
repo
stringlengths 26
115
| file
stringlengths 54
212
| language
stringclasses 2
values | license
stringclasses 16
values | content
stringlengths 19
1.07M
|
|---|---|---|---|---|
https://github.com/dadn-dream-home/documents
|
https://raw.githubusercontent.com/dadn-dream-home/documents/main/contents/09-hien-thuc/index.typ
|
typst
|
= Hiện thực
Hiện thực của nhóm được đăng tải tại địa chỉ https://github.com/dadn-dream-home.
Giao diện ứng dụng được mô tả ở hình @fig:ui.
#figure(
image("ui.drawio.svg", width: 100%),
caption: "Giao diện ứng dụng",
) <fig:ui>
Giao diện gồm có 5 màn hình chính:
/ Dashboard: là giao diện để người dùng xem thông tin tổng quan về các cảm biến
cũng như điều khiển thiết bị.
/ Activity: là giao diện để người dùng xem lại lịch sử hoạt động của thiết bị.
/ Settings: là giao diện để người dùng chỉnh sửa danh sách thiết bị.
/ Sensor config: là giao diện để người dùng chỉnh sửa cấu hình của các cảm biến.
/ Actuator config: là giao diện để người dùng chỉnh sửa cấu hình của các thiết
bị.
|
|
https://github.com/TGM-HIT/typst-protocol
|
https://raw.githubusercontent.com/TGM-HIT/typst-protocol/main/template/glossaries.typ
|
typst
|
MIT License
|
#import "@preview/tgm-hit-protocol:0.1.0": *
#glossary-entry(
"ac:tgm",
short: "TGM",
long: "Technologisches Gewerbemuseum",
// group: "Acronyms",
)
#glossary-entry(
"syt",
short: "SYT",
long: "Systemtechnik",
desc: ["Als Systemtechnik bezeichnet man verschiedene Aufbau- und Verbindungstechniken, aber auch eine Fachrichtung der Ingenieurwissenschaften. Er bedeutet in der Unterscheidung zu den Mikrotechnologien die Verbindung verschiedener einzelner Module eines Systems und deren Konzeption." @wiki:syt]
)
|
https://github.com/Skimmeroni/Appunti
|
https://raw.githubusercontent.com/Skimmeroni/Appunti/main/Matematica4AI/LinAlg/Decomposition.typ
|
typst
|
Creative Commons Zero v1.0 Universal
|
#import "../Math4AI_definitions.typ": *
A symmetric matrix $A$ is said to be *definite positive* if, for any vector
$underline(x)$, $angle.l underline(x), A underline(x) angle.r > 0$. It is
instead said to be *semidefinite positive* if, for any vector $underline(x)$,
$angle.l underline(x), A underline(x) angle.r gt.eq 0$.
#theorem[
If a symmetric matrix is definite positive, each one of its eigenvalues
is real and strictly positive.
] <Definite-positive-is-positive-eigenvalues>
#proof[
// To be retrieved from lectures (messed up)
]
#theorem[
If a symmetric matrix is definite positive, each one of its eigenvalues
is real and either positive or equal to $0$.
] <Semidefinite-positive-is-positive-or-null-eigenvalues>
#proof[
The idea is the same as in @Definite-positive-is-positive-eigenvalues but
considering $gt.eq$ instead of $>$.
]
#theorem("Cholesky Decomposition")[
For any positive definite matrix $A$ there exists a lower triangular
matrix $L$ such that $A = L L^(T)$.
]
#proof[
The theorem can be proven in a constructive way by defining an algorithm
that recursively retrieves said $L$ matrix.
First, the three matrices at play ought to have such form:
#grid(
columns: (0.33fr, 0.33fr, 0.33fr),
[$ A = mat(
a_(1, 1), a_(1, 2), dots, a_(1, n);
a_(1, 2), a_(2, 2), dots, a_(2, n);
dots.v, dots.v, dots.down, dots.v;
a_(1, n), a_(2, n), dots, a_(n, n);
) $],
[$ L = mat(
l_(1, 1), 0, dots, 0;
l_(1, 2), l_(2, 2), dots, 0;
dots.v, dots.v, dots.down, dots.v;
l_(1, n), l_(2, n), dots, l_(n, n);
) $],
[$ L^(T) = mat(
l_(1, 1), l_(1, 2), dots, l_(1, n);
0, l_(2, 2), dots, l_(2, n);
dots.v, dots.v, dots.down, dots.v;
0, 0, dots, l_(n, n);
) $]
)
The $(1, 1)$ entry of the product between $L$ and $L^(T)$ is given by the
inner product of the first row of $L$ and the first column of $L^(T)$:
$ l_(1, 1) dot l_(1, 1) + 0 dot 0 + 0 dot 0 + dots +
0 dot 0 = l_(1, 1)^(2) $
This means that, for the equality $A = L L^(T)$ to be true, $l_(1, 1)$
ought to be equal to $sqrt(a_(1, 1))$.
