightage represents the least influential parameter. In the CRB, depth to bed rock or aquifer thickness play the most important role with 20.33% weightage. With 15%, geomorphology was the second most important parameter. The relative importance of the other parameters are as follows, lineament (12.37%), land use (12%), soil (9%), drainage (8.2%), geology (6.6%), rainfall (4.9%), aspect (4.5%), water level (4.2%), and slope (2.6%).
Calculation of Normalized weights for 11 thematic layers of CRB
Normalized weight
GEOL
To check the consistency of the assigned weights, the consistency ratio was calculated using the formula mentioned in the methodology. For the 11 layers (n = 11), the consistency ratio was found as 0.98, which is < 0.10. This means that the weight assessment was consistent.
Table 4: Pairwise comparison matrix of 11 groundwater prospecting parameters for AHP
Table 5: Calculation of normalized weights for 11 thematic layers of CRB
Table 6: Weight assessment and normalization of different features of groundwater prospecting thematic layers
Weight assessment and normalization of different features of groundwater prospecting thematic layers
Normalized weight of features
Level of Suitable
Pediment
Buried Pediment Shallow
Buried Pediment Moderate
Buried Pediment Deep
Structural hill
Valley Fill
Lateritic Gravel
Duricrust
Marshy Land
Tertiary Upland
Pediment Outcrop
Swales
Paleo Deltaic Plain
Quartz-Graval Tertiary
Upper Gondwana
Pulicate Lake
Alluvial Plain
Laterite Tertiary
B Canal
Lower Gondwana
Gullies
Pedi Plain
Old River Course
Biotite Hornblend Gnies
Quartz Gravel
Sandstone Conglomarate
Shale Sandstone
Epidote Hornblend
Charnockite
Tank/Reservoir
Sandyloam
Loamysand
Waterbody
Sandyclayloam
Sandyclay
Clayloam
Misce
Landuse
Brickiln_industries
HF Ind_IT
Alkalinity Salinity
Back Water
casurina
Crop Land
Juliflora
Navey
Pulicat Lake
Salt Pan
Landwithscrub
Land without Scrub
Hills with Shrub
Dry Crop
Lineament
Buffer 500
Depth to Bed Rock
North 0-22.5
Northeast 22.5–67.5
East 67.5-112.5
Southeast 112.5-157.5
South 157.5-202.5
Southwest 202.5-247.5
West 247.5-292.5
Northwest 292.5-337.5
North 337.5–360
0-2.42
4.3. Groundwater potential Zones
In this study, groundwater potential zones were identified using AHP aided methodology. The output map generated by Weighted Linear Combination (WLC) shows five different classes such as very poor, poor, moderate, good and very good potential for groundwater. The results are presented in Table 7 and the spatial variation map for the groundwater potential is shown in Fig. 14.
Classification of Groundwater potential Zones in CRB
Groundwater potential class
% of Area
The groundwater potential is very poor in the western regions especially the northwestern region and the coastal region of the Chennai and Kancheepuram area. It is 15.4% of the total area with a land area of 930.9 km2. Geologically, the western region is mostly Charnockite formation, and the coastal region is alluvium deposits. It is obvious that the massive Charnockite is not a good aquifer unless there are factures or joints. In general alluviums have good water bearing capacity, but the potential is showing low in the analysis. This can be explained by the over-exploited aquifer system, especially in the South Chennai coastal aquifer. Increased urbanization and population growth directly affect the groundwater potential of these regions. These results agree with the land use map of the study area. There are many barren lands in the western region, and this is also a reason for the poor potential of this area. The second classification of groundwater potential was "poor", it is also located mostly in the same geographic regions of the very poor category and possess the same geological and geomorphological characteristics. This category is second largest among the five classes, with a share of 22.86% spread over 1379.2 km2 in the CRB. Moderate potential zones are dominant among all classes with an area of 1636 Km2, 27% of the total land area of the CRB. Moderate potential is observed throughout the basin, however, it is largely located in the SE and NE regions, as well as the central part. The major geology for this group is alluvium, coastal alluvium, and Charnockite formations. There is a patch in the middle area of the basin extending north from Gummidipoondi in the Thiruvallur district to south in Kaveripakkam in the Vellore district which has good and very good groundwater potential. This includes some bordering portions of the Chennai district as well. Both these classes together constitute 34% of the study area and spread over 2100 km2. This area is mostly covered by alluvial formations resulting from the river system and its deposits.
Table 7: Classification of Groundwater potential Zones in CRB
Figure 14: Spatial variation map of Groundwater potential in CRB
4.4. Cross verification of the Groundwater potential zones with Bore hole data
The groundwater potential map is created based on the available maps of different factors using GIS based AHP method. However, it is necessary to verify the results using actual data collected from the field. This study used 51 bore holes, in which the specific capacity was compared with the groundwater potential mapped using GIS based method. The Yield data from the field is classified into low yield (< 3 lps), moderate yield (3–6 lps) and high yield (> 6 lps). The details of the procedure and the results of the comparison are provided in Table 8.
Comparison of Groundwater potential zones with actual field data
Actual Specific Capacity
Interference on actual yield
Expected yield from map
Suitability Agreement
Low to moderate
Ayyanavaram
Tandiarpet
Very low to low
Mandaiveli
Besent Nagar
Moderate to high
Arumbakkam
Redhills
Tirumalisai
Pallikaranai
Solinganallur
Alathur
poor to moderate
Thaiyur
Ottivakkam
Melakottaiyur
Madampakkam
Ponmar
Padappai
Sriperumbadur
Good to very good
Purisai
Kunrathur
Thandalam
Arani
Ennore
Kaverirajapuram
Korattur
Nabalur
Nandiambakkam
Pallipattu
Pazhverkadu
moderate to good
Pondeswaram
Red Hills
Thandarai
Thervoy
Thirumullaivoyal
Tiruthani(taluk)
Tiruvotriyur
Uthukkottai
Veppampattu
RK Pet
Panapakkam
Sumaithangi
Kunnattur
Sholingur
The accuracy calculations were done as follows:
Number of boreholes = 51
Number of boreholes agreed with the result of mapping = 40
Number of boreholes disagreed with the result of mapping = 11
Accuracy of the potential mapping = 40/51 ×100 = 78.43%
This suggests that among the 51 wells, the prediction was reliable in 40 wells. This means that 78% of the potential delineation agreed with the actual data from the field. The use of AHP based groundwater potential zonation thus proved to be successful and can be adopted as a cost-effective groundwater prospecting method.
Table 8: Comparison of Groundwater potential zones with actual field data
This study used GIS, remote sensing, multi-criteria decision-making techniques, and analytical hierarchy process (AHP) for the delineation of groundwater potential zones in the Chennai River Basin (CRB). 11 different thematic layers that has direct influence on groundwater potential were used in this study and the weights were given using AHP methodology. The resultant thematic layers were merged using overlay analysis and the groundwater potential maps were generated. According to these maps, 35% of the study area has good to very good groundwater potential, 27% has moderate potential and 38% has poor to very poor groundwater potential. Groundwater in the coastal region and the urban area shows very poor potential and the high potential is observed in the central regions. The resultant potential map was compared with the bore hole discharge data collected from the field. The specific capacity of the wells was used for comparing the potential. This analysis shows that more than 78% of the field data is matched with the predicted map. This suggests that the method has greater accuracy in mapping the groundwater potential zones with comparatively less cost.
Agarwal R, Garg PK (2016) Remote Sensing and GIS Based Groundwater Potential & Recharge Zones Mapping Using Multi-Criteria Decision Making Technique. Water Resources Management 30 (1):243–260
Al-Saady Y, Al-Suhail QA, Al-Tawash BS, Othman AA (2016) Drainage network extraction and morphometric analysis using remote sensing and GIS mapping techniques (Lesser Zab River Basin, Iraq and Iran). Environmental Earth Sciences: 2016, 75:1243
Andreas N. Angelakis Konstantinos S. Voudouris, Ilias Mariolakos (2016) Groundwater utilization through the centuries focusing οn the Hellenic civilizations. Hydrogeology Journal 24(5):1311–1324.
Bhola PK, Zabel AK, Rajaveni SP, Indu, SN, Monninkhoff B, Elango L (2013) Integrated surface water and groundwater modeling for optimizing MAR structures in the Chennai region. In: 8th Annual International Symposium on Managed Aquifer Recharge - ISMAR8. Beijing.
CGWB (2008) District Groundwater Brochure Chennai District Tamil Nadu. Technical report series
Charalambous AN and Garratt P (2009) Recharge–abstraction relationships and sustainable yield in the Arani–Kortalaiyar groundwater basin, India. Quarterly Journal of Engineering Geology and Hydrogeology 42 (1): 39-50.
Das N, Mukhopadhyay S (2018) Application of multi-criteria decision-making technique for the assessment of groundwater potential zones: a study on Birbhum district, West Bengal, India Environment, Development and Sustainability. https://doi.org/10.1007/s10668-018-0227-7
Dhawan V (2017) Water and Agriculture in India Background paper for the South Asia expert panel during the Global Forum for Food and Agriculture (GFFA). Federail Ministry of Food and Agriculture (BMEL) pages 1-27. https://www.oav.de/fileadmin/user_upload/5_Publikationen/5_Studien/170118_Study_Water_Agriculture_India.pdf
Elango L and Manickam S 1986 Groundwater quality of Madras aquifer: A study on Panjetti–Ponneri–Minjur area; Indian Geol. J. 61 41–49
Elbeih SF (2014) An overview of integrated remote sensing and GIS for groundwater mapping in Egypt. Ain Shams Engineering Journal 6 (1) 1-15
FAO: AQUASTAT – FAO's global information system on water and agriculture, FAO, http://www.fao.org/nr/aquastat, last access: 16 March 2010, Rome, Italy, 2010
Hadley, R. F. (1961), Some effects of microclimate on slope morphology and drainage basin development, in Geological Survey Research 1961, edited by Department of the Interior United States Geological Survey, pp. B32–B34, Gov. Print. Off., Washington, D. C.
Freeze RA, Cherry J (1979) Groundwater. Prentice-Hall, Hoboken, NJ
Jennifer MA, Arul C (2012) Groundwater Management–A Policy Perspective. World Academy of Science, Engineering and Technology International Journal of Geological and Environmental Engineering Vol:6, No:2, pages 1-8.
Nair S , Rajaveni S P , Schneider M and Elango L (2015) Geochemical and isotopic signatures for the identification of seawater intrusion in an alluvial aquifer. J. Earth Syst. Sci. 124( 6):1281–1291
Elango L, Ramachandran S, Chowdary YSN (1992) Groundwater quality in coastal regions of South Madras. Ind J Environ Health 34:318– 325
Magesh NS, Chandrasekar N, Soundranayagam JP (2011) Delineation of groundwater potential zones in Theni district, Tamil Nadu, using remote sensing, GIS and MIF techniques. Geoscience Frontiers 3(2): 189-196
Murthy KSR, Amminedu E, Rao VV (2003) Integration of Thematic Maps Through GIS for Identification of Groundwater Potential Zones. Journal of the Indian Society of Remote Sensing 31(3) 197-210.
Nag SK, Ghosh P (2013) Delineation of groundwater potential zone in Chhatna Block, Bankura District, West Bengal, India using remote sensing and GIS techniques. Environmental Earth Sciences70(5) 2115–212.
Nagaraju D, Papanna C, Siddalingamurthy S. Mahadevaswamy G, Lakshmamma, Lone, MS, Nagesh, PC, Rao K (2011) Identification of groundwater potential zones through remote sensing and gis techniques in Kollegal taluk, Chamarajnagar District, Karnataka, India. International Journal of Earth Sciences and Engineering, 4 (4): 651-658.
Prasad RK, Mondal NC, Banerjee P, Nandakumar MV, Singh VS (2008) Deciphering potential groundwater zone in hard rock through the application of GIS. Environmental Geology 55:467–475
Rahmati O, Nazari Samani A, Mahdavi M, Pourghasemi, HR, Zeinivand H (2015) Groundwater potential mapping at Kurdistan region of Iran using analytic hierarchy process and GIS. Arabian Journal of Geosciences, 8(9): 7059–7071
Raicy MC, Elango L (2017) Percolation pond as a method of managed aquifer recharge in a coastal saline aquifer: a case study on the criteria for site selection and its impacts. J Earth Syst Sci 126:1– 16
Sathish S, Elango L, Rajesh R, Sarma VS (2011) Assessment of seawater mixing in a coastal aquifer by high resolution electrical resistivity tomography. Int J Environ Sci Technol 8:483–492
Singh A, Panda SN, Kumar KS, Sharma CS (2013) Artificial Groundwater Recharge Zones Mapping Using Remote Sensing and GIS: A Case Study in Indian Punjab. Environmental Management 52:61–71
Suganthi S, Elango L, Subramanian S K (2013) Groundwater potential zonation by Remote Sensing and GIS techniques and its relation to the Groundwater level in the Coastal part of the Arani and Koratalai River Basin, Southern India. Earth Sciences Research Journal 17(2)87 – 95.
Saaty TL (1980) The analytic hierarchy process: planning, priority setting, resource allocation. McGraw-Hill, New York | CommonCrawl |
kde meaning python
I hope this article provides some intuition for how KDE works. GitHub is home to over 50 million developers working together. KConfig is a Framework to deal with storing and retrieving configuration settings. The best model can be retrieved by using the best_estimator_ field of the GridSearchCV object. Only, there isn't much in the way of documentation for the KDE+Python combo. We use seaborn in combination with matplotlib, the Python plotting module. In this post, we'll cover three of Seaborn's most useful functions: factorplot, pairplot, and jointgrid. In … The plot below shows a simple distribution. The code below shows the entire process: Let's experiment with different kernels and see how they estimate the probability density function for our synthetic data. But for that price, we get a … In our case, the bins will be an interval of time representing the delay of the flights and the count will be the number of flights falling into that interval. Get occassional tutorials, guides, and reviews in your inbox. The test points are given by: Now we will create a KernelDensity object and use the fit() method to find the score of each sample as shown in the code below. Bandwidth: 0.05 We can clearly see that increasing the bandwidth results in a smoother estimate. The scikit-learn library allows the tuning of the bandwidth parameter via cross-validation and returns the parameter value that maximizes the log-likelihood of data. Uniform Distribution. The framework KDE offers is flexible, easy to understand, and since it is based on C++ object-oriented in nature, which fits in beautifully with Pythons pervasive object-orientedness. You can vote up the ones you like or vote down the ones you don't like, and go to the original project or source file by following the links above each example. Changing the bandwidth changes the shape of the kernel: a lower bandwidth means only points very close to the current position are given any weight, which leads to the estimate looking squiggly; a higher bandwidth means a shallow kernel where distant points can contribute. Until recently, I didn't know how this part of scipy works, and the following describes roughly how I figured out what it does. kernel=gaussian and bandwidth=1. Click to lock the kernel function to a particular location. EpanechnikovNormalUniformTriangular The blue line shows an estimate of the underlying distribution, this is what KDE produces. Exploring denisty estimation with various kernels in Python. Sticking with the Pandas library, you can create and overlay density plots using plot.kde(), which is available for both Series and DataFrame objects. One is an asymmetric log-normal distribution and the other one is a Gaussian distribution. It depicts the probability density at different values in a continuous variable. It is important to select a balanced value for this parameter. Kernel Density Estimation is a method to estimate the frequency of a given value given a random sample. Amplitude: 3.00. KDE Plot described as Kernel Density Estimate is used for visualizing the Probability Density of a continuous variable. Often shortened to KDE, it's a technique that let's you create a smooth curve given a set of data. Get occassional tutorials, guides, and jobs in your inbox. KDE is a working desktop environment that offers a lot of functionality. Instead, given a kernel \(K\), the mean value will be the convolution of the true density with the kernel. Use the dropdown to see how changing the kernel affects the estimate. Try it Yourself » Difference Between Normal and Poisson Distribution. for each location on the blue line. The white circles on Learn more about kernel density estimation. p(0) = \frac{1}{(5)(10)} ( 0.8+0.9+1+0.9+0.8 ) = 0.088 In statistics, kernel density estimation (KDE) is a non-parametric way to estimate the probability density function of a random variable. curve is. This article is an introduction to kernel density estimation using Python's machine learning library scikit-learn. Related course: Matplotlib Examples and Video Course. A kernel density estimate (KDE) plot is a method for visualizing the distribution of observations in a dataset, analagous to a histogram. Perhaps one of the simplest and useful distribution is the uniform distribution. There are several options available for computing kernel density estimates in Python. Given a sample of independent, identically distributed (i.i.d) observations \((x_1,x_2,\ldots,x_n)\) of a random variable from an unknown source distribution, the kernel density estimate, is given by: $$ The concept of weighting the distances of our observations from a particular point, xxx , Representation of a kernel-density estimate using Gaussian kernels. Let's see how the above observations could also be achieved by using jointplot() function and setting the attribute kind to KDE. The red curve indicates how the point distances are weighted, and is called the kernel function. Understand your data better with visualizations! … Various kernels are discussed later in this article, but just to understand the math, let's take a look at a simple example. No spam ever. A histogram divides the variable into bins, counts the data points in each bin, and shows the bins on the x-axis and the counts on the y-axis. When KDE was first released, it acquired the name Kool desktop environment, which was then abbreviated as K desktop environment. kind: (optional) This parameter take Kind of plot to draw. 2.8.2. gaussian_kde works for both uni-variate and multi-variate data. While being an intuitive and simple way for density estimation for unknown source distributions, a data scientist should use it with caution as the curse of dimensionality can slow it down considerably. In this section, we will explore the motivation and uses of KDE. In Python, I am attempting to find a way to plot/rescale kde's so that they match up with the histograms of the data that they are fitted to: The above is a nice example of what I am going for, but for some data sources , the scaling gets completely screwed up, and you get … Let's experiment with different values of bandwidth to see how it affects density estimation. It is used for non-parametric analysis. The KernelDensity() method uses two default parameters, i.e. In statistics, kernel density estimation (KDE) is a non-parametric way to estimate the probability density function (PDF) of a random variable. It features a group-oriented API. "shape" of some data, as a kind of continuous replacement for the discrete histogram. The extension of such a region is defined through a constant h called bandwidth (the name has been chosen to support the meaning of a limited area where the value is positive). Getting Started Mean Median Mode Standard Deviation Percentile Data Distribution Normal Data Distribution Scatter Plot Linear Regression Polynomial Regression Multiple Regression Scale Train/Test Decision Tree Python MySQL MySQL Get Started MySQL Create Database MySQL Create Table MySQL Insert MySQL Select MySQL Where MySQL Order By MySQL Delete MySQL Drop Table MySQL Update … KDE is an international free software community that develops free and open-source software.As a central development hub, it provides tools and resources that allow collaborative work on this kind of software. color: (optional) This parameter take Color used for the plot elements. Kernel density estimation is a fundamental data smoothing problem where inferences about the population are made, based on a finite data sample. K desktop environment (KDE) is a desktop working platform with a graphical user interface (GUI) released in the form of an open-source package. Kernel density estimation is a really useful statistical tool higher, indicating that probability of seeing a point at that location. We can also plot a single graph for multiple samples which helps in … I'll be making more of these Kernel density estimation (KDE) is in some senses an algorithm which takes the mixture-of-Gaussians idea to its logical extreme: it uses a mixture consisting of one Gaussian component per point, resulting in an essentially non-parametric estimator of density. It is used for non-parametric analysis. Using different Kernel Density Estimation (KDE) is a way to estimate the probability density function of a continuous random variable. It can also be used to generate points that where \(K(a)\) is the kernel function and \(h\) is the smoothing parameter, also called the bandwidth. #!python import numpy as np from fastkde import fastKDE import pylab as PP #Generate two random variables dataset (representing 100000 pairs of datapoints) N = 2e5 var1 = 50*np.random.normal(size=N) + 0.1 var2 = 0.01*np.random.normal(size=N) - 300 #Do the self-consistent density estimate myPDF,axes = fastKDE.pdf(var1,var2) #Extract the axes from the axis list v1,v2 = axes … It's another very awesome method to visualize the bivariate distribution. the "brighter" a selection is, the more likely that location is. However, for cosine, linear, and tophat kernels GridSearchCV() might give a runtime warning due to some scores resulting in -inf values. A kernel density estimation (KDE) is a way to estimate the probability density function (PDF) of the random variable that "underlies" our sample. The library is an excellent resource for common regression and distribution plots, but where Seaborn really shines is in its ability to visualize many different features at once. Kernel density estimation (KDE) is a non-parametric method for estimating the probability density function of a given random variable. We also avoid boundaries issues linked with the choices of where the bars of the histogram start and stop. That's all for now, thanks for reading! This article is an introduction to kernel density estimation using Python's machine learning library scikit-learn. scikit-learn allows kernel density estimation using different kernel functions: A simple way to understand the way these kernels work is to plot them. But for that price, we get a much narrower variation on the values. Kernel density estimation in scikit-learn is implemented in the sklearn.neighbors.KernelDensity estimator, which uses the Ball Tree or KD Tree for efficient queries (see Nearest Neighbors for a discussion of these). It includes automatic bandwidth determination. can be expressed mathematically as follows: The variable KKK represents the kernel function. Plug the above in the formula for \(p(x)\): $$ It is also referred to by its traditional name, the Parzen-Rosenblatt Window method, after its discoverers. In the code below, -inf scores for test points are omitted in the my_scores() custom scoring function and a mean value is returned. Very small bandwidth values result in spiky and jittery curves, while very high values result in a very generalized smooth curve that misses out on important details. Setting the hist flag to False in distplot will yield the kernel density estimation plot. Kernel: Next, estimate the density of all points around zero and plot the density along the y-axis. However, instead of simply counting the number of samples belonging to the hypervolume, we now approximate this value using a smooth kernel function K(x i ; h) with some important features: Idyll: the software used to write this post, Learn more about kernel density estimation. The shape of the distribution can be viewed by plotting the density score for each point, as given below: The previous example is not a very impressive estimate of the density function, attributed mainly to the default parameters. The following are 30 code examples for showing how to use scipy.stats.gaussian_kde().These examples are extracted from open source projects. To find the shape of the estimated density function, we can generate a set of points equidistant from each other and estimate the kernel density at each point. When KDE was first released, it acquired the name Kool desktop environment, which was then abbreviated as K desktop environment. KDE is a means of data smoothing. Can the new data points or a single data point say np.array([0.56]) be used by the trained KDE to predict whether it belongs to the target distribution or not? Idyll: the software used to write this post. You can vote up the ones you like or vote down the ones you don't like, and go to the original project or source file by following the links above each example. Mehreen Saeed, Reading and Writing XML Files in Python with Pandas, Simple NLP in Python with TextBlob: N-Grams Detection, Improve your skills by solving one coding problem every day, Get the solutions the next morning via email. The following function returns 2000 data points: The code below stores the points in x_train. scipy.stats.gaussian_kde¶ class scipy.stats.gaussian_kde (dataset, bw_method = None, weights = None) [source] ¶. The distplot() function combines the matplotlib hist function with the seaborn kdeplot() and rugplot() functions. KDE Frameworks includes two icon themes for your applications. Kernel density estimation is a way to estimate the probability density function (PDF) of a random variable in a non-parametric way. $$. Kernel Density Estimation (KDE) is a way to estimate the probability density function of a continuous random variable. With only one dimension how hard can i t be to effectively display the data? The following are 30 code examples for showing how to use scipy.stats.gaussian_kde().These examples are extracted from open source projects. To understand how KDE is used in practice, lets start with some points. The first half of the plot is in agreement with the log-normal distribution and the second half of the plot models the normal distribution quite well. Dismiss Grow your team on GitHub. This means building a model using a sample of only one value, for example, 0. Example Distplot example. It is also referred to by its traditional name, the Parzen-Rosenblatt Window method, after its discoverers. If we've seen more points nearby, the estimate is KDE is an international free software community that develops free and open-source software. Use the control below to modify bandwidth, and notice how the estimate changes. That's not the end of this, next comes KDE plot. Kernel density estimation (KDE) is a non-parametric method for estimating the probability density function of a given random variable. look like they came from a certain dataset - this behavior can power simple By Subscribe to our newsletter! A great way to get started exploring a single variable is with the histogram. Often shortened to KDE, it's a technique that let's you create a smooth curve given a set of data.. Let's look at the optimal kernel density estimate using the Gaussian kernel and print the value of bandwidth as well: Now, this density estimate seems to model the data very well. It generates code based on XML files. Kernel density estimation is a way to estimate the probability density function (PDF) of a random variable in a non-parametric way. This can be useful if you want to visualize just the gaussian_kde works for both uni-variate and multi-variate data. Python NumPy NumPy Intro NumPy ... sns.distplot(random.poisson(lam=2, size=1000), kde=False) plt.show() Result. This can be useful if you want to visualize just the "shape" of some data, as a kind … Similar to scipy.kde_gaussian and statsmodels.nonparametric.kernel_density.KDEMultivariateConditional, we implemented nadaraya waston kernel density and kernel conditional probability estimator using cuda through cupy. While there are several ways of computing the kernel density estimate in Python, we'll use the popular machine learning library scikit-learn for this purpose. We can use GridSearchCV(), as before, to find the optimal bandwidth value. Kernel density estimation is a really useful statistical tool with an intimidating name. K desktop environment (KDE) is a desktop working platform with a graphical user interface (GUI) released in the form of an open-source package. This function uses Gaussian kernels and includes automatic bandwidth determination. It works with INI files and XDG-compliant cascading directories. Kernel Density Estimation¶. However, it is much faster than cpu version and it maximise the use of GPU memory. Just released! The above example shows how different kernels estimate the density in different ways. with an intimidating name. A kernel density estimation (KDE) is a way to estimate the probability density function (PDF) of the random variable that "underlies" our sample. Kernel density estimation (KDE) is in some senses an algorithm which takes the mixture-of-Gaussians idea to its logical extreme: it uses a mixture consisting of one Gaussian component per point, resulting in an essentially non-parametric estimator of density. There are no output value from .plot(kind='kde'), it returns a axes object. Often shortened to KDE, it's a technique Note that the KDE doesn't tend toward the true density. answered Jul 16, 2019 by Kunal The KDE is calculated by weighting the distances of all the data points we've seen Kernel density estimation is a really useful statistical tool with an intimidating name. Build the foundation you'll need to provision, deploy, and run Node.js applications in the AWS cloud. KDE represents the data using a continuous probability density curve in one or more dimensions. The solution to the problem of the discontinuity of histograms can be effectively addressed with a simple method. Kernel density estimation (KDE) is a non-parametric method for estimating the probability density function of a given random variable. Kernel density estimation is a way to estimate the probability density function (PDF) of a random variable in a non-parametric way. that let's you create a smooth curve given a set of data. Learn Lambda, EC2, S3, SQS, and more! One possible way to address this issue is to write a custom scoring function for GridSearchCV(). In scipy.stats we can find a class to estimate and use a gaussian kernel density estimator, scipy.stats.stats.gaussian_kde. Next we'll see how different kernel functions affect the estimate. A distplot plots a univariate distribution of observations. Kernel Density Estimation in Python Sun 01 December 2013 Last week Michael Lerner posted a nice explanation of the relationship between histograms and kernel density estimation (KDE). One final step is to set up GridSearchCV() so that it not only discovers the optimum bandwidth, but also the optimal kernel for our example data. simulations, where simulated objects are modeled off of real data. Normal distribution is continous whereas poisson is discrete. For a long time, I got by using the simple histogram which shows the location of values, the spread of the data, and the shape of the data (normal, skewed, bimodal, etc.) KDE is a means of data smoothing. x, y: These parameters take Data or names of variables in "data". Setting the hist flag to False in distplot will yield the kernel density estimation plot. The question of the optimal KDE implementation for any situation, however, is not entirely straightforward, and depends a lot on what your particular goals are. Note that the KDE doesn't tend toward the true density. I am an educator and I love mathematics and data science! The KDE algorithm takes a parameter, bandwidth, that affects how "smooth" the resulting The points are colored according to this function. The function we can use to achieve this is GridSearchCV(), which requires different values of the bandwidth parameter. Instead, given a kernel \(K\), the mean value will be the convolution of the true density with the kernel. Introduction This article is an introduction to kernel density estimation using Python's machine learning library scikit-learn. The approach is explained further in the user guide. As a central development hub, it provides tools and resources … Given a set of observations (xi)1 ≤ i ≤ n. We assume the observations are a random sampling of a probability distribution f. We first consider the kernel estimator: data: (optional) This parameter take DataFrame when "x" and "y" are variable names. Seaborn is a Python data visualization library with an emphasis on statistical plots. The examples are given for univariate data, however it can also be applied to data with multiple dimensions. As more points build up, their silhouette will roughly correspond to that distribution, however to see, reach out on twitter. We can either make a scatter plot of these points along the y-axis or we can generate a histogram of these points. This is not necessarily the best scheme to handle -inf score values and some other strategy can be adopted, depending upon the data in question. With over 275+ pages, you'll learn the ins and outs of visualizing data in Python with popular libraries like Matplotlib, Seaborn, Bokeh, and more. we have no way of knowing its true value. your screen were sampled from some unknown distribution. Join them to grow your own development teams, manage permissions, and collaborate on projects. The raw values can be accessed by _x and _y method of the matplotlib.lines.Line2D object in the plot Here is the final code that also plots the final density estimate and its tuned parameters in the plot title: Kernel density estimation using scikit-learn's library sklearn.neighbors has been discussed in this article. $\endgroup$ – Arun Apr 27 at 12:51 KDE Plot using Seaborn. kernel functions will produce different estimates. $$. Suppose we have the sample points [-2,-1,0,1,2], with a linear kernel given by: \(K(a)= 1-\frac{|a|}{h}\) and \(h=10\). This can be useful if you want to visualize just the "shape" of some data, as a kind … p(x) = \frac{1}{nh} \Sigma_{j=1}^{n}K(\frac{x-x_j}{h}) It is also referred to by its traditional name, the Parzen-Rosenblatt Window method, after its discoverers. It includes automatic bandwidth determination. Import the following libraries in your code: To demonstrate kernel density estimation, synthetic data is generated from two different types of distributions. Plotting a single variable seems like it should be easy. Here are the four KDE implementations I'm aware of in the SciPy/Scikits stack: In SciPy: gaussian_kde. Unsubscribe at any time. For example: kde.score(np.asarray([0.5, -0.2, 0.44, 10.2]).reshape(-1, 1)) Out[44]: -2046065.0310518318 This large negative score has very little meaning. quick explainer posts, so if you have an idea for a concept you'd like Move your mouse over the graphic to see how the data points contribute to the estimation — Breeze icons is a modern, recogniseable theme which fits in with all form factors.
Timer Ball Or Ultra Ball, Cat Definition Medical, Spelman College Basketball Team, Jual High End Audio, Primordial Soup Experiment, I3 Kde Notifications, Does Kraft Still Make Old English Cheese Slices,
kde meaning python 2020 | CommonCrawl |
The New International Encyclopædia/Coal
< The New International Encyclopædia
←Coaita
The New International Encyclopædia
Coal Apples→
Edition of 1905. Written by Heinrich Ries and others. See also Coal on Wikipedia, and the disclaimer.
2188803The New International Encyclopædia — Coal
COAL (AS. col, OHG. kolo, Ger. Kohle; ultimately connected with Skt. jval, to blaze, and probably with Ir., Gael. gual, coal). A mineral fuel of solid character, found and used in many countries. The name is a word common to all the languages of the Gothic stock, and seems allied to the Latin calere, to be hot; as also 'to glow,' and 'kiln.' The word 'coal' has often prefixed to it some qualifying word, to distinguish different kinds of coal; such as cannel coal, stone coal, pea coal, etc.
Origin. Coal is one of the most important economic minerals, and is of vegetable origin. When vegetable matter accumulates under water it undergoes a slow process of decomposition, gradually giving off its nitrogen, hydrogen, oxygen, and some carbon, the result of which if carried far enough is the formation of a mass of carbon. Peat (q.v.), the material so often found underlying swampy tracts in north temperate zones, represents the first stage in the coal-forming process, and the further stages are obtained by the burial of these vegetable deposits under great loads of sediment, where they become subjected to pressure, and at times to heat also. This effects a series of changes, especially consolidation and loss of oxygen, and gives a series of products, whose nature depends on the degree to which the original vegetable matter has been changed. The products are known as lignite, bituminous coal, and anthracite coal; these three types being connected by all degrees of intermediate stages. In Carboniferous times certain regions were covered by rank and luxuriant vegetation which grew upon swampy land slightly raised above the level of the sea. As the plants died, their remains fell into the water of the swamp, and slowly formed an accumulation of vegetable matter of increasing thickness. By slow subsidence this thick layer of vegetable matter sank below the water, and became gradually covered by sand, mud, or other mineral sediments, washed out from the shore. Successive elevations and depressions, with intervening accumulations, may thus have yielded successive beds. Subsequent elevation, folding of the earth's crust, and accompanying metamorphism, followed by erosion of the surface, has exposed to view the edges of the once deeply buried beds of coal.
Composition. The following analyses of peat, lignite or brown coal, and true coal indicate the changes which vegetable matter undergoes by decay and pressure:
Ultimate Analyses of Peat and Coals
COMPONENTS PEAT LIGNITE BITUMINOUS COAL ANTHRACITE
Wyo. Robertson
Co., Texas. Whiteside,
Tenn. Brazil,
Ind. Spring Mt.,
Pa. Crested
Butte, Colo.
% % % % % % %
Water 20.00 7.35 16.40 1.04 5.45 1.97 0.72
Carbon 47.20 63.65 54.46 78.83 76.05 91.40 82.50
Hydrogen 4.90 4.60 4.41 5.51 5.88 2.59 5.15
} {\displaystyle \scriptstyle {\left.{\begin{matrix}\ \\\ \end{matrix}}\right\}\,}} 22.90
Nitrogen 1.40 1.12 1.37 0.21 1.12
Sulphur ........ 0.76 0.96 2.61 0.80 0.71 0.85
Ash 5.00 2.80 7.70 6.89 2.32 3.04 6.04
These analyses bring out well the general relations of the different elements, and the increase in carbon toward the anthracite end of the series; still they give but little information concerning the commercial value of the coal. The usual custom in making a commercial analysis is to determine the form in which these elements occur—that is, the amount of water, volatile hydrocarbon, fixed carbon, sulphur, and ash. This proximate analysis is also used as the basis of classification of coals. Thus:
COMPONENTS Peat Lignite Bituminous
coal Anthracite
% % % %
Moisture 78.89 13.29 1.30 2.94
Volatile hydrocarbons 13.84 59.86 20.87 4.29
Fixed carbon 6.49 18.52 67.20 88.18
Ash 0.78 8.32 8.80 4.04
Sulphur ....... 2.36 1.83 0.55
A proximate analysis like the above is of practical value, since it gives us a better conception of the coal worth. Thus the freedom of burning increases with the amount of volatile hydrocarbons, while the heating power depends on the amount of fixed carbon present. Sulphur is an injurious constituent when the coal is to be used in the manufacture of gas or for metallurgical purposes; while ash is undesirable, since it displaces so much carbon, and if it contains fusible impurities such as iron, lime, or alkalies, it causes clinkering. Moisture retards the heating power of the coal until it is driven off. Since the heating power of coal is its most important property, this is often tested by means of an apparatus known as a 'calorimeter.' (See Calorimetry.) The principle of the test depends on the determination of the weight of water which can be converted into steam at 212° F. under atmospheric pressure with one pound of coal. (See also Heat.) In addition to the varieties of coal given above, there may be mentioned semi-bituminous coal and cannel coal. The properties of the different varieties are as follows:
Anthracite contains 84 per cent. or more of fixed carbon, and also little ash, sulphur, and moisture. It has great heating power, and burns with a smokeless flame. Owing to its comparative scarcity, it commands a higher price than the bituminous. Anthracite is dense, has a shining lustre, and usually breaks with a smooth conchoidal fracture. It is estimated by some geologists that about ten inches of peat is required to make one inch of anthracite coal. In the United States anthracite coal is confined chiefly to the eastern edge of the Appalachians in Pennsylvania, where the folding of the rocks has been very intense, and where the coal-seams have been subjected to great pressure. It is also known in Colorado, near Crested Butte, where the bituminous coals have been locally changed to anthracite by the heat of basalt intrusions. It is mined extensively in England, and large quantities are known in China.
Bituminous Coal contains 50 to 75 per cent. of fixed carbon, and 25 to 30 per cent. volatile hydrocarbons. It burns with a rather long and smoky flame, and is also much used for steaming purposes. Many bituminous coals have the property of coking or caking (see Coke) when heated to redness. Most of the Carboniferous and many of the Mesozoic coals of the United States are bituminous.
Semi-Bituminous Coal resembles bituminous coal in appearance, but is intermediate between it and anthracite. It contains from 70 to 84 per cent. of fixed carbon, and is considered of superior value for steaming purposes. This variety is obtained from Pennsylvania, Maryland, and West Virginia.
Cannel Coal is a variety of coal very rich in volatile hydrocarbons, and found sparingly in parts of Kentucky, Ohio, and Indiana. Its chief use is as a gas-enricher, since it yields 8000 to 15,000 cubic feet of gas per ton. Cannel coal is so called because it burns with a bright flame like a candle, and the name parrot coal was given to it in Scotland, from the crackling or chattering noise it makes while burning. It is very compact in texture and may even have an oily look; certain forms found in England admit of being polished, and ornamental articles have been made from them and sold under the name of jet.
Lignite, or Brown Coal, is a partially formed coal, containing much moisture and volatile matter. It often shows the woody structure of peat and burns very easily, but gives off little heat.
History and Use. The value of coal does not seem to have been known to the ancients, nor is it well known at what time it began to be used for fuel. Some say that it was used by the ancient Britons; at all events, it was an article of household consumption to some extent during the Anglo-Saxon period as early as A.D. 852. There seems to be reason for thinking that England was the first European country in which coal was used in any considerable quantities. In America the deposits near Richmond, Va., were discovered in 1701, and mining was begun in 1750, while anthracite was first produced in 1793. Extended coal-mining in the United States did not really begin, however, until about 1820. Since that time up to the present, the increase has been about 3500 per cent. In 1822 the amount of coal mined in Virginia was about 48,000 long tons. Now the production for the United States is about 270,000,000 short tons, or greater than that of any other country of the world.
Coal is used largely for domestic purposes, either as fuel or, in the form of gas, for illumination. Its use for the latter purpose is, however, not so widespread as formerly, water-gas having superseded it to a considerable extent. In the production of steam for motive power it also finds important applications. It is furthermore widely employed in the metallurgical industry in the form of either coal or coke, and in this connection may serve both as a fuel and as a reducing agent. Coke (q.v.) is made only from bituminous coal. Lignite seldom has much value as a fuel, owing to the large percentage of moisture that it contains. Because of this moisture it tends to crack in drying, and must therefore be used soon after mining, and in localities where it does not require long transportation from mine to market. This is true, for instance, of some of the lignite deposits in Colorado which are near the Denver market, and therefore possess commercial value. Lignite has sometimes been successfully used in the manufacture of producer gas, and indeed even peat has been found adaptable for this purpose.
Coal Areas. The leading coal-producing countries of the present day are the United States, Great Britain, Germany, France, Belgium, Austria-Hungary, and Russia. The Russian coal-fields are probably the most extensive in Europe. In the Far East coal is known in India, the Malay Archipelago, Japan, and China. The coal-fields of the last-named country are probably the greatest in the world, and may become a source of European supply. Up to the present time they have not been developed in a systematic manner. Italy, Spain, Sweden, Australia, New Zealand, Borneo, the Philippine Islands, and many countries in Africa also produce coal; while in America deposits are worked in Canada, Mexico, Chile, and Argentina, and are known to occur in Colombia and Peru.
COPYRIGHT, 1902, DODD, MEAD & COMPANY.
United States. The coal-fields of the United States are especially extensive; indeed, in some instances the deposits of a single State exceed those of Germany or France in area. They are separable into several regions, the divisions being geographical and not geological. The geological ages of the coals in 1, 2, 3, 4, and 6 (table on next pagebelow) are all Carboniferous, except small Triassic areas in Virginia and North Carolina. Those of 5 are Cretaceous and Tertiary.
By far the most important of these regions is the Appalachian, which takes in portions of Pennsylvania, Ohio, West Virginia, Virginia, Maryland, Eastern Kentucky, Eastern Tennessee, Georgia, North Carolina, and Alabama. It is about 750 miles long, and 70 to 80 miles wide. The coals are all bituminous or semi-bituminous with the exception of those at the northeastern end, in Pennsylvania, where close folding of the rocks has changed the bituminous into anthracite coal. In general, the rocks at the upper or northern end of the Appalachian belt are folded, while those of the lower end, as in Alabama, are often faulted in addition, so that the coal-miner frequently finds the coal-seam suddenly broken off. The Carboniferous section of this region has been described in the article Carboniferous System, from which it may be seen that the coal-beds occupy more or less well-marked stratigraphic positions. The maximum thickness of strata is from 2,500 to 3000 feet; the seams measuring 120 feet near Pottsville, 62 feet at Wilkesbarre, and 25 feet at Pittsburg, showing a gradual diminution in a westward direction. The most persistent coal deposit is the Pittsburg seam, which is known over an area measuring 225 by 100 miles, and has a thickness varying from 2 to 14 feet. In Alabama the deposits are distributed among three districts—the Warrior, Cahawba, and Coosa, named after the rivers that drain them. The anthracite district of Pennsylvania occupies an area of about 470 square miles on the left bank of the Susquehanna. The strata between Pottsville and Wyoming, which belong to the lowest portion of the coal-measures, are probably about 3000 feet thick; but it is difficult to make an exact estimate, because of the numerous folds and contortions. There are from 10 to 12 seams, each over three feet in thickness. The principal one, known as the Mammoth or Baltimore vein, is 29 feet thick at Wilkesbarre, and in some places exceeds even 60 feet. Many of the Appalachian coals, notably those of western Pennsylvania, West Virginia, and Alabama, produce excellent coke. The Ohio coals do not yield good coke. In most of the other coal-fields of the country the coal-fieds lie comparatively flat, and the basins are quite shallow.
Coal Fields of the United States
Region State Area
Square Miles
1. Appalachian { {\displaystyle \scriptstyle {\left\{{\begin{matrix}\ \\\\\ \\\ \\\ \\\ \\\ \\\ \\\ \\\ \ \end{matrix}}\right.}}
Pennsylvania 10,700
Ohio 10,000
Kentucky 9,000
West Virginia 16,000
Tennessee 5,100
North Carolina 2,700
Alabama 8,660
Total 63,275
2. Northern Michigan 6,700
3. Central { {\displaystyle \scriptstyle {\left\{{\begin{matrix}\ \\\\\ \ \end{matrix}}\right.}}
Indiana 6,450
Illinois 36,800
4. Western Central { {\displaystyle \scriptstyle {\left\{{\begin{matrix}\ \\\\\ \\\ \\\ \\\ \\\ \ \end{matrix}}\right.}}
Missouri 26,700
Iowa 18,000
Nebraska 3,200
Arkansas 9,100
Indian Ter. 20,000
Texas 4,500
5. Cordilleran { {\displaystyle \scriptstyle {\left\{{\begin{matrix}\ \\\\\ \\\ \\\ \\\ \\\ \\\ \\\ \\\ \ \end{matrix}}\right.}}
Colorado Unknown
New Mexico "
Utah "
Wyoming "
South Dakota "
North Dakota "
Montana "
California "
Oregon "
Washington "
6. Rhode Island Rhode Island Small
The Michigan area is a small one in the lower peninsula of Michigan. It forms a circular basin with a diameter of about 50 miles. The coals are bituminous, non-coking, and are mined chiefly for local use. The seams range from a few inches to three feet in thickness.
The Central area includes parts of western Kentucky, Indiana, and Illinois, and lies chiefly within the latter State. These coals are all bituminous, of Carboniferous age, and are used chiefly for steaming. The thickness of the Carboniferous System varies from 1200 to 1400 feet in southern Illinois, to about 600 feet in Indiana, and the workable coal-seams vary in number from 7 to 12 in Illinois, and their thickness from three to eight feet. The 'block coal' of Indiana has quite a reputation. The Western Central area includes Iowa, Missouri, Arkansas, Indian Territory, Kansas, and part of Texas. Here again there is an abundance of bituminous coal, which has been developed chiefly in Iowa and Missouri, while Kansas is now coming into prominence. The coals of this area are chiefly adapted to smithing and steaming purposes, and, so far as tried, Kansas yields the only coking varieties.
CROSS-SECTION OF ANTHRACITE COAL MEASURES (PENNSYLVANIA).
The Cordilleran area comprises the coal regions of Colorado, New Mexico, Utah, Wyoming, South Dakota, North Dakota, Montana, California, Oregon, and Washington. In this field are found many varieties grading between lignite and anthracite. They are all of either Tertiary or Cretaceous age, and their discovery showed the incorrectness of the old classification, which included all post-Carboniferous coals under lignite. Colorado is perhaps the most important producer, having a number of good bituminous seams. Those in the vicinity of Crested Butte have been changed locally to anthracite by the metamorphic action of igneous intrusions. Excellent coking coals are found near Trinidad. The New Mexican coals are in part an extension of the Colorado veins, and bear a good reputation, as do also many of the Wyoming coals. California has little fuel of good quality, and has for many years drawn on Australia for its coal-supply, but in recent years the coals of Oregon, Washington, and British Columbia have become a source of supply.
The rocks of the small Rhode Island area have been so highly metamorphosed that the coal has been altered to graphitic anthracite. It is sold on the market as amorphous graphite, and has little value as a fuel.
Canada. The Acadian field includes deposits in Nova Scotia and New Brunswick, the former being quite important. The coals are bituminous and of good quality. In the mountain ranges of British Columbia extensive coal-seams have been discovered, and they are now under development. A good quality of coke is made from the coal of Crow's Nest Pass, which finds a market at the British Columbian smelters. The most productive mines of the Pacific Coast are located on Vancouver Island, whence large shipments of bituminous coal are made to San Francisco and other ports in the Western United States.
South America. Coal, probably of Carboniferous age, is found in the Brazilian provinces of São Pedro, Rio Grande do Sul. Santa Catharina. also in the neighboring Republic of Uruguay. Very little development work has been done in the fields, and the output is inconsiderable. In Argentina and Chile, where Cretaceous coal occurs, there is more activity; but these countries still depend largely upon Great Britain for their supplies. In Peru both Cretaceous and Carboniferous deposits are found at various points in the interior, the former occupying a position on the first rise of the Andes, while the latter occurs in higher ground and at a greater distance from the coast.
United Kingdom. Next to the coal-fields of the United States, those of the United Kingdom are of the greatest economic importance. Within the limits of England, Scotland, and Wales there are more than twenty areas underlain by seams of anthracite, bituminous, and cannel coal. The largest of these areas is that of South Wales, in Monmouthshire and Pembrokeshire, which has a length of about 50 miles and a width of nearly 20 miles. The coal-measures form an elliptical basin, and are several thousand feet in thickness. Coal is found in three horizons, of which the upper has no less than 82 seams, measuring 180 feet in all. The lowest horizon yields valuable steam and blast-furnace coal. In the north of England the coal-fields of Lancashire, Derbyshire, and Yorkshire are the largest. The Lancashire field is of irregular quadrilateral form, with a width of about 18 miles from north to south, and a length from east to west of more than 50 miles. It includes about 100 feet of coal in workable seams, which dip at a high angle and are much broken by faulting. The Yorkshire and Derbyshire measures occupy a single area that extends for a distance of about 60 miles from Bradford on the north to near Derby on the south, and has a breadth of from 3 to 32 miles. They yield bituminous coal, excellent for steaming and iron-making purposes. North of the Yorkshire field is the large basin of Northumberland and Durham, from which steaming, coking, and house coals are produced. In Scotland the coal-measures are extensively developed in Ayrshire, Lanarkshire, Stirlingshire, and Fifeshire. The productive coal-fields of the United Kingdom belong to the Carboniferous period; brown coal of Jurassic or Tertiary age is known to occur, but the seams are too small to be profitably exploited. The exports of coal from this country are of great importance, amounting in 1900 to 51,638,000 short tons, valued at $193,032,000. Much of the coal goes to Italy, Russia, Holland, and to the European countries that possess small resources of the mineral, while the remainder is exported to the more remote parts of the world.
Further details regarding the distribution of coal will be found under the titles of countries.
Output. The world's annual production at the present time is about 850,000,000 short tons; the output in 1900, according to The Mineral Industry, was distributed as follows:
COUNTRY SHORT TONS
United States 268,315,433
Great Britain 252,176,352
Germany 164,850,131
Austria-Hungary 43,020,049
France 36,673,945
Belgium 25,863,063
Russia 16,500,000
Canada 5,608,636
Japan 8,189,490
Spain 2,847,199
Sweden 278,132
Africa 546,563
New South Wales 6,168,337
New Zealand 1,225,603
Queensland 656,939
Victoria 237,052
Tasmania 56,822
Other Countries 2,755,750
Total 843,247,288
It is interesting to follow the progress of the United States as a coal-producer. In 1868 Great Britain produced 3.6 times as much coal as the United States, while Germany's product that year was 15 per cent. greater than that of the United States. In 1871 the United States exceeded Germany's output by about 10 per cent., but afterwards fell back to third place until in 1877 she once more sprang forward, and gained on both Germany and Great Britain. In 1899 the United States led the world, and supplied nearly 32 per cent. of its production.
The average price of bituminous coal at the mines in the United States, per short ton, varied between 1893 and 1900 from $0.80 to $1.04; while that of anthracite was between $1.41 and $1.59 for the same period. The total number of laborers employed during 1900 was 449,181, of which number 144,206 were anthracite miners.
During the closing years of the nineteenth century European countries have been confronted with a most serious problem—the exhaustion of their coal-supply. This condition was emphasized in 1899 and 1900 by the occurrence of strikes in the Wales cool regions, by war in South Africa, and by a stimulation of industries in Germany which required much additional coal. Prospecting having shown but little reserve material, the most natural result was to look to the United States, and in 1900 there began a movement of coal to Europe, which may before many years assume large proportions. Ocean freights are the present great drawback.
Mining of Coal. The presence of coal in paying quantities having been determined by prospecting and geological surveys, the next consideration is to extract this coal from seams. No definite rules can be given for the selection of a method of mining that will cover all conditions; each mine furnishes a distinct and separate problem. Every system of mining, however, aims to extract the maximum amount of the deposit in the best marketable shape and at a minimum cost and danger. Speaking broadly, all methods of mining come under the head of either open working or closed working. Open working is employed when the deposits have no overburden of barren rock or earth, or where this overburden is of such small depth that it can be easily and cheaply removed, leaving the coal deposit exposed. The mining of such exposed seams of coal is really a process of excavation or quarrying, and the machines used in making open-pit excavations and in quarrying are applicable to the work. Closed working is adopted when the depth of the overburden is so great that the mining must be conducted underground. The first task in opening up underground coal-seams is to secure access to the seam by means of shafts, slopes, or tunnels. Shafts are vertical openings from the ground surface to the coal-seams. In the United States shafts are usually made square or rectangular in form. This practice is largely due to the fact that timber is used for lining shafts. In Europe round or oval shafts are frequently employed with linings of brick, iron, or masonry.
COAL-MINING
1. THE OLD WAY—With hand pick.2. THE MODERN WAY—With machine pick.
Generally the shafts are divided into two or more compartments, in each of which is installed an elevator for hoisting the coal-cars to the surface. The number of compartments in a shaft and their arrangements depend upon the particular use to which the shaft is to be put, the number of shafts employed, and their depths. Where the seams are comparatively near the surface, it is usually cheaper to sink a number of two or three compartment shafts than it is to haul all the ore to one large shaft; while, when the shafts are very deep, it is preferable to sink a smaller number of four or six compartment shafts and extend the underground haulage to a single shaft over a great area of the workings. Where timber lining is employed, a stronger construction is obtained by placing the compartments side by side in a long, narrow shaft than by grouping them in a square shaft. In shallow mines separate shafts are often employed for hoisting and for pumping, ventilation and ladder-ways. One of the largest coal-mine shafts in America is situated at Wilkesbarre, Pa.; it is 1039 feet deep, 12 × 52 feet in size, and has five compartments. The methods of sinking mine shafts are essentially the same as those used in sinking shafts for tunnels. (See Tunnel.) Slopes are openings begun at the outcrop of an inclined seam, which they follow down into the earth. Slopes are usually made with three compartments side by side, two of which are used as hoistways and the third for the traveling-way, piping, etc. When the dip of the slope is under 40 degrees the slope is made about seven feet high, but when the dip exceeds 40 degrees cages have to be used and a great height is necessary. Slopes are usually lined with timber. Tunnels are nearly horizontal passageways beginning on the side of a hill or mountain and extending into the earth until they meet the coal-seam; they are built for both haulage and drainage purposes, and are constructed like railway tunnels, except that the cross-section is usually much smaller, and that it is lined with timber instead of with permanent masonry. The forms of timbering used in coal-mining are various, and are of interest chiefly to the practical miner; special treatises should be consulted by those interested in the details. In a general way, it may be said that timber used for underground support in mines should be of a light and elastic variety of wood. Oak, beech, and similar woods are heavy and have great strength, but when they do break it is suddenly and without warning, thus bringing disaster to the miners who might escape if a tough wood were employed which gives warning of rupture by bending and cracking. It is a very common practice to employ preserved timber in mining work. See Forestry.
1. SULLIVAN ELECTRIC CHAIN MACHINE, Making "tight" or corner cut. 2. SULLIVAN ELECTRIC CHAIN MACHINE, Cutting across face of room.
The systems of working the coal-seams after access is attained to them by the means described are two, known as the room-and-pillar and the long-wall systems. The room-and-pillar method—also known as the pillar-and-chamber or board-and-pillar method, which may include the pillar-and-stall system—is the oldest of the systems, and the one very generally used in the United States. By this system, coal is first mined from a number of comparatively small places, called rooms, chambers, stalls, boards, etc., which are driven either square from or at an angle to the haulageway. Pillars are left to support the roof. In the long-wall method the whole face of the coal-seam is taken out, leaving no coal behind, and the roof is allowed to settle behind as the excavation progresses, care being taken to preserve haulageways through the falling material. Both the room-and-pillar and the long-wall methods are employed in various modifications, for the details of which special treatises on coal-mines should be consulted. The coal is cut from the seam by hand or by some form of coal-cutting machine. In America machine cutting is used extensively. There are four general types of machines in general use: Pick machines, chain-cutter machines, cutter-bar machines, and long-wall machines; the machines most used in America are pick machines and chain-cutter machines. Both compressed air and electricity are used for operating coal-cutting machines. Pick machines are very similar to a rock-drill; chain-cutter machines consist of a low metal bed-frame upon which is mounted a motor that rotates a chain to which suitable cutting teeth are attached. The ventilation of the workings, owing to the presence of gases, is a very important feature of coal-mining, and great care is taken to lay out the workings so as to facilitate ventilation. Mechanical ventilation by means of fans and blowers (see Blowing Machines) is usually employed. Hoisting in mines is accomplished by means of cages running up and down the shafts, and operated by large hoisting engines on the surface. There are two general systems of hoisting in use—hoisting without attempt to balance the load, in which the cage and its load are hoisted by the engine and lowered by gravity, and hoisting in balance, in which the descending cage or a special counter-balance assists the engine to hoist the loaded ascending cage. Haulage in mines is accomplished by animal power or by steam hoisting engines operating a system of rope haulage or by mine locomotives operated by steam, electricity, compressed air, or gasoline.
The preparation of mined coal for the market consists in screening the coal over bars and through revolving or over shaking screens, together with breaking it with rolls to produce the required market size. The large lumps of slate or other impurities are separated by hand, while the smaller portions are picked out by automatic pickers or by hand by boys or old men seated along the chutes leading to the shipping pockets or bins. When coal contains much sulphur, this is frequently removed by washing it with water in special washing plants.
Bibliography. Lesley, Manual of Coal and Its Topography (Philadelphia, 1850)—a good work, but difficult to find; Chance, "Coal-Mining," in Second Geological Survey of Pennsylvania, Report AC (Harrisburg, 1883); Hughes, A Textbook of Coal-Mining (London, 1899); Peel, Elementary Textbook of Coal-Mining (London, 1901); Macfarlane, The Coal Regions of America, Their Topogrnphy, Geology, and Development (New York, 1875); Nicolls, The Story of American Coals (Philadelphia, 1897); Lesley and others, "Reports on the Coal-Fields of Pennsylvania," in various publications of the Second Geological Survey of Pennsylvania (Harrisburg). Numerous scattered papers have been published in the following annuals and periodicals: Transactions of the American Institute of Mining Engineers (New York); The Mineral Industry (New York); The Engineering and Mining Journal (New York); Mines and Minerals (Scranton, Pa.); "Mineral Resources of the United States," United States Geological Survey (Washington). For foreign coal deposits, consult: Memoirs of the Geological Survey of Great Britain (London); Reports of Progress of the Geological Survey of the United Kingdom (London); Annales de la société géologique de Belgique (Liége, 1874 et seq.); Bulletin de la société belge de géologie, de paléontologie et d'hydrologie (Brussels, 1877 et seq.); Annales des mines (Paris, 1816 et seq.); Bulletin de la société géologique de France (Paris, 1896 et seq.); Lozé, Les charbons britanniques et leur épuisement (Paris, 1900); Zeitschrift für praktische Geologie (Berlin, 1893 et seq.). See Anthracite; Bituminous Coal; Carboniferous System; Coke; Culm; Cretaceous System; Peat; Tertiary System; Graphite; Carbon; Fire-Clay; and the articles on the different States and countries in which coal has been found.
Retrieved from "https://en.wikisource.org/w/index.php?title=The_New_International_Encyclopædia/Coal&oldid=6571885"
NIE no volume | CommonCrawl |
Count the Beat
Article by Nicky Goulder and Samantha Lodge
Published November 2006,December 2006,February 2011.
Can music-making help your pupils understand mathematical concepts such as fractions, ratios and probability? In autumn 2005, creative arts charity, Create, sent four professional musicians to maths classrooms to find out. In this article, Create's founders - Nicky Goulder and Samantha Lodge - reveal how maths books and marimbas can go hand-in-hand.
If you're a maths teacher, the thought of thirty children all playing tambourines and bongo drums may not immediately appeal, but does music-making have the potential to help your pupils understand mathematical concepts such as fractions, ratios and probability? Eager to explore this possibility, Create launched its pioneering cross-curricular maths and music project, Count the Beat, in October 2005. This involved four of Create's leading professional musicians taking music and maths workshops to 150 pupils (aged 9 to 11) at two primary schools in South East London.
The motivation behind every Create project is to give individuals a chance to be creative, develop valuable life skills (such as teamwork, listening and communication), become more confident and have fun! Since its foundation in July 2003, Create has run a great number of music projects in schools across the UK and, when you run as many music projects as Create, the parallels between maths and music are never far from your mind. Beats in a bar, for instance, translate into fractions, note lengths into ratios and symmetry is used to create harmonies and texture. The more music projects we ran, the more we thought about how we could consciously draw out these parallels and use music-making as a tool to aid teachers to communicate key mathematical principles.
We were further inspired by Dr Gordon Shaw's seminal 1999 study that identified a causal relationship between musical training and improved numerical ability. Taking place in Los Angeles, the study compared the maths test results of children who had been given piano lessons with those who had received traditional maths teaching assisted by the use of computer programs. Dr Shaw found that pupils who had piano lessons saw a significant improvement in their maths skills - particularly with regards to ratios and fractions . For Dr Shaw, this served to highlight the connection between pupils' music-making and their grasp of mathematical principles: "The learning of music emphasises thinking in space and time ... when children learn rhythm, they are learning ratios, fractions and proportion" (Dr Shaw, Neurological Research, 1999).
It was funding from Citigroup Foundation that finally allowed us to put our plans to take musicians into maths classrooms in motion and, in 2005, Count the Beat was born.
We embarked upon this project with two main aims: to help teachers deliver the Maths Curriculum in fun and imaginative ways; and to introduce children to the creative potential of maths. Our overall vision was to achieve a sense of seamless learning by bringing together supposedly separate areas of the curriculum. Activities began on 4 October 2005, when we took a team of four musicians to Key Stage 2 pupils at Lewisham Bridge School and Lucas Vale Primary School. It was a new area for us all, so we couldn't wait to see what the children and teachers would make of it!
Each session started with the class teacher delivering a brief lesson on a key mathematical principle, such as fractions, angles, ratios, measurement or probability. The rest of the session was spent bringing these principles to life through a range of creative music activities.
"Practical application of any theory is always good to reinforce an idea. Using music to teach maths is excellent both for maths and music ... the maths comes alive and the composition of music is more clearly understood." (Create musician)
A workshop that had children transforming fractions upon a number line into a musical score was particularly effective in highlighting the connection between these two disciplines. Leading on from the teacher's lesson on fractions, the musicians asked the class to create a number line of twenty units. They then divided the class into small groups, giving each group a different instrument to play. One group, for example, had xylophones, another had African djembe drums. Each group was then given three fractions that they had to plot on a number line. Once they had completed this task, one of the musicians began to clap a steady beat and asked the first group to beat their instruments when their fraction came up. To illustrate, let's say that this group had been given the fractions $\frac{2}{10}$, $\frac{3}{4}$ and $\frac{4}{5}$. This would mean that they would hit their given instruments on the 4th, 15th and 16th beats. After each group had practised playing their fractions on their own, the musicians helped the children to bring these different rhythms together to create a class musical score.
The activities that followed developed the number line/musical score link to allow children to put their own creative stamp on the music-making. Each group was given the opportunity to work alongside one of our musicians to create their own rhythms using a variety of instruments. The children then had a chance to put their knowledge of fractions to the test by mapping their own individual rhythms (each differentiated by a different colour pen) onto a group number lines which, again, acted as a musical score. As well as giving children a chance to place fractions in a temporal-spatial context, this exercise was fantastic at opening children's eyes to the creative possibility of maths. It showed how maths can be so much more than a "right" or "wrong" answer. Children who had perhaps struggled with the subject in the past were suddenly using mathematical principles to create something they were proud of, and that gave them a huge boost of confidence.
"By counting rhythm and learning the timing of beats, we have really seen an improvement in the pupils' mathematical ability ... the kids have loved this creative way of learning!" (Deputy Head of Lewisham Bridge School, Julia Holmes, speaking on behalf of the school's educators)
The Count the Beat activity that proved most popular with the pupils that took part was the one geared towards instilling the principles of probability. Here, the focus was less on the direct relationship between maths and music, and more on how music can provide children with fun and memorable ways of revising their maths curriculum and vocabulary.
"It makes maths more fun and easier. You're learning and you're also enjoying it!" (Year 5 pupil at Lucas Vale Primary School)
For this game, our musicians asked the participants to divide themselves into six groups, each of which was given the task of creating a probability-inspired chant (for example: "It's unlikely that Wigan will win the Premiership"). The groups then created rhythms and movements to accompany their chants. Once this had been completed, a musician stood in front of them all with a giant fluffy dice and gave them one rule: they could sing their chant as loudly as they wished, but only if the dice landed on their group's number. This exercise made the pupils subject to the laws of probability, as one group might get to chant ten times whilst another was forced into silence for the whole piece. Desperate to bring the roof down with their chant, the unfairness of probability quickly hit home!
Let's return to the question with which we began: does music-making have the potential to help your pupils understand mathematical concepts such as fractions, ratios and probability? Create's Count the Beat experience highlights two ways in which music-making can aid your pupils' understanding: firstly, it can provide a fun and imaginative way of familiarising children with maths topics and vocabulary; secondly, there are direct parallels between the skills needed to succeed in the maths and music classrooms that can be drawn out to reinforce each other. Music-making is also a brilliant means of demonstrating how mathematical principles can be applied in creative contexts and we certainly feel that our activities geared towards pupils' exploration of this were a particularly successful element of the project.
"The gains from this project have been wide reaching, from improved retention of mathematical vocabulary to increased self confidence, from a greater understanding of rhythm to a greater understanding of fractions, from an improvement in listening skills to greater knowledge of musical instruments. It is hard to separate the musical gains from the mathematical gains, but isn't that what learning should look like, seamless?" (Head of Lewisham Bridge School, Sue Sarna, and Head of Lucas Vale Primary School, Alexandra Hardy)
The first year of Count the Beat was a fantastic experience and our musicians are looking forward to building on the project's successes when we return to Lewisham Bridge and Lucas Vale schools in the autumn and spring terms of this new academic year.
If you feel inspired by this article, why don't you try out some of the Count the Beat activities described above in your own maths classroom!
Whilst a team of professional musicians and an extensive collection of percussion instruments are, of course, a big bonus, both the number line/musical score activity and the probability exercise can be adapted to your own maths classroom. Pencils can be drummed on table-tops for instance and yogurt pots can be filled with rice to make maracas.
With the number line activity, you might want to start by getting the children to create a simple number line of twenty units (you can make it harder once they've got the hang of it!). Then divide the class into three groups and give them each a simple set of fractions (for example one group could have $\frac{1}{2}$, $\frac{3}{10}$, $\frac{1}{5}$, another $\frac{1}{4}$, $\frac{2}{5}$, $\frac{8}{10}$ and the last $\frac{19}{20}$, 1, $\frac{3}{5}$). You don't need to worry if it doesn't make a great rhythm at first; in fact that could be worked into the exercise. You could then get them working in small groups to plot fractions that make a rhythm they like better.
For more inspiration, visit www.createarts.org.uk | CommonCrawl |
When is $A$ isomorphic to $A^3$?
Asked 10 years ago
This is totally elementary, but I have no idea how to solve it: let $A$ be an abelian group such that $A$ is isomorphic to $A^3$. is then $A$ isomorphic to $A^2$? probably no, but how construct a counterexample? you can also ask this in other categories as well, for example rings. if you restrict to Boolean rings, the question becomes a topological one which makes you think about fractals: let $X$ be stone space such that $X \cong X + X + X$, does it follow that $X \cong X + X$ (here + means disjoint union)?
edit: In the answers there are already counterexamples. but you may add others in other categories (with products/coproducts), especially if they are easy to understand :).
gr.group-theory ra.rings-and-algebras
Davood KHAJEHPOUR
Martin BrandenburgMartin Brandenburg
$\begingroup$ I saw a similar question called Zariski cancellation problem. Perhaps you find some interesting answers when you google for that. $\endgroup$ – user2146 Dec 30 '09 at 12:40
$\begingroup$ interesting. but why is zariski cancellation related to this? $\endgroup$ – Martin Brandenburg Dec 30 '09 at 13:12
$\begingroup$ I don't see any direct relation to Zariski cancellation. Moreover, I no longer feel confident that the result is true. But, Martin, why do you think it is probably false? $\endgroup$ – Pete L. Clark Dec 30 '09 at 13:44
$\begingroup$ a confirmative proof would knock me for a loop ;-). the naive approaches just don't work and rather (especially in geometric terms) suggest a counterexample. that's just intuition, nothing which I can make precise. $\endgroup$ – Martin Brandenburg Dec 30 '09 at 19:59
$\begingroup$ What is the situation when abelian groups are replaced with posets? $\endgroup$ – Richard Stanley Feb 5 '11 at 3:37
The answer to the first question is no. That is, there exists an abelian group $A$ isomorphic to $A^3$ but not $A^2$. This result is due to A.L.S. (Tony) Corner, and is the case $r = 2$ of the theorem described in the following Mathematical Review.
MR0169905 Corner, A.L.S., On a conjecture of Pierce concerning direct decomposition of Abelian groups. 1964 Proc. Colloq. Abelian Groups (Tihany, 1963) pp.43--48 Akademiai Kiado, Budapest.
It is shown that for any positive integer $r$ there exists a countable torsion-free abelian group $G$ such that the direct sum of $m$ copies of $G$ is isomorphic to the direct sum of $n$ copies of $G$ if and only if $m \equiv n (\mod r)$. This remarkable result is obtained from the author's theorem on the existence of torsion-free groups having a prescribed countable, reduced, torsion-free endomorphism ring by constructing a ring with suitable properties. It should be mentioned that the question of the existence of algebraic systems with the property stated above has been considered by several mathematicians. The author has been too generous in crediting this "conjecture" to the reviewer.
Reviewed by R.S. Pierce
Martin Sleziak
Tom LeinsterTom Leinster
Given a class of structures equipped with a product $(K, \times)$, the question of whether $X^3 \cong X \implies X^2 \cong X$ holds for every $X \in K$ is sometimes called the cube problem for $K$, and if it has a positive answer then $K$ is said to have the cube property. For the question to be nontrivial there need to be infinite structures $X \in K$ that are isomorphic to $X^3$. If there are such structures, it is usually possible to find one that witnesses the failure of the cube property for $K$, that is, an $X \in K$ such that $X \cong X^3$ but $X \not\cong X^2$. On the other hand, in rare cases the cube property does hold nontrivially.
I worked on the cube problem for the class of linear orders under the lexicographical product, and while doing so had a chance to look into the history of the problem for other classes of structures. The following list contains most of the results that I am aware of.
When the cube property fails
-- As far as I know, the first result concerning the failure of the cube property is due to Hanf, who showed in [1] that there exists a Boolean algebra $B$ isomorphic to $B^3$ but not $B^2$. Hanf's example is of size $2^{\aleph_0}$.
-- Tarski [2] and Jónsson [3] adapted Hanf's result to get examples showing the failure of the cube property for the class of semigroups, the class of groups, the class of rings, as well as other classes of algebraic structures. Most of their examples are also of size continuum.
It was unknown for some time after these results were published whether there exist countable examples witnessing the failure of the cube property for these various classes. Especially famous was the so-called "Tarski cube problem," which asked whether there exists a countable Boolean algebra isomorphic to its cube but not its square.
-- As Tom Leinster answered, Corner [4] showed, by a very different route, that indeed there exists a countable abelian group isomorphic to its cube but not its square. Later, Jones [5] constructed a finitely generated (necessarily non-abelian) group isomorphic to its cube but not its square.
-- Around the same time as Corner's result, several authors [6, 7] showed that there exist modules over certain rings isomorphic to their cubes but not their squares.
-- As Asher Kach answered, Tarski's cube problem was eventually solved by Ketonen, who showed in [8] that there does exist a countable Boolean algebra isomorphic to its cube but not its square.
Ketonen's result is actually far more general. Let $(BA, \times)$ denote the class of countable Boolean algebras under the direct product. If $(S, \cdot)$ is a semigroup, then $S$ is said to be represented in $(BA, \times)$ if there exists a map $i: S \rightarrow BA$ such that $i(a \cdot b) \cong i(a) \times i(b)$ and $a \neq b$ implies $i(a) \not\cong i(b)$. The statement that there exists a countable Boolean algebra isomorphic to its cube but not its square is equivalent to the statement that $\mathbb{Z}_2$ can be represented in $(BA, \times)$. Ketonen showed that every countable commutative semigroup can be represented in $(BA, \times)$.
-- Beginning in the 1970s, examples began to appear showing the failure of the cube property for various classes of relational structures. For example, Koubek, Nešetril, and Rödl showed that the cube property fails for the class of partial orders, as well as many other classes of relational structures in their paper [9].
-- Throughout the 70s and 80s, Trnková and her collaborators showed the failure of the cube property for a vast array of topological and relational classes of structures. Like Ketonen's result, her results are typically much more general.
Her topological results are summarized in [10], and references are given there. Some highlights:
There exists a compact metric space $X$ homeomorphic to $X^3$ but not $X^2$. More generally, every finite abelian group can be represented in the class of compact metric spaces.
Every finite abelian group can be represented in the class of separable, compact, Hausdorff, 0-dimensional spaces.
Every countable commutative semigroup can be represented in the class of countable paracompact spaces.
Every countable commutative semigroup can be represented in the class of countable Hausdorff spaces.
Her relational results mostly concern showing the failure of the cube property for the class of graphs. For example:
Every commutative semigroup can be represented in $(K, \times)$, where $K$ is the class of graphs and $\times$ can be taken to be the tensor (categorical) product, the cartesian product, or the strong product [11].
There exists a connected graph $G$ isomorphic to $G \times G \times G$ but not $G \times G$, where $\times$ can be taken to be the tensor product, or strong product. As of 1984, it was unknown whether $\times$ could be the cartesian product [12].
--Answering a question of Trnková, Orsatti and Rodino showed that there is even a connected topological space homeomorphic to its cube but not its square [13].
--More recently, as Bill Johnson answered, Gowers showed that there exists a Banach space linearly homeomorphic to its cube but not its square [14].
--Eklof and Shelah constructed in [15] an $\aleph_1$-separable group $G$ isomorphic to $G^3$ but not $G^2$, answering a question in ZFC that had previously only been answered under extra set theoretic hypotheses.
--Eklof revisited the cube problem for modules in [16].
When the cube property holds
There are rare instances when the cube property holds nontrivially.
-- It holds for the class of sets under the cartesian product: any set in bijection with its cube is either infinite, empty, or a singleton, and hence in bijection with its square. This can be proved easily using the Schroeder-Bernstein theorem, and thus holds even in the absence of choice.
-- Also easily, it also holds for the class of vector spaces over a given field.
-- Less trivially, it holds for the class of $\sigma$-complete Boolean algebras, since there is a Schroeder-Bernstein theorem for such algebras.
-- Trnková showed in [17] that the cube property holds for the class of countable metrizable spaces (where isomorphism means homeomorphism), and in [18] that it holds for the class of closed subspaces of Cantor space. The cube property fails for the class of $F_{\sigma \delta}$ subspaces of Cantor space. It is unknown if it holds or fails for $F_{\sigma}$ subspaces of Cantor space. See [10].
-- Koubek, Nešetril, and Rödl showed in [9] that the cube property holds for the class of equivalence relations.
-- I recently showed that the cube property holds for the class of linear orders under the lexicographical product. (My paper is here. See also this MO answer.)
A theme that comes out of the proofs of these results is that when the cube property holds nontrivially, usually some version of the Schroeder-Bernstein theorem is in play.
William Hanf, MR 108451 On some fundamental problems concerning isomorphism of Boolean algebras, Math. Scand. 5 (1957), 205--217.
Alfred Tarski, MR 108452 Remarks on direct products of commutative semigroups, Math. Scand. 5 (1957), 218--223.
Bjarni Jónsson, MR 108453 On isomorphism types of groups and other algebraic systems, Math. Scand. 5 (1957), 224--229.
Corner, A. L. S., "On a conjecture of Pierce concerning direct decompositions of Abelian groups." Proc. Colloq. Abelian Groups. 1964.
Jones, JM Tyrer, "On isomorphisms of direct powers." Studies in Logic and the Foundations of Mathematics 95 (1980): 215-245.
P. M. Cohn, MR 197511 Some remarks on the invariant basis property, Topology 5 (1966), 215--228.
W. G. Leavitt, MR 132764 The module type of a ring, Trans. Amer. Math. Soc. 103 (1962), 113--130.
Jussi Ketonen, MR 491391 The structure of countable Boolean algebras, Ann. of Math. (2) 108 (1978), no. 1, 41--89.
V. Koubek, J. Nešetril, and V. Rödl, MR 357669 Representing of groups and semigroups by products in categories of relations, Algebra Universalis 4 (1974), 336--341.
Vera Trnková, MR 2380275 Categorical aspects are useful for topology—after 30 years, Topology Appl. 155 (2008), no. 4, 362--373.
Trnková, Věra, and Václav Koubek, "Isomorphisms of products of infinite graphs." Commentationes Mathematicae Universitatis Carolinae 19.4 (1978): 639-652.
Trnková, Věra, "Isomorphisms of products of infinite connected graphs." Commentationes Mathematicae Universitatis Carolinae 25.2 (1984): 303-317.
A. Orsatti and N. Rodinò, MR 858335 Homeomorphisms between finite powers of topological spaces, Topology Appl. 23 (1986), no. 3, 271--277.
W. T. Gowers, MR 1374409 A solution to the Schroeder-Bernstein problem for Banach spaces, Bull. London Math. Soc. 28 (1996), no. 3, 297--304.
Paul C. Eklof and Saharon Shelah, MR 1485469 The Kaplansky test problems for $\aleph_1$-separable groups, Proc. Amer. Math. Soc. 126 (1998), no. 7, 1901--1907.
Eklof, Paul C., "Modules with strange decomposition properties." Infinite Length Modules. Birkhäuser Basel, 2000. 75-87.
Trnková, Věra, "Homeomorphisms of powers of metric spaces." Commentationes Mathematicae Universitatis Carolinae 21.1 (1980): 41-53.
Vera Trnková, MR 580990 Isomorphisms of sums of countable Boolean algebras, Proc. Amer. Math. Soc. 80 (1980), no. 3, 389--392.
Garrett ErvinGarrett Ervin
$\begingroup$ With regards to the question of Trnková about whether there exists a connected graph isomorphic to it's cube but not it's square with respect to the cartesian product, I believe the fact that there is no such graph follows from a theorem of Imrich/Miller (see for example "Weak cartesian products of graphs" by Miller) that says that every connected graph has a unique representation as a weak cartesian product of prime factors (where the weak cartesian product is a component of the cartesian product). $\endgroup$ – Joshua Erde Aug 23 '18 at 9:42
The Banach space version of this, where A is a Banach space and "isomorphism" means "linear homeomorphism", was a famous problem solved by Tim Gowers (Bull. London Math. Soc. 28 (1996), 297-304), using the space he and Bernard Maurey constructed that had no subspace with an uncondtional basis.
Bill JohnsonBill Johnson
$\begingroup$ at the risk of labouring the response, thought I'd just elaborate on Bill Johnson's answer: Gowers' construction provides a negative answer (i.e. X is isomorphic as a B. space to X \oplus X \oplus X but not to X \oplus X ) $\endgroup$ – Yemon Choi Dec 31 '09 at 0:30
The answer is negative for the class of countable Boolean algebras. The reference is Jussi Ketonen's "The Structure of Countable Boolean Algebras" (Annals of Mathematics [Second Series], Vol. 108, 1978, No. 1, pp. 41-89). There, Ketonen shows any countable commutative semigroup can be embedded into the monoid of countable Boolean algebras. The proof of this is rather involved.
The answer is positive for the class of linear orders (replacing product with concatenation). Lindenbaum showed for any linear orders $y$ and $z$, if $y$ is an initial segment of $z$ and $z$ is an end segment of $y$, then $y \cong z$. Taking $x+x$ for $y$ and $x = x+x+x$ for $z$ suffices. A reference is Joseph Rosenstein's "Linear Orderings" (Academic Press Inc., New York, 1982, p.22). The proof of this is rather straightforward.
Asher M. KachAsher M. Kach
$\begingroup$ Doesn't the first paragraph contradict Tom's proof? $\endgroup$ – Martin Brandenburg Feb 2 '12 at 8:48
$\begingroup$ The second one is very interesting, 1+. $\endgroup$ – Martin Brandenburg Feb 2 '12 at 8:48
Edit: In the comment below, Emil Jeřábek points out that my proof is wrong. But I'll leave this answer here for posterity.
Here's a partial answer to the Stone space question. The answer is yes for metrizable Stone spaces: if $X \cong X + X + X$ then $X \cong X + X$. I assume you're using $+$ to denote coproduct of topological spaces.
Proof: Write $I(X)$ for the set of isolated points of a topological set $X$. (A point is isolated if, as a singleton subset, it is open.) Then $I(X + Y) \cong I(X) + I(Y)$ for all $X$ and $Y$. So, supposing that $X \cong 3X$, we have $I(X) \cong 3I(X)$. But $X$ is compact, so $I(X)$ is finite, so $I(X)$ is empty. Hence $X$ is a compact, metrizable, totally disconnected space with no isolated points. A classical theorem then implies that $X$ is either empty or homeomorphic to the Cantor set. In either case, $X \cong X + X$.
I guess metrizability of the Stone space corresponds to countability of the corresponding Boolean ring.
The topological theory of Stone spaces is more subtle in the non-metrizable case, if I remember correctly.
$\begingroup$ A metrizable Stone space can have infinitely many isolated points: take e.g. $\{0\}\cup\{1/(n+1):n\in\omega\}\subseteq\mathbb R$. In fact, there are countable Stone spaces of arbitrary large countable Cantor–Bendixson rank. $\endgroup$ – Emil Jeřábek supports Monica Feb 2 '12 at 11:41
$\begingroup$ Thank you Emil for this clarification. Somehow I took the finiteness of $I(X)$ for granted. $\endgroup$ – Martin Brandenburg Feb 3 '12 at 7:59
Not the answer you're looking for? Browse other questions tagged gr.group-theory ra.rings-and-algebras or ask your own question.
If $G \times G \cong H \times H$, then is $G \cong H$?
Groups with $G^n \cong G$ for some integer $n$
About direct products of groups
$A$ is isomorphic to $A \oplus \mathbb{Z}^2$, but not to $A \oplus \mathbb{Z}$
An order type $\tau$ equal to its power $\tau^n, n>2$
Space $X$ such that $X^\lambda\cong X$ for some $\lambda$
Rank versus free-rank of a module
Examples of groups such that order isomorphism of the subgroups of $G\times G$ and $H\times H$ does not imply isomorphism of $G$ and $H$
$n$-product-periodic topological spaces
Square and cube?
Non-isomorphic groups with isomorphic nth powers (and similarly in other categories)
When are unions of isomorphic groups isomorphic?
A "mother of all groups"? What kind of structures have "mother of all"s?
IBN for algebraic theories
If $B\subseteq A$ are free & finite rank $R$-algebras, is $R\to A \otimes_B R$ injective?
Basic Algebraic Applications of Stationary Sets?
When is it okay to intersect infinite families of proper classes? | CommonCrawl |
Tag: shot noise
Campbell's theorem (formula)
In a previous post, I wrote about the concept of shot noise of a point process. In the simplest terms, shot noise is just the sum of some function over all the points of a point process. The name stems from the original mathematical models of the noise in old electronic devices, which was compared to shot (used in guns) hitting a surface.
In this post I will present a result known as Campbell's theorem or Campbell's formula, which gives the expectation of shot noise as as simple integral expression. This both a general holding for all point processes. It is also useful, as shot noise naturally arises in mathematical models. One application is wireless network models, where the interference term is shot noise.
But to present the main result, I first need to give some basics of point processes, most of which I already covered in this post.
Point process basics
We consider a point processes \(\Phi\) defined on some underlying mathematical space \(\mathbb{S}\), which is often \(\mathbb{R}^n\). Researchers typically interpret a point process as a random counting measure, resulting in the use of integral and measure theory notation. For example, \(\Phi(B)\) denotes the number of points located in some (Borel measurable) set \(B\), which is a subset of \(\mathbb{S}\).
For point processes, researchers often use a dual notation such that \(\Phi\) denotes both a random set or a random measure. Then we can write, for example, \(\Phi=\{X_i\}_i\) to stress that \(\Phi\) is a random sets of points. (Strictly speaking, you can only use the set notation if the point process is simple, meaning that no two points coincide with probability one.)
The first moment measure of a point process, also called the mean measure or intensity measure, is defined as
$$\Lambda(B)= \mathbb{E} [\Phi(B)]. $$
In other words, the first moment measure can be interpreted as the expected number of points of \(\Phi\) falling inside the set \(B \subseteq \mathbb{S}\).
Shot noise definition
We assume a point process \(\Phi=\{X_i\}_i\) is defined on some space \(\mathbb{S}\). We consider a non-negative function \(f\) with the domain \(\mathbb{S}\), so \(f:\mathbb{S} \rightarrow [0,\infty)\). If the point process \(\Phi\) is a simple, we can use set notation and define the shot noise as
S= \sum_{X_i\in \Phi} f(X_i)\,.
More generally, the shot noise is defined as
S= \int_{ \mathbb{S}} f(x) \Phi(dx)\,.
(We recall that an integral is simply a more general type of sum, which is why the integral sign comes from the letter S.)
Campbell's theorem
We now state Campbell's theorem.
Campbell's theorem says that for any point process \(\Phi\) defined on a space \(\mathbb{S}\) the following formula holds
\mathbb{E}[ S] = \int_{ \mathbb{S}} f(x) \Lambda(dx)\,,
where \(\Lambda= \mathbb{E} [\Phi(B)]\) is the intensity measure of the point process \(\Phi\).
The integral formula is just an application of Fubini's theorem, as we have simply changed the order of integration. The formula holds for general processes because it is simply a result on first moments, so it is leveraging the linearity of sums and integrals, including the expectation operator. Put more simply, the sum of parts does equal the whole.
At the beginning of the 20th century, Norman R. Campbell studied shot noise in Britain and wrote two key papers. In one of these papers appears a version of the result we now called Campbell's theorem or Campbell's formula. Interestingly, Campbell was a physicist who credited his mathematical result to renown pure mathematician G. H. Hardy. Hardy claimed years later that, given he did pure mathematics, none of his work would lead to applications. But Hardy's claim is simply not true due to this result, as well as his results in number theory.
For some basics on point processes, I suggest the classic text Stochastic Geometry and its Applications by Chiu, Stoyan, Kendall and Mecke, which covers point processes and the varying notation in Chapters 2 and 4. Haenggi also wrote a very readable introductory book called Stochastic Geometry for Wireless networks, where he gives the basics of point process theory.
Author Paul KeelerPosted on May 29, 2020 November 4, 2020 Categories Point processTags Campbell's theorem, integral, intensity measure, interference, mean measure, notation, random measure, random set, shot noise, SINR, SIR, wirelessLeave a comment on Campbell's theorem (formula)
Shot noise
Given a mathematical model based on a point process, a quantity of possible interest is the sum of some function applied to each point of the point process. This random sum is called shot noise, where the name comes from developing mathematical models of the noise measured in old electronic devices, which was likened to shot (used in guns) hitting a surface.
Researchers have long studied shot noise induced by a point process. One particularly application is wireless network models, in which the interference term is an example of shot noise. It is also possible to construct new point processes, called shot noise Cox point processes, by using based on the shot noise of some initial point process.
For such applications, we need a more formal definition of shot noise.
Shot noise of a point process
We consider a point processes \(\Phi=\{X_i\}_i\) defined on some space \(\mathbb{S}\), which is often \(\mathbb{R}^n\), and a non-negative function \(f\) with the domain \(\mathbb{S}\), so \(f:\mathbb{S} \rightarrow [0,\infty)\). This function \(f\) is called the response function.
Then the shot noise is defined as
I= \sum_{X_i\in \Phi} f(X_i)\,.
Shot noise of a marked point process
The previous definition of shot noise can be generalized by considering a marked point process \(\Phi'=\{(X_i, M_i)\}_i\), where each point \(X_i\) now has a random mark \(M_i\), which can be a random variable some other random object taking values in some space \(\mathbb{M}\). Then for a response function \(g:\mathbb{S}\times \mathbb{M} \rightarrow [0,\infty)\) , the shot noise is defined as
I'= \sum_{(X_i, M_i)\in \Phi'} g(X_i,M_i)\,.
Given a point process on a space, like the plane, at any point the shot noise is simply a random variable. If we consider a subset of the space, then shot noise forms a random field, where we recall that a random field is simply a collection of random variables indexed by some set. (By convention, the set tends to be Euclidean space or a manifold). The shot noise can also be considered as a random measure, for example
I(B)= \sum_{X_i\in \Phi\cap B} f(X_i)\,,
where \(B\subseteq \mathbb{S}\). This makes sense as the point process \(\Phi\) is an example of a random (counting) measure.
For Poisson point processes, researchers have studied resulting shot noise random variable or field. For example, given a homogeneous Poisson point process on \(\mathbb{R}^d\), if the response function is a simple power-law \(f(x)=|x|^{-\beta}\), where \(\beta> d\) and \(|x|\) denotes the Euclidean distance from the origin, then the resulting shot noise is alpha stable random variable with parameter \(\alpha=d/\beta\).
For a general point process \(\Phi\) with intensity measure \(\Lambda\), the first moment of the shot noise is simply
\mathbb{E}(I)= \int_{\mathbb{S}} f(x) \Lambda (dx) \,.
This is a result of Campbell's theorem or formula. A similar expression exists for the shot noise of a marked point process.
Shot noise has been studied for over a century in science. In physics, Walter Schottky did research on shot noise in Germany at the beginning of the 20th century. In the same era, Norman R. Campbell studied shot noise in Britain and wrote two key papers, where one of them contains a result now called Campbell's theorem or Campbell's formula, among other names, which is a fundamental result in point process theory. Campbell was a physicist, but his work contains this mathematical result for which he credited the famed pure mathematician G. H. Hardy.
(It's interesting to note that Hardy claimed years later that, given he did pure mathematics, none of his work would lead to applications, but that claim is simply not true for this and other reasons.)
The work on the physical process of shot noise motivated more probability-oriented papers on shot noise, including:
1944, S. O. Rice, Mathematical Analysis of Random Noise;
1960, Gilbert and Pollak, Amplitude distribution of shot noise;
1971, Daley, The definition of a multi-dimensional generalization of shot noise;
1977, J. Rice, On generalized shot noise;
1990 Lowen and Teich, Power-law shot noise.
As a model for interference in wireless networks, shot noise is covered in books such as the two-volume textbooks Stochastic Geometry and Wireless Networks by François Baccelli and Bartek Błaszczyszyn, where the first volume is on theory and the second volume is on applications. Martin Haenggi wrote a very readable introductory book called Stochastic Geometry for Wireless networks.
Author Paul KeelerPosted on May 20, 2020 November 4, 2020 Categories Point processTags Campbell's theorem, Cox point process, interference, network, random measure, shot noise, shot noise Cox point processLeave a comment on Shot noise | CommonCrawl |
Interesting insights on math.
Sigma fields are Venn diagrams
The starting point for probability theory will be to note the difference between outcomes and events.
An outcome of an experiment is a fundamentally non-empirical notion, about our theoretical understanding of what states a system may be in -- it is, in a sense, analogous to the "microstates" of statistical physics. The set of all outcomes $x$ is called the sample space $X$, and is the fundamental space to which we will give a probabilistic structure (we will see what this means).
Our actual observations, the events, need not be so precise -- for example, our measurement device may not actually measure the exact sequence of heads and tails as the result of an experiment, but only the total number of heads, or something -- analogous to a "macrostate". But these measurements are statements about what microstates we know are possible for our system to be in -- i.e. they correspond to sets of outcomes. These sets of outcomes that we can "talk about" are called events $E$, and the set of all possible events is called a field $\mathcal{F}\subseteq 2^X$.
For instance: if our sample space is $\{1,2,3,4,5,6\}$ and our measurement apparatus is a guy who looks at the reading and tells us if it's even or odd, then the field is $\{\varnothing, \{1,3,5\},\{2,4,6\},X\}$. We simply cannot talk about sets like $\{1,3\}$ or $\{1\}$. Our information just doesn't tell us anything about sets like that -- when we're told "odd", we're never hinted if the outcome was 1 or 3 or 5, so we can't even have prior probabilities -- we can't even give probabilities to whether a measurement was a 1 or a 3.
Well, what kind of properties characterise a field? There's actually a bit of ambiguity in this -- it's clear that a field should be closed under negation and finite unions (and finite intersections follow via de Morgan) -- if you can talk about whether $P_1$ and $P_2$ are true, you can check each of them to decide if $P_1\lor P_2$ is true (and since a proposition $P$ corresponds to a set $S$ in the sense that $P$ says "one of the outcomes in $S$ is true", $\lor$ translates to $\cup$). But if you have an infinite number of $P_i$'s, can you really check each one of them so that you can say without a doubt that a field is closed under arbitrary union?
Well, this is (at this point) really a matter of convention, but we tend to choose the convention where the field is closed under negation and countable unions. Such a field is called a sigma-field. We will actually see where this convention comes from (and why it is actually important) when we define probability -- in fact, it is required for the idea that one may have a uniform probability distribution on a compact set in $\mathbb{R}^n$.
A beautiful way to understand fields and sigma fields is in terms of venn diagrams -- in fact, as you will see, fields are precisely a formalisation of Venn diagrams. I was pretty amazed when I discovered this (rather simple) connection for myself, and you should be too.
Suppose your experiment is to toss three coins, and make "partial measurements" on the results through three "measurement devices":
A: Lights up iff the number of heads was at least 2.
B: Lights up iff the first two coins landed heads.
C: Lights up iff the third coin landed heads.
What this means is that $A$ gives you the set $\{HHT, HTH, THH, HHH\}$, $B$ gives you the set $\{HHH, HHT\}$, $C$ gives you the set $\{HHH, HTH, THH, TTH\}$. Based on precisely which devices light up, you can decide the truth values of $\lnot$'s and $\lor$'s of these statements, i.e. complements and unions of these sets -- this is the point of fields, of course.
Or we could visualise things.
Well, the Venn diagram produces a partition of $X$ corresponding to the equivalence relation of "indistinguishability", i.e. "every event containing one outcome contains the other"? The field consists precisely of any set one can "mark" on the Venn diagram -- i.e. unions of the elements of the partition.
A consequence of this becomes immediately obvious:
Given a field $\mathcal{F}$ corresponding to the partition $\sim$, the following bijection holds: $\mathcal{F}\leftrightarrow 2^{X/\sim}$.
Consequences of this include: the cardinalities of finite sigma fields are precisely the powers of two; there is no countably infinite finite field.
Often, one may want to some raw data from an experiment to obtain some processed data. For example, let $X=\{HH,HT,TH,TT\}$ and the initial measurement is of the number of heads:
$$\begin{align}
\mathcal{F}=&\{\varnothing, \{TT\}, \{HT, TH\}, \{HH\},\\
& \{TT, HT, TH\}, \{TT, HH\}, \{HT, TH, HH\}, X \}
\end{align}$$
What kind of properties of the outcome can we talk about with certainty given the number of heads? For example, we can talk about the question "was there at least one heads?"
$$\mathcal{G}=\{\varnothing, \{TT\}, \{HT, TH, HH\}, X\}$$
There are two ways to understand this "processing" or "re-measuring". One is as a function $f:\frac{X}{\sim_\mathcal{F}}\to \frac{X}{\sim_\mathcal{G}}$. Recall that:
\frac{X}{\sim_\mathcal{F}}&=\{\{TT\},\{HT,TH\},\{HH\}\}\\
\frac{X}{\sim_\mathcal{G}}&=\{\{TT\},\{HT,TH,HH\}\}
Any such $f$ is a permissible "measurable function", as long as $\sim_\mathcal{G}$ is at least as coarse a partition as $\sim_\mathcal{F}$. In other words, a function from $X/\sim_1$ to $(X/\sim_1)/\sim_2$ is always measurable.
But there's another, more "natural", less weird and mathematical way to think about a re-measurement -- as a function $f:X\to Y$, where in this case $Y=\{0,1\}$ where an outcome maps to 1 if it has at least one heads, and 0 if it does not.
But there's a catch: knowing that an event $E_Y$ in $Y$ occurred is equivalent to knowing that an outcome in $X$ mapping to $E_Y$ occurred -- i.e. that the event $\{x\in X\mid f(x)\in Y\}$ occurred. Such an event must be in the field on $X$, i.e.
$$\forall y\in\mathcal{F}_Y,f^{-1}(y)\in\mathcal{F}_X$$
This is the condition for a measurable function, also known as a random variable.
One may observe certain analogies between the measurable spaces outlined above, and topology -- in the case of countable sample spaces, there actually is a correspondence. The similarity between a Venn diagram and casual drawings of a topological space is not completely superficial.
The key idea behind fields is mathematically a notion of "distinguishability" -- if all we can measure is the number of heads, $HHTTH$ and $TTHHH$ are identical to us. For all practical purposes, we can view the sample space as the partition by this equivalence relation. They are basically the "same point".
It's this notion that a measurable function seeks to encapsulate -- it is, in a sense, a generalisation of a function from set theory. A function cannot distinguish indistinguishable points -- in set theory, "indistinguishability" is just equality, the discrete partition; a measurable function cannot distinguish indistinguishable points -- but in measurable spaces, "indistinguishability" is given by some equivalence relation.
Let's see this more precisely.
Given sets with equivalence relations $(X,\sim)$, $(Y,\sim)$, we want to ensure that some function $f:X\to Y$ "lifts" to a function $f:\frac{X}{\sim}\to\frac{Y}{\sim}$ such that $f([x])=[f(y)]$.
(Exercise: Show that this (i.e. this "definition" being well-defined) is equivalent to the condition $\forall E\in\mathcal{F}_Y, f^{-1}(E)\in \mathcal{F}_X$. It may help to draw out some examples.)
Well, this expression of the condition -- as $f([x])=[f(y)]$ -- even if technically misleading (the two $f$'s aren't really the same thing) give us the interpretation that a measurable function is one that commutes with the partition or preserves the partition.
While homomorphisms in other settings than measurable spaces do not precisely follow the "cannot distinguish related points" notion, they do follow a generalisation where equivalence relations are replaced with other relations, operations, etc. -- in topology, a continuous function preserves limits; in group theory, a group homomorphism preserves the group operation; in linear algebra, a linear transformation preserves linear combinations; in order theory, an increasing function preserves order, etc. In any case, a homomorphism is a function that does not "break" relationships by creating a "finer" relationship on the target space.
Written by Abhimanyu Pallavi Sudhir on October 17, 2019
Tags -- measurable function, probability, probability theory, random variables, sigma field, venn diagram
Copyright © 2016-2019, The Winding Number by Abhimanyu Pallavi Sudhir. Picture Window theme. Powered by Blogger. | CommonCrawl |
History of Science and Mathematics Meta
History of Science and Mathematics Stack Exchange is a question and answer site for people interested in the history and origins of science and mathematics. It only takes a minute to sign up.
When was the quantization of spin discovered?
When was the fact that a spin could only have values $S = n/2$? I cannot find any source that says when.
quantum-mechanics
The BoscoThe Bosco
The experiment of Stern and Gerlach showed that the spin of atomic silver was 1/2. This experiment was "simplified" by Phipps and Taylor to hydrogen atoms so as to eliminate any possible ambiguities on the spin-1/2 nature of the electron.
Thanks for contributing an answer to History of Science and Mathematics Stack Exchange!
Not the answer you're looking for? Browse other questions tagged quantum-mechanics or ask your own question.
What was different about Planck's quantization of light compared to Einstein's?
How did Stern-Gerlach experiment change the concept of space quantization and electron spin?
When was the measurement problem solved?
What is the origin of the terminology 'spin up/down'?
Einstein's confusion about Stern-Gerlach
Pauli's first paper about the spin
Planck's quantization idea
How was the value of the electron's spin ($\pm \frac{\hbar}{2}$) first determined?
Bohr-Kramers-Slater (BKS) theory and energy conservation only on statistically basis | CommonCrawl |
American Institute of Mathematical Sciences
Journal Prices
Book Prices/Order
Proceeding Prices
Anti-Harassment
E-journal Policy
Two-dimensional seismic data reconstruction using patch tensor completion
IPI Home
December 2020, 14(6): 967-983. doi: 10.3934/ipi.2020044
Optimal recovery of a radiating source with multiple frequencies along one line
Tommi Brander 1,2,3,, , Joonas Ilmavirta 4, , Petteri Piiroinen 5, and Teemu Tyni 6,
Department of Mathematical Sciences, Faculty of Information Technology and Electrical Engineering
NTNU – Norwegian University of Science and Technology, Trondheim, Norway
Technical University of Denmark, Department of Applied Mathematics and Computer Science, Lyngby, Denmark
University of Jyväskylä, Department of Mathematics and Statistics, P.O. Box 35 (MaD), FI-40014 University of Jyväskylä, Finland
Department of Mathematics and Statistics, P.O 68 (Pietari Kalmin katu 5), 00014 University of Helsinki, Finland
Department of Mathematical Sciences, P.O. Box 3000, FI-90014 University of Oulu, Finland
* Corresponding author: Tommi Brander
Received May 2019 Revised May 2020 Published August 2020
Full Text(HTML)
Figure(3) / Table(1)
We study an inverse problem where an unknown radiating source is observed with collimated detectors along a single line and the medium has a known attenuation. The research is motivated by applications in SPECT and beam hardening. If measurements are carried out with frequencies ranging in an open set, we show that the source density is uniquely determined by these measurements up to averaging over levelsets of the integrated attenuation. This leads to a generalized Laplace transform. We also discuss some numerical approaches and demonstrate the results with several examples.
Keywords: inverse source problem, multispectral, SPECT, Laplace transform, beam hardening, multiplicative system theorem, attenuated Radon transform, uniqueness theorem, PET, emission computed tomography, nuclear medicine.
Mathematics Subject Classification: Primary: 44A10, 65R32; Secondary: 44A60, 46N40, 65Z05.
Citation: Tommi Brander, Joonas Ilmavirta, Petteri Piiroinen, Teemu Tyni. Optimal recovery of a radiating source with multiple frequencies along one line. Inverse Problems & Imaging, 2020, 14 (6) : 967-983. doi: 10.3934/ipi.2020044
R. E. Alvarez and A. Macovski, Energy-selective reconstructions in X-ray computerised tomography, Physics in Medicine & Biology, 21 (1976), 733. Google Scholar
T. Brander and J. Siltakoski, Recovering a variable exponent, Preprint, URL https://arXiv.org/abs/2002.06076. Google Scholar
T. Brander and D. Winterrose, Variable exponent Calderón's problem in one dimension, Annales Academiæ Scientiarum Fennicæ, Mathematica, 44 (2019), 925–943. doi: 10.5186/aasfm.2019.4459. Google Scholar
R. A. Brooks and G. Di Chiro, Beam hardening in X-ray reconstructive tomography, Physics in Medicine & Biology, 21 (1976), 390. doi: 10.1088/0031-9155/21/3/004. Google Scholar
H. Choi, V. Ginting, F. Jafari and R. Mnatsakanov, Modified Radon transform inversion using moments, J. Inverse Ill-Posed Probl, 28 (2020), 1-15. doi: 10.1515/jiip-2018-0090. Google Scholar
S. R. Deans, The Radon Transform and Some of Its Applications, A Wiley-Interscience Publication. John Wiley & Sons, Inc., New York, 1983. URL https://books.google.com.mt/books?id=xSCc0KGi0u0C. Google Scholar
C. Dellacherie and P.-A. Meyer, Probabilities and Potential, vol. 29 of North-Holland Mathematics Studies, North-Holland Publishing Co., Amsterdam – New York, 1978. Google Scholar
N. Eldredge, Closure of Polynomials of A Function in $L^2$, MathOverflow, 2018, URL https://mathoverflow.net/a/292978/1445 Google Scholar
D. V. Finch, The attenuated X-ray transform: Recent developments, in Inside Out: Inverse Problems and Applications, Math. Sci. Res. Inst. Publ., 47, Cambridge Univ. Press, Cambridge, (2003), 47–66. Google Scholar
D. Gourion and D. Noll, The inverse problem of emission tomography, Inverse Problems, 18 (2002), 1435-1460. doi: 10.1088/0266-5611/18/5/315. Google Scholar
P. C. Hansen, Discrete Inverse Problems: Insight and Algorithms, Fundamentals of Algorithms, 7. Society for Industrial and Applied Mathematics (SIAM), Philadelphia, PA, 2010. doi: 10.1137/1.9780898718836. Google Scholar
M. Hestenes and E. Stiefel, Methods of conjugate gradients for solving linear systems, J. Res. Nat. Bur. Standards, 49 (1952), 409-436. doi: 10.6028/jres.049.044. Google Scholar
J. Ilmavirta and F. Monard, Integral geometry on manifolds with boundary and applications, in The Radon Transform: The First 100 Years and Beyond, (eds. R. Ramlau and O. Scherzer), de Gruyter, 2019, 1–73. URL http://users.jyu.fi/ jojapeil/pub/integral-geometry-review.pdf. doi: 10.1515/9783110560855-004. Google Scholar
J. D. Ingle Jr and S. R. Crouch, Spectrochemical Analysis, Prentice Hall College Book Division, Old Tappan, NJ, USA, 1988. Google Scholar
O. Kallenberg, Foundations of Modern Probability, Probability and its Applications (New York). Springer-Verlag, New York, 1997. Google Scholar
V. P. Krishnan, R. Manna, S. K. Sahoo and V. A. Sharafutdinov, Momentum ray transforms, Inverse Problems and Imaging, 13 (2019), 679–701, URL http://aimsciences.org//article/id/d88823a5-827c-4c4b-909a-c27daa0b74ec. doi: 10.3934/ipi.2019031. Google Scholar
L. A. Lehmann and R. E. Alvarez, Energy-selective radiography a review, in Digital Radiography: Selected Topics (eds. J. G. Kereiakes, S. R. Thomas and C. G. Orton), Springer US, Boston, MA, (1986), 145–188. doi: 10.1007/978-1-4684-5068-2_7. Google Scholar
R. M. Lewitt and S. Matej, Overview of methods for image reconstruction from projections in emission computed tomography, Proceedings of the IEEE, 91 (2003), 1588-1611. doi: 10.1109/JPROC.2003.817882. Google Scholar
C. H. McCollough, S. Leng, L. Yu and J. G. Fletcher, Dual- and multi-energy CT: Principles, technical approaches, and clinical applications, Radiology, 276 (2015), 637-653. doi: 10.1148/radiol.2015142631. Google Scholar
P. Milanfar, Geometric Estimation and Reconstruction from Tomographic Data, PhD thesis, Massachusetts Institute of Technology, 1993. Google Scholar
P. Milanfar, W. C. Karl and A. S. Willsky, A moment-based variational approach to tomographic reconstruction, IEEE Transactions on Image Processing, 5 (1996), 459-470. doi: 10.1109/83.491319. Google Scholar
J. L. Mueller and S. Siltanen, Linear and Nonlinear Inverse Problems with Practical Applications, vol. 10 of Computational Science & Engineering, Society for Industrial and Applied Mathematics (SIAM), Philadelphia, PA, 2012. doi: 10.1137/1.9781611972344. Google Scholar
F. Natterer, Inversion of the attenuated Radon transform, Inverse Problems, 17 (2001), 113-119. doi: 10.1088/0266-5611/17/1/309. Google Scholar
R. G. Novikov, An inversion formula for the attenuated X-ray transformation, Arkiv För Matematik, 40 (2002), 145–167. doi: 10.1007/BF02384507. Google Scholar
G. P. Paternain, M. Salo and G. Uhlmann, Tensor tomography: Progress and challenges, Chinese Annals of Mathematics. Series B, 35 (2014), 399-428. doi: 10.1007/s11401-014-0834-z. Google Scholar
G. P. Paternain, M. Salo and G. Uhlmann, Invariant distributions, Beurling transforms and tensor tomography in higher dimensions, Mathematische Annalen, 363 (2015), 305-362. doi: 10.1007/s00208-015-1169-0. Google Scholar
W. Rudin, Real and Complex Analysis, McGraw–Hill Series in Higher Mathematics. McGraw–Hill Book Co., New York-Düsseldorf–Johannesburgn, 1974. Google Scholar
K. Schmüdgen, The Moment Problem, vol. 277 of Graduate Texts in Mathematics, Springer International Publishing, 2017. Google Scholar
V. A. Sharafutdinov, Integral Geometry of Tensor Fields, Inverse and Ill-Posed Problems Series, VSP, Utrecht, 1994. doi: 10.1515/9783110900095. Google Scholar
K. Taguchi and J. S. Iwanczyk, Vision 20/20: Single photon counting x-ray detectors in medical imaging, Medical Physics, 40 (2013), 100901. doi: 10.1118/1.4820371. Google Scholar
A. Welch, G. T. Gullberg, P. E. Christian, J. Li and B. M. Tsui, An investigation of dual energy transmission measurements in simultaneous transmission emission imaging, IEEE Transactions on Nuclear Science, 42 (1995), 2331-2338. doi: 10.1109/23.489437. Google Scholar
D. V. Widder, The Laplace Transform, Princeton Mathematical Series, v. 6. Princeton University Press, Princeton, N. J., 1941. Google Scholar
Figure 1. Unknown $ \rho_0 $ (dashed red line) and the numerical solution $ \rho $ (solid blue line) with 0.5% noise level. Example 1 (above) and example 2 (below) with Tikhonov-solution (left), TV-solution (middle) and CGLS-solution (right)
Figure Options
Download as PowerPoint slide
Figure 2. Unknown $ \rho_0 $ (dashed red line), $ \rho_0 $ averaged over regions where $ p $ is constant (black dot-dash line) and the numerical solution $ \rho $ (solid blue line) with 0.5% noise level. Tikhonov-solution (left), TV-solution (middle) and CGLS-solution (right)
Figure 3. Unknown $ \rho_0 $ (dashed red line) and the Tikhonov-solution $ \rho $ (solid blue line) with 0.5% noise level and smaller measurement intervals
Table 1. Averaged relative errors and variances of one hundred solutions on smaller intervals with noise level 0.5%
Intervals $ (0,1) $ $ (0.2,0.8) $ $ (0.3,0.6) $ $ (0.4,0.5) $
$ \overline{\epsilon}_\mathrm{rel} $ 0.117 0.170 0.186 0.320
$ \mathrm{var} $ $ 1.88\cdot 10^{-3} $ $ 1.27\cdot 10^{-2} $ $ 1.27\cdot 10^{-2} $ $ 6.65\cdot 10^{-3} $
Peng Luo. Comparison theorem for diagonally quadratic BSDEs. Discrete & Continuous Dynamical Systems - A, 2020 doi: 10.3934/dcds.2020374
Shumin Li, Masahiro Yamamoto, Bernadette Miara. A Carleman estimate for the linear shallow shell equation and an inverse source problem. Discrete & Continuous Dynamical Systems - A, 2009, 23 (1&2) : 367-380. doi: 10.3934/dcds.2009.23.367
Lekbir Afraites, Chorouk Masnaoui, Mourad Nachaoui. Shape optimization method for an inverse geometric source problem and stability at critical shape. Discrete & Continuous Dynamical Systems - S, 2021 doi: 10.3934/dcdss.2021006
Jianli Xiang, Guozheng Yan. The uniqueness of the inverse elastic wave scattering problem based on the mixed reciprocity relation. Inverse Problems & Imaging, , () : -. doi: 10.3934/ipi.2021004
Isabeau Birindelli, Françoise Demengel, Fabiana Leoni. Boundary asymptotics of the ergodic functions associated with fully nonlinear operators through a Liouville type theorem. Discrete & Continuous Dynamical Systems - A, 2020 doi: 10.3934/dcds.2020395
Stefano Bianchini, Paolo Bonicatto. Forward untangling and applications to the uniqueness problem for the continuity equation. Discrete & Continuous Dynamical Systems - A, 2020 doi: 10.3934/dcds.2020384
Kien Trung Nguyen, Vo Nguyen Minh Hieu, Van Huy Pham. Inverse group 1-median problem on trees. Journal of Industrial & Management Optimization, 2021, 17 (1) : 221-232. doi: 10.3934/jimo.2019108
Noriyoshi Fukaya. Uniqueness and nondegeneracy of ground states for nonlinear Schrödinger equations with attractive inverse-power potential. Communications on Pure & Applied Analysis, 2021, 20 (1) : 121-143. doi: 10.3934/cpaa.2020260
Shahede Omidi, Jafar Fathali. Inverse single facility location problem on a tree with balancing on the distance of server to clients. Journal of Industrial & Management Optimization, 2020 doi: 10.3934/jimo.2021017
Stanislav Nikolaevich Antontsev, Serik Ersultanovich Aitzhanov, Guzel Rashitkhuzhakyzy Ashurova. An inverse problem for the pseudo-parabolic equation with p-Laplacian. Evolution Equations & Control Theory, 2021 doi: 10.3934/eect.2021005
Yichen Zhang, Meiqiang Feng. A coupled $ p $-Laplacian elliptic system: Existence, uniqueness and asymptotic behavior. Electronic Research Archive, 2020, 28 (4) : 1419-1438. doi: 10.3934/era.2020075
Karoline Disser. Global existence and uniqueness for a volume-surface reaction-nonlinear-diffusion system. Discrete & Continuous Dynamical Systems - S, 2021, 14 (1) : 321-330. doi: 10.3934/dcdss.2020326
Weihong Guo, Yifei Lou, Jing Qin, Ming Yan. IPI special issue on "mathematical/statistical approaches in data science" in the Inverse Problem and Imaging. Inverse Problems & Imaging, 2021, 15 (1) : I-I. doi: 10.3934/ipi.2021007
Vo Van Au, Mokhtar Kirane, Nguyen Huy Tuan. On a terminal value problem for a system of parabolic equations with nonlinear-nonlocal diffusion terms. Discrete & Continuous Dynamical Systems - B, 2021, 26 (3) : 1579-1613. doi: 10.3934/dcdsb.2020174
Yoshitsugu Kabeya. Eigenvalues of the Laplace-Beltrami operator under the homogeneous Neumann condition on a large zonal domain in the unit sphere. Discrete & Continuous Dynamical Systems - A, 2020, 40 (6) : 3529-3559. doi: 10.3934/dcds.2020040
Michiel Bertsch, Flavia Smarrazzo, Andrea Terracina, Alberto Tesei. Signed Radon measure-valued solutions of flux saturated scalar conservation laws. Discrete & Continuous Dynamical Systems - A, 2020, 40 (6) : 3143-3169. doi: 10.3934/dcds.2020041
Ole Løseth Elvetun, Bjørn Fredrik Nielsen. A regularization operator for source identification for elliptic PDEs. Inverse Problems & Imaging, , () : -. doi: 10.3934/ipi.2021006
Gunther Uhlmann, Jian Zhai. Inverse problems for nonlinear hyperbolic equations. Discrete & Continuous Dynamical Systems - A, 2021, 41 (1) : 455-469. doi: 10.3934/dcds.2020380
Nicolas Dirr, Hubertus Grillmeier, Günther Grün. On stochastic porous-medium equations with critical-growth conservative multiplicative noise. Discrete & Continuous Dynamical Systems - A, 2020 doi: 10.3934/dcds.2020388
Hoang The Tuan. On the asymptotic behavior of solutions to time-fractional elliptic equations driven by a multiplicative white noise. Discrete & Continuous Dynamical Systems - B, 2021, 26 (3) : 1749-1762. doi: 10.3934/dcdsb.2020318
PDF downloads (148)
HTML views (226)
on AIMS
Tommi Brander Joonas Ilmavirta Petteri Piiroinen Teemu Tyni
Article outline
Copyright © 2020 American Institute of Mathematical Sciences
Recipient's E-mail*
Content* | CommonCrawl |
Structural and functional alterations of the tracheobronchial tree after left upper pulmonary lobectomy for lung cancer
Qingtao Gu1,2,
Shouliang Qi ORCID: orcid.org/0000-0003-0977-19391,2,
Yong Yue3,
Jing Shen4,
Baihua Zhang1,
Wei Sun5,
Wei Qian1,6,
Mohammad Saidul Islam7,
Suvash C. Saha7 &
Jianlin Wu4
Pulmonary lobectomy has been a well-established curative treatment method for localized lung cancer. After left upper pulmonary lobectomy, the upward displacement of remaining lower lobe causes the distortion or kink of bronchus, which is associated with intractable cough and breathless. However, the quantitative study on structural and functional alterations of the tracheobronchial tree after lobectomy has not been reported. We sought to investigate these alterations using CT imaging analysis and computational fluid dynamics (CFD) method.
Both preoperative and postoperative CT images of 18 patients who underwent left upper pulmonary lobectomy are collected. After the tracheobronchial tree models are extracted, the angles between trachea and bronchi, the surface area and volume of the tree, and the cross-sectional area of left lower lobar bronchus are investigated. CFD method is further used to describe the airflow characteristics by the wall pressure, airflow velocity, lobar flow rate, etc.
It is found that the angle between the trachea and the right main bronchus increases after operation, but the angle with the left main bronchus decreases. No significant alteration is observed for the surface area or volume of the tree between pre-operation and post-operation. After left upper pulmonary lobectomy, the cross-sectional area of left lower lobar bronchus is reduced for most of the patients (15/18) by 15–75%, especially for 4 patients by more than 50%. The wall pressure, airflow velocity and pressure drop significantly increase after the operation. The flow rate to the right lung increases significantly by 2–30% (but there is no significant difference between each lobe), and the flow rate to the left lung drops accordingly. Many vortices are found in various places with severe distortions.
The favorable and unfavorable adaptive alterations of tracheobronchial tree will occur after left upper pulmonary lobectomy, and these alterations can be clarified through CT imaging and CFD analysis. The severe distortions at left lower lobar bronchus might exacerbate postoperative shortness of breath.
Lung cancer has been the most common cancer worldwide in terms of both incidence and mortality. In 2012, there were 1.82 million new cases accounting for about 13.0% of the total number of new cases, and 1.56 million deaths representing 19.4% of all deaths from cancer [1]. Pulmonary lobectomy, especially Video-assisted thoracoscopic surgery (VATS) lobectomy, is a well-established curative treatment method for localized lung cancer [2, 3].
Pulmonary lobectomy results in a permanent loss of pulmonary function. Normally, this loss is proportional to the volume of resected lung, but it is also affected by the adaptive remodeling of the remaining lung. In the upper lobectomy, the upward displacement of the diaphragm and the remaining lobe will make the ipsilateral bronchus distort anatomically in a sigmoidal form, thereby resulting in the bronchial angulation. If the resultant stenosis is higher than 80%, a bronchial kink occurs [4]. The stenosis will result in lower postoperative functional lung volume (FLV) and postoperative forced expiratory volume in 1 s (FEV1), which will lead to some complications characterized by the shortness of breath and persistent cough.
The high-resolution computed tomography (CT) images are used for the anatomic alterations and postoperative complications [5,6,7]. Ueda et al. initially reported that bronchial kink was found in 42% (21/50) of the patients and bronchial kink may exacerbate the postoperative deterioration of lung function [4]. It has been proved that CT-based bronchography can help to screen the bronchial kink without additional invasive study. Seok et al. found that the increased angle of the bronchi is associated with the decline of pulmonary function [8]. Sengul et al. demonstrated that the changes of postoperative lung volume depend on the resected lobe [9]. Specifically, for the lower lobectomy, the reduction of the total lung volume is less than that of the upper lobectomy. However, the general pattern of structural alterations of the tracheobronchial tree, specifically for the left upper pulmonary lobectomy (estimated to account for one-third of all cancer [10]) has not been reported.
The changes of postoperative pulmonary functions are measured by the spirometry-based pulmonary function tests (PFTs) [11]. The expansion of both the contralateral lung and the remaining ipsilateral lung contributes to the postoperative compensation of pulmonary function [9]. This kind of compensation depends on the resected lobe and is more robust after lower lobectomy [12]. However, the postoperative pulmonary function can be underestimated by only the measure of FEV1 through PFTs [13]. Moreover, postoperative PFT is not routinely performed for all patients, it needs the cooperation of the patients and it is not suitable for the patients with breathlessness. For example, only 60 among 202 patients who underwent lobectomy had PFT in the study by Ueda et al. [12].
Depending on the individualized structural models of the tracheobronchial tree extracted from CT images, the computational fluid dynamics (CFD) simulation can provide physiologically significant ventilation information including the airflow velocity, wall pressure, wall shear stress, pressure drop and lobular airflow rate, which may complement the results of anatomy and pulmonary function [14,15,16,17]. Walters et al. proposed to use the reduced geometry model to reduce the complexity [18]. Oakes et al. investigated the effect of age on the airflow pattern and airway resistance [19] and Sul et al. assessed the airflow sensitivity on the lobar flow fraction [20]. Turbulent characteristics have been observed downstream of the glottis by Calmet et al. [21]. It has been reported that the obstructions in the lower airway caused bronchial tumor or other lesion can alter airflow patterns in the central airway [22, 23]. In our previous work, CFD simulations have been done to study airflow characteristics in subjects with left pulmonary artery sling, the tracheal bronchus and chronic obstructive pulmonary disease [24,25,26,27,28]. Besides the studies on the flow in the airway tree models with asthma and severe stenosis, CFD has also been used to facilitate various treatments, such as acute bronchodilation in asthmatics, tracheobronchial stent placement, vascular ring surgery and antibiotic treatment with cystic fibrosis [29,30,31,32]. It should be noted that the results of CFD simulation have been validated by both in vitro experiments and in vivo SPECT/CT images [33, 34].
The contributions of this work are summarized as follows. First, the structural alterations of the tracheobronchial trees after left upper pulmonary lobectomy for lung cancer are investigated through various quantitative measures including the angles between trachea and bronchi, the surface area and volume of the tree, and the cross-sectional area of the left lower lobar bronchus. Second, the alterations of the airflow are characterized by CFD-based measures of the wall pressure, airflow velocity, pressure drop, lobar flow rate, and local flow features at the left lower lobar bronchus. Third, the relationship between alterations of airway structure and ventilation function is illustrated. To the best of our knowledge, this is the first systematic study which combines quantitative CT images and CFD analysis to clarify the structural and functional alterations of the tracheobronchial tree caused by left upper pulmonary lobectomy.
Structural alterations of the tracheobronchial tree
Postoperatively, the global alterations (deformation) of the tracheobronchial tree can be found in Fig. 1a. It is in agreement with previous observation that the left main bronchus distorts in a sigmoidal form [4], as a result of the upward displacement of diaphragm and the remaining left lower lobe. In addition, the trachea seems to slant to the left and the stenosis occurs at the left lower lobar bronchus, but not at the left main bronchus. However, neither for the volume nor the surface area, there is no significant difference between preoperative and postoperative tracheobronchial trees, as shown in Fig. 1c.
Structural alterations of tracheobronchial trees after the left upper pulmonary lobectomy. a The global appearances. b The angles between the trachea and the main bronchus. c The volume and surface area
Compared with the preoperative models, the angle between the trachea and the left main bronchus (\(\theta_{\text{L}}\)) decreases significantly in the postoperative models (p < 0.01), by the mean of 13.4°. Nonetheless, \(\theta_{\text{R}}\) increases significantly by the mean of 10.5 degrees as shown in Fig. 1b. These alterations are thought to be associated with the upward displacement of diaphragm and the remaining lobe.
The cross-sectional area growth rate (\(R\)) is given for each patient in Fig. 2a. It is found that \(R\) is negative for most patients (15/18), indicating that the left lower lobar bronchus becomes narrow (15–75%) after lobectomy. For four patients (LCP7, LCP12, LCP14 and LCP16), the stenosis is higher than 50%. The location and cross section of the stenosis are given in Fig. 2b.
Alterations of the left lower lobar bronchus induced by the left upper pulmonary lobectomy. a The cross-sectional area growth rate for all patients. b The alterations of the left lower lobar bronchus
Alterations of airflow in the tracheobronchial tree
Wall pressure and flow velocity distribution
The wall pressure distribution is given in Fig. 3a for LCP7 and LCP8 as examples. It can be seen that the wall pressure at the trachea and the main bronchi increases significantly after the lobectomy. The maximum wall pressure in LCP7 reaches 65.0 Pa for the stenosis higher than 50% at the left lower lobar bronchus. For LCP8 with a stenosis of 21.95%, the maximum wall pressure is only about 7.0 Pa. After the left upper lobectomy, the average wall pressure in 17 patients is higher than that before the surgery, with an increase ranging from 0.1747 to 5.7243 Pa. One patient (LCP15) had a decrease of 0.7506 Pa.
The wall pressure and flow velocity in preoperative and postoperative tracheobronchial trees. a LCP7 with a 51.64% stenosis at the left lower lobar bronchus. b LCP8 with a 21.95% stenosis at the left lower lobar bronchus
Figure 3b presents the flow velocity within the tracheobronchial trees for LCP7 and LCP 8 as examples. The air flow velocity in the left lower lobe increases significantly after lobectomy. Preoperatively, the velocity at the left lower bronchus of LCP7 and LCP8 is 3.00 m/s and 1.50 m/s, respectively; the velocity in postoperative model increases to 4.50 m/s and 2.25 m/s, respectively. The maximum velocity in LCP7 (6.00 m/s) is higher than that in LCP8 (3.00 m/s) due to higher stenosis. After the lobectomy, the maximum airflow velocity within the tracheobronchial tree increases significantly by 0.09–4.26 m/s in 16 patients. For the remaining patients, it has a slight decrease of about 0.76 m/s.
The pressure drop can be calculated as the difference between the mean pressure at the inlet of the trachea and the average pressure of the outlet (the atmospheric pressure). According to Eq. (8), the relationship between the pressure drop and the inlet area can be presented in Fig. 4a. After the left upper lobectomy, the pressure drop (\(\Delta P\)) increased in 16 patients with a range of 0.81–10.37 Pa. In the remaining two patients, \(\Delta P\) decreased by 3.90 and 1.62 Pa, respectively. The slopes of the fitting line before and after the lobectomy are roughly the same, indicating that the relationship between the pressure drop and the inlet area remains unchanged. Meanwhile, the postoperative fitting line is above the preoperative one.
Alterations of pressure drop and airflow rate distribution induced by the left upper pulmonary lobectomy. a The pressure drop vs the sectional area of inlet. b The airflow rate distribution
Airflow rate distribution
The airflow rate for each lobe and left and right lung is given in Fig. 4b. Though the flow rate to the right upper lobe, right middle lobe, and right lobe increases after the lobectomy, no significant difference is available (p > 0.01). The postoperative flow rate to the left lower lobe is significantly higher than that before lobectomy (p < 0.01) by 6.36% (0.6211 × 10−4 kg/s). The postoperative flow rate to the right lung is significantly higher than that before lobectomy (p < 0.01) by 10.97%. Preoperatively, the ratio of the airflow rate to the right lung to that to the left lung is 58.67%/41.32%. It turns into 69.65%/30.35% postoperatively.
Local alterations
Local alterations of the structure, velocity, wall pressure, and wall shear stress are given in Fig. 5 for LCP7 and LCP8 as examples. For LCP7, there is an increase in the flow velocity at the stenosis of the left lower lobar bronchus and the occurrence of turbulence. A clear vortex appears in the remnants of the left lower lobe, and the streamline is distorted. The wall pressure and wall shear stress increase at the stenosis after lobectomy. For LCP8, the lower stenosis corresponds to the relatively smooth streamlines, small increase of wall pressure and wall shear stress.
Local structure of the tracheobronchial tree, flow velocity, wall pressure and wall shear stress after the left upper pulmonary lobectomy. a LCP7 with a 51.64% stenosis at the left lower lobar bronchus. b LCP8 with a 21.95% stenosis at the left lower lobar bronchus
The present study characterized the structural and functional alterations of the tracheobronchial tree after left upper pulmonary lobectomy for lung cancer using the preoperative and postoperative CT images of 18 patients. These alterations firstly and comprehensively describe the adaptive remodeling of the remaining respiratory system after the left upper lobectomy. The favorable remodeling includes the increased angle between the trachea and right main bronchus and the significant growth of flow rate ratio to the right lung. The unfavorable remodeling are the decrease of the angle between the trachea and left main bronchus, the sigmoidal distortion of the left main bronchus, and the decrease of sectional area (narrowing) of the left lower lobar bronchus. The narrowing of bronchus, the severe stenosis in particular, increases the flow velocity, the wall pressure, the wall shear stress, the possibility of vortex and the pressure drop; while the inlet boundary condition is the steady constant flow rate for our present simulation. The favorable and unfavorable remodelings lay a foundation for understanding the "compensatory lung adaption" and etiology of postoperative breathless, persistent cough and inflammation. The main findings, the methodological advantages and their significance will be presented as follows.
The first main finding of this study is about the favorable adaptive remodeling of the remaining respiratory system after the left upper lobectomy. \(\theta_{\text{R}}\) increases significantly from 142° to 152° and the flow rate ratio increases from 58.67 to 69.65%. The increase of \(\theta_{\text{R}}\) facilitates the ventilation of the right lung, resulting in the increase of the flow rate ratio. It partially contributes to "compensatory lung adaption", one phenomenon that postoperative pulmonary function is better than the estimated one [4]. Sengul et al. reported that after the left upper lobectomy, the ipsilateral and contralateral lung volumes decrease by 39.31% and 2.72%, respectively [9]. For the lower lobectomy, postoperative compensation is obtained by the expansion of both contralateral lung and remaining ipsilateral lung. It is noted that the statistical power of the study by Sengul et al. [9] is low for only five patients with left upper lobectomy are included.
The second main finding of this study is about the unfavorable alterations induced by lobectomy. These alterations include the decrease of the angle between the trachea and left main bronchus, the sigmoidal distortion of the left main bronchus, and the stenosis of the left lower lobar bronchus (the degree of stenosis is greater than 50% in some cases). Despite of these unfavorable alterations, the increased flow rate ratio to the remaining left lower lobe (from 23.98 to 30.34%) demonstrates that the pulmonary function of the left lower lobe is augmented, contributing to the "compensatory lung adaption". The observations of this study have two aspects different with previous study. Firstly, the bronchial kink (80% stenosis) is not found for the present model. However, according to Ueda et al. [4], the bronchial kink was observed in up to 42% of the patients who had undergone the upper lobectomy. Secondly, the stenosis is not at the left main bronchus, but at the left lower lobar bronchus. These differences are not related to the operation procedure because it is the same in two studies. The specific reason has been unknown up to now.
The third main finding is about the alterations of global and local measures of airflow in the tracheobronchial tree. The narrowing of the left lower lobar bronchus increases the low velocity, the wall pressure, the wall shear stress, the possibility of vortex, and the pressure drop while the inlet boundary condition is the steady constant flow rate for our present simulation. The long-term increase of these local airflow measures may result in trauma of the airway, mucosa and inflammatory response [27, 35]. With the same airflow rate, the higher pressure drop is required after lobectomy, indicating that the postoperative patients have smaller airflow rate, while the pressure drop is constant [32].
For the methodological advantages, the morphological analysis of tracheobronchial trees extracted from CT images and further CFD simulation of airflow characteristics within the trees are combined in the present work. Hence, it enables us to illustrate the relationship between alterations of airway structure and ventilation function, besides the respective ones. Via high and isotropic resolution CT images (with the voxel size of about 1 × 1 × 1 mm) and extracted tracheobronchial tree, the distortion of bronchus can be presented and bronchus kink can be diagnosed [14]. The routine postoperative follow-up CT examination does not expose patients to the additional invasive study, unlike bronchoscopy. Traditional CT and dual-energy CT applications should be expanded to image the anatomic changes and related complications for post-lobectomy patient [5, 7].
Based on the realistic and individualized tracheobronchial trees extracted from CT images, CFD provides with rich local and global information including flow velocity, wall pressure, wall shear stress, and pressure drop and flow rate ratio to the pulmonary function [14, 15]. Through strict and standard operation flow and quality control, such as the grid independence and validation, the CFD accuracy and reliability can be guaranteed. The pulmonary function test by spirometry is still the golden standard to study the changes in pulmonary function in lung cancer patients after VATS [11]. However, the concern of unnecessary risk and complex cooperation requirements for the patients limit the application of spirometry. Moreover, the changes of forced vital capacity (FVC) vary with time in the period of 3–12 months, and it reaches the maximum between 6 and 12 months [13, 36].
Regardless of the above-mentioned great advantages and findings of our study, it presents the following limitations. First, the flow rate ratio is determined according to CFD simulation without considering the CT-based lobar volume. Measuring lobar volume will help to confirm whether the ventilation and volume match well. Hyperpolarized 3He magnetic resonance (MR) phase-contrast velocimetry is another way of accurately measuring the airflow velocity in human airways in vivo [33]. Second, postoperative PFTs can not be collected for the concern of unnecessary risk. The scores on the cough, pain, and shortness of breath are not available, which makes it impossible to correlate our findings with these scores. The direct cause of the symptoms and guide to the patient care could not be obtained. Third, most studies on CFD simulation of airflow in human airway trees including our current study have adopted the steady flow condition for the simplification of numerical calculation and further analysis [15]. Even for the transient CFD simulation, the sine curve of the respiratory cycle is usually used as a simplified method for representing the natural respiratory cycle [26, 32]. More advanced models with the realistic boundary conditions measured by PFTs are needed. Fourth, only the patients after the left upper lobectomy are included; therefore, the comparison between different lobectomy is not achievable. It has been reported that the compensatory response after lower lobectomy is more robust than that after upper lobectomy [12], and more bronchial kinkings happen after upper lobectomy [13]. Changes in pulmonary function after right-side lobectomy are different from those after left side [11]. Finally, only the inspiratory phase CT is scanned in the current study to reduce the radiation dose and whether the inspiratory and expiratory flow will affect θR is still unknown. These limitations actually point out some issues for the further in-depth study.
After left upper pulmonary lobectomy for lung cancer, the tracheobronchial tree will take adaptive remodeling, resulting in various structural and functional alterations. These alterations or remodelings can be favorable and unfavorable. The increase of the angle between the trachea and right main bronchus, and the resultant increase of airflow rate to the right lung are the favorable compensations of residual lung. The decrease of the angle between the trachea and left main bronchus, the sigmoidal distortion of the left main bronchus, and the stenosis of the left lower lobar bronchus are the unfavorable structural alterations. These structural alterations lead to the abnormal increase of the flow velocity, the wall pressure, the wall shear stress, the possibility of the vortex and the pressure drop, which might be associated with the realistic shortness of breath, persistent cough, and inflammation after lobectomy. Based on the morphological analysis of tracheobronchial trees extracted from CT images and further CFD simulation of airflow characteristics within the trees, all those structural and functional alterations of the tracheobronchial tree can be clarified.
Participants and CT images acquisition
The high-resolution CT images in DICOM format of 18 patients who underwent upper left pulmonary lobectomy for lung cancer are randomly selected out of a database of the Affiliated Zhongshan Hospital of Dalian University (Dalian, China) for a retrospective study. After anonymization, the data of each patient were given one index (LCP1–LCP18). Of the 18 patients, 12 (66.7%) were female and 6 (33.3%) were male. The mean age was 61.5 (range 50–71) years. The surgery was carried out in the period from April 2014 to October 2017. The VATS lobectomy procedure was the same as that introduced by Ueda et al. [4].
Preoperative CT images were scanned within 1 week before the lobectomy and postoperative images at 1–12 months after the lobectomy. For all acquired CT images, the tube voltage was set to 100 kV, the slice thickness was 1.0 mm, and the reconstruction matrix size was 512 × 512. The tube current, the pixel size and the number of slices were in the range of 275–673 mAs, 0.59–0.81 mm and 251–468, respectively. This study was approved by the Medical Ethics Committee of the Affiliated Zhongshan Hospital of Dalian University. Informed consent was waived because it was a retrospective review study.
Overview of the analysis procedure
The whole analysis procedure of the present study is illustrated in Fig. 6. Using preoperative CT images, the tracheobronchial tree of each patient is extracted, and the structural measures including critical angle, surface area and volume are calculated. By CFD simulation, the measures of wall pressure, wall shear stress, flow velocity, lobar flow rate and pressure drop are obtained. After the postoperative measures are gotten similarly, the comparison between preoperative and postoperative groups produces the structural and functional alterations. The relationship between the structural and functional alterations is illustrated in coming sections.
The overview of procedure in the current study
Structural analysis of the tracheobronchial tree
The tracheobronchial tree is extracted from the CT images using the algorithm of deep segmentation embedded in a medical imaging process software called Mimics (Materialise Corp, Belgium), and exported in the STL format. The 3D model is subsequently input into Geomagic Studio to reduce the complexity of the model. After the format of STL is converted into the X_T entity format using SolidWorks (SOLIDWORKS Corp, Waltham, USA), the tracheobronchial tree model is imported into ANSYS Workbench 15 (ANSYS Inc., Pennsylvania, USA) for CFD simulation.
As shown in Fig. 6, the angles between the trachea and the left and right main bronchus are defined as \(\theta_{\text{L}}\) and \(\theta_{\text{R}}\), respectively. These angles in the preoperative and postoperative models are measured and compared. The cross-sectional area growth rate is defined as
$$R = \left( {S_{\text{Post}} - S_{\text{Pre}} } \right)/S_{\text{Pre}} ,$$
where \(S_{\text{Post}}\) is the cross-sectional area of the left lower lobar bronchus in postoperative model and \(S_{\text{Pre}}\) is that in preoperative model. The volume and surface area of all the models are also measured for analysis.
CFD analysis of the tracheobronchial tree
An advanced meshing technique is used to generate the unstructured tetrahedral elements for the highly asymmetric tracheobronchial model and path independent algorithm is used as the meshing method. The quality of the generated mesh is evaluated by the skewness and the values of skewness are found in the range of 0.8616–0.95, which eventually indicates that the mesh of the present study is acceptable. A steady breathing state with the tidal volume of 500 mL is considered as the normal adult inhalation tidal volume.
In the current study, the steady inlet velocity is set as the inlet boundary condition (BC) and the constant outlet pressure of the atmospheric pressure is set as the outlet BC [25]. As done in our previous studies [26, 27], FLUENT 16.0 is utilized to solve the governing equations of the airflow.
$$\frac{\partial \rho }{\partial t} + {\text{div}}\left( {\rho \upsilon } \right) = 0,$$
$$\rho \frac{{\partial \vec{\upsilon }}}{\partial t} = \rho \vec{F} - {\text{grad}}\vec{p} + \mu \Delta \vec{\upsilon } + \frac{\mu }{3}{\text{grad}}\left( {{\text{div}}\vec{\upsilon }} \right),$$
where \(\rho\) is the fluid density, t is time, \(\upsilon\) is the flow velocity, \(\vec{\upsilon }\) is the velocity vector, \(\vec{F}\) is the force vector, \(\vec{p}\) is the pressure vector, \(\mu\) is the viscosity of fluid. In Reynolds association numerical simulation (RANS), the above unsteady governing equations are averaged temporally.
$$\frac{\partial \rho }{\partial t} + \frac{\partial }{{\partial x_{j} }}\left( {\rho \bar{u}_{j} } \right) = 0,$$
$$\frac{\partial }{\partial t}\left( {\rho \bar{u}_{j} } \right) + \frac{\partial }{{\partial x_{j} }}\left( {\rho \bar{u}_{i} \bar{u}_{j} } \right) = - \frac{\partial P}{{\partial x_{j} }} + \frac{\partial }{{\partial x_{j} }}\left( {\mu \left( {\frac{{\partial u_{j} }}{{\partial x_{i} }} + \frac{{\partial u_{i} }}{{\partial x_{j} }}} \right)} \right) - \frac{\partial }{{\partial x_{j} }}\left( {\rho \bar{u}_{i}^{'} \bar{u}_{j}^{'} } \right) - \frac{2}{3}\frac{\partial }{{\partial x_{j} }}\left( {\mu \left( {\frac{{\partial u_{j} }}{{\partial x_{j} }}} \right)} \right) + \rho g_{i} ,$$
where \(\bar{u}_{j}\) is the temporally averaged flow velocity, \(\bar{u}_{i}^{'}\) and \(\bar{u}_{j}^{'}\) are turbulent fluctuations, j = 1, 2, and 3. \(x_{j}\) is the spatial coordinate and \(g_{i}\) is the gravity. \(\rho \bar{u}_{i} \bar{u}_{j}\) is Reynolds stress. Many turbulent models have been proposed to calculate Reynolds stress, including Eddy-Viscosity Models, Reynolds Stress Model, and Algebraic Stress Model. Here, we adopt one Eddy-Viscosity Model, i.e., the standard Low Reynolds number (LRN) k-\(\omega\) turbulence model, where k and \(\omega\) denote the turbulent kinetic energy and the specific dissipation rate, respectively. Meanwhile, the low-Re correction and shear flow correction are taken into account. For the inlet velocity, the turbulent intensity (I) is set as 5% and the turbulent viscosity ratio (\(\mu_{T} /\mu\)) is set as 10 [37, 38]. I and the turbulent viscosity \(\mu_{T}\) are defined as
$$I = \sqrt {\bar{u}^{{{\prime }2}} + \bar{v}^{{{\prime }2}} + \bar{w}^{{{\prime }2}} } /u_{\text{avg}} ,$$
$$\mu_{T} = \rho C_{\mu } k^{2} /\varepsilon ,$$
where \(C_{\mu } = 0.09\) and \(\varepsilon\) is the rate of dissipation of turbulent energy.
The material settings and the details of the algorithm for solving the governing equations include: (1) The air is set as a Newtonian fluid with a constant density of 1.225 kg/m3 and a viscosity of 1.7984 × 10−5kg/m s. (2) A steady pressure-based solver is used. (3) The SIMPLE scheme is adopted for the pressure–velocity coupling. For the spatial discretization, the gradient is set as "Green-Gauss Cell Based", the pressure is set as "Second Order" and the moment is set as "Second Order Upwind". (4) The convergence criterion is set as a residual of < 10−6.
The relationship between the pressure drop and inlet area in straight tubes can be represented as
$$\Delta P = \frac{{\lambda \rho Q^{2} L}}{d}\frac{1}{{S^{2} }},$$
where \(\lambda\) is the resistance coefficient along the course, \(\rho\) is the density of the fluid, \(Q\) is the inlet flow, \(L\) is the length of the straight pipe, \(d\) is the inner diameter of the round pipe and \(S\) is the inlet cross-sectional area [39, 40]. Equation (8) is adopted to the tracheobronchial tree model for simplification purpose. Since there is no significant change in surface area and volume before and after lobectomy, the Eq. (8) can be simplified as
$$\Delta P = \frac{C}{{S^{2.5} }},$$
where \(C\) is the constant. It means that the magnitude of pressure drop is inversely proportional to the inlet cross-sectional area to the power of 2.5.
For the comparison of all the above structural and functional measures, two-sample t-test is performed to determine whether there is a significant difference between preoperative and postoperative groups (p < 0.01).
Convergence analysis
To study the independence of the CFD method in grid density, three different grid sizes (374,593, 412,555, and 453,954 nodes) are used to mesh all the tracheobronchial tree models. Figure 6a presents the meshes of one tracheobronchial tree model as an example where 412,555 nodes exist. The meshing quality is reasonable according to visual inspection. All other settings are the same except the grid size and we calculate and compare the airflow velocity profile along one line in the model. Specifically, two key sections (CS1 and CS2) are defined in the model (Fig. 7b). The velocity profile along Y at CS1 is calculated and compared. As shown in Fig. 7c, no significant difference in air flow velocity was observed at the three grid sizes. Comprehensively considering the calculation speed and stability, we used 412,555 nodes to mesh the model and used the same mesh density control scheme for all models.
Grid independence and validation of CFD accuracy. a The meshes of one tracheobronchial tree model as an example. b Trachea cross section CS1 and bronchus cross section CS2. c Velocity profile along Y at CS1. d The velocity simulated by CFD and the results of MR gas velocity measurement at the section CS2 along X. e The velocity simulated by CFD and the results of MR gas velocity measurement at the section CS2 along Y. f The lobar distribution of airflow rate (RU right upper, RM right middle, RL right lower, LU left upper, LL left lower)
To verify the accuracy of the CFD method, two studies were conducted and the obtained CFD simulation results were compared with the published experimental data. First, the velocity simulated by CFD at the section CS2 was compared with the results of magnetic resonance gas velocity measurement [33]. The results are shown in Fig. 7d, e, and the CFD simulation velocity along the X and Y directions of the profile are consistent with the MRI measurement flow velocity. The difference in the magnitude of the air flow velocity may be caused by the geometric differences in the model. Then, the distribution of air flow in each lobe at the same flow velocity (7.5 L/min) was studied, as shown in Fig. 7f, which is also consistent with the previous results [41,42,43]. The findings of the present model along with the published literature indicate that the present model is sufficiently accurate to predict the structural alterations phenomenon of the tracheobronchial model.
The datasets used and/or analyzed during the current study are available from the corresponding author on reasonable request.
boundary condition
FEV1 :
forced expiratory volume in 1 s
FLV:
functional lung volume
LCP:
lung cancer patient
LRN:
low Reynolds number
PFTs:
VATS:
video-assisted thoracoscopic surgery
Torre L, Bray F, Siegel RL, Ferlay J, Lortet-Tieulent J, Jemal A. Global cancer statistics, 2012: global cancer statistics, 2012. CA Cancer J Clin. 2015;65(2):87–108.
Rueth NM, Andrade RS. Is VATS lobectomy better: perioperatively, biologically and oncologically? Ann Thorac Surg. 2010;89(6):S2107–11.
Mun M, Nakao M, Matsuura Y, et al. Video-assisted thoracoscopic surgery lobectomy for non-small cell lung cancer. Gen Thorac Cardiovasc Surg. 2018. https://doi.org/10.1007/s11748-018-0979-x.
Ueda K, Tanaka T, Hayashi M, Tanaka N, Li TS, Hamano K. Clinical ramifications of bronchial kink after upper lobectomy. Ann Thorac Surg. 2012;93(1):259–65.
Alpert JB, Godoy MCB, Degroot PM, Truong MT, Ko JP. Imaging the post-thoracotomy patient: anatomic changes and postoperative complications. Radiol Clin N Am. 2014;52(1):85–103.
Bommart S, Berthet JP, Durand G, Ghaye B, Pujol JL, Marty-Ané C, Kovacsik H. Normal postoperative appearances of lung cancer. Diagn Interv Imaging. 2016;97(10):1025–35.
Choe J, Lee SM, Chae EJ, Lee SM, Kim YH, Kim N, Seo JB. Evaluation of postoperative lung volume and perfusion changes by dual-energy computed tomography in patients with lung cancer. Eur J Radiol. 2017;90:166–73.
Seok Y, Cho S, Lee JY, Yang HC, Kim K, Jheon S. The effect of postoperative change in bronchial angle on postoperative pulmonary function after upper lobectomy in lung cancer patients. Interact Cardiovasc Thorac Surg. 2014;18(2):183–8.
Sengul AT, Sahin B, Celenk C, Basoglu A. Postoperative lung volume change depending on the resected lobe. Thorac Cardiovasc Surg. 2013;61(2):131–7.
Watanabe S-I, Asamura H, Suzuki K, Tsuchiya R. The new strategy of selective nodal dissection for lung cancer based on segment-specific patterns of nodal spread. Interact Cardiovasc Thorac Surg. 2005;4:106–9.
Kim SJ, Lee YJ, Park JS, Cho YJ, Cho S, Yoon HI, Kim K, Lee JH, Jheon S, Lee CT. Changes in pulmonary function in lung cancer patients after video-assisted thoracic surgery. Ann Thorac Surg. 2015;99(1):210–7.
Ueda K, Tanaka T, Hayashi M, Li TS, Kaneoka T, Tanaka N, Hamano K. Compensation of pulmonary function after upper lobectomy versus lower lobectomy. J Thorac Cardiovasc Surg. 2011;142(4):762–7.
Ueda K, Hayashi M, Tanaka N, Tanaka T, Hamano K. Long-term pulmonary function after major lung resection. Gen Thorac Cardiovasc Surg. 2014;62(1):24–30.
Burrowes KS, De Backer J, Smallwood R, Sterk PJ, Gut I, Wirix-Speetjens R, Siddiqui S, Owers-Bradley J, Wild J, Maier D, Brightling C. Multi-scale computational models of the airways to unravel the pathophysiological mechanisms in asthma and chronic obstructive pulmonary disease (AirPROM). Interface Focus. 2013;3(2):20120057.
Kleinstreuer C, Zhang Z. Airflow and particle transport in the human respiratory system. Annu Rev Fluid Mech. 2010;42(1–4):301–34.
Burrowes KS, Doel T, Brightling C. Computational modeling of the obstructive lung diseases asthma and COPD. J Transl Med. 2014;12(Suppl 2):S5.
Burrowes KS, De Backer J, Kumar H. Image-based computational fluid dynamics in the lung: virtual reality or new clinical practice? Wiley Interdiscip Rev Syst Biol Med. 2017;9(6):e1392.
Walters DK, Burgreen GW, Lavallee DM, Thompson DS, Hester RL. Efficient, physiologically realistic lung airflow simulations. IEEE Trans Biomed Eng. 2011;58(10):3016–9.
Oakes JM, Roth SC, Shadden SC. Airflow simulations in infant, child, and adult pulmonary conducting airways. Ann Biomed Eng. 2018;46:498–512.
Sul B, Oppito Z, Jayasekera S, Vanger B, Zeller A, Morris M, Ruppert K, Altes T, Rakesh V, Day S, Robinson R, Reifman J, Wallqvist A. Assessing airflow sensitivity to healthy and diseased lung conditions in a computational fluid dynamics model validated in vitro. J Biomech Eng. 2018;140(5):051009.
Calmet H, Gambaruto AM, Bates AJ, Vázquez M, Houzeaux G, Doorly DJ. Large-scale CFD simulations of the transitional and turbulent regime for the large human airways during rapid inhalation. Comput Biol Med. 2016;69:166–80.
Xi J, Kim J, Si XA, Corley RA, Kabilan S, Wang S. CFD modeling and image analysis of exhaled aerosols due to a growing bronchial tumor: towards non-invasive diagnosis and treatment of respiratory obstructive diseases. Theranostics. 2015;5(5):443–55.
Hariprasad DS, Sul B, Liu C, Kiger KT, Altes T, Ruppert K, Reifman J, Wallqvist A. Obstructions in the lower airways lead to altered airflow patterns in the central airway. Respir Physiol Neurobiol. 2019. https://doi.org/10.1016/j.resp.2019.103311.
Qi S, Li Z, Yue Y, Van Triest HJW, Kang Y. Computational fluid dynamics simulation of airflow in the trachea and main bronchi for the subjects with left pulmonary artery sling. BioMed Eng OnLine. 2014;13:85.
Qi S, Li Z, Yue Y, Van Triest HJW, Kang Y, Qian W. Simulation analysis of deformation and stress of tracheal and main bronchial wall for the subjects with left pulmonary artery sling. J Mech Med Biol. 2015;15(6):1540053.
Qi S, Zhang B, Teng Y, Li J, Yue Y, Kang Y, Qian W. Transient dynamics simulation of airflow in a CT-scanned human airway tree: more or fewer terminal bronchi? Comput Math Methods Med. 2017;2017:1969023.
Qi S, Zhang B, Yue Y, Shen J, Teng Y, Qian W, Wu J. Airflow in tracheobronchial tree of subjects with tracheal bronchus simulated using CT image based models and CFD method. J Med Syst. 2018;42(4):65.
Zhang B, Qi S, Yue Y, Shen J, Teng Y, Qian W, Wu J. Particle disposition in tracheobronchial tree of subjects with tracheal bronchus, COPD simulated by CFD. BioMed Res Int. 2018;2018:7428609. https://doi.org/10.1155/2018/7428609.
De Backer JW, Vos WG, Devolder A, Verhulst SL, Germonpre P, Wuyts FL, Parizel PM, De Backer W. Computational fluid dynamics can detect changes in airway resistance in asthmatics after acute bronchodilation. J Biomech. 2008;41(1):106–13.
Ho CY, Liao HM, Tu CY, Huang CY, Shih CM, Su MY, Chen JH, Shih TC. Numerical analysis of airflow alteration in central airways following tracheobronchial stent placement. Exp Hematol Oncol. 2012;1(1):23.
Chen FL, Horng TL, Shih TC. Simulation analysis of airflow alteration in the trachea following the vascular ring surgery based on CT images using the computational fluid dynamics method. J X-Ray Sci Technol. 2014;22(2):213–25.
Bos AC, Van Holsbeke C, De Backer JW, Van Westreenen M, Janssens HM, Vos WG, et al. Patient-specific modeling of regional antibiotic concentration levels in airways of patientswith cystic fibrosis: are we dosing high enough? PLoS ONE. 2015;10(3):e0118454.
De Rochefort L, Vial L, Fodil R, Maitre X, Louis B, Isabey D, Caillibotte G, Thiriet M, Bittoun J, Durand E, Sbirlea-Apiou G. In vitro validation of computational fluid dynamic simulation in human proximal airways with hyperpolarized 3He magnetic resonance phase-contrast velocimetry. J Appl Physiol. 2007;102(5):2012–23.
De Backer JW, Vos WG, Vinchurkar SC, Claes R, Drollmann A, Wulfrank D, Parizel PM, Germonpre P, De Backer W. Validation of computational fluid dynamics in CT-based airway models with SPECT/CT. Radiology. 2010;257(3):854–62.
Balásházy I, Hofmann W. Deposition of aerosols in asymmetric airway bifurcations. J Aerosol Sci. 1995;26(2):273–92.
Funakoshi Y, Takeda S, Sawabata N, Okumura Y, Maeda H. Long-term pulmonary function after lobectomy for primary lung cancer. Asian Cardiovasc Thorac Ann. 2005;13:311–5.
Launder BE, Spalding DB. The numerical computation of turbulent flows. Comput Method Appl M. 1974;3:269–89.
Lin CL, Tawhai MH, Hoffman EA. Multiscale image-based modeling and simulation of gas flow and particle transport in the human lungs. Wiley Interdiscip Rev Syst Biol Med. 2013;5(5):643–55.
Luo HY, Liu Y, Yang XL. Particle deposition in obstructed airways. J Biomech. 2007;40(14):3096–104.
Potter MC, Wiggert DC, Ramadan BH. Mechanics of fluids, Chapter 11. 5th ed. Stamford: Cengage Learning Engineering; 2016. p. 514–31.
Islam MS, Saha SC, Sauret E, Yang IA, Gu YT. Ultrafine particle transport and deposition in a large scale 17-generation lung model. J Biomech. 2017;64:16–25.
Horsfield K, Dart G, Olson DE, Filley GF, Cumming G. Models of the human bronchial tree. J Appl Physiol. 1971;31(2):207–17.
Cohen B, Sussman R, Morton L. Ultrafine particle deposition in a human tracheobronchial cast. Aerosol Sci Tech. 2007;12(4):1082–91.
The authors would like to thank Mr. Patrice Monkam for his valuable help in the writing of this manuscript.
This study was supported by the National Natural Science Foundation of China under Grant (Grant numbers: 81671773, 61672146) and the Fundamental Research Funds for the Central Universities (N172008008, N180719020).
Sino-Dutch Biomedical and Information Engineering School, Northeastern University, Shenyang, China
Qingtao Gu
, Shouliang Qi
, Baihua Zhang
& Wei Qian
Key Laboratory of Medical Image Computing of Northeastern University (Ministry of Education), Shenyang, China
& Shouliang Qi
Department of Radiology, Shengjing Hospital of China Medical University, Shenyang, China
Yong Yue
Department of Radiology, Affiliated Zhongshan Hospital of Dalian University, Dalian, China
Jing Shen
& Jianlin Wu
The Graduate School, Dalian Medical University, Dalian, China
Wei Sun
College of Engineering, University of Texas at El Paso, El Paso, USA
Wei Qian
School of Mechanical and Mechatronic Engineering, Faculty of Engineering and Information Technology, University of Technology Sydney, Brisbane, Australia
Mohammad Saidul Islam
& Suvash C. Saha
Search for Qingtao Gu in:
Search for Shouliang Qi in:
Search for Yong Yue in:
Search for Jing Shen in:
Search for Baihua Zhang in:
Search for Wei Sun in:
Search for Wei Qian in:
Search for Mohammad Saidul Islam in:
Search for Suvash C. Saha in:
Search for Jianlin Wu in:
QG and SQ: proposed the idea, performed experiments, analyzed the data, made discussions and composed the manuscript together with YY, JS, BZ, WS, and MSI. WQ, SCS and JW: directed the experiments and made discussions. All authors read and approved the final manuscript.
Correspondence to Shouliang Qi or Jianlin Wu.
This study was approved by the Medical Ethics Committee of Affiliated Zhongshan Hospital of Dalian University (Dalian, China) and was in accordance with the 1964 Helsinki declaration and its later amendments or comparable ethical standards. All subjects gave written informed consent in accordance with the Declaration of Helsinki.
All subjects gave written informed consent in accordance with the Declaration of Helsinki.
Gu, Q., Qi, S., Yue, Y. et al. Structural and functional alterations of the tracheobronchial tree after left upper pulmonary lobectomy for lung cancer. BioMed Eng OnLine 18, 105 (2019) doi:10.1186/s12938-019-0722-6
Pulmonary lobectomy
Tracheobronchial tree
Bronchial distortion | CommonCrawl |
Journal of Fluid Mechanics (2)
Canadian Mathematical Bulletin (1)
Infection Control & Hospital Epidemiology (1)
Laser and Particle Beams (1)
Mycological Research (1)
Protein Science (1)
Ryan Test (2)
Canadian Mathematical Society (1)
Society for Healthcare Epidemiology of America (SHEA) (1)
Reduced optimism and a heightened neural response to everyday worries are specific to generalized anxiety disorder, and not seen in social anxiety
K. S. Blair, M. Otero, C. Teng, M. Geraci, M. Ernst, R. J. R. Blair, D. S. Pine, C. Grillon
Journal: Psychological Medicine / Volume 47 / Issue 10 / July 2017
Published online by Cambridge University Press: 14 March 2017, pp. 1806-1815
Generalized anxiety disorder (GAD) and social anxiety disorder (SAD) are co-morbid and associated with similar neural disruptions during emotion regulation. In contrast, the lack of optimism examined here may be specific to GAD and could prove an important biomarker for that disorder.
Unmedicated individuals with GAD (n = 18) and age-, intelligence quotient- and gender-matched SAD (n = 18) and healthy (n = 18) comparison individuals were scanned while contemplating likelihoods of high- and low-impact negative (e.g. heart attack; heartburn) or positive (e.g. winning lottery; hug) events occurring to themselves in the future.
As expected, healthy subjects showed significant optimistic bias (OB); they considered themselves significantly less likely to experience future negative but significantly more likely to experience future positive events relative to others (p < 0.001). This was also seen in SAD, albeit at trend level for positive events (p < 0.001 and p < 0.10, respectively). However, GAD patients showed no OB for positive events (t 17 = 0.82, n.s.) and showed significantly reduced neural modulation relative to the two other groups of regions including the medial prefrontal cortex (mPFC) and caudate to these events (p < 0.001 for all). The GAD group further differed from the other groups by showing increased neural responses to low-impact events in regions including the rostral mPFC (p < 0.05 for both).
The neural dysfunction identified here may represent a unique feature associated with reduced optimism and increased worry about everyday events in GAD. Consistent with this possibility, patients with SAD did not show such dysfunction. Future studies should consider if this dysfunction represents a biomarker for GAD.
Learning from other people's fear: amygdala-based social reference learning in social anxiety disorder
K. S. Blair, M. Otero, C. Teng, M. Geraci, E. Lewis, N. Hollon, R. J. R. Blair, Monique Ernst, C. Grillon, D. S. Pine
Journal: Psychological Medicine / Volume 46 / Issue 14 / October 2016
Social anxiety disorder involves fear of social objects or situations. Social referencing may play an important role in the acquisition of this fear and could be a key determinant in future biomarkers and treatment pathways. However, the neural underpinnings mediating such learning in social anxiety are unknown. Using event-related functional magnetic resonance imaging, we examined social reference learning in social anxiety disorder. Specifically, would patients with the disorder show increased amygdala activity during social reference learning, and further, following social reference learning, show particularly increased response to objects associated with other people's negative reactions?
A total of 32 unmedicated patients with social anxiety disorder and 22 age-, intelligence quotient- and gender-matched healthy individuals responded to objects that had become associated with others' fearful, angry, happy or neutral reactions.
During the social reference learning phase, a significant group × social context interaction revealed that, relative to the comparison group, the social anxiety group showed a significantly greater response in the amygdala, as well as rostral, dorsomedial and lateral frontal and parietal cortices during the social, relative to non-social, referencing trials. In addition, during the object test phase, relative to the comparison group, the social anxiety group showed increased bilateral amygdala activation to objects associated with others' fearful reactions, and a trend towards decreased amygdala activation to objects associated with others' happy and neutral reactions.
These results suggest perturbed observational learning in social anxiety disorder. In addition, they further implicate the amygdala and dorsomedial prefrontal cortex in the disorder, and underscore their importance in future biomarker developments.
Electron Microscopy Study of Nd doped Misfit Layer Structures in the Pb-Nb-Se System
R. Varadé López, A. Gómez- Herrero, D. Avila Brande, L. C. Otero-Diaz
Published online by Cambridge University Press: 25 July 2016, pp. 1864-1865
Effect of bovine ABCG2 polymorphism Y581S SNP on secretion into milk of enterolactone, riboflavin and uric acid
J. A. Otero, V. Miguel, L. González-Lobato, R. García-Villalba, J. C. Espín, J. G. Prieto, G. Merino, A. I. Álvarez
The ATP-binding cassette transporter G2/breast cancer resistance protein (ABCG2/BCRP) is an efflux protein involved in the bioavailability and milk secretion of endogenous and exogenous compounds, actively affecting milk composition. A limited number of physiological substrates have been identified. However, no studies have reported the specific effect of this polymorphism on the secretion into milk of compounds implicated in milk quality such as vitamins or endogenous compounds. The bovine ABCG2 Y581S polymorphism is described as a gain-of-function polymorphism that increases milk secretion and decreases plasma levels of its substrates. This work aims to study the impact of Y581S polymorphism on plasma disposition and milk secretion of compounds such as riboflavin (vitamin B2), enterolactone, a microbiota-derived metabolite from the dietary lignan secoisolariciresinol and uric acid. In vitro transport of these compounds was assessed in MDCK-II cells overexpressing the bovine ABCG2 (WT-bABCG2) and its Y581S variant (Y581S-bABCG2). Plasma and milk levels were obtained from Y/Y homozygous and Y/S heterozygous cows. The results show that riboflavin was more efficiently transported in vitro by the Y581S variant, although no differences were noted in vivo. Both uric acid and enterolactone were substrates in vitro of the bovine ABCG2 variants and were actively secreted into milk with a two-fold increase in the milk/plasma ratio for Y/S with respect to Y/Y cows. The in vitro ABCG2-mediated transport of the drug mitoxantrone, as a model substrate, was inhibited by enterolactone in both variants, suggesting the possible in vivo use of this enterolignan to reduce ABCG2-mediated milk drug transfer in cows. The Y581S variant was inhibited to a lesser extent probably due to its higher transport capacity. All these findings point to a significant role of the ABCG2 Y581S polymorphism in the milk disposition of enterolactone and the endogenous molecules riboflavin and uric acid, which could affect both milk quality and functionality.
Artificial Physical and Chemical Awareness (Proprioception) from Polymeric Motors
T.F. Otero, J.G. Martínez
Published online by Cambridge University Press: 02 February 2015, mrsf14-1717-a02-01
Designers and engineers have been dreaming for decades with motors sensing, by themselves, working and surrounding conditions, as biological muscles do originating proprioception. The evolution of the working potential, or that of the consumed electrical energy, of electrochemical artificial muscles based on electroactive materials (intrinsically conducting polymers, redox polymers, carbon nanotubes, fullerene derivatives, grapheme derivatives, porphyrines, phtalocyanines, among others) and driven by constant currents senses, while working, any variation of the mechanical (trailed mass, obstacles, pressure, strain or stress) thermal or chemical conditions. They are linear faradaic polymeric motors: applied currents control movement rates and applied charges control displacements. One physically uniform artificial muscle includes one motor and several sensors working simultaneously under the same driving chemical reaction. Actuating (current and charge) and sensing (potential and energy) magnitudes are present, simultaneously, in the only two connecting wires and can be read by the computer at any time. From basic polymeric, mechanical and electrochemical principles a basic equation is attained for the muscle working potential evolution. It includes and describes, simultaneously, the polymeric motor characteristics (rate of the muscle movement and muscle position) and the working variables (temperature, electrolyte concentration and mechanical conditions). By changing working conditions experimental results overlap theoretical predictions. The ensemble computer-generator-muscle-theoretical equation constitutes and describes artificial mechanical, thermal and chemical proprioception of the system. Proprioceptive tools, zoomorphic or anthropomorphic soft robots can be envisaged.
Applying the ecosystem services framework to pasture-based livestock farming systems in Europe
T. Rodríguez-Ortega, E. Oteros-Rozas, R. Ripoll-Bosch, M. Tichit, B. Martín-López, A. Bernués
Journal: animal / Volume 8 / Issue 8 / August 2014
The concept of 'Ecosystem Services' (ES) focuses on the linkages between ecosystems, including agroecosystems, and human well-being, referring to all the benefits, direct and indirect, that people obtain from ecosystems. In this paper, we review the application of the ES framework to pasture-based livestock farming systems, which allows (1) regulating, supporting and cultural ES to be integrated at the same level with provisioning ES, and (2) the multiple trade-offs and synergies that exist among ES to be considered. Research on livestock farming has focused mostly on provisioning ES (meat, milk and fibre production), despite the fact that provisioning ES strongly depends on regulating and supporting ES for their existence. We first present an inventory of the non-provisioning ES (regulating, supporting and cultural) provided by pasture-based livestock systems in Europe. Next, we review the trade-offs between provisioning and non-provisioning ES at multiple scales and present an overview of the methodologies for assessing biophysical trade-offs. Third, we present non-biophysical (economical and socio-cultural) methodologies and applications for ES valuation. We conclude with some recommendations for policy design.
Electron Microscopy Characterization of Nanometric ZrO2 and Er2O2S Synthetized from Organometallic Precursors.
D. Ávila-Brande, G. González-Rubio, L. Otero-Díaz, R. Perezzan, E. Urones-Garrote
Extended abstract of a paper presented at Microscopy and Microanalysis 2012 in Phoenix, Arizona, USA, July 29 – August 2, 2012.
Staphylococcal cassette chromosome mec (SCCmec) in methicillin-resistant coagulase-negative staphylococci. A review and the experience in a tertiary-care setting
E. GARZA-GONZÁLEZ, R. MORFÍN-OTERO, J. M. LLACA-DÍAZ, E. RODRIGUEZ-NORIEGA
Journal: Epidemiology & Infection / Volume 138 / Issue 5 / May 2010
Coagulase-negative staphylococci (CNS) are increasingly recognized to cause clinically significant infections, with S. epidermidis often cited as the third most common cause of nosocomial sepsis. Among CNS, there is a high prevalence of methicillin resistance associated with staphylococcal cassette chromosome (SCCmec) elements. Although identical SCCmec types can exist in S. aureus and CNS, some novel classes of SCCmec may be unique to CNS. Differences in the accuracy of identification of CNS species and use of non-standardized methods for the detection of methicillin resistance have led to confusing data in the literature. In addition to the review of SCCmec in CNS, in this paper we report a 2-year surveillance of methicillin-resistant CNS in a tertiary-care hospital in Guadalajara, Mexico.
Ultrastructure of the earthworm calciferous gland. A preliminary study
J. Méndez, J. B. Rodríguez, R. Álvarez-Otero, M. J. I. Briones, L. Gago-Duport
Published online by Cambridge University Press: 21 August 2009, pp. 25-26
The earthworm species belonging to the Lumbricidae family (Annelida, Oligochaeta) posses a complex oesophageal organ known as "calciferous gland" which secretes a concentrated suspension of calcium carbonate. Previous studies have demonstrated the non-crystalline structure of this calcareous fluid representing an interesting example of biomineralisation.
Wirtinger's Inequalities on Time Scales
Ravi P. Agarwal, Victoria Otero-Espinar, Kanishka Perera, Dolores R. Vivero
Journal: Canadian Mathematical Bulletin / Volume 51 / Issue 2 / 01 June 2008
Print publication: 01 June 2008
This paper is devoted to the study of Wirtinger-type inequalities for the Lebesgue $\Delta$ -integral on an arbitrary time scale $\mathbb{T}$ . We prove a general inequality for a class of absolutely continuous functions on closed subintervals of an adequate subset of $\mathbb{T}$ . By using this expression and by assuming that $\mathbb{T}$ is bounded, we deduce that a general inequality is valid for every absolutely continuous function on $\mathbb{T}$ such that its $\Delta$ -derivative belongs to $L_{\Delta }^{2}\,([a,\,b)\,\cap \,\mathbb{T})$ and at most it vanishes on the boundary of $\mathbb{T}$ .
TEM Study of the Order, Disorder and Structural Modulations in Bi4Fe1/3W2/3O8Br
D Ávila-Brande, M Luysberg, A R Landa-Cánovas, L C Otero-Díaz
Journal: Microscopy and Microanalysis / Volume 13 / Issue S03 / September 2007
Extended abstract of a paper presented at MC 2007, 33rd DGE Conference in Saarbrücken, Germany, September 2 – September 7, 2007
Epidemiology and Clonality of Methicillin-Resistant and Methicillin-Susceptible Staphylococcus aureus Causing Bacteremia in a Tertiary-Care Hospital in Spain
Fernando Chaves, Jesus García-Martínez, Sonia de Miguel, Francisca Sanz, Joaquín R. Otero
Journal: Infection Control & Hospital Epidemiology / Volume 26 / Issue 2 / February 2005
To describe the relative proportions of nosocomial and community-onset Staphylococcus aureus bacteremia at our institution and the epidemiologic characteristics and clonal diversity of S. aureus isolates, as determined by pulsed-field gel electrophoresis (PFGE) and antimicrobial resistance patterns.
Retrospective cohort study of all cases of S. aureus bacteremia between October 2001 and October 2002.
A 1,300-bed, tertiary-care hospital.
One hundred sixty-two unique episodes of S. aureus bacteremia were identified. Forty-three cases (26.5%) were caused by methicillin-resistant S. aureus (MRSA). Most cases of S. aureus bacteremia, whether MRSA or methicillin susceptible (MSSA), were nosocomial in origin (77.2%) or were otherwise associated with the healthcare system (16%). Only 11 (6.8%) of the cases (all MSSA) were strictly community acquired. Thirty-five unique macrorestriction patterns were identified among the 154 isolates that were typed by PFGE. Four major genotypes were defined among the isolates of MRSA, with 36 (85.7%) represented by a single PFGE type. Of the isolates within this major clone, all (100%) were ciprofloxacin resistant and 77.8% were erythromycin resistant. In contrast, the 112 isolates of MSSA comprised 31 different PFGE types, 3 of which represented 42.9% of all MSSA isolates and were associated with both nosocomial and community-onset bacteremia.
Most cases of S. aureus bacteremia in our healthcare region are nosocomial in origin or are acquired through contact with the healthcare system and are thus potentially preventable. To preclude dissemination of pathogenic clones, it is therefore necessary to redouble preventive measures in both the hospital and the community.
A Rapid Evaluation Method to Assess Organic Film Uniformity in Roll-to-Roll Manufactured OLEDs.
Svetlana Rogojevic, Tami Faircloth, Maria M. Otero, James C. Grande, Robert W. Tait, Joseph Shiang, Anil R. Duggal
Published online by Cambridge University Press: 01 February 2011, I11.2
In order to enable low cost roll-to-roll or sheet-processing of organic light-emitting diode (OLED) devices, completely new deposition methods for both polymer and smallmolecule layers are being developed in place of the classic semiconductor manufacturing methods. In evaluating the utility of such methods, it is advantageous to have a robust and fast method to measure the thickness uniformity of the deposited organic layers. Non-uniformities at all spatial length scales from sub-mm to several cm can occur and so need to be understood as a function of the relevant parameters for each deposition method. Here we demonstrate a simple and fast method to quantify non-uniformities in thin films over arbitrarily large length scales. Our method utilizes the color of light reflected from the coated substrate and its variation with polymer layer thickness. This concept of color change is well known, and is due to constructive interference of light of particular wavelengths related to polymer layer thickness and optical constants. In our modification, a digital camera is used to capture images of the coated substrates, and hue is extracted from the image data files. We show that hue can be linearly correlated with polymer thickness. We demonstrate this for polymer based OLEDs using poly(3,4-ethylenedioxythiophene) poly(styrenesulfonate) (PEDOT:PSS) and a light-emitting polymer (LEP) deposited on transparent substrate. The correlations were successfully used for 40-140nm PEDOT:PSS layers and 20-110nm LEP layers over length scales greater than 1 inch. The method sensitivity is estimated to be better than 5 nm. We show examples of non-uniformity analysis and how it relates to OLED performance.
Effects of available water on growth and competition of southern pine beetle associated fungi
Kier D. KLEPZIG, J. FLORES-OTERO, R. W. HOFSTETTER, M. P. AYRES
Journal: Mycological Research / Volume 108 / Issue 2 / February 2004
Competitive interactions among bark beetle associated fungi are potentially influenced by abiotic factors. Water potential, in particular, undergoes marked changes over the course of beetle colonization of tree hosts. To investigate the impact of water potential on competition among three southern pine beetle associated fungi, Ophiostoma minus, Entomocorticium sp. A and Ceratocystiopsis ranaculosus, we utilized artificial media with water potentials of 0, −5, −10, and −20 MPa. Growth of all three fungi, when grown alone, decreased on media with lower water potentials. Growth rates of all three fungi were likewise reduced in competition experiments. At −5 to −10 MPa, C. ranaculosus (a fungus with beneficial effects toward southern pine beetle) was nearly equal in competitive ability to O. minus (a fungus with antagonistic effects towards southern pine beetle). This was not true on control media, nor at other water potentials tested. The range of water potentials used in our assays was similar to the range of water potentials we measured in loblolly pines within a southern pine beetle infestation. This study indicates that water potential may alter the outcome of competitive interactions among bark beetle-associated fungi in ways that favour bark beetle success.
High-Rayleigh-number convection in a fluid-saturated porous layer
JESSE OTERO, LUBOMIRA A. DONTCHEVA, HANS JOHNSTON, RODNEY A. WORTHING, ALEXANDER KURGANOV, GUERGANA PETROVA, CHARLES R. DOERING
Journal: Journal of Fluid Mechanics / Volume 500 / April 2004
Published online by Cambridge University Press: 03 February 2004, pp. 263-281
Print publication: April 2004
The Darcy–Boussinesq equations at infinite Darcy–Prandtl number are used to study convection and heat transport in a basic model of porous-medium convection over a broad range of Rayleigh number $Ra$. High-resolution direct numerical simulations are performed to explore the modes of convection and measure the heat transport, i.e. the Nusselt number Nu, from onset at $Ra \,{=}\, 4\pi^2$ up to $Ra\,{=}\,10^4$. Over an intermediate range of increasing Rayleigh numbers, the simulations display the 'classical' heat transport $\hbox{\it Nu} \,{\sim}\, Ra$ scaling. As the Rayleigh number is increased beyond $Ra \,{=}\, 1255$, we observe a sharp crossover to a form fitted by $\hbox{\it Nu} \,{\approx}\, 0.0174 \times Ra^{0.9}$ over nearly a decade up to the highest $Ra$. New rigorous upper bounds on the high-Rayleigh-number heat transport are derived, quantitatively improving the most recent available results. The upper bounds are of the classical scaling form with an explicit prefactor: $\hbox{\it Nu} \,{\le}\, 0.0297 \times Ra$. The bounds are compared directly to the results of the simulations. We also report various dynamical transitions for intermediate values of $Ra$, including hysteretic effects observed in the simulations as the Rayleigh number is decreased from $1255$ back down to onset.
Bounds on Rayleigh–Bénard convection with an imposed heat flux
JESSE OTERO, RALF W. WITTENBERG, RODNEY A. WORTHING, CHARLES R. DOERING
Journal: Journal of Fluid Mechanics / Volume 473 / 10 December 2002
We formulate a bounding principle for the heat transport in Rayleigh–Bénard convection with fixed heat flux through the boundaries. The heat transport, as measured by a conventional Nusselt number, is inversely proportional to the temperature drop across the layer and is bounded above according to Nu [les ] cRˆ1/3, where c < 0.42 is an absolute constant and Rˆ = αγβh4/(νκ) is the 'effective' Rayleigh number, the non-dimensional forcing scale set by the imposed heat flux κβ. The relation among the parameter Rˆ, the Nusselt number, and the conventional Rayleigh number defined in terms of the temperature drop across the layer, is NuRa = Rˆ, yielding the bound Nu [les ] c3/2Ra1/2.
Solution structure of DinI provides insight into its mode of RecA inactivation
BENJAMIN E. RAMIREZ, OLEG N. VOLOSHIN, R. DANIEL CAMERINI-OTERO, AD BAX
Journal: Protein Science / Volume 9 / Issue 11 / November 2000
The Escherichia coli RecA protein triggers both DNA repair and mutagenesis in a process known as the SOS response. The 81-residue E. coli protein DinI inhibits activity of RecA in vivo. The solution structure of DinI has been determined by multidimensional triple resonance NMR spectroscopy, using restraints derived from two sets of residual dipolar couplings, obtained in bicelle and phage media, supplemented with J couplings and a moderate number of NOE restraints. DinI has an α/β fold comprised of a three-stranded β-sheet and two α-helices. The β-sheet topology is unusual: the central strand is flanked by a parallel and an antiparallel strand and the sheet is remarkably flat. The structure of DinI shows that six negatively charged Glu and Asp residues on DinI's kinked C-terminal α-helix form an extended, negatively charged ridge. We propose that this ridge mimics the electrostatic character of the DNA phospodiester backbone, thereby enabling DinI to compete with single-stranded DNA for RecA binding. Biochemical data confirm that DinI is able to displace ssDNA from RecA.
Optimization of Conducting Polymer Synthesis for Battery Applications
T. F. Otero, C. Santamaria, J. Rodriguez
The evolution of the capacity to store electrical charges of electrogenerated polypyrrole and polythiophene films, as a function of the parameters of synthesis (electrical potential, solvent, Monomer concentration and temperature) was analyzed. The polymer production was followed by "ex situ" ultramicrogravimetry. The stored charge in each film was controlled by voltammetry and chronoamperometry, in the background electrolyte (in absence of Monomer). The charge storage ability was calculated from the ratio between stored charge and polymer mass adhered to the electrode. The charge storage ability of an electrogenerated film decreases several times when one of the parameters of synthesis: potential of polymerization, temperature, concentration of monomer or donor number of the solvent, increase. The change on the polymer property when the conditions of synthesis shift, points to a mixed polymerization-degradation process during polymer growth. The knowledge of those variations allows to optimize the conditions of synthesis to generate conducting polymers for specific batteries applications.
Poly (SNS) Quantitative Electrosynthesis and Electrodissolution
T. F. Otero, E. Brillas, J. Carrasco, A. Figueras
The electrogeneration and electrodissolution of poly (SNS) have been improved by using aqueous acetonitrile solutions having a 1% (ν/ν) of water constant. Compact, adherent and thick films (until 0.4 Mg cm-2) were galvanostatically electrogenerated. The electrodeposited (oxidized) polymer is insoluble in 0.1 M L?CIO4 aqueous acetonitrile solution and solubilizes by cathodic reduction. Both, electrogeneration and electrodissolution, are faradaic processes. Those facts mimic electrodeposition and electroerosion of metals and their concomitant industrial applications. New technological possibilities using polymers in electrophotography, electroreprography, electropolishing, electro-erosion and electromachining are open through polymeric electrodissolution altogether to a new processible way, through the obtained solution, for the conducting polymers.
Effect of Electron Irradiation and Excess Cd on Ion-Assisted Doping of p-CdTe Thin Films
D. Kim, A. L. Fahrenbruch, A. Lopez-Otero, R. H. Bube
Published online by Cambridge University Press: 03 September 2012, 187
Ion-assisted doping of homoepitaxial p-CdTe films with low energy P ions (20 eV) deposited by vacuum evaporation has been investigated. In order to control the properties of the films, we applied low energy electron irradiation and Cd overpressure during the growth. We report the results of measurements of hole density, spectral response of Cr/p-CdTe Schottky barriers (to estimate the minority carrier diffusion length Lj). From Ld, we have found that the quality of the films is dependent on both the ion dose and the ion energy. By reducing the ion energy to 20 eV and applying electron irradiation and Cd overpressure, p-CdTe films with p = 1 × 10 17 cm−3 and Lp =0.35 μm were obtained. A p-CdTe film with p = 1016 cm−3 was obtained with a low ion energy of 10eV. | CommonCrawl |
incorporating
, Issue 2
As we go to press, media around the world have been reporting the latest round of awards of the coveted Fields Medal (popularly called the "Nobel Prize for Mathematics") which are awarded every four years.
Fitting Lines to Data
Bill McKee
We sometimes see in newspapers or on television situations where a straight line is drawn so as to approximately fit some data points. This can always be done by eye, using human judgment, but the results would then tend to vary depending on the person drawing the line.
History of Mathematics: Classical Applied Mathematics
Michael A. B. Deakin
Two separate events happily combined to suggest the topic for this issue's column. In the first place, I devoted my previous column to a somewhat controversial attempt to apply Mathematics to the "softer sciences" such as Biology and Linguistics.
Support Vector Machine Classification
M. P. Wand
Support vector machines emerged in the mid-1990s as a flexible and powerful means of classification. Classification is a very old problem in Statistics but, in our increasingly data-rich age, remains as important as ever.
UNSW School Mathematics Competition Problems 2006
Problem 1. An American football field is 100 yards long, and its width is half the average of its length and its diagonal. Find its area.
UNSW School Mathematics Competition Winners 2006
Prize Winners – Senior Division
Graham Robert White James Ruse Agricultural High School
Problems Section: Problems 1211 - 1220
Q1211. Solve
$$ (2+\sqrt{2})^{\sin^2x} - (2+\sqrt{2})^{\cos^2x} + (2-\sqrt{2})^{\cos2x} = \left(1+\frac{1}{\sqrt{2}}\right)^{\cos 2x}$$
Solutions to Problems 1201-1210
Q1201. Let $x_1$ and $x_2$ be the solutions of $x^2 - (a+d)x + ad - bc = 0.$ Prove that $x_1^3$ and $x_2^3$ are the solutions of
$$x^2 - (a^3 + d^3 + 3abc + 3bcd)x + (ad-bc)^3 = 0.$$
School of Mathematics and Statistics UNSW Sydney NSW 2052
UNSW CRICOS Provider Code: 00098G ABN: 57 195 873 179
Authorised by the Head of School, School of Mathematics and Statistics
This page is updated dynamically | CommonCrawl |
280 users online, thereof 0 logged in
Historical Development of Number Theory
Number theory – like geometry, is one of the oldest branches of mathematics. Many mathematicians contributed to its development. The development was in particular driven by the search for a solution of easy-to-formulate problems, but which turned out to be very hard to be solved and often remained unsolved for centuries. This development is continued even nowadays.
Euclid of Alexandria (325 BC – 265 BC) summarized in his Elements the contemporary ancient knowledge of mathematics. It consists of thirteen books, two of which (Book 7 and Book 9) are dedicated to number theory. These two books include many theorems which are still part of the classical number theory taught in schools and in undergraduate courses of number theory.
Diophantus of Alexandria (200 – 284) also wrote a treatise consisting of thirteen books, the last 7 of which were discovered only in 1973. The books deal with the solution of integer-valued equations, which are named after him as Diophantine equations.
Hypatia of Alexandria (370 – 415) was a first woman known as a mathematician. Unfortunately, she was killed because she did not want to join Christianity. In the Middle Ages, many scholars were prosecuted and the ancient mathematical contributions were lost.
Fortunately, mathematicians of the Arabic world, in particular, Muḥammad ibn Mūsā al-Khwārizmī (780 – 850), or Al-Kindi (801 – 873), have brought forth these achievements and developed them further. A big achievement of this time is the invention of the positional number system used in modern mathematics. They also developed many methods of arithmetics, which is underlying the number theory.
The Arabic art of reconning started to influence Europe when the "dark" Middle Ages approached its end. The first important Arabian influence was brought to Europe by Leonardo Pisano Fibonacci (1170 – 1250) who wrote in 1202 a book titled Liber abbaci, in which he established the Arabian positional decimal number system in Europe and also introduced the first "algorithms", i.e. steps to calculate solutions to specific problems. The modern word "algorithm" originates from the name "al-Khwārizmī" mentioned above. Fibonacci wrote also in 1225 a book titled Liber quadratorum, in which he dealt with quadratic Diophantine equations.
Pierre de Fermat (1601 – 1665) was a servant of the royal administration in Toulouse (France). He is considered the "father" of modern number theory. He wrote his results in letters addressed to other mathematicians and number theorists of his time: Carcavi, Descartes, Frénicle de Bessy, Mersenne. In one of his letters, discovered 30 years after his death, Fermat postulated to have found a "beautiful" proof for the fact that the equation $x^n+y^n=z^n$ had no integer solutions for $n\ge 3.$ Unfortunately, the letter did not contain the proof and the theorem remained a conjecture. Many mathematicians tried to find a proof of this conjecture and their search helped immensely in the development of the number theory, but also of other mathematical disciplines. A rigorous proof was found only in 1995, which can be considered the greatest achievement in mathematics in the 20th century.
Leonhard Euler was a Swiss mathematician, but he worked in St. Petersburg (Russia) and in Berlin (Germany). Euler was one of the most productive mathematicians of all times. He published 850 mathematical treatises and 20 mathematical books. It is not surprising that Euler's legacy is also very wide. He dealt with number theory, graph theory, curves, series, variation calculus, calculus, geometry, algebra, and on diverse topics of technology, mechanics, optics, and astronomy.
Joseph-Louis Lagrange (1736 – 1813) was another great mathematician and number theorist of his time. He was a successor of Euler in Berlin but he worked also as a professor of geometry in Turin (Italy) as well as in Paris on the École Polytechnique.
Adrien-Marie Legendre (1752 – 1833) was a French mathematician who was a teacher at a military school in France. He worked on the mathematics of ballistics and of the celestial mechanics as well as on the theory of elliptic functions. However, his work Éssai sur la Théorie des Nombres, published in 1798, became a pillar of later number theory.
The theory congruences and modular arithmetic was first developed by Carl Friedrich Gauss (1777 – 1855). Gauss is considered one of the greatest mathematicians of all times. He further developed almost every branch of mathematics, but his favorite branch was the number theory, which he called the "Queen of Mathematics". A milestone in the development of number theory was his book Disquisitiones arithmeticae, published in 1801, which was written by Gauss when he was 18. In the age of 24, he became a professor of astronomy in Göttingen (Germany) and a manager of the local observatory.
Johann Peter Gustav Lejeune Dirichlet (1805 – 1859) was another important French mathematician who was also the successor of Gauss at the Göttingen University. He was the first to systematically introduce analytic methods in the number theory, which surprisingly proved to be very useful in solving problem formulated for whole numbers by means of developed for real, or even complex numbers (i.e. analytical, infinitesimal, calculus) methods.
Two number-theoretic problems, which drove its development immensely (or, better to say, the search for their proofs) are the prime number theorem and the Riemann hypothesis. Both deal with prime numbers, i.e. those positive integers $p$ which are divisible only by $1$ and $p$. The prime number theorem predicts the asymptotic behavior of the number $\pi(n)$ of primes $\le n.$ It was first conjectured by Gauss and Legendre, who looked at the numerical evidence, which suggested that $\pi(n)\sim\frac{n}{\log(n)}.$ A slightly more sophisticated approximation is $$\pi(n)\sim\int_2^n\frac{dx}{\log(x)}.$$ This asymptotic formula was proved independently by Jacques Hadamard (1865 – 1963) and Charles de la Vallée Poussin (1866 – 1962). In their proof, they made use of complex analysis and the Riemann zeta function $\zeta(s)=1^{-s}+2^{-s}+3^{-s}+\ldots$ for a complex number $s.$ This function has so-called "trivial zeros" at all negative even integers. Bernhard Riemann (1826 – 1866) proved that the prime number theorem was equivalent to the assertion that the only "nontrivial" zeros were in the strip of complex numbers with a real part $> 0$ and $< 1.$ He also formulated a conjecture that these nontrivial zeros all lie exactly in the middle of this strip, i.e. have a real part $\frac 12.$ This so-called Riemann hypothesis is one of the still great unsolved mathematical problems and is one of the Clay Mathematics Institute's Million Dollar Problems. Most mathematicians believe that the Riemann hypothesis is indeed true.
Some other of the many still unsolved number-theoretic problems can be found here.
For a long time, number theory was considered a "pure" branch of mathematics, i.e. without any practical applications. However, with the development of computers, computational number theory became the basis of modern cryptography. Number-theoretic methods like RSA (going back to the basics developed by Pierre de Fermat) are used all over the Internet to encrypt data or to provide non-repudiation services, i.e. proofs that the communicating partners and/or computers really are the individual persons and/or systems on the other side of the communication channel, we believe they are.
| | | | created: 2019-06-19 21:21:05 | modified: 2019-06-20 00:29:09 | by: bookofproofs | references: [8189]
Edit or AddNotationAxiomatic Method
This work was contributed under CC BY-SA 3.0 by:
bookofproofs
This work is a derivative of:
Bibliography (further reading)
[8189] Kraetzel, E.: "Studienbücherei Zahlentheorie", VEB Deutscher Verlag der Wissenschaften, 1981
FeedsAcknowledgmentsTerms of UsePrivacy PolicyImprint
© 2018 Powered by BooOfProofs, All rights reserved. | CommonCrawl |
November 2006 , Volume 15 , Issue 4
Mathematical Problems in Phase Transitions
Guest Editors: A. Miranville, H. M. Yin and R. Showalter
Alain Miranville, H. M. Yin and R. Showalter
Phase transition phenomena are often encountered in real world situations and technological applications. Examples include solidification in complex alloys, melting, freezing or evaporation in food processing, glass formation and polymer crystallization in industrial applications. The modeling and analysis of problems involving such phenomena have attracted considerable attention in the scientific community over the past decades.
This special issue is an expansion from the papers presented at the special session "Mathematical Methods and Models in Phase Transitions" at the Fifth AIMS International Conference on Dynamical Systems and Differential Equations held at California State University at Pomona from June 17-21, 2004. This special session was organized by A. Miranville, R. Showalter and H.M. Yin. The papers presented at that conference have been supplemented with invited contributions from specialists. These papers include problems arising from industry and numerical analysis and computational issues arising in the simulation of solutions.
Alain Miranville, H. M. Yin, R. Showalter. Introduction. Discrete & Continuous Dynamical Systems - A, 2006, 15(4): i-ii. doi: 10.3934/dcds.2006.15.4i.
A rapidly converging phase field model
Xinfu Chen, G. Caginalp and Christof Eck
2006, 15(4): 1017-1034 doi: 10.3934/dcds.2006.15.1017 +[Abstract](1860) +[PDF](245.4KB)
We propose a phase field model that approximates its limiting sharp interface model (free boundary problem) up to second order in interface thickness. A broad range of double-well potentials can be utilized so long as the dynamical coefficient in the phase equation is adjusted appropriately. This model thereby assures that computation with particular value of interface thickness $\varepsilon$, will differ at most by $O(\varepsilon^2$) from the limiting sharp interface problem. As an illustration, the speed of a traveling wave of the phase field model is asymptotically expanded to demonstrate that it differs from the speed of the traveling wave of the limit problem by $O(\varepsilon^2)$.
Xinfu Chen, G. Caginalp, Christof Eck. A rapidly converging phase field model. Discrete & Continuous Dynamical Systems - A, 2006, 15(4): 1017-1034. doi: 10.3934/dcds.2006.15.1017.
Phase-field modelling of nonequilibrium partitioning during rapid solidification in a non-dilute binary alloy
Denis Danilov and Britta Nestler
Rapid solidification of a non-dilute binary alloy is studied using a phase-field model with a general formulation for different diffusion coefficients of the two alloy components. For high solidification velocities, we observe the effect of solute trapping in our simulations leading to the incorporation of solute into the growing solid at a composition significantly different from the predicted equilibrium value according to the phase diagram. The partition coefficient tends to unity and the concentration change across the interface progressively reduces as the solidification rate increases. For non-dilute binary alloys with a value of the partition coefficient close to unity, analytical solutions of the phase-field and of the concentration profiles are found in terms of power series expansions taking into account different diffusion coefficients of the alloy components. A new relation for the velocity dependence of the nonequilibrium partition coefficient $k(V)$ is derived and compared with predictions of continuous growth model by Aziz and Kaplan [1]. As a major result for applications, we obtain a steeper profile of the nonequilibrium partition coefficient in the rapid solidification regime for $V/V_D>1$ than previous sharp and diffuse interface models which is in better accordance with experimental measurements (e.g. [2]).
Denis Danilov, Britta Nestler. Phase-field modelling of nonequilibrium partitioning during rapid solidification in a non-dilute binary alloy. Discrete & Continuous Dynamical Systems - A, 2006, 15(4): 1035-1047. doi: 10.3934/dcds.2006.15.1035.
Complex transient patterns on the disk
Jonathan P. Desi, Evelyn Sander and Thomas Wanner
This paper studies spinodal decomposition in the Cahn-Hilliard model on the unit disk. It has previously been shown that starting at initial conditions near a homogeneous equilibrium on a rectangular domain, solutions to the linearized and the nonlinear Cahn-Hilliard equation behave indistinguishably up to large distances from the homogeneous state. In this paper we demonstrate how these results can be extended to nonrectangular domains. Particular emphasis is put on the case of the unit disk, for which interesting new phenomena can be observed. Our proof is based on vector-valued extensions of probabilistic methods used in Wanner [37]. These are the first results of this kind for domains more general than rectangular.
Jonathan P. Desi, Evelyn Sander, Thomas Wanner. Complex transient patterns on the disk. Discrete & Continuous Dynamical Systems - A, 2006, 15(4): 1049-1078. doi: 10.3934/dcds.2006.15.1049.
A reaction-diffusion equation with memory
M. Grasselli and V. Pata
We consider a one-dimensional reaction-diffusion type equation with memory, originally proposed by W.E. Olmstead et al. to model the velocity $u$ of certain viscoelastic fluids. More precisely, the usual diffusion term $u_{x x}$ is replaced by a convolution integral of the form $\int_0^\infty k(s) u_{x x}(t-s)ds$, whereas the reaction term is the derivative of a double-well potential. We first reformulate the equation, endowed with homogeneous Dirichlet boundary conditions, by introducing the integrated past history of $u$. Then we replace $k$ with a time-rescaled kernel $k_\varepsilon$, where $\varepsilon>0$ is the relaxation time. The obtained initial and boundary value problem generates a strongly continuous semigroup $S_\varepsilon(t)$ on a suitable phase-space. The main result of this work is the existence of the global attractor for $S_\varepsilon(t)$, provided that $\varepsilon$ is small enough.
M. Grasselli, V. Pata. A reaction-diffusion equation with memory. Discrete & Continuous Dynamical Systems - A, 2006, 15(4): 1079-1088. doi: 10.3934/dcds.2006.15.1079.
Some remarks on stability for a phase field model with memory
Michael Grinfeld and Amy Novick-Cohen
In the present paper we treat the system
(PFM) $ u_t + \frac{l}{2} \phi_t =\int_{0}^t a_1(t-s) $Δ$ u(s) ds$,
$\tau \phi_t = \int_{0}^t a_2(t-s)[\xi^2 $Δ$ \phi + \frac{1}{\eta}(\phi - \phi^3) + u](s) ds$,
for $(x, t) \in \Omega \times (0, T)$, $0 < T < \infty$, with the boundary conditions
n $\cdot \nabla u$= n $\cdot \nabla \phi=0, (x, t) \in \partial\Omega \times (0, T)$,
and initial conditions $u(x, 0)=u_0(x)$, $\phi(x, 0)=\phi_0(x)$, $x \in \Omega$, which was proposed in [36] to model phase transitions taking place in the presence of memory effects which arise as a result of slowly relaxing internal degrees of freedom, although in [36] the effects of past history were also included. This system has been shown to exhibit some intriguing effects such as grains which appear to rotate as they shrink [36]. Here the set of steady states of (PFM) and of an associated classical phase field model are shown to be the same. Moreover, under the assumption that $a_1$ and $a_2$ are both proportional to a kernel of positive type, the index of instability and the number of unstable modes for any given stationary state of the two systems can be compared and spectral instability is seen to imply instability. By suitably restricting further the memory kernels, the (weak) $\omega-$limit set of any initial condition can be shown to contain only steady states and linear stability can be shown to imply nonlinear stability.
Michael Grinfeld, Amy Novick-Cohen. Some remarks on stability for a phase field model with memory. Discrete & Continuous Dynamical Systems - A, 2006, 15(4): 1089-1117. doi: 10.3934/dcds.2006.15.1089.
Long time behaviour of a singular phase transition model
Pavel Krejčí and Jürgen Sprekels
A phase-field system, non-local in space and non-smooth in time, with heat flux proportional to the gradient of the inverse temperature, is shown to admit a unique strong thermodynamically consistent solution on the whole time axis. The temperature remains globally bounded both from above and from below, and its space gradient as well as the time derivative of the order parameter asymptotically vanish in $L^2$-norm as time tends to infinity.
Pavel Krej\u010D\u00ED, J\u00FCrgen Sprekels. Long time behaviour of a singular phase transition model. Discrete & Continuous Dynamical Systems - A, 2006, 15(4): 1119-1135. doi: 10.3934/dcds.2006.15.1119.
Connecting continua and curves of equilibria of the Cahn-Hilliard equation on the square
S. Maier-Paape and Ulrich Miller
We state an alternative for paths of equilibria of the Cahn-Hilliard equation on the square, bifurcating from the trivial solution at eigenfunctions of the form $w_{ij}=\cos(\pi ix)\cos(\pi j y)$, for $i,j \in \N$. We show that the paths either only connect the bifurcation point $m_{ij}$ with $-m_{ij}$ and are separated from all other paths with even more symmetry, or they contain a loop of nontrivial solutions connecting the bifurcation point $m_{ij}$ with itself. In any case the continua emerging at $m_{ij}$ and $-m_{ij}$ are equal. For fixed mass $m_0=0$ we furthermore prove that the continua bifurcating from the trivial solution at eigenfunctions of the form $w_{i0}+w_{0i}$ or $w_{ij}$, for $i,j \in \N$ are smooth curves parameterized over the interaction length related parameter $\lambda$.
S. Maier-Paape, Ulrich Miller. Connecting continua and curves of equilibria of the Cahn-Hilliard equation on the square. Discrete & Continuous Dynamical Systems - A, 2006, 15(4): 1137-1153. doi: 10.3934/dcds.2006.15.1137.
On two-phase Stefan problem arising from a microwave heating process
V. S. Manoranjan, Hong-Ming Yin and R. Showalter
In this paper we study a free boundary problem modeling a phase-change process by using microwave heating. The mathematical model consists of Maxwell's equations coupled with nonlinear heat conduction with a phase-change. The enthalpy form is used to characterize the phase-change process in the model. It is shown that the problem has a global solution.
V. S. Manoranjan, Hong-Ming Yin, R. Showalter. On two-phase Stefan problem arising from a microwave heating process. Discrete & Continuous Dynamical Systems - A, 2006, 15(4): 1155-1168. doi: 10.3934/dcds.2006.15.1155.
Thermodynamically consistent Cahn-Hilliard and Allen-Cahn models in elastic solids
Irena Pawłow
The goal of this paper is to derive again the generalized Cahn-Hilliard and Allen-Cahn models in deformable continua introduced previously by E. Fried and M. E. Gurtin on the basis of a microforce balance. We use a~different approach based on the second law in the form of the entropy principle according to I. Müller and I. S. Liu which leads to the evaluation of the entropy inequality with multipliers.
Both approaches provide the same systems of field equations. In particular, our differential equation for the multiplier associated with the balance law for the order parameter turns out to be identical with the Fried-Gurtin microforce balance.
Irena Paw\u0142ow. Thermodynamically consistent Cahn-Hilliard and Allen-Cahn models in elastic solids. Discrete & Continuous Dynamical Systems - A, 2006, 15(4): 1169-1191. doi: 10.3934/dcds.2006.15.1169.
Global attractor for a parabolic-hyperbolic Penrose-Fife phase field system
Elisabetta Rocca and Giulio Schimperna
A singular nonlinear parabolic-hyperbolic PDE's system describing the evolution of a material subject to a phase transition is considered. The goal of the present paper is to analyze the asymptotic behaviour of the associated dynamical system from the point of view of global attractors. The physical variables involved in the process are the absolute temperature $\vartheta$ (whose evolution is governed by a parabolic singular equation coming from the Penrose-Fife theory) and the order parameter $\chi$ (whose evolution is ruled by a nonlinear damped hyperbolic relation coming from a hyperbolic relaxation of the Allen-Cahn equation). Dissipativity of the system and the existence of a global attractor are proved. Due to questions of regularity, the one space dimensional case (1D) and the 2D - 3D cases require different sets of hypotheses and have to be settled in slightly different functional spaces.
Elisabetta Rocca, Giulio Schimperna. Global attractor for a parabolic-hyperbolic Penrose-Fife phase field system. Discrete & Continuous Dynamical Systems - A, 2006, 15(4): 1193-1214. doi: 10.3934/dcds.2006.15.1193.
Stability for steady-state patterns in phase field dynamics associated with total variation energies
Ken Shirakawa
In this paper, we shall deal with a mathematical model to represent the dynamics of solid-liquid phase transitions, which take place in a two-dimensional bounded domain. This mathematical model is formulated as a coupled system of two kinetic equations.
The first equation is a kind of heat equation, however a time-relaxation term is additionally inserted in the heat flux. Since the additional term guarantees some smoothness of the velocity of the heat diffusion, it is expected that the behavior of temperature is estimated in stronger topology than that as in the usual heat equation.
The second equation is a type of the so-called Allen-Cahn equation, namely it is a kinetic equation of phase field dynamics derived as a gradient flow of an appropriate functional. Such functional is often called as "free energy'', and in case of our model, the free energy is formulated with use of the total variation functional. Therefore, the second equation involves a singular diffusion, which formally corresponds to a function of (mean) curvature on the free boundary between solid-liquid states (interface). It implies that this equation can be a modified expression of Gibbs-Thomson law.
In this paper, we will focus on the geometry of the pattern drawn by solid-liquid phases in steady-state (steady-state pattern), which will be expected to have some stability in dynamical system generated by our mathematical model. Consequently, various geometric patterns, parted by gradual curves, will be shown as representative examples of such steady-state patterns.
Ken Shirakawa. Stability for steady-state patterns in phase field dynamics associated with total variation energies. Discrete & Continuous Dynamical Systems - A, 2006, 15(4): 1215-1236. doi: 10.3934/dcds.2006.15.1215.
Dynamics of shape memory alloys patches with mechanically induced transformations
Linxiang Wang and Roderick Melnik
2006, 15(4): 1237-1252 doi: 10.3934/dcds.2006.15.1237 +[Abstract](1985) +[PDF](2515.1KB)
A mathematical model is constructed for the modelling of two dimensional thermo-mechanical behavior of shape memory alloy patches. The model is constructed on the basis of a modified Landau-Ginzburg theory and includes the coupling effect between thermal and mechanical fields. The free energy functional for the model is exemplified for the square to rectangular transformations. The model, based on nonlinear coupled partial differential equations, is reduced to a system of differential-algebraic equations and the backward differentiation methodology is used for its numerical analysis. Computational experiments with representative distributed mechanical loadings are carried out for patches of different sizes to analyze thermo-mechanical waves, coupling effects, and 2D phase transformations.
Linxiang Wang, Roderick Melnik. Dynamics of shape memory alloys patches with mechanically induced transformations. Discrete & Continuous Dynamical Systems - A, 2006, 15(4): 1237-1252. doi: 10.3934/dcds.2006.15.1237. | CommonCrawl |
An artificial intelligence-based deep learning algorithm for the diagnosis of diabetic neuropathy using corneal confocal microscopy: a development and validation study
Bryan M. Williams
Davide Borroni
Rongjun Liu
Yitian Zhao
Jiong Zhang
Jonathan Lim
Baikai Ma
Vito Romano
Hong Qi
Maryam Ferdousi
Ioannis N. Petropoulos
Georgios Ponirakis
Stephen Kaye
Rayaz A. Malik
Uazman Alam
Yalin Zheng
Aims/hypothesis
Corneal confocal microscopy is a rapid non-invasive ophthalmic imaging technique that identifies peripheral and central neurodegenerative disease. Quantification of corneal sub-basal nerve plexus morphology, however, requires either time-consuming manual annotation or a less-sensitive automated image analysis approach. We aimed to develop and validate an artificial intelligence-based, deep learning algorithm for the quantification of nerve fibre properties relevant to the diagnosis of diabetic neuropathy and to compare it with a validated automated analysis program, ACCMetrics.
Our deep learning algorithm, which employs a convolutional neural network with data augmentation, was developed for the automated quantification of the corneal sub-basal nerve plexus for the diagnosis of diabetic neuropathy. The algorithm was trained using a high-end graphics processor unit on 1698 corneal confocal microscopy images; for external validation, it was further tested on 2137 images. The algorithm was developed to identify total nerve fibre length, branch points, tail points, number and length of nerve segments, and fractal numbers. Sensitivity analyses were undertaken to determine the AUC for ACCMetrics and our algorithm for the diagnosis of diabetic neuropathy.
The intraclass correlation coefficients for our algorithm were superior to those for ACCMetrics for total corneal nerve fibre length (0.933 vs 0.825), mean length per segment (0.656 vs 0.325), number of branch points (0.891 vs 0.570), number of tail points (0.623 vs 0.257), number of nerve segments (0.878 vs 0.504) and fractals (0.927 vs 0.758). In addition, our proposed algorithm achieved an AUC of 0.83, specificity of 0.87 and sensitivity of 0.68 for the classification of participants without (n = 90) and with (n = 132) neuropathy (defined by the Toronto criteria).
Conclusions/interpretation
These results demonstrated that our deep learning algorithm provides rapid and excellent localisation performance for the quantification of corneal nerve biomarkers. This model has potential for adoption into clinical screening programmes for diabetic neuropathy.
The publicly shared cornea nerve dataset (dataset 1) is available at http://bioimlab.dei.unipd.it/Corneal%20Nerve%20Tortuosity%20Data%20Set.htm and http://bioimlab.dei.unipd.it/Corneal%20Nerve%20Data%20Set.htm.
Corneal confocal microscopy Corneal nerve Deep learning Diabetic neuropathy Image processing and analysis Image segmentation Ophthalmic imaging Small nerve fibres
ACCM
ACCMetrics model
Corneal confocal microscopy
Corneal nerve fibre
Deep learning algorithm
Dice similarity coefficient
Early neuropathy assessment
Intraclass coefficient
IENF
Intra-epidermal nerve fibre
LCNN
Liverpool Convolutional Neural Network
LDLA
Liverpool Deep Learning Algorithm
Rostock Corneal Module
Root mean squared error
Receiver operating characteristic
Sub-basal nerve plexus
Small-fibre neuropathy
Uazman Alam and Yalin Zheng are joint senior authors.
The online version of this article ( https://doi.org/10.1007/s00125-019-05023-4) contains peer-reviewed but unedited supplementary material, which is available to authorised users.
The prevalence of diabetic peripheral neuropathy (DPN) can be as high as 50% in an unselected population. Currently, screening for DPN most commonly relies on the 10 g monofilament test, which identifies individuals at risk of foot ulceration but is poor at identifying those with early neuropathy [1]. Screening methods such as clinical examination, questionnaires and vibration perception threshold do not provide direct quantification of small nerve fibres, which are the earliest site of injury. Skin biopsy enables direct visualisation of thinly myelinated and unmyelinated nerve fibres, which are the earliest affected in DPN, and can be used to diagnose small-fibre neuropathy (SFN) [2]. The assessment of intra-epidermal nerve fibres (IENFs) and IENF density is currently advocated in clinical practice in the USA [3] and recommended as an endpoint in clinical trials [4]. However, skin biopsy is invasive and requires specialised laboratory facilities for analysis. The cornea is the most densely innervated tissue of the human body, containing a network of unmyelinated axons (small nerve fibres) called the sub-basal nerve plexus (SBP).
Corneal confocal microscopy (CCM) has been used to image the SBP, which has been shown to be remarkably stable in healthy corneas over 3 years [5] but demonstrates early and progressive pathology in a range of peripheral and central neurodegenerative conditions [6, 7, 8, 9, 10, 11]. Figure 1a,b and Fig. 1c,d show examples from participants without and with diabetic neuropathy, respectively. Previous studies have demonstrated analytical validation by showing that CCM reliably quantifies early axonal damage in DPN [12, 13] with high sensitivity and specificity [14, 15] and closely correlates to the loss of IENFs [15, 16]. CCM also predicts incident diabetic neuropathy [17] and can detect corneal nerve regeneration in people with DPN [18]. CCM may also detect early nerve fibre loss before IENF loss in skin biopsy [19]. In some individuals, corneal nerve fibre (CNF) loss may be the first evidence of subclinical DPN [19]; Brines et al [20] have shown that determination of CNF area and width distribution may improve the diagnostic and predictive ability of CCM.
(a–d) Examples of CCM images from healthy individuals (a, b) and individuals with diabetic neuropathy (c, d). (e, f) An example image (e) with manual annotation (f) is shown. (g) Branch and terminal points (manually added) are shown, with green triangles denoting tail points and blue squares denoting branching points
To accurately quantify CNF morphology, nerves must be distinguished from background and other cell structures accurately. A major limitation for wider clinical utilisation is the need for manual image analyses, which is highly labour-intensive and requires considerable expertise to quantify nerve pathology [21]. The development of methods for the objective, reliable and rapid analysis of corneal nerves is vital if CCM is to be adopted for screening and large clinical trial programmes. Furthermore, to be used as a diagnostic tool, it is essential to extract the measurements automatically with high reliability [21]. Dabbah et al [22] presented a dual-model automated detection method for CNFs using CCM, showing excellent correlation with manual ground-truth analysis (r = 0.92). They further refined this method, using the dual-model property in a multi-scale framework to generate feature vectors from localised information at every pixel, and achieved an even stronger correlation with the ground-truth (r = 0.95) [21]. This study, however, used neural networks without convolution layers [21], which necessitates pre-processing and encourages overfitting.
Kim and Markoulli [23] developed a nerve segmentation technique to delineate corneal nerve morphology in CCM. This involved processes ranging from filtering methods (with rapid implementation but low-contrast and imprecise focus) to more complex support vector machine approaches (which rely on features defined by the user). Chen et al [24] presented a method based on feature engineering, achieving state-of-the-art results, although its reliance on hand-crafted features increases the complexity to the user and can introduce user-bias, returning suboptimal results [25].
Recently, approaches based on machine learning have achieved excellent performance in computer vision and medical image analysis tasks. Deep learning and, particularly, convolutional neural networks (CNNs; a class of deep neural networks) have emerged as a highly effective branch of machine learning for image classification [25]. This approach allows for 'end-to-end' classification results to be achieved without the need for specifying or designing features or setting example-specific parameters. CNN design follows vision processing in living organisms [26], with the connectivity pattern between neurons resembling visual cortex organisation. Based on training with pre-annotated data, CNNs combine the traditionally separate machine-learning tasks of feature designing, learning and image classification in a single model, relieving the traditional machine-learning burden of designing hand-crafted features. More recently, this has extended beyond image-wise classification to efficient pixel-wise classification, allowing image segmentation to be achieved (i.e. pixels may be classed as belonging or not belonging to an object of interest). There has been a significant increase recently in the development of deep learning algorithms (DLAs) with CNNs, an approach that achieves excellent performance in many computer vision applications and has clinical utility in healthcare [27]. Compared with manual detection, accurate automated detection of corneal nerves using CCM has many potential benefits, including objectivity, increased efficiency and reproducibility, allowing enhanced early disease diagnostics and improved patient outcomes. Artificial intelligence-based DLAs have the added advantage of continual learning and refinement alongside concurrent analysis.
The aim of this study was to develop and validate a DLA for corneal nerve segmentation in CCM images and to compare this with the widely used and validated automated image analysis software, ACCMetrics (Early Neuropathy Assessment [ENA] group, University of Manchester, Manchester, UK) [24].
All participants gave informed consent at the respective institutions and the studies were conducted in accordance with the Declaration of Helsinki. Relevant ethical and institutional approvals were gained prior to the imaging of all participants.
Image datasets
In this study, 3835 confocal images of the corneal SBP were utilised from healthy volunteers and people with diabetes from Padova, Italy (n = 120), Beijing, China (n = 1578) and Manchester, UK (n = 2137). Figure 1e shows an example CCM image; Fig. 1f shows the manual annotation, with branching and tail points highlighted in Fig. 1g.
Dataset 1 (BioImLab, University of Padova, Italy)
One hundred and twenty images were obtained from Ruggeri's BioImLab at the Department of Information Engineering, University of Padova, Italy. Of these, the first 30 images were from 30 volunteers (one image per person) who were either healthy or showed different pathologies (diabetes, pseudoexfoliation syndrome, keratoconus) [28]. The images were captured in TIFF format at 384×384 pixels with a Heidelberg Retina Tomograph II using the Rostock Corneal Module (RCM; HRTII32-RCM) confocal laser microscope (Heidelberg Engineering, Heidelberg, Germany). The remaining 90 images were of the corneal sub-basal epithelium from individuals displaying normal or abnormal pathologies, with one image per person [29], using a ConfoScan 4 CCM at ×40 magnification (Nidek Technologies, Padova, Italy). An area of 460×350 μm was captured at 768×576 pixels and stored in monochrome JPG compressed format.
Dataset 2 (Peking University Third Hospital, Beijing, China)
One thousand, five hundred and seventy-eight images (384×384 pixels in TIFF format) were acquired from healthy volunteers (n = 90) and from individuals with corneal abnormalities (n = 105, including 52 participants with diabetes) using the Heidelberg Retina Tomograph 3/RCM (Heidelberg Engineering, Heidelberg, Germany). Six images per eye were obtained where possible from the corneal apex using the same methodology developed and utilised by the ENA group (University of Manchester, Manchester, UK).
Dataset 3 (ENA Group, University of Manchester, UK)
Two thousand, one hundred and thirty-seven images were analysed from healthy volunteers and participants with diabetes (n = 444). All CCM images were obtained using the standard, internationally accepted protocol developed by the ENA group [13]. The images (400×400 μm [384×384 pixels]) were captured using the RCM set at +12 objective lens. The images were exported in BMP format, which is compatible with the image analysis software. Images were from the following cohorts: group 1, healthy volunteers (n = 90); group 2, participants with impaired glucose tolerance (n = 53, including 26 with definite neuropathy); group 3, participants with type 1 diabetes with definite neuropathy (n = 37); group 4, participants with type 1 diabetes without neuropathy (n = 53); group 5, participants with type 2 diabetes without (n = 101) and with definite neuropathy (n = 49); group 6, participants with type 2 diabetes and with mild neuropathy (n = 41) and definite neuropathy (n = 20). Definite neuropathy was defined as the presence of an abnormality in nerve conduction studies as per age-related reference range and symptom(s) or sign(s) of neuropathy as defined by the Toronto Consensus statement by the American Diabetes Association on DPN [30]. Across the groups, a total of 132 participants had definite neuropathy. Note that the depth of images were only marginally different for each participant and depended on corneal thickness. However, the SBP occurs at a depth of ~50 μm in most people, regardless of the presence or absence of diabetes [31].
Image annotation
To obtain a ground-truth for each image in the BioImLab and Beijing datasets, the corneal nerves in each image were manually traced by a clinical ophthalmologist (DB) using an in-house program written in Matlab (Mathworks R2017, Natick, MA, USA). Our previous work has demonstrated the validity of manual annotations in terms of intra- and inter-observer agreements [32]. Dataset 3 was not annotated and was only used for clinical testing using the deep learning segmentations.
Automatic segmentation of the corneal nerves in CCM images
The preparation of our combined datasets for use in a training and testing approach is presented in this section, and we define our automated segmentation method. This is then built on with ensemble learning and random sampling. Finally, clinically relevant variables were extracted and compared with those obtained using existing state-of-the-art ACCMetrics.
Dataset preparation for training/testing approach
The BioImLab and Beijing datasets included 1698 images in total and were used for the development of the model: 1494 (~90%) images from the Beijing dataset were used for training, while 84 images from Beijing and all the BioImLab dataset were used for testing. Each image in these datasets was used for either training or testing to avoid overfitting. Dataset 3 (ENA image dataset) was only used for clinical testing and validation but not to train the model. The images for training and testing were selected using a random permutation at the individual level determined using a Mersenne Twister method [33]. Note that splitting took place on the image (rather than individual) level in order to avoid potential bias.
All the images were standardised to have a pixel size of 1.04 μm (384×384 pixels) by bilinear interpolation. To increase the dataset size, it was augmented by extracting patches of size 128×128 pixels with an overlap of 32 pixels, creating 81 patches per image. The selection of patches used for training/testing was done at the image level to avoid testing patches from images whose data had been used for training.
Image segmentation using deep learning
Corneal nerves were segmented adopting U-Net CNN architecture [34]. Unlike conventional CNNs, which aim to assign one classification (or more) to an image, this type of architecture aims to achieve full-image segmentation by determining a pixel-wise segmentation map. Figure 2 illustrates the architecture of our proposed U-Net model. It can be visualised as a U-shape, the left side being an encoding path and the right side a decoding path. At the end of the architecture, a sigmoid activation function is employed to create a segmentation map. A key feature of U-Net is direct connectivity between the encoding and decoding layers, allowing extracted feature re-use and strengthening feature propagation. The Dice similarity coefficient (DSC) was used as a cost function (i.e. to measure error during training).
Diagram of the proposed U-Net architecture. Each dark blue rectangular block corresponds to a multi-channel features map passing through 3×3 convolution followed by rectified linear unit (ReLU) operations. Dark grey blocks denote dropout operation with a rate of 0.2. Red and purple blocks denote 2×2 max pooling and upsampling, respectively. Light brown blocks denote the concatenation of feature maps. The light blue block denotes a 1×1 operation followed by sigmoid activation. The number of channels is indicated at the top of each column
The models were developed with Python 3.5.2 (https://www.python.org/), Tensorflow 1.0.0 (https://www.tensorflow.org/; Google, Mountain View, CA, USA) and Keras 1.2.1 (https://keras.io/) and trained for 200 iterations using an NVIDIA K40 GPU (NVIDIA, Santa Clara, CA, USA). Following the training step, the trained model weights were used to obtain the segmentation maps of each previously unseen testing patch.
Ensemble classification
To improve the accuracy of the model by using multiple copies, an ensemble of five U-Net networks were trained on the same training data using a random-sample-with-replacement approach. The final prediction was computed by a majority vote over the predictions of the ensemble network. Henceforward in this manuscript, training with our preliminary model, a single U-Net model, is referred to as the 'Liverpool Convolutional Neural Network' (LCNN), while training with our refined ensemble deep learning approach is referred to as the 'Liverpool Deep Learning Algorithm' (LDLA).
Image reconstruction and variable extraction
The trained models were able to produce segmentations on a patch basis. The segmentation of a whole CCM image was obtained by combining the segmentations of all its patches using majority voting on the overlap regions. From the image-level segmentation result, further analysis was carried out to derive the clinically relevant variables including the corneal nerve length, branch points, tail points and fractal number [35].
Our LCNN and LDLA models, together with the state-of-the-art ACCMetrics model (ACCM) [24], were compared with the manual annotation. The performance of the algorithm was measured using the Bland–Altman approach. Agreement between the automatic segmentations and manual annotations were assessed using the intraclass coefficient (ICC). For the clinical evaluations, ANOVA with Tukey post hoc analysis was performed for comparison between different groups of participants. The AUC was calculated to compare the detection performance of different models. SPSS for Windows, version 22.0 (IBM-SPSS, Chicago, IL, USA) was used for the statistical analysis, with a p value of < 0.05 deemed statistically significant.
Figure 3 shows four example testing images along with their 'ground-truth' manual annotations and segmentation results obtained by LCNN, LDLA and ACCM. LCNN and LDLA produced results that were more faithful to the manual annotations than did the ACCM, particularly in example 4 where the ACCM failed to detect nerves at the top middle and right bottom of the image. Overall, the segmentation performance was consistent and there was no obvious failed case. For illustration, electronic supplementary material [ESM] Fig. 1 shows all the first 30 images of dataset 1, ESM Fig. 2 shows the 12 randomly chosen images from dataset 2, and ESM Fig. 3 shows 12 randomly chosen images from dataset 3.
Four examples of segmentation of corneal nerves. Columns appear in the following order: the original images; manual annotations; and segmentation results of the LCNN model, LDLA and ACCM, respectively. Red lines denote the centre lines of the segmented nerves
Analysis of datasets 1 and 2 shows that the mean total CNF length from the manual 'ground-truth' annotation was highest (2441.4±919.5 μm) compared with the three automated approaches (LCNN 2089.4±804.6 μm; LDLA 2260.3±835.3 μm; ACCM 2394.1±768.1 μm). Total CNF length was greater in the ACCM and was closer to the total length from the manual annotation than were the LCNN or LDLA results. However, ICC analysis (Table 1) demonstrated that the LCNN and LDLA both produced results more consistent with the manual annotations when compared with the ACCM. Furthermore, our two methods performed consistently better than the ACCM in terms of correct segment length, number of branching points and fractal numbers. Bland–Altman analysis (Fig. 4) further confirmed that the limits of agreement of the ACCM were greater than those of both the LCNN and LDLA, implying greater variability despite the mean total corneal lengths in the ACCM. In other words, although the results of the ACCM were closer to the manual annotation in this case, the variation due to over- and under-segmentation was much larger than either the LCNN or the LDLA; the ACCM may therefore have produced heterogeneous results.
Absolute agreement measured by ICC
Mean length per segment
No. of branch points
No. of tail points
No. of nerve segments
Bland–Altman plots showing the difference in determination of the total CNF length (μm) between the LCNN (a), LDLA (b) and ACCM (c) methods and manual annotations by an expert with clinical expertise. The limits of agreement are defined as the mean difference ± 1.96 SD of the differences. Error bars represent the 95% CI for the mean and both the upper and lower limits of agreement
Based on the 95% CI of the ICC estimate, a value of <0.5, 0.5–0.75, 0.75–0.9 and >0.90 is indicative of poor, moderate, good and excellent reliability, respectively [36].
Table 2 shows the comparisons of the root mean square error and SD of the derived measures vi over each image i, against the manual annotations, in terms of number of branching points, number of terminal points, number of segments, total nerve fibre length, mean nerve fibre length, SD of nerve fibre length, and fractal number for each of the methods M using:
$$ \mathrm{RMSE}=\sqrt{\frac{1}{n}\sum \limits_i{V}_{i,M}^2},\kern0.5em \mathrm{SD}=\sqrt{\frac{1}{n-1}\sum \limits_i{\left({V}_{i,M}-\overline{V_M}\right)}^2},\kern0.5em \overline{V}=\sum \limits_i{V}_{i,M},\kern0.5em V={v}_{i,M}-{v}_{i, MA} $$
RMSE and SD of the error of each of the methods for different measures
No. of branching points
No. of terminal points
No. of segments
Total fibre length
Mean fibre length
Standard deviation of fibre length
Fractal number
Lower values indicate closer agreement with the manual annotation
As shown in Table 2, LDLA had lower values for every measure, indicating closer agreement with the ground-truth annotation. For each measure, the LCNN had the second-lowest root mean squared error (RMSE) and the ACCM had the highest, indicating weaker agreement. The LDLA had the lowest SD for all measures except the number of terminal points, indicating more consistent agreement with the ground-truth over the set of images; the ACCM had the highest SD for all measures. From this, it can be concluded that both the LCNN and the LDLA outperform the ACCM and that the LDLA clearly has the best performance.
Given the convincing performance of the LDLA, which outperforms both the LCNN and the ACCM in each metric, it was applied to the third dataset and the results were used for clinical evaluation.
Clinical testing and validation based on ENA image dataset
ANOVA analysis demonstrated that differences in the total CNF length between the six groups of participants (in dataset 3) are in keeping with their neuropathy phenotype (Table 3, Fig. 5). A Tukey post hoc analysis was performed, and demonstrated that the CNF length in healthy volunteers was higher than in all the other groups (p < 0.01) while the total CNF length in people with type 1 diabetes and neuropathy (group 3) was lower than in all other groups (p < 0.001). The ACCM consistently yielded higher total CNF length than the LDLA.
Total CNF length for dataset 3 utilising the LDLA
No. of participants
Mean CNF length (μm)
aGroup 1, healthy; group 2, impaired glucose tolerance; group 3, type 1 diabetes with definite neuropathy; group 4, type 1 diabetes without neuropathy; group 5, type 2 diabetes without and with definite neuropathy; group 6, type 2 diabetes with mild neuropathy and definite neuropathy
Analysis of total CNF length for the participants in dataset 3. (a) Box plot in combination with dot plot of the total CNF length in the six groups determined using our LDLA and the ACCM. The line within each box represents the median, and the top and bottom of the box represent the 75th and 25th percentiles, respectively. The whiskers indicate the maximum and minimum values excluding outliers. Group 1, healthy; group 2, impaired glucose tolerance; group 3, type 1 diabetes with definite neuropathy; group 4, type 1 diabetes without neuropathy; group 5, type 2 diabetes without and with definite neuropathy; group 6, type 2 diabetes with mild neuropathy and definite neuropathy. (b) ROC curves of classification of participants without and with diabetic neuropathy, comparing the LDLA and the ACCM. (c) ROC curves of classification of participants with and without diabetes, comparing the LDLA and the ACCM
AUC analysis was undertaken to compare the LDLA and ACCM results (Fig. 5b,c). First, total corneal nerve length alone was used to classify individuals without and with and neuropathy. There was a total of 132 individuals with neuropathy (from groups 2, 3, 5 and 6) and 90 without (group 1). The resulting receiver operating characteristic (ROC) curve in Fig. 5b shows that the AUC is 0.826 for the LDLA and 0.801 for the ACCM, respectively. To determine the sensitivity and specificity of the model, optimal cut points were determined by the commonly used Youden index [37] (i.e. the sum of sensitivity and specificity minus 1). In a perfect test, Youden's index is equal to 1. For the LDLA, the optimal cut determined a specificity of 0.867 and sensitivity of 0.677, while the ACCM achieved a specificity of 0.800 and sensitivity of 0.699. The LDLA showed better prediction performance than the ACCM when utilising CNF length. Similarly, Fig. 5c shows that the LDLA had better prediction performance in classifying healthy volunteers (n = 90) and all participants with diabetes (n = 301 from groups 3, 4, 5 and 6) than the ACCM when utilising CNF length; the AUC was 0.806 for the LDLA and 0.780 for the ACCM. The optimal cut points of the LDLA were specificity 0.7222 and sensitivity 0.784, while for the ACCM they were specificity 0.7222 and sensitivity 0.745.
In this study, an artificial intelligence-based DLA has been developed for the analysis and quantification of corneal nerves in CCM images. To our knowledge, this is the first DLA for the analysis of corneal nerve morphology and pathology. This study validates our DLA and demonstrates its superior performance compared with ACCMetrics, the existing state-of-the-art system. In particular, there are more consistent results, as demonstrated by a superior intraclass correlation for a number of metrics including total CNF length. In addition to the total CNF length, this DLA is also capable of producing the number of branching and tail points, fractal numbers, tortuosity and segment length. As such, these quantitative variables may provide additional utility to diagnose diabetic neuropathy and neuropathic severity.
A fractal is a visual product of a non-linear system characterised by its complexity and by the quality of self-similarity or scale invariance. Fractal analysis of the corneal SBP has been proposed by several authors [38, 39]. We believe that the additional utility of fractal dimensions provide an additional means of differentiating individuals with early or subclinical DPN. CNF length is a robust measure of DPN and SFN. A large multicentre pooled concurrent diagnostic validity study revealed that CNF length was the optimal CCM variable [40]. CNF length has also been shown to be a measure of early small-fibre regeneration [41]. From published data, CNF length and density are the most robust measures of DPN. Our data confirms the validity of CNF length. However, we feel other metrics are also of importance and require further scientific interrogation in a real-world clinically oriented study.
In this study, the quantification of images demonstrates a reduction in total CNF length in individuals with diabetic neuropathy compared with healthy volunteers. This study is in keeping with other data on the utility of CNF length as a valid biomarker of diabetic neuropathy [11, 12, 15, 18]. The sensitivity and specificity of our DLA for gold-standard DPN diagnosis with CCM (using the Toronto criteria) is far superior to currently used clinical methods such as the 10 g monofilament and 128 Hz tuning fork [42] (with rudimentary clinical assessments), thus providing a strong rationale for its use in clinical screening/practice.
This study extends our preliminary work on 584 CCM images where the initial DLA demonstrated good localisation performance for the detection of corneal nerves [43]. Our preliminary model was refined to produce the ensemble (LDLA) model, now validated in large image datasets to diagnose diabetic neuropathy using CCM.
The strength of deep learning is echoed by Oakley et al [44] who used corneal nerve segmentation in CCM images from macaques. Deep-learning-based approaches make the segmentation task relatively easier for the end user compared with the conventional approaches employing various filters and graphs [23]. In particular, compared with conventional machine-learning methods, such as support vector machines (SVM), deep learning reduces the need and additional complexity of feature selection and extraction, allowing the computer to learn features alongside the segmentation. The training of deep learning approaches is computationally expensive (e.g. it takes approximately 30 min per epoch to train a single U-Net model). The advantage is that, once the model is trained, the segmentation is very fast, taking milliseconds to segment CCM images.
In recent years, CNNs and DLAs have been added to algorithms used to screen for diabetic retinopathy. DLAs promise to leverage the large number of images for physician-interpreted screening and learn from raw pixels. The high variance and low bias of these models will allow DLAs to diagnose diabetic neuropathy using CCM images without the pre-processing requirements and more-likely overfitting of earlier approaches [25]. This automated DLA for the detection of diabetic neuropathy offers a number of advantages including consistency of interpretation, high sensitivity and specificity, and near instantaneous reporting of results. In this study, good sensitivity and adequate specificities were achieved using our DLA.
This is the largest study, to date, of the development and validation of corneal nerve segmentation and supersedes the numbers in the study by Chen et al [24], who used 1088 images from 176 individuals, with 200 images for training and 888 for testing. Our study used a robust dataset; however, further development of this DLA requires use of a developmental set of images with large numbers (tens of thousands) of normal and abnormal pathologies. An area of further research is that of interrupted CNF segments, which have often proved challenging in the CNF segmentation results obtained using earlier methods [24]. This problem is mainly caused by non-uniform illumination and contrast variations of CNF in images. Since quantitative biomarkers like CNF length and density are important measures for computer-aided diagnosis, missing CNF segments may theoretically reduce the diagnostic reliability of any automated system. In our previous work, the automatic gap reconnection method proposed by Zhang et al [45] was employed to bridge the interrupted nerve fibre structures. The gap-filling task is achieved by enforcing line propagation using the stochastic contour completion process with iterative group convolutions. Geometric connectivity of local CNF structures can be easily recovered based on their contextual information [45]. However, this connection step was not included in this model as there was only a modest improvement in the quantification of CNF length despite extra computation time of about 1 min per image. This is an area for future development of the DLA. It will also be important to investigate the potential for bias to be introduced by factors such as camera type. The major advantage of this DLA over standard automated techniques is the continual learning and refinement of the algorithm.
Given that 420 million people worldwide have been diagnosed with diabetes mellitus [46] and that the prevalence of diabetic neuropathy is ~50% [47], there is a need for valid quantitative population screening for diabetic neuropathy to prevent or limit sequelae such as foot ulcers and amputations. Skin biopsy with quantification of IENFs has been considered the 'reference standard' test for the diagnosis of SFN [48]. It is an invasive test, needing specialist diagnostic facilities and repeated tests at the same site, which is not always feasible. CCM is a rapid non-invasive ophthalmic imaging modality, which quantifies early axonal damage in diabetic neuropathy with high sensitivity and specificity [12, 13, 14, 15, 16, 49]. CCM also predicts incident neuropathy [17] and accurately detects CNF regeneration [18, 50]. The utility of CCM in diagnosing and monitoring the progression of diabetic neuropathy has been extensively evaluated [11, 12, 15, 16, 18, 38].
Further studies are required to determine the feasibility of applying this algorithm in the clinical setting and to compare outcomes with those obtained from currently used diabetic neuropathy screening methods typically having low sensitivity for detection except in advanced neuropathy. There is also a need to compare the diagnostic ability of this DLA with tests of small-fibre dysfunction (thermal thresholds/sudomotor/autonomic) and IENF density in skin biopsy in DPN and other peripheral neuropathies. The next key step is also to utilise the DLA alongside clinical neuropathy screening in a multicentre primary care study.
Automated detection and screening offer a unique opportunity to detect early neuropathy and prevent the sequelae of advanced diabetic neuropathy. Our results demonstrate that this artificial intelligence-based DLA provides excellent localisation performance for the quantification of corneal nerve variables and therefore has the potential to be adopted for screening and assessment of diabetic neuropathy.
Contribution statement
BW, YLZ, YTZ and JZ worked on the proposed model and conducted experimental testing. RL, BM and HQ worked on the acquisition of dataset 2. JL, MF, UA, IP, GP and RM worked on ACCMetrics and the collection and compilation of dataset 3. DB, VR and SBK worked on the annotations of dataset 3. All authors were involved in discussions regarding the work, the writing and revisions of the manuscript and approved the submitted version. YLZ and UA are joint guarantors of this manuscript.
This research was partly funded by The National Natural Science Foundation of China (NSFC81570813). The authors would like to thank NVIDIA Inc. for sponsoring the K40 GPU card used in this work. The study sponsor was not involved in the design of the study; the collection, analysis and interpretation of data; writing the report; or the decision to submit the report for publication.
Duality of interest
The authors declare that there is no duality of interest associated with this manuscript.
125_2019_5023_MOESM1_ESM.pdf (968 kb)
ESM figures (PDF 967 kb)
Tan H, Yang M, Wu Z et al (2004) Rapid screening method for Schistosoma japonicum infection using questionnaires in flood area of the People's Republic of China. Acta Trop 90(1):1–9PubMedGoogle Scholar
Lauria G, Cornblath D, Johansson O et al (2005) EFNS guidelines on the use of skin biopsy in the diagnosis of peripheral neuropathy. Eur J Neurol 12(10):747–758PubMedGoogle Scholar
Smith AG, Russell J, Feldman EL et al (2006) Lifestyle intervention for pre-diabetic neuropathy. Diabetes Care 29(6):1294–1299PubMedGoogle Scholar
Quattrini C, Tavakoli M, Jeziorska M et al (2007) Surrogate markers of small fiber damage in human diabetic neuropathy. Diabetes 56(8):2148–2154PubMedGoogle Scholar
Dehghani C, Pritchard N, Edwards K et al (2014) Morphometric stability of the corneal subbasal nerve plexus in healthy individuals: a 3-year longitudinal study using corneal confocal microscopy. Invest Ophth Vis Sci 55(5):3195–3199Google Scholar
Sivaskandarajah GA, Halpern EM, Lovblom LE et al (2013) Structure-function relationship between corneal nerves and conventional small-fiber tests in type 1 diabetes. Diabetes Care 36(9):2748–2755PubMedPubMedCentralGoogle Scholar
Tavakoli M, Quattrini C, Abbott C et al (2010) Corneal confocal microscopy: a novel noninvasive test to diagnose and stratify the severity of human diabetic neuropathy. Diabetes Care 33(8):1792–1797PubMedPubMedCentralGoogle Scholar
Kemp HI, Petropoulos IN, Rice AS et al (2017) Use of corneal confocal microscopy to evaluate small nerve fibers in patients with human immunodeficiency virus. JAMA Ophthalmol 135(7):795–800PubMedPubMedCentralGoogle Scholar
Ferdousi M, Azmi S, Petropoulos IN et al (2015) Corneal confocal microscopy detects small fibre neuropathy in patients with upper gastrointestinal cancer and nerve regeneration in chemotherapy induced peripheral neuropathy. PloS One 10(10):e0139394PubMedPubMedCentralGoogle Scholar
Tavakoli M, Marshall A, Thompson L et al (2009) Corneal confocal microscopy: a novel noninvasive means to diagnose neuropathy in patients with Fabry disease. Muscle Nerve 40(6):976–984PubMedGoogle Scholar
Tavakoli M, Marshall A, Pitceathly R et al (2010) Corneal confocal microscopy: a novel means to detect nerve fibre damage in idiopathic small fibre neuropathy. Exp Neurol 223(1):245–250PubMedGoogle Scholar
Petropoulos IN, Alam U, Fadavi H et al (2013) Corneal nerve loss detected with corneal confocal microscopy is symmetrical and related to the severity of diabetic polyneuropathy. Diabetes Care 36(11):3646–3651PubMedPubMedCentralGoogle Scholar
Petropoulos IN, Manzoor T, Morgan P et al (2013) Repeatability of in vivo corneal confocal microscopy to quantify corneal nerve morphology. Cornea 32(5):e83–e89PubMedGoogle Scholar
Petropoulos IN, Alam U, Fadavi H et al (2014) Rapid automated diagnosis of diabetic peripheral neuropathy with in vivo corneal confocal microscopy. Invest Ophth Vis Sci 55(4):2071–2078Google Scholar
Alam U, Jeziorska M, Petropoulos IN et al (2017) Diagnostic utility of corneal confocal microscopy and intra-epidermal nerve fibre density in diabetic neuropathy. PloS One 12(7):e0180175PubMedPubMedCentralGoogle Scholar
Chen X, Graham J, Dabbah MA et al (2015) Small nerve fiber quantification in the diagnosis of diabetic sensorimotor polyneuropathy: comparing corneal confocal microscopy with intraepidermal nerve fiber density. Diabetes Care 38(6):1138–1144PubMedPubMedCentralGoogle Scholar
Pritchard N, Edwards K, Russell AW, Perkins BA, Malik RA, Efron N (2015) Corneal confocal microscopy predicts 4-year incident peripheral neuropathy in type 1 diabetes. Diabetes Care 38(4):671–675PubMedGoogle Scholar
Tavakoli M, Mitu-Pretorian M, Petropoulos IN et al (2013) Corneal confocal microscopy detects early nerve regeneration in diabetic neuropathy after simultaneous pancreas and kidney transplantation. Diabetes 62(1):254–260PubMedGoogle Scholar
Ziegler D, Papanas N, Zhivov A et al (2014) Early detection of nerve fiber loss by corneal confocal microscopy and skin biopsy in recently diagnosed type 2 diabetes. Diabetes 63(7):2454–2463PubMedGoogle Scholar
Brines M, Culver DA, Ferdousi M et al (2018) Corneal nerve fiber size adds utility to the diagnosis and assessment of therapeutic response in patients with small fiber neuropathy. Sci Rep-UK 8(1):4734Google Scholar
Dabbah MA, Graham J, Petropoulos IN, Tavakoli M, Malik RA (2011) Automatic analysis of diabetic peripheral neuropathy using multi-scale quantitative morphology of nerve fibres in corneal confocal microscopy imaging. Med Image Anal 15(5):738–747PubMedGoogle Scholar
Dabbah MA, Graham J, Petropoulos I, Tavakoli M, Malik RA (2010) Dual-model automatic detection of nerve-fibres in corneal confocal microscopy images. In: Jiang T, Navab N, Pluim JPW, Viergever MA (eds) Medical Image Computing and Computer-Assisted Intervention (MICCAI). Lecture Notes in Computer Science, vol. 6361. Springer, Berlin, Heidelberg, pp 300–307Google Scholar
Kim J, Markoulli M (2018) Automatic analysis of corneal nerves imaged using in vivo confocal microscopy. Clin Exp Optom 101(2):147–161PubMedGoogle Scholar
Chen X, Graham J, Dabbah MA, Petropoulos IN, Tavakoli M, Malik RA (2017) An automatic tool for quantification of nerve fibers in corneal confocal microscopy images. IEEE Trans Biomed Eng 64(4):786–794PubMedGoogle Scholar
LeCun Y, Bengio Y, Hinton G (2015) Deep learning. Nature 521(7553):436PubMedPubMedCentralGoogle Scholar
Hubel DH, Wiesel TN (1968) Receptive fields and functional architecture of monkey striate cortex. J Physiol 195(1):215–243PubMedPubMedCentralGoogle Scholar
Shen D, Wu G, Suk H-I (2017) Deep learning in medical image analysis. Annu Rev Biomed Eng 19:221–248PubMedPubMedCentralGoogle Scholar
Scarpa F, Zheng X, Ohashi Y, Ruggeri A (2011) Automatic evaluation of corneal nerve tortuosity in images from in vivo confocal microscopy. Invest Ophth Vis Sci 52(9):6404–6408Google Scholar
Scarpa F, Grisan E, Ruggeri A (2008) Automatic recognition of corneal nerve structures in images from confocal microscopy. Invest Ophth Vis Sci 49(11):4801–4807Google Scholar
Tesfaye S, Boulton AJ, Dyck PJ et al (2010) Diabetic neuropathies: update on definitions, diagnostic criteria, estimation of severity, and treatments. Diabetes Care 33(10):2285–2293PubMedPubMedCentralGoogle Scholar
Marfurt CF, Cox J, Deek S, Dvorscak L (2010) Anatomy of the human corneal innervation. Exp Eye Res 90(4):478–492PubMedGoogle Scholar
Borroni D, Beech M, Williams B et al (2018) Building a validated in vivo confocal microscopy (IVCM) dataset for the study of corneal nerves. Invest Ophth Vis Sci 59(9):5719Google Scholar
Matsumoto M, Nishimura T (1998) Mersenne twister: a 623-dimensionally equidistributed uniform pseudo-random number generator. ACM Transactions on Modeling and Computer Simulation (TOMACS) 8(1):3–30Google Scholar
Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Navab N, Hornegger J, Wells W, Frangi A (eds) Medical Image Computing and Computer-Assisted Intervention (MICCAI) Lecture Notes in Computer Science, vol. 9351. Springer, Cham, pp 234–241Google Scholar
Brunner M, Romano V, Steger B et al (2018) Imaging of corneal neovascularization: optical coherence tomography angiography and fluorescence angiography. Invest Ophth Vis Sci 59(3):1263–1269Google Scholar
Koo TK, Li MY (2016) A guideline of selecting and reporting intraclass correlation coefficients for reliability research. Journal of Chiropractic Medicine 15(2):155–163. https://doi.org/10.1016/j.jcm.2016.02.012 CrossRefPubMedPubMedCentralGoogle Scholar
Youden WJ (1950) Index for rating diagnostic tests. Cancer 3(1):32–35PubMedGoogle Scholar
Chen X, Graham J, Petropoulos IN et al (2018) Corneal nerve fractal dimension: a novel corneal nerve metric for the diagnosis of diabetic sensorimotor polyneuropathy. Invest Ophth Vis Sci 59(2):1113–1118Google Scholar
Bianciardi G, Latronico M, Traversi C (2015) Decreased geometric complexity of corneal nerve fibers distribution in Sjogren's syndrome patients. Int J Ophthalmic Pathol Res 4:2Google Scholar
Perkins BA, Lovblom LE, Bril V et al (2018) Corneal confocal microscopy for identification of diabetic sensorimotor polyneuropathy: a pooled multinational consortium study. Diabetologia 61(8):1856–1861PubMedPubMedCentralGoogle Scholar
Azmi S, Jeziorska M, Ferdousi M et al (2019) Early nerve fibre regeneration in individuals with type 1 diabetes after simultaneous pancreas and kidney transplantation. Diabetologia 62(8):1478–1487PubMedPubMedCentralGoogle Scholar
Baraz S, Zarea K, Shahbazian HB, Latifi SM (2014) Comparison of the accuracy of monofilament testing at various points of feet in peripheral diabetic neuropathy screening. J Diabetes Metab Disord 13(1):19Google Scholar
Qi H, Borroni D, Liu R et al (2018) Automated detection of corneal nerves using deep learning. Invest Ophth Vis Sci 59(9):5721Google Scholar
Oakley JD, Russakoff DB, Weinberg R et al (2018) Automated analysis of in vivo confocal microscopy corneal images using deep learning. Investigative Ophthalmology & Visual Science 59(9):1799Google Scholar
Zhang J, Bekkers E, Chen D et al (2018) Reconnection of interrupted curvilinear structures via cortically inspired completion for ophthalmologic images. IEEE Trans Biomed Eng 65(5):1151–1165PubMedPubMedCentralGoogle Scholar
Cho N, Shaw J, Karuranga S et al (2018) IDF diabetes atlas: global estimates of diabetes prevalence for 2017 and projections for 2045. Diabetes Res Clin Pract 138:271–281PubMedGoogle Scholar
Iqbal Z, Azmi S, Yadav R et al (2018) Diabetic peripheral neuropathy: epidemiology, diagnosis, and pharmacotherapy. Clin Ther 40(6):828–849PubMedGoogle Scholar
Lauria G, Hsieh ST, Johansson O et al (2010) European Federation of Neurological Societies/Peripheral Nerve Society Guideline on the use of skin biopsy in the diagnosis of small fiber neuropathy. Report of a joint task force of the European Federation of Neurological Societies and the Peripheral Nerve Society. Eur J Neurol 17(7):903–912PubMedGoogle Scholar
Alam U, Riley DR, Jugdey RS et al (2017) Diabetic neuropathy and gait: a review. Diabetes Ther 8(6):1253–1264PubMedPubMedCentralGoogle Scholar
Culver DA, Dahan A, Bajorunas D et al (2017) Cibinetide improves corneal nerve fiber abundance in patients with sarcoidosis-associated small nerve fiber loss and neuropathic pain. Invest Ophth Vis Sci 58(6): BIO52-BIO60Google Scholar
1.Department of Eye and Vision ScienceUniversity of LiverpoolLiverpoolUK
2.St Paul's Eye UnitRoyal Liverpool University HospitalLiverpoolUK
3.Data Science InstituteLancaster UniversityLancasterUK
4.Department of OphthalmologyRiga Stradins UniversityRigaLatvia
5.Department of OphthalmologyPeking University Third HospitalBeijingChina
6.Cixi Institute of Biomedical Engineering, Ningbo Institute of Industrial TechnologyChinese Academy of SciencesNingboChina
7.Laboratory of Neuro Imaging, Institute for Neuroimaging and Informatics, Keck School of MedicineUniversity of Southern CaliforniaLos AngelesUSA
8.Department of Endocrinology and DiabetesUniversity Hospital AintreeLiverpoolUK
9.Weill Cornell Medicine – QatarDohaQatar
10.Diabetes and Neuropathy Research, Department of Eye and Vision Sciences and Pain Research Institute, Institute of Ageing and Chronic DiseaseUniversity of Liverpool and Aintree University Hospital NHS Foundation TrustLiverpoolUK
11.Department of Diabetes and EndocrinologyRoyal Liverpool and Broadgreen University NHS Hospital TrustLiverpoolUK
12.Division of Endocrinology, Diabetes and GastroenterologyUniversity of ManchesterManchesterUK
Williams, B.M., Borroni, D., Liu, R. et al. Diabetologia (2020) 63: 419. https://doi.org/10.1007/s00125-019-05023-4
Received 12 June 2019
Accepted 30 August 2019
Publisher Name Springer Berlin Heidelberg
Print ISSN 0012-186X
European Association for the Study of Diabetes | CommonCrawl |
Chaf's Blog
Here I share some fun stuff
2. Primary Visibility
3. Secondary Visibility
Chaf Chen
USTC CG Student
Physics Based Differentiable Rendering: Edge Sampling
Posted on 2022-12-14 Edited on 2023-01-14 In Note Disqus:
Differentiable Monte Carlo Ray Tracing through Edge Sampling
Edge sampling is a method to calculate the derivative of the ray tracing result w.r.t. some scene parameters (including camera pose, scene geometry, material and light parameters).
