
repo
stringlengths 26
115
| file
stringlengths 54
212
| language
stringclasses 2
values | license
stringclasses 16
values | content
stringlengths 19
1.07M
|
|---|---|---|---|---|
https://github.com/LeoDog896/CirCetz
|
https://raw.githubusercontent.com/LeoDog896/CirCetz/main/README.md
|
markdown
|
MIT License
|
# CirCetz
typst+cetz circuit drawing library built on top of fletcher
|
https://github.com/MALossov/YunMo_Doc
|
https://raw.githubusercontent.com/MALossov/YunMo_Doc/main/template/reference.typ
|
typst
|
Apache License 2.0
|
#import "font.typ": *
// #pagebreak()
// 支持的引文格式:"apa", "chicago-author-date", "ieee", or "mla"
// [] TODO: DIY 国标引文格式
#let bibliography_file = "../reference/FPGA创新赛.bib"
// 展示参考文献
#if bibliography_file != none {
show bibliography: set text(font_size.xiaosi)
show heading : it => {
// set align(center)
set text(font:songti, size: 0pt)
it
}
bibliography(bibliography_file,
title: [],
style: "chicago-author-date")
}
|
https://github.com/ivaquero/lang-speeches
|
https://raw.githubusercontent.com/ivaquero/lang-speeches/main/fr%20-%20charles%20de%20gaulle%20-%20je%20vous%20ai%20compris.typ
|
typst
|
#import "@local/scibook:0.1.0": *
#show: doc => conf(
title: "Je Vous Ai Compris",
author: ("<NAME>"),
footer-cap: "",
header-cap: "Speech Collection",
outline-on: false,
lang: "en",
doc,
)
#tip[
Dès le vote du projet de loi qui délègue à son Gouvernement la charge de soumettre à l'approbation du peuple français une nouvelle Constitution, le général de Gaulle se rend en Algérie du 4 au 7 juin 1958, pour y manifester la restauration du pouvoir de l'Etat.
Des diverses allocutions qu'il prononce au cours de ce voyage, seule celle du Forum d'Alger a été rédigée à l'avance.
]
Je vous ai compris !
Je sais ce qui s’est passé ici. Je vois ce que vous avez voulu faire. Je vois que la route que vous avez ouverte en Algérie, c’est celle de la rénovation et de la fraternité.
Je dis la rénovation à tous égards. Mais très justement vous avez voulu que celle-ci commence par le commencement, c’est-à-dire par nos institutions, et c’est pourquoi me voilà. Et je dis la fraternité parce que vous offrez ce spectacle magnifique d’hommes qui, d’un bout à l’autre, quelles que soient leurs communautés, communient dans la même ardeur et se tiennent par la main.
Eh bien ! de tout cela, je prends acte au nom de la France et je déclare, qu’à partir d’aujourd’hui, la France considère que, dans toute l’Algérie, il n’y a qu’une seule catégorie d’habitants : il n’y a que des Français à part entière, des Français à part entière, avec les mêmes droits et les mêmes devoirs.
Cela signifie qu’il faut ouvrir des voies qui, jusqu’à présent, étaient fermées devant beaucoup.
Cela signifie qu’il faut donner les moyens de vivre à ceux qui ne les avaient pas.
Cela signifie qu’il faut reconnaître la dignité de ceux à qui on la contestait.
Cela veut dire qu’il faut assurer une patrie à ceux qui pouvaient douter d’en avoir une.
L’armée, l’armée française, cohérente, ardente, disciplinée, sous les ordres de ses chefs, l’armée éprouvée en tant de circonstances et qui n’en a pas moins accompli ici une œuvre magnifique de compréhension et de pacification, l’armée française a été sur cette terre le ferment, le témoin, et elle est le garant, du mouvement qui s’y est développé.
Elle a su endiguer le torrent pour en capter l’énergie. Je lui rends hommage. Je lui exprime ma confiance. Je compte sur elle pour aujourd’hui et pour demain.
Français à part entière, dans un seul et même collège ! Nous allons le montrer, pas plus tard que dans trois mois, dans l’occasion solennelle où tous les Français, y compris les 10 millions de Français d’Algérie, auront à décider de leur propre destin.
Pour ces 10 millions de Français, leurs suffrages compteront autant que les suffrages de tous les autres.
Ils auront à désigner, à élire, je le répète, en un seul collège leurs représentants pour les pouvoirs publics, comme le feront tous les autres Français.
Avec ces représentants élus, nous verrons comment faire le reste.
Ah ! Puissent-ils participer en masse à cette immense démonstration tous ceux de vos villes, de vos douars, de vos plaines, de vos djebels ! Puissent-ils même y participer ceux qui, par désespoir, ont cru devoir mener sur ce sol un combat dont je reconnais, moi, qu’il est courageux… car le courage ne manque pas sur la terre d’Algérie, qu’il est courageux mais qu’il n’en est pas moins cruel et fratricide !
Oui, moi, de Gaulle, à ceux-là, j’ouvre les portes de la réconciliation.
Jamais plus qu’ici et jamais plus que ce soir, je n’ai compris combien c’est beau, combien c’est grand, combien c’est généreux, la France !
Vive la République !
Vive la France !
|
|
https://github.com/AU-Master-Thesis/thesis
|
https://raw.githubusercontent.com/AU-Master-Thesis/thesis/main/lib/note.typ
|
typst
|
MIT License
|
#import "@preview/drafting:0.2.0": margin-note
#import "catppuccin.typ": *
#let note-gen(note, c: color.red, scope: "") = {
let note = [
#set text(size: 8pt)
#set par(justify: false)
#text(c, scope) \
// #line(length: 100%, stroke: c + 0.5pt)
#note
]
margin-note(side: left, stroke: c + 1pt, note)
}
#let kristoffer = note-gen.with(c: catppuccin.latte.blue, scope: "Kristoffer")
#let k = kristoffer
#let kevork = note-gen.with(c: catppuccin.latte.yellow, scope: "Kevork")
#let ke = kevork
#let jens = note-gen.with(c: catppuccin.latte.teal, scope: "Jens")
#let j = jens
#let jonas = note-gen.with(c: catppuccin.latte.mauve, scope: "Jonas")
#let jo = jonas
#let layout = note-gen.with(c: catppuccin.latte.maroon, scope: "Layout")
#let l = layout
#let wording = note-gen.with(c: catppuccin.latte.green, scope: "Wordings")
#let w = wording
#let attention = note-gen.with(c: catppuccin.latte.peach, scope: "Attention")
#let a = attention
// #let krisoffer(note) = {
// let c = catppuccin.latte.yellow
// let note = [
// #text(c, "Kristoffer")
// #note
// ]
//
// margin-note(side: left, stroke: c + 1pt, note)
// }
// #let jens(note) = {
// let c = catppuccin.latte.mauve
// let note = [
// #text(c, "Jens")
// #note
// ]
//
// margin-note(side: right, stroke: c + 1pt, note)
// }
//
// #let jonas(note) = {
// let c = catppuccin.latte.blue
// let note = [
// #text(c, "Jonas")
// #note
// ]
//
// margin-note(side: right, stroke: c + 1pt, note)
// }
//
// #let layout(note) = {
// let c = catppuccin.latte.maroon
// let note = [
// #text(c, "Layout")
// #note
// ]
//
// margin-note(side: right, stroke: c + 1pt, note)
// }
//
// #let wording(note) = {
// let c = catppuccin.latte.teal
// let note = [
// #text(c, "Layout")
// #note
// ]
//
// margin-note(side: right, stroke: c + 1pt, note)
// }
|
https://github.com/typst/packages
|
https://raw.githubusercontent.com/typst/packages/main/packages/preview/curryst/0.1.0/curryst.typ
|
typst
|
Apache License 2.0
|
#let rule(name: [], ccl, ..prem) = (
name: name,
ccl: ccl,
prem: prem.pos()
)
#let proof-tree(
rule,
prem-min-spacing: 15pt,
title-inset: 2pt,
stroke : 0.4pt,
horizontal-spacing : 0pt
) = {
let aux(styles, rule) = {
let prem = rule.at("prem").map(r => if type(r) == "dictionary" {
aux(styles, r)
} else {
(left-blank: 0, right-blank: 0, content: box(inset: (x: title-inset), r))
})
let prem-content = prem.map(p => p.content)
let number_prem = prem.len()
let top = stack(dir: ltr, ..prem-content)
let name = rule.name
let ccl = box(inset: (x: title-inset), rule.ccl)
let top-size = measure(top, styles).width.pt()
let ccl-size = measure(ccl, styles).width.pt()
let total-size = calc.max(top-size, ccl-size)
let name-size = measure(name, styles).width.pt()
let complete_size = total-size * 1pt + name-size * 1pt + title-inset
let left-blank = 0
let right-blank = 0
if number_prem >= 1 {
left-blank = prem.at(0).left-blank
right-blank = prem.at(number_prem - 1).right-blank
}
let prem_spacing = 0pt
if number_prem >= 1 {
// Same spacing between all premisses
prem_spacing = calc.max(prem-min-spacing, (total-size - top-size) / (number_prem + 1) * 1pt)
}
let top = stack(dir: ltr, spacing: prem_spacing, ..prem-content)
top-size = measure(top, styles).width.pt()
total-size = calc.max(top-size, ccl-size)
complete_size = total-size * 1pt + name-size * 1pt + title-inset
if ccl-size > total-size - left-blank - right-blank {
let d = (total-size - left-blank - right-blank - ccl-size) / 2
left-blank += d
right-blank += d
}
let line-size = calc.max(total-size - left-blank - right-blank, ccl-size)
let blank-size = (line-size - ccl-size) / 2
let top_height = measure(top, styles).height.pt()
let ccl_height = measure(ccl, styles).height.pt()
let content = block(
// stroke: red, // DEBUG
width: complete_size,
stack(
spacing: horizontal-spacing,
{
let alignment = center
// If there are only one premisses
if top_height <= 1.5 * ccl_height {
alignment = left
}
align(alignment,
block(
// stroke: green + 0.3pt, // DEBUG
width : total-size * 1pt,
align(center + bottom, top),
)
)
},
align(left + horizon,
stack(dir: ltr,
h(left-blank * 1pt),
line(start: (0pt, 2pt), length: line-size * 1pt, stroke: stroke),
h(title-inset),
name
)
),
align(left,
stack(
dir: ltr,
h(left-blank * 1pt),
block(
// stroke: blue + 0.3pt, // DEBUG
width : line-size * 1pt,
align(center, ccl)
)
)
)
)
)
return (
left-blank: blank-size + left-blank,
right-blank: blank-size + right-blank,
content: content
)
}
style(styles => {
box(
// stroke : black + 0.3pt, // DEBUG
aux(styles, rule).content
)
})
}
|
https://github.com/taooceros/CV
|
https://raw.githubusercontent.com/taooceros/CV/main/modules_en/open-source.typ
|
typst
|
// Imports
#import "@preview/brilliant-cv:2.0.2": cvSection, cvEntry
#let metadata = toml("../metadata.toml")
#let cvSection = cvSection.with(metadata: metadata)
#let cvEntry = cvEntry.with(metadata: metadata)
#cvSection("Open Source Experience")
#cvEntry(
title: [Core Member],
society: link("https://flowlauncher.com")[Flow Launcher #text(weight: "light")[(a powerful launchpad for apps, files, and websites with keyboard shortcuts for windows)]],
logo: link("https://flowlauncher.com", image("../src/logos/flowlauncher.png")),
date: [2020 - Present],
location: [Global],
description: [
- Collaborated with a team of \~10 active members and many other contributors across countries to develop a Windows application.
- Awarded more than 7,000 GitHub stars and received more than 50,000 downloads per release.
- Created and managed the CI/CD Pipeline of Internationalization with _Crowdin_ (supported more than 20 languages).
- Wrote Plugin Development Document for plugins written in .NET family (C\#, F\#, VB.NET, etc.).
],
tags: ([WPF], [C\#], [Desktop Development]),
)
|
|
https://github.com/LDemetrios/Typst4k
|
https://raw.githubusercontent.com/LDemetrios/Typst4k/master/src/test/resources/suite/math/underover.typ
|
typst
|
// Test under/over things.
--- math-underover-brace ---
// Test braces.
$ x = underbrace(
1 + 2 + ... + 5,
underbrace("numbers", x + y)
) $
--- math-underover-line-bracket ---
// Test lines and brackets.
$ x = overbracket(
overline(underline(x + y)),
1 + 2 + ... + 5,
) $
--- math-underover-brackets ---
// Test brackets.
$ underbracket([1, 2/3], "relevant stuff")
arrow.l.r.double.long
overbracket([4/5,6], "irrelevant stuff") $
--- math-underover-parens ---
// Test parentheses.
$ overparen(
underparen(x + y, "long comment"),
1 + 2 + ... + 5
) $
--- math-underover-shells ---
// Test tortoise shell brackets.
$ undershell(
1 + overshell(2 + ..., x + y),
"all stuff"
) $
--- math-underover-line-subscript ---
// Test effect of lines on subscripts.
$A_2 != overline(A)_2 != underline(A)_2 != underline(overline(A))_2 \
V_y != overline(V)_y != underline(V)_y != underline(overline(V))_y \
W_l != overline(W)_l != underline(W)_l != underline(overline(W))_l$
--- math-underover-line-superscript ---
// Test effect of lines on superscripts.
$J^b != overline(J)^b != underline(J)^b != underline(overline(J))^b \
K^3 != overline(K)^3 != underline(K)^3 != underline(overline(K))^3 \
T^i != overline(T)^i != underline(T)^i != underline(overline(T))^i$
|
|
https://github.com/OverflowCat/BUAA-Digital-Image-Processing-Sp2024
|
https://raw.githubusercontent.com/OverflowCat/BUAA-Digital-Image-Processing-Sp2024/master/chap09/report.typ
|
typst
|
#set text(lang: "zh", cjk-latin-spacing: auto, font: "Noto Serif CJK SC")
#set page(numbering: "1", margin: (left: 1.4cm, right: 1.9cm))
#show figure.caption: set text(font: "Zhu<NAME>angsong (technical preview)")
#show "。": "."
= 第九章作业
1. 较小的方块在腐蚀后完全消失,而较大的方块超过了结构元大小这一阈值,并且和结构元形状一致,没有被完全腐蚀,所以能够保留下来。
2. 可以,因为两张图片都是类似的互不接触的圆点。
#figure(caption: "处理结果", image("9-50/result.svg", height: 6cm, width: 125%))
代码如下:
#raw(read("9-50/p2.m"), lang: "m")
3. #set enum(numbering: "(a)")
+ 找出所有触碰到图像边界的粒子,可通过在图像边缘一圈的值为 1 的像素开始,寻找 4 连通分量。
+ 可以根据面积确定。先找一个合适的面积值 $A$ 和标准差 $sigma$,查找所有连通分量并分别计算面积 $A_i$,若 $A_i$ 在 $A plus.minus 3 sigma$ 外可认为是仅彼此重叠的颗粒;
+ 在 $A plus.minus 3 sigma$ 内的连通分量可认为是仅彼此重叠的颗粒。
4. 将图像二值化处理,然后与取反后的标准图像进行 AND 操作,留下的差异区域为 1。然后根据连通分量将这些差异区域分组,并根据连通分量的数量、大小、形状等特征判断垫圈是否合格。如果连通分量为 0 说明垫圈非常完美,个数越多、大小越大说明质量越低,以此类推。
|
|
https://github.com/Myriad-Dreamin/typst.ts
|
https://raw.githubusercontent.com/Myriad-Dreamin/typst.ts/main/fuzzers/corpora/text/lang_06.typ
|
typst
|
Apache License 2.0
|
#import "/contrib/templates/std-tests/preset.typ": *
#show: test-page
//
// // Error: 17-20 expected two or three letter language code (ISO 639-1/2/3)
// #set text(lang: "ӛ")
|
https://github.com/DashieTM/ost-5semester
|
https://raw.githubusercontent.com/DashieTM/ost-5semester/main/compiler/weeks/week12.typ
|
typst
|
#import "../../utils.typ": *
#subsection("Garbage Collector Metadata")
The garbage collector needs to know what every single object in the program is
-> e.g. it needs to know at runtime how to interpret something in order to
understand A: where it lives? and B: how big it is.
- offset inside the object
- offset in stack
- pointer in register
#subsection("GC for C/C++/Rust")
- only plausible as interpreter GC
- check all memory of program
- check if memory can possibly be a pointer
- if it can -> leave it be
- memory leaks very much still possible
- no metadata leads to shit GC
#subsection("Finalizer")
This is a method that handles open connections etc of garbage. E.g. If an object
becomes garbage, the *finalizer* handles the closing of all problematic things
for this particular object, this resolves potential infinite loops.\
```java
class Block {
@Override
protected void finalize() {}
}
```
#text(red)[Will be run after GC-phase!]
- could potentially block GC!
- aka finalizer might cause an infinite loop
- finalizer can potentially create new objects
- finalizer can crash
- finalizer might resurrect object
#set text(14pt)
#text(
red,
)[Note, with finalizer, you need to wait until you can sweep! -> E.g. you need a
second mark phase for potentially resurrected objects!]
```cs
System.gc();
System.runFinalization();
System.gc();
```
#set text(11pt)
#subsubsection("Resurrection")
As mentioned the finalizer can resurrect objects again, it does this by binding
the objects reference to itself, hence it is no longer garbage.
#align(
center,
[#image("../../Screenshots/2023_12_04_08_28_01.png", width: 100%)],
)
#subsubsubsection("Internals of Finalizer")
Note, the finalizer has 2 sets for references, the first is the *weak reference
list -> "finalizer set"*, in here, references will not lead to the object not
becoming garbage, it just exists to get the reference if needed.\
The other set -> *pending queue* is the actual set that leads to the
resurrection -> e.g. it is the strong reference.
#align(
center,
[#image("../../Screenshots/2023_12_04_08_30_10.png", width: 100%)],
)
After resurrection, the strong reference is removed from the pending queue, this
makes you require a new mark phase!\
E.g. the garbage collector needs to check for potential changes and hence needs
to mark again before sweeping memory.
#align(
center,
[#image("../../Screenshots/2023_12_04_08_33_40.png", width: 100%)],
)
#subsubsection("Finalizer Notes")
- finalizers are concurrent
- finalizers run in random order
- finalizers run after a timeout
- finalizers *do NOT run after resurrection*
- never for java
- optionally resurrection opt-in -> "GC.ReRegisterForFinalize(this)"
#subsection("Weak References")
- don't count to GC collection
- used to still get a reference when needed
- can be casted to strong
#text(
red,
)[Ok, cool for Rust and co. But how is this dealt with in Object Object languages?\
-> *Weak references need to be set to null when referenced object gets cleaned
up!*\
This is done via a weak reference table:]
#align(
center,
[#image("../../Screenshots/2023_12_04_08_45_47.png", width: 100%)],
)
#subsubsection("Java Weak")
The question remains, do weak references get removed (set to null) before or
after the finalizer?\
- Java has 3 weak references
- weak
- soft
- phantom
#subsection("Compacting GC")
The compacting GC tries to solve the issue of *external fragmentation*. E.g. a
regular GC might free many random small memory pieces, this leaves new objects
with many small empty spaces that might not be big enough for new objects.
#align(
center,
[#image("../../Screenshots/2023_12_04_08_52_15.png", width: 100%)],
)
- also called mark & copy GC
- allocation at the end of the heap
- GC moves objects to end -> alongside references
- conservative method -> not really possible
#align(
center,
[#image("../../Screenshots/2023_12_04_08_53_09.png", width: 100%)],
)
#subsection("Incremental GC")
This tries to make the garbage collector run in parallel to the
mutator(program), by making the gc run only in small *incremental* steps.
#align(
center,
[#image("../../Screenshots/2023_12_04_08_54_16.png", width: 100%)],
)
There are different incremental GCs:
- generational GC
- frees younger objects faster
- partitioned GC
- heap is managed via partitions
- Concurrent GC
- Real-Time GC
- Shenondoah GC
- forwarding pointers for concurrent evacuation(incremental GC for evacuation)
- still requires stop of mutator
- Z GC
- read barriers for concurrent evacuation
- fast with colored pointers -> (uses MMU)
- guarantees short stops of mutator
#subsubsection("Generational GC")
#align(
center,
[#image("../../Screenshots/2023_12_04_08_56_19.png", width: 100%)],
)
#align(
center,
[#image("../../Screenshots/2023_12_04_08_56_32.png", width: 100%)],
)
#align(
center,
[#image("../../Screenshots/2023_12_04_08_56_44.png", width: 100%)],
)
- references from old to new generations
- additional root set for older generations per newer generation
- G2 to G1, G2 to G0, etc.
- Write barriers
- writing of references in old generations must be noticed
- aka no references are allowed to be written into older generations
- software wise: (use of hardware instruction aligned code -> Atomics, barriers, Semaphores)
- hardware wise: Page faults via memory access rights
- Garbage collector of older generation must also clear younger generation
- G2 gets cleared -> G1 and G0 must also be cleared
#subsubsection("Partitioned GC")
- concurrent mark phase
- focus on partitions with a lot of garbage
- moves alive objects into a different partition
- clear entire partition
- problem: garbage can point to other partitions
- this requires *a stop of the program in order to mark*
#align(
center,
[#image("../../Screenshots/2023_12_04_09_05_31.png", width: 100%)],
)
#columns(2, [
#align(
center,
[#image("../../Screenshots/2023_12_04_09_05_42.png", width: 100%)],
)
#colbreak()
#align(
center,
[#image("../../Screenshots/2023_12_04_09_06_15.png", width: 100%)],
)
])
|
|
https://github.com/jgm/typst-hs
|
https://raw.githubusercontent.com/jgm/typst-hs/main/test/typ/visualize/shape-square-02.typ
|
typst
|
Other
|
// Test relative-sized child.
#square(fill: eastern)[
#rect(width: 10pt, height: 5pt, fill: green)
#rect(width: 40%, height: 5pt, stroke: green)
]
|
https://github.com/mumblingdrunkard/mscs-thesis
|
https://raw.githubusercontent.com/mumblingdrunkard/mscs-thesis/master/src/processor-security/index.typ
|
typst
|
= Processor Security <ch:processor-security>
This thesis revolves around microarchitectural optimisations in the context of secure speculation.
We should therefore explain what is meant by _security_ of processors.
== Secrets in Processors
During execution of programs, some values are _secrets_.
Revealing these values to attackers would allow the attackers to affect the normal operation of the program.
For example, extracting encryption keys from a program would allow an attacker to interfere with the private communications of a program by listening in on private messages or pretending to be one of the communicating parties.
The security of a system relies on it protecting secret values---like encryption keys---from attackers.
The framework for analysing security is called a _threat model_.
The most conservative models may assume as much as:
+ The attacker has physical access to the system and knows the microarchitecture.
+ The attacker can run any self-chosen code on the system at any time.
+ The attacker knows the other code running on the system.
+ The attacker can measure how long execution takes.
+ The attacker can measure the power consumption of the system.
== Why Processors are Vulnerable in the First Place
Processors are _virtualised_:
The processing capacity is being shared between many applications in the same span of time.
This is done by stopping applications, saving their state, loading the state of some other application, and resuming execution on this new application.
This is great for users of computer systems because even with a single core, it is possible to run many applications.
Applications are isolated from each other by virtualising their address spaces so that they can only access their own memory.
When swapping applications, only the architectural state needs to be properly replaced to ensure correct operation.
Microarchitectural structures like branch predictor storage and cache do not need to be cleared and commonly are not because doing so would reduce performance.
== Attacks on In-Order Processors
Because microarchitectural state is not flushed when switching applications, malicious applications can often observe the effects that other applications have had on the system.
By timing memory accesses to its own address space, an application can use information about the cache implementation to determine _something_ about the addresses that applications have accessed previously.
For example, if it can determine that one of its cache blocks was flushed since the last time it ran, it is likely because another application accessed a block with an equal index.
If this memory access used an address that was calculated using a secret value, the attacker can know part of the secret.
In this case, microarchitectural state---state that only exists due to the specific implementation of an ISA---is used to make accurate assertions about the execution of another program.
This is called a _side-channel attack_.
Side-channels reveal information about execution of a program in a way that is not visible in the ISA, but is visible through other observations such as the passing of time, or the consumption of power.
Searching for side-channel attacks on an algorithm, protocol, or system is a subject of _cryptanalysis_.
Side-channels are not exclusive to processors and their microarchitectures, but appear in most any system.
The _advanced encryption standard_ (AES) @bib:aes-standard ---a symmetric encryption algorithm famous for securing internet communications for more than two decades---has been broken through various side-channels.
AES has been broken through the cache timing side-channel @bib:aes-cache, analysis of power consumption @bib:aes-power, and even through electromagnetic radiation while being completely detached from the system @bib:aes-em.
None of these attacks directly attack the mathematical properties of the AES algorithm.
The maths of AES are sound as far as we [researchers] know.
Side-channel attacks focus on other information that can be gained by observing execution of the specific implementation of the AES algorithm.
=== Anatomy of a Vulnerable Application
@lst:vulnerable shows a C program that is vulnerable to various side-channel attacks.
The number of iterations executed in the loop is dependent on the secret value.
A normal timing attack to determine how long the application takes to execute could easily reveal how many iterations were executed, meaning the secret is revealed.
In the next case, the secret value is used to derive an index into an array and a value is loaded from that index.
This is a common pattern for various cryptographic algorithms that use lookup tables.
An attacker that can determine which cache block is affected by that access would be able to determine the lower 8 bits of the secret value.
#figure(
```c
extern int *p_secret_value;
int secret_value = *p_secret_value;
for (int i = 0; i < secret_value; i++) {
// perform some iteration
}
extern int* prng_vals;
int prng_val = prng_vals[secret_value % 256];
```,
caption: "A possibly vulnerable program"
) <lst:vulnerable>
=== Defending Against Attacks on In-Order Processors
There are generally two approaches to preventing side-channel attacks on InO processors: preventing leaks, or making leaks independent of secrets.
The first approach is universal and secures all applications in the system.
Making leaked information independent of secrets requires programmers to make careful considerations about what instructions are executed, when they are executed, and which data those instructions depend upon.
==== Stopping the Leaks
The first and most intuitive approach to stopping leaks is to prevent leaky behaviour in the first place, or at least prevent other applications from observing leaks.
For example, the OS might ensure the entire microarchitectural state is flushed before switching applications, ensuring malicious applications cannot possibly read any microarchitectural state left behind by a victim application.
This obviously has a potentially big impact on application performance as each application has to rebuild its microarchitectural state every time it is given time on the processor.
Even with such a mitigation, applications may be vulnerable through other side-channels such as timing or power analysis.
Making all execution spend the same amount of time, independent of secrets is not an easy feat.
Because of such downsides, this approach is rarely taken as it slows down applications that have no need for such security measures.
==== Secret-Independent and Constant Time Programming
The other approach is to make execution independent of secrets such that a secret leaked through a side-channel cannot effectively be distinguished from other data or noise.
For example, the loop might be reprogrammed to iterate to an upper bound of the secret value every time, and the results of unused iterations can be discarded.
The array access can be reprogrammed to access all values in order and using a copy with a mask generated from a comparison as shown in @lst:secret-independent-load.
There are many guidelines for writing such code @bib:intel-guidelines.
#figure(
```c
int val = 0;
for (int i = 0; i < 256; i++) {
// == evaluates to 1 if the condition is true, and 0 otherwise
// -1 is a number with all bits set---an appropriate mask value
int mask = -(i == (secret_val % 256));
val |= mask & prng_vals[i];
}
```,
caption: "Pseudocode for accessing the array values in a safe manner",
) <lst:secret-independent-load>
== Speculative Execution Vulnerabilities in Out-of-Order Processors
While InO processors may be vulnerable to some attacks, the applications are mostly in control of what they leak through various side-channels.
This is not the case in OoO processors, as has been demonstrated by the _speculative execution vulnerabilities_: _Spectre_ @bib:spectre and _Meltdown_ @bib:meltdown.
The nature of OoO processors means an application may leak values through various side-channels during transient execution---execution that is not even supposed to take place.
OoO processors are uniquely vulnerable to a class of attacks that are not possible on InO processors.
=== Anatomy of a Speculative Execution Attack
A speculative execution attack is performed:
+ When the malicious application runs, it intentionally mis-train the branch predictor (or some other predicting structure) such that
+ when the victim application is run, it enters an incorrect path of execution that depends on secret values and leaks this secret value through a side-channel before
+ the malicious application is again given time on the processor and determines the secret by observing the side-channel.
This attack relies on locating or injecting vulnerable code (called a _gadget_)that the processor can execute while executing the victim application.
The attacking application then "tricks" the processor into mispredicting in a way that leaks the secret through a _covert channel_.
A side-channel forms a covert channel for applications to communicate.
In general, anything not intended for communication being used for communication is called a covert channel.
Processes may not be allowed to communicate directly, but if both processes can access some shared structure and leave traces, they can effectively communicate anyway.
This is the Spectre attack at a high level:
locating or injecting a vulnerable sequence of instructions, and then forcing the processor to execute that sequence of instructions while running the victim process because of misprediction, causing the processor to spill the secrets of a victim application through a covert channel.
While the most popular example of Spectre uses the cache side-channel to communicate secrets, it is not the only variant of the attack.
Far from it, in fact.
Instead of being one vulnerability with a simple fix, Spectre is presented as a whole class of vulnerabilities that have a common general approach as outlined above.
Several structures and mechanisms have successfully been used as covert channels such as the cache, timing differences, port contention, and branches.
Because of these many variants and mechanisms that are difficult to close, speculative execution attacks form an incredibly powerful technique that is difficult to protect against.
=== Covert Channels and Meltdown
Modern operating systems will commonly map unrelated, privileged memory into the virtual address space of all processes and only mark those privileged regions as such---relying on permission checking for security.
There is a "bug" in some implementations of processors where the permission to perform a load instruction is not checked or handled until long after the load in question was performed and the value is allowed to propagate to dependent instructions.
Under mis-speculated transient execution, rules can be broken without a program crashing because the work is bound to be squashed.
The above three facts combine to create Meltdown.
+ Mis-train the branch predictor.
+ Under mis-speculated transient execution, access memory that the process does not have permission for and read a secret value.
+ During the same transient execution, leak the secret value through a side-channel such as the cache.
+ During normal execution, determine the leaked secret value through the side-channel, for example by timing cache accesses.
Here, there is no need for the victim application to even execute or perform any action than to be mapped into virtual memory.
The process cannot directly use the secret value or store it somewhere that it has access to, but it can leak it through the cache side-channel by performing a load based on the secret value such as the array access example earlier.
== Threat Modelling
As mentioned, a threat model is a framework for analysing the security of a processor.
_Defining such a model is difficult_.
A threat model contains a few different assumptions about the attacker, the system under attack, and the applications under attack.
Threat modelling does not only apply to processor design and a system may still be vulnerable despite a secure processor.
On the flipside, a system may be secure in spite of an "insecure" processor because the system restricts the access an attacker has to the processor.
When building threat models for any system, the first question is "what is being protected?", then "how can it be attacked?", and finally "how to mitigate those attacks?".
In terms of speculative execution vulnerabilities, the main focus of threat modelling is on how a speculating OoO processor is vulnerable in ways that InO processors are not.
For this case, practically any structure that can be speculatively modified that is not reverted on mis-speculation poses the risk of a speculative execution vulnerability.
=== Analysis
The first step to constructing a threat model consists of determining the possible threats such as which code is allowed to execute on the system and who controls that code.
A good number of systems are expected to run applications such as web browsers where a web server is in control of code executed on a user's system.
Similarly, cloud platforms allow uploading code to be run on a system that is potentially shared with many other applications uploaded in a similar fashion.
Because of these cases, it is reasonable for a threat model to consider all deployments of processors as potentially vulnerable and in need of protection.
As has been mentioned earlier, it is an acceptable solution to make the processor as secure as a normal in-order processor, allowing for non-speculative leaks.
Thus _our goal is to make an out-of-order processor at least as secure as an in-order processor_.
=== Secrets
The next stage is to determine which values are in fact secret and of interest to an attacker.
This may be values like encryption keys, or unencrypted data.
These values are potentially stored in memory.
Because there are no special instructions to execute when loading secret data from memory as opposed to non-secret data, all threat models may make the reasonable assumption that all values loaded from memory in a speculative manner are potentially secrets and should be protected.
The big difference between some of the models is what happens to values once they are in registers and no longer speculative.
If values are loaded in registers, it is reasonable to assume that the values are going to be used and there is a high likelihood that the value is about to be leaked through some side-channel, even in an in-order system.
Some models act on the assumption that non-speculative values in registers are leaked and only provide protection for values that are loaded speculatively from memory.
Other models intend to provide protection for registers as well.
=== Attack Mechanisms
Next, the threat model should consider mechanisms for gaining the secret knowledge and which of them should be protected against.
Some attacks on in-order processors were presented.
As these attacks are possible on in-order processors, our threat model can ignore them seeing as our goal is only to make an out-of-order processor as safe as an in-order processor.
The threat of speculative execution attacks is unique to out-of-order processors and requires protecting against.
Attacks rely on being able to perform three distinct steps:
+ access the secret,
+ transmit the secret through a covert channel, and
+ recover the secret.
Barring implementation errors causing Meltdown-like bugs, Spectre-like attacks rely on applications containing exploitable sequences of instructions and being able to intentionally train a speculative microarchitectural structure to cause the processor to mis-speculate and enter the exploitable section in a victim application.
Transmitting the secret is done through a side-channel---most popularly the cache.
Load instructions are popular for the purpose of leaking information during speculation as they only affect the microarchitectural state.
Finally, the malicious application depends on being able to access the side-channel to recover the secret that was transmitted.
In the case of the cache acting as the side-channel, this is generally performed as a cache-timing attack.
By preventing one or more of these distinct stages, Spectre attacks are prevented.
==== Chosen-Code and Control-Steering
Accessing the secret is generally done in one of two ways:
a chosen-code attack is able to inject arbitrary code to be executed in some context where secrets are mapped into memory and may be accessed.
A control-steering attack has to find exploitable code in the victim application and intentionally steer the processor to execute instructions along that exploitable path.
==== Implicit and Explicit Channels
The difficult part of preventing speculative execution attacks is enumerating all of the possible side-channels that exist and may be able to transmit secret values.
Explicit channels exist when a known leaky instruction depends on unsafe speculative data, such as a load instruction using the result of another load instruction as an address.
Implicit channels are less overt and exist when non-leaky instructions are allowed to execute and end up affecting the execution of leaky instructions.
Take the example in @lst:implicit-channel.
Here, all the obviously leaky actions for the code under `// implicit channel` use values that are non-speculatively loaded.
A scheme that does not provide register protection may accidentally leak a secret here.
Because the branch instruction depends on a speculatively loaded value, the instructions executed after the branch may reveal information about the speculatively loaded value.
#figure(
```c
extern int** pp_other_secret;
extern int* p_secret;
extern int* p_a;
extern int* p_b;
if (/* Misprediction */) {
// implicit channel
int tmp = *p_secret;
int val;
if (tmp) {
val = *p_a;
} else {
val = *p_b;
}
// explicit channel
int* p_other_secret = *pp_other_secret;
int other_val = *p_other_secret;
}
```,
caption: "An possible implicit channel",
) <lst:implicit-channel>
== Defending Against Attacks on Out-of-Order Processors
Defending against speculative execution attacks is not so simple.
The obvious solution is to disable speculation, but this has such a large performance impact that it is not a practical solution.
=== Secure Speculation Schemes
Several schemes have been proposed to patch the speculative execution vulnerabilities of out-of-order processors.
The most conservative approach is to delay all instructions that potentially access secrets until they are deemed non-speculative.
This has a big performance impact.
Below we describe a few schemes that try to improve on this conservative scheme without sacrificing on security, or make concious decisions about which security guarantees are given up.
==== Non-Speculative Data Access
_Non-speculative data access_ (NDA) presents various possible threats @bib:nda.
First, leaking memory contents via control-steering, then leaking register contents with control-steering, and finally leaking memory contents with chosen-code attacks.
Finally, they present their most conservative model that combines all of the threats.
NDA considers an attacker that has the ability to monitor any covert channel from anywhere and is able to introduce arbitrary speculation.
For the control-steering attacks, they assume the attacker is able to direct instruction fetch at any branch point.
The difference between spilling memory contents and spilling register contents is that with the register contents, the access phase has possibly already been performed non-speculatively.
When protecting memory contents, it would possibly be enough to prevent the access phase of a Spectre attack.
This is not the case when protecting register contents that are already non-speculative and protections must therefore focus on blocking the transmission phase.
For the chosen-code attack, they consider an attacker that can decide code executed both correctly and transiently (incorrectly executed, then squashed).
In this variant, correct path instructions that retire cannot leak secrets accessed in the wrong path of execution.
At least not directly.
One of the NDA variants, called "strict data propagation", considers instructions to be _unsafe_ if they may be affected by branches or store instructions that have not yet had their address resolved.
That is, a later load may depend on a store, but perform its access ahead of time only to be squashed because the store resolves to access overlapping addresses#footnote[Unresolved store addresses are a problem in a so-called speculative store bypass (SSB) attack that we have not discussed here.].
Instructions after a branch may obviously be unsafe as they are possibly on the wrong path of execution due to a misprediction.
Under this variant, unsafe instructions are allowed to execute as long as their dependencies are not from unsafe instructions.
This is achieved by not propagating the results of unsafe instructions until they are marked as no longer unsafe.
This approach protects secrets in memory and in registers.
A second variant called "permissive data propagation" only protects secrets in memory.
In this variant only load instructions may be marked unsafe.
All other instructions are considered safe with the observation that only load instructions can access secrets.
This allows for more parallelism as chains of instructions are allowed to dispatch and complete as long as the chain does not contain a load instruction.
The first approach has a reported performance overhead of 36.1% while the second, permissive scheme has a performance overhead of 10.7%.
NDA also has several other variants to protect against chosen-code attacks, but we have focused mainly on control-steering attacks.
==== Speculative Taint Tracking
_Speculative taint tracking_ (STT) is a different scheme with a similar threat model to NDA with permissive propagation, aiming to protect secrets in memory @bib:stt.
Secrets accessed non-speculatively, then transmitted speculatively are not protected by STT.
This with the observation that the arguably most dangerous attacks are those where the access is performed speculatively as it can be induced to access data that would not have been accessed non-speculatively.
This kind of attack allows forming _universal read gadgets_ that read any address in mapped memory.
The reasoning behind this is that security-minded programmers are already aware that they have to be careful with handling secrets.
A universal read gadget may be accidentally introduced anywhere and allow an attacker to read the secret from code that never intentionally accessed the secret.
One of the important observations made by the authors of STT is that predictive mechanisms can be used to leak secrets in two different ways.
If the predictor is updated speculatively, an attacker may induce behaviour such that the predictor learns the secret value.
The attacker can then determine the secret by observing differences in timing that arise because the processor does or does not squash later instructions.
This first mechanism is referred to as _prediction_-based leakage.
The second mechanism is called _resolution_-based leakage and allows an attacker to determine a secret even if the predictor has not been trained speculatively.
Instead, the attacker trains a prediction so that the branch result resolves in a certain way, then observes the actual behaviour of the branch during execution by differences in timing or observing other behaviour.
STT refers to speculatively loaded values as secrets.
STT works by "tainting" secrets---hence the name.
The authors define three characteristics:
+ which values should be tainted,
+ when values can be marked as no longer tainted, and
+ which instructions have to be careful when handling tainted values.
Values in memory that are accessed speculatively are considered tainted.
Values may be untainted when the instructions generating them can no longer be squashed (i.e. bound to commit).
A more relaxed approach only requires all explicit previous speculation to be resolved while still potentially allowing instructions to be squashed for other reasons.
Instructions that can leak values have to be careful about handling tainted values.
A wide variety of instructions can potentially leak values through various explicit or implicit channels.
STT builds on the assumptions that the prediction- and resolution-based channels are eliminated by only training on untainted data, and delaying the effects of branch resolution until the dependencies of the branch become untainted.
The two main pieces to implementing STT is tainting and untainting instructions, and blocking instructions that may leak.
Tainting is trivial while untainting and propagating untaint information is non-trivial.
STT solves untainting with a novel algorithm.
==== Delay-on-Miss
_Delay-on-miss_ (DoM) takes an entirely different approach.
DoM protects secrets in memory by delaying all updates to the memory hierarchy caused by loads until the loads are non-speculative @bib:dom.
If a load hits, the value is allowed to propagate, but updates to microarchitectural state is delayed.
For example, the replacement policy would normally be updated immediately, but is delayed under DoM until loads are known to be non-speculative.
This idea can be extended to start performing loads from deeper cache levels, but this requires changes to all affected levels of the cache to allow delaying effects.
DoM does not attempt to hide differences in timing that can occur due to misspeculation and only attempts to block side-channels based on modifying stored microarchitectural state.
|
|
https://github.com/topdeoo/NENU-Thesis-Typst
|
https://raw.githubusercontent.com/topdeoo/NENU-Thesis-Typst/master/other/lab-report.typ
|
typst
|
#let font-size = (
初号: 42pt,
小初: 36pt,
一号: 26pt,
小一: 24pt,
二号: 22pt,
小二: 18pt,
三号: 16pt,
小三: 15pt,
四号: 14pt,
中四: 13pt,
小四: 12pt,
五号: 10.5pt,
小五: 9pt,
六号: 7.5pt,
小六: 6.5pt,
七号: 5.5pt,
小七: 5pt,
)
#let font-family = (
// 宋体,属于「有衬线字体」,一般可以等同于英文中的 Serif Font
// 这一行分别是「新罗马体(有衬线英文字体)」、「思源宋体(简体)」、「思源宋体」、「宋体(Windows)」、「宋体(MacOS)」
宋体: ("Times New Roman", "Source Han Serif SC", "Source Han Serif", "Noto Serif CJK SC", "SimSun", "Songti SC", "STSongti"),
// 黑体,属于「无衬线字体」,一般可以等同于英文中的 Sans Serif Font
// 这一行分别是「Arial(无衬线英文字体)」、「思源黑体(简体)」、「思源黑体」、「黑体(Windows)」、「黑体(MacOS)」
黑体: ("Arial", "Source Han Sans SC", "Source Han Sans", "Noto Sans CJK SC", "SimHei", "Heiti SC", "STHeiti"),
// 楷体
楷体: ("Times New Roman", "KaiTi", "Kaiti SC", "STKaiti", "FZKai-Z03S"),
// 仿宋
仿宋: ("Times New Roman", "FangSong", "FangSong SC", "STFangSong", "FZFangSong-Z02S"),
// 等宽字体,用于代码块环境,一般可以等同于英文中的 Monospaced Font
// 这一行分别是「Courier New(Windows 等宽英文字体)」、「思源等宽黑体(简体)」、「思源等宽黑体」、「黑体(Windows)」、「黑体(MacOS)」
等宽: ("Courier New", "Menlo", "IBM Plex Mono", "Source Han Sans HW SC", "Source Han Sans HW", "Noto Sans Mono CJK SC", "SimHei", "Heiti SC", "STHeiti"),
)
#let colorize(svg, color) = {
let blk = black.to-hex()
// You might improve this prototypical detection.
if svg.contains(blk) {
// Just replace
svg.replace(blk, color.to-hex())
} else {
// Explicitly state color
svg.replace("<svg ", "<svg fill=\"" + color.to-hex() + "\" ")
}
}
#let datetime-display-cn-cover(date) = {
date.display("[year] 年 [month] 月")
}
#let report-cover(
fonts: (:),
info: (:),
stoke-width: 0.5pt,
info-inset: (x: 0pt, bottom: 1pt),
info-key-width: 72pt,
info-key-font: "宋体",
info-value-font: "宋体",
info-col-gutter: -3pt,
info-row-gutter: 5pt,
) = {
fonts = fonts + font-family
info = (
year: "2024",
season: "春",
lesson: "人工智能导论",
teacher: "李四",
author: "张三",
student-id: "123456",
grade: "2024",
submit-date: datetime.today(),
) + info
if type(info.submit-date) == datetime {
info.submit-date = datetime-display-cn-cover(info.submit-date)
}
let info-key(body) = {
rect(
width: 100%,
inset: info-inset,
stroke: none,
text(
font: fonts.at(info-key-font, default: "宋体"),
size: font-size.小三,
body,
),
)
}
let info-value(key, body) = {
set align(center)
rect(
width: 100%,
inset: info-inset,
stroke: (bottom: stoke-width + black),
text(
font: fonts.at(info-value-font, default: "宋体"),
size: font-size.三号,
bottom-edge: "descender",
body,
),
)
}
let info-long-value(key, body) = {
grid.cell(
colspan: 2,
info-value(
key,
body,
),
)
}
pagebreak(weak: true)
v(50pt)
set align(center)
let nenu-logo = read("../assets/nenu-logo.svg")
nenu-logo = colorize(nenu-logo, blue.darken(30%))
image.decode(nenu-logo, width: 7.28cm)
pad(image("../assets/nenu-title.svg", width: 6.14cm), top: 0cm, bottom: 0cm)
text(font: fonts.黑体, size: font-size.小二, "信 息 科 学 与 技 术 学 院\n\n")
text(font: fonts.黑体, size: font-size.小初, weight: "medium", "实 验 报 告\n")
text(font: fonts.宋体, size: font-size.四号, weight: "medium")[
( #info.year 年 #info.season 季 学期 )
]
v(20pt)
pad(
left: 20pt,
block(
width: 318pt,
grid(
columns: (info-key-width, info-key-width, 1fr),
column-gutter: info-col-gutter,
row-gutter: info-row-gutter,
info-key("课程名称:"), info-long-value("lession", info.lesson), info-key("指导教师:"),
info-long-value("major", info.teacher), info-key("学生姓名:"), info-long-value("author", info.author),
info-key("学 号:"), info-long-value("student-id", info.student-id), info-key("年 级:"),
info-long-value("grade", info.grade),
),
),
)
v(80pt)
text(size: font-size.四号, font: fonts.宋体)[
#info.submit-date
]
}
#let report-content(
fonts: (:),
lab-info: (:),
body,
) = {
fonts = font-family + fonts
lab-info = (
lab-title: "A*算法",
lab-for: "理解A*算法",
lab-dev: "Intel 13th i5",
lab-requirement: "实验要求实验要求",
lab-result: "实验结果与结论,简要概括",
) + lab-info
pagebreak(weak: true)
set page(margin: (left: 2.5cm, right: 2cm))
{
set align(center)
text(font: fonts.宋体, size: font-size.小初, weight: "medium")[
实验报告
]
}
{
set text(font: fonts.宋体, size: font-size.小三)
table(
columns: (120pt, 1fr, 90pt, 1fr),
stroke: .5pt,
align: center + horizon,
[#text(weight: "medium")[实验题目]], table.cell(colspan: 3)[#lab-info.lab-title],
[#text(weight: "medium")[实验目的]], table.cell(colspan: 3)[#lab-info.lab-for],
[#text(weight: "medium")[实验设备]], table.cell(colspan: 3)[#lab-info.lab-dev],
[#text(weight: "medium")[实验基本要求]], table.cell(colspan: 3)[#lab-info.lab-requirement],
)
v(-1.2em)
table(
columns: 1fr,
stroke: .5pt,
inset: 10pt
)[
#v(1em)
#pad(left: 1.5em, right: 1em)[
#set align(left)
#body
]
#v(22em)
]
v(-1.2em)
table(
columns: (.5fr, 1fr),
stroke: .5pt,
align: center + horizon,
[#text(weight: "medium")[实验结果或结论]], [#lab-info.lab-result],
)
}
}
#let report(
fonts: (:),
info: (:),
lab-info: (:),
) = {
fonts = font-family + fonts
return (
info: info,
cover: (..args) => {
report-cover(
..args,
fonts: fonts + args.named().at("fonts", default: (:)),
info: info + args.named().at("info", default: (:)),
)
},
ctx: (..args) => {
report-content(
..args,
fonts: fonts + args.named().at("fonts", default: (:)),
lab-info: lab-info + args.named().at("lab-info", default: (:)),
)
},
)
}
#let (info, cover, ctx) = report(
fonts: (:),
info: (
year: "2024",
season: "春",
lesson: "算法设计与分析",
teacher: "李四",
author: "张三",
student-id: "123456",
grade: "2022",
submit-day: datetime.today(),
),
lab-info: (
lab-title: "SVM",
lab-for: "理解SVM算法",
lab-dev: "RTX 4080 Super",
lab-requirement: "实验要求实验要求",
lab-result: "实验结果与结论,简要概括",
),
)
#cover()
#ctx()[
实验实验实验实验实验实验
实验实验实验
实验实验实验
实验实验实验实验实验实验实验实验实验实验实验实验实验实验实验
实验实验实验实验实验实验
实验实验实验实验实验实验
]
|
|
https://github.com/rousbound/typst-lua
|
https://raw.githubusercontent.com/rousbound/typst-lua/main/README.md
|
markdown
|
Apache License 2.0
|
# typst-lua
Lua binding to [typst](https://github.com/typst/typst),
a new markup-based typesetting system that is powerful and easy to learn. Also has arguments that enable lua to pass certain values directly to typst.
## Installation
```bash
luarocks install typst-lua
```
## Usage/Docs
```lua
local typst = require"typst"
local pdf_bytes, err = typst.compile( "helloworld.typ", { who = "World!"} )
```
## Example
Example with the lua code above in the following "helloworld.typ" file:
```typst
Hello #_LUADATA.who
```
Output in pdf will be:
```
Hello World!
```
## License
This work is released under the Apache-2.0 license. A copy of the license is provided in the [LICENSE](./LICENSE) file.
|
https://github.com/soul667/typst
|
https://raw.githubusercontent.com/soul667/typst/main/PPT/MATLAB/touying/docs/docs/themes/dewdrop.md
|
markdown
|
---
sidebar_position: 3
---
# Dewdrop Theme

This theme is inspired by [BeamerTheme](https://github.com/zbowang/BeamerTheme) created by <NAME> and transformed by [OrangeX4](https://github.com/OrangeX4).
The Dewdrop theme features an elegant and aesthetic navigation, including `sidebar` and `mini-slides` modes.
## Initialization
You can initialize the Dewdrop theme using the following code:
```typst
#import "@preview/touying:0.2.1": *
#let s = themes.dewdrop.register(
s,
aspect-ratio: "16-9",
footer: [Dewdrop],
navigation: "mini-slides",
// navigation: "sidebar",
// navigation: none,
)
#let s = (s.methods.info)(
self: s,
title: [Title],
subtitle: [Subtitle],
author: [Authors],
date: datetime.today(),
institution: [Institution],
)
#let s = (s.methods.enable-transparent-cover)(self: s)
#let (init, slide, slides, title-slide, focus-slide, touying-outline, alert) = utils.methods(s)
#show: init
#show strong: alert
```
The `register` function takes parameters such as:
- `aspect-ratio`: The aspect ratio of the slides, either "16-9" or "4-3," with the default being "16-9."
- `navigation`: Style of the navigation bar, which can be "sidebar," "mini-slides," or `none`, with the default being "sidebar."
- `sidebar`: Settings for the sidebar navigation, with the default being `(width: 10em)`.
- `mini-slides`: Settings for mini-slides, with the default being `(height: 2em, x: 2em, section: false, subsection: true)`.
- `footer`: Content to be displayed in the footer, with the default being `[]`. You can also pass a function like `self => self.info.author`.
- `footer-right`: Content to be displayed on the right side of the footer, with the default being `states.slide-counter.display() + " / " + states.last-slide-number`.
- `primary`: Primary color, with the default being `rgb("#0c4842")`.
- `alpha`: Transparency, with the default being `70%`.
The Dewdrop theme also provides an `#alert[..]` function that you can use with the `#show strong: alert` syntax.
## Color Themes
Dewdrop uses the following default color theme:
```typst
#let s = (s.methods.colors)(
self: s,
neutral-darkest: rgb("#000000"),
neutral-dark: rgb("#202020"),
neutral-light: rgb("#f3f3f3"),
neutral-lightest: rgb("#ffffff"),
primary: primary,
)
```
You can modify the color theme using `#let s = (s.methods.colors)(self: s, ..)`.
## Slide Function Family
Dewdrop theme provides a series of custom slide functions:
```typst
#title-slide(extra: none, ..args)
```
The `title-slide` reads information from `self.info` for display. You can also pass an `extra` parameter to display additional information.
---
```typst
#slide(
repeat: auto,
setting: body => body,
composer: utils.side-by-side,
section: none,
subsection: none,
// Dewdrop theme
footer: auto,
)[
...
]
```
This is the default ordinary slide function with a navigation bar and footer according to your settings.
---
```typst
#focus-slide[
...
]
```
Used to draw attention. The background color is `self.colors.primary`.
## Special Functions
```typst
#d-outline(enum-args: (:), list-args: (:), cover: true)
```
Displays the current outline. The `cover` parameter specifies whether to hide sections that are inactive.
---
```typst
#d-sidebar()
```
An internal function for displaying the sidebar.
---
```typst
#d-mini-slides()
```
An internal function for displaying mini-slides.
## `slides` Function
The `slides` function has parameters:
- `title-slide`: Default is `true`.
- `outline-slide`: Default is `true`.
- `outline-title`: Default is `[Outline]`.
You can set these using `#show: slides.with(..)`.
```typst
#import "@preview/touying:0.2.1": *
#let s = themes.dewdrop.register(s, aspect-ratio: "16-9", footer: [Dewdrop])
#let s = (s.methods.info)(
self: s,
title: [Title],
subtitle: [Subtitle],
author: [Authors],
date: datetime.today(),
institution: [Institution],
)
#let s = (s.methods.enable-transparent-cover)(self: s)
#let (init, slide, slides, title-slide, focus-slide, touying-outline, alert) = utils.methods(s)
#show: init
#show strong: alert
#show: slides
= Title
== First Slide
Hello, Touying!
#pause
Hello, Typst!
```

## Example
```typst
#import "@preview/touying:0.2.1": *
#let s = themes.dewdrop.register(
s,
aspect-ratio: "16-9",
footer: [Dewdrop],
navigation: "mini-slides",
// navigation: "sidebar",
// navigation: none,
)
#let s = (s.methods.info)(
self: s,
title: [Title],
subtitle: [Subtitle],
author: [Authors],
date: datetime.today(),
institution: [Institution],
)
#let s = (s.methods.enable-transparent-cover)(self: s)
// #let s = (s.methods.appendix-in-outline)(self: s, false)
#let (init, slide, title-slide, focus-slide, touying-outline, alert) = utils.methods(s)
#show: init
#show strong: alert
#title-slide()
#slide[
== Outline
#touying-outline(cover: false)
]
#slide(section: [Section A])[
== Outline
#touying-outline()
]
#slide(subsection: [Subsection A.1])[
== Title
A slide with equation:
$ x_(n+1) = (x_n + a/x_n) / 2 $
]
#slide(subsection: [Subsection A.2])[
== Important
A slide without a title but with *important* infos
]
#slide(section: [Section B])[
== Outline
#touying-outline()
]
#slide(subsection: [Subsection B.1])[
== Another Subsection
#lorem(80)
]
#focus-slide[
Wake up!
]
// simple animations
#slide(subsection: [Subsection B.2])[
== Dynamic
a simple #pause dynamic slide with #alert[alert]
#pause
text.
]
// appendix by freezing last-slide-number
#let s = (s.methods.appendix)(self: s)
#let (slide,) = utils.methods(s)
#slide(section: [Appendix])[
== Outline
#touying-outline()
]
#slide[
appendix
]
```
|
|
https://github.com/RafDevX/distinction-cybsoc
|
https://raw.githubusercontent.com/RafDevX/distinction-cybsoc/master/mod3-threat-actors/report.typ
|
typst
|
#let title = [The Viasat Hack: Analysis Report]
#let kthblue = rgb("#004791")
#set page("a4", header: {
set text(10pt)
smallcaps[#title]
h(1fr)
smallcaps[DD2510 - Module 3]
line(length: 100%, stroke: 0.5pt + rgb("#888"))
}, footer: {
set text(10pt)
line(length: 100%, stroke: 0.5pt + rgb("#888"))
smallcaps[Rafael Serra e Oliveira]
h(1fr)
[Page ]
counter(page).display("1 of 1", both: true)
})
#set par(justify: true)
#align(
center,
)[
= #underline(title)
== DD2510 Cybersecurity in a Socio-Technical Context
=== Module 3: Threat Actors in a Socio-Technical Context
==== #smallcaps(text(fill: kthblue, [KTH Royal Institute of Technology, January 2024]))
#v(7pt)
*<NAME> (#link("mailto:<EMAIL>", "<EMAIL>"))*
#line(length: 60%, stroke: 1.5pt + black)
#v(7pt)
]
#set heading(numbering: "1.")
= Background and Overview
The _*Viasat Hack*_ was a cyber attack against Viasat's KA-SAT Network that took
place on the 24#super[th] of February 2022 @viasat-press-release-overview and
resulted in a significant disruption with widespread impact. Viasat is a
multi-billion-dollar, global communications company based in California that
provides high-speed satellite connectivity to individuals, companies, and
governments (including for defense and military) @viasat-what-we-do, and within
the scope of its such core business it owns the KA-SAT Network, which comprises
a telecommunications satellite and its related ground infrastructure. KA-SAT is
a key asset for Viasat and allows it to provide high-throughput internet
coverage to Europe and other mediterranean areas, whose markets have come to
rely on the services rendered @viasat-ka-sat - in particular, more remote
regions without cable infrastructure have to resort to satellite technology for
communications.
In short and as a high-level simplification, the KA-SAT network has three main
components and works as follows: customer devices communicate with modems at
their premises (such as a family's home or a company headquarters), which in
turn use a powerful antenna to communicate with the KA-SAT satellite. This
satellite then simply proxies communications to KA-SAT ground stations (gateways
\/ teleports) which have fiber-optic internet connections and thus provide
customers the connectivity they need. In this case, the Viasat Hack focused
almost exclusively on the first of these three high-level components (modems /
satellite / ground stations), impacting primarily the devices in customers'
premises @defcon-viasat.
It is also worth noting that while Viasat owned the KA-SAT network at the time
of the incident, the company had only purchased it recently, so the network was
still being operated by an Eutelsat subsidiary, Skylogic, under a transition
agreement @viasat-press-release-overview. Nevertheless, Viasat was the one
affected in branding, and the one coordinating incident response for this
multi-faceted attack that disrupted communications all over Europe.
Finally, for context, it should also be mentioned that the geopolitical
situation between Russia and Ukraine serves as the backdrop for this hack,
wherein long-standing tensions between the two countries (including after a
Russian annexation of Crimea in 2014 @kremlin-crimea) culminated in Russia's
invasion of Ukraine approximately an hour after this incident @ukraine-invasion.
= Threat and Threat Actor Analysis
== The Threat
The Viasat Hack is frequently described as multifaceted as it consisted, in
reality, of two distinct, coordinated attacks, appearing to be perpetrated by
the same threat actors and happening near-simultaneously, but using two
different methods to disrupt the KA-SAT network @defcon-viasat. The most
prominent and impactful of these was able to wipe (erase the flash memory of)
tens of thousands of customer modems making them inoperable
@viasat-press-release-overview, while the second one caused mild but repeated
network disruptions @defcon-viasat.
=== Attack \#1: AcidRain Wiper Malware
For this attack, Viasat claims that the malicious actors managed to penetrate
KA-SAT's management network using compromised VPN credentials, subsequently
using different sets of compromised credentials to access a network operations
server that was used for KA-SAT diagnostics and monitoring. This server gave the
attackers the necessary access to perform reconnaissance as it had information
on all connected modems, and the former then compromised an FTP server that was
used to push firmware updates to modems, which allowed them to stage the malware
as a legitimate update and use KA-SAT's own supply-chain to install the malware
in customer modems and trigger a reboot, rendering them inoperable (due to
having their memory wiped and thus no filesystem to boot from)
@viasat-press-release-overview.
The malware itself was discovered by SentinelLabs researchers to be _AcidRain_ (which
was later confirmed by Viasat), a wiper designed to target modems and routers in
order to overwrite key flash memory data in hopes of rendering it inoperable and
in need of reflashing or replacing @sentinel-acid-rain.
It is possible to outline this threat using Lockheed Martin's Cyber Kill Chain
@cyber-kill-chain:
+ *Reconnaissance:* collect information on how the KA-SAT network works and find
compromised credentials for VPN and other services;
+ *Weaponization:* craft the AcidRain wiper malware, a MIPS executable to wipe
flash memory and erase its partition tables;
+ *Delivery:* breach into KA-SAT's Turin Core Node, stage the malware in its FTP
server, and push it to the target devices using legitimate commands;
+ *Exploitation:* reaching the modems as a legitimate firmware update, the malware
is executed in a trusted context;
+ *Installation:* _not applicable as persistent remote control is not required_;
+ *Command and Control:* _not applicable as persistent remote control is not required_;
and
+ *Actions on Objectives:* erase the modem's flash memory and reboot it so that it
cannot function.
=== Attack \#2: DHCP Denial of Service
The second attack (in terms of prominence, but actually the first one to be
executed) was a Denial of Service that leveraged a bug in KA-SAT's ground
stations to mislead them into disconnecting modems from the network. Using
legitimate modems with valid identities and subscriptions, the malicious actors
sent DHCP control messages referring to IP addresses being used by the targeted
customer modems - then, KA-SAT's DHCP server would reject the request by sending
the gateway a negative acknowledgment (NAK), but the latter was not adequately
programmed to handle that case and thus ejected the targeted modem from the
network @defcon-viasat. It is unclear how the attackers were able to initiate
this from real, authenticated modems, as there was no clear pattern to them
(including any particular location-based clustering), and it is not known
whether they simply purchased and distributed them or if they somehow
compromised them in another fashion and avoided detection. It should also be
noted that this attack was not a one-off, occurring intermittently over a long
period of time and resorting to slightly-different variants every time Viasat
managed to mitigate each variant.
For this attack, the seven Cyber Kill Chain phases @cyber-kill-chain would be:
+ *Reconnaissance:* analyze how KA-SAT's DHCP works, acquire modems with
legitimate subscriptions, and scan for target modems on the KA-SAT network;
+ *Weaponization:* craft DHCP messages that target the discovered weakness;
+ *Delivery:* send messages through satellite to gateway, which forwards them to
the DHCP server;
+ *Exploitation:* have the server reject the request and reply with a NAK to the
gateway;
+ *Installation:* _not applicable as persistent remote control is not required_;
+ *Command and Control:* _not applicable as persistent remote control is not required_;
and
+ *Action:* confused, the gateway kicks the target modem off the network,
rendering it offline.
== The Threat Actor
Researchers have linked the AcidRain malware with the Russian Federation's GRU
directorate, due to close similarities with other malware @sentinel-acid-rain,
which suggests that Russia may have been behind the Viasat Hack. This is also
consistent with the timing of the attack, as it took place around an hour before
Russia invaded Ukraine, and with the fact that no attempt at data exfiltration
was made, showing that the attackers were not financially motivated (nothing was
stolen for ransom or selling).
In addition, it is possible that more evidence of Russian ties was silently
discovered by other governments, as on May 10#super[th] 2022 several states
publicly attributed the hack to Russia and heavily condemned it - this includes
the UK @uk-attribution, the United States @us-attribution, the European Union,
and several other European countries @eu-attribution.
Although the attack almost certainly came from the GRU, there is not a clear
consensus regarding which specific unit (within it) it originated from
("Sandworm" operated by Military Unit 74455, "Fancy Bear" operated by Military
Unit 26165, or others) - as such, since more granularity is not possible, the
threat actor is considered to be the GRU itself. Nevertheless, this attacker has
nation-state capabilities and motivations, and is most likely an Advanced
Persistent Threat (APT), meaning a "well-resourced adversary engaged in
sophisticated malicious cyber activity that is targeted and aimed at prolonged
network/system intrusion" @cisa-apt.
= Political and Socio-Technical Analysis
Although Russia's motives remain a mystery, it is speculated that they simply
wished to disrupt Ukrainian communications during the initial period of the
invasion, in order to cripple the enemy's military response (since they relied
on KA-SAT for military communications @wired-spill) and generate confusion and
chaos for its citizens living in more remote regions, who would be unable to
access information regarding the conflict and communicate with others. This
attack corroborates the fact that cyber is being used in wars, but only with a
supporting role and not as a leading actor.
The key aspect to understand here is, however, that the threat actor favored
impact and speed (as they were likely on a schedule, given the timing), but had
to do so at the expense of precision: despite much of the aftermath being
limited to the Ukraine, thousands of households in other European countries were
affected too, including in Poland, the UK, France, the Czech Republic, Hungary,
Greece, Germany, and Italy. In addition, more than 5,800 wind turbines in
Germany were affected, and after a month \~60% were still offline @wired-spill
@cyberpeace-case-study. This emphasizes the _*spillover effect*_ that is
prevalent within the Viasat Hack, and shows that Russia probably caused more
damage than intended.
This hack can also be classified as a _large-scale cyber incident_, as it had
very serious effects (both in terms of military sabotage, per Ukrainian SSSCIP
@reuters-comms-loss, and with regard to civilians affected as collateral
damage), and is a transboundary crisis, the latter being characterized by not
adhering to conventional boundaries @ansell-transboundary-crisis:
- Political Boundaries: the hack's effects were not limited by geographical
borders and jurisdictions, affecting thousands of people in different countries;
- Functional Boundaries: all kinds of people and organizations were affected,
across sectors and regardless of any military affiliation (or lack thereof); and
- Temporal Boundaries: despite there being a clear point in time where the attack
was most prominent, there is no clear time delimitation on when it began
(reconnaissance took place beforehand and several questions are still
unanswered) and when it ended (effects were still felt months after, and it took
place at a critical moment that likely shaped the war and still has
repercussions today).
#pagebreak()
In addition, this attack can be analyzed from the perspective of Perrow's Normal
Accidents Theory in its more modern variant applied to Cyber Accidents
@sarah-normal-accidents - we can find evidence of both interactive complexity
and tight coupling for each of the three layers described in the framework:
#{ // scope marker setting
set list(marker: "‣")
[
- Technology:
#set list(marker: "◦")
- Complexity: as previously described, the system has many different moving parts
across three main components, and each (potentially-legacy) part must be kept in
mind at all times;
- Coupling: ISPs are critical infrastructure and have little to no allowance for
downtime, which might prevent maintenance of devices and modules.
- Organizational:
#set list(marker: "◦")
- Complexity: Viasat "found it extremely difficult, especially on older networks,
to find out what normal behavior was" @cso-lessons-learned;
- Coupling: better-protected components connected to more-vulnerable components.
- Macro:
#set list(marker: "◦")
- Complexity: Viasat's inter-organizational dependency on Skylogic for operating
KA-SAT;
- Coupling: complex supply-chain ecology (e.g., wind turbines, airlines, and
governments relying on KA-SAT)
]
}
Thus, given a system with these system characteristics as described, Normal
Accidents Theory claims that accidents will be more likely, more difficult to
analyze, and more consequential - and the empirical data associated with the
Viasat Hack corroborates this. These NA-dynamics make KA-SAT a risky target, and
any attack can have unpredictable consequences, which is what happened in this
case.
Finally, this incident raises several ethical concerns, such as spillover being
able to cause cyber warfare attacks to affect unintended parties (e.g.,
civilians and neutral sovereign countries), especially when the target exhibits
NA-dynamics. Furthermore, offensive cyber postures with attacks that may have
unpredictable effects cannot guarantee adherence to the principle of
proportionality and may be unwillingly interpreted by others as an escalation.
Moreover, targeting communication networks erodes public trust in digital
technologies and hinders global efforts to promote digitalization, which may
cause setbacks on all levels. Lastly, it should be considered whether it is
ethical for Viasat to host military and civilian entities within the same
infrastructure, as Russia would perhaps not have attacked the latter otherwise,
and in doing this Viasat unwittingly put their customers at risk.
In summary, Russia's February 2022 (dual-)cyber-attack against Viasat's KA-SAT
Network had unpredictable effects that were likely outside of what was
originally intended, leading to a large-scale, transboundary crisis that proved
historic and elicited various ethical considerations.