The generic $(1, i)$ entry of the product between $L$ and $L^(T)$
is given by the inner product of the first row of $L$ and the $i$-th
column of $L^(T)$:
$ l_(1, 1) dot l_(1, i) + 0 dot l_(2, i) + 0 dot l_(3, i) + dots +
0 dot 0 = l_(1, 1) l_(1, i) $
This means that, for the equality $A = L L^(T)$ to be true, $a_(1, i)$
ought to be equal to $l_(1, 1) l_(1, i)$, which in turn means that
$l_(1, i)$ ought to be equal to $a_(1, i) slash l_(1, 1)$.
The $(2, 2)$ entry of the product between $L$ and $L^(T)$ is given by the
inner product of the second row of $L$ and the second column of $L^(T)$:
$ l_(1, 2) dot l_(1, 2) + l_(2, 2) dot l_(2, 2) + 0 dot 0 + dots +
0 dot 0 = l_(1, 2)^(2) + l_(2, 2)^(2) $
This means that, for the equality $A = L L^(T)$ to be true, $l_(2, 2)$
must be equal to $sqrt(a_(2, 2) - l_(1, 2)^(2))$.
// To be completed (lectures?)
/*
The generic $(2, i)$ entry of the product between $L$ and $L^(T)$
is given by the inner product of the second row of $L$ and the $i$-th
column of $L^(T)$:
$ l_(2, 1) dot l_(1, i) + l_(2, 2) dot l_(2, i) + 0 dot l_(3, i) + dots +
0 dot 0 = l_(1, 1) l_(1, i) + l_(2, 2) dot l_(2, i) $
This means that, for the equality $A = L L^(T)$ to be true, $a_(2, i)$
ought to be equal to $l_(1, 1) l_(1, i) + l_(2, 2) l_(2, i)$, which
in turn means that $l_(2, 2)$ ought to be equal to $(a_(2, i) - l_(1, 1)
l_(1, i)) slash l_(2, i)$.
*/
]
|
https://github.com/typst-doc-cn/tutorial
|
https://raw.githubusercontent.com/typst-doc-cn/tutorial/main/src/basic/reference-visualization.typ
|
typst
|
Apache License 2.0
|
#import "mod.typ": *
#show: book.ref-page.with(title: [参考:图形与几何元素])
== 直线
A line from one point to another. #ref-bookmark[`line`]
#code(```typ
#line(length: 100%)
#line(end: (50%, 50%))
#line(
length: 4cm,
stroke: 2pt + maroon,
)
```)
== 线条样式
Defines how to draw a line. #ref-bookmark[`stroke`]
A stroke has a paint (a solid color or gradient), a thickness, a line cap, a line join, a miter limit, and a dash pattern. All of these values are optional and have sensible defaults.
#code(```typ
#set line(length: 100%)
#let rainbow = gradient.linear(
..color.map.rainbow)
#stack(
spacing: 1em,
line(stroke: 2pt + red),
line(stroke: (paint: blue, thickness: 4pt, cap: "round")),
line(stroke: (paint: blue, thickness: 1pt, dash: "dashed")),
line(stroke: 2pt + rainbow),
)
```)
== 贝塞尔路径(曲线)
A path through a list of points, connected by Bezier curves. #ref-bookmark[`path`]
#code(```typ
#path(
fill: blue.lighten(80%),
stroke: blue,
closed: true,
(0pt, 50pt),
(100%, 50pt),
((50%, 0pt), (40pt, 0pt)),
)
```)
== 圆形
A circle with optional content. #ref-bookmark[`circle`]
#code(```typ
// Without content.