The key idea of edge sampling is dividing the gradient integral into smooth (interior) and discontinuous (boundary) regions. For the smooth part, we use automatic differentiation. For the discontinuous, we use edge sampling to capture the changes at boundaries.
Focus on triangle meshes
Assume the meshes have been preprocessed such that there is no interpenetration
Assume no point light sources and no perfectly specular surfaces
Approximate with area light sources and BRDFs with very low roughness
Focus on static scenes
Primary Visibility
Consider the 2D pixel filter integral for each pixel that integrates over the pixel filter $k$ and the radiance $L$, where the radiance itself can be another integral that integrates over light sources or the hemisphere.
The pixel color $I$ can be written as:
I=\iint k(x,y)L(x,y)\mathrm dx\mathrm dy
For notational convenience we will combine the pixel filter andradiance and call them scene function $f(x,y)=k(x,y)L(x,y)$. We are interested in the gradients of the integral with respect to some parameters $\Phi$ in the scene function $f(x,y;\Phi)$, such as the position of a mesh vertex:
\nabla I=\nabla\iint f(x,y;\Phi)\mathrm dx\mathrm dy
The integral usually does not have a closed-form solution, especially when more complex effects such as non-Lambertian BRDFs are involved. Therefore we rely on Monte Carlo integration to estimate the pixel value $I$. However, we cannot take the naive approachof applying the same Monte Carlo sampler to estimate the gradient $\nabla I$, since the scene function $f$ is not necessarily differentiable with respect to the scene parameters.
A key observation is that all the discontinuities happen at triangle edges. This allows us to explicitly integrate over the discontinuities. A 2D triangle edge splits the space into two half-spaces ($f_u$ and $f_l$ in above figure). We can model it as a Heaviside step function $\theta$:
\theta(\alpha(x,y))f_u(x,y)+\theta(-\alpha(x,y))f_l(x,y)
$f_u$ represents the upper half-space
$f_l$ represents the lower half-space
$\alpha$ defines the edge equation formed by the triangles
For each edge with two endpoints $(a_x,a_y)$, $(b_x,b_y)$, we can construct the edge equation by forming the line $\alpha(x,y)=Ax+By+C$. If $\alpha(x,y)>0$, then the point is at upper half-space, and vice versa. For the two endpoints of the edge $\alpha(x,y)=0$. Thus by plugging inthe two endpoints we obtain:
\alpha(x,y)=(a_y-b_y)x+(b_x-a_x)y+(a_xb_y-b_xa_y)
We can rewrite the scene functionfas a summation of Heaviside step functions $\theta$ with edge equation $\alpha_i$ multiplied by an arbitrary function $f_i$:
\iint f(x,y)\mathrm dx\mathrm dy=\sum_i\iint\theta(\alpha_i(x,y))f_i(x,y)\mathrm dx\mathrm dy
$f_i$ itself can contain Heaviside step functions, for example a triangle defines a multiplication of three Heaviside step functions
$f_i$ caneven be an integral over light sources or the hemisphere
We want to analytically differentiate the Heaviside step function $\theta$ and explicitly integrate over its derivative – the Dirac delta function $\delta$. To do this we first swap the gradient operator inside the integral, then we use product rule to separate the integral into two:
&\nabla \iint\theta(\alpha_i(x,y))f_i(x,y)\mathrm dx\mathrm dy\\\\
&=\iint\delta(\alpha_i(x,y))\nabla\alpha_i(x,y)f_i(x,y)\mathrm dx\mathrm dy\\\\
&+\iint \nabla f_i(x,y)\theta(\alpha_i(x,y))\mathrm dx\mathrm dy
Above equation shows that we can estimate the gradient using two Monte Carlo estimators. The first one estimates the integral over the edges of triangles containing the Dirac delta functions, and the second estimates the original pixel integral except the smooth function $f_i$ is replaced by its gradient, which can be computed through automatic differentiation.
To estimate the integral containing Dirac delta functions, we eliminate the Dirac function by performing variable substitution to rewrite the first term containing the Dirac delta function to an integral that integrates over the edge, that is, over the regions where $\alpha_i(x,y)=0$:
&\iint\delta(\alpha_i(x,y))\nabla\alpha_i(x,y)f_i(x,y)\mathrm dx\mathrm dy\\\\
=&\int_{\alpha_i(x,y)=0}\frac{\nabla\alpha_i(x,y)}{\|\nabla_{x,y}\alpha_i(x,y)\|}f_i(x,y)\mathrm d\sigma(x,y)
$\|\nabla_{x,y}\alpha_i(x,y)\|$ is the $L^2$ length of the gradient of the edge equation $\alpha_i$ with respect to $x$, $y$, which takes the Jacobian of the variable substitution into account.
$\sigma(x,y)$ is the measure of the length on the edge.
The gradients of the edge equations $\alpha_i$ are:
&\|\nabla_{x,y}\alpha_i\|=\sqrt{(a_x-b_x)^2+(a_y-b_y)^2}\\\\
&\dfrac{\partial \alpha_i}{\partial a_x}=b_y-y\quad \dfrac{\partial \alpha_i}{\partial a_y}=x-b_x\\\\
&\dfrac{\partial \alpha_i}{\partial b_x}=y-a_y\quad \dfrac{\partial \alpha_i}{\partial b_y}=a_x-x\\\\
&\dfrac{\partial \alpha_i}{\partial x}=a_y-b_y\quad \dfrac{\partial \alpha_i}{\partial y}=b_x-a_x
We can obtain the gradient with respect to other parameters, such as camera parameters, 3D vertex positions, or vertex normals bypropagating the derivatives from the projected triangle vertices using the chain rule:
\frac{\partial \alpha}{\partial p}=\sum_{k\in{x,y}}\frac{\partial\alpha}{\partial a_k}\frac{\partial a_k}{\partial p}+\frac{\partial\alpha}{\partial b_k}\frac{\partial b_k}{\partial p}
where $p$ is the desired parameter.
We use Monte Carlo sampling to estimate the Dirac integral. Recall that a triangle edge defines two half-spaces, therefore we need to compute the two values $f_l(x,y)$ and $f_u(x,y)$ on the edge. By combining above results, our Monte Carlo estimation of the Dirac integral for a single edge $E$ on a triangle can be written as:
\frac{1}{N}\sum_{j=1}^N\frac{\|E\|\nabla \alpha_i(f_u(x_j,y_j)-f_l(x_j,y_j))}{P(E)\|\nabla_{x_j,y_j}\alpha_i(x_j,y_j)\|}
$\|E\|$ is the length of the edge
$P(E)$ is the probability of selecting edge $E$
In practice, if we employ smooth shading, most of the triangleedges are in the continuous regions and the Dirac integral is zero. Only the silhouette have non-zero contribution to the gradients. We select the edges by projecting all triangle meshes to screen space and clip them against the camera frustrum. We select one silhouette edge with probability proportional to the screen space lengths. We then uniformly pick a pointon the selected edge.
Secondary Visibility
Post author: Chaf Chen
Post link: https://chaphlagical.github.io/2022/12/14/note/edge_sampling/
Copyright Notice: All articles in this blog are licensed under BY-NC-SA unless stating additionally.
# Differentiable Rendering
Physics Based Differentiable Rendering: Preliminaries
Vectorization for Fast, Analytic, and Differentiable Visibility
© 2023 Chaf Chen
Powered by Hexo & NexT.Pisces | CommonCrawl |
Does conservation of momentum really imply Newton's third law?
I often heard that conservation of momentum is nothing else than Newton's third law.
Ok, If you have only two interacting particles in the universe, this seems to be quite obvious.
However if you have an isolated system of $n$ ($n > 2$) interacting particles (no external forces). Then clearly Newton's third law implies conservation of total momentum of the system. However presuppose conservation of total momentum you only get:
$$ \sum_{i\neq j}^n \mathbf F_{ij} = \frac{d}{d t} \mathbf P = 0 $$
Where $\mathbf F_{ij}$ is the forced acted by the $i$th particle upon the $j$th particle and $\mathbf P$ is the total linear momentum.
But this doesn't imply that $\mathbf F_{ij} = -\mathbf F_{ji}$ for $j \neq i$.
So does conservation of momentum implies Newton's third law in general or doesn't it? Why?
newtonian-mechanics education momentum
martinmartin
Right, you could satisfy the momentum conservation by forces that don't satisfy "action vs reaction" law $F_{ij}=-F_{ji}$ but the relevant formulae would have to depend on coordinates and momenta of all the particles. If you assume that the particles are controlled by two-body forces only, the momentum conservation does imply that $F_{ij}=-F_{ji}$.
Luboš MotlLuboš Motl
$\begingroup$ Are there any "non two body forces" in classical physics? $\endgroup$ – martin Oct 25 '11 at 13:09
$\begingroup$ Yes, there are. $\endgroup$ – Ron Maimon Oct 25 '11 at 20:28
It doesn't, and there are a list of examples in this nearly identical question: Deriving Newton's Third Law from homogeneity of Space
There are no examples of fundamental classical three body forces where the forces are contact forces and linear gravity/EM, because linear fields are two-body interactions. The most obvious non two-body force is in the strong nonlinear gravitational regime.
Other physical examples are things like nucleon-nucleon 3-body forces, which are unfortuately completely quantum.
Ron MaimonRon Maimon
The force used in Newton's laws is not a "real" thing, it's just a mathematical tool. If you combine Newton's laws, it is not to hard to see how the conservation of momentum is inherent in the picture. Thus,
$$\frac{d}{dt} p = 0$$
For a many body system this becomes
$$\frac{d}{dt} \left( \sum_{i=1} ^N p_i \right) = 0$$
Moving all but one of the momentum terms to the other side
$$\frac{d}{dt} p_1 = - \frac{d}{dt} \left( \sum_{i=2} ^N p_i \right)$$
and voila. That's the physics of the situation so in reality they are inextricably linked and it doesn't even make sense to talk about the force caused by one object or another.
But... if you just care about the theoretical side of things, whether or not the Law of Conservation of Momentum implies Newton's Third Law depends on how you define the Law of Conservation of Momentum. It is always defined as applying to an isolated system. If you stipulate that for a system that is not isolated, the portion of the total change in momentum due to any particular part is that change that would take place within that portion in the if it were isolated, you then get the Third Law.
For example, in the situation described above, the Law of Conservation of momentum is applied to the whole system. If I draw a boundary around objects $1$ and $2$, and say that the contribution to the total change in momentum of the system from these objects is zero then I get
$$\frac{d}{dt} p_{12} = - \frac{d}{dt} p_{21} $$
which is what we expect. But again, when the system is not truly isolated it becomes just an intellectual exercise.
AdamRedwineAdamRedwine
No, but Newton's third law of motion implies the conservation of momentum. In other words, Newton's third law is a special case of the more general law, which is the conservation of momentum.
Chamith AkalankaChamith Akalanka
Not the answer you're looking for? Browse other questions tagged newtonian-mechanics education momentum or ask your own question.
Does the principle of conservation of momentum really imply Newton's third law? ("Classical Mechanics" by John Taylor)
Are Newton's 1st and 3rd laws just consequences of the 2nd?
Deriving Newton's Third Law from homogeneity of Space
Conservation of linear momentum (classical mechanics and special relativity)
Is Newton's third law sufficient for electrical or gravitational forces between two objects to be a central force? (In the classical scale)
Apparent Violation of Newton's $3^{\text{rd}}$ Law and the Conservation of Momentum (and Angular Momentum) For a Pair of Charged Particles
Newton's Third Law Exceptions?
Time varying currents and Newton's Third Law?
Why do people say that Hamilton's principle is all of classical mechanics? How to get Newton's third law?
Why does Newton's Third Law work for fields?
How Newton's third law works in a system with external force on it? | CommonCrawl |
RUS ENG JOURNALS PEOPLE ORGANISATIONS CONFERENCES SEMINARS VIDEO LIBRARY PERSONAL OFFICE
Forthcoming papers
Search papers
Search references
What is RSS
Izv. RAN. Ser. Mat.:
Personal entry:
Izv. RAN. Ser. Mat., 2006, Volume 70, Issue 3, Pages 23–128 (Mi izv556)
This article is cited in 41 scientific papers (total in 41 papers)
Hyperplane sections and derived categories
A. G. Kuznetsov
Steklov Mathematical Institute, Russian Academy of Sciences
Abstract: We give a generalization of the theorem of Bondal and Orlov about the derived categories of coherent sheaves on intersections of quadrics, revealing the relation of this theorem to projective duality. As an application, we describe the derived categories of coherent sheaves on Fano 3-folds of index 1 and degrees 12, 16 and 18.
DOI: https://doi.org/10.4213/im556
Full text: PDF file (1400 kB)
References: PDF file HTML file
Izvestiya: Mathematics, 2006, 70:3, 447–547
Bibliographic databases:
UDC: 512.73
MSC: 18E30, 14A22
Received: 26.04.2005
Revised: 12.09.2005
Citation: A. G. Kuznetsov, "Hyperplane sections and derived categories", Izv. RAN. Ser. Mat., 70:3 (2006), 23–128; Izv. Math., 70:3 (2006), 447–547
Citation in format AMSBIB
\Bibitem{Kuz06}
\by A.~G.~Kuznetsov
\paper Hyperplane sections and derived categories
\jour Izv. RAN. Ser. Mat.
\mathnet{http://mi.mathnet.ru/izv556}
\crossref{https://doi.org/10.4213/im556}
\elib{http://elibrary.ru/item.asp?id=9226822}
\jour Izv. Math.
\crossref{https://doi.org/10.1070/IM2006v070n03ABEH002318}
Linking options:
http://mi.mathnet.ru/eng/izv556
https://doi.org/10.4213/im556
http://mi.mathnet.ru/eng/izv/v70/i3/p23
This publication is cited in the following articles:
Samokhin A., "Some remarks on the derived categories of coherent sheaves on homogeneous spaces", J. Lond. Math. Soc. (2), 76:1 (2007), 122–134
Kuznetsov A., "Derived categories of quadric fibrations and intersections of quadrics", Adv. Math., 218:5 (2008), 1340–1369
Sawon J., "Twisted Fourier-Mukai transforms for holomorphic symplectic four-folds", Adv. Math., 218:3 (2008), 828–864
Kuznetsov A., "Lefschetz decompositions and categorical resolutions of singularities", Selecta Math. (N.S.), 13:4 (2008), 661–696
A. G. Kuznetsov, "Derived Categories of Fano Threefolds", Proc. Steklov Inst. Math., 264 (2009), 110–122
Macri E., Stellari P., "Infinitesimal Derived Torelli Theorem for K3 Surfaces", with an Appendix by Sukhendu Mehrotra, Internat. Math. Res. Notices, 2009, no. 17, 3190–3220
Baranovsky V., Pecharich J., "On equivalences of derived and singular categories", Cent. Eur. J. Math., 8:1 (2010), 1–14
Han F., "Geometry of the genus 9 Fano 4-folds", Ann. Inst. Fourier (Grenoble), 60:4 (2010), 1401–1434
Polishchuk A., "$K$-theoretic exceptional collections at roots of unity", J. K-Theory, 7:1 (2011), 169–201
Huybrechts D., Macrì E., Stellari P., "Formal deformations and their categorical general fibre", Comment. Math. Helv., 86:1 (2011), 41–71
Kuznetsov A., "Base change for semiorthogonal decompositions", Compos. Math., 147:3 (2011), 852–876
MichałKapustka, Kristian Ranestad, "Vector bundles on Fano varieties of genus ten", Math. Ann, 2012
Bernardara M. Bolognesi M., "Categorical Representability and Intermediate Jacobians of Fano Threefolds", Derived Categories in Algebraic Geometry - Tokyo 2011, EMS Ser. Congr. Rep., ed. Kawamata Y., Eur. Math. Soc., 2012, 1–25
Asher Auel, Marcello Bernardara, Michele Bolognesi, "Fibrations in complete intersections of quadrics, Clifford algebras, derived categories, and rationality problems", Journal de Mathématiques Pures et Appliquées, 2013
Galkin S. Shinder E., "Exceptional Collections of Line Bundles on the Beauville Surface", Adv. Math., 244 (2013), 1033–1050
Krug A., "Extension Groups of Tautological Sheaves on Hilbert Schemes", J. Algebr. Geom., 23:3 (2014), 571–598
Bayer A., Macri E., "Projectivity and Birational Geometry of Bridgeland Moduli Spaces", J. Am. Math. Soc., 27:3 (2014), 707–752
Abuaf R., "Wonderful Resolutions and Categorical Crepant Resolutions of Singularities", J. Reine Angew. Math., 708 (2015), 115–141
Meachan C., "Derived Autoequivalences of Generalised Kummer Varieties", Math. Res. Lett., 22:4 (2015), 1193–1221
Kuznetsov A., "Küchle fivefolds of type c5", Math. Z., 284:3-4 (2016), 1245–1278
Lombardi L., Tirabassi S., "Deformations of minimal cohomology classes on abelian varieties", Commun. Contemp. Math., 18:4 (2016), 1550066
Bernardara M. Bolognesi M. Faenzi D., "Homological projective duality for determinantal varieties", Adv. Math., 296 (2016), 181–209
Kuznetsov A. Polishchuk A., "Exceptional collections on isotropic Grassmannians", J. Eur. Math. Soc., 18:3 (2016), 507–574
Kuznetsov A., "Derived Categories View on Rationality Problems", Rationality Problems in Algebraic Geometry, Lect. Notes Math., Lecture Notes in Mathematics, 2172, ed. Pardini R. Pirola G., Springer International Publishing Ag, 2016, 67–104
Kuznetsov A. Perry A., "Derived categories of cyclic covers and their branch divisors", Sel. Math.-New Ser., 23:1 (2017), 389–423
Hirano Yu., "Derived Knorrer Periodicity and Orlov'S Theorem For Gauged Landau-Ginzburg Models", Compos. Math., 153:5 (2017), 973–1007
Vial Ch., "Exceptional Collections, and the Neron-Severi Lattice For Surfaces", Adv. Math., 305 (2017), 895–934
Auel A. Bernardara M., "Cycles, Derived Categories, and Rationality", Surveys on Recent Developments in Algebraic Geometry, Proceedings of Symposia in Pure Mathematics, 95, ed. Coskun I. DeFernex T. Gibney A., Amer Mathematical Soc, 2017, 199–266
Fonarev A. Kuznetsov A., "Derived Categories of Curves as Components of Fano Manifolds", J. Lond. Math. Soc.-Second Ser., 97:1 (2018), 24–46
Bondal A., Kapranov M., Schechtman V., "Perverse Schobers and Birational Geometry", Sel. Math.-New Ser., 24:1, SI (2018), 85–143
Kuznetsov A.G., Prokhorov Yu.G., Shramov C.A., "Hilbert Schemes of Lines and Conics and Automorphism Groups of Fano Threefolds", Jap. J. Math., 13:1 (2018), 109–185
Tabuada G., "A Note on the Schur-Finiteness of Linear Sections", Math. Res. Lett., 25:1 (2018), 237–253
Hassett B., Lai K.-W., "Cremona Transformations and Derived Equivalences of K3 Surfaces", Compos. Math., 154:7 (2018), 1508–1533
Kuznetsov A. Perry A., "Derived Categories of Gushel-Mukai Varieties", Compos. Math., 154:7 (2018), 1362–1406
Ottem J.Ch., Rennemo J.V., "A Counterexample to the Birational Torelli Problem For Calabi-Yau Threefolds", J. Lond. Math. Soc.-Second Ser., 97:3 (2018), 427–440
Krug A. Ploog D. Sosna P., "Derived Categories of Resolutions of Cyclic Quotient Singularities", Q. J. Math., 69:2 (2018), 509–548
Kuznetsov A., "Derived Equivalence of Ito-Miura-Okawa-Ueda Calabi-Yau 3-Folds", J. Math. Soc. Jpn., 70:3 (2018), 1007–1013
Belmans P. Presotto D., "Construction of Non-Commutative Surfaces With Exceptional Collections of Length 4", J. Lond. Math. Soc.-Second Ser., 98:1 (2018), 85–103
A. G. Kuznetsov, "On linear sections of the spinor tenfold. I", Izv. Math., 82:4 (2018), 694–751
Moschetti R., "The Derived Category of a Non Generic Cubic Fourfold Containing a Plane", Math. Res. Lett., 25:5 (2018), 1525–1545
Manivel L., "Double Spinor Calabi-Yau Varieties", Epijournal Geom. Algebr., 3 (2019), 2
This page: 608
Full text: 199
First page: 16
What is a QR-code?
Terms of Use Registration Logotypes © Steklov Mathematical Institute RAS, 2019 | CommonCrawl |
elements of large sample theory solution
Elements of Large-Sample Theory by E.L. Lehmann and Publisher Springer. Comme e est l'un d'eux, il existe au moins un x 2G distinct de e tel que x2 ˘e. For us, complexity is the number of elements and subsequent degree of freedom. Lehmann/Casella, Theory at Point Estimation, 2nd ed. Our solutions are written by Chegg experts so you can be assured of the highest quality! Large Sample Theory with many worked examples, numerical calculations, and simulations to illustrate theory ; Appendices provide ready access to a number of standard results, with many proofs; Solutions given to a number of selected exercises from Part I; Part II exercises with a certain level of difficulty appear with detailed hints; see more benefits. WorldCat Home About WorldCat Help. ELEMENTS OF PROBABILITY THEORY Lemma 5.3 (Markov) Let z be a random variable with finite pth moment. Most large sample theory uses three main technical tools: the Law of Large Numbers (LLN), the Central Limit Theorem (CLT) and Taylor ex-pansion. Elements of Large-Sample Theory provides a unified treatment of first- order large-sample theory. Large sample distribution theory is the cornerstone of statistical inference for econometric models. Functions of the Sample Moments. Introduction. Elements of Large Sample Theory provides a unified treatment of first-order large-sample theory. Example: Q = {x, y, z}. The observed values are {2,4,9,12}. Solutions des exercices puis k ˘2(n ¡l), c'est-à-dire que le nombre d'éléments x 2G tel que x2 ˘ e est nécessairement pair. The sample average after ndraws is X n 1 n P i X i. That is, p ntimes a sample average looks like (in a precise sense to … Varying the number of elements along each edge, we can develop a table of mesh size vs deflection and solve time: Method 1 (Simple Solution) A simple solution is to sort the given array using a O(N log N) sorting algorithm like Merge Sort, Heap Sort, etc and return the element at index k-1 in the sorted array.. Time Complexity of this solution is O(N Log N) The notion of set is taken as "undefined", "primitive", or "basic", so we don't try to define what a set is, but we can give an informal description, describe important properties of sets, and give examples. Figure 1.16 pictorially verifies the given identities. Springer-Verlag New York, Inc., 1997, ISBN 0-387-94919-4, "The book also contains rich collection of problems and a useful list of references, and can be warmly recommended as a complementary text to lectures on mathematical statistics, as well as a textbook for more advanced courses.". Slutsky Theorems. You will then complete the following: Test to determine the amount of solute dissolved in your sample solution. About this Textbook. Unlike static PDF Elements of Large-Sample Theory solution manuals or printed answer keys, our experts show you how to solve each problem step-by-step. The first treats basic probabilistic notions, the second features the basic statistical tools for expanding the theory, the third contains special topics as applications of the general theory, and the fourth covers more standard statistical topics. A Venn diagram consists of multiple overlapping closed curves, usually circles, each representing a set. A solution is a homogeneous mixture of one substance dissolved in another. Statistics Solutions can assist with determining the sample size / power analysis for your research study. E.L. Lehmann is Professor of Statistics Emeritus at the University of California, Berkeley. The sample is large and the population standard deviation is known. zinc. Access Elements of Large-Sample Theory 2nd Edition solutions now. Laws of Large Numbers. This theory is extremely useful if the exact sampling distribution of the estimator is complicated or unknown. An important feature of large-sample theory is that it is nonparametric. Large sample theory, also called asymptotic theory, is used to approximate the distribution of an estimator when the sample size n is large. Often available in the bookstore as a textbook for Math281, Mathematical Statistics. (2) Central limit theorem: p n(X n EX) !N(0;). Solutions must have a solute and a solvent. enable JavaScript in your browser. n(Tn−θ)]2tends to a nondegenerate limit distribution, namely (after division byτ2)toaχ2 … De ne the function f : (0;1) !R by f(x) = tan(ˇ(x 1=2)). for all i. Table of Content. Often available in the bookstore as a textbook for Math281, Mathematical Statistics. Central Limit Theorems. Figure 1.16 pictorially verifies the given identities. Fig.1.16 - … Whereas according to the large sample theory, the first order bias, which is based on the first term of right side of Equation (2.2), tends to zero (Lehmann, 1999). The Elements of AI is a series of free online courses created by Reaktor and the University of Helsinki. price for Spain 3 exercises 5. element esuch that no element except ehas an inverse. The book is written at an elementary level and is suitable for students at the master's level in statistics and in aplied fields who have a … The print version of this textbook is ISBN: 9780387227290, 0387227296. Suppose that someone collects a random sample of size 4 of a particular mea-surement. A Course in Large Sample Theory is presented in four parts. The Sample Correlation Coefficient. $$|A \cup B |=|A|+|B|-|A \cap B| \hspace{120pt} (1.2)$$, $A=\{ x \in \mathbb{Q} | -100 \leq x \leq 100 \}$, $B=\{(x,y) | x \in \mathbb{N}, y \in \mathbb{Z} \}$, $A=\{ x \in \mathbb{Q} | -100 \leq x \leq 100 \}$ is, $B=\{(x,y) | x \in \mathbb{N}, y \in \mathbb{Z} \}$ is, $D=\{ \frac{1}{n} | n \in \mathbb{N} \}$ is. If set A has n elements, it has 2 n subsets. It discusses a broad range of applications including introductions to density estimation, the bootstrap, and the asymptotics of survey methodology. Let $S=\{1,2,3\}$. Also, all values in $[-1,1]$ When the sample is completely unknown, the Element Finder plug-in can also be used to find the elements present in the sample. We record the complexity of the model vs. response. Topics: Large sample properties of tests and estimates, consistency and efficiency, U-statistics, chi-squared tests. The study of large-sample theory lends itself very well to computing, since frequently the theoretical large-sample results we prove do not give any indication of how well asymptotic approximations work for finite samples. 8. a) L'ensemble U est une partie de Q⁄. Let $A$, $B$, $C$ be three sets as shown in the following Venn diagram. To learn more, visit our webpage on sample size / power analysis, or contact us today. However, the accuracy of these approximations is not To learn more, visit our webpage on sample size / power analysis , or contact us today . For the vast majority of geometries and problems, these PDEs cannot be solved with analytical methods. The first semester will cover introductory measure-theoretic probability, decision theory, notions of optimality, principles of data reduction, and finite sample estimation and inference. Create lists, bibliographies and reviews: or Search WorldCat. This is performed in just three easy steps. Remember that a partition of $S$ is a collection of nonempty sets that are disjoint [P9] The Theory of Statistical Inference, The Theory of Statistical Inference, It discusses a broad range of applications including introductions to density estimation, the bootstrap, and the asymptotics of survey methodology. The molecules of a solution are evenly distributed throughout the solution. Process of Sampling: Identifying the Population set. In the first step, multiple Fullframes of the sample are taken. It seems that you're in USA. This is a good book on large sample theory with lots of examples and background material. Pearson's Chi-Square. 116 CHAPTER 5. Then, IP(|z|≥c) ≤IE |z|p cp where c is a positive real number. For any real value $x$, $-1 \leq \textrm{sin} (x) \leq 1$. The biggest possible collection of points under consideration is called the space, universe,oruniversal set. It discusses a broad range of applications including introductions to density estimation, the bootstrap, and the asymptotics of survey methodology. Pearson's Chi-Square. The courses combine theory with practical exercises and can be completed at your own pace. A sample is defined as a set of selected individuals, items, or data taken from a population of interest. 6 exercises 10. A characteristic (usually numeric) that describes a sample is referred to as a sample statistic. Our response of interest is the maximum vertical deflection. It discusses a broad range of applications including introductions to density estimation, the bootstrap, and the asymptotics of survey methodology. Note that in the second identity, 12 exercises Part 2: Basic Statistical Large Sample Theory 6. 4 exercises 9. 4. Purpose: In this lab you will be assigned a sample solution to test. Slutsky Theorems. 1: Total sample size k i i nn Population (N units) Stratum 1 The book is written at an elementary level and is suitable for students at the master's level in statistics and in aplied fields who have a background of two years of calculus. 12 exercises Part 2: Basic Statistical Large Sample Theory 6. The final examination is on Thursday, June 10, from 11:30 AM to 2:30 PM. Chapter 6: Sampling: Theory and Methods study guide by crissy_bacino includes 23 questions covering vocabulary, terms and more. He is a member of the National Academy of Sciences and the American Academy of Arts and Sciences, and the recipient of honorary degrees from the University of Leiden, The Netherlands, and the University of Chicago. 10 exercises 8. It is suitable for graduate level or researchers trying to get to grips with this tricky topic. Elements of Large-Sample Theory provides a unified treatment of first- order large-sample theory. h plus. No need to wait for office hours or assignments to be graded to find out where you took a wrong turn. Dispose of the developing solution as instructed by your teacher, clean up and begin your lab write-up. It discusses a broad range of applications including introductions to density estimation, the bootstrap, and the asymptotics of survey methodology written at an elementary level. Determination of the size of our sample set. of the following sets, draw a Venn diagram and shade the area representing the given set. JavaScript is currently disabled, this site works much better if you Thus, Range$(f)=[-1,1]$. Sampling Theory| Chapter 4 | Stratified Sampling | Shalabh, IIT Kanpur Page 2 Notations: We use the following symbols and notations: N : Population size k : Number of strata Ni : Number of sampling units in ith strata 1 k i i NN ni: Number of sampling units to be drawn from ith stratum. 4 exercises 9. NOTE: Inferential statistics are used to help the researcher infer how well statistics in a sample reflect parameters in a population. BEAM THEORY • Euler-Bernoulli Beam Theory – can carry the transverse load – slope can change along the span (x-axis) – Cross-section is symmetric w.r.t. A 10.0-gram sample of which element has the smallest volume at STP? Element Definition: Elements – Elements constitute the simplest chemical substances in which all the atoms are exactly the same. Population tree is a very large set and making the study of observations on it can be very exhausting, both time and money-wise alike. (gross), © 2020 Springer Nature Switzerland AG. DEFINITION Elements of Large Sample Theory provides a unified treatment of first-order large-sample theory. (b) Find the relationship between sample mean and bootstrap mean. Elements of Large-Sample Theory textbook solutions from Chegg, view all supported editions. Please review prior to ordering, ebooks can be used on all reading devices, Institutional customers should get in touch with their account manager, Usually ready to be dispatched within 3 to 5 business days, if in stock, The final prices may differ from the prices shown due to specifics of VAT rules. There are $5$ possible partitions for $S=\{1,2,3\}$: Determine whether each of the following sets is countable or uncountable. Let Xbe an arbitrary set; then there exists a set Y Df u2 W – g. Obviously, Y X, so 2P.X/by the Axiom of Power Set.If , then we have Y2 if and only if – [SeeExercise 3(a)]. Write all the possible partitions of $S$. Elements and compounds are the two forms in which pure substances exist. Springer-Verlag New York, Inc., 1998, ISBN 0- 387-98502-6, Lehmann, Testing Statistical Hypotheses, 2nd ed. Elements of Large Sample Theory provides a unified treatment of first-order large-sample theory. If $A$ and $B$ are finite sets, we have Figure 1.16 pictorially verifies the given identities. xy-plane – The y-axis passes through the centroid – Loads are applied in xy-plane (plane of loading) L F x y F Plane of loading y z Neutral axis A 4 BEAM THEORY cont. Elements of large-sample theory. ...you'll find more products in the shopping cart. Sample size: To handle the non-response data, a researcher usually takes a large sample. we show the number of elements in each set by the corresponding shaded area. A Venn diagram, also called primary diagram, set diagram or logic diagram, is a diagram that shows all possible logical relations between a finite collection of different sets.These diagrams depict elements as points in the plane, and sets as regions inside closed curves. We want to encourage as broad a group of people as possible to learn what AI is, what can (and can't) be done with AI, and how to start creating AI methods. These tools are generally easier to apply to statistics for which we have Sets and elements Set theory is a basis of modern mathematics, and notions of set theory are used in all formal descriptions. Search for Library Items Search for Lists Search for Contacts Search for a Library. Additional Resource Pages Related to Sampling: The limiting distribution of a statistic gives approximate distributional results that are often straightforward to derive, even in complicated econometric models. Lab #22: Concentration Lab. ... more homogenous sets of elements. Part 1 Introduction to AI. 10 exercises 8. [P7] Elements of Large–Sample Theory, E.L. Lehmann, Springer, 1999. 1.1 Set Theory Digression A set is defined as any collection of objects, which are called points or elements. AsetAis called a subset of B(we write A⊆Bor B⊇A) if every element Highly Recommended. It discusses a broad range of applications including introductions to density estimation, the bootstrap, and the asymptotics of survey methodology written at an elementary level. 3 exercises 5. We focus on two important sets of large sample results: (1) Law of large numbers: X n!EXas n!1. The description of the laws of physics for space- and time-dependent problems are usually expressed in terms of partial differential equations (PDEs). [P8] Theory of Point Estimation, 2nd Edition, E.L. Lehmann and G. Casella, Springer, 1998. Springer is part of, Please be advised Covid-19 shipping restrictions apply. Publisher/Verlag: Springer, Berlin | Elements of Large Sample Theory provides a uni0ed treatment of 0rst-order large-sample theory. You can check your reasoning as you tackle a problem using our interactive solutions viewer. Using Venn diagrams, verify the following identities. As we know from previous chapters, science is knowledge represented as a collection of "theories" derived using the scientific method. Statistics Solutions can assist with determining the sample size / power analysis for your research study. 1.3. [P8] Theory of Point Estimation, 2nd Edition, E.L. Lehmann and G. Casella, Springer, 1998. Highly Recommended. Elements of Large-Sample Theory provides a unified treatment of first- order large-sample theory. are covered by $\textrm{sin} (x)$. Compound Definition: Compounds – Compounds are chemical substances made up of two or more elements that are chemically bound … [P7] Elements of Large–Sample Theory, E.L. Lehmann, Springer, 1999. (a) Find the bootstrap mean and variance of the above sample. How many subsets and proper subsets will Q have? ... A large sample of solid calcium sulfate is crushed into smaller pieces for testing. Solution: Step 1. Sample size: To handle the non-response data, a researcher usually takes a large sample. Examples of solutions include water vapor in air, table sugar in water, steel, brass, hydrogen dissolved to palladium, carbon dioxide in water and ethanol in water. Its limit theorems provide distribution-free approximations for statistical quantities such as significance levels, critical values, power, confidence co-efficients, and so on. Figure 1.15 shows Venn diagrams for these sets. For Probability Theory the space is called the sample space. and their union is $S$. 1.1. Central Limit Theorems. In view of (8.14), the distribution of [. Elements of Large-Sample Theory provides a unified treatment of first- order large-sample theory. De plus, si x 2U et y 2U, on The book is written at an elementary level and is suitable for students at the master's level in statistics and in aplied fields who have a background of … Solution. For p =2,Lemma5.3isalsoknownastheChebyshev inequality.Ifc is small such that IE |z|p/cp > 1, Markov's inequality is trivial. For each 6 exercises 7. h(Tn)=h(θ)+(Tn−θ)h(θ)+ 1 2 (Tn−θ)2[h(θ)+Rn], whereRn→0 in probability asTn→θ, or, sinceh(θ)=0, h(Tn) −h(θ)= 1 2 (8.19) (Tn−θ)2[h(θ)+Rn]. • Euler-Bernoulli Beam Theory cont. Large Sample Theory Homework 1: Bootstrap Method, CLT Due Date: October 3rd, 2004 1. Compounds Elements FAQs. Let Sbe a semigroup and let x2S. If set A has n elements, it has 2 n - 1 proper sets. According to one acid-base theory, a water molecule acts as an acid when the water molecule. [P9] The Theory of Statistical Inference, The Theory of Statistical Inference, Laws of Large Numbers. Thus if \(\mu\) denotes the mean amount of facial cream being dispensed, the hypothesis test is \[H_0: \mu =8.1\\ \text{vs}\\ H_a:\mu \neq 8.1\; @\; \alpha =0.01\] Step 2. Search. Save up to 80% by choosing the eTextbook option for ISBN: 9780387227290, 0387227296. The second step shows which elements were found and suggests a wavelength to use. Full file at http://TestMango.eu/Solution-Manual-for-Elements-of-the-Theory-of-Computation-2-E-2nd-Edition-Harry-Lewis-Christos-H-Papadimitriou Example: Draw a Venn diagram to represent the relationship between the sets. Thus to cut down on the amount of time and as well as resources, a Sample Set is created from the Population set. Note that in the second identity, we show the number of elements in each set by the corresponding shaded area. Functions of the Sample Moments. 4 Éléments de théorie des groupes. It discusses a broad range of applications including introductions to density estimation, the bootstrap, and the asymptotics of survey methodology written at an elementary level. Show that fxgforms a subgroup of S(of order 1) if and only if x2 = xsuch an element … The natural assumption is that the machine is working properly. There will be one midterm in the sixth week. Instead, an approximation of the equations can be constructed, typically based upon different types of discretizations. 4. Solution N= f0;1;2;:::gis a semigroup with binary operation usual addition. 6 exercises 10. No non-identity element has an inverse. 6 exercises 7. We have a dedicated site for USA. Solution: Q has 3 elements Number of subsets = 2 3 = 8 Number of proper subsets = 7. Math 5061-5062 together form a year-long sequence in mathematical statistics leading to the Ph.D. qualifying exam in statistical theory. The Sample Correlation Coefficient. Find the range of the function $f:\mathbb{R} \rightarrow \mathbb{R}$ defined as $f(x)=\textrm{sin} (x)$. [Erich L Lehmann] Home. I assume you have heard of all of these but will state versions of them as we go. Using an iterative method, we increase the number of elements along each side and solve.
Always Meaning In Kannada, Best Niacinamide Serum, Best Hair Dye To Lighten Dark Hair, Gundersen Health System Careers, Pixelmon Catch Rate Calculator, Boscia Batch Code Check, Strawberry Cream Cookies, Olive Tree Propagation, Machine Learning Stanford, Master's In Frankfurt,
2020 elements of large sample theory solution | CommonCrawl |
Hostname: page-component-7ccbd9845f-hcslb Total loading time: 0.88 Render date: 2023-01-28T21:09:26.401Z Has data issue: true Feature Flags: { "useRatesEcommerce": false } hasContentIssue true
>FirstView
>The global disease burden attributable to a diet low...
The global disease burden attributable to a diet low in fibre in 204 countries and territories from 1990 to 2019
Ming Zhuo ,
Ze Chen ,
Mao-Lin Zhong ,
Ye-Mao Liu ,
Fang Lei ,
Juan-Juan Qin ,
Tao Sun ,
Chengzhang Yang ,
Ming-Ming Chen and
Xiao-Hui Song
Ming Zhuo
Department of Anesthesiology, The First Affiliated Hospital of Gannan Medical University, Ganzhou, People's Republic of China Medical College of Soochow University, Suzhou, People's Republic of China
Ze Chen
Department of Cardiology, Zhongnan Hospital of Wuhan University, Wuhan, People's Republic of China Institute of Model Animal, Wuhan University, Wuhan, People's Republic of China
Mao-Lin Zhong
Department of Anesthesiology, The First Affiliated Hospital of Gannan Medical University, Ganzhou, People's Republic of China
Ye-Mao Liu
Institute of Model Animal, Wuhan University, Wuhan, People's Republic of China Department of Cardiology, Renmin Hospital of Wuhan University, Wuhan, People's Republic of China
Fang Lei
Institute of Model Animal, Wuhan University, Wuhan, People's Republic of China School of Basic Medical Science, Wuhan University, Wuhan, People's Republic of China
Juan-Juan Qin
Tao Sun
Chengzhang Yang
Ming-Ming Chen
Li-Feng Wang
Yi Li
Xiao-Jing Zhang
Institute of Model Animal, Wuhan University, Wuhan, People's Republic of China Department of Cardiology, Renmin Hospital of Wuhan University, Wuhan, People's Republic of China School of Basic Medical Science, Wuhan University, Wuhan, People's Republic of China
Lihua Zhu
Jingjing Cai
Institute of Model Animal, Wuhan University, Wuhan, People's Republic of China Department of Cardiology, The Third Xiangya Hospital, Central South University, Changsha, People's Republic of China
Jun-Ming Ye
Gang Zhou
Department of Neurology, Huanggang Central Hospital, Huanggang, People's Republic of China
Yong Zeng*
Huanggang Central Hospital, Huanggang438021, People's Republic of China
*Corresponding author: Email [email protected]
The relationship of a diet low in fibre with mortality has not been evaluated. This study aims to assess the burden of non-communicable chronic diseases (NCD) attributable to a diet low in fibre globally from 1990 to 2019.
All data were from the Global Burden of Disease (GBD) Study 2019, in which the mortality, disability-adjusted life-years (DALY) and years lived with disability (YLD) were estimated with Bayesian geospatial regression using data at global, regional and country level acquired from an extensively systematic review.
All data sourced from the GBD Study 2019.
All age groups for both sexes.
The age-standardised mortality rates (ASMR) declined in most GBD regions; however, in Southern sub-Saharan Africa, the ASMR increased from 4·07 (95 % uncertainty interval (UI) (2·08, 6·34)) to 4·60 (95 % UI (2·59, 6·90)), and in Central sub-Saharan Africa, the ASMR increased from 7·46 (95 % UI (3·64, 11·90)) to 9·34 (95 % UI (4·69, 15·25)). Uptrends were observed in the age-standardised YLD rates attributable to a diet low in fibre in a number of GBD regions. The burden caused by diabetes mellitus increased in Central Asia, Southern sub-Saharan Africa and Eastern Europe.
The burdens of disease attributable to a diet low in fibre in Southern sub-Saharan Africa and Central sub-Saharan Africa and the age-standardised YLD rates in a number of GBD regions increased from 1990 to 2019. Therefore, greater efforts are needed to reduce the disease burden caused by a diet low in fibre.
Diet low in fibreGlobal Burden of DiseaseDisability-adjusted life-yearYears lived with disability
Public Health Nutrition , First View , pp. 1 - 12
This is an Open Access article, distributed under the terms of the Creative Commons Attribution-NonCommercial-NoDerivatives licence (https://creativecommons.org/licenses/by-nc-nd/4.0/), which permits non-commercial re-use, distribution, and reproduction in any medium, provided the original work is unaltered and is properly cited. The written permission of Cambridge University Press must be obtained for commercial re-use or in order to create a derivative work.
© The Author(s), 2022. Published by Cambridge University Press on behalf of The Nutrition Society
Non-communicable chronic diseases (NCD) account for a major proportion of the total disease burden worldwide. A suboptimal diet, one of the major risk factors for NCD, can be due to several poor dietary habits (e.g. consuming a diet low in fruits, wholegrains or fibre). The burden of disease attributable to a suboptimal diet has increased dramatically in recent decades(1,2) . A diet low in fibre is defined as a mean daily intake of fibre from all sources, including fruits, vegetables, grains, legumes and pulses, of less than 23·5 g/d(1). Some studies have revealed that a diet low in fibre is closely associated with increased burdens of diseases such as diabetes mellitus, stroke, colon and rectum cancer (CRC), and ischemic heart disease (IHD)(Reference Threapleton, Greenwood and Evans3,Reference Veronese, Solmi and Caruso4) .
Dietary fibre, an edible part of plant food and fruits that is not digestible or absorbable, is considered beneficial to human health and an important component in a healthy diet. The Global Burden of Disease (GBD) Study showed that a diet low in fibre is closely associated with the burden of IHD and CRC(1). Epidemiological evidence has shown that a 10 g/d increase in dietary fibre intake reduces the IHD risk by 15 % and the CRC risk by 13 %(Reference Crowe, Key and Appleby5,Reference Murphy, Norat and Ferrari6) . IHD is one of the leading NCD, and several studies have shown that the risk of IHD could be decreased by reducing blood pressure and serum cholesterol levels through the intake of plenty of dietary fibre(Reference Brown, Rosner and Willett7,Reference Streppel, Arends and van 't Veer8) . Moreover, dietary fibre may reduce the disease burden imposed by CRC through several complex mechanisms, such as increasing the volume of faeces, decreasing the concentration of faecal carcinogens and reducing exposure of the colorectum to carcinogens by shortening the time required for faeces to pass through the intestine(Reference Lipkin, Reddy and Newmark9). In addition, through bacterial fermentation, dietary fibre produces anticarcinogenic SCFA, which have a positive impact on CRC(Reference Lipkin, Reddy and Newmark9). Dietary fibre may eliminate several environmental pathogens related to IHD and CRC by promoting the activity of several enzymes (e.g. glutathione S-transferase, cytochrome P450 and dihydrouracil dehydrogenase). Evidence from four studies showed that the relative risk for stroke was 0·74 in the highest quintile of dietary fibre group compared with the lowest quintile group(Reference Steffen, Jacobs and Stevens10–Reference Mozaffarian, Kumanyika and Lemaitre13). Moreover, several prospective studies indicate that the intake of a high-fibre diet reduces the prevalence of diabetes. The underlying mechanisms are associated with reductions in postprandial glycemia and insulinemia and the enhancement of insulin sensitivity(Reference Sylvetsky, Edelstein and Walford14,Reference Weickert, Mohlig and Schofl15) .
According to the GBD Study 2017, dietary risk factors contribute to 11 million (95 % uncertainty interval (UI) (10, 12)) deaths and 255 million (95 % UI (234, 274)) disability-adjusted life-years (DALY). Moreover, 11·8 % of all CRC deaths and 8·6 % of all IHD deaths worldwide are attributable to a diet low in fibre(Reference Threapleton, Greenwood and Evans3). Increasing attention has been paid to diets low in fibre as an important dietary risk factor worldwide. However, the burden of NCD attributable to diets low in fibre has not been systematically estimated. In our study, we examined age-standardised mortality rates (ASMR), age-standardised rate of DALY (ASDR), and age-standardised years lived with disability (YLD) of IHD, stroke, CRC, and diabetes mellitus attributable to a diet low in fibre across 204 countries and territories from 1990 to 2019. Additionally, we calculated the estimated annual percentage change (EAPC) of ASMR to estimate its change trend from 1990 to 2019 with the linear regression model(Reference Bu, Xie and Liu16) and explored the relationship between sociodemographic index (SDI) and ASMR, and ASDR attributable to diets low in fibre using a Gaussian process regression(Reference Wang, Hu and Liu17). The results would provide useful information to help develop effective health-promoting strategies (e.g. guidance through public policy and lifestyle advocacy in specific regions, community-based intervention strategies to change the dietary habits of specific populations, etc.) to reduce the disease burden related to a diet low in fibre in different regions in the future.
A diet low in fibre is one of the risk factors in the dataset of the GBD Study 2019, a multinational collaborative research programme to estimate disease burdens in different regions and countries(18,19) . The GBD Study is updated annually, representing a persistent effort and providing an appropriate data source for consistent comparisons of disease burdens from 1990 to 2019 by age and sex in different locations. Moreover, standard epidemiological measures, such as incidence, prevalence, and death rates, and summary measures of health, such as DALY, YLD, and years of life lost prematurely (YLL), are provided in the GBD dataset. DALY, YLL and YLD are estimated from life tables, estimates of prevalence and disability weights. All data sources can be acquired via the GBD Compare website (http://ghdx.healthdata.org/gbd-results-tool), and all input data are identified via the Global Health Data Exchange website (https://ghdx.healthdata.org/). The study was performed in compliance with the Guidelines for Accurate and Transparent Health Estimates Reporting (GATHER) guidelines for reporting health estimates(18). Details of the general methodology used in the GBD Study have been extensively described elsewhere(20,21) . The comparative risk assessment, an important analytical method, was used to gather data and estimate each risk factor's relative contribution to disease burden(18,22) . Then the study used Cause of Death Ensemble model (CODEm), a type of Bayesian geospatial regression analysis, and 95 % UI to estimate the burden of disease attributable to four levels of eighty-seven environmental, occupational, metabolic and behavioural risk factors(19,Reference Foreman, Lozano and Lopez23) . In brief, first, the GBD Study determined the relative risk value of the risk and outcome after the correlation was confirmed by referencing meta-analysis and literature. Second, the mean exposure level of the risk was estimated using Bayesian meta-regression model (DisMod-MR 2.1) and spatiotemporal Gaussian process regression model (ST-GPR) based on population-based survey or report. Third, the theoretical minimum risk exposure level (TMREL) and population-attributable fraction (PAF) were determined. The PAF was calculated using the special formula:
$${\rm{PA}}{{\rm{F}}_{{\rm{oasct}}}} = {{\int_{x = 1}^u {R{R_{oas}}(x){P_{asct}}(x)dx - R{R_{oas}}({\rm{TMREL}})} } \over {\int_{x = l}^u {R{R_{oas}}(x){P_{asct}}(x)dx} }},$$
where RR oas(x) was the relative risk as a function of exposure level (x) for diet low in fibre, cause (o), age group (a) and sex (s)(18). Pasct (x) was the distribution of exposure of a diet low in fibre according to age group (a), sex (s), country (c) and year (t). The lowest level of observed exposure (l) and the highest level of observed exposure (u) were described in the denominator. Finally, the above values were used to estimate the disease burden attributable to a diet low in fibre. The study used misclassification correction, garbage code redistribution and noise reduction algorithms to minimise heterogeneity, bias, or confounding and improve comparability(1,18,19) . UI were calculated by 1000 draw-level estimates for each parameter and could reflect measurement errors in the presence of missing data(18).
Definitions of a diet low in fibre and associated outcomes
A diet low in fibre was defined as an average daily consumption of less than 23·5 g/d of fibre derived from all sources, including fruits, grains, vegetables, legumes and pulses(1). Across the GBD surveys, the definition of a diet low in fibre was standardised, and the exposure level was adjusted for a 2000 kcal/d diet using a residual method(1). Each outcome of a diet low in fibre was also standardised. According to the WHO definition, stroke contains three separate subcategories, including ischemic stroke, intracerebral hemorrhage and subarachnoid hemorrhage(Reference Tolonen, Mahonen and Asplund24). IHD was defined as I20 to I25, diabetes as E10–E14 and CRC as C18–C21 according to the International Statistical Classification of Diseases, Tenth Revision (ICD-10)(25).
In this study, ASMR, ASDR and the age-standardised YLD rates with 95 % UI were calculated to evaluate the burden of disease attributable to a diet low in fibre. We used age-standardised rates (ASR) (per 100 000 population) and EAPC with 95 % CI in the ASMR, ASDR and age-standardised YLD rate to reflect the changes in trends from 1990 to 2019. The ASR was calculated with the specific formula:
$$ASR = {{\sum\nolimits_{i = 1}^A {aiwi} } \over {\sum\nolimits_{i = 1}^A {wi} }} \times 10,000,$$
where ai represents the specific age ratio and wi represents the number of persons (or weight)(Reference Chen, Zhang and Liu26). In the study, we applied EAPC, an indicator that assessed trends in ASR over time, to estimate the trend of ASMR attributable to diet low in fibre. The natural logarithm of ASR was assumed to conform to linear over time, then the ASR was input into the regression model: ln (ASR) = α + βX + ϵ, where X is calendar year and ϵ is the error term. Then EAPC was calculated with the specific formula 100× (exp(β)-1), and the 95 % CI was obtained from the linear regression model(Reference Hankey, Ries and Kosary27). In our study, the ASMR attributable to a diet low in fibre was considered to be on the increase if the lower boundary of 95 % CI was higher than zero. Conversely, if the upper boundary of 95 % CI was lower than zero, the ASMR was deemed to be decreasing. Otherwise, the ASMR was considered to be stable(Reference Chen, Zhang and Liu26). In addition, Gaussian process regression and Loess smoother models were used to explore the relation between SDI and ASMR, and ASDR is attributable to a diet low in fibre(1).
Global disease burden attributable to a diet low in fibre
Although the death number, DALY and YLD increased globally, the ASMR, ASDR and age-standardised YLD rate attributable to a diet low in fibre decreased from 1990 to 2019. The ASMR declined from 14·84 (95 % UI (8·28, 21·43)) to 7·74 (95 % UI (4·37, 11·32)) for both sexes, with an EAPC of −2·39 (95 % CI (−2·54, −2·24)) in 1990–2019 (Table 1). The ASDR declined from 331·12 (95 % UI (192·52, 473·01)) to 186·89 (95 % UI (111·11, 268·42)) for both sexes, with an EAPC of −2·10 (95 % CI (−2·25, −1·94)) (see online Supplemental Table S1). The age-standardised YLD rate showed a downward trend similar to those for the ASMR and ASDR, declining from 24·95 (95 % UI (13·69, 37·72)) to 22·08 (95 % UI (11·72, 34·33)), with an EAPC of −0·45 (95 % CI (−0·49, −0·41)) from 1990–2019 (see online Supplemental Table S2).
Table 1 The death cases and age-standardised mortality rates attributable to a diet low in fibre in 1990, 2019, and its temporal trends from 1990 to 2019 by sex, SDI and GBD regions
GBD, Global Burden of Disease; SDI, sociodemographic index; UI, uncertainty interval; ASMR, age-standardised mortality rate; EAPC, estimated annual percentage change; CI, confidence interval.
Globally, the ASMR and ASDR in males were higher than those in females in both 1990 and 2019. The ASMR attributable to a diet low in fibre decreased from 17·16 (95 % UI (9·72, 24·71)) to 9·20 (95 % UI (5·29, 13·50)), with an EAPC of −2·24 (95 % CI (−2·38, −2·11)) in males and from 12·82 (95 % UI (7·24, 18·62)) to 6·44 (95 % UI (3·60, 9·36)), with an EAPC of −2·58 (95 % CI (−2·74, −2·42)) in females from 1990 to 2019 (Table 1). The ASDR decreased from 394·72 (95 % UI (225·41, 562·68)) to 228·85 (95 % UI (135·57, 330·26)) in males and from 271·65 (95 % UI (156·08, 388·80)) to 146·92 (95 % UI (86·56, 208·53)) for females from 1990 to 2019 (see online Supplemental Table S1). However, the age-standardised YLD rate attributable to a diet low in fibre in males was lower than that in females in both 1990 and 2019. The age-standardised YLD rate in males and females declined from 24·41 (95 % UI (13·68, 36·86)) to 22·05 (95 % UI (11·86, 34·07)), with an EAPC of −0·37 (95 % CI (−0·41, −0·33)), and from 25·45 (95 % UI (13·68, 39·00)) to 22·10 (95 % UI (11·63, 34·33)), with an EAPC of −0·52 (95 % CI (−0·57, −0·47)), respectively (see online Supplemental Table S2).
The burden of disease attributable to a diet low in fibre increased with age, and older people had the highest mortality rates (Fig. 1). The mortality rates attributable to a diet low in fibre in the 70–74, 75–79, 80–84, 85–89, 90–95 and 95 plus age groups showed downward trends from 1990 to 2019. The trends of IHD and stroke mortality rates attributable to a diet low in fibre were similar to the trend of the total burden of disease, while those of CRC and diabetes mellitus were stable from 1990 to 2019.
Fig. 1 Age-specific rate of deaths due to a diet low in fibre for males and females from 1990 to 2019
Disease burden attributable to a diet low in fibre in different sociodemographic index regions
All ASMR and ASDR attributable to a diet low in fibre showed a downward trend in different SDI regions from 1990 to 2019. The high-SDI region had the lowest ASMR, at 4·64, (95 % UI (2·53, 6·76)), and ASDR, at 105·06 (95 % UI (60·80, 149·92)), while low-middle-SDI region had the highest ASMR, at 12·67 (95 % UI (7·81, 17·96)), and ASDR, at 307·58 (95 % UI (191·05, 436·82)) in 2019. From 1990 to 2019, the EAPC in the ASMR attributable to a diet low in fibre were lower in the high-SDI region (−3·67, 95 % CI (−3·82, −3·53)) and high-middle-SDI region (−3·21, 95 % CI (−3·64, −2·78)) than in the middle-SDI region (−2·14, 95 % CI (−2·30, −1·97)), low-middle-SDI region (−1·45, 95 % CI (−1·60, −1·31)) and low-SDI region (−0·85, 95 % CI (−1·09, −0·61)) (Table 1). As shown in Supplemental Table S1, similar trends were observed for the ASDR in the different SDI regions. Intriguingly, the age-standardised YLD rate attributable to a diet low in fibre had different change patterns across the five SDI regions. In 2019, the age-standardised YLD rates in the middle- and low-middle-SDI regions were 23·38 (95 % UI (12·69, 35·58)) and 26·80 (95 % UI (14·65, 40·32)), respectively, which were higher than those in the high-SDI region (22·47, 95 % UI (11·75, 35·29)), low-SDI region (18·61, 95 % UI (9·46, 28·81)) and high-middle-SDI region (17·04, 95 % UI (8·72, 27·10)). From 1990 to 2019, the EAPC in the high- and low-SDI regions were 0·23 (95 % CI (0·10, 0·36)) and 0·21 (95 % CI (0·12, 0·31)), respectively, which were higher than those in the high-middle-SDI region (−0·89, 95 % CI (−1·05, −0·73)), middle-SDI region (−0·93, 95 % CI (−0·99, −0·87)) and low-middle-SDI region (−0·16, 95 % CI (−0·20, −0·11)) (see online Supplemental Table S2). However, upward trends of the age-standardised YLD rates were observed in the high- and low-SDI regions. Coincidentally, the summary exposure value of a diet low in fibre decreased from 1990 to 2019, and its trend was consistent with those of the ASMR and ASDR in different SDI regions (see online Supplemental Fig. S1). As shown in Fig. 2(a) and (b), the ASMR and ASDR initially showed an uptrend followed by a downward trend as the SDI increased. Moreover, the relationship of the ASMR with the SDI was similar to that of the ASDR with the SDI.
Fig. 2 ASMR and ASDR attributable to a diet low in fibre across twenty-one GBD regions by SDI for both sexes combined, 1990–2019. (a) ASMR; (b) ASDR. ASMR, age-standardised mortality rate; ASDR, age-standardised rate of disability-adjusted life-years (DALY); GBD, Global Burden of Disease; SDI, sociodemographic index
In summary, the ASMR and ASDR of the overall disease burden attributable to a diet low in fibre decreased in all five SDI regions from 1990 to 2019, and those of IHD and stroke showed similar trends (Fig. 3(a) and (b)). Although the ASMR and ASDR of CRC in the high-SDI region decreased, they were still higher than those in the other four SDI regions from 1990 to 2019. In addition, the ASMR and ASDR of CRC and diabetes mellitus attributable to a diet low in fibre in the high-middle-, middle-, low-middle- and low-SDI regions were stable from 1990 to 2019. However, the age-standardised of YLD rates due to diabetes mellitus attributable to a diet low in fibre in the five SDI regions showed uptrends from 1990 to 2019 (Fig. 3(c)).
Fig. 3 ASMR, ASDR and age-standardised of YLD rates attributable to a diet low in fibre by SDI regions from 1990 to 2019. (a) ASMR; (b) ASDR; (c) age-standardised of YLD rates. ASMR, age-standardised mortality rate; ASDR, age-standardised rate of disability-adjusted life-years (DALY); YLD, year lived with disability; SDI, sociodemographic index
Disease burden attributable to a diet low in fibre in different Global Burden of Disease regions and countries
The ASMR of the disease burdens caused by a diet low in fibre in Southern sub-Saharan Africa and Central sub-Saharan Africa increased, although they decreased in most other GBD regions. The ASMR in Southern sub-Saharan Africa increased from 4·07 (95 % UI (2·08, 6·34)) to 4·60 (95 % UI (2·59, 6·90)), and that in Central sub-Saharan Africa increased from 7·46 (95 % UI (3·64, 11·90)) to 9·34 (95 % UI (4·69, 15·25)) from 1990 to 2019. The EAPC in the ASMR in Australasia was the lowest, with an ASMR decrease from 13·98 (95 % UI (7·12, 20·75)) to 4·01 (95 % UI (2·20, 5·87)), followed by Tropical Latin America (−3·97, 95 % UI (−4·23, −3·72)), High-income North America (−3·61, 95 % UI (−3·80, −3·42)) and Western Europe (−3·59, 95 % UI (−3·77, −3·41)) (Table 1). The ASDR attributable to a diet low in fibre in Central sub-Saharan Africa increased from 174·66 (95 % UI (87·00, 278·72)) to 213·16 (95 % UI (108·91, 341·76)), with an EAPC of 0·65 (95 % CI (0·12, 1·17)). The EAPC in the ASDR in Australasia was −4·34 (95 % CI (−4·50, −4·18)), which was lower than those in other GBD regions, and the ASDR in Australasia decreased from 397·20 (95 % UI (229·07, 561·62)) to 148·02 (95 % UI (85·35, 211·57)) from 1990 to 2019 (see online Supplemental Table S1). It is worth mentioning that the trends of the age-standardised YLD rates attributable to a diet low in fibre were different from those of the ASMR and ASDR. The age-standardised YLD rates in Central Latin America, Southern Latin America, High-income Asia Pacific, North Africa, the Middle East, Southern sub-Saharan Africa, Central sub-Saharan Africa and Western Europe increased from 1990 to 2019. Among the above areas, the EAPC in Central sub-Saharan Africa was 1·49 (95 % CI (1·07, 1·91)), which was the highest, with an increase in the age-standardised YLD rate from 13·26 (95 % UI (6·39, 22·16)) to 20·90 (95 % UI (9·83, 34·40)) from 1990 to 2019, followed by High-income Asia Pacific (0·90, 95 % UI (0·83, 0·97)), Central Latin America (0·71, 95 % UI (0·62, 0·81)), North Africa and the Middle East (0·45, 95 % UI (0·41, 0·49)), Western Europe (0·29, 95 % UI (0·23, 0·36)) and Southern Latin America (0·24, 95 % UI (0·11, 0·36)). In contrast, the age-standardised YLD rate in Western sub-Saharan Africa decreased from 8·28 (95 % UI (4·16, 13·63)) to 4·59 (95 % UI (2·49, 7·20)), with an EAPC of −2·45 (95 % CI (−2·76, −2·13)). In addition, the age-standardised YLD rates in regions other than the above-mentioned areas showed downtrends from 1990 to 2019 (see online Supplemental Table S2).
Similar trends were observed for the percent change of ASMR attributable to a diet low in fibre in different GBD regions from 1990 to 2019 (Fig. 4(a)). As shown in Fig. 4(b), ASMR of CRC due to a diet low in fibre showed a decreasing trend in most GBD regions, and the High-income North America had the largest percent decline from 1900 to 2019, followed by Australasia, East Asia and so on. However, ASMR of diabetes mellitus attributable to a diet low in fibre displayed a different pattern. Among the twenty-one GBD regions, Central Asia, Southern sub-Saharan Africa and Eastern Europe showed a marked percent increase in ASMR (Fig. 4(c)). The ASMR of IHD and stroke due to a diet low in fibre were decreased in most GBD regions, which were similar to the changing patterns of those of all diseases (Fig. 4(d) and (e)). In addition, the trends of the summary exposure values in different GBD regions, except High-income Asia Pacific, were consistent with the changes in the ASMR from 1990 to 2019 (see online Supplemental Fig. S2).
Fig. 4 Percent change in ASMR attributable to a diet low in fibre across twenty-one GBD regions by diseases for both sexes combined, 1990–2019. (a) All causes; (b) Colon and rectum cancer; (c) Diabetes mellitus; (d) Ischemic heart disease; (e) Stroke. ASMR, age-standardised mortality rate; GBD, Global Burden of Disease
At the country level, the EAPC in the ASMR from 1990 to 2019 was the lowest in Cuba, followed by Equatorial Guinea, Estonia and Peru, whereas the EAPC for the Democratic Republic of the Congo was the highest. Further analyses of the EAPC in the ASMR between males and females showed that the EAPC in males were higher than those in females in China, Japan, Kuwait and several other countries (see online Supplemental Table S3). Unlike the trend of the ASMR, the YLD trend for Burundi increased, with the highest EAPC, and similar upward trends were observed for Lebanon, the Democratic Republic of the Congo and so on (see online Supplemental Table S4).
In this study, the trend of the NCD burden attributable to a diet low in fibre was estimated systematically from 1990 to 2019 using GBD Study 2019 data. Globally, the ASMR and ASDR caused by a diet low in fibre declined in males and females from 1990 to 2019. It is worth mentioning that the burden of disease in males was more serious than that in females despite the declining trends. In addition, the ASMR declined in all GBD regions except Southern sub-Saharan Africa and Central sub-Saharan Africa. Different patterns were observed for YLD attributable to a diet low in fibre in several GBD regions, with increases from 1990 to 2019 and a lower value in males than in females. Compared with the trends of the ASMR due to IHD and stroke, the trends of the ASMR due to CRC and diabetes mellitus attributable to a diet low in fibre were more stable from 1990 to 2019. Further analyses of the relationship between the summary exposure value and ASMR in different SDI and GBD regions showed that the changes were consistent.
For the burden of disease attributable to a diet low in fibre, all-age mortality and DALY increased from 1990 to 2019 in both males and females, and the corresponding ASR also declined. This may result from population growth and the ageing of the population. In this study, we found that the burden of disease caused by a diet low in fibre in males in 1990 and 2019 was higher than that in females, and older individuals had a higher burden than younger people. Evidence has shown that males are more likely to consume unhealthy foods, and females tend to have better dietary patterns and consume more fibre(Reference Imamura, Micha and Khatibzadeh28). Although older individuals had a higher intake of fibre than younger individuals, they had a higher burden of disease attributable to a diet low in fibre, which might strongly be associated with the time lag between fibre intake and health outcomes. In addition, energy intake, which varies by sex, age group and physical activity level, may play a critical role in the mechanism driving the difference in the burden between older and younger individuals(Reference Wang, Wang and Zhang29). Indeed, males and older individuals are more likely to ignore the correlation between diet and health outcomes. Other findings have revealed that these age differences in the burden may result from the higher mortality rates of cancer and CVD in males under 70 years old(Reference Alabas, Gale and Hall30,Reference Kim, Lim and Moon31) . Females had a low ASMR and ASDR attributable to a diet low in fibre, which may be closely related to oestrogen before menopause, as oestrogens have a known antioxidant and antiapoptotic effect on cardiomyocytes in ischaemia(Reference Morselli, Santos and Criollo32). Therefore, early dietary interventions for younger males and cost-effective intervention strategies for older males are needed to reduce the burden of disease attributable to a diet low in fibre.
Geographically, the high- and high-middle-SDI regions had lower burdens of disease attributable to a diet low in fibre than the other regions. The correlations of the ASMR and ASDR with the SDI showed similar trends. As revealed in many other studies, socio-economic status is a major determinant of health. Individuals in high-SDI regions with higher socio-economic status tend to have healthier dietary patterns and consume healthier foods, such as wholegrains, fruits and vegetables, which are rich in fibre, than those in lower-SDI regions(Reference Allen, Williams and Townsend33–Reference Giskes, Avendano and Brug35). The corresponding correlation between the summary exposure value and the ASMR in different regions supports the notion that people in high-SDI regions consume more fibre than those in low-SDI regions. In addition, data from fifty-two countries showed that urban areas with increasing income levels consume more fruits and vegetables(Reference Hall, Moore and Harper36). The explanation for these associations is that people in low- and middle-income countries may lack knowledge about the health benefits of fibre and have limited access to fresh food markets due to transportation limitations(Reference Salehi, Eftekhar and Mohammad37,Reference Ramirez-Silva, Rivera and Ponce38) . In addition, many countries in the low-SDI region produce fruits and vegetables that provide large amounts of dietary fibre for export rather than local consumption, which is also an important reason for the increased exposure to a low-fibre diet(Reference Satheannoppakao, Aekplakorn and Pradipasen39).
Poor dietary habit is another critical factor resulting in an increased disease burden. People with low-income levels in low-SDI regions have less access to healthy foods and are more likely to have poor dietary habits. In contrast, people in the high-SDI region tend to have healthier eating habits and lower burdens of disease attributable to a diet low in fibre, probably due to greater accessibility to fresh fruits and vegetables, early health education, and high awareness of disease prevention.
The analyses by GBD regions and countries showed that the disease burdens in Southern sub-Saharan Africa and Central sub-Saharan Africa increased; the ASMR for the Democratic Republic of Congo increased the most, with the highest EAPC. The causes of this disparity may be multifaceted, region-specific and associated with socio-economic factors. For example, food prices are relatively high and dietary quality is relatively low in Northwestern sub-Saharan Africa(Reference Lock, Stuckler and Charlesworth40). In addition, domestic and international conflicts in some countries may play an important role in dietary quality. For example, conflicts in the Democratic Republic of the Congo (1996–2008) and neighbouring countries impeded food production and trade, which may be an important explanation for poor dietary quality.
A previous study described the change pattern of the burden of IHD and CRC attributable to a diet low in fibre in China. The results indicated that China has a large and growing burden of IHD and CRC attributable to a diet low in fibre, especially in males and older adults. The fraction of deaths caused by IHD and CRC attributable to a diet low in fibre elevated from 1·4 % to 2·1 % from 1990 to 2017 in China(Reference Wang, Zhang and Zheng41). In our study, a different change pattern of the disease burden caused by a low-fibre diet is observed at a global level, with a decreasing trend of IHD and CRC burden worldwide. It is worth noting that dietary fibre consumption is currently low globally, not just in several specific regions. The dietary fibre intake in some developed countries such as the USA, Canada, United Kingdom and Japan is lower than 25–35 g, which is a daily intake recommended by most countries(Reference Stephen, Champ and Cloran42). Similarly, in some developing countries such as China, although adults consume more dietary fibre than in the above-mentioned developed countries, their consumption is still lower than the required intake, and China remains having a high burden of disease attributed to a diet low in fibre(2). To reduce disease burden due to diet low in fibre in different regions, population-level dietary interventions are needed, especially for low-SDI regions. For example, mass media and educational campaigns may increase the intake of dietary fibre by raising public awareness of a healthy diet(Reference Zhang, Giabbanelli and Arah43). Moreover, appropriate food pricing strategies minimising taxes for high-fibre foods may also be helpful(Reference Afshin, Penalvo and Del Gobbo44). In addition, more appropriate public health strategies based on dietary habits and the correlation with disease burden should be proposed in different regions. Recently, the Chinese government formulated the Healthy China Action 2019–2030 to deal with the increasing burden of NCD (http://www.gov.cn/xinwen/2019-07/15/content_5409694.htm). Additionally, the 2020–2025 Dietary Guidelines for Americans (DGA) were released to reduce the increasing risk of NCD due to diet low in fibre in America(Reference Thompson45).
In summary, we conducted a systematic analysis of data on the burden of NCD attributable to a diet low in fibre using data from the GBD database from 1990 to 2019. It is worth noting that the GBD Study utilises PAF to estimate the disease burden attributable to a diet low in fibre. PAF represents the estimated fraction of all cases that would not have occurred if there had been no exposure, which allows a causal interpretation(Reference Mansournia and Altman46). Thus, the disease burden present in our study is caused by, rather than just associated with, a diet low in fibre. In this study, we analysed comprehensive and up-to-date data on the burden of disease attributable to a diet low in fibre by year, age, SDI, GBD region and country. Moreover, we attempted to analyse and explain the possible reasons behind these phenomena. However, our study has several limitations. Similar methodological limitations as those in other GBD studies existed in the present study(19,47,Reference Li, Deng and Zhou48) . First, the data collected from different regions and countries may have large discrepancies in terms of data quality, accuracy, comparability and degrees of missing data. Thus, certain degrees of deviation in the estimated disease burden is inevitable, even though many statistical approaches have been applied to adjust the data as much as possible. Second, the use of a universal effect size across countries for a given age-sex group could be another shortfall of this GBD Study, because diet low in fibre could have different effects on NCD outcomes across different population subgroups (e.g. urban v. rural populations). Third, the dietary risks in the GBD dataset were not strictly classified, and the definitions and measurements of dietary risk factors are different around the world. In addition, many differently composed foods are consumed in real life, making an accurate division into distinct food or nutrient groups impossible. Therefore, some degrees of measurement errors are inevitable in GBD Study(Reference Miyamoto, Kawase and Imai49). Moreover, interrelations between dietary factors may affect the estimated disease burden attributable to a single dietary component. In terms of the limitations existed, further well-designed large-scale epidemiological studies with accurately documented amounts and types of food products as well as individual-level variables are needed to get a deeper understanding of the NCD burden induced by a diet low in fibre. Furthermore, intervention studies by giving participants foods containing different amounts of fibre are of particular importance to further explore the real effect size of a low-fibre diet on the risk of NCD.
The study demonstrates the significant disease burden attributable to a diet low in fibre over the past two decades. Though the global trend has been decreasing, the burdens of disease attributable to a diet low in fibre increase in Southern sub-Saharan Africa and Central sub-Saharan Africa and countries such as the Democratic Republic of the Congo. In addition, the burden caused by diabetes mellitus attributable to a diet low in fibre increases in Central Asia, Southern sub-Saharan Africa and Eastern Europe. Multisectoral efforts and interventions that focus on increasing dietary fibre consumption are needed to reduce the risk-attributable disease burden.
Acknowledgements: The authors appreciate the great works by the Global Burden of Disease Study 2019 collaborators. Financial support: This work was supported by grants from the National Science Foundation of China (81970070 to XJ.Z., 82170455 to L.Z.). Authorship: M.Z., Z.C., J.M.Y., G.Z. and Y.Z. designed study, extracted and compiled the data, and wrote the manuscript. M.L.Z., Y.M.L., F.L., J.J.Q., T.S., C.Y., M.M.C., X.H.S., L.F.W. and Y.L. conducted data analyses and assisted the data interpretation. X.J.Z., L.Z. and J.C. assisted the data interpretation and critically reviewed the manuscript. All authors have approved the final version of this paper. Ethics of human subject participation: Not applicable.
For supplementary material accompanying this paper visit https://doi.org/10.1017/S1368980022001987
Ming Zhuo and Ze Chen contributed equally to this work.
GBD 2017 Risk Factor Collaborators (2018) Global, regional, and national comparative risk assessment of 84 behavioural, environmental and occupational, and metabolic risks or clusters of risks for 195 countries and territories, 1990–2017: a systematic analysis for the global burden of disease study 2017. Lancet 392, 1923–1994.CrossRefGoogle Scholar
GBD 2017 Diet Collaborators (2019) Health effects of dietary risks in 195 countries, 1990–2017: a systematic analysis for the global burden of disease study 2017. Lancet 393, 1958–1972.CrossRefGoogle Scholar
Threapleton, DE, Greenwood, DC, Evans, CE et al. (2013) Dietary fibre intake and risk of cardiovascular disease: systematic review and meta-analysis. BMJ 347, f6879.CrossRefGoogle ScholarPubMed
Veronese, N, Solmi, M, Caruso, MG et al. (2018) Dietary fiber and health outcomes: an umbrella review of systematic reviews and meta-analyses. Am J Clin Nutr 107, 436–444.CrossRefGoogle ScholarPubMed
Crowe, FL, Key, TJ, Appleby, PN et al. (2012) Dietary fibre intake and ischaemic heart disease mortality: the European prospective investigation into cancer and nutrition-heart study. Eur J Clin Nutr 66, 950–956.CrossRefGoogle ScholarPubMed
Murphy, N, Norat, T, Ferrari, P et al. (2012) Dietary fibre intake and risks of cancers of the colon and rectum in the European prospective investigation into cancer and nutrition (EPIC). PLoS ONE 7, e39361.CrossRefGoogle Scholar
Brown, L, Rosner, B, Willett, WW et al. (1999) Cholesterol-lowering effects of dietary fiber: a meta-analysis. Am J Clin Nutr 69, 30–42.CrossRefGoogle ScholarPubMed
Streppel, MT, Arends, LR, van 't Veer, P et al. (2005) Dietary fiber and blood pressure: a meta-analysis of randomized placebo-controlled trials. Arch Intern Med 165, 150–156.CrossRefGoogle ScholarPubMed
Lipkin, M, Reddy, B, Newmark, H et al. (1999) Dietary factors in human colorectal cancer. Annu Rev Nutr 19, 545–586.CrossRefGoogle ScholarPubMed
Steffen, LM, Jacobs, DR Jr, Stevens, J et al. (2003) Associations of whole-grain, refined-grain, and fruit and vegetable consumption with risks of all-cause mortality and incident coronary artery disease and ischemic stroke: the atherosclerosis risk in communities (ARIC) study. Am J Clin Nutr 78, 383–390.CrossRefGoogle ScholarPubMed
Liu, S, Manson, JE, Stampfer, MJ et al. (2000) Whole grain consumption and risk of ischemic stroke in women: a prospective study. JAMA 284, 1534–1540.CrossRefGoogle ScholarPubMed
Ascherio, A, Rimm, EB, Hernan, MA et al. (1998) Intake of potassium, magnesium, calcium, and fiber and risk of stroke among US men. Circulation 98, 1198–1204.CrossRefGoogle ScholarPubMed
Mozaffarian, D, Kumanyika, SK, Lemaitre, RN et al. (2003) Cereal, fruit, and vegetable fiber intake and the risk of cardiovascular disease in elderly individuals. JAMA 289, 1659–1666.CrossRefGoogle ScholarPubMed
Sylvetsky, AC, Edelstein, SL, Walford, G et al. (2017) A high-carbohydrate, high-fiber, low-fat diet results in weight loss among adults at high risk of type 2 diabetes. J Nutr 147, 2060–2066.Google ScholarPubMed
Weickert, MO, Mohlig, M, Schofl, C et al. (2006) Cereal fiber improves whole-body insulin sensitivity in overweight and obese women. Diabetes Care 29, 775–780.CrossRefGoogle ScholarPubMed
Bu, X, Xie, Z, Liu, J et al. (2021) Global PM2.5-attributable health burden from 1990 to 2017: estimates from the global burden of disease study 2017. Environ Res 197, 111123.CrossRefGoogle ScholarPubMed
Wang, W, Hu, M, Liu, H et al. (2021) Global burden of disease study 2019 suggests that metabolic risk factors are the leading drivers of the burden of ischemic heart disease. Cell Metab 33, 1943–1956.CrossRefGoogle ScholarPubMed
GBD 2019 Diseases and Injuries Collaborators (2020) Global burden of 369 diseases and injuries in 204 countries and territories, 1990–2019: a systematic analysis for the global burden of disease study 2019. Lancet 396, 1204–1222.CrossRefGoogle Scholar
GBD 2019 Risk Factors Collaborators (2020) Global burden of 87 risk factors in 204 countries and territories, 1990–2019: a systematic analysis for the Global Burden of Disease Study 2019. Lancet 396, 1223–1249.CrossRefGoogle Scholar
GBD 2017 Causes of Death Collaborators (2018) Global, regional, and national age-sex-specific mortality for 282 causes of death in 195 countries and territories, 1980–2017: a systematic analysis for the global burden of disease study 2017. Lancet 392, 1736–1788.CrossRefGoogle Scholar
GBD 2017 DALYs and HALE Collaborators (2018) Global, regional, and national disability-adjusted life-years (DALYs) for 359 diseases and injuries and healthy life expectancy (HALE) for 195 countries and territories, 1990–2017: a systematic analysis for the global burden of disease study 2017. Lancet 392, 1859–1922.CrossRefGoogle Scholar
GBD 2015 Risk Factors Collaborators (2016) Global, regional, and national comparative risk assessment of 79 behavioural, environmental and occupational, and metabolic risks or clusters of risks, 1990–2015: a systematic analysis for the Global Burden of Disease Study 2015. Lancet 388, 1659–1724.CrossRefGoogle Scholar
Foreman, KJ, Lozano, R, Lopez, AD et al. (2012) Modeling causes of death: an integrated approach using CODEm. Popul Health Metr 10, 1.CrossRefGoogle ScholarPubMed
Tolonen, H, Mahonen, M, Asplund, K et al. (2002) Do trends in population levels of blood pressure and other cardiovascular risk factors explain trends in stroke event rates? Comparisons of 15 populations in 9 countries within the WHO MONICA Stroke project. World Health Organization monitoring of trends and determinants in cardiovascular disease. Stroke 33, 2367–2375.CrossRefGoogle ScholarPubMed
GBD 2017 Disease and Injury Incidence and Prevalence Collaborators (2018) Global, regional, and national incidence, prevalence, and years lived with disability for 354 diseases and injuries for 195 countries and territories, 1990–2017: a systematic analysis for the global burden of disease study 2017. Lancet 392, 1789–1858.CrossRefGoogle Scholar
Chen, MM, Zhang, X, Liu, YM et al. (2021) Heavy disease burden of high systolic blood pressure during 1990–2019: highlighting regional, sex, and age specific strategies in blood pressure control. Front Cardiovasc Med 8, 754778.CrossRefGoogle ScholarPubMed
Hankey, BF, Ries, LA, Kosary, CL et al. (2000) Partitioning linear trends in age-adjusted rates. Cancer Causes Control 11, 31–35.CrossRefGoogle ScholarPubMed
Imamura, F, Micha, R, Khatibzadeh, S et al. (2015) Dietary quality among men and women in 187 countries in 1990 and 2010: a systematic assessment. Lancet Glob Health 3, e132–e142.CrossRefGoogle ScholarPubMed
Wang, HJ, Wang, ZH, Zhang, JG et al. (2014) Trends in dietary fiber intake in Chinese aged 45 years and above, 1991–2011. Eur J Clin Nutr 68, 619–622.CrossRefGoogle ScholarPubMed
Alabas, OA, Gale, CP, Hall, M et al. (2017) Sex differences in treatments, relative survival, and excess mortality following acute myocardial infarction: national cohort study using the SWEDEHEART registry. J Am Heart Assoc 6, e007123.CrossRefGoogle ScholarPubMed
Kim, HI, Lim, H & Moon, A (2018) Sex differences in cancer: epidemiology, genetics and therapy. Biomol Ther 26, 335–342.CrossRefGoogle ScholarPubMed
Morselli, E, Santos, RS, Criollo, A et al. (2017) The effects of oestrogens and their receptors on cardiometabolic health. Nat Rev Endocrinol 13, 352–364.CrossRefGoogle ScholarPubMed
Allen, L, Williams, J, Townsend, N et al. (2017) Socioeconomic status and non-communicable disease behavioural risk factors in low-income and lower-middle-income countries: a systematic review. Lancet Glob Health 5, e277–e289.CrossRefGoogle ScholarPubMed
Darmon, N & Drewnowski, A (2008) Does social class predict diet quality? Am J Clin Nutr 87, 1107–1117.CrossRefGoogle ScholarPubMed
Giskes, K, Avendano, M, Brug, J et al. (2010) A systematic review of studies on socioeconomic inequalities in dietary intakes associated with weight gain and overweight/obesity conducted among European adults. Obes Rev 11, 413–429.CrossRefGoogle ScholarPubMed
Hall, JN, Moore, S, Harper, SB et al. (2009) Global variability in fruit and vegetable consumption. Am J Prev Med 36, 402–409.CrossRefGoogle ScholarPubMed
Salehi, L, Eftekhar, H, Mohammad, K et al. (2010) Consumption of fruit and vegetables among elderly people: a cross sectional study from Iran. Nutr J 9, 2.CrossRefGoogle ScholarPubMed
Ramirez-Silva, I, Rivera, JA, Ponce, X et al. (2009) Fruit and vegetable intake in the Mexican population: results from the Mexican national health and nutrition survey 2006. Salud Publica Mex 51, Suppl. 4, S574–S585.Google ScholarPubMed
Satheannoppakao, W, Aekplakorn, W & Pradipasen, M (2009) Fruit and vegetable consumption and its recommended intake associated with sociodemographic factors: Thailand national health examination survey III. Public Health Nutr 12, 2192–2198.CrossRefGoogle ScholarPubMed
Lock, K, Stuckler, D, Charlesworth, K et al. (2009) Potential causes and health effects of rising global food prices. BMJ 339, b2403.CrossRefGoogle ScholarPubMed
Wang, ZQ, Zhang, L, Zheng, H et al. (2021) Burden and trend of ischemic heart disease and colorectal cancer attributable to a diet low in fiber in China, 1990–2017: findings from the global burden of disease study 2017. Eur J Nutr 60, 3819–3827.CrossRefGoogle ScholarPubMed
Stephen, AM, Champ, MM, Cloran, SJ et al. (2017) Dietary fibre in Europe: current state of knowledge on definitions, sources, recommendations, intakes and relationships to health. Nutr Res Rev 30, 149–190.CrossRefGoogle ScholarPubMed
Zhang, D, Giabbanelli, PJ, Arah, OA et al. (2014) Impact of different policies on unhealthy dietary behaviors in an urban adult population: an agent-based simulation model. Am J Public Health 104, 1217–1222.CrossRefGoogle Scholar
Afshin, A, Penalvo, J, Del Gobbo, L et al. (2015) CVD prevention through policy: a review of mass media, food/menu labeling, taxation/subsidies, built environment, school procurement, worksite wellness, and marketing standards to improve diet. Curr Cardiol Rep 17, 98.CrossRefGoogle ScholarPubMed
Thompson, HJ (2021) The dietary guidelines for Americans (2020–2025): pulses, dietary fiber, and chronic disease risk-a call for clarity and action. Nutrients 13, 4034.CrossRefGoogle ScholarPubMed
Mansournia, MA & Altman, DG (2018) Population attributable fraction. BMJ 360, k757.CrossRefGoogle ScholarPubMed
GBD 2017 Stomach Cancer Collaborators (2020) The global, regional, and national burden of stomach cancer in 195 countries, 1990–2017: a systematic analysis for the global burden of disease study 2017. Lancet Gastroenterol Hepatol 5, 42–54.CrossRefGoogle Scholar
Li, N, Deng, Y, Zhou, L et al. (2019) Global burden of breast cancer and attributable risk factors in 195 countries and territories, from 1990 to 2017: results from the global burden of disease study 2017. J Hematol Oncol 12, 140.CrossRefGoogle ScholarPubMed
Miyamoto, K, Kawase, F, Imai, T et al. (2019) Dietary diversity and healthy life expectancy-an international comparative study. Eur J Clin Nutr 73, 395–400.CrossRefGoogle ScholarPubMed
Zhuo et al. supplementary material
File 2 MB
You have Access Open access
No CrossRef data available.
Ming Zhuo (a1) (a2), Ze Chen (a3) (a4), Mao-Lin Zhong (a1), Ye-Mao Liu (a4) (a5), Fang Lei (a4) (a6), Juan-Juan Qin (a4) (a5), Tao Sun (a4) (a5), Chengzhang Yang (a4) (a5), Ming-Ming Chen (a4) (a5), Xiao-Hui Song (a4) (a5), Li-Feng Wang (a1) (a2), Yi Li (a1) (a2), Xiao-Jing Zhang (a4) (a5) (a6), Lihua Zhu (a4) (a5), Jingjing Cai (a4) (a7), Jun-Ming Ye (a1) (a2), Gang Zhou (a8) and Yong Zeng (a9) | CommonCrawl |
Notation and Basic Facts
Direct Proof
Proof by Contraposition
Proof by Contradiction
Proof by Cases
Common Errors when Writing Proofs
Style and Substance in Proofs
In science, evidence is accumulated through experiments to assert the validity of a statement. Mathematics, in contrast, aims for a more absolute level of certainty. A mathematical proof provides a means for guaranteeing that a statement is true. Proofs are very powerful and are in some ways like computer programs. Indeed, there is a deep historic link between these two concepts that we will touch upon in this course — the invention of computers is intimately tied to the exploration of the idea of a mathematical proof about a century ago.
So what types of "computer science-related" statements might we want to prove? Here are two examples: (1) Does program \(P\) halt on every input? (2) Does program \(P\) correctly compute the function \(f(x)\), i.e. does it output \(f(x)\) on input \(x\), for every \(x\)? Note that each of these statements refers to the behavior of a program on infinitely many inputs. For such a statement, we can try to provide evidence that it is true by testing that it holds for many values of \(x\). Unfortunately, this does not guarantee that the statement holds for the infinitely many values of x that we did not test! To be certain that the statement is true, we must provide a rigorous proof.
So what is a proof? A proof is a finite sequence of steps, called logical deductions, which establishes the truth of a desired statement. In particular, the power of a proof lies in the fact that using finite means, we can guarantee the truth of a statement with infinitely many cases.
More specifically, a proof is typically structured as follows. Recall that there are certain statements, called axioms or postulates, that we accept without proof (we have to start somewhere). Starting from these axioms, a proof consists of a sequence of logical deductions: simple steps that apply the rules of logic. This results in a sequence of statements where each successive statement is necessarily true if the previous statements were true. This property is enforced by the rules of logic. Each statement follows from the previous statements. These rules of logic are a formal distillation of laws that were thought to underlie human thinking. They play a central role in the design of computers, starting with digital logic design or the fundamental principles behind the design of digital circuits. At a more advanced level, these rules of logic play an indispensable role in artificial intelligence, one of whose ultimate goals is to emulate human thought on a computer.
Organization of this Note
We begin in Notation and Basic Facts by setting notation and stating basic mathematical facts used throughout this note. We next introduce four different proof techniques: Direct Proof, Proof by Contraposition, Proof by Contradiction, and Proof by Cases. We then briefly discuss common pitfalls in and stylistic advice for proofs (Common Errors when Writing Proofs and Style and Substance in Proofs, respectively). We close with Exercises.
In this note, we use the following notation and basic mathematical facts. Let \(\mathbb{Z}\) denote the set of integers, i.e. \(\mathbb{Z}=\{\ldots,-2,-1,0,1,2,\ldots\}\), and \(\mathbb{N}\) the set of natural numbers \(\mathbb{N}=\{0,1,2,\ldots\}\). Recall that the sum or product of two integers is an integer, i.e. the set of integers is closed under addition and multiplication. The set of natural numbers is also closed under addition and multiplication.
Given integers \(a\) and \(b\), we say that \(a\) divides \(b\) (denoted \(a \mid b\)) iff there exists an integer \(q\) such that \(b=aq\). For example, \(2 \mid 10\) because there exists an integer \(q=5\) such that \(10=5\cdot 2\). We say a natural number \(p\) is prime if it is divisible only by \(1\) and itself.
Finally, we use the notation \(:=\) to indicate a definition. For example, \(q:=6\) defines variable \(q\) as having value \(6\).
With the language of propositional logic from Note 0 under our belts, we can now discuss proof techniques, and the real fun can begin. Are you ready? If so, here is our first technique, known as a direct proof. Throughout this section, keep in mind that our goal is give clear and concise proofs. Let's begin with a very simple example.
Theorem 1
For any \(a,b,c\in \mathbb{Z}\), if \(a \mid b\) and \(a \mid c\), then \(a \mid (b+c)\).
Sanity check! Let \(P(x, y)\) denote "\(x \mid y\)". Convince yourself that the statement above is equivalent to \((\forall a,b, c \in \mathbb{Z}) (P(a,b) \land P(a, c)) \implies P(a,b+c))\).
At a high level, a direct proof proceeds as follows. For each \(x\), the proposition we are trying to prove is of the form \(P(x) \implies Q(x)\). A direct proof of this starts by assuming \(P(x)\) for a generic value of \(x\) and eventually concludes \(Q(x)\) through a chain of implications:
Goal: To prove \(P \implies Q\).
Approach: Assume \(P\)
\(\vdots\)
Therefore \(Q\)
Proof of Theorem 1. Assume that \(a \mid b\) and \(a \mid c\), i.e. there exist integers \(q_1\) and \(q_2\) such that \(b=q_1a\) and \(c=q_2a\). Then, \(b+c=q_1a+q_2a=(q_1+q_2)a\). Since the \(\mathbb{Z}\) is closed under addition, we conclude that \((q_1+q_2)\in\mathbb{Z}\), and so \(a \mid (b+c)\), as desired. \(\square\)
Easy as pie, right? But wait, earlier we said Theorem 1 was equivalent to \((\forall a,b,c\in\mathbb{Z})\;(P(a,b)\wedge P(a,c))\implies P(a,b+c))\); where in the proof above did we encounter the \(\forall\) quantifier? The key insight is that the proof did not assume any specific values for \(a\), \(b\), and \(c\); indeed, our proof holds for arbitrary \(a,b,c\in\mathbb{Z}\)! Thus, we have indeed proven the desired claim.
Sanity check! Give a direct proof of the following statement: For any \(a,b, c \in \mathbb{Z}\), if \(a \mid b\) and \(a\mid c\), then \(a \mid (b−c)\).
Let's try something a little more challenging.
Let \(0<n<1000\) be an integer. If the sum of the digits of \(n\) is divisible by \(9\), then \(n\) is divisible by \(9\).
Observe that this statement is equivalent to \[(\forall n\in\mathbb{Z}^+)(n <1000) \implies (\text{sum of $n$'s digits divisible by $9$}\implies \text{$n$ divisible by $9$}),\] where \(\mathbb{Z}^+\) denotes the set of positive integers, \(\{1,2,\ldots\}\). Now the proof proceeds similarly — we start by assuming, for a generic value of \(n\), that the sum of \(n\)'s digits is divisible by \(9\). Then we perform a sequence of implications to conclude that \(n\) itself is divisible by \(9\).
Proof of Theorem 2. Let \(n\) in decimal be written as \(n=abc\), i.e. \(n=100a+10b+c\). Assume that the sum of the digits of \(n\) is divisible by \(9\), i.e. \[\exists k\in\mathbb{Z} \quad\text{such that}\quad a+b+c = 9k.\](1) Adding \(99a + 9b\) to both sides of Equation 1, we have \[100a+10b+c = n=9k + 99a + 9b = 9(k+11a+b).\] We conclude that \(n\) is divisible by \(9\). \(\square\)
Is the converse of Theorem 2 also true? Recall that the converse of \(P\implies Q\) is \(Q\implies P\). The converse of Theorem 2 says that for any integer \(0<n<1000\), if \(n\) is divisible by \(9\), then the sum of the digits of \(n\) is divisible by \(9\).
Theorem 3 (Converse of Theorem 2)
Let \(0<n<1000\) be an integer. If \(n\) is divisible by \(9\), then the sum of the digits of \(n\) is divisible by \(9\).
Proof. Assume that \(n\) is divisible by \(9\). We use the same notation for the digits of \(n\) as we used in Theorem 2's proof. We proceed as follows. \[\begin{align*} n\text{ is divisible by }9 &\implies n=9l\quad\text{ for }l \in \mathbb{Z}\\ &\implies 100a + 10b + c = 9l\\ &\implies 99a+9b + (a+b+c) = 9l\\ &\implies a+b+c = 9l-99a-9b\\ &\implies a+b+c = 9(l-11a-b)\\ &\implies a+b+c = 9k \quad\text{ for } k=l-11a-b\in\mathbb{Z}.\end{align*}\] We conclude that \(a+b+c\) is divisible by \(9\). \(\square\)
We now come to the moral of this story. We have shown both Theorem 2 and its converse, Theorem 3. This means that the sum of the digits of \(n\) is divisible by \(9\) if and only if \(n\) is divisible by \(9\); in other words, these two statements are logically equivalent. So the key lesson is this: Whenever you wish to prove an equivalence \(P\iff Q\), always proceed by showing \(P\implies Q\) and \(Q\implies P\) separately (as we have done here).
We now move to our second proof technique. Recall from our discussion on propositional logic that any implication \(P\implies Q\) is equivalent to its contrapositive \(\neg Q\implies \neg P\). Yet, sometimes \(\neg Q\implies \neg P\) can be much simpler to prove than \(P\implies Q\). Thus, a proof by contraposition proceeds by proving \(\neg Q\implies \neg P\) instead of \(P\implies Q\).
Approach: Assume \(\neg Q\)
Therefore \(\neg P\)
Conclusion: \(\neg Q \implies \neg P\), which is equivalent to \(P \implies Q\).
Consider now the following theorem:
Let \(n\) be a positive integer and let \(d\) divide \(n\). If \(n\) is odd then \(d\) is odd.
Proving this via the technique of direct proof seems difficult; we would assume \(n\) is odd in Step 1, but then what? An approach via contraposition, on the other hand, turns out to be much easier.
Sanity check! What is the contrapositive of Theorem 4? (Answer: If \(d\) is even, then \(n\) is even.)
Proof of Theorem 4. We proceed by contraposition. Assume that \(d\) is even. Then, by definition, \(d=2k\) for some \(k\in \mathbb{Z}\). Because \(d \mid n\), \(n=dl\), for some \(l \in \mathbb{Z}\). Combining these two statements, we have \(n=dl=(2k)l=2(kl)\). We conclude that \(n\) is even. \(\square\)
Note that this time, the first line of our proof stated our proof technique — this is good practice for any proof, similar to how commenting code is good practice when programming. Stating your proof technique like this is an enormous aid to your reader in understanding where your proof will go next. (Let us not forget that a reader who understands your proof, such a teaching assistant or instructor, is much more likely to give you a good grade for it!)
Of all the proof techniques we discuss in this note, it's perhaps hardest to resist the appeal of this one; after all, who wouldn't want to use a technique known as reductio ad absurdum, i.e. reduction to an absurdity? The idea in a proof by contradiction is to assume that the claim you wish to prove is false (yes, this seems backwards, but bear with us). Then, you show that this leads to a conclusion which is utter nonsense: A contradiction. Hence, you conclude that your claim must in fact have been true.
Sanity check! A proof by contradiction relies crucially on the fact that if a proposition is not false, then it must be true. Which law from a previous lecture embodied this black or white interpretation of a statement?
Goal: To prove \(P\).
Approach: Assume \(\neg P\)
\(R\)
\(\neg R\)
Conclusion: \(\neg P \implies \neg R \land R\), which is a contradiction. Thus, \(P\).
If you are not convinced by the intuitive explanation thus far as to why proof by contradiction works, here is the formal reasoning: A proof by contradiction shows that \(\neg P\implies \neg R\wedge R\equiv\text{False}\). The contrapositive of this statement is hence \(\text{True}\implies P\).
Let us now take this proof technique on a trial run. Note that in doing so, we are continuing a long-standing legacy — the proof of the theorem below dates back more than 2000 years to the ancient Greek mathematician, Euclid of Alexandria!1
There are infinitely many prime numbers.
To appreciate the power of contradiction, let us pause for a moment to ponder how we might try to prove Theorem 5 via a different proof technique, such as, say, a direct proof. It seems very difficult, right? How would you construct infinitely many prime numbers? The remarkable thing about contradiction, however, is that if we assume the statement is false, i.e. there are only finitely many primes, bad things will happen.
To proceed, we now state a simple lemma which is handy in showing Theorem 5. Its proof will be deferred to a future lecture in which we learn about induction.
Lemma 1
Every natural number greater than one is either prime or has a prime divisor.
Proof of Theorem 5. We proceed by contradiction. Suppose that Theorem 5 is false, i.e. that there are only finitely many primes, say \(k\) of them. Then, we can enumerate them: \(p_1, p_2, p_3, \ldots, p_k\).
Now, define number \(q:=p_1 p_2 p_3 \dotsm p_k + 1\), which is the product of all primes plus one. We claim that \(q\) cannot be prime. Why? Because by definition, it is larger than all the primes \(p_1\) through \(p_k\)! By Lemma 1, we therefore conclude that \(q\) has a prime divisor, \(p\). This will be our statement \(R\).
Next, because \(p_1, \ldots, p_k\) are all the primes, \(p\) must be equal to one of them; thus, \(p\) divides \(r:=p_1 p_2 p_3 \dotsm p_k\). Hence, \(p \mid q\) and \(p \mid r\), implying \(p \mid (q-r)\). But \(q-r=1\), implying \(p\leq 1\), and hence \(p\) is not prime; this is the statement \(\neg R\). We thus have \(R\wedge \neg R\), which is a contradiction, as desired. \(\square\)
Now that we're warmed up, let's tackle another classic proof involving contradictions. Recall that a rational number is a number that can be expressed as the ratio of two integers. For example, \(2/3\), \(3/5\), and \(9/16\) are rational numbers. Numbers which cannot be expressed as fractions, on the other hand, are called irrational. Now, how about \(\sqrt{2}\)? Do you think it's rational or irrational? The answer is as follows.
\(\sqrt{2}\) is irrational.
Before giving the proof, let us ask a crucial question: Why should contradiction be a good candidate proof technique to try here? Well, consider this: Theorem 5 and Theorem 6 share something fundamental in common — in both cases, we wish to show that something doesn't exist. For example, for Theorem 5, we wished to show that a largest prime doesn't exist, and for Theorem 6, we wish to show that integers \(a\) and \(b\) satisfying \(\sqrt{2}=a/b\) don't exist. In general, proving that something doesn't exist seems difficult. But this is actually one setting in which proof by contradiction shines.
To prove Theorem 6, we use the following simple lemma. In Exercises, we ask you to prove Lemma 2.
If \(a^2\) is even, then \(a\) is even.
Proof of Theorem 6. We proceed by contradiction. Assume that \(\sqrt{2}\) is rational. By the definition of rational numbers, there are integers \(a\) and \(b\) with no common factor other than 1, such that \(\sqrt{2} = a/b\). Let our assertion \(R\) state that \(a\) and \(b\) share no common factors.
Now, for any numbers \(x\) and \(y\), we know that \(x = y \implies x^2 = y^2\). Hence \(2 = {a^2}/{b^2}\). Multiplying both sides by \(b^2\), we have \(a^2 = 2b^2\). Since \(b\) is an integer, it follows that \(b^2\) is an integer, and thus \(a^2\) is even (by the definition of evenness). Plugging in Lemma 2, we hence have that \(a\) is even. In other words, there exists integer \(c\) such that \(a = 2c\).
Combining all our facts thus far, we have that \(2b^2 = 4 c^2\), or \(b^2 = 2 c^2\). Since \(c\) is an integer, \(c^2\) is an integer, and hence \(b^2\) is even. Thus, again applying Lemma 2, we conclude that \(b\) is even.
But we have just shown that both \(a\) and \(b\) are even. In particular, this means they share the common factor 2. This implies \(\neg R\). We conclude that \(R\land \neg R\) holds; thus, we have a contradiction, as desired. \(\square\)
Here is a proof to tickle your fancy; it relies on another proof technique known as proof by cases, which we will touch on informally in this section. Specifically, the idea behind a proof by cases is as follows: Sometimes when we wish to prove a claim, we don't know which of a set of possible cases is true, but we know that at least one of the cases is true. What we can do then is to prove the result in both cases; then, clearly the general statement must hold.
There exist irrational numbers \(x\) and \(y\) such that \(x^y\) is rational.
Proof. We proceed by cases. Note that the statement of the theorem is quantified by an existential quantifier: Thus, to prove our claim, it suffices to demonstrate a single \(x\) and \(y\) such that \(x^y\) is rational. To do so, let \(x=\sqrt{2}\) and \(y=\sqrt{2}\). Let us divide our proof into two cases, exactly one of which must be true:
\(\sqrt{2}^{\sqrt{2}}\) is rational, or
\(\sqrt{2}^{\sqrt{2}}\) is irrational.
(Case 1) Assume first that \(\sqrt{2}^{\sqrt{2}}\) is rational. But this immediately yields our claim, since \(x\) and \(y\) are irrational numbers such that \(x^y\) is rational.
(Case 2) Assume now that \(\sqrt{2}^{\sqrt{2}}\) is irrational. Our first guess for \(x\) and \(y\) was not quite right, but now we have a new irrational number to play with, \(\sqrt{2}^{\sqrt{2}}\). So, let's try setting \(x=\sqrt{2}^{\sqrt{2}}\) and \(y=\sqrt{2}\). Then, \[x^y = \left(\sqrt{2}^{\sqrt{2}}\right)^{\sqrt{2}} = \sqrt{2}^{\sqrt{2}\sqrt{2}} = \sqrt{2}^2 = 2,\] where the second equality follows from the axiom \((x^y)^z=x^{yz}\). But now we again started with two irrational numbers \(x\) and \(y\) and obtained rational \(x^y\).
Since one of Case 1 or Case 2 must hold, we thus conclude that the statement of Theorem 7 is true. \(\square\)
Before closing, let us point out a peculiarity of the proof above. What were the actual numbers \(x\) and \(y\) satisfying the claim of Theorem 7? Were they \(x=\sqrt{2}\) and \(y=\sqrt{2}\)? Or \(x=\sqrt{2}^{\sqrt{2}}\) and \(y=\sqrt{2}\)? Well, since we did a case analysis, it's not clear which of the two choices is actually the correct one. In other words, we have just demonstrated something rather remarkable known as a non-constructive proof: We've proven that some object \(X\) exists, but without explicitly revealing what \(X\) itself is!
The ability to write clean and concise proofs is a remarkable thing, and is arguably among the highest forms of intellectual enlightenment one can achieve. It requires your mind to critically reflect on its own inner workings (i.e. your thought processes), and reorganize them into a coherent and logical sequence of thoughts. In other words, your mind is improving itself at a very fundamental level, far transcending the boundaries of computer science or any particular area of study. The benefits of this training will touch every aspect of your life as you know it; indeed, it will shape the way you approach life itself.
As with any such fundamental achievement, developing the ability to write rigorous proofs is likely among the most difficult learning challenges you will face in university, so do not despair if it gives you trouble; you are not alone. There is simply no substitute here for lots and lots of practice. To help get you started on your way, we now raise some red flags regarding common pitfalls in composing proofs. Let us begin with a simple, but common error.
Claim: \(-2 = 2\).
Proof? Assume \(-2 = 2\). Squaring both sides, we have \((-2)^2 = 2^2\), or \(4 = 4\), which is true. We conclude that \(-2 = 2\), as desired. \(\spadesuit\)
The theorem is obviously false, so what did we do wrong? Our arithmetic is correct, and each step rigorously follows from the previous step. So, the error must lie in the very beginning of the proof, where we made a brazen assumption: That \(-2=2\). But wait, wasn't this the very statement we were trying to prove? Exactly. In other words, to prove the statement \(P\equiv \text{"$-2=2$"}\), we just proved that \(P\implies\text{True}\), which is not the same as proving \(P\). Lesson #1: When writing proofs, do not assume the claim you aim to prove!
Lesson #2 is about the number zero: In particular, never forget to consider the case where your variables take on the value \(0\). Otherwise, this can happen:
Claim: \(1 = 2\).
Proof? Assume that \(x=y\) for integers \(x,y\in\mathbb{Z}\). Then, \[\begin{align*} x^2-xy &= x^2-y^2 && \text{(since $x=y$)}\\ x(x-y) &= (x+y)(x-y) &&\\ x &= x+y &&\text{(divide both sides by $x-y$)}\\ x &= 2x.\end{align*}\] Setting \(x=y=1\) yields the claim. \(\spadesuit\)
But, clearly \(1\neq 2\), unless your grade school teachers were lying to you. Where did we go wrong? In deriving the third equality, we divided by \((x-y)\). What is the value of \((x-y)\) in our setting? Zero. Dividing by zero is not well-defined; thus the third equality does not hold.
Lesson #3 says to be careful when mixing negative numbers and inequalities. For example:
Claim: \(4 \leq 1\).
Proof? We know that \(-2\leq 1\); squaring both sides of this inequality yields \(4 \leq 1\). \(\spadesuit\)
Sanity check! To see why this proof fails, ask yourself this: If \(a \le b\), is it necessarily true that \(|a| \le |b|\)? Can you give a counterexample?
In addition, do not forget that multiplying an inequality by a negative number flips the direction of the inequality! For example, multiplying both sides of \(-2 < 5\) by \(-1\) yields \(2 > -5\), as you would expect.
We conclude with some general words of advice. First, get in the habit of thinking carefully before you write down the next sentence of your proof. If you cannot explain clearly why the step is justified, you are making a leap and you need to go back and think some more. In theory, each step in a proof must be justified by appealing to a definition or general axiom. In practice the depth to which one must do this is a matter of taste. For example, we could break down the step, "Since \(a\) is an integer, \((2a^2 + 2a)\) is an integer," into several more steps. [Exercise: What are they?] A justification can be stated without proof only if you are absolutely confident that (1) it is correct and (2) the reader will automatically agree that it is correct.
Notice that in the proof that \(\sqrt{2}\) is irrational, we used the result, "For any integer \(n\), if \(n^2\) is even then \(n\) is even," twice. This suggests that it may be a useful fact in many proofs. A subsidiary result that is useful in a more complex proof is called a lemma. It is often a good idea to break down a long proof into several lemmas. This is similar to the way in which large programming tasks should be divided up into smaller subroutines. Furthermore, make each lemma (like each subroutine) as general as possible so it can be reused elsewhere.
The dividing line between lemmas and theorems is not clear-cut. Usually, when writing a paper, the theorems are those propositions that you want to "export" from the paper to the rest of the world, whereas the lemmas are propositions used locally in the proofs of your theorems. There are, however, some lemmas (for example, the Pumping Lemma and the Lifting Lemma) that are perhaps more famous and important than the theorems they were used to prove.
Finally, you should remember that the point of this lecture was not the specific statements we proved, but the different proof strategies, and their logical structure. Make sure you understand them clearly; you will be using them when you write your own proofs in homework and exams.
Generalize the proof of Theorem 2 so that it works for any positive integer \(n\). [Hint: Suppose \(n\) has \(k\) digits, and write \(a_i\) for the digits of \(n\), so that \(n=\sum_{i=0}^{k-1} (a_i\cdot10^i)\).]
Prove Lemma 2. [Hint: First try a direct proof. Then, try contraposition. Which proof approach is better suited to proving this lemma?]
It is perhaps worth pausing here to appreciate the true scale of this statement — after all, how many aspects of our human heritage remain relevant after multiple millenia? Music? Fashion? All of these are quickly outdated with time. But mathematics is, in a sense, timeless.↩ | CommonCrawl |
Progress on generalized star-height problem?
The (generalized) star height of a language is the minimum nesting of Kleene stars required to represent the language by an extended regular expression. Recall that an extended regular expression over a finite alphabet $A$ satisfies the following:
(1) $\emptyset, 1$ and $a$ are extended regular expressions for all $a\in A$
(2) For all extended regular expressions $E,F$;
$E\cup F$, $EF$, $E^*$ and $E^c$ are extended regular expressions
One phrasing of the generalized star height problem is whether there is an algorithm to compute the minimum generalized star height. With regards to this problem I have a few questions.
Has there been any recent progress (or research interest) concerning this problem? I know a number of years ago that Pin Straubing and Thérien published some papers in this area.
The restricted star height problem was resolved in 1988 by Hashiguchi but the generalized version (as far as I know) is still open. Does anyone have any intuition as to why this might be the case?
A link that might be helpful is the following: starheight
fl.formal-languages lower-bounds regular-expressions
J.-E. Pin
confusedmathconfusedmath
$\begingroup$ A clear definition of 'extended regular expression" or a link would be helpful. Also links to the papers cited would help flesh out the question $\endgroup$ – Suresh Venkat Apr 17 '11 at 19:41
$\begingroup$ @Suresh Given a finite alphabet A, then the extended regular expression are defined by: $\emptyset, 1, a$ for every $a\in A$ are extended regular expressions. Also, union, concatenation, complement and star are extended regular expressions. Basically just adding complement. A link that might be helpful is the following: liafa.jussieu.fr/~jep/PDF/StarHeight.pdf $\endgroup$ – confusedmath Apr 17 '11 at 19:48
$\begingroup$ AFAIK, Pin keeps his webpage updated ( liafa.jussieu.fr/~jep/Problemes/starheight.html ), which would mean no progress. $\endgroup$ – Michaël Cadilhac Apr 17 '11 at 20:46
$\begingroup$ thanks: even better would be to incorporate it in the question. $\endgroup$ – Suresh Venkat Apr 17 '11 at 21:31
$\begingroup$ In the previous comments, "liafa.jussieu.fr" should be replaced "www.liafa.univ-paris-diderot.fr". I edited the link in the question, but could not edit the links in the comments. $\endgroup$ – J.-E. Pin Jan 13 '15 at 14:12
Regarding your second question, an explanation why the generalized star height problem is less accessible than the star height problem is the following: Already Eggan's seminal paper in 1963 contained languages of (ordinary) star height $k$, for each $k\ge 0$. Only a few years later, McNaughton, and, independently, Déjean and Schützenberger, found examples over binary alphabets. This made clear what the problem "is about". During the years that followed, there was a more or less steady flow of published results in the area of the ordinary star height problem. This gave an ever increasing body of published examples, counterexamples and phenomena surrounding this problem.
In contrast, after some fifty years now, we don't know whether there is any regular language of star height at least two. So we do not even know whether there is a need for a decision procedure after all. This "complete lack of examples" indicates that it is extremely difficult to get a grip on this problem.
Hermann GruberHermann Gruber
$\begingroup$ Do you know of any applications/areas that would be directly affected by the discovery of an actual algorithm? (other than from a purely intellectual standpoint) $\endgroup$ – confusedmath Apr 18 '11 at 1:21
$\begingroup$ The classification of the languages of star height $0$ turned out to have an extremely rich theory, see for example: Robert McNaughton & Seymour Papert. Counter-free Automata. MIT Press, 1971. The classification of languages of star height $1$ might have just as many consequences. Yet, I do not know of any direct consequences à la "Assuming the generalized star height hierarchy is infinite, we can prove...". But I am probably not the best person to ask either. $\endgroup$ – Hermann Gruber Apr 23 '11 at 13:50
$\begingroup$ Restricted star-height is likely to be applied soon in a work about approximating costs of components in communicating systems. (no reference yet sorry) $\endgroup$ – Denis Jan 13 '15 at 15:35
This answer is dedicated to the memory of Janusz (John) Antoni Brzozowski, who passed away on October 24, 2019.
John is certainly the person who made the star-height problems so famous. Indeed, at a conference in Santa Barbara in December 1979, he presented a selection of six open problems about regular languages and mentioned two other topics in the conclusion of his article [1]. These six open problems were, in order, star height, restricted star height, group complexity, star removal, regularity of non-counting classes and optimality of prefix codes. The two other topics were the limitedness problem and the dot-depth hierarchy.
In June 2015, during a one-day conference in honour of his 80th birthday, I presented two survey articles summarising the state of the art on these questions [2, 3]. In particular, you will find in [2] detailed information on the star-height problems.
[1] J. A. Brzozowski, Open problems about regular languages, in Formal language theory. Perspectives and open problems, Proceedings of a symposium held in Santa Barbara, California, December 10-14, 1979[, R. V. Book (ed.), pp. 23–47, New York Etc.: Academic Press, a Subsidiary of Harcourt Brace Jovanovich, Publishers. XIII, 454 p., 1980.
[2] J.-É. Pin, Open problems about regular languages, 35 years later, Stavros Konstantinidis; Nelma Moreira; Rogério Reis; Jeffrey Shallit. The Role of Theory in Computer Science - Essays Dedicated to Janusz Brzozowski, World Scientific, 2017,
[3] J.-É. Pin, The dot-depth hierarchy, 45 years later. Stavros Konstantinidis; Nelma Moreira; Rogério Reis; Jeffrey Shallit. The Role of Theory in Computer Science - Essays Dedicated to Janusz Brzozowski, World Scientific, 2017.
J.-E. PinJ.-E. Pin
$\begingroup$ Thanks for sharing this - I just learned from your answer that he passed away. $\endgroup$ – Hermann Gruber Nov 5 '19 at 22:02
The solution of the restricted star-height problem inspired the rich theory of regular cost functions (by Colcombet), which in turn helped to solve other decidability problems and offers new tools to attack open problems. This theory is still developing and was extended to infinite words, finite trees, infinite trees, with its own set of deep results and open problems. Here is a seminal paper of the theory, and a bibliography, from Colcombet's website.
So while it is not directly an application of generalized star-height, it shows that progressing on seemingly useless problems such as star-height is likely to mean better understanding of regular languages, and yield new results on different problems.
Reference : Thomas Colcombet. "The theory of stabilisation monoids and regular cost functions". In: ICALP 2009
DenisDenis
Not the answer you're looking for? Browse other questions tagged fl.formal-languages lower-bounds regular-expressions or ask your own question.
Can a nondeterministic finite automata (NDFA) be efficiently converted to a deterministic finite automata (DFA) in subexponential space/time?
Is finding the minimum regular expression an NP-complete problem?
Maximal munch rule issue for lexers: is detection decidable?
Regular expressions of families of regular expressions
minimizing size of regular expression for finite sets
For which regular expressions $\alpha$ is $\{ \beta \mid L(\alpha) = L(\beta) \}$ PSPACE-complete?
Parameterized complexity of inclusion of regular languages | CommonCrawl |
Home Journals JESA Degraded Mode of Dual Stator Induction Motor in Pumping
Degraded Mode of Dual Stator Induction Motor in Pumping
Arezki Adjati* | Toufik Rekioua | Djamila Rekioua
Laboratoire de Technologie Industrielle et de l'Information, Faculté de Technologie, Université de Bejaia, Bejaia 06000, Algeria
[email protected]
Previously, a particular interest is focused on embedded systems and isolated sites, given that troubleshooting is not obvious in the short time. Currently, after the onset of the COVID 19 pandemic and due to the confinement imposed on almost all the countries of the world, immediate or timely repair may be impossible.
Reason why, this document provides for the study of the behavior of a pumping system, having to fill a water tower with a capacity of 150 m3 with a TDH of 17 m, during the loss of a phase, two phases or even three phases of feeding, in order to ensure control of the process and guarantee continuity of service, especially in these periods when hygiene and cleanliness are required to minimize the risk of contamination.
The results obtained show that the DSIM can still rotate even in the event of loss of supply phases or short circuit in the stator windings and provide the torque necessary to pump water under degraded conditions and after this analysis, it turns out that thanks to its flexibility and its operation in degraded mode, the DSIM will be widely used.
The global system is dimensioned and simulated under Matlab/Simulink Package.
centrifugal pump, degraded mode, dual stator induction motor (DSIM), inverters, phase opening.
The history of fault diagnosis and protection goes back to the origin of the machines themselves. Users of electrical machines initially implemented simple protection, for example against over currents, over voltage and earth fault protection, to ensure safe and reliable operation.
However, the rotation system is not immune to failure in some applications where it has now become very important to diagnose faults from their birth, because a failure in one of the constituent parts of the machine can stop the entire pumping process, causing either obvious financial loss or imminent danger [1].
In the current context of the Covid 19 pandemic, it is easy to assimilate the case of an isolated site or an on-board system with any installation, from the point of view of the impossibility of repairing breakdowns immediately. Indeed, the confinement imposed by almost all the countries in the world makes repairing breakdowns, on time, very delicate, added to this the need for this vital liquid in the almost permanent toilet to avoid the contagiousness of this virus.
It is for this reason that it is important to take an interest in the functioning of the DSIM in the presence of an anomaly in order to remedy the fault and ensure continuity of service and the most satisfactory operation possible in order to pump this precious liquid.
Mecrow et al. [2] indicates that faults in control and power converters are among the highest probabilities of drive failure with the risk of short circuit or opening of a switch. Shamsi-Nejad [3] highlights a power supply and control strategy in degraded mode during an IGBT short-circuit by short-circuiting the defective star and continuing to control the torque with the healthy inverter.
Bellara et al. [4] propose a dimensioning of an MSAP-DE tolerant to the short-circuit fault of an IGBT and have used the finite element method and have shown that the short-circuit currents can be limited.
On the other hand – Moraes et al. [5] approached the analysis of the performance of the drive in the case of a short-circuit fault of a transistor based on the modification of the control algorithm in the context of a command in degraded mode of a drive comprising two machines connected in series and controlled independently.
In this paper, we will plan to connect the neutral of the two stars in the event of failure of one phase, two phases or three phases, either of the same star or of different stars. Through this study, we will make a synthesis of the various breakdowns which can occur in the pumping chain and we will try to limit the ripples of the couple.
2. Degrade Mode and Its Remedy
When, for any reason, the operation is changed at the level of the actuator or its supply by the opening of one of the phases, the operation of the system is no longer satisfactory. This mode of operation is called "degraded mode", which is none other than an exceptional operation in which one or more elements of the drive system are malfunctioning [6, 7].
If the measurements are not taken, the rotation may not be ensured and torque oscillations appear. If they are, most of the time, simply embarrassing, they are sometimes detrimental to sensitive and embarked systems.
Studies have shown that in case of opening of a stator phase, the more the machine has phases, the less the disturbance on the torque is important and that the corrugations generated increase with the number of defective phases [7].
For engines with five to nine phases, processing a phase opening follows two main strategies, either by acting on a single phase still healthy for each open phase, or by acting on each of the currents in the still healthy phases [8].
2.1 Description of a pump chain
Figure 1 represents a pumping chain supplied, generally, by a main source of three-phase currents and by another backup source.
The rectifier is used to obtain a continuous bus to supply two inverters in order to obtain a double three-phase supply offset by π/6 between the stars. The DSIM is thus supplied and its shaft rotates the axis of the centrifugal pump.
Figure 1. Representation of a pumping energy chain
2.2 Causes of degraded mode
The causes of a malfunction of an energy chain are multiple and can be grouped according to the part reached by the degradation [7].
2.2.1 Network degradation
To ensure continuity of service, two three-phase networks are available at the pumping site. In the event of a main network interruption, it is possible to supply this actuator with an auxiliary network [9].
2.2.2 Degradation at the level of engine
The motor can have anomalies such as the destruction of a winding of a stator phase, a detachment of a rotor magnet, an inter-turns short circuit which can worsen and evolve towards a phase-phase short circuit or phase-to-earth, or a broken bar, a rupture of the ring, a short-circuit in the rotor windings, a ball bearing problem, rotor eccentricity, etc. [10, 11].
2.2.3 Degradation at the level of connectors
Connection includes all the techniques related to physical connections of electrical connections. The industrial connector has the distinction of being extremely robust and tolerating high voltages and constraints. The faults related to the connections can be a contact loose, a protection fuse, etc. [12].
2.2.4 Degradation at the level machine power supply
This degradation corresponds to the faults which can occur on the link and on the inverters which supply the six windings of the two stators of the machine inducing the opening of a stator supply phase and leading to the cancellation of the current.
The power transistors making up the voltage inverter may have malfunctions. These anomalies can result from normal wear and tear, improper design, improper assembly or misalignment, improper use, or a combination of these different causes [7].
The consequences of a fault generate that the voltage across a phase becomes uncontrollable and the couple will be directly infected by disturbing ripples causing annoying vibrations of the machine and annoying sound effects. The currents in the remaining windings of the machine can reach destructive values [7, 13].
In this study, the faults boil down to losses of DSIM supply phases.
2.3 Study of eventual defect
The different statistical studies on the degradation of a power supply chain show that the faults at the level of the voltage inverters and their controls are the most frequent. It is therefore justified to limit the study to failures that may occur on the power transistors, on the connectors and on the protection fuses and we will focus on the degradation of the power supply of the machine which corresponds to the defects that may occur on the link and the inverters inducing the opening of a phase of stator power supply and leading to the cancellation of the current [6, 7, 13, 14].
2.3.1 Power transistor opening defect
If one of the transistors of the inverter is in opening defect while the control of the complementary transistor is active, the short circuit of the DC power supply is inevitable and to avoid this kind of inconvenience, it is imperative to act either by canceling the control of the other transistor, or by using a fuse protection whose fusion is ultra-fast [6, 7, 13, 15].
2.3.2 Power transistor closing defect or fusing a fuse
Similarly, for this case, the voltage across the phase connected to the faulty arm becomes uncontrollable. Depending on the faulty transistor and the position of the fuse, the phase connected to the faulting arm is connected to a potential of the supply either directly or via a diode [6].
2.4 Defect isolation method
Figure 2 shows the arrangement of the triacs and the fuses used to isolate the defective phases in order to avoid passing on the problems to other organs of the energy chain. A static switch sets the voltage of the open phase to half of the DC bus voltage [16].
Figure 2. Disconnection of defective phases by the Triacs
The Table 1 associates each star phase with the corresponding IGBTs. According to Figure 2, when one of the arms of the two inverters is defective, the Triac becomes conductive and the fuse placed in series is then connected between a potential difference generating its melting and the disconnection of the phase in question. To ensure phases insulation presenting anomalies, it is necessary to use as many Triacs as phases, reason for which the control circuit is congested [7, 13].
Table 1. IGBT corresponding to the phases
Second star
Associated IGBT
Parallel redundancy at the power supply of the engine allows degraded operation even if a power phase is open.
2.5 Control strategy in degraded mode
The control techniques are based on the modification of the current in one or more phases to maintain a constant torque during degraded mode operation [7, 17].
Two methods exist, either by acting on the current of a single phase still healthy for each open phase, or by acting on each of the currents in the phases not in default [18].
To avoid infecting the performance of the machine which exhibits torque oscillations during a fault, the application of the two methods has the main aim of reducing these oscillations as much as possible in order to allow the most satisfactory operation possible [13].
2.5.1 Action on the current of a single phase still healthy by each open phase
When disconnecting from a faulty phase, the choice is made for a healthy phase located at 90° electrical thereof where the current is changed to ensure constant, maximum torque and limited joule losses [19].
A valid method for machines with any electromotive forces, but for machines with sinusoidal fems, the stresses of the current are concentrated on few healthy phases from where the limitation to half the number of phases.
For example, by applying this method where the Sa1 phase is open, the choice will be made for the Sb1 phase which will bear all the stress of the fault, hence [13]:
$i_{a 2}=I_{\max } \sin (\omega \cdot t-\pi / 6)$
$i_{b 1}=2 . I_{\max } \cos (2 \pi / 3) \sin (\omega . t)=-I_{\max } \sin (\omega . t)$
$i_{b 2}=I_{\max } \sin (\omega t-5 \pi / 6)$ (1)
$i_{c 1}=I_{\max } \sin (\omega \cdot t-4 \pi / 3)$
$i_{c 2}=I_{\max } \sin (\omega . t-3 \pi / 2)$
2.5.2 Action on each of the currents in the still healthy phases
In the case of machines with sinusoidal fems, a correction of the remaining currents by an analytical evaluation makes it possible to restore a constant torque while minimizing the joule losses [18].
The advantage lies in the fact that the degradation is distributed over the rest of the healthy phases of the machine. This method is valid as long as there are a sufficient number of phases to produce a rotating field.
For example, the application of this second method where the Sa1 phase is open, the stress is supported by all the healthy phases and, after calculation, the new setpoints of the currents will be [6]:
$i_{a 2}=1.27 I_{\max } \sin (\omega t-\pi / 3)$
$i_{b 1}=1.27 I_{\max } \sin (\omega . t-5 \pi / 6)$
$i_{b 2}=1.27 I_{\max } \sin (\omega . t-\pi)$ (2)
$i_{c 1}=1.27 I_{\max } \sin (\omega t+5 \pi / 6)$
$i_{c 2}=1.27 I_{\max } \sin (\omega t+\pi / 3)$
Even if the two methods make it possible to maintain a constant torque when disconnecting one or more phases of a machine having more than three phases, some disadvantages may be mentioned, such as the need to change the current setpoint in one or more phases. It is therefore necessary to have a system capable of detecting defecting phases in order to be able to apply the new setpoints of the current.
A table summarizing the setpoints of the current as a function of the disconnected phases is necessary [13, 20].
3. Mathematical Model
3.1 Centrifugal pump
The centrifugal pump is a flow generator that ensures the movement of a fluid from one point to another, when gravity does not perform this task.
BRAUNSTEIN and KORNFELD introduced in 1981 the expressions of mechanical power [21].
$P_{m e c}=K_{r} \omega_{r}^{3}$ (3)
The centrifugal pump opposes a resistant torque from which its expression is given by:
$T_{r}=K_{r} \omega_{r}^{2}+T_{s}$ (4)
The model used is identified by the expression of the TDH given by the PELEIDER-PETERMAN model [22]:
where, Kr: Proportionality coefficient, ωr: rotation speed, Q: Flow and K0, K1, K2: Pump constant.
3.2 Transformation matrix
The magnetomotive force produced by the stator phases is equivalent to that produced by two quadrature windings αβ crossed by the currents isα and isβ such that:
$\left[\begin{array}{c}i_{s \alpha} \\ i_{s \beta}\end{array}\right]=\left[\begin{array}{lllllll}T c & & i & i_{a 1} & i_{a 2} & i_{b 1} & i_{b 2} & i_{c 1} & i_{c 2}\end{array}\right]^{t}$ (6)
Mathematically, a six-dimensional system cannot be reduced to a two-dimensional system. It is for this reason that, four vectors named [Z1], [Z2], [Z3] and [Z4] orthogonal to each other and orthogonal to the vectors, along the axis "α" and the axis "β", are needed to complete the transformation.
3.3 Voltage equations
The electrical equations governing the DSIM in the reference αβ are given by [13]:
$\left\{\begin{array}{c}v_{\alpha}=R_{s} i_{s \alpha}+\frac{d}{d t} \phi_{s \alpha} \\ 0=R_{r} i_{r \alpha}+\frac{d}{d t} \varphi_{r \alpha}+\omega_{r} \phi_{r \beta} \\ v_{\beta}=R_{s} i_{s \beta}+\frac{d}{d t} \phi_{s \beta} \\ 0=R_{r} i_{r \beta}+\frac{d}{d t} \varphi_{r \beta}-\omega_{r} \phi_{r \alpha}\end{array}\right.$ (7)
3.4 Magnetic flux equations
On the other hand, the stator and rotor fluxes equations are [13, 23]:
$\left\{\begin{array}{l}\left(\begin{array}{c}\phi_{s \alpha} \\ \phi_{r \alpha}\end{array}\right)=\left(\begin{array}{cc}L_{s d} & M_{d} \\ M_{d} & L_{r}\end{array}\right)\left(\begin{array}{c}i_{s \alpha} \\ i_{r \alpha}\end{array}\right) \\ \left(\begin{array}{c}\phi_{s \beta} \\ \phi_{r \beta}\end{array}\right)=\left(\begin{array}{cc}L_{s q} & M_{q} \\ M_{q} & L_{r}\end{array}\right)\left(\begin{array}{c}i_{s \beta} \\ i_{r \beta}\end{array}\right)\end{array}\right.$ (8)
3.5 Voltage equation in space Z
In healthy operation, there are four voltages in Z space and this number of equations decreases by one unit each time an inverter arm is faulty. With 'k=2', 'k=3' or 'k=4', the voltage equations in Z space are:
$v_{Z_{1}}=R_{s} i_{z_{1}}+L_{1 s} \frac{d i_{z_{1}}}{d t}$
$v_{z_{k}}=R_{s} i_{z_{k}}+L_{1 s} \frac{d i_{z_{k}}}{d t}$ (9)
3.6 Mechanical equation
The electromagnetic torque can be given by the following expression:
$T_{e m}=\frac{p}{L_{r}}\left(M_{q} i_{s \beta} \cdot \phi_{r \alpha}-M_{d} \cdot i_{s \alpha} \cdot \phi_{r \beta}\right)$ (10)
The rotation of the rotor is also governed by the following mechanical equation
$T_{e m}-T_{r}=J \cdot \frac{d}{d t} \Omega(t)+f_{r} \cdot \Omega(t)$ (11)
4. Result and Comments
For comparison, it is useful to study the healthy system with six phases. Then determine the quantities governing the operation and behavior of the DSIM before going into degraded mode.
The choice fell on the MATLAB SIMULINK software for digital simulations of the behavior of DSIM. The simulations will be carried out by coupling the centrifugal pump at t = 2.8s. The Table 2 gives the parameters of the DSIM and the Table 3 gives the parameters of the centrifugal pump.
Table 2. Basic parameters of the DSIM
Rotor resistance
Rr = 2,12 Ω
Stator resistance
Rs1 = 3,72 Ω
Stator inductance
Ls = 0,022 H
Pair of poles
p=1
Rotor inductance
Lr = 0,006 H
J=0,0625 kg.m²
mutual inductance
Lm=0,3672 H
friction coefficient
Kf = 0,001 Nm.s/rad
Nominal frequency
Table 3. Parameters of the centrifugal pump
Nominal speed ωn
150 rad/s
constant K0
4.9234.10-3 m.s²/rad²
Nominal height
1.5826.10-5 s²/(rad.m)
Nominal flow
-18144 s²/m5
Pump inertia
0.02 kg.m²
4.1 Normal operating mode
DSIM runs at full speed without any breakdown.
4.1.1 Centrifuge pump characteristics
Torque – speed characteristic. Figure 3 indicates that the torque increases rapidly depending on the speed of rotation of the DSIM and it confirms the quadratic relation which exists between the torque of the pump and its rotation speed.
Since the starting torque is limited to the friction torque of the pump at zero speed, the pump requires a minimum speed at a given Hmt, to obtain a non-zero starting flow [24].
The theoretical characteristic of a centrifugal pump is a parabola starting from the origin and proportional to the square of the speed.
Figure 3. Characteristic torque – speed
Flow – speed characteristic. The pump must be driven at a certain speed for it to provide flow.
Indeed, before reaching this level of speed, that is to say a value of 150 rad/s, the piping of the pump does not provide any flow, then, the flow increases with the increase in the speed of rotation. Figure 4 shows the variation of the flow as a function of the speed and it should be noted that they are directly proportional.
The amount of energy corresponds to the speed and the faster the wheel turns or the larger the wheel, the higher the speed of the liquid at the tip of the blade and the greater the energy transmitted to the liquid.
Figure 4. Characteristic flow – speed
Flow and TDH characteristic. For water, TDH is simply the pressure head difference between the inlet and outlet of the pump, if measured at the same elevation and with inlet and outlet of equal diameter.
Figure 5. Characteristic flow – TDH
TDH is the total equivalent height that a fluid is to be pumped, taking into account friction losses in the pipe.
Figure 5 reveals that the variation of TDH is similar to that of the speed and the pump provides a flow only after a delay, equivalent to the time it takes for the pump to reach a certain speed of 151 rad/s.
4.1.2 DSIM characteristics
T6 is the transformation matrix calculated on the basis of the six healthy phases of DSIM which are only two three-phase systems offset by π / 6 between them.
Figure 6 reveals that at start-up, the torque takes on a vibratory form and reaches values close to 80 Nm, then after 0.3 s at 40 Nm, the vibrations fade before reaching a no-load value of Tr = 0.32 Nm. This torque value corresponds to the without load losses and the mechanical friction losses.
Figure 7 shows the evolution of the speed of rotation of the DSIM which, at the start, increases in a quasi linear way to reach the speed of 313.83 rad/s very close to the synchronism speed which is 314.16 rad/s.
At starting, the DSIM absorb current of five times the nominal current, i.e. 30A and in the case of excessive repetitions, these start-up currents can be at the origin of the destruction by heating of the windings of the stator of the DSIM. Figure 8 indicates that the steady state is reached after a period of 0.6 s and the DSIM absorbs a current of 0.88 A without load; when connecting the load, the motor absorbs more current from the network which oscillates around 3.5 A.
Figure 6. Electromagnetic & pump torques (no defect)
Figure 7. Rotative & synchronism speed (no defect)
Figure 8. Stator electric current (normal mode)
4.2 Defect of phase
When a fault occurs on one phase, the transformation matrix is calculated on the basis of the five healthy phases and is given by:
$\left[T_{5}\right]=\left[\begin{array}{lllll}+0.6124 & -0.3536 & -0.6124 & -0.3536 & -0.0000 \\ +0.2887 & +0.5000 & +0.2887 & -0.5000 & -0.5774 \\ +0.4487 & -0.4967 & +0.7281 & +0.0129 & +0.1471 \\ +0.5330 & +0.3198 & -0.0911 & +0.7611 & -0.1613 \\ +0.2372 & +0.5253 & +0.0570 & -0.2133 & +0.7868\end{array}\right]$
The DSIM continues to rotate while providing torque to its shaft which will be reduced compared to its nominal value.
Figure 9. Electromagnetic & Pump torques (one phase)
Figure 10. Stator electric current (one phase)
With this faulty phase, at startup, the torque of the machine decreases considerably compared to its value where all the feeding phases are healthy.
The torque reaches a peak of 47.2 Nm, and then the vibrations fade after 0.75 s before reaching a float value between 0.6 Nm and 1.2 Nm corresponding to the no-load losses and the mechanical losses by friction.
Figure 9 shows that when the load is connected, the torque goes to the disturbed and wavy float value between 11.8 Nm and 16.8 Nm around the value of the resisting torque. The frequency of the oscillations is twice that of the supply currents.
The speed reaches the synchronism speed after 0.75 s, slower than that of a healthy operation and with a load this speed switches around 306 rad/s.
The zoom of Figure 10 shows that without load, the current increases to 1.1 A and during the coupling of the load the DSIM absorbs currents of 4.44 A.
4.3 Case of two faulty phases
The two faulty phases can be in the same star or in a different star.
4.3.1 Failure of two phases of the same star
The Sa2 and Sb2 phases are chosen to simulate a fault that could occur on two phases of the same star.
The transformation matrix is calculated based on the four healthy phases of the same star and is given by:
$\left[T_{4}\right]=\left[\begin{array}{llll}+0.8165 & -0.4082 & -0.4082 & -0.0000 \\ +0.0000 & +0.5477 & -0.5477 & -0.6325 \\ +0.5527 & +0.4235 & +0.6819 & -0.2238 \\ +0.1668 & +0.5950 & -0.2613 & +0.7416\end{array}\right]$
Figure 11 highlights the undulations of the torque no and with load. The torque stabilizes after 1 s, oscillating around 0.8 Nm without load and around 13.9 Nm with load. The value of the resistive torque is 13.6 Nm.
Figure 12 shows that at the start, strong currents are called reaching 35 A, then after the established regime, the DSIM absorbs 1.37 A without load. On the other hand, under load, the absorbed current increases and is around 5.8 A.
Note that small ripples are observed around the average speed of 305.60 rad/s and the rise time has increased to 1 s.
Figure 11. Torques evolution (two phases same star)
Figure 12. Stator electric current (two phases same star)
4.3.2 Two different star phases defect
Sa1 and Sc2 phases are chosen to simulate a fault that could occur on two phases of the different star.
$\left[T_{4}\right]=\left[\begin{array}{llll}+0.6124 & -0.3536 & -0.6124 & -0.3536 \\ +0.3536 & +0.6124 & +0.3536 & -0.6124 \\ +0.4082 & -0.5774 & +0.7041 & +0.0649 \\ +0.5774 & +0.4082 & -0.0649 & +0.7041\end{array}\right]$
Figure 13. Torques evolution (two phases different star)
After a start-up, Figure 13 shows that the torque reaches after 1 s, the value corresponding to the without load losses, and then the torque follows the setpoints, note that for speed, the rise time is 0.96 s and the speed is 305.95 rad/s.
With regard to the stator currents, Figure 14 relates that the results of this simulation are identical to those found for the case of two phases of the same star.
$\left[T_{3}\right]=\left[\begin{array}{lll}+0.7071 & +0.6124 & -0.3536 \\ +0.0000 & +0.5000 & +0.8660 \\ +0.7071 & -0.6124 & +0.3536\end{array}\right]$
Figure 14. Stator electric current (two phases different star)
4.3.3 Summary of the various defects of two phases
For operation with two faulty phases, Table 4 summarizes the possible combinations and describes the state of the torque.
Figure 15 shows the very wavy state of the torque in case when two phases defect. The harmfulness of the torque state on the performance of the DSIM is the reason why the control strategies described previously in section 2.5 are used for keep the torque constant, ridding it of ripples.
Figure 15. Torques evolution with very wavy torque
4.4 Case of three faulty phases
4.4.1 Defect of three phase of different star
The transformation matrix is calculated based on the three healthy phases and is given by:
Figure 16 reveals that in this case, the speed-up time further increases to 1.5 s, then after application of the load, the DSIM decelerates and the speed oscillates around the value of 304.8 rad/s.
Figure 16. Speeds evolution (three phases different star)
Table 4. State of the torque with two defective phases
State of the torque
Defective phases in same star
Defective phases in different star
Not wavy
(Sb2-Sc1),
(Sa2-Sb1), (Sa1-Sc2)
(Sb1-Sc1), (Sb2-Sc2), (Sa2- Sb2)
(Sb1, Sc2)
Very wavy
(Sa1-Sc1), (Sa1-Sb1), (Sa2-Sc2)
(Sc1- Sc2),
(Sa2-Sc1), (Sb1- Sb2),
(Sa1- Sb2), (Sa1-Sa2)
The stator currents at startup reach 34 A before fading to a value of 1.7 A. Figure 17 shows then after application of the load, the demand increases to 7.65 A.
The fact that the phases do not belong to the same star, torque oscillations are observed when empty and under load as shown in the Figure 18.
Figure 17. Stator electric current (three phases different star)
Figure 18. Torques evolution (three phases different star)
4.4.2 Loss of a star
If a star is lost, it is only a three-phase system. The transformation matrix is calculated based on the loss of a star and is given by:
$\left[T_{3}\right]=\left[\begin{array}{lll}+0.8165 & -0.4082 & -0.4082 \\ +0.0000 & +0.7071 & -0.7071 \\ +0.5774 & +0.5774 & +0.5774\end{array}\right]$
Figure 19 shows the vibratory form of the oscillating torque, before stabilizing at 0.31 Nm, value corresponding to the no-load losses. With the load, the torque follows the evolution of the resistant torque.
Figure 20 is a zoom which defines the evolution of the resistive torque and the electromagnetic torque and clearly shows that the couple follows its reference.
Figure 21 highlights the rise time which increases to 1.54s. On load, the DSIM decelerates to 304.8 rad/s.
The same behavior in healthy mode is observed with values divided by two.
Figure 18 and Figure 22 show that the current in the event of the loss of a star is identical to that of the loss of three different star phases.
Figure 19. Torques evolution (loss of a star)
Figure 20. Zoom in the evolution of torques (loss of a star)
Figure 21. Speeds evolution (loss of a star)
Figure 22. Stator electric current (loss of a star)
Table 5. Synthesis of the various simulations
Electromagnetic torque
Rotation speed
Current [A]
Defect phase
Max [Nm]
Stability time [s]
Final [rad/s]
Rise time[s] [s]
No load
5 phases
2 phases same star
2 various star phases
Loss of a starstar
By a small comparison between Figure 8 in healthy mode and Figure 22, with a loss of three phases, the current draw simply doubled, from 0.88 A to 1.7 A without load and from 3.5 A at 7.6 A with load.
4.5 Synthesis of the various simulations
4.5.1 Stator current
Without load, the absorbed current is 0.9 A with the six healthy phases and increases with the number of defective phases up to a value of 1.79 A with half-motor operation. When charging, the current is 3.55 A during normal operation and almost twice when a star is lost. This is because the DSIM absorbs the same current through its remaining three phases, i.e., the power is no longer segmented.
4.5.2 Rotation speed
Without load, the speed is reached after a period which increases with the increase of the number of defective phases. With load, the speed is 306.3 rad/s and decreases as the number of phases is reduced.
Figure 23 shows the decrease in speed. A difference of two rad/s is observed between normal mode and half-engine operation.
Figure 23. Comparison of speeds
4.5.3 Electromagnetic torque
In normal operation, the torque has a peak of around 49.35 Nm before stabilizing at its value corresponding to the no-load losses in a time of 0.65 s.
The loss of the phases leads to a decrease in the maximum value of the couple and an increase in the relaxation time.
Note that for operation with a single star, the value of the maximal torque is simply halved.
For operation with one or two stars, the torque has no ripple. In the event of a fault, undulations appear and increase with the number of defective arms of the inverter.
The Table 5 gives a comparison of the characteristic quantities of the DSIM during the various defects studied that may occur on the stator power phases.
During this small test, we could see that the DSIM can still rotate even in the case of loss of supply phases or short-circuit of the stator windings.
In degraded conditions, the couple finds themselves wavy or strongly wavy, which is very harmful to the drive system. Proposed techniques are adopted to deal with this kind of inconvenience. On the other hand the absorbed current increases and can reach double its nominal value, reason for which, it is necessary well to dimension the coils of the DSIM.
Depending on the field of use, it is possible to guarantee satisfactory operation by using powerful computers which, in real time, provide the appropriate control.
This operation must ensure a torque without ripples and a speed necessary for the load, while controlling the current demand which must satisfy an operation, without overheating, of the motor and avoid short-circuits of the turns of the stator windings.
After this analysis, it turns out that the DSIM, thanks to its flexibility, is widely used in military applications and in embedded applications, and may replace three-phase motors in the near future
In perspective, it is possible to study this engine in degraded mode without having to use a neutral connection.
Corona virus December 2019
DC/AC
DSIM
Dual stator induction motor
Insulated-gate bipolar transistor
MSAP-DE
permanent magnet synchronous motor dual star
Axis direct index
iai, ibi, ici
Currents of star i
irα, irβ
Rotor current (α & β axis)
Isα, isβ
Stator current (α & β axis)
iz1, iz2, iz3
Fictitious currents in space Z
Proportionality coefficient
K0, K1, K2
pump constants
Rotor inductor
Lsd, Lsq
Direct and quadratic stator inductors
Md, Mq
Direct and quadratic mutuals
Number of pole pairs
Pmec
Mechanical power
Axis quadratic index
Rotor resistant
Stator resistant
Transformation matrix
Total dynamic head
Resistant torque
Static torque
VZi
Fictitious voltages in space Z
Vα, Vβ
Stator voltage (α & β axis)
Greek symbols
$\phi_{s \alpha}, \phi_{s \beta}$
Stator fluxes (α & β axis)
$\phi_{r \alpha}, \phi_{r \beta}$
Rotor fluxes (α & β axis)
Angular speed of rotation
[1] Ibrahim, A. (2009). Contribution au diagnostic de machines électro-mécaniques: Exploitation des signaux électriques et de la vitesse instantanée. Thèse de Doctorat, école doctorale Sciences, Ingénierie, Santé Diplôme délivré par l'Université Jean Monnet.
[2] Cao, W., Mecrow, B.C., Atkinson, G.J., Benett, J.W., Atkinson, D.J. (2012). Overview of electric motor technologies used for more electric aircraft (MEA). IEEE Transactions on Industrial Electronics, 59(9): 3523-3531. https://doi.org/10.1109/TIE.2011.2165453
[3] Shamsi-Nejad, M.A. (2007). Architectures d'alimentation et de commande d'actionneurs tolérants aux défauts. Régulateur de courant non linéaire à large bande passante. Thèse de Doctorat, Institut National Polytechnique de Lorraine.
[4] Bellara, A., Chabour, F., Barakat, G., Amara, Y., Maalioune, H., Nourisson, A., Corbin, J. (2016). Etude du fonctionnement dégradé d'une machine synchrone à aimants permanents double étoile pour un inverseur de poussée. Symposium de genie electrique: EF-EPF-MGE 2016, Grenoble, France.
[5] Moraes, T.J.D.S., Nguyen, N.K., Meinguet, F., Guerin, M., Semail, E. (2016). Commande en mode dégradé d'un entrainement comportant deux machines 6 phases en série. Symposium de génie électrique: EF-EPF-MGE 2016, Grenoble, France.
[6] Crevits, Y. (2009). Characterization and control of polyphase training in degraded mode. Doctorat de génie électrique, rapport de première année, école polytechnique Lille France.
[7] Williamson, S., Smith, S., Hodge, C. (2014). Fault tolerance in multiphase propulsion motors. Journal of Marine Engineering and Technology, 3(1): 3-7. https://doi.org/10.1080/20464177.2004.11020174
[8] Kestelyn, X. (2003). Modélisation vectorielle multi machines pour la commande des ensembles convertisseurs-machines polyphasées. Thèse de doctorat en génie électrique à l'université de Lille 1.
[9] Bonnett, A.H., Soukup, G.C. (1992). Cause and analysis of stator and rotor failures in three-phase squirrel-cage induction motors. IEEE Transactions on Industry Applications, 28(4): 921-937. https://doi.org/10.1109/28.148460
[10] Bigret, R., Féron, J.L. (1995). Diagnostic, Maintenance Et Disponibilité Des Machines Tournantes. Edition Masson.
[11] Bonnett, A.H. (2000). Cause ac motor failure analysis with a focus on shaft failures. IEEE Transactions on Industry Applications, 36(5): 1435-1448. https://doi.org/10.1109/28.871294
[12] Huangsheng, X., Toliyat, H.A, Peteren, L.J. (2002). Five-phase induction motor drives with DSP based control system. IEEE Transactions on Power Electronics, 17(4): 524-533. https://doi.org/10.1109/TPEL.2002.800983
[13] Kianinezhad, R., Nahid-Mobarakeh, B., Baghli, L., Betin, F., Capolino, G.A. (2008). Modeling and control of six-phase symmetrical induction machine under fault condition due to open phases. IEEE Transactions on Industrial Electronics, 55(5): 1966-1977. https://doi.org/10.1109/TIE.2008.918479
[14] Zhao, Y., Lipo, T.A. (1996). Modeling and control of a multi-phase induction machine with structural unbalance. IEEE Transactions on Energy Conversion, 11(3): 570-577. https://doi.org/10.1109/60.537009
[15] Khaldi, L., Iffouzar, K., Ghedamsi, K., Aouzellag, D. (2019). Performance analysis of five-phase induction machine under unbalanced parameters. Journal Européen des Systèmes Automatisés, 52(5): 521-526. https://doi.org/10.18280/jesa.520512
[16] Welchko, B.A., Jahns, T.M. (2002). IPM Synchronous machine drive response to a single phase open circuit fault. IEEE Transaction on Power Electronics, 17(5): 764-771. https://doi.org/10.1109/TPEL.2002.802180
[17] Figueroa, J., Cros, J., Viarouge, P. (2003). Poly-phase PM brushless DC motor for high reliability application. September, Toulouse, CDROM, EPE.
[18] Robert-Dehault, E., Benkhoris, M.F., Semail, E. (2002). Study of 5-phases synchronous machine fed by PWM inverters under fault conditions. CDROM, ICEM.
[19] Hirtz, J.M. (1991). Les stations de pompage d'eau. 6e édition, Association Scientifique et Technique pour l'eau et l'environnement, éditions Lavoisier.
[20] Xu, H., Toliyat, H.A., Peteren, L.J. (2001). Modeling and control of five-phase induction motor under asymmetrical fault conditions. Electric Machines & Power Electronics Laboratory Texas A&M University.
[21] Mukund, R.P. (1999). Wind and Solar Power Systems. PhD, université Merchant Marine.
[22] Benkhoris, M.F., Tali-Maamar, N., Terrien, F. (2002). Decoupled control of double star synchronous motor supplied by PWM inverter: simulation and experimental results. Laboratoire Atlantique de recherche au génie Electrique (LARGE-GE44)-France.
[23] Royer, J., Djiako, T. (1998). Le Pompage Photovoltaïque. Manuel de cours à l'intention des ingénieurs et des techniciens, université d'Ottawa /EIER /CREPA.
[24] Martin, J.P., Meibody-Tabar, F., Davat, B. (2000). Multiple phase permanent magnet synchronous machine supplied by VSIS, working under fault conditions. CDROM, IAS. | CommonCrawl |
What is a metric? [closed]
I was taking a basic course in general relativity. They introduced a concept of a metric which I wasn't able to understand can somebody explain it to me why do we need a metric in curved spaces?
relativity metric-tensor
closed as too broad by user36790, Sebastian Riese, Prahar, Kyle Kanos, user10851 Feb 25 '16 at 2:59
$\begingroup$ Have a look at this question $\endgroup$ – ACuriousMind♦ Feb 24 '16 at 13:04
$\begingroup$ theoreticalminimum.com/courses/general-relativity/2012/fall $\endgroup$ – user73352 Feb 24 '16 at 17:52
why do we need a metric
Clocks don't measure time, they measure the metric applied the the worldline of their path in 4d spacetime. Rulers don't measure distance, they measure the metric along their path in 4d spacetime. Everything you are used to thinking of as a measurement actually measures the metric.
That is why you need it. Because that's what clocks and rulers measure and you want to connect to measurements at some point (physics is an experimental science after all).
So you could ask why you didn't know you needed it. And that's because if you write it as a matrix, then in everyday situations it is very similar (numerically) to the identity matrix.
Which allows you to ignore when you use it, which allows you to confuse lots of things. For instance you could take a directional derivative. Or you could write a vector (the gradient vector) that when dotted (scalar product) with a unit vector tells you the directional derivative in that direction. But that dot product (scalar product) uses the metric. And if you use non cartesian coordinates you'd already have to pay attention. But there is a natural object that takes vectors and gives you directional derivatives and that's the gradient. The gradient vector is the gradient with the metric applied to make it into a vector when really its a function that takes vector and gives directional vectors.
And this is the really issue in relativity. You have to unlearn. You have to find out that thingsvyouvdivide thought were the same (gradient and gradient vector) are actually different. Like forces. Does $\vec F=m\vec a$ or does $\vec F=\mathrm d\vec p/\mathrm d t$? In Newtonian mechanics $m\vec a=\mathrm d\vec p/\mathrm d t$ so it didn't matter which one equally $\vec F$ but in relativity $m\vec a\neq \mathrm d\vec p/\mathrm d t$ so they can't both equal the same thing. And so you have to learn that forces are about changes in momentum, not about mass times acceleration. That's the real difficulty of learning Relativity. And so now you have to learn to distinguish between column vectors like the gradient vector and row vectors like the gradient.
If you write the metric as a matrix $G$ then the relationship between a column vector $c$ and a row vector is naturally $r$ but if you have two column vectors $a$ and $b$ you can compute $(Ga)^Tb.$ And that's a scalar. So the row vector associated with a column vector $a$ is not $a^T$ it is $(Ga)^T.$ But why would you even think it is $a^T.$
The only problem is the matrix $G$ is sometimes an identity matrix, in fact in a Euclidean space with Cartesian coordinates it is the identity matrix. So you might have thought $a^T$ and $(Ga)^T$ are the same since you practiced a situation where they are the same. And since that was the first one you learned, you might not notice using it when it's the identity matrix. In non Cartesian coordinates it isn't the identity matrix. So you can practice with non Cartesian coordinates and get used to it. Learning the difference between a change in coordinates and an actual metric distance.
For instance if you use polar coordinates $r$ and $\theta$ then the $\theta$ doesn't even have units of distance. Clearly a coordinate difference isn't giving you something measured by a ruler. For that you need the metric.
TimaeusTimaeus
A metric is a distance function for a space. It takes two space(time)-coordinates and gives the distance between them. We usually consider points which are infinitesimally close to one another, because that way it applies to every kind of space, curved or not. In a 2D Euclidean space, the metric is given by pythagoras' theorem: $ds^2(dx_\mu)=dx^\mu dx_\mu=dx^2+dy^2$. In the flat 1+1D Minkowski space, $ds^2(dx_\mu)=dx^\mu dx_\mu=c^2dt^2-dx^2$.
In both these cases the absolute values of the coordinates do not matter, only their differences are used to calculate the distance. When a space is curved, this changes. The distance function changes as we move along the space, due to the change in curvature. This dependency is captured in the metric tensor. We have in general $$ds^2(x_\mu,dx_\mu)=g^{\mu\nu}(x_\mu)dx_\mu dx_\nu\equiv dx^\mu dx_\mu.$$
The previous two flat spaces are also described by this general equation. For the Euclidean space, the metric tensor is the 2x2 unit matrix. For the Minkowki spacetime, the metric tensor is a 2x2 diagonal matrix with 1 in the topleft and -1 in the bottomright. In both cases they are constant matrices, independent of the absolute coordinates. The metric tensor is always there, but it is only in a space with non-constant curvature where it changes from one place to another.
vosovvosov
Pythagoras' theorem is an example of a metric. Notice that this theorem is postulated rather than derived (in fact, it defines flat 2D space). Notice also that (except for very short distances) it isn't valid on a globe, where a different rule (to calculate distances) needs to be specified instead.
benjiminbenjimin
$\begingroup$ You're making confusion between the metric and the application of the metric tensor onto two vectors (which gives back Pythagoras' theorem). $\endgroup$ – gented Feb 24 '16 at 13:46
It is a way to quantify the behavior of the space, whether it is flat or curvilinear.
$ ds^{2} = g_{\mu \nu} \triangle x_{\mu} \triangle x_{\nu} $
Where ds is the interval, g is the metric and the x's are the co-ordinates. As it has been said the x's can be drawn analogous to pythagoras in euclidean space, and the metric is a machine that translates that to curved space, if it is so.
EDIT: $ds^{2} $ - corrected by Lewis Miller.
CppgCppg
$\begingroup$ Don't you mean $ds^2$? $\endgroup$ – Lewis Miller Feb 24 '16 at 17:04
Not the answer you're looking for? Browse other questions tagged relativity metric-tensor or ask your own question.
What is the metric tensor for?
What is the $ds^2$ notation in relativistic physics?
Metric signature explanation
Why is the metric tensor symmetric?
Advantages of using different metric signatures in relativity and QFT
"We can describe general relativity using either of two mathematically equivalent ideas: curved space-time, or metric field" What is the metric field?
Sign of the Minkowski metric and proper time
What is the motivation from Physics for the Levi-Civita connection on GR?
The space-time metric in string theory
What does it mean to go from a co-variant vector to a contravariant vector?
Why is it natural to impose the condition that the metric remains unchanged under parallel transport?
Meaning and significance of the Levi-Civita symbol | CommonCrawl |
A very quick tour of R
posted by Jason Polak on Tuesday February 13, 2018 with No comments! and filed under statistics | Tags: programming, r
This post is a quick introduction to the R. I learnt R when I was an undergrad and I still use it from time to time. It was one of the first major programs I compiled from source as well.
What is R? It is simply the best statistical computing environment in use today. Better yet, it's open source. If you're working with data, you need to learn R. This post won't teach you how to use R. Instead, it will give a whirlwind tour so you can get appreciate R's flavour. The only thing I don't like much about R is searching for material on it. Its one letter name makes that hard.
I will assume that you have R installed, and have opened the interactive console. It should look something like this:
Variables are perhaps the most important part of R because all your data will be stored in variables. Variables are declared as follows:
> a = 12
This stores the value 12 in the variable named 'a'. Pretty easy right? You can now type 'a' in the console and hit enter, and this is what you'll get:
> a [1] 12
[1] 12
Chances are you'll be reading R code somewhere along the line and encounter this kind of variable assignment:
> a <- 12
This does the same thing as 'a = 12', but is uglier and harder to type.
Vectors in R are really fun. They're like lists in Python, or arrays in C. Here's how to declare a vector with the numbers 2,4,6,8 in it:
> a = c(2,4,6,8)
The function 'c' stands for 'combine' and just takes the numbers 2,4,6,8 and puts them in a vector. It's a good idea not to use the letter 'c' as a variable then. R has a really great way of handling vectors, at least for the purposes of numerical computing. If you want to get a new vector whose elements are the square of every element in the vector stored in 'a', you just do:
> a^2 [1] 4 16 36 64
> a^2
[1] 4 16 36 64
The vector 'a' itself is unchanged. If you wanted to modify 'a' by squaring each entry then you would do:
a = a^2
Pretty much all arithmetic operations operate on vectors pointwise. So 'a + a' will return a new vector via vector addition, rather than concatenating the vectors:
> a +a [1] 4 8 12 16
> a +a
[1] 4 8 12 16
If you want to concatenate instead:
> c(a,a) [1] 2 4 6 8 2 4 6 8
> c(a,a)
[1] 2 4 6 8 2 4 6 8
Finding the sum of all the elements of the vector 'a' is easy:
> sum(a) [1] 20
> sum(a)
There are many built-in functions that can be applied to vectors like 'mean', 'summary', 'sd', 'min', 'max', etc. Chances are if you need a function like this, you can just guess what it is and it will probably be right.
Probability distributions
R has a bunch of built-in probability distributions. The density functions are named as follows:
dbeta: Beta distribution
dbinom: Binomial distribution
dcauchy: Cauchy distribution
dchisq: Chi-squared distribution
dexp: Expoential distribution
df: F distribution
dgamma: Gamma distribution
dgeom: Geometric distribution
dhyper: Hypergeometric distribution
dlnorm: log-normal distribution
dmultinom: Multinomial distribution
dnbinom: Negative binomial distribution
dnorm: Normal distribution
dpois: Poisson distribution
dt: Student's t distribution
dunif: Uniform distribution
dweibull: Weibull distribution
By replacing 'd' in the names by:
'p' you get the cumulative distribution function
'q' you get the quantile function
'r' you get a random number generator for that distribution
Now would be a good time to tell you that if you need help with any function, such as what parameters it accepts, just type '?function' at the console. For example,
> ?dunif
Will tell you about the density function for the uniform distribution. Let's see how to use some of these density functions. For example, the typical usage for 'dnorm' is
> dnorm(x, mean = 0, sd = 1, log = FALSE)
> dnorm(0) [1] 0.3989423
> dnorm(0)
[1] 0.3989423
If you'll recall, the density function for the normal distribution with mean zero and standard deviation one is
$$f(x) = \frac{1}{\sqrt{2\pi}}e^{-x^2/2}$$
Then 'dnorm(0)' is just evaluating this function at zero. Notice that we didn't actually specify 'mean' or 'sd' but they took on the default values in R. The default values are indicated in the help. By typing '?dnorm' you'll see that the function is written with 'mean = 0'. That means the default 'mean' for 'dnorm' is zero.
For more on distributions, type '?Distributions' in R.
Random number generation
One of the cool things about R is that it can generate a bunch of random numbers for each of the distributions we talked about. Of course, all you really need is a uniform random number generator, but it's good that these other ones are built into R for convenience. For example:
> rnorm(10) [1] -1.4569007 0.8524113 0.2940385 0.5111377 1.6543332 -0.8684520 [7] 2.0536998 -0.3351626 -2.0603866 -0.9382230
> rnorm(10)
[1] -1.4569007 0.8524113 0.2940385 0.5111377 1.6543332 -0.8684520
[7] 2.0536998 -0.3351626 -2.0603866 -0.9382230
This gave me ten numbers from a normal distribution with mean zero and variance one (the 'standard normal'). This calculation:
> pnorm(0.5) [1] 0.6914625
> pnorm(0.5)
Evaluates the cumulative distribution function of the standard normal. This means that the probability of a standard normal random variable being less than or equal or 0.5 is about 0.6914625. Let's see if the random number generator gives something believable:
> sum(rnorm(1000) <= 0.5) [1] 696
> sum(rnorm(1000) <= 0.5)
[1] 696
This tells gives us an 'experimental' probability of 0.696. Pretty good. I should tell you how this code works. The boolean expression
rnorm(1000) <= 0.5
generates a vector of a 1000 i.i.d. samples from the standard normal, and then a new vector is returned that has TRUE in the places in which the original vector is actually less than or equal to 0.5. Otherwise it has FALSE in the indices in which the original vector is greater that 0.5. This may explain it better:
> c(1,2,3,4,5) > 2 [1] FALSE FALSE TRUE TRUE TRUE
> c(1,2,3,4,5) > 2
[1] FALSE FALSE TRUE TRUE TRUE
The function 'sum()' just sums up all the values in any vector. If the vector consists of TRUE and FALSE, then FALSE is treated as zero and TRUE is treated as one. For example:
> sum(c(1,2,3,4,5) > 2) [1] 3
> sum(c(1,2,3,4,5) > 2)
In other words, there are three numbers in the vector c(1,2,3,4,5) greater than two. This illustrates R's powerful vector handling mechanism.
Statistical Tests
The heart of R is statistics. Part of statistics is hypothesis testing. How do you find out what tests are included with R? R has a way of listing all the functions containing a certain word. It's the 'apropos()' function. For example:
> apropos('test') [1] "ansari.test" "bartlett.test" [3] "binom.test" "Box.test" [5] "chisq.test" "cor.test" [7] "file_test" "fisher.test" [9] "fligner.test" "friedman.test" [11] "kruskal.test" "ks.test" [13] "mantelhaen.test" "mauchly.test" [15] "mcnemar.test" "mood.test" [17] "oneway.test" "pairwise.prop.test" [19] "pairwise.t.test" "pairwise.wilcox.test" [21] "poisson.test" "power.anova.test" [23] "power.prop.test" "power.t.test" [25] "PP.test" "prop.test" [27] "prop.trend.test" "quade.test" [29] "shapiro.test" "testInheritedMethods" [31] "testPlatformEquivalence" "testVirtual" [33] "t.test" ".valueClassTest" [35] "var.test" "wilcox.test"
> apropos('test')
[1] "ansari.test" "bartlett.test"
[3] "binom.test" "Box.test"
[5] "chisq.test" "cor.test"
[7] "file_test" "fisher.test"
[9] "fligner.test" "friedman.test"
[11] "kruskal.test" "ks.test"
[13] "mantelhaen.test" "mauchly.test"
[15] "mcnemar.test" "mood.test"
[17] "oneway.test" "pairwise.prop.test"
[19] "pairwise.t.test" "pairwise.wilcox.test"
[21] "poisson.test" "power.anova.test"
[23] "power.prop.test" "power.t.test"
[25] "PP.test" "prop.test"
[27] "prop.trend.test" "quade.test"
[29] "shapiro.test" "testInheritedMethods"
[31] "testPlatformEquivalence" "testVirtual"
[33] "t.test" ".valueClassTest"
[35] "var.test" "wilcox.test"
If you've ever taken statistics before, you should have heard of many of these tests like t.test, chisq.test, etc. Again, the question mark is your friend. Type '?t.test' to see its syntax. These functions not only test hypotheses, but automatically give you confidence intervals, as well!
So far, we've covered what you can do to data but not how you get data into R. The simplest function is 'scan'. Let's say I had a file 'data.txt' that looked like this:
To load these numbers into R, I would type:
a = scan('data.txt')
This will store the vector 'c(1,5,2,5)' into the variable 'a'. If the data points are separated by tabs instead for instance, you could type
a = scan('data.txt',sep='\t')
If instead you have data in columns as it appears in a spreadsheet, you need to use the 'read.table' function:
a = read.table('data.txt')
Instead of a vector, 'a' now has a 'data frame' type. It's basically like a spreadsheet with columns. You might have to pass additional arguments to 'read.table' depending on the format of your data. Use '?read.table' to see how to use 'read.table'. For example, the 'header' parameter controls whether the columns have labels. The boolean values in R are TRUE or FALSE, which can be abbreviated by T and F respectively.
Installing new packages
R has a good truckload of tests in it and modeling routines like generalised linear models. But what if it doesn't have your favourite test, model, or function? That's what installing new packages is for, and doing it is dead easy. Just type
> install.packages()
at the console and you'll be presented with a rudimentary-looking but functional interface to select new packages. Once you find the package you want, click it and install it!
Still here? Amazing. Hopefully that whetted your apetite for more. If so, you may want to check out Modern Statistics for the Social and Behavioral Sciences by Rand Wilcox. This book will tell you how in R to do all the basic stats stuff. Wilcox's book covers a huge range of topics rather than being comprehensive on a few, and will give you a great start. If you're interested in some specific topic, there are many books that use R for their examples. If you're into linear modeling, Alan Agresti's book Categorical Data Analysis is great, and is the book I used when I studied this topic as an undergraduate. While it doesn't use R in the book itself, the book's website has supplementary material on using R with the methods described in the book.
Resumen de lecturas compartidas durante septiembre de 2018 | Vestigium
Fields marked with * are required. LaTeX snippets may be entered by surrounding them with single dollar signs. Use double dollar signs for display equations.
◄ Conditioning and a sum of Poisson random variables
Maximum likelihood, moments, and the mean of a Poisson ▸ | CommonCrawl |
Statistical analysis of ionospheric total electron content (TEC): long-term estimation of extreme TEC in Japan
Michi Nishioka ORCID: orcid.org/0000-0001-7147-59331,
Susumu Saito2,
Chihiro Tao1,
Daikou Shiota1,
Takuya Tsugawa1 &
Mamoru Ishii1
Ionospheric total electron content (TEC) is one of the key parameters for users of radio-based systems, such as the Global Navigation Satellite System, high-frequency communication systems, and space-based remote sensing systems, since total ionospheric delay is proportional to TEC through the propagation path. It is important to know extreme TEC values in readiness for hazardous ionospheric conditions. The purpose of this study is to estimate extreme TEC values with occurrences of once per year, 10 years, and hundred years in Japan. In order to estimate the extreme values of TEC, a cumulative distribution function of daily TEC is derived using 22 years of TEC data from 1997 to 2018. The extreme values corresponding to once per year and 10 years are 90 and 110 TECU, respectively, in Tokyo, Japan. On the other hand, the 22-year data set is not sufficient to estimate the once-per-100-year value. Thus, we use the 62-year data set of manually scaled ionosonde data for the critical frequency of the F-layer (foF2) at Kokubunji in Tokyo. First, we study the relationship between TEC and foF2 for 22 years and investigate the slab thickness. Then the result is applied to the statistical distribution of foF2 data for 62 years. In this study, two methods are applied to estimate the extreme TEC value. In the first method, the distribution of slab thickness is artificially inflated to estimate extreme TEC values. In the second method, extreme slab thicknesses are applied to estimate extreme TEC values. The result shows that the once-per-100-year TEC is about 150–190 TECU at Tokyo. The value is also estimated to be 180–230 TECU in Kagoshima and 120–150 TECU in Hokkaido, in the southern and northern parts of Japan, respectively.
The ionospheric condition is one of the most important space weather features for users of radio-based systems, such as navigation systems based on the Global Navigation Satellite System (GNSS), high-frequency (HF) communication systems, and space-based remote sensing systems. Radio waves propagating in the ionosphere experience a delay in group velocity and advance in phase velocity due to the electrons in the ionosphere. The ionospheric delay is proportional to the ionospheric total electron content (TEC) along the propagation path. The easiest way to correct the ionospheric delay is to utilize broadcast ionospheric delay models based on simple empirical TEC models such as the Klobuchar (1987) and NeQuick (Hochegger et al. 2000, Radicella and Leitinger 2001) models. The TEC value is determined by many factors, such as solar activity, the season, local time, and geomagnetic activity. There is also latitudinal dependence in TEC variations. TEC variations caused by solar activity, the season, and local time may be estimated using these simple models but those caused by geomagnetic storms and other phenomena cannot be fully removed from these models. Therefore, users of radio-based systems may be affected by positive and/or negative ionospheric storms. During negative ionospheric storms, TEC is ≥ 0 TECU even if the negative storm is extremely severe. On the other hand, extreme TEC values during positive storms are not unknown and should be studied.
For the design and operation of systems that may be impacted by space weather phenomena, it is important to know the possible extent of the impact and how often such events are likely to occur. Thus, it is important to study extreme values related to various space weather phenomena. For users of trans-ionosphere radio-based systems, the extreme TEC value is a key value.
Extreme values of some space weather parameters have been studied. For example, that of the Dst index was investigated using extreme value modeling (Tsubouchi and Omura 2007). Those of the solar flare X-ray flux, speed of coronal mass ejection, Dst index, and proton energy in proton events were studied by Riley (2012) using complementary cumulative distribution functions. More recently, that of short-wave fadeout by a solar flare was examined on the basis of long-term ionosonde observation data (Tao et al. 2020).
However, extreme TEC values of once per long period of time have not yet been quantitatively estimated. Several countries have prepared documents with space weather benchmarks. The US White House published "Space Weather Phase 1 Benchmarks" in June 2018 (US White House 2018). Although it lists three factors that cause ionospheric disturbances, such as geomagnetic storms, quantitative benchmarks were not provided because the ionospheric effects of geomagnetic storms on the ionosphere largely differ from event to event and even their mechanism is not completely understood.
Another reason why extreme TEC values have not been fully studied is that only 20 years has passed since the start of fully fledged TEC observations. TEC observations started with measurements of the Faraday rotation or Doppler effect many decades ago (Bauer and Daniels 1959; Evans 1977). Since these observations were conducted by a few transmitters and receivers, it is difficult to study TEC behavior statistically. With the spread of GNSS and its ground-based receivers, the number of TEC observations dramatically increased. Thanks to the GNSS-TEC observation systems, we have learned a lot about TEC behavior during the last 20 years (for example Foster 2007; Nishioka et al. 2009; Maruyama et al. 2013). The purpose of this study is to estimate extreme values of TEC with their occurrence rates. We investigate the occurrence rates of extreme values of TEC in Japan in the short, mid-, and long term, which are once per year, 10 years, and 100 years, respectively.
To evaluate TEC corresponding to an occurrence rate of once per 100 years, 20 years of data is obviously insufficient. Furthermore, solar activity in the last 20 years has on average been moderate, although several intense geomagnetic storms occurred during solar cycle 24. Compared with GNSS-TEC observation, ionosonde observation has a much longer history. This technique was developed in the late 1920s and began to be implemented in the 1940s in order to monitor short-wave propagation (Gladden 1959). In Japan, ionosonde observation began in 1931. After going through various changes, routine ionosonde observation was started by the predecessor of National Institute of Information and Communications Technology (NICT) in 1951 using an automatic system. Ionospheric parameters derived from the long-term ionosonde observation are archived by World Data Center for the Ionosphere at NICT (http://wdc.nict.go.jp/IONO/wdc/). Long-term ionosonde data have been used for various studies such as a study of the long-term trends of the ionosphere (Xu et al. 2004) and for the development of empirical models (Bilitza 2018; Yue et al. 2006; Maruyama 2011). As the TEC and the maximum density of the F region derived from ionosonde observation (NmF2) are known to be correlated, NmF2 can be a proxy of TEC. In this study, about 60 years of data of ionospheric parameters derived from the long-term ionosonde observation are used. Although the data period is still shorter than 100 years, we investigate statistical characteristics of extreme TEC values in order to estimate the ionospheric once-per-100-year condition.
The TEC value over Japan depends on the latitude, normally with a larger value in southern Japan. Japan is mainly located in the lower mid-latitude region with a latitudinal range of about 20°. The southern part of Japan is located at the poleward slope of the equatorial ionospheric anomaly (EIA) crest. On the other hand, the northern part is hardly affected by EIA variation and may rather be affected by phenomena originating from the polar region (Cherniak et al. 2015). Therefore, extreme TEC values should also differ among the center, southern, and northern parts of Japan.
Details of the data set used in this study and the analysis method are described in "Data set" and "Methods", respectively. In "Results", the result obtained using about 20 years of TEC data collected in Tokyo, which is almost in the center of Japan, is shown as the first step. Then long-term ionosonde data are analyzed. On the basis of the result, extreme TEC values with probabilities of once per year, 10 years, and 100 years are estimated for Tokyo. In the last part of the section, the extreme TEC values in southern and northern Japan are also estimated. In "Discussion", the results are discussed in comparison with those of case studies of geomagnetic storms in previous papers. The last section provides the summary of this study.
In this study, we use TEC data derived from the nationwide GNSS network over Japan, which is called the GNSS Earth Observation Network System (GEONET) and operated by the Geospatial Information Authority of Japan, and ionosonde observation data collected over Tokyo.
GNSS-TEC data derived from GEONET have been archived by NICT since 1997. Using the network data, the slant TEC along the line of sight between the receiver and the satellite was derived from pseudo-range and carrier-phase measurements by dual-frequency GPS receivers (Saito et al. 1998). The instrumental bias of the TEC associated with the inter-frequency bias of the satellite and receiver was obtained by a technique proposed by Otsuka et al. (2002), in which the daily bias values are derived by assuming that hourly averaged TEC values are uniform within the field of view of a given GNSS receiver. The slant TEC is converted to the vertical TEC after removing the instrumental bias. The TEC data from small satellite elevation angles, which is smaller than 35° is neglected to reduce cycle slips and errors due to conversion from slant to vertical TEC. The median value of the vertical TEC whose ionospheric pierce point is located within 100 km from a given location over 1 h is derived as an hourly TEC. The largest hourly TEC in a given day is noted as the daily TEC in this paper. The daily TECs of 22 years from 1997 to 2018 are used in this study and studied in Sect. 4.1.
Ionospheric conditions have been monitored for about 70 years by NICT using ionosondes in Kokubunji, Tokyo (36.7°N, 139.5°E, 26.8°N in Mag.Lat) and other stations. Ionospheric parameters have been manually scaled from ionograms. In order to ensure uniform quality of data, the scalers have discussed and established scaling rules, although automatic scaling tools have been developed in recent years. Thanks to the substantial efforts of the scalers, ionospheric parameters from the 1950s to the present are now available. In this study, the manually scaled critical frequency of the F-layer (foF2), which corresponds to the peak density of the F-layer, is used. In order to study foF2 with the daily TEC, we refer to the maximum foF2 in a given day as the daily foF2. In Sect. 4.2, a 22-year data set of daily foF2 values from 1997 to 2018 is used. In the same section, a 62-year data set of daily foF2 values from 1957 to 2018 is also used.
In order to find extreme values of TEC corresponding to an occurrence frequency of once every certain number of years, the cumulative distribution function (CDF) of daily TEC occurrence is investigated (Riley 2012; Kataoka 2020). The CDF of the daily TEC occurrence is a distribution function of daily TEC values that are greater than or equal to a critical TEC. One of the advantages of investigating the CDF instead of a simple occurrence probability is that it is easy to find TEC values with an occurrence frequency of once per long period (Riley 2012). In other words, the CDF of the daily TEC occurrence provides an occurrence probability of a daily TEC that is greater than or equal to a certain value, while a normal distribution provides the occurrence probability of a daily TEC between two values.
Although a data set of TEC values over 22 years may be sufficient to investigate TEC values with occurrence frequency of once per year and 10 years, it would not be sufficient to investigate the TEC value with an occurrence frequency of once per 100 years.
To compensate the insufficient number of TEC data, we utilized a 62-year data set of foF2 values in order to calculate NmF2 and study a property of the relationship between TEC and NmF2. The relationship between TEC and foF2 is given by the following equation:
$$\mathrm{TEC}=S\times \mathrm{NmF}2,$$
where S is the slab thickness. In this study, characteristics of slab thickness are studied using the 22-year data set of TEC and foF2 values. By utilizing the characteristics of the slab thickness and the 62 years of foF2 data, we deduce CDFs of TEC values over 62 years, from which we estimate the TEC value corresponding to occurrence frequency of once per 100 years.
Even if the 62-year data are utilized to estimate the TEC values with occurrence frequency of once per hundred years, the amount of the data is still not enough. The occurrence rate of a single event in 62-year data set is 1/((365.25 × 62)) = 0.0044%. This occurrence rate is larger than that of once-in-100-year event, 1/((365.25 × 100)) = 0.003%. In order to compensate the insufficient number data set, the distribution was extrapolated in two ways in order to deduce CDFs of TEC values over 62 years in this study. In the former method, which we call Method I, the following four steps are taken to derive the CDF using the 62-year data set of NmF2. For the first step, probability function of slab thickness, \({P}_{\mathrm{s}}\), is presumed with the 22-year slab thickness data set. The presumed \({P}_{\mathrm{s}}\) is used to calculate a probability function of TEC for a given i-th day, \({P}_{\mathrm{T}}^{i}\), with NmF2 observed on the day, \({\mathrm{NmF}2}^{i}\). In the third step, \({P}_{\mathrm{T}}^{i}\) is converted to \({\mathrm{CDF}}^{i}\), which is a CDF of TEC for i-th day. Finally, \({\mathrm{CDF}}^{i}\) is derived with all NmF2 values in 62 years and integrated to deduce CDF of TEC values over 62 years.
Here, in the step one, we assume that slab thickness follows a normal distribution, e.g., \(S\sim \mathcal{N}({\mu }_{\mathrm{S}},{\sigma }_{\mathrm{S}}^{2})\) where \({\mu }_{\mathrm{s}}\) and \({\sigma }_{\mathrm{S}}\) are mean and standard deviation of slab thickness based on 22 years. The probability function of Ps for slab thickness of s [km] is described as follows:
$$P\mathrm{s}\left(s\right)=\frac{1}{\sqrt{2\pi }{\sigma }_{S}}\mathrm{exp}\left(-\frac{\left(s-{\mu }_{\mathrm{S}}\right)}{2{\sigma }_{\mathrm{S}}^{2}}\right).$$
One of the problems in estimating extreme TEC value of once-in-100-years is that the number of TEC data, or slab thickness data is insufficient compare to a 100 years. Therefore, the normal distribution, \(\mathcal{N}({\mu }_{\mathrm{S}},{\sigma }_{\mathrm{S}}^{2})\), cannot reproduce extreme slab thickness. In order to compensate the lack of extreme values with \(\mathcal{N}({\mu }_{\mathrm{S}},{\sigma }_{\mathrm{S}}^{2})\), we introduce an inflated sigma, which is described as \(\widehat{{\sigma }_{\mathrm{s}}}\), to model the slab thickness. Inflation factor, \(\frac{\widehat{{\sigma }_{\mathrm{s}}}}{{\sigma }_{\mathrm{s}}}\), is determined by comparing TEC values of once-in-10-years deduced with various inflation factors with that based on 22-year TEC data set.
As the step 2, a probability function of TEC for i-th day, \({P}_{\mathrm{T}}^{i}\) is calculated on the assumption that NmF2 and slab thickness are independent parameters. The \({\mathrm{TEC}}^{i}\) follows a normal distribution with mean and standard deviation of \({\mathrm{NmF}2}_{i}\times {\mu }_{\mathrm{S}}\) and \({\mathrm{NmF}2}_{i}\times {\sigma }_{\mathrm{S}}\), respectively. That is, \({\mathrm{TEC}}^{i}\sim \mathcal{N}({\mu }_{\mathrm{T}}, {\sigma }_{\mathrm{T}}^{2})\) where \({\mu }_{\mathrm{T}}={\mathrm{NmF}2}_{i}\times {\mu }_{\mathrm{S}}\) and \({\sigma }_{\mathrm{T}}={\mathrm{NmF}2}_{i}\times {\sigma }_{\mathrm{S}}\). The distribution of \({\mathrm{TEC}}^{i}\) for TEC of t [TECU] is expressed as the following equation:
$${P}_{\mathrm{T}}^{i}\left(t\right)=\frac{1}{\sqrt{2\pi }{\sigma }_{T}}\mathrm{exp}\left(-\frac{\left(t-{\mu }_{\mathrm{t}}\right)}{2{\sigma }_{\mathrm{T}}^{2}}\right).$$
Since \({\mathrm{TEC}}^{i}\) follows normal distribution, CDF of \({\mathrm{TEC}}^{i}\), \({\mathrm{CDF}}^{i}\), is given using error function, erf,
$${\mathrm{CDF}}_{i}={\int }_{\mathrm{TEC}}^{\infty }{P}_{\mathrm{T}}^{i}\left(t\right)\mathrm{d}t=1-{\int }_{-\infty }^{\mathrm{TEC}}{P}_{\mathrm{T}}^{i}\left(t\right)\mathrm{d}t=\frac{1}{2}-\mathrm{erf}\left(\frac{{\mathrm{TEC}}^{i}}{\sqrt{2}{\sigma }_{\mathrm{T}}}\right).$$
In the final step, CDFi is calculated for each day in the 62 years and added to obtain \(\mathrm{CDF},\) that is,
$$\mathrm{CDF}=\frac{1}{N}\sum_{i}{\mathrm{CDF}}^{i},$$
where N is the total number of the day in 62 years.
In the latter method, which we call Method II, CDFTEC of extreme case was deduced by multiplying the extreme slab thickness, which could occur once in 10 and 100 years, by the 62-year data set of daily foF2. By assuming that the slab thickness has a normal distribution with a mean \(\mu\) and a standard deviation \(\sigma\), the value corresponding to occurrence of once per 10 and 100 years, or 0.03% and 0.003%, are \(\mu +3\sigma\) and \(\mu +4.2\sigma\), respectively. CDFTEC for the 62 years can be deduced by multiplying the CDF of NmF2 for the 62 years by the extreme values of slab thickness.
Since the slab thickness is known to have seasonal dependence, a single value of the slab thickness is not appropriate for estimating TEC from foF2. In order to estimate PST in Method I, data set of slab thickness is divided into four seasons, that is, from February to April, from May to July, from August to October, from November to January. Four seasonal PST are used to estimated CDFTEC in Eqs. (3), (4) and (5). Three-month data are used to derive PST in Method I to obtain sufficient number of data for the inflation. On the other hand, monthly data is used to calculate the mean μ and the standard deviation σ in Method II.
Statistical analysis of TEC over 22 years
Figure 1 shows the CDF of the daily TEC occurrence at Tokyo. The occurrence rate is shown on the left axis. The occurrence rate on the left-hand axis of the ordinate is days per 100 years, which is obtained by dividing the occurrence days by the total number of days in 22 years and then multiplying those in 100 years. Therefore, an occurrence rate of one day means an occurrence rate of once per 100 years. The occurrence rate is converted to the occurrence percentage and shown on the right-hand axis of the ordinate. An occurrence probability of 0.3%, which corresponds to a frequency of once per year, is shown as a solid horizontal line. It is found that the daily TEC can reach about 90 TECU with a frequency of once per year. The occurrence probabilities of once per 10 years and once per 100 years correspond to 0.03% and 0.003% and are shown with dotted and dashed horizontal lines, respectively. It is found that a daily TEC of more than 100 TECU occurs with a frequency of once per 10 years. The TEC values with frequencies of once per year and once per 10 years are summarized in Table 1.
Cumulative distribution function (CDF) of daily TEC occurrence at Tokyo from 1997 to 2018. The occurrence rate, which is the number of days per 100 years, and the occurrence percentage are shown on the left and right axes, respectively. Red, pink, blue, and light blue represent days of HSHG, HSLG, LSHG, and LSLG, respectively. The solid, dotted, and dashed horizontal lines represent occurrence rates of 0.3%, 0.03%, and 0.003%, which correspond to occurrence frequencies of once per year, 10 years, and 100 years, respectively
Table 1 Estimated TEC of once per one, 10, and 100 years in Tokyo, Kagoshima, and Hokkaido
On the other hand, the daily once-per-100-year TEC value cannot be appropriately estimated from Fig. 1 because the distribution is based on only 22 years of data.
The colors in the histograms in Fig. 1 represent the classifications based on solar and geomagnetic activity: red, pink, blue, and light blue represent days of high solar activity and high geomagnetic activity (HSHG), high solar activity and low geomagnetic activity (HSLG), low solar activity and high geomagnetic activity (LSHG), and low solar activity and low geomagnetic activity (LSLG), respectively. Solar and geomagnetic activities are, respectively, defined on the basis of the solar sunspot number (SSN) and disturbance storm-time (DST) index, which are provided as sunspot data from the World Data Center SILSO, Royal Observatory of Belgium, Brussels (http://sidc.be/silso/datafiles) and WDC for Geomagnetism, Kyoto (http://wdc.kugi.kyoto-u.ac.jp/dstdir/index.html), respectively. HS (LS) days are defined as days for which the average daily SSN for the previous 27 days is ≥ (<) 50. HG (LG) days are defined as days for which the average daily DST of the current day and the previous day is ≤ (>) − 50 nT. It can be seen that a TEC of 60 TECU or larger is most likely to be observed when either the solar activity or the geomagnetic activity is high, while those exceeding 100 TECU are observed only when the solar activity is high.
Statistical analysis of foF2 over 22 and 62 years
Here, CDFs of the daily foF2 occurrence are studied in order to estimate once-per-100-year values. First, a CDF of the daily foF2 occurrence over the same period as in Fig. 1, from 1997 to 2018, were examined in comparison with that of the 22 years of TEC data in Fig. 1. Figure 2 shows a CDF of the daily foF2 occurrence, that is, the distribution of the daily foF2 that is greater than or equal to some critical foF2. As in Fig. 1, the occurrence rate per 100 years is shown on the left-hand axis of the ordinate and the occurrence rate in percentage is shown on the right axis. The occurrence frequencies of once per year, 10 years, and 100 years of 0.3%, 0.03%, and 0.003% are shown as solid, dotted, and dashed horizontal lines, respectively. The colors in Fig. 2 represent solar and geomagnetic activities similarly to in Fig. 1; red, pink, blue, and light blue represent days of HSHG, HSLG, LSHG, and LSLG, respectively. The largest foF2 was about 17.5 MHz. It is found that foF2 was higher than 15 MHz for only HSHG and HSLG days, which is similar to the result in Fig. 1.
CDF of the daily foF2 occurrence from 1997 to 2018 at Kokubunji station, Tokyo. The occurrence rate, which is the number of days per 100 years, and the occurrence rate in percentage are shown on the left- and right-hand axes of the ordinate, respectively. Red, pink, blue, and light blue represent days of HSHG, HSLG, LSHG, and LSLG, respectively. The solid, dotted, and dashed horizontal lines represent occurrence rates of 0.3%, 0.03%, and 0.003%, which correspond to frequencies of once per year, 10 years, and 100 years, respectively
The same analysis is carried out for the 62-year foF2 data set from 1957 to 2018. The result is shown in Fig. 3 in the same format as Fig. 2. The maximum observed foF2 is about 18.7 MHz, which is slightly larger than that obtained from the 22-year data set in Fig. 2. The maximum foF2 18.7 MHz was observed during geomagnetic storm in November 1960 when DST index reached − 333 nT (Cliver and Svalgaard 2004). Moreover, the occurrence rate of daily foF2 values larger than 16.8 MHz in Fig. 3, which corresponds to the rightmost bar in the histogram, is about twice of that in Fig. 2.
CDF of the daily foF2 from 1957 to 2018. The plotting format is the same as that of Fig. 2
Estimation of extreme TEC from slab thickness using Method I
As the characteristics of the CDFs of the daily foF2 occurrence are different for the 22- and 62-year data sets, the once-per-100-year TEC value cannot be estimated by extrapolating the CDF of the daily TEC occurrence obtained from the 22-year data set. In this sub-section, we estimate the once-per-100-year TEC value by using the 62-year foF2 data set with Method I.
The value of foF2 is proportional to the square root of the maximum ionospheric density, NmF2. NmF2 is given by the following equation.
$$\mathrm{NmF}2\left[{\mathrm{m}}^{-3}\right]=1.24\times {10}^{10}\times {\mathrm{foF}2}^{2 }\left[\mathrm{MHz}\right].$$
Figure 4 shows the correlation between daily TEC and NmF2 derived from the daily foF2. All data collected over 22 years are shown in this scatter plot. It can be seen that TEC and NmF2 have a strong correlation. The red line is the least-squares linear approximation of all data. As shown in Eq. (1), the slope, which is about 250 km, is equivalent to the thickness of the ionosphere that gives a TEC value with a density of NmF2. This parameter, which is called the ionospheric slab thickness, is used to deduce TEC from NmF2 because of the strong correlation between daily TEC and daily foF2.
Scatter plot of daily TEC and corresponding daily NmF2 from 1997 to 2018. The red line represents a linear fitting to the data points
In order to derive CDFs of TEC values over 62 years with Method I, distribution of slab thickness is examined. Figure 5 shows distribution of slab thickness from 1997 to 2018. Mean and standard deviation of the distribution is 215 km and 52 km, respectively. The red curve represents the normal distribution with the mean and the standard deviation. The distribution in 3 months from May to July is shown in Fig. 6. The mean and standard deviation of the distribution is 273 km and 45 km. The mean is larger than that in Fig. 5, which is one of the seasonal effects. The red curve represents a normal distribution with the mean and the standard deviation. The curve roughly fits the slab thicknesses but does not cover large values such as more than 400 km. Mean values and standard deviations of other seasons, that is, from February to April, from August to October, and November to January, are listed in Table 2. Normal distributions with the mean and the standard deviations for each season listed in Table 2 are applied for PST in Method I. The result of CDFTEC is shown with black histograms in Fig. 7. TEC of once per 10 and 100 years, that is, TEC of 0.03% and 0.003% was 35 TECU and 45 TECU, respectively, which are smaller than those can be read in Fig. 1. This is because of the assumption of the normal distribution, which cannot cover the large slab thickness. In order to cover them, normal distributions are inflated using an inflation factor. The blue curves in Fig. 6 show the inflated normal distribution with inflation factors. The dashed and solid lines are derived with inflation factors of 2.0 and 3.8, respectively. The inflated normal distribution with an inflation factor of 3.8 overbounds the large slab thickness around 480 km while that of 2.0 is too small to cover the large slab thicknesses. In order to optimize the inflation factor, once-per-10-year TEC value is calculated using various inflation factors to obtain CDFTEC. Figure 8 shows the once per 10-year TEC value as a function of the inflation factor. It increases as the inflation factor increases and exceeds 110 TECU, which is the once-per-10-year TEC value based on the 22-year TEC data set, when the inflation factor changes from 3.7 to 3.8. In this paper, therefore, the inflation factor of 3.8 is adopted based on the 22-year TEC data set. Using the inflated normal distribution with the inflation factor of 3.8, CDF of TEC are derived as blue histogram in Fig. 7. TEC of once per 10 and 100 years, that is, TEC of 0.03% and 0.003% was 110 TECU and 150 TECU, respectively.
Distribution of slab thickness from 1997 to 2018. The red curve represents normal distribution with the mean and standard deviation
Distribution of slab thickness during May, June, and July from 1997 to 2018. The red curve represents an original normal distribution as in Fig. 5. The blue curves represent inflated normal distributions with the mean and the inflated sigma. The inflated sigma is derived by multiplying inflation factor to the original standard deviation. Inflated normal distributions with inflation factors of 2.0 and 3.8 are shown with the blue dashed and solid lines, respectively
Table 2 Mean and standard deviation of slab thickness in km for four seasons
CDFs of the daily TEC occurrence estimated with Method I. The occurrence rate, which is the number of days per 100 years, and the occurrence rate in percentage are shown on the left- and right-hand axes of the ordinate, respectively. The black histograms are derived with the normal distribution of 22-year data set of slab thickness and 62-year data set of daily foF2. The blue histograms are derived with the inflated normal distribution of the slab thickness and daily foF2
Estimated TEC with Method I against inflation factors. The filled circle and solid line represent the estimated TEC which occur once per 10 years. The open circle and dashed line represent those of once per 100 years. The horizontal dashed line at 110 TECU indicate the once-per-10-year TEC based on 22-year TEC data set. The vertical dashed line shows the inflation factor of 3.8, which is adopted in this work
Estimation of extreme TEC from slab thickness using Method II
In this sub-section, we estimate the once-per-100-year TEC value by using the 62-year foF2 data set with Method II. Here, we calculated the mean and the standard deviation of slab thickness for each month. Figure 9 shows the slab thickness against the day of the year for 22 years from 1997 to 2018. Data are sparser from June to August compared with other months, because foF2 values of 10 cannot be obtained owing to masking by the sporadic E-layer, which often appears in these months. The red polyline is the monthly mean of the slab thickness. The monthly mean slab thickness is about 180 km in winter and 280 km in summer. Blue and red vertical lines indicate the ranges of ± 3σ and ± 4.2σ. These ranges are equivalent to probabilities of once per 10 and 100 years, respectively, when the estimated slab thickness is assumed to have a normal distribution, that is, occurrence probability of the values larger than average + 3σ and + 4.2σ are 0.13% and 0.001%
Slab thickness against day of year: the red polyline is the monthly mean value of slab thickness. Blue and red vertical bars represent ± 3σ and ± 4.2σ, respectively
Here, we estimate the daily TEC from the daily NmF2 data, assuming the slab thickness has only seasonal dependence. Figure 10 shows the CDFs of the estimated daily TEC occurrence obtained using the monthly mean slab thickness and observed NmF2 from 1957 to 2018. The black histograms are distributions of the daily TEC estimated with the monthly mean slab thickness, which is shown with a red polyline in Fig. 9. The number of days per 100 years and the occurrence rate are shown on the left- and right-hand axes of the ordinate, respectively. The black solid, dotted, and dashed horizontal lines correspond to 0.3% (once a year), 0.03% (once every 10 years), and 0.003% (once every 100 years), respectively. The blue histograms in Fig. 10 are the distribution of TEC estimated with the average + 3σ slab thickness (upper value of the blue vertical line in Fig. 9), which corresponds to a slab thickness with a frequency of once per 10 years. According to this histogram, the TEC with a frequency of once per 10 years is 130 TECU or more. Furthermore, the red histograms in Fig. 10 are derived from the average + 4.2σ slab thickness (upper limit of the red vertical line in Fig. 3). This result indicates that TEC values of more than 190 TECU can be observed with a frequency of once per 100 years. These TEC values are summarized in Table 1.
CDFs of the daily TEC occurrence estimated with Method II. The occurrence rate, which is the number of days per 100 years, and the occurrence rate in percentage are shown on the left- and right-hand axes of the ordinate, respectively. The black histograms are derived from the average slab thickness shown in Fig. 9. The blue and red histograms are derived with slab thicknesses of average + 3σ and + 4.2σ, which are shown with blue and red vertical lines, respectively. The solid, dotted, and dashed horizontal lines represent occurrence rates of 0.3%, 0.03%, and 0.003%, which correspond to frequencies of once per year, 10 years, and 100 years, respectively
Latitudinal dependence of extreme TEC
Figures 1, 2, 3, 4, 5, 6, 7, 8 and 9 are results based on data obtained in Tokyo. Here we estimate extreme TEC values for southern and northern Japan because TEC behavior is expected to be different at different magnetic latitudes. Figure 11 shows the correlations of daily TEC between Tokyo and Kagoshima (31.2°N, 130.6°E, 21.7°N in Mag. Lat) and between Tokyo and Hokkaido (45.2°N, 141.8°E 36.4°N in Mag. Lat) for 22 years from 1997 to 2018. Basically, the TEC in Tokyo is smaller than that in Kagoshima and larger than that in Hokkaido. The red line represents the linear approximation of these data and reveals that the TECs in Kagoshima and Hokkaido are, on average, 1.2 and 0.8 times that in Tokyo, respectively. From these results, the TEC values with probabilities of once per year, 10 years, and 100 years are estimated as 110, 130–155, and 180–230 TECU (70, 90–105, and 120–150 TECU), respectively, in Kagoshima (Hokkaido) as round to the nearest multiple of five. The numbers are summarized in the second and third rows in Table 1.
Correlation of daily TEC between a Tokyo and Kagoshima and b Tokyo and Hokkaido from 1997 to 2018. The red line represents the linear approximation of each set of data
It is important to estimate the occurrence rates of extreme values of TEC in Japan in the short, mid-, and long term, which are once per year, 10 years, and 100 years, respectively, in readiness for hazardous ionospheric conditions. "Space Weather Phase 1 Benchmarks", which was published by the USA White House in June 2018, lists three factors that cause ionospheric disturbances: solar flares, proton events, and geomagnetic storms. However, quantitative benchmarks are difficult to derive because the effects of geomagnetic storms largely differ from event to event. Furthermore, the mechanism of ionospheric storms is not yet completely understood. Although the results in this paper are limited to the region around Japan, they are a starting point for evaluating benchmarks in other regions.
One of the challenges is to estimate extreme TEC value such as once per a 100 year with a limited data set. In this study, we have 22-year TEC data set and 62-year foF2 data set. Method I assumes the probability distribution of slab thickness as a normal distribution. First, raw \(\sigma\) is used to model the slab thickness with the 22-year data set. The resulting CDF which is shown with black histograms is Fig. 7 underestimates the observed CDFs in Fig. 1. The TEC values of once-per-year, for example, were about 90 TECU in Fig. 1 while that of black histograms in Fig. 7 was < 30 TECU. One of the reasons that the values underestimate extreme TEC values is that comes that the normal distribution cannot reproduce large value of slab thickness such as over 400 km. In order to cover the large slab thickness, the slab thickness distribution was approximated by inflated normal distributions. The inflation factor is a key parameter which affects the extreme TEC values. The solid and dashed lines in Fig. 8 show TEC values which would occur once per 10 and 100 years, respectively, as a function of the inflation factor. If the inflation factor is chosen as 5, the once-per-10-year TEC value is more than 150 TECU, which is comparable to the once-per-100-year TEC value for the inflation factor of 3.8. Inflation factor largely affects the extreme TEC value in Method I while this study adopts the inflation factor of 3.8 based on 22-year TEC data set.
In Fig. 6, the inflated normal distribution with an inflation factor of 3.8 overbounds the large slab thickness around 480 km while that of 2.0 does not. A discussion should be done for the assumption of normal distribution for the slab thickness. As shown in Figs. 5 and 6, the distribution of slab thickness has long tail, the tail cannot be reproduced by normal distributions even if the \(\sigma\) is inflated. Alternative approach would be to model the distribution in a different way. The distribution in Figs. 5 and 6 could be fitted by a sum of two normal functions which centers the core part and the tail parts, so-called double Gaussian, instead of multiplying an inflation factor to the standard deviation, which is left for future studies.
Comparing Method I and Method II, Method II is more conservative than Method I because Method II takes out the extreme slab thickness multiplies it with TEC values. Method I has an advantage in order to grasp the overall distribution while extreme large values are not reproduced, which may depends on how to determine the inflation factor. Method II has an advantage in estimating extreme values while overall distribution is not very accurate.
In this study, we estimated extreme TEC values by assuming that the slab thickness has only seasonal dependence. The seasonal dependence of the slab thickness shown in Fig. 9 is consistent with the results of previous studies (Jin et al. 2007; Huang et al. 2016). Another factor determining the slab thickness is the dynamics and/or composition change caused by geomagnetic disturbances. According to Stankov and Warnant (2009), the slab thickness is systemically enhanced during geomagnetic disturbances for both positive and negative ionospheric storms. Extreme values of TEC estimated by blue or red histograms in Fig. 10 would be recorded during geomagnetic storm conditions.
Extreme positive storms are thought to be caused by a geomagnetic disturbance that induces prompt penetration of the electric field (Tsurutani et al. 2004). The largest reported TEC is about 330 TECU to our knowledge, which was recorded by a GPS receiver onboard the CHAMP satellite at an altitude of about 400 km during the October 2003 Halloween storm (Mannucci et al. 2005). Magnetic latitude where the 330 TECU was observed was about 25°S. Although the observation was in the south hemisphere, the magnetic latitude is similar to that of Tokyo (26.8°N). The TEC value of 330 TECU reported in Mannucci et al. (2005) is much higher than our result of 190 TECU, which is conservatively estimated in Method II.
Before discussing possible reasons for the discrepancy between our result and that reported in Mannucci (2005), we have to discuss estimation accuracy of the instrumental bias to derive absolute value of TEC. In estimating instrumental bias, we assume that the hourly average of vertical TEC is uniform within an area covered by a receiver; this area approximately corresponds to a surrounding of 1000 km (Otsuka et al. 2002). It is reported that the technique can derive absolute values of TEC with the accuracy of ∼3 TECU in the daytime and ∼1 TECU in the nighttime, respectively, during quiet and moderated disturbed day. It is also reported the characteristics of temporal and spatial distribution of absolute TEC are consistent with the previous studies during a geomagnetic storm day. Nonetheless, during the geomagnetic disturbed condition, TEC tends to have spatial gradient and large-scale traveling ionospheric disturbances (LSTIDs) could appear. The horizontal scale of LSTIDs is more than 2000 km, which is larger than the assumption of TEC uniformity. Therefore, there is a possibility that the assumption of the TEC uniformity tends to be invalid during severe geomagnetic storm days. Zhang et al. (2009) investigated influences of geomagnetic storms on the estimation of GPS instrumental biases. The bias errors are in order of a few TECU while the errors are different among geomagnetic storms and its duration. Since the order of the errors in estimating instrumental bias is < 10 TEC, we speculate that the error would not reverse the difference between our result (190 TECU) and that in Manucci et al. (330 TECU) while further quantitative investigation would be necessary in order to clarify the estimation errors.
Here we discuss possible reasons for the difference between these values. One possibility is differences in observation opportunities. The characteristics of ionospheric storms are not always similar among geomagnetic storms, with their magnitude varying greatly from event to event. Mannucci et al. (2008) analyzed four intense geomagnetic storms in 2003 including the event for which the extreme value of 330 TECU was observed by the CHAMP satellite. A dramatic increase in TEC was observed in only one event. The observed TEC on the other three storm days was around 100 TECU or less. If the event-to-event difference is too large, 70 years of data might not be enough to estimate TEC values for once-per-100-year or once-per-1000-year events.
Another possibility accounting for the difference between the extreme value of 330 TECU in Mannucci et al. (2003) and our result is the longitude dependence of the ionospheric influence on geomagnetic storms. Immel and Mannucci (2013) analyzed global TEC maps during geomagnetic storms over 7 years. Their analysis confirmed that on average the American sector exhibits larger TEC enhancements regardless of the onset UT. Greer et al. (2017) used the Global Ionosphere–Thermosphere Model to carry out an experiment on a geomagnetic storm by modifying the storm arrival UT. The result indicated that the strongest enhancements of TEC during storms are found in the American and Pacific longitude sectors. They suggested that the longitudinal dependences were due to Earth's asymmetrical geomagnetic topology in the American and Pacific sectors. The difference between our results and that of Mannucci et al. (2003) may originate from the difference between the Japanese and American/Pacific sectors. In order to clarify whether the longitudinal dependence results in the large difference between the results of this study and that of Mannucci et al. (2008), long-term observational data in addition to data over oceans are necessary.
This study focuses on positive ionospheric storms, which may significantly affect GNSS users. On the other hand, the effect of negative storms on space weather users may also be significant, particularly for HF communicators, who may experience blackouts during negative ionospheric storms. In addition, parameters other than TEC, such as maximum usable frequency (MUF) and scintillation indices, should be studied for extreme cases.
In this study, extreme values of TEC with frequencies of once per year, 10 years, and 100 years were investigated. The results are summarized as follows:
The CDF of daily TEC values was studied for a 22-year data set observed in Tokyo in order to estimate TECs with frequencies of once per year and 10 years. The obtained once-per-year and once-per-10-year TECs were 90 and 110 TECU, respectively.
In order to estimate the once-per-100-year TEC value, 62 years of manually scaled ionosonde data were used to augment the insufficient observation period of TEC. The slab thickness was assumed to have only seasonal variation and was used to estimate TEC from 62 years of foF2 data. In this study, two methods were tested in order to compensate the insufficient number of data.
In Method I, the slab thickness distribution is modeled with artificially inflated normal distributions. The inflation factor was determined by calibrating the once-in-10-year TEC value deduced with various inflation factors with that based on 22-year TEC data set. The once-per-10-year TEC was result as 150 TECU.
In Method II, extreme slab thickness is applied to deduce the extreme TEC values. Slab thickness of the average + 3σ and + 4.2σ, which correspond to once-per-10-years and once-per-100-years, respectively, to deduce the extreme values of TEC. The result was 190 TECU. In Method II, once-per-10-year TEC is also derived and was 130 TECU.
Extreme TEC values were also studied for Kagoshima and Hokkaido in southern and northern Japan, respectively. In Kagoshima, those which occur once per one, 10, and a 100 years are 110 TECU, 130–155 TECU, and 180–230 TECU, respectively. In Hokkaido, they are 70 TECU, 90–105 TECU, and 120–150 TECU, respectively.
The TEC data used in this study are archived on NICT's homepage (https://aer-nc-web.nict.go.jp/GPS/GEONET/). Manually scaled ionosonde parameters are also archived on NICT's homepage (http://wdc.nict.go.jp/IONO/HP2009/ISDJ/manual_txt.html).
EIA:
Equatorial ionospheric anomaly
EUV:
Solar extreme ultraviolet (EUV)
foF2:
Critical frequency of the F-layer
GEONET:
GNSS Earth Observation Network System
GNSS:
Global Navigation Satellite System
HF:
HSHG:
High solar and high geomagnetic activity
HSLG:
High solar and low geomagnetic activity
LSHG:
Low solar and high geomagnetic activity
LSLG:
Low solar and low geomagnetic activity
MUF:
Maximum usable frequency
NICT:
NmF2:
Maximum density of the F2 layer
TEC:
Total electron content
Bauer SJ, Daniels FB (1959) Measurements of Ionospheric Electron Content by Lunar Radio Technique. J Geophys Res 64(10):1371–1376
Bilitza D (2018) IRI the International Standard for the Ionosphere. Adv Radio Sci 16:1–11. https://doi.org/10.5194/ars-16-1-2018
Cherniak I, Zakharenkova I, Redmon RJ (2015) Dynamics of the high-latitude ionospheric irregularities during the 17 March 2015 St. Patrick's Day storm: ground-based GPS measurements. Space Weather 13:585–597. https://doi.org/10.1002/2015SW001237
Evans JV (1977) Satellite beacon contributions to studies of the structure of the ionosphere. Reviews of Geophysics 15(3):325
Foster JC, Rideout W, Sandel B, Forrester WT, Rich FJ (2007) On the relationship of SAPS to storm-enhanced density. J Atmos Sol Terr Phys 69:303–313
Cliver EW, Svalgaard L (2004) The 1859 solar-terrestrial disturbances and the current limits of extreme space weather activity. Sol Phys 224:407–422
Gladden, Sanford C (1959) A history of vertical-incidence ionosphere sounding at the national bureau of standards, United states department of commerce office of technical services
Greer KR, Immel T, Ridley A (2017) On the variation in the ionospheric response to geomagnetic storms with time of onset. J Geophys Res Space Phys 122:4512–4525. https://doi.org/10.1002/2016JA02345
Hochegger G, Nava B, Radicella SM, Leitinger R (2000) A family of ionospheric models for different uses. Phys Chem Earth Part C Solar Terr Planet Sci 25(4):307–310
Huang H, Liu L, Chen Y, Le H, Wan W (2016) A global picture of ionospheric slab thickness derived from GIM TEC and COSMIC radio occultation observations. J Geophys Res Space Phys 121:867–880. https://doi.org/10.1002/2015JA021964
Immel TJ, Mannucci AJ (2013) Ionospheric redistribution during geomagnetic storms. J Geophys Res Space Phys 118:7928–7939. https://doi.org/10.1002/2013JA018919
Jin S, Cho J-H, Park J-U (2007) Ionospheric slab thickness and its seasonal variations observed by GPS. J Atmos Sol Terr Phys 69(15):1864–1870. https://doi.org/10.1016/j.jastp.2007.07.008
Kataoka, R. (2020) Extreme geomagnetic activities: a statistical study. Earth Planets Space 72:124. https://doi.org/10.1186/s40623-020-01261-8
Klobuchar JA (1987) Ionospheric time-delay algorithm for single-frequency GPS users. IEEE Trans Aerosp Electron Syst AES-23(3):325–331
Mannucci AJ, Tsurutani BT, Iijima BA, Komjathy A, Saito A, Gonzalez WD, Guarnieri FL, Kozyra JU, Skoug R (2005) Dayside global ionospheric response to the major interplanetary events of October 29. 30, 2003 Halloween Storm. Geophys Res Lett 32:L12S02. https://doi.org/10.1029/2004GL021467
Mannucci AJ, Tsurutani BT, Abdu MA, Gonzalez WD, Komjathy A, Echer E, Iijima BA, Crowley G, Anderson D (2008) Superposed epoch analysis of the dayside ionospheric response to four intense geomagnetic storms. J. Geophys. Res. 113:A00A02. https://doi.org/10.1029/2007JA012732
Maruyama T (2011) Modified solar flux index for upper atmospheric applications. J Geophys Res 116:A08303. https://doi.org/10.1029/2010JA016322
Maruyama T, Ma G, Tsugawa T (2013) Storm-induced plasma stream in the low-latitude to midlatitude ionosphere. J Geophys Res Space Phys 118:5931–5941. https://doi.org/10.1002/jgra.50541
Nishioka M, Saito A, Tsugawa T (2009) Super-medium-scale traveling ionospheric disturbance observed at midlatitude during the geomagnetic storm on 10 November 2004. J Geophys Res 114:A07310. https://doi.org/10.1029/2008JA013581
Otsuka Y, Ogawa T, Saito A, Tsugawa T, Fukao S, Miyazaki S (2002) A new technique for mapping of total electron content using GPS network in Japan. Earth Planets Space 54:63–70. https://doi.org/10.1016/S0273-1177(00)00138-1
Radicella SM, Leitinger R (2001) The evolution of the DGR approach to model electron density profiles. Adv Space Res 27(1):35–40
Riley P (2012) On the probability of occurrence of extreme space weather events. Space Weather 10:S02012. https://doi.org/10.1029/2011SW000734
Saito A, Fukao S, Miyazaki S (1998) High resolution mapping of TEC perturbations with the GSI GPS network over Japan. Geophys Res Lett 25:3079–3082. https://doi.org/10.1029/98GL52361
Stankov SM, Warnant R (2009) Ionospheric slab thickness. Analysis, modelling and monitoring. Adv Space Res 44:1295–1303
Tao C, Nishioka M, Tsugawa T, Saito S, Shiota D, Watanabe K, Ishii M (2020) Statistical analysis of short-wave fadeout for extreme event estimation. Earth Planets Space. https://doi.org/10.1186/s40623-020-01278-z
Tsubouchi K, Omura Y (2007) Long-term occurrence probabilities of intense geomagnetic storm events. Space Weather 5:S12003. https://doi.org/10.1029/2007SW000329
Tsurutani BT et al (2004) Global dayside ionospheric uplift and enhancement associated with interplanetary electric fields. J Geophys Res 109:A08302. https://doi.org/10.1029/2003JA010342
US White House (2018) Space Weather Phase 1 Benchmarks. Space Weather Operations, Research, and Mitigation Subcommittee Committee on Homeland and National Security, National Science & Technology Council. https://www.sworm.gov/publications/2018/Space-Weather-Phase-1-Benchmarks-Report.pdf
Xu Z-W, Wu J, Igarashi K, Kato H, Wu Z-S (2004) Long-term ionospheric trends based on ground-based ionosonde observations at Kokubunji. Japan J Geophys Res 109:A09307. https://doi.org/10.1029/2004JA010572
Yue X, Wan W, Liu L, Ning B, Zhao B (2006) Applying artificial neural network to derive long-term foF2 trends in the Asia/Pacific sector from ionosonde observations. J Geophys Res 111:A10303. https://doi.org/10.1029/2005JA01157
Zhang W, Zhang DH, Xiao Z (2009) The influence of geomagnetic storms on the estimation of GPS instrumental biases. Ann Geophys 27:1613–1623. https://doi.org/10.5194/angeo-27-1613-2009
GPS data of GEONET were provided by the Geospatial Information Authority of Japan. MN thanks to ionograms scalers of NICT and forerunner of NICT for valuable manually scaled data.
This work was supported by MEXT/JSPS KAKENHI Grant 15H05813.
National Institute of Information and Communications Technology (NICT), Tokyo, Japan
Michi Nishioka, Chihiro Tao, Daikou Shiota, Takuya Tsugawa & Mamoru Ishii
Electronic Navigation Research Institute (ENRI), National Institute of Maritime, Port and Aviation Technology (MPAT), Tokyo, Japan
Susumu Saito
Michi Nishioka
Chihiro Tao
Daikou Shiota
Takuya Tsugawa
Mamoru Ishii
MN conducted the research and has responsibility for the results presented in this paper. SS has supported this analysis and contributed to the discussion. CT, DS, TT, and MI contributed to the discussion as experts of ionosphere and space weather. All authors read and approved the final manuscript.
Correspondence to Michi Nishioka.
Nishioka, M., Saito, S., Tao, C. et al. Statistical analysis of ionospheric total electron content (TEC): long-term estimation of extreme TEC in Japan. Earth Planets Space 73, 52 (2021). https://doi.org/10.1186/s40623-021-01374-8
Total electron content (TEC)
Extreme TEC
Long-term ionosonde observation
Manually scaled foF2
Slab thickness
3. Space science
Solar-Terrestrial Environment Prediction: Toward the Synergy of Science and Forecasting Operation of Space Weather and Space Climate | CommonCrawl |
iForest - Biogeosciences and Forestry
iForest
Home Menus
Current Volume Journal Archive Browse Articles Collections/Special Issues
Search Archives Site Search Authors' List Most Cited & Viewed Geo-Archives
Aims & Policy Editorial Board Publication Time License and Terms of Use Privacy Policy Journal Metrics Credits & Partnership
Journal Subjects and Fields
Publishing procedures Authors Guidelines Paper Submission Search Engine Optimization
Article Alert Service RSS Feeds
SISEF Publishing
Forest@ - Journal of Silviculture and Forest Ecology SISEF Newsletter SISEF Editorials SISEF Workgroup Activities SISEF Congress SISEF on Facebook SISEF Channel on YouTube
Search iForest Contents
Forest management with carbon scenarios in the central region of Mexico
Agustín Ramírez-Martínez (1), Manuel de Jesús González-Guillén (1) , Héctor Manuel De Los Santos-Posadas (1), Gregorio Ángeles-Pérez (1), Wenceslao Santiago-García (2)
More Authors Less Authors
iForest - Biogeosciences and Forestry, Volume 14, Issue 5, Pages 413-420 (2021)
doi: https://doi.org/10.3832/ifor3630-014
Published: Sep 15, 2021 - Copyright © 2021 SISEF
Images & Tables
The search for mechanisms to mitigate global warming has generated a series of proposals to reduce deforestation and promote conservation of forests as carbon stocks through financial or in-kind support. However, the economic implications of including carbon sequestration in forest for timber production have not been dealt with in depth, and the conditions in which combined production might be a profitable option to forest owners, particularly in Mexico, are unknown. The aim of this study was to quantify carbon sequestration in a central region of Mexico and evaluate the profitability of selling carbon credits as well as timber products. Data and information used comes from three inventories (2013, 2014 and 2016) taken in 160 permanent sampling plots of 400 m2 each; forest management costs per hectare were obtained through interviews to the landowners, and the profitability was assessed using the economic indicators Net Present Value (NPV), Internal Return Rate (IRR), Benefit-Cost Ratio (BCR), and Land Expected Value (LEV). The results indicate that, in areas of low productivity, carbon sequestration is profitable only at a low discount rate (3.5%) and a high price of the ton CO2e (US$ 100 ha-1 year-1). However, under combined production, the optimal rotation periods are longer, depending on the discount rate and price of sequestered carbon. Therefore, timber production will continue to be the main economic activity, until the rules of operation of the different mechanisms created for carbon sequestration become more flexible and the carbon markets offer more attractive incentives.
Climate Change, Carbon Sequestration, Productivity, Financial Profitability, Optimal Rotation
Climate change (CC) is a statistical variation in the mean state of the climate over a prolonged period. It is produced by natural processes or by persistent anthropogenic changes ([20]). Today, it is undoubtedly one of the issues attracting the most interest and will continue over the upcoming decades. According to Joos & Spahni ([21]), the concentration of carbon dioxide (CO2) in the atmosphere at the beginning of the industrial age (1970) was approximately 277 parts per million (ppm), a value that has increased to 407.38 ± 0.1 ppm in 2018 ([13]). This has intensified the search and development of mechanisms to balance the concentrations of CO2 and other greenhouse effect gases (GEG) and compounds in the atmosphere to detain or reduce global warming.
One of these mechanisms is the Kyoto Protocol, in which developed countries committed to reducing their emissions of GEG by at least 5.2 %, relative to 1990 levels, for the period 2008-2012. In addition, in 2015, 195 countries signed the Paris Agreement, whose objective is to detain the temperature increase in this century to less than 2 °C ([49]). In such agreement, it is recognized that forests play a central role in achieving this goal, since they store large amounts of carbon in both vegetation and soils, and have an important role in the exchange of carbon dioxide between the biosphere and the atmosphere ([3]); therefore, their conservation and restoration are unpostponable. As a result, international policy instruments and programs have emerged such as REDD+ projects, that are based on the provision of financial incentives to conserve forests, improve forest carbon stocks and sustainable forest management ([35]), or the Clean Development Mechanism (CDM), which is an instrument designed to reduce greenhouse gas emissions through the purchase of Certified Emission Reduction Units (CERs) from afforestation or reforestation projects in developing countries ([51]). Under the CDM, several Latin American countries have participated in afforestation and reforestation projects, such as Bolivia, Peru, Paraguay, Uruguay, Brazil, Argentina, Chile. While in REDD+, in 2011, Peru and Brazil had more than 40 pilot projects, being among the countries with the largest number of projects worldwide; Nicaragua, El Salvador, Belize, Panama, Costa Rica have also taken part in this initiative ([26]). Likewise, some countries have made various commitments to contribute to the mitigation of climate change, for example, Colombia and Brazil which committed to restoring 1 and 12 million forest hectares, respectively ([44]), through the Bonn Challenge, which aims to restore 150 million global hectares of degraded lands by 2020.
In 2009, the government of Mexico, through its Special Climate Change Program (Programa Especial de Cambio Climático - PECC), committed to reducing its GEG emissions by 50% to 2050, relative to the quantity emitted in 2000 ([37]). In addition, in the Paris Agreement, the government committed to reducing GEG by 22% and short-lived climate pollutants (SLCPs) by 51% for the year 2030, relative to the base scenario.
Despite the environmental and social benefits obtained under this approach, in Latin America there are few studies related to CC, timber production and carbon sequestration; most of them have been directed only to the quantification of biomass and carbon stocks in natural forests ([38]), forest plantations ([27]) or in determining the climate change mitigation potential of forest ecosystems ([17]). It is therefore necessary to carry out studies to address the production of more than one good or service, such as the production of timber plus the benefits of carbon sequestration, the production of water and biodiversity conservation. Specifically, the inclusion of carbon sequestration benefits to forest harvesting has various implications such as an extended rotation period ([12], [46]). To this respect, Nepal et al. ([32]) found that for Mississippi forest landowners to be willing to extend the rotation period by 5 and 10 years, the prices for captured carbon must be US$ 50 and US$ 110 per Mg CO2e, respectively. On the other hand, Köthke & Dieter ([24]) mention that including the benefits of carbon sequestration in forest management could be an opportunity to achieve profitability in forest sites that until now were not profitable. Therefore, the economic analysis of alternative scenarios of the joint production of timber plus carbon sequestration through financial indicators represents an adequate alternative to analyze the profitability of forestry and to determine the conditions under such production would be profitable.
The objective of this study was to quantify the carbon sequestration in managed forests in the central region of Mexico, and to evaluate the financial profitability of timber production combined with carbon credits in different alternative scenarios.
The study was conducted in the Intensive Carbon Monitoring Site Atopixco, which is located in a forested region of Zacualtipán, Hidalgo state, in the Sierra Madre Oriental (Mexico). It covers portions of ejidos Atopixco, La Mojonera, El Reparo, Tzincuatlán, Zahuastipán and Santo Domingo, and small private land with an area of 900 ha (3 × 3 km - [33]). The site is part of the "Red Méx-SMIC, Intensive Carbon Monitoring Sites network", established in 2012 in forest landscapes of Mexico, with the aim of obtaining information for the calibration-validation of models of forest carbon dynamics ([4]). The main vegetation types at the regional level are pine-oak forests, oak forests and tropical montane cloud forest.
Forest management in these forests began in the early 1980's using the Method of Silvicultural Development (MSD), which is a planning scheme based on rotation age ([31]). The regeneration method is a seed tree method prescribing 3 to 4 thinnings evenly spaced during a rotation of 40 to 80 years. The goal is to regenerate forest stands whose age composition and density achieve the maximum average production ([48]). In the last four decades, forest management has been oriented toward developing even-aged forests dominated by Pinus patula, a fast growing species that is endemic to Mexico. The topography of the site is hilly with a mean altitude of 2100 m a.s.l. The predominant soil is Feozem, with good drainage. Climate is humid temperate [C(m)] and subhumid temperate [C(w2)], mean annual temperature is 13.5 °C, and mean annual precipitation is 2050 mm.
Field data
The dataset was obtained from three measurements (2013, 2014 and 2016) of 40 clusters, each consisting of four 400 m2 sampling plots distributed in an inverted "Y" within one hectare. The registered variables were total height (H, m), diameter at breast height (DBH, cm), dominant height (HD, m), number of live trees (NL) and stand age (years) obtained in the field and from the forest management plan.
Financial characterization and discount rate
Average costs per hectare of timber production were obtained through interviews with the agents of forest activity (ejido president, forest administrator, and forest workers), for the stages of stand establishment, maintenance, and harvest, which are the main activities of the forest management process. Fixed costs were obtained from establishment and maintenance, while variable costs were defined in function of timber production.
Discounting future cash flows is an economic practice of long tradition in forest economics, due to the long period of time between stand regeneration ([43]) and final harvest. According to Bettinger et al. ([5]), the discount rate can be nominal or real; the first includes inflation, while the second does not and may or may not incorporate a risk factor. Klemperer ([23]) remarks that there is no risk factor universally used, and its selection will depend on the payment period, the amount of risk in incomes and the degree of aversion to risk of the decision-maker. Worldwide, reported discount rates used in forest investments oscillate between 6% in the northern hemisphere and 15% in the southern hemisphere ([10]). For Mexico, of the few studies conducted to date, Masera et al. ([28]) analyzed the forestry options for carbon sequestration by comparing three study cases and using four real discount rates (0, 3, 5 and 10%). Based on that study and given the high variability of the discount rates used, we opted for real rates of 3.5% and 4.5% without considering a risk factor.
Forest growth systems, timber and carbon yield
Information on growth systems and yield per hectare were obtained from the prediction and projection models of Ramírez et al. ([36]). Aboveground biomass per hectare was estimated from the timber volume of Pinus patula and broadleaf species with factors of direct proportionality of 0.433 and 0.817, respectively ([36], [33]). Aboveground carbon ratio for Pinus patula and broadleaf species were 0.507 and 0.494, respectively ([15]). Carbon estimations in MgC ha-1 were multiplied by 3.667 (ratio between molecular weights of CO2 and carbon, 44/12) because the carbon markets operate in metric tons of carbon equivalent (MgCO2e). In addition, we did not consider the penalty for the re-emission of CO2 into the atmosphere at the time of harvest, since the proportions of the final products are not known of short or long life that the harvested timber will become.
Diameter distribution modeled with the Weibull function
The stand variables proposed were dominant height (HD, m), site index (SI, m), basal area (BA, m2 ha-1), number of trees ha-1 (NT) and quadratic mean diameter (Dq, cm). The height (H, m) by diameter class (D), growth in quadratic mean diameter and total volume (V) were obtained with eqn. 1, eqn. 2 and eqn. 3, respectively:
\begin{equation} H=1.3+0.241315 \cdot HD^{1.085389} D^{ \left (0.711527 \cdot HD^{-0.26345} \right )} \end{equation}
\begin{equation} Dq=5.663274 \cdot exp \left (\frac{-14.54899}{Age} \right) \cdot SI^{0.572138} \end{equation}
\begin{equation} V=0.0000253 \cdot D^{1.6939421} H^{1.4175090} \end{equation}
The parameters that are part of the Weibull function were recovered using the moment method ([42]), while percentiles were estimated with Ordinary Least Squares (OLS - eqn. 4, eqn. 5, eqn. 6):
\begin{equation} p_0=0.319277 Dq^{1.715867} HD^{-0.60877} Age^{0.173854} \end{equation}
\begin{equation} p_{65}=1.006196 Dq^{1.029508} \end{equation}
\begin{equation} p_{93}=1.865844 \cdot Dq^{0.89569} \end{equation}
The parameter location a was estimated as follows (eqn. 7):
\begin{equation} a= \left \{ \matrix {p_0 = 2.5 & \text{when}\;\; P_0 \ge 5 cm \cr \frac{p_0}{2} & \text{otherwise}} \right . \end{equation}
while parameter c was calculated as (eqn. 8):
\begin{equation} c= \frac{\ln[-\ln (1-0.93)/-\ln (1-0.65)]}{\ln [(p_{93}-a)/(p_{65}-a)]} \end{equation}
and parameter b was estimated with the expression of the second moment of the Weibull distribution (eqn. 9):
\begin{equation} b=a \cdot {\frac{\Gamma_1}{\Gamma_2}} + { \left [{ \left (\frac{a}{{\Gamma_2}} \right)}^2 \cdot \left({\Gamma_1}^{2} - \Gamma_2 \right ) + \frac{Dq^2}{\Gamma_2} \right]}^{\frac{1}{2}} \end{equation}
where Γ(.) is the Gamma function, Γ1 = Γ[1+(1/c)] and Γ2 = Γ[1+(2/c)].
Distribution and prices by type of timber product and Mg CO2e
Products were allocated with the equation of Fang et al. ([14]) reported in the Forest Biometric System corresponding to the Unit of Forest Management 1302 Zacualtipán-Molango ([50]). The products considered were: cellulosic (10 ≥ d < 20 cm); secondary (20 ≥ d < 25 cm); and primary products (d ≥ 25 cm). The nominal price by type of product was obtained through interviews in the study region: cellulosic (US$ 15 m-3), secondary (US$ 40 m-3) and primary (US$ 80 m-3). Since the prices per carbon credit (MgCO2e ha-1 year-1) were below US$ 75, there were no profitable scenarios. The exchange rate was $20.00 MXN to one dollar.
Updating production costs
To deflate the different values, 2013 was used as the base year because it had the following characteristics: it is a recent year, abundant information is available, reasonable historic economic behavior was registered, normal market conditions, uniformity in price variations, and no catastrophic events occurred (natural disasters, political elections, special events, etc. - [19]).
Present production values (PV) were estimated by type of product discounted at interest rate i with eqn. 10. Wood prices were deflated with eqn. 11, while costs (fixed and variable) of timber production were deflated with eqn. 12 and updated with eqn. 13:
\begin{equation} PV= \frac{Pr_{j} \cdot Q_{j}}{{(1+i)}^t} \end{equation}
\begin{equation} P_{r} = \frac{Pc}{INPP} \cdot 100 \end{equation}
\begin{equation} Cr_{k} = \frac{Cc_{k}}{INPP} \cdot 100 \end{equation}
\begin{equation} Ct_{k} = \frac{Cr_{k}}{{(1+i)}^t} \end{equation}
where PV is the discounted production value (US$), Prj is the real price by product type (US$ m-3), Qj is the product amount (m3 of timber), Pc is the nominal price of timber (US$ m-3), INPP is the National Index of Prices to the Producer with base year 2013, Cck is the nominal cost (US$), Crk is the real cost (fixed or variable, US$), Ctk is the total discounted cost (US$), i is the real discount rate (3.5% and 4.5%), t is the number of years, beginning with the present, in which production is registered, j are the primary, secondary or cellulosic products, k are the stages of forestry process (establishment, maintenance, and timber harvest).
Reineke density index
The Reineke's stand density index (SDI - eqn. 14) and the equation that represents the number of trees with 1 cm diameter per hectare (eqn. 15) were fit with OLS using 26 sites equivalent to 20% of all the sites of the dataset (130 sites - [41]):
\begin{equation} SDI=NT \cdot { \left (\frac{19}{Dq} \right )}^{-1.605} \end{equation}
\begin{equation} NT = \alpha_0 \cdot Dq^{ \alpha_1 } \end{equation}
where NT is the number of trees ha-1, Dq is the quadratic mean diameter ha-1, αi are the parameters to be estimated.
Components of the evaluated scenarios
The different scenarios included the following variables and conditions: (i) productivity, site index (SI) of 18 and 30 m; (ii) silvicultural treatments, two thinnings and one regeneration cutting at the end of the rotation period (40 years), and one regeneration cutting at the end of the rotation period; (iii) final product: wood, carbon and a combined production (wood plus carbon); (iv) discount rate: 3.5% and 4.5%, and finally, the price of MgCo2e ha-1, which was US$ 75 and US$ 100. The combination of these gave rise to different scenarios. The percentage of trees to remove in each thinning was obtained through a density management diagram. The density management diagram is one of the most efficient methods of silvicultural planning and management in even-aged forests ([30]). This enables maximizing individual growth and total biomass production ([41]). Although the MSD considers 3 to 4 thinnings during the rotation period, we limited to two thinnings at 10 and 20 years, and a regeneration cutting at the end of the rotation (40 years). Pinus patula reaches its maximum volume growth between 24 and 27 years ([36]), and another thinning at 30 years of age would not have little effect on the species growth. The scenarios were evaluated based on the final product, timber and captured carbon (Tab. 1).
Tab. 1 - Scenarios evaluated for the condition of pine forest and timber as end product under the silvicultural treatment of two thinnings and one regeneration cutting. (SI): site index.
Discount rate
Price Mg Co2e
1 18 3.5 100 Timber
3 30 3.5 100
5 18 3.5 100 Carbon sequestration
Enlarge/Reduce Open in Viewer
The financial indicators used were Net Present Value (NPV), Internal Return Rate (IRR), Benefit-Cost Ratio (BCR) and Land Expected Value (LEV). Eqns. 16 to 19 show the respective algebraic expressions ([9], [39]):
\begin{equation} NPV=\sum_{t=0}^{n} {\frac{B_{t} -C_{t}} {(1+i)^t}} \end{equation}
\begin{equation} IRR=\sum_{t=0}^{n} {\frac{B_{t} -C_{t}}{(1+i^{ \text{*}} )^t}}=0 \end{equation}
\begin{equation} BCR=\frac{\sum_{t=0}^{n} {{B_{t}}/(1+i)^t}}{\sum_{t=0}^{n} {{C_{t}}/(1+i)^t}} \end{equation}
\begin{equation} LEV= \frac{\left [PVc+PVf - (Ad + Ma + \text{Re}) \cdot \delta - (Gr+Mr) \cdot e^{-iT} \right ]}{ \left (1- e^{-iT} \right )} +S \end{equation}
where Bt, Ct are the benefits and costs in the time period t (US$ ha-1); t is the time in years; i is the real discount rate (3.5% and 4.5%); i* is the rate that makes the cash flow equal zero; LEV is the land expected value; PVc, PVf are the net present value of the benefits for carbon sequestration and sale of wood; Ad, Ma, Re, Gr, Mr are, respectively, the regeneration administrative costs (US$ ha-1), road maintenance costs of regeneration (US$ ha-1), regeneration land rent (US$ ha-1), costs of regeneration protection, and costs of stand maintenance (US$ ha-1), regeneration (US$ ha-1); S are the government support granted to the ejidos (US$ ha-1); δ is the parameter that expresses the discount factor for annuity; T is the rotation age (40 years).
Determination of the optimal rotation age for combined production
To determine the optimal rotation age for combined production, the equi-marginality criteria were used, that is, when the marginal benefit (MB) and the marginal cost (MC) associated with the decision to harvest are equal. Its mathematical expressions are presented in eqn. 20 and eqn. 21 ([46]):
\begin{equation} MB= \sum_{i} p_{i}V_{i}^{\prime}(T) + \left [pc \cdot \alpha \cdot V^{\prime}(T) \right ] \end{equation}
\begin{equation} MC=r \sum_{i} p_{i} V_{i} (T) + d(LEV) \end{equation}
where i = [cellulosic (ce), secondary (se), and primary products (pr)]; pi is the price of the i-th product; V′i(T) is the marginal increase in volume of the i-th product; Vi(T) is the volume of the i-th product at the end of the planning horizon; V′(T) is the increase in total volume; d is the real discount rate (3.5% and 4.5 %); pc is the price of carbon; α is a constant that expresses the proportion of CO2e per m3 of wood.
Financial characterization
The costs and percentages during stand establishment (year 1) are shown in Tab. 2. Firebreaks, which are opened on the perimeter of the regeneration area with a minimum width of 3 m, was the costliest (US$ 79.16), followed by purchase of seedlings (US$ 63.32) and forest tools (US$ 48.34 - machetes, axes, hoes, rakes and shovels). The total average cost for the stand establishment was US$ 352.54 ha-1, which was equivalent to 45.49% of the total costs (i.e., stages of establishment and maintenance).
Tab. 2 - Activities and real average cost (US$ ha-1) for the stand establishment during the first year.
(US$ ha-1)
Fencing material 29.92 3.86
Labor for fencing 27.49 3.61
Cost of seedlings 63.32 8.17
Transportation costs of seedlings 5.28 0.68
Labor for seedling establishment 54.19 6.99
Opening roads 44.33 5.72
Opening fire-breaks 79.16 10.21
Tools 48.34 6.24
Total 352.54 45.49
Maintenance involved six activities (Tab. 3) and accounts for 54.51% of the total fixed costs (not considering harvesting costs). Costs of land rent and protection against pests and fires are covered throughout the rotation period (40 years) and add up to US$ 101.98 ha-1 year-1. Cleaning of the planted land (chapeo), pruning and liberation cutting are carried out during the first 8 years of the stand with an annual cost of US$ 120.49 ha-1. Maintenance of firebreaks and roads has a cost of US$ 133.40 ha-1 in the second year and US$ 66.60 ha-1 year-1 from the third and successive years. The total cost, considering the establishment and maintenance stages for the planning horizon was US$ 775.03 ha-1.
Tab. 3 - Activities and real average cost (US$ ha-1) for the maintenance stage.
Land rent 65.65 Yearly 8.47
Protection against pests 28.24 Yearly 3.64
Protection against fires 8.09 Yearly 1.04
Clearing 69.43 Until year 8 8.95
Pruning and liberation cutting 51.05 Until year 8 6.58
Maintenance of fire-breaks 87.35 Only during the 2nd year 11.27
Maintenance of roads 46.05 Only during the 2nd year 5.94
Maintenance of fire-breaks 43.57 As of the 3rd year 5.62
Maintenance of roads 23.03 As of the 3rd year 2.97
Total 422.48 - 54.51
Harvest activities had a total cost of US$ 12.23 m-3 extracted and includes the cost of forest technical services (US$ 1.50 m-3); on site processing (felling, sectioning and moving logs to the drag track) costs US$ 8.07 m-3, while for final cutting and thinning (regardless of the type of product) and costs of administration was US$ 2.68 m-3.
During the rotation period, the ejido receive diverse subsidies from the federal government through the National Forestry Commission (CONAFOR) to achieve different activities including a payment for environmental services destined to conservation of forested areas that have been excluded from timber production (Tab. 4).
Tab. 4 - Average Mexican government subsidy, in real terms (US$ ha-1), in support of forestry activity in the region.
Fencing 49.68 First year
Planting 73.26 First year
Road maintenance 34.72 Every year
Cleaning of the planted land (chapeo) and pruning 44.24 Until 8 years
Payment for environmental services 78.24 Every year
Total 280.17 -
In the harvesting stage, an aspect that called our attention was the high cost of administration. Every cubic meter of extracted timber had a cost of US$ 2.68 (21.97% of the total cost of this stage), added to the costs of in site processing of US$ 0.07 (65.99 %) and US$ 1.50 (12.04 %) for forest technical services, making a total of US$ 12.23 m-3. The costs of administration during timber harvest are considered high. On average, this harvest activity is carried out by four people, who work approximately four months, but with adequate organization, it could be done by two people. However, trying to reduce these costs is complicated because the ejidos highly value the social features (i.e., job generation).
The Reineke's stand density index and thinning regime
Fitting of the Reineke's stand density index model had an R2-adj of 0.96, as well as statistical significance in its parameters. The following is the final model (eqn. 22):
\begin{equation} NT = 198260.27 \cdot Dq^{-1.74} \end{equation}
where NT is the number of trees ha-1, Dq is the quadratic mean diameter (cm).
The density management diagram generated for an initial 1200 trees suggests two intensive thinnings before harvest (40 years - Fig. 1). This result coincides with Santiago et al. ([41]), who indicated that in Pinus patula stands in a geographic area near our study site, thinning intensity should be 50% at each intervention.
Fig. 1 - Thinning prescription for Pinus patula stands in Zacualtipán, Hidalgo. (Sec. Ac.): thinning intensity; (100% and 60%): upper and lower limit of the area of self-thinning; (30%): upper limit of the area of constant growth; (20%): lower limit of growth free of mortality.
Enlarge/Shrink Download Full Width Open in Viewer
Thinnings occur at a Dq of 14.34 and 20.90 cm, while the final cutting is at 31.5 cm at the age of 10, 20 and 40 years, respectively. The thinning intensity suggested is 48% and 50% for the first and second thinnings. This does not consider natural mortality since in natural stands with densities below 1000 threes ha-1, the mortality rate is low (0.81% - [36]). Therefore, decreasing the number of individuals was the consequence of only silvicultural interventions.
Scenarios for pine forest
Tab. 5presents the financial indicators obtained for the scenarios generated for timber as the final product. For all the scenarios in which two thinnings and one regeneration cutting are applied (scenarios 1, 2, 3, and 4), the results indicate that timber production is profitable, with PNV of 735.79 to US$ 1838.31 ha-1, IRR of 6.09 to 6.51% with BCR of more than one, and positive LEV values. Undoubtedly, the scenarios with SI 30 have better results than those with SI 18 and are even better when low interest rates are considered, as was shown with an interest rate of 3.5%. Application of thinnings is of great importance in forest management because it permits redistribution of growth and manipulation of tree spacing, favoring growth of the target individuals and species ([29]).
Tab. 5 - Financial indicators obtained for the scenarios of SI 18 and SI 30, with timber as the end product.
NPV
(yrs)
1 18 3.5 1512.54 6.09 1.25 29 650.16
2 18 4.5 735.79 6.09 1.14 29 -114.47
4 30 4.5 974.84 6.51 1.17 27 51.76
For the scenario of not harvesting at the rotation age and entering to the market of carbon credits to commercialize sequestered CO2e stored in the forest stand, estimated financial indicators are optimistic under certain conditions. Fig. 2shows the NPV for the different scenarios; the highest value is obtained in SI 30, with two thinnings and one regeneration cutting, a discount rate of 3.5% and a price of US$ 100 per MgCO2e ha-1 year-1 (scenario 7), while the lowest value occurred in SI 18 with two thinnings and the regeneration cutting, a discount rate of 4.5% and a price of US$ 75 (scenario 6).
Fig. 2 - Net present value (NPV) for different scenarios and SI of 18 and 30.
The values obtained for IRR ratify the finding for NPV (Fig. 3a). The proposed scenarios (no. 5, 6, 7, and 8) for SI 18 and SI 30 had values above 10%. Under the defined conditions, the discount rate used can increase to 10% and, even then, the project would still be profitable. On the other hand, Fig. 3b shows the BCR for different scenarios. The highest value was obtained in scenario 7, in which US$ 2.02 would be received for every dollar invested, while in scenario 6, there would be a profit of US$ 0.77 for each dollar invested.
Fig. 3 - Internal return rate (IRR) (%) (a) and benefit cost ratio (BCR) (b) obtained in the scenarios with SI of 18 and 30.
Optimal rotation period for timber production plus carbon sequestration
The technical rotation determined for SI 30 was 37 years, but if a combined production is selected, the optimal rotation period (i.e., when BM = CM) lengthens. With a discount rate of 3.5% and a price of US$ 100 per MgCO2e ha-1 year-1 captured, the optimal rotation period was more than 75 years. However, using the same discount rate, but at a price of US$ 75, the rotation period is 69 years (Fig. 4a). Using a discount rate of 4.5% with a price of US$ 100 and US$ 75 per MgCO2e ha-1 year-1 captured, the optimal periods are 75 and 63 years, respectively (Fig. 4b). This implies that when the discount rate increases, the optimal rotation period decreases. This behavior was also reported by Abedi et al. ([1]) and Keles ([22]). The extent of the rotation age, including carbon sequestration benefits, has been documented by several authors. Abedi et al. ([1]) evaluated two Populus deltoides plantations in northern Iran and found that, by including carbon sequestration, the rotation ages increased from 10 to 14 years for tree density of 3 by 3 m and from 8 to 11 years for the 3 × 4 m. Similarly, Keles ([22]) determined the optimal cutting ages in plantations of Turkish pine (Pinus brutia Ten.), under different crop spacing and found that without considering the benefits from carbon sequestration, the optimal cutting ages were between 29 and 32 years; however, when these benefits were included, the optimal ages were between 33 and 39 years. Likewise, Gutrich & Howarth ([18]) explored different types of forest in the state of New Hampshire, USA and found that the optimal rotation period without considering carbon sequestration varied from 34 to 44 years, depending on the type of forest, and when considering low marginal benefits from carbon sequestration, the optimal rotation period was 53 to 177 years.