#pagebreak()
#bibliography("references.yml", title: "References")
|
|
https://github.com/davawen/Cours
|
https://raw.githubusercontent.com/davawen/Cours/main/Physique/Optique/4-Association/association.typ
|
typst
|
#import "@local/physique:0.1.0": *
#import optique: *
#import xarrow: xarrow
#show: doc => template(doc)
#titleb[Association de lentilles \ Instruments d'optique]
#let lc = math.cal($L$)
= Association de lentilles
== Méthode générale
Systématiquement faire un schéma synoptique:
$ A -->^(lc_1) B -->^(lc_2) A' -->^(lc_3) ... $
On peut utiliser des conditions particulières dans ce schéma. Par exemple, si notre objet est à l'infini:
$ oo -->^(lc_1) F'_1 -->^(lc_2) ... $
Ou si on sait qu'une de nos lentilles donne une image à l'infini:
$ F'_1 -->^(lc_1) oo -->^(lc_2) ... $
== Cas d'une système afocal
Mis à part les deux cas particuliers qu'on va voir (système afocal et #todo[]), on ne va pas beaucoup parler d'association de lentilles
Dans un système afocal, l'infini est conjugué à l'infini:
$ oo -->^(lc_1) F'_1 -->^(lc_2) ... --> F'_n -->^(lc_n) oo $
Dans le cas particulier de deux lentilles, on a:
$ oo -->^(lc_1) F'_1 = F'_2 -->^(lc_2) oo $
Les foyer images et objets des deux lentilles sont nécessairement confondues. On a:
$ ov(O_1 O_2) = ov(O_1 F'_1) + ov(F'_1 O_2) = f'_1 + f'_2 $
== Lentilles accolées
#def[Lentilles accoléés]: Lentilles dont les centre sont confondus.
Si deux lentilles $lc_1$ et $lc_2$ sont accolées, on considère que leurs centre respectifs $O_1$ et $O_2$ sont égaux.
Si on a:
$ A -->^(lc_1) A_1 -->^(lc_2) A' $
On va chercher le système optique équivalent possédant une seule lentille $lc_3$ tel que:
$ A -->^(lc_3) A' $
On utilise la relation de conjugaison:
$ 1/ov(O A_1) = 1/f'_1 + 1/ov(O A) $
$ 1/ov(O A') &= 1/f'_2 + 1/ov(O A_1) \
&= 1/f'_2 + 1/f'_1 + 1/ov(O A) \
&= (f'_1 + f'_2)/(f'_1 f'_2) + 1/ov(O A)
$
Une lentille de distance focale $(f'_1 f'_2)/(f'_1 + f'_2)$ est équivalente à un système focale de deux lentilles #underline[accolées].
On appelle cette relation *théorème des vergences*, car on a $V_3 = V_1 + V_2$
= L'œil
== Description
L'œil est constitué de plusiers parties:
1. Le nerf optique qui transmet le signal au cerveau
2. La rétine, où les images se forment à l'aide de cellules photosensibles
3. La pupille (la partie qui nous interésse)
L'objet traverse un premier dioptre, l'humeure aqueuse, puis passe dans la pupille qui agit comme une lentille.
L'œil capte des rayons de toute direction, on peut donc difficilement se placer dans les conditions de Gauss. L'iris agit ainsi comme un diaphragme qui va limiter l'angle des rayons incident.
L'indice entre l'humeur aqueuse et le cristallin sont généralement très proche, donc on va ignorer la traversée de ce dioptre et on considérera une seule lentille.
== Caractéristiques de l'œil
=== L'accomodation
La principale caractéristique de l'œil est *l'accomodation*.
Dans un œil, on ne peut déplacer ni l'écran, ni la lentille. Pour voir à différentes distances, le cristallin, qui est un muscle, va se contracter afin de modifier la distance focale de la pupille et changer.
De ce fait, cela permet de voir toute une zone. On va définir deux choses:
- Le Punctum Remotum (PR), le point le plus éloigné qu'on peut observer.
- Le Punctum Proximum (PP), le point le plus proche qu'on peut observer.
Ces valeures sont des *points*, #underline[PAS] des distances.
Lorsque l'œil regarde le PR avec la rétine, il est au repos. Le cristallin n'a pas besoin de se contracter. \
Lorsque l'œil regarde le PP, il est le plus contracté.
Pour un œil normal, sans défaut, le PR est à l'infini et le PP est à $25 "cm"$.
=== L'acuité visuelle
#def[Acuité visuelle]: Capacité à distinguer deux points
On parle aussi de résolution angulaire. Un œil normal est capable de distinguer deux points à partir du moment où l'angle des rayon incidents dépasse $4 dot 10^(-4) "rad"$
#figcan({
import draw: *
line((-2, 0), (2, 0), mark: (end: "straight"))
line((-2, 0.5), (2, 0))
})
=== Champ de l'œil
Espace où l'image se forme sur la zone sensible de la rétine.
== Modélisation de l'œil
On va modéliser l'œil par une lentille pour le cristallin et par un écran pour la rétine.
On peut modeliser l'accomodation par un changement de lentille (ce qui n'est pas très pratique), ou par déplacement de l'écran sur l'axe optique.
On détermine la position de l'écran pour un objet à $25 "cm"$, et un objet à l'infini.
En plaçant l'écran entre ces deux positions, on pourra recueillir l'image d'un objet entre $25 "cm"$ et l'infini.
== Défauts de l'œil
On va parler des 4 défauts principaux.
=== Myopie
Le cristallin est trop convergent.
Les rayons à l'infini viennent converger avant la rétine.
Le PR est proche de l'œil, on ne peut pas voir au-delà.
Pour rectifier la miopie, on place une lentille divergente (dîte correctrice) avant le cristallin afin d'envoyer les rayons à l'infini sur le PR de l'œil myope:
$ oo -->^(lc_c) "PR" xarrow("œil myope") "rétine" $
=== Hypermétropie
L'hypermétropie est l'inverse de la myopie. Le cristallin n'est pas assez convergent, les rayons convergent derrière la rétine.
Or, tout les œils peuvent accomoder, l'hypermétropie peut se "régler d'elle même" en accomodant constamment. Cela-dit, l'accomodage est fatigant et l'hypermétropie se détecte par une fatigue visuelle constante.
Pour la rectifier, on place une lentille correctrice convergente avannt le cristallin.
=== Astigmatie
Le cristallin n'est pas parfaitement sphérique, la lentille n'est pas symmétrique.
=== Presbytie
Le cristallin est moins souple, on peut moins accomoder.
|
|
https://github.com/ludwig-austermann/typst-funarray
|
https://raw.githubusercontent.com/ludwig-austermann/typst-funarray/main/funarray.typ
|
typst
|
MIT License
|
#import "funarray-unsafe.typ"
/// splits the array into chunks of given size.
#let chunks(arr, size) = {
assert.eq(type(arr), array, message: "Argument `arr` must be an array.")
assert.eq(type(size), int, message: "Argument `size` must be an integer.")
assert(size > 0, message: "Argument `size` must be > 0.")
funarray-unsafe.chunks(arr, size)
}
/// inverse of zip method. array(pair) -> pair(array)
#let unzip(arr) = {
assert.eq(type(arr), array, message: "Argument `arr` must be an array.")
if arr.len() > 0 {
let n = arr.at(0).len()
assert(arr.all(p => p.len() == n), message: "Argument `arr`'s elements must have equal length (" + str(n) + ").")
funarray-unsafe.unzipN(arr, n: n)
} else {
()
}
}
/// cycles through arr until length is met
#let cycle(arr, length) = {
assert.eq(type(arr), array, message: "Argument `arr` must be an array.")
assert.eq(type(length), int, message: "Argument `length` must be an integer.")
assert(arr != (), message: "Argument `arr` cannot be empty.")
assert(length >= 0, message: "Argument `length` must be >= 0.")
funarray-unsafe.cycle(arr, length)
}
/// provides a running window of given size
#let windows(arr, size) = {
assert.eq(type(arr), array, message: "Argument `arr` must be an array.")
assert.eq(type(size), int, message: "Argument `size` must be an integer.")
assert(size > 0, message: "Argument `size` must be > 0.")
funarray-unsafe.windows(arr, size)
}
/// same as windows, but continues wrapping at the border
#let circular-windows(arr, size) = windows(arr + arr.slice(size - 1), size)
/// creates two arrays, 1. where f returns true, 2. where f returns false
#let partition(arr, f) = {
assert.eq(type(arr), array, message: "Argument `arr` must be an array.")
// no check of function signature
funarray-unsafe.partition(arr, f)
}
/// after partition, maps each partition according to g
#let partition-map(arr, f, g) = {
// no check for function signature
let parts = partition(arr, f)
(parts.at(0).map(g), parts.at(1).map(g))
}
/// groups the array into maximally sized chunks, where each elements yields same predicate value
#let group-by(arr, f) = {
assert.eq(type(arr), array, message: "Argument `arr` must be an array.")
// no check of function signature
funarray-unsafe.group-by(arr, f)
}
/// returns all elements until the predicate returns false
#let take-while(arr, f) = {
assert.eq(type(arr), array, message: "Argument `arr` must be an array.")
// no check of function signature
funarray-unsafe.take-while(arr, f)
}
/// returns all elements starting when the predicate returns false
#let skip-while(arr, f) = {
assert.eq(type(arr), array, message: "Argument `arr` must be an array.")
// no check of function signature
funarray-unsafe.skip-while(arr, f)
}
/// maps over elements together with a state, also refered to as accumulate
#let accumulate(arr, init, f) = {
assert.eq(type(arr), array, message: "Argument `arr` must be an array.")
funarray-unsafe.accumulate(arr, init, f)
}
/// similar to accumulate, but f : (state, value) -> (state, value), simulating mutable state
#let scan(arr, init, f) = {
assert.eq(type(arr), array, message: "Argument `arr` must be an array.")
funarray-unsafe.scan(arr, init, f)
}
/// f : state -> (state, value)
#let unfold(init, f, take) = {
assert(take >= 0, message: "take argument must be >= 0")
funarray-unsafe.unfold(init, f, take)
}
/// iteratively applies f to last value
#let iterated(init, f, take) = {
assert(take >= 0, message: "take argument must be >= 0")
funarray-unsafe.iterated(init, f, take)
}
|
https://github.com/Greacko/typyst_library
|
https://raw.githubusercontent.com/Greacko/typyst_library/main/library/template_setup.typ
|
typst
|
#set page(numbering: "1")
#outline(indent:true)
|
|
https://github.com/CFiggers/typst-companion
|
https://raw.githubusercontent.com/CFiggers/typst-companion/main/CHANGELOG.md
|
markdown
|
Other
|
# Change Log
All notable changes to Typst Companion will be documented here.
## 0.0.5
- Will no longer warn if [tinymist](https://github.com/Myriad-Dreamin/tinymist) LSP is installed rather than [Typst LSP](https://github.com/nvarner/typst-lsp).
## 0.0.4
- Added out-dent/de-dent with `enter` when cursor is at start of an empty list item.
- Added skip to next line with `ctrl/cmd + enter` when in a list context.
- Added insert a page break with `ctrl/cmd + enter` when not in a list context.
## 0.0.3
- Added toggle Bold with `ctrl/cmd + b`.
- Added toggle Italic with `ctrl/cmd + i`.
- Added toggle Underline with `ctrl/cmd + u`.
- Added increase/decrease Header level with `ctrl/cmd + shift + ]` and `ctrl/cmd + shift + ]`, respectively.
- Added 'Typst Companion: Toggle List' command to command palette.
## 0.0.2
- New logo.
## 0.0.1
- Initial release of Typst Companion.
|
https://github.com/k0tran/cont_labs
|
https://raw.githubusercontent.com/k0tran/cont_labs/master/reports/lab7.typ
|
typst
|
#import "template.typ": *
#show: lab.with(n: 7)
= Кластер
У главной ноды 10-й айпишник и проброшены порты 1101, 1102, 1103. Так же скопированы необходимые docker-compose файлы (используемые скрипты будут приведены позже).
#pic(img: "lab7/vagrant1.png")[Главная нода]
Для рабочих нод необходимо поставить докер и завести в swarm.
#pic(img: "lab7/vagrant2.png")[Работяги]
Используемые скрипты включают в себя скрипт для основной ноды, рабочих и скрипт для деплоя.
#pic(img: "lab7/vagrant3.png")[Скрипты]
= Развертывание сервиса Viz
Ключевые моменты:
- доступ к docker.sock
- ограничение работы по hostname
#pic(img: "lab7/visualizer1.png")[visualizer docker-compose]
#pic(img: "lab7/visualizer2.png")[Запуск]
#pic(img: "lab7/visualizer3.png")[Отображение в браузере]
= Развертывание сервиса Portainer
Ключевые моменты:
- глобальный режим развертывания (по инстансу на ноде)
- коммуникация
- `AGENT_CLUSTER_ADDR: tasks.agent` задание адреса агента
- `command: -H tcp://tasks.agent:9001 --tlsskipverify` подключение к агенту по порту 9001
- сеть типа overlay (можно быть в одной сетке даже на разных компах, не говоря уже о виртуалках)
- прослушивание на порту 1102
#pic(img: "lab7/portainer1.png")[portainer docker-compose]
#pic(img: "lab7/portainer2.png")[Запуск]
#pic(img: "lab7/portainer3.png")[Отображение в visualizer]
#pic(img: "lab7/portainer4.png")[Отображение в браузере]
= Load-Balancing Web сервиса
В качестве веб сервиса был выбран itzg/web-debug-server (https://hub.docker.com/r/itzg/web-debug-server)
Ключевые моменты docker-compose:
- глобальный режим развертывания
- web-server слушает на 8080 порту, nginx на 80 (но доступ будет по 1103)
- nginx работает только на главной ноде
- сеть типа оверлей
#pic(img: "lab7/web1.png")[web docker-compose]
#pic(img: "lab7/web2.png")[nginx.conf]
#pic(img: "lab7/web3.png")[stack deploy]
#pic(img: "lab7/web4.png")[Отображение в visualizer]
#pic(img: "lab7/web5.png")[Отображение в браузере]
|
|
https://github.com/TeddyHuang-00/typpuccino
|
https://raw.githubusercontent.com/TeddyHuang-00/typpuccino/main/src/frappe.typ
|
typst
|
MIT License
|
#let rosewater = rgb(242, 213, 207)
#let flamingo = rgb(238, 190, 190)
#let pink = rgb(244, 184, 228)
#let mauve = rgb(202, 158, 230)
#let red = rgb(231, 130, 132)
#let maroon = rgb(234, 153, 156)
#let peach = rgb(239, 159, 118)
#let yellow = rgb(229, 200, 144)
#let green = rgb(166, 209, 137)
#let teal = rgb(129, 200, 190)
#let sky = rgb(153, 209, 219)
#let sapphire = rgb(133, 193, 220)
#let blue = rgb(140, 170, 238)
#let lavender = rgb(186, 187, 241)
#let text = rgb(198, 208, 245)
#let subtext1 = rgb(181, 191, 226)
#let subtext0 = rgb(165, 173, 206)
#let overlay2 = rgb(148, 156, 187)
#let overlay1 = rgb(131, 139, 167)
#let overlay0 = rgb(115, 121, 148)
#let surface2 = rgb(98, 104, 128)
#let surface1 = rgb(81, 87, 109)
#let surface0 = rgb(65, 69, 89)
#let base = rgb(48, 52, 70)
#let mantle = rgb(41, 44, 60)
#let crust = rgb(35, 38, 52)
#let color-entries = (
"rosewater": rosewater,
"flamingo": flamingo,
"pink": pink,
"mauve": mauve,
"red": red,
"maroon": maroon,
"peach": peach,
"yellow": yellow,
"green": green,
"teal": teal,
"sky": sky,
"sapphire": sapphire,
"blue": blue,
"lavender": lavender,
"text": text,
"subtext1": subtext1,
"subtext0": subtext0,
"overlay2": overlay2,
"overlay1": overlay1,
"overlay0": overlay0,
"surface2": surface2,
"surface1": surface1,
"surface0": surface0,
"base": base,
"mantle": mantle,
"crust": crust,
)
|
https://github.com/npujol/npujol.github.io
|
https://raw.githubusercontent.com/npujol/npujol.github.io/main/Me/basic-cv/basic-cv-en.typ
|
typst
|
#import "@preview/basic-resume:0.1.0": *
// Put your personal information here, replacing mine
#let name = "<NAME>"
#let location = "Berlin, Germany"
#let email = "<EMAIL>"
#let github = "github.com/npujol"
#let linkedin = "linkedin.com/in/npujolm"
#let personal-site = "npujol.github.io"
#show: resume.with(
author: name,
location: location,
email: email,
github: github,
linkedin: linkedin,
personal-site: personal-site,
)
== Work Experience
#work(
title: "Software Developer",
location: "Berlin, Germany",
company: "InterContent Group",
dates: dates-helper(start-date: "2021", end-date: "Today"),
)
- Development and deployment of microservices on Amazon Web Services (AWS) infrastructure, including Amazon EC2, Amazon ECS, AWS Lambda, and Microsoft Azure Containers Apps, customizing each service to meet specific requirements. Employed Docker containers for efficient packaging and deployment.
- Management and automation of the infrastructure provisioning and deployment process through Continuous Integration/Continuous Deployment (CI/CD) pipelines using GitHub Actions, Infrastructure as Code (IaC) with Terraform, and configuration management with YAML.
- Implementation of monitoring and logging solutions using Amazon CloudWatch and Sentry, enabling efficient troubleshooting and performance analysis. Utilized the Postman API for testing and validating API endpoints.
#work(
title: "Software Developer",
location: "Havanna, Cuba",
company: "Universidad de las Ciencias Informáticas",
dates: dates-helper(start-date: "2014", end-date: "2019"),
)
- Development of the university's postgraduate activities' management website using Python, Django, Django REST Framework, and PostgreSQL as the primary databases. Implemented backend functionality, adhering to best practices in back-end web development.
- Automatization of data cleaning tasks and error identification processes using Celery and Redis, streamlining data preprocessing and ensuring data integrity.
- Data analysis, pattern finding, and predictive modeling using Python libraries such as Jupyter, scikit-learn, NumPy, pandas, and Cython; enabling data-driven decision-making and insights.
== Education
#edu(
institution: "Universidad de las Ciencias Informáticas",
location: "Havanna, Cuba",
dates: dates-helper(start-date: "May 2016 ", end-date: "December 2018"),
degree: "Master's degree in advanced informatic",
)
- *Cumulative GPA:* 4.82\/5.0
- *Relevant Coursework:* Advanced Mathematics, Advanced Programming Topics Computational Mathematics, Computer Security, Flexible methods for data consultation and analysis, Functional programming, Statistical Methods for Scientific Research.
#edu(
institution: "Universidad de las Ciencias Informáticas",
location: "Havanna, Cuba",
dates: dates-helper(start-date: "November 2009 ", end-date: "July 2014"),
degree: "Bachelor of Software Engineering",
)
- *Cumulative GPA:* 4.71\/5.0
- *Relevant Coursework:* Data Structures, Algebra I and II, Discrete Mathematics, Software Engineering, Programming, Mathematics, Computational Intelligence, Digital Systems
== Projects
#project(
name: "anki_wiktionary",
dates: dates-helper(start-date: "2020", end-date: "Today"),
url: "github.com/npujol/anki_wiktionary",
)
- Development of a project that generates Anki notes by using the linguistic data from Wiktionary. Implemented a Telegram bot as the primary interface, allowing users to interact and request the creation of Anki notes. Utilization of the python-telegram-bot library to build and manage the Telegram bot, facilitating real-time communication and note generation requests. Employed deep-translator and pydantic libraries for automatic language translation and data validation, respectively. Integration with Selenium WebDriver and Selenium for web automation, enabling the programmatic creation and management of Anki note decks directly within the Anki application.
== Skills
- *Skills:* python, django, terraform, golang, aws, azure, devops, docker, javascript, postgresql, celery, redis, github actions, yaml, latex, pandas, pydantic, git, linux, postman, sentry, bash, typst
- *Languages:* Spanish(Native), German(B1), English(B1)
|
|
https://github.com/PabloRuizCuevas/numty
|
https://raw.githubusercontent.com/PabloRuizCuevas/numty/master/lib.typ
|
typst
|
MIT License
|
// == types ==
#let arrarr(a,b) = (type(a) == array and type(b) == array)
#let arrflt(a,b) = (type(a) == array and type(b) != array)
#let fltarr(a,b) = (type(a) != array and type(b) == array)
#let fltflt(a,b) = (type(a) != array and type(b) != array)
#let is-arr(a) = (type(a) == array)
#let is-mat(m) = (is-arr(m) and is-arr(m.at(0)))
#let matmat(m,n) = is-mat(m) and is-mat(n)
#let matflt(m,n) = is-mat(m) and type(n) != array
#let fltmat(m,n) = is-mat(n) and type(m) != array
// == boolean ==
#let isna(v) = {
if is-arr(v){
v.map(i => if (type(i)==float){i.is-nan()} else {false})
}
else{
if (type(v)==float){v.is-nan()} else {false}
}
}
#let all(v) ={
if is-arr(v){
v.flatten().all(a => a == true or a ==1)
}
else{
v == true or v == 1
}
}
#let _eq(i,j, equal-nan) ={
i==j or (all(isna((i,j))) and equal-nan)
}
#let eq(u,v, equal-nan: false) = {
// Checks for equality element wise
// still to implement mat flt comparisons
// eq((1,2,3), (1,2,3)) = (true, true, true)
// eq((1,2,3), 1) = (true, false, false)
if matmat(u,v) {
u.zip(v).map(((m,n)) => eq(m,n, equal-nan:equal-nan))
}
else if arrarr(u,v) {
u.zip(v).map(((i,j)) => (_eq(i,j, equal-nan)))
}
else if arrflt(u,v) {
u.map(i => _eq(i,v,equal-nan))
}
else if fltarr(u,v) {
v.map(i => _eq(i,u,equal-nan))
}
else if fltflt(u,v) {
_eq(u,v, equal-nan)
}
else{
panic("Not supported broadcasting data types", type(u), type(v))
}
}
#let any(v) ={
// check if any item is true after iterating everything
if is-arr(v){
v.flatten().any(a => a == true or a ==1)
}
else{
v == true or v == 1
}
}
#let all-eq(u,v) = all(eq(u,v))
#let apply(a,fun) ={
// vectorize
// consider returnding a function of a instead?
if is-mat(a){
a.map(v=>v.map(i=>fun(i)))
}
else if is-arr(a){
a.map(v=>fun(v))
}
else{
fun(a)
}
}
#let abs(a)= apply(a, calc.abs)
// == Operators ==
#let _add(a,b)=(a + b)
#let _sub(a,b)=(a - b)
#let _mul(a,b)=(a * b)
#let _div(a,b)= if (b!=0) {a/b} else {float.nan}
#let op(a,b, fun) ={
// generic operator with broacasting
if matmat(a,b) {
a.zip(b).map(((a,b)) => op(a,b, fun))
}
else if matflt(a,b){
a.map(v=> v.map(a => fun(a,b)))
}
else if fltmat(a,b){
b.map(v=> v.map(a => fun(a,b)))
}
else if arrarr(a,b) {
a.zip(b).map(((i,j)) => fun(i,j))
}
else if arrflt(a,b) {
a.map(a => fun(a,b))
}
else if fltarr(a,b) {
b.map(i => fun(a,i))
}
else {
fun(a,b)
}
}
#let add(u,v) = op(u,v, _add)
#let sub(u, v) = op(u,v, _sub)
#let mult(u, v) = op(u,v, _mul)
#let div(u, v) = op(u,v, _div)
#let pow(u, v) = op(u,v, calc.pow)
// == vectorial ==
#let normalize(a, l:2) = {
// normalize a vector, defaults to L2 normalization
let aux = pow(pow(abs(a),l).sum(),1/l)
a.map(b => b/aux)
}
// dot product
#let dot(a,b) = mult(a,b).sum()
// == Algebra, trigonometry ==
#let sin(a) = apply(a,calc.sin)
#let cos(a) = apply(a,calc.cos)
#let tan(a) = apply(a,calc.tan)
#let log(a) = apply(a, j => if (j>0) {calc.log(j)} else {float.nan} )
// others:
#let linspace = (start, stop, num) => {
// mimics numpy linspace
let step = (stop - start) / (num - 1)
range(0, num).map(v => start + v * step)
}
#let logspace = (start, stop, num, base: 10) => {
// mimics numpy logspace
let step = (stop - start) / (num - 1)
range(0, num).map(v => calc.pow(base, (start + v * step)))
}
#let geomspace = (start, stop, num) => {
// mimics numpy geomspace
let step = calc.pow( stop / start, 1 / (num - 1))
range(0, num).map(v => start * calc.pow(step,v))
}
#let to-str(a) = {
if (type(a) == bool){
if(a){
"value1"
}
else {
"value2"
}
}
else{
str(a)
}
}
#let print(M) = {
if is-mat(M) {
eval("$ mat(" + M.map(v => v.map(j=>to-str(j)).join(",")).join(";")+ ") $")
}
else if is-arr(M){
eval("$ vec(" + M.map(v => str(v)).join(",")+ ") $")
}
else{
eval(" $"+str(M)+"$ ")
}
}
#let p(M) = {
let scope = (value1: "true", value2: "false")
if is-mat(M) {
eval("$mat(" + M.map(v => v.map(j=>to-str(j)).join(",")).join(";")+ ")$", scope: scope)
}
else if is-arr(M){
eval("$vec(" + M.map(v => str(v)).join(",")+ ")$")
}
else{
eval("$"+str(M)+"$")
}
}
|
https://github.com/meel-hd/s6-paper
|
https://raw.githubusercontent.com/meel-hd/s6-paper/main/index.typ
|
typst
|
// Initial Config
#set page(paper: "a4",margin: (x: 35pt, y: 20pt))
#set par(justify: true,leading: 1.5em)
#set text(font: "New Computer Modern", hyphenate: false, size: 11pt)
#set heading(numbering: "I.")
#set footnote.entry(separator: repeat[.])
#set bibliography(style: "apa")
// Extra Information
#grid(
figure(image("assets/umi.svg"),)
)
/// SECTION: Cover Page
#align(center)[
#set par(justify:false)
#set text(size: 24pt)
\ \ \ \
Investigating Moroccans' Interest in Adopting a New Written System for Darija
\ \
]
#grid(
columns: (1fr, 1fr),
align(center)[
Submitted by \
#text(weight: "bold")[<NAME>] \
#link("mailto:<EMAIL>")
],
align(center)[
Supervised by\
#text(weight: "bold")[Prof. <NAME>] \
]
)
#align(center)[
#set par(justify:false)
#set text(size: 10pt, weight: "semibold")
\ \ \
This Monograph is Submitted in Partial Fulfillment of the Requirements \ of a BA Degree in English Studies.
\
]
#align(center)[
#set par(justify:false)
#set text(size: 10pt, weight: "bold")
\ \ \ \ \ \ \
June, 2024
\
]
#pagebreak()
/// SECTION: Preliminary pages
#set page(margin: (x: 60pt, y: 60pt))
// Acknowledgements
#align(center)[
\ \ \ \ \ \ \ \ \ \ \ \
= Acknowledgments
]
~~ I would like to express my sincere gratitude to my professors at Moulay Ismail University, especially Professor <NAME>, for their invaluable support throughout this research project. This project was a serious commitment of time and energy. Professor Laabidi's guidance and encouragement were instrumental, and his expertise greatly shaped this research. I would also like to extend my thanks to the research participants whose contributions were vital to this study.
#pagebreak()
// Dedications
#align(center)[
\ \ \ \ \ \ \ \ \ \ \
= Dedications
]
\
#align(center)[
#text(font: "Andalus")[
To my dearest Mom, and Dad. This work is dedicated to you.
#linebreak()
Your guidance and unconditional support is the foundation of my love reflected on the world.
#linebreak()
]
]
#pagebreak()
// Abstract
#align(center)[
\ \ \ \ \ \ \ \
= Abstract
]
// ~~#lorem(200)
~~ Darija has widespread adoption in Morocco but it does not have a native script. This paper assesses the public’s current perception of the current non standard written forms of Darija using Latin and Arabic. And measures interest in adopting a completely new writing script instead. This was achieved through the collection and measurement of opinions about the current written forms and the newly created writing script. We found that *the current written forms are thought to be enough, but not perfect*. Especially in their inherent incompleteness for representing Darija. Also we found *adopting a new written system is undesired by Moroccans*. This was done in order to lay ground for further research on the written forms of Darija and help concerned parties test possibility of making a standard form.
#pagebreak()
// Outline
= Contents
#outline(indent: true, title: none)
#pagebreak()
// SECTION: Content
#set heading(numbering: "1.1")
#counter(heading).update(0)
= Introduction
~~ Darija #footnote[Known in Arabic as الدارجة] is the vernacular Arabic used by Moroccans. It is mainly spoken and used informally in everyday interactions. Whereas Classical Arabic #footnote[Al-Fosha or الفصحى] is used in formal situations, official media, books, and newspapers. In current times Darija gives a sense of identity and belonging to its speakers, the collective feeling of Moroccanness @Caubet. People want Darija to escape its status as a dialect and develop it into something bigger. This work is an endorsement of this idea and an action toward its actualization.
~~ Darija through most of its history hasn't been written. In past times Moroccans, mostly intellectuals, used Classical Arabic for their writings. Nowadays, with the spread of digital media this is not the case anymore. Most Moroccans don't use Classical Arabic for what they write, while writing on their phones or computers. Given Darija doesn't have a native script, people use either the Latin or the Arabic script to write it. This is limiting in terms of expression and creative freedom. As an example the Arabic script doesn't have a standard representation of the sound "V" that exists in Darija. The Latin script may seem that it can fill the space the Arabic script can't, but it also has its shortcomings. The "ق" sound that exists in Darija, as well in Arabic, doesn't exist in the Latin script. As a result the users of the Language #footnote[Others prefer to label Darija as a dialect] use the digit "9" as a substitution for the missing sound. These two examples are not the only ones, but too many to mention.
== Purpose
~~ This paper aims to understand the public’s sentiment toward the current written forms of Darija, and the probability of using a completely new written system.
== Significance
- Lay foundation for further investigation on the written forms of Darija.
- Help concerned bodies test the feasibility of standardizing a written system.
== Questions
Given Darija is written using two forms, either with Latin or Arabic:
- Do Moroccans face problems with these current written forms?
- To what extent Moroccans are ready to adopt a completely new written system?
== Hypothesis
~~ Current written forms of Darija are problematic, Moroccans want a completely new written system for Darija.
== Structure of Study
~~ Our study is divided into seven sections to comprehensively explore Darija's current written forms. The first section, _Introduction_, provides essential background information on the issue and outlines the specific research questions and purpose that guides this investigation. Then, the second section, the _Literature Review_ section synthesizes relevant research on Darija, and identifying any gaps in knowledge that this study aims to address. Following that, the _Theoretical Framework_, presenting the grounds this research is built upon. The fourth section, _Methodology_, delves into the research design we employed. Here, we detail the method used for data collection and the data analysis technique chosen to examine the research questions. The fifth section, _Findings_, presents the research results in a concise manner. The sixth section, _Discussion_, interprets the meaning of these results. Finally, the seventh and concluding section, _Conclusion and Recommendation_, offers a summary of the key findings, along with a discussion of their broader implications. We will propose recommendation for future research endeavors that can build upon our findings.
\
= Literature Review
~~ Scholarly work previously done on Darija focus primarily on its vocabulary, grammar, and phonological characteristics.
== Vocabulary
~~ Most of Darija's lexicon is derived from classical Arabic @Duri. Tamazight #footnote[Or Berber, a term we do not prefer to use] also played an important role in the development of Darija's vocabulary @Chtatou @Sadiqi. As well French and Spanish during the colonial period in Morocco @Burke.
== Grammar and Phonology
~~ The similarity between Darija and Classical Arabic ends in vocabulary. It starts to deviate from Al-Fusha toward the Tamazight grammatical and phonological features @Rouchdy. The difference is appearing in the compression of vowels, a great divergence in its phonology, and unsimilar sentence structure (SVO #footnote[Subject-Verb-Object] as opposed to the VSO #footnote[Verb-Subject-Object] in Al-Fosha).
== Gap
~~ While these studies provide valuable insights to the researcher on Darija, they stand short in presenting a practical framework that benefits its development. The Moroccan variety is understudied in its written forms. Plus there has been no attempt to test it with a completely new written system. So it is our duty to do so, as in this paper.
\
= Theoretical Framework
== Standardization
~~ Language standardization, as in language policy and planing, is the process of elevating a language variety to a standard form @Haugen1966. Through a four stage process: _selection_ of the variety to elevate to a standard, _codification_ of its rules by creating documentations, dictionaries, and grammar books, _elaboration of function_ in various domains (i.e. education, media, administration, literature, etc.), and at last the _acceptance_ of the developed variety by the mass speech community it is designed for @Haugen1982. While this process my seem ideal and effortless to the recipient and happens naturally, it is not. It requires coordinated effort from various actors and involvement of multiple parties. Otherwise, the result is undesired to the speakers of the unstandardized variety as stated by @Crystal2000.
~~ Darija is unstandardized. And debates are rising, whether it is a language or a dialect. We argue it is a language. Because it has unique grammatical features and different phonology than the argued parent variety _Standard Arabic_. Moreover, while Darija seem to have a rich culture; it does not have a standard written system. Which puts it in an awkward position toward its standardization.
== A New Written System
~~ There are three types of written systems @Forrester. One, _logographic_, where full words or ideas are represented by a shape. Two, _syllabic_, where an individual item (letter or shape) represents a syllable. And three, _alphabetic_, where each letter represents a phoneme (sound). All contemporary written systems sits in one of these categories. In example, Chinese is logographic, the Vai script, used in Liberia, is syllabic, and Latin is alphabetic. Though, other written systems use more than one. As Japanese, which is composed of three scripts, two syllabic (Hiragana and Katakana), and one is logographic, the Kanji. All of these systems proved their correctness and usefulness in representing language in a written form, yet they vary in difficulty of learning. Logographic being the hardest and alphabetic the easiest @Forrester.
~~ Developing a new written system for Darija should be alphabetic, for easiness of learning and application. Also, it should consider the big effects that Classical Arabic has on Darija in its history and vocabulary; while not dismissing the need of visual uniqueness and reflection of the Moroccan identity, even though this is subjective, the pursuer of such a job should consider it. And most importantly, the written system should be sufficient for representing Darija correctly and completely; in contrast to the current non standard forms using the Latin and the Arabic scripts.
~~ This study proposes a new written system with consideration to these requirements. That is alphabetic, and contains 30 consonants and 6 vowels.
#figure(
image("assets/vowels.svg", width: 50%),
caption: "Vowels: 3 short + 3 long."
)
\
~~ There are only 3 vowels for simplicity. When a dark dot added they are lengthened.
\
#figure(
image("assets/alphabet.svg", width: 100%),
caption: "The full alphabet."
)
\
~~ The coding behind this alphabet is following the exact coding of the Arabic alphabet. Similar letters in Arabic are similar in this alphabet too. This makes it easy to learn and remember for the seeker familiar with the Arabic alphabet. In addition, it includes the missing sounds (or non standard ones) used by Darija and absent in Arabic.
~~ This was created to test to what extent Moroccans are ready to adopt a completely new written system, as in the 2nd research question. This alphabet is used for writing Darija mimicking a native script. An online keyboard and a quiz were made to test if the participants in this research will be able to read and write using it (more about this in the _Methodology_ Section).
\
= Methodology
== Research Approach and design
~~ This study followed a quantitative research approach. Due its offer of an objective, formal, and systematic process to test our hypothesis and describe why or why not Moroccans want a completely new written system.
~~ A descriptive survey was employed. This was chosen to examine the current levels of interest, attitudes, and perceptions among Moroccans, concerning Darija's current written forms. A structured questionnaire was used. Designed with close ended questions to assess respondents' interest and attitudes. The survey was distributed online to a sample of Moroccan residents to ensure broader and appropriate coverage. The data collected from this survey will provide comprehensive insights about the population's views on the current written forms of Darija, as well the new one. Helping in evaluating key factors influencing their interests.
== Research Setting, Population, and Sample
~~ This study was conducted in Morocco. Because, when speaking about Darija it is mainly concerned with the Morocco region in North Africa. The population of this study consisted of Moroccans, between the age of 5 and 70 years old, with the will to participate.
~~ A convenient sample of 63 people was selected. This sample included a diverse set of Moroccans with different ethnicities, ages, and language preferences. But, unified with the use of Darija in everyday interactions. Available participants were handed an online questionnaire to fill during a period of 7 days. Participants included in the sample were selected because they met this selection criteria. That they are Moroccan residents, between the age of 5 and 70, mentally sound, willing to participate, and of any sex or any race.
== Data Collection Instrument and Procedure
~~ A questionnaire was chosen to collect data. That will help evaluate Moroccans' attitudes and perceptions about the current written forms of Darija and the new written system we created. A questionnaire was used because it allows high response volumes, requires less energy and time to administer, anonymous, less biased, and easy to compare responses.
~~ Three questionnaires were used to collect the data. One in English, one in Arabic, and one in French. Because of Morocco's multilingual ground and to ensure broader participation. They were distributed and shared to participants, primarily in Moulay Ismail University in Meknes and on social media. Which upon finalizing of data collection, responses were combined and translated to English.
~~ The survey was composed of two sections #link(<appendix_one>)[[See Appendix I]]. Section 1 was concerned with the current written forms of Darija. After collecting the usual demographic data about participants, the questions were interested with the participants' views about using Arabic and Latin for writing Darija. Section 2 was concerned with the new written system: after finishing the first section the participants were asked if they wanted to try a new written system, to measure interest in such idea. Participants responded positively were taken to a fully guided introduction to the new written system. Then to a small quiz of 6 questions #link(<appendix_two>)[[See Appendix II]]. Presenting small Darija words for them to read or identity, using the full new alphabet reference included with the quiz #link(<appendix_three>)[[See Appendix III]]. After finishing the quiz participants were given their scores and an option to try a custom made keyboard of the new alphabet for writing freely in it #link(<appendix_four>)[[See Appendix IV]]. All of this was to help participants build attitudes and views about the new written system that they will tell us about in section 2 of the questionnaire.
== Reliability and Validity
~~ The questionnaires were distributed with very minimal interference. Also, they were online based, using Google Forms, so no direct interaction with the researcher was possible minimizing errors and biases. And through standardized conditions where similar personal attributes were exhibited to all the participants. The questionnaires were based on knowledge gathered during the literature review to ensure they were aligned with the current state of Moroccan society. The questions were in a simple language for ease of understanding. And clear guidance and instructions were included from start to finish.
~~ For validity, participants were required to include their emails. This was enforced by Google to avoid the same participant from filling the questionnaires more than once. However, to ensure anonymity of the participants and their privacy, their emails were turned into _hashes_ using the _sha-256_ algorithm. It turns input given to it into a hash that can't be reversed to its original content,#link(<appendix_five>)[[See Appendix V]]. So the same emails will result the same hash, indicating duplication of answers. This resulted in a valid and anonymous data set.
== Ethical Considerations
~~ To render this study ethical, the rights of anonymity, confidentiality, determination, and informed consent were assured.
~~ The consent of subjects was obtained before filling the questionnaire. The participants were informed of their rights to voluntarily consent or decline to participate, and withdraw and edit their response, at anytime during the week of data collection, without any penalty. They were also informed about the purpose of this study and the procedure that will be followed.
~~ Anonymity and confidentiality guidelines were followed throughout the course of the study. The participants cannot be linked, even by the researcher, with their responses. In this study anonymity was proven by not collecting participants names on the questionnaire and protecting their emails with industry standards to not be used for any purpose except for data validation.
== Data Analysis
~~ After the data was collected and organized it was analyzed. For analysis of closed-ended questions, a computer programme called Google Sheets was used. Data was analyzed and presented in pie diagrams and bar graphs.
== Conclusion
~~ We used a quantitative, descriptive survey design. Three questionnaires were handed in English, Arabic, and French to the participants. To collect the data from a convenient sample of 63 subjects. The questionnaires had close ended questions. The sample characteristics included Moroccans who were mentally sound and use Darija daily, and were willing to participate.
~~ Consent was obtained from the participants. Anonymity, self-determination and confidentiality were ensured during administration of the questionnaires and in report writing. Questionnaires were distributed to subjects online using Google Forms. Data collected for a period of 7 days. Then organized, translated, and transformed into diagrams and charts.
#pagebreak()
// SECTION: Findings
= Findings
~~ Data collected, presented with great details in #link(<appendix_six>)[[Appendix VI]], gave four key findings.
== First Finding
#figure(image("assets/charts/findings/1.svg", width: 70%), caption: "A pie chart showing the importance of Darija for Moroccans' identity.")
~~ This chart shows the result from the 3rd question of the questionnaire asking about the importance of Darija for the Moroccan identity. All participants think that Darija is somewhat important to very important for their identity. This was previously labeled by @Caubet as the sense of Moroccanness.
== Second Finding
#figure(image("assets/charts/findings/2.svg", width: 75%), caption: "A bar chart presenting why the current scripts are not suitable.")
~~ It shows the number of participants' choices of why the currently used scripts are not suitable for Darija. The majority of participants think the current scripts are not suitable because of the missing sounds, misrepresenting the Moroccan identity, and the differences in vocabulary. On the contrary, the rest thinks the current scripts are suitable for Darija. This shows that while it is thought that the current writing methods of Darija are enough, there are big issues with room for possible improvements.
== Third Finding
#figure(image("assets/charts/findings/3.svg", width: 67%), caption: "A bar chart showing the desired features of a new script if to be developed.")
~~ There is a substantial stress on that the new script should be complete for representing Darija; plus easy to learn and read, and reflects the Moroccan culture and identity. Also, it should be compatible with existing technologies. The new script we developed seems to meet the first desired feature #link(<res_18>)[[See Appendix VI: Result 18]]. Yet needs improvement on the other aspects of easiness and compatibility with existing technologies #link(<res_14>)[[See Appendix VI: Result 14]]
== Fourth Finding
#figure(image("assets/charts/findings/4.svg", width: 60%), caption: "A bar chart showing the comfort level in using the new script in comparison to the old ones.")
~~ The majority were uncomfortable using the new written system in comparison to using Arabic or Latin. A minority stated it was on similar comfort level. While the rest stated they were comfortable. Indicating lack of interest in using the script instead of the more developed and agreed upon Latin and Arabic scripts.
// SECTION: Discussion
= Discussion
~~ This study confirms that Darija gives a sense of identity to Moroccans, as was stated by @Caubet. Also the speakers face troubles with the incompleteness of the Latin and the Arabic scripts as a writing method for Darija. Due to the missing sounds and identity issues concerning the use of these scripts. The current written forms are thought to be enough and suitable for Darija, yet not perfect. Moreover, it was shown if a new writing system were to be developed preferably it should be complete for representing Darija, easy to learn and read, and reflects the Moroccan identity while being compatible with existing technologies. So any attempts of dealing with these issues should consider these demands and needs for a complete, and fulfilling form.
\
~~ While a significant portion of the participants expressed interest in trying the new writing system, the results regarding its comfort of use in comparison to other writing methods were negative. This might be attributed to limited exposure or a lack of practical everyday use. Nevertheless, the participants generally perceived the new system as a complete and suitable representation of Darija, highlighting the effectiveness of a well-designed and inherently comprehensive writing system.
\
~~ I hypothesized that the current written forms of Darija are problematic and Moroccans want a completely new written system. However, the results did not support this hypothesis. In fact, while the current written forms of Darija are not perfect they are thought to be enough. Moreover, Moroccans are not ready to adopt a completely new written system. This suggest that there may be other factors influencing interest in such an idea.
\
~~ *Key takeaway:* Developing a new writing system for Darija that gains widespread acceptance necessitates a comprehensive approach that addresses the identified needs and preferences. The script should be complete, user-friendly, reflective of Moroccan identity, and technologically compatible. Future efforts should build upon these findings to create a solution that resonates with the Moroccan people.
= Conclusion and Recommendation
~~ This study investigated Moroccans' interest in adopting a new written system for Darija. The findings reveal a complex interplay between identity, practicality, and potential change.
\
~~ The study confirms the strong connection between Darija and Moroccan identity, aligning with previous research by @Caubet. This reinforces the importance of a writing system that reflects this unique cultural element. Also, participants acknowledged the shortcomings of using Arabic and Latin scripts for Darija. These scripts struggle to represent all Darija sounds and lack a clear connection to Moroccan identity. While some participants felt current writing methods were sufficient, they expressed a desire for improvement. The ideal new script, as envisioned, should be comprehensive, user-friendly, and embody Moroccan identity while remaining technologically compatible. Our proposed script demonstrated success in comprehensively representing Darija, but further development is needed for ease of use and technological integration. But despite interest in trying it, user comfort fell short compared to established scripts like Arabic and Latin. Widespread adoption requires significant development efforts to create a solution that is not only functional but also resonates with the Moroccan public. The standardization process is complex, and handcrafted solutions often face limitations. Future endeavors should involve broader collaboration and address the identified needs for a complete and culturally fulfilling writing system.
\
~~ In conclusion, this study lays the groundwork for further exploration of a new writing system for Darija. By understanding the desires and challenges, future efforts can create a solution that fosters a sense of Moroccan identity while offering a practical and user-friendly writing method for Darija.
\ \
*Recommendation:* Moroccans are exposed to 3 different scripts (Arabic, Latin, and Tifinagh) introducing a new one is highly not recommended. And given that we have tested Latin and Arabic as writing methods for Darija, they are not ideal. We advise further investigation on using _Tifinagh_ as a method for writing Darija.
// SECTION: Bibliography
#pagebreak()
#bibliography("refs.bib")
// SECTION: Appendices
#set heading(numbering: none)
#pagebreak()
= Appendices
== Appendix I: The Questionnaire (English Version) <appendix_one>
#text(style: "oblique")[
\
#text(weight: "bold", size: 20pt)[Ways of Writing Darija]
This questionnaire is part of a research project.
We are very interested in understanding your thoughts and experiences. Your honest responses are crucial to this research and will be kept strictly confidential. They will only be used for research purposes and will not be linked to you in any way.
Thank you for your time and willingness to contribute.
\ \
#text(weight: "bold", size: 18pt)[Section 1]
#text(weight: "bold")[Gender]
- Male
- Female
\
#text(weight: "bold")[Age]
- 5-20
- 21-30
- 31-40
- 41-50
- 51-60
- 61-70
\
#text(weight: "bold")[How important Darija is to your Moroccan identity?]
- Not important at all
- Somewhat important
- Important
- Very important
\
#text(weight: "bold")[Do you believe Darija is a legitimate language?]
- Yes
- No
- Unsure
\
#text(weight: "bold")[How comfortable are you reading and writing Darija in Arabic?]
- Not comfortable at all
- Somewhat comfortable
- Comfortable
- Very comfortable
\
#text(weight: "bold")[Do you find writing using Arabic suitable for Darija?]
- Yes
- No
- Unsure
\
#text(weight: "bold")[Why you don't find Arabic suitable for writing Darija?]
- Missing sounds (like "g" and "v")
- Different vocabulary
- Hurts the Moroccan identity
- No, Arabic is suitable
- Other: ...
\
#text(weight: "bold")[How comfortable are you in reading and writing Darija in the Latin alphabet (ABCDEF...)?]
- Not comfortable at all
- Somewhat comfortable
- Comfortable
- Very comfortable
\
#text(weight: "bold")[Do you find writing using the Latin alphabet suitable for Darija?]
- Yes
- No
- Unsure
\
#text(weight: "bold")[Why you don't find the Latin alphabet suitable for writing Darija?]
- Missing sounds (like "ق", "ع", "خ", etc)
- Different vocabulary
- Hurts the Moroccan identity
- No, Latin is suitable for Darija
- Other: ...
\
#text(weight: "bold")[In your opinion, would adopting a new writing system for Darija be beneficial for Morocco?]
- Strongly disagree
- Disagree
- Neutral
- Agree
- Strongly agree
\
#text(weight: "bold")[If a new writing system for Darija were to be developed, what features would you consider important? (Select all that apply)]
- Easy to learn and read
- Phonetically accurate (compatible with all sounds of Darija)
- Reflects Moroccan culture and identity
- Compatible with existing technologies
- Other: ...
\
#text(weight: "bold")[We have developed one would you like trying it?]
- Yes
- No
\
#text(weight: "bold", size: 18pt)[Section 2: Trying the new writing system]
Please visit this #link("https://darija-quiz.vercel.app/")[new writing system demo] (https://darija-quiz.vercel.app/). Then comeback and tell us what you think about it.
\
#text(weight: "bold")[After trying the new alphabet for Darija, how easy did you find it to learn the basic characters?]
- Very easy
- Somewhat easy
- Neutral
- Somewhat difficult
- Very difficult
\
#text(weight: "bold")[Did the new alphabet seem intuitive in representing the sounds of Darija:]
- Yes
- No
- Unsure
\
#text(weight: "bold")[Were you able to read simple Darija words using the new alphabet?]
- Yes, with ease
- Yes, with some effort
- No, but I think I could learn with practice
- No, and I don't think it would be easy to learn
\
#text(weight: "bold")[Compared to the Latin and Arabic scripts, how comfortable do you feel using this new alphabet for Darija?]
- Much more comfortable
- Somewhat more comfortable
- Similar comfort level
- Somewhat less comfortable
- Much less comfortable
\
#text(weight: "bold")[What are some of the strengths you see in this new alphabet for writing Darija? [Multiselect]]
- Easy to learn and read
- Represents Darija sounds accurately
- Seems clear and visually distinct
- Feels appropriate for Moroccan culture
- Works well with existing technologies (computers, displays)
- Other: ...
\
#text(weight: "bold")[Do you have any suggestions for improvement for this new alphabet]
- ...
\
]
#pagebreak()
== Appendix II: The Quiz Tool <appendix_two>
~~ The quiz tool is a web site. It contains an interactive introduction to the alphabet. Plus a simple 6 questions quiz. It is available at https://darija-quiz.vercel.app, as of 2024. Contact us if the site is not available in the future.
#figure(
image("assets/appendix/alph_intro.jpeg", width: 70%),
caption: "A screenshot of the 2nd step of the alphabet introduction."
)
\ \ \
The introduction is used to familiarize the participants with the completely new written system.
#figure(
image("assets/appendix/quiz_ques.jpeg", width: 70%),
caption: "A screenshot of a question from the quiz."
)
This quiz will help the participants test if they can read basic words in this new alphabet.
#pagebreak()
== Appendix III: The Quiz Alphabet Reference <appendix_three>
Reading words in a completely new and unfamiliar written system is very hard. This why the quiz included a reference to the alphabet used for writing the words. Making it easier for the participants to identity them.
#figure(
image("assets/appendix/quiz_alph_ref.jpeg", width: 70%),
caption: "A screenshot of the alphabet reference from the quiz."
)
#pagebreak()
== Appendix IV: The Custom Keyboard <appendix_four>
Text support may seem straightforward and easy to integrate on digital devices, it is not. It requires multiple bodies working together to implement and standardize. Then at the end brought to computers and digital devices. This is of course beyond the power of one person. So we had to come up with a solution for participants to try writing using the new alphabet. The solution was this custom keyboard, available at https://darija-demo.vercel.app, as of 2024.
#figure(
image("assets/appendix/keyboard.jpeg", width: 70%),
caption: "A screenshot of the alphabet's custom keyboard."
)
#pagebreak()
== Appendix V: Hashing and SHA-256 <appendix_five>
Explained with great details at https://en.wikipedia.org/wiki/sha-2
#pagebreak()
== Appendix VI: Data Collected <appendix_six>
~~ Each questionnaire entry resulted in a result.
== Result One
#figure(image("assets/charts/1-Gender.svg", width: 90%), caption: "Participants's gender.")
~~ Participants' gender was symmetric. Roughly, half females, and half males.
== Result Two
#figure(image("assets/charts/2-Age.svg", width: 90%), caption: "A pie chart showing participants' age.")
~~ Most of respondents age between 21 and 30 years old. Followed by a modest amount less than 20 years old. And a small fraction between 31 and 40. And none aged 41 or more.
== Result Three
#figure(image("assets/charts/3.svg", width: 88%), caption: "A pie chart showing Darija importance for Moroccans' identity.")
~~ The majority considers Darija is very important to their Moroccan identity. A notable portion of participants considers it important to somewhat important. While no one indicated it is not important for their Moroccanness.
== Result Four
#figure(image("assets/charts/4.svg", width: 88%), caption: "A pie chart presenting Moroccans's conception of Darija.")
~~ Almost half of respondents think Darija is a language. A modest minority is unsure. The rest thinks Darija is not a language.
== Result Five
#figure(image("assets/charts/5.svg", width: 90%), caption: "A pie chart presenting Moroccans's comfort in writing Darija in Arabic.")
~~ The majority feels somewhat comfortable, comfortable, to very comfortable in writing Darija using Arabic. While a small minority is not comfortable at all.
== Result Six
#figure(image("assets/charts/6.svg", width: 90%), caption: "A pie chart showing if Moroccans think Arabic is suitable for Darija.")
~~ A third thinks Arabic is suitable for Darija. The second third thinks it is not. While a third is unsure.
== Result Seven
#figure(image("assets/charts/7.svg", width: 85%), caption: "A pie chart showing why Arabic isn't suitable for Darija.")
~~ A third thinks Arabic is suitable for Darija as presented in the previous result. The second third thinks it is not suitable for Darija because of the missing sounds. A minority also thinks it is not suitable because of the different vocabulary. And some others also thinks it hurts the Moroccan identity.
== Result Eight
#figure(image("assets/charts/8.svg", width: 85%), caption: "A pie chart presenting Moroccans's comfort in writing Darija in Latin.")
~~ The majority stated they are somewhat comfortable, to very comfortable in using Latin for writing Darija. While only a minority are not comfortable at all.
== Result Nine
#figure(image("assets/charts/9.svg", width: 90%), caption: "A pie chart showing if Moroccans think Latin is suitable for Darija.")
~~ Almost half thinks Latin is suitable for Darija. A third thinks it is not. The rest is unsure.
== Result Ten
#figure(image("assets/charts/10.svg", width: 90%), caption: "A pie chart showing why Latin isn't suitable for Darija.")
~~ A significant portion thinks Latin is suitable, same as in the previous result. But, almost a half thinks Latin is not suitable for Darija because it has missing sounds. And a minority thinks it is not suitable because it hurts the Moroccan identity.
== Result Eleven
#figure(image("assets/charts/11.svg", width: 74%), caption: "A pie chart showing opinion about the benefit of Morocco from the adoption of a new written system.")
~~ The biggest third are neutral. The second biggest third agree with the statement that Morocco would benefit from adopting a new written system for Darija. The rest disagree to strongly disagree with this statement.
== Result Twelve
#figure(image("assets/charts/12.svg", width: 85%), caption: "A bar chart showing the features of a new written system if to be developed.")
~~ A large portion wants the new system to be phonetically accurate, easy to learn and read, and reflects the Moroccan identity. And also compatible with existing technologies, but not stressed on the same as the aforementioned features.
== Result Thirteen
#figure(image("assets/charts/13.svg", width: 90%), caption: "A pie chart showing the interest in trying a new written system.")
~~ The majority showed interest in trying the new written system. But, only a minority did not.
== Result Fourteen <res_14>
#figure(image("assets/charts/14.svg", width: 100%), caption: "A pie chart about how the participants found the new written system.")
~~ Opinions were not so apparent. But the first biggest portion found it somewhat easy to very easy. While the second largest portion found somewhat difficult to very difficult. The rest were neutral.
== Result Fifteen
#figure(image("assets/charts/15.svg", width: 95%), caption: "A pie chart representing if the new written system was intuitive, according to participants.")
~~ Half said the new written system was intuitive. A quarter were unsure. The rest quarter said the new written system was not intuitive.
== Result Sixteen
#figure(image("assets/charts/16.svg", width: 90%), caption: "A pie chart showing participants ability to read in the new written system.")
~~ The majority were able to read words using the new written system. A third were not, but mentioned they could learn with practice.
== Result Seventeen
#figure(image("assets/charts/17.svg", width: 90%), caption: "A pie chart showing participants comfort using the new written system compared to the old ones.")
~~ The majority were uncomfortable using the new written system in comparison to using Arabic or Latin. A minority stated it was on similar comfort. While the rest stated they were comfortable.
== Result Eighteen <res_18>
#figure(image("assets/charts/18.svg", width: 90%), caption: "A bar chart showing the features of the new written system, according to participants.")
~~ The majority of choices were that the new written system represents Darija sounds accurately, and that it seems clear and visually distinct. Followed by choices on that it feels appropriate for the Moroccan culture, and easy to learn and read. The least of choices were on that it works well with existing technologies.
|
|
https://github.com/linhduongtuan/DTU-typst-presentation
|
https://raw.githubusercontent.com/linhduongtuan/DTU-typst-presentation/main/example.typ
|
typst
|
#import "dtu.typ": *
#import "slides.typ": *
#import "th_bipartite.typ": *
#import "latex_symbol.typ": *
#import "slide_footnotes.typ": *
//#set heading(numbering: "1.1.1.")
#show link: set text(blue)
// Show Latex like LaTeX logo
#show "La!!TeX": [La]+[!TeX]
#show "La!TeX": [#h(-0.2em)#latex-symbol#h(-0.3em)]
#set text(
font: "New Computer Modern Sans", lang: "vi"
)
#show: slides.with(
authors: "", //better not type your name here.
short-authors: "Dương",
title: "WHY WE SHOULD USE TYPST AS ALTERNATION OF La!TeX FOR TYPSETTING",
subtitle: "CÓ PHẢI La!TeX ĐÃ LỖI THỜI HAY?",
short-title: "CHATGPT ASSISTS YOUR WRITTING",
date: "June 10 2023",
theme: dtu-theme(mail: "Contact me via: <EMAIL>",
college: "DUY TAN UNIVERSITY - ĐÀ NẴNG - VIET NAM",
usage: "DƯƠNG TUẤN LINH",
color: rgb("#0080FE"), // fill a color of header and footer
),
)
#let task(description, solution) = [
#slide[
#counter("main_task_counter").step()
#text(size: 1.25em, strong([Câu hỏi ]+locate(loc => counter("main_task_counter").at(loc).first())))
#par(justify: true, description)
]
#slide[
#text(size: 1.25em, strong([Cách thực hiện ]+locate(loc => counter("main_task_counter").at(loc).first())))
#solution]
]
#slide(theme-variant: "title slide")[
// you can write some text here
Supervisor: <NAME> \
Student: DƯƠNG <NAME>
]
// TODO: need to improve this TOC
/*
#slide[
#outline(depth:1)
]
*/
#align(center)[
#new-section(
text(size:36pt, "BÀI GIẢNG NÀY GỒM 2 PHẦN:
PHẦN 1. TẠI SAO NÊN DÙNG TYPST
PHẦN 2. MỘT SỐ HƯỚNG DẪN CƠ BẢN CHO THƯ VIỆN SOẠN THẢO SLIDE
")
)
]
#align(center)[
#new-section(
text(size:40pt, "PHẦN 1. TẠI SAO NÊN DÙNG TYPST")
)
]
#slide(title: "LƯỢC SỬ PHÁT TRIỂN TeX?")[
//#align(center)[
- Ai đã từng sử dụng LaTeX? → Bạn sẽ thấy mình may mắn
- Ai có viết các API? → Làm cho nó dễ dàng hơn
]
#align(center)[
#new-section(
text(size:50pt, "Một số vấn đề với La!TeX")
)
]
#slide(title: "Cha để của La!TeX là ai????")[
#align(center)[
#image("images/donald_e_knuth.png", height: 35%)
<NAME>. Knuth#slide-footnote("Foto: Brian Flaherty / The New York Times") #text(size: 0.75em, "(born. 10. Jan. 1938)")
]
- Tác giả của TeX và METAFONT, phát triển từ 1977.
- Tác phẩm nổi tiếng nhất bên cạnh TeX: The Art of Computer Programming
- Đặc biệt phát triển TeX cho cuốn sách của anh ấy vì anh ấy có những yêu cầu thẩm mỹ đặc biệt mà các nhà xuất bản không đáp ứng được
]
#slide(title: "Tiếp theo có những ai đóng góp vào sự phát triển của La!TeX?????")[
#align(center)[
#image("images/leslie_lamport.png", height: 35%)
Leslie Lamport#slide-footnote("Foto: <NAME> / Quanta Magazine")
#text(size: 0.75em, "(born 7. Feb. 1941)")
]
- Tác giả của LaTeX, phát triển từ đầu những năm 1980
- LaTeX là tập hợp các macro để mở rộng và đơn giản hóa TeX
]
#slide(title: "NHỮNG VẤN ĐỀ TỒN ĐỌNG CỦA La!TeX")[
+ Kích thước chương trình lớn
+ Lựa chọn trình biên dịch
+ Lỗi khó hiểu
]
#slide(title: "Kích thước của chương trình lớn?")[
#align(center)[
#image("images/installation_size_latex.png", width: 30%)
#v(-0.5em)
So với `21MB` của trình biên dịch của Typst...
#v(-0.5em)
#image("images/installation_size_typst.png", width: 30%)
]
- Kích thước cài đặt có thể thay đổi rất nhiều, 300MB..7GB, tuỳ vào các thư viện như TexStudio với texlive hay MiKTex,...
- vô cùng nhiều gói (đây vừa là thuận lợi nhưng cũng là khó khăn)
]
#slide(title: "Sự đa dạng của chương trình TeX")[
"La!TeX" không phải là một chương trình duy nhất mà còn:
- pdfLaTeX
- LuaTeX
- XeTeX
- MikTeX
- KaTeX
- ...
]
#slide(title: "Thông báo lỗi của Typst, một số ví dụ điển hình")[
#columns(2, [
Typst:
```typst
$a+b
```
#colbreak()
#set text(size: 16pt)
```
error: expected dollar sign
┌─ test.typ:1:5
│
1 │ $a+b
│ ^
```
])
]
#slide(title: "Thông báo lỗi của La!TeX")[
#columns(2, [
#v(2em)
La!TeX:
#set text(size: 22pt)
```tex
\documentclass{article}
\begin{document}
$a+b
\end{document}
```
#colbreak()
#set text(size: 7pt)
#raw(read("latex_error.log"))
])
]
#slide(title: "So sánh thông báo lỗi giữa Typst và La!TeX")[
#set text(size: 18pt)
#align(center)[
#table(columns: (auto, auto),
inset: 0.5em,
[Typst], [La!TeX],
```typ
#set par(leading: [Hello])
^^^^^^^
expected integer, found content
```,
```latex
\baselineskip=Hello
Missing number, treated as zero.
Illegal unit of measure (pt inserted).
```,
```typ
#heading()
^^
missing argument: body
```,
```latex
\section
Missing \endcsname inserted.
Missing \endcsname inserted.
...
```,
)
#set text(size: 12pt)
(Nguồn: Mädje, Laurenz: #emph["Typst -- A Programmable Markup Language for Typesetting."] Luận văn thạc sĩ Đại học Kĩ thuật Berlin (Technische Universität, 2022.))
]
]
#align(center)[
#new-section(
text(size:50pt,"Giải pháp cho vấn đề này là Typst")
)
]
#slide(title: "Typst")[
#align(center, block(width: 60%)[
#set text(size: 0.65em)
#grid(columns: (auto, auto),
gutter: 1em,
[ #image(height: 40%, width: auto, "images/martin_haug.png")
<NAME>\
(Người phát triển ứng dụng nền web)
],
[ #image(height: 40%, width: auto, "images/laurenz_maedje.png")
<NAME>\
(Người phát triển trình biên dịch)
])
#set text(size: 0.75em)
#link("https://typst.app/about/"), (Cập nhật lần gần nhất: 26.05.2023, 10:16)
])
#align(horizon)[#block(align(top)[
- Năm 2019, dự án được bắt đầu tại Technische Universität Berlin
- Lí do chính là sự thất vọng khi sử dụng La!TeX
])]
]
#slide(title: "Mục Đích của việc phát triển Typst")[
_"Während bestehende Lösungen langsam, schwer zu bedienen oder einschränkend sind, ist Typst sorgfältig entworfen, um leicht erlernbar, flexibel und schnell zu sein. Dafür haben wir eine komplett eigene Markupsprache und Textsatzengine von Grund auf entwickelt. Dadurch sind wir in allen Bereichen des Schreib- und Textsatzprozesses innovationsfähig."_
+ Tạm dịch:
// _"Mặc dù các giải pháp hiện tại chậm, khó sử dụng hoặc hạn chế, nhưng Typst được thiết kế cẩn thận để dễ học, linh hoạt và nhanh chóng. Chúng tôi đã xây dựng một ngôn ngữ đánh dấu và công cụ sắp chữ hoàn toàn độc quyền ngay từ đầu. Quá trình viết và sắp chữ đổi mới sáng tạo. "_
_"Trong khi các giải pháp hiện có chậm chạp, khó sử dụng hoặc có hạn chế, Typst đã được thiết kế cẩn thận để dễ học, linh hoạt và nhanh chóng. Để làm được điều đó, chúng tôi đã phát triển một ngôn ngữ đánh dấu và hệ thống xuất bản văn bản hoàn toàn riêng từ đầu. Điều này giúp chúng tôi có khả năng đổi mới trong tất cả các khía cạnh của quá trình viết và xuất bản văn bản."_
#set text(size: 0.5em)
#link("https://www.tu.berlin/entrepreneurship/startup-support/unsere-startups/container-profile/startups-2023-typst"), (Truy cập lần gần nhất: 03.05.2023, 10:13)
]
#slide(title: "So sánh một chút giữa Typst và La!TeX")[
#set text(size: 20pt)
#align(horizon, table(columns: (auto, auto, auto),
inset: 1em,
stroke: none,
[La!TeX], [Typst], [Kết quả],
align(top, ```latex
\documentclass{article}
\begin{document}
\begin{enumerate}
\item Dies
\item Ist
\item Eine
\item Liste!
\end{enumerate}
\end{document}
```),
align(top, ```typst
+ Cái này
+ Là
+ một
+ danh sách!
```), align(top)[
+ Cái này
+ Là
+ một
+ danh sách!
]))
]
#align(center)[
#new-section(text(size:50pt, "Ứng dụng Web-App")
)
]
#slide(title: "Nào chúng ta cùng tiến lên!")[
#set text(size: 20pt)
*Thuận lợi:*
- Tất cả các tập tin trực tuyến
- Các dự án khác nhau có thể được tạo ra
- Trình soạn thảo trực tuyến tốt
- Làm việc trên các tệp theo nhóm cùng một lúc
- Tài liệu tích hợp
#link("https://typst.app/")
Tài khoản tạm thời (với $1 <= #[`N`] <= 15$):
- E-Mail: `<EMAIL>`
- Passwort: `<PASSWORD>`
Đường dẫn tới: #link("https://github.com/linhduongtuan/DTU-typst-presentations")
- Mở trình duyệt và trang web
- Tạo tài khoản của riêng bạn
]
#align(center)[
#new-section(text(size:50pt, "Định dạng trang cơ bản")
)
]
#slide(title: "Định dạng trang cơ bản")[
- Tiêu đề
- Đậm, nghiêng
- danh sách
- Những bức ảnh
- Đặt và hiển thị các quy tắc
- Thay đổi kích thước phông chữ và màu sắc
- Căn chỉnh văn bản
- Viết công thức Toán học (tài liệu có ký hiệu)
]
#slide(title: "Heading level")[#{
let code = ```
= Heading 1!
== Heading 2!
=== Heading 3!
Text ~ Câu chữ
Đoạn văn mới!
```
table(stroke: none,
columns: (1fr, auto),
align(top, text(size: 20pt, raw(lang: "typst", code.text))), align(top)[
#strong[
#text(size: 36pt, [1. Heading 1!])
#text(size: 30pt, [1.1. Đầu mục 2!])
#text(size: 24pt, [1.1.1. Đầu mục 3!])
]
Text
Đoạn văn mới!
])
}]
#slide(title: "Đoạn văn")[#{
let code = ```
= Tiêu đề thú của tôi
Một đoạn mới bắt đầu trong Typst ngay khi có một dòng trống trong mã.