#circle(radius: 25pt)
// With content.
#circle[
#set align(center + horizon)
Automatically \
sized to fit.
]
```)
== 椭圆
An ellipse with optional content. #ref-bookmark[`ellipse`]
#code(```typ
// Without content.
#ellipse(width: 35%, height: 30pt)
// With content.
#ellipse[
#set align(center)
Automatically sized \
to fit the content.
]
```)
== 正方形
A square with optional content. #ref-bookmark[`square`]
#code(```typ
// Without content.
#square(size: 40pt)
// With content.
#square[
Automatically \
sized to fit.
]
```)
== 矩形
A rectangle with optional content. #ref-bookmark[`rect`]
#code(```typ
// Without content.
#rect(width: 35%, height: 30pt)
// With content.
#rect[
Automatically sized \
to fit the content.
]
```)
== 多边形
A closed polygon. #ref-bookmark[`ellipse`]
The polygon is defined by its corner points and is closed automatically.
#code(```typ
#polygon(
fill: blue.lighten(80%),
stroke: blue,
(20%, 0pt),
(60%, 0pt),
(80%, 2cm),
(0%, 2cm),
)
```)
== 图形库
+ typst-fletcher
+ typst-syntree
+ cetz
|
https://github.com/EGmux/ControlTheory-2023.2
|
https://raw.githubusercontent.com/EGmux/ControlTheory-2023.2/main/unit2/main.typ
|
typst
|
#include "./stabilitiy.typ"
#include "./multipleSubsystemReduction.typ"
|
|
https://github.com/CarlColglazier/northwestern-thesis-quarto
|
https://raw.githubusercontent.com/CarlColglazier/northwestern-thesis-quarto/master/_extensions/northwestern-thesis/typst/typst-template.typ
|
typst
|
MIT License
|
#let nuthesis(
title: "Paper Title",
author: "<NAME>",
date: "Month Year",
abstract: none,
paper-size: "us-letter",
bibliography-file: none,
toc: false,
lof: false,
lot: false,
toc_title: "Table of Contents",
toc_depth: none,
document-type: "dissertation",
field: "Computer Science",
mainfont: "Times New Roman",
body
) = {
// Set document metadata.
set document(title: title, author: author)
// Set the body font.
set text(font: mainfont, size: 12pt)
// Configure the page.
set page(
paper: paper-size,
// The margins depend on the paper size.
margin: {
(
x: 1in,
y: 1in,
)
}
)
// Display the paper's title.
align(center, "NORTHWESTERN UNIVERSITY")
v(48pt, weak: true)
align(center, text(title))
v(48pt, weak: true)
align(center, "A " + document-type)
v(48pt, weak: true)
align(center, "SUBMITTED TO THE GRADUATE SCHOOL")
align(center, "IN PARTIAL FULFILLMENT OF THE REQUIREMENTS")
v(48pt, weak: true)
align(center, "for the degree")
v(48pt, weak: true)
align(center, "DOCTOR OF PHILOSOPHY")
v(48pt, weak: true)
align(center, "Field of " + field)
v(48pt, weak: true)
align(center, "By")
v(48pt, weak: true)
align(center, text(author))
v(48pt, weak: true)
align(center, "Evanston, Illinois")
v(48pt, weak: true)
align(center, text(date))
v(8.35mm, weak: true)
// newpage
pagebreak()
// Now after the title page
set page(
header: align(right)[
#counter(page).display("1")]
)
//set heading()
show heading.where(level: 1): it => [
#set align(center)
#set text(12pt, weight: "bold")
#set block(spacing: 1.3em)
#block(it.body)
]
show heading.where(level: 2): it => [
#set align(center)
#set text(12pt, weight: "regular")
#set block(spacing: 1.3em)
#block(it.body)
]
// Third level headings
show heading.where(
level: 3
): it => [
#set text(
weight: "regular",
style: "italic"
)
#set block(spacing: 1.3em)
// Add new line
//[#set block(spacing: 1.3em)
//#par(first-line-indent: 0em, it.body + linebreak())
//],
#block(it.body)
]
set quote(block: true)
show quote: set par(leading: 0.65em)
//set par(
// leading: 1.3em,
//)
// Rules
// Paragraph
// https://github.com/typst/typst/issues/106
set text(top-edge: 0.7em, bottom-edge: -0.3em)
set par(
first-line-indent: 0.5in,
leading: 1em,
justify: false,
)
show figure: it => box(width:100%)[
#align(center)[#it.body]
//#v(if it.has("gap") {it.gap} else {0.65em})
#set text(
size: 10pt,
top-edge: "cap-height",
bottom-edge: "baseline"
)
#set align(left)
#set par(
first-line-indent: 0em,