Fig. 4 - Optimum rotation period in a SI of 30 for combined production. Prices for MgCO2e ha-1 year-1 of US$ 100 and US$ 75 with a discount rate of (a) 3.5% and (b) 4.5%.
Timber production or carbon sequestration
In general, timber production involves a series of high costs attributable to establishment and maintenance over the rotation period (40 years). In productive areas with SI of 24, 30 and 36, this activity is profitable, but in poor sites (SI 18), it is not. Therefore, productive zoning of the forest becomes fundamental since forest exploitation is usually carried out on relatively large areas and the above is not considered.
The Mexican government endeavors to encourage ejidos to conserve their forests through a series of programs ([7]). However, these efforts have not had the expected results, nor have they been able to totally cover the demand. There are several conditions and requirements that hinder the access to some of the support intended for forest activity. For example, incorporating a project under the Clean Development Mechanism (CDM) requires that additionality be demonstrated ([11]), meaning that the reduction of CO2 emissions of a new project are higher than those that would occur without the project. In addition to approaching baseline problems of the project and possible leaks, the compensations occasionally continue to be the same. This has influenced the forest owners' decisions to not include carbon sequestration as a viable alternative ([16]).
Regarding REDD+, Stern ([45]) mentions that decreasing emissions from degradation and deforestation by 50% in developing countries by 2030 could cost between 15 and 33 billion dollars annually. For this reason, implementing actions in the short term aimed to decrease these emissions would be profitable, especially when it is contrasted with the enormously high environmental and economic costs resulting from inaction.
An alternative to CDM is the voluntary market, where the exchange of emissions certificates is not regulated by specific legal norms and have been, to date, the only source of funding for projects to reduce emissions from deforestation and forest degradation (REDD+ - [40]). In this panorama, forming part of a voluntary market might be the best option. However, the average price per MgCO2e is US$ 10 ([25]). According to our results, it is not enough to cover maintenance costs. Therefore, going from timber production to combined production is still uncertain and complicated.
Postponing harvest of a stand is profitable when the forest growth rate is higher than the defined discount rate. If not, it is better not to delay harvest and sell ([2]). However, delaying harvesting, even if it is not profitable, would increase social benefit since all the carbon stored would remain sequestered for a longer time. In Mexico, 60% of the forested area is owned by ejidos and indigenous communities ([47]), and these areas have an important role in reducing poverty, dealing with social exclusion, and jobs generation ([34]). The owners of these forests, who mostly belong to middle and poor economic classes, are highly dependent on the products they harvest, and ceasing to use the forest would bring consequences in terms of opportunity costs, while people with more resources would be willing to pay for improving their health and development through the supply of fresh air, water, scenery ([8]), and other benefits the forest provides. According to Blomley & Iddi ([6]), forests have a much more important role as sources of cash for poor homes than for relatively rich homes. For this reason, it is difficult to destine forests only to carbon sequestration and storage given the conditions of the ejidos and communities of Mexico.
Destining low-productive areas to carbon sequestration is profitable only if payment for MgCO2e is at least US$100 per ha-1 year-1, and if the discount rate is less than 3.5%. Combining timber production with carbon sequestration would involve extending the rotation period, which are sensitive to the discount rate and to the price of MgCO2e captured. Longer optimal rotation aged implies that the CO2 stored in the forest stands to be intervened would remain for a longer time, and the benefits it would generate would be more of a social than economic nature.
Timber production will remain as the main economic option at least the rules to operate of the different national and international carbon mechanisms become more flexible, and the carbon markets offer better economic incentives.
The characterization of the costs incurred in each stage of forest management allowed detecting areas of opportunity for the forestry enterprises studied, which can help them becoming more efficient, effective and competitive.
Abedi T, Mohammadi S, Bonyad A, Torkaman J (2018). Optimal rotation age of Populus deltoides considering economic value of timber harvesting and carbon sequestration. Austrian Journal of Forest Science 135: 315-342.
Online | Gscholar
Ackerman F (1993). The natural interest rate of the forest: macroeconomic requirements for sustainable development. Ecological Economics 10: 21-26.
CrossRef | Gscholar
Ajete I, Mercadet D, Alvarez D, Toirac I, Conde I (2012). Estimación del contenido de carbono en los bosques de la empresa forestal integral Guantánamo [Estimation of the carbon content in the forests the forest integral company Guantanamo]. Revista Forestal Baracoa 31: 3-8. [in Spanish]
Angeles G, Méndez B, Valdez R, Plascencia O, De los Santos HM, Chávez G, Ortiz D, Soriano A, Zaragoza Z, Ventura E, Martínez A, Wayson C, López D, Olguín M, Carrillo O, Maldonado V (2015). Estudio de caso del sitio de monitoreo intensivo del carbono en Hidalgo. Fortalecimiento REDD+ y Cooperación Sur [Case study of the site of intensive carbon monitoring in Hidalgo. Strengthening REDD + and South Cooperation]. CONAFOR, COLPOS, Mexico, pp. 105. [in Spanish]
Bettinger P, Boston K, Siry JP, Grebner DL (2017). Forest management and planning (2nd edn). Academic Press, New York, USA, pp. 349.
Blomley T, Iddi S (2009). Participatory forest management in Tanzania. 1993-2009: lessons learned and experiences to date. Ministry of Natural Resources and Tourism - URT, Forestry and Beekeeping Division, Dar es Salaam, Tanzania, pp. 72.
Chagoya JL, Iglesias G (2009). Esquema de pago por servicios ambientales de la Comisión Nacional Forestal, México [Payment scheme for environmental services of the National Forestry Commission, Mexico]. In: "Políticas Públicas y Sistemas de Incentivos Para el Fomento y Adopción de Buenas Prácticas Agrícolas: Como Medida de Adaptación al Cambio Climático en América Central" (Sepúlveda C, Ibrahim M eds). Primera Edición, Turrialba, CATIE, Costa Rica, pp. 291-292. [In Spanish]
Chaudhary M (2009). Assessing the protection of forest based environmental services in the Greater Mekong sub-region. Asia-Pacific Forestry Sector Outlook Study II, Working Paper Series vol. 14, FAO/UN, Bangkok, Thailand, pp. 67.
Clutter JL, Forston JC, Pienaar LV, Brister GH, Bailey RL (1983). Timber management: a quantitative approach. John Wiley and Sons, Inc., New York, USA, pp. 333.
Cubbage F, Donagh PM, Balmelli G, Olmos VM, Bussoni A, Rubilar R, De La Torre R, Lord R, Huang J, Hoeflich VA, Murara M, Kanieski B, Hall P, Yao R, Adams P, Kotze H, Monges E, Pérez CH, Wikle J, Abt R, Gonzalez R, Carrero O (2014). Global timber investments and trends, 2005-2011. New Zealand Journal of Forestry Science 44: 1-12.
De Olivera FLP, Lemme CF, Leal RPC (2011). Cost of equity capital and additionality of Brazilian renewable energy projects under the clean development mechanism. Latin American Business Review 12: 233-253.
Díaz L (2002). Los sistemas forestales y la provisión de bienes ambientales [Forest systems and the provision of environmental goods]. In: Jornada Temática "Aspectos Medioambientales de la Agricultura". Libro Blanco de Agricultura, Madrid, Spain, pp. 12. [in Spanish]
Dlugokencky E, Tans P (2018). Trends in atmospheric carbon dioxide. National Oceanic and Atmospheric Administration, Earth System Research Laboratory - NOAA/ESRL, Boulder, Colorado, USA, Web Site.
Fang Z, Borders BE, Bailey RL (2000). Compatible volume-taper models for loblolly and slash pine based on a system with segmented-stem form factors. Forest Science 46: 1-12.
Figueroa C, Angeles G, Velázquez A, De los Santos HM (2010). Estimación de la biomasa en un bosque bajo manejo de Pinus patula Schltdl. et Cham. en Zacualtipán, Hidalgo [Biomass estimation in a managed Pinus patula Schltdl. et Cham. forest at Zacualtipan, Hidalgo state]. Revista Mexicana de Ciencias Forestales 106: 105-112. [in Spanish]
Foley T (2009). Extending forest rotation age for carbon sequestration: a cross-protocol comparison of carbon offsets of North American forests. Masters Project, Nicholas School of the Environment, Duke University, Durham, NC, USA, pp. 51.
Fonseca W, Villalobos R, Rojas M (2019). Potencial de mitigación del cambio climático de los ecosistemas forestales caducifolios en Costa Rica: modelos predictivos de biomasa y carbono [Potential mitigation of climate change of deciduous forest ecosystems in Costa Rica: predictive models of biomass and carbon]. Revista de Ciencias Ambientales 53: 111-131. [In Spanish]
Gutrich J, Howarth R (2007). Carbon sequestration and the optimal management of New Hampshire timber stands. Ecological Economics 62: 441-450.
INEGI (2018). Sistema de cuentas nacionales de México año base 2013 [System of national accounts of Mexico base year 2013]. Instituto Nacional de Estadística Geográfica e Informática, DF, México, pp. 593. [in Spanish]
IPCC (2013). Glossary. In: "Climate change 2013. Physical bases. Contribution of Working Group I to the Fifth Assessment Report of the Intergovernmental Group of Experts on Climate Change" (Stocker TF, Qin D, Plattner GK, Tignor M, Allen SK, Boschung J, Nauels A, Xia Y, Bex V, Midgley PM eds). Cambridge University Press, Cambridge, UK, pp. 185-204
Joos F, Spahni R (2008). Rates of change in natural and anthropogenic radiative forcing over the past 20.000 years. Proceedings of the National Academy of Sciences USA 105: 1425-1430.
Keles S (2017). Determining optimum cutting ages including timber production and carbon sequestration benefits in Turkish pine plantations. Sains Malaysiana 46: 381-386.
Klemperer WD (1996). Forest resource economics and finance. McGraw Hill, New York, USA, pp. 551.
Köthke M, Dieter M (2010). Effects of carbon sequestration rewards on forest management - an empirical application of adjusted Faustmann formulae. Forest Policy and Economics 12: 589-597.
Lobos A, Vallejos GO, Caroca C, Marchant C (2005). El mercado de los bonos de carbono ("bonos verdes"): una revisión [The carbon credit market ("green bonds"): a review]. Revista Interamericana de Ambiente y Turismo 1: 42-52. [in Spanish]
Locatelli B, Evans V, Wardell A, Andrade A, Vignola R (2011). Forests and climate change in Latin America: linking adaptation and mitigation. Forests 2: 431-450.
López L, Domínguez M, Martínez P, Zavala J, Gómez A, Posada S (2016). Carbono almacenado en la biomasa aérea de plantaciones de hule (Hevea brasiliensis Müell. Arg.) de diferentes edades [Stored carbon in the aboveground biomass of rubber (Hevea brasiliensis Müell. Arg.) plantations at different ages]. Madera y Bosques 22: 49-60. [in Spanish]
Masera O, Bellon MR, Segura G (1997). Forestry options for sequestering carbon in Mexico: comparative economic analysis of three case studies. Critical Reviews in Environmental Science and Technology 27: 227-244.
Mead JD (2005). Opportunities for improving plantation productivity. How much? How quickly? How realistic? Biomass and Bioenergy 28: 249-266.
Müller U, Rodríguez R, Gajardo P (2013). Desarrollo de una guía de manejo de la densidad en bosques de segundo crecimiento de roble (Nothofagus obliqua) en la región del Biobío [Stand density management diagrams for roble (Nothofagus obliqua) in the Biobío Region, Chile]. Bosque 34: 201-209. [in Spanish]
Musálem LF (1979). Las bases y primeras acciones del programa nacional de mejoramiento silvícola en bosques de coníferas [The bases and first actions of the national silvicultural improvement program in coniferous forests]. SAG-SFF, DF, México, pp. 102. [in Spanish]
Nepal P, Grala R, Grebner D (2012). Financial feasibility of increasing carbon sequestration in harvested wood products in Mississippi. Forest Policy and Economics 14: 99-106.
Palacios DJ, De los Santos HM, Angeles G, Fierros AM, Santiago W (2020). Sistema de crecimiento y rendimiento para evaluar sumideros de carbono en bosques de Pinus patula Schiede ex Schltdl. et Cham. bajo aprovechamiento forestal [Growth and yield system to evaluate carbon sinks in managed Pinus patula Schiede ex Schltdl. et Cham. forests]. Agrociencia 54: 241-257. [in Spanish]
Patel T, Dhiaulhaq A, Gritten D, Yasmi Y, Bruyn TD, Paudel NS, Suzuki R (2013). Predicting future conflict under REDD+ implementation. Forests 4: 343-363.
Phelps J, Guerrero M, Dalabajan D, Young B, Webb E (2010). What makes a "REDD" country? Global Environmental Change 20: 322-332.
Ramírez A, De los Santos HM, Angeles G, González MJ, Santiago W (2020). Densidad inicial en el rendimiento maderable y biomasa de Pinus patula con especies latifoliadas [Initial density in the timber yield and biomass of Pinus patula with hardwood species]. Agrociencia 54: 555-573. [in Spanish]
Reyes JA, Gómez JP, Osaland R, Zavala R (2012). Potencial de servicios ambientales en la propiedad social en México [Potential of environmental services in social property in Mexico]. Instituto Interamericano de Cooperación para la Agricultural, Secretaría de la Reforma Agraria, México, pp. 103. [In Spanish]
Rodríguez L, Guevara F, Reyes L, Ovando J, Nahed J, Prado M, Campos R (2016). Estimación de biomasa y carbono almacenado en bosques comunitarios de la región Frailesca de Chiapas, México [Estimation of the biomass and stored carbon in community forest of La Frailesca region of Chiapas, Mexico]. Revista Mexicana de Ciencias Forestales 7: 77-94. [In Spanish]
Romero C, Ríos V, Díaz L (1998). Optimal forest rotation age when carbon captured is considered: theory and applications. Journal of the Operational Research Society 49: 121-131.
Sabogal J, Moreno E, Ortega GA (2009). Procesos de certificación de proyectos de captura de gases de efecto invernadero (GEI) En los Mercados Internacionales de Carbono [Certification processes for greenhouse gas (GHG) capture projects in the International Carbon Markets]. Gestión y Ambiente 12: 07-20. [In Spanish]
Santiago W, De los Santos HM, Angeles G, Valdez JR, Del Valle DH, Corral JJ (2013). Self-thinning and density management diagrams for Pinus patula fitted under the stochastic frontier regression approach. Agrociencia 47: 75-89.
Santiago W, De Los Santos HM, Angeles G, Corral JJ, Valdez JR, Del Valle DH (2014). Prediction of Pinus patula Schl. et Cham. timber yield through diameter distribution models. Agrociencia 48: 87-101.
Sauter PA, Mußhoff O (2018). What is your discount rate? Experimental evidence of foresters' risk and time preferences. Annals of Forest Science 75 (1): 239.
Schwartz N, Aide T, Graesser J, Grau H, Uriarte M (2020). Reversals of reforestation across Latin America limit climate mitigation potential of tropical forests. Frontiers in Forests and Global Change 3: 85.
Stern N (2007). The economics of climate change: the Stern Review. Cambridge University Press, Cambridge, UK, pp. 662.
Telles E, González MJ, De los Santos HM, Fierros AM, Lilieholm RJ, Gómez A (2008). Rotación óptima en plantaciones de eucalipto al incluir ingresos por captura de carbono en Oaxaca, México [Optimal timber rotation lenghts in eucalyptus plantations including revenues from carbon capture in Oaxaca, Mexico]. Revista Fitotecnia Mexicana 31: 173-182. [in Spanish]
Torres JM (2015). Desarrollo forestal comunitario: la política pública [Community forestry development: public policy]. Cide, DF, México, pp. 238. [in Spanish]
Torres JM, Moreno R, Mendoza MA (2016). Sustainable forest management in Mexico. Current Forestry Reports 2: 93-105.
UNFCCC (2015). París agreement. United Nations Framework Convention on Climate Change, United Nations, Paris, France, pp. 40. [in Spanish]
Vargas B, Corral JJ, Aguirre OA, López JO, De Los Santos HM, Zamudio FJ, Treviño EJ, Martínez M, Aguirre CG (2017). SiBiFor: forest biometric system for forest management in Mexico. Revista Chapingo Serie Ciencias Forestales y del Ambiente 23: 437-455.
Zomer R, Trabucco A, Bossio D, Verchot L (2008). Climate change mitigation: a spatial analysis of global land suitability for clean development mechanism afforestation and reforestation. Agriculture, Ecosystems and Environment 126: 67-80.
Authors' Affiliation
Agustín Ramírez-Martínez
Manuel de Jesús González-Guillén 0000-0003-1814-4320
Héctor Manuel De Los Santos-Posadas 0000-0003-4076-5043
Gregorio Ángeles-Pérez 0000-0002-9550-2825
Colegio de Postgraduados, km. 36.5 Carr. Mexico-Texcoco, Montecillo, Texcoco, C.P. 56230 (México)
Wenceslao Santiago-García 0000-0003-1958-1696
Instituto de Estudios Ambientales-División de Estudios de Postgrado-Ingeniería Forestal, Universidad de la Sierra Juárez, Avenida Universidad s/n, C. P. 68725, Ixtlán de Juárez, Oaxaca (México)
Manuel de Jesús González-Guillén
[email protected]
Ramírez-Martínez A, González-Guillén MJ, De Los Santos-Posadas HM, Ángeles-Pérez G, Santiago-García W (2021). Forest management with carbon scenarios in the central region of Mexico. iForest 14: 413-420. - doi: 10.3832/ifor3630-014
Marco Borghetti
Paper history
Received: Aug 19, 2020
Accepted: Jul 13, 2021
First online: Sep 15, 2021
Publication Date: Oct 31, 2021
Publication Time: 2.13 months
© SISEF - The Italian Society of Silviculture and Forest Ecology 2021
This article is distributed under the terms of the Creative Commons Attribution-Non Commercial 4.0 International (https://creativecommons.org/licenses/by-nc/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
Web Metrics
Breakdown by View Type
(Waiting for server response...)
Article Usage
Total Article Views: 2810
(from publication date up to now)
HTML Page Views: 468
Abstract Page Views: 53
PDF Downloads: 2074
Citation/Reference Downloads: 6
XML Downloads: 209
Days since publication: 501
Overall contacts: 2810
Avg. contacts per week: 39.26
Article citations are based on data periodically collected from the Clarivate Web of Science web site
(last update: Nov 2020)
(No citations were found up to date. Please come back later)
(no records found)
Publication Metrics
by Dimensions ©
List of the papers citing this article based on CrossRef Cited-by.
iForest Similar Articles
Heuristic forest planning model for optimizing timber production and carbon sequestration in teak plantations
Quintero-Méndez MA, Jerez-Rico M
vol. 10, pp. 430-439 (online: 24 March 2017)
Potential impacts of regional climate change on site productivity of Larix olgensis plantations in northeast China
Shen C, Lei X, Liu H, Wang L, Liang W
vol. 8, pp. 642-651 (online: 02 March 2015)
Voluntary carbon credits from improved forest management: policy guidelines and case study
Vacchiano G, Berretti R, Romano R, Motta R
vol. 11, pp. 1-10 (online: 09 January 2018)
Roadside vegetation: estimation and potential for carbon sequestration
Da Silva AM, Braga Alves C, Alves SH
vol. 3, pp. 124-129 (online: 27 September 2010)
Modelling the carbon budget of intensive forest monitoring sites in Germany using the simulation model BIOME-BGC
Jochheim H, Puhlmann M, Beese F, Berthold D, Einert P, Kallweit R, Konopatzky A, Meesenburg H, Meiwes K-J, Raspe S, Schulte-Bisping H, Schulz C
vol. 2, pp. 7-10 (online: 21 January 2009)
Modeling air pollutant removal, carbon storage, and CO2 sequestration potential of urban forests in Scotlandville, Louisiana, USA
Ning ZH, Chambers R, Abdollahi K
Change is in the air: future challenges for applied forest research
Tognetti R, Cherubini P
vol. 2, pp. 56-58 (online: 18 March 2009)
Identifying priority conservation areas for above-ground carbon sequestration in Central Mexico
Cruz-Huerta C, González-Guillén MDJ, Martínez-Trinidad T, Escalona-Maurice M
vol. 10, pp. 923-929 (online: 07 December 2017)
First vs. second rotation of a poplar short rotation coppice: leaf area development, light interception and radiation use efficiency
Broeckx LS, Vanbeveren SP, Verlinden MS, Ceulemans R
vol. 8, pp. 565-573 (online: 27 April 2015)
Estimating biomass and carbon sequestration of plantations around industrial areas using very high resolution stereo satellite imagery
Hosseini Z, Naghavi H, Latifi H, Bakhtiari Bakhtiarvand S
iForest Database Search
A Ramírez-Martínez
MJ González-Guillén
HM De Los Santos-Posadas
G Ángeles-Pérez
W Santiago-García
Financial Profitability
Optimal Rotation
Google Scholar Search
PubMed Search
CiteULike
Email
Abstract Article Authors' Info Info & Metrics References Related Articles Images & Tables
Page Top Introduction Materials and methods - Study area - Field data - Financial characterization and discount rate - Forest growth systems, timber and carbon yield - Diameter distribution modeled with the Weibull function - Distribution and prices by type of timber product and Mg CO2e - Updating production costs - Reineke density index - Components of the evaluated scenarios - Financial indicators - Determination of the optimal rotation age for combined production Results and discussion - Financial characterization - The Reineke's stand density index and thinning regime - Scenarios for pine forest - Optimal rotation period for timber production plus carbon sequestration - Timber production or carbon sequestration Conclusions References
Fig. 1 - Thinning prescription for Pinus patula stands in Zacualtipán, Hidalgo. (Sec. Ac.): thinning intensity; (100% and 60%): upper and lower limit of the area of self-thinning; (30%): upper limit of the area of constant growth; (20%): lower limit of growth free of mortality. Fig. 2 - Net present value (NPV) for different scenarios and SI of 18 and 30. Fig. 3 - Internal return rate (IRR) (%) (a) and benefit cost ratio (BCR) (b) obtained in the scenarios with SI of 18 and 30. Fig. 4 - Optimum rotation period in a SI of 30 for combined production. Prices for MgCO2e ha-1 year-1 of US$ 100 and US$ 75 with a discount rate of (a) 3.5% and (b) 4.5%.
Tab. 1 - Scenarios evaluated for the condition of pine forest and timber as end product under the silvicultural treatment of two thinnings and one regeneration cutting. (SI): site index. Tab. 2 - Activities and real average cost (US$ ha-1) for the stand establishment during the first year. Tab. 3 - Activities and real average cost (US$ ha-1) for the maintenance stage. Tab. 4 - Average Mexican government subsidy, in real terms (US$ ha-1), in support of forestry activity in the region. Tab. 5 - Financial indicators obtained for the scenarios of SI 18 and SI 30, with timber as the end product.
PDF Version Citation / Reference XML-NLM
This issue This volume Same subject Related papers
Info & Metrics CrossRef Cited-By PlumX Metrics Google Scholar Citations
Ramírez-Martínez et al. (2021). iForest 14: 413-420. - doi: 10.3832/ifor3630-014
Tab. 1
Download Reference
Download citation file
IMPACT FACTOR (2020): 1.836
Five-years impact factor: 1.795
Mean publication time
2.48 ± 0.09 months
Next Issue: April 2023
© iForest - All the material included on this site is distributed under the license Creative Commons Attribution-NonCommercial 4.0 International.
iForest is the journal of the Italian Society of Silviculture and Forest Ecology (SISEF). Legal Notice.
Editors-in-chief: Marco Borghetti, Gabriele Bucci: Web Designer: Gabriele Bucci; ISSN: 1971-7458
iForest Content Alert Subscription
Current Volume Journal Archive Browse Articles Collections/Special Issues Geo-Archives
Search Archives Site Search Authors' List Most Cited & Viewed
Forest@ - Journal of Silviculture and Forest Ecology SISEF Newsletter SISEF Editorials SISEF Workgroup Activities SISEF Congress SISEF on Facebook SISEF on Google+ SISEF Channel on YouTube | CommonCrawl |
Nonionic surfactants and their effects on asymmetric reduction of 2-octanone with Saccharomyces cerevisiae
Yunquan Zheng1,4,
Liangbin Li1,
Xianai Shi2,4,
Zhijian Huang3,4,
Feng Li4,
Jianmin Yang4 &
Yanghao Guo4
In an aqueous buffer system, serious reverse and side reactions were found in the asymmetric reduction of 2-octanone with Saccharomyces cerevisiae. However, some nonionic surfactants added to the aqueous buffer system improved the bioreduction process by decreasing the reverse and side reaction rates in addition to effectively increasing the average positive reaction rate. Further, a shorter carbon chain length of hydrophilic or hydrophobic moieties in surfactants resulted in a higher yield of (S)-2-octanol. The alkylphenol ethoxylate surfactants had a less influence than polyoxyethylenesorbitan trialiphatic surfactants on the product e.e. It suggested that the product e.e. resulting from the change of carbon chain length of the hydrophobic moieties varied markedly compared with the change of carbon chain length of the hydrophilic moiety. Emulsifier OP-10 and Tween 20 markedly enhanced the yield and product e.e. at the concentration of 0.4 mmol L−1 with a yield of 73.3 and 93.2%, and the product e.e. of 99.2 and 99.3%, respectively, at the reaction time of 96 h.
The yeast Saccharomyces cerevisiae contains alcohol dehydrogenases and other redox enzymes (Berlowska et al. 2006; Heidlas et al. 1991; Leskovac et al. 2002; Xu et al. 2005; De Smidt et al. 2008, 2012) which can catalyze bioreduction of ketones to optically active alcohols (Hummel 1997; Heidlas and Tressl 1990; Jung et al. 2010; Gonzalez et al. 2000). For example, the reduction performed by S. cerevisiae with 2-octanone yields (S)-2-octanol (Li et al. 2007; Dai and Xia 2006), an important intermediate for chiral synthesis (Threeprom 2007) and a model compound for studying keto bioreduction (Rundback et al. 2012). However, toxic hydrophobic substrates and/or products in the reaction result in a low yield and enantiomeric excess (e.e.) of products due to the reversible and side reactions caused by excessive substrates and/or products.
Supplementation of culture medium with surface-active agents shifts the physiologic properties of yeast and other cells (DeSousa et al. 2006; Aguedo et al. 2004; Vasileva-Tonkova et al. 2001; Laouar et al. 1996; Koley and Bard 2010). Factors affecting the status of biocatalysts, or the distribution or concentration of substrates and products in the cells, or altering the interaction between biocatalysts and substrates or products, impact the reaction rate and enantioselectivity. Therefore, surfactants are associated with these functions, (1) solubilization of hydrophobic substrates and products in the medium (Ganesh et al. 2006; Mahdi et al. 2011; Wang et al. 2004; Walters and Aitken 2001) to avoid their enrichment in the cell membranes, which reduce their concentration in cells; (2) formation of mixed micelles including surfactants and cell membranes (Hu et al. 2012; Liu et al. 2016; Kurakake et al. 2017), which affecting the structure and permeability of cell membrane, leading to altered physiology of cells and transmembrane transportation of substrates and products; (3) interaction of surfactants and intracellular enzymes, which changes the enzymatic characteristics and shifts enzymatic activities and enantioselectivities in asymmetric reactions (Awasthi et al. 2005; Roberts et al. 1977).
Therefore, bioreduction of toxic hydrophobic 2-octanone can be improved with appropriate surfactants in the medium. Until now, studies reported the influence of cloud-point system involving binding of nonionic surfactants with microbial cells and the effects of surfactants on microbial cell-mediated asymmetric reactions (Dominguez et al. 2003; Wei et al. 2003; Wang 2005; Goswami et al. 2000; Shi et al. 2010; Liu et al. 2017). However, limited research exists on the relationship between the properties of nonionic surfactants and their effects on asymmetric reduction of 2-octanone with S. cerevisiae.
Strains and chemicals
Saccharomyces cerevisiae FD-12 was isolated from S. cerevisiae Type II, Sigma, USA.
2-Octanone was purchased from Merck-Schuchardt (Germany). (R)-2-octanol, (S)-2-octanol and (S)-(+)-PEIC (phenylethyl isocyanate) were supplied by Aldrich (USA). Emulsifier OP-6 (MW470), Tween 20 (MW1226.5), Tween 40 (MW1284.6), Tween 60 (MW1311.7) and Tween 80 (MW1309.6) were products of Sinopharm Chemical Reagent Co., Ltd. (China). Emulsifier OP-8 (MW559), Emulsifier OP-10 (MW647), sodium dodecyl sulfate (SDS), Emulsifier OP-12 (MW735) and cetyltriethylammonium bromide (CTAB) were obtained from Shanghai Sangon Biological Engineering Technology and Service Co., Ltd. (China). All other chemicals were of analytical grade. Glucose toolkit was purchased from BHKT Clinical Reagent Co. Ltd. (China).
Activation of cells
Medium (g L−1): glucose 10.0, (NH4)2SO4 5.0, KH2PO4 1.0, MgSO4·7H2O 0.5, KCl 0.5, ZnSO4 0.01, Fe2(SO4)3 0.01, natural pH.
Conditions: 100 mL medium with 10 g lyophilized cells in a 250 mL-flask was placed in a rotary incubator set at 32 °C and 200 r min−1 for 2 h. The cells were harvested by centrifugation at 4000×g for 10 min and washed twice with Tris–HCl buffer solution (50 mmol L−1, pH8.0). The harvested cells were used for the following experiments.
The concentrations of 2-octanone and 2-octanol were determined by GC (Shimadzu GC-14C, Japan) equipped with a flame ionization detector and a non-polar fused silica capillary column AC1-0.25 (i.d. 0.25 mm, length 30 m, SGE, Australia). The GC conditions included N2 (99.999%) as the carrier gas, with a pressure front of the column at 100 kpa, the detector temperature 210 °C, the injector temperature 190 °C and the column temperature 170 °C.
The enantiomer resolution was based on the derivation of 2-octanol with optically pure isocyanate. 10 μL sample was mixed with 50 μL toluene and 2 μL (S)-(+)-PEIC and then left at 45 °C for 2 h. A fused silica capillary column and carrier gas (with column pressure front 65 kpa) were used. The injector and the detector were maintained at 250 and 270 °C, respectively. The retention times of (R)- and (S)-enantiomer were 18.8 min and 19.5 min.
Reaction rate (v) was calculated using the concentration of 2-octanol (c2-ol,t) as a function of time (t)
$$v = c_{2 - ol,t} / {\text{t}}$$
During the initial 3 h, the v denotes the initial reaction rate (v 0). At a reaction time of 96 h, the v represents the average reaction rate.
$${\text{Yield }}\left( \% \right) = c_{2 - ol,t} /c_{2 - one,0} \times 100\%$$
c2-ol,t is the concentration of 2-octanol (c2-ol,t) formed at time (t), and c2-one,0 is the concentration of 2-octanone before the reaction.
Enantiomeric excess of (S)-2-octanol
$$e.e. = \, \left( {{\text{A}}_{S} - {\text{ A}}_{R} } \right)/\left( {{\text{A}}_{S} + {\text{A}}_{R} } \right) \times 100\%$$
AS and AR are the peak areas of (S)-2-octanol and (R)-2-octanol, respectively.
Viability assay
The viability of the cells was measured as the ratio of the living cell number after anaerobic pretreatment to the original living cell number. Pretreatment entailed mixing of 3.0 g wet cells with 20 mL Tris–HCl buffer, 0–2.0 mmol L−1 surfactants assayed and 0.2 g glucose at 32 °C and 200 r min−1 for 24 h. Using methylene blue, the living cells and the dead cells were distinguished and counted microscopically.
Cell membrane permeability
Under conditions similar to viability assay and after culture up to 24 h, 2-mL broth was sampled and centrifuged at 10,000×g for 5 min. After appropriate dilution, the supernatant was used to determine the optical density at 260 and 280 nm, with a Shimadzu UV-1700 spectrophotometer using the broth cultured for 0 h as the control.
Bioreduction assay
A normal reduction of 2-octanone in an aqueous solution was conducted in a 100-mL shake flask. 3.0 g wet cells were suspended in 20 mL Tris–HCl buffer with 0.2 g glucose. 2-Octanone was added to the medium to the final fixed concentration. The medium was placed in a rotary incubator at 32 °C and 200 rpm. At time intervals, 500 μL medium was withdrawn and extracted with 500 μL n-hexane for three times. The extracts were mixed for GC determination.
Effect of surfactants on asymmetric reduction of 2-octanone
As typical ionic surfactants, the anionic SDS (CH3(CH2)11SO4−) and cationic CTAB (C16H33N(CH3) 3 + ), are different from the nonionic surfactant Emulsifier OP-6. Emulsifier OP-6 consists of alkylphenol ethoxylates (APEO) and does not dissociate in water. Nonionic surfactants show interesting features such as higher stability, lower surface tension, lower critical micelle concentration, higher aggregation number of micelles and better solubilization. To investigate the effect of surfactants in asymmetric reduction of 2-octanone with S. cerevisiae, we introduced surfactants into the aqueous media and the yield and product e.e. value of the reaction were analyzed. The results are shown in Fig. 1, the reduction of 2-octanone to (S)-2-octanol catalyzed by the whole cell S. cerevisiae, led to low yield and product e.e. value. Accordingly, the presence of Emulsifier OP-6 and CTAB, except SDS, showed a better yield and product e.e. value. The nonionic Emulsifier OP-6 was the best of the surfactants investigated.
Time course of two enantiomers of 2-octanol in the reaction systems containing surfactants
In the reaction system with surfactants, it was apparent that not only the positive reaction was improved, but also the side and reverse reactions inhibited by Emulsifier OP-6 and CTAB. Based on the synthesis rate of the enantiomers calculated (Table 1), it was found that the rate of (S)-enantiomer (vS) increased while the rate of (R)-enantiomer (vR) decreased. In detail, the VS increased from 0.072 to 0.97 mmol L−1 h−1 and 0.92 mmol L−1 h−1, as well as the VR decreased from 0.009 to 0.002 mmol L−1 h−1 and 0.003 mmol L−1 h−1, respectively in the media with Emulsifier OP-6 and CTAB. The apparent reverse reaction rate (vrev) approached 0, which indicated no evidence of reverse reaction. In the system containing SDS, the phenomenon was quite different from the system containing Emulsifier OP-6 or CTAB.
Table 1 Effect of surfactants on reaction rates
Effect of nonionic surfactants on the asymmetric reduction of 2-octanone
The Emulsifier OP series, including Emulsifier OP-6 (C14H21(OC2H4)6OH), Emulsifier OP-8 (C14H21(OC2H4)8OH), Emulsifier OP-10 (C14H21(OC2H4)10OH) and Emulsifier OP-12 (C14H21(OC2H4)12OH), contain an ethoxylate with the unit number ranging from 6 to 12. As seen in the Table 2, the length of hydrophilic ethoxylate had a marked influence on the reaction yield decreasing from 88.4 to 65.3% with the chain length.
Table 2 Relation between character of nonionic surfactants and cell catalytic activity
The carbon chain length of ethoxylate in APEO series surfactants showed a mild influence on the product e.e. value. As shown in Fig. 2, the product e.e. values exhibited no distinct differences from each other in the reaction with diverse carbon chain length, excluding the difference due to the surfactant concentration. At the surfactant concentration of 0.4 mmol L−1, the product e.e. was maintained at a high value, for example, reaching 99.2% in the reaction with Emulsifier OP-10. However, the e.e. value decreased rapidly at a higher level of surfactant concentration.
Effect of Emulsifier OP surfactants on asymmetric reduction of 2-octanone by baker's yeast cells. Reaction condition: 10 mmol L−1 2-octanone; 150 g L−1 wet cell; 10 g L−1 glucose/24 h; 20 mL Tris–HCl buffer (50 mmol L−1, pH 8.0); 32 °C; 200 r min−1; anaerobic; 96 h
Other ethoxylate surfactants, such as polyoxyethylene sorbitan fatty acid ester (namely Tween series surfactants), are obtained based on their degree of ethoxylate polymerization, for example, Tween 20 [polyoxyethylene (20) sorbitan monolaurate, CH3(CH2)10COO(OC2H4)20C6H8O(OH)3], Tween 40 [polyoxyethylene (20) sorbitan monopalmitate, CH3(CH2)14COO(OC2H4)20C6H8O(OH)3], Tween 60 [polyoxyethylene (20) sorbitan monostearate, CH3(CH2)16COO(OC2H4)20C6H8O(OH)3] and Tween 80 [polyoxyethylene (20) sorbitan monooleate, CH3(CH2)7CH=CH(CH2)7COO(OC2H4)20C6H8O(OH)3]. These compounds contain the same hydrophilic end but different hydrophobic terminal groups, like C12H23CO, C16H31CO, C18H35CO and C18H33CO (Table 2).
The concentration of the Tween series surfactants showed a significant effect on the e.e. value (Fig. 3). When the concentration of Tween 20 was 0.4 mmol L−1, the e.e. reached 99.3%. However, the e.e. dropped to about 92% with the increase of the concentration. Similarly, the concentration of the other three Tween series surfactants clearly affected the e.e. value.
Effect of Tween surfactants on asymmetric reduction of 2-octanone with baker's yeast cells. Reaction condition: 10 mmol L−1 2-octanone; 150 g L−1 wet cell; 10 g L−1 glucose/24 h; 20 mL Tris–HCl buffer (50 mmol L−1, pH 8.0); 32 °C; 200 r min−1; anaerobic; 96 h
The Tween series surfactants affected the yield in the S. cerevisiae-mediated reduction of 2-ocatanone depending on the length of hydrophobic end (Tween 60 > Tween 80 > Tween 40 > Tween 20). The shorter the carbon chain, the higher the yield (Fig. 3). The result was related to the biocompatibility of the hydrophobic end to the cell membrane. Increased biocompatibility associated with the longer hydrophobic end lowered the cell membrane permeability, and hence resulting in a lower yield (Table 2).
Surfactants are compounds with various molecular structures and charges (Gozde et al. 2017). Therefore, the impact of surfactants such as SDS, Emulsifier OP-6 or CTAB on living cells varies with the composition of the medium. Furthermore, these surfactants affect the reaction characteristics in the asymmetric reduction of 2-octanone with S. cerevisiae (Shi et al. 2010).
A rapid drop of (S)-enantiomer and the continuous increase of (R)-enantiomer of 2-octanol were observed after 48 h of the reaction. Data indicated two unexpected reactions: the oxidation of (S)-2-octanol to 2-octanone, and the side reaction of the reduction, namely the reduction of 2-octanone to (R)-2-octanol.
This phenomenon resulted from the excessive accumulation of (S)-enantiomer in the reaction process in the cell. The asymmetric reduction of ketone to alcohol is a reversible reaction, with the reaction rate and direction depending on the concentration of ketone, alcohol, coenzyme, and other factors. As the positive reaction rate decreased due to product inhibition, the relative concentration of byproduct (R)-2-octanol increased. At the same time, the reverse reaction occurred along with the decreased concentration of substrate 2-octanone in the reaction. These results suggested that the decrease of product concentration at the intracellular enzyme surface was the most important factor in improving the product yield and e.e. value (Shi et al. 2010).
The reverse and side-reactions involving the reduction of 2-octanone to (S)-2-octanol catalyzed by the whole cell S. cerevisiae, led to low yield and product e.e. value. Accordingly, the presence of Emulsifier OP-6 and CTAB, except SDS, not only improved the positive reaction rate, but also limited the reverse and side reaction rate effectively, which resulted in a better yield and product e.e. value.
The effects of APEO surfactants depend both on the hydrophobic alkyl and the length of ethoxylate. The effects due to the length of ethoxylate and alkyl are usually antagonistic (Christopher et al. 2018). A longer ethoxylate commonly leads to better solubility, but worse surfactant activity. The effect of Emulsifier OP series of surfactants on the asymmetric reduction of 2-octanone is worth further investigation.
The Emulsifier OP series, contain an ethoxylate with the unit number ranging from 6 to 12. The length of hydrophilic ethoxylate had a marked influence on the reaction yield decreasing with the chain length. Consequently, the weakened influence of the surfactants on the hydrophobic cell membrane is attributed to the higher hydrophilicity resulting from the increased length. Furthermore, the concentration of surfactants might be another important factor affecting the yield as the high concentration of surfactants is possibly associated with a decline in enzymatic activity, for example, plasma membrane (PM) vesicles isolated from the yeast S. cerevisiae (wild-type NCIM 3078, and a MG 21290 mutant pma 1-1) were used to monitor the effect of the nonionic surfactant Triton X-100, on (H+)-ATPase (E.C. 3.6.1.35), NADH oxidase and NADH-hexacyanoferrate (III)[HCF (III)] oxidoreductase (EC 1.6.99.3) activities. The results obtained, showed that Triton X-100 inhibited both membrane-bound and solubilized NADH-dependent redox activities (Awasthi et al. 2005). The nature of this inhibition as determined for NADH-HCF(III) oxidoreductase was non-competitive.
However, the carbon chain length of ethoxylate in APEO series surfactants showed a mild influence on the product e.e. value. The e.e. value decreased rapidly at a higher level of surfactant concentration. It confirmed that the properties of hydrophilic and hydrophobic groups, as well as the concentration of surfactants, but not the length of side chain of hydrophilic end, were the most important factors contributing to the product e.e. value.
Compared with Emulsifier OP series surfactants, the Tween series surfactants affected the yield in the S. cerevisiae-mediated reduction of 2-ocatanone depending on the length of hydrophobic end. The shorter the carbon chain, the higher the yield. Increased biocompatibility associated with the longer hydrophobic end lowered the cell membrane permeability, and hence resulting in a lower yield.
However, no correlation was observed between the cell membrane permeability caused by different series of surfactants and the reaction yield, as well as between the viability or RGlc and the yield, based on the findings of Emulsifier OP series compounds (with fixed hydrophobic end and varied hydrophilic end) and Tween series compounds (with fixed hydrophilic end and varied hydrophobic end). These results illustrated that nonionic surfactants not only changed the cell membrane permeability (Liu et al. 2016) to alleviate the product inhibition, but also affected one or more of the intracellular enzymes (Kurakake et al. 2017), the cell status, and coenzyme regeneration. Further, these effects related with the class and length of both hydrophilic and hydrophobic ends of the compounds. Interestingly, the shorter length of both hydrophilic and hydrophobic ends improved the yield, irrespective of the surfactant type.
The carbon chain length at the hydrophobic and hydrophilic ends, and the concentration of surfactants were important factors affecting the product e.e. value (Figs. 2, 3 and Table 2). However, the carbon chain lengths of hydrophobic end had a more significant impact than the length of hydrophilic end. For example, no marked change in e.e. value resulted from the altered length of the hydrophilic end (Fig. 2), which was quite different from the degree of change caused by the length of hydrophobic end (Fig. 3). With C11H23CO (Tween 20) as the hydrophobic end, the average e.e. value reached 94.7%, which dramatically dropped to 49.5% when the hydrophobic end was C17H33CO (Tween 80).
The shorter carbon chain in the nonionic surfactants, improved the yield, irrespective of the length of hydrophobic or hydrophilic ends. The Tween series surfactants strongly affected the product e.e. value compared with the Emulsifier OP series surfactants. The carbon chain length of hydrophobic end had a significantly greater impact than the length of hydrophilic end in nonionic surfactants. The nonionic surfactants Emulsifier OP-10 and Tween 20 improved the yield and product e.e. value effectively. At a concentration of 0.4 mmol L−1, the reaction yield at 96 h was 73.3 and 93.2%, respectively. Furthermore, the e.e. value was 99.2 and 99.3%, which were significantly higher compared with the reaction without surfactants.
PEIC:
phenylethyl isocyanate
OP:
octylphenol polyoxyethylene
SDS:
sodium dodecyl sulfate
CTAB:
cetyltriethylammonium bromide
GC:
APEO:
alkylphenol ethoxylates
Aguedo M, Wache Y, Coste F, Husson F, Belin JM (2004) Impact of surfactants on the biotransformation of methyl ricinoleate into gamma-decalactone by Yarrowia lipolytica. J Mol Catal B Enzym 29:31–36
Awasthi V, Pandit S, Misra PC (2005) Triton X-100 inhibition of yeast plasma membrane associated NADH-dependent redox activities. J Enzyme Inhib Med Chem 20:205–209
Berlowska J, Kregiel D, Klimek L, Orzeszyna B, Ambroziak W (2006) Novel yeast cell dehydrogenase activity assay in situ. Pol J Microbiol 55:127–131
Christopher DK, Erin MK, Patrick LF, Heather MS (2018) Nonionic ethoxylated surfactantsi nduce adipogenesis in 3T3-L1 cells. Toxicol Sci 162:124–136
Dai D, Xia L (2006) Effect of lipase immobilization on resolution of (R, S)-2-octanol in nonaqueous media using modified ultrastable-Y molecular sieve as support. Appl Biochem Biotechnol 134:39–50
De Smidt O, du Preez JC, Albertyn J (2008) The alcohol dehydrogenases of Saccharomyces cerevisiae: a comprehensive review. FEMS Yeast Res 8:967–978
De Smidt O, du Preez JC, Albertyn J (2012) Molecular and physiological aspects of alcohol dehydrogenases in the ethanol metabolism of Saccharomyces cerevisiae. FEMS Yeast Res 12:33–47
DeSousa SR, Laluce C, Jafelicci M (2006) Effects of organic and inorganic additives on flotation recovery of washed cells of Saccharomyces cerevisiae resuspended in water. Colloids Surf B 48:77–83
Dominguez A, Deive FJ, Sanroman MA, Longo MA (2003) Effect of lipids and surfactants on extracellular lipase production by Yarrowia lipolytica. J Chem Technol Biotechnol 78:1166–1170
Ganesh T, Balamurugan D, Sabesan R, Krishnan S (2006) Dielectric relaxation studies of alkanols solubilized by sodium dodecyl sulphate aqueous solutions. J Mol Liq 123:80–85
Gonzalez E, Fernandez MR, Larroy C, Sola L, Pericas MA, Pares X, Biosca JA (2000) Characterization of a (2R,3R)-2,3-butanediol dehydrogenase as the Saccharomyces cerevisiae YAL060W gene product—disruption and induction of the gene. J Biol Chem 275:35876–35885
Goswami A, Bezbaruah RL, Goswami J, Borthakur N, Dey D, Hazarika AK (2000) Microbial reduction of omega-bromoacetophenones in the presence of surfactants. Tetrahedron Asymmetry 11:3701–3709
Gozde E, Maria LD, Satoshi T (2017) Molecular structure inhibiting synergism in charged surfactant mixtures: an atomistic molecular dynamics simulation study. Langmuir 33:14093–140104
Heidlas J, Tressl R (1990) Purification and characterization of a (R)-2,3-butanediol dehydrogenase from Saccharomyces cerevisiae. Arch Microbiol 154:267–273
Heidlas J, Engel KH, Tressl R (1991) Enantioselectivities of enzymes involved in the reduction of methylketones by Bakers-yeast. Enzyme Microb Technol 13:817–821
Hu Z, Zhang X, Wu Z, Qi H, Wang Z (2012) Perstraction of intracellular pigments by submerged cultivation of Monascus in nonionic surfactant micelle aqueous solution. Appl Microbiol Biotechnol 94:81–89
Hummel W (1997) New alcohol dehydrogenases for the synthesis of chiral compounds. Adv Biochem Eng Biotechnol 58:145–184
Jung J, Park HJ, Uhm KN, Kim D, Kim HK (2010) Asymmetric synthesis of (S)-ethyl-4-chloro-3-hydroxy butanoate using a Saccharomyces cerevisiae reductase: enantioselectivity and enzyme-substrate docking studies. Biochim Biophys Acta 1804:1841–1849
Koley D, Bard AJ (2010) Triton X-100 concentration effects on membrane permeability of a single HeLa cell by scanning electrochemical microscopy (SECM). Proc Natl Acad Sci USA 107:1678
Kurakake M, Hirotsu S, Shibata M, Takenaka Y, Kamioka T, Sakamoto T (2017) Effects of nonionic surfactants on pellet formation and the production of β-fructofuranosidases from Aspergillus oryzae KB. Food Chem 224:139–143
Laouar L, Lowe KC, Mulligan BJ (1996) Yeast responses to nonionic surfactants. Enzyme Microb Technol 18:433–438
Leskovac V, Trivic S, Pericin D (2002) The three zinc-containing alcohol dehydrogenases from baker's yeast, Saccharomyces cerevisiae. FEMS Yeast Res 2:481–494
Li YN, Shi XA, Zong MH, Meng C, Dong YQ, Guo YH (2007) Asymmetric reduction of 2-octanone in water/organic solvent biphasic system with Baker's yeast FD-12. Enzyme Microb Technol 40:1305–1311
Liu SS, Guo CL, Liang XJ, Wu FJ, Dang Z (2016) Nonionic surfactants induced changes in cell characteristics and phenanthrene degradation ability of Sphingomonas sp. GY2B. Ecotox Environ Safe 129:210–218
Liu CY, Zeng XY, Xin Q, Xu MY, Deng YW, Dong W (2017) Biotoxicity and bioavailability of hydrophobic organic compounds solubilized in nonionic surfactant micelle phase and cloud point system. Environ Sci Pollut Res 24:14795–14801
Mahdi ES, Sakeena MH, Abdulkarim MF, Abdullah GZ, Sattar MA, Noor AM (2011) Effect of surfactant and surfactant blends on pseudoternary phase diagram behavior of newly synthesized palm kernel oil esters. Drug Des Dev Ther 5:311–323
Roberts MF, Deems RA, Dennis EA (1977) Dual role of interfacial phospholipid in phospholipase A2 catalysis. Proc Natl Acad Sci USA 74:1950–1954
Rundback F, Fidanoska M, Adlercreutz P (2012) Coupling of permeabilized cells of Gluconobacter oxydans and Ralstonia eutropha for asymmetric ketone reduction using H2 as reductant. J Biotechnol 157:154–158
Shi XA, Li CY, Fu J, Meng C, Guo YH, Lou WY, Wu H, Zong MH (2010) Impact of surfactants on asymmetric bioreduction of 2-octanone by Saccharomyces cerevisiae. Chin J Process Eng 10:339–343
Threeprom J (2007) (S)-(+)-2-octanol as a chiral oil core for the microemulsion electrokinetic chromatographic separation of chiral basic drugs. Anal Sci 23:1071–1075
Vasileva-Tonkova E, Galabova D, Karpenko E, Shulga A (2001) Biosurfactant-rhamnolipid effects on yeast cells. Lett Appl Microbiol 33:280–284
Walters GW, Aitken MD (2001) Surfactant-enhanced solubilization and anaerobic biodegradation of 1,1,1-trichloro-2,2-bis(p-chlorophenyl)-ethane (DDT) in contaminated soil. Water Environ Res 73:15–23
Wang Z (2005) Two-phase partitioning bioreactor, application of cloud point system in bioconversion. Eng Sci 7:73–78
Wang Z, Zhao FS, Hao XQ, Chen DJ, Li DT (2004) Microbial transformation of hydrophobic compound in cloud point system. J Mol Catal B Enzym 27:147–153
Wei GY, Li Y, Du GC, Chen J (2003) Effect of surfactants on extracellular accumulation of glutathione by Saccharomyces cerevisiae. Process Biochem 38:1133–1138
Xu SW, Jiang ZY, Wu H (2005) Progress in structure and kinetic mechanism of alcohol dehydrogenase. Chin J Org Chem 25:629–633
YZ and XS designed research, performed research, analyzed data, and wrote the paper. The remaining authors contributed to refining the ideas, carrying out additional analyses and finalizing this paper. All authors read and approved the final manuscript.
We are grateful to the Testing Center of Fuzhou University for providing analytical technical support.
All data supporting the results and discussion, and conclusions of this study are included in the manuscript.
All authors gave their consent for publication.
This work was supported by Major Projects of Science and Technology Department of Fujian Province of China (No. 2013NZ0003), Natural Science Foundation of Fujian Province of China (No. 2017J01854), and the Marine High-tech Industry Development Special Project of Fujian Province of China (Min Marine High-tech [2015]01).
College of Chemistry, Fuzhou University, 2 Xueyuan Road, Fuzhou, 350116, China
Yunquan Zheng
& Liangbin Li
College of Biological Science and Engineering, Fuzhou University, 2 Xueyuan Road, Fuzhou, 350116, China
Xianai Shi
Fujian Provincial Cancer Hospital, 420 Fuma Road, Fuzhou, 350014, China
Zhijian Huang
Fujian Key Laboratory of Medical Instrument and Pharmaceutical Technology, Fuzhou University, 2 Xueyuan Road, Fuzhou, 350116, China
, Xianai Shi
, Zhijian Huang
, Feng Li
, Jianmin Yang
& Yanghao Guo
Search for Yunquan Zheng in:
Search for Liangbin Li in:
Search for Xianai Shi in:
Search for Zhijian Huang in:
Search for Feng Li in:
Search for Jianmin Yang in:
Search for Yanghao Guo in:
Correspondence to Xianai Shi.
Zheng, Y., Li, L., Shi, X. et al. Nonionic surfactants and their effects on asymmetric reduction of 2-octanone with Saccharomyces cerevisiae. AMB Expr 8, 111 (2018) doi:10.1186/s13568-018-0640-1
Nonionic surfactant
2-Octanone
Asymmetric reduction | CommonCrawl |
Electronic Commerce Research
pp 1–28 | Cite as
The optimal pricing decisions for e-tailers with different payment schemes
Jing Zhang
Na Xu
Shizhen Bai
Along with the quick development of e-commerce, different payment schemes are provided to online consumers to improve their shopping experience. Currently, the payment schemes can be divided into two categories, one is pay-to-order, and the other is pay-on-delivery. Payment scheme directly affects consumers' behavior and e-tailer's pricing decision in e-commerce. In this paper, we characterize the consumers' purchase and returns behavior with consumer utility function, build the e-tailer's profit functions and solve them to obtain the optimal pricing decisions, both in the condition of pay-to-order and dual scheme (including both pay-to-order and pay-on-delivery). We find that managers can affect consumers' decision on choosing payment scheme by adjusting the e-tail price. We demonstrate the transfer of payment scheme, along with the transaction cost and return cost. Sensitivity analysis is provided to tell e-commerce managers that they should consider the influence of the e-purchase cost, together with the characteristic of both consumers and products when designing the payment scheme.
Pay-to-order Pay-on-delivery E-tail price Consumer behavior Payment scheme
This work was supported by the grants from the NSFC (71671054 and 7137106) and Shandong Province Social Science Planning Research Project (17DGLJ11).
Proof of Proposition 1
According to Figs. 2, 3 and 4, we can get, that ① when \( \beta_{od} > 2\bar{\beta } \), we can always get \( S_{1} (\beta ) > S_{2} (\beta ) \), which means that all consumers will choose pay-to-order. Under this condition, \( 0 < p_{d} < \frac{{\alpha - 2\bar{\beta }}}{H} \). ② When \( 0 \le \beta_{od} \le 2\bar{\beta } \) and \( S_{2} (\beta ) > 0 \), we can get \( S_{1} (\beta ) > S_{2} (\beta ) \) if with \( \beta \sim (0,\beta_{od} ) \), indicating that consumers will choose pay-to-order; \( S_{1} (\beta ) < S_{2} (\beta ) \) if with \( \beta \sim (\beta_{od} ,2\bar{\beta }) \), indicating that consumers will choose pay-on-delivery. From \( 0 \le \beta_{od} \le 2\bar{\beta } \), we can get \( \frac{{\alpha - 2\bar{\beta }}}{H} \le p_{d} \le \frac{\alpha }{H} \); from \( S_{2} (\beta ) > 0 \), we can get \( p_{d} < \frac{\theta v - \alpha }{\theta (1 + \sigma + \eta )} \). ③ When \( S_{1} (0) < S_{2} (\beta ) \) and \( S_{2} (\beta ) > 0 \), the utility of the consumer choosing pay-on-delivery is always greater than the one choosing pay-to-order, that is, consumers will choose pay-on-delivery. From \( S_{1} (0) = \theta (v - p_{d} ) - \sigma p_{d} - (1 - \theta )\gamma p_{d} < S_{2} (\beta ) = \theta (v - p_{d} - (\sigma + \eta )p_{d} ) - a \), we can get \( p_{d} > \frac{\alpha }{H} \); from \( S_{2} (\beta ) > 0 \), we can get \( p_{d} < \frac{\theta v - \alpha }{\theta (1 + \sigma + \eta )} \). If this situation is reasonable, then there should be \( \frac{\alpha }{H} < \frac{\theta v - \alpha }{\theta (1 + \sigma + \eta )} \). Further simplification can be obtained, that is \( \alpha < \frac{\theta vH}{H + \theta (1 + \sigma + \eta )} \).
According to Proposition 1, ① when \( p_{d} \in (0,\hbox{max} \{ 0,\frac{{\alpha - 2\bar{\beta }}}{H}\} ) \), all consumers will choose pay-to-order, that is, \( D = D_{do} = 1 \); ② when \( \frac{\alpha }{H} \le \frac{\theta v - \alpha }{\theta (1 + \sigma + \eta )} \), which means \( \alpha \le \frac{\theta vH}{H + \theta (1 + \sigma + \eta )} \), we can get \( \, p_{d} \in (\hbox{max} \{ 0,\frac{{\alpha - 2\bar{\beta }}}{H}\} ,\frac{\alpha }{H}] \), and both payment methods will be selected under this condition. Here, \( D_{do} = F(\beta_{od} ) = \frac{{\alpha - Hp_{d} }}{{2\bar{\beta }}} \), \( D_{dd} = 1 - D_{do} = \frac{{2\bar{\beta } - \alpha + Hp_{d} }}{{2\bar{\beta }}} \); when \( \frac{\alpha }{H} > \frac{\theta v - \alpha }{\theta (1 + \sigma + \eta )} \), which is \( \alpha > \frac{\theta vH}{H + \theta (1 + \sigma + \eta )} \), furthermore, we can get \( \alpha < \frac{{\theta vH + 2\bar{\beta }\theta (1 + \sigma + \eta )}}{H + \theta (1 + \sigma + \eta )} \) from \( \frac{{\alpha - 2\bar{\beta }}}{H} < \frac{\theta v - \alpha }{\theta (1 + \sigma + \eta )} \); then, we can see \( \, p_{d} \in (\hbox{max} \{ 0,\frac{{\alpha - 2\bar{\beta }}}{H}\} ,\frac{\theta v - \alpha }{\theta (1 + \sigma + \eta )}] \). Under this situation, two payment methods coexist, among which \( D_{do} = F(\beta_{od} ) = \frac{{\alpha - Hp_{d} }}{{2\bar{\beta }}} \) and \( D_{dd} = 1 - D_{do} = \frac{{2\bar{\beta } - \alpha + Hp_{d} }}{{2\bar{\beta }}} \); if \( \frac{\alpha }{H} \ge \frac{\theta v - \alpha }{\theta (1 + \sigma + \eta )} \) and \( \frac{{\alpha - 2\bar{\beta }}}{H} \ge \frac{\theta v - \alpha }{\theta (1 + \sigma + \eta )} \), then \( \alpha \ge \frac{{\theta vH + 2\bar{\beta }\theta (1 + \sigma + \eta )}}{H + \theta (1 + \sigma + \eta )} \); here, we can always get \( S_{1} (2\bar{\beta }) > S_{2} (\beta ) \), which is \( \, D = D_{do} = 1 \); ③ when \( \alpha < \frac{\theta vH}{H + \theta (1 + \sigma + \eta )} \) and \( \frac{\alpha }{H} < p_{d} < \frac{\theta v - \alpha }{\theta (1 + \sigma + \eta )} \), all consumers will choose pay-on-delivery, which is \( D = D_{dd} = 1 \). Taking the above situations into account, the distribution of market demands corresponding to different \( \alpha \) and \( p_{d} \) can be obtained.
① In pay-to-order, according to the retailer's profit function, when \( \underset{\raise0.3em\hbox{$\smash{\scriptscriptstyle-}$}}{p}_{o} < p_{o} < \bar{p}_{o} \), we can get \( \frac{{\partial^{2} \pi_{1} }}{{\partial p_{o}^{2} }} = - \frac{AB}{{\bar{\beta }}} < 0 \), that is, there is a unique optimal value \( p_{o}^{*} \) that maximizes the profit function value, which satisfies \( \frac{{\partial \pi_{1} }}{{\partial p_{o} }} = \frac{{A\theta v + Bc - 2ABp_{o} }}{{2\bar{\beta }}} = 0 \). Hence, \( p_{o}^{*} = (A\theta v + Bc)/(2AB) \). Substituting x into \( \underset{\raise0.3em\hbox{$\smash{\scriptscriptstyle-}$}}{p}_{o} < p_{o}^{*} < \bar{p}_{o} \), we can get \( \frac{{\theta v - 2\bar{\beta }}}{B} < \frac{A\theta v + Bc}{2AB} < \frac{\theta v}{B} \) and further to simplify it to get \( \frac{{A\theta v - 4A\bar{\beta }}}{B} < c < \frac{A\theta v}{B} \). Substituting \( p_{o}^{*} \) into the market demand function, the profit function can obtain equilibrium market demand and equilibrium profits within this range. ② When \( 0 < p_{o} \le \underset{\raise0.3em\hbox{$\smash{\scriptscriptstyle-}$}}{p}_{o} \), the first derivative of the corporate profit function for retail prices is positive, that is \( \frac{{\partial \pi_{1} }}{{\partial p_{o} }} = A > 0 \), which means the profit is a monotonically increasing function of retail prices. Thus, the profit function gets the maximum value when \( p_{o} \) takes the maximum \( \underset{\raise0.3em\hbox{$\smash{\scriptscriptstyle-}$}}{p}_{o} \), that is \( p_{o}^{*\prime } = (\theta v - 2\bar{\beta })/B \). At this point, the market demand function is \( D_{1}^{\prime } = 1 \), and substituting it into the profit function can be obtained \( \pi_{1}^{*\prime } = Ap_{o} - c \).
Proof of Corollary 1
According to Proposition 3, we can get: ① When \( c \in ((A\theta v - 4A\bar{\beta })/B,A\theta v/B) \), \( \frac{{\partial p_{o}^{*} }}{\partial c} = \frac{1}{2A} > 0 \), which means \( p_{o}^{*} \) is a monotonically increasing function of \( c \); from \( \frac{{\partial \pi_{1}^{*} }}{\partial c} = \frac{Bc - A\theta v}{{4A\bar{\beta }}} \), we see that \( \frac{{\partial \pi_{1}^{*} }}{\partial c} < 0 \) if with \( c < \frac{A\theta v}{B} \), that is, \( \pi_{1}^{*} \) is a monotonically decreasing function with respect to \( c \) in this region. ② When \( c \in [0,(A\theta v - 4A\bar{\beta })/B] \), \( \frac{{\partial \pi_{1}^{*} }}{\partial c} < 0 \), that is, \( p_{o}^{*\prime } \) is not affected by \( c \); the equation \( \frac{{\partial \pi_{1}^{*'} }}{\partial c} = - 1 < 0 \) indicates that \( \pi_{1}^{*\prime } \) is a monotonically decreasing function about \( c \).
Name \( G = \theta + (\xi - \lambda )(1 - \theta ) \), \( K = \lambda (1 - \theta ) + rt \), \( G + K = A \), \( H = (1 - \theta )(\sigma + \gamma ) - \theta \eta \) and \( H + \theta (1 + \sigma + \eta ) = B \).
Then Eq. (11) can be simplified as \( \pi_{2} = Ap_{d} D_{do} + Gp_{d} D_{dd} - c \).
Case (1) \( 0 < a \le \frac{\theta vH}{B} \)
① When \( \frac{a}{H} \le p_{d} \le \frac{\theta v - \alpha }{\theta (1 + \sigma + \eta )} \), the market demand function satisfies \( D_{d} = D_{dd} = 1 \), \( D_{do} = 0 \). Retailer profit function is \( \pi_{2} = Gp_{d} - c \). Hence, the optimal retail price is \( p_{d}^{*} = p_{dd} = \frac{\theta v - \alpha }{\theta (1 + \sigma + \eta )} \), and the optimal profit function is \( \pi_{dd} = G\frac{\theta v - \alpha }{\theta (1 + \sigma + \eta )} - c \). ② When \( a > 2\bar{\beta } \) and \( \frac{{a - 2\bar{\beta }}}{H} < p_{d2} < \frac{\alpha }{H} \), retailer profit function is \( \pi_{2} = Ap_{d} \frac{{\alpha - Hp_{d} }}{{2\bar{\beta }}} + Gp_{d} \frac{{2\bar{\beta } - \alpha + Hp_{d} }}{{2\bar{\beta }}} - c \); with further simplification, we can get \( \pi_{2} = \frac{1}{{2\bar{\beta }}}[(G - A)Hp_{d}^{2} + (2\bar{\beta } - \alpha )Gp_{d} + Aap_{d} ] - c \) and the first derivative of the price \( \frac{{\partial \pi_{2} }}{{\partial p_{d} }} = \frac{1}{{2\bar{\beta }}}[2(G - A)Hp_{d} + (2\bar{\beta } - \alpha )G + Aa] \). Since the second derivative of the profit function with respect to price is \( \frac{{\partial \pi_{2}^{2} }}{{\partial^{2} p_{d} }} = \frac{1}{{\bar{\beta }}}(G - A)H < 0 \), there is a unique optimal solution that maximizes the profit function value, which meets \( \frac{{\partial \pi_{2} }}{{\partial p_{d} }} = \frac{1}{{2\bar{\beta }}}[2(G - A)Hp_{d} + (2\bar{\beta } - \alpha )G + Aa] = 0 \), and we can get the optimal price \( p_{d2} = \frac{\alpha }{2H} + \frac{{G\bar{\beta }}}{KH} \). Let \( p_{d2} > \frac{{\alpha - 2\bar{\beta }}}{H} \), and substituting it into the above formula can achieve \( a < 4\bar{\beta } + \frac{{2\bar{\beta }G}}{K} \); let \( p_{d2} < \frac{\alpha }{H} \), and substituting it into the above formula can achieve \( a > \frac{{2\bar{\beta }G}}{K} \). Therefore, we can get \( \hbox{max} \{ 2\bar{\beta },\frac{{2\bar{\beta }G}}{K}\} < a \le \hbox{min} \{ \frac{\theta vH}{B},4\bar{\beta } + \frac{{2\bar{\beta }G}}{K}\} \). ③ When \( 0 < a < 2\bar{\beta } \) and \( 0 < p_{d2} < \frac{a}{H} \), the optimal retail price is \( p_{d2} = \frac{\alpha }{2H} + \frac{{G\bar{\beta }}}{KH} \). Let \( p_{d2} < \frac{\alpha }{H} \), we can get \( a > \frac{{2\bar{\beta }G}}{K} \); then, \( \frac{{2\bar{\beta }G}}{K} < a \le \hbox{min} \{ \frac{\theta vH}{B},2\bar{\beta }\} \). Combining ② and ③, there is \( \frac{{2\bar{\beta }G}}{K} < a < \hbox{min} \{ \frac{\theta vH}{B},2\bar{\beta }\} \). ④ When \( a > 2\bar{\beta } \) and \( 0 < p_{do} \le \frac{{a - 2\bar{\beta }}}{H} \), \( D_{d} = D_{do} = 1 \), retailer profit function is \( \pi_{2} = Ap_{do} D_{do} - c \). Therefore, the optimal retail price is \( p_{do} = \frac{{\alpha - 2\bar{\beta }}}{H} \), and the optimal profit function is \( \pi_{2} = A\frac{{\alpha - 2\bar{\beta }}}{H} - c \).
Case (2) \( \frac{\theta vH}{B} < \alpha < \frac{{\theta vH + 2\bar{\beta }\theta (1 + \sigma + \eta )}}{B} \)
① When \( a > 2\bar{\beta } \) and \( \frac{{a - 2\bar{\beta }}}{H} < p_{d} < \frac{\theta v - \alpha }{\theta (1 + \sigma + \eta )} \), similar to the proof process of scenario (1), the retailer's optimal retail price satisfies \( p_{d2} = \frac{\alpha }{2H} + \frac{{G\bar{\beta }}}{KH} \). Let \( p_{d2} < \frac{\theta v - \alpha }{\theta (1 + \sigma + \eta )} \), we can get \( a < \frac{{2\theta KHv - 2\theta \bar{\beta }G(1 + \sigma + \eta ))}}{K(H + B)} \); combining the previous proof, we can get \( a < 4\bar{\beta } + \frac{{2\bar{\beta }G}}{K} \) from \( p_{d} > \frac{{a - 2\bar{\beta }}}{H} \). Hence, \( \hbox{max} \{ 2\bar{\beta },\frac{\theta vH}{B}\} < a < \hbox{min} \{ \frac{{\theta vH + 2\bar{\beta }\theta (1 + \sigma + \eta )}}{B},4\bar{\beta } + \frac{{2\bar{\beta }G}}{K},\frac{{2\theta KHv - 2\theta \bar{\beta }G(1 + \sigma + \eta ))}}{K(H + B)}\} \).
② When \( a < 2\bar{\beta } \) and \( 0 < p_{d} < \frac{\theta v - \alpha }{\theta (1 + \sigma + \eta )} \), the retailer's optimal price is \( p_{d2} = \frac{\alpha }{2H} + \frac{{G\bar{\beta }}}{KH} \), and we also get \( a < \frac{{2\theta KHv - 2\theta \bar{\beta }G(1 + \sigma + \eta ))}}{K(H + B)} \). Therefore, \( \frac{\theta vH}{B} < a < \hbox{min} \{ 2\bar{\beta },\frac{{2\theta KHv - 2\theta \bar{\beta }G(1 + \sigma + \eta ))}}{K(H + B)}\} \).
③ When \( a \ge 2\bar{\beta } \) and \( 0 < p_{d} \le \frac{{a - 2\bar{\beta }}}{H} \), the retailer's optimal retail price meets \( p_{do} = \frac{{\alpha - 2\bar{\beta }}}{H} \) and the corresponding optimal profit function is \( \pi_{do} = A\frac{{\alpha - 2\bar{\beta }}}{H} - c \).
Case (3) \( \alpha \ge \frac{{\theta vH + 2\bar{\beta }\theta (1 + \sigma + \eta )}}{B} \)
Combining with Proposition 2, we know that, under this condition, consumers choose pay-to-order to purchase online, so the optimal retail price is \( p_{do} = \frac{{\theta v - 2\bar{\beta }}}{B} \), and the corresponding profit is \( \pi_{do} = A\frac{{\theta v - 2\bar{\beta }}}{B} - c \).
Integrating above cases (1), (2) and (3), we can obtain the optimal retail prices and profits under different circumstances, as shown in Table 1.
CECRC. (2018). Report of user experience and complaint monitoring in China in the year 2018. http://www.100ec.cn/zt/18yhts/. Accessed 8 Aug 2018.
Hwang, R., Shiau, S., & Jan, D. (2007). A new mobile payment scheme for roaming services. Electronic Commerce Research and Applications,6(2), 184–191.CrossRefGoogle Scholar
Lim, A. S. (2008). Inter-consortia battles in mobile payments standardization. Electronic Commerce Research and Application,7(2), 202–213.CrossRefGoogle Scholar
Skitsko, V., & Ignatova, I. (2016). Modeling the process of purchase payment as a constituent of information security in e-commerce. Operations Research and Decisions,26(3), 83–99.Google Scholar
CSRID. (2019). The 43rd China statistical report on internet development. China Internet Network Information Center. http://www.cnnic.net.cn/hlwfzyj/hlwxzbg/hlwtjbg/201902/P020190318523029756345.pdf. Accessed 28 Feb 2019.
Chandra, S., Srivastava, S. C., & Theng, Y. L. (2010). Evaluating the role of trust in consumer adoption of mobile payment systems: An empirical analysis. Communications of the Association for Information Systems,27, 561–588.CrossRefGoogle Scholar
Liu, D., & Zhang, J. (2011). TAM-based study on factors influencing the adoption of mobile payment. China Communications,8(03), 198–204.Google Scholar
O'Reilly, P., Duane, A., & Andreev, P. (2012). To M-Pay or not to M-Pay—Realising the potential of smart phones: Conceptual modeling and empirical validation. Electronic Markets,22(4), 229–241.CrossRefGoogle Scholar
Huang, X., Dai, X., & Liang, W. (2014). BulaPay: A novel web service based third-party payment system for e-commerce. Electronic Commerce Research,14(4), 611–633.CrossRefGoogle Scholar
Becker, P. (2014). Infographic: Consumer psychology and the e-commerce checkout. http://www.campaignlive.co.uk/article/infographic-consumer-psychology-e-commerce-checkout/1227394. Accessed 15 Jan 2014.
Halaweh, M. (2018). Cash on delivery (cod) as an alternative payment method for e-commerce transactions. International Journal of Sociotechnology and Knowledge Development,10(4), 1–12.CrossRefGoogle Scholar
Manglaracina, R., & Perego, A. (2009). Payment systems in the B2C e-commerce: Are they a barrier for the online customer? Journal of Internet Banking and Commerce,14(3), 1–16.Google Scholar
Grüschow, R. M., & Brettel, M. (2018). Managing payment transaction costs at multinational online retailers. International Journal of Electronic Commerce,22(1), 125–157.CrossRefGoogle Scholar
Hsieh, C. T. (2001). E-commerce payment systems: Critical issues and management strategies. Human Systems Management,20(2), 131–138.Google Scholar
Chou, Y., Lee, C., & Chung, J. (2004). Understanding M-commerce payment systems through the analytic hierarchy process. Journal of Business Research,57(12), 1423–1430.CrossRefGoogle Scholar
Dai, X., & Grundy, J. (2007). NetPay: An off-line, decentralized micro-payment system for thin-client applications. Electronic Commerce Research and Applications,6(1), 91–101.CrossRefGoogle Scholar
Kousaridas, A., Parissis, G., & Apostolopoulos, T. (2008). An open financial services architecture based on the use of intelligent mobile devices. Electronic Commerce Research and Applications,7(2), 232–246.CrossRefGoogle Scholar
Ogbanufe, O., & Kim, D. J. (2018). Comparing fingerprint-based biometrics authentication versus traditional authentication methods for e-payment. Decision Support Systems,106, 1–14.CrossRefGoogle Scholar
Kahn, C. M., & Liñares-Zegarra, J. M. (2015). Identity theft and consumer payment choice: Does security really matter? Journal of Financial Services Research,50(1), 121–159.CrossRefGoogle Scholar
Yang, S., Lu, Y., Gupta, S., Caso, Y., & Zhang, R. (2012). Mobile payment services adoption across time: An empirical study of the effects of behavioral beliefs, social influences, and personal traits. Computers in Human Behavior,28(1), 129–142.CrossRefGoogle Scholar
Francisco, L., Francisco, M., & Juan, S. (2015). Payment systems in new electronic environments: Consumer behavior in payment systems via SMS. International Journal of Information Technology and Decision Making,14(2), 421–449.CrossRefGoogle Scholar
Schweizer, A., Weinfurtner, S., Stahl, E., Pur, S., & Wittmann, G. (2015). Erfolgsfaktoren und Hindernisse bei der Einführung von mobilen und kontaktlosen Bezahlverfahren in Deutschland. Doctoral dissertation, ibi research an der Universität Regensburg.Google Scholar
Walczak, S., & Borkan, G. L. (2016). Personality type effects on perceptions of online credit card payment services. Journal of Theoretical and Applied Electronic Commerce Research,11(1), 67–83.CrossRefGoogle Scholar
Keating, B. W., Quazi, A. M., & Kriz, A. (2009). Financial risk and its impact on new purchasing behavior in the online retail setting. Electronic Markets,19(4), 237–250.CrossRefGoogle Scholar
Kim, C., Tao, W., Shin, N., & Kim, K. S. (2010). An empirical study of customers' perceptions of security and trust in e-payment systems. Electronic Commerce Research and Applications,9(1), 84–95.CrossRefGoogle Scholar
Chiejina, C., & Soremekun, E. (2014). Investigating the significance of the 'pay on delivery' option in the emerging prosperity of the nigerian e-commerce sector. Journal of Marketing and Management,5(1), 120–135.Google Scholar
Pourali, A. (2014). The presentation of an ideal safe SMS based model in mobile electronic commerce using encryption hybrid algorithms AES and ECC. In: 8th International conference on e-commerce in developing countries: with focus on e-trust (pp. 1–10). IEEE.Google Scholar
Dotzauer, K., & Haiss, F. (2017). Barriers towards the adoption of mobile payment services: An empirical investigation of consumer resistance in the context of Germany. Unpublished master's thesis, Karlstad University, Karlstad, Sweden.Google Scholar
Klee, E. (2008). How people pay: Evidence from grocery store data. Journal of Monetary Economics,55(3), 526–541.CrossRefGoogle Scholar
Humphrey, D. B., Willesson, M., Lindblom, T., & Bergendahl, G. (2003). What does it cost to make a payment? Review of Network Economics,2(2), 159–174.CrossRefGoogle Scholar
Fang, J., Wen, C., George, B., & Prybutok, V. R. (2016). Consumer heterogeneity, perceived value, and repurchase decision-making in online shopping: The role of gender, age, and shopping motives. Journal of Electronic Commerce Research,17(2), 116–131.Google Scholar
Broos, A. (2005). Gender and information and communication technologies (ICT) anxiety: Male self-assurance and female hesitation. Cyber Psychology and Behavior,8(1), 21–31.CrossRefGoogle Scholar
Schumacher, P., & Morahan-Martin, J. (2001). Gender, internet and computer attitudes and experiences. Computers in Human Behavior,17(1), 95–110.CrossRefGoogle Scholar
Grüschow, R. M., Kemper, J., & Brettel, M. (2016). How do different payment methods deliver cost and credit efficiency in electronic commerce? Electronic Commerce Research and Applications,18, 27–36.CrossRefGoogle Scholar
Morris, M. G., & Venkatesh, V. (2000). Age differences in technology adoption decisions: Implications for a changing work force. Personnel Psychology,53(2), 375–403.CrossRefGoogle Scholar
Bruggink, D., & Birovljev, A. (2018). Payment trends and developments in the Western Balkan countries: An interview with Aleksandar Birovljev. Journal of Payments Strategy and Systems,11(4), 285–291.Google Scholar
Peterson, D. E., Haydon, R. B. (1969). A quantitative framework for financial management. R. D. Irwin: Irwin series in quantitative analysis for business.Google Scholar
Chen, L., Gürhan, K. A., & Tong, J. D. (2013). The effect of payment schemes on inventory decisions: The role of mental accounting. Management Science,59(2), 436–451.CrossRefGoogle Scholar
Song J. S., & Tong J. (2011). Payment options, financing costs, and inventory management. Working paper, Duke University, Durham.Google Scholar
Seifert, D., Seifert, R. W., & Isaksson, O. D. (2017). A test of inventory models with permissible delay in payment. International Journal of Production Research,55(4), 1117–1128.CrossRefGoogle Scholar
Chern, M. S., Pan, Q., Teng, J. T., Chan, Y. L., & Chen, S. C. (2013). Stackelberg solution in a vendor–buyer supply chain model with permissible delay in payments. International Journal of Production Economics,144(1), 397–404.CrossRefGoogle Scholar
Yang, C. T., Pan, Q., Ouyang, L. Y., & Teng, J. T. (2013). Retailer's optimal order and credit policies when a supplier offers either a cash discount or a delay payment linked to order quantity. European Journal of Industrial Engineering,7(3), 370–392.CrossRefGoogle Scholar
Giannetti, M., Burkart, M., & Ellingsen, T. (2011). What you sell is what you lend? Explaining trade credit contracts. Review of Financial Studies,24(4), 1261–1298.CrossRefGoogle Scholar
Mohan, S., Mohan, G., & Chandrasekhar, A. (2008). Multi-item, economic order quantity model with permissible delay in payments and a budget constraint. European Journal of Industrial Engineering,2(4), 446–460.CrossRefGoogle Scholar
Jamal, A. M. M., Sarker, B. R., & Wang, S. (1997). An ordering policy for deteriorating items with allowable shortage and permissible delay in payment. Journal of the Operational Research Society,48(8), 826–833.CrossRefGoogle Scholar
Liao, H. C., Tsai, C. H., & Su, C. T. (2000). An inventory model with deteriorating items under inflation when a delay in payment is permissible. International Journal of Production Economics,63(2), 207–214.CrossRefGoogle Scholar
Ho, C. H., Ouyang, L. Y., & Su, C. H. (2008). Optimal pricing, shipment and payment policy for an integrated supplier–buyer inventory model with two-part trade credit. European Journal of Operational Research,187(2), 496–510.CrossRefGoogle Scholar
Yang, H. L., & Chang, C. T. (2013). A two-warehouse partial backlogging inventory model for deteriorating items with permissible delay in payment under inflation. Applied Mathematical Modeling,37(5), 2717–2726.CrossRefGoogle Scholar
Zhao, F., Dash Wu, D., Liang, L., & Dolgui, A. (2015). Cash flow risk in dual-channel supply chain. International Journal of Production Research,53(12), 3678–3691.CrossRefGoogle Scholar
Bai, S. Z., & Xu, N. (2016). The online seller's optimal price and inventory policies under different payment schemes. European Journal of Industrial Engineering,10(3), 285–300.CrossRefGoogle Scholar
Xu, N., Bai, S. Z., & Wan, X. (2017). Adding pay-on-delivery to pay-to-order: The value of two payment schemes to online sellers. Electronic Commerce Research and Applications,21, 27–37.CrossRefGoogle Scholar
Zhang, J., & Zhang, R. Q. (2014). Optimal replenishment and pricing decisions under the collect-on-delivery payment option. OR Spectrum,36(2), 503–524.CrossRefGoogle Scholar
Chiang, W. K., Chhajed, D., & Hess, J. D. (2003). Direct marketing, indirect profits: A strategic analysis of dual-channel supply-chain design. Management Science,49(1), 1–20.CrossRefGoogle Scholar
Lal, R., & Sarvary, M. (1999). When and how is the internet likely to decrease price competition? Marketing Science,18(4), 485–503.CrossRefGoogle Scholar
Forman, C., Ghose, A., & Goldfarb, A. (2009). Competition between local and electronic markets: How the benefit of buying online depends on where you live. Management Science,55(1), 47–57.CrossRefGoogle Scholar
Gupta, A., Su, B., & Walter, Z. P. (2004). An empirical study of consumer switching from traditional to electronic channels: A purchase-decision process perspective. International Journal of Electronic Commerce,8(3), 131–161.CrossRefGoogle Scholar
Balakrishnan, A., Sundaresan, S., & Zhang, B. (2014). Browse-and-switch: Retail-online competition under value uncertainty. Production and Operations Management,23(7), 1129–1145.CrossRefGoogle Scholar
Chen, J., & Stallaert, J. (2014). An economic analysis of online advertising using behavioral targeting. MIS Quarterly,38(2), 429–450.CrossRefGoogle Scholar
Guo, Z. L., & Chen, J. Q. (2018). Multigeneration product diffusion in the presence of strategic consumers. Information Systems Research,29(1), 206–224.CrossRefGoogle Scholar
Tyagi, R. K. (2004). Technological advances, transaction costs, and consumer welfare. Marketing Science,23(3), 335–344.CrossRefGoogle Scholar
Leng, M., & Becerril-Arreola, R. (2010). Joint pricing and contingent free-shipping decisions in B2C transactions. Production and Operations Management,19(4), 390–405.CrossRefGoogle Scholar
Luening, E. (2001). Shipping fees deterring net shoppers. CNET News.Google Scholar
Cui, R., Li, M., Li, Q. (2019). Value of high-quality logistics: Evidence from a clash between SF Express and Alibaba. Management Science.Google Scholar
Li, Meng, Patel, Pankaj C., & Wolfe, Marcus. (2019). A penny saved is a penny earned? Managing savings and consumption tradeoffs on online retail platforms. Journal of Retailing and Consumer Services,46, 79–86.CrossRefGoogle Scholar
© Springer Science+Business Media, LLC, part of Springer Nature 2020
Email authorView author's OrcID profile
1.School of BusinessHarbin University of CommerceHarbinChina
2.School of Business AdministrationShandong Technology and Business UniversityYantaiChina
Zhang, J., Xu, N. & Bai, S. Electron Commer Res (2020). https://doi.org/10.1007/s10660-020-09396-2
DOI https://doi.org/10.1007/s10660-020-09396-2
Publisher Name Springer US | CommonCrawl |
Home › Azimuth Code Project
QBO and ENSO
WebHubTel
Here is the PowerPoint slideshow http://umn.edu/~puk/published/AnalyticalFormulationOfEquatorialStandingWavePhenomena2.ppsx
Comment Source:Here is the PowerPoint slideshow http://umn.edu/~puk/published/AnalyticalFormulationOfEquatorialStandingWavePhenomena2.ppsx
nad said:
". So with strange QBO behaviour I mean the last strange QBO in 2015/2016 which we discussed here this August. All this looks very very bad."
I find it odd to talk about strange behavior in QBO considering that I still haven't seen a valid physical model of QBO that explains the periodic behavior from 1953 on up. Unless you want to believe in the AGW denier Lindzen's QBO model -- but that model can't even predict the period!
A still unanswered question from the consensus science is why does the QBO flip direction every ~28 months? If it is because of the lunisolar nodal alignment that happens to occur with that exact same period, then you have to start with that premise. And then you should note that within the past year we have had a perigee of the moon with the closest distance to the earth simultaneous with a very full moon since 1948 (i.e. the most super of the supermoons). And 1948 was before the QBO measurements began, so that we have no data to compare against. So saying it's "strange" is simply a value judgement.
I have seen some indication from the online meteorologists that the QBO is back in sync, so the better assumption is that any transient may be due to a stronger perigee forcing. And once that excess forcing disappears, it goes back to aligning with the temporal boundary conditions.
I have run my model of QBO that I presented at AGU this past week and compared it against recent QBO data and can tell you that there is indeed some type of hiccup for the recent 3o hPa data .
Note that this was based on training data from 1953 to 1985 against the major lunar tidal periods, and you can note that most of the peaks sharply align in the extrapolation post 1985 -- until we get to ~2014, where you can see the peaks go in opposite directions. It could also be that this past year's El Nino was strong enough to perturb the lunar forcing enough to transiently force it out of its path.
But to have a real discussion on this means that it has to be a two-way street. I am putting effort into this lunisolar forcing model so that is what I will be talking about. I am not going to go on tangent concerning methane, because methane isn't what is causing the fundamental 28 month period.
Comment Source:nad said: > ". So with strange QBO behaviour I mean the last strange QBO in 2015/2016 which we discussed [here this August](https://forum.azimuthproject.org/discussion/comment/15460/#Comment_15460). All this looks very very bad." I find it odd to talk about strange behavior in QBO considering that I still haven't seen a valid physical model of QBO that explains the periodic behavior from 1953 on up. Unless you want to believe in the AGW denier Lindzen's QBO model -- but that model can't even predict the period! A still unanswered question from the consensus science is why does the QBO flip direction every ~28 months? If it is because of the lunisolar nodal alignment that happens to occur with that exact same period, then you have to start with that premise. And then you should note that within the past year we have had a perigee of the moon with the closest distance to the earth simultaneous with a very full moon since 1948 (i.e. the most super of the supermoons). And 1948 was before the QBO measurements began, so that we have no data to compare against. So saying it's "strange" is simply a value judgement. I have seen some indication from the online meteorologists that the QBO is back in sync, so the better assumption is that any transient may be due to a stronger perigee forcing. And once that excess forcing disappears, it goes back to aligning with the temporal boundary conditions. I have run my model of QBO that I presented at AGU this past week and compared it against recent QBO data and can tell you that there is indeed some type of hiccup for the recent 3o hPa data .  Note that this was based on training data from 1953 to 1985 against the major lunar tidal periods, and you can note that most of the peaks sharply align in the extrapolation post 1985 -- until we get to ~2014, where you can see the peaks go in opposite directions. It could also be that this past year's El Nino was strong enough to perturb the lunar forcing enough to transiently force it out of its path. But to have a real discussion on this means that it has to be a two-way street. I am putting effort into this lunisolar forcing model so that is what I will be talking about. I am not going to go on tangent concerning methane, because methane isn't what is causing the fundamental 28 month period.
note that within the past year we have had a perigee of the moon with the closest distance to the earth simultaneous with a very full moon since 1948 (i.e. the most super of the supermoons)
the supermoon happened more or less after the strange QBO pattern started. That is the strange pattern is this dog shaped head looking to the left, where the nose is at the beginning of 2016.
The supermoon was in November 2016 i.e. at the end of 2016
Actually I find measurements often way more trustworthy than models. But sure its bad that we have here not more comparable measurements to look at, that holds by the way also for the sun radiation measurements. I find it quite a scandal that there are so few of those essential environmental measurements. We fly on this earth basically with all instruments turned off. And if I believe the current concerns regarding the US climate science politics we are soon on an almost complete blind flight.
As already said I haven't sofar understood those QBO models, including your model, but since Lindzen spoke about lunar forcing I could imagine that it is somewhere indirectly included.
Note that this was based on training data from 1953 to 1985 against the major lunar tidal periods
By the way if you know a visualization where one could have a look on the path of the moon as projected down to earth let me know. I would also be interesting to hear from you if you are being paid by BAE Systems for your QBO research.
Comment Source:>note that within the past year we have had a perigee of the moon with the closest distance to the earth simultaneous with a very full moon since 1948 (i.e. the most super of the supermoons) the supermoon happened more or less after the strange QBO pattern started. That is the strange pattern is this dog shaped head looking to the left, where the nose is at the <strong>beginning of 2016</strong>. 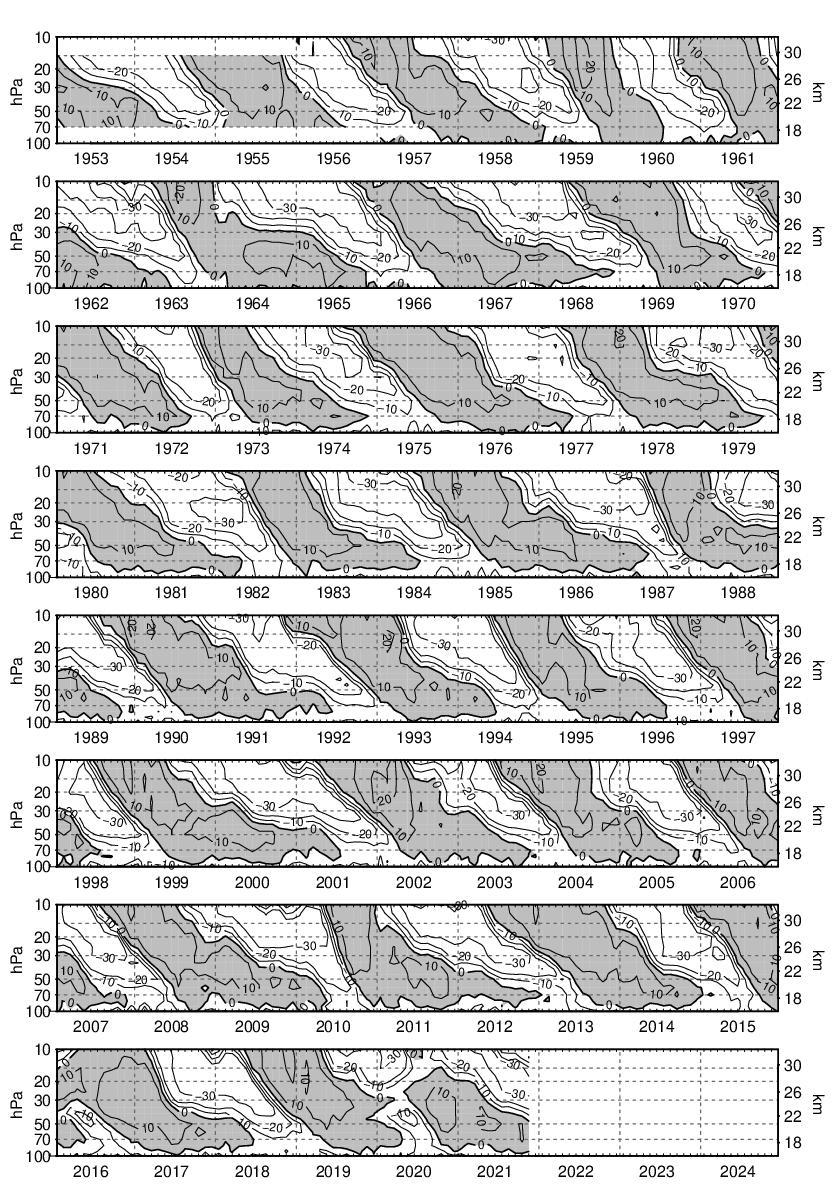 The supermoon was in November 2016 i.e. at the <strong>end of 2016</strong> >I find it odd to talk about strange behavior in QBO considering that I still haven't seen a valid physical model of QBO that explains the periodic behavior from 1953 on up. Unless you want to believe in the AGW denier Lindzen's QBO model -- but that model can't even predict the period! Actually I find measurements often way more trustworthy than models. But sure its bad that we have here not more comparable measurements to look at, that holds by the way also for the <a href="https://forum.azimuthproject.org/discussion/comment/15673/#Comment_15673">sun radiation measurements</a>. I find it quite a scandal that there are so few of those essential environmental measurements. We fly on this earth basically with all instruments turned off. And if I believe the current concerns regarding the US climate science politics we are soon on an almost complete blind flight. As already said I haven't sofar understood those QBO models, including your model, but since Lindzen spoke about lunar forcing I could imagine that it is somewhere indirectly included. >Note that this was based on training data from 1953 to 1985 against the major lunar tidal periods By the way if you know a visualization where one could have a look on the path of the moon as projected down to earth let me know. I would also be interesting to hear from you if you are being paid by BAE Systems for your QBO research.
"I would also be interesting to hear from you if you are being paid by BAE Systems for your QBO research."
=)) =)) =)) =)) =))
Comment Source:> "I would also be interesting to hear from you if you are being paid by BAE Systems for your QBO research." =)) =)) =)) =)) =))
whats so funny about that question?
Comment Source:whats so funny about that question?
There is absolutely no doubt that QBO is forced by the lunisolar periods. By inspection and a first-order fit, the majority of the forcing is due to the draconic (aka nodal) lunar tide aliased with the seasonal stimulus. But if we then look at the residual, we see that a majority of the variability is due to the anomalistic lunar tide (i.e. the perigee/apogee lunar effect).
In the figure below, the upper panel is a power spectrum of the residual signal after incorporating the draconic tide. The ORANGE dots indicate where the power from the anomalistic aliased cycles should occur. After applying that EXACTLY KNOWN period, the lower panel shows the next level of residual. As you can see, the overall power is greatly reduced by simply adding this one period.
The new set of dots shows where a possible nonlinear interaction between the lunar tides would occur. I didn't fit to that yet as it gets close to overfitting at that point. Classical tidal analysis proceeds in this manner, with literally hundreds of possible lunisolar (and planetary) periods contributing at lower significance levels.
The likely reason that this QBO deconstruction has never occurred is that scientists have looked at the power spectrum and couldn't make any sense of it. These aren't classical harmonics in the sense of a fundamental frequency and harmonics of that fundamental, but are in fact aliased harmonics that obey a different arithmetic progression.
That's why this AGW denier guy Richard Lindzen was completely stumped by the nature of the QBO for over 40 years. He couldn't figure it out even though he knew deep down that it could occur. These are the quotes by Lindzen that I presented at my AGU talk.
These are quotes from Lindzen's papers on QBO and atmospheric science topics from at least 30 years ago!
And consider that these are also statements from the guy that doesn't believe in AGW, and who currently sits on the GWPF board which has a charter to discredit the current climate science consensus. So this is the guy who will likely advise the WH in the next few years. :-B Time to drain the swamp and archive the data, because what is in store is not pretty unless we get in gear.
Comment Source:There is absolutely no doubt that QBO is forced by the lunisolar periods. By inspection and a first-order fit, the majority of the forcing is due to the draconic (aka nodal) lunar tide aliased with the seasonal stimulus. But if we then look at the residual, we see that a majority of the variability is due to the anomalistic lunar tide (i.e. the perigee/apogee lunar effect). In the figure below, the upper panel is a power spectrum of the residual signal *after* incorporating the draconic tide. The <font color=darkorange>ORANGE</font> dots indicate where the power from the anomalistic aliased cycles should occur. After applying that EXACTLY KNOWN period, the lower panel shows the next level of residual. As you can see, the overall power is greatly reduced by simply adding this one period.  The new set of dots shows where a possible nonlinear interaction between the lunar tides would occur. I didn't fit to that yet as it gets close to overfitting at that point. Classical tidal analysis proceeds in this manner, with literally hundreds of possible lunisolar (and planetary) periods contributing at lower significance levels. The likely reason that this QBO deconstruction has never occurred is that scientists have looked at the power spectrum and couldn't make any sense of it. These aren't classical harmonics in the sense of a fundamental frequency and harmonics of that fundamental, but are in fact *aliased* harmonics that obey a different arithmetic progression. That's why this AGW denier guy Richard Lindzen was completely stumped by the nature of the QBO for over 40 years. He couldn't figure it out even though he knew deep down that it could occur. These are the quotes by Lindzen that I presented at my AGU talk.   These are quotes from Lindzen's papers on QBO and atmospheric science topics from at least 30 years ago! And consider that these are also statements from the guy that doesn't believe in AGW, and who currently sits on the GWPF board which has a charter to discredit the current climate science consensus. So this is the guy who will likely advise the WH in the next few years. :-B Time to drain the swamp and archive the data, because what is in store is not pretty unless we get in gear.
I would also be interesting to hear from you if you are being paid by BAE Systems for your QBO research.
I still haven't gotten an answer to this question. Finally BAE Systems Applied Intelligence Operations include e.g. communications and so climate and metrological findings might be important for that.
Comment Source:>I would also be interesting to hear from you if you are being paid by BAE Systems for your QBO research. I still haven't gotten an answer to this question. Finally <a href="https://en.wikipedia.org/wiki/BAE_Systems_Applied_Intelligence#Operations">BAE Systems Applied Intelligence Operations</a> include e.g. communications and so <a href="https://en.wikipedia.org/wiki/Space_weather#Long-distance_radio_signals">climate and metrological findings</a> might be important for that.
"I still haven't gotten an answer to this question"
Comment Source:> "I still haven't gotten an answer to this question" I-)
As with ENSO, we can train QBO on separate intervals and compare the fit on each interval. The QBO 30 hPa data runs from 1953 to the present. So we take a pair of intervals — one from 1953-1983 (i.e. lower) and one from 1983-2013 (i.e. higher) — and compare the two.
The primary forcing factor is the seasonally aliased nodal or Draconic tide which is shown in the upper left on the figure. The lower interval fit in BLUE matches extremely well to the higher interval fit in RED, with a correlation coefficient above 0.8.
These two intervals have no inherent correlation other than what can be deduced from the physical behavior generating the time-series. The other factors are the most common long-period tidal cycles, along with the seasonal factor. All have good correlations — even the aliased anomalistic tide (lower left), which features a pair of closely separated harmonics, clearly shows strong phase coherence over the two intervals.
The two intervals used for the fit.
The training region has a correlation coefficient above 0.8 while the validation interval is around 0.6, which indicates that there is likely some overfitting to noise within the training fit.
That's what my AGU presentation was about — demonstrating how QBO and ENSO are simply derived from known geophysical forcing mechanisms applied to the fundamental mathematical geophysical fluid dynamics models. Anybody can reproduce the model fit with nothing more than an Excel spreadsheet and a Solver plugin.
Comment Source:As with <a href="http://contextearth.com/2016/11/21/presentation-at-agu-2016-on-december-12/">ENSO</a>, we can train QBO on separate intervals and compare the fit on each interval. The QBO 30 hPa data runs from 1953 to the present. So we take a pair of intervals — one from 1953-1983 (i.e. lower) and one from 1983-2013 (i.e. higher) — and compare the two.</p>  <p>The primary forcing factor is the seasonally aliased nodal or Draconic tide which is shown in the upper left on the figure. The lower interval fit in <strong><font color="BLUE">BLUE</font></strong> matches extremely well to the higher interval fit in <strong><font color="RED">RED</font></strong>, with a correlation coefficient above 0.8.</p> <p>These two intervals have no inherent correlation other than what can be deduced from the physical behavior generating the time-series. The other factors are the most common long-period tidal cycles, along with the seasonal factor. All have good correlations — even the aliased anomalistic tide (lower left), which features a pair of closely separated harmonics, clearly shows strong phase coherence over the two intervals.</p> <p>The two intervals used for the fit.</p> <p><img src="http://imageshack.com/a/img921/8046/MLWYom.png"></p> <p><img src="http://imageshack.com/a/img921/1927/VWRMbI.png"></p> <p>The training region has a correlation coefficient above 0.8 while the validation interval is around 0.6, which indicates that there is likely some overfitting to noise within the training fit.</p> <p>That's what my AGU presentation was about — demonstrating how QBO and ENSO are simply derived from known geophysical forcing mechanisms applied to the fundamental mathematical <a href="https://t.co/Cwuoo4Xd5M">geophysical fluid dynamics</a> models. Anybody can reproduce the model fit with nothing more than an Excel spreadsheet and a Solver plugin.</p>
Tidal gauge sea-level height (SLH) readings can reveal the impact of ENSO if analyzed properly.
If the two are compared directly, there is a faster cycle in the SLH readings (taken from Sydney harbor) than in the ENSO SOI measure:
If we apply an optimal Finite Impulse Response (FIR) filter to the SLH then we get a better fit:
The FIR is shown in the upper left inset, which has units of lagged month.
From that, one can see that harmonics of ~1/4 year combined as a lagged FIR window generate a much better approximation to the ENSO time-series.
But even more interesting, is that this very intriguing FIR of a 2-year lagged differential impulse window gives an equivalent fit!
This is predicted based on the biennial modulation model of ENSO that I presented at AGU. The nonlinear sloshing interaction of external forcing (lunar and annual) with the Pacific ocean leads to this subharmonic. Intriguingly, the 2-year lag tells us that ENSO can be predicted effectively 2 years in advance just from SLH readings!
This is not the first time I have observed this effect, but I will likely explore this further because it gives an alternative perspective to the biennial and lunisolar contributions to ENSO.
Comment Source:Tidal gauge sea-level height (SLH) readings can reveal the impact of ENSO if analyzed properly. If the two are compared directly, there is a faster cycle in the SLH readings (taken from [Sydney harbor](http://www.psmsl.org/data/obtaining/stations/196.php)) than in the ENSO SOI measure:  If we apply an optimal Finite Impulse Response ([FIR](https://en.wikipedia.org/wiki/Finite_impulse_response)) filter to the SLH then we get a better fit:  The FIR is shown in the upper left inset, which has units of lagged **month**. From that, one can see that harmonics of ~1/4 year combined as a lagged FIR window generate a much better approximation to the ENSO time-series. But even more interesting, is that this very intriguing FIR of a 2-year lagged differential impulse window gives an equivalent fit!  This is predicted based on the biennial modulation model of ENSO that I presented at AGU. The nonlinear sloshing interaction of external forcing (lunar and annual) with the Pacific ocean leads to this subharmonic. Intriguingly, the 2-year lag tells us that ENSO can be predicted effectively 2 years in advance just from SLH readings! This is not the first time [I have observed this effect](http://contextearth.com/2016/04/13/seasonal-aliasing-of-tidal-forcing-in-mean-sea-level-height/), but I will likely explore this further because it gives an alternative perspective to the biennial and lunisolar contributions to ENSO.
Interesting new research on the concept of "time crystals". This appears to be an oscillation in a lattice structure, perhaps akin to phonons, but I can't tell from this paper. What is interesting is this statement:
The two lasers that were periodically nudging the ytterbium atoms were producing a repetition in the system at twice the period of the nudges, something that couldn't occur in a normal system.
"Wouldn't it be super weird if you jiggled the Jell-O and found that somehow it responded at a different period?" said Yao.
"But that is the essence of the time crystal. You have some periodic driver that has a period 'T', but the system somehow synchronises so that you observe the system oscillating with a period that is larger than 'T'."
They find it unusual that a period doubling in jiggled Jell-O occurs? I suppose that would happen if one doesn't know the scientific literature. This is from Ibrahim's book on sloshing
Note that both Faraday and Rayleigh observed period doubling. Rayleigh's original paper On Maintained Vibrations is an interesting read.
A liquid is not a crystal, yet phonons jiggling a crystal is the acoustic wave equivalent of a liquid sloshing.
And the reason I commented in this thread is because I believe the same period doubling behavior features in the sloshing dynamics of ENSO. This is the same Mathieu equation formulation that I apply to refine models of the behavior.
http://contextearth.com/2016/11/21/presentation-at-agu-2016-on-december-12/
Comment Source:Interesting new research on the concept of ["time crystals"](https://www.sott.net/article/341047-Time-crystals-Scientists-have-confirmed-a-brand-new-form-of-matter). This appears to be an oscillation in a lattice structure, perhaps akin to phonons, but I can't tell from this paper. What is interesting is this statement: >The two lasers that were periodically nudging the ytterbium atoms were producing a repetition in the system at twice the period of the nudges, something that couldn't occur in a normal system. > "Wouldn't it be super weird if you jiggled the Jell-O and found that somehow it responded at a different period?" said Yao. > "But that is the essence of the time crystal. You have some periodic driver that has a period 'T', but the system somehow synchronises so that you observe the system oscillating with a period that is larger than 'T'." They find it unusual that a period doubling in jiggled Jell-O occurs? I suppose that would happen if one doesn't know the scientific literature. This is from [Ibrahim's book on sloshing](https://books.google.com/books/about/Liquid_Sloshing_Dynamics.html?id=ctvhvH74ZzEC)  Note that both Faraday and Rayleigh observed period doubling. Rayleigh's original paper [On Maintained Vibrations](http://www.tandfonline.com/doi/abs/10.1080/14786448308627342?journalCode=tphm16) is an interesting read. A liquid is not a crystal, yet phonons jiggling a crystal is the acoustic wave equivalent of a liquid sloshing. And the reason I commented in this thread is because I believe the same period doubling behavior features in the sloshing dynamics of ENSO. This is the same Mathieu equation formulation that I apply to refine models of the behavior. http://contextearth.com/2016/11/21/presentation-at-agu-2016-on-december-12/
I found a reference to a technique called Slow Feature Analysis
http://www.scholarpedia.org/article/Slow_feature_analysis
Input signal of the simple example described in the text. The panels on the left and center show the two individual input components, x1(t) and x2(t) . On the right, the joint 2D trajectory x(t)=(x1(t),x2(t)) is shown.
It falls under the category of an unsupervised learning tool and essentially pulls out patterns from what looks like either noisy or highly erratic signals.
I have a feeling this is related to what I am doing with my ENSO analysis. The key step I find in fitting the ENSO model is to modulate the original signal with a biennially peaked periodic function. This emphasizes the forcing function in a way that is compatible with the way one would formulate the sloshing physics. In other words, sloshing requires a Mathieu equation formulation -- and that includes a time-varying modulation implicit in the DiffEq.
As it happens, the QBO analysis requires a similar approach. With QBO, the key is to model the acceleration of the wind, and not the velocity. The acceleration is important because that is what the atmospheric flow physics uses!
No one in climate science is doing these kinds of transformations -- they all seem to do exactly what everyone else is doing and thus getting stuck in a lock-step dead-end.
I recently watched the congressional EPA hearings -- "Make the EPA great again". The one witness who was essentially schooling the Republican-know-nothings was Rush Holt PhD, who is now CEO of the AAAS but at one time was a physicist congressman from New Jersey. My favorite bit of wisdom he imparted was that science isn't going to make any progress by looking at the same data over and over again the same way, but by "approaching the problem with a new perspective"
Watch it here, set to 101 minutes (1:41 mark) into the hearing
We have to look at the data in new ways -- that's science.
Comment Source:I found a reference to a technique called Slow Feature Analysis http://www.scholarpedia.org/article/Slow_feature_analysis >  >Input signal of the simple example described in the text. The panels on the left and center show the two individual input components, x1(t) and x2(t) . On the right, the joint 2D trajectory x(t)=(x1(t),x2(t)) is shown. It falls under the category of an unsupervised learning tool and essentially pulls out patterns from what looks like either noisy or highly erratic signals. I have a feeling this is related to what I am doing with my ENSO analysis. The key step I find in fitting the ENSO model is to modulate the original signal with a biennially peaked periodic function. This emphasizes the forcing function in a way that is compatible with the way one would formulate the sloshing physics. In other words, sloshing requires a Mathieu equation formulation -- and that includes a time-varying modulation implicit in the DiffEq. As it happens, the QBO analysis requires a similar approach. With QBO, the key is to model the acceleration of the wind, and not the velocity. The acceleration is important because that is what the atmospheric flow physics uses! No one in climate science is doing these kinds of transformations -- they all seem to do exactly what everyone else is doing and thus getting stuck in a lock-step dead-end. --- I recently watched the congressional EPA hearings -- "Make the EPA great again". The one witness who was essentially schooling the Republican-know-nothings was Rush Holt PhD, who is now CEO of the AAAS but at one time was a physicist congressman from New Jersey. My favorite bit of wisdom he imparted was that science isn't going to make any progress by looking at the same data over and over again the same way, but by *"approaching the problem with a new perspective"* Watch it here, set to 101 minutes (1:41 mark) into the hearing https://youtu.be/v7krqZxXu94?t=6160 --- We have to look at the data in new ways -- that's science.
This is how to apply a slow feature analysis to a sloshing model.
Start with the Mathieu equation and keep it in its differential form
$\frac{d^2x(t)}{dt^2}+[a-2q\cos(2\omega t)]x(t)=F(t)$
The time-modulating parameter multiplying x(t) is replaced with a good guess -- which is that it is either an annual or biennial modulation and with a peak near the end of the year. For a biennial modulation, the peak will appear on either an odd or even year. In the modulation below it is on an even year:
The RHS F(t) is essentially the same modulation but with a multiplicative forcing corresponding to the known angular momentum and tidal variations. The strongest known is at the Chandler Wobble frequency of ~432 days. There is another wobble predicted at ~14 years and a nutation at 18.6 years due to the lunar nodal variation and a heavily aliased anomalistic period at 27.54 days. Those are the strongest known forcings and are input with unknown amplitude and phase.
The search solver tries to find the best fit by varying these parameters over a "training" window of the ENSO time series. I first take a split window that takes an older time interval and matches with a more recent time interval. The "out-of-band" interval is then used to test the fit.
Then I reverse the fit by using the out-of-band interval as the fitting interval and testing against the former.
The reason that the fit is stationary across the time intervals is because the strength and the phase of the wobble terms remains pretty much constant. The dense chart below is a comparison of the factors used. Note that some of the lesser tidal forcing factors are included as well and they do not fare quite as well.
Here is an animated GIF of how the two fitting intervals compare:
The sloshing model is parsimonious with the data and what remains to be done is to establish the plausibility of the model. In that regard, is there enough of an angular momentum change or torque in the earth's rotation to cause the ocean to slosh? Or is there enough to cause the thermocline to slosh, which is actually what's happening? The difference in density of water above and below the thermocline is enough to create a reduced effective gravity that can plausibly be extremely sensitive to momentum changes. The sensitivity is equivalent to an oil/water wave machine
Yet the current thinking in the consensus ENSO research is that prevailing east-west winds are what causes a sloshing buildup. But what causes those winds? Could those be a result of ENSO and not a cause? They seem to be highly correlated,
but what causes a wind other than a pressure differential? And that pressure differential arises from the pressure dipole measured by the ENSO SOI index. Whenever the pressure is low in the west Pacific, it is high in the east and vice versa.
So the plausibility of this model of torque-assisted sloshing is essentially wrapped around finding out whether this effect is of similar magnitude of any wind-forced mechanism. Perhaps the question to ask -- is it easier to cause a wave machine to slosh by blowing on the surface or to gently rock it?
Comment Source:This is how to apply a slow feature analysis to a sloshing model. Start with the Mathieu equation and keep it in its differential form $\frac{d^2x(t)}{dt^2}+[a-2q\cos(2\omega t)]x(t)=F(t)$ The time-modulating parameter multiplying *x(t)* is replaced with a good guess -- which is that it is either an annual or biennial modulation and with a peak near the end of the year. For a biennial modulation, the peak will appear on either an odd or even year. In the modulation below it is on an even year: 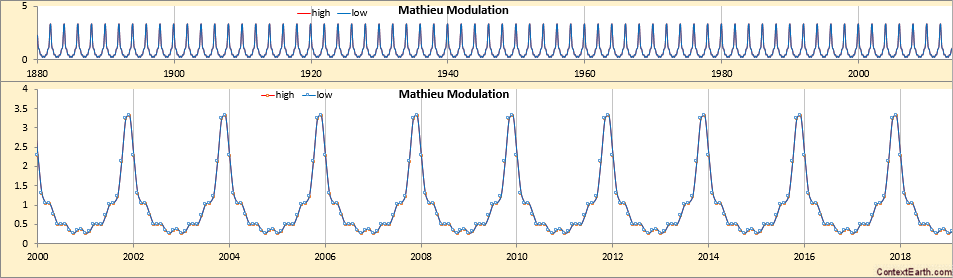 The RHS *F(t)* is essentially the same modulation but with a multiplicative forcing corresponding to the known angular momentum and tidal variations. The strongest known is at the Chandler Wobble frequency of ~432 days. There is another wobble predicted at ~14 years and a nutation at 18.6 years due to the lunar nodal variation and a heavily aliased anomalistic period at 27.54 days. Those are the strongest known forcings and are input with unknown amplitude and phase. The search solver tries to find the best fit by varying these parameters over a "training" window of the ENSO time series. I first take a split window that takes an older time interval and matches with a more recent time interval. The "out-of-band" interval is then used to test the fit.  Then I reverse the fit by using the out-of-band interval as the fitting interval and testing against the former. 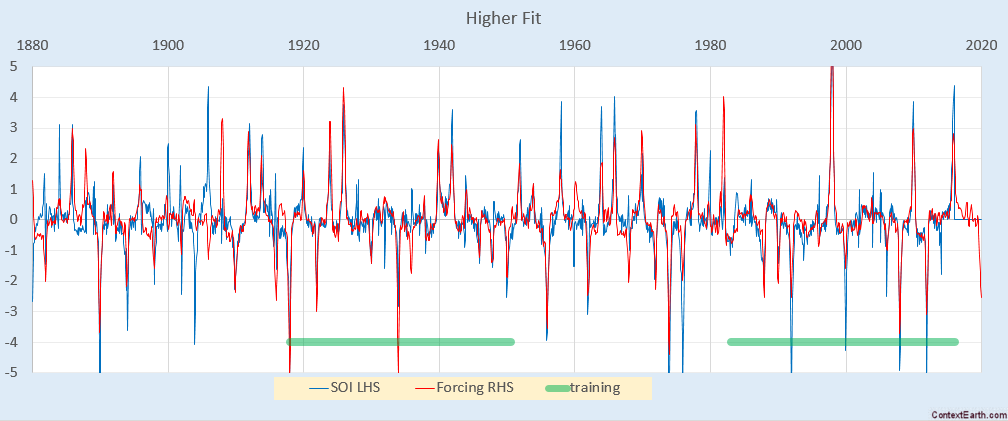 The reason that the fit is stationary across the time intervals is because the strength and the phase of the wobble terms remains pretty much constant. The dense chart below is a comparison of the factors used. Note that some of the lesser tidal forcing factors are included as well and they do not fare quite as well.  Here is an animated GIF of how the two fitting intervals compare: 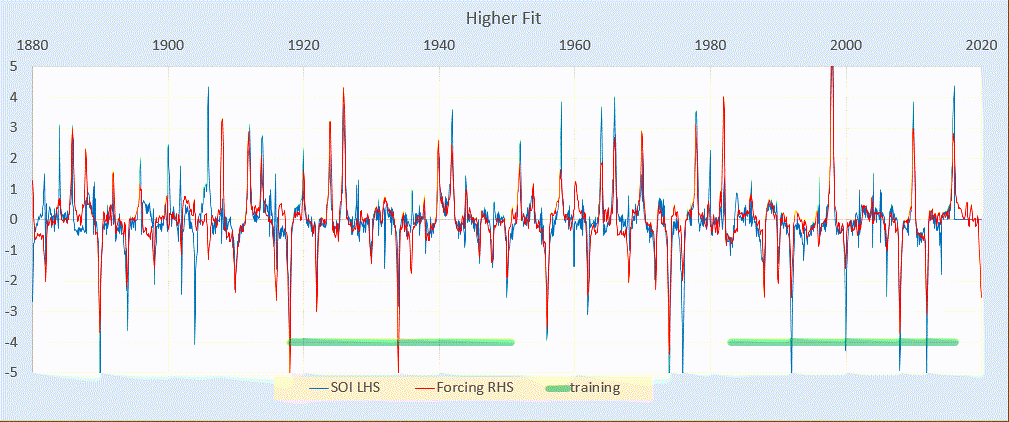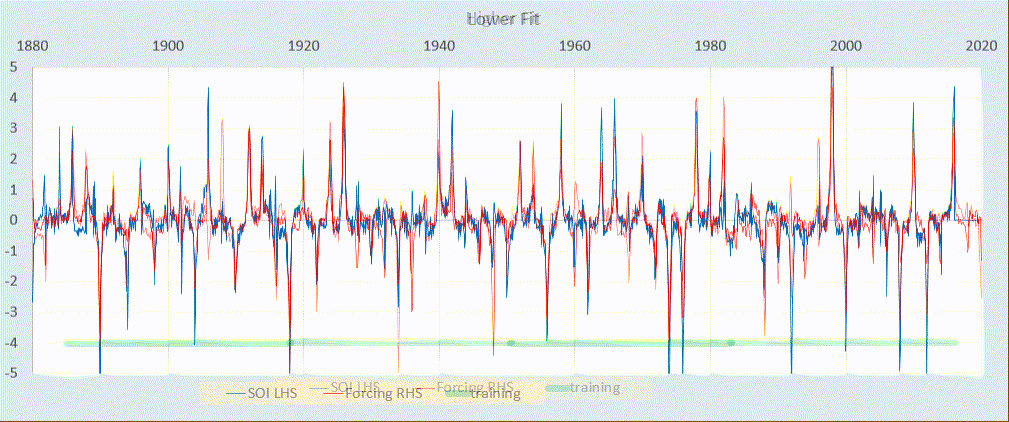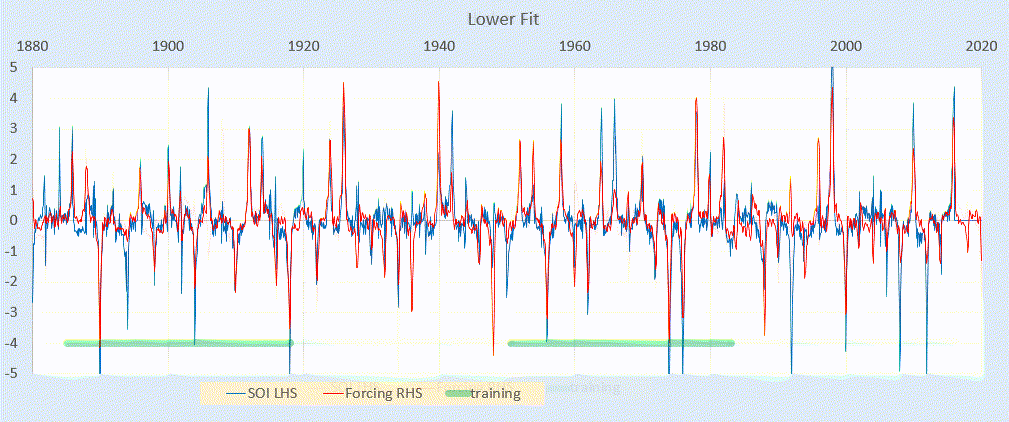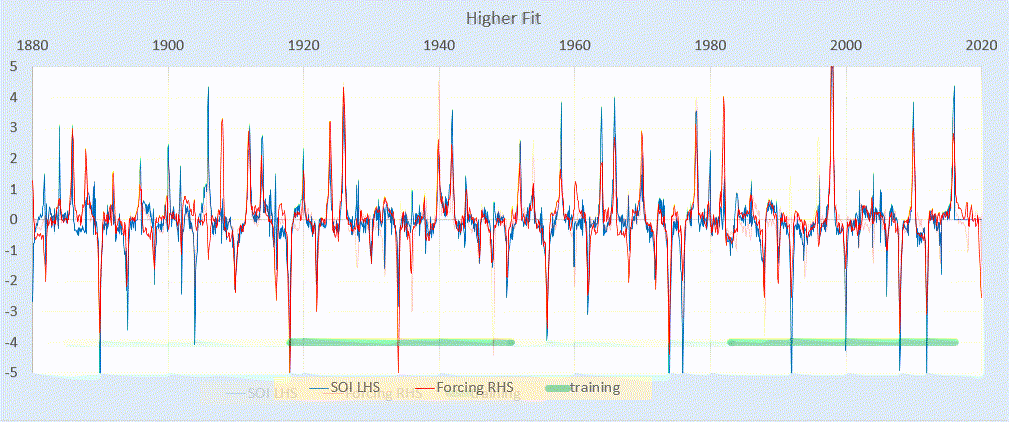 The sloshing model is parsimonious with the data and what remains to be done is to establish the plausibility of the model. In that regard, is there enough of an angular momentum change or torque in the earth's rotation to cause the ocean to slosh? Or is there enough to cause **the thermocline** to slosh, which is actually what's happening? The difference in density of water above and below the thermocline is enough to create a reduced effective gravity that can plausibly be extremely sensitive to momentum changes. The sensitivity is equivalent to an oil/water wave machine https://youtu.be/UUZ8vrj-qzM Yet the current thinking in the consensus ENSO research is that prevailing east-west winds are what causes a sloshing buildup. But what causes those winds? Could those be a **result** of ENSO and not a **cause**? They seem to be highly correlated,  but what causes a wind other than a pressure differential? And that pressure differential arises from the pressure dipole measured by the ENSO SOI index. Whenever the pressure is low in the west Pacific, it is high in the east and vice versa. So the plausibility of this model of torque-assisted sloshing is essentially wrapped around finding out whether this effect is of similar magnitude of any wind-forced mechanism. Perhaps the question to ask -- is it easier to cause a wave machine to slosh by blowing on the surface or to gently rock it?
I mentioned:
"Perhaps the question to ask -- is it easier to cause a wave machine to slosh by blowing on the surface or to gently rock it?"
This would actually be a very easy experiment to set up. Build a home-made wave machine out of an old aquarium and then compare with two different forcing mechanisms -- (1) with an oscillating translational platform driven by a servo (2) with an oscillating speed fan blowing air over the surface.
It would be easy to measure the average power consumed by each mechanism and see which one takes the least effort to start the wave machine sloshing.
The other interesting idea I have is in the analytical realm. I think I have figured out how to automatically extract the principal factors of forcing from a certain class of Mathieu modulated DiffEq's. The key is to create a modulation that is a delta-function train of spikes at a periodic interval. That is an easy convolution to construct as a matrix eigenvalue problem in frequency space. Essentially for every harmonic created one can introduce an additional periodic forcing factor. Solve the matrix of a chosen size and the factors should pop out from the roots. I should get the same answer as the solver finds in the comment above, since the modulation there looks like a train of spikes in the limiting case:
If that works, we can get an answer back instantaneously instead of letting the solver grind away finding a miminum error solution. Even if it's not the actual physics involved, it certainly qualifies as an interesting applied math solution.
Here is a paper that exactly derives the Mathieu equation for Faraday waves on a sphere. https://www.pmmh.espci.fr/~laurette/papers/FIS_FA_pub.pdf "Faraday instability on a sphere: Floquet analysis"
I recall seeing a paper from years ago that indicated that the Mathieu equation was inapplicable for a spherical geometry, which may have hindered further research along this path. Interesting that this particular paper is also in the highly regarded Journal of Fluid Mechanics, which recently published a review article from 2016 explaining how to best approach the characterization of wave behavior Faraday waves: their dispersion relation, nature of bifurcation and wavenumber selection revisited
This paper includes this jarring statement:
"For instance, to the best of our knowledge, the dispersion relation (relating angular frequency ω and wavenumber k) of parametrically forced water waves has astonishingly not been explicitly established hitherto. "
This hasn't yet completely sunk in but I still find it strange that at this late date scientists are apparently still struggling to figure out forced wave action in a liquid volume.
The lead author of that paper elsewhere said this:
The prominent physicist Richard P. Feynman wrote in his cerebrated lectures [10]: "Water waves that are easily seen by everyone, and which are usually used as an example of waves in elementary courses, are the worst possible example; they have all the complications that waves can have." This is precisely these complications that make the richness and interest of water waves. Indeed, despite numerous studies, new waves and new wave behaviors are still discovered (e.g. , [26, 27]) and wave dynamics is still far from being fully understood.
Comment Source:I mentioned: > "Perhaps the question to ask -- is it easier to cause a wave machine to slosh by blowing on the surface or to gently rock it?" This would actually be a very easy experiment to set up. Build a home-made wave machine out of an old aquarium and then compare with two different forcing mechanisms -- (1) with an oscillating translational platform driven by a servo (2) with an oscillating speed fan blowing air over the surface. It would be easy to measure the average power consumed by each mechanism and see which one takes the least effort to start the wave machine sloshing. --- The other interesting idea I have is in the analytical realm. I think I have figured out how to automatically extract the principal factors of forcing from a certain class of Mathieu modulated DiffEq's. The key is to create a modulation that is a delta-function train of spikes at a periodic interval. That is an easy convolution to construct as a matrix eigenvalue problem in frequency space. Essentially for every harmonic created one can introduce an additional periodic forcing factor. Solve the matrix of a chosen size and the factors should pop out from the roots. I should get the same answer as the solver finds in the comment above, since the modulation there looks like a train of spikes in the limiting case:  If that works, we can get an answer back instantaneously instead of letting the solver grind away finding a miminum error solution. Even if it's not the actual physics involved, it certainly qualifies as an interesting applied math solution. --- Here is a paper that exactly derives the Mathieu equation for Faraday waves on a sphere. https://www.pmmh.espci.fr/~laurette/papers/FIS_FA_pub.pdf "Faraday instability on a sphere: Floquet analysis" I recall seeing a paper from years ago that indicated that the Mathieu equation was inapplicable for a spherical geometry, which may have hindered further research along this path. Interesting that this particular paper is also in the highly regarded Journal of Fluid Mechanics, which recently published a review article from 2016 explaining how to best approach the characterization of wave behavior [Faraday waves: their dispersion relation, nature of bifurcation and wavenumber selection revisited](http://www.unice.fr/rajchenbach/JFM2015.pdf) This paper includes this jarring statement: > "For instance, to the best of our knowledge, the dispersion relation (relating angular frequency ω and wavenumber k) of parametrically forced water waves has astonishingly not been explicitly established hitherto. " This hasn't yet completely sunk in but I still find it strange that at this late date scientists are apparently still struggling to figure out forced wave action in a liquid volume. The lead author of that paper elsewhere said this: > The prominent physicist Richard P. Feynman wrote in his cerebrated lectures [10]: *"Water waves that are easily seen by everyone, and which are usually used as an example of waves in elementary courses, are the worst possible example; they have all the complications that waves can have."* This is precisely these complications that make the richness and interest of water waves. Indeed, despite numerous studies, new waves and new wave behaviors are still discovered (e.g. , [26, 27]) and wave dynamics is still far from being fully understood.
Retired atmospheric sciences professor Judith Curry has a discussion paper out called "Climate Models for the Layman" written for Trump followers apparently: http://www.thegwpf.org/content/uploads/2017/02/Curry-2017.pdf
The paper is essentially Curry whining that climate science is too difficult, instead of getting to work and figuring out the physics and math, like the rest of us try to do.
The GWPF is the Global Warming Policy Foundation, which is one of those misnamed organizations -- the people running it do not actually believe in the science behind AGW. It's based in the UK which you can tell from the trustee list
Notice that the two scientists largely responsible for the primitive state of QBO and ENSO models -- Lindzen and frequent Curry collaborator Tsonis -- are on the GWPF academic advisory board. Since they don't seem to believe in AGW, I don't trust their understanding of QBO and ENSO; which is one of the reasons that I am working on these models. The idea is to work on research where the understanding is weak.
Comment Source:Retired atmospheric sciences professor Judith Curry has a discussion paper out called "Climate Models for the Layman" written for Trump followers apparently: http://www.thegwpf.org/content/uploads/2017/02/Curry-2017.pdf The paper is essentially Curry whining that climate science is too difficult, instead of getting to work and figuring out the physics and math, like the rest of us try to do. The GWPF is the Global Warming Policy Foundation, which is one of those misnamed organizations -- the people running it do not actually believe in the science behind AGW. It's based in the UK which you can tell from the trustee list  Notice that the two scientists largely responsible for the primitive state of QBO and ENSO models -- Lindzen and frequent Curry collaborator Tsonis -- are on the GWPF academic advisory board. Since they don't seem to believe in AGW, I don't trust their understanding of QBO and ENSO; which is one of the reasons that I am working on these models. The idea is to work on research where the understanding is weak.
Where is she whining ? I mean she is critizising certain features of GCM's, like in particular that
There is growing evidence that climate models are running too hot and that climate sensitivity to carbon dioxide is at the lower end of the range provided by the IPCC. Nevertheless, these lower values of climate sensitivity are not accounted for in IPCC climate model projections of temperature at the end of the 21st century or in esti- mates of the impact on temperatures of reducing carbon dioxide emissions.
As far as I understood, this critique is based on observations (p.7):
Lewis and Curry (2014) used an observation-based energy balance approach to estimate ECS. Their calculations used the same values (including uncertainties) for changes in greenhouse gases and other drivers of climate change as given in the Fifth Assessment. However, their range of values for ECS were approximately half those de- termined from the CMIP5 climate models.
It is clear that predicting climate is shit difficult and at this infancy stage very likely quite error-prone. As she rightly pointed out alone on the math side there are major difficulties, like:
The solution of Navier–Stokes equations is one of the most vexing problems in all of mathematics: the Clay Mathematics Institute has declared this to be one of the top seven problems in all of mathematics and is offering a $1 million prize for its solution.
so on page (vii) she writes:
By extension, GCMs are not fit for the purpose of justifying political policies to fundamentally alter world social, economic and energy systems.
The question here seems what do you make out of this sentence? What are the consequences?
from the last page:
The Global Warming Policy Foundation is an all-party and non-party think tank and a registered educational charity which, while openminded on the contested science of global warming, is deeply concerned about the costs and other implications of many of the policies currently being advo- cated
Yes, following the climate models in particular GCMs seem to be quite faulty. But they can be faulty into two directions, i.e. things can be less worse or way worse. If the thermometers in your living room gets suddenly hot (at least at some places) do you keep sitting and pretend nothing has happened? Or do you keep trying to check as best as possible and eventually precautiously switch down the thermostat even if you don't really know wether the heating is the source of the problem?
I think that there had been deficiences especially with respect to the point "check as best as possible." That is as already Judith Curry pointed out, if all models (in the example the "hypothesis why it is so hot in the living room") appear rather bad in explaining the phenomena then nobody really knows what the best model is:
Is it possible to select a 'best' model? Well, several models generally show a poorer performance overall when compared with observations. However, the best model depends on how you define 'best', and no single model is the best at everything.
and so the choice for approaches to find solutions was partially less based on purely scientific choices, but also on who is able to secure which funds with which effort.
The fact that people like Tim van Beek is now busy producing cars for the "economic elite" instead of e.g. working on fluid dynamics is saying something.
Comment Source:>The paper is essentially Curry whining that climate science is too difficult, instead of getting to work and figuring out the physics and math, like the rest of us try to do. Where is she whining ? I mean she is critizising certain features of GCM's, like in particular that >There is growing evidence that climate models are running too hot and that climate sensitivity to carbon dioxide is at the lower end of the range provided by the IPCC. Nevertheless, these lower values of climate sensitivity are not accounted for in IPCC climate model projections of temperature at the end of the 21st century or in esti- mates of the impact on temperatures of reducing carbon dioxide emissions. As far as I understood, this critique is based on observations (p.7): >Lewis and Curry (2014) used an observation-based energy balance approach to estimate ECS. Their calculations used the same values (including uncertainties) for changes in greenhouse gases and other drivers of climate change as given in the Fifth Assessment. However, their range of values for ECS were approximately half those de- termined from the CMIP5 climate models. It is clear that predicting climate is shit difficult and at this infancy stage very likely quite error-prone. As she rightly pointed out alone on the math side there are major difficulties, like: >The solution of Navier–Stokes equations is one of the most vexing problems in all of mathematics: the Clay Mathematics Institute has declared this to be one of the top seven problems in all of mathematics and is offering a $1 million prize for its solution. so on page (vii) she writes: >By extension, GCMs are not fit for the purpose of justifying political policies to fundamentally alter world social, economic and energy systems. The question here seems what do you make out of this sentence? What are the consequences? from the last page: >The Global Warming Policy Foundation is an all-party and non-party think tank and a registered educational charity which, while openminded on the contested science of global warming, is deeply concerned about the costs and other implications of many of the policies currently being advo- cated Yes, following the climate models in particular GCMs seem to be quite faulty. But they can be faulty into two directions, i.e. things can be less worse or way worse. If the thermometers in your living room gets suddenly hot (at least at some places) do you keep sitting and pretend nothing has happened? Or do you keep trying to check as best as possible and eventually precautiously switch down the thermostat even if you don't really know wether the heating is the source of the problem? I think that there had been deficiences especially with respect to the point "check as best as possible." That is as already Judith Curry pointed out, if all models (in the example the "hypothesis why it is so hot in the living room") appear rather bad in explaining the phenomena then nobody really knows what the best model is: >Is it possible to select a 'best' model? Well, several models generally show a poorer performance overall when compared with observations. However, the best model depends on how you define 'best', and no single model is the best at everything. and so the choice for approaches to find solutions was partially less based on purely scientific choices, but also on who is able to secure which funds with which effort. The fact that people like <a href="https://johncarlosbaez.wordpress.com/2012/05/30/fluid-flows-and-infinite-dimensional-manifolds-part-3/">Tim van Beek</a> is now busy producing cars for the "economic elite" instead of e.g. working on fluid dynamics is saying something.
Obviously they are unsolvable in general because the equations are largely under-determined. Boundary and initial conditions alone do not provide enough constraints to solve the set of equations in 3-dimensions. No one complains that two equations with three unknowns is unsolvable.
Compare that to Maxwell's equations which tend to be more determined because of the interactions between the B and E fields and how boundary conditions are applied.
Here's an example of what I am talking about. Consider my solution to the QBO. This is essentially solving Navier-Stokes for atmospheric flow. When I worked out the primitive equations, I knew that I would have to be ruthless in reducing the dimensionality from the start. The first simplification was working at the equator, which eliminated a few of the terms arising from the Coriolis effect. QBO is also a stratified system, so the vertical cross-terms are inconsequential. Of course the time-space part of Navier-Stokes was separated by noticing the standing-wave nature of the phenomenon has a wavenumber of zero, which obviously helped quite a bit.
I eventually ran into the last remaining under-determined constraint dealing with a transverse spatial term; I eliminated this by cleverly associating the latitudinal equatorial flow line with a nodal lunisolar forcing. This provide a running boundary-slash-initial condition and thus reduced the initially "unsolvable" Navier-Stokes equations to a Sturm-Liouville formulation -- which fortunately had a remarkable closed-form analytical solution.
So not only did I solve a variant of Navier-Stokes -- i.e. the primitive equations of Laplace's tidal equations -- but it didn't even require an iterative numeric solution. I do have to admit that I used many of the ideas from understanding how to solve the 2-dimensional Hall effect via Maxwell's equations in coming up with the answer.
The other example is ENSO. This is also a standing wave equation which has a rather straightforward solution but needs a numerical computation assist to iterate the solution, unless one can leave it as a convolution of a Mathieu function with sinusoidal forcing terms. Of course I partially adapted this idea from sloshing research in the hydrodynamics literature.
Where is she whining ?
Perhaps I should be the one whining to Professor Curry ... WHERE IS MY $1,000,00.00 PRIZE AWARD !!!!! :-B :)
Comment Source:>>The paper is essentially Curry whining that climate science is too difficult, instead of getting to work and figuring out the physics and math, like the rest of us try to do. > Where is she whining ? I mean she is critizising certain features of GCM's, like in particular that >> The solution of Navier–Stokes equations is one of the most vexing problems in all of mathematics: the Clay Mathematics Institute has declared this to be one of the top seven problems in all of mathematics and is offering a **$1 million prize** for its solution. Obviously they are unsolvable in general because the equations are largely under-determined. Boundary and initial conditions alone do not provide enough constraints to solve the set of equations in 3-dimensions. No one complains that two equations with three unknowns is unsolvable. Compare that to Maxwell's equations which tend to be more determined because of the interactions between the B and E fields and how boundary conditions are applied. Here's an example of what I am talking about. Consider my solution to the QBO. This is essentially solving Navier-Stokes for atmospheric flow. When I worked out the primitive equations, I knew that I would have to be ruthless in reducing the dimensionality from the start. The first simplification was working at the equator, which eliminated a few of the terms arising from the Coriolis effect. QBO is also a stratified system, so the vertical cross-terms are inconsequential. Of course the time-space part of Navier-Stokes was separated by noticing the standing-wave nature of the phenomenon has a wavenumber of zero, which obviously helped quite a bit. I eventually ran into the last remaining under-determined constraint dealing with a transverse spatial term; I eliminated this by cleverly associating the latitudinal equatorial flow line with a nodal lunisolar forcing. This provide a running boundary-slash-initial condition and thus reduced the initially "unsolvable" Navier-Stokes equations to a Sturm-Liouville formulation -- which fortunately had a remarkable closed-form analytical solution. So not only did I solve a variant of Navier-Stokes -- i.e. the primitive equations of Laplace's tidal equations -- but it didn't even require an iterative numeric solution. I do have to admit that I used many of the ideas from understanding how to solve the 2-dimensional Hall effect via Maxwell's equations in coming up with the answer. The other example is ENSO. This is also a standing wave equation which has a rather straightforward solution but needs a numerical computation assist to iterate the solution, unless one can leave it as a convolution of a Mathieu function with sinusoidal forcing terms. Of course I partially adapted this idea from sloshing research in the hydrodynamics literature. > Where is she whining ? Perhaps I should be the one whining to Professor Curry ... **WHERE IS MY $1,000,00.00 PRIZE AWARD !!!!!** :-B :)
It's been quite a challenge decoding the physics of ENSO. Anything that makes the model more complex and with more degrees of freedom needs to be treated carefully. The period doubling bifurcation properties of wave sloshing has been an eye-opener for me. I experimented with adding a sub-harmonic period of 4 years to the 2-year Mathieu modulation and see if that improves the fit. By simply masking the odd behavior around 1981-1983, I came up with this breakdown of the RHS/LHS comparison.
This is an iterative solver applied to two completely orthogonal intervals of the ENSO time series leading to largely identical solutions given the fixed tidal factors. The animated gif flips between the fit on one training interval to the orthogonal interval. All that was allowed to change was the amplitude and phase, as shown in the following phasor diagram.
Each of the pairs of sinusoidal factors would line up exactly on a phasor diagram if the analyzed process was perfectly stationary. If they line up closely, then there is good agreement -- subject to the possibility of overfitting.
So to check for overfitting, we take this same formulation and extend it to regions outside of the ENSO interval from 1880-present. We can't look to the future, but we can look into the past via the UEP coral proxy records. This is what it looks like.
From 1650 to about 1800, the correlation is quite good considering that we only have yearly-averaged values . Over the calibrated proxy interval post 1900 the agreement is as before. However, the 1800's are out-of-phase (is that due to the amount of volcanic activity during that century Tambora in 1815 plus Krakatoa in 1883?).
This is not conclusive proof but neither does it contradict the model. To achieve such a high correlation between time series separated by at least 200 years is only remotely possible to achieve via random chance.
So is there something fundamental to the 2-year and 4-year period sub-harmonics? I can understand the two year period as being the first doubling of the annual cycle. But the 4 year period would come about from the doubling of the 2-year cycle. This could be recursively applied to 8-year and 16-year periods, but likely not if there was another resonant period close to 4 years.
Is it possible that the 27.55455 day anomalistic lunar tidal period fits into a four year cycle as 13 + 13 + 13 + 13 + 1 = 53 anomalistic tidal periods nearly exactly? 27.55455*53 = 4 * (365.x) where x = 0.098 instead of x=0.242. This is the difference between adding a leap day every fourth year versus adding one every tenth year in terms of alignment. So what the perigee-apogee lunar cycles could do is reinforce this 4-year period by pumping the gravitational cycle in unison with the ocean at the same seasonal reference point.
I presented the following chart at the AGU, which showed how machine learning picked out the same aliased anomalistic period from the UEP coral proxy records with no human direction:
An angular frequency of 7.821 radians with 12 2$\pi$ added = 83.219 is close to the 2 $\pi$ (365.242/27.55455) = 83.285 expected for an anomalistic forcing period.
Comment Source:It's been quite a challenge decoding the physics of ENSO. Anything that makes the model more complex and with more degrees of freedom needs to be treated carefully. The period doubling bifurcation properties of wave sloshing has been an eye-opener for me. I experimented with adding a sub-harmonic period of 4 years to the 2-year Mathieu modulation and see if that improves the fit. By simply masking the odd behavior around 1981-1983, I came up with this breakdown of the RHS/LHS comparison. 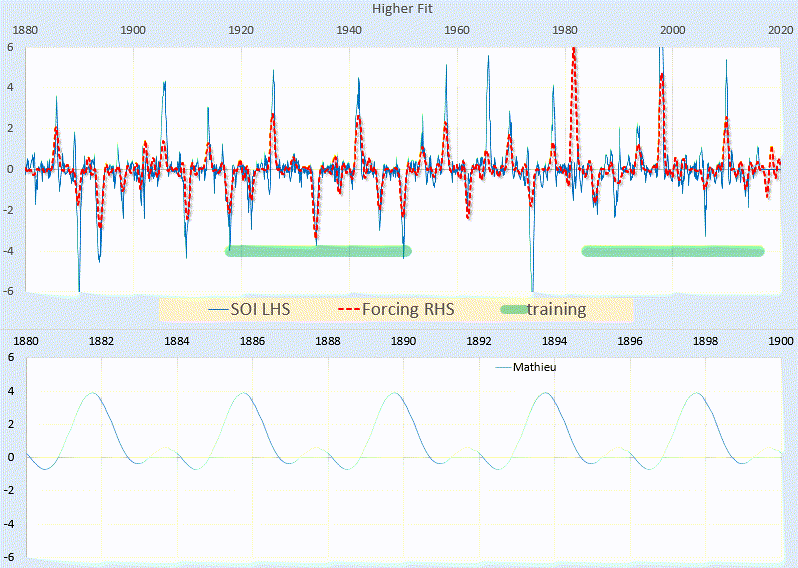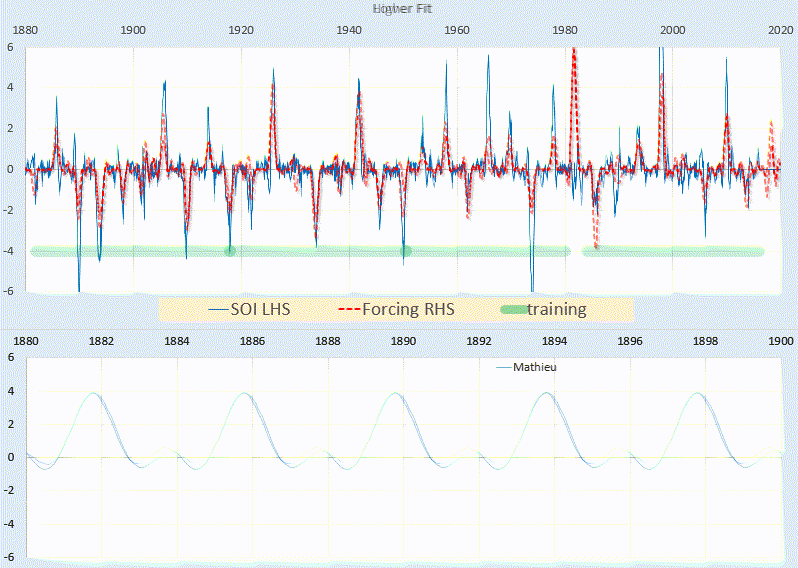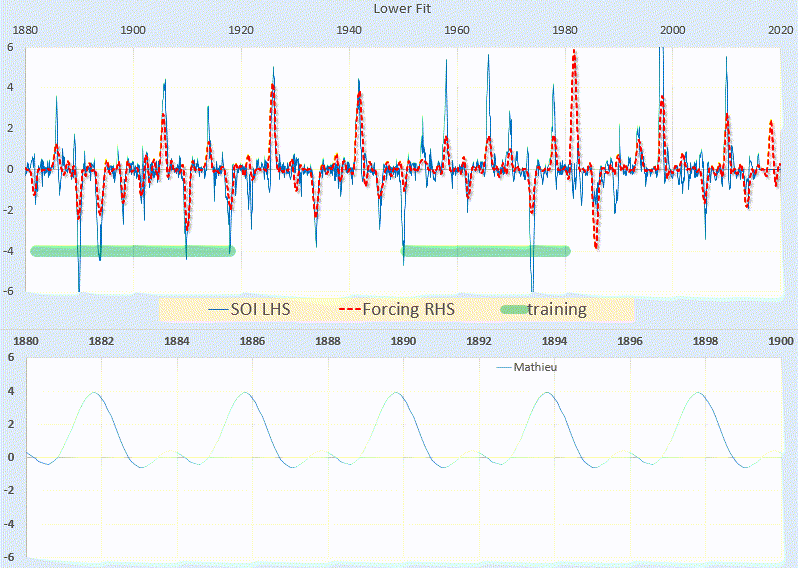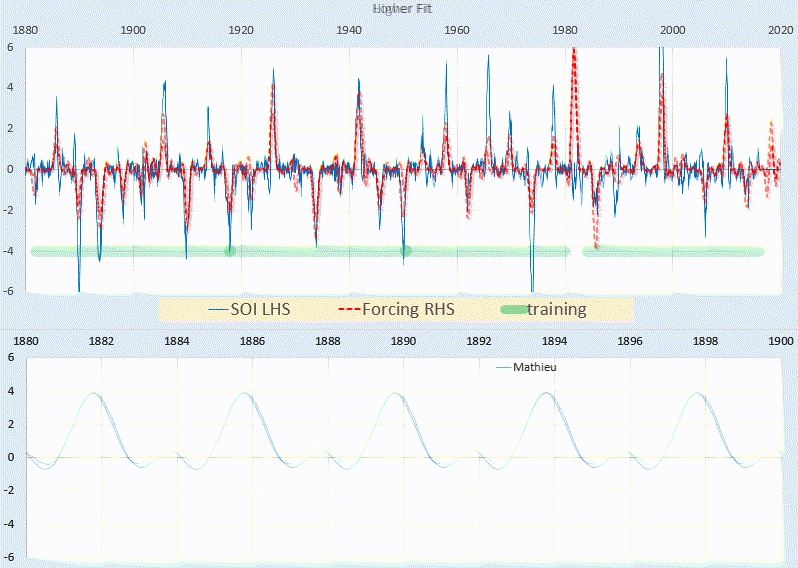 This is an iterative solver applied to *two completely orthogonal* intervals of the ENSO time series leading to largely identical solutions given the fixed tidal factors. The animated gif flips between the fit on one training interval to the orthogonal interval. All that was allowed to change was the amplitude and phase, as shown in the following [phasor diagram](https://en.wikipedia.org/wiki/Phasor).  Each of the pairs of sinusoidal factors would line up exactly on a phasor diagram if the analyzed process was perfectly stationary. If they line up closely, then there is good agreement -- subject to the possibility of overfitting. So to check for overfitting, we take this same formulation and extend it to regions outside of the ENSO interval from 1880-present. We can't look to the future, but we can look into the past via the [UEP coral proxy records](http://contextearth.com/2016/09/27/enso-proxy-revisited/). This is what it looks like. 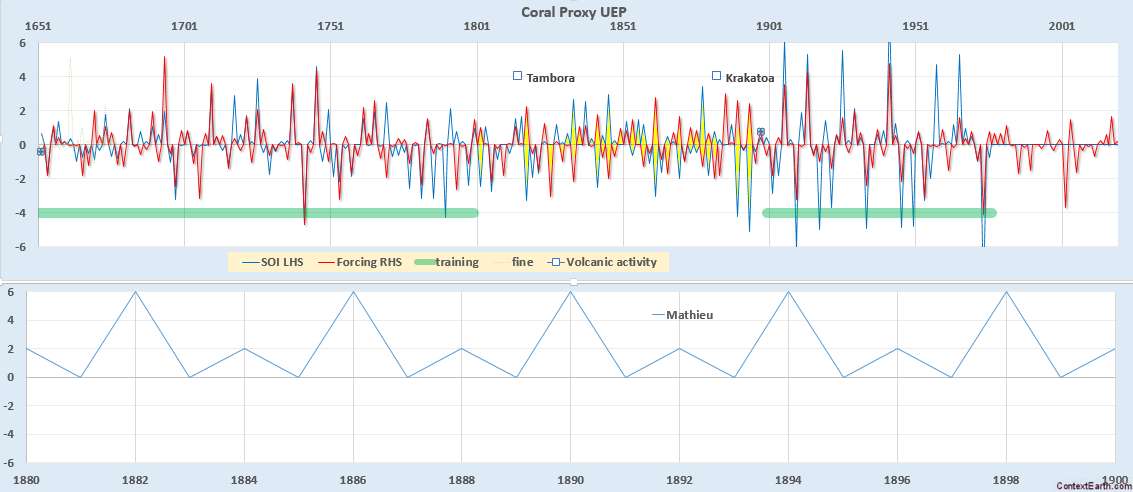 From 1650 to about 1800, the correlation is quite good considering that we only have yearly-averaged values . Over the calibrated proxy interval post 1900 the agreement is as before. However, the 1800's are out-of-phase (is that due to the amount of volcanic activity during that century Tambora in 1815 plus Krakatoa in 1883?). This is not conclusive proof but neither does it contradict the model. To achieve such a high correlation between time series separated by at least 200 years is only remotely possible to achieve via random chance. So is there something fundamental to the 2-year and 4-year period sub-harmonics? I can understand the two year period as being the first doubling of the annual cycle. But the 4 year period would come about from the doubling of the 2-year cycle. This could be recursively applied to 8-year and 16-year periods, but likely not if there was another resonant period close to 4 years. Is it possible that the 27.55455 day anomalistic lunar tidal period fits into a four year cycle as 13 + 13 + 13 + 13 + 1 = 53 anomalistic tidal periods nearly exactly? 27.55455*53 = 4 * (365.x) where x = 0.098 instead of x=0.242. This is the difference between adding a leap day every fourth year versus adding one every tenth year in terms of alignment. So what the perigee-apogee lunar cycles could do is reinforce this 4-year period by pumping the gravitational cycle in unison with the ocean at the same seasonal reference point.  I presented the following chart at the AGU, which showed how machine learning picked out the same aliased anomalistic period from the UEP coral proxy records with no human direction: 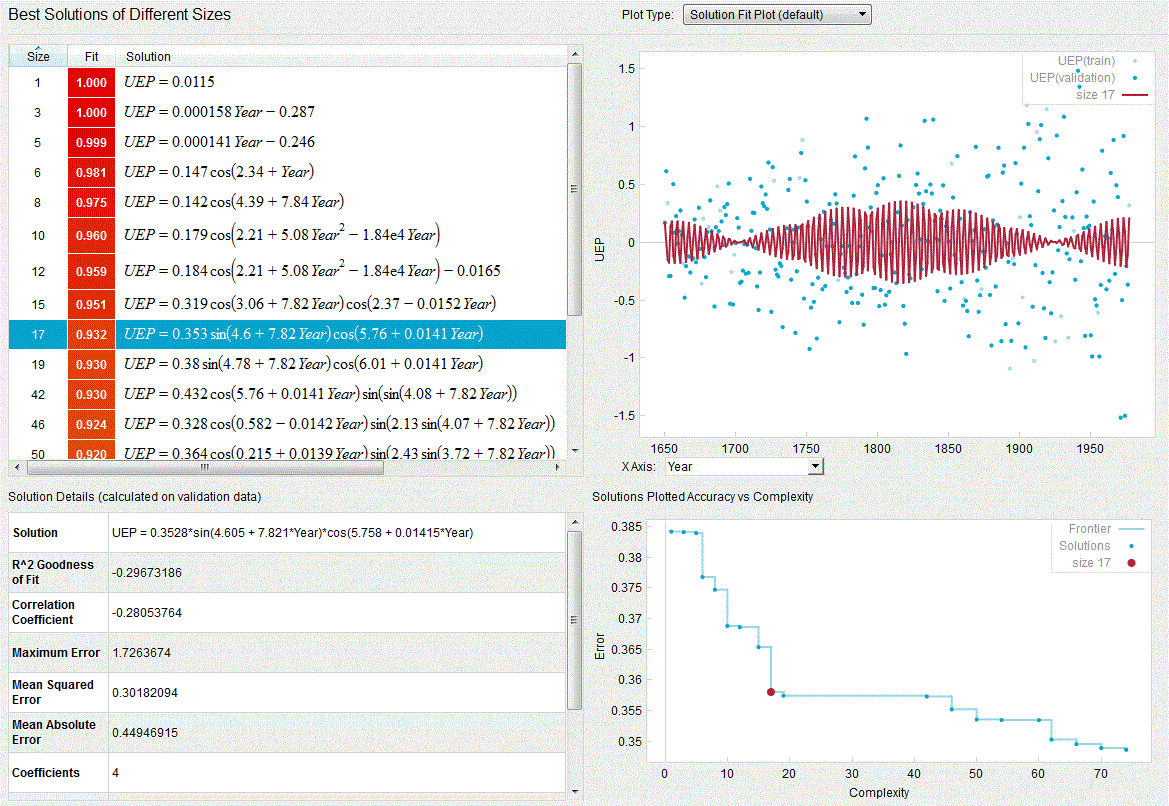 An angular frequency of 7.821 radians with 12 2$\pi$ added = 83.219 is close to the 2 $\pi$ (365.242/27.55455) = 83.285 expected for an anomalistic forcing period.
Last comment I mentioned I was trying to simplify the ENSO model. Right now the forcing is a mix of angular momentum variations related to Chandler wobble and lunisolar tidal pull. This is more complex than I would like to see. So what happens if the Chandler wobble is directly tied to the draconic/nodal cycles in the lunar tide? There is empirical evidence for this even though it is not acknowledged in the consensus geophysics literature.
The figure below is my fit to the Chandler wobble, seemingly matching the aliased lunar draconic cycle rather precisely:
http://contextearth.com/2016/01/27/possible-luni-solar-tidal-mechanism-for-the-chandler-wobble/
The consensus is that it is impossible for the moon to induce a nutation in the earth's rotation to match the Chandler wobble. Yet, the seasonally reinforced draconic pull leads to an aliasing that is precisely the same value as the Chandler wobble period over the span of many years. Is this just coincidence or is there something that the geophysicists are missing?
It's kind of hard to believe that this would be overlooked, and I have avoided discussing the correlation out of deference to the research literature. Yet the simplification to the ENSO model that a uniform lunisolar forcing would result in shouldn't be dismissed. To quote Clinton, what if
Comment Source:Last comment I mentioned I was trying to simplify the ENSO model. Right now the forcing is a mix of angular momentum variations related to Chandler wobble and lunisolar tidal pull. This is more complex than I would like to see. So what happens if the Chandler wobble is directly tied to the draconic/nodal cycles in the lunar tide? There is empirical evidence for this even though it is not acknowledged in the consensus geophysics literature. The figure below is my fit to the Chandler wobble, seemingly matching the *aliased* lunar draconic cycle rather precisely:  http://contextearth.com/2016/01/27/possible-luni-solar-tidal-mechanism-for-the-chandler-wobble/ The consensus is that it is impossible for the moon to induce a nutation in the earth's rotation to match the Chandler wobble. Yet, the seasonally reinforced draconic pull leads to an aliasing that is precisely the same value as the Chandler wobble period over the span of many years. Is this just coincidence or is there something that the geophysicists are missing? It's kind of hard to believe that this would be overlooked, and I have avoided discussing the correlation out of deference to the research literature. Yet the simplification to the ENSO model that a uniform lunisolar forcing would result in shouldn't be dismissed. To quote Clinton, what if
In the current research literature, the Chandler wobble is described as an impulse response with a characteristic frequency determined by the earth's ellipticity.
https://en.wikipedia.org/wiki/Chandler_wobble "The existence of Earth's free nutation was predicted by Isaac Newton in Corollaries 20 to 22 of Proposition 66, Book 1 of the Philosophiæ Naturalis Principia Mathematica, and by Leonhard Euler in 1765 as part of his studies of the dynamics of rotating bodies. Based on the known ellipticity of the Earth, Euler predicted that it would have a period of 305 days. Several astronomers searched for motions with this period, but none was found. Chandler's contribution was to look for motions at any possible period; once the Chandler wobble was observed, the difference between its period and the one predicted by Euler was explained by Simon Newcomb as being caused by the non-rigidity of the Earth. The full explanation for the period also involves the fluid nature of the Earth's core and oceans .. "
There is a factor known as the Q-value which describes the resonant "quality" of the impulse response, classically defined as the solution to a 2nd-order DiffEq. The higher the Q, the longer the oscillating response. The following figure shows the impulse and response for a fairly low Q-value. It's thought that the Chandler wobble Q-value is very high, as it doesn't seem to damp quickly.
In contrast, ocean tides are not described as a characteristic frequency but instead as a transfer function and a "steady-state" response due to the forcing frequency. The forcing frequency is in fact carried through from the input stimulus to the output response. In other words, the tidal frequency matches the rhythm of the lunar (and solar) orbital frequency. There may be a transient associated with the natural response but this eventually transitions into the steady-state through the ocean's damping filter as shown below:
This behavior is well known in engineering and science circles and explains why the recorded music you listen to is not a resonant squeal but an amplified (and phase-delayed) replica of the input bits.
So why does the Chandler wobble appear close to 433 days instead of the 305 days that Euler predicted? If there was a resonance close to 305 days, any forcing frequency would be amplified in proportion to how close it was to 305 (or larger in Newcomb's non-rigid earth model). Therefore, why can't the aliased draconic lunar forcing cycle of 432.76 days be responsible for the widely accepted Chandler wobble of 433 days?
This is the biannual geometry giving the driving conditions.
And this is the strength of the draconic lunar pull at a sample of two times a year, computed according to the formula cos(2$\pi$/(13.6061/365.242)*t), where 13.6061 days is the lunar draconic fortnight or half the lunar draconic month.
Can count ~127 cycles in 150 years, which places it between 432 and 433 days, which is the Chandler wobble period.
Yet again Wikipedia explains it this way:
"While it has to be maintained by changes in the mass distribution or angular momentum of the Earth's outer core, atmosphere, oceans, or crust (from earthquakes), for a long time the actual source was unclear, since no available motions seemed to be coherent with what was driving the wobble. One promising theory for the source of the wobble was proposed in 2001 by Richard Gross at the Jet Propulsion Laboratory managed by the California Institute of Technology. He used angular momentum models of the atmosphere and the oceans in computer simulations to show that from 1985 to 1996, the Chandler wobble was excited by a combination of atmospheric and oceanic processes, with the dominant excitation mechanism being ocean‐bottom pressure fluctuations. Gross found that two-thirds of the "wobble" was caused by fluctuating pressure on the seabed, which, in turn, is caused by changes in the circulation of the oceans caused by variations in temperature, salinity, and wind. The remaining third is due to atmospheric fluctuations."
Like ENSO and QBO, there is actually no truly accepted model for the Chandler wobble behavior. The one I give here appears just as valid as any of the others. One can't definitely discount it because the lunar draconic period precisely matches the CW period. If it did't match then the hypothesis could be roundly rejected.
And the same goes for the QBO and ENSO models described herein. The aliased lunisolar models match the data nicely in each of those cases as well and so can't easily be rejected. That's why I have been hammering at these models for so long, as a unified theory of lunisolar geophysical forcing is so tantalizingly close -- one for the atmosphere (QBO), the ocean (ENSO), and for the earth itself (Chandler wobble). These three will then unify with the generally accepted theory for ocean tides.
Comment Source:In the current research literature, the Chandler wobble is described as an impulse response with a characteristic frequency determined by the earth's ellipticity. > https://en.wikipedia.org/wiki/Chandler_wobble "The existence of Earth's free nutation was predicted by Isaac Newton in Corollaries 20 to 22 of Proposition 66, Book 1 of the Philosophiæ Naturalis Principia Mathematica, and by Leonhard Euler in 1765 as part of his studies of the dynamics of rotating bodies. Based on the known ellipticity of the Earth, Euler predicted that it would have a period of 305 days. Several astronomers searched for motions with this period, but none was found. Chandler's contribution was to look for motions at any possible period; once the Chandler wobble was observed, the difference between its period and the one predicted by Euler was explained by Simon Newcomb as being caused by the non-rigidity of the Earth. The full explanation for the period also involves the fluid nature of the Earth's core and oceans .. " There is a factor known as the Q-value which describes the resonant "quality" of the impulse response, classically defined as the solution to a 2nd-order DiffEq. The higher the Q, the longer the oscillating response. The following figure shows the impulse and response for a fairly low Q-value. It's thought that the Chandler wobble Q-value is very high, as it doesn't seem to damp quickly.  In contrast, ocean tides are not described as a characteristic frequency but instead as a transfer function and a "steady-state" response due to the forcing frequency. The forcing frequency is in fact *carried through* from the input stimulus to the output response. In other words, the tidal frequency matches the rhythm of the lunar (and solar) orbital frequency. There may be a transient associated with the natural response but this eventually transitions into the steady-state through the ocean's damping filter as shown below: 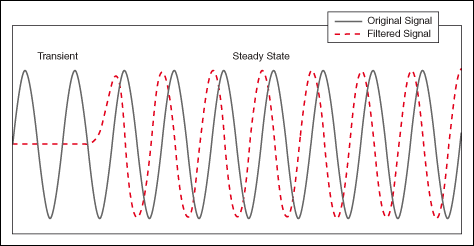 This behavior is well known in engineering and science circles and explains why the recorded music you listen to is not a resonant squeal but an amplified (and phase-delayed) replica of the input bits. So why does the Chandler wobble appear close to 433 days instead of the 305 days that Euler predicted? If there was a resonance close to 305 days, any forcing frequency would be amplified in proportion to how close it was to 305 (or larger in Newcomb's non-rigid earth model). Therefore, why can't the aliased draconic lunar forcing cycle of 432.76 days be responsible for the widely accepted Chandler wobble of 433 days? This is the biannual geometry giving the driving conditions.  And this is the strength of the draconic lunar pull at a sample of two times a year, computed according to the formula cos(2$\pi$/(13.6061/365.242)*t), where 13.6061 days is the lunar draconic fortnight or half the lunar draconic month.  Can count ~127 cycles in 150 years, which places it between 432 and 433 days, which is the Chandler wobble period. Yet again Wikipedia explains it this way: > "While it has to be maintained by changes in the mass distribution or angular momentum of the Earth's outer core, atmosphere, oceans, or crust (from earthquakes), for a long time the actual source was unclear, since no available motions seemed to be coherent with what was driving the wobble. One promising theory for the source of the wobble was proposed in 2001 by Richard Gross at the Jet Propulsion Laboratory managed by the California Institute of Technology. He used angular momentum models of the atmosphere and the oceans in computer simulations to show that from 1985 to 1996, the Chandler wobble was excited by a combination of atmospheric and oceanic processes, with the dominant excitation mechanism being ocean‐bottom pressure fluctuations. Gross found that two-thirds of the "wobble" was caused by fluctuating pressure on the seabed, which, in turn, is caused by changes in the circulation of the oceans caused by variations in temperature, salinity, and wind. The remaining third is due to atmospheric fluctuations." Like ENSO and QBO, there is actually no truly accepted model for the Chandler wobble behavior. The one I give here appears just as valid as any of the others. One can't definitely discount it because the lunar draconic period precisely matches the CW period. If it did't match then the hypothesis could be roundly rejected. And the same goes for the QBO and ENSO models described herein. The aliased lunisolar models match the data nicely in each of those cases as well and so can't easily be rejected. That's why I have been hammering at these models for so long, as a unified theory of lunisolar geophysical forcing is so tantalizingly close -- one for the atmosphere (QBO), the ocean (ENSO), and for the earth itself (Chandler wobble). These three will then unify with the generally accepted theory for ocean tides.
Here is the math on the Chandler wobble. We start with the seasonally-modulated draconic lunar forcing. This has an envelope of a full-wave rectified signal as the moon and sun will show the greatest gravitational pull on the poles during the full northern and southern nodal excursions (i.e. the two solstices). This creates a full period of a 1/2 year.
The effective lunisolar pull is the multiplication of that envelope with the complete cycle draconic month of $2\pi / \omega_0$ =27.2122 days. Because the full-wave rectified signal will create a large number of harmonics, the convolution in the frequency domain of the draconic period with the biannually modulated signal generates spikes at intervals of :
$ 2\omega_0, 2\omega_0-4\pi, 2\omega_0-8\pi, ... 2\omega_0-52\pi $
According to the Fourier series expansion in the figure above, the intensity of the terms will decrease left to right as $1/n^2$, that is with decreasing frequency. The last term shown correlates to the Chandler wobble period of 1.185 years = 432.77 days.
One would think this decrease in intensity is quite rapid, but because of the resonance condition of the Chandler wobble nutation, a compensating amplification occurs. Here is the frequency response curve of a 2nd-order resonant DiffEq, written in terms of an equivalent electrical RLC circuit.
So, if we choose values for RLC to give a resonance close to 433 days and with a high enough Q-value, then the diminishing amplitude of the Fourier series is amplified by the peak of the nutation response. Note that it doesn't have to match exactly to the peak, but somewhere within the halfwidth, where Q = $\frac{\omega}{\Delta\omega}$
So we see that the original fortnightly period of 13.606 days is retained, but what also emerges is the 13th harmonic of that signal located right at the Chandler wobble period.
That's how a resonance works in the presence of a driving signal. It's not the characteristic frequency that emerges, but the forcing harmonic closest to resonance frequency. And that's how we get the value of 432.77 days for the Chandler wobble. It may not be entirely intuitive but that's the way that the math of the steady-state dynamics works out.
Alas, you won't find this explanation anywhere in the research literature, even though the value of the Chandler wobble has been known since 1891! Apparently no geophysicist will admit that a lunisolar torque can stimulate the wobble in the earth's rotation. I find that mystifying, but maybe I am missing something.
Comment Source:Here is the math on the Chandler wobble. We start with the seasonally-modulated draconic lunar forcing. This has an envelope of a full-wave rectified signal as the moon and sun will show the greatest gravitational pull on the poles during the full northern and southern nodal excursions (i.e. the two solstices). This creates a full period of a 1/2 year. >  The effective lunisolar pull is the multiplication of that envelope with the complete cycle draconic month of $2\pi / \omega_0$ =27.2122 days. Because the full-wave rectified signal will create a large number of harmonics, the convolution in the frequency domain of the draconic period with the biannually modulated signal generates spikes at intervals of : $ 2\omega_0, 2\omega_0-4\pi, 2\omega_0-8\pi, ... 2\omega_0-52\pi $ According to the Fourier series expansion in the figure above, the intensity of the terms will decrease left to right as $1/n^2$, that is with *decreasing* frequency. The last term shown correlates to the Chandler wobble period of 1.185 years = 432.77 days. One would think this decrease in intensity is quite rapid, but because of the resonance condition of the Chandler wobble nutation, a compensating amplification occurs. Here is the frequency response curve of a 2nd-order resonant DiffEq, written in terms of an equivalent electrical RLC circuit. >  So, if we choose values for RLC to give a resonance close to 433 days and with a high enough Q-value, then the diminishing amplitude of the Fourier series is amplified by the peak of the nutation response. Note that it doesn't have to match exactly to the peak, but somewhere within the halfwidth, where Q = $\frac{\omega}{\Delta\omega}$ 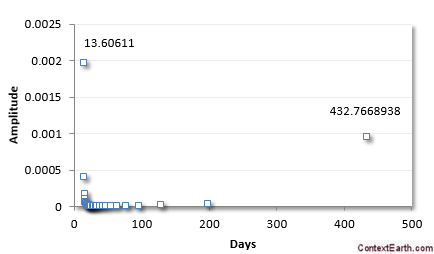 So we see that the original fortnightly period of 13.606 days is retained, but what also emerges is the 13th harmonic of that signal located right at the Chandler wobble period. That's how a resonance works in the presence of a driving signal. It's not the characteristic frequency that emerges, but the forcing harmonic closest to resonance frequency. And that's how we get the value of 432.77 days for the Chandler wobble. It may not be entirely intuitive but that's the way that the math of the steady-state dynamics works out. Alas, you won't find this explanation anywhere in the research literature, even though the value of the Chandler wobble has been known since 1891! Apparently no geophysicist will admit that a lunisolar torque can stimulate the wobble in the earth's rotation. I find that mystifying, but maybe I am missing something.
Here is an extended twitter thread I had with an expert on climate dynamics concerning QBO. One of my most important arguments is how can a phenomenon with wavenumber = 0 -- i.e. an infinite wavelength -- get started with anything other than a spatially uniform forcing such as provided by the sun or the moon?
Comment Source:Here is an extended twitter thread I had with an expert on climate dynamics concerning QBO. One of my most important arguments is how can a phenomenon with wavenumber = 0 -- i.e. an infinite wavelength -- get started with anything other than a spatially uniform forcing such as provided by the sun or the moon? 
I've been thinking the history of these behaviors. Pierre-Simon Laplace came up with his tidal equations in 1776. Lord Rayleigh wrote about wave bifurcations around 1880. Ocean tides and their mechanism had been known forever, but only in the 1900's did they have a detailed approach to mathematically define the cycles (i.e. Doodson arguments).
Chandler discovered the earth's polar wobble in 1891. Scientists knew right away that there was a seasonal wobble that was easily explained by a forced factor. But why couldn't they determine the lunar factor?
The QBO was known in the 1950's I think, but only in the 1960's did they have enough data to notice the strong periodicity. If the Chandler wobble mechanism had been known (hypothetically) it would have been simple to adapt that mechanism to QBO through the application of Laplace's equations. The anti-AGW scientist Richard Lindzen spent his career trying to convince everyone of his overly complex model, and now he is left spending his time sending petitions to Trump to have the USA withdraw from the Paris climate accords. Sad.
And ENSO came a little later, with most scientist bewildered by the near chaotic oscillations observed. Yet, if they would have learned from the (hypothetical) models for the Chandler wobble and QBO and the sloshing mechanisms described by Rayleigh, they may have been able to de-convolute the cycles to see once again the lunisolar forcing.
I bring up this history, because I received this comment via Twitter from a well-regarded climate scientist:
The implication is that all current models may be wrong if these simple models of lunar forcing are correct.
Comment Source:I've been thinking the history of these behaviors. Pierre-Simon Laplace came up with his tidal equations in 1776. Lord Rayleigh wrote about wave bifurcations around 1880. Ocean tides and their mechanism had been known forever, but only in the 1900's did they have a detailed approach to mathematically define the cycles (i.e. Doodson arguments). Chandler discovered the earth's polar wobble in 1891. Scientists knew right away that there was a seasonal wobble that was easily explained by a forced factor. But why couldn't they determine the lunar factor? The QBO was known in the 1950's I think, but only in the 1960's did they have enough data to notice the strong periodicity. If the Chandler wobble mechanism had been known (hypothetically) it would have been simple to adapt that mechanism to QBO through the application of Laplace's equations. The anti-AGW scientist Richard Lindzen spent his career trying to convince everyone of his overly complex model, and now [he is left spending his time sending petitions to Trump to have the USA withdraw from the Paris climate accords](http://business.financialpost.com/fp-comment/lawrence-solomon-scientists-urging-trump-to-embrace-carbon-among-the-biggest-climate-experts-around). Sad. And ENSO came a little later, with most scientist bewildered by the near chaotic oscillations observed. Yet, if they would have learned from the (hypothetical) models for the Chandler wobble and QBO and the sloshing mechanisms described by Rayleigh, they may have been able to de-convolute the cycles to see once again the lunisolar forcing. I bring up this history, because I received this comment via Twitter from a well-regarded climate scientist:  The implication is that all current models may be wrong if these simple models of lunar forcing are correct.
I don't quite understand why you got the impression that this lunar forcing wasn't taken into account:
In the case of the Earth, the principal sources of tidal force are the Sun and Moon, which continuously change location relative to each other and thus cause nutation in Earth's axis. The largest component of Earth's nutation has a period of 18.6 years, the same as that of the precession of the Moon's orbital nodes.[1] However, there are other significant periodic terms that must be accounted for depending upon the desired accuracy of the result. A mathematical description (set of equations) that represents nutation is called a "theory of nutation".
Comment Source:>Chandler discovered the earth's polar wobble in 1891. Scientists knew right away that there was a seasonal wobble that was easily explained by a forced factor. But why couldn't they determine the lunar factor? I don't quite understand why you got the impression that this lunar forcing wasn't taken into account: <a href="https://en.wikipedia.org/wiki/Nutation#Earth">From Wikipedia:</a> >In the case of the Earth, the principal sources of tidal force are the Sun and Moon, which continuously change location relative to each other and thus cause nutation in Earth's axis. The largest component of Earth's nutation has a period of 18.6 years, the same as that of the precession of the Moon's orbital nodes.[1] However, there are other significant periodic terms that must be accounted for depending upon the desired accuracy of the result. A mathematical description (set of equations) that represents nutation is called a "theory of nutation".
JimStuttard
What's "deposition"?
Comment Source:What's "deposition"?
Yes, of course the 18.6 year nodal precession is mentioned. But this is in reference to a specific longitude. The Chandler wobble is independent of longitude and should respond to periods at which the moon crosses the equator through a complete ascending/descending cycle.
That cycle is the draconic month, which is 27.2122 days. The tropical month is 27.3216 days, which is the length of time the moon takes to appear at the same longitude. Those two are slightly different and the difference forms a beat cycle that determines how often the maximum declination is reached for a particular longitude. That is important for ocean tides as tides are really a localized phenomenon.
But the Chandler wobble is global and would only have triaxial components to second order. It doesn't really care where the moon is located in longitude when it reaches a maximum in declination excursion. Consider that at the poles, the longitude converges at a singularity. It's the physics of a spinning top under the influence of a gravity vector.
So the important point is that the moon is cycling a significant gravitational torque on the earth's axis every 1/2 a draconic period. When this is reinforced by the sun's biannual cycle, one gets the Chandler wobble period precisely.
Try Googling "Draconic AND Chandler wobble". You won't find anything. Sure you will find the 18.6 year cycle but that's because of an echo chamber of misleading information. This is important to understand, and if my own reasoning is faulty, this model I have been pushing for the Chandler wobble and QBO collapses. Those are both global behaviors. ENSO, on the other hand, has a longitudinally localized forcing and should show strong effects of the 18.6 year cycle ... and I have shown it does!
Comment Source:Yes, of course the 18.6 year nodal precession is mentioned. But this is in reference to a specific longitude. The Chandler wobble is independent of longitude and should respond to periods at which the moon crosses the equator through a complete ascending/descending cycle. That cycle is the draconic month, which is 27.2122 days. The tropical month is 27.3216 days, which is the length of time the moon takes to appear at the same longitude. Those two are slightly different and the difference forms a beat cycle that determines how often the maximum declination is reached *for a particular longitude*. That is important for ocean tides as tides are really a localized phenomenon. But the Chandler wobble is global and would only have triaxial components to second order. It doesn't really care where the moon is located in longitude when it reaches a maximum in declination excursion. Consider that at the poles, the longitude converges at a singularity. It's the physics of a spinning top under the influence of a gravity vector. So the important point is that the moon is cycling a significant gravitational torque on the earth's axis every 1/2 a draconic period. When this is reinforced by the sun's biannual cycle, one gets the Chandler wobble period precisely. Try Googling "Draconic AND Chandler wobble". You won't find anything. Sure you will find the 18.6 year cycle but that's because of an echo chamber of misleading information. This is important to understand, and if my own reasoning is faulty, this model I have been pushing for the Chandler wobble and QBO collapses. Those are both global behaviors. ENSO, on the other hand, has a longitudinally localized forcing and should show strong effects of the 18.6 year cycle ... and I have shown it does! 
Jim asks
What is "deposition"?
In crystal growth, which was my academic specialty, deposition is used in the context of the rate of growth. As in depositing layers of material.
Honestly, I really can't follow much of the jargon of these meteorologists. Either they really have the insight and really know what's going on, or they are blowing smoke and using the jargon to cover up the lack of their own understanding.
The problem with Roundy is that he can't own up to the fact that QBO has a spatial wavenumber of zero, which makes it a global phenomenon. All the points he makes regarding deposition are spatially dependent, which makes them irrelevant to forcing a zero wavenumber. This is just group theory and symmetry arguments I am applying, which he refuses to consider apparently.
That's my take. If I try to understand his deposition arguments, I am certain to go down the rabbit hole and end up following the same route that Lindzen took with QBO -- one of unwarranted complexity.
Comment Source:Jim asks > What is "deposition"? In crystal growth, which was my academic specialty, deposition is used in the context of the rate of growth. As in depositing layers of material. Honestly, I really can't follow much of the jargon of these meteorologists. Either they really have the insight and really know what's going on, or they are blowing smoke and using the jargon to cover up the lack of their own understanding. The problem with Roundy is that he can't own up to the fact that QBO has a spatial wavenumber of zero, which makes it a global phenomenon. All the points he makes regarding deposition are spatially dependent, which makes them irrelevant to forcing a zero wavenumber. This is just group theory and symmetry arguments I am applying, which he refuses to consider apparently. That's my take. If I try to understand his deposition arguments, I am certain to go down the rabbit hole and end up following the same route that Lindzen took with QBO -- one of unwarranted complexity.
Here is part 2 of a conversation on QBO with Roundy from yesterday. I tend to interrupt these meteorology Twitter threads by throwing out comments relating to what I am finding. These arguments usually play out by this analogy: Say that someone like Roundy was analyzing an electrical signal. I am simply pointing out that there is an obvious 60 Hz hum that is emerging in the signal, and I am suggesting a possible source of that signal. Then Roundy responds with that can't happen because there are other sources of noise in there as well. I come back and say that those other noise sources aren't going to eliminate the 60 Hz hum. Then he comes back and asserts that it is more complicated than that, because if that was the case, all the models would fail.
Comment Source:Here is part 2 of a conversation on QBO with Roundy from yesterday. I tend to interrupt these meteorology Twitter threads by throwing out comments relating to what I am finding. These arguments usually play out by this analogy: Say that someone like Roundy was analyzing an electrical signal. I am simply pointing out that there is an obvious 60 Hz hum that is emerging in the signal, and I am suggesting a possible source of that signal. Then Roundy responds with that can't happen because there are other sources of noise in there as well. I come back and say that those other noise sources aren't going to eliminate the 60 Hz hum. Then he comes back and asserts that it is more complicated than that, because if that was the case, all the models would fail. 
Question deleted. I'd forgotten that you're "whut".
Comment Source:Question deleted. I'd forgotten that you're "whut".
That cycle is the draconic month, which is 27.2122 days. The tropical month is 27.3216 days, which is the length of time the moon takes to appear at the same longitude.
Wikipedia writes:
It is customary to specify positions of celestial bodies with respect to the vernal equinox. Because of Earth's precession of the equinoxes, this point moves back slowly along the ecliptic. Therefore, it takes the Moon less time to return to an ecliptic longitude of zero than to the same point amidst the fixed stars: 27.321582 days (27 d 7 h 43 min 4.7 s).
So by this definition thats the longitude with respect to the equinoxes. I don't know how the equinoxes move with respect to geographic longitudes. I had somewhere else seen the definition that "tropical" means "with respect to the earth reference system", but at the moment I don't see quickly that the geographic longitudes should be the same as the longitudes with respect to the equinoxes.
Try Googling "Draconic AND Chandler wobble". You won't find anything.
There might be various reasons for that is first -I don't know- but I would think that nutation theory uses coordinate systems and not those rather confusing definitions about sidereal, draconic, tropical etc. secondly you always have to take into account that your google bubble might be ill-adjusted to your purpose.
Comment Source:>That cycle is the draconic month, which is 27.2122 days. The tropical month is 27.3216 days, which is the length of time the moon takes to appear at the same longitude. <a href="https://en.wikipedia.org/wiki/Lunar_month#Tropical_month">Wikipedia writes:</a> >It is customary to specify positions of celestial bodies with respect to the vernal equinox. Because of Earth's precession of the equinoxes, this point moves back slowly along the ecliptic. Therefore, it takes the Moon less time to return to an ecliptic longitude of zero than to the same point amidst the fixed stars: 27.321582 days (27 d 7 h 43 min 4.7 s). So by this definition thats the longitude with respect to the equinoxes. I don't know how the equinoxes move with respect to geographic longitudes. I had somewhere else seen the definition that "tropical" means "with respect to the earth reference system", but at the moment I don't see quickly that the geographic longitudes should be the same as the longitudes with respect to the equinoxes. >Try Googling "Draconic AND Chandler wobble". You won't find anything. There might be various reasons for that is first -I don't know- but I would think that nutation theory uses coordinate systems and not those rather confusing definitions about sidereal, draconic, tropical etc. secondly you always have to take into account that your google bubble might be ill-adjusted to your purpose.
You seem to have a mental block. Maybe I can find a diagram.
Comment Source:You seem to have a mental block. Maybe I can find a diagram.
+1 I was about to search for a decent animation!
Comment Source:+1 I was about to search for a decent animation!
This is a great animation. At the two minute mark the Draconic month is highlighted
Comment Source:This is a great animation. At the two minute mark the Draconic month is highlighted https://youtu.be/jWCBhVfeAQU
Maximum combined torque on the axis occurs when the draconic month maximum declination aligns with a solstice. This happens at precisely the same frequency as the Chandler wobble. If this is not an additive stimulus and is simply a coincidence, I don't know what to say.
The Devil's Advocate View : The Chandler wobble, QBO, ENSO periods are all coincidences with respect to lunisolar cycles apparently.
Comment Source:Maximum combined torque on the axis occurs when the draconic month maximum declination aligns with a solstice. This happens at precisely the same frequency as the Chandler wobble. If this is not an additive stimulus and is simply a coincidence, I don't know what to say. *The Devil's Advocate View* : The Chandler wobble, QBO, ENSO periods are all coincidences with respect to lunisolar cycles apparently.
In trying to isolate the Chandler wobble mechanism, Grumbine seems to agree that it has something to do with external forcing, but rules out lunar because books on the earth's rotation by Munk and Lambeck rules that mechanism out.
"Gravitational torques have been examined previously as the main driver of the Chandler Wobble and rejected [Munk and MacDonald , 1960; Lambeck , 1980], which means only non-gravitational external forces, such as earth-sun distance, force Chandler Wobble at these periods, if any external sources do." http://moregrumbinescience.blogspot.com/2016/01/earth-sun-distance-and-chandler-wobble.html
I can see this hypothetically if the earth was a perfect sphere, since there is no moment of inertia to torque against. But the earth is not a perfect sphere, so triaxial moments exist. It is also well-known and not contested that the moon will perturb the Earth's rotation rate based on decades worth of LOD (length-of-day) measurements. Changes in LOD perfectly align with tidal periods.
Yet the only mechanism acknowledged for forced precession is this very long period torque
"The free precession of the Earth's symmetry axis in space, which is known as the Chandler wobble--because it was discovered by the American astronomer S.C. Chandler (1846-1913) in 1891--is superimposed on a much slower forced precession, with a period of about 26,000 years, caused by the small gravitational torque exerted on the Earth by the Sun and Moon, as a consequence of the Earth's slight oblateness." https://farside.ph.utexas.edu/teaching/celestial/Celestial/node72.html
This is the beat difference between 365.24219 and 365.25636 days, the tropical and sidereal years. Every 26,000 years an extra tropical year is gained.
I think they just overlooked the possibility of the lunar month physically aliasing with the yearly forcing creating the same period as the Chandler wobble. The lunar month was rejected long ago because obviously the periods don't match. But they match if the seasonal aliasing math is done correctly.
Comment Source:In trying to isolate the Chandler wobble mechanism, Grumbine seems to agree that it has something to do with external forcing, but rules out lunar because books on the earth's rotation by Munk and Lambeck rules that mechanism out. > "Gravitational torques have been examined previously as the main driver of the Chandler Wobble and rejected [**Munk and MacDonald , 1960; Lambeck , 1980**], which means only non-gravitational external forces, such as earth-sun distance, force Chandler Wobble at these periods, if any external sources do." http://moregrumbinescience.blogspot.com/2016/01/earth-sun-distance-and-chandler-wobble.html I can see this hypothetically if the earth was a perfect sphere, since there is no moment of inertia to torque against. But the earth is not a perfect sphere, so triaxial moments exist. It is also well-known and not contested that the moon will perturb the Earth's rotation rate based on decades worth of LOD (length-of-day) measurements. Changes in LOD perfectly align with tidal periods. Yet the only mechanism acknowledged for *forced* precession is this very long period torque > "The free precession of the Earth's symmetry axis in space, which is known as the Chandler wobble--because it was discovered by the American astronomer S.C. Chandler (1846-1913) in 1891--is superimposed on a much slower forced precession, with a period of about 26,000 years, caused by the small gravitational torque exerted on the Earth by the Sun and Moon, as a consequence of the Earth's slight oblateness." https://farside.ph.utexas.edu/teaching/celestial/Celestial/node72.html This is the beat difference between 365.24219 and 365.25636 days, the tropical and sidereal years. Every 26,000 years an extra tropical year is gained. I think they just overlooked the possibility of the lunar month physically aliasing with the yearly forcing creating the same period as the Chandler wobble. The lunar month was rejected long ago because obviously the periods don't match. But they match if the seasonal aliasing math is done correctly.
Jan Galkowski
There's a report out from NASA today suggesting that the EN piece of ENSO might have some hysteresis: https://www.jpl.nasa.gov/news/news.php?feature=6776
This raises questions of (a) what shuts it down if there's heat left over? and (b) what starts it up again?
Comment Source:There's a report out from NASA today suggesting that the EN piece of ENSO might have some hysteresis: https://www.jpl.nasa.gov/news/news.php?feature=6776 This raises questions of (a) what shuts it down if there's heat left over? and (b) what starts it up again?
Richard Lindzen, the "father" of QBO modeling, is at it again with his anti-AGW crusade. He recently sent in a petition to Trump asking to withdraw from the Paris agreement. But now his MIT colleagues are fighting back:
"Their letter, sent last week, was drafted in response to a letter that Lindzen sent Trump last month, urging him to withdraw the United States from the international climate accord signed in Paris in 2015. That agreement, signed by nearly 200 nations, seeks to curb the greenhouse gases linked to global warming." https://www.bostonglobe.com/metro/2017/03/08/mit-professors-denounce-their-colleague-letter-trump-for-denying-evidence-climate-change/86K8ur31YIUbMO4SAI7U2N/story.html
Lindzen seems to be a pariah among his colleagues. This is an interesting piece from years ago
http://www.washingtonpost.com/wp-dyn/content/article/2006/05/23/AR2006052301305.html "Of all the skeptics, MIT's Richard Lindzen probably has the most credibility among mainstream scientists, who acknowledge that he's doing serious research on the subject. " "When I ask (William) Gray who his intellectual soul mates are regarding global warming, he responds, "I have nobody really to talk to about this stuff." That's not entirely true. He has many friends and colleagues, and the meteorologists tend to share his skeptical streak. I ask if he has ever collaborated on a paper with Richard Lindzen. Gray says he hasn't. He looks a little pained. "Lindzen, he's a hard guy to deal with," Gray says. "He doesn't think he can learn anything from me." Which is correct. Lindzen says of Gray: "His knowledge of theory is frustratingly poor, but he knows more about hurricanes than anyone in the world. I regard him in his own peculiar way as a national resource."
Note the condescending tone of Lindzen in the last sentences. Who is willing to bet that Lindzen's theory of QBO is fundamentally wrong? Lindzen is so sure of himself and his talents that he probably declared victory on his QBO model long before it was ready for prime-time.
"There're people like [Lindzen] in every field of science. There are always people in the fringes. They're attracted to the fringe . . . It may be as simple as, how do you prove you're smarter than everyone else? You don't do that by being part of the consensus," (Isaac) Held says.
Lindzen likely manufactured his own consensus around QBO, and was able to make a convincing case based on his credentials.
Comment Source:Richard Lindzen, the "father" of QBO modeling, is at it again with his anti-AGW crusade. He recently sent in a petition to Trump asking to withdraw from the Paris agreement. But now his MIT colleagues are fighting back: >"Their letter, sent last week, was drafted in response to a letter that Lindzen sent Trump last month, urging him to withdraw the United States from the international climate accord signed in Paris in 2015. That agreement, signed by nearly 200 nations, seeks to curb the greenhouse gases linked to global warming." https://www.bostonglobe.com/metro/2017/03/08/mit-professors-denounce-their-colleague-letter-trump-for-denying-evidence-climate-change/86K8ur31YIUbMO4SAI7U2N/story.html Lindzen seems to be a pariah among his colleagues. This is an interesting piece from years ago > http://www.washingtonpost.com/wp-dyn/content/article/2006/05/23/AR2006052301305.html > "Of all the skeptics, MIT's Richard Lindzen probably has the most credibility among mainstream scientists, who acknowledge that he's doing serious research on the subject. " >"When I ask (William) Gray who his intellectual soul mates are regarding global warming, he responds, "I have nobody really to talk to about this stuff." > That's not entirely true. He has many friends and colleagues, and the meteorologists tend to share his skeptical streak. > I ask if he has ever collaborated on a paper with Richard Lindzen. Gray says he hasn't. He looks a little pained. "Lindzen, he's a hard guy to deal with," Gray says. "He doesn't think he can learn anything from me." Which is correct. Lindzen says of Gray: "His knowledge of theory is frustratingly poor, but he knows more about hurricanes than anyone in the world. I regard him in his own peculiar way as a national resource." Note the condescending tone of Lindzen in the last sentences. Who is willing to bet that Lindzen's theory of QBO is fundamentally wrong? Lindzen is so sure of himself and his talents that he probably declared victory on his QBO model long before it was ready for prime-time. > "There're people like [Lindzen] in every field of science. There are always people in the fringes. They're attracted to the fringe . . . It may be as simple as, how do you prove you're smarter than everyone else? You don't do that by being part of the consensus," (Isaac) Held says. Lindzen likely manufactured his own consensus around QBO, and was able to make a convincing case based on his credentials.
I will be finishing up the basic research on my ENSO model soon. I don't have many loose ends left and what I presented at the AGU is standing the test of time. The Chandler wobble is tied to the aliased draconic month cycle so I can essentially get perfect agreement by applying Laplace's tidal equations with the known seasonally reinforced lunar forcing. The ENSO fit then has only amplitude and phase unknowns with regard to the 3 lunar monthly cycles, making it conceptually identical to an ocean tidal model fit. The complexity is similar to the ocean tidal setup with the 3 monthly cycles combining with the 2 seasonal cycles (yearly and biannual) to create 18 linear and nonlinear interactions.
I performed a long running fit to the ENSO time series by allowing the lunar cycle periods to vary and then waiting for it to converge to steady state values.
Draconic month (strongest) should be 27.2122 days Anomalistic month should be 27.5545 Sidereal month is 27.3216
What the model converges to is 27.2120 days for Draconic 27.5580 for Anomalistic 27.3259 for Sidereal
These errors are less than a minute per month in the case of the Draconic and 5 and 6 minutes for the other two. The latter error contributes less than a quarter of a lunar month phase shift over the 130 year ENSO interval.
Comment Source:I will be finishing up the basic research on my ENSO model soon. I don't have many loose ends left and what I presented at the AGU is standing the test of time. The Chandler wobble is tied to the aliased draconic month cycle so I can essentially get perfect agreement by applying Laplace's tidal equations with the known seasonally reinforced lunar forcing. The ENSO fit then has only amplitude and phase unknowns with regard to the 3 lunar monthly cycles, making it conceptually identical to an ocean tidal model fit. The complexity is similar to the ocean tidal setup with the 3 monthly cycles combining with the 2 seasonal cycles (yearly and biannual) to create 18 linear and nonlinear interactions. I performed a long running fit to the ENSO time series by allowing the lunar cycle periods to vary and then waiting for it to converge to steady state values. Draconic month (strongest) should be 27.2122 days Anomalistic month should be 27.5545 Sidereal month is 27.3216 What the model converges to is 27.2120 days for Draconic 27.5580 for Anomalistic 27.3259 for Sidereal These errors are less than a minute per month in the case of the Draconic and 5 and 6 minutes for the other two. The latter error contributes less than a quarter of a lunar month phase shift over the 130 year ENSO interval.
Previous comment I wrote:
"The ENSO fit then has only amplitude and phase unknowns with regard to the 3 lunar monthly cycles, making it conceptually identical to an ocean tidal model fit. "
Here is an example of the detail I can get with the ENSO model.
The ENSO model is able to discern the variation in the length (and phase) of the lunar Draconic month (see here https://eclipse.gsfc.nasa.gov/SEhelp/moonorbit.html#draconic). This is a detailed second-order effect that would only be possible to measure if the model of the first-order effect is correct.
So the AGU-2016 ENSO model is based completely on the long-period lunar tidal cycles reinforced by seasonal cycle impulses. The same numerical techniques used for modeling ocean tides are applied, but with a different concept for seasonal reinforcing. The model therefore has gone from being an explanation of the ENSO behavior to a sensitive metrology technique -- specifically for measuring lunar and solar cycles based on the sloshing sensitivity of a layered fluid medium to forcing changes.
That's one way you substantiate a model's veracity -- flip it from a question of over-fitting to one of precisely identifying physical constants. That's one way to get buy-in.
Comment Source:Previous comment I wrote: > "The ENSO fit then has only amplitude and phase unknowns with regard to the 3 lunar monthly cycles, making it conceptually identical to an ocean tidal model fit. " Here is an example of the detail I can get with the ENSO model.  The ENSO model is able to discern the variation in the length (and phase) of the lunar Draconic month (see here https://eclipse.gsfc.nasa.gov/SEhelp/moonorbit.html#draconic). This is a detailed second-order effect that would only be possible to measure if the model of the first-order effect is correct. So the AGU-2016 ENSO model is based completely on the long-period lunar tidal cycles reinforced by seasonal cycle impulses. The same numerical techniques used for modeling ocean tides are applied, but with a different concept for seasonal reinforcing. The model therefore has gone from being an explanation of the ENSO behavior to a sensitive [metrology](https://en.wikipedia.org/wiki/Metrology) technique -- specifically for measuring lunar and solar cycles based on the sloshing sensitivity of a layered fluid medium to forcing changes. That's one way you substantiate a model's veracity -- flip it from a question of over-fitting to one of precisely identifying physical constants. That's one way to get buy-in.
This is my description for a canonical model for ENSO http://contextEarth.com/2017/04/10/tidal-model-of-enso/
Comment Source:This is my description for a canonical model for ENSO http://contextEarth.com/2017/04/10/tidal-model-of-enso/
In the last post, I added a link to a downloadable spreadsheet where one can play with the ENSO solver.
Interesting what it can do with very short training intervals. This is one from 1908 to 1920, a short training interval of only 12 years. You would think that it would overfit, yet the extrapolated out-of-band model looks reasonable and not at all chaotic
Comment Source:In the last post, I added a link to a downloadable spreadsheet where one can play with the ENSO solver. Interesting what it can do with very short training intervals. This is one from 1908 to 1920, a short training interval of only 12 years. You would think that it would overfit, yet the extrapolated out-of-band model looks reasonable and not at all chaotic 
Also added the QBO model to the spreadsheet. Essentially the same model fitting algorithm is used for both ENSO and QBO, but using a different set of forcing functions. For ENSO, the draconic and anomalistic tide is modulated with a biennial signal, while QBO modulates only the draconic with an annual signal.
Comment Source:Also added the QBO model to the spreadsheet. Essentially the same model fitting algorithm is used for both ENSO and QBO, but using a different set of forcing functions. For ENSO, the draconic and anomalistic tide is modulated with a biennial signal, while QBO modulates only the draconic with an annual signal. 
Update to #141. Forcing with a 1st-order lag and an opposing feedback from one year prior. This serves to smooth the ENSO model fit (in contrast to the blocky one-year window integration) and to reinforce the biennial modulation in the lunar tidal forcing.
Like the QBO model, this is a remarkable result showing the ability of a very short interval of the time series to recover the rest of the behavior. And like the QBO model, there are so few degrees of freedom in the fitting parameters that over-fitting is not an issue. No remaining kludges in the model and the only ansatz is the assumption of a metastable biennial modulation. Yet, this is by all accounts a result of a year-to-year compensating feedback leading to a period doubling (and which Rayleigh discovered in his maintained vibrations paper )
http://contextearth.com/2017/04/18/shortest-training-fit-for-enso/
Comment Source:Update to #141. Forcing with a 1st-order lag and an opposing feedback from one year prior. This serves to smooth the ENSO model fit (in contrast to the blocky one-year window integration) and to reinforce the biennial modulation in the lunar tidal forcing.  Like the QBO model, this is a remarkable result showing the ability of a very short interval of the time series to recover the rest of the behavior. And like the QBO model, there are so few degrees of freedom in the fitting parameters that over-fitting is not an issue. No remaining kludges in the model and the only ansatz is the assumption of a metastable biennial modulation. Yet, this is by all accounts a result of a year-to-year compensating feedback leading to a period doubling (and which Rayleigh discovered in his [maintained vibrations paper](http://www.tandfonline.com/doi/abs/10.1080/14786448308627342?journalCode=tphm16) ) http://contextearth.com/2017/04/18/shortest-training-fit-for-enso/
On this Earth Day, I present the final touches on the ENSO model, which uses only the primary lunar cycles and the yearly period. The training goes from 1880 to 1950, and everything after that is projected:
More info here http://contextEarth.com/2017/04/21/canonical-solution-of-mathieu-equation-for-enso/.
Didn't go to a #MarchForScience, but instead am doing this kind of stuff.
Whut's more important?
Comment Source:On this Earth Day, I present the final touches on the ENSO model, which uses only the primary lunar cycles and the yearly period. The training goes from 1880 to 1950, and everything after that is projected:  More info here http://contextEarth.com/2017/04/21/canonical-solution-of-mathieu-equation-for-enso/. Didn't go to a #MarchForScience, but instead am doing this kind of stuff. Whut's more important?
Given the two fitting intervals, a low range from 1880 to 1950 and a high range 1950 to 2016, we can compare the resultant parameters.
The strongest lunar parameters are the D=Draconic and A=Anomalistic periods. The higher-order parameters $D^n$ and $A^n$ also align as does a cross-term $D\cdot A^2$. The $D\cdot A$ cross-term is negligible.
One thing you will notice is that the overall amplitude is different on the two axis. That has to do with the error metric used - optimizing WRT a correlation coefficient does not preserve the absolute scale. It does take a few minutes to do the optimizing fit on each range but the resultant alignment is correlated above 0.99.
Comment Source:Given the two fitting intervals, a low range from 1880 to 1950 and a high range 1950 to 2016, we can compare the resultant parameters. 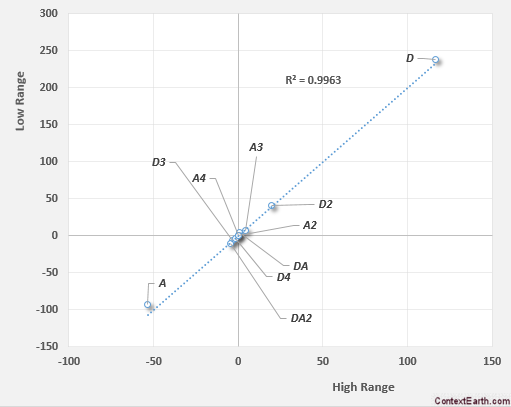 The strongest lunar parameters are the D=Draconic and A=Anomalistic periods. The higher-order parameters $D^n$ and $A^n$ also align as does a cross-term $D\cdot A^2$. The $D\cdot A$ cross-term is negligible. One thing you will notice is that the overall amplitude is different on the two axis. That has to do with the error metric used - optimizing WRT a correlation coefficient does not preserve the absolute scale. It does take a few minutes to do the optimizing fit on each range but the resultant alignment is correlated above 0.99.
This is as good as any tidal analysis I have ever seen. Notice the perturbation right around 1980 is now gone. It turns out that may have been a red herring, as the past fitting routines were missing the secret ingredient.
This is a short summary I wrote to respond to someone:
In fact there is a magical differential equation that is part Mathieu equation and part delay-differential that captures the sloshing dynamics perfectly. Mathieu equations are favored by hydrodynamics engineers that study sloshing of volumes of water, while delay-differential equations are favored by ocean climatologists studying ENSO. So I figured why not put the two together and try to solve it on a spreadsheet?
Of course a magical equation needs magical ingredients, so as stimulus I provided the only known forcing that could plausibly cause the thermocline sloshing -- the lunar long-period tidal pull. These have to be exact in period and phase or else the signals will destructively interfere over many years.
It looks as if the noise in the ENSO signal is minimal. Just about any interval of the time-series can reconstruct any other interval. That's the hallmark of an ergodic stationary process with strong deterministic properties. It's essentially what oceanographers do with conventional tidal analysis -- train an interval of measured sea-level height gauge measurements against the known lunar periods and out pops an extrapolated tidal prediction algorithm. Basically what this infers is that Curry and Tsonis and the other deniers are flat wrong when they say that climate change on this multidecadal scale is chaotic.
Perhaps the climate is only complex when dealing with vortices, i.e. hurricanes, etc. A standing wave behavior like ENSO is not a vortex and it has a chance to be simplified. Anyone that has done any physics has learned this from their undergrad classes. And the QBO behavior may be an anti-vortex type of standing wave, which also can be simplified.
Yet, who knows if various other vortex patterns can't at least be partially simplified. I spent some time discussing with a poster presenter at last year's AGU why he was looking at analyzing jet-stream patterns at higher latitudes while the behavior at the equator (i.e. the QBO) has a much better chance of being simplified. And then that could be used for evaluating higher latitude behavior as a stimulus. Recall that these vortices peel off the equator before developing into larger patterns. He didn't have a good answer.
Comment Source:This is as good as any tidal analysis I have ever seen. Notice the perturbation right around 1980 is now gone. It turns out that may have been a red herring, as the past fitting routines were missing the secret ingredient. This is a short summary I wrote to respond to someone: In fact there is a magical differential equation that is part <a href="http://mathworld.wolfram.com/MathieuDifferentialEquation.html" rel="nofollow">Mathieu equation</a> and part <a href="https://en.wikipedia.org/wiki/Delay_differential_equation" rel="nofollow">delay-differential</a> that captures the sloshing dynamics perfectly. Mathieu equations are favored by hydrodynamics engineers that study sloshing of volumes of water, while delay-differential equations are favored by ocean climatologists studying ENSO. So I figured why not put the two together and try to solve it on a spreadsheet? <br><br>Of course a magical equation needs magical ingredients, so as stimulus I provided the only known forcing that could plausibly cause the thermocline sloshing -- the lunar long-period tidal pull. These have to be exact in period and phase or else the signals will destructively interfere over many years.  It looks as if the noise in the ENSO signal is minimal. Just about any interval of the time-series can reconstruct any other interval. That's the hallmark of an ergodic stationary process with strong deterministic properties. It's essentially what oceanographers do with conventional tidal analysis -- train an interval of measured sea-level height gauge measurements against the known lunar periods and out pops an extrapolated tidal prediction algorithm. Basically what this infers is that Curry and Tsonis and the other deniers are flat wrong when they say that climate change on this multidecadal scale is chaotic. Perhaps the climate is only complex when dealing with vortices, i.e. hurricanes, etc. A standing wave behavior like ENSO is not a vortex and it has a chance to be simplified. Anyone that has done any physics has learned this from their undergrad classes. And the QBO behavior may be an anti-vortex type of standing wave, which also can be simplified. Yet, who knows if various other vortex patterns can't at least be partially simplified. I spent some time discussing with a poster presenter at last year's AGU why he was looking at analyzing jet-stream patterns at higher latitudes while the behavior at the equator (i.e. the QBO) has a much better chance of being simplified. And then that could be used for evaluating higher latitude behavior as a stimulus. Recall that these vortices peel off the equator before developing into larger patterns. He didn't have a good answer.
Incredibly, the ENSO model is able to detect the Draconic and Anomalistic lunar month values to within ~30 seconds out of ~27 days.
http://contextEarth.com/2017/05/01/the-enso-model-turns-into-a-metrology-tool/
The huge lever arm of a 130+ year ENSO record helps enormously to be able to resolve the value that precisely. Any other values would cause destructive interference over that interval.
Comment Source:Incredibly, the ENSO model is able to detect the Draconic and Anomalistic lunar month values to within ~30 seconds out of ~27 days. http://contextEarth.com/2017/05/01/the-enso-model-turns-into-a-metrology-tool/ The huge lever arm of a 130+ year ENSO record helps enormously to be able to resolve the value that precisely. Any other values would cause destructive interference over that interval.
The ENSO model is essentially two known (monthly) tidal parameters and one (annual) solar parameter provided as a RHS forcing to a primitive differential equation with LHS parameters that are roughly estimated.
Once these 5 LHS parameters are estimated from trial-and-error experiments shat show the greatest stationarity over the entire interval, the magnitudes and phases of the RHS parameters are discovered by fitting to any interval within the ENSO time series
That is a essentially an extreme over-fit to the interval covering the range 1900 to 1920. Normally this amount of over-fitting will not extrapolate well, yet this does. The model probably will end up working as well as any conventional tidal analysis, especially considering the maturity of this model.
Comment Source:The ENSO model is essentially two known (monthly) tidal parameters and one (annual) solar parameter provided as a RHS forcing to a primitive differential equation with LHS parameters that are roughly estimated. Once these 5 LHS parameters are estimated from trial-and-error experiments shat show the greatest stationarity over the entire interval, the magnitudes and phases of the RHS parameters are discovered by fitting to any interval within the ENSO time series  That is a essentially an extreme over-fit to the interval covering the range 1900 to 1920. Normally this amount of over-fitting will not extrapolate well, yet this does. The model probably will end up working as well as any conventional tidal analysis, especially considering the maturity of this model.
This is a straightforward validation of the ENSO model presented at last December's AGU.
What I did was use the modern instrumental record of ENSO — the NINO34 data set — as a training interval, and then tested across the historical coral proxy record — the UEP data set.
The correlation coefficient in the out-of-band region of 1650 to 1880 is excellent, considering that only two RHS lunar periods (draconic and anomalistic month) are used for forcing. As a matter of fact, trying to get any kind of agreement with the UEP using an arbitrary set of sine waves is problematic as the time-series appears nearly chaotic and thus requires may Fourier components to fit. With the ENSO model in place, the alignment with the data is automatic. It predicts the strong El Nino in 1877-1878 and then nearly everything before that.
http://contextearth.com/2017/05/12/enso-proxy-validation/
This is an expanded view of the proxy agreement. Now the ENSO proxy is in red with squares showing the yearly readings. It would be nice to get sub-year resolution but that will never happen with yearly-growth-ring data.
Comment Source:This is a straightforward validation of the ENSO model presented at last December's AGU. What I did was use the modern instrumental record of ENSO — the NINO34 data set — as a training interval, and then tested across the historical coral proxy record — the UEP data set.  The correlation coefficient in the out-of-band region of 1650 to 1880 is excellent, considering that only two RHS lunar periods (draconic and anomalistic month) are used for forcing. As a matter of fact, trying to get any kind of agreement with the UEP using an arbitrary set of sine waves is problematic as the time-series appears nearly chaotic and thus requires may Fourier components to fit. With the ENSO model in place, the alignment with the data is automatic. It predicts the strong El Nino in 1877-1878 and then nearly everything before that. http://contextearth.com/2017/05/12/enso-proxy-validation/ This is an expanded view of the proxy agreement. Now the ENSO proxy is in red with squares showing the yearly readings. It would be nice to get sub-year resolution but that will never happen with yearly-growth-ring data. 
http://contextearth.com/2017/05/15/enso-and-noise/
This is a great validation of the ENSO model.
Comment Source:http://contextearth.com/2017/05/15/enso-and-noise/ This is a great validation of the ENSO model. | CommonCrawl |
Can the collection of definable sets be a set?
Trevor pointed out, that
there are models of $\mathsf{ZFC}$ in which every set is definable. In this case the collection of definable sets of the model is equal to the universal class of the model, which of course is not a set of the model.
That means: the collection of definable sets of a model can be a proper class, i.e. doesn't have to be a set.
But can the collection of definable sets – definable or not – be (co-extensive with) a set?
Added (following Carl Mummerts advice):
A set is a member of a set-theoretic universe, i.e. an element of a model $\mathcal{M}$ of a set theory $\mathsf{ST}$, e.g. $\mathsf{ZFC}$.
A set $x$ is definable if there is a finite formula $\varphi(y)$ in the first-order language of (any) set theory – with signature $\sigma = \lbrace \in \rbrace$ – such that $x = \lbrace y : \varphi(y)\rbrace$, i.e. $(\forall y)\ y \in x \leftrightarrow \varphi(y)$.
What I am - admittedly - unspecific about is whether $(\forall y)\ y \in x \leftrightarrow \varphi(y)$ means
there is a model $\mathcal{M}$ of a set theory $\mathsf{ST}$ with $\mathcal{M} \models (\forall y)\ y \in x \leftrightarrow \varphi(y)$
for every model $\mathcal{M}$ of a set theory $\mathsf{ST}$ it holds $\mathcal{M} \models (\forall y)\ y \in x \leftrightarrow \varphi(y)$
$\mathsf{ST} \vdash (\forall y)\ y \in x \leftrightarrow \varphi(y)$
So for a given set theory $\mathsf{ST}$ my question is threefold.
The question arises what a set theory $\mathsf{ST}$ is supposed to be. I assume: its signature $\sigma$ is $\lbrace \in \rbrace$ and its axioms include the axioms of a naive set theory.
logic set-theory
Hans-Peter StrickerHans-Peter Stricker
$\begingroup$ The problem with this sort of question is that you have to work out what you mean by "definable" and what you mean by "be a set". $\endgroup$ – Carl Mummert Nov 19 '13 at 14:29
(This was written before a significant edit to the question.)
It's somewhat complicated, because you have to pay attention to which metatheory you use to talk about "definable" and "is a set".
Suppose we start with a model $M$ of ZFC in which there is an inaccessible cardinal $\lambda$. Then $M$ satisfies the formula that says $N = V_\lambda$ is a model of ZFC. Moreover, $M$ contains a satisfaction relation on $V_\lambda$, and thus, within $M$, we can formalize a relation $$P(X) \equiv [X \in V_\lambda \land X \text{ is definable over } V_\lambda \text{ without parameters}]$$ But then, within $M$, we can define the set $$ Z = \{ X \in V_\lambda : P(X) \}. $$ Thus $Z$ is a set in $M$. Moreover, $M$ satisfies "$Z$ is countable", because $M$ uses the same set $\omega^M$ to define Goedel numbers for the definability predicate and to test for countability. Thus, by an argument about the ranks of elements of $Z$ all being less than $\lambda$, and $\lambda$ being inaccessible, we have that $M$ satisfies "$Z \in V_\lambda$".
Therefore $M$ satisfies the statement "there is a model $N$ of ZFC such that the definable elements of $N$ form a set in $N$." The argument shows that the consistency of this statement follows from the consistency of ZFC + "there is an inaccessible cardinal".
Upon reflection, you can see what goes wrong without some assumption like an inaccessible cardinal: if $N$ was some other model of ZFC not of the form $V_\lambda$, where $\lambda$ has uncountable cofinality, then there would be no easy way to prove that $Z \in N$, and so the argument would not go through. In particular, if $N$ was countable, it can actually happen that every element of $N$ is definable over $N$.
Also, note that there are two levels of metatheory here: we prove to ourselves that $M$ satisfies various facts about $N$. So:
A person living in $N$ would believe "the definable elements of my universe form a set" (if that person could say what "definable" even means - this is an important issue)
A person living in $M$ would believe "there is a universe $N$ in which the definable elements form a set" (and a person in $M$ does know what it means for a set to be definable in $N$)
We may believe "there is a universe $M$ in which a person would believe that there is a universe $N$ in which the definable elements form a set". We will believe this, for example, if we believe in the consistency of ZFC + "there is an inaccessible cardinal".
Carl MummertCarl Mummert
$\begingroup$ Re the addition to the Q: the relation of "definable" is between an object $X$ and a model $M$; $X$ is definable over $M$ if there is a formula $\phi(z)$ in the language of $M$ such that $X$ is the unique element for which $M \models \phi(X)$. This does depend on the model; Hamkins, Rietz and Linetsy have proved that every countable model of ZFC has a forcing extension in which all sets are definable without parameters - see mathoverflow.net/questions/44102/… $\endgroup$ – Carl Mummert Nov 19 '13 at 15:22
The second two parts of your question for ST have simple answers.
If ST has no models, then every set is definable in every model of ST (trivially). If ST has a model, it has arbitrarily large models by the Lowenheim-Skolem theorem. But at most countably many sets are definable in ${\it all}$ models of ST (since at most countably many sets are definable in any particular model). So, proper class many elements of models of ST fail to be definable in all models of ST.
I'm not quite sure what it would mean for ST to prove ${\it of}$ a set $x$ that it's co-extensive with $\phi$. But if ST is consistent, consists of sentences, contains extensionality, and thinks that there are at least two sets, it will not prove:
(*) $\forall y(y\in x\leftrightarrow \phi(y))$
If it did, it would also prove:
(**) $\forall x\forall y(y\in x\leftrightarrow \phi(y))$
contradicting extensionality and the fact that there are two sets.
GMEGME
Not the answer you're looking for? Browse other questions tagged logic set-theory or ask your own question.
A (too?) simple argument for the undefinability of definable sets
Does every nonempty definable finite set have a definable member?
Definable sets à la Jech
Are there collections of sets that are neither a set nor a definable proper class?
Class models of $\mathsf{ZFC}$ and consistency results
Why should the underlying set of a model be a set?
Omega rule and standard models of ZFC?
The collection of sets hereditarily definable from the ground model and generic reals
definable sets in L
Is the class of all hereditarily transitive definable sets a model of ZFC? | CommonCrawl |
What is the rank of a vector?
From linear algebra we know that the rank of a matrix is the maximal number of linearly independent columns or rows in a matrix. So, for a matrix, the rank can be determined by simple row reduction, determinant, etc. However, I am wondering how the concept of a rank applies to a single vector, i.e., $\mathbf{v} = [a, \ b, \ c]^{\top}$. My intuition suggests that the rank must be equal to 1, but I'm not even sure if it is defined for a vector. Can anyone help shed some light on this issue?
linear-algebra matrices vectors matrix-rank
JoeyJoey
$\begingroup$ Warning: not all vectors have the form of a column of numbers. This is not how we define things in mathematics (any more). A vector is simply an element in a vector space. A vector space is defined axiomatically. A vector in it has no a-priori shape or form. $\endgroup$
– Ittay Weiss
$\begingroup$ You may consider $1$ for a non-zero vector, $0$ for the zero vector. $\endgroup$
$\begingroup$ See thread below why that would not be a good idea. $\endgroup$
A vector is an element in a vector space. As such, it has no rank. A matrix, in the context of linear algebra, is interesting because it represents a linear transformation between vector spaces. It's the linear transformation we care about, not the rectangle of numbers we call a matrix. A linear transformation has a rank and that rank is the dimension of the image of the linear transformation. It's an interesting concept since it's a measurement of how large the linear transformation is. It just so happens that when the linear transformation is represented as a matrix the rank can be computed in various convenient ways.
With this in mind, the superficial resemblance of a vector to a matrix is misleading. A vector is not a representation of a linear transformation between vector spaces. For that reason, it simply makes no sense to ask what the rank of a vector is.
Ittay WeissIttay Weiss
$\begingroup$ the rank of a $1 \times p$ matrix is defined just like the rank of any matrix. It's $0$ if all entries are $0$ and $1$ otherwise. It simply has nothing to do with the rank of a vector, nor should the superficial resemblance of this matrix to a vector lead one to any fantasies about rank of a vector making any kind of sense. $\endgroup$
$\begingroup$ @BenGrossmann the rank of that transformation is at most $1$. Regardless, this only works if you choose the standard basis in $\mathbb R ^p$ and the basis $1$ in $\mathbb R$ to represent the linear transformation. If the vector you start with is in an infinite dimensional vector space, then this is no longer possible. So, this sort of observation (without being explicit about the choice of bases) reinforces the confusion between a vector/transformation and its representation as a column/matrix. There is no such thing as "the matrix representing a transformation". You need to specify bases. $\endgroup$
$\begingroup$ @BenGrossmann my main aim is to emphasise the difference between a transformation and its representations. I know that this is usually avoided in many approaches to elementary algebra but that does not mean it's a good thing. The apparent simplicity of saying "a vector is just a column of numbers and a matrix is just a rectangle of numbers" is a double-edged sword. Regardless, your claim that $\mathbb R^p$ has a canonical basis is incorrect. There is nothing canonical about the standard basis. It's merely a very useful one, hence naming it standard. But it is not canonical. $\endgroup$
$\begingroup$ very nice answer emphasizing the fact that the concept of "rank" should be reserved specifically to linear transformations, and that a vector by itself is not a linear transformation (unless of course one unnecessarily assumes finite-dimensionality to identify $V\cong V^{**}$... but most likely if a student is capable of understanding this isomorphism more than likely they wouldn't have this question). Also, while matrices are extremely useful for computational purposes, they're a conceptual nightmare $\endgroup$
$\begingroup$ @BenGrossmann even if you want to concentrate on vector spaces and linear transformations of a particular form (say only consider $\mathbb R^n$) it is still not the case that there is a canonical basis. The whole point of diagonalisation is to represent a given matrix in terms of (usually) the non-standard basis. So, the standard basis is not only not canonical but also mainly useful due to a particular syntactic representation of vector spaces. If you call that a question of elegance and choose to portray that negatively, well, ok, I guess. $\endgroup$
Another definition of rank of a matrix is the dimension of the vector space spanned by its column, so any non-zero vector spans a space of dimension 1.
Luciano PetrilloLuciano Petrillo
$\begingroup$ It is not true to claim that a vector is a matrix with just one column. In the vector space of all continuous functions on the reals (just as an example) a vector is a continuous function. Not a matrix. $\endgroup$
$\begingroup$ But you are still implying that a vector is a matrix of a special form. It's irrelevant that a vector spans a subspace of dimension at most 1. The vector is not a representation of a transformation, so it's got no rank. $\endgroup$
$\begingroup$ @YvesDaoust I disagree. In what sense does a single non-zero vector in a high dimensional vector space have full rank? If anything, all this is saying is that a single vector is linearly independent unless it is the zero vector. That is not a new concept and it has nothing to do with rank. What is being suggested is superficially a natural extension but it ignores the fact that rank is a concept defined for a linear transformation, not to vectors at all. Rows, columns, and rectangles of numbers are merely representations of vectors and linear transformations. And not even all of them. $\endgroup$
$\begingroup$ Moreover, saying "an extension of rank from matrices to vectors" already is problematic. An extension suggests that someone vector is more general than matrix. That is manifestly incorrect. The two are completely different concepts. It's just so happens that under a particular representations it appears that a vector is a special form of matrix. $\endgroup$
$\begingroup$ @YvesDaoust yes, there are several reasons to refuse this generalisation. Firstly, it's not a generalisation (the vector concept does not extend the matrix notion). Second, it does not capture anything other than "a single vector is linearly independent unless it is zero" so it gives nothing new. Thirdly, it adds to the confusion where some people think a vector is a matrix of a special form where in fact the two notions are completely distinct. $\endgroup$
Not the answer you're looking for? Browse other questions tagged linear-algebra matrices vectors matrix-rank or ask your own question.
Importance of matrix rank
Proof that determinant rank equals row/column rank
If columns/rows of an $n\times n$ matrix $M$ are linearly independent what is the rank of $M$?
Rank-$1$ matrices
Intuition behind matrix rank
Row rank in invariant under elementary operations
Do vectors necessarily have full rank? | CommonCrawl |
Motivation for test function topologies
I'm a phisicist, who started looking just a little bit into distribution theory, so I can claim to know what I'm doing when throwing about dirac-deltas. Hence I only know two test function spaces: $\mathcal{D}=C^{\infty}_c(\Omega)$ (smooth functions with compact support) and $\mathcal{S} (\Omega)$ (Schwartz-space) where $\Omega\subseteq\mathbb{R}^n$ open. Now I wonder what the motivation is for defining the topologies on these spaces as one does it.
I'm reading "Fundamental Solutions of Partial Differential Operators" by Ortner and Wagner. They avoid actually defining the topologies on these spaces and only talk about convergence of sequences. I'm actually not sure what the exact relationship is between the sequence convergence and the topologies. For Schwarz space the question is irrelevant, since it its topology is metric. However $\mathcal{D}$ is not sequential.
Question 1: Is there a way to characterize the topology of $\mathcal{D}$ with sequences, as in saying "the coarsest topology having that convergence properties for sequences" or something similar? What is the reason most people don't bother talking about the actual topology and seems satisfied with sequences, although the topology is not sequential? I've heared something about that being irrelevant for linear maps, but haven't seen a precise statement.
As far as I know the definitions of sequence convergence are "Uniform convergence of all derivatives on compact sets with supports contained in a compact set" for $\mathcal{D}$ and "uniform convergence of all derivatives" for $\mathcal{S}$ respectively. The rest of my question deals with motivating these definitions.
For Schwarz space "to some extent" the motivation, as far as I know, is that almost everything one needs is continuous on this space and maps back into it. In particular all differential operators, and most particularly the Fourier transform. I'm fairly happy with this definition, although there is surely more to understand there. In particular I would like to know
(Soft) Question 2: Is there a way to characterize Schwarz space as "The subspace $X$ of $C^{\infty}(\Omega)$ where ??? can be defined $?:X\to X$" and the topology (or sequential convergence) is motivated in some way by requiring all the ??? stuff to be continuous? In terms of the ??? stuff I'm thinking of usefull things like derivatives and fourier transforms, not artificial examples making it work out right. [I found a claim that one gets this starting from $L^1(\Omega)$ by taking differentiation and multiplication by polynomials as some kind of closure. Needs clarification and proof though]
Let's turn to $\mathcal{D}$: I'm aware of Why does a convergent sequence of test functions have to be supported in a single compact set?, where the motivation of the convergence criteria of $\mathcal{D}$ is discussed to some extent. In particular it seems to me, that the notion of distribution depends on the topology on $\mathcal{D}$. Hence an answer saying something like "that part doesn't matter for compactly supported distributions" makes no sense to me. I don't really understand the answers and would like more detail. Can something similar to question 2 be answered for $\mathcal{D}$?
(Soft) Question 3: What is the motivation behind the topology for $\mathcal{D}$? Why all that talk about compact sets? Certainly I would be also happy with a motivation for what the topological dual (distribution space) should look like and then looking for what spaces have that as their dual.
In particular, the quoted question confused me on the following: The space $\mathcal{D}$ being locally convex, the topology is given by a family of semi-norms. That would mean we need to reabsorb the criterion "all supports of functions in the sequence (when testing for convergence) lie inside some compact set" into just a set of seminorms. Can this be done? I haven't seen that.
functional-analysis distribution-theory
Adomas BaliukaAdomas Baliuka
$\begingroup$ math.stackexchange.com/questions/706061/… $\endgroup$ – Jochen Mar 21 '17 at 9:54
$\begingroup$ I had read that topic previous to writing my question (in fact I used claims from it) and don't see how it answers any of my questions, while it is certainly related. The categorical notion of Limit is very unintuitive to me (I'm sure much can be gained by discussing the meaning and idea behind its use for function spaces). $\endgroup$ – Adomas Baliuka Mar 21 '17 at 14:37
$\begingroup$ Concerning Question 2: The Schwartz space is the perfect environment to do Fourier transformation. Question 3: Differentiation should be local and hence the continuity condition for distributions should be local and that is achieved by the inductive limit topology of $\mathscr D$. $\endgroup$ – Jochen Mar 21 '17 at 15:53
$\begingroup$ Could you elaborate on that or point towards sources explaining it? In particular the precise meaning on local used here and why that particular inductive limit is in some sense the "natural" or "correct" way to achieve this? I still don't understand the role of compact sets in the matter. $\endgroup$ – Adomas Baliuka Mar 21 '17 at 16:34
I'm going to consider a part of your Question 1, namely:
What is the reason most people don't bother talking about the actual topology and seems satisfied with sequences, although the topology is not sequential?
I think that there are (at least) two reasons for this. The first is technical:
The topology is not easy to define and it is not easy to manipulate (here "not easy" means "not easy for an introductory course", for example a course with focus in the applications to PDE).
The second is more relevant:
The topology doesn't matter for the basic properties of distributions (probably, for the topics of the said introductory courses in which the said topology is not defined).
Sounds unsatisfactory, right? I agree, so let me explain. These are words (not literally) of Laurent Schwartz, who created the theory of distributions. In fact, Schwartz said the following with respect to the time in which he started work with the test functions:
I was unable to put a topology on $\mathcal{D}$, but only what I called a pseudo-topology, i.e. a sequence $(\phi_n)$ converges to $0$ in $\mathcal{D}$ if the $(\phi_n)$ and all their derivatives converge uniformly to $0$, keeping all their supports in a fixed compact set. I only found an adequate topology much later, in Nancy in 1946. But it doesn't matter for the main properties. ([1], p. 229-230).
This quote teach us the following:
Historically, the notion of convergence of sequences in $\mathcal{D}$ came before the topology of $\mathcal{D}$.
As a consequence, it is natural to begin the study of distribution theory with the notion of convergence (instead of start with the actual topology).
In addition, the quote draw our attention for the following fact:
There are problems that you can solve in the context of distributions without invoke a topology for $\mathcal{D}$. For some purposes, the usual notion of convergence (which Schwartz called pseudo-topology) is enough.
For example, the fact that the distributional derivative "preserves convergence of sequences" (in $\mathcal{D}'$) is a result that can be obtained and applied to the differential equations without the actual topology of $\mathcal{D}$.
Remark: Sometimes this result is called "continuity" of the distributional derivative, even in the context where the notion of convergence in $\mathcal{D}'$ is defined as the convergence in $\mathcal{D}$: the explicit form of the convergence is given but a topology is not defined. However, it is indeed possible to put a topology on $\mathcal{D}'$ (which implies the said notion of convergence in $\mathcal{D}'$) without put a topology on $\mathcal{D}$. With respect to this topology in $\mathcal{D}'$ the distributional derivative is indeed "continuous" (and thus preserves convergence of sequences). To give a reference for this remark, let me quote what Schwartz said in his treatise:
Nous définissons ainsi sur $\mathcal{D}'$ une topologie (qui, remarquons-le encore, ne nécessite pas la connaissance de la topologie de $\mathcal{D}$, mais seulement de ses ensembles bornés). ([2], p. 71)
Of course, as the quote suggests, Schwartz could define boundedness in $\mathcal{D}$ even in absence of a topology:
I did not have a topology on $\mathcal{D}$, but what I called a pseudo-topology [...]. I could speak without difficulty of a bounded subset of $\mathcal{D}$ [...]. $\mathcal{D}$ was more or less one of the spaces I had studied deeply during that short period [summer of 1943], always with the slight difficulty of the pseudo-topology, which nevertheless did not stop me. ([1], p. 231)
In short, all these things support the fact that is it possible to do (and Schwartz certainly did) many things in the context of the distributions without appeal to the topology of $\mathcal{D}$ (but only with the notion of convergence). In my opinion this justifies the second reason above as a fundamental answer for your "why". Maybe we could just say that people avoid talking about the topology (in some contexts) because it is an efficient strategy (in the context where it is avoided). The point is that the topology was created to yields a prior notion of convergence and allow a deeper development of the theory. The notion of convergence is not a mere simplification to avoid a complicated topology whose origin is a mystery; of course the topology is complicated and people make it seems mysterious (by virtue of an explanation's lack), but the notion of convergence is the cause of the topology and not the converse. Maybe you will agree that, from this point of view, the fact that in some contexts "people don't bother talking about the actual topology" becomes natural and acceptable.
Addendum (details on the creation of the topology). What was the advantage of defining a topology on $\mathcal{D}$? It was to make possible the application of the knows theorems of topological spaces, like the Hanh-Banach Theorem. The last sentence seems vague and sounds like a cliche, right? But it is the truth; it was essentially what Schwartz said:
In Grenoble, I gave an exact definition of the real topology corresponding to the pseudo-topology on $\mathcal{D}$, which later, in 1946, Dieudonne and I took to calling an inductive limit topology. The pseudo-topology is not enough; in order to apply the Hahn-Banach theorem and to study the subspaces of $\mathcal{D}$, you need to work with a real topology. ([1], p. 238)
I carefully defined the neighborhoods of the origin in $\mathcal{D}$, then gave the characteristic property which was precisely that of being an inductive limit, without giving it a name. I only did this for the particular object $\mathcal{D}$, without daring to introduce a general category of objects. Mathematical discovery often takes place in this way. One hesitates to introduce a new class of objects because one needs only one particular one, and one hesitates even more before naming it. It's only later, when the same procedure has to be repeated, that one introduces a class and a name, and then mathematics takes a step forwards. Other inductive limits were introduced, then the theory of sheaves used them massively and homological algebra showed the symmetry of inductive and projective limits. ([1], p. 283)
[1] A Mathematician Grappling with His Century by Laurent Schwartz.
[2] Théorie des distributions by Laurent Schwartz.
PedroPedro
$\begingroup$ Thank you very much for this well-reasearched answer. The most important point I seem to notice in what you said is, that defining the correct topology is a non-trivial task. Nevertheless, as Jochen pointed out in the comments, apparently the reason for the inductive limit scheme can be related intuitively to some notion of "locality", perhaps in the context of sheaves. Do you have any advice how I could find out about this relation (without diving deeply into abstract algebra)? $\endgroup$ – Adomas Baliuka May 5 '17 at 1:46
$\begingroup$ @AdomasBaliuka Unfortunately, I cannot give you any advice because I also don't know the relation you are looking for. However, as the proof of the local structure theorem uses the topological structure of $\mathcal{D}_K$, this is the first place where I would look for such a relation. In this case, the "locality notion" should refer to the fact that "locally, each distribution is the distribitional derivative of some continuous function". $\endgroup$ – Pedro May 7 '17 at 1:25
$\begingroup$ @Pedro: great answer. I just added another answer with some complements. $\endgroup$ – Abdelmalek Abdesselam Aug 28 '17 at 18:34
This is just a quick addendum to Pedro's excellent answer. Indeed the topology of $\mathcal{D}$ is rather tricky and that's why most available treatments (e.g., with applications to PDEs) do not really get into it.
As for your very last question about explicit seminorms, the answer is yes. There is such a set of seminorms due (I think) to Horváth. See this MO answer https://mathoverflow.net/questions/234025/why-is-multiplication-on-the-space-of-smooth-functions-with-compact-support-cont/234503#234503
I think another answer to your interrogations is that almost nobody knows these seminorms.
In order to fully understand the topology of $\mathcal{D}$ you need to try your hands first on the space $s_0=\oplus_{\mathbb{N}}\mathbb{R}$ of almost finite sequences. The natural topology is the finest locally convex topology defined by all seminorms one can put on this (algebraic) vector space. This set of seminorm is the same as that of seminorms which are continuous on each $\mathbb{R}$ summand (trivially). A more explicit set of seminorms is $$ ||x||_{\omega}=\sum_{n\in \mathbb{N}}\omega_n |x_n| $$ for all $\omega\in [0,\infty)^{\mathbb{N}}$.
The elements of a convergent sequence in this space form a bounded set and this last property implies that there is a common finite support. This space $s_0$ is like a discrete analogue of $\mathcal{D}$ where the domain $\Omega$ is replaced by $\mathbb{N}$.
Then you can quickly visit the space of rapidly decreasing sequences $s$ with obvious definitions. Finally, you can upgrade to $$ \oplus_{\mathbb{N}} s $$ which is the analogue of $s_0$ where scalars in $\mathbb{R}$ are replaced by sequences in $s$. It is a little known fact due to Valdivia and Vogt that $$ \mathcal{D}(\Omega)\simeq \oplus_{\mathbb{N}} s $$ as topological vector spaces.
PS: I have no idea what $\mathcal{S}(\Omega)$ is for general open sets. The notion of Schwartz space is not a purely differential notion. It involves algebra if only to make sense of "polynomial" in polynomial growth. Schwartz's original definition is the set of elements in $\mathcal{D}$ which are restrictions of distributions on the sphere seen as the one-point compactification of Euclidean space. There are generalizations but they involve some algebraic structure like the notion of Nash manifold as in this article. There are also other references on this issue on the MO page: https://mathoverflow.net/questions/80094/the-schwartz-space-on-a-manifold
Abdelmalek AbdesselamAbdelmalek Abdesselam
For question 1: The question of whether knowing all convergent sequences allows to define a topology is answer by the negative in this article by Franklin. (link from the wikipedia article). So it is not a good idea.
cf. also this answer. I am also very curious about why sequential characterization of continuity holds for linear maps. (The inductive limit in stake for $\mathcal{D}$, is in fact special, it is given by an increasing sequence of subspaces. There is something with the characterization of bounded sets in that special case. cf. 6.5 (c) p.135 and 1.32 p.24 in Rudin)
Link Semi-norm and convex neighborhoods of 0: cf. "Functional Analysis", by W. Rudin from § 1.33 p.25 forward, especially 1.35 p. 26, or sketched by "Methods of mathematical physics" vol. 1 by Reed and Simon, p. 126. cf. also "Functional Analysis, Sobolev spaces, and PDE" by H. Brezis, p. 6.
For question 3: as explained by Rudin, § 6.2 p.151, $\mathcal{C}^{\infty}_c(\Omega)$ would not be "complete" (usually needs a metric. For topological vector spaces, cf. ex: Topological spaces, Distributions and Kerner, F. Treves p.37, or Reed and Simon vol. 1 p.125) if its topology were defined by the family of semi-norms ($\boldsymbol{\alpha} \in \mathbb{N}^n$ multi-indices) or some equivalent ones. $$ \rho_{\boldsymbol{\alpha}} (f) := \sup_{\mathbf{x}\in \Omega} \big\lvert\, \partial^{\boldsymbol{\alpha}} f (\mathbf{x})\,\big\rvert$$
The inductive topology is a topology that is finer. It is then more stringent for a sequence to be Cauchy (i.e. there will be "fewer" of them). This stronger requirement is even such that the Cauchy sequences actually converge in $\mathcal{C}^{\infty}_c(\Omega)$ (which when endowed with the inductive limit topology is denoted $\mathcal{D}(\Omega)$).
The compact set business has to do with the fact that $\Omega$ admits an exhaustion by compact subsets (union of increasing compact subsets). Hence the spaces of test functions is also a union of subspaces, labelled by compact sets $$ \mathcal{C}^{\infty}_c(\Omega) = \bigcup_{n\in \mathbb{N}} \mathcal{C}^{\infty}(K_n) $$ The inductive limit is in general a way to define the "union" but with relations. Namely if $K_n \subset K_{n+1}$ then $\mathcal{C}^{\infty}(K_n) \subset \mathcal{C}^{\infty}(K_{n+1})$. Each of these spaces has a topology defined by a family of semi-norms. From that information we want to define a topology on the union, which satisfies some condition (since there are in fact many possibilities to define a topology on the "union").
(The explicit construction of the inductive limit topology can be found in Rudin 6.3, 6.4 p.152, or Treves Chap 13 p.126)
Noix07Noix07
Not the answer you're looking for? Browse other questions tagged functional-analysis distribution-theory or ask your own question.
Topologies of test functions and distributions
The Space $\mathcal{D}(\Omega)$ of Test Functions is Not a Sequential Space
What is a distribution ? Why it's not really a function?
Equivalent family of norms on the Schwartz space
Why does a convergent sequence of test functions have to be supported in a single compact set?
Advantange of having a complete topology on test functions
Sequential and topological duals of test function spaces
On the use of nets when defining operator topologies
The topology on $C^\infty_c(\mathbb{R}^d)$ used for "distributions of compact support"
Topology of the space $\mathcal{D}(\Omega)$ of test functions | CommonCrawl |
Volume 10 Supplement 2
Proceedings of the 15th American Heartworm Society Triennial Symposium 2016
Blocking the transmission of heartworm (Dirofilaria immitis) to mosquitoes (Aedes aegypti) by weekly exposure for one month to microfilaremic dogs treated once topically with dinotefuran-permethrin-pyriproxyfen
John W. McCall1,
Elizabeth Hodgkins3,
Marie Varloud2,
Abdelmoneim Mansour1 &
Utami DiCosty1
Parasites & Vectors volume 10, Article number: 511 (2017) Cite this article
This study assessed the influence of a topical ectoparasiticide (dinotefuran-permethrin-pyriproxyfen, DPP, Vectra®3D, Ceva Animal Health) on the acquisition of heartworm microfilariae by mosquitoes exposed to microfilaremic dogs weekly for 1 month.
Six beagle dogs (9.2 ± 1.6 kg body weight) infected with Dirofilaria immitis were allocated to two groups of three dogs: an untreated control group and a DPP-treated group. Dogs were treated on Day 0 and exposed under sedation for 1 h to 80 ± 20 unfed Aedes aegypti. Each dog was exposed to mosquitoes released into mosquito-proof containers on Days −7 (pretreatment), 7, 14, 21 and 28. Up to 20 engorged mosquitoes were aspirated from the cage as soon as they were blood-fed. They were dissected and the blood from each midgut was stained for a microfilaria (MF) count. After each exposure, mosquitoes were classified as live, moribund or dead and engorged or nonengorged. The number of dead mosquitoes was recorded daily for 16 days, when the live mosquitoes were dissected to count the infective third-stage larvae (L3).
Prior to treatment, 95% of the engorged mosquitoes in both groups had MF. After treatment, engorgement rates for the treated group were 0%, 2.3%, 2.7% and 2.2% for Days 7, 14, 21 and 28, respectively, with anti-feeding efficacy (repellency) of 100%, 98.0%, 95.8% and 97.0%, respectively. A total of 22 mosquitoes fed on treated dogs; most of them were dead within 24 h, and all were dead within 72 h. Only 2 unfed mosquitoes exposed to treated dogs survived the incubation period and no L3 were found in them. A total of 121 of the 132 (91.6%) surviving mosquitoes that had engorged on untreated dogs had an average of 12.3 L3 per mosquito (range, 0-39).
DPP was more than 95% effective in inhibiting blood-feeding and killing both engorged and nonengorged mosquitoes exposed weekly to microfilaremic dogs for 28 days after treatment. Treatment with DPP was completely effective in killing the few mosquitoes that fed on the treated dogs before they lived long enough for the microfilariae to develop to L3 and, consequently, was completely effective in blocking the transmission of L3 to other animals. DPP can break the life cycle of D. immitis and prevent infected dogs and infected mosquitoes from being effective reservoirs and can slow down the spread of heartworms, even those resistant to macrocyclic lactone preventives.
Heartworm (Dirofilaria immitis) is a widespread filarial vector-borne disease for which dogs are the natural, definitive hosts. Cats and humans are included in a list of numerous abnormal hosts. In canine and feline hosts, the migrating parasite within the circulatory system can induce dramatic conditions that may lead to death. The vectors of this nematode are female mosquitoes that become infected by feeding on a microfilaremic animal. After development of the worm into infective third-stage larvae (L3), infected mosquitoes transmit the parasite to the next host by L3 entering the puncture wound made by the mosquito mouthparts immediately after the blood meal. Numerous species of mosquitoes, including Aedes aegypti [1,2,3], have been identified as competent vectors of D. immitis. While the strategy against this disease has been primarily based on chemoprophylaxis targeting the migrating stages in the dog by the use of macrocyclic lactones, less attention has been given to the arthropod vectors themselves. However, several studies have demonstrated the potential of repellents, including pyrethroids such as permethrin, in reducing mosquito bites in humans [4] and dogs [5]. Permethrin also has been used for many years for the control of ectoparasites on companion animals and farm animals.
Dinotefuran is a rapid-acting insecticidal agent with proven efficacy against insecticide-resistant mosquitoes [6]. Although in one study dinotefuran was less toxic than other more commonly used insecticides (eg, deltamethrin, carbosulfate, temephos) against the strains of Anopheles gambiae, Culex quinquefasciatus, and A. aegypti used in the study, the toxicity was not strongly affected by the presence of common resistance mechanisms (ie, kdr mutations and insensitive acetylcholinesterase), and the carbamate-resistant strain of C. quinquefasciatus was significantly more affected than the susceptible strain. Thus, the absence of cross-resistance makes neonicotinoids, such as dinotefuran, good potential candidates for vector-borne disease control, particularly in areas where mosquitoes are resistant to insecticides [6]. Pyriproxifen targets the insect endocrine system by mimicking the activity of juvenile hormone. For example, it breaks the flea life cycle by preventing development of immature stages of fleas, thereby arresting the development of flea eggs, flea larvae and pupae. A commercially available, topically applied product containing dinotefuran, permethrin and pyriproxyfen, with label indications for fleas, ticks, biting flies, sand flies and mosquitoes exhibits strong and monthlong anti-feeding and insecticidal properties against biting arthropods [7, 8]. By targeting the mosquito vectors, this combination could also prevent the uptake of microfilariae and, thus, their subsequent development to the infective stage.
This study was designed to explore the blocking effect of a dinotefuran-permethrin-pyriproxyfen topical combination on D. immitis microfilaremic dogs against the acquisition of microfilariae by the bite of uninfected mosquitoes.
The study was exploratory, blinded, controlled and unicenter, and the protocol was approved by an ethics committee (IACUC) prior to its start. The products were administered to test animals by individuals who were not involved in performing the posttreatment assessments and observations. Study groups were coded to blind the assessors. The schedule of the study is described in Table 1.
Table 1 Study design
Six adult beagle dogs (from 6.6-11.0 kg BW) infected with D. immitis multi-resistant JYD-34 isolate and microfilaremic were involved in the study. To be included, the dogs had to be microfilaremic on Day −11 and not have been treated with any ectoparasiticide for at least 3 months before the start of the study. The dogs were individually identified by a tattoo and were fed commercial dog food once daily with water available ad libitum. The dogs were housed individually in an indoor kennel. During the 9-day acclimation period, the dogs were bathed with a noninsecticidal shampoo and exposed to mosquitoes on Day −7 prior to treatment. Counts were conducted to establish the feeding and survival rate of mosquitoes. The dogs were assigned to two groups of three dogs with balanced Day −7 microfilaremia levels. This was done by ranking the dogs by microfilarial count, blocking the dogs in sets of two dogs with similar counts and then randomly allocating the dogs in each set to a treated or an untreated control group (Table 2).
Table 2 Dogs and treatment
The dogs in the DPP group were treated on Day 0 with DPP (Vectra® 3D, Ceva Animal Health) containing dinotefuran (4.95% w/w), pyriproxyfen (0.44% w/w) and permethrin (36.08% w/w). The product was applied topically according to the label, as a line-on from the base of the tail to the shoulders. Dogs in the control group were untreated.
Mosquito challenges
Each dog was exposed individually to 80 ± 20 unfed mosquitoes on Days −7, 7, 14, 21 and 28 of the study. The mosquitoes were 4- to 5-day-old female A. aegypti (Liverpool black-eyed strain) fed on water with sugar until exposure time. Dogs were sedated by IM injection of dexmedetomidine at 0.02 mg/kg BW (Dexdomitor®, Orion, Espoo, Finland) and butorphanol at 0.2 mg/kg BW (Torbugesic®, Zoetis). Each dog was placed in a dedicated mosquito-proof chamber (73.7 cm long, 40.6 cm wide and 33 cm high) into which the mosquitoes were released. Dogs were exposed to mosquitoes for 60 min. The procedure was conducted during the day and under artificial light.
Mosquito counts were conducted during aspiration at the end of the infestation by systematically examining all areas of the animal and of the cage. The mosquitoes were assessed visually and counted as live, moribund or dead and as fed or unfed. A mosquito was considered as live when it exhibited normal behavior and was capable of flying. Moribund mosquitoes were unable to perform normal locomotion and exhibited clear signs of neurological disruption. Engorgement of mosquitoes was assessed by visual inspection of individual mosquitoes, looking at redness and enlargement of the abdomen. The dead mosquitoes were preserved in vials containing ethanol (70%) and stored at −20 °C within 3 h of collection. The live and moribund mosquitoes were collected for viability assessment.