Thật không may, theo mặc định, các đoạn văn được căn trái, không được căn đều. Chúng ta sắp học cách thay đổi điều đó!
```
// Điều chỉnh khoảng cách giữa các đoạn một chút để bạn có thể
// nhưng vì vậy nó không giống như một dòng trống
set block(spacing: 0.75em)
table(stroke: none,
columns: (50%, 50%),
align(top, text(size: 20pt, raw(lang: "typst", code.text))),
align(top)[
#strong(text(size: 28pt, [\1. <NAME>uj]))
#set text(size: 20pt)
- Một đoạn mới bắt đầu trong Typst ngay khi có một dòng trống trong mã.
- Thật không may, theo mặc định, các đoạn văn được căn trái, không được căn đều. Chúng ta sắp học cách thay đổi điều đó!
])
}]
#slide(title: "Chú ý")[#{
let code = ```
+ Một danh sách được đánh số
+ Có thể rất đẹp!
1. Đó là cách cô ấy đi!
2. Vâng!
- Và ở đây không đánh số!
- Không có bất kỳ con số nào!
```
table(stroke: none,
columns: (1fr, auto),
align(top, text(size: 20pt, raw(lang: "typst", code.text))),
align(top, text(size: 20pt, eval("["+code.text+"]"))))
}]
#slide(title: "Kiểu font chữ")[#{
let code = ```
#text(font: "Arial", [Xin chào!])
#text(font: "Courier New", [Xin chào!])
#text(font: "New Computer Modern", [Xin chào!])
```
table(stroke: none,
columns: (1fr, auto),
align(top, text(size: 20pt, raw(lang: "typst", code.text))),
align(top, text(size: 20pt, eval("["+code.text+"]"))))
}]
#slide(title: "Nội dung, chuỗi, tập lệnh")[
#set text(size: 16pt)
- Có hai loại nội dung trong Typst:
- Nội dung trong `[...]`
- Tập lệnh trong `{...}`
- từ nội dung đến tập lệnh với `#`
- Mọi tài liệu về cơ bản là nội dung
#v(1em)
#table(columns: (50%, 50%),
stroke: none,
```typ
#strong([Đây là nội dung trong tập lệnh!])
#{
strong([In đậm!])
[Một lần nữa, đây là nội dung trong tập lệnh!]
}
#{ 3/4 }
```, align(top)[
#strong([Đây là nội dung.])
#{
strong([In đậm!])
[Một lần nữa, đây là nội dung trong tập lệnh!]
}
#{ 3/4 }
])
]
#slide(title: "Định dạng font chữ" + slide-footnote(link("https://typst.app/docs/reference/syntax/")))[#{
let code = ```
*Xin chào!* #strong([Xin chào!])
_Xin chào!_ #emph([Xin chào!])
Xin chào!#super([Xin chào!])
Xin chào!#sub([Xin chào!])
#text(fill: red, [Xin chào chữ màu đỏ!])
#text(fill: rgb("#ff00ff"), [Xin chào chữ màu hồng!])
#text(fill: rgb("#ff00ff"), strong([Xin chào chữ màu hồng!]))
```
table(stroke: none,
columns: (1fr, auto),
align(top, text(size: 20pt, raw(lang: "typst", code.text))),
align(top, text(size: 20pt, eval("["+code.text+"]"))))
}]
#slide(title: "Định dạng vị trí chữ")[#{
let code = ```
#align(left, [Xin chào!])
#align(center, [Xin chào!])
#align(right, [Xin chào!])
#align(right, strong([Xin chào!]))
```
table(stroke: none,
columns: (60%, 1fr),
align(top, text(size: 20pt, raw(lang: "typst", code.text))),
align(top, text(size: 20pt, eval("["+code.text+"]"))))
}]
#task[Làm thế nào để bạn thực hiện những điều sau đây trong Typst?
#block(stroke: black,
inset: 1em, [
#align(center, emph[Trích đoạn từ ngẫu nhiên với lorem])
#lorem(20)
])
][
```typ
#align(center, emph[Trích đoạn từ ngẫu nhiên với lorem])
#lorem(20)
```
]
#slide(title: "Thiết lập khoảng cách #1")[#{
let code = ```
#align(right, [Chiều ngang])
#v(2cm)
Khoảng cách #h(2cm) theo chiều ngang
```
table(stroke: none,
columns: (1fr, auto),
align(top, text(size: 18pt, raw(lang: "typst", code.text))),
align(top, text(size: 18pt, eval("["+code.text+"]"))))
}]
#slide(title: "Thiết lập khoảng cách (Dọc)")[#{
let code = ```
Liệt kê ví dụ từ slide 21 với khoảng cách dọc.
+ Một danh sách được đánh số
+ Có thể rất đẹp!
#v(2em)
1. Đó là cách cô ấy đi!
2. Vâng!
#v(2em)
- Và ở đây không đánh số!
- Không có bất kỳ con số nào!
```
table(stroke: none,
columns: (50%, 50%),
align(top, text(size: 18pt, raw(lang: "typst", code.text))),
align(top, text(size: 18pt, eval("["+code.text+"]"))))
}]
#slide(title: "Thiết lập khoảng cách (Ngang)")[#{
let code = ```
+ Mọi đức tính hoàn hảo đều thuộc về Đức Chúa Trời vì bản chất hoàn hảo của ngài.
+ Tồn tại hoàn hảo hơn là không tồn tại.
+ Vì vậy sự tồn tại là một tài sản hoàn hảo.
+ Vậy là có Chúa. #h(1fr) QED
```
table(stroke: none,
columns: (auto),
align(top, text(size: 18pt, raw(lang: "typst", code.text))),
v(1em),
align(top, text(size: 18pt, eval("["+code.text+"]"))))
}]
#slide(title: "Với ảnh")[#{
let code = ```
#image(height: 50%, "leslie_lamport.png")
```
table(stroke: none,
columns: (auto),
align(top, text(size: 20pt, raw(lang: "typst", code.text))),
align(top + center, v(1em) + image(width: 50%, "images/leslie_lamport.png")))
}]
#slide(title: [`#block()` và `#box()`])[#{
let code = ```
Điều này có thể được thực hiện với `#block`: #block(stroke: black, inset: 0.5em, [ `#block()` tạo một dòng mới và có thể được ngắt giữa các trang. Nó có nhiều đối số tùy chọn.])
Đó là cách nó trông ra sao.
```
table(stroke: none,
columns: (auto, auto),
align(top, text(size: 18pt, raw(lang: "typst", code.text))),
align(top, text(size: 18pt, eval("["+code.text+"]"))))
}]
#slide(title: [`#block()` và `#box()`])[#{
let code = ```
Mặt khác: #box(stroke: black, inset: 2pt, [`#box()`]) tạo ngắt dòng #box(stroke: (bottom: black), inset: 2pt, [không]) và cho phép #box(stroke: (bottom: black), inset: 2pt, [không]) ngắt giữa các trang. Nhưng bạn có thể sử dụng nó để đóng khung mọi thứ chẳng hạn. Để gạch chân, bạn nên sử dụng #underline[`#underline`] thay thế.
```
table(stroke: none,
columns: (auto, auto),
align(top, text(size: 18pt, raw(lang: "typst", code.text))),
align(top, text(size: 18pt, eval("["+code.text+"]"))))
}]
#slide(title: "Bảng")[#{
let code = ```
#table(
columns: (auto, 3cm, auto),
[Xin chào A!],
[2a],
[Xin chào B!],
[Thiên đàng!],
[2b],
[Địa ngục!]
)
```
table(stroke: none,
columns: (1fr, auto),
align(top, text(size: 18pt, raw(lang: "typst", code.text))),
align(top, text(size: 18pt, eval("["+code.text+"]"))))
}]
#slide(title: "Công thức toán")[#{
let code = ```
$ sum_(k=0)^n k = 1 + ... + n $
$ A = pi r^2 $
$ "area" = pi dot.op "radius"^2 $
$ cal(A) :=
{ x in RR | x "is natural" } $
$ frac(a^2, 2) $
```
table(stroke: none,
columns: (60%, 40%),
align(top, text(size: 18pt, raw(lang: "typst", code.text))),
align(top, text(size: 18pt, [
#set text(font: "New Computer Modern Math")
#eval("["+code.text+"]")
])))
}]
#task[Làm thế nào để bạn thực hiện những điều sau đây trong typst?
#table(columns: (auto, auto),
strong[Công thức], strong[Cho là],
$a^2 + b^2 = c^2$, [Định lý Pythagoras],
$c <= a + b$, [Không xác định])
][
```typ
#table(columns: (auto, auto),
strong[Công thức], strong[Cho là],
$a^2 + b^2 = c^2$, [Định lý Pythagoras],
$c <= a + b$, [Không xác định])
```
]
#slide(title: "Thiết lập quy tắc" + slide-footnote(link("https://typst.app/docs/reference/styling/")))[#{
let code = ```
Đây là phông chữ mặc định! Q
#set text(font: "New Computer Modern", fill: blue)
Q Từ bây giờ mọi thứ hoàn toàn ở phông chữ khác và thậm chí cả màu xanh lam!
#set par(first-line-indent: 1.5em, justify: true)
Từ bây giờ, mọi dòng đầu tiên của đoạn văn sẽ được thụt vào và căn đều!
Thực sự, tôi chắc chắn! #lorem(20)
```
table(stroke: none,
columns: (1fr, 1fr),
align(top, text(size: 18pt, raw(lang: "typst", code.text))),
align(top, text(size: 18pt, eval("["+code.text+"]"))))
}]
#slide(title: "Thiết lập quy tắc" + slide-footnote(link("https://typst.app/docs/reference/styling/")))[#{
let code = ```
#show heading: set text(red)
=== Xin chào!
==== Thiên đàng!
// Từ trang giới thiệu
// cách sử dụng chính thức của Typst
#show "Project": smallcaps
#show "badly": "great"
*We started Project in 2019
and are still working on it.
Project is progressing badly.*
(_Chúng tôi bắt đầu Dự án vào năm 2019
và vẫn đang làm việc trên nó.
Dự án đang tiến triển không mấy khả quan._)
```
table(stroke: none,
columns: (60%, auto),
align(top, text(size: 20pt, raw(lang: "typst", code.text))),
align(top, text(size: 20pt, eval("["+code.text+"]"))))
}]
#task[Làm thế nào để bạn thực hiện những điều sau đây trong Typst? Lưu ý: Quy tắc `show` không áp dụng cho `#lorem()`.
#block(inset: 1em, stroke: black, [
#set par(justify: true)
#show "Typst": strong
Trong typst hiển thị và thiết lập quy tắc là rất mạnh mẽ. Bạn có thể, bạn có thể gõ. Typst phải luôn được in đậm. Đoạn văn có lý. _Lặp lại một chút: Làm thế nào để bạn tạo lại một cái gì đó in nghiêng trong Typst?_
])
][
```typ
#set par(justify: true)
#show "Typst": strong
Trong typst hiển thị và thiết lập quy tắc là rất mạnh mẽ. Bạn có thể, bạn có thể gõ. Typst phải luôn được in đậm. Đoạn văn có lý. _Lặp lại một chút: Làm thế nào để bạn tạo lại một cái gì đó in nghiêng trong Typst?_
```
]
#slide[
#table(columns: (50%, 50%),
stroke: none,
inset: 1em, [
#set text(size: 12pt)
#align(left, raw(lang: "latex", read("Beispiele/MatheDeltaEpsilon/edk_latex.tex")))
], align(top)[
#set text(size: 12pt)
#align(left, raw(lang: "typst", read("Beispiele/MatheDeltaEpsilon/edk_typst.typ")))
])
]
#slide[
#align(center, [
#image(width: 90%, "Beispiele/MatheDeltaEpsilon/edk_latex.svg")
#image(width: 90%, "Beispiele/MatheDeltaEpsilon/edk_typst.svg")
])
]
#new-section("Tài liệu tham khảo chính thức của Typst...")
#slide[
- #link("https://typst.app/docs") như một công việc tham khảo
- Tài liệu rất quan trọng!
]
#slide(title: [Ví dụ về tài liệu tham khảo: Hàm `image`])[#{
[`image` có thể có nhiều chức năng hơn bạn nghĩ!]
let code = ```
#image("leslie_lamport.png")
```
table(stroke: none,
columns: (auto),
align(top, text(size: 20pt, raw(lang: "typst", code.text))),
align(top + center, v(1em) + [
#image("images/leslie_lamport.png")
]))
}]
#slide(title: [Ví dụ về tài liệu tham khảo: Hàm `image`])[#{
[`image` có thể có nhiều chức năng hơn bạn nghĩ!]
let code = ```
#image(height: 50%, "leslie_lamport.png")
```
table(stroke: none,
columns: (auto),
align(top, text(size: 20pt, raw(lang: "typst", code.text))),
align(top + center, v(1em) + [
#image(height: 50%, "images/leslie_lamport.png")
]))
}]
#slide(title: [Ví dụ về tài liệu tham khảo: Hàm `image`])[#{
// Làm thế nào để tôi có được tất cả thông tin này bây giờ,
// hình ảnh với mọi thứ có thể? -> tham khảo Tài liệu hướng dẫn!
[`image` có thể có nhiều chức năng hơn bạn nghĩ!]
let code = ```
#image(fit: "stretch", width: 100%, height: 100%, "leslie_lamport.png")
```
table(stroke: none,
columns: (auto),
align(top, text(size: 20pt, raw(lang: "typst", code.text))),
align(top + center, v(1em) + block(height: 50%, width: 100%, [
#image(fit: "stretch", width: 100%, height: 100%, "images/leslie_lamport.png")
])))
}]
#slide[#image("images/doku_image_1.png", fit: "contain")]
#slide[#image("images/doku_image_2.png", fit: "contain")]
#slide[#image("images/doku_image_3.png", fit: "contain")]
#slide[#image("images/doku_image_4.png", fit: "contain")]
#slide[#image("images/doku_image_5.png", fit: "contain")]
#slide[
Ví dụ `#enum()`:
#image("images/doku_image_6.png", fit: "contain")
]
#slide[
Ví dụ `#enum()`:
#image("images/doku_image_7.png", height: 80%)
]
#task[Tham số nào có thể được sửa đổi theo quy tắc `set` để định dạng danh sách liệt kê (`#enum()`) như sau? tài liệu!
#block(inset: 1em, width: 100%, stroke: black, [
#set enum(numbering: "I.")
+ Tài liệu tham khảo số 1
+ Tài liệu tham khảo số 2
+ Tài liệu tham khảo số 3
])
][
```typ
#set enum(numbering: "I.")
+ Tài liệu tham khảo số 1
+ Tài liệu tham khảo số 2
+ Tài liệu tham khảo số 3
```
]
#task[Tham số nào có thể được sửa đổi theo quy tắc `set` để định dạng một danh sách không được đánh số như thế này? Hãy đọc tài liệu tham khảo tài liệu!
#block(inset: 1em, width: 100%, stroke: black, [
#set list(marker: ">")
- Tài liệu tham khảo số 1
- Tài liệu tham khảo số 2
- Tài liệu tham khảo số 3
])
][
```typ
#set list(marker: ">")
- Tài liệu tham khảo số 1
- Tài liệu tham khảo số 2
- Tài liệu tham khảo số 3
```
]
#new-section("Cách tạo mẫu và tập lệnh trong Typst")
//- Chỉnh sửa trang, kích thước trang, header, footer,...
//- Tập lệnh (chú ý: đây là chức năng thuần túy!)
//Không liên quan, bạn có thể tra cứu:
// ----------------------------------
#slide(title: "Sử dụng nhiều tập lệnh")[
#set text(size: 20pt)
#table(stroke: none,
columns: (50%, 50%),
image("images/file_list2.png", width: 90%), [
`chapter1.typ`:
#pad(left: 1em)[```typst
== Caption 1
#lorem(10)
```]
`chapter2.typ`:
#pad(left: 1em)[```typst
== Caption 2
#lorem(10)
```]
])
`main.typ`:
#pad(left: 1em)[```typst
= Cuốn sách tuyệt vời của tôi
Đây, chapter!
#include "chapter1.typ"
#include "chapter2.typ"
```]
]
#slide(title: "Các hàm và biến #1")[#{
let code = ```
#let var = 3.14159
#let double(e) = {
return 2*e
}
$pi$ xấp xỉ #var! \
$tau$ xấp xỉ #double(var)!
$pi approx var$ \
$tau approx double(var)$
```
table(stroke: none,
columns: (60%, auto),
align(top, text(size: 20pt, raw(lang: "typst", code.text))),
align(top, text(size: 20pt, eval("["+code.text+"]"))))
}]
#slide(title: "Các hàm và biến #2")[
Một lưu ý: chúng tôi đang làm việc với #emph[tên hàm].
#{
let code = ```
#let var = 2
#let change_var(new_v) = {
var = new_v
return var
}
#change_var(100)
```
table(stroke: none,
columns: (50%, auto),
align(top, text(size: 18pt, [Không hoạt động:] + par(raw(lang: "typst", code.text)))),
align(top, text(size: 18pt, [
SAI:
```typc
#let change_var(new_v) = {
var = new_v
``` ```
^^^
variables from outside the function are read-only and cannot be modified
```])))
}]
#slide(title: "Các hàm và biến #3")[#{
set text(size: 22pt)
let code = ```
#let names = ("Peter", "Petra", "Josef", "Josefa")
#let greet(names) = {
[Xin chào ]
names.join(last: " và ", ", ")
[! #names.len() Tên rất hay!]
}
#greet(names)
```
raw(lang: "typst", code.text)
v(1em)
eval("["+code.text+"]")
}]
// Kann man auch nachschlagen:
// ---------------------------
#slide(title: "Hàm chức năng khác từ tệp bên ngoài")[
#set text(size: 20pt)
#table(stroke: none,
columns: (50%, 50%),
image("images/file_list.png", width: 90%), [
`greet_me.typ` definiert:
- `greet(names)`
- `double(n)`
])
```typst
#import "greet_me.typ": *
#import "greet_me.typ": greet
```
]
#task[Chúng ta muốn tạo một hàm cộng hai số và định dạng kết quả #text(red, [red]) và #strong[bold]. Như thế này:
#let add(a, b) = strong(text(red, [#(a+b)]))
```typ
#add(20, 40)
```
#add(20, 40)
][
#set text(18pt)
#grid(columns: (auto, auto),
gutter: 1em,
[Cách phổ biến nhất:
```typ
#let add(a, b) = strong(text(red, [#(a+b)]))
#add(20, 40)
```
hoặc biến số thành chuỗi bằng `#str()`:
```typ
#let add(a, b) = strong(text(red, str(a+b)))
#add(20, 40)
```], align(top)[hoặc với dấu ngoặc:
```typ
#let add(a, b) = {
let result = a+b
strong(text(red, str(result)))
}
#add(20, 40)
```
])
]
#new-section("Typst có thể còn làm được nhiều việc hơn nữa!")
#slide(title: "Typst có thể còn làm được nhiều việc hơn nữa!")[
// #set text(size: 20pt)
- Thư mục
- Số liệu và tài liệu tham khảo
- hiển thị tài liệu!!!
- Raytracing #link("https://github.com/elteammate")
]
#slide(title: "Hình và Tài liệu tham khảo " + slide-footnote(link("https://typst.app/docs/reference/meta/figure/")))[
#align(center, table(stroke: none,
columns: (auto),
align(left, text(size: 18pt, raw(lang: "typst",
```
@glacier shows a glacier. Glaciers
are complex systems.
#figure(
image("glacier.jpg", height: 80%),
caption: [A curious figure.],
) <glacier>
```.text) + v(1em))),
image(height: 50%, "images/figures_and_references.png")))
]
#slide(title: "TÀI LIỆU THAM KHẢO" + slide-footnote(link("https://typst.app/docs/reference/meta/bibliography/")))[
#align(center, table(stroke: none,
columns: (auto, auto),
align(left)[#text(size: 14pt)[`works.bib`: ```bib
@article{netwok,
title={At-scale impact of the {Net Wok}: A culinarically holistic investigation of distributed dumplings},
author={<NAME> and <NAME>},
journal={Armenian Journal of Proceedings},
volume={61},
pages={192--219},
year={2020},
publisher={Automattic Inc.}
}
@article{arrgh,
title={The Pirate Organization},
author={<NAME>.},
}
```]],
align(left, text(size: 18pt, raw(lang: "typst",
```
This was already noted by
pirates long ago. @arrgh
Multiple sources say ...
#cite("arrgh", "netwok").
#bibliography("works.bib")
```.text) + v(1em))) +
image(height: 50%, "images/bibliography.png")))
]
#slide(title: "Raytracing")[
#image("images/raytracer.png")
Công cụ dò tia đầy đủ chức năng để kết xuất 3D.#slide-footnote([Autor: ] + link("https://github.com/elteammate"))
]
#new-section("TẠM KẾT")
#slide(title: [Typst còn thiếu những gì?#slide-footnote(link("https://github.com/typst/typst/issues/712"))])[
- Bản cập nhật version 0.4.0 ngày 10.06.2023
- Quản lý thư viện #text(size: 20pt, fill: rgb("#8a8a8a"))[(Xem nhanh tại đây: GitHub)]
- StackOverflow #text(size: 20pt, fill: rgb("#8a8a8a"))[(Thảo luận tại đây: Discord)]
]
#slide(title: [Một số cập nhật tiếp theon#slide-footnote(link("https://github.com/typst/typst/issues/712"))])[
#block[#align(top)[
- Cải thiện công cụ bố trí
- Quản lý gói
- Cải thiện bố cục toán học
- Đầu ra HTML
- Tham khảo thêm về lộ trình phát triển Typst tại đây https://typst.app/docs/roadmap
]]
]
#slide(title: "Ai (không) nên dùng Typst?")[#box[#align(top)[
Việc cần làm: mở rộng và đánh giá nghiêm túc Typst để giải thích các câu hỏi:
- Tại sao tôi nên sử dụng Typst khi LaTeX đang chạy khắp mọi nơi?
- Vấn đề con gà và quả trứng
- Chúng ta không thể hào hứng với những công nghệ mới chỉ vì chúng ta nghĩ rằng chúng hay sao?
- Làm sao mọi thứ có thể bắt kịp nếu chúng ta cứ nghĩ, "Ừ, nhưng chúng ta đã từng làm khác đi."?
LaTeX có nhiều gói hỗ trợ hơn. Typst thậm chí chưa hỗ trợ công cụ vẽ hình như TikZ (tôi biết có người đang phát triển công cụ tương đương).
- Các lựa chọn thay thế: Tạo SVG bằng TikZ và nhúng nó vào Typst hoặc sử dụng GraphViz
- https://github.com/johannes-wolf/typst-canvas làm thư viện cơ bản để vẽ các hình
Tổng quát: vấn đề con gà và quả trứng. Đôi khi bạn không thể làm những việc ngoài sở thích? Chúng ta không thể chỉ quan tâm đến các công nghệ mới sao? Tôi có thực sự cần tất cả "khả năng" không, con quái vật LaTeX?
]
]
]
#slide(title: "Ai (không) nên dùng Typst?")[#box[#align(top)[
#set text(size: 18pt)
#set list(marker: text(fill: green, emoji.checkmark))
#underline[*Thuận lợi:*]
- #strong[steile] Đường cong học tập
- Lập trình viên có nhiều cách tiếp cận, và cực kỳ dễ mở rộng
- Cộng đồng tích cực
- Thời gian biên cực dịch nhanh
- IDE trực tuyến
- Thông báo lỗi dễ hiểu
#set list(marker: text(fill: red, [✗]))
#underline[*Khó khăn:*]
- Lập trình viên có nhiều cách tiếp cận khác nhau
- Bố cục phức tạp (chưa có hình nổi)
- Các hàm thuần túy có thể nặng (trạng thái, bộ đếm, ...)
- Cho đến nay chưa có sự hỗ trợ từ các tạp chí lớn
- Chưa quản lý gói trung tâm
#emph[(Stand: 10.06.2023)]
]
]
]
#slide(title: "Tiếp theo")[
#set text(size: 18pt)
*Lưu ý:* Toàn bộ bản trình bày này chỉ được tạo bằng Typst và Typst-LPS trên VSC.
- Tài liệu Typst: https://typst.app/docs/
- Hướng dẫn Typst chính thức: https://typst.app/docs/tutorial
- Typst Discord chính thức: https://discord.gg/2uDybryKPe
- Mã cho bài thuyết trình này và các ví dụ khác: https://github.com/linhduongtuan/DTU-typst-presentations
- Luận văn thạc sĩ về Typst của <NAME>: https://www.user.tu-berlin.de/laurmaedje/programmable-markup-lingu-for-typesetting.pdf
- Luận văn thạc sĩ về Typst của <NAME>: https://www.user.tu-berlin.de/mhaug/fast-typesetting-incremental-compilation.pdf
- Lambdas, Bang và Bộ đếm: https://typst.app/project/rpnqiqoQNfxXjHQmpJ81nF
- Danh sách dự án về Typst: https://github.com/qjcg/awesome-typst
]
#align(center)[
#new-section(
text(size:36pt, "PHẦN 2. MỘT SỐ HƯỚNG DẪN CƠ BẢN CHO THƯ VIỆN SOẠN THẢO SLIDE")
)
]
#slide(title: "Về soạn thảo slides sử dụng mã nguồn này")[
- Phần trình bày này nhằm giới thiệu ngắn gọn những gì bạn có thể làm với phần mềm này bản mẫu.
- Để có tài liệu đầy đủ, hãy đọc
#link("https://andreaskroepelin.github.io/typst-slides/book/")[online book].
]
#slide(title: "Who are you")[
+ Hãy khám phá những gì chúng ta có ở đây.
- Trên đầu trang chiếu này, bạn có thể thấy tiêu đề trang chiếu.
- Chúng tôi đã sử dụng đối số `title` của hàm `#slide` cho điều đó:
```typ
#slide(title: "First slide")[
...
]
```
]
#slide[
- Tiêu đề không bắt buộc, slide này không có tiêu đề.
- Nhưng bạn có để ý rằng tên phần hiện tại được hiển thị phía trên
dòng trên cùng?
- Chúng tôi đã xác định nó bằng cách sử dụng
#raw("#new-section(\"Introduction\")", lang: "typst", block: false).
- Điều này giúp khán giả của chúng tôi không bị lạc sau một giấc ngủ ngắn.
]
#slide(title: "Phần bên dưới mỗi slide")[
- Bây giờ, hãy nhìn xuống dưới mỗi slide!
- Ở đó chúng tôi có một số thông tin chung cho khán giả về những gì họ đang nói
thực sự tham dự ngay bây giờ.
- Bạn cũng có thể thấy số slide ở đó.
]
#new-section("Nội dung cho mỗi slide động")
#slide(title: [Slide động với hàm `pause`s])[
- Đôi khi chúng ta không muốn hiển thị mọi thứ cùng một lúc.
#let pc = 1
#{ pc += 1 } #show: pause(pc)
- Đó là mục đích của chức năng `pause`!
- Sử dụng nó như sau:
```typ
#show: pause(n)
```
#{ pc += 1 } #show: pause(pc)
Nó làm cho mọi thứ sau nó xuất hiện ở trang phụ thứ `n`.
#text(.6em)[(Cũng lưu ý rằng số trang chiếu không thay đổi khi chúng tôi ở đây.)]
]
#slide(title: "Kiểm soát những chi tiết nhỏ")[
+ Khi `#pause` không đủ, bạn có thể sử dụng các lệnh nâng cao hơn để hiển thị hoặc ẩn nội dung.
+ Đây là những lựa chọn của bạn:
- `#uncover`
- `#only`
- `#alternatives`
- `#one-by-one`
- `#line-by-line`
#set text(size: 24pt, style: "oblique")
Hãy khám phá chúng chi tiết hơn!
]
#let example(body) = block(
width: 100%,
inset: .5em,
fill: aqua.lighten(80%),
radius: .5em,
text(size: .8em, body)
)
#slide(title: [`#uncover`: Bảo tồn Khoảng cách])[
Sử dụng hàm `#uncover`, nội dung vẫn chiểm khoảng không gian, thậm chí not sẽ không hiện nội dung.
Ví dụ , #uncover(2)[Từ này] chỉ nhìn thấy ở slide phụ ("subslide") thứ hai.
Trong `()` đằng sau `#uncover`, bạn chỉ định _when_ để hiển thị nội dung và trong
`[]` sau đó bạn nói _what_ để hiển thị:
#example[
```typ
#uncover(3)[chỉ nhìn thấy ở slide phụ ("subslide") thứ ba"]
```
#uncover(3)[chỉ nhìn thấy ở slide phụ ("subslide") thứ ba]
]
]
#slide(title: "Các nguyên tắc hiển thị phức tạp")[
- Cho đến nay, chúng tôi chỉ sử dụng các chỉ mục trang chiếu con duy nhất để xác định thời điểm hiển thị nội dung nào đó.
- Chúng ta cũng có thể sử dụng các mảng số...
#example[
```typ
#uncover((1, 3, 4))[Hiển thị các slides thứ 1, 3, và 4]
```
#uncover((1, 3, 4))[Hiển thị các slides thứ 1, 3, và 4]
]
...hay với một dictionary khi sử dụng `beginning` hay `until`:
#example[
```typ
#uncover((beginning: 2, until: 4))[Hiển thị các slides phụ 2, 3, và 4]
```
#uncover((beginning: 2, until: 4))[Hiển thị các slides phụ 2, 3, và 4]
]
]
#slide(title: "Nguyên tắc đơn giản với chuỗi")[
- Là một tùy chọn ngắn gọn, bạn cũng có thể chỉ định các quy tắc dưới dạng các chuỗi trong một tùy chọn đặc biệt với cú pháp.
- Được phân tách bằng dấu phẩy, bạn có thể sử dụng các quy tắc có dạng
#table(
columns: (auto, auto),
column-gutter: 1em,
stroke: none,
align: (x, y) => (right, left).at(x),
[`1-3`], [Từ slide phụ số 1 tới 3 (bao gồm cả slide số 2)],
[`-4`], [Tất cả các slides cho tới slide số 4],
[`2-`], [Từ slide thứ 2 trở đi],
[`3`], [Chỉ hiện thị slide số 3],
)
#example[
```typ
#uncover("-2, 4-6, 8-")[Hiển thị các slides số 1, 2, 4, 5, 6, và tất cả các từ slide thứ 8 trở đi]
```
#uncover("-2, 4-6, 8-")[Hiển thị các slides số 1, 2, 4, 5, 6, và tất cả các từ slide thứ 8 trở đi]
]
]
#slide(title: [`#only`: Bảo tồn không giữ khoảng cách])[
- Mọi thứ hoạt động với `#uncover` cũng hoạt động với `#only`.
- Tuy nhiên, nội dung hoàn toàn biến mất khi nó không được hiển thị.
- Ví dụ: #only(2)[#text(red)[see how]] phần còn lại của câu này di chuyển.
- Một lần nữa, bạn có thể sử dụng các quy tắc chuỗi phức tạp nếu muốn.
#example[
```typ
#only("2-4, 6")[Hiển thị các slides 2, 3, 4, và 6]
```
#only("2-4, 6")[Hiển thị các slides 2, 3, 4, và 6]
]
]
#slide(title: [`#alternatives`: Thay thế nội dụng])[
- Bạn có thể bị cám dỗ khi thử
#example[
```typ
#only(1)[Ann] #only(2)[Bob] #only(3)[Christopher] likes #only(1)[chocolate] #only(2)[strawberry] #only(3)[vanilla] ice cream.
```
#only(1)[Ann] #only(2)[Bob] #only(3)[Christopher]
likes
#only(1)[chocolate] #only(2)[strawberry] #only(3)[vanilla]
ice cream.
]
- Nhưng thật khó để thấy đoạn văn bản nào thực sự thay đổi vì mọi thứ Di chuyển xung quanh.
- Tốt hơn:
#example[
```typ
#alternatives[Ann][Bob][Christopher] likes #alternatives[chocolate][strawberry][vanilla] ice cream.
```
#alternatives[Ann][Bob][Christopher] likes #alternatives[chocolate][strawberry][vanilla] ice cream.
]
]
#slide(title: [`#one-by-one`: An alternative for `#pause`])[
`#alternatives` là để `#only` khi hàm `#one-by-one` dùng để `#uncover`.
`#one-by-one` hoạt động tương tự như sử dụng `#pause` nhưng bạn cũng có thể
trạng thái khi khám phá nên bắt đầu.
#example[
```typ
#one-by-one(start: 2)[one ][by ][one]
```
#one-by-one(start: 2)[one ][by ][one]
]
`start` cũng có thể được bỏ qua, sau đó nó bắt đầu với phần phụ đầu tiên:
#example[
```typ
#one-by-one[one ][by ][one]
```
#one-by-one[one ][by ][one]
]
]
#slide(title: [`#line-by-line`: Cú pháp dễ dàng với `#one-by-one`])[
- Đôi khi thật thuận tiện khi viết các nội dung khác nhau để khám phá một
tại một thời điểm trong các dòng tiếp theo.
- Điều này đặc biệt hữu ích cho danh sách dấu đầu dòng, kiểu liệt kê và danh sách thuật ngữ.
#example[
#grid(
columns: (1fr, 1fr),
gutter: 1em,
```typ
#line-by-line(start: 2)[
- first
- second
- third
]
```,
line-by-line(start: 2)[
- first
- second
- third
]
)
]
`start` là tùy chọn và mặc định là `1`.
]
#slide(title: "Các cách khác nhau để bao phủ nội dung")[
- Khi nội dung được che phủ, nó sẽ hoàn toàn ẩn theo mặc định.
- Tuy nhiên, bạn cũng có thể chỉ hiển thị nó bằng màu xám nhạt bằng cách sử dụng
đối số `mode` với giá trị `"transparent"`:
#let pc = 1
#{ pc += 1 } #show: pause(pc, mode: "transparent")
- Nội dung bị che phủ sau đó được hiển thị khác nhau.
#{ pc += 1 } #show: pause(pc, mode: "transparent")
- Mọi chức năng dựa trên `uncover` đều có đối số `mode` tùy chọn:
- `#show: pause(...)`
- `#uncover(...)[...]`
- `#one-by-one(...)[...][...]`
- `#line-by-line(...)[...][...]`
]
#new-section("Themes")
#slide(title: "Các diện mạo mỗi slide được chiếu ...")[
... được xác định bởi _theme_ của bản trình bày.
- Bản trình diễn này sử dụng chủ đề mặc định.
- Chính vì vậy, tiêu đề slide và phần trang trí trên mỗi slide (có
tên phần, tiêu đề ngắn, số trang, v.v.) trông giống như cách họ làm.
- Chủ đề cũng có thể cung cấp các biến thể, ví dụ...
]
#slide(theme-variant: "wake up")[
... với hàm này!
- Nó rất tối giản và giúp khán giả tập trung vào một điểm quan trọng.
]
#slide(title: "Your own theme?")[
Nếu bạn muốn tạo thiết kế của riêng mình cho các trang chiếu, bạn có thể xác định tùy chỉnh
themes!
#link("https://andreaskroepelin.github.io/typst-slides/book/themes.html#create-your-own-theme")[Xem sách này]
explains how to do so.
]
#new-section("TẠM KẾT")
#slide(title: "Chúc các bạn học vui!")[
- Hy vọng rằng bây giờ bạn đã có một số ý tưởng về những gì bạn có thể làm với mẫu này.
- Mong các bạn cho mình nhiều sao
#link("https://github.com/linhduongtuan/DTU-typst-presentation")[GitHub của mình tại đây #text(font: "OpenMoji")[#emoji.star]]
- Hoặc mở một `issuse` nếu bạn gặp lỗi hoặc có yêu cầu về tính năng.
]
#slide(theme-variant: "wake up")[
= HÃY CHỨNG MINH ĐỊNH LÝ GAUSS, TỈNH DẬY NÀO CÁC BẠN!
]
#slide(title: "Problem statement")[
Let $n in NN$.
We are interested in sums of the form
$ 1 + ... + n = sum_(i=1)^n i $
]
#slide(title: "The theorem")[
I discovered that
$ sum_(i=1)^n i = n(n+1)/2 $
Let's prove that!
]
#new-section("CHỨNG MINH")
#slide(title: "PHƯƠNG PHÁP CHỨNG MINH")[
We will prove the theorem by induction, following these steps:
+ base case
+ induction hypothesis
+ induction step
]
#slide(title: "Proof")[
#set text(.7em)
#one-by-one[
*base case:* Let $n = 1$. Then $sum_(i=1)^1 i = (1 dot.c 2)/2 = 1$ $checkmark$
][
*ind. hypothesis:* Let $sum_(i=1)^k i = k(k+1)/2$ for some $k >= 1$.
][
*ind. step:* Show that
$sum_(i=1)^(k+1) i = ((k+1)(k+2))/2$
$sum_(i=1)^(k+1) i = sum_(i=1)^k i quad + quad (k+1)$
][
$= k(k+1)/2 + (k+1)$
][
$= (k+1) dot.c (k/2 + 1)
= (k+1) dot.c (k/2 + 2/2)
= ((k+1)(k+2))/2
#h(1em) checkmark$
]
]
#slide(theme-variant: "wake up")[
= CHÚNG TA ĐÃ CHỨNG MINH XONG ĐỊNH LÝ GAUSS, TỈNH DẬY NÀO CÁC BẠN!
]
|
|
https://github.com/LDemetrios/Typst4k
|
https://raw.githubusercontent.com/LDemetrios/Typst4k/master/src/test/resources/suite/layout/inline/bidi.typ
|
typst
|
// Test bidirectional text and language configuration.
--- bidi-en-he-top-level ---
// Test reordering with different top-level paragraph directions.
#let content = par[Text טֶקסט]
#text(lang: "he", content)
#text(lang: "de", content)
--- bidi-consecutive-embedded-ltr-runs ---
// Test that consecutive, embedded LTR runs stay LTR.
// Here, we have two runs: "A" and italic "B".
#let content = par[أنت A#emph[B]مطرC]
#set text(font: ("PT Sans", "Noto Sans Arabic"))
#text(lang: "ar", content)
#text(lang: "de", content)
--- bidi-consecutive-embedded-rtl-runs ---
// Test that consecutive, embedded RTL runs stay RTL.
// Here, we have three runs: "גֶ", bold "שֶׁ", and "ם".
#let content = par[Aגֶ#strong[שֶׁ]םB]
#set text(font: ("Libertinus Serif", "Noto Serif Hebrew"))
#text(lang: "he", content)
#text(lang: "de", content)
--- bidi-nesting ---
// Test embedding up to level 4 with isolates.
#set text(dir: rtl)
א\u{2066}A\u{2067}Bב\u{2069}?
--- bidi-manual-linebreak ---
// Test hard line break (leads to two paragraphs in unicode-bidi).
#set text(lang: "ar", font: ("Noto Sans Arabic", "PT Sans"))
Life المطر هو الحياة \
الحياة تمطر is rain.
--- bidi-spacing ---
// Test spacing.
L #h(1cm) ריווחR \
Lריווח #h(1cm) R
--- bidi-obj ---
// Test inline object.
#set text(lang: "he")
קרנפיםRh#box(image("/assets/images/rhino.png", height: 11pt))inoחיים
--- bidi-whitespace-reset ---
// Test whether L1 whitespace resetting destroys stuff.
الغالب #h(70pt) ن#" "ة
--- bidi-explicit-dir ---
// Test explicit dir
#set text(dir: rtl)
#text("8:00 - 9:00", dir: ltr) בבוקר
#linebreak()
ב #text("12:00 - 13:00", dir: ltr) בצהריים
--- bidi-raw ---
// Mixing raw
#set text(lang: "he")
לדוג. `if a == b:` זה תנאי
#set raw(lang: "python")
לדוג. `if a == b:` זה תנאי
#show raw: set text(dir:rtl)
לתכנת בעברית `אם א == ב:`
--- bidi-vertical ---
// Test setting a vertical direction.
// Error: 16-19 text direction must be horizontal
#set text(dir: ttb)
--- issue-1373-bidi-tofus ---
// Test that shaping missing characters in both left-to-right and
// right-to-left directions does not cause a crash.
#"\u{590}\u{591}\u{592}\u{593}"
#"\u{30000}\u{30001}\u{30002}\u{30003}"
|
|
https://github.com/sebaseb98/clean-math-thesis
|
https://raw.githubusercontent.com/sebaseb98/clean-math-thesis/main/chapter/introduction.typ
|
typst
|
MIT License
|
= Introduction<chap:introduction>
#lorem(350)
|
https://github.com/alex-touza/fractal-explorer
|
https://raw.githubusercontent.com/alex-touza/fractal-explorer/main/paper/src/annexes/glossary.typ
|
typst
|
#let glossary(items) = {
return () => {
v(1em)
for (term, definition) in items.sorted() [/ #term: #definition]
}
}
== Glossari
=== Termes matemàtics
#let math_terms = glossary((
(
"derivabilitat",
[
Propietat d'un punt d'una funció de ser derivable, és a dir, que s'hi pugui traçar una recta tangent.
]
),
(
"conjunt obert",
[
Conjunt que no inclou el seu contorn. Per exemple, $(0, 1)$ és un conjunt obert però $[0, 1]$ no ho és.
]
),
(
"conjunt tancat",
[
Conjunt que inclou el seu contorn. Per exemple, $[0, 1]$ és un conjunt obert però $(0, 1)$ no ho és.
]
),
(
"conjunt fitat",
[
Conjunt tal que existeix alguna distància $d$ tal que qualsevol parella de punts del conjunt tinguin una distància menor que $d$. Per exemple, $(3, 4)$ i $[-1, 1]$ són conjunts fitats però $(-infinity, 10]$ no ho és.
]
),
(
"producte cartesià",
[
Operació binària denotada amb $times$ entre conjunts que retorna totes les parelles possibles formades per un element de cada operand.
]
)
))
#math_terms()
=== Termes d'algorísmia
#let algorithms_terms = glossary((
(
"complexitat temporal",
[
Com creix el temps que triga a executar-se un algoritme en funció de les variables d'entrada. Per exemple, $O(n^2)$ indica que si es dobla el nombre d'ítems d'entrada, es quadruplica el temps d'execució.
]
),
(
"recursivitat",
[
Propietat d'alguna a cosa a estar definida a partir d'una versió o una còpia de si mateixa. Moltes fractals són conjunts recursivament definits. En algorísmia, per exemple, una algorisme és recursiu quan un dels passos és l'algorisme mateix.
]
)
))
#algorithms_terms()
|
|
https://github.com/N4tus/types-for-typst
|
https://raw.githubusercontent.com/N4tus/types-for-typst/main/types_for_typst.typ
|
typst
|
MIT License
|
#let t_assert(ty, val) = {
let err = (ty.check)(val)
if err.len() > 0 {
panic("Value does not match '" + ty.name + "'", err, val)
}
}
#let t_check(ty, val) = {
let err = (ty.check)(val)
err.len() == 0
}
#let t_require(ty, val) = {
let err = (ty.check)(val)
if err.len() > 0 {
panic("Value does not match '" + ty.name + "'", err, val)
}
val
}
#let t_type_def(t_name, t_check) = (
name: t_name,
check: value => if not t_check(value) {
("Value does not match '" + t_name + "'",)
} else {
()
}
)
#let _primitive_def(primitive_name) = t_type_def(primitive_name, v => type(v) == primitive_name)
#let _surround(str) = if str.starts-with("(") and str.ends-with(")") {
str
} else {
"(" + str + ")"
}
#let t_or(..tys) = {
let n = _surround(tys.pos().map(t => t.name).join(" | "))
(
name: n,
check: value => {
let res = tys.pos().fold((check: false, reason: ("Value does not match '" + n + "'",)), (acc, ty) => {
let err = (ty.check)(value)
(check: acc.check or err.len() == 0, reason: acc.reason + err.map(r => " -> " + r))
})
if not res.check {
res.reason
} else {
()
}
}
)
}
#let TAny = t_type_def("any", _v => true)
#let TBoolean = _primitive_def("boolean")
#let TInteger = _primitive_def("integer")
#let TFloat = _primitive_def("float")
#let TLength = _primitive_def("length")
#let TAngle = _primitive_def("angle")
#let TRatio = _primitive_def("ratio")
#let TRelativeLength = _primitive_def("relative length")
#let TFraction = _primitive_def("fraction")
#let TColor = _primitive_def("boolean")
#let TSymbol = _primitive_def("symbol")
#let TString = _primitive_def("string")
#let TContent = _primitive_def("content")
#let TFunction = _primitive_def("function")
#let TNumber = t_or(TInteger, TFloat)
#let TLit(lit) = t_type_def("literal(" + str(lit) + ")", v => v == lit)
#let TNone = t_type_def("none", v => v == none)
#let TArray(values) = (
name: "array" + _surround(values.name),
check: value => {
if type(value) != "array" {
return ("Value is no array",)
}
let errs = value.enumerate()
.map(e => (e.at(0), (values.check)(e.at(1))))
.filter(e => e.at(1).len() > 0)
.map(e => ("Value at index " + str(e.at(0)) + " does not match '" + values.name + "'",) + e.at(1).map(err => " -> " + err))
if errs.len() == 0 {
()
} else {
errs.join()
}
}
)
#let optional(ty) = (ty: ty, optional: true)
#let TDict(..fields) = {
let fields = fields.named().pairs().map(f => {let d = (:); d.insert(f.at(0), if type(f.at(1)) == "dictionary" and f.at(1).len() == 2 and "ty" in f.at(1) and "optional" in f.at(1) {f.at(1)} else {(ty: f.at(1), optional: false)}); d}).join()
let n = "dict(" + fields.pairs().map(entry => entry.at(0) + if entry.at(1).optional {"?"} + ": " + entry.at(1).ty.name).join(", ") + ")"
(
name: n,
check: value => {
if type(value) != "dictionary" {
return ("Value is not a dictionary",)
}
// check missing and wrong fields
let errs = fields.pairs().map(e => {
let name = e.at(0)
let e = e.at(1)
if e.optional and not name in value {
(name: name, errs: ())
} else if not name in value {
(name: name, errs: ("Missing required field '" + name + "' in dict with type '" + e.ty.name + "'",))
} else {
(
name: name,
errs: (e.ty.check)(value.at(name)),
ty_name: e.ty.name
)
}
})
.filter(e => e.errs.len() > 0)
.map(e => if e.len() == 3 {
("Value at key '" + e.name + "' does not match '" + e.ty_name + "'",) + e.errs.map(err => " -> " + err)
} else {
e.errs
})
// check extra fields
let extra_err = value.keys().map(k => if not k in fields {"Value has extra field '" + k + "' in dict"}).filter(e => e != none)
if errs.len() > 0 {
errs.join() + extra_err
} else {
extra_err
}
}
)
}
#let TTuple(..elems) = {
let n = "tuple" + _surround(elems.pos().map(t => t.name).join(", "))
(
name: n,
check: value => {
if type(value) != "array" {
return ("Value is not a tuple",)
}
let elems = elems.pos()
let errs = elems.enumerate().map(e => {
if e.at(0) >= value.len() {
(e.at(0), ("Missing element at index " + str(e.at(0)) + " in tuple with type '" + e.at(1).name + "'",))
} else {
let v = value.at(e.at(0))
(
e.at(0),
(e.at(1).check)(v),
e.at(1).name
)
}
})
.filter(e => e.at(1).len() > 0)
.map(e => if e.len() == 3 {
("Value at index " + str(e.at(0)) + " does not match '" + e.at(2) + "'",) + e.at(1).map(err => " -> " + err)
} else {
e.at(1)
})
let extra_err = if value.len() > elems.len() { ("Value has " + str(value.len() - elems.len()) + " extra elements in tuple",) } else {()}
if errs.len() > 0 {
errs.join() + extra_err
} else {
extra_err
}
}
)
}
#let TMap(values) = {
let n = "map" + _surround(values.name)
(
name: n,
check: value => {
if type(value) != "dictionary" {
return ("Value is not a map",)
}
let errs = value.pairs()
.map(e => (e.at(0), (values.check)(e.at(1))))
.filter(e => e.at(1).len() > 0)
.map(e => ("Value at key '" + e.at(0) + "' does not match '" + values.name + "'",) + e.at(1).map(e => " -> " + e))
if errs.len() > 0 {
errs.join()
} else {
()
}
}
)
}
|
https://github.com/Skimmeroni/Appunti
|
https://raw.githubusercontent.com/Skimmeroni/Appunti/main/Matematica4AI/LinAlg/Eigen.typ
|
typst
|
Creative Commons Zero v1.0 Universal
|
#import "../Math4AI_definitions.typ": *
// What's the point of eigen stuff?
Let $A$ be an $n times n$ square matrix, and let $lambda$ be a real value.
The $n$-dimensional vector $underline(x)$ is said to be an *eigenvector*
of $A$ if it's not null and if:
$ A underline(x) = lambda underline(x) $
Where $lambda$ is the corresponding *eigenvalue* of $A$.
Retrieving the eigenvectors of a matrix $A$ by applying such definition is
not possible, since the information contained in the equation is insufficient.
Infact:
$ A underline(x) = lambda underline(x) =>
mat(a_(1, 1), a_(1, 2), dots, a_(1, n);
a_(2, 1), a_(2, 2), dots, a_(2, n);
dots.v, dots.v, dots.down, dots.v;
a_(n, 1), a_(n, 2), dots, a_(n, n))
mat(x_(1); x_(2); dots.v; x_(n)) =
lambda mat(x_(1); x_(2); dots.v; x_(n)) =>
cases(
a_(1, 1) dot x_(1) + a_(1, 2) dot x_(2) + dots + x_(n) a_(1, n) =
lambda x_(1),
a_(2, 1) dot x_(1) + a_(2, 2) dot x_(2) + dots + x_(n) a_(2, n) =
lambda x_(2),
dots.v,
a_(n, 1) dot x_(1) + a_(n, 2) dot x_(2) + dots + x_(n) a_(n, n) =
lambda x_(n)) $
Even assuming the $A$ matrix to be known, this system of equation has $n$
equations but $n + 1$ unknowns (the $n$ components of $underline(x)$ and
$lambda$). It is still possible to retrieve the eigenvectors of a matrix
by following a different approach, by first retrieving its eigenvalues and
then applying such definition.
Given a square matrix $A$ and a real value $lambda$, the *characteristic
polynomial* of $A$ is defined as:
$ p_(A)(lambda) = det(A - lambda I) = c_(0) + c_(1) lambda + c_(2) lambda^(2)
+ dots + c_(n − 1) lambda^(n − 1) + (−1)^(n) lambda^(n) $
Where:
#grid(
columns: (0.5fr, 0.5fr),
[$ c_(0) = det(A) $],
[$ c_(n − 1) = (−1)^(n − 1) tr(A) $]
)
#theorem[
A real value is an eigenvalue for a given matrix if and only if
it is a root of its characteristic polynomial.
] <Eigenvalues-as-polynomial-roots>
#proof[
First, suppose that $lambda in RR$ is an eigenvalue for a $n times n$
square matrix $A$. By definition of eigenvalue, there must exist a
non-null vector $underline(x)$ such that $A underline(x) = lambda
underline(x)$. Then:
$ A underline(x) = lambda underline(x) =>
A underline(x) = lambda I underline(x) =>
A underline(x) - lambda I underline(x) = underline(0) =>
(A - lambda I) underline(x) = underline(0) $
This means that $underline(x)$ is a vector that belongs to the kernel of
the matrix $(A - lambda I)$. Therefore, the nullity of $(A - lambda I)$
can't be zero.
By @Rank-nullity-theorem, $dim(A - lambda I) = "rank"(A - lambda I) +
"null"(A - lambda I)$. But $(A - lambda I)$ and $A$ have the same
dimension, therefore $n = "rank"(A - lambda I) + "null"(A - lambda I)$.
Since $"null"(A - lambda I)$ is non zero, for this equality to hold
the rank of $(A - lambda I)$ has to be less than $n$.
By @Full-rank-matrices-are-invertible, the matrix $(A - lambda I)$
cannot be invertible, and by @Invertible-matrices-not-null-determinant
this must mean that the determinant of $(A - lambda I)$ is $0$.
Suppose then that $lambda$ is a root for the characteristic
polynomial of $A$. This means that $det(A - lambda I)$ is
equal to $0$. By @Invertible-matrices-not-null-determinant,
this must mean that $(A - lambda I)$ is not invertible, which
in turn by @Full-rank-matrices-are-invertible must mean that
the rank of $(A - lambda I)$ is less than $n$. By @Rank-nullity-theorem,
$n = "rank"(A - lambda I) + "null"(A - lambda I)$, and being the rank
less than $n$ in turn implies that the kernel of $(A - lambda I)$ does
not contain just the null vector. This means that it exists a vector
$underline(x)$ such that $(A - lambda I) underline(x) = underline(0)$.
But then:
$ (A - lambda I) underline(x) = underline(0) =>
A underline(x) - lambda I underline(x) = underline(0) =>
A underline(x) = lambda I underline(x) =>
A underline(x) = lambda underline(x) $
Which is the definition of eigenvalue.
]
Knowing how to compute eigenvalues, it is then possible to solve the
aforementioned equation and retrieve the eigenvectors.
// ADD AN EXAMPLE
Eigenvectors and eigenvalues can be defined with respect to linear
transformations as well. Given a linear transformation $T: V |-> V$,
a vector $underline(v) in V$ is an eigenvector for $T$ if $T underline(v)
= lambda underline(v)$, where $lambda$ is an eigenvalue for $T$. Notice
how it has been imposed that the transformation $T$ is an endomorphism,
since otherwise mirroring the definition of eigenvector for matrices
could not have been possible.
As stated in @Eigenvalues-as-polynomial-roots, to compute the eigenvalues
of a matrix, it suffices to compute its characteristic polynomial. But any
matrix can be associated to a linear transformation and vice versa, therefore
to compute the eigenvalues of a linear transformation it suffices to compute
the characteristic polynomial of the associated matrix of the linear
transformation.
#theorem[
Let $T: V |-> V$ be an endomorphism, and let $A$ and $A'$ be two
matrices associated to $T$ with respect to the bases $cal(B)$ and
$cal(B')$ respectively. The characteristic polynomials of $A$ and
$A'$ are equivalent.
] <Characteristic-polynomial-is-of-transformation>
#proof[
The result follows from applying
@Matrix-basis-change-is-matrix-multiplication
to the characteristic polynomial of one of the matrices:
$ p_(A)(lambda) = det(A - lambda I) = det(P A' P^(-1) - lambda I) =
det(P A' P^(-1) - lambda P I P^(-1)) = \
det(P (A' P^(-1) - lambda I P^(-1))) =
det(P (A' - lambda I) P^(-1)) =
cancel(det(P)) det(A' - lambda I) cancel(det(P^(-1))) = \
det(A' - lambda I) = p_(A')(lambda) $
]
@Characteristic-polynomial-is-of-transformation justifies referring
to such polynomial as the characteristic polynomial of the linear
transformation itself, and not to one of the possible associated
matrices to such transformation, since the choice of the matrix is
irrelevant. Of course, the best choice for the associated matrix is
the one constructed with respect to the canonical basis, because in
general it requires the least amount of effort.
#theorem("Diagonalization theorem")[
- *With respect to endomorphisms*. Let $T: V |-> V$ be an endomorphism
of dimension $n$ that has $n$ linearly independent eigenvectors
$underline(e_(1)), dots, underline(e_(n))$. Let $E$ be the set that
contains such vectors, forming a basis for $V$. Let $P$ be the matrix
associated to $T$ with respect to the vectors in $E$. The matrix $P$
is a diagonal matrix whose non-zero element are the eigenvalues of $T$.
- *With respect to matrices*. Let $A$ be a $n times n$ matrix that has
$n$ linearly independent eigenvectors $underline(e_(1)), dots,
underline(e_(n))$. Then there exist two matrices $P$ and $D$ such
that $A = P D P^(-1)$, where $P$ is an invertible matrix whose columns
are the eigenvectors of $A$ and $D$ is a diagonal matrix whose non-zero
elements are the eigenvalues of $A$.
] <Diagonalization-theorem>
#proof[
// To be revisited with respect to both points
The first point is trivial
For the second point, consider the two matrices $P$ and $D$:
#grid(
columns: (0.5fr, 0.5fr),
[$ P = mat(underline(e_(1)), underline(e_(2)), dots, underline(e_(n))) =
mat(e_(1, 1), e_(2, 1), dots, e_(n, 1);
e_(1, 2), e_(2, 2), dots, e_(n, 2);
dots.v, dots.v, dots.down, dots.v;
e_(1, n), e_(2, n), dots, e_(n, n);) $],
[$ D = mat(lambda_(1), 0, dots, 0;
0, lambda_(2), dots, 0;
dots.v, dots.v, dots.down, dots.v;
0, 0, dots, lambda_(n);) $])
The matrix multiplication $A P$ is by definition equivalent to
multiplying $A$ with each column vector of $P$. That is, the $i$-th
column of $A P$ is given by multiplying the matrix $A$ with the $i$-th
column vector of $P$, giving $A underline(e_(i))$. But by definition
multiplying the matrix representation of an endomorphism with one of
his eigenvectors is equivalent to multiplying said eigenvector by its
corresponding eigenvalue. Therefore:
$ A P = mat(A underline(e_(1)), A underline(e_(2)), dots,
A underline(e_(n))) = mat(lambda_(1) underline(e_(1)),
lambda_(2) underline(e_(2)), dots, lambda_(n) underline(e_(n))) $
Consider the matrix multiplication $P D$. By definition, the $i$-th
element of such matrix is given by the sum of the products of the
corresponding elements of the $i$-th row of $P$ and the $i$-th column
of $D$. By construction, the elements in $D$ are zero except for the
ones on its diagonal, therefore the $i$-th column of $P D$ is just
the $i$-th column vector of $P$ multiplied by the $i, i$-th element
of $D$, which is $lambda_(i)$. Therefore:
$ P D = mat(lambda_(1) underline(e_(1)), lambda_(2) underline(e_(2)),
dots, lambda_(n) underline(e_(n))) $
This shows that the two matrix products $A P$ and $P D$ are equivalent.
Since by assumption the set of the eigenvectors of $A$ form a basis, by
@Full-rank-matrices-are-invertible $P$ has to be invertible. But then:
$ A P = P D => A cancel(P) cancel(P^(-1)) = P D P^(-1) => A = P D P^(-1) $
]
If for a given square matrix $A$ there exist an invertible matrix $P$
and a diagonal matrix $D$ such that $A = P D P^(-1)$, matrix $A$ is
said to be *diagonalizable*. As stated in @Diagonalization-theorem,
the matrix $P$ is an invertible matrix whose columns are the eigenvectors
of $A$ while $D$ is a diagonal matrix whose non-zero elements are the
eigenvalues of $A$.
By the Fundamental Theorem of Algebra, the characteristic polynomial
of any matrix will always have at least $n$ roots, albeit they might
be complex numbers. Therefore, any square matrix will always have $n$
(not necessarely distinct) eigenvalues. Despite this, the fact that the
set of its eigenvectors forms a basis for the vector space associated to
$A$ isn't always true, therefore not all matrices are diagonalizable. A
matrix whose set of eigenvectors does not form a basis is said to be
*defective*.
// Add an example of a diagonalizable matrix
#exercise[
Prove that the matrix $A = mat(0, 1; 0, 0)$ is defective.
]
#solution[
Computing the characteristic polynomial of $A$ gives:
$ p_(A)(lambda) =
det(A - lambda I) =
mat(delim: "|", 0 - lambda, 1 - 0; 0 - 0, 0 - lambda) =
mat(delim: "|", -lambda, 1; 0, -lambda) =
(-lambda) dot (-lambda) - (0 dot 1) =
lambda^(2) $
Such polynomial has only two roots, both being $0$. Therefore, the
eigenvalues of $A$ are $lambda_(1) = lambda_(2) = 0$. By applying the
definition:
$ A underline(x) = lambda underline(x) =>
mat(0, 1; 0, 0)
mat(x; y) =
0 mat(x; y) =>
mat(0 dot x + 1 dot y; 0 dot x + 0 dot y)
= mat(0 dot x; 0 dot y) =>
mat(y; 0) = mat(0; 0) =>
cases(y = 0, 0 = 0) $
This means that the eigenvectors of $A$ are all the vectors in the
form $mat(0; k)$ with $k in RR$. Of course, the set $E = {mat(0; k)}
subset RR^(2)$ is not linearly independent (at least two vectors are
needed) and therefore $A$ is defective.
]
Determining whether a matrix is diagonalizable through such definition can
quickly become cumbersome, but there are necessary and sufficient conditions
that are equivalent and that can ease the process.
Let $A$ be a matrix and $lambda$ one of its eigenvalues. The number of
times $lambda$ appears as a root of the characteristic polynomial of $A$
is the *algebraic multiplicity* of $lambda$, and is denoted as $m_(a)(lambda)$.
The dimension of the vector space generated by the set of eigenvectors that
have $lambda$ as their eigenvalue is the *geometric multiplicity* of $lambda$,
and is denoted as $m_(g)(lambda)$.
#theorem[
For any eigenvalue $lambda$, the following inequality holds:
$ 1 lt.eq m_(g)(lambda) lt.eq m_(a)(lambda) $
] <Eigenvalues-inequality>
// #proof[
// To be added
// ]
#theorem[
A matrix is diagonalizable if and only if, for each of its eigenvalues
$lambda_(i)$, $m_(g)(lambda_(i)) = m_(a)(lambda_(i))$.
] <Same-multiplicity-is-diagonalizable>
// #proof[
// To be added
//]
#corollary[
Any $n times n$ matrix that has $n$ distinct eigenvalues is diagonalizable.
] <Single-multiplicity-is-diagonalizable>
#proof[
If a matrix has as many distinct eigenvalues as its dimension it means
that the algebraic multiplicity of any of its eigenvalues is $1$. By
@Eigenvalues-inequality, for any eigenvalue $lambda_(i)$ its geometric
multiplicity must also be $1$, because $1 lt.eq m_(g)(lambda_(i)) lt.eq
1$. The fact that such matrix is diagonalizable follows from applying
@Same-multiplicity-is-diagonalizable.
]
#theorem[
A symmetric matrix is always diagonalizable.
]
|
https://github.com/CreakZ/mirea-algorithms
|
https://raw.githubusercontent.com/CreakZ/mirea-algorithms/master/reports/work_6/work_6.typ
|
typst
|
#import "../title_page_template.typ": title_page
#import "../layouts.typ": *
#set text(font: "New Computer Modern", size: 14pt)
#set heading(numbering: "1.")
#title_page(6, [Таблица])
#un_heading([Оглавление])
#outline(
title: none
)
#par(align(center, [РАБОТА ПРОПУЩЕНА В СВЯЗИ С НЕКОТОРЫМИ ПРИЧИНАМИ]))
|
|
https://github.com/dizzyi/resume
|
https://raw.githubusercontent.com/dizzyi/resume/main/src/resume.typ
|
typst
|
#import "@preview/basic-resume:0.1.0": *
// Put your personal information here, replacing mine
#let name = "Alan, <NAME>"
#let location = "Hong Kong"
#let email = "<EMAIL>"
#let github = "github.com/dizzyi"
#let linkedin = "linkedin.com/in/alan-chung-165044194/"
#let phone = "+852 9851 9438"
#let personal-site = "dizzyi.github.io/portfolio/"
#show: resume.with(
author: name,
// All the lines below are optional.
// For example, if you want to to hide your phone number:
// feel free to comment those lines out and they will not show.
location: location,
email: email,
github: github,
// linkedin: linkedin,
phone: phone,
personal-site: personal-site,
accent-color: "#26428b",
)
== Profile
Highly motivated and driven by a passion for *robotics*, *AI*, and *automation* R&D. Adept at self-learning and quickly mastering new technologies and skills.
== Work Experience
#work(
title: "Mechanical Engineer",
location: "Hong Kong",
company: "Inovo Robotics",
dates: dates-helper(start-date: "Aug 2022", end-date: "Present"),
)
- Design and integrate *industrial automation solutions*, using robot arms, various sensors, and actuators.
- Conduct experiments and interpret data for quality control, with scientific computing skills.
#work(
title: "Research Intern",
location: "Hong Kong",
company: "CUHK Engineeringg Faculty & HKCLR",
dates: dates-helper(start-date: "Apr 2021", end-date: "Aug 2021"),
)
- Read academic papers on cutting edge Machine Learning Methods e.g., Deep Reinforcement Learning and graph Neural Networks.
- Aided research team in construction solution for industrial palletizing, using PyTorch
== Projects
#project(
role: "Architect, Engineer",
name: "<NAME>",
dates: dates-helper(start-date: "Aug 2023", end-date: "May 2024"),
url: "youtube.com/watch?v=mWT8CetyHb8",
)
- Developed a robotic bartending system *("Robo-Mixologist")* for a Hong Kong Airport installation, featuring automated cocktail mixing and a touchscreen ordering interface.
- Designed and implemented advanced algorithms for precise ingredient measurement, drink mixing, and stylish presentation within a futuristic bar setting.
#project(
role: "Architect, Engineer",
name: "TSS Process Automation",
dates: dates-helper(start-date: "Aug 2022", end-date: "Aug 2023"),
url: "youtube.com/watch?v=SwUt4mq-EXE",
)
- Developed robotic solutions to automate repetitive lab processes like Total Suspended Solids wastewater tests, integrating data capture into business systems.
- Streamlined environmental testing workflows by implementing robotics for increased efficiency and reduced manual data entry.
== Education
#edu(
institution: "The Chinese University of Hong Kong",
location: "Hong Kong",
dates: dates-helper(start-date: "Aug 2018", end-date: "Jul 2022"),
degree: "Bachelor's of Engineering, Mechanical and Automation Engineering",
)
=== Minor
- *Computer Science*
=== Honors
- Cumulative GPA: *3.371\/4.000 *
- Second-up honors
- Dean's List of 2020-2021
- Relevant Coursework: Advanced Robotics, Modern Control, Artifical Intelligent, Software Engineering.
== Extracurricular
#project(
role: "Contributor",
name: "Library `sciport-rs`",
dates: dates-helper(start-date: "Aug 2023", end-date: "Present"),
url: "https://github.com/ChristianBelloni/sciport-rs",
)
- Contribute library sciport-rs (a pure Rust implementation of SciPy), implement to numerical method for scientific computing.
== Skills and Awards
- *Programming Languages*: Rust, Python, C/C++, C\#, JavaScript, Dart, Prolog, Zig, PLC programming.
- *Engineering Software*: MATLAB, SOLIDWORKS, Solid Edge, AutoCAD, TwinCAT, Embedded, RISC-V assembly,
- *Software Framework*: OpenCV, Yew.rs, PyTorch/TF, React.js, Vue.js, node.js, flutter
|
|
https://github.com/timon-schelling/uni-phi111-essay-2023-12-01
|
https://raw.githubusercontent.com/timon-schelling/uni-phi111-essay-2023-12-01/main/src/template/cite.typ
|
typst
|
#let cite_link(key, text) = {
cite(key, supplement: text, style: "cite_styles/only-supplement.csl")
}
#let custom_cite_format(pre, post, body) = {
let ret = ""
ret += if pre != "" { pre + " " } else { "" }
ret += body
ret += if post != "" { ": " + post } else { "" }
ret
}
#let custom_cite(key, pre, post, body) = {
let text = custom_cite_format(pre, post, body)
cite_link(key, text)
}
#let custom_cite_auto(key, pre, post) = {
let ref = cite(key, style: "cite_styles/main-no-brackets.csl")
custom_cite(key, pre, post, ref)
}
#let custom_cite_ebd(key, pre, post) = {
custom_cite(key, pre, post, "ebd.")