hanging-indent: 0em,
justify: false,
leading: 0.65em,
)
//
// #it.supplement #it.counter.display(it.numbering):
//#pad(x: 1cm)[#it.caption]
#it.caption
// TODO: one line margin
]
if abstract != none [
#set align(center)
#block[
#set text(weight: "bold")
Abstract
]
#set align(left)
#abstract
#pagebreak()
]
if toc {
let title = if toc_title == none {
auto
} else {
toc_title
}
block(above: 0em, below: 2em)[
#outline(
title: toc_title,
depth: toc_depth,
indent: 2em
);
]
pagebreak()
}
if lof == true{
//"List of Figures"
show outline.entry: it=> if <no-prefix> != it.fields().at(
default: {},
"label",
) [#outline.entry(
it.level,
it.element,
{
it.element.caption.supplement
" "
numbering(
it.element.numbering,
..it.element.counter.at(it.element.location()),
)
//figure.caption.separator
//it.element.caption.body
},
it.fill,
it.page
)<no-prefix>] else {it}
{
show heading: none
heading[List of Figures]
}
block(above: 0em, below: 2em)[
/*#show outline.entry.where(
level: 1
): it => {
[
#block(it.body)
]
}*/
#outline(
title: "List of Figures",
target: figure.where(kind: "quarto-float-fig"), //.where(kind: image),
//depth: none,
)
]
pagebreak()
}
if lot == true {
{
show heading: none
heading[List of Tables]
}
outline(
title: [List of Tables],
target: figure.where(kind: table),
)
pagebreak()
}
//contents
body
}
|
https://github.com/typst/packages
|
https://raw.githubusercontent.com/typst/packages/main/packages/preview/tidy/0.2.0/src/tidy.typ
|
typst
|
Apache License 2.0
|
// Source code for the typst-doc package
#import "styles.typ"
#import "tidy-parse.typ"
#import "utilities.typ"
#import "show-example.typ"
#import "testing.typ"
/// Parse the docstrings of a typst module. This function returns a dictionary
/// with the keys
/// - `name`: The module name as a string.
/// - `functions`: A list of function documentations as dictionaries.
/// - `label-prefix`: The prefix for internal labels and references.
/// The label prefix will automatically be the name of the module if not given
/// explicity.
///
/// The function documentation dictionaries contain the keys
/// - `name`: The function name.
/// - `description`: The function's docstring description.
/// - `args`: A dictionary of info objects for each function argument.
///
/// These again are dictionaries with the keys
/// - `description` (optional): The description for the argument.
/// - `types` (optional): A list of accepted argument types.
/// - `default` (optional): Default value for this argument.
///
/// See @@show-module() for outputting the results of this function.
///
/// - content (string): Content of `.typ` file to analyze for docstrings.
/// - name (string): The name for the module.
/// - label-prefix (auto, string): The label-prefix for internal function
/// references. If `auto`, the label-prefix name will be the module name.
/// - require-all-parameters (boolean): Require that all parameters of a
/// functions are documented and fail if some are not.
/// - scope (dictionary): A dictionary of definitions that are then available
/// in all function and parameter descriptions.
#let parse-module(
content,
name: "",
label-prefix: auto,
require-all-parameters: false,
scope: (:)
) = {
if label-prefix == auto { label-prefix = name }
let parse-info = (
label-prefix: label-prefix,
require-all-parameters: require-all-parameters,
)
let matches = content.matches(tidy-parse.docstring-matcher)
let function-docs = ()
let variable-docs = ()
for match in matches {
if content.len() <= match.end or content.at(match.end) != "(" {
variable-docs.push(tidy-parse.parse-variable-docstring(content, match, parse-info))
} else {
function-docs.push(tidy-parse.parse-function-docstring(content, match, parse-info))
}
}
return (
name: name,
functions: function-docs,
variables: variable-docs,
label-prefix: label-prefix,
scope: scope
)
}
/// Show given module in the given style.