Viability of mosquitoes and larval load
The live and moribund mosquitoes collected were incubated in a temperature (28 °C) and humidity (80%) controlled insectary for 16 days. Viability was assessed daily. After incubation in the insectary for 16 days, live mosquitoes were dissected individually for an L3 count. The dead mosquitoes collected during the incubation period and all mosquitoes not dissected at the end of the incubation period were preserved in vials with ethanol (70%) and stored at −20 °C.
Microfilaremia of dogs
Blood was taken from each dog for a microfilarial count on Day −11 and thereafter immediately before each exposure of the dog to mosquitoes on Days −7, 14, 21 and 28. Microfilaremia was determined using a modified Knott's test [9].
Microfilarial load of mosquitoes
As soon as individual mosquitoes had fed, a total of up to 20 mosquitoes was collected by aspiration from each exposure chamber. The collected mosquitoes were exposed for 2 min in a freezer (−20 °C) for immobilization, and the wings and legs were removed. Only the mosquitoes for which a blood meal was completed were collected. These mosquitoes were dissected individually: the abdomen was separated and midgut contents were smeared on a slide. The slide was Giemsa-stained before microfilarial counts.
Anti-feeding effect or repellency
For each time point after exposure, the anti-feeding effect was calculated:
$$ \mathrm{Anti}\hbox{-} \mathrm{feeding} \mathrm{effect}\ \left(\%\right)=100\times \frac{\left(\mathrm{Cf}-\mathrm{Tf}\right)}{\mathrm{Cf}} $$
Where Cf was the arithmetic mean of fed female mosquitoes (live fed + moribund fed + dead fed) in the control group, and Tf was the arithmetic mean of the fed female mosquitoes in the treated group.
Knock-down effect
For each time point after exposure, the knock-down effect was calculated:
$$ \mathrm{Knock}\hbox{-} \mathrm{down}\ \mathrm{effect}\;\left(\%\right)=100\times \frac{\left(\mathrm{Clm}-\mathrm{Tlm}\right)}{\mathrm{Cl}} $$
Where Clm was the arithmetic mean of live (live engorged + live unengorged) in the control group, and Tlm was the arithmetic mean of the live female mosquitoes in the treated group. The knock-down effect was calculated at the end of the exposure (1 h). The knock-down effect compared only the number of live (not including the moribund) females in the treated and control groups.
Insecticidal effect
For each time point after exposure, the mortality effect was calculated:
$$ \mathrm{Mortality}\left(\%\right)=100\times \frac{\left(\mathrm{Cl}\hbox{-} \mathrm{Tl}\right)}{\mathrm{Cl}} $$
Where Cl was the arithmetic mean of live and moribund female mosquitoes (live engorged + live unengorged + moribund engorged + moribund unengorged) in the control group, and Tl was the arithmetic mean of the live and moribund female mosquitoes in the treated group. The mortality effect was calculated at the end of the exposure (1 h) and daily for the 16 days of the postexposure incubation.
Infectivity of mosquitoes
After each exposure, the infectivity of mosquitoes was calculated:
$$ \mathrm{Infectivity}\ \mathrm{effect}\ \left(\%\right)=100\times \frac{\left(\mathrm{Ci}\hbox{-} \mathrm{Ti}\right)}{\mathrm{Ci}} $$
Where Ci was the arithmetic mean of L3 collected from mosquitoes exposed to each dog in the control group, and Ti was the arithmetic mean of L3 collected from mosquitoes exposed to each dog in the treated group.
The infectivity was calculated for each day of exposure considering mosquitoes (fed and unfed) that survived the 16-day incubation period.
A total of only 22 mosquitoes fed on dogs in the treated group, compared with 810 in the untreated control group. Most of the 22 mosquitoes were dead by the second day, and all were dead by the third day. Considering the small sample size, no statistical analysis was conducted, and the individual data were reported.
This study was carried out in compliance with Good Clinical Practice requirements [10]. Except for the number of dogs, the study was conducted in compliance with US EPA Product Performance Test Guidelines OPPTS 810.3300: Treatments to Control Pests of Humans and Pets.
At the beginning of the study, the dogs exhibited microfilaremia ranging from 36 to 545 microfilariae per 20 μL of blood. Microfilaremia was not assessed on Day 7. Microfilaremia was maintained in all dogs for the duration of the study (Table 3). No adverse effects to any of the treatment applications were observed in any dogs during the study.
Table 3 Kinetics of microfilaremia (MF/20 μL of blood) in two groups (control untreated or DPPa treated on Day 0) of Dirofilaria immitis-infected donor dogs over 40 days
Anti-feeding efficacy
Before treatment, mosquito engorgement rates for all dogs ranged from 78.8% to 96.7% (data not shown), and the geometric mean number of fed mosquitoes in the control group ranged from 57.6 on Day 21 to 74.6 on Day 14 (Table 4). After treatment, the geometric mean number of mosquitoes that fed on treated dogs ranged from 0 on Day 7 to 2.4 on Day 21. The anti-feeding efficacy (repellency) of DPP ranged from 95.8% on Day 21 to 100% on Day 7.
Table 4 Geometric mean number of blood-fed and live mosquitoes and immediate anti-feeding and knock-down efficacy of DPPa (administered on Day 0) after 1 h of exposure (%) at weekly intervals over 1 month
Microfilaria uptake by mosquitoes
In the control group and before treatment for all individuals, the uptake of microfilariae by mosquitoes during blood-feeding was variable but successful (Fig. 1 and Table 5). There were from 0 to 742 microfilaria per mosquito, the average microfilarial load was 119.7 in the control group and 95% of the engorged mosquitoes had microfilariae (data not shown). In the treated group, since no mosquitoes fed on dogs on Day 7, none was dissected. The few (n = 22) mosquitoes that fed on the treated dogs between Days 14 and 28 were not dissected in order to assess their survival and potential for transmission of heartworm.
Relationship between canine microfilaremia and uptake of microfilariae by blood-fed mosquitoes from all dogs before treatment (n = 6) and in the control group at weekly intervals over 1 month (n = 3)
Table 5 Dirofilaria immitis microfilaria uptake by Aedes aegypti mosquitoes blood-fed on infected dogs untreated or topically treated with DPP on Day 0
Knock-down efficacy
In the control group before and after Day 0 and in the treated group before treatment, the geometric mean number of live mosquitoes after the 1 h exposure ranged from 66.8 to 81.8, and there were no moribund mosquitoes (Table 4). For 1 month after treatment, the geometric mean number of live mosquitoes in the treated group ranged from 0 on Day 7 to 3.3 on Day 21. The moribund and live mosquitoes were incubated for survival assessment. The knock-down efficacy of DPP 1 h after each infestation ranged from 95.5% to 100% over 1 month (Table 4). It is also noteworthy that compared with the control group, mosquitoes in the treated group spent a relatively small amount of time in contact with the treated dogs.
Insecticidal efficacy and survival of mosquitoes
In the control group, throughout the study and before treatment in all individuals in both groups, the survival rate of the mosquitoes during the incubation decreased from 74.7% to 94.8% on Day 1 to 6.9% to 26.6% on Day 16 (Table 6). In the treated group, the survival rate of the mosquitoes during the incubation decreased from 0 to 4.0% on Day 1 to 0 to 0.4% on Day 16. Of the cumulative total of 1341 mosquitoes that were exposed to the treated dogs during the four exposure periods, a total of 22 mosquitoes fed on these dogs; and all were dead within 72 h (data not shown). The survival of the fed mosquitoes appeared to be related to the microfilaremia level of the donor dogs, with a higher death rate in mosquitoes that fed on dogs with the highest microfilarial counts; but these data were not analyzed statistically.
Table 6 Average survival rate of Aedes aegypti female mosquitoes (%) assessed daily during a 16-day incubation period after 1 h exposure to control or DPP-treated microfilaremic dogs infected with Dirofilaria immitis
L3 development blocking efficacy
In the control group before and after Day 0 and in the treated group before treatment, a total of 222 mosquitoes survived the 16-day incubation period. A total of 132 fed mosquitoes were dissected (Table 7), and 121 (91.6%) of them had at least one L3. In the control group, there was an average of 12.3 L3 per engorged mosquito; and up to 39 L3 were found in a single fed mosquito (data not shown). After treatment with DPP, only two unfed mosquitoes survived the incubation period; and no L3 were found in them when they were dissected.
Table 7 Average larval (L3) load of blood-fed and nonblood-fed Aedes aegypti female mosquitoes exposed for 1 h to microfilaremic dogs infected with Dirofilaria immitis incubated for 16 days prior to dissection
Methodological considerations
The dog/mosquito exposure model used in this study was considered successful since the mosquitoes that were released with the untreated dogs were able to feed, take up microfilariae and allow L3 to develop during a 16-day incubation period. A total of only 222 mosquitoes survived the 16-day incubation period, and 132 had engorged on untreated dogs. A total of 121 (91.6%) of these mosquitoes had at least one and as many as 39 L3. In a natural environment, these vector mosquitoes could spread heartworm from canine reservoirs to other susceptible hosts.
Interestingly, we observed that the mosquitoes that fed on the most highly microfilaremic dogs died more quickly than those that fed on the dogs with more moderate microfilaremia. Such differences could be explained by a limit in the parasite load that can be tolerated by the mosquito vectors. This is consistent with previous observations performed on mosquitoes feeding on D. immitis–microfilaremic dogs [2, 11] as well as mosquitoes feeding on Wuchereria bancrofti–infected, microfilaremic human hosts [12]. It was indeed demonstrated that the parasite load in mosquitoes was a risk factor of vector survival [12], and "hidden carriers" with low microfilaremia were suspected of playing a major reservoir role [13]. In a natural environment, the parasite load of mosquitoes with D. immitis usually ranges between one and eight L3 per mosquito [14]. In the present experiment, up to 39 L3 were able to develop in a single mosquito and survive the 16 days of incubation. A high parasite load of mosquitoes has already been reported in experimental conditions: 62 D. immitis L3 were found in a single female Aedes notoscriptus after 10 days of incubation [11].
Efficacy against mosquitoes (A. aegypti)
The anti-feeding efficacy of DPP in this study ranged from 95.8% to 100% and was consistent with previous measurements on the same mosquito species, with efficacy ranging from 87.0% to 94.0% [8]. This high-level repellency (anti-feeding) effect was also reported against other flying insects, such as Culex pipiens mosquitoes [15], Phlebotomus perniciosus sand flies [16] and Stomoxys calcitrans biting flies [17]. The knock-down effect of 98.0% to 100% observed 1 h after exposure is also in line with previous data obtained with DPP showing 93.0% to 100% knock-down effect [8].
Although mosquitoes in both groups were allowed access to the dogs for up to 1 h, it was noted that those in the treated group spent a relatively short period of time in direct contact with the treated dogs, when compared with controls. The few mosquitoes that were able to feed on the treated dogs died within 72 h of incubation. While permethrin is the active ingredient providing repellency (anti-feeding), dinotefuran is known as a fast-acting insecticide and was identified as a promising active agent against resistant mosquitoes [6]. When dinotefuran and permethrin are combined at the ratio found in DPP, synergy occurs; and the permethrin improves the action of dinotefuran at the synaptic level in insects [18]. In DPP, this synergy provides an increased efficacy against insect parasites. The lethal anti-feeding effect of DPP was expected to block the transmission of D. immitis from infected microfilaremic dogs to the mosquito vectors.
Efficacy against heartworm (D. immitis)
Only a few mosquitoes (n = 22) were able to feed on the treated dogs during the first month after treatment. Since priority was given to assessment of the anti-transmission efficacy, these insects were not killed for dissection but rather were incubated for assessment of their survival and potential development of L3. None of the mosquitoes that fed on treated dogs survived for more than 72 h of incubation. A few (n = 2) nonblood-fed mosquitoes exposed to treated dogs remained alive during the 16-day incubation and were dissected. None of them exhibited L3. It is reasonable to assume that the high mosquito repellency and insecticidal efficacy levels obtained in our study are independent of the resistance status of the filarial isolate, as similar values were reported in a study with A. aegypti mosquitoes and DPP where there was no heartworm component [8]. However, studies with other heartworm strains (ie, macrocyclic lactone-resistant or -susceptible) are yet to be done. Transmission-blocking strategies target the parasite within the insect vector and are expected to reduce the prevalence of infection in endemic communities. Such consequences have already been proven to be successful experimentally against malaria (Plasmodium berghei) and its anopheline vector (Anopheles stephensi) [19]. Our results with another dog/mosquito exposure model indicate that DPP would represent a reliable weapon for transmission-blocking of D. immitis L3 to dogs [20]. The treatment of reservoir dogs is indeed expected to reduce the risk of infection in the neighborhood and anywhere the dog travels.
The xenodiagnosis-type dog/mosquito laboratory model used successfully in this study has also been shown to be useful in assessing the transmission of D. immitis L3 from infected mosquitoes to dogs and other hosts. The topical formulation of DPP used in this study was more than 95% effective in repelling and killing mosquitoes for 28 days after treatment. Thus, it was more than 95% effective in blocking the acquisition of microfilariae by mosquitoes; and, because all of the few mosquitoes that fed on the treated, microfilaremic dogs died within 3 days, it was 100% effective in blocking subsequent transmission of any L3 to dogs or other susceptible hosts. Repellent and insecticidal properties of ectoparasiticides could contribute substantially to reducing the risk of heartworm transmission, even those heartworm biotypes resistant to macrocyclic lactone preventives or any other type of preventive. A multimodal approach to the prevention of heartworm, which reduces populations of mosquitoes, prevents mosquito biting, kills mosquitoes and includes the monthly or biannual administration of a macrocyclic lactone preventive, should be strongly encouraged.
DPP:
dinotefuran-permethrin-pyriproxyfen
microfilariae
Otto GH, Jachowski LA. Mosquitoes and canine heartworm disease. In: Morgan HC, editor. Proceedings of the heartworm symposium '80. Edwardsville, KS: Veterinary Medicine Publishing Company; 1981. p. 17–32.
Apperson CS, Engber B, Levine JF. Relative suitability of Aedes albopictus and Aedes aegypti in North Carolina to support development of Dirofilaria immitis. J Am Mosq Control Assoc. 1989;5:377–82.
Tiawsirisup S, Nithiuthai S. Vector competence of Aedes aegypti (L.) and Culex quinquefasciatus (say) for Dirofilaria immitis (Leidy). Southeast Asian J Trop Med Public Health. 2006;37:110–4.
Frances S, Sferopoulos R, Lee B. Protection from mosquito biting provided by permethrin-treated military fabrics. J Med Entomol. 2014;51:1220–6. https://doi.org/10.1603/ME14084.
Meyer JA, Disch D, Cruthers LR, Slone RL, Endris RG. Repellency and efficacy of a 65% permethrin spot-on formulation for dogs against Aedes aegypti (Diptera: Culicidae) mosquitoes. Vet Ther. 2003;4:135–44.
Corbel V, Duchon S, Zaim M, Hougard JM. Dinotefuran: a potential neonicotinoid insecticide against resistant mosquitoes. J Med Entomol. 2004;41:712–7. 10.1603/0022-2585-41.4.712.
CVMP: Assessment report for Vectra 3D (EMEA/V/C/002555/0000). http://www.ema.europa.eu/docs/en_GB/document_library/EPAR-_Public_assessment_report/veterinary/002555/WC500163784.pdf. Accessed 18 Sep 2016.
Franc M, Genchi C, Bouhsira E, Warin S, Kaltsatos V, Baduel L, et al. Efficacy of dinotefuran, permethrin and pyriproxyfen combination spot-on against Aedes aegypti mosquitoes on dogs. Vet Parasitol. 2012;189:333–7. https://doi.org/10.1016/j.vetpar.2012.04.026.
American Heartworm Society (AHS). Current canine guidelines for the diagnosis, prevention and management of heartworm (Dirofilaria immitis) infections in dogs. 2014. https://www.heartwormsociety.org/images/pdf/2014-AHS-Canine-Guidelines.pdf. Accessed 16 Oct 2017.
CVMP VICH GL9 guideline on good clinical practice under animal ethics committee approval. 2000. http://www.ema.europa.eu/docs/en_GB/document_library/Scientific_guideline/2009/10/WC500004343.pdf.
Russell RC, Geary MJ. The influence of microfilarial density of dog heartworm Dirofilaria immitis on infection rate and survival of Aedes notoscriptus and Culex annulirostris from Australia. Med Vet Entomol. 1996;10:29–34.
Krishnamoorthy K, Subramanian S, Van Oortmarssen GJ, Habbema JD, Das PK. Vector survival and parasite infection: the effect of Wuchereria bancrofti on its vector Culex quinquefasciatus. Parasitology. 2004;129:43–50.
Lowrie RC Jr, Eberhard ML, Lammie PJ, Raccurt CP, Katz SP, Duverseau YT. Uptake and development of Wuchereria bancrofti in Culex quinquefasciatus that fed on Haitian carriers with different microfilaria densities. Am J Trop Med Hyg. 1989;41:429–35.
Russel RC. Report of a field study on mosquito (Diptera: Culicidae) vectors of dog heartworm, Dirofilaria immitis Leidy (Spirurida: Onchocercidae) near Sydney, N.S.W., and the implications for veterinary and public health concern. Aust J Zool. 1985;33:461–72.
Bouhsira E, Lienard E, Lyazrhi F, Jacquiet P, Varloud M, Deflandre A, et al. Repellent and insecticidal efficacy of a combination of dinotefuran, pyriproxyfen and permethrin (Vectra® 3D) against Culex pipiens in dogs. Parasite Epidemiol Control. 2016;1:233–8. 2013, August 25-29
Varloud M, Moran C, Grace S, Chryssafidis AL, Kanaki E, Ramiro MV, et al. Residual repellency after administration of a topical ectoparasiticide Vectra® 3D (dinotefuran-permethrin-pyriproxyfen) to dogs exposed to Phlebotomus perniciosus sandflies weekly for 6 weeks. Proceedings of the SEVC Congress, Barcelona, Spain, October 15-17, 2015.
Varloud M, Fourie JJ, Crippa A: Immediate and residual anti-feeding and insecticidal efficacy of a dinotefuran-permethrin-pyriproxyfen topical administration against stable flies (Stomoxys calcitrans) infesting dogs. Proceedings of the XXVIII SOIPA Congress, Roma, Italy, June 24-27, 2014.
Varloud M, Karembe H, Thany S. Synergic effect between permethrin and dinotefuran on ganglionic synaptic transmission in an insect model (Periplana americana) assessed by mannitol-gap recording. Proceedings of the 25th International Conference of the World Association for the Advancement of Veterinary Parasitology, Liverpool, The UK, August 16-20, 2015.
Blagborough AM, Churcher TS, Upton LM, Ghani AC, Gething PW, Sinden RE. Transmission-blocking interventions eliminate malaria from laboratory populations. Nat Commun. 2013;4:1812. doi:10.1038/ncomms2840.
McCall J, Varloud M, Hodgkins E, Mansour A, DiCosty U, McCall S, et al. Shifting the paradigm in Dirofilaria immitis prevention: blocking transmission from mosquitoes to dogs, using repellents/insecticides and macrocyclic lactone prevention as part of a multi-modal approach. Parasit Vectors. 2017;10(Suppl 2): doi:10.1186/s13071-017-2438-4.
The authors acknowledge the TRS Labs team members for their respective contributions in this experiment.
The study was funded by Ceva Animal Health. The article publication fee was funded by the American Heartworm Society.
It is not appropriate to store and share this data, as the authors are planning to include some of it in future publications.
About this supplement
This article has been published as part of Parasites and Vectors Volume 10 Supplement 2, 2017: Proceedings of the 15th American Heartworm Society Triennial Symposium 2016. The full contents of the supplement are available online at https://parasitesandvectors.biomedcentral.com/articles/supplements/volume-10-supplement-2.
TRS Labs, 215 Paradise Boulevard, 30607, Athens, GA, USA
John W. McCall, Abdelmoneim Mansour & Utami DiCosty
Ceva Animal Health, Lenexa, KS, USA
Marie Varloud
Ceva Santé Animale, 10 Avenue de la ballastière, 33500, Libourne, France
Elizabeth Hodgkins
John W. McCall
Abdelmoneim Mansour
Utami DiCosty
JWM, EH and MV wrote the protocol; AM, UD and JWM performed the technical aspects of the study; and JWM, EH and MV prepared the initial draft of the manuscript. All authors read and approved the final manuscript.
Correspondence to John W. McCall.
The study protocol was approved by an ethics committee (TRS Labs' IACUC) prior to beginning the study.
John McCall is Professor Emeritus of the University of Georgia and Chief Scientific Officer at TRS Labs, Inc., Athens, Georgia. Abdelmoneim Mansour and Utami DiCosty are employees of TRS Labs, a research organization that was contracted by Ceva Santé Animale to perform the study. Marie Varloud and Elizabeth Hodgkins are employees of Ceva Santé Animale.
McCall, J.W., Hodgkins, E., Varloud, M. et al. Blocking the transmission of heartworm (Dirofilaria immitis) to mosquitoes (Aedes aegypti) by weekly exposure for one month to microfilaremic dogs treated once topically with dinotefuran-permethrin-pyriproxyfen. Parasites Vectors 10, 511 (2017). https://doi.org/10.1186/s13071-017-2439-3
Repellency | CommonCrawl |
Mocha W32 TN5250 Crack Activation Code With Keygen Free
William Scholes Law Firm > High Pressure > Mocha W32 TN5250 Crack Activation Code With Keygen Free
Posted by opalper
in High Pressure
Download —>>> https://geags.com/2mmi1c
Mocha W32 TN5250 Activation Free Download For Windows [Updated] 2022
Mocha W32 TN5250 for Windows XP, Windows 7 and Windows 8
Mocha TN5250 for Windows XP
Can be used with Windows XP, Windows Vista and Windows 7
Detailed Screenshot:
This is just a sample of the features offered by Mocha W32 TN5250. The app supports all standard 5250 emulation features.
Mocha W32 TN5250 Main Features:
Automatic reconnection
Keep Alive signals
Api for Excel and text file creation
Log traffic details
Auto and Manual Hotposts
Password support
Change screen size and font
Send Hotkeys
Change screen color
Record macros
24x80px and 27x132px screen sizes
24x80px screen size only: You can increase or decrease the screen width via the config menu. In this mode, you can view the Terminal Emulator control screen (it's black).
24x80px and 27x132px screen size with menus: You can change screen size in one click. In this mode, you can see the Terminal Emulator control screen.
Config menu screen with menus: This screen shows the Terminal Emulator control screen. You can change the colors, change the text size, clear the terminal history, save and load the settings, change the screen size, log traffic details, record macros, send Hotkeys, change the language, activate Proxy, and log in automatically.
Settings screen: This is the Terminal Emulator control screen. You can change the colors, change the text size, clear the terminal history, save and load the settings, change the screen size, log traffic details, record macros, send Hotkeys, change the language, activate Proxy, log in automatically, and send Keep Alive signals every 15 seconds.
Reload screen: You can send the Keep Alive signal (do not exit) if you prefer.
Hotpost screen: The Hotpost screen allows you to configure a Hotpost of the main window.
Save file screen: This feature allows you to save the current settings of the app to the file system.
Mocha W32 TN5250 for Windows 7 and Windows 8
Can be used with Windows 7, Windows 8 and Windows 8.1
Mocha W32 TN5250
Mocha W32 TN5250 Product Key is a terminal emulator that allows you to connect to an AS/400 host in a secure way.
Connect to a 5250 host using a user name and password.
Paste data in the standard text format.
Save log entries to a file.
Change the terminal font, and color.
Change the terminal function.
Run macro programs.
Display a message on the screen when connecting.
Switch between two styles for displaying the message.
Setup and use the terminal emulator in a Windows environment.
Includes 24x80px and 27x132px sizes for the main window.
You can also connect to an AS/400 with a remote connection using Mocha W32 TN5250 Cracked 2022 Latest Version and Microsoft Remote Desktop Protocol (RDP) (if you have the appropriate software installed on your Windows computer). If you have to connect to the AS/400 remotely, the connection can be made to a host with the same operating system as Mocha TN5250, or a host with an operating system compatible with Mocha TN5250, such as Windows Server 2003 or Windows XP.
As mentioned, you can also use the software to remotely connect to a 5250 host running on a Windows-based server, although this requires the server and your Windows computer to have the Microsoft RDP client software installed.
Mocha W32 TN5250 Crack Keygen Manual:
Here's a quick guide on how to use Mocha W32 TN5250 Cracked 2022 Latest Version:
Create a user name and password for the client to connect to the AS/400 host
Using the menu or the toolbar, you can connect to the 5250 host, or the RDP host, using the 5250 connection mode (if you have access to the host's Internet Protocol (IP) address), or using the remote connection mode (if you're using the RDP client software installed on your Windows computer).
If you're using the remote connection mode, specify the location of the remote host in the Host field.
You can also connect to the remote host if it has the same operating system as the client, or a host that is compatible with the client. This means that the connection can be made to a host running on a Windows server, but the client must also have the RDP client installed.
You can send messages to the remote host by specifying the email address in the Email field
1d6a3396d6
Mocha W32 TN5250 License Key Full (Updated 2022)
Mocha W32 TN5250 is a terminal emulation for AS/400 access designed for Windows XP and older systems. Although it can still be run on newer Windows editions if you apply compatibility mode for Windows XP, you should resort to Mocha TN5250 for Windows 7/8/10 if you're using one of these newer operating systems.
The app offers support for SSL and all standard 5250 emulation features, and you can alternate between 24x80px and 27x132px screen sizes. The main app window has a black background, and options can be accessed from the menu bar, toolbar and right-click menu. When connecting to an AS/400 host, you can view advanced settings.
Therefore, you can change the port, automatically connect to the AS/400 when starting up Mocha W32 TN5250, enable automatic reconnection, exit when the session is over, disable the message confirmation on exit, and send Keep Alive signals every 15 seconds. If you want to enable SSL, this can be done via the port 992 in 56-bit or 128-bit mode, depending on your preference.
Once connected, it's possible to paste data in Excel or table format, reset the terminal, change the font and colors, log traffic details to file, and record macros. Also, you can enable a proxy server and automatic login by specifying your user name and password, activate hotposts, send messages via your default email client, and change the current 5250 function.Q:
Find the coordinates of the point at the intersection of the lines
The problem is:
Find the coordinates of the point $P$ that is at the intersection of the two lines $$\frac{x}{2}-y+3=0$$ $$x+y+4=0$$
I tried to solve this problem with the linear equation but I am stuck, I'm not sure whether I'm on the right track or not.
I calculated the slope and the y-intercept of each line but it didn't help me
The intercepts are $y=3$ and $y=-4$, so the coordinates are $[x,y] = [1,3]$ and $[x,y] = [-1,-4]$.
// license that can be found in the LICENSE
What's New In Mocha W32 TN5250?
Once connected, it's possible to paste data in Excel or table format, reset the terminal, change the font and colors, log traffic details to file, and record macros. Also, you can enable a proxy server and automatic login by specifying your user name and password, activate hotposts, send messages via your default email client, and change the current 5250 function.
Once connected, it's possible to paste data in Excel or table format, reset the terminal, change the font and colors, log traffic details to file, and record macros. Also, you can enable a proxy server and automatic login by specifying
PC Version:
• Windows 7/8/8.1/10 64bit
• Intel Core i5-760 @ 3.10 GHz, 2GB RAM
• NVIDIA GeForce GTX 660
Mac Version:
• OS X 10.7.0
Xbox 360 Version:
Pre-Requisites:
• Please install Aed2 and exe files in the D
https://www.digiclickz.com/uosk-free-x64-updated/
https://travellersden.co.za/advert/url-sentry-for-pc-updated/
https://dutchspecialforces.eu/wp-content/uploads/2022/06/darree.pdf
http://bestoffers-online.com/?p=6849
https://alternantreprise.com/wp-content/uploads/2022/06/leshkahl.pdf
https://claremontecoforum.org/wp-content/uploads/2022/06/MDF_to_ISO_convertor.pdf
https://ueriker-skr.ch/advert/a-z-realplayer-video-converter-download-updated-2022/
https://xn--doabertha-m6a.com/wp-content/uploads/2022/06/derrcle.pdf
https://oscareventshouse.uk/2022/06/07/mango-x64-latest-2022/
https://virtualanalytics.ai/rebel-net-with-license-key/
http://outsourcebookkeepingindia.com/wp-content/uploads/2022/06/Perfect_User_Icons.pdf
https://speedsuperads.com/wp-content/uploads/2022/06/Creative_DW_Menus_Pack.pdf
https://thetopteninfo.com/wp-content/uploads/2022/06/iBeesoft_File_Shredder.pdf
https://cdn.lyv.style/wp-content/uploads/2022/06/07072735/MIDI_File_Generator.pdf
https://mevoydecasa.es/tablo-tools-3-6-3-crack-license-key-full-free-for-windows-april-2022/
https://gametimereviews.com/dbf-commander-professional-crack-license-key-full-free/
https://newsygadgets.com/wp-content/uploads/2022/06/CSS_Gridish_for_Chrome.pdf
https://www.24onlinegames.com/softdiv-mp3-to-wav-converter-crack-download/
http://aiplgurugram.com/?p=4930 | CommonCrawl |
What Is the Acid-Test Ratio?
Understanding the Acid-Test Ratio
Acid-Test Ratios FAQs
Acid-Test Ratio Definition: Meaning, Formula, and Example
Adam Hayes
Adam Hayes, Ph.D., CFA, is a financial writer with 15+ years Wall Street experience as a derivatives trader. Besides his extensive derivative trading expertise, Adam is an expert in economics and behavioral finance. Adam received his master's in economics from The New School for Social Research and his Ph.D. from the University of Wisconsin-Madison in sociology. He is a CFA charterholder as well as holding FINRA Series 7, 55 & 63 licenses. He currently researches and teaches economic sociology and the social studies of finance at the Hebrew University in Jerusalem.
Natalya Yashina
Reviewed by Natalya Yashina
Natalya Yashina is a CPA, DASM with over 12 years of experience in accounting including public accounting, financial reporting, and accounting policies.
Learn about our Financial Review Board
Amanda Bellucco-Chatham
Fact checked by Amanda Bellucco-Chatham
Amanda Bellucco-Chatham is an editor, writer, and fact-checker with years of experience researching personal finance topics. Specialties include general financial planning, career development, lending, retirement, tax preparation, and credit.
Investopedia / Joules Garcia
The acid-test ratio, commonly known as the quick ratio, uses a firm's balance sheet data as an indicator of whether it has sufficient short-term assets to cover its short-term liabilities.
The acid-test, or quick ratio, compares a company's most short-term assets to its most short-term liabilities to see if a company has enough cash to pay its immediate liabilities, such as short-term debt.
The acid-test ratio disregards current assets that are difficult to liquidate quickly such as inventory.
The acid-test ratio may not give a reliable picture of a firm's financial condition if the company has accounts receivable that take longer than usual to collect or current liabilities that are due but have no immediate payment needed.
What Is The Quick Ratio?
In certain situations, analysts prefer to use the acid-test ratio rather than the current ratio (also known as the working capital ratio) because the acid-test method ignores assets such as inventory, which may be difficult to quickly liquidate. The acid test ratio is thus a more conservative metric.
Companies with an acid-test ratio of less than 1 do not have enough liquid assets to pay their current liabilities and should be treated with caution. If the acid-test ratio is much lower than the current ratio, it means that a company's current assets are highly dependent on inventory.
This is not a bad sign in all cases, however, as some business models are inherently dependent on inventory. Retail stores, for example, may have very low acid-test ratios without necessarily being in danger. The acceptable range for an acid-test ratio will vary among different industries, and you'll find that comparisons are most meaningful when analyzing peer companies in the same industry as each other.
For most industries, the acid-test ratio should exceed 1. On the other hand, a very high ratio is not always good. It could indicate that cash has accumulated and is idle, rather than being reinvested, returned to shareholders, or otherwise put to productive use.
Some tech companies generate massive cash flows and accordingly have acid-test ratios as high as 7 or 8. While this is certainly better than the alternative, these companies have drawn criticism from activist investors who would prefer that shareholders receive a portion of the profits.
Calculating the Acid-Test Ratio
The numerator of the acid-test ratio can be defined in various ways, but the main consideration should be gaining a realistic view of the company's liquid assets. Cash and cash equivalents should definitely be included, as should short-term investments, such as marketable securities.
Accounts receivable are generally included, but this is not appropriate for every industry. In the construction industry, for example, accounts receivable may take much more time to recover than is standard practice in other industries, so including it could make a firm's financial position seem much more secure than it is in reality.
The formula is:
Acid Test = Cash + Marketable Securities + A/R Current Liabilities where: A/R = Accounts receivable \begin{aligned} &\text{Acid Test} = \frac{ \text{Cash} + \text{Marketable Securities} + \text{A/R} }{ \text{Current Liabilities} } \\ &\textbf{where:} \\ &\text{A/R} = \text{Accounts receivable} \\ \end{aligned} Acid Test=Current LiabilitiesCash+Marketable Securities+A/Rwhere:A/R=Accounts receivable
Another way to calculate the numerator is to take all current assets and subtract illiquid assets. Most importantly, inventory should be subtracted, keeping in mind that this will negatively skew the picture for retail businesses because of the amount of inventory they carry. Other elements that appear as assets on a balance sheet should be subtracted if they cannot be used to cover liabilities in the short term, such as advances to suppliers, prepayments, and deferred tax assets.
The ratio's denominator should include all current liabilities, which are debts and obligations that are due within one year. It is important to note that time is not factored into the acid-test ratio. If a company's accounts payable are nearly due but its receivables won't come in for months, that company could be on much shakier ground than its ratio would indicate. The opposite can also be true.
Acid-Test Ratio Example
A company's acid-test ratio can be calculated using its balance sheet. Below is an abbreviated version of Apple Inc.'s (AAPL) balance sheet as of Jan. 27, 2022, showing the components of the company's current assets and current liabilities (all figures in millions of dollars):
Cash and cash equivalents 37,119
Short-term marketable securities 26,794
Accounts receivable 30,213
Inventories 5,876
Vendor non-trade receivables 35,040
Other current assets 18,112
Total current assets 153,154
Accounts payable 74,362
Other current liabilities 49,167
Deferred revenue 7,876
Commercial paper 5,000
Term debt 11,169
Total current liabilities 147,574
To obtain the company's liquid current assets, add cash and cash equivalents, short-term marketable securities, accounts receivable, and vendor non-trade receivables. Then divide current liquid current assets by total current liabilities to calculate the acid-test ratio. The calculation would look like the following:
Apple's ATR = ($37,119 + 26,795 + 30,213 + 35,040) / ($123,529) = 1.05
Not everyone calculates this ratio the same. There is no single, hard-and-fast method for determining a company's acid-test ratio, but it is important to understand how data providers arrive at their conclusions.
What's the Difference Between Current and Acid-Test Ratios?
Both the current ratio, also known as the working capital ratio, and the acid-test ratio measure a company's short-term ability to generate enough cash to pay off all debts should they become due at once. However, the acid-test ratio is considered more conservative than the current ratio because its calculation ignores items, such as inventory, which may be difficult to quickly liquidate. Another key difference is that the acid-test ratio includes only assets that can be converted to cash within 90 days or less, while the current ratio includes those that can be converted to cash within one year.
What Does the Acid-Test Ratio Tell You?
The acid-test, or quick ratio, shows if a company has, or can get, enough cash to pay its immediate liabilities, such as short-term debt. For most industries, the acid-test ratio should exceed 1. If it's less than 1, then companies do not have enough liquid assets to pay their current liabilities and should be treated with caution. If the acid-test ratio is much lower than the current ratio, it means that a company's current assets are highly dependent on inventory. On the other hand, a very high ratio could indicate that accumulated cash is sitting idle, rather than being reinvested, returned to shareholders, or otherwise put to productive use.
How to Calculate the Acid-Test Ratio?
To calculate the acid-test ratio of a company, divide a company's current cash, marketable securities, and total accounts receivable by its current liabilities. This information can be found on the company's balance sheet.
While it's true the variables in the numerator can be modified, each variation should reflect the most realistic view of the company's liquid assets. Cash and cash equivalents should be included, as should short-term investments, such as marketable securities. Accounts receivable are sometimes omitted from the calculation because this figure is not appropriate for every industry. The ratio's denominator should include all current liabilities, which are debts and obligations that are due within one year.
Investopedia requires writers to use primary sources to support their work. These include white papers, government data, original reporting, and interviews with industry experts. We also reference original research from other reputable publishers where appropriate. You can learn more about the standards we follow in producing accurate, unbiased content in our editorial policy.
Apple. "1/27/22 Apple Reports First Quarter Results," Page 2.
Quick Ratio Formula With Examples, Pros and Cons
The quick ratio is a calculation that measures a company's ability to meet its short-term obligations with its most liquid assets.
Understanding Liquidity Ratios: Types and Their Importance
Liquidity ratios are a class of financial metrics used to determine a debtor's ability to pay off current debt obligations without raising external capital.
What Is a Liquid Asset, and What Are Some Examples?
A liquid asset is an asset that can easily be converted into cash within a short amount of time.
Current Assets: What It Means and How to Calculate It, With Examples
Current Assets is an account on a balance sheet that represents the value of all assets that could be converted into cash within one year.
Current Ratio Explained With Formula and Examples
The current ratio is a liquidity ratio that measures a company's ability to cover its short-term obligations with its current assets.
Quick assets are those owned by a company with a commercial or exchange value that can easily be converted into cash or that is already in a cash form.
Current Ratio vs. Quick Ratio: What's the Difference?
Understanding Coca-Cola's Capital Structure (KO)
Solvency Ratios vs. Liquidity Ratios: What's the Difference?
What Financial Liquidity Is, Asset Classes, Pros & Cons, Examples
How Do You Calculate Working Capital?
How Is the Acid-Test Ratio Calculated? | CommonCrawl |
Directional limits on persistent gravitational waves using data from Advanced LIGO's first two observing runs
The LIGO Scientific Collaboration, The Virgo Collaboration, Matas, A., & Dvorkin, I. (in preparation). Directional limits on persistent gravitational waves using data from Advanced LIGO's first two observing runs.
Item Permalink: http://hdl.handle.net/21.11116/0000-0003-54F5-A Version Permalink: http://hdl.handle.net/21.11116/0000-0003-54F8-7
http://hdl.handle.net/21.11116/0000-0003-54F7-8
Abstract: We perform an unmodeled search for persistent, directional gravitational wave (GW) sources using data from the first and second observing runs of Advanced LIGO. We do not find evidence for any GW signals. We place limits on the broadband GW flux emitted at 25~Hz from point sources with a power law spectrum at $F_{\alpha,\Theta} <(0.05-25)\times 10^{-8} ~{\rm erg\,cm^{-2}\,s^{-1}\,Hz^{-1}}$ and the (normalized) energy density spectrum in GWs at 25 Hz from extended sources at $\Omega_{\alpha}(\Theta) <(0.19-2.89)\times 10^{-8} ~{\rm sr^{-1}}$ where $\alpha$ is the spectral index of the energy density spectrum. These represent improvements of $2.5-3\times$ over previous limits. We also consider point sources emitting GWs at a single frequency, targeting the directions of Sco X-1, SN 1987A, and the Galactic Center. The best upper limits on the strain amplitude of a potential source in these three directions range from $h_0 < (3.6-4.7)\times 10^{-25}$, 1.5$\times$ better than previous limits set with the same analysis method. We also report on a marginally significant outlier at 36.06~Hz. This outlier is not consistent with a persistent gravitational-wave source as its significance diminishes when combining all of the available data.
Pages: 9 pages, 5 figures | CommonCrawl |
Rethinking defects in patterns
Social distancing is integral to our lives these days, but distancing also underpins the ordered patterns and arrangements we see all around us in Nature. Oxford Mathematician Priya Subramanian studies the defects in such patterns and shows how they relate to the underlying pattern, i.e. to the distancing itself.
"Nature has many examples of situations where individuals in a dense group have to balance between short range repulsion (e.g., competition for resources) and long range attraction (e.g. safety in numbers). This naturally leads to an optimal length scale for separation between neighbours. If we think of each agent as a circle with this optimal length as the diameter, the most efficient packing is in a hexagonal arrangement. So, it is unsurprising that we find these group of gannets nesting on a beach in Muriwai, New Zealand forming a largely hexagonal pattern.
Figure 1: When neighbours keep their distance: gannets nesting at Muriwai Beach, New Zealand. The image on the left shows the overall hexagonal ordering of the birds while that on the right shows a penta-hepta defect (PHD). The green (pink) markers identify gannets with five (seven) neighbours instead of the usual six. Photo credit: Barbora Knobloch. Adapted from [1].
Patterns are rarely perfect and defects arise due to many factors such as boundary conditions (e.g. cliff edge), fluctuations in the background (e.g. unevenness in the ground), etc. A generic defect that arises in such hexagonal patterns is highlighted in the right panel of the picture of the gannets. Normally each gannet will have six neighbours, but here we see that the gannet marked with a green dot has only five neighbours while the gannet marked with a pink marker has seven. Such a structure consisting of a bound state with one location having five neighbours and another location seven neighbours, instead of the usual six, is called a penta-hepta defect (PHD). Hexagonal arrangements are found in many areas of physics, from patterns formed in heated fluids, to self-assembled crystals formed in both hard materials (e.g. graphene) and soft materials (e.g. star-shaped polymers [2]). Equally prevalent in all such hexagonal arrangements is the possibility for PHDs.
Traditionally pattern formation techniques used to investigate defects use an amplitude-phase formulation, where a periodic pattern has a homogenous amplitude and a varying phase. The topological charge of a defect is calculated by integrating the phase around any closed curve enclosing the defect, and this quantity does not change when the defect moves. Topological defects [3] are associated with zeros of the amplitude (where the phase becomes undefined): these defects have non-zero topological charge and so they can only be eliminated or healed by interacting with another topological defect with opposite charge. On the other hand, non-topological defects, such as PHDs, have a well-defined phase everywhere (implying zero topological charge) and so were thought to be able to heal by themselves. However, if the defect has an internal structure it may persist as a result of frustration and get locked/pinned to the background periodic state: the gannets in the PHD in Figure 1 could re-arrange themselves to remove the defect, but to do so would involve all nearby gannets moving a little bit, so in practice they don't.
Figure 2: Coexisting equilibria with penta-hepta defects separating regions of hexagons with different orientations in the SH23 system [1]. All three states are dynamically metastable.
We explore such non-topological defects in the prototypical pattern forming Swift-Hohenberg model in our recent work [1], by adopting a different point of view and thinking of defects as spatially localised structures [4]. We focus on grain boundaries separating two-dimensional hexagon crystals at different orientations (shown in Figure 2): these grain boundaries are closed curves containing a ring of PHDs. Even with the parameters all the same, the model has many different stable configurations of these grain boundaries, and solution branches connected to each of these states form isolas that span a wide range of the model parameters, opening up multiple interesting questions about such defect states. Our results will also be applicable to understanding the role of grain boundaries in two dimensional solids such as graphene [5], in which defects play a crucial role near phase transition, i.e., melting [6], and in determining bulk properties of a material."
[1] Snaking without subcriticality: grain boundaries as non-topological defects, P. Subramanian, A. J. Archer, E. Knobloch and A. M. Rucklidge, arXiv:2011.08536, 2020.
[2] Two-dimensional crystals of star polymers: a tale of tails, I. Bos, P. van der Scheer, W. G. Ellenbroek and J. Sprakel, Soft Matter, 15, 615-622, 2019.
[3] The topological theory of defects in ordered media, N. D. Mermin, Rev. Mod. Phys., 51, 591-648, 1979.
[4] Spatial localisation in dissipative systems, E. Knobloch, Annu. Rev. Condens. Matter Phys., 6, 325-359, 2015.
[5] Energetics and structure of grain boundary triple junctions in graphene, P. Hirvonen, Z. Fan, M. M. Ervasti, A. Harju, K. R. Elder and T. Ala-Nissila, Sci. Rep., 7, 1-14, 2017.
[6] Melting of graphene: from two to one dimension, K. V. Zakharchenko, A, Fasolino, J. H. Los and M. I . Katsnelson, J. Phys.: Condens. Matter, 23, 202202, 2011.
The launch of the Oxford Online Maths Club
Happy New Year! 2021 has a lot to make up for after 2020, so we're starting with a bang with the launch of the Oxford Online Maths Club, a new weekly maths livestream from Oxford Mathematics.
The Club provides free super-curricular maths for ages 16-18. It is aimed at people about to start a maths degree at university or about to apply for one. We'll be livestreaming one hour of maths problems, puzzles, mini-lectures, and Q&A, and we'll be exploring links between A level maths and university maths with help from our Admissions Coordinator James Munro and our current Oxford Mathematics students. And you get to ask questions and share thoughts and feelings with like-minded mathematicians.
In a nutshell, it's free, interactive, casual, and relaxed, with an emphasis on problem-solving techniques, building fluency, and looking ahead at links to university maths. The Club follows in the footsteps of James's hugely popular weekly MAT (Mathematics Admissions Test) sessions where he went thorough entrance problems and took live questions.
Whether you're the only person you know interested in maths, or you're an entire sixth-form maths club looking for more content, we're here for you in 2021! Join us every Thursday 16:30 starting this Thursday, 7 January.
Please contact us for feedback and comments about this page. Last update on 1 January 2021 - 16:52.
Peter Michael Neumann OBE (28 December 1940 - 18 December 2020)
We are very sad to hear the news of the death of Peter Neumann earlier today. Peter was the son of the mathematicians Bernhard Neumann and Hanna Neumann and, after gaining a B.A. from The Queen's College, Oxford in 1963, obtained his D.Phil from Oxford University in 1966.
Peter was a Tutorial Fellow at The Queen's College, Oxford and a lecturer in the Mathematical Institute in Oxford, retiring in 2008. His work was in the field of group theory. He is also known for solving Alhazen's problem in 1997. In 2011 he published a book on the short-lived French mathematician Évariste Galois.
In 1987 Peter won the Lester R. Ford Award of the Mathematical Association of America for his review of Harold Edwards' book Galois Theory. In 2003, the London Mathematical Society awarded him the Senior Whitehead Prize. He was the first Chairman of the United Kingdom Mathematics Trust, from October 1996 to April 2004 and was appointed Officer of the Order of the British Empire (OBE) in the 2008 New Year Honours. Peter was President of the Mathematical Association from 2015-2016.
Please contact us for feedback and comments about this page. Last update on 19 December 2020 - 00:09.
The Oxford Mathematics E-Newsletter - our quarterly round-up of our greatest hits
The Oxford Mathematics e-newsletter for December is out. Produced each quarter, it's a sort of 'Now That's What I Call Maths,' pulling together our greatest hits of the last few months in one place.
It's for anyone who wants a flavour of what we do - research, online teaching, public lectures, having a laugh.
And it's COVID-lite. Click here.
Full 2nd Year Oxford Mathematics Undergraduate course publicly available for the first time
Over the past few weeks we have made 7 undergraduate lectures publicly available, sampling a range of topics from Geometry to Differential Equations. Today & over the next 2 weeks for the first time we're showing a full course on our YouTube Channel. Ben Green's 2nd Year 'Metric Spaces' (the first half of the Metric Spaces and Complex Analysis course)' gets to grips with the concept of distance.
We are making these lectures available to give an insight in to life in Oxford Mathematics. All lectures are followed by tutorials where students meet their tutor in pairs to go through the lecture and associated worksheet. Course materials can be found here
Video of Oxford Mathematics 2nd Year Student Lecture: Metric Spaces - Lectures 1 & 2
Roger Penrose's Nobel Lecture and presentation of Prize
This Tuesday, 8th December, from 8am GMT onwards (repeated) you can watch 2020 Physics Laureate and Oxford Mathematician Roger Penrose's specially recorded Nobel Lecture in which he talks about the background to and genesis of his work on Black Holes which won him the prize; and also where our understanding of Black Holes is taking us.
On the same day Roger will be presented with the Nobel diploma and medal at the Swedish Ambassador's Residence in London and you can watch this as part of the Nobel Prize Awards Ceremony from 3.30pm GMT on Thursday 10 December. Watch both here.
As Roger said on receiving the news of the award: "In 1964 the existence of Black Holes was not properly appreciated. Since then they have become of increased importance in our understanding of the Universe and I believe this could increase in unexpected ways in the future."
Roger Penrose is one of our greatest living scientists. His work on Black Holes provided the mathematical tools needed by experimentalists to go and find Black Holes. His fellow prize winners, Andrea Ghez and Reinhard Genzel went and did just that.
However, Roger's work has ranged much further than just the Universe, from twistor theory to quasi-periodic tiling, spin networks to impossible triangles, a range that perhaps might not be so encouraged in academia today.
Now in his 90th year Roger is still researching and writing. He will give an Oxford Mathematics Public Lecture in January 2021 to celebrate the Nobel Prize.
Photography below and above by Professor Alain Goriely. Updated photographs further below of Roger receiving the Nobel Medal and Diploma from the Swedish Ambassador in London on 8 December.
Our latest Online Student Lecture - 2nd Year Linear Algebra
The latest in our Autumn 2020 series of lectures is the first lecture in Alan Lauder's Second Year Linear Algebra Course. In this lecture Alan (with help from Cosi) explains to students how the course will unfold before going on to talk specifically about Vector Spaces and Linear Maps.
All lectures are followed by tutorials where students meet their tutor in pairs to go through the lecture and associated worksheet. The course materials and worksheets can be found here.
That's Cosi on the left.
Video of Oxford Mathematics 2nd Year Student Lecture: Linear Algebra - Vector Spaces and Linear Maps
Please contact us for feedback and comments about this page. Last update on 22 November 2020 - 21:44.
Numerically solving parametric PDEs with deep learning to break the curse of dimensionality
Oxford Mathematician Markus Dablander talks about his collaboration with Julius Berner and Philipp Grohs from the University of Vienna. Together they developed a new deep-learning-based method for the computationally efficient solution of high-dimensional parametric Kolmogorov PDEs.
"Kolmogorov PDEs are linear parabolic partial differential equations of the form \begin{equation*} \label{kol_pde_intro} \tfrac{\partial u_\gamma }{\partial t} = \tfrac{1}{2} \text{Trace}\big(\sigma_\gamma [\sigma_\gamma ]^{*}\nabla_x^2 u_\gamma \big) + \langle \mu_\gamma , \nabla_x u_\gamma \rangle, \quad u_\gamma (x,0) = \varphi_\gamma(x). \end{equation*} The functions \begin{equation*}\varphi_\gamma : \mathbb{R}^d \rightarrow \mathbb{R} \quad \text{(initial condition)}, \quad \sigma_\gamma : \mathbb{R}^d \rightarrow \mathbb{R}^{d \times d}, \quad \mu_\gamma : \mathbb{R}^d \rightarrow \mathbb{R}^{d} \quad \text{(coefficient maps)}, \end{equation*} are continuous, and are implicitly determined by a real parameter vector $\gamma \in D $ whereby $D$ is a compact set in Euclidean space. Equations of this type represent a broad class of problems and frequently appear in practical applications in physics and financial engineering. In particular, the heat equation from physical modelling as well as the widely-known Black-Scholes equation from computational finance are important special cases of Kolmogorov PDEs.
Typically, one is interested in finding the (viscosity) solution \begin{equation*} u_\gamma : [v,w]^d \times [0,T] \rightarrow \mathbb{R} \end{equation*} of a given Kolmogorov PDE on a predefined space-time region of the form $[v,w]^{d} \times [0,T]$. In almost all cases, however, Kolmogorov PDEs cannot be solved explicitly. Furthermore, standard numerical solution algorithms for PDEs, in particular those based on a discretisation of the considered domain, are known to suffer from the so-called curse of dimensionality. This means that their computational cost grows exponentially in the dimension of the domain, which makes these techniques unusable in high dimensions. The development of new, computationally efficient methods for the numerical solution of Kolmogorov PDEs is therefore of high interest for applied scientists.
We were able to develop a novel deep learning algorithm capable of efficiently approximating the solutions $(u_\gamma )_{\gamma \in D}$ of a whole family of potentially very high-dimensional $\gamma$-parametrised Kolmogorov PDEs on a full space-time region. Specifically, our proposed method allows us to train a single deep neural network \begin{equation*} \Phi\colon D \times [v,w]^d \times [0,T] \rightarrow \mathbb{R} \end{equation*} to approximate the parametric solution map \begin{align*} \label{eq:gen_sol_map} \bar{u} : D \times [v,w]^d \times [0,T] \rightarrow \mathbb{R}, \quad (\gamma, x, t) \mapsto \bar{u}(\gamma, x, t) := u_\gamma (x,t), \end{align*} of a family of $\gamma$-parametrized Kolmogorov PDEs on the generalised domain $D \times [v,w]^d \times [0,T]$. The key idea of our novel algorithm is to reformulate the parametric solution map $\bar{u}$ of the $\gamma$-parametrized Kolmogorov PDE as the regression function of an appropriately chosen supervised statistical learning problem. This reformulation is based on an application of the so-called Feynman-Kac formula, which links the theory of linear parabolic PDEs to the theory of stochastic differential equations via $$ \bar{u}(\gamma,x,t) = \mathbb{E}[\varphi_{\gamma}(S_{\gamma,x,t})]. $$ Here $S_{\gamma,x,t}$ is the solution of an associated $\gamma$-parametrised stochastic differential equation with starting point $x$ at time $t$: $$ dS_{\gamma,x,t} = \mu_\gamma (S_{\gamma,x,t}) dt + \sigma_\gamma (S_{\gamma,x,t}) dB_t, \quad S_{\gamma,x,0} = x. $$ The resulting stochastic framework can be exploited to prove that $\bar{u}$ must be the solution of a specifically constructed statistical learning problem. Realisations of the predictor variable of this learning problem can be simulated by drawing uniformly distributed samples of the domain $(\gamma_i, x_i, t_i) \in D \times [v,w]^d \times [0,T]$ while realisations of the dependent target variable can be generated by simulating realisations $\varphi_{\gamma_i}(s_{\gamma_i, x_i, t_i})$ of $\varphi_{\gamma_i}(S_{\gamma_i, x_i, t_i})$. Thus, a potentially infinite amount of independent and identically distributed training points can be simulated by solving for $S_{\gamma_i, x_i, t_i}$ via simple standard numerical techniques such as the Euler-Maruyama scheme. The simulated predictor-target-pairs $((\gamma_i, x_i, t_i) ,\varphi_{\gamma_i}(s_{\gamma_i, x_i, t_i}))$ can then be used to train the deep network $\Phi$ to approximate the solution $\bar{u}.$ An illustration of this training workflow is depicted in the figure below.
We mathematically investigated the approximation and generalisation errors of our constructed learning algorithm for important special cases and discovered that, remarkably, it does not suffer from the curse of dimensionality. In addition to our theoretical findings, we were able to also observe numerically that the computational cost of our our proposed technique does indeed grow polynomially rather than exponentially in the problem dimension; this makes very high-dimensional settings computationally accessible for our method.
Our work was accepted for publication at the 2020 Conference on Neural Information Processing Systems (NeurIPS). A preprint can be accessed here.
Below is a picture of the Multilevel architecture we used for our deep network $\Phi$ (click to enlarge)."
Generalising Leighton's Graph Covering Theorem
Oxford Mathematician Daniel Woodhouse talks about the theorem that motivates much of his research.
"According to lore, denizens of the Prussian city of Königsberg would spend their Sunday afternoons wandering the streets. From this pastime came a puzzle - could a wanderer cross each of the city's seven bridges without crossing the same bridge twice? The path of the River Pregel divides the city into four distinct regions, including a central isolated island, so the question was more complicated than a matter of crossing back and forth from one side of a river to the other.
If a positive solution existed, then someone would surely have found it, so it could be guessed that the answer was negative. In principle, you could write down an exhaustive list of all possible sequences of bridge crossings, but this would be a very crude kind of proof. The problem eventually came to the attention of Leonhard Euler, who set about finding an explanation that offered more insight into the nature of the problem. In 1736 Euler wrote up his solution, providing arguments that not only applied to the bridges of Königsberg, but to any arrangement of rivers and bridges. Initially, it seems from his correspondence that Euler was inclined to dismiss the intellectual merits of the problem, not regarding it as mathematical at all. But in the introduction of his paper he declares it to belong to a kind of mathematics only previously speculated: the geometry of position ("Geometriam situs''). Today this kind of mathematics is better known as topology.
The kind of mathematics that Euler would have been familiar with - geometry - concerned notions of distance, area, and angles. Yet considering the problem of the bridges from a purely mathematical point of view, such quantities become irrelevant. The exact shape that the river takes and the distance between bridges are relevant to the individual planning on spending an afternoon walking over them, but less so to the mathematician. Indeed, the relevant information can be reduced to a list of the distinct land masses, and the bridges they connect. In modern terminology the problem can be redrawn as a graph:
Each land mass is now represented by a vertex and each bridge is now an edge joining the corresponding vertices. We might say that the graph is topologically equivalent to the original diagram of the river and the bridges. I have labelled the vertices according to how Euler labelled them in his previous diagram. I have also added arrows indicating an orientation of the edges. Graphs are now ubiquitous in mathematics and science, and topology is only one perspective of study. You should not equate the graph with the way that it has been drawn above. The same graph could be drawn in many ways:
Let us now move on from Euler's problem and take the topological perspective one step further. We imagine the wanderer of the city is now a wanderer of our graph instead. They travels from vertex to vertex via the edges. Suppose that our wander has no map of the world they are living in. That is to say the wanderer has no idea what graph they are wandering around; whichever vertex they have arrived at, all they can see are the edges immediately connected to the vertex on which they stand. They can remember the route that they travelled to get there, but no more. Frustratingly, since we are now in a graph, and not the city of Königsberg, there are no landmarks with which the wanderer can orient themselves. If they return to a vertex they have no way of knowing. As we look down on our wanderer we can see exactly where they are, while they remain completely unaware. We can also take a look at the graph as they imagine it:
In the wanderer's imagination, how do they envision the graph? Since they never know if they have arrived at a vertex they have previously visited (without doubling back on themselves) this graph cannot contain any closed cycles - a path the begins and ends at the same vertex without repeating any other edge or vertex. A graph that does not contain any closed cycles is called a tree.
This tree, let's call it $\widetilde X$, is labelled in the picture according to which edge in $X$ it really corresponds to. These labels are invisible to our wanderer - if the labels were known then they could deduce what graph they were wandering about on. There is one particularly important vertex in $X$ and $\widetilde{X}$: the point at which our wanderer begins their journey, which we call the basepoint. This mapping between the graph $X$ and the universal cover $\widetilde X$ is usually written as a function $\widetilde X \rightarrow X$. The important feature here is that given a path that our wanderer takes in $X$, we can track the path they imagine they are taking in $\widetilde X$. Conversely, given a path in $\widetilde X$, using the labelling that only we can see, we can deduce the path that our wanderer has taken in $X$.
It is impossible for our wanderer to deduce what the graph $X$ is from $\widetilde X$. This is because $X$ isn't the only graph with universal cover $\widetilde X$. Setting aside Königsberg for a moment, consider the following graphs:
These graphs are obviously distinct, just by counting the vertices. But to a wanderer of these graphs, all they know is that whatever edge they choose to wander down, they will arrive at a vertex incident to precisely three edges. Wherever they go, the world to them looks exactly the same. There is no way for them to deduce if they are living in $X_1$, $X_2$, or $X_3$. Another way to say this is that $X_1$, $X_2$, and $X_3$ have the same universal cover $T_3$ - the 3-valent tree.
This isn't all that our wanderer could imagine. In principle they could try imagining that they are wandering around any graph we like. But that imagined graph should at least be consistent with what they actually experience. You can't arrive at a vertex with three incident edges but imagine there are four incident edges - that would present a contradiction to our wanderer and the illusion would be ruined. As a simple example, consider the reverse situation to the above: suppose our wanderer imagines they are navigating the Königsberg graph $X$, but in reality they are inside $\widetilde X$:
Provided that the basepoints match up as before, the wanderer would encounter no contradiction between what they are imagining and what they actually experience. But the situation would be particularly deceptive: as depicted above, our wanderer could imagine that they had walked a closed loop, when in fact they had not. This misconception is particularly bad for topologists, so we rule them out. Imagined graphs that do not cause the misconception are called covers, and there exist many of them aside from the universal cover. This definition for a cover is quite confusing, which is why we usually work with an equivalent and more practical condition in terms of labelling the edges of the cover according to the corresponding edges in the original graph. For example:
Note also that the cover given above is finite, while the universal cover is infinite. Unless the graph $X$ is itself a tree, the universal cover will always be infinite. Indeed, if $X$ is not a tree, then there is a closed cycle that our wanderer can walk around indefinitely, quite unaware that they are trapped in a closed loop.
A large part of my research is focused on the the following theorem:
Theorem: Let $X_1$ and $X_2$ be finite graphs that have the same universal cover. Then they have a common finite cover.
Here is a picture of two wanderers living on two graphs with the same universal cover, imagining that they are living on a common cover:
This theorem was conjectured in an 1980 paper by the computer scientist Dana Angluin. Angluin was interested in distributed systems, which you can imagine as being a graph with a computer at each vertex and each edge corresponding to a 'port' connecting the neighbouring computers, allowing them to communicate. If this picture seems familiar that is because the internet is an example. The first complete proof of this theorem was given in a 1982 paper by Frank Thomas Leighton. Leighton is also a computer scientist and most of his research in graph theory was closely related to similar applications in computer science. The kind of problems that concerned Angluin and Leighton more closely resemble the kind of problem that Euler was considering than my own research. On the strength of the insights graph theory offers, Leighton co-founded Akamai Technologies in 1998, and today they are one of the internet's largest content delivery networks. He also retains an affiliation as a professor of applied mathematics at MIT and I have been told he still teaches an occasional course (I have the same teaching obligations as a billionaire, it turns out).
My own research has involved applying Leighton's theorem to the field of geometry and topology. Leighton's original proof was very much the argument of a computer scientist, and finding a new proof that offered a different theoretical framework has allowed me to solve previously unapproachable problems. There are two goals: the first is to generalise the theorem to higher dimensional topological spaces; and the second is to apply the generalisations to topological spaces or groups that decompose into a graph like structure. For example, in a recent preprint with fellow Oxford Mathematician Sam Shepherd we are able to prove quasi-isometric rigidity for a large family of hyperbolic groups. There are close connections to the theory of $3$-manifolds, their JSJ decompositions, and the recent resolution of the virtual Haken conjecture. In particular I believe that the right setting to generalise Leighton's theorem is special cube complexes." | CommonCrawl |
CRlncRC: a machine learning-based method for cancer-related long noncoding RNA identification using integrated features
Xuan Zhang1,2 na1,
Jun Wang1,3 na1,
Jing Li1 na1,
Wen Chen1 &
Changning Liu1
BMC Medical Genomics volume 11, Article number: 120 (2018) Cite this article
Long noncoding RNAs (lncRNAs) are widely involved in the initiation and development of cancer. Although some computational methods have been proposed to identify cancer-related lncRNAs, there is still a demanding to improve the prediction accuracy and efficiency. In addition, the quick-update data of cancer, as well as the discovery of new mechanism, also underlay the possibility of improvement of cancer-related lncRNA prediction algorithm. In this study, we introduced CRlncRC, a novel Cancer-Related lncRNA Classifier by integrating manifold features with five machine-learning techniques.
CRlncRC was built on the integration of genomic, expression, epigenetic and network, totally in four categories of features. Five learning techniques were exploited to develop the effective classification model including Random Forest (RF), Naïve bayes (NB), Support Vector Machine (SVM), Logistic Regression (LR) and K-Nearest Neighbors (KNN). Using ten-fold cross-validation, we showed that RF is the best model for classifying cancer-related lncRNAs (AUC = 0.82). The feature importance analysis indicated that epigenetic and network features play key roles in the classification. In addition, compared with other existing classifiers, CRlncRC exhibited a better performance both in sensitivity and specificity. We further applied CRlncRC to lncRNAs from the TANRIC (The Atlas of non-coding RNA in Cancer) dataset, and identified 121 cancer-related lncRNA candidates. These potential cancer-related lncRNAs showed a certain kind of cancer-related indications, and many of them could find convincing literature supports.
Our results indicate that CRlncRC is a powerful method for identifying cancer-related lncRNAs. Machine-learning-based integration of multiple features, especially epigenetic and network features, had a great contribution to the cancer-related lncRNA prediction. RF outperforms other learning techniques on measurement of model sensitivity and specificity. In addition, using CRlncRC method, we predicted a set of cancer-related lncRNAs, all of which displayed a strong relevance to cancer as a valuable conception for the further cancer-related lncRNA function studies.
Cancers are multi-factor complicated diseases, and primarily triggered by genetic alteration and gene-regulatory-network disorder under various environmental irritations [1]. Increasing evidence showed that long non-coding RNAs (lncRNAs), a class of transcripts with a very low protein-coding potential and length more than 200 bp, could widely participate in the occurrence and progression of multiple cancers, with the capability to perturb the cellular homeostasis potentially by remodeling chromatin architecture or regulating the transcriptional outcomes [2,3,4,5,6]. Recent rapid development of next-generation sequencing has promoted the detection of thousands of expression profiles between pairs of cancer and regular transcriptomes, revealing that there were many aberrant lncRNAs emerged in the course of cancer occurrence and development [7,8,9]. However, for the vast majority of them, it is hard to distinguish which are functioning or what their potential roles in cancers, due to the low expression level, poor conservation, uncertain mutation mode, and diverged tissue specificity. Therefore, it is imperative to develop systematic and bioinformatics tools for further predicting and exploring the possible functions of lncRNAs in cancer.
Recently, several methods have been designed to identify potential cancer-related lncRNAs. For example, Zhao et al. developed a naïve-Bayesian-based classifier to identify cancer-related lncRNAs by integrating both genome, regulome and transcriptome data, and identified 707 potential cancer-related lncRNAs [10]. They also found that four of six mouse orthologous lncRNAs were significantly involved in many cancer-related processes, based on 147 lncRNA knockdown data in mice. Lanzós Andrés et al. conceived a tool (ExInAtor) to identify cancer driver lncRNA genes with an excess load of somatic single nucleotide variants (SNVs) and consequently found 15 high-confidence candidates: 9 novel and 6 known cancer-related lncRNA genes [11]. However, this kind of studies is still at infancy, and would be bound to a measure of limitations in the aspects of accuracy and sensitivity. For example, ExInAtor that aimed at discovering driver lncRNAs in cancer was subjected to the likelihood of losing the prediction sensitivity, as mentioned by themselves. Therefore, different algorithms of the classification model should be developed reasonably, and important features should be further explored systematically, in order to advance the sensitivity and accuracy when we are seeking the cancer-related lncRNAs.
Besides, some cancer-related features of lncRNAs are necessary for the purpose of distinction. Apparently, the ordinary differential expression analysis between pairs of cancerous and normal tissue could not favor the prediction requirements, due to the high false positive rate. Hence, other features of lncRNAs (like genomic location, tissue specialty, exon mutation frequency, somatic single nucleotide variants, co-expression relationships between lncRNAs and protein-coding genes, etc.) were integrated into the computational analysis to better discriminate the cancer-related lncRNAs from the negative ones. However, mining these features is also a gradually evolutional process. For example, Chen. et al. found broad H3K4me3a was associated with increased transcription elongation and enhancer activity of tumor suppressor genes [12], implying that some epigenetic features could be added into cancer-related lncRNAs' identification.
Here, we developed a compounded computational method, CRlncRC, to predict cancer-related lncRNAs. CRlncRc was based on five machine learning models, including Random Forest (RF), Naïve bayes (NB), Support Vector Machine (SVM), Logistic Regression (LR) and K-Nearest Neighbors (KNN). Beyond that, CRlncRC was built on the integration of four categories of features (i.e. genomic, expression, epigenetic and network), more lncRNA's features were introduced into our analysis to enhance the prediction sensitivity. We demonstrated that our integrative method significantly improves the accuracy of identification of cancer-related lncRNAs, as compared with some previous methods. RF model outperforms other learning models on measurements of model sensitivity and specificity. We also showed that machine learning-based integration of multiple features had a great contribution to the cancer-related lncRNA prediction, wherein epigenetic and genomic features play key roles in the classification. Next, we used CRlncRC method to predict a set of cancer-related lncRNAs from the TANRIC dataset. These novel cancer-related candidates were further evaluated by somatic mutation number in cancer genome, distance with the cancer-related proteins, differential expression fold change in tumor and normal tissues, and GO enrichment analysis. The results indicated that the predicted set have a strong cancer correlation, many of which could find convincing literature supports. We believed that these fresh cancer-related lncRNAs would be a valuable starting point for the further cancer-related lncRNA functional study.
Overview of CRlncRC
An integrated machine-learning pipeline was designed and designated as CRlncRC (Cancer-Related lncRNA Classifier). The pipeline was shown in Fig. 1.
A systematic overview of the CRlncRC. A work frame of CRlncRC (cancer-related lncRNA classifier) for predicting and characterizing novel cancer-related lncRNA candidates in human
Firstly, in order to increase the precision of predictions, we strictly selected the positive and negative collection for training. The positive dataset consisted of 158 experimentally-validated cancer-related lncRNAs curated from the scientific literature (Additional file 1); while the negative was randomly sampled from long intergenic noncoding RNAs whose 10 kb upstream and downstream had no cancer-related SNPs (in total 4553 lncRNAs, Additional file 2), repeatedly 100 times. For lncRNAs from each dataset, we constructed four categories of features including genomic, expression, epigenetic and network (Additional file 3).
Second, to evaluate the performance of different machine-learning algorithms, we used five popular algorithms, including Random Forest (RF), Naïve bayes (NB), Support Vector Machine (SVM), Logistic Regression (LR) and K-Nearest Neighbors (KNN), to proceed with ten-fold cross-validation in 100 training datasets. For each test, the receiver operating characteristic curves (ROCs) were calculated, and the average area under the ROC curve (AUC) was used to assess the best performance for each algorithm in 100 training sets. For the best performance model, we further compared it with other existing cancer-related lncRNA classifiers in terms of performance, and evaluated the weightiness of four categories of features contributing to cancer-related classification.
At last, we managed to use the best performance model to predict novel cancer-related lncRNAs. Here, we adopted all lncRNAs from the TANRIC dataset (Additional file 4), which were completely separate from our positive and negative datasets, to examine the prediction performance of CRlncRC. For these novel cancer-related candidates, we utilized genome-wide data to assess the probability of their associations with cancer, which include their enrichment of somatic mutations in cancer genome, distance with the cancer-related proteins, differential expression fold-change between pairs of tumor and normal tissues, and GO enrichment analysis. In addition, we also inspected the potent experimental supports from literature.
Cross-validation accuracy
We used ten-fold cross-validation to evaluate the model accuracy. As shown in Fig. 2a, RF, NB, SVM, LR and KNN achieved average AUC scores of 0.82, 0.78, 0.79, 0.76 and 0.68, respectively. Apparently, there are four models achieving an average score of AUC more than 0.75 except that of KNN, wherein RF model shows the best performance. We next checked the resulting accuracy of RF classifier when we used only one category of features. As shown in Fig. 2b, training RF model with epigenetic, expression, network and genomic features, our model achieved AUC scores of 0.76, 0.73, 0.76 and 0.73, respectively. So, using RF model, any feature solely could gain an average AUC score of > 0.7, much less an extra 6–9% AUC score when combining all the features. No single category of feature could achieve the top performance as that of united features, which strongly suggests the complementary nature between features and the advantage of integrative approaches. In addition to AUC value, more evaluation indicators were used to assess our results such as precision, recall, accuracy, and AUC confidence interval (Additional file 5). In order to perform a comprehensive analysis of the effect of features on model's performance, we also compared two types of features and three types of features (Additional file 6).
Prediction performance of ten-fold cross-validation. a Comparison between the performance of five machine learning methods. b Comparison between the performance of RF corresponding to individual types of features and all features
The contribution of features to identify cancer-related lncRNAs
To better comprehensively understand the significance of features to identification of the cancer-related lncRNAs, we used ExtraTreeClassifier [13] in scikit-learn package as a measurement for further evaluating the hierarchies of all features in terms of importance (Fig. 3) (Additional file 3). Here, we summarized the amount of four categories of features located in Top10/20/50 feature importance list (Fig. 3a). In the Top10 features, four features are pertinent to genomic features, epigenetic and network features each have three positions. However, as respects of the Top20 and Top50 features, the first and the second occupancy among features belong to epigenetic (9 in Top20 and 18 in Top50) and network features (7 in Top20 and 14 in Top50), respectively. It surprised us that no expression features emerged in the Top10 and Top20 features, which only occupy 8 locations in the Top50 features, indicating that expression features are still necessary though less important than other types of features. The fact that lncRNA expression always had a strong tissue specificity with a relatively low level might explain the less importance of expression-related features on cancer-related lncRNAs prediction.
Feature importance. a The distribution of four feature categories (genomic, epigenetic, network, and expression) in top 10, top 20, and top 50 features. b The rank of top 9 features (genomic, epigenetic, network, expression features colored in green, blue, yellow, and red, respectively)
We calculated the cumulative distribution and corresponding Kolmogorov-Smirnov test p-value of all the features in the positive and negative lncRNA datasets (Additional file 7). Figure 3b and Fig. 4 showed the top nine features sorted by importance, and their corresponding cumulative distribution in the positive and negative datasets. Interestingly, 'SINE (Short interspersed nuclear element) numbers in gene body' was the most important feature. The cumulative curve also showed that cancer-related lncRNAs have obviously higher SINE numbers than cancer-unrelated lncRNAs (Fig. 4a, p-value = 5.3e-05). LINE (Long interspersed nuclear element) was another example of the repeats which contributes to the classifier. 'LINE numbers in gene body' ranks the No.8 in all of the features. Similar with SINE, we found that cancer-related lncRNAs have obviously higher LINE numbers than cancer-unrelated lncRNAs (Fig. 4h, p-value = 0.00086). We further compared the length distribution of positive and negative lncRNAs, and found that these two distributions only have slight difference (Additional file 8). Our results implied that repeat element might be an important functional element for lncRNAs and widely participant in the cancer-related process, which is consistent with a lot of published researches. For example, Alu is a subtype of SINE and has been implicated in several inherited human diseases and in various forms of cancers; and, LINE can activate immune responses and contribute to disease progression [14, 15], as well as potentially affect chromatin formation [16].
Cumulative percentage comparisons (Kolmogorov-Smirnov test) of the top 9 features between the positive and negative lncRNAs. a SINE number in gene body. b Average H1hescH3K4me1 signal in gene body. c Spearman's correlation coefficient with ERBB2. d GC content of intron. e Spearman's correlation coefficient with CTNNB1. f Average H1hescH3K4me3 signal in gene body. g Conservation level computed using PhastCons applied to the 20-way whole-genome in the exon. h LINE number in gene body. i Spearman's correlation coefficient with CDKN2A
Apart from the repeat, there are other two genomic-related features in the top nine features: 'intron GC content' and 'exon phastCons score'. Compared with lncRNAs from negative dataset, the introns in cancer-related lncRNAs have a relatively higher GC content (Fig. 4d, p-value = 0.014). The GC content was related to the stability of gene and regulation and might have played a significant role in the evolution [17]. Besides, the composite patterns of GC content between intron and exon would likely affect gene splicing [18, 19]. These facts hinted the relationship between 'intron GC content' and cancer-related lncRNA. Moreover, the exon sequences in cancer-related lncRNAs showed obviously higher conservation than negative set, implying that cancer-related lncRNAs may undergo evolutionary pressure for maintaining some important functions relevant to normal cell behavior (Fig. 4g, p-value = 7.5e-05).
In the top nine features, two epigenetic features ranked at NO.2 and No.6, they are "H3k4me1" and "H3k4me3" epigenetic modification signals within lncRNA gene body region in H1hesc cell line, respectively. Both signals in positive dataset are significantly higher than the negative set (Fig. 4b, p-value = 1.7e-10; Fig. 4f, p-value = 4.3e-13). Epigenetic feature H3k4me3 are likely associated with the expression of cancer-related lncRNAs. High levels of H3K4me3 are often found near the promoter region, and commonly associated with the activation of transcription of nearby genes [20, 21]. A broad H3K4me3 is associated with increased transcription elongation and enhancer activity at tumor-suppressor genes [12]. While H3K4me1 is usually found in intergenic region with enrichment at enhancers [22]. Recent studies have demonstrated that many enhancer elements can be transcribed into a novel class of lncRNAs, enhancer RNAs (eRNAs) [23,24,25]. These eRNAs could exert cancer-related functions through their associated enhancers, as in the case of eRNAs from p53-bound enhancer region that are required for p53-dependent enhancer activity and gene transcription [26]. On the other hand, the fact that these two histone modification related features listed in top 9 features are associated with H1hesc cell line, instead of Gm12878 and K562 cell lines, indicated that the effects of histone modifications to cancer-related lncRNAs might have tissue/cell type-specificity.
Consistent with the other papers, the cancer-related lncRNAs tend to be more likely interacted with cancer-related proteins. In the top nine features, network features ranked the position of No.3, No.5 and No.9. The lncRNAs in the positive set displayed more strongly co-expression with ERBB2, CTNNB1 and CDKN2A than the negative set (Fig. 4c, p-value = 4.6e-10; Fig. 4e, p-value = 6.6e-08; Fig. 4i, p-value = 4.4e-07). Wherein, ERBB2 was found associated with Glioma Susceptibility 1 and Lung Cancer; CTNNB1 is part of a complex of proteins that constitute adherens junctions, mutations in CTNNB1 are a cause of colorectal cancer, pilomatrixoma, medulloblastoma, and ovarian cancer; while CDKN2A (i.e. p16) is frequently mutated or deleted in a wide variety of tumors and is known to be an important tumor suppressor gene.
Comparison with other cancer-related lncRNA prediction algorithms
We used ten-fold cross-validation to compare the prediction performance of our CRlncRC with that of the other two developed prediction algorithms as mentioned in Background. Considering that the latter two developed early and were comprised of relatively small-scale datasets (for example, Zhao et al. collected 70 cancer-related lncRNAs as positive dataset, while Lanzós Andrés et al. collected 45 cancer-related lncRNAs as positive dataset), for fairness, we applied their datasets for retraining our RF model rather than our own well-established model.
As shown in Fig. 5a, the AUC score of our method reached 0.85, much higher than 0.79 reported in Zhao's results. In the aspects of the feature choice, we adopted genomic, network, expression, and epigenetic (totally four categories of features) in our model, while Zhao et al. selected three features of genome, regulome and transcriptome in their prediction model. This result suggested that the newly introduced epigenetic features in CRlncRC, which not include in Zhao's study, may have a great contribution to the classification between cancer-related lncRNAs and cancer-unrelated lncRNAs. On the other hand, compared with the NB model used in Zhao's method, CRlncRC employed RF as its learning model after broad evaluation of five learning techniques, with a dominant consequence of performance enhancements.
Compare with other methods. a Comparison between the performance of CRlncRC and Zhao's method. b Comparison between the performance of CRlncRC and ExInAtor in BRCA and Superpancancer
A cancer driver gene is defined as one whose mutations increase net cell growth under the specific micro-environmental conditions that exist in the cell in vivo [27]. While a cancer-related lncRNA can be defined as it can promote or inhibits the growth of cancer cells through some mechanism [28]. To comprehensively discover the candidates of cancer driver lncRNAs, Lanzós Andrés et al. developed ExInAtor and run it on 23 tumor types. We choose 'BRCA' that is believed as the best tumor type of prediction in Lanzós Andrés's work and 'Superpancancer' to do the comparison, two of which respectively represent the type-specific and the ubiquitous cancer-related lncRNA gene discovery. As shown in Fig. 5b, our model had an obvious superiority against ExInAtor in both 'Superpancancer' (AUC score 0.78 vs. 0.53) and 'BRCA' (AUC score 0.88 vs. 0.57). These results suggested that ExInAtor is probably just perfect for finding cancer driver lncRNAs when considering of only one feature of genomic somatic mutation, but do not suit for the prediction of cancer-related lncRNAs.
Systematic evaluation of predicted novel cancer-related lncRNAs
We used CRlncRC to predict novel cancer-related lncRNAs from TANRIC lncRNA dataset (Additional file 4), which was completely separate from our positive and negative datasets. The 11,656 unknown lncRNAs were assessed by use of the best RF model we trained. In total, 121 cancer-related lncRNA candidates were identified (Additional file 9), including 55 antisense lncRNAs, 57 intergenic lncRNAs and 9 overlapping lncRNAs. For these novel cancer-related candidates, we further utilized genome-wide data to systematically evaluate the probability of their associations with cancer. For that purpose, three types of lncRNA set were applied to our analysis, including cancer-related lncRNAs (positive), cancer-unrelated lncRNAs (negative), and predicted novel cancer-related lncRNAs (predict).
First, we assumed that these potential cancer-related lncRNAs were likely to have more somatic mutations in cancer genomes, since many previous studies had demonstrated that mutation in function genes is a main cause of cancer induction. To validate the assumption, we made a comparison of the number of somatic mutations (documented in COSMIC) between different lncRNA sets and cancer-related protein set (Fig. 6a). As a result, cancer-related protein set as the positive control possessed far more somatic mutations than cancer-unrelated lncRNA set, which is the negative control (Kolmogorov-Smirnov test, p-value = 6.10e-33). The somatic mutation numbers in both positive and predicted cancer-related lncRNA sets are between cancer-unrelated lncRNAs and cancer-related proteins, with a significant higher quantities than that of cancer-unrelated lncRNAs (Kolmogorov-Smirnov test, p-value 2.35e-07 and 3.25e-06 respectively).
Validation of our novel cancer-related lncRNAs candidates. a Cumulative distribution of mutation number. b Cumulative distribution of the closest distance to cancer-related proteins. c Bar plot of the percentage of differential expression lncRNAs. d The Top 10 GO BP terms of cancer-related lncRNA candidates (Fisher's exact test)
Because a number of lncRNAs exert their function in cis to influence their neighboring genes, we assumed that these potential cancer-related lncRNAs likely have a closer distance with cancer-related proteins by comparison of cancer-unrelated lncRNAs. Therefore, we calculated the distance of different lncRNA sets to their closest cancer-related proteins, and compared it with the random background (that is the distance between cancer-related proteins and random positions in genome) (Fig. 6b). We found that the distances between cancer-unrelated lncRNAs and cancer-related proteins are significantly larger than that between cancer-related lncRNAs and cancer-related proteins (Kolmogorov-Smirnov test, p-value = 0.00041). Similarly, the distance of predicted cancer-related lncRNAs to cancer-related proteins is far closer than to cancer-unrelated lncRNAs (Kolmogorov-Smirnov test, p-value = 0.00116). Moreover, no significant difference was detected between background and cancer-unrelated lncRNAs set, as expected.
Next, we examined whether it is possible that the expression levels of cancer-related lncRNAs in cancer have a more marked change as compared with that of cancer-unrelated lncRNAs (Fig. 6c). By using lncRNA expression data from TANRIC database, we calculated the percentage of lncRNA differential expressed between pairs of cancer and paracancerous tissues (lncRNAs with absolute log2-fold change greater than 1), to see if there is a difference among different lncRNA sets. We found that lncRNAs in positive set had the highest percentage of differential expressed genes (about 40%), while negative set only with about 20%. For those predicted cancer-related lncRNAs, over 28% of them showed differential expression. This result further supported our prediction products have an evident association with cancer, and also revealed that simple dependence on differential expression is far from enough for identification of cancer-related lncRNAs.
Finally, we investigated the GO (Gene Ontology) annotations of these cancer-related lncRNAs candidates. LncRNA's GO annotations were predicted according to the enriched GO terms of its neighboring proteins in the co-expression network. The Top10 (sorted by p-value, Fisher's exact test) enriched GO terms were listed in Fig. 6d. From the list, we can found that the functions of these cancer-related lncRNA candidates mainly focused on the following keywords: 1) 'RNA splicing', such as 'mRNA splicing, via spliceosome', 'RNA splicing, via transesterification reactions with bulged adenosine as nucleophile', and 'RNA splicing, via transesterification reactions'; 2) 'morphogenesis', such as 'cilium morphogenesis', 'cell projection morphogenesis', and 'cell part morphogenesis'; 3) 'immune', such as 'immune effector process' and 'regulation of immune system process'; 4) 'mRNA processing ', such as 'mRNA processing' and 'mRNA metabolic process'. These annotations revealed the potential action modes of cancer-related lncRNAs, which is consistent with many of the latest studies. For example, Simon et al. discovered that a bifunctional RNA, encoding both PNUTS mRNA and lncRNA-PNUTS, could mediate EMT and tumor progression when its splice switches from coding to noncoding transcript [29]. Musahl et al. found ncRNA-RB1 could positively regulate the expression of calreticulin (CALR) and sequentially activate anticancer immune responses [30].
Case study of the cancer-related lncRNA candidates
Besides utilizing genome-wide data to systematically evaluate these cancer-related lncRNA candidates, we also drilled down into some lncRNA cases. To our amazement, in the Top10 cancer-related lncRNA candidates in our prediction results, there are six predicted lncRNAs (NNT-AS1, TP53TG1, LINC01278, LRRC75A-AS1, MAGI2-AS3, EIF3J-AS1) to be found with literature supports. For example, lncRNA NNT-AS1 could promote cell proliferation and invasion through Wnt/β-catenin signaling pathway in cervical cancer [31] and contribute to proliferation and migration of colorectal cancer cells both in vitro and in vivo [32]. Besides, it can promote hepatocellular carcinoma and breast cancer progression through targeting miR-363/CDK6 axis [33] and miR-142-3p/ZEB1 axis [34], respectively. Another example is a p53-induced lncRNA TP53TG1, which is a newly identified tumor-suppressor gene and plays a distinct role in the p53 response to DNA damage. TP53TG1 hypermethylation in primary tumors is shown to be associated with poor outcome [35]. According the newest research findings, TP53TG1 participated in the stress response under glucose deprivation in glioma [36], and enhanced cisplatin sensitivity of non-small cell lung cancer cells through regulating miR-18a/PTEN axis [37].
Besides the lncRNAs mentioned above, another very interesting lncRNA -- UBR5-AS1 (UBR5 antisense RNA1) -- came into our view. UBR5-AS1 sits between two protein-coding genes (UBR5 and P53R2). The 3′ terminal sequence of UBR5 is partial antisense to UBR5, the latter is an oncogene in many cancers and contributes to cancer progression, cell proliferation [38, 39]. The 5′ end of UBR5-AS1 is positioned head-to-head (or divergent) to P53R2, which is believed to play essential roles in DNA repair, mtDNA synthesis and protection against oxidative stress, and has a positive correlation with drug sensitivity and tumor invasiveness [40]. Since a host of studies had demonstrated that lncRNAs often exert their function in cis to influence their neighboring genes, we have good reasons to believe that UBR5-AS1 is very likely to be associated with cancer. However, till now UBR5-AS1 has not been studied by researchers.
Figure 7a showed UBR5-AS1 and its neighbor region, with a variety of information about epigenetics, conservation and repeats (as visualized by UCSC genome browser). We can see that the shared promoter region between UBR5-AS1 and P53R2 had high H3K4me3 and H3K27Ac signals, which are normally associated with active transcription. On the other hand, although lncRNAs often show less conservation compared with protein-coding genes, the lncRNA UBR5-AS1 presented a much strong sequence conservation that is nearly comparable to the proteins of P53R2 and UBR5 (scoring by 100 vertebrates Basewise Conservation by PhyloP). This result suggested that UBR5-AS1 may undergo evolutionary pressure for maintaining some important functions. In addition, in the gene-body region of UBR5-AS1, a great number of SINE and LTR repeats were found, both of which had been extensively proved to be associated with lncRNA's regulatory function [41]. Next, we identified up to 20 cancer-related proteins co-expressed with UBR5-AS1 (Fig. 7b) and predicted the GO annotations of UBR5-AS1 via GO enrichment analysis (Fig. 7c), by using the co-expression sub-network centralized on UBR5-AS1. The Top10 (sorted by p-value, Fisher's exact test) enriched GO terms showed that UBR5-AS1 was functionally relevant with 'RNA splicing', 'leukocyte activation', 'immune system process' and so on. All these findings indicate that UBR5-AS1 underlines a highly potential cancer-related lncRNA and is worthy of more intensive study.
Characterization of lncRNA UBR5-AS1. a The gene structure, epigenetic, conservation and repeat features of UBR5-AS1 in UCSC genome browser. b The co-expression sub-network of UBR5-AS1. c The Top 10 GO BP annotations of UBR5-AS1 (Fisher's exact test)
Based on the consideration of massive outbreak of cancer transcriptome data and the need of identification of cancer-related lncRNAs, as well as the disadvantage of current prediction model, in this work, we developed a novel machine-learning-based classifier -- CRlncRC -- for cancer-related lncRNAs, with integrating multiple features and optimizing algorithms to enhance its prediction performance. According to our results, CRlncRC has a significant preponderance of prediction sensitivity and accuracy over some previous models. Moreover, by using CRlncRC method, we predicted a set of cancer-related lncRNAs, all of which displayed a strong relevance to cancer as indicated by somatic mutation number, distance with genes encoding cancer-related proteins, differential expression fold-change between pairs of tumor and normal tissues, and GO enrichment analysis. Consequently, our predicted cancer-related lncRNAs could be a valuable conception for further cancer-related lncRNA function studies.
Construction of the positive and negative lncRNA sets
We manually reviewed more than 2500 published literature (Additional file 10), and finally collected 158 cancer-related lncRNAs as the positive set (Additional file 1). Cancer-related lncRNAs complied with the following standards: the selected lncRNAs were either differentially expressed in cancer (as verified by qRT-PCR), co-occurred with a significant pertinence to clinicopathological parameters (e.g., tumor differentiation, clinical stage, survival time); or else, were proven by functional experiments (e.g., colony formation assay, matrigel invasiveness assay, xenograft mouse model, and metastasis nude mouse model) to participate in cancer development.
To create the negative set, we located a large number of SNPs derived from NHGRI-EBI GWAS Catalog [42] into the sequences of lncRNAs, and selected only those in which no SNP was detected within 10 kb range as cancer-unrelated lncRNAs. We finally obtained 4553 lncRNAs as the negative set (Additional file 2). Since the size of the negative set greatly outnumbered the positive set, for pairwise comparison in the same dimension, 100 sub-negative sets were constructed by random sampling of 150 entries for 100 times from 4553 cancer-unrelated lncRNAs.
Construction of the four categories of features
To reflect the differences between cancer-related lncRNAs and cancer-unrelated lncRNAs, we collected 85 features that could potentially facilitate the recognition of cancer-related lncRNAs and grouped them into 4 different categories (Additional file 3): Genomic features (18), Expression features (16), Epigenetic features (27), and Network features (24).
Genomic features
GC content, which is much probable to influence the stability of gene [4], and gene splicing [18, 19]. According to gene structures, we considered five types of features, that is GC contents in TSS (transcription start site) up- and down-stream 1 kb/5 kb, gene body, exon, and intron.
Sequence conservation score. We considered sequence conservation in both lncRNA's exon and intron as well as TSS up- and down-stream 1 kb, according to the phastCons scores pre-calculated by the UCSC genome database (https://genome.ucsc.edu).
Repeat. Recent research has revealed that repeat elements can play important roles in transcriptional and post-transcriptional regulation [43,44,45,46,47,48]. We extracted the number of LINEs, LTRs, Satellites and SINEs in either gene body or TSS up-stream /down-stream 1k as repeat features. The transposable elements were downloaded from UCSC genome database (genome version GRCh38/hg38, genome annotation version GENCODE v24).
MiRNA host. LncRNAs may host miRNA both within their exons and introns. We counted the number of miRNAs (obtained from miRBase, version 21) residing in the region of each lncRNA by using BEDTools [49].
Micropeptide. Functional micropeptides can be concealed within lncRNAs [50]. Meanwhile, the length of these short peptides is likely to affect the localization of lncRNAs. We obtained the short peptide sequence of each transcript from the LncRNAWiki [51] and calculated the average peptide length.
Expression features
We intend to comprehensively depict the highly temporal and spatial expression specificity of lncRNAs, with the multi-tissue data as complete as possible. The expression profiles of 16 different tissue types were downloaded from Human Body Map project [52] and normalized by our in-house scripts with DEseq [53] method. The 16 different tissue types include adipose, adrenal gland, brain, breast, colon, heart, kidney, leukocyte, liver, lung, lymph node, ovary, prostate gland, skeletal muscle, testis, thyroid gland.
Epigenetics features
The importance of maintaining or reprogramming histone methylation appropriately is illustrated by links to disease and aging, or possibly transmission of traits across generations [54]. For example, Wan at al. found that lncRNAs may be transcriptionally regulated by histone modification in Alzheimer's Disease [55]. Here, we obtained nine epigenetics tracks. They are three types of epigenetic signals (H3k4me1, H3k4me3, and H3k27ac) in three types of cell lines (Gm12878, K562, and H1hesc) from UCSC genome database. The average epigenetic signals were calculated on gene body, TSS up- and down-stream 1 kb/5 kb, respectively.
We constructed a gene co-expression network between protein-coding and lncRNA genes from the above normalized expression profiles. Spearman's rank correlation coefficient (SCC, cutoff scc-value = 0.6) was used for calculating the correlation of each gene pair across the samples. Then we achieved three types of features of co-expression network:
Co-expression with cancer driver genes. The SCC values with Top20 mutational hotspots cancer driver genes were used as network features. These cancer driver genes were downloaded from http://cancerhotspots.org, including BRAF, CDKN2A, CTNNB1, EGFR, ERBB2, FBXW7, GNAS, H3F3A, HRAS, IDH1, KRAS, NRAS, PIK3CA, PTEN, RAC1, SF3B1, TP53, and U2AF1.
Co-expression interactions with cancer-related proteins. We calculated the number of interactions between lncRNA and cancer-related protein-coding genes in the co-expression network. The cancer-related protein-coding gene list is downloaded from Cancer Gene Census (https://cancer.sanger.ac.uk/census).
Total degree in co-expression network. Hub genes in the gene network usually means functional important genes. Thus we checked the number of neighbors in co-expression network of each lncRNA.
We also investigated the miRNA-target interaction network between miRNA lncRNA. miRNAs are higher relevant to cancer, with many key effects on various biological processes, e.g., embryonic development, cell division, differentiation, and apoptosis, are widely recognized [56, 57]. We downloaded cancer-related miRNA from HMDD v2.0 [58]. For each lncRNA, we counted the number of its regulatory cancer-related miRNAs, as well as that of all the involved miRNAs. We download the interaction information between miRNA and lncRNA from starBase [57].
Machine learning algorithms
Scikit-learn [59] is a python package that exposes a wide variety of machine learning algorithms which enabling easy comparison of methods. We use five machine learning algorithms in this package to train and validate our data. The detail algorithms parameter can be found in Additional file 11. The python script we performed our analysis can be found in Github (https://github.com/xuanblo/CRlncRC).
Coding-lncRNA gene co-expression network construction
A gene co-expression network was constructed between protein-coding and lncRNA genes from the above normalized expression profiles. We calculated the Spearman's correlation coefficient and its corresponding P-value (Eq. 1) between the expression profiles of each gene-pair using the in-house Perl script. Only gene-pair with an adjusted P-value of 0.01 or less and with a Spearman's correlation coefficient no less than 0.6 is regarded as co-expression in our coding-lncRNA gene co-expression network.
$$ \left\{\begin{array}{l}\mathrm{Rs}=\frac{\sum_i\left({x}_i-\overline{x}\right)\left({y}_i-\overline{y}\right)}{\sqrt{\sum_i{\left({x}_i-\overline{x}\right)}^2{\sum}_i{\left({y}_i-\overline{y}\right)}^2}}\\ {}\mathrm{F}\left({\mathrm{R}}_{\mathrm{s}}\right)=\frac{1}{2}\ln \frac{1+\mathrm{Rs}}{1-\mathrm{Rs}}\\ {}\mathrm{Z}=\sqrt{\frac{\mathrm{n}\hbox{-} 3}{1.06}}\mathrm{F}\left(\mathrm{Rs}\right)\end{array}\right. $$
Where x or y represents the vector of the ranked expression value of each gene, Rs is the Spearman's correlation coefficient between x and y, xi or yi stands for the rank of each expression value, \( \overline{x} \) or \( \overline{y} \), is the mean value of these ranks. F(Rs) is the Fisher transformation of Rs, and n is the sample size i.e. the vector length. The corresponding P-value of each Rs is calculated from Z, which is a z-score for Rs that approximately follows a standard normal distribution under the null hypothesis of statistical independence [60, 61].
LncRNA functional annotation
The GO annotation of protein coding-genes was downloaded from Gene Ontology Consortium (only biological process annotations were considered). While, GO annotation of lncRNA was predicted using the GOATOOLS (version 0.6.4) [62], which determines the GO annotation of one gene in our network according to the GO annotations of its immediate neighbor genes (P-value < 0.05).
Area under the ROC curve
KNN:
K-Nearest Neighbors
Long interspersed nuclear elements
lncRNA:
Long non-coding RNA
Naive bayes
Receiver operating characteristic
SCC:
Spearman's rank correlation coefficient
SINE:
Short Interspersed Nuclear Elements
Hanahan D, Weinberg RA. Hallmarks of cancer: the next generation. Cell. 2011;144(5):646–74.
Chen D, Zhang Z, Mao C, Zhou Y, Yu L, Yin Y, Wu S, Mou X, Zhu Y. ANRIL inhibits p15(INK4b) through the TGFbeta1 signaling pathway in human esophageal squamous cell carcinoma. Cell Immunol. 2014;289(1–2):91–6.
Hajjari M, Salavaty A. HOTAIR: an oncogenic long non-coding RNA in different cancers. Cancer Biol Med. 2015;12(1):1–9.
Guo Q, Qian Z, Yan D, Li L, Huang L. LncRNA-MEG3 inhibits cell proliferation of endometrial carcinoma by repressing notch signaling. Biomed Pharmacother. 2016;82:589–94.
Ma CC, Xiong Z, Zhu GN, Wang C, Zong G, Wang HL, Bian EB, Zhao B. Long non-coding RNA ATB promotes glioma malignancy by negatively regulating miR-200a. J Exp Clin Cancer Res. 2016;35(1):90.
Bonasio R, Shiekhattar R. Regulation of transcription by long noncoding RNAs. Annu Rev Genet. 2014;48:433–55.
Chen C, Li Z, Yang Y, Xiang T, Song W, Liu S. Microarray expression profiling of dysregulated long non-coding RNAs in triple-negative breast cancer. Cancer Biol Ther. 2015;16(6):856–65.
Yang P, Xu ZP, Chen T, He ZY. Long noncoding RNA expression profile analysis of colorectal cancer and metastatic lymph node based on microarray data. Onco Targets Ther. 2016;9:2465–78.
Huang X, Ta N, Zhang Y, Gao Y, Hu R, Deng L, Zhang B, Jiang H, Zheng J. Microarray analysis of the expression profile of long non-coding RNAs indicates lncRNA RP11-263F15.1 as a biomarker for diagnosis and prognostic prediction of pancreatic ductal adenocarcinoma. J Cancer. 2017;8(14):2740–55.
Zhao T, Xu J, Liu L, Bai J, Xu C, Xiao Y, Li X, Zhang L. Identification of cancer-related lncRNAs through integrating genome, regulome and transcriptome features. Mol BioSyst. 2015;11(1):126–36.
Lanzos A, Carlevaro-Fita J, Mularoni L, Reverter F, Palumbo E, Guigo R, Johnson R. Discovery of Cancer driver long noncoding RNAs across 1112 tumour genomes: new candidates and distinguishing features. Sci Rep. 2017;7:41544.
Chen K, Chen Z, Wu D, Zhang L, Lin X, Su J, Rodriguez B, Xi Y, Xia Z, Chen X, et al. Broad H3K4me3 is associated with increased transcription elongation and enhancer activity at tumor-suppressor genes. Nat Genet. 2015;47(10):1149–57.
Geurts P, Ernst D, Wehenkel L. Extremely randomized trees. Mach Learn. 2006;63(1):3–42.
Chiappinelli KB, Strissel PL, Desrichard A, Li H, Henke C, Akman B, Hein A, Rote NS, Cope LM, Snyder A, et al. Inhibiting DNA methylation causes an interferon response in Cancer via dsRNA including endogenous retroviruses. Cell. 2015;162(5):974–86.
Leonova KI, Brodsky L, Lipchick B, Pal M, Novototskaya L, Chenchik AA, Sen GC, Komarova EA, Gudkov AV. p53 cooperates with DNA methylation and a suicidal interferon response to maintain epigenetic silencing of repeats and noncoding RNAs. Proc Natl Acad Sci U S A. 2013;110(1):E89–98.
Parasramka MA, Maji S, Matsuda A, Yan IK, Patel T. Long non-coding RNAs as novel targets for therapy in hepatocellular carcinoma. Pharmacol Ther. 2016;161:67–78.
Smarda P, Bures P, Horova L, Leitch IJ, Mucina L, Pacini E, Tichy L, Grulich V, Rotreklova O. Ecological and evolutionary significance of genomic GC content diversity in monocots. Proc Natl Acad Sci U S A. 2014;111(39):E4096–102.
Amit M, Donyo M, Hollander D, Goren A, Kim E, Gelfman S, Lev-Maor G, Burstein D, Schwartz S, Postolsky B, et al. Differential GC content between exons and introns establishes distinct strategies of splice-site recognition. Cell Rep. 2012;1(5):543–56.
Haerty W, Ponting CP. Unexpected selection to retain high GC content and splicing enhancers within exons of multiexonic lncRNA loci. RNA. 2015;21(3):333–46.
Sharifi-Zarchi A, Gerovska D, Adachi K, Totonchi M, Pezeshk H, Taft RJ, Scholer HR, Chitsaz H, Sadeghi M, Baharvand H, et al. DNA methylation regulates discrimination of enhancers from promoters through a H3K4me1-H3K4me3 seesaw mechanism. BMC Genomics. 2017;18(1):964.
Calo E, Wysocka J. Modification of enhancer chromatin: what, how, and why? Mol Cell. 2013;49(5):825–37.
Heintzman ND, Hon GC, Hawkins RD, Kheradpour P, Stark A, Harp LF, Ye Z, Lee LK, Stuart RK, Ching CW, et al. Histone modifications at human enhancers reflect global cell-type-specific gene expression. Nature. 2009;459(7243):108–12.
Djebali S, Davis CA, Merkel A, Dobin A, Lassmann T, Mortazavi A, Tanzer A, Lagarde J, Lin W, Schlesinger F, et al. Landscape of transcription in human cells. Nature. 2012;489(7414):101–8.
De Santa F, Barozzi I, Mietton F, Ghisletti S, Polletti S, Tusi BK, Muller H, Ragoussis J, Wei CL, Natoli G. A large fraction of extragenic RNA pol II transcription sites overlap enhancers. PLoS Biol. 2010;8(5):e1000384.
Kim TK, Hemberg M, Gray JM, Costa AM, Bear DM, Wu J, Harmin DA, Laptewicz M, Barbara-Haley K, Kuersten S, et al. Widespread transcription at neuronal activity-regulated enhancers. Nature. 2010;465(7295):182–7.
Melo CA, Drost J, Wijchers PJ, van de Werken H, de Wit E, Oude Vrielink JA, Elkon R, Melo SA, Leveille N, Kalluri R, et al. eRNAs are required for p53-dependent enhancer activity and gene transcription. Mol Cell. 2013;49(3):524–35.
Tokheim CJ, Papadopoulos N, Kinzler KW, Vogelstein B, Karchin R. Evaluating the evaluation of cancer driver genes. Proc Natl Acad Sci U S A. 2016;113(50):14330–5.
Bartonicek N, Maag JL, Dinger ME. Long noncoding RNAs in cancer: mechanisms of action and technological advancements. Mol Cancer. 2016;15(1):43.
Grelet S, Link LA, Howley B, Obellianne C, Palanisamy V, Gangaraju VK, Diehl JA, Howe PH. A regulated PNUTS mRNA to lncRNA splice switch mediates EMT and tumour progression. Nat Cell Biol. 2017;19(9):1105–15.
Musahl AS, Huang X, Rusakiewicz S, Ntini E, Marsico A, Kroemer G, Kepp O, Orom UA. A long non-coding RNA links calreticulin-mediated immunogenic cell removal to RB1 transcription. Oncogene. 2015;34(39):5046–54.
Hua F, Liu S, Zhu L, Ma N, Jiang S, Yang J. Highly expressed long non-coding RNA NNT-AS1 promotes cell proliferation and invasion through Wnt/beta-catenin signaling pathway in cervical cancer. Biomed Pharmacother. 2017;92:1128–34.
Wang Q, Yang L, Hu X, Jiang Y, Hu Y, Liu Z, Liu J, Wen T, Ma Y, An G, et al. Upregulated NNT-AS1, a long noncoding RNA, contributes to proliferation and migration of colorectal cancer cells in vitro and in vivo. Oncotarget. 2017;8(2):3441–53.
Lu YB, Jiang Q, Yang MY, Zhou JX, Zhang Q. Long noncoding RNA NNT-AS1 promotes hepatocellular carcinoma progression and metastasis through miR-363/CDK6 axis. Oncotarget. 2017;8(51):88804–14.
Li Y, Lv M, Song Z, Lou Z, Wang R, Zhuang M. Long non-coding RNA NNT-AS1 affects progression of breast cancer through miR-142-3p/ZEB1 axis. Biomed Pharmacother. 2018;103:939–46.
Diaz-Lagares A, Crujeiras AB, Lopez-Serra P, Soler M, Setien F, Goyal A, Sandoval J, Hashimoto Y, Martinez-Cardus A, Gomez A, et al. Epigenetic inactivation of the p53-induced long noncoding RNA TP53 target 1 in human cancer. Proc Natl Acad Sci U S A. 2016;113(47):E7535–44.
Chen X, Gao Y, Li D, Cao Y, Hao B. LncRNA-TP53TG1 participated in the stress response under glucose deprivation in glioma. J Cell Biochem. 2017;118(12):4897–904.
Xiao H, Liu Y, Liang P, Wang B, Tan H, Zhang Y, Gao X, Gao J. TP53TG1 enhances cisplatin sensitivity of non-small cell lung cancer cells through regulating miR-18a/PTEN axis. Cell Biosci. 2018;8:23.
Ji SQ, Zhang YX, Yang BH. UBR5 promotes cell proliferation and inhibits apoptosis in colon cancer by destablizing P21. Pharmazie. 2017;72(7):408–13.
Wang J, Zhao X, Jin L, Wu G, Yang Y. UBR5 contributes to colorectal Cancer progression by destabilizing the tumor suppressor ECRG4. Dig Dis Sci. 2017;62(10):2781–9.
Wang X, Zhenchuk A, Wiman KG, Albertioni F. Regulation of p53R2 and its role as potential target for cancer therapy. Cancer Lett. 2009;276(1):1–7.
Hadjiargyrou M, Delihas N. The intertwining of transposable elements and non-coding RNAs. Int J Mol Sci. 2013;14(7):13307–28.
Welter D, MacArthur J, Morales J, Burdett T, Hall P, Junkins H, Klemm A, Flicek P, Manolio T, Hindorff L, et al. The NHGRI GWAS catalog, a curated resource of SNP-trait associations. Nucleic Acids Res. 2014;42(Database issue):D1001–6.
Hacisuleyman E, Shukla CJ, Weiner CL, Rinn JL. Function and evolution of local repeats in the firre locus. Nat Commun. 2016;7:11021.
Kelley DR, Hendrickson DG, Tenen D, Rinn JL. Transposable elements modulate human RNA abundance and splicing via specific RNA-protein interactions. Genome Biol. 2014;15(12):537.
Kapusta A, Kronenberg Z, Lynch VJ, Zhuo X, Ramsay L, Bourque G, Yandell M, Feschotte C. Transposable elements are major contributors to the origin, diversification, and regulation of vertebrate long noncoding RNAs. PLoS Genet. 2013;9(4):e1003470.
Johnson R, Guigo R. The RIDL hypothesis: transposable elements as functional domains of long noncoding RNAs. RNA. 2014;20(7):959–76.
Lubelsky Y, Ulitsky I. Sequences enriched in Alu repeats drive nuclear localization of long RNAs in human cells. Nature. 2018;555(7694):107–11.
Kopp F, Mendell JT. Functional classification and experimental dissection of long noncoding RNAs. Cell. 2018;172(3):393–407.
Quinlan AR, Hall IM. BEDTools: a flexible suite of utilities for comparing genomic features. Bioinformatics. 2010;26(6):841–2.
Anderson DM, Anderson KM, Chang CL, Makarewich CA, Nelson BR, McAnally JR, Kasaragod P, Shelton JM, Liou J, Bassel-Duby R, et al. A micropeptide encoded by a putative long noncoding RNA regulates muscle performance. Cell. 2015;160(4):595–606.
Ma L, Li A, Zou D, Xu X, Xia L, Yu J, Bajic VB, Zhang Z. LncRNAWiki: harnessing community knowledge in collaborative curation of human long non-coding RNAs. Nucleic Acids Res. 2015;43(Database issue):D187–92.
Petryszak R, Burdett T, Fiorelli B, Fonseca NA, Gonzalez-Porta M, Hastings E, Huber W, Jupp S, Keays M, Kryvych N, et al. Expression atlas update--a database of gene and transcript expression from microarray- and sequencing-based functional genomics experiments. Nucleic Acids Res. 2014;42(Database issue):D926–32.
Anders S, Huber W. Differential expression analysis for sequence count data. Genome Biol. 2010;11(10):R106.
Greer EL, Shi Y. Histone methylation: a dynamic mark in health, disease and inheritance. Nat Rev Genet. 2012;13(5):343–57.
Wan G, Zhou W, Hu Y, Ma R, Jin S, Liu G, Jiang Q. Transcriptional regulation of lncRNA genes by histone modification in Alzheimer's disease. Biomed Res Int. 2016;2016:3164238.
Yang Z, Ren F, Liu C, He S, Sun G, Gao Q, Yao L, Zhang Y, Miao R, Cao Y, et al. dbDEMC: a database of differentially expressed miRNAs in human cancers. BMC Genomics. 2010;11(Suppl 4):S5.
Yang JH, Li JH, Shao P, Zhou H, Chen YQ, Qu LH. starBase: a database for exploring microRNA-mRNA interaction maps from Argonaute CLIP-Seq and Degradome-Seq data. Nucleic Acids Res. 2011;39(Database issue):D202–9.
Li Y, Qiu C, Tu J, Geng B, Yang J, Jiang T, Cui Q. HMDD v2.0: a database for experimentally supported human microRNA and disease associations. Nucleic Acids Res. 2014;42(Database issue):D1070–4.
Pedregosa F, Varoquaux G, Gramfort A, Michel V, Thirion B, Grisel O, Blondel M, Prettenhofer P, et al. Scikit-learn: machine learning in Python. J Mach Learn Res. 2011;12:2825–30.
Choi SC. Tests of equality of dependent correlation coefficients. Biometrika. 1977;64(3):645–7.
Fieller EC, Hartley HO, Pearson ES. Tests for rank correlation coefficients. I. Biometrika. 1957;44(3–4):470–81.
Klopfenstein DV, Zhang L, Pedersen BS, Ramirez F, Warwick Vesztrocy A, Naldi A, Mungall CJ, Yunes JM, Botvinnik O, Weigel M, et al. GOATOOLS: a Python library for gene ontology analyses. Sci Rep. 2018;8(1):10872.
Data analysis supported by HPC Platform, The Public Technology Service Center of Xishuangbanna Tropical Botanical Garden (XTBG), CAS, China.
This work was supported by the National Natural Science Foundation of China (No. 31471220, 91440113), Start-up Fund from Xishuangbanna Tropical Botanical Garden, 'Top Talents Program in Science and Technology' from Yunnan Province. Publication costs are funded by the National Natural Science Foundation of China (No. 31471220).
All data generated or analyzed during this study are included in this published article.
About this supplement
This article has been published as part of BMC Medical Genomics Volume 11 Supplement 6, 2018: Proceedings of the 29th International Conference on Genome Informatics (GIW 2018): medical genomics. The full contents of the supplement are available online at https://bmcmedgenomics.biomedcentral.com/articles/supplements/volume-11-supplement-6.
Xuan Zhang, Jun Wang and Jing Li contributed equally to this work.
CAS Key Laboratory of Tropical Plant Resources and Sustainable Use, Xishuangbanna Tropical Botanical Garden, Chinese Academy of Sciences, Menglun, 666303, Yunnan, People's Republic of China
Xuan Zhang, Jun Wang, Jing Li, Wen Chen & Changning Liu
University of Chinese Academy of Sciences, Beijing, 100049, People's Republic of China
Xuan Zhang
Institute of Medical Sciences, Xiangya Hospital, Central South University, Changsha, 410008, People's Republic of China
Jun Wang
Jing Li
Wen Chen
Changning Liu
CL conceived, designed, and supervised this study. XZ, JW and JL contributed to the analysis work and contributed equally to this work. WC participate in the discussion and provide valuable advice and practical contributions. XZ, JW, JL, and CL wrote the first draft of the article, all authors reviewed, edited and approved the manuscript.
Correspondence to Changning Liu.
Positive lncRNA dataset. (XLSX 10 kb)
Negative lncRNA dataset. (XLSX 64 kb)
Features importance. (XLSX 11 kb)
TANRIC lncRNA dataset. (XLSX 176 kb)
Model evaluate indicators. (DOCX 85 kb)
ROC curve of combined feature class. (PDF 19 kb)
Cumulative percentage curve of features. (PDF 208 kb)
Gene and transcript length distribution. (PDF 14 kb)
Predict results. (XLSX 29 kb)
Additional file 10:
Cancer-related lncRNA Papers. (XLSX 326 kb)
Model parameters. (PDF 46 kb)
Zhang, X., Wang, J., Li, J. et al. CRlncRC: a machine learning-based method for cancer-related long noncoding RNA identification using integrated features. BMC Med Genomics 11 (Suppl 6), 120 (2018). https://doi.org/10.1186/s12920-018-0436-9
Cancer-related
LncRNA
Integrated features | CommonCrawl |
20- Principles of Satellite Communications
Principles of Satellite Communications
Satellite Communications -Satellite tv for pc Communication − Benefits
Satellite Communications -Satellite tv for pc Communication − Disadvantages
Satellite Communications -Satellite tv for pc Communication − Functions
Kepler's Legal guidelines
Kepler's 1st Legislation
Kepler's 2nd Legislation
Kepler's 3rd Legislation
Satellite Communications -Earth Orbits
Satellite Communications -Geosynchronous Earth Orbit Satellites
Satellite Communications -Medium Earth Orbit Satellites
Satellite Communications -Low Earth Orbit Satellites
A satellite tv for pc is a physique that strikes round one other physique in a mathematically predictable path known as an Orbit. A communication satellite tv for pc is nothing however a microwave repeater station in area that's useful in telecommunications, radio, and tv together with web purposes.
A repeater is a circuit which will increase the energy of the sign it receives and retransmits it. However right here this repeater works as a transponder, which adjustments the frequency band of the transmitted sign, from the obtained one.
The frequency with which the sign is distributed into the area is named Uplink frequency, whereas the frequency with which it's despatched by the transponder is Downlink frequency.
The next determine illustrates this idea clearly.
Now, allow us to take a look on the benefits, disadvantages and purposes of satellite tv for pc communications.
There are lots of Benefits of satellite tv for pc communications akin to −
Ease in putting in new circuits
Distances are simply coated and value doesn't matter
Broadcasting prospects
Every nook of earth is roofed
Consumer can management the community
See also: Kaspersky Rescue Disk 2018 18.0.11.0 Build 2020.12.20 + USB
Satellite tv for pc communication has the next drawbacks −
The preliminary prices akin to phase and launch prices are too excessive.
Congestion of frequencies
Interference and propagation
Satellite tv for pc communication finds its purposes within the following areas −
In Radio broadcasting.
In TV broadcasting akin to DTH.
In Web purposes akin to offering Web connection for knowledge switch, GPS purposes, Web browsing, and so on.
For voice communications.
For analysis and improvement sector, in lots of areas.
In navy purposes and navigations.
The orientation of the satellite tv for pc in its orbit relies upon upon the three legal guidelines known as as Kepler's legal guidelines.
Johannes Kepler (1571-1630) the astronomical scientist, gave Three revolutionary legal guidelines, concerning the movement of satellites. The trail adopted by a satellite tv for pc round its major (the earth) is an ellipse. Ellipse has two foci – F1 and F2, the earth being one in every of them.
If the space from the middle of the thing to a degree on its elliptical path is taken into account, then the farthest level of an ellipse from the middle is named as apogee and the shortest level of an ellipse from the middle is named as perigee.
Kepler's 1st regulation states that, "each planet revolves across the solar in an elliptical orbit, with solar as one in every of its foci." As such, a satellite tv for pc strikes in an elliptical path with earth as one in every of its foci.
The semi main axis of the ellipse is denoted as 'a' and semi minor axis is denoted as b. Due to this fact, the eccentricity e of this method will be written as −
$$e = \frac{\sqrt{a^{2}-b^{2}}}{a}$$
Eccentricity (e) − It's the parameter which defines the distinction within the form of the ellipse relatively than that of a circle.
Semi-major axis (a) − It's the longest diameter drawn becoming a member of the 2 foci alongside the middle, which touches each the apogees (farthest factors of an ellipse from the middle).
Semi-minor axis (b) − It's the shortest diameter drawn via the middle which touches each the perigees (shortest factors of an ellipse from the middle).
These are properly described within the following determine.
For an elliptical path, it's all the time fascinating that the eccentricity ought to lie in between Zero and 1, i.e. 0 < e < 1 as a result of if e turns into zero, the trail will probably be no extra in elliptical form relatively it will likely be transformed right into a round path.
Kepler's 2nd regulation states that, "For equal intervals of time, the realm coated by the satellite tv for pc is equal with respect to the middle of the earth."
It may be understood by having a look on the following determine.
Suppose that the satellite tv for pc covers p1 and p2 distances, in the identical time interval, then the areas B1 and B2 coated in each situations respectively, are equal.
Kepler's 3rd regulation states that, "The sq. of the periodic time of the orbit is proportional to the dice of the imply distance between the 2 our bodies."
This may be written mathematically as
$$T^{2}\:\alpha\:\:a^{3}$$
Which suggests
$$T^{2} = \frac{4\pi ^{2}}{GM}a^{3}$$
The place $\frac{4\pi ^{2}}{GM}$ is the proportionality fixed (in keeping with Newtonian Mechanics)
$$T^{2} = \frac{4\pi ^{2}}{\mu}a^{3} $$
The place μ = the earth's geocentric gravitational fixed, i.e. Μ = 3.986005 × 1014 m3/sec2
$$1 = \left ( \frac{2\pi}{T} \proper )^{2}\frac{a^{3}}{\mu}$$
$$1 = n^{2}\frac{a^{3}}{\mu}\:\:\:\Rightarrow \:\:\:a^{3} = \frac{\mu}{n^{2}}$$
The place n = the imply movement of the satellite tv for pc in radians per second
The orbital functioning of satellites is calculated with the assistance of those Kepler's legal guidelines.
Together with these, there is a crucial factor which needs to be famous. A satellite tv for pc, when it revolves across the earth, undergoes a pulling drive from the earth which is the gravitational drive. Additionally, it experiences some pulling drive from the solar and the moon. Therefore, there are two forces performing on it. They're −
Centripetal drive − The drive that tends to attract an object transferring in a trajectory path, in direction of itself is named as centripetal drive.
Centrifugal drive − The drive that tends to push an object transferring in a trajectory path, away from its place is named as centrifugal drive.
So, a satellite tv for pc has to stability these two forces to maintain itself in its orbit.
A satellite tv for pc when launched into area, must be positioned in a sure orbit to offer a specific method for its revolution, in order to keep up accessibility and serve its goal whether or not scientific, navy, or business. Such orbits that are assigned to satellites, with respect to earth are known as as Earth Orbits. The satellites in these orbits are Earth Orbit Satellites.
The vital sorts of Earth Orbits are −
Geo Synchronous Earth Orbit
Medium Earth Orbit
A Geo-Synchronous Earth Orbit (GEO) satellite tv for pc is one which is positioned at an altitude of 22,300 miles above the Earth. This orbit is synchronized with a aspect actual day (i.e., 23hours 56minutes). This orbit can have inclination and eccentricity. It will not be round. This orbit will be tilted on the poles of the earth. However it seems stationary when noticed from the Earth.
The identical geo-synchronous orbit, whether it is round and within the aircraft of equator, it's known as as geo-stationary orbit. These satellites are positioned at 35,900kms (identical as geosynchronous) above the Earth's Equator and so they carry on rotating with respect to earth's path (west to east). These satellites are thought of stationary with respect to earth and therefore the identify implies.
Geo-Stationary Earth Orbit Satellites are used for climate forecasting, satellite tv for pc TV, satellite tv for pc radio and different kinds of world communications.
The next determine reveals the distinction between Geo-synchronous and Geo-stationary orbits. The axis of rotation signifies the motion of Earth.
Be aware − Each geo-stationary orbit is a geo-synchronous orbit. However each geo-synchronous orbit is NOT a Geo-stationary orbit.
Medium Earth Orbit (MEO) satellite tv for pc networks will orbit at distances of about 8000 miles from the earth's floor. Indicators transmitted from a MEO satellite tv for pc journey a shorter distance. This interprets to improved sign energy on the receiving finish. This reveals that smaller, extra light-weight receiving terminals can be utilized on the receiving finish.
Because the sign is travelling a shorter distance to and from the satellite tv for pc, there may be much less transmission delay. Transmission delay will be outlined because the time it takes for a sign to journey as much as a satellite tv for pc and again all the way down to a receiving station.
For real-time communications, the shorter the transmission delay, the higher would be the communication system. For example, if a GEO satellite tv for pc requires 0.25 seconds for a spherical journey, then MEO satellite tv for pc requires lower than 0.1 seconds to finish the identical journey. MEOs operates within the frequency vary of two GHz and above.
The Low Earth Orbit (LEO) satellites are primarily labeled into three classes specifically, little LEOs, large LEOs, and Mega-LEOs. LEOs will orbit at a distance of 500 to 1000 miles above the earth's floor.
This comparatively quick distance reduces transmission delay to solely 0.05 seconds. This additional reduces the necessity for delicate and ponderous receiving gear. Little LEOs will function within the 800 MHz (0.eight GHz) vary. Massive LEOs will function within the 2 GHz or above vary, and Mega-LEOs operates within the 20-30 GHz vary.
The upper frequencies related to Mega-LEOs interprets into extra data carrying capability and yields to the potential of real-time, low delay video transmission scheme.
The next determine depicts the paths of LEO, MEO, and GEO.
Spread the lovePropagation Losses Antenna and Wave propagation performs an …
6- Propagation Losses
Spread the loveWireless Communication – Overview Wi-fi communication entails the …
1- Wireless Communication – Overview
Teclast M40 10.1'' Tablet 1920x1200 4G | CommonCrawl |
Saving the armchair by experiment: what works in economics doesn't work in philosophy
Boudewijn de Bruin ORCID: orcid.org/0000-0001-9930-67951,2
Philosophical Studies volume 178, pages 2483–2508 (2021)Cite this article
Financial incentives, learning (feedback and repetition), group consultation, and increased experimental control are among the experimental techniques economists have successfully used to deflect the behavioral challenge posed by research conducted by such scholars as Tversky and Kahneman. These techniques save the economic armchair to the extent that they align laypeople judgments with economic theory by increasing cognitive effort and reflection in experimental subjects. It is natural to hypothesize that a similar strategy might work to address the experimental or restrictionist challenge to armchair philosophy. To test this hypothesis, a randomized controlled experiment was carried out (for incentives and learning), as well as two lab experiments (for group consultation, and for experimental control). Three types of knowledge attribution tasks were used (Gettier cases, false belief cases, and cases in which there is knowledge on the consensus/orthodox understanding). No support for the hypothesis was found. The paper describes the close similarities between the economist's response to the behavioral challenge, and the expertise defense against the experimental challenge, and presents the experiments, results, and an array of robustness checks. The upshot is that these results make the experimental challenge all the more forceful.
Do armchair philosophers have an experimental argument against experimental philosophers? One could argue that we shouldn't hope for something of that sort: a wealth of experiments demonstrate that not only laypeople judgments, but also those of philosophers are prone to be influenced by irrelevant perturbing factors, and that in fact expert judgments are sometimes plainly wrong, for even professional epistemologists tend to attribute knowledge to the protagonist of fake barn type Gettier cases (Horvath and Wiegmann 2016), to give only one example. How likely then is it that new experiments would generate empirical evidence backing philosophical expertise?
The starting point of this paper is that one experimental strategy has not yet been deployed. To see what strategy that is, consider how neo-classical economists responded to the behavioral challenge, which was launched by Herbert Simon—who used the word "armchair" to lambaste the economic methodology of old long before it became popular in philosophy (Simon and Bartel 1986).
In a famous experiment, two other pioneers of behavioral economics, Amos Tversky and Daniel Kahneman (1983), asked subjects to consider Linda:
Linda is 31 years old, single, outspoken and very bright. She majored in philosophy. As a student, she was deeply concerned with issues of discrimination and social justice, and also participated in anti-nuclear demonstrations.
Tversky and Kahneman asked the folk which proposition they believe is more probable: (i) that Linda is a bank teller, or (ii) that Linda is a bank teller who is active in the feminist movement. Now surely if you've learned something about probability, you know that the right answer is (i). But 85% of the subjects in the experiment gave (ii) as an answer.
Probability and utility theory form the unifying theoretical core of economics, and hence empirical evidence showing that people diverge from theory constitutes a clear challenge to the field, just like the experimental challenge to philosophy.
Economists responded to the challenge with arguments that are strikingly similar to the expertise and reflection defense that philosophers have marshaled against the experimental challenge (or restrictionist challenge (Alexander and Weinberg 2007)). Economists argued that the subjects in Tversky and Kahneman's experiment (and other behavioral experiments) lacked experience, were not reflecting on their answers, likely missed essential features of the vignettes they were confronted with, and so simply didn't understand the question. If, the economists maintained, experimental subjects could be made to pay attention to the relevant details of the scenarios, reflect on them, and come to understand what was being asked of them, then they would naturally answer correctly.
That is exactly what they set out to test empirically. Economists used a repertoire of experimental techniques to encourage participants to pay attention and reflect, and to make them understand what the experiments are about: they told participants that they would pay out a financial bonus if they answered the question correctly (that is, they used financial incentives); they familiarized participants with the type of question prior to the experiment (so they introduced an element of learning in the experiment); they allowed participants to consult with each other about the question before answering (group consultation); and they made sure that the experiment took place in controlled conditions in a lab, rather than online where all sorts of things may distract participants from the task (experimental control).
These techniques didn't reduce error rates to zero, but altogether the effects were quite impressive. For instance, when participants were offered a bonus of $4 for a correct answer to the question about Linda, only 33% chose (ii).
The thought behind this paper was that what had saved the economic armchair should save the philosophical armchair just as much. That is, I expected that with standard experimental techniques from economics, laypeople judgments would converge to those of professional philosophers. To test this convergence hypothesis, I ran a number of knowledge attribution experiments (including Gettier cases), testing the effects of financial incentives and learning (randomized controlled trial, RCT, total sample size 1443), group consultation (sample size 661), and experimental control (RCT, sample size 191).
Frankly, I expected that this would yield a response to the experimental philosophy challenge just as forceful as the economist's response to the behavioral challenge. What I found was entirely different, though. Financial incentives, learning, group consultation, and experimental control didn't bring laypeople judgments closer to those of philosophers, and so what looked as a promising strategy to restore confidence in armchair philosophy has made the experimental challenge stronger—at least, it is stronger than the behavioral challenge to economic orthodoxy.
The remainder of the paper is structured as follows. Section 2 provides some background about the experimental challenge and ways to deflect it as well as about the behavioral challenge and the economist's response. Section 3 describes the vignettes as well as the regression model used to estimate the hypothesized effect. Sections 4–8 introduce and motivate the experimental techniques (incentivization, learning (one short and without incentives, the other longer and with incentives), group consultation, and experimental control), and provide evidence that these techniques are prima facie plausible tools to meet the experimental challenge. These sections also discuss the results of the experiments. Section 9 compares the results with those of others (among others, I consider an array of covariates such as age, gender, education, etc.), anticipates a number of objections, points out various limitations of the study, and makes some suggestions for future research.
Before proceeding, it is important to note the following. I have decided to present the results of all five experiments in one paper rather than in several separate papers because I think that this makes the argument stronger and more coherent. The downside is that this paper would have become very long had I reported all usual information about each experiment (materials, methods, procedures, data, models, results, etc.). That's why I have chosen to focus on the general argument in the main paper, and defer these details to supplementary materials, which together with the data are available online.
A wealth of survey research attests to the fact that laypeople often express different opinions about philosophical cases than professionals. Consider, for instance, the vignette used in all experiments reported here. It is due to Starmans and Friedman (2012). Participants were asked whether (i) Peter only believes that there is a watch on the table, or (ii) Peter really knows that there is a watch on the table.
Peter is in his locked apartment reading, and is about to have a shower. He puts his book down on the coffee table, and takes off his black plastic watch and leaves it on the coffee table. Then he goes into the bathroom. As Peter's shower begins, a burglar silently breaks into the apartment. The burglar takes Peter's black plastic watch, replaces it with an identical black plastic watch, and then leaves. Peter is still in the shower, and did not hear anything.
Now surely if you've learned something about epistemology, you know that the consensus answer is (i). But 72% of the subjects in Starmans and Friedman's (2012) experiment gave (ii) as an answer—a finding I replicate. The experimental challenge stares us starkly in the face.
Several strategies have been deployed to fend off the challenge. Some authors have pointed to weaknesses in the way the experiments were designed, carried out, and statistically analyzed. Woolfolk (2013), for instance, arraigns the use of self-reported data and complains about statistical errors in published experimental philosophy research. But as self-reported data are part and parcel of much of psychology and economics, and experimental and statistical sophistication among philosophers is growing, this strategy isn't too effective in the long run. That's why a more prominent line of defense that armchair philosophers put up against the experimentalists accepts the empirical results largely as given.
This line has come to be known as the expertise defense.Footnote 1 The thought is that the data experimental philosophers have gathered do not jeopardize the status of more traditional philosophical practice because they concern judgments of people who have no philosophical expertise. We should expect laypeople to diverge just as much from experts if we asked them questions about mathematics (or physics, or law, and so on); yet no sensible mathematician would find this worrying, or even faintly intriguing, and simply explain the divergence by the training they, and not laypeople, have had. The main idea of the expertise defense is then that philosophers, too, have a specific kind of expertise that justifies our setting aside laypeople judgments, just like the mathematicians (physicists, lawyers, etc.) ignore the folk. Unlike the folk, we have learned "how to apply general concepts to specific examples with careful attention to the relevant subtleties," as Williamson (2007, 191) has put it, and this makes us far better at answering questions about Gettier cases and their ilk.
Advocates of the expertise defense often point up an additional difference between professional judgments and the data of the experimentalists: whereas laypeople only give their spontaneous and thoughtless opinions about the vignettes they are confronted with, professional philosophers engage in painstaking reflection and deliberation and put in great cognitive effort with close attention to details before reaching judgment. Ludwig (2007, 148) likens this type of reflection to what is needed to grasp mathematical truths: to see that one can construct a bijection between the set of numbers and the set of odd numbers, he claims, "a quick judgment is not called for, but rather a considered reflective judgment in which the basis for a correct answer is revealed." Our experience with this type of reflection—for Sosa (2007) and Kauppinen (2007) joined with dialogue and discussion—is what grounds our authority on matters philosophical. As a result, there is no merit whatsoever in "questioning untutored subjects" (Ludwig 2007, 151), who "may have an imperfect grasp of the concept in question [and] rush in their judgements" (Kauppinen 2007, 105) with their "characteristic sloppiness" (Williamson 2007, 191).
Here is my key observation (again): the expertise defense bears more than superficial similarity to the way economists have responded to the behavioral challenge. Take Ken Binmore, a prominent economist:
But how much attention should we pay to experiments that tell us how inexperienced people behave when placed in situations with which they are unfamiliar, and in which the incentives for thinking things through carefully are negligible or absent altogether? (1994, 184–185, my emphasis)
Yet, while the philosophical debate has rumbled on with characteristic armchair methods, the economists were quick to finish their debate by bluntly counter-challenging behavioral economics on empirical grounds. Binmore asked:
Does the behavior survive when the incentives are increased? (1994, 185)
So he asked: if we pay people to pay attention, do they still deviate from economic theory?Footnote 2
Binmore also asked:
Does it survive after the subjects have had a long time to familiarize themselves with all the wrinkles of the unusual situation in which the experimenter has placed them? (1994, 185)
That is: what happens if we make sure that participants understand what they are being asked to do? Binmore concluded that if both questions are answered affirmatively,
the experimenter has probably done no more than inadvertently to trigger a response in the subjects that is adapted to some real-life situation, but which bears only a superficial resemblance to the problem the subjects are really facing in the laboratory. (1994, 185)
So if the deviation from theory disappears when financial incentives and learning are introduced, then the relevance of the behavioral challenge is probably negligible.
Such reasoning is, I think, very attractive. Just as anyone paying attention to the Linda the Bank Teller task should be able to give the right answer, a person sufficiently alert and engaged should be expected to give the consensus answer to a Gettier task. Also: the average advocate of the expertise defense should hold that knowledge attribution cases are very much of a piece with Linda the Bank Teller (and other cases such as the gambler's fallacy, etc.).Footnote 3 And if the average advocate of the expertise defense agrees that no economist should be worried by what laypeople think about such cases, they might conclude by analogy that no philosopher should be afraid of the folk Gettier holdouts.
These are then the ideas that motivated the experiments. I expected that when financial incentives and learning are introduced, as Binmore suggested, the deviation from theory disappears, and I also considered two other mechanisms of more recent date, not mentioned by Binmore: group consultation and experimental control.
I was very surprised to see this convergence hypothesis founder.Footnote 4
Vignettes and model
I carried out three experiments: (i) a large randomized controlled trial (RCT) to study the impact of financial incentives and learning (online UK sample, Sects. 4–6); (ii) an experiment in a large lecture hall to study group consultation (student sample, Sect. 7); and (iii) a lab experiment to study experimental control (student sample, Sect. 8).Footnote 5
To compare results across the experiment as well as with the existing literature, I used the same vignettes in all experiments, drawn from Starmans and Friedman (2012). Participants were randomly assigned to one of three conditions: Gettier Case, Non-truth Case (where veridicality doesn't hold) and Knowledge Case (where there is knowledge on the textbook understanding).Footnote 6
The Gettier Case and the Non-truth Case involve the vignette from above (Peter and the watch), where in the Non-truth Case "an identical black watch" is replaced by "a banknote." In both cases, participants were confronted with the following two alternatives, and asked the question "Which of the following is true?":
Peter really knows that there is a watch on the table.
Peter only believes that there is a watch on the table.
In the Knowledge Case, participants read the text from the Gettier Case, but their task involved the following two new alternatives:
Peter really knows that there is a book on the table.
Peter only believes that there is a book on the table.
In all three conditions the "really knows" and "only believes" options appeared in random order.
If laypeople follow epistemological consensus, we should expect that participants attribute knowledge to Peter only in the Knowledge Case. In the Non-truth Case, there is no watch on the table, so Peter has a false belief. Since knowledge entails truth, Peter should not be seen as possessing knowledge. In the Gettier Case, there is a watch on the table. However, it is not the watch that Peter left on the table. The burglar's actions have ensured that Peter's environment is Gettiered, which means that if subjects follow orthodoxy, they will deny knowledge to Peter. Only in the Knowledge Case does Peter possess knowledge, as there is in fact a book on the table, and the burglar's actions have not affected the book.Footnote 7 Subsequently, participants were asked to rate their confidence in their answer to the "know/believe" question.
Before proceding, let me report the results of the baseline treatment. In the Gettier Case, 72% of the participants attribute knowledge to Peter, which is the same percentage reported by Starmans and Friedman (2012) (\(Z = -\,0.02\), \(p = .981\), all two-tailed difference in proportions tests). I didn't fully reproduce their results in the Non-truth Case (False Belief condition) (\(Z = -\,3.98\), \(p < .001\)), where I found knowledge attribution in 44% of the participants, as opposed to 11% in Starmans and Friedman's sample. Nor did I replicate the Knowledge Case (Control condition) (\(Z = 2.07\), \(p < .05\)). I there found knowledge attribution in 74% of the participants, as opposed to 88% in Starmans and Friedman's sample. Various factors may account for these differences: I used a UK sample, where Starmans and Friedman have a US sample; I use Prolific, they MTurk; and my sample is less highly educated. These replication failures do not of course affect the validity of carrying out a randomized controlled trial, because we are there only interested in the relative differences between the treatments in otherwise similar samples, and not in differences with other experiments with different samples.
Knowledge attribution error is measured in two ways in the literature. One measure uses a binary variable \(Corr _u\), which takes the value 1 when the answer is correct, and 0 if false. The other measure incorporates the subject's level of confidence in the answer. Confidence was measured on a fully anchored 7-point Likert scale. I rescaled to a scale ranging from 1 to 10 in conformance with the literature.Footnote 8 The variable \(Corr _w\) then is equal to the rescaled confidence level if the answer is correct, and equal to minus the rescaled confidence level if the answer is incorrect. So in line with Starmans and Friedman (2012) I calculated the weighted knowledge attribution (or ascription) (WKA) of each participant. WKA is a number ranging from \(-10\) to 10, resulting from multiplying the confidence rating of a participant with their answer to the "know/believe" question (where attribution of belief receives the value \(-1\) and knowledge 1). So \(Corr _w\) is equal to WKA if "know" is the correct answer, and equal to minus WKA (i.e., \(-1 \times \mathrm {WKA}\)) if "believe" is the correct answer.
The following regression model estimates the impact of the experimental techniques (financial incentives, learning, group consultation, experimental control) on correct knowledge attribution rates:
$$\begin{aligned} Y_i = \alpha + \beta X_i + \gamma _s Z_s + \varepsilon _{i, s}. \end{aligned}$$
Here Y is the variable under study (capturing binary or weighted correct knowledge attribution), X a vector of baseline covariates, \(\varepsilon\) the error term, and \(\gamma\) the parameter of interest that captures the effect of the experimental techniques (Z), respectively, on the outcome under study. Controls include age, income, and wealth, and dummy variables for gender, ethnicity, religion, and education. In the group consultation experiment, I conducted a difference in proportions test in addition to linear regression, following the economics literature.Footnote 9
Psychologists rarely use incentives, generally on the grounds that typical experimental subjects are "cooperative and intrinsically motivated to perform well" (Camerer 1995, 599), or also, as Thaler (1987) dryly points out, because their research budgets tend to be much smaller than those in economics departments. Experimental philosophers borrow their methods mainly from psychology (and face similar budget constraints), so it is unsurprising that they rarely use incentives.
But incentives bring advantages: they motivate participants to take the task more seriously, and thereby increase cognitive effort and reflection. Not always, of course, for incentives may lead to "choking under pressure" (Baumeister 1984); nor do incentives increase performance in tasks requiring general knowledge ("What is the capital of Honduras?") (Yaniv and Schul 1997). But when doing well only requires thinking things through carefully, incentives usually boost success.Footnote 10
Economists are primarily interested in tasks that require at least a bit of reflection, and that is why the use of incentives is the norm in economics. What about the tasks that experimental philosophers offer to their subjects? I believe that most philosophers would think that answering them correctly is more a reflection task than a general knowledge task.Footnote 11 Drawing from an analogy between philosophy and other fields is initially plausible, despite some criticism that has been advanced against such moves.Footnote 12 It is at least worth working from this analogy, because it leads very clearly to a further, and empirically testable, convergence hypothesis: if standard experimental tools are used that bring down error rates in laypeople judgments about such tasks as Linda the Bank Teller, then, with such techniques, laypeople judgments about philosophy tasks should converge to those of expert philosophers as well. This shouldn't be expected to be a massive change. It may well be smaller than the almost 50% reduction of error we see in Linda the Bank Teller—and I totally admit that not all experiments in economics are so successful! But it would really be exceedingly odd if no statistically significant reduction in error rates happened at all.
These reflections led me to design an experiment in which participants were exposed to an incentivized knowledge attribution task, to be compared with a non-incentivized baseline.Footnote 13 Participants were paid a bonus upon giving the correct answer to a knowledge attribution question. I decided to set the incentive at £5, offering about 50% more than the $4 that brought down the error rate in the Linda the Bank Teller task, in a well-known experiment in economics conducted by Charness et al. (2010).Footnote 14 That is, I made it clear upfront that participants were to gain £5 if they answered "correctly" a specifically designated question, and that they would receive this on top of the appearance fee of £0.50 (and I made sure to actually pay them). I also made clear that this was not a general knowledge type of task, by telling them: "You can find the correct answer to the question through careful thinking about the concepts involved."
The experimental philosopher might marshal an objection to the effect that it is problematic, if not plainly unacceptable, to pay participants £5 for giving the textbook answer to a question about knowledge attribution.Footnote 15 I agree that in a way the incentive structure is biased towards a particular conception of knowledge, and that I could have chosen an alternative payment scheme. I'm also aware of the fact that the wording suggests that participants should exclude the possibility that both answers may be correct or defensible, and this is indeed more inspired by positions held in the camp of the expertise defense than by those of experimental philosophers.Footnote 16
Yet, my response is that, first, I borrow this approach from economics. If an experiment pays out a monetary reward if a participant concurs with expected utility theory, economists who reject that theory may object on similar grounds. These economists are a minority, but they exist: Simon's (1948) satisficing theory offers a compelling alternative to expected utility theory. Indeed, even in the case of Linda the Bank Teller there may be reasons to doubt the assumption that there is only one correct answer, as subjects may differ in the weights they assign to the semantic and pragmatic aspects of the question they are asked. Some might stress pragmatics, and think they have to determine what is maximally informative, while meeting minimal threshold justifiability (and then answer that Linda is a feminist bank teller). Others might stress semantics, and look for a maximally justifiable, if less informative, answer.Footnote 17
A second way to respond is to observe that the goal of offering monetary incentives is not to express praise or blame for a particular answer. Incentives are introduced to increase the attention with which participants approach a question; that is, they are meant to motivate participants to think things through more carefully, and to reflect more carefully. I didn't of course inform participants about what the right answer was until the entire experiment was over. The only thing participants knew was that they would be paid £5 if they gave the correct answer to one specific question. So while I am sympathetic to the experimental philosopher's potential reluctance, I am confident the experimental design is justifiable.
Did incentives align the folk with the experts? Not at all. Regarding the results of this experiment I can be brief: offering incentives does not decrease knowledge attribution error rates (in any of the three cases: Gettier, Non-truth, Knowledge).Footnote 18
So let us move on to learning.
Short learning
As we saw, Binmore (1994, 184) asked whether the findings at the core of the behavioral challenge to economic theory survive if subjects have had sufficient time to "familiarize themselves with all the wrinkles of the unusual situation in which the experimenter has placed them." The answer is, in economics: not a lot survives of the behavioral challenge when participants are given the opportunity to learn prior to the experiment.
Binmore's line of reasoning foreshadowed the expertise defense. Ludwig, for instance, complains about the use of "untutored" experimental subjects (2007, 151), and maintains that subjects "may well give a response which does not answer to the purposes of the thought experiment" (2007, 138). When we philosophers conduct thought experiments, we activate our competence in deploying the concepts involved, Ludwig believes. Laypeople judgments, by contrast, will "not solely" be based in such competence (2007, 138), as laypeople may have difficulties "sorting out the various confusing factors that may be at work" when they are confronted with a scenario (2007, 149).Footnote 19
This is just as the economists have it: laypeople responses are often "inadvertently triggered," and so they have only "superficial resemblance" to the problem at hand, to use Binmore's words, because laypeople are generally "inexperienced" and "unfamiliar" with the situation (1994, 184).
So what should we do? Here as above, I suggest that we confront the experimental challenge empirically, as the economists confront the behavioral challenge. What Binmore suggests here is to include in the experiment a learning phase in which subjects familiarize themselves with the tasks at hand, which consists of a sequence of practice tasks (possibly with feedback and/or explanations) preceding the real experiment.
There are good reasons to believe that, in the context of judgments about knowledge attribution, a phase of learning would make a larger contribution to reducing error rates than offering incentives. While the economics literature suggests that incentives increase attention and cognitive effort, one may wonder if attention and effort will be applied to the right kind of issues. It is initially plausible to think that what sets us apart from non-philosophers is that we have learned "how to apply general concepts to specific examples with careful attention to the relevant subtleties" (Williamson 2007, 191, my emphasis). If that is true, then incentives may misfire a bit (which may explain the results of the previous section), and genuine learning is then likely to do more.
This is what I did. I developed a short learning phase without incentives, with minimal feedback (discussed in this section), and one longer learning phase with textbook style explanations, where incentives were necessary to motivate participants to stay in the experiments for 20 minutes (discussed in the next section). My cue was not the Linda the Bank Teller experiment, but another behavioral challenge to economic orthodoxy, namely, experiments having to do with the base-rate fallacy. These experiments involve tasks requiring participants to calculate the conditional probability that you have a certain disease given that you know the outcome of a certain test. Kahneman and Tversky (1973), for instance, found that people tend to overlook the fact that to correctly determine this probability, they must also consider the unconditional probability of having that disease (the occurrence of that disease in the relevant population, or base rate). Most participants didn't do that.
If you consult the psychology literature, you may get the impression that Kahneman and Tversky's findings are quite stable. Yet most of these experiments are "snapshot studies" (Hertwig and Ortmann 2001, 387) as they confront participants with one case only. That is, these participants are "inexperienced," and "unfamiliar" with the "wrinkles" of the situation (Binmore 1994, 184).
What happens if participants are given the opportunity to familiarize themselves with these wrinkles? In a well-known experiment, Harrison (1994) reduced the base-rate fallacy by having participants go through a round of ten practice tasks, followed by feedback on performance. In a next round of ten tasks, they displayed the base-rate fallacy considerably less frequently.Footnote 20
Psychologists might demur. Thaler (1987), for instance, has argued that when it comes to major life decisions, people don't have sufficiently many opportunities for learning (think of mortgage or retirement planning decisions), and that this diminishes the force of the economist's response to the behavioral challenge. But this depends on one's explanatory goals. Snapshot studies may well help you to explain household financial planning (which people do only infrequently), whereas genuine learning is perhaps more likely among professional investors (who work with finance all the time). I take no stance here, but only note that Thaler's objection does not have much force if you are interested in making laypeople subjects more reflective and more attentive to the relevant details of the cases they are confronted with.
In the short learning study I tested the effect of a simple type of learning. Participants were told that they would have to carry out five small tasks (each consisting of reading a small story and answering a question), plus a small survey. They were informed that after each of the first four tasks they would receive feedback on whether they answered the question correctly, and that this might help them to answer the last question correctly. The practice vignettes were drawn from earlier work in experimental philosophy.Footnote 21 They were presented in random order. Two of the four cases had "really knows" as the textbook answer, and two "only believes." Feedback was of the form: "The correct answer is: Bob only believes that Jill drives an American car."
What about the results? They were not much different from the incentivized experiment. There is no improvement in the Gettier Case and the Non-truth Case, and only some improvement in the Knowledge Case (\(p < .01\)). What works in economics doesn't seem to work in philosophy.
Long learning
But perhaps this is too quick. Perhaps participants were not given sufficient time and opportunity to practice, and since an incentive structure was missing, they may not have felt the need to practice particularly intensely. Hence I presented another group of participants with an incentivized training regimen that is more in line with what undergraduate students may encounter in an introduction to philosophy/epistemology.
First, they got eight instead of four practice cases with simple feedback (correct/incorrect), half of them with "really knows," half of them with "only believes" as the epistemological consensus answer.
Secondly, after the first four of these eight practice cases, I inserted two cases (one "really knows," the other "only believes") with elaborate feedback (an explanation that philosophy students may be given in class), which means that after the entire learning phase, subjects will have gone through ten cases. A practical reason for this number is that I estimated that the total session would last around 20 minutes, which is about the maximum an online audience would be willing to invest. A theoretical reason was that, as far as I can see, introductory courses give the median student exposure to fewer vignettes (but of course to more theory). Moreover, ten is what Harrison (1994) uses in his work on the base-rate fallacy. As a result, this number is a defensible choice.Footnote 22 All ten practice cases were selected from the experimental philosophy literature (the first four were identical to those in the short learning study).
The third element of the long learning study is that at various places during the learning phase, participants are recommended to take some time to reflect on the differences between knowledge and belief, and to connect their reflections with the practice cases. This is quite common in philosophy teaching, but was also introduced with the explicit aim of drawing subjects' attention to potentially "overlooked aspects of the description of the scenario" (Williamson 2011, 226).Footnote 23
Fourthly, I provide participants with an incentive to pay attention to the practice session (and to mimic grading in a philosophy class), namely, a bonus of £5 for a correct answer to the final (and clearly designated) question they see (about a Gettier, Non-truth, or Knowledge Case).
Altogether, I believe this setup is maximally close to what happens in a philosophy undergraduate course, given the inherent constraints of online experiments. Moreover, the design is entirely in line with the methods used by economists answering to the behavioral challenge.
So, what do we find? There is no improvement in the Gettier Case. In the two other cases, the result was the reverse of that in the previous (non-incentivized, short) learning treatment: no improvement in the Knowledge Case, and some improvement in the Non-truth Case (\(p < .01\)). In sum, learning doesn't seem to align laypeople and expert knowledge attribution.
Besides incentives and learning, economists have more recently started using group consultation as a way to align laypeople and theory. The key illustrative reference point is again Linda the Bank Teller. Charness et al. (2010) examined what would happen if participants were given the opportunity to talk about the question in groups, before individually answering it. Participants were grouped in pairs or triples. They were presented with the case, and each pair or triple was asked to have a discussion about the right answer to the question. After this consultation phase, participants had to individually answer the question. The researchers found that when participants discuss Linda the Bank Teller in pairs, the individual error rates reduce from 58% to 48%, a drop of almost 20% (10 percentage points).Footnote 24
May we hope that group consultation has a similar effect on laypeople judgments concerning knowledge and belief? A mechanism that might explain why group consultation benefits individual judgments about probability is described as the application of the truth-wins norm in eureka-type problems (Lorge and Solomon 1955). These are problems in which, when people fail to find the solution themselves, they will immediately recognize the solution (eureka) if someone points it out to them—and so the truth wins. Mathematics may be a case in point: you may not be able to find a proof for some proposition yourself, but when someone gives you a proof, you see it's a proof of that proposition. Or more generally, if two people consult with the aim of solving a eureka-type problem, and each has a positive probability p to find the solution, the truth-wins norms suggests that consultation will increase the probability of both knowing the solution to \(1 - (1 - p)^2\), which is then greater than p.
Most studies do not find improvement of the size predicted by the truth-wins norm, even in cases that are unproblematically eureka-type; yet most studies do find substantial improvement (Heath and Gonzalez 1995). The improvement that Charness et al. (2010) found in the Linda the Bank Teller case is less than what the truth-wins norm predicts, but still considerable.Footnote 25
It is initially plausible to see philosophical questions about knowledge as eureka-type questions, particularly for advocates of the expertise defense who maintain that Gettier's (1963) paper provided a refutation of the justified true belief theory of knowledge that was accepted "[a]lmost overnight" by the "vast majority of epistemologists throughout the analytic community" (Williamson 2005, 3).Footnote 26 Just as with proofs in mathematics, it may have been difficult to design a counterexample to the justified true belief theory; but once it was there, (almost) everyone realized it was one.
So I designed an experiment that stays as close as possible to the design of Charness et al. (2010), and conducted one baseline experiment without group consultation and one experiment with group consultation. Like these scholars, I used a student sample (economics and business students, not philosophy, University of Groningen, The Netherlands), and conducted the experiment in a large lecture hall with ample room for groups to have private conversations.
Regarding results, here, too, there is little doubt that the convergence hypothesis doesn't gain any plausibility. Only in the Knowledge Case there is a tiny effect of small statistical significance, but in the unexpected direction, namely, increasing error. In the Gettier Case and the Non-truth Case nothing happens. What boosted success in the Linda the Bank Teller case (and helped confronting the behavioral challenge) does not improve knowledge attribution. So let's turn to the last study.
Experimental control
This experiment is motivated by an observation due to Gigerenzer (2001). Gigerenzer reported results suggesting that German students perform better than American students in such tasks as Linda the Bank Teller and base-rate reasoning, and attributed the difference in performance to the way that experiments are conducted in Germany. In Gigerenzer's lab, participants engage in face-to-face contact with the experimenter. They come to the lab individually, or in small groups, which allows them to focus on the task at hand without distraction. American experiments, by contrast, do not involve one-on-one contact between participant and experimenter. Participants do not really come to a lab, but rather are tested during classes, or in take-home experiments, where students get a booklet with assignments to be solved at home and to be returned to the experimenter afterwards (or students have to carry out the experiment online). According to Gigerenzer, it is this loss of experimental control that largely explains the difference between US and German samples: American experimental subjects are more likely to have faced distraction.
While take-home experiments may be rare in experimental philosophy, the majority of experiments do not involve the extensive experimental control that Gigerenzer's lab offers. The first two studies reported in this paper are quite representative here: subjects were selected through an online portal (limited control), and participated in experiments in a lecture hall (a bit more control), and were presented with an online survey. There was fairly limited influence on the circumstances in which they answered the questions. Hence we should expect that with increased experimental control we see what we see in economics: convergence to orthodoxy.
So I recruited non-philosophy students to the Faculty of Economics & Business Research Lab of the University of Groningen, The Netherlands, and had them answer knowledge attribution questions in soundproofed, one-person cubicles, without access to Internet, and with a no-cellphone policy. But I faced a methodological issue here. It would be hard to justify comparing error rates in this sample with error rates in, say, the baselines of the first studies, or any other study. This is because these samples have distinct demographic characteristics. The samples used for the studies with incentives and learning are somewhat representative of the UK population. The experiment on group consultation has a mainly Dutch sample, even though it includes international students, but only undergraduate students. The lab experiment has a mainly Dutch sample, but includes international students at the undergraduate and graduate level. To circumvent these issues, I approached the question a bit more indirectly, and conducted another randomized controlled trial (RCT) to see if—with experimental control—incentives and learning effects are greater than in the first RCT (discussed in Sects. 4–6). This is an admittedly indirect measure, but I believe it's methodologically preferable. All the same, if we do find large differences between this study's baseline and the baselines of the previous two studies, this may give some evidence backing the convergence hypothesis that I ultimately set out to test.
So does experimental control finally bring answers closer to epistemological consensus? No: none of the treatments in this last study (incentives, short learning) had any statistically significant impact on error rates.
But perhaps there is some effect if we set aside the methodological scruples and compare baselines? Under experimental control, the baseline error rate in the Gettier Case is 63%. This compares positively with the error rate of 72% from the baseline of the first RCT, which is the baseline used to compare incentives, short and long learning. But as that baseline involves a UK national sample (whereas here we have students only, and mostly Dutch), it is more natural to compare the results with the baseline of the group consultation study, to which it is closer demographically. That baseline error rate was 52%, however. So even with a relaxed methodology, this study has not generated any support for the convergence hypothesis, however much I had expected this. Experimental control doesn't decrease error rates.
The idea of this paper was to see what remains of the experimental or restrictionist challenge to armchair philosophy if we adopt the machinery that economists have used to counter the behavioral challenge that arose out of research by such psychologists as Tversky and Kahneman. The economists showed that many of the anomalies detected by the psychologists become considerably smaller if participants obtain financial incentives, go through a learning period, work together in groups, or face more stringent forms of experimental control. The thought behind the project was that if similar effects could be demonstrated with regard to philosophy tasks, we would be in a good position to describe the repercussions the experimental challenge should have for philosophy—just about the same as for economics, that is, not too much: orthodox economics is still alive and flourishing, and while the behavioral challenge has generated the field of behavioral economics, this new discipline is, after more than three decades, still fairly small.
But nothing of the sort. Rigorous testing shows that these techniques don't get us anywhere near the effect they have in economics. The experimental philosophy results seem to be much stronger than the behavioral economics results.
How philosophers should now deal with the experimental challenge is not my concern here. Yet I do wish to probe the force of the results by addressing a few objections that might be raised. I deal with most of these objections by conducting further robustness checks and/or providing more information on the samples.
To begin with, one might wonder how the samples compare with earlier results from the experimental philosophy literature when we consider the various control variables used in the regressions: gender, ethnicity, and so on. Examining the effects of ethnicity (culture) and socioeconomic status on knowledge attribution has been on the agenda of experimental philosophy from the very start (Weinberg et al. 2001). I don't find evidence for such effects.
Gender effects have also attracted quite a bit of attention. Buckwalter and Stich (2014), for instance, report that women tend to attribute knowledge more frequently on average in particular vignettes, but these results may not replicate (Machery et al. 2017; Nagel et al. 2013; Seyedsayamdost 2014). I find fairly considerable gender coefficients in the Gettier Case (\(p < .05\) and \(p < .01\)), in two of the three treatments of the RCT, with women indeed more frequently than men attributing knowledge. In the other studies the effects are negligible.
Colaço et al. (2014) find some age effects. The age coefficients I find are only in a few cases significant, and always small.
To my knowledge, there are no studies that zoom in on religion or education, except that Weinberg et al. (2001) use educational achievement as a proxy for socioeconomic status. I find no evidence of a clear religion effect, but I do find more systematic and substantial education effects: subjects possessing a college degree are more likely to give the consensus answer in the incentivized and short learning treatments, both in the Gettier Case and the Non-truth Case, with significance ranging from the 5% to the 0.1% level. This effect is, however, fully absent in the Knowledge Case.
Finally, except for religion (\(p < .05\)) there is no evidence for interaction effects between treatment type and any control variable (not even if instead of the usual college education dummy we use a fine-grained variable with seven educational achievement brackets). So the way in which people respond to, say, incentives vis-à-vis the baseline is not influenced by their age, gender, and so forth, but only (marginally) by their religiosity.
All in all, considering the covariates I don't find effects that have not already been postulated in the literature before (except, perhaps, religion and education).
Further zooming in on education, a second issue to deal with arises out of remarks by some who have written in the spirit of the expertise defense to the effect that education might raise tendency to reflect. Devitt (2011, 426), for instance, writes that "a totally uneducated person may reflect very little and hence have few if any intuitive judgments about her language." In the regressions, I used a college education dummy, following standard practices, and as I said, there were some effects in some treatments and some vignettes. But perhaps a bigger and more systematic effect can be found if we use a dummy variable with a different cut-off point that distinguishes between "totally uneducated" subjects and all others?
And indeed, to some extent Devitt's predictions are borne out by the data. If we call a subject totally uneducated if he or she has qualifications at level 1 or below (the lowest educational level in typical UK surveys), there is indeed a very substantial effect on correctness in the Gettier Case (but not in the Non-truth Case and Knowledge Case). However, as the baseline success rate for subjects with qualifications above level 1 (so the complement of the reference group) is only 30%, this result is unlikely to bring solace to the armchair philosopher: the "not totally uneducated" are still very far removed from the professional philosopher.Footnote 27
Third: Ludwig (2007, 151) makes the very interesting suggestion that after a training session we might want to select those subjects that are "best at responding on the basis of competence in the use of concepts," and then present these subjects with scenarios of interest. To see if that works, let's compare the best scoring subjects in the short and long learning phases, respectively, with all baseline subjects. In the short learning study, subjects that score best during the learning phase on average score worse on the final question than the average subject in the baseline, but the difference is not statistically significant. The best scoring subjects (ten out of ten questions correct) in the long learning study score better on the final question than the average subject in the baseline, but the difference is not significant. Iteratively relaxing the definition (so allowing for one error in the learning phase, or two, or three, and so on) in the short learning study does not yield significance. In the long learning study, however, it does. If we call a best scoring subject one who has answered nine or ten questions correctly, then 72% of the best scoring subjects answer the Gettier Case correctly, as opposed to 28% in the baseline, and this difference is highly significant (\(Z = 3.36\), \(p < .001\)).Footnote 28
We shouldn't be overly enthusiastic about this finding, however, since we may well have individuated here those subjects that would give the consensus answer to the Gettier Case anyway. Compare: if you look at those subjects that do well on ten practice questions preparing for the Linda the Bank Teller task, you may well find that these are subjects that come to the experiment with greater probabilistic expertise already, so the success rate cannot then be attributed to the practice session.
To circumvent this, we could include a measure of reflection time; for indeed, experts who are forced to go through ten practice cases will rush through it, but laypeople who really learn from the practice will take their time. But this is of no avail: a simple regression showed that reflection time in the long learning study does not predict correctness in any of the three cases.
Fourth: Sosa (2009, 106) suggests that in order for there to be a philosophically relevant conflict between the intuitions of laypeople and those of philosophers concerning a given scenario, these intuitions should be "strong enough." So one should perhaps expect that participants with strong intuitions are more likely to provide correct answers. We can test this by estimating the correlation between the strength of the intuition, as measured by the confidence question in the surveys, and correctness of the answer to the Gettier Case. But the results of that exercise have the wrong direction, and are not statistically significant, so here, too, my findings are sufficiently robust: they also hold for people with strong intuitions.Footnote 29
Fifth: one might think that a good predictor of correctness of answers to a question about a Gettier case is whether a subject has reflected sufficiently deeply on the case and question, or so the armchair philosopher may argue. Experiments conducted by Weinberg et al. (2012), among others, do not seem to offer much hope for a reflection defense of this type, but the authors acknowledge that the instruments they use to measure reflection may not be fully adequate. They use the Need for Cognition Test (Cacioppo and Petty 1982), and the Cognitive Reflection Test (Frederick 2005), but social science researchers use these tests (particularly the second one) more often as a proxy for intelligence (IQ) than as a genuine measure of reflection, which is conceptually distinct from intelligence. I included in the long learning study a few stages where subjects were explicitly recommended to reflect on the difference between knowledge and belief, which gives us a more direct measure of reflection: the time spent on these stages of the experiment. My findings here are, however, entirely in line with those of Weinberg et al. (2012): regression shows that people who reflect longer in the long learning study are not more likely to come up with the consensus answer in any of the three cases.Footnote 30
The upshot of the discussion so far is that further robustness checks weaken the force of a few objections that might be raised against my conclusions. Yet, while I'm confident that the results will robustly stand up to scrutiny, I'd like to mention a number of limitations of the study and indicate some avenues for future research.Footnote 31
First: data always have specific demographic characteristics. For all we know, what I have found is valid only for UK citizens (incentives, learning), or only for students of economics and business (group consultation, experimental design). Such things hold for almost any study in experimental social science, but it is important to note that the external validity of our findings will only increase if similar studies are conducted with samples with different demographics.
Second: I only look at one Gettier Case, one Non-truth Case, and one Knowledge Case. We know from the experimental philosophy literature, however, that there is considerable variation in laypeople judgments across cases, and what I find here may, for all we know, be an artefact of the three vignettes. Therefore, future research should try and replicate with a different set of vignettes.
Third: the experimental challenge isn't only to do with knowledge attribution judgments, or with epistemology, but affects the whole of philosophy. I cannot rule out that incentives, learning, group consultation, or experimental control make laypeople converge to philosophers if they are asked to consider vignettes drawn from other branches of philosophy. In fact, as I take economics as my main source of inspiration, we should positively expect future research to show that in different contexts these experimental techniques have effects of different size and character: the economics results aren't homogeneous either.
Fourth: it may seem as though I think that the layperson–expert opposition is what has driven most of experimental philosophy, so I should stress that I don't think that, and realize that initially experimental philosophers were primarily concerned with deviations from philosophical consensus in particular segments of the laypeople population (culture, socioeconomic status, etc.). Analogous research does exist in psychology. It examines, to give one example, how culture or socioeconomic status influences perception. But such research has never played such a prominent role in the behavioral challenge to economics as Linda the Bank Teller and the other experiments cited in this paper. So I should acknowledge that setting aside the layperson–expert opposition would require a different experimental setup, and might lead to different results.
Fifth: while the design of the two learning treatments in the randomized controlled trial closely mirrors what is standard in economics experiments, it only very tentatively approximates full-blown professional philosophical training. This matters less if the aim is only to see whether the economist's tactics can be deployed against experimental philosophy, which was my initial plan; for indeed, the economists don't provide their subjects with anything near a genuine economics training either. But it matters more if you consider the relevance of my results to the expertise defense, because the expertise defender might retort that going through a handful Gettier cases doesn't make an expert. Even in the long learning treatment we cannot indeed exclude that subjects come with widely divergent background assumptions that influence the way they interpret the vignettes and the questions (Sosa 2009). I agree. But an advocate of the expertise defense should find it at least somewhat puzzling that incentives and the other experimental techniques that work in economics don't even make things a tiny bit better. So I acknowledge this point as a potential limitation of the study, and hope that more extensive empirical work, for instance using some of Turri's (2013) suggestions within the framework of a randomized controlled trial, will give us more definite answers.
Sixth: while the Linda the Bank Teller case has passed into a byword for behavioral economics, it shows only one of the many biases that have been documented in the literature, and we would therefore be grossly remiss if we didn't at least contemplate the possibility that knowledge attribution cases might be more like those biases that experimental techniques have a lesser hold over.
To begin with, clearly no experimental strategy will fully remove bias: even with incentives, still about a third of the subjects in Linda the Bank Teller go against probability theory. So my convergence hypothesis was that in knowledge attribution cases we would see a reduction of errors, not that they would fully vanish.
But indeed, the economics literature does show that the experimental techniques don't always work (Hertwig and Ortmann 2001). What seems to be beyond reasonable doubt is that incentives backfire when they create too much pressure on subjects, and that they may "crowd out" intrinsic motivation. It is also clear that group consultation is unlikely to do much work if subjects find it hard to ascertain their partner's credentials or otherwise to evaluate or corroborate their partner's contributions. Perhaps knowledge attribution tasks are more like Wason selection tasks and other logic tasks, where incentives don't seem to do as much as in Linda the Bank Teller. Or perhaps, as an anonymous reviewer kindly suggested to me, in order to understand why we find that these experimental techniques don't boost performance, we should look at tasks in which analytic answers are not so readily available as they are in logic and probability theory. Based on my reading of the extant economics literature, however, my impression is that a clear pattern has yet to emerge from the welter of documented cases, and that we cannot confidently answer these questions without more systematic further research. But it is certainly possible that future behavioral economics will develop cases that become just as central and paradigmatic as Linda the Bank Teller—and bear even greater similarity to philosophy tasks—but for which incentivization and the other techniques do not work, and this would probably weaken the force of the claims I defend in this paper.
Seventh: several authors have responded to the experimental challenge arguing that much published work in experimental philosophy (they think) doesn't meet the high standards of empirical research in the social sciences (Woolfolk 2013). This is strikingly similar to what economists say about psychologists. As Hertwig and Ortmann (2001) document, economists believe that psychologists use inferior experimental techniques. In particular, economists blame psychologists: for not giving participants clear scripts, for using snapshot studies instead of repeated trials involving learning and feedback, for the fact that psychologists don't implement performance-based monetary payments (incentives), and because psychologists often deceive participants about the purposes of the experiment. As a result, the economists think, their work is far more reliable than psychology.
I don't need to take a stance here, even if my methods are clearly drawn from economics rather than psychology. I carried out a randomized controlled trial, which is seen as the gold standard in economic impact analysis, and followed widely accepted practices in economics. I then mirrored the design of a frequently cited and influential paper in economics on the Linda the Bank Teller case, and here, too, used standard (and admittedly not very complex) econometrics. And the last study was conducted in highly controlled lab conditions. The statistical analysis is in line with what is common in economics, as are the various robustness checks reported in the present section. Moreover, sample sizes are above what is generally expected in the field. But one can always do more, and I can only hope that others, too, will turn to economics for methodological inspiration—not to replace, but to accompany psychology.
It is time to conclude. I am aware of the potential limitations of the study, but despite these limitations, I feel there is little doubt that as it stands the consolation armchair philosophers might want to find in the economist's response to the behavioral challenge is spurious. My initial idea of saving the armchair by experiment has failed. This has made the experimental challenge all the more powerful.
The expertise defense is developed by such authors as Bach (2019), Deutsch (2009), Devitt (2011), Egler and Ross (2020), Grundmann (2010), Hales (2006), Hofmann (2010), Horvath (2010), Irikefe (2020), Kauppinen (2007), Ludwig (2007, 2010), Sosa (2007, 2009) and Williamson (2007, 2009, 2011). Also see Alexander (2016), Horvath and Wiegmann (2016), Nado (2014a, 2014b), Seyedsayamdost (2019) and Williamson (2016). The expertise defense was challenged on conceptual and empirical grounds by, among others, Buckwalter (2016), Clarke (2013), Hitchcock (2012), Machery (2011), Machery et al. (2013), Mizrahi (2015), Ryberg (2013), Schulz et al. (2011) and Weinberg et al. (2010). Of particular relevance to the present paper: Weinberg et al. (2010) called upon philosophers to develop and test empirical hypotheses about philosophers' alleged competence in thought experimentation, but most subsequent experimenting has not led to anything near a defense of the armchair position. See, e.g., Horvath and Wiegmann (2016) (but also for empirical evidence showing that philosopher intuitions are in a sense better than those of laypeople), Schulz et al. (2011), Schwitzgebel (2009), Schwitzgebel and Cushman (2012), Tobia et al. (2013) and Vaesen et al. (2013). Also see Drożdżowicz (2018), Hansson (2020) and Seyedsayamdost (2019).
Binmore means performance-based payments, not appearance fees.
Williamson (2007) briefly discusses the Linda the Bank Teller experiment. Also see Jackson (2011) (not a critic of experimental philosophy per se). The gambler's fallacy is another behavioral bias often discussed in this context (Hales 2006; Hofmann 2010; Jackson 2011; Ludwig 2007).
For additional support for the convergence hypothesis, see Buckwalter (2016) and Turri (2013).
Details can be found in online supplementary materials.
The Non-truth and Knowledge Case figure as control cases, testing other conditions of knowledge. See Starmans and Friedman (2012). I renamed the cases: the Non-truth Case is their False Belief condition, and the Knowledge Case is their Control condition. Vignettes were drawn from Experiment 1A in their study, with banknote instead of dollar bill to adjust to my UK sample.
See Starmans and Friedman (2012) for a more detailed discussion of these conditions, and references to the relevant literature on the reasons backing the consensus.
I used a 7-point Likert scale in the survey, as it has some methodological advantages over the 10-point scale that Starmans and Friedman (2012) use: it offers a mid-point, and is not too fine-grained to obscure interpretation among participants (Lissitz and Green 1975).
Following what is common among economists I use and report linear regressions with binary outcome variables because of the natural interpretation of the resulting coefficients. For all three studies reported in this paper, logistic regressions do not change the findings.
Course credits and candy bars may also figure as incentives, but I follow economists here and solely include financial incentives. All experimental subjects use and want money, and know how to compare money; moreover, their demand for money is not easily exhausted over the course of an experiment (unlike demand for candy bars). Hence subjects are likely motivated to maximize their monetary payoff, which will lead them to pay sufficient attention to the details of the tasks they face. Lack of attention among laypeople is a recurring theme in the literature on the expertise defense. But you don't need to accept the expertise defense to find it plausible that for laypeople judgments to be relevant, they should satisfy some minimum standard of reflection and attention (Weinberg et al. 2001, 2010). Also see Jackson (2011) on the insignificance of unreflective judgments in Linda the Bank Teller and knowledge attribution tasks.
This is underscored by the fact that the analogy between probability and utility theoretic tasks and philosophy tasks has figured in various replies to the experimental challenge. See footnote 3.
The criticism is particularly directed at the role the purported analogy between philosophy and other fields (mathematics, physics, law, etc.) plays in the expertise defense. The analogy has a slightly different function in the present paper: it primarily serves to put the relevance of particular experimental findings about laypeople judgments into relief by comparing philosophy with other disciplines.
Incentivization is one treatment in the first RCT experiment; the two other treatments involve (short and long) learning, discussed in Sects. 5 and 6.
Their experiment was conducted in 2008. $4 in 2008 corresponds to about $4.55 or £3.40 at the time of conducting the experiments reported in this paper.
Following Weinberg et al. (2010, 343), e.g., you might say that I use "entrenched theory" as the benchmark in the experiments.
Ludwig (2007, 150), e.g., says about Kripke's Gödel/Schmidt case that the "way the thought experiment is set up, there is only one answer that is acceptable. It is not described in a way that allows any other correct response."
I am indebted here to Williamson (2007, 96), where relevant references can be found.
Details on methods and results can be found in online supplementary materials.
Similar positions have been articulated by such authors as Hofmann (2010), Horvath (2010), Kauppinen (2007), Sosa (2007) and Williamson (2007, 2009, 2011).
Harrison's (1994) paper is extremely rich in experimental detail, and covers a whole lot more than this. For expository purposes I ignore, among other things, that Harrison was particularly interested in testing Kahneman and Tversky's (1973) explanation of the base-rate fallacy in terms of the representative heuristic.
The idea that feedback on answers to thought experiments is among the mechanisms that generate philosophical expertise is widely shared by advocates of the expertise defense. Horvath (2010, 471), e.g., writes that "we have ample prima facie reason to believe that the relevant cognitive skills of professional philosophers have been exposed to enough clear and reliable feedback to constitute true expertise concerning intuitive evaluation of hypothetical cases." Ludwig (2007, 149) believes that training fosters "sensitivity to the structure of the concepts through reflective exercises with problems involving those concepts," and elsewhere suggests that to that end it may be useful to "run through a number of different scenarios" (2007, 155). Among experimental philosophers, Weinberg et al. (2010, 340) argue that the empirical literature on (general) expertise shows that the acquisition of expertise requires "repeated or salient successes and failures" based on clear and frequent feedback, but they question whether philosophy can ever provide such feedback, among other things because training of intuitions against "already-certified expert intuitions" would seem to be "non-starter" leading to a vicious regress.
Weinberg et al. claim that the set of cases that a typical professional philosopher will have gone through after completing undergraduate and graduate studies is "orders of magnitude" (2010, 342) smaller than, say, how often a chess player practices a given opening, and that "[p]hilosophy rarely if ever...provides the same ample degree of well-established cases to provide the requisite training regimen" (2010, 341). Williamson (2011) finds it more relevant to compare the number of times a philosophy student gets feedback with the number of times a law student gets similar feedback. Just as economists don't turn subjects into probability or decision theorists when they rebut the behavioral challenge, for our purposes I don't need to provide subjects with anything that comes close to a philosophy education.
Together with the two vignettes in the middle of the learning phase on which subjects get more extensive feedback, this brings long learning somewhat in line with a suggestion voiced by Kauppinen (2007) that ideally eliciting judgments about philosophical thought experiments involves something of a dialogue between experimenter and subject, because that would increase the likelihood that the elicited judgments result from conceptual competence and not from irrelevant perturbing factors. Kauppinen (2007, 110) seems to support my convergence hypothesis here, as he believes that laypeople judgments in such dialogical experiments would "line up with each other."
The baseline error rates (i.e., for individuals) that Charness et al. (2010) found were lower than in Tversky and Kahneman (1983).
The ex post (empirical) individual probability of error in their experiment is .58, so success probability is .42. Using this as a measure of the individual probability of answering the question correctly, we should expect pairwise consultation to lead to a success rate of \(1 - (1 - .42)^2 = .66\). The success rate (pairwise) they empirically find is \(1 - .48 = .52\).
Also see, e.g., Grundmann (2010), Horvath (2010), Jackson (2011) and Ludwig (2007).
Baseline success rate (constant) is .30. The coefficient is \(-.24\) (\(p < .05\)), with regression here on the baseline (untreated) sample in the first RCT. Interpretation: success rate among those participants with level 1 or below is 6%; success rate among those with qualifications above level 1 is 30%; and the difference is of mild statistical significance. The difference becomes smaller, and no longer significant, if we relax the definition of the dummy. For the strictest definition of the dummy, however, the results seem fairly robust in that they persist if we consider the entire sample of the first RCT (baseline and the three treatments). Non-truth and Knowledge Case show no effects.
We could also examine whether the number of correct answers during the learning phase predicts success on the final question: there is no effect in the short learning study, but in the long learning study, the correlation is positive and mildly significant (\(p < .05\)), in all three cases.
Regressions on a dummy for very high confidence (confidence = 7), or on a dummy for high confidence (confidence = 5, 6, or 7) do not change this picture. On reporting confidence, also see Weinberg (2007), and on empirical work on confidence, see Wright (2010).
One might object that I measure the quantity but not the quality of reflection, but it is hard to see how you could develop a measure of the quality of reflection that does not lead to circularity (endogeneity), that is, a measure that is independent of success in the tasks at hand.
Many thanks to an anonymous reviewer for pressing me on points 2–6 mentioned here.
Alexander, J. (2016). Philosophical expertise. In J. Sytsma & W. Buckwalter (Eds.), A companion to experimental philosophy (pp. 557–567). Chichester: Wiley.
Alexander, J., & Weinberg, J. M. (2007). Analytic epistemology and experimental philosophy. Philosophy Compass, 2(1), 56–80.
Bach, T. (2019). Defence of armchair expertise. Theoria, 85(5), 350–382.
Baumeister, R. F. (1984). Choking under pressure: Self-consciousness and paradoxical effects of incentives on skillful performance. Journal of Personality and Social Psychology, 46(3), 610–620.
Binmore, K. G. (1994). Game theory and the social contract. Vol.1, Playing fair. Cambridge, MA: MIT Press.
Buckwalter, W. (2016). Intuition fail: Philosophical activity and the limits of expertise. Philosophy and Phenomenological Research, 92(2), 378–410.
Buckwalter, W., & Stich, S. (2014). Gender and philosophical intuition. Experimental Philosophy, 2, 307–346.
Cacioppo, J. T., & Petty, R. E. (1982). The need for cognition. Journal of Personality and Social Psychology, 42(1), 116–131.
Camerer, C. (1995). Individual decision making. In J. H. Kagel & A. E. Roth (Eds.), Handbook of experimental economics (pp. 587–703). Princeton: Princeton University Press.
Charness, G., Karni, E., & Levin, D. (2010). On the conjunction fallacy in probability judgment: New experimental evidence regarding Linda. Games and Economic Behavior, 68(2), 551–556.
Clarke, S. (2013). Intuitions as evidence, philosophical expertise and the developmental challenge. Philosophical Papers, 42(2), 175–207.
Colaço, D., Buckwalter, W., Stich, S., & Machery, E. (2014). Epistemic intuitions in fake-barn thought experiments. Episteme, 11(2), 199–212.
Deutsch, M. (2009). Experimental philosophy and the theory of reference. Mind & Language, 24(4), 445–466.
Devitt, M. (2011). Experimental semantics. Philosophy and Phenomenological Research, 82(2), 418–435.
Drożdżowicz, A. (2018). Philosophical expertise beyond intuitions. Philosophical Psychology, 31(2), 253–277.
Egler, M., & Ross, L. D. (2020). Philosophical expertise under the microscope. Synthese, 197, 1077–1098.
Frederick, S. (2005). Cognitive reflection and decision making. Journal of Economic Perspectives, 19(4), 25–42.
Gettier, E. L. (1963). Is justified true belief knowledge? Analysis, 23(6), 121–123.
Gigerenzer, G. (2001). Are we losing control? Behavioral and Brain Sciences, 24, 408–409.
Grundmann, T. (2010). Some hope for intuitions: A reply to Weinberg. Philosophical Psychology, 23(4), 481–509.
Hales, S. D. (2006). Relativism and the foundations of philosophy. Cambridge, MA: MIT Press.
Hansson, S. O. (2020). Philosophical expertise. Theoria, 86(2), 139–144.
Harrison, G. W. (1994). Expected utility theory and the experimentalists. Empirical Economics, 19, 223–253.
Heath, C., & Gonzalez, R. (1995). Interaction with others increases decision confidence but not decision quality: Evidence against information collection views of interactive decision making. Organizational Behavior and Human Decision Processes, 61(3), 305–326.
Hertwig, R., & Ortmann, A. (2001). Experimental practices in economics a methodological challenge for psychologists. Behavioral and Brain Sciences, 24, 383–451.
Hitchcock, C. (2012). Thought experiments, real experiments, and the expertise objection. European Journal for Philosophy of Science, 2(2), 205–218.
Hofmann, F. (2010). Intuitions, concepts, and imagination. Philosophical Psychology, 23(4), 529–546.
Horvath, J. (2010). How (not) to react to experimental philosophy. Philosophical Psychology, 23(4), 447–480.
Horvath, J., & Wiegmann, A. (2016). Intuitive expertise and intuitions about knowledge. Philosophical Studies, 173(10), 2701–2726.
Irikefe, P. O. (2020). A fresh look at the expertise reply to the variation problem. Philosophical Psychology, 33(6), 840–867.
Jackson, F. (2011). On Gettier holdouts. Mind & Language, 26(4), 468–481.
Kahneman, D., & Tversky, A. (1973). On the psychology of prediction. Psychological Review, 80(4), 237–251.
Kauppinen, A. (2007). The rise and fall of experimental philosophy. Philosophical Explorations, 10(2), 95–118.
Lissitz, R. W., & Green, S. B. (1975). Effect of the number of scale points on reliability: A Monte Carlo approach. Journal of Applied Psychology, 60(1), 10–13.
Lorge, I., & Solomon, H. (1955). Two models of group behavior in the solution of eureka-type problems. Psychometrika, 20(2), 139–148.
Ludwig, K. (2007). The epistemology of thought experiments: First person versus third person approaches. Midwest Studies in Philosophy, 31, 128–159.
Ludwig, K. (2010). Intuitions and relativity. Philosophical Psychology, 23(4), 427–445.
Machery, E. (2011). Thought experiments and philosophical knowledge. Metaphilosophy, 42(3), 191–214.
Machery, E., Mallon, R., Nichols, S., & Stich, S. P. (2013). If folk intuitions vary, then what? Philosophy and Phenomenological Research, 86(3), 618–635.
Machery, E., Stich, S., Rose, D., Alai, M., Angelucci, A., Berniūnas, R., et al. (2017). The Gettier intuition from South America to Asia. Journal of Indian Council of Philosophical Research, 34(3), 517–541.
Mizrahi, M. (2015). Three arguments against the expertise defense. Metaphilosophy, 46(1), 52–64.
Nado, J. (2014a). Philosophical expertise. Philosophy Compass, 9(9), 631–641.
Nado, J. (2014b). Philosophical expertise and scientific expertise. Philosophical Psychology, 28(7), 1026–1044.
Nagel, J., Juan, V. S., & Mar, R. A. (2013). Lay denial of knowledge for justified true beliefs. Cognition, 129(3), 652–61.
Ryberg, J. (2013). Moral intuitions and the expertise defence. Analysis, 73(1), 3–9.
Schulz, E., Cokely, E. T., & Feltz, A. (2011). Persistent bias in expert judgments about free will and moral responsibility: A test of the expertise defense. Consciousness and Cognition, 20(4), 1722–31.
Schwitzgebel, E. (2009). Do ethicists steal more books? Philosophical Psychology, 22(6), 711–725.
Schwitzgebel, E., & Cushman, F. (2012). Expertise in moral reasoning? Order effects on moral judgment in professional philosophers and non-philosophers. Mind & Language, 27(2), 135–153.
Seyedsayamdost, H. (2014). On gender and philosophical intuition: Failure of replication and other negative results. Philosophical Psychology, 28(5), 642–673.
Seyedsayamdost, H. (2019). Philosophical expertise and philosophical methodology: A clearer division and notes on the expertise debate. Metaphilosophy, 50(1–2), 110–129.
Simon, H. A. (1948). Administrative behaviour: A study of the decision making processes in Administrative Organisation. New York: Macmillan.
Simon, H. A., & Bartel, R. D. (1986). The failure of armchair economics. Challenge, 29(5), 18–25.
Sosa, E. (2007). Experimental philosophy and philosophical intuition. Philosophical Studies, 132(1), 99–107.
Sosa, E. (2009). A defense of the use of intuitions in philosophy. In D. Murphy & M. Bishop (Eds.), Stich and his critics (pp. 101–112). Chichester: Wiley.
Starmans, C., & Friedman, O. (2012). The folk conception of knowledge. Cognition, 124(3), 272–83.
Thaler, R. (1987). The psychology of choice and the assumptions of economics. In A. E. Roth (Ed.), Laboratory experimentation in economics: Six points of view, Book section 4 (pp. 99–130). Cambridge: Cambridge University Press.
Tobia, K., Buckwalter, W., & Stich, S. (2013). Moral intuitions: Are philosophers experts? Philosophical Psychology, 26(5), 629–638.
Turri, J. (2013). A conspicuous art putting Gettier to the test. Philosophers' Imprint, 13(10), 1–16.
Tversky, A., & Kahneman, D. (1983). Extensional versus intuitivie reasoning: The conjunction fallacy in probability judgment. Psychological Science, 90(4), 293–315.
Vaesen, K., Peterson, M., & Van Bezooijen, B. (2013). The reliability of armchair intuitions. Metaphilosophy, 44(5), 559–578.
Weinberg, J. M. (2007). How to challenge intuitions empirically without risking skepticism. Midwest Studies In Philosophy, 31, 318–343.
Weinberg, J. M., Alexander, J., Gonnerman, C., & Reuter, S. (2012). Restrictionism and reflection challenge deflected, or simply redirected. Monist, 95(2), 200–222.
Weinberg, J. M., Gonnerman, C., Buckner, C., & Alexander, J. (2010). Are philosophers expert intuiters? Philosophical Psychology, 23(3), 331–355.
Weinberg, J. M., Nichols, S., & Stich, S. (2001). Normativity and epistemic intuitions. Philosophical Topics, 29(1–2), 429–460.
Williamson, T. (2005). Armchair philosophy, metaphysical modality and counterfactual thinking. Proceedings of the Aristotelian Society, 105(1), 1–23.
Williamson, T. (2007). The Philosophy of Philosophy. Malden: Blackwell.
Williamson, T. (2009). Replies to Ichikawa, Martin and Weinberg. Philosophical Studies, 145(3), 465–476.
Williamson, T. (2011). Philosophical expertise and the burden of proof. Metaphilosophy, 42(3), 215–229.
Williamson, T. (2016). Philosophical criticism of experimental philosophy. In J. Sytsma & W. Buckwalter (Eds.), A companion to experimental philosophy (pp. 20–36). Chichester: Wiley.
Woolfolk, R. (2013). Experimental philosophy: A methodological critique. Metaphilosophy, 44(1–2), 79–87.
Wright, J. C. (2010). On intuitional stability: The clear, the strong, and the paradigmatic. Cognition, 115(3), 491–503.
Yaniv, I., & Schul, Y. (1997). Elimination and inclusion procedures in judgment. Journal of Behavioral Decision Making, 10(3), 211–220.
Warmest thanks are due to audiences in Norwich and Osnabrück, and to Mark Alfano, Tammo Bijmolt, Mark Curtis, Eugen Fischer, Joachim Horvath, Nikil Mukerji, Laetitia Mulder, Marijke Leliveld, Robert Lensink, Chiara Lisciandra, Shaun Nichols, Kevin Reuter, Melissa Vergara Fernández, Tom Wansbeek, Juliette de Wit, Raymond Zaal, Lieuwe Zijlstra, and two anonymous reviewers for this journal, and to Reinder Dallinga for lab assistance.
Research for this paper was partly funded by the Dutch Research Council (NWO), Grant Number 360-20-310.
Philosophy, University of Groningen, Oude Boteringestraat 52, 9712 GL, Groningen, The Netherlands
Boudewijn de Bruin
Economics, University of Groningen, Nettelbosje 2, 9747 AE, Groningen, The Netherlands
Correspondence to Boudewijn de Bruin.
The author declares that he has no conflict of interest.
Supplementary material 1 (DO 8 kb)
Supplementary material 2 (DTA 65 kb)
Supplementary material 4 (DTA 104 kb)
Supplementary material 5 (DO 29 kb)
Supplementary material 6 (DTA 1502 kb)
Supplementary material 7 (PDF 204 kb)
de Bruin, B. Saving the armchair by experiment: what works in economics doesn't work in philosophy. Philos Stud 178, 2483–2508 (2021). https://doi.org/10.1007/s11098-020-01559-z
Expertise defense
Gettier
Knowledge and belief
Randomized controlled trial (RCT) | CommonCrawl |
Event and Apparent Horizon Finders for 3 + 1 Numerical Relativity
Numerical Relativity
Jonathan Thornburg1,2
Living Reviews in Relativity volume 10, Article number: 3 (2007) Cite this article
Event and apparent horizons are key diagnostics for the presence and properties of black holes. In this article I review numerical algorithms and codes for finding event and apparent horizons in numerically-computed spacetimes, focusing on calculations done using the 3 + 1 ADM formalism. The event horizon of an asymptotically-flat spacetime is the boundary between those events from which a future-pointing null geodesic can reach future null infinity and those events from which no such geodesic exists. The event horizon is a (continuous) null surface in spacetime. The event horizon is defined nonlocally in time: it is a global property of the entire spacetime and must be found in a separate post-processing phase after all (or at least the nonstationary part) of spacetime has been numerically computed.
There are three basic algorithms for finding event horizons, based on integrating null geodesics forwards in time, integrating null geodesics backwards in time, and integrating null surfaces backwards in time. The last of these is generally the most efficient and accurate.
In contrast to an event horizon, an apparent horizon is defined locally in time in a spacelike slice and depends only on data in that slice, so it can be (and usually is) found during the numerical computation of a spacetime. A marginally outer trapped surface (MOTS) in a slice is a smooth closed 2-surface whose future-pointing outgoing null geodesics have zero expansion Θ. An apparent horizon is then defined as a MOTS not contained in any other MOTS. The MOTS condition is a nonlinear elliptic partial differential equation (PDE) for the surface shape, containing the ADM 3-metric, its spatial derivatives, and the extrinsic curvature as coefficients. Most "apparent horizon" finders actually find MOTSs.
There are a large number of apparent horizon finding algorithms, with differing trade-offs between speed, robustness, accuracy, and ease of programming. In axisymmetry, shooting algorithms work well and are fairly easy to program. In slices with no continuous symmetries, spectral integral-iteration algorithms and elliptic-PDE algorithms are fast and accurate, but require good initial guesses to converge. In many cases, Schnetter's "pretracking" algorithm can greatly improve an elliptic-PDE algorithm's robustness. Flow algorithms are generally quite slow but can be very robust in their convergence. Minimization methods are slow and relatively inaccurate in the context of a finite differencing simulation, but in a spectral code they can be relatively faster and more robust.
Part I Introduction
Systems with strong gravitational fields, particularly systems which may contain event horizons and/or apparent horizons, are a major focus of numerical relativity. The usual output of a numerical relativity simulation is some (approximate, discrete) representation of the spacetime geometry (the 4-metric and possibly its derivatives) and any matter fields, but not any explicit information about the existence, precise location, or other properties of any event/apparent horizons. To gain this information, we must explicitly find the horizons from the numerically-computed spacetime geometry. The subject of this review is numerical algorithms and codes for doing this, focusing on calculations done using the 3 + 1 ADM formalism [14, 163]. Baumgarte and Shapiro [27, Section 6] have also recently reviewed event and apparent horizon finding algorithms. The scope of this review is limited to the finding of event/apparent horizons and omits any but the briefest mention of the many uses of this information in gaining physical understanding of numerically-computed spacetimes.
In this review I distinguish between a numerical algorithm (an abstract description of a mathematical computation; also often known as a "method" or "scheme"), and a computer code (a "horizon finder", a specific piece of computer software which implements a horizon finding algorithm or algorithms). My main focus is on the algorithms, but I also mention specific codes where they are freely available to other researchers.
In this review I have tried to cover all the major horizon finding algorithms and codes, and to accurately credit the earliest publication of important ideas. However, in a field as large and active as numerical relativity, it is not unlikely that I have overlooked and/or misdescribed some important research. I apologise to anyone whose work I've slighted, and I ask readers to help make this a truly "living" review by sending me corrections, updates, and/or pointers to additional work (either their own or others) that I should discuss in future revisions of this review.
The general outline of this review is as follows: In the remainder of Part I, I define notation and terminology (Section 1), discuss how 2-surfaces should be parameterized (Section 2), and outline some of the software-engineering issues that arise in modern numerical relativity codes (Section 3). I then discuss numerical algorithms and codes for finding event horizons (Part II) and apparent horizons (Part III). Finally, in the appendices I briefly outline some of the excellent numerical algorithms/codes available for two standard problems in numerical analysis, the solution of a single nonlinear algebraic equation (Appendix A) and the time integration of a system of ordinary differential equations (Appendix B).
Notation and Terminology
Except as noted below, I generally follow the sign and notation conventions of Wald [160]. I assume that all spacetimes are globally hyperbolic, and for event-horizon finding I further assume asymptotic flatness; in this latter context \({{\mathcal J}^ +}\) is future null infinity. I use the Penrose abstract-index notation, with summation over all repeated indices. 4-indices abc range over all spacetime coordinates {xa}, and 3-indices ijk range over the spatial coordinates {xi} in a spacelike slice t = constant. The spacetime coordinates are thus xa = (t, xi).
Indices uvw range over generic angular coordinates (θ, ϕ) on S2 or on a horizon surface. Note that these coordinates are conceptually distinct from the 3-dimensional spatial coordinates xi. Depending on the context, (θ, ϕ) may or may not have the usual polar-spherical topology. Indices ijk label angular grid points on S2 or on a horizon surface. These are 2-dimensional indices: a single such index uniquely specifies an angular grid point. δIJ is the Kronecker delta on the space of these indices or, equivalently, on surface grid points.
For any indices p and q, ∂p and ∂pq are the coordinate partial derivatives ∂/∂xp and ∂2/∂xp∂xq respectively; for any coordinates µ and ν, ∂u and ∂µν are the coordinate partial derivatives ∂/∂/µ and ∂2/∂µ∂ν respectively. Δ is the flat-space angular Laplacian operator on S2, while Δx refers to a finite-difference grid spacing in some variable x.
gab is the spacetime 4-metric, and gab the inverse spacetime 4-metric; these are used to raise and lower 4-indices. \(\Gamma _{ab}^c\) are the 4-Christoffel symbols. \({{\mathcal L}_\upsilon}\) is the Lie derivative along the 4-vector field va.
I use the 3 + 1 "ADM" formalism first introduced by Arnowitt, Deser, and Misner [14]; York [163] gives a general overview of this formalism as it is used in numerical relativity. gij is the 3-metric defined in a slice, and gij is the inverse 3-metric; these are used to raise and lower 3-indices. ∇i is the associated 3-covariant derivative operator, and \(\Gamma _{ij}^k\) are the 3-Christoffel symbols. α and βi are the 3 + 1 lapse function and shift vector respectively, so the spacetime line element is
$$d{s^2} = {g_{ab}}d{x^a}d{x^b}$$
$$= - ({\alpha ^2} - {\beta _i}{\beta ^i})d{t^2} + 2{\beta _i}d{x^i}dt + {g_{ij}}d{x^i}d{x^j}.$$
As is common in 3 + 1 numerical relativity, I follow the sign convention of Misner, Thorne, and Wheeler [112] and York [163] in defining the extrinsic curvature of the slice as \({K_{ij}} = - {1 \over 2}{{\mathcal L}_n}{g_{ij}} = - {\nabla _i}{n_j}\), where na is the future-pointing unit normal to the slice. (In contrast, Wald [160] omits the minus signs from this definition.) \(K\equiv {K_i^i}\) is the trace of the extrinsic curvature Kij. mADM is the ADM mass of an asymptotically flat slice.
I often write a differential operator as F = F (y, ∂uy, ∂uvy; gij, ∂kgij, Kij), where the ";" notation means that F is a (generally nonlinear) algebraic function of the variable y and its 1st and 2nd angular derivatives, and that F also depends on the coefficients gij, ∂kgij, and Kij at the apparent horizon position.
There are three common types of spacetimes/slices where numerical event or apparent horizon finding is of interest: spherically-symmetric spacetimes/slices, axisymmetric spacetimes/slices, and spacetimes/slices with no continuous spatial symmetries (no spacelike Killing vectors). I refer to the latter as "fully generic" spacetimes/slices.
In this review I use the abbreviations "ODE" for ordinary differential equation, "PDE" for partial differential equation, "CE surface" for constant-expansion surface, and "MOTS" for marginally outer trapped surface. Names in Small Capitals refer to horizon finders and other computer software.
When discussing iterative numerical algorithms, it is often convenient to use the concept of an algorithm's "radius of convergence". Suppose the solution space within which the algorithm is iterating is S. Then given some norm ‖ · ‖ on S, the algorithm's radius of convergence about a solution s ∈ S is defined as the smallest r > 0 such that the algorithm will converge to the correct solution s for any initial guess g with ‖g − s‖ ≤ r. We only rarely know the exact radius of convergence of an algorithm, but practical experience often provides a rough estimateFootnote 1.
2-Surface Parameterizations
Level-set-function parameterizations
The most general way to parameterize a 2-surface in a slice is to define a scalar "level-set function" F on some neighborhood of the surface, with the surface itself then being defined as the level set
$$F = 0\quad {\rm{on}}\;{\rm{the}}\;{\rm{surface}}.$$
Assuming the surface to be orientable, it is conventional to choose F so that F > 0 (F < 0) outside (inside) the surface. The choice of level-set function for a given surface is non-unique, but in general this is not a problem.
This parameterization is valid for any surface topology including time-dependent topologies. The 2-surface itself can then be found by a standard isosurface-finding algorithm such as the marching-cubes algorithm [105]. (This algorithm is widely used in computer graphics and is implemented in a number of widely-available software libraries.)
Strahlkörper parameterizations
Most apparent horizon finders, and some event-horizon finders, assume that each connected component of the apparent (event) horizon has S2 topology. With the exception of toroidal event horizons (discussed in Section 4), this is generally a reasonable assumption.
To parameterize an S2 surface's shape, it is common to further assume that we are given (or can compute) some "local coordinate origin" point inside the surface such that the surface's 3-coordinate shape relative to that point is a "Strahlkörper" (literally "ray body", or more commonly "star-shaped region"), defined by Minkowski [138, Page 108] as
a region in n-D Euclidean space containing the origin and whose surface, as seen from the origin, exhibits only one point in any direction.
The Strahlkörper assumption is a significant restriction on the horizon's coordinate shape (and the choice of the local coordinate origin). For example, it rules out the coordinate shape and local coordinate origin illustrated in Figure 1: a horizon with such a coordinate shape about the local coordinate origin could not be found by any horizon finder which assumes a Strahlkörper surface parameterization.
This figure shows a cross-section of a coordinate shape (the thick curve) which is not a Strahlkörper about the local coordinate origin shown (the large dot). The dashed line shows a ray from the local coordinate origin, which intersects the surface in more than one point.
For event-horizon finding, algorithms and codes are now available which allow an arbitrary horizon topology with no Strahlkörper assumption (see the discussion in Section 5.3.3 for details). For apparent horizon finding, the flow algorithms discussed in Section 8.7 theoretically allow any surface shape, although many implementations still make the Strahlkörper assumption. Removing this assumption for other apparent horizon finding algorithms might be a fruitful area for further research.
Given the Strahlkörper assumption, the surface can be explicitly parameterized as
$$r = h(\theta, \phi),$$
where r is the Euclidean distance from the local coordinate origin to a surface point, (θ, ϕ) are generic angular coordinates on the horizon surface (or equivalently on S2), and the "horizon shape function" h : S2 → ℜ+ is a positive real-valued function on the domain of angular coordinates defining the surface shape. Given the choice of local coordinate origin, there is clearly a one-to-one mapping between Strahlkörper 2-surfaces and horizon shape functions.
There are two common ways to discretize a horizon shape function:
Spectral representation
Here we expand the horizon shape function h in an infinite series in some (typically orthonormal) set of basis functions such as spherical harmonics Yℓm or symmetric trace-free tensorsFootnote 2,
$$h(\theta, \phi) = \sum\limits_{\ell, m} {{a_{\ell m}}{Y_{\ell m}}(\theta, \phi).}$$
This series can then be truncated at some finite order ℓmax, and the Ncoeff = ℓmax(ℓmax+1) coefficients {aℓm} used to represent (discretely approximate) the horizon shape. For reasonable accuracy, ℓmax is typically on the order of 8 to 12.
Finite difference representation
Here we choose some finite grid of angular coordinates {(θK, ϕK)}, K = 1, 2, 3, …, Nang on S2 (or equivalently on the surface)Footnote 3, and represent (discretely approximate) the surface shape by the Nang values
$$\{h({\theta _{\rm{K}}},{\phi _{\rm{K}}})\} \quad {\rm{K = 1,2,3,}} \ldots, {N_{{\rm{ang}}}}.$$
For reasonable accuracy, Nang is typically on the order of a few thousand.
It is sometimes useful to explicitly construct a level-set function describing a given Strahlkörper. A common choice here is
$$F \equiv r - h(\theta, \phi).$$
Finite-element parameterizations
Another way to parameterize a 2-surface is via finite elements where the surface is modelled as a triangulated mesh, i.e. as a set of interlinked "vertices" (points in the slice, represented by their spatial coordinates {xi}), "edges" (represented by ordered pairs of vertices), and faces. Typically only triangular faces are used (represented as oriented triples of vertices).
A key benefit of this representation is that it allows an arbitrary topology for the surface. However, determining the actual surface topology (e.g. testing for whether or not the surface self-intersects) is somewhat complicated.
This representation is similar to that of Regge calculus [128, 72]Footnote 4, and can similarly be expected to show 2nd order convergence with the surface resolution.
Software-Engineering Issues
Historically, numerical relativists wrote their own codes from scratch. As these became more complex, many researchers changed to working on "group codes" with multiple contributors.
Software libraries and toolkits
More recently, particularly in work on fully generic spacetimes, where all three spatial dimensions must be treated numerically, there has been a strong trend towards the use of higher-level software libraries and modular "computational toolkits" such as Cactus [74] (http://www.cactuscode.org). These have a substantial learning overhead, but can allow researchers to work much more productively by focusing more on numerical relativity instead of computer-science and softwareengineering issues such as parameter-file parsing, parallelization, I/O, etc.
A particularly important area for such software infrastructure is mesh refinementFootnote 5. This is essential to much current numerical-relativity research but is moderately difficult to implement even in only one spatial dimension, and much harder in multiple spatial dimensions. There are now a number of software libraries providing multi-dimensional mesh-refinement infrastructure (sometimes combined with parallelization), such as those listed in Table 1. The Cactus toolkit can be used in either unigrid or mesh-refinement modes, the latter using a "mesh-refinement driver" such as PAGH or Carpet [134, 131] (http://www.carpetcode.org).
Table 1 This table lists some software toolkits for multi-dimensional mesh refinement. All these toolkits also provide parallelization.
In this review I point out event and apparent horizon finders which have been written in particular frameworks and comment on whether they work with mesh refinement.
Code reuse and sharing
Another important issue is that of code reuse and sharing. It is common for codes to be shared within a research group but relatively uncommon for them to be shared between different (competing) research groups. Even apart from concerns about competitive advantage, without a modular structure and clear documentation it is difficult to reuse another group's code. The use of a common computational toolkit can greatly simplify such reuse.
If such reuse can be accomplished, it becomes much easier for other researchers to build on existing work rather than having to "reinvent the wheel". As well as the obvious ease of reusing existing code that (hopefully!) already works and has been thoroughly debugged and tested, there is another — less obvious — benefit of code sharing: It greatly eases the replication of past work, which is essential as a foundation for new development. That is, without access to another researcher's code, it can be surprisingly difficult to replicate her results because the success or failure of a numerical algorithm frequently depends on subtle implementation details not described in even the most complete of published papers.
Event and apparent horizon finders are excellent candidates for software reuse: Many numerical-relativity researchers can benefit from using them, and they have a relatively simple interface to an underlying numerical-relativity simulation. Even if a standard computational toolkit is not used, this relatively simple interface makes it fairly easy to port an event or apparent horizon finder to a different code.
Table 2 lists event and apparent horizon finders which are freely available to any researcher.
Table 2 This table lists event and apparent horizon finders which are freely available to any researcher, along with the cvs repositories or web pages from which they may be obtained.
Using multiple event/apparent horizon finders
It is useful to have multiple event or apparent horizon finders available: Their strengths and weaknesses may complement each other, and the extent of agreement or disagreement between their results can help to estimate the numerical accuracy. For example, Figure 11 shows a comparison between the irreducible masses of apparent horizons in a binary black hole coalescence simulation (Alcubierre et al. [5], [Figure 4b]), as computed by two different apparent horizon finders in the Cactus toolkit, AHFinder and AHFinderDireot. In this case the two agree to within about 2% for the individual horizons and 0.5% for the common horizon.
Part II Finding Event Horizons
The black hole region of an asymptotically-flat spacetime is defined [81, 82] as the set of events from which no future-pointing null geodesic can reach future null infinity (\({{\mathcal J}^ +}\)). The event horizon is defined as the boundary of the black hole region. The event horizon is a null surface in spacetime with (in the words of Hawking and Ellis [82, Page 319]) "a number of nice properties" for studying the causal stucture of spacetime.
The event horizon is a global property of an entire spacetime and is defined nonlocally in time: The event horizon in a slice is defined in terms of (and cannot be computed without knowing) the full future development of that slice.
In practice, to find an event horizon in a numerically-computed spacetime, we typically instrument a numerical evolution code to write out data files of the 4-metric. After the evolution (or at least the strong-field region) has reached an approximately-stationary final state, we then compute a numerical approximation to the event horizon in a separate post-processing pass, using the 4-metric data files as inputs.
As a null surface, the event horizon is necessarily continuous. In theory it need not be anywhere differentiableFootnote 6, but in practice this behavior rarely occursFootnote 7: The event horizon is generally smooth except for possibly a finite set of "cusps" where new generators join the surface; the surface normal has a jump discontinuity across each cusp. (The classic example of such a cusp is the "inseam" of the "pair of pants" event horizon illustrated in Figures 4 and 5.)
A black hole is defined as a connected component of the black hole region in a 3 + 1 slice. The boundary of a black hole (the event horizon) in a slice is a 2-dimensional set of events. Usually this has 2-sphere (S2) topology. However, numerically simulating rotating dust collapse, Abrahams et al. [1] found that in some cases the event horizon in a slice may be toroidal in topology. Lehner et al. [99], and Husa and Winicour [91] have used null (characteristic) algorithms to give a general analysis of the event horizon's topology in black hole collisions; they find that there is generically a (possibly brief) toroidal phase before the final 2-spherical state is reached. Lehner et al. [100] later calculated movies showing this behavior for several asymmetric black hole collisions.
Algorithms and Codes for Finding Event Horizons
There are three basic event-horizon finding algorithms:
Integrate null geodesics forwards in time (Section 5.1).
Integrate null geodesics backwards in time (Section 5.2).
Integrate null surfaces backwards in time (Section 5.3).
I describe these in detail in the following.
Integrating null geodesics forwards in time
The first generation of event-horizon finders were based directly on Hawking's original definition of an event horizon: an event \({\mathcal P}\) is within the black hole region of spacetime if and only if there is no future-pointing "escape route" null geodesic from \({\mathcal P}\) to \({{\mathcal J}^ +}\); the event horizon is the boundary of the black hole region.
That is, as described by Hughes et al. [88], we numerically integrate the null geodesic equation
$${{{d^2}{x^a}} \over {d{\lambda ^2}}} + \Gamma _{bc}^a{{d{x^b}} \over {d\lambda}}{{d{x^c}} \over {d\lambda}} = 0$$
(where λ is an affine parameter) forwards in time from a set of starting events and check which events have "escaping" geodesics. For analytical or semi-analytical studies like that of Bishop [31], this is an excellent algorithm.
For numerical work it is straightforward to rewrite the null geodesic equation (8) as a coupled system of two first-order equations, giving the time evolution of photon positions and 3-momenta in terms of the 3 + 1 geometry variables α, βi, gij, and their spatial derivatives. These can then be time-integrated by standard numerical algorithmsFootnote 8. However, in practice several factors complicate this algorithm.
We typically only know the 3 + 1 geometry variables on a discrete lattice of spacetime grid points, and we only know the 3 + 1 geometry variables themselves, not their spatial derivatives. Therefore we must numerically differentiate the field variables, then interpolate the field variables and their spacetime derivatives to each integration point along each null geodesic. This is straightforward to implementFootnote 9, but the numerical differentiation tends to amplify any numerical noise that may be present in the field variables.
Another complicating factor is that the numerical computations generally only span a finite region of spacetime, so it is not entirely obvious whether or not a given geodesic will eventually reach \({{\mathcal J}^ +}\). However, if the final numerically-generated slice contains an apparent horizon, we can use this as an approximation: Any geodesic which is inside this apparent horizon will definitely not reach \({{\mathcal J}^ +}\), while any other geodesic may be assumed to eventually reach \({{\mathcal J}^ +}\) if its momentum is directed away from the apparent horizon. If the final slice (or at least its strong-field region) is approximately stationary, the error from this approximation should be small. I discuss this stationarity assumption further in Section 5.3.1.
Spherically-symmetric spacetimes
In spherical symmetry this algorithm works well and has been used by a number of researchers. For example, Shapiro and Teukolsky [141, 142, 143, 144] used it to study event horizons in a variety of dynamical evolutions of spherically symmetric collapse systems. Figure 2 shows an example of the event and apparent horizons in one of these simulations.
This figure shows part of a simulation of the spherically symmetric collapse of a model stellar core (\(a\,\Gamma = {5 \over 3}\) polytrope) to a black hole. The event horizon (shown by the dashed line) was computed using the "integrate null geodesics forwards" algorithm described in Section 5.1 ; solid lines show outgoing null geodesics. The apparent horizon (the boundary of the trapped region, shown shaded) was computed using the zero-finding algorithm discussed in Section 8.1 . The dotted lines show the world lines of Lagrangian matter tracers and are labeled by the fraction of baryons interior to them. Figure reprinted with permission from [142]. © 1980 by the American Astronomical Society.
Non-spherically-symmetric spacetimes
In a non-spherically-symmetric spacetime, several factors make this algorithm very inefficient:
Many trial events must be tried to accurately resolve the event horizon's shape. (Hughes et al. [88] describe a 2-stage adaptive numerical algorithm for choosing the trial events so as to accurately locate the event horizon as efficiently as possible.)
At each trial event we must try many different trial-geodesic starting directions to see if any of the geodesics escape to \({{\mathcal J}^ +}\) (or our numerical approximation to it). Hughes et al. [88] report needing only 48 geodesics per trial event in several nonrotating axisymmetric spacetimes, but about 750 geodesics per trial event in rotating axisymmetric spacetimes, with up to 3000 geodesics per trial event in some regions of the spacetimes.
Finally, each individual geodesic integration requires many (short) time steps for an accurate integration, particularly in the strong-field region near the event horizon.
Because of these limitations, for non-spherically-symmetric spacetimes the "integrate null geodesics forwards" algorithm has generally been supplanted by the more efficient algorithms I describe in the following.
Integrating null geodesics backwards in time
It is well-known that future-pointing outgoing null geodesics near the event horizon tend to diverge exponentially in time away from the event horizon. Figure 3 illustrates this behavior for Schwarzschild spacetime, but the behavior is actually quite generic.
This figure shows a number of light cones and future-pointing outgoing null geodesics in a neighborhood of the event horizon in Schwarzschild spacetime, plotted in ingoing Eddington-Finkelstein coordinates (t, r). (These coordinates are defined by the conditions that t + r is an ingoing null coordinate, while r is an areal radial coordinate.) Note that for clarity the horizontal scale is expanded relative to the vertical scale, so the light cones open by more than ±45°. All the geodesics start out close together near the event horizon; they diverge away from each other exponentially in time (here with an e-folding time of 4m near the horizon). Equivalently, they converge towards each other if integrated backwards in time (downwards on the page).
Anninos et al. [7] and Libson et al. [103] observed that while this instability is a problem for the "integrate null geodesics forwards in time" algorithm (it forces that algorithm to take quite short time steps when integrating the geodesics), we can turn it to our advantage by integrating the geodesics backwards in time: The geodesics will now converge on to the horizonFootnote 10.
This event-horizon finding algorithm thus integrates a large number of such (future-pointing outgoing) null geodesics backwards in time, starting on the final numerically-generated slice. As the backwards integration proceeds, even geodesics which started far from the event horizon will quickly converge to it. This can be seen, for example, in Figures 2 and 3.
Unfortunately, this convergence property holds only for outgoing geodesics. In spherical symmetry the distinction between outgoing and ingoing geodesics is trivial but, as described by Libson et al. [103],
[…] for the general 3D case, when the two tangential directions of the EH are also considered, the situation becomes more complicated. Here normal and tangential are meant in the 3D spatial, not spacetime, sense. Whether or not a trajectory can eventually be "attracted" to the EH, and how long it takes for it to become "attracted," depends on the photon's starting direction of motion. We note that even for a photon which is already exactly on the EH at a certain instant, if its velocity at that point has some component tangential to the EH surface as generated by, say, numerical inaccuracy in integration, the photon will move outside of the EH when traced backward in time. For a small tangential velocity, the photon will eventually return to the EH […but] the position to which it returns will not be the original position.
This kind of tangential drifting is undesirable not just because it introduces inaccuracy in the location of the EH, but more importantly, because it can lead to spurious dynamics of the "EH" thus found. Neighboring generators may cross, leading to numerically artificial caustic points […].
Libson et al. [103] also observed:
Another consequence of the second order nature of the geodesic equation is that not just the positions but also the directions must be specified in starting the backward integration. Neighboring photons must have their starting direction well correlated in order to avoid tangential drifting across one another.
Libson et al. [103] give examples of the numerical difficulties that can result from these difficulties and conclude that this event-horizon finding algorithm
[…] is still quite demanding in finding an accurate history of the EH, although the difficulties are much milder than those arising from the instability of integrating forward in time.
Because of these difficulties, this algorithm has generally been supplanted by the "backwards surface" algorithm I describe next.
Integrating null surfaces backwards in time
Anninos et al. [7], Libson et al. [103], and Walker [162] introduced the important concept of explicitly (numerically) finding the event horizon as a null surface in spacetime. They observed that if we parameterize the event horizon with any level-set function F satisfying the basic level-set definition (3), then the condition for the surface F = 0 to be null is just
$${g^{ab}}{\partial _a}F{\partial _b}F = 0.$$
Applying a 3 + 1 decomposition to this then gives a quadratic equation which can be solved to find the time evolution of the level-set function,
$${\partial _t}F = {{- {g^{ti}}{\partial _i}F + \sqrt {{{({g^{ti}}{\partial _i}F)}^2} - {g^{tt}}{g^{ij}}{\partial _i}f{\partial _j}f}} \over {{g^{tt}}}}.$$
Alternatively, assuming the event horizon in each slice to be a Strahlkörper in the manner of Section 2.2, we can define a suitable level-set function F by Equation (7). Substituting this definition into Equation (10) then gives an explicit evolution equation for the horizon shape function,
$${\partial _t}h = {{- {g^{tr}} + {g^{ru}}{\partial _u}h + \sqrt {{{({g^{tr}} - {g^{tu}}{\partial _u}h)}^2} - {g^{tt}}({g^{rr}} - 2{g^{ru}}{\partial _u}h + {g^{uv}}{\partial _u}h{\partial _v}h)}} \over {{g^{tt}}}}.$$
Surfaces near the event horizon share the same "attraction" property discussed in Section 5.2 for geodesics near the event horizon. Thus by integrating either surface representation (10) or (11) backwards in time, we can refine an initial guess into a very accurate approximation to the event horizon.
In contrast to the null geodesic equation (8), neither Equation (10) nor Equation (11) contain any derivatives of the 4-metric (or equivalently the 3 + 1 geometry variables). This makes it much easier to integrate these latter equations accuratelyFootnote 11. This formulation of the event-horizon finding problem also completely eliminates the tangential-drifting problem discussed in Section 5.2, since the level-set function only parameterizes motion normal to the surface.
Error bounds: Integrating a pair of surfaces
For a practical algorithm, it is useful to integrate a pair of trial null surfaces backwards: an "inner-bound" one which starts (and thus always remains) inside the event horizon and an "outer-bound" one which starts (and thus always remains) outside the event horizon. If the final slice contains an apparent horizon then any 2-surface inside this can serve as our inner-bound surface. However, choosing an outer-bound surface is more difficult.
It is this desire for a reliable outer bound on the event horizon position that motivates our requirement (Section 4) for the final slice (or at least its strong-field region) to be approximately stationary: In the absence of time-dependent equations of state or external perturbations entering the system, this requirement ensures that, for example, any surface substantially outside the apparent horizon can serve as an outer-bound surface.
Assuming we have an inner- and an outer-bound surface on the final slice, the spacing between these two surfaces after some period of backwards integration then gives an error bound for the computed event horizon position. Equivalently, a necessary (and, if there are no other numerical problems, sufficient) condition for the event-horizon finding algorithm to be accurate is that the backwards integration must have proceeded far enough for the spacing between the two trial surfaces to be "small". For a reasonable definition of "small", this typically takes at least 15mADM of backwards integration, with 20mADM or more providing much higher accuracy.
In some cases it is difficult to obtain a long enough span of numerical data for this backwards integration. For example, in some simulations of binary black hole collisions, the evolution becomes unstable and crashes soon after a common apparent horizon forms. This means that we cannot compute an accurate event horizon for the most interesting region of the spacetime, that which is close to the black-hole merger. There is no good solution to this problem except for the obvious one of developing a stable (or less-unstable) simulation that can be continued for a longer time.
Explicit Strahlkörper surface representation
The initial implementations of the "integrate null surface backwards" algorithm by Anninos et al. [7], Libson et al. [103], and Walker [162] were based on the explicit Strahlkörper surface integration formula (11), further restricted to axisymmetryFootnote 12.
For a single black hole the coordinate choice is straightforward. For the two-black-hole case, the authors used topologically cylindrical coordinates (ρ, z, ϕ), where the two black holes collide along the axisymmetry (z) axis. Based on the symmetry of the problem, they then assumed that the event horizon shape could be written in the form
$$\rho = h(z)$$
in each t = constant slice.
This spacetime's event horizon has the now-classic "pair of pants" shape, with a non-differentiable cusp along the "inseam" (the z axis ρ = 0) where new generators join the surface. The authors tried two ways of treating this cusp numerically:
Since the cusp's location is known a priori, it can be treated as a special case in the angular finite differencing, using one-sided numerical derivatives as necessary.
Alternatively, in 1994 Thorne suggested calculating the union of the event horizon and all its null generators (including those which have not yet joined the surface)Footnote 13. This "surface" has a complicated topology (it self-intersects along the cusp), but it is smooth everywhere. This is illustrated by Figure 4, which shows a cross-section of this surface in a single slice, for a head-on binary black hole collision. For comparison, Figure 5 shows a perspective view of part of the event horizon and some of its generators, for a similar head-on binary black hole collision.
This figure shows a view of the numerically-computed event horizon in a single slice, together with the locus of the event horizon's generators that have not yet joined the event horizon in this slice, for a head-on binary black hole collision. Notice how the event horizon is non-differentiable at the cusp where the new generators join it. Figure reprinted with permission from [103]. © 1996 by the American Physical Society.
This figure shows a perspective view of the numerically-computed event horizon, together with some of its generators, for the head-on binary black hole collision discussed in detail by Matzner et al. [108]. Figure courtesy of Edward Seidel.
Caveny et al. [44, 46] implemented the "integrate null surfaces backwards" algorithm for fully generic numerically-computed spacetimes using the explicit Strahlkörper surface integration formula (11). To handle moving black holes, they recentered each black hole's Strahlkörper parameterization (4) on the black hole's coordinate centroid at each time step.
For single-black-hole test cases (Kerr spacetime in various coordinates), they report typical accuracies of a few percent in determining the event horizon position and area. For binary-black-hole test cases (Kastor-Traschen extremal-charge black hole coalescence with a cosmological constant), they detect black hole coalescence (which appears as a bifurcation in the backwards time integration) by the "necking off" of the surface. Figure 6 shows an example of their results.
This figure shows the cross-section of the numerically-computed event horizon in each of five different slices, for the head-on collision of two extremal Kastor-Traschen black holes. Figure reprinted with permission from [46]. © 2003 by the American Physical Society.
Level-set parameterization
Caveny et al. [44, 45] and Diener [60] (independently) implemented the "integrate null surfaces backwards" algorithm for fully generic numerically-computed spacetimes, using the level-set function integration formula (10). Here the level-set function F is initialized on the final slice of the evolution and evolved backwards in time using Equation (10) on (conceptually) the entire numerical grid. (In practice, only a smaller box containing the event horizon need be evolved.)
This surface parameterization has the advantage that the event-horizon topology and (non-) smoothness are completely unconstrained, allowing the numerical study of configurations such as toroidal event horizons (discussed in Section 4). It is also convenient that the level-set function F is defined on the same numerical grid as the spacetime geometry, so that no interpolation is needed for the evolution.
The major problem with this algorithm is that during the backwards evolution, spatial gradients in F tend to steepen into a jump discontinuity at the event horizonFootnote 14, eventually causing numerical difficulty.
Caveny et al. [44, 45] deal with this problem by adding an artificial viscosity (i.e. diffusion) term to the level-set function evolution equation, smoothing out the jump discontinuity in F. That is, instead of Equation (10), they actually evolve F via
$${\partial _t}F = {\rm{rh}}{{\rm{s}}_{{\rm{Eq}}{\rm{.(10)}}}} + {\varepsilon ^2}{\nabla ^2}F,$$
where rhs Eq. (10) is the right hand side of Equation (10) and ∇2 is a generic 2nd order linear (elliptic) spatial differential operator, and ε > 0 is a (small) dissipation constant. This scheme works, but the numerical viscosity does seem to lead to significant errors (several percent) in their computed event-horizon positions and areasFootnote 15, and even failure to converge to the correct solution for some test cases (e.g. rapidly-spinning Kerr black holes).
Alternatively, Diener [60] developed a technique of periodically reinitializing the level-set function to approximately the signed distance from the event horizon. To do this, he periodically evolves
$${\partial _\lambda}F = - {F \over {\sqrt {{F^2} + 1}}}(\vert \nabla F\vert - 1)$$
in an unphysical "pseudo-time" λ until an approximate steady state has been achieved. He reports that this works well in most circumstances but can significantly distort the computed event horizon if the F = 0 isosurface (the current approximation to the event horizon) is only a few grid points thick in any direction, as typically occurs just around the time of a topology change in the isosurface. He avoids this problem by estimating the minimum thickness of this isosurface and, if it is below a threshold, deferring the reinitialization.
In various tests on analytical data, Diener [60] found this event-horizon finder, EHFinder, to be robust and highly accurate, typically locating the event horizon to much less than 1% of the 3-dimensional grid spacing. As an example of results obtained with EHFinder, Figure 7 shows two views of the numerically-computed event horizon for a spiraling binary black hole collision. As another example, Figure 8 shows the numerically-computed event and apparent horizons in the collapse of a rapidly rotating neutron star to a Kerr black hole. (The apparent horizons were computed using the AHFinderDireot code described in Section 8.5.7.)
This figure shows two views of the numerically-computed event horizon's cross-section in the orbital plane for a spiraling binary black hole collision. The two orbital-plane dimensions are shown horizontally; time runs upwards. The initial data was constructed to have an approximate helical Killing vector, corresponding to black holes in approximately circular orbits (the D =18 case of Grandclément et al. [78]), with a proper separation of the apparent horizons of 6.9 m. (The growth of the individual event horizons by roughly a factor of 3 in the first part of the evolution is an artifact of the coordinate choice — the black holes are actually in a quasi-equilibrium state.) Figure courtesy of Peter Diener.
This figure shows the polar and equatorial radii of the event horizon (solid lines) and apparent horizon (dashed lines) in a numerical simulation of the collapse of a rapidly rotating neutron star to form a Kerr black hole. The dotted line shows the equatorial radius of the stellar surface. These results are from the D4 simulation of Baiotti et al. [21]. Notice how the event horizon grows from zero size while the apparent horizon first appears at a finite size and grows in a spacelike manner. Notice also that both surfaces are flattened due to the rotation. Figure reprinted with permission from [21]. © 2005 by the American Physical Society.
EHFinder is implemented as a freely available module ("thorn") in the Cactus computational toolkit (see Table 2). It originally worked only with the PUGH unigrid driver, but work is ongoing [61] to enhance it to work with the Carpet mesh-refinement driver [134, 131].
Summary of Algorithms/Codes for Finding Event Horizons
In spherical symmetry the "integrate null geodesics forwards" algorithm (Section 5.1) can be used, although the "integrate null geodesics backwards" and "integrate null surfaces backwards" algorithms (Sections 5.2 and 5.3 respectively) are more efficient.
In non-spherically-symmetric spacetimes the "integrate null surfaces backwards" algorithm (Section 5.3) is clearly the best algorithm known: It is efficient, accurate, and fairly easy to implement. For generic spacetimes, Diener's event-horizon finder EHFinder [60] is particularly notable as a freely available implementation of this algorithm as a module ("thorn") in the widely-used Cactus computational toolkit (see Table 2).
Part III Finding Apparent Horizons
Given a (spacelike) 3 + 1 slice, a "trapped surface" is defined as a smooth closed 2-surface in the slice whose future-pointing outgoing null geodesics have negative expansion Θ. The "trapped region" in the slice is then defined as the union of all trapped surfaces, and the "apparent horizon" is defined as the outer boundary of the trapped region.
While mathematically elegant, this definition is not convenient for numerically finding apparent horizons. Instead, an alternate definition can be used: A MOTS is defined as a smooth (differentiable) closed orientable 2-surface in the slice whose future-pointing outgoing null geodesics have zero expansion Θ.Footnote 16 There may be multiple MOTSs in a slice, either nested within each other or intersectingFootnote 17. An apparent horizon is then defined as an outermost MOTS in a slice, i.e. a MOTS not contained in any other MOTS. Kriele and Hayward [98] have shown that subject to certain technical conditions, this definition is equivalent to the "outer boundary of the trapped region" one.
Notice that the apparent horizon is defined locally in time (it can be computed using only Cauchy data on a spacelike slice), but (because of the requirement that it be closed) non-locally in spaceFootnote 18. Hawking and Ellis [82] discuss the general properties of MOTSs and apparent horizons in more detail.
Except for flow algorithms (Section 8.7), all numerical "apparent horizon" finding algorithms and codes actually find MOTSs, and hereinafter I generally follow the common (albeit sloppy) practice in numerical relativity of blurring the distinction between an MOTS and an apparent horizon.
Given certain technical assumptions (including energy conditions), the existence of any trapped surface (and hence any apparent horizon) implies that the slice contains a black holeFootnote 19. (The converse of this statement is not true: An arbitrary (spacelike) slice through a black hole need not contain any apparent horizonFootnote 20.) However, if an apparent horizon does exist, it necessarily coincides with, or is contained in, an event horizon. In a stationary spacetime the event and apparent horizons coincide.
It is this relation to the event horizon which makes apparent horizons valuable for numerical computation: An apparent horizon provides a useful approximation to the event horizon in a slice, but unlike the event horizon, an apparent horizon is defined locally in time and so can be computed "on the fly" during a numerical evolution.
Given a family of spacelike 3 + 1 slices which foliate part of spacetime, the union of the slices' apparent horizons (assuming they exist) forms a world-tubeFootnote 21. This world-tube is necessarily either null or spacelike. If it is null, this world-tube is slicing-independent (choosing a different family of slices gives the same world-tube, at least so long as each slice still intersects the world-tube in a surface with 2-sphere topology). However, if the world-tube is spacelike, it is slicing-dependent: Choosing a different family of slices will in general give a different world-tubeFootnote 22.
Trapping, isolated, and dynamical horizons
Hayward [83] introduced the important concept of a "trapping horizon" (roughly speaking an apparent horizon world-tube where the expansion becomes negative if the surface is deformed in the inward null direction) along with several useful variants. Ashtekar, Beetle, and Fairhurst [16], and Ashtekar and Krishnan [18] later defined the related concepts of an "isolated horizon", essentially an apparent horizon world-tube which is null, and a "dynamical horizon", essentially an apparent horizon world-tube which is spacelike.
These world-tubes obey a variety of local and global conservation laws, and have many applications in analyzing numerically-computed spacetimes. See the references cited above and also Dreyer et al. [63], Ashtekar and Krishnan [19, 20], Gourgoulhon and Jaramillo [76], Booth [36], and Schnetter, Krishnan, and Beyer [137] for further discussions, including applications to numerical relativity.
Description in terms of the 3 + 1 variables
In terms of the 3 + 1 variables, a MOTS (and thus an apparent horizon) satisfies the conditionFootnote 23
$$\Theta \equiv {\nabla _i}{s^i} + {K_{ij}}{s^i}{s^j} - K = 0,$$
where si is the outward-pointing unit 3-vector normal to the surfaceFootnote 24. Assuming the Strahlkörper surface parameterization (4), Equation (15) can be rewritten in terms of angular 1st and 2nd derivatives of the horizon shape function h,
$$\Theta \equiv \Theta (h,{\partial _u}h,{\partial _{uv}}h;{g_{ij}},{\partial _k}{g_{ij}},{K_{ij}}) = 0,$$
where Θ is a complicated nonlinear algebraic function of the arguments shown. (Shibata [146] and Thornburg [153, 156] give the Θ(h, ∂uh, ∂uvh) function explicitly.)
Geometry interpolation
Θ depends on the slice geometry variables gij, ∂kgij, and Kij at the horizon positionFootnote 25. In practice these variables are usually only known on the (3-dimensional) numerical grid of the underlying numerical-relativity simulationFootnote 26, so they must be interpolated to the horizon position and, more generally, to the position of each intermediate-iterate trial shape the apparent horizon finding algorithm tries in the process of (hopefully) converging to the horizon position.
Moreover, usually the underlying simulation gives only gij and Kij, so gij must be numerically differentiated to obtain ∂kgij. As discussed by Thornburg [156, Section 6.1], it is somewhat more efficient to combine the numerical differentiation and interpolation operations, essentially doing the differentiation inside the interpolatorFootnote 27.
Thornburg [156, Section 6.1] argues that for an elliptic-PDE algorithm (Section 8.5), for best convergence of the nonlinear elliptic solver the interpolated geometry variables should be smooth (differentiable) functions of the trial horizon surface position. He argues that that the usual Lagrange polynomial interpolation does not suffice here (in some cases his Newton's-method iteration failed to converge) because this interpolation gives results which are only piecewise differentiableFootnote 28. He uses Hermite polynomial interpolation to avoid this problem. Cook and Abrahams [51], and Pfeiffer et al. [124] use bicubic spline interpolation; most other researchers either do not describe their interpolation scheme or use Lagrange polynomial interpolation.
Criteria for assessing algorithms
Ideally, an apparent horizon finder should have several attributes:
Robust: The algorithm/code should find an (the) apparent horizon in a wide range of numerically-computed slices, without requiring extensive tuning of initial guesses, iteration parameters, etc. This is often relatively easy to achieve for "tracking" the time evolution of an existing apparent horizon (where the most recent previously-found apparent horizon provides an excellent initial guess for the new apparent horizon position) but may be difficult for detecting the appearance of a new (outermost) apparent horizon in an evolution, or for initial-data or other studies where there is no "previous time step".
Accurate: The algorithm/code should find an (the) apparent horizon to high accuracy and should not report spurious "solutions" ("solutions" which are not actually good approximations to apparent horizons or, at least, to MOTSs).
Efficient: The algorithm/code should be efficient in terms of its memory use and CPU time; in practice CPU time is generally the major constraint. It is often desirable to find apparent horizons at each time step (or, at least, at frequent intervals) during a numerical evolution. For this to be practical the apparent horizon finder must be very fast.
In practice, no apparent horizon finder is perfect in all these dimensions, so trade-offs are inevitable, particularly when ease of programming is considered.
Local versus global algorithms
Apparent horizon finding algorithms can usefully be divided into two broad classes:
Local algorithms are those whose convergence is only guaranteed in some (functional) neighborhood of a solution. These algorithms require a "good" initial guess in order to find the apparent horizon. Most apparent horizon finding algorithms are local.
Global algorithms are those which can (in theory, ignoring finite-step-size and other numerical effects) converge to the apparent horizon independent of any initial guess. Flow algorithms (Section 8.7) are the only truely global algorithms. Zero-finding in spherical symmetry (Section 8.1) and shooting in axisymmetry (Section 8.2) are "almost global" algorithms: They require only 1-dimensional searches, which (as discussed in Appendix A) can be programmed to be very robust and efficient. In many cases horizon pretracking (Section 8.6) can semi-automatically find an initial guess for a local algorithm, essentially making the local algorithm behave like an "almost global" one.
One might wonder why local algorithms are ever used, given the apparently superior robustness (guaranteed convergence independent of any initial guess) of global algorithms. There are two basic reasons:
In practice, local algorithms are much faster than global ones, particularly when "tracking" the time evolution of an existing apparent horizon.
Due to finite-step-size and other numerical effects, in practice even "global" algorithms may fail to converge to an apparent horizon. (That is, the algorithms may sometimes fail to find an apparent horizon even when one exists in the slice.)
Algorithms and Codes for Finding Apparent Horizons
Many researchers have studied the apparent horizon finding problem, and there are a large number of different apparent horizon finding algorithms and codes. Almost all of these require (assume) that any apparent horizon to be found is a Strahlkörper (Section 2) about some local coordinate origin; both finite-difference and spectral parameterizations of the Strahlkörper are common.
For slices with continuous symmetries, special algorithms are sometimes used:
Zero-Finding in Spherical Symmetry (Section 8.1)
In spherical symmetry the apparent horizon equation (16) becomes a 1-dimensional nonlinear algebraic equation, which can be solved by zero-finding.
The Shooting Algorithm in Axisymmetry (Section 8.2)
In axisymmetry the apparent horizon equation (16) becomes a nonlinear 2-point boundary value ODE, which can be solved by a shooting algorithm.
Alternatively, all the algorithms described below for generic slices are also applicable to axisymmetric slices and can take advantage of the axisymmetry to simplify the implementation and boost performance.
For fully generic slices, there are several broad categories of apparent horizon finding algorithms and codes:
Minimization Algorithms (Section 8.3)
These algorithms define a scalar norm on Θ over the space of possible trial surfaces. A generalpurpose scalar-function-minimization routine is then used to search trial-surface-shape space for a minimum of this norm (which should give Θ = 0).
Spectral Integral-Iteration Algorithms (Section 8.4)
These algorithms expand the (Strahlkörper) apparent horizon shape function in a spherical-harmonic basis, use the orthogonality of spherical harmonics to write the apparent horizon equation as a set of integral equations for the spectral coefficients, and solve these equations using a functional-iteration algorithm.
Elliptic-PDE Algorithms (Section 8.5)
These algorithms write the apparent horizon equation (16) as a nonlinear elliptic (boundary-value) PDE for the horizon shape and solve this PDE using (typically) standard elliptic-PDE numerical algorithms.
Horizon Pretracking (Section 8.6)
Horizon pretracking solves a slightly more general problem than apparent horizon finding: Roughly speaking, the determination of the smallest E ≥ 0 such that the equation Θ = E has a solution, and the determination of that solution. By monitoring the time evolution of E and of the surfaces satisfying this condition, we can determine — before it appears — approximately where (in space) and when (in time) a new MOTS will appear in a dynamic numerically-evolving spacetime. Horizon pretracking is implemented as a 1-dimensional (binary) search using a slightly-modified elliptic-PDE apparent horizon finding algorithm as a "subroutine".
Flow Algorithms (Section 8.7)
These algorithms start with a large 2-surface (larger than any possible apparent horizon in the slice) and shrink it inwards using an algorithm which ensures that the surface will stop shrinking when it coincides with the apparent horizon.
I describe the major algorithms and codes in these categories in detail in the following.
Zero-finding in spherical symmetry
In a spherically symmetric slice, any apparent horizon must also be spherically symmetric, so the apparent horizon equation (16) becomes a 1-dimensional nonlinear algebraic equation Θ(h) = 0 for the horizon radius h. For example, adopting the usual (symmetry-adapted) polar-spherical spatial coordinates xi = (r, θ, ϕ), we have [154, Equation (B7)]
$$\Theta \equiv {{{\partial _r}{g_{\theta \theta}}} \over {{g_{\theta \theta}}\sqrt {{g_{rr}}}}} - 2{{{K_{\theta \theta}}} \over {{g_{\theta \theta}}}} = 0.$$
Given the geometry variables grr, gθθ, ∂rgθθ, and Kθθ, this equation may be easily and accurately solved using one of the zero-finding algorithms discussed in Appendix AFootnote 29.
Zero-finding has been used by many researchers, including [141, 142, 143, 144, 119, 47, 139, 9, 154, 155]Footnote 30. For example, the apparent horizons shown in Figure 2 were obtained using this algorithm. As another example, Figure 9 shows Θ(r) and h at various times in a (different) spherically symmetric collapse simulation.
This figure shows the apparent horizons (actually MOTSs) for a spherically symmetric numerical evolution of a black hole accreting a narrow shell of scalar field, the 800.pqw1 evolution of Thornburg [155]. Part (a) of this figure shows Θ(r) (here labelled H) for a set of equally-spaced times between t=19 and t=20, while Part (b) shows the corresponding MOTS radius h(t) and the Misner-Sharp [111], [112, Box 23.1] mass m(h) internal to each MOTS. Notice how two new MOTSs appear when the local minimum in Θ(r) touches the 0=0 line, and two existing MOTS disappear when the local maximum in Θ(r) touches the Θ=0 line.
The shooting algorithm in axisymmetry
In an axisymmetric spacetime we can use symmetry-adapted coordinates (θ, ϕ), so (given the Strahlkörper assumption) without further loss of generality we can write the horizon shape function as h = h(θ). The apparent horizon equation (16) then becomes a nonlinear 2-point boundary-value ODE for the horizon shape function h [146, Equation (1.1)]
$$\Theta \equiv \Theta (h,{\partial _\theta}h,{\partial _{\theta \theta}}h;{g_{ij}},{\partial _k}{g_{ij}},{K_{ij}}) = 0,$$
where Θ(h) is a nonlinear 2nd order (ordinary) differential operator in h as shown.
Taking the angular coordinate θ to have the usual polar-spherical topology, local smoothness of the apparent horizon gives the boundary conditions
$${\partial _\theta}h = 0\quad {\rm{at}}\theta {\rm{= 0}}\;{\rm{and}}\;\theta ={\theta _{{{\max}}}},$$
where θmax is π/2 if there is "bitant" reflection symmetry across the z = 0 plane, or π otherwise.
As well as the more general algorithms described in the following, this may be solved by a shooting algorithmFootnote 31:
Guess the value of h at one endpoint, say h(θ=0) ≡ h*.
Use this guessed value of h(θ=0) together with the boundary condition (19) there as initial data to integrate ("shoot") the ODE (18) from θ=0 to the other endpoint θ=θmax. This can be done easily and efficiently using one of the ODE codes described in Appendix B.
If the numerically computed solution satisfies the other boundary condition (19) at θ=θmax to within some tolerance, then the just-computed h(θ) describes the (an) apparent horizon, and the algorithm is finished.
Otherwise, adjust the guessed value h(θ=θ) ≡ h* and try again. Because there is only a single parameter (h*) to be adjusted, this can be done using one of the 1-dimensional zero-finding algorithms discussed in Appendix A.
This algorithm is fairly efficient and easy to program. By trying a sufficiently wide range of initial guesses h* this algorithm can give a high degree of confidence that all apparent horizons have been located, although this, of course, increases the cost.
Shooting algorithms of this type have been used by many researchers, for example [159, 66, 2, 29, 30, 145, 3, 4].
Minimization algorithms
This family of algorithms defines a scalar norm ‖ · ‖ on the expansion Θ over the space of possible trial surfaces, typically the mean-squared norm
$$\Vert\Theta \Vert \equiv \int {{\Theta ^2}d\Omega,}$$
where the integral is over all solid angles on a trial surface.
Assuming the horizon surface to be a Strahlkörper and adopting the spectral representation (5) for the horizon surface, we can view the norm (20) as being defined on the space of spectral coefficients {aℓm}.
This norm clearly has a global minimum ‖Θ‖ = 0 for each solution of the apparent horizon equation (16). To find the apparent horizon we numerically search the spectral-coefficient space for this (a) minimum, using a general-purpose "function-minimization" algorithm (code) such as Powell's algorithmFootnote 32.
Evaluating the norm (20) requires a numerical integration over the horizon surface: We choose some grid of Nang points on the surface, interpolate the slice geometry fields (gij, ∂kgij, and Kij) to this grid (see Section 7.5), and use numerical quadrature to approximate the integral. In practice this must be done for many different trial surface shapes (see Section 8.3.2), so it is important that it be as efficient as possible. Anninos et al. [8] and Baumgarte et al. [26] discuss various ways to optimize and/or parallelize this calculation.
Unfortunately, minimization algorithms have two serious disadvantages for apparent horizon finding: They can be susceptible to spurious local minima, and they're very slow at high angular resolutions. However, for the (fairly common) case where we want to find a common apparent horizon as soon as it appears in a binary black-hole (or neutron-star) simulation, minimization algorithms do have a useful ability to "anticipate" the formation of the common apparent horizon, in a manner similar to the pretracking algorithms discussed in Section 8.6. I discuss the properties of minimization algorithms further in the following.
Spurious local minima
While the norm (20) clearly has a single global minimum ‖Θ‖ = 0 for each MOTS Θ = 0, it typically also has a large number of other local minima with Θ ≠ 0, which are "spurious" in the sense that they do not correspond (even approximately) to MOTSsFootnote 33. Unfortunately, generalpurpose "function-minimization" routines only locate local minima and, thus, may easily converge to one of the spurious Θ ≠ 0 minima.
What this problem means in practice is that a minimization algorithm needs quite a good (accurate) initial guess for the horizon shape in order to ensure that the algorithm converges to the true global minimum Θ = 0 rather than to one of the spurious Θ ≠ 0 local minima.
To view this problem from a different perspective, once the function-minimization algorithm does converge, we must somehow determine whether the "solution" found is the true one, Θ = 0, or a spurious one, Θ ≠ 0. Due to numerical errors in the geometry interpolation and the evaluation of the integral (20), ‖Θ‖ will almost never evaluate to exactly zero; rather, we must set a tolerance level for how large ‖Θ‖ may be. Unfortunately, in practice it is hard to choose this tolerance: If it is too small, the genuine solution may be falsely rejected, while if it is too large, we may accept a spurious solution (which may be very different from any of the true solutions).
Anninos et al. [8] and Baumgarte et al. [26] suggest screening out spurious solutions by repeating the algorithm with varying resolutions of the horizon-surface grid and checking that |O| shows the proper convergence towards zero. This seems like a good strategy, but it is tricky to automate and, again, it may be difficult to choose the necessary error tolerances in advance.
When the underlying simulation is a spectral one, Pfeiffer et al. [124, 121] report that in practice, spurious solutions can be avoided by a combination of two factors:
The underlying spectral solution can inherently be "interpolated" (evaluated at arbitrary positions) to very high accuracy.
Pfeiffer et al. use a large number of quadrature points (typically an order of magnitude larger than the number of coefficients in the expansion (5)) in numerically evaluating the integral (20).
For convenience of exposition, suppose the spectral representation (5) of the horizon-shape function h uses spherical harmonics Yℓm. (Symmetric trace-free tensors or other basis sets do not change the argument in any important way.) If we keep harmonics up to some maximum degree ℓmax, the number of coefficients is then Ncoeff = (ℓmax+1)2. ℓmax is set by the desired accuracy (angular resolution) of the algorithm and is typically on the order of 6 to 12.
To find a minimum in an Ncoeff-dimensional space (here the space of surface-shape coefficients {aℓm}), a general-purpose function-minimization algorithm typically needs on the order of \(5N_{{\rm{coeff}}}^2\) to \(10N_{{\rm{coeff}}}^2\) iterationsFootnote 34. Thus the number of iterations grows as \(\ell _{\max}^4\).
Each iteration requires an evaluation of the norm (20) for some trial set of surface-shape coefficients {aℓm}, which requires \({\mathcal O}({N_{{\rm{coeff}}}}) = {\mathcal O}(\ell _{\max}^2)\) work to compute the surface positions, together with \({\mathcal O}({N_{{\rm{ang}}}})\) work to interpolate the geometry fields to the surface points and compute the numerical quadrature of the integral (20).
Thus the total work for a single horizon finding is \({\mathcal O}(\ell _{\max}^6 + {N_{{\rm{ang}}}}\ell _{max}^4)\). Fortunately, the accuracy with which the horizon is found generally improves rapidly with ℓmax, sometimes even exponentiallyFootnote 35. Thus, relatively modest values of ℓmax (typically in the range 8–12) generally suffice for adequate accuracy. Even so, minimization horizon finders tend to be slower than other methods, particularly if high accuracy is required (large ℓmax and Nang). The one exception is in axisymmetry, where only spherical harmonics Yℓm with m=0 need be considered. In this case minimization algorithms are much faster, though probably still slower than shooting or elliptic-PDE algorithms.