}
#let show_custom_cite(citation) = {
if citation.supplement == none {
return citation
}
let to_string(content) = {
if content.has("text") {
content.text
} else if content.has("children") {
content.children.map(to_string).join("")
} else if content.has("body") {
to_string(content.body)
} else if content == [ ] {
" "
}
}
let str = to_string(citation.supplement)
let s = str.split("&")
let pre = ""
let post = ""
if s.len() == 1 {
post = s.at(0)
}
if s.len() > 1 {
pre = s.at(0)
post = s.at(1)
}
let force = post.starts-with("!")
if force {
post = post.slice(1)
return custom_cite_auto(citation.key, pre, post)
}
locate(loc => {
let headings = query(selector(heading).before(loc), loc)
let elems = if headings.len() >= 0 {
query(selector(ref).after(headings.last().location()).before(loc, inclusive: false), loc)
} else {
query(selector(ref).before(loc, inclusive: false), loc)
}
let is_ebd = true
if elems.len() <= 1 {
is_ebd = false
} else {
let elem = elems.at(-2)
let cite = elem.citation
if cite == none or cite.key == none or cite.key != citation.key {
is_ebd = false
}
}
if is_ebd {
custom_cite_ebd(citation.key, pre, post)
} else {
custom_cite_auto(citation.key, pre, post)
}
})
}
#let show_custom_ref(ref) = {
if ref.citation == none {
return ref
}
show_custom_cite(ref.citation)
}
|
|
https://github.com/cetz-package/cetz-venn
|
https://raw.githubusercontent.com/cetz-package/cetz-venn/master/src/venn.typ
|
typst
|
Apache License 2.0
|
#import "@preview/cetz:0.2.2"
#let default-style = (
stroke: auto,
fill: white,
padding: 2em,
)
#let venn-prepare-args(num-sets, args, style) = {
assert(2 <= num-sets and num-sets <= 3,
message: "Number of sets must be 2 or 3")
let set-combinations = if num-sets == 2 {
("a", "b", "ab", "not-ab")
} else {
("a", "b", "c", "ab", "ac", "bc", "abc", "not-abc")
}
let keys = (
"fill": style.fill,
"stroke": style.stroke,
"layer": 0,
"ab-stroke": none,
"ac-stroke": none,
"bc-stroke": none,
)
let new = (:)
for combo in set-combinations {
for (key, def) in keys {
key = combo + "-" + key
new.insert(key, args.at(key, default: keys.at(key, default: def)))
}
}
return new
}
/// Draw a venn diagram with two sets a and b
///
/// *Set attributes:* \
/// The `venn2` function has two sets `a` and `b`, each of them having the following attributes:
/// - `*-fill`: Fill color
/// - `*-stroke`: Stroke style
/// - `*-layer`: CeTZ layer index
/// To set a set-attribute, combine the set name (`a`) and the attribute key (`fill`) with a dash: `a-fill`.
///
/// ```example
/// cetz.canvas({
/// cetz-venn.venn2(a-fill: red, b-fill: green)
/// })
/// ```
///
/// The following set names exist and also act as anchors (for labels):
/// - `a`
/// - `b`
/// - `ab`
/// - `not-ab`
///
/// - ..args (any): Set and style attributes
/// - name (none, string): Element name
#let venn2(..args, name: none) = {
import cetz.draw: *
let distance = 1.25
group(name: name, ctx => {
let style = cetz.styles.resolve(ctx.style, base: default-style, root: "venn", merge: args.named())
let padding = cetz.util.as-padding-dict(style.padding)
for (k, v) in padding {
padding.insert(k, cetz.util.resolve-number(ctx, v))
}
let args = venn-prepare-args(2, args.named(), style)
let pos-a = (-distance / 2,0)
let pos-b = (+distance / 2,0)
let a = circle(pos-a, radius: 1)
let b = circle(pos-b, radius: 1)
intersections("ab", {
hide(a);
hide(b);
})
on-layer(args.not-ab-layer,
rect((rel: (-1 - padding.left, -1 - padding.bottom), to: pos-a),
(rel: (+1 + padding.right, +1 + padding.top), to: pos-b),
fill: args.not-ab-fill, stroke: args.not-ab-stroke, name: "frame"))
on-layer(args.ab-layer,
merge-path(name: "ab-shape", {
arc-through("ab.0", (rel: (-1, 0), to: pos-b), "ab.1")
arc-through("ab.1", (rel: (+1, 0), to: pos-a), "ab.0")
}, fill: args.ab-fill, stroke: args.ab-stroke, close: true))
on-layer(args.a-layer,
merge-path(name: "a-shape", {
arc-through("ab.0", (rel: (-1, 0), to: pos-a), "ab.1")
arc-through("ab.1", (rel: (-1, 0), to: pos-b), "ab.0")
}, fill: args.a-fill, stroke: args.a-stroke, close: true))
on-layer(args.b-layer,
merge-path(name: "b-shape", {
arc-through("ab.0", (rel: (+1, 0), to: pos-b), "ab.1")
arc-through("ab.1", (rel: (+1, 0), to: pos-a), "ab.0")
}, fill: args.b-fill, stroke: args.b-stroke, close: true))
anchor("a", (rel: (-1 + distance / 2, 0), to: pos-a))
anchor("b", (rel: (+1 - distance / 2, 0), to: pos-b))
anchor("ab", (pos-a, 50%, pos-b))
anchor("not-ab", (rel: (padding.left / 2, padding.bottom / 2), to: "frame.south-west"))
})
}
/// Draw a venn diagram with three sets a, b and c
///
/// See `venn2` for the attribute documentation.
///
/// ```example
/// cetz.canvas({
/// cetz-venn.venn3(not-abc-fill: red)
/// })
/// ```
///
/// The following set names exist and also act as anchors (for labels):
/// - `a`
/// - `b`
/// - `c`
/// - `ab`
/// - `bc`
/// - `ac`
/// - `abc`
/// - `not-abc`
///
/// - ..args (any): Set attributes
/// - name (none, string): Element name
#let venn3(..args, name: none) = {
import cetz.draw: *
let distance = .75
group(name: name, ctx => {
let style = cetz.styles.resolve(ctx.style, base: default-style, root: "venn", merge: args.named())
let padding = cetz.util.as-padding-dict(style.padding)
for (k, v) in padding {
padding.insert(k, cetz.util.resolve-number(ctx, v))
}
let args = venn-prepare-args(3, args.named(), style)
let pos-a = cetz.vector.rotate-z((distance,0), -90deg + 2 * 360deg / 3)
let pos-b = cetz.vector.rotate-z((distance,0), -90deg + 360deg / 3)
let pos-c = cetz.vector.rotate-z((distance,0), -90deg)
let angle-ab = cetz.vector.angle2(pos-a, pos-b)
let angle-ac = cetz.vector.angle2(pos-a, pos-c)
let angle-bc = cetz.vector.angle2(pos-b, pos-c)
// Distance between set center points
let d-ab = cetz.vector.dist(pos-a, pos-b)
let d-ac = cetz.vector.dist(pos-a, pos-c)
let d-bc = cetz.vector.dist(pos-b, pos-c)
// Midpoints between set center points
let m-ab = cetz.vector.lerp(pos-a, pos-b, .5)
let m-ac = cetz.vector.lerp(pos-a, pos-c, .5)
let m-bc = cetz.vector.lerp(pos-b, pos-c, .5)
// Intersections (0 = outer, 1 = inner)
let i-ab-0 = cetz.vector.add(m-ab, cetz.vector.rotate-z((+calc.sqrt(1 - calc.pow(d-ab / 2, 2)), 0), angle-ab + 90deg))
let i-ab-1 = cetz.vector.add(m-ab, cetz.vector.rotate-z((-calc.sqrt(1 - calc.pow(d-ab / 2, 2)), 0), angle-ab + 90deg))
let i-ac-0 = cetz.vector.add(m-ac, cetz.vector.rotate-z((-calc.sqrt(1 - calc.pow(d-ac / 2, 2)), 0), angle-ac + 90deg))
let i-ac-1 = cetz.vector.add(m-ac, cetz.vector.rotate-z((+calc.sqrt(1 - calc.pow(d-ac / 2, 2)), 0), angle-ac + 90deg))
let i-bc-0 = cetz.vector.add(m-bc, cetz.vector.rotate-z((+calc.sqrt(1 - calc.pow(d-bc / 2, 2)), 0), angle-bc + 90deg))
let i-bc-1 = cetz.vector.add(m-bc, cetz.vector.rotate-z((-calc.sqrt(1 - calc.pow(d-bc / 2, 2)), 0), angle-bc + 90deg))
on-layer(args.not-abc-layer,
rect((rel: (-1 - padding.left, +1 + padding.top), to: pos-a),
(rel: (+1 + padding.right, -1 - padding.bottom), to: (pos-b.at(0), pos-c.at(1))),
fill: args.not-abc-fill, stroke: args.not-abc-stroke, name: "frame"))
for (name, angle) in (("ab", 0deg), ("ac", 360deg / 3), ("bc", 2 * 360deg / 3)) {
on-layer(args.at(name + "-layer"),
merge-path(name: name + "-shape", {
group({
rotate(angle)
arc-through(i-bc-1, (rel: (-1, 0), to: pos-b), i-ab-0)
arc-through((), (rel: (+1, 0), to: pos-a), i-ac-1)
arc-through((), (rel: (0, +1), to: pos-c), i-bc-1)
})
}, fill: args.at(name + "-fill"), stroke: args.at(name + "-stroke"), close: true))
}
on-layer(args.abc-layer,
merge-path(name: "abc-shape", {
arc-through(i-ab-1, (rel: cetz.vector.rotate-z((+1,0), (angle-ab + angle-ac) / 2), to: pos-a), i-ac-1)
arc-through((), (rel: cetz.vector.rotate-z((-1,0), (angle-ac + angle-bc) / 2), to: pos-c), i-bc-1)
arc-through((), (rel: cetz.vector.rotate-z((-1,0), (180deg + angle-ab + angle-bc) / 2), to: pos-b), i-ab-1)
}, fill: args.abc-fill, stroke: args.abc-stroke, close: true))
for (name, angle) in (("a", 0deg), ("c", 360deg / 3), ("b", 2 * 360deg / 3)) {
on-layer(args.at(name + "-layer"),
merge-path(name: "a-shape", {
group({
rotate(angle)
arc-through(i-ab-0, (rel: (-1, 0), to: pos-a), i-ac-0)
arc-through((), (rel: cetz.vector.rotate-z((-1,0), angle-ac), to: pos-c), i-bc-1)
arc-through((), (rel: (-1, 0), to: pos-b), i-ab-0)
})
}, fill: args.at(name + "-fill"), stroke: args.at(name + "-stroke"), close: true))
}
let a-a = cetz.vector.lerp(i-bc-0, i-bc-1, 1.5)
let a-b = cetz.vector.lerp(i-ac-0, i-ac-1, 1.5)
let a-c = cetz.vector.lerp(i-ab-0, i-ab-1, 1.5)
anchor("a", a-a)
anchor("b", a-b)
anchor("c", a-c)
anchor("ab", cetz.vector.lerp(a-a, a-b, .5))
anchor("bc", cetz.vector.lerp(a-b, a-c, .5))
anchor("ac", cetz.vector.lerp(a-a, a-c, .5))
anchor("abc", (0,0))
anchor("not-abc", (rel: (padding.left / 2, padding.bottom / 2), to: "frame.south-west"))
})
}
|
https://github.com/enseignantePC/2023-24
|
https://raw.githubusercontent.com/enseignantePC/2023-24/master/Chapitre1/act1/act1.typ
|
typst
|
#import "../../act_template.typ": *
#show : it => activité(
title: [ L'expérience historique de Lavoisier ],
chapter_name: [Identification des espèces chimiques.],
number: 1,
it,
)
#show footnote: it => box(scale(x: 120%, y: 120%)[*#it*])
#introduction[
C'est An<NAME>, le célèbre chimiste français, qui, en 1777, découvre
que l'air est constitué de plusieurs gaz. L'expérience de Lavoisier consiste à
faire chauffer du mercure dans une enceinte fermée contenant de l'air et à
observer les changements ayant lieu.
*_Quelles observations ont permis à Lavoisier de déterminer la composition de
l'air ?_*
]
#set align(center)
#doc(
title: [Une expérience historique],
)[
J'ai pris un matras (vase) de 36 pouces cubiques environ de capacité dont le col
était très long. Je l'ai courbé de manière qu'il pût être placé dans un
fourneau, tandis que l'extrémité de son col irait s'engager sous la cloche,
placée dans un bain de mercure. J'ai introduit dans ce matras quatre onces de
mercure très pur. [Puis] le mercure fût échauffé presqu'au degré nécessaire pour
le faire bouillir.
Le second jour, j'ai commencé à voir nager sur la surface du mercure de petites
parcelles rouges
#footnote[*_Il se produit dans le matras une transformation chimique au cours de laquelle le
dioxygène réagit avec le mercure pour former de l'oxyde de mercure HgO, rouge._*],
qui, pendant quatre ou cinq jours ont augmenté en nombre et en volume ; après
quoi elles ont cessé de grossir et sont restées absolument dans le même état. Au
bout de douze jours, [ ...] la calcination du mercure ne faisait plus aucun
progrès [ ...].
Le volume de l'air contenu tant dans le matras que dans son col et sous la
partie vide de la cloche, réduit à une pression de 28 pouces et à 10 degrés du
thermomètre, était avant l'opération de 50 pouces cubiques environ.
Lorsque l'opération a été finie, ce même volume à pression et à température
égales, ne s'est plus trouvé que de 42 à 43 pouces : il y avait eu par
conséquent une diminution de volume d'un sixième environ.
]
#box(width: 50%)[
#figure(caption: [Montage de Lavoisier], image("lavoisier.png"))
]#box(
width: 50%,
)[
#v(10pt)
#doc(
title: [Un chimiste remarquable],
)[
Antoine de Lavoisier (1743-1794), est considéré comme le père de la chimie
moderne. Avec ses multiples expériences sur l'air, le dioxygène, ou le dioxyde
de carbone, il montre que la matière est constituée d'espèces chimiques (même
s'il n' emploie pas ce terme), et non de quatre éléments (feu, terre, eau et
air) comme les anciens chimistes l'admettaient. Plus tard, ses expériences ont
montré le caractère acide du dioxyde de carbone, et ont abouti à la célèbre loi
de conservation de la matière lors d'une réaction chimique : « rien ne se perd,
rien ne se crée, tout se transforme ».
]
]
#v(10pt)
#set align(left)
#question[
L'expérience montre qu'un gaz disparaît: *_Donner la formule chimique de ce
gaz._*
]
#question[
L'air est constitué principalement de deux gaz. *_Nommer_* le gaz encore présent
dans l'air à la fin de l'expérience ?
]
#question[
En utilisant les résultats de l'expérience,
- *_Déterminer_* le volume d'air qui a disparu.
- *_En déduire_* l'espèce chimique qui s'est transformée.
- *_En déduire_* sa proportion en volume de l'air.
]
#v(-20pt)
#question[
#place(dx: 100pt, dy: -26pt)[
- *Déterminer* la masse d'un $"mètre"^3$ d'air.
- *Déterminer* la masse d'un litre d'air.
]
#v(10pt)
Données:
- Masse volumique de l'air $rho_"air"= 1,225 "kg·m"^(-3) ("à 15 °C").$
- $1m^3 = 10^3 "litres"$.
]
|
|
https://github.com/the-JS-hater/typst_cv
|
https://raw.githubusercontent.com/the-JS-hater/typst_cv/main/cv_2024HT.typ
|
typst
|
#set text(font: "IBM Plex Sans")
#set page(margin: (
top: 2cm,
bottom: 1cm,
x: 1cm,
))
#grid(
rows: (1fr, 10fr),
gutter: 5pt,
inset: 6pt,
[
#set align(center)
#set text(weight: "bold", size: 24pt)
#underline[<NAME> \ ]
#set text(weight: "regular", size: 11pt)
*Email*: <EMAIL> | *Telefon*: +358 4573445201 | *Adress*: Björnskärrsgatan 9B
], grid.hline(),
[
#grid(
columns: (6fr, 4fr),
gutter: 8pt,
inset: 8pt,
[
#set text(size: 11pt)
= Arbetslivserfarenhet
== Mindroad AB, Linköping
#text(gray)[Juni 2024 - Augusti 2024]
\ Sommarjobb där jag hjälpte till med att utforma kursmaterial för en utbildning i React Native. Utöver detta hade jag även som uppgift att felsöka ett cmake byggskript för ett tidigare utfört examensarbete på företaget.
== Kurs assistent vid Linköpings universitet
Under min studietid har jag jobbat deltid som kursassietent inom ett flertal kurser. Arbetsuppgifter har inkluderat att handleda laborations tillfällen, agera seminariehandledare, samt granska och bedöma inlämningsuppgifter och projekt.
=== Funktionell och imperativ programmering, del 1 & 2 (TDDE23/24)
#text(gray)[Augusti 2024 - Januari 2025]
\ Grundkurs i Python med utgångspunkt i de imperativa och funktionella paradigmerna.
=== Objektorienterad programmering och Java (TDDE30)
#text(gray)[Januari 2024 - Maj 2024]
\ Grundkurs i Java och objekt orienterad programmering.
=== Funktionell och imperativ programmering, del 1 & 2 (TDDE23/24)
#text(gray)[Augusti 2023 - Januari 2024]
=== Projekt: Mobila och sociala applikationer (TDDD80)
#text(gray)[Januari 2023 - Maj 2023]
\ Projektkurs där de studerande bygger en Android applikation i Java, med en tillhörande _backend_ och databas i Python & PostreSQL.
== Övrig erfarenhet
=== Lagerarbete i livsmedelsbutik
#text(gray)[Juni 2020 - Augusti 2022]
\ Sommarjobbade på färskavdelningen på Sparhallen, Mariehamn.
=== Säsongsarbete på jordbruk
#text(gray)[Juni 2016 - Augusti 2019]
\ Sommarjobbade med grönsaksodlarna Anki & <NAME>, Jomala.
], grid.vline(),
[
#set text(size: 11pt)
= Utbildning
== Civilingenjör i Mjukvaruteknik
#text(gray)[Augusti 2021 - Nuvarande] \
En datateknologisk utbildning med fokus på mjukvara, och master profil intriktad på algoritmisk problemlösning
== Naturvetenskapliga programmet, Ålands Lyceum
#text(gray)[Augusti 2017 - Juni 2021]
= Kompetenser
- C/C++
- Rust
- Java
- Javascript/Typescript
- React Native
- Python
- SQL
- Prolog
- Haskell
- Matlab
- Linux
- Svenska
- Engelska
= Mjuka kompetenser
- Social
- Kommunikativ
- Nyfiken
- Flexibel
= Övrigt engagemang
- Ordförande för programmerings föreningen LiTHe Kod, verksamhetsåret 2024-2025
- Ideelt engagerad vid <NAME>
// = Länkar
// - #link("https://www.linkedin.com/in/morgan-nordberg-31457522b/")[
// LinkedIn: \
// ]
// #link("https://www.linkedin.com/in/morgan-nordberg-31457522b/")
// - #link("https://github.com/the-JS-hater")[
// Github: \
// ]
// #link("https://github.com/the-JS-hater")
= Intressen
- Schack
- Styrketräning
- Musik
]
)
]
)
|
|
https://github.com/GeorgeDong32/GD-Typst-Templates
|
https://raw.githubusercontent.com/GeorgeDong32/GD-Typst-Templates/main/README.md
|
markdown
|
Apache License 2.0
|
# GD Typst Templates
> 根据个人喜好创建的一些 Typst 模板
部分文件来自于 [GZTimeWalker/GZ-Typst-Templates: Typst Templates for my personal usage. (github.com)](https://github.com/GZTimeWalker/GZ-Typst-Templates)项目,遵循 MIT 协议。
## 使用准备
### 字体
你可能需要自己安装一些字体以实现最佳效果
- text: ("CMU Serif", "Source Han Serif SC"),
- sans: ("Source Han Sans SC"),
- code: ("Cascadia Code", "Consolas"),
|
https://github.com/7sDream/fonts-and-layout-zhCN
|
https://raw.githubusercontent.com/7sDream/fonts-and-layout-zhCN/master/chapters/06-features-2/substitution/extension.typ
|
typst
|
Other
|
#import "/template/template.typ": web-page-template
#import "/template/components.typ": note
#import "/lib/glossary.typ": tr
#show: web-page-template
// ### Extension Substitution
=== 扩展#tr[substitution]
// An extension substitution ("GSUB lookup type 7") isn't really a different kind of substitution so much as a different *place* to put your substitutions. If you have a very large number of rules in your font, the GSUB table will run out of space to store them. (Technically, it stores the offset to each lookup in a 16 bit field, so there can be a maximum of 65535 bytes from the lookup table to the lookup data. If previous lookups are too big, you can overflow the offset field.)
扩展#tr[substitution](也被称为 `GSUB lookup type 7`)并不和其他类型那样是另一种#tr[substitution]方法,而更像是另一个可以存放#tr[substitution]规则的地方。如果字体中有大量的规则,`GSUB`表中的储存空间可能会被用尽。(技术上的原因是,表示#tr[lookup]所在位置的偏移量字段是一个16位的数字,所以储存#tr[lookup]的整个数据表不能超过65525个字节。如果#tr[lookup]太大,就可能会让偏移量字段溢出。)
// Most of the time you don't need to care about this: your font editor may automatically use extension lookups; in some cases, the feature file compiler will rearrange lookups to use extensions when it determines they are necessary; or it may not support extension lookups at all. But if you are getting errors and your font is not compiling because it's running out of space in the GSUB or GPOS table, you can try adding the keyword `useExtension` to your largest lookups:
大多数时候你不需要为此操心,字体编辑软件会在需要时自动使用扩展#tr[lookup]。特性文件编译器可能会重排#tr[lookup],并在觉得必要时让其中一些使用扩展方式,或者也有可能不支持扩展#tr[lookup]。但如果在编译字体时出现`GSUB`或`GPOS`表空间不足的错误提示,你可以尝试给最大的#tr[lookup]添加一个`useExtension`关键字:
```fea
lookup EXTENDED_KERNING useExtension {
# 大量字偶矩规则
} EXTENDED_KERNING;
```
#note[
// > Kerning tables are obviously an example of very large *positioning* lookups, but they're the most common use of extensions. If you ever get into a situation where you're procedurally generating rules in a loop from a scripting language, you might end up with a *substitution* lookup that's so big it needs to use an extension. As mention in the previous chapter `fonttools feaLib` will reorganise rules into extensions automatically for you, whereas `makeotf` will require you to place things into extensions manually - another reason to prefer `fonttools`.
虽然`kern`表确实是扩展#tr[lookup]最常见的用例,但显然其中数量可能会超限的其实是#tr[positioning]规则。#tr[substitution]规则太多的情况也是有可能的,比如在为某种复杂的#tr[script]系统开发字体时,需要使用程序生成的方式编写规则,最终可能会因为产生了一个巨大的#tr[substitution]#tr[lookup],从而需要使用扩展方式。上一章中提到的`fontTools feaLib`工具会自动将规则重新组织为扩展#tr[lookup],而`makeotf`需要你手动处理它们。这也是更推荐使用`fontTools`的另一个原因。
]
|
https://github.com/Kasci/LiturgicalBooks
|
https://raw.githubusercontent.com/Kasci/LiturgicalBooks/master/SK/molebeny/molebenKBohorodicke.typ
|
typst
|
#import "/style.typ": *
#import "/styleMoleben.typ": *
= Moleben k Prečistej Bohorodičke
#align(horizon + center)[#primText[
#text(50pt)[Moleben k \
Prečistej \
Bohorodičke]
]]
#let values = (
"tropar1": (4, none, "My hriešni pokorne a vrúcne sa teraz utiekame k Bohorodičke. – Pokloňme sa jej a z hlbín duše volajme: – „Pomôž nám, Vládkyňa, a zľutuj sa nad nami. – Zachráň nás, lebo hynieme pre množstvo našich hriechov. – Neprepúšťaj naprázdno svojich služobníkov, – lebo ty jediná si naša Orodovnica.“"),
"tropar2": (none, none, "Nikdy neprestaneme my nehodní – ospevovať tvoju moc, Bohorodička. – Lebo, keby si ty neprosila a nezastávala sa nás, – ktože by nás zbavil toľkých bied? – Kto by nám doteraz zaistil slobodu? – Neopustíme ťa, Vládkyňa, – lebo ty, jediná požehnaná, – chrániš svojich služobníkov pred každým nešťastím."),
"velebenie": none,
"prokimen": (4, "Spomínať budem tvoje meno – z pokolenia na pokolenie.", "Lebo zhliadol na poníženosť svojej služobnice. Hľa, od tejto chvíle blahoslaviť ma budú všetky pokolenia."),
"evanjelium": ("Lk", "V tých dňoch sa Mária vydala na cestu a ponáhľala sa do istého judejského mesta v hornatom kraji. Vošla do Zachariášovho domu a pozdravila Alžbetu. Len čo Alžbeta začula Máriin pozdrav, dieťa v jej lone sa zachvelo a Alžbetu naplnil Svätý Duch. Vtedy zvolala veľkým hlasom: „Požehnaná si medzi ženami a požehnaný je plod tvojho života. Čím som si zaslúžila, že matka môjho Pána prichádza ku mne? Lebo len čo zaznel tvoj pozdrav v mojich ušiach, radosťou sa zachvelo dieťa v mojom lone. A blažená je tá, ktorá uverila, že sa splní, čo jej povedal Pán.“ Mária hovorila: „Velebí moja duša Pána a môj duch jasá v Bohu, mojom Spasiteľovi, lebo zhliadol na poníženosť svojej služobnice. Hľa, od tejto chvíle blahoslaviť ma budú všetky pokolenia, lebo veľké veci mi urobil ten, ktorý je mocný, a sväté je jeho meno.“ Mária zostala pri nej asi tri mesiace a potom sa vrátila domov."),
"verse": ("Presvätá <NAME>, Bohorodička najmilostivejšia, raduj sa a spas v teba dúfajúcich.", (
"Ó, Mária, <NAME>, pros vždy Boha za nás.",
"Matka nekonečnej lásky, raduj sa a spas v teba dúfajúcich.",
"<NAME>, raduj sa a spas v teba dúfajúcich.",
"Panna bez poškvrny hriechu počatá, raduj sa a spas v teba dúfajúcich.",
"Panna nad cherubínov uctievanejšia, raduj sa a spas v teba dúfajúcich.",
"Panna nad serafínov slávnejšia, raduj sa a spas v teba dúfajúcich.",
"Panna, holubica nepoškvrnená, raduj sa a spas v teba dúfajúcich.",
"Mária, nevädnúci kvet ľúbeznej vône, raduj sa a spas v teba dúfajúcich.",
"Mária, ochrankyňa panien, raduj sa a spas v teba dúfajúcich.",
"Mária, plášť sveta širší nad oblaky, raduj sa ..",
"Mária, uprosenie spravodlivého Sudcu, raduj sa a spas v teba dúfajúcich.",
"Mária, útecha plačúcich, raduj sa a spas v teba dúfajúcich.",
"Mária, orodovnica, pri svojom nanebovzatí nás neopúšťajúca, raduj sa a spas v teba dúfajúcich.",
"Mária, jediná čistá a milostiplná, raduj sa a spas v teba dúfajúcich."
)),
"stichiry": (
(2, "Jehda ot dreva", "Za všetkých modlíš sa, Dobrotivá, – ktorí sa s vierou utiekajú pod tvoj ochranný plášť. – Lebo my hriešni obťažení mnohými vinami, – nemáme pred Bohom iného osloboditeľa z bied a úzkostí, – len teba, Matka najvyššieho Boha. – Preto pred tebou padáme a prosíme: – Vysloboď svojich služobníkov z každého nebezpečenstva."),
("Spomínať budem tvoje meno z pokolenia na pokolenie."),
(none, none, "Radosť všetkých utrápených, – zástankyňa prenasledovaných, – živiteľka hladujúcich, – tešiteľka pohŕdaných, – prístav po mori plaviacich sa, – navštívenie nemocných, – ochrankyňa a orodovnica slabých, – opora staroby. – Matka najvyššieho Boha, – ty si najčistejšia, – ponáhľaj sa, prosíme, zachrániť svojich služobníkov."),
("Čuj, dcéra, a pozoruj a nakloň svoje ucho."),
(none, none, "Raduj sa, prečistá Panna. – Raduj sa, drahocenné žezlo Krista Kráľa. – Raduj sa, Rodička tajomného Viniča. – Raduj sa, brána nebeská a ker nespáliteľný. – Raduj sa, svetlo celého sveta. – Raduj sa, radosť všetkých. – Raduj sa, spása veriacich. – Raduj sa, Vládkyňa, orodovnica – a útočište všetkých kresťanov."),
(8, none, "Raduj sa, pochvala celého sveta. – Raduj sa, chrám Pána. – Raduj sa, hora zatienená. – Raduj sa, útočište všetkých. – Raduj sa, svietnik zlatý. – Raduj sa, velebená sláva pravoverných. – Raduj sa, <NAME>. – Raduj sa, rajská záhrada. – Raduj sa, božský stôl. – Raduj sa, stánok. – Raduj sa, rúčka zo zlata. – Raduj sa, nádej všetkých.")
),
"modlitba": "Moja najmilostivejšia Vládkyňa a nádej, Bohorodička, útočište sirôt, maják putujúcich, radosť utrápených, ochrana ukrivdených, vidíš moju biedu, vidíš moju úzkosť. Pomôž mi teda slabému. Nasýť ma putujúceho. Ty poznáš moje krivdy. Odstráň ich, keď chceš, lebo nemám inú pomoc okrem teba ani inú orodovnicu a dobrú tešiteľku, len teba, Božia Matka. Prijmi ma pod svoju ochranu a spas ma.",
"ektenia": (
"Zmiluj sa, Bože, nad nami pre svoje veľké milosrdenstvo, prosíme ťa, vypočuj nás a zmiluj sa.",
"Prosme, aby naše mesto (alebo obec) i ostatné mestá, obce a celá krajina boli uchránené od hladu, pohrôm, zemetrasenia, povodní, krupobitia, ohňa, meča, vpádu nepriateľa. Nech dobrý a láskyplný Boh vypočuje naše prosby a odvráti od nás svoj spravodlivý hnev a zmiluje sa nad nami.",
"Ešte sa modlime k Pánovi, Bohu nášmu, aby sa zmiloval nad nami, svojimi služobníkmi i nad všetkými kresťanmi, ktorí prichádzajú do tohoto svätého chrámu, aby nám odpustil hriechy a udelil nám hojné milosti a vždy vypočul naše prosby.",
"Vypočuj nás, Bože, Spasiteľu náš, nádej všetkých končín zeme, i tých, ktorí sú ďaleko na mori. Odpusť milostivo naše hriechy a zmiluj sa nad nami, lebo si dobrý a miluješ nás. Tebe, Otcu i Synu i Svätému Duchu, vzdávame slávu teraz i vždycky i na veky vekov."
)
)
#pagebreak()
#nacaloPoOtcenas
#tropar(..values.at("tropar1"))
#sit(..values.at("tropar2"))
#if values.at("velebenie") != none [#velebenie(..values.at("velebenie"))]
#note[Ľud sa postaví.]
#K[Vnímajme! Pokoj všetkým! Premúdrosť, vnímajme!]
#prokimen(..values.at("prokimen"))
#chvaly()
#pagebreak()
#evanjelium(..values.at("evanjelium"))
#pagebreak()
#verse(..values.at("verse"))
#pagebreak()
#stichiry(values.at("stichiry"))
#modlitba(values.at("modlitba"))
#ektenia(values.at("ektenia"))
#pagebreak()
#prepustenie
|
|
https://github.com/frectonz/the-pg-book
|
https://raw.githubusercontent.com/frectonz/the-pg-book/main/book/053.%20procrastination.html.typ
|
typst
|
procrastination.html
Good and Bad Procrastination
December 2005The most impressive people I know are all terrible procrastinators.
So could it be that procrastination isn't always bad?Most people who write about procrastination write about how to cure
it. But this is, strictly speaking, impossible. There are an
infinite number of things you could be doing. No matter what you
work on, you're not working on everything else. So the question
is not how to avoid procrastination, but how to procrastinate well.There are three variants of procrastination, depending on what you
do instead of working on something: you could work on (a) nothing,
(b) something less important, or (c) something more important. That
last type, I'd argue, is good procrastination.That's the "absent-minded professor," who forgets to shave, or eat,
or even perhaps look where he's going while he's thinking about
some interesting question. His mind is absent from the everyday
world because it's hard at work in another.That's the sense in which the most impressive people I know are all
procrastinators. They're type-C procrastinators: they put off
working on small stuff to work on big stuff.What's "small stuff?" Roughly, work that has zero chance of being
mentioned in your obituary. It's hard to say at the time what will
turn out to be your best work (will it be your magnum opus on
Sumerian temple architecture, or the detective thriller you wrote
under a pseudonym?), but there's a whole class of tasks you can
safely rule out: shaving, doing your laundry, cleaning the house,
writing thank-you notes—anything that might be called an errand.Good procrastination is avoiding errands to do real work.Good in a sense, at least. The people who want you to do the errands
won't think it's good. But you probably have to annoy them if you
want to get anything done. The mildest seeming people, if they
want to do real work, all have a certain degree of ruthlessness
when it comes to avoiding errands.Some errands, like replying to letters, go away if you
ignore them (perhaps taking friends with them). Others, like mowing
the lawn, or filing tax returns, only get worse if you put them
off. In principle it shouldn't work to put off the second kind of
errand. You're going to have to do whatever it is eventually. Why
not (as past-due notices are always saying) do it now?The reason it pays to put off even those errands is that real work
needs two things errands don't: big chunks of time, and the
right mood. If you get inspired by some project, it can be a net
win to blow off everything you were supposed to do for the next few
days to work on it. Yes, those errands may cost you more time when
you finally get around to them. But if you get a lot done during
those few days, you will be net more productive.In fact, it may not be a difference in degree, but a difference in
kind. There may be types of work that can only be done in long,
uninterrupted stretches, when inspiration hits, rather than dutifully
in scheduled little slices. Empirically it seems to be so. When
I think of the people I know who've done great things, I don't
imagine them dutifully crossing items off to-do lists. I imagine
them sneaking off to work on some new idea.Conversely, forcing someone to perform errands synchronously is
bound to limit their productivity. The cost of an interruption is
not just the time it takes, but that it breaks the time on either
side in half. You probably only have to interrupt someone a couple
times a day before they're unable to work on hard problems at all.I've wondered a lot about why
startups are most productive at the
very beginning, when they're just a couple guys in an apartment.
The main reason may be that there's no one to interrupt them yet.
In theory it's good when the founders finally get enough money to
hire people to do some of the work for them. But it may be better
to be overworked than interrupted. Once you dilute a startup with
ordinary office workers—with type-B procrastinators—the whole
company starts to resonate at their frequency. They're interrupt-driven,
and soon you are too.Errands are so effective at killing great projects that a lot of
people use them for that purpose. Someone who has decided to write
a novel, for example, will suddenly find that the house needs
cleaning. People who fail to write novels don't do it by sitting
in front of a blank page for days without writing anything. They
do it by feeding the cat, going out to buy something they need for
their apartment, meeting a friend for coffee, checking email. "I
don't have time to work," they say. And they don't; they've made
sure of that.(There's also a variant where one has no place to work. The cure
is to visit the places where famous people worked, and see how
unsuitable they were.)I've used both these excuses at one time or another. I've learned
a lot of tricks for making myself work over the last 20 years, but
even now I don't win consistently. Some days I get real work done.
Other days are eaten up by errands. And I know it's usually my
fault: I let errands eat up the day, to avoid
facing some hard problem.The most dangerous form of procrastination is unacknowledged type-B
procrastination, because it doesn't feel like procrastination.
You're "getting things done." Just the wrong things.Any advice about procrastination that concentrates on crossing
things off your to-do list is not only incomplete, but positively
misleading, if it doesn't consider the possibility that the to-do
list is itself a form of type-B procrastination. In fact, possibility
is too weak a word. Nearly everyone's is. Unless you're working
on the biggest things you could be working on, you're type-B
procrastinating, no matter how much you're getting done.In his famous essay You and Your Research
(which I recommend to
anyone ambitious, no matter what they're working on), <NAME>
suggests that you ask yourself three questions:
What are the most important problems in your field? Are you working on one of them? Why not?
Hamming was at Bell Labs when he started asking such questions. In
principle anyone there ought to have been able to work on the most
important problems in their field. Perhaps not everyone can make
an equally dramatic mark on the world; I don't know; but whatever
your capacities, there are projects that stretch them. So Hamming's
exercise can be generalized to:
What's the best thing you could be working on, and why aren't
you?
Most people will shy away from this question. I shy away from it
myself; I see it there on the page and quickly move on to the next
sentence. Hamming used to go around actually asking people this,
and it didn't make him popular. But it's a question anyone ambitious
should face.The trouble is, you may end up hooking a very big fish with this
bait. To do good work, you need to do more than find good projects.
Once you've found them, you have to get yourself to work on them,
and that can be hard. The bigger the problem, the harder it is to
get yourself to work on it.Of course, the main reason people find it difficult to work on a
particular problem is that they don't
enjoy it. When you're young,
especially, you often find yourself working on stuff you don't
really like-- because it seems impressive, for example, or because
you've been assigned to work on it. Most grad students are stuck
working on big problems they don't really like, and grad school is
thus synonymous with procrastination.But even when you like what you're working on, it's easier to get
yourself to work on small problems than big ones. Why? Why is it
so hard to work on big problems? One reason is that you may not
get any reward in the forseeable future. If you work on something
you can finish in a day or two, you can expect to have a nice feeling
of accomplishment fairly soon. If the reward is indefinitely far
in the future, it seems less real.Another reason people don't work on big projects is, ironically,
fear of wasting time. What if they fail? Then all the time they
spent on it will be wasted. (In fact it probably won't be, because
work on hard projects almost always leads somewhere.)But the trouble with big problems can't be just that they promise
no immediate reward and might cause you to waste a lot of time. If
that were all, they'd be no worse than going to visit your in-laws.
There's more to it than that. Big problems are terrifying.
There's an almost physical pain in facing them. It's like having
a vacuum cleaner hooked up to your imagination. All your initial
ideas get sucked out immediately, and you don't have any more, and
yet the vacuum cleaner is still sucking.You can't look a big problem too directly in the eye. You have to
approach it somewhat obliquely. But you have to adjust the angle
just right: you have to be facing the big problem directly enough
that you catch some of the excitement radiating from it, but not
so much that it paralyzes you. You can tighten the angle once you
get going, just as a sailboat can sail closer to the wind once it
gets underway.If you want to work on big things, you seem to have to trick yourself
into doing it. You have to work on small things that could grow
into big things, or work on successively larger things, or split
the moral load with collaborators. It's not a sign of weakness to
depend on such tricks. The very best work has been done this way.When I talk to people who've managed to make themselves work on big
things, I find that all blow off errands, and all feel guilty about
it. I don't think they should feel guilty. There's more to do
than anyone could. So someone doing the best work they can is
inevitably going to leave a lot of errands undone. It seems a
mistake to feel bad about that.I think the way to "solve" the problem of procrastination is to let
delight pull you instead of making a to-do list push you. Work on
an ambitious project you really enjoy, and sail as close to the
wind as you can, and you'll leave the right things undone.Thanks to <NAME>, <NAME>, and <NAME> for reading drafts of this.Romanian TranslationRussian TranslationHebrew TranslationGerman TranslationPortuguese TranslationItalian TranslationJapanese TranslationSpanish Translation
|
|
https://github.com/kumatheworld/kurose-ross-solutions
|
https://raw.githubusercontent.com/kumatheworld/kurose-ross-solutions/main/main.typ
|
typst
|
#import "template.typ": *
#show: project.with(
title: "Exercise Solutions to Computer Networking: A Top-Down Approach, 8th edition by <NAME> and <NAME>",
authors: (
"<NAME>",
),
date: datetime.today().display(),
)
#set heading(numbering: (..args) => {
let nums = args.pos()
if nums.len() == 1 {
return "Chapter " + numbering("1:", ..nums)
}
})
= Computer Networks and the Internet
== Review Questions
#show: enumb.with(pref: "R")
+ A host and an end system are the same thing. Phones or laptops connected to the Internet are examples of end systems. A Web server is also an end system.
+ #quote(block: true, attribution: link("https://en.wikipedia.org/wiki/Protocol_(diplomacy)"))[Protocol is commonly described as a set of international courtesy rules. These well-established and time-honored rules have made it easier for nations and people to live and work together. Part of protocol has always been the acknowledgment of the hierarchical standing of all present. Protocol rules are based on the principles of civility.—Dr. P.<NAME> on behalf of the International Association of Protocol Consultants and Officers.]
+ Standards are important so that people can create products and systems that can interoperate.
+ Access technologies can be classified as follows.
/ Home access: digital subscriber line (DSL), cable Internet access, fiber to the home (FTTH), 5G fixed wireless, Ethernet, Wi-Fi.
/ Enterprise access: Ethernet, Wi-Fi.
/ Wide-area wireless access: 3G, LTE 4G, 5G.
+ HFC transmission rate is shared among users. Collisions are not possible as it is a shared broadcast medium.
+ Below are a few examples.
#table(
columns: 5,
table.header[*Name*][*Type of access*][*Downstream rate*][*Upstream rate*][*monthly price*],
[#link("https://www.catv-yokohama.ne.jp/customer/internet/")[YCV NET 1G]], [DOCSIS], [Up to 1 Gbps], [Up to 100 Mbps], [7,788 JPY/month],
[#link("https://network.mobile.rakuten.co.jp/hikari/")[Rakuten Hikari]], [FTTH], [Up to 1 Gbps], [Up to 1 Gbps], [5,280 JPY/month],
[#link("https://www.uqwimax.jp/wimax/")[UQ WiMax]], [BWA], [Up to 4.2 Gbps], [Up to 286 Mbps], [5,346 JPY/month],
)
+ Users typically have 100 Mbps to tens of Gbps.
+ Some examples are twisted-pair copper wire, coaxial cable, and optical fiber.
+ The table below shows transmission rates according to some standards for HFC and DSL. In the case of FTTH, the transmission rate is potentially several Gbps fast.
#table(
columns: 3,
table.header[*Type of access*][*Downstream transmission*][*Upstream transmission*],
[HFC], [Dedicated, 1.2 Gbps], [Dedicated, 100 Mbps], [DSL], [Dedicated, 52 Mbps], [Dedicated, 16 Mbps],
[FTTH], [Dedicated, several Gbps], [Dedicated, several Gbps],
)
+ Cellular network technologies (3G and LTE 4G and 5G) and Wi-Fi seem the most popular ones today. From the user's perspective, the biggest difference would be the range. With a cellular network, a user need only be within a few tens of kilometers of the base station, whereas with Wi-Fi, they have to be within a few tens of meters of the access point.
+ $L(1/R_1+1/R_2)$.
+ Dircuit-switching is better than packet-switching in that it establishes an end-to-end connection between the hosts, in which the transmission rate is guaranteed constant. In a circuit-switched network, every circuit of TDM has the same transmission rate, which might make TDM a better choice than FDM.
+
+ 2 Mbps / (1 Mbps / user) = 2 users
+ We can see from the above that a queuing delay can occur if and only if more than 2 users transmit simultaneously.
+ 20% = 0.2 as given.
+ The queue grows if and only if all three users are transmitting simultaneously, the probability of which is $(0.2)^3=0.008$.
+ Two ISPs at the same level of the hierarchy will often peer with each other because it is typically settlement-free as opposed to paying the upstream ISPs. IXPs earn money by charging the traffic exchanged by the downstream access ISPs.
+ Google has many data centers all over the world interconnected via their private TCP/IP network, separate from the public Internet. The network is connected with tier-1 ISPs as well as peering with lower-tier ISPs. By creating its own network, a content provider not only reduces its payments to upper-tier ISPs but also has greater control over how its services are ultimately delivered to end users.
+ The nodal delays consist of the processing delay, queuing delay, transmission delay, and propagation delay. The queuing delay is variable as it depends on how many packets are sent to each link. The other three are constant given that the packet length and transmission rates are fixed.
+ Length, Rate and Packet size are shown as configurable parameters on the website. When (Length, Rate, Packet size) = (10 km, 100 Mbps, 100 Bytes), the sender finishes transmitting before the first bit of the packet reaches the receiver. When (Length, Rate, Packet size) = (10 km, 1 Mbps, 100 Bytes), the first bit of the packet reaches the receiver before the sender finishes transmitting.
+ In general, given $L$ [bytes], $d$ [m], $s$ [m/s], and $R$ [bit/s], the transmission delay and propagation delay are $8L\/R$ [s] and $d\/s$ [s] respectively. The transmission delay depends on both the packet length and the transmission rate, but the propagation delay doesn't depend on either of them. When $L=1,000$, $d=2,500times 10^3$, $s=2.5times 10^8$, and $R=2times 10^6$, it takes $8dot 1,000\/(2dot 10^6)+(2,500dot 10^3)\/(2.5times 10^8)=0.004+0.01=0.014$ seconds to propagate.
+
+ $min(R_1,R_2,R_3)=500$ kbps.
+ $8dot 4dot 10^6\/(500dot 10^3)=64$ seconds.
+ The throughput will be $min(R_1,R_2,R_3)=100$ kbps. It will take $64dot 500\/100=320$ seconds to transfer the file.
+ End system A creates packets by dividing the file and attaching to each chunk an IP header including the source and destination IP addresses. The router uses the destination IP address to determine the link onto which the packet is forwarded. Packet switching in the Internet is analogous to driving from one city to another and asking directions along the way because the end-to-end route is determined on the fly rather than ahead of time.
+ The maximum emission rate is 500 packets/s and the minimum transmission rate is 350 packets/s. With those rates, the traffic intensity is the ratio $500\/350=1.43$. It takes about 9.5 mses for packet loss to occur. Repeating the experiment gives you the same amount of time for packet loss to occur because packets arrive periodically.
+ Skipped for now.
+ The five layers are as follows, from the top to the bottom:
- *Application layer* is where network applications and their application-layer protocols reside.
- *Transport layer* transports application-layer messages between application endpoints.
- *Network layer* moves datagrams from one host to another, determining the route between them.
- *Link layer* moves frames from one node to the next along the route from one host to another.
- *Physical layer* moves the individual bits within frames from one node to the next.
+ Those are what a packet is called in each layer.
+ A router processes the network layer. A link-layer switch processes the link layer. A host processes all five layers.
+ A self-replicating malware is malicious software that continues to infect hosts through the Internet from an already infected host.
+ A botnet can be created by forming a network of infected hosts. The attacker can then have the compromised hosts blast traffic at the target.
== Problems
#show: enumb.with(pref: "P")
+ Skipped for now.
+ $d#sub[end-to-end]=(N+P-1)L/R$ as it takes $N L/R$ to send one packet and adding another from the rest $P-1$ packets will each take an additional $L/R$ by pipelining.
+
+ A circuit-switched network would be more appropriate for this application as it would have to establish a connection repeatedly with packet switching.
+ No form of congestion control is needed as all the packets will travel across the network without any queuing delay.
+
+ There are $4dot 4=16$ links and there can be as many connections when every connection is made between neighboring nodes.
+ $4plus 4$ connections can be made, each by way of either switch $B$ or $D$.
+ Yes we can by establishing 2 connections on each of the following paths: ABC, ADC, BAD, and BCD.
+ Since the assumption in the analogy that tollbooths are located every 100km is not consistent with this problem, we instead assume that the first and third tollbooths are 175km away, having the second one somewhere in between. We also assume that each tollbooth services a car at a rate of one car per 12 seconds as in the former setting of the analogy.
+ The transmission delay is $3dot 10dot 12$ seconds $=6$ minutes. The propagation delay is $175\/100$ hours $=105$ minutes. Therefore, the end-to-end delay is $6+105=111$ minutes long.
+ The transmission delay is now $3dot 8dot 12$ seconds $=4.8$ minutes, whereas the propagation delay remains the same. Thus the total delay is $4.8+105=109.8$ minutes long.
+
+ $d#sub[prop]=m\/s$.
+ $d#sub[trans]=L\/R$.
+ $d#sub[end-to-end]=d#sub[prop]+d#sub[trnas]=m\/s+L\/R$.
+ It is at the A-side end of the link.
+ It is at the B-side end of the link.
+ It is somewhere between the two ends of the link.
+ $m=s dot L\/R=2.5dot 10^5 "[km/sec]"dot 8dot 1500 "bits"\/(10dot 10^6 "bps")=300$ km.
+ We have 3 kinds of delays to consider:
- The conversion delay $d#sub[conv]$, which we define as the time needed to convert the rest of the bits including the bit we are interested in. If it is the $n$-th bit in the packet counting from the back where $1<=n<=448$ is an integer, $d#sub[conv]=n\/(64 "kbps")=0.016n$ [msec].
- The transmission delay $d#sub[trans]=56 "bytes" \/(10 "Mbps")=0.0448$ msec.
- The propagation delay $d#sub[prop]=10$ msec.
Therefore, the overall delay is $d#sub[conv]+d#sub[trans]+d#sub[prop]=0.016n+10.448$ msec. The first bit ($n=448$) has a delay of 17.45 msec and the last bit ($n=1$) has a delay of 10.46 msec.
+
+ $10 "[Mbps]"\/(200 "[kbps]/user")=50$ users can be supported.
+ 10 percent as given.
+ $vec(120,n)dot 9^(120-n)\/10^120$.
+ $sum_(n=51)^120 vec(120,n)dot 9^(120-n)\/10^120=2.1dot 10^(-20)$.
+
+ $N=1 "[Gbps]"\/(100 "[kbps]")=10,000$.
+ $sum_(n=N+1)^M vec(M,n)dot p^n (1-p)^(M-n)$ or equivalently, $sum_(n=1)^N vec(M,n)dot p^(M-n) (1-p)^n$.
+ The processing, transmission, and propagation delay are $2d#sub[proc]$, $L sum_(i=1)^3 1\/R_i$, and $sum_(i=1)^3 d_i\/s_i$, respectively. Therefore, the total end-to-end delay $d#sub[end-to-end]$ is the sum $2d#sub[proc]+L sum_(i=1)^3 1\/R_i+sum_(i=1)^3 d_i\/s_i$. For those values given, $d#sub[end-to-end]=2dot 3 "msec"+3dot 1,500 "bytes"\/(2.5 "Mbps")+(5,000+4,000+1,000) "km"\/(2.5dot 10^8 "m/s")=(6+14.4+40) "msec"=60.4$ msec.
+ The processing, transmission, and propagation delay are 0, $L\/R$, and $sum_(i=1)^3 d_i\/s_i$, respectively. Therefore, the total end-to-end delay is the sum $L\/R+sum_(i=1)^3 d_i\/s_i$.
+ The queuing delay $d#sub[queue]$ is given by $d#sub[queue]=(n L-x)\/R$, being equal to the transmission delay of the bits ahead. For those values given, we have $d#sub[queue]=4.5dot 1,500 "bytes"\/(2.5 "Mbps")=21.6$ msec.
+
+ The $n$-th packet has the queuing delay $(n-1)L\/R$ as the transmission delay of the $(n-1)$ packets ahead. Therefore, the average queuing delay is $(sum_(n=1)^N (n-1)L\/R)\/N=(N-1)L\/2R$.
+ Since $L N\/R$ is long enough to transmit $N$ packets, the average queuing delay is the same as above $(N-1)L\/2R$.
+
+ The queuing and transmission delay are $I L\/R(1-I)$ and $L\/R$ respectively. Therefore, the total delay $d$ is the sum $d=I L\/R(1-I)+L\/R=L\/R(1-I)$.
+ Let $r=L\/R$. The total delay $d=L\/R(1-I)=r\/(1-a r)$ as a function of $r$ looks like the following. Here we set $a=5$, but the shape of the curve will remain the same with other values as well.
#image("extra/c1p14b.png")
+ $I=a\/mu$ holds. Hence the total delay is $L\/R(1-I)=I\/(1-I)a=1\/(mu-a)$.
+ From Little's formula, it holds that $a=N\/(d#sub[trans]+d#sub[queue])$, where $d#sub[trans]$ and $d#sub[queue]$ are the transmission and queuing delay, respectively. With those values given, we have $d#sub[trans]=1\/(100 "packets/sec")=10$ msec/packet, $d#sub[queue]=20 "msec/packet"$, and $a=100\/((10+20) "msec/packet")=3.33$ packets/msec.
+
+ It holds that $d#sub[end-to-end]=sum_i^N (d_"proc"^i+d_"trans"^i+d_"prop"^i)$, where $d_"proc"^i$, $d_"trans"^i$, and $d_"prop"^i$ are $i$-th router's processing, transmission, and propagation delay, respectively.
+ $d#sub[end-to-end]=(N-1)d_"queue"+sum_i^N (d_"proc"^i+d_"trans"^i+d_"prop"^i)$.
+ See #link("extra/c1p18.sh") and #link("extra/c1p18.txt") for reference.
+ 15.22 #sym.plus.minus 0.23 ms, 15.30 #sym.plus.minus 0.62 ms, and 14.05 #sym.plus.minus 0.07 ms.
+ The paths and the number of routers did not change.
+ There are at least 3 ISP networks, namely ntlworld.ie, aorta.net, and Google. The largest delay occurred within Google's network.
+ The traceroute program does not show the hops close to the destination, but the farthest routers show values around 110ms, which should be close to the actual end-to-end RTT to the destination. The path changed slightly within the gw.umass.edu network. There are at least 3 ISP networks, namely ntlworld.ie, aorta.net, and gtt.net. The largest delay occurred within gtt.net, which was between ae6.cr0-dub2.ip4.gtt.net and et-0-0-5.cr1-bos1.ip4.gtt.net. Those intra-continental and inter-continental results show that the latter was an order of magnitude slower due to the inter-continental link.
+ $n(n-1)$ messages will be sent. Yes, it does support Metcalfe's law.
+ $min{R_s,R_c,R\/M}$.
+ If the server can only use one path to send data to the client, the maximum throughput is $max_(k=1,dots,M)min_(i=1,dots,n)R_i^k$. If the server can use all $M$ paths to send data, the maximum throughput is $sum_(k=1)^M min_(i=1,dots,n)R_i^k$.
+ The probability that a packet sent by the server is successfully received by the receiver is $(1-p)^N$. On average, the server will re-transmit the packet as many times as $sum_(i=0)^infinity i(1-(1-p)^N)^i (1-p)^N=1\/(1-p)^N-1$. The formula diverges to infinity if $p=1$, showing that retransmissions continue indefinitely.
+
+ It is $L\/R_s$, which is the bigger of the two transmission delays since there will be no queuing at the router.
+ The second packet queues if and only if the transmission delay $L\/R_c$ of the first packet at the router is bigger than $L\/R_s+d#sub[prop]$, which is the time it takes for the second packet to reach the router. If that is the case, the second packet will have to wait for $T=L\/R_c-L\/R_s-d#sub[prop]$ seconds to ensure no queuing.
+ It would take $50 "TB"\/(100 "Mbps")=4dot 10^6 "seconds"approx 46.3$ days via the link, so I would prefer FedEx overnight delivery.
+
+ $d#sub[prop]=20,000 "km"\/(2.5dot 10^8 "m/sec")=0.08$ sec, so that $R dot d#sub[prop]=5 "Mbps"dot 0.08 "sec"=4dot 10^5$ bits.
+ If we denote it as $L$ bits, by the time the first bit arrives at Host B, $L\/R$ bits will have been transmitted. Hence $L\/R=d_#sub[prop]$ holds and we get $L=R dot d#sub[prop]=4dot 10^5$ bits. This is smaller than the file size of $8dot 10^6$ bits.
+ From the above, it can be seen as the maximum number of bits that will be in the link at any given time.
+ A bit is $20,000 "km"\/(4dot 10^5)=50$ meters long. It is shorter than the football field length of 360 feet.
+ It is $s\/(R dot d#sub[prop])=m\/(R dot m\/s)=s\/R$.
+ $m=s\/R$ holds, so that $R=s\/m=(2.5dot 10^8 "m/s")\/(20,000 "km")=12.5$ bps.
+
+ $R dot d#sub[prop]=500 "Mbps"dot 0.08 "sec"=4dot 10^7$ bits.
+ Now that the file size is smaller, all of the $800,000$ bits will be in the link when the last bit is transmitted.
+ $s\/R=(2.5dot 10^8 "m/s")\/(500 "Mbps")=0.5$ meters/bit.
+
+ The transmission delay $d#sub[trans]$ is $800,000 "bits"\/(5 "Mbps")=0.160$ seconds, so that the total delay is $d#sub[trans]+d#sub[prop]=0.160+0.08 "sec"=240$ msec.
+ The transmission delay of one packet is $40,000 "bits"\/(5 "Mbps")=0.008$ seconds, so it takes $0.008+0.08 "sec"=0.088$ sec to send it and get it acknowledged. Since the packets cannot be pipelined, it takes $20dot 0.088 "sec"=1.76$ sec to send the file.
+ The latter takes more than 7 times as much time.
+
+ The altitude of a geostationary satellite is 35,786 km high, so the propagation delay is $35,786 "km"\/(2.4dot 10^8 "m/s")=149$ msec.
+ $R dot d#sub[prop]=10 "Mbps"dot 149 "msec"=1.49dot 10^6$ bits.
+ $x\/R=d#sub[prop]$ holds, so that $x_min=R dot d#sub[prop]=1.49dot 10^6$ bits.
+ Baggage tags are equivalent to header information.
+
+ It takes as much as the transmission delay of $10^6 "bits"\/(5 "Mbps")=200$ msec to move the message from the source host to the first packet switch. Since there are 3 links and each switch uses store-and-forward packet switching, it takes 3 times as much time, which is 600 msec, to move the message to the destination host.
+ It takes $10^4 "bits"\/(5 "Mbps")=2$ msec to move the first packet from the source host to the first packet switch. The second packet to arrive at the first router at time $2 "msec"+2 "msec"=4$ msec.
+ At time $100dot 2 "msec"=200$ msec, the last packet will be at the first router. It takes another $2dot 2 "msec"=4$ msec to deliver it to the destination, so it takes $200 "msec"+4 "msec"=204$ msec in total to move all of the packets to the destination. It is nearly 3 times as fast as sending the whole message at once, showing that the speedup rate you could get from message segmentation is up to as much as the number of links.
+ Message integrity check and encryption will be easier. Moreover, other packets will queue less since they can interleave the segmented messages.
+ Additional header information will be required, which increases the number of bits to be sent. Message reassembly might not be trivial when a packet is lost halfway through.
+ The delays in the interactive animation indeed correspond to the delays in the previous problem. Message switching with message size 16 took nearly 3 times as much as message segmentation with package size 1 kbit. Link propagation delays equally increase the overall end-to-end delay regardless of the package size, making the ratio a little smaller.
+ It takes $(F\/S+2)L\/R=(2S+80F\/S+F+160)\/R$ to move the file from Host A to Host B. By the AM-GM inequality, this value is at minimum when $2S=80F\/S$, which is $S=4sqrt(10F)$.
+ It is conceivable that Skype manages routers that both understand IP and a telephone network protocol, through which a PC and an ordinary phone can be connected.
== Wireshark Lab: Getting Started
#set enum(numbering: "1.")
My experimental result is saved as #link("extra/c1w.pcapng").
+ TLSv1, ARP and SSDP were found.
+ It took 106 msec.
+ The address of gaia.cs.umass.edu is 192.168.3.11. The address of my computer is 10.15.14.11.
+ See #link("extra/c1w.pcapng").
= Application Layer
== Review Questions
#show: enumb.with(pref: "R")
+ Below are a few examples.
#table(
columns: 2,
table.header[*Application*][*Protocol*],
[Web], [HTTP],
[Email], [SMTP],
[Remote terminal access], [Telnet],
[File transfer], [FTP],
[IP address resolution], [DNS]
)
+ The network architecture determines how network devices communicate with each other. It is the five-layer architecture in today's Internet. On the other hand, the application architecture dictates how the application is structured over the various end systems. Common application architectural paradigms include the client-server architecture and the peer-to-peer (P2P) architecture.
+ The client is the host that initiates the connection. The server is the other, waiting for the connection to begin.
+ I do not agree because each session is governed by two hosts just as in the client-server architecture, the one downloading the file being the client and the one uploading it being the server.
+ An IP address and a port number.
+ I would use UDP to circumvent the congestion control and flow control of TCP.
+ Collaborative document editing would be an example.
+ Below are the four classes of services and whether each is supported by TCP or UDP.
#table(
columns: 2,
table.header[*Service*][*Supported by*],
[Reliable data transfer], [TCP],
[Throughput], [Neither],
[Timing], [Neither],
[Security], [Neither],
)
+ TLS operates at the application layer. If the application developer wants TCP to be enhanced with TLS, the developer has to pass the cleartext data through the TLS socket.
+ To establish a connection between the two hosts before exchanging actual messages.
+ Those protocols require no data loss to occur. TCP guarantees reliable data transfer but UDP does not.
+ When the customer's browser visits the website for the first time, the server generates a cookie, stores it in its database and includes it in the HTTP response message. The browser then stores the cookie and includes it in the subsequent HTTP request messages. The server stores customer's information such as a purchase record by using the cookie as the key, which the browser can retrieve by the stored cookie.
+ A web cache sits between the client and the server and delivers objects requested by the client on the server's behalf, avoiding potentially slow links on the way from the server. Web caching reduces the delay for requested objects that have not been modified.
+ ```sh
$ telnet gaia.cs.umass.edu 80
Trying 192.168.3.11...
Connected to gaia.cs.umass.edu.
Escape character is '^]'.
HEAD /index.html HTTP/1.1
Host: gaia.cs.umass.edu
If-Modified-Since: Fri, 24 May 2024 12:34:56 GMT
HTTP/1.1 304 Not Modified
Date: Sat, 25 May 2024 19:20:25 GMT
Server: Apache/2.4.6 (CentOS) OpenSSL/1.0.2k-fips PHP/7.4.33 mod_perl/2.0.11 Perl/v5.16.3
ETag: "a5b-52d015789ee9e"
```
+ WhatsApp, WeChat and LINE are some popular messaging apps. WhatsApp uses a variation of XMPP @xmpp, WeChat uses MMTLS @8711267, and LINE uses ECDH @ecdh, all running on the TCP/IP protocol suite of the Internet. On the other hand, while SMS messages can be transmitted over XMPP, SMS usually uses different sets of protocols, which might or might not incorporate TCP/IP.
+ The message is transmitted as follows: Alice's host $limits(arrow.r)^"HTTP"$ Alice's mail server $limits(arrow.r)^"SMTP"$ Bob's mail server $limits(arrow.r)^"IMAP"$ Bob's host.
+ There were 4 `Received:` header lines in the latest email in my inbox. @email_headers explains some of the following headers in the email: `Arc-Seal`, `X-Sg-Eid`, `X-Sg-Id`, `X-Received`, `Return-Path`, `Arc-Authentication-Results`, `X-Google-Smtp-Source`, `Mime-Version`, `Authentication-Results`, `X-Entity-Id`, `Arc-Message-Signature`, `Dkim-Signature`, `Dkim-Signature`, `X-Feedback-Id`, `Content-Type`, `Received-Spf`, `Delivered-To`, `Received`. For example, `Delivered-To` shows the recipient, which in the email coincided with my email address.
+ HOL blocking is a phenomenon where a large object in transmission prevents the subsequent elements from being transmitted. HTTP/2 attempts to solve it by sending objects in a round-robin manner, transmitting small chunks of objects alternatingly.
+ Yes, an organization’s Web server and mail server can have the exact same alias for a hostname because the host can open ports for both HTTP/HTTPS and SMTP at the same time. The type for the RR that contains the hostname of the mail server would be MX.
+ In my received email from `harvard.edu`, several headers including `Received` had a common IP address associated with `amazonses.com`, which is supposedly used by harvard.edu. I did not find an IP address in the header of another email from `gmail.com`.
+ Bob will not necessarily return the favor and provide chunks to Alice in this same interval as she might not want any chunks during that time. However, he'll be a more likely peer to give chunks to Alice if she needs them during and within 10 seconds after the interval.
+ She will be randomly selected as an optimistically unchoked peer and get her first chunks.
+ An overlay network is a graph on top of another network, where the vertices are hosts and the edges are connections. Routers are abstracted away as part of an edge.
+ The two philosophies are Enter Deep and Bring Home. The former deploys server clusters in access ISPs all over the world while the latter builds large clusters at a smaller number of sites, typically placing those in Internet Exchange Points (IXPs). The former offers lower delay and higher throughput to end users while the latter has lower maintenance and management overhead.
+ UDP needs one socket on the server side because it is a connectionless protocol. On the other hand, TCP is a connection-oriented protocol, having a welcoming socket separately from the connection socket. If the TCP server were to support $n$ simultaneous connections, each from a different client host, the TCP server would need at least $n+1$ sockets, one welcoming socket for all the clients and one connection socket for each client.
+ Load balancing and ISP delivery cost are some important factors.
+ Precisely speaking, both the UDP program pair and the TCP program pair need the server to be ready first. However, there is a difference between the two in how late the server can be ready and in how the client fails if the server is not running. In the UDP case, the server has to be ready by the time the client executes `clientSocket.sendto()`. If the server is not ready, `clientSocket.sendto()` will not err and `clientSocket.recvfrom()` will hang up. On the other hand, in the TCP case, the server has to be ready by the time the client executes `clientSocket.connect()`, where an exception `ConnectionRefusedError` will be raised if the server is not ready. This is because TCP needs an interactive handshake before actual data is sent while UDP allows the client to send data without a connection.
== Problems
#show: enumb.with(pref: "P")
+
+ False. There will be four requests and four responses since there are four objects, each of which needs one request and one response.
+ True as long as the two web pages reside on the same host.
+ False. With nonpersistent connections, a connection is closed after sending a message.
+ False. It shows the time the HTTP message was created.
+ False. For example, a `304 Not Modified` response will not include a message body.
+ Below is a table of applications and the protocols they use. iMessage and WeChat use proprietary protocols. In terms of security, PQ3 is more secure than XMPP, which is more secure than MMTLS, according to @pq3.
#table(
columns: 2,
table.header[*Application*][*Protocol(s)*],
[SMS], [Standardized protocols such as SMPP @smpp],
[iMessage], [It is based on Apple Push Notification service (APNs) @apns and leverages PQ3 @pq3 for security],
[WeChat], [MMTLS @8711267],
[WhatsApp], [XMPP @xmpp],
)
+ DNS is needed to resolve the hostname, which needs UDP. In the case of HTTP/3, QUIC is used, which also needs UDP. TCP is needed otherwise.
+
+ `GET /cs453/index.html HTTP/1.1` and `gaia.cs.umass.edu` show that the requested URL is `http://gaia.cs.umass.edu/cs453/index.html`.
+ `HTTP/1.1` shows that HTTP version 1.1 is used.
+ Both `Keep-Alive: 300` and `Connection:keep-alive` show that a persistent connection is used.
+ It is not shown in the request.
+ A Netscape browser initiates the message @netscape. The browser type is needed in an HTTP request message because the server may use the information to process the request. For example, the server can reject the request from a specific type of browser.
+
+ `HTTP/1.1 200 OK` and `Date: Tue, 07 Mar 2008 12:39:45GMT` show that the document was found and the reply was provided at that time.
+ `Last-Modified: Sat, 10 Dec2005 18:27:46 GMT` shows that the document was modified at that time.
+ `Accept-Ranges: bytes` and `Content-Length: 3874` show that the returned document had 3,874 bytes.
+ `Content-Type: text/html; charset= ISO-8859-1<cr><lf><cr><lf><!doc` shows that the first 5 bytes being returned are "`<!doc`". `Connection: Keep-Alive` shows that the server agreed to a persistent connection.
+
+ The following part from RFC2616 section 14.10 shows that both the client and server can close a persistent connection by including `Connection: close` in the message.
```
HTTP/1.1 defines the "close" connection option for the sender to signal that the connection will be closed after completion of the response. For example,
Connection: close
in either the request or the response header fields indicates that the connection SHOULD NOT be considered `persistent' (section 8.1) after the current request/response is complete.
```
+ HTTP does not provide encryption services on its own.
+ A client can open as many connections as possible, but the following part from RFC2616 section 8.1.4 suggests at most two simultaneous connections.
```
Clients that use persistent connections SHOULD limit the number of simultaneous connections that they maintain to a given server. A single-user client SHOULD NOT maintain more than 2 connections with any server or proxy.