/// This displays all (documented) functions in the module.
///
/// - module-doc (dictionary): Module documentation information as returned by
/// @@parse-module().
/// - first-heading-level (integer): Level for the module heading. Function
/// names are created as second-level headings and the "Parameters"
/// heading is two levels below the first heading level.
/// - show-module-name (boolean): Whether to output the name of the module at
/// the top.
/// - break-param-descriptions (boolean): Whether to allow breaking of parameter
/// description blocks.
/// - omit-empty-param-descriptions (boolean): Whether to omit description blocks
/// for parameters with empty description.
/// - show-outline (function): Whether to output an outline of all functions in
/// the module at the beginning.
/// - sort-functions (auto, none, function): Function to use to sort the function
/// documentations. With `auto`, they are sorted alphabetically by
/// name and with `none` they are not sorted. Otherwise a function can
/// be passed that each function documentation object is passed to and
/// that should return some key to sort the functions by.
/// - style (module, dictionary): The output style to use. This can be a module
/// defining the functions `show-outline`, `show-type`, `show-function`,
/// `show-parameter-list` and `show-parameter-block` or a dictionary with
/// functions for the same keys.
/// - enable-tests (boolean): Whether to run docstring tests.
/// - colors (auto, dictionary): Give a dictionary for type and colors and other colors. If set to auto, the style will select its default color set.
/// -> content
#let show-module(
module-doc,
style: styles.default,
first-heading-level: 2,
show-module-name: true,
break-param-descriptions: false,
omit-empty-param-descriptions: true,
show-outline: true,
sort-functions: auto,
enable-tests: true,
colors: auto
) = {
let label-prefix = module-doc.label-prefix
if sort-functions == auto {
module-doc.functions = module-doc.functions.sorted(key: x => x.name)
} else if type(sort-functions) == "function" {
module-doc.functions = module-doc.functions.sorted(key: sort-functions)
}
let style-functions = utilities.get-style-functions(style)
let style-args = (
style: style-functions,
label-prefix: label-prefix,
first-heading-level: first-heading-level,
break-param-descriptions: break-param-descriptions,
omit-empty-param-descriptions: omit-empty-param-descriptions,
colors: colors
)
let eval-scope = (
// Predefined functions that may be called by the user in docstring code
example: style-functions.show-example.with(
inherited-scope: module-doc.scope
),
test: testing.test.with(
inherited-scope: testing.assertations + module-doc.scope,
enable: enable-tests
),
// Internally generated functions
tidy: (
show-reference: style-functions.show-reference.with(style-args: style-args)
)
)
eval-scope += module-doc.scope
style-args.scope = eval-scope
// Show the docs
if "name" in module-doc and show-module-name and module-doc.name != "" {
heading(module-doc.name, level: first-heading-level)
parbreak()
}
if show-outline {
(style-functions.show-outline)(module-doc, style-args: style-args)
}
for (index, fn) in module-doc.functions.enumerate() {
(style-functions.show-function)(fn, style-args)
}
for (index, fn) in module-doc.variables.enumerate() {
(style-functions.show-variable)(fn, style-args)
}
}
|
https://github.com/typst/packages
|
https://raw.githubusercontent.com/typst/packages/main/packages/preview/georges-yetyp/0.1.0/README.md
|
markdown
|
Apache License 2.0
|
# Georges Yétyp
[French version](README.fr.md)
Typst template for Polytech (Grenoble) internship reports.
[](thumbnail.png)
## Usage
Either use this template [in the Typst web app](https://typst.app/?template=georges-yetyp&version=0.1.0), or use the command line to initialize a new project based on this template:
```bash
typst init @preview/georges-yetyp
```
Then, replace `logo.png` with the logo of the company you worked for, fill in all the details in the `rapport` parameters, and start writing below.