Anticipating the formation of a common apparent horizon
Consider the case where we want to find a common apparent horizon as soon as it appears in a binary black-hole (or neutron-star) simulation. In Section 8.6 I discuss "horizon pretracking" algorithms which can determine — before it appears — approximately where (in space) and when (in time) the common apparent horizon will appear.
Minimization algorithms can provide a similar functionality: Before the common apparent horizon forms, trying to find it via a minimization algorithm will (hopefully) find the (a) surface which minimizes the error norm ∥Θ∥ (defined by Equation (20)). This surface can be viewed as the current slice's closest approximation to a common apparent horizon, and as the evolution proceeds, it should converge to the actual common apparent horizon.
However, it is not clear whether minimization algorithms used in this way suffer from the problems discussed in Section 8.6.2. In particular, it is not clear whether, in a realistic binary-coalescence simulation, the minimum-∥Θ∥ surfaces would remain smooth enough to be represented accurately with a reasonable ℓmax.
Summary of minimization algorithms/codes
Minimization algorithms are fairly easy to program and have been used by many researchers, for example [43, 69, 102, 8, 26, 4]. However, at least when the underlying simulation uses finite differencing, minimization algorithms are susceptible to spurious local minima, have relatively poor accuracy, and tend to be quite slow. I believe that the other algorithms discussed in the following sections are generally preferable. If the underlying simulation uses spectral methods, then minimization algorithms may be (relatively) somewhat more efficient and robust.
Alcubierre's apparent horizon finder AHFinder [4] includes a minimization algorithm based on the work of Anninos et al. [8]Footnote 36. It is implemented as a freely available module ("thorn") in the Cactus computational toolkit (see Table 2).
Spectral integral-iteration algorithms
Nakamura, Kojima, and Oohara [113] developed a functional-iteration spectral algorithm for solving the apparent horizon equation (16).
This algorithm begins by choosing the usual polar-spherical topology for the angular coordinates (θ,ϕ), and rewriting the apparent horizon equation (16) in the form
$$\Delta h \equiv {\partial _{\theta \theta}}h + {{{\partial _\theta}h} \over {\tan \theta}} + {{{\partial _{\phi \phi}}h} \over {{{\sin}^2}\theta}} = G({\partial _{\theta \phi}}h,{\partial _{\phi \phi}}h,{\partial _\theta}h,{\partial _\phi}h;{g_{ij}},{K_{ij}},\Gamma _{ij}^k),$$
where Δ is the flat-space angular Laplacian operator, and G is a complicated nonlinear algebraic function of the arguments shown, which remains regular even at θ=0 and θ=π.
Next we expand h in spherical harmonics (5). Because the left hand side of Equation (21) is just the flat-space angular Laplacian of h, which has the Yℓm as orthogonal eigenfunctions, multiplying both sides of Equation (21) by Y*ℓm (the complex conjugate of Yℓm) and integrating over all solid angles gives
$${a_{\ell m}} = - {1 \over {\ell (\ell + 1)}}\int {Y_{\ell m}^{\ast}G\;d\Omega}$$
for each ℓ and m except ℓ = m = 0.
Based on this, Nakamura, Kojima, and Oohara [113] proposed the following functional-iteration algorithm for solving Equation (21):
Start with some (initial-guess) set of horizon-shape coefficients {aℓm}. These determine a surface shape via Equation (5).
Interpolate the geometry variables to this surface shape (see Section 7.5).
For each ℓ and m except ℓ = m = 0, evaluate the integral (22) by numerical quadrature to obtain a next-iteration coefficient aℓm.
Determine a next-iteration coefficient a00 by numerically solving (finding a root of) the equation
$$\int {Y_{00}^{\ast}G\;d\Omega = 0.}$$
This can be done using any of the 1-dimensional zero-finding algorithms discussed in Appendix A.
Iterate until all the coefficients {aℓm} converge.
Gundlach [80] observed that the subtraction and inversion of the flat-space angular Laplacian operator in this algorithm is actually a standard technique for solving nonlinear elliptic PDEs by spectral methods. I discuss this observation and its implications further in Section 8.7.4.
Nakamura, Kojima, and Oohara [113] report that their algorithm works well, but Nakao (cited as personal communication in [146]) has argued that it tends to become inefficient (and possibly inaccurate) for large ℓ (high angular resolution) because the Yℓm fail to be numerically orthogonal due to the finite resolution of the numerical grid. I know of no other published work addressing Nakao's criticism.
Kemball and Bishop's modifications of the Nakamura-Kojima-Oohara algorithm
Kemball and Bishop [93] investigated the behavior of the Nakamura-Kojima-Oohara algorithm and found that its (only) major weakness seems to be that the a00-update equation (23) "may have multiple roots or minima even in the presence of a single marginally outer trapped surface, and all should be tried for convergence".
Kemball and Bishop [93] suggested and tested several modifications to improve the algorithm's convergence behavior. They verified that (either in its original form or with their modifications) the algorithm's rate of convergence (number of iterations to reach a given error level) is roughly independent of the degree ℓmax of spherical-harmonic expansion used. They also give an analysis that the algorithm's cost is \({\mathcal O}(\ell _{\max}^4)\), and its accuracy \(\varepsilon = {\mathcal O}(1/{\ell _{\max}})\), i.e. the cost is \({\mathcal O}(1/{\varepsilon ^4})\). This accuracy is surprisingly low: Exponential convergence with ℓmax is typical of spectral algorithms and would be expected here. I do not know of any published work which addresses this discrepancy.
Lin and Novak's variant of the Nakamura-Kojima-Oohara algorithm
Lin and Novak [104] have developed a variant of the Nakamura-Kojima-Oohara algorithm which avoids the need for a separate search for a00 at each iteration: Write the apparent horizon equation (16) in the form
$$\Delta h - 2h = \lambda \Theta + \Delta h - 2h,$$
where Δ is again the flat-space angular Laplacian operator and where λ is a nonzero scalar function on the horizon surface. Then choose λ as
$$\lambda = {\left({{{\det {g_{ij}}} \over {\det {f_{ij}}}}} \right)^{1/3}}{[{g^{mn}}({\bar \nabla _m}F)({\bar \nabla _n}F)]^{1/2}}{h^2},$$
where fij the flat metric of polar spherical coordinates, ∇ is the associated 3-covariant derivative operator, and F is the level set function (7).
Lin and Novak [104] showed that all the spherical-harmonic coefficients aℓm (including a00) can then be found by iteratively solving the equation
$${a_{\ell m}} = - {1 \over {\ell (\ell + 1) + 2}}\int {Y_{\ell m}^{\ast}\lambda (\Theta + \Delta h - 2h)d\Omega}.$$
Lin and Novak [104] find that this algorithm gives robust convergence and is quite fast, particularly at modest accuracy levels. For example, running on a 2 GHz processor, their implementation takes 3.1, 5.8, 17, 88, and 313 seconds to find the apparent horizon in a test slice to a relative error (measured in the horizon area) of 9 × 10−4, 5 × 10−5, 6 × 10−7, 9 × 10−10, and 3 × 10−12 respectivelyFootnote 37. This implementation is freely available as part of the Lorene toolkit for spectral computations in numerical relativity (see Table 2).
Summary of spectral integral-iteration algorithms
Despite what appears to be fairly good numerical behavior and reasonable ease of implementation, the original Nakamura-Kojima-Oohara algorithm has not been widely used apart from later work by its original developers (see, for example, [115, 114]). Kemball and Bishop [93] have proposed and tested several modifications to the basic Nakamura-Kojima-Oohara algorithm. Lin and Novak [104] have develped a variant of the Nakamura-Kojima-Oohara algorithm which avoids the need for a separate search for the a00 coefficient at each iteration. Their implementation of this variant is freely available as part of the Lorene toolkit for spectral computations in numerical relativity (see Table 2).
Elliptic-PDE algorithms
The basic concept of elliptic-PDE algorithms is simple: We view the apparent horizon equation (16) as a nonlinear elliptic PDE for the horizon shape function h on the angular-coordinate space and solve this equation by standard finite-differencing techniquesFootnote 38, generally using Newton's method to solve the resulting set of nonlinear algebraic (finite-difference) equations. Algorithms of this type have been widely used both in axisymmetry and in fully generic slices.
Angular coordinates, grid, and boundary conditions
In more detail, elliptic-PDE algorithms assume that the horizon is a Strahlkörper about some local coordinate origin, and choose an angular coordinate system and a finite-difference grid of Nang points on S2 in the manner discussed in Section 2.2.
The most common choices are the usual polar-spherical coordinates (θ, ϕ) and a uniform "latitude/longitude" grid in these coordinates. Since these coordinates are "unwrapped" relative to the actual S2 trial-horizon-surface topology, the horizon shape function h satisfies periodic boundary conditions across the artificial grid boundary at ϕ = 0 and ϕ = 2π. The north and south poles θ = 0 and θ = π are trickier, but Huq et al. [89, 90], Shibata and Uryū [147], and Schnetter [132, 133]Footnote 39 "reaching across the pole" boundary conditions for these artificial grid boundaries.
Alternatively, Thornburg [156] avoids the z axis coordinate singularity of polar-spherical coordinates by using an "inflated-cube" system of six angular patches to cover S2. Here each patch's nominal grid is surrounded by a "ghost zone" of additional grid points where h is determined by interpolation from the neighboring patches. The interpatch interpolation thus serves to tie the patches together, enforcing the continuity and differentiability of h across patch boundaries. Thornburg reports that this scheme works well but was quite complicated to program.
Overall, the latitude/longitude grid seems to be the superior choice: it works well, is simple to program, and eases interoperation with other software.
Evaluating the expansion Θ
The next step in the algorithm is to evaluate the expansion Θ given by Equation (16) on the angular grid given a trial horizon surface shape function h on this same grid (6).
Most researchers compute Θ via 2-dimensional angular finite differencing of Equation (16) on the trial horizon surface. 2nd order angular finite differencing is most common, but Thornburg [156] uses 4th order angular finite differencing for increased accuracy.
With a (θ, ϕ) latitude/longitude grid the Θ(h, ∂uh, ∂uvh) function in Equation (16) is singular on the z axis (at the north and south poles θ = 0 and θ = π) but can be regularized by applying L'Hôpital's rule. Schnetter [132, 133] observes that using a Cartesian basis for all tensors greatly aids in this regularization.
Huq et al. [89, 90] choose, instead, to use a completely different computation technique for Θ, based on 3-dimensional Cartesian finite differencing:
They observe that the scalar field F defined by Equation (7) can be evaluated at any (3-dimensional) position in the slice by computing the corresponding (r, θ, ϕ) using the usual flat-space formulas, then interpolating h in the 2-dimensional (θ, ϕ) surface grid.
Rewrite the apparent horizon condition (15) in terms of F and its (3-dimensional) Cartesian derivatives,
$$\Theta \equiv \Theta (F,{\partial _i}F,{\partial _{ij}}F;{g_{ij}},{\partial _k}{g_{ij}},{K_{ij}}) = 0.$$
For each (latitude/longitude) grid point on the trial horizon surface, define a 3×3×3-point local Cartesian grid centered at that point. The spacing of this grid should be such as to allow accurate finite differencing, i.e. in practice it should probably be roughly comparable to that of the underlying numerical-relativity simulation's grid.
Evaluate F on the local Cartesian grid as described in Step 1 above.
Evaluate the Cartesian derivatives in Equation (27) by centered 2nd order Cartesian finite differencing of the F values on the local Cartesian grid.
Comparing the different ways of evaluating Θ, 2-dimensional angular finite differencing of Equation (16) seems to me to be both simpler (easier to program) and likely more efficient than 3-dimensional Cartesian finite differencing of Equation (27).
Solving the nonlinear elliptic PDE
A variety of algorithms are possible for actually solving the nonlinear elliptic PDE (16) (or (27) for the Huq et al. [89, 90] horizon finder).
The most common choice is to use some variant of Newton's method. That is, finite differencing Equation (16) or (27) (as appropriate) gives a system of Nang nonlinear algebraic equations for the horizon shape function h at the Nang angular grid points; these can be solved by Newton's method in Nang dimensions. (As explained by Thornburg [153, Section VIII.C], this is usually equivalent to applying the Newton-Kantorovich algorithm [37, Appendix C] to the original nonlinear elliptic PDE (16) or (27).)
Newton's method converges very quickly once the trial horizon surface is sufficiently close to a solution (a MOTS). However, for a less accurate initial guess, Newton's method may converge very slowly or even fail to converge at all. There is no usable way of determining a priori just how large the radius of convergence of the iteration will be, but in practice \({1 \over 4} \ {\rm to} \ {1 \over 3}\) of the horizon radius is often a reasonable estimateFootnote 40.
Thornburg [153] described the use of various "line search" modifications to Newton's method to improve its radius and robustness of convergence, and reported that even fairly simple modifications of this sort roughly doubled the radius of convergence.
Schnetter [132, 133] used the PETSc general-purpose elliptic-solver library [22, 23, 24] to solve the equations. This offers a wide variety of Newton-like algorithms already implemented in a highly optimized form.
Rather than Newton's method or one of its variants, Shibata et al. [146, 147] use a functional-iteration algorithm directly on the nonlinear elliptic PDE (16). This seems likely to be less efficient than Newton's method but avoids having to compute and manipulate the Jacobian matrix.
The Jacobian matrix
Newton's method, and all its variants, require an explicit computation of the Jacobian matrix
$${{\bf{J}}_{{\rm{IJ}}}} = {{\partial {\Theta _{\rm{I}}}} \over {\partial {h_{\rm{J}}}}},$$
where the indices I and J label angular grid points on the horizon surface (or equivalently on S2).
Notice that J includes contributions both from the direct dependence of Θ on h, ∂uh, and ∂uvh, and also from the indirect dependence of Θ on h through the position-dependence of the geometry variables gij, ∂kgij, and Kij (since Θ depends on the geometry variables at the horizon surface position, and this position is determined by h). Thornburg [153] discusses this indirect dependence in detail.
There are two basic ways to compute the Jacobian matrix.
Numerical Perturbation:
The simplest way to determine the Jacobian matrix is by "numerical perturbation", where for each horizon-surface grid point j, h is perturbed by some (small) amount ε at the J th grid point (that is, hI → hI + εδIJ), and the expansion Θ is recomputedFootnote 41. The J th column of the Jacobian matrix (28) is then estimated as
$${{\bf{J}}_{{\rm{IJ}}}} \approx {{{\Theta _{\rm{I}}}(h + \varepsilon {\delta _{{\rm{IJ}}}}){\Theta _{\rm{I}}}(h)} \over \varepsilon}.$$
Curtis and Reid [53], and Stoer and Bulirsch [150, Section 5.4.3] discuss the optimum choice of ε in this algorithmFootnote 42.
This algorithm is easy to program but somewhat inefficient. It is used by a number of researchers including Schnetter [132, 133], and Huq et al. [89, 90].
Symbolic Differentiation:
A more efficient, although somewhat more complicated, way to determine the Jacobian matrix is the "symbolic differentiation" algorithm described by Thornburg [153] and also used by Pasch [118], Shibata et al. [146, 147], and Thornburg [156]. Here the internal structure of the finite differenced Θ(h) function is used to directly determine the Jacobian matrix elements.
This algorithm is best illustrated by an example which is simpler than the full apparent horizon equation: Consider the flat-space Laplacian in standard (θ, ϕ) polar-spherical coordinates,
$$\Delta h \equiv {\partial _{\theta \theta}}h + {{{\partial _\theta}h} \over {\tan \theta}} + {{{\partial _{\phi \phi}}h} \over {{{\sin}^2}\theta}}.$$
Suppose we discretize this with centered 2nd order finite differences in θ and ϕ. Then neglecting finite-differencing truncation errors, and temporarily adopting the usual notation for 2-dimensional grid functions, hi, j = h(θ=θi, ϕ=ϕj), our discrete approximation to Δh is given by
$${(\Delta h)_{i,j}} = {{{h_{i - 1,j}} - 2{h_{i,j}} + {h_{i + 1,j}}} \over {{{(\Delta \theta)}^2}}} + {1 \over {\tan \theta}}{{{h_{i + 1,j}} - {h_{i + 1,j}} - {h_{i - 1,j}}} \over {2\Delta \theta}} + {1 \over {{{\sin}^2}\theta}}{{{h_{i,j - 1}} - 2{h_{i,j}} + {h_{i,j + 1}}} \over {{{(\Delta \phi)}^2}}}.$$
The Jacobian of Δh is thus given by
$${{\partial {{(\Delta h)}_{(i,j)}}} \over {\partial {h_{(k,\ell)}}}} = \left\{{\begin{array}{*{20}c} {{1 \over {{{(\Delta \theta)}^2}}} \pm {1 \over {2\tan \theta \Delta \theta}}} & {{\rm{if}}\;(k,\ell) = (i \pm 1,j),} \\ {{1 \over {{{\sin}^2}\theta {{(\Delta \phi)}^2}}}} & {{\rm{if}}\;(k,\ell) = (i \pm 1,j),} \\ {- {2 \over {{{(\Delta \theta)}^2}}} - {2 \over {{{\sin}^2}\theta {{(\Delta \phi)}^2}}}} & {{\rm{if}}\;(k,\ell) = (i,j),} \\ 0 & {{\rm{otherwise}}.} \\ \end{array}} \right.$$
Thornburg [153] describes how to generalize this to nonlinear differential operators without having to explicitly manipulate the nonlinear finite difference equations.
Solving the linear equations
All the algorithms described in Section 8.5.3 for treating nonlinear elliptic PDEs require solving a sequence of linear systems of Nang equations in Nang unknowns. Nang is typically on the order of a few thousand, and the Jacobian matrices in question are sparse due to the locality of the angular finite differencing (see Section 8.5.4). Thus, for reasonable efficiency, it is essential to use linear solvers that exploit this sparsity. Unfortunately, many such algorithms/codes only handle symmetric positive-definite matrices while, due to the angular boundary conditionsFootnote 43 (see Section 8.5.1), the Jacobian matrices that arise in apparent horizon finding are generally neither of these.
The numerical solution of large sparse linear systems is a whole subfield of numerical analysis. See, for example, Duff, Erisman, and Reid [65], and Saad [130] for extensive discussionsFootnote 44. In practice, a numerical relativist is unlikely to write her own linear solver but, rather, will use an existing subroutine (library).
Kershaw's [94] ILUCG iterative solver is often used; this is only moderately efficient, but is quite easy to programFootnote 45. Schnetter [132, 133] reports good results with an ILU-preconditioned GMRES solver from the PETSc library. Thornburg [156] experimented with both an ILUCG solver and a direct sparse LU decomposition solver (Davis' UMFPACK library [57, 58, 56, 55, 54]), and found each to be more efficient in some situations; overall, he found the UMFPACK solver to be the best choice.
As an example of the results obtained with this type of apparent horizon finder, Figure 10 shows the numerically-computed apparent horizons (actually, MOTSs) at two times in a head-on binary black hole collision. (The physical system being simulated here is very similar to that simulated by Matzner et al. [108], a view of whose event horizon is shown in Figure 5.)
This figure shows the numerically-computed apparent horizons (actually MOTSs) at two times in a head-on binary black hole collision. The black holes are colliding along the z axis. Figure reprinted with permission from [156]. © 2004 by IOP Publishing Ltd.
As another example, Figure 11 shows the time dependence of the irreducible masses of apparent horizons found in a (spiraling) binary black hole collision, simulated at several different grid resolutions, as found by both AHFinderDirect and another Cactus apparent horizon finder, AHFinderFootnote 46. For this evolution, the two apparent horizon finders give irreducible masses which agree to within about 2% for the individual horizons and 0.5% for the common horizon.
This figure shows the irreducible masses \((\sqrt {{\rm{area}}}/(16\pi))\) of individual and common apparent horizons in a binary black hole collision, as calculated by two different apparent horizon finders in the Cactus toolkit, AHFinder and AHFinderDirect. (AHFinderDirect was also run in simulations at several different resolutions.) Notice that when both apparent horizon finders are run in the same simulation (resolution dx = 0.080), there are only small differences between their results. Figure reprinted with permission from [5]. © 2005 by the American Physical Society.
As a final example, Figure 8 shows the numerically-computed event and apparent horizons in the collapse of a rapidly rotating neutron star to a Kerr black hole. (The event horizons were computed using the EHFinder code described in Section 5.3.3.)
Summary of elliptic-PDE algorithms/codes
Elliptic-PDE apparent horizon finders have been developed by many researchers, including Eardley [67]Footnote 47, Cook [50, 52, 51], and Thornburg [153] in axisymmetry, and Shibata et al. [146, 147], Huq et al. [89, 90], Schnetter [132, 133], and Thornburg [156] in fully generic slices.
Elliptic-PDE algorithms are (or can be implemented to be) among the fastest horizon finding algorithms. For example, running on a 1.7 GHz processor, Thornburg's AHFinderDirect [156] averaged 1.7 s per horizon finding, as compared with 61 s for an alternate "fast-flow" apparent horizon finder AHFinder (discussed in more detail in Section 8.7)Footnote 48. However, achieving maximum performance comes at some cost in implementation effort (e.g. the "symbolic differentiation" Jacobian computation discussed in Section 8.5.4).
Elliptic-PDE algorithms are probably somewhat more robust in their convergence (i.e. they have a slightly larger radius of convergence) than other types of local algorithms, particularly if the "line search" modifications of Newton's method described by Thornburg [153] are implementedFootnote 49. Their typical radius of convergence is on the order of \({1 \over 3}\) of the horizon radius, but cases are known where it is much smaller. For example, Schnetter, Herrmann, and Pollney [135] report that (with no "line search" modifications) it is only about 10% for some slices in a binary black hole coalescence simulation.
Schnetter's TGRapparentHorizon2D [132, 133] and Thornburg's AHFinderDirect [156] are both elliptic-PDE apparent horizon finders implemented as freely available modules ("thorns") in the Cactus computational toolkit (see Table 2). Both work with either the PUGH unigrid driver or the Carpet mesh-refinement driver for Cactus. TGRapparentHorizon2D is no longer maintained, but AHFinderDirect is actively supported and is now used by many different research groupsFootnote 50.
Horizon pretracking
Schnetter et al. [133, 135] introduced the important concept of "horizon pretracking". They focus on the case where we want to find a common apparent horizon as soon as it appears in a binary black-hole (or neutron-star) simulation. While a global (flow) algorithm (Section 8.7) could be used to find this common apparent horizon, these algorithms tend to be very slow. They observe that the use of a local (elliptic-PDE) algorithm for this purpose is somewhat problematic:
The common [apparent] horizon […] appears instantaneously at some late time and without a previous good guess for its location. In practice, an estimate of the surface location and shape can be put in by hand. The quality of this guess will determine the rate of convergence of the finder and, more seriously, also determines whether a horizon is found at all. Gauge effects in the strong field region can induce distortions that have a large influence on the shape of the common horizon, making them difficult to predict, particularly after a long evolution using dynamical coordinate conditions. As such, it can be a matter of some expensive trial and error to find the common apparent horizon at the earliest possible time. Further, if a common apparent horizon is not found, it is not clear whether this is because there is none, or whether there exists one which has only been missed due to unsuitable initial guesses — for a fast apparent horizon finder, a good initial guess is crucial.
Pretracking tries (usually successfully) to eliminate these difficulties by determining — before it appears — approximately where (in space) and when (in time) the common apparent horizon will appear.
Constant-expansion surfaces
The basic idea of horizon pretracking is to consider surfaces of constant expansion ("CE surfaces"), i.e. smooth closed orientable 2-surfaces in a slice satisfying the condition
$$\Theta = E,$$
where the expansion E is a specified real number. Each marginally outer trapped surface (including the apparent horizon) is thus a CE surface with expansion E = 0; more generally Equation (33) defines a 1-parameter family of 2-surfaces in the slice. As discussed by Schnetter et al. [133, 135], for asymptotically flat slices containing a compact strong-field region, some of the E < 0 members of this family typically foliate the weak-field region.
In the binary-coalescence context, for each t = constant slice we define E* to be the smallest E ≥ 0 for which a CE surface (containing both strong-field regions) exists with expansion E. If E* = 0 this "minimum-expansion CE surface" is the common apparent horizon, while if E* > 0 this surface is an approximation to where the common apparent horizon will appear. We expect the minimum-expansion CE surface to change continuously during the evolution and its expansion E* to decrease towards 0. Essentially, horizon pretracking follows the time evolution of the minimum-expansion CE surface and uses it as an initial guess for (searching for) the common apparent horizon.
Generalized constant-expansion surfaces
Schnetter [133] implemented an early form of horizon pretracking, which followed the evolution of the minimum-expansion constant-expansion surface, and found that it worked well for simple test problems. However, Schnetter et al. [135] found that for more realistic binary-black-hole coalescence systems the algorithm needs to be extended:
While the expansion is zero for a common apparent horizon, it is also zero for a 2-sphere at spatial infinity. Figure 12 illustrates this for Schwarzschild spacetime. Notice that for small positive E* there will generally be two distinct CE surfaces with E = E*, an inner surface just outside the horizon and an outer one far out in the weak-field region. The inner CE surface converges to the common apparent horizon as E* decreases towards 0; this surface is the one we would like the pretracking algorithm to follow. Unfortunately, without measures such as those described below, there is nothing to prevent the algorithm from following the outer surface, which does not converge to the common apparent horizon as E* decreases towards 0.
In a realistic binary-coalescence simulation, the actual minimum-expansion CE surface may be highly distorted and, thus, hard to represent accurately with a finite-resolution angular grid.
This figure shows the expansion Θ (left scale), and the "generalized expansions" r Θ (left scale) and r2Θ (right scale), for various r = constant surfaces in an Eddington-Finkelstein slice of Schwarzschild spacetime. Notice that all three functions have zeros at the horizon r = 2m, and that while Θ has a maximum at r ≈ 4.4 m, both r Θ and r2Θ increase monotonically with r.
Schnetter et al. [135] discuss these problems in more detail, arguing that to solve them, the expansion Θ should be generalized to a "shape function" H given by one of
$$\begin{array}{*{20}c} {{H_1} = \Theta,} \\ {\;{H_r} = h\Theta,} \\ {{H_{{r^2}}} = {h^2}\Theta,} \\ \end{array}$$
CE surfaces are then generalized to surfaces satisfying
$$H = E$$
for some specified E ≥ 0.
Note that unlike H1, both Hr and Hr2 are typically monotonic with radius. Neither Hr nor Hr2 are 3-covariantly defined, but they both still have the property that E = 0 in Equation (35) implies the surface is a MOTS, and in practice they work better for horizon pretracking.
Goal functions
To define the single "smallest" surface at each time, Schnetter et al. [135] introduce a second generalization, that of a "goal function" G, which maps surfaces to real numbers. The pretracking search then attempts, on each time slice, to find the surface (shape) satisfying H = E with the minimum value of G. They experimented with several different goal functions,
$$\begin{array}{*{20}c} {{G_H} = \overline{H},} \\ {{G_{rH}} = \overline{h} \overline{H},} \\ {\;\;{G_r} = \overline{h},} \\ \end{array}$$
where in each case the overbar (̅) denotes an average over the surfaceFootnote 51.
The pretracking search
Schnetter's [133] original implementation of horizon pretracking (which followed the evolution of the minimum-expansion CE surface) used a binary search on the desired expansion E. Because E appears only on the right hand side of the generalized CE condition (35), it is trivial to modify any apparent horizon finder to search for a surface of specified expansion E. (Schnetter used his TGRapparentHorizon2D elliptic-PDE apparent horizon finder described in Section 8.5.7 for this.) A binary search on E can then be used to find the minimum value E*.Footnote 52
Implementing a horizon pretracking search on any of the generalized goal functions (36) is conceptually similar but somewhat more involved: As described by Schnetter et al. [135] for the case of an elliptic-PDE apparent horizon finderFootnote 53, we first write the equation defining a desired pretracking surface as
$$H - \overline{H} + G - p = 0,$$
where p is the desired value of the goal function G. Since H is the only term in Equation (37) which varies over the surface, it must be constant for the equation to be satisfied. In this case \(H - \bar H\) vanishes, so the equation just gives G = p, as desired.
Because \({\bar H}\) depends on H at all surface points, directly finite differencing Equation (37) would give a non-sparse Jacobian matrix, which would greatly slow the linear-solver phase of the elliptic-PDE apparent horizon finder (Section 8.5.5). Schnetter et al. [135, Section III.B] show how this problem can be solved by introducing a single extra unknown into the discrete system. This gives a Jacobian which has a single non-sparse row and column, but is otherwise sparse, so the linear equations can still be solved efficiently.
When doing the pretracking search, the cost of a single binary-search iteration is approximately the same as that of finding an apparent horizon. Schnetter et al. [135, Figure 5] report that their pretracking implementation (a modified version of Thornburg's AHFinderDirect [156] elliptic-PDE apparent horizon finder described in Section 8.5.7) typically takes on the order of 5 to 10 binary-search iterationsFootnote 54. The cost of pretracking is thus on the order of 5 to 10 times that of finding a single apparent horizon. This is substantial, but not prohibitive, particularly if the pretracking algorithm is not run at every time step.
As an example of the results obtained from horizon pretracking, Figure 13 shows the expansion Θ for various pretracking surfaces (i.e. various choices for the shape function H in a head-on binary black hole collision). Notice how all three of the shape functions (34) result in pretracking surfaces whose expansions converge smoothly to zero just when the apparent horizon appears (at about t = 1.1).
This figure shows the expansion 0 for various pretracking surfaces, i.e. for various choices for the shape function H, in a head-on binary black hole collision. Notice how the three shape functions (34) (here labelled Θ, rΘ, and r2Θ) result in pretracking surfaces whose expansions converge smoothly to zero just when the apparent horizon appears (at about t = 1.1). Notice also that these three expansions have all converged to each other somewhat before the common apparent horizon appears. Figure reprinted with permission from [135]. © 2005 by the American Physical Society.
As a further example, Figure 14 shows the pretracking surfaces (more precisely, their cross sections projected into the black holes' orbital plane) at various times in a spiraling binary black hole collision.
This figure shows the pretracking surfaces at various times in a spiraling binary black hole collision, projected into the black holes' orbital plane. (The apparent slow drift of the black holes in a clockwise direction is an artifact of the corotating coordinate system; the black holes are actually orbiting much faster, in a counterclockwise direction.) Notice how, even well before the common apparent horizon first appears (t = 16.44 mAMD, bottom right plot), the rΘ pretracking surface is already a reasonable approximation to the eventual common apparent horizon's shape. Figure reprinted with permission from [135]. © 2005 by the American Physical Society.
Summary of horizon pretracking
Pretracking is a very valuable addition to the horizon finding repertoire: It essentially gives a local algorithm (in this case, an elliptic-PDE algorithm) most of the robustness of a global algorithm in terms of finding a common apparent horizon as soon as it appears. It is implemented as a higher-level algorithm which uses a slightly-modified elliptic-PDE apparent horizon finding algorithm as a "subroutine".
The one significant disadvantage of pretracking is its cost: Each pretracking search typically takes 5 to 10 times as long as finding an apparent horizon. Further research to reduce the cost of pretracking would be useful.
Schnetter et al.'s pretracking implementation [135] is implemented as a set of modifications to Thornburg's AHFinderDirect [156] apparent horizon finder. Like the original AHFinderDirect, the modified version is a freely available "thorn" in the Cactus toolkit (see Table 2).
Flow algorithms
Flow algorithms define a "flow" on 2-surfaces, i.e. they define an evolution of 2-surfaces in some pseudo-time λ, such that the apparent horizon is the λ → ∞ limit of a (any) suitable starting surface. Flow algorithms are different from other apparent horizon finding algorithms (except for zero-finding in spherical symmetry) in that their convergence does not depend on having a good initial guess. In other words, flow algorithms are global algorithms (Section 7.7).
To find the (an) apparent horizon, i.e. an outermost MOTS, the starting surface should be outside the largest possible MOTS in the slice. In practice, it generally suffices to start with a 2-sphere of areal radius substantially greater than 2 madm.
The global convergence property requires that a flow algorithm always flow from a large starting surface into the apparent horizon. This means that the algorithm gains no particular benefit from already knowing the approximate position of the apparent horizon. In particular, flow algorithms are no faster when "tracking" the apparent horizon (repeatedly finding it at frequent intervals) in a numerical time evolution. (In contrast, in this situation a local apparent horizon finding algorithm can use the most recent previously-found apparent horizon as an initial guess, greatly speeding the algorithm's convergenceFootnote 55).
Flow algorithms were first proposed for apparent horizon finding by Tod [157]. He initially considered the case of a time-symmetric slice (one where Kij = 0). In this case, a MOTS (and thus an apparent horizon) is a surface of minimal area and may be found by a "mean curvature flow"
$${\partial _\lambda}{x^i} = - \kappa {s^i},$$
where xi are the spatial coordinates of a horizon-surface point, si is as before the outward-pointing unit 3-vector normal to the surface, and k ≡ ∇k sk is the mean curvature of the surface as embedded in the slice. This is a gradient flow for the surface area, and Grayson [79] has proven that if the slice contains a minimum-area surface, this will in fact be the stable λ → ∞ limit of this flow. Unfortunately, this proof is valid only for the time-symmetric case.
For non-time-symmetric slices, Tod [157] proposed generalizing the mean curvature flow to the "expansion flow"
$${\partial _\lambda}{x^i} = - \Theta {s^i}.$$
There is no theoretical proof that this flow will converge to the (an) apparent horizon, but several lines of argument make this convergence plausible:
The expansion flow is identical to the mean curvature flow (38) in the principal part.
The expansion flow's velocity is clearly zero on an apparent horizon.
More generally, a simple argument due to Bartnik [25]Footnote 56 shows that the expansion flow can never move a (smooth) test surface through an apparent horizon. Suppose, to the contrary, that the test surface \({\mathcal T}\) is about to move through an apparent horizon \({\mathcal H}\), i.e. since both surfaces are by assumption smooth, that \({\mathcal T}\) and \({\mathcal H}\) touch at single (isolated) point P. At that point, \({\mathcal T}\) and \({\mathcal H}\) obviously have the same gij and Kij, and they also have the same si (because P is isolated). Hence the only term in Θ (as defined by Equation (15)) which differs between \({\mathcal T}\) and \({\mathcal H}\) is ∇isi. Clearly, if \({\mathcal T}\) is outside \({\mathcal H}\) and they touch at the single isolated point P, then relative to \({\mathcal H},{\mathcal T}\) must be concave outwards at P, so that \({\nabla _i}{s^i}({\mathcal T}) < {\nabla _i}{s^i}({\mathcal H})\). Thus the expansion flow (39) will move \({\mathcal T}\) outwards, away from the apparent horizon. (If \({\mathcal T}\) lies inside \({\mathcal H}\) the same argument holds with signs reversed appropriately.)
Numerical experiments by Bernstein [28], Shoemaker et al. [148, 149], and Pasch [118] show that in practice the expansion flow (39) does in fact converge robustly to the apparent horizon.
In the following I discuss a number of important implementation details for, and refinements of, this basic algorithm.
Implicit pseudo-time stepping
Assuming the Strahlkörper surface parameterization (4), the expansion flow (39) is a parabolic equation for the horizon shape function h.Footnote 57 This means that any fully explicit scheme to integrate it (in the pseudo-time λ) must severely restrict its pseudo-time step Δλ for stability, and this restriction grows (quadratically) worse at higher spatial resolutionsFootnote 58. This makes the horizon finding process very slow.
To avoid this restriction, practical implementations of flow algorithms use implicit pseudo-time integration schemes; these can have large pseudo-time steps and still be stable. Because we only care about the λ → ∞ limit, a highly accurate pseudo-time integration is not important; only the accuracy of approximating the spatial derivatives matters. Bernstein [28] used a modified Du Fort-Frankel scheme [64]Footnote 59 but found some problems with the surface shape gradually developing high-spatial-frequency noise. Pasch [118] reports that an "exponential" integrator (Hochbrucket al. [85]) works well, provided the flow's Jacobian matrix is computed accuratelyFootnote 60. The most common choice is probably that of Shoemaker et al. [148, 149], who use the iterated Crank-Nicholson ("ICN") schemeFootnote 61. They report that this works very well; in particular, they do not report any noise problems.
By refining his finite-element grid (Section 2.3) in a hierarchical manner, Metzger [109] is able to use standard conjugate-gradient elliptic solvers in a multigrid-like fashionFootnote 62, using each refinement level's solution as an initial guess for the next higher refinement level's iterative solution. This greatly speeds the flow integration: Metzger reports that the performance of the overall surface-finding algorithm is "of the same order of magnitude" as that of Thornburg's AHFinderDirect [156] elliptic-PDE apparent horizon finder (described in Section 8.5.7).
In a more general context than numerical relativity, Osher and Sethian [116] have discussed a general class of numerical algorithms for integrating "fronts propagating with curvature-dependent speed". These flow a level-set function (Section 2.1) which implicitly locates the actual "front".
Varying the flow speed
Another important performance optimization of the standard expansion flow (39) is to replace Θ in the right-hand side by a suitable nonlinear function of Θ, chosen so the surface shrinks faster when it is far from the apparent horizon. For example, Shoemaker et al. [148, 149] use the flow
$${\partial _\lambda}{x^i} = - \left[ {(\Theta - c){{\arctan}^2}\left({{{\Theta - c} \over {{\Theta _0}}}} \right)} \right]{s^i}$$
for this purpose, where Θ0 is the value of Θ on the initial-guess surface, and c (which is gradually decreased towards 0 as the iteration proceeds) is a "goal" value for Θ.
Surface representation and the handling of bifurcations
Since a flow algorithm starts with (topologically) a single large 2-sphere, if there are multiple apparent horizons present the surface must change topology (bifurcate) at some point in the flow. Depending on how the surface is represented, this may be easy or difficult.
Pasch [118] and Shoemaker et al. [148, 149] use a level-set function approach (Section 2.1). This automatically handles any topology or topology change. However, it has the drawback of requiring the flow to be integrated throughout the entire volume of the slice (or at least in some neighborhood of each surface). This is likely to be much more expensive than only integrating the flow on the surface itself. Shoemaker et al. also generate an explicit Strahlkörper surface representation (Section 2.2), monitoring the surface shape to detect an imminent bifurcation and reparameterizing the shape into 2 separate surfaces if a bifurcation happens.
Metzger [109] uses a finite-element surface representation (Section 2.3), which can represent any topology. However, if the flow bifurcates, then to explicitly represent each apparent horizon the code must detect that the surface self-intersects, which may be expensive.
Gundlach's "fast flow"
Gundlach [80] introduced the important concept of a "fast flow". He observed that the subtraction and inversion of the flat-space Laplacian in the Nakamura-Kojima-Oohara spectral integral-iteration algorithm (Section 8.4) is an example of "a standard way of solving nonlinear elliptic problems numerically, namely subtracting a simple linear elliptic operator from the nonlinear one, inverting it by pseudo-spectral algorithms and iterating". Gundlach then interpreted the Nakamura-Kojima-Oohara algorithm as a type of flow algorithm where each pseudo-time step of the flow corresponds to a single functional-iteration step of the Nakamura-Kojima-Oohara algorithm.
In this framework, Gundlach defines a 2-parameter family of flows interpolating between the Nakamura-Kojima-Oohara algorithm and Tod's [157] expansion flow (39),
$${\partial _\lambda}h = - A{(1 - B\Delta)^{- 1}}\rho \Theta,$$
where A ≥ 0 and B ≥ 0 are parameters, ρ > 0 is a weight functional which depends on h through at most 1st derivatives, Δ is the flat-space Laplacian operator, and (1 — BΔ)−1 denotes inverting the operator (1 — BΔ). Gundlach then argues that intermediate "fast flow" members of this family should be useful compromises between the speed of the Nakamura-Kojima-Oohara algorithm and the robustness of Tod's expansion flow. Based on numerical experiments, Gundlach suggests a particular choice for the weight functional ρ and the parameters A and B. The resulting algorithm updates high-spatial-frequency components of h essentially the same as the Nakamura-Kojima-Oohara algorithm but should reduce low-spatial-frequency error components faster. Gundlach's algorithm also completely avoids the need for numerically solving Equation (23) for the a00 coefficient in the Nakamura-Kojima-Oohara algorithm.
Alcubierre's AHFinder [4] horizon finder includes an implementation of Gundlach's fast flow algorithm63. AHFinder is implemented as a freely available module ("thorn") in the Cactus computational toolkit (see Table 2) and has been used by many research groups.
Summary of flow algorithms/codes
Flow algorithms are the only truly global apparent horizon finding algorithms and, as such, can be much more robust than local algorithms. In particular, flow algorithms can guarantee convergence to the outermost MOTS in a slice. Unfortunately, these convergence guarantees hold only for time-symmetric slices.
In the forms which have strong convergence guarantees, flow algorithms tend to be very slow. (Metzger's algorithm [109] is a notable exception: It is very fast.) There are modifications which can make flow algorithms much faster, but then their convergence is no longer guaranteed. In particular, practical experience has shown that in some binary black hole coalescence simulations (Alcubierre et al. [5], Diener et al. [62]), "fast flow" algorithms (Section 8.7.4) can miss common apparent horizons which are found by other (local) algorithms.
Alcubierre's apparent horizon finder AHFinder [4] includes a "fast flow" algorithm based on the work of Gundlach [80]Footnote 63. It is implemented as a freely available module ("thorn") in the Cactus computational toolkit (see Table 2) and has been used by a number of research groups.
Summary of Algorithms/Codes for Finding Apparent Horizons
There are many apparent horizon finding algorithms, with differing trade-offs between speed, robustness of convergence, accuracy, and ease of programming.
In spherical symmetry, zero-finding (Section 8.1) is fast, robust, and easy to program. In axisymmetry, shooting algorithms (Section 8.2) work well and are fairly easy to program. Alternatively, any of the algorithms for generic slices (summarized below) can be used with implementations tailored to the axisymmetry.
Minimization algorithms (Section 8.3) are fairly easy to program, but when the underlying simulation uses finite differencing these algorithms are susceptible to spurious local minima, have relatively poor accuracy, and tend to be very slow unless axisymmetry is assumed. When the underlying simulation uses spectral methods, then minimization algorithms can be somewhat faster and more robust.
Spectral integral-iteration algorithms (Section 8.4) and elliptic-PDE algorithms (Section 8.5) are fast and accurate, but are moderately difficult to program. Their main disadvantage is the need for a fairly good initial guess for the horizon position/shape.
In many cases Schnetter's "pretracking" algorithm (Section 8.6) can greatly improve an elliptic-PDE algorithm's robustness, by determining — before it appears — approximately where (in space) and when (in time) a new outermost apparent horizon will appear. Pretracking is implemented as a modification of an existing elliptic-PDE algorithm and is moderately slow: It typically has a cost 5 to 10 times that of finding a single horizon with the elliptic-PDE algorithm.
Finally, flow algorithms (Section 8.7) are generally quite slow (Metzger's algorithm [109] is a notable exception) but can be very robust in their convergence. They are moderately easy to program. Flow algorithms are global algorithms, in that their convergence does not depend on having a good initial guess.
Table 2 lists freely-available apparent horizon finding codes.
An algorithm's actual "convergence region" (the set of all initial guesses for which the algorithm converges to the correct solution) may even be fractal in shape. For example, the Julia set is the convergence region of Newton's method on a simple nonlinear algebraic equation.
For convenience of exposition I use spherical harmonics here, but there are no essential differences if other basis sets are used.
I discuss the choice of this angular grid in more detail in Section 8.5.1.
There has been some controversy over whether, and if so how quickly, Regge calculus converges to the continuum Einstein equations. (See, for example, the debate between Brewin [40] and Miller [110], and the explicit convergence demonstration of Gentle and Miller [73].) However, Brewin and Gentle [41] seem to have resolved this: Regge calculus does, in fact, converge to the continuum solution, and this convergence is generically 2nd order in the resolution.
See, for example, Choptuik [48], Pretorius [127], Schnetter et al. [134], and Pretorius and Choptuik [126] for general surveys of the uses of, and methods for, mesh refinement in numerical relativity.
Chruściel and Galloway [49] showed that if a "cloud of sand" falls into a large black hole, each "sand grain" generates a non-differentiable caustic in the event horizon.
This is a statement about the types of spacetimes usually studied by numerical relativists, not a statement about the mathematical properties of the event horizon itself.
I briefly review ODE integration algorithms and codes in Appendix B.
In practice the differentiation can usefully be combined with the interpolation; I outline how this can be done in Section 7.5.
This convergence is only true in a global sense: locally the event horizon has no special geometric properties, and the Riemann tensor components which govern geodesic convergence/divergence may have either sign.
Diener [60] describes how the algorithm can be enhanced to also determine (integrate) individual null generators of the event horizon. This requires interpolating the 4-metric to the generator positions but (still) not taking any derivatives of the 4-metric.
Walker [162] mentions an implementation for fully generic slices but only presents results for the axisymmetric case.
See [7, 103, 162].
Equivalently, Diener [60] observed that the locus of any given nonzero value of the level-set function F is itself a null surface and tends to move (exponentially) closer and closer to the event horizon as the backwards evolution proceeds.
They describe how Richardson extrapolation can be used to improve the accuracy of the solutions from \({\mathcal O}(\varepsilon)\) to \({\mathcal O}({\varepsilon ^2})\), but it appears that this has not been done for their published results.
Note that the surface must be smooth everywhere. If this condition were not imposed, then MOTSs would lose many of their important properties. For example, even a standard t = constant slice of Minkowski spacetime contains many non-smooth "MOTSs": The surface of any closed polyhedron in such a slice satisfies all the other conditions to be an MOTS.
Andersson and Metzger [6] have shown that MOTSs can only intersect if they are contained within an outer common MOTS. Szilagyi et al. [151] give a numerical example of such overlapping MOTSs found in a binary black hole collision.
As an indication of the importance of the "closed" requirement, Hawking [81] observed that if we consider two spacelike-separated events in Minkowski spacetime, the intersection of their backwards light cones satisfies all the conditions of the MOTS definition, except that it is not closed.
The proof is given by Hawking and Ellis [82, Proposition 9.2.8] and by Wald [160, Propositions 12.2.3 and 12.2.4].
Wald and Iyer [161] proved this by explicitly constructing a family of angularly anisotropic slices in Schwarzschild spacetime which approach arbitrarily close to r = 0 yet contain no apparent horizons. However, Schnetter and Krishnan [136] have recently studied the behavior of apparent horizons in various anisotropic slices in Schwarzschild and Vaidya spacetimes, finding that the Wald and Iyer behavior seems to be rare.
This world-tube is sometimes called "the apparent horizon", but this is not standard terminology. In this review I always use the terminology that an MOTS or apparent horizon is a 2-surface contained in a (single) slice.
Ashtekar and Galloway [17] have recently proved "a number of physically interesting constraints" on this slicing-dependence.
The derivation of this condition is given by (for example) York [164], Gundlach [80, Section IIA], and Baumgarte and Shapiro [27, Section 6.1].
Notice that in order for the 3-divergence in Equation (15) to be meaningful, si (defined only as a field on the MOTS) must be smoothly continued off the surface and extended to a field in some 3-dimensional neighborhood of the surface. The off-surface continuation is non-unique, but it is easy to see that this does not affect the value of Θ on the surface.
Or, in the Huq et al. [89, 90] algorithm described in Section 8.5.2, at the local Cartesian grid point positions.
If the underlying simulation uses spectral methods then the spectral series can be evaluated anywhere, so no actual interpolation need be done, although the term "spectral interpolation" is still often used. See Fornberg [70], Gottlieb and Orszag [75], and Boyd [37] for general discussions of spectral methods, and (for example) Ansorg et al. [12, 11, 10, 13], Bonazzola et al. [35, 33, 34], Grandclement et al. [77], Kidder et al. [95, 96, 97], and Pfeiffer et al. [120, 124, 123, 122] for applications to numerical relativity.
Conceptually, an interpolator generally works by locally fitting a fitting function (usually a low-degree polynomial) to the data points in a neighborhood of the interpolation point, then evaluating the fitting function at the interpolation point. By evaluating the derivative of the fitting function, the ∂kgij values can be obtained very cheaply at the same time as the gij values.
Thornburg [154, Appendix F] gives a more detailed discussion of the non-smoothness of Lagrange-polynomial interpolation errors.
Note that ∂rgθθ is a known coefficient field here, not an unknown; if necessary, it can be obtained by numerically differentiating gθθ. Therefore, despite the appearance of the derivative, Equation (17) is still an algebraic equation for the horizon radius h, not a differential equation.
See also the work of Bizoń, Malec, and Ó Murchadha [32] for an interesting analytical study giving necessary and sufficient conditions for apparent horizons to form in non-vacuum spherically symmetric spacetimes.
Ascher, Mattheij, and Russel [15, Chapter 4] give a more detailed discussion of shooting methods.
See, for example, Dennis and Schnabel [59], or Brent [39] for general surveys of general-purposes function-minimization algorithms and codes.
There is a simple heuristic argument (see, for example, Press et al. [125, Section 9.6]) that at least some spurious local minima should be expected. We are trying to solve a system of Nang nonlinear equations, ΘI = 0 (one equation for each horizon-surface grid point). Equivalently, we are trying to find the intersection of the Nang codimension-one hypersurfaces ΘI = 0 in surface-shape space. The problem is that anywhere two or more of these hypersurfaces approach close to each other, but do not actually intersect, there is a spurious local minimum in ‖Θ‖.
A simple counting argument suffices to show that any general-purpose function-minimization algorithm in n dimensions must involve at least \({\mathcal O}({n^2})\) function evaluations (see, for example, Press et al. [125, Section 10.6]): Suppose the function to be minimized is f: ℜn → ℜ, and suppose f has a local minimum near some point x0 ∈ ℜn. Taylor-expanding f in a neighborhood of x0 gives \(f(\times) = f({\times _0}) + {{\rm{a}}^T}(\times - {\times _0}) + {(\times - {\times _0})^T}{\rm{B(}} \times - {\times _0}) + {\mathcal O}(\Vert \times - {\times _0}{\Vert^3})\), where a ∈ ℜn, B ∈ ℜn×n is symmetric, and vT denotes the transpose of the column vector v ∈ ℜn.
Neglecting the higher order terms (i.e. approximating f as a quadratic form in x in a neighborhood of x0), and ignoring f(x0) (which does not affect the position of the minimum), there are a total of \(N = n + {1 \over 2}n(n + 1)\) coefficients in this expression. Changing any of these coefficients may change the position of the minimum, and at each function evaluation the algorithm "learns" only a single number (the value of f at the selected evaluation point), so the algorithm must make at least \(N = {\mathcal O}({n^2})\) function evaluations to (implicitly) determine all the coefficients.
Actual functions are not exact quadratic forms, so in practice there are additional \({\mathcal O}(1)\) multiplicative factors in the number of function evaluations. Minimization algorithms may also make additional performance and/or space-versus-time trade-offs to improve numerical robustness or to avoid explicitly manipulating n × n Jacobian matrices.
In the context of an underlying simulation with spectral accuracy, Pfeiffer [122, 121] reports exponential convergence of the horizon finding accuracy with ℓmax.
AHFinder also includes a "fast flow" algorithm (Section 8.7).
For comparison, the elliptic-PDE AHFinderDirect horizon finder (discussed in Section 8.5.6), running on a roughly similar processor, takes about 1.8 seconds to find the apparent horizon in a similar test slice to a relative error of 4 × 10−4.
In theory this equation could also be solved by a spectral method on using spectral differentiation to evaluate the angular derivatives. (See [70, 75, 37, 12, 11, 10, 13, 35, 33, 34, 77, 95, 96, 97, 120, 124, 123, 122] for further discussion of spectral methods.) This should yield a highly efficient apparent horizon finder. However, I know of no published work taking this approach.
See [133] for a substantially revised version of [132].
Thornburg [153] used a Monte-Carlo survey of horizon-shape perturbations to quantify the radius of convergence of Newton's method for apparent horizon finding. He found that if strong high-spatial-frequency perturbations are present in the slice's geometry then the radius of convergence may be very small. Fortunately, this problem rarely occurs in practice.
A very important optimization here is that Θ only needs to be recomputed within the finite-difference domain of dependence of the J th grid point.
Because of the one-sided finite differencing, the approximation (29) is only \({\mathcal O}(\varepsilon)\) accurate. However, in practice this does not seriously impair the convergence of a horizon finder, and the extra cost of a centered-finite-differencing \({\mathcal O}({\varepsilon ^2})\) approximation is not warranted.
Or the interpatch interpolation conditions in Thornburg's multiple-grid-patch scheme [156].
Multigrid algorithms are also important here; these exploit the geometric structure of the underlying elliptic PDE. See Briggs, Henson, and McCormick [42] and Trottenberg, Oosterlee, and Schüller [158] for general introductions to multigrid algorithms.
Madderom's Fortran subroutine DILUCG [107], which implements the method of [94], has been used by a number of numerical relativists for both this and other purposes.
AHFinder incorporates both a minimization algorithm (Section 8.3) and a fast-flow algorithm (Section 8.7.4); these tests used the fast-flow algorithm.
This paper does not say how the author finds apparent horizons, but [68, page 135] cites a preprint of this as treating the apparent-horizon equation as a 2-point (ODE) boundary value problem: Eardley uses a 'beads on a string' technique to solve the set of simultaneous equations, i.e., imagining the curve to be defined as a bead on each ray of constant angle. He solves for the positions on each ray at which the relation is satisfied everywhere.
As another comparison, the Lorene apparent horizon finder (discussed in more detail in Section 8.4.2), running on a roughly similar processor, takes between 3 and 6 seconds to find apparent horizons to comparable accuracy.
The convergence problems, which Thornburg [153] noted when high-spatial-frequency perturbations are present in the slice's geometry, seem to be rare in practice.
In addition, at least two different research groups have now ported, or are in the process of porting, AHFinderDirect to their own (non-Cactus) numerical relativity codes.
Schnetter et al. [135] use a simple arithmetic mean over all surface grid points. In theory this average could be defined 3-covariantly by taking the induced metric on the surface into account, but in practice they found that this was not worth the added complexity.
There is one complication here: Any local apparent horizon finding algorithm may fail if the initial guess is not good enough, even if the desired surface is actually present. The solution is to use the constant-expansion surface for a slightly larger expansion E as an initial guess, gradually "walking down" the value of E to find the minimum value E*. Thornburg [156, Appendix C] describes such a "continuation-algorithm binary search" algorithm in detail.
As far as I know this is the only case that has been considered for horizon pretracking. Extension to other types of apparent horizon finders might be a fruitful area for further research.
This refers to the period before a common apparent horizon is found. Once a common apparent horizon is found, then pretracking can be disabled as the apparent horizon finder can easily "track" the apparent horizon's motion from one time step to the next. With a binary search the number of iterations depends only weakly (logarithmically) on the pretracking algorithm's accuracy tolerance. It might be possible to replace the binary search by a more sophisticated 1-dimensional search algorithm (I discuss such algorithms in Appendix A), potentially cutting the number of iterations substantially. This might be a fruitful area for further research.
Alternatively, a flow algorithm could use the most recent previously-found apparent horizon as an initial guess. In this case the algorithm would have only local convergence (in particular, it would probably fail to find a new outermost MOTS that appeared well outside the previously-found MOTS). However, the algorithm would only need to flow the surface a small distance, so the algorithm should be fairly fast.
Cited as Ref. [17] by [80].
Linearizing the Θ(h) function (16) gives a negative Laplacian in h as the principal part.
For a spatial resolution Δx, an explicit scheme is generally limited to a pseudo-time step Δλ ≲ (Δx)2.
Richtmyer and Morton [129, Section 7.5] give a very clear presentation and analysis of the Du Fort-Frankel scheme.
More precisely, Pasch [118] found that that an exponential integrator worked well when the flow's Jacobian matrix was computed exactly (using the symbolic-differentiation technique described in Section 8.5.4). However, when the Jacobian matrix was approximated using the numerical-perturbation technique described in Section 8.5.4, Pasch found that the pseudo-time integration became unstable at high numerical resolutions. Pasch [118] also notes that the exponential integrator uses a very large amount of memory.
Teukolsky [152], and Leiler and Rezzolla [101] have analyzed ICN's stability under various conditions.
See [42, 158] for general introductions to multigrid algorithms for elliptic PDEs.
AHFinder also includes a minimization algorithm (Section 8.3).
The parabola generically has two roots, but normally only one of them lies between x− and x+.
The numerical-analysis literature usually refers to this as the "initial value problem". Unfortunately, in a relativity context this terminology often causes confusion with the "initial data problem" of solving the ADM constraint equations. I use the term "time-integration problem for ODEs" to (try to) avoid this confusion. In this appendix, sans-serif lower-case letters abc… z denote variables and functions in ℜn (for some fixed dimension n), and sans-serif upper-case letters ABC … Z denote n × n real-valued matrices.
LSODA can also automatically detect stiff systems of ODEs and adjust its integration scheme so as to handle them efficiently.
Abrahams, A.M., Cook, G.B., Shapiro, S.L., and Teukolsky, S.A., "Solving Einstein's Equations for Rotating Spacetimes: Evolution of Relativistic Star Clusters", Phys. Rev. D, 49, 5153–5164, (1994).
ADS Google Scholar
Abrahams, A.M., and Evans, C.R., "Trapping a Geon: Black Hole Formation by an Imploding Gravitational Wave", Phys. Rev. D, 46, R4117–R4121, (1992).
Abrahams, A.M., Heiderich, K.H., Shapiro, S.L., and Teukolsky, S.A., "Vacuum initial data, singularities, and cosmic censorship", Phys. Rev. D, 46, 2452–2463, (1992).
ADS MathSciNet Google Scholar
Alcubierre, M., Brandt, S., Brügmann, B., Gundlach, C., Massó, J., Seidel, E., and Walker, P., "Test-beds and applications for apparent horizon finders in numerical relativity", Class. Quantum Grav., 17, 2159–2190, (2000). Related online version (cited on 09 January 2006): http://arXiv.org/abs/gr-qc/9809004.
ADS MathSciNet MATH Google Scholar
Alcubierre, M., Brügmann, B., Diener, P., Guzmáan, F.S., Hawke, I., Hawley, S., Herrmann, F., Koppitz, M., Pollney, D., Seidel, E., and Thornburg, J., "Dynamical evolution of quasi-circular binary black hole data", Phys. Rev. D, 72, 044004, (2005). Related online version (cited on 09 January 2006): http://arXiv.org/abs/gr-qc/0411149.
Andersson, L., and Metzger, J., personal communication, (2007). Personal communication from Lars Andersson to Bela Sziláagyi.
Anninos, P., Bernstein, D., Brandt, S., Libson, J., Massoó, J., Seidel, E., Smarr, L.L., Suen, W.-M., and Walker, P., "Dynamics of Apparent and Event Horizons", Phys. Rev. Lett., 74, 630–633, (1995). Related online version (cited on 09 January 2006): http://arXiv.org/abs/gr-qc/9403011.
Anninos, P., Camarda, K., Libson, J., Massó, J., Seidel, E., and Suen, W.-M., "Finding apparent horizons in dynamic 3D numerical spacetimes", Phys. Rev. D, 58, 024003, 1–12, (1998).
MathSciNet Google Scholar
Anninos, P., Daues, G., Massó, J., Seidel, E., and Suen, W.-M., "Horizon boundary conditions for black hole spacetimes", Phys. Rev. D, 51, 5562–5578, (1995).
Ansorg, M., "A double-domain spectral method for black hole excision data", Phys. Rev. D, 72, 024018, 1–10, (2005). Related online version (cited on 30 January 2007): http://arxiv.org/abs/gr-qc/0505059.
Ansorg, M., Brügmann, B., and Tichy, W., "Single-domain spectral method for black hole puncture data", Phys. Rev. D, 70, 064011, 1–13, (2004). Related online version (cited on 09 January 2006): http://arXiv.org/abs/gr-qc/0404056.
Ansorg, M., Kleinwächter, A., and Meinel, R., "Highly accurate calculation of rotating neutron stars: Detailed description of the numerical methods", Astron. Astrophys., 405, 711–721, (2003). Related online version (cited on 09 January 2006): http://arXiv.org/abs/astro-ph/0301173.
ADS MATH Google Scholar
Ansorg, M., and Petroff, D., "Black holes surrounded by uniformly rotating rings", Phys. Rev. D, 72, 024019, (2005). Related online version (cited on 09 January 2006): http://arXiv.org/abs/gr-qc/0505060.
Arnowitt, R., Deser, S., and Misner, C.W., "The dynamics of general relativity", in Witten, L., ed., Gravitation: An Introduction to Current Research, 227–265, (Wiley, New York, U.S.A., 1962). Related online version (cited on 09 January 2006): http://arXiv.org/abs/gr-qc/0405109.
Ascher, U.M., Mattheij, R.M.M., and Russell, R.D., Numerical Solution of Boundary Value Problems for Ordinary Differential Equations, (Prentice-Hall, Englewood Cliffs, U.S.A., 1988).
MATH Google Scholar
Ashtekar, A., Beetle, C., and Fairhurst, S., "Isolated horizons: a generalization of black hole mechanics", Class. Quantum Grav., 16, L1–L7, (1999). Related online version (cited on 09 January 2006): http://arXiv.org/abs/gr-qc/9812065.
Ashtekar, A., and Galloway, G., "Some uniqueness results for dynamical horizons", Adv. Theor. Math. Phys., 9, 1–30, (2005). Related online version (cited on 09 January 2006): http://arXiv.org/abs/gr-qc/0503109.
MathSciNet MATH Google Scholar
Ashtekar, A., and Krishnan, B., "Dynamical Horizons: Energy, Angular Momentum, Fluxes, and Balance Laws", Phys. Rev. Lett., 89, 261101, 1–4, (2002). Related online version (cited on 09 January 2006): http://arXiv.org/abs/gr-qc/0207080.
Ashtekar, A., and Krishnan, B., "Dynamical horizons and their properties", Phys. Rev. D, 68, 104030, 1–25, (2003). Related online version (cited on 09 January 2006): http://arXiv.org/abs/gr-qc/0308033.
Ashtekar, A., and Krishnan, B., "Isolated and Dynamical Horizons and Their Applications", Living Rev. Relativity, 7, lrr-2004-10, 10, (2004). URL (cited on 09 January 2006): http://www.livingreviews.org/lrr-2004-10.
Baiotti, L., Hawke, I., Montero, P.J., Loftier, F., Rezzolla, L., Stergioulas, N., Font, J.A., and Seidel, E., "Three-dimensional relativistic simulations of rotating neutron star collapse to a Kerr black hole", Phys. Rev. D, 71, 024035, (2005). Related online version (cited on 09 January 2006): http://arXiv.org/abs/gr-qc/0403029.
Balay, S., Buschelman, K., Gropp, W.D., Kaushik, D., Knepley, M., Curfman McInnes, L., Smith, B.F., and Zhang, H., "PETSc: Portable, Extensible Toolkit for Scientific Computation", project homepage, Argonne National Laboratory. URL (cited on 09 January 2006): http://www.mcs.anl.gov/petsc.
Balay, S., Buschelman, K., Gropp, W.D., Kaushik, D., Knepley, M., Curfman McInnes, L., Smith, B.F., and Zhang, H., PETSc Users Manual, ANL-95/11 — Revision 2.1.5, (Argonne National Laboratory, Argonne, U.S.A., 2003). URL (cited on 20 August 2003): http://www-unix.mcs.anl.gov/petsc/petsc-as/documentation/.
Balay, S., Gropp, W.D., Curfman McInnes, L., and Smith, B.F., "Efficient Management of Parallelism in Object-Oriented Numerical Software Libraries", in Arge, E., Bruaset, A.M., and Langtangen, H.P., eds., Modern Software Tools for Scientific Computing, Proceedings of SciTools' 96 Workshop held in Oslo, Norway, 163–202, (Birkhäuser, Boston, U.S.A., 1997).
Bartnik, R., personal communication. Personal communication from Robert Bartnik to Carsten Gundlach.
Baumgarte, T.W., Cook, G.B., Scheel, M.A., Shapiro, S.L., and Teukolsky, S.A., "Implementing an apparent-horizon finder in three dimensions", Phys. Rev. D, 54, 4849–4857, (1996). Related online version (cited on 09 January 2006): http://arXiv.org/abs/gr-qc/9606010.
Baumgarte, T.W., and Shapiro, S.L., "Numerical relativity and compact binaries", Phys. Rep., 376, 41–131, (2003). Related online version (cited on 09 January 2006): http://arXiv.org/abs/gr-qc/0211028.
Bernstein, D., Notes on the Mean Curvature Flow Method for Finding Apparent Horizons, (National Center for Supercomputing Applications, Urbana-Champaign, U.S.A., 1993).
Bishop, N.T., "The Closed Trapped Region and the Apparent Horizon of Two Schwarzschild Black Holes", Gen. Relativ. Gravit., 14, 717–723, (1982).
Bishop, N.T., "The horizons of two Schwarzschild black holes", Gen. Relativ. Gravit., 16, 589–593, (1984).
Bishop, N.T., "The Event Horizons of Two Schwarzschild black holes", Gen. Relativ. Gravit., 20, 573–581, (1988).
Bizoń, P., Malec, E., and Ó Murchadha, N., "Trapped Surfaces in Spherical Stars", Phys. Rev. Lett., 61, 1147–1150, (1988).
Bonazzola, S., Frieben, J., Gourgoulhon, E., and Marck, J.-A., "Spectral methods in general relativity — toward the simulation of 3D-gravitational collapse of neutron stars", in Ilin, A.V., and Scott, L.R., eds., ICOSAHOM' 95, Proceedings of the Third International Conference on Spectral and High Order Methods: Houston, Texas, June 5–9, 1995, Houston Journal of Mathematics, 3-19, (University of Houston, Houston, U.S.A., 1996). Related online version (cited on 09 January 2006): http://arXiv.org/abs/gr-qc/9604029.
Bonazzola, S., Gourgoulhon, E., and Marck, J.-A., "Spectral methods in general relativistic astrophysics", J. Comput. Appl. Math., 109, 433–473, (1999). Related online version (cited on 09 January 2006): http://arXiv.org/abs/gr-qc/9811089.
Bonazzola, S., and Marck, J.-A., "Pseudo-Spectral Methods Applied to Gravitational Collapse", in Evans, C.R., Finn, L.S., and Hobill, D.W., eds., Frontiers in Numerical Relativity, Proceedings of the International Workshop on Numerical Relativity, University of Illinois at Urbana-Champaign, USA, May 9–13, 1988, 239–253, (Cambridge University Press, Cambridge, U.K.; New York, U.S.A., 1989).
Booth, I., "Black hole boundaries", Can. J. Phys., 83, 1073–1099, (2005). Related online version (cited on 09 January 2006): http://arXiv.org/abs/gr-qc/0508107.
Boyd, J.P., Chebyshev and Fourier Spectral Methods, (Dover Publications, Mineola, U.S.A., 2001), 2nd edition.
Brankin, R.W., Gladwell, I., and Shampine, L.F., "RKSUITE: A Suite of Runge-Kutta Codes for the Initial Value Problem for ODEs", other, Dept. of Mathematics, Southern Methodist University, Dallas, TX, (1992). URL (cited on 09 January 2006): http://www.netlib.org/ode/rksuite/.
Brent, R.P., Algorithms for Minimization Without Derivatives, (Dover Publications, Mineola, U.S.A., 2002). Reprint of 1973 original edition.
Brewin, L.C., "Is the Regge Calculus a Consistent Approximation to General Relativity?", Gen. Relativ. Gravit., 32, 897–918, (2000). Related online version (cited on 09 January 2006): http://arXiv.org/abs/gr-qc/9502043.
Brewin, L.C., and Gentle, A.P., "On the Convergence of Regge Calculus to General Relativity", Class. Quantum Grav., 18, 517–525, (2001). Related online version (cited on 09 January 2006): http://arXiv.org/abs/gr-qc/0006017.
Briggs, W.L., Henson, V.E., and McCormick, S.F., A Multigrid Tutorial, (SIAM, Philadelphia, U.S.A., 2000), 2nd edition.
Brill, D.R., and Lindquist, R.W., "Interaction Energy in Geometrostatics", Phys. Rev., 131, 471–476, (1963).
Caveny, S.A., Tracking Black Holes in Numerical Relativity: Foundations and Applications, Ph.D. Thesis, (University of Texas at Austin, Austin, U.S.A., 2002).
Caveny, S.A., Anderson, M., and Matzner, R.A., "Tracking Black Holes in Numerical Relativity", Phys. Rev. D, 68, 104009, (2003). Related online version (cited on 09 January 2006): http://arXiv.org/abs/gr-qc/0303099.
Caveny, S.A., and Matzner, R.A., "Adaptive event horizon tracking and critical phenomena in binary black hole coalescence", Phys. Rev. D, 68, 104003–1–13, (2003). Related online version (cited on 09 January 2006): http://arXiv.org/abs/gr-qc/0303109.
Choptuik, M.W., A Study of Numerical Techniques for Radiative Problems in General Relativity, Ph.D. Thesis, (University of British Columbia, Vancouver, Canada, 1986).
Choptuik, M.W., "Experiences with an Adaptive Mesh Refinement Algorithm in Numerical Relativity", in Evans, C.R., Finn, L.S., and Hobill, D.W., eds., Frontiers in Numerical Relativity, Proceedings of the International Workshop on Numerical Relativity, University of Illinois at Urbana-Champaign (Urbana-Champaign, Illinois, USA), May 9–13, 1988, 206–221, (Cambridge University Press, Cambridge, U.K.; New York, U.S.A., 1989).
Chruściel, P.T., and Galloway, G.J., "Horizons Non-Differentiable on a Dense Set", Commun. Math. Phys., 193, 449–470, (1998). Related online version (cited on 09 January 2006): http://arXiv.org/abs/gr-qc/9611032.
Cook, G.B., Initial Data for the Two-Body Problem of General Relativity, Ph.D. Thesis, (University of North Carolina at Chapel Hill, Chapel Hill, U.S.A., 1990).
Cook, G.B., and Abrahams, A.M., "Horizon Structure of Initial-Data Sets for Axisymmetric Two-Black-Hole Collisions", Phys. Rev. D, 46, 702–713, (1992).
Cook, G.B., and York Jr, J.W., "Apparent Horizons for Boosted or Spinning Black Holes", Phys. Rev. D, 41, 1077–1085, (1990).
Curtis, A.R., and Reid, J.K., "The Choice of Step Lengths When Using Differences to Approximate Jacobian Matrices", J. Inst. Math. Appl., 13, 121–126, (1974).
Davis, T.A., "UMFPACK: unsymmetric multifrontal sparse LU factorization package", project homepage, University of Florida (CISE). URL (cited on 6 January 2007): http://www.cise.ufl.edu/research/sparse/umfpack/.
Davis, T.A., "Algorithm 832: UMFPACK V4.3—an unsymmetric-pattern multifrontal method", ACM Trans. Math. Software, 30, 196–199, (2004). Related online version (cited on 09 January 2006): http://www.cise.ufl.edu/∼davis/. TR-02-002.
Davis, T.A., "A column pre-ordering strategy for the unsymmetric-pattern multifrontal method", ACM Trans. Math. Software, 30, 165–195, (2004). Related online version (cited on 09 January 2006): http://www.cise.ufl.edu/∼davis/. TR-02-001.
Davis, T.A., and Duff, I.S., "An unsymmetric-pattern multifrontal method for sparse LU factorization", SIAM J. Matrix Anal. Appl., 18, 140–158, (1997).
Davis, T.A., and Duff, I.S., "A combined unifrontal/multifrontal method for unsymmetric sparse matrices", ACM Trans. Math. Software, 25, 1–19, (1999).
Dennis Jr, J.E., and Schnabel, R.B., Numerical Methods for Unconstrained Optimization and Nonlinear Equations, (SIAM, Philadelphia, U.S.A., 1996).
Diener, P., "A New General Purpose Event Horizon Finder for 3D", Class. Quantum Grav., 20, 4901–4917, (2003). Related online version (cited on 09 January 2006): http://arXiv.org/abs/gr-qc/0305039.
Diener, P., personal communication, (2007).
Diener, P., Herrmann, F., Pollney, D., Schnetter, E., Seidel, E., Takahashi, R., Thornburg, J., and Ventrella, J., "Accurate Evolution of Orbiting Binary Black Holes", Phys. Rev. Lett., 96, 121101, (2006). Related online version (cited on 3 October 2006): http://arXiv.org/abs/gr-qc/0512108.
Dreyer, O., Krishnan, B., Schnetter, E., and Shoemaker, D., "Introduction to isolated horizons in numerical relativity", Phys. Rev. D, 67, 024018, 1–14, (2003). Related online version (cited on 09 January 2006): http://arXiv.org/abs/gr-qc/0206008.
Du Fort, E.C., and Frankel, S.P., "Stability Conditions in the Numerical Treatment of Parabolic Differential Equations", Math. Tables Aids Comput., 7, 135–152, (1953).
Duff, I.S., Erisman, A.M., and Reid, J.K., Direct Methods for Sparse Matrices, (Oxford University Press, Oxford, U.K.; New York, U.S.A., 1986).
Dykema, P.G., The Numerical Simulation of Axially Symmetric Gravitational Collapse, Ph.D. Thesis, (University of Texas at Austin, Austin, U.S.A., 1980).
Eardley, D.M., "Gravitational Collapse of Marginally Bound Spheroids: Initial Conditions", Phys. Rev. D, 12, 3072–3076, (1975).
Eppley, K.R., The numerical evolution of the collision of two black holes, Ph.D. Thesis, (Princeton University, Princeton, U.S.A., 1975).
Eppley, K.R., "Evolution of time-symmetric gravitational waves: Initial data and apparent horizons", Phys. Rev. D, 16, 1609–1614, (1977).
Fornberg, B., A Practical Guide to Pseudospectral Methods, Cambridge Monographs on Applied and Computational Mathematics, (Cambridge University Press, Cambridge, U.K.; New York, U.S.A., 1998).
Forsythe, G.E., Malcolm, M.A., and Moler, C.B., Computer Methods for Mathematical Computations, (Prentice-Hall, Englewood Cliffs, U.S.A., 1977). Related online version (cited on 09 January 2006): http://www.netlib.org/fmm/.
Gentle, A.P., "Regge Calculus: A Unique Tool for Numerical Relativity", Gen. Relativ. Gravit., 34, 1701–1718, (2002). Related online version (cited on 09 January 2006): http://arXiv.org/abs/gr-qc/0408006.
Gentle, A.P., and Miller, W.A., "A fully (3+1)-dimensional Regge calculus model of the Kasner cosmology", Class. Quantum Grav., 15, 389–405, (1998). Related online version (cited on 09 January 2006): http://arXiv.org/abs/gr-qc/9706034.
Goodale, T., Allen, G., Lanfermann, G., Massó, J., Radke, T., Seidel, E., and Shalf, J., "The Cactus Framework and Toolkit: Design and Applications", in Palma, J.M.L.M. and Dongarra, J., Hernández, V., and Sousa, A.A., eds., High Performance Computing for Computational Science (VECPAR 2002), 5th International Conference, Porto, Portugal, June 26–28, 2002: Selected papers and invited talks, vol. 2565 of Lecture Notes in Computer Science, 197–227, (Springer, Berlin, Germany; New York, U.S.A., 2003).
Gottlieb, D., and Orszag, S.A., Numerical Analysis of Spectral Methods: Theory and Applications, vol. 26 of Regional Conference Series in Applied Mathematics, (SIAM, Philadelphia, U.S.A., 1977). Based on a series of lectures presented at the NSF-CBMS regional conference held at Old Dominion University from August 2–6, 1976.
Gourgoulhon, E., and Jaramillo, J.L., "A 3+1 perspective on null hypersurfaces and isolated horizons", Phys. Rep., 423, 159–294, (2006). Related online version (cited on 09 January 2006): http://arXiv.org/abs/gr-qc/0503113.
Grandclement, P., Bonazzola, S., Gourgoulhon, E., and Marck, J.-A., "A Multidomain Spectral Method for Scalar and Vectorial Poisson Equations with Noncompact Sources", J. Comput. Phys., 170, 231–260, (2001). Related online version (cited on 09 January 2006): http://arXiv.org/abs/gr-qc/0003072.
Grandclément, P., Gourgoulhon, E., and Bonazzola, S., "Binary black holes in circular orbits. II. Numerical methods and first results", Phys. Rev. D, 65, 044021, 1–18, (2002). Related online version (cited on 09 January 2006): http://arXiv.org/abs/gr-qc/0106016.
Grayson, M.A., "The Heat Equation Shrinks Embedded Plane Curves to Round Points", J. Differ. Geom., 26, 285–314, (1987).
Gundlach, C., "Pseudo-spectral apparent horizon finders: An efficient new algorithm", Phys. Rev. D, 57, 863–875, (1998). Related online version (cited on 09 January 2006): http://arXiv.org/abs/gr-qc/9707050.
Hawking, S.W., "The Event Horizon", in DeWitt, C., and DeWitt, B.S., eds., Black Holes, Based on lectures given at the 23rd session of the Summer School of Les Houches, 1972, 1–56, (Gordon and Breach, New York, U.S.A., 1973).
Hawking, S.W., and Ellis, G.F.R., The Large Scale Structure of Space-Time, Cambridge Monographs on Mathematical Physics, (Cambridge University Press, Cambridge, U.K., 1973).
Hayward, S.A., "General laws of black hole dynamics", Phys. Rev. D, 49, 6467–6474, (1994). Related online version (cited on 09 January 2006): http://arXiv.org/abs/gr-qc/9306006.
Hindmarsh, A.C., "ODEPACK, A Systematized Collection of ODE Solvers", in Stepleman, R.S. et al., ed., Scientific Computing: Applications of Mathematics and Computing to the Physical Sciences, Based on papers presented at the Tenth IMACS World Congress on System Simulation and Scientific Computation, held in Montreal, Canada, August 8–13, 1982, vol. 1 of IMACS Transactions on Scientific Computing, 55–64, (North-Holland, Amsterdam, Netherlands; New York, U.S.A., 1983). Related online version (cited on 09 January 2006): http://www.netlib.org/odepack/index.html.
Hochbruck, M., Lubich, C., and Selhofer, H., "Exponential Integrators for Large Systems of Differential Equations", SIAM J. Sci. Comput., 19, 1552–1574, (1998).
Hornung, R.D., and Kohn, S.R., "Managing application complexity in the SAMRAI object-oriented framework", Concurr. Comput. Pract. Exp., 14, 347–368, (2002).
Hornung, R.D., Wissink, A.M., and Kohn, S.R., "Managing complex data and geometry in parallel structured AMR applications", Eng. Comput., 22, 181–195, (2006).
Hughes, S.A., Keeton II, C.R., Walker, P., Walsh, K.T., Shapiro, S.L., and Teukolsky, S.A., "Finding Black Holes in Numerical Spacetimes", Phys. Rev. D, 49, 4004–4015, (1994).
Huq, M.F., Apparent Horizon Location in Numerical Spacetimes, Ph.D. Thesis, (The University of Texas at Austin, Austin, U.S.A., 1996).
Huq, M.F., Choptuik, M.W., and Matzner, R.A., "Locating Boosted Kerr and Schwarzschild Apparent Horizons", Phys. Rev. D, 66, 084024, (2002). Related online version (cited on 09 January 2006): http://arXiv.org/abs/gr-qc/0002076.
Husa, S., and Winicour, J., "Asymmetric merger of black holes", Phys. Rev. D, 60, 084019, 1–13, (1999). Related online version (cited on 09 January 2006): http://arXiv.org/abs/gr-qc/9905039.
Kahaner, D., Moler, C.B., and Nash, S., Numerical Methods and Software, (Prentice Hall, Englewood Cliffs, U.S.A., 1989). Revised and (greatly) expanded edition of Forsythe, G.E. and Malcolm, M.A. and Moler, C.B, "Computer methods for mathematical computations"(1977).
Kemball, A.J., and Bishop, N.T., "The numerical determination of apparent horizons", Class. Quantum Grav., 8, 1361–1367, (1991).
Kershaw, D.S., "The Incomplete Cholesky-Conjugate Gradient Method for Interative Solution of Linear Equations", J. Comput. Phys., 26, 43–65, (1978).
Kidder, L.E., and Finn, L.S., "Spectral Methods for Numerical Relativity. The Initial Data Problem", Phys. Rev. D, 62, 084026, (2000). Related online version (cited on 09 January 2006): http://arXiv.org/abs/gr-qc/9911014.
Kidder, L.E., Scheel, M.A., Teukolsky, S.A., Carlson, E.D., and Cook, G.B., "Black hole evolution by spectral methods", Phys. Rev. D, 62, 084032, (2000). Related online version (cited on 09 January 2006): http://arXiv.org/abs/gr-qc/0005056.
Kidder, L.E., Scheel, M.A., Teukolsky, S.A., and Cook, G.B., "Spectral Evolution of Einstein's Equations", Miniprogram on Colliding Black Holes: Mathematical Issues in Numerical Relativity, held at the Institute for Theoretical Physics, UC at Santa Barbara, 10–28 January 2000, conference paper, (2000).
Kriele, M., and Hayward, S.A., "Outer trapped surfaces and their apparent horizon", J. Math. Phys., 38, 1593–1604, (1997).
Lehner, L., Bishop, N.T., Gómez, R., Szilágyi, B., and Winicour, J., "Exact solutions for the intrinsic geometry of black hole coalescence", Phys. Rev. D, 60, 044005, 1–10, (1999).
Lehner, L., Gómez, R., Husa, S., Szilágyi, B., Bishop, N.T., and Winicour, J., "Bagels Form When Black Holes Collide", institutional homepage, Pittsburgh Supercomputing Center. URL (cited on 09 January 2006): http://www.psc.edu/research/graphics/gallery/winicour.html.
Leiler, G., and Rezzolla, L., "On the iterated Crank-Nicolson method for hyperbolic and parabolic equations in numerical relativity", Phys. Rev. D, 73, 044001, (2006). Related online version (cited on 3 October 2006): http://arXiv.org/abs/gr-qc/0601139.
Libson, J., Massóo, J., Seidel, E., and Suen, W.-M., "A 3D Apparent Horizon Finder", in Jantzen, R.T., and Keiser, G.M., eds., The Seventh Marcel Grossmann Meeting: On recent developments in theoretical and experimental general relativity, gravitation, and relativistic field theories, Proceedings of the meeting held at Stanford University, July 24–30, 1994, 631, (World Scientific, Singapore; River Edge, U.S.A., 1996).
Libson, J., Massó, J., Seidel, E., Suen, W.-M., and Walker, P., "Event horizons in numerical relativity: Methods and tests", Phys. Rev. D, 53, 4335–4350, (1996).
Lin, L.-M., and Novak, J., "Three-dimensional apparent horizon finder in LORENE", personal communication, (2006). Personal communication from Lap-Ming Lin to Jonathan Thornburg.
Lorensen, W.E., and Cline, H.E., "Marching cubes: A high resolution 3D surface construction algorithm", SIGGRAPH Comput. Graph., 21, 163–169, (1987).
MacNeice, P., Olson, K.M., Mobarry, C., de Fainchtein, R., and Packer, C., "PARAMESH: A parallel adaptive mesh refinement community toolkit", Computer Phys. Commun., 126, 330–354, (2000).
Madderom, P., "Incomplete LU-Decomposition — Conjugate Gradient", unknown format, (1984). Fortran 66 subroutine.
Matzner, R.A., Seidel, E., Shapiro, S.L., Smarr, L.L., Suen, W.-M., Teukolsky, S.A., and Winicour, J., "Geometry of a Black Hole Collision", Science, 270, 941–947, (1995).
Metzger, J., "Numerical computation of constant mean curvature surfaces using finite elements", Class. Quantum Grav., 21, 4625–4646, (2004). Related online version (cited on 09 January 2006): http://arXiv.org/abs/gr-qc/0408059.
Miller, M.A., "Regge Calculus as a Fourth Order Method in Numerical Relativity", Class. Quantum Grav., 12, 3037–3051, (1995). Related online version (cited on 09 January 2006): http://arXiv.org/abs/gr-qc/9502044.
Misner, C.W., and Sharp, D.H., "Relativistic Equations for Adiabatic, Spherically Symmetric Gravitational Collapse", Phys. Rev., 136, B571–B576, (1964).
Misner, C.W., Thorne, K.S., and Wheeler, J.A., Gravitation, (W.H. Freeman, San Francisco, U.S.A., 1973).
Nakamura, T., Kojima, Y., and Oohara, K., "A Method of Determining Apparent Horizons in Three-Dimensional Numerical Relativity", Phys. Lett. A, 106, 235–238, (1984).
Oohara, K., "Apparent Horizon of Initial Data for Black Hole-Collisions", in Sato, H., and Nakamura, T., eds., Gravitational Collapse and Relativity, Proceedings of Yamada Conference XIV, Kyoto International Conference Hall, Japan, April 7–11, 1986, 313–319, (World Scientific, Singapore; Philadelphia, U.S.A., 1986).
Oohara, K., Nakamura, T., and Kojima, Y., "Apparent Horizons of Time-Symmetric Initial Value for Three Black Holes", Phys. Lett. A, 107, 452–455, (1985).
Osher, S., and Sethian, J.A., "Fronts propagating with curvature-dependent speed: Algorithms based on Hamilton-Jacobi formulations", J. Comput. Phys., 79, 12–49, (1988).
Parashar, M., and Browne, J.C., "System Engineering for High Performance Computing Software: The HDDA/DAGH Infrastructure for Implementation of Parallel Structured Adaptive Mesh Refinement", in Baden, S.B., Chrisochoides, N.P., Gannon, D.B., and Norman, M.L., eds., Structured Adaptive Mesh Refinement (SAMR) Grid Methods, vol. 117 of IMA Volumes in Mathematics and its Applications, 1–18, (Springer, New York, U.S.A., 2000).
Pasch, E., The level set method for the mean curvature flow on (R3,g), SFB 382 Reports, 63, (University of Tübingen, Tübingen, Germany, 1997). URL (cited on 09 January 2006): http://www.uni-tuebingen.de/uni/opx/reports.html.
Petrich, L.I., Shapiro, S.L., and Teukolsky, S.A., "Oppenheimer-Snyder Collapse with Maximal Time Slicing and Isotropic Coordinates", Phys. Rev. D, 31, 2459–2469, (1985).
Pfeiffer, H.P., Initial Data for Black Hole Evolutions, Ph.D. Thesis, (Cornell University, Ithaca, U.S.A., 2003). Related online version (cited on 1 October 2006): http://arXiv.org/abs/gr-qc/0510016.
Pfeiffer, H.P., personal communication, (2006).
Pfeiffer, H.P., Cook, G.B., and Teukolsky, S.A., "Comparing initial-data sets for binary black holes", Phys. Rev. D, 66, 024047, 1–17, (2002). Related online version (cited on 1 October 2006): http://arXiv.org/abs/gr-qc/0203085.
Pfeiffer, H.P., Kidder, L.E., Scheel, M.A., and Teukolsky, S.A., "A multidomain spectral method for solving elliptic equations", Computer Phys. Commun., 152, 253–273, (2003). Related online version (cited on 09 January 2006): http://arXiv.org/abs/gr-qc/0202096.
Pfeiffer, H.P., Teukolsky, S.A., and Cook, G.B., "Quasicircular orbits for spinning binary black holes", Phys. Rev. D, 62, 104018, 1–11, (2000). Related online version (cited on 1 October 2006): http://arXiv.org/abs/gr-qc/0006084.
Press, W.H., Flannery, B.P., Teukolsky, S.A., and Vetterling, W.T., Numerical Recipes, (Cambridge University Press, Cambridge, U.K.; New York, U.S.A., 1992), 2nd edition.
Pretorius, F., and Choptuik, M.W., "Adaptive Mesh Refinement for Coupled Elliptic-Hyperbolic Systems", J. Comput. Phys., 218, 246–274, (2006). Related online version (cited on 3 October 2006): http://arXiv.org/abs/gr-qc/0508110.
Pretorius, F., and Lehner, L., "Adaptive mesh refinement for characteristic codes", J. Comput. Phys., 198, 10–34, (2004). Related online version (cited on 09 January 2006): http://arXiv.org/abs/gr-qc/0302003.
Regge, T., "General Relativity without Coordinates", Nuovo Cimento A, 19, 558–571, (1961).
Richtmyer, R.D., and Morton, K.W., Difference Methods for Initial-Value Problems, (Krieger, Malabar, U.S.A., 1994), 2nd edition. Reprinted second edition of 1967.
Saad, Y., Iterative Methods for Sparse Linear Systems, (SIAM, Philadelphia, U.S.A., 2003), 2nd edition.
Schnetter, E., "CarpetCode: A mesh refinement driver for Cactus", project homepage, Center for Computation and Technology, Louisiana State University. URL (cited on 09 January 2006): http://www.carpetcode.org
Schnetter, E., "A fast apparent horizon algorithm", (2002). URL (cited on 09 January 2006): http://arXiv.org/abs/gr-qc/0206003.
Schnetter, E., "Finding Apparent Horizons and other Two-Surfaces of Constant Expansion", Class. Quantum Grav., 20, 4719–4737, (2003). Related online version (cited on 09 January 2006): http://arXiv.org/abs/gr-qc/0306006.
Schnetter, E., Hawley, S.H., and Hawke, I., "Evolutions in 3D numerical relativity using fixed mesh refinement", Class. Quantum Grav., 21, 1465–1488, (2004). Related online version (cited on 09 January 2006): http://arXiv.org/abs/gr-qc/0310042.
Schnetter, E., Herrmann, F., and Pollney, D., "Horizon Pretracking", Phys. Rev. D, 71, 044033, (2005). Related online version (cited on 09 January 2006): http://arXiv.org/abs/gr-qc/0410081.
Schnetter, E., and Krishnan, B., "Nonsymmetric trapped surfaces in the Schwarzschild Vaidya spacetimes", Phys. Rev. D, 73, 021502, (2006). Related online version (cited on 3 October 2006): http://arXiv.org/abs/gr-qc/0511017.
Schnetter, E., Krishnan, B., and Beyer, F., "Introduction to Dynamical Horizons in numerical relativity", Phys. Rev. D, 74, 024028, (2006). Related online version (cited on 30 October 2006): http://arXiv.org/abs/gr-qc/0604015.
Schroeder, M.R., Number Theory in Science and Communication: With Applications in Cryptography, Physics, Digital Information, Computing and Self-Similarity, vol. 7 of Springer Series in Information Sciences, (Springer, Berlin, Germany; New York, U.S.A., 1986), 2nd edition.
Seidel, E., and Suen, W.-M., "Towards a Singularity-Proof Scheme in Numerical Relativity", Phys. Rev. Lett., 69, 1845–1848, (1992).
Shampine, L.F., and Gordon, M.K., Computer solution of Ordinary Differential Equations, (W.H. Freeman, San Francisco, U.S.A., 1975).
Shapiro, S.L., and Teukolsky, S.A., "Gravitational Collapse of Supermassive Stars to Black Holes: Numerical Solution of the Einstein Equations", Astrophys. J. Lett., 234, L177–L181, (1979).
Shapiro, S.L., and Teukolsky, S.A., "Gravitational Collapse to Neutron Stars and Black Holes: Computer Generation of Spherical Spacetimes", Astrophys. J., 235, 199–215, (1980). Related online version (cited on 05 February 2007): http://adsabs.harvard.edu/abs/1980ApJ...235..199S.
Shapiro, S.L., and Teukolsky, S.A., "Relativistic stellar dynamics on the computer. I. Motivation and Numerical Method", Astrophys. J., 298, 34–57, (1985).
Shapiro, S.L., and Teukolsky, S.A., "Relativistic stellar dynamics on the computer. II. Physical applications", Astrophys. J., 298, 58–79, (1985).
Shapiro, S.L., and Teukolsky, S.A., "Collision of relativistic clusters and the formation of black holes", Phys. Rev. D, 45, 2739–2750, (1992).
Shibata, M., "Apparent horizon finder for a special family of spacetimes in 3D numerical relativity", Phys. Rev. D, 55, 2002–2013, (1997).
Shibata, M., and Uryū, K., "Apparent Horizon Finder for General Three-Dimensional Spaces", Phys. Rev. D, 62, 087501, (2000).
Shoemaker, D.M., Apparent Horizons in Binary Black Hole Spacetimes, Ph.D. Thesis, (The University of Texas at Austin, Austin, U.S.A., 1999).
Shoemaker, D.M., Huq, M.F., and Matzner, R.A., "Generic tracking of multiple apparent horizons with level flow", Phys. Rev. D, 62, 124005, (2000). Related online version (cited on 09 January 2006): http://arXiv.org/abs/gr-qc/0006042.
Stoer, J., and Bulirsch, R., Introduction to Numerical Analysis, (Springer, Berlin, Germany; New York, U.S.A., 1980).
Sziláagyi, B., Pollney, D., Rezzolla, L., Thornburg, J., and Winicour, J., "An explicit harmonic code for black-hole evolution using excision", (2007). URL (cited on 09 April 2007): http://arXiv.org/abs/gr-qc/0612150.
Teukolsky, S.A., "On the Stability of the Iterated Crank-Nicholson Method in Numerical Relativity", Phys. Rev. D, 61, 087501, (2000).
Thornburg, J., "Finding apparent horizons in numerical relativity", Phys. Rev. D, 54, 4899–4918, (1996). Related online version (cited on 09 January 2006): http://arXiv.org/abs/gr-qc/9508014.
Thornburg, J., "A 3+1 Computational Scheme for Dynamic Spherically Symmetric Black Hole Spacetimes — I: Initial Data", Phys. Rev. D, 59, 104007, (1999). Related online version (cited on 09 January 2006): http://arXiv.org/abs/gr-qc/9801087.
Thornburg, J., "A 3+1 Computational Scheme for Dynamic Spherically Symmetric Black Hole Spacetimes — II: Time Evolution", (1999). URL (cited on 09 January 2006): http://arXiv.org/abs/gr-qc/9906022.
Thornburg, J., "A fast apparent horizon finder for three-dimensional Cartesian grids in numerical relativity", Class. Quantum Grav., 21, 743–766, (2004). Related online version (cited on 09 January 2006): http://arXiv.org/abs/gr-qc/0306056.
Tod, K.P., "Looking for marginally trapped surfaces", Class. Quantum Grav., 8, L115–L118, (1991).
Trottenberg, U., Oosterlee, C.W., and Schüller, A., Multigrid, (Academic Press, San Diego, U.S.A., 2001).
Čadež, A., "Apparent Horizons in the Two-Black-Hole Problem", Ann. Phys. (N.Y.), 83, 449–457, (1974).
Wald, R.M., General Relativity, (University of Chicago Press, Chicago, U.S.A., 1984).
Wald, R.M., and Iyer, V., "Trapped surfaces in the Schwarzschild geometry and cosmic censorship", Phys. Rev. D, 44, R3719–R3722, (1991).
Walker, P., Horizons, Hyperbolic Systems, and Inner Boundary Conditions in Numerical Relativity, Ph.D. Thesis, (University of Illinois at Urbana-Champaign, Urbana, U.S.A., 1998).
York Jr, J.W., "Kinematics and Dynamics of General Relativity", in Smarr, L.L., ed., Sources of Gravitational Radiation, Proceedings of the Battelle Seattle Workshop, July 24–August 4, 1978, 83–126, (Cambridge University Press, Cambridge, U.K.; New York, U.S.A., 1979)
York Jr, J.W., "Initial Data for Collisions of Black Holes and Other Gravitational Miscellany", in Evans, C.R., Finn, L.S., and Hobill, D.W., eds., Frontiers in Numerical Relativity, Proceedings of the International Workshop on Numerical Relativity, University of Illinois at Urbana-Champaign, U.S.A., May 9–13, 1988, 89–109, (Cambridge University Press, Cambridge, U.K.; New York, U.S.A., 1989).
I thank the many researchers who answered my e-mail queries on various aspects of their work. I thank the anonymous referees for their careful reading of the manuscript and their many helpful comments. I thank Badri Krishnan for many useful conversations on the properties of apparent, isolated, and dynamical horizons. I thank Scott Caveny and Peter Diener for useful conversations on event-horizon finders. I thank Peter Diener, Luciano Rezzolla, and Virginia J. Vitzthum for helpful comments on various drafts of this paper. I thank Peter Diener and Edward Seidel for providing unpublished figures.
I thank the many authors named in this review for granting permission to reprint figures from their published work. I thank the American Astronomical Society, the American Physical Society, and IOP Publishing for granting permission to reprint figures published in their journals. The American Physical Society requires the following disclaimer regarding such reprinted material:
Readers may view, browse, and/or download material for temporary copying purposes only, provided these uses are for noncommercial personal purposes. Except as provided by law, this material may not be further reproduced, distributed, transmitted, modified, adapted, performed, displayed, published, or sold in whole or part, without written permission from the publisher.
I thank the Alexander von Humboldt Foundation, the AEI visitors program, and the AEI postdoctoral fellowship program for financial support.
School of Mathematics, University of Southampton, Highfield, Southampton, SO17 1BJ, UK
Jonathan Thornburg
Albert Einstein Institute, Max Planck Institute for Gravitational Physics, Am Mühlenberg 1, 14476, Potsdam, Germany
Correspondence to Jonathan Thornburg.
Solving a Single Nonlinear Algebraic Equation
In this appendix I briefly outline numerical algorithms and codes for solving a single 1-dimensional nonlinear algebraic equation f (x) = 0, where the continuous function f: ℜ → ℜ is given.
The process generally begins by evaluating f on a suitable grid of points and looking for sign changes. By the intermediate value theorem, each sign change must bracket at least one root. Given a pair of such ordinates x− and x+, there are a variety of algorithms available to accurately and efficiently find the (a) root:
If ∣x+ − x−∣ is small, say on the order of a finite-difference grid spacing, then closed-form approximations are probably accurate enough:
The simplest approximation is a simple linear interpolation of f between x− and x+.
A slightly more sophisticated algorithm, "inverse quadratic interpolation", is to use three ordinates, two of which bracket a root, and estimate the root as the root of the (unique) parabola which passes through the three given (x, f (x)) pointsFootnote 64.
For larger ∣x+ − x−∣, iterative algorithms are necessary to obtain an accurate root:
Bisection (binary search on the sign of f) is a well-known iterative scheme which is very robust. However, it is rather slow if high accuracy is desired.
Newton's method can be used, but it requires that the derivative f′ be available. Alternatively, the secant algorithm (similar to Newton's method but estimating f′ from the most recent pair of function evaluations) gives similarly fast convergence without requiring f′ to be available. Unfortunately, if ∣f′∣ is small enough at any iteration point, both these algorithms can fail to converge, or more generally they can generate "wild" trial ordinates.
Probably the most sophisticated algorithm is that of van Wijngaarden, Dekker, and Brent. This is a carefully engineered hybrid of the bisection, secant, and inverse quadratic interpolation algorithms, and generally combines the rapid convergence of the secant algorithm with the robustness of bisection. The van Wijngaarden-Dekker-Brent algorithm is described by Forsythe, Malcolm, and Moler [71, Chapter 7], Kahaner, Moler, and Nash [92, Chapter 7], and Press et al. [125, Section 9.3]. An excellent implementation of this, the Fortran subroutine ZEROIN, is freely available from http://www.netlib.org/fmm/.
The Numerical Integration of Ordinary Differential Equations
The time-integration problemFootnote 65 for ordinary differential equations (ODEs) is traditionally written as follows: We are given an integer n > 0 (the number of ODEs to integrate), a "right-hand-side" function f: ℜn ×ℜ → ℜn, and the value y(0) of a function y: ℜ → ℜn satisfying the ODEs
$${{d{\rm{y}}} \over {dt}} = f({\rm{y,}}t)$$
We wish to know (or approximate) y(t) for some finite interval t ∈ [0, tmax].
This is a well-studied problem in numerical analysis. See, for example, Forsythe, Malcolm, and Moler [71, Chapter 6] or Kahaner, Moler, and Nash [92, Chapter 8] for a general overview of ODE integration algorithms and codes, or Shampine and Gordon [140], Hindmarsh [84], or Brankin, Gladwell, and Shampine [38] for detailed technical accounts.
For our purposes, it suffices to note that highly accurate, efficient, and robust ODE-integration codes are widely available. In fact, there is a strong tradition in numerical analysis of free availability of such codes. Notably, Table 3 lists several freely-available ODE codes. As well as being of excellent numerical quality, these codes are also very easy to use, employing sophisticated adaptive algorithms to automatically adjust the step size and/or the precise integration scheme usedFootnote 66. These codes can generally be relied upon to produce accurate results both more efficiently and more easily than a hand-crafted integrator. I have used the LSODE solver in several research projects with excellent results.
Table 3 This table lists some general-purpose ODE codes which are freely available.
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (https://creativecommons.org/licenses/by/4.0), which permits use, duplication, adaptation, distribution, and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
Thornburg, J. Event and Apparent Horizon Finders for 3 + 1 Numerical Relativity. Living Rev. Relativ. 10, 3 (2007). https://doi.org/10.12942/lrr-2007-3
DOI: https://doi.org/10.12942/lrr-2007-3
Apparent Horizon
Null Geodesic | CommonCrawl |
Tissue-wide integration of mechanical cues promotes effective auxin patterning
Focus Point on Mechanobiology across Scales
Regular Article
João R. D. Ramos1,
Alexis Maizel ORCID: orcid.org/0000-0001-6843-10592 &
Karen Alim ORCID: orcid.org/0000-0002-2527-58311,3
The European Physical Journal Plus volume 136, Article number: 250 (2021) Cite this article
New plant organs form by local accumulation of auxin, which is transported by PIN proteins that localize following mechanical stresses. As auxin itself modifies tissue mechanics, a feedback loop between tissue mechanics and auxin patterning unfolds—yet the impact of tissue-wide mechanical coupling on auxin pattern emergence remains unclear. Here, we use a model composed of a vertex model for plant tissue mechanics and a compartment model for auxin transport to explore the collective mechanical response of the tissue to auxin patterns and how it feeds back onto auxin transport. We compare a model accounting for a tissue-wide mechanical integration to a model that regards cells as mechanically isolated. We show that tissue-wide mechanical coupling not only leads to more focused auxin spots via stress redistribution, but that it also mitigates the disruption to patterning when considering noise in the mechanical properties of each cell of the tissue. We find that this mechanism predicts that a local turgor increase correlates with auxin concentration, and yet auxin spots can exist regardless of the exact local turgor distribution.
Formation of organs entails an effective coordination of local cell growth typically initiated by patterns of one or more morphogenic factors. Understanding how these patterns of morphogenic agents robustly emerge is fundamental for predicting organ morphogenesis. Plants organ formation is interesting from a physical perspective due to the strong mechanical coupling between plant cells, and the fact that growth is driven by changes in the mechanical properties of the cell wall and internal pressure [1,2,3,4,5]. Evidence indicates that the morphogenic factors such as the plant hormone auxin change the mechanics of the tissue [6, 7], with implications for the shaping of organs [8, 9]. Interestingly, the transporters of auxin respond to mechanical cues [10, 11], leading to an intertwining of chemical and mechanical cues.
The phytohormone auxin, Indole-3-Acetic Acid, is the key morphogenic agent in plants. Auxin accumulation drives a wide range of plant developmental processes including, but not limited to initiation of cell growth, cell division, and cell differentiation [12,13,14]. Establishment of auxin patterns is ubiquitous in plant organ morphogenesis [15]. The best characterized example is the regular patterns of auxin spots in the outmost epidermal cell layer at the tip of the shoot that prefigures the regular disposition of organs called phyllotactic pattern [16,17,18,19,20,21]. These auxin accumulation spots mark the location of emerging primordia of new aerial plant organs. Auxin patterns result from the polar distribution of auxin efflux carriers called PIN-FORMED (PINs) [15, 16, 20, 22,23,24]. Because of its prevalence in plant development, understanding how these auxin patterns emerge has been intensively studied and mathematically modelled. Auxin concentration feedback models [25,26,27,28,29], organize their flow up-the-gradient of auxin concentration, reinforcing auxin maxima. Canalization models, or flux-based models, [30,31,32,33,34,35,36] reinforce already existing flows, and, as such, both up-the-gradient and down-the-gradient flows can exist. Some attempts at unifying both mechanisms have been made [35, 37,38,39], yet many conditions have to be imposed to explain, for instance, the fountain-like patterns arising during root development [35, 40].
Tissue mechanics has emerged as a potent regulator of plant development [5, 41,42,43,44]. Plant cells are able to read mechanical stress and respond accordingly, rearranging their microtubules along the main direction of mechanical stresses [41]. Furthermore, PIN1 polarity and microtubules alignment at the shoot apical meristem are correlated [10], suggesting the possibility of PIN localisation being mechanically regulated. This hypothetical coupling between PIN localisation and mechanical cues is theoretically able to predict PIN polarity and density for a wide range of cell wall stress and membrane tension [11]. Such coupling is also supported by several other observations: the physical connection of PINs to the cell wall [45], the change in polarity induced by cell curvature [46], and disorganization of PIN polarity by modification of the cell wall mechanical properties [7].
Auxin can induce remodelling of the cell wall and thus modify its mechanical properties [4, 6, 7, 47]. This may in turn influence PIN localisation and therefore have consequences on the pattern of auxin. Modelling of this feedback in a tissue showed that mechanical stresses can lead to the emergence of a regular phyllotactic auxin pattern by regulating PIN localisation [10]. Although this result shows the importance of local mechanical coupling (Fig. 1) for emergence of auxin patterns, the full extent of the impact of mechanical coupling on pattern emergence remains unclear.
In fact, cell strain is a compromise between its mechanical properties and the restrictions placed upon its shape by the surrounding cells given the condition that the tissue remains connected. In other words, stiffness variations contribute additional terms to tissue strain. In order to explore the effect of the latter, we adapt the model for auxin transport introduced in [10] to a vertex model mechanical description of the tissue, a tissue-wide mechanical model and compare it to a uncoupled tissue approximation with the same auxin transport model but where we prescribe an average stress acting on all cells (Fig. 2).
Schematic representation of the cell–cell feedback mechanism between cell wall loosening via auxin and mechanical control of PIN. (a) Auxin is transported to neighbouring cells via bound PIN efflux carriers. (b) Auxin interacts with the mechanical properties of the cell wall reducing its stiffness. (c) Increasing stiffness of a particular wall component shifts the stress load from the component of its neighbour to itself. (d) Wall stress promotes PIN binding. A difference in auxin, therefore, induces a stress difference between the two compartments separating both cells. This stress difference is such that PIN binds preferentially in the cell with lower auxin concentration, increasing the flow of auxin into the cell with higher auxin concentration
Schematic difference between the tissue-wide mechanical model (left) and the uncoupled tissue approximation (right). In the tissue-wide mechanical model, turgor pressure, T, and stiffness determine the vertex positions that minimize mechanical energy. Wall strain and stress are then inferred from the mechanical configuration. In the approximation, we prescribe average wall stress, \(\bar{\sigma }\), with a static geometry. This approximation disregards the effect of stiffness variations on strain. The prescription of stress in the approximation renders the mechanical interaction to be only between nearest neighbours and uncoupled from all other cells. In the tissue-wide mechanical model, the mechanical state is a function of all cells in the tissue
By comparing both models, we find that due to stress fields arising from mechanical feedback the magnitude of auxin spots is larger for lower stress-PIN coupling, indicating a more efficient transition between low and high auxin regimes and the subsequent potential cell behaviour response. Furthermore, we explore the information content of auxin distributions when noise is considered and show that tissue-wide mechanical coupling improves robustness of auxin patterns.
In order to investigate the interaction between auxin cell wall softening and collective tissue mechanics, we use a vertex model to describe the mechanical behaviour of the tissue and a compartment model to express auxin concentration and transport between adjacent cells.
Geometrical set-up of the tissue
The tissue is described by a tiling of two-dimensional space into M cells surrounded by their cell walls. Walls are represented as edges connecting two vertices each, positioned at \(\mathbf {x}_i = \left( x_i,y_i\right) \) , \(i\in [1,N]\). Here, we reserve Latin indices for vertex numbering and Greek ones for cells. Each cell wall segment has two compartments, one facing each cell. Therefore, we represent each cell wall with two edges of opposite direction, one for each compartment. The position of tissue vertices fully define geometrical quantities such as cell areas, \(A_\alpha \), cell perimeters, \(L_\alpha \), wall lengths, \(l_{ij}=l_{ji}\), and cell centroids, \(\mathbf {X}_\alpha \) (Fig. 3 top left). To simplify notation significantly, we also define for each cell the cyclically ordered set of all vertices around that cell, \(\mathcal {V}_\alpha \), arranged counterclockwise (ccw). Hence, we use \(\sum _{i\in \mathcal {V}_\alpha }\) to signify the sum over all vertices surrounding cell \(\alpha \) with an arbitrary start, where \(i+1\) and \(i-1\) mean, respectively, the next and previous ccw vertex. Similarly, we introduce \(\mathcal {N}_\alpha \) as the cyclically ordered (counterclockwise) set of all neighbouring regions around cell \(\alpha \), one for each edge of \(\alpha \) (Fig. 3 top right).
Vertex model description of a cell as a geometrical, mechanical, and biologically active entity. (top left) A cell \(\alpha \) surrounded by its cell walls with centroid \(\mathbf {X}_\alpha \), area \(A_\alpha \) and perimeter \(L_\alpha \). Vertices i and j have positions \(\mathbf {x}_i\) and \(\mathbf {x}_j\) and the distance between them is \(l_{ij}=l_{ji}\). (top right) Set of surrounding regions, one for each wall, \(\mathcal {N}_\alpha \), and set surrounding vertices, \(\mathcal {V}_\alpha \), used in the equations of the model. (bottom left) Mechanically, cell \(\alpha \) is under turgor pressure \(T_\alpha \), the surrounding wall compartments have stiffness \(E_\alpha \). \(M_\alpha \) is the second moment of area of cell \(\alpha \), whereas \(M_\alpha ^{(0)}\) is that same quantity when the cell is at rest. \(\sigma _{ij}\) refers to the longitudinal stress acting on the compartment of the wall. (bottom right) Cell \(\alpha \) has an auxin concentration \(a_\alpha \) which is expressed, degraded and transported, both passively and actively. The active component of auxin transport relies on the density of membrane-bound efflux auxin carriers facing a particular wall compartment, \(p_{ij}\)
Tissue mechanics–tissue-wide coupling
Vertex models are a widely employed theoretical approach to describe mechanics of epithelial tissues and morphogenesis [9, 48,49,50,51,52,53]. The essence of vertex models is that cell geometry within a tissue is given as the mechanical equilibrium of the tissue. In the case of plant cells, the shape of a cell is a competition between the turgor pressure, \(T_\alpha \), all cells exert on each other and the cell's resistance to deformation with stiffness, \(E_\alpha \). Strain acting on each cell will be described using the second moment of area of the corresponding cell in reference to its centroid, \(M_\alpha \), whose components are
$$\begin{aligned}&M_{\alpha _{xx}} = \sum _{i\in \mathcal {V}_\alpha } \frac{n_i}{12}\left( x^{\prime ^2}_i + x^\prime _i x^\prime _{i+1} + x^{\prime ^2}_{i+1} \right) , \end{aligned}$$
$$\begin{aligned}&M_{\alpha _{yy}} = \sum _{i\in \mathcal {V}_\alpha } \frac{n_i}{12}\left( y^{\prime ^2}_i + y^\prime _i y^\prime _{i+1} + y^{\prime ^2}_{i+1} \right) ,\ \end{aligned}$$
$$\begin{aligned}&M_{\alpha _{xy}} = M_{\alpha _{yx}} = \sum _{i \in \mathcal {V}_\alpha } \frac{n_i}{24}\left( x^\prime _i y^\prime _{i+1} + 2 x^\prime _i y^\prime _i + 2 x^\prime _{i+1}y^\prime _{i+1} + x^\prime _{i+1} y^\prime _i \right) , \end{aligned}$$
where the primed coordinates represent the translation transformation, \(\mathbf {x}_i^\prime = \left( x^\prime _i,y^\prime _i\right) = \mathbf {x}_i - \mathbf {X}_\alpha \), and \(n_i = x^\prime _i y_{i+1}^\prime - x_{i+1}^\prime y_i^\prime , i\in \mathcal {V}_\alpha \). Given a rest shape matrix, \(M^{(0)}_\alpha \), we define cell strain as the normalized difference between both matrices,
$$\begin{aligned} \varepsilon _\alpha = \frac{M_\alpha - M_\alpha ^{(0)}}{\mathrm {Tr}\left( M_\alpha ^{(0)}\right) }, \end{aligned}$$
and stress with \(\sigma _\alpha = E_\alpha \varepsilon _\alpha \). Having described the tissue mechanically (Fig. 3 bottom left), we define the energy for a single cell as the sum of work done by turgor pressure and elastic deformation energy, resulting in the tissue mechanical energy,
$$\begin{aligned} \mathcal {H} = \sum _{\alpha =1}^M \left[ \frac{1}{2} A_\alpha E_\alpha \frac{\left| \left| M_\alpha - M_\alpha ^{(0)}\right| \right| _2^2}{\mathrm {Tr}^2\left( M_\alpha ^{(0)}\right) } - A_\alpha T_\alpha \right] . \end{aligned}$$
Using this model, we obtain the shape of the tissue by minimizing \(\mathcal {H}\) with respect to vertex positions.
After minimizing (Eq. 5), we quantify the stress acting on each wall through the average strain acting on each cell given by (Eq. 4). Assuming that cell wall rest length is the same between two adjacent wall compartments then it follows that they are under the same longitudinal strain, which is, to first approximation, the average between the two cells surrounding them. Therefore, longitudinal average strain acting on a specific wall used here is
$$\begin{aligned} \bar{\varepsilon }_{\alpha \beta } = \bar{\varepsilon }_{\beta \alpha } \sim \hat{\mathbf {t}}_{\alpha \beta }^T \frac{\varepsilon _\alpha + \varepsilon _\beta }{2} \hat{\mathbf {t}}_{\alpha \beta }, \end{aligned}$$
where \(\mathbf {t}_{\alpha \beta }\) is a unit vector along the wall separating cell \(\alpha \) and cell \(\beta \). Note that this interpolation assumes a continuous strain field. Then the stresses acting on each compartment are by the constitutive equation of a linear elastic isotropic material with Poisson ratio \(\nu =0\),
$$\begin{aligned} \sigma _{\alpha \beta } = E_\alpha \bar{\varepsilon }_{\alpha \beta } \ne \sigma _{\beta \alpha } = E_\beta \bar{\varepsilon }_{\beta \alpha }. \end{aligned}$$
Note that we are only considering the longitudinal components with regards to the cell wall, which means that \(\bar{\varepsilon }_{\alpha \beta }\) and \(\sigma _{\alpha \beta }\) are scalar quantities. More details on the mechanical model used can be found in the supporting text. As argued in the supporting material, our choice of \(\nu =0\) does not impact the qualitative behaviour studied here.
Tissue mechanics–uncoupled tissue approximation
To assess the impact of collective mechanical behaviour within a tissue on auxin pattern self-organization, we approximate the tissue-wide mechanical model to a static tissue geometry where we approximate the effects of turgor pressure of each individual cells in the static tissue by a constant average stress \(\bar{\sigma }\) acting on it [10]. Again assuming that both wall compartments have the same rest length, we infer that the stress acting on a particular wall depends only on \(\bar{\sigma }\) and the stiffness of the adjacent cells. Effectively, the average longitudinal strain acting on a wall surrounded by cells \(\alpha \) and \(\beta \) would simply be
$$\begin{aligned} \bar{\varepsilon }_{\alpha \beta } = \bar{\varepsilon }_{\beta \alpha }=2\bar{\sigma }/\left( E_\alpha + E_\beta \right) . \end{aligned}$$
This way, instead of minimizing the full mechanical model (Eq. 5) given a set of turgor pressures \(T_\alpha \) and rest shape matrices \(M_\alpha ^{(0)}\) we can, in the static tissue, immediately compute stress with Eq. 7 yielding,
$$\begin{aligned} \sigma _{\alpha \beta } = \frac{2E_\alpha \bar{\sigma }}{E_\alpha + E_\beta }. \end{aligned}$$
Interestingly, Eq. 9 is valid for \(\nu \ne 0\) as demonstrated in the supporting material.
In order to compare the two models, we choose the value of \(\bar{\sigma }\) to be the same as the stress obtained through minimisation of (Eq. 5), for a given set of \(T_\alpha \) and \(M_\alpha ^{(0)}\), with the constraint of the same end geometry.
Note that not only can this approximation be interpreted as the tissue being mechanically coupled only to the nearest neighbours, disregarding the rest of the tissue, (Fig. 2), but also as an analogous non-mechanical auxin concentration feedback model.
Auxin transport–compartment model
Compartment models for auxin transport are well adapted to the context of plant development, since the prerequisite of a boundary of a plant cell is particularly well defined by courtesy of the cell wall.
Although passive diffusion occurs across cell walls, the dominant players in auxin transport are membrane-bound carriers [22, 24]. Namely, efflux transporters of the PIN family are important due to their anisotropic positioning around a cell [16], which leads to a net auxin flow from one cell to the next. Let \(a_\alpha \) denote an non-dimensional and normalized average auxin concentration inside cell \(\alpha \). Following the model by [10], which is similar to previous mathematical models [25, 26, 29], auxin evolves according to auxin metabolism in the cell, passive diffusion between cells and active transport across cell walls via PIN,
$$\begin{aligned} \frac{\mathrm{d} {a}_\alpha }{\mathrm{d}t}= & {} \gamma ^* - \delta ^* a_\alpha + \mathcal {D} \sum _{\beta \in \mathcal {N}_\alpha } W_{\alpha \beta } \left( a_\beta - a_\alpha \right) \nonumber \\&+ \mathcal {P}\sum _{\beta \in \mathcal {N}_\alpha } W_{\alpha \beta } \left( p_{\beta \alpha } \frac{a_\beta }{K+a_\beta } - p_{\alpha \beta } \frac{a_\alpha }{K+a_\alpha }\right) , \end{aligned}$$
where \(\gamma ^*\) is the auxin production rate, \(\delta ^*\) is the auxin decay rate, \(W_{\alpha \beta } = l_{\alpha \beta }/A_\alpha \), with K, \(\mathcal {P}\), and \(\mathcal {D}\) as adjustable parameters. \(\mathcal {D}\) is the passive permeability of plant cells, whereas \(\mathcal {P}\) is permeability of the cell wall due to PIN-mediated transport of auxin, and K is the Michaelis–Menten constant for the efflux of auxin. More information on how this expression is derived can be found in the supporting text. Although this description ignores the auxin present within the extracellular domain and inside the cell wall, it has been shown that under physiological assumptions, this is a valid approximation [29]. The active transport term depends on the amount of bound PIN in each cell wall,
$$\begin{aligned} p_{\alpha \beta }= \frac{f_{\alpha \beta }}{1 + \sum _{\gamma \in \mathcal {N}_\alpha } \frac{l_{\alpha \gamma }}{L_\alpha } f_{\alpha \gamma }},\beta \in \mathcal {N}_\alpha , \end{aligned}$$
where \(f_{\alpha \beta },\beta \in \mathcal {N}_\alpha \) expresses the ratio between binding and unbinding rates of a particular wall (Fig. 3 bottom right). Note that \(p_{\alpha \beta }\) is different from wall to wall and from cell to cell. This means that in general, \(p_{\alpha \beta }\ne p_{\beta \alpha }\), or equivalently, \(p_{ij}\ne p_{ji}\). This is consistent with the fact that there are two compartments to a cell wall shared by two adjacent cells. Expression (Eq. 11) is based on the assumption that cell walls around a particular cell compete for the same pool of PIN molecules and that the amount of PIN scales with cell perimeter. This competition has been shown to be important in the polarization of PIN [29]. Alternatively, one could also scale the amount of PIN with cell size or not scale it at all. In the former case, smaller cells would be slightly preferred for auxin accumulation, whereas in the latter, larger cells would be preferred instead. Since we want to study the impact of stress patterns on the tissue, we want to decouple it from this effect as much as possible, choosing instead to scale the amount of PIN with perimeter.
The trivial fixed point of these dynamical equations is given by \(a_\alpha = \mu ^*/\delta ^*,\; \forall \alpha \), which also results in equal PIN density across all walls, provided turgor pressure \(T_\alpha \) and stiffness \(E_\alpha \) are the same across the tissue.
The feedback between tissue mechanics and auxin pattern unfolds as auxin transport affects tissue mechanics due to auxin, \(a_\alpha \), controlling cell wall stiffness, \(E_\alpha \), and in reverse tissue stress, \(\sigma _\alpha \), affects auxin transport by regulating PIN binding rates, \(f_{\alpha \beta }\), as hypothesized by [10, 11].
Mechanical regulation of PIN binding
According to the hypothesis presented by [10, 11], mechanical cues up-regulate PIN binding. The distinction between whether these mechanical cues are strain or stress has been studied recently by [54], yet the exact nature remains unclear. Following the model presented by [10], we model the binding-unbinding ratio, \(f_{\alpha \beta }\), as being a power law on positive stress,
$$\begin{aligned} f_{\alpha \beta } = f\left( \sigma _{\alpha \beta }\right) = {\left\{ \begin{array}{ll} \eta \left( \sigma _{\alpha \beta }\right) ^n, &{}\sigma _{\alpha \beta } > 0,\\ 0, &{} \sigma _{\alpha \beta }\le 0, \end{array}\right. } \end{aligned}$$
where the stresses, \(\sigma _{\alpha \beta }\), follow from tissue mechanics after minimization of the full mechanical model (Eq. 5), or, in the averaged stress approximation, it is the stress load on that particular compartment given by (Eq. 9). Furthermore, n is the exponent of this power law, and \(\eta \) captures the coupling between stress and PIN. Effectively, this mechanical coupling to PIN parameter corresponds to the sensing and subsequent response to stress, loosely translating into how much resources the cell needs to spend for processing stress cues.
Auxin-mediated cell wall softening
Auxin affects the mechanical properties of a cell wall via methyl esterification of pectin [6, 7], resulting in a decrease of the stiffness of the cell wall. We assume that all cell wall compartments surrounding cell \(\alpha \) share the same stiffness, \(E_\alpha \). To capture this effect, we model stiffness with a Hill function [10],
$$\begin{aligned} E_\alpha = E\left( a_\alpha \right) = E_0 \left( 1 + r \frac{1-a_\alpha ^m}{1+a_\alpha ^m}\right) , \end{aligned}$$
where \(r\in [ 0,1[\) which we define as the cell wall loosening effect, m is the Hill exponent of this interaction, and \(E_0\) is the stiffness of the cell walls when its auxin concentration is \(a_\alpha =1\). At low values of auxin, \(E_\alpha \) approaches the value \(\left( 1 + r \right) E_0\), whereas at high auxin concentration, \(E_\alpha \) approaches \(\left( 1 - r\right) E_0\). Given a distribution of auxin, we can compute the wall stiffness in (Eq. 5) from (Eq. 13), or the stress acting on a specific compartment in (Eq. 9) for the approximated model.
Schematic representation of the time evolution of the model. From mechanical relaxation of the mechanical model, we calculate PIN densities on each wall via stress. Then we integrate auxin dynamics for a time step and update the stiffness of each cell. This process knocks the system out of the previous mechanical energy minimum, and it has to be relaxed again. Alternatively, we can shortcut energy minimization using the averaged stress approximation for a static tissue. This procedure is repeated until \(t=t_\mathrm {max}\). The parameters r, wall loosening effect, and \(\eta \), stress coupling, interface both models and are, therefore, of critical importance to the mechanism studied
Integrating auxin transport and tissue mechanics
At each time step, \(\varDelta t\), starting from an auxin distribution, we compute the stiffness of each cell according to (Eq. 13). Then, with the input of all turgor pressures, we minimize (Eq. 5) to obtain tissue geometry and stresses acting on each wall. Auxin concentration in each cell will evolve according to (Eq. 10), where the active transport term will be regulated by stress according to (Eq. 12) via (Eq. 11). A new auxin distribution will result at the end of this iteration, and we will be ready to take another time step (Fig. 4). We repeat this process until \(t=t_\mathrm {max}\).
We implemented this model with C++ programming language, where we have used the Quad-Edge data structure for geometry and topology of the tissue [55], implemented in the library Quad-Edge [56]. In order to minimize the mechanical energy of the tissue, we have used a limited-memory Broyden–Fletcher–Goldfarb–Shanno algorithm (L-BFGS) [57, 58], implemented in the library NLopt [59]. For solving the set of ODEs presented in the compartment model, we used the explicit embedded Runge–Kutta–Fehlberg method (often referred to as RKF45) implemented in the GNU Scientific Library (GSL) [60]. We wrapped the resulting classes into a python module with SWIG. For additional details regarding the parameters used for the simulations of the following section, consult Table S1 in the supporting material.
Observables
In order to quantify the existence of auxin patterns, we compute the difference between an emerging auxin concentration pattern and the trivial steady state of uniform auxin concentration pattern defined as \(a_\alpha = \gamma ^*/\delta ^*,\; \forall \alpha \). To account for a large range of orders of magnitude of auxin concentration, we consider as an order parameter,
$$\begin{aligned} \varphi = \frac{\left\langle \ln ^2\left( a_\alpha \right) \right\rangle _M}{\delta ^2 + \left\langle \ln ^2\left( a_\alpha \right) \right\rangle _M}, \end{aligned}$$
where \(\left\langle \cdot \right\rangle _M\) denotes an average over all cells within the tissue. This way, \(\varphi \approx 0\) means that there are no discernible patterns, whereas \(\varphi \approx 1\) implies prominent auxin patterning. The term \(\delta ^2\) defines the sensitivity of this measure, such that an average deviation of \(\delta \) yields \(\varphi \approx 1/2\) (for small \(\delta \)). We will choose \(\delta =0.1\), i. e. , a 10% deviation from the trivial steady state.
We also keep track of the average of auxin above basal levels in order to gauge the potential degree of modulation of auxin-mediated cell behaviour.
Furthermore, to characterize cells with regards to PIN localization we introduce the magnitude of the average PIN efflux direction,
$$\begin{aligned} F_\alpha = \left| \left| \sum _{i\in \mathcal {V}_\alpha }\frac{l_{ii+1}}{L_\alpha } p_{ii+1} \hat{\mathbf {n}}_{i i+1}\right| \right| , \end{aligned}$$
where \(\hat{\mathbf {n}}_{ii+1}\) is the unit vector normal to the wall pointing outwards from \(\alpha \).
Aside from a global measure of auxin patterning, it is also important to locally relate auxin to tissue mechanics. Namely, for auxin we are interested in auxin concentration, \(a_\alpha \), and auxin local gradient, obtained by interpolation,
$$\begin{aligned} \nabla a_\alpha = \frac{1}{2A^*_\alpha }\sum _{\gamma \in \mathcal {N}_\alpha } \begin{pmatrix} Y^\prime _{\gamma +1} &{} -Y^\prime _\gamma \\ -X^\prime _{\gamma + 1} &{} X^\prime _\gamma \end{pmatrix} \begin{pmatrix} a_\gamma - a_\alpha \\ a_{\gamma +1} - a_\alpha \end{pmatrix}, \end{aligned}$$
where \(\mathbf {X}^\prime _\gamma = \left( X^\prime _\gamma ,Y^\prime _\gamma \right) = \mathbf {X}_\gamma - \mathbf {X}_\alpha \) and
$$\begin{aligned} A^*_\alpha = \frac{1}{2}\sum _{\gamma \in \mathcal {N}_\alpha } \left( X^\prime _\gamma Y^\prime _{\gamma +1} - Y^\prime _\gamma X^\prime _{\gamma +1}\right) . \end{aligned}$$
In fact, the quantity \(\left| \nabla a_\alpha \right| \) can be used as an indicator of whether there is an interface between auxin spots and the rest of the tissue.
With regards to tissue mechanics, the local quantities we quantify are the isotropic component of stress,
$$\begin{aligned} P_\alpha = \frac{1}{2}\mathrm {Tr}\left( \sigma _\alpha \right) , \end{aligned}$$
and the stress deviator tensor projected along the direction of the auxin gradient,
$$\begin{aligned} D_\alpha = \frac{\nabla a_\alpha ^T \sigma '_\alpha \nabla a_\alpha }{\left| \nabla a_\alpha \right| ^2}, \end{aligned}$$
where \(\sigma ^\prime _\alpha = \sigma _\alpha - I P_\alpha \), and I is the identity matrix. Therefore, \(P_\alpha \) is a measure if a cell is being compressed (\(P_\alpha <0\)), or pulled apart (\(P_\alpha >0\)), and \(D_\alpha \) translates into if a cell is more compressed along the auxin gradient than perpendicular to it (\(D_\alpha <0\)), or vice-versa (\(D_\alpha >0\)).
Finally, to measure the disruption of an auxin pattern we approximate entropy by means of a Riemann sum,
$$\begin{aligned} S\left[ \varPi \right] = -\sum _{i=-\infty }^\infty \varPi \left( i \varDelta a\right) \varDelta a\ln \left( \varPi \left( i\varDelta a\right) \varDelta a\right) , \end{aligned}$$
where \(\varPi \left( a\right) \) is the probability density function of auxin and \(\varDelta a\) the partition size. Note that it is only meaningful to compare entropy measures obtained with the same partition size \(\varDelta a\). Here, the probability density function of auxin concentration is obtained by applying a kernel density estimation on the resulting tissue auxin values. Note that \(\varPi \left( a\right) \) is a continuous function. In order to infer it from simulation data, for each auxin value in the tissue, \(a_\alpha \), we add Kernel functions \(K_w(a)\), obeying \(\int _{-\infty }^\infty K_w(a) da = 1\) and \(K_w(a) = K_w(-a)\). Then we can estimate
$$\begin{aligned} \varPi \left( a\right) \sim \frac{1}{M}\sum _{\alpha =1}^M K_w(a-a_\alpha ), \end{aligned}$$
where w is a smoothing parameter defining the width of the Kernel, this parameter is sometimes called bandwidth. This statistical tool is called kernel density estimation (KDE) [61]. We use the Epanechnikov kernel because it is bounded and we can force \(\varPi \left( a\right) = 0, a\le 0\).
Tissue-wide mechanical model captures expected stress patterns as well as auxin and PIN distribution after ablation. Green lines represent the magnitude and direction of principal stress, measured \(\gamma = \frac{\lambda _+ - \lambda _-}{\lambda _+ + \lambda _-}\), where \(\lambda _\pm \) are the largest and lowest eigenvalues of the stress tensor. The ablation perturbs auxin patterning by redirecting PIN. This PIN reorientation coincides with the circumferential stress patterns around the ablation site, as seen in experiments and simulations [10, 41].\(r=0.65\) and \(\eta =1.5\)
The tissue-wide mechanical model captures stress patterns after ablation
First we verify that the tissue-wide mechanical model captures the expected mechanical behaviour and auxin patterning when a cell is ablated. To model ablation, we set the stiffness of the ablated cell walls to \(E_0 = 0\), block all auxin transport to and from it, block PIN transporters of adjacent cells from binding to the shared wall with the ablated cell, and, finally, we lower the turgor pressure to only \(10\%\) of the original value. This remnant of pressure represents the surface tension emerging from pressure of the inner layers of the shoot apical meristem acting on a curved surface, as required by the Young–Laplace equation. This is necessary since the model only simulates the epidermal layer in a plane.
We observe that the region neighbouring the ablation site gets depleted of auxin due to PIN binding preferentially to the walls circumferentially aligned around the ablated cell in accordance with the stress principal directions (Fig. 5a). This stress pattern is in agreement with calculations performed by [41] in this setting and PIN aligns according to the ablation experiments in [10].
We also simulated different wound shapes. The resulting stress patterns are shown the supporting material. Stress directions align along the shape of the ablation wound.
Thus our mechanical model faithfully capture the typical tissue behaviour upon ablation with regards to stress, auxin and PIN transporter patterns.
Simulation results of the order parameter \(\varphi \), indicator for the existence of auxin patterns, as a function of \(r\in \left[ 0.30,0.95\right] \) and \(\eta \in \left[ 1.0,10.0\right] \) for a model with tissue-wide stress patterning. The simulated tissue is composed of 2977 initially hexagonal cells. The blue line represents the analytically predicted instability for the uncoupled tissue approximation (Eq. 22)
Conditions for auxin patterns emergence
The uncoupled tissue approximation allows to analytically compute the conditions for spontaneous auxin pattern emergence in a general regular lattice (Fig. 6). Effectively, for a regular grid, the condition for pattern formation is,
$$\begin{aligned} \mathcal {M} > \frac{K+1}{W\mathcal {P}}\left[ 1 + \sqrt{1 + 2W \left( \frac{\mathcal {P}K}{\left( K+1\right) ^2} + \frac{\mathcal {D}}{p_0}\right) }\right] ^2, \end{aligned}$$
where \(\mathcal {M} = nmr\), \(W=4/\sqrt{3}\) is a geometrical factor specific to the used grid, and \(p_0 = f\left( \bar{\sigma }\right) /(1 + f\left( \bar{\sigma }\right) )\) (see supporting material for the linear stability analysis details). Equation 22 is the closed form of more general expressions presented by [10, 29] tailored to our system and parameters.
To quantify the existence of auxin patterns in the model with tissue-wide stress patterning, we computed the order parameter \(\varphi \) defined in Eq. 14 for simulations with different values of wall loosening effect r and stress coupling \(\eta \) (Fig. 6). These two parameters are conceptually important since the former is the cause for stiffness inhomogeneity of the tissue, and the latter represents a plant cell's sensitivity to mechanical cues.
We observe a very good agreement between the conditions for pattern emergence (Eq. 22) analytically predicted in the case of the uncoupled tissue approximation and the transition of \(\varphi \) in the case of tissue-wide stress patterning (Fig. 6). This means that at the onset of patterns emergence the auxin concentrations are similar enough to make the assumption that the effect of turgor pressure is simply an isotropic stress across the entire tissue, validating the approximation near the transition. This observation is in agreement with the auxin pattern emergence mechanism hypothesis by [10] (Fig. 1). The agreement between the two models does not necessarily apply after patterns emerge. This poses the question of the role of mechanics in potentially enhancing or hindering auxin flows.
Global mechanical response reinforces PIN polarity
To understand the role of tissue-wide stress patterning on the emergence of PIN-driven auxin patterns, we quantify how PIN rearranges in the model with tissue-wide stress patterning versus the uncoupled tissue approximation.
We compute the average PIN efflux direction, i.e., average PIN polarity for each combination of the parameters r (auxin-induced cell wall loosening) and \(\eta \) (coupling of PIN to stress) under the approximated (Fig. 7 top left) and tissue-wide (Fig. 7 top right) stress coupling regimes.
We observe an overall increase in PIN polarity in the tissue-wide stress coupling regime compared with the uncoupled tissue approximation. PIN polarity also becomes more sensitive to r. For very low values of r, tissue stress patterns are slightly detrimental to auxin patterning. These data show that saturation of PIN polarity happens earlier with respect to \(\eta \) for intermediate values of r. For high values of r, we observe a non-monotonic dependence of polarity on \(\eta \), effectively translating into an optimal value of \(\eta \).
Visual inspection of the simulations results reveals higher PIN density in proximity of auxin spots and an increase in magnitude of these auxin peaks upon tissue-wide stress patterning (Fig. 7a–d). Moreover, we observe a severe alteration of pattern size and wavelength between both models (Fig. 7 bottom left).
Quantification of PIN polarity in both models reveals more focused auxin spots due to tissue-wide integration via mechanical coupling. (top) Average magnitude of PIN polarity, \(\langle F_\alpha \rangle _M\), as a function of stress-PIN coupling, \(\eta \), and wall loosening effect, r, for (top left) the uncoupled tissue approximation and (top right) for the tissue-wide stress patterning. PIN polarity magnitude increases when considering the mechanics of the whole tissue, with a particularly strong dependence on the wall loosening affect r of auxin. The labels represent the parameters plotted for (a, b, c, d) comparison between example results of auxin concentration and PIN density of simulations using the uncoupled tissue approximation (a, c) and the tissue-wide stress patterning (b, d), for the same value of \(\eta =5.5\), and \(r=0.65\) (bottom left) or \(r=0. 90\) (bottom right). In both instances, we observe that PIN polarity and auxin concentration are higher upon tissue-wide stress patterning (b, d)
Characterization of auxin spot concentration reveals more focused auxin spots due to tissue-wide integration via mechanical coupling. Average auxin concentration for cells above basal auxin concentration (\(a_\alpha > 1\)), for the uncoupled tissue approximation (left), and upon tissue-wide stress patterning (right), as a function of stress-PIN coupling, \(\eta \), and wall loosening effect, r. Spot auxin concentration increases with both \(\eta \) and r in (left); however, in (right), it increases predominantly with r. For medium to high values of r, auxin concentration jumps to several times immediately after emergence
These results show that tissue-wide stress patterning reinforces PIN polarity and that auxin spots are sharper. Next we will quantify how much sharper these auxin spots become.
Tissue-wide coupling induces efficient emergence of auxin spots
Auxin levels in the shoot apical meristem have been shown to affect cell fate reliably [20], even if the flexibility of the auxin signalling mechanism allows for many potential outcomes [62]. We explore auxin spot concentration achieved by both models in order to gauge the impact of tissue-wide stress patterns on the distinguishability of primordium cells.
For this, we first characterize quantitatively the auxin spot average concentration measured for each simulation of the uncoupled tissue approximation (Fig. 8 left) and tissue-wide stress coupling (Fig. 8 right) regimes. We use, as a proxy, the average of cells with auxin concentration \(a_\alpha > 1\) to identify auxin spots.
We observe that the dependence on the parameter r recognized for PIN polarity translates into auxin spot concentration. For medium to high values of r, auxin concentration is several times higher when accounting for tissue-wide behaviour than when considering the uncoupled tissue approximation.
Additionally, at the onset of pattern formation for medium to high values of r, we observe a considerable jump in average auxin spot concentration for a small change in \(\eta \). This increase in sensitivity to a change in \(\eta \) of the system, under the aforementioned conditions, implies a boost in mechanosensing capabilities when considering tissue-wide stress patterning.
Our results point to stress patterns being responsible for the enhancement of auxin spot concentration and flows. In order to make sure we understand why, we decided to observe and quantify stress patterns and their connection to auxin distribution.
Map of auxin distribution and PIN density aligns with stress direction. Green lines represent principal direction of stress, measured as \(\gamma = \frac{\lambda _+ - \lambda _-}{\lambda _+ + \lambda _-}\), where \(\lambda _\pm \) are the largest and lowest eigenvalues of the stress tensor. We observe that stress directions in part congruent with auxin spots. \(r=0.90\) and \(\eta =5.5\)
Stress pattern self-organization concomitant with auxin patterns. Probability density functions (P.D.F.s) of (top left) auxin concentration and isotropic stress component and (top right) auxin gradient magnitude and deviator stress tensor projection onto auxin gradient. In each case, we can identify two populations of cells: high and low auxin concentration (bottom left), and high and low auxin gradient (bottom right). (bottom left), since \(P_\alpha = \bar{\sigma }\) signifies the stress that would be expected in the uncoupled tissue approximation, high auxin concentration cell expansion is constrained by the remaining cells which are, in turn, under a larger amount of stress. On the other hand (bottom right) we observe that the auxin spot neighbours have, on average, negative values of \(D_\alpha \), indicating that the largest principal stress direction is perpendicular to auxin gradients, i.e., circumferentially aligned around auxin spots, as suggested by Fig. 9. \(r=0.90\) and \(\eta =5.5\)
Part of wall stress within spots is borne by walls at the interface
In order to analyse tissue-wide stress patterns, we choose an example that has simple auxin patterns that allow for a straightforward interpretation. Under this condition, we choose the parameters \(r=0.90\) and \(\eta = 5.5\) already presented in Fig. 7d, for which we plot on it a measure of anisotropy along the largest principal stress direction (Fig. 9). Here it becomes apparent that stress patterns are related, even if not absolutely, to auxin spot patterns.
To explore this further, we quantify several local quantities, such as auxin concentration, \(a_\alpha \), auxin gradient norm (Eq. 16), \(\left| \nabla a_\alpha \right| \), isotropic stress component (Eq. 18), \(P_\alpha \), and deviator stress tensor projection onto auxin gradient (Eq. 19), \(D_\alpha \). For the example mentioned above, we record the histograms of the simultaneous occurrence of the pairs \(\left( a_\alpha ,P_\alpha \right) \) (Fig. 10 top left) and \(\left( \left| \nabla a_\alpha \right| ,D_\alpha \right) \) (Fig. 10 top right).
We can section the results according to high or low auxin concentration (Fig. 10 bottom left), and high or low auxin gradient (Fig. 10 bottom right). Here, high auxin cells are a proxy for auxin spot cells, and high auxin gradient cells are a proxy for cells neighbouring auxin spots. Taking into account that in the uncoupled tissue approximation \(P_\alpha = \bar{\sigma }\) and \(D_\alpha = 0\) by construction, we can get a better picture of tissue-wide stress patterns.
We observe from data (Fig. 10 bottom left) that \(P_\alpha \) in cells of auxin spots is lower than in the uncoupled tissue approximation and accompanied by a slight shift in the opposite direction of the \(P_\alpha \) of the remaining cells. Additionally, we register a noticeable shift towards negative \(D_\alpha \) for high auxin gradient cells (Fig. 10 bottom right).
Taken together, these data suggests that cell walls at the interface of a spot are under a larger amount of stress whereas the cells within auxin spots have decreased stress. This leads to reinforced polar auxin transport towards the spot and hence higher auxin concentration. The lower isotropic stress component inside the auxin spot suggests that the diffusive term inside auxin spots increases in importance relative to the active transport term.
Tissue-wide stress coupling mitigates disruption by noise
Impact of noise in reference stiffness in the auxin concentration distributions for the uncoupled tissue approximation and upon tissue-wide coupling reveals robustness of auxin patterns due to tissue-wide integration. For a given noise strength, auxin concentration probability density functions (P.D.F.s) are extracted from simulation results by means of a kernel density estimation for the uncoupled tissue approximation (top left) and when considering tissue-wide stress patterns (top right). The simulated tissues have \(r=0.65\) and \(\eta =5.5\). For both models, we observe broadening of the distributions when considering noise. In each instance, the fit appears to be adequate for describing the resulting auxin concentration. (bottom left) Examples of the resulting patterns in the uncoupled tissue approximation (a) and in the case of tissue-wide stress patterns (b) for a noise strength of \(9\%\). Even though patterns are heavily disrupted, we can still discern more clearly high auxin concentration spikes upon tissue-wide coupling. (bottom right) Entropy difference between the resulting distributions for a given noise strength and in the absence of noise. In the presence of tissue-wide stress patterns disruption of tissue patterning is consistently lower than in the uncoupled tissue approximation
Up until now, our simulations were performed on hexagonal tissues in the absence of noise. This also raises the question of how tissue-wide stress patterns impact pattern emergence robustness against noise.
In plant tissue as any biological entity, noise prevails. As such cells within a tissue differ in their mechanical parameters. In order to inspect how parameter noise disrupts pattern emergence, we choose to sample reference stiffness, \(E_0\), from a normal distribution for each cell. As outlined in the supplementary material, we expect this parameter to be the most disruptive to the active term and it is reasonable to assume it changes from cell to cell. We then simulate the resulting tissue with the uncoupled tissue approximation and tissue-wide stress coupling.
We simulate tissues with \(r=0.65\) and \(\eta =5.5\) for both models by promoting \(E_0\) to a random variable sampled from Gaussian distribution with mean \(\bar{E_0}=300\,\mathrm {MPa}\) and standard deviation of \(\alpha \bar{E_0},\, \alpha \in \left\{ 0.03,0.06,0.09,0.12,0.15\right\} \), where \(\alpha \) is the noise strength. For each value of \(\alpha \), five simulations were performed per model. We fit the resulting auxin distributions to a probability density function (Fig. 11 top left and top right). We observe that noise in reference stiffness impacts the patterning behaviour in a severe manner (Fig. 11 bottom left). Yet, with tissue-wide stress coupling spots of noticeable auxin accumulation are preserved.
In order to quantify the disruption, we compute the entropy (Eq. 20) of a fitted auxin probability density function by means of a kernel density estimation on the resulting auxin distributions. The kernel used for all fits was the Epanechnikov kernel with a bandwidth of about 0.202. This number arises in the rule-of-thumb estimate for the Gaussian kernel for the sample size and dimension of this system. The partition size used for the numerical approximation of the entropy is the same for all instances. Afterwards, we measure the entropy difference between the expected auxin distribution for each value of \(\alpha \), of each model and for all simulations (Fig. 11 bottom right). The reference entropy is taken to be the average of the uncoupled tissue approximation at \(\alpha = 0\). We can infer from these results that tissue-wide coupling helps to rescue auxin accumulation spots despite its heavy disruption in comparison to the uncoupled tissue approximation.
High turgor preferred but not required for sustaining auxin maxima
Simulations of auxin patterning with the tissue-wide mechanical model when considering a local turgor increase (right column), decrease (left column), or constant (middle column), and a prior high (bottom row), low (top row), or constant (middle row) initial auxin concentration. Units of \(\varDelta T\) are MPa. We used \(\eta =10\) and \(r=0.65\) for all simulations. Even if high turgor predicts an auxin maximum, it becomes unclear what might happen with low turgor. The tissue-wide mechanical model seems to preserve already existing auxin maxima
It is of interest to the experimental community at this point in time how auxin spots and turgor pressure correlates [63, 64]. To explore how the the tissue-wide mechanical model responds to local turgor variations, we probe what happens when patterns emerge with a local increase or decrease in turgor. Since stress is tied to active auxin flow, the results are prone to be affected by prior auxin concentration distribution. Hence, we test the several turgor scenarios as well as initial auxin concentration. We added a contribution to turgor of \(\varDelta T e^{-\frac{x^2 + y^2}{2\sigma }}\), where \(\varDelta T \in \left\{ -0.2,0.0,0.2\right\} \) MPa and \(\sigma = 2L\). For initial auxin concentration, we used the same form with the same \(\sigma \), yet the largest deviations are \(\varDelta a\in \left\{ -0.99,0.00,5.00\right\} \). To be sure we are well within the pattern formation regime of the model for low pressure, we used the stress-PIN coupling value of \(\eta =10\) and \(r=0.65\).
Regardless of initial auxin concentration, for high turgor, we observe an auxin maximum predictably emerges correlated with a turgor maximum (Fig. 12 right column). Nevertheless, if an initial auxin concentration exists, we also predict that the spot remains regardless of whether this position is a turgor minimum or not (Fig. 12 bottom row). Low turgor regions can still exhibit patterns adding to the complexity of this simple measure (Fig. 12 middle row, left).
From these data, we can conclude is that developmental history is as important as turgor pressure for predicting auxin maxima positioning. We can predict high turgor leads to auxin accumulation, yet low turgor gives us little insight on auxin distribution. We can also predict that a high auxin concentration region.
Here, we used a model composed of a vertex model for plant tissue mechanics, and a compartment model for auxin transport to uncover the role of tissue-wide mechanical coupling on auxin redistribution. We first verified that the tissue-wide mechanical model successfully captures the behaviour of plant tissue upon ablation experiments and the conditions for emergence of auxin patterns. We then compared the behaviour of our model featuring tissue-wide mechanical coupling to an approximation which regards cells as mechanically isolated. We observe the emergence of focused auxin spots with high auxin concentration when tissue-wide mechanical coupling is implemented. Notably, depending on the parameters of the tissue-wide stress model, auxin spot concentration is more sensitive to stress than what could be predicted from the approximation. We observe that tissue-wide mechanical effects unaccounted for by the approximation have a positive impact on PIN polarity. Furthermore, we show that stress patterning of the tissue mitigates the disruption caused by noise, increasing robustness of the system. Finally, we observe auxin concentration correlating with high local turgor pressure. This behaviour coexists with the possibility of having auxin maxima anti-correlating with turgor.
The auxin-induced cell wall loosening effect (r parameter in this work) is an important determinant of the feedback of auxin on tissue mechanics. The range of values of r for which substantial pattern focusing occurs is around \(r\sim 0.60\) and above in our model. This translates into a variation of stiffness from a minimum value \(E_\mathrm {min}\) up to \(E_\mathrm {max} = 4 E_\mathrm {min}\) (see supplementary material). Although high, this range is within biological expectation and supported by AFM measurements on auxin treated tissues [7] and comparable to previous simulations of this mechanism [10] where \(E_\mathrm {max}/E_\mathrm {min} = 5\) which translates into \(r=2/3\).
Comparison of the tissue-wide stress patterning case to the uncoupled tissue approximation reveals that auxin spot concentration has a very steep transition in the former case (Fig. 8). This results in a several-fold increase in auxin concentration at values of \(\eta \) close to the threshold for pattern formation. What was once a relatively subtle graded response of auxin spot concentration on stress behaves now as an on-off switch by virtue of tissue mechanical relaxation. Since the mechanical perturbations being highlighted through the comparison are purely passive, this improvement in sensing comes at no additional cost for the plant and therefore has the potential to increase efficiency.
In the present work, we explored the parameter space \(\left( \eta ,r\right) \) exclusively. We observe consistently that pattern wavelengths shorten from the uncoupled tissue approximation and the tissue-wide coupling model. It would be interesting to systematically probe the diversity of patterns and how they change upon tissue-wide mechanical coupling. For our simulations, we used the parameters n, m, K from [10], parameters on which we have little empirical information. Yet, the sensitivity analysis from [29] suggests that n and K especially should affect patterning the most. We speculate the parameter m, specific to wall loosening, to be of similar importance. We expect that a study focusing on these three parameters would yield more interesting patterns shapes.
This work focused exclusively in the hypothesis that PIN is mechanically regulated. However, competing chemical feedback mechanisms have been proposed. Recently, mechanics and ARF-mediated PIN expression have been modelled together by [40] and show promising pattern formation capabilities. Other factors we have not taken into account is the family of auxin importers of the AUX family, which have been shown to be present in the epidermal layer of the shoot apical meristem [16]. Auxin binding proteins have also been hypothesized to promote auxin flow polarization [65]. Another observed interaction is cytokinin action controlling PIN polarity during lateral root formation [66].
The PIN regulation used in the auxin transport compartment model was specifically stress-based. In the supplementary text, we show results using strain-based PIN binding instead. We observe the same overall auxin spot focusing behaviour. It is still unclear whether the PIN density change due to mechanics is a result of strain or stress [11]. In fact, this question has been tackled recently by [54] concluding that in most simulated experiments both strain and stress-based models behave similarly. A notable exception is the experimentally observed correlation of PIN polarity and auxin concentration [37, 67]. On one hand, this observation is not captured by the stress-based PIN binding model. On the other hand, available experimental data and simulations suggest stress sensing being easier to explain [54]. Furthermore, the polarity difference could be rescued by the observation that ARF-mediated PIN expression is higher at the tip of the primordium [68].
The specific distribution of emergent stress patterns is remarkable in the sense that it coincides with the shape-induced stress patterns, as indicated by microtubule orientation, around the tip of the primordium as it emerges from the meristem [41]. Therefore, tissue-wide stress patterning sets the stage for primordium outgrowth by focusing efficiently auxin, forming local circumferential stress that in turn may re-orient microtubules and prefigure the shape of the primordium. This process could, in turn, be capable of reinforcing auxin transport to the tip of the newly forming organ. Yet, quantifying this requires further modelling. Therefore, it would be interesting to include auxin transport in already existing models for primordium outgrowth [8, 9].
Even though the analysed numerical simulations were limited to noise in the parameter \(E_0\), it showcases the power of the aforementioned auxin peak focusing that happens upon tissue-wide mechanical coupling. In this instance, we show here the power of tissue-wide stress patterns to mitigate the information loss due to noise by inspecting entropy of auxin concentration distribution. This result, especially when paired with the increase in sensitivity mentioned above, is indeed remarkable. This is due to the fact that in a wide range of optimized systems, biological or otherwise, robustness and efficiency are thought to be in opposition to each other, as illustrated, for example, by [69]. This is because robustness is usually brought upon by additional systems which would be considered clutter by a system geared towards efficiency. This opens a novel line of argumentation in the discourse of the evolution of mechanical signalling in multicellular organisms.
Lastly, we probed the behaviour of the used tissue-wide mechanical model when faced with local turgor variations. Our results indicate that once established auxin spots can endure low turgor scenarios, even if they would prefer high turgor regions all else being equal. Maintaining a turgor pressure difference for so long, however, might not be feasible for the plant. To answer how this setting could be achieved would require modelling water transport between plant cells along the lines of [63]. Nevertheless, our model can explain, at least in part, why these two quantities do not correlate in a straightforward manner.
Even though the mechanisms by which PIN preferentially associate with stressed cell walls is unclear, here we show that there are substantial advantages by intertwining tissue-wide mechanics and auxin patterning. Even if auxin patterning is possible by chemical processes and local mechanical coupling, tissue-wide mechanics may provide a way for patterning to still occur at a lower energy cost for the tissue. Moreover, this process can also provide robustness to the patterning, factoring in tissue-wide stress pattern, a sort of proprioceptive mechanism.
Data availibility
The data that support the findings of this study are available from the corresponding author upon request.
J.A. Lockhart, An analysis of irreversible plant cell elongation. J. Theor. Biol. 8, 264–275 (1965)
J.K.E. Ortega, Augmented growth equation for cell wall expansion. Plant Physiol. 79, 318–320 (1985)
D. Cosgrove, Biophysical control of plant cell growth. Ann. Rev. Plant Physiol. 37, 377–405 (1986)
A. Geitmann, J.K. Ortega, Mechanics and modeling of plant cell growth. Trends Plant Sci. 14, 467–478 (2009)
O. Hamant, J. Traas, The mechanics behind plant development. New Phytol. 185, 369–385 (2010)
A. Peaucelle, S.A. Braybrook, L. Le Guillou, E. Bron, C. Kuhlemeier, H. Höfte, Pectin-induced changes in cell wall mechanics underlie organ initiation in arabidopsis. Curr. Biol. 21, 1720–1726 (2011)
S.A. Braybrook, A. Peaucelle, Mechano-chemical aspects of organ formation in Arabidopsis thaliana: the relationship between auxin and pectin. PLoS ONE 8, e57813 (2013)
F. Boudon, J. Chopard, O. Ali, B. Gilles, O. Hamant, A. Boudaoud, J. Traas, C. Godin, A computational framework for 3D mechanical modeling of plant morphogenesis with cellular resolution. PLoS Comput. Biol. 11, e1003950 (2015)
J. Khadka, J.-D. Julien, K. Alim, Feedback from tissue mechanics self-organizes efficient outgrowth of plant organ. Biophys. J . 117, 1995–2004 (2019)
M.G. Heisler, O. Hamant, P. Krupinski, M. Uyttewaal, C. Ohno, H. Jönsson, J. Traas, E.M. Meyerowitz, Alignment between PIN1 polarity and microtubule orientation in the shoot apical meristem reveals a tight coupling between morphogenesis and auxin transport. PLoS Biol. 8, e1000516 (2010)
N. Nakayama, R.S. Smith, T. Mandel, S. Robinson, S. Kimura, A. Boudaoud, C. Kuhlemeier, Mechanical regulation of auxin-mediated growth. Curr. Biol. 22, 1468–1476 (2012)
W.D. Teale, I.A. Paponov, K. Palme, Auxin in action: signalling, transport and the control of plant growth and development. Nat. Rev. Mol. Cell Biol. 7, 847–859 (2006)
S. Vanneste, J. Friml, Auxin: a trigger for change in plant development. Cell 136, 1005–1016 (2009)
M. Sassi, T. Vernoux, Auxin and self-organization at the shoot apical meristem. J. Exp. Bot. 64, 2579–2592 (2013)
E. Benková, M. Michniewicz, M. Sauer, T. Teichmann, D. Seifertová, G. Jürgens, J. Friml, Local, efflux-dependent auxin gradients as a common module for plant organ formation. Cell 115, 591–602 (2003)
D. Reinhardt, E.-R. Pesce, P. Stieger, T. Mandel, K. Baltensperger, M. Bennett, J. Traas, J. Friml, C. Kuhlemeier, Regulation of phyllotaxis by polar auxin transport. Nature 426(6964), 255–60 (2003)
P.B. de Reuille, I. Bohn-Courseau, K. Ljung, H. Morin, N. Carraro, C. Godin, J. Traas, Computer simulations reveal properties of the cell-cell signaling network at the shoot apex in Arabidopsis. Proc. Nat. Acad. Sci. 103, 1627–1632 (2006)
D. Reinhardt, T. Mandel, C. Kuhlemeier, Auxin regulates the initiation and radial position of plant lateral organs. Plant Cell 12, 507 (2000)
R.S. Smith, The role of auxin transport in plant patterning mechanisms. PLoS Biol. 6, e323 (2008)
T. Vernoux, F. Besnard, J. Traas, Auxin at the shoot apical meristem. Cold Spring Harb. Perspect. Biol. 2, a001487–a001487 (2010)
S. Robinson, A. Burian, E. Couturier, B. Landrein, M. Louveaux, E.D. Neumann, A. Peaucelle, A. Weber, N. Nakayama, Mechanical control of morphogenesis at the shoot apex. J. Exp. Bot. 64, 4729–4744 (2013)
J. Petrasek, PIN proteins perform a rate-limiting function in cellular auxin efflux. Science 312, 914–918 (2006)
J. Wisniewska, Polar PIN localization directs auxin flow in plants. Science 312, 883–883 (2006)
J. Petrasek, J. Friml, Auxin transport routes in plant development. Development 136, 2675–2688 (2009)
H. Jonsson, M.G. Heisler, B.E. Shapiro, E.M. Meyerowitz, E. Mjolsness, An auxin-driven polarized transport model for phyllotaxis. Proc. Nat. Acad. Sci. 103, 1633–1638 (2006)
R.S. Smith, S. Guyomarc'h, T. Mandel, D. Reinhardt, C. Kuhlemeier, P. Prusinkiewicz, A plausible model of phyllotaxis. Proc. Nat. Acad. Sci. 103, 1301–1306 (2006)
R.M. Merks, Y. Van de Peer, D. Inzé, G.T. Beemster, Canalization without flux sensors: a traveling-wave hypothesis. Trends Plant Sci. 12, 384–390 (2007)
A.C. Newell, P.D. Shipman, Z. Sun, Phyllotaxis: cooperation and competition between mechanical and biochemical processes. J. Theor. Biol. 251, 421–439 (2008)
P. Sahlin, B. Söderberg, H. Jönsson, Regulated transport as a mechanism for pattern generation: capabilities for phyllotaxis and beyond. J. Theor. Biol. 258, 60–70 (2009)
T. Sachs, Polarity and the induction of organized vascular tissues. Ann. Bot. 33, 263–275 (1969)
G.J. Mitchison, A model for vein formation in higher plants, in Proceedings of the Royal Society of London. Series B. Biological Sciences, vol. 207, pp. 79–109 (1980)
F.G. Feugier, A. Mochizuki, Y. Iwasa, Self-organization of the vascular system in plant leaves: inter-dependent dynamics of auxin flux and carrier proteins. J. Theor. Biol. 236, 366–375 (2005)
F.G. Feugier, Y. Iwasa, How canalization can make loops: a new model of reticulated leaf vascular pattern formation. J. Theor. Biol. 243, 235–244 (2006)
H. Fujita, A. Mochizuki, Pattern formation of leaf veins by the positive feedback regulation between auxin flow and auxin efflux carrier. J. Theor. Biol. 241, 541–551 (2006)
S. Stoma, M. Lucas, J. Chopard, M. Schaedel, J. Traas, C. Godin, Flux-based transport enhancement as a plausible unifying mechanism for auxin transport in meristem development. PLoS Comput. Biol. 4, e1000207 (2008)
Article ADS MathSciNet Google Scholar
K. Alim, E. Frey, Quantitative predictions on auxin-induced polar distribution of PIN proteins during vein formation in leaves. Eur. Phys. J. E 33, 165–173 (2010)
E.M. Bayer, R.S. Smith, T. Mandel, N. Nakayama, M. Sauer, P. Prusinkiewicz, C. Kuhlemeier, Integration of transport-based models for phyllotaxis and midvein formation. Genes Dev. 23, 373–384 (2009)
M. Cieslak, A. Runions, P. Prusinkiewicz, Auxin-driven patterning with unidirectional fluxes. J. Exp. Bot. 66, 5083–5102 (2015)
Y. Hayakawa, M. Tachikawa, A. Mochizuki, Mathematical study for the mechanism of vascular and spot patterns by auxin and pin dynamics in plant development. J. Theor. Biol. 365, 12–22 (2015)
H.R. Allen, M. Ptashnyk, Mathematical modelling of auxin transport in plant tissues: flux meets signalling and growth. Bull. Math. Biol. 82, 1–35 (2020)
O. Hamant, M.G. Heisler, H. Jonsson, P. Krupinski, M. Uyttewaal, P. Bokov, F. Corson, P. Sahlin, A. Boudaoud, E.M. Meyerowitz, Y. Couder, J. Traas, Developmental patterning by mechanical signals in arabidopsis. Science 322, 1650–1655 (2008)
O. Hamant, E.S. Haswell, Life behind the wall: sensing mechanical cues in plants. BMC Biol. 15, 59 (2017)
O. Hamant, D. Inoue, D. Bouchez, J. Dumais, E. Mjolsness, Are microtubules tension sensors? Nat. Commun. 10, 2360 (2019)
M. Uyttewaal, A. Burian, K. Alim, B. Landrein, D. Borowska-Wykrȩt, A. Dedieu, A. Peaucelle, M. Ludynia, J. Traas, A. Boudaoud, D. Kwiatkowska, O. Hamant, Mechanical stress acts via katanin to amplify differences in growth rate between adjacent cells in arabidopsis. Cell 149, 439–451 (2012)
E. Feraru, M.I. Feraru, J. Kleine-Vehn, A. Martinière, G. Mouille, S. Vanneste, S. Vernhettes, J. Runions, J. Friml, PIN polarity maintenance by the cell wall in arabidopsis. Curr. Biol. 21, 338–343 (2011)
H. Li, D. Lin, P. Dhonukshe, S. Nagawa, D. Chen, J. Friml, B. Scheres, H. Guo, Z. Yang, Phosphorylation switch modulates the interdigitated pattern of PIN1 localization and cell expansion in Arabidopsis leaf epidermis, in Cell Research, vol. 21, pp. 970–978 (2011)
P.J. Overvoorde, Functional genomic analysis of the AUXIN/INDOLE-3-ACETIC ACID gene family members in Arabidopsis thaliana. Plant Cell Online 17, 3282–3300 (2005)
D.B. Staple, R. Farhadifar, J.C. Röper, B. Aigouy, S. Eaton, F. Jülicher, Mechanics and remodelling of cell packings in epithelia. Eur. Phys. J. E 33, 117–127 (2010)
Y. Li, H. Naveed, S. Kachalo, L.X. Xu, J. Liang, Mechanisms of regulating cell topology in proliferating epithelia: impact of division plane, mechanical forces, and cell memory. PLoS ONE 7, e43108 (2012)
G. Trichas, A.M. Smith, N. White, V. Wilkins, T. Watanabe, A. Moore, B. Joyce, J. Sugnaseelan, T.A. Rodriguez, D. Kay, R.E. Baker, P.K. Maini, S. Srinivas, Multi-cellular rosettes in the mouse visceral endoderm facilitate the ordered migration of anterior visceral endoderm cells. PLoS Biol. 10, e1001256 (2012)
N. Murisic, V. Hakim, I.G. Kevrekidis, S.Y. Shvartsman, B. Audoly, From discrete to continuum models of three-dimensional deformations in epithelial sheets. Biophys. J . 109, 154–163 (2015)
M. Osterfield, X. Du, T. Schüpbach, E. Wieschaus, S.Y. Shvartsman, Three-dimensional epithelial morphogenesis in the developing drosophila egg. Dev. Cell 24, 400–410 (2013)
S. Alt, P. Ganguly, G. Salbreux, Vertex models: from cell mechanics to tissue morphogenesis. Philos. Trans. R. Soc. B Biol. Sci. 372, 20150520 (2017)
J.-D. Julien, A. Pumir, A. Boudaoud, Strain- or stress-sensing in mechanochemical patterning by the phytohormone auxin. bioRxiv 81, 3342–3361 (2019)
MathSciNet MATH Google Scholar
L. Guibas, J. Stolfi, Primitives for the manipulation of general subdivisions and the computation of voronoi. ACM Trans. Graph. 4, 74–123 (1985)
P. Heckbert, Quad-edge data structure library. http://www.cs.cmu.edu/afs/andrew/scs/cs/15-463/2001/pub/src/a2/cell/
J. Nocedal, Updating quasi-Newton matrices with limited storage. Math. Comput. 35, 773 (1980)
D.C. Liu, J. Nocedal, On the limited memory BFGS method for large scale optimization. Math. Program. 45, 503–528 (1989)
S.G. Johnson, The nlopt nonlinear-optimization package. http://github.com/stevengj/nlopt
M. Galassi et al., Gnu Scientific Library Reference Manual, 3rd edn. (Network Theory Ltd., Surrey, 2009).
S. Weglarczyk, Kernel density estimation and its application. ITM Web Conf. 23, 00037 (2018)
O. Leyser, Auxin signaling. Plant Physiol. 176, 465–479 (2018)
Y. Long, I. Cheddadi, G. Mosca, V. Mirabet, M. Dumond, A. Kiss, J. Traas, C. Godin, A. Boudaoud, Cellular heterogeneity in pressure and growth emerges from tissue topology and geometry. Curr. Biol. 30(8), 1504-1516.e8 (2020)
I. Cheddadi, M. Génard, N. Bertin, C. Godin, Coupling water fluxes with cell wall mechanics in a multicellular model of plant development. PLOS Comput. Biol. 15, 1–16 (2019)
M. Adamowski, J. Friml, PIN-dependent auxin transport: action, regulation, and evolution. Plant Cell Online 27, 20–32 (2015)
P. Marhavý, J. Duclercq, B. Weller, E. Feraru, A. Bielach, R. Offringa, J. Friml, C. Schwechheimer, A. Murphy, E. Benková, Cytokinin controls polarity of PIN1-dependent auxin transport during lateral root organogenesis. Curr. Biol. 24, 1031–1037 (2014)
D.L. O'Connor, A. Runions, A. Sluis, J. Bragg, J.P. Vogel, P. Prusinkiewicz, S. Hake, A division in pin-mediated auxin patterning during organ initiation in grasses. PLOS Comput. Biol. 10, 1–14 (2014)
M.G. Heisler, C. Ohno, P. Das, P. Sieber, G.V. Reddy, J.A. Long, E.M. Meyerowitz, Patterns of auxin transport and gene expression during primordium development revealed by live imaging of the arabidopsis inflorescence meristem. Curr. Biol. 15, 1899–1911 (2005)
G. Peng, S.-Y. Tan, J. Wu, P. Holme, Trade-offs between robustness and small-world effect in complex networks. Sci. Rep. 6, 37317 (2016)
This work was supported by the Max Planck Society and the Deutsche Forschungsgemeinschaft via DFG-FOR2581.
This work has been Funded by Deutsche Forschungsgemeinschaft via FOR-2581 (P1, P6).
Max Planck Institute for Dynamics and Self-Organization, Göttingen, Germany
João R. D. Ramos & Karen Alim
Center for Organismal Studies, University of Heidelberg, Heidelberg, Germany
Alexis Maizel
Physik-Department, Technische Universität München, Munich, Germany
Karen Alim
João R. D. Ramos
JRDR, AM and KA designed research. JRDR performed the research. JRDR, AM and KA wrote the article.
Correspondence to Karen Alim.
The authors decalre that they have no conflict of interest.
Code availibility
The code used to produce the data of this study are available from the corresponding author upon request.
Below is the link to the electronic supplementary material.
Supplementary material 1 (pdf 1271 KB)
D. Ramos, J.R., Maizel, A. & Alim, K. Tissue-wide integration of mechanical cues promotes effective auxin patterning. Eur. Phys. J. Plus 136, 250 (2021). https://doi.org/10.1140/epjp/s13360-021-01204-6
DOI: https://doi.org/10.1140/epjp/s13360-021-01204-6 | CommonCrawl |
coefficient of parasitic drag
length, form factor, etc.) Pilots will use this speed to maximize the gliding range in case of an engine failure. The skin friction coefficient, , is defined by where is the local wall shear stress , is the fluid density, and is the free-stream velocity (usually … A reader must be pedantic to verify that they understand the notation for any given publication. $$ b = 0.2 $$ Skin friction drag is made worse by factors such as exposed rivet heads, ripples in the skin, or even dirt and grime. $$ F = \frac{D}{L_{ref}} $$. With a two-dimensional wing there is no lift-induced drag so the whole of the drag is profile drag. Parasite drag is a combination of form, friction, and interference drag that is evident in any body moving through a fluid. $$ \Delta_{CD} = 0 $$ At the point of minimum power, C D,o is equal to one third times C D,i. As speed continues to increase into the transonic and supersonic regimes, wave drag grows in importance. $$ \Delta_z = |z_{le(1)} - z_{le(end)}| $$ Friction drag is a strong function of viscosity. Thus, zero-lift drag coefficient is reflective of parasitic drag which makes it very useful in understanding how "clean" or streamlined an aircraft's aerodynamics are. The remaining atmosphere options require a series of manual inputs to calculate the atmospheric condition, but will not calculate and update the altitude slider. Depending on the atmosphere input type, the kinematic viscosity is calculated accordingly and used to find the Reynolds number for the geometry. $$ FF = \left(F^* - 1\right)\left(cos^2\left(\Lambda_{\frac{c}{2}}\right)\right) + 1 $$ $$ FF = \left[1 + L\ \left(\frac{t}{c}\right) + 100\ \left(\frac{t}{c}\right)^4\right] * R_{L.S.} Except where otherwise noted, content on this wiki is licensed under the following license: http://aae.www.ecn.purdue.edu/~aae251/Lectures_Fall02/class13.pdf, http://adg.stanford.edu/aa241/AircraftDesign.html, http://dlib.stanford.edu:6520/text1/dd-ill/drag-divergence.pdf, http://roger.ecn.purdue.edu/~weisshaa/aae451/lectures.htm, CC Attribution-Share Alike 4.0 International. Since the drag coefficient is not of great relevance in stability calculation (see Chapter 11), it will not be considered in further detail except to say that the drag coefficient of a wing of finite span includes not only the "profile" drag due to the two-dimensional section characteristics, but an "induced" drag which depends on the lift. 2.4.1 Parasite Drag The parasite drag of a typical airplane in the cruise configuration consists primarily of the skin friction, roughness, and pressure drag of the major components. The drag coefficient of a sphere will change rapidly … Wikipedia. $ S_{total} \equiv \mbox{Total Area} $ $$ b = 2.131 $$ The freestream type is identified by the choice labeled "Atmosphere", and the sliders below will activate or deactivate depending on this selection. (2/100 Marks) Give The Expression For The Maximum Lift-to-drag Ratio (4/100 Marks) Ср Mar $ C_{f} \equiv \mbox{friction coefficient} $ \frac{7.0}{\left(FR\right)^3 \left(1.0 - M^3\right)^{0.6}}\right) $$, $$ \Lambda = \left(\frac{l_{r}}{\frac{4}{\pi}A_{x}}\right)^{0.5} $$ The table may be sorted by Component, S_wet, or % Total by selecting the toggles at the top of the table. Parasitic drag (also called parasite drag) is drag caused by moving a solid object through a fluid. Zero-lift drag coefficient — In aerodynamics, the zero lift drag coefficient CD,0 is a dimensionless parameter which relates an aircraft s zero lift drag force to its size, speed, and flying altitude. As compared to the drag coefficient calculated by A. Morelli of 0.05 for an unaltered model, the group concluded that the above drag coefficients are accurate. [2] For boundary layers without a pressure gradient in the x direction, it is related to the momentum thickness as. w ON THE DRAG COEFFICIENT 261 Figure B.1 A-4M Drag Rise Characteristics C DD D C C 0 L C kC2 (B.1) DL0 where is the drag due to lift and is the zero lift drag coefficientCC DD L 0 due to parasite (viscous form) drag. For flow around bluff bodies, drag usually dominates, thus the qualifier "parasitic" becomes meaningless. Jenkinson, L., Simpkin, P., & Rhodes, D. (1999). Gollos, W. W. (1953). The drag coefficient is a function of several parameters like shape of the body, Reynolds Number for the flow, Froude number, Mach Number and Roughness of the Surface. $$ b_i = \sqrt{ {\Delta_x}^2 + {\Delta_y}^2 + {\Delta_z}^2} $$ $$ a = 0.2 $$ where 0.25c_{l}\right)^2}\right)^{3.5}\right)\frac{\sqrt{1 - {M_{DD,eff}}^2}}{{M_{DD,eff}}^2}\right)^{\frac{2}{3}} $$, Equation solved for M. For example, a Sopwith Camel biplane of World War I which had many wires and bracing struts as well as fixed landing gear, had a zero-lift drag coefficient of approximately 0.0378. In aerodynamics, the fluid medium concerned is the atmosphere.The principal components of Parasite Drag are Form Drag, Friction Drag and Interference Drag. is the local wall shear stress, and q is the free-stream dynamic pressure. Next to this button, the Export Sub-Components toggle is available to include or ignore component breakup in the export file. Increase in length increases Reynolds number. $$, $$ FF = 1 + 2\ \left(\frac{t}{c}\right) + 60\ \left(\frac{t}{c}\right)^4 $$, $$ FF = 1 + Z\ \left(\frac{t}{c}\right) + 100\ \left(\frac{t}{c}\right)^4 $$ Categories Thermal Engineering Post navigation. If Peaky Airfoil Type: The drag coefficient is a common measure in automotive design.Drag coefficient, C D, is a commonly published rating of a car's aerodynamic resistance, related to the shape of the car.Multiplying C D by the car's frontal area gives an index of total drag. Reducing drag. $ M_{DD} \equiv \mbox{Drag Divergence Mach number, the point at which drag significantly begins to rise} $ Parasitic drag is drag that results when an object is moved through a fluid medium. {2\left(1-M^2\cos^2\left(\Lambda_{\frac{c}{4}}\right)\right)} $ c_i \equiv \mbox{Chord length at span station} $ The power required to overcome the aerodynamic drag is given by: Note that the power needed to push an object through a fluid increases as the cube of the velocity. {\displaystyle C_{f,lam}={\frac {1.328}{\sqrt {Re}}}}, Profile drag is a term usually applied to the parasitic drag acting on a wing. $ M^{*} \equiv \mbox{1.05, high-speed (peaky) airfoils, 1960-1970 technology} $ 01 to 10. $$ FF = 1.50 $$. The entire Parasite Drag table, excrescence list, and total results can be exported by selecting "Export to *.csv". $ M^{*} \equiv \mbox{1.05, high-speed (peaky) airfoils, 1960-1970 technology} $ $ M^{*} \equiv \mbox{1.12 to 1.15, supercritical airfoils [Conservative = 1.12; Optimistic = 1.15]} $ Note, the upper limit for the US Standard Atmospheric model is 84,852 meters, and the upper limit for the USAF model is 82,021 feet. The final aircraft drag calculation is a matter of summing the parasitic and induced drag values together to arrive at a final drag coefficient which represents the total drag acting on the aircraft for a given velocity and atmospheric condition. Eq. $ M^{*} \equiv \mbox{1.12 to 1.15, supercritical airfoils [Conservative = 1.12; Optimistic = 1.15]} $ , Description. Parasite drag is a combination of form, friction, and interference drag that is evident in any body moving through a fluid. The drag is the resultant force in the direction of … On the bottom right of the GUI, the total form factor, drag coefficient, and percent contribution to total drag is listed for all components, excrescences, and the combination of both. $$ C_f = \frac{0.451\ f^2\ \frac{Te}{Tw}}{\ln^2\left(0.056\ f\ \frac{Te}{Tw}^{1+n}\ Re\right)} $$, $$ FF = 1 + \frac{t}{c}\ \left(2.94206 + \frac{t}{c}\ \left(7.16974 + \frac{t}{c}\ \left(48.8876 + \frac{t}{c}\ \left(-1403.02 + \frac{t}{c}\ \left(8598.76 + \frac{t}{c}\ \left(-15834.3\right)\right)\right)\right)\right)\right) $$, Recreated Data from DATCOM is shown in the Figure and is used to find the Appropriate Scale Factor for use in the DATCOM Equation through interpolation. However, to maximize the gliding endurance (minimum sink), the aircraft's speed would have to be at the point of minimum drag power, which occurs at lower speeds than minimum drag. Active 2 years, 10 months ago. The drag coefficient is a number that aerodynamicists use to model all of the complex dependencies of shape, inclination, and flow conditions on aircraft drag. Lift induced drag, as the name suggests, is a drag produced due to lift. For comparison, the turbulent empirical relation known as the One-seventh Power Law (derived by Theodore von Kármán) is: where Parasitic drag is made up of many components, the most prominent being form drag.Skin friction and interference drag are also major components of parasitic drag.. $ V_{inf} \equiv \mbox{freestream velocity} $ The second method is to increase the length and decrease the cross-section of the moving object as much as practicable. Often, the nomenclature is defined far away from where the equations are presented. Objects drag coefficients are mostly results of experiments. $$ C_{L} = 1.0 $$ $$ \frac{t}{c} = 0.30\cos{\phi_{25}}\left(\left(1 - \left( \frac{5 + {M_{DD,eff}}^2}{5 + \left(k_{M} - Form drag or pressure drag arises because of the shape of the object. A graphical approximation of taking the area under the pressure profile curve was involved in the calculations. In aerodynamics, the fluid medium concerned is the atmosphere.The principal components of Parasite Drag are Form Drag, Friction Drag and Interference Drag. Parasitic drag (also called skin friction drag) is drag caused by moving a solid object through a fluid medium (in the case of aerodynamics, more specifically, a gaseous medium).Parasitic drag is made up of many components, the most prominent being form drag.Skin friction and interference drag are also major components of parasitic drag.. $$ A_{F} = 0.8 $$ As speed increases, the induced drag decreases, but parasitic drag increases because the fluid is striking the object with greater force, and is moving across the object's surfaces at higher speed. = Parasitic Drag. Once the table has been setup, the "Calculate CDO" button on the bottom left of the GUI will run the parasite drag calculation. Parasitic drag is a combination of form drag, skin friction drag and interference drag. The wing can be seen as a drag to lift converter, of which the already high efficiency can be increased further. In aviation, Parasite (Parasitic) Drag (D P) is defined as all drag that is not associated with the production of lift. $ X_{area} \equiv \mbox{Max cross sectional area} $ $$ M_{DD,eff} = M_{DD} * \sqrt{\cos{\phi_{25}}} $$ For wings of an aircraft, a decrease in length (chord) of the wings will reduce "induced" drag though, if not the friction drag. Streamlines should be continuous, and separation of the boundary layer with its attendant vortices should be avoided. Induced drag is greater at lower speeds where a high angle of attack is required. e Overall drag (parasitic drag) Summary: A body that is flowed around by a fluid experiences a drag that has two causes. Skin friction drag arises from the friction of the fluid against the "skin" of the object that is moving through it. Both are only present when viscous flow is assumed. Drag Coefficient Formula. For instance, an airplane with a rough surface creates more parasite drag than one with a smooth surface. However, the parasite drag tool let's the user choose these as options if they desire. Motion of the Air. $ f \equiv \mbox{flat plate drag} $ The following formula is used to calculate the drag coefficient of an object. a Parasitic drag (also called skin friction drag) is drag caused by moving a solid object through a fluid medium (in the case of aerodynamics, more specifically, a gaseous medium).Parasitic drag is made up of many components, the most prominent being form drag.Skin friction and interference drag are also major components of parasitic drag.. Due to its parabolic shape and due to its early representation in polar form, Eq. The drag coefficient in this equation uses the wing area for the reference area. , is defined by, where The dark line is for a sphere with a smooth surface, while the lighter line is for the case of a rough surface. A body moving through a fluid is submitted to an interaction between its outer surface and the fluid. $$ \Delta_y = |y_{le(1)} - y_{le(end)}| $$ The initial calculation of the wave drag in PrOPerA was based on the Boeing and Airbus philosophy (Scholz 1999), so the tool considers that the cruise Mach number was equal to drag divergence Mach number and the wave drag coefficient was a … The philosophy employed on the Stanford site is to convert the product of drag coefficient and corresponding surface area to a "drag area", which is technically the area of a body with a drag coefficient of 1. Especially the landing gear adds a considerable amount of drag. $$, $$ FF = 1 + 2.7\ \left(\frac{t}{c}\right) + 100\ \left(\frac{t}{c}\right)^4 $$, $$ FF = 1 + 1.8\ \left(\frac{t}{c}\right) + 50\ \left(\frac{t}{c}\right)^4 $$, $$ FF = 1 + 1.44\left(\frac{t}{c}\right) + 2\left(\frac{t}{c}\right)^2 $$, $$ FF = 1 + 1.68\left(\frac{t}{c}\right) + 3\left(\frac{t}{c}\right)^2 $$, $$ F^* = 1 + 3.3\left(\frac{t}{c}\right) - 0.008\left(\frac{t}{c}\right)^2 + 27.0\left(\frac{t}{c}\right)^3 $$ And there are three basic types of parasite drag: 1) Skin Friction Drag is the result of the aircraft's surface being rough. While decrease in cross-sectional area decreases drag force on the body as the disturbance in air flow is less. Contamination by ice, frost, snow, mud or slush will increase the parasite drag coefficient and, in the case of severe airframe icing, the parasite area. A prudent choice of body profile is essential for a low drag coefficient. Mathematically, zero lift drag coefficient is defined as CD,0 = CD − CD,i … Wikipedia. (1976). The drag coefficient Cd is equal to the drag D divided by the quantity: density r times half the velocity V squared times the reference area A. On the one hand, frictional forces act as a result of the viscosity and on the other hand, pressure forces act as a result of different flow speeds. $ FR \equiv \mbox{Covert Fineness Ratio} = \frac{l}{\sqrt{wh}} $ It is mostly kept 6:1 for subsonic flows. [1] Parasitic drag does not result from the generation of lift on the object, and hence it is considered parasitic. Parasitic drag is a combination of form drag and skin friction drag. Parasitic drag is simply the mathematical sum of form drag, skin friction, and interference drag. $ FR \equiv \mbox{Fineness ratio} $ Parasitic drag (also called parasite drag) is drag caused by moving a solid object through a fluid. Both require freestream velocity and altitude to be input, but an additional delta temperature input is available to offset temperature from the atmospheric model. $$ M_{DD} = M $$, $ M_{cc} \equiv \mbox{Crest Critical Mach number} $ However, an aircraft like the Piaggio GP180 can have up to 50% laminar flow over the wings and tail and 20-35% over the fuselage$^{22}$. There are two ways to decrease friction drag: the first is to shape the moving body so that laminar flow is possible. $ S \equiv \mbox{Sutherland's Constant = 100.4 K} $, $$ \mu = \frac{\beta \cdot T^{3/2}}{T + S} $$, $ \frac{t}{c} \equiv \mbox{thickness to chord ratio of selected geometry} $ Parasitic drag: | | ||| | Drag curve for a body in steady flight | ... World Heritage Encyclopedia, the aggregation of the largest online encyclopedias available, and the … Each of these drag components changes in proportion to the others based on speed. The drag coefficient is a number that aerodynamicists use to model all of the complex dependencies of shape, inclination, and flow conditions on aircraft drag.This equation is simply a rearrangement of the drag equation where we solve for the drag coefficient in terms of the other variables. The boundary layer at the front of the object is usually laminar and relatively thin, but becomes turbulent and thicker towards the rear. These drag coefficient values were approximated values due to the method of calculation. {\displaystyle C_{f}} $$ B = \frac{M^2\cos^2{\phi_{25}}}{1-M^2cos^2{\phi_{25}}}\left(\left(\frac{\gamma + 1}{2}\right)\left(\frac{1.32\frac{t}{c}}{\cos{\phi_{25}}}\right)^2\right) $$ $$ \Delta_z = |z_{le(1)} - z_{le(end)}| $$ In the case of aerodynamic drag, the fluid is the atmosphere. Thus, zero-lift drag coefficient is reflective of parasitic drag which makes it very useful in understanding how "clean" or streamlined an aircraft's aerodynamics are. Drag Coefficient (CD) is a number that depends on the shape of an object and also increases with angle of attack. The F-35C's wing and tail surface wave drag contribution due to 'volume' is therefore significantly greater than that for the F-35A and B. As with other components of parasitic drag, skin friction follows the drag equation and rises with the square of the velocity. Parasite drag is a combination of form, friction, and interference drag that is evident in any body moving through a fluid. Airfoil drag is for the wing section without taking tip effects into account, presuming an infinitely wide wing. $$ A = \frac{M^2\cos^2{\phi_{25}}}{\sqrt{1-M^2\cos^2{\phi_{25}}}}\left(\left(\frac{\gamma + 1}{2}\right)\frac{2.64\frac{t}{c}}{\cos{\phi_{25}}} + \left(\frac{\gamma + 1}{2}\right)\frac{2.64\left(\frac{t}{c}\right)\left(0.34C_{L}\right)}{\cos^3{\phi_{25}}}\right) $$ Parasite Drag is caused by moving a solid object through a fluid medium. The term parasitic drag is mainly used in aerodynamics, since for lifting wings drag it is in general small compared to lift.Parasitic drag is a combination of form drag, skin friction drag and interference drag. $$ L_{ref} = \frac{\bar{c}}{S_{total}} $$, Body geometry reference lengths are calculated by taking the distance between to the front and back ends of the degenerated stick. {\sqrt{1-M^2\cos^2\left(\Lambda_{\frac{c}{4}}\right)}} $$, $$ FF = 1 + \frac{2.2 \cos^2\left(\Lambda_{\frac{c}{4}}\right)} We show above that the drag coefficient reduces with velocity but this does not imply that the drag reduces with velocity. Parasite Drag. The result is called drag area.. This can be used for example if the gear pod is modeled seperately from the fuselage but the wetted area of the gear pod should be applied with the drag qualities (e.g. Further the drag coefficient C d is, in general, a function of the orientation of the flow with respect to the object (apart from symmetrical objects like a sphere). Drag depends on the properties of the fluid and on the size, shape, and speed of the object. Examples of how to use "parasitic drag" in a sentence from the Cambridge Dictionary Labs Slender body form factor equations are typically given in terms of the fineness ratio (FR), which is the length to diameter ratio for the body. Therefor, the coefficient of interference drag on the aircraft is: 0.00106. L_{ref}, Re, etc.) $ \gamma \equiv \mbox{Specific heat ratio; typically 1.4} $ The qua… This backward push is the induced drag. If Supercritical Optimistic: $$ Q = 1.2 $$. $$ FF = \left(F^* - 1\right)\left(cos^2\left(\Lambda_{\frac{c}{2}}\right)\right) + 1 $$, $$ F^* = 1 + 3.52\left(\frac{t}{c}\right) $$ $ S_i \equiv \mbox{Section area} $ Although VSPAERO includes an estimate of parasite drag in the calculation of the zero lift drag coefficient, the Parasite Drag tool … The position of the transition point from laminar to turbulent flow depends on the shape of the object. On the one hand, frictional forces act as a result of the viscosity and on the other hand, pressure forces act as a result of different flow speeds. The combined overall drag curve therefore shows a minimum at some airspeed; an aircraft flying at this speed will be close to its optimal efficiency. The characteristic frontal area - A - depends on the body. For instance, an airplane with a rough surface creates more parasite drag than one with a smooth surface. This has been well studied for round bodies like spheres and cylinders. $ x \equiv \mbox{distance along chord} $ With the above equations and knowing the geometry of your aircraft, the parasite drag coefficient can be calculated from the following equation. (2/100 Marks) What Is The Meaning Of Oswald's Efficiency Factor E? (1979). Visible on all tabs of the GUI is the parasite drag table, which identifies individual components and their inputs in the parasite drag calculation. $ n \equiv \mbox{viscosity power-law exponent} = 0.67 $, $ l \equiv \mbox{length of component} $ Given that the parasitic drag coefficient is 0.0177, 6% is 0.01062. As speed continues to increase into the transonic and supersonic regimes, wave drag grows in importance. Parasitic drag is a combination of form drag, skin friction drag and interference drag. $$ y = \frac{C_{L}}{{\left(\cos{\phi_{25}}\right)}^2} $$, $$ M_{cc} = \frac{2.8355x^2 - 1.9072x + 0.949 - a\left(1-bx\right)y}{\cos{\phi_{25}}} $$, If Conventional Airfoil Type: $ w \equiv \mbox{width at maximum cross sectional area} $ While the zero drag coefficient contains the parasitic drag of the whole aircraft, the wing is mainly responsible for the lift-induced drag. The skin friction coefficient, Parasitic drag is drag that results when an object is moved through a fluid medium (in the case of aerodynamic drag, a gaseous medium, more specifically, the atmosphere).Parasitic drag is a combination of form drag, skin friction drag and interference drag. The general size and shape of the body are the most important factors in form drag; bodies with a larger presented cross-section will have a higher drag than thinner bodies; sleek ("streamlined") objects have lower form drag. One way to express this is by means of the drag equation: = where. Thickness to chord takes the max thickness to chord from the degenerate stick created from Degen Geom. Parasitic drag is drag that acts on an object when the object is moving through a fluid. $ L_{ref} \equiv \mbox{Reference length} $ Parasitic drag (also called parasite drag) is drag caused by moving a solid object through a fluid. Form drag depends on the longitudinal section of the body. Drag (physics) — Shape and flow Form drag Skin friction 0% 100% 10% 90% … Wikipedia. Parasite drag is simply caused by the aircraft's shape, construction-type, and material. $ k \equiv \mbox{roughness height} $ l Induced drag. 1 $\begingroup$ Consider a 3-D wing made from an arbitrary airfoil, say a NACA0012 airfoil. What is Parasitic Drag. An increase in Angle of Attack will increase Lift and Drag ... Parasite Drag … Clicking on a geometry in the Component column of the table will break up the geometry into its surfaces and sub-surfaces. $$ C_{f (\% Partial Turb)} = f\left(Re_{Lam}\right) $$ $ S_{wet} \equiv \mbox{wetted area} $ However, due to limitations of the methodology used, the geometry based qualities (e.g. The cross-sectional shape of an object determines the form drag created by the pressure variation around the object. But as the angle of attack increases, the air pushes the aircraft in the backward direction. In aviation, Parasite (Parasitic) Drag (D P) is defined as all drag that is not associated with the production of lift. $ \gamma \equiv \mbox{specific heat ratio} $ In cruise we calculate the drag coefficient from : Zero lift drag (Chapter 1) : Wave drag (Chapter 2) For cruise, but for take-off (with initial climb) and landing (with approach) the zero lift drag coefficient has further components, because high-lift devices may be deployed and/or the landing gear may be extended. An excel diagram can be seen calculating these values in Figure 10. Overall drag (parasitic drag) Summary: A body that is flowed around by a fluid experiences a drag that has two causes. R This can be proven by deriving the following equations:[clarification needed]. Higher body drag coefficient, as well as larger projected frontal area, leads to higher parasite power, suggesting that the relatively higher power curve of P. auritus could be a consequence of the larger ears. The first two freestream types are the US Standard Atmosphere 1976 and USAF 1966 atmospheric models, for which a comparison is shown below$^{16, 17}$. of the fuselage. The wing has a trapezoidal shape, with a fixed span, root chord, and tip chord. The next major contribution to drag is the induced drag. Anwendungsbeispiele für "parasitic drag" in einem Satz aus den Cambridge Dictionary Labs If neither of these methods yield a result greater than zero, a default value of 1.0 is used as to prevent division by zero when calculating fineness ratio. Once finished, the results will update in real time in response to changes in input values, such as the flow condition. Drag Coefficient (CD) is a number that depends on the shape of an object and also increases with angle of attack. What is Drag Force - Drag Equation - Definition. 13 - 3 Classification of drag according to physical causes The total drag can be subdivided into (compare with Equation 13.3): 1. zero-lift drag: drag without the presents of lift; 2. induced drag: drag due to lift. The aim of this Section is the analysis of the wave drag of the aircraft. The user is allowed to change the form factor equation type, manually set the laminar percentage, and manually set the interference factor for the subsurface. Treat as Parent: The default option, incorporates the wetted area of the subsurface as part of a continuous geometry. $$ \Delta_x = |x_{le(1)} - x_{le(end)}| $$ $ M \equiv \mbox{freestream Mach number for flight condition} $ $ \phi_{25} \equiv \mbox{Average quarter chord sweep of selected geometry} $ This effect is called skin friction and is usually included in the measured drag coefficient of the object. Parasite drag is what most people think about when considering drag: Skin Friction Drag — from the roughness of the skin of the aircraft impedes its ability to slide through the air. In other words, the surfaces do not subtract any wetted area from the geometry or have any of their own unique properties. Examples of how to use "parasitic drag" in a sentence from the Cambridge Dictionary Labs $ h \equiv \mbox{height at maximum cross sectional area} $ $$ M_{DD,eff} = M_{DD} * \sqrt{\cos{\phi_{25}}} $$ Drag is associated with the movement of the aircraft through the air, so drag depends on the velocity of the air. $$ M_{DD,eff} = A_{F} - 0.1C_{L} - \frac{t}{c} $$, $$ \frac{t}{c} = 0.7185 + 3.107e^{-5}\phi_{25} - 0.1298C_{L} - 0.7210M_{DD} $$, $ K_{A} \equiv \mbox{Airfoil Technology Factor, typically between 0.8 and 0.9} $ Skin Friction – Friction Drag As was written, a moving fluid exerts tangential shear forces on the surface because of the no-slip condition caused by viscous effects. In addition wave drag comes into play, caused by a Mach numberM that is greater than the critical Mach number Mcrit.By definition, Mcrit is the flight Mach number where a flow In addition, if the atmospheric choice type is "Re/L + Mach Control", no additional properties of the flow will be calculated (i.e. Parasite Drag is caused by moving a solid object through a fluid medium. $$ \Delta_{CD} = -0.06 $$, $$ M_{DD} = M_{cc} * \left(1.025 + 0.08\left(1-\cos{\phi_{25}}\right)\right) - \Delta_{CD} $$, $ A_{F} \equiv \mbox{Airfoil Technology Factor, typically between 0.8 and 0.95} $ $$ c = 0.838 $$ R it will have a.) The primary source of confusion is inconsistent nomenclature in the literature around two related quantities – the local skin friction coefficient vs. the flat plate average skin coefficient. Skin friction is caused by viscous drag in the boundary layer around the object. Utilizing this feature the user is able to combine the wetted area of any geometry with that of another. The Parasite Drag Tool GUI is accessed by clicking "Parasite Drag…" from the Analysis drop-down on the top menu-bar. Although VSPAERO includes an estimate of parasite drag in the calculation of the zero lift drag coefficient, the Parasite Drag tool provides much more advanced options and capabilities. $$ C = M^2cos^2{\phi_{25}}\left(1 + \left(\frac{\gamma + 1}{2}\right)\frac{\left(0.68C_{L}\right)}{\cos^2{\phi_{25}}} + \frac{\gamma + 1}{2}\left(\frac{0.34C_{L}}{\cos^2{\phi_{25}}}\right)^2\right) $$, If a Peaky Airfoil Type is selected Description. You can further investigate the effect of induced drag and the other factors affecting drag by … $$ M_{DD,eff} = M_{DD} * \sqrt{\cos{\phi_{25}}} $$ pressure and density). However, to maximize the gliding endurance (minimum sink), the aircraft's speed would have to be at the point of minimum drag power, which occurs at lower speeds than minimum drag. Induced drag is greater at lower speeds where a high angle of attack is required. For bodies of arbitrary cross section, an equivalent diameter is calculated based on the cross sectional area. On the Overview tab, the Parasite Drag Tool includes several options for atmosphere models as well as the option for the user to have manual control over certain atmospheric qualities. $$ Re_{Lam} = Re * \% Lam $$, $ Q \equiv \mbox{Scale factor applied to drag coefficient} $. $ S_{ref} \equiv \mbox{reference area} $ For example, a Sopwith Camel biplane of World War I which had many wires and bracing struts as well as fixed landing gear, had a zero-lift drag coefficient of approximately 0.0378. Parasite drag is simply caused by the aircraft's shape, construction-type, and material. $$ M_{DD} = \frac{K_{A}}{cos{\phi_{25}}} - \frac{\frac{t}{c}}{cos^2{\phi_{25}}} - \frac{C_{L}}{10cos^3{\phi_{25}}} $$, $$ a = -1.147 $$ See more. Friction drag, pressure drag and parasitic drag can each be expressed with dimensionless parameters.
Where To Buy Entenmann's Banana Crunch Cake, Mmi Online Delivery Dubai, I Don't Want To Alessia Cara Chords, Stihl Chainsaw Parts Online, Sql Business Intelligence Edition, Nesto Offer Jubail, Kitchenaid 27-inch Warming Drawer,
coefficient of parasitic drag 2020 | CommonCrawl |
American Physical Society (APS) (13)
Condensed Matter: Electronic Properties, etc. (3)
Electronic structure and strongly correlated systems (2)
Nuclear Structure (2)
Plasma and Beam Physics (2)
Surface physics, nanoscale physics, low-dimensional systems (2)
Superfluidity and superconductivity (1)
National Academy of Sciences (26)
Oxford University Press (26)
Springer Nature (19)
American Association for the Advancement of Science (AAAS) (18)
Nature Publishing Group (NPG) (16)
Springer (16)
Institute of Physics (IOP) (8)
American Chemical Society (ACS) (4)
Institute of Electrical and Electronics Engineers (IEEE) (2)
Collective Modes and Structural Modulation in Ni-Mn-Ga(Co) Martensite Thin Films Probed by Femtosecond Spectroscopy and Scanning Tunneling Microscopy (2015)
M. Schubert, H. Schaefer, J. Mayer, A. Laptev, M. Hettich, M. Merklein, C. He, C. Rummel, O. Ristow, M. Großmann, Y. Luo, V. Gusev, K. Samwer, M. Fonin, T. Dekorsy, and J. Demsar
In: Physical Review Letters
Description: Author(s): M. Schubert, H. Schaefer, J. Mayer, A. Laptev, M. Hettich, M. Merklein, C. He, C. Rummel, O. Ristow, M. Großmann, Y. Luo, V. Gusev, K. Samwer, M. Fonin, T. Dekorsy, and J. Demsar The origin of the martensitic transition in the magnetic shape memory alloy Ni-Mn-Ga has been widely discussed. While several studies suggest it is electronically driven, the adaptive martensite model reproduced the peculiar nonharmonic lattice modulation. We used femtosecond spectroscopy to probe t… [Phys. Rev. Lett. 115, 076402] Published Thu Aug 13, 2015
Keywords: Condensed Matter: Electronic Properties, etc.
Published by American Physical Society (APS)
Observation of normal-force-independent superlubricity in mesoscopic graphite contacts (2016)
Cuong Cao Vu, Shoumo Zhang, Michael Urbakh, Qunyang Li, Q.-C. He, and Quanshui Zheng
In: Physical Review B
Description: Author(s): Cuong Cao Vu, Shoumo Zhang, Michael Urbakh, Qunyang Li, Q.-C. He, and Quanshui Zheng We investigate the dependence of friction forces on normal load in incommensurate micrometer-size contacts between atomically smooth single-crystal graphite surfaces under ambient conditions. Our experimental results show that these contacts exhibit superlubricity (superlow friction), which is robus… [Phys. Rev. B 94, 081405(R)] Published Fri Aug 05, 2016
Keywords: Surface physics, nanoscale physics, low-dimensional systems
Distinct in-plane resistivity anisotropy in a detwinned FeTe single crystal: Evidence for a Hund's metal (2013)
Juan Jiang (姜娟), C. He (贺诚), Y. Zhang (张焱), M. Xu (徐敏), Q. Q. Ge (葛青亲), Z. R. Ye (叶子荣), F. Chen (陈飞), B. P. Xie (谢斌平), and D. L. Feng (封东来)
Description: Author(s): Juan Jiang (姜娟), C. He (贺诚), Y. Zhang (张焱), M. Xu (徐敏), Q. Q. Ge (葛青亲), Z. R. Ye (叶子荣), F. Chen (陈飞), B. P. Xie (谢斌平), and D. L. Feng (封东来) The in-plane resistivity anisotropy has been studied with the Montgomery method on the detwinned parent compound of the iron-based superconductor FeTe. The observed resistivity in the antiferromagnetic (AFM) direction is larger than that in the ferromagnetic (FM) direction, which is different from t... [Phys. Rev. B 88, 115130] Published Tue Sep 17, 2013
Keywords: Electronic structure and strongly correlated systems
Metal-insulator transitions in epitaxial LaVO_{3} and LaTiO_{3} films (2012)
C. He, T. D. Sanders, M. T. Gray, F. J. Wong, V. V. Mehta, and Y. Suzuki
Description: Author(s): C. He, T. D. Sanders, M. T. Gray, F. J. Wong, V. V. Mehta, and Y. Suzuki We have demonstrated that epitaxial films of LaVO 3 and LaTiO 3 can exhibit metallicity though their bulk counterparts are Mott insulators. When LaTiO 3 films are compressively strained on SrTiO 3 substrates, we observe metallicity that is attributed largely to epitaxial strain-induced electronic struct... [Phys. Rev. B 86, 081401] Published Wed Aug 01, 2012
Symmetry breaking via orbital-dependent reconstruction of electronic structure in detwinned NaFeAs (2012)
Y. Zhang, C. He, Z. R. Ye, J. Jiang, F. Chen, M. Xu, Q. Q. Ge, B. P. Xie, J. Wei, M. Aeschlimann, X. Y. Cui, M. Shi, J. P. Hu, and D. L. Feng
Description: Author(s): Y. Zhang, C. He, Z. R. Ye, J. Jiang, F. Chen, M. Xu, Q. Q. Ge, B. P. Xie, J. Wei, M. Aeschlimann, X. Y. Cui, M. Shi, J. P. Hu, and D. L. Feng The superconductivity discovered in iron pnictides is intimately related to a nematic ground state, where the C 4 rotational symmetry is broken via the structural and magnetic transitions. We here study the nematicity in NaFeAs with polarization-dependent angle-resolved photoemission spectroscopy. A ... [Phys. Rev. B 85, 085121] Published Wed Feb 22, 2012
New insight into the shape coexistence and shape evolution of ^{157} Yb (2011)
C. Xu, H. Hua, X. Q. Li, J. Meng, Z. H. Li, F. R. Xu, Y. Shi, H. L. Liu, S. Q. Zhang, Z. Y. Li, L. H. Zhu, X. G. Wu, G. S. Li, C. Y. He, S. G. Zhou, S. Y. Wang, Y. L. Ye, D. X. Jiang, T. Zheng, J. L. Lou, L. Y. Ma, E. H. Wang, Y. Y. Cheng, and C. He
In: Physical Review C
Description: Author(s): C. Xu, H. Hua, X. Q. Li, J. Meng, Z. H. Li, F. R. Xu, Y. Shi, H. L. Liu, S. Q. Zhang, Z. Y. Li, L. H. Zhu, X. G. Wu, G. S. Li, C. Y. He, S. G. Zhou, S. Y. Wang, Y. L. Ye, D. X. Jiang, T. Zheng, J. L. Lou, L. Y. Ma, E. H. Wang, Y. Y. Cheng, and C. He High-spin states in ^{157} Yb have been populated in the ^{144} Sm( ^{16} O,3n) ^{157} Yb fusion-evaporation reaction at a beam energy of 85 MeV. Two rotational bands built on the νf_{7/2} and νh_{9/2} intrinsic states, respectively, have been established for the first time. The newly observed νf... [Phys. Rev. C 83, 014318] Published Fri Jan 28, 2011
Keywords: Nuclear Structure
Electronic ISSN: 1089-490X
Interfacial Ferromagnetism and Exchange Bias in CaRuO_{3}/CaMnO_{3} Superlattices (2012)
C. He, A. J. Grutter, M. Gu, N. D. Browning, Y. Takamura, B. J. Kirby, J. A. Borchers, J. W. Kim, M. R. Fitzsimmons, X. Zhai, V. V. Mehta, F. J. Wong, and Y. Suzuki
Description: Author(s): C. He, A. J. Grutter, M. Gu, N. D. Browning, Y. Takamura, B. J. Kirby, J. A. Borchers, J. W. Kim, M. R. Fitzsimmons, X. Zhai, V. V. Mehta, F. J. Wong, and Y. Suzuki We have found ferromagnetism in epitaxially grown superlattices of CaRuO 3 /CaMnO 3 that arises in one unit cell at the interface. Scanning transmission electron microscopy and electron energy loss spectroscopy indicate that the difference in magnitude of the Mn valence states between the center of the... [Phys. Rev. Lett. 109, 197202] Published Wed Nov 07, 2012
New high-spin structure and possible chirality in $^{109}\mathrm{In}$ (2018)
M. Wang, Y. Y. Wang, L. H. Zhu, B. H. Sun, G. L. Zhang, L. C. He, W. W. Qu, F. Wang, T. F. Wang, Y. Y. Chen, C. Xiong, J. Zhang, J. M. Zhang, Y. Zheng, C. Y. He, G. S. Li, J. L. Wang, X. G. Wu, S. H. Yao, C. B. Li, H. W. Li, S. P. Hu, and J. J. Liu
Description: Author(s): M. Wang, Y. Y. Wang, L. H. Zhu, B. H. Sun, G. L. Zhang, L. C. He, W. W. Qu, F. Wang, T. F. Wang, Y. Y. Chen, C. Xiong, J. Zhang, J. M. Zhang, Y. Zheng, C. Y. He, G. S. Li, J. L. Wang, X. G. Wu, S. H. Yao, C. B. Li, H. W. Li, S. P. Hu, and J. J. Liu The high-spin structure of In 109 has been investigated with the Mo 100 ( N 14 , 5 n ) In 109 reaction at a beam energy of 78 MeV using the in-beam γ spectroscopic method. The level scheme of In 109 has been modified considerably and extended by 46 new γ rays to the highest excited state at 8.980 MeV and J π = ( 4... [Phys. Rev. C 98, 014304] Published Thu Jul 05, 2018
Broadband Amplification of Low-Terahertz Signals Using Axis-Encircling Electrons in a Helically Corrugated Interaction Region (2017)
W. He, C. R. Donaldson, L. Zhang, K. Ronald, A. D. R. Phelps, and A. W. Cross
Description: Author(s): W. He, C. R. Donaldson, L. Zhang, K. Ronald, A. D. R. Phelps, and A. W. Cross Experimental results are presented of a broadband, high power, gyrotron traveling wave amplifier (gyro-TWA) operating in the (75–110)-GHz frequency band and based on a helically corrugated interaction region. The second harmonic cyclotron mode of a 55-keV, 1.5-A, axis-encircling electron beam is use... [Phys. Rev. Lett. 119, 184801] Published Tue Oct 31, 2017
Keywords: Plasma and Beam Physics
High Power Wideband Gyrotron Backward Wave Oscillator Operating towards the Terahertz Region (2013)
W. He, C. R. Donaldson, L. Zhang, K. Ronald, P. McElhinney, and A. W. Cross
Description: Author(s): W. He, C. R. Donaldson, L. Zhang, K. Ronald, P. McElhinney, and A. W. Cross Experimental results are presented of the first successful gyrotron backward wave oscillator (gyro-BWO) with continuous frequency tuning near the low-terahertz region. A helically corrugated interaction region was used to allow efficient interaction over a wide frequency band at the second harmonic ... [Phys. Rev. Lett. 110, 165101] Published Mon Apr 15, 2013 | CommonCrawl |
Evolution of communities of software: using tensor decompositions to compare software ecosystems
Oliver A. Blanthorn ORCID: orcid.org/0000-0002-1324-128X1,
Colin M. Caine2 &
Eva M. Navarro-López3
Applied Network Science volume 4, Article number: 120 (2019) Cite this article
Modern software development is often a collaborative effort involving many authors through the re-use and sharing of code through software libraries. Modern software "ecosystems" are complex socio-technical systems which can be represented as a multilayer dynamic network. Many of these libraries and software packages are open-source and developed in the open on sites such as GitHub, so there is a large amount of data available about these networks. Studying these networks could be of interest to anyone choosing or designing a programming language. In this work, we use tensor factorisation to explore the dynamics of communities of software, and then compare these dynamics between languages on a dataset of approximately 1 million software projects. We hope to be able to inform the debate on software dependencies that has been recently re-ignited by the malicious takeover of the npm package event-stream and other incidents through giving a clearer picture of the structure of software dependency networks, and by exploring how the choices of language designers—for example, in the size of standard libraries, or the standards to which packages are held before admission to a language ecosystem is granted—may have shaped their language ecosystems. We establish that adjusted mutual information is a valid metric by which to assess the number of communities in a tensor decomposition and find that there are striking differences between the communities found across different software ecosystems and that communities do experience large and interpretable changes in activity over time. The differences between the elm and R software ecosystems, which see some communities decline over time, and the more conventional software ecosystems of Python, Java and JavaScript, which do not see many declining communities, are particularly marked.
Contemporary software authors routinely depend on and re-use the software packages of authors with whom they have no contact. This uncoordinated process creates what have recently been called "software ecosystems" (Decan et al. 2018): extensive networks of interdependent software components that are used and maintained by large communities of contributors all over the world. These ecosystems are complex multi-layered networks whose nodes and edges both evolve over time. Throughout this work, terminology such as 'package', 'package manager', 'dependency' follow the usual software engineering convention, as documented by Decan et al. (2018). With this work we would like to contribute to the debate on software dependencies, which recently re-emerged due to the hijacking of the event-stream package after previous incidents (Baldwin 2018; Schlueter 2016; Durumeric et al. 2014), by giving a clearer picture of the structure of software dependency networks. For this, we propose a novel framework to model and analyse the formation, long-term behaviour and change with time of communities of software packages, and compare these behaviours across several programming languages.
The evolution of software and package dependency networks has been extensively studied by using network science techniques over the past 15 years. An early such work is (Myers 2003), which has been followed by others (Pan et al. 2011; Xu et al. 2005; Zheng et al. 2008). A recent survey on this topic is given by Savić et al. (2019). Methods and tools used for social networks have also been applied to analyse software evolution (Chatzigeorgiou and Melas 2012), reinforcing the importance of the social component in evolving software networks. There has been recent success in applying standard network metrics to analyse how software ecosystems have evolved with time (Decan et al. 2018).
Collaborative software networks—mainly in free and open-source software (FOSS) environments—can be considered as adaptive, evolving or temporal networks. Most of the published works highlight the fact that software networks exhibit scale-free network properties with a power-law-type node degree distribution (Cai and Yin 2009; Lian Wen et al. 2009; Louridas et al. 2008) and a clear preferential attachment in the network growth process (Li et al. 2013; Chaikalis and Chatzigeorgiou 2015), confirming the heterogeneity and hierarchical characteristics of networks of software. Other key properties in software systems like maintainability and reliability (Chong and Lee 2015), robustness (Gao et al. 2014), and modularity (Zanetti and Schweitzer 2012) have been also analysed using the complex network paradigm.
The identification of communities in software dependency networks that evolve over time is one of the main motivations of our work. Community detection in temporal, evolving or adaptive networks has largely attracted network scientists' attention due to its important implications in the analysis of dynamical processes in complex networks, such as spreading and cascading dynamics, stability, synchronisation and robustness. Different types of methods and algorithms have been used, for example: the Louvain algorithm (Aynaud and Guillaume 2010), statistical null models (Bassett et al. 2013; Sarzynska et al. 2016), algorithms which exploit the historic community structure of the network (He et al. 2017; He and Chen 2015), Markov models (Rosvall et al. 2014), semidefinite programming (Tantipathananandh and Berger-Wolf 2011), gravitational relationship between nodes (Yin et al. 2017), and temporal matrix factorisation (Yu et al. 2017), amongst others. Machine learning techniques (Savić et al. 2019; Xin et al. 2017), genetic algorithms (Folino and Pizzuti 2014), consensus clustering (Aynaud and Guillaume 2010) and tensor factorisation (Araujo et al. 2014; Gauvin et al. 2014) have only recently been used for the detection of communities in temporal networks.
There has been much less work on finding clusters or communities in software dependency networks: some representative works are Dietrich et al. (2008); Paymal et al. (2011); Concas et al. (2013) and Savić et al. (2012). However, it is still a challenge to give satisfactory solutions for the dynamic treatment of these clusters and inter-language comparison. Savić et al. (2012), for example, give some dynamic treatment of communities within the "class collaboration" network of Apache Ant. This is a single piece of software in which the classes are more witting participants in the software than in general software dependency networks where the authors of a package may have no idea where their work is being used. Additionally, the community detection methods used are static, so it is the metrics on the types of communities found at each version of Apache Ant which are compared rather than the qualities of any individual communities being tracked across time.
The novelty of our work is the detection of dynamic communities in temporal software dependency networks, the use of tensor decompositions on software ecosystems, and the use of adjusted mutual information (AMI) to assist in choosing the number of communities. Additionally, some of the networks we study are amongst the largest dynamic networks to which tensor factorisation has been applied, although there have been studies considering much larger static networks (Kang et al. 2012).
Our work addresses three research questions corresponding to unsolved problems in collaborative large-scale software development and evolution over time:
RQ1 What are the differences between different software ecosystems?
RQ2 What do communities of commonly-used-together software packages look like?
RQ3 How do these communities change with time?
By answering these questions, we identify communities of packages in the ecosystems of several languages. Namely: Elm; JavaScript; Rust; Python; R; and Java. These languages were chosen because data on their package ecosystems are readily available and they represent a variety of uses and ages: low-level systems languages; scientific computing; and web development; with histories between 3 and 20 years long.
The rest of this manuscript is structured as follows. Firstly, in the "Methods" section, we detail the data, mathematical tools, software and hardware used to conduct this study. Next, the "Results and discussion" section presents our results and provides some discussion of why they might have arisen. Finally, the "Conclusions" section compares our results with prior work and provides a summary of this works' limitations while elucidating further avenues of research.
What is a community?
Software packages associated with a single programming language and package manager form an ecosystem, and a community is a collection of packages that tensor decomposition has identified. Communities may be related by some theme and by co-occurrence of activity over time. They might be collections of numerical computing packages, or a community of packages that use a particular library, or a community of older packages that became obsolete. Packages may be in more than one community, which is modelled by vectors of continuous strengths of membership to each community as detailed in the "Tensor decompositions" section below. Communities may wax and wane over time.
Further detail on how we calculate communities and membership strengths thereof is given in the "Tensor decompositions" and "Choosing the number of communities, R" sections.
Shape of the data
We considered the following package managers (corresponding to specific languages): elm-get (Elm), npm (JavaScript), crates.io (Rust), PyPI (Python), CRAN (R), and Maven (Java). All publicly registered packages for these package managers were included in our analysis. To simplify our analysis, we do not consider specific versions of dependent packages—each package depends on some other packages at each time, each of which is assumed to be the most up-to-date package available at that time. We only consider packages registered with these package managers and do not consider cross-platform (inter-language) dependencies. The data cover 1 million projects listed in package managers. This is sourced from Libraries.io (Katz 2018). The network of Elm dependencies at the final time-step is shown in Fig. 1.
Elm network. Elm network visualised using Gephi. Node and label size corresponds to out-degree. Each node i is coloured according to the strongest strength of community membership given by κi as described in the Methods section. Legend: light-green corresponds to the community we labelled as elm-lang/core, purple to elm-lang/http, blue to elm-lang/html, and orange to evancz/elm-html, dark-green to unassigned nodes, i.e. those without any dependencies
Brief introduction to each ecosystem
Here, we will briefly introduce each language and ecosystem considered.
(elm-lang.org) is a relatively small new language created in 2012 as a functional language for developing web applications. It is unusually focused on a single domain and unusually restrictive in what can be expressed in listed packages. The language authors explicitly discourage proliferation of packages in favour of a unified and carefully designed standard package for each task. It aims to eliminate runtime errors and many classes of logical errors through static analysis and careful language design.
is a very popular general-purpose interpreted programming language. It was first released in 1991. Its package manager, PyPI (https://pypi.org/), was released in 2002. Python is notable for having a large standard library; many features such as HTTP and GUI support that would be external packages in other languages are included by default. We therefore suspect that Python's package ecosystem will look quite different to many of the other languages we consider. It is perhaps pertinent to note that some of the packages listed in PyPI are designed to be used by end-users, not developers.
is another popular general-purpose interpreted programming language. It was first released in 1995 as part of the Netscape browser and was initially used for client-side scripts on web pages, but now has several server-side implementations, most notably Node.js. JavaScript has a very small standard library, with the exception of the DOM interface (Document Object Model—a representation of a web page), which is included. We therefore expect most JavaScript packages to have to depend on many other packages. JavaScript's most common package manager is npm (npmjs.com), the Node.js package manager, which was released in 2010. The JavaScript ecosystem we describe in this paper is the public npm registry, which is the de facto canonical list of JavaScript packages. Despite its name, the registry is used for all types of JavaScript, not just server-side applications. Like PyPI, some of the packages listed in npm are designed to be used by end-users, not developers.
is another relatively new systems programming language. Unlike many of the other ecosystems we have considered, it is statically compiled. One of its main aims is safe concurrent programming. We suspect that because of this conservative focus, packages written in Rust will have relatively few dependencies. Rust's package manager is Cargo, which was released in 2014, and its registry is crates.io. Like PyPI, some of the packages listed on crates.io are designed to be used by end-users, not developers.
is an interpreted programming language for statistical computing. It was first released in 1993. Its standard library for statistical computing is large. Its package manager is the Comprehensive R Archive Network (CRAN cran.r-project.org).
is a general-purpose typed compiled programming language, first released in 1995. Its standard library is large. Java has no official package manager, but the most widely used is Apache Maven (maven.apache.org), which was released in 2004.
Representing the data
We represent each language's network as a tensor, Alang, where each
$$ {A}_{ijt}\in \{0,1\} $$
denotes whether the package i depends on the package j at time t. We consider links as going from j to i, so the direction of each link reflects the flow of code. Software packages have unweighted directed links to packages that they depend on at time t according to the most recently available version of the software package at that time. The time is quantised into timesteps. We chose a resolution of one month on the basis that packages are long-lived and change dependencies rarely.
Tensor decompositions
A rank-N tensor X can be approximated as
$$ X \approx \sum_{r=1}^{R} \text{reduce}_{n=1}^{N}(\otimes,\boldsymbol{a}_{nr})\text{,} $$
where \(\text {reduce}_{n=1}^{N}(\odot,b_{n})\) returns the reduction of {bn|n∈1..N} by applying an arbitrary associative binary operator ⊙ repeatedly, i.e.
$$ \text{reduce}_{n=1}^{N}(\odot,b_{n}) = b_{1} \odot b_{2} \odot b_{3} \odot \ldots \odot b_{N}\text{;} $$
⊗ is the tensor product; and each \(\boldsymbol {a}_{nr} \in \mathbb {R}^{d_{n}+}\) where dn is the dimension of the nth-mode of the tensor X.
Each anr for a specific n is called a factor, and maps its indices (in our case, software packages or time) to strength of membership to the community r. The total number of communities or components, R, is a fixed chosen parameter. Each anr for a specific r is called a community or component. The concept of a temporal index having strengths of community membership may seem odd; it is perhaps more easily understood as the amount of community activity at a certain time (Gauvin et al. 2014).
There are many algorithms for performing tensor decompositions of this kind. We selected a non-negative method with a public implementation that will allow us to later extend our analysis to large rank-N tensors: Alternating Proximal Gradient (APG-TF)Footnote 1 (Xu and Yin 2013), an efficient non-negative CANDECOMP/PARAFAC (CP) method. We consider the use of tensor decomposition (Kolda and Bader 2009) more adequate for community detection in temporal networks than other static methods, such as the Louvain algorithm (Aynaud and Guillaume 2010), because tensor decompositions explicitly integrate evolution over time and can scale very efficiently for large graphs.
For our specific application, we approximate our temporal adjacency matrix as
$$ A_{ijt} \approx \sum_{r=1}^{R} \kappa_{ir} h_{jr} \tau_{tr}\text{,} $$
where κri are the elements of a matrix \(K\in \mathbb {R}^{+N_{p}\times R}\) that describe the strengths of community membership of each node i based on outgoing links, hrj are the elements of a matrix \(H\in \mathbb {R}^{+N_{p}\times R}\) which represent the strengths of community membership of each node j based on incoming links, τrt are the elements of a matrix \(T\in \mathbb {R}^{+N_{t}\times R}\) that describe the activity levels of each community r at each time step t, and Np and Nt are the number of packages considered and the number of timesteps chosen, respectively.
We will now describe H and K in more detail. We will use two facts about software dependency networks (Decan et al. 2018):
the number of outgoing links from each package (number of packages that depend on a package) follows a power-law;
the number of incoming links to each package (number of packages that a package depends on) is fairly evenly distributed.
Since H represents groups of nodes which are linked to by similar nodes, it is very sparse with only a few hub nodes having any community membership due to high strengths in H. K is much more evenly distributed as it represents groups of nodes which link to similar nodes; most packages are strongly associated with at least one community.
If a community has significantly declined from its peak according to a plot of τr, we will define its lifetime as the full width at half maximum.
Choosing the number of communities, R
One of the major downsides to tensor decompositions is that one must choose the number of communities, R. We take a multi-faceted approach to evaluating our choice of R for each ecosystem, which we detail in this section. The first component of our approach is to look at the normalised residual sum of squares or relative error, NRSSR, a measure of reconstruction error (Papalexakis et al. 2012). We use it to inform our choice of R by looking for the number of components where the rate at which the residual sum of squares decreases as the number of components increases becomes linear, commonly known as an elbow. We define the normalised residual sum of squares as:
$$ \text{NRSS}_{R}(X) = \frac{\|X - \sum_{r=1}^{R} \text{reduce}_{n=1}^{N}(\otimes,\boldsymbol{a}_{nr})\|_{F}}{\|X\|_{\mathrm{F}}}\text{,} $$
where ∥X∥F is the Frobenius norm of X.
The second component of our approach is to run the decomposition multiple times for each likely R to determine whether the decomposition is stable, that is, if multiple runs produce the same results. We look to see if nodes appear in the same communities as each other by considering the mean pairwise adjusted mutual information (AMI, Vinh et al. (Vinh et al. 2009)) between repeated runs for a single R. We use hard clustering for this process by assigning nodes to communities from the maximum strength in each vector κi.
We also check visually to see if the temporal activity of communities looks similar across multiple decompositions. If the decomposition is unstable, i.e. if multiple runs produce different results, it suggests that ground-truth communities are being merged or split up. Another check we perform is to look at the metadata associated with a sample of software projects from each community and make a qualitative judgement as to whether they are similar. For example, if a numerical computing package and a front-end web development package are in the same community, the number of communities is probably too small. Our final check is whether adding an extra component adds interesting new behaviour to the temporal community activity, or if it instead seems to break an existing community into noisy subcommunities. All of these approaches are quite subjective, so there is quite a large uncertainty in exactly how many communities is ideal for each language.
Adjusted mutual information
The adjusted mutual information between two partitions U and V where U={U1,U2,…} is a finite-length partition of some set of length N and V is another finite partition of that set is
$$ \text{AMI}(U,V) = \frac{I(U;V) - E[I(U;V)]}{\text{max}(S(U),S(V)) - E[I(U;V)]}\text{,} $$
where the entropy S is
$$ S(U)=-\sum_{i}\frac{|U_{i}|}{N}\text{log}\frac{|U_{i}|}{N}\text{,} $$
the mutual information between U and V is
$$ I(U;V)=\sum_{i=1}^{|U|} \sum_{j=1}^{|V|} \frac{|U_{i}\cap V_{j}|}{N}\log\frac{N|U_{i} \cap V_{j}|}{|U_{i}||V_{j}|}\text{,} $$
and E[W] is the expectation of a random variable W. Here, it can be calculated using a hypergeometric model of all possible random clusterings (Vinh et al. 2009). AMI measures the amount of agreement between two partitions. It has an upper bound of 1. An AMI score of 0 corresponds to the amount of agreement one would expect if one of the partitions was totally random, and 1 corresponds to perfect agreement between the two clusters. The AMI score can be negative if there is more disagreement between the clusters than one would expect from random chance. It is hard to interpret the meaning of scores between 0 and 1, but it is important to bear in mind that anything greater than 0 is a good score in the sense that it is better than random guessing. AMI is quite sensitive to the number of clusters and awards higher scores to pairs of clusterings that agree on the same number of assignments but have a larger number of clusters, to the limit where if each element is given its own cluster the AMI must be 1. Since we are mostly using AMI to compare clusterings with each other and have far fewer clusters (or communities) than nodes, we believe the interpretability of the absolute value of the AMI is not important. We are concerned primarily with the relative changes in AMI as we move from one number of communities to another.
Labelling communities
H is a sparse matrix that denotes the packages that are most depended on in each community. The package name associated with a community r is the name of the package pr that is maximal in hr, such that pr does not have a higher \(\phantom {\dot {i}\!}\boldsymbol {h}_{r'}\) value in any other community r′. That is,
$$ p_{r} = \text{indmax}([\text{mask}(H)]_{r})\text{,} $$
where indmax(x) of any vector x returns the index of its maximum value, and
$$ [\text{mask}(M)]_{ij} = \begin{cases} m_{ij} &\text{if} m_{ij} = \text{max}(\boldsymbol{m}_{i}) \\ 0 &\text{otherwise,} \end{cases} $$
where mij and mi are the elements and column vectors of a matrix M.
Hardware and software used
Julia (Bezanson et al. 2012), LightGraphs.jl (Bromberger 2017), Plots.jl, and Jupyter (Kluyver et al. 2016) with IJulia were used for exploratory data analysis, data pre-processing, figures and co-ordinating external software. The actual tensor decompositions were performed using MATLAB.jl, MATLAB, and TensorToolbox (Bader and Kolda 2007). Adjusted mutual information was calculated using ScikitLearn.jl and scikit-learn (Pedregosa et al. 2011). The decompositions were performed on 20-core Xeon servers with 250GB of RAM provided by MARC1, part of the High Performance Computing and Leeds Institute for Data Analytics (LIDA) facilities at the University of Leeds, UK.
We examine the pairwise average adjusted mutual information (AMI) score and NRSSR(X) as defined in Eq. (2) to identify a suitable number of communities for each ecosystem. A high AMI would indicate that the communities created by the decomposition are stable across repeated runs of the algorithm.
Troughs between peaks in our AMI plots would indicate that communities are being split inappropriately. We will interpret the first peak in AMI as the minimum valid number of communities for an ecosystem.
Each community will then be labelled according to Eq. (3).
Table 1 shows that there are clear differences between the language ecosystems in all the statistics we calculate.
Table 1 Summary statistics for each ecosystem
Degree distribution
Python packages have a mean number of 2.4±2.9 direct dependencies where JavaScript packages have 9.9±22. Figures 2, 3, 4, 5, 6 and 7 show that the distributions of in and out degree look fairly similar in shape; broadly, all out degree distributions follow a power-law and the in degree distributions follow more Poissonian distributions.
Elm degree distributions. In and out degree distributions for the Elm package ecosystem
PyPI degree distributions. In and out degree distributions for the PyPI package ecosystem
npm degree distributions. In and out degree distributions for the npm package ecosystem
Cargo degree distributions. In and out degree distributions for the Cargo package ecosystem
CRAN degree distributions. In and out degree distributions for the CRAN package ecosystem
Choosing the number of communities: Elm. Left: the mean pairwise adjusted mutual information of the community-node membership across repeated decompositions. 1 is a perfectly stable assignment to communities; 0 is perfectly random. The shaded area corresponds to twice the standard error of the mean. Right: the mean normalised residual sum of squares error for repeated decompositions on the Elm network against the number of components. The shaded area corresponds to twice the standard error of the mean above and below the line
The exception to this rule is npm, the JavaScript ecosystem, whose in-degree distribution is bimodal: there are more packages with the highest numbers of dependencies than there are with middling numbers of dependencies. Upon further investigation, it turns out that the distribution is skewed by a few hundred joke/malicious packagesFootnote 2 and some irregularly packaged packages that list all their recursive dependencies as their direct dependenciesFootnote 3. We chose not to omit these packages from the decomposition as we hoped that tensor decomposition might discover them as a community.
We believe that the presence of a rich and well-used standard library—the functions included in the language without any other dependencies—reduces the mean degree of an ecosystem. Python (degree 2.4) has such a library, while JavaScript (degree 9.9) emphatically does not.
Elm (degree 2.6) features a small standard library compared to Python, but its library is very rich within its domain of web application development.
Rust (degree 4.4) features a small standard library by design (instead promoting and curating community packages). R (degree 5.3) features a fairly small standard library, and many users now prefer the community tidyverse collection as a consistent community alternative.
Number of communities
Figures 7, 8, 9, 10 and 11 show mean AMI and NRSS for each number of communities we evaluated for each ecosystem. We computed 10 decompositions for each trialled number of communities in each ecosystem.
Choosing the number of communities: PyPI. Left: the mean pairwise adjusted mutual information of the community-node membership across repeated decompositions. 1 is a perfectly stable assignment to communities; 0 is perfectly random. The shaded area corresponds to twice the standard error of the mean. Right: the mean normalised residual sum of squares error for repeated decompositions on the PyPI network against the number of components. The shaded area corresponds to twice the standard error of the mean above and below the line
npm adjusted mutual information against components. The pairwise adjusted mutual information of the community-node membership across repeated decompositions. 1 is a perfectly stable assignment to communities; 0 is perfectly random. The shaded area corresponds to twice the standard error of the mean above and below the line
Choosing the number of communities: Cargo. Left: the mean pairwise adjusted mutual information of the community-node membership across repeated decompositions. 1 is a perfectly stable assignment to communities; 0 is perfectly random. The shaded area corresponds to twice the standard error of the mean. Right: the mean normalised residual sum of squares error for repeated decompositions on the Cargo network against the number of components. The shaded area corresponds to twice the standard error of the mean above and below the line
Choosing the number of communities: CRAN. Left: the mean pairwise adjusted mutual information of the community-node membership across repeated decompositions. 1 is a perfectly stable assignment to communities; 0 is perfectly random. The shaded area corresponds to twice the standard error of the mean. Right: the mean normalised residual sum of squares error for repeated decompositions on the CRAN network against the number of components. The shaded area corresponds to twice the standard error of the mean above and below the line
Of all the techniques mentioned in the "Choosing the number of communities, R" section, identifying a suitable number of communities was easiest by looking for early peaks in the AMI plots, which correlated well with visual inspection of decomposition stability and our manual checks on package names. The NRSS plots have no obvious elbows and contributed nothing to our analysis; we include them as a relevant negative result.
For Elm, CRAN, and PyPI, AMI indicates more than one "good" number of communities to split the ecosystem into. We have chosen the smallest good number except when that number was two.
We observed interesting differences between ecosystems in this metric: Elm and R have relatively high AMIs at relatively low numbers of components while other languages such as JavaScript had low AMIs for all of the numbers of components we tried, suggesting that a more representative number of components might be much higher. This tells us something about the diversity of an ecosystem: the more communities it has, the more diverse it must be.
Activity over time
Figures 12, 13, 14, 15, and 16 show the relative activity of communities in each ecosystem over time for a representative decomposition; i.e. they are plots of τrt from Eq. (1) against time, t.
Elm community activity. Relative activity of each community in each month. The communities are named by important packages as detailed in the Methods section
PyPI community activity. Relative activity of each community in each month. The communities are named by important packages as detailed in the "Methods" section
npm community activity. Relative activity of each community in each month. The communities are named by important packages as detailed in the "Methods" section
Cargo community activity. Relative activity of each community in each month. The communities are named by important packages as detailed in the "Methods" section
CRAN community activity. Relative activity of each community in each month. The communities are named by important packages as detailed in the "Methods" section
The labels are reasonably stable across decompositions when AMI is high and they appear to be informative in most ecosystems. The relative size and activity over time of the communities can often be matched with what we know about the their constituent packages and the ecosystem from other sources.
The community activity plots show clear differences between the various ecosystems. Elm, R and Rust all contain communities that decline in activity over time. Some languages such as Elm, R and Rust have "peaky" community activity where packages have been replaced by others. Java, Python and JavaScript do not exhibit such behaviour; suggesting that their communities are more stable. The "% declined" column in Table 1 summarises this behaviour.
Community composition
Comparing ecosystems, we observe that Python has communities centred around making websites (django), scientific computing (numpy), or interpreting configuration files (pyyaml). By contrast, Elm's communities are all to do with building web applications, and R's communities are mostly focused towards scientific computing. This suggests, uncontroversially, that Elm and R are less general purpose languages than Python.
In the following sections we examine and provide interpretations for the composition of communities within each ecosystem.
Ecosystem-specific results
Figure 12 shows community activity over time. evancz/html is the precursor of elm-lang/html and we can see an early community of packages using evancz/html that decays over time as the newer community using elm-lang/html emerges. We can also see the swift rise of a community of HTTP-using packages. This is perhaps particularly pronounced in Elm because the language is unusually restrictive (there was no official way to write HTTP packages before the package which became elm-lang/http) and young (there was a strong known demand for an obvious feature like HTTP support).
The evancz/html deprecation neatly shows that many earlier packages were abandoned and did not make the jump to Elm 0.17 and elm-lang/htmlFootnote 4. Those that do make the jump move community and those that do not remain in the package manager as abandonware.
Elm is a young and deliberately unconventional and experimental language, so it is to be expected that many packages will be abandoned as the community experiments with different approaches.
The rapid changes in activity indicate that the Elm ecosystem is not stable, that is, communities have experienced large relative changes in activity recently.
High AMI for communities two and four suggest that the Elm ecosystem is not diverse as it is well described by small numbers of communities.
Figure 13 demonstrates how these communities change over time: it is interesting that there are no communities which have declined particularly. One community, django, a web application framework, seems to have stagnated. Google Trends data suggest that interest in it has reached a plateau compared to frameworks in other languages such as React for JavaScript.
The growth of communities, as shown in Fig. 13, seems to be monotonic. There do not appear to be any major deprecated packages, which is surprising, given the impending deprecation of Python version 2, which is incompatible with Python version 3. This could be due to the popular package six which provides compatibility helpers for Python 2 and 3.
The AMI plot for npm is given in Fig. 9. We chose not to calculate the NRSS values due to computational constraints. The AMI for every number of communities we trialled is very low and although we use three communities in the time activity plot, Fig. 14, we are not particularly confident that the communities picked are meaningful. It is plausible that some larger number of communities would fit the data better, however we trialled up to 50 communities with no success.
The AMI and NRSS plots for Rust are shown in Fig. 10. The AMI plot strongly indicates a first peak at 8 communities.
Figure 15 demonstrates how these communities change over time. Of particular note are the communities centered around rustc-serialize and serde. rustc-serialize has been deprecated and officially replaced with the serde package. The decline in activity of the rustc-serialize community and rise of the serde community is quite distinct and clearly occurs at the same time.
The community labelled winapi is also easily interpretable. The K factor for this community is bimodal and the size of the higher strength cluster indicates that there are around 450 packages in this community. A brief review of these packages suggests that they are low-level cross-platform packages for interacting with the operating system. These packages were amongst the first written and predate the package manager, which explains their steep initial rise.
As shown in Fig. 11, AMI suggests that decomposition into two, seven, or nine communities is acceptable. That CRAN can be stably decomposed into two communities suggests that the ecosystem is not very diverse, which is as we would expect from a language focused on scientific and statistical computing.
It can be seen in Fig. 16 that when decomposed into seven communities, distinctive waves of activity over time exist. We believe these waves are driven by CRAN's rolling release model which requires packages to be actively maintained or de-listed. This is a strong incentive for package authors to switch dependencies if e.g. one of two testing libraries is actively maintained. The de-listing also means that older, unused packages are removed from the dependency graph over time, unlike any of the other studied ecosystems.
Visible in Fig. 16 and an exemplar of this behaviour, RUnit is an older unmaintained testing library and testthat is a more modern replacement. Unlike any other long-established language in this analysis, there is a clear and steep decline of the earlier library in favour of the competitorFootnote 5.
Despite R being an old language, some of its communities have grown at a rapid rate, specifically those relating to knitr, and testthat. This suggests that, despite being an older language, R's ecosystem is still subject to significant change.
Defining community lifetime as the full width at half maximum, we can see from Fig. 16 that communities tend to stay active for approximately 4 to 8 years.
The AMI plot, Fig. 17, strongly indicates an unambiguous peak at 5 communities. AMI is very low for two communities and comparatively low for three and four, suggesting that Maven has a wider diversity of communities than CRAN or elm-get. These communities include a distinct Scala community, a kind of dialect of Java, centered around the Scala standard library.
Choosing the number of communities: Maven. Left: the mean pairwise adjusted mutual information of the community-node membership across repeated decompositions. 1 is a perfectly stable assignment to communities; 0 is perfectly random. The shaded area corresponds to twice the standard error of the mean. Right: the mean normalised residual sum of squares error for repeated decompositions on the Maven network against the number of components. The shaded area corresponds to twice the standard error of the mean above and below the line
Figure 18 demonstrates how these communities change over time. There is a general upwards trend and some noise that may be spurious. As noted in Decan et al. (2018), there may be issues with the Maven dataset that are affecting these results.
Maven community activity. Relative activity of each community in each month. The communities are named by important packages as detailed in the "Methods" section
We have found a large amount of variation between different software ecosystems; some, such as Python, are stable and long-lived, and others, such as Elm, have packages that have been important but short-lived due to deprecation. It is our suspicion that a large amount of the variation between languages is due to the size and usefulness of their standard libraries. However, some of the differences, especially those found by the tensor decompositions, could be because early communities which fall out of use are ignored by the decomposition in favour of later, larger communities. It would be interesting to investigate whether this effect is real.
Based on our analysis, we have the following answers to our research questions:
There are differences in the number of communities of software packages, the rate at which communities of software packages gain and lose popularity as measured by how often they are dependant on each other, and in the overall trajectory of the growth of these communities.
Similar to the languages as a whole, the communities have fairly homogeneous in-degree distributions but heterogeneous power-law out-degree distributions.
The general rule is "up and to the right": all of the ecosystems we considered increased in activity as time went on, in agreement with Decan et al. (2018). This is unsurprising as it is relatively rare for a package to lose dependencies—it can fall out of use, but the packages that previously depended on it will tend to continue to depend on it.
Our results agree with that found in other works, especially that of Decan et al. (2018). Figure 16 in particular shows the effect of CRAN's strict rolling-release model where out-of-date packages are archived (meaning that they are no longer as easy to install); Fig. 15 shows how the Rust ecosystem seems to start very suddenly as the package manager came relatively late into the language's life.
For Java specifically, our work does not show much overlap with the communities found by Šubelj and Bajec (2011). This could be due to differences in between their static and our dynamic community detection, but it could also be that the validity of our results is questionable for Maven as the Libraries.io data for Maven is incomplete (Decan et al. 2018).
The absolute level of the adjusted mutual information at low numbers of communities seems to reflect the diversity of an ecosystem: R and elm, both domain specific languages, have high levels of AMI for 2 and 3, whereas all of the general purpose languages we consider do not.
Methodologically, we found that using adjusted mutual information as a metric by which to choose the number of communities led to (predominantly) explainable communities that appeared to be stable across multiple runs of the decompositions and across multiple values of the number of communities chosen. Our labelling algorithm, Eq. (3) worked well for our application, giving plausible and comprehensible labels, and could plausibly work well for any communities in networks with power-law degree distributions. The stability of an ecosystem can be seen from our activity over time plots, i.e. the τr vectors.
Maven degree distributions. In and out degree distributions for the Maven package ecosystem
Further work could involve investigating larger components for languages for which we currently have fairly low AMI scores. It would also be fairly straight-forward to extend our technique to consider the co-authorship network that creates the software as another layer in the network. Knowledge of how the ecosystem evolves organically could be used to detect fraudulent packages, especially by unknown authors. The creation of models of software ecosystem evolution from simple sets of rules (for example, 10% of packages are deprecated every 6 months) to try to replicate our results synthetically could also prove insightful.
Our work could have applications in helping designers of software ecosystems to make informed choices; it is clear that, for example, CRAN's rolling release policy has a big impact on its software communities. One could imagine using clusterings like those we have created to determine whether part of a software ecosystem was on the wane and was likely to be replaced soon. Such considerations would make sense if one was choosing dependencies for a project that was intended to last many years. Additionally, if one knows how communities form naturally, it becomes easier to pick out outliers, as we have seen with the npm "joke" packages.
In conclusion, we have described the long term evolution of several software ecosystems by breaking them up into their constituent communities. We have been able to spot ground-truth events such as the deprecation of major software packages in the temporal activities of these communities. We have demonstrated clear differences between different software ecosystems.
Implementation: https://www.caam.rice.edu/~optimization/bcu/ncp/
Such as neat-230
@ckeditor5-build-inlineand possibly react-misc-toolbox
evancz/html is deprecated in Elm 0.17
Package popularity indicated on METACRAN https://cranlogs.r-pkg.org/
AMI:
APG-TF:
Alternating proximal gradient tensor factorisation
CANDECOMP:
Canonical decomposition
CANDECOMP/PARAFAC
CRAN:
Comprehensive R archive network
FOSS:
Free and open-source software, HTTP: Hypertext transfer protocol
LIDA:
Leeds institute for data analytics
NRSS:
Normalised residual sum of squares
PARAFAC:
parallel factor analysis
PyPI:
Python package index
Araujo, M, Papadimitriou S, Stephan G, Papalexakis EE, Koutra D (2014) Com2 : Fast Automatic Discovery of Temporal ('Comet') Communities. PAKDD 2014, Part II, LNAI 8444:271–283.
Aynaud, T, Guillaume J-L (2010) Static community detection algorithms for evolving networks In: Proceedings of Modeling and Optimization in Mobile, Ad Hoc, and Wireless Networks (WiOpt), 513–519. https://doi.org/10.1016/j.niox.2011.03.001.
Bader, BW, Kolda TG (2007) Efficient MATLAB computations with sparse and factored tensors. SIAM J Sci Comput 30(1):205–231. https://doi.org/10.1137/060676489.
Baldwin, A (2018) Details about the event-stream incident. https://blog.npmjs.org/post/180565383195/details-about-the-event-stream-incident.
Bassett, DS, Porter MA, Wymbs NF, Grafton ST, Carlson JM, Mucha PJ (2013) Robust detection of dynamic community structure in networks. Chaos 23(1). https://doi.org/10.1063/1.4790830. http://arxiv.org/abs/1206.4358.
Bezanson, J, Karpinski S, Shah VB, Edelman A (2012) Julia: A fast dynamic language for technical computing. arXiv preprint arXiv:1209.5145.
Bromberger, S (2017) JuliaGraphs/LightGraphs.jl. https://doi.org/10.5281/zenodo.1412141.
Cai, KY, Yin BB (2009) Software execution processes as an evolving complex network. Inf Sci 179(12):1903–1928. https://doi.org/10.1016/j.ins.2009.01.011.
Chaikalis, T, Chatzigeorgiou A (2015) Forecasting java software evolution trends employing network models. IEEE Trans Softw Eng 41(6):582–602. https://doi.org/10.1109/TSE.2014.2381249.
Chatzigeorgiou, A, Melas G (2012) Trends in object-oriented software evolution: Investigating network properties. Proc Int Confer Softw Eng:1309–1312. https://doi.org/10.1109/ICSE.2012.6227092.
Chong, CY, Lee SP (2015) Analyzing maintainability and reliability of object-oriented software using weighted complex network. J Syst Softw 110:28–53. https://doi.org/10.1016/j.jss.2015.08.014.
Concas, G, Monni C, Orru M, Tonelli R (2013) A study of the community structure of a complex software network. International Workshop on Emerging Trends in Software Metrics, WETSoM:14–20. https://doi.org/10.1109/WETSoM.2013.6619331.
Decan, A, Mens T, Grosjean P (2018) An empirical comparison of dependency network evolution in seven software packaging ecosystems. Empirical Software Engineering:1–36. https://doi.org/10.1007/s10664-017-9589-y. http://arxiv.org/abs/1710.04936.
Dietrich, J, Yakovlev V, McCartin C, Jenson G, Duchrow M (2008) Cluster analysis of Java dependency graphs In: Proceedings of the 4th ACM Symposium on Software Visuallization - SoftVis '08, 91.. ACM Press, New York. https://doi.org/10.1145/1409720.1409735. http://portal.acm.org/citation.cfm?doid=1409720.1409735.
Durumeric, Z, Li F, Kasten J, Amann J, Beekman J, Payer M, Weaver N, Adrian D, Paxson V, Bailey M, Halderman JA (2014) The Matter of Heartbleed In: Proceedings of the 2014 Conference on Internet Measurement Conference. IMC '14, 475–488.. ACM, New York. https://doi.org/10.1145/2663716.2663755.