```
+ The following part from RFC2616 section 8.1.4 shows that it is possible for one side to start closing a connection while the other side is transmitting data via an idle connection.
```
A client, server, or proxy MAY close the transport connection at any time. For example, a client might have started to send a new request at the same time that the server has decided to close the "idle" connection. From the server's point of view, the connection is being closed while it was idle, but from the client's point of view, a request is in progress.
```
+ It takes $"RTT"_1+"RTT"_2+dots+"RTT"_n+2"RTT"_0$ because each DNS lookup needs 1 RTT and the HTTP request and response need 2 RTTs.
+ Below is the answer to each question. Note that it takes $"RTT"_1+"RTT"_2+dots+"RTT"_n+2"RTT"_0$ in each case to get the HTML file as shown in the previous solution.
+ It takes $"RTT"_1+"RTT"_2+dots+"RTT"_n+18"RTT"_0$ because it takes another 16 RTTs as each object requires two RTTs.
+ It takes $"RTT"_1+"RTT"_2+dots+"RTT"_n+6"RTT"_0$ because it takes another $2*ceil(8/6)=4$ RTTs.
+ It takes $"RTT"_1+"RTT"_2+dots+"RTT"_n+3"RTT"_0$ because it takes another RTT with pipelining.
+
+ The average time required to send an object over the access link is $Delta=(1,000,000 "bits"\/"request")\/(15 "Mbps")=0.067 "sec/request"$ the arrival rate of objects to the access link is $beta=16$ requests/sec. Since the traffic intensity $Delta beta=1.07$ exceeds 1, the queuing delay will grow without bound, in which case the total average response time cannot be computed.
+ Let $r=0.4$. Since the arrival rate $beta$ is now $r$ times as much, the average access delay is given by $Delta\/(1-r Delta beta)=1\/(1\/Delta-r beta)=(15-0.4dot 16)^(-1) "sec/request"=0.12$ sec/request. Thus the average total response time via the Internet is $t_"WAN"=3.12$ sec/request, adding the Internet delay. On the other hand, the response time through the LAN is $t_"LAN"=(1,000,000 "bits"\/"request")\/(100 "Mbps")=0.01 "sec/request"$. Therefore, the average total response time is $(1-r)dot t_"LAN"+r dot t_"WAN"=(0.6dot 0.01+0.4dot 3.12) "sec/request"=1.25 "sec/request"$.
+ We ignore the propagation delay because the link is short. Parallel downloads via parallel instances of non-persistent HTTP would not be any better than non-persistent serial HTTP as long as we consider one shared link that evenly splits the bandwidth. Persistent HTTP would reduce $2dot 9=18$ RTTs for packets containing only control, which is $18dot 200=3,600$ bits long as opposed to $10dot 100 "Kbits"=1$ Mbits of objects that have to be sent over the link in any case.
+
+ They do because each connection is given an even bandwidth, in which case the transmission is $(10+4)\/(1+4)=2.8$ times as quick.
+ They still would because the transmission would be $(10+5dot 4)\/(1+5dot 4)=1.4$ times as quick.
+ The following log from #link("extra/c2p12.py") shows that the browser indeed generated a conditional GET message.
```
GET http://example.com/ HTTP/1.1
Host: example.com
Proxy-Connection: keep-alive
Cache-Control: max-age=0
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7
Accept-Encoding: gzip, deflate
Accept-Language: en
If-None-Match: "3147526947+gzip"
If-Modified-Since: Thu, 17 Oct 2019 07:18:26 GMT
```
+
+ $2,000+5dot 3=2,015$ frame times are needed.
+ $3dot (1+5)=18$ frame times are needed.
+ $2dot 3=6$ frame times are needed because the frames of the first two images will be sent first.
+ `MAIL FROM:` is not part of the message and is an address that mail servers use to determine where to return undeliverable emails.
+ According to #link("https://www.rfc-editor.org/rfc/rfc5321#section-3.3")[RFC5321 Section 3.3], SMTP indicates the end of the mail data by sending a line containing only a ".". On the other hand, according to #link("https://www.rfc-editor.org/rfc/rfc9110#name-content-length")[RF9110 Section 8.6], HTTP uses the `Content-Length` header field to indicate the size of the message. HTTP cannot use the same method as SMTP to mark the end of a message body as the content might be binary.
+ According to #link("https://www.rfc-editor.org/rfc/rfc5321#section-2.3.3")[RFC5321 Section 2.3.3], MTA stands for "Mail Transfer Agents". The following table shows the intermediate senders and recipients of the spam email:
#table(
columns: 2,
table.header[*Received from*][*Received by*],
[barmail.cs.umass.edu [192.168.3.11]], [cs.umass.edu (8.13.1/8.12.6)],
[asusus-4b96 (localhost [127.0.0.1])], [barmail.cs.umass.edu (Spam Firewall)],
[asusus-4b96 ([192.168.127.12])], [barmail.cs.umass.edu],
[[192.168.127.12]], [inbnd55.exchangeddd.com]
)
Here, the host `asusus-4b96 ([58.88.21.177])` is considered malicious because it does not report where it received the email from.
+
+ A _whois_ database is a public database that stores information about domain names including the owners and IP addresses.
+ The following DNS servers are listed in #link("https://public-dns.info/")[Public DNS Server List]. The names and databases were found by the `whois` command.
#table(
columns: 3,
table.header[*IP address*][*Name*][*Whois database*],
[192.168.127.12], [DMCI Broadband, LLC.], [#link("https://whois.arin.net")[ARIN]],
[172.16.58.3], [SingNet Pte Ltd], [#link("https://whois.apnic.net")[APNIK]]
)
+ In my Wi-Fi network, Google's DNS servers 8.8.8.8 and 8.8.4.4 are used according to the output of `scutil --dns | grep nameserver`. I tried `nslookup` for the three different DNS servers 8.8.8.8, 192.168.127.12 and 172.16.58.3, with three different options `-type=A`, `-type=NS` and `-type=MX`. There were no differences between the outputs of the different record types. `nslookup 8.8.8.8` showed a non-authoritative answer `name = dns.google`, `nslookup 192.168.127.12` showed a non-authoritative answer `name = dns3.dmcibb.net`, and `nslookup 172.16.58.3` said that the server could not find 172.16.31.10.in-addr.arpa: NXDOMAIN.
+ My organization has multiple IP addresses as the following command output shows:
```sh
$ nslookup amazon.com
Server: 8.8.8.8
Address: 8.8.8.8#53
Non-authoritative answer:
Name: amazon.com
Address: 172.16.17.32
Name: amazon.com
Address: 192.168.3.11
Name: amazon.com
Address: 192.168.3.11
```
+ The following shows the IP address range:
```sh
$ nslookup www.u-tokyo.ac.jp | tail -2 | head -1 | cut -d' ' -f2 | xargs whois -a | grep CIDR:
CIDR: 172.16.31.10/8
```
+ As described above, anyone could get the IP address range used by an organization by using `nslookup` to get an IP address and then using `whois` to get the range of addresses.
+ Whois databases should be publicly available to make sure that all hosts are transparent and accountable for their activities.
+
+ The output of `dig +trace @a.root-servers.net www.is.s.u-tokyo.ac.jp` showed the following chain of name servers in order.
#table(
columns: 3,
table.header[*DNS server type*][*Domain name*][*IP address*],
[Root], [a.root-servers.net], [172.16.17.32],
[Root], [h.root-servers.net], [172.16.58.3],
[TLD], [g.dns.jp], [172.16.58.3],
[Authoritative], [dns-x.sinet.ad.jp], [192.168.3.11],
[Authoritative], [dns3.nc.u-tokyo.ac.jp], [192.168.127.12],
[Authoritative], [ns2.s.u-tokyo.ac.jp], [172.16.31.10],
)
Finally, the last authoritative server had `CNAME ut-is.github.io`, for which `nslookup` returned four IP addresses.
+ `dig +trace @a.root-servers.net google.com` showed the following and 6 IP addresses:
#table(
columns: 3,
table.header[*DNS server type*][*Domain name*][*IP address*],
[Root], [a.root-servers.net], [172.16.17.32],
[Root], [j.root-servers.net], [192.168.127.12],
[TLD], [h.gtld-servers.net], [172.16.17.32],
[Authoritative], [ns3.google.com], [172.16.31.10]
)
`dig +trace @a.root-servers.net yahoo.com` showed the following and 6 IP addresses:
#table(
columns: 3,
table.header[*DNS server type*][*Domain name*][*IP address*],
[Root], [a.root-servers.net], [172.16.17.32],
[Root], [g.root-servers.net], [192.168.3.11],
[TLD], [g.gtld-servers.net], [172.16.58.3],
[Authoritative], [ns3.yahoo.com], [172.16.31.10]
)
`dig +trace @a.root-servers.net amazon.com` showed the following and 3 IP addresses:
#table(
columns: 3,
table.header[*DNS server type*][*Domain name*][*IP address*],
[Root], [a.root-servers.net], [172.16.17.32],
[Root], [c.root-servers.net], [172.16.31.10],
[TLD], [b.gtld-servers.net], [192.168.127.12],
[Authoritative], [ns2.amzndns.net], [192.168.127.12]
)
+ If the caching strategy is Least-Frequently Used (LFU), the most frequently used caches are the most popular websites. If it is Least-Recently Used (LRU), the most recently used caches are likely the most popular websites. Otherwise, by taking snapshots of the caches, one can regard the most frequent caches as the most popular websites.
+ I am not sure. One can run `dig` commands on the web server host and another host that is unlikely in the cache. If the query times are not so different, one can assume that the web server was unlikely accessed a couple of seconds ago. If the query time for the web server is much shorter, that probably means it was in the cache, but I am not certain how long ago it was accessed last time.
+ Below is a 3D plot generated with #link("extra/c2p22.py").
#image("extra/c2p22.png")
+
+ Consider a distribution scheme in which the server sends data in parallel to each client at the rate of $u_s\/N$. Since the download rate of each client is higher by assumption, the upload rate $u_s\/N$ is the bottleneck. Thus, it takes $F\/(u_s\/N)=N F\/u_s$ to send the file to each client.
+ Consider the above distribution again. The overall distribution time is that of the slowest client because the data is distributed in parallel. Since the slowest download rate $d_"min"$ is lower than the upload rate by assumption, it takes $F\/d_"min"$ to send the file.
+ It is shown in the textbook that $max\{N F\/u_s,F\/d_"min"\}$ is a lower bound to the distribution time. Since the above shows that the lower bound is achievable, we have the value as the minimum distribution time.
+
+ Skipped for now.
+ Skipped for now.
+ It is shown in the textbook that $max\{F\/u_s,F\/d_"min",N F\/(u_s+u_1+dots+u_N)\}$ is a lower bound to the distribution time. It can be written as $max\{F\/u_s,N F\/(u_s+u_1+dots+u_N)\}$ since $F\/d_"min"$ is much smaller than the other two expressions by the assumption that $d_"min"$ is very large. Since the above shows that the lower bound is achievable, we have the value as the minimum distribution time.
+ There are $N$ nodes and $N(N-1)\/2$ edges since the graph is the complete graph on $N$ vertices. Note that the number of routers does not matter since the routers are abstracted away.
+
+ Bob's claim is possible because he can be optimistically unchoked repeatedly until he receives the complete copy.
+ He can do so by sharing the chunks among his hosts.
+
+ $N^2$ files will be stored since each video and each audio will have to be mixed ahead of time.
+ $2N$ files will be stored since each video and each audio will be mixed on the client side.
+
+ TCPClient raises `ConnectionRefusedError` when the client socket tries to connect to the server that has not started to run. This is because TCP is connection-oriented.
+ UDPClient hangs up when it tries to receive data from the server but does not stop when it sends data. This is because UDP is not connection-oriented.
+ With either TCP or UDP, the client fails even if the server is running.
+ It will not become necessary to change the server code. The client uses port 5432 while the server uses port 12000 as specified in the code. Before making the change, the client used a randomly assigned port number such as 54572, which can be checked by calling the `getsockname()` method of the client socket after it has sent data. The server used port 12000.
+ Google Chrome does not seem to offer a way to configure multiple TCP connections, but it is enabled by default. Having a large number of simultaneous TCP connections allows the client to have a virtually faster connection while imposing more burden on the server and potentially doing harm to the well-being of the Internet.
+ One advantage is that the packet payload can be always maximized, which leads to faster delivery of the entire message. One disadvantage is that the receiver will have more trouble constructing the message when packets have not been delivered properly.
+ The Apache HTTP Server @apache_webserver is a free and open-source cross-platform web server software. Features include authentication, server-side programming language support, TLS support, proxy support, URL rewriting, custom log files, and filtering support.
== Socket Programming Assignments
=== Assignment 1: Web Server
#link("extra/c2a1_server.py") is a multithreaded web server and #link("extra/c2a1_client.py") is a web client. Note that the server continues to use the same port after accepting a connection.
=== Assignment 2: UDP Pinger
#link("extra/c2a2_server.py") and #link("extra/c2a2_client.py") implement UDP Ping including the optional exercises.
=== Assignment 3: Mail Client
#link("extra/c2a3.py") is a program that sends an email from a Gmail account to itself. Note that the address and password have to be set as environment variables.
=== Assignment 4: Web Proxy
#link("extra/c2a4.py") implements an HTTP proxy server.
== Wireshark Lab: HTTP
#set enum(numbering: "1.")
+ Both of the client and server used HTTP 1.1. The request included `GET /wireshark-labs/HTTP-wireshark-file1.html HTTP/1.1\r\n` while the response included `HTTP/1.1 304 Not Modified\r\n`.
+ English as in `Accept-Language: en\r\n` from the request.
+ The IP address of my computer and the server are 10.15.14.27 and 192.168.3.11 respectively as Wireshark shows `Internet Protocol Version 4, Src: 10.15.14.27, Dst: 192.168.3.11` in the request.
+ 304 as in `HTTP/1.1 304 Not Modified\r\n` from the response.
+ It is not shown as the response status code was 304. It is before Tue, 17 Sep 2024 05:59:01 GMT because the request included `If-Modified-Since: Tue, 17 Sep 2024 05:59:01 GMT\r\n`.
+ Wireshark shows 293 bytes.
+ All the headers within the data were displayed in the packet-listing window.
+ No, `If-Modified-Since` was not included in the request.
+ Yes, the server explicitly return the contents of the file because the text data was included in the response.
+ Yes, the request had the following line: `If-Modified-Since: Wed, 18 Sep 2024 05:59:02 GMT\r\n`. The request was made around Wed, 18 Sep 2024 21:00 GMT.
+ The status code was 304. The server did not explicitly return the content of the file because the text data was not included in the response.
+ The browser just sent 1 HTTP GET request message. Packet number 245 contained the GET message for the Bill or Rights.
+ Packet number 247 contained the status code and phrase associated with the response to the HTTP GET request.
+ HTTP/1.1 200 OK.
+ Four segments were needed to carry the single HTTP response and the text of the Bill of Rights.
+ Three HTTP GET request messages were sent by the browser. Two GET requests `GET /wireshark-labs/HTTP-wireshark-file4.html HTTP/1.1` and `GET /pearson.png HTTP/1.1` were sent to `192.168.3.11`. The other GET request `GET /8E_cover_small.jpg HTTP/1.1` was sent to `192.168.127.12`.
+ The browser downloaded the two images in parallel because it got the response from `https://kurose.cslash.net` first whereas the first request was sent to `http://gaia.cs.umass.edu`.
+ HTTP/1.1 401 Unauthorized (text/html).
+ `Cache-Control: max-age=0` and `Authorization: Basic d2lyZXNoYXJrLXN0dWRlbnRzOm5ldHdvcms=` were added. The latter was decoded to `Credentials: wireshark-students:network`.
== Wireshark Lab: DNS
+ It is 172.16.31.10, shown by running `nslookup www.iitb.ac.in`.
+ It is 192.168.3.11, shown by first running `nslookup -type=NS www.iitb.ac.in` and then running `nslookup dns3.iitb.ac.in`. The first command output showed the DNS server name dns1.iitb.ac.in.
+ It came from a non-authoritative server.
+ dns3.iitb.ac.in was the name of the first authoritative server returned by `nslookup iitb.ac.in`. I would run `nslookup dns3.iitb.ac.in` to find the IP address.
+ The packet number in the trace for the first DNS query message was 213. It was sent over UDP.
+ The packet number of the corresponding DNS response was 223. It was sent over UDP.
+ The destination port for the DNS query message and the source port of the DNS response message were both 53.
+ The DNS query message sent to 8.8.8.8.
+ The DNS query message contained one query and no question.
+ The DNS response message contained one query and one question.
+ The packet numbers are as follows. Only one DNS query of type A was sent to gaia.cs.umass.edu because of DNS caching.
#table(
columns: 2,
table.header[*Message*][*Packet Number*],
[Initial HTTP GET request for the base file http://gaia.cs.umass.edu/kurose_ross/], [236],
[DNS query made to resolve gaia.cs.umass.edu], [213],
[Received DNS response], [223],
[HTTP GET request for the image object http://gaia.cs.umass.edu/kurose_ross/header_graphic_book_8E2.jpg], [486],
[DNS query made to resolve gaia.cs.umass.edu so that this second HTTP request can be sent to the gaia.cs.umass.edu IP address], [213],
)
+ The destination port for the DNS query message and the source port of the DNS response message were both 53.
+ The DNS query message sent to 8.8.8.8. It is the IP address of my default local DNS server as another command `scutil --dns` shows.
+ The type of DNS query is A. The query message does not contain any answers.
+ The DNS response message contained one query and one question.
+ The DNS query message sent to 172.16.58.3. It is not the IP address of my default local DNS server.
+ The DNS query message contained one query and no question.
+ The DNS response message was not found. The nslookup command showed the following error: `connection timed out; no servers could be reached`.
= Transport Layer
== Review Questions
#show: enumb.with(pref: "R")
+
+ The simplest possible transport layer protocol would be similar to UDP with the header format of a 4-byte destination port field and a 2-byte length field. Note that the checksum field would not be necessary as the underlying network is assumed reliable.
+ A 4-byte source port field would be included in the header.
+ No, just as UDP does not.
+
+ The sending delegates would make sure that each letter has the sender name and the reciever name in it. The receiving delegates would deliver letters to the family members based on the receiver names. Since it is assumed that each family has six members, assigning an integer from 0 to 5 to each family member ahead of time would also work.
+ No, just as TCP and UCP do not.
+ The source and destination port numbers for the segments traveling from Host B to Host A are y and x respectively.
+ An application developer might choose to run an application over UDP rather than TCP because they might not want everything that TCP offers. For example, if the application protocol needs a few packets to exchange, they might want to implement a simple reliable transport scheme on top of UDP to get around potentially heavy TCP workloads like congestion control.
+ It is because voice or video applications need real-time communication and can accept some packet losses that their traffic is often sent over TCP rather than UDP in today's Internet.
+ The application can implement reliable dara transer on its own on top of UDP.
+ The process at Host C will know that these two segments originated from two different hosts by looking at the source IP address field of the datagrams.
+ The requests from Host A are being sent to a different socket from those from Host B since a new socket is assinged after creating a connection based on the source IP address. Both of the sockets on Host C have port 80.
+ We needed to introduce sequence numbers because the ACK or NAK packet could be corrupted.
+ We needed to introduce timers for the sender to retransmit packets whose ACKs have not arrived in time.
+ Yes, a timer would still be necessary in protocol rdt 3.0 because the sender would have to wait for an RTT to retransmit a packet.
+
+ All five packets got retransmitted.
+ All five packets got delivered without any retransmission.
+ The sixth packets could not be sent as the sending window was limited to 5.
+ When a packet is lost before reaching the destination, Go-Back-N retransmits all of the packets in the sending window whereas Selective Repeat only retransmits the lost packet. When an ACK packet is lost, Go-Back-N does not retransmit any packet whereas Selective Repeat retransmits all of the packets in the sending window. The corresponding simulation results were as follows:
+ Only the first packet got retransmitted.
+ All five packets got retransmitted.
+ The sixth packets could not be sent as the sending window was limited to 5.
+
+ False. Piggyback is only for efficiency.
+ False. However, the size of the receiver's buffer never changes.
+ True. The number of unacknowleged bytes that A sends cannot exceed the size of the receiver's window size, which is smaller than the receive buffer.
+ False. The sequence number of the subsequent segment will be $m$ plus the number of bytes in the current segment.
+ True. The 16-bit receive window field is it.
+ True, if the parameter $beta$ in the formula is the recommended value $1\/4$. Given the sample RTT $S "[sec]"$, previous estimated RTT $E "[sec]"$, and previous estimated deviation $D "[sec]"$ of RTT, the newly estimated RTT $E' "[sec]"$ and deviation $D "[sec]"$ are given by the following:
$ E'=(1-alpha)E+alpha S $
$ D'=(1-beta)D+beta|S-E| $
When $S=1$, $beta=1\/4$ and $E<1$, the timeout interval $T' "[sec]"$ is proved greater than or equal to 1:
$ T'=E'+4D'=(1-alpha)E+alpha+3D+|1-E|>=(1-alpha)E+alpha+(1-E)=1+alpha(1-E)>=1 $
It is clear that $T'>=E'>=1$ when $E>=1$.
+ True. The acknowledgment number is the sequence number of the segment sent to Host B plus the number of data bytes.
+
+ $110-90=20$ bytes.
+ The acknowledgement number will be 90, which Host B will know during the 3-way handshake.
+ The following three segments are sent.
+ Client to server, Seq=43, ACK=80, data='R'
+ Server to client, Seq=80, ACK=44, data='R'
+ Client to server, Seq=44, ACK=81
+ TCP would like to give the transmission rate of $R\2$ to each of the connections as it would aim for full bandwidth utilization while keeping equal bandwidth share.
+ False. The value of `ssthresh` is set to one half of the congestion window value.
+ The client first establishes a TCP connection to the front-end server and sends data through the connection, which takes 4RTT#sub[FE]. The front-end server then sends the data through the persistent connection to the back-end server, which takes RTT#sub[BE] since the connection is already established and the congestion window is large enough to hold all of the data. By adding the processing time to the above, we get the response time formula.
== Problems
#show: enumb.with(pref: "P")
+
+ Possible source port number: 54321, destination port number: 23
+ Possible source port number: 54321, destination port number: 23
+ Source port number: 23, destination port number: 54321
+ Source port number: 23, destination port number: 54321
+ Yes, it is possible because the connections would still be distinguishable since the client hosts are different.
+ No, it is not possible because the connections would be indistinguishable.
= The Network Layer: Data Plane
= The Network Layer: Control Plane
= The Link Layer and LANs
= Wireless and Mobile Networks
= Security in Computer Networks
#bibliography("main.bib")
|
|
https://github.com/Kasci/LiturgicalBooks
|
https://raw.githubusercontent.com/Kasci/LiturgicalBooks/master/CSL_old/oktoich/Hlas8/5_Piatok.typ
|
typst
|
#let V = (
"HV": (
("","O preslávnaho čudesé!","Živonósnyj sád, krest presvjatýj, na vysotú voznosím javľájetsja dnés: slavoslóvjat vsí koncý zemníji, ustrašájutsja démonskija polkí. o kakovýj dár zemným darovásja! Ímže Christé spasí dúšy náša, jáko jedín blahoutróben."),
("","","O preslávnaho čudesé! Jáko hrózd ispólnen životá, ponesýj výšňaho, ot zemlí vozdvizájem krest víditsja dnés: ímže vsí k Bóhu privlekóchomsja, i požérta býsť do koncá smérť. O drévo prečestnóje! ímže vosprijáchom vo Jedémi bezsmértnuju píšču, Christá slávjašče."),
("","","O mnóhija tvojejá bláhosti, jáže k nám Iisúse bláže! Káko sebé smiríl jesí, i býl jesí čelovík, i postradáti izvólil jesí, krest i smérť ponósnuju, za nepotrébnyja rabý preterpív? kotóryj tí dostójnyj dár prinesém Bohopodóbnyj? Tóčiju slávim ťá blahodarjášče vírniji."),
("","","O neizrečénnyja bláhosti voplóščšahosja iz tebé Bohoródice vsepítaja! Krest bo i smérť jáko čelovikoľúbec preterpív, da mír spasét, jehóže sozdá. Tohó molí i mené okajánnaho i mnohoboľíznennaho da izbávit múki: i iďíže svít sijájet nevečérnij, vselít mjá."),
("","","Čtó zrímoje viďínije, jéže mojíma očíma víditsja, o Vladýko, soderžáj vsjú tvár, na drévo vozdvížen býv, i umiráješi vsím dajáj žízň? Bohoródica pláčuščisja hlahólaše, jehdá uzrí na kresťí voznosíma iz nejá neizrečénno vozsijávšaho Bóha i čelovíka."),
("","","Stádo jéže sťažá, prečístaja, Sýn tvój i Bóh, okropívyj króviju, ot bíd izbávi čestnými molítvami tvojími, vídimyja i nevídimyja vrahí jákože zvíri othoňášči: i ťích líca bezčéstija ispólni, jákože Davíd drévle provozhlasí pisnopívec, čístaja."),
("Krestobohoródičen","","Ťá víďašči prihvoždájema na kresťí Iisúse, i strásti prijémľušča vóleju, Ďíva i Máti tvojá, Vladýko, uvý mňí, vopijáše, čádo sládkoje, rány neprávedno káko terpíši, vračú iscilívyj čelovíčeskoje nemožénije, i ot tlí vsích izbávivyj milosérdijem tvojím?"),
),
"S": (
("","","Voznéslsja jesí na krest Christé Bóže, i spásl jesí čelovíčeskij ród: slávim stradánija tvojá."),
("","","Prihvozdílsja jesí na kresťí Christé Bóže, i otvérzl jesí rájskija dvéri: ťímže slávim Božestvó tvojé."),
("Múčeničen","","Múčenicy Hospódni, vsjáko místo osvjáščájete, i vsják nedúh uvračújete. I nýňi molítesja, izbávitisja ot sítej vrážijich dušám nášym, mólim vás."),
("Krestobohoródičen","","Júnica neskvérnaja juncá víďašči na drévi prihvoždájema vóleju, rydájušči žálostňi, uvý mňí, vopijáše, ľubímijšeje čádo! Čtó tebí sónm vozdadé bezblahodátnyj jevréjskij, choťá mja obezčádstvovati ot tebé vseľubézne?"),
),
)
#let P = (
"1": (
("","","Poím Hóspodevi, provédšemu ľúdi svojá skvozé čermnóje móre, jáko jedín slávno proslávisja."),
("","","Mílostiva mňí Christá soďílaj, Ďívo preneporóčnaja, v déň prí strášnaho osuždénija izimájušči."),
("","","Odoždí mi Vladýčice, moľúsja, kápli umilénija, súščuju mí skvérnu otmyvájušči, jáko da slávľu ťá."),
("","","Prosvití mja Ďívo, jáže svít nezachodímyj róždšaja, mojejá ľínosti hlubókuju ťmú othoňájušči."),
("","","Spasí mja Bohoródice, vo mnóhich hrisích pohíbšaho, i múki vsjákija, i ľútaho osuždénija izbávi."),
),
"3": (
("","","Nebésnaho krúha verchotvórče Hóspodi, i cérkve ziždíteľu, tý mené utverdí v ľubví tvojéj, želánij kráju, vírnych utverždénije, jedíne čelovikoľúbče."),
("","","Svjáščénnaho žitijá otpád prečístaja, priložíchsja skotóm, i osuždén vés bých: no tý jáže sudijú róždšaja, ot vsjákaho osuždénija izbávi mjá i spasí."),
("","","K tebí pribiháju Vladýčice, vsehdá mnóžestvom napástej obstojíma uščédrivši spasí mja, jáže Spása róždšaja vsjáčeskich i Hóspoda, jedína prepítaja."),
("","","Neprochodímaja dvére, jáže k Bóhu privoďášči otrokovíce, dvéri pokajánija mí otvérzi moľúsja, očístivši hrichóv mojích skvérnu, túčami mílosti tvojejá, Bohoblahodátnaja."),
("","","Izbávi mjá strastéj naviďínija Vladýčice, i borjúščyjasja vrahí mojá nýňi pobidí: utverdí mja na kámeni Bóžijich choťínij, i dúšu mojú prosvití, dvére božéstvennaho svíta."),
),
"4": (
("","","Uslýšach Hóspodi, smotrénija tvojehó tájinstvo, razumích ďilá tvojá, i proslávich tvojé Božestvó."),
("","","Duší mojejá jázvy iscilí, Bohoblahodátnaja Ďívo: úm mój prosvití čístaja, omračénnyj strástnymi nachódy."),
("","","Unýnijem spjáščaho, i hrichóm pokrovénnaho, k pokajániju mjá prečístaja, prizoví, jáko Máti slóva."),
("","","Neiskusobráčnaja Vladýčice, jáže voploščénnoje Slóvo róždšaja, dúšu mojú prosvití, i ot hejénny izbávi i mučénija."),
("","","Na ťá nadéždu mojú vozložích vsjú, Máti Ďívo: dúšu mojú sobľudí, jáže Bóha róždši Spása mojehó."),
),
"5": (
("","","Vskúju mjá otrínul jesí ot licá tvojehó Svíte nezachodímyj, i pokrýla mjá jésť čuždája ťmá okajánnaho? No obratí mja, i k svítu zápovidej tvojích putí mojá naprávi moľúsja."),
("","","Duší mojejá strásti vseneiscíľnyja otrokovíce iscilí, i uhásšij ľínostiju svitíľnik mój vozžzí, i k pokajánija putém nastávi Ďívo, da víroju i ľubóviju ťá slávľu."),
("","","Sebé osuždáju préžde ispytánija Bohorádovannaja, stúdnaja ďilá nošú jedín osuždénnyj: no predstáni mí jáko predstáteľnica súšči vsím, i ľútaho osuždénija izbávi mjá."),
("","","Izbavľájušči mjá ot pľinénija, i oderžáščyja dušetľínnyja molvý, i strastéj ľútych umerščvľájuščich mjá, ne prestáj presvjatája otrokovíce, hríšnikom zastúpnice, čelovíkom hotóvaja pomóščnice."),
("","","Umerščvléna mjá vsehó žálom smértnym ot prestuplénija oživí prečístaja, jáže žízň začénšaja mírovi izbáviteľa i carjá, i k svítu nastávi mjá."),
),
"6": (
("","","Očísti mjá Spáse, mnóha bo bezzakónija mojá, i iz hlubiný zól vozvedí, moľúsja: k tebí bo vozopích, i uslýši mjá, Bóže spasénija mojehó."),
("","","Umerščvléna mjá mnóhimi prestupléňmi, prečístaja Ďívo, oživí, jáže žízň čelovíkom neizrečénno róždšaja Bohoródice, i tvoríti mí vóľu Hospódňu nastávi."),
("","","Ťá predstáteľnicu i sťinu vírniji vsí sťažáchom, íže vo hlubiňí zól, i mólv, i pečálej potopľájemiji prísno Bohoródice, jedína vírnym pribížišče."),
("","","Uvjadívšaja sadý bezbóžija preneporóčnaja, tvojím svjatým prozjabénijem, rastúščuju vo mňí prísno vrážiju zlóbu potrebí, prečístaja."),
("","","Osvjatí mój úm, i prosvití sérdce mojé svjatája Máti Bóžija, i oderžáščich mjá zól izminí: da ťá slávľu tvérduju zastúpnicu mojú."),
),
"S": (
("","","O čudesé nóvaho! o strášnaho táinstva! Vzyváše Áhnica, Sýna zrjášči na drévi krestňim prostérta: čtó sé Slóve Bóžij bezsmértnyj? Káko mértv zríšisja, i zémľu kolébleši jáko vsesílen? No vospiváju tvojé strášnoje i božéstvennoje schoždénije."),
),
"7": (
("","","Ótrocy jevréjstiji v peščí popráša plámeň derznovénno, i na rósu óhň preložíša, vopijúšče: blahoslovén jesí Hóspodi Bóže vo víki."),
("","","Mílostiva búdi mí Ďívo, i uránena mjá orúžijem hrichá, plástyrem iscilí tvojejá molítvy: i ohňá nehasímaho ischití mja vo víki."),
("","","Izbávi mjá Máti Spásova, oderžáščaho ľútaho pľinénija, pomyšlénij lukávych, i oderžánij prehrišénija, jáko da prísno spasájem, po dólhu ťá slávľu."),
("","","Nýňi k tebí pribiháju Bohomáti, prehrišénij plenícami sťáhnut: za milosérdije mílosti razriší mja Ďívo, i ot bisóv izbávi mučénija i zlóby."),
("","","uščédri i spasí mja Ďívo, jáže ščédraho róždši Bóžija Slóva: i svítom, íže v tebí, ozarí dúšu mojú, i ot bisóv izbávi mjá ľútaho kovárstva."),
),
"8": (
("","","Sedmeríceju péšč chaldéjskij mučítel Bohočestívym neístovno razžžé, síloju že lúčšeju spásény sijá víďiv, tvorcú i izbáviteľu vopijáše: ótrocy blahoslovíte, svjaščénnicy vospójte, ľúdije prevoznosíte vo vsjá víki."),
("","","Íže po vsemú soveršén, i jestestvóm nepristúpen, javísja prikosnovén mňí, plótiju obložén iz tebé neiskusobráčnaja: jehóže priľížno molí, bezzakónij mojích brémja oblehčíti, i sudá búduščaho izbáviti mjá."),
("","","Jáže sudijú i Hóspoda róždši páče slóva, sehó jáko Sýna tvojehó presvjatája, umolí: v čás sudá osuždénija, i ohňá, i ťmý nesvitímyja, i skréžeta zubnáho izbáviti mjá, víroju blahočéstno pojúščaho ťá vsehdá."),
("","","Bohorodítelnice prečístaja, duší mojejá jázvy, i hrichóvnyja soblázny očísti, istóčnikom otmyvájušči, íže iz rébr roždestvá tvojehó, i íže ot ních potékšimi strujámi: k tebí bo vzyváju, i k tebí pribiháju, i tebé moľú Bohoblahodátnuju."),
("","","Umerščvlénnuju dúšu mojú uhryzénijem zmijínym, jedína jávi živót róždšaja, preneporóčnaja oživí: i nás rádi Ďívo roždénnaho, ďíjstvovati pospiší choťínija, vopijúšču: ótrocy blahoslovíte, svjaščénnicy vospójte, ľúdije prevoznosíte jehó vo víki."),
),
"9": (
("","","Užasésja o sém nébo, i zemlí udivíšasja koncý, jáko Bóh javísja čelovíkom plótski, i črévo tvojé býsť prostránňijšeje nebés. Ťím ťá Bohoródicu ánhelov i čelovík činonačálija veličájut."),
("","","Prosvití, dvére svíta, osľiplénnuju dúšu mojú strasťmí, i lukávymi pómysly očerňívšuju, i bídstvujuščuju: i izbávi mjá napástej, i ot bisóv ozloblénija i isťazánija ľútaho, i búduščaho plámene i múki."),
("","","Poščadí mja Spáse, roždéjsja ot Ďívy, i sochranívyj róždšuju ťá netľínnu i po roždeství: jehdá sjádeši sudíti ďilóm mojím, bezzakónija i hrichí mojá prézri, jáko bezhríšen, i jáko Bóh mílostiv i čelovikoľúbec."),
("","","Nosjášči nebésnyj óhň rukáma jáko kleščámi, Bohoblahodátnaja, dúši mojejá strásti popalí čístaja, i strášnaho osuždénija i ohňá, i tomlénija ľútaho bisóvskaho svobodí mja."),
("","","osijánijem tvojím mýslennym prosvetí náša pomyšlénija, i serdcá i rázumy, otrokovíce Bohoblahodátnaja, jáko da stezjámi živótnymi právi choďášče, mílosť polučím, vozviščájušče prísno chvalý tvojá."),
),
)
#let U = (
"S1": (
("","","Víďa razbójnik načáľnika žízni na kresťí vísjašča, hlahólaše: ášče ne bý Bóh býl voplóščsja, íže s námi raspnýjsja, ne by sólnce lučý svojá potajílo, nižé by zemľá trepéščušči trjaslásja. No vsjá terpjáj, pomjaní mja Hóspodi, vo cárstviji tvojém."),
("","","Posreďí dvojú razbójniku mírilo právednoje obrítesja krest tvój, óvomu úbo nizvodímu vo ád ťahotóju chulénija, druhómu že lehčáščusja ot prehrišénij k poznániju bohoslóvija: Christé Bóže, sláva tebí."),
("Krestobohoródičen","","Sýna tvojehó Ďívo, i Bóha krestóm sochraňájemi prísno, bisóvskija prilóhi othoňájem i kózni: súščuju ťá Bohoródicu voístinnu vospivájušče, i ľubóviju vsí ródi blažím prečístaja, jákože proreklá jesí: ťímže nám sohrišénij ostavlénije molítvami tvojími dáruj."),
),
"S2": (
("","","Posreďí Jedéma drévo procvité smérť, posreďí že vsejá zemlí drévo prozjabé živót: vkusívše bo pérvoje netľínniji súšče, tľínni býchom: polučívše že vtoróje, netľínija napitáchomsja: krestóm bo spasáješi jáko Bóh ród čelovíčeskij."),
("","","V rají mjá úbo préžde drévo obnaží, vkušénijem vráh vnosjá umerščvlénije: krestnoje že drévo životá víčnaho oďijánije čelovíkom nosjá, vodruzísja na zemlí, i mír vés ispólnisja vsjákija rádosti: jehóže zrjášče voznosíma, Bóhu víroju ľúdije sohlásno vozopijím: ispólň slávy dóm tvój."),
("Múčeničen","","Svítom nebésnym prosviščájetsja dnés séj chrám: v ném bo vójinstva ánheľskaja rádujutsja, s nímiže i čelovíčestiji lícy veseľátsja, v pámjať strastotérpec. Ťích moľbámi nizposlí Christé, míru tvojemú mír, i véliju mílosť."),
("Krestobohoródičen","","Íže ot krovéj tvojích čístych voplóščšahosja, i páče umá ot tebé čístaja rodívšahosja, na drévi vísjašča posreďí zloďíjev zrjášči, utróboju boľáše, i Máterski pláčušči vopijáše: uvý mňí čádo mojé! Čtó božéstvennoje i neizrečénnoje smotrénije tvojé, ímže oživíl jesí sozdánije tvojé? Vospiváju tvojé blahoutróbije."),
),
"S3": (
("","Poveľínnoje tájno","Tvojím krestóm Christé Spáse i smértiju, mučíteľstvo vrážije nizložísja, i smérť umertvísja, i mértvyja jáže imíjaše ád ot víka v sebí svjázannyja, vnezápu otpustí pľínniki vsjá, vospivájuščyja deržávu tvojú, i strášnoje tvojé bláže, i božéstvennoje schoždénije, ímže vsích spásl jesí."),
("","","Obožénija lóžnaho upovánija rodonačálnik tľínija, jáže ot nehó vsím vinóven javísja. Tý že krestóm tvojím žízň istočáješi jáko prebláhíj: vóleju bo prihvoždén býl jesí, da ot pérvaho razrišíši osuždénija. Ťímže vospivájem tvojú Christé vóľnuju strásť."),
("Krestobohoródičen","","Neskvérnaja áhnica, áhnca i pástyrja vísjašča na kresťí zrjášči, vopijáše: čádo mojé, čtó stránnoje úbo i nenadéžnoje sijé zrínije? Káko žízň vsích smértiju osuždájetsja zemným podóbňi? No voskresní tridnévno iz mértvych Slóve, jákože rékl jesí: da rádujuščisja slávľu ťá."),
),
"K": (
"P1": (
"1": (
("","","Krest načertáv Moiséj vprjámo žezlóm čermnóje presičé, Izráiľu pišechoďášču, tóže obrátno faraónovym kolesnícam udáriv sovokupí, voprekí napisáv nepobidímoje orúžije. Ťím Christú pojím Bóhu nášemu, jáko proslávisja."),
("","","Dláni božéstvennyja na kresťí Iisúse rasprostér, k sebí sobrál jesí rukú tvojéju sozdánije: i ot rúki lukávaho vsích svobodíl jesí, i pokoríl jesí i rukóju deržávnoju carjú vsích. Ťímže vírniji pojím velíčestvu tvojemú, jáko proslávisja."),
("","","Vrédno býsť vo Jedémi dréva hórkoje vkušénije, smérť vvédšeje: Christós že umertvívsja na drévi, vsím živót istočí, i ubív zmíja božéstvennoju síloju. Ťímže tomú pojím Bóhu nášemu, jáko proslávisja."),
("Múčeničen","","Chrábrstvovavše Iisúse múčenik mnóžestvo, krestóm že i strástiju tvojéju na strásti protívu vostáša, i pred vrahí ťá cárstvujuščaho tváriju ispovídaša: terpíša že mučénija i bidý bezmírnyja. Ťímže tvojú ulučíša slávu vsí, slávy Hóspoda."),
("Múčeničen","","Kroplénijem Bohoďíteľnyja čéstnýja tvojejá króve, múčenicy tvojí Hóspodi, izbavlénije obrítše, króvi svojá voístinnu izlijáša, neprávedno múčimi býša žértvy prinosíti skvérnym bisóm dušetľínnym. Ťímže čestnája zakolénija tebí prinesóša, carjú vsích."),
("Bohoródičen","","Jáko víďi ťá na kresťí prihvoždájema, vsjá víďaščaho, neporóčnaja rydájušči hlahólaše: čtó sijé čádo mojé? Čtó tí vozdáša nasláždšijisja mnóhich tvojích darovánij? Káko preterpľú boľízni? Sláva tvojemú blahoutróbiju, i smotréniju strášnomu dolhoterpilíve."),
),
"2": (
("","","Vódu prošéd jáko súšu, i jehípetskaho zlá izbižáv, Izráiľťanin vopijáše: izbáviteľu i Bóhu nášemu pojím."),
("","","Omračénnuju slasťmí žitijá dúšu mojú Bohomáti, i mirskími pečáľmi bezvrémenno smuščájemu, prosviščénijem tvojím prosvití."),
("","","Otverzóšasja dvéri nebésnyja božéstvennym tvojím roždestvóm Bohomáti: v níchže vchód dážď duší mojéj jáko mílostiva, i k ťím nastávi mjá."),
("","","Ustrilénuju strilóju lukávaho, i kózňmi ónaho, i kovárstvy ujazvlénuju dúšu mojú, Ďívo, mílostiju tvojéju iscilí."),
("","","Jáže nenaďíjuščichsja nadéžda, pádšich ispravlénije, svít božéstvennyj róždšaja, dúšu mojú súščuju vo ťmí prosvití."),
),
),
"P3": (
"1": (
("","","Žézl vo óbraz tájny prijémletsja, prozjabénijem bo predrazsuždájet svjaščénnika, neploďáščej že préžde cérkvi, nýňi procvité drévo krestá v deržávu i utverždénije."),
("","","V čérnuju útvar izminísja sólnce, zrjá na drévi tebé neprávedno vozdvížena: i raspadésja kámenije, i zemľá vsjá stráchom trjasášesja, jedíne Spáse, vsích izbavlénije."),
("","","Rasprostér rúci Mojséj, voobražáše krest čestnýj: jehóže mý nýňi voobražájušče blahomúdrenňi, polkí inopleménnyja vsjá bisóvskija pobiždájem, vréda vsjákaho ťích kromí prebyvájušče."),
("Múčeničen","","Strásti terpjášče strastotérpcy, strásť obrazováchu, mnohoobráznym strastém pričastíšasja, vóleju stradávšaho, i strásti umertvívšaho, i živót míru vozsijávšaho."),
("Múčeničen","","Nevozvrátno mučénija púť šéstvovavše, pretknovénija prélesti ot serdéc nizložíša blahoslávniji strastonóscy, i ustremíšasja ko upokojéniju božéstvennomu veseľáščesja."),
("Bohoródičen","","Zakónnych kromí obýčajev čelovíčeskich, tebé čádo rodích, Bohoródica pláčušči viščáše: i káko bezzakónniji vozdvihóša ťá na drévo, posreďí bezzakónnych, jedínaho zakón žízni položívšaho?"),
),
"2": (
("","","Nebésnaho krúha verchotvórče Hóspodi, i cérkve ziždíteľu, tý mené utverdí v ľubví tvojéj, želánij kráju, vírnych utverždénije, jedíne čelovikoľúbče."),
("","","Vozdychánija nemólčnaja, i priľížnyja slézy, i sokrušénno sérdce dážď mí Ďívo, da pláčusja soďíjannych mnóju, i sovozrastájuščyja mojá strásti potrebí, jedína vsepítaja."),
("","","Dremáňmi oťahčénnuju hrichóvnymi, i ko ádovi utróbi nizpopólzšujusja dúšu mojú ischití Vladýčice, i pomyšlénije pokajánija ístinnaho podážď mí Bohoblažénnaja."),
("","","Umilénija ľubóv, i dobroďítelej dáruj vseneporóčnaja, pohružénňij duší mojéj prehrišéňmi, i nebésnoje žitijé vozľubíti, i Bóžije želánije imíti."),
("","","Na ťá upovánije vozlaháju Máti Bóžija, i otčájanija vskóri izbávľusja: vím bo, vím tvojehó blahoutróbija bohátstvo, i kríposť svídyj derznovénija tvojehó."),
),
),
"P4": (
"1": (
("","","Uslýšach Hóspodi, smotrénija tvojehó táinstvo, razumích ďilá tvojá, i proslávich tvojé Božestvó."),
("","","Jáko kédr blahočéstije, víru jáko kiparís, ľubóv že jáko pévk nosjášče, krestú božéstvennomu poklonímsja."),
("","","Krestóm tvojím Spáse, ráj otvérzesja, i osuždénnyj čelovík páki vníde vóň, tvojú veličája blahostýňu."),
("","","Umerščvlényja oživíl jesí Spáse čelovíki, mértv býv, i zmíja umertvíl jesí hrích vvédšaho."),
("Múčeničen","","Strástém bývše soobrázni Christóvym božéstvenniji múčenicy, pričástnicy že i svítlosti nebésnyja javíšasja."),
("Múčeničen","","Ukrasístesja múčenicy, Slóvu krásnomu sojedinívšesja: i svítlo prosvitístesja, sólnce právednoje vozľubívše."),
("Bohoródičen","","Nóvo otročá rodilá jesí, préžde vík súšča soveršénnaho, otrokovíce vseneporóčnaja, i krestóm soveršájušča vsjáčeskaja, i bláhostiju."),
),
"2": (
("","","Tý mojá kríposť Hóspodi, tý mojá i síla, tý mój Bóh, tý mojé rádovanije, ne ostávľ ňídra Ótča, i nášu niščetú positív. Ťím s prorókom Avvakúmom zovú ti: síľi tvojéj sláva čelovikoľúbče."),
("","","Jáže Bóha Slóva neizrečénno róždšaja, duší mojejá strúpy objaží, ďíjstvennym býlijem, króv Sýna tvojehó čéstnúju vozlijávši, razrušívšaho ádovo dušetľínnoje črévo, i istočívšaho míru voskresénije."),
("","","Nevísto Bóžija, prehrišénij očiščénije duší mojéj strují nizposlí, i lukávaja otmýj pomyšlénija, čísťi býti tój spodóbi: k tvojemú bo chodátajstvu, i tvojéj pómošči, Bohoródice Ďívo pribihóch."),
("","","K tvojemú nýňi pribiháju zastupléniju prečístaja, predvarí mja izbáviti ľútyja búri vrážija, i smuščájuščich potókov bezzakónija: k tvojemú že pristánišču, i k tvojéj tišiňí neuklónno Bohomáti nastávi mjá."),
("","","Vráh hrichóvnymi strilámi dúšu mojú vsjú ujazví, i oskverní slasťmí mojé sérdce, i otvratí ot putí právaho. Sehó rádi vopijú ti: obratívši iscilí mja, i spasí."),
),
),
"P5": (
"1": (
("","","O treblážénnoje drévo! Na némže raspjásja Christós, cár i Hospóď: ímže padé drévom preľstívyj, tobóju preľstívsja, Bóhu prihvozdívšusja plótiju, podajúščemu mír dušám nášym."),
("","","Odéždeju netľínija, obnažényja ný obleščí vozžeľív, sovléklsja jesí, i na kresťí raspjátsja, obnažíl jesí vrážija Christé kovárstva: sehó rádi tvojá stradánija slávim."),
("","","Króv iz rébr istékšaja spasíteľnaja jávi, mír očístila jésť, kápiščnyja že króvi razruší, i istľívšyja plodóm razúmnym obnoví, i istočí netľínije dušám nášym."),
("Múčeničen","","Prosviščéni dobrótoju mnohovídnych rán, múčenicy slávniji, božéstvennoju že króviju známenavšesja, vozbraňájuščeje préžde orúžije proidóša jávi, i vselíšasja rádujuščesja v ráj."),
("Múčeničen","","Jáko díven tý jesí vo svjatých Christé, víroju tebí vozľubívšich: ot tebé bo obohatívšesja božéstvennyja iscilénij ríki mírovi istočájut, i izsušájut izlijánije strastéj nášich."),
("Bohoródičen","","Nedúhovavšyja hrichóm ný iscilíla jesí Ďívo, róždši Spása i vračá vsích, na drévi krestňim prihvoždénnaho prečístaja, i istočívša spasénije dušám nášym."),
),
"2": (
("","","Vskúju mjá otrínul jesí ot licá tvojehó svíte nezachodímyj, i pokrýla mjá jésť čuždája ťmá okajánnaho? no obratí mja, i k svítu zápovidej tvojích putí mojá naprávi, moľúsja."),
("","","So vsím usérdijem tščúsja k tvojemú vseneporóčnaja zastupléniju i dušévnoje óko vozvoždú: ne otvratí mené, no zastupí mja jáko blahája, i izbávi mjá, i prehrišénij mojích skvérnu otmýj."),
("","","Jád smertonósen hrichóvnymi zubý vložísja: no tohó pohubí hvozďmí i kopijém božéstvennym roždestvá tvojehó, za milosérdije nás rádi plótiju postradávšaho, jedína vsepítaja."),
("","","Umerščvlénna mjá nrávom, i istľívšaho prehrišéňmi, oživí róždšaja živót víčnyj, i obnovlénijem duchóvnym, k netľíniju pretvorí mja, Bohoblažénnaja."),
("","","Lukávstva bisóvskaho, i zlóby čelovíčeskija izbávi mjá, Vladýčice, i dušévnuju boľízň, i ťilésnuju vskóri iscilí, róždšaja jedína vsjákija plóti i sohrišénij vračá, Spása i Hóspoda."),
),
),
"P6": (
"1": (
("","","Vódnaho zvírja vo utróbi dláni Jóna krestovídno rasprostér, spasíteľnuju strásť proobražáše jávi: ťím tridnéven izšéd, premírnoje voskresénije propisáše, plótiju prihvoždénaho Christá Bóha, i tridnévnym voskresénijem mír prosvíščšaho."),
("","","Krest vodruzísja na mísťi lóbňim posreďí zemlí, i posreďí rajá prozjábšuju drévom jázvu iscilí: Messíja bo Iisús posreďí bezzakónnych razbójnik, jedín právednyj javísja, s sobóju sovozdvíže vsjá, i s vysotý pádšaho v propásť vvérže."),
("","","Lúk Christé naprjáh božéstvennyj, vsečestnýj tvój krest, ispustíl jesí stríly na ubíjcu: hvózdi že rukú tvojéju Vladýko, vonzíl jesí v tohó hňivlívoje i vseskvernávoje sérdce: i do koncá tohó umertvíl jesí, i ot nehó umerščvlényja ščédre oživíl jesí."),
("Múčeničen","","Króvnym istékšym strujám, iz ťilés svjatých stradálec, uhasíša Dúchom vés idolobísija plámeň, i cérkve čestnýja brazdý napojíša, i klás izrastíti sotvoríša spasénija nadéždy i víry: ímže pitájetsja vsjáka dušá, božéstvennoju blahodátiju ."),
("Múčeničen","","Vospaľáchusja ohňá mnóžaje nrávom, strážduščiji slávniji strastotérpcy, jehdá veščéstvennym ohném opaľátisja. Lukávnymi sudijámi sudóm otdavájemi, i neujázvleni sochraňájemi byváchu ďíjstvom i blahodátiju svjatáho Dúcha, vinčávšaho ťích zakónno postradávšich."),
("Bohoródičen","","Orúžije sérdce tvojé prójde, prečístaja otrokovíce, zrjášči Sýna tvojehó na kresťí prostérta, i strásti terpjášča, i kopijém v božéstvennaja rébra probodájema vóleju, i zakalájušča ťmý boríteľnaho zmíja: ťímže pláčušči Máterski, tohó veličála jesí."),
),
"2": (
("","","Očísti mjá Spáse, mnóha bo bezzakónija mojá, i iz hlubiný zól vozvedí, moľúsja: k tebé bo vozopích, i uslýši mjá, Bóže spasénija mojehó."),
("","","Otstupích ot Bóha blúdno žív, i ráb slastéj okajánnyj bých, i vsjákija obnažíchsja dobroďíteli božéstvennyja: no posití mjá prečístaja."),
("","","Bižáteľ bých ot zápovidej dánnych mí, i udalívsja ot životá k smérti priblížichsja: no nastávi mjá k vozvraščéniju, Bohomáti prečístaja."),
("","","Žitijé mojé lukávno, ispólneno neraďínija: no mílosť tvojá mnóhaja i neizrečénnaja, prečístaja, da odoľíjet i milosérdije bláhosti tvojejá nemoščňíj mýsli mojéj."),
("","","Spása i izbáviteľa róždši, i vseščédraho, uščédri mjá čístaja, i spasí, i izbávi ot obyšédšich mjá, i napádajuščich nemílostivno na némošč mojú."),
),
),
"P7": (
"1": (
("","","Bezúmnoje veľínije mučíteľa zločestívaho ľúdi pokolebá, dýšuščeje preščénije i zlochulénije bohomérzkoje: obáče trí ótroki ne ustraší járosť zvírskaja, ni óhň sňidájaj, no protívo dýšušču rosonósnomu dúchu, so ohném súšče pojáchu: prepítyj otcév i nás Bóže blahoslovén jesí."),
("","","Jehdá rasprostérsja na drévi krestňim, jákože vinohrád Slóvo Ótčeje, mstó iskápal jesí tájny, izmiňájuščeje pijánstvo prestuplénija, i vsích veseľáščeje, víduščich ťá Bóha i ziždíteľa, vóleju stráždušča, i spasájuščeje pojúščyja: prepítyj otcév i nás Bóže blahoslovén jesí."),
("","","Raspjátije preterpíl jesí Christé mój Iisúse, ponósnoje, ustavľájuščeje čelovíkom vsé ponošénije i vozdychánije, žélči že vkusíl jesí, hóresť vsjáku zlóbnuju otjémľa, ujazvíl jesí rúci tvojí, jázvy ščédre dušévnyja náša isciľája, i píti poveľivája: prepítyj otéc nášich Bóže blahoslovén jesí."),
("Múčeničen","","Boľízňmi neboľíznennyj živót dóbliji stradáľcy priťažáli jesté: ťímže náša boľízni oblehčájete otňúd, blahodáť prijémše svýše svjatíji, isciliváti strásti, i dúchi othoňáti: i vírnym predstojité, i spasájete vopijúščyja: prepítyj otéc nášich Bóže blahoslovén jesí."),
("Múčeničen","","Stáste múčenicy pred sudíšči Christá ispovídajušče, plóť nás rádi vosprijémšaho po nám kromí tľínija: i podóbnicy strastém jehó javľájemi voístinnu, ohňá ozloblénija, i vsjákija inýja múki preterpíste, v veséliji zovúšče: prepítyj otéc nášich Bóže blahoslovén jesí."),
("Bohoródičen","","Pečáli ispólnichsja zrjášči tebé Sýne bez právdy stráždušča, ujazvľájusja dušéju, kopijém ujázvlenu tí v rébra, Bohoródica vopijáše pláčušči i rydájušči, jedína Vladýčica, júže dostójno vsí ublažájem, i blahočéstno zovém: prepítyj otéc nášich Bóže blahoslovén jesí."),
),
"2": (
("","","Ótrocy jevréjstiji v peščí popráša plámeň derznovénno, i na rósu óhň preložíša, vopijúšče: blahoslovén jesí Hóspodi Bóže vo víki."),
("","","Vsjá jesí svitonósna, svít nezachodímyj Ďívo, prijémši, i prosviščájušči čístaja, víroju tebí vopijúščyja: blahoslovén prečístaja, plód tvojehó čréva."),
("","","Da tvojé čelovikoľúbije i mílosť Ďívo javíši, iz hlubiný mja zól vozvedí vopijúšča: blahoslovén prečístaja, plód tvojehó čréva."),
("","","K tebí Máti Ďívo, pritekáju, ujazvľájem strilámi dušetľínnymi: vsehó mja molítvoju tvojéju ohradí vopijúšča: blahoslovén prečístaja, plód tvojehó čréva."),
("","","Izbávi mjá Máti Spásova, oderžáščaho ľútaho pľinénija, pomyšlénij lukávych, i vín hrichóvnych: jáko da prísno spasájem po dólhu ťá slávľu."),
),
),
"P8": (
"1": (
("","","Blahoslovíte ótrocy, Tróicy ravnočíslenniji, soďíteľa Otcá Bóha, pójte snizšédšeje Slóvo, i óhň v rósu pretvóršeje, i prevoznosíte vsím žízň podavájuščaho, Dúcha vsesvjatáho vo víki."),
("","","Blahoslovítsja drévo, ímže vsjá potrebísja jáže vo Jedémi léstnaja kľátva, vozrástšaja sňídiju lukávoju dréva, i Christós voznósitsja preproslávlennyj, íže voznestísja na ném vóleju svojéju voschoťívyj za milosérdije."),
("","","Svjaščénno vo preminéniji rukáma prisnoslávnyj, blahoslovľája vnúki inohdá, óbraz javľája svjaščénnaho dréva, ímže blahoslovénije vsím darovásja, prokľátym zlóju dréva sňídiju, i popólzšymsja vo hlubinú zól."),
("","","Ispravľájetsja vsé čelovíčestvo Vladýko, tebí rasprostértu bývšu na kresťí, i pólk padé lukávych bisóv, i razstojáščajasja sovokuplénije prijémľut: i prevoznósitsja deržáva vlásti tvojejá, i síla tvojá vo víki."),
("Múčeničen","","Blážénnuju slávu, i píšču netľínnuju, i svitozárna selénija nasľídovaste nýňi božéstvenniji stradáľcy Hospódni, i nebésnym primisístesja činóm, i prisnoslávnych nadéžd vášich konéc nýňi vosprijáste s vesélijem."),
("Múčeničen","","Váše múžestvo páče sólnca vozsijá, svitovídniji Christóvy stradáľcy, i vsjú dijávoľu prélesť božéstvennoju síloju pomračí i vírnych vsích serdcá blahočestnomúdrenňi prosvití vo víki."),
("Bohoródičen","","Mýslennyj óblak, i síň svjaščénija, prestól Bóžij, i dvér svíta, svitíľnik, i vostók slóva, vírniji vsí imenújem ťá, prečístaja Ďívo, vsjá sotvóršaho Máti súšči blahoslovénnaja."),
),
"2": (
("","","Sedmeríceju péšč chaldéjskij mučíteľ Bohočestívym neístovno razžžé, síloju že lúčšeju spasény sijá víďiv, tvorcú i izbáviteľu vopijáše: ótrocy blahoslovíte, svjaščénnicy vospójte, ľúdije prevoznosíte vo vsjá víki."),
("","","Vsederžíteľ Hospóď vselívyjsja vo utróbu tvojú, i stólp utverždénija vírnym ťá pokazá: k nemúže pribihájušče napástej izbavľájemsja i bíd, i svoboždájemsja iskušénija, sohlásno pojúšče: svjaščénnicy vospójte, ľúdije prevoznosíte jehó vo víki."),
("","","Svjaščénnaho Vladýčice otpadóch žitijá, ko hrichú nevozderžímo vlekóm, i sím poraboščájem, svoboždénija jéže o Chrisťí i právdy ístinnyja obnažíchsja: no ne prézri mjá, sokróvišče spasénija, k tebí pribihájuščaho, náha i obniščávšaho."),
("","","Da isprávitsja moľbá molítvy mojejá ko Hóspodu, iz utróby tvojejá proizšédšemu, Vladýčice: i ot prestuplénija zápovidej da izbávit mjá, i osuždénija i kľátvy zakónnyja, i skvérnu da otmýjet ľútych mojích prehrišénij, jáko jedín mílostiv."),
("","","Bohorodíteľnice prečístaja, duší mojejá jázvy, i hrichóvnyja soblázny očísti, istóčnikom otmyvájušči, íže iz rébr Sýna tvojehó, ot ních potékšimi strujámi: k tebí bo vzyváju, i k tebí pribiháju, i tebé prizyváju Bohoblahodátnuju."),
),
),
"P9": (
"1": (
("","","Sňídiju dréva ródu pribývšaja smérť, krestóm uprazdnísja dnés: íbo pramáterňaja vseródnaja kľátva razrušísja, prozjabénijem čístyja Bohomátere: júže vsjá síly nebésnyja veličájut."),
("","","Svjaščénňijše ťá voznosjášče ščédre, poklaňájemsja tvojemú krestú, kopijú že i húbi, i trósti, i v rukú vonzénnym i v nohú svjatým hvozdém Vladýko: ímiže obritóchom soveršénnoje ostavlénije, i rájskaho žitijá spodóbichomsja."),
("","","O káko neprávedno osuždén býl jesí prihvozdítisja na drévi raspinájem, právedňijšij jedíne vsích carjú, opravdáti vsích iščjáj, víroju slávjaščich stradánija tvojá vóľnaja, i smotrénije, i tebé Christé mój vírno veličájuščich."),
("Múčeničen","","Ťílo predávše múkam vsedúšno múčenicy slávniji, preterpíša rány i núžnuju smérť, otsičénije udóv, i rasterzánija, i óhnennoje opalénije, ľubóviju že razharájemi ko Hóspodu. Ťímže vincenóscy na nebesích živút."),
("Múčeničen","","Íže apóstolov i múčenikov sládoste, molítvami ích vsích nás mílosti ispólni, jáko blahoutróben, sohrišénij razrišénije podajá, i ľútych vsích izbavlénije, i tvojehó cárstvija vselénije Christé Bóže, íže nás rádi javléjsja čelovík."),
("Bohoródičen","","Svitovídnyj čertóh javílasja jesí Ďívo, vséľšemusja v tvojú netľínnuju utróbu, i strásť blažénnuju preterpívšemu choťínijem, i vsím bezstrástije podávšemu za neizrečénnuju mílosť: jemúže víroju poklaňájuščesja, tebé blahočéstno veličájem."),
),
"2": (
("","","Užasésja o sém nébo, i zemlí udivíšasja koncý, jáko Bóh javísja čelovíkom plótski, i črévo tvojé býsť prostránňijšeje nebés. Ťím ťá Bohoródicu ánhelov i čelovík činonačálija veličájut."),
("","","Voístinnu Bohomáti súščaho Bóha, moľášči ne prestáj jehóže rodilá jesí, hrichóv ostavlénije rabóm tvojím podáti, i vsesoveršénnoje proščénije ťím nýňi soďíjannych zól: i sích spodóbiti so vsími svjatými víčnaho naslaždénija."),
("","","Krípostiju i síloju duchóvnoju, i orúžijem, i deržávoju, prepojáši smirénnuju dúšu mojú presvjatája Bohoródice, i krestnym orúžijem oblecý, i hrichá mojehó rány očísti, rosóju tvojehó čelovikoľúbija, i velíkoju mílostiju tvojéju."),
("","","Spasénija búdi mí stólp, čístaja, bisóv bezďíľny sotvorí polkí, i napástej molvú, i bidý othoňájušči, i strastéj nachódy daléče prohoňájušči, i čístoje dajúšči svoboždénije."),
("","","Čístaja preproslávlennaja Máti Bóžija, pojúščyja ťá ľubóviju spasí, i iskušénij molvú razorjájušči mílostivno: jáko Bóha bo róždši Ďívo, vsjá jelíko chóščeši tvoríti móžeši, i podajéši mílosť nevozbránno. Ťímže ťá vsí veličájem."),
),
),
),
"CH": (
("","","Mojséev žézl proobražáše čestnýj krest tvój, Spáse náš: ťím bo spasáješi, jáko iz hlubiný morskíja, ľúdi tvojá čelovikoľúbče."),
("","","Jéže drévle vo Jedémi v rají, drévo sňídnoje prozjabló jésť posreďí sadóv: cérkov že tvojá Christé, krest tvój procvité, istočájušč vsemú míru žízň. No óno úbo umertví sňídiju jádšaho Adáma: sijé že žíva sotvorí, víroju spásšasja razbójnika. Jehóže spasénija pričástniki i nás javí Christé Bóže, íže strástiju tvojéju razrušívyj, jáže na ný kózni vrážija, i spodóbi nás cárstvija tvojehó Hóspodi."),
("Múčeničen","","Čtó vás narečém svjatíji? Cheruvímy li? Jáko na vás počíl jésť Christós. Serafímy li? Jáko neprestánno prosláviste jehó. Ánhely li? Ťíla bo otvratístesja. Síly li? Ďíjstvujete bo čudesý. Mnóhaja váša imená, i bóľšaja darovánija. Molíte spastísja dušám nášym."),
("Krestobohoródičen","","Ne terpľú čádo, víďašči ťá na drévi usnúvša, bódrosť vsím podajúščaho, jáko da íže drévle prestuplénija plodóm, snóm pohíbeľnym usnúvšym, božéstvennuju i spasíteľnuju bódrosť podási: Ďíva hlahólaše pláčuščisja, júže veličájem."),
),
)
#let L = (
"B": (
("","","Pomjaní nás Christé Spáse míra, jákože razbójnika pomjanúl jesí na drévi: i spodóbi vsích, jedíne ščédre, nebésnomu cárstviju tvojemú."),
("","","Rasprostérl jesí Christé dláni na drévi, i lukávaja načála i vlásti obličív, spásl jesí ot ťích vréda blahočéstno slavoslóvjaščyja ťá."),
("","","Kopijém probodésja vísja na drévi, istočíl jesí nám potóki bezsmértija, umerščvlénym bez umá prestuplénijem: ťímže so stráchom slávim ťá."),
("","","Stránni zemných javľájemych sládkich vvedénija, stránnym sebé izdáša múkam stradáľcy, ujazvľájušče otstúpnika svojími svjátými jázvami."),
("","","Íže ot beznačáľnyja Tróicy jedín sýj, strásť na kresťí preterpíl jesí vóleju: strastéj mojích izsuší vsjá potóki, i spasénija spodóbi mjá."),
("","","Jemmanújila áhnca Bóžija i Slóva, víďašči plótiju vísjašča na drévi, áhnica jedína neskvérnaja i Ďíva, pečáliju oderžíma bjáše slezjášči."),
),
)
|
|
https://github.com/sena-nana/typstrender
|
https://raw.githubusercontent.com/sena-nana/typstrender/master/README.md
|
markdown
|
# typstrender
Describe your project here.
|
|
https://github.com/Myriad-Dreamin/typst.ts
|
https://raw.githubusercontent.com/Myriad-Dreamin/typst.ts/main/docs/cookery/guide/renderer/get-artifact.typ
|
typst
|
Apache License 2.0
|
#import "/docs/cookery/term.typ" as term
The artifact can be only in #term.vector-format to this time.