## Other schools
Adding support for other schools of the Polytech network would be fairly easy if you want to re-use this template. All that is needed is a copy of their logo (with the authorization to use it). Submissions are welcome.
|
https://github.com/7sDream/fonts-and-layout-zhCN
|
https://raw.githubusercontent.com/7sDream/fonts-and-layout-zhCN/master/chapters/06-features-2/substitution/rev-chaining.typ
|
typst
|
Other
|
#import "/template/template.typ": web-page-template
#import "/template/components.typ": note
#import "/lib/glossary.typ": tr
#show: web-page-template
// ### Reverse chained contextual substitution
=== 逆向#tr[chaining]#tr[substitution]
// The final substitution type is designed for Nastaliq style Arabic fonts (often used in Urdu and Persian typesetting). In that style, even though the input text is processed in right-to-left order, the calligraphic shape of the word is built up in left-to-right order: the form of each glyph is determined by the glyph which *precedes* it in the input order but *follows* it in the writing order.
最后一个#tr[substitution]类型是为波斯体的阿拉伯文字体设计的,通常用于乌尔都或波斯文的#tr[typeset]中。在这种书体中,虽然输入文本是按从右向左的方式处理的,但词语在书法上的形状需要按照从左向右的顺序构建。因为每个#tr[glyph]的样式需要根据在输入文本中之前、书写顺序上是之后的那个#tr[glyph]决定。
// So reverse chained contextual substitution is a substitution that is applied by the shaper *backwards in time*: it starts at the end of the input stream, and works backwards, and the reason this is so powerful is because it allows you to contextually condition the "current" lookup based on the results from "future" lookups.
逆向#tr[chaining]#tr[contextual]#tr[substitution]是一种会被#tr[shaper]在时间上反向应用的#tr[substitution]。它会从输入流的末尾开始,从后向前进行工作。它功能强大的原因是允许你以“未来的”#tr[lookup]的匹配结果作为上下文,来决定当前#tr[lookup]的结果。
// As an example, try to work out how you would convert *all* the numerator digits in a fraction into their numerator form. Tal Leming suggests doing something like this:
举个例子,你可以尝试思考,如何才能为文本中所有分数的分子数字都应用上分子的样式?Tal Leming 提议可以这么做:
```fea
lookup Numerator1 {
sub @figures' fraction by @figuresNumerator;
} Numerator1;
lookup Numerator2 {
sub @figures' @figuresNumerator fraction by @figuresNumerator;
} Numerator2;
lookup Numerator3 {
sub @figures' @figuresNumerator @figuresNumerator fraction by @figuresNumerator;
} Numerator3;
lookup Numerator4 {
sub @figures' @figuresNumerator @figuresNumerator @figuresNumerator fraction by @figuresNumerator;
} Numerator4;
# ...
```
// But this is obviously limited: the number of digits processed will be equal to the number of rules you write. To write it for any number of digits, you have to think about the problem in reverse. Start thinking not from the position of the *first* digit, but from the position of the *last* digit and work backwards. If a digit appears just before a slash, it gets converted to its numerator form. If a digit appears just before a digit which has already been converted to numerator form, this digit also gets turned into numerator form. Applying these two rules in a reverse substitution chain gives us:
但这明显是有局限的,我们可以处理的分子数字的长度被我们写了多少条规则所限制。为了能处理任意长度的分子,你需要逆向思考。也就是不从分子中的第一位数开始考虑,而是从最后一位开始,从后向前处理。如果有个数字出现在斜线之前,就把这个数字转换成分子形式;如果有个数字出现在已经转换成了分子形式的数字之前,就也把这个数字转换成分子形式。我们希望反向应用这两条规则,需要这样写:
```fea
rsub @figures' fraction by @figuresNumerator;
rsub @figures' @figuresNumerator by @figuresNumerator;
```
#note[
// > Notice that although the lookups are *processed* with the input stream in reverse order, they are still *written* with the input stream in normal order of appearance.