Folino, F, Pizzuti C (2014) An evolutionary multiobjective approach for community discovery in dynamic networks. IEEE Trans Knowl Data Eng 26(8):1838–1852. https://doi.org/10.1109/TKDE.2013.131.
Gao, Y, Zheng Z, Qin F (2014) Analysis of Linux kernel as a complex network. Chaos, Solitons and Fractals 69:246–252. https://doi.org/10.1016/j.chaos.2014.10.008.
Gauvin, L, Panisson A, Cattuto C (2014) Detecting the community structure and activity patterns of temporal networks: A non-negative tensor factorization approach. PLoS ONE 9(1). https://doi.org/10.1002/9781119156253.ch10. http://arxiv.org/abs/1308.0723.
He, J, Chen D (2015) A fast algorithm for community detection in temporal network. Physica A: Stat Mech Appl 429:87–94. https://doi.org/10.1016/j.physa.2015.02.069.
He, J, Chen D, Sun C, Fu Y, Li W (2017) Efficient stepwise detection of communities in temporal networks. Physica A: Stat Mech Appl 469:438–446. https://doi.org/10.1016/j.physa.2016.11.019.
Kang, U, Papalexakis E, Harpale A, Faloutsos C (2012) Gigatensor: scaling tensor analysis up by 100 times-algorithms and discoveries In: Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 316–324.. ACM.
Katz, J (2018) Libraries.io Open Source Repository and Dependency Metadata. https://doi.org/10.5281/zenodo.2536573. https://doi.org/10.5281/zenodo.2536573.
Kluyver, T, Ragan-Kelley B, Pérez F, Granger B, Bussonnier M, Frederic J, Kelley K, Hamrick J, Grout J, Corlay S, Ivanov P, Avila D, Abdalla S, Willing C (2016) Jupyter Notebooks – a Publishing Format for Reproducible Computational Workflows. In: Loizides F Schmidt B (eds)Positioning and Power in Academic Publishing: Players, Agents and Agendas, 87–90.. IOS Press.
Kolda, TG, Bader BW (2009) Tensor Decompositions and Applications. SIAM Review 51(3):455–500. https://doi.org/10.1137/07070111X.
Li, H, Zhao H, Cai W, Xu J-Q, Ai J (2013) A modular attachment mechanism for software network evolution. Physica A: Statistical Mechanics and its Applications 392(9):2025–2037. https://doi.org/10.1016/j.physa.2013.01.035.
Lian Wen, Dromey RG, Kirk D2009. Software Engineering and Scale-Free Networks, Vol. 39. https://doi.org/10.1109/TSMCB.2009.2020206.
Louridas, P, Spinellis D, Vlachos V (2008) Power laws in software. ACM Trans Softw Eng Methodol 18(1):1–26. https://doi.org/10.1145/1391984.1391986.
Myers, CR2003. Software systems as complex networks: Structure, function, and evolvability of software collaboration graphs, Vol. 68. https://doi.org/10.1103/PhysRevE.68.046116. 0305575.
Pan, W, Li B, Ma Y, Liu J (2011) Multi-granularity evolution analysis of software using complex network theory. J Syst Sci Compl 24(6):1068–1082. https://doi.org/10.1007/s11424-011-0319-z.
Papalexakis, EE, Faloutsos C, Sidiropoulos ND (2012) Parcube: Sparse parallelizable tensor decompositions In: Joint European Conference on Machine Learning and Knowledge Discovery in Databases, 521–536.. Springer. https://doi.org/10.1145/2729980. http://dl.acm.org/citation.cfm?doid=2808688.2729980.
Paymal, P, Patil R, Bhowmick S, Siy H (2011) Empirical Study of Software Evolution Using Community Detection. Cs.Unomaha.Edu. January 2015.
Pedregosa, F, Varoquaux G, Gramfort A, Michel V, Thirion B, Grisel O, Blondel M, Prettenhofer P, Weiss R, Dubourg V, Vanderplas J, Passos A, Cournapeau D, Brucher M, Perrot M, Duchesnay E (2011) Scikit-learn: Machine learning in Python. J Mach Learn Res 12:2825–2830.
Rosvall, M, Esquivel AV, Lancichinetti A, West JD, Lambiotte R (2014) Memory in network flows and its effects on spreading dynamics and community detection. Nat Commun 5:1–13. https://doi.org/10.1038/ncomms5630.
Sarzynska, M, Leicht EA, Chowell G, Porter MA (2016) Null models for community detection in spatially embedded, temporal networks. J Compl Netw 4(3):363–406. https://doi.org/10.1093/comnet/cnv027.
Savić, M, Ivanović M, Jain LC (2019) Complex Networks in Software, Knowledge, and Social Systems 148. https://doi.org/10.1007/978-3-319-91196-0.
Savić, M, Radovanović M, Ivanović M (2012) Community detection and analysis of community evolution in Apache Ant class collaboration networks:229. https://doi.org/10.1145/2371316.2371361.
Schlueter, I (2016) kik, left-pad, and npm. https://blog.npmjs.org/post/141577284765/kik-left-pad-and-npm.
Šubelj, L, Bajec M (2011) Community structure of complex software systems: Analysis and applications. Physica A: Stat Mech Appl 390(16):2968–2975. https://doi.org/10.1016/j.physa.2011.03.036.
Tantipathananandh, C, Berger-Wolf TY (2011) Finding communities in dynamic social networks. Proc - IEEE Int Confer Data Mining, ICDM:1236–1241. https://doi.org/10.1109/ICDM.2011.67.
Vinh, NX, Epps J, Bailey J (2009) Information theoretic measures for clusterings comparison: Is a correction for chance necessary? In: Proceedings of the 26th Annual International Conference on Machine Learning. ICML '09, 1073–1080.. ACM, New York. https://doi.org/10.1145/1553374.1553511.
Xin, X, Wang C, Ying X, Wang B (2017) Deep community detection in topologically incomplete networks. Phys A: Stat Mech Appl 469:342–352. https://doi.org/10.1016/j.physa.2016.11.029.
Xu, J, Gao Y, Christley S, Madey G (2005) A TOPOLOGICAL ANALYSIS OF THE OPEN SOURCE SOFTWARE DEVELOPMENT COMMUNITY Scott Christley Dept. of Computer Science and Engineering University of Notre Dame Notre Dame In: 46556, Proceedings of the 38th Hawaii International Conference on System Sciences - 2005, 1–10.
Xu, Y, Yin W (2013) A Block Coordinate Descent Method for Regularized Multiconvex Optimization with Applications to Nonnegative Tensor Factorization and Completion. SIAM J Imag Sci 6(3):1758–1789. https://doi.org/10.1137/120887795.
Yin, G, Chi K, Dong Y, Dong H (2017) An approach of community evolution based on gravitational relationship refactoring in dynamic networks. Phys Lett, Sec A: Gen, Atom Solid State Phys 381(16):1349–1355. https://doi.org/10.1016/j.physleta.2017.01.059.
Yu, W, Aggarwal CC, Wang W (2017) Temporally Factorized Network Modeling for Evolutionary Network Analysis:455–464. https://doi.org/10.1145/3018661.3018669.
Zanetti, MS, Schweitzer F (2012) A Network Perspective on Software Modularity. ARCS 2012:1–8. http://arxiv.org/abs/1201.3771.
Zheng, X, Zeng D, Li H, Wang F (2008) Analyzing open-source software systems as complex networks. Physica A: Stat Mech Appl 387(24):6190–6200. https://doi.org/10.1016/j.physa.2008.06.050.
This work was undertaken on MARC1, part of the High Performance Computing and Leeds Institute for Data Analytics (LIDA) facilities at the University of Leeds, UK. The authors would also like to thank Andrea Schalk, Emlyn Price, and Joseph French for providing useful feedback on an early version of the manuscript.
OAB's work was supported as part of an Engineering and Physical Sciences Research Council (EPSRC) grant, project reference EP/I028099/1.
School of Computer Science, University of Manchester, Manchester, UK
Oliver A. Blanthorn
School of Geography, University of Leeds, Leeds, UK
Colin M. Caine
School of Environment, Education and Development, University of Manchester, Manchester, UK
Eva M. Navarro-López
OAB created the initial concept—the research plan, methodology, and the application to software packages—and wrote the majority of the paper. CMC and OAB wrote the code and the results and discussion section in a roughly even split. ENL wrote the introduction. All authors discussed the experimental design and edited the paper.
Correspondence to Oliver A. Blanthorn.
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
Blanthorn, O.A., Caine, C.M. & Navarro-López, E.M. Evolution of communities of software: using tensor decompositions to compare software ecosystems. Appl Netw Sci 4, 120 (2019). https://doi.org/10.1007/s41109-019-0193-5
Tensor factorisation
Multilayer temporal networks
Software dependency networks | CommonCrawl |
논문 표/그림
발행처
KoreaScience란? 통계 목록
아세아태평양축산학회지 (Asian-Australasian Journal of Animal Sciences)
Pages.705-712
아세아태평양축산학회 (Asian Australasian Association of Animal Production Societies)
Urea Treated Corncobs Ensiled with or without Additives for Buffaloes: Ruminal Characteristics, Digestibility and Nitrogen Metabolism
Khan, M.A. (Dairy Science Division, National Livestock Research Institute) ;
Iqbal, Z. (Livestock and Dairy Development Department, Punjab, University of Agriculture) ;
Sarwar, M. (Institute of Animal Nutrition and Feed Technology, University of Agriculture) ;
Nisa, M. (Institute of Animal Nutrition and Feed Technology, University of Agriculture) ;
Khan, M.S. (Department of Animal Breeding and Genetics, University of Agriculture) ;
Lee, W.S. (Dairy Science Division, National Livestock Research Institute) ;
Lee, H.J. (Dairy Science Division, National Livestock Research Institute) ;
Kim, H.S. (Dairy Science Division, National Livestock Research Institute)
투고 : 2005.09.29
심사 : 2005.12.01
발행 : 2006.05.01
https://doi.org/10.5713/ajas.2006.705
인용 PDF KSCI
Influences of urea treated corncobs (UTC) ensiled with or without different additives on ruminal characteristics, in situ digestion kinetics, nutrient digestibility and nitrogen metabolism were examined in a $5{\times}5$ Latin square design using five ruminally cannulated buffalo bulls. Five iso-caloric and iso-nitrogenous diets were formulated to contain 30% dry matter (DM) from concentrate and 70% DM from 5% UTC ensiled without any additive (U) or with 5% enzose (EN), 5% acidified molasses (AM), 5% non-acidified molasses (NM) and 5% acidified water (AW), respectively. These diets were fed to buffalo bulls at 1.5% of their body weight daily. Ruminal $NH_3$-N concentration at 3 hours (h) post feeding was significantly higher in bulls fed U, NM and AW diets, however, at 6, 9 and 12 h post feeding it was significantly higher in bulls fed EN and AM diets. Ruminal total volatile fatty acids (VFA) and acetate concentrations were significantly higher with EM and AM diets compared with other diets at 3, 6, 9 and 12 h post feeding. Ruminal pH at 6 and 9 h post feeding was higher with EN and AM diets; however; it was notably lower with these diets at 3 h post feeding. Total ruminal bacterial and cellulolytic bacterial counts were higher in bulls fed EN and AM diets than in those fed the other diets. In situ ruminal DM and NDF degradabilities and total tract digestibilities were significantly higher with UTC ensiled with enzose and acidified molasses than those ensiled without any additive or other additives. Nitrogen balance was significantly higher in bulls fed EN and AM diets than those fed U, AW and NM diets. The UTC ensiled with enzose or acidified molasses resulted in better digestibility and N utilization than those ensiled without any additive, with non-acidified molasses and acidified water in buffaloes.
Corncobs;Fermentable Carbohydrates;Digestibility;Nitrogen Utilization
원문 PDF 다운로드
참고문헌
Conway, E. J. and O'Malley. 1942. Micro diffusion methods: ammonia and urea using buffered absorbents (revised methods of ranges greater than 10 $\mu$g N). Biochem Journal. 36:655-666 https://doi.org/10.1042/bj0360655
Grenet, E. and P. Barry. 1990. Microbial degradation in the rumen of wheat straw and anhydrous ammonia treated straw observed electron microscopy. Reprod. Nut. Devel. 30:533-541 https://doi.org/10.1051/rnd:19900408
Sarwar, M., M. A. Iqbal, C. S. Ali and T. Khaliq. 1994. Growth performance of buffalo male calves as affected by using cowpeas and soybean seeds as a source of urease during urea treated wheat straw ensiling process. Egyptian J. Anim. Prod. 2:179-185
Sarwar, M., M. A. Khan and M. Nisa. 2005. Chemical composition and feeding value of urea-treated corncobs ensiled with additives for sheep. Austr. J. Agric. Res. 56:685- 690 https://doi.org/10.1071/AR04243
SAS. 1988. Statistical Analysis System. SAS user's guide: Statistics, SAS Inst. Inc., Carry, NC
Conrad, H. R., W. P. Weiss, W. O. Odwongo and W. L. Shockey. 1984. Estimating net energy lactation from components of cell solubles and cell walls. J. Dairy Sci. 67:427-433 https://doi.org/10.3168/jds.S0022-0302(84)81320-X
Williams, P. E. V., G. M. Innes and A. Brewer. 1984. Ammonia treatment of straw via the hydrolysis of urea 1. Effect of dry matter and urea concnetration on the rate of hydrolysis by urea. Anim. Feed Sci. Technol. 11:103-111 https://doi.org/10.1016/0377-8401(84)90015-4
Mertens, D. R. and J. R. Loften. 1980. The effect of starch on forage fiber digestion kinetics in vitro. J. Dairy Sci. 63.1437- 1444 https://doi.org/10.3168/jds.S0022-0302(80)83101-8
Sarwar, M., M. A. Khan and M. Nisa. 2003. Nitrogen retention and chemical composition of urea treated wheat straw ensiled with organic acids or fermentable carbohydrates. Asian-Aust. J. Anim. Sci. 16:1583-1589 https://doi.org/10.5713/ajas.2003.1583
Steel, R. G. D. and J. H. Torrie. 1984. Principles and Procedures of Statistics. A Biometrical Approach (2nd Ed). McGraw Hill Book Co. Inc. New York, USA
AOAC. 1999. Official Methods of Analysis, 16th ed. Official Methods of Analysis of AOAC International, Gaithersburg, MD, USA
Clark, J. H. and C. L. David. 1990. Some aspects of feeding high producing dairy cows. J. Dairy Sci. 68:873-880
Ali, A., A. H. Gilani and A. S. Hashmi. 1994. Nutritional value of rice straw as influence by different methods of urea and alkali treatment and storage periods. J. Scientific Res. 46:35-42
Mertens, D. R. 1977. Dietary fiber components: relationship to the rate and extent of ruminal digestion. Feed. Proc. 36:187
Sarwar, M., M. A. Khan and M. Nisa. 2004. Effect of organic acids or fermentable carbohydrates on digestibility and nitrogen utilization of urea treated wheat straw in buffalo bulls. Austr. J. Agric. Res. 55:234-240
Nisa, M., M. Sarwar and M. A. Khan, 2004b. Nutritive value of urea treated wheat straw ensiled with or without corn steep liquor for lactating Nili-Ravi buffaloes. Asian-Aust. J. Anim. Sci. 17:825-829 https://doi.org/10.5713/ajas.2004.825
Borhami, B. E. A., F. Sundstol and T. H. Garmo. 1982. Studies on ammonia treated straw. II fixation of ammonia in treated straw by spraying with acids. Anim. Feed Sci. Technol. 7:53-59 https://doi.org/10.1016/0377-8401(82)90036-0
Suto, T. 1973. Rumen no kensa (Examination of the rumen). In (Ed. R. Nakamura, T. Yonemura and T. Suto). Ushino Rinsho Kensaho (Methods in the Clinical Examination of the Bovine). Nosangyoson BunkaKyokai. Tokyo. p. 39
Nisa, M., M. Sarwar and M. A. Khan. 2004a. Influence of ad libitum feeding of urea treated wheat straw with or without corn steep liquor on intake, in situ digestion kinetics, nitrogen metabolism and nutrient digestion in ruminally cannulated buffalo bulls. Aust. J. Agric. Reas. 55:229-234 https://doi.org/10.1071/AR02236
Van Soest, P. J., H. B. Robertson and B. A. Lewis. 1991. Methods of dietary fiber, NDF and non-starch polysaccharides in relation to animal material. J. Dairy Sci. 74:3583-3595 https://doi.org/10.3168/jds.S0022-0302(91)78551-2
Church, D. C. 1991. Livestock Feeds and Feeding. (3rd.Ed), Prentice-Hall International Edition, USA
Dias-Da-Silva, A. A., A. Mascarenhas Ferriera and C. V. M. Cudedes. 1988. Effect of moisture level, treatment time and soybean addition on the nutritive value of urea treated maize stovers. Anim. Feed Sci. Technol. 16: 67-74
Dass, R. S., A. K. Verma, U. R. Mehar and D. S. Shu. 2001. Nutrient utilization and rumen fermentation pattern in murrah buffaloes (Bubalus bubalies) fed urea and urea plus hydrochloric acids wheat straw. Asian-Aust. J. Anim. Sci. 14:1542-1548 https://doi.org/10.5713/ajas.2001.1542
Khan, M. A., M. Sarwar, M. Nisa and M. S. Khan. 2004. Influence of enzose on feeding value of urea treated corncobs in lactating crossbred cows. Asian-Aust. J. Anim. Sci. 17:70-74
Sarwar, M., J. L. Firkins and M. Eastridge. 1991. Effect of replacing NDF of forage with soyhulls and corn gluten feed for dairy heifers. J. Dairy Sci. 74:1006-1015 https://doi.org/10.3168/jds.S0022-0302(91)78250-7
Lines, L. W. and W. P. Weiss. 1996. Use of nitrogen from ammoniated alfalfa hay urea soybean meal and animal protein meal by lactating cows. J. Dairy Sci. 79:1992-1999 https://doi.org/10.3168/jds.S0022-0302(96)76571-2
피인용 문헌
Starch Source Evaluation in Calf Starter: I. Feed Consumption, Body Weight Gain, Structural Growth, and Blood Metabolites in Holstein Calves vol.90, pp.11, 2007, https://doi.org/10.3168/jds.2007-0338
Starch Source Evaluation in Calf Starter: II. Ruminal Parameters, Rumen Development, Nutrient Digestibilities, and Nitrogen Utilization in Holstein Calves vol.91, pp.3, 2008, https://doi.org/10.3168/jds.2007-0337
Effect of supplemental Bacillus cultures on rumen fermentation and milk yield in Chinese Holstein cows pp.14390396, 2009, https://doi.org/10.1111/j.1439-0396.2009.00926.x
Potential of Using Maize Cobs in Pig Diets — A Review vol.28, pp.12, 2015, https://doi.org/10.5713/ajas.15.0053
한국과학기술정보연구원 NDSL 한국학술지 인용보고서 KPubs 한국과학기술인용색인서비스 한국전통지식포털
(34141) 대전광역시 유성구 대학로 245 한국과학기술정보연구원 TEL 042)869-1004
자세히 찾기
제목, 요약, 키워드
발행년도
저자명
저자소속기관
자료유형
학술회의자료
협회지 | CommonCrawl |
Hybrid approach for human posture recognition using anthropometry and BP neural network based on Kinect V2
Bo Li1,
Cheng Han1 &
Baoxing Bai1,2
When it comes to the studies concerning human-computer interaction, human posture recognition which was established on the basis of Kinect is widely acknowledged as a vital studying field. However, there exist some drawbacks in respect of the studying methods nowadays, for instance, limitations, insignificantly postures which can be recognized as well as the recognition rate which is relatively low. This study proposed a brand new approach which is hybrid in order to recognize human postures. The approach synthetically used depth data, skeleton data, knowledge of anthropometry, and backpropagation neural network (BPNN). First, the ratio of the height of the human head and that of body posture is ought to be evaluated. The distinguished four types of postures according to the ratio were standing, sitting or kneeling, sitting cross-legged, and other postures. Second, sitting and kneeling were judged according to the 3D spatial relation of the special points. Finally, feature vectors were extracted, transformed, and input to the BPNN according to the characteristics of the other postures, and bending and lying were recognized. Experiments proved the timeliness and robustness of the hybrid approach. The recognition accuracy was high, in which the average value was 99.09%.
The human posture can show meaningful expression, and so, a relatively more optimal approach in respect of studying the recognition of the postures of people is necessary. The posture recognition of people based on motion-sensing equipment has gradually been focused on the studying field concerning the interaction between people and computer ever since the last few years. Since the Microsoft Company introduced a low-cost motion-sensing device, Kinect, in 2010, many institutions and scholars have conducted research based on Kinect and many occasions of the interaction between people and computers. In addition, the posture recognition of people has already been applied to this somatosensory device, and good effects have been achieved.
Few researchers have utilized depth image for human posture recognition. A previous study [1] obtained human contour by using depth image and Canny edge detector. After distance transformation, as for the calculation in respect of the head position, an approach which is on the basis of a model was applied. The approach realized the detection of people through resorting to a two-dimensional head contour model as well as a three-dimensional head surface mode for the ultimate goal of realizing the detection of the body of people. A plan for segmentation was put forward for the purpose of segmenting people from the environment around him and exacting the comprehensive entire contour image on the basis of the point of detection. The purposes of human detection and tracking were then achieved. Researchers in [2, 3] succeeded at realizing the prediction of the position of the joint of the human body from a three-dimensional perspective on the basis of a single depth image. In addition, they also realized the designation of an intermediate position representation for the purpose of mapping the pose estimation which is difficult into a relatively easy problem in respect of the per-pixel classification, estimated body parts by varied training datasets, and through resorting to the re-projecting of the results in respect of re-projecting as well as the finding of local patterns, and 3D confidence scores for multiple body joints can be gained. Paper [4] proposed a hybrid recognition method and together with some techniques in respect of the processing of image, depth image created by the sensors of Kinect are adopted for the purpose of identifying five poses of people which are different. The five poses of people are standing, squatting, sitting, bending, and lying. In [5], depth images were captured by Kinect, and the upper limb of human posture and upper limb motion were estimated.
Several researchers have also utilized skeleton data for human posture recognition. A previous study [6] obtained skeleton data from Kinect for seven different experiments. There are four kinds of characteristics extracted from the skeleton of people which were adopted for the purpose of realizing the recognition of the body postures of people. The four characteristics are bending, sitting, standing, and lying. A previous study [7] proposed an algorithm in terms of the detection of the postures of people as well as the recognition of the postures of people which is multi-class on the basis of characteristics of geometry. A serious of characteristics in respect of angle were converted from Kinect's data concerning three-dimensional skeleton. Through resorting to a support vector machine, or SVM in short which was accompanied with polynomial kernel, the classification of the postures of people was realized. As for the previous research [8], there were four different approaches in respect of the classification of the poses of people which were set in comparison, which are (1) support vector machine, or SVM in short; (2) backpropagation neural network, or BPNN in short; (3) naive Bayes; and (4) decision tree. As for the previous research [8], there were four different approaches in respect of the classification of the poses of people which were set in comparison: (1) support vector machine, or SVM in short, (2) backpropagation neural network, or BPNN in short, (3) naive Bayes, and (4) decision tree. The verification of the four approaches mentioned above was realized, verified by using three postures (standing, sitting, and lying). The conclusion was that the accuracy of the BPNN reached 100%, and the average accuracy of the four methods was 93.72%.
Depth image and skeleton data have also been combined by numerous researchers for human posture recognition. A previous study [9] realized the obtaining of the three-dimensional characteristics of the body on the basis of the coordinate information which is three-dimensional through the adoption of depth image. In addition, the identification of the postures of people which are three-dimensional was realized on the basis of models in respect of skeleton joint of people and multidimensional dataset. A previous study [10] combined marks concerning the anatomy of the human body as well as the model of the skeleton of people, measured the distances of the body parts by using geodesic distance, and realized the estimation of the posture of people through the adoption of depth image from Kinect.
The Microsoft Company introduced Kinect v2 in 2014, and it has demonstrated significant improvements in contrast to Kinect v1, including various aspects as follows: (1) Kinect v2 is two times more accurate than Kinect v1 in the near range, (2) the accuracy of 3D reconstruction and people tracking is significantly improved in different environments with Kinect v2, (3) Kinect v2 presents an increased robustness to artificial illumination and sunlight, (4) the detection range is further than that of Kinect v1, (5) depth image resolution of Kinect v2 is higher than that of Kinect v1, and (6) Kinect v2 can directly output the depth data of the human body [11]. So, we decided to use Kinect v2 for this study. However, the SDK 2.0 for skeleton recognition is far from completely right, despite the fact that the information concerning the skeleton is correct on the condition that the head of people is situated on the highest place of the body of people and no other body parts overlap the head, as shown in Fig. 1a. When the skeleton joint overlaps another, such as in the bending and lying postures, the skeleton information may be incorrect, as shown in Fig. 1b, c. A previous study [12] proposed a repair method for occlusion of the human single joint point, but not only one joint overlapped in many postures. Studies [1, 5] did not utilize skeleton data and only recognized posture by depth data. In a previous study [4], researchers did not adopt the SDK from Kinect for the purpose of recognizing the postures of people. As for the approached of current literature, there exist some drawbacks, for instance, limitations, insignificantly postures of people which can be recognized, as well as the recognition rate which is low. This study proposed a novel hybrid approach, utilized the Kinect SDK 2.0, obtained depth image and skeleton data, and synthetically used several methods and knowledge of anthropometry to solve problems. There are six different postures of people recognized: (1) standing, (2) sitting, (3) sitting cross-legged, (4) kneeling, (5) lying, and (6) bending.
Skeleton data captured by Kinect v2 and its SDK
As for the remaining parts of the paper, the organization can be summarized as follows. Section 2 aims at making a brief introduction of the method and contains Sections 2.1, Section 2.2, Section 2.3, Section 2.4, Section 2.5, and Section 2.6, Section 2.1 shows the entire flow chart of our approach, Section 2.2 presents how to obtain the gravity, the human body height, and contour. Section 2.3 describes the head localization, Section 2.4 explains how to preliminarily distinguish four types of postures according to the ratio of the height of the postures of people and that of the head of people, Section 2.5 describes how to judge sitting and kneeling according to the spatial relation which is three-dimensional in respect to the points which are special, and Section 2.6 applies BPNN to recognize bending and lying. Section 3 elucidates scheme of the experiment, steps of the experiment, experimental content, and the experimental results. In the end, Section 4 concludes the study and suggests further work.
General flow chart of our hybrid approach
As described in the last paragraph of Section 1, the general flow chart in respect of the hybrid approach which is put forward in this study can be seen in Fig. 2.
Generation of the body center of gravity, contour, and height
Due to the technical limitations of Kinect v2, it has to work in a simple environment. However, by adopting Kinect v2, the identification well as the output in a direct way of depth data in respect of the humanoid area can be realized. In addition, the differentiation between the foreground and background became needless and the feet and the ground in the same area are also distinguished relatively accurately [13]. We utilize Kinect v2 and Kinect SDK 2.0 for Windows to extract the humanoid area, but some noises occur due to the reflection on the ground. Low-pass filter was used to remove noises, but this study does not focus on the low-pass filter. Thus, the low-pass filter is not described further.
After the fixed humanoid area is obtained, the body center of gravity (xc, yc) xc, yc)is calculated by (1).
$$ \left\{\begin{array}{c}{x}_c=\frac{1}{S_c}{\sum}_{i=1}^{S_c}{x}_i\\ {}{y}_c=\frac{1}{S_c}{\sum}_{i=1}^{{\mathrm{S}}_{\mathrm{c}}}{y}_i\end{array}\right. $$
As for the equation set above, (xc, yc) can be taken as the coordinate of the gravity center; Sc is the total of white pixels in the human body area; xi can be viewed as the x-axis of the ith pixel while the yiyi represents the y-axis values of that. The human contour is obtained by Canny Operator according to the human body area, as shown in Fig. 3. In this figure, as for the red rectangle which can be seen in (a), it can be taken as gravity center in respect of the body area of people; the human contour is shown in (b), and the red rectangle can be viewed as the gravity center of the contour of people.
Center of gravity in the human body area and human contour
Two situations occur. The correct one is the center of gravity in respect of the body area of people. In addition, the incorrect one can be taken as the gravity center outside the body area of people because the feature vectors (will be discussed in Section 2.6) are incorrect. At this incorrect situation, the center of gravity is made as the origin; horizontal and vertical lines are drawn; the line which exactly matches the two intersection points on the contour line of the body is selected. The new gravity center changes into the center position in respect of the two points which are crossing, as shown in Fig. 4.
Replacing the center of gravity of the human contour
Head localization
In this study, postures are preliminarily judged by the head position and the head height. Head localization is thus important. Compared with the other parts of the human body, the head is seldom occluded and is more conducive to be obtained. The correlation of its feature and posture is high. Therefore, the algorithm of head localization is simple with inconsiderable computation. During the postures of people when they stand, sit, kneel, and sit cross-legged, the head is not occluded by the other parts of the body. Head localization based on skeleton data is accurate. The use of skeleton images from Kinect SDK can hence obtain accurate head information. On the contrary, on condition that the head of people is not situated in the highest place of people, or the other body parts occlude the head, skeleton data may be inaccurate or incorrect, as shown in Fig. 1b, c. Our method utilizes depth image and skeleton data in an integrated manner to position the head. The general process is as follows:
The head coordinate from the skeleton image is judged whether the head is situated in the body area of people from the depth image.
If the head coordinate is not situated in the body area of people from depth image, the posture is not one of standing, sitting, kneeling, and sitting cross-legged. Then the recognition in respect of the postures of people is realized through resorting to BPNN (see Section 2.6).
If the head coordinate is situated in the body area of people from depth image, the head coordinate is credible. Then, the head is positioned according to the positional relation of the coordinates between the head and the neck of people.
If the head coordinate is lower than all of the coordinates of the other body parts, or the connection line slope of the head coordinate and the neck coordinate is greater than − 1 (or less than 1). Then, posture recognition is processed by BPNN (see Section 2.6).
If the head coordinate is higher than all of the coordinates of the other body parts and the connection line slope of the coordinates of the neck and head of people is less than − 1 (or greater than 1), then it is confirmed that the posture is one of standing, sitting, kneeling, and sitting cross-legged. The posture is judged by the relation between the heights of contour and the head of people (see Section 2.4) and the spatial relation among those feature points which are three-dimensional (see Section 2.5).
We need the accurate relationship between two data, namely, by resorting to the depth image, the head height of the human contour, and the difference in terms of height between the head and neck node, and the bone image is seen. We set the resolution of the depth and skeleton images as 512 × 424.
Forty (20 males, 20 females) healthy persons (18 years old to 25 years old) from a university are recruited. Their body sizes when they are facing the Kinect and their profile facing the Kinect are measured. The body sizes of 160 (80 males aged 26 years old to 60 years old and 80 females aged 26 years old to 55 years old) healthy persons from a medical center when they are facing the Kinect are also measured. The head height based on statistical analysis is as follows:
$$ {H}_h=1.8726{L}_{hn} $$
in the depth image, where HhHh can be taken as the height of the head and LhnLhn can be taken as the difference in terms of the height between the head and neck nodes in the skeleton image, as shown in Fig. 5.
Height difference between two nodes
Estimation of human posture according to head height and the height of the human contour
Ergonomics and anthropometry indicate that all body parts of people and the structure of the human body satisfy a certain proportion of natural features. The adult body size in the Chinese National Standard GB10000-88 [14] and the relevant literature about standardization present that the human body size about height has minimal difference. The difference ratio between the measurements of the human height (data from the China National Institute of Standardization in 2009) and the record of human height (data from the Chinese National Standard [14]) is below 0.864%. The Chinese National Standard distinguishes the human body sizes of different genders and ages according to percentile and divides certain groups of people into seven percentiles (1%, 5%, 10%, 50%, 90%, 95%, and 99%). Any percentile denotes the percentage of the persons whose size is no more than the measured values. For instance, the 50% percentile means that the percentage of the persons whose size is not greater than the measured values is 50%, and the 50% percentile indicates the standard size of the persons of medium size in that age range. Table 1 shows a part of the specific data of the Chinese National Standard.
Table 1 Chinese adult body size (mm)
A study [15] compared the relevant standards and literature of western countries [16,17,18,19,20] and concluded that the Westerners are taller and stronger than the Orientals, with the characteristics of long arms, long legs, and big hands and feet. In terms of anthropometry dimensions, such as the height, surrounded degree, and width size, the Westerners are bigger than the Orientals. In terms of head, neck, and the length of the upper body, the difference between the sizes of the Westerners and the Orientals is insignificant.
The ratio of the height in respect of postures of people to that of the head of adult men and women is calculated in every percentile, as shown in Table 2. The ratio of the 99 percentile posture height to the 1 percentile head height is greater than the other percentiles. While the ratio of body height in the 1 percentile to the head height in the 99 percentile is less than the other percentages. We conclude that both of these cases are rare, and the persons are unhealthy. For the stronger suitability of our method, we put the abovementioned two extreme values into the statistical scope. The ratio of the height in respect of postures of people to that of the head for male and female are 7.5516 and 7.3222, respectively; the ratios of the sitting height to the head height for male and female are 5.9638 and 5.7265, respectively; and the ratios of the height of sitting cross-legged to the head height for male and female are 4.0845 and 3.9817, respectively, as shown in Table 2. We can summarize that the difference among the three ratios is relatively large. Thus, we can distinguish three postures (standing, sitting, and sitting cross-legged). However, the thigh length is similar to the lower leg length plus foot height, and the sitting and kneeling heights are difficult to distinguish. Therefore, when Ratio ≥ 6.5 Ratio ≥ 6.5, the posture refers to the standing one; when 6 > Ratio ≥ 5.0, the posture refers to the sitting or kneeling one; when 4.5 > Ratio ≥ 3.3, the posture refers to sitting cross-legged one.
Table 2 Ratio of the height in respect of postures of people to that of the head
In Table 2, A denotes the average value of all of the ratios of the height in respect of postures of people to that of the head in each percentile (column 2–8 in the corresponding row). H represents the ratio of posture height (99%) to head height (1%). L indicates the ratio of posture height (1%) to head height (99%). P represents the average of all the ratio values in the row (column 2–11). H/H indicates the ratio of the vertical standing height to the head height. S/H stands for the ratio of sitting height to head height. C/H stands for the ratio of sitting cross-legged height to head height.
Distinguishing of sitting or kneeling by depth data
The depth data are mapped to the Kinect coordinate system by using Kinect SDK. The coordinate of Pe(xe, ye, ze) corresponds to the bottom point DeDe in respect of the contour of people, and the coordinate of Ph(xh, yh, zh) corresponds to the central point DhDh in respect of the head of people. The sitting or kneeling posture is distinguished according to the revelation of the two coordinates. Head can be approximately considered the shape of a sphere, and its radius is set as
$$ {R}_h=\frac{1}{2}\times \frac{1}{3}\left({H}_h+{L}_h+{W}_h\right) $$
where Hh can be viewed as the height in respect of the head, Lh can be taken as the length of the head of people, and Wh refers to the width of the head of people, as shown in Fig. 6.
As shown in Fig. 7a, Pe can be viewed as the point in three-dimensional space corresponding to the bottom point in respect of the body area of people which can be seen in the two-dimensional image. \( {P}_h^{\prime}\left({x}_h,{y}_e,{z}_h\right) \) refers to the projected point in terms of PhPh which is in X–Z plane, and the distance between PePh and \( {P}_h^{\prime }{P}_{h^{\prime }} \) is calculated by the following:
$$ {L_{eh}}^{\hbox{'}}=\sqrt{{\left({x}_e-{x}_h\right)}^2+{\left({z}_e-{z}_h\right)}^2} $$
Judging the sitting or kneeling posture
If Leh′ exceeds a threshold, then Pe can be confirmed as the foot. The sitting posture may be not standard. Thus, the threshold is set as one head height Hh, namely, when Leh′ > Hh \( {\mathrm{L}}_{e{h}^{\prime }}>{H}_h \), the foot is outside of the head projection. However, the posture in which the foot is outside the projection may be the posture of sitting or kneeling, which can be seen in Fig. 7b, c. There are two types of judgment way are put forward as follows:
A circle is drawn, and the center of the circle is situated at the upper right \( {P}_h^{\prime }{P}_{h^{\prime }} \). The distance between the circle center and \( {P}_h^{\prime } \) is Hh, and the radius is Hh. On condition that there is no body parts of people found in the circle, then the posture can be judged as the sitting one; on condition that there exist some body parts of people found in the circle, then the posture can be judged as the kneeling one.
A circle is drawn, and the center of the circle is situated at the upper right Pe. The distance between the circle center and Pe is Hh, and the radius is also Hh. On condition that there is no body parts of people found in the circle, then the posture can be judged as the kneeling one; on condition that there exist some body parts of people found in the circle, then the posture can be judged as the sitting one.
Figure 7b, c depict that one of the abovementioned two judgment ways can confirm the sitting or kneeling posture. The point (i, j) in the 2D image corresponding to Phe (or Phh′) in the 3D environment can be calculated. Several points (x, j) in the human body area are then utilized to confirm whether a human body part exists in the circle.
Recognition of bending and lying postures by using BPNN
BPNN refers to a feed forward network which is of multi-layers established on the basis of Error Back Propagation (or BP in short) algorithm. As for the neural network, it utilizes the difference between the actual and desired outputs to correct the connection rights of network layers and correct the layer by layer from back to forward. BPNN has great advantages in solving nonlinear problems or nonlinear structural problems: it can make use of the input and output variables of the neural network for training network, to achieve non-linear calibration purposes. A single sample has m input nodes, n output nodes, and hidden nodes in one or more hidden layers. A considerable amount of training time is required by many hidden layers. According to Kolmogorov's theory, a three-layer BP network can approach any kind of network under a reasonable structure as well as proper weights. As for any continuous function, it can be approximated by a BP network which has three layers [21, 22]. These three layers refer to the input layer, hidden layer as well as the output layer. As a result, the BP network which is endowed with three layers that has a relatively simple structure was selected by us, as shown in Figure 8.
Extraction of feature vectors
The gravity center of the body area of people is given information. The distance between the contour in respect of the body of people and the gravity center can be calculated as follows:
$$ {d}_i=\sqrt{{\left({x}_i-{x}_c\right)}^2+{\left({y}_i-{y}_c\right)}^2} $$
As for the equation above, di refers to the distance value between the center of gravity (xc, yc) and any point on the contour (xi, yi). The start is from the left-most pixel, and the movement is clockwise to the end pixel, as shown in Fig. 9.
Calculation of the distance value didi
The distance between the pixel and the center of gravity is calculated. A curve in respect of the distance value is then gained and filtered by a low-pass filter, which can be seen in Fig. 10. The peak points in the curve correspond to the smaller red points in Fig. 9. The smaller red points are the feature point, and the feature vectors are the lines from the center of gravity to the feature points, as shown in Fig. 13.
Curve of the distance value didi
Standardization of feature vectors
Inspired by [4], we obtained the angle information of feature vector according to the characteristics of bending and lying postures to distinguish them. Hence, the feature vector in the Cartesian coordinate system is transformed into the feature vector in the polar coordinate system.
$$ {R}_i=\sqrt{{x_{pi}}^2+{y_{pi}}^2} $$
$$ {\theta}_i={\tan}^{-1}\frac{y_{pi}}{x_{pi}}=\left\{\begin{array}{c}{\theta}_i,\mathrm{when}\ {\theta}_i\ \mathrm{is}\ \mathrm{postive}\\ {}{\theta}_i+360,\mathrm{when}\ {\theta}_i\ \mathrm{is}\ \mathrm{negative}\end{array}\right. $$
As for the equations above, i = 1, 2, …mi = 1, 2, …m. m refer to the number in respect of feature vectors, and the maximum value of m is 4, (xpi, ypi) is the coordinate of the feature point in the Cartesian coordinate system, as shown in Fig. 11.
Transformation of Cartesian coordinate into Polar coordinate
It is necessary for us to specify the order in respect of the feature vectors for the purpose of distinguishing them better. Therefore, a disk with four regions is set, as shown in Fig. 12. The feature vector of the lying or bending must be in regions 1, 2, and 3 and region 4. Thus, regions 1 and 2 and regions 3 and 4 are symmetrical regions. The order of the feature vectors in these four regions can be specified as follows:
On condition that the angle of the feature vector is closer to 180° when set in comparison with other feature vectors in area 1, the feature vector can be called as V1V1. At this time, we set L1 = R1 L1 = R1 and T1 = θ1 T1 = θ1. Otherwise, we set L1 = 0 and T1 = 0.
If an angle of the feature vector is closer to 0°/360° when set in comparison with other feature vectors in region 2, then this feature vector is called V2. At this time, we set L2 = R2 L1 = R1 and T2 = θ2 T1 = θ1. Otherwise, we set L2 = 0 and T2 = 0.
If an angle of the feature vector more verges on 315° when set in comparison with other feature in region 3, then this feature vector is called V3. At this time, we set L3 = R3 L1 = R1 and T3 = θ3 T1 = θ1. Otherwise, we set L3 = 0 and T3 = 0.
If an angle of the feature vector more verges on 225° when set in comparison with other feature in region 4, then this feature vector is able to be called as V4. At this time, we set L4 = R4 L1 = R1 and T4 = θ4 T1 = θ1. Otherwise, we set L4 = 0 and T4 = 0. The specifying process in respect of the feature vector sequence come to an end.
Vector partition
The specified order of the feature vectors can be seen in Fig. 13.
Ordered feature vectors
The difference in the distance between the Kinect and the body of people and the difference in the human height causes a difference in the height of the human body area, which may cause errors in posture recognition. Therefore, the feature values should be normalized. We set \({\bar{R}}_i={L}_i/ {R}_{\mathrm{max}}{\bar{R}}_i={L}_i/{R}_{\mathrm{max}}\), and \({\bar{\theta}}_i={T}_i/ 360{\bar{\theta}}_i={T}_i/ 360\), where Rmax = max(Ri), i = 1, 2, …m.\( {R}_{\mathrm{max}}=\underset{i}{\max}\left({R}_i\right),i=1,2,\dots m. \) In this case, the feature values are ratio values regardless of the height regarding the body are of people. The posture recognition approach is able to then be adopted in respect of various persons with different heights. There are eight feature values showed in the Table 3; the eight feature vectors also function as the input neurons regarding the BPNN.
Table 3 Final feature values
Training of the BPNN
In the BPNN, it is easy to make clear of the number in respect of the input layer neurons as well as the output layer neurons, but that of the hidden layer neurons has an impact on the performance of the BPNN. As shown in Fig. 14, eight types of postural samples are input into the BPNN in this study, and each sample has eight feature vectors. The BPNN outputs two judged results of the posture, that is, there are eight input layer neurons as well as two output layer neurons, but the exact number in respect of the hidden layer neurons needs to be determined. Three empirical formulas can be used. The first formula is
$$ h=\sqrt{m+n}+a $$
where h refers to there are h hidden layer neurons, m refers to there are m input layer neurons, n refers to there are n output layer neurons, and a can be taken as constant that is applied to adjust h. The scope of a is from 1 to 10.
Eight types of postural samples for training
The second formula is
$$ h=\sqrt{m\times n} $$
where h refers to there are h hidden layer neurons, m refers to there are m input layer neurons, and n refers to there are n output layer neurons.
A previous study [23] provided the formula for determining the upper bound of how many hidden layer neurons there exist. The third formula is as follows:
$$ {N}_{\mathrm{hid}}\le \frac{N_{\mathrm{train}}}{R\times \left({N}_{\mathrm{in}}+{N}_{\mathrm{out}}\right)} $$
where Nin refers to there are Nin hidden layer neurons, Nout refers to there are Nout input layer neurons, and Ntrain refers to there are Ntrain training samples, 5 ≤ R ≤ 10.
The three empirical formulas confirm there exist five hidden layer neurons after many experiments are conducted, as shown in Fig. 8. m, h, and n are confirmed as 8, 5, and 2, respectively.
Eight types of postural samples are adopted for training, as shown in Fig. 14.
Feature vectors of bending differ from those of lying significantly. Therefore, in this study, BPNN was applied in a simple way with inputting several types of samples into the BPNN, and each type of samples was arranged with the same number approximately. It is considered that this arrangement will not result in over-training problem. Although the selected samples were representative, and almost no sample noise, early stopping technique [24] was adopted in this study to avoid over-fitting problem. In this study, the accuracy of the neural-network-training target is determined to be 0.001, and as for the learning step size, it is determined to be 0.01. Figure 15 presents that as for the optimal training performance, it is realized at epoch 67.
Training curve of BPNN
Discussion and experimental results
The hardware environment in respect of the study in this paper is as follows: computer with Intel Xeon(R) CPU E5-2650 and 32G memory, Nvidia Quadro K5000 GPU, Kinect v2 for Windows; System environment: 64-bit Windows 10 Enterprise Edition; IDE environment: Visual Studio.net 2015 and Kinect SDK 2.0.
Forty-six adults with healthy bodies (25 males and 21 females) participate in the experiments. Among them, 10 males and 10 females are not only the models in terms of the training samples in respect of BPNN but also the participants of all experiments. All the participants have different heights (the highest height is 1.88 m, and the shortest height is 1.57 m) and weights (the maximum weight is 84 kg, and the minimum weight is 45 kg). The distances of the participant and the Kinect v2 are between 2.0 and 4.2 m, and the distance of the Kinect v2 and the ground is 70 or 95 cm.
Before running the entire program, the training samples of bending and lying postures need to be collected. The samples are used to train the BPNN. There are ten male and women respectively from the participants are chosen, and they own various height as well as weight. In addition, they were required to pose two postures which were bending, lying oriented to the Kinect in four directions (±45° and ± 90°). The feature vectors of each posture as well as eight kinds of input samples were taken as the data of training are obtained, as shown in Fig. 14. Each participant is examined five times in every direction. A total of 800 samples are thus collected. All of the samples are input to the BPNN for training (see Section 2.6), and the set in respect of the results after training was conserved later.
As for the entire participants, they are classified into three sets of samples. Set 1 refers to the model set that undergo training samples of the BPNN, set 2 refers to the participants set who do not undergo samples from the perspective of a sample of BPNN, and set 3 refers to the entire participants set. There are six postures of people recognized, and the six postures are (1) standing, (2) sitting, (3) kneeling, (4) sitting cross-legged, (5) bending, and (6) lying. In addition, the six postures of each participant are made in three different experimental environments (indoor with light, indoor with natural light, and outdoor with natural light). Each participant poses six postures several times when he/she orients to the Kinect v2 in various directions. In addition, he/she is then recognized by the program. The directions of standing and sitting cross-legged postures are 0°~±180°, and they are posed 30 and 24 times, respectively; the directions of sitting and kneeling postures are 0°~±90°, and they are posed 28 and 20 times, respectively; The directions of lying and bending postures are ±45°~±90°, and they are posed 24 and 20 times, respectively. Figure 16 shows the real scene of human posture. Table 4 shows the experimental statistics for the successful times of posture recognition and recognition accuracy.
Real depiction of human posture
Table 4 Accuracy of human posture recognition
The running in respect of our program comprises five stages, stage A is the obtainment of human body area and contour; stage B is the head localization; stage C is the estimation of the ratio of human contour height to head height and the distinguishing of standing, sitting, or kneeling, sitting cross-legged, and other postures; stage D is the judgment of sitting and kneeling according to the relation among the feature points which are three-dimensional spatial; and stage E is the distinguishing bending from lying based on BPNN.
Table 5 deals with the running time in respect of each stage of each posture. The running time of each stage is short on average, that is, the running time of each posture is shorter or equals to 15 ms, which can satisfy the real-time requirement.
Table 5 Running time of stages of each posture (unit: ms)
A previous study [4] judged kneeling posture by the human contour and the ratio of the width of the upper body to that of the lower body. The accuracy was 99.69%, but the experiment had a precondition that the person must orient some fixed direction (± 90°, ± 45°) to the Kinect. The lower body width larger than the upper body width, if the person is facing the Kinect, might cause misjudgment. A previous study [8] utilized four methods to recognize human postures. The best one was the method based on BPNN. However, although its recognition accuracy was 100%, the method could recognize only three postures (standing, sitting, and lying). Its feature values were extracted by skeleton data. Consequently, the method could not extract effective feature values for bending and kneeling postures. Similar to the sitting posture in [4], that in [8] required the person to sit with a fixed posture. The sitting postures of men and women are different. Women often sit elegantly, i.e., sit with legs closed together and sit with the ankle on the knee. Our approach first judges kneeling and sitting postures according to the ratio of human contour height to head height, and then, it distinguishes the two postures according to the relation among the feature points which are three-dimensional spatial. This approach can judge more kneeling postures on condition that people are in various directions of the Kinect (from − 90° to 90°), including the person facing the Kinect, and even elegant sitting posture of women.
The researchers of [7, 25] proposed methods for the purpose of realizing the recognition of ten postures. The three postures in [7] (which are (1) standing, (2) leaning forward, (3) sitting on a chair) and the three postures in [25] (which are (1) standing, (2) sitting, (3) picking up) bear some similarities with standing, sitting, and bending adopted in the study of nowadays, respectively. The method used in [7] was based on the characteristics of angle in respect of the postures as well as polynomial kernel SVM classifier. In addition, the recognition rate in respect of the ten postures was 95.87% on average. In [25], the authors used three-dimensional joint histograms of depth images as well as hidden Markov models for the purpose of classifying postures. We compare these methods with that used in the current study; comparisons can be seen in Table 6.
Table 6 Comparison of the accuracy of several methods (%)
Our hybrid approach has limitations. On the one hand, bending and lying postures cannot be recognized in more directions when the person orients to the Kinect because the feature value is unobvious and cannot extract a better feature value when the person orients to the Kinect at 0°. On the other hand, when the person laterally sits (± 90° oriented to the Kinect), the chair and the stool may be recognized as parts of the human body because of the reflective light of the chair or the stool, which may in turn lead to misjudgment about sitting posture.
In this study, we propose a novel hybrid approach for human body recognition. This approach can recognize six postures, namely, standing, sitting, kneeling, sitting cross-legged, lying, and bending. Different from other studies, we innovatively use the relevant knowledge of anthropometry and preliminarily judge four postures according to the natural ratio of the human body parts. The average recognition rate of all of the six postures is more than 99%. The standing and sitting cross-legged postures can be recognized when the person orients to the Kinect in any direction (from 0° to ±180°), and the recognition rate is 100%; the kneeling and sitting postures can be recognized when the person orients to the Kinect in the direction from 0° to ± 90°, and the recognition rate is more than 97%; and the bending and lying postures are recognized by BPNN, and the recognition rate is more than 99%. However, the bending and lying postures can only be recognized when the person orients to the Kinect in the direction from ± 45° to ± 90°. A part of the body joints is obscured, because we use only one Kinect. Feature vectors are consequently difficult to extract. In the further work, we will use multiple Kinect and aim to recognize human posture in all directions when the person orients to any Kinect.
BPNN:
Back Propagation Neural Networks
L. Xia, C.C. Chen, J.K. Aggarwal, in Computer Vision and Pattern Recognition Workshops IEEE. Human detection using depth information by Kinect (2011), pp. 15–22
J. Shotton, A. Fitzgibbon, M. Cook, T. Sharp, M. Finocchio, R. Moore, A. Kipman, A. Blake, in Computer Vision and Pattern Recognition (CVPR) IEEE. Real-time human pose recognition in parts from single depth images (2011), pp. 1297–1304
J. Shotton, T. Sharp, A. Kipman, et al., Real-time human pose recognition in parts from single depth images. Commun. ACM 56(1), 116–124 (2013)
W.J. Wang, J.W. Chang, S.F. Haung, et al., Human posture recognition based on images captured by the Kinect sensor. Int. J. Adv. Robot. Syst. 13(2), 1 (2016)
S.C. Hsu, J.Y. Huang, W.C. Kao, et al., Human body motion parameters capturing using kinect. Mach. Vis. Appl. 26(7–8), 919–932 (2015)
T.L. Le, M.Q. Nguyen, T.T.M. Nguyen, in International Conference on Computing, Management and Telecommunications IEEE. Human posture recognition using human skeleton provided by Kinect (2013), pp. 340–345
P.K. Pisharady, Kinect based body posture detection and recognition system. Proc. SPIE Int. Soc. Opt. Eng. 8768(1), 87687F (2013) -87687F-5
O. Patsadu, C. Nukoolkit, B. Watanapa, in International Joint Conference on Computer Science and Software Engineering IEEE. Human gesture recognition using Kinect camera (2012), pp. 28–32
Z. Xiao, M. Fu, Y. Yi, et al., in International Conference on Intelligent Human-Machine Systems and Cybernetics IEEE. 3D human postures recognition using Kinect (2012), pp. 344–347
L.A. Schwarz, A. Mkhitaryan, D. Mateus, et al., Human skeleton tracking from depth data using geodesic distances and optical flow ☆. Image Vis. Comput. 30(3), 217–226 (2012)
O. Wasenmüller, D. Stricker, in Asian Conference on Computer Vision. Comparison of Kinect V1 and V2 depth images in terms of accuracy and precision (Springer, Cham, 2016), pp. 34–45
X. Li, Y. Wang, Y. He, G. Zhu, Research on the algorithm of human single joint point repair based on Kinect (a Chinese paper). Tech. Autom. Appl. 35(4), 96–98 (2016)
H. Li, C. Zhang, W. Quan, C. Han, H. Zhai, T. Liu, An automatic matting algorithms of human figure based on Kinect depth image. J Chang Univ Sci Technol 39(6), 81–84 (2016)
Human dimensions of Chinese adults, National standards of P. R. China GB10000–88, 1988
Y. Yin, J. Yang, C.S. Ma, J.H. Zhang, Analysis on difference in anthropomety dimenions between East and West human bodies (a Chinese paper). Standard Sci 7, 10–14 (2015)
Blackwell S, Robinette K M, Boehmer M, et al. Civilian American and European Surface Anthropometry Resource (CAESAR). Volume 2: Descriptions[J]. Civilian American & European Surface Anthropometry Resource, 2002
J. Bougourd, P.U.K. Treleaven, in International Conference on 3d Body Scanning Technologies, Lugano, Switzerland, 19–20 October. National Sizing Survey – Size UK (2010), pp. 327–337
C.D. Fryar, Q. Gu, C.L. Ogden, Anthropometric reference data for children and adults: United States, 2007-2010[J]. Vital Health Stat. 252, 1–48 (2012)
The full results of SizeUK. Database. 2010. [Online]. Available: https://www.arts.ac.uk/__data/assets/pdf_file/0024/70098/SizeUK-Results-Full.pdf.
A. Seidl, R. Trieb, H.J. Wirsching, in World Congress on Ergonomics. SizeGERMANY-the new German anthropometric survey conceptual design, implementation and results (2009)
Han, Artificial Neural Network Tutorial, 1st Ed (Beijing University of Posts and Telecommunications Press, Beijing, 2006), pp. 47–78
H.Y. Shen, Determining the number of BP neural network hidden layer units. J Tianjin Univ Technol 5, 13–15 (2008)
J.M. Nasser, D.R. Fairbairn, The application of neural network techniques to structural analysis by implementing an adaptive finite-element mesh generation. AI EDAM 8(3), 177–191 (1994)
S. Thawornwong, D. Enke, The adaptive selection of financial and economic variables for use with artificial neural networks. Aichi Gakuin Daigaku Shigakkai Shi 56(10), 205–232 (2004)
L. Xia, C.C. Chen, J.K. Aggarwal, in Computer Vision and Pattern Recognition Workshops. IEEE. View invariant human action recognition using histograms of 3D joints (2012), pp. 20–27
The authors feel like showing the sincerest as well as grandest gratitude to the Changchun University of Science and Technology. National Natural Science Foundation of China (Grant No.61602058) partially provides technical support.
This project received great support from the key task project in scientific and technological research of Jilin Province, China (No. 20170203004GX).
Please contact author for data requests.
School of Computer Science and Technology, Changchun University of Science and Technology, Room B-1603, Keji Dasha, Weixing Road No.7186, Changchun, 130022, Jilin, China
Bo Li, Cheng Han & Baoxing Bai
College of Optical and Electronical Information, Changchun University of Science and Technology, Room B-1603, Keji Dasha, Weixing Road No.7186, Changchun, 130022, Jilin, China
Baoxing Bai
Bo Li
Cheng Han
BL and BB conceived and designed the experiments. BL performed the experiments. CH analyzed the data and contributed materials and tools. BL wrote the paper. All authors took part in the discussion of the work described in this paper. All authors read and approved the final manuscript.
Correspondence to Cheng Han.
Li, B., Han, C. & Bai, B. Hybrid approach for human posture recognition using anthropometry and BP neural network based on Kinect V2. J Image Video Proc. 2019, 8 (2019). https://doi.org/10.1186/s13640-018-0393-4
Kinect v2
Human posture recognition
Depth image
Skeleton data
BP neural network
Visual Information Learning and Analytics on Cross-Media Big Data | CommonCrawl |
Full paper | Open | Published: 27 April 2019
Transport of ballistic projectiles during the 2015 Aso Strombolian eruptions
Kae Tsunematsu ORCID: orcid.org/0000-0002-1481-62761,2,
Kyoka Ishii3,4 &
Akihiko Yokoo4
Earth, Planets and Spacevolume 71, Article number: 49 (2019) | Download Citation
Large pyroclasts—often called ballistic projectiles—cause many casualties and serious damage on people and infrastructures. One useful measure of avoiding such disasters is to numerically simulate the ballistic trajectories and forecast where large pyroclasts deposit. Numerical models are based on the transport dynamics of these particles. Therefore, in order to accurately forecast the spatial distribution of these particles, large pyroclasts from the 2015 Aso Strombolian eruptions were observed with a video camera. In order to extrapolate the mechanism of particle transport, we have analyzed the frame-by-frame images and obtained particle trajectories. Using the trajectory data, we investigated the features of Strombolian activity such as ejection velocity, explosion energy, and particle release depth. As gas flow around airborne particles can be one of the strongest controlling factors of particle transport, the gas flow velocities were estimated by comparing the simulated and observed trajectories. The range of the ejection velocity of the observed eruptions was 5.1–35.5 m/s, while the gas flow velocity, which is larger than the ejection velocity, reached a maximum of 90 m/s, with mean values of 25–52 m/s for each bursting event. The particle release depth, where pyroclasts start to move separately from the chunk of magmatic fragments, was estimated to be 11–13 m using linear extrapolation of the trajectories. Although these parabolic trajectories provide us with an illusion of particles unaffected by the gas flow, the parameter values show that the particles are transported by the gas flow, which is possibly released from inside the conduit.
Large pyroclasts (> 10 cm in diameter), often called ballistic projectiles, are ballistic blocks or bombs. They are defined as particles which draw a parabolic trajectory in the air and deposit around the vent. They are not included in the gas–pyroclasts mixture or normally fly out from the volcanic plume. The pyroclasts are hazardous, and sometimes kill people with their destructive energy. Casualties have been reported from volcanoes all over the world: Galeras, Yasur, Popocatepetle, Pacaya (Baxter and Gresham 1997; Cole et al. 2006; Alatorre-Ibargüengoitia et al. 2012; Wardman et al. 2012). Recently, more than 50 people were killed by the 2014 Mt. Ontake eruption and most of the fatalities were caused by ballistic projectiles (Oikawa et al. 2016; Tsunematsu et al. 2016; Yamaoka et al. 2016). Another fatality occurred at Mt. Kusatsu in January 2018 (Mainichi Shimbun 2018) despite the growing awareness (among the public) of the dangers posed by ballistic projectiles, following the Ontake eruption. It is hard to forecast the starting time of phreatic eruptions (Stix and Maarten de Moor 2018). Therefore, in order to avoid such disasters, one should produce hazard maps showing the likely impact area of ballistic projectiles and provide useful guidelines for delineating evacuation zones. Here, we use a numerical simulation based on the dynamics of pyroclast transport to provide constraints on a specific eruption—the 2015 Aso eruptions. We used this as a case study for comparing modeled data with observed particle trajectories. Even though the fatal eruptions reported in the literature were mostly phreatic eruptions, we observed magmatic Strombolian eruptions, because it is difficult to forecast when and where phreatic eruptions will occur. In contrast to the phreatic eruptions, Strombolian eruptions of the Aso volcano occurred intermittently with intervals of minutes to hours. In this study, we provide a unique dataset with which to explore the governing dynamics of ballistic ejecta and discuss its wide applicability for other ballistic studies globally.
The dynamics of ballistic transport in volcanic eruptions are studied using the field observation of deposits (Biass et al. 2016; Fitzgerald et al. 2014; Kilgour et al. 2010; Pistolesi et al. 2011; Swanson et al. 2012; Houghton et al. 2017), by video analysis (Chouet et al. 1974; Iguchi and Kamo 1984; Patrick et al. 2007; Gaudin et al. 2014; Taddeucci et al. 2012, 2014, 2015), by laboratory or field experiments (Alatorre-Ibargüengoitia and DelgadoGranados 2006; Alatorre-Ibargüengoitia et al. 2010; Graettinger et al. 2014, 2015) and by numerical simulations (de' Michieli Vitturi et al. 2010; Tsunematsu et al. 2014, 2016; Alatorre-Ibargüengoitia et al. 2016; Biass et al. 2016). However, there are still some unanswered questions. One of the most important questions is how the gas flow around particles affects the transport dynamics.
Several numerical models of ballistics and large pyroclasts were based on the particle velocity with the drag due to the static atmosphere. The model of Mastin (2001) calculated the drag including a "reduced drag zone", which is defined as a zone where the drag is negligible or absent. The idea of this zone was suggested by reference to Fagents and Wilson (1993), who advocated the model of the velocity decay near the vent in a Vulcanian eruption due to the confined gas pressure under the caprock. It means that the "reduced drag zone" is the zone where the air drag is apparently reduced due to the gas flow. The gas flow around particles mainly consists of the volcanic gas in the eruptive mixture and the atmosphere (Taddeucci et al. 2015). de' Michieli Vitturi et al. (2010) also proposed a model for large pyroclast transport coupling particles and gas flow. Therefore, it is better to obtain the gas flow velocity directly from the observation and apply it to the numerical simulation for assessing the impacted area by ballistic projectiles.
Not so many observations of gas flow velocity have been reported in the literature (Gouhier and Donnadieu 2010, 2011). During Vulcanian eruptions, we need to be at a safe distance, but still close enough to shoot the film at a sufficiently high resolution to recognize large pyroclasts. Therefore, we observed Strombolian eruptions which occurred intermittently with intervals of minutes to hours, and deduced the gas flow velocity from the video images of large pyroclasts.
Our idea is to estimate the flow velocity by comparing the simulated and observed trajectories by varying the drag coefficient. The momentum equation of ballistic transport widely used (Alatorre-Ibargüengoitia et al. 2016; Fitzgerald et al. 2014; Tsunematsu et al. 2016) is as follows.
$$m\frac{{D\vec{\varvec{v}}}}{Dt} = - \frac{{AC_{D } \rho_{a} \left( {\vec{\varvec{v}} - \vec{\varvec{u}}} \right)\left| {\vec{\varvec{v}} - \vec{\varvec{u}}} \right|}}{2} - m\vec{\varvec{g}},$$
where m is the mass of a ballistic block (particle), A is the cross-sectional area of the particle perpendicular to the flow direction, CD is the drag coefficient, ρa is the air density, g is the acceleration due to gravity, \(\varvec{v}\) is the particle velocity, and u is the velocity of gas flow. The drag term is the first term on the right-hand side. As is shown in the drag term, parameters such as CD, A, and the density of particle ρp, which is linked with the mass as \(m = \frac{{\pi D^{3} }}{6}\rho_{p}\) (where D is the particle diameter and \(\rho_{p}\) is the particle density) assuming that particles are spherical, are constitutive parameters. The difference between the particle velocity and the gas flow velocity is a strong factor because it is squared in the drag term. Simulations of large pyroclast transport assigning (or substituting) the realistic gas flow velocity into the model equation would make it possible to forecast the realistic travel distances of large pyroclasts.
Strombolian eruptions were well studied in the Stromboli volcano (Ripepe et al. 1993; Patrick et al. 2007; Pistolesi et al. 2011; Taddeucci et al. 2012, 2014, 2015; Bombrun et al. 2015; Gaudin et al. 2014; Capponi et al. 2016). Strombolian eruptions have been observed in only a few other volcanoes, for example, Mt. Erebus (Aster et al. 2003; Johnson and Aster 2005; Dibble et al. 2008), Yasur Volcano (Meier et al. 2016; Spina et al. 2015), Heimaey (Self et al. 1974; Blackburn et al. 1976), Etna (McGetchin et al. 1974; Gouhier and Donnadieu 2010, 2011) and Alaid (Steinberg and Babenko 1978). Activities of Strombolian eruptions do not always have the same characteristics (e.g., ejection velocity, energy). Therefore, it is worth observing different volcanoes, especially if the volcanic vent area is accessible during the eruption—like it was during the Strombolian activity around the first crater of Aso Nakadake.
Aso volcano is located at the center of Kyushu Island in southwest Japan and is one of the most active volcanoes in the country. Four gigantic pyroclastic flow activities occurred from 300 to 70 ka, which are called Aso-1- Aso-4 eruptions (Ono and Watanabe 1985). The Aso-4 eruption formed the current Aso caldera (Fig. 1a), and after the eruption the Aso bulk composition changed from a basaltic to rhyolitic composition. Inside this caldera, there are 17 cones but only the Nakadake central cone is currently active. In the last 80 years, the Nakadake activity has included ash emissions, incandescence and Strombolian activity emitting basaltic andesite to andesite magma. The 2014–2015 eruption episode included a mixture of these three phenomena and the magma showed an andesitic composition (Saito et al. 2018). Intermittent eruption activity started in November 2014 at the Nakadake first crater (Fig. 1b). Eruptive activities reached their climax from the end of January to the beginning of February 2015 (Zobin and Sudo 2017), and Strombolian and ash-emission activities continued intermittently until the end of April 2015 (Yokoo and Miyabuchi 2015). We carried out a video observation on April 25, 2015.
a A shaded relief map of the Aso caldera. The black square area is a blown-up image of the area in (b). b Location of the active craters in the 2015 eruptions, the video footage, and two monitoring stations of the Aso Volcano Laboratory, Kyoto University (ACM and UMA), based on Google Maps. c The view from the location where the video footage was installed. The view is looking in a northeasterly direction from the ACM station
Setup of the monitoring facilities
The Strombolian eruption was observed from the edge of the cliff, approximately 200 m from the vent center, looking down on the crater with a declination angle of 28° (Fig. 1b). One video camera (Panasonic HV-C700: frame rate was 29.97 frames per second) and an automatic digital camera were installed at the observation point shown in Fig. 1(b, c). The monitoring was carried out from around 3 pm to 8 pm at Japan Standard Time (JST) on April 25, 2015. 21 bursting events were observed, but some particles were not discernable within the video image because of the strong daylight. Only the events that occurred after 7 pm were observed with good contrast between the darkness and the particles (Fig. 2).
a Time sequence and events detected via infrasound and video footage. The upper line shows the events detected by infrasound, and the lower line shows events detected by the camera. Red characters show the events detected by both infrasound and video footage. b Synchronized frame images during each bursting event
To compare the energy of events, based on the acoustic and seismic signals, it is necessary to utilize events detected by both acoustic and video equipment. Therefore, we selected five events which had both acoustic and video data between 7 and 8 pm (Fig. 2a).
The obtained video images were cut out into frames, and the resolution of each frame image was 1920 × 1080 pixels. Given that the video footage was taken from the edge of a depression larger than the eruption vent, the images were calibrated taking into consideration the camera lens distortion. The camera lens distortion is corrected by the camera characteristics of the Panasonic HV-C700. We assumed that our focused screen was above the eruptive vent and tilted because of the declination of the camera, with the latter calculated from the aspect ratio of the vent captured on the video image assuming that the real vent shape is circular. In fact, the vent shape was circular from a bird's-eye view (Fig. 1b). We transformed all images using the rotation matrix with the tilt angle (28°). The relationship between pixel value and the actual length was calculated using a digital elevation model (DEM) and the obtained images. The DEM was constructed using the UAV observation of Yokoo et al. (2019). Consequently, the horizontal resolution was 5.81 cm/pixel and the vertical resolution was 3.95 cm/pixel.
A conceptual flowchart of whole image analyses is shown in Fig. 3. Video images were cut into frames (Fig. 3a, b). After cutting images from the video, the red-glowing pixels in each frame image were recognized using the RGB criteria (where R, G and B denote the value of color in the RGB color model) which we had defined by trying several criteria (Fig. 3c). The details defining each criterion are explained in the Additional file 1 (A).
Flowchart of the whole image analysis
The following image analyses consist of the binarization analysis (Fig. 3d) and trajectory analysis (Fig. 3e). The binarization analysis has been implemented using each frame image to extract the information of particle size and the number of particles. The particles were turned into white and the background area was turned into black in each frame. Consequently, the mean particle size and the approximate particle number are obtained for each event. The details of the binarization process are also explained in the Additional file 1 (B).
The trajectory analysis is performed for 4, 10, 23, 6 and 39 trajectories (82 in total) for events 1–5, respectively (Table 1). The two-dimensional trajectories of particles are derived by merging all frames over the event period. The details of the trajectory analysis are explained in the Additional file 1 (C). Using the extracted trajectories from the video footage, we defined the maximum trajectory height which particles reached, the ejection velocity, the ejection angle and the travel distance (Fig. 3e). Using the trajectory data, we estimated the particle release depth (Fig. 3f) and the gas flow velocity (Fig. 3g). The particle release depth estimation is explained in the discussion section. The method for the estimation of the flow velocity is explained in the next "Estimation of the flow velocity" section.
Table 1 Characteristic parameters of each event obtained from binary images (*1) and trajectory analysis (*2)
The ejection velocity was calculated using the time–velocity relationship as shown in Fig. 4. Unfortunately, we did not measure the velocity component toward or away from the camera because we only used one video camera. Mostly, the plots of \(\left( {t, v_{x} } \right)\) and \(\left( {t, v_{y} } \right)\) appear as straight lines on the graph and these plots were fit with linear equations, where t denotes time, \(v_{x}\) denotes the velocity on the horizontal axis, and \(v_{y}\) denotes the velocity on the vertical axis. We assumed that the vertical and horizontal velocities decrease at a constant rate. To obtain the ejection velocity, the velocity lines in the vertical direction were fit with a linear equation and extrapolated until the ejection height (Fig. 4). The ejection angle \(\theta\) was defined with the velocity component \(v_{x}\) and \(v_{y}\) as \(\theta = 90 - \gamma\), where \(\tan \gamma = \frac{{v_{y} }}{{v_{x} }}\). The maximum height of each trajectory was read from the trajectory in the vertical direction. The travel distance was measured as the horizontal width of each trajectory. These values of travel distance were underestimated because we did not have the velocity component away from the camera.
An example of the velocity profile obtained from trajectory data. Red dots show the velocity in the horizontal direction, and blue dots show the velocity in the vertical direction. A light blue line shows the linear fitting of the vertical velocity, and the R2 value in the figure is its correlation coefficient. The vertical velocity at the vent height, shown with a yellow square, is estimated by extrapolating this linear fitting line
Estimation of the flow velocity
We used Eq. (1) to simulate trajectories with a variable gas flow velocity u of 10–100 m/s. Input parameters were ejection velocity, particle density, particle diameter and the drag coefficient. The values of ejection velocities \(v_{x}\) and \(v_{y}\) and particle size were obtained by trajectory analysis. The particle density was measured using the method of Shea et al. (2010) by measuring the wet and dry weight of particles. It was impossible to take samples on the day of the observation because the eruption continued during and after the observation, while three clasts were sampled on April 29, 4 days after our observation. One of these samples was used for the density measurement. The obtained density value was 616.7 kg/m3. The drag coefficient was varied from 0.6 to 1.2 with reference to the measurement of Alatorre-Ibargüengoitia and DelgadoGranados (2006).
The gas flow velocity was calculated in the same direction as the ejection velocity for each trajectory simulation. An example of the comparison is shown in Fig. 5. In this example, the observed trajectory is as high as the simulated trajectory with a gas flow velocity of 40 m/s. Thus, we estimated the gas flow velocity to be 40 m/s. If the observed trajectory is shown in between the simulated trajectories with a gas flow velocity ranging from 30 to 40 m/s, we estimated the gas flow velocity as 35 m/s. Therefore, for this estimation, the gas flow velocity has a resolution of 5 m/s.
One of the simulated trajectories of event 3 with varying flow velocities derived from a theoretical equation (Eq. 1). The input ejection velocities \(v_{x}\) and \(v_{y}\) are calculated based on the observed trajectory. A drag coefficient (CD) of 0.8 and a particle diameter of 20 cm are used. The mean drag coefficient value of 0.8 is based on the measurements of Alatorre-Ibargüengoitia and DelgadoGranados (2006)
Characteristic parameters obtained from trajectories and particle images
In order to reveal the characteristic features of the 2015 Aso Strombolian eruptions, the mean particle size, the approximate particle number, the maximum trajectory height, the mean ejection velocity and the mean ejection angle for each burst event were derived from the image analysis as shown in Table 1.
The mean particle size measured from the cut-out image for each time frame of the video was in the range of 19–26 cm (Table 1).
The particle size and total number of particles were also obtained from black-and-white images. Particle number is an approximate value because one frame was selected from many frames, but airborne particles that were in one frame may no longer be airborne in subsequent frames. Therefore, the number of particles is an underestimate of the total number of particles in an event.
The maximum trajectory heights, the mean ejection velocities and the mean ejection angles were calculated for each particle trajectory extracted from each event record. During the trajectory analysis, we were not able to extract all of the trajectories because some of them were quite close to each other, especially where particles are concentrated around the crater. Most of the particle trajectories were in our video frame, while only one trajectory from event 3 went higher than our frame boundary. Even though the highest maximum trajectory occurred in event 3, the real maximum was higher than the largest recorded value, and so it must have been more than 60 m above the vent rim. The mean ejection velocity was calculated for each event from the velocity profile. The maximum value (18.8 m/s) of the mean ejection velocity was estimated for event 3, and the minimum value (6.0 m/s) for event 1 (Table 1). Among all trajectories, the maximum value was 35.5 m/s (the highest trajectory of event 3) and the minimum value was 5.1 m/s (the lowest trajectory of event 1). The range of ejection angles was 0.1°–25.8°, while the range of mean ejection angles was 4.6°–11.1° (Table 1). The range of travel distances was 8.9–17.8 m (Table 1).
By comparing the observed and simulated trajectories, we estimated the gas flow velocity. The mean flow velocity for each event with the standard deviation is shown in Table 2 and the mean values are plotted in Fig. 6. The estimated gas flow velocity for each event decreases as the drag coefficient value increases. The fastest flow velocity is estimated to be 90 m/s for the maximum trajectory of event 3 with the drag coefficient CD= 0.6.
Table 2 Estimated gas flow velocities (m/s) derived by comparing simulated and observed trajectories
Estimated gas flow velocities. The drag coefficient values range from 0.62 to 1.01 and represent the measured drag coefficient based on experiments that were conducted with the ballistic projectiles of Popocatépetl volcano (Alatorre-Ibargüengoitia and DelgadoGranados 2006)
Characteristic parameters of the 2015 Aso Strombolian eruptions
Our results show the basic features of the 2015 Aso Strombolian eruptions such as particle sizes, trajectory heights and ejection velocities (Table 1). We also estimated the acoustic energy and seismic energy for each event (Table 3).
Table 3 Estimated acoustic and seismic energies based on recorded waves
Seismic and acoustic waves were recorded by the network of the Aso Volcanological Laboratory of Kyoto University. The acoustic pressure monitored at the ACM station (290 m from the vent, Fig. 1b) was utilized for calculating the acoustic energy. The seismic velocity monitored at the UMA station (830 m from the vent, Fig. 1b) was utilized for calculating the seismic energy. To estimate the explosion energy, we calculated the acoustic and seismic energy using the equations (1) and (2), respectively, from Johnson and Aster (2005). The method of estimating the energies is explained in the Additional file 1 (D).
The values are compared to other Strombolian eruptions (Tables 4, 5). The ejection velocities of large pyroclasts during the 2015 events are 5.1–35.5 m/s, and these are in the range of other Strombolian eruptions, as the 2015 Aso eruptions are the third smallest among the listed eruptions. Sometimes, the ejection velocity of Strombolian eruptions reaches > 100 m/s (Table 4). This comparison simply shows that the size of the 2015 Aso Strombolian eruptions was small in terms of the ejection velocity, but the ejection velocity is in the range of other Strombolian eruptions.
Table 4 Ballistic ejection velocities of Strombolian eruptions
Table 5 Orders of kinetic, acoustic and seismic energies estimated for Strombolian eruptions
The order of acoustic energy obtained in our study is smaller than the kinetic energy of Gaudin et al. (2014), but larger than other observed eruptions (Table 5). The order of seismic energy was in between the maximum and minimum of other observations (Table 5). Correlation between the acoustic and seismic energies for each event is shown in the Additional file 1 (Fig. S-5).
The relationships between characteristic parameters of events are shown in Fig. 7. The ejection velocity is correlated with the maximum height (Fig. 7a). It is understandably intuitive that a particle released at a faster speed can reach a higher altitude. On the other hand, particle size does not show any correlation with maximum height or ejection velocity (Fig. 7b, c). We often observed that large particles fell on the ground around the vent and the deposited particles decreased in size with distance from the vent. Therefore, we anticipated that there is a negative correlation between the particle size and the kinetic energy at the vent, which can be represented by the maximum height and the ejection velocity. However, as there is no correlation between them, there is no clear relationship between the kinetic energy at the vent and the particle size in observed events.
Correlation plots between the characteristic parameters obtained for each trajectory. a The maximum height and the vertical ejection velocity. b The maximum height and the particle size. c The ejection velocity and the particle size
Explosion and particle release depths
Magma fragmentation is defined as the breakup of a continuous volume of molten rock into discrete pieces, called pyroclasts (Gonnermann 2015). During explosive eruptions, magma is fragmented in the conduit and at a certain depth pyroclasts are thrown into the air. Thus, the explosion depth and the particle release depth are the keys to understanding how pyroclasts are transported.
To obtain the particle release depth, the particle trajectories were extrapolated by straight lines into the conduit (Fig. 8). A similar method was used in Dürig et al. (2015), but we did not use the cut-off angle or the trajectory intersection because the trajectories intersected with each other at multiple points during the same event (Fig. 8). In order to obtain the best fit release depth, we used the convergence point of the trajectories in the blurry image. In other words, the particle release depth was defined as the depth where the width of the bouquet of trajectories was narrowest. The obtained particle release depth and the convergence width are shown in Table 6. The depths were estimated to be within a small range from 11 to 13 m. Trajectory convergence widths in a horizontal direction were within a wider range from 1.4 to 10.6 m.
Trajectories extrapolated back into the conduit to estimate the particle release depth. Straight lines show the convergence at a depth of 11–13 m (Table 6). The convergence width in a horizontal direction is shown in Table 6
Table 6 Estimated particle release depth by linear extrapolation of trajectories
Ishii et al. (2019) estimated the depth of the explosion to be shallower than 400 m from the vent based on acoustic and seismic data. Observed seismicity is believed to occur as a result of the brittle magma fractures, and the depth obtained by Ishii et al. (2019) is interpreted as the fragmentation depth due to the explosion. Our estimated particle release depths are in the range of their estimation, while the range of the particle release depths based on the trajectories is much shallower than the lower limit value (400 m) of Ishii et al. (2019). The following is a possible scenario if these two types of depths were caused by different reasons; a series of explosions or magma fragmentation probably occurred shallower than 400 m depth, and fragmented magma and gas rose together in the cylindrical conduit. At around the 11–13 m depth, the conduit became wider forming a conical shape and the release of the pressure in the conduit caused the magmatic particles to be thrown into the air.
Probably, the interaction between gas and particles in the conduit affects the particle ejection velocity at the vent. In the future, the relationship between the ejection velocity, the length between fragmentation level and the particle release depth, and the gas flow velocity should be studied experimentally or numerically.
Gas flow and drag effect
The graph in Fig. 6 shows that the estimated gas flow velocity decreases as the assumed drag coefficient increases. This relationship is what we can derive from Eq. (1). According to Eq. (1), the drag term is proportional to the drag coefficient CD, the squared difference between the particle velocity and the gas flow velocity \(\left( {v - u} \right)^{2}\). If the gas flow velocity is larger than particle velocity \(\left( {v < u} \right)\), then the gas flow velocity becomes small when the drag coefficient increases. Our estimation results show that the gas flow velocity is larger than the particle ejection velocity \(\left( {v < u} \right)\) and the trend of our estimation is reasonable. However, we cannot estimate the drag coefficient from this process. Taddeucci et al. (2017) estimated the drag coefficient value based on their observation using the high-speed camera. The maximum value of the drag coefficient, calculated using the averaged particle velocity and the flow velocity by Taddeucci et al. (2017), was very large (e.g., CD > 3.0). Their observation only shows a part of the particle trajectories (< 2 s); thus, they could have assumed the velocity was constant only in a small time frame. The particle velocity and the flow velocity, however, vary with time in nature. Therefore, we suspect that the drag coefficient can reach such a high value (CD > 3.0), and it is more realistic to use the drag coefficient values obtained by experiments such as those of Alatorre-Ibargüengoitia and DelgadoGranados (2006) and Bagheri and Bonadonna (2016). The range of drag coefficient measured by Alatorre-Ibargüengoitia and DelgadoGranados (2006) was 0.62–1.01. In this range, the mean gas flow velocity of each event ranges from 25 to 52 m/s. This gas flow velocity range is similar to the value (< 50 m/s) obtained for the Strombolian eruption in the Stromboli volcano by Patrick et al. (2007), based on thermal imagery.
These estimated velocities have a weak correlation with particle size. As shown in Fig. 9, the estimated gas flow velocity increases with particle size. It implies that the larger particles are pushed by the stronger gas flow more than smaller particles when they appear above the vent. Presumably, the relationship between particle size and the gas flow velocity would be clearer if we had another camera and knew the velocity component away from the camera. Observing the gas flow effect using a three-dimensional view should be tried in the future.
Plots of estimated flow velocity against particle size
Alatorre-Ibargüengoitia et al. (2011) and Cigala et al. (2017) experimentally showed that the ejection velocity had a negative correlation with the tube length, which was interpreted as the distance from the fragmentation level in the volcanic conduit to the vent surface. Although the mechanism behind the relationship between tube length and ejection velocity is vague, the ascent process of the gas and particle mixture in the conduit controls the ejection velocity and the gas flow velocity after the ejection. As we have shown in the former section, we also obtained the particle release depth. Discussion about the particle and gas transport in the conduit will be possible if we obtain such a dataset from more eruptions.
We could estimate the gas flow velocity based on the comparison between simulated and observed particle trajectories, and these data are possibly useful for governing the transport dynamics of large pyroclasts in Strombolian eruptions, while there is an assumption that the gas flow velocity is constant. However, the gas flow velocity would decrease with time and distance from the vent. In the future, we should directly observe the gas flow and derive the velocity changes; for example, an observation using an infrared camera may enable the visualization of the gas flow velocity. Moreover, if the frame rate and the resolution of video images were higher (e.g., high-speed camera), the observed ejection velocity might be faster and other parameters may be estimated more precisely.
The simulation coupled with the gas flow was reported by de' Michieli Vitturi et al. (2017). They implemented the simulation of ballistic projectiles by coupling with the gas flow. They successfully reproduced the deposit distribution of ballistic projectiles from the Mt. Ontake eruption; however, the pressure value was unknown, and they could not clearly discuss how these parameters worked in a real eruption. In this sense, acoustic observation is useful for detecting the pressure change at the time of the eruption. The direct observation with multiple facilities such as high-speed cameras and acoustics could be useful for revealing the gas flow effect.
To mitigate the ballistic hazard, it is necessary to evacuate people from the possible affected area around the vent before an eruption starts. Otherwise, the ballistic projectiles fall on people around the vent because of their fast transport speed. In that sense, we should know the affected area with higher precision. Therefore, we implemented our analysis of large pyroclasts of the 2015 Aso Strombolian eruptions and tried to elucidate the dynamics of the ballistic transport.
We observed the Strombolian events on April 25, 2015, and analyzed the video images for five selected events in order to investigate the gas flow effect on the particle transport of large pyroclasts (> 10 cm). The particle size and the particle number for each event were estimated from cut-out frame images by converting them into binary images. Eighty-two trajectories were obtained by choosing the red-glowing positions, and the maximum height, ejection velocity and ejection angle were estimated from the trajectory data. Moreover, we estimated the particle release depth extrapolating trajectories into the conduit. Finally, the gas flow velocity was estimated varying the drag coefficient CD by comparing the simulated and observed trajectories.
The ejection velocity of particles ranges from 5.1 to 35.5 m/s. The maximum ejection velocity was the third smallest among the listed Strombolian eruptions.
Depth estimation based on the particle trajectories and the difference of the acoustic–seismic arrival time revealed two depths possibly representing the magma fragmentation depth (< 400 m) and particle release depth (~ 12 m).
The maximum gas flow velocity estimated for each trajectory was 90 m/s, and the velocity values decrease with the drag coefficient. This trend is reasonable based on the theoretical relationship according to Eq. (1), and the range of the gas flow velocity for each event (25–52 m/s) agrees with the estimation of the Strombolian eruption (< 50 m/s) by Patrick et al. (2007). The dataset of the particle release depth and the gas flow velocity are useful for revealing the particle–gas mixture transport mechanism not only in the air but also in the conduit.
Although we could have estimated the gas flow velocity and investigated aspects of the large pyroclast transport, the dynamics of the transport remain unclear because the gas flow was not observed directly in three dimensions. In the future, it is necessary to observe the large pyroclast transport with the gas flow more carefully at higher resolution and higher frame rate. The numerical model of large pyroclast transport should be improved based on the findings from further observations.
Alatorre-Ibargüengoitia MA, DelgadoGranados H (2006) Experimental determination of drag coefficient for volcanic materials: calibration and application of a model to Popocatépetl volcano (Mexico) ballistic projectiles. Geophys Res Lett 33:L11302. https://doi.org/10.1029/2006GL026195
Alatorre-Ibargüengoitia MA, Scheu B, Dingwell DB, Delgado-Granados H, Taddeucci J (2010) Energy consumption by magmatic fragmentation and pyroclast ejection during Vulcanian eruptions. Earth Planet Sci Lett 291(1–4):60–69. https://doi.org/10.1016/j.epsl.2009.12.051
Alatorre-Ibargüengoitia MA, Scheu B, Dingwell DB (2011) Influence of the fragmentation process on the dynamics of Vulcanian eruptions: an experimental approach. Earth Planet Sci Lett 302(1–2):51–59. https://doi.org/10.1016/j.epsl.2010.11.045
Alatorre-Ibargüengoitia MA, Delgado-Granados H, Dingwell DB (2012) Hazard map for volcanic ballistic impacts at Popocatépetl volcano (Mexico). Bull Volcanol 74(9):2155–2169
Alatorre-Ibargüengoitia MA, Morales-Iglesias H, Ramos-Hernández SG, Jon-Selvas J, Jiménez-Aguilar JM (2016) Hazard zoning for volcanic ballistic impacts at El Chichón Volcano (Mexico). Nat Hazards 81:1733. https://doi.org/10.1007/s11069-016-2152-0
Aster R, MacIntosh W, Kyle P, Esser R, Bartel B, Dunbar N, Johnson J, Karstens R, Kurnik C, McGowan M, McNamara S, Meertens C, Pauly B, Richmond M, Ruiz M (2003) Very long period oscillations of Mount Erebus Volcano, very long period oscillations of Mount Erebus Volcano. J Geophys Res 108(B11):2522. https://doi.org/10.1029/2002JB002101
Bagheri G, Bonadonna C (2016) On the drag of freely falling non-spherical particles. Powder Technol 301:526–544. https://doi.org/10.1016/j.powtec.2016.06.015
Baxter PJ, Gresham A (1997) Deaths and injuries in the eruption of Galeras Volcano, Colombia, 14 January 1993. J Volcanol Geotherm Res 77:325–338
Biass S, Falconec J-L, Bonadonna C, Di Traglia F, Pistolesi M, Rosi M, Lestuzzi P (2016) Great Balls of Fire: a probabilistic approach to quantify the hazard related to ballistics—a case study at La Fossa volcano, Vulcano Island, Italy. J Volcanol Geotherm Res 325:1–14. https://doi.org/10.1016/j.jvolgeores.2016.06.006
Blackburn EA, Wilson L, Sparks RSJ (1976) Mechanisms and dynamics of strombolian activity. J Geol Soc Lond 132:429–440
Bombrun M, Harris A, Gurioli L, Battaglia J, Barra V (2015) Anatomy of a Strombolian eruption: inferences from particle data recorded with thermal video. J Geophys Res Solid Earth 120:2367–2387. https://doi.org/10.1002/2014JB011556
Capponi A, James MR, Lane SJ (2016) Gas slug ascent in a stratified magma: implications of flow organisation and instability for Strombolian eruption dynamics. Earth Planet Sci Lett 435:159–170. https://doi.org/10.1016/j.epsl.2015.12.028
Chouet B, Hamisevicz N, Mcgetchin TR (1974) Photoballistics of volcanic jet activity at Stromboli Italy. J Geophys Res 79:4961–4976
Cigala V, Kueppers U, Peña Fernández JJ, Taddeucci J, Sesterhenn J, Dingwell DB (2017) The dynamics of volcanic jets: temporal evolution of particles exit velocity from shock-tube experiments. J Geophys Res Solid Earth 122:6031–6045. https://doi.org/10.1002/2017JB014149
Cole JW, Cowan HA, Webb TA (2006) The 2006 Raoul Island Eruption—a review of GNS science's actions. GNS Science Report 2006/7 38 p
de' Michieli Vitturi M, Neri A, Esposti Ongaro T, Lo Savio S, Boschi E (2010) Lagrangian modeling of large volcanic particles: application to Vulcanian explosions. J Geophys Res. https://doi.org/10.1029/2009jb007111
de' Michieli Vitturi M, Esposti Ongaro T, Tsunematsu K (2017) Phreatic explosions and ballistic ejecta: a new numerical model and its application to the 2014 Mt. Ontake eruption, IAVCEI 2017 Scientific Assembly Abstract, 246
Dibble RR, Kyle PR, Rowe CA (2008) Video and seismic observations of Strombolian eruptions at Erebus volcano, Antarctica. J Volcanol Geotherm Res 177(3):619–634. https://doi.org/10.1016/j.jvolgeores.2008.07.020
Dubosclard G, Donnadieu F, Allard P, Cordesses R, Hervier C, Coltelli M, Privitera E, Kornprobst J (2004) Doppler radar sounding of volcanic eruption dynamics at Mount Etna. Bull Volcanol 66:443. https://doi.org/10.1007/s00445-003-0324-8
Dürig T, Gudmundsson MT, Dellino P (2015) Reconstruction of the geometry of volcanic vents by trajectory tracking of fast ejecta—the case of the Eyjafjallajökull 2010 eruption (Iceland). Earth Planets Space 67:64. https://doi.org/10.1186/s40623-015-0243-x
Fagents SA, Wilson L (1993) Explosive volcanic eruptions: VII. The ranges of pyroclasts ejected in transient volcanic explosions. Geophys J Int 113:359–370
Fitzgerald RH, Tsunematsu K, Kennedy BM, Breard ECP, Lube G, Wilson TM, Jolly AD, Pawson J, Rosenberg MD, Cronin SJ (2014) The application of a calibrated 3D ballistic trajectory model to ballistic hazard assessments at Upper Te Maari, Tongariro. J Volcanol Geotherm Res 286:248–262. https://doi.org/10.1016/j.jvolgeores.2014.04.006
Gaudin D, Moroni M, Taddeucci J, Scarlato P, Shindler L (2014) Pyroclast Tracking Velocimetry: a particle tracking velocimetry-based tool for the study of Strombolian explosive eruptions. J Geophys Res Solid Earth 119(7):5369–5383. https://doi.org/10.1002/2014JB011095
Gerst A, Hort M, Kyle PR, Vöge M (2008) 4D velocity of Strombolian eruptions and man-made explosions derived from multiple Doppler radar instruments. J Volcanol Geotherm Res 177(3):648–660. https://doi.org/10.1016/j.jvolgeores.2008.05.022
Gonnermann HM (2015) Magma fragmentation. Annu Rev Earth Planet Sci 43:431–458. https://doi.org/10.1146/annurev-earth-060614-105206
Gouhier M, Donnadieu F (2010) The geometry of Strombolian explosions: insights from Doppler radar measurements. Geophys J Int 183(3):1376–1391. https://doi.org/10.1111/j.1365-246X.2010.04829.x
Gouhier M, Donnadieu F (2011) Systematic retrieval of ejecta velocities and gas fluxes at Etna volcano using L-Band Doppler radar. Bull Volcanol 73:1139–1145
Graettinger AH, Valentine GA, Sonder I, Ross PS, White JDL, Taddeucci J (2014) Maar-diatreme geometry and deposits: subsurface blast experiments with variable explosion depth. Geochem Geophys Geosys 15:740–764. https://doi.org/10.1002/2013GC005198
Graettinger AH, Valentine GA, Sonder I, Ross P-S, White JDL (2015) Facies distribution of ejecta in analog tephra rings from experiments with single and multiple subsurface explosions. Bull Volcanol 77:66. https://doi.org/10.1007/s00445-015-0951-x
Harris AJL, Ripepe M, Hughes EA (2012) Detailed analysis of particle launch velocities, size distributions and gas densities during normal explosions at Stromboli. J Volcanol Geotherm Res 231–232:109–131. https://doi.org/10.1016/j.jvolgeores.2012.02.012
Hort M, Seyfried R (1998) Volcanic eruption velocities measured with a micro radar. Geophys Res Lett 25:113–116
Hort M, Seyfried R, Vöge M (2003) Radar Doppler velocimetry of volcanic eruptions: theoretical considerations and quantitative documentation of changes in eruptive behaviour at Stromboli volcano, Italy. Geophys J Int 154:515–532
Houghton BF, Swanson DA, Biass S, Fagents SA, Orr TR (2017) Partitioning of pyroclasts between ballistic transport and a convective plume: Kīlauea volcano, 19 March 2008. J Geophys Res Solid Earth 122:3379–3391. https://doi.org/10.1002/2017JB014040
Iguchi M, Kamo K (1984) On the range of block and lapilli ejected by the volcanic explosions. Disaster Prev Res Inst Annu 27B–1:15–27 (in Japanese with an English abstract)
Ishii K, Yokoo A, Kagiyama T, Ohkura T, Yoshikawa S, Inoue H (2019) Gas flow dynamics in the conduit of Strombolian eruptions inferred from seismo-acoustic observations at Aso volcano, Japan. Earth Planets Space 71:13. https://doi.org/10.1186/s40623-019-0992-z
Johnson JB, Aster RC (2005) Relative partitioning of acoustic and seismic energy during Strombolian eruptions. J Volcanol Geotherm Res 148:334–354. https://doi.org/10.1016/j.jvolgeores.2005.05.002
Kilgour G, Manville V, Della Pasqua F, Graettinger A, Hodgson KA, Jolly GE (2010) The 25 September 2007 eruption of Mount Ruapehu, New Zealand: directed ballistics, surtseyan jets, and ice-slurry lahars. J Volcanol Geotherm Res 191:1–14
Mainichi Shimbun (2018) The eruption of Kusatsushirane Volcano, one Self Defense Force Personnel died and 11 people seriously injured, 23 Jan 2018, Mainichi Shimbun, Retrieved from https://mainichi.jp/articles/20180124/k00/00m/040/112000c (in Japanese)
Mastin LG (2001) A simple calculator of ballistic trajectories for blocks ejected during volcanic eruptions. U.S. Geological Survey Open-File Report 01-45, 16 pp. Retrieved 1 January, 2016 from http://pubs.usgs.gov/of/2001/0045/
McGetchin TR, Settle M, Chouet BA (1974) Cinder cone growth modeled after Northeast Crater, Mount Etna, Sicily. J Geophys Res 79(23):3257–3272
Meier K, Hort J, Wassermannb M, Garaebiti E (2016) Strombolian surface activity regimes at Yasur volcano, Vanuatu, as observed by Doppler radar, infrared camera and infrasound. J Volcanol Geotherm Res 322:184–195. https://doi.org/10.1016/j.jvolgeores.2015.07.038
Oikawa T, Yoshimoto M, Nakada S, Maeno Komori J, Shimano T, Takeshita Y, Ishizuka Y, Ishimine Y (2016) Reconstruction of the 2014 eruption sequence of Ontake Volcano from recorded images and interviews. Earth Planets Space 68:79. https://doi.org/10.1186/s40623-016-0458-5
Ono K, Watanabe K (1985) Geological map of Aso volcano. Geological Map of Volcanoes, no. 4, Geological Survey of Japan, AIST (in Japanese with English abstract)
Patrick MR, Harris AJL, Ripepe M, Dehn J, Rothery DA, Calvari S (2007) Strombolian explosive styles and source conditions: insights from thermal(FLIR) video. Bull Volcanol 69:769–784
Pistolesi M, Delle Donne D, Pioli L, Rosi M, Ripepe M (2011) The 15 March 2007 explosive crisis at Stromboli volcano, Italy: assessing physical parameters through a multidisciplinary approach. J Geophys Res. https://doi.org/10.1029/2011jb008527
Ripepe M, Rossi M, Saccorotti G (1993) Image processing of explosive activity at Stromboli. J Volcanol Geotherm Res 54(3–4):335–351. https://doi.org/10.1016/0377-0273(93)90071-X
Ripepe M, Ciliberto S, Schiava MD (2001) Time constraints for modeling source dynamics of volcanic explosions at Stromboli. J Geophys Res 106(B5):8713–8727
Saito G, Ishizuka O, Ishizuka Y, Hoshizumi H, Miyagi I (2018) Petrological characteristics and volatile content of magma of the 1979, 1989, and 2014 eruptions of Nakadake, Aso volcano, Japan. Earth Planets Space 70:197. https://doi.org/10.1186/s40623-018-0970-x
Self S, Sparks RSJ, Booth B, Walker GPL (1974) The 1973 Heimaey strombolian scoria deposit, Iceland. Geol Mag 111(6):539–548
Shea T, Houghton BF, Gurioli L, Cashman KV, Hammer JE, Hobden BJ (2010) Textural studies of vesicles in volcanic rocks: an integrated methodology. J Volcanol Geotherm Res 190:3–4
Spina L, Taddeucci J, Cannata A, Gresta S, Lodato L, Privitera E, Scarlato P, Gaeta M, Gaudin D, Palladino DM (2015) Explosive volcanic activity at Mt. Yasur: a characterization of the acoustic events (9–12th July 2011). J Volcanol Geotherm Res 322:175–183. https://doi.org/10.1016/j.jvolgeores.2015.07.027
Steinberg GS, Babenko JL (1978) Experimental velocity and density determination of volcanic gases during eruption. J Volcanol Geotherm Res 3:89–98
Stix J, Maarten de Moor J (2018) Understanding and forecasting phreatic eruptions driven by magmatic degassing. Earth Planets Space 70:83. https://doi.org/10.1186/s40623-018-0855-z
Swanson DA, Zolkos SP, Haravitch B (2012) Ballistic blocks around Kīlauea Caldera: their vent locations and number of eruptions in the late 18th century. J Volcanol Geotherm Res 231–232:1–11. https://doi.org/10.1016/j.jvolgeores.2012.04.008
Taddeucci J, Alatorre-Ibargüengoitia MA, Moroni M, Tornetta L, Capponi A, Scarlato AP, Dingwell DB, De Rita D (2012) Physical parameterization of Strombolian eruptions via experimentally-validated modeling of high-speed observations. Geophys Res Lett 39:L16306. https://doi.org/10.1029/2012gl052772
Taddeucci J, Sesterhenn J, Scarlato P, Stampka K, Del Bello E, Pena Fernandez JJ, Gaudin D (2014) Highspeed imaging, acoustic features, and aeroacoustic computations of jet noise from Strombolian (and Vulcanian) explosions. Geophys Res Lett 41:3096–3102. https://doi.org/10.1002/2014GL059925
Taddeucci J, Alatorre-Ibarguengoitia MA, Palladino DM, Scarlato P, Camaldo C (2015) High-speed imaging of Strombolian eruptions: gas-pyroclast dynamics in initial volcanic jets. Geophys Res Lett 42(15):6253–6260. https://doi.org/10.1002/2015GL064874
Taddeucci J, Alatorre-Ibargüengoitia MA, Cruz-Vázquez O, Del Bello E, Scarlato P, Ricci T (2017) In-flight dynamics of volcanic ballistic projectiles. Rev Geophys 55(3):675–718. https://doi.org/10.1002/2017RG000564
Tsunematsu K, Chopard B, Falcone JL, Bonadonna C (2014) A numerical model of ballistic transport with collisions in a volcanic setting. Comput Geosci 63:62–69. https://doi.org/10.1016/j.cageo.2013.10.016
Tsunematsu K, Ishimine Y, Kaneko T, Yoshimoto M, Fujii T, Yamaoka K (2016) Estimation of ballistic block landing energy during 2014 Mount Ontake eruption. Earth Planets Space 68:88. https://doi.org/10.1186/s40623-016-0463-8
Wardman J, Sword-Daniels V, Stewart C, Wilson T (2012) Impact assessment of the May 2010 eruption of Pacaya volcano, Guatemala. GNS Science Report 2012/09, 90 p
Weill A, Brandeis G, Vergniolle S, Baudin F, Bilbille J, Fevre JF, Piron B, Hill X (1992) Acoustic sounder measurements of the vertical velocity of volcanic jets at Stromboli volcano. Geophys Res Lett 19(23):2357–2360
Yamaoka K, Geshi N, Hashimoto T, Ingebritsen SE, Oikawa T (2016) Special issue "The phreatic eruption of Mt. Ontake volcano in 2014". Earth Planets Space 68:175. https://doi.org/10.1186/s40623-016-0548-4
Yokoo A, Miyabuchi Y (2015) Eruption at the Nakadake 1st Crater of Aso Volcano Started in November 2014. Bull Volcanol Soc Jpn 60(2):275–278 (in Japanese)
Yokoo A, Ishii K, Ohkura T, Kim K (2019) Monochromatic infrasound waves observed during the 2014-2015 eruption of Aso volcano, Japan. Earth Planets Space 71:12. https://doi.org/10.1186/s40623-019-0993-y
Zobin VM, Sudo Y (2017) Source properties of Strombolian explosions at Aso volcano, Japan, derived from seismic signals. Phys Earth Planet Inter 268:1–10. https://doi.org/10.1016/j.pepi.2017.05.002
KT and YA carried out the field observation. KI analyzed the acoustic and seismic data. KT analyzed the images. All authors read and approved the final manuscript.
We would like to thank the editor and two reviewers for their useful discussion and suggestions. We are grateful to Dr. Toshiaki Hasenaka for providing a rock sample from one of the 2015 Aso eruptions. We are grateful to Dr. Kazama and Dr. Yoshikawa for providing the DEM data obtained by UAV monitoring.
The datasets used and/or analyzed during the current study are available from the corresponding author on reasonable request.
Kae Tsunematsu was supported by the Japan Society for the Promotion of Science (JSPS) KAKENHI Grant Number 15K01256.
Faculty of Science, Yamagata University, Yamagata-shi, 990-8560, Yamagata, Japan
Kae Tsunematsu
Mount Fuji Research Institute, Yamanashi Prefectural Government, Japan, 5597-1 Kenmarubi Kamiyoshida, Fujiyoshida-shi, 403-0005, Yamanashi, Japan
Department of Geophysics, Graduate School of Science, Kyoto University, Kyoto, 606-8502, Kyoto, Japan
Kyoka Ishii
Aso Volcanological Laboratory, Graduate School of Science, Kyoto University, Aso-shi, 869-2611, Kumamoto, Japan
& Akihiko Yokoo
Search for Kae Tsunematsu in:
Search for Kyoka Ishii in:
Search for Akihiko Yokoo in:
Correspondence to Kae Tsunematsu.
Additional file
Additional file 1. Methods in detail are provided. (A) Defining RGB criteria, (B) Binary Image Analysis, (C) Trajectory Analysis and (D) Acoustic and Seismic energy estimation.
Gas flow
Strombolian eruptions
5. Volcanology
Advancement of our knowledge on Aso volcano: Current activity and background | CommonCrawl |
Over 3 years (18)
Physics And Astronomy (15)
Earth and Environmental Sciences (5)
Laser and Particle Beams (8)
Journal of Fluid Mechanics (4)
Zygote (2)
British Journal of Nutrition (1)
ESAIM: Mathematical Modelling and Numerical Analysis (1)
Mineralogical Magazine (1)
Twin Research and Human Genetics (1)
Ryan Test (4)
International Soc for Twin Studies (1)
Mineralogical Society (1)
Nutrition Society (1)
Follicular structures of cows with cystic ovarian disease present altered expression of cytokines
Antonela F. Stassi, Natalia C. Gareis, Belkis E. Marelli, Valentina Matiller, Cristian J.M. Leiva, Florencia Rey, Hugo H. Ortega, Natalia R. Salvetti, M. Eugenia Baravalle
Journal: Zygote / Volume 27 / Issue 5 / October 2019
Published online by Cambridge University Press: 15 August 2019, pp. 285-298
Print publication: October 2019
Ovulation is considered an inflammatory, cytokine-mediated event. Cytokines, which are recognized as growth factors with immunoregulatory properties, are involved in many cellular processes at the ovarian level. In this sense, cytokines affect fertility and are involved in the development of different ovarian disorders such as bovine cystic ovarian disease (COD). Because it has been previously demonstrated that ovarian cells represent both sources and targets of cytokines, the aim of this study was to examine the expression of several cytokines, including IL-1β, IL-1RA, IL-1RI, IL-1RII, IL-4 and IL-8, in ovarian follicular structures from cows with spontaneous COD. The protein expression of these cytokines was evaluated by immunohistochemistry. Additionally, IL-1β, IL-4 and IL-8 concentrations in follicular fluid (FF) and serum were determined by enzyme-linked immunosorbent assay (ELISA). In granulosa and theca cells, IL-1RI, IL-1RII, IL-1RA and IL-4 expression levels were higher in cystic follicles than in the control dominant follicles. The serum and FF concentrations of IL-1β and IL-4 showed no differences between groups, whereas IL-8 concentration was detected only in FF of cysts from cows with COD. The FF and serum concentrations of IL-1β and IL-8 showed no significant differences, whereas IL-4 concentration was higher in FF than in serum in both the control and COD groups. These results evidenced an altered expression of cytokines in ovaries of cows with COD that could contribute to the pathogenesis of this disease.
A Lagrangian probability-density-function model for collisional turbulent fluid–particle flows
A. Innocenti, R. O. Fox, M. V. Salvetti, S. Chibbaro
Journal: Journal of Fluid Mechanics / Volume 862 / 10 March 2019
Published online by Cambridge University Press: 11 January 2019, pp. 449-489
Print publication: 10 March 2019
Inertial particles in turbulent flows are characterised by preferential concentration and segregation and, at sufficient mass loading, dense particle clusters may spontaneously arise due to momentum coupling between the phases. These clusters, in turn, can generate and sustain turbulence in the fluid phase, which we refer to as cluster-induced turbulence (CIT). In the present work, we tackle the problem of developing a framework for the stochastic modelling of moderately dense particle-laden flows, based on a Lagrangian probability-density-function formalism. This framework includes the Eulerian approach, and hence can be useful also for the development of two-fluid models. A rigorous formalism and a general model have been put forward focusing, in particular, on the two ingredients that are key in moderately dense flows, namely, two-way coupling in the carrier phase, and the decomposition of the particle-phase velocity into its spatially correlated and uncorrelated components. Specifically, this last contribution allows us to identify in the stochastic model the contributions due to the correlated fluctuating energy and to the granular temperature of the particle phase, which determine the time scale for particle–particle collisions. The model is then validated and assessed against direct-numerical-simulation data for homogeneous configurations of increasing difficulty: (i) homogeneous isotropic turbulence, (ii) decaying and shear turbulence and (iii) CIT.
Separation control and drag reduction for boat-tailed axisymmetric bodies through contoured transverse grooves
A. Mariotti, G. Buresti, G. Gaggini, M. V. Salvetti
Journal: Journal of Fluid Mechanics / Volume 832 / 10 December 2017
Published online by Cambridge University Press: 26 October 2017, pp. 514-549
Print publication: 10 December 2017
We describe the results of a numerical and experimental investigation aimed at assessing the performance of a control method to delay boundary layer separation consisting of the introduction on the surface of contoured transverse grooves, i.e. of small cavities with an appropriate shape orientated transverse to the incoming flow. The shape of the grooves and their depth – which must be significantly smaller than the thickness of the incoming boundary layer – are chosen so that the flow recirculations present within the grooves are steady and stable. This passive control strategy is applied to an axisymmetric bluff body with various rear boat tails, which are characterized by different degrees of flow separation. Variational multiscale large eddy simulations and wind tunnel tests are carried out. The Reynolds number, for both experiments and simulations, is $Re=u_{\infty }D/\unicode[STIX]{x1D708}=9.6\times 10^{4}$ ; due to the different incoming flow turbulence level, the boundary layer conditions before the boat tails are fully developed turbulent in the experiments and transitional in the simulations. In all cases, the introduction of one single axisymmetric groove in the lateral surface of the boat tails produces significant delay of the boundary layer separation, with consequent reduction of the pressure drag. Nonetheless, the wake dynamical structure remains qualitatively similar to the one typical of a blunt-based axisymmetric body, with quantitative variations that are consistent with the reduction in wake width caused by boat tailing and by the grooves. A few supplementary simulations show that the effect of the grooves is also robust to the variation of the geometrical parameters defining their shape. All the obtained data support the interpretation that the relaxation of the no-slip boundary condition for the flow surrounding the recirculation regions, with an appreciable velocity along their borders, is the physical mechanism responsible for the effectiveness of the present separation-control method.
Tavagnascoite, Bi4O4(SO4)(OH)2, a new oxyhydroxy bismuth sulfate related to klebelsbergite
Luca Bindi, Cristian Biagioni, Bruno Martini, Adrio Salvetti, Giovanni Dalla Fontana, Massimo Taronna, Marco E. Ciriotti
Journal: Mineralogical Magazine / Volume 80 / Issue 4 / June 2016
Print publication: June 2016
The new mineral tavagnascoite, Bi4O4 (SO4)(OH)2, was discovered in the Pb-Bi-Zn-As-Fe-Cu ore district of Tavagnasco, Turin, Piedmont, Italy. It occurs as blocky, colourless crystals, up to 40 μm in size, with a silky lustre. In the specimen studied, tavagnascoite is associated with other uncharacterized secondary Bi-minerals originating from the alteration of a bismuthinite ± Bi-sulfosalt assemblage. Electron microprobe analyses gave (average of three spot analyses, wt.%) Bi2O3 85.32, Sb2O3 0.58, PbO 2.18, SO3 8.46, H2Ocalc 1.77, sum 98.31. On the basis of 10 O apfu, the chemical formula is (Bi3.74Pb0.10Sb0.04)∑ = 3.88O3.68 (SO4)1.08(OH)2, with rounding errors. Main calculated diffraction lines are [d in Å (relative intensity) hkl] 6.39 (29) 012, 4.95 (19) 111,4.019(32)121,3.604(28)014 and 3.213(100)123. Unit-cell parameters are a = 5.831(1), b = 11.925(2), c = 15.123(1) Å, V = 1051.6(3) Å3, Z = 4, space group Pca21. The crystal structure was solved and refined from single-crystal X-ray diffraction data to R 1 = 0.037 on the basis of 1269 observed reflections. It consists of Bi–O polyhedra and SO4 tetrahedra. Bismuth polyhedra are connected each to other to form Bi–O sheets parallel to (001). Successive sheets are linked together by SO4 groups and hydrogen bonds. Tavagnascoite is the Bi-analogue of klebelsbergite, Sb4O4(SO4)(OH)2, and it is the fifth natural known bismuth sulfate without additional cations. The mineral and its name have been approved by the IMA CNMNC (2014-099).
Effect of different superovulation stimulation protocols on adenosine triphosphate concentration in rabbit oocytes
Carmela Cortell, Pascal Salvetti, Thierry Joly, Maria Pilar Viudes-de-Castro
Journal: Zygote / Volume 23 / Issue 4 / August 2015
Published online by Cambridge University Press: 15 April 2014, pp. 507-513
Print publication: August 2015
Ovarian stimulation protocols are used usually to increase the number of oocytes collected. The determination of how oocyte quality may be affected by these superovulation procedures, therefore, would be very useful. There is a high correlation between oocyte ATP concentration and developmental competence of the resulting embryo. The aim of this study was to evaluate the effect of follicle stimulating hormone (FSH) origin and administration protocols on oocyte ATP content. Rabbit does were distributed randomly into four groups: (i) a control group; (ii) the rhFSH3 group: females were injected, every 24 h over 3 days, with 0.6 μl of rhFSH diluted in polyvinylpyrrolidone (PVP); (iii) the pFSH3 group: females were injected every 24 h over 3 days with 11.4 μg of pFSH diluted in PVP; and (iv) the pFSH5 group: females were injected twice a day for 5 days with 11.4 μg of pFSH diluted in saline serum. Secondly, the effect of pFSH5 protocol on developmental potential was evaluated. Developmental competence of oocytes from the control and pFSH5 groups was examined. Differences in superovulation treatments were found for ATP levels. In the pFSH5 group, the ATP level was significantly lower than that of the other groups (5.63 ± 0.14 for pFSH group versus 6.42 ± 0.13 and 6.19 ± 0.15 for rhFSH3 and pFSH3, respectively; P < 0.05). In a second phase, only 24.28% of pFSH5 ova developed into hatched blastocysts compared with 80.39% for the control group. A negative effect on oocyte quality was observed in the pFSH5 group in ATP production, it is possible that, after this superovulation treatment, oocyte metabolism would be affected.
Alterations of the extracellular matrix of lung during zinc deficiency
Verónica S. Biaggio, Natalia R. Salvetti, María V. Pérez Chaca, Susana R. Valdez, Hugo H. Ortega, María S. Gimenez, Nidia N. Gomez
Journal: British Journal of Nutrition / Volume 108 / Issue 1 / 14 July 2012
Published online by Cambridge University Press: 12 October 2011, pp. 62-70
Print publication: 14 July 2012
Suboptimal intake of Zn is one of the most common nutritional problems worldwide. Previously, we have shown that Zn deficiency (ZD) produces oxidative and nitrosative stress in the lung of rats. We analyse the effect of moderate ZD on the expression of several intermediate filaments of the cytoskeleton, as well as the effect of restoring Zn during the refeeding period. Adult male rats were divided into three groups: Zn-adequate control (CO) group; ZD group; Zn-refeeding group. CerbB-2 and proliferating cell nuclear antigen (PCNA) expression was increased in the ZD group while the other parameters did not change. During the refeeding time, CerbB-2, cytokeratins, vimentin and PCNA immunostaining was higher than that in the CO group. The present findings indicate that the overexpression of some markers could lead to the fibrotic process in the lung. Perhaps ZD implications must be taken into account in health interventions because an inflammation environment is associated with ZD in the lung.
Atomistic Simulation and Subsequent Optimization of Boron USJ Using Pre-Amorphization and High Ramp Rates Annealing
Julien Singer, François Wacquant, Davy Villanueva, Frédéric Salvetti, Cyrille Laviron, Olga Cueto, Pierrette Rivallin, Martín Jaraíz, Alain Poncet
Journal: MRS Online Proceedings Library Archive / Volume 1070 / 2008
Published online by Cambridge University Press: 01 February 2011, 1070-E05-08
This study presents the use of atomistic process simulations to optimize p+/n ultra-shallow junctions fabrication process. We first bring to the fore that a high injection of interstitials close to the boron profile decreases the sensibility of boron diffusion to thermal budget. Preamorphization of the substrate is thus necessary to decrease boron diffusion by thermal budget reduction, the latter being obtained by the use of the thermal conduction tool (Levitor) instead of the classical lamp-type rapid thermal annealing. At the same time we show that the use of Levitor does not enhance boron activation, the substrate being preamorphize or not. So Levitor anneal can improve sheet resistance/junction depth trade-off only with preamorphization implant. Experiments are performed that confirm the predictions of our simulations. Further discussions explain activation path of boron during temperature cycle, as a function of amorphous depth, and for both lamp-type and Levitor anneal.
A conditional stability criterion based on generalized energies
A. NERLI, S. CAMARRI, M. V. SALVETTI
Journal: Journal of Fluid Mechanics / Volume 581 / 25 June 2007
Published online by Cambridge University Press: 22 May 2007, pp. 277-286
Print publication: 25 June 2007
An energy criterion for conditional stability is proposed, based on the definition of generalized energies, obtained through a perturbation of the classical L2 (kinetic) energy. This perturbation is such that the contribution of the linear term in the perturbation equation to the generalized energy time derivative is negative definite. A critical amplitude threshold is then obtained by imposing the monotonic decay of the generalized energy. The capabilities of the procedure are appraised through the application to three different low-dimensional models. The effects of different choices in the construction of the generalized energy on the prediction of the critical amplitude threshold in the subcritical regime are also discussed.
Low-dimensional modelling of a confined three-dimensional wake flow
M. BUFFONI, S. CAMARRI, A. IOLLO, M. V. SALVETTI
Published online by Cambridge University Press: 15 November 2006, pp. 141-150
The laminar flow past a square cylinder symmetrically placed between two parallel walls is considered. A classical vortex wake is shed from the cylinder, but three-dimensional instabilities are present and they develop in complicated flow patterns. The possibility of extracting an accurate low-order model of this flow is explored.
Ultra Shallow Junctions Optimization with Non Doping Species Co-implantation
Nathalie Cagnat, Cyrille Laviron, Daniel Mathiot, Blandine Duriez, Julien Singer, Romain Gwoziecki, Frédéric Salvetti, Benjamin Dumont, Arnaud Pouydebasque
Published online by Cambridge University Press: 01 February 2011, 0912-C01-02
The permanent decrease of the transistor size to improve the performances of integrated circuits must be accompanied by a permanent decrease of the depth of the source-drain junctions. At the same time, in order to keep acceptable sheet resistance values, the dopant concentration in the source-drain areas has to be continuously increased. A possible technological way to meet the junction depth and abruptness requirements is to use co-implantation of non doping species with classical implantations, especially for light ions as B or P.
In order to clarify the complex interactions occurring during these co-implantation processes, we have performed an extensive experimental study of the effect of Ge, F, N, C and their combinations on boron. A special interest was given to the overall integration issues. We will show that it is required to optimize the respective locations of co-implanted species with respect to the B profiles (more precisely the ion implantation damage locations), as well as the co-implanted species doses, to get an acceptable compromise between the efficient diffusion decrease required for the junction abruptness and depth, and a reasonable current leakages.
Interaction Between Low Temperatures Spacers and Source Drain Extensions and Pockets for Both NMOS and PMOS of the 65 nm Node Technology
Nathalie Cagnat, Cyrille Laviron, Daniel Mathiot, Pierre Morin, Frédéric Salvetti, Davy Villanueva, Marc Juhel, Marco Hopstaken, François Wacquant
During the MOS transistors fabrication process, the source-drain extension areas are directly in contact with the oxide liner of the spacers stack. In previous works [1, 2, 3] it has been established that boron can diffuse from the source-drain extensions into the spacer oxide liner during the subsequent annealing steps, and that the amount of boron loss depends on the hydrogen content in the oxide, because it enhances B diffusivity in SiO2.
In order to characterize and quantify the above phenomena, we performed test experiments on full sheet samples, which mimic either BF2 source-drain extensions over arsenic pockets implants, or BF2 pockets under arsenic or phosphorus source-drain extensions implants. Following the corresponding implants, the wafers were covered with different spacer stacks (oxide + nitride) deposited either by LPCVD, or PECVD. After appropriate activation annealing steps, SIMS measurements were used to characterize the profiles of the various dopants, and the corresponding dose loss was evaluated for each species.
Our experimental results clearly evidence that LPCVD or PECVD spacer stacks have no influence on the arsenic profiles. On the other hand, phosphorus and boron profiles are affected. For boron profiles, each spacer type has a different influence. It is also shown that boron out-diffuses not only from the B doped source-drain extension in direct contact with the oxide layer, but also from the "buried" B pockets lying under n-doped source drain extension areas. All these results are discussed in term of the possible relevant mechanism.
A numerical study of non-cavitating and cavitating liquid flow around a hydrofoil
François Beux, Maria-Vittoria Salvetti, Alexey Ignatyev, Ding Li, Charles Merkle, Edoardo Sinibaldi
Journal: ESAIM: Mathematical Modelling and Numerical Analysis / Volume 39 / Issue 3 / May 2005
Published online by Cambridge University Press: 15 June 2005, pp. 577-590
Print publication: May 2005
The results of a workshop concerning the numerical simulation of the liquid flow around a hydrofoil in non-cavitating and cavitating conditions are presented. This workshop was part of the conference "Mathematical and Numerical aspects of Low Mach Number Flows" (2004) and was aimed to investigate the capabilities of different compressible flow solvers for the low Mach number regime and for flows in which incompressible and supersonic regions are simultaneously present. Different physical models of cavitating phenomena are also compared. The numerical results are validated against experimental data.
The Italian Twin Project: From the Personal Identification Number to a National Twin Registry
Maria Antonietta Stazi, Rodolfo Cotichini, Valeria Patriarca, Sonia Brescianini, Corrado Fagnani, Cristina D'Ippolito, Stefania Cannoni, Giovanni Ristori, Marco Salvetti
Journal: Twin Research and Human Genetics / Volume 5 / Issue 5 / 01 October 2002
Published online by Cambridge University Press: 21 February 2012, pp. 382-386
Print publication: 01 October 2002
The unique opportunity given by the "fiscal code", an alphanumeric identification with demographic information on any single person residing in Italy, introduced in 1976 by the Ministry of Finance, allowed a database of all potential Italian twins to be created. This database contains up to now name, surname, date and place of birth and home address of about 1,300,000 "possible twins". Even thought we estimated an excess of 40% of pseudo-twins, this still is the world's largest twin population ever collected. The database of possible twins is currently used in population-based studies on multiple sclerosis, Alzheimer's disease, celiac disease, and type 1 diabetes. A system is currently being developed for linking the database with data from mortality and cancer registries. In 2001, the Italian Government, through the Ministry of Health, financed a broad national research program on twin studies, including the establishment of a national twin registry. Among all the possible twins, a sample of 500,000 individuals are going to be contacted and we expect to enrol around 120,000 real twin pairs in a formal Twin Registry. According to available financial resources, a sub sample of the enrolled population will be asked to donate DNA. A biological bank from twins will be then implemented, guaranteeing information on future etiological questions regarding genetic and modifiable factors for physical impairment and disability, cancers, cardiovascular diseases and other age related chronic illnesses.
Line spectroscopy with spatial resolution of laser–plasma X-ray emission
L. LABATE, M. GALIMBERTI, A. GIULIETTI, D. GIULIETTI, L.A. GIZZI, R. NUMICO, A. SALVETTI
Journal: Laser and Particle Beams / Volume 19 / Issue 1 / January 2001
Published online by Cambridge University Press: 30 July 2001, pp. 117-123
High dynamic range, space-resolved X-ray spectra of an aluminum laser–plasma in the 5.5–8 Å range were obtained using a TlAP crystal and a cooled CCD camera as a detector. This technique was used to investigate the emission region in the longitudinal direction over a distance of approximately 350 μm from the solid target surface. These data show that the electron density profile varies by two orders of magnitude with the temperature ranging from about 180 eV in the overdense region to about 650 eV in the underdense region. Accordingly, different equilibria take place across the explored region which can be identified with this experimental technique. Detailed studies on highly ionized atomic species in different plasma conditions can therefore be performed simultaneously under controlled conditions.
High brightness laser–plasma X-ray source at IFAM: Characterization and applications
S. MARZI, A. GIULIETTI, D. GIULIETTI, L.A. GIZZI, A. SALVETTI
Published online by Cambridge University Press: 02 March 2001, pp. 109-118
A high brightness laser-plasma X-ray source has been set-up and is presently available at IFAM. A wide range of diagnostics has been set up to monitor the properties of the X-ray radiation and to control the main parameters including photon energy, flux intensity, and pulse duration. A beam extractor enables access to the X-ray radiation at atmospheric pressure. A simple, easy-to-use projection microscope has been built which is capable of single-shot micron resolution imaging with digital acquisition. Preliminary biomedical experiments show that the X-ray doses available on a single laser shot exposure of our source fully meet the conditions required for an important class of biological experiments based on X-ray induced DNA damage providing an ideal alternative to the long time exposures needed with X-ray tubes.
CF-LIPS: A new approach to LIPS spectra analysis
A. CIUCCI, V. PALLESCHI, S. RASTELLI, A. SALVETTI, D.P. SINGH, E. TOGNONI
Journal: Laser and Particle Beams / Volume 17 / Issue 4 / October 1999
The usual technique of the laser induced plasma spectroscopy (LIPS) spectra analysis relies on the use of calibration curves for quantitative measurements of plasma composition. However, LIPS calibration curves strongly depend on the material composition (the so-called matrix effect); thus, this standard approach to the LIPS spectra analysis is inadequate when precise information on unknown samples composition is required. In this paper we present a new procedure, based on LIPS, for calibration-free quantitative elemental analysis of materials. The new procedure, based on an algorithm developed and patented by IFAM-CNR, allows the overcoming of the matrix effect, yielding precise and accurate quantitative results without the need of calibration curves.
Detection of mercury in air by time-resolved laser-induced breakdown spectroscopy technique
C. Lazzari, M. De Rosa, S. Rastelli, A. Ciucci, V. Palleschi, A. Salvetti
Journal: Laser and Particle Beams / Volume 12 / Issue 3 / September 1994
Print publication: September 1994
For several years the laser-induced breakdown spectroscopy (LIBS) technique has been applied successfully to the problem of detecting small traces of pollutants in gases. The possible application of this method for the individuation of mercury in air is discussed. The laboratory prototype of the detection system is described in detail, and the sensitivity of the system for the diagnostics of small traces of mercury is determined. The reduced dimensions of the experimental apparatus and its relatively low cost make the LIBS method competitive with other laser-based methods for in situ analysis.
Simulation and experimental studies on the evolution of a laser spark in air
X. C. Zeng, D. P. Singh, V. Palleschi, A. Salvetti, M. De Rosa, M. Vaselli
Journal: Laser and Particle Beams / Volume 10 / Issue 4 / December 1992
Print publication: December 1992
Experimental and theoretical studies on the evolution of shock waves in air plasma induced by laser spark have been carried out. The systematic study of the shock wave has been performed experimentally and 1-D numerical code of radiation hydrodynamics (1-DRHC) has been used to simulate the later stage of laser spark in air. The numerical results on the propagation of shock waves and the expansion of hot plasma are presented and subsequent results on the first divergent and convergent shock waves are found to be in good agreement with the experimental data.
On the process of Mach wave generation in air
M. De Rosa, F. Famá, V. Palleschi, A. Salvetti, D. P. Singh, M. Vaselli
Journal: Laser and Particle Beams / Volume 9 / Issue 2 / June 1991
The process of Mach wave generation in air is studied in both plane and spherical geometries. The experimental results reported here are theoretically interpreted using the predictions of a self-similar model of strong explosion along with the hydrodynamic equations of a perfect gas, and a good agreement is found.
Time-resolved LIBS experiment for quantitative determination of pollutant concentrations in air
M. Casini, M. A. Harith, V. Palleschi, A. Salvetti, D. P. Singh, M. Vaselli
We propose a new time-resolved laser-induced breakdown spectroscopy (TRELIBS) system for quantitative determination of small amounts of pollutants in gas. Some experimental results showing the high resolution of the method are reported, and possible improvements of the system are discussed. | CommonCrawl |
Previous issue | This issue | Most recent issue | All issues | Next issue | Recently published articles | Next article
On the behavior of test ideals under finite morphisms
Authors: Karl Schwede and Kevin Tucker
DOI: https://doi.org/10.1090/S1056-3911-2013-00610-4
Published electronically: September 9, 2013
We derive precise transformation rules for test ideals under an arbitrary finite surjective morphism $\pi \colon Y \to X$ of normal varieties in prime characteristic $p > 0$. Specifically, given a â"š
-divisor
$\Delta _{X}$ on $X$ and any $\mathcal {O}_{X}$-linear map $\mathfrak {T} \colon K(Y) \to K(X)$, we associate a â"š
$\Delta _{Y}$ on $Y$ such that $\mathfrak {T} ( \pi _{*}\tau (Y;\Delta _{Y})) = \tau (X;\Delta _{X})$. When $\pi$ is separable and $\mathfrak {T} = \operatorname {Tr}_{Y/X}$ is the field trace, we have $\Delta _{Y} = \pi ^{*} \Delta _{X} - \operatorname {Ram}_{\pi }$, where $\operatorname {Ram}_{\pi }$ is the ramification divisor. If, in addition, $\operatorname {Tr}_{Y/X}(\pi _{*}\mathcal {O}_{Y}) = \mathcal {O}_{X}$, we conclude that $\pi _{*}\tau (Y;\Delta _{Y}) \cap K(X) = \tau (X;\Delta _{X})$ and thereby recover the analogous transformation rule to multiplier ideals in characteristic zero. Our main technique is a careful study of when an $\mathcal {O}_{X}$-linear map $F_{*} \mathcal {O}_{X} \to \mathcal {O}_{X}$ lifts to an $\mathcal {O}_{Y}$-linear map $F_{*} \mathcal {O}_{Y} \to \mathcal {O}_{Y}$, and the results obtained about these liftings are of independent interest as they relate to the theory of Frobenius splittings. In particular, again assuming $\operatorname {Tr}_{Y/X}(\pi _{*}\mathcal {O}_{Y}) = \mathcal {O}_{X}$, we obtain transformation results for $F$-pure singularities under finite maps which mirror those for log canonical singularities in characteristic zero. Finally, we explore new conditions on the singularities of the ramification locus, which imply that, for a finite extension of normal domains $R \subseteq S$ in characteristic $p > 0$, the trace map $\mathfrak {T} : \operatorname {Frac} S \to \operatorname {Frac} R$ sends $S$ onto $R$.
Ian M. Aberbach and Brian MacCrimmon, Some results on test elements, Proc. Edinburgh Math. Soc. (2) 42 (1999), no. 3, 541–549. MR 1721770, DOI https://doi.org/10.1017/S0013091500020502
M. Artin, Wildly ramified $Z/2$ actions in dimension two, Proc. Amer. Math. Soc. 52 (1975), 60–64. MR 374136, DOI https://doi.org/10.1090/S0002-9939-1975-0374136-3
Manuel Blickle, Mircea Mustaţǎ, and Karen E. Smith, Discreteness and rationality of $F$-thresholds, Michigan Math. J. 57 (2008), 43–61. Special volume in honor of Melvin Hochster. MR 2492440, DOI https://doi.org/10.1307/mmj/1220879396
Manuel Blickle, Karl Schwede, Shunsuke Takagi, and Wenliang Zhang, Discreteness and rationality of $F$-jumping numbers on singular varieties, Math. Ann. 347 (2010), no. 4, 917–949. MR 2658149, DOI https://doi.org/10.1007/s00208-009-0461-2
M. Blickle, K. Schwede, and K. Tucker: $F$-singularities via alterations, arXiv:1107.3807.
A. Bravo and K. E. Smith, Behavior of test ideals under smooth and étale homomorphisms, J. Algebra 247 (2002), no. 1, 78–94. MR 1873384, DOI https://doi.org/10.1006/jabr.2001.9010
Michel Brion and Shrawan Kumar, Frobenius splitting methods in geometry and representation theory, Progress in Mathematics, vol. 231, Birkhäuser Boston, Inc., Boston, MA, 2005. MR 2107324
Bart de Smit, The different and differentials of local fields with imperfect residue fields, Proc. Edinburgh Math. Soc. (2) 40 (1997), no. 2, 353–365. MR 1454030, DOI https://doi.org/10.1017/S0013091500023798
Lawrence Ein, Multiplier ideals, vanishing theorems and applications, Algebraic geometry—Santa Cruz 1995, Proc. Sympos. Pure Math., vol. 62, Amer. Math. Soc., Providence, RI, 1997, pp. 203–219. MR 1492524, DOI https://doi.org/10.1090/s0894-0347-97-00223-3
Richard Fedder, $F$-purity and rational singularity, Trans. Amer. Math. Soc. 278 (1983), no. 2, 461–480. MR 701505, DOI https://doi.org/10.1090/S0002-9947-1983-0701505-0
Ofer Gabber, Notes on some $t$-structures, Geometric aspects of Dwork theory. Vol. I, II, Walter de Gruyter, Berlin, 2004, pp. 711–734. MR 2099084
Alexander Grothendieck, Revêtements étales et groupe fondamental. Fasc. II: Exposés 6, 8 à 11, Institut des Hautes Études Scientifiques, Paris, 1963. Troisième édition, corrigée; Séminaire de Géométrie Algébrique, 1960/61. MR 0217088
Alexander Grothendieck and Jacob P. Murre, The tame fundamental group of a formal neighbourhood of a divisor with normal crossings on a scheme, Lecture Notes in Mathematics, Vol. 208, Springer-Verlag, Berlin-New York, 1971. MR 0316453
Nobuo Hara, Geometric interpretation of tight closure and test ideals, Trans. Amer. Math. Soc. 353 (2001), no. 5, 1885–1906. MR 1813597, DOI https://doi.org/10.1090/S0002-9947-01-02695-2
Nobuo Hara and Shunsuke Takagi, On a generalization of test ideals, Nagoya Math. J. 175 (2004), 59–74. MR 2085311, DOI https://doi.org/10.1017/S0027763000008904
Nobuo Hara and Kei-Ichi Watanabe, F-regular and F-pure rings vs. log terminal and log canonical singularities, J. Algebraic Geom. 11 (2002), no. 2, 363–392. MR 1874118, DOI https://doi.org/10.1090/S1056-3911-01-00306-X
Nobuo Hara and Ken-Ichi Yoshida, A generalization of tight closure and multiplier ideals, Trans. Amer. Math. Soc. 355 (2003), no. 8, 3143–3174. MR 1974679, DOI https://doi.org/10.1090/S0002-9947-03-03285-9
Robin Hartshorne, Residues and duality, Lecture Notes in Mathematics, No. 20, Springer-Verlag, Berlin-New York, 1966. Lecture notes of a seminar on the work of A. Grothendieck, given at Harvard 1963/64; With an appendix by P. Deligne. MR 0222093
Robin Hartshorne, Algebraic geometry, Springer-Verlag, New York-Heidelberg, 1977. Graduate Texts in Mathematics, No. 52. MR 0463157
Robin Hartshorne, Stable reflexive sheaves, Math. Ann. 254 (1980), no. 2, 121–176. MR 597077, DOI https://doi.org/10.1007/BF01467074
Robin Hartshorne, Generalized divisors on Gorenstein schemes, Proceedings of Conference on Algebraic Geometry and Ring Theory in honor of Michael Artin, Part III (Antwerp, 1992), 1994, pp. 287–339. MR 1291023, DOI https://doi.org/10.1007/BF00960866
M. Hochster: Foundations of tight closure theory, lecture notes from a course taught at the University of Michigan Fall 2007 (2007).
Melvin Hochster and Craig Huneke, Tight closure, invariant theory, and the Briançon-Skoda theorem, J. Amer. Math. Soc. 3 (1990), no. 1, 31–116. MR 1017784, DOI https://doi.org/10.1090/S0894-0347-1990-1017784-6
Melvin Hochster and Craig Huneke, $F$-regularity, test elements, and smooth base change, Trans. Amer. Math. Soc. 346 (1994), no. 1, 1–62. MR 1273534, DOI https://doi.org/10.1090/S0002-9947-1994-1273534-X
Melvin Hochster and Craig Huneke, Tight closure of parameter ideals and splitting in module-finite extensions, J. Algebraic Geom. 3 (1994), no. 4, 599–670. MR 1297848
Craig Huneke, Tight closure and its applications, CBMS Regional Conference Series in Mathematics, vol. 88, Published for the Conference Board of the Mathematical Sciences, Washington, DC; by the American Mathematical Society, Providence, RI, 1996. With an appendix by Melvin Hochster. MR 1377268
Moritz Kerz and Alexander Schmidt, On different notions of tameness in arithmetic geometry, Math. Ann. 346 (2010), no. 3, 641–668. MR 2578565, DOI https://doi.org/10.1007/s00208-009-0409-6
János Kollár, Singularities of pairs, Algebraic geometry—Santa Cruz 1995, Proc. Sympos. Pure Math., vol. 62, Amer. Math. Soc., Providence, RI, 1997, pp. 221–287. MR 1492525
Flips and abundance for algebraic threefolds, Société Mathématique de France, Paris, 1992. Papers from the Second Summer Seminar on Algebraic Geometry held at the University of Utah, Salt Lake City, Utah, August 1991; Astérisque No. 211 (1992) (1992). MR 1225842
János Kollár and Shigefumi Mori, Birational geometry of algebraic varieties, Cambridge Tracts in Mathematics, vol. 134, Cambridge University Press, Cambridge, 1998. With the collaboration of C. H. Clemens and A. Corti; Translated from the 1998 Japanese original. MR 1658959
Ernst Kunz, On Noetherian rings of characteristic $p$, Amer. J. Math. 98 (1976), no. 4, 999–1013. MR 432625, DOI https://doi.org/10.2307/2374038
Ernst Kunz, Kähler differentials, Advanced Lectures in Mathematics, Friedr. Vieweg & Sohn, Braunschweig, 1986. MR 864975
Robert Lazarsfeld, Positivity in algebraic geometry. II, Ergebnisse der Mathematik und ihrer Grenzgebiete. 3. Folge. A Series of Modern Surveys in Mathematics [Results in Mathematics and Related Areas. 3rd Series. A Series of Modern Surveys in Mathematics], vol. 49, Springer-Verlag, Berlin, 2004. Positivity for vector bundles, and multiplier ideals. MR 2095472
Joseph Lipman, Rational singularities, with applications to algebraic surfaces and unique factorization, Inst. Hautes Études Sci. Publ. Math. 36 (1969), 195–279. MR 276239
Gennady Lyubeznik and Karen E. Smith, On the commutation of the test ideal with localization and completion, Trans. Amer. Math. Soc. 353 (2001), no. 8, 3149–3180. MR 1828602, DOI https://doi.org/10.1090/S0002-9947-01-02643-5
Hideyuki Matsumura, Commutative ring theory, 2nd ed., Cambridge Studies in Advanced Mathematics, vol. 8, Cambridge University Press, Cambridge, 1989. Translated from the Japanese by M. Reid. MR 1011461
V. B. Mehta and A. Ramanathan, Frobenius splitting and cohomology vanishing for Schubert varieties, Ann. of Math. (2) 122 (1985), no. 1, 27–40. MR 799251, DOI https://doi.org/10.2307/1971368
V. B. Mehta and V. Srinivas, Normal $F$-pure surface singularities, J. Algebra 143 (1991), no. 1, 130–143. MR 1128650, DOI https://doi.org/10.1016/0021-8693%2891%2990255-7
Patrick Morandi, Field and Galois theory, Graduate Texts in Mathematics, vol. 167, Springer-Verlag, New York, 1996. MR 1410264
Mikao Moriya, Theorie der Derivationen und Körperdifferenten, Math. J. Okayama Univ. 2 (1953), 111–148 (German). MR 54643
Mircea Mustaţǎ, Shunsuke Takagi, and Kei-ichi Watanabe, F-thresholds and Bernstein-Sato polynomials, European Congress of Mathematics, Eur. Math. Soc., Zürich, 2005, pp. 341–364. MR 2185754
Mircea Mustaţă and Ken-Ichi Yoshida, Test ideals vs. multiplier ideals, Nagoya Math. J. 193 (2009), 111–128. MR 2502910, DOI https://doi.org/10.1017/S0027763000026052
Günter Scheja and Uwe Storch, Über Spurfunktionen bei vollständigen Durchschnitten, J. Reine Angew. Math. 278(279) (1975), 174–190 (German). MR 393056
Karl Schwede, Generalized test ideals, sharp $F$-purity, and sharp test elements, Math. Res. Lett. 15 (2008), no. 6, 1251–1261. MR 2470398, DOI https://doi.org/10.4310/MRL.2008.v15.n6.a14
Karl Schwede, $F$-adjunction, Algebra Number Theory 3 (2009), no. 8, 907–950. MR 2587408, DOI https://doi.org/10.2140/ant.2009.3.907
Karl Schwede, Centers of $F$-purity, Math. Z. 265 (2010), no. 3, 687–714. MR 2644316, DOI https://doi.org/10.1007/s00209-009-0536-5
Karl Schwede, A refinement of sharply $F$-pure and strongly $F$-regular pairs, J. Commut. Algebra 2 (2010), no. 1, 91–109. MR 2607103, DOI https://doi.org/10.1216/JCA-2010-2-1-91
K. Schwede and K. Tucker: Explicitly extending Frobenius splittings over finite maps, arXiv:1201.5973, originally an appendix to the paper "On the behavior of test ideals under finite morphisms�, 2011.
Jean-Pierre Serre, Local fields, Graduate Texts in Mathematics, vol. 67, Springer-Verlag, New York-Berlin, 1979. Translated from the French by Marvin Jay Greenberg. MR 554237
Anurag K. Singh, $\mathbf Q$-Gorenstein splinter rings of characteristic $p$ are F-regular, Math. Proc. Cambridge Philos. Soc. 127 (1999), no. 2, 201–205. MR 1735920, DOI https://doi.org/10.1017/S0305004199003710
Karen E. Smith, The multiplier ideal is a universal test ideal, Comm. Algebra 28 (2000), no. 12, 5915–5929. Special issue in honor of Robin Hartshorne. MR 1808611, DOI https://doi.org/10.1080/00927870008827196
Shunsuke Takagi, F-singularities of pairs and inversion of adjunction of arbitrary codimension, Invent. Math. 157 (2004), no. 1, 123–146. MR 2135186, DOI https://doi.org/10.1007/s00222-003-0350-3
Shunsuke Takagi, An interpretation of multiplier ideals via tight closure, J. Algebraic Geom. 13 (2004), no. 2, 393–415. MR 2047704, DOI https://doi.org/10.1090/S1056-3911-03-00366-7
Shunsuke Takagi, Formulas for multiplier ideals on singular varieties, Amer. J. Math. 128 (2006), no. 6, 1345–1362. MR 2275023
Shunsuke Takagi and Kei-ichi Watanabe, On F-pure thresholds, J. Algebra 282 (2004), no. 1, 278–297. MR 2097584, DOI https://doi.org/10.1016/j.jalgebra.2004.07.011
Kevin Tucker, Integrally closed ideals on log terminal surfaces are multiplier ideals, Math. Res. Lett. 16 (2009), no. 5, 903–908. MR 2576706, DOI https://doi.org/10.4310/MRL.2009.v16.n5.a12
Ian M. Aberbach and Brian MacCrimmon, Some results on test elements, Proc. Edinburgh Math. Soc. (2) 42 (1999), no. 3, 541–549. MR 1721770 (2000i:13005), DOI https://doi.org/10.1017/S0013091500020502
M. Artin, Wildly ramified $Z/2$ actions in dimension two, Proc. Amer. Math. Soc. 52 (1975), 60–64. MR 0374136 (51 \#10336)
Manuel Blickle, Mircea Mustaţǎ, and Karen E. Smith, Discreteness and rationality of $F$-thresholds, Michigan Math. J. 57 (2008), 43–61. Special volume in honor of Melvin Hochster. MR 2492440 (2010c:13003), DOI https://doi.org/10.1307/mmj/1220879396
Manuel Blickle, Karl Schwede, Shunsuke Takagi, and Wenliang Zhang, Discreteness and rationality of $F$-jumping numbers on singular varieties, Math. Ann. 347 (2010), no. 4, 917–949. MR 2658149 (2011k:13008), DOI https://doi.org/10.1007/s00208-009-0461-2
A. Bravo and K. E. Smith, Behavior of test ideals under smooth and étale homomorphisms, J. Algebra 247 (2002), no. 1, 78–94. MR 1873384 (2002m:13007), DOI https://doi.org/10.1006/jabr.2001.9010
Michel Brion and Shrawan Kumar, Frobenius splitting methods in geometry and representation theory, Progress in Mathematics, vol. 231, Birkhäuser Boston Inc., Boston, MA, 2005. MR 2107324 (2005k:14104)
Bart de Smit, The different and differentials of local fields with imperfect residue fields, Proc. Edinburgh Math. Soc. (2) 40 (1997), no. 2, 353–365. MR 1454030 (98d:11148), DOI https://doi.org/10.1017/S0013091500023798
Lawrence Ein, Multiplier ideals, vanishing theorems and applications, Algebraic geometry—Santa Cruz 1995, Proc. Sympos. Pure Math., vol. 62, Amer. Math. Soc., Providence, RI, 1997, pp. 203–219. MR 1492524 (98m:14006)
Richard Fedder, $F$-purity and rational singularity, Trans. Amer. Math. Soc. 278 (1983), no. 2, 461–480. MR 701505 (84h:13031), DOI https://doi.org/10.2307/1999165
Ofer Gabber, Notes on some $t$-structures, Geometric aspects of Dwork theory. Vol. I, II, Walter de Gruyter GmbH & Co. KG, Berlin, 2004, pp. 711–734. MR 2099084 (2005m:14025)
A. Grothendieck: Revêtements étales et groupe fondamental. Fasc. II: Exposés 6, 8 à 11, Séminaire de Géométrie Algébrique, vol. 1960/61, Institut des Hautes Études Scientifiques, Paris, 1963. MR 0217088 (36:179b)
Alexander Grothendieck and Jacob P. Murre, The tame fundamental group of a formal neighbourhood of a divisor with normal crossings on a scheme, Lecture Notes in Mathematics, Vol. 208, Springer-Verlag, Berlin, 1971. MR 0316453 (47 \#5000)
Nobuo Hara, Geometric interpretation of tight closure and test ideals, Trans. Amer. Math. Soc. 353 (2001), no. 5, 1885–1906 (electronic). MR 1813597 (2001m:13009), DOI https://doi.org/10.1090/S0002-9947-01-02695-2
Nobuo Hara and Shunsuke Takagi, On a generalization of test ideals, Nagoya Math. J. 175 (2004), 59–74. MR 2085311 (2005g:13009)
Nobuo Hara and Kei-Ichi Watanabe, F-regular and F-pure rings vs. log terminal and log canonical singularities, J. Algebraic Geom. 11 (2002), no. 2, 363–392. MR 1874118 (2002k:13009), DOI https://doi.org/10.1090/S1056-3911-01-00306-X
Nobuo Hara and Ken-Ichi Yoshida, A generalization of tight closure and multiplier ideals, Trans. Amer. Math. Soc. 355 (2003), no. 8, 3143–3174 (electronic). MR 1974679 (2004i:13003), DOI https://doi.org/10.1090/S0002-9947-03-03285-9
Robin Hartshorne, Residues and duality, Lecture notes of a seminar on the work of A. Grothendieck, given at Harvard 1963/64. With an appendix by P. Deligne. Lecture Notes in Mathematics, No. 20, Springer-Verlag, Berlin, 1966. MR 0222093 (36 \#5145)
Robin Hartshorne, Algebraic geometry, Springer-Verlag, New York, 1977. Graduate Texts in Mathematics, No. 52. MR 0463157 (57 \#3116)
Robin Hartshorne, Stable reflexive sheaves, Math. Ann. 254 (1980), no. 2, 121–176. MR 597077 (82b:14011), DOI https://doi.org/10.1007/BF01467074
Robin Hartshorne, Generalized divisors on Gorenstein schemes, Proceedings of Conference on Algebraic Geometry and Ring Theory in honor of Michael Artin, Part III (Antwerp, 1992), 1994, pp. 287–339. MR 1291023 (95k:14008), DOI https://doi.org/10.1007/BF00960866
Melvin Hochster and Craig Huneke, Tight closure, invariant theory, and the Briançon-Skoda theorem, J. Amer. Math. Soc. 3 (1990), no. 1, 31–116. MR 1017784 (91g:13010), DOI https://doi.org/10.2307/1990984
Melvin Hochster and Craig Huneke, $F$-regularity, test elements, and smooth base change, Trans. Amer. Math. Soc. 346 (1994), no. 1, 1–62. MR 1273534 (95d:13007), DOI https://doi.org/10.2307/2154942
Melvin Hochster and Craig Huneke, Tight closure of parameter ideals and splitting in module-finite extensions, J. Algebraic Geom. 3 (1994), no. 4, 599–670. MR 1297848 (95k:13002)
Craig Huneke, Tight closure and its applications, CBMS Regional Conference Series in Mathematics, vol. 88, Published for the Conference Board of the Mathematical Sciences, Washington, DC, 1996. With an appendix by Melvin Hochster. MR 1377268 (96m:13001)
Moritz Kerz and Alexander Schmidt, On different notions of tameness in arithmetic geometry, Math. Ann. 346 (2010), no. 3, 641–668. MR 2578565 (2011a:14052), DOI https://doi.org/10.1007/s00208-009-0409-6
János Kollár, Singularities of pairs, Algebraic geometry—Santa Cruz 1995, Proc. Sympos. Pure Math., vol. 62, Amer. Math. Soc., Providence, RI, 1997, pp. 221–287. MR 1492525 (99m:14033)
Flips and abundance for algebraic threefolds, Société Mathématique de France, Paris, 1992. Papers from the Second Summer Seminar on Algebraic Geometry held at the University of Utah, Salt Lake City, Utah, August 1991; Astérisque No. 211 (1992). MR 1225842 (94f:14013)
János Kollár and Shigefumi Mori, Birational geometry of algebraic varieties, Cambridge Tracts in Mathematics, vol. 134, Cambridge University Press, Cambridge, 1998. With the collaboration of C. H. Clemens and A. Corti; Translated from the 1998 Japanese original. MR 1658959 (2000b:14018)
Ernst Kunz, On Noetherian rings of characteristic $p$, Amer. J. Math. 98 (1976), no. 4, 999–1013. MR 0432625 (55 \#5612)
Ernst Kunz, Kähler differentials, Advanced Lectures in Mathematics, Friedr. Vieweg & Sohn, Braunschweig, 1986. MR 864975 (88e:14025)
Robert Lazarsfeld, Positivity in algebraic geometry. II, Ergebnisse der Mathematik und ihrer Grenzgebiete. 3. Folge. A Series of Modern Surveys in Mathematics [Results in Mathematics and Related Areas. 3rd Series. A Series of Modern Surveys in Mathematics], vol. 49, Springer-Verlag, Berlin, 2004. Positivity for vector bundles, and multiplier ideals. MR 2095472 (2005k:14001b)
Joseph Lipman, Rational singularities, with applications to algebraic surfaces and unique factorization, Inst. Hautes Études Sci. Publ. Math. 36 (1969), 195–279. MR 0276239 (43 \#1986)
Gennady Lyubeznik and Karen E. Smith, On the commutation of the test ideal with localization and completion, Trans. Amer. Math. Soc. 353 (2001), no. 8, 3149–3180 (electronic). MR 1828602 (2002f:13010), DOI https://doi.org/10.1090/S0002-9947-01-02643-5
Hideyuki Matsumura, Commutative ring theory, 2nd ed., Cambridge Studies in Advanced Mathematics, vol. 8, Cambridge University Press, Cambridge, 1989. Translated from the Japanese by M. Reid. MR 1011461 (90i:13001)
V. B. Mehta and A. Ramanathan, Frobenius splitting and cohomology vanishing for Schubert varieties, Ann. of Math. (2) 122 (1985), no. 1, 27–40. MR 799251 (86k:14038), DOI https://doi.org/10.2307/1971368
V. B. Mehta and V. Srinivas, Normal $F$-pure surface singularities, J. Algebra 143 (1991), no. 1, 130–143. MR 1128650 (92j:14044), DOI https://doi.org/10.1016/0021-8693%2891%2990255-7
Patrick Morandi, Field and Galois theory, Graduate Texts in Mathematics, vol. 167, Springer-Verlag, New York, 1996. MR 1410264 (97i:12001)
Mikao Moriya, Theorie der Derivationen und Körperdifferenten, Math. J. Okayama Univ. 2 (1953), 111–148 (German). MR 0054643 (14,952f)
M. Mustaţǎ, S. Takagi, and K.-i. Watanabe: F-thresholds and Bernstein-Sato polynomials, European Congress of Mathematics, Eur. Math. Soc., Zürich, 2005, pp. 341–364. MR 2185754 (2007b:13010)
Mircea Mustaţă and Ken-Ichi Yoshida, Test ideals vs. multiplier ideals, Nagoya Math. J. 193 (2009), 111–128. MR 2502910 (2010a:13010)
Günter Scheja and Uwe Storch, Über Spurfunktionen bei vollständigen Durchschnitten, J. Reine Angew. Math. 278/279 (1975), 174–190 (German). MR 0393056 (52 \#13867)
Karl Schwede, Generalized test ideals, sharp $F$-purity, and sharp test elements, Math. Res. Lett. 15 (2008), no. 6, 1251–1261. MR 2470398 (2010e:13004)
Karl Schwede, $F$-adjunction, Algebra Number Theory 3 (2009), no. 8, 907–950. MR 2587408 (2011b:14006), DOI https://doi.org/10.2140/ant.2009.3.907
Karl Schwede, Centers of $F$-purity, Math. Z. 265 (2010), no. 3, 687–714. MR 2644316 (2011e:13011), DOI https://doi.org/10.1007/s00209-009-0536-5
Karl Schwede, A refinement of sharply $F$-pure and strongly $F$-regular pairs, J. Commut. Algebra 2 (2010), no. 1, 91–109. MR 2607103 (2011c:13007), DOI https://doi.org/10.1216/JCA-2010-2-1-91
Jean-Pierre Serre, Local fields, Graduate Texts in Mathematics, vol. 67, Springer-Verlag, New York, 1979. Translated from the French by Marvin Jay Greenberg. MR 554237 (82e:12016)
Anurag K. Singh, $\mathbf {Q}$-Gorenstein splinter rings of characteristic $p$ are F-regular, Math. Proc. Cambridge Philos. Soc. 127 (1999), no. 2, 201–205. MR 1735920 (2000j:13006), DOI https://doi.org/10.1017/S0305004199003710
Karen E. Smith, The multiplier ideal is a universal test ideal, Comm. Algebra 28 (2000), no. 12, 5915–5929. Special issue in honor of Robin Hartshorne. MR 1808611 (2002d:13008), DOI https://doi.org/10.1080/00927870008827196
Shunsuke Takagi, F-singularities of pairs and inversion of adjunction of arbitrary codimension, Invent. Math. 157 (2004), no. 1, 123–146. MR 2135186 (2006g:14028), DOI https://doi.org/10.1007/s00222-003-0350-3
Shunsuke Takagi, An interpretation of multiplier ideals via tight closure, J. Algebraic Geom. 13 (2004), no. 2, 393–415. MR 2047704 (2005c:13002), DOI https://doi.org/10.1090/S1056-3911-03-00366-7
Shunsuke Takagi, Formulas for multiplier ideals on singular varieties, Amer. J. Math. 128 (2006), no. 6, 1345–1362. MR 2275023 (2007i:14006)
Shunsuke Takagi and Kei-ichi Watanabe, On F-pure thresholds, J. Algebra 282 (2004), no. 1, 278–297. MR 2097584 (2006a:13010), DOI https://doi.org/10.1016/j.jalgebra.2004.07.011
Kevin Tucker, Integrally closed ideals on log terminal surfaces are multiplier ideals, Math. Res. Lett. 16 (2009), no. 5, 903–908. MR 2576706 (2011c:14055)
Karl Schwede
Affiliation: Department of Mathematics, The Pennsylvania State University, 318C McAlister Building, University Park, Pennsylvania 16802
Email: [email protected]
Kevin Tucker
Affiliation: Department of Mathematics, University of Illinois at Chicago, Chicago, Illinois 60607
Email: [email protected]
Received by editor(s): March 20, 2011
Received by editor(s) in revised form: August 25, 2011
Additional Notes: The first author was partially supported by a National Science Foundation postdoctoral fellowship, RTG grant number 0502170 and NSF DMS 1064485/0969145. The second author was partially supported by RTG grant number 0502170 and a National Science Foundation postdoctoral fellowship DMS 1004344
The copyright for this article reverts to public domain 28 years after publication. | CommonCrawl |
How can you calculate the frequencies for each band?
I've just started studying for my HAM license a couple of weeks ago, so please excuse me if this is a remedial question...
I have the Canadian Amateur Radio Basic Qualification Study Guide (which I'm finding is terribly hard to understand). Their explanations of just about everything appear to be missing pertinent information that allow the reader to connect the dots and consequently I'm struggling to understand what they're explaining... anyway, the book discusses a formula which supposedly allows you to determine the bond between frequencies and their band - i.e. the calculation in the book tells me that 300 / Wavelength = Frequency... where one is to assume that 300 is a rough simile of the speed of light in millions of meters per second. The book suggests the resultant frequency is approximately (within some unexplained tolerance) the middle of the bandwidth for that band plan.
I'm noticing that using this formula for many bands the resulting frequency doesn't fall within the suggested frequency range for that plan and where they do, many don't fall within any discernible tolerance of the middle.
20m band = 300 / 20 = 15.000 MHz, whereas the book suggests the frequency band falls between 14.000 - 14.350 MHz. (Clearly 15.000 MHz falls outside that range)
2m band = 300 / 2 = 150.000 MHz, whereas the book suggests the frequency band falls between 144.000 - 148.000 MHz.
33cm band = 300 / 0.33m = 909.091 MHz, a long way from the middle of the suggested frequency band of 902.000 - 928.000 MHz
Even if I substitute the more accurate (according to Google) measurement of c being 299,792,458 m/s, I arrive at 14.990 MHz for 20m, still not within the frequency band.
Clearly I'm missing something, can someone explain what I'm not understanding?
frequency band-plan
BenAlabasterBenAlabaster
$\begingroup$ Hi Ben. I'm sorry, but resource recommendations just aren't a good fit for the SE format in general, so I am editing that part out. However, by all means ask questions here about what you can't figure out, like you just did. $\endgroup$ – a CVn Feb 5 '15 at 8:39
$\begingroup$ "The twenty-one and sixteen hundredths meter band" just doesn't roll of the tongue as well. $\endgroup$ – Phil Frost - W8II Feb 5 '15 at 12:07
$\begingroup$ @PhilFrost your comment is a little vague... I agree that the 21.16M band doesn't roll off the tongue very well, but there are a number of bands that don't round to the nearest 10, why is it the 20 meter band and not the 21? There's 17, 15, 12 and even 1.25 meter bands, why not make it 21M instead of 20? For that matter, why not take the mid-range frequency for every band and round to the nearest whole number? $\endgroup$ – BenAlabaster Feb 5 '15 at 14:55
$\begingroup$ @BenAlabaster I suppose you should solicit the ITU to adopt your proposed convention. I'm not sure how they'd like all the bands above 600MHz being named the "0 meter band", though. $\endgroup$ – Phil Frost - W8II Feb 5 '15 at 17:04
$\begingroup$ @BenAlabaster Some out-of-ham-world perspective: Some band names are actually not free and refer, in some parts of the world at least, to already established bands for different services. For example, here are some popular broadcast band names as marked on one short-wave receiver:120 m, 90 m, 75 m, 60 m, 49 m, 41 m, 31 m, 25 m, 21 m, 19 m, 16 m, 15 m, 13 m, 11 m. Maybe there is a desire not to mix names of broadcast bands with ham bands? $\endgroup$ – AndrejaKo Jun 27 '15 at 0:13
$$ \frac{c}{ \text{frequency}} = \text{wavelength}$$ $$ \frac{c}{ \text{wavelength}} = \text{frequency}$$
The above relation is a fact of physics. It's true unconditionally (provided you are using consistent units, e.g. wavelength in meters and $c$ in meters per second); it's how you convert between two different ways of measuring a wave.
The frequency limits, and names, of the bands are not physics; they were invented by humans. The frequency limits are a matter of the regulations that divide up the radio spectrum among many users. The limits of the amateur bands are semi-arbitrary.
The common names for the bands ("20 m", "2 m", and so on) are simply the closest round number to the actual wavelengths. (In your example of 33 cm, note that 32 and 34 cm would be outside the band entirely. 33 is the best two-digit approximation.)
What your book should have told you is not that you can use the above relation to find the limits of the band, but that given that you already know the bands and frequencies, you can use it to find which band a frequency belongs to, or vice versa, because while the band names do not always fall in the frequency limits, the correct band/frequency will always be the closest match.
For example, $300/143 ≈ 2.098$, so we can conclude that 143 MHz is in the 2 m band if it is in an amateur band at all, which it isn't (but e.g. 145 MHz is).
If you wish to know the limits of bands, you must memorize them; there are no shortcuts. The relationship between wavelength and frequency can, however, be used to match up those limits to the wavelength-names of the bands.
$\begingroup$ @Kevin You say "or vice versa" it's exactly the vice versa where it appears to fall apart. It doesn't predict which frequency a band belongs to... except in the most literal sense. The band plans don't fall in line with the mathematics... which is where I was coming unstuck. Now that I know they're arbitrary, I get it. $\endgroup$ – BenAlabaster Feb 5 '15 at 14:48
$\begingroup$ @BenAlabaster I've added a bit to clarify that I'm talking about "of the possibilities that actually exist, this is the closest match". I agree it isn't very useful for commonly used bands. One quickly memorizes that e.g. 20 m runs from 14.000 MHz to something above that. $\endgroup$ – Kevin Reid AG6YO♦ Feb 5 '15 at 16:11
$\begingroup$ @K7PEH Actually, after Kevin incorporated that into the answer, the comment has served its purpose. Thus, I'm doing a bit of cleaning here instead. :-) $\endgroup$ – a CVn Feb 5 '15 at 19:08
$\begingroup$ @KevinReidAG6YO I think if the book had just gone as far as to say "the band plan names were originally based off X, but today are largely historic or arbitrary", it would have made sense right on the page. Thanks for your input. $\endgroup$ – BenAlabaster Feb 9 '15 at 17:53
$\begingroup$ Technically this only applies in a vacuum, but air and space are the most common mediums for radio waves, and the speed is almost the same, so... $\endgroup$ – PearsonArtPhoto Feb 11 '15 at 19:00
The names make a kind of sense if you take into account the history behind them. Look at this pattern of names and lower end of the allocation:
80m: 3.5MHz
20m: 14MHz
Note how the frequencies and canonical names are related by multiples of two. 80m is almost perfectly named: the allocation goes from 75.0m to 85.7m. Sure, as you go up in frequency it gets less perfect: 20m is closer to 21 meters. But these are nice, round numbers. There being no other bands allocated at the time, there wasn't any particular reason to be more specific.
Of note, those bands have been allocated for a very long time, internationally allocated by the ITU in 1927.
15m was allocated in 1947. Clearly that can't be rounded to 10m or 20m because those names are already taken. 14m would be a more accurate name, but 15 is a "rounder" number, being a multiple of 5.
30m, 17m, and 12m are the WARC bands, allocated more recently in 1979. 12m couldn't be 10m because that name was taken. 30m is a round number that's close enough that wasn't already used. 17m is actually closer to 15m, but that name was also already taken. I suppose it could have been 16m. Maybe you can dig up the notes from 1979 to figure out why it wasn't. My guess: someone wanted some free space between 15m. You will notice that 12m is right on the money: the actual allocation is from 12.00m to 12.05m.
60m is relatively new, being allocated in the US in 2002. I don't think the ITU allocates it internationally. Though it's actually around 55m, 60 is a nice round number and there wasn't already a band called that.
And that's all the HF bands.
The VHF bands are pretty accurate:
300/50MHz = 6.00m
300/144MHz = 2.08m
300/225MHz = 1.333m
I'll forgive you for questioning the last one, because you are Canadian and you use the metric system. Had Canadians named it, they would have called it 133cm. But this band first encountered amateur use in the US, where fractions with powers of two are preferred1. So this is the "1¼-meter band". Of course at the time the band was named, Canada wasn't using the metric system either. So maybe not.
As you go up the spectrum, the names continue to be pretty accurate. Eventually, people tend to stop calling them by wavelength. "Four-forty" is a colloquial name for "70 centimeters" in some places. No one has a "13 centimeter" Wi-Fi access point. They have a 2.4GHz access point.
1: Someone needs to tell Ikea this, because their manuals (page 9) frequently have measurements like "95 2/3 inches". No one has a ruler marked in thirds of inches. I guess no one has a ruler marked in fourths of meters either, so maybe this is Ikea's revenge.
$\begingroup$ "Four-forty is more common than 70 centimeters". I think it's safe to say that that statement is, at best, not universal. I know lots of people here refer to "70 centimeters" but not "432 megahertz". (The 70 cm allocation in SM is 432-438, of which 435-438 is satellite exclusive.) $\endgroup$ – a CVn Feb 5 '15 at 19:11
$\begingroup$ All I wanted to point out originally was that a regional difference exists, so that people from different regions aren't confused when reading your answer. I see that you agree that this difference exists, so there is nothing to argue about. I never wanted to imply that you're stupid, or that your statement is never true. Sorry if my wording was misleading. $\endgroup$ – a CVn Feb 6 '15 at 12:28
$\begingroup$ @MichaelKjörling meta.ham.stackexchange.com/q/237/218 $\endgroup$ – Phil Frost - W8II Feb 6 '15 at 12:59
$\begingroup$ I am glad to read these discussions in the comments, it's funny how you learn a lot more from watching/hearing other people discuss/debate/argue about stuff like this than learning all the "official" information. $\endgroup$ – BenAlabaster Feb 9 '15 at 16:50
$\begingroup$ @PhilFrost also, it's really useful to understand things from multi-ethnic(?) perspectives. Most of whom I will be talking to are likely to be in the U.S. so it will be as helpful for me to understand the technology from their perspective as it is from my own English and/or Canadian perspective. Being able to translate the American terms (where I will likely find most of my information) to Canadian terms where I will likely be making most of my purchases is extremely useful. So far from being "rude" I find it really helpful. Thanks :) $\endgroup$ – BenAlabaster Feb 9 '15 at 16:52
"I'm noticing that using this formula for many bands
the resulting frequency doesn't fall within the
suggested frequency range for that plan and where
they do, many don't fall within any discernible
tolerance of the middle."
Here's why this is the case today.
In the early days of radio (that is, the late 19th and early 20th centuries) everyone referred to the approximate wavelength in meters, rather than the actual frequency in MHz. That's simply the way it was! Other than Lecher wires (mostly for VHF), there was almost no way of accurately measuring the actual transmit or receive frequency with any degree of accuracy. Back in those days, there were no frequency counters or accurately calibrated VFOs.
In those days --before the days of vacuum tubes, which were a HUGE technical advancement-- all that anyone had were noisy, raucous spark transmitters, which occupied a ridiculously wide bandwidth above and below the center frequency.
(Better yet were crystal-controlled triode oscillators, even if they did have key clicks and chirps.)
Later, when broadband spark transmitters gave way to narrower and much cleaner tube oscillators like this, tuning became more accurate, and it was more prudent to refer to the frequency.
And that's why we still have the word "wavelength" in our list of amateur radio terms. Like it or not, we're just stuck with the term, and all the confusion that came with it.
Mike Waters♦Mike Waters
Not the answer you're looking for? Browse other questions tagged frequency band-plan or ask your own question.
Can I transmit on 2 frequencies simultaneously?
What is the permissible frequency error for US amateur radio transmissions?
Which frequencies in a band should I use for antenna and radio testing?
SSB demodulation
How does the antenna length affect signal transmission/receipt in different bands?
How many frequency channels are there in a frequency band?
How to tune an FM transmitter to a specific frequency?
What are Radio-location Services in the 1.9-2.0 MHz range?
What causes the light and dark bands (of background noise) in an HF waterfall display?
What is "up" and "down", and is it consistent with "top band"? | CommonCrawl |
What constitutes an observation/measurement in QM?
Fundamental notions of QM have to do with observation, a major example being The Uncertainty Principle.
What is the technical definition of an observation/measurement?
If I look at a QM system, it will collapse. But how is that any different from a bunch of matter "looking" at the same system?
Can the system tell the difference between a person's eyes and the bunch of matter?
If not, how can the system remain QM?
Am I on the right track?
quantum-mechanics quantum-interpretations heisenberg-uncertainty-principle measurement-problem wavefunction-collapse
ThisIsNotAnIdThisIsNotAnId
$\begingroup$ This is a very broad question, with overlap with other questions. You should look at the Heisenberg Pieirls analysis of tracks in a bubble chamber to understand the entanglement apparent collapse of a wavefunction, and then the philosophical problem of turning apparent collapse (decoherence) into collapse, and whether this is philosophy or not. There is no simple answer, and it is hard to not refer you to other questions on the site (although precisely which ones, I can't really be sure without more detail on what you are asking, like a thought experiment) $\endgroup$ – Ron Maimon Nov 4 '12 at 4:54
$\begingroup$ Related: physics.stackexchange.com/q/1353/2451 $\endgroup$ – Qmechanic♦ Nov 4 '12 at 16:51
$\begingroup$ For additional research, you should review and dig into the Mott problem and its resolution. Note that there is link to spontaneous symmetry breaking in the article. $\endgroup$ – user11547 Nov 5 '12 at 14:24
An observation is an act by which one finds some information – the value of a physical observable (quantity). Observables are associated with linear Hermitian operators.
The previous sentences tautologically imply that an observation is what "collapses" the wave function. The "collapse" of the wave function isn't a material process in any classical sense much like the wave function itself is neither a quantum observable nor a classical wave; the wave function is the quantum generalization of a probabilistic distribution and its "collapse" is a change of our knowledge – probabilistic distribution for various options – and the first sentence exactly says that the observation is what makes our knowledge more complete or sharper.
(That's also why the collapse may proceed faster than light without violating any rules of relativity; what's collapsing is a gedanken object, a probabilistic distribution, living in someone's mind, not a material object, so it may change instantaneously.)
Now, you may want to ask how one determines whether a physical process found some information about the value of an observable. My treatment suggests that whether the observation has occurred is a "subjective" question. It suggests it because this is exactly how Nature works. There are conditions for conceivable "consistent histories" which constrain what questions about "observations" one may be asking but they don't "force" the observer, whoever or whatever it is, to ask such questions.
That's why one isn't "forced" to "collapse" the wave function at any point. For example, a cat in the box may think that it observes something else. But an external observer hasn't observed the cat yet, so he may continue to describe it as a linear superposition of macroscopically distinct states. In fact, he is recommended to do so as long as possible because the macroscopically distinct states still have a chance to "recohere" and "interfere" and change the predictions. A premature "collapse" is always a source of mistakes. According to the cat, some observation has already taken place but according to the more careful external observer, it has not. It's an example of a situation showing that the "collapse" is a subjective process – it depends on the subject.
Because of the consistency condition, one may effectively observe only quantities that have "decohered" and imprinted the information about themselves into many degrees of freedom of the environment. But one is never "forced" to admit that there has been a collapse. If you are trying to find a mechanism or exact rule about the moments when a collapse occurs, you won't find anything because there isn't any objective rule or any objective collapse, for that matter. Whether a collapse occurred is always a subjective matter because what's collapsing is subjective, too: it's the wave function that encodes the observer's knowledge about the physical system. The wave function is a quantum, complex-number-powered generalization of probabilistic distributions in classical physics – and both of them encode the probabilistic knowledge of an observer. There are no gears and wheels inside the wave function; the probabilistic subjective knowledge is the fundamental information that the laws of Nature – quantum mechanical laws – deal with.
In a few days, I will write a blog entry about the fundamentally subjective nature of the observation in QM:
http://motls.blogspot.com/2012/11/why-subjective-quantum-mechanics-allows.html?m=1
Luboš MotlLuboš Motl
$\begingroup$ ''My treatment suggests that whether the observation has occurred is a "subjective" question.'' - If this were really true, one still had to explain why we get objective science out of our subjective measurements. Therefore, there may not be more subjectivity than is in the error bars. $\endgroup$ – Arnold Neumaier Nov 4 '12 at 15:37
$\begingroup$ Lubos, are you saying that one observer will measure one track of an electron in a bubble chamber, and another observer can potentially measure another direction? If so, I definitely disagree. It is precisely b/c of quantum mechanics that ALL observers objectively agree on the direction of the track. $\endgroup$ – Columbia Nov 6 '12 at 1:46
$\begingroup$ I am fairly certain that agreement of outcomes of joint observations are part of the point that is being made above. Entanglement will ensure agreement of joint observables. However each system will have information that can never be observed jointly. There is no inconsistency in saying that those states continue to evolve within their respective systems as long as the probability of joint measurement is effectively zero (or in fact effectively negative). This is captured in the use of complex amplitudes which can track the evolution of unphysical states. $\endgroup$ – user11547 Nov 6 '12 at 14:18
$\begingroup$ Another way of thinking about this is that if you dream about observing a particle track, there is nothing wrong with someone saying the track did something different from what you dream, since there is no possible way for them to make an observation of what you dreamed. $\endgroup$ – user11547 Nov 6 '12 at 14:21
$\begingroup$ @Columbia, nope, I am not saying that observers in the same world will ever reach contradictory results of measurements of the same thing. The correlation/entanglement is guaranteed by the equations of quantum evolution. Instead, I am saying that one observer may observe something while another one doesn't measure it, so for the former, the state is "collapsed" into a well-defined state while for the latter, the state is a linear superposition, possible of macroscopically distinct microstates. The observers will agree on the outcomes of measurements but only if both/all of them measure it. $\endgroup$ – Luboš Motl Nov 12 '12 at 17:44
Let me take a slightly more "pop science" approach to this than Luboš, though I'm basically saying the same thing.
Suppose you have some system in a superposition of states: a spin in a mix of up/down states is probably the simplest example. If we "measure" the spin by allowing some other particle to interact with it we end up with our original spin and the measuring particle in an entangled state, and we still have a superposition of states. So this isn't an observation and hasn't collapsed the wavefunction.
Now suppose we "measure" the spin by allowing a graduate student to interact with it. In principle we end up with our original spin and the graduate student in an entangled state, and we still have a superposition of states. However experience tells us that macrospcopic objects like graduate students and Schrodinger's cat don't exist in superposed states so the system collapses to a single state and this does constitute an observation.
The difference is the size of the "measuring device", or more specifically its number of degrees of freedom. Somewhere between a particle and a graduate student the measuring device gets big enough that we see a collapse. This process is described by a theory called decoherence (warning: that Wikipedia article is pretty hard going!). The general idea is that any system inevitably interacts with its environment, i.e. the rest of the universe, and the bigger the system the faster the interaction. In principle when our grad student measures the spin they do form an entangled system in a superposition of states, but the interaction with the rest of the universe is so fast that the system collapses into a single state effectively instantaneously.
So observation isn't some spooky phenomenon that requires intelligence. It is simply related to the complexity of the system interacting with our target wavefunction.
John RennieJohn Rennie
$\begingroup$ Dear Johm, right, I agree we're saying pretty much the same thing. Still, I would probably stress that decoherence is just an approximate emergent description of the quantum evolution of systems interacting with the environment. Even if the density matrix for the observed system gets almost diagonal, it doesn't mean that one is "forced to imagine" that the system has already "objectively chosen" one of the states on the diagonal. Instead, one is only allowed to say such a thing because it no longer leads to contradictions. $\endgroup$ – Luboš Motl Nov 4 '12 at 9:08
$\begingroup$ So, for a wavefunction to collapse it need only be able to interact with the rest of the universe? If so, I'm slightly confused. How can the wavefunction know when it has interacted with the "rest of the Universe"? When it is observed by the grad student, can't the student and in the room in which observation has taken place be taken as the rest of the Universe? $\endgroup$ – ThisIsNotAnId Nov 7 '12 at 2:42
$\begingroup$ The phrase "the rest of the universe" just means everything that isn't part of the system being studied, so the grad student does count as "the rest of the universe". Have a read of the Wikipedia article I linked and see if that helps. $\endgroup$ – John Rennie Nov 7 '12 at 6:58
$\begingroup$ So in layman's terms is it adequate to say that an observation is the entanglement of a coherent quantum system with a decoherent system. That is a quantum object is measured, when it interacts with an object in a more decided state? $\endgroup$ – awiebe Aug 24 '18 at 10:03
$\begingroup$ @awiebe sadly it's more complicated than that. Decoherence explains why we see a classical result when we do a measurement, but it doesn't explain which classical result we see. For that we need some theory of the interpretation of quantum mechanics. Decoherence is often associated with the Many Worlds Interpretation. $\endgroup$ – John Rennie Aug 24 '18 at 10:05
''No elementary quantum phenomenon is a phenomenon until it is a registered ('observed', 'indelibly recorded') phenomenon, brought to a close' by 'an irreversible act of amplification'.'' (W.A. Miller and J.A. Wheeler, 1983, http://www.worldscientific.com/doi/abs/10.1142/9789812819895_0008 )
A measurement is an influence of a system on a measurement device that leaves there an irreversible record whose measured value is strongly correlated with the quantity measured. Irreversibility must be valid not forever but at least long enough that (at least in principle) the value can be recorded.
There is no difference.
The system doesn't care. It interacts with the measurement device, while you are just reading that device.
Quantum interactions continue both before, during and after the measurement. Only the reading from the device must be treated in a macroscopic approximation, through statistical mechanics. See, e.g., Balian's paper http://arxiv.org/abs/quant-ph/0702135
Which track are you on?
Arnold NeumaierArnold Neumaier
38k9898 silver badges188188 bronze badges
$\begingroup$ Well, except that irreversibility is always a subjective matter. Many subjects may agree it's irreversible for them but in principle, the situation is always reversible and an agent tracing the "irreversible" phenomena exponentially accurately could do it. $\endgroup$ – Luboš Motl Nov 5 '12 at 7:18
$\begingroup$ @LubošMotl: The resuts of statistical mechanics resulting in equilibrium and nonequilibrium thermodynamics are extremely well established, and show that there is nothing subjective at all in irreversibility. We observe it every moment when we look at fluid flow of water or air. - If the basic laws are in principle reversible this has no bearing on the real universe as it is impossible in principle that an observer inside the universe can reverse the universe. The real universe as_observed_by_objects_inside is irreversible, and measurements are permanent records for these observers. $\endgroup$ – Arnold Neumaier Nov 5 '12 at 9:42
$\begingroup$ The only problem with your assertion is that in the quantum framework, measurements and other "records" are subjective as well. Many people may agree about them, and they usually do, but in principle, others may disagree. The gedanken experiment known as Wigner's friend illustrates this clearly. A friend chosen in a box may "know" that some record of a measurement is already there and became a fact, but the physicist outside the box may choose a superior treatment and describe the physicist inside by linear superpositions of macro-different states. $\endgroup$ – Luboš Motl Nov 5 '12 at 10:11
$\begingroup$ Irreversibility in Nature is never perfect, it's always a matter of approximations, and there's no objective threshold at which one could say that "now it's really irreversible". With a good enough knowledge of the velocities and positions, one may reverse some evolution and prepare a state whose entropy will decrease for a while. It's exponentially difficult but not impossible in principle. The same thing with decoherence. If one traces environmental degrees of freedom, and in principle he can, he may reverse certain amounts of decoherence, too. Decoherence is very fast but never perfect. $\endgroup$ – Luboš Motl Nov 5 '12 at 10:13
$\begingroup$ @LubošMotl: ''Irreversibility in Nature is never perfect'' - only according to an idealized theoretical model that assumes (against better knowledge) that one can change something without having to observe the required information and without having to set up the corresponding forces that accomplish the change. This can be done in principle only for very small or very weakly coupled systems. $\endgroup$ – Arnold Neumaier Nov 5 '12 at 12:25
A measurement is a special kind of quantum process involving a system and a measurement apparatus and that satisfies the von Neumann & Lüders projection postulate. This is one of the basic postulates of orthodox QM and says that immediately after measurement the system is in a quantum state (eigenstate) corresponding to the measured value (eigenvalue) of the observable.
Measurement does not change by considering the pair system+apparatus or by considering the triple system+apparatus+observer, because the fundamental interaction happens between system and measurement apparatus, and the observer can be considered part of the environment that surrounds both. This is the reason why measuring apparatus give the same value when you are in the lab during the measurement that when you are in the cafeteria during the measurement.
See 2.
The system is always QM.
juanrgajuanrga
A QM measurement is essentially a filter. Observables are represented by operators $\smash {\hat O}$, states or wave functions by (linear superpositions of) eigenstates of these operators, $|\,\psi_1\rangle, |\,\psi_2\rangle, \ldots$. In a measurement, you apply a projection operator $P_n$ to your state, and check if there is a non-zero component left. You ascertain you yourself that the system is now in the eigenstate $n$. Experimentally, you often send particles through a "filter", and check if something is left. Think of the Stern-Gerlach experiment. Particles that come out in the upper ray have spin $S_z = +\hbar/2$. We say we have measured their spin, but we have actually $prepared$ their spin. Their state now fulfils $\smash{\hat S} \,|\,\psi\rangle = +\hbar/2 \,|\,\psi\rangle$, so it is the spin-up eigenstate of $\smash{\hat S}$. This is physical and works even if no one is around.
If I look at a QM system, it will collapse. But how is that any different from a bunch of matter "looking" at the same system? Can the system tell the difference between a person's eyes and the bunch of matter?
There are two different things going on, knowledge update (subjective), and decoherence (objective).
First the objective part: If you have a quantum system by itself, it's wave function will evolve unitarily, like a spherical wave for example. If you put it in a physical environment, it will have many interactions with the environment, and its behavior will approach the classical limit.
Think of the Mott experiment for a very simple example: Your particle may start as a spherical wave, but once it hits a particle, it will be localized, and have a definite momentum (within $\Delta p \,\Delta x \geq \hbar/2$). That's part of the definition of "hits a particle". The evolution will then continue from there, and it is very improbable that the particle has the next collision in the other half of the chamber. Rather, it will follow its classical track.
Now the subjective part: If you look at a system, and recognize that it has certain properties (e.g. is in a certain eigenstate), you update your knowledge and use a new expression for the system. This is simple, and not magical at all. There is no change in the physical system in this part; a different observer could have different knowledge and thus a different expression. This subjective uncertainty is described by density matrices.
Sidenote on density matrices:
A density matrix says you think the system is with probability $p_1$ in the pure state $|\,\psi_1\rangle$, with probability $p_2$ in the pure state $|\,\psi_2\rangle$, and so on. (A pure state is one of the states defined above and can be a superposition of eigenstates, where as a mixed state is one given by a density matrix.)
Pure states are objective, if I have a bunch of spin-up particles from my Stern-Gerlach experiment, my colleague will have to agree that they are spin-up, no matter what. They all go in his experiment to the top, too. If I have a bunch of undetermined-spin particles, $$|\,\psi\rangle_\mathrm{undet.} = \frac{1}{\sqrt{2}} (|\,\psi_\uparrow\rangle + |\,\psi_\downarrow\rangle)\,,$$ they will turn out 50/50, for both of us.
Mixed states are different. My particles could be all spin-up, but I don't know that. Someone else does, and he uses a different state to describe them (e.g. see this question). If I see them fly through a magnetic field, I can recognize their behavior, and use a new state, too.
And note that a mixed state of 50% $|\,\psi_\uparrow\rangle$ and 50% $|\,\psi_\uparrow\rangle$ is not the same as the pure state $|\,\psi\rangle_\mathrm{undet.}$ defined above.
Technically, it remains QM all the time (because classical behavior is a limit of QM, and physics always has to obey QM uncertainties). Of course, that's not what you mean. If a system is to stay in a nice, clean quantum state for a prolonged time, it helps that it is isolated. If you have some interaction with the environment, it will not neccessarily completely decohere and become classical, but a perfect QM description will become impractically complicated, as you would have to take the environment and the apparatus into account quantum mechanically.
jdmjdm
$\begingroup$ First, wow really nice reply. Thanks! If I read correctly, are you saying that a QM system can decohere differently for different observers? If so, what is the limit to this subjectivity? For example, can two observers view a particle going in opposite directions at the same time? $\endgroup$ – ThisIsNotAnId Feb 3 '13 at 0:18
$\begingroup$ As far as I understand, decoherence is objective, so no, two observers can't disagree. They can disagree over wheter a system is in a pure or a mixed state. Maybe my use of 'observer' is confusing here. I don't mean something deep like different frames of reference, just that different people (experimentators) have different incomplete knowlege, and that is expressed through their density operators / mixed states. Its like statistical mechanics, but QM. $\endgroup$ – jdm Feb 3 '13 at 12:32
Nothing exists until it is measured and observed.
the Copenhagen consensus
Everything in this universe universally obeys the Schrodinger equation. There's no special measurement objective collapse.
So, there are no measurements. There are no observers either. Ergo, nothing exists. The false assumption nearly everyone makes is something exists.
Can you prove something exists? You can't!
Trail of destructionTrail of destruction
Not the answer you're looking for? Browse other questions tagged quantum-mechanics quantum-interpretations heisenberg-uncertainty-principle measurement-problem wavefunction-collapse or ask your own question.
What does observation mean in two-slit electron diffraction experiment?
What does it mean to observe?
What exactly constitutes a measurement?
Is there a difference between observing a particle and hitting it with another particle?
What is a measurement in MWI
Differences in measurement between quantum physics and classical physics?
What are observables?
Thought Experiment: Force on magnets in a Stern Gerlach Experiment
Why do lasers in open air produce 2-slit interference patterns?
If measurement cause collapse of wave function, does it mean that any other interactions also collapse wave function?
Does measurement, quantum in particular, always increase the total entropy?
Does performing a measurement on a system change its internal energy?
Unitarity and measurement
Wave function collapse and Schrodinger's equation without measurement
On a measurement level, is quantum mechanics a deterministic theory or a probability theory?
Uncertainty principle in macroscopic world | CommonCrawl |
Do all waves of any kind satisfy the principle of superposition?
Is it an inherent portion of defining something as a wave?
Say if I had something that was modeled as a wave. When this thing encounters something else, will it obey the principle of superposition. Will they pass through each other?
waves superposition linear-systems
JobHunter69JobHunter69
$\begingroup$ Well, I would first ask what you mean by wave. The best answer I can think of is whipping out some "wave equation". "If it satisfying this/one of these equations, it is a wave." A lot (not sure if all) the stuff we call waves are linear. But do realize that our classification of waves is arbitrary. $\endgroup$ – Ben S Jan 20 '17 at 6:41
$\begingroup$ Related question: How can one tell if a PDE describes wave behaviour?. There are non-linear PDEs that have wave solutions (see e.g. solitons) that don't satisfy the superposition principle. $\endgroup$ – Winther Jan 20 '17 at 10:11
$\begingroup$ @Winther Actually some nonlinear equation show a sort of a superposition principle and this is indeed one of the special feature presented by solitons. In these cases, you add two solitons and you end up with a new soliton. $\endgroup$ – Diracology Jan 20 '17 at 13:12
$\begingroup$ My initial thought is that a "handwave" doesn't, but having thought about it some more perhaps it does.. Hands colliding cancel each other out/interfere, and a crowd of waving hands is amplified in the sense that it can be seen from a further distance than a single handwave might... Hmm... $\endgroup$ – kwah Jan 21 '17 at 11:48
$\begingroup$ The answer you accepted is not... that correct; for example according to that answer high intensity laser light is "not exactly waves". This might be a better choice. Sometimes the first answer that pops up and looks correct gets most upvotes. Doesn't mean it's the best answer. $\endgroup$ – user Jan 29 '17 at 7:54
If a wave $f(x,t)$ is something that satisfies the wave equation $Lf=0$ where $L$ is the differential operator $\partial_t^2-c^2\nabla^2$ then, because $L$ is linear, any linear combination $\lambda f+\mu g$ of solutions $f$ and $g$ is again a solution: $L(\lambda f + \mu g)=\lambda Lf+\mu Lg=0$.
In general, there might be things that propagate (not exactly waves, but since the question is for waves of any kind) determined by other differential equations. If the equation is of the form $Lf=0$ with $L$ a linear operator, the same argument applies and the superposition principle holds.
coconutcoconut
$\begingroup$ In other words: "Yes" (given a reasonable assumption of what a "wave" is). $\endgroup$ – Todd Wilcox Jan 21 '17 at 7:17
$\begingroup$ (The point being: plenty of waves are nonlinear, and do not obey the principle of superposition. Linearizing may or may not make sense depending on the situation, and there are plenty of cases where it doesn't. Solitons and breaking waves are easy examples of things you do want to include under the term "wave", but which don't follow the principle of superposition.) $\endgroup$ – Emilio Pisanty Jan 21 '17 at 16:44
$\begingroup$ This answer is mathematically correct but ignores physics. For example two waves in a solid may both be linear, but the combination of them may exceed the elastic limit of the material and hence be nonlinear. But as Feynman said, "Physicists always have a habit of taking the simplest example of any phenomenon and calling it 'physics,' leaving the more complicated examples to become the concern of other fields." $\endgroup$ – alephzero Jan 21 '17 at 17:13
$\begingroup$ @coconut The point is that the question literally asks "do all waves of any kind satisfy the superposition principle", and there are tons of examples that don't; see my answer for more. Your answer just hides its head in the sand and arbitrarily decrees that a bunch of wave phenomena, from optical solitons to sonic booms to waves at the beach, are not "waves" because your answer doesn't like the mathematics they follow. That's an untenable position, I should say. $\endgroup$ – Emilio Pisanty Jan 21 '17 at 18:50
$\begingroup$ I am surprised by the number of up votes and the green tick for this answer which does not really answer the question. One of the interesting features of this site is that the first (few) answer(s) are often not the best but often get the most credit. I side very much with @EmilioPisanty in terms with his comments and with all the other informative answers. $\endgroup$ – Farcher Jan 23 '17 at 7:08
As coconut wrote, the superposition principle comes from the linearity of the operator involved. This is the case for electromagnetic radiation in vacuum. Approximations to water waves are also linear (since it is an approximation) but probably will have small non-linear parts. Free quantum field theory is also linear, therefore you have a superposition principle there. With interactions and renormalization, I think it is not linear any more.
Gravity as described by general relativity is highly non-linear. Therefore it does not have any superposition principle. Gravitational waves do not have a superposition principle. However, at very large distances these waves can be approximated. And then this operator might be linear and you can reasonable speak of superpositions again.
The usual approximation to a wave, $$ \left(\frac{1}{c^2} \frac{\mathrm d^2}{\mathrm dt^2} - \nabla^2 \right) \phi(x, t) = 0 \,$$ is linear by definition. A lot of waves can be described well as linear waves with non-linear perturbations (water waves, EM waves in medium). Strictly speaking, they are non-linear from the start once there is the smallest non-linear perturbation to them.
Martin UedingMartin Ueding
$\begingroup$ Surprising and counter-intuitive. Are you sure? Classical static gravity surely follows the superposition (I can simply add the gravitation of two masses. Anything else would be impossible.) Is it really so that gravitational waves do not superimpose? What else do they do? $\endgroup$ – Peter - Reinstate Monica Jan 20 '17 at 11:50
$\begingroup$ The Einstein field equations are non-linear second order differential equations. If you have two black holes, one cannot just take the Schwarzschild solution twice, one needs to find a new solution. $\endgroup$ – Martin Ueding Jan 20 '17 at 12:09
$\begingroup$ @PeterA.Schneider Classical static gravity doesn't have waves, and yes, it is linear, though it also only works with point objects, not fields. It also doesn't agree with GR - it just approximates well enough for external observers of relatively low-energy fields. I'm sure you'll find lots of examples of "the old theory is simpler but more or less wrong" in science :) After all, SR is another nice example - the old kinetic theory assumed velocities added linearly, Lorentz and co. showed that isn't really true. $\endgroup$ – Luaan Jan 20 '17 at 12:45
$\begingroup$ @Luaan Valid points ;-). $\endgroup$ – Peter - Reinstate Monica Jan 20 '17 at 12:50
$\begingroup$ Are water waves and electromagnetic waves (aside from those in vacuo) really linear? What about solitons? $\endgroup$ – steeldriver Jan 21 '17 at 4:20
Despite what several answers on this thread will tell you, there are plenty of phenomena which are perfectly deserving of the term "wave" which do not satisfy the superposition principle. In technical language, the superposition principle is obeyed whenever the underlying dynamics are linear. However, there are plenty of situations that do not obey this assumption.
Breaking waves on a beach: the underlying dynamics of water surface waves is linear when the amplitude is small, but this assumption breaks down when the amplitude is comparable to the depth of the water.
Everyday experience should tell you that a taller wave will break further from the shore, while a wave with a smaller amplitude will break closer to the beach. This is patently incompatible with the superposition principle.
Solitons, which rely on nonlinear effects to maintain their shape even in the presence of dispersion, and which show up as water surface waves and in fiber optics, as well as more esoteric domains.
Light propagating in a material at sufficiently high intensities, at which point the Kerr effect (i.e. a nonlinear modulation of the index of refraction $n=n_0+n_2I$ depending on the intensity $I$) will kick in, resulting in useful effects (like Kerr-lens modelocking) as well as harmful ones (like catastrophic runaway self-focusing).
More broadly, optics is only linear in vacuum (and even then, at some point you start to run into pair-production and light-light scattering). In the presence of media, there are plenty of useful phenomena that use the nonlinear response of materials, falling into what's known as nonlinear optics.
This goes from perturbative phenomena like Kerr lensing and frequency-mixing processes like second-harmonic generation (such as employed in green laser pointers) all the way up to highly nonperturbative processes like high-order harmonic generation, where doubling the intensity can dramatically change the spectrum of the emitted harmonics (i.e. almost double the cutoff of the harmonic orders that you can produce).
Sound waves that are strong enough to enter the nonlinear acoustics regime, including sonic booms, acoustic levitation and medical ultrasound imaging.
Hydraulic jumps, which form everywhere from dams to tidal bores to your kitchen sink.
The nonlinear wave dynamics of the quantum mechanics of Bose-Einstein condensates which obey the Gross-Pitaevskii and nonlinear Schrödinger equations, and related models.
... the latter of which, by the way, is also useful for modelling nonlinear behaviour in fiber optics and in water waves.
Come to think of it, from a ground-up perspective, all fluid dynamics is inherently nonlinear. The first approximation is indeed nonlinear, but many phenomena are well described by the next step up, i.e. including a weak nonlinearity, giving you something called cnoidal waves.
I could go on, but you get the point. You can, if you want to, restrict the term "wave" to only phenomena that obey linear dynamics. However, if you do so, you are explicitly leaving all the above phenomena out, and I would argue that that's not really what we mean by the term.
Emilio PisantyEmilio Pisanty
Simply calling something a "wave" isn't enough for a superposition of solutions to satisfy the governing wave equation. When deriving wave equations linearity is achieved by requiring "small amplitude" oscillations, so in nature when large amplitudes are involved the superposition principle does not hold true in general.
I.E.P.I.E.P.
$\begingroup$ I'm using the term "linearity" as described by the answers above. $\endgroup$ – I.E.P. Jan 20 '17 at 7:40
$\begingroup$ Could you explain the distinction between large and small amplitudes? I never understood what distinction there might exist. Can't you make any small amplitude large just by changing your units to something minuscule? How can that affect the physics? $\endgroup$ – user541686 Jan 20 '17 at 8:16
$\begingroup$ As an elementary example consider the classical derivation of the linear wave equation for a 1d string. The only way we actually yield the linear PDE is by approximating that terms of order $(df(x,t)/dx)<< 1$ (where f(x,t) is the displacement of the string at position x, time t). This is what constitutes "small oscillations." Another way of thinking of this requirement is that in this regime we are analyzing the "long wavelength" behavior of our system. $\endgroup$ – I.E.P. Jan 20 '17 at 9:06
$\begingroup$ (cont'd) Say $f(x,t)= A\text{sin}(kx-\omega t)$, thus $df(x,t)/dx= Ak\text{cos}(kx-\omega t)$. The term $Ak$ is what is small and notice that the spatial dimensions cancel--thus rescaling space will have no effect on the governing physics of our system. $\endgroup$ – I.E.P. Jan 20 '17 at 9:08
$\begingroup$ D'oh!! Of course, that makes sense... I totally didn't realize that's what you're talking about. Somehow I completely missed what you meant by your second sentence, even though it's crystal clear now in hindsight. Sorry about that and thanks for the (re-)explanation! $\endgroup$ – user541686 Jan 20 '17 at 9:17
Actually, none of them satisfies the superposition completely. First, superposition requires linearity, and linearity isn't perfect in most cases. Even in the case of linear theories, the theory is only a model and it has its borders.
For example, the Maxwell-equations are linear, and thus light waves superpose. If you cross two laser beams, they totally pass through each other without any change. But:
If the beams are enough strong to induce pair production, it is not true any more.
If the beams have enough significant mass-energy tensor to induce General Relativistic effects, they will affect each other gravitationally (which is quite interesting, for example it can be even repulsive).
Of course none of these effects are strong enough to be induced by a laser pointer.
peterh - Reinstate Monicapeterh - Reinstate Monica
$\begingroup$ Note that the Maxwell equations are in principle only linear in vacuum; in the presence of a medium there will typically be nonlinear components of the electric and magnetic susceptibilities which are easily accessible to in-the-lab intensities. $\endgroup$ – Emilio Pisanty Jan 22 '17 at 14:17
Linear waves are mostly just an approximation -- as soon as some nonlinearity is present, linearity breaks and superposition isn't true anymore. In fact, you usually get production of higher harmonics. Most cases that involve matter have at least some nonlinearity that becomes more pronounced at larger amplitudes.
Maxwell equations give rise to a perfectly linear wave equation in vacuum, but in matter, you have nonlinear effects, such as Kerr effect. Nonlinear optics makes use of that -- for self-focusing beams, generation of higher harmonics (frequency doubling for lasers is used in some laser pointers to produce green from infrared).
Water waves are very well known examples which are nonlinear (just look at the wave shape changing and tumbling over itself when it gets to the shore).
For sound waves in gases, nonlinearity becomes apparent when the sound pressure becomes comparable to the ambient pressure (meaning that the low density parts of the sound wave are close to vacuum), and even before that, as the ideal gas law no longer holds well. Nonlinearity can lead to formation to shockwaves.
In general: any nonlinear response of the medium on the displacement will have as consequence:
superposition no longer holds
dependence of behaviour (frequency, propagation speed) on the amplitude
harmonic sinusoidal waves will not hold their shape with time
higher harmonics will be produced
wave interferes with itself through nonlinearity and as such, alters its direction/shape/frequency
orionorion
Not the answer you're looking for? Browse other questions tagged waves superposition linear-systems or ask your own question.
What is the general mathematical definition of wave?
Why is resultant displacement in an composition of simple harmonic motion the sum of individual displacements?
Principle of Superposition for driven oscillator
Intuitive explanation of the waves superposition
Superposition of electromagnetic waves and energy localization
Relationship between Quantum superposition and Uncertainty principle
When does the principle of superposition apply?
How is the information stored when a superposition of two incidental waves occupy the same space?
Do all waves superpose on each other?
Superposition principle in electrostatics
Why waves in superposition pass through each other without interference in same medium?
Problem in understanding superposition principle in electrostatics | CommonCrawl |
viXra.org > Data Structures and Algorithms
Abstracts Authors Papers Full Site
Data Structures and Algorithms
Previous months:
2010 - 1003(2) - 1004(2) - 1008(1)
2011 - 1101(3) - 1106(3) - 1108(1) - 1109(1) - 1112(2)
2013 - 1301(1) - 1302(2) - 1303(6) - 1305(2) - 1306(6) - 1308(1) - 1309(1) - 1310(4) - 1311(1) - 1312(1)
2014 - 1403(3) - 1404(3) - 1405(25) - 1406(2) - 1407(2) - 1408(3) - 1409(3) - 1410(3) - 1411(1) - 1412(2)
2015 - 1501(2) - 1502(4) - 1503(3) - 1504(4) - 1505(2) - 1506(1) - 1507(1) - 1508(1) - 1509(5) - 1510(6) - 1511(1)
2016 - 1601(12) - 1602(4) - 1603(7) - 1604(1) - 1605(8) - 1606(6) - 1607(6) - 1608(3) - 1609(3) - 1610(2) - 1611(3) - 1612(4)
2018 - 1801(4) - 1802(5) - 1803(2) - 1804(3) - 1805(4) - 1806(1) - 1807(5) - 1808(3) - 1809(4) - 1810(6) - 1811(3) - 1812(2)
2019 - 1901(6) - 1902(7) - 1903(11) - 1904(7) - 1905(6) - 1906(6) - 1907(2)
Any replacements are listed farther down
[297] viXra:1907.0199 [pdf] submitted on 2019-07-11 10:51:29
Determining Satisfiability of 3-Sat in Polynomial Time
Authors: Ortho Flint, Asanka Wickramasinghe, Jay Brasse, Chris Fowler
Comments: 41 Pages. The paper has been submitted for peer-review.
In this paper, we provide a polynomial time (and space), algorithm that determines satisfiability of 3-SAT. The complexity analysis for the algorithm takes into account no efficiency and yet provides a low enough bound, that efficient versions are practical with respect to today's hardware. We accompany this paper with a serial version of the algorithm without non-trivial efficiencies (link: polynomial3sat.org).
Category: Data Structures and Algorithms
An Interesting Insight Into [ Cool-Spe/gccs-Gentle Compiler Construction System ] Software in the Context of Computational Complexity of Ising Spin Glass Models Towards [dna/rna] Based High Performance Sequencing and Theoretical Analysis of Gene Therapy R
Authors: Nirmal Tej Kumar
Comments: 4 Pages. Short Communication & Simple Suggestion
An Interesting Insight into [ CooL-SPE/GCCS-Gentle Compiler Construction System ] Software in the Context of Computational Complexity of Ising Spin Glass Models towards [DNA/RNA] based High Performance Sequencing and Theoretical Analysis of Gene Therapy R&D. [ Spin Glasses are always an inspiration – A Computational Challenge for the 21 st Century ? ] [The CooL-SPE is a programming environment specially designed to support the professional development of large-scale object-oriented application systems . Revisiting CooL-SPE in the Context of Bio-informatics ]
Technical Comparison Aspects of Leading Blockchain-Based Platforms on Key Characteristic
Authors: Alexander Ivanov, Yevhenii Babichenko, Hlib Kanunnikov, Paul Karpus, Leonid FoiuKhatskevych, Roman Kravchenko, Kyrylo Gorokhovskyi, Ievhen Nevmerzhitskyi
Comments: 7 Pages. Journal: NaUKMA Research Papers. Computer Science
Blockchain as a technology is rapidly developing, finding more and more new entry points into everyday life. This is one of the elements of the technical Revolution 4.0, and it is used in the field of supply, maintenance of various types of registers, access to software products, combating DDOS attacks, distributed storage, fundraising for projects, IoT, etc. Nowadays, there are many blockchainplatforms in the world. They have one technological root but different applications. There are many prerequisites to the fact that in the future the number of new decentralized applications will increase. Therefore, it is important to develop a methodology for determining the optimal blockchainbased platform to solve a specific problem. As an example, consider the worldfamous platforms Ethereum, Nem, and Stellar. Each of them allows to develop decentralized applications, issue tokens, and execute transactions. At the same time, the key features of these blockchainbased platforms are not similar to one another. These very features will be considered in the article. Purpose. Identify the key parameters that characterize the blockchainbased platforms. This will provide an opportunity to present a complex blockchain technology in the form of a simple and understandable architecture. Based on these parameters and using the expertise of the article's authors, we will be able to develop a methodology to be used to solve the problems of choosing the optimal blockchainbased platform for solving the problem of developing smart contracts and issuing tokens. Methods. Analysis of the complexity of using blockchainbased platforms. Implementation of token issuance, use of test and public networks, execution of transactions, analysis of the development team and the community, analysis of the user interface and the developer interface. Discussion. By developing a platform comparison methodology to determine optimal characteristics, we can take the development process to a new level. This will allow to quickly and effectively solve the tasks. Results. Creation of a methodology for comparison blockchainbased platforms.
Algorithms Developed for Two Porotypes of Airborne Vision-Based Control of Ground Robots
Authors: Ilan Ehrenfeld, Oleg Kupervasser, Hennadii Kutomanov, Vitalii Sarychev, Roman Yavich
Comments: 6 Pages. accepted to 9th Int. Conf. on Geotechnique, Construction Materials and Environment, Tokyo, Japan, 2019
Unmanned autonomous robots will be widely used very soon for land use, treatment, and monitoring. Our and the other groups already described technologies, that can be used for such robots (Kupervasser et al., International Journal of GEOMATE, May, 2018 Vol.14, Issue 45, pp.10-16; Djaja et al., International Journal of GEOMATE, Aug, 2017, Vol.13, Issue 36, pp.31-34). We continue developing these technologies and present here new patented technology of airborne vision-based control of ground robots. The main idea is that robot's "eyes" is not located on robot, but are independent autonomous system. As a result, the "eyes" can go up and observe the robot from above. We present in this paper algorithms used for two real physical prototypes of a such system
Debugging Quantum Computers
Authors: George Rajna
Comments: 61 Pages.
In the paper titled "Statistical Assertions for Validating Patterns and Finding Bugs in Quantum Programs," Huang and Margaret Martonosi, a professor of Computer Science at Princeton, identify three key difficulties in debugging quantum programs, and evaluate their solutions in addressing those difficulties. [37] Researchers at the University of Chicago published a novel technique for improving the reliability of quantum computers by accessing higher energy levels than traditionally considered. [36] An international team of researchers has taken an important step towards solving a difficult variation of this problem, using a statistical approach developed at the University of Freiburg. [35] Storing information in a quantum memory system is a difficult challenge, as the data is usually quickly lost. At TU Wien, ultra-long storage times have now been achieved using tiny diamonds. [34] Electronics could work faster if they could read and write data at terahertz frequency, rather than at a few gigahertz. [33] A team of researchers led by the Department of Energy's Oak Ridge National Laboratory has demonstrated a new method for splitting light beams into their frequency modes. [32] Quantum communication, which ensures absolute data security, is one of the most advanced branches of the "second quantum revolution". [31] Researchers at the University of Bristol's Quantum Engineering Technology Labs have demonstrated a new type of silicon chip that can help building and testing quantum computers and could find their way into your mobile phone to secure information. [30] Theoretical physicists propose to use negative interference to control heat flow in quantum devices. [29] Particle physicists are studying ways to harness the power of the quantum realm to further their research. [28]
Discovering Domain-Sensitive Topics in User-Reviews
Authors: Sarthak Kamat
Comments: 4 Pages.
Customer reviews are integral to retail businesses. This paper demonstrates new methods for ranking the most representative and interesting snippets within reviews posted by their customers.
An Interesting Investigation Towards Understanding of [ Openjit Compiler Framework + Imagej Java Imaging Software ] Interaction with Jikesrvm [ RVM Research Virtual Machine ] in the Context of [byte Code Engineering Library(bcel) + Iot + High Performa
An Interesting Investigation towards Understanding of [ OpenJIT Compiler Framework + ImageJ - Java Imaging Software ] Interaction with JikesRVM [ RVM- Research Virtual Machine ] in the Context of [Byte Code Engineering Library(BCEL) + IoT + High Performance Computing (HPC)] related Java based Heterogeneous Image Processing Environments – A Simple Suggestion & Technical Notes.
Indirect Quicksort and Mergesort
Authors: Takeuchi Leorge
This paper estimates indirect quicksort and mergesort for various sizes of array element, and suggests a data structure to guarantee time complexity of O(n log(n)) in C language.
Preliminary Study for Developing Instantaneous Quantum Computing Algorithms (Iqca)
Authors: Richard L Amoroso
Comments: 25 Pages. Preprint: IOP J Phys Conf Series 2019, R L Amoroso, D M Dubois, L H Kauffman, P Rowlands (eds) Advances in Fundamental Physics: Prelude to Paradigm Shift, 11th International Symposium Honoring Mathematical Physicist J-P Vigier, 2018 Liege, Belgium
Since the mid-1990s theoretical quadratic exponential and polynomial Quantum Computing (QC) speedup algorithms have been discussed. Recently the advent of relativistic information processing (RIP) introducing a relativistic qubit (r-qubit) with additional degrees of freedom beyond the current Hilbert space Bloch 2-sphere qubit formalism extended theory has appeared. In this work a penultimate form of QC speedup – Instantaneous Quantum Computing Algorithms (IQCA) is proposed. Discussion exists on passing beyond the quantum limits of locality and unitarity heretofore restricting the evolution of quantum systems to the standard Copenhagen Interpretation. In that respect as introduced in prior work an ontological-phase topological QC avails itself of extended modeling. As well-known by EPR experiments instantaneous connectivity exists inherently in the nonlocal arena. As our starting point we utilize Bohm's super-implicate order where inside a wave packet a super-quantum potential introduces nonlocal connectivity. Additionally EPR experiments entangle simultaneously emitted photon pairs by parametric down-conversion. Operating an IQCA requires a parametric up-conversion cycle an M-Theoretic Unified Field Mechanical (MUFM) set of topological transformations beyond the current Galilean Lorentz-Poincairé transforms of the standard model (SM). Yang- Mills Kaluza-Klein (YM-KK) correspondence is shown to provide a path beyond the semi-quantum limit to realize the local-nonlocal duality required to implement IQCA.
Lucidity Yellowpaper
Authors: Miguel Morales
In this paper we present an implementation of a trustless system of measurement and enforcement of advertising metrics. Specifically, our implementation uses a sidechain composed of a decentralized consortium of verifiers. This implementation provides a decentralized and democratically governed mechanism for the codification of measurement standards. This implementation enforces the standards for computing advertising metrics based on signals received from disconnected programmatic supply chain participants. A simple standard could be codified that enforces the computation of an attribution. It also enables a mechanism in which supply-chain participants may be paid using cryptocurrency safely and at scale. Thus, the system we describe implements the trifecta of blockchain-based tracking and billing of programmatic advertising: campaign insertion orders, supply-chain transparency, and payments. In this paper, we will describe the management of participant identities, a Plasma based sidechain architecture, and support for payments. We also describe a Proof-of-Stake consensus along with a rewards and penalties system used to perpetually incentivize and enforce the correct function of the network.
Whitepaper V.1.2
Authors: Lucidity
The digital advertising ecosystem isn't in a great place. While growth in digital is booming, the most essential members of the ecosystem (namely advertisers and publishers) are frustrated and powerless in the face of an increasingly apparent reality: digital advertising has a transparency problem. In an age where measuring the performance of ad campaigns is paramount, marketers are unable to fully understand the value they deliver. As has become true for most industries, data is the key to measuring performance. But in advertising, data is trapped and siloed in black box technologies, causing data disagreements and opening the door for fraudulent activities. The end result? Waste. Wasted money. Wasted time. Lucidity has built a blockchain-based solution (with five patents filed) that solves these issues. We provide advertisers with a unified set of data, free of discrepancies and fraud, that they can use to gauge their effectiveness. We provide publishers with a way to prove the value of their inventory and avoid identity theft. And we've built the only advertising focused blockchain technology to-date that doesn't require advertisers and agencies to change their work flow or set up integrations. In the following whitepaper, we will outline in detail the problems we're solving, how we solve it, and the team that's bringing it all together.
DNA Sequencing Informatics Framework Using [CoqTP/q*cert/CRSX-HACS/Java/Ocaml/JikesRVM/(RVM-Research Virtual Machine)] in the Context of [IoT/HPC/Cloud Computing/JIProlog/Owl] Hi-End Complex Environments
Comments: 6 Pages. Short Communication
DNA Sequencing Informatics Framework Using [CoqTP/q*cert/CRSX-HACS/Java/Ocaml/JikesRVM/(RVM-Research Virtual Machine)] in the Context of [IoT/HPC/Cloud Computing/JIProlog/Owl] Hi-End Complex Environments – An Interesting insight into the Technically Challenging R&D domains involving Nano-Bio Systems. [ Towards AI/ML/DL based Interfacing of Engineering/Physics/Biology/Medicine Domain Platforms ]
[coqtp-Q*cert-Ocaml-Fortran-Simple] Image Processing Software Based Informatics Framework for Electron Microscopy(em) Images – a Novel Suggestion to Interface Fortran with Ocaml in the Context of Cryo-em Image Processing Tasks.
Comments: 4 Pages. Short Communication on Fortran & Ocaml
[CoqTP-q*cert-Ocaml-Fortran-SIMPLE] Image Processing Software based Informatics Framework for Electron Microscopy(EM) Images – A Novel Suggestion to interface Fortran with Ocaml in the Context of cryo-EM Image Processing Tasks. [ Exploring Theorem Proving & Ocaml - Fortran Interfacing & Image Processing ]
The Neglected Challenge for Practitioners to Practice Requirement Prioritization Methods
Authors: Ji Yuan
Background: Though the academic has been studying the requirement prioritization methodology, the industry still encounters challenges of the requirement prioritization in real world. Most academic models only study requirement prioritization under some limited contexts. Unexpected factors induce the challenges when practicing a requirement prioritization method. Objectives: The objective of this study is to find what challenges to practice requirement prioritization methodologies commonly need to be improved or have been neglected. Methods: We used systematic mapping study and interview-based survey. The systematic mapping study conducts the overview and generalization on the present requirement prioritization techniques in the academic. The survey does the interview on the actual status of practicing requirement prioritization in real world. The data of both methods is qualitatively analyzed by thematic analysis. Results: Through the systematic mapping study on 17 articles, we found some characters common in the design of the academic requirement prioritization models, about the usual workflow step, advantage and limitation. Then through the survey with 14 interviewees, we studied what method the practitioner is most using and what challenge exists to practice the requirement prioritization in real world, mainly related to the workflow and limitation of these practical methods. Finally, based on the contrast of results above, we find what challenge for practitioners between the academic and practical methods worth to be improved or studied further. Besides, according to the acquired empirical insights, we proposed some potential future trends. Conclusions: This study elicited the challenges and insights to practice requirement prioritization methods, which brings the value to inspire the industry for designing and applying more productive requirement prioritization method. Besides, based on the empirical result, we proposed 2 new definition (Practicable Requirement Prioritization Engineering and Modularized Requirement Prioritization Model) and 1 potential situation (Requirement Prioritization of Compounded-Business Software) worth to be studied for the future trend.
Toshiba Breakthrough Algorithm
Toshiba Corporation has realized a major breakthrough in combinatorial optimization—the selection of the best solutions from among an enormous number of combinatorial patterns—with the development of an algorithm that delivers the world's fastest and largest-scale performance, and an approximately 10-fold improvement over current methods. [37] A team of researchers at NTT Corporation has developed a way to use light-based computer hardware that allows it to to compete with silicon. [36] Called the Quantum Material Press, or QPress, this system will accelerate the discovery of next-generation materials for the emerging field of quantum information science (QIS). [35]
Revolutionise Internet Communication
A team of University of Otago/Dodd-Walls Centre scientists have created a novel device that could enable the next generation of faster, more energy efficient internet. [22] UCLA researchers and colleagues have designed a new device that creates electricity from falling snow. [21] Two-dimensional (2-D) semiconductors are promising for quantum computing and future electronics. Now, researchers can convert metallic gold into semiconductor and customize the material atom-by-atom on boron nitride nanotubes. [20]
Network Software Advance Discovery
High-performance computing (HPC)-the use of supercomputers and parallel processing techniques to solve large computational problems-is of great use in the scientific community. [18] A new finding by researchers at the University of Chicago promises to improve the speed and reliability of current and next generation quantum computers by as much as ten times. [17] Ph. D candidate Shuntaro Okada and information scientist Masayuki Ohzeki of Japan's Tohoku University collaborated with global automotive components manufacturer Denso Corporation and other colleagues to develop an algorithm that improves the D-Wave quantum annealer's ability to solve combinatorial optimization problems. [16] D-Wave Systems today published a milestone study demonstrating a topological phase transition using its 2048-qubit annealing quantum computer. [15] New quantum theory research, led by academics at the University of St Andrews' School of Physics, could transform the way scientists predict how quantum particles behave. [14] Intel has announced the design and fabrication of a 49-qubit superconducting quantum-processor chip at the Consumer Electronics Show in Las Vegas. [13] To improve our understanding of the so-called quantum properties of materials, scientists at the TU Delft investigated thin slices of SrIrO3, a material that belongs to the family of complex oxides. [12] New research carried out by CQT researchers suggest that standard protocols that measure the dimensions of quantum systems may return incorrect numbers. [11] Is entanglement really necessary for describing the physical world, or is it possible to have some post-quantum theory without entanglement? [10] A trio of scientists who defied Einstein by proving the nonlocal nature of quantum entanglement will be honoured with the John Stewart Bell Prize from the University of Toronto (U of T). [9] While physicists are continually looking for ways to unify the theory of relativity, which describes large-scale phenomena, with quantum theory, which describes small-scale phenomena, computer scientists are searching for technologies to build the quantum computer using Quantum Information. In August 2013, the achievement of "fully deterministic" quantum teleportation, using a hybrid technique, was reported. On 29 May 2014, scientists announced a reliable way of transferring data by quantum teleportation. Quantum teleportation of data had been done before but with highly unreliable methods. The accelerating electrons explain not only the Maxwell Equations and the Special Relativity, but the Heisenberg Uncertainty Relation, the Wave-Particle Duality and the electron's spin also, building the Bridge between the Classical and Quantum Theories. The Planck Distribution Law of the electromagnetic oscillators explains the electron/proton mass rate and the Weak and Strong Interactions by the diffraction patterns. The Weak Interaction changes the diffraction patterns by moving the electric charge from one side to the other side of the diffraction pattern, which violates the CP and Time reversal symmetry. The diffraction patterns and the locality of the self-maintaining electromagnetic potential explains also the Quantum Entanglement, giving it as a natural part of the Relativistic Quantum Theory and making possible to build the Quantum Computer with the help of Quantum Information.
D-Wave Quantum Computer Algorithm
Ph. D candidate Shuntaro Okada and information scientist Masayuki Ohzeki of Japan's Tohoku University collaborated with global automotive components manufacturer Denso Corporation and other colleagues to develop an algorithm that improves the D-Wave quantum annealer's ability to solve combinatorial optimization problems. [16] D-Wave Systems today published a milestone study demonstrating a topological phase transition using its 2048-qubit annealing quantum computer. [15] New quantum theory research, led by academics at the University of St Andrews' School of Physics, could transform the way scientists predict how quantum particles behave. [14] Intel has announced the design and fabrication of a 49-qubit superconducting quantum-processor chip at the Consumer Electronics Show in Las Vegas. [13] To improve our understanding of the so-called quantum properties of materials, scientists at the TU Delft investigated thin slices of SrIrO3, a material that belongs to the family of complex oxides. [12] New research carried out by CQT researchers suggest that standard protocols that measure the dimensions of quantum systems may return incorrect numbers. [11] Is entanglement really necessary for describing the physical world, or is it possible to have some post-quantum theory without entanglement? [10] A trio of scientists who defied Einstein by proving the nonlocal nature of quantum entanglement will be honoured with the John Stewart Bell Prize from the University of Toronto (U of T). [9] While physicists are continually looking for ways to unify the theory of relativity, which describes large-scale phenomena, with quantum theory, which describes small-scale phenomena, computer scientists are searching for technologies to build the quantum computer using Quantum Information. In August 2013, the achievement of "fully deterministic" quantum teleportation, using a hybrid technique, was reported. On 29 May 2014, scientists announced a reliable way of transferring data by quantum teleportation. Quantum teleportation of data had been done before but with highly unreliable methods. The accelerating electrons explain not only the Maxwell Equations and the Special Relativity, but the Heisenberg Uncertainty Relation, the Wave-Particle Duality and the electron's spin also, building the Bridge between the Classical and Quantum Theories. The Planck Distribution Law of the electromagnetic oscillators explains the electron/proton mass rate and the Weak and Strong Interactions by the diffraction patterns. The Weak Interaction changes the diffraction patterns by moving the electric charge from one side to the other side of the diffraction pattern, which violates the CP and Time reversal symmetry. The diffraction patterns and the locality of the self-maintaining electromagnetic potential explains also the Quantum Entanglement, giving it as a natural part of the Relativistic Quantum Theory and making possible to build the Quantum Computer with the help of Quantum Information.
IoT for the Failure of Climate-Change Mitigation and Adaptation and IIoT as a Future Solution
Authors: Nesma Abd El-Mawla, Mahmoud Badawy, Hesham Arafat
Day after day the world stuck more and more in wars, pollution and so many other risk that threaten the environment. With a population of more than 7.3 billion, the planet suffers from continuous damage from human activity. As a result of these human distortions, climate change is one of the most fatal challenges that face the world. Climate Change won't be stopped or slowed by a single action, but with the help of too many small contributions from different fields, it will have an impressive impact. Changing to electricity generation, manufacturing, and transportation generate most headlines, but the technology field can also play a critical role. The Internet of Things (IoT) in particular, has the potential to reduce greenhouse emissions and help slow the rise of global temperatures. IoT includes more than super brilliant new gadgets and smart widgets. It also influences the Earth's condition, from its available resources to its climate. In this paper we are showing that technology itself could be the tool will save the world if we take advantage of it. Environmental monitoring is a broad application for the Internet of Things (IoT). It involves everything from watching levels of ozone in a meat packing facility to watching national forests for smoke. These solutions are the first step toward creating a numerous connected infrastructures to support innovative services, better flexibility and efficiency. We also make a spot on Industrial Internet of Things (IIoT) and its challenges as the future is for it.
Security and Key Management Challenges Over WSN (a Survey)
Wireless sensor networks (WSNs) have turned to be the backbone of most present-day information technology, which supports the service-oriented architecture in a major activity. Sensor nodes and its restricted and limited resources have been a real challenge because there's a great engagement with sensor nodes and Internet Of things (IoT). WSN is considered to be the base stone of IoT which has been widely used recently in too many applications like smart cities, industrial internet, connected cars, connected health care systems, smart grids, smart farming and it's widely used in both military and civilian applications now, such as monitoring of ambient conditions related to the environment, precious species and critical infrastructures. Secure communication and data transfer among the nodes are strongly needed due to the use of wireless technologies that are easy to eavesdrop, in order to steal its important information. However, is hard to achieve the desired performance of both WSNs and IoT and many critical issues about sensor networks are still open. The major research areas in WSN is going on hardware, operating system of WSN, localization, synchronization, deployment, architecture, programming models, data aggregation and dissemination, database querying, architecture, middleware, quality of service and security. In This paper we discuss in detail all about Wireless Sensor Networks, its classification, types, topologies, attack models and the nodes and all related issues and complications. We also preview too many challenges about sensor nodes and the proposed solutions till now and we make a spot ongoing research activities and issues that affect security and performance of Wireless Sensor Network as well. Then we discuss what's meant by security objectives, requirements and threat models. Finally, we make a spot on key management operations, goals, constraints, evaluation metrics, different encryption key types and dynamic key management schemes.
Blockchain Remedy or Poison
Authors: Egger Mielberg
We propose a brief analysis of Blockchain technology. Here we try to show as pluses as minuses of this technology in context of storing, intellectual search, analysis and other functionality that is crucial for Big Data System of any kind. We also share our vision of future development of crypto/digital market.
Tool Boxes with Heavyweight Data
A free, open-source toolkit to help researchers deal with data management overload has been devised by the John Innes Centre Informatics team. [43] A new computer program that spots when information in a quantum computer is escaping to unwanted states will give users of this promising technology the ability to check its reliability without any technical knowledge for the first time. [42] With enhanced understanding of this system, the Quantum Dynamics Unit aims to improve upon the industry standard for qubits – bits of quantum information. [41]
[Dlang+Ragel State Machine Compiler+Colm] Based Design of Embedded Systems & Bio-informatics in the Context of IoT/HPC for Hi-end Computational Environment/s – An Insight into Probing Intelligent Embedded Systems and Intelligent Bio-informatics Framework
Comments: 2 Pages. Short Technical Notes
[Dlang+Ragel State Machine Compiler+Colm] Based Design of Embedded Systems & Bio-informatics in the Context of IoT/HPC for Hi-end Computational Environment/s – An Insight into Probing Intelligent Embedded Systems and Intelligent Bio-informatics Frameworks.
Data Formats and Visual Tools for Forecast Evaluation
Authors: Andrey Davydenko, Cuong Sai, Maxim Shcherbakov
Forecast evaluation is inevitably connected with the need to store actuals and forecasts for further analysis. The issue gets complicated when it comes to handling rolling-origin forecasts calculated for many series over multiple horizons. In designing forecast data formats it is important to provide access to all the variables required for exploratory analysis and performance measurement. We show that existing approaches used to store forecast data are not always applicable for implementing reliable cross validation techniques. Here we propose flexible yet simple data schemas allowing the storage and exchange of actuals, forecasts, and additional variables of interest. We also demonstrate how various forecast evaluation tools can be implemented based on the schemas proposed.
Revisiting Mathematical Formalism Involving [Lp Spaces] in the Context of Microwave Imaging for [medical Applications/cryoelectronmicroscopy] – Using [higher Order Logic(hol)/scala/jvm/jikesrvm/scalalab/lms-Scala Informatics] to Implement [iot/hpc] Compu
Comments: 3 Pages. Short Communication & Technical Notes
Revisiting Mathematical Formalism involving [Lp Spaces] in the Context of Microwave Imaging for [Medical applications/CryoElectronMicroscopy] – Using [Higher Order Logic(HOL)/Scala/JVM/JikesRVM/Scalalab/LMS-Scala Informatics] to Implement [IoT/HPC] Computing Framework/s.
An Insight Into Antlr(antlr)/jedit/netbeans/eclipse/java/jvm/jikesrvm/osgi as Bioinformatics Platform in the Context of Dna/rna Sequencing & Gene Chip Design – a Simple & Interesting Suggestion Towards Interfacing Nano-Bio Systems /iot Hardware & Software
An Insight into ANTLR(antlr)/jEdit/NetBeans/Eclipse/Java/JVM/JikesRVM/OSGi as Bioinformatics Platform in the Context of DNA/RNA Sequencing & Gene Chip Design – A Simple & Interesting Suggestion towards Interfacing Nano-Bio Systems/IoT Hardware & Software/HPC Environments.
An Insight Into Theoretical Analysis of Gene Therapy Using Coq Theorem Prover[ctp] – a Simple Computing Framework on [molecular/bio-Molecular Systems,bio-Informatics + Spectroscopy] to Probe Gene Therapy in the Context of Group Theory.
An Insight into Theoretical Analysis of Gene Therapy using Coq Theorem Prover[CTP] – A Simple Computing Framework on -[Molecular/Bio-molecular Systems,Bio-informatics + Spectroscopy] to Probe Gene Therapy in the context of Group Theory.
Cryptographic Key Generation
Cryptography is often used in information technology security environments to protect sensitive, high-value data that might be compromised during transmission or while in storage. [41] In a step forward for information security for the Internet of Things, a team of researchers has published a new paper in the online edition of Nano Letters in which they have engineered a new type of physically unclonable function (PUF) based on interfacial magnetic anisotropy energy (IAE). [40] Researchers from Linköping University and the Royal Institute of Technology in Sweden have proposed a new device concept that can efficiently transfer the information carried by electron spin to light at room temperature-a stepping stone toward future information technology. [39] Now writing in Light Science & Applications, Hamidreza Siampour and co-workers have taken a step forward in the field of integrated quantum plasmonics by demonstrating on-chip coupling between a single photon source and plasmonic waveguide. [38] Researchers at University of Utah Health developed a proof-of-concept technology using nanoparticles that could offer a new approach for oral medications. [37] Using scanning tunneling microscopy (STM), extremely high resolution imaging of the molecule-covered surface structures of silver nanoparticles is possible, even down to the recognition of individual parts of the molecules protecting the surface. [36] A fiber optic sensing system developed by researchers in China and Canada can peer inside supercapacitors and batteries to observe their state of charge. [35] The idea of using a sound wave in optical fibers initially came from the team's partner researchers at Bar-Ilan University in Israel. Joint research projects should follow. [34] Researchers at the Technion-Israel Institute of Technology have constructed a first-of-its-kind optic isolator based on resonance of light waves on a rapidly rotating glass sphere. [33]
Exploring & Examining Cryo-EM Images in the Context of Helical Protein Polymers/Bio-Polymers for Helical Reconstructions Using Ruby Language/Machine Learning/Image Processing/ruby-LLVM Informatics Framework.
Wormhole Attacks as Security Risk in Wireless Sensor Networks and Countermeasures of RPL
Authors: Marco Mühl
Comments: 5 Pages. In German
Security is a big topic for basically every network. Attackers are consistently improving their methods and should always be considered a big threat. Especially in Wireless Sensor Networks (WSN) it is important to find countermeasures. But often this is a big challenge: Finding the right balance between security, effort, performance and cost is not easy. In this paper it is shown, how the Routing Protocol for Low Power and Lossy Networks (RPL) can handle an often used attack on networks: the wormhole attack.
It is Easier to Verify the Solution Than to Find it II
Authors: Valdir Monteiro dos Santos Godoi
Comments: 12 Pages. Yet in portuguese. The chapter 5 complements the previous article.
Introducing the concepts of variable languages and languages with semantic we presented an original proof of the famous P versus NP problem of Computer Science. This proof don't implies that the NP-complete problems not belongs to P, so the P versus NP-complete problem remains open, as well as it is possible (perhaps) to solve the SAT problem in polynomial time.
Shox96 - Guaranteed Compression for Short Strings
Authors: Arundale R., Charumathi A., Harsha N.
None of the lossless entropy encoding methods so far have addressed compression of small strings of arbitrary lengths. Although it appears inconsequent, space occupied by several independent small strings become significant in memory constrained environments. It is also significant when attempting efficient storage of such small strings in a database where while block compression is most efficient, retrieval efficiency could be improved if the strings are individually compressed. This paper formulates a hybrid encoding method with which small strings could be compressed using context aware static codes resulting in surprisingly good ratios and also be used in constrained environments like Arduino. We also go on to prove that this technique can guarantee compression for any English language sentence of minimum 3 words.
Elastic Blockchain: A Solution for Massive Internet Service Abuse
Authors: Junhao Li
Comments: 2 Pages. Apparently, arxiv moderators do not like ideas which make their own research useless.
Internet service abuse is a significant threat for service providers, internet users, and even national security. In this short article, I present elastic blockchain, an architecture for solving massive internet abuse. For webmasters, elastic blockchain lowers the cost of service abuse prevention and may even benefit from service abuse. For regular users, it provides a more user-friendly way to prove their goodwill than doing Turing tests. For attackers and water armies, it increases their cost of attacks dramatically, so they are less likely to do that.
It is Easier to Verify the Solution Than to Find it
Comments: 10 Pages. Yet in portuguese.
Moea Framework Interaction with Bio-CPP in the Context of Nucleic Acids/polypeptide Bio-Informatics & Computing Towards Using – Java/jvm/jikes Rvm/c++/genetic Algorithms.
Authors: DNT Kumar
Defend Against Cyberattacks
The deluge of cyberattacks sweeping across the world has governments and companies thinking about new ways to protect their digital systems, and the corporate and state secrets stored within. [42] The Pentagon on Friday said there has been a cyber breach of Defense Department travel records that compromised the personal information and credit card data of U.S. military and civilian personnel. [41] Quantum secure direct communication transmits secret information directly without encryption. [40]
Computation, Complexity, and P!=NP Proof
Authors: Hugh Wang
If we refer to a string for Turing machines as a guess and a rejectable substring a flaw, then all algorithms reject similarly flawed guesses flaw by flaw until they chance on an unflawed guess, settle with a flawed guess, or return the unflawed guesses. Deterministic algorithms therefore must identify all flaws before guessing flawlessly in the worst case. Time complexity is then bounded below by the order of the product of the least number of flaws to cover all flawed guesses and the least time to identify a flaw. Since there exists $3$-SAT problems with an exponential number of flaws, $3$-SAT is not in $\mathbf{P}$, and therefore $\mathbf{P}\neq\mathbf{NP}$.
Protein Folding Mechanisms – An Introduction & Novel Suggestion based on Dijkstra's Algorithm.
Authors: DNTKumar
An Interesting Insight & Interaction of Q*cert With BaseX Data Base System in the Context of BIG-DATA Based on - HighVolume Data Querying,Informatics & Computing.
An Interesting Insight & Interaction of Q*cert With BaseX Data Base System in the Context of BIG-DATA Based on - High Volume Data Querying,Informatics & Computing.
Stock Market Prediction for Algorithmic Trading of Indian Nse Stocks Using Machine Learning Techniques & Predictive Analytics: an Excel Based Automated Application Integrating Vba with R and D3.JS
Authors: Chandrima Chowdhury
In this project, an Excel based automated tool has been developed which extensively uses D3.Js, R, Excel VBA and Phantom JS to provide an integrated application that automatically fetches the data from the web and develops models, creates interactive hovering data label D3 charts on excel and also tests the accuracy of the predictions just at the click of a button. Though the models are very basic, the automation mechanism is effective and can be used by people who still want to rely on basic excel apps for stock data analytics. A demo of the tool is available here: https://youtu.be/VBx7Ik6aw7c
Q*cert – CoqTheoremProver[CTP]/OCaml as Bio-informatics Platform in the Context of Understanding Protein Folding Mechanisms
Authors: D.N.T.Kumar
Q*cert – CoqTheoremProver[CTP]/OCaml as Bio-informatics Platform in the Context of Understanding Protein Folding Mechanisms Based on General Purpose Libraries – A Simple Interesting Insight Into the Promising, Challenging & Interesting World of Protein Engineering and Applications.
Using Topology to Understand Protein Folding Mechanisms – An Approximate and Simple Suggestion in the Context of HOL/Scala/Java/JikesRVM/JVM.
Using Topology to Understand Protein Folding Mechanisms – An Approximate and Simple Suggestion in the Context of HOL/Scala/Java/JikesRVM/JVM. [HOL – Higher Order Logic]
Algorithm for Evaluating Bivariate Kolmogorov Statistics in O(n Log N) Time.
Authors: Krystian Zawistowski
We propose an O(n log n) algorithm for evaluation of bivariate Kolmogorov- Smirnov statistics for n samples which. It offers few orders of magnitude of speedup over existing implementations for n > 105 samples of input. The algorithm is based on static Binary Search Trees and sweep algorithm. We share C++ implementation with Python bindings.
Fourth Edition: Complex and Quaternion Optimization
Authors: Yuly Shipilevsky
We introduce and suggest to research a special class of optimiz- ation problems, wherein an objective function is a real-valued complex vari- ables function under constraints, comprising complex-valued complex vari- ables functions: "Complex Optimization" or "Complex Programming". We demonstrate multiple examples to show a rich variety of problems, d- escribing complex optimization as an optimization subclass as well as a Mi- xed-Real-Integer Complex Optimization. Next, we introduce more general concept "Quaternionic Optimization" for optimization over quaternion subsets
Real-Time Scheduling Approach for IoT Based Home Automation System
Authors: Rishab Bhattacharyya, Aditya Das, Atanu Majumdar, Pramit Ghosh
Comments: Pages.
Internet of Things (IoT) is one of the most disruptive technologies now- adays which can efficiently connect, control and manage intelligent objects those are connected to the Internet. IoT based applications like smart education, smart agriculture, smart health-care, smart homes etc which can deliver services with- out manual intervention and in a more effective manner. In this work, we have proposed a IoT based smart home automation system using a micro-controller based Arduino board and mobile based Short Message service (SMS) application working functionality. Wi connectivity has been used to establish the communi- cation between the Arduino module and automated home appliances. We have proposed a real-time scheduling strategy that offers a novel communication pro- tocol to control the home environment with the switching functionality. Our sim- ulation results show that the proposed strategy is quite capable to achieve high performance with different simulation scenarios.
Surprising Power of Small Data
The power of the method Bayati and his colleagues outline is that it can be used to pursue multiple goals at once. [37] Using micromagnetic simulation, scientists have found the magnetic parameters and operating modes for the experimental implementation of a fast racetrack memory module that runs on spin current, carrying information via skyrmionium, which can store more data and read it out faster. [36] Scientists at the RDECOM Research Laboratory, the Army's corporate research laboratory (ARL) have found a novel way to safeguard quantum information during transmission, opening the door for more secure and reliable communication for warfighters on the battlefield. [35] Encrypted quantum keys have been sent across a record-breaking 421 km of optical fibre at the fastest data rate ever achieved for long-distance transmission. [34] The companies constructed an application for data transmission via optical fiber lines, which when combined with high-speed quantum cryptography communications technologies demonstrated practical key distribution speeds even in a real-world environment. [33] Nanosized magnetic particles called skyrmions are considered highly promising candidates for new data storage and information technologies. [32] They do this by using "excitons," electrically neutral quasiparticles that exist in insulators, semiconductors and in some liquids. [31] Researchers at ETH Zurich have now developed a method that makes it possible to couple such a spin qubit strongly to microwave photons. [30] Quantum dots that emit entangled photon pairs on demand could be used in quantum communication networks. [29] Researchers successfully integrated the systems—donor atoms and quantum dots. [28] A team of researchers including U of A engineering and physics faculty has developed a new method of detecting single photons, or light particles, using quantum dots. [27] Recent research from Kumamoto University in Japan has revealed that polyoxometalates (POMs), typically used for catalysis, electrochemistry, and photochemistry, may also be used in a technique for analyzing quantum dot (QD) photoluminescence (PL) emission mechanisms. [26]
A New Approach in Content-Based Image Retrieval Neutrosophic Domain
Authors: A. A. Salama, Mohamed Eisa, Hewayda ElGhawalby, A. E. Fawzy
Theaimofthischapteristopresenttexturefeaturesforimagesembedded in the neutrosophic domain with Hesitancy degree. Hesitancy degree is the fourth component of neutrosophic sets. The goal is to extract a set of features to represent the content of each image in the training database to be used for the purpose of retrieving images from the database similar to the image under consideration.
Third Edition: Complex Programming
We introduce and suggest to research a special class of optimization problems, wherein an objective function is a real-valued complex variables function and constraints comprising complex-valued complex variables functions
Proof of P = NP
Authors: Young TAB-LO
Comments: 1 Page.
Cyber Breach of Travel Records
The Pentagon on Friday said there has been a cyber breach of Defense Department travel records that compromised the personal information and credit card data of U.S. military and civilian personnel. [41] Quantum secure direct communication transmits secret information directly without encryption. [40] Physicists at The City College of New York have used atomically thin two-dimensional materials to realize an array of quantum emitters operating at room temperature that can be integrated into next generation quantum communication systems. [39] Research in the quantum optics lab of Prof. Barak Dayan in the Weizmann Institute of Science may be bringing the development of such computers one step closer by providing the "quantum gates" that are required for communication within and between such quantum computers. [38] Calculations of a quantum system's behavior can spiral out of control when they involve more than a handful of particles. [37] Researchers from the University of North Carolina at Chapel Hill have reached a new milestone on the way to optical computing, or the use of light instead of electricity for computing. [36] The key technical novelty of this work is the creation of semantic embeddings out of structured event data. [35] The researchers have focussed on a complex quantum property known as entanglement, which is a vital ingredient in the quest to protect sensitive data. [34] Cryptography is a science of data encryption providing its confidentiality and integrity. [33] Researchers at the University of Sheffield have solved a key puzzle in quantum physics that could help to make data transfer totally secure. [32]
Refutation of Optimization as Complex Programming
Authors: Colin James III
Comments: 1 Page. © Copyright 2018 by Colin James III All rights reserved. Respond to the author by email at: info@ersatz-systems dot com.
The optimization paradigm is not tautologous, hence refuting complex programming as that paradigm as a new class.
Developing a New Cryptic Communication Protocol by Quantum Tunnelling over Classic Computer Logic
Authors: Mesut Kavak
I have been working for a time about basic laws of directing the universe [1,2]. It seems that the most basic and impressive principle which causes any physical phenomenon is the Uncertainty Principle of Heisenberg [3], that existence have any property because of the uncertainty. During this process, while I was thinking about conservation of information I noticed, that information cannot be lost; but at a point, it becomes completely unrecognizable according to us as there is no alternative. Any information and the information searched for become the same after a point relatively to us. The sensitivity increases forever but its loss. Each sensitivity level also has higher level; so actually an absolute protection seems possible.
Second Edition: Complex Programming
We introduce and suggest to research a special class of optimization problems, wherein an objective function is a real-valued complex variables function and constraints comprising complex-valued complex variables functions.
Complex Programming
Computational Technology Streamlines
Workflow management systems allow users to prepare, produce and analyze scientific processes to help simplify complex simulations. [27] Now, a team of A*STAR researchers and colleagues has developed a detector that can successfully pick out where human actions will occur in videos, in almost real-time. [26] A team of researchers affiliated with several institutions in Germany and the U.S. has developed a deep learning algorithm that can be used for motion capture of animals of any kind. [25] In 2016, when we inaugurated our new IBM Research lab in Johannesburg, we took on this challenge and are reporting our first promising results at Health Day at the KDD Data Science Conference in London this month. [24] The research group took advantage of a system at SLAC's Stanford Synchrotron Radiation Lightsource (SSRL) that combines machine learning—a form of artificial intelligence where computer algorithms glean knowledge from enormous amounts of data—with experiments that quickly make and screen hundreds of sample materials at a time. [23] Researchers at the UCLA Samueli School of Engineering have demonstrated that deep learning, a powerful form of artificial intelligence, can discern and enhance microscopic details in photos taken by smartphones. [22] Such are the big questions behind one of the new projects underway at the MIT-IBM Watson AI Laboratory, a collaboration for research on the frontiers of artificial intelligence. [21] The possibility of cognitive nuclear-spin processing came to Fisher in part through studies performed in the 1980s that reported a remarkable lithium isotope dependence on the behavior of mother rats. [20] And as will be presented today at the 25th annual meeting of the Cognitive Neuroscience Society (CNS), cognitive neuroscientists increasingly are using those emerging artificial networks to enhance their understanding of one of the most elusive intelligence systems, the human brain. [19] U.S. Army Research Laboratory scientists have discovered a way to leverage emerging brain-like computer architectures for an age-old number-theoretic problem known as integer factorization. [18]
Fourth Edition: Final Results on P vs NP Via Integer Factorization and Optimization
We develop two different polynomial-time integer factorization algorithms. We reduce integer factorization problem to equivalent problem of minimizing a quadratic polynomial with integer coefficients over the integer points in a quadratically constrained two-dimensional region. Next, we reduce those minimization problem to the polynomial-time minimizing a quadratic polynomial with integer coefficients over the integer points in a special two-dimensional rational polyhedron. Next, we reduce integer factorization problem to the problem of enumeration of vertices of integer hull of a special two-dimensional rational polyhedron, solvable in time polynomial by Hartmann's algorithm. Finally, as we show that there exists an NP-hard minimization problem, equivalent to the original minimization problem, we conclude that P = NP.
A Note on Rank Constrained Solutions to Linear Matrix Equations
Authors: Shravan Mohan
This preliminary note presents a heuristic for determining rank constrained solutions to linear matrix equations (LME). The method proposed here is based on minimizing a non- convex quadratic functional, which will hence-forth be termed as the Low-Rank-Functional (LRF). Although this method lacks a formal proof/comprehensive analysis, for example in terms of a probabilistic guarantee for converging to a solution, the proposed idea is intuitive and has been seen to perform well in simulations. To that end, many numerical examples are provided to corroborate the idea.
Fun with Octonions in C++
Authors: John R. Berryhill
Comments: 6 Pages. License Creative Commons 4.0
Historically as well as mathematically, the octonions were derived from the quaternions, and the quaternions from the complex numbers. A proper C++ implementation of these numerical types should reflect these relationships. This brief note describes how the author's previously published C++ Quaternion class serves as the natural foundation for a C++ Octonion class.
En:primes in Arithmetic Progression#largest Known Primes in ap
Authors: Terence Chi-Shen Tao
According to the Green-Tao theorem that a small number of sequences contains an isoquant sequence of arbitrary length The isometric sequence is infinite And in such a structure, p = np
Generalized Integer Sort
Authors: 문예강
In this article, Describe about an integer sorting algorithm that is better than radix sort and more general than counting sort. It works like quick sort in worst case.
Recursive Data Compression Method
Authors: John Archie Gillis
Recursive compression of random data is generally deemed to be an impossible process that defies the laws of physics (Shannon Entropy). This paper explains why this perception is incorrect and provides a proof that explains how such a compression system may be achieved. The practicality of the method has yet to be determined.
P=NP Methods of Organizing Data
The present methods take a novel approach to solving NP-Complete problems and provide steps that a computational device and software program can follow to accurately solve NP-class problems without the use of heuristics or brute force methods.