To get `artifact` data, please refer to #term.ts-cli or #term.node-js-lib.
|
https://github.com/jamesrswift/chemicoms-paper
|
https://raw.githubusercontent.com/jamesrswift/chemicoms-paper/main/src/lib.typ
|
typst
|
#import "@preview/valkyrie:0.2.0" as z;
#import "./elements.typ" as elements;
#let abstracts = z.dictionary(
(
title: z.string(default: "Abstract"),
content: z.content(),
),
pre-transform: z.coerce.dictionary(it => (content: it)),
)
#let template-schema = z.dictionary(
aliases: (
"author": "authors",
"running-title": "short-title",
"running-head": "short-title",
"affiliation": "affiliations",
"abstract": "abstracts",
"date": "dates",
),
(
header: z.dictionary(
(
article-type: z.content(default: "Article"),
article-color: z.color(default: rgb(167,195,212)),
article-meta: z.content(default: [])
),
),
fonts: z.dictionary(
(
header: z.string(default: "Century Gothic"),
body: z.string(default: "CMU Sans Serif")
),
),
title: z.content(optional: true),
subtitle: z.content(optional: true),
short-title: z.string(optional: true),
authors: z.array(z.schemas.author, pre-transform: z.coerce.array),
abstracts: z.array(abstracts, pre-transform: z.coerce.array),
citation: z.content(optional: true),
open-access: z.boolean(optional: true),
venue: z.content(optional: true),
doi: z.string(optional: true),
keywords: z.array(z.string()),
dates: z.array(
z.dictionary(
(
type: z.content(optional: true),
date: z.date(pre-transform: z.coerce.date),
),
pre-transform: z.coerce.dictionary(it => (date: it)),
),
pre-transform: z.coerce.array,
),
),
)
#let template(body, ..args) = {
let args = z.parse(args.named(), (template-schema));
// setup
set text(font: args.fonts.header, lang: "en", size:9pt)
set page(footer: elements.footer(args))
show heading: set block(above: 1.4em, below: 0.8em)
show heading: set text(size: 12pt)
set heading(numbering: "1.1")
set par(leading: 0.618em, justify: true)
v(1.2em)
elements.header-journal(args)
elements.header-block(args)
elements.precis(args)
v(0.8em)
// Main body.
set text( font: args.fonts.body, lang: "en", size:9pt )
set par( first-line-indent: 0.45cm );
show par: set block(above: 0pt, below: 0.618em,)
show: columns.with(2, gutter: 1.618em)
show figure.caption: c => {
set par(justify: true, first-line-indent: 0cm);
align(left, par(justify: true, first-line-indent: 0cm)[*#c.supplement #c.counter.display(c.numbering)#c.separator*#c.body])
}
set math.equation(numbering: "(Eq. 1)")
show math.equation: set block(spacing: 1em, above: 1.618em, below: 1em)
body;
}
|
|
https://github.com/Myriad-Dreamin/typst.ts
|
https://raw.githubusercontent.com/Myriad-Dreamin/typst.ts/main/fuzzers/corpora/text/edge_02.typ
|
typst
|
Apache License 2.0
|
#import "/contrib/templates/std-tests/preset.typ": *
#show: test-page
//
// // Error: 24-26 expected "baseline", "descender", "bounds", or length
// #set text(bottom-edge: "")
|
https://github.com/kaarmu/typst.vim
|
https://raw.githubusercontent.com/kaarmu/typst.vim/main/tests/leaky-modes.typ
|
typst
|
MIT License
|
= Leaky Bodies
== Issue #69
// Broken
#show link: underline
#show link: set text(navy)
#show par: set block(spacing: 1.75em)
// Not Broken
#show link: underline
#show link: set text(navy);;
#show par: set block(spacing: 1.75em)
== Issue #46 (solved)
// Not Broken
#{ // Function body
[ // Content block
+ text
+ text
+ #box()[text another text]
+ text
+ text
]
}
// Broken
#{ // Function body
[ // Content block
+ text
+ text
+ #box()[text
another text]
+ text
+ text
]
}
== Issue #43 (solved)
#while index < 3 {
let x = "abc" // Wrong highlighting
}
#{
while index < 3 {
let x = "abc" // Correct highlighting
}
}
|
https://github.com/typst-jp/typst-jp.github.io
|
https://raw.githubusercontent.com/typst-jp/typst-jp.github.io/main/docs/changelog/0.8.0.md
|
markdown
|
Apache License 2.0
|
---
title: 0.8.0
description: Changes in Typst 0.8.0
---
# Version 0.8.0 (September 13, 2023)
## Scripting
- Plugins (thanks to [@astrale-sharp](https://github.com/astrale-sharp) and
[@arnaudgolfouse](https://github.com/arnaudgolfouse))
- Typst can now load [plugins]($plugin) that are compiled to WebAssembly
- Anything that can be compiled to WebAssembly can thus be loaded as a plugin
- These plugins are fully encapsulated (no access to file system or network)
- Plugins can be shipped as part of [packages]($scripting/#packages)
- Plugins work just the same in the web app
- Types are now first-class values **(Breaking change)**
- A [type] is now itself a value
- Some types can be called like functions (those that have a constructor),
e.g. [`int`] and [`str`]
- Type checks are now of the form `{type(10) == int}` instead of the old
`{type(10) == "integer"}`. [Compatibility]($type/#compatibility) with the
old way will remain for a while to give package authors time to upgrade, but
it will be removed at some point.
- Methods are now syntax sugar for calling a function scoped to a type,
meaning that `{"hello".len()}` is equivalent to `{str.len("hello")}`
- Added support for [`import`]($scripting/#modules) renaming with `as`
- Added a [`duration`] type
- Added support for [CBOR]($cbor) encoding and decoding
- Added encoding and decoding functions from and to bytes for data formats:
[`json.decode`]($json.decode), [`json.encode`]($json.encode), and similar
functions for other formats
- Added [`array.intersperse`]($array.intersperse) function
- Added [`str.rev`]($str.rev) function
- Added `calc.tau` constant
- Made [bytes] joinable and addable
- Made [`array.zip`]($array.zip) function variadic
- Fixed bug with [`eval`] when the `mode` was set to `{"math"}`
- Fixed bug with [`ends-with`]($str.ends-with) function on strings
- Fixed bug with destructuring in combination with break, continue, and return
- Fixed argument types of [hyperbolic functions]($calc.cosh), they don't allow
angles anymore **(Breaking change)**
- Renamed some color methods: `rgba` becomes `to-rgba`, `cmyk` becomes
`to-cmyk`, and `luma` becomes `to-luma` **(Breaking change)**
## Export
- Added SVG export (thanks to [@Enter-tainer](https://github.com/Enter-tainer))
- Fixed bugs with PDF font embedding
- Added support for page labels that reflect the
[page numbering]($page.numbering) style in the PDF
## Text and Layout
- Added [`highlight`] function for highlighting text with a background color
- Added [`polygon.regular`]($polygon.regular) function for drawing a regular
polygon
- Added support for tabs in [`raw`] elements alongside
[`tab-width`]($raw.tab-size) parameter
- The layout engine now tries to prevent "runts" (final lines consisting of just
a single word)
- Added Finnish translations
- Added hyphenation support for Polish
- Improved handling of consecutive smart quotes of different kinds
- Fixed vertical alignments for [`number-align`]($page.number-align) argument on
page function **(Breaking change)**
- Fixed weak pagebreaks after counter updates
- Fixed missing text in SVG when the text font is set to "New Computer Modern"
- Fixed translations for Chinese
- Fixed crash for empty text in show rule
- Fixed leading spaces when there's a linebreak after a number and a comma
- Fixed placement of floating elements in columns and other containers
- Fixed sizing of block containing just a single box
## Math
- Added support for [augmented matrices]($math.mat.augment)
- Removed support for automatic matching of fences like `|` and `||` as
there were too many false positives. You can use functions like
[`abs`]($math.abs) or [`norm`]($math.norm) or an explicit [`lr`]($math.lr)
call instead. **(Breaking change)**
- Fixed spacing after number with decimal point in math
- Fixed bug with primes in subscript
- Fixed weak spacing
- Fixed crash when text within math contains a newline
## Tooling and Diagnostics
- Added hints when trying to call a function stored in a dictionary without
extra parentheses
- Fixed hint when referencing an equation without numbering
- Added more details to some diagnostics (e.g. when SVG decoding fails)
## Command line interface
- Added `typst update` command for self-updating the CLI
(thanks to [@jimvdl](https://github.com/jimvdl))
- Added download progress indicator for packages and updates
- Added `--format` argument to explicitly specify the output format
- The CLI now respects proxy configuration through environment variables and has
a new `--cert` option for setting a custom CA certificate
- Fixed crash when field wasn't present and `--one` is passed to `typst query`
## Miscellaneous Improvements
- Added [page setup guide]($guides/page-setup-guide)
- Added [`figure.caption`]($figure.caption) function that can be used for
simpler figure customization (**Breaking change** because `it.caption` now
renders the full caption with supplement in figure show rules and manual
outlines)
- Moved `caption-pos` argument to `figure.caption` function and renamed it to
`position` **(Breaking change)**
- Added [`separator`]($figure.caption.separator) argument to `figure.caption`
function
- Added support for combination of and/or and before/after
[selectors]($selector)
- Packages can now specify a
[minimum compiler version](https://github.com/typst/packages#package-format)
they require to work
- Fixed parser bug where method calls could be moved onto their own line for
`[#let]` expressions in markup **(Breaking change)**
- Fixed bugs in sentence and title case conversion for bibliographies
- Fixed supplements for alphanumeric and author-title bibliography styles
- Fixed off-by-one error in APA bibliography style
## Development
- Made `Span` and `FileId` more type-safe so that all error conditions must be
handled by `World` implementors
## Contributors
<contributors from="v0.7.0" to="v0.8.0" />
|
https://github.com/SWATEngineering/Docs
|
https://raw.githubusercontent.com/SWATEngineering/Docs/main/src/2_RTB/PianoDiProgetto/sections/ConsuntivoSprint/SecondoSprint.typ
|
typst
|
MIT License
|
#import "../../const.typ": Re_cost, Am_cost, An_cost, Ve_cost, Pr_cost, Pt_cost
#import "../../functions.typ": rendicontazioneOreAPosteriori, rendicontazioneCostiAPosteriori, glossary
== Secondo #glossary[sprint]
*Inizio*: Venerdì 24/11/2023
*Fine*: Giovedì 07/12/2023
#rendicontazioneOreAPosteriori(sprintNumber: "02")
#rendicontazioneCostiAPosteriori(sprintNumber: "02")
=== Analisi a posteriori
Il consuntivo delinea come il numero di ore preventivate sia ancora notevolmente inferiore rispetto a quelle effettivamente utilizzate, in questo caso non a causa di una pianificazione irrealistica (dato che le ore preventivate sono simili in numero a quelle effettive dello #glossary[sprint] precedente), ma principalmente a causa di un imprevisto pertinente all'_Analisi dei Requisiti_; infatti, dal consuntivo emerge una notevole sottostima del tempo richiesto al ruolo di Analista. Ciò è dovuto al fatto che il team, dopo il colloquio con il professor Cardin e una discussione con la Proponente, si è focalizzato sulla ristrutturazione della maggior parte del documento, il che ha richiesto un notevole sforzo aggiuntivo.
Inoltre, dato che era previsto che i componenti assumessero più di un ruolo nel corso di questo #glossary[sprint], i ruoli sono stati nuovamente ruotati a metà di esso. L'emergere del rischio RC5 o Context switch si è rivelato di difficile gestione a metà #glossary[sprint], poiché non è stata identificata un'opportunità per valutare con precisione il progresso attuale del team rispetto alla prossima #glossary[milestone]. In particolare, il dover affidare attività compiute solo parzialmente ad un altro membro del team, a causa del cambio dei ruoli, non si è rivelata una scelta efficiente. Questo è uno dei motivi per i quali si è deciso di adottare #glossary[sprint] di una settimana e, di conseguenza, preventivare un quantitativo più piccolo di ore in futuro (pur mantenendo la possibilità per i membri di assumere più di un ruolo).
Ciononostante, il team ha portato a termine gli obiettivi prefissati nei tempi previsti, aggiungendo una pianificazione a lungo termine (fino alla #glossary[CA]) al _Piano di Progetto_, ultimando una prima ristesura dei casi d'uso nell'_Analisi dei Requisiti_ e ultimando anche una prima versione funzionante del #glossary[PoC]. Oltre al rischio citato sopra, l'unico altro rischio degno di nota è nuovamente RT1 o Conoscenza tecnologica limitata; per contrastarlo è stato scelto l'approccio di lavoro in coppia, decidendo di assegnare le attività relative allo sviluppo del #glossary[PoC] a due Programmatori che hanno lavorato in modo sinergistico e spesso in modalità sincrona per unire le loro conoscenze e velocizzare la terminazione della prima versione.
|
https://github.com/whooie/typst-lib
|
https://raw.githubusercontent.com/whooie/typst-lib/master/0.1.0/whooie.typ
|
typst
|
#let indentlen = 1em
#let maketitle(
title: none,
author: none,
date: none,
) = {
if title != none { pad(align(center, text(size: 18pt, title)), bottom: 0.5mm) }
if author != none { pad(align(center, text(size: 12pt, author)), bottom: 0.5mm) }
if date != none { pad(align(center, text(size: 10pt, date)), bottom: 0.5mm) }
if (title, author, date).any(thing => thing != none) { v(9mm) }
}
#let document(
title: none,
author: none,
date: none,
papersize: "us-letter",
margins: (x: 0.8in, y: 0.8in),
latexfont: true,
numeq: true,
linkcolor: rgb(0, 0, 255),
refcolor: rgb(0, 0, 255),
doc,
) = {
set page(paper: papersize, margin: margins)
set text(font: "New Computer Modern") if latexfont
set math.equation(numbering: "(1)") if numeq
set math.op(limits: true)
set heading(numbering: "1.1.1")
show heading: set block(above: 1.4em, below: 1em)
set par(justify: true, leading: 0.55em, first-line-indent: indentlen)
show par: set block(spacing: 0.55em)
show link: it => text(fill: linkcolor, it)
show ref: it => text(fill: refcolor, it)
show "Schrodinger": "Schrödinger"
maketitle(title: title, author: author, date: date)
doc
}
#let indent = h(indentlen)
#let pheq = hide([$=$])
#let mkeq = [$accent(=, !)$]
#let pm = [$plus.minus$]
#let mp = [$minus.plus$]
#let text(x) = [$upright(#x)$]
#let slashed(x) = [$cancel(#x, rotation: #165deg)$]
// #import "@preview/babble-bubbles" // callouts
// #import "@preview/codetastic" // bar/qr codes
// #import "@preview/digraph" // graphviz
// #import "@preview/funarray" // array processing
// #import "@preview/i-figured" // figure numbering
// #import "@preview/lovelace" // algorithms/pseudocode
// #import "@preview/ouset" // over/underset
// #import "@preview/oxifmt" // rust-style string formatting
// #import "@preview/physica" // physics
// #import "@preview/plotst" // plotting
// #import "@preview/polylux" // presentation slides
// #import "@preview/quill" // quantum circuit diagrams
// #import "@preview/rubby" // furigana overset
// #import "@preview/showybox" // fancy boxes
// #import "@preview/splash" // colors
// #import "@preview/statastic" // statistics functions
// #import "@preview/tablex" // table rendering
// #import "@preview/tbl" // ```tbl concise table rendering
// #import "@preview/unify" // units
// #import "@preview/xarray" // variable-length arrows
|
|
https://github.com/Maso03/Bachelor
|
https://raw.githubusercontent.com/Maso03/Bachelor/main/Bachelorarbeit/thesis.typ
|
typst
|
MIT License
|
#import "../template.typ" : template
#show: template.with(
title: "Entwurf & Implementierung eines 3D-Avatars basierend auf künstlicher Intelligenz als Verkaufsberater",
author: "<NAME>",
date: datetime(year: 2024, month: 9, day: 9),
logos: (
image("assets/dhbw.svg", width: 30%),
image("assets/telekom.svg", width: 15%),
),
details: (
"Course, Student ID": "TINF21A, 9769728",
"Company": "Deutsche Telekom AG",
"Supervisor": "Nguygen, <NAME>",
),
abstract: include "abstract.typ",
acronyms: yaml("acronyms.yml"),
)
#include "chapters/introduction.typ"
#include "chapters/grundlagen.typ"
#include "chapters/GenAI.typ"
#include "chapters/ConvAI.typ"
#include "chapters/conclusion.typ"
#bibliography("references.yml")
|
https://github.com/polarkac/MTG-Stories
|
https://raw.githubusercontent.com/polarkac/MTG-Stories/master/stories/014_Khans%20of%20Tarkir.typ
|
typst
|
#import "@local/mtgset:0.1.0": conf
#show: doc => conf("Khans of Tarkir", doc)
#include "./014 - Khans of Tarkir/001_The Madness of Sarkhan.typ"
#include "./014 - Khans of Tarkir/002_Awakening the Bear.typ"
#include "./014 - Khans of Tarkir/003_Sorin's Revelation.typ"
#include "./014 - Khans of Tarkir/004_Taigam's Scheming.typ"
#include "./014 - Khans of Tarkir/005_Way of the Mantis.typ"
#include "./014 - Khans of Tarkir/006_The Chensal Twins.typ"
#include "./014 - Khans of Tarkir/007_Enlightened.typ"
#include "./014 - Khans of Tarkir/008_The Salt Road.typ"
#include "./014 - Khans of Tarkir/009_Mercy.typ"
#include "./014 - Khans of Tarkir/010_Victory.typ"
#include "./014 - Khans of Tarkir/011_Bond and Blood.typ"
#include "./014 - Khans of Tarkir/012_Journey to the Nexus.typ"
|
|
https://github.com/napleon-liu/my-cv
|
https://raw.githubusercontent.com/napleon-liu/my-cv/main/template.typ
|
typst
|
// 图标
#let icon(path) = box(
baseline: 0.125em,
height: 0.8em,
width: 0.8em,
align(center,image(path))
)
#let faAngleRight = icon("fa-angle-right.svg")
// 个人信息
#let info(
color: black,
name: "",
phone:"",
email:"",
infos:(),
) ={
set text(fill: color)
//姓名 电话 邮箱
show par: set block(spacing: .5em)
[
#text(font: "Microsoft YaHei",fill: color,size: 1.5em,name)
#icon("fa-phone.svg") #phone | #icon("fa-envelope.svg") #email
]
set text(fill: black)
//其他信息
rect(
width: 100%,
fill: rgb(250,250,250),
grid(
columns: (1fr,1fr),
row-gutter: 1em,
..infos
)
)
}
// 主体
#let resume(
size: 10pt,
themeColor: rgb(38, 38, 125),
photograph: "",
infos,
body
) = {
// 页边距设定
set page( margin: (
top: 1cm,
bottom: 1cm,
left: 2cm,
right: 2cm,
))
// 基础字体设定
set text(size: size, lang: "zh")
// 标题
show heading: set text(themeColor, 1.1em)
show heading: set block(
stroke: (bottom: 1pt + themeColor),
// inset: 3pt,
outset: 3pt,
width: 100%,
)
// 更改 bullet list 的图标
set list(
indent: 1em,
body-indent: 0.2em,
marker: faAngleRight
)
// 主体设定
set par(justify: true)
// 首部与照片
grid(
columns: (80%,15%),
gutter: 20pt,
infos,
image(photograph)
)
show par: set block(spacing: 0.65em)
v(-25pt)
body
}
#let sidebar(..contents) = grid(
columns: (auto, auto),
gutter: (0.75em),
..contents
)
// 颜色变灰
#let graytext = text.with(
fill: rgb(32, 32, 32),
size: 0.9em,
)
// 项目
#let award(
title,
desc,
endnote
) = {
grid(
columns: (0.5fr , 2.5fr, 1.5fr),
row-gutter: (0.25em),
column-gutter: 2em,
graytext(endnote),title, desc,
)
}
#let honor(
title,
endnote
) = {
grid(
columns: (0.6fr , 2.5fr+ 2.5fr),
row-gutter: (0.25em),
column-gutter: 2em,
graytext(endnote),title,
)
}
#let item(
title,
desc,
endnote
) = {
grid(
columns: ( 3.5fr, 0.9fr,0.7fr,),
row-gutter: (0.25em),
column-gutter: 2em,
text(fill:rgb(38, 38, 125),size:1.1em,"• "+strong(title)), desc, graytext(endnote)
)
}
|
|
https://github.com/pluttan/electron
|
https://raw.githubusercontent.com/pluttan/electron/main/lab4/lab4.typ
|
typst
|
#import "@docs/bmstu:1.0.0":*
#import "@preview/tablex:0.0.8": tablex, rowspanx, colspanx, cellx
#show: student_work.with(
caf_name: "Компьютерные системы и сети",
faculty_name: "Информатика и системы управления",
work_type: "лабораторной работе",
work_num: "4",
discipline_name: "Электроника",
theme: "Мультивибратор на основе операционного усилителя с",
themecol2: "интегрирующей RC-цепью (Вариант 13)",
author: (group: "ИУ6-42Б", nwa: "<NAME>"),
adviser: (nwa: "<NAME>"),
city: "Москва",
table_of_contents: true,
)
= Задание
== Цель работы
Экспериментальное исследование генератора прямоугольных импульсов, работающего в автоколебательном режиме.
#v(-10pt)
== Параметры схемы
#align(center)[
#tablex(
columns: 11,
inset: 10pt,
align: center+horizon,
rowspanx(2)[Вариант],
colspanx(2)[Хронирующая RC цепь],
colspanx(2)[Нагрузочный конденсатор],
colspanx(2)[Делитель напряжения],
colspanx(2)[Хронирующая RC цепь],
colspanx(2)[Делитель напряжения],
[$C_1$, нФ],[$C_2$, нФ],[$C_3$, мФ],[$C_4$, мФ],[$R_1$,\ кОм],[$R_2$,\ кОм],[$R_3$,\ кОм],[$R_4$,\ кОм],[$R_5$,\ кОм],[$R_6$,\ кОм],
[$13$],[$35$],[$70$],[$0.02$],[$0.15$],[$30$],[$60$],[$30$],[$30$],[$60$],[$30$],
)
]
= Часть 1
Схема с мультивибратором, данная по условию показана на рисунке 1:
#img(image("1.png", width:90%), [Схема с мультивибратором])
Исследование влияния постоянной времени хронирующей RC-цепи на период генерируемых колебаний:
1) Графически показано на рисунке 2:
#img(image("2.png", width:90%), [Анализ переходных процессов для $С_1$])
Красное – область прямоугольных импульсов – на выходе, синее – хронирующая RC-цепь, зеленое – цепь делителя
$ Т = 1,4905 * 10^"-3" "для" С_1 $
$ Т = 2,9441 * 10^"-3" "для" С_2 $
2) Аналитически:
$ Т = 2 * С_1 * R_3 * ln (1 + 2 (R_1)/(R_5)) = 1,455 * 10^"-3" с, "погрешность" 3% $
$ τ = R_3 * C_1 = 10^"-3" с $
$ Т = 2 * С_2 * R_4 * ln (1+2 (R_5)/(R_6)) = 2,911 * 10^"-3" с, "погрешность" 2% $
$ τ = R_4 * C_2 = 21*10^"-4" с $
= Часть 2
Исследование влияния коэффициента передачи $β$ цепи положительной обратной связи на период генерируемых колебаний:
Используем нижеперечисленные формулы для заполнения таблицы:
$ β = (R_1)/(R_1+R_5) $
$ Т = 2 С_1 R_3 ln (1+2 (R_1)/(R_5)) $
#align(center)[
#tablex(
columns: 6,
inset: 10pt,
align: center+horizon,
[$R_1$], [$R_5$],[$β$], [$T_"выч cек"$],[$T_"граф cек"$], [$Ϭ%$],
[30], [60], [0,333], [0,001455609], [0,00149], [2],
[30], [30], [0,5], [0,002307086], [0,00233], [1],
[60], [30], [0,667], [0,00337982], [0,0034], [1],
[90], [30], [0,75], [0,004086411], [0,0041], [0]
)
]
= Часть 3
Исследование влияния ёмкости нагрузочного конденсатора на длительность фронта и среза выходных:
#img(image("3.png", width:90%), [Анализ переходных процессов для $С_2$])
Пример графика для $С_3$ с значением 0,02пФ показан на рисунке 4:
#img(image("4.png", width:90%), [Анализ переходных процессов для $С_3 = 0,25 "пФ" (τ_ф)$])
#img(image("5.png", width:90%), [Анализ переходных процессов для $С_3 = 0,15 "пФ" (τ_"сp")$])
Вычисления, сделанные по 4-ем графикам показаны в таблице:
#align(center)[
#tablex(
columns: 4,
inset: 10pt,
align: center+horizon,
[$С_3$, мФ],[$τ_"конд"$, с], [$τ_ф$, с], [$τ_"ср"$, с],
[0,02], [0,0000002], [0,0000192], [0,0000192],
[0,15], [0,0000015], [0,000116], [0,000116],
[0,25], [0,0000025], [0,000193], [0,0001931],
[0,35], [0,0000035], [0,000271], [0,000271]
)
]
Из таблицы видно, что значение нагруженной ёмкости влияет на значение переднего и заднего фронта.
= Вывод
Экспериментально исследовал генератор прямоугольных импульсов, работающего в автоколебательном режиме.
|
|
https://github.com/pluttan/trps
|
https://raw.githubusercontent.com/pluttan/trps/main/lab3/lab3.typ
|
typst
|
#import "@docs/bmstu:1.0.0":*
#import "@preview/tablex:0.0.8": tablex, rowspanx, colspanx, cellx
#show: student_work.with(
caf_name: "Компьютерные системы и сети",
faculty_name: "Информатика и системы управления",
work_type: "лабораторной работе",
work_num: "3",
discipline_name: "Технология разработки программных систем",
theme: "Оценка эффективности и качества программы (Вариант 11)",
author: (group: "ИУ6-42Б", nwa: "<NAME>"),
adviser: (nwa: "<NAME>"),
city: "Москва",
table_of_contents: true,
)
= Задание
== Цель работы
Цель данной работы — изучить известные критерии оценки и способы
повышения эффективности и качества программных продуктов.
== Задание по варианту
Написать программу вычисления суммы ряда $S = 1/4 - 1/16 + 1/96 - ... + (-1)^(n+1) 1/(4^n times n!)$ с точностью 0,0001. Ряд сходится и имеет множитель $m = -1/(4 times n)$.
== Код
#code(read("vr11.c"), "c", [Заданный по варианту код])
= Выполнение
Технологичность определяет качество проекта и, как правило, важна
при разработке сложных программных систем. От технологичности зависят трудовые и материальные затраты на реализацию и последующую модификацию программного продукта. Факторами, которые определяют технологичность, являются: проработанность модели, уровень независимости модулей, стиль программирования и степень повторного использования кодов. Обычно в рамках лабораторных работ из-за ограниченного объема времени оценка этого качества не выполняется.
Эффективность программы можно оценить отдельно по каждому ресурсу вычислительной машины. Критериями оценки являются:
- Время ответа на вопрос или выполнения операции (оценивают для программ,работающихвинтерактивномрежимеиливрежимереальноговремени);
- Объем оперативной памяти (важен для вычислительных систем, где оперативная память является дефицитным ресурсом);
- Объем внешней памяти (оценивают, если внешняя память является дефицитным ресурсом или при интенсивной работе с данными);
- Количество обслуживаемых терминалов и др.
Выбор критерия оценки эффективности программы существенно зависит от выполняемых ею функций. Например, если основной функцией является поиск данных, то уменьшить время выполнения можно, обеспечив избыточный объем оперативной памяти. В этом случае оценка памяти будет уже второстепенной задачей.
== Добавление фиксаций времени
Добавим фиксации по времени: для этого используем функцию ```c clock()``` из библиотеки `time.h`. Данная функция возвращает количество тиков процессора, которые прошли с момента запуска программы. Что бы получить из данного значения миллисекунды воспользуемся формулой: ```cpp (ticks * 1000) / CLOCKS_PER_SEC;```. В коде измерим 3 времени: время начала программы `t0` время начала цикла `t1` и время конца цикла `t2`, так мы можем получить время выполнения цикла и время выполнения всего кода до цикла. Считаем, что инициализация временных меток выполняется всегда за одно и то же время, таким образом убрав временные метки все оптимизации останутся эффективными. Код, получившийся после добавления временных меток:
В результате выполнения программы время ее работы составило 0.4 нс, выполнение цикла 0.1 нс. Данные цифры не очень информативны, поэтому используем линзу, чтобы получить более информативное время. Сделаем цикл, в котором прогоним код 1000000. Получаем 347.505 мс -- общее время работы программы, таким образом точное время выполнения кода 0.347505 нс. Следует отметить, что в код я добавил очищение памяти, которое занимает некоторое время, но без него будет выделено большое количество памяти без очищения.
== Улучшения качества кода
Качество программных продуктов может оцениваться следующими критериями:
- правильность — функционирование в соответствии с заданием;
- универсальность — обеспечение правильной работы при любых допустимых данных и содержание средств защиты от неправильных данных;
- надежность (помехозащищенность) — обеспечение полной повторяемости результатов, т. е. обеспечение их правильности при наличии различного рода сбоев;
- проверяемость — возможность проверки получаемых результатов;
- точность результатов — обеспечение погрешности результатов не выше заданной;
- защищенность — сохранение конфиденциальности информации;
- эффективность — использование минимально возможного объема ресурсов технических средств;
- адаптируемость — возможность быстрой модификации с целью приспособления к изменяющимся условиям функционирования;
- повторная входимость — возможность повторного выполнения без перезагрузки с диска (для резидентных программ);
- реентерабельность — возможность «параллельного» использования несколькими процессами.
Для улучшения качества кода введем несколько улучшений и исправлений:
+ Названия переменных: изменим названия переменных на более понятные, для улучшения читаемости кода.
- `s` переименуем на `sum`
- `ms` переименуем на `terms`
- `mss` переименуем на `cumulative_sums`
- `o` переименуем на `index`
+ Выделение Памяти: Добавим проверку успешного выделения памяти и очистку памяти.
+ Математическая библиотека: Включён заголовок ```cpp <math.h>``` для использования ```cpp fabs``` для вычисления абсолютного значения. ```cpp fabs``` использован для уменьшения преобразования типов.
+ Читаемость кода: Улучшена читаемость кода за счёт добавления правильных отступов и пробелов.
После улучшения качества кода получаем следующий код:
== Способы уменьшения времени выполнения
Время выполнения программы в первую очередь зависит от используемых в ней методов реализации операций. Важную роль играют циклические фрагменты с большим количеством повторений, поэтому по возможности необходимо минимизировать тело цикла.
При написании циклов рекомендуется:
+ Выносить из тела цикла выражения, не зависящие от параметров цикла;
+ Заменять «длинные» операции умножения и деления вычитанием и сдвигами;
+ Уменьшать количество преобразования типов в выражениях;
+ Исключать лишние проверки;
+ Исключать многократные обращения к элементам данных сложных структур (например, многомерных массивов, так как при вычислении адреса элемента используются операции умножения на значение индексов);
+ Исключать лишние вызовы предопределенных процессов (например, процедур, функций, методов классов и др.).
Посмотрим, насколько все рекомендации применимы к коду:
+ Все выражения, используемые в цикле зависят (иногда косвенно) от параметров цикла
+ Операцию умножения `o` на 4 можно заменить сдвигом вправо на 2, операцию деления заменить сдвигом нельзя, так как деление не целочисленное
+ Можно уменьшить количество преобразований типов в выражениях:
- `abs` заменяем на `fabs`, таким образом числа с плавающей точкой не будут переводиться в целочисленный тип, а будут сразу же сравниваться
+ Исключать лишние проверки мы не можем, так как проверка всего одна.
+ Все массивы одномерные, таким образом при формировании адреса не будут использоваться операции умножения.
При этом есть ошибка в самой реализации(не правильные индексы) и лишние массивы: нам нет необходимости находить все элементы ряда, нужна только сумма, поэтому цикл весь перепишем.
Суммируя все вышесказанное в пунктах 2.1-2.3 можно получить следующий код:
#code(read("vr11c2.c"), "c", [Исправленный код], size:13pt)
Опять используем линзу для замера времени. В этот раз получили 83.374 мс. Тогда сама программа работает за 0.083374 нс.
== Оценка эффективности
#set text(10pt)
#align(center)[
#tablex(
columns: 5,
inset: 10pt,
align: horizon+center,
rowspanx(2)[Критерий оценки], colspanx(2)[Исходная программа], colspanx(2)[Исправленная программа],
[Недостатки],[Количественная оценка],
[Недостатки],[Количественная оценка],
[Время выполнения],[Лишние преобразования типов, деление на 4, из-за использования лишних массивов лишние присваивания], [0.347505 нс], [Удалены лишние массивы, заменена функция abs на fabs], [0.083374 нс],
[Оперативная память],[Оба массива лишние, не предусмотрены проверки на верное выделение памяти, не предусмотрена проверка на освобождение памяти], [8032 байт], [Убраны массивы и не нужные переменные для их индексации], [16 байт],
)
]
#set text(14pt)
== Оценка качества
#set text(10pt)
#align(center)[
#tablex(
columns: 5,
inset: 10pt,
align: horizon+center,
rowspanx(2)[Результаты оценки], colspanx(4)[Критерий оценки],
[Правильность],[Универсальность],[Проверяемость],[Точность результатов],
[Недостатки], [Ошибка при использовании\ индексов], [Входными данными является точность, выделяется фиксированное количество памяти, значит при большой точности массивы могут быть переполнены], [Выводится результат и индекс, до которого считается сумма. Для лучшей проверяемости необходимо знать еще последние 2 элемента массива и их разность], [Результат неверный, так как в начале ошибка в индексах массива],
[Оценка], [2], [2], [3], [0]
)
]
#set text(14pt)
= Заключение
В результате проведенных экспериментов были выполнены замеры времени работы программы, оценки памяти, а также предложены способы повышения эффективности и качества программы.
|
|
https://github.com/leesum1/brilliant-cv
|
https://raw.githubusercontent.com/leesum1/brilliant-cv/master/modules_zh/projects.typ
|
typst
|
// Imports
#import "@preview/brilliant-cv:2.0.2": *
#import "@preview/fontawesome:0.4.0": *
#let metadata = toml("../metadata.toml")
#let cvSection = cvSection.with(metadata: metadata)
#let cvEntry = cvEntry.with(metadata: metadata)
#cvSection("项目经历")
#cvEntry(
society: [一生一芯-第四期],
title: [学号:ysyx_22041514],
date: [2022.6 - 2022.11],
location: [一生一芯是涉及处理器设计、系统软件开发、SOC 构建的综合性实践项目],
description: list(
[使用 *Verilog* 设计 RV64IM 指令集的*经典 5 级流水线处理器*;使用 C 语言设计并完成*RISC-V 模拟器*],
[从系统底层为处理器移植软件,熟练掌握*交叉编译、链接脚本、操作系统移植、GDB 调试、Makefile 脚本等知识*],
[完成*「一生一芯-第四期」*所有内容,使用 *AXI4 总线*将处理器接入到 「ysyx-SOC」 环境,通过了 riscv-tests 等测试],
),
)
#cvEntry(
society: link("https://github.com/leesum1/RV64emu-rs")[RV64emu-rs],
title: link("https://github.com/leesum1/RV64emu-rs")[#fa-icon("github") leesum1/RV64emu-rs],
date: [2022.12 - now],
location: [RV64emu-rs 是用 RUST 编写一个 RISC-V 的 ISA 模拟器],
description: list(
[*精通 C/C++、RUST 语言*,使用 RUST 编写了支持 RV64IMAC 的模拟器,添加了 ICahce, DCache 等缓存],
[对外设的*底层驱动开发*有丰富的经验,实现了一个完善的设备框架,添加了 PLIC 中断控制器、VGA,、UART 等多种外设],
[能够独自完成*系统软件*的移植工作,成功移植 RT-Thread 、FreeRTOS、*Linux* 等多种操作系统到模拟器上],
[对*处理器调试技术*有深入的了解,为模拟器实现了 Debug 模式,能够使用 openOCD/GDB 通过 SimJTAG 连接到模拟器,执行单步调试、寄存器读写、内存读写等操作],
),
)
#cvEntry(
society: link("https://github.com/leesum1/FishCore")[FishCore],
title: link("https://github.com/leesum1/FishCore")[#fa-icon("github") leesum1/FishCore],
date: [2023.6 - now],
location: [FishCore 是一个用 Chisel 编写的 RISC-V 内核],
description: list(
[熟悉*计算机体系架构*,对多级*分支预测*、*乱序执行*等内容有深入了解,使用 Chisel 实现了*乱序双发射 7 级流水线*的 RISC-V 处理器设计,运行*Linux*、CoreMark 等复杂应用时,*IPC 可达 1.0 以上*],
[深入理解 *RISC-V 调试机制*,实现了 *JtagDMI* 与 *DebugModule*,能够通过 *JTAG* 连接到 FishCore 进行调试操作],
// [熟悉处理器缓存技术,实现了 ICache(VIPT) 和 DCache(PIPT), 以及 TLB 缓存加速处理器运行。],
// [实现了 PLIC, CLINT, UART, MEM 等多种外设,并且通过 AXI4 总线进行互连搭建了一个最小 SOC 系统(FishSOC),能够成功运行 Linux],
[熟悉*AMBA等总线协议*,对*SOC芯片架构*有一定的理解,实现了*AXI4 总线桥、AXI4Demux、AXI4Arbiter、多端口 FIFO、异步 FIFO、跨时钟握手协议*等多种IP ;从零开始为 FishCore
构建了一个*完整的 SOC 系统*,通过了仿真与验证],
// [按照 riscv-debug-specification 实现了 Debug 模式,能够使用 openOCD/GDB 通过 SimJTAG 连接到处理器,进行寄存器读写、内存读写、单步执行、监视点、断点等调试操作],
[有 *FPGA 开发经验*,使用 Vivado 对 FishSOC 进行综合、布局布线,成功在 FPGA 上*运行了 Linux 操作系统*],
[*熟练使用各种 EDA 工具*,例如 *Vivado、VCS、Verdi、Iverilog* 等],
),
)
#cvEntry(
society: [开源社区贡献],
title: [拥有丰富的开源社区经验,为 riscv-tests、xmake、rt-thread、ibex 等项目贡献过 PR],
date: [2022.6 - now],
location: [热衷于使用开源工具,完善开源工具],
description: list(
[#link("https://github.com/RT-Thread/rt-thread/pull/7040")[ *#fa-icon("code-merge") rt-thread/pull/7040* ]:修复
qemu-riscv-virt64 bsp 中 smode 下无法启动的问题,提升了系统稳定性],
[#link("https://github.com/lowRISC/ibex/pull/2044")[ *#fa-icon("code-merge") ibex/pull/2044* ]:为 Ibex 添加了 MTVEC 的 Direct
Mode 支持,完善了处理器的功能],
[#link("https://github.com/xmake-io/xmake/pull/3944")[ *#fa-icon("code-merge") xmake/pull/3944* ]:修复了 xmake 对 Verilator
工程构建的支持, 添加了必要的说明文档],
[#link("https://github.com/riscv-software-src/riscv-tests/pull/549")[ *#fa-icon("code-merge") riscv-tests/pull/549* ]:修复了
riscv-tests 中 Debug 测试集中 GDB TEST 中的初始化程序错误, 提高了测试集的兼容性],
),
)
|
|
https://github.com/teshu0/CLIT-report-typst
|
https://raw.githubusercontent.com/teshu0/CLIT-report-typst/main/template/reset.typ
|
typst
|
Creative Commons Zero v1.0 Universal
|
#import "./utils.typ": font_gothic, font_serif
// 書式をセットアップする
#let reset = (content) => {
set page(paper: "a4")
set text(lang: "ja", font: font_serif)
set heading(numbering: "1.1")
show heading: it => [
#set text(
font: font_gothic,
// size: 14pt,
spacing: 1em, // 一文字分あける
weight: "semibold", // 太字にしない
)
// 上下に余白を追加
#pad(
top: 0.75em,
bottom: 0.75em,
)[
#if it.numbering != none {
[
#set text(font: font_serif)
#counter(heading).display(
it.numbering
)
]
}
#box(it.body)
]
// 一時的な対処: https://zenn.dev/mkpoli/articles/34a5ea47468979
#par(text(size: 0pt, ""))
]
content
}
|
https://github.com/HEIGVD-Experience/docs
|
https://raw.githubusercontent.com/HEIGVD-Experience/docs/main/S4/WEB/docs/6-ClientServerApplications/arrays%26iterables.typ
|
typst
|
#import "/_settings/typst/template-note-en.typ": conf
#show: doc => conf(
title: [
Arrays and Iterables,
],
lesson: "WEB",
chapter: "6 - Client Server applications",
definition: "TBD",
col: 1,
doc,
)
= Educational objectives
- Read and use the Array object’s methods.
- Resolve problems using the Array object’s methods.
- Read and use the functional methods of the Array object.
- Resolve problems using the functional methods of the Array object.
- Read and use the Iterator and Generator objects.
- Read and use the Map and Set objects.
- Describe the anatomy of a web application.
- Describe alternatives to ExpressJS.
= Arrays
== Array methods
- `concat()` concatenates two or more arrays and returns a new array.
- `join()` joins all elements of an array into a string.
- `pop()` removes the last element from an array and returns that element.
- `push()` adds one or more elements to the end of an array and returns the new length of the array.
- `reverse()` reverses the order of the elements of an array.
- `shift()` removes the first element from an array and returns that element.
- `slice()` selects a part of an array, and returns it as a new array.
- `sort()` sorts the elements of an array.
- `includes()` determines whether an array contains a specified element.
- `flat()` flattens an array up to the specified depth.
=== concat()
```javascript
const a = ['a', 'b', 'c'];
const b = ['d', 'e', 'f'];
const c = a.concat(b);
console.log(c); // ['a', 'b', 'c', 'd', 'e', 'f']
console.log(a); // ['a', 'b', 'c']
console.log(b); // ['d', 'e', 'f']
```
=== join()
```javascript
const a = ['a', 'b', 'c'];
const b = a.join(' - ');
console.log(b); // 'a - b - c'
const c = [{ name: 'John' }, { name: 'Jane' }];
const d = c.join(', ');
console.log(d); // '[object Object], [object Object]'
```
=== pop()
```javascript
const a = ['a', 'b', 'c'];
const b = a.pop();
console.log(b); // 'c'
console.log(a); // ['a', 'b']
```
=== push()
```javascript
const a = ['a', 'b', 'c'];
const b = a.push('d');
console.log(b); // 4
console.log(a); // ['a', 'b', 'c', 'd']
```
=== reverse()
```javascript
const a = ['a', 'b', 'c'];
const b = a.reverse();
console.log(b); // ['c', 'b', 'a']
console.log(a); // ['c', 'b', 'a']
```
=== shift()
```javascript
const a = ['a', 'b', 'c'];
const b = a.shift();
console.log(b); // 'a'
console.log(a); // ['b', 'c']
```
=== slice()
```javascript
const a = ['a', 'b', 'c'];
const b = a.slice(1, 2);
console.log(b); // ['b']
console.log(a); // ['a', 'b', 'c']
```
=== sort()
```javascript
const a = ['c', 'a', 'b'];
const b = a.sort();
console.log(b); // ['a', 'b', 'c']
console.log(a); // ['a', 'b', 'c']
const c = [{ name: 'John' }, { name: 'Jane' }];
const d = c.sort((a, b) => a.name.localeCompare(b.name)); // yes, the 'a' and 'b' are the parameters of the function and not the arrays
// const d = c.sort((x, y) => x.name.localeCompare(y.name)); // equivalent
console.log(d); // [{ name: 'Jane' }, { name: 'John' }]
```
=== includes()
```javascript
const a = ['a', 'b', 'c'];
const b = a.includes('b');
console.log(b); // true
const c = [1, 2, 3];
const d = c.includes('2');
console.log(d); // false
console.log(c['2']); // 3
console.log(c[2]); // 3
```
=== flat()
```javascript
const a = [1, 2, [3, 4, [5, 6]]];
const b = a.flat();
console.log(b); // [1, 2, 3, 4, [5, 6]]
console.log(a); // [1, 2, [3, 4, [5, 6]]]
```
== Functional methods
=== forEach
```javascript
const a = ['a', 'b', 'c'];
const b = a.forEach(element => console.log(element));
console.log(b); // undefined
console.log(a); // ['a', 'b', 'c']
```
=== map
```javascript
var a = ["apple", "banana", "pear"];
const b = a.map(a => a.length)
console.log(b); // [5, 6, 4]
console.log(a); // ["apple", "banana", "pear"]
```
=== flatMap
```javascript
var a = ['Yverdon is', 'a', 'beautiful city'];
a.flatMap(s => s.split(" "));
// First executes map: [['Yverdon', 'is'], 'a', ['beautiful', 'city']]
// Then flattens: ['Yverdon', 'is', 'a', 'beautiful', 'city'].
```
=== filter
```javascript
const words = ['Yverdon', 'is', 'a', 'beautiful', 'city'];
const result = words.filter(word => word.length > 6);
console.log(words); // ['Yverdon', 'is', 'a', 'beautiful', 'city']
console.log(result); // ['Yverdon', 'beautiful']
```
=== reduce
```javascript
const array1 = [1, 2, 3, 4];
// 0 + 1 + 2 + 3 + 4
const initialValue = 0;
const sumWithInitial = array1.reduce(
(accumulator, currentValue) => accumulator + currentValue,
initialValue,
);
console.log(sumWithInitial);
// Expected output: 10
```
=== every & some
```javascript
var a = [1, 2, 3];
a.every(a => a > 0) // true
a.every(a => a > 1) // false
a.some(a => a > 1) // true
```
=== find & findIndex
```javascript
var a = [1, 2, 3];
console.log(a.find(a => a > 2)) // 3
console.log(a.findIndex(a => a > 2)) // 2
console.log(a.find(a => a > 3)) // undefined
```
= Iterators and Generators
== Iterator
*Iterators* are objects that provide a `next()` method which returns an object with two properties:
- value: the next value in the iterator, and
- done: whether the last value has already been provided.
Iterables are objects that have a `Symbol.iterator` method that returns an iterator over them.
```javascript
let idGenerator = {};
idGenerator[Symbol.iterator] = function() {
return {
nextId: 0,
next() {
if (this.nextId < 10) {
return { value: this.nextId++, done: false };
} else {
return { done : true };
}
}
}
}
for (let id of idGenerator) {
console.log(id); // 0 /n 1 /n 2 /n ... 9
}
```
== Generator
*Generators* are functions that can be paused and resumed. They are created using the `function*` syntax and yield values using the `yield` keyword.
```javascript
let idGenerator = {};
idGenerator[Symbol.iterator] = function() {
return {
nextId: 0,
next() {
if (this.nextId < 10) {
return { value: this.nextId++, done: false };
} else {
return { done : true };
}
}
}
}
idGenerator[Symbol.iterator] = function* () {
let nextId = 0;
while (nextId < 10) {
yield nextId++;
}
};
for (let id of idGenerator) {
console.log(id); // 0 /n 1 /n 2 /n ... 9
}
```
== Built-in iterables
=== Map
```javascript
let map = new Map();
map.set("key", "value");
map.get("key");
map.delete("key");
map.has("key");
map.forEach((key, value) => console.log(key, value));
```
=== Set
```javascript
let set = new Set();
set.add("value");
set.has("value");
set.delete("value");
```
== Exemple
=== Flattening generator
```javascript
const arr = [1, [2, [3, 4], 5], 6];
const flattened = [...flatten(arr)];
console.log(flattened); // [1, 2, 3, 4, 5, 6]
function* flatten(arr) {
for (const elem of arr) {
if (Array.isArray(elem)) {
yield* flatten(elem);
} else {
yield elem;
}
}
}
```
=== Sum of squares
```javascript
const arr = [1, 2, 3, 4, 5];
const sum = sumOfSquares(arr);
console.log(sum); // 55 (1^2 + 2^2 + 3^2 + 4^2 + 5^2)
function sumOfSquares(arr) {
return arr
.map(num => num ** 2)
.reduce((acc, num) => acc + num, 0);
}
```
=== Counting words
```javascript
const countWords = () => {
return text.split(" ")
.map(word => word.toLowerCase())
.filter(word => /^[a-z]+$/.test(word))
.reduce((count, word) => {
count[word] = (count[word] || 0) + 1;
return count;
}, {});
}
const text = "the quick brown fox jumps over the lazy dog";
const wordCount = countWords(text);
console.log(wordCount);
// Output:
// {
// "the": 2,
// "quick": 1,
// "brown": 1,
// "fox": 1,
// "jumps": 1,
// "over": 1,
// "lazy": 1,
// "dog": 1
// }
```
|
|
https://github.com/Myriad-Dreamin/typst.ts
|
https://raw.githubusercontent.com/Myriad-Dreamin/typst.ts/main/fuzzers/corpora/meta/outline-indent_02.typ
|
typst
|
Apache License 2.0
|
#import "/contrib/templates/std-tests/preset.typ": *
#show: test-page
//
// // Error: 2-35 expected relative length or content, found dictionary
// #outline(indent: n => (a: "dict"))
//
// = Heading
|
https://github.com/WhiteBlackGoose/typst-hello-world
|
https://raw.githubusercontent.com/WhiteBlackGoose/typst-hello-world/master/hello.typ
|
typst
|
= Hello
_hello world!_
+ a
- b
- 54
- *324*
- 111
- @aaa
+ b
$ sum_x^2 root(3, 23) round(product_{2323}^{ Rho + "Hell" + nabla }) + "had" $
#figure(
image("wbg.png", width: 40%),
caption: [
Hehhehehe
]
) <aaa>
$
a arrow.squiggly b
$
#show "ArtosFlow": name => box[
#box(image(
"./wbg.png",
height: 0.7em,
))
#name
]
#align(right, lorem(30))
#lorem(50)
#align(center, text(17pt)[
*A fluid dynamic model
for glacier flow*
])
#let Exp(frog)=$bb(E)(frog)$
#Exp($chi^2 / 34 ~~> 5 <==>6$)
#Exp($chi$)
\
\
->
$ -> \
--> $
|
|
https://github.com/Myriad-Dreamin/typst.ts
|
https://raw.githubusercontent.com/Myriad-Dreamin/typst.ts/main/fuzzers/corpora/meta/document_08.typ
|
typst
|
Apache License 2.0
|
#import "/contrib/templates/std-tests/preset.typ": *
#show: test-page
//
// #box[
// // Error: 4-15 pagebreaks are not allowed inside of containers
// #pagebreak()
// ]
|
https://github.com/LDemetrios/Typst4k
|
https://raw.githubusercontent.com/LDemetrios/Typst4k/master/src/test/resources/suite/math/interactions.typ
|
typst
|
// Test interactions with styling and normal layout.
// Hint: They are bad ...
--- math-nested-normal-layout ---
// Test images and font fallback.
#let monkey = move(dy: 0.2em, image("/assets/images/monkey.svg", height: 1em))
$ sum_(i=#emoji.apple)^#emoji.apple.red i + monkey/2 $
--- math-table ---
// Test tables.
$ x := #table(columns: 2)[x][y]/mat(1, 2, 3)
= #table[A][B][C] $
--- math-equation-auto-wrapping ---
// Test non-equation math directly in content.
#math.attach($a$, t: [b])
--- math-font-switch ---
// Test font switch.
// Warning: 29-40 unknown font family: noto sans
#let here = text.with(font: "Noto Sans")
$#here[f] := #here[Hi there]$.
--- math-box-without-baseline ---
// Test boxes without a baseline act as if the baseline is at the base
#{
box(stroke: 0.2pt, $a #box(stroke: 0.2pt, $a$)$)
h(12pt)
box(stroke: 0.2pt, $a #box(stroke: 0.2pt, $g$)$)
h(12pt)
box(stroke: 0.2pt, $g #box(stroke: 0.2pt, $g$)$)
}
--- math-box-with-baseline ---
// Test boxes with a baseline are respected
#box(stroke: 0.2pt, $a #box(baseline:0.5em, stroke: 0.2pt, $a$)$)
--- math-at-par-start ---
// Test that equation at start of paragraph works fine.
$x$ is a variable.
--- math-at-par-end ---
// Test that equation at end of paragraph works fine.
One number is $1$
--- math-at-line-start ---
// Test math at the natural end of a line.
#h(60pt) Number $1$ exists.
--- math-at-line-end ---
// Test math at the natural end of a line.
#h(50pt) Number $1$ exists.
--- math-consecutive ---
// Test immediately consecutive equations.
$x$$y$
--- issue-2821-missing-fields ---
// Issue #2821: Setting a figure's supplement to none removes the field
#show figure.caption: it => {
assert(it.has("supplement"))
assert(it.supplement == none)
}
#figure([], caption: [], supplement: none)
--- math-symbol-show-rule ---
// Test using rules for symbols
#show sym.tack: it => $#h(1em) it #h(1em)$
$ a tack b $
--- issue-math-realize-show ---
// Test that content in math can be realized without breaking
// nested equations.
#let my = $pi$
#let f1 = box(baseline: 10pt, [f])
#let f2 = context f1
#show math.vec: [nope]
$ pi a $
$ my a $
$ 1 + sqrt(x/2) + sqrt(#hide($x/2$)) $
$ a x #link("url", $+ b$) $
$ f f1 f2 $
$ vec(1,2) * 2 $
--- issue-math-realize-hide ---
$ x^2 #hide[$(>= phi.alt) union y^2 0$] z^2 $
Hello #hide[there $x$]
and #hide[$ f(x) := x^2 $]
--- issue-math-realize-scripting ---
// Test equations can embed equation pieces built by functions
#let foo(v1, v2) = {
// Return an equation piece that would've been rendered in
// inline style if the piece is not embedded
$v1 v2^2$
}
#let bar(v1, v2) = {
// Return an equation piece that would've been rendered in
// block style if the piece is not embedded
$ v1 v2^2 $
}
#let baz(..sink) = {
// Return an equation piece built by joining arrays
sink.pos().map(x => $hat(#x)$).join(sym.and)
}
Inline $2 foo(alpha, (M+foo(a, b)))$.
Inline $2 bar(alpha, (M+foo(a, b)))$.
Inline $2 baz(x,y,baz(u, v))$.
$ 2 foo(alpha, (M+foo(a, b))) $
$ 2 bar(alpha, (M+foo(a, b))) $
$ 2 baz(x,y,baz(u, v)) $
|
|
https://github.com/jgm/typst-hs
|
https://raw.githubusercontent.com/jgm/typst-hs/main/test/typ/math/op-00.typ
|
typst
|
Other
|
// Test predefined.
$ max_(1<=n<=m) n $
|
https://github.com/polarkac/MTG-Stories
|
https://raw.githubusercontent.com/polarkac/MTG-Stories/master/stories/024%20-%20Shadows%20over%20Innistrad/003_Unwelcome.typ
|
typst
|
#import "@local/mtgstory:0.2.0": conf
#show: doc => conf(
"Unwelcome",
set_name: "Shadows Over Innistrad",
story_date: datetime(day: 16, month: 03, year: 2016),
author: "<NAME>",
doc
)
#emph[<NAME> has come to Innistrad searching for the vampire lord Sorin Markov, who he hopes can help him unravel a puzzle. But Innistrad is unfamiliar territory, and the only person Jace knows who might be able to guide him is likely to be less than helpful—particularly given the way ] their last encounter#emph[ ended.]
#figure(image("003_Unwelcome/01.png", height: 40%), caption: [], supplement: none, numbering: none)
#v(0.35em)
#line(length: 100%, stroke: rgb(90%, 90%, 90%))
#v(0.35em)
Horses' hoofbeats drummed a leisurely rhythm. The jagged mountains of the province called Stensia loomed ahead of them, but Jace's goal wasn't far beyond the border, and he had read enough of his guide's thoughts to know that they were close.
"I don't know why I'm even bothering with her," said Jace. "I know better."
"Mm," said his guide. He was weathered and bearded, a man of few words. Jace had started filling the silence out of boredom, and had eventually gotten around to the subject of his visit.
"I mean, I've made a lot of bad decisions in my life, even just counting the ones I can remember. And an awful lot of them involve her."
"Hm," said his guide.
A chill rain fell from patchy clouds, and something howled in the night. Jace had only been on Innistrad for two days, and he already hated it. The only saving grace so far was a new leather coat he'd bought to keep the rain and some of the cold at bay.
"Hell, part of me's hoping she'll throw me out on my ear and I can be done with her."
"Ah," said his guide.
The full moon peeked out from behind the clouds, its huge silver face marked with a shape that the locals called a heron. Jace could see the resemblance.
"Problem is, I actually need her help this time," he said.
"Ahhhhh," said his guide, a strangled sound that Jace took to indicate boredom.
"I'm sorry," said Jace. "I shouldn't be burdening you with my problems."
He prepared a spell that would cleanly excise the last few minutes of conversation from the man's mind.
"Ahhhhhrrrrrrrrrgggggghhhhh," said his guide. Not boredom. Anger?
Jace reached into the man's mind—and hit a wall of pure, all-encompassing rage, the savage half-thoughts of a predator.
His guide turned to him, accompanied by the stomach-churning sounds of bones cracking and clothes tearing. His face had bulged horribly, one eye grown large and yellow, his jaw jutting outward. Both horses shifted nervously.
"Oh," said Jace.
The transformation was complete in moments. Fur sprouted over the man's body, claws erupted from his fingers, teeth grew long and sharp, and his face elongated into a muzzle. The guide's horse panicked beneath him, and the man—the wolf-man—sank its teeth into the horse's neck.
Time to go.
Jace spurred his own horse to a gallop, past the thing that had been his guide and the terrified, screaming horse. He was close. He could get there on his own.
Behind him, the horse's scream was cut short with a wet crunch. The werewolf let loose a full-throated howl, and howls broke out in answer from the woods around them—one, then two, then more, mingled together until he couldn't be sure how big the pack might be.
Jace's moonlit gallop ate up the road, faster than was safe. He saw the lights of a large manor house ahead, tantalizingly close, but a ravine yawned before it. He jerked the horse's reins to the left and stole a glance backward.
There were at least three of them bounding after him, hideous amalgamations of human and wolf. They weren't like the krasis experiments of the Simic Combine, whose parts always seemed to show that they had come from separate species. Human-like hands with sharp claws, muscular arms covered in fur, lupine faces that nonetheless held a spark of intelligence—these were almost fully human, and almost fully wolf, all at once.
#figure(image("003_Unwelcome/02.jpg", width: 100%), caption: [Art by <NAME>], supplement: none, numbering: none)
He'd heard of werewolves, but had hoped never to see them.
Jace let his horse run as fast as he dared, the lights of the manor taunting him. The trail wound around the ravine, cut through thickets, and splashed across little rills that tumbled noisily into the ravine in the darkness to his right. He couldn't hear the footfalls of the wolf-things over his horse's hoofbeats and the furious pounding of his own heart.
He sent an illusionary double of himself tumbling from the horse behind him. His duplicate rose and assumed a fighting stance, but the werewolves ran right through it. He risked a glance back and saw five of the things gaining on him, nostrils flaring.
Scent. Of course. They'd disregard anything that didn't smell real.
He could work with that.
He summoned another illusion, this one with substance and form. A hulking bear made of shining blue light took form behind him, a being of pure magic rather than a trick of the light—but still with no scent.
#figure(image("003_Unwelcome/03.jpg", width: 100%), caption: [Phantasmal Bear | Art by <NAME>], supplement: none, numbering: none)
The werewolves ran toward it, heedless, thinking it was another insubstantial phantom, as it rose up on its hind legs in a threat display. It lunged and tackled one of them, and Jace glanced back to see the two combatants fall in a furious tangle of fur and light.
As he turned forward again in his saddle, his horse stumbled, just for a moment. It was enough. In a few breaths the rest of the pack was close behind him, claws swiping and jaws snapping. Their breath was hot and rank, steaming in the cool night air.
Jace extended his mind and found the one that had been his guide, the one whose thoughts he had already touched. Now its mind was a chaos of hunger and anger, but Jace still recognized the memories and inclinations of the man he had hired to guide him into Stensia. Interesting.
Jace's mind worked its way into the werewolf's, buffeted by thoughts of tearing and biting and eating. In the werewolf's vision, the moon was swollen in the sky, its light a baleful red, the heron leering and lurid. At last, the connection was complete. Jace was in control.
His guide lunged sideways, snapping at one of the other pack members, the one that the wolf-man's dull thoughts identified as the alpha. Jace only took control for a moment, but it was enough—the alpha swiped back at her attacker. Jace's guide, now back under its own control, growled and fought back. They didn't seem to have communication sophisticated enough to say #emph[the mind mage made me do it] —although even among speaking beings, that excuse didn't usually work.
Soon the two wolf-things were circling each other, the hunt forgotten, and another—a mate? Another challenger?—stayed behind to watch them. That left Jace with one assailant. But the trail now hugged the ravine in treacherous switchbacks, and it took all of Jace's attention to keep his horse on the trail.
The poor horse was frothing now, exhausted and panicked. Jace could almost feel the werewolf's hot breath on his neck. He looked back—he was imagining it, but not by much. The agile creature could navigate the switchbacks much better than Jace's horse, and it was gaining fast.
At last, the terrain opened up ahead of him and the ravine curved away, leaving nothing but a flat, muddy road between him and the welcoming lights of the manor. And not just any manor, he realized as it loomed. #emph[Her] manor. His destination.
Hopefully she'd forgive him for bringing a guest.
He was within shouting distance of the gate when the werewolf struck. One claw raked sideways across the horse's rump, sending its rear legs tumbling sideways. Jace sprang from the saddle, landed in the mud, and rolled. He clambered to his feet and started running. Behind him, the werewolf attacked the fallen horse with a growl.
The gates were closed and locked, with no doorman, and the yard was dark. Jace looked back over his shoulder to see the werewolf look up from the horse's carcass, muzzle bloody in the moonlight. It rose and stepped toward him, the horse forgotten.
Breaking and entering, then. Even better.
He calmed himself and focused on the lock, pushing away all thoughts of the monster behind him. Jace's telekinesis was weak—no stronger than his own muscles, and far more exhausting to use—but his fine control was good. Invisible mental fingers felt around inside the lock, found the tumblers, and quickly twirled them into place. The lock released with a click, and Jace pushed against the enormous black iron gates. They were stuck—rusty, maybe—and Jace had to shove. They opened with a squeal loud enough to wake the dead, and Jace stumbled into the yard and fell to his knees.
He turned and kicked the gates shut behind him, then mentally sent the tumblers in the lock spinning back into place just as the werewolf slammed into the gate. Jace crawled backward, away from its reaching claws, but the werewolf sniffed loudly—once, then twice—and then it was gone, off to hunt some other prey.
Something moved behind Jace. He rose to his feet and turned. In the darkness of the manor's yard, he could just barely make out a dozen figures standing silently around him. Now he smelled it, too, the stench of rot that had sent the werewolf on its way. A quick mental check confirmed it—there were no minds in these bodies. They were dead.
They crowded around him without a sound, backing him up against the gates. Zombies crowding around him, a werewolf somewhere behind him, that damned moon glaring down over all of it...
The zombies stopped, then stirred and parted, leaving him a clear path to the mansion's ornate door. A welcoming committee. Her hospitality was everything he'd expected and then some.
He walked among the gathered dead, trying to ignore them, as he got his first real look at the house. It was large, with enough rooms for a substantial family and servants, but none of the rooms seemed to be lit by anything more than an eerie purple glow. One corner rose into a stone tower that looked like newer construction, crowned by a complicated metal apparatus whose purpose Jace couldn't discern. It looked like something an Izzet electromancer would build right before being hauled off for psychological evaluation.
Just as he reached the top of a small flight of stone stairs that led to the entryway, the door swung open to reveal a dark hallway. He stopped at the threshold.
"Can I come in?" he asked.
Another zombie stepped out from behind the door, this one clothed in some mockery of a servant's livery, and beckoned for Jace to follow. Fine.
Jace lowered his hood and followed this new guide, surprised to find that the smell was musty but not foul. Must be some spell to keep the help fresh. At last, his guide led him into a large room illuminated by moonlight and spellcraft, where half a dozen zombies shuffled about.
And there, sitting easily on a chair—more a throne—was <NAME>. She shut a large, leather-bound tome she'd been reading and handed it to one of her undead servants.
#figure(image("003_Unwelcome/04.jpg", width: 100%), caption: [Art by <NAME>], supplement: none, numbering: none)
"Hello, Jace," she said. She looked him up and down in obvious appraisal. "Nice coat."
She rose and walked toward him, her movements as fluid and languorous as a cat's, and stopped when she was standing just slightly too close to him. She studied him with those ancient violet eyes, took in his face one detail at a time. She must be quite aware, it occurred to him, of how his muscles moved beneath the skin.
This time he looked her in the eye, despite the memories it dredged up.
She reached up to his face...and flicked the tip of his nose.
"Ow! What—"
"Just making sure you came in person," she said.
"I can make my illusions solid, you know," said Jace, rubbing his nose.
"Oh yes. But I doubt you can make them yelp so convincingly."
"I was hoping for a warmer welcome," said Jace. "You've got some very disagreeable neighbors."
"I heard," she said. "There's worse out there than werewolves."
"Like vampires?"
"Angels," she said with disgust.
Jace rolled his eyes.
"Your feelings on the subject are well documented," he said. "Personally, I'd have been thankful for a little angelic assistance out there."
"That's not—" said Liliana, then cut herself off. "Well. Who you choose to trust is your own business, I suppose. But I wouldn't trust an angel if I were you."
"My default stance is to trust no one," said Jace. "Nothing that's happened so far has changed my mind."
"Clever boy," she said. "Something to drink?"
Liliana walked back to her throne and sat, as a zombie shuffled forward with a bottle of...something.
"Thanks, but I'll pass," he said.
Liliana poured herself a glass and sipped from it.
"Now then," she said. "This is a first. To what do I owe the pleasure?"
"I..." Jace weighed pride against practicality and finally reached a decision. "I'm here to apologize."
Liliana raised an eyebrow in feigned curiosity. "Really? Whatever for?"
"For leaving Ravnica with...unfinished business between us."
"For abandoning me, you mean," she said, with a cruel smile. "And heading off to some wilderness plane with that walking anatomical diagram."
Gideon, she meant. Jace stifled a laugh.
"I doubt he'd take that as a compliment."
"It is!" she said. "He'll make a perfect corpse, if he gets around to dying before it all goes soft."
"And I'm certain he wouldn't take that as a compliment," said Jace. She always had to push.
"So you regret going with him?" said Liliana.
"Oh, I wouldn't say that," said Jace. "We did good work. Saved the whole plane, in fact, with help from two other Planeswalkers."
He smiled.
"We even took an oath, to...to keep doing this. Keep going after interplanar threats."
"Lovely," said Liliana. "Very heroic. And now...what? You're here to ask me to join your little club?"
"No," said Jace. "I know you better than that."
Liliana waited. She knew him better than that, too.
"I considered it, of course," he said, with a shrug. "You could use a few friends to watch your back. But I knew you wouldn't go for it."
"I'm not interested," said Liliana. "In your friends, or your oaths."
"I didn't think you were," said Jace.
Liliana sighed.
"Jace, I know you're not here to recruit me," she said. "You're not here to help me. And you're not here to apologize."
"What makes you say that?" he asked, then added: "I #emph[did] apologize."
"You said it yourself," she went on. "I betrayed you. I cursed Garruk. I still have the Chain Veil. I've never been a friend to you, not really. And you know, I never did ask for your help. Has any of that changed?"
"No."
"Which means that you're actually here because you need something from me. You know I have troubles, and you think you can make a deal."
She waited long enough for him to say "I—" then cut him off.
"Prove me wrong," she said. She stood and raised her head proudly. "I refuse your freely given aid, <NAME>. If you're here to help me and ask nothing in exchange, turn around and walk out that door."
Jace said nothing. Even if it was a bluff, he couldn't afford to call it.
"All right then," said Liliana, draping herself back over her throne. "Now that we both know exactly how much our personal history means to us...what can I do for you, dear?"
She smiled, predatory and alluring. She could be quite magnanimous, provided she was in complete control of the situation.
"Out of curiosity," said Jace, "would you really have kicked me out if I were just here to help you?"
"Fascinating question," said Liliana. "If it ever comes up, perhaps you'll find out."
She took a sip from her glass and waited.
"I'm looking for <NAME>," said Jace.
Liliana's face betrayed genuine surprise. Jace let himself take a little pleasure in that.
"Jace, do you know what you're asking?" she said. "Do you know who he is? What he is?"