注意,虽然这些#tr[lookup]会从后向前处理输入的文本,但最终还是会按照正常从前向后的顺序进行输出和显示。
]
// XXX Nastaliq
// 原作者应该是希望在这里加一个波斯体的例子,待补
|
https://github.com/7sDream/fonts-and-layout-zhCN
|
https://raw.githubusercontent.com/7sDream/fonts-and-layout-zhCN/master/chapters/01-history/vector-font.typ
|
typst
|
Other
|
#import "/template/template.typ": web-page-template
#import "/template/components.typ": note
#import "/lib/glossary.typ": tr
#show: web-page-template
// Digital fonts go vector
== 矢量化的数字字体
// As we saw, the first computer fonts were stored in *bitmap* (also called *raster*) format. What this means is that their design was based on a rectangular grid of square pixels. For a given glyph, some portion of the grid was turned on, and the rest turned off. The computer would store each glyph as a set of numbers, 1 representing a pixel turned on and 0 representing a pixel turned off - a one or zero stored in a computer is called a *bit*, and so the instructions for drawing a letter were expressed as a *map* of *bits*:
我们提到过,第一个计算机字体是储存在*#tr[bitmap]*(Bitmap)或者说*#tr[raster]*(Raster)格式中的。这意味着它们的设计基于方形像素组成的网格。对于给定的#tr[glyph],网格的一部分开启显示,其余则关闭。计算机会把每个#tr[glyph]储存为一组数字,1代表像素开启,0 代表像素关闭。计算机中储存的0或1被称为*比特*(bit),因而绘制一个字母的指令即可表述为一组比特的*映射*(map)。
#figure(caption: [
// Capital aleph, from the Hebrew version of the IBM CGA 8x8 bitmap font.
字母 Aleph,来自 IBM CGA 8x8 #tr[bitmap]字体的希伯来文版。
])[#include "aleph.typ"] <figure:aleph>
// This design, however, is not *scalable*. The only way to draw the letter at a bigger point size is to make the individual pixels bigger squares, as you can see on the right. The curves and diagonals, such as they are, become more "blocky" at large sizes, as the design does not contain any information about how they could be drawn more smoothly. Perhaps we could mitigate this by designing a new aleph based on a bigger grid with more pixels, but we would find ourselves needing to design a new font for every single imaginable size at which we wish to use our glyphs.
然而,这种设计并不是*可缩放*的。绘制更大尺寸字母的唯一方法就是使单个像素的方块更大,就像你在@figure:aleph 中看到的那样。像这样的曲线和斜线在大尺寸下会呈现出“块状感”,因为设计中完全没有包含如何使它们更平滑的信息。也许可以通过重新设计一个基于更大的网格和更多像素的Aleph字母来缓解这个问题。但我们立刻就会发现,这样就需要为这些#tr[glyph]的每个尺寸单独设计一套新的字体。
// At some point, when we want to see our glyphs on the screen, they will need to become bitmaps: screens are rectangular grids of square pixels, and we will need to know which ones to turn on and which ones to turn off. But we've seen that, while this is necessary to represent a *particular* glyph at a *particular* size, this is a bad way to represent the design of the glyph. If you think back to metal fonts, punchcutters and metalworkers would produce a new set of type for each distinct size at which the type was used, but underlying this was a single design. With a bitmap font, you have to do the punchcutting work yourself, translating the design idea into a separate concrete instance for each size. What we'd like to do is represent the *design idea*, so that the same font can be used at any type size.
在某种意义上,当我们想在屏幕上看到#tr[glyph]时,它们必须是#tr[bitmap]。因为屏幕是正方形像素组成的矩形网格,我们需要知道哪些像素应当开启、哪些又应当关闭。但我们已经看到,尽管当显示特定尺寸的#tr[glyph]时这一手段是必要的,但这对于#tr[glyph]的设计而言是一种糟糕的方式。回顾一下金属字体,刻字师和铸字师会为每种尺寸单独做一套#tr[type],而它们都是基于相同的设计。使用#tr[bitmap]字体时,你却需要承担刻字师的工作,把设计转换为不同尺寸的具体实例。我们想做的是表现*设计理念*,以便相同的字体可以用于任何尺寸。
// We do this by telling the computer about the outlines, the contours, the shapes that we want to see, and letting the computer work out how to turn that into a series of ones and zeros, on pixels and off pixels. Because we want to represent the design not in turns of ones and zeros but in terms of lines and curves, geometric operations, we call this kind of representation a *vector* representation. The process of going from a vector representation of a design to a bitmap representation to be displayed is called *rasterization*, and we will look into it in more detail later.