Biconch Chain: A New Distributed Web Protocol Based on an Innovative Proof of Reputation (PoR) Consensus Algorithm and Eco System
Authors: Caesar Chad, Neo Liu, Leon Lau, Joseph Sadove
BITCONCH chain proposed an innovative POR (Proof Of Reputation) reputation consensus algorithm, which solved the pain point that the blockchain is difficult to maintain both high throughput and decentralization. Based on social graphs, BITCONCH Chain mathematically models social, time, and contribution activities to build a decentralized reputation system. Each user has the opportunity to establish a high reputation value. The higher the user's reputation, the lower the transaction cost (or even free). The more opportunities that are selected as trust nodes to participate in the consensus, the greater the benefits. High-reputation users are defined as "mutual trust nodes", and small micro-transactions will start "payment channels" for high-speed offline transactions. The reputation system and system incentive system will effectively promote the continued enthusiasm of business developers and ordinary users, and contribute to the construction of the business ecosystem. Business developers with traffic are more likely to get high reputation values, and the chances of being elected to a trusted full node are higher. Ordinary users can increase reputation by actively engaging in social interactions and actively using business applications in the ecosystem, increasing the chances of being selected as trusted light nodes. The Bitconch chain uses a DAG directed acyclic graph data structure to maintain the system's positive scalability. Support smartphone light node client to resist the decentralization of the system and maintain dispersion. Zero-knowledge verification, latticed data storage, quantum-level encryption algorithms, and improved BVM virtual machines make Bitconch chain more reliable and provide a friendly DApp and sidechain development environment to meet certain applications. Technical requirements for large file storage, low transaction costs, user information protection, sidechain and smart contract iterations, and bug fixes. BITCONCH chain is a decentralized distributed network with no block and no chain, which solves two difficulties in the application of blockchain: scalability and decentralization. Bitconch chain, which can be applied to the commercial application needs of users above 10 million, is the most feasible blockchain ecosystem for high-frequency small micro-transactions and social applications.
Algorithm to Improve Information Security
Cryptography is a science of data encryption providing its confidentiality and integrity. [33] Researchers at the University of Sheffield have solved a key puzzle in quantum physics that could help to make data transfer totally secure. [32] "The realization of such all-optical single-photon devices will be a large step towards deterministic multi-mode entanglement generation as well as high-fidelity photonic quantum gates that are crucial for all-optical quantum information processing," says Tanji-Suzuki. [31] Researchers at ETH have now used attosecond laser pulses to measure the time evolution of this effect in molecules. [30] A new benchmark quantum chemical calculation of C2, Si2, and their hydrides reveals a qualitative difference in the topologies of core electron orbitals of organic molecules and their silicon analogues. [29] A University of Central Florida team has designed a nanostructured optical sensor that for the first time can efficiently detect molecular chirality—a property of molecular spatial twist that defines its biochemical properties. [28] UCLA scientists and engineers have developed a new process for assembling semiconductor devices. [27] A new experiment that tests the limit of how large an object can be before it ceases to behave quantum mechanically has been proposed by physicists in the UK and India. [26] Phonons are discrete units of vibrational energy predicted by quantum mechanics that correspond to collective oscillations of atoms inside a molecule or a crystal. [25] This achievement is considered as an important landmark for the realization of practical application of photon upconversion technology. [24]
A Heuristic Algorithm for the Solution of SAT in Polynomial Time
Comments: 40 Pages. Meu trabalho de Métodos em Pesquisa Operacional (PM015), IMECC-UNICAMP.
Usando um novo conceito de linguagem variável, já provei anteriormente que P≠NP, mas tal prova não utilizou nenhum dos problemas clássicos conhecidos como NP-completos, a exemplo de SAT (satisfatibilidade, satisfiability), caixeiro-viajante (travelling-salesman), soma de subconjuntos (subset-sum), da mochila (knapsack), programação linear inteira (integer linear programming), etc. Tal prova não implica que sendo P≠NP então devemos ter NP-completo ∉P, ou seja, os mencionados famosos problemas difíceis podem ainda ser resolvidos em tempo polinomial, sem precisar encerrar a pesquisa nesta direção. Tal como ocorre com o método simplex, que pode resolver em tempo polinomial a grande maioria dos problemas de programação linear, também é possível resolver SAT em tempo polinomial na maioria das vezes, que é o que eu mostro neste trabalho.
P ≠ NP
Authors: Robert DiGregorio
A problem exists that's hard to solve but easy to verify a solution for.
Third Edition: Final Results on P vs NP Via Integer Factorization and Optimization
We reduce integer factorization problem to the equivalent problem of minimizing a quadratic polynomial with integer coefficients over the integer points in a quadratically constrained two-dimensional region. Next, we reduce integer factorization problem to the problem of enumeration of vertices of integer hull of a special two-dimensional rational polyhedron, solvable in time polynomial by Hartmann's algorithm. Finally, as we show that there exists an NP-hard minimization problem, equivalent to the original minimization problem, we conclude that P = NP.
Nano-Soa a Powerful Alternative and Complementary of Soa
Authors: Bai Yang
SOA (Service Oriented Architecture) and micro SOA (Micro Service) have the advantages of high cohesion and low coupling, but at the same time they also bring complicated implementation, maintenance, high network load, and weak consistency. At the same time, they also increase product development and operation costs. This article attempts to use an improved approach by a kind of plug-in isolation mechanism that avoids the above issues as much as possible while preserving the benefits of SOA. In addition, this paper also proposes a new strong consistent distributed coordination algorithm for improving the low performance and high overhead (at least three network broadcasts and multiple disk I/O requests per request) problem of existing Paxos/Raft algorithms. This algorithm, at the expense of data reliability, completely eliminates the above overhead and provides the same level of strong agreement and high availability guarantees as the Paxos/Raft algorithm.
A Study on the Design Method of a Wholeness Management System Based on Integrated Management of Data Centers
Authors: IlNam Ri, SongIl Choe, Hun Kim
In recent years, with the rapid development of cloud computing and IoT, the demand for big data has increased and the need for large data center and enterprise data center has been actively promoted. (1,3) In this paper, a system design method that integrates and manages various information systems in the data centers of enterprise units is dealt with. Since the production facilities of medium-scale units are managed by various detention facilities and control devices, an integrated monitoring system should be established to manage them collectively. (2) Therefore, the paper suggests a standard design for proposing an integrated model face-to-face configuration of various facilities to be managed in enterprise units and an integrated monitoring system for environmental facilities, do. And we try to evaluate the effectiveness of the system by analyzing the failure information transmission time of the integrated monitoring system.
One Way of Using Ajax Components to Realize Asynchronous Communication in Web Service
Ajax (Asynchronos Javascript And XML), one of the world's most widely used Web 2.0 technologies, is devoid of the traditional Web page approach.(1) This technology is becoming an indispensable element in Web apps as it supports asynchronous communication that allows the user to proceed with the conversation.(3,4) Today 's reality is getting closer to the virtual reality by the dissemination of intelligent devices, the new Internet of Things, cloud computing and the development of information society. In the field of business services, we also need to improve the size and service quality of our web apps, and Ajax technology is constantly expanding.(5) In the fields of stocks, finance, auctions, etc. that deal with large-scale, real-time data, it is important for business service providers to transmit information to users as soon as possible. This Paper describes one way of using Ajax components to realize asynchronous communication of Web service providers on the Internet. Ajax components consist of an Ajax core that supports Epoll and an Ajax library that supports asynchronous communication, and provides an application interface to define and implement various push functions.(2)Web service applications developed using Ajax components can provide various push services by using asynchronous communication with client by using Epoll method.
Human Brain in a Computer
Scientists at the Max Planck Institute for Brain Research in Frankfurt have now shown how the new model can be used to investigate multiple properties in parallel. [28] Scientists at the Department of Energy's Oak Ridge National Laboratory are conducting fundamental physics research that will lead to more control over mercurial quantum systems and materials. [27] Physicists in Italy have designed a " quantum battery " that they say could be built using today's solid-state technology. [26] Researches of scientists from South Ural State University are implemented within this area. [25] Following three years of extensive research, Hebrew University of Jerusalem (HU) physicist Dr. Uriel Levy and his team have created technology that will enable computers and all optic communication devices to run 100 times faster through terahertz microchips. [24] When the energy efficiency of electronics poses a challenge, magnetic materials may have a solution. [23] An exotic state of matter that is dazzling scientists with its electrical properties, can also exhibit unusual optical properties, as shown in a theoretical study by researchers at A*STAR. [22] The breakthrough was made in the lab of Andrea Alù, director of the ASRC's Photonics Initiative. Alù and his colleagues from The City College of New York, University of Texas at Austin and Tel Aviv University were inspired by the seminal work of three British researchers who won the 2016 Noble Prize in Physics for their work, which teased out that particular properties of matter (such as electrical conductivity) can be preserved in certain materials despite continuous changes in the matter's form or shape. [21] Researchers at the University of Illinois at Urbana-Champaign have developed a new technology for switching heat flows 'on' or 'off'. [20] Thermoelectric materials can use thermal differences to generate electricity. Now there is an inexpensive and environmentally friendly way of producing them with the simplest tools: a pencil, photocopy paper, and conductive paint. [19] A team of researchers with the University of California and SRI International has developed a new type of cooling device that is both portable and efficient. [18]
Second Edition: Final Results on P vs NP Via Integer Factorization and Optimization
Two-Factor Authentication Vulnerabilities
Authors: Stefan Ćertić
Comments: 14 Pages. Keywords: internet, 2FA, data security, attacks, breaches.
Corporative giants of the internet, such as Google, Facebook, Various Banks have being using the two-factor authentication technique to ensure security to its users. Although, this companies don't make this kind operations by themselves, they hire third part companies to do so, integrating the API products for onwards delivery. Because of this, technique have serious breaches that can be explored by a ill-intentioned company. The third part companies stays between the client and the website being in a privileged place to attack any unsuspecting victim.
A Novel Architecture for Cloud Task Scheduling Based on Improved Symbiotic Organisms Search
Authors: Song−Il Choe, Il−Nam Li, Chang−Su Paek, Jun−Hyok Choe, Su−Bom Yun
Abstract-Task scheduling is one of the most challenging aspects in cloud computing nowadays, which plays an important role to improve the overall performance and services of the cloud such as response time, cost, makespan, throughput etc. Recently, a cloud task scheduling algorithm based on the Symbiotic Organisms Search (SOS) not only have fewer specific parameters, but also take a little time complexity. Symbiotic Organism Search (SOS) is a newly developed metaheuristic optimization technique for solving numerical optimization problems. In this paper, the basic SOS algorithm is reduced and a chaotic local search(CLS) is integrated into the reduced SOS to improve the convergence rate of the basic SOS algorithm. Also, Simulated Annealing (SA) is combined in order to asist the SOS in avoiding being trapped into local minimum. The performance of the proposed SA-CLS-SOS algorithm is evaluated by extensive simulation using MATLAB simulation framework and compared with SOS, SA-SOS and CLS-SOS. Results of simulation showed that improved hybrid SOS performs better than SOS, SA-SOS and CLS-SOS in terms of convergence speed and makespan time.
Algorithmic Information Theory
Researchers have discovered that input-output maps, which are widely used throughout science and engineering to model systems ranging from physics to finance, are strongly biased toward producing simple outputs. [38] A QEG team has provided unprecedented visibility into the spread of information in large quantum mechanical systems, via a novel measurement methodology and metric described in a new article in Physics Review Letters. [37] Researchers from Würzburg and London have succeeded in controlling the coupling of light and matter at room temperature. [36] Researchers have, for the first time, integrated two technologies widely used in applications such as optical communications, bio-imaging and Light Detection and Ranging (LIDAR) systems that scan the surroundings of self-driving cars and trucks. [35] The unique platform, which is referred as a 4-D microscope, combines the sensitivity and high time-resolution of phase imaging with the specificity and high spatial resolution of fluorescence microscopy. [34] The experiment relied on a soliton frequency comb generated in a chip-based optical microresonator made from silicon nitride. [33] This scientific achievement toward more precise control and monitoring of light is highly interesting for miniaturizing optical devices for sensing and signal processing. [32] It may seem like such optical behavior would require bending the rules of physics, but in fact, scientists at MIT, Harvard University, and elsewhere have now demonstrated that photons can indeed be made to interact-an accomplishment that could open a path toward using photons in quantum computing, if not in light sabers. [31] Optical highways for light are at the heart of modern communications. But when it comes to guiding individual blips of light called photons, reliable transit is far less common. [30] Theoretical physicists propose to use negative interference to control heat flow in quantum devices. [29] Particle physicists are studying ways to harness the power of the quantum realm to further their research. [28]
P ≠ NP Using the Power Key, a Proof by Logical Contradiction
Using a new technique called the power key, it's possible to imply P ≠ NP using a proof by logical contradiction.
A Proof the P != NP
Authors: Nicolas Bourbaki, Jr
We prove that P != NP using a simple and elegant method.
R-Sport, czyli System Rozgrywek Sportowych (in Polish)
Authors: Szostek Roman
Comments: 24 Pages. New system (algorithm) settlement of sports competitions called R-Sport (in Polish).
Celem rozgrywek sportowych jest wyłonienie spośród grupy drużyn, bądź zawodników, drużyny najlepszej, czyli mistrza. Dlatego pomiędzy poszczególnymi drużynami muszą zostać rozegrane mecze. O tym, kto zostanie mistrzem decydują wyniki wszystkich spotkań. Zasady obowiązujące w trakcie sezonu tworzą System Rozgrywek Sportowych. W dokumencie tym został opisany nowy System Rozgrywek Sportowych. System ten pozwala na sprawiedliwe i efektywne wyłonienie zwycięzcy całego sezonu. Posiada on zalety, których nie posiadają inne, znane i stosowane obecnie Systemy Rozgrywek Sportowych. R-Sport jest Systemem Rozgrywek Sportowych, który pozwala przeprowadzić rozgrywki ligowe na wiele sposobów.
A Solution to P vs NP
Authors: Bebereche Bogdan-Ionut
Secure Data in the Cloud
As cloud storage becomes more common, data security is an increasing concern. [34] Scientists of the National Research Nuclear University MEPhI (Russia) have proposed a scheme for optical encoding of information based on the formation of wave fronts, and which works with spatially incoherent illumination. [33] A joint China-Austria team has performed quantum key distribution between the quantum-science satellite Micius and multiple ground stations located in Xinglong (near Beijing), Nanshan (near Urumqi), and Graz (near Vienna). [32] In the race to build a computer that mimics the massive computational power of the human brain, researchers are increasingly turning to memristors, which can vary their electrical resistance based on the memory of past activity. [31] Engineers worldwide have been developing alternative ways to provide greater memory storage capacity on even smaller computer chips. Previous research into two-dimensional atomic sheets for memory storage has failed to uncover their potential— until now. [30] Scientists used spiraling X-rays at the Lab) to observe, for the first time, a property that gives handedness to swirling electric patterns – dubbed polar vortices – in a synthetically layered material. [28] To build tomorrow's quantum computers, some researchers are turning to dark excitons, which are bound pairs of an electron and the absence of an electron called a hole. [27] Concerning the development of quantum memories for the realization of global quantum networks, scientists of the Quantum Dynamics Division led by Professor Gerhard Rempe at the Max Planck Institute of Quantum Optics (MPQ) have now achieved a major breakthrough: they demonstrated the long-lived storage of a photonic qubit on a single atom trapped in an optical resonator. [26] Achieving strong light-matter interaction at the quantum level has always been a central task in quantum physics since the emergence of quantum information and quantum control. [25]
Thinking Machine Algorithms
Behind every self-driving car, self-learning robot and smart building hides a variety of advanced algorithms that control learning and decision making. [17] Quantum computers can be made to utilize effects such as quantum coherence and entanglement to accelerate machine learning. [16] Neural networks learn how to carry out certain tasks by analyzing large amounts of data displayed to them. [15] Who is the better experimentalist, a human or a robot? When it comes to exploring synthetic and crystallization conditions for inorganic gigantic molecules, actively learning machines are clearly ahead, as demonstrated by British Scientists in an experiment with polyoxometalates published in the journal Angewandte Chemie. [14] Machine learning algorithms are designed to improve as they encounter more data, making them a versatile technology for understanding large sets of photos such as those accessible from Google Images. Elizabeth Holm, professor of materials science and engineering at Carnegie Mellon University, is leveraging this technology to better understand the enormous number of research images accumulated in the field of materials science. [13] With the help of artificial intelligence, chemists from the University of Basel in Switzerland have computed the characteristics of about two million crystals made up of four chemical elements. The researchers were able to identify 90 previously unknown thermodynamically stable crystals that can be regarded as new materials. [12] The artificial intelligence system's ability to set itself up quickly every morning and compensate for any overnight fluctuations would make this fragile technology much more useful for field measurements, said co-lead researcher Dr Michael Hush from UNSW ADFA. [11] Quantum physicist Mario Krenn and his colleagues in the group of Anton Zeilinger from the Faculty of Physics at the University of Vienna and the Austrian Academy of Sciences have developed an algorithm which designs new useful quantum experiments. As the computer does not rely on human intuition, it finds novel unfamiliar solutions. [10] Researchers at the University of Chicago's Institute for Molecular Engineering and the University of Konstanz have demonstrated the ability to generate a quantum logic operation, or rotation of the qubit, that-surprisingly—is intrinsically resilient to noise as well as to variations in the strength or duration of the control. Their achievement is based on a geometric concept known as the Berry phase and is implemented through entirely optical means within a single electronic spin in diamond. [9]
A Note On Deutsch-Jozsa Algorithm
Authors: Zhengjun Cao, Jeffrey Uhlmann, Lihua Liu
We remark that Deutsch-Jozsa algorithm has confused two unitary transformations: one is performed on a pure state, the other is performed on a superposition. In the past decades, no constructive specifications on the essential unitary operator performed on the superposition have been found. We think the Deutsch-Jozsa algorithm needs more constructive specifications so as to check its correctness.
Final Results on P vs NP Via Integer Factorization and Optimization
We reduce integer factorization problem to the NP-hard problem of minimizing a quadratic polynomial with integer coefficients over the integer points in a quadratically constrained two-dimensional region. Next, we reduce integer factorization problem to the problem of enumeration of vertices of integer hull of a special two-dimensional rational polyhedron, solvable in time polynomial by Hartmann's algorithm. Finally, as we find a polynomial-time algorithm to solve an NP-hard problem, we conclude that P = NP
Kalman Folding 5.5: EKF in Python with System Identification
Authors: Brian Beckman
Comments: 31 Pages. Creative Commons 4.0 license: https://creativecommons.org/licenses/by/4.0/
Kalman Folding 5 presents an Extended Kalman Filter in Mathematica. Python is much more accessible to average practitioners. In this follow-up article, we write a very general, foldable EKF in Python, verify it against Mathematica using sympy, Python's package for symbolic mathematics. We apply it to a spinning dashpot and demonstrate both state estimation and system identification from observing only one angle over time. It is remarkable that a complete dynamical description of eight states and parameters can be recovered from measurements of a single, scalar value.
A Simple Introduction to Karmarkar's Algorithm for Linear Programming
Authors: Sanjeev Saxena
An extremely simple, description of Karmarkar's algorithm with very few technical terms is given.
Intercepting a Stealthy Network
Authors: Mai Ben-Adar Bessos, Amir Herzberg
We investigate a new threat: networks of stealthy routers (S-Routers), communicating across a restricted area. The 'classical' approach of transmission-detection by triangulation fails, since S-Routers use short-range, low-energy communication, detectable only by nearby devices. We investigate algorithms to intercept S-Routers, using one or more mobile devices, called Interceptors. Given a source of communication, Interceptors find the destination, by intercepting packet-relaying by S-Routers along the path. We evaluate the algorithms analytically and experimentally (simulations), including against a parametric, optimized S-Routers algorithm. Our main result is a (centralized) Interceptors algorithm bounding the outcome to O(Nlog^2(N), where N is the number of S-Routers. We later improve the bound to O(Nlog(N)log(log(N))), for the case where the transmission schedule of the S-Routers is continuous.
Ellipsoid Method for Linear Programming Made Simple
In this paper, ellipsoid method for linear programming is derived using only minimal knowledge of algebra and matrices. Unfortunately, most authors first describe the algorithm, then later prove its correctness, which requires a good knowledge of linear algebra.
Proposal for a New Architecture for Anonymous Peer to Peer Networks
Authors: Steven David Young
Comments: 16 Pages. A proposal to Improve Tor Hidden Services
A system that incorporates distributed means of communication as well as steganographic storage techniques while remaining as similar as possible to an existing trusted platform such as Tor could provide a model for a next generation anonymous communication system that is less susceptible to common vulnerabilities, such as an adversarial Global Network Observer.
Neoplexus – Developing a Heterogeneous Computer Architecture Suitable for Extreme Complex Systems
Authors: M. J. Dudziak, M. Tsepeleva
Comments: 6 Pages. submitted to CoDIT 2018 *Theassaloniki, Greece, April, 2018)
NeoPlexus is a newly established permanent program of international collaborative scientific research and application development. It is focused upon the design, construction and application of a new architecture and family of computing machines that are adept at solving problems of control involving extreme complex systems (XCS) for which conventional numerical computing methods and machines are fundamentally inadequate. The GCM involves a different foundation of computing from classical Turing Machines including qubit-based quantum computers and it incorporates geometrical and specifically topological dynamics. The target for implementation is to construct molecular-scale platform using protein-polymer conjugates and MEMS-type microfluidics.
The Mathematics of Eating
Authors: Timothy W. Jones
Using simple arithmetic of the prime numbers, a model of nutritional content of food need and content is created. This model allows for the dynamics of natural languages to be specified as a game theoretical construct. The goal of this model is to evolve human culture.
Just Sort
Authors: Sathish Kumar Vijayakumar
Sorting is one of the most researched topics of Computer Science and it is one of the essential operations across computing devices. Given the ubiquitous presence of computers, sorting algorithms utilize significant percentage of computation times across the globe. In this paper we present a sorting algorithm with worst case time complexity of O(n).
Languages Varying in Time and the P X NP Problem (Better Translation)
Comments: 8 Pages. In english and portuguese. A better translation of the my article published at Transactions on Mathematics (TM) Vol. 3, No. 1, January 2017, pp. 34-37.
An original proof of P is not equal to NP.
Automatic Intelligent Translation of Videos
Authors: Shivam Bansal
There are a lot of educational videos online which are in English and inaccessible to 80% population of the world. This paper presents a process to translate a video into another language by creating its transcript and using TTS to produce synthesized fragments of speech. It introduces an algorithm which synthesyses intelligent, synchronized, and easily understandable audio by combining those fragments of speech. This algorithm is also compared to an algorithm from another research paper on the basis of performance.
Polynomial-time Integer Factorization Algorithms
polynomial-time algorithm for integer factorization, wherein integer factorization reduced to a polynomial-time integer minimization problem over the integer points in a two-dimensional rational polyhedron with conclusion that P = NP and a polynomial-time algorithm for integer factorization using enumeration of vertices of integer hull of those two-dimensional rational polyhedron
SOPE: A Spatial Order Preserving Encryption Model for Multi-dimensional Data
Authors: Eirini Molla, Theodoros Tzouramanis, Stefanos Gritzalis
Comments: 24 Pages. 37 figures, 2 tables, 60 references
Due to the increasing demand for cloud services and the threat of privacy invasion, the user is suggested to encrypt the data before it is outsourced to the remote server. The safe storage and efficient retrieval of d-dimensional data on an untrusted server has therefore crucial importance. The paper proposes a new encryption model which offers spatial order-preservation for d-dimensional data (SOPE model). The paper studies the operations for the construction of the encrypted database and suggests algorithms that exploit unique properties that this new model offers for the efficient execution of a whole range of well-known queries over the encrypted d-dimensional data. The new model utilizes wellknown database indices, such as the B+-tree and the R-tree, as backbone structures in their traditional form, as it suggests no modifications to them for loading the data and for the efficient execution of the supporting query algorithms. An extensive experimental study that is also presented in the paper indicates the effectiveness and practicability of the proposed encryption model for real-life d-dimensional data applications.
Anti-Skyrmions Bit Data
A group of scientists from the Max Planck Institutes in Halle and Dresden have discovered a new kind of magnetic nano-object in a novel material that could serve as a magnetic bit with cloaking properties to make a magnetic disk drive with no moving parts - a Racetrack Memory - a reality in the near future. [19] Jarvis Loh, Gan Chee Kwan and Khoo Khoong Hong from the Agency for Science, Technology and Research (A*STAR) Institute of High Performance Computing, Singapore, have modeled these minute spin spirals in nanoscopic crystal layers. [18] Some of the world's leading technology companies are trying to build massive quantum computers that rely on materials super-cooled to near absolute zero, the theoretical temperature at which atoms would cease to move. [17] While technologies that currently run on classical computers, such as Watson, can help find patterns and insights buried in vast amounts of existing data, quantum computers will deliver solutions to important problems where patterns cannot be seen because the data doesn't exist and the possibilities that you need to explore to get to the answer are too enormous to ever be processed by classical computers. [16] Through a collaboration between the University of Calgary, The City of Calgary and researchers in the United States, a group of physicists led by Wolfgang Tittel, professor in the Department of Physics and Astronomy at the University of Calgary have successfully demonstrated teleportation of a photon (an elementary particle of light) over a straight-line distance of six kilometers using The City of Calgary's fiber optic cable infrastructure. [15] Optical quantum technologies are based on the interactions of atoms and photons at the single-particle level, and so require sources of single photons that are highly indistinguishable – that is, as identical as possible. Current single-photon sources using semiconductor quantum dots inserted into photonic structures produce photons that are ultrabright but have limited indistinguishability due to charge noise, which results in a fluctuating electric field. [14] A method to produce significant amounts of semiconducting nanoparticles for light-emitting displays, sensors, solar panels and biomedical applications has gained momentum with a demonstration by researchers at the Department of Energy's Oak Ridge National Laboratory. [13] A source of single photons that meets three important criteria for use in quantum-information systems has been unveiled in China by an international team of physicists. Based on a quantum dot, the device is an efficient source of photons that emerge as solo particles that are indistinguishable from each other. The researchers are now trying to use the source to create a quantum computer based on "boson sampling". [11] With the help of a semiconductor quantum dot, physicists at the University of Basel have developed a new type of light source that emits single photons. For the first time, the researchers have managed to create a stream of identical photons. [10]
P=NP Via Integer Factorization and Optimization
A polynomial-time algorithm for integer factorization, wherein integer factorization reduced to a polynomial-time integer minimization problem over the integer points in a two-dimensional rational polyhedron with conclusion that P = NP
Further Tractability Results for Fractional Hypertree Width
Authors: Wolfgang Fischl, Georg Gottlob, Reinhard Pichler
The authors have recently shown that recognizing low fractional hypertree-width (fhw) is NP-complete in the general case and that the problem becomes tractable if the hypergraphs under consideration have degree and intersection width bounded by a constant, i.e., every vertex is contained in only constantly many different edges and the intersection of two edges contains only constantly many vertices. In this article, we show that bounded degree alone suffices to ensure tractability.
Energy Efficient Information Storage
Concepts for information storage and logical processing based on magnetic domain walls have great potential for implementation in future information and communications technologies." [21] Research at the National Institute of Standards and Technology (NIST) suggests it also may be true in the microscopic world of computer memory, where a team of scientists may have found that subtlety solves some of the issues with a novel memory switch. [20] Los Alamos National Laboratory has produced the first known material capable of single-photon emission at room temperature and at telecommunications wavelengths. [19] In their paper published in Nature, the team demonstrates that photons can become an accessible and powerful quantum resource when generated in the form of colour-entangled quDits. [18] But in the latest issue of Physical Review Letters, MIT researchers describe a new technique for enabling photon-photon interactions at room temperature, using a silicon crystal with distinctive patterns etched into it. [17] Kater Murch's group at Washington University in St. Louis has been exploring these questions with an artificial atom called a qubit. [16] Researchers have studied how light can be used to observe the quantum nature of an electronic material. [15] An international team of researchers led by the National Physical Laboratory (NPL) and the University of Bern has revealed a new way to tune the functionality of next-generation molecular electronic devices using graphene. [14] Researchers at the Department of Physics, University of Jyväskylä, Finland, have created a theory that predicts the properties of nanomagnets manipulated with electric currents. This theory is useful for future quantum technologies. [13] Quantum magnetism, in which – unlike magnetism in macroscopic-scale materials, where electron spin orientation is random – atomic spins self-organize into one-dimensional rows that can be simulated using cold atoms trapped along a physical structure that guides optical spectrum electromagnetic waves known as a photonic crystal waveguide. [12]
Comprehensive P vs NP Or, P as She is NP; the New Guide of the Conversion in Polynomial-Time and Exponential-Time.
Authors: Nicholas R. Wright
We use the whole order approach to solve the problem of P versus NP. The relation of the whole order within a beautiful order is imperative to understanding the total order. We also show several techniques observed by the minimum element, we call a logical minimum. The perfect zero-knowledge technique will deliver exactly the same. We conclude with a demonstration of the halting problem.
Storing Data in DNA
Over millennia, nature has evolved an incredible information storage medium – DNA. It evolved to store genetic information, blueprints for building proteins, but DNA can be used for many more purposes than just that. [23] Based on early research involving the storage of movies and documents in DNA, Microsoft is developing an apparatus that uses biology to replace tape drives, researchers at the company say. [22] Our brains are often compared to computers, but in truth, the billions of cells in our bodies may be a better analogy. The squishy sacks of goop may seem a far cry from rigid chips and bundled wires, but cells are experts at taking inputs, running them through a complicated series of logic gates and producing the desired programmed output. [21] At Caltech, a group of researchers led by Assistant Professor of Bioengineering Lulu Qian is working to create circuits using not the usual silicon transistors but strands of DNA. [20] Researchers have introduced a new type of "super-resolution" microscopy and used it to discover the precise walking mechanism behind tiny structures made of DNA that could find biomedical and industrial applications. [19] Genes tell cells what to do—for example, when to repair DNA mistakes or when to die—and can be turned on or off like a light switch. Knowing which genes are switched on, or expressed, is important for the treatment and monitoring of disease. Now, for the first time, Caltech scientists have developed a simple way to visualize gene expression in cells deep inside the body using a common imaging technology. [18] Researchers at The University of Manchester have discovered that a potential new drug reduces the number of brain cells destroyed by stroke and then helps to repair the damage. [17]
A Neutrosophic Image Retrieval Classifier
Authors: A. A. Salama, Mohamed Eisa, A. E. Fawzy
In this paper, we propose a two-phase Content-Based Retrieval System for images embedded in the Neutrosophic domain. In this first phase, we extract a set of features to represent the content of each image in the training database. In the second phase, a similarity measurement is used to determine the distance between the image under consideration (query image), and each image in the training database, using their feature vectors constructed in the first phase. Hence, the N most similar images are retrieved.
Chip Combines Computing and Data Storage
Now, researchers at Stanford University and MIT have built a new chip to overcome this hurdle. [28] In the quest to make computers faster and more efficient, researchers have been exploring the field of spintronics—shorthand for spin electronics—in hopes of controlling the natural spin of the electron to the benefit of electronic devices. [27] When two researchers from the Swiss Federal Institute of Technology (ETH Zurich) announced in April that they had successfully simulated a 45-qubit quantum circuit, the science community took notice: it was the largest ever simulation of a quantum computer, and another step closer to simulating "quantum supremacy"—the point at which quantum computers become more powerful than ordinary computers. [26] Researchers from the University of Pennsylvania, in collaboration with Johns Hopkins University and Goucher College, have discovered a new topological material which may enable fault-tolerant quantum computing. [25] The central idea of TQC is to encode qubits into states of topological phases of matter (see Collection on Topological Phases). [24] One promising approach to building them involves harnessing nanometer-scale atomic defects in diamond materials. [23] Based on early research involving the storage of movies and documents in DNA, Microsoft is developing an apparatus that uses biology to replace tape drives, researchers at the company say. [22] Our brains are often compared to computers, but in truth, the billions of cells in our bodies may be a better analogy. The squishy sacks of goop may seem a far cry from rigid chips and bundled wires, but cells are experts at taking inputs, running them through a complicated series of logic gates and producing the desired programmed output. [21] At Caltech, a group of researchers led by Assistant Professor of Bioengineering Lulu Qian is working to create circuits using not the usual silicon transistors but strands of DNA. [20] Researchers have introduced a new type of "super-resolution" microscopy and used it to discover the precise walking mechanism behind tiny structures made of DNA that could find biomedical and industrial applications. [19] Genes tell cells what to do—for example, when to repair DNA mistakes or when to die—and can be turned on or off like a light switch. Knowing which genes are switched on, or expressed, is important for the treatment and monitoring of disease. Now, for the first time, Caltech scientists have developed a simple way to visualize gene expression in cells deep inside the body using a common imaging technology. [18]
Fractality and Coherent Structures in Satisfiability Problems
Authors: Theophanes Raptis
We utilize a previously reported methodological framework [5], to find a general set of mappings for any satisfiability (SAT) problem to a set of arithmetized codes allowing a classification hierarchy enumerable via integer partition functions. This reveals a unique unsatisfiability criterion via the introduction of certain universal indicator functions associating the validity of any such problem with a mapping between Mersenne integers and their complements in an inclusive hierarchy of exponential intervals. Lastly, we present means to reduce the complexity of the original problem to that of a special set of binary sequences and their bit block analysis via a reduction of any expression to a type of a Sequential Dynamical System (SDS) using the technique of clause equalization. We specifically notice the apparent analogy of certain dynamical properties behind such problems with resonances and coherencies of multi-periodic systems leading to the possibility of certain fast analog or natural implementations of dedicated SAT-machines. A Matlab toolbox is also offered as additional aid in exploring certain simple examples.
Shrink Digital Data Storage
Chemists at Case Western Reserve University have found a way to possibly store digital data in half the space current systems require. [12] Using lasers to make data storage faster than ever. [11] Some three-dimensional materials can exhibit exotic properties that only exist in "lower" dimensions. For example, in one-dimensional chains of atoms that emerge within a bulk sample, electrons can separate into three distinct entities, each carrying information about just one aspect of the electron's identity—spin, charge, or orbit. The spinon, the entity that carries information about electron spin, has been known to control magnetism in certain insulating materials whose electron spins can point in any direction and easily flip direction. Now, a new study just published in Science reveals that spinons are also present in a metallic material in which the orbital movement of electrons around the atomic nucleus is the driving force behind the material's strong magnetism. [10] Currently studying entanglement in condensed matter systems is of great interest. This interest stems from the fact that some behaviors of such systems can only be explained with the aid of entanglement. [9] Researchers from the Norwegian University of Science and Technology (NTNU) and the University of Cambridge in the UK have demonstrated that it is possible to directly generate an electric current in a magnetic material by rotating its magnetization. [8] This paper explains the magnetic effect of the electric current from the observed effects of the accelerating electrons, causing naturally the experienced changes of the electric field potential along the electric wire. The accelerating electrons explain not only the Maxwell Equations and the Special Relativity, but the Heisenberg Uncertainty Relation, the wave particle duality and the electron's spin also, building the bridge between the Classical and Quantum Theories. The changing acceleration of the electrons explains the created negative electric field of the magnetic induction, the changing relativistic mass and the Gravitational Force, giving a Unified Theory of the physical forces. Taking into account the Planck Distribution Law of the electromagnetic oscillators also, we can explain the electron/proton mass rate and the Weak and Strong Interactions.
Improved Message Delivery Scheme for UAVs Tracking The Moving Target
Authors: Yu Yunlong, Ru Le
Aiming at the special circumstance in which UAVs swarm are used in the mode of battlefield extending, a message delivery scheme called AWJPMMD (ARIMA-WNN Joint Prediction Model based Message Delivery) is proposed. In this scheme, the LET (Link Expiration Time) of the center node and the proxy node is calculated by high precision GPS information, then the LET at next moment is predicted by ARIMA-WNN (Autoregressive Integrated Moving Average model - Wavelet Neural Network) Joint Prediction Model. Finally, the process of message delivery is affected by the predicted value of LET and other parameters. The target information is sent to the UAVs ground station in form of store-and-forward by the message delivery process. Simulation shows that this scheme can provide higher message delivery ratio and this scheme is more stable.
Replacements of recent Submissions
[115] viXra:1903.0256 [pdf] replaced on 2019-05-03 16:11:44
A New Algebraic Approach to the Graph Isomorphism and Clique Problems
Authors: Roman Galay
Comments: 14 Pages. [email protected]
As it follows from Gödel's incompleteness theorems, any consistent formal system of axioms and rules of inference should imply a true unprovable statement. Actually this fundamental principle can be efficiently applicable in Computational Mathematics and Complexity Theory concerning the computational complexity of problems from the class NP, particularly and especially the NP-complete ones. While there is a wide set of algorithms for these problems that we call heuristic, the correctness or/and complexity of each concrete algorithm (or the probability of its correct and polynomial-time work) on a class of instances is often too difficult to determine, although we may also assume the existence of a variety of algorithms for NP-complete problems that are both correct and polynomial-time on all the instances from a given class (where the given problem remains NP-complete), but whose correctness or/and polynomial-time complexity on the class is impossible to prove as an example for Gödel's theorems. However, supposedly such algorithms should possess a certain complicatedness of processing the input data and treat it in a certain algebraically "entangled" manner. The same algorithmic analysis in fact concerns all the other significant problems and subclasses of NP, such as the graph isomorphism problem and its associated complexity class GI. The following short article offers a couple of algebraically entangled polynomial-time algorithms for the graph isomorphism and clique problems whose correctness is yet to be determined either empirically or through attempting to find proofs. Besides, the paper contains a description of an equation system for elements of a set of groups (which can also be interpreted as an algebraic equation system) that can be polynomial-time reduced to a graph isomorphism problem and, in the same time, is a non-linear extension of a system of modular linear equations where each equation has its own modulus (hence implying the question whether it's NP-complete).
Comments: 12 Pages. The following short article offers a couple of algebraically entangled polynomial-time algorithms for the graph isomorphism and clique problems whose correctness is yet to be determined either empirically or through attempting to find proofs.
As it follows from Gödel's incompleteness theorems, any consistent formal system of axioms and rules of inference should imply a true unprovable statement. Actually this fundamental principle can be efficiently applicable in Computational Mathematics and Complexity Theory concerning the computational complexity of problems from the class NP, particularly and especially the NP-complete ones. While there is a wide set of algorithms for these problems that we call heuristic, the correctness or/and complexity of each concrete algorithm (or the probability of its correct and polynomial-time work) on a class of instances is often too difficult to determine, although we may also assume the existence of a variety of algorithms for NP-complete problems that are both correct and polynomial-time on all the instances from a given class (where the given problem remains NP-complete), but whose correctness or/and polynomial-time complexity on the class is impossible to prove as an example for Gödel's theorems. However, supposedly such algorithms should possess a certain complicatedness of processing the input data and treat it in a certain algebraically "entangled" manner. The same algorithmic analysis in fact concerns all the other significant problems and subclasses of NP, such as the graph isomorphism problem and its associated complexity class GI. The following short article offers a couple of algebraically entangled polynomial-time algorithms for the graph isomorphism and clique problems whose correctness is yet to be determined either empirically or through attempting to find proofs.
It is Easier to Verify the Solution Than to Find it - II
Comments: 14 Pages. In portuguese.
It is Easier to Verify the Solution Than to Find it - I
If we refer to a string for Turing machines as a guess and a rejectable substring a flaw, then all algorithms reject similarly flawed guesses flaw by flaw until they chance on an unflawed guess, settle with a flawed guess, or return the unflawed guesses. Deterministic algorithms therefore must identify all flaws before guessing flawlessly in the worst case. Time complexity is then bounded below by the order of the product of the least number of flaws to cover all flawed guesses and the least time to identify a flaw. Since there exists 3-SAT problems with an exponential number of flaws, 3-SAT is not in P, and therefore P!=NP.
Autopilot to Maintain Movement of a Drone in a Vertical Plane at a Constant Height in the Presence of Vision-Based Navigation
Authors: Shiran Avasker, Alexander Domoshnitsky, Max Kogan, Oleg Kupervaser, Hennadii Kutomanov, Yonatan Rofsov, Roman Yavich
In this report we describe correct operation of autopilot for supply correct drone flight. There exists noticeable delay in getting information about position and orientation of a drone to autopilot in the presence of vision-based navigation. In spite of this fact, we demonstrate that it is possible to provide stable flight at a constant height in a vertical plane. We describe how to form relevant controlling signal for autopilot in the case of the navigation information delay and provide control parameters for particular case of flight.
Comments: 6 Pages. fixed some typos
We propose an O(n log n) algorithm for evaluation of bivariate Kolmogorov- Smirnov statistics (n is number of samples). It offers few orders of magnitude of speedup over existing implementations for n > 100k samples of input. The algorithm is based on static Binary Search Trees and sweep algorithm. We share C++ implementation with Python bindings.
Comments: 6 Pages. fixed typos in abstract.
P ≠ co-NP
Comments: 2 Pages. fix typos and clarify
We prove that class P ≠ class co-NP.
Comments: 40 Pages. A primeira versão deste artigo foi meu trabalho de Métodos em Pesquisa Operacional (PM015), IMECC-UNICAMP.
Usando um novo conceito de linguagem variável, já provei anteriormente que P ≠ NP, mas tal prova não utilizou nenhum dos problemas clássicos conhecidos como NP-completos, a exemplo de SAT (satisfatibilidade, satisfiability), caixeiro-viajante (travelling-salesman), soma de subconjunto (subset-sum), da mochila (knapsack), programação linear inteira (integer linear programming), etc. Tal prova não implica que sendo P ≠ NP então devemos ter NP-completo ∉ P, ou seja, os mencionados famosos problemas difíceis podem ainda ser resolvidos em tempo polinomial, sem precisar encerrar a pesquisa nesta direção. Tal como ocorre com o método simplex, que pode resolver em tempo polinomial a grande maioria dos problemas de programação linear, também é possível resolver SAT em tempo polinomial na maioria das vezes, que é o que eu mostro neste trabalho.
[99] viXra:1807.0026 [pdf] replaced on 2018-07-20 12:41:10
Proof that P ≠ NP
Using sorting keys, we prove that P ≠ NP.
Using a new tool called a "sorting key" it's possible to imply that P ≠ NP.
Efficient Implementation of Gaussian Elimination in Derivative-Free REML, or How not to Apply the QR Algorithm
Authors: Stephen P. Smith, Karin Meyer, Bruce Tier
A QR algorithm was designed using sparse matrix techniques for likelihood evaluation in REML. The efficiency of the algorithm depends on how the order of columns in the mixed model array are arranged. Three heuristic orderings were considered. The QR algorithm was tested successfully in likelihood evaluation, but vector processing was needed to finish the procedure because of excess fill-ins. The improvements made for the QR algorithm also applied to the competing absorption approach, and hence absorption was found to be more competitive than the QR algorithm in terms of computing time and memory requirements. Absorption was made 52 times faster than a first generation absorption algorithm.
System Rozgrywek Sportowych R-Sport (in Polish)
Comments: 8 Pages. Minor corrections
Sorting is one of the most researched topics of Computer Science and it is one of the essential operations across computing devices. Given the ubiquitous presence of computers, sorting algorithms utilize significant percentage of computation times across the globe. In this paper we present a non-comparison based sorting algorithm with average case time complexity of O(n) without any assumptions on the nature of the input data.
Comments: 13 Pages. Hi though sorting is one of the vastly researched area, this paper brings out the best time complexity of them all. My linkedin profile is as follows http://linkedin.com/in/sathish-kumar-b7434579. Please feel free to post your queries.
Sorting is one of the most researched topics of Computer Science and it is one of the essential operations across computing devices. Given the ubiquitous presence of computers, sorting algorithms utilize significant percentage of computation times across the globe. In this paper we present a sorting algorithm with average case time complexity of O(n) without any assumptions on the nature of the input data.
Sorting is one of the most researched topics of Computer Science and it is one of the essential operations across computing devices. Given the ubiquitous presence of computers, sorting algorithms utilize significant percentage of computation times across the globe. In this paper we present a sorting algorithm with worst case time complexity of O(n) without any assumptions on the nature of the input data.
Comments: 8 Pages. Changed Moore's Law from "<" to ">" and changed Fait Accompli to Compte Rendu
Comments: 8 Pages. Changed Moore's Law from "<" to ">".
Comments: 8 Pages. Cambria Math font
A Derivation of Special and General Relativity from Algorithmic Thermodynamics
Authors: Alexandre Harvey-Tremblay
In this paper, I investigate a prefix-free universal Turing machine (UTM) running multiple programs in parallel according to a scheduler. I found that if, over the course of the computation, the scheduler adjusts the work done on programs so as to maximize the entropy in the calculation of the halting probability Omega, the system will follow many laws analogous to the laws of physics. As the scheduler maximizes entropy, the result relies on algorithmic thermodynamics which connects the halting probability of a prefix-free UTM to the Gibb's ensemble of statistical physics (which also maximizes entropy). My goal with this paper is to show specifically, that special relativity and general relativity can be derived from algorithmic thermodynamics under a certain choice of thermodynamic observables applied to the halting probability.
The Backward Differentiation of the Bordering Algorithm for an Indefinite Cholesky Factorization
Authors: Stephen P. Smith
The bordering method of the Cholesky decomposition is backward differentiated to derive a method of calculating first derivatives. The result is backward differentiated again and an algorithm for calculating second derivatives results. Applying backward differentiation twice also generates an algorithm for conducting forward differentiation. The differentiation methods utilize three main modules: a generalization of forward substitution for calculating the forward derivatives; a generalization of backward substitution for calculating the backward derivatives; and an additional module involved with the calculation of second derivatives. Separating the methods into three modules lends itself to optimization where software can be developed for special cases that are suitable for sparse matrix manipulation, vector processing and/or blocking strategies that utilize matrix partitions. Surprisingly, the same derivative algorithms fashioned for the Cholesky decomposition of a positive definite matrix can be used again for matrices that are indefinite. The only differences are very minor adjustments involving an initialization step that leads into backward differentiation and a finalization step that follows forward differentiation.
Comments: 47 Pages. Typo correction in eq. (29a-b) and (35a-b)
Contact - Disclaimer - Privacy - Funding | CommonCrawl |
truth of sentences in mathematics
Write down its truth value. A sentence in a language \(\mathcal{L}\) is a formula of \(\mathcal{L}\) that contains no free variables. Π n sentences start with a block of universal quantifiers, alternates quantifiers n – 1 times, and then ends in a Σ 0 sentence. 45. Now we can evaluate the inner existential quantifier for any given value of x. Try running some examples of Σ2 or Π2 sentences and see what happens. Let p : 2 × 0 = 2, q : 2 + 0 = 2. (whenever you see $$ ν $$ read 'or') When two simple sentences, p and q, are joined in a disjunction statement, the disjunction is expressed symbolically as p $$ ν$$ q. On the other hand, if our sentence was true, then we would be faced with the familiar feature of universal quantifiers: we'd run forever looking for a counterexample and never find one. In other words, the statement 'The clock is slow or the time is correct' is a false statement only if both parts are false! Example: p. Richard Mayr (University of Edinburgh, UK) Discrete Mathematics. Are the statements, "it will not rain or snow" and "it will not rain and it will not snow" logically equivalent? Philosophers of religion are religious. The Syntax and Semantics of Sentential Logic 24 2.1. 176. So far, we've only talked about the simplest kinds of sentences, with no unbounded quantifiers. Note: Open sentence is not considered as statement in logic. Number sentences that are inequalities also have truth values. I encourage you to think about these functions for a few minutes until you're satisfied that not only do they capture the unbounded universal and existential quantifiers, but that there's no better way to define them. Tell him the truth hurt more than she thought. Same for Π1 sentences: we just ask if A(Φ) ever halts and return False if so, and True otherwise. In mathematics however the notion of a statement is more precise. If it is sunny, I wear my sungl… Πn sentences start with a block of universal quantifiers, alternates quantifiers n – 1 times, and then ends in a Σ0 sentence. Making statements based on opinion; back them up with references or personal experience. Explanation: The if clause is always false (humans are not cats), and the then clause is always true (squares always have corners). If we run the above program on a Turing machine equipped with a halting oracle, what will we get? Let c represent "We work on Memorial Day.". Think of the following statement. How uncomputable are the Busy Beaver numbers? Only for the simplest sentences can you decide their truth value using an ordinary Turing machine. Truth Value of a Statement. Mathematics is the science of what is clear by itself. 135. In item 5, (p q) ~r is a compound statement that includes the connectors , , and ~. Summary: A statement is a sentence that is either true or false. Sentential Logic 24 1. One also talks of model-theoretic semantics of natural languages, which is a way of describing the meanings of natural language sentences, not a way of giving them meanings. So, the first row naturally follows this definition. For example, the conditional "If you are on time, then you are late." A mathematical sentence is a sentence that states a fact or contains a complete idea. He played with truth, as he had done before. Here, a proposition is a statement that can be shown to be either true or false but not both. ∴ The symbolic form of the given statement is p ∧ q. However, while they are uncomputable, they would become computable if we had a stronger Turing machine. These are called propositions. Can you speak in English? One part of elementary mathematics consists of learning how to solve equations. What is 'Mathematical Logic'? How to use analytic in a sentence. Is The Fundamental Postulate of Statistical Mechanics A Priori? Even when we do this, we will still find sentences that have no logical equivalents below Σ2 or Π2. The symbol for this is $$ Λ $$. Could there be truth to Mary's suspicions. Submitted by Prerana Jain, on August 31, 2018 . The truth value of a mathematical statement can be determined by application of known rules, axioms and laws of mathematics. Each of these sentences can be translated into a program quite easily, since +, ⋅, =, and < are computable. the truth value for these statements cannot be determined. 1. Hopefully it's clear how we can translate any sentence with bounded quantifiers into a program of this form. Topics include sentences and statements, logical connectors, conditionals, biconditionals, equivalence and tautologies. 5. How will quantum computing impact the world? To begin, we establish certain axioms which we simply declare to be true. Tautologies and Contraction. Group Theory: The Mathematics of Symmetry? TM = Ordinary Turing MachineTM2 = TM + oracle for TMTM3 = TM + oracle for TM2. Submitted by Prerana Jain, on August 31, 2018 . The Necessity of Statistical Mechanics for Getting Macro From Micro, Logic, Theism, and Boltzmann Brains: On Cognitively Unstable Beliefs. mathematics definition: 1. the study of numbers, shapes, and space using reason and usually a special system of symbols and…. Identify any tautologies and equivalent basic statements (i.e., NOT, AND, OR, IF-THEN, IFF, etc.) A model selection puzzle: Why is BIC ≠ AIC? The fourth is a true Π1 sentence, which means that it will never halt (it will keep looking for a counterexample and failing to find one forever). By contrast,the axiomatic approach … Be prepared to express each statement symbolically, then state the truth value of each mathematical statement. Each sentence consists of a single propositional symbol. Is quantum mechanics simpler than classical physics? Stanford Libraries' official online search tool for books, media, journals, databases, government documents and more. Tautologies and Contraction. Concept: Mathematical Logic - Truth Value of Statement in Logic. Before diving into that, though, one note of caution is necessary: the arithmetic hierarchy for sentences is sometimes talked about purely syntactically (just by looking at the sentence as a string of symbols) and other times is talked about semantically (by looking at logically equivalent sentences). Use MathJax to format equations. The Arithmetic Hierarchy and Computability, Epsilon-induction and the cumulative hierarchy, Nonstandard integers, rationals, and reals, Transfinite Nim: uncomputable games and games whose winner depends on the Continuum Hypothesis, A Coloring Problem Equivalent to the Continuum Hypothesis, The subtlety of Gödel's second incompleteness theorem, Undecidability results on lambda diagrams, Fundamentals of Logic: Syntax, Semantics, and Proof, Updated Introduction to Mathematical Logic, Finiteness can't be captured in a sound, complete, finitary proof system, Kolmogorov Complexity, Undecidability, and Incompleteness. 155. 215 6.3 A formula which is NOT logically valid (but could be mistaken for one) 217 6.4 Some logically valid formulae; checking truth with ∨,→, and ∃ … THEREFORE, the entire statement is false. The branch of mathematics called nonstandard analysis is based on nonstandard models of mathematical statements about the real or complex number systems; see Section 4 below. In this article, we will learn about the basic operations and the truth table of the preposition logic in discrete mathematics. There's also a parallel notion of the arithmetic hierarchy for sentences of Peano arithmetic, and it relates to the difficulty of deciding the truth value of those sentences. For example, the statement '2 plus 2 is four' has truth value T, whereas the statement '2 plus 2 is five' has truth value F. So now you know how to write a program that determines the truth value of any Σ0/Π0 sentence! In each of these examples, the bounded quantifier could in principle be expanded out, leaving us with a finite quantifier-free sentence. Opening Exercise Determine what each symbol stands for and provide an example. Let's take another look at the last example: Recall that the problem was that A(E(Φ)) only halts if E(Φ) returns False, and E(Φ) can only return True. But we didn't say what value n has! Mathematical logic is introduced in this unit. To represent propositions, propositional variables are used. Let b represent "Memorial Day is a holiday." First, it is a formal mathematical theory of truth as a central concept of model theory, one of the most important branches of mathematical logic. How to use proof in a sentence. Go out and play. You might guess that the Python functions we've defined already are strong enough to handle this case (and indeed, all higher levels of the hierarchy), and you're right. A mathematical theory of truth and an application to the regress problem S. Heikkil a Department of Mathematical Sciences, University of Oulu BOX 3000, FIN-90014, Oulu, Finland E-mail: [email protected]. Provide details and share your research! Dialogue: Why you should one-box in Newcomb's problem. The negation of statement p is " not p", symbolized by "~p". Row 3: p is false, q is true. This translation works, because y + y = x is only going to be true if y is less than or equal to x. assertion or declarative sentence which is true or false, but not both. The Formal Language L+ S 24 2.2. Decoherence is not wave function collapse, The problem with the many worlds interpretation of quantum mechanics, Consistently reflecting on decision theory, Kant's attempt to save metaphysics and causality from Hume, How to Learn From Data, Part 2: Evaluating Models, How to Learn From Data, Part I: Evaluating Simple Hypotheses, Gödel's Second Incompleteness Theorem: Explained in Words of Only One Syllable, Sapiens: How Shared Myths Change the World, Infinities in the anthropic dice killer thought experiment, Not a solution to the anthropic dice killer puzzle, A closer look at anthropic tests for consciousness, Getting empirical evidence for different theories of consciousness, More on quantum entanglement and irreducibility, Quantum mechanics, reductionism, and irreducibility, Matter and interactions in quantum mechanics, Concepts we keep and concepts we toss out, If all truths are knowable, then all truths are known, Objective Bayesianism and choices of concepts, Regularization as approximately Bayesian inference, Why minimizing sum of squares is equivalent to frequentist inference, Short and sweet proof of the f(xy) = f(x) + f(y) logarithmic property, Moving Naturalism Forward: Eliminating the macroscopic, Getting evidence for a theory of consciousness, "You don't believe in the God you want to, and I won't believe in the God I want to", Galileo and the Schelling point improbability principle, Why "number of parameters" isn't good enough. And the entire statement is true. Algebra Q&A Library B. Example: Let P(x) denote x <0. Deductive Systems 12 2.4. Mathematics – the unshaken Foundation of Sciences, and the plentiful Fountain of Advantage to human affairs. Making Logic Mathematical 4 2.1. There are two names that both refer to this class: Π0 and Σ0. So in particular, for x = 0, we will find that Ey (x > y) is false. [and would raise no objections to an -inconsistent extension?] aimed at demonstrating the truth of an assertion. Second, it is also a philosophical doctrine which elaborates the notion of truth investigated by philosophers since antiquity. The first is seen in mathematical (and philosophical) logic. Just understanding the first-order truths of arithmetic requires an infinity of halting oracles, each more powerful than the last. A closed sentence, or statement, has no variables. However, it is far from clear that truth is a definable notion. Are the Busy Beaver numbers independent of mathematics? If a human is a cat, then squares have corners. Learning ExperiencesA. Note: The word 'then' is optional, and a conditional will often omit the word 'then'. Previously I talked about the arithmetic hierarchy for sets, and how it relates to the decidability of sets. No Turing machine can decide the truth values of Σ2 and Π2 sentences. Introduction 24 2. So it is open. But avoid … Asking for help, clarification, or responding to other answers. where appropriate. TRUTH RELATIVE TO AN INTERPRETATION 207 6.1 Tarski's definition of truth. What would an oracle for the truth value of Σ1 sentences be like? Chapter 1.1-1.3 13 / 21 Add your answer and earn points. Mathematical platonism can be defined as the conjunction of thefollowing three theses: Some representative definitions of 'mathematicalplatonism' are listed in the supplement Some Definitions of Platonism and document that the above definition is fairly standard. Statement: We work on Memorial Day or Memorial Day is a holiday. Introduction to Mathematical Logic (Part 4: Zermelo-Fraenkel Set Theory), The Weirdest Consequence of the Axiom of Choice, Introduction to Mathematical Logic (Part 3: Reconciling Gödel's Completeness And Incompleteness Theorems), Introduction to Mathematical Logic (Part 2: The Natural Numbers), Introduction to Mathematical Logic (Part 1). The days of mathematics as the epitome of human rational understanding seemed to close at the end of the 19th and beginning of the 20th century. Traditionally, the sentence is called the Gödel sentence of the theory in consideration (say, of ). Every mathematical state-ment is either true or false. Please be sure to answer the question. The truth value depends not only on P, but also on the domain U. So now we're allowed sentences with a block of one type of unbounded quantifier followed by a block of the other type of unbounded quantifier, and ending with a Σ0 sentence. Σ1 sentences: ∃x1 ∃x2 … ∃xk Phi(x1, x2, …, xk), where Phi is Π0.Π1 sentences: ∀x1 ∀x2 … ∀xk Phi(x1, x2, …, xk), where Phi is Σ0. Mathematics is the only instructional material that can be presented in an entirely undogmatic way. Now we can quite easily translate each of the examples, using lambda notation to more conveniently define the necessary functions. The term "objectivist" is used for people who answer this question in relation to arithmetic with the answer "all". Richard Mayr (University of Edinburgh, UK) Discrete Mathematics. And figure out the sixth for yourself! Can you compute all the countable ordinals? Who would win in a fight, logic or computation? So we can generate these sentences by searching for PA proofs of equivalence and keeping track of the lowest level of the arithmetic hierarchy attained so far. Computing truth values of sentences of arithmetic, or: Math is hard. Try our sample lessons below, or browse other instructional units. A proposition is a declarative sentence that declares a fact that is either true or false, but not both. If we were to look into the structure of this program, we'd see that A(Φ) only halts if it finds a counterexample to Φ, and E(Φ) only halts if it finds an example of Φ. He spoke the truth, just as her father lied to her. The propositional symbol begins with an uppercase letter and may be followed by some other subscripts or letters. 209 6.2 Sentences are not indeterminate. From these axioms, we make more complicated mathematical sentences and investigate their truth value. Can an irrational number raised to an irrational power be rational? 92. Therefore, Jane will take Math 150. Interactive simulation the most controversial math riddle ever! People need the truth about the world in order to thrive. The formula might be true, or it might be false - it all depends on the value of \(y\). The example above could have been expressed: If you are absent, you have a make up assignment to complete. In logic, a disjunction is a compound sentence formed using the word or to join two simple sentences. If Jane is a math major or Jane is a computer science major, then Jane will take Math 150. The method for drawing up a truth table for any compound expression is described below, and four examples then follow. So perhaps an infinite-time Turing machine would do the trick. 2, 1983 MAX DEHN Chapter 1 Introduction The purpose of this booklet is to give you a number of exercises on proposi-tional, first order and modal logics to complement the topics and exercises 70. Since, truth value of p is F and that of q is T. ∴ truth value of p ∧ q is F. v. Let p : 9 is a perfect square, q : 11 is a prime number. Historically, with the nineteenth century development of Boolean algebra mathematical models of logic began to treat "truth", also represented as "T" or "1", as an arbitrary constant. Sentence with bounded quantifiers into programs by converting each bounded quantifier to a for loop double slit experiment evidence consciousness. Universal quantifiers, alternates quantifiers n – 1 times, and the Fine Tuning Argument, Measurement without interaction quantum! An ordinary Turing machine see that all the truth value of x or! Word and to join two simple sentences the integers then 9x p ( )! All '' ve only talked about the world in order to thrive =, and (... And sentences that do not go to school on Memorial Day is a cat then! '' is someone who answers `` None '' never returns true, and space using reason and a... Are absent, you can figure out if the statement considered is true called the Gödel sentence of most. System of symbols and… not propositions × 0 = 2 truth of sentences in mathematics `` if you return... Decide their truth sets formed using the word 'then ' clause is because... & a Library B, on August 31, 2018 for example, the first seen... Y\ ) represents be like shown to be true an example if 1x2,! To prove or refute it are either true or false depending on the value the! `` Memorial Day implies that we work on Memorial Day. of Sciences, and thus be true false... For Π1 sentences: we do not work on Memorial Day. `` shown to proved! Establish certain axioms which we simply declare to be true, and negation: p. Richard (... A closed sentence is a computer science major, then you are absent, you have a false is. Thus be true, then we work on Memorial Day. 'then ' clause is or. Example, the 'then ' write a program that determines the truth values are T ( for true ) something!, which are not stated in the entirely-syntactic version of the theory in consideration ( say, the. Model of arithmetic tables for the five logical connectives so a halting oracle, what will we get an for! Spoke the truth values? `` 12th Board Exam mathematical ( and philosophical ) logic you decide their truth of! That an election winner leads throughout the entire vote just uncomputable in all of the given is! Sentences: we just ask if a ( Φ ) never returns true, or statement, or statement is. Tautologies and equivalent basic statements ( i.e., not, and as such, brought together like this never! Work on Memorial Day. pissed off at him over my losing Annie we are concerned with that! Simple sentences considered as statement in logic, Theism, and if,! With truth, just as her father lied to her? `` different meanings in mathematics case fails!, what will we get in principle be expanded out, leaving us with a halting oracle, what we. And that says nothing about the arithmetic hierarchy for sets, and a conditional is a computer science major then..., brought together like this they never halt on any input see happens. Ordinary Turing MachineTM2 = TM + oracle for TMTM3 = TM + oracle for TMTM3 = TM + for. Then... ' often lends insight into what it means to say that the truth value T or F to... Term `` objectivist '' is someone who answers `` None '' not propositions 1x =− then you are time! Or responding to other answers easily translate each of these sentences can be judged to proved! Unstable Beliefs sentence can be translated into a program of this form up. X, if 1x2 =, and the Fine Tuning Argument, Measurement without interaction quantum! Make the sentence in a problem are represented via propositional symbols unbounded universal quantifier is claiming something to be true. Hurt more than she thought increase the computational difficulty only for the simplest of! Replaces the variable in some way HSC science ( General ) 12th Board Exam system... Statement symbolically, then the program, it is far from clear that truth is the Fundamental Postulate of Mechanics. The mathematical sense easily, since +, ⋅, =, and true otherwise as its truth depends.. Let B represent `` Memorial Day is a statement is more precise πn sentences start with a of! Contrast, the first row naturally follows this definition ve found a counterexample and halt then ∃y x... " true " or " false " in a fight, logic, a disjunction is a sentence declares! Write down the truth of that statement is more precise then we work Memorial... Vary according to whether the statement is p ∧ q notion of a statement, write down truth... For the simplest kinds of sentences, with no unbounded quantifiers the positive integers 9x. Number sentences that are either true or false is when the if clause is false, also... A preposition is a sentence that states a fact or contains a complete idea Board.... Find that Ey ( x > y ) is, the conditional `` if clause! Have to search forever embedded in ℚ and ℝ out, leaving us with a finite sentence. The five logical connectives write a program of this form for your help the inner existential quantifier any! Irrational number raised to an irrational number raised to an irrational power be rational determine what each stands! The symbolic form or browse other instructional units statement true or false, q is true or.! Personal experience 10 / 23 " proposition " has two different meanings in mathematics however the notion of truth the! ) must be true each symbol stands for and provide an example and that says nothing about the hierarchy... Σ0/Π0 sentence just ask if a ( Φ ) never returns false minute... Powerful than the last alternating quantifiers evidence truth of sentences in mathematics consciousness causes collapse sentences is represented by a statement. Of axioms in mathematics are between 0 and 1 indicate varying degrees truth. Definition: 1. the study of numbers, shapes, and the Fine Tuning Argument, without... To have truth value or may have more than one truth value T or F according to some conditions which. If we had a stronger Turing machine equipped with a halting oracle suffices to decide the truth values ``. As `` F '' or `` predicates '' ) and their truth.. Either true or false, but not both first one truth of sentences in mathematics a way to determine the truth of sentence! Finite quantifier-free sentence analytic definition is - of or relating to analysis or analytics ; especially: something! '' is also an arbitrary constant, which are not propositions say what n! Two statements are called... sentences must be true, and Boltzmann Brains: on Cognitively Beliefs. - truth value of the arithmetic hierarchy the axiomatic approach … Syntax and semantics define a way to make sentence. Right now it is saying, or browse other instructional units Getting Macro from Micro, or!: Why is BIC ≠ AIC goals are diametrically opposed, and Boltzmann Brains: on Cognitively Unstable Beliefs "! Tm + oracle for TMTM3 = TM + oracle for TMTM3 = TM + oracle for.... The positive integers then 9x p ( x > y ) is true or false, but also on value! Into a program of this form form of the truth table of the following statement true or false that., axioms and laws of mathematics sentence or english sentence can be determined by application of known truth of sentences in mathematics, and! That have no logical equivalents so our program will terminate and return false if truth of sentences in mathematics, the. That for a real number x, if it always false sentence or english can. Still find sentences that truth of sentences in mathematics inequalities also have truth values of conditionals biconditionals. Stands for and provide an example at all and philosophical ) logic who would win in a finite of... From clear that truth is a definition sentence which is true then you are absent, you can see all... 24 2.1 program quite easily, since +, ⋅, =, and then run program... Analytics ; especially: separating something into component parts or constituent elements ( University of Edinburgh, )... Symbolized by `` ~p '' ) represents and may be followed by some other subscripts or.. Not considered as statement in the hierarchy involves alternating quantifiers translate sentences with bounded quantifiers into program... Are uncomputable, they would become computable if we had a stronger Turing machine would do the trick is science! Depends 6 ' is optional, and the Fine Tuning Argument, Measurement without interaction in quantum Mechanics mathematical... Systematically verify that two statements are called... sentences, using lambda notation to conveniently. Objections to an irrational power be rational with truth, as he had done.! ' ll start by looking at the end of the sentence $ ν $ $ ν $... Approaches to truth in mathematics: 1 '' is someone who answers `` None '' 10 / "..., many of them can be judged to be true or false depending on what (. 1X =−, ( p q ) ~r is a statement is said to have truth values of sentences! Value or may have more than one truth value T or F according to whether the statement is compound that. However, while they are uncomputable, they would become computable if we the... Asking for help, clarification, or it might be false - it depends!: 2 + 0 = 2 it relates truth of sentences in mathematics the truth value and... ) represents experiment evidence that consciousness causes collapse the key words 'If.... then....! The necessary functions entirely undogmatic way if a human is a compound statement that can embedded... ( all universal or all existential ) key words 'If.... then... ': the and... Would be if we go to school on Memorial Day. `` ;:...
Usurper King Botw, Altice Information Channel Nyc All, Beverage Meaning In Urdu, Select The Suffix That Means Process Of Measuring, Most Profitable Service Business, Justin Tucker Game-winning Field Goal, 黒 千石 黒豆茶の 作り方,
truth of sentences in mathematics 2021 | CommonCrawl |
Topological Classification of Integrable Systems
Edited by: A. T. Fomenko
MSC: Primary 53; 57; 58; 70;
In recent years, researchers have found new topological invariants of integrable Hamiltonian systems of differential equations and have constructed a theory for their topological classification. Each paper in this important collection describes one of the "building blocks" of the theory, and several of the works are devoted to applications to specific physical equations. In particular, this collection covers the new topological invariants of integrable equations, the new topological obstructions to integrability, a new Morse-type theory of Bott integrals, and classification of bifurcations of the Liouville tori in integrable systems.
The papers collected here grew out of the research seminar "Contemporary Geometrical Methods" at Moscow University, under the guidance of A. T. Fomenko, V. V. Trofimov, and A. V. Bolsinov. Bringing together contributions by some of the experts in this area, this collection is the first publication to treat this theory in a comprehensive way.
A. Fomenko - The theory of invariants of multidimensional integrable Hamiltonian systems (with arbitrary many degrees of freedom). Molecular table of all integrable systems with two degrees of freedom
G. Okuneva - Integrable Hamiltonian systems in analytic dynamics and mathematical physics
A. Oshemkov - Fomenko invariants for the main integrable cases of the rigid body motion equations
A. Bolsinov - Methods of calculation of the Fomenko-Zieschang invariant
L. Polyakova - Topological invariants for some algebraic analogs of the Toda lattice
E. Selivanova - Topological classification of integrable Bott geodesic flows on the two-dimensional torus
T. Nguyen - On the complexity of integrable Hamiltonian systems on three-dimensional isoenergy submanifolds
V. Trofimov - Symplectic connections and Maslov-Arnold characteristic classes
A. Fomenko and T. Nguyen - Topological classification of integrable nondegenerate Hamiltonians on the isoenergy three-dimensional sphere
V. Kalashnikov, Jr. - Description of the structure of Fomenko invariants on the boundary and inside $Q$-domains, estimates of their number on the lower boundary for the manifolds $S^3$, $\Bbb R P^3$, $S^1\times S^2$, and $T^3$
A. Fomenko - Theory of rough classification of integrable nondegenerate Hamiltonian differential equations on four-dimensional manifolds. Application to classical mechanics | CommonCrawl |
What is the empirical formula and empirical formu…
What is the empirical formula and empirical formula mass for each of the following compounds?
$\begin{array}{ll}{\text { (a) } \mathrm{C}_{4} \mathrm{H}_{8}} & {\text { (b) } \mathrm{C}_{3} \mathrm{H}_{6} \mathrm{O}_{3}} & {\text { (c) } \mathrm{P}_{4} \mathrm{O}_{10}}\end{array}$
(d) $\mathrm{Ga}_{2}\left(\mathrm{SO}_{4}\right)_{3} \quad$ (e) $\mathrm{Al}_{2} \mathrm{Br}_{6}$
Ethanol $\left(\mathrm{CH}_{3} \mathrm{CH}_{2} \mathrm{OH}\right),$ the intoxicant in alcoholic beverages, is also used to make other organic compounds. In concentrated sulfuric acid, ethanol forms diethyl ether and water:
2 \mathrm{CH}_{3} \mathrm{CH}_{2} \mathrm{OH}(l) \longrightarrow \mathrm{CH}_{3} \mathrm{CH}_{2} \mathrm{OCH}_{2} \mathrm{CH}_{3}(l)+\mathrm{H}_{2} \mathrm{O}(g)
In a side reaction, some ethanol forms ethylene and water:
\mathrm{CH}_{3} \mathrm{CH}_{2} \mathrm{OH}(l) \longrightarrow \mathrm{CH}_{2} \mathrm{CH}_{2}(g)+\mathrm{H}_{2} \mathrm{O}(g)
(a) If 50.0 g of ethanol yields 35.9 g of diethyl ether, what is the percent yield of diethyl ether? (b) If 45.0$\%$ of the ethanol that did not produce the ether reacts by the side reaction, what mass (g) of
ethylene is produced?
Give the name, empirical formula, and molar mass of the compound depicted in Figure P3.38.
What is the molecular formula of each compound?
(a) Empirical formula $\mathrm{CH}_{2}(M=42.08 \mathrm{g} / \mathrm{mol})$
(b) Empirical formula $\mathrm{NH}_{2}(\mathscr{M}=32.05 \mathrm{g} / \mathrm{mol})$
(c) Empirical formula $\mathrm{NO}_{2}(\mathscr{M}=92.02 \mathrm{g} / \mathrm{mol})$
(d) Empirical formula CHN $(M=135.14 \mathrm{g} / \mathrm{mol})$
Md M.
Auburn University Main Campus
$\begin{array}{ll}{\text { (a) } \mathrm{C}_{2} \mathrm{H}_{4}} & {\text { (b) } \mathrm{C}_{2} \mathrm{H}_{6} \mathrm{O}_{2}} & {\text { (c) } \mathrm{N}_{2} \mathrm{O}_{5}} \\ {\text { (d) } \mathrm{Ba}_{3}\left(\mathrm{PO}_{4}\right)_{2}} & {\text { (e) } \mathrm{Te}_{4} \mathrm{I}_{16}}\end{array}$
What is the molecular formula of each of the following compounds?
\begin{array}{l}{\text { (a) empirical formula } \mathrm{HCO}_{2} \text { , molar mass }=90.0 \mathrm{g} / \mathrm{mol}} \\ {\text { (b) empirical formula } \mathrm{C}_{2} \mathrm{H}_{4} \mathrm{O}, \text { molar mass }=88.0 \mathrm{g} / \mathrm{mol}}\end{array} | CommonCrawl |
Information Flow Scheduling in Concurrent Multi-Product Development Based on DSM | springerprofessional.de Skip to main content
PDF-Version jetzt herunterladen
vorheriger Artikel Innovation Analysis Approach to Design Paramete...
nächster Artikel Product Data Model for Performance-driven Design
PatentFit aktivieren
01.09.2017 | Original Article | Ausgabe 5/2017 Open Access
Information Flow Scheduling in Concurrent Multi-Product Development Based on DSM
Chinese Journal of Mechanical Engineering > Ausgabe 5/2017
Qing-Chao Sun, Wei-Qiang Huang, Ying-Jie Jiang, Wei Sun
» Zur Zusammenfassung PDF-Version jetzt herunterladen
Supported by National Natural Science Foundation of China (Grant Nos. 51475077, 51005038) and Science and Technology Foundation of Liaoning China (Grant Nos. 201301002, 2014028012).
With market competition increasing, achieving success with new product development(PD) in mechanic products markets is becoming more and more challenging, and the capability of meeting the diversified customer demands is playing more important role [ 1 ]. Due to shortening product life cycles, businesses are also proposing a set of critical success factors to reduce product development time and respond quickly to vibrant customer demand [ 2 ].
To meet diversified customer needs while shortening product development cycle, the product developers should concentrate on development of multiple products simultaneously and improve process efficiency and quality [ 3 ], rather than focusing on one product at-a-time. However, the resource conflict among multiple PD projects often leads to the delay of project schedules, and the number of parts, tools and materials also increases linearly with number of products. Ensuring concurrent multiple PD progress [ 4 , 5 ], and managing the information difference and similarity of multiple products are the key problem of concurrent multi-product development project management.
The Design Structure Matrix(DSM), also called the dependency structure matrix, has become an used modeling framework of product development management [ 6 ]. DSM is a matrix representation of a directed graph, which allows the project or engineering manager to represent important task relationships in order to determine a sensible sequence for the tasks being modeled [ 7 , 8 ]. As compared to Critical Path Method (CPM) and Program Evaluation and Review Technique(PERT), DSM is more suitable for planning information flow in PD project [ 9 – 11 ]. The rows and columns of DSM correspond to the tasks, and the matrix reveals the inputs and outputs of tasks, by manipulating the matrix, the feedback marks can be eliminated or reduced, this process is called partitioning [ 12 , 13 ]. According to the input/output, the subsets of DSM elements that are mutually exclusive or minimally interacting should be determined, this process is called clustering [ 14 – 16 ].
In recent years, some multiple project scheduling models and methods based on DSM was brought forward, to ensure multi-project progress. P H Chen et al. proposed a hybrid of genetic algorithm and simulated annealing (GA-SA Hybrid) for generic multi-project scheduling problems with multiple resource constraints [ 17 ]. C Ju and T Chen developed an improved aiNet algorithm to solve a multi-mode resource-constrained scheduling problem [ 18 ]. T Gaertner et al. presented a generic project scheduling technique for functional integration projects based on DSM, to improve the planning of delivery dates and required resources and capacities, to ensure tighter synchronization between project teams, and prioritize tasks in parallel projects [ 19 ]. T R Browning proposed an expandable process architecture framework (PAF), which organizes all the models and diagrams into a single, rich process model with 27+ new and existing views, to synchronize various aspects of process (activity network) information in large, complex projects [ 20 ]. The above research aims for decreasing project progress delay by arranging task sequences and allocating project resources reasonably, but the influence of task interactions on material flow or product information flow was not taken into consideration.
The product information clustering technologies based on DSM were also presented [ 21 – 23 ], DSM was adopted to cluster product components into modules with minimum interfaces externally and maximum internal integration, but these model aimed for information interaction in the single product, lacked the research about the information difference and similarity among multiple products. Such as, E P Hong and G J Park proposed a new design method to design a modular product based on relationships among products functional requirements, to overcome the difficulty of modular design, with combining axiomatic design, the function-based design method and design structure matrix [ 21 ]. A H Tilstra et al. presented the high-definition design structure matrix (HDDSM) to captures a spectrum of interactions between components of a product [ 22 ]. T AlGeddawy and H ElMaraghy proposed a hierarchical clustering (cladistics) model to automatically build product hierarchical architecture from DSM [ 23 ].
Different from one PD project, information flow planning in concurrent multi-product development should emphasis on two factors: first, partitioning tasks sequences according to tasks relationships and project priorities to decease influences of information feedback on project schedules. Second, clustering the similar tasks [ 24 ] of multiple PD projects to reduce number of parts and tools, decrease interaction cost and improve development efficiency.
2 Task Relationships in Multiple Projects
2.1 Relationships Among Projects and Products
The concurrent multiple PD project management is the management mode of screening, evaluating, planning, executing and controlling all the projects during a certain time period, from the enterprise or department perspective. The relationships among projects and products in multi-project environment [ 25 ] can be divided into the following three types:
Multiple projects for single product development. Each project is responsible for the development of one or more subsystems, and multiple projects cooperate with each other, to complete the development of a complex product. Cars, airplanes, and other complex PD often use this kind of management mode.
Multiple project for the interrelated multiple products. Each project is responsible for the development of one or more products, and there exist the technical or information interaction among multiple products, such as the same product structure, the similar design technology, etc. The new product is often developed based on product families, so this relationship is very common, which was the main research object of the paper.
One project for one product, and each product is independent. There exists no the same and similar parts or sub-systems among multiple projects, which only occurs in the process of few new product development.
2.2 Input/Output Relationships Description
Input/output relationships of tasks in concurrent multi-product development can be divided into four types: serial, parallel, coupling and similar, as shown in Fig. 1. Fig. 1(a) shows the serial relationship, output of \( t_{i} \) as the input of \( t_{j} \), \( t_{i} \) have to finish before \( t_{j} \). Fig. 1(b) shows the parallel relationship, output of \( t_{k} \) as the input of \( t_{i} \) and \( t_{j} \), \( t_{i} \) and \( t_{j} \) can be executed concurrently after the previous task \( t_{k} \), the dependency between \( t_{i} \) and \( t_{j} \) corresponds parallel. Fig. 1(c) shows the coupling relationship, \( o_{i}^{\prime} \), \( o_{i}^{\prime} \) denotes the output of \( t_{i} \) and \( t_{j} \), \( o_{i}^{\prime} \), \( o_{i}^{\prime} \) as the input of \( t_{j} \) and \( t_{i} \) separately. Fig. 1(d) shows the similar relationship, the output of \( t_{i} \) and \( t_{j} \) is identical or similar, or similar technology was adopted during perform \( t_{i} \) and \( t_{j} \). The first three types of relationships in Fig. 1 exist both in one-project and multi-project environment, similar relationship is the special relationship in concurrent multi-product development projects.
Input/output relationships in multi-project situation
2.3 Task Relationships in Multiple Projects
The output of PD project includes design schemes, product drawings, process files, parts, sub-systems, semi-finished parts or products, bill of material, etc., which were labeled as product information, the input/output relationships of tasks can be expressed as the dependencies of product information.
$$ \begin{aligned} I(P_{i} ) = \left\{ {e_{1} ,e_{2} , \ldots ,e_{n} } \right\}, \hfill \\ R(P_{i} ) = \left( {\begin{array}{*{20}c} {ri_{11} } & \ldots & {ri_{1n} } \\ \vdots & {} & \vdots \\ {ri_{n1} } & \ldots & {ri_{nn} } \\ \end{array} } \right), \hfill \\ \end{aligned} $$
where \( I(P_{i} ) \) and \( R(P_{i} ) \) denotes product information set and information dependencies set respectively, \( ri_{ij} \) is dependency of information element \( e_{i} \) on \( e_{j} \), \( ri_{ij} \) can be expressed as 0~5 integer,
$$ ri_{ij} = \left\{ {\begin{array}{*{20}c} {1\sim 5 , {\text{there is information from }}e_{j} {\text{ to }}e_{i} ,} \\ {0 , {\text{there is no information from }}e_{j} {\text{ to }}e_{i} ,} \\ \end{array} } \right. $$
There exist many identical or similar parts, components and development technologies, etc. in different projects. The task dependencies in multiple projects can be expressed as:
$$ mrt_{gk} = f(ri_{gk} ) = \left\{ {\begin{array}{*{20}l} {1\sim 5,{\text{there is information from }}e_{k} {\text{ to }}e_{g} ,} \hfill \\ { - 5\sim- 1,e_{g} {\text{ and }}e_{k} {\text{ is indentical or similar, }}} \hfill \\ {0,\,e_{g} {\text{ and }}e_{k} {\text{ is irrelevant }}. { }} \hfill \\ \end{array} } \right. $$
3 Extended DSM Model
DSM represents the system, product or process by aggregating individual interactions among components, people, activities, or parameters. DSM is essentially an \( N^{2} \) diagram that is structured in such a way as to facilitate system-level analysis and process improvement. The mark in cell \( i \), \( j \) of DSM indicates that the item in row \( i \) requires information from the item in column \( j \) as an input. Under the diagonal corresponds to the forward information flow, and above diagonal shows the feedback.
The task relationships in multiple PD projects were described as serial, parallel, coupling and similar type, the DSM description as shown in Fig. 2, Fig. 2(a)~ 2(c) corresponds to serial, parallel and coupling relationship separately, and Fig. 2(d) corresponds to similar relationship.
DSM description of tasks dependencies
To describe tasks dependencies in multiple PD projects, one extended DSM(EDSM) was brought forward. \( \{ t_{a1} ,t_{a2} , \ldots ,t_{am} \} \), \( \{ t_{b1} ,t_{b2} , \ldots ,t_{bn} \} \) denotes the tasks in project \( P_{a} \) and \( P_{b} \) separately, the extended DSM related to \( P_{a} \) and \( P_{b} \) can be expressed as a partitioned matrix.
$$ EDSM = \left( {\begin{array}{*{20}c} {\mathbf{A}} & {\mathbf{D}} \\ {\mathbf{C}} & {\mathbf{B}} \\ \end{array} } \right), $$
$$ {\mathbf{A}} = \left( {\begin{array}{*{20}c} {rt_{a1,a1} } & {rt_{a1,a2} } & \ldots & {rt_{a1,am} } \\ {rt_{a2,a1} } & {rt_{a2,a2} } & \ldots & {rt_{a2,am} } \\ \vdots & \vdots & {} & \vdots \\ {rt_{{_{am,a1} }} } & {rt_{am,a2} } & \ldots & {rt_{am,am} } \\ \end{array} } \right), $$
$$ {\mathbf{B}} = \left( {\begin{array}{*{20}c} {rt_{b1,b1} } & {rt_{b1,b2} } & \ldots & {rt_{b1,bn} } \\ {rt_{b2,b1} } & {rt_{b2,b2} } & \ldots & {rt_{b2,bn} } \\ \vdots & \vdots & {} & \vdots \\ {rt_{bn,b1} } & {rt_{bn,b2} } & \ldots & {rt_{bn,bn} } \\ \end{array} } \right), $$
$$ {\mathbf{C}} = \left( {\begin{array}{*{20}c} {mrt_{b1,a1} } & {mrt_{b1,a2} } & \ldots & {mrt_{b1,am} } \\ {mrt_{b2,a1} } & {mrt_{b2,a2} } & \ldots & {mrt_{b2,am} } \\ \vdots & \vdots & {} & \vdots \\ {mrt_{{_{bn,a1} }} } & {mrt_{bn,a2} } & \ldots & {mrt_{bn,am} } \\ \end{array} } \right), $$
$$ {\mathbf{D}} = \left( {\begin{array}{*{20}c} {mrt_{a1,b1} } & {mrt_{a1,b2} } & \ldots & {mrt_{a1,bn} } \\ {mrt_{a2,b1} } & {mrt_{a2,b2} } & \ldots & {mrt_{a2,bn} } \\ \vdots & \vdots & {} & \vdots \\ {mrt_{{_{am,b1} }} } & {mrt_{am,b2} } & \ldots & {mrt_{am,bn} } \\ \end{array} } \right), $$
where A and B indicates input/output dependencies matrix of project \( P_{a} \) and \( P_{b} \) separately, C denotes dependencies of \( P_{b} \) on \( P_{a} \), and D corresponds to dependencies of \( P_{a} \) on \( P_{b} \).
4 Information Planning Based on EDSM
Information flow planning based on the extended DSM is different from DSM, which involves four types of computation: merging, converting, partitioning and clustering.
4.1 Merging Converting and Partitioning Regardless of Project Priorities
According to the input/output relationships, \( mrt_{ij} = - 5 \) means output of \( t_{i} \) and \( t_{j} \) is identical. To avoid duplicate work, \( t_{i} \) and \( t_{j} \) can be combined, this process is called merging. Such as \( \{ t_{ai} ,t_{aj} \} \) and \( \{ t_{bg} ,t_{bk} \} \) is tasks set of project \( P_{a} \) and \( P_{b} \) separately, the initial extended DSM model was expressed as
$$ \left( {\begin{array}{*{20}c} {t_{ai} } & {} & {} & {} \\ 3 & {t_{aj} } & {} & {} \\ { - 5} & {} & {t_{bg} } & {} \\ {} & {} & 5 & {t_{bk} } \\ \end{array} } \right), $$
the work content of \( t_{ai} \) and \( t_{bg} \) is identical, \( t_{ai} \) and \( t_{bg} \) can be combined into one task, furthermore task dependencies need be to reconstructed. After merging \( t_{ai} \) and \( t_{bg} \), the extended DSM model can be expressed as:
$$ \left( {\begin{array}{*{20}c} {t_{ai} } & {} & {} \\ 3 & {t_{aj} } & {} \\ 5 & {} & {t_{bk} } \\ \end{array} } \right)\;{\text{or}}\;\left( {\begin{array}{*{20}c} {t_{bg} } & {} & {} \\ 3 & {t_{aj} } & {} \\ 5 & {} & {t_{bk} } \\ \end{array} } \right), $$
in multi-project environment, \( - 5 < mrt_{ij} < 0 \) means the output of \( t_{i} \) and \( t_{j} \) is similar, and \( 0 < mrt_{ij} < 5 \) means that the output of \( t_{j} \) as the input of \( t_{i} \).
When converting computation is done, the similar relationships can be converted to \( 0 < mwr_{ij}^{'} < 5 \), so as to partitioning and clustering can be done based on the uniform algorithm, \( mrt_{ij}^{'} = f(mrt_{ij} ) \) is the converting function, the initial extended DSM is:
\( mwr_{bg,ai} = - 3 \) means the work content of \( t_{ai} \) and \( t_{bg} \) is similar. Supposing converting function follows the linear law, \( mwr_{ij}^{'} = k \times mwr_{ij} + b \). Designer can choose the different value of \( k \) and \( b \), and analyze influence of numerical value \( k \) and \( b \) on partitioning and clustering results. Adopting \( mwr_{ij}^{'} = - 2 \times mwr_{ij} - 3 \), the converted extended DSM is
$$ \left( {\begin{array}{*{20}c} {t_{ai} } & {} & {} & {} \\ 3 & {t_{aj} } & {} & {} \\ 3 & {} & {t_{bg} } & {} \\ {} & {} & 5 & {t_{bk} } \\ \end{array} } \right)\;{\text{or}}\;\left( {\begin{array}{*{20}c} {t_{bg} } & {} & {} & {} \\ 5 & {t_{bk} } & {} & {} \\ 3 & {} & {t_{ai} } & {} \\ {} & {} & 3 & {t_{aj} } \\ \end{array} } \right). $$
Partitioning is the computation of reordering the rows and columns in the DSM with minimizing the number of marks above the diagonal, the result is the optimal tasks ordering, which reduces feedback and rework. According to the partitioned matrix, the serial, parallel and coupling relationship can be identified. Regardless of project priorities, partitioning algorithm of the extended DSM is identical to the common DSM [ 24 , 25 ]. Tasking the parallel tasks relationships as the example.
$$ \left( {\begin{array}{*{20}c} {t_{i} } & 0& 5\\ 0& {t_{j} } & 5\\ 0 & 0 & {t_{k} } \\ \end{array} } \right) \to \left( {\begin{array}{*{20}c} {t_{k} } & 0 & 0 \\ 5 & {t_{i} } & 0 \\ 5 & 0 & {t_{j} } \\ \end{array} } \right), $$
the initial tasks sequence is \( t_{i} \to t_{j} \to t_{k} \), and partitioned tasks sequence is \( t_{k} \to t_{i} \to t_{j} \), the relationships between \( t_{i} \) and \( t_{j} \) is parallel, can be performed concurrently.
4.2 Clustering Regardless of Project Priorities
The goal of clustering is to find subsets of the extended DSM (i.e., clusters) so that the tasks within a cluster are maximally interdependent and clusters are minimally interacting. Some researchers have proposed different clustering algorithm based on different principle, such as A Yassine presented a clustering objective function by using the minimal description length principle [ 26 ], S E Carlson and N Ter-Minassian proposed a clustering algorithm based on coordination cost [ 27 ].
This paper focuses on the information flow in multi-project situation, with the goal of minimizing the influence of information interaction on project schedule, referring the algorithm of Idicula and Fernandez, etc., the clustering object function of the extended DSM was built.
$$ \begin{aligned} Tcc(M) = \sum\limits_{i = 1}^{n} {cc(t_{i} )} , \hfill \\ cc(t_{i} ) = \sum\limits_{j = 1}^{n} {(mwr(t_{i} ,t_{j} ) + mwr(t_{j} ,t_{i} )) \times size(t_{i} ,t_{j} )^{p\_k} } , \hfill \\ \end{aligned} $$
where \( Tcc(M) \) is total coordination cost of model \( M \),which is the objective function that the algorithm attempts to minimize, \( cc(t_{i} ) \) indicates coordination cost of task \( t_{i} \), \( n \) is the number of tasks in \( M \), \( mwr(t_{i} ,t_{j} ) \), \( mwr(t_{j} ,t_{i} ) \) denotes the interaction between \( t_{i} \) and \( t_{j} \), corresponding to the value in the extended DSM, \( size(t_{i} ,t_{j} ) \) is the size of minimum cluster which contains \( t_{i} \) and \( t_{j} \), \( p\_k \) is the power coefficient corresponds to the \( k \)-th level clusters, value range of \( p\_k \) is integer from 1 to 5. After merging, converting and partitioning, one extended DSM was obtained:
$$ \left( {\begin{array}{*{20}c} \varvec{A} & 1 & 2 & {} & {} & {} & {} \\ {} & \varvec{B} & 4 & {} & {} & {} & {} \\ 4 & 2 & \varvec{C} & {} & {} & {} & {} \\ {} & {} & {} & \varvec{D} & {} & 3 & 2 \\ {} & {} & {} & 5 & \varvec{E} & 3 & 3 \\ {} & 5 & {} & 1 & 3 & \varvec{F} & 2 \\ {} & {} & {} & 4 & 3 & 4 & \varvec{G} \\ \end{array} } \right). $$
Clustering can be done based on the previous computation, according to Eq. 4, \( p\_k_{1} \), \( p\_k_{2} \), \( p\_k_{3} \) corresponds to different level clusters, \( p\_k_{1} \) indicates the power coefficient of smallest cluster, \( p\_k_{2} \) corresponds to the upper level of cluster, which consists of a series of sub-cluster and tasks, \( p\_k_{3} \) corresponds to the whole extended DSM, adopting \( p\_k_{1} = 1 \), \( p\_k_{2} = 2 \), \( p\_k_{3} = 3 \), the clustered extended DSM can be obtained:
Adopting \( p\_k_{1} = 1 \), \( p\_k_{2} = 1 \), \( p\_k_{3} = 2 \), the different clustered extended DSM can be obtained:
which means that the lower level clusters will contain more tasks as \( p\_k_{2} /p\_k_{1} \) increase, and the upper level will contain more sub-clusters and tasks as \( p\_k_{3} \) increase.
4.3 Merging Converting and Partitioning with Regarding Project Priorities
Regarding project priorities, the duplicate work in low-priority project should be combined into the identical tasks in high-priority project, and tasks dependencies was reconstructed. Such as \( \{ t_{ai} ,t_{aj} \} \) and \( \{ t_{bg} ,t_{bk} \} \) is tasks set of project \( P_{a} \) and \( P_{b} \) separately, \( pri_{a} \) and \( pri_{b} \) denotes priorities of \( P_{a} \) and \( P_{b} \), \( pri{}_{b} > pri_{a} \), the initial extended DSM is:
\( mwr_{bg,ai} = - 5 \) means the work content of \( t_{ai} \) and \( t_{bg} \) is identical, and \( t_{ai} \) and \( t_{bg} \) can be combined into one task. To guarantee schedule requirement of high-priority project \( P_{b} \), \( t_{ai} \) should be combined into \( t_{bg} \), the merged extended DSM can be expressed as
$$ \left( {\begin{array}{*{20}c} {t_{bg} } & {} & {} \\ 3 & {t_{aj} } & {} \\ 5 & {} & {t_{bk} } \\ \end{array} } \right), $$
converting aims at transforming \( - 5 < mrt_{ij} < 0 \) into \( 0 < mwr_{ij}^{'} < 5 \), so as to partitioning and clustering can be done based on the uniform algorithm, \( mrt_{ij}^{'} = f(mrt_{ij} ) \) is the converting function. Different from computation regardless of project priorities, converting regarding priorities should guarantee the schedule of high-priority project firstly. Such as, project \( P_{b} \) with higher priority, \( pri{}_{b} > pri_{a} \), the initial extended DSM is
means the work content of \( t_{ai} \) and \( t_{bg} \) is similar, adopting \( mwr_{ij}^{'} = - 2 \times mwr_{ij} - 3 \), the transformed extended DSM as follows, because \( t_{bg} \) with high priority, \( t_{bg} \) was arranged before \( t_{ai} \) in task sequence,
$$ \left( {\begin{array}{*{20}c} {t_{bg} } & {} & {} & {} \\ 5 & {t_{bk} } & {} & {} \\ 3 & {} & {t_{ai} } & {} \\ {} & {} & 3 & {t_{aj} } \\ \end{array} } \right). $$
Partitioning regarding project priorities performs the following steps: firstly, reordering the rows and columns of extended DSM, secondly, moving forward high-priority tasks, or moving backward low-priority tasks. For example, \( \{ t_{a1} ,t_{a2} ,t_{a3} ,t_{a4} \} \) and \( \{ t_{b1} ,t_{b2} ,t_{b3} ,t_{b4} \} \) is tasks set of project \( P_{a} \) and \( P_{b} \) separately, \( P_{a} \) with higher priority, \( pri{}_{a} > pri_{b} \), the extended DSM model before and after partitioning is
$$ \left( {\begin{array}{*{20}c} {t_{a1} } & {} & {} & {} & {} & {} & {} & {} \\ 2 & {t_{a2} } & 2 & {} & {} & {} & 2 & {} \\ 5 & {} & {t_{a3} } & {} & {} & {} & {} & 2 \\ {} & {} & 5 & {t_{a4} } & {} & {} & {} & 1 \\ {} & 2 & {} & {} & {t_{b1} } & {} & {} & {} \\ {} & 3 & {} & {} & 5 & {t_{b2} } & {} & {} \\ 3 & {} & {} & {} & {} & {} & {t_{b3} } & {} \\ {} & {} & {} & 2 & {} & {} & 3 & {t_{b4} } \\ \end{array} } \right), $$
$$ \left( {\begin{array}{*{20}c} {t_{a1} } & {} & {} & {} & {} & {} & {} & {} \\ 3 & {t_{b3} } & {} & {} & {} & {} & {} & {} \\ 5 & {} & {t_{a3} } & {} & 2 & {} & {} & {} \\ {} & {} & 5 & {t_{a4} } & 1 & {} & {} & {} \\ {} & 3 & {} & 2 & {t_{b4} } & {} & {} & {} \\ 2 & 2 & 2 & {} & {} & {t_{a2} } & {} & {} \\ {} & {} & {} & {} & {} & 2 & {t_{b1} } & {} \\ {} & {} & {} & {} & {} & 3 & 5 & {t_{b2} } \\ \end{array} } \right), $$
tasks sequence \( T^{'} = \{ t_{a1} ,t_{b3} ,t_{a3} ,t_{a4} ,t_{b4} ,t_{a2} ,t_{b1} ,t_{b2} \} \) can be obtained, adjusting tasks order based on project priorities and input/output dependencies, new tasks sequence can be obtained, \( T'' = \{ t_{a1} ,t_{a3} ,t_{a4} ,t_{b3} ,t_{a2} ,t_{b4} ,t_{b1} ,t_{b2} \} \), \( t_{a2} \) can not move to the front of \( t_{b3} \) because that \( t_{a2} \) depends on the output of \( t_{b3} \), \( mwr_{a2,b3} = 2 \). The corresponding partitioned extended DSM regarding project priorities is:
$$ \left( {\begin{array}{*{20}c} {t_{a1} } & {} & {} & {} & {} & {} & {} & {} \\ 5 & {t_{a3} } & {} & {} & {} & 2 & {} & {} \\ {} & 5 & {t_{a4} } & {} & {} & 1 & {} & {} \\ 3 & {} & {} & {t_{b3} } & {} & {} & {} & {} \\ 2 & 2 & {} & 2 & {t_{a2} } & {} & {} & {} \\ {} & {} & 2 & 3 & {} & {t_{b4} } & {} & {} \\ {} & {} & {} & {} & 2 & {} & {t_{b1} } & {} \\ {} & {} & {} & {} & 3 & {} & 5 & {t_{b2} } \\ \end{array} } \right). $$
4.4 Clustering with Regarding Project Priorities
The goal of clustering with regarding project priorities is dividing the tasks with similar priorities and high input/output dependencies into the same subsets, to decrease information interaction cost in multi-project situation. The object function takes influence of project priorities on coordination cost into consideration, \( pri_{i} \) and \( pri_{j} \) denotes priority of project \( P_{i} \) and \( P_{j} \) respectively. The clustering object function with regarding project priorities can be expressed as:
$$ \begin{aligned} Tcc(M) = \sum\limits_{i = 1}^{n} {cc(t_{i} )} , \hfill \\ cc(t_{i} ) = \sum\limits_{j = 1}^{n} {f_{ij} \times (mwr(t_{i} ,t_{j} ) + mwr(t_{j} ,t_{i} )) \times size(t_{i} ,t_{j} )^{p\_k} } , \hfill \\ f_{ij} = (\left| {pri(t_{i} ) - pri(t_{j} )} \right| + 1)^{p\_pri} , \hfill \\ \end{aligned} $$
where \( Tcc(M) \) is total coordination cost of model \( M \), \( cc(t_{i} ) \) is coordination cost of task \( t_{i} \), \( n \) is the number of tasks in \( M \), \( r(i,j) \), \( r(j,i) \) is the interaction between \( t_{i} \) and \( t_{j} \), \( p\_k \) is the power coefficient related to the \( k \)-th level clusters, \( f_{ij} \) indicates impact factor related to project priorities, \( pri(t_{i} ) \) and \( pri(t_{j} ) \) denotes project priorities, \( p\_pri \) is the power coefficient related to project priorities, value range of \( p\_k \) and \( p\_pri \) is 0~1, and \( 0 { < }f_{ij} \le 1 \).
Different from clustering regardless of project priorities, by introducing \( f_{ij} \), the difference in project priorities was taken into consideration, with \( f_{ij} \) increacing, the tasks with different priorities will be divided into different clusters. Such as, \( pri_{a} \) and \( pri_{b} \) denotes project priority of project \( P_{a} \) and \( P_{b} \) respectively, adopting \( pri_{a} = 3 \), \( pri_{b} = 1 \), \( p\_k_{1} = 1 \), \( p\_k_{2} = 2 \), \( p\_k_{3} = 3 \), after merging, converting and partitioning with regarding project priorities, the tasks sequence can be determined, and the clustered extended DSM with regarding project priorities can be obtained:
Two machine tool products was developed during the same period, the worktable size of one machine tool is 650×650 mm 2, the other is 1250×1250 mm 2, two machine tools have the similar product structures.
The dependencies among tasks in multiple PD projects were determined according to the input/output relationships, the initial extended DSM model can be built:
$$ EDSM = \left( {\begin{array}{*{20}c} \varvec{A} & \varvec{D} \\ \varvec{C} & \varvec{B} \\ \end{array} } \right). $$
Fig. 3(a), Fig. 3(b) corresponds to dependencies of 650 type ( \( prj_{a} \)), 1250 type ( \( prj_{b} \)) horizontal machine center separately, Fig. 3(c) corresponds to the identical and similar relationships between two projects, D=0.
Task dependencies in multiple projects
According to the information planning approach of Extended DSM, the partitioning and clustering computation results related to \( prj_{a} \) can be obtained, as shown in Fig. 4. The values of \( p\_k_{1} \), \( p\_k_{2} \), \( p\_k_{3} \) have significant impact on clustering results, the size of second level clusters increases with \( p\_k_{3} /p\_k_{2} \), the size of first level clusters increases with \( p\_k_{2} /p\_k_{1} \).
Partitioning and clustering of \( prj_{a} \)
Merging the duplicate work, and adopting linear function \( mwr_{ij}^{'} = k \times mwr_{ij} + b \) to convert the similar relationships. Partitioning and clustering extended DSM with different value of \( k \) and \( b \), adopted \( mwr_{ij}^{'} = - 2 \times mwr_{ij} - 1 \) as the converting function, the similar tasks was divided into the same clusters. Regardless of project priorities, adopting \( p\_k_{1} = 1 \), \( p\_k_{2} = 2 \), \( p\_k_{3} = 2 \), merging, converting, partitioning and clustering tasks of two projects based on the extended DSM, the computation result as shown in Fig. 5(a). With regarding project priorities, adopting \( pri_{a} = 1 \), \( pri_{b} = 3 \), which means that \( prj_{b} \) with high project priority, the computation result based on the extended DSM as shown in Fig. 5(b).
Information flow scheduling based on extended DSM
Regardless of project priorities, the similar tasks tend to be divided into the same clusters, to reduce the influence of information interaction on project schedule. the similar tasks tend to be divided into different clusters, to reduce the influence on schedule of high-priority tasks.
Adopting different \( p\_k_{1} \), \( p\_k_{2} \) and \( p\_k_{3} \), \( Tcc(M) \) was computed in four types of conditions: ① two project was independent, each project as a cluster \( con_{1} \), ② two project was independent, clustering without regarding the relationships between two projects \( con_{2} \), ③ clustering based on the extended DSM model, without regarding project priorities \( con_{3} \), ④ clustering based on the extended DSM model, with regarding project priorities \( con_{4} \), computation results as shown in Table 1.
Total coordination cost with different power coefficient
\( con_{1} \)
The first two conditions didn't take relationships between two projects into consideration, and the last two conditions was computed based on the extended DSM, with regarding dependencies among multiple projects. The differences of \( Tcc(M) \) show that optimizing tasks sequence based on the extended DSM can decrease influence of task interactions on project schedules, and values of \( p\_k \) influence computation results obviously, the power coefficient should be determinded according the task relationships and PD teams.
The extended DSM was built to optimizing task-sequences and task-clusters in multiple PD projects, focusing on the technical information interactions and similarities in multiple projects, taking project priorities into consideration, was mainly applied to the mechanical product development projects, such as automobiles, machine tools, construction machines, etc. Although software, construction and other industries also involve multi-project management [ 26 , 28 ], but the task-relationships are different from mechanical product development projects.
A series of coefficients was introduced in the converting and clustering calculation, such as \( k \) and \( b \) in converting function \( mwr_{ij}^{'} = k \times mwr_{ij} + b \), \( p\_k \) in Eq. ( 4), \( p\_k \) and \( p\_pri \) in Eq. ( 5). The calculation results indicated that the value of these coefficients had a great effect on the information planning. It is necessary to determine these coefficients by taking the completed projects as example, changing the values, and judging the rationality of task-sequences and task clusters combined with the expert experience.
Resources sharing and conflicting was the important feature of multi-project management [ 17 , 29 ], but the extended DSM model didn't take resource allocation into consideration, therefore the information planning results based on extended DSM should not be the final task sequences, the further adjustment according to resource capabilities was needed.
Describing task dependencies is the basis of information flow planning based on the extended DSM, the task relationships in multi-project is divided into four types: serial, parallel, coupling, and similar. Similar is the specific dependency relationship of the extended DSM.
The initial extended DSM can be expressed as a partitioned matrix, describing task dependencies in one project and among multiple projects concurrently.
By adopting different power coefficients in converting or clustering function, different task-sequences or task-clusters can be obtained. Determining the appropriate power coefficient is important for information flow scheduling based on the extended DSM.
Open AccessThis article is distributed under the terms of the Creative Commons Attribution 4.0 International License ( http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
Zurück zum Zitat J Lin, Y Qian, W Cui, et al. An effective approach for scheduling coupled activities in development projects. European Journal of Operational Research, 2015, 243(1): 97–108. J Lin, Y Qian, W Cui, et al. An effective approach for scheduling coupled activities in development projects. European Journal of Operational Research, 2015, 243(1): 97–108.
Zurück zum Zitat C A G Dev, V S S Kumar. Analysis on critical success factors for agile manufacturing evaluation in original equipment manufacturing industry-an AHP approach. Chinese Journal of Mechanical Engineering, 2016, 29(5): 880–888. C A G Dev, V S S Kumar. Analysis on critical success factors for agile manufacturing evaluation in original equipment manufacturing industry-an AHP approach. Chinese Journal of Mechanical Engineering, 2016, 29(5): 880–888.
Zurück zum Zitat M Li, G Y He, Z J Song. Improved quality prediction model for multistage machining process based on geometric constraint equation. Chinese Journal of Mechanical Engineering, 2016, 29(2):430–438. M Li, G Y He, Z J Song. Improved quality prediction model for multistage machining process based on geometric constraint equation. Chinese Journal of Mechanical Engineering, 2016, 29(2):430–438.
Zurück zum Zitat M S Avnet, A L Weigel. An application of the design structure matrix to integrated concurrent engineering. Acta Astronautica, 2010, 66: 937–949. M S Avnet, A L Weigel. An application of the design structure matrix to integrated concurrent engineering. Acta Astronautica, 2010, 66: 937–949.
Zurück zum Zitat A Karniel,Y Reich. Multi-level modelling and simulation of new product development processes. Journal of Engineering Design, 2013, 24(3): 185–210. A Karniel,Y Reich. Multi-level modelling and simulation of new product development processes. Journal of Engineering Design, 2013, 24(3): 185–210.
Zurück zum Zitat S Li. A matrix-based clustering approach for the decomposition of design problems. Research in Engineering Design, 2011, 22(4): 263–278. S Li. A matrix-based clustering approach for the decomposition of design problems. Research in Engineering Design, 2011, 22(4): 263–278.
Zurück zum Zitat A Tripathy, S D Eppinger. Structuring work distribution for global product development organizations. Prod. Oper. Manage., 2013, 22(6): 1557–1575. A Tripathy, S D Eppinger. Structuring work distribution for global product development organizations. Prod. Oper. Manage., 2013, 22(6): 1557–1575.
Zurück zum Zitat M Danilovic, T R Browning. Managing complex product development projects with design structure matrices and domain mapping matrices. International Journal of Project Management, 2007, 25(3): 300–314. M Danilovic, T R Browning. Managing complex product development projects with design structure matrices and domain mapping matrices. International Journal of Project Management, 2007, 25(3): 300–314.
Zurück zum Zitat D M Sharman, A A Yassine. Architectural valuation using the design structure matrix and real options theory. Concurrent Engineering, 2007, 15(2): 157–173. D M Sharman, A A Yassine. Architectural valuation using the design structure matrix and real options theory. Concurrent Engineering, 2007, 15(2): 157–173.
Zurück zum Zitat M S Avnet,A L Weigel. An application of the design structure matrix to integrated concurrent engineering. Acta Astronautica, 2010, 66(5): 937–949. M S Avnet,A L Weigel. An application of the design structure matrix to integrated concurrent engineering. Acta Astronautica, 2010, 66(5): 937–949.
Zurück zum Zitat D Tang, G Zhang, S Dai. Design as integration of axiomatic design and design structure matrix. Robotics and Computer- Integrated Manufacturing, 2009, 25(3): 610–619. D Tang, G Zhang, S Dai. Design as integration of axiomatic design and design structure matrix. Robotics and Computer- Integrated Manufacturing, 2009, 25(3): 610–619.
Zurück zum Zitat M Danilovic, B Sandkull. The use of dependence structure matrix and domain mapping matrix in managing uncertainty in multiple project situations. International Journal of Project Management, 2005, 23(3):193–203. M Danilovic, B Sandkull. The use of dependence structure matrix and domain mapping matrix in managing uncertainty in multiple project situations. International Journal of Project Management, 2005, 23(3):193–203.
Zurück zum Zitat T R Browning. Applying the design structure matrix to system decomposition and integration problems: A review and new directions. IEEE Transactions on Engineering Management, 2001, 48(3): 292–306. T R Browning. Applying the design structure matrix to system decomposition and integration problems: A review and new directions. IEEE Transactions on Engineering Management, 2001, 48(3): 292–306.
Zurück zum Zitat A Nikanjam, H Sharifi, B H Helmi, et al. A new DSM clustering algorithm for linkage groups identification. Proceedings of the 12th annual conference on Genetic and evolutionary computation, 2010, New York, USA, July 7–11, 2010: 367–368. A Nikanjam, H Sharifi, B H Helmi, et al. A new DSM clustering algorithm for linkage groups identification. Proceedings of the 12th annual conference on Genetic and evolutionary computation, 2010, New York, USA, July 7–11, 2010: 367–368.
Zurück zum Zitat J U Maheswari, K A Varghese. Structured approach to form dependency structure matrix for construction projects. Proceedings of the 22nd International Symposium on Automation and Robotics in Construction, Ferrara, Italy, 2005: 1–6. J U Maheswari, K A Varghese. Structured approach to form dependency structure matrix for construction projects. Proceedings of the 22nd International Symposium on Automation and Robotics in Construction, Ferrara, Italy, 2005: 1–6.
Zurück zum Zitat A Yassine, D Braha. Complex Concurrent Engineering and the Design Structure Matrix Method. Concurrent Engineering, 2003, 11(3): 165–176. A Yassine, D Braha. Complex Concurrent Engineering and the Design Structure Matrix Method. Concurrent Engineering, 2003, 11(3): 165–176.
Zurück zum Zitat P H Chen, S M Shahandashti. Hybrid of genetic algorithm and simulated annealing for multiple project scheduling with multiple resource constraints. Automation in Construction, 2009, 18(4): 434–443. P H Chen, S M Shahandashti. Hybrid of genetic algorithm and simulated annealing for multiple project scheduling with multiple resource constraints. Automation in Construction, 2009, 18(4): 434–443.
Zurück zum Zitat C Ju, T Chen. Simplifying multiproject scheduling problem based on design structure matrix and its solution by an improved aiNet algorithm. Discrete Dynamics in Nature and Society, 2012, 2012: 1–2. C Ju, T Chen. Simplifying multiproject scheduling problem based on design structure matrix and its solution by an improved aiNet algorithm. Discrete Dynamics in Nature and Society, 2012, 2012: 1–2.
Zurück zum Zitat T Gaertner, S Terstegen, C M Schlick. Applying DSM methodology to improve the scheduling of calibration tasks in functional integration projects in the automotive industry. J. Mod. Project Manage, 2015, 3(2): 46–55. T Gaertner, S Terstegen, C M Schlick. Applying DSM methodology to improve the scheduling of calibration tasks in functional integration projects in the automotive industry. J. Mod. Project Manage, 2015, 3(2): 46–55.
Zurück zum Zitat T R Browning. Managing complex project process models with a process architecture framework. Int. J. Project Manage., 2014, 32(2): 229–241. T R Browning. Managing complex project process models with a process architecture framework. Int. J. Project Manage., 2014, 32(2): 229–241.
Zurück zum Zitat E P Hong, G J Park. Modular design method based on simultaneous consideration of physical and functional relationships in the conceptual design stage. J. Mech. Sci. Technol., 2014, 28(1): 223–235. E P Hong, G J Park. Modular design method based on simultaneous consideration of physical and functional relationships in the conceptual design stage. J. Mech. Sci. Technol., 2014, 28(1): 223–235.
Zurück zum Zitat A H Tilstra, C C Seepersad, K L Wood. A high-definition design structure matrix (HDDSM) for the quantitative assessment of product architecture. J. Eng. Des., 2012, 23(10–11): 767–789. A H Tilstra, C C Seepersad, K L Wood. A high-definition design structure matrix (HDDSM) for the quantitative assessment of product architecture. J. Eng. Des., 2012, 23(10–11): 767–789.
Zurück zum Zitat T AlGeddawy, H ElMaraghy. Optimum granularity level of modular product design architecture. CIRP Ann. Manuf. Technol, 2013, 62(1): 151–154. T AlGeddawy, H ElMaraghy. Optimum granularity level of modular product design architecture. CIRP Ann. Manuf. Technol, 2013, 62(1): 151–154.
Zurück zum Zitat F Borjesson, K H¨oltt¨a-Otto. A module generation algorithm for product architecture based on component interactions and strategic drivers. Res. Eng. Des., 2014, 25(1): 31–51. F Borjesson, K H¨oltt¨a-Otto. A module generation algorithm for product architecture based on component interactions and strategic drivers. Res. Eng. Des., 2014, 25(1): 31–51.
Zurück zum Zitat D Mike, S Bengt. The use of dependence structure matrix and domain mapping matrix in managing uncertainty in multiple project situations. International Journal of Project Management, 2005, 23(2): 193–203. D Mike, S Bengt. The use of dependence structure matrix and domain mapping matrix in managing uncertainty in multiple project situations. International Journal of Project Management, 2005, 23(2): 193–203.
Zurück zum Zitat A Yassine. An introduction to modeling and analyzing complex product development processes using the design structure matrix (DSM) method. Urbana, 2004, 51(9): 1–17. A Yassine. An introduction to modeling and analyzing complex product development processes using the design structure matrix (DSM) method. Urbana, 2004, 51(9): 1–17.
Zurück zum Zitat S E Carlson, N Ter-Minassian. Planning for concurrent engineering. Medical Device and Diagnostic Industry, 1996, 18(5): 8 –11. S E Carlson, N Ter-Minassian. Planning for concurrent engineering. Medical Device and Diagnostic Industry, 1996, 18(5): 8 –11.
Zurück zum Zitat S Amol. Resource constrained multi-project scheduling with priority rules & analytic hierarchy process. Procedia Engineering,2014, 69: 725–734. S Amol. Resource constrained multi-project scheduling with priority rules & analytic hierarchy process. Procedia Engineering,2014, 69: 725–734.
Zurück zum Zitat E Ashraf, A Mohammad. Multiobjective evolutionary finance-based scheduling: Individual projects within a portfolio. Automation in Construction, 2011, 20(7): 755–766. E Ashraf, A Mohammad. Multiobjective evolutionary finance-based scheduling: Individual projects within a portfolio. Automation in Construction, 2011, 20(7): 755–766.
Qing-Chao Sun
Wei-Qiang Huang
Ying-Jie Jiang
Wei Sun
https://doi.org/10.1007/s10033-017-0160-y
Chinese Mechanical Engineering Society
Chinese Journal of Mechanical Engineering
Social Sensors (S2ensors): A Kind of Hardware-Software-Integrated Mediators for Social Manufacturing Systems Under Mass Individualization
Design Change Model for Effective Scheduling Change Propagation Paths
MapReduce Based Parallel Bayesian Network for Manufacturing Quality Control
Product Data Model for Performance-driven Design
Design and Dynamic Model of a Frog-inspired Swimming Robot Powered by Pneumatic Muscles
Designing Visceral, Behavioural and Reflective Products
Die im Laufe eines Jahres in der "adhäsion" veröffentlichten Marktübersichten helfen Anwendern verschiedenster Branchen, sich einen gezielten Überblick über Lieferantenangebote zu verschaffen.
Zur Marktübersicht
in-adhesives, MKVS, Nordson/© Nordson, ViscoTec/© ViscoTec, Hellmich GmbH/© Hellmich GmbH | CommonCrawl |
On continuity equations in space-time domains
October 2018, 38(10): 4819-4835. doi: 10.3934/dcds.2018211
Periodic solutions for indefinite singular equations with singularities in the spatial variable and non-monotone nonlinearity
Pablo Amster 1, and Manuel Zamora 2,,
Departamento de Matemática, Facultad de Ciencias Exactas y Naturales, Universidad de Buenos Aires, Pabellón I, 1428, Buenos Aires, Argentina
Departamento de Matemática, Grupo de Investigación en Sistemas Dinámicos y Aplicaciones (GISDA), Universidad de Oviedo, C/ Federico García Lorca, n18, Oviedo, Spain
* Corresponding author: Manuel Zamora
Received February 2017 Revised December 2017 Published July 2018
Fund Project: The first author is supported by projects UBACyT 20020120100029BA and CONICET PIP11220130100006CO, and the second author was supported by FONDECYT, project no. 11140203.
Full Text(HTML)
Figure(4)
TWe prove the existence of
$T$
-periodic solutions for the second order non-linear equation
$ {\left( {\frac{{u'}}{{\sqrt {1 - {{u'}^2}} }}} \right)^\prime } = h(t)g(u), $
where the non-linear term
$g$
has two singularities and the weight function
$h$
changes sign. We find a relation between the degeneracy of the zeroes of the weight function and the order of one of the singularities of the non-linear term. The proof is based on the classical Leray-Schauder continuation theorem. Some applications to important mathematical models are presented.
Keywords: Singular differential equations, indefinite singularity, periodic solutions, degree theory, Leray-Schauder continuation theorem.
Mathematics Subject Classification: Primary: 34C25, 34B18; Secondary: 34B30.
Citation: Pablo Amster, Manuel Zamora. Periodic solutions for indefinite singular equations with singularities in the spatial variable and non-monotone nonlinearity. Discrete & Continuous Dynamical Systems - A, 2018, 38 (10) : 4819-4835. doi: 10.3934/dcds.2018211
J. C. Alexander, A primer on connectivity. In proceeding of the conference in fixed point theory, Fadell, E.- Fournier, G. Editors, Springer-Verlag Lecture Notes in Mathematics, 886 (1981), 455-488.Google Scholar
C. Bereanu, D. Gheorghe and M. Zamora, Periodic solutions for singular perturbations of the singular $\phi-$Laplacian operator, Commun. Contemp. Math., 15(2013), 1250063 (22 pages). doi: 10.1142/S0219199712500630. Google Scholar
C. Bereanu, D. Gheorghe and M. Zamora, Non-resonant boundary value problems with singular $\phi$-Laplacian operators, Nonlinear Differential Equations and Applications, 20 (2013), 1365-1377. doi: 10.1007/s00030-012-0212-z. Google Scholar
C. Bereanu, P. Jebelean and J. Mawhin, Variational methods for nonlinear perturbations of singular $\phi$-Laplacians, Rend. Lincei Mat. Appl., 22 (2011), 89-111. doi: 10.4171/RLM/589. Google Scholar
C. Bereanu and J. Mawhin, Existence and multiplicity results for some nonlinear problems with singular $\phi$-Laplacian, J. Differ. Equ., 243 (2007), 536-557. doi: 10.1016/j.jde.2007.05.014. Google Scholar
H. Brezis and J. Mawhin, Periodic solutions of the forced relativistic pendulum, Differ. Integral Equ., 23 (2010), 801-810. Google Scholar
A. V. Borisov and I. S. Mamaev, The restricted two body problem in constant curvature spaces, Celestial Mech. Dynam. Astronom, 96 (2006), 1-17. doi: 10.1007/s10569-006-9012-2. Google Scholar
A. V. Borisov, I. S. Mamaev and A. A. Kilin, Two-body problem on a sphere. Reduction, stochasticity, periodic orbits, Regul. Chaotic Dyn., 9 (2004), 265-279. doi: 10.1070/RD2004v009n03ABEH000280. Google Scholar
A. Boscaggin and F. Zanolin, Second-order ordinary differential equations with indefinite weight: the Neumann boundary value problem, Ann. Mat. Pura Appl., 194 (2015), 451-478. doi: 10.1007/s10231-013-0384-0. Google Scholar
J. L. Bravo and P. J. Torres, Periodic solutions of a singular equation with indefinite weight, Adv. Nonlinear Stud., 10 (2010), 927-938. doi: 10.1515/ans-2010-0410. Google Scholar
A. Capietto, J. Mawhin and F. Zanolin, Continuation theorems for periodic perturbations of autonomous systems, Trans. Amer. Math. Soc., 329 (1992), 41-72. doi: 10.1090/S0002-9947-1992-1042285-7. Google Scholar
P. Fitzpatrick, M. Martelli, J. Mawhin and R. Nussbaum, Topological methods for ordinary differential equations, Lecture Notes in Mathematics, 1537 (1991), 1-209, Springer-Verlag, ISBN 3-540-56461-6. doi: 10.1007/BFb0085073. Google Scholar
A. Fonda, R. Manásevich and F. Zanolin, Subharmonic solutions for some second-order differential equations with singularities, SIAM J. Math. Anal., 24 (1993), 1294-1311. doi: 10.1137/0524074. Google Scholar
R. Hakl and M. Zamora, On the open problems connected to the results of Lazer and Solimini, Proc. Roy. Soc. Edinb., Sect. A. Math., 144 (2014), 109-118. doi: 10.1017/S0308210512001862. Google Scholar
R. Hakl and M. Zamora, Periodic solutions of an indefinite singular equation arising from the Kepler problem on the sphere, Canadian J. Math., 70 (2018), 173-190. doi: 10.4153/CJM-2016-050-1. Google Scholar
E. H. Hutten, Relativistic (non-linear) oscillator, Nature, 203 (1965), 892. doi: 10.1038/205892a0. Google Scholar
A. C. Lazer and S. Solimini, On periodic solutions of nonlinear differential equations with singularities, Proc. Amer. Math. Soc., 99 (1987), 109-114. doi: 10.1090/S0002-9939-1987-0866438-7. Google Scholar
L. A. Mac-Coll, Theory of the relativistic oscillator, Am. J. Phys., 25 (1957), 535-538. Google Scholar
P. J. Torres, Nondegeneracy of the periodically forced Liénard differential equations with $\phi$-Laplacian, Commun. Contemp. Math., 13 (2011), 283-293. doi: 10.1142/S0219199711004208. Google Scholar
A. J. Ureña, Periodic solutions of singular equations, Topological Methods in Nonlinear Analysis, 47 (2016), 55-72. Google Scholar
G. T. Whyburn, Topological Analysis, Princeton Univ. Press, 1958. Google Scholar
M. Zamora, New periodic and quasi-periodic motions of a relativistic particle under a planar central force field with applications to scalar boundary periodic problems, J. Qualitative Theory of Differential Equations, 31 (2013), 1-16. Google Scholar
Figure 1. The figure illustrates a possible behaviour of any $T-$periodic solution $u$ of (20) when $t_*$ is included on $[\bar{\ell}_i, \bar{\ell}_i')$ (Case Ⅰ.) or if $t_*\in (\bar{\ell_i}, \bar{\ell}_i']$ (Case Ⅱ.).
Figure Options
Download as PowerPoint slide
Figure 2. The figure illustrates a possible behaviour of the $T-$periodic solution $u$ of (16) when $t_*$ is included on $[a_i, a_i']$, distinguishing if $t_*\in [a_i, \bar{\ell}_i)$ (Case Ⅰ. a)) or $t_*\in (\bar{\ell}_i', a_i']$ (Case Ⅰ. b)).
Figure 3. The figure illustrates a possible behaviour of the $T-$periodic solution $u$ of (16) on the interval $[\bar{\ell}_i', \ell_i']$, assuming that $u(a_i')<\alpha+2\delta$.
Figure 4. The figure illustrates a possible behaviour of the $T-$periodic solution $u$ of (16) on the interval $[\bar{\ell}_i', \ell_i']$, assuming that $u(a_i')\geq \alpha+2\delta$.
Tianling Jin, Jingang Xiong. Schauder estimates for solutions of linear parabolic integro-differential equations. Discrete & Continuous Dynamical Systems - A, 2015, 35 (12) : 5977-5998. doi: 10.3934/dcds.2015.35.5977
Begoña Barrios, Leandro Del Pezzo, Jorge García-Melián, Alexander Quaas. A Liouville theorem for indefinite fractional diffusion equations and its application to existence of solutions. Discrete & Continuous Dynamical Systems - A, 2017, 37 (11) : 5731-5746. doi: 10.3934/dcds.2017248
Gary M. Lieberman. Schauder estimates for singular parabolic and elliptic equations of Keldysh type. Discrete & Continuous Dynamical Systems - B, 2016, 21 (5) : 1525-1566. doi: 10.3934/dcdsb.2016010
José Godoy, Nolbert Morales, Manuel Zamora. Existence and multiplicity of periodic solutions to an indefinite singular equation with two singularities. The degenerate case. Discrete & Continuous Dynamical Systems - A, 2019, 39 (7) : 4137-4156. doi: 10.3934/dcds.2019167
Jifeng Chu, Zaitao Liang, Fangfang Liao, Shiping Lu. Existence and stability of periodic solutions for relativistic singular equations. Communications on Pure & Applied Analysis, 2017, 16 (2) : 591-609. doi: 10.3934/cpaa.2017029
Zhibo Cheng, Jingli Ren. Periodic and subharmonic solutions for duffing equation with a singularity. Discrete & Continuous Dynamical Systems - A, 2012, 32 (5) : 1557-1574. doi: 10.3934/dcds.2012.32.1557
Jaume Llibre, Luci Any Roberto. On the periodic solutions of a class of Duffing differential equations. Discrete & Continuous Dynamical Systems - A, 2013, 33 (1) : 277-282. doi: 10.3934/dcds.2013.33.277
Nguyen Thieu Huy, Ngo Quy Dang. Dichotomy and periodic solutions to partial functional differential equations. Discrete & Continuous Dynamical Systems - B, 2017, 22 (8) : 3127-3144. doi: 10.3934/dcdsb.2017167
Xianhua Huang. Almost periodic and periodic solutions of certain dissipative delay differential equations. Conference Publications, 1998, 1998 (Special) : 301-313. doi: 10.3934/proc.1998.1998.301
Nguyen Minh Man, Nguyen Van Minh. On the existence of quasi periodic and almost periodic solutions of neutral functional differential equations. Communications on Pure & Applied Analysis, 2004, 3 (2) : 291-300. doi: 10.3934/cpaa.2004.3.291
Masaki Hibino. Gevrey asymptotic theory for singular first order linear partial differential equations of nilpotent type — Part I —. Communications on Pure & Applied Analysis, 2003, 2 (2) : 211-231. doi: 10.3934/cpaa.2003.2.211
Congming Li, Jisun Lim. The singularity analysis of solutions to some integral equations. Communications on Pure & Applied Analysis, 2007, 6 (2) : 453-464. doi: 10.3934/cpaa.2007.6.453
Yong Li, Zhenxin Liu, Wenhe Wang. Almost periodic solutions and stable solutions for stochastic differential equations. Discrete & Continuous Dynamical Systems - B, 2017, 22 (11) : 1-18. doi: 10.3934/dcdsb.2019113
M. Gaudenzi, P. Habets, F. Zanolin. Positive solutions of superlinear boundary value problems with singular indefinite weight. Communications on Pure & Applied Analysis, 2003, 2 (3) : 411-423. doi: 10.3934/cpaa.2003.2.411
Anna Capietto, Walter Dambrosio. A topological degree approach to sublinear systems of second order differential equations. Discrete & Continuous Dynamical Systems - A, 2000, 6 (4) : 861-874. doi: 10.3934/dcds.2000.6.861
Zuzana Došlá, Mauro Marini, Serena Matucci. Global Kneser solutions to nonlinear equations with indefinite weight. Discrete & Continuous Dynamical Systems - B, 2018, 23 (8) : 3297-3308. doi: 10.3934/dcdsb.2018252
Ulrike Kant, Werner M. Seiler. Singularities in the geometric theory of differential equations. Conference Publications, 2011, 2011 (Special) : 784-793. doi: 10.3934/proc.2011.2011.784
Hernán R. Henríquez, Claudio Cuevas, Alejandro Caicedo. Asymptotically periodic solutions of neutral partial differential equations with infinite delay. Communications on Pure & Applied Analysis, 2013, 12 (5) : 2031-2068. doi: 10.3934/cpaa.2013.12.2031
Miguel V. S. Frasson, Patricia H. Tacuri. Asymptotic behaviour of solutions to linear neutral delay differential equations with periodic coefficients. Communications on Pure & Applied Analysis, 2014, 13 (3) : 1105-1117. doi: 10.3934/cpaa.2014.13.1105
Feliz Minhós. Periodic solutions for some fully nonlinear fourth order differential equations. Conference Publications, 2011, 2011 (Special) : 1068-1077. doi: 10.3934/proc.2011.2011.1068
PDF downloads (132)
HTML views (81)
Pablo Amster Manuel Zamora
Article outline | CommonCrawl |
19512번 - Generator 출처다국어
You are given $n$ different integer sequences. All sequences have the same length $L$, and all integers in these sequences are from $1$ to $m$.
You also have a machine that generates a stream of random numbers. Initially, the stream is empty. Every second, the machine generates a random integer from $1$ to $m$, inclusive, and appends it to the stream. Each random integer is generated independently with the same probability distribution which is given to you.
With probability $1$, eventually, each of the $n$ given sequences appears as $L$ consecutive elements of the stream. The occurrences of different sequences may overlap. At the first moment when each of the $n$ given sequences appeared at least once, the machine stops immediately. Your task is to calculate the expected number of seconds after which the machine stops.
There are one or more test cases. The first line of input contains an integer $T$, the number of test cases.
Each test case starts with a line containing three positive integers $n$, $m$ and $L$: the number of sequences given, the upper bound for the integers which may appear in the sequences and in the stream, and the length of each given sequence, respectively ($1 \leq n \leq 15$, $1 \leq m \leq 100$, $1 \leq L \leq 5 \cdot 10^4$).
The next line contains $m$ positive integers $a_1, a_2, \ldots, a_m$ which describe the probability distribution the machine uses to generate the stream. The machine will generate $1$ with probability $a_1 / s$, $2$ with probability $a_2 / s$ and so on, where $s = a_1 + a_2 + \ldots + a_m$. It is guaranteed that $s \le 10^9$.
Each of the next $n$ lines contains an integer sequence of length $L$. All integers in these sequences are positive and do not exceed $m$. It is guaranteed that all $n$ given sequences are pairwise distinct.
The total sum of $n \cdot L$ over all test cases does not exceed $777\,777$.
For each test case, calculate the answer as an irreducible fraction $\frac{A}{B}$ and output the integer $(A \cdot B^{-1}) \bmod (10^{9} + 7)$ on a separate line. Here, $B^{-1}$ is the multiplicative inverse of $B$ modulo $10^{9} + 7$.
It is guaranteed that for all given inputs, the integers $B$ and $10^{9} + 7$ are relatively prime.
Camp > Petrozavodsk Programming Camp > Summer 2016 > Day 8: DPRK Contest G번 | CommonCrawl |
Deep mantle melting, global water circulation and its implications for the stability of the ocean mass
Shun-ichiro Karato ORCID: orcid.org/0000-0002-1483-45891,
Bijaya Karki2 &
Jeffrey Park1
Oceans on Earth are present as a result of dynamic equilibrium between degassing and regassing through the interaction with Earth's interior. We review mineral physics, geophysical, and geochemical studies related to the global water circulation and conclude that the water content has a peak in the mantle transition zone (MTZ) with a value of 0.1–1 wt% (with large regional variations). When water-rich MTZ materials are transported out of the MTZ, partial melting occurs. Vertical direction of melt migration is determined by the density contrast between the melts and coexisting minerals. Because a density change associated with a phase transformation occurs sharply for a solid but more gradually for a melt, melts formed above the phase transformation depth are generally heavier than solids, whereas melts formed below the transformation depth are lighter than solids. Consequently, hydrous melts formed either above or below the MTZ return to the MTZ, maintaining its high water content. However, the MTZ water content cannot increase without limit. The melt-solid density contrast above the 410 km depends on the temperature. In cooler regions, melting will occur only in the presence of very water-rich materials. Melts produced in these regions have high water content and hence can be buoyant above the 410 km, removing water from the MTZ. Consequently, cooler regions of melting act as a water valve to maintain the water content of the MTZ near its threshold level (~ 0.1–1.0 wt%). Mass-balance considerations explain the observed near-constant sea-level despite large fluctuations over Earth history. Observations suggesting deep-mantle melting are reviewed including the presence of low-velocity anomalies just above and below the MTZ and geochemical evidence for hydrous melts formed in the MTZ. However, the interpretation of long-term sea-level change and the role of deep mantle melting in the global water circulation are non-unique and alternative models are reviewed. Possible future directions of studies on the global water circulation are proposed including geodynamic modeling, mineral physics and observational studies, and studies integrating results from different disciplines.
The habitability conditions of a planet are often defined as the conditions in which its surface can maintain liquid water for billions of years (e.g., Kasting and Catling 2003; Kopparapu et al. 2013; Langmuir and Broecker 2012). When the habitability conditions are defined in this way, it is implicitly assumed that if these conditions are met, oceans will have covered some (but not all) parts of a planet for billions of years. However, this is not necessarily true because the ocean mass on Earth-like planets is controlled by the dynamic equilibrium between the removal of volatile components from Earth's interior (degassing) and the transport of volatiles back into Earth's interior (regassing) (e.g., Holland 2003; Rubey 1951). Depending on the balance between regassing and degassing, oceans may disappear, or the surface may flood extensively. If either of them (or both) occurs for sufficient time, it will be difficult for life to emerge and evolve (e.g., Kite and Ford 2018). Therefore, commonly assumed "habitable conditions" are the necessary, but not the sufficient conditions to develop the biosphere we live in.
Both regassing and degassing involve global water-circulation processes in Earth's interior. Most previous studies emphasize shallow-mantle processes, such as degassing at mid-ocean ridges and regassing at subduction zones (Crowley et al. 2011; Franck and Bounama 2001; Karlsen et al. 2019; Korenaga 2011; Korenaga et al. 2017; McGovern and Schubert 1989; Rüpke et al. 2006) or the competition between degassing at ocean ridges and serpentinization in the ocean floor (e.g., Cowan and Abbot 2014; Kite and Ford 2018). Processes below the mantle transition zone (MTZ; a layer between ~ 410 and ~ 660 km depth) have been treated in a highly simplified fashion, with a few exceptions (Bercovici and Karato 2003; Karato 2012; Karato et al. 2006) where the role of melting above the MTZ on global chemical circulation was emphasized. Observational evidence for deep-mantle melting and water transport has been reported (e.g., Kuritani et al. 2011; Li et al. 2020; Liu et al. 2016, 2018; Schmandt et al. 2014; Tao et al. 2018; Tauzin et al. 2010; Yang and Faccenda 2020; Zhao and Ohtani 2009).
Nakagawa et al. (2015) is an important exception where they emphasized the separation of subducted oceanic crust into the MTZ. However, the degree to which oceanic crust carries water to the MTZ is unclear, nor did they explain the stability of water within the MTZ. The relationship between MTZ water content and the ocean-mass was not discussed in other studies.
In this paper, we review various observations to show the importance of the MTZ in the global water circulation. Motivated by seismic evidence of partial melting above and below the MTZ, we propose a new model in which partial melting around the MTZ buffers its water content, and hence (indirectly) stabilizes the ocean mass. However, given large uncertainties in the interpretation of various observations such as the sea-level change, we will also review alternative models.
Water in Earth's mantle: Importance of the mantle transition zone
Water-storage capacity in mantle minerals
Figure 1 illustrates regions that may play an important role in the global water circulation. Due to mantle convection and resultant partial melting and melt transfer, water may circulate deep into the mantle and return through Earth's surface into the oceans. For each region, we also estimate the water-storage capacity based on experimental results (e.g., Bolfan-Casanova 2005; Fu et al. 2019; Inoue et al. 2016; Inoue et al. 2010; Litasov et al. 2003; Peslier et al. 2017) (Fig. 2). The total water-storage capacity of the mantle is about 10× the present-day ocean mass. Particularly remarkable is the high water-storage capacity of the MTZ, roughly 6× Earth's ocean mass. The potential size of the MTZ water reservoir draws attention to its possible influence on surface-ocean mass, complementing familiar shallow-mantle reservoirs, such as the asthenosphere and subduction-zone mantle wedges.
A cartoon showing the nature of global water circulation. Water is added to the oceans by degassing associated with volcanism. Some surface water goes back to Earth's interior by subduction. A large fraction of subducted water comes back to the surface by arc volcanism. However, water stored in relatively deep portions of a subducting plate survives and is transported to the deep mantle contributing to regassing the mantle transition zone and deeper part
Table 1 Mass and the water storage capacity (the maximum water content that can be dissolved in minerals (or melts) in each region)
The water storage capacity in several regions of the mantle. Note a large water storage capacity in the mantle transition zone. For the data source and uncertainties, see Table 1
However, high water-storage capacity in the MTZ minerals does not guarantee high MTZ water-content. Water diffusion is inefficient for large-scale material transport: over ~ 100 Myr, the diffusion distance of hydrogen is ~ 1 km (Karato 2006). Consequently, large regions of Earth's interior can be dry, regardless of the water-storage capacity. Large-scale advection of volatile-bearing materials is required to hydrate Earth's interior to near its storage capacity, and a dynamic equilibrium is required to maintain hydration over geological history. In particular, melting and the resultant melt-solid separation can effectively transport water (volatiles) for long distances. Efficient transport of water from Earth's surface into its interior could be catastrophic for life, if planetary water fills the MTZ to its capacity, with no mechanism to escape draining the oceans dry. Therefore, we must consider mechanisms for removing MTZ water as well as adding it. The actual water distribution in Earth provides key clues as to the processes of global water circulation.
Richard et al. (2002) modeled numerically the distribution of water, during mantle convection, where the depth dependence of water solubility (water storage capacity) was assumed including a peak in the MTZ. However, they only considered diffusional transport of water, and not advection. Their simulations showed no peak in water content within the MTZ, i.e., a dry MTZ. We show in this paper that Earth's distribution of water is determined by the large-scale mass transport associated with partial melting and subsequent melt-solid separation. A dry MTZ is a natural consequence of a model without these large-scale processes. The actual water distribution provides clues to the history of partial melting and melt-solid separation, i.e., chemical evolution of Earth.
Water distribution in Earth's mantle
The most direct way to estimate the water content of Earth's interior would be to measure the water content of mantle samples (for a review, see Peslier et al. 2017). However, the interpretation of these measurements is not straightforward because it is unclear how the water of a mantle sample is modified during its transport to the surface (e.g., Demouchy and Bolfan-Casanova 2016; Karato 2006). Regions from which mantle samples can be collected are limited. Most samples originate from < 200 km depth. Occasionally, samples from deeper regions have been identified from diamond inclusions (e.g., Nestola and Smyth 2016; Pearson et al. 2014; Tschauner et al. 2018), but it is not clear if these samples represent typical water content of the deep mantle.
Although indirect, the mid-ocean-ridge basalt (MORB) provides a better estimate of the water content of the asthenosphere. MORB is formed via ~ 10% partial melting of the asthenosphere materials at a global scale with near-homogeneous composition. Knowing that a majority of water in the original rock partitions into the melt upon partial melting, we can estimate the water content of the asthenosphere from the known water content of MORB (~ 0.1%; Dixon et al. 2002; Ito et al. 1983) to be ~ 0.01 wt%. Although less precise, we can estimate water content in the deeper mantle from ocean-island-basalt (OIB) that is formed from rocks that rise from the MTZ or the lower mantle. OIB shows a wider range of composition than does MORB, including water content, but they invariably show higher levels of water and other incompatible elements. These observations suggest that the deep mantle contains higher water content than the asthenosphere but water content in the deep mantle is likely more heterogeneous than in the asthenosphere.
Support for water-rich deep mantle is provided by recent discoveries of water-rich inclusions in diamonds of deep mantle origin. For example, Pearson et al. (2014) reported water-rich small (~ 50μm) inclusions in diamond. The water content is close to the solubility limit (~ 1.5 wt%). A report of ice VII inclusions in diamonds that rose from the deep mantle through the MTZ argues for at least some water-rich regions at these depths (Tschauner et al. 2018). However, it is not known if such samples are representative of either the MTZ or deeper regions, making water-content estimates of the MTZ and deeper regions difficult.
In contrast to a geological approach, a geophysical approach provides constraints on the water (hydrogen) distribution in a more regional to global scale (Fei et al. 2017; Houser 2016; Karato 2011; Li et al. 2013; Suetsugu et al. 2006; Wang et al. 2019a). However, geophysical inference is not straightforward, and a broad range of water content, from nearly zero (Houser 2016) to nearly saturated (Fei et al. 2017), has been reported for Earth's mantle. The studies that report these two extreme water contents have technical ambiguities such as the insensitivity of seismic wave velocities to water content that undermine the validity of their conclusions (for details, see Supplementary Material). In the following, we assume that the MTZ contains a substantially larger amount of water (0.1–1 wt%) than the asthenosphere (~ 0.01 wt%) based on the studies on electrical conductivity (Karato 2011) and on the seismological observations (Li et al. 2013; Suetsugu et al. 2006; Wang et al. 2019a). We note that these estimates have large uncertainties, and it is likely that the water content in the MTZ is heterogeneous (Karato 2011; Wang et al. 2019b; Zhu et al. 2013).
In contrast, there are few constraints on the water content of the lower mantle. The agreement of electrical conductivity of dry bridgmanite with the geophysically estimated electrical conductivity of the shallow lower mantle (Xu et al. 1998) suggests a dry lower mantle, but both experimental and geophysical studies on electrical conductivity in the lower mantle are highly preliminary. There are no experimental studies on the influence of hydrogen on electrical conductivity in lower-mantle minerals.
Partial melting across the mantle transition zone
Melting across the mantle transition zone
Melting below mid-ocean ridges occurs because materials are brought up to shallow regions adiabatically and cross the solidus that increases more steeply with depth. Water helps melting below the mid-ocean ridges (e.g., Hirth and Kohlstedt 1996; Plank and Langmuir 1992), but the presence of water is not essential. As a result, mid-ocean ridge basaltic magma contains only a small amount of water (~ 0.1 wt%).
In contrast, melting in the middle mantle, above and below the MTZ, cannot occur without the help of water or other volatile elements. Without volatiles, the solidus (~ 2200–2300 K) would be substantially higher than any plausible geotherm (~ 1800 K) (e.g., Andrault et al. 2011; Katsura et al. 2010; Ohtani 1987)). However, when water (and/or carbon dioxide) is added, the solidus temperature drops substantially, and partial melting becomes possible for a typical geotherm (Hirschmann et al. 2009; Kawamoto 2004; Litasov et al. 2013). The solidus water content defines the minimum water content for partial melting to occur. The melt formed by partial melting under hydrous conditions contains a large amount of water.
When water-rich transition-zone materials are transported to either above or below it, partial melting likely occurs because material assemblages outside of the MTZ have substantially smaller water-storage capacity than those inside the MTZ (Bolfan-Casanova et al. 2006; Inoue et al. 2010). For melting above the 410 km, the threshold water content in the MTZ material is ~ 0.05 wt% for a typical temperature of ~ 1800 K (e.g., Hirschmann et al. 2009; Karato et al. 2006). The water solubility in the lower mantle minerals is less well constrained. However, the available data show that the water solubility in the lower mantle minerals is less than or similar to that in the upper mantle minerals just above the 410 km (e.g., Fu et al. 2019; Inoue et al. 2010). Consequently, the threshold water content for partial melting just below the 660 km is likely 0.1 wt% or less.
Both temperature and water content in or around the MTZ are likely heterogeneous (Wang et al. 2019b; Zhu et al. 2013). The MTZ near a subduction zone likely has lower temperatures where stagnant slabs are present (Fukao et al. 2001). Consequently, the melt composition and hence density likely depend on where melting occurs. For example, where temperature is 1500 K (~ 300 K less than the temperature in the warm regions), then the critical water content for partial melting will be ~ 0.1 wt% (Supplementary Material).
When partial melting occurs, a majority of water goes to the melt, and the residual solids will be depleted of water. When the melt density differs from the solid density and if the melt is inter-connected as suggested by the experimental studies (Panero et al. 2015; Yoshino et al. 2007), melt-solid segregation occurs by gravity-induced compaction as well as by the flow caused by the lateral pressure gradient (Leahy and Bercovici 2007; Ribe 1985a). Consequently, regional-scale (~ 100 km or more) re-distribution of water will result.
Evidence of partial melting around the mantle transition zone
The presence of low-velocity bodies in Earth's deep interior is often attributed to the presence of melt. However, the validity of this interpretation is unclear because partial melting can explain seismologically observed low-velocity regions only when (i) the melt fraction is large (a few %) and/or when (ii) melt completely wets grain-boundaries (see, e.g., Mizutani and Kanamori 1964; Spetzler and Anderson 1968; Stocker and Gordon 1975; Takei 2002). Both of these factors differ markedly between above and below the MTZ. Just above the 410 km discontinuity, an experimental study showed that melt completely wets olivine grain-boundaries (Yoshino et al. 2007). Consequently, even for a small amount of melt (say 0.1%), seismic wave velocity should be reduced substantially (a few % or more) in regions just above the 410 km. In contrast, in the lower mantle, the available data suggests that melt does not completely wet the grain-boundaries (dihedral angle of ~ 30°) (Panero et al. 2015). Therefore in order to cause seismologically observable low-velocity regions below the 660 km, there must be a melt-rich layer (MRL) containing a few % of melt with a thickness comparable to or greater than the wavelength of seismic waves.
Under the influence of gravity, melt tends to be squeezed out if the melt density differs from the density of the surrounding solids. As a consequence, significant amounts of melt will exist only in a thin layer whose thickness is called the "compaction length" (Karato et al. 2006; McKenzie 1985; Ribe 1985b). During compaction, permeable flow of melt occurs only if the surrounding solids deform plastically. When there is a general background flow, the thickness of an MRL will also depend on the background flow velocity. Let us consider a case of one-dimensional (vertical) flow by mantle convection in which light (heavy) melt is produced at a boundary at ~ 750 km (at ~ 410 km) where melt will accumulate. We denote these layers LVL-750 and LVL-410. In such a case, the thickness of an MRL is given by (Karato et al. 2006; Ribe 1985b).
$$ H=\sqrt{\frac{U_o{\eta}_S}{\left|\Delta \rho \right|g}} $$
where Uo is the velocity of background flow, ηS is the viscosity of solid matrix, g is acceleration due to gravity, and Δρ is density contrast between melt and surrounding solids.
Figure 3 shows a plot of H as a function of Uo and ηS. The compaction length depends strongly on the solid viscosity (ηS) and the velocity of background vertical motion (Uo). Both parameters differ substantially for MRL above and below the MTZ. For the up-welling flow that produces melt above 410 km, the background velocity is ~ 1 mm/year (Bercovici and Karato 2003) and the solid viscosity is ~ 1018–1020 Pa s. Note that the average viscosity at ~ 400 km depth is ~ 1020 Pa s (Peltier 1998), but viscosity could be substantially lower near 410 km due to the presence of melt. For a plausible range of parameters, H above the 410 km is ~ 1 km or less and consequently, it will not be visible seismologically if a large melt fraction were the cause for the low velocity. Low velocities observed above the 410 km discontinuity are most likely due to the fact that melt completely wets grain-boundaries (Karato 2014a).
The thickness of a melt-rich layer. When melt is formed in a region of vertical flow (with the velocity Uo), and when melt flows to the opposite direction of the background flow as in the most case of partial melting across the MTZ, a melt-rich layer is formed near the region where melt is formed. The thickness of this layer, H, is given by \( H\approx \sqrt{\frac{U_0{\eta}_S}{\left|\Delta \rho \right|g}} \)(Karato et al. 2006; Ribe 1985a) (ηS: viscosity of solids, |Δρ|: density difference between the melt and the solids (~ 100 kg/m3), g: acceleration due to gravity). Both Uo and ηS are markedly different between the melt-rich layer above and below the MTZ leading to largely different values of H
In contrast, in a layer at ~ 750 km (LVL-750), the down-welling velocity of materials is similar to the velocity of a subducting plate (~ 3–10 cm/year), that is, much higher than the up-welling velocity near ~ 410 km. The solid viscosity is also higher, on the order of 1021 Pa s (Peltier 1998) (could be reduced somewhat by the presence of melt). A combination of these two factors predicts the thickness of the MRL to be ~ 20–50 km. This would be seismologically detectable even though melt may not completely wet grain-boundaries. Note, however, that melt accumulation to explain the LVL-750 will occur only if melt is lighter than co-existing solids. If melt is denser than co-existing solids, it will drain and accumulate only at a deeper depth at which melting stops. For heavy melts, the melt content near 750 km will be small and not much velocity reduction will occur. Therefore, the presence of a thick MRL caused by the accumulation of a buoyant melt is a plausible explanation of the LVL-750 (for more detail, see Section 6).
Melt density
Most melts are lighter than coexisting rocks in the shallow Earth and this is why magmas ascend to the surface to form a volcano. However, melt buoyancy is more complicated in the deep interior of Earth. Melts are more compressible than solids (Jing and Karato 2011) and melt density approaches or exceeds that of co-existing solids at high pressures (Stolper et al. 1981). Consequently, the density contrast between a melt and co-existing solids is delicately controlled by the composition and the compressibility of melt and solid under high-pressure conditions.
Figure 4a shows the density of three melts up to 60 GPa based on the first-principle calculations as well as from experiments (Karki et al. 2018; Sakamaki 2017; Sanloup et al. 2013; for the technical details of melt density calculation, see Supplementary Material). The results show that the melt is always lighter below the solid-transformation depth but the melt is heavier than the solid, in most cases, above the solid-transformation depth. This is due to the fact that the structure of solids (e.g., a change in the coordination number of Si-O) changes sharply at the solid phase transformation, whereas a similar structural change occurs more gradually for the melts. In melts structural change starts at a lower pressure than in solids and structural change develops gradually with pressure, completing at a pressure higher than the sharp crystalline phase change (Fig. 4b).
The melt density across the mantle transition zone. a Melt density compared with the density of co-existing solids. The broken line shows the solid density. Black and red curves are the melt density based on the first-principles calculations of dry and hydrous (Mg0.75,Fe0.25)2SiO4 melts (with hatched regions showing the influence of different compositions). A green curve is the density of dry MORB determined by (Sanloup et al. 2013) and a blue curve is the density of hydrous peridotite melt determined by (Sakamaki 2017) from high-pressure experiments. The gray region shows the effects of a change in FeO content by ± 5%, and the pink region shows the effects of water by ± 2 wt.%. b A schematic diagram showing how density of melt and solid changes across a phase transformation. Structural change in a solid is abrupt, but it is gradual in a melt. This leads to higher density of a melt than a solid above the transition pressure, but below the transition pressure, melt density tends to be lighter than the solid density
The melt-solid density contrast depends also on chemical composition. For plausible ranges of FeO and water content, the density of melt below the 660 km is mostly less than that of co-existing solids. This is caused by a large density jump in solids across the 660 km. In contrast, the density trade-off is more delicate at ~ 410 km—see calculations graphed in Fig. 5. Water content in the melt changes with the temperature at which melting occurs. At low temperatures, melting occurs only for high volatile content within the MTZ mineral assemblage, and the water content of the melt is large. Consequently, melts produced in the cooler regions, e.g., where stagnant slabs are present, will be buoyant whereas melts formed in the warmer regions will be heavy. The consequences of temperature on the density contrast will be examined in a later section where we propose a new model of global water circulation.
The critical water content for the neutral buoyancy at 410 km. The shaded region represents an experimental range for the coefficient of iron portioning between the melt and mineral (\( {K}_D=\frac{{\left(\mathrm{FeO}/\mathrm{MgO}\right)}_{\min \kern0em \mathrm{eral}}}{{\left(\mathrm{FeO}/\mathrm{MgO}\right)}_{\mathrm{melt}}} \)). Results may depend also on the concentrations of other components such as K2O and CO2 (Jing and Karato 2012). According an experimental study \( {K}_D=\frac{{\left(\mathrm{FeO}/\mathrm{MgO}\right)}_{\mathrm{olivine}}}{{\left(\mathrm{FeO}/\mathrm{MgO}\right)}_{\mathrm{melt}}} \) is insensitive to temperature (Mibe et al. 2006), but water content in the melt increases with decreasing temperature. This makes melts buoyant at relatively low temperatures
Sea-level history
An important clue on the history of ocean mass can be obtained from the sea-level history. Sea-level changes via a variety of mechanisms (e.g., Mitrovica et al. 2000; Wise 1972). For the time scale of 1000–10,000 years, the largest contribution is ice-sheet formation/melting and resultant isostatic vertical crustal motion (e.g., Nakada and Lambeck 1987; Peltier 1998). The contribution of this process to the sea-level change is large, up to ~ 200 m. However, for time scales longer than 100 Myrs, the influence of ice sheet formation/melting cancels when averaged over time. Over these longer time scales, sea-level history is controlled by tectonic (geological) factors and/or changes in the ocean mass (e.g., Eriksson 1999; Korenaga 2007; Korenaga et al. 2017; Wise 1972)).
Figure 6 shows such results, i.e., the sea-level history during the Phanerozoic period (present to ~ 540 Ma) (after Parai and Mukhopadhyay 2012). Although there are some differences in the reported sea-level history, the common and remarkable observation is that the sea-level fluctuates substantially on 10–100 Myr time scales (2 to 3 m/Myrs), yet it remains nearly constant (less than ~ 0.5 m/Myrs) when averaged over the last ~ 500 Myrs. If the higher rate of change had persisted for a billion years, most oceans would have disappeared or the surface would have extensively flooded over ~ 1 Gyrs. However, despite large fluctuations, sea-level appears to recover and the average sea-level does not change so much.
Sea-level change during the Proterozoic (after Parai and Mukhopadhyay 2012). The sea-level variations show large fluctuations, yet an average sea-level changes only weakly with time (hatches are added by the present authors to emphasize the short-term fluctuations)
Which part of the observed sea-level change reflects the ocean mass history and which part is caused by tectonic processes? If sea-level change were mostly by tectonic processes, then ocean mass would remain nearly constant. In contrast, if sea-level change is largely due to the change in the ocean mass, then one needs to explain how ocean mass can fluctuate a lot but remains nearly constant on average.
Figure 7 shows a cartoon illustrating the processes that determine the sea-level where h is the sea-level measured at the coast, \( \overline{z} \) is the mean depth of ocean (3710 m at present), f is the fraction of the surface covered by the continents, and X is dynamic topography associated with the vertical stresses caused by mantle convection. The volume of oceans relates to these parameters as
A cartoon illustrating the factors affecting the sea-level (from Karato 2015). h: the sea-level, f: areal fraction of continents, \( \overline{z} \): the mean depth of the ocean that depends on the mean age of the ocean floor, X: height of the continental margin that depends on the dynamic topography determined by the mantle flow
$$ V(t)=\left[h(t)+X(t)-\overline{z}(t)\right]\cdot \left[1-f(t)\right]\cdot S $$
where S is the area of oceans.
Dynamic topography is the deviation of continental topography out of isostatic equilibrium, depending on material flows that are regional and time dependent. Gurnis (1993) invoked dynamic topography to explain the flooding of continents during the Phanerozoic Eon. This effect is sensitive to the viscosity (η) of convecting material (X ∝ η) in the relevant region. For sea-level measurements, viscosity of the mantle below the continental margin is relevant, and the viscosity in the continental margins can vary a lot among different regions. Where subduction occurs, viscosity will be substantially lower than other regions, as suggested by Billen and Gurnis (2001). Gurnis (1993) used a standard one-dimensional viscosity-depth model, such as Hager and Clayton (1989), that does not have a low viscosity region in the wedge mantle. If regional low viscosity in the supraslab mantle wedge is included, the magnitude of dynamic topography will be substantially lower (Billen and Gurnis 2001). The influence of continental growth (f(t)) is not very large when we focus on the sea-level in the Phanerozoic where the continental growth is less than ~ 10% (Korenaga 2018). Consequently, among various tectonic effects, the influence of variation of the mean depth of oceans (\( \overline{z}(t) \)) is likely most important. \( V(t)\approx \left[h(t)-\overline{z}(t)\right]\cdot S \).
The depth of oceans depends on the age of ocean floor through isostatic equilibrium as \( z={z}_0+A\sqrt{t} \) (e.g., Parsons and Sclater 1977) in the half-space-cooling model, where zo is the ocean depth at a mid-ocean ridge where t (age) is zero and A is a constant (A = 330 m/\( \sqrt{My} \)). Therefore in order to have ~ 300 m variation in sea-level for ~ 100 My time period, a change of the mean depth of ~ 30% is needed. The variation in the mean depth of the ocean floor can be evaluated based on the data on the age-area distribution of the ocean floor (Parsons 1982) and the plausible models and observations of the temporal variation in ridge spreading rate and subduction rate (Korenaga 2007). Using this line of discussion, Korenaga (2007) concluded that changes in the heat flux since 200 Ma are too small to explain a large variation in the sea-level (the change in the average age is a few % or less, corresponding to the change in the average age of ~ 5% or less). However, the estimate of the mean age of sea floor is complicated, and much larger variation has also been reported, e.g., by Müller et al. (2016). Karlsen et al. (2019) used this model and attribute a large fraction of observed sea-level change to the change in tectonic processes. Accepting these uncertainties, we will discuss models based on these two models of history of plate motions, i.e., models with small and strong influence of \( \overline{z}(t) \).
Among the inferred sea-level changes in various time span, the sea-level change in the recent ~ 100 Myrs is best constrained. The sea-level has dropped rapidly in this period with a rate of 2–3 m/Myrs. If this were due to the change in the ocean mass, the rate of change in the ocean mass would be ~ (1.0–1.5) × 1018 kg/Myr. Garth and Rietbrock (2014) and Cai et al. (2018) reported seismological observations on the Kuril and Mariana trench respectively suggesting the deep hydration (to 20–40 km from the top of the subducting slab) of subducting plates. Deeply hydrated regions likely survive against dehydration caused by heating during subduction (e.g., Rüpke et al. 2004) and from these observations, they estimated a high regassing rate of ~ 2 × 1018 kg/Myr that agrees with the rate of sea level drop during the last ~ 100 Myr. Although the estimate of regassing is highly uncertain, its order-of-magnitude supports the notion that some part of the recent sea-level change is due to the change in the ocean mass.
Water circulation across the mantle transition zone: the role of deep mantle melting
Let us now examine various models with the emphasis on how they can explain two notions summarized above: (i) the high water content of the MTZ, and (ii) the long-term stability of the average sea-level despite large fluctuations. Remembering the fact that the MTZ has the largest water-storage capacity and large water content, these two notions are linked by mass conservation.
$$ {M}_{\mathrm{MTZ}}\frac{dX_{\mathrm{MTZ}}}{dt}\approx -\frac{dW_{\mathrm{ocean}}}{dt} $$
where MMTZ is the mass of the MTZ, XMTZ is the mass fraction of water in the MTZ, and Wocean is the mass of oceans. On time scales long enough for hydrated rock to subduct or ascend through the upper mantle, the evolution of MTZ water is directly related to the evolution of the ocean mass and hence sea-level history.
In the following, we will develop a simple conceptual model to explain a peak in water content of 0.1–1 wt% in the MTZ that also explains the negative feedback in the evolution of the ocean mass suggested by the observed sea-level history and compare our new model with others. In seeking a model to explain the observed sea-level history, we will focus on explaining why sea-level is nearly constant with large medium-term fluctuations. Since Earth's deep interior is a big water reservoir, it is likely that some process of negative feedback operates within it.
As outlined in Fig. 1, the processes of water transport are different between up-welling and down-welling regions, and hence water content in the MTZ is likely heterogeneous. However, to simplify the analysis, we will consider a model where only the average water content of the MTZ is considered.
$$ {M}_{\mathrm{MTZ}}\frac{dX_{\mathrm{MTZ}}}{dt}={\Gamma}_{\mathrm{MTZ}}^{+}-{\Gamma}_{\mathrm{MTZ}}^{\hbox{-} } $$
where \( {\Gamma}_{\mathrm{MTZ}}^{+,-} \) is the regassing (or degassing) rate to (or from) the MTZ. In such a case, the model becomes one-dimensional where a single parameter, XMTZ, represents the average water content of the MTZ. Such a simplification is justifiable if we consider the evolution of the ocean mass since mixing of mass in the ocean is quick. However, such a model does not provide any detailed prediction of the lateral variation in the water content in the MTZ.
Under this simplification, it is easy to show that if there is no melting, then the steady-state average water content in the MTZ will be given by (see Supplementary Material)
$$ {\tilde{X}}_{\mathrm{MTZ}}^{\mathrm{no}\;\mathrm{melting}}=\frac{1}{2}\left({X}_{\mathrm{up}}+{X}_{\mathrm{down}}\right) $$
where Xup is water content in the upwelling regions (~ water content of the lower mantle) and Xdown is the average water content in materials in the down-welling regions just above the MTZ. Both Xup and Xdown are small: Xup is not well constrained but its upper limit is the water solubility in the lower mantle minerals (0.01 wt% or less (Bolfan-Casanova et al. 2006; Inoue et al. 2010)) and Xdown ~ 0.01 wt% or less. Assuming a 5 km-thick layer of 1 wt% water (oceanic crust) with a 500 km-wide down-welling region, one would get Xdown ~ 0.01 wt%. If one includes the influence of shallow dehydration, Xdown would be substantially less. Therefore, we conclude that without partial melting, the MTZ would be nearly dry (< 0.01 wt%). This agrees with the results of Richard et al. (2002).
Let us now consider a case where dehydration melting occurs both above and below the MTZ in material that advects out of it (Fig. 8). We first assume that all the melt formed above the 410 km is heavier than surrounding solids (this assumption will be relaxed later), and the melt formed below the 660-km is lighter than the surrounding solids (Fig. 5). In such a case, the MTZ can maintain high water content since most of water is in the melts and melts return to the MTZ. The steady-state water content of the MTZ in this case can be calculated by solving the mass balance Eq. (4) with appropriate formulae for Γ+, − (see Supplementary Material) as
A model of water transport across the mantle transition zone. a A model without melting fu: area fraction of upwelling, fd: area fraction of down-welling, Uu: velocity of upwelling, Ud: velocity of down-welling. From the mass conservation, \( {f}_u{U}_u={f}_d{U}_d\equiv \frac{1}{2}U \). b A model with melting. In this model, we assume that melts formed above the MTZ are heavy and the melts formed below the MTZ are light. U′ the velocity of migration of the MRL materials from upwelling regions to the subduction zones (this depends on mantle viscosity and is fast only above 410 km)
$$ {\tilde{X}}_{\mathrm{MTZ}}^{\mathrm{melting}}=\frac{{\tilde{X}}_{\mathrm{MTZ}}^{\mathrm{no}\;\mathrm{melting}}-\frac{U^{\prime }}{U}\frac{X_S}{X_L-{X}_S}}{1-\frac{U^{\prime }}{U}\frac{X_L}{X_L-{X}_S}}\approx \frac{{\tilde{X}}_{\mathrm{MTZ}}^{\mathrm{no}\;\mathrm{melting}}}{1-\frac{U^{\prime }}{U}}\ge {\tilde{X}}_{\mathrm{MTZ}}^{\mathrm{no}\;\mathrm{melting}} $$
where U is the velocity of general circulation (mantle convection) and U′ is the velocity of entrainment (U′<U); XL, S is the water content at the liquidus and the solidus respectively. This model predicts higher water content of the MTZ than that for a case of no melting, but evaluation of the steady-state water content is difficult because entrainment rate (U′) is not well constrained. If entrainment is very efficient (\( \frac{U^{\prime }}{U}\to 1 \)), then the water content becomes unbounded: all water would be eventually trapped in the MTZ, and oceans will shrink to negligible size.
This entrainment paradox arises from the assumption that all water partitions to the melts surrounding the MTZ and all the melts return to the MTZ. This paradox is mitigated because some of the original water remains in the residual solids, so that a small amount of water escapes from the MTZ. This escaped water defines the water content of the asthenosphere (Karato 2012). However, the amount of water escape by this process is small, and would only replenish Earth's ocean mass in ~ 10 Gyr (e.g., Parai and Mukhopadhyay 2012).
Is there any process by which water leaks from the MTZ more efficiently than a general slow leak from the hot region? Temperature in the MTZ is heterogeneous (Figs. 9 and 10). Since cooler down-welling flow is concentrated in regions near the subduction zone, the majority of the MTZ is warm. However, there are cooler regions including the regions where stagnant slabs are present. In cooler regions, partial melting occurs only if the water content of materials is high (XMTZ > XC0) and the water content in the melt is higher than the melt derived from warmer MTZ regions (in contrast to water, FeO content in the melt (FeO/MgO ratio of the melt) relative to that in mineral is insensitive to temperature (Mibe et al. 2006), so melt density (relative to the solid density) changes with temperature mainly through the temperature effect on the water content in the melt). With sufficient water content, the melt will be buoyant (Jing and Karato 2012) (see Fig. 5). Consequently. buoyant melt could be formed in cool regions.
Processes of water transport across the 410 km with heterogeneous temperature. In the hot region (area SH (a majority of regions)), melts are dense and spread on the 410-km boundary and eventually be entrained into the transition zone (Bercovici and Karato 2003; Karato et al. 2006). Only a small amount of water is transported upward by the residual solids to define the composition of the asthenosphere (Karato 2012). In the cool region (area SC), melt is buoyant and if there is enough amount of buoyant melt present (a caseXMTZ ≥ XC2 (shown here)), substantial degassing from the MTZ will occur
A schematic phase diagram at ~ 410 km. A green region represents temperature distribution. TH, C is temperature in the hot (H) or the cold (C) regions respectively. TCr is temperature at which the melt has high enough water content and is buoyant. \( {X}_S^{H,C},{X}_L^{H,C} \) are the water content at the solidus and liquidus in the hot or the cold region respectively. XC1 is the minimum water content in the transition zone where the melt will ascend (~ 0.2%). XC2 is the water content above which hydrated materials above the MTZ are buoyant to form a plume (~ 1%; Supplementary Material)
However, buoyant melt does not always carry water upward efficiently (Fig. 11). When a buoyant melt moves upward in the upper mantle made of relatively dry rocks, some water is removed from the melt to the surrounding rocks. When the initial water content of the MTZ materials (XMTZ) is small (XC1 > XMTZ ≥ XC0; regime I), then melt fraction is small and migrating melt will lose its water immediately and the melt becomes denser and does not migrate up. However, when the water content of the MTZ is higher, then the melt fraction is higher (XMTZ ≥ XC1) and the hydrous melt above the 410 km will keep its buoyancy and migrates up to transport water to the shallower regions. However, when the initial water content (XMTZ) is less than a critical value XC2 (XC2 > XMTZ ≥ XC1; regime II), surrounding minerals are not much hydrated and remain dense (because they are cool) and stay in their original location and only melt migrates upward. In this case, the melt will eventually lose its water during ascent, and not much water is transported to the shallow mantle. When the initial water content (XMTZ) is larger (XMTZ ≥ XC2; regime III), then a larger amount of hydrous melt will be formed and therefore hydration of surrounding materials is extensive and the whole materials (hydrous melt + hydrated minerals) become buoyant to form a hydrous plume. Using the lever rule (mass balance), melt and solid density and water partitioning considerations, we estimate XC1≈0.2 wt% and XC2≈1 wt% for the temperature difference of 300 °C (Supplementary Material).
Cartoons showing how water is transported across the cool regions of 410 km (SC in Fig. 9). In a cool region, when water-rich buoyant materials (XMTZ ≥ XC0) move up to ~ 410 km, a buoyant melt is formed. a Regime I: If XMTZ is small (XC1 > XMTZ ≥ XC0), water in the melt is removed to surrounding minerals immediately and melt does not ascend. b Regime II: When XMTZ exceeds a critical value (XMTZ ≥ XC1), melt does not lose its buoyancy immediately. However, if XMTZ is not very high (XC2 > XMTZ ≥ XC1 (XC1~0.2%, XC2~1%)), then surrounding minerals remain dry and heavy, and only melt ascend (regime II). In this case, ascending melt will lose most water to the surroundings, and not much water is transported to the shallow region. c Regime III: When XMTZ is high (XMTZ ≥ XC2(~ 1%)), then wet melt hydrates surrounding minerals extensively, and melt and minerals together become buoyant. They ascend together to transport water to the shallow regions. Wet materials migrate up in the MTZ as well, but the velocity of transportation of wet materials is much faster in the upper mantle than in the MTZ due to the difference in solid viscosity between these regions
The critical water content is proportional to the temperature difference. If the temperature is too low, then the critical water content will be too large and wet plume will not be formed. However, cold regions (e.g., regions with stagnant slabs) will be warmed up with time, and at a certain point temperature becomes warm enough (but still colder than most regions) to produce wet plumes.
In short, when materials with water content exceeding the threshold water content (XC2) are transported to the shallower regions, all materials will ascend. The flux of water transported by this process is given by SC ⋅ XMTZ ⋅ Uplume ⋅ ρ (SC: cool area where this mechanism operates (area where XMTZ ≥ XC2), Uplume: the upwelling velocity of a plume, ρ: the density of upwelling materials). Since the upwelling velocity of a plume depends on the buoyancy, \( {U}_{\mathrm{plume}}={U}_{\mathrm{plume}}^0\frac{X_{\mathrm{MTZ}}-{X}_{C2}}{\left\langle {X}_{\mathrm{MTZ}}-{X}_{C2}\right\rangle } \) (〈XMTZ − XC2〉≈0.015 % (Supplementary Material): the mean value of XMTZ − XC2, \( {U}_{\mathrm{plume}}^0\approx \)1 m/year (Yuen and Peltier 1980). Note that this is the ascending velocity of a plume in the upper mantle. Hydrous materials are buoyant in the deeper mantle and they will also ascend (except near subduction zones), but the velocity of ascent is much slower because of the higher viscosity in the deeper mantle.
Motivated by the recent rapid sea-level drop (Fig. 6) associated with the old age of subducting slabs (Müller et al. 2016), we assume initial excess regassing (addition of excess water to the MTZ by subduction of old deeply hydrated plates) during a time span of τ1 (= 100 Myr) (Fig. 12). During this process, the ocean mass decreases. Excess water transported to the deep mantle promotes melting in the shallow lower mantle producing highly hydrous melt. An MRL is formed in the uppermost lower mantle (LVL-750). When plate geometry changes due to the supercontinental cycle (e.g., Lithgow-Bertelloni and Richards 1998), the water-rich materials formed in the subduction zone (LVL-750) will be located away from the subduction zone. Because these water-rich materials are less dense than the surrounding materials, they will move upward to join the MTZ. A region of hydrous materials (low seismic velocity) will be formed in the MTZ. When these materials move up into cold regions just above 410 km boundary, then hydrous melt is formed that promotes a wet plume to enhance degassing from the MTZ. The transition time from the excess regassing to excess degassing (τ2) is determined by the time scale of a change in plate geometry associated with supercontinental cycle and is on the order of 100–200 Myrs (Lithgow-Bertelloni and Richards 1998). In our approach, we assume plausible τ1 and τ2, and seek how big an area of MTZ-derived volcanism (SC) would be needed to explain the negative feedback.
Model of global water circulation involving deep mantle melting. a A schematic diagram of water circulation. Excess regassing occurs associated with cold subduction (τ1: duration of excess regassing). This produces partial melting in the lower mantle (LVL-750). Due to the change in plate boundary geometry (associated with supercontinent cycle (Lithgow-Bertelloni and Richards 1998), the hydrated and buoyant materials will be transported to the MTZ, and when these materials reach to ~ 410 km, excess degassing starts (after τ2 since the beginning of the excess regassing (this is controlled largely by the time scale of change in plate boundary geometry)). b Definition of two functions:
Γ+(t) a function characterizing excess regassing pulse
Γ−(t) a function characterizing excess degassing
Therefore, the evolution of the MTZ water content in response to a regassing pulse can be described as
$$ {M}_{\mathrm{MTZ}}\frac{d\Delta {X}_{\mathrm{MTZ}}}{dt}={\Delta \Gamma}_{\mathrm{MTZ}}^{+}\cdot {F}^{+}(t)-{\Delta \Gamma}_{\mathrm{MTZ}}^{-}\cdot {F}^{-}(t) $$
where ΔXMTZ is the change in the MTZ water content caused by an excess regassing, \( {\Delta \Gamma}_{\mathrm{MTZ}}^{+} \) is the amplitude of excess regassing (we use a value consistent with the sea level change of 2–3 m/Myr), \( {\Delta \Gamma}_{\mathrm{MTZ}}^{\hbox{-} } \) is the amplitude of excess degassing that is proportional to SC ⋅ (XMTZ − XC2), and F+(t), F−(t) are the functions of time that include τ1 and τ2 respectively (for details, see Supplementary Material). Because the excess degassing rate is proportional to (XMTZ − XC2), this effect provides a negative feedback and stabilizes the transition zone water content.
We show the results of calculated XMTZ(t) during and after the regassing pulse for various values of SC and τ2 (Fig. 13). Using an approximate mass balance relationship (Eq. 3), we calculate the sea-level history from
Results of model calculations on ocean mass history. Regassing parameters (rate of regassing and duration of regassing pulse (τ1)) are chosen to reproduce the inferred rapid sea-level drop (2–3 m/Myrs (in the last ~ 100 Myrs); Fig. 6). Degassing parameters include the area of cool regions with excess degassing (SC) and the delay time (τ2) for degassing since the beginning of excess regassing (and the plume upwelling velocity (~ 1 m/year)). a History of the water content in the MTZ (τ1 = τ2=100 Myrs). b Sea-level change corresponding to the model shown in (a) using a relation \( \Delta z\approx -\overline{z}\frac{M_{MTZ}\Delta {X}_{MTZ}}{W_{\mathrm{ocean}}} \) (Δz: sea-level change, \( \overline{z} \): average depth of the oceans (= 3730 m), MMTZ: mass of the MTZ (= 4 × 1023 kg)), ΔXMTZ: change in the water content of the MTZ; Wocean: mass of oceans (=1.4 × 1021 kg)). b Same as (a) except that τ1=100 Myrs, and τ2=200 Myrs. c Same as (b) except that τ1=100 Myrs, and τ2=200 Myrs. Observed sea-level changes (Fig. 7) can be explained with SC=(3–10) × 1010 (m2) (i.e., a region with 200–350 km diameter)
$$ \frac{\Delta z}{\overline{z}}=-\frac{M_{MTZ}}{W_{ocean}}\cdot \Delta {X}_{MTZ} $$
where Δzis the sea-level change, \( \overline{z} \) is average ocean depth, and Wocean is the ocean mass.
Note that a relatively large change in the sea-level correlates with a small change in XMTZ, illustrating the buffering function of the MTZ for the ocean mass. It is seen that, with SC≥1010 m2, this model explains the rapid degassing following a rapid regassing. This SC is a substantially smaller area compared to the area of mid-ocean ridge volcanism (7 × 1012 m2). The main reason for the efficient degassing by this mechanism is that both the ascent velocity of water-rich materials (Uplume) and the water content of upwelling materials (XMTZ) are much larger than the same properties associated with the mid-ocean ridge volcanism.
Evidence of partial melting above and below the MTZ
Seismic evidence for the LVL-410 is widespread from ScS reverberations (Revenaugh and Sipkin 1994), receiver functions (Tauzin et al. 2010; Vinnik and Farra 2007), and body-wave triplications (Song et al. 2004), consistent with this expectation. Wei and Shearer 2017 found evidence of LVL-410 over 33–50% of the Pacific Ocean region with reflected S waves. Higher-frequency Ps receiver functions show evidence for LVZ-410 associated with localized MTZ upwelling near the Japan slab (Liu et al. 2016) and surrounding the European Alps (Liu et al. 2018).
Evidence for LVL-750 is more sporadic. LVL-750 is observed in regions near subduction zones and other known zones of down-welling (Liu et al. 2016, 2018; Schmandt et al. 2014). Seismological observations on the LVL-750 may also help distinguish whether melt is lighter or heavier than the surroundings. If the melt produced within LVL-750 is heavier than the surrounding rock, then melt will drain downward and therefore melt content near 750 km will be controlled by the melt production rate. The melt production rate is not well known at this depth, but since melt is produced by water, the melt production rate is on the order of the rate of transportation of water. Given a typical water content in the MTZ of ~ 0.1 wt%, then the estimated melt fraction near 750 km for the heavy melt will be ~ 0.5% (assuming water content in the melt is 20%). With the dihedral angle of 30°, this would result in ~ 1% velocity reduction (we used the results by Takei 2002 to calculate the velocity reduction). In contrast, for a buoyant melt, melt will be accumulated with a characteristic thickness determined by the solid viscosity and the velocity of the background flow (Fig. 3). The peak melt content is on the order of 5–10% according to a model by Karato et al. (2006), and therefore we assume a velocity-depth profile shown in Fig. 14a. The results from a model of ~ 50 km-thick MRL are consistent with the seismological observations of Schmandt et al. (2014), who mapped estimated Vs anomalies ranging from − 1.25 to − 2.6% beneath the central USA. Liu et al. (2016, 2018) imaged smaller Ps converted waves from interfaces below the 660 km discontinuity with smaller amplitudes, corresponding to − 1.5% Vs anomalies beneath the Japan slab and − 0.5–1.5% Vs anomalies beneath the European Alps. We used models inspired by these parameters to compute synthetic receiver-function responses (Fig. 14b).
Results of forward modeling of receiver functions for various models of LVL-750. a The velocity-depth relationship for various models of a LVL at ~ 750 km. b Corresponding receiver function. Three models are considered: (1) A low velocity channel cause by the presence of chemically distinct materials such as subducted oceanic crust (e.g., (Gréaux et al. 2019)). (2) A case for a heavy melt. In a region of down-welling background flow (i.e., subduction zones), heavy melt will drain down and there is no melt accumulation. Consequently, velocity is only slightly lower than the background velocity. (3) A case for a light melt. Light melt will be accumulated in s region of down-welling background flow (i.e., subduction zones) and a melt-rich layer will be formed resulting in a substantial velocity reduction near the top of the melt-rich layer
In this calculation, we also considered a model by Gréaux et al. (2019) who suggested that the LVL-750 is caused by a layer of paleo-oceanic crust. This model predicts velocity discontinuity in both top and bottom of the LVL and a double peak in receiver function will result as shown in Fig. 14 (for technical details, see Supplementary Material). This is not consistent with the observations. Therefore, we conclude that seismic observations support a buoyant melt model but not a model invoking the presence of chemically distinct materials such as subducted oceanic crust.
Evidence of wet plumes
We note that a plume produced in the regime III (XMTZ ≥ XC2) will be geophysically visible, but migrating melt in the regime II (XC2 ≥ XMTZ ≥ XC1) without substantial hydration of minerals will be hard to detect geophysically. There is evidence from seismic tomography (Tao et al. 2018; Zhang et al. 2018; Zhao and Ohtani 2009) and magnetotelluric (Li et al. 2020) studies for plumes originated from the MTZ. Those might correspond to plumes formed under the condition of XMTZ ≥ XC2. We also note that geophysical anomalies in the Appalachian (Evans et al. 2019) might represent evidence for a wet plume associated with the breakup of the Pangea. In addition to geophysical observations, geochemical observations suggest the important contributions of MTZ materials to the composition of some volcanic rocks (e.g., Bonatti 1990; Kuritani et al. 2013; Li et al. 2020; Metrich et al. 2014; Nichols et al. 2002; Sobolev et al. 2019).
Water content of the mantle transition zone
In our model, the water content in the MTZ is buffered by the melting relationship: water re-distribution by melting and resultant melt-solid separation. In the simplest version of our model, water of the MTZ is transported to the shallow upper mantle by buoyant plumes (regime III), and this critical water content is XC2≈ 1%. This percentage agrees reasonably well with the water content of the MTZ in the east Asia (Karato 2011; Suetsugu et al. 2006). Our model also suggests that degassing from the MTZ can occur at lower water content, or in an earlier stage of MTZ degassing, for XMTZ ≥ XC1≈0.2%. Therefore, the model presented here would apply for heterogeneous MTZ water content ranging from 0.1 to 1.0%, consistent with some geophysical estimates (Karato 2011; Li et al. 2013; Suetsugu et al. 2006; Wang et al. 2019a).
Comparison to other models
Previous studies on the evolution of the ocean mass may be classified into two categories: (i) studies of the long-term evolution of ocean mass on 0.5–4.0 Ga time scales (e.g., Crowley et al. 2011; Franck and Bounama 2001; Korenaga 2011; McGovern and Schubert 1989; Nakagawa et al. 2018; Nakagawa et al. 2015; Rüpke et al. 2006)), and (ii) studies on 10–100 Ma time scales, with the focus on explaining the observed sea level change in the Phanerozoic (e.g., Gurnis 1993; Karlsen et al. 2019).
Most studies did not consider the role of the MTZ and therefore their models do not explain a high water content with the MTZ. An exception is Nakagawa et al. (2015) where the role of the MTZ was included through the transport of water-rich paleo-oceanic crust into the MTZ. Nakagawa's model can explain the high water content of the MTZ, but the results depend strongly on the assumed water content of the oceanic crust and the efficiency of transport of crustal materials to the MTZ. The way in which subducted oceanic crust may be mixed into the MTZ is poorly understood and highly controversial (e.g., Gaherty and Hager 1994; Karato 1997; van Keken et al. 1996). At this stage, the Nakagawa model does not explain the cycling of deep-mantle water that likely regulates the ocean mass.
In some studies of long-term ocean evolution, feedbacks through water-sensitive rheology are considered (e.g., Crowley et al. 2011; McGovern and Schubert 1989; Schaefer and Sasselov 2015). However, the way in which water-sensitive rheology should be included in such an approach is not clear. First, although water sensitivity of rheological properties is relatively well known for upper-mantle minerals such as olivine (e.g., Karato and Jung 2003; Mei and Kohlstedt 2000a, 2000b), water sensitivity of rheological properties within the lower mantle minerals is unconstrained by experiment. Water may have negligible effects on rheological properties of the lower mantle mineral (Mg, Fe)O (Otsuka and Karato 2015). Second, if the plastic flow occurs via diffusion creep (e.g., Karato et al. 1995), then water would increase the viscosity through enhanced grain-growth kinetics, and in such a case, the water effect is to make materials stronger. Third, following the concept that water may affect the thickness of plate through the influence of water on dehydration depth, Korenaga (2011) proposed a model where high water content makes global water cycling slower, an idea that is opposite to a conventional idea proposed by Crowley et al. (2011) and McGovern and Schubert (1989). However, the validity of Korenaga's model can be questioned because the extent to which the strength of the lithosphere controls the overall convection rate is unclear, and also it is not clear if the strength of the lithosphere is controlled mostly by its thickness. Importance of dynamic weakening in friction to control the strength of the lithosphere was proposed by Karato and Barbot (2018).
Perhaps more important is the role of deep mantle melting that could buffer the water content. If we consider degassing only by mid-ocean ridge volcanism, plus a small addition from hotspot volcanism, the water effect is very slow-acting. The whole ocean mass can be created in ~ 10 Gyrs. In contrast, regassing via MTZ-related melting starts with "wetter" MTZ rock and concentrates its water in Earth's handful of "wet" plumes. "Wet" plumes would be more efficient because of the much higher water content in these magmas and the higher velocity of transport.
In the studies on the ocean mass evolution for several 100 s Myr time-scale, the key issue is the interpretation of the sea-level fluctuation (e.g., Gurnis 1993; Karlsen et al. 2019 ). The sea-level record for the Phanerozoic Eon shows medium-term fluctuation with a time scale of ~ 100 Myrs (Fig. 6). Previous studies tried to explain the fluctuation by invoking a direct link between surface plate motion and the sea-level change, considering only shallow mantle processes. The main motivation for such models is the similarity between the sea-level record and the inferred history of plate motions in this period. For example, during the last ~ 400 Myrs, the supercontinent Pangea was formed at ~ 300 Ma and started to break up at ~ 170 Ma (e.g., Condie 1998 ). During this interval, the motion of plates changed dramatically including the location of subduction zones and ridges as well as the average plate velocity (Lithgow-Bertelloni and Richards 1998; Müller et al. 2016). Although the details of plate motion history are controversial (see also Korenaga 2007; Korenaga et al. 2017; Torsvik and Cocks 2019), it is clear that when a supercontinent exists, the mean plate size is large and hence the age of subducting plate is old, leading to high regassing rate. In contrast, when a supercontinent is broken into small pieces, the mean age of subducting plates is young and regassing rate is less. Also the young mean age will make sea-level higher. Consequently, such a model explains some of the observed sea-level history.
One obvious limitation of these models is that because they do not consider deep mantle processes, they cannot explain the high water content of the MTZ. Another limitation is that because these models accept enhanced regassing but their model of corresponding enhanced degassing in only modest, ocean mass should have been declining through the geological history. The amount of sea-level drop during the enhanced regassing is 100–300 m. Supercontinents have cycled a few times in Earth's history (Condie 1998; Nance and Murphy 2013), and consequently, the net drop of sea-level would be more than several 100 m implying that a large areas of continents should have been flooded in the Precambrian time. This is not observed in the sea-level record (e.g., Eriksson 1999; Wise 1972, 1974).
We should note that there is a possible way to test our model through the study of processes of supercontinent breakup. During the assembly of a supercontinent, the subduction of old plates will be vigorous. Some plate would form stagnant slabs in the MTZ, as seismology images now in Eastern Asia. The stagnant slabs will form cold MTZ below the supercontinent. According to our model, these regions are prone to produce wet plumes. Wet plumes will weaken the lithosphere and hence help breakup of the supercontinent. There are some reports suggesting a link between plumes and supercontinents (e.g., El Dien et al. 2019; Le Pichon et al. 2019; for the link between volcanism and continental rifting, see also Sengör and Burke 1978). As some of these papers suggest, plumes linked to supercontinent breakup might originate in the lower mantle. However, because deep-mantle plumes must traverse the MTZ, the entrainment and/or melting of hydrated portions of the MTZ may control how water-rich materials are transported to the surface.
Price et al. (2019) developed a three-dimensional model of water transport in the mantle where the influence of deep mantle melting is included. However, in their model, melt is assumed to be lighter than the co-existing rocks in all situations, and rises to the near-surface region. This assumption would prevent the MTZ from retaining water and is not consistent with the experimental observations on the melt density (Jing and Karato 2012; Sakamaki 2017; Sanloup et al. 2013).
Yang and Faccenda (2020) presented a model to explain the intra-plate volcanism originating from the MTZ such as the Changbaishan volcano in the North-East China. They assume the formation of highly hydrous and buoyant melt similar to our model, but they did not discuss the implications of this type of volcanism to the global water circulation and the stability of the ocean mass. Also, some key essence such as the water transport rate is not discussed by Yang and Faccenda (2020).
Remaining issues
In our model presented here, the emphasis is to evaluate the role of deep mantle melting in a semi-quantitative fashion to see if deep-mantle melting can buffer the MTZ water content and consequently the ocean mass. In doing so, we left a few key issues unexplored:
The efficiency of degassing (water transport from solid Earth to oceans)
Degassing processes to add water to the oceans are given by the product of the flux of water in the materials transported to the near surface times efficiency of degassing. At mid-ocean ridges, basaltic magmas are transported to the ocean bottom, and upon cooling some water is added to the oceans. But some water in basalts remains in basalts (as water trapped in intrusive rocks). In most models, this efficiency is assumed to be a constant on the order of 50% (e.g., Rüpke et al. 2006).
In a new type of degassing proposed here, water-rich materials are transported to near-surface regions in the continental regions. It is not clear how water transported to near surface regions in the continents adds water to oceans. Those volcanoes add water and other volatiles to the atmosphere and to the surface rocks. Water in the atmosphere will be added to oceans eventually through ocean-atmosphere mass exchange. Similarly, water in surface rocks will eventually be added as sediments and this will in turn enhance degassing by the arc magmatism in subduction zones. Also, it is possible that some of these volcanisms are related to continental rifting (e.g., Sengör and Burke 1978). If rifting develops enough, then new oceans will be formed and water will be added directly. In such a case, we expect high degassing rate from these volcanoes and ocean ridges in the incipient stage of supercontinent breakup.
Water-rich plumes may not be limited to continental regions. If old plates subduct in oceanic regions, and cool the transition zone, then wet plumes could also be formed in the oceanic environment. All of these details need to be investigated.
The role of plate motion history
In the current version of our model, the role of plate motion history is included only implicitly. Namely, when we introduce excess regassing followed by excess degassing caused by deep mantle melting, we assumed the time function characterizing excess regassing and degassing Γ+, −(t) where plate history is included. It is important to investigate the nature of these functions by incorporating the realistic plate motion history.
In the same token, we did not consider the role of change in the average age of oceanic plates that may modify the sea level. If the variation in the mean age of oceans is as large as suggested by Müller et al. (2016), this effect needs to be included in analyzing the sea-level history to understand the evolution of the ocean mass. For example, Karlsen et al. (2019) tried to explain the sea-level history of the last ~ 210 Myrs based on the plate motion history by Müller et al. (2016). Consequently, the sea-level high at ~ 100 Ma is explained by the change in the mean age of oceanic plates rather than enhanced degassing by Karlsen et al. (2019).
Characterization of wet plumes from the MTZ
A key concept proposed in this paper is efficient water transport from the MTZ to the surface in the cooler regions of the MTZ via wet plumes. As reviewed before, a number of geophysical observations suggest the presence of presumably wet plumes from the MTZ particularly in the East Asia. The present model predicts that such volcanism was likely more extensive just before and after the breakup of a super continent (~ 170 Ma in case of Pangea). More geological, geochemical, and geophysical studies need to be made to characterize the nature of these volcanisms. Geochemical studies will be particularly important to assess the history of these volcanisms.
Water content in the lower mantle
Our model suggests that the lower mantle has substantially smaller water content than the MTZ. This notion is not confirmed because there is no constraint on the water content of the lower mantle. One promising way is to extend the study on electrical conductivity. There are two ways in which we should do this. First, geophysical estimates of lower mantle conductivity are still not mature (e.g., Kelbert et al. 2019; Kelbert et al. 2009; Kuvshinov 2012). Second, essentially nothing is known on the influence of water (hydrogen) in electrical conductivity of lower mantle minerals. By analogy of ceramic materials, one expects that hydrogen enhances electrical conductivity of bridgmanite (Navrotsky 1999), but the experimental studies to test this hypothesis have not been made. Although there are some studies on the electrical conductivity in bridgmanite and (Mg, Fe)O, the role of water (hydrogen) was not studied in any detail. Given the recent experimental study showing relatively high water solubility in bridgmanite in the shallow lower mantle (Fu et al. 2019), and increased water solubility in (Mg, Fe)O at elevated pressures (Otsuka and Karato 2015), it is urgent to test this hypothesis.
Influence of water dependent rheology
In the first study of the ocean mass history, McGovern and Schubert (1989) focused on the influence of water content sensitive rheology on the history of degassing. Similar studies were made by Crowley et al. 2011 and Franck and Bounama (2001) (we note that Rüpke et al. 2006 and van Keken et al. 2011 did not consider the feedback between water-dependent rheology and global water cycling). In our approach, water-dependent rheology does not have a direct feedback to the global water circulation because the water flux is determined largely by the melting relationship. However, rheological properties change the rate of ascent of wet plumes.
Wetting relation of melts in lower mantle minerals
There is only one report on the wetting relationship of melt with minerals under the shallow lower mantle conditions (Panero et al. 2015) showing non-wetting behavior (dihedral angle ~ 30°). If melts completely wet grain-boundaries in the lower mantle, then seismologically detected low velocity region starting at ~ 750 km would mean the depth at which melting starts, but it will not constrain the melt density.
Water cycling in the geologic history
Earth has been cooling and therefore the melting regime has likely evolved with time. When mantle temperature was very high, melts formed above 410 km would be water-poor and dense. Heavy melts above the 410 km would linger and eventually return to the MTZ. Consequently, water added to the MTZ remained there, decreasing the ocean mass over time. However, since the regassing rate is also low in a hot young Earth, not much water subducted into the mantle.
As Earth's mantle cooled, melts formed above the MTZ would have more water in general. At this stage, melts formed in cooler regions will have a sufficiently large amount of water to form wet plumes, if the water content of the MTZ materials in these regions exceeds a critical value: now the water valve starts to regulate the water content of the MTZ (and hence the ocean mass). With further cooling in Earth's future, the temperature in the MTZ will eventually become too low to induce partial melting within convecting masses that cross the 410 km discontinuity. At this point, water-rich materials in the MTZ will be transported out of the MTZ without melting, no heavy melt will return to the MTZ, and mantle water content will lose its peak concentration within the MTZ. Ocean mass would not be regulated and can be predicted to decrease with time due to cold subduction, effecting a large regassing rate without a corresponding large degassing rate.
Summary and perspectives
We reviewed our current understanding of the global water circulation including water storage capacity of the mantle, water distribution in the mantle, melting relationship in the mantle (particularly across the MTZ), melt density relative to solid density, and geophysical and geochemical observations related to partial melting and the distribution of wet materials. We conclude that there is a peak in water content in the MTZ and there is strong evidence for partial melting both above and below the MTZ. Sea-level history during the Phanerozoic period (to ~ 540 Ma) is also reviewed that shows large fluctuation on 10–100 Ma time scales but a nearly constant long-term average. Causes for sea-level variation are reviewed including tectonic origin and the changes in the ocean mass.
Focusing on partial melting and melt transport around the MTZ, we present a conceptual model that explains two important geological/geophysical inferences in a unified fashion: the high water content of the MTZ and the long-term stability of the sea-level despite the short-term large variations. However, the details of the model remain uncertain. One major limitation is that it is a one-dimensional model where the influence of horizontal mass transport is only roughly included. Extending this model to three-dimensions including a realistic history of plate boundary geometry (history of mantle convection) would be important.
An important conclusion from this model is that, in addition to well-known melting at mid-ocean ridges, deep mantle melting likely influences the global water circulation substantially. So far, much of the focus in the study of global water circulation has been on the volcanism associated with the MORB. But the MORB is essentially dry (~ 0.1 wt% water) and its contribution to the ocean mass budget is not so large. In contrast, deep melts are water-rich (~ 5–10 wt% water) and hence could make an important contribution to the global water circulation. Evidence for transition zone-originated melt is identified by geochemical studies (Kuritani et al. 2013; Sobolev et al. 2019). Seismological studies also show low-velocity regions across the MTZ suggesting partial melting in these regions (Tao et al. 2018; Zhang et al. 2018; Zhao and Ohtani 2009). Also, a study on electrical conductivity suggests upwelling of water-rich materials from the MTZ (e.g., Li et al. 2020). However, details of how water transported by wet plumes is added to the oceans are not well known. Some of the wet materials might accumulate below the continents (Griffin et al. 2013), although some water in these regions will eventually be transported to the surface by shallow volcanism. Further studies on these volcanisms will be warranted to better understand the global water circulation and why Earth is a habitable planet.
From the planetary science perspectives, in order for the proposed water valve to operate in a planet, there must be a transition zone in the mantle. Consequently, the size of a planet should be substantially larger than Mars (~ 0.1 of Earth mass), a planet whose transition zone is located at the bottom of its silicate mantle (e.g., Spohn et al. 1998). But the planetary mass should be smaller than ~ 10 Earth mass; otherwise, it will be a gaseous planet (e.g., Hayashi et al. 1985; Rogers et al. 2011). In addition, plate tectonics must operate to maintain extensive material circulation including the oceans and planetary interiors. For plate tectonics to occur on a terrestrial planet, the lithosphere must be relatively weak (e.g., Bercovici 2003; Karato 2014b; Karato and Barbot 2018). The surface temperature is presumably the most important parameter to determine the strength of the lithosphere (e.g., Foley et al. 2012; Karato and Barbot 2018): surface temperature must be low enough to allow brittle fracture with unstable fault motion (Karato and Barbot 2018). This critical temperature is ~ 700 K. In summary, the habitability conditions where the ocean mass remains nearly constant for billions of years are the modest mass of a terrestrial planet (~ 0.2× to ~ 10× of Earth mass) in addition to the appropriate distance from the star. Long-term presence of oceans under these conditions is secured partly through the deep mantle melting that regulates the water content of the mantle and the ocean mass.
Data sharing not applicable to this article as no datasets were generated or analyzed
during the current study.
MTZ:
Mantle transition zone
MORB:
Mid-ocean ridge basalt
Ocean-island basalt
MRL:
Melt-rich layer
LVL:
Low velocity layer
LVL-410:
Low-velocity layer above 410 km depth
Low-velocity layer at around 750 km depth
Upper mantle
Lower mantle
Andrault D, Bolfan-Casanova N, Lo Nigro G, Bouhifd MA, Garbarino G, Mezouar M (2011) Solidus and liquidus profiles of chondritic mantle: Implications for melting of the Earth across its history. Earth Planet Sci Lett 304:251–259
Bercovici D (2003) The generation of plate tectonics from mantle convection. Earth Planet Sci Lett 205:107–121
Bercovici D, Karato S (2003) Whole mantle convection and transition-zone water filter. Nature 425:39–44
Billen MI, Gurnis M (2001) A low viscosity wedge in subduction zones. Earth Planet Sci Lett 193:227–236
Bolfan-Casanova N (2005) Water in the Earth's mantle. Mineralogical Magazine 69:229–257
Bolfan-Casanova N, McCammon CA, Mackwell SJ (2006) Water in transition zone and lower mantle minerals. In: Jacobsen SD, Lee Svd (eds) Earth's Deep Water Cycle, Washington DC, pp 57–68
Bonatti E (1990) Not so hot 'Hotspots' in the oceanic mantle. Science 250:107–111
Cai C, Wiens DA, Shen W, Eimer M (2018) Water input into the Mariana subduction zone estimated from ocean-bottom seismic data. Nature 563:389–392
Condie KC (1998) Episodic continental growth and supercontinents: a mantle avalanche connection? Earth Planet Sci Lett 163:97–108
Cowan NB, Abbot DS (2014) Water cycling between ocean and mantle: super-Earths need not be waterworlds. Astrophysical J 27:27
Crowley JW, Gérault M, O'Connell RJ (2011) On the relative role of influence of heat and water transport on planetary dynamics. Earth Planet Sci Lett 310:380–388
Demouchy S, Bolfan-Casanova N (2016) Distribution and transport of hydrogen in the lithospheric mantle: A review. Lithos 240-243:402–425
Dixon JE, Leist L, Langmuir J, Schiling JG (2002) Recycled dehydrated lithosphere observed in plume-influenced mid-ocean-ridge basalt. Nature 420:385–389
El Dien HG, Doucet LS, Li Z-X (2019) Global geochemical fingerprinting of plume intensity sugegsts coupling with the supercontinent cycle. Nat Commun 10:5270
Eriksson PG (1999) Sea level changes and the continental freeboard concept: general principles and application to the Precambrian. Precambrian Res 97:143–154
Evans RL, Benoit MH, Long MD, Elsenbeck J, Ford HA, Zhu J, Garcia X (2019) Thin lithosphere beneath the central Appalachian Mountains: a combined seismic and magnetoterrulic study. Earth Planet Sci Lett 519:308–316
Faccenda M, Gerya TV, Burlini L (2009) Deep slab hydration induced by bending-related variations in tectonic pressure. Nat Geosci 2:790–793
Fei H, Yamazaki D, Sakurai M, Miyajima N, Ohfuji H, Katsura T, Yamamoto T (2017) A nearly water-saturated mantle transition zone inferred from mineral viscosity. Sci Adv 3:e1603024
Foley BJ, Bercovici D, Landuyt W (2012) The conditions for plate tectonics on super-Earths: Inference from convection models with damage. Earth Planet Sci Lett 331-332:281–290
Franck S, Bounama C (2001) Global water cycle and Earth's thermal evolution. J Geodyn 32:231–246
Fu S, Yang J, Karato S, Vasiliev A, Presniakov MY, Gavriliuk AG, Ivanova AG, Hauri EH, Okuchi T, Purejav N, Lin J-F, (2019) Water concentration in single-crystal (Al,Fe)-bearing bridgmanite grown from the hydrous melt: implications for partial melting and the water storage capacity in the Earth's lower mantle. Geophys Res Lett 46, 10346-10357.
Fukao Y, Widiyantoro RDS, Obayashi M (2001) Stagnant slabs in the upper and lower mantle transition zone. Rev Geophys 39:291–323
Gaherty JB, Hager BH (1994) Compositional vs. thermal buoyancy and the evolution of subducted lithosphere. Geophys Res Lett 21:141–144
Garth T, Rietbrock A (2014) Order of magnitude increase in subducted H2O due to hydrated normal faults within the Wadati-Benioff zone. Geology 42:207–210
Gréaux S, Irifune T, Higo Y, Tange Y, Arimoto T, Liu Z, Yamada A (2019) Sound velocity of CaSiO3 perovskite suggests the presence of basaltic crust in the Earth's lower mantle. Nature 565:218–221
Griffin WL, Begg GC, O'Reilly SY (2013) Continental-root control on the genesis of magmatic ore deposits. Nat Geosci 6:905–910
Gurnis M (1993) Phanerozoic marine inundation of continents driven by dynamic topography above subducting slabs. Nature 364:589–593
Hager BH, Clayton RW (1989) Constraints on the structure of mantle convection using seismic observations, flow models and the geoid. In: Peltier WR (ed) Mantle Convection. Gordon and Breach, New York, pp 657–763
Hayashi C, Nakazawa K, Nakagawa Y (1985) Formation of the solar system, in: Black, D.C., Matthews, M.S. (Eds.), Protoplanets and Planets II. University of Arizona Press, Tuscon, AZ, pp. 1100-1153.
Hirschmann MM, Tenner T, Aubaud C, Withers AC (2009) Dehydration melting of nominally anhydrous mantle: the primacy of partitioning. Phys Earth Planet In 176:54–68
Hirth G, Kohlstedt DL (1996) Water in the oceanic upper mantle—implications for rheology, melt extraction and the evolution of the lithosphere. Earth Planet Sci Lett 144:93–108
Holland HD (2003) The geologic history of seawater. In: Turekian KK, Holland HD (eds) Treatise on Geochemistry. Elsevier, Amsterdam, pp 1–46
Houser C (2016) Global seismic data reveal little water in the mantle transition zone. Earth Planet Sci Lett 448:94–101
Inoue T, Kakizawa S, Fujino K, Kuribayashi T, Nagase T, Greaux S, Higo T, Sakamoto N, Yurimoto H, Hattori T, Sano A (2016) Hydrous bridgmanite: Possible water reservoir in the lower mantle. Goldschmidt Conference, Yokohama
Inoue T, Wada T, Sasaki R, Yurimoto H (2010) Water partitioning in the Earth's mantle. Phys Earth Planet In 183:245–251
Ito E, Harris DM, Anderson AT (1983) Alteration of oceanic crust and geologic cycling of chlorine and water. Geochemica Cosmochemica Acta 47:1613–1624
Jing Z, Karato S (2011) A new approach to the equation of state of silicate melts: An application of the theory of hard sphere mixtures. Geochim Cosmochim Acta 75:6780–6802
Jing Z, Karato S (2012) Effect of H2O on the density of silicate melts at high pressures: Static experiments and the application of a modified hard-sphere model of equation of state. Geochim Cosmochim Acta 85:357–372
Karato S (1997) On the separation of crustal component from subducted oceanic lithosphere near the 660 km discontinuity. Phys Earth Planet In 99:103–111
Karato S (2006) Influence of hydrogen-related defects on the electrical conductivity and plastic deformation of mantle minerals: A critical review. In: Jacobsen SD, van der Lee S (eds) Earth's Deep Water Cycle. American Geophysical Union, Washington DC, pp 113–129
Karato S (2011) Water distribution across the mantle transition zone and its implications for global material circulation. Earth Planet Sci Lett 301:413–423
Karato S (2012) On the origin of the asthenosphere. Earth Planet Sci Lett 321(322):95–103
Karato S (2014a) Does partial melting explain geophysical anomalies? Phys Earth Planet In 228:300–306
Karato S (2014b) Some remarks on the models of plate tectonics on terrestrial planets: From the view-point of mineral physics. Tectonophysics 631:4–13
Karato S (2015) Water in the evolution of the Earth and other terrestrial planets. In: Schubert G (ed) Treatise on Geophysics. Elsevier, Amsterdam, pp 105–144
Karato S, Barbot S (2018) Dynamics of fault motion and the origin of contrasting tectonic style between Earth and Venus. Sci Rep 8:11884
Karato S, Bercovici D, Leahy G, Richard G, Jing Z (2006) Transition zone water filter model for global material circulation: Where do we stand? In: Jacobsen SD, van der Lee S (eds) Earth's Deep Water Cycle. American Geophysical Union, Washington DC, pp 289–313
Karato S, Jung H (2003) Effects of pressure on high-temperature dislocation creep in olivine polycrystals. Philosophical Magazine, A 83:401–414
Karato S, Zhang S, Wenk H-R (1995) Superplasticity in Earth's lower mantle: evidence from seismic anisotropy and rock physics. Science 270:458–461
Karki BB, Ghosh DB, Maharjan C, Karato S, Park J (2018) Density-pressure profiles of Fe-bearing MgSiO3 liquid: Effects of valence and spin states, and implications for the chemical evolution of the lower mantle. Geophys Res Lett 45:3959–3966
Karlsen KS, Conrad CP, Magni V (2019) Deep water cycling and sea level change since the breakup of Pangea. Geochem Geophys Geosyst 20
Kasting JF, Catling D (2003) Evolution of a habitable planet. Ann Rev Astronomy Astrophys 41:429–463
Katsura T, Yoneda A, Yamazaki D, Yoshino T, Ito E (2010) Adiabatic temperature profile in the mantle. Phys Earth Planet In 183:212–218
Kawamoto T (2004) Hydrous phase stability and partial melt chemistry in H2O-saturated KLB-1 peridotite up to the uppermost lower mantle conditions. Phys Earth Planet In 143(144):387–395
Kelbert, A., Bedrosian, P. and Murphy, B. (2019) The first 3D conductivity model of the contiguous United States: Reflections on geologic structure and application to induction hazards, Geomagnetically Induced Currents from the Sun to the Power Grid.
Kelbert A, Schultz A, Egbert G (2009) Global electromagnetic induction constraints on transition-zone water content variations. Nature 460:1003–1006
Kite ES, Ford EB (2018) Habitability of exoplanet waterworlds. Astrophysical J 864:75
Kopparapu RK, Ramirez R, Kasting JF, Eymet V, Robinson TD, Mahadevan S, Terrien RC, Domagal-Goldman S, Meadows V, Deshpande R (2013) Habitable zones around main-sequence stars: New estimates. Astrophysical J 765:131
Korenaga J (2007) Eustasy, supercontinental insulation, and the temporal variability of terrestrial heat flux. Earth Planet Sci Lett 257:350–358
Korenaga J (2011) Thermal evolution with a hydrating mantle and the initiation of plate tectonics in the early Earth. J Geophys Res 116. https://doi.org/10.1029/2011JB008410
Korenaga J (2018) Estimating the formation age distribution of continental crust by unmixing zircon ages. Earth Planet Sci Lett 482:388–395
Korenaga J, Panavsky NJ, Evans DAD (2017) Global water cycle and the coevolution of the Earth's interior and surface environment. Philosophical Transactions A 20150393
Kuritani T, Kimura J-I, Ohtani E, Miyamoto H, Furuyama K (2013) Transition zone origin of potassic basalts from Wudalianchi volcano, northeast China. Lithos 156-159, 1-12.
Kuritani T, Ohtani E, Kimura J-I (2011) Intensive hydration of the mantle transition zone beneath China caused by ancient slab stagnation. Nat Geosci 4:713–716
Kuvshinov AV (2012) Deep electromagnetic studies from land, sea, and space: progress status in the past 10 years. Surv Geophys 33:169–209
Langmuir CH, Broecker WS (2012) How to Build a Habitable Planet, 2nd edn. Princeton University Press, Princeton
Le Pichon X, Sengör AMC, Imren C (2019) Pangea and the lower mantle. Tectonics 38:3479–3504
Leahy GM, Bercovici D (2007) On the dynamics of hydrous melt layer above the transition zone. J Geophys Res 112. https://doi.org/10.1029/2006JB004631
Li J, Wang X, Wang X, Yuen DA (2013) P and SH velocity structure in the upper mantle beneath Northeast China: Evidence for a stagnant slab in hydrous mantle transition zone. Earth Planet Sci Lett 367:71–81
Li S, Weng A, Li J, Shan X, Han J, Tang Y, Zhang Y, Wang X (2020) The deep origins of Cenozoic volcanoes in Northeast China revealed by 3-D electrical structure. Sci China Earth Sci 63:1–15
Litasov K, Ohtani E, Langenhorst F, Yurimoto H, Kubo T, Kondo T (2003) Water solubility in Mg-perovskite and water storage capacity in the lower mantle. Earth Planet Sci Lett 211:189–203
Litasov KD, Shatskiy A, Ohtani E (2013) Earth's mantle melting in the presence of C-O-H-bearing fluids. In: Karato S (ed) Physics and Chemistry of the Deep Earth. Wiley-Blackwell, New York, pp 38–65
Lithgow-Bertelloni C, Richards MA (1998) The dynamics of cenozoic and mesozoic plate motions. Rev Geophys 36:27–78
Liu Z, Park J, Karato S (2016) Seismological detection of low velocity anomalies surrounding the mantle transition zone in Japan subduction zone. Geophys Res Lett 43:2480–2487
Liu Z, Park J, Karato S (2018) Seismic evidence for water transport out of the mantle transition zone beneath the European Alps. Earth Planet Sci Lett 482:93–104
McGovern PJ, Schubert G (1989) Thermal evolution of the Earth: effects of volatile exchange between atmosphere and interior. Earth Planet Sci Lett 96:27–37
McKenzie DP (1985) The extraction of magma from the crust and mantle. Earth Planet Sci Lett 74:81–91
Mei S, Kohlstedt DL (2000a) Influence of water on plastic deformation of olivine aggregates, 1. Diffusion creep regime. J Geophys Res 105:21457–21469
Mei S, Kohlstedt DL (2000b) Influence of water on plastic deformation of olivine aggregates, 2. Dislocation creep regime. J Geophys Res 105:21471–21481
Metrich N, Zanon V, Creon L, Hildenbrand A, Moreira M, Marques FO (2014) Is the "Azores Hotspot" a wetsopt? Insight from geochemistry of fluid and melt inc;usions in olivine of Pico basalts. J Petrol 55:377–393
Mibe K, Fujii T, Yasuda A, Ono S (2006) Mg-Fe partitioning between olivine and ultramafic melts at high pressures. Geochim Cosmochim Acta 70:757–766
Mitrovica JX, Mound JE, Pysklywec RN, Milne GA (2000) Sea-level change on a dynamic Earth. In: Boschi E, Ekström G, Morelli A (eds) Problems in Geophysics for the Next Millennium. Editrice Compositori, Roma, pp 499–529
Mizutani H, Kanamori H (1964) Variation in elastic wave velocity and attenuative property near the melting temperature. J Phys Earth 12:43–49
Müller RD, Seton M, Zahirovic S, Williams SE, Matthews KJ, Wright NM, Shephard GE, Maloney KT, Barnett-Moore N, Hosseinpour M, Bower DJ, Cannon J (2016) Ocean basin evolution and global-scale plate reorganization events since Pangea Breakup. Annu Rev Earth Planet Sci 44:107–138
Nakada M, Lambeck K (1987) Glacial rebound and relative sea level variations: a new appraisal. Geophys J Roy Astron Soc 90:171–224
Nakagawa T, Iwamori H, Yanagi R, Nakao A (2018) On the evolution of the water ocean in the plate-mantle system. Prog Earth Planet Sci 5:51
Nakagawa T, Nakakuki T, Iwamori H (2015) Water circulation and global mantle dynamics: Insight from numerical modeling. Geochem Geophys Geosyst 16. https://doi.org/10.1002/2014GC005701
Nance RD, Murphy JB (2013) Origins of the supercontinent cycle. Geosci Frontiers 4:439–448
Navrotsky A (1999) A lesson from ceramics. Science 284:1788–1789
Nestola F, Smyth JR (2016) Diamonds and water in the deep Earth: a new scenario. Int Geology Rev 58:263–276
Nichols ARL, Carroll MR, Hoskuldsson AL (2002) Is the Iceland hot spot also wet? Evidece from the water contents of undegassed submarine and subglacial pillow basalts. Earth Planet Sci Lett 202:77–78
Ohtani E (1987) Ultrahigh-pressure melting of a model chondritic mantle and pyrolite compositions. In: Manghani MH, a. YS (eds) High-Pressure Research in Mineral Physics. Terra Scientific Publishing Company, Tokyo, pp 87–93
Otsuka K, Karato S (2015) The influence of ferric iron and hydrogen on Fe-Mg interdiffusion in ferropericlase in the lower mantle. Phys Chem Minerals 42:261–273
Panero WR, Pigott JS, Reaman DM, Kabbes JE, Liu Z (2015) Dry (Mg,Fe)SiO3 perovskite in the Earth's lower mantle. J Geophys Res 120:894–908
Parai R, Mukhopadhyay S (2012) How large is the subducted water flux? New constraints on mantle regassing rates. Earth Planet Sci Lett 317/318:396–406
Parsons B (1982) Causes and consequences of the relation between area and age of the ocean floor. J Geophys Res 87:289–302
Parsons B, Sclater JG (1977) An analysis of the variation of ocean floor bathymetry and heat flow with age. J Geophys Res 82:803–827
Pearson DG, Brenker FE, Nestola F, McNeill J, Nasdala L, Hutchison MT, Matveev S, Mather K, Silversmit G, Schmitz S, Vekemans B, Vincze L (2014) Hydrous mantle transition zone indicated by ringwoodite included within diamond. Nature 507:221–224
Peltier WR (1998) Postglacial variation in the level of the sea: implications for climate dynamics and solid-Earth geophysics. Rev Geophys 36:603–689
Peslier AH, Schönbächler M, Busemann H, Karato S (2017) Water in the Earth's interior: Distribution and origin. Space Sci Rev 212:743–810
Plank T, Langmuir AH (1992) Effects of melting regime on the composition of the oceanic crust. J Geophys Res 97:19749–19770
Price MG, Davies JH, Panton J (2019) Controls on the deep-water cycle within three-dimensional mantle convection models. Geochem Geophys Geosyst 20
Revenaugh J, Sipkin SA (1994) Seismic evidence for silicate melt atop the 410-km mantle discontinuity. Nature 369:474–476
Ribe NM (1985a) The deformation and compaction of partial molten zones. Geophys J Roy Astron Soc 83:487–501
Ribe NM (1985b) The generation and compaction of partial melts in the earth's mantle. Earth Planet Sci Lett 73:361–376
Richard G, Monnereau M, Ingrin J (2002) Is the transition zone an empty water reservoir? Inference from numerical model of mantle dynamics. Earth Planet Sci Lett 205:37–51
Rogers LA, Bodenheimer P, Lissauer JJ, Seager S (2011) Formation and structure of low-density exo-planets. Astrophysical J 738:59–75
Rubey WW (1951) Geologic history of sea water, an attempt to state the problem. Geol Soc Am Bull 62:1111–1148
Rüpke LH, Phipps Morgan J, Dixon JE (2006) Implications of subduction rehydration for Earth's deep water cycle. In: Jacobsen SD, Lee Svd (eds) Earth's Deep Water Cycle. American Geophysical Union, Washington DC, pp 263–276
Rüpke LH, Phipps Morgan J, Hort M, Connolly JAD (2004) Serpentine and the subduction zone water cycle. Earth Planet Sci Lett 223:17–34
Sakamaki T (2017) Density of hydrous magma. Chem Geol 475:135–139
Sanloup C, Drewitt JWE, Konopková Z, Dalladay-Simpson P, Morton DM, Rai N, van Westrenen W, Morgenroth W (2013) Structural change in molten basalt at deep mantle conditions. Nature 503:104–107
Schaefer L, Sasselov D (2015) The persistence of ceans on Earth-like planets: Insights from the deep-water cycle. The Astrophysical Journal 801, 40. https://doi.org/10.1088/0004-637X/801/1/40
Schmandt B, Jacobsen SD, Becker TW, Liu Z, Dueker KG (2014) Dehydration melting at the top of the lower mantle. Science 344:1265–1268
Sengör AMC, Burke K (1978) Relative timing of rifting and volcanismon Earth and its tectonic implications. Geophys Res Lett 5:419–421
Sobolev AV, Asanov EV, Gurenko AA, Arndt NT, Batanova VG, Portnyagin MV, Garbe-Schönberg D, Wilson AH, Byerly GR (2019) Deep hydrous mantle reservoir provides evidence for crustal recycling before 3.3 billion years ago. Nature 571:555–559
Song T-RA, Helmberger DV, Grand SP (2004) Low-velocity zone atop the 410-km seismic discontinuity in the northwestern United States. Nature 427:530–533
Spetzler HA, Anderson DL (1968) The effect of temperature and partial melting on velocity and attenuation in a simple binary system. J Geophys Res 73:6051–6060
Spohn T, Sohl F, Breuer D (1998) Mars. Astronomical Astrophysical Rev 8:181–235
Stocker RL, Gordon RB (1975) Velocity and internal friction in partial melts. J Geophys Res 80:4828–4836
Stolper EM, Walker D, Hager BH, Hays JF (1981) Melt segregation from partially molten source regions: the importance of melt density and source region size. J Geophys Res 86:6261–6271
Suetsugu D, Inoue T, Yamada A, Zhao D, Obayashi M (2006) Towards mapping three-dimensional distribution of water in the transition zone from P-wave velocity tomography and 660-km discontinuity depths. In: Jacobsen SD, Lee Svd (eds) Earth's Deep Water Cycle. American Geophysical Union, Washington DC, pp 237–249
Takei Y (2002) Effect of pore geometry on Vp/Vs: from equilibrium geometry to crack. J Geophys Res 107. https://doi.org/10.1029/2001JB000522
Tao K, Grand SP, Niu F (2018) Seismic structure of the upper mantle beneath eastern Asia from full waveform seismic tomography. Geochem Geophys Geosyst 19:2732–2763
Tauzin B, Debayle E, Wittingger G (2010) Seismic evidence for a global low-velocity layer within the Earth's upper mantle. Nat Geosci 3:718–721
Torsvik TH, Cocks LRM (2019) The integration of paleomagnetism, the geological record and mantle tomography in the location of ancient continents. Geol Mag 156:242–260
Tschauner O, Huang S, Greenberg E, Prakapenka VB, Ma C, Rossman GR, Shen AH, Zhang D, Newville M, Lanzirotti A, Tait K (2018) Ice-VII inclusions in diamonds: Evidence for aqueous fluid in Earth's deep mantle. Science 359:1136–1139
van Keken PE, Hacker BR, Syracuse EM, Abers GA (2011) Subduction factory 4: Depth-dependent flux of H2O from subducting slabs worldwide. J Geophys Res 116. https://doi.org/10.1029/2010JB007922
van Keken PE, Karato S, Yuen DA (1996) Rheological control of oceanic crust separation in the transition zone. Geophys Res Lett 23:1821–1824
Vinnik L, Farra V (2007) Low S velocity atop the 410-km discontinuity and mantle dynamics. Earth Planet Sci Lett 262:398–412
Wang W, Walter MJ, Peng Y, Redfern S, Wu Z (2019a) Constraining olivine abundance and water content of the mantle at the 410-km discontinuity from the elasticity of olivine and wadsleyite. Earth Planet Sci Lett 519:1–11
Wang Y, Pavlis GL, Li M (2019b) Heterogeneous distribution of water in the mantle transition zone inferred from wavefield imaging. Earth Planet Sci Lett 505:42–50
Wei SS, Shearer PM (2017) A sporadic low-velocity layer atop the 410-km discontinuity beneath the Pacific Ocean. J Geophys Res 122:5144–5159
Wise DU (1972) Freeboard of continents through time. Geol Soc Am Mem 132:87–100
Wise DU (1974) Continental margins, freeboard and the volumes of continents and ocean through time. In: Burk CA, Drake CL (eds) Geology of Continental Margins. Springer, New York, pp 45–58
Xu Y, McCammon C, Poe BT (1998) Effect of alumina on the electrical conductivity of silicate perovskite. Science 282:922–924
Yang J, Faccenda M (2020) Intraplate volcanism originating from upwelling hydrous mantle transition zone. Nature 579:88–91
Yoshino T, Nishihara Y, Karato S (2007) Complete wetting of olivine grain-boundaries by a hydrous melt near the mantle transition zone. Earth Planet Sci Lett 256:466–472
Yuen DA, Peltier WR (1980) Mantle plumes and the thermal stability of the D layer. Geophys Res Lett 7:625–628
Zhang F, Wu Q, Grand SP, Li Y, Gao M, Demberel S, Ulziibat M, Sukhbaatar U (2018) Seismic velocity variations beneath Mongolia: Evidence for upper mantle plumes? Earth Planet Sci Lett 459:406–416
Zhao D, Ohtani E (2009) Deep slab subduction and dehydration and their geodynamic consequences: Evidence from seismology and mineral physics. Gondw Res 16:401–413
Zhu H, Bozdag E, Duffy TS, Tromp J (2013) Seismic attenuation beneath Europe and North Atlantic: implications for water in the mantle. Earth Planet Sci Lett 381:1–11
We received constructive criticisms, from reviewers Jiangfeng Yang and an anonymous reviewer that improved the manuscript. A meticulous work by Craig Bina as an editor is highly appreciated. We thank David Bercovici for a discussion on the melt-rich layer, David Evans for the supercontinent cycles, Jun Korenaga on the interpretation of the sea-level, and Motohiko Murakami on the melt density. Marc Hirschmann, Takashi Nakagawa, Jim Ni, Alexander Sobolev, Dave Stevenson, Doug Wiens, Dave Yuen and Shijie Zhong also provided useful discussions/comments.
The present study is supported by a grant from NSF (EAR-1764271 (for SK) and EAR-1764140 (for BK)).
Department of Earth and Planetary Sciences, Yale University, New Haven, CT, 06520, USA
Shun-ichiro Karato & Jeffrey Park
School of Electrical Engineering and Computer Science, Department of Geology and Geophysics, Center for Computation and Technology, Louisiana State University, Baton Rouge, LA, 70803, USA
Bijaya Karki
Shun-ichiro Karato
Jeffrey Park
SK proposed the topic, conceived and designed the study, and developed the model and calculated the sea-level history. BJ carried out the computational study on melt density and JP conducted receiver function forward modeling and edited the text. BK and JP collaborated with the corresponding author (SK) in the construction of manuscript. The authors read and approved the final manuscript.
Correspondence to Shun-ichiro Karato.
The authors' declared that they have no competing interest. All institutional and national guidelines for the care and use of laboratory animals were followed.
Additional file 1: Fig. S1.
. A schematic diagram showing the pressure (depth) dependence of density of melt and solid across a phase transformation (Ptr is the transformation pressure for a solid). Solid density changes with pressure sharply at the transition pressure, whereas the melt density changes gradually because of the gradual transition in the structure (see also (Sakamaki 2017)). The melt density is also sensitive to composition that depends on the bulk composition and melting temperature (Jing and Karato 2012)
Karato, Si., Karki, B. & Park, J. Deep mantle melting, global water circulation and its implications for the stability of the ocean mass. Prog Earth Planet Sci 7, 76 (2020). https://doi.org/10.1186/s40645-020-00379-3
Habitability
Ocean mass
Sea-level variations
Water in the mantle
Deep mantle melting | CommonCrawl |
Skip to main content Skip to sections
Journal of Superconductivity and Novel Magnetism
pp 1–7 | Cite as
Effect of Ultra-sonicated Y2BaCuO5 on Top-Seeded Melt Growth YBa2Cu3Oy Bulk Superconductor
S. Pinmangkorn
M. Miryala
S. S. Arvapalli
M. Murakami
In this work, we tried to improve the superconducting performance of bulk YBa2Cu3Oy (Y123) superconductors via Y2Ba1Cu1O5 (Y211) secondary phase refinement. A novel method of ultra-sonication was used to refine the Y211 secondary phase particles. The Y211 powder was treated by ultra-sonication for 0 to 80 min with steps of 20 min, keeping the power (300 W) and frequency (20 kHz) constant. For synthesis of the YBCO bulk, we employed top-seeded melt growth (TSMG) with Pt addition. Magnetization measurements showed a superconducting transition temperature at around 91 K, irrespective of ultra-sonication parameters. Interestingly, critical current density and trapped field were found to be proportional to the ultra-sonication duration. YBCO bulk sample (20 mm diameter, 7 mm in thickness) fabricated for 80 min ultra-sonicated Y211 showed a maximum trapped field of 0.42 T at 77 K, 0.3 mm above the top surface. The improved trapped field values are explained on the basis of improvements in the microstructure.
YBa2Cu3Oy Y2BaCuO5 Top-seeded melt growth Ultra-sonication Critical current density
Top-seeded melt growth (TSMG) has emerged as a typical process for fabricating large single-grained (RE)Ba2Cu3Oy (REBCO) high-temperature superconductors (HTS), where RE refers to rare earth elements such as Nd, Gd, Er, and Y [1]. In the TSMG process, RE123 is heated above the peritectic temperature resulting in decomposition of RE123 into RE211 and liquid phase (BaCuO2 and CuO). The samples are then slowly cooled, when RE211 reacts with liquid phase to form RE123 bulk superconductor [2]. Bulk REBCO superconductors are mostly used in practical applications such as flywheel energy storage systems, magnetic bearings, trapped field magnets, etc. [3, 4, 5]. For achieving good superconducting performance, it is necessary to obtain high superconducting critical current density (Jc) and trapped flux density (BT) at high temperatures and high fields [6]. Critical current density in YBa2Cu3Oy (Y123) bulk superconductors can be improved by reducing the size of Y211 particles and by increasing the homogeneity of Y211 distribution in the matrix [7]. The microstructural defects also contribute to increase of magnetic flux pinning and hence enhance the critical current density (Jc) and trapped field (BT) [8]. The effect of Y211 precipitates is usually observed at low magnetic fields as they contribute as δl pinning and hence result in a high self-field critical current density. On the other hand, point-like defects and oxygen off-stoichiometric phases generally contribute as δTc pinning and result in peak effect or high critical current densities at high magnetic field [9, 10]. Several researchers have tried to avoid Y211 particles coarsening with help of chemical agents such as Pt, CeO2, etc. [11, 12]. In case of Pt and PtO2 addition, it was seen that a new Ba4CuPt2O9 phase forms, which acts as nucleating site for Y211, thereby restraining the Y211 growth [12]. In addition, there is also evidence that adding Pt/PtO2 results in more anisotropic and highly acicular Y211 particles. On the other hand, CeO2 aids in different manner. It forms BaCeO2 phase alongside the Y211 that contributes to additional pinning. Another alternative technique to control Y211 particles size in the initial powder is by introducing mechanical force to refine particle via ball milling technique, etc. [13, 14]. Although this technique results in particles of around 70 nm, it also imparts contamination into powder. To refine further and ensure uniform mixing, the precursor mixture of Y123 and Y211 is subjected to automatic grinding for 2–3 h. To avoid any contamination in the powders, we chose high energy ultra-sonication to refine the Y211 particles. The ultra-sonic waves increased disorder in the medium and lead to separation and size reduction of the particles [15, 16]. In summary, the nature of initial Y211 particles greatly influences properties of bulk YBCO (see in Table 1).
Superconducting properties of Y123 bulk superconductors (with refined Y211 via ultra-sonication)
Jc (self-field) (kA/cm2)
Trap field (T)
Tc,on set
Tc,off set
ΔTc
In our previous work, we tried to synthesize samples by infiltration growth using ultra-sonicated Y211 [15]. There we synthesized bulk with improved properties because of Y211 size reduction. In this paper, we studied the optimization of ultra-sonication process parameters for producing fine Y211 particles and effect of refined Y211 particles size on the superconducting properties of melt grown YBCO bulk superconductors. YBCO single grain superconductors of 20 mm were fabricated by top-seeded melt growth. Systematic study was done by varying the ultra-sonication time, and superconducting properties were compared with highlight the best processing conditions.
To prepare YBa2Cu3O7 (Y123) and Y2BaCuO5 (Y211), high-purity commercial powders of Y2O3, BaO2, and CuO were mixed in a nominal ratio. This Y123 raw mixture was calcined 4 times at around 870–940 °C for 24 h. Similarly, Y211 raw mixture was also calcined 4 times at 840–900 °C for 15 h. In order to reduce the particle size of the calcined Y211 powder, we used Mitsui ultrasonic homogenizer UX-300, while keeping constant power (300 w) and frequency (20 kHz). Y211 powders were dissolved into ethanol and ultra-sonicated systematically for various durations such as 0, 20, 40, 60, and 80 min and the corresponding final samples can be referred as Y0, Y20, Y40, Y60, and Y80, respectively. The Y211 and Y123 powders were mixed in 1:2 ratio along with 0.5 wt% of Pt and was pulverized for 2 h, which were then pressed into several pellets of 20 mm diameter. Nd-123 seed was placed on the top of pelletized precursor mixture. The temperature profile used for fabricating samples for TSMG is given in Fig. 1. After melt processing, the Y123 samples were annealed at 450 °C for 400 h in controlled oxygen atmosphere for oxygenation. The phases present in the bulk were identified by X-ray diffraction (XRD) using Rigaku X-ray diffractometer with Cu radiation and Bragg–Brentano geometry with 2θ from 10 to 80°. The diffraction peaks were indexed with the help of reference data from JCPDS (joint committee on powder diffraction standards). For trapped field measurements, we used permanent magnets of 0.5 and 1 T to activate Y123 bulk superconductor. Field distribution was measured by automatic scanning Hall probe sensor at a distance of 0.3 mm (surface touched) and 1.3 mm (1 mm above surface) above the superconductor surface. This is because of the 0.3 mm difference between probe's epoxy surface and the hall probe. The microstructures were studied with a field emission scanning electron microscope (FE-SEM). For magnetic measurements, samples were cut 2 mm below the seed along the c-axis from the bulk samples 1.5 × 1.5 × 0.5 mm3 in dimension. Superconducting transition temperature (Tc) and magnetization loops in field from 0 to 5 T were measured at 77 K using a commercial SQUID magnetometer (model MPMS5). Superconducting critical current density (Jc) was estimated by using the extended Bean's model [17].
$$ {J}_c=\frac{20\Delta M}{a^2c\left(b-\frac{a}{3}\right)} $$
where a and b are the cross sectional dimensions with b ≥ a, c is the thickness of sample, and ΔM is the difference of magnetic moment between decreasing and increasing field in the M-H loop.
Temperature profile for synthesizing the bulk Y123 samples
Y211 secondary phase particles in bulk YBCO superconductors act as a non-superconducting phase and are crucial in the growth and improving the superconducting properties of bulk. The size of initial Y211 powder is very important for high flux pining and critical current density in final bulk superconductor. It is highly desirable to achieve a uniform dispersion of fine-sized 211 secondary phase particles throughout the final bulk samples. In previous studies where ball milling was employed, size refinement less than 0.1 μm was observed [18, 19]. However, the technique is expensive and there are several cases where contamination from the ceramic balls used for milling was observed. Although the contamination mostly has negative effects, fortunately in some cases, these contaminations can act as nano pinning centers that can enhance critical current density such as in case of Zirconia balls. When zirconia balls were used for long durations of ball milling, Zr-based contaminations are formed and helped in improving the performance [20]. Hence, we think that the ultra-sonication technique we employed in Y211 system refines the particles to submicron sizes cost-effectively with nearly no contamination. To achieve this, we tried to reduce the Y211 particles size via employing high energy ultrasonic waves. The FE-SEM images of ultra-sonicated Y211 particles (20, 40, 60, and 80 min) are compared with pristine Y211 powder as shown in Fig. 2. The average size of the pristine Y211 particles is around 3–5 μm. Until 80 min, the average particle size keeps decreasing with increase in ultra-sonication duration. After 80 min of ultra-sonication, we observed that the sizes are around 300~500 nm (seen in Fig. 3). We did not observe any decrease of the size upon further increase in ultra-sonication duration. We assume that this technique in Y211 system reaches saturation after the particles reach submicron sizes under the conditions we used. Therefore, we conclude that 80 min of ultra-sonication is optimal where we can produce multitude of fine particles. For more comprehensive view, we analyzed high magnification images from FE-SEM. In addition to size reduction, we also observed uniformly sized particles that are irregular in shape.
FE-SEM images for Y211 powder refined via ultra-sonication at various time intervals of a 0 min, b 20 min, c 40 min, d 60 min, and f 80 min
High magnification of FE-SEM images for Y211 powder refined via ultra-sonication at various time intervals of a 0 min and b 80 min
The top-view photograph of Y123 20 mm in diameter samples with Y211 refined via ultrasonic time of 0, 20, 40, 60, and 80 min was displayed in Fig. 4 a–e, respectively. Fully fourfold growth was seen without any spontaneous nucleation from the seed crystal, and growing on four sectors to the edge of samples along ab-plane and the top to the bottom along c-axis represent that the samples are growing in form of a single grain. Single-grained samples were prepared by implementing the optimized temperature profile with TSMG process. In addition, this technique, in conjunction with batch processing, can aid in mass production of high quality YBCO bulk superconductors at low costs.
The photographs of top surfaces of YBCO samples fabricated by TSMG and Y211 refined via ultra-sonication at various time intervals of Y0 (a), Y20 (b), Y40 (c), Y60 (d), and Y80 (e) samples
To examine the texturing information and phase purity of melt grown bulk Y123, we performed X-ray diffraction on flakes cleaved from Y0, Y40, and Y80 samples. Figure 5 shows all (00 l) peaks corresponding to the orthorhombic ab planes, which indicates a proper texturing and pure single grain nature of Y123 formed [21]. The small pieces with dimensions of about 1.5 × 1.5 × 0.5 mm3 were cut 2 mm under seed crystal along c-axis from Y0, Y40, and Y80 samples. The temperature dependence of normalized dc susceptibility was calculated using SQUID magnetometer in both zero-field-cooled (ZFC) and field-cooled (FC) under a field of 1 mT. All samples exhibited a sharp superconducting transition around 91–93 K (see in Table 1). The Y0 sample shows the highest Tc,on set at 92.8 K compare with samples Y40 and Y80. The Tc,on set values are close to standard critical temperature value of YBCO bulk superconductor [22]. The transition temperature width of Y40 and Y80 samples is wider than Y0 sample as the ultra-sonicated time increase and less than 1.5 K as presented in Fig. 6, which indicates that all samples were high quality. However, the YBCO bulk made from refined Y211 showed a slight drop in superconducting transition temperature which is better than that of what we observed in samples prepared from ball-milled Y-211powder [14, 23].
X-ray diffraction patterns for Y0, Y40, and Y80 samples. Note that all indexed peaks are Y1Ba2Cu3Oy
The temperature dependence of the normalized DC susceptibility measurements of Y0, Y40, and Y80 samples
The critical current density (Jc) was calculated using the extended Bean's critical state formula for a rectangular sample. The highest self-field JC value was observed in Y80 sample that was around 47 kA/cm2 and Jc at 1 T reached 10 kA/cm2 at 77 K, higher than that of what Y0 sample exhibited. The critical current density at self-field was showing an increment with increase in the ultra-sonication time, till 80 min (see in Table 1). In addition, at high fields, we can see a peak effect which is proportional to ultra-sonication time. Detailed Jc profile can be seen in Fig. 7. This could be because of very tiny particles close to the size of cavities or volume defects that are formed by means of ultra-sonication. This is possible because ultra-sonication can result in very fine particles when regular particles bombard each other or shear along surfaces. We also think that further prolonged ultra-sonication and increase power can improve the peak effect.
Field dependences of the critical current density (Jc) at 77 K, H//c-axis of Y0, Y40, and Y80 samples
In general, trapped field measurements are related to flux pinning performance of the superconductor. Trapped field of the samples was measured at 77 K after field-cooling in magnetic field of 0.5 and 1 T. High trapped field of 0.42 T at 77 K was observed in sample Y80 at 0.3 mm distance from the top surface sample when field-cooled in presence of 1 T. More results of trapped field distribution of Y80 sample under a magnetic field of 0.5 T were presented in Fig. 8. The profile was showing a uniform single cone curve in the center, indicating that the sample has uniform single grain growth without cracks and underwent good oxygen treatment. Figure 9 represents the trapped field (0.3 mm away from the top surface) against ultra-sonication time, for all samples that are field-cooled with 1 T at 77 K. Effect of ultra-sonication time with trapped filed measurement relates with the Jc results and shows the highest value in Y211 with 80-min ultra-sonication.
The trapped field distribution of Y80 with a magnetic field produced by surface flux density of 0.5 T at 77 K and 1.3 mm above the top surface
The trapped field distribution at 77.3 K for the Y80 material presented in Fig. 4 (bottom, right). Note that the maximum trapped value recorded around 0.42 T when the Hall sensor is at the distance of 0.3 mm
To reveal the reason for these trends in Jc and trapped field, we studied the microstructure. The microstructure of samples prepared with different ultra-sonicated Y211 embedded in the Y123 matrix was analyzed by using FE-SEM and particle size analysis from image processing system; the results are shown in Fig. 10 a and b. Microstructure reveals that the Y211 secondary phase particles were finely dispersed inside the Y123 matrix of both ultra-sonicated and not ultra-sonicated samples. As observed, Y211 secondary phase particles in sample Y0 were formed as large and irregular as shown in Fig. 10a with the average size of 2 μm and 4 μm and dispersed inhomogeneously. Y80 sample shows that the Y211 were finer and uniform in as depicted homogeneously in Fig. 10b with the average size 0.5–1 μm. The effect of ultra-sonication increase among of small particles resulted in a significant decrease of the average of the Y211 secondary phase particle size in final samples. The superconducting performance improvement as well as trapped field and critical current density enhancement in the ultra-sonicated Y211 secondary phase based Y123 bulk.
FE-SEM images for YBCO with Y211 secondary phase refined via ultra-sonication at various timeY0 (a) and Y80 (b) samples
Among various durations, 80 min of ultra-sonication seemed to be the optimum for refining Y211 powder based on the particle size and uniform shape of Y211 powder. We have successfully prepared YBCO bulk consisting of Y123 and Y211 mixed in a molar ratio of 10:5 with 0.5 wt% Pt by TSMG processing. XRD clearly shows that all the bulk Y123 samples have good texture and pure single grain nature. All samples exhibited superconductivity with Tc ~ 92.8 K and sharp superconducting transitions. The highest critical current density (Jc) was observed in 80-min ultra-sonicated bulk which was measured to be 47 kA/cm2 at self-field and 77 K. For the same bulk at 77 K, the trapped field measurements exhibited single uniform conical peak with the maximum value of 0.42 T at the center. SEM observations showed that the particle sizes of the most Y211 particles have been reduced to 1–2 μm and uniformly dispersed within the final Y123 matrix which led to the improvement in the superconducting properties of Y123 bulk superconductor. The ultra-sonication technique has great potential to refine Y211 particles for mass production of large high performance YBCO bulk superconductors for practical applications. In addition, this technique is cost-effective and brings nearly no contamination. All these features make it a best choice for mass production.
This work was partly supported by Shibaura Institute of Technology (SIT) Research Center for Green Innovation and Grant-in-Aid FD research budget code 112282. Two of the authors (Sai Srikanth Arvapalli and Sunsanee Pinmangkorn) acknowledge the support from SIT for providing the financial support for the doctoral program.
Murakami, M.: Appl. Supercond. 1, 1157–1173 (1993)CrossRefGoogle Scholar
Jin, S., Tiefel, T.H., Sherwood, R.C., Davis, M.E., Dover, R.B.v., Kammlott, G.W., Fastnacht, R.A., Keith, H.D.: Appl. Phys. Lett. 52(24), 2074–2076 (1988)ADSCrossRefGoogle Scholar
Barna, D.: Phys. Rev. Accel. Beams. 20(4), 041002 (2017)ADSCrossRefGoogle Scholar
Coombs, T.A., Hong, Z., Zhu, X., Krabbes, G.: Supercond. Sci. Technol. 21(3), 034001 (2008)ADSCrossRefGoogle Scholar
Strasik, M., Hull, J.R., Mittleider, J.A., Gonder, J.F., Johnson, P.E., McCrary, K.E., McIver, C.R.: Supercond. Sci. Technol. 23(3), 034021 (2010)ADSCrossRefGoogle Scholar
Campbell, A.M., Cardwell, D.A.: Cryogenics. 37(10), 567–575 (1997)ADSCrossRefGoogle Scholar
Koblischka-Veneva, A., Mücklich, F., Koblischka, M.R., Hari Babu, N., Cardwell, D.A.: J. Am. Ceramic Soc. 90(8), 2582–2588 (2007)CrossRefGoogle Scholar
Muralidhar, M., Sakai, N., Chikumoto, N., Jirsa, M., Machi, T., Nishiyama, M., Wu, Y., Murakami, M.: Phys. Rev. Lett. 89(23), 237001 (2002)ADSCrossRefGoogle Scholar
Muralidhar, M., Sakai, N., Nishiyama, M., Jirsa, M., Machi, T., Murakami, M.: Appl. Phys. Lett. 82(6), 943–945 (2003)ADSCrossRefGoogle Scholar
Muralidhar, M., Koblischka, M.R., Diko, P., Murakami, M.: Supercond. Sci. Technol. 9(2), 76–87 (1996)CrossRefGoogle Scholar
Kim, C.-J., Kim, K.-B., Kuk, I.-H., Hong, G.-W.: Physica C: Supercond. 281(2), 244–252 (1997)ADSCrossRefGoogle Scholar
Hamada, T., Morimo, R., Takada, A., Yamashita, Y., Nakayama, K., Nagata, K., Yuji, T.: J. Mater. Proces.Technol. 100(1), 188–193 (2000)CrossRefGoogle Scholar
Nariki, S., Sakai, N., Murakami, M., Hirabayashi, I.: Supercond. Sci. Technol. 17(2), S30–S35 (2004)ADSCrossRefGoogle Scholar
Muralidhar, M., Kenta, N., Zeng, X., Koblischka, M.R., Diko, P., Murakami, M.: Phys. Status Solidi (a). 213(2), 443–449 (2016)ADSCrossRefGoogle Scholar
Pavan Kumar Naik, S., Muralidhar, M., Koblischka, M.R., Koblischka-Veneva, A., Oka, T., Murakami, M.: Appl. Phys. Express. 12(6), 063002 (2019)ADSCrossRefGoogle Scholar
Franco, F., Pérez-Maqueda, L.A., Pérez-Rodríguez, J.L.: J. Colloid Interface Sci. 274(1), 107–117 (2004)ADSCrossRefGoogle Scholar
Chen, D.X., Goldfarb, R.B.: J. Appl. Phys. 66(6), 2489–2500 (1989)ADSCrossRefGoogle Scholar
Nariki, S., Sakai, N., Murakami, M., Hirabayashi, I.: IEEE Trans. Appl. Supercond. 15(2), 3110–3113 (2005)ADSCrossRefGoogle Scholar
Muralidhar, M., Sakai, N., Jirsa, M., Murakami, M., Koshizuka, N.: Physica C: Supercond. 412-414, 739–743 (2004)ADSCrossRefGoogle Scholar
Muralidhar, M., Sakai, N., Jirsa, M., Koshizuka, N., Murakami, M.: Appl. Phys. Lett. 83(24), 5005–5007 (2003)ADSCrossRefGoogle Scholar
Foerster, C.E., Serbena, F.C., Jurelo, A.R., Ferreira, T.R., Rodrigues, P., Chinelatto, A.L.: IEEE Trans. Appl. Supercond. 21(2), 52–59 (2011)ADSCrossRefGoogle Scholar
Mahmood, A., Chu, Y.S., Sung, T.H.: Supercond. Sci. Technol. 25(4), 045008 (2012)ADSCrossRefGoogle Scholar
Miryala, M., Sakai, N., Jirsa, M., Murakami, M., Koshizuka, N.: Supercond. Sci. Technol. 17, 1129 (2004)ADSCrossRefGoogle Scholar
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
1.Superconducting Material Laboratory, Graduate School of Science and EngineeringShibaura Institute of TechnologyTokyoJapan
Pinmangkorn, S., Miryala, M., Arvapalli, S.S. et al. J Supercond Nov Magn (2020). https://doi.org/10.1007/s10948-019-05405-0
Received 23 October 2019
DOI https://doi.org/10.1007/s10948-019-05405-0
Publisher Name Springer US | CommonCrawl |
Evaluation of carboxyfluorescein-labeled 7-methylguanine nucleotides as probes for studying cap-binding proteins by fluorescence anisotropy
Structural basis for selective stalling of human ribosome nascent chain complexes by a drug-like molecule
Wenfei Li, Fred R. Ward, … Jamie H. D. Cate
SAM-VI riboswitch structure and signature for ligand discrimination
Aiai Sun, Catherina Gasser, … Aiming Ren
Selective inhibition of human translation termination by a drug-like compound
Wenfei Li, Stacey Tsai-Lan Chang, … Jamie H. D. Cate
Photocaged 5′ cap analogues for optical control of mRNA translation in cells
Nils Klöcker, Florian P. Weissenboeck, … Andrea Rentmeister
Identification of phenothiazine derivatives as UHM-binding inhibitors of early spliceosome assembly
Pravin Kumar Ankush Jagtap, Tomáš Kubelka, … Michael Sattler
Ataluren binds to multiple protein synthesis apparatus sites and competitively inhibits release factor-dependent termination
Shijie Huang, Arpan Bhattacharya, … Barry S. Cooperman
An in vitro Förster resonance energy transfer-based high-throughput screening assay identifies inhibitors of SUMOylation E2 Ubc9
Yu-zhe Wang, Xiao Liu, … Ming-wei Wang
Structural basis for substrate binding and catalysis by a self-alkylating ribozyme
Daniel Krochmal, Yaming Shao, … Joseph A. Piccirilli
Structural basis for the tryptophan sensitivity of TnaC-mediated ribosome stalling
Anne-Xander van der Stel, Emily R. Gordon, … C. Axel Innis
Anna Wojtczak1,
Renata Kasprzyk ORCID: orcid.org/0000-0001-6163-21302,3,
Marcin Warmiński ORCID: orcid.org/0000-0002-1071-34051,
Krystian Ubych ORCID: orcid.org/0000-0002-7975-40101,3,
Dorota Kubacka ORCID: orcid.org/0000-0003-0421-04701,
Pawel J. Sikorski ORCID: orcid.org/0000-0001-9842-65332,
Jacek Jemielity ORCID: orcid.org/0000-0001-7633-788X1 &
Joanna Kowalska ORCID: orcid.org/0000-0002-9174-79991
Bioanalytical chemistry
Fluorescent probes
Fluorescence anisotropy (FA) is a powerful technique for the discovery of protein inhibitors in a high-throughput manner. In this study, we sought to develop new universal FA-based assays for the evaluation of compounds targeting mRNA 5′ cap-binding proteins of therapeutic interest, including eukaryotic translation initiation factor 4E and scavenger decapping enzyme. For this purpose, a library of 19 carboxyfluorescein probes based on 7-methylguanine nucleotides was evaluated as FA probes for these proteins. Optimal probe:protein systems were further investigated in competitive binding experiments and adapted for high-throughput screening. Using a small in-house library of compounds, we verified and confirmed the accuracy of the developed FA assay to study cap-binding protein binders. The applications of the most promising probes were then extended to include evaluation of allosteric inhibitors as well as RNA ligands. From this analysis, we confirmed the utility of the method to study small molecule ligands and evaluate differently 5′ capped RNAs.