"I know he's a vampire, the so-called Lord of Innistrad," said Jace. "I know he's ancient and more than a little untrustworthy, and I know right now he's either in trouble or causing trouble. Either way, I need to find him."
#figure(image("003_Unwelcome/05.jpg", width: 100%), caption: [Barter in Blood | Art by <NAME>], supplement: none, numbering: none)
"Why?" said Liliana.
"Thousands of years ago—"
Liliana groaned.
"Short version, then. Three Planeswalkers worked together to trap extraplanar, world-devouring monstrosities called the Eldrazi on Zendikar. Sorin was one of the three."
"Really?" said Liliana. "That doesn't sound like him."
"My source—one of Sorin's old allies—said he did it out of a sense of...'high-minded self-interest,' something like that. He knew that eventually the Eldrazi might make their way to Innistrad, so he cooperated to trap them somewhere else."
"And then...you let them out," she said, smiling. "Am I remembering that right?"
He wished she weren't enjoying this quite so much.
"Yes," said Jace. "Manipulated and coerced, two other Planeswalkers and I inadvertently released the Eldrazi titans from their prison. Sorin showed up, briefly, then departed after trying to use some kind of failsafe to keep them in. He was supposed to meet one of his allies, my source, back on Zendikar, but he hasn't shown."
"That sounds more like him," said Liliana.
"Of course, now there's no need for him to go to Zendikar," Jace went on. "But the Planeswalker I was working with won't speak to me anymore, and Sorin and the third member of the trio are missing in action. I'm worried that a certain dragon Planeswalker might have taken an interest in them...but you wouldn't know anything about that, would you?"
"I told you, I don't work for him anymore."
"You have many fine qualities, Liliana, but scrupulous honesty is not among them."
"Jace," said Liliana, "listen to me. Sorin won't help you. You think I'm selfish? You think I'm cruel? Sorin's had thousands of years to get used to the idea that humans are cattle and mortal lives are cheap."
"You know him?"
"I met him," said Liliana. "Once, shortly after I first arrived on Innistrad. He sought me out, tested my strength in battle, and pronounced me too weak to be a threat. Then he told me that Innistrad was his, and that I'd best be a civil guest—or he'd find me and kill me."
"Charming," said Jace. "When was this?"
"Long ago," said Liliana. "And yes, that kind of run-in was a lot more common then. But I see no reason to believe he's changed. Sorin has no more reason to be friendly to you than this other Planeswalker you've been talking to, and his take on not speaking to you might just be to kill you. Don't go."
"That's not an option," said Jace.
"He's ancient, he's ruthless, and he's powerful. You're in over your head."
"#emph[I'm] in over my head?" said Jace. "You're one to talk."
"Yes," said Liliana. There was no more mirth in her voice. "I am. And I am telling you, don't go. He's not going to help you, and you can't clever your way out of being killed by a millennia-old vampire."
"If I didn't know better," said Jace, "I'd say you were concerned for my safety."
"Don't make this about us!" she said. "You wouldn't be here if you didn't have something to offer me. I'd like to find out what it is before you throw yourself on Sorin's sword, if it's all the same to you."
"If you're that worried about me, come along. Maybe you can introduce us."
"What?" she said. "No. I already told you, I have my own problems, and my own solutions. And I don't care how much help you think you can be to me in exchange—none of it does me any good if Sorin kills both of us. And that's assuming we can even find him, when the roads out there are worse than ever. I'm not going anywhere."
"Fine," said Jace. "I was hoping you could help me, but I guess I'll have to follow the only lead I have left. Markov Manor is that way, right?"
He pointed in what he was fairly sure was the right direction.
"<NAME>?" she said. She rolled her eyes, grabbed his wrist, and moved it several inches. "Jace, that's even worse!"
"It's his ancestral home, right? Wouldn't his family know where he is?"
"Do you know #emph[anything] about Innistrad?" Liliana snapped. "Or did you just see 'Markov Manor' on a map and think, 'Hey, great, there's no way that could result in me being brutally murdered'?"
"I read a few minds, but they didn't know much," he said. "Why, what am I missing?"
"Sorin's a pariah among his own people," she said. "He hasn't been welcome in Markov Manor for hundreds of years at least. Maybe longer. If you show up asking about him, they'll kill you or worse."
"Even so," said Jace, "if you won't help me, I don't have much choice. Markov Manor is the best lead I have."
Liliana settled back in her chair. Her expression hardened, and her eyes began to glow purple.
"What—"
Her zombie servants lurched forward. Jace's heart pounded.
"Lili, what are you doing?"
The zombies kept coming.
"Making a point," she said.
Too close. They were too close.
Jace cast a quick invisibility spell, but the zombies still stumbled toward him. Half of them didn't have eyes anyway.
A cold hand clamped around his arm.
He concentrated, and a cloud of illusionary duplicates sprang from his body. Half a dozen Jaces, casting spells or diving for the window or running to attack Liliana.
The zombies ignored them. Now there were grasping hands all over him, the mob of zombies pushing him against the wall—frigid stone, icy flesh. Fingers closed around his arms, his legs, his throat. Sleep spells, illusionary bindings—the zombies were immune to some of it, and there were too many of them for the rest. Jace was helpless.
She wouldn't really hurt him. Not without a reason, anyway.
"Lili," he choked out. "I'm no good against the dead, but I can fight...a necromancer. If this were a real fight, I'd have blanked your mind by now."
The zombie mob stopped, holding him in place.
"Perhaps," she said, rising and walking toward him. "Of course, without my control, they'd tear you apart. Wouldn't be much consolation to me...but I doubt that would be much consolation to you, either."
"What's your point?"
She stood over him, the zombies parting so she could glare down at him.
#figure(image("003_Unwelcome/06.jpg", width: 100%), caption: [Endless Obedience | Art by Kar<NAME>], supplement: none, numbering: none)
"This world is dangerous," she said. "For you especially. And you can't beat an ancient Planeswalker whose mind you can't—or won't—touch."
She seemed very alien in that moment, bathed in moonlight and necromantic power. He sometimes forgot how old she was—a century older than him at least, a relic of a time when Planeswalkers were something more and less than human. And Sorin was far older.
"This is a dead end," she said. "Go home, Jace. I'm sure you've got forms to file."
Undead hands released him, and he rose, rubbing his throat. He felt the sudden need for a bath.
"I'm sorry for bothering you," he croaked. "I'll head to Markov Manor on my own, then."
He turned toward the door.
"Nine hells, you are a reckless fool!"
He turned back to her.
"Of course I am," he said. "That's how I got tangled up with you. I'll be going now."
He turned to leave again, trying not to think about moonlight and bloody muzzles and Liliana's eyes and the fact that his guide and his horse were both gone.
"Don't be stupid," she said. "You can leave in the morning."
"Really?" he asked, incredulous. "After that grand display of mutual indifference, you're asking me to stay the night?"
She walked toward him and leaned close, her lips almost touching his ear. His throat tightened.
"Indifference," she whispered, "doesn't make your heartbeat quicken or your face flush."
He could feel the warmth of her body, but her breath on his cheek was cold as ice. The chill lingered as she stepped away. A momentary impulse fled back into the shadows, where it belonged.
"Don't flatter yourself," she said aloud. "I have a guest room."
"Ah."
"In the basement," she said. "More a dungeon, really."
"Lovely," he said.
She turned and walked away.
"The servants will show you to your room," she said. "Good night, Jace."
She turned, standing in the moonlight, looking back at him from a distance that seemed much longer than it was.
"Until morning," she said firmly. "After that, you're on your own."
"I know," he said.
He hesitated, wanting to say more, unsure what to say. Liliana walked away, out of the beam of moonlight, and vanished into darkness.
|
|
https://github.com/Toniolo-Marco/git-for-dummies
|
https://raw.githubusercontent.com/Toniolo-Marco/git-for-dummies/main/book/actions.typ
|
typst
|
= GitHub Actions
Le *GitHub Actions* sono una potente piattaforma di automazione integrata in GitHub@gh-actions che consente agli sviluppatori di automatizzare workflow direttamente nei repository di codice. Può essere utilizzata per un'ampia varietà di scopi, come la continua integrazione (CI), la distribuzione continua (CD), la gestione delle versioni, l'esecuzione di script personalizzati e altro ancora.
== Caratteristiche principali di GitHub Actions:
+ *Workflow personalizzabili*: Consente di creare flussi di lavoro per automatizzare qualsiasi processo, dal testing all'aggiornamento della documentazione.
+ *Event-driven*: Le azioni possono essere attivate da eventi, come commit, apertura di pull request o push nel repository.
+ *Supporto multi-linguaggio*: GitHub Actions supporta qualsiasi linguaggio di programmazione, tra cui JavaScript, Python, Rust, Go e molti altri.
+ *Scalabilità*: È possibile eseguir=e workflow su macchine virtuali ospitate da GitHub (i cosiddetti "runner") o su macchine self-hosted.
+ *Marketplace*: Esiste un marketplace che contiene migliaia di GitHub Actions pronte all'uso create dalla community, riducendo il tempo di setup.
== Esempio di workflow: Test di una libreria Rust
Immagina di avere un progetto Rust e di voler automatizzare i test con GitHub Actions ogni volta che viene fatto un commit o una pull request. Creiamo un workflow che esegua i test su tre sistemi operativi: Ubuntu, macOS e Windows.
=== Passaggi per configurare il workflow:
+ *Crea la directory e il file per il workflow*:
All'interno del tuo repository, crea una directory `.github/workflows/` e un file YAML al suo interno (es. `rust.yml`).
+ *Configura il workflow*:
Nel file `rust.yml` si definirà il workflow che esegue i test per la libreria.
Ecco un esempio di file di configurazione:
```yaml
name: Test Pull Request
on:
pull_request:
branches: [ "main" ]
paths:
- src/**
jobs:
TestPullRequest:
runs-on: [ self-hosted, linux, rust ]
steps:
- name: Checkout
uses: actions/checkout@v4
- name: Update local toolchain
id: updateToolchain
run: |
rustup update
- name: Toolchain info
id: info
run: |
echo "# Rust toolchain info" >> $GITHUB_STEP_SUMMARY
cargo --version --verbose >> $GITHUB_STEP_SUMMARY
rustc --version >> $GITHUB_STEP_SUMMARY
cargo clippy --version >> $GITHUB_STEP_SUMMARY
rustfmt --version >> $GITHUB_STEP_SUMMARY
- name: Check RustFmt
id: checkFmt
continue-on-error: true
run: cargo fmt --all -- --check
- name: Comment pull request
id: commentPr
if: steps.checkFmt.outcome == 'failure'
uses: ntsd/auto-request-changes-action@v2
with:
comment-body: "The code is not formatted correctly, run `cargo fmt --all`"
github-token: ${{ secrets.GITHUB_TOKEN }}
- name: Check Clippy
uses: actions-rs/clippy-check@v1
continue-on-error: true
id: checkClippy
with:
token: ${{ secrets.GITHUB_TOKEN }}
args: --all-features
- name: Run Cargo Tests
run: |
cargo test --all --no-fail-fast --color always
```
#pagebreak()
== Spiegazione del workflow:
- *on*: Definisce gli eventi che attivano il workflow. In questo caso, viene attivato su ogni `push` e `pull_request` nel branch `main` solo se i file all'interno di *src* vengono modificati.
- *jobs*: Definisce i job da eseguire. In questo caso, c'è un solo job chiamato `build`.
- *strategy*: Usa una strategia matrix per eseguire il workflow su ubuntu, ultima versione usando Rust stable.
- *steps*: Elenca i singoli step del workflow:
+ *Checkout code*: Usa l'azione `actions/checkout` per scaricare il codice del repository.
+ *Install Rust*: Usa l'azione `actions-rs/toolchain` per installare la versione di Rust specificata nel matrix.
+ *Run tests*: Esegue i test del progetto con `cargo test`.
come detto in precedenza le GitHub Actions sono uno strumento potente e flessibile per automatizzare flussi di lavoro legati allo sviluppo, dalla CI/CD ai controlli di sicurezza, all'aggiornamento della documentazione. I runner consentono l'esecuzione dei job su macchine virtuali fornite da GitHub o su macchine fisiche configurate dall'utente, offrendo sia convenienza che flessibilità. Il workflow di esempio per Rust mostra come eseguire automaticamente i test inclusi nel vostro progetto di Rust. Come detto prima, questo workflow viene eseguito su un runner hostato da GitHub, il quale offre solo un tot di ore gratutite ogni mese per eseguire le action, per questo più avanti spiegheremo come hostare i propri runner per avere esecuzioni illimitate e maggior controllo sull'ambiente.
Per approfondire e imparare a scrivere Actions specifiche il posto da cui iniziare è la documentazione ufficiale, che potete trovare #link("https://docs.github.com/en/actions")[qui], se invece volete una quick start guide vi consigliamo il tutorial del sito dev.to intitolato #link("https://dev.to/kanani_nirav/getting-started-with-github-actions-a-beginners-guide-og7")[Getting Started with GitHub Actions: A Beginner’s Guide] #footnote([Stranamente ChatGPT si dimostra molto utile nella stesura delle Actions, spesso riesce a dare la struttura generale del workflow e risparmiandovi un pò di tempo.])
e di controllare il #link("https://github.com/marketplace")[Marketplace], dove probabilmente troverete tutti i pezzi necessari per comporre il vostro workflow.
Un consiglio che ci sentiamo di darvi è di creare un repo separato in cui testare le Actions prima di metterle in quello principale.
== Actions secrets and variables
Alcune Actions avranno bisogno di accedere a dati sensibili come password, api key o token di GitHub per compiere azioni specifiche, per evitare che questi dati siano visibili pubblicamente si utilizzano i secrets,
in pratica, vengono memorizzati in modo sicuro nei repository GitHub, e sono accessibili solo all'interno delle Actions, esse infatti vengono anche nascoste dai log die esecuzione e una volta salvate non sono più leggibili nemmeno dalla ui.
Ad esempio, se la action deve usare una chiave API, è sufficente aggiungerla ai secrets del repository e poi richiamarla nella workflow in questo modo:
```yaml
jobs:
build:
runs-on: ubuntu-latest
steps:
- name: Example step
env:
API_KEY: ${{ secrets.MY_API_KEY }}
run: echo "Using API key in this step"
```
In questo esempio, `secrets.MY_API_KEY` fa riferimento a un secret chiamato `MY_API_KEY` presente nel repository.
per aggiungere un nuovo secret andate nella pagina del repository, poi *Settings*, nel menù di sinistra cliccate su *Secrets and variables*, poi su *Actions* e in fine cliccando sul tasto verde *New repository secret*, compilate il form scegliendo il nome (seguite la convenzione SNAKE_CASE), inserite il secret e poi cliccate su *Add secret*.
== Runners
Il concetto di *runner* è fondamentale per capire come funzionano le GitHub Actions. Un runner è un ambiente dove è in esecuzione il #link("https://github.com/actions/runner")[Runner] (software) il quale è collegato a GitHub ed è in ascolto per eseguire le Actions. "L'ambiente" può essere una macchina fisica, virtuale o ancora meglio un container.
=== Tipi di runner:
+ *GitHub-hosted runners*: Sono macchine virtuali fornite da GitHub su cui vengono eseguite le azioni del workflow. GitHub offre runner con tre principali sistemi operativi:
- Ubuntu (il più comune)
- Windows
- macOS
Questi runner vengono automaticamente avviati, eseguono il workflow e vengono distrutti una volta completato.
Vantaggi:
- *Convenienza*: Non è necessario configurare nulla, sono pronti all'uso.
- *Aggiornamenti*: Sono mantenuti da GitHub e sempre aggiornati con le ultime versioni degli strumenti più utilizzati (come Node.js, Python, Rust, ecc.).
Svantaggi:
- *Limiti di esecuzione*: Sono imposti limiti di tempo e di risorse, specialmente per i repository gratuiti.
- *Inefficenti*: Ogni esecuzione il runner deve scaricare tutto il necessario, per esempio installare rust.
+ *Self-hosted runners*: Sono macchine fisiche o virtuali configurate dall'utente e connesse al repository GitHub@gh-runner-doc. Questi runner sono completamente personalizzabili e permettono di avere più controllo sulle risorse hardware e software disponibili.
Vantaggi:
- *Maggiore controllo*: Puoi configurare il sistema operativo, le dipendenze e le risorse hardware secondo le tue esigenze.
- *Nessun limite di esecuzione*: Non sono soggetti alle restrizioni dei GitHub-hosted runners.
Svantaggi:
- *Manutenzione*: L'utente è responsabile della manutenzione, aggiornamento e sicurezza del runner.
Per farla beve, noi vi sconsigliamo di appoggiarvi a GitHub per eseguire le vostre Actions, durante il picco, circa una settimana prima della software fair vi ritroverete ad accettare decine di pull request, questo vuol dire che le action verranno eseguite molte volte e nonostante il caching sarà facile terminare le ore gratuite.
=== Hostare un runner (bare metal)
Per hostare un runner ci sono due strade principali, la prima e più semplice consiste nell'installare il runner direttamente sul sistema come software, il runner può essere eseguito su ogni piattaforma (Linux, Windows e macOS e cpu amd64, arm64 e arm32), ma vi consigliamo di usare Linux su amd64 o arm64 per la maggior compatibilità dei software e facilità di setup. Per iniziare recatevi nella *homepage dell'organizzazione*, *Settings*, nel menù di sinistra cliccate su *Actions*, poi su *Runners* e sul tasto verde *New runner*, ora non vi resta che seguire le istruzioni, ma attenzione, se ora chiudete il terminale il runner smetterà di funzionare se invece volete installarlo come servizio e far si che parta automaticamente all'avvio dovete seguire #link("https://docs.github.com/en/actions/hosting-your-own-runners/managing-self-hosted-runners/configuring-the-self-hosted-runner-application-as-a-service")[questa guida], prestando attenzione a scegliere il sistema opertivo corretto in alto. Il runner appena creato dovrebbe essere presente nell'elenco della vostra organizzazione e sarà automaticamente utilizzabile su tutte le actions in ogni repository e avrà accesso ad ogni software presente nel sistema host, perciò se dovete compilare e testare un progetto Rust allora dovrete aver installato la toolchain e cargo.
=== Hostare un runner (container Docker)
L'alternativa a installare il runner direttamente sul sistema host è quello di isolarlo mettendolo in un container, questo complica un pò la fase di setup ma vi garantisce maggiore sicurezza a livello di esecuzione, in quanto tutto sarà eseguito in un ambiente isolato e protteto che potrete ricreare in qualsiasi momento e soprattuto in caso si corrompa.
Questo pezzo della guida presuppone che siate su un sistema Linux sui cui è presente Docker e che abbiate un pò di dimestichezza con i Dockerfile, per iniziare *create una cartella* ed *entrateci con un terminale*, *create un file* chiamato esattamente `Dockerfile` senza estensione e incollateci dentro:
```dockerfile
FROM debian:stable-slim
ADD ./runner runner
WORKDIR /runner
ARG DEBIAN_FRONTEND=noninteractive
SHELL ["bash", "-c"]
# Add the software to be installed here (after 'curl' and before ' \')
RUN ./bin/installdependencies.sh && apt-get install -y curl \
&& apt-get autoclean && apt-get autoremove --yes && rm -rf /var/lib/{apt,dpkg,cache,log}/
ADD --chmod=754 ./start.sh start.sh
ENV RUNNER_MANAGER_TOKEN=""
ENV GITHUB_ORG=""
ENV RUNNER_NAME=""
ENV ACTIONS_RUNNER_INPUT_REPLACE=true
ENV RUNNER_ALLOW_RUNASROOT=true
ENTRYPOINT ["bash", "-c", "./start.sh"]
```
questo è il file che dovete modificare per poter aggiungere i software necessari all'esecuzione delle vostre Actions.
Successivamente *create un'altro file* chiamato `start.sh`@docker-github-runner con il seguente contenuto:
```bash
#!/bin/bash
set -eux
reg_token=$(curl -L \
-X POST \
-H "Accept: application/vnd.github+json" \
-H "Authorization: Bearer $RUNNER_MANAGER_TOKEN" \
-H "X-GitHub-Api-Version: 2022-11-28" \
https://api.github.com/orgs/${GITHUB_ORG}/actions/runners/registration-token | jq -r .token)
/bin/bash config.sh --unattended --url https://github.com/${GITHUB_ORG} --name ${RUNNER_NAME} --work _work --token ${reg_token} --labels latex,x64,linux
remove () {
local rem_token=$(curl -L \
-X POST \
-H "Accept: application/vnd.github+json" \
-H "Authorization: Bearer $RUNNER_MANAGER_TOKEN" \
-H "X-GitHub-Api-Version: 2022-11-28" \
https://api.github.com/orgs/${GITHUB_ORG}/actions/runners/remove-token | jq -r .token)
./config.sh remove --token $rem_token
}
trap remove EXIT
./bin/runsvc.sh
```
questo script si occupa, all'avvio del container di recuperare il token necessario per autenticare il runner quando si collega a GitHub #footnote([il token non va confuso con quello che andrà fornito come variabile d'ambiente al container, è un token univoco e generato da GitHub partendo da quello fornito]), aggiunge il runner, cattura l'uscita (spegnimento del container o riavvio) aggiungendo una funzione che cancella il runner dal GitHub. In fine viene eseguito il software del runner.
in fine *create un file* chiamato `build.sh` e come contenuto inserite il seguente:
```bash
#!/bin/bash
IMAGE_NAME="github-runner"
echo "retrieving latest version number from release page"
LATEST=`curl -s -i https://github.com/actions/runner/releases/latest | grep location:`
LATEST=`echo $LATEST | sed 's#.*tag/v##'`
LATEST=`echo $LATEST | sed 's/\r//'`
echo "downloading latest GitHub runner (${LATEST})"
curl --progress-bar -L "https://github.com/actions/runner/releases/download/v${LATEST}/actions-runner-linux-${ARCH}-${LATEST}.tar.gz" -o runner.tgz
mkdir -p runner
echo "unpacking runner.tgz"
tar -zxf runner.tgz -C runner
docker build -t ${IMAGE_NAME} .
echo "cleaning"
rm -rf runner runner.tgz
```
quello che fa questo script è scaricare l'ultima versione del runner per Linux amd64 dal repository ufficiale di GitHub, estrarlo e effettuare la build del Dockerfile presente nella stessa cartella generando l'immagine chiamata `github-runner:latest`, se avete letto il Dockerfile, noterete che vengono definite 5 variabili d'ambiente, quelle che interessano a voi sono: `RUNNER_MANAGER_TOKEN`, `GITHUB_ORG` e `RUNNER_NAME` per eseguire l'immagine appena creata, vi abbiamo preparato un `docker-compose.yml`:
```yaml
services:
github-runner:
container_name: github-runner
image: github-runner
labels:
- "com.centurylinklabs.watchtower.enable=false"
restart: "no"
volumes:
- /etc/localtime:/etc/localtime:ro
environment:
- RUNNER_MANAGER_TOKEN=
- RUNNER_NAME=
- GITHUB_ORG=
```
non vi resta che configurarlo coi parametri richiesti e poi dare `docker compose up -d`
==== RUNNER_MANAGER_TOKEN
Questo token è come quello dell'inviter, per poter aggiungere e riumovere i runner è necessario che il token abbia lettura e scrittura su *Self-hosted runners*, vi consigliamo caldamente di creare un token univoco per i runner.
|
|
https://github.com/TheWebDev27/Calc-II-Honors-Project
|
https://raw.githubusercontent.com/TheWebDev27/Calc-II-Honors-Project/main/main.typ
|
typst
|
#show heading: set text(size: 14pt)
#include "part1.typ"
#include "part2.typ"
#include "part3.typ"
#include "references.typ"
|
|
https://github.com/Enter-tainer/typstyle
|
https://raw.githubusercontent.com/Enter-tainer/typstyle/master/tests/assets/content.typ
|
typst
|
Apache License 2.0
|
#[
123123123
]123
a#emph[abc]d
_123_
#1231231
#false
#none
#auto
|
https://github.com/TomVer99/FHICT-typst-template
|
https://raw.githubusercontent.com/TomVer99/FHICT-typst-template/main/documentation/manual.typ
|
typst
|
MIT License
|
#import "@preview/mantys:0.1.4": *
#import "@preview/codly:1.0.0": *
#import "../template/fhict-template.typ"
#import "../template/fhict-template.typ": *
#show: mantys.with(
name: "FHICT-Template",
title: [Unofficial FHICT Template],
subtitle: [An unofficial template for FHICT document generation.],
authors: "TomVer99",
url: "https://github.com/TomVer99/FHICT-typst-template",
version: "1.0.2",
date: datetime.today(),
abstract: [
This template allows the user to easily generate documents in the style of the Fontys Hogeschool ICT.
The template provides a set style and layout for the document.
It also provides a set of commands and macros to help the user generate content.
],
)
#let fontys-blue-2 = rgb("2F5496")
#let code-name-color = fontys-blue-2.lighten(35%)
#show: codly-init.with()
#codly(
languages: (
rust: (name: "Rust", color: code-name-color),
rs: (name: "Rust", color: code-name-color),
cmake: (name: "CMake", color: code-name-color),
cpp: (name: "C++", color: code-name-color),
c: (name: "C", color: code-name-color),
py: (name: "Python", color: code-name-color),
java: (name: "Java", color: code-name-color),
js: (name: "JavaScript", color: code-name-color),
sh: (name: "Shell", color: code-name-color),
bash: (name: "Bash", color: code-name-color),
json: (name: "JSON", color: code-name-color),
xml: (name: "XML", color: code-name-color),
yaml: (name: "YAML", color: code-name-color),
typst: (name: "Typst", color: code-name-color),
),
number-format: none,
display-icon: false,
)
= Usage
== Pre Requisites
To use this template, you need to have the `roboto` font installed and a way to render Typst documents.
== Importing the template
There are two ways to import the template.
The first way is to download the template file and import it using the `#import` command with a relative path to the local file.
```typst
#import "./../fhict-template.typ": *
```
The second way is to import the template from the Typst Universe. If you have a method to render Typst documents that supports the Typst Universe, you can import the template using the following command:
```typst
#import "@preview/fhict-template:1.5.1": *
```
== First Document
To create a document using this template, you can use the `fhict-doc` command.
This command has a lot of arguments to customize the document.
Here is an example of a simple document:
```typst
#show: fhict-doc.with(
title: "My Document",
subtitle: "A simple document",
authors: (
(name: "TomVer99"),
),
)
= Introduction
This is a simple document.
```
= Available commands
<fhict-doc>
#command(
"fhict-doc",
arg[title],
arg[subtitle],
arg[language],
arg[available-languages],
arg[date],
arg[authors-title],
arg[authors],
arg[assessors-title],
arg[assessors],
arg[version-history],
arg[glossary-terms],
arg[glossary-front],
arg[bibliography-file],
arg[citation-style],
arg[toc-depth],
arg[disable-toc],
arg[disable-chapter-numbering],
arg[disable-version-on-cover],
arg[chapter-on-new-page],
arg[pre-toc],
arg[table-of-figures],
arg[table-of-listings],
arg[table-of-tables],
arg[appendix],
arg[watermark],
arg[censored],
arg[print-extra-white-page],
arg[secondary-organisation-color],
arg[secondary-organisation-logo],
arg[secondary-organisation-logo-height],
arg[enable-index],
arg[index-columns],
barg[body],
)[
Renders a document in the style of the Fontys Hogeschool ICT.
#argument("title", types: "string", default: "Document Title")[
The title of the document.
]
#argument("subtitle", types: "string", default: "Document Subtitle")[
The subtitle of the document.
]
#colbreak()
#argument("language", types: "string", default: "en")[
The language of the document.
]
#argument("available-languages", types: "array", default: none)[
The available languages for the document.
```typst
("en", "nl", ...)
```
]
#argument("date", types: "string", default: none)[
Allows the user to manually specify a date to be displayed on the cover page.
```typst
date: "28日8月24年"
```
Can be any string.
```typst
date: "I am not a date, but who cares?"
```
]
#argument("authors-title", types: "string", default: none)[
The title of the authors section.
]
#argument("authors", types: "dict", default: none)[
The author(s) of the document.
Has the following structure:
```typst
(
name: "",
email: "",
),
```
Name can be a string or complex type. Email must be a string.
Email is optional.
If the `name` attribute is a complex type, it should have the following structure:
```typst
name: (content: [Tom #sensitive("V.")], string: "<NAME>."),
```
Appart from using this complex type for sensitive information, there is not much use for it.
]
#colbreak()
#argument("assessors-title", types: "string", default: none)[
The title of the assessors section.
]
#argument("assessors", types: "dict", default: none)[
The assessors of the document.
Has the following structure:
```typst
(
(
title: "",
name: "",
email: "",
),
...
)
```
All fields need to be strings.
]
#argument("version-history", types: "dict", default: none)[
The version history of the document.
Has the following structure:
```typst
(
(
version: "",
date: "",
author: "",
changes: "",
),
...
)
```
All fields can be strings or content.
]
#argument("glossary-terms", types: "dict", default: none)[
A dictionary of glossary terms.
For information on what fields are available, check the #hlink("https://typst.app/universe/package/glossarium", content: "Glossarium documentation").
]
#argument("glossary-front", types: "bool", default: false)[
Whether to show the glossary at the front of the document.
]
#colbreak()
#argument("bibliography-file", types: "bibliography", default: none)[
The bibliography element to include in the document.
```typst
#bibliography("your file path")
```
]
#argument("citation-style", types: "string", default: "ieee")[
The citation style to use for the bibliography.
]
#argument("toc-depth", types: "int", default: 3)[
The depth of the table of contents.
]
#argument("disable-toc", types: "bool", default: false)[
Whether to disable the table of contents.
]
#argument("disable-chapter-numbering", types: "bool", default: false)[
Whether to disable chapter numbering.
]
#argument("disable-version-on-cover", types: "bool", default: false)[
Whether to display the latests version number on the cover page or not.
]
#argument("chapter-on-new-page", types: "bool", default: false)[
Whether to start each chapter on a new page.
]
#argument("pre-toc", types: "content", default: none)[
Content to show before the table of contents.
]
#argument("table-of-figures", types: "bool", default: false)[
Whether to show a table of figures.
]
#argument("table-of-listings", types: "bool", default: false)[
Whether to show a table of listings.
]
#colbreak()
#argument("table-of-tables", types: "bool", default: false)[
Whether to show a table of tables.
]
#argument("appendix", types: "content", default: none)[
Content to show in the appendix.
]
#argument("watermark", types: "string", default: none)[
The watermark to show on the document.
]
#argument("censored", types: "int", default: 0)[
Whether to show a censored watermark on the document.
`1` for censorship, `0` for no censorship.
]
#argument("print-extra-white-page", types: "bool", default: false)[
Wether to make sure the beginning of sections start on the 'right hand' page.
This does not affect chapter headings.
]
#argument("secondary-organisation-color", types: "color", default: none)[
The color of the secondary organisation.
]
#argument("secondary-organisation-logo", types: "read", default: none)[
The logo of the secondary organisation.
```typst
#read("your file path")
```
]
#argument("secondary-organisation-logo-height", types: "size", default: 6%)[
The height of the secondary organisation logo.
]
#argument("enable-index", types: "bool", default: false)[
Whether to enable the index.
]
#argument("index-columns", types: "int", default: 2)[
The number of columns in the index.
]
#argument("body", types: "content")[
The content of the document.
]
]
#pagebreak()
#command(
"ftable",
arg[style],
arg[columns],
arg[content],
)[
Renders a table in the style of the Fontys Hogeschool ICT.
#argument("style", types: "int", default: 2)[
The style of the table.
Can be `1` through `8`.
]
#argument("columns", types: "array", default: ())[
The spacing and the number of columns. Just like a normal table.
```typst
(size1, size2, ...)
```
]
#argument("content", types: "array", default: ())[
An array of contents for the table.
Each element is a cell in the table.
```typst
[], [], [], ...
```
]
]
#command("sensitive", arg[textl])[
Renders a sensitive text block.
#argument("text", types: "string")[
The text to render.
]
]
#command(
"hlink",
arg[url],
arg[content],
)[
Renders a hyperlink.
#argument("url", types: "string")[
The URL to link to.
]
#argument("content", types: "string", default: none)[
The text that replaces the URL as the hyperlink.
]
]
#command(
"set-code-line-nr",
arg[start],
)[
Sets the starting line number for code blocks.
#argument("start", types: "int", default: 1)[
The starting line number.
If `-1` is given, the line numbers will be hidden.
]
]
#pagebreak()
#command(
"text-box",
arg[background-color],
arg[stroke-color],
arg[text-color],
barg[content],
)[
Renders a text box.
#argument("background-color", types: "color", default: luma(240))[
The background color of the text box.
]
#argument("stroke-color", types: "color", default: black)[
The stroke color of the text box.
]
#argument("text-color", types: "color", default: black)[
The text color of the text box.
]
#argument("content", types: "content")[
The content of the text box.
]
]
#command(
"lined-box",
arg[title],
arg[body],
arg[line-color],
)[
Renders a box with a line on the left side.
#argument("title", types: "string")[
The title of the box.
]
#argument("body", types: "content")[
The content of the box.
]
#argument("line-color", types: "color", default: red)[
The color of the line.
]
]
= 3rd Party Libraries
== Codly
#emph[Current version: 1.0.0]
Library can be found at the #hlink("https://typst.app/universe/package/codly", content: "Typst Universe page").
This library improves the code rendering in the document. There are no additional commands to use this library. More information can be found on the Typst Universe page.
== Glossarium
#emph[Current version: 0.4.1]
Library can be found at the #hlink("https://typst.app/universe/package/glossarium", content: "Typst Universe page").
This library provides functionality to manage and render and manage a glossary in the document. For more information on how to use this library, check the documentation on the Typst Universe page.
== In-Dexter
#emph[Current version: 0.4.2]
Library can be found at the #hlink("https://typst.app/universe/package/in-dexter", content: "Typst Universe page").
This library provides functionality to manage and render an index in the document.
For more information on how to use this library, check the documentation on the Typst Universe page.
= Issues
If you have any issues with this template, you can report them on the GitHub repository.
Create a new issue and describe the problem you are experiencing.
Also include the version of the template you are using, and your document if possible.
If you have a solution to the problem, you can also create a pull request.
|
https://github.com/NaviHX/bupt-master-dissertation.typ
|
https://raw.githubusercontent.com/NaviHX/bupt-master-dissertation.typ/main/chinese-cover.typ
|
typst
|
#import "@preview/tablex:0.0.7": gridx, hlinex
#let chinese-cover(
roman: "Times New Roman", songti: "Noto Serif CJK SC", heiti: "Noto CJKSans SC",
secret: [公开], title: [硕/博士学位论文(学术学位)], method: [全日制], dissertation-title,
student-id, name, major, supervisor,
institute, date,
) = {
set page(paper: "a4", margin: (x: 3.17cm, y: 2.54cm))
align(right, text(font: songti, weight: "bold", size: 14pt)[密级:#secret])
align(center, image("./image/name.png", width: 80%))
align(center, text(font: heiti, weight: "bold", size: 32pt, title))
align(center, image("./image/logo.png", width: 20%))
v(1em)
set underline(evade: false, offset: 8pt, stroke: 1.5pt)
set par(justify: true)
set text(font: (roman, songti), weight: "bold")
{
set text(size: 18pt)
align(center, grid(columns: (20%, 70%), [题目:], [
#underline(dissertation-title)
]))
}
{
set text(size: 14pt)
gridx(
columns: (6.05em, 25%, 30%), row-gutter: 1em, [], [学#h(2em)号:],
[#student-id], hlinex(start: 2, gutter-restrict: top), [], [姓#h(2em)名:],
[#name], hlinex(start: 2, gutter-restrict: top), [], [学科专业:],
[#major], hlinex(start: 2, gutter-restrict: top), [], [培养方式:],
[#method], hlinex(start: 2, gutter-restrict: top), [], [导#h(2em)师:],
[#supervisor], hlinex(start: 2, gutter-restrict: top), [], [学#h(2em)院:],
[#institute], hlinex(start: 2, gutter-restrict: top),
)
}
v(1em)
align(
center + bottom, text(size: 14pt, date.display("[year] 年 [month] 月 [day] 日")),
)
}
|
|
https://github.com/CarloSchafflik12/typst-ez-today
|
https://raw.githubusercontent.com/CarloSchafflik12/typst-ez-today/main/ez-today.typ
|
typst
|
MIT License
|
#let get-month(lang, month) = {
let months = ()
if lang == "de" {
months = ("Januar", "Februar", "März", "April", "Mai", "Juni", "Juli", "August", "September", "Oktober", "November", "Dezember")
} else if lang == "en" {
months = ("January", "February", "March", "April", "May", "June", "July", "August", "September", "October", "November", "December")
} else if lang == "fr" {
months = ("Janvier", "Février", "Mars", "Avril", "Mai", "Juin", "Juillet", "Août", "Septembre", "Octobre", "Novembre", "Décembre")
} else if lang == "it" {
months = ("Gennaio", "Febbraio", "Marzo", "Aprile", "Maggio", "Giugno", "Luglio", "Agosto", "Settembre", "Ottobre", "Novembre", "Dicembre")
} else {
return ""
}
months.at(month - 1)
}
#let today(lang: "de", format: "d. M Y", custom-months: ()) = {
let use-custom = false;
if custom-months.len() == 12 {
use-custom = true;
}
for f in format {
if f == "d" {
[#datetime.today().day()]
} else if f == "M" {
if use-custom {
[#custom-months.at(datetime.today().month() - 1)]
} else {
[#get-month(lang, datetime.today().month())]
}
} else if f == "m" {
[#datetime.today().month()]
} else if f == "Y" {
[#datetime.today().year()]
} else if f == "y" {
[#datetime.today().display("[year repr:last_two]")]
}
else {
f
}
}
}
|
https://github.com/mrcinv/nummat-typst
|
https://raw.githubusercontent.com/mrcinv/nummat-typst/master/02_koren.typ
|
typst
|
#import "admonitions.typ": opomba
#import "julia.typ": jlfb, out, repl, blk, code_box, pkg, readlines
= Računanje kvadratnega korena
Računalniški procesorji navadno implementirajo le osnovne številske operacije:
seštevanje, množenje in deljenje. Za računanje drugih matematičnih funkcij
mora nekdo napisati program. Večina programskih jezikov vsebuje implementacijo elementarnih funkcij v standardni knjižnici. V tej vaji si bomo ogledali, kako implementirati korensko funkcijo.
#opomba(
naslov: [Implementacija elementarnih funkcij v julii],
[ Lokacijo metod, ki računajo določeno funkcijo lahko dobite z ukazoma ```jl methods``` in ```@match```. Tako bo ukaz ```jl methods(sqrt)``` izpisal implementacije kvadratnega korena za vse podatkovne tipe, ki jih julia podpira. Ukaz ```jl @which(sqrt(2.0))``` pa razkrije metodo, ki računa koren za vrednost `2.0`, to je za števila s plavajočo vejico.]
)
== Naloga
Napiši funkcijo `y = koren(x)`, ki bo izračunala približek za kvadratni koren števila `x`. Poskrbi, da bo rezultat pravilen na 10 decimalnih mest in da bo časovna zahtevnost neodvisna od argumenta `x`.
=== Podrobna navodila
- Zapiši enačbo, ki ji zadošča kvadratni koren.
- Uporabi #link("https://en.wikipedia.org/wiki/Newton%27s_method")[Newtonovo metodo] in izpelji #link("https://en.wikipedia.org/wiki/Methods_of_computing_square_roots#Heron's_method")[Heronovo rekurzivno formulo] za računanje kvadratnega korena.
- Kako je konvergenca odvisna od vrednosti `x`?
- Nariši graf potrebnega števila korakov v odvisnosti od argumenta `x`.
- Uporabi lastnosti #link("https://sl.wikipedia.org/wiki/Plavajo%C4%8Da_vejica")[zapisa s plavajočo vejico] in izpelji formulo za približno vrednost korena, ki uporabi eksponent (funkcija #link("https://docs.julialang.org/en/v1/base/numbers/#Base.Math.exponent")[exponent] v Juliji).
- Implementiraj funkcijo `koren(x)`, tako da je časovna zahtevnost neodvisna od argumenta `x`. Grafično preveri, da funkcija dosega zahtevano natančnost za poljubne vrednosti argumenta `x`.
== Rešitev naloge
Najprej ustvarimo projekt za trenutno vajo in ga dodamo v delovno okolje.
#code_box(
[
#pkg("generate Vaja02", none, env: "nummat")
#pkg("develop Vaja02//", none, env: "nummat")
]
)
Tako bomo imeli v delovnem okolju dostop do vseh funkcij, ki jih bomo definirali v paketu `Vaja02`.
=== Izbira algoritma
Z računanjem kvadratnega korena so se ukvarjali že pred 3500 leti v Babilonu. O tem si lahko več preberete v #link("http://www.presek.si/21/1160-Domajnko.pdf")[članku v reviji Presek]. če želimo poiskati algoritem za računanje kvadratnega korena, se moramo najprej vprašati, kaj sploh je kvadratni koren. Kvadratni koren števila $x$ je definiran kot pozitivna vrednost $y$, katere kvadrat je enak $x$. Število $y$ je torej pozitivna rešitev enačbe
$ y^2 = x. $ <eq:02koren>
Da bi poiskali vrednost $sqrt(x)$, moramo rešiti _nelinearno enačbo_ @eq:02koren. Za numerično reševanje nelinearnih enačb obstaja cela vrsta metod. Ena najbolj popularnih metod je #link("https://sl.wikipedia.org/wiki/Newtonova_metoda")[Newtonova ali tangentna] metoda, ki jo bomo uporabili tudi mi. Pri Newtonovi metodi rešitev enačbe
$ f(x) = 0 $
poiščemo z rekurzivnim zaporedjem približkov
$ x_(n+1) = x_n - f(x_n)/(f'(x_n)). $ <eq:02newton>
Če zaporedje @eq:02newton konvergira, potem konvergira k rešitvi enačbe $f(x)=0$.
Enačbo @eq:02koren najprej preoblikujemo v obliko, ki je primerna za reševanje z Newtonovo metodo. Premaknemo vse člene na eno stran, da je na drugi strani nič
$
y^2 - x = 0,
$
V formulo za Newtonovo metodo vstavimo funkcijo $f(y) = y^2 - x$ in odvod $f'(y) = 2y$, da dobimo formulo
$
y_(n+1) &= y_n - (y_n^2 - x)/(2y_n) = (2y_n^2 - y_n^2 + x)/(2y_n) = 1/2((y_n^2 + x)/(y_n))\
y_(n+1) &= 1/2(y_n + x/y_n)
$ <eq:02heron>
Rekurzivno formulo @eq:02heron imenujemo #link("https://en.wikipedia.org/wiki/Methods_of_computing_square_roots#Heron's_method")[Haronov obrazec]. Zgornja formula določa zaporedje, ki vedno konvergira bodisi k $sqrt(x)$ ali $-sqrt(x)$, odvisno od izbire začetnega približka. Poleg tega, da zaporedje hitro konvergira k limiti, je program, ki računa člene izjemno preprost. Poglejmo si za primer, kako izračunamo $sqrt(2)$:
#code_box([
#repl(blk("scripts/02_koren.jl","# koren1"), read("out/02_koren_1.out"))
]
)
Vidimo, da se približki začnejo ponavljati že po 4. koraku. To pomeni, da se zaporedje ne bo več spreminjalo in smo dosegli najboljši približek, kot ga lahko predstavimo z 64 bitnimi števili s plavajočo vejico.
Napišimo zgornji algoritem še kot funkcijo.
#figure(
jlfb(
"Vaja02/src/koren.jl",
"# koren_heron"
),
caption: [Funkcija, ki računa kvadratni koren s Heronovim obrazcem.]
)
Preskusimo funkcijo na številu 3.
#jlfb("scripts/02_koren.jl", "# koren3")
#out("out/02_koren_3.out")
#opomba(
naslov: "Metoda navadne iteracije in tangentna metoda",
[Metoda računanja kvadratnega korena s Heronovim obrazcem je poseben primer
#link("https://sl.wikipedia.org/wiki/Newtonova_metoda")[tangentne metode], ki je poseben
primer #link("https://sl.wikipedia.org/wiki/Metoda_navadne_iteracije")[metode fiksne točke]. Obe metodi, si bomo podrobneje ogledali, v poglavju o nelinearnih enačbah.
]
)
=== Določitev števila korakov
Funkcija `koren_heron(x, x0, n)` ni uporabna za splošno rabo, saj mora uporabnik poznati tako začetni približek, kot tudi število korakov, ki so potrebni, da dosežemo želeno natančnost. Da bi bila funkcija zares uporabna, bi morala sama izbrati začetni približek, kot tudi število korakov. Najprej bomo poskrbeli, da je število korakov ravno dovolj veliko, da dosežemo želeno natančnost.
#opomba(naslov: [Relativna in absolutna napaka])[
Kako vemo, kdaj smo dosegli želeno natančnost? Navadno nekako ocenimo napako približka in jo primerjamo z želeno natančnostjo. To lahko storimo na dva načina, tako da preverimo, če je absolutna napaka manjša od *absolutne tolerance* ali pa če je relativna napaka manjša od *relativne tolerance*.
Julia za namen primerjave dveh števil ponuja funkcijo #link("https://docs.julialang.org/en/v1/base/math/#Base.isapprox")[`isapprox`], ki pove ali sta dve vrednosti približno enaki. Funkcija `isapprox` omogoča relativno in absolutno primerjavo vrednosti. Primerjava števil z relativno toleranco $delta$ se
prevede na neenačbo
$
| a - b | < delta(max(|a|, |b|))
$ <eq:02-isapprox>
Ko uporabljamo relativno primerjavo, moramo biti previdni, če primerjamo vrednosti s številom $0$. Če je namreč eno od števil, ki ju primerjamo, enako 0 in $delta < 1$, potem neenačba @eq:02-isapprox nikoli ni izpolnjena. *Število $0$ nikoli ni približno enako nobenemu neničelnemu številu, če ju primerjamo z relativno toleranco.*
]
#opomba(naslov: [Število pravilnih decimalnih mest])[
Ko govorimo o številu pravilnih decimalnih mest, imamo navadno v mislih število signifikantnih mest v zapisu s plavajočo vejico. V tem primeru moramo poskrbeti, da je relativna napaka dovolj majhna. Če želimo, da bo 10 signifikantnih mest pravilnih, mora biti relativna napaka manjša od $5 dot 10^(-11)$. Naslednja števila so vsa podana s 5 signifikantnimi mesti:
$
1/70 approx& 0.014285, quad 1/7 approx& 0.14285\
10/7 approx& 1.4285, quad 10^(10)/7 approx& 1428500000.
$
]
Pri iskanju kvadratnega korena lahko napako ocenimo tako, da primerjamo kvadrat približka z danim argumentom. Pri tem je treba raziskati, kako sta povezani relativni napaki približka za kore in njegovega kvadrata. Naj bo $y$ točna vrednost kvadratnega korena $sqrt(x)$. Če je $hat(y)$ približek z relativno napako $delta$, potem je $hat(y)=y(1+delta)$. Poglejmo si kako je relativna napaka $delta$ povezana z relativno napako kvadrata $hat(y)^2$.
$
epsilon = (hat(y)^2 - x)/x = ((y(1 + delta))^2 - x)/x =
(x(1+delta)^2 - x)/x = (1 + delta)^2 - 1 = 2delta + delta^2.
$
Pri tem smo upoštevali, da je $y^2=x$. Relativna napaka kvadrata je enaka $epsilon = 2delta + delta^2$. Ker je $delta^2 << delta$, dobimo dovolj natančno oceno, če $delta^2$ zanemarimo
$
delta = 1/2(epsilon - delta^2) < epsilon/2.
$
Od tod dobimo pogoj, kdaj je približek dovolj natančen. Če je
$
|hat(y)^2 - x| < 2delta dot x
$
potem je
$
|hat(y) - sqrt(x)| < delta dot sqrt(x).
$ <eq:02pogoj>
#opomba(naslov: [Ocene za napako ni vedno lahko poiskati])[
V primeru računanja kvadratnega korena je bila analiza napak relativno enostavna in smo lahko dobili točno oceno za relativno napako metode. Večinoma ni tako. Točne ocene za napako ni vedno lahko ali sploh mogoče poiskati. Zato pogosto v praksi napako ocenimo na podlagi različnih indicev brez zagotovila, da je ocena točna.
Pri iterativnih metodah konstruiramo zaporedje približkov $x_n$, ki konvergira k iskanemu številu. Razlika med dvema zaporednima približkoma $|x_(n+1) - x_n|$ je pogosto dovolj dobra ocena za napako iterativne metode. Toda zgolj dejstvo, da je razlika med zaporednima približkoma majhna, še ne zagotavlja, da je razlika do limite prav tako majhna. Če poznamo oceno za hitrost konvergence (oziroma odvod iteracijske funkcije), lahko izpeljemo zvezo med razliko dveh sosednjih približkov in napako metode. Vendar se v praksi pogosto zanašamo, da sta razlika sosednjih približkov in napaka sorazmerni. Problem nastane, če je konvergenca počasna.]
Če uporabimo pogoj @eq:02pogoj, lahko napišemo
funkcijo, ki sama določi število korakov iteracije.
#figure(
jlfb("Vaja02/src/koren.jl", "# koren2"),
caption: [Metoda `koren(x, y0)`, ki avtomatsko določi število korakov iteracije.]
) <code:02-koren-x-y0>
=== Izbira začetnega približka
Kako bi učinkovito izbrali dober začetni približek? Dokazati je mogoče, da rekurzivno zaporedje @eq:02heron konvergira ne glede na izbran začetni približek. Problem je, da je število korakov iteracije večje, dlje kot je začetni približek oddaljen od rešitve. Če želimo, da bo časovna zahtevnost funkcije neodvisna od argumenta, moramo poskrbeti, da za poljubni argument uporabimo dovolj dober začetni približek. Poskusimo lahko za začetni približek uporabiti kar samo število $x$. Malce boljši približek dobimo s Taylorjevem razvojem korenske funkcije okrog števila 1
$
sqrt(x) = 1 + 1/2(x-1) + ... approx 1/2 + x/2.
$
Vendar opazimo, da za večja števila, potrebuje iteracija več korakov.
#code_box(
repl(blk("scripts/02_koren.jl", "# koren5"), read("out/02_koren_5.out"))
)
Začetni približek $1/2 + x/2$ dobro deluje za števila blizu 1, če isto formulo za začetni približek preskusimo za večja števila, dobimo večjo relativno napako. Oziroma potrebujemo več korakov zanke, da pridemo do enake natančnosti.
#code_box(
jlfb("scripts/02_koren.jl", "# koren6")
)
#figure(
image("img/02_koren_tangenta.svg", width: 80%),
caption: [Korenska funkcija in tangenta v $x=1$.]
)
Da bi dobili boljši približek, si pomagamo s tem, kako so števila predstavljena v računalniku. Realna števila predstavimo s #link("https://sl.wikipedia.org/wiki/Plavajo%C4%8Da_vejica")[števili s plavajočo vejico]. Število je zapisano v obliki
$
x = m 2^e
$
kjer je $1 <= m < 2$ mantisa, $e$ pa eksponent. Za 64 bitna števila s plavajočo vejico se za
zapis mantise uporabi 53 bitov (52 bitov za decimalke, en bit pa za predznak), 11 bitov pa za
eksponent (glej #link("https://en.wikipedia.org/wiki/IEEE_754")[IEE 754 standard]). Koren števila
$x$ lahko potem izračunamo kot
$
sqrt(x) = sqrt(m) dot 2^(e/2).
$
Koren mantise lahko približno ocenimo s tangento v $x=1$
$
sqrt(m) = 1/2 + m/2.
$
Če eksponent delimo z $2$ in upoštevamo ostanek $e = 2d + o$, lahko $sqrt(2^e)$ zapišemo kot
$
sqrt(2^e) approx 2^d dot cases(1";" quad o = 0, sqrt(2)";" quad o=1)
$
Formula za približek je enaka:
$
sqrt(x) approx (1/2 + m/2) dot 2^d dot cases(1";" quad o = 0, sqrt(2)";" quad o=1)
$
Potenco števila $2^n$ lahko izračunamo z binarnim premikom števila $1$ v levo za $n$ mest.
Tako lahko zapišemo naslednjo funkcijo za začetni približek:
#figure(
code_box(
jlfb("Vaja02/src/koren.jl", "# zacetni")
),
caption: [Funkcija `zacetni(x)`, ki izračuna začetni približek.]
)
Primerjajmo izboljšano verzijo začetnega približka s pravo korensko funkcijo.
#code_box(
jlfb("scripts/02_koren.jl", "# koren7")
)
#figure(
image("img/02_koren_zacetni.svg", width: 80%),
caption: [Korenska funkcija in začetni približek.]
)
=== Zaključek
Ko smo enkrat izbrali dober začetni približek, tudi Newtonova iteracija hitreje konvergira, ne glede na velikost argumenta. Tako
lahko definiramo metodo ```jl koren(x) ``` brez dodatnega argumenta.
#figure(
jlfb("Vaja02/src/koren.jl", "# koren_x"),
caption: [Funkcija `koren(x)`.]
) <code:02-koren-x>
#opomba(naslov: [Julia omogoča več definicij iste funkcije])[
Julia uporablja posebno vrsto #link("https://en.wikipedia.org/wiki/Polymorphism_(computer_science)")[polimorfizma] imenovano #link("https://docs.julialang.org/en/v1/manual/methods/#Methods")[večlična razdelitev] (angl. multiple dispatch). Večlična razdelitev omogoča, da za isto funkcijo definiramo več različic, ki se uporabijo glede na to, katere argumente podamo funkciji. Tako smo definirali dve metodi za funkcijo `koren`. Prva metoda sprejme 2 argumenta, druga pa en argument. Ko pokličemo ```jl koren(2.0, 1.0)``` se izvede različica @code:02-koren-x-y0, ko pokličemo ```jl koren(2.0)``` se izvede @code:02-koren-x.
Metode, ki so definirane za neko funkcijo ```jl fun``` lahko vidimo z ukazom ```jl methods(fun)```. Metodo, ki se uporabi za določen klic funkcije lahko poiščemo z makrojem ```jl @which```, npr. ```jl @which koren(2.0, 1.0)```.
]
Opazimo, da se število korakov ne spreminja več z naraščanjem argumenta, to pomeni, da je časovna zahtevnost funkcije ```jl koren(x)``` neodvisna od izbire argumenta.
#code_box(
repl(blk("scripts/02_koren.jl", "# koren8"), read("out/02_koren_8.out"))
)
#opomba(naslov: [Hitro računanje obratne vrednosti kvadratnega korena])[
Pri razvoju računalniških iger, ki poskušajo verno prikazati 3 dimenzionalni svet na zaslonu, se veliko uporablja normiranje
vektorjev. Pri operaciji normiranja je potrebno komponente vektorja deliti s korenom vsote kvadratov komponent. Kot smo
spoznali pri računanju kvadratnega korena s Heronovim obrazcem, je posebej problematično poiskati ustrezen začetni približek, ki je dovolj blizu pravi rešitvi. Tega problema so se zavedali tudi inženirji igre Quake, ki so razvili posebej
zvit, skoraj magičen način za dober začetni približek. Metoda uporabi posebno vrednost `0x5f3759df`, da pride do začetnega
približka, nato pa še en korak #link("https://sl.wikipedia.org/wiki/Newtonova_metoda")[Newtonove metode].
Več o #link("https://en.wikipedia.org/wiki/Fast_inverse_square_root")[računanju obratne vrednosti kvadratnega korena].
]
|
|
https://github.com/MatheSchool/typst-g-exam
|
https://raw.githubusercontent.com/MatheSchool/typst-g-exam/develop/src/lib.typ
|
typst
|
MIT License
|
#let version = version((0,3,0))
#import "g-exam.typ": g-exam, g-question, g-subquestion, g-option, g-solution, g-clarification
|
https://github.com/jgm/typst-hs
|
https://raw.githubusercontent.com/jgm/typst-hs/main/test/typ/compiler/show-node-00.typ
|
typst
|
Other
|
// Override lists.
#show list: it => "(" + it.children.map(v => v.body).join(", ") + ")"
- A
- B
- C
- D
- E
|
https://github.com/Ttajika/class
|
https://raw.githubusercontent.com/Ttajika/class/main/seminar/lib/translation.typ
|
typst
|
#let trans = (
en: (Proposition: "Proposition",
Theorem: "Theorem",
Table: "Table",
Figure: "Figure",
Assumption: "Assumption",
Definition: "Definition",
Corollary: "Corollary",
Lemma: "Lemma",
Remark: "Remark",
Example: "Example",
Claim: "Claim",
Fact: "Fact",
Proof: "Proof"
),
jp: (Proposition: "命題",
Theorem: "定理",
Table: "表",
Figure: "図",
Assumption: "仮定",
Definition: "定義",
Corollary: "系",
Lemma: "補題",
Remark: "注意",
Example: "例",
Claim: "主張",
Fact: "事実",
Proof:"証明")
)
#let plurals_dic = ("Proposition": "Propositions", "Theorem":"Theorems", "Lemma":"Lemmata", "Definition":"Definitions", "Table":"Tables", "Assumption":"Assumptions", "Figure":"Figures", "Example": "Examples", "Fact":"Facts", "Claim":"Claims")
#let proofname(name,lang) ={
if lang == "en" {return "Proof of "+ name + "."}
if lang == "jp" {return name + "の証明."}
}
#let QERmark(lang) ={
if lang == "en" {return $qed$}
if lang == "jp" {return [(証了)]}
}
#let tjk_month_name = ("en":
("1": "January",
"2": "February",
"3": "March",
"4": "April",
"5": "May",
"6": "June",
"7": "July",
"8": "August",
"9": "September",
"10": "October",
"11": "November",
"12": "December"
),
"en-abr":
("1": "Jan.",
"2": "Feb.",
"3": "Mar.",
"4": "Apr.",
"5": "May",
"6": "Jun.",
"7": "Jul.",
"8": "Aug.",
"9": "Sep.",
"10": "Oct.",
"11": "Nov.",
"12": "Dec."
),
"jp": ("1": "睦月",
"2": "如月",
"3": "弥生",
"4": "卯月",
"5": "皐月",
"6": "水無月",
"7": "文月",
"8": "葉月",
"9": "長月",
"10": "神無月",
"11": "霜月",
"12": "師走"
)
)
#let tjk_wareki(year) = {
if year >= 2019 {
return "令和 " + str(year - 2018)
}
}
|
|
https://github.com/sses7757/sustech-graduated-thesis
|
https://raw.githubusercontent.com/sses7757/sustech-graduated-thesis/main/sustech-graduated-thesis/pages/nonfinal-cover.typ
|
typst
|
Apache License 2.0
|
#import "../utils/datetime-display.typ": datetime-display, datetime-en-display
#import "../utils/justify-text.typ": justify-text
#import "../utils/style.typ": 字号, 字体
#import "../utils/degree-names.typ": degree-types
// 硕士研究生封面
#let nonfinal-cover(
// documentclass 传入的参数
doctype: "midterm",
anonymous: false,
twoside: false,
fonts: (:),
info: (:),
// 其他参数
stoke-width: 0.5pt,
min-title-lines: 1,
info-inset: (x: 0pt, bottom: 0.5pt),
info-key-width: 96pt,
info-column-gutter: 4pt,
info-row-gutter: 14pt,
datetime-display: datetime-display,
datetime-en-display: datetime-en-display,
) = {
// 1. 默认伪粗体
show text.where(weight: "bold").or(strong): it => {
show regex("\p{script=Han}"): set text(stroke: 0.02857em)
it
}
// 2. 对参数进行处理
// 2.1 如果是字符串,则使用换行符将标题分隔为列表
if type(info.title) == str {
info.title = info.title.split("\n")
}
if type(info.title-en) == str {
info.title-en = info.title-en.split("\n")
}
// 2.2 根据 min-title-lines 填充标题
info.title = info.title + range(min-title-lines - info.title.len()).map((it) => " ")
// 2.3 处理日期
assert(type(info.submit-date) == datetime, message: "submit-date must be datetime.")
if type(info.defend-date) == datetime {
info.defend-date = datetime-display(info.defend-date)
}
if type(info.confer-date) == datetime {
info.confer-date = datetime-display(info.confer-date)
}
if type(info.bottom-date) == datetime {
info.bottom-date = datetime-display(info.bottom-date)
}
// 3. 内置辅助函数
let info-key(body, info-inset: info-inset) = {
set text(
font: fonts.宋体,
size: 字号.三号,
weight: "bold",
)
rect(
width: 100%,
inset: info-inset,
stroke: none,
justify-text(with-tail: false, body)
)
}
let info-value(body, info-inset: info-inset, no-stroke: false) = {
set align(center)
rect(
width: 100%,
inset: info-inset,
stroke: if no-stroke { none } else { (bottom: stoke-width + black) },
text(
font: fonts.宋体,
size: 字号.三号,
bottom-edge: "descender",
weight: "bold",
if type(body) == datetime [#body.display("[year]年[month]月[day]日")] else {body},
),
)
}
// 4. 正式渲染
pagebreak(weak: true, to: if twoside { "odd" })
// 居中对齐
set align(center)
// 开头标识
// 将中文之间的空格间隙从 0.25 em 调整到 0.5 em
v(字号.小一 * 2)
text(size: 字号.小一, font: fonts.楷体, spacing: 100%, weight: "bold",
"南 方 科 技 大 学"
)
v(字号.小一)
text(size: 字号.小一, font: fonts.宋体, spacing: 100%, weight: "bold",
if info.degree == "PhD" {
if doctype == "midterm" { "博 士 研 究 生 中 期 考 核 报 告" } else { "博 士 研 究 生 开 题 报 告" }
} else {
if doctype == "midterm" { "硕 士 研 究 生 中 期 考 核 报 告" } else { "硕 士 研 究 生 开 题 报 告" }
},
)
v(字号.小一)
// 题目
align(left, par(hanging-indent: 3.4em, text(size: 字号.小二, font: fonts.宋体, spacing: 100%, weight: "bold")[
题 目:#info.title.join()
]))
// 中间标识
v(字号.小一 * 2)
block(width: 294pt, grid(
columns: (info-key-width, 1fr),
column-gutter: info-column-gutter,
row-gutter: info-row-gutter,
info-key("院 (系)"),
info-value(info.dept),
info-key("学 科"),
info-value(info.major),
info-key("导 师"),
info-value(info.supervisor.intersperse(" ").sum()),
..(if info.supervisor-ii != () {(
info-key(" "),
info-value(info.supervisor-ii.intersperse(" ").sum()),
)} else { () }),
info-key("研 究 生"),
info-value(info.author),
info-key("学 号"),
info-value(info.student-id),
info-key(if doctype == "midterm" {"中 期 考 核 日 期"} else {"开 题 报 告 日 期"}),
info-value(info.submit-date),
))
v(字号.二号 * 6)
text(size: 字号.三号, font:fonts.宋体, weight: "bold")[研究生院制]
}
|
https://github.com/piepert/grape-suite
|
https://raw.githubusercontent.com/piepert/grape-suite/main/examples/exam02.typ
|
typst
|
MIT License
|
#import "/src/library.typ": exercise, colors
#import exercise: project, task, subtask
#import colors: *
#show: project.with(
title: [History Exam],
type: "Exam",
show-point-distribution-in-tasks: true,
show-namefield: true,
show-timefield: true,
max-time: 25,
show-lines: true,
show-solutions: true,
solutions-as-matrix: true,
university: [],
institute: [],
abstract: [Task 1 is a facultative task. For each task 2 and 3, choose either version A or B. If both are solved, neither are scored.],
)
#task(numbering-format: (..) => "1")[Ingredients][
Name the three necessary ingredients to make bread!
]
For each of the following tasks, choose either A or B!
#grid(columns: 2, column-gutter: 1em, row-gutter: 1.25em)[
#task(numbering-format: (..) => "2A")[Hey][
#lorem(20)
]
][
#task(numbering-format: (..) => "2B")[Hey][
#lorem(20)
]
][
#task(numbering-format: (..) => "3A")[Hey][
#lorem(20)
]
][
#task(numbering-format: (..) => "3B")[Hey][
#lorem(20)
]
]
|
https://github.com/kazuyanagimoto/quarto-awesomecv-typst
|
https://raw.githubusercontent.com/kazuyanagimoto/quarto-awesomecv-typst/main/_extensions/awesomecv/typst-template.typ
|
typst
|
MIT License
|
#import "@preview/fontawesome:0.1.0": *
//------------------------------------------------------------------------------
// Style
//------------------------------------------------------------------------------
// const color
#let color-darknight = rgb("#131A28")
#let color-darkgray = rgb("#333333")
#let color-middledarkgray = rgb("#414141")
#let color-gray = rgb("#5d5d5d")
#let color-lightgray = rgb("#999999")
// Default style
#let color-accent-default = rgb("#dc3522")
#let font-header-default = ("Roboto", "Arial", "Helvetica", "Dejavu Sans")
#let font-text-default = ("Source Sans Pro", "Arial", "Helvetica", "Dejavu Sans")
#let align-header-default = center
// User defined style
$if(style.color-accent)$
#let color-accent = rgb("$style.color-accent$")
$else$
#let color-accent = color-accent-default
$endif$
$if(style.font-header)$
#let font-header = "$style.font-header$"
$else$
#let font-header = font-header-default
$endif$
$if(style.font-text)$
#let font-text = "$style.font-text$"
$else$
#let font-text = font-text-default
$endif$
//------------------------------------------------------------------------------
// Helper functions
//------------------------------------------------------------------------------
// icon string parser
#let parse_icon_string(icon_string) = {
if icon_string.starts-with("fa ") [
#let parts = icon_string.split(" ")
#if parts.len() == 2 {
fa-icon(parts.at(1), fill: color-darknight)
} else if parts.len() == 3 and parts.at(1) == "brands" {
fa-icon(parts.at(2), fa-set: "Brands", fill: color-darknight)
} else {
assert(false, "Invalid fontawesome icon string")
}
] else if icon_string.ends-with(".svg") [
#box(image(icon_string))
] else {
assert(false, "Invalid icon string")
}
}
// contaxt text parser
#let unescape_text(text) = {
// This is not a perfect solution
text.replace("\\", "").replace(".~", ". ")
}
// layout utility
#let __justify_align(left_body, right_body) = {
block[
#box(width: 4fr)[#left_body]
#box(width: 1fr)[
#align(right)[
#right_body
]
]
]
}
#let __justify_align_3(left_body, mid_body, right_body) = {
block[
#box(width: 1fr)[
#align(left)[
#left_body
]
]
#box(width: 1fr)[
#align(center)[
#mid_body
]
]
#box(width: 1fr)[
#align(right)[
#right_body
]
]
]
}
/// Right section for the justified headers
/// - body (content): The body of the right header
#let secondary-right-header(body) = {
set text(
size: 10pt,
weight: "thin",
style: "italic",
fill: color-accent,
)
body
}
/// Right section of a tertiaty headers.
/// - body (content): The body of the right header
#let tertiary-right-header(body) = {
set text(
weight: "light",
size: 9pt,
style: "italic",
fill: color-gray,
)
body
}
/// Justified header that takes a primary section and a secondary section. The primary section is on the left and the secondary section is on the right.
/// - primary (content): The primary section of the header
/// - secondary (content): The secondary section of the header
#let justified-header(primary, secondary) = {
set block(
above: 0.7em,
below: 0.7em,
)
pad[
#__justify_align[
#set text(
size: 12pt,
weight: "bold",
fill: color-darkgray,
)
#primary
][
#secondary-right-header[#secondary]
]
]
}
/// Justified header that takes a primary section and a secondary section. The primary section is on the left and the secondary section is on the right. This is a smaller header compared to the `justified-header`.