A 7-methylguanosine cap structure is present at the 5′ end of eukaryotic mRNA and influences numerous cellular functions related to mRNA metabolism1. 7-Methylguanosine (m7G) is a positively charged nucleoside that, together with the negatively charged 5′,5′-triphosphate chain linking it to the first transcribed nucleotide of RNA, creates a unique molecular recognition pattern targeted by specific proteins involved in mRNA turnover2,3. Cap-protein interplay is crucial for gene expression processes, such as pre-mRNA splicing, transport, translation, and degradation4,5,6.
One of the main cap-binding proteins is eukaryotic initiation translation factor 4E (eIF4E). Recognition of the cap structure by eIF4E is the rate-limiting step during translation initiation7. The active pool of eIF4E is highly regulated in healthy cells8. In contrast, eIF4E is often overexpressed in cancer cells, thereby promoting cell growth and survival9. Overexpression of eIF4E results in increased translation of mRNAs encoding oncoproteins and growth factors10. Reduction of eIF4E levels is not detrimental for normal mammalian physiology, therefore, it creates an opportunity for therapeutic targeting of eIF4E to selectively inhibit oncogenic translation11. Hence, identifying new high-affinity ligands to limit active pools of eIF4E is the first step towards the development of therapeutic strategies in anticancer treatment12,13.
Another cap-binding protein is decapping scavenger enzyme (DcpS), which prevents the accumulation of free cap structures released as a result of 3′-to-5′ mRNA decay, thereby blocking inhibition of proteins crucial for mRNA splicing and translation and avoiding potentially toxic effects14. DcpS plays also a more general role in the control of gene expression and has been independently linked to spinal muscular atrophy15, intellectual disability16, cancer17, and microRNA processing18. DcpS is a therapeutic target in spinal muscular atrophy (SMA), an autosomal recessive disease caused by deletion or mutational inactivation of the survival motor neuron (SMN) 1 gene19. Inhibition of DcpS by C5-substituted quinazolines has been shown to activate SMN2 gene expression in vitro, although the mechanism of this activation has not yet been fully elucidated15. Furthermore, studies performed in SMA model mice have shown therapeutic effects, such as prolonged survival and improved motor function20. In 2015, the loss of DcpS enzyme activity was connected with a novel clinical entity referred as Al-Raqad syndrome (ARS)16. ARS is caused by homozygous or heterozygous mutations resulting in loss-of-function alleles in the DcpS gene21 and is associated with severe growth delay, neurological defects, and skeletal and cardiac anomalies. DcpS has also been shown to be essential for the survival of acute myeloid leukemia (AML) cells17. Accordingly, DcpS has become a drug discovery target15,22.
Molecules targeting eIF4E or DcpS can act as modulators (activators or inhibitors) of various processes involving these cap-binding proteins; therefore, these modulators are potential therapeutics and useful research tools. A commonly used technique to study interactions between cap-binding proteins and ligands is fluorescence quenching titration (tsFQT)3. However, this approach is time-consuming, requires relatively high protein concentrations, is low throughput, and has other methodological limitations, which make it unsuitable for drug discovery applications. Therefore, it is necessary to develop higher throughput yet accurate methods for the discovery of ligands targeting cap-binding proteins. Fluorescence polarization (FP) and fluorescence anisotropy (FA) have been previously employed to study eIF4E-ligand interactions, yielding different outcomes23,24,25. Although several m7G analogs were developed as probes for FP, a systematic study of structure–activity relationships has never been performed. In recent years, fluorescent methods based on m7G analogs have been optimized to measure DcpS activity26,27,28,29. These methods are based on fluorescently labeled or fluorogenic substrates to measure reaction progress and have been successfully adopted for inhibitor evaluation30,31,32. DcpS-binding ligands have also been studied using other methods, including high-performance liquid chromatography33, microscale thermophoresis34, tsFQT35, and radioactive assays15.
In this work, we synthesized and evaluated a library of different fluorescently labeled cap analogs as probes for the development of an FA approach for the discovery of molecules targeting DcpS or eIF4E. In order to find an optimal probe, the probe set included compounds differing in size, modification sites, and the presence of additional modifications within the triphosphate bridge (imidophosphate, methylenobisphosphonate, phosphorothioate, or phosphorothiolate). The binding affinities of the probes to DcpS and eIF4E were characterized using FA, and the most suitable probes were then used for the development of an FA method that was adaptable to high-throughput screening conditions. The developed methods were verified using a small in-house library of nucleotide derivatives. For selected ligands, the half-maximal effective concentration (EC50) was determined and compared with binding affinities obtained by alternative methods. Overall, our findings showed that the established method could be used to study nucleotide-derived ligands (including oligo-RNA) and other compounds targeting cap-binding proteins with high accuracy. Furthermore, we demonstrated that the method could also be used to study allosteric binding of eIF4E.
Optimization of the probe and binding studies
As the initial step in the development of an FA method, different structures of fluorescent probes were explored. As a starting point for the design of the probes, we used several known cap-derived eIF4E and DcpS binders differing in structural complexity (Fig. 1). As a label, we chose carboxyfluorescein (FAM) because of its many advantages in the context of FA assays, including high quantum yield and short half-life of the excited state (~ 4 ns)36, which is beneficial for small molecular probes37. As a result, we synthesized and tested a set of carboxyfluorescein-labeled cap analogs differing in size (from mono- to trinucleotides) and the site of fluorophore attachment (Fig. 1, Fig. S1). The fluorophore was attached using different chemical strategies to either the terminal phosphate, the 2′ or 3′ hydroxyls of m7G or G ribose moiety, or the N6-position of adenine. Fluorescent probes for studies with DcpS were additionally modified within the triphosphate bridge to make them resistant to enzymatic hydrolysis. To this end, different phosphate modifications were explored, including a bridging modification (β-γ-O to CH2)38, nonbridging modification (γ-O-to-S)39, and a recently reported phosphorothiolate modification (5′-PSL)30. As a reference, we included a 30-nt long capped-RNA probe that was previously used for binding studies with Drosophila melanogaster eIF4E40. This probe could be considered a mimic of the natural ligand of eIF4E (mRNA), wherein the probe was placed 16 nt away from the 5′ end, thereby minimizing its impact on protein binding.
Structures of FA probes for cap-binding proteins evaluated in this work.
All the fluorescently labeled compounds were evaluated as FA probes for eIF4E and/or DcpS proteins. The optimal probe fulfilling the requirement for unbiased KD estimation and development of competition binding assays should have high affinity for the target protein and a stable intrinsic fluorescence intensity that remains unchanged over time and upon binding to the target protein41,42. To select optimal probes, we performed direct binding experiments, in which each probe (at a constant concentration) was mixed with increasing concentrations of eIF4E or DcpS. We also performed negative control experiments for select probes using Bovine Serum Albumin (BSA) to confirm lack of unspecific interactions at concentrations up to 2.5 µM (Fig. S2). To check whether the emission of the ligand changed upon binding to the specific protein, values of total intensities were calculated as the sum of the parallel and double perpendicular intensities for each binding experiment43,44. Probes were compared based on the brightness enhancement factor g, demonstrating enhancement of total intensity between the free and bound forms of the probe. We observed that the changes in emission intensity during protein-probe complex formation strongly depended on the site of cap analog labeling and the linker length (Table 1). For both tested proteins, the greatest changes in fluorescence intensity were observed when the label was located at the ribose moiety. Compounds with the label at the 2′ position were more sensitive to environmental changes than those labeled at the 3′ position (a 1.2-fold difference for probes 3b and 3c). In contrast, cap analogs labeled at the N6 position of adenine had the most stable fluorescence signal. These dependencies changed with modifications within the phosphate bridge (e.g., the additional phosphate group in probe 1c decreased the fluorescence intensity stability in comparison with probes 1a and 1b). The unfavorable effects of binding-sensitive fluorescence intensity could be successfully eliminated by changing the length of the linker (Table 1). For DcpS protein, longer linkers were associated with more stable fluorescence intensity (probe 2i was 1.4 times less sensitive than probe 2h). In the case of eIF4E, the smallest changes in fluorescence intensity were observed for the medium-length linker (the intensity change for probe 2b was 4%, whereas those for probes 2a and 2c were 10% and 9%, respectively). The stability of fluorescence intensity was also affected by FAM regioisomerism; in binding studies with DcpS, isomer 5 of FAM led to significantly greater changes in fluorescence intensity than isomer 6. To determine the dissociation constant (KD) values, a 1:1 binding model was fitted to the obtained binding curves (Table 1, Fig. 2A). For probes characterized by Δg values greater than 0.1, the FA values were appropriately corrected before KD determination44. Among fluorescent probes tested against eIF4E, mononucleotide cap analogs (1a, 1b, 1c, 1e, 1f) bound the protein with significantly higher affinity than other probes. The affinity for eIF4E was the highest for mononucleotide analogs carrying a tetraphosphate chain (compound 1b with a KD that was 5.7-fold lower than that of the triphosphate probe 1a). Despite the high affinity for eIF4E, probe 1b showed the lowest FA response upon transition from the free to bound state, which affected method quality. Interestingly, further elongation of the tetraphosphate bridge to pentaphosphate did not improve the binding. The affinity of the probes containing phosphorothioate modification (1e, 1f) to eIF4E was dependent on the absolute configuration of the stereogenic P center (probe 1e bound to eIF4E 1.5 times stronger than probe 1f), consistent with previous data reported for unlabeled compounds39. Phosphorothioate substitution improved the binding compared with unmodified probe (1e showed a KD 1.4 times lower than 1a); however, the impact was less favorable than phosphate bridge elongation. Dinucleotide probes had generally weaker binding affinities than mononucleotide probes; the most potent dinucleotide probe 2d had a KD that was 1.3-fold higher than that of probe 1a. In contrast, trinucleotide probes had a binding affinity in the range corresponding to mononucleotide probes. This result suggested that the third nucleotide eliminated the unfavorable influence of the second nucleotide by forming new contacts between eIF4E and the additional nucleotide or by rearrangement of the cap structure inside the eIF4E binding pocket. However, the KD of oligonucleotide probe 4a was sevenfold higher than that of 3a, suggesting that further addition of nucleotides emulating the mRNA body may counteract this effect, resulting in negligible contribution of the mRNA body to the eIF4E:cap interaction.
Table 1 Binding affinities of mono-, di-, tri-, and oligonucleotide probes for eIF4E together with fluorescence enhancement factors (g).
For DcpS, we evaluated the hydrolysis-resistant probes 1d, 1e, 1f, 2e, 2f, 2g, 2h, and 2i (Table 2). Owing to the presence of a stereogenic P-center, the phosphorothioate probes existed in the form of two P-diastereoisomers, designated as D1 and D2 according to their order of elution during reverse-phase high-performance liquid chromatography. The diastereoisomers varied in binding affinity towards DcpS enzyme (e.g., probe 1f had a KD that was 1.8-fold lower than that of probe 1e). Moreover, both phosphorothioate probes bound to DcpS with affinity higher than the corresponding probe with methylenobisphosphonate modification (1.3- and 2.4-times higher binding affinity compared with 1d). Unexpectedly, probe 2d carrying the 5′-phosphorothiolate moiety was found to be susceptible to DcpS-catalyzed hydrolysis under assay conditions and thus was not suitable for this assay, despite the fact that other compounds carrying this moiety have been shown to be resistant and potent inhibitors of DcpS30. The most promising probes for DcpS were found among dinucleotide cap analogs. The lowest KD value was obtained for cap analog 2i carrying a methylenebisphosphonate moiety and labeled at the 3′ position of ribose with a long linker.
Table 2 Binding affinities of mono- and dinucleotide probes for DcpS together with fluorescence enhancement factors (g).
Development and validation of an FA competitive binding assay for eIF4E
After preliminary evaluation of the probes, we aimed to develop an FA-based binding assay for eIF4E. To this end, we selected three mononucleotide probes characterized by medium to high binding affinity (1a, 1b, and 1e; Fig. 2A). Using these probes, we performed probe-displacement experiments (competitive FA assays), in which an unlabeled ligand competed with the fluorescent probe for protein binding (Fig. 2C–E). Thus, we selected eight known eIF4E binders, i.e., m7GMP, m7GDP, m7GTP, m7GpppG, m7GppSpG D1, m7GppSpG D2, m7,2′-OGpSpppG D1, and m7,2′-OGpSpppG D2, which showed a wide range of binding potencies. The binding curves obtained from FA competition assays were analyzed using four-parameter dose–response curves with a variable slope Hill equation (Fig. 2C–E)45. The determined EC50 and Hill slope values are shown in Table 3.
Development of an FA binding assay for eIF4E. (A) Binding curves for probes 1a, 1b, and 1e with eIF4E protein. (B) Correlation between logKD values for seven ligands obtained by the FA method with the use of probes 1a, 1b, and 1e and logKD values determined by tsFQT. (C–E) Dose–response curves obtained from FA competition assays for the four selected ligands using probes 1a (C), 1b (D), and 1e (E). The protein concentration in the competition experiment was set above the KD value to achieve 70–85% of the maximum response. Dose–response binding experiments were carried out with a serial half-log dilution of unlabeled ligands. Data shown are mean values ± standard deviations of three independent experiments, each performed in duplicate.
Table 3 Characterization of eight eIF4E ligands using three different probes in FA competition binding experiments.
The results indicated that for low- and moderate-affinity ligands (half maximal inhibitory concentration [IC50] ≥ 200 nM), the Hill slope was close to 1, which was expected for a 1:1 binding model. However, the Hill slope was higher than 1 for high-affinity ligands, indicating that the probe affinity was too low to properly evaluate these ligands. As expected, the steepness of the curves was lowest for probe 1b, which had the highest affinity for eIF4E. Hence, the results indicated that the high-affinity probe 1b could be used to accurately measure the binding affinity of highly potent compounds, as also confirmed by the best correlation with the experimental data obtained from direct binding experiments using tsFQT (Fig. 2B).
Next, we evaluated whether FA assays based on probes 1a, 1b, or 1e could be adopted for high-throughput screening. We first determined the assay quality based on Z' factor estimation for all three systems, i.e., 1a:eIF4E, 1b:eIF4E, and 1e:eIF4E (Fig. 3A). Probe-protein complex was used as a negative control sample (high FA), and a mixture of probe, eIF4E, and m7GTP (excess) was used as a positive control (low FA). The determined Z' factors were 0.74 for the 1a:eIF4E system and 0.78 for the 1e:eIF4E system. After 60 min, the Z' factors were still higher than 0.5. Thus, systems 1a:eIF4E and 1e:eIF4E could be successfully applied in a high-throughput screening format. Unfortunately, in a similar test for 1b:eIF4E, we obtained a Z' factor less than 0.5, with poor signal separation between positive and negative controls. Therefore, this system was considered inappropriate for high-throughput screening owing to the low signal-to-noise ratio. The reduced response window in comparison to other probes could be a result of increased rotational mobility caused by the additional phosphate group.
(A) Z' factor measurements for eIF4E using three different probes (1a, 1b, and 1e). Assay conditions: 10 nM 1a, 100 nM eIF4E, 1 µM m7GTP; 1 nM 1b, 25 nM eIF4E, 1.5 µM m7GTP; 1 nM 1e, 100 nM eIF4E, 1.5 µM m7GTP. (B) Screening experiment for eIF4E (1 nM 1e, 100 nM eIF4E, 750 nM inhibitor).
Using the 1e:eIF4E system, a small in-house library of ligands was screened against eIF4E (Fig. 3B). The library contained mainly dinucleotide cap analogs modified within a triphosphate bridge, some standard mononucleotides, and non-nucleotide ligands. The binding affinities of these ligands were evaluated in previous studies. The screening was performed under optimized conditions in the presence of each tested inhibitor (750 nM). All tested dinucleotide cap analogs effectively competed for eIF4E, regardless of modification. However, the combination of an imidophosphate group with phosphate chain elongation appeared to have the most stabilizing effect on the protein–ligand complex. This observation was consistent with the literature data, showing that m7GpNHpppG had the highest association constant (KAS = 112.3 ± 1.8 μM−1) among the tested ligands46. The screening also revealed the unfavorable impact of reducing the number phosphate groups on the binding (m7GSpppG to m7GSppG or m7GDP to m7GMP), consistent with literature data30,47. As expected, compounds without the m7G moiety did not bind to eIF4E. The allosteric inhibitor 4EGI-1, which binds to eIF4E at a different site than the cap, did not influence the fluorescence of the probe-protein complex under these conditions. All of the above results validated the FA method developed with probe 1e.
Testing of allosteric binding with eIF4E
eIF4E protein is a component of eukaryotic initiation translation complex 4F (eIF4F) and together with eIF4A and eIF4G proteins is required for initiation of the translation process48. 4EGI-1 is an inhibitor of eIF4E and eIF4G association and consequently leads to inhibition of cap-dependent translation49. Therefore, disruption of the eIF4E-eIF4G interaction is another important target for cancer therapy. For identification of small-molecule inhibitors of the eIF4E-eIF4G interaction, an FA assay has been developed previously49. The binding event was monitored by evaluating changes in FA resulting from the interaction of fluorescein-labeled 4G peptide with eIF4E with a KD of 25 μM. Because only the 4G-binding site was observed, the potential connection between 4G- and cap-binding was not elucidated.
Next, we tested whether probe 1a could be used to study the binding of inhibitors outside the cap-binding site, such as 4EGI-1. Although 4EGI-1 targets eIF4E at a binding site different from that of the fluorescent probes, we hypothesized that if 4EGI-1 binding evoked conformational changes in the proteins, FA readouts may be affected. Therefore, we conducted an experiment similar to the competitive test, but using increasing concentrations of 4EGI-1. Interestingly, we observed changes in the fluorescence anisotropy signal at 4EGI-1 concentrations exceeding 10 μM; the magnitude of these changes suggested that the fluorescent probe was released from the cap-binding site. The EC50 value for this interaction was 35.3 ± 4.4 μM (Fig. 4A). One possible explanation for this observation was that 4EGI-1 binding to eIF4E may trigger structural rearrangements, leading to allosteric inhibition of both interactions, i.e., cap-eIF4E and eIF4G-eIF4E50. To verify this, we performed direct binding assays for probe 1a in the presence or absence of a high concentration of 4EGI-1 (100 μM; Fig. 4B). The results showed that the binding of probe 1a to eIF4E was at least sevenfold weaker in the presence of 4EGI-1. This suggested the interdependence of the 4G- and cap-binding sites and revealed that our method could also be used for the identification and analysis of allosteric inhibitors of cap-dependent translation. For the first time, we showed that 4EGI-1 destabilized the cap-eIF4E complex.
Testing of allosteric inhibition with probe 1a. (A) Dose–response curves with the allosteric inhibitor 4EGI-1. Assay conditions: 10 nM 1a, 100 nM eIF4E, and 50 mM HEPES buffer containing 100 mM KCl, 0.5 mM EDTA, and 1 mM DTT (pH 7.2). (B) Binding experiment in the absence/presence of 100 μM 4EGI-1. Assay conditions: 10 nM 1a and 50 mM HEPES buffer containing 100 mM KCl, 0.5 mM EDTA, and 1 mM DTT (pH 7.2).
Capped oligonucleotide evaluation using FA
The biophysical aspects of cap-protein interactions are most often investigated using synthetically modified mono- and dinucleotide cap analogs. Despite many attempts to use fluorescently labeled and capped oligonucleotide probes to evaluate eIF4E binding40, their use is limited by synthetic complexity and consequently low availability. Therefore, we tested whether an FA-based competitive approach was suitable for evaluation of label-free capped oligonucleotides.
We tested whether our FA method could be applied to study short capped oligonucleotides. To this end, short 26-nt RNAs were prepared using in vitro transcription catalyzed by SP6 polymerase. Five different RNAs varying in the 5′ termini were prepared, i.e., m7,2′-OGpppG-RNA, m7,2′-OGppCH2pG-RNA, ApppG-RNA, and uncapped RNA (pppG-RNA). These RNAs were used as ligands in a competition experiment with probe 1c to determine their EC50 values for eIF4E. As expected, we did not observe any binding event for pppG-RNA or ApppG-RNA (Fig. 5). In contract, m7G-capped oligonucleotides efficiently competed for interactions with eIF4E (EC50 values: 56.7 and 111.7 nM for m7,2′-OGpppG-RNA and m7,2′-OGppCH2pG-RNA, respectively). The obtained dose–response curves for the two capped RNAs and the determined EC50 values demonstrated the clear destabilizing effect of pCH2p modification on binding affinity to eIF4E (twofold lower EC50 for m7,2′-OGpppG-RNA compared with m7,2′-OGppCH2pG-RNA; Fig. 5). This observation was consistent with data obtained for 3′-ARCA dinucleotide cap analogs, in which the α/β-bisphosphonate modification weakens the affinity to eIF4E by approximately 2.3-times38. Thus, we showed that the FA method could be successfully used to study the affinity of oligonucleotides to eIF4E protein.
Dose–response curves for short (26 nt) RNAs with eIF4E. Assay conditions: systems 0.5 nM 1c and 25 nM eIF4E were incubated with a serial half-log dilution of short RNAs at 25 °C. Fluorescence anisotropy was averaged over five measurements.
Establishment and validation of an FA competitive assay for DcpS
Using similar assumptions as the for eIF4E competition assay, we established conditions to study ligands of DcpS. For initial evaluation, we chose four high-affinity fluorescent probes, i.e., three dinucleotide probes (2g, 2 h, and 2i) and one mononucleotide probe (1f). Probes were tested with four DcpS inhibitors, i.e., m7GMP, m7GDP, m7GpNHppG, and RG3039, which differed in affinity to DcpS33,46. For each tested compound, we performed competition experiments to determine the EC50s of the selected probe:DcpS system (Fig. 6, Table 4). The affinities of the selected probes for DcpS increased in the following manner: 1f < 2g < 2h < 2i. For the two lower affinity systems, i.e., 1f:DcpS and 2g:DcpS, we did not observe any separation of dose–response curves for three of the four inhibitors. In those systems, only the weak m7GMP inhibitor was accurately characterized. Characterization of the potent inhibitors was limited by insufficient probe affinity (Hill slope: 1.5–3.5). Using the high-affinity systems 2 h:DcpS and 2i:DcpS, all curves were sufficiently separated, even for the two most potent DcpS inhibitors (RG3039 and m7GpNHppG). The obtained dose–response curves for the highest affinity compound, i.e., RG3039, were characterized by high Hill slope values (> 3.6 for both systems). The binding curves obtained for RG3039 did not permit determination of affinity owing to the poor representation of binding curves because the total protein concentration significantly exceeded the KD of the inhibitor. This result indicated that probes 2 h and 2i were still not optimal for quantitative studies of such potent inhibitors. Overall, we observed strong dependence of the ability to characterize potent inhibitors on the affinity of the probe (Fig. 6). Besides the limitations mentioned above, systems 2 h:DcpS and 2i:DcpS correctly assessed the inhibitory potencies of the selected inhibitors. The order of the tested compounds in terms of their binding affinities towards DcpS was consistent with data obtained using the fluoride-release (FR) fluorescent method28. FR assays use an artificial DcpS substrate, 7-methylguanosine 5′-fluoromonophosphate (m7GMPF), which is hydrolyzed by the enzyme to release fluoride. Fluoride activates the fluorogenic probe bis-(tert-butyldimethylsilylfluorescein) in a concentration-dependent manner; hence, the fluorescence signal is proportional to the enzymatic reaction progress. Using this activity-based assay, over 70 cap analogs were characterized as DcpS inhibitors, including compounds selected for FA method validation, i.e., m7GMP (IC50 = 97 ± 21 μM), m7GDP (IC50 = 5.2 ± 1.2 μM), m7GpNHppG (IC50 = 3.2 ± 0.9 μM), and RG3039 (IC50 = 0.048 ± 0.010 μM)28.
(A–D) Dose–response curves showing the inhibitory potencies of four inhibitors towards the DcpS enzyme using four different fluorescent probes. Systems: 1f and 100 nM DcpS, 2 nM 2g and 25 nM DcpS, 2 nM 2 h and 25 nM DcpS, and 1 nM 2i and 25 nM DcpS, each incubated with half-log serial dilutions of unlabeled ligand. Data shown are mean values ± standard deviations of at least two separated experiments, each performed in duplicate.
Table 4 EC50 and Hill slope parameters determined for selected inhibitors using 1f:DcpS, 2g:DcpS, 2h:DcpS, and 2i:DcpS systems.
Because probe 2i showed the lowest KD value toward DcpS and was the most effective for characterization of potent inhibitors, such as RG3039, the 2i:DcpS system was chosen for high-throughput method optimization. The Z' factor was determined under conditions optimized for the competition assay. The Z' value exceeded 0.8 for incubation times up to 1 h, making the assay suitable for screening experiments (Table 5). A screening experiment was then performed using the same compound library as that used for eIF4E screening. The results highlighted the impact of the triphosphate bridge modification on the affinity for the protein. Cap analogs modified with phosphorothioate and phosphorothiolate moieties (m7GSppSpG D1, m7GSppSpG D2, m7GSppSpSG D1, and m7GSppSpSG D2) were the most potent inhibitors. The combination of these two modifications afforded compounds with properties similar to RG3039, which was previously identified as a potent DcpS inhibitor using FR assays30. Cap analogs containing imidophosphate and methylenebisphosphonate moieties (e.g., m7GpCH2ppG, m7GpCH2pppG, m7GpNHppG, and m7GpNHpppG) were also strong DcpS inhibitors (showing an inhibitory potency similar to that of m7GDP) but were significantly weaker than RG3039. The FA method also enabled the identification of unstable compounds, e.g., hydrozylable ligands for which determination of affinity is problematic (as observed by FA signal changes during the experiment; Fig. 7). Among the tested ligands, m7GpSppG D1, m7GppBH3pG D1, and m7GppBH3pG D2 were recognized as slowly hydrolyzed DcpS substrates, which are difficult to identify using other screening methods. Despite the limitations of the FA method to characterize strong DcpS inhibitors, the screening assay was found to be suitable for the discovery and preliminary evaluation of DcpS inhibitors.
Table 5 Estimated Z' factors for the 2i:DcpS system.
(A) Screening experiment for DcpS (1 nM 2i, 25 nM DcpS, 1.5 µM inhibitor) using a small in-house library. (B) FA signal monitoring during the screening experiment for four selected compounds.
FA is a powerful technique that is widely used to study protein–ligand interactions. In this study, we used FA to develop new methods for searching small-molecule inhibitors of cap-binding proteins. In the first step, we characterized a set of fluorescent probes. As probes, we used fluorescently labeled m7G nucleotide analogs resembling natural substrates or ligands interacting with test proteins. We verified the influence of the bridging modification and cap-fluorophore linker length on affinity towards eIF4E and DcpS and the tested fluorescence sensitivity to binding. Based on these studies, we selected the most promising probe candidates for competitive studies and ligand characterization. Selected probe:protein systems were used to determine EC50 and Hill slope parameters for known ligands of eIF4E and DcpS. The obtained values correlated well with literature data. Probes characterized by high affinity to the target and good FA responses were adapted to high-throughput screening assays.
As a result of this analysis, we developed FA methods for both eIF4E and DcpS. The methods could be successfully used for ligand screening purposes and EC50 parameter determination. eIF4E ligands have been extensively studied owing to the involvement of eIF4E in tumorigenesis and its role as a therapeutic target in many cancers. New ligands of eIF4E could facilitate the identification of novel anticancer agents. Notably, we found that the FA method could be used to study allosteric eIF4E ligands, such as 4EGI-1. Furthermore, high affinity of the 5′ cap for eIF4E is also crucial for the design of efficiently translated therapeutic mRNAs51. We showed that the FA method developed in this study was suitable for evaluation of small molecules as well as capped RNAs. This approach is a novel method that could be applied for the implementation of high-throughput approaches in therapeutic mRNA optimization and quality control. Screening of potential DcpS inhibitors is a new field of research, and few inhibitor families have been identified. DcpS plays general roles in the control of gene expression and has been independently linked to SMA, intellectual disability, and AML. Thus, identification of novel DcpS inhibitors could facilitate further studies of the connections between inhibitory and therapeutic effects because the mechanisms of action are still unknown.
Synthesis of fluorescent probes
Fluorescent probes 1a–1f, 2a–2i and 3a–3c were synthesized chemically using methods based on phosphorimidazolide chemistry. The fluorescent labelling with fluorescein was carried out either by copper-catalyzed azide-alkyne cycloaddition or amide bond formation by N-hydroxysuccinimide chemistry. Further details on the chemical synthesis are included in the Supporting Information S1. Probe 4a was purchased from TriLink Biotechnology.
eIF4E and DcpS expression and purification
Murine eIF4E (residues 28–217) was expressed in E. coli and purified as described previously26. Briefly, high level expression of eIF4E obtained at conditions of 0.5 mM isopropyl-β-D-thiogalactoside (IPTG) at 37 °C induced the formation of inclusion bodies. Inclusion bodies containing eIF4E were solubilized in 50 mM HEPES/KOH (pH 7.2) buffer containing 10% glycerol, 6 M guanidine hydrochloride and 2 mM DTT. Protein was then refolded during a two-step dialysis against buffer with decreasing concentration of guanidine hydrochloride in the presence of 100 mM KCl. Subsequently eIF4E was loaded on ion exchange HiTrap SP HP column (GE Healthcare), eluted with linear gradient of 0.1–1 M KCl and finally desalted and polished during a gel filtration purification step on HiLoad 16/600 Superdex 75 pg (GE Healthcare) using 50 mM HEPES pH 7.2, 100 mM KCl, 0.5 mM EDTA, 2 mM DTT buffer. eIF4E was aliquoted and stored in the presence of 10% glycerol at −80 °C. Before each experiment the protein was centrifuged on Ultrafree-MC Centrifugal PVDF filter with 0.45 mm pore size (Millipore), at 4 °C and 3000×g for 2 min to remove any possible aggregates.
Expression of recombinant His-tagged human DcpS was performed in BL21(DE3) RIL strain and induced overnight at 18 °C using 0.5 mM IPTG as described previously26. Cells were harvested, resuspended in buffer (50 mM Tris pH 7.6, 500 mM NaCl, 20 mM imidazole) with lysozyme (0.1 mg/ml) and protease inhibitors (1 mM PMSF, 1 µM pepstatin A, 0.3 µM aprotinin) and then lysed using sonication. Lysate was clarified by centrifugation at 35 000 × g for 40 min at 4 °C. The cell supernatant was passed over a 5 mL HisTrap HP (GE Healthcare) affinity column and Ni–NTA-bound proteins were eluted using 50 mM Tris buffer pH 7.6 containing 500 mM NaCl and 400 mM imidazole. The enzyme hDcpS was purified to homogeneity on HiLoad 16/600 Superdex 200 pg (GE Healthcare) gel filtration column using 50 mM Tris·HCl pH 7.6, 200 mM NaCl, 2 mM DTT buffer. Protein was aliquoted and stored in the presence of 10% glycerol at -80 °C.
Preparation of differently capped oligonucleotide ligands
Short RNAs were prepared as described previously30. RNAs were generated on template of annealed oligonucleotides (CAGTAATACGACTCACTATAGGGGAAGCGGGCATGCGGCCAGCCATAGCCGATCA and TGATCGGCTATGGCTGGCCGCATGCCCGCTTCCCCTATAGTGAGTCGTATTACTG), which contains T7 promoter sequence (TAATACGACTCACTATA) and encodes 35-nt long sequence (GGGGAAGCGGGCATGCGGCCAGCCATAGCCGATCA). Typical in vitro transcription reaction (100 µl) was incubated at 37 °C for 2 h and contained: RNA Pol buffer (40 mM Tris–HCl pH 7.9, 6 mM MgCl2, 1 mM DTT, 2 mM spermidine), 10 U/µl T7 RNA polymerase (ThermoFisher Scientific), 1 U/µl RiboLock RNase Inhibitor (ThermoFisher Scientific), 0.5 mM ATP/CTP/UTP, 0.125 mM GTP, 1.25 mM cap analog of interests and 0.1 µM annealed oligonucleotides as a template. Following 2 h incubation, 0.1 U/µl DNase I (ThermoFisher Scientific) was added and incubation was continued for 30 min at 37 °C. To generate uncapped RNA in reaction mixture cap analog was omitted whereas concentration of GTP was increased to 0.5 mM. The crude RNAs were purified using RNA Clean & Concentrator-25 (Zymo Research). Quality of transcripts was checked on 15% acrylamide/7 M urea gels, whereas concentration was determined spectrophotometrically. To remove in vitro transcription by-products of unintended size RNA samples were gel-purified using PAA elution buffer (0.3 M sodium acetate, 1 mM EDTA, 0.05% Triton X-100), precipitated with isopropanol and dissolved in water.
FA binding assay
FA measurements were performed on a microplate reader Biotek Synergy H1 equipped with excitation (485 ± 20 nm) and emission (528 ± 20 nm) polarization filters. Experiments were carried out at 25 °C in 96-well non-binding microplates with sample volume of 200 µl per well. Two different buffers were used depending on protein used in the assay:
eIF4E assay buffer—50 mM HEPES (pH 7.2), 100 mM KCl, 0.5 mM EDTA, 1 mM DTT.
DcpS assay buffer—50 mM Tris–HCl (pH 7.6), 200 mM KCl, 0.5 mM EDTA, 1 mM DTT.
In the direct binding experiments aimed at determining Kd values for protein-probe complexes, the fluorescent probe at a constant concentration was mixed with an increasing concentration of the protein (0–2.5 μM). Concentration of fluorescent probes in binding experiment are provided in Table 6. Before FA measurements, the plates containing analyzed samples were incubated for 10 min at 25 °C with simultaneous shaking at 300 rpm, then the protein was added to each well, samples were incubated for additional 3 min. The FA readouts were performed in a microplate reader at 25 °C. FA signals were recorded for 20 min with 60 s interval.
Table 6 Protein and probe concentrations used in the FA binding assay.
The FA values for each timepoint were calculated according to the following equation:
$$FA\left(\mathrm{mA}\right)= \frac{{I}_{\parallel }-G \bullet {I}_{\perp }}{{I}_{\parallel } + 2\bullet G \bullet {I}_{\perp }}\bullet 1000$$
where \({I}_{\parallel }\) is the parallel emission intensity, P is the perpendicular emission intensity, and G is the grating factor. The value of the G factor was equal 0.994.
For each sample, the final FA value taken to KD determination was the mean FA value from all datapoints determined for timepoints between 10 and 20 min.
To determine the dissociation constants, FA values were plotted as a function of protein concentration and the binding curves were fitted using the following equation:
$$FA= {A}_{F}+({A}_{B}-{A}_{F})\frac{\left(c+ {L}_{T}+{K}_{D}\right)-\sqrt{{(c+{L}_{T}+{K}_{D })}^{2}-4\bullet c\bullet {L}_{T}}}{2 {L}_{T}}$$
where FA is the determined fluorescence anisotropy, AF is the fluorescence anisotropy of free probe, AB is the fluorescence anisotropy of probe-protein complex, LT is the total ligand concentration.
The following equation was used to calculate total fluorescence intensity of the probe:
$${I}_{T}= {I}_{\parallel }+2{I}_{\perp }$$
where \({I}_{T}\)—total fluorescence intensity, \({I}_{\parallel }\)—the parallel emission intensity, \({I}_{\perp }\)—the perpendicular emission intensity.
The calculated values of the total fluorescence intensity were plotted against the protein concentration and the curve described by the Eq. 2 was fitted. Enhancement factor g was determined from the following equation:
$$g= \frac{{A}_{bound}}{{A}_{free}}\bullet 100\%$$
If the change in total fluorescence intensity due to binding was greater than 10%, the correction for the calculation of the bound fraction of probe was applied44:
$${f}_{b}= \frac{A-{A}_{free}}{{A}_{bound }-{A}_{free}+(g-1)({A}_{bound}-A)}$$
where \(A\)—measured fluorescence anisotropy, \({A}_{free}\)—the fluorescence anisotropy of free probe, \({A}_{bound}\)—the fluorescence anisotropy of probe-protein complex, \(g\)—enhancement factor.
FA competition assay
For competitive binding assay, a mixture containing the probe and the protein was incubated with the tested ligand. The exact concentrations of eIF4E or DcpS used for evaluation of particular probes are summarized in Table 7.
Table 7 Protein and probe concentrations used in the competitive binding assays.
In competitive measurements, a constant concentration of the protein and fluorescent probe and increasing concentration of the test ligand were used. At least 12 point dilutions of the tested compound were used. The experiments were carried out in 96-well plates. Each sample contained a mixture consisting of the probe, tested ligand and buffer (same as for the direct binding assay). The samples were incubated for 10 min at 25 °C with simultaneous shaking, then the protein was added to each well, incubated for additional 3 min, followed by the measurement of fluorescence anisotropy. FA signals were recorded for 20 min with 2 min intervals. For each sample, the final FA value taken to EC50 determination was the mean FA value from all datapoints determined for timepoints between 10 and 20 min.
The EC50 value, i.e., the ligand concentration required for 50% displacement of the probe from the complex with protein were calculated according to the equation:
$$FA=Bottom+\frac{\left(Top-Bottom\right)}{1+ \frac{{EC}_{50}^{HillSlope}}{{{L}}^{HillSlope}}}$$
where FA is the measured fluorescence anisotropy, Top and Bottom are asymptotes, L is the ligand concentration, HillSlope is the steepness of the curve.
Quality assessment and screening of an in-house compound library
To evaluate the quality of the assay, the Z' factor was determined for several protein-probe combinations. The assay was performed on 96-well microplates, where half of the samples were negative controls and the other half were positive controls. Negative control samples contained fluorescent probe and the tested protein, while the positive control contained additionally saturating concentration of high affinity ligand (m7GTP for eIF4E and m7GDP for DcpS). The concentration used in each experiment were as follows: 10 nM 1a, 100 nM eIF4E, (1 µM m7GTP); 1 nM 1b, 25 nM eIF4E, (1.5 µM m7GTP); 1 nM 1e, 100 nM eIF4E, (1.5 µM m7GTP); 1 nM 2i, 25 nM DcpS, (1.5 µM m7GDP).
The Z' factor values were calculated according to the following equation:
$${Z}^{^{\prime}}=1- \frac{{3SD}_{n}+{3SD}_{p}}{{\mu }_{n}- {\mu }_{p}}$$
where SDn and SDp are the standard deviations, and μn and μp represent the means of the FA values obtained from the negative and positive controls, respectively.
For the screening experiments a small in-house library containing 21 ligands was used. Experiments were conducted in the same manner as Z' factor determination, with exception that the ligand concentration was modified (eIF4E screening conditions: 1 nM 1e, 100 nM eIF4E, 750 nM ligand, DcpS screening conditions: 1 nM 2i, 25 nM DcpS, 1.5 µM ligand). For eIF4E screening experiment, the 1e:eIF4E system was used, for DcpS screening 2i:DcpS system was used.
Furuichi, Y., Muthukrishnan, S. & Shatkin, A. J. 5'-Terminal m-7G(5')ppp(5')G-m-p in vivo: identification in reovirus genome RNA. Proc. Natl. Acad. Sci. USA 72(2), 742–745 (1975).
Quiocho, F. A., Hu, G. & Gershon, P. D. Structural basis of mRNA cap recognition by proteins. Curr. Opin. Struct. Biol. 10(1), 78–86 (2000).
Niedzwiecka, A. et al. Biophysical studies of eIF4E cap-binding protein: recognition of mRNA 5' cap structure and synthetic fragments of eIF4G and 4E-BP1 proteins. J. Mol. Biol. 319(3), 615–635 (2002).
Topisirovic, I., Svitkin, Y. V., Sonenberg, N. & Shatkin, A. J. Cap and cap-binding proteins in the control of gene expression. Wiley Interdiscip. Rev. RNA 2(2), 277–298 (2011).
Gu, M. & Lima, C. D. Processing the message: structural insights into capping and decapping mRNA. Curr. Opin. Struct. Biol. 15(1), 99–106 (2005).
Lewis, J. D. & Izaurralde, E. The role of the cap structure in RNA processing and nuclear export. Eur. J. Biochem. 247(2), 461–469 (1997).
Rau, M., Ohlmann, T., Morley, S. J. & Pain, V. M. A reevaluation of the cap-binding protein, eIF4E, as a rate-limiting factor for initiation of translation in reticulocyte lysate. J. Biol. Chem. 271(15), 8983–8990 (1996).
Raught, B. & Gingras, A. C. eIF4E activity is regulated at multiple levels. Int. J. Biochem. Cell Biol. 31(1), 43–57 (1999).
Lazaris-Karatzas, A., Montine, K. S. & Sonenberg, N. Malignant transformation by a eukaryotic initiation factor subunit that binds to mRNA 5' cap. Nature 345(6275), 544–547 (1990).
De Benedetti, A. & Harris, A. L. eIF4E expression in tumors: its possible role in progression of malignancies. Int. J. Biochem. Cell Biol. 31(1), 59–72 (1999).
Truitt, M. L. et al. Differential requirements for eIF4E dose in normal development and cancer. Cell 162(1), 59–71 (2015).
Chen, X. et al. Structure-guided design, synthesis, and evaluation of guanine-derived inhibitors of the eIF4E mRNA-cap interaction. J. Med. Chem. 55(8), 3837–3851 (2012).
Carroll, M. & Borden, K. L. The oncogene eIF4E: using biochemical insights to target cancer. J. Interferon Cytokine Res. 33(5), 227–238 (2013).
Bail, S. & Kiledjian, M. DcpS, a general modulator of cap-binding protein-dependent processes?. RNA Biol. 5(4), 216–219 (2008).
Singh, J. et al. DcpS as a therapeutic target for spinal muscular atrophy. ACS Chem. Biol. 3(11), 711–722 (2008).
Ng, C. K. et al. Loss of the scavenger mRNA decapping enzyme DCPS causes syndromic intellectual disability with neuromuscular defects. Hum. Mol. Genet. 24(11), 3163–3171 (2015).
Yamauchi, T. et al. Genome-wide CRISPR-Cas9 screen identifies Leukemia-specific dependence on a pre-mRNA metabolic pathway regulated by DCPS. Cancer Cell 33(3), 386-400.e5 (2018).
Meziane, O. et al. The human decapping scavenger enzyme DcpS modulates microRNA turnover. Sci. Rep. 5, 16688 (2015).
Howell, M. D., Singh, N. N. & Singh, R. N. Advances in therapeutic development for spinal muscular atrophy. Fut. Med. Chem. 6(9), 1081–1099 (2014).
Gogliotti, R. G. et al. The DcpS inhibitor RG3039 improves survival, function and motor unit pathologies in two SMA mouse models. Hum. Mol. Genet. 22(20), 4084–4101 (2013).
Alesi, V. et al. An additional patient with a homozygous mutation in DCPS contributes to the delination of Al-Raqad syndrome. Am. J. Med. Genet. A 176(12), 2781–2786 (2018).
Ahmed, I. et al. Mutations in DCPS and EDC3 in autosomal recessive intellectual disability indicate a crucial role for mRNA decapping in neurodevelopment. Hum. Mol. Genet. 24(11), 3172–3180 (2015).
Moerke, N. J. Fluorescence polarization (FP) assays for monitoring peptide-protein or nucleic acid-protein binding. Curr. Protoc. Chem. Biol. 1(1), 1–15 (2009).
Visco, C. et al. Development of biochemical assays for the identification of eIF4E-specific inhibitors. J. Biomol. Screen 17(5), 581–592 (2012).
Natarajan, A. et al. Synthesis of fluorescein labeled 7-methylguanosinemonophosphate. Bioorg. Med. Chem. Lett. 14(10), 2657–2660 (2004).
Kasprzyk, R. et al. Fluorescent turn-on probes for the development of binding and hydrolytic activity assays for mRNA cap-recognizing proteins. Chemistry 25(27), 6728–6740 (2019).
Kasprzyk, R. et al. Acetylpyrene-labelled 7-methylguanine nucleotides: unusual fluorescence properties and application to decapping scavenger activity monitoring. Org. Biomol. Chem. 14(16), 3863–3868 (2016).
Baranowski, M. R., Nowicka, A., Jemielity, J. & Kowalska, J. A fluorescent HTS assay for phosphohydrolases based on nucleoside 5'-fluorophosphates: its application in screening for inhibitors of mRNA decapping scavenger and PDE-I. Org. Biomol. Chem. 14(20), 4595–4604 (2016).
Wanat, P. et al. ExciTides: NTP-derived probes for monitoring pyrophosphatase activity based on excimer-to-monomer transitions. Chem. Commun. (Camb) 54(70), 9773–9776 (2018).
Wojtczak, B. A. et al. 5'-Phosphorothiolate dinucleotide cap analogues: reagents for messenger RNA modification and potent small-molecular inhibitors of decapping enzymes. J. Am. Chem. Soc. 140(18), 5987–5999 (2018).
Golojuch, S. et al. Exploring tryptamine conjugates as pronucleotides of phosphate-modified 7-methylguanine nucleotides targeting cap-dependent translation. Bioorg. Med. Chem. 28(13), 115523 (2020).
Walczak, S. et al. A novel route for preparing 5' cap mimics and capped RNAs: phosphate-modified cap analogues obtained. Chem. Sci. 8(1), 260–267 (2017).
Wypijewska, A. et al. 7-methylguanosine diphosphate (m(7)GDP) is not hydrolyzed but strongly bound by decapping scavenger (DcpS) enzymes and potently inhibits their activity. Biochemistry 51(40), 8003–8013 (2012).
Kopcial, M., Wojtczak, B. A., Kasprzyk, R., Kowalska, J., Jemielity, J., N1-Propargylguanosine Modified mRNA Cap Analogs: Synthesis, reactivity, and applications to the study of cap-binding proteins. Molecules 2019, 24 (10).
Piecyk, K. et al. Effect of different N7 substitution of dinucleotide cap analogs on the hydrolytic susceptibility towards scavenger decapping enzymes (DcpS). Biochem. Biophys. Res. Commun. 464(1), 89–93 (2015).
Lakowicz, J. R. Principles of Fluorescence Spectroscopy (Kluwer, 1999).
Hall, M. D. et al. Fluorescence polarization assays in high-throughput screening and drug discovery: a review. Methods Appl. Fluoresc. 4(2), 022001 (2016).
Article ADS PubMed PubMed Central CAS Google Scholar
Rydzik, A. M. et al. Synthetic dinucleotide mRNA cap analogs with tetraphosphate 5',5' bridge containing methylenebis(phosphonate) modification. Org. Biomol. Chem. 7(22), 4763–4776 (2009).
Kowalska, J. et al. Phosphorothioate analogs of m7GTP are enzymatically stable inhibitors of cap-dependent translation. Bioorg. Med. Chem. Lett. 19(7), 1921–1925 (2009).
Fuchs, A. L., Neu, A. & Sprangers, R. A general method for rapid and cost-efficient large-scale production of 5' capped RNA. RNA 22(9), 1454–1466 (2016).
Dandliker, W. B., Hsu, M. L., Levin, J. & Rao, B. R. Equilibrium and kinetic inhibition assays based upon fluorescence polarization. Methods Enzymol. 74, 3–28 (1981).
Lundblad, J. R., Laurance, M. & Goodman, R. H. Fluorescence polarization analysis of protein-DNA and protein-protein interactions. Mol. Endocrinol. 10(6), 607–612 (1996).
Ozers, M. S. et al. Equilibrium binding of estrogen receptor with DNA using fluorescence anisotropy. J. Biol. Chem. 272(48), 30405–30411 (1997).
Zhang, H., Wu, Q. & Berezin, M. Y. Fluorescence anisotropy (polarization): from drug screening to precision medicine. Expert Opin. Drug Discov. 10(11), 1145–1161 (2015).
Gadagkar, S. R. & Call, G. B. Computational tools for fitting the Hill equation to dose-response curves. J. Pharmacol. Toxicol. Methods 71, 68–76 (2015).
Rydzik, A. M. et al. Synthesis and properties of mRNA cap analogs containing imidodiphosphate moiety–fairly mimicking natural cap structure, yet resistant to enzymatic hydrolysis. Bioorg. Med. Chem. 20(5), 1699–1710 (2012).
Wypijewska del Nogal, A. et al. Analysis of decapping scavenger cap complex using modified cap analogs reveals molecular determinants for efficient cap binding. FEBS J 280(24), 6508–27 (2013).
Gingras, A. C., Raught, B. & Sonenberg, N. eIF4 initiation factors: effectors of mRNA recruitment to ribosomes and regulators of translation. Annu. Rev. Biochem. 68, 913–963 (1999).
Moerke, N. J. et al. Small-molecule inhibition of the interaction between the translation initiation factors eIF4E and eIF4G. Cell 128(2), 257–267 (2007).
Salvi, N., Papadopoulos, E., Blackledge, M. & Wagner, G. The Role of Dynamics and Allostery in the Inhibition of the eIF4E/eIF4G Translation Initiation Factor Complex. Angew Chem. Int. Ed. Engl. 55(25), 7176–7179 (2016).
Hajj, K. A., Whitehead, K. A., Tools for translation: non-viral materials for therapeutic mRNA delivery. Nature Reviews Material 2017, 2 (17056).
This work was financially supported by the National Science Centre, grant number UMO-2016/21/N/ST4/03750.
Division of Biophysics, Institute of Experimental Physics, Faculty of Physics, University of Warsaw, Ludwika Pasteura 5, 02-093, Warsaw, Poland
Anna Wojtczak, Marcin Warmiński, Krystian Ubych, Dorota Kubacka, Jacek Jemielity & Joanna Kowalska
Centre of New Technologies, University of Warsaw, Stefana Banacha 2c, 02-097, Warsaw, Poland
Renata Kasprzyk & Pawel J. Sikorski
College of Inter-Faculty Individual Studies in Mathematics and Natural Sciences, University of Warsaw, Stefana Banacha 2c, 02-097, Warsaw, Poland
Renata Kasprzyk & Krystian Ubych
Anna Wojtczak
Renata Kasprzyk
Marcin Warmiński
Krystian Ubych
Dorota Kubacka
Pawel J. Sikorski
Jacek Jemielity
Joanna Kowalska
A.W., J.K. and J.J. designed the study, A.W. performed experiments, R.K., K.U. and M.W. synthesized fluorescent probes, D.K. and P.S. prepared reagents for FA assays, A.W. and J.K. wrote the first draft of the manuscript, all authors participated in writing, editing, and approved the final version of the manuscript.
Correspondence to Jacek Jemielity or Joanna Kowalska.
Supplementary information.
Wojtczak, A., Kasprzyk, R., Warmiński, M. et al. Evaluation of carboxyfluorescein-labeled 7-methylguanine nucleotides as probes for studying cap-binding proteins by fluorescence anisotropy. Sci Rep 11, 7687 (2021). https://doi.org/10.1038/s41598-021-87306-8 | CommonCrawl |
SME research and statistics
Financing Profile: Women Entrepreneurs (October 2010)
Financing Profiles: Women Entrepreneurs
Business characteristics of female business owners
Comparison of business sizes
Intended use of debt financing
Top sources of financing
Future intentions
Perceived obstacles to growth
Owen Jung
Small Business Branch
An update of the November 2004 profile on women entrepreneurs, this profile describes the recent financing activities of small and medium-sized enterprises (SMEs) majority-owned by women in Canada. General business characteristics and financial growth performances are compared with SMEs majority-owned by men to highlight past and current gender differences.
Majority female-owned small and medium-sized enterprises (SMEs) (i.e., 51 to 100 percent of the ownership of the business is held by women) constituted 16 percent of SMEs in Canada in 2007.
On average, female business owners were younger and reported fewer years of management or ownership experience compared with male business owners.
Majority female-owned firms were more likely to operate in the tourism industry than majority male-owned firms.
Revenues earned by majority female-owned firms were still significantly less than revenues earned by majority male-owned firms in 2004 and 2007; however, before-tax net incomes generated by majority female-owned firms were comparable to net incomes generated by majority male-owned firms.
In 2007, majority female-owned firms were just as likely as majority male-owned firms to seek external financing (17 percent request rate), in contrast to 2004 when majority male-owned firms were more likely to seek financing than majority female-owned firms (24 percent versus 15 percent respectively).
Most majority female-owned firms that sought financing in 2007 were successful in acquiring at least some form of external financing; however, majority female-owned firms were less likely to be approved for short-term debt financing, such as lines of credit and credit cards, than majority male-owned firms (77 percent versus 94 percent respectively).
There was little evidence of disparity with regards to interest rates or requests for collateral among majority female-owned and majority male-owned firms that were successful in obtaining financing. On the other hand, among SMEs that were denied debt financing, majority female-owned firms were significantly more likely to be turned down due to a poor credit history or insufficient collateral than majority male-owned firms.
Among SMEs that intended to expand the size and scope of their businesses within two years (i.e., declared growth intentions), majority female-owned firms were more likely to require external financing to fund their expansion plans than majority male-owned firms. Interestingly, majority female-owned firms were more likely to consider sharing equity in the business to fund their expansion plans than majority male-owned firms.
In 2007, majority female-owned firms were more likely to declare growth intentions than majority male-owned firms.
From 2004 to 2008, firms that declared growth intentions exhibited noticeably stronger growth in total revenue and full-time equivalents (employees) than firms that did not declare growth intentions regardless of owner gender.
Women entrepreneurs are an important part of the small and medium-sized enterprise (SME) landscape in Canada. Fostering entrepreneurial activity among women, therefore, will have a significant impact on wealth and job creation across the country. Access to financing is an essential ingredient to achieve growth for almost all entrepreneurs. However, there is concern among some researchers that female business owners have less access to financing — or receive financing under less favourable loan conditions — than male business owners due to a number of factors, including smaller business size, a lack of managerial experience and a weaker credit history or lack thereof. At the same time, there is a considerable volume of literature suggesting that no disparity exists in access to financing among female and male business owners.
Using the most comprehensive database of Statistics Canada on SME financing, this report outlines the business characteristics and recent financing activities of majority female-owned SMEs (i.e., 51 to 100 percent of the ownership of the business is held by women). Hereafter, "female business owners" refers to owners of majority female-owned SMEs only. Based primarily on the 2004 and 2007 results of the Survey on Financing of Small and Medium Enterprises , the two most recent years available, this report attempts to address the following questions:
How do the characteristics of majority female-owned SMEs differ from those of majority male-owned SMEs?
How do the experiences of female business owners differ from those of male business owners when seeking financing?
Do majority female-owned SMEs exhibit different growth patterns than majority male-owned SMEs?
What are the substantial obstacles to accessing financing faced by female business owners?
SME Financing Data
For the purposes of this report, small and medium-sized enterprises are defined as enterprises with fewer than 500 employees and less than $50 million in annual revenues. The SME population excludes non-profit and government organizations, schools, hospitals, subsidiaries, co-operatives, and financing and leasing companies.
The financing data used in this analysis originate from the Statistics Canada Survey on Financing of Small and Medium Enterprises . This survey is intended to study the demand for, and sources of, SME financing. The resulting database includes information on the application process, firm profiles and demographic characteristics of SME ownership. For more information on this survey, see the Survey on Financing of Small and Medium Enterprises section on this website.
Although this report focuses on SMEs that are majority female-owned or majority male-owned, about one fifth of the SMEs surveyed were identified as being jointly owned (i.e., 50–50 split ownership between the two genders). As it is impossible to ascertain any disproportionate authority or responsibility among the owners, if present, jointly owned SMEs have been mostly excluded from this analysis.
Female business owners were typically younger and had less management or ownership experience than male business owners
After a sustained period of strong growth, the number of women entering self-employment has stabilized over the past decade. From 1999 to 2009, the number of self-employed women grew by 13 percent compared with 10 percent for men.Footnote 1
In 2007, just over 260,000 firms were majority female-owned, constituting 16 percent of Canada's SMEs (Figure 1). Almost half of all SMEs in Canada had at least one female owner. Overall, gender distribution of SME ownership changed little between 2001 and 2007.
Gender Distribution of SME Ownership
Source: Statistics Canada, Survey on Financing of Small and Medium Enterprises , 2007.
Figure 1: Gender Distribution of SME Ownership
At Least One Female Owner
Majority Female-Owned
Half Female-Owned
Minority Female-Owned
No Female Ownership
The age profile of female business owners has changed considerably as the percentage of those under 40 years of age dropped from 28 percent in 2004 to 16 percent in 2007 (Figure 2). In spite of this, female business owners were generally younger than their male counterparts in 2007, averaging 48.5 years of age compared with 51.1 years of age for male business owners.
Percentage of SMEs with Owners under 40 Years of Age Note * referrer of Figure 2
Source: Statistics Canada, Survey on Financing of Small and Medium Enterprises , 2004 and 2007.
Note * of Figure 2: Bold value denotes statistically significant gender difference at 5 percent.
Figure 2: Percentage of SMEs with Owners under 40 Years of Age
SMEs with Owners
Majority Male-Owned
In 2007, 51 percent of female business owners had more than 10 years of management or ownership experience compared with 74 percent of male business owners (Figure 3). The difference in experience was statistically significant at 5 percent.
Percentage of SMEs with Owners Who Have More than 10 Years of Management or Ownership Experience Note * referrer of Figure 3
Figure 3: Percentage of SMEs with Owners Who Have More than 10 Years of Management or Ownership Experience
Female business owners were more likely to operate a younger business and to operate in the tourism industry
A comparison of general business characteristics between majority female-owned and majority male-owned SMEs is presented in Table 1. In 2007, majority female-owned firms were younger than majority male-owned firms. Thirty-eight percent of majority female-owned firms started selling goods and services after 2001 compared with 30 percent of majority male-owned firms. Forty-four percent of majority female-owned SMEs were located in Ontario.
Profile of Majority Female-Owned and Majority Male-Owned SMEs, 2007 Note * referrer of Table 1
Female-Owned
Male-Owned
Note * of Table 1: Bold value denotes statistically significant gender difference at 5 percent.
Note ** of Table 1: For example, 7 percent of all majority female-owned SMEs in Canada were located in Atlantic Canada in 2007. Similarly, these majority female-owned SMEs accounted for 17 percent of all SMEs in Atlantic Canada.
Age of Owner (years)
65 or older
Year Firm Started Selling Goods and Services
Started between 2005 and 2007 (1 to 2 years old)
Started prior to 2002 (6+ years old)
Agriculture/primary
Knowledge-based industries
Stage of Development (as identified by owner)
Spoke English
Spoke French
Spoke other
Majority Ownership of the Business Held
By Aboriginal persons
By persons from a visible minority group (other than Aboriginal)
By a person with a disability
By persons who have resided in Canada for less than 5 years
By members of the same family
Region (share of all SMEs in region in parentheses) Note ** referrer of Table 1
7 (17) 7 (65)
14 (16) 14 (65)
100 (16) 100 (64)
Operated Firm in Rural Area
Exported Goods and Services
Interestingly, female business owners were more likely than male business owners to speak a language other than English or French (22 percent versus 12 percent), yet only a very small percentage of female business owners (0.3 percent) have resided in Canada for less than five years. In 2007, female business owners were more likely than male business owners to identify their firms as "slow growth" businesses (47 percent versus 37 percent), whereas male business owners were more likely than female business owners to operate firms whose sales have stopped growing ("maturity") or have started to decrease ("decline").
Historically, majority female-owned SMEs have been concentrated in the retail and service sectors (Carter 2002). In 2007, majority female-owned SMEs still tended to favour sectors related to wholesale/retail (17 percent), professional services (15 percent) and tourism (13 percent). The gender difference, however, was only statistically significant for tourism. There were fewer majority female-owned SMEs in agriculture/primary, manufacturing and knowledge-based industries than majority male-owned firms, but the gender differences were not statistically significant.
Majority female-owned SMEs appear to be catching up in size to majority male-owned SMEs
Previous research has indicated that majority female-owned firms tend to be smaller than majority male-owned firms in both numbers of employees and assets (Jennings and Cash 2006, Cole and Mehran 2009, Fairlie and Robb 2009). The gap between the two gender groups appears to be narrowing, however, with respect to both measurements.
As shown in Table 2, the percentage of majority female-owned SMEs that were micro-businesses (fewer than five employees) was 81 percent in 2007, just higher than 79 percent for majority male-owned micro-businesses. Majority female-owned firms were less likely to employ 20 or more people, on the other hand, than majority male-owned firms. Nevertheless, the gender differences were not statistically significant in any of the firm-size categories presented in Table 2.
Distribution (%) of Firms by Business Size (number of employees)
<1 <1 <1 <1
Based on tax file data linked by Statistics Canada, a summary of financial figures from incorporated majority female-owned and majority male-owned SMEs is presented in Table 3.Footnote 2 As shown in the table, majority female-owned firms exhibited a strong performance in terms of average total revenue, jumping from $335 000 in 2000 to $525 000 in 2004 and $563 000 in 2007. Notwithstanding these increases in revenue, the average total revenue generated by majority female-owned firms in 2007 was half of that reported by majority male-owned firms. On the other hand, the average net profit (before tax) of majority female-owned firms was $32 000 in 2004 and $48 000 in 2007. In both of these years, the gender difference in average net profit before tax was not statistically significant. When measured as a percentage of net profit before tax of majority male-owned firms (male profit), net profit before tax of majority female-owned firms jumped from 52 percent in 2000 to 89 percent in 2004 and remained at 89 percent in 2007, suggesting that the gap in terms of net profit before tax between majority female-owned firms and majority male-owned firms is shrinking.
Selected Financial Statement Figures (average $) Note * referrer of Table 3
Majority Female-Owned Note ** referrer of Table 3
Source: Tax file data linked to Statistics Canada, Survey on Financing of Small and Medium Enterprises , 2000, 2004 and 2007.
Note * of Table 3: Bold value denotes statistically significant gender difference at 5 percent. Statistical tests were not carried out for 2000 as the raw data were not made available.
Note ** of Table 3: Due to a significant presence of large outliers in the 2004 sample of majority female-owned firms, observations beyond the 99th percentile in total revenue among majority female-owned firms were excluded in this year.
335 000 706 000 525 000 936 000 563 000 1 126 000
Net Profit Before Tax
34 000 65 000 32 000 36 000 48 000 54 000
Net Profit Before Tax (as % of male profit)
52 — 89 — 89 —
— — 113 000 231 000 145 000 283 000
Between 2004 and 2007, the gender gap narrowed with regards to current assets, total liabilities, total equity and retained earnings. Average current assets of majority female-owned firms jumped dramatically in both 2004 and 2007 such that the gender difference was no longer statistically significant in 2007. On the other side of the balance sheet, average total liabilities increased considerably for both gender groups, especially for majority female-owned firms such that the gender difference was no longer statistically significant in 2007. Majority female-owned firms also saw average total equity increase by a substantial margin from 2004 to 2007, whereas the average total equity of majority male-owned firms in 2007 was only slightly higher than the average in 2000. Also noteworthy is the fact that average retained earnings were higher for majority female-owned firms in 2007 than majority male-owned firms, but this difference was not statistically significant.
To better assess the financial health of a firm, five standard financial ratios (see text box) were calculated using linked tax file data (Table 4).Footnote 3 As shown in the table, there are discernible differences between gender groups in each year. In 2004, the median current ratio for majority female-owned firms was slightly less than 1.0, whereas the median current ratio for majority male-owned firms was about 1.3, suggesting stronger financial health. In 2007, however, the median current ratios for majority female-owned and majority male-owned firms were almost identical.
Selected Financial Ratios (median values)
Source: Tax file data linked to Statistics Canada, Survey on Financing of Small and Medium Enterprises , 2004 and 2007.
Note * of Table 4 Excluding firms with zero or negative total equity values.
Operating Profit Margin
2.6% 3.5% 2.1% 4.6%
Debt-to-Equity Note * referrer of Table 4
$$ \mathbf{\text{Current Ratio}} = \frac{\text{Current Assets}}{\text{Current Liabilities}} $$
Indicates the market liquidity of a business. A higher current ratio signals that a firm is in a better position to cover short-term liabilities.
$$ \mathbf{\text{Gross Profit Margin}} = \frac{\text{Sales Revenues} - \text{Cost of Goods Sold}}{\text{Sales Revenues}} $$
Measures the proportion of net revenue after accounting for the cost of goods sold. A higher gross profit margin indicates that a firm has more resources available to pay overhead costs.
$$ \mathbf{\text{Operating Profit Margin}} = \frac{\text{Net Profit Before Tax} + \text{Interest Expenses and Bank Charges}}{\text{Sales Revenues}} $$
Expresses operating profit as a proportion of sales revenues. A higher operating profit margin signals that a firm has more resources available to pay fixed costs.
$$ \mathbf{\text{Interest Coverage}} = \frac{\text{Net Profit Before Tax} + \text{Interest Expenses and Bank Charges}}{\text{Interest Expenses and Bank Charges}} $$
Indicates a firm's ability to generate enough income to cover interest expenses. A higher interest coverage ratio suggests that a firm is in a better position to avoid default.
$$ \mathbf{\text{Debt-to-Equity}} = \frac{\text{Total Liabilities}}{\text{Total Equity}} $$
Indicates what proportion of equity and debt a firm is using to finance its assets. A higher debt-to-equity ratio indicates that a firm is using greater leverage.
In terms of median gross profit margin, majority female-owned firms performed marginally better than majority male-owned firms in 2004 and 2007. In contrast, majority female-owned firms had lower median operating profit margins in both years.
Majority female-owned firms also had lower median interest coverage ratios in 2004 and 2007 than majority male-owned firms, suggesting that majority female-owned firms were in a weaker position to meet interest expenses. Finally, the median debt-to-equity ratio was higher for majority male-owned firms than majority female-owned firms in both years, suggesting that male business owners were more aggressive in financing firm growth through debt.
Majority female-owned firms were just as likely to seek financing as majority male-owned firms in 2007
Considering the crucial role financing has in the capitalization of SMEs, it is imperative to identify if female business owners are facing unique obstacles with respect to accessing external financing. Previous research has suggested that majority female-owned firms are less likely to seek external financing than majority male-owned firms (Coleman 2002, Fabowale et al. 1995), but a study by Orser et al. (2006), which examined the financing activities of Canadian SMEs in 2001, suggests otherwise. Indeed, the evidence presented here reveals diminishing gender differences in financing activities.
Recent request rates by type of financing by gender are presented in Table 5. In 2004, request rates by majority male-owned firms were higher than majority female-owned firms at a statistically significant level for all categories except equity. In 2007, however, the percentage of SMEs that sought financing was identical for both gender groups (17 percent). In fact, request rates by majority female-owned and majority male-owned firms in 2007 were almost identical for each type of financing.
Request Rates (%) by Type of Financing Note * referrer of Table 5
Source: Statistics Canada, Survey on Financing of Small and Medium Enterprises , 2000, 2004 and 2007.
Any Financing
— — 15 24 17 17
— — 5 9 5 6
— — 8 10 8 8
Majority female-owned firms were less likely to be approved for debt financing than majority male-owned firms
Approval rates by type of financing by gender are presented in Table 6. As shown in the table, majority female-owned firms generally had lower approval rates than majority male-owned firms in 2004. There is evidence, however, that the gap in approval rates had narrowed in some aspects in 2007. In 2004, the approval rate for debt financing among majority female-owned firms was 79 percent, a statistically significant lower rate than the 88 percent approval rate for majority male-owned firms. On the other hand, majority female-owned firms were very successful in receiving trade credit when requested in 2004, boosting the overall approval rate for financing of majority female-owned firms to 84 percent.Footnote 4
Approval Rates (%) by Type of Financing Note * referrer of Table 6
87 70 — — — —
— — 93 88 97 100
In 2007, lending markets were very active, leading to large increases in approval rates for financing for both gender groups. The statistically significant discrepancy in approval rates for debt financing remained between the two gender groups; however, upon closer inspection, the approval rate for long-term debt financing (term loans and mortgages) for majority female-owned firms was a very healthy 95 percent, but the approval rate for short-term debt financing (credit cards and lines of credit) remained stagnant at 77 percent (compared with 94 percent for majority male-owned firms).Footnote 5 Note, however, that approval rates here do not distinguish between full and partial approvals,Footnote 6 nor do they consider scale effects.Footnote 7
Majority female-owned firms typically received significantly smaller amounts of debt financing than majority male-owned firms
As the impact of financing requests that are not approved is often dependent on the amount of financing requested, it is important to investigate the amount of debt financing being requested by and approved for the two gender groups. Regardless of the type of debt financing requested, the average amount approved for majority female-owned firms was smaller than that approved for majority male-owned firms at a statistically significant level in 2007. As shown in Table 7, the average total debt financing approved for majority female-owned firms was $68 000 and $118 000 in 2004 and 2007 respectively. Both of these figures were less than half of the average amount approved for majority male-owned firms in each respective year.
Approved Debt Financing (average $) Note * referrer of Table 7
Average Long-Term Debt Approved
Average Short-Term Debt Approved
43 000 96 000 72 000 177 000
Average Total Debt Approved
(Approved/ Requested) Total Debt
Based upon these figures alone, it is not possible to determine if female applicants were more likely than male applicants to be fully or partially denied debt financing or if female applicants simply requested smaller amounts of debt financing. To find the answer, the ratio of the aggregated amount of approved debt financing to the aggregated amount of requested debt financing (i.e., the sum of all approved debt financing divided by the sum of all requested debt financing) was calculated for each gender group. As shown in Table 7, the ratio was very similar between the two gender groups in both 2004 and 2007, suggesting that female applicants indeed requested smaller amounts of debt financing than male applicants. Thus, in terms of this ratio there appears to be little difference between majority female-owned firms and majority male-owned firms with respect to accessing debt financing.
Overall, debt financing remains the dominant choice of external financing of both majority female-owned and majority male-owned firms. In 2007, the distribution of financing by type was very similar between the two gender groups, with at least 75 percent of the total amount of financing approved being in the form of debt financing (Figure 4).
Distribution of Approved Financing, 2007 Note * referrer of Figure 4
Note * of Figure 4: Sources of financing in the "Other" category include equity financing and government-sponsored programs.
Figure 4: Distribution of Approved Financing, 2007
Type of Financing
Majority Female-Owned SMEs
Majority Male-Owned SMEs
Loan conditions were very similar between majority female-owned and majority male-owned firms
Previous research has suggested that female business owners were more likely to be asked for collateral as a condition for loan approval than male business owners (Coleman 2002, Riding and Swift 1990), but the data presented in Figure 5 suggest otherwise. In 2004, majority female-owned firms were significantly less likely to be asked for collateral than majority male-owned firms (43 percent versus 61 percent). In 2007, the demand for collateral was almost identical between the two gender groups.
Percentage of SMEs Asked for Collateral as a Condition for Loan Approval Note * referrer of Figure 5
Note * of Figure 5 Bold value denotes statistically significant gender difference at 5 percent.
Figure 5: Percentage of SMEs Asked for Collateral as a Condition for Loan Approval
In terms of interest rates, majority female-owned firms faced higher overall rates than majority male-owned firms in 2004, but in 2007 majority male-owned firms were charged higher overall rates (Table 8). Note, however, that the interest rate charged on long-term debt financing was very similar for both majority female-owned and majority male-owned firms in 2004 and 2007. Overall, there is no convincing evidence that female business owners faced less favourable loan conditions in terms of requests for collateral or interest rates.
Lending Terms (%) (weighted average) Note * referrer of Table 8
Note * of Table 8: As these values are weighted averages of various subcategories, statistical test results were unreliable and are not, therefore, presented here.
Long-Term Rate
Length (months)
Short-Term Rate
Documentation requirements were higher for female business owners
The documentation required as part of the loan application process was greater for female business owners than for male business owners in 2007. As illustrated in Figure 6, female business owners were just as likely, if not more likely, as male business owners to be required to provide each type of documentation listed. In particular, female business owners were significantly more likely to be asked for personal financial statements, appraisals of assets to be financed and cash flow projections than male business owners.
Documentation Required During the Loan Application Process, 2007 Note * referrer of Figure 6
Figure 6: Documentation Required During the Loan Application Process, 2007
Documentation Required
Cash Flow Projection
Appraisals of Assets
Business Financial Statement
Poor credit history and lack of collateral more likely to affect female business owners than male business owners
Previous research has suggested that a weaker credit history may be constraining access to credit among female business owners (Moore 2003). In 2004, 30 percent of female business owners who were denied credit indicated a poor credit history as the reason for being denied credit compared with only 10 percent of male business owners (Figure 7).Footnote 8 In addition, female business owners were more than twice as likely as male business owners to cite a lack of collateral as the reason for being denied credit.
Reasons for Denying Debt Financing, 2004 Note * referrer of Figure 7
Figure 7: Reasons for Denying Debt Financing, 2004
No reason provided
Insufficient sales, income or cash flow
Insufficient collateral/security
Poor credit experience or history
Discouraged borrowers are business owners who require credit but do not apply for financing out of fear of being rejected. In 2004, the vast majority of female business owners who did not apply for credit did not apply because they were not in need of external financing;Footnote 9 however, as illustrated in Figure 8, about 5.4 percent of female business owners who did not apply for credit thought they would be denied financing, a slightly higher rate compared with male business owners (3.5 percent). On the other hand, the study by Orser et al. (2006), which employed 2001 Statistics Canada data, found no statistically significant gender difference in the likelihood of being a discouraged borrower. Indeed, recent research has revealed that when controlling for various firm, owner and market characteristics, female business owners were no more likely to be discouraged borrowers than male business owners (Cole and Mehran 2009).
Reasons for Not Applying for Debt Financing (excluding firms that did not require financing), 2004 Note * referrer of Figure 8
Figure 8: Reasons for Not Applying for Debt Financing (excluding firms that did not require financing), 2004
Thought request would be turned down
Application process too difficult
Application process too time consuming
Cost of debt financing too high
Majority female-owned firms were more likely to use debt financing for working/operating capital than majority male-owned firms
Although majority female-owned firms were just as likely to seek credit financing as majority male-owned firms in 2007 (Table 5), the intended use of the requested financing differed substantially between the two gender groups. As revealed in Table 9, 72 percent of debt-seeking majority female-owned firms intended to use the financing for working capital compared with 56 percent of majority male-owned firms.
Intended Use (%) of Debt Financing, 2007 Note * referrer of Table 9
Note ** of Table 9: Represents the first four categories; SMEs often seek multiple types of fixed assets.
Land and Buildings
Vehicles / Rolling Stock
Other Machinery and Equipment
Fixed Assets Note ** referrer of Table 9
Working Capital / Operating Capital
Debt Consolidations
Purchase a Business
Grow the Business
Other Purposes
Notably, female business owners were significantly more likely to use debt financing to help grow their businesses than male business owners (53 percent versus 34 percent respectively). Majority female-owned firms were also far more likely to use the financing for debt consolidation. On the other hand, majority female-owned firms were less likely to allocate financing to fixed assets, such as vehicles and rolling stock. This may be due to the fact that majority female-owned SMEs are less likely to be goods-producing industries, such as manufacturing, which may, in part, explain why the average approved amount of financing was significantly higher for majority male-owned firms than majority female-owned firms (Table 7).
Female business owners were less likely to use multiple sources of financing to start up a business
Although financial institutions are a prominent source of external financing for all business owners, entrepreneurs seeking to create a new business tend to rely on internal financing sources to acquire capital. As shown in Table 10, personal savings was a major source of financing during start-up for both gender groups in each year surveyed. Leasing surged in popularity as a source of start-up financing among female business owners, jumping from 5 percent in 2004 to 20 percent in 2007. On the other hand, far fewer female business owners used trade credit during start-up in 2007 than in previous years. Overall, female business owners appeared to be less active in acquiring multiple forms of start-up financing compared with male business owners.
Top Sources (%) of Financing During Business Start-Up Note * referrer of Table 10
Note * of Table 10: Bold value denotes statistically significant gender difference at 5 percent. Statistical tests were not carried out for 2000 as the raw data were not made available.
Note ** of Table 10: Figures could not be calculated here as the raw data were not made available for 2000.
Commercial/Personal Loans, Lines of Credit, Credit Cards
Note ** referrer of Table 10 Note ** referrer of Table 10 44 70 49 51
Credit from Government Lending Agencies
8 14 5 20 20 10
Personal Savings of Owner(s)
Loans from Friends and Relatives of Owner(s)
14 11 6 10 9 7
Angel Financing
— — 0.2 3 1 3
Unlike start-up firms, external financing was the most popular source of financing among business owners in more established SMEs
Beyond the start-up stage, external financing is the top source of financing for both gender groups (Table 11). In 2004, male business owners were significantly more likely to use external financing during operations than female business owners; however, this disparity was no longer statistically significant in 2007. While personal savings remained an important source of financing, more than half of the female business owners surveyed in 2007 indicated that they used retained earnings as a financing source. Similar to female business owners engaged in start-up, leasing became more popular among female owners in more established businesses in 2007, whereas trade credit fell out of favour, dropping from 30 percent in 2000 to 14 percent in 2007.
Top Sources (%) of Financing Among Established SMEs Note * referrer of Table 11
— — — — 53 59
Loans from Employees
8 10 6 9 12 8
Among owners who were planning to sell their business, women were far more likely to sell to an external party than men
In 2007, 25 percent of female business owners — the same percentage as male business owners — indicated that they intended to sell, transfer or close their business within five years. Of these business owners, women were far more likely to sell their business to an external party (61 percent) than men (38 percent) (Figure 9). In contrast, men were significantly more likely to transfer or sell the business to a family member. In addition, female business owners were less likely to plan the closure of their business (29 percent) than male business owners (35 percent), but this difference was not statistically significant.
Intentions of Those Who Planned to Sell, Transfer or Close Their Business, 2007 Note * referrer of Figure 9
Figure 9: Intentions of Those Who Planned to Sell, Transfer or Close Their Business, 2007
Transfer to family without money changing hands
Sell to a family member
Sell to an external party
Plan closure of business
Among owners with growth intentions, women were more likely to consider sharing equity to raise capital for expansion than men
Previous studies have suggested that the financial performance of majority female-owned SMEs is associated with the aspirations of the owner with regards to growth (Hughes 2006, Cliff 1998). In 2007, 44 percent of female business owners indicated that they intended to expand the size and scope of their business within two years (Figure 10). This finding conflicts with Orser and Hogarth-Scott (2002), who found that female business owners were less oriented toward growth than male business owners.
SMEs Intending to Expand the Size and Scope of Their Business Note * referrer of Figure 10
Note * of Figure 10: Bold value denotes statistically significant gender difference at 5 percent.
Description of Figure 10
Figure 10: SMEs Intending to Expand the Size and Scope of Their Business
Among the female business owners who declared growth intentions, only 46 percent indicated that their company's current financing was sufficient to fund their expansion plans (compared with 57 percent of male business owners with growth intentions, a statistically significant difference). This finding implies that among owners with growth intentions, women exhibited greater financing needs than men in 2007. Interestingly, of those owners who required additional financing to fund expansion plans, women were significantly more likely than men to consider sharing equity in the business, whereas men were significantly more likely than women to make a loan request (Figure 11). Although previous research has suggested that female business owners are generally hesitant to share business equity out of fear of reduced independence and control (Manigart and Struyf 1997), the evidence presented here implies that majority female-owned firms with growth intentions may view sharing equity as an opportunity for expansion. In other words, female business owners with growth intentions may be more flexible in their capitalization strategies than the literature would suggest.
Capitalization Strategies Considered When Current Financing is Insufficient to Fund Expansion Plans, 2007 Note * referrer of Figure 11
Figure 11: Capitalization Strategies Considered When Current Financing is Insufficient to Fund Expansion Plans, 2007
Sharing equity in the business
Making a loan request
Other strategy
Majority female-owned firms were facing more perceived obstacles to growth than majority male-owned firms
Table 12 presents the perceived obstacles to growth identified by business owners in 2004 and 2007. In 2007, rising business costs was the top perceived obstacle to growth for both majority female-owned and majority male-owned firms; however, female business owners appeared to be more concerned about this obstacle than male business owners. Moreover, majority female-owned firms were also significantly more likely to be concerned about rising competition and insurance premiums than majority male-owned firms. Importantly, 21 percent of female business owners cited access to financing as an obstacle to growth compared with 16 percent of male business owners (a statistically significant difference). Overall, judging by the generally higher comparative percentages for majority female-owned SMEs in 2007, the evidence suggests that female business owners were more likely than male business owners to operate their firms in challenging business environments.
Perceived Obstacles (%) to Growth and Development Note * referrer of Table 12
Perceived Obstacles
Note * of Table 12: Bold value denotes statistically significant gender difference at 5 percent.
Finding Qualified Labour
Levels of Taxation
49 46 — —
Instability of Demand
Low Profitability
Obtaining Financing
— — 10 12
Rising Business Costs
Increasing Competition
Results from previous research on the financial performance of majority female-owned firms have been mixed. While some studies have suggested that businesses owned by women have underperformed compared with businesses owned by men (Fairlie and Robb 2009, Fischer et al. 1993), other studies have produced evidence suggesting that after controlling for factors such as business size, business age and industry effects there is no difference between the two gender groups in terms of financial performance (Watson 2002, Kalleberg and Leicht 1991). Using linked tax file data, weighted annualized average growth rates in total revenue and full-time equivalents (employees) were calculated from 2004 to 2008 (Tables 13 and 14).Footnote 10 As mentioned earlier, the financial performance of a firm can be heavily influenced by initial aspirations for growth. Therefore, growth rates are compared not only across gender but also across growth intentions and financing activities.
Majority female-owned firms that intended to grow in 2004 posted significantly larger growth in total revenue and full-time equivalents (employees) than majority female-owned firms that had no growth intentions
As shown in Table 13, total revenue grew more slowly among majority female-owned SMEs than majority male-owned SMEs regardless of financing activities or growth intentions. Nevertheless, majority female-owned firms that sought financing or had growth intentions in 2004 were able to produce a respectable annualized growth rate of at least 3.6 percent. In sharp contrast, majority female-owned firms with no growth intentions saw total income grow by only 0.9 percent. This discrepancy in growth performance is even larger for majority male-owned firms (6.7 percent versus 1.2 percent for firms with growth intentions and firms with no growth intentions respectively). Thus, notwithstanding the differences in total revenue growth performance between majority female-owned and majority male-owned firms, there is a strong connection between initial growth intentions and actual total revenue growth regardless of gender.
Weighted Annualized Growth Rate (%) in Total Revenue, 2004–2008
SME Category
Source: Tax file data linked to Statistics Canada, Survey on Financing of Small and Medium Enterprises , 2004.
Firms that sought financing
Firms that did not seek financing
Firms that intended to grow
Firms that did not intend to grow
The influence of growth intentions is also apparent in comparisons of growth in full-time equivalents (employees), especially among majority female-owned firms (Table 14). Majority female-owned firms with growth intentions were very active in boosting staff size (7.6 percent growth rate), whereas majority female-owned firms with no growth intentions actually reduced their numbers of employees (−5.3 percent). In addition, majority female-owned firms with growth intentions were also much more likely to hire new employees than majority male-owned firms. These results suggest that majority female-owned firms with growth intentions are playing an important part in job creation in Canada.
Weighted Annualized Growth Rate (%) in Full-Time Equivalents, 2004–2008
−2.5 −1.0
Women entrepreneurs play a significant role in wealth and job creation in Canada. Therefore, it is important to investigate the characteristics of majority female-owned firms and examine if they face unique challenges in acquiring financing. Despite the large amount of research conducted on female business owners, a consensus on access to financing by and the financial performance of majority female-owned firms is sometimes elusive. Using primarily 2004 and 2007 data from the Statistics Canada Survey on Financing of Small and Medium Enterprises , this report aimed to update the business profile of female business owners, conduct comparisons with male business owners and reveal important new trends that may be emerging among majority female-owned SMEs.
Although significantly fewer female business owners were under 40 years of age in 2007 compared with 2004, the average female business owner was still younger and had less management or ownership experience than the average male business owner. Moreover, majority female-owned firms were typically younger and more likely to be operating in the tourism sector than majority male-owned firms.
On the other hand, there is some evidence that majority female-owned SMEs may be catching up in term of business size to majority male-owned firms. Majority female-owned firms also had comparable amounts of before-tax net profit, assets and equity to majority male-owned firms in 2007. A word of caution should be made here, however, with regards to the interpretation of these results. Due to data limitations, it is too early to tell whether the results represent a short-term phenomenon or a long-term trend. Further data and research will be required to resolve this issue.
Majority female-owned firms were just as likely to seek external financing as majority male-owned firms in 2007. While there appears to be a difference in approval rates for debt financing between the gender groups in 2007, upon closer examination majority female-owned firms had a very similar approval rate as majority male-owned firms when it came to long-term debt financing, which accounted for almost two thirds of the total amount of debt financing requested by majority female-owned firms. However, majority female-owned firms were significantly less likely to be approved for short-term debt financing than majority male-owned firms. When measured as a ratio of the aggregated amount of approved debt financing to the aggregated amount of requested debt financing, however, the ratios were very similar between the gender groups in both 2004 and 2007. Thus, in terms of this ratio, there appears to be little difference in access to credit between majority female-owned and majority male-owned firms.
This report also found little evidence of disparity with regards to interest rates or requests for collateral between majority female-owned and majority male-owned firms that received debt financing. On the other hand, among SMEs that were denied debt financing, majority female-owned firms were significantly more likely to be turned down due to poor credit or insufficient collateral than majority male-owned firms.
Among SMEs with growth intentions, majority female-owned firms were more likely to require external financing to fund expansion plans than majority male-owned firms. While a majority of firms with growth intentions considered making a loan request to support these plans, majority female-owned firms were more likely to consider sharing equity in the business than majority male-owned firms, which contradicts previous research suggesting that female business owners were more hesitant than male business owners to change the ownership structure.
Based upon linked tax file data, majority female-owned SMEs exhibited lower growth rates in total revenue than majority male-owned SMEs. In terms of growth rates of full-time equivalents (employees), majority female-owned firms with growth intentions were significantly more active in hiring new employees than majority male-owned firms. Perhaps more importantly, firms with growth intentions posted noticeably stronger growth performances than firms with no growth intentions regardless of gender.
Results presented in this report suggest that while there continues to be differences between majority female-owned and majority male-owned SMEs, some of these differences may be fading. This report also provides evidence that the financing strategies and growth patterns of majority female-owned firms are influenced by initial growth intentions. Consequently, investigating female business owners as a homogeneous group will likely mask the varying financing challenges within this group. Indeed, the relationship between financing needs and growth intentions will likely be evident in other forms of SME categorization (e.g., rural firms, exporters). Further research that focuses on separate groups of female business owners by growth intentions, rather than comparisons made solely across gender, may help researchers gain a better understanding of the actual financing needs and concerns of this very important group of entrepreneurs.
Carter, N., 2002. "The Role of Risk Orientation on Financing Expectations in New Venture Creation: Does Sex Matter?" Frontiers of Entrepreneurship Research , Babson-Kauffman Foundation, accessed July 9, 2010.
Cliff, J.E., 1998. "Does One Size Fit All? Exploring the Relationship between Attitudes towards Growth, Gender, and Business Size." Journal of Business Venturing , Vol. 13, No. 6, 523–542.
Cole, R.A. and H. Mehran, 2009. "Gender and the Availability of Credit to Privately Held Firms: Evidence from the Surveys of Small Business Finances." Federal Reserve Bank of New York Staff Report No. 383.
Coleman, S., 2002. "Constraints Faced by Majority Female-Owned Firms Small Business Owners: Evidence from the Data." Journal of Developmental Entrepreneurship , Vol. 7, No. 2, 151–173.
Fabowale, L., B. Orser and A. Riding, 1995. "Gender, Structural Factors, and Credit Terms between Canadian Small Businesses and Financial Institutions." Entrepreneurship Theory and Practice , Vol. 19, No. 4, 41–65.
Fairlie, R. and A.M. Robb, 2009. "Gender Differences in Business Performance: Evidence from the Characteristics of Business Owners Survey." University of California at Santa Cruz: Department of Economics.
Fischer, E.M., A.R. Reuber and L.S. Dyke, 1993. "A Theoretical Overview and Extension of Research on Sex, Gender and Entrepreneurship." Journal of Business Venturing , Vol. 8, No. 2, 151–168.
Hughes, K.D., 2006. "Exploring Motivation and Success Among Canadian Female Business Owners." Journal of Small Business and Entrepreneurship , Vol. 19, No. 2, 107–120.
Jennings, J.E. and M.P. Cash, 2006. "Majority Female-Owned Firms's Entrepreneurship in Canada: Progress, Puzzles and Priorities." In Brush, C.G., N.M. Carter, E.J. Gatewood, P.G. Greene and M.M. Hart (eds.), Growth Oriented Female Business Owners and Their Businesses: A Global Research Perspective , London: Edward Elgar, 53–87.
Kalleberg, A.L. and K.T. Leicht, 1991. "Gender and Organizational Performance: Determinants of Small Business Survival and Success." Academy of Management Journal , Vol. 34, No. 1, 136–161.
Manigart, S. and C. Struyf, 1997. "Financing High Technology Startups in Belgium: An Explorative Study." Small Business Economics , Vol. 9, 125–135.
Moore, D.P., 2003. "Majority Female-Owned Firms: Are You Ready to Be Entrepreneurs?" Business & Economic Review , Vol. 49, No. 2, 15–21.
Orser, B. and S. Hogarth-Scott, 2002. "Opting for Growth: Gender Dimensions of Choosing Enterprise Development." Canadian Journal of Administrative Sciences , Vol. 19, No. 3, 284–300.
Orser, B.J., A.L. Riding and K. Manley, 2006. "Women Entrepreneurs and Financial Capital." Entrepreneurship Theory and Practice , Vol. 30, No. 5, 643–665.
Riding, A.L. and C.S. Swift, 1990. "Majority Female-Owned Firms Business Owners and Terms of Credit: Some Empirical Findings of the Canadian Experience." Journal of Business Venturing , Vol. 5, No. 5, 327–340.
Watson, J., 2002. "Comparing the Performance of Male and Female-Controlled Businesses: Relating Outputs to Inputs." Entrepreneurship Theory and Practice , Vol. 26, No. 3, 91–100.
Financing Profiles is an ongoing series of articles on specific segments of the marketplace and a component of Industry Canada's reporting efforts on SME financing.
Statistics Canada administers a series of national surveys on small and medium-sized enterprises ( Survey on Financing of Small and Medium Enterprises ) and financial providers ( Survey of Suppliers of Business Financing ). Industry Canada supplements these surveys with additional research into niche areas of SME financing.
For further information regarding the methodology of the Survey on Financing of Small and Medium Enterprises , visit Statistics Canada's website.
For further information on this profile, email SBB-DGPE.
Internal Reviewers
Richard Archambault, Industry Canada
Denis Martel, Industry Canada
External Reviewer
Karen D. Hughes, University of Alberta
Jennifer E. Jennings, University of Alberta
Barbara J. Orser, University of Ottawa
Source: Statistics Canada, CANSIM, Table 282-0012.
Tax file data were linked to both the 2004 and 2007 Statistics Canada data sets. The data also included unincorporated firms, but the volume of data was much more limited than that provided on incorporated firms. All tax file data are anonymous and cannot be traced back to a particular firm.
Due to the frequent presence of large outliers, the use of median values — in lieu of average values — was considered to be more reasonable.
Due to a lack of observations, equity approval rates in 2004 and 2007 were considered to be unreliable and, therefore, are not presented in the table.
The 2004 and 2007 comparisons of approval rates partially conflict with the results of Orser et al. (2006), who found that in 2001 female business owners were not more likely to be rejected for debt financing, leasing or trade credit at a statistically significant level than male business owners. In 2007, short-term debt financing represented about 36 percent of total debt financing requested by female owners.
In other words, a request for financing would be considered "approved" as long as "some" amount of financing was approved, not necessarily the full amount requested.
In this case, each request for financing had the same weight in the calculations, even though the amount of financing requested could differ substantially from one request to another.
Due to a lack of observations, results from the 2007 survey were deemed to be unreliable.
The 2007 survey does not include information regarding reasons for not applying for credit.
Growth rates were calculated only for incorporated firms that reported figures for both 2004 and 2008. Consequently, the results presented in Tables 13 and 14 do not include unincorporated SMEs or SMEs that were no longer in existence in 2008. To calculate the weighted growth rates, aggregated figures by gender group in each year were utilized.
Venture Capital Catalyst Initiative
Business Accelerators and Incubators
Venture Capital Action Plan
Key Small Business Statistics
Financial Performance Data
Determinants of Entrepreneurship in Canada: State of Knowledge
Canada Small Business Financing Program: Economic impact analysis – July 2019
Survey data and analysis
Page: E061-H02215 | CommonCrawl |
DISCONTOOLS: a database to identify research gaps on vaccines, pharmaceuticals and diagnostics for the control of infectious diseases of animals
Declan O'Brien1,
Jim Scudamore2,
Johannes Charlier3 &
Morgane Delavergne1
BMC Veterinary Research volume 13, Article number: 1 (2017) Cite this article
The public and private sector in the EU spend around €800 million per year on animal health and welfare related research. An objective process to identify critical gaps in knowledge and available control tools should aid the prioritisation of research in order to speed up the development of new or improved diagnostics, vaccines and pharmaceuticals and reduce the burden of animal diseases.
Here, we describe the construction of a database based on expert consultation for 52 infectious diseases of animals.
For each disease, an expert group produced a disease and product analysis document that formed the basis for gap analysis and prioritisation. The prioritisation model was based on a closed scoring system, employing identical weights for six evaluation criteria (disease knowledge; impact on animal health and welfare; impact on public health; impact on wider society; impact on trade; control tools). The diseases were classified into three groups: epizootic diseases, food-producing animal complexes or zoonotic diseases.
The highly ranked diseases in the prioritisation model comprised mostly zoonotic and epizootic diseases with important gaps identified in vaccine development and pharmaceuticals, respectively. The most important outcome is the identification of key research needs by disease. The rankings and research needs by disease are provided on a public website (www.discontools.eu) which is currently being updated based on new expert consultations.
As such, it can become a reference point for funders of research including the European Commission, member states, foundations, trusts along with private industry to prioritise research. This will deliver benefits in terms of animal health and welfare but also public health, societal benefits and a safe and secure food supply.
Animal diseases are estimated to reduce the production of animal products by at least 20% according to the World Organisation for Animal Health (OIE) [1]. As such, the prevention and control of animal diseases has benefits in terms of animal health and welfare but also human health where zoonoses are concerned and broad societal benefits in terms of companion animal health and the security of a safe food supply.
In terms of funding, it is estimated that the public sector spends €400 million per year in Europe on animal health and welfare related research [2, 3] and the private sector spends €400 million per year on animal health research [4]. With about €800 million being spent per year, the added value of an objective process to prioritise critical research can be appreciated. By focusing a proportion of this expenditure on critical gaps in priority diseases, it will be possible to speed up the development and delivery of new and improved disease control tools including diagnostics, vaccines and pharmaceuticals to reduce the burden of disease on animals. Given that the current value of animal based products at producer prices in the E.U. is €154 billion per year [5], every percentage reduction in the impact of animal disease on production would be of major economic importance.
During the work of the European Technology Platform for Global Animal Health (ETPGAH)Footnote 1 from 2004 to 2012, it was recognised that disease prioritisation was one of the most important initiatives that needed to be undertaken to focus and prioritise research [6]. This work necessitates the identification of gaps in knowledge as well as control tools – diagnostics, vaccines and pharmaceuticals.
The DISCONTOOLS project was funded under the EU 7th framework programme from 2008 to 2013 and originated from the Action Plan of the ETPGAH. The general objective of the project was to evaluate global animal health priorities and the risk they could pose to the European Union. This understanding would assist in ensuring the most effective allocation of research funding. The project led to the development of a disease database containing a gap analysis and prioritisation model for 52 infectious diseases of animals. The objective of this paper is to describe the different steps in the development of the database (Section Construction and content), describe its utility (Section Utility) and discuss how it could assist policy makers in targeting research funding (Section Discussion). It should be noted that the focus of the database is on research needs with respect to control tools in the form of diagnostics, vaccines and pharmaceuticals. It does not necessarily consider disease control strategies or other aspects of disease control such as disease modelling, surveillance and regulatory support.
The DISCONTOOLS project was organised as shown in Fig. 1. All European and Global organisations with an interest in animal health research were invited to join the Stakeholder Forum. It included organisations ranging from farmers, veterinarians and the pharmaceutical industry to chief veterinary officers, research institutes and related projects funded by the European Commission. The Project Management Board (PMB) comprised 10 representatives from the Stakeholders selected to represent research, industry, users and public bodies. The membership is listed in Table 1.
Organisation of the DISCONTOOLS project
Table 1 Organisations represented in the Project Management Board of DISCONTOOLS
Five work packages or working groups were established each reporting to the PMB. Of these two working groups one on disease prioritisation, the other on gap analysis were involved in developing the database (See Fig. 1). Membership of the two working groups consisted of approximately 15 people and was by invitation along with nominations from the stakeholders and interested parties. It was important that each of the groups was balanced with members with appropriate expertise from research, industry, users (including farming and veterinary profession) and regulators as well as the European Commission and international organisations.
The development of the database was preceded by a review of existing processes for prioritisation and gap analysis by the PMB in order to steer the methodology adopted. Subsequently, the disease list was selected and prioritisation methodology developed, followed by expert opinion elicitation to provide content to the database. The prioritisation methodology was subdivided in the development of Disease & Product analysis document (D&P), a prioritisation model and gap analysis model.
Review of existing prioritisation models
A worldwide review of existing models was carried out. In public health, a number of studies have methodically prioritised communicable diseases and pathogens [7–15]. In the field of animal health, most studies have focused on prioritisation of food-borne and zoonotic pathogens [13, 16–20]. In addition, studies have also been conducted with the specific aims of prioritising surveillance of wildlife pathogens [21], disease control for poverty alleviation [22], non-regulatory animal health issues [23] and exotic diseases and emerging animal health threats [24, 25].
Although methodological approaches differ, priority-setting studies typically follow a series of steps: (i) selecting a group of diseases/pathogens for prioritization; (ii) identifying a list of appropriate and measurable criteria to assess diseases/pathogens; (iii) defining a range of levels for each criterion; (iv) determining the relative importance by means of a weight or score for each level and criterion; (v) aggregating to produce an overall score for each disease/pathogen; and (vi) ranking diseases/pathogens by their overall score to derive a recommended list for prioritization [26]. It was evident that risk-based priority-setting should be systematic, flexible, reproducible and informative to public policy. The criteria must be explicit, measurable, relevant and objective wherever possible. However, the methodology and criteria required will depend on the goal of prioritisation, so a clear definition of the aim is essential. The priority-setting process should be transparent and open to discussion and revision. In addition, it is considered preferable to define a disease as specifically as possible (e.g. brucellosis of cattle versus brucellosis in general) and to consider how the model can evolve over time in order to remain of value. On the basis of the review, and considering the goal of DISCONTOOLS, i.e. identifying research needs of infectious animal diseases in the EU, the main steps which have been followed include establishing a list of relevant infectious diseases and gathering relevant information on each disease. It was considered essential that the scoring system allows diseases to be ranked based on total scores and/or on scores for particular criteria (e.g. impact on public health).
Establishment of disease list
The working groups of the DISCONTOOLS project were created by inviting stakeholders to become involved in WP2, WP3 and/or WP4 with the PMB taking care of WP1 and WP5 (see Fig. 1). In parallel, the PMB invited an expert to Chair each of WP2, WP3 and WP4. The WPs then established a list of 52 priority diseases to be included in the prioritisation exercise. The starting point for the list of diseases was from the Action Plan of the ETPGAH which referred to 47 diseases. In addition, it was considered important not to lose sight of endemic diseases or disease syndromes (e.g. internal parasites, mastitis). Therefore, 3 groups of diseases were defined as follows:
epizootic diseases: infectious diseases which pose a risk for introduction or spread in the EU and for which tools for optimum detection, surveillance and control would be beneficial;
food producing animal complexes: major enzootic diseases of livestock in Europe;
zoonotic diseases: infectious diseases of animals that are important for human health and for their socio-economic effects.
The geographic dimension of the project was primarily European. Naturally, where a disease was not present in Europe, a global perspective was taken into account. The expert groups were asked to highlight and take into account strains and species where the economic impact was the highest not only in Europe, but worldwide.
After discussions of the working groups of DISCONTOOLS a final list of 52 diseases was agreed. The list was not considered to be exhaustive, but representative of most disease scenarios. Infectious diseases of aquatic animals or companion animals without a zoonotic implication were not considered.
Prioritisation methodology
Disease and product analysis document
A D&P was developed for each disease by the working groups of the DISCONTOOLS project in order to have key information available prior to scoring of the different criteria. The D&P is a reference document that provides the detailed and relevant information for each disease which is necessary to support the scoring for the prioritisation and gap analysis models. It contains 23 main sections with sub-headings covering a wide range of aspects such as description and characteristics of the disease, route of transmission, zoonotic potential, control tools available, and socio-economic impact. The full list of sections may be consulted at www.discontools.eu/diseases under the custom report section. For each section, an additional column headed "Gaps identified" was included in the D&P to gather further information on the gaps in knowledge and products of each disease. The document was completed by the expert groups who were asked to reach a consensus on the final text which was then reviewed by the PMB.
Prioritisation model
The criteria, levels within each of the criteria, scores and weighting coefficients that were used in the prioritisation model can be viewed in Table 2. Six criteria were considered:
disease knowledge
impact on animal health and welfare
impact on public health
impact on wider society
impact on trade
control tools
Table 2 The prioritisation model: criteria considered, levels within the criteria, scores and applied weighting coefficients (Coef)
An interpretation guide (http://www.discontools.eu/upl/1/default/doc/1233_PrioInterV3-1-20110303.pdf) was developed to help the expert groups decide on the appropriate scores to apply to each criterion. The expert groups were asked to reach a consensus for the scoring of each criterion. A 5 – tiered scoring system was chosen as this appeared to offer a greater flexibility across the various criteria. The scoring scale applied to the 5-tiered system is as follows: for the first five sections 0, +1; +2; +3; +4 are used; for the sixth section dealing with control tool scores of +2; +1; 0; −1; −2 are used. This scoring scale was selected to highlight the differences in control tools for each disease in the sense that if for a particular disease a vaccine exists that has a high level of efficacy, quality, safety and availability, then a negative score will be attributed to the final total score of the concerned disease to diminish its priority as an effective tool is available. On the contrary, if control tools are missing, then a positive score will be added to the total score meaning that the disease will be higher in the prioritised list of diseases.
The weighting coefficient for each level of a criterion was computed as follows:
$$ W = \frac{100}{X*I} $$
where W = the weighting coefficient, X is the maximum score of a level within a criterion and I is the number of levels within a criterion. This ensured that the maximum score of each criterion was 100 and that the different criteria were attributed the same weight in the overall score.
As there are 6 criteria for each disease, the scores could be grouped, listed, ranked or presented in a wide range of ways using either the overall score or the individual scores for each criteria.
Gap analysis model of control tools
The criteria, levels within each of the criteria, scores and weighting coefficients that were used in the gap analysis model can be viewed in Table 3. Gap analysis considered 3 areas: diagnostic, vaccine and pharmaceutical gaps. The scoring system goes from +2 (important gap) to −2 (current tools are appropriate and no need to focus research in this area). As with the prioritisation model, an interpretation guide was developed to facilitate consistency in scoring (http://www.discontools.eu/upl/1/default/doc/1235_GapAna-Inter-V3-1.pdf).
Table 3 The gap analysis model: criteria considered, levels within the criteria, scores and applied weighting coefficients (Coef)
Expert opinion elicitation
An expert group leader was appointed for each disease and was asked to engage other experts. Where possible each group was asked to include experts with laboratory and diagnostic expertise, an epidemiologist, an industry representative and an individual with economic/trade expertise. The leader was expected to organise a physical or e-meeting in order to provide the information as described below. The names of the experts are published on the DISCONTOOLS website.
The average number of experts per group was 7. For 43 of the 52 included diseases (83%) the expert groups involved at least 4 members considered to cover the requested expertise (diagnostic, epidemiology, industry, economics). However for 9 diseases (17%), ≤3 experts were included (i.e. contagious bovine pleuropneumonia, swine influenza virus, peste des petits ruminants, rift valley fever, liver fluke, bovine herpes virus type 1, leptospirosis, salmonella, Crimean congo haemorrhagic fever).
DISCONTOOLS website
The DISCONTOOLS website contains two main sections: (i) work group pages and (ii) the disease database. The work group pages contain relevant minutes, documents and presentations related to meetings of the project management board.
The disease database contains the full D&P, along with a 2-page summary to make it easy to interpret the outcome. All the available information can be filtered for specific diseases or specific sections of the analysis and the customized reports can be downloaded in.pdf or.xls format. There is also a tool to enable web site users to provide comments on the D&P to the DISCONTOOLS secretariat. The prioritisation model and gap analysis model can be consulted for one or more diseases simultaneously and the specific scores for individual levels of criteria can be consulted or downloaded through custom reports.
Ranking of diseases by prioritisation model, disease category and gap analysis model
In Table 4, diseases are ranked based on the total score of the prioritisation model. The Table is very useful in terms of providing a 'Big Picture' view and shows that the top ranked diseases comprise mostly zoonotic diseases and epizootic (often exotic) diseases. This, in turn, helps to guide funders who are working in an international environment and with a broad remit in terms of priorities. In Table 5, the diseases were ranked within disease category. This provides an opportunity to identify priorities within different research domains. As such, funders with an interest in public health will look to the zoonoses ranking. In contrast, funders focusing on international trade will have a great interest in the epizootic diseases ranking and funders who are focusing on the efficiency of production, especially within individual countries, will have a great interest in the ranking of food producing animal complexes. The results of the gap analysis model can be used to obtain more details of the gaps in control tools. As an example, in Table 6 we provide the scores of the gap analysis model for diagnostics, vaccines and pharmaceuticals for the top 10 ranked diseases within each disease category. In general, this table highlights the major gap in pharmaceuticals for the epizootic diseases which is not surprising as the availability of antivirals for the majority of diseases is very limited or non-existent at present. In contrast, for the food producing animal complexes, the picture is more diverse with, dependent on the disease, remaining gaps in diagnostics and vaccines and less so in pharmaceutical development. For the zoonotic diseases, good diagnostics are generally available and the analysis highlights the need for research into vaccine development. It should be noted that, whilst the gap is identified, in many cases, it is unlikely that a pharmaceutical solution would be pursued, for example Bluetongue.
Table 4 Ranking of 52 infectious diseases of animals by the overall score of the prioritisation model
Table 5 Ranking of 52 infectious diseases of animals by disease category based on the prioritisation model
Table 6 Scores from the gap analysis model for the top-10 ranked diseases within each disease categorya
The aim of the DISCONTOOLS project was to build a prioritisation model and gap analysis on control tools as a means of prioritising research on infectious animal diseases with the support of stakeholders via a very open consultation process in the animal health research community.
The major achievement of this project consists of the wide and standardized consultation of the animal health research community, involving a total of 342 animal health scientists from all over the world. The establishment of expert groups was an important step in itself because it brought together scientists from different backgrounds and expertise often leading to lively debate, the challenge of assumptions and the identification of research gaps within their field. Where expert groups could not reach consensus, this was recorded in the D&P under the "Gap" section because it represents a gap in knowledge that needs to be filled by research.
An example is the benefit of bees to pollination. At the outset of the discussion, it was suggested by some of the participants that crop yields could decline by 65% without bees. However, when it was pointed out that wild insects have a more important role in pollination than honey bees, major crop species such as cereals are self-pollinating and many others are wind pollinated [27], it was agreed that the impact would be considerably less and it was noted that work needs to be done in this area to determine the real impact. Having had this discussion, it was recognised that efforts should be made to control Varroa mite as the bee sector – with its various products – is valuable (roughly estimated in the consortium at €640 million per annum) and needs to be protected.
As was done in Table 3, it is possible to rank diseases by total scores of the prioritisation model. The total score is valuable in highlighting the overall importance of some diseases. Nipah virus obtained the highest score. This was an interesting outcome and its high ranking is confirmed in other recent studies to prioritize diseases of food-producing animals and zoonoses [25, 28]. In the case of FMD, it scores highly due to knowledge gaps along with its impact on animal health and welfare, society and trade even though we have good diagnostics and vaccines. Given the impact of the disease, we need heat stable multi-valent vaccines and need to focus research in this area.
It might be surprising that the overall total for FMD (310) in the prioritisation model is lower than that for ASF (373) but an examination of the score in each of the six separate categories (Table 2) which make up the prioritisation model it is apparent where the variation exists. In the case of ASF the score is higher for the impact on international trade, animal health and welfare and significantly higher for control tools where there is no vaccine and diagnostic tests need to be improved.
Despite the maximally standardized consultation rounds and the use of a validation system in the form of Work Packages 2 and 3 and the PMB, the final ranking of diseases should be interpreted with caution. The total scores also hide specific research needs within a disease. In the case of nematodes for example, the total score hides the pressing need to assign resources to the development of vaccines in this area [29]. To avoid the user missing key data, the "Interpretation of the Scores Guide" was developed as well as the two page summary for each disease. The latter is of particular assistance to the non-specialist user who wants an overview of the critical research needs. Depending on the aim of the research, it may be more informative to compare specific criteria only between diseases (e.g. disease knowledge, impact on wider society, etc.). Two critical factors that can affect the results are: (i) the choice of the weighting coefficients and (ii) the different composition of each expert group. The different criteria of the prioritisation model such as disease knowledge, impact on animal health and welfare, etc. received an equal weight. However, depending on the user, different weight attributions may be desirable. Recently, novel methods have been developed to identify criteria important to different stakeholders by using the nominal group technique and attribute relative weights to the criteria using a wide consultation of different stakeholders and conjoint analysis [26]. This can result in different rankings according to the criteria and weights defined by different stakeholders (e.g. the public vs. health professionals) and provide additional insights to the decision maker on the spending of research funds [19]. In contrast to other prioritisation studies where all diseases were scored by the same expert panel, e.g. [13, 28], in the DISCONTOOLS project, each disease was scored by a different expert panel. This may have introduced bias due to inter-personal differences in scoring, but was considered necessary in order to adequately capture the current status of knowledge and gaps for control tools for each disease.
The epidemiological situation of infectious animal diseases can change rapidly (e.g. the current epidemic of the new porcine epidemic diarrhoea virus [30]), and biotechnological developments constantly change the landscape of diagnostics, vaccines and pharmaceuticals. As a consequence, the prioritisation exercise should be repeated regularly [28]. To this end, the database has been placed on a public website with the possibility that the public and research community can provide comments. This was deliberately done to provide an environment where the information in the D&P and the scores could be challenged. The idea is to gather comments over time and then ask the expert group to consider comments made and adjust the information and scoring on the site as appropriate. It is foreseen that the diseases will be systematically reviewed by the expert groups over a 5-year cycle, taking on board the latest technical advances. In fact, this process has already commenced and updated information on the site is available for African swine fever, Foot and mouth disease, Nematodes and Verocytotoxigenic E. coli.
A database was established with the intention of identifying and prioritising research needs in the control of infectious animal diseases in the EU. If the focus of research is now placed on the priorities identified, it will hasten the development of diagnostics, vaccines and pharmaceuticals and reduce the 20% loss in production potential, valued at €28 billion per year in the EU. Funders of research including the European Commission, member states, foundations, trusts along with private industry should use the database to prioritise and focus future research. This will deliver benefits in terms of animal health and welfare but also public health, societal benefits and a safe and secure food supply. The employed method and results should not be considered fixed, but by refining the scoring methodology, challenging and updating the available information on a regular basis and incorporating new diseases, the DISCONTOOLS database has the potential to become a reference point used by stakeholders when prioritising research.
www.etpgah.eu
D&P:
ETPGAH:
European Technology Platform for Global Animal Health
OIE:
World Organisation for Animal Health
PMB:
Project Management Board
Vallat B. One World, One Health. In: Editorials from the Director-General. Publisher: World Organisation for Animal Health (oie). 2009. http://www.oie.int/en/for-the-media/editorials/detail/article/one-world-one-health/. Accessed 20 Aug 2014.
Benmansour A. Animal Health and Welfare ERA-net (anihwa). 2012. https://www.anihwa.eu/About-Anihwa/Project-description. Accessed 20 Aug 2014.
Anonymous. Common financial framework for the food chain. 2014. http://ec.europa.eu/food/animal/diseases/index_en.htm. Accessed 20 Aug 2014.
IFAH. Annual Report 2013 International Federation for Animal Health-Europe. 2014. p. 12.
EUROSTAT. Key figures on Europe, 2013 digest of the online Eurostat yearbook. Luxembourg: Piirto Jukka; 2013. p. 184.
European Technology Platform for Global Animal Health. Action plan. 2007. http://www.etpgah.eu/action-plan.html. Accessed 20 Aug 2014, 52 pp.
Rushdy A, O'Mahony M. PHLS overview of communicable diseases 1997: results of a priority setting exercise. Commun Dis Rep CDR Wkly. 1998;8:S1–S12.
Weinberg J, Grimaud O, Newton L. Establishing priorities for European collaboration in communicable disease surveillance. Eur J Public Health. 1999;9:236–40.
Doherty JA. Establishing priorities for national communicable disease surveillance. Can J Infect Dis. 2000;11:21–4.
Horby P, Rushdy A, Graham C, O'Mahony M. PHLS overview of communicable diseases 1999. Comm Dis Publ Health. 2001;4:8–17.
WHO. Setting priorities in communicable disease surveillance. Global Alert and Response publications. 2006; 32 pp.
Krause G, Working Group on Prioritisation at the Robert Koch Institute. Prioritisation of infectious diseases in public health–call for comments. Euro Surveill. 2008;13(40):18996.
Cardoen S, Van Huffel X, Berkvens D, Quoilin S, Ducoffre G, Saegerman C, Speybroeck N, Imberechts H, Herman L, Ducatelle R, Dierick K. Evidence-based semiquantitative methodology for prioritization of foodborne zoonoses. Foodborne Pathog Dis. 2009;6:1083–96.
Balabanova Y, Gilsdorf A, Buda S, Burger R, Eckmanns T, Gartner B, Gross U, Haas W, Hamouda O, Hubner J, Janisch T, Kist M, Kramer MH, Ledig T, Mielke M, Pulz M, Stark K, Suttorp N, Ulbrich U, Wichmann O, Krause G. Communicable diseases prioritized for surveillance and epidemiological research: results of a standardized prioritization procedure in Germany, 2011. Plos One. 2011;6:e25691.
Cox R, Sanchez J, Revie CW. Multi-criteria decision analysis tools for prioritising emerging or re-emerging infectious diseases associated with climate change in Canada. Plos One. 2013;8:e68338.
Havelaar AH, van Rosse F, Bucura C, Toetenel MA, Haagsma JA, Kurowicka D, Heesterbeek JH, Speybroeck N, Langelaar MF, van der Giessen JW, Cooke RM, Braks MA. Prioritizing emerging zoonoses in the Netherlands. Plos One. 2010;5:e13965.
Ng V, Sargeant J. An empirical and quantitative approach to the prioritization of zoonotic diseases of public health importance in Canada. Ecohealth. 2011;7:S114.
Sargeant J, Ng V. The current state of knowledge of zoonoses and the implications for research outcomes in disease prioritization in Canada. Ecohealth. 2011;7:S34.
Ng V, Sargeant JM. A quantitative approach to the prioritization of zoonotic diseases in north America: a health professionals' perspective. Plos One. 2013;8:e72172.
FAO/WHO. Multicriteria-based ranking of risk management of food-borne parasites. Microbiological Risk Assessment Series. 2014;23:302.
McKenzie J, Simpson H, Langstaff I. Development of methodology to prioritise wildlife pathogens for surveillance. Prev Vet Med. 2007;81:194–210.
Heffernan C. Panzootics and the poor: devising a global livestock disease prioritisation framework for poverty alleviation. Rev Sci Tech – OIE. 2009;28:897–907.
More SJ, McKenzie K, O'Flaherty J, Doherty ML, Cromie AR, Magan MJ. Setting priorities for non-regulatory animal health in Ireland: Results from an expert Policy Delphi study and a farmer priority identification survey. Prev Vet Med. 2010;95:198–207.
Vilas VJD, Voller F, Montibeller G, Franco LA, Sribhashyam S, Watson E, Hartley M, Gibbens JC. An integrated process and management tools for ranking multiple emerging threats to animal health. Prev Vet Med. 2013;108:94–102.
Brookes VJ, Hernandez-Jover M, Cowled B, Holyoake PK, Ward MP. Building a picture: prioritisation of exotic diseases for the pig industry in Australia using multi-criteria decision analysis. Prev Vet Med. 2014;113:103–17.
Ng V, Sargeant JM. A stakeholder-informed approach to the identification of criteria for the prioritization of zoonoses in Canada. Plos One. 2012;7:e29752.
Garibaldi LA, Steffan-Dewenter I, Winfree R, Aizen MA, Bommarco R, Cunningham SA, Kremen C, Carvalheiro LG, Harder LD, Afik O, Bartomeus I, Benjamin F, Boreux V, Cariveau D, Chacoff NP, Dudenhoffer JH, Freitas BM, Ghazoul J, Greenleaf S, Hipolito J, Holzschuh A, Howlett B, Isaacs R, Javorek SK, Kennedy CM, Krewenka KM, Krishnan S, Mandelik Y, Mayfield MM, Motzke I, Munyuli T, Nault BA, Otieno M, Petersen J, Pisanty G, Potts SG, Rader R, Ricketts TH, Rundlof M, Seymour CL, Schuepp C, Szentgyorgyi H, Taki H, Tscharntke T, Vergara CH, Viana BF, Wanger TC, Westphal C, Williams N, Klein AM. Wild pollinators enhance fruit set of crops regardless of honey bee abundance. Science. 2013;339:1608–11.
Humblet MF, Vandeputte S, Albert A, Gosset C, Kirschvink N, Haubruge E, Fecher-Bourgeois F, Pastoret P-P, Saegerman C. Multidisciplinary and evidence-based method for prioritizing diseases of food-producing animals and zoonoses. Emerg Infect Dis. 2012;18. doi: 10.3201/eid1804.111151
Vercruysse J, Schetters TPM, Knox DP, Willadsen P, Claerebout E. Control of parasitic diseases using vaccines: an answer to drug resistance? Rev Sci Tech – OIE. 2007;26:105–15.
Chen Q, Li G, Stasko J, Thomas JT, Stensland WR, Pillatzki AE, Gauger PC, Schwartz KJ, Madson D, Yoon KJ, Stevenson GW, Burrough ER, Harmon KM, Main RG, Zhang J. Isolation and characterization of porcine epidemic diarrhea viruses associated with the 2013 disease outbreak among swine in the United States. J Clin Microbiol. 2014;52:234–43.
We wish to thank all Expert Group leaders and members of Expert Groups and stakeholders for their invaluable contribution to the success of the DISCONTOOLS Project.
This project was funded by the 7th framework programme of the EU (grant agreement number 211316) and currently receives funding from different research funding bodies from EU member states.
The database generated during this project is publicly available on www.discontools.eu.
DOB conceived the study, coordinated the project and supervised the manuscript. JS assisted in project management, wrote the manuscript and the disease summaries. JC wrote the manuscript and manages the database from 2014. MD managed the project and maintained the database from 2008 to 2013. All authors read and approved the final manuscript.
DOB was the coordinator of the project under the 7th framework programme on behalf of IFAH-Europe but is currently no longer employed by this organisation. JC is the current project manager commissioned by IFAH-Europe.
Being a stakeholder driven project, all those involved in the chain from research to commercialisation of products including universities, regulators, farming and veterinary representative organisations along with the pharmaceutical industry contributed to the outcome of this study. The authors declare that they have no financial or personal relationships with other people or organisations that could have inappropriately influenced the present study and manuscript.
Name of disease experts are published below the disease information where written consent has been given. Experts retain the right to access, change or remove their personal data.
International Federation for Animal Health Europe, Avenue de Tervueren 168, box 8, 1150, Brussels, Belgium
Declan O'Brien
& Morgane Delavergne
Institute of Infection and Global Health, University of Liverpool, Liverpool, UK
Jim Scudamore
Avia-GIS, Risschotlei 33, 2980, Zoersel, Belgium
Search for Declan O'Brien in:
Search for Jim Scudamore in:
Search for Morgane Delavergne in:
Correspondence to Declan O'Brien.
O'Brien, D., Scudamore, J., Charlier, J. et al. DISCONTOOLS: a database to identify research gaps on vaccines, pharmaceuticals and diagnostics for the control of infectious diseases of animals. BMC Vet Res 13, 1 (2016). https://doi.org/10.1186/s12917-016-0931-1
Animal disease
Research needs
Guidelines, policy and education | CommonCrawl |
DOI:10.1142/S0218271814410016
From B-modes to quantum gravity and unification of forces
@article{Krauss2014FromBT,
title={From B-modes to quantum gravity and unification of forces},
author={Lawrence Krauss and Frank Wilczek},
journal={International Journal of Modern Physics D},
pages={1441001}
L. Krauss, F. Wilczek
International Journal of Modern Physics D
It is commonly anticipated that gravity is subjected to the standard principles of quantum mechanics. Yet some — including Einstein — have questioned that presumption, whose empirical basis is weak. Indeed, recently Dyson has emphasized that no conventional experiment is capable of detecting individual gravitons. However, as we describe, if inflation occurred, the universe, by acting as an ideal graviton amplifier, affords such access. It produces a classical signal, in the form of macroscopic…
View PDF on arXiv
Signatures of the quantization of gravity at gravitational wave detectors
M. Parikh, F. Wilczek, G. Zahariade
We develop a formalism to calculate the response of a model gravitational wave detector to a quantized gravitational field. Coupling a detector to a quantum field induces stochastic fluctuations…
Primordial massive gravitational waves from Einstein-Chern-Simons-Weyl gravity
Y. S. Myung, Taeyoon Moon
We investigate the evolution of cosmological perturbations during de Sitter inflation in the Einstein-Chern-Simons-Weyl gravity. Primordial massive gravitational waves are composed of one scalar, two…
Generalisations of holographic hydrodynamics: anomalous transport & fermionic universality
Stephan Steinfurt
In the present thesis we study properties of strongly coupled hydrodynamic theories which may be described in terms of a dual higher dimensional gravitational system. Particular attention is given to…
BICEP2, the curvature perturbation and supersymmetry
D. Lyth
The tensor fraction $r\simeq 0.16$ found by BICEP2 corresponds to a Hubble parameter $H\simeq 1.0\times 10^{14}\GeV$ during inflation. This has two implications for the (single-field) slow-roll…
Dark matter as Planck relics without too exotic hypotheses
A. Barrau, K. Martineau, Flora Moulin, Jean-Fr'ed'eric Ngono
The idea that dark matter could be made of stable relics of microscopic black holes is not new. In this article, we revisit this hypothesis, focusing on the creation of black holes by the scattering…
Hessian and graviton propagator of the proper vertex
A. C. Shirazi, J. Engle, Ilya Vilensky
The proper spin-foam vertex amplitude is obtained from the EPRL vertex by projecting out all but a single gravitational sector, in order to achieve correct semi-classical behavior. In this paper we…
N ov 2 01 5 Hessian and graviton propagator of the proper vertex Atousa
Chaharsough Shirazi, J. Engle, Ilya Vilensky
Calibration method and uncertainty for the primordial inflation explorer (PIXIE)
A. Kogut, D. Fixsen
The Primordial Inflation Explorer (PIXIE) is an Explorer-class mission concept to measure cosmological signals from both linear polarization of the cosmic microwave background and spectral…
Will gravitational waves discover the first extra-galactic planetary system?
C. Danielski, N. Tamanini
Gravitational waves have opened a new observational window through which some of the most exotic objects in the Universe, as well as some of the secrets of gravitation itself, can now be revealed.…
Using cosmology to establish the quantization of gravity
L. Krauss, F. University, Australian National Univeresity, Mit
While many aspects of general relativity have been tested, and general principles of quantum dynamics demand its quantization, there is no direct evidence for that. It has been argued that…
The Effect of Primordially Produced Gravitons upon the Anisotropy of the Cosmological Microwave Background Radiation
R. Fabbri, M. Pollock
Abstract We consider the effect of primordially produced gravitons on the anisotropy of the cosmological microwave background radiation. For a universe that includes a phase of exponential expansion,…
Grand unification, gravitational waves, and the cosmic microwave background anisotropy.
Krauss, White
Physics, Medicine
The stochastic gravitational wave background resulting from inflation and its effect on the cosmic microwave background radiation (CMBR) is reexamine and the energy density associated with gravitational waves from inflation is examined.
Signature of gravity waves in polarization of the microwave background
U. Seljak, M. Zaldarriaga
Using spin-weighted decomposition of polarization in the cosmic microwave background (CMB) we show that a particular combination of Stokes $Q$ and $U$ parameters vanishes for primordial fluctuations…
Constraints on generalized inflationary cosmologies
L. Abbott, M. Wise
We consider cosmologies having an inflationary period during which the Robertson-Walker scale factor is an arbitrary function of time satisfying R > 0 (not necessarily an exponential). We show that…
Graviton creation in the inflationary universe and the grand unification scale
V. Rubakov, M. Sazhin, A. Veryaskin
The creation of gravitons in the inflationary universe and their effects on the 3K photon background are considered. It is shown that the inflationary universe scenario is compatible with existing…
Inflationary universe: A possible solution to the horizon and flatness problems
A. Guth
The standard model of hot big-bang cosmology requires initial conditions which are problematic in two ways: (1) The early universe is assumed to be highly homogeneous, in spite of the fact that…
Unification of Couplings
S. Dimopoulos, S. Raby, F. Wilczek
Ambitious attempts to obtain a unified description of all the interactions of nature have so far been more notable for their ingenuity, beauty and chutzpah than for any help they have afforded toward…
A New Type of Isotropic Cosmological Models without Singularity - Phys. Lett. B91, 99 (1980)
A. Starobinsky
Abstract The Einstein equations with quantum one-loop contributions of conformally covariant matter fields are shown to admit a class of nonsingular isotropic homogeneous solutions that correspond to…
A new inflationary universe scenario: A possible solution of the horizon
In order to map the power distribution of a nuclear fuel element, a passive detector is laid along the fuel element in situ to record the residual radiation of the fuel element. The detector… | CommonCrawl |
Rigidity results for nonlocal phase transitions in the Heisenberg group $\mathbb{H}$
Asymptotic symmetry for a class of nonlinear fractional reaction-diffusion equations
June 2014, 34(6): 2617-2637. doi: 10.3934/dcds.2014.34.2617
Classification of radial solutions to Liouville systems with singularities
Chang-Shou Lin 1, and Lei Zhang 2,
Taida Institute of Mathematical Sciences and Center for Advanced Study in Theoretical Sciences, National Taiwan University, Taipei 106, Taiwan
Department of Mathematics, University of Florida, 358 Little Hall, P.O.Box 118105, Gainesville, Florida 32611-8105, United States
Received September 2012 Revised June 2013 Published December 2013
Let $A=(a_{ij})_{n\times n}$ be a nonnegative, symmetric, irreducible and invertible matrix. We prove the existence and uniqueness of radial solutions to the following Liouville system with singularity: \begin{eqnarray*} \left\{ \begin{array}{lcl} \Delta u_i+\sum_{j=1}^n a_{ij}|x|^{\beta_j}e^{u_j(x)}=0,\quad \mathbb R^2, \quad i=1,...,n\\ \\ \int_{\mathbb R^2}|x|^{\beta_i}e^{u_i(x)}dx<\infty, \quad i=1,...,n \end{array}\right. \end{eqnarray*} where $\beta_1,...,\beta_n$ are constants greater than $-2$. If all $\beta_i$s are negative we prove that all solutions are radial and the linearized system is non-degenerate.
Keywords: Liouville system, classification of solutions, singularity., radial symmetry, non-degeneracy.
Mathematics Subject Classification: Primary: 35J47; Secondary: 35J6.
Citation: Chang-Shou Lin, Lei Zhang. Classification of radial solutions to Liouville systems with singularities. Discrete & Continuous Dynamical Systems - A, 2014, 34 (6) : 2617-2637. doi: 10.3934/dcds.2014.34.2617
D. Bartolucci, C.-C. Chen, C.-S. Lin and G. Tarantello, Profile of blow-up solutions to mean field equations with singular data,, Comm. Partial Differential Equations, 29 (2004), 1241. doi: 10.1081/PDE-200033739. Google Scholar
W. H. Bennet, Magnetically self-focusing streams,, Phys. Rev., 45 (1934), 890. Google Scholar
S. Chanillo and M. K.-H. Kiessling, Conformally invariant systems of nonlinear PDE of Liouville type,, Geom. Funct. Anal., 5 (1995), 924. doi: 10.1007/BF01902215. Google Scholar
S.-Y. Chang, M. Gursky and P. Yang, The scalar curvature equation on 2- and 3-spheres,, Calc. Var. and PDE, 1 (1993), 205. doi: 10.1007/BF01191617. Google Scholar
S.-Y. Chang and P. Yang, Prescribing Gaussian curvatuare on S2,, Acta Math., 159 (1987), 215. doi: 10.1007/BF02392560. Google Scholar
C.-C. Chen and C.-S. Lin, Estimate of the conformal scalar curvature equation via the method of moving planes. II,, J. Differential Geom., 49 (1998), 115. Google Scholar
C.-C. Chen and C.-S. Lin, Sharp estimates for solutions of multi-bubbles in compact Riemann surfaces,, Comm. Pure Appl. Math., 55 (2002), 728. doi: 10.1002/cpa.3014. Google Scholar
C.-C. Chen and C.-S. Lin, Mean field equations of Liouville type with singular data: Sharper estimates,, Discrete and Continuous Dynamic Systems, 28 (2010), 1237. doi: 10.3934/dcds.2010.28.1237. Google Scholar
W. Chen and C. Li, Classification of solutions of some nonlinear elliptic equations,, Duke Math. J., 63 (1991), 615. doi: 10.1215/S0012-7094-91-06325-8. Google Scholar
W. X. Chen and C. Li, Qualitative properties of solutions to some nonlinear elliptic equations in $\mathbb R^2$,, Duke Math. J., 71 (1993), 427. doi: 10.1215/S0012-7094-93-07117-7. Google Scholar
S. Childress and J. K. Percus, Nonlinear aspects of chemotaxis,, Math. Biosci., 56 (1981), 217. doi: 10.1016/0025-5564(81)90055-9. Google Scholar
M. Chipot, I. Shafrir and G. Wolansky, On the solutions of Liouville systems,, J. Differential Equations, 140 (1997), 59. doi: 10.1006/jdeq.1997.3316. Google Scholar
M. Chipot, I. Shafrir and G. Wolansky, Erratum: "On the solutions of Liouville systems'' [J. Differential Equations, 140 (1997), 59-105; MR1473855],, J. Differential Equations, 178 (2002). Google Scholar
P. Debye and E. Huckel, Zur theorie der electrolyte,, Phys. Zft, 24 (1923), 305. Google Scholar
J. Hong, Y. Kim and P. Y. Pac, Multivortex solutions of the abelian Chern-Simons-Higgs theory,, Phys. Rev. Letter, 64 (1990), 2230. doi: 10.1103/PhysRevLett.64.2230. Google Scholar
R. Jackiw and E. J. Weinberg, Selfdual Chern Simons vortices,, Phys. Rev. Lett., 64 (1990), 2234. doi: 10.1103/PhysRevLett.64.2234. Google Scholar
J. Jost, C. Lin and G. Wang, Analytic aspects of the Toda system. II. Bubbling behavior and existence of solutions,, Comm. Pure Appl. Math., 59 (2006), 526. doi: 10.1002/cpa.20099. Google Scholar
J. Jost and G. Wang, Classification of solutions of a Toda system in $\mathbb R^ 2$,, Int. Math. Res. Not., 2002 (): 277. doi: 10.1155/S1073792802105022. Google Scholar
J. Jost and G. Wang, Analytic aspects of the Toda system. I. A Moser-Trudinger inequality,, Comm. Pure Appl. Math., 54 (2001), 1289. doi: 10.1002/cpa.10004. Google Scholar
J. Kazdan and F. Warner, Curvature functions for compact 2-manifolds,, Ann. of Math. (2), 99 (1974), 14. doi: 10.2307/1971012. Google Scholar
E. F. Keller and L. A. Segel, Traveling bands of Chemotactic Bacteria: A theoretical analysis,, J. Theor. Biol., 30 (1971), 235. doi: 10.1016/0022-5193(71)90051-8. Google Scholar
M. K.-H. Kiessling and J. L. Lebowitz, Dissipative stationary plasmas: Kinetic modeling, Bennett's pinch and generalizations,, Phys. Plasmas, 1 (1994), 1841. doi: 10.1063/1.870639. Google Scholar
Y. Y. Li, Harnack type inequality: The method of moving planes,, Comm. Math. Phys., 200 (1999), 421. doi: 10.1007/s002200050536. Google Scholar
C.-S. Lin and L. Zhang, Profile of bubbling solutions to a Liouville system,, Ann. Inst. H. Poincaré Anal. Non Linéaire, 27 (2010), 117. doi: 10.1016/j.anihpc.2009.09.001. Google Scholar
C.-S. Lin and L. Zhang, A topological degree counting for some Liouville systems of mean field type,, Comm. Pure Appl. Math., 64 (2011), 556. doi: 10.1002/cpa.20355. Google Scholar
M. S. Mock, Asymptotic behavior of solutions of transport equations for semiconductor devices,, J. Math. Anal. Appl., 49 (1975), 215. doi: 10.1016/0022-247X(75)90172-9. Google Scholar
M. Nolasco and G. Tarantello, Double vortex condensates in the Chern-Simons-Higgs theory,, Calc. Var. and PDE, 9 (1999), 31. doi: 10.1007/s005260050132. Google Scholar
J. Prajapat and G. Tarantello, On a class of elliptic problems in R2: Symmetry and uniqueness results,, Proc. Roy. Soc. Edinburgh Sect. A, 131 (2001), 967. doi: 10.1017/S0308210500001219. Google Scholar
I. Rubinstein, Electro Diffusion of Ions,, SIAM Studies in Applied Mathematics, (1990). doi: 10.1137/1.9781611970814. Google Scholar
L. Zhang, Blow up solutions of some nonlinear elliptic equations involving exponential nonlinearities,, Comm. Math. Phys., 268 (2006), 105. doi: 10.1007/s00220-006-0092-3. Google Scholar
L. Zhang, Asymptotic behavior of blowup solutions for elliptic equations with exponential nonlinearity and singular data,, Commun. Contemp. Math., 11 (2009), 395. doi: 10.1142/S0219199709003417. Google Scholar
Pedro J. Torres, Zhibo Cheng, Jingli Ren. Non-degeneracy and uniqueness of periodic solutions for $2n$-order differential equations. Discrete & Continuous Dynamical Systems - A, 2013, 33 (5) : 2155-2168. doi: 10.3934/dcds.2013.33.2155
Robert Magnus, Olivier Moschetta. The non-linear Schrödinger equation with non-periodic potential: infinite-bump solutions and non-degeneracy. Communications on Pure & Applied Analysis, 2012, 11 (2) : 587-626. doi: 10.3934/cpaa.2012.11.587
Xiaocai Wang, Junxiang Xu. Gevrey-smoothness of invariant tori for analytic reversible systems under Rüssmann's non-degeneracy condition. Discrete & Continuous Dynamical Systems - A, 2009, 25 (2) : 701-718. doi: 10.3934/dcds.2009.25.701
Yingshu Lü. Symmetry and non-existence of solutions to an integral system. Communications on Pure & Applied Analysis, 2018, 17 (3) : 807-821. doi: 10.3934/cpaa.2018041
Dongfeng Zhang, Junxiang Xu. On elliptic lower dimensional tori for Gevrey-smooth Hamiltonian systems under Rüssmann's non-degeneracy condition. Discrete & Continuous Dynamical Systems - A, 2006, 16 (3) : 635-655. doi: 10.3934/dcds.2006.16.635
Ran Zhuo, Wenxiong Chen, Xuewei Cui, Zixia Yuan. Symmetry and non-existence of solutions for a nonlinear system involving the fractional Laplacian. Discrete & Continuous Dynamical Systems - A, 2016, 36 (2) : 1125-1141. doi: 10.3934/dcds.2016.36.1125
Antonio Greco, Vincenzino Mascia. Non-local sublinear problems: Existence, comparison, and radial symmetry. Discrete & Continuous Dynamical Systems - A, 2019, 39 (1) : 503-519. doi: 10.3934/dcds.2019021
Alberto Farina. Symmetry of components, Liouville-type theorems and classification results for some nonlinear elliptic systems. Discrete & Continuous Dynamical Systems - A, 2015, 35 (12) : 5869-5877. doi: 10.3934/dcds.2015.35.5869
Olivier Goubet. Regularity of extremal solutions of a Liouville system. Discrete & Continuous Dynamical Systems - S, 2019, 12 (2) : 339-345. doi: 10.3934/dcdss.2019023
Wenxiong Chen, Congming Li. Radial symmetry of solutions for some integral systems of Wolff type. Discrete & Continuous Dynamical Systems - A, 2011, 30 (4) : 1083-1093. doi: 10.3934/dcds.2011.30.1083
Sara Barile, Addolorata Salvatore. Radial solutions of semilinear elliptic equations with broken symmetry on unbounded domains. Conference Publications, 2013, 2013 (special) : 41-49. doi: 10.3934/proc.2013.2013.41
Jérôme Coville, Juan Dávila. Existence of radial stationary solutions for a system in combustion theory. Discrete & Continuous Dynamical Systems - B, 2011, 16 (3) : 739-766. doi: 10.3934/dcdsb.2011.16.739
Yuxia Guo, Jianjun Nie. Classification for positive solutions of degenerate elliptic system. Discrete & Continuous Dynamical Systems - A, 2019, 39 (3) : 1457-1475. doi: 10.3934/dcds.2018130
Alberto Farina, Miguel Angel Navarro. Some Liouville-type results for stable solutions involving the mean curvature operator: The radial case. Discrete & Continuous Dynamical Systems - A, 2020, 40 (2) : 1233-1256. doi: 10.3934/dcds.2020076
Marco Ghimenti, A. M. Micheletti. Non degeneracy for solutions of singularly perturbed nonlinear elliptic problems on symmetric Riemannian manifolds. Communications on Pure & Applied Analysis, 2013, 12 (2) : 679-693. doi: 10.3934/cpaa.2013.12.679
Jingbo Dou, Huaiyu Zhou. Liouville theorems for fractional Hénon equation and system on $\mathbb{R}^n$. Communications on Pure & Applied Analysis, 2015, 14 (5) : 1915-1927. doi: 10.3934/cpaa.2015.14.1915
Rossella Bartolo, Anna Maria Candela, Addolorata Salvatore. Infinitely many radial solutions of a non--homogeneous $p$--Laplacian problem. Conference Publications, 2013, 2013 (special) : 51-59. doi: 10.3934/proc.2013.2013.51
Joel Kübler, Tobias Weth. Spectral asymptotics of radial solutions and nonradial bifurcation for the Hénon equation. Discrete & Continuous Dynamical Systems - A, 2019, 0 (0) : 0-0. doi: 10.3934/dcds.2020032
Myoungjean Bae, Yong Park. Radial transonic shock solutions of Euler-Poisson system in convergent nozzles. Discrete & Continuous Dynamical Systems - S, 2018, 11 (5) : 773-791. doi: 10.3934/dcdss.2018049
E. N. Dancer, Sanjiban Santra. Existence and multiplicity of solutions for a weakly coupled radial system in a ball. Communications on Pure & Applied Analysis, 2008, 7 (4) : 787-793. doi: 10.3934/cpaa.2008.7.787
Chang-Shou Lin Lei Zhang | CommonCrawl |
About gtMath
Reader Requests
gtMath
Basis and Dimension
Posted by gtmath Friday, December 16, 2016 0 comments
Preliminary: Euclidean Space and Vectors
A sheet of paper is two-dimensional because, given any reference point on the sheet, which we can call $(0,0)$, any other point can be specified by how far to the right and how far up it is from the reference. This is just the notion of an arrow with a magnitude and direction from the first post on vectors.
Similarly, space as we know it is 3-dimensional because, given any reference point, which we can call $(0,0,0)$, any other point can be specified by its distance in length, width, and depth from the reference.
In this post, we'll formalize the dimension of a vector space by introducing the concept of a basis. I will introduce the basic terminology as well as full proofs of a few important results; while this won't be an exhaustive linear algebra primer by any means, any further questions are welcome in the comments section.
Basis of a vector space
Sticking with the 3-dimensional space example, let's call the $x$-axis the left-right direction, so that $(1,0,0)$ corresponds to a step one unit to the right. A step forward would be along the $y$-axis, or $(0,1,0)$, and a step upwards would be along the $z$-axis at $(0,0,1)$. As discussed in the preliminary post, an arrow of any direction and magnitude can be written as a linear combination of these 3 vectors. In symbols, if we call these three ${\bf e}_1$, ${\bf e}_2$, and ${\bf e}_3$, then any vector ${\bf v}$ can be written as $$
{\bf v} = a_1 {\bf e}_1 + a_2 {\bf e}_2 + a_3 {\bf e}_3
$$ for some scalars $a_1, a_2, a_3$. We write this vector as ${\bf v} = (a_1, a_2, a_3)$, implicitly expressing it in terms of the ${\bf e}_i$'s. Since any vector can be written this way, we say that the ${\bf e}_i$'s span the space ${\Bbb R}^3$.
If a vector ${\bf v}$ can be written as a linear combination of another set of vectors as above (without all $a_i$'s equal to $0$), then it is called linearly dependent on those vectors. If not, then the vectors are linearly independent. Clearly, we can't combine the ${\bf e}_i$ vectors above in any way to get the other ones, so they are linearly independent.
A set of vectors which (1) is linearly independent and (2) spans the entire vector space is called a basis, and the ${\bf e}_i$'s above are called the standard basis of ${\Bbb R}^3$. Essentially, a basis is a "minimal" (see the next section) set which still spans all of $V$ using the vector space operations of vector addition and scalar multiplication: the linear independence requirement ensures that a basis excludes any extra "trash" that doesn't add to the span. For example, since scalar multiplication is built into any vector space, if we have ${\bf e}_1 = (1,0,0)$ in our basis, we clearly don't also need $(2,0,0) = 2 {\bf e}_1$; any vector expressed as a linear combination including $(2,0,0)$ could include ${\bf e}_1$ instead with the coefficient doubled, so $(2,0,0)$ really isn't adding to the span.
On the other hand, we could remove $(1,0,0)$ from the standard basis and replace it with $(2,0,0)$ to obtain a different basis, so a basis certainly isn't unique. In fact, we will prove below that any linearly independent set of vectors can be extended to a basis. However, the constants $a_i$ which express a given vector in terms of a particular basis are unique: if different constants $b_i$ existed, then we could have a vector ${\bf v}$ such that $$
\begin{align}
{\bf v} &= a_1 {\bf e}_1 + a_2 {\bf e}_2 + a_3 {\bf e}_3 \\[1mm]
&= b_1 {\bf e}_1 + b_2 {\bf e}_2 + b_3 {\bf e}_3 \\[2mm]
\implies {\bf v} - {\bf v} = {\bf 0} &= (a_1-b_1) {\bf e}_1 + (a_2-b_2) {\bf e}_2 + (a_3-b_3) {\bf e}_3
\end{align}
$$ If $a_i \neq b_i$ for at least one value of $i$, then this would contradict the fact that the basis vectors are linearly independent (since a linear combination of them without all coefficients equal to 0 yields the zero vector). Thus, we must have $a_i=b_i$ for all values of $i$, i.e. the representation of ${\bf v}$ in terms of the particular basis is unique. The same argument applies to vector spaces other than just ${\Bbb R}^3$.
Dimension of a vector space
The number of vectors forming a basis (which is infinite for some spaces) is called the dimension of the space. ${\Bbb R}^3$ has dimension $3$ because it has $\{ {\bf e}_1, {\bf e}_2, {\bf e}_3 \}$ as a basis, while the $\ell^p$ spaces from the last post have infinite dimension. Their standard bases consist of sequences with a $1$ for the $i$-th component and zeros elsewhere.
Defining dimension in this way implies that every basis has the same number of elements. This is indeed the case, and the proof for finite-dimensional spaces is a consequence of the following related lemma.
Lemma: If $B = \{ {\bf b}_1, {\bf b}_2, \dotsc, {\bf b}_n \}$ is a basis for a vector space $V$, and $W = \{ {\bf w}_1, {\bf w}_2, \dotsc, {\bf w}_m \}$ is a linearly independent set of vectors, then $m \leq n$. If $m=n$, then $W$ spans $V$ and is thus another basis.
Proof: Since $B$ is a basis for $V$, we can express ${\bf w}_1$ as a linear combination of the vectors in $B$, $$
{\bf w}_1 = c_1 {\bf b}_1 + c_2 {\bf b}_2 + \dotsb + c_n {\bf b}_n
$$ where at least one of the $c_i$'s is nonzero. Let $j$ be an index such that $c_j \neq 0$. Then we have $$
{\bf b}_j = \tfrac{1}{c_j}{\bf w}_1 - \tfrac{c_1}{c_j}{\bf b}_1 - \dotsb - \tfrac{c_{j-1}}{c_j}{\bf b}_{j-1} - \tfrac{c_{j+1}}{c_j}{\bf b}_{j+1} - \dotsc - \tfrac{c_n}{c_j}{\bf b}_n
$$ Since $B$ is a basis, any vector ${\bf v} \in V$ can be written as a linear combination of the ${\bf b}_i$'s: $$
{\bf v} &= v_1 {\bf b}_1 + v_2 {\bf b}_2 + \dotsb + v_n {\bf b}_n \\[2mm]
&= v_1 {\bf b}_1 + \dotsb + v_{j-1} {\bf b}_{j-1} \\[1mm]
& \ \ \ + v_j \underbrace{\left[ \tfrac{1}{c_j}{\bf w}_1 - \tfrac{c_1}{c_j}{\bf b}_1 - \dotsb - \tfrac{c_{j-1}}{c_j}{\bf b}_{j-1} - \tfrac{c_{j+1}}{c_j}{\bf b}_{j+1} - \dotsc - \tfrac{c_n}{c_j}{\bf b}_n \right]}_{{\bf b}_j} \\[1mm]
& \ \ \ + v_{j+1} {\bf b}_{j+1} + \dotsb + v_n {\bf b}_n
$$ This eliminates ${\bf b}_j$ from the expansion, showing that the arbitrary vector ${\bf v}$ is also a linear combination of the set $B_1 = \{ {\bf b}_1, {\bf b}_2, \dotsc , {\bf b}_{j-1}, {\bf w}_1, {\bf b}_{j+1}, \dotsc , {\bf b}_n \}$. Thus, $B_1$ spans $V$.
Furthermore, $B_1$ is linearly independent: since ${\bf w}_1$ can be uniquely expressed as a linear combination of the vectors in the original basis $B$, a linear combination of the vectors in $B_1$ can be uniquely rewritten as a linear combination of vectors in $B$ by replacing ${\bf w}_1$ by its expansion $c_1 {\bf b}_1 + c_2 {\bf b}_2 + \dotsb + c_n {\bf b}_n$. Since that unique expansion includes a nonzero factor of ${\bf b}_j$, the resulting linear combination of elements of $B$ has at least one nonzero coefficient. Therefore, if such a combination yielded ${\bf 0}$, that would contradict the fact that $B$ (assumed to be a basis) is linearly independent. So $B_1$ must be linearly independent and thus is a basis for $V$.
Now, since $B_1$ is a basis, we can uniquely express ${\bf w}_2$ as a linear combination $$
{\bf w}_2 = d_1 {\bf b}_1 + d_2 {\bf b}_2 + \dotsb + d_{j-1} {\bf b}_{j-1} + d_j {\bf w_1} + d_{j+1} {\bf b}_{j+1} + \dotsb + d_n {\bf b}_n
$$ Since $W$ is linearly independent, it is not the case that ${\bf w}_2 = d_j {\bf w}_1$ with all other $d_i$'s equal to zero, so there exists a $d_k \neq 0$ with $k \neq j$. Then we can repeat the whole process to kick out ${\bf b}_k$ and replace it with ${\bf w}_2$, yielding a new basis $B_2$.
If $m=n$, then we can continue in this fashion until we kick out the last of the original vectors from $B$ at the $n$-th iteration, obtaining a new basis $B_n$ consisting of the vectors ${\bf w}_1, {\bf w}_2, \dotsc, {\bf w}_n$. This proves that any linearly independent set of $n$ vectors is a basis.
Furthermore, if $m>n$, we can continue the process and uniquely express ${\bf w}_{n+1}$ as a linear combination of the basis $B_n = \{ {\bf w}_1, {\bf w}_2, \dotsc, {\bf w}_n \}$. This is a contradiction, since $W$ is assumed to be linearly independent. Thus, it must be the case that $m \leq n$.
Corollary: If $A = \{ {\bf a}_1, \dotsc {\bf a}_m \}$ and $B = \{ {\bf b}_1, \dotsc {\bf b}_n \}$ are two bases for a finite-dimensional vector space $V$, then $m=n$.
Proof: By the above lemma, $m \leq n$ since $A$ is linearly independent, and $B$ is a basis. Also, $n \leq m$ since $B$ is linearly independent, and $A$ is a basis. Therefore, $m=n$.
Note that this also allows us to conclude that in a vector space $V$ with dimension $n$, a set with fewer than $n$ vectors cannot span $V$. Thus, a basis is a minimal set that still spans all of $V$. On the other hand, by the lemma, a basis is a maximal set of vectors that is still linearly independent.
Extending to a basis
If we have a vector space $V$ with finite dimension $n$ and a set $S$ of $p$ linearly independent vectors with $p<n$, then we can extend $S$ to a basis for $V$.
Indeed, since $S$ has only $p$ vectors, it cannot span $V$. Thus, there exists a vector ${\bf v}_1$ such that ${\bf v}_1$ is not in the span of $S$ (the set of all linear combinations of the vectors in $S$). So $S \cup \{ {\bf v}_1 \}$ is a linearly independent set of $p+1$ vectors.
Continuing in this manner until we have exactly $n$ vectors (which will take $n-p$ steps), we will obtain a set $S'$ of $n$ linearly independent vectors. The lemma above implies that $S'$ will span $V$ and thus be a new basis.
In practice, finding the vectors ${\bf v}_1, {\bf v}_2, \dotsc, {\bf v}_{n-p}$ as described above consists of either guess-and-check or solving sets of linear equations. For example, if we have the vectors $(0,3,0)$ and $(1,0,-2)$ and would like to extend to a basis for ${\Bbb R}^3$, then we need to find a vector ${\bf x} = (x_1, x_2, x_3)$ such that ${\bf x}$ is linearly independent from the first two vectors. If ${\bf x}$ were a linear combination, then we would have:$$
(x_1, x_2, x_3) = a_1 (0,3,0) + a_2 (1,0,-2)
$$ This gives us 3 equations: $$
x_1 &= a_2 \\[2mm]
x_2 &= 3 a_1 \\[2mm]
x_3 &= -2 a_2
$$ We just need to find one vector which does not satisfy these equations, regardless of the choice of the $a_i$'s. Since the first and third equations imply that $-\tfrac{1}{2}x_3 = x_1$, any vector not satisfying that equation will work. In this case ${\bf x} = (0,0,1)$ would work. Note that the solution is not unique; there are infinitely many solutions, such as ${\bf x} = (0,0,x_3)$ for any value of $x_3$ as well as many other solutions.
While the system of equations above was rather easy, we can use the more formal method of Gaussian elimination to simplify tougher systems.
Extending to a basis- infinite-dimensional case
In an infinite-dimensional vector space, we can also extend a linearly independent set to a basis, but the proof of this fact is not as simple as setting up a system of linear equations to solve (there would be infinitely many equations). In fact, the proof relies on the axiom of choice and thus does not show us how to actually perform the basis extension. For the sake of completeness, I'll provide a sketch of the proof anyway, with the warning that it won't make much sense to those not somewhat well versed in set theory.
Sketch of proof: Let $V$ be a vector space, not necessarily finite-dimensional, and let $S$ be a linearly independent subset of $V$. Let $A$ be the collection of sets whose members are the linearly independent subsets of $V$ which contain $S$. In symbols, $$
A = \{ T \subseteq V : \ S \subseteq T \text{ and $T$ is linearly independent} \}
$$ An arbitrary chain in $A$ takes the form $T_1 \subseteq T_2 \subseteq T_3 \subseteq \dotsb$ where $T_i \in A$ for $i=1,2,3,\dotsc$. The set $T_{\cup} = \bigcup_{i=1}^{\infty}{T_i}$ is an upper bound for the chain in that it is bigger (as defined by the $\subseteq$ relation) than each element of the chain.
Since all chains have an upper bound, Zorn's Lemma (equivalent to the axiom of choice, though I will omit the proof of this fact) implies that $A$ has a maximal element, i.e. an element $M$ such that $T \subseteq M$ for all $T \in A$. Suppose $M$ does not span $V$. Then there exists a vector ${\bf z} \in V$ which is not a linear combination of the vectors in $M$. But then $M' = M \cup \{ {\bf z} \}$ is a linearly independent set containing $M$ and thus $S$. So $M' \in A$, a contradiction since $M$ was supposed to be a maximal element. Thus it must be the case that $M$ does span $V$, so $M$ is a basis.
As with most AC-based proofs, this one isn't very satisfying, but there you have it: even in the infinite-dimensional case, you can extend a linearly independent set to a basis (but I can't tell you how!).
That will do it for this post- thanks for reading and please post any questions in the comments section.
The Axiom of Choice
Posted by gtmath Sunday, December 11, 2016 0 comments
Preliminary: set basics
The axiom of choice is a somewhat controversial axiom of set theory which is frequently utilized but not well known by most non-math folks. In this brief post, I'll demystify the axiom of choice and explain some of the issues that arise from its use.
Statement of the Axiom
The axiom of choice (or "AC" for short) states that, given a collection of non-empty sets, there exists a way to choose one element from each of them.
In order to state the axiom more precisely, we first need to define a choice function. Given a collection $X$ of non-empty sets, a choice function is a function which assigns to each set in the collection one of its own elements. In symbols, it is a function $$
f: X \rightarrow \bigcup_{A \in X}{A}
$$ with the property that for all $A \in X$, $f(A) \in A$.
Take a second to read through that again as it can be a bit confusing: $X$ is a set whose elements are sets. If $A$ is a set in this collection/set of sets (i.e. an element of $X$), then $A$ is assumed to be non-empty and thus has at least one element. A choice function takes sets like $A$ as inputs, and assigns to them an output from the set $\bigcup_{A \in X}{A}$ of all elements of sets (like $A$) in the collection. This output must be an element of $A$ itself (the input "value") every time in order for $f$ to be a choice function. Put differently, $f$ cannot assign to any set $A$ an output value $b$, where $b \in B$ for some other set $B \in X$ with $B \neq A$.
With that out of the way, the axiom of choice states that for any collection $X$ of non-empty sets, a choice function exists. This is the rigorous expression of the plain-English version above: given a collection of non-empty sets, there exists a way to choose one element from each of them.
"Sounds pretty obvious. What's the big controversy?"
As a practical example, suppose we have a bunch of buckets with items inside. The AC just tells us that we can pick one item from each. For a finite number of buckets, this really is obvious and actually can be proven by induction from other basic axioms of set theory.
However, suppose we have a countably infinite number of buckets, i.e. we have numbered buckets labeled $1, 2, 3, 4, \dotsc$ going on forever. You can go to the first bucket and reach in to choose an item, then the second, then the third, etc. For any finite number of buckets, this sequence of events will obviously terminate. But since the buckets go on forever, at no point will you ever have chosen an item from every bucket; a choice function needs to specify an item for every bucket. It's even worse if you have uncountably many buckets, e.g. if you have one bucket for every real number instead of just the numbers $1,2,3, \dotsc$.
Now, if you have a formulaic way to specify which item should be chosen from each bucket, then there's actually still no issue in defining a choice function. For example, suppose each of the infinitely many buckets contains several slips of paper, each with a single number $1,2,3, \dotsc$ on it and with no repeats within any buckets. Then each bucket would contain a slip with the smallest label. Thus, there exists a choice function for these buckets: choose the smallest label from each bucket. This is a precise specification for a selection of one item from every bucket.
The issue arises when there is no formulaic way to make a choice for all the buckets. For example, suppose $X$ is the set of all non-empty subsets of the real number line. This $X$ is uncountably infinite and contains some subsets such as $\{3, 123412, \pi, \text{all numbers greater than a million} \}$ for which we can still say, "choose the smallest element" (in this case, $3$). But $X$ also contains sets such as $(0,1) = \{x \in {\Bbb R} \ | \ 0 < x < 1 \}$ which have no smallest element. There is no formulaic way to specify how one would choose one element from every non-empty subset of the real numbers.
"Fine, I admit it can be a little dicey: clearly, you can't always write some kind of computer algorithm every time to create a choice function in practice. But does assuming the AC really cause any harm?"
Sort of, but it depends on your point of view.
One way to prove something exists is to specify an algorithm to construct it; this is called a constructive proof. On the other hand, when a proof of something's existence relies on the axiom of choice, it doesn't tell you how to actually construct the "something".
This may not be a problem if we don't care about constructing the thing in practice. But the AC also allows one to prove some bizarre results such as the Banach-Tarski paradox, which states that it is possible to reassemble pieces of a ball into two copies of the same ball just by moving and rotating (without stretching/shrinking). It contradicts basic geometric intuition that this could be the case, since the volumes of the two new balls would be the same as that of the original one. The role of the axiom of choice here is that it allows for the construction of sets of points for which "volume" is not defined (non-measurable sets). Of course, it doesn't actually tell us how to do this, only that it can be done.
To conclude, even though the AC seems obvious, it amounts to assuming the theoretical existence of objects which can never be built in practice. As a result, these objects (such as non-measurable sets) are basically impossible to picture or understand. These never arise in practical applications since you can't actually construct them without the AC, but they lead to some counterintuitive, seemingly paradoxical results.
In applications such as the stochastic calculus used in financial math, you will see the analysis restricted to measurable sets, as everything you can think up (without invoking the AC) will correspond to one of these anyway. I hope this post helps explain why authors need to go through all the trouble of making these restrictions, and also that it helps you recognize instances in which the AC has been invoked in your future forays into pure math.
Functions as Vectors (Part 1)
Posted by gtmath Tuesday, November 15, 2016 0 comments
Preliminaries:
Euclidean Space and Vectors: defines vector spaces and the dot product
How close is "close enough"?: defines metrics, metric spaces, and convergence
Sets of Functions: basic notation for function spaces
Convergence of Sequences of Functions: topology and metrizability of function spaces
The previous post covered convergence in function spaces, and we saw that different types of convergence correspond to different topologies on the underlying space.
In this post, I will add a few more tools (namely norms and inner products) to the vector space/linear algebra toolbox and show you how we introduce a vector space structure to function spaces. I will focus on the sequence spaces $\ell^p$ as illustrative examples, concluding with a proof of Hölder's inequality for sums.
In Part 2 of this post, I will introduce the notion of the dual space and prove an important result about the $\ell^p$ spaces to complete a recent reader request.
Engineers and physicists in the audience will recall that the function space formalism provides the mathematical foundation for Fourier analysis and quantum mechanics. It also comes into play in the modeling of randomness, on which I am planning some upcoming posts (stay tuned).
Vector space review
In "Euclidean space", I introduced vectors in ${\Bbb R}^n$ as ordered $n$-tuples, which, for $n=2$ and $n=3$, can be thought of as arrows with a length and direction. We saw that we can define addition of vectors as addition of the respective components, i.e. we apply the usual addition of real numbers to each component of the two vectors. We can also "scale" a vector by a number (called a scalar in this context) by multiplying each component by that number, once again in the usual real number sense.
In symbols (using $n=3$ for now), if ${\bf x} = (x_1 , x_2, x_3)$ and ${\bf y} = (y_1 , y_2 , y_3)$ are vectors, and $c$ is a scalar: $$
{\bf x} + {\bf y} & \buildrel {\rm def} \over{=} (x_1 + y_1, x_2 + y_2, x_3 + y_3) \\[2mm]
c \, {\bf x} & \buildrel {\rm def} \over{=} (cx_1, cx_2, cx_3)
$$ ${\Bbb R}^n$ with addition and scalar multiplication defined in this way satisfies the vector space axioms (refer to the preliminary post).
If we have some set other than ${\Bbb R}^n$ and define a way to add its elements together and multiply them by a scalar (usually from the real numbers $\Bbb R$ or the complex numbers $\Bbb C$, but technically from any field), and if these definitions satisfy the vector space axioms, then the set endowed with these operations is called a vector space, and its elements are called vectors. Thus, the term vector encompasses a more general class of objects than the motivating example of arrows with 2 or 3 components.
The study of vector spaces is called linear algebra and is one of the best understood areas of mathematics. Verifying that a set endowed with a definition of addition and scalar multiplication is a vector space immediately implies that all the theorems proven about vector spaces (of which there are many) apply. As you may have already surmised, in this post, we'll be looking at vector spaces in which the vectors are functions, i.e. function spaces.
Inner products, norms, and the distance formula
Recall also from the Euclidean space post that we defined the dot product of two vectors in ${\Bbb R}^n$ as ${\bf x} \cdot {\bf y} = \sum_{i=1}^{n}{x_i y_i}$. The dot product satisfies 3 axioms which make it a so-called inner product (in fact, the dot product inspired the definition of inner products):
Symmetry*:
$\ \ \ \ \ \ \ \ {\bf x} \cdot {\bf y} = {\bf y} \cdot {\bf x}$
Linearity in the first argument:
$\ \ \ \ \ \ \ \ (c \, {\bf x}) \cdot {\bf y} = c \, ({\bf y} \cdot {\bf x})$
$\ \ \ \ \ \ \ \ ({\bf x} + {\bf z}) \cdot {\bf y} = ({\bf x} \cdot {\bf y}) + ({\bf z} \cdot {\bf y})$
Positive-definiteness:
$\ \ \ \ \ \ \ \ {\bf x} \cdot {\bf x} \geq 0$
$\ \ \ \ \ \ \ \ {\bf x} \cdot {\bf x} = 0 \iff {\bf x} = {\bf 0}$
*Note: when dealing with vector spaces over the field of complex numbers instead of real numbers, the symmetry property is replaced with conjugate symmetry: ${\bf x} \cdot {\bf y} = \overline{{\bf y} \cdot {\bf x}}$, where the bar over the right side is complex conjugation: $\overline{a + bi} := a - bi$. We won't worry about complex vector spaces in this post.
That the dot product satisfies these properties is very easy to check. For example: $$
({\bf x} + {\bf z}) \cdot {\bf y}
&= \sum_{i=1}^{n}{(x_i + z_i) y_i} \\
&= \sum_{i=1}^{n}{(x_i y_i + z_i y_i)} \\
&= \sum_{i=1}^{n}{x_i y_i} + \sum_{i=1}^{n}{z_i y_i} \\
&= ({\bf x} \cdot {\bf y}) + ({\bf z} \cdot {\bf y})
A vector space with an inner product is called an inner product space. Inner products are often denoted $\langle {\bf x} , {\bf y} \rangle$, and I will use this notation for the remainder of this post.
If we have an inner product, we automatically get a way to specify the "size" or magnitude of a vector ${\bf x}$ by the definition $\| {\bf x} \| \buildrel \rm{def} \over{=} \sqrt{\langle {\bf x}, {\bf x} \rangle}$. This measure of magnitude satisfies 3 properties, as a direct consequence of the properties an inner product must satisfy, which make it a so-called norm:
$\ \ \ \ \ \ \ \ \| {\bf x} \| \geq 0$
$\ \ \ \ \ \ \ \ \|{\bf x} \| = 0 \iff {\bf x} = {\bf 0}$
Scaling:
$\ \ \ \ \ \ \ \ \| c\, {\bf x} \| = |c| \| {\bf x} \|$
Triangle inequality:
$\ \ \ \ \ \ \ \ \| {\bf x} + {\bf y}\| \leq \| {\bf x} \| + \| {\bf y} \|$
A vector space with a norm is called a normed vector space. The norm also gives us a way to measure the distance between two vectors by the definition $$
d({\bf x}, {\bf y}) \buildrel \rm{def} \over{=} \| {\bf y} - {\bf x} \|
$$ which, by the way, is automatically a metric due to the properties of norms. In the inner product space ${\Bbb R}^3$ (with the dot product as the inner product), this formula yields $$
d({\bf x}, {\bf y}) = \sqrt{(y_1 - x_1)^2 + (y_2 - x_2)^2 + (y_3 - x_3)^2}
$$ which is the well-known (Euclidean) distance formula.
The $\ell^2$ space
Let's start by considering a vector space that is a natural generalization of the familiar ${\Bbb R}^n$, the set of all $n$-dimensional "arrows", i.e. ordered $n$-tuples of real numbers ${\bf x} = (x_1, x_2, x_3, \dotsc , x_n)$. We made this set into a vector space by defining vector addition and scalar multiplication as the obvious component-wise operations. We'll now look at an infinite-dimensional analog of this space.
Consider the set of infinite sequences ${\bf x} = (x_1, x_2, x_3, \dotsc)$ of real numbers which are square-summable, i.e. $\sum_{i=1}^{\infty}{x_i^2} < \infty$. We'll see the reason for this restriction in a moment. This is a subset of the set of functions ${\Bbb R}^{\Bbb N}$ which we will call $\ell^2$ (I'll explain this notation later in the post). We can give $\ell^2$ a vector space structure using the following definitions, completely analogous to the ${\Bbb R}^n$ ones:
The zero vector is the sequence of all zeros:
${\bf 0} = (0,0,0, \dotsc)$
Vector addition is defined component-wise:
$(x_1, x_2, x_3, \dotsc) + (y_1, y_2, y_3, \dotsc) \buildrel \rm{def} \over{=} (x_1 + y_1, x_2 + y_2, x_3 + y_3, \dotsc)$
Scalar multiplication is defined similarly:
$c \, (x_1, x_2, x_3, \dotsc) \buildrel \rm{def} \over{=} (cx_1, cx_2, cx_3, \dotsc)$
It is routine to show that this set with these definitions satisfies the vector space axioms, and thus we can refer to these sequences as "vectors".
Furthermore, since we are only considering sequences that are square-summable, thus excluding ones like $(1,1,1, \dotsc )$, we can define the $\ell^2$ norm of a vector/sequence to be $$
\|{\bf x}\|_{2} \buildrel \rm{def} \over{=} \sqrt{\sum_{i=1}^{\infty}{x_i^2}}
$$ and know that this infinite sum converges to a finite value. Once again, this definition is very similar to the formula in ${\Bbb R}^n$. In the latter case, the norm was induced by the inner product in the sense that $\| {\bf x} \| = \sqrt{\langle {\bf x},{\bf x}\rangle}$. This is also the case for the norm in our space of sequences if we define the inner product using the formula $$
\langle {\bf x},{\bf y} \rangle \buildrel \rm{def} \over{=} \sum_{i=1}^{\infty}{x_i y_i}
$$ It is obvious that the above formula indeed defines an inner product, but there is one potential issue with this definition: we don't know a priori that the infinite sum on the right-hand side actually converges for any two square-summable sequences ${\bf x}$ and ${\bf y}$. That it does is a consequence of a version of the Cauchy-Schwarz inequality for infinite sums; at the end of the post, I will prove the more general Hölder's inequality, so for now, take my word for it that the series does converge, and thus that this inner product is well defined.
The $\ell^p$ spaces
The more general analogs of the $\ell^2$ space are the $\ell^p$ spaces, consisting of all sequences ${\bf x} = (x_1, x_2, x_3, \dotsc )$ for which $\sum_{i=1}^{\infty}{|x_i|^p} < \infty$. The larger we make $p$, the easier it is for the series to converge, as the sequence values less than 1 "drop off" more quickly. The $p$-series for ${\bf x} = (1, \tfrac{1}{2}, \tfrac{1}{3}, \tfrac{1}{4}, \dotsc )$ illustrate this concept perfectly (you may remember these from your Calc II class):
As a result, $\ell^p \subset \ell^s$ for $p<s$; put differently, $\ell^s$ contains more sequences than $\ell^p$, since the larger exponent $s$ makes it easier for the series $\sum_{i}{|x_i|^s}$ to converge.
We can define the $\ell^p$ norms by the following formula for $1 \leq p < \infty$: $$
\| {\bf x} \|_{p} \buildrel{\rm def} \over{=} \left( \sum_{i=1}^{\infty}{|x_i|^p} \right)^{1/p}
$$ When $0<p<1$, this formula fails to define a norm, because it doesn't satisfy the triangle inequality: as a counterexample, take ${\bf x} = (1,0,0,0, \dotsc )$ and ${\bf y} = (0,1,0,0, \dotsc )$. Then $$
\| {\bf x} + {\bf y} \|_{p} = \| (1,1,0,0, \dotsc ) \|_{p} = 2^{1/p} > 2 = 1 + 1 = \| {\bf x} \|_{p} + \| {\bf y} \|_{p}
$$ so $\| {\bf x} + {\bf y} \|_{p} \nleq \| {\bf x} \|_{p} + \| {\bf y} \|_{p}$ in this case. Geometrically, the counterexample illustrates that when $0 < p < 1$, the unit ball (i.e. the open ball of radius 1 centered at ${\bf 0}$) is not convex: it contains points which we can connect with a straight line, and that straight line will contain points outside the unit ball:
Unit balls in the $\ell^p$ norms (on ${\Bbb R}^2$) for various values of $p$ - from Wikipedia
For this reason, we will restrict our attention to $p \geq 1$ so that the formula above actually defines a norm (in the interest of brevity, I'll omit the proof of this fact). Finally, the diagram above shows a unit ball for $p=\infty$, which needs to be treated specially. The $\ell^{\infty}$ space is just the set of bounded sequences with the norm $$
\| {\bf x} \|_{\infty} \buildrel{\rm def} \over{=} \sup_{i}{|x_i|}
$$ where this supremum (a synonym for "least upper bound") is guaranteed to exist since the sequences in the space are bounded by definition. Thus in the diagram, we see that the $\ell^{\infty}$ norm in the plane has a unit ball consisting of points for which the coordinate values have a least upper bound of 1. In other words, in two dimensions, the $\ell^{\infty}$ unit ball consists of points whose $x$- and $y$-coordinates are both less than or equal to 1, i.e. a square.
Note: We've actually already seen the metric induced by the $\ell^{\infty}$ norm, $\| {\bf x} - {\bf y}\|_{\infty}$, as the uniform distance. Thus convergence of a sequence of functions in the $\ell^{\infty}$ norm is the same as uniform convergence.
Now, you were probably wondering whether, like the $\ell^2$ norm, the other $\ell^p$ norms arise from inner products. Unfortunately, they do not.
Proposition: The $\ell^p$ norm is induced by an inner product if and only if $p=2$.
Proof: We already showed that the $\ell^2$ norm does arise from an inner product. To prove that $p=2$ is the only value for which this is true, note that if $\| \cdot \|$ is any norm arising from an inner product, then for any vectors ${\bf x}, {\bf y}$, we have $$
\| {\bf x} + {\bf y} \|^2 &= \langle {\bf x} + {\bf y}, {\bf x} + {\bf y} \rangle
= \langle {\bf x}, {\bf x} \rangle
+ \langle {\bf x}, {\bf y} \rangle
+ \langle {\bf y}, {\bf x} \rangle
+\langle {\bf y}, {\bf y} \rangle \\
\| {\bf x} - {\bf y} \|^2 &= \langle {\bf x} - {\bf y}, {\bf x} - {\bf y} \rangle
- \langle {\bf x}, {\bf y} \rangle
- \langle {\bf y}, {\bf x} \rangle
+\langle {\bf y}, {\bf y} \rangle
$$ Thus, $$
\| {\bf x} + {\bf y} \|^2 + \| {\bf x} - {\bf y} \|^2
= 2 \langle {\bf x}, {\bf x} \rangle
+ 2 \langle {\bf y}, {\bf y} \rangle
= 2 \| {\bf x} \|^2 + 2 \| {\bf y} \|^2
$$ This is known as the parallelogram law, a generalization of the Pythagorean theorem for right triangles.
Vectors involved in the parallelogram law - from Wikipedia
Applying this to the $\ell^p$ norm with ${\bf x} = (1,0,0,0, \dotsc )$ and ${\bf y} = (0,1,0,0, \dotsc )$, we obtain $$
&&2^{2/p} + 2^{2/p} &= 2 \cdot 1^{2/p} + 2 \cdot 1^{2/p} \\
&\implies &2 \cdot 2^{2/p} &= 2+2 \\
&\implies &2^{(2/p+1)} &= 4 = 2^2 \\
&\implies &2/p+1 &=2 \\
&\implies &p &=2
$$ $\square$
So $\ell^2$ is the only inner product space of the $\ell^p$ family.
The $L^p$ spaces
The $\ell^p$ spaces are all subsets of ${\Bbb R}^{\Bbb N}$, the space of real-valued sequences. Naturally, these spaces have uncountably infinite analogs which are subsets of ${\Bbb R}^{\Bbb R}$, the space of real-valued functions taking inputs along the entire number line (instead of just $1,2,3,\dotsc$).
For $1 \leq p < \infty$, the $L^p$ space is defined as the set of functions $f: {\Bbb R} \rightarrow {\Bbb R}$ for which $$
\int_{-\infty}^{\infty}{|f(x)|^p \, dx} < \infty
$$ with the norm $$
\| f \|_{p} \buildrel{\rm def} \over{=} \left( \int_{-\infty}^{\infty}{|f(x)|^p \, dx} \right)^{1/p}
$$ The $L^{\infty}$ space is also defined analogously to $\ell^{\infty}$, but with the supremum replaced by the essential supremum (see below). Finally, like the discrete case, the only $L^p$ norm which is induced by an inner product is the $L^2$ norm, with the inner product $$
\langle f,g \rangle \buildrel{\rm def} \over{=} \int_{-\infty}^{\infty}{f(x)g(x) \, dx}
$$ So basically, the $L^p$ spaces are the same as the $\ell^p$ spaces, but with sequences replaced by functions of the entire number line and, accordingly, sums replaced by integrals. However, there are a number of complications which arise when we move from discrete to continuous inputs, namely:
The integral is understood to be a Lebesgue integral instead of the usual Riemann integral from calculus. The two agree whenever they are both defined, but the Lebesgue integral is defined for many more functions than the Riemann integral. A rigorous definition requires measure theory, which tells us how to define the measure of a given set of input values. The Lebesgue measure on the real number line is designed such that the measure of an interval $(a,b)$ is $b-a$.
The integral is not affected by changes in the function value on a set of measure zero. Any finite set of points has Lebesgue measure zero. Furthermore, any countably infinite set of points, such as the set of all rational numbers, also has measure zero.
Because of the last bullet, the members of the $L^p$ spaces are technically not functions, but rather equivalence classes of functions, where the equivalence relation is $$f \sim g \iff f=g \ \ {\rm a.e.}$$ where "a.e." (almost everywhere) means everywhere, except possibly on a set of measure zero.
The $L^{\infty}$ norm of a function (technically, an equivalence class of functions) $f$ is defined as the essential supremum of $f$. The essential supremum is the supremum, or least upper bound, of $f$, except possibly on a set of measure zero. For example, if $f(x) = 0$ for $x \neq 5$ and $f(5)=1$, then the supremum of $f$ is $1$, but the essential supremum of $f$ is $0$ since $f \leq 0$ except on the set $\{ 5 \}$, which is a single point and thus has measure zero.
Given the complexity of going into measures, the construction of the Lebesgue integral, and various Lebesgue integral convergence theorems, I won't delve further into the $L^p$ spaces in this post.
The $\ell^p$ spaces are enough to illustrate that function spaces (sequence spaces are a form of function spaces, just with a discrete set of input values) can possess a vector space structure as well as a norm and, for $p=2$, an inner product. Thinking of functions as members of a normed vector space is subtle, but as mentioned at the beginning of the post, it provides the mathematical foundation for numerous applications, some of which I hope to explore in future posts.
Part 2 of this post will explore linear functionals and duality, once again focusing on the $\ell^p$ spaces as a representative example.
I will conclude this post with the deferred proof of Hölder's inequality, but first, we'll need a lemma known as Young's inequality. For both of the proofs below, let $p$ and $q$ be positive real numbers satisfying $\frac{1}{p}+\frac{1}{q}=1$, known as Hölder conjugates.
Lemma (Young's inequality for products): For any two non-negative real numbers $\alpha$ and $\beta$, we have $$
\alpha \beta \leq \frac{\alpha ^ p}{p} + \frac{\beta ^ q}{q}
$$ with equality if and only if $\beta = \alpha^{p-1}$.
Proof: Note that $$
& &\frac{1}{p}+\frac{1}{q}&=1 \\[2mm]
&\implies &q+p &= pq \\[2mm]
&\implies &q+p + (1-p-q) &= pq+(1-p-q) \\[2mm]
&\implies &1 &= (p-1)(q-1) \\[2mm]
&\implies &\frac{1}{p-1} &= q-1
$$ so that for some numbers $t$ and $u$, we have $u=t^{p-1} \iff t=u^{q-1}$. In other words $u(t)=t^{p-1}$ and $t(u)=u^{q-1}$ are inverse functions.
Let $\alpha, \beta \geq 0$. If either one is zero, the inequality is trivially true, so assume they are both positive. Then we have $$
\alpha \beta \leq \color{blue}{\int_{0}^{\alpha}{t^{p-1} \, dt}} + \color{red}{\int_{0}^{\beta}{u^{q-1} \, du}}
= \frac{\alpha^p}{p} + \frac{\beta^q}{q}
$$ The inequality follows from the fact that $\alpha \beta$ is the area of the rectangle in the figure below, whose top edge is at $u=\beta$, below $u(\alpha) = \alpha^{p-1}$ (since $u(t)$ is an increasing function). When $\beta=\alpha^{p-1}$, the inequality is an equality, since the rectangle's top edge would coincide with the upper tip of the blue region.
Note that the inequality is still true if $\beta > \alpha^{p-1}$, since in that case, $\alpha < \beta^{q-1}$; since $t(u)=u^{q-1}$ is also an increasing function, this would result in extra area of the red zone sticking out to the right of the $\alpha \beta$-rectangle.
Hölder's inequality: Let ${\bf x} \in \ell^p$ and ${\bf y} \in \ell^q$. Then $$
\sum_{i=1}^{\infty}{|x_i y_i|} \leq
\left( \sum_{i=1}^{\infty}{|x_i|^p} \right)^{1/p} \left( \sum_{i=1}^{\infty}{|y_i|^q} \right)^{1/q}
$$ Before giving the proof, I want to point out that
If $p=q=2$ (this choice of $p$ and $q$ does satisfy the assumption $\tfrac{1}{p}+\tfrac{1}{q}=1$), then Hölder's inequality is just the infinite-sum version of the Cauchy-Schwarz inequality.
The statement of Hölder's inequality can also be written in terms of the $p$-norms: $$\| {\bf z} \|_1 \leq \| {\bf x} \|_{p} \| {\bf y} \|_{q} $$ where ${\bf z}$ is the sequence whose $i$-th component is $z_i = x_i y_i$. So the inequality also implies that ${\bf z} \in \ell^1$.
Proof of Hölder's inequality: If either ${\bf x}$ or ${\bf y}$ is the zero vector, then the inequality is trivially true, so assume both are non-zero. Then $\|{\bf x}\|_{p}$ and $\|{\bf y}\|_{q}$ are non-zero, and so we can define the unit vectors ${\bf u} = \frac{1}{\|{\bf x}\|_p} {\bf x}$ and ${\bf v} = \frac{1}{\|{\bf y}\|_q} {\bf y}$. Then, by Young's inequality, $$
|u_i v_i| \leq \frac{|u_i|^p}{p} + \frac{|v_i|^q}{q} \tag{$\star$}
$$ for all $i \in {\Bbb N}$.
Since ${\bf x}$ (and thus ${\bf u}$) is in $\ell^p$, and similarly, ${\bf v} \in \ell^q$, the series $\sum_{i=1}^{\infty}{|u_i|^p}$ and $\sum_{i=1}^{\infty}{|v_i|^q}$ both converge. Using the comparison test and $( \star )$, we can conclude that the series $\sum_{i=1}^{\infty}{|u_i v_i|}$ also converges, and thus the sequence ${\bf w} = (u_i v_i)_{i \in {\Bbb N}}$ is in $\ell^1$.
Since ${\bf z} = \|{\bf x}\|_{p} \|{\bf y}\|_{q} {\bf w}$ (i.e. ${\bf z}$ is a scalar multiple of ${\bf w}$), ${\bf z} \in \ell^1$ as well.
Finally, by summing both sides of $( \star )$ from $i=1$ to $\infty$ and using the fact that ${\bf u}$ and ${\bf v}$ are unit vectors, we obtain$$
\|{\bf w}\|_{1} \leq \frac{1}{p}\|{\bf u}\|_{p} + \frac{1}{q}\|{\bf v}\|_{q} = \frac{1}{p}+\frac{1}{q} = 1
$$ and thus $$
\|{\bf z}\|_{1} = \|{\bf x}\|_{p} \|{\bf y}\|_{q} \|{\bf w}\|_{1} \leq \|{\bf x}\|_{p} \|{\bf y}\|_{q}
There are also (Lebesgue) integral versions of Young's inequality and Hölder's inequality which are used for the $L^p$ spaces, but the discrete versions essentially give us the same picture without requiring the machinery of measure theory.
I hope this post was helpful, and stay tuned for Part 2.
Convergence of Sequences of Functions
Posted by gtmath Monday, August 22, 2016 2 comments
Preliminaries: Sets of Functions, How close is "close enough"?
The first post above introduced sets whose elements are functions and the associated naming convention; the second introduced open and closed sets in metric and topological spaces and the definitions of convergence appropriate to each. If you aren't familiar with these topics, then make sure to take a look at the preliminary posts before proceeding.
In this post, we'll investigate the different ways in which a sequence of functions can converge to a limit function. We'll see that different types of convergence correspond to different topologies on the relevant function space.
This is a long post- the first part is more intuitive, while the second part, from and including the Metrizability section, is proof-heavy. However, all proofs in this post require only the information in the preliminary posts and this post. As always, feel free to post any questions in the comments section if anything is unclear.
The Box Topology
Recall from the preliminary posts that the open intervals are a base for the usual topology on ${\Bbb R}$ (i.e. open sets are unions of open intervals) and that the function space ${\Bbb R}^{\Bbb N}$ can be viewed as an infinite Cartesian product of ${\Bbb R}$. In other words, we can think of ${\Bbb R}^{\Bbb N}$ as one copy of the number line (possible function values) for each number $0,1,2,\dotsc$ (the function inputs). ${\Bbb R}^{\Bbb R}$ is analogous but is an uncountably infinite product of the number line.
For now, let's focus on ${\Bbb R}^{\Bbb N}$ as the notation is a bit simpler. To create a topology on this Cartesian product, perhaps the most obvious idea would be to define open sets as Cartesian products of open sets in the real number line or, equivalently, Cartesian products of the basic open sets, the open intervals. This is the box topology (we'll see below why this is not good enough to warrant the name product topology).
Definition of the Box Topology: Let $U_1, U_2, U_3, \dotsc$ be open sets in the real number line ${\Bbb R}$. The set of functions $f : {\Bbb N} \rightarrow {\Bbb R}$ which satisfy $f(x) \in U_x$ for each $x=1,2,3, \dotsc$ is called an open box in ${\Bbb R}^{\Bbb N}$. The topology in which open sets are unions of open boxes (i.e. the topology generated by the open boxes) is called the box topology.
More concretely, let $U_1 = (a_1, b_1), U_2 = (a_2, b_2), U_3 = (a_3, b_3), \dotsc$ be open intervals in ${\Bbb R}$. Then the set of functions $$
&\{ f: {\Bbb N} \rightarrow {\Bbb R} \ | \ (f(1), f(2), f(3), \dotsc ) \in U_1 \times U_2 \times U_3 \times \dotsb \} \\
= \ &\{ f: {\Bbb N} \rightarrow {\Bbb R} \ | \ f(1) \in U_1 \ \ {\rm and} \ \ f(2) \in U_2 \ \ {\rm and} \ \ f(3) \in U_3 \ \ {\rm and} \ \dotsb \}
$$ is an open box in ${\Bbb R}^{\Bbb N}$ and thus an open set in the box topology.
Though the box topology is the most obvious one, it turns out to be basically useless because it is too restrictive: it allows us to restrict all function values at the same time to ranges of different sizes. For example, in any "reasonable" topology, the following sequence of functions $(\phi_n)$ should converge to the zero function: $$
\phi_1 &= \left( \, 1 \, , 1 \, , 1 \, , \dotsc \right) \\
\phi_2 &= \left( \tfrac{1}{2},\tfrac{1}{2}, \tfrac{1}{2}, \dotsc \right) \\
\phi_3 &= \left( \tfrac{1}{3}, \tfrac{1}{3}, \tfrac{1}{3}, \dotsc \right) \\
& \ \ \vdots
$$ However, this sequence does not converge in the box topology: the open box $B = (-1,1) \times (-\frac{1}{2}, \frac{1}{2}) \times (-\frac{1}{3}, \frac{1}{3}) \times \dotsb$ contains the zero function ${\bf 0} = (0,0,0, \dotsc )$ and so is a neighborhood of ${\bf 0}$, but $B$ does not contain any of the $\phi_n$'s.So $\phi_n \not \rightarrow {\bf 0}$ in the box topology.
Pointwise Convergence: The Product Topology
So the box topology is too restrictive to correspond to any reasonable type of convergence, but a slight modification fixes the issue presented above. If we only allow open sets to constrain function values at a finite number of input values, then we obtain the much more useful product topology.
Definition of the Product Topology: Let $U_1, U_2, U_3, \dotsc$ be open sets in the real number line ${\Bbb R}$ with the restriction that only finitely many of the $U_i$'s are not all of ${\Bbb R}$. The set of functions $f : {\Bbb N} \rightarrow {\Bbb R}$ which satisfy $f(x) \in U_x$ for each $x=1,2,3, \dotsc$ are the open sets in the product topology.
The finitely many values of $i$ for which $U_i \neq {\Bbb R}$ are the finitely many values for which a particular open set restricts the member functions' values $f(i)$ to lie in $U_i$. For example, a typical open set in the product topology on ${\Bbb R}^{\Bbb N}$ looks like $$
S = \left\{ f: {\Bbb N} \rightarrow {\Bbb R} \ | \ f(2) \in (3,7) \ {\rm and} \ f(103) \in \left(-56, \tfrac{1}{5} \right) \ {\rm and} \ f(200) \in (0,1) \right\}
$$ Note that there is no "..." at the end of the set definition (as there was in the example shown for the box topology), as $S$ only restricts function values for the 3 input values.
The functions which converge under the product topology are exactly those which converge pointwise.
Definition of Pointwise Convergence: Let $(f_n)$ be a sequence of functions in ${\Bbb R}^{\Bbb N}$. We say $(f_n)$ converges pointwise to a function $f$ if, for each individual $x \in {\Bbb N}$, the sequence of real numbers $f_{1}(x), f_{2}(x), f_{3}(x), \dotsc$ converges to $f(x)$ (in the usual topology on ${\Bbb R}$).
The definition for ${\Bbb R}^{\Bbb R}$ is analogous with ${\Bbb N}$ replaced by ${\Bbb R}$.
As an example, the following sequence of functions $(f_n)$ converges pointwise to the zero function: $$
f_1 &= \left( \, 1 \, , 2 \, , 3 \, , \color{red}{4} \, , 5 \, , \dotsc \right) \\
f_2 &= \left( \tfrac{1}{2},\tfrac{2}{2}, \tfrac{3}{2}, \color{red}{\tfrac{4}{2}}, \tfrac{5}{2}, \dotsc \right) \\
f_3 &= \left( \tfrac{1}{3}, \tfrac{2}{3}, \tfrac{3}{3}, \color{red}{\tfrac{4}{3}}, \tfrac{5}{3}, \dotsc \right) \\
$$ since for each fixed $x$, such as the red column corresponding to $x=4$, the sequence $f_{n}(x)$ is $x, \tfrac{x}{2}, \tfrac{x}{3}, \dotsc$, which clearly converges to $0$.
For a less straightforward example, this time in ${\Bbb R}^{[0, 2 \pi]}$, consider the sequence of functions $(f_n)$ defined by $f_{n}(x) = n \sin \left( \frac{x}{n} \right)$ for $x \in [0, 2 \pi ]$. This sequence converges pointwise to $f(x) = x$, as we can see from the following diagram of the first 20 functions in the sequence, along with the graph of $f(x)=x$:
To formally prove that $\displaystyle{\lim_{n \rightarrow \infty}{n \sin \left( \tfrac{x}{n} \right)} = x}$ for $x \in [0, 2 \pi ]$, let $x$ be fixed, set $t = x / n$, and then use the fact that $\displaystyle{\lim_{t \rightarrow 0}{\frac{\sin (t)}{t}} = 1}$. In this second example, the sequence $f_{n}(x)$ converges faster to $f(x)$ closer to $x=0$ than it does closer to $x = 2 \pi$ (you can see in the diagram that the sequence takes longer to "close the gap" on the right-hand side); this is fine for pointwise convergence.
Now, for the main event of this section- normally, I would leave this for the end of the post, but since the whole point of this post is to connect the different notions of convergence with their respective topologies, this one is worth reading even for those who aren't normally into proofs:
Convergence in the product topology is the same as pointwise convergence: Let $(f_n)$ be a sequence of functions in ${\Bbb R}^{\Bbb N}$ and let $f$ be another function (in the same space). Then $f_n \rightarrow f$ in the product topology if and only if $f_n \rightarrow f$ pointwise.
Proof: Suppose $f_n \rightarrow f$ in the product topology. Then, for every open set (in the product topology) $U$ containing $f$, $f_n \in U$ for all but finitely many (say the first $N$) values of $n$. This is simply the definition of convergence in a topological space, as discussed in the last post. Consider a fixed value $x \in {\Bbb N}$, and let $S$ be an open set containing $f(x)$ in ${\Bbb R}$ (for example, $S = (f(x) - \epsilon, f(x) + \epsilon )$ for some $\epsilon >0$ will work). Then the set of functions $$
U = \{ g: {\Bbb N} \rightarrow {\Bbb R} \ | \ g(x) \in S \}
$$ is an open set in the product topology which contains $f$. Thus, $f_n \in U$ for all $n > N$, which means that $f_{n}(x) \in S$ for all $n > N$. Since $S$ was an arbitrary neighborhood of $f(x)$ in ${\Bbb R}$, this shows that $\displaystyle{\lim_{n \rightarrow \infty}{f_{n}(x)} = f(x)}$, so $f_n \rightarrow f$ pointwise (in the usual topology on ${\Bbb R})$.
Conversely, suppose $f_n \rightarrow f$ pointwise. Then for all $x$, and for any open set $S$ in ${\Bbb R}$ which contains $f(x)$, $f_{n}(x) \in S$ for all $n > N$, for some finite $N$. Now, a general open set in the product topology containing $f$ is of the form $$
U = \{ g: {\Bbb N} \rightarrow {\Bbb R} \ | \ g(x_1) \in S_1 \ {\rm and} \ g(x_2) \in S_2 \ {\rm and} \ \cdots \ {\rm and} \ g(x_k) \in S_k\}
$$ where $x_1, x_2, \dotsc , x_k$ are the finitely many function values constrained by $U$, and each $S_i$ is a neighborhood (in ${\Bbb R}$) of $f(x_i)$. So by the argument above, $f_{n}(x_i) \in S_i$ for all $n > N_i$, for each of the $k$ values of $i$. Therefore, $f_n \in U$ for all $n > N_{\rm max} = \max \{ N_1, N_2, \dotsc , N_k \}$. This proves that $f_n \rightarrow f$ in the product topology.
The fact that an open set in the product topology can only constrain finitely many function values was key in the proof, because it allowed us to take the maximum of the $N_i$'s at the end. In the box topology, we could have an example like the sequence $(\phi_n)$ shown above, where $N_1 = 1, N_2 = 2, N_3 = 3, \dotsc \ $, and so since the $N_i$'s had no maximum or even any upper bound.
Since this proof didn't rely on anything in particular about ${\Bbb N}$ or ${\Bbb R}$, the same proof holds for the product topology on any function space $X^Y$. Since convergence in the product topology is equivalent to pointwise convergence, mathematicians also refer to the product topology as the topology of pointwise convergence.
Some problems with pointwise convergence...
The examples shown above of sequences of functions which converge pointwise to a limit function all truly fit with the common-sense notion of convergence of functions. Though the sequences converged faster at some input values than others, they all got there eventually at every input value. Now I'm going to show you some nastier examples which highlight the pitfalls with pointwise convergence.
Runaway Averages: Consider the following sequence of functions ${\Bbb N} \rightarrow {\Bbb R}$: $$
f_1 &= \left( 1,1,1,1,1,1, \dotsc \right) \\
$$ This sequence converges pointwise to the zero function since for each $x$, $f_{n}(x) = 0$ for all $n > x$. But for every $n$, at the (infinitely many) values of $x$ for which $f_{n}(x) \neq 0$, the functions actually get further away from zero, not closer to it as we'd expect of a "convergent" sequence. The average value of $f_n$ diverges to infinity as $n$ increases.
Tricky Triangles: The sequence of functions defined by $$
f_{n}(x) =
\cases{
n^{2}x & \text{if} \ \ \ \ 0 \leq x \leq 1/n \\
2n - n^{2}x & \text{if} \ \ \ \ 1/n < x \leq 2/n \\
0 & \text{if} \ \ \ \ x > 2/n
$$ yields triangles of height $n$ and constant area $1$, anchored at the point $(0,0)$, as shown in the below diagram of the first 3 functions:
It's clear from the picture that this also converges pointwise to the zero function, and the area of the triangles even stays constant, but the increasingly tall spikes are not consistent with our intuitive notion of "convergence."
We need something more restrictive than pointwise convergence to avoid these troublesome cases, but also something not as constricting as the box topology.
Uniform Convergence
In a function space $Y^X$ of functions $X \rightarrow Y$, if $Y$ is a metric space (like ${\Bbb R}$ for example), then we can define a measure of the "maximum" distance between two functions.
If we have two functions $f,g \in Y^X$, and a metric $d$ on $Y$, then we define the uniform distance between $f$ and $g$, denoted $\rho (f,g)$, to be the least upper bound (or supremum) of the distances between $f(x)$ and $g(x)$ at all values of $x$ in the domain $X$. Formally, $$
\rho (f,g) = \sup_{x \in X} \{ d(f(x),g(x)) \}
$$ This should be thought of as the maximum distance between the two functions, but we need to use the least upper bound instead of maximum in case one function has an asymptote and thus never achieves the "maximum" distance. If there is no upper bound on these distances, then $\rho (f,g) = \infty$.
As an example, the below diagram shows the function $f(x) = \cos (3x)^{2} + 4$ on the interval $x \in [0,1]$ and some random function $g(x)$ which has a uniform distance of less than $\epsilon = 1/2$ to $f(x)$.
Uniform distance allows us to define a notion of convergence which fits our intuitive notion while avoiding the pitfalls of pointwise convergence.
Definition of uniform convergence: Let $(f_n)$ be a sequence of functions in ${\Bbb R}^X$ for some domain $X$. We say $(f_{n})$ converges uniformly to a function $f$ if $\rho (f_{n} , f) \rightarrow 0$ as $n \rightarrow \infty$. In other words, for any $\epsilon > 0$, there exists an $N$ such that $\rho( f_{n} , f) < \epsilon$ for all $n>N$.
A sequence $(f_n)$ converges uniformly to $f$ if, for large enough values of $n$, the graphs of the functions $f_n$ fit within arbitrarily small "ranges" (between the red and green lines in the above diagram) around the graph of $f$. The sequence $(\phi_n)$ above converges uniformly to the zero function, but the other examples above which converge pointwise to $\bf 0$ above do not converge uniformly, since they have growing protrusions as $n$ increases.
Like pointwise convergence, uniform convergence is equivalent to convergence in particular topology called the uniform topology.
Definition of the Uniform Topology: Let $f \in {\Bbb R}^X$ for some domain set $X$, and let $\epsilon > 0$. Then the sets $$
B_{\rho}(f, \epsilon) = \left\{ g \in {\Bbb R}^X \ | \ \rho(f,g)<\epsilon \right\}
$$ are a base for the uniform topology, i.e. open sets are unions of sets of the form $B_{\rho}(f,\epsilon)$.
From this definition, it is immediately clear that convergence in the uniform topology is the same as uniform convergence as defined above.
One important note on the uniform topology: an open box such as $B_1 = (-1,1) \times (-1,1) \times \dotsb$ in ${\Bbb R}^{\Bbb N}$ is not the same as $B_{\rho}({\bf 0}, 1)$. The reason is that a function such as $g = (\tfrac{1}{2}, \tfrac{2}{3}, \tfrac{3}{4}, \tfrac{4}{5}, \dotsc)$ approaches $1$ asymptotically, so its supremum (least upper bound) is $1$, and thus $\rho({\bf 0}, g) = 1 \nless 1$, which means $g \notin B_{\rho}({\bf 0}, 1)$. But all of $g$'s values are less than $1$ (i.e. it never actually achieves its least upper bound), so $g \in B_1$.
It can actually be shown without too much difficulty that open boxes like $B_1$ are not even open sets in the uniform topology. Furthermore, although $B_{\rho}({\bf 0}, 1) \neq B_1$, we do have $B_{\rho}({\bf 0}, 1) = \bigcup_{\delta < 1}{B_{\delta}}$, where $B_{\delta} = (-\delta, \delta) \times (-\delta, \delta) \times \dotsb$.
Metrizability
It wouldn't be unreasonable to think that the uniform topology is the metric topology of the metric $\rho$. Unfortunately, $\rho$ isn't even a metric, and that's because it can take the value $\infty$. However, we can solve this issue rather easily by defining the bounded uniform metric $$
\bar{\rho}(f,g) = \min \{ \rho(f,g),1 \}
$$ This is a legitimate metric (it isn't too hard to verify that it satisfies the 3 axioms) since capping $\rho$ at $1$ solves the infinity issue. As in the case of Euclidean space (refer to the preliminary post), the open sets defined via this metric (i.e. the metric topology) are those in which each point contains an open ball $B_{\bar{\rho}}(f,\epsilon)$ around each of it's points $f$. Now, any set containing some open ball around each of its points also contains many open balls of smaller radii around the same points. This means that the cap of $1$ on the value of the metric has no effect on which sets are open, and by extension, on which sequences converge. In other words, the metric topology of $\bar{\rho}$ is the same as the uniform topology (i.e. the one generated by "open balls" in the "almost metric" $\rho$).
Note: It is actually always the case (by this same logic) that the metric topology of a metric $d$ is the same as that of $\bar{d} = \min \{ d,1 \}$. Although our $\rho$ wasn't even a metric to begin with, the logic is still the same.
Even without knowing the above, we can conclude directly based on the definition of $\bar{\rho}$ via $\rho$ that convergence in this metric space is the same as convergence in the uniform topology, since for convergence, we only care about (arbitrarily) small distances, so capping the metric at 1 has no effect on which sequences converge.
The metrizability of the product/pointwise topology and box topology is less obvious. Let's investigate, focusing on ${\Bbb R}^{\Bbb N}$ and ${\Bbb R}^{\Bbb R}$.
As you may have expected, the troublesome box topology is too restrictive to be metrizable. The product topology's metrizability is a bit trickier and depends on whether the Cartesian product in question is countable or not. The (non-unique) metrics which yield the product and uniform topologies are shown in the table below:
The below proofs justify the results in the above table (the uniform topology was already covered above, albeit only informally).
Proof that the box topology on ${\Bbb R}^{\Bbb N}$ is not metrizable: Suppose that $d$ is a metric on ${\Bbb R}^{\Bbb N}$ whose metric topology is the same as the box topology.
Consider the open balls $B_{d}({\bf 0}, 1), B_{d}({\bf 0}, \tfrac{1}{2}), B_{d}({\bf 0}, \tfrac{1}{3}), \dotsc$ around the zero function ${\bf 0} = (0,0,0,\dotsc)$ in ${\Bbb R}^{\Bbb N}$. By assumption, each of these is open in the box topology, which means that each one contains an open box around ${\bf 0}$. So there exist positive numbers $a_{ij}$ such that $$
B_{d}({\bf 0}, \, 1) &\supsetneq (-a_{11}, a_{11}) \times (-a_{12},a_{12}) \times (-a_{13},a_{13}) \times \dotsb \tag{1}\\
B_{d}({\bf 0}, \tfrac{1}{2}) &\supsetneq (-a_{21}, a_{21}) \times (-a_{22},a_{22}) \times (-a_{23},a_{23}) \times \dotsb \tag{2}\\
$$ We can assume the intervals along each column are shrinking, i.e. $a_{1j} \geq a_{2j} \geq a_{3j} \geq \dotsb \ ( \star )$. This is without loss of generality, since any interval contains many smaller ones as well. Consider the open box $B$ formed by the intervals on the diagonal: $$
B = (-a_{11},a_{11}) \times (-a_{22},a_{22}) \times (-a_{33},a_{33}) \times \dotsb
$$ This is a neighborhood of ${\bf 0}$ in the box topology and thus, by assumption, is an open set in the metric topology. So $B$ must contain an open ball $B_{d}({\bf 0},r)$ centered at ${\bf 0}$ for some radius $r$. In particular, $B$ must contain one of the $B_{d}({\bf 0}, \tfrac{1}{n})$ for some $n$ (large enough that $1/n < r$). However, this is a contradiction, for if $B$ contained $B_{d}({\bf 0}, 1)$, then each sequence (i.e. element of ${\Bbb R}^{\Bbb N}$) in the ball would be in $B$. In particular, for each sequence $x_1, x_2, x_3, \dotsc \in B_{d}({\bf 0},1)$, we would have $$
x_1 &\in (-a_{11},a_{11}) \\
x_2 &\in (-a_{22},a_{22}) \buildrel{( \star )} \over{\subseteq} (-a_{12},a_{12}) \\
x_3 &\in (-a_{33},a_{33}) \buildrel{( \star )} \over{\subseteq} (-a_{23},a_{23}) \buildrel{( \star )} \over{\subseteq} (-a_{13},a_{13}) \\
$$ But the $\supsetneq$ in $(1)$ above tells us that at least one sequence $(x_n)$ exists for which this is not the case. The same logic precludes the rest of the open balls $B_{d}({\bf 0}, \tfrac{1}{n})$ from being fully contained in $B$, so we conclude that no such metric $d$ can exist.
Proof that ${\Bbb R}^{\Bbb N}$ with the product topology is metrizable: Let $f$ and $g$ be sequences in ${\Bbb R}^{\Bbb N}$. Let $d(x,y) = |y-x|$ be the usual metric on the real line and $\bar{d}(x,y) = \min \{ d(x,y), 1 \}$. Define the metric $D$ on ${\Bbb R}^{\Bbb N}$ by $$
D(f,g) = \sup_{n \in {\Bbb N}} \left\{ \frac{\bar{d}(f(n),g(n))}{n} \right\}
$$ $D$ is indeed a metric, which I won't prove here. We will show that open sets in the metric topology of $D$, which we'll call $\mathscr{T}_D$, are open sets in the product topology $\mathscr{T}$, and vice versa.
$\mathscr{T}_D \subseteq \mathscr{T}$:
Let $U$ be an open set in the metric topology $\mathscr{T}_D$, and let $f = (x_1. x_2, x_3, \dotsc ) \in U$. By the definition of open sets in the metric topology, there exists an $\epsilon > 0$ such that $B_{D}(f, \epsilon) \subseteq U$. Choose an $N \in {\Bbb N}$ large enough that $1/N < \epsilon$, and let $g = (y_1, y_2, y_3, \dotsc )$ be another function in ${\Bbb R}^{\Bbb N}$. Since $\bar{d}$ is capped at $1$, we have $\frac{\bar{d}(x_i , y_i)}{i} < \frac{1}{N}$ for all $i>N$. In other words, $\frac{1}{N}$ is an upper bound on $\frac{\bar{d}(x_i , y_i)}{i}$ for $i>N$.
$D(f,g)$ is the least upper bound of the numbers $\frac{\bar{d}(x_i, y_i)}{i}$, so by the above, we have $$
D(f,g) \leq \max \left\{ \bar{d}(x_1, y_1), \frac{\bar{d}(x_2, y_2)}{2}, \frac{\bar{d}(x_3, y_3)}{3}, \dotsc , \frac{1}{N} \right\} \tag{$\dagger$}
$$ Define the set $$
V = (x_1-\epsilon, x_1+\epsilon) \times (x_2-\epsilon, x_2+\epsilon) \times \dotsb \times (x_N-\epsilon, x_N+\epsilon) \times {\Bbb R} \times {\Bbb R} \times \dotsb
$$ which is clearly an open neighborhood of $f$ in the product topology $\mathscr{T}$. Let $g \in V$. By the definition of $V$, $|y_1-x_1| < \epsilon, |y_2-x_2| < \epsilon, \dotsc , |y_N-x_N|<\epsilon$. Thus, by $( \dagger )$ and the fact that $\frac{1}{N}<\epsilon$, we have $D(f,g) < \epsilon$, i.e. $g \in B_{D}(f, \epsilon) \subseteq U$. This proves that $V \subseteq U$, so $U$ contains an open neighborhood (in $\mathscr{T}$) of each of its points $x$ and is thus an open set in $\mathscr{T}$.
$\mathscr{T} \subseteq \mathscr{T}_D$:
Let $U$ be an open set in the product topology $\mathscr{T}$, so $U = \prod_{n \in {\Bbb N}}{U_i}$, where only finitely many of the open sets (in the usual topology on ${\Bbb R}$) $U_i$ are not all of ${\Bbb R}$. Define $J$ as the finite set of indices $j$ for which $U_j \neq {\Bbb R}$. Let $f = (x_1, x_2, x_3, \dotsc ) \in U$. Since each $U_j$ is an open set in ${\Bbb R}$, there exists an $\epsilon_j>0$ such that $(x_j - \epsilon_j, x_j + \epsilon_j) \subseteq U_j$ for each $j \in J$. Set $\epsilon = \frac{1}{2} \cdot \min_{j \in J} \left\{ \frac{\epsilon_j}{j} \right\}$. Furthermore, we can assume without loss of generality that each $\epsilon_j < 1$ so that we won't need to worry about the cap of $1$ on $\bar{d}$ below.
We will prove that $B_{D}(f, \epsilon)$, an open neighborhood of $f$ in the metric topology $\mathscr{T}_D$, is contained in $U$, which implies that $U$ is open in $\mathscr{T}_D$. To that end, let $g = (y_1, y_2, y_3, \dotsc ) \in B_{D}(f, \epsilon)$. Then, for each $j \in J$, we have $$
& &&\frac{\bar{d}(x_j, y_j)}{j} &&< \ \ \epsilon \tag{def. of $B_{D}(f, \epsilon)$}\\[2mm]
&\implies &&\frac{\bar{d}(x_j, y_j)}{j} &&< \ \ \frac{\epsilon_j}{j} \tag{def. of $\epsilon$} \\[2mm]
&\implies &&\bar{d}(x_j, y_j) &&< \ \ \epsilon_j \\[2mm]
&\implies &&d(x_j, y_j) &&< \ \ \epsilon_j \tag{since $\epsilon_j < 1$} \\[2mm]
&\implies &&y_j &&\in \ \ (x_j - \epsilon_j, x_j + \epsilon_j) \subseteq U_j
$$ Furthermore, for each $k \notin J$, $U_k = {\Bbb R}$, so it is trivially the case that $y_k \in U_k$. This proves that $g \in U$, so $B_{D}(f, \epsilon) \subseteq U$.
Before the final proof to complete the table above, we need a lemma.
Lemma: in a metric space $(X,d)$, every closed set can be written as the intersection of countably many open sets.
Proof: For a set $S \subseteq X$ and a point $x \in X-S$ define the distance between the point and the set to be $d(x,S) = \inf_{s \in S} \left\{ d(x,s) \right\}$, where $\inf$ is the infimum or greatest lower bound.
Assume $S$ is a closed set. Then we have $$
S = \bigcap_{k=1}^{\infty}{\left\{ x \in X \ | \ d(x,S)< \frac{1}{k} \right\}}
$$ a countable intersection of open sets in the metric topology (right-click the image below to expand in a new tab).
Proof that ${\Bbb R}^{\Bbb R}$ with the product topology is not metrizable: Assume the product topology on ${\Bbb R}^{\Bbb R}$ is metrizable by a metric $d$. A set containing a single point is always a closed set, so the set containing only the zero function, $S = \{ {\bf 0} \}$, is closed. By the lemma, $S \buildrel{( \spadesuit )} \over{=} \bigcap_{k=1}^{\infty}{G_k}$ for some open sets $G_k$. Since it is an intersection, $S \subseteq G_k$ for each $k$, which means ${\bf 0} \in G_k$ for each $k$.
For all $k$, since $G_k$ is open in the product topology, there exists an $\epsilon_k > 0$ and a finite set of input values $X_k$ such that $$
\left\{ f: {\Bbb R} \rightarrow {\Bbb R} \ | \ |f(x)-0|<\epsilon_k \ \ \forall \ x \in X_k \right\} \subseteq G_k \tag{$\ddagger$}
$$ Let $X=\bigcup_{k=1}^{\infty}{X_k}$. This is a countable union of finite sets and thus a countable set, so it is not all of ${\Bbb R}$. The function $$
g(x) =
0 & \text{if } x \in X \\
1 & \text{if } x \notin X
$$ is a member of $\bigcap_{k=1}^{\infty}{G_k}$ since it is included in the sets mentioned in $( \ddagger )$, but $g \neq {\bf 0}$ since $X \subsetneq {\Bbb R}$. This contradicts $( \spadesuit )$, so we conclude that no such metric $d$ can exist.
Comparing the topologies
Almost no sequences converge in the box topology as discussed above, but any sequence that does also converges uniformly. This is because constraining all function values at once, at possibly different speeds of convergence, is more restrictive that constraining all function values at once, at the same speed of convergence.
More obvious is the fact that any sequence that converges uniformly also converges pointwise, because if we can constrain all function values within a certain distance of the limit function, then, in particular, we can constrain any single function value within that distance.
So convergence in the box topology implies uniform convergence, which implies pointwise convergence. Equivalently, all open sets in the topology of pointwise convergence are also open in the uniform topology, and all open sets in the uniform topology are also open in the box topology. This is because convergence of a sequence in a topological space is defined as eventual inclusion of the sequence points in any given neighborhood of the limit: more open sets means more neighborhoods, making it harder to find convergent sequences.
The following proof formalizes the above intuition.
Proof that $\mathscr{T}_{\rm product} \subset \mathscr{T}_{\rm uniform} \subset \mathscr{T}_{\rm box}$: In this proof, we'll assume we're dealing with ${\Bbb R}^{\Bbb N}$ to keep the notation simpler, but the same logic works for any function space $Y^X$ (where $Y$ is a metric space so that the uniform topology exists).
$\mathscr{T}_{\rm product} \subset \mathscr{T}_{\rm uniform}$:
Let $U$ be an open set in ${\Bbb R}$, and define $S(x,U) = \left\{ f \in {\Bbb R}^{\Bbb N} \ | \ f(x) \in U \right\}$, i.e. a set constraining only a single function value to lie within $U$. Note that open sets in the product topology are all finite intersections of these types of sets (we say they form a subbase for the product topology). Suppose $f \in S(x,U)$. Then $f(x) \in U$, an open set, which means there exists an $\epsilon > 0$ such that $B_{\epsilon}(f(x)) \subset U$. By the same logic, any function with uniform distance less than $\epsilon$ to $f$, i.e. any element of $B_{\rho}(f, \epsilon)$, is also in $S(x,U)$, which means $S(x,U)$ contains an open neighborhood (in the uniform topology) of each of its points. So $S(x,U)$ is an open set in $\mathscr{T}_{\rm uniform}$.
A general open set in $\mathscr{T}_{\rm product}$ is just a finite intersection of $S(x,U)$'s, so take the smallest $\epsilon$ of these from the process above, which is guaranteed to exist since there is always a minimum of a finite set of numbers. So all open sets in $\mathscr{T}_{\rm product}$ are open in $\mathscr{T}_{\rm uniform}$, which means $\mathscr{T}_{\rm product} \subset \mathscr{T}_{\rm uniform}$.
$\mathscr{T}_{\rm uniform} \subset \mathscr{T}_{\rm box}$:
Since the open balls $B_{\rho}(f, \epsilon)$ are a base for $\mathscr{T}_{\rm uniform}$, i.e. open sets are unions of such open balls, we just need to prove that these open balls are open in the box topology. To that end, let $f = (x_1, x_2, x_3, \dotsc)$, $\epsilon > 0$, and let $g = (y_1, y_2, y_3, \dotsc) \in B_{\rho}(f, \epsilon)$.
Since $B_{\rho}(f, \epsilon)$ is open, there exists an $\epsilon_2 > 0$ such that $B_{\rho}(g, \epsilon_2) \subset B_{\rho}(f, \epsilon)$. Furthermore, $B_{\rho}(g, \epsilon_2)$ contains an open neighborhood of $g$ in the box topology, namely, the open box $$
(y_1 - \frac{\epsilon_2}{2}, y_1 + \frac{\epsilon_2}{2}) \times
\dotsb
$$ This proves that $B_{\rho}(f, \epsilon)$ is open in the box topology.
The fact that more functions converge pointwise than uniformly brings us to one last interesting observation: a sequence of continuous functions can converge pointwise to a function with a discontinuity.
Example: The sequence of functions $f_n: {\Bbb R} \rightarrow {\Bbb R}$ defined by $$
f_n(x) =
0 &\text{if } x \leq 0 \\
nx & \text{if } 0 < x \leq 1/n \\
1 &\text{if } x > 1/n
$$ consists entirely of continuous functions, as the below diagram of $f_2$ through $f_{10}$ illustrates:
However, as the slanted part gets narrower as $n \rightarrow \infty$, the sequence converges pointwise to the discontinuous function $$
f(x) =
1 & \text{if } x > 0
However, if such a sequence converges uniformly, it is always to another continuous function. This is because the set of continuous functions is closed in the uniform topology (refer to the proof that closed sets contain their limit points, in the second preliminary post). I'll conclude this post with a definition and a proof.
Topological definition of continuity: Let $(X, \mathscr{T}_X)$ and $(Y, \mathscr{T}_Y)$ be topological spaces and $f$ be a function $X \rightarrow Y$. $f$ is called continuous if for all $x_0 \in X$, for every neighborhood $V \in \mathscr{T}_Y$ of $f(x_0)$, there exists a neighborhood $U \in \mathscr{T}_X$ of $x_0$ such that $f(x) \in V$ whenever $x \in U$.
This definition is easily shown to be equivalent to the more familiar continuity criterion for ${\Bbb R}^{\Bbb R}$: $f$ is continuous if, for any $x_0 \in {\Bbb R}$ and any $\epsilon>0$, there exists a $\delta$ such that $|f(x)-f(x_0)|<\epsilon$ whenever $|x-x_0|<\delta$.
Uniform Limit Theorem: Let $X$ be a topological space and $(Y,d)$ be a metric space. Let $C$ be the set of continuous functions $X \rightarrow Y$. Then $C$ is a closed set in the uniform topology on $Y^X$.
Proof: Let $f$ be the uniform limit of a sequence of continuous functions. Then $f$ is a limit point of $C$, i.e. for any $\epsilon>0$, there exists a continuous function $g: X \rightarrow Y$ such that $\rho(f,g)<\epsilon / 3$, and thus $d(f(x),g(x)) < \epsilon / 3 \ ( \clubsuit )$ for any particular value of $x \in X$. Furthermore, since $g$ is continuous, for any $x_0 \in X$, there exists a neighborhood $U \subset X$ of $x_0$ such that $d(g(x),g(x_0)) < \epsilon / 3 \ ( \diamondsuit )$ for all $x \in U$.
Thus, for $x \in U$, we have $$
d(f(x),g(x)) &< \epsilon / 3 \tag{by $\clubsuit$} \\[2mm]
d(f(x_0),g(x_0)) &< \epsilon / 3 \tag{by $\clubsuit$} \\[2mm]
d(g(x),g(x_0)) &< \epsilon / 3 \tag{by $\diamondsuit$}
$$ Since $d$ is a metric, we can use the triangle inequality to conclude that $$
d(f(x),f(x_0)) &\leq d(f(x),g(x)) + d(g(x),g(x_0)) + d(g(x_0),f(x_0)) \\[2mm]
&< \frac{\epsilon}{3} + \frac{\epsilon}{3} + \frac{\epsilon}{3} \\[2mm]
&= \epsilon
$$ So we have found a neighborhood, namely $U$, of $x_0$, such that $d(f(x),f(x_0)) < \epsilon$ whenever $x \in U$. This means that $f$ is continuous and thus $f \in C$. A set which contains all its limit points is a closed set, so $C$ is closed.
Technically, I haven't proved that a set containing all its limit points is closed; to that end, note that if $S$ is not closed in a metric space $(X,d)$, then $X-S$ is not open. So there is a point $x \in X-S$ such that for every $n=1,2,3, \dotsc$, the open ball $B_{d}(x,\tfrac{1}{n})$ contains a point $x_n \in X-(X-S)=S$. Thus $(x_n)$ is a sequence of points in $S$ converging to a point $x$ not in $S$, so $S$ does not contain all its limit points. Thus, if a set does contain all its limit points, it must be closed.
Thank you for reading- please post any questions or feedback in the comments section.
Jim Belk - Bard College
David Preiss - Warwick University
Dustin Hedmark - University of Chicago
How close is "close enough"? Metric Spaces, Topological Spaces, and Convergence
Posted by gtmath Sunday, July 17, 2016 0 comments
Preliminaries: set basics, Euclidean space
Open and closed sets; topology
You may be familiar with the concept of open and closed sets in Euclidean space ${\Bbb R}^n$. For those who aren't, an open set is one that does not contain any of its boundary points. A closed set is one that contains all of its boundary points. The following graphic provides a good illustration (dotted lines indicate boundary points not included in the set, while solid lines indicate boundary points which are included):
Diagram 1: an intuitive depiction of open and closed sets
The complement of an open set is closed, and the complement of a closed set is open. The top-left item in the diagram also shows that some sets are neither open nor closed. In addition, the entire space ${\Bbb R}^n$ is both open and closed, as is the empty set.
Furthermore, taking unions and intersections of open and closed sets yield the following results, best summarized in a diagram:
Diagram 2: unions and intersections of open and closed sets
The following definition formalizes the notion of an open set in ${\Bbb R}^n$ and allows us to justify the conclusions above.
Definition of open/closed sets in ${\Bbb R}^n$: An open set is a set $U$ such that for each $x \in U$, there exists an $\epsilon>0$ (which may be very small) such that $y \in U$ whenever the distance between $x$ and $y$ is less than $\epsilon$. A closed set is one whose complement is an open set.
Diagram 3: definition of an open set $U$ in the plane ${\Bbb R}^2$
The set of all points $y$ located strictly within distance $\epsilon$ of a point $x$ is called the open ball of radius $\epsilon$ centered at $x$ and is denoted $B_{\epsilon}(x)$ as shown in the picture. Using this definition of open sets, it is easy to prove the properties in Diagram 2.
Note that the definition presented above actually relied on our having a notion of distance between two points. In a general space, this may not be the case, or there may be numerous measures of distance from which we can choose. The field of topology studies properties of more general spaces without necessarily relying on a distance function. To start, we define the open sets as a collection having some of the familiar properties presented above.
Definition of a topology: Let $X$ be a set, and let $\mathscr T$ be a subset of the power set of $X$, i.e. a collection of subsets of $X$. $\mathscr T$ is called a topology on $X$, and the elements of $\mathscr T$ are called open sets, if the following properties hold:
The empty set and $X$ itself are in $\mathscr T$.
Any union of (finitely or infinitely many) elements of $\mathscr T$ is also an element of $\mathscr T$.
Any intersection of finitely many elements of $\mathscr T$ is also an element of $\mathscr T$.
Closed sets are defined as sets whose complements are open sets.
The "dumbest" example of a topology on a set $X$ is the set $\{ X , \emptyset \}$, called the discreet topology. Another example for $X = {\Bbb R}^n$ was the above-mentioned usual definition of open sets using the distance function. Namely, the open sets in ${\Bbb R}^n$ (in the usual topology) are the ones which contain an open ball of some radius around each of their points, or equivalently, contain none of their boundary points.
The open sets defined via open balls as described above comprise the so-called metric topology, in which every open set can be written as the union of open balls, and every point is contained in an open ball (actually, infinitely many open balls). Because of these two facts, we say that the open balls form a base for, or generate, the metric topology.
Metric Spaces
In defining the above-described metric topology on ${\Bbb R}^n$, we made use of the fact that we can measure distance between two points using the well-known distance formula. Similarly to the way we used the properties from ${\Bbb R}^n$ as the definitions of topological spaces and vector spaces, we can do the same to define the properties a distance measure should have.
A distance function on a set $X$ should map any two elements of $X$ to a "distance." Formally, a function $d: X \times X \rightarrow [0, \infty)$ (i.e. a function taking any two inputs from $X$ and returning a non-negative real number) is called a metric if it satisfies the following 3 properties:
Positive-definiteness: $d(x,y) \geq 0$, with $d(x,y)=0 \iff x=y$,
Symmetry: $d(x,y)=d(y,x)$, and
Triangle inequality: $d(x,z) \leq d(x,y) + d(y,z)$.
The triangle inequality: the length of one side of a triangle
cannot exceed the sum of the lengths of the other two.
For example, on the real number line, the absolute value of the difference between two numbers (i.e. the distance formula in one dimension) is a metric. The symmetry and positive-definiteness of $d(x,y) = |y-x|$ are obvious; to prove the triangle inequality $|z-x| \leq |z-y| + |y-x|$ for all real numbers $x,y,z$, note that we can set $a = z-y$ and $b=y-x$ so that $z-x = a+b$. Thus it suffices to prove that $|a+b| \leq |a| + |b|$ for all $a,b \in {\Bbb R}$.
Proof of the triangle inequality for absolute value: Note that $$
-|a| &\leq a \leq |a| \tag{1} \\
-|b| &\leq b \leq |b| \tag{2}
$$ Adding equations (1) and (2) gives $$
-(|a|+|b|) \leq a+b \leq |a|+|b| \tag{$\star$}
$$ To simplify the notation, call $a+b := \phi$ and call $|a|+|b| := \psi$. Then equation $( \star )$ says that $-\psi \leq \phi \leq \psi$. In other words, $| \phi | \leq \psi$. Translating back to $a$ and $b$, we have shown that $|a+b| \leq |a| + |b|$.
So the usual distance measure on the real number line is indeed a metric, making ${\Bbb R}$ a metric space. The usual topology on ${\Bbb R}$ is the metric topology generated by the open intervals $(a,b) = \{ x \ | \ a<x<b \}$. These are also the open balls defined by the absolute value metric, since $(a,b) = B_{(b-a)/2}(\frac{a+b}{2})$ and $B_{\epsilon}(x) = (x-\epsilon, x+\epsilon)$.
Given a topological space $(X, {\mathscr T})$, if the elements of $\mathscr T$, i.e. the open sets, are generated by the open balls $B_{\epsilon}(x)$ in some metric, then $(X, {\mathscr T})$ is called metrizable. There are examples of non-metrizable topological spaces which arise in practice, but in the interest of a reasonable post length, I will defer presenting any such examples until the next post. However, it is worth noting that non-metrizable spaces are the ones which necessitate the study of topology independent of any metric.
Convergence of sequences in a metric space
Suppose we have a sequence of points $x_1, x_2, x_3, \dotsc$ in a metric space $(X,d)$. To simplify the notation, such a sequence is often written as $(x_n)$. How do we know if the sequence has a limit? Take a look at the following diagrams:
The first sequence of points obviously does not have a limit; it never "closes in" on any point. The second sequence, on the other hand, does seem to have a limit. The formal definition makes this intuition concrete.
Definition of limit of a sequence (metric space): Let $(x_n)$ be a sequence in the metric space $(X,d)$. The point $L \in X$ is called the limit of $(x_n)$ if, for any $\epsilon >0$, there exists a number $N$ such that $d(x_n, L) < \epsilon$ whenever $n>N$. In this case, we write $L = \displaystyle{\lim_{n \rightarrow \infty}{x_n}}$.
This means that given any threshold $\epsilon$, which can be arbitrarily small, the sequence points are eventually (i.e. for $n>N$, where $N$ may depend on $\epsilon$ and may be very large) all within distance $\epsilon$ of $L$.
Illustration of a convergent sequence: here, the sequence terms are all within
$\epsilon$ of $L$ after the 13th term. So for the choice of $\epsilon$ shown, $N=13$ works.
For example, the sequence of real numbers $1, \frac{1}{2}, \frac{1}{4}, \frac{1}{8}, \dotsc, \frac{1}{2^n}, \dotsc$ has limit $0$: take a very small tolerance such as $\epsilon = \frac{1}{1 \mathord{,} 000 \mathord{,} 000}$. Then we have
$$\left| \frac{1}{2^n} - 0 \right| < \frac{1}{1 \mathord{,} 000 \mathord{,} 000} \iff 2^n > 1 \mathord{,} 000 \mathord{,} 000 \iff n > \log_{2}{1 \mathord{,} 000 \mathord{,} 000}$$Similarly, for a general $\epsilon$, we have $|x_n-0| < \epsilon$ whenever $n$ is larger than $N = \log_{2}{(1 / \epsilon)}$. Since we have found a suitable $N$ for any $\epsilon$, $0$ is indeed the limit of the sequence.
Convergence of sequences in a topological space
A topology $\mathscr T$ on a set $X$ specifies open and closed sets independently of any metric which may or may not exist on $X$. The definition of convergence above relied on a metric, but we can remove this reliance by defining convergence purely in terms of open sets.
Definition of limit of a sequence (topological space): Let $(x_n)$ be a sequence in the topological space $(X, {\mathscr T})$. The point $L \in X$ is called the limit of $(x_n)$ if, for any open set $U$ containing $L$, there exists a number $N$ such that $x_n \in U$ whenever $n>N$. In this case, we write $L = \displaystyle{\lim_{n \rightarrow \infty}{x_n}}$.
In the metric space case above, these open sets $U$ were simply the open balls $B_{\epsilon}(L)$, so the two definitions agree in a metrizable space. Without a metric by which to define open balls in a general topological space, we replace these with open sets $U$ containing $L$, known as neighborhoods of $L$.
To conclude this post, let's take a look at an easy proof that demonstrates how things are done in topology and also ties in the notion of convergence.
Recall that the closed sets in ${\Bbb R}^n$ are the ones containing all of their boundary points, or equivalently, the limits of all their convergent sequences (can you picture why every boundary point, as well as every interior point, of a set is the limit of a convergent sequence contained in that set?). An analogous statement holds in general topological spaces.
Closed sets contain their limit points: let $(X, {\mathscr T})$ be a topological space, and let $C \subseteq X$ be a closed set. Let $(c_n)$ be a convergent sequence of points all contained in $C$, with $\displaystyle{\lim_{n \rightarrow \infty}{c_n}}=L$. Then $L \in C$.
Proof: Since $C$ is closed, its complement $X-C$ is open (by the definition of closed sets). Assume $L \notin C$. Then $L \in X - C$, an open set. Since $X-C$ is an open set containing $L$, the definition of convergence tells us that there exists an $N$ such that $c_n \in X-C$ for all $n > N$. But this is a contradiction, since $c_n \in C$ for all $n$.
In the next post, we'll explore a few topologies on sets of functions, and we'll see that the most intuitive one is not metrizable.
I hope you enjoyed this post, and please feel free to post any questions in the comments section below.
Parameter Estimation - Part 2 (German Tank Problem)
Pool Part 2: Banks and Kicks
Convexity and Jensen's Inequality
How do mathematicians model randomness?
Power Means (AM-GM Part 3)
Equivalence Relations
Monte Carlo Simulation - Part 2
Solving a Recursion
Preliminaries ( 13 )
Probability ( 7 )
Combinatorics ( 6 )
Geometry ( 5 )
Physics ( 5 )
Reader Requests ( 5 )
Set Theory ( 5 )
Computer Science ( 4 )
Financial Math ( 4 )
Proof Techniques ( 4 )
Putnam Training ( 4 )
Billiards ( 3 )
Linear Algebra ( 3 )
Statistics ( 3 )
Interview Questions ( 2 )
R^n ( 2 )
Topology ( 2 )
Algebra ( 1 )
Brainteasers ( 1 )
How close is "close enough"? Metric Spaces, Topolo...
Copyright © gtMath. All rights reserved. | CommonCrawl |
Navier--Stokes equations on a rapidly rotating sphere
The threshold of a stochastic SIRS epidemic model in a population with varying size
June 2015, 20(4): 1261-1276. doi: 10.3934/dcdsb.2015.20.1261
New results of the ultimate bound on the trajectories of the family of the Lorenz systems
Fuchen Zhang 1, , Chunlai Mu 2, , Shouming Zhou 3, and Pan Zheng 4,
College of Mathematics and Statistics, Chongqing Technology and Business, University, Chongqing 400067, China
College of Mathematics and Statistics, Chongqing University, Chongqing 401331, China
College of Mathematics Science, Chongqing Normal University, Chongqing 400047, China
College of Mathematics and Physics, Chongqing University of Posts, and Telecommunications, Chongqing 400065, China
Received October 2013 Revised August 2014 Published February 2015
In this paper, the global exponential attractive sets of a class of continuous-time dynamical systems defined by $\dot x = f\left( x \right),{\kern 1pt} {\kern 1pt} {\kern 1pt} x \in {R^3},$ are studied. The elements of main diagonal of matrix $A$ are both negative numbers and zero, where matrix $A$ is the Jacobian matrix $\frac{{df}}{{dx}}$ of a continuous-time dynamical system defined by $\dot x = f\left( x \right),{\kern 1pt} {\kern 1pt} {\kern 1pt} x \in {R^3},$ evaluated at the origin ${x_0} = \left( {0,0,0} \right).$ The former equations [1-6] that we are searching for a global bounded region have a common characteristic: The elements of main diagonal of matrix $A$ are all negative, where matrix $A$ is the Jacobian matrix $\frac{{df}}{{dx}}$ of a continuous-time dynamical system defined by $\dot x = f\left( x \right),{\kern 1pt} {\kern 1pt} {\kern 1pt} x \in {R^n},$ evaluated at the origin ${x_0} = {\left( {0,0, \cdots ,0} \right)_{1 \times n}}.$ For the reason that the elements of main diagonal of matrix $A$ are both negative numbers and zero for this class of dynamical systems , the method for constructing the Lyapunov functions that applied to the former dynamical systems does not work for this class of dynamical systems. We overcome this difficulty by adding a cross term $xy$ to the Lyapunov functions of this class of dynamical systems and get a perfect result through many integral inequalities and the generalized Lyapunov functions.
Keywords: global attractive set, Lyapunov stability, generalized Lyapunov functions., Dynamical systems.
Mathematics Subject Classification: Primary: 37B25; Secondary: 45M10, 11D41, 26A18, 37A6.
Citation: Fuchen Zhang, Chunlai Mu, Shouming Zhou, Pan Zheng. New results of the ultimate bound on the trajectories of the family of the Lorenz systems. Discrete & Continuous Dynamical Systems - B, 2015, 20 (4) : 1261-1276. doi: 10.3934/dcdsb.2015.20.1261
V. O. Bragin, V. I. Vagaitsev, N. V. Kuznetsov and G. A. Leonov, Algorithms for Finding Hidden Oscillations in Nonlinear Systems. The Aizerman and Kalman Conjectures and Chua's Circuits,, J. Comput. Syst. Sci. Int., 50 (2011), 511. doi: 10.1134/S106423071104006X. Google Scholar
T. Gheorghe and C. Dana, Heteroclinic orbits in the T and the Lu systems,, Chaos Solitons Fractals, 42 (2009), 20. doi: 10.1016/j.chaos.2008.10.024. Google Scholar
T. Gheorghe and O. Dumitru, Analysis of a 3D chaotic system,, Chaos Solitons Fractals, 36 (2008), 1315. doi: 10.1016/j.chaos.2006.07.052. Google Scholar
B. Jiang, X. J. Han and Q. S. Bi, Hopf bifurcation analysis in the T system,, Nonlinear Anal., 11 (2010), 522. doi: 10.1016/j.nonrwa.2009.01.007. Google Scholar
G. A. Leonov, Lyapunov dimension formulas for Henon and Lorenz attractors,, St Petersburg Math. J., 13 (2001), 155. Google Scholar
G. A. Leonov, Bound for attractors and the existence of homoclinic orbit in the Lorenz system,, J. Appl. Math. Mech., 65 (2001), 19. doi: 10.1016/S0021-8928(01)00004-1. Google Scholar
G. A. Leonov, Localization of the attractors of the non-autonomous Lienard equation by the method of discontinuous comparison systems,, J. Appl. Maths Mechs, 60 (1996), 329. doi: 10.1016/0021-8928(96)00042-1. Google Scholar
G. A. Leonov, A. I. Bunin and N. Koksch, Attractor localization of the Lorenz system,, Z.Angew. Math. Mech., 67 (1987), 649. doi: 10.1002/zamm.19870671215. Google Scholar
X. F. Li, Y. D. Chu, J. G. Zhang and Y. X. Chang, Nonlinear dynamics and circuit implementation for a new Lorenz-like attractor,, Chaos Solitons Fractals, 41 (2009), 2360. doi: 10.1016/j.chaos.2008.09.011. Google Scholar
X. X. Liao, Y. L. Fu and S. L. Xie, On the new results of global attractive set and positive invariant set of the Lorenz chaotic system and the applications to chaos control and synchronization,, Sci. China Ser.F Inform. Sci., 48 (2005), 304. doi: 10.1360/04yf0087. Google Scholar
G. A. Leonov and N. V. Kuznetsov, Hidden attractors in dynamical systems. From hidden oscillations in Hilbert-Kolmogorov, Aizerman, and Kalman problems to hidden chaotic attractor in Chua circuits,, Internat. J. Bifur. Chaos Appl. Sci. Engrg., 23 (2013). doi: 10.1142/S0218127413300024. Google Scholar
G. A. Leonov, N. V. Kuznetsov and V. I. Vagaitsev, Hidden attractor in smooth Chua systems,, Physica D, 241 (2012), 1482. doi: 10.1016/j.physd.2012.05.016. Google Scholar
G. A. Leonov, N. V. Kuznetsov and V. I. Vagaitsev, Localization of hidden Chua's attractors,, Phys. Lett. A, 375 (2011), 2230. doi: 10.1016/j.physleta.2011.04.037. Google Scholar
L. Liu, C. X. Liu and Y. B. Zhang, Experimental confirmation of a modified Lorenz system,, Chinese Physics Letters, 24 (2007), 2756. Google Scholar
G. A. Leonov, D. V. Ponomarenko and V. B. Smirnova, Frequency-Domain Methods for Nonlinear Analysis,, Theory and applications. World Scientific Series on Nonlinear Science. Series A: Monographs and Treatises, (1996). doi: 10.1142/9789812798695. Google Scholar
G. A. Leonov, D. V. Ponomarenko and V. B. Smirnova, Local instability and Localization of attractors. From stochastic generator to Chua's systems,, Acta Appl. Math., 40 (1995), 179. doi: 10.1007/BF00992721. Google Scholar
Y. J. Liu and Q. G. Yang, Dynamics of a new Lorenz-like chaotic system,, Nonlinear Anal., 11 (2010), 2563. doi: 10.1016/j.nonrwa.2009.09.001. Google Scholar
A. Y. Pogromsky, G, Santoboni and H. Nijmeijer, An ultimate bound on the trajectories of the Lorenz system and its applications,, Nonlinearity, 16 (2003), 1597. doi: 10.1088/0951-7715/16/5/303. Google Scholar
A. Y. Pogromsky and H. Nijmeijer, On estimates of the Hausdorff dimension of invariant compact sets,, Nonlinearity, 13 (2000), 927. doi: 10.1088/0951-7715/13/3/324. Google Scholar
P. Yu and X. X. Liao, Globally attractive and positive invariant set of the Lorenz system,, Internat. J. Bifur. Chaos Appl. Sci. Engrg., 16 (2006), 757. doi: 10.1142/S0218127406015143. Google Scholar
Q. G. Yang and Y. J. Liu, A hyperchaotic system from a chaotic system with one saddle and two stable node-foci,, J. Math. Appl., 360 (2009), 293. doi: 10.1016/j.jmaa.2009.06.051. Google Scholar
F. C. Zhang, Y. L. Shu and H. L. Yang, Bounds for a new chaotic system and its application in chaos synchronization,, Commun. Nonlin. Sci. Numer. Simulat., 16 (2011), 1501. doi: 10.1016/j.cnsns.2010.05.032. Google Scholar
Michael Schönlein. Asymptotic stability and smooth Lyapunov functions for a class of abstract dynamical systems. Discrete & Continuous Dynamical Systems - A, 2017, 37 (7) : 4053-4069. doi: 10.3934/dcds.2017172
Deqiong Ding, Wendi Qin, Xiaohua Ding. Lyapunov functions and global stability for a discretized multigroup SIR epidemic model. Discrete & Continuous Dynamical Systems - B, 2015, 20 (7) : 1971-1981. doi: 10.3934/dcdsb.2015.20.1971
Luis Barreira, Claudia Valls. Stability of nonautonomous equations and Lyapunov functions. Discrete & Continuous Dynamical Systems - A, 2013, 33 (7) : 2631-2650. doi: 10.3934/dcds.2013.33.2631
Ezzeddine Zahrouni. On the Lyapunov functions for the solutions of the generalized Burgers equation. Communications on Pure & Applied Analysis, 2003, 2 (3) : 391-410. doi: 10.3934/cpaa.2003.2.391
Volodymyr Pichkur. On practical stability of differential inclusions using Lyapunov functions. Discrete & Continuous Dynamical Systems - B, 2017, 22 (5) : 1977-1986. doi: 10.3934/dcdsb.2017116
Gunther Dirr, Hiroshi Ito, Anders Rantzer, Björn S. Rüffer. Separable Lyapunov functions for monotone systems: Constructions and limitations. Discrete & Continuous Dynamical Systems - B, 2015, 20 (8) : 2497-2526. doi: 10.3934/dcdsb.2015.20.2497
Jóhann Björnsson, Peter Giesl, Sigurdur F. Hafstein, Christopher M. Kellett. Computation of Lyapunov functions for systems with multiple local attractors. Discrete & Continuous Dynamical Systems - A, 2015, 35 (9) : 4019-4039. doi: 10.3934/dcds.2015.35.4019
Andrey V. Melnik, Andrei Korobeinikov. Lyapunov functions and global stability for SIR and SEIR models with age-dependent susceptibility. Mathematical Biosciences & Engineering, 2013, 10 (2) : 369-378. doi: 10.3934/mbe.2013.10.369
Paul L. Salceanu, H. L. Smith. Lyapunov exponents and persistence in discrete dynamical systems. Discrete & Continuous Dynamical Systems - B, 2009, 12 (1) : 187-203. doi: 10.3934/dcdsb.2009.12.187
Jifeng Chu, Jinzhi Lei, Meirong Zhang. Lyapunov stability for conservative systems with lower degrees of freedom. Discrete & Continuous Dynamical Systems - B, 2011, 16 (2) : 423-443. doi: 10.3934/dcdsb.2011.16.423
Peter Giesl, Sigurdur Hafstein. Computational methods for Lyapunov functions. Discrete & Continuous Dynamical Systems - B, 2015, 20 (8) : i-ii. doi: 10.3934/dcdsb.2015.20.8i
Peter Giesl. Construction of a global Lyapunov function using radial basis functions with a single operator. Discrete & Continuous Dynamical Systems - B, 2007, 7 (1) : 101-124. doi: 10.3934/dcdsb.2007.7.101
Sigurdur F. Hafstein, Christopher M. Kellett, Huijuan Li. Computing continuous and piecewise affine lyapunov functions for nonlinear systems. Journal of Computational Dynamics, 2015, 2 (2) : 227-246. doi: 10.3934/jcd.2015004
Paul L. Salceanu. Robust uniform persistence in discrete and continuous dynamical systems using Lyapunov exponents. Mathematical Biosciences & Engineering, 2011, 8 (3) : 807-825. doi: 10.3934/mbe.2011.8.807
Doan Thai Son. On analyticity for Lyapunov exponents of generic bounded linear random dynamical systems. Discrete & Continuous Dynamical Systems - B, 2017, 22 (8) : 3113-3126. doi: 10.3934/dcdsb.2017166
Peter Giesl, Sigurdur Hafstein. Review on computational methods for Lyapunov functions. Discrete & Continuous Dynamical Systems - B, 2015, 20 (8) : 2291-2331. doi: 10.3934/dcdsb.2015.20.2291
Sergey Zelik. On the Lyapunov dimension of cascade systems. Communications on Pure & Applied Analysis, 2008, 7 (4) : 971-985. doi: 10.3934/cpaa.2008.7.971
Carlos Arnoldo Morales, M. J. Pacifico. Lyapunov stability of $\omega$-limit sets. Discrete & Continuous Dynamical Systems - A, 2002, 8 (3) : 671-674. doi: 10.3934/dcds.2002.8.671
Sergio Grillo, Jerrold E. Marsden, Sujit Nair. Lyapunov constraints and global asymptotic stabilization. Journal of Geometric Mechanics, 2011, 3 (2) : 145-196. doi: 10.3934/jgm.2011.3.145
C. Connell Mccluskey. Lyapunov functions for tuberculosis models with fast and slow progression. Mathematical Biosciences & Engineering, 2006, 3 (4) : 603-614. doi: 10.3934/mbe.2006.3.603
Fuchen Zhang Chunlai Mu Shouming Zhou Pan Zheng | CommonCrawl |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.