/// - primary (content): The primary section of the header
/// - secondary (content): The secondary section of the header
#let secondary-justified-header(primary, secondary) = {
__justify_align[
#set text(
size: 10pt,
weight: "regular",
fill: color-gray,
)
#primary
][
#tertiary-right-header[#secondary]
]
}
//------------------------------------------------------------------------------
// Header
//------------------------------------------------------------------------------
#let create-header-name(
firstname: "",
lastname: "",
) = {
pad(bottom: 5pt)[
#block[
#set text(
size: 32pt,
style: "normal",
font: (font-header),
)
#text(fill: color-gray, weight: "thin")[#firstname]
#text(weight: "bold")[#lastname]
]
]
}
#let create-header-position(
position: "",
) = {
set block(
above: 0.75em,
below: 0.75em,
)
set text(
color-accent,
size: 9pt,
weight: "regular",
)
smallcaps[
#position
]
}
#let create-header-address(
address: ""
) = {
set block(
above: 0.75em,
below: 0.75em,
)
set text(
color-lightgray,
size: 9pt,
style: "italic",
)
block[#address]
}
#let create-header-contacts(
contacts: (),
) = {
let separator = box(width: 2pt)
if(contacts.len() > 1) {
block[
#set text(
size: 9pt,
weight: "regular",
style: "normal",
)
#align(horizon)[
#for contact in contacts [
#set box(height: 9pt)
#box[#parse_icon_string(contact.icon) #link(contact.url)[#contact.text]]
#separator
]
]
]
}
}
#let create-header-info(
firstname: "",
lastname: "",
position: "",
address: "",
contacts: (),
align-header: center
) = {
align(align-header)[
#create-header-name(firstname: firstname, lastname: lastname)
#create-header-position(position: position)
#create-header-address(address: address)
#create-header-contacts(contacts: contacts)
]
}
#let create-header-image(
profile-photo: ""
) = {
if profile-photo.len() > 0 {
block(
above: 15pt,
stroke: none,
radius: 9999pt,
clip: true,
image(
fit: "contain",
profile-photo
)
)
}
}
#let create-header(
firstname: "",
lastname: "",
position: "",
address: "",
contacts: (),
profile-photo: "",
) = {
if profile-photo.len() > 0 {
block[
#box(width: 5fr)[
#create-header-info(
firstname: firstname,
lastname: lastname,
position: position,
address: address,
contacts: contacts,
align-header: left
)
]
#box(width: 1fr)[
#create-header-image(profile-photo: profile-photo)
]
]
} else {
create-header-info(
firstname: firstname,
lastname: lastname,
position: position,
address: address,
contacts: contacts,
align-header: center
)
}
}
//------------------------------------------------------------------------------
// Resume Entries
//------------------------------------------------------------------------------
#let resume-item(body) = {
set text(
size: 10pt,
style: "normal",
weight: "light",
fill: color-darknight,
)
set par(leading: 0.65em)
set list(indent: 1em)
body
}
#let resume-entry(
title: none,
location: "",
date: "",
description: ""
) = {
pad[
#justified-header(title, location)
#secondary-justified-header(description, date)
]
}
//------------------------------------------------------------------------------
// Resume Template
//------------------------------------------------------------------------------
#let resume(
title: "CV",
author: (:),
date: datetime.today().display("[month repr:long] [day], [year]"),
profile-photo: "",
body,
) = {
set document(
author: author.firstname + " " + author.lastname,
title: title,
)
set text(
font: (font-text),
size: 11pt,
fill: color-darkgray,
fallback: true,
)
set page(
paper: "a4",
margin: (left: 15mm, right: 15mm, top: 10mm, bottom: 10mm),
footer: [
#set text(
fill: gray,
size: 8pt,
)
#__justify_align_3[
#smallcaps[#date]
][
#smallcaps[
#author.firstname
#author.lastname
#sym.dot.c
CV
]
][
#counter(page).display()
]
],
)
// set paragraph spacing
set heading(
numbering: none,
outlined: false,
)
show heading.where(level: 1): it => [
#set block(
above: 1.5em,
below: 1em,
)
#set text(
size: 16pt,
weight: "regular",
)
#align(left)[
#text[#strong[#text(color-accent)[#it.body.text.slice(0, 3)]#text(color-darkgray)[#it.body.text.slice(3)]]]
#box(width: 1fr, line(length: 100%))
]
]
show heading.where(level: 2): it => {
set text(
color-middledarkgray,
size: 12pt,
weight: "thin"
)
it.body
}
show heading.where(level: 3): it => {
set text(
size: 10pt,
weight: "regular",
fill: color-gray,
)
smallcaps[#it.body]
}
// Contents
create-header(firstname: author.firstname,
lastname: author.lastname,
position: author.position,
address: author.address,
contacts: author.contacts,
profile-photo: profile-photo,)
body
}
|
https://github.com/julius2718/wareki
|
https://raw.githubusercontent.com/julius2718/wareki/main/README.md
|
markdown
|
# Description
A calendar converter from the Common Era year notation (occidental system) to the Japanese notation (referred to as Wareki, 和暦) for Typst.
The conversion is available for years after 1926 A.D.
# 説明
Typst向けの、西暦から和暦への変換ツール。
昭和元年(西暦1926年)以降の変換に対応している。
|
|
https://github.com/sabitov-kirill/comp-arch-conspect
|
https://raw.githubusercontent.com/sabitov-kirill/comp-arch-conspect/master/questions/4_memory.typ
|
typst
|
#import "/commons.typ": imagebox
= Память.
_Память (статическая и динамическая ячейки, их преимущества и недостатки)._
Модули памяти отличаются типом ячеек и способом их организации.
== Типы ячеек памяти
В современном мире существует два основных типа ячеек памяти -- _статические_ и _динамические_. Статическии ячейки памяти имеют быстрый доступ к чтению и записи, обладают полным набором всех возможностей. Динамичнеские ячейки памяти более медленные, но намного дешевле и имеют более компактную схему.
Статические ячейки памяти используються в кэш памяти и регистровых файлах, где не нужен большой объем, но важна скорость доступа. Динамические ячейки памяти из-за дешевизны и компактности используються в оперативной памяти (DDR\*).
=== Статический
Как уже было упомянуто, статические ячейки памяти достаточно громостки и дороги в производстве. Ячейка состоит из 6 транзисторов. Транзисторы $M_1, M_2$ и $M_3, M_4$ -- 2 разнонаправленных инвертора. Чтение состояния ячейки всегда доступно на $"BL", accent("BL", macron)$ (подав $1$ на $"WL"$). Для записи подаем необходимые значения на $"BL", accent("BL", macron)$, и $1$ на $"WL"$.
Состояние ячейки хранят два инвертора, оно стабильно пока подаеться напряжение на $V_"dd"$ (ячейка энергозависима). Получение состояния возможно почти сразу после подачи сигнала на $"WL"$, что обеспечивает большую скорость доступа.
#imagebox("static_memory_cell.png", height: 120pt, label: [Схема статической ячейки памяти.])
=== Динамический
Динамические ячейки памяти намного более простые и компактные. Состоят из транзистора и конденсатора.
#imagebox("dinamic_memory_cell.png", height: 50pt, label: [Схема динамической ячейки памяти.])
Для чтения подается $1$ на $"AL"$, что увеличит или уменьшит напряжение на $"DL"$ (если увеличилось, то конденсатор был заряжен и стостояние ячейки -- $1$, если уменьшилось, то разряжен, мы его начали заряжать, состояние -- $0$). Для записи значения ячейки необходимо подать соответвующий сигнал на $"DL"$ и на $"AL"$ на достаточное для зарядки/разрядки конденсатора время.
Состояние динамической ячейки памяти хранится в конденсаторе ($"C"$), который немного разряжается после каждого чтения и с течением времени -- ячейка памяти не стабильна. Решениие -- дозаряжать конденсатор после каждого чтения.
Время для чтения достаточно большое из-за необходимости периодически (примерно каждые 64мс) и после каждого чтения памяти заряжать конденсатор.
#imagebox("dinamic_memory_time.png", height: 150pt, label: [График $Q(t)$ зарядки и разрядки конденсатора, $Q_"charge"=Q_0(1-e^(-t/(R C))), Q_"discharge" = Q_0e^(-t/(R C))$])
== Организация ячеек памяти
- *Одиночная организация*. На каждую яческу памяти собственные контакты чтения/записи. Абсолютно не практична из-за количесва проводов -- на 4GiB ОЗУ их потребуется $2^32$.
- *Линейная организация*. В линию распологаем ячейки, подсоединяем шину для записи к демультиплексору, для чтения к мультиплесору. Намного компактнее предыдущего, всего 23 контакта на 1GiB. Для доступа к $2^N$ линиям нужен $N "to" 1$ DMUX/MUX, имеющий большие размеры (увеличиваеться экспоненциально). Также возникают проблемы с синхронизацией большого количества ячеек, расположенных линейно.
#columns(2)[
#imagebox("simple_memory.png", height: 120pt)
#colbreak()
_Пример. Схема игрушечного модуля памяти на D-триггерах._ Непреемлем в жизни из-за того, что:
+ сами ячейки памяти очень дороги в производстве (целый D-триггер -- много транзисторов)
+ доступ к ним происходит линейно через 1 мультиплексор и демультиплексор
+ шина для передачи адреса чтения/записи очень длинная, отдельно соединена с мультиплексором.
]
- *Матричная организация*. Распологаем ячейки в ряды и колонки, доступ происходит через 1 демультиплексор для кодирования ряда, 1 мультиплексор для кодирования колонки.
#imagebox("dynamic_memory_matrix.png", height: 180pt, label: "Пример организации 16 динамических ячеек памяти в матрицу.")
На практике, безусловно, применяется матричный вариант из-за компактости.
|
|
https://github.com/PhilChodrow/cv
|
https://raw.githubusercontent.com/PhilChodrow/cv/main/src/content/papers.typ
|
typst
|
#import "../template.typ": *
#cvSection("Papers")
#cvSubSection("Peer Reviewed")
// #cvPublication(
// bibPath: "pubs.bib",
// keyList: (
// "chodrow2020",
// "jones2023"),
// refStyle: "apa" cv
// )
14. #pub(label: <brooksEmergencePolarizationSigmoidal2024>)
13. #pub(label: <kritschgauCommunityDetectionHypergraphs2024>)
12. #pub(label: <jonesDataScienceSocial2023>)
11. #pub(label: <chodrowNonbacktrackingSpectralClustering2023>)
10. #pub(label: <demetilloSpaceBasedObservational2021>)
9. #pub(label: <chodrowGenerativeHypergraphClustering2021>)
8. #pub(label: <kawakatsuEmergenceHierarchyNetworked2021>) (three equal first authors)
7. #pub(label: <chodrowConfigurationModelsRandom2020>)
6. #pub(label: <chodrowMomentsUniformRandom2020>)
5. #pub(label: <chodrowLocalSymmetryGlobal2020>)
4. #pub(label: <chodrowAnnotatedHypergraphsModels2020>)
3. #pub(label: <chodrowStructureInformationSpatial2017>)
2. #pub(label: <chodrow2016demand>)
1. #pub(label: <chodrow2013upper>)
#cvSubSection("Working Papers")
4. #pub(label: <chodrowDynamicsFemaleGender>)
3. #pub(label: <luoEfficientSamplingConfigurationModel>) #text("(*Undergraduate mentee)")
2. #pub(label: <heEdgeCorrelatedGrowingHypergraphs>)
1. #pub(label: <thompsonInferringInteractionKernels>)
#cvSubSection("Other Writings")
2. #pub(label: <chodrowPersonsChargedViolations2021>)
1. #pub(label: <siamnews2021>)
#show bibliography: none
#bibliography("../pubs.bib")
|
|
https://github.com/Error-418-SWE/Documenti
|
https://raw.githubusercontent.com/Error-418-SWE/Documenti/src/2%20-%20RTB/Documentazione%20interna/Verbali/24-01-28/24-01-28.typ
|
typst
|
#import "/template.typ": *
#show: project.with(
date: "28/01/24",
subTitle: "Meeting di retrospettiva e pianificazione",
docType: "verbale",
authors: (
"<NAME>",
),
timeStart: "15:00",
timeEnd: "15:45",
);
= Ordine del giorno
- Valutazione del progresso generale;
- Discussione sul colloquio RTB;
- Pianificazione.
== Valutazione del progresso generale
Ogni membro del gruppo, supportato dall'evidenza della board Jira, ha esposto lo stato di avanzamento delle proprie attività assegnate. \
Come già previsto durante la pianificazione i lavori risultano ancora rallentati causa esami. \
Si prevede di procedere a ritmo rallentato fino al termine dello sprint 13.
=== Piano di Progetto
Sono stati inseriti nel documento i grafici relativi all'andamento dei vari sprint.
L'aggiunta è stata effettuata mediante l'utilizzo della libreria Cetz e non tramite Plotst come precedentemente pianificato.
=== Revisione documenti
Il gruppo ha deciso di sospendere l'utilizzo di ChatGPT per la correzione grammaticale e sintattica dei documenti, in quanto i risultati prodotti non sono stati soddisfacenti e venivano riscontrati parecchi falsi positivi.
== Discussione sul colloquio RTB
Il gruppo ha tenuto una discussione sull'esito provvisorio del colloquio RTB tenutosi in data 25/01/24. \
Sono state analizzate le considerazioni del professor Cardin e si è discusso sia degli aspetti positivi del colloquio, sia di quelli con possibilità di miglioramento.
Il gruppo resta in attesa del riscontro finale da parte del professore.
== Pianificazione
Durante la pianificazione è stato deciso di attendere l'esito del colloquio RTB e nel frattempo, essendo questo sprint coincidente temporalmente con la settimana più impegnativa della sessione d'esami, i membri del gruppo si concentreranno sullo studio individuale. \
Le attività del gruppo riprenderanno regolarmente dallo sprint 14.
|
|
https://github.com/saveriogzz/curriculum-vitae
|
https://raw.githubusercontent.com/saveriogzz/curriculum-vitae/main/modules/certificates.typ
|
typst
|
Apache License 2.0
|
#import "../brilliant-CV/template.typ": *
#cvSection("Certificates")
#cvHonor(
date: [2020],
title: [Apache Cassandra 3.x Developer Associate],
issuer: [Datastax],
online: "https://www.datastax.com/academy/certs/lookup/8bddb923-8542-466a-b272-54ee2672ba07"
)
#cvHonor(
date: [2021],
title: [Astronomer Certification DAG Authoring for Apache Airflow],
issuer: [Astronomer],
online: "https://www.credly.com/badges/bd2c0db0-43ef-4548-b685-8d913e840dde"
)
#cvHonor(
date: [2021],
title: [Astronomer Certification for Apache Airflow Fundamentals],
issuer: [Astronomer],
online: "https://www.credly.com/badges/73839142-d9cd-4845-b978-7fbae587f11d"
)
|
https://github.com/gongke6642/tuling
|
https://raw.githubusercontent.com/gongke6642/tuling/main/布局/角度/角度.typ
|
typst
|
= 角度
描述旋转的角度。
Typst 支持以下角度单位:
- 学位:180deg
- 弧度:3.14rad
== 例子
#image("屏幕截图 2024-04-14 153827.png")
|
|
https://github.com/katamyra/Notes
|
https://raw.githubusercontent.com/katamyra/Notes/main/Compiled%20School%20Notes/CS1332/Modules/DandCSorts.typ
|
typst
|
#import "../../../template.typ": *
= Divide and Conquer Sorts
== Merge Sort
*Merge sort* recursively divides an array into half, sorts that half, and then merges the two sorted halves back together.
*Pseudocode*
```java
if array.length = base case
return array
length = arr.length
midIndex = length / 2
left = arr[0:midIndex-1]
right = arr[midIndex:length-1]
merge(left)
merge(right)
initialize i, j
while i and j are not at the end of the left and right arrays:
if left[i] <= right[i]:
arr[i+j] = left[i]
i++
else:
array[i+j] = right[j]
j++
while i < left.length
arr[i+j] = left[i]
i++
while j < right.length
arr[i+j] = right[j]
j++
```
#theorem[
*Time Complexities*
For all cases, merge sort is O(nlogn).
Merge sort is stable, but not adaptive and not in place.
]
|
|
https://github.com/dantevi-other/kththesis-typst
|
https://raw.githubusercontent.com/dantevi-other/kththesis-typst/main/parts/1-first-page.typ
|
typst
|
MIT License
|
//-- Imports
#import "../utils/content-stylers.typ" as cs
//-- Configurations
#set page(
margin: (
top: 65mm,
bottom: 30mm,
x: 40mm
),
numbering: none
)
//-- Content
// Title
#align(left)[
#cs.font-size-0[*Title*]
]
#v(2.5em)
// Names
#align(left)[
#grid(
columns: (auto, auto),
gutter: 2em,
cs.font-size-1[Name], cs.font-size-1[Name],
)
]
// Vertical spacing
#v(1fr)
Degree Project in Computer Science and Engineering, First Cycle
15 credits
*Date*: #datetime.today().display("[month repr:long] [day], [year]")
*Supervisor*:
*Examiner*:
*Swedish title*:
School of Electrical Engineering and Computer Science
|
https://github.com/OverflowCat/sigfig
|
https://raw.githubusercontent.com/OverflowCat/sigfig/neko/lib.typ
|
typst
|
MIT License
|
#import "utils.typ": getHighest, getFirstDigit
/**
Returns a string containing the float x represented either in decimal exponential notation with one digit before the significand's decimal point and p - 1 digits after the significand's decimal point or in decimal fixed notation with precision significant digits.
*/
#let round(x, p) = {
if type(p) != int {
p = int(p)
}
// 5. If $p < 1$ or $p > 30$, throw a ```js RangeError``` exception. (The spec uses 100, but Chromium uses 21. A 64-bit double has about 16 digits of precision. Actually, the calc.pow() will overflow if p is 20.)
if (p < 1 or p > 21) {
panic("precision argument must be between 1 and 21")
}
if type(x) != float {
x = float(x)
}
// 7. Let s be the empty string.
let s = ""
// 8. If $x < 0$, then
if x < 0 {
// a. Set $s$ to the code unit 0x002D (HYPHEN-MINUS).
s = "-"
// b. Set $x$ to $-x$.
x = -x
}
let m = ""
let e = 0
// 9. If $x = 0$, then
if x == 0 {
// a. Let $m$ be the string value consisting of $p$ occurrences of the code unit 0x0030 (DIGIT ZERO).
m = "0" * p
// b. Let $e$ be 0.
e = 0
// 10. Else,
} else {
// a. Let $e$ and $n$ be integers such that $10^(p - 1) <= n < 10^p$ and for which $n times 10^(e - p + 1) - x$ is as close to zero as possible. If there are two such sets of $e$ and $n$, pick the $e$ and $n$ for which $n times 10^(e - p + 1)$ is larger.
// let n = calc.round(x / calc.pow(10, e - p + 1))
let firstDigit = getFirstDigit(x)
// let n = getFirstDigit(x) * calc.pow(10, p - 1)
let n = calc.round(x * calc.pow(10, p - 1 - getHighest(x)))
if n >= calc.pow(10, p) {
// https://github.com/WebKit/WebKit/blob/77066932cc7ee957e46a518146c597404144cbdb/JavaScriptCore/kjs/number_object.cpp
n /= 10
e += 1
}
assert(calc.pow(10, p - 1) <= n and n < calc.pow(10, p))
// To make abs(n * calc.pow(10, e - p + 1) - x) as close to zero as possible,
// $e = log10 (x / n) + p - 1$.
// If, say, calc.log(x / n) + p - 1 is 3.50, then e can be 3 or 4. Rounding it yields 4, which is picking the larger $e$ for which $n times 10^(e - p + 1)$ is larger.
e = int(calc.round(calc.log(x / n) + p - 1))
// b. Let $m$ be the string value consisting of the digits of the decimal representation of $n$ (in order, with no leading zeroes).
m = str(n)
// c. If e < -6 or e ≥ p, then
if e < -6 or e >= p {
// ⅰ. Assert: $e != 0$.
assert(e != 0)
// ⅱ. If $p != 1$, then
if p != 1 {
// 1. Let $a$ be the first code unit of $m$.
let a = m.at(0)
// 2. Let $b$ be the other $p - 1$ code units of $m$.
let b = m.slice(1)
// assert(a + b == m)
// 3. Set $m$ to the string-concatenation of $a$, ```"."```, and $b$.
m = a + "." + b
}
// ⅲ. If $e > 0$, then
let c = if e > 0 {
// 1. In ECMAScript, let $c$ be the code unit 0x002B (PLUS SIGN). Here we use an empty string.
""
// ⅳ. Else,
} else {
// 1. Assert: $e < 0$.
assert(e < 0)
// 3. Set $e$ to $-e$.
e = -e
// 2. Let c be the code unit 0x002D (HYPHEN-MINUS).
"-"
}
// ⅴ. Let $d$ be the String value consisting of the digits of the decimal representation of $e$ (in order, with no leading zeroes).
let d = str(e)
// ⅶ. Return the string-concatenation of $s$, $m$, the code unit 0x0065 (LATIN SMALL LETTER E), $c$, and $d$.
return s + m + "e" + c + d
}
}
// 11. If $e = p - 1$,
if e == p - 1 {
// return the string-concatenation of s and m.
return s + m
}
// 12. If $e >= 0$, then
m = if e >= 0 {
// a. Set $m$ to the string-concatenation of the first $e + 1$ code units of $m$, the code unit 0x002E (FULL STOP), and the remaining $p - (e + 1)$ code units of $m$.
// assert(m.slice(0, e + 1) + m.slice(e + 1) == m and m.len() == p)
m.slice(0, e + 1) + "." + m.slice(e + 1)
// 13. Else,
} else {
// a. Set $m$ to the string-concatenation of the code unit 0x0030 (DIGIT ZERO), the code unit 0x002E (FULL STOP), $-(e + 1)$ occurrences of the code unit 0x0030 (DIGIT ZERO), and the string $m$.
"0." + "0" * (-(e + 1)) + m
}
// 14. Return the string-concatenation of s and m.
return s + m
}
#let uround(n, u) = {
let e_u = getHighest(u)
let e_n = getHighest(n)
assert(e_u >= 0 and e_n >= 0)
assert(e_u <= e_n)
let sigfig = e_n - e_u + 1
let uncertainty = round(u, 1)
let value = round(n, sigfig)
value + "+-" + uncertainty
}
#let urounds(n, u) = {
let e_u = getHighest(u)
let e_n = getHighest(n)
let sigfig = e_n - e_u + 1
let value = round(n, sigfig)
let splitted = value.split("e")
if splitted.len() == 2 {
let uncertainty = calc.round(u / calc.pow(10, e_u)) * calc.pow(10, e_u - e_n)
splitted.at(0) + "+-" + str(uncertainty) + "e" + splitted.at(1)
} else {
let uncertainty = round(u, 1)
value + "+-" + str(uncertainty)
}
}
|
https://github.com/DawnEver/csee-typst-template
|
https://raw.githubusercontent.com/DawnEver/csee-typst-template/main/main.typ
|
typst
|
MIT License
|
#import "template.typ": *
#show: project.with(
title: "Typist Template for CSEE",
authors: ("Alice","Bob","Cindy","David"),
address: "School of Electric and Electrical Engineering, Huazhong University of Science and Technology, Wuhan, 430074, China",
title_cn: "标题二号,黑体,英文字体为Arial,希腊字母保持不变,段前空12pt",
authors_cn: ("张三","李四","王五","赵六"),
address_cn: "华中科技大学电气与电子工程学院,武汉市 洪山区 430074",
abstract: [
#lorem(100)
],
abstract_cn:[
英文摘要为小五号Times New Roman字体,行距为14pt,标点为半角。
中文摘要为小五号宋体,行距为14pt,中间标点为全角,段首空6pt。],
keywords: ("A", "B", "C", "D"),
keywords_cn:("啊", "啵", "呲", "嘚"),
bibliography-file: "refs.bib",
)
= 引言
正文字号五号,首行缩进0.74cm,中文宋体,英文及数字为Times New Roman,
行距为单倍行距(“根据页面设置确定行高线”选项选中),段尾不要单字成行。
文中字母与公式中字
#lorem(30)
= 二级标题为小四黑,英文字体为Arial,换行时悬挂缩进为0,段前段后均空6pt,希腊字母保持不变
== 三级标题五号黑体,英文及数字用Arial,希腊字母保持不变
=== 四级标题五号宋体,英文及数字用Times New Roman 字体,换行时悬挂缩进为0,段前段
Citation example of reference papers#cite(<example>).
中文引用案例。#cite(<example_cn>)
= Theoretical Framework
#lorem(30)
Citation example of Fig @a.
#grid(
columns: (auto, auto),
rows: (auto, auto),
gutter: 1pt,
[ #figure(
image("./img/image.png"),
caption: [字为Times New Roman, 行距为],
)<a> ],
[ #figure(
image("./img/image.png"),
caption: [字为Times New Roman, 行距为],
)<b> ],
[ #figure(
image("./img/image.png"),
caption: [Times New Roman],
)<c> ],
[ #figure(
image("./img/image.png"),
caption: [字为行距为],
)<d> ],
)\
正文字号五号,首行缩进0.74cm,中文宋体,英文及数字为Times New Roman, 行距为单倍行距(“根据页面设置确定行高线”选项选中),段尾不要单字成行。文中字母与公式中字
= Methodological Framework
#figure(
table(
columns: (auto, auto, auto,auto, auto, auto),
inset: 3pt,
align: horizon,
[*Parameter*], [*Value*], [*Unit*],[*Parameter*], [*Value*], [*Unit*],
[#lorem(2)],[#lorem(2)],[],
[#lorem(2)],[#lorem(2)],[],
[#lorem(2)],[#lorem(2)],[],
[#lorem(2)],[#lorem(2)],[mm],
[#lorem(2)],[#lorem(2)],[mm],
),
caption: [(文字黑体顶格,数字Times],
)<baseline_motor_parameter>\
#text(font: font_def)[*定义1*]
#text(font: font_def)[*定理1* (文字黑体顶格,数字Times New Roman,加黑。)]
== 公式的输入要求
使用MathType公式编辑器。
尺寸定义:完全10.5pt、上标/下标6.5pt、次上标/下标4.5pt、符号15pt、次符号12pt;有编号的公式右对齐。
公式1行排不下时第2行以下应有明显缩进,公式转行时就优先在=,>,<,→等关系符号处,其次在+,-,×,÷,/等运算符号处转行;
转行时关系符号和运算符号应位于上行末,下行首不再重复。对于“ ”类型的公式,改成横排时,不要排成“a/b*c”应改为“a/(bc)”,公式转行时排列格式如下:
引用公式@aa。
$
a + b = c/d
$<aa>
== 表格的要求
1)中文表题小五黑,数字与英文字体及英文表题为Times New Roman(加黑),居中,段前及英文表题后空3 pt,行距为固定值14磅。
2)表中物理量:单位用分数形式表示,单位与物理量需折行排时,分数线要划在上一行的行末。以百分数表示的量,一般用“φB/%”表示。
3)表内栏目线0.5pt,顶线和底线0.75pt。表中文字为六宋,数字及英文为Times New Roman,行距为14pt。列间一律用制表位对齐。
#lorem(1000)
\
|
https://github.com/Quaternijkon/QUAD
|
https://raw.githubusercontent.com/Quaternijkon/QUAD/main/theme.typ
|
typst
|
#import "@preview/touying:0.4.2": *
// University theme
// Originally contributed by <NAME> - https://github.com/drupol
#let dark_theme=false
#let (
theme-primary,
theme-secondary,
theme-tertiary,
theme-error,
theme-background,
theme-outline,
) = if dark_theme {
(
rgb("#ADC6FF"),
rgb("#9CD49F"),
rgb("#EAC16C"),
rgb("#FFB4A9"),
rgb("#111318"),
rgb("#8E9099"),
)
} else {
(
rgb("#445E91"),
rgb("#36693E"),
rgb("#785A0B"),
rgb("#904A41"),
rgb("#F9F9FF"),
rgb("#74777F"),
)
}
// #let colors = [
// #theme-primary,
// #theme-secondary,
// #theme-tertiary,
// #theme-error,
// ]
// #let color_text(text,colors)={
// for i in range(0, 11) {
// let color = colors[i % 4];
// let char = text[i];
// // 用指定的颜色包裹每个字符
// set text(color: color)
// [#char]
// }
// }
// #let dye(text)={
// let colors = [
// #theme-primary,
// #theme-secondary,
// #theme-tertiary,
// #theme-error,
// ]
// for i in range(0, text.length()) {
// let color = colors[i % 4];
// let char = text[i];
// // 用指定的颜色包裹每个字符
// set text(color: color)
// [#char]
// }
// }
#let slide(
self: none,
title: auto,
subtitle: auto,
header: auto,
footer: auto,
display-current-section: auto,
..args,
) = {
if title != auto {
self.quad-title = title
}
if subtitle != auto {
self.quad-subtitle = subtitle
}
if header != auto {
self.quad-header = header
}
if footer != auto {
self.quad-footer = footer
}
if display-current-section != auto {
self.quad-display-current-section = display-current-section
}
(self.methods.touying-slide)(
..args.named(),
self: self,
setting: body => {
show: args.named().at("setting", default: body => body)
body
},
..args.pos(),
)
}
#let title-slide(self: none, ..args) = {//首页
self = utils.empty-page(self)
let info = self.info + args.named()
info.authors = {
let authors = if "authors" in info { info.authors } else { info.author }
if type(authors) == array { authors } else { (authors,) }
}
let content = {
if info.logo != none {
align(right, info.logo)
}
align(center + horizon, {
block(
fill: self.colors.primary,
inset: 1.5em,
radius: 0.5em,
breakable: false,
{
text(size: 1.22em, fill: white, weight: "bold", info.title)
if info.subtitle != none {
parbreak()
text(size: 1.0em, fill: white, weight: "bold", info.subtitle)
}
}
)
// set text(size: .8em)
grid(
columns: (1fr,) * calc.min(info.authors.len(), 3),
column-gutter: 1em,
row-gutter: 1em,
..info.authors.map(author => text( author ))
)
v(0.5em)
if info.institution != none {
parbreak()
text(size: .7em, info.institution)
}
if info.date != none {
parbreak()
text(size: 1.0em, utils.info-date(self))
}
})
}
(self.methods.touying-slide)(self: self, repeat: none, content)
}
#let quad-outline(self: none) = states.touying-progress-with-sections(dict => {
let (current-sections, final-sections) = dict
current-sections = current-sections.filter(section => section.loc != none).map(section => (
section,
section.children,
)).flatten().filter(item => item.kind == "section")
final-sections = final-sections.filter(section => section.loc != none).map(section => (
section,
section.children,
)).flatten().filter(item => item.kind == "section")
let current-index = current-sections.len() - 1
for (i, section) in final-sections.enumerate() {
if i == 0 {
continue
}
set text(fill: if current-index == 0 or i == current-index {
self.colors.primary
} else {
self.colors.primary.lighten(80%)
})
block(
spacing: 1.5em,
[#link(section.loc, utils.section-short-title(section))<touying-link>],
)
}
})
#let outline-slide(self: none) = {
// Generates an outline slide with a title and content.
// The title is displayed as "目录" if the text language is "zh", otherwise it is displayed as "Outline".
// The content includes alignment settings, bold text, and the buaa-outline function.
// The outline slide is created using the touying-slide method.
// Parameters:
// - self: The self parameter of the outline-slide function.
// Returns:
// - The generated outline slide.
self.quad-title = context if text.lang == "zh" [目录] else [目录]
let content = {
set align(horizon)
set text(weight: "bold")
hide([-])
quad-outline(self: self)
}
(self.methods.touying-slide)(self: self, repeat: none, section: (title: context if text.lang == "zh" [目录] else [目录]), content)
}
#let new-section-slide(self: none, short-title: auto, title) = {
self = utils.empty-page(self)
let content(self) = {
set align(horizon)
show: pad.with(20%)
set text(size: 1.5em, fill: self.colors.primary, weight: "bold")
states.current-section-title
v(-.5em)
block(height: 2pt, width: 100%, spacing: 0pt, utils.call-or-display(self, self.quad-progress-bar))
}
(self.methods.touying-slide)(self: self, repeat: none, section: (title: title, short-title: short-title), content)
}
#let focus-slide(self: none, background-color: none, background-img: none, body) = {
let background-color = if background-img == none and background-color == none {
rgb(self.colors.primary)
} else {
background-color
}
self = utils.empty-page(self)
self.page-args += (
fill: self.colors.primary-dark,
margin: 1em,
..(if background-color != none { (fill: background-color) }),
..(if background-img != none { (background: {
set image(fit: "stretch", width: 100%, height: 100%)
background-img
})
}),
)
set text(fill: white, weight: "bold", size: 2em)
(self.methods.touying-slide)(self: self, repeat: none, align(horizon, body))
}
#let matrix-slide(self: none, columns: none, rows: none, ..bodies) = {
self = utils.empty-page(self)
(self.methods.touying-slide)(self: self, composer: (..bodies) => {
let bodies = bodies.pos()
let columns = if type(columns) == int {
(1fr,) * columns
} else if columns == none {
(1fr,) * bodies.len()
} else {
columns
}
let num-cols = columns.len()
let rows = if type(rows) == int {
(1fr,) * rows
} else if rows == none {
let quotient = calc.quo(bodies.len(), num-cols)
let correction = if calc.rem(bodies.len(), num-cols) == 0 { 0 } else { 1 }
(1fr,) * (quotient + correction)
} else {
rows
}
let num-rows = rows.len()
if num-rows * num-cols < bodies.len() {
panic("number of rows (" + str(num-rows) + ") * number of columns (" + str(num-cols) + ") must at least be number of content arguments (" + str(bodies.len()) + ")")
}
let cart-idx(i) = (calc.quo(i, num-cols), calc.rem(i, num-cols))
let color-body(idx-body) = {
let (idx, body) = idx-body
let (row, col) = cart-idx(idx)
let color = if calc.even(row + col) { white } else { silver }
set align(center + horizon)
rect(inset: .5em, width: 100%, height: 100%, fill: color, body)
}
let content = grid(
columns: columns, rows: rows,
gutter: 0pt,
..bodies.enumerate().map(color-body)
)
content
}, ..bodies)
}
#let slides(self: none, title-slide: true, slide-level: 1, ..args) = {
if title-slide {
(self.methods.title-slide)(self: self)
}
(self.methods.touying-slides)(self: self, slide-level: slide-level, ..args)
}
#let register(
self: themes.default.register(),
aspect-ratio: "16-9",
progress-bar: true,
display-current-section: true,
footer-columns: (10%,75%,10%,5%),
footer-a: self => self.info.author,
footer-b: self => if self.info.short-title == auto { self.info.title } else { self.info.short-title },
footer-c: self => {
h(1fr)
utils.info-date(self)
h(1fr)
// states.slide-counter.display() + " / " + states.last-slide-number
// h(1fr)
},
footer-d: self => {
h(1fr)
states.slide-counter.display() + " / " + states.last-slide-number
h(1fr)
},
) = {
// color theme
self = (self.methods.colors)(
self: self,
primary: rgb("#4285F4"),
secondary: rgb("#34A853"),
tertiary: rgb("#FBBC05"),
error: rgb("#EA4335"),
// primary: rgb("#445E91"),
// secondary: rgb("#36693E"),
// tertiary: rgb("#785A0B"),
// error: rgb("#904A41"),
// background: rgb("#F9F9FF"),
// outline: rgb("#74777F"),
// primary: rgb("#ADC6FF"),
// secondary: rgb("#9CD49F"),
// tertiary: rgb("#EAC16C"),
// error: rgb("#FFB4A9"),
// background: rgb("#111318"),
// outline: rgb("#8E9099"),
// (
// theme-primary,
// theme-secondary,
// theme-tertiary,
// theme-error,
// theme-background,
// theme-outline,
// )=if(dark_theme){
// (
// rgb("#ADC6FF"),
// rgb("#9CD49F"),
// rgb("#EAC16C"),
// rgb("#FFB4A9"),
// rgb("#111318"),
// rgb("#8E9099"),
// )
// }else{
// (
// rgb("#445E91"),
// rgb("#36693E"),
// rgb("#785A0B"),
// rgb("#904A41"),
// rgb("#F9F9FF"),
// rgb("#74777F"),
// )
// }
light-primary: rgb("#445E91"),
light-secondary: rgb("#36693E"),
light-tertiary: rgb("#785A0B"),
light-error: rgb("#904A41"),
light-background: rgb("#F9F9FF"),
light-outline: rgb("#74777F"),
dark-primary: rgb("#ADC6FF"),
dark-secondary: rgb("#9CD49F"),
dark-tertiary: rgb("#EAC16C"),
dark-error: rgb("#FFB4A9"),
dark-background: rgb("#111318"),
dark-outline: rgb("#8E9099"),
)
// save the variables for later use
self.quad-enable-progress-bar = progress-bar
self.quad-progress-bar = self => states.touying-progress(ratio => {
grid(
columns: (ratio * 100%, 1fr),
rows: 2pt,
components.cell(fill: self.colors.secondary),
components.cell(fill: self.colors.tertiary)
)
})
self.quad-display-current-section = display-current-section
self.quad-title = none
self.quad-subtitle = none
self.quad-footer = self => {
let cell(fill: none, it) = rect(
width: 100%, height: 100%, inset: 1mm, outset: 0mm, fill: fill, stroke: none,
align(horizon, text(fill: white, it))
)
show: block.with(width: 100%, height: auto, fill: self.colors.secondary)
grid(
columns: footer-columns,
rows: (1.5em, auto),
cell(fill: self.colors.primary, utils.call-or-display(self, footer-a)),
cell(fill: self.colors.secondary, utils.call-or-display(self, footer-b)),
cell(fill: self.colors.tertiary, utils.call-or-display(self, footer-c)),
cell(fill: self.colors.error, utils.call-or-display(self, footer-d)),
)
}
self.quad-header = self => {
if self.quad-title != none {
block(inset: (x: .5em),
grid(
columns: 1,
gutter: .3em,
grid(
columns: (auto, 1fr, auto),
align(top + left, text(fill: self.colors.primary, weight: "bold", size: 1.2em, self.quad-title)),
[],
if self.quad-display-current-section {
align(top + right, text(fill: self.colors.secondary.lighten(65%), states.current-section-title))
}
),
text(fill: self.colors.primary.lighten(65%), size: .8em, self.quad-subtitle)
)
)
}
}
// set page
let header(self) = {
set align(top)
grid(
rows: (auto, auto),
row-gutter: 3mm,
if self.quad-enable-progress-bar {
utils.call-or-display(self, self.quad-progress-bar)
},
utils.call-or-display(self, self.quad-header),
)
}
let footer(self) = {
set text(size: .4em)
set align(center + bottom)
utils.call-or-display(self, self.quad-footer)
}
self.page-args += (
paper: "presentation-" + aspect-ratio,
header: header,
footer: footer,
header-ascent: 0em,
footer-descent: 0em,
margin: (top: 2.5em, bottom: 1.25em, x: 2em),
)
// register methods
self.methods.slide = slide
self.methods.title-slide = title-slide
self.methods.outline-slide = outline-slide
self.methods.new-section-slide = new-section-slide
self.methods.touying-new-section-slide = new-section-slide
self.methods.focus-slide = focus-slide
self.methods.matrix-slide = matrix-slide
self.methods.slides = slides
self.methods.touying-outline = (self: none, enum-args: (:), ..args) => {
states.touying-outline(self: self, enum-args: (tight: false,) + enum-args, ..args)
}
self.methods.alert = (self: none, it) => text(fill: self.colors.primary, it)
self.methods.init = (self: none, body) => {
set text(size: 20pt, font: "PingFang SC")
//TODO:目录从0开始编号
show footnote.entry: set text(size: .6em)
body
}
self
}
|
|
https://github.com/padix-key/kmer-article
|
https://raw.githubusercontent.com/padix-key/kmer-article/main/README.md
|
markdown
|
MIT License
|
# Raw files for the article 'A fast and simple approach to k-mer decomposition'
## Running benchmarks
The k-mer decomposition method is implemented in *Rust* and can be executed with
```
cargo run --release
```
which generates the run times for each method.
To generate the plot from the raw run times, run
```
python plot.py
```
This script not only create the benchmark figure, but the linear fits as well.
## Compiling article
The article is written using [`Typst`](https://github.com/typst/typst).
To compile the document after the benchmark was created, run
```
typst compile article.typ article.pdf
```
|
https://github.com/k0tran/typst
|
https://raw.githubusercontent.com/k0tran/typst/sisyphus/vendor/pdf-writer/README.md
|
markdown
|
# pdf-writer
[](https://crates.io/crates/pdf-writer)
[](https://docs.rs/pdf-writer)
A step-by-step PDF writer.
```toml
[dependencies]
pdf-writer = "0.9"
```
The entry point into the API is the main `Pdf`, which constructs the document
into one big internal buffer. The top-level writer has many methods to create
specialized writers for specific PDF objects. These all follow the same general
pattern: They borrow the main buffer mutably, expose a builder pattern for
writing individual fields in a strongly typed fashion and finish up the object
when dropped.
There are a few more top-level structs with internal buffers, like the builder
for `Content` streams, but wherever possible buffers are borrowed from parent
writers to minimize allocations.
## Minimal example
The following example creates a PDF with a single, empty A4 page.
```rust
use pdf_writer::{Pdf, Rect, Ref};
// Define some indirect reference ids we'll use.
let catalog_id = Ref::new(1);
let page_tree_id = Ref::new(2);
let page_id = Ref::new(3);
// Write a document catalog and a page tree with one A4 page that uses no resources.
let mut pdf = Pdf::new();
pdf.catalog(catalog_id).pages(page_tree_id);
pdf.pages(page_tree_id).kids([page_id]).count(1);
pdf.page(page_id)
.parent(page_tree_id)
.media_box(Rect::new(0.0, 0.0, 595.0, 842.0))
.resources();
// Finish with cross-reference table and trailer and write to file.
std::fs::write("target/empty.pdf", pdf.finish())?;
```
For more examples, check out the [examples folder] in the repository.
## Safety
This crate forbids unsafe code, but it depends on a few popular crates that use
unsafe internally.
## License
This crate is dual-licensed under the MIT and Apache 2.0 licenses.
[examples folder]: https://github.com/typst/pdf-writer/tree/main/examples
|
|
https://github.com/Chwiggy/cv
|
https://raw.githubusercontent.com/Chwiggy/cv/main/cv.typ
|
typst
|
#import "@preview/fontawesome:0.2.0": *
#set page(paper: "a4", numbering: none, margin: 1.5cm)
#set par(justify: true)
#set text(font: "Atkinson Hyperlegible", lang: "de", size: 11pt)
#grid(
columns: (50%, 50%),
column-gutter: 2em,
rows: auto,
row-gutter: 2em,
align:auto,
align(left, text(30pt, hyphenate: false, fill: blue.darken(50%))[
= <NAME>
]),
text(11pt)[
== Persönliche Daten
#table(
columns: (auto, auto, auto),
rows: (auto),
stroke: none,
inset: 0pt,
column-gutter: 6pt,
row-gutter: 1em,
fa-calendar-alt(fill: blue.darken(50%)),
[*Geburtstag:*],
[1997-09-05],
fa-address-card(fill: blue.darken(50%)),
[*E-Mail:*],
[<EMAIL>],
fa-phone(fill: blue.darken(50%)),
[*Telefon:*],
[+49 176 4428 1439],
fa-location-pin(fill: blue.darken(50%)),
[*Adresse:*],
[
Albert-Schweitzer-Str. 14 \
69168 Wiesloch
],
fa-github(fill: blue.darken(50%)),
[*Github:*],
[#link("https://github.com/Chwiggy")],
fa-linkedin(fill: blue.darken(50%)),
[*Linkdin:*],
[#link("https://www.linkedin.com/in/emily-c-wilke-0bb20b100/")]
)
],
)
#set text(11pt)
#table(
columns: (24%, 76%),
rows: (auto),
stroke: none,
inset: 5pt,
column-gutter: 6pt,
row-gutter: 5pt,
[== Kenntnisse], [],
[=== Computer], [],
table.cell(colspan: 2, [
#grid(
columns: (50%, 50%),
column-gutter: 2em,
rows: auto,
row-gutter: 2em,
align:auto,
table(
columns: (5%, 75%, 15%),
rows: (auto),
stroke: none,
inset: 0pt,
column-gutter: 6pt,
row-gutter: 1em,
fa-python(blue.darken(50%)),
[*Python*], [#fa-circle(solid: true, fill: blue.darken(50%))#fa-circle(solid: true, fill: blue.darken(50%))#fa-circle(solid: true,fill: blue.darken(50%))],
fa-map(blue.darken(50%)),
[
*GIS-Tools* \
#set text(10pt)
ArcGIS, QGIS
], [#fa-circle(solid: true, fill: blue.darken(50%))#fa-circle(solid: true, fill: blue.darken(50%))#fa-circle(solid: true,fill: blue.darken(50%))],
fa-file(blue.darken(50%)),
[
*Office-Anwendungen* \
#set text(10pt)
wie z.B. Microsoft-Office
], [#fa-circle(solid: true, fill: blue.darken(50%))#fa-circle(solid: true, fill: blue.darken(50%))#fa-circle(solid: true,fill: blue.darken(50%))],
fa-file-pen(fill: blue.darken(50%)),
[
*Grafik-Anwendungen* \
#set text(10pt)
wie z.B. Adobe Creative Cloud
], [#fa-circle(solid: true, fill: blue.darken(50%))#fa-circle(solid: true, fill: blue.darken(50%))#fa-circle(solid: false,fill: blue.darken(50%))],
fa-file-pen(fill: blue.darken(50%)),
[
*Forschungs-Anwendungen* \
#set text(10pt)
wie MaxQDA, SPSS
], [#fa-circle(solid: true, fill: blue.darken(50%))#fa-circle(solid: true, fill: blue.darken(50%))#fa-circle(solid: false,fill: blue.darken(50%))],
),
table(
columns: (5%, 75%, 15%),
rows: (auto),
stroke: none,
inset: 0pt,
column-gutter: 6pt,
row-gutter: 1em,
fa-rust(blue.darken(50%)),
[*Rust*], [#fa-circle(solid: true, fill: blue.darken(50%))#fa-circle(solid: true, fill: blue.darken(50%))#fa-circle(solid: true,fill: blue.darken(50%))],
fa-code(blue.darken(50%)),
[ *Other Programming Languages* \
#set text(10pt)
Nix, C++, javascript, Java
], [#fa-circle(solid: true, fill: blue.darken(50%))#fa-circle(solid: true, fill: blue.darken(50%))#fa-circle(solid: false,fill: blue.darken(50%))],
fa-code(blue.darken(50%)),
[ *Markup Languages* \
#set text(10pt)
Typst, Markdown, XML, HTML, LaTeX
], [#fa-circle(solid: true, fill: blue.darken(50%))#fa-circle(solid: true, fill: blue.darken(50%))#fa-circle(solid: false,fill: blue.darken(50%))],
fa-code(blue.darken(50%)),
[ *Deployment Tools* \
#set text(10pt)
Docker, Nix
], [#fa-circle(solid: true, fill: blue.darken(50%))#fa-circle(solid: false, fill: blue.darken(50%))#fa-circle(solid: false,fill: blue.darken(50%))],
)
)
]),
[=== Sprachen], [],
table.cell(colspan: 2, [
#grid(
columns: (50%, 50%),
column-gutter: 2em,
rows: auto,
row-gutter: 2em,
align:auto,
table(
columns: (5%, 75%, 15%),
rows: (auto),
stroke: none,
inset: 0pt,
column-gutter: 6pt,
row-gutter: 1em,
fa-comment(blue.darken(50%)),
[*Deutsch*], [#fa-circle(solid: true, fill: blue.darken(50%))#fa-circle(solid: true, fill: blue.darken(50%))#fa-circle(solid: true,fill: blue.darken(50%))],
fa-comment(blue.darken(50%)),
[
*Latein*
], [#fa-circle(solid: true, fill: blue.darken(50%))#fa-circle(solid: true, fill: blue.darken(50%))#fa-circle(solid: false,fill: blue.darken(50%))],
fa-comment(blue.darken(50%)),
[
*Niederländisch* \
], [#fa-circle(solid: true, fill: blue.darken(50%))#fa-circle(solid: false, fill: blue.darken(50%))#fa-circle(solid: false,fill: blue.darken(50%))],
),
table(
columns: (5%, 75%, 15%),
rows: (auto),
stroke: none,
inset: 0pt,
column-gutter: 6pt,
row-gutter: 1em,
fa-comment(blue.darken(50%)),
[*Englisch*], [#fa-circle(solid: true, fill: blue.darken(50%))#fa-circle(solid: true, fill: blue.darken(50%))#fa-circle(solid: true,fill: blue.darken(50%))],
fa-comment(blue.darken(50%)),
[
*Französisch*
], [#fa-circle(solid: true, fill: blue.darken(50%))#fa-circle(solid: false, fill: blue.darken(50%))#fa-circle(solid: false,fill: blue.darken(50%))],
),
)]
),
[== Berufserfahrung], [],
[*2024-03 - Heute*], [
HeiGIT gGmbH, #fa-location-pin(fill: blue.darken(50%)) Heidelberg \
*Wissenschaftliche Hilfskraft* \
#set text(10pt)
Wissenchaftliche Datenanalysen mit Python und Rust
],
table.hline(stroke: blue.lighten(50%)),
[*2023-02 - 2023-07*], [
Stadt Heidelberg, #fa-location-pin(fill: blue.darken(50%)) Heidelberg \
*Freie Mitarbeiterin in der Stadteilenwicklung* \
#set text(10pt)
Bearbeitung, Entwicklung und Präsentation von Stadtentwicklungskonzepten im Rahmen eines Bürgerbeteiligungsverfahrens
],
[*2022-09 - 2022-12*], [
*Praktikantin in der Koordinierungstelle Stadteilentwicklung* \
#set text(10pt)
Bearbeitung, Entwicklung und Präsentation von Stadtentwicklungskonzepten für einzelne Stadtteile
],
table.hline(stroke: blue.lighten(50%)),
[*2018-04 - 2019-04*], [
Albert-Ludwigs-Universität Freiburg, #fa-location-pin(fill: blue.darken(50%)) Freiburg im Breisgau \
*Studentische Hilfskraft im Seminar für Alte Geschichte* \
#set text(10pt)
Identifizierung von römischen Münzen des 4. Jhds. n. Chr.
],
table.hline(stroke: blue.lighten(50%)),
[*2018-02 - 2018-03*], [
Badischer Verlag GmbH & Co. KG, #fa-location-pin(fill: blue.darken(50%)) Freiburg im Breisgau \
*Prakikantin in der Redaktion BZ-extra* \
#set text(10pt)
Verfassen von neuen Texten und Veranstaltungshinweisen
],
[== Ausbildung], [],
[*2020-10 - 2024-09*], [
Ruprecht-Karls-Universität Heidelberg, #fa-location-pin(fill: blue.darken(50%)) Heidelberg \
#fa-graduation-cap(blue.darken(50%)) *Bachelor of Science Geographie* \
#set text(10pt)
Bachelor-Arbeit: "Simple Open Data Measures of Public Transit Service Availability" \
Wahlpflichtfach: Geschichte
],
table.hline(stroke: blue.lighten(50%)),
[*2022-09*], [
VDV Akademie, #fa-location-pin(fill: blue.darken(50%)) Wiesbaden \
#fa-bus(blue.darken(50%)) *7. VDV Sommeruniversität* \
#set text(10pt)
Nachhaltige Mobilität im Rhein-Main-Neckar-Gebiet
],
table.hline(stroke: blue.lighten(50%)),
[*2016-10 - 2020-09*], [
Albert-Ludwigs-Universität Freiburg, #fa-location-pin(fill: blue.darken(50%)) Freiburg im Breisgau \
#fa-university(blue.darken(50%)) *Studium der Geschichte* \
#set text(10pt)
Nebenfach: Geographie
],
table.hline(stroke: blue.lighten(50%)),
[*2015-10 - 2016-09*], [
Ruprecht-Karls-Universität Heidelberg, #fa-location-pin(fill: blue.darken(50%)) Heidelberg \
#fa-university(blue.darken(50%)) *Studium der Physik* \
#set text(10pt)
],
table.hline(stroke: blue.lighten(50%)),
[*2020-10 - 2024-09*], [
Gymnasium Walldorf, #fa-location-pin(fill: blue.darken(50%)) Walldorf \
#fa-school(blue.darken(50%)) *Abitur* \
#set text(10pt)
],
[== Ehrenamt], [],
[*2020-07 - heute*], [
Nerdfighteria Discord, #fa-globe(fill: blue.darken(50%)) Remote \
*Community-Moderatorin* \
#set text(10pt)
Moderation einer wachsenden englisch-sprachigen Online-Community mit über 9000 Mitgliedern auf Discord
],
table.hline(stroke: blue.lighten(50%)),
[*2021-12 - 2022-09*], [
Querreferat der VS der Universität Heidelberg, #fa-location-pin(fill: blue.darken(50%)) Heidelberg \
*Referentin des Queerreferats* \
#set text(10pt)
Hochschulpolitische Aufgaben wie Sitzungsleitung und Berichterstattung an übergeordnete Gremien, sowie Vernetzung mit externen Gruppen
],
[*2020-09 - heute*], [
*Aktives Mitglied* \
#set text(10pt)
Hochschulpolitisches Engagement für queere Studierende
],
)
|
|
https://github.com/typst/packages
|
https://raw.githubusercontent.com/typst/packages/main/packages/preview/pointless-size/0.1.0/README.md
|
markdown
|
Apache License 2.0
|
# Typst Pointless Size——字号 zìhào
中文字号的号数制及字体度量单位。
Chinese size system (hào-system) and type-related measurements units.
```typst
#import "@preview/pointless-size:0.1.0": zh, zihao
#set text(size: zh(5)) // 五号(10.5pt)
// or
#set text(zh(5))
#show: zihao(5)
// 小号用负数表示 use negative numbers for small sizes
#zh(-4) // 小四(12pt)
#zh(1) // 一号(26pt)
#zh(-1) // 小一(24pt)
#zh("-0") // 小初(36pt)
#zh(0) // 初号(42pt)
```
字号没有统一规定,本包默认与 CTeX、MS Word、WPS、Adobe 的中文规则一致。
Chinese size systems were not standardized. By default, this package is consistent with Chinese rules of CTeX, MS Word, WPS, Adobe.
如想覆盖定义:If you want to override:
```typst
#import "@preview/pointless-size:0.1.0": zh as _zh
#let zh = _zh.with(overrides: ((7, 5.25pt),))
#assert.eq(_zh(7), 5.5pt)
#assert.eq(zh(7), 5.25pt)
```
## 相关链接 Relevant links
> [!TIP]
>
> - ✅ = 一致 consistent
> - 👪 = 与描述的规则之一一致 consistent with one of the described rules
> - 🚸 = 不完全一致 not fully consistent
- 🚸[§2.3.5 基本版式设计的注意事项 - 中文排版需求 | W3C 编辑草稿](https://www.w3.org/International/clreq/#considerations_in_designing_type_area)(中/英)\[2024-09-13\]
> “号”由于当年金属活字各地厂家的规范不一而不尽相同……不作为规范性规定。
§2.3.5 Considerations when Designing the Type Area - Requirements for Chinese Text Layout | W3C Editor's Draft (Chinese & English)
> These hào-systems were not standardized by the various foundries in the past. …It is not normative information.
- ✅表25 中文字号 - [CTeX v2.5.0 (2022-07-14) 宏集手册 | CTAN](http://mirrors.ctan.org/language/chinese/ctex/ctex.pdf)(中文)
Table 25 Chinese text size - Documentation of the package CTeX v2.5.10 (2022-07-14) (Chinese)
https://github.com/CTeX-org/ctex-kit/blob/0fb196c42c56287403fecca6eb6b137c00167f40/ctex/ctex.dtx#L9974-L9993
- 👪[字体度量单位 - CJK Type Blog | Adobe](https://ccjktype.fonts.adobe.com/2009/04/post_1.html)(中/英)\[2009-04-02\] ([archive.today](https://archive.today/QxXuk))
Type-related Measurements Units (Chinese & English)
- ✅[如何转换字号、磅、px?- 技巧问答 | WPS学堂](https://www.wps.cn/learning/question/detail/id/2940)(中文)\[2020-05-07\]
How to convert between hào, point, and pixel? - Tech Q&A | WPS learning (Chinese)
- [#135 显明解行号号珍 - 字谈字畅 | The Type](https://www.thetype.com/typechat/ep-135/)(中文,带文字说明的播客)\[2020-09-09\] ([archive.today](https://archive.today/qaG8D))
(Chinese, podcast with show notes)
- [#543 ctexsize: 重设各级字号大小 - CTeX-org/ctex-kit | GitHub](https://github.com/CTeX-org/ctex-kit/issues/543)(中文)\[2020-10-13\]
#543 ctextsize: Redesign the font size system (Chinese)
- ✅[GB 40070–2021 儿童青少年学习用品近视防控卫生要求 - 国家标准 | 全国标准信息公共服务平台](https://std.samr.gov.cn/gb/search/gbDetailed?id=BBE32B661B7E8FC8E05397BE0A0AB906)(中文)\[2021-02-20\]
其中用到了号数制,例如4.3.1“小学一、二年级用字应不小于16P(3号)字”。总结下来是三号 16pt、四号 14pt、小四 12pt、五号 10.5pt、小五 9pt。
GB 40070–2021 Hygienic requirements of study products for myopia prevention and control in children and adolescents - National standards | National public service platform for standards information (Chinese)
The standard uses hào-system, e.g. 4.3.1 “texts for grade 1/2 of primary school should not be less than 16P (size 3)”. To summarize, size 3 = 16pt, size 4 = 14pt, size small 4 = 12pt, size 5 = 10.5pt, size small 5 = 9pt.
- 👪[字号(印刷)| 维基百科](https://zh.wikipedia.org/wiki/%E5%AD%97%E5%8F%B7_(%E5%8D%B0%E5%88%B7))(中文)
Hào (typography) | Wikipedia (Chinese)
|
https://github.com/jamesrswift/pixel-pipeline
|
https://raw.githubusercontent.com/jamesrswift/pixel-pipeline/main/src/pipeline/stages/lib.typ
|
typst
|
The Unlicense
|
#import "validation.typ": validation
#import "typeset.typ": typeset
#import "computation.typ": compute
|
https://github.com/typst-community/valkyrie
|
https://raw.githubusercontent.com/typst-community/valkyrie/main/src/assertions/string.typ
|
typst
|
Other
|
/// Asserts that a tested value contains the argument (string)
#let contains(value) = {
return (
condition: (self, it) => it.contains(value),
message: (self, it) => "Must contain " + str(value),
)
}
/// Asserts that a tested value starts with the argument (string)
#let starts-with(value) = {
return (
condition: (self, it) => it.starts-with(value),
message: (self, it) => "Must start with " + str(value),
)
}
/// Asserts that a tested value ends with the argument (string)
#let ends-with(value) = {
return (
condition: (self, it) => it.ends-with(value),
message: (self, it) => "Must end with " + str(value),
)
}
/// Asserts that a tested value matches with the needle argument (string)
#let matches(needle, message: (self, it) => { }) = {
return (
condition: (self, it) => it.match(needle) != none,
message: message,
)
}
|
https://github.com/yukukotani/typst-coins-thesis
|
https://raw.githubusercontent.com/yukukotani/typst-coins-thesis/main/README.md
|
markdown
|
Apache License 2.0
|
# typst-coins-thesis
筑波大学情報科学類の卒業論文向けの[Typst](https://typst.app/)テンプレートです。他の大学でも改変して使えるかもしれません。
## Example
[オンラインエディタ](https://typst.app/project/r-McyFP1wMu4Sq7FK5yTpf)でサンプルを見たりフォークしたりできます。
本リポジトリの[GitHub Pages](https://yukukotani.github.io/typst-coins-thesis/main.pdf)にもサンプルの出力があります。
|
https://github.com/freundTech/typst-typearea
|
https://raw.githubusercontent.com/freundTech/typst-typearea/main/README.md
|
markdown
|
MIT License
|
# typst-typearea
A KOMA-Script inspired package to better configure your typearea and margins.
```typst
#import "@preview/typearea:0.2.0": typearea
#show: typearea.with(
paper: "a4",
div: 9,
binding-correction: 11mm,
)
= Hello World
```
## Reference
`typearea` accepts the following options:
### two-sided
Whether the document is two-sided. Defaults to `true`.
### binding-correction
Binding correction. Defaults to `0pt`.
Additional margin on the inside of a page when two-sided is true. If two-sided is false it will be on the left or right side, depending on the value of `binding`. A `binding` value of `auto` will currently default to `left`.
Note: Before version 0.2.0 this was called `bcor`.
### div
How many equal parts to split the page into. Controls the margins. Defautls to `9`.
The top and bottom margin will always be one and two parts respectively. In two-sided mode the inside margin will be one part and the outside margin two parts, so the combined margins between the text on the left side and the text on the right side is the same as the margins from the outer edge of the text to the outer edge of the page.
In one-sided mode the left and right margin will take 1.5 parts each.
### header-height / footer-height
The height of the page header/footer.
### header-sep / footer-sep
The distance between the page header/footer and the text area.
### header-include / footer-include
Whether the header/footer should be counted as part of the text area when calculating the margins. Defaults to `false`.
### ..rest
All other arguments are passed on to `page()` as is. You can see which arguments `page()` accepts in the [typst reference for the page function](https://typst.app/docs/reference/layout/page/).
You should prefer this over calling or setting `page()` directly as doing so could break some of `typearea`'s functionality.
|
https://github.com/typst/packages
|
https://raw.githubusercontent.com/typst/packages/main/packages/preview/drafting/0.1.2/README.md
|
markdown
|
Apache License 2.0
|
# Drafting
This package hosts several utilities that are useful for drafting documents, namely margin notes and precise positioning
helpers. Over time, hopefully more utilities will be contributed. A quick, comprehensive overview is provided by the
[example document](https://github.com/ntjess/typst-drafting/blob/v0.1.2/docs/main.pdf):
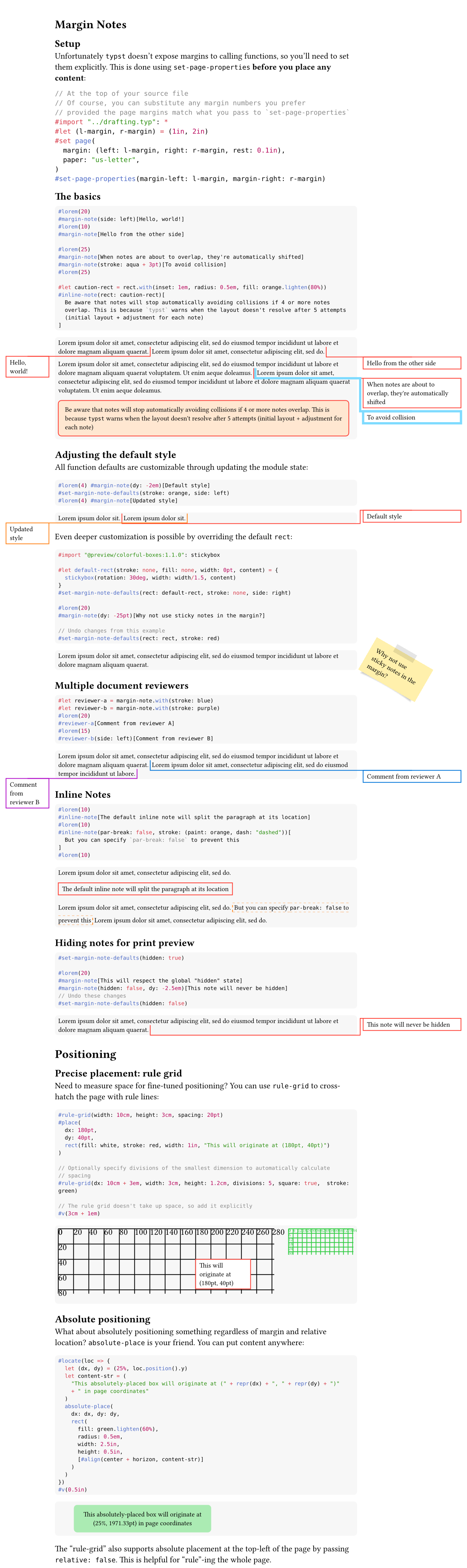
|
https://github.com/chendaohan/bevy_tutorials_typ
|
https://raw.githubusercontent.com/chendaohan/bevy_tutorials_typ/main/14_load_assets_with_asset_server/load_assets_with_asset_server.typ
|
typst
|
#set page(fill: rgb(35, 35, 38, 255), height: auto, paper: "a3")
#set text(fill: color.hsv(0deg, 0%, 90%, 100%), size: 22pt, font: "Microsoft YaHei")
#set raw(theme: "themes/Material-Theme.tmTheme")
= 1. 使用 AssetServer 从文件加载资产
要从文件加载资产,请使用 AssetServer 资源。
```Rust
fn setup(mut commands: Commands, asset_server: Res<AssetServer>) {
commands.spawn(Camera2dBundle::default());
commands.spawn(SpriteBundle {
texture: asset_server.load("14_load_assets/bevy_bird_dark.png"),
..default()
});
}
```
这会将资产加载排队到后台,并返回一个句柄。资产需要一些时间才能变得可用。您无法在同一系统中立即访问实际数据,但可以使用句柄。
您可以使用句柄生成实体,如 2D 精灵、3D 模型和 UI,即使在资产加载之前也是如此。它们将在资产准备好后“弹出”。
请注意,即使资产当前正在加载或已经加载,您也可以随时调用 asset_server.load(…)。它只会为您提供相同的句柄。每次调用时,它只会检查资产的状态,如果需要,开始加载并给您一个句柄。
Bevy 支持加载各种资产文件格式,并且可以扩展以支持更多格式。要使用的资产加载器实现是根据文件扩展名选择的。
= 2. 资产路径和标签
用于从文件系统中识别资产的资产路径实际上是一个特殊的 AssetPath,它由文件路径和标签组成。标签用于在同一个文件中包含多个资产的情况。例如,GLTF 文件可以包含网格、场景、纹理、材质等。
资产路径可以从字符串创建,标签(如果有)附加在 \# 符号之后。
```Rust
fn setup(
mut commands: Commands,
asset_server: Res<AssetServer>,
) {
commands.spawn(SceneBundle {
// asset_server.load("14_load_assets/grass.glb#Scene0");
scene: asset_server.load(GltfAssetLabel::Scene(0).from_asset("14_load_assets/grass.glb")),
..default()
});
}
```
|
|
https://github.com/htlwienwest/da-vorlage-typst
|
https://raw.githubusercontent.com/htlwienwest/da-vorlage-typst/main/lib/fontchecker.typ
|
typst
|
MIT License
|
#let _error_msg(font, download_url) = block(
stroke: red + 2pt,
inset: 8mm,
radius: 4pt,
width: 100%,
)[
#let rf = raw(font)
#set text(font: ("Arials", "Roboto"), fallback: true)
= 😢 Schriftart #rf konnte nicht gefunden werden!
Damit das Dokument korrekt generiert werden kann, muss #rf
installiert sein.
#if download_url != none [
Du kannst die Schriftart über #link(download_url) herunterladen.
] else [
Dafür lade dir als erstes die Schriftart herunter.
]
Je nachdem wie du mit Typst arbeitest, müssen folgende Schritte durchgeführt werden.
== Typst Web App
Erstelle einen Ordner `fonts/` und ziehe *alle* heruntergeladenen `.ttf` Dateien hinein. Schon erledigt!
== Lokal
Wenn du Lokal arbeitest hast du zwei Möglichkeiten:
=== *Installation*
Installiere *alle* Schriftarten auf deinem Rechner.
Sobald das getan ist, sollte Typst die Schriftart finden.
=== *Fonts Ordner*
- Erstelle einen Ordner `fonts/` und ziehe *alle* heruntergeladenen `.ttf` Dateien hinein.
- Übergib den Pfad zu dem erstellten Ordner mit dem `--font-path` Argument an Typst oder setze die `TYPST_FONT_PATHS` Umgebungsvariable
Mehr dazu findest du in der #link("https://typst.app/docs/reference/text/text#font")[Dokumentation].
]
#let checkfont(font, download_url: none) = context {
let size = measure(text(font: font, fallback: false)[
Test
])
if size.width == 0pt {
_error_msg(font, download_url)
pagebreak()
}
}
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.