为此,我们需要告诉计算机想看到的#tr[outline]形状,并让它计算出那些代表像素开启或关闭的0和1。此时我们不再用0和1来承载设计,而是用直线、曲线和几何操作,这被称为*矢量*表示。从矢量表示转化为最终显示的#tr[bitmap]表示的过程称为*#tr[rasterization]*。之后我们将对此做进一步探讨。
// The first system to represent typographical information in geometrical, vector terms - in terms of the lines and curves which make up the abstract design, not the ones and zeros of a concrete instantiation of a letter - was Dr Peter Karow's IKARUS system in 1972.[^4] The user of IKARUS (so called because it frequently crashed) would trace over a design using a graphics tablet, periodically clicking along the outline to add *control points* to mark the start point, a sharp corner, a curve, or a tangent (straight-to-curve transition):
第一个用几何矢量化形式——即描绘抽象设计的直线和曲线,而不是描述具体实例的0和1——来描述字体信息的系统是1972年Peter Karow博士发明的<EMAIL>。起这个名字是因为它经常崩溃(IKARUS 读音类似 I crashed)。用户会使用数位板来描摹设计图,通过单击轮廓线来添加*控制点*,从而标记起始点、转角、曲线或切线(直线到曲线的过渡),见@figure:ikarus。
#figure(caption: [
// A glyph in IKARUS, showing start points (red), straight lines (green), curve-to-straight tangents (cyan) and curves (blue).
IKARUS 中的一个#tr[glyph]。标记出了起始点(红色)、直线(绿色)、曲线到直线的切点(青色)和曲线(蓝色)。
])[#image("ikarus.png")] <figure:ikarus>
// The system would join the line sections together and use circular arcs to construct the curves. By representing the *ideas* behind the design, IKARUS could automatically generate whole systems of fonts: not just rasterizing designs at multiple sizes, but also adding effects such as shadows, outlines and deliberate distortions of the outline which Karow called "antiquing". By 1977, IKARUS also supported interpolation between multiple masters; a designer could draw the same glyph in, for example, a normal version "A" and a bold version "B", and the software would generate a semi-bold by computing the corresponding control points some proportion of the way between A and B.
该系统使用首尾相连的圆弧来构造曲线。通过展现设计背后的“想法”,IKARUS可以自动生成整套字体。它不仅可以将设计#tr[rasterization]为不同的尺寸,还可以添加如阴影、轮廓以及Karow称之为“复古化(antiquing)”的故意扭曲轮廓的效果。到1977年,IKARUS还支持了#tr[multiple master]之间的插值。例如,设计师可以为常规版本的A和粗体的B绘制/*相同的?*/字形,软件会通过在A和B之间按某一比例计算出控制点来生成半粗体。
// In that same year, 1977, the Stanford computer scientist <NAME> began work on a very different way of representing font outlines. His METAFONT system describes glyphs *algorithmically*, as a series of equations. The programmer - and it does need to be a programmer, rather than a designer - states that certain points have X and Y coordinates in certain relationships to other points; unlike IKARUS which describes outer and inner outlines and fills in the interior of the outline with ink, METAFONT uses the concept of a *pen* of a user-defined shape to trace the curves that the program specifies. Here, for example, is a METAFONT program to draw a "snail":
同样是在1977年,斯坦福大学的计算机科学家<NAME>开始研究一种非常不同的字体#tr[outline]表示方法。他的 METAFONT 系统将#tr[glyph]*以算法的方式*描述为一系列方程。程序员——它的确需要一位程序员,而不仅仅是一位设计师——声明某些点的X、Y坐标,以及点和点之间关系。与IKARUS描述内外#tr[outline]并用墨水填满内部不同,METAFONT 使用“笔”的概念,通过用户定义的形状描绘程序规定的曲线。例如这个用于绘制“涡形”的 METAFONT 程序:
/*
```
% Define a broad-nibbed pen held at a 30 degree angle.
pen mypen;
mypen := pensquare xscaled 0.05w yscaled 0.01w rotated 30;
% Point 1 is on the baseline, a quarter of the way along the em square.
x1 = 0.25 * w; y1 = 0;
% Point 2 is half-way along the baseline and at three-quarter height.
x2 = 0.5 * w; y2 = h * 0.75;
% Point 3 is below point 2 and parallel with point 1.
x3 = x2; y3 = y1;
% Point 4 is half way between 1 and 3 on the X axis and a quarter of
% the way between 2 and 1 on the Y axis.
x4 = (x1 + x3) / 2;
y4 = y1 + (y2-y1) * 0.25;
% Use our calligraphic pen
pickup mypen;
% Join 1, 2, 3 and 4 with smooth curves, followed by a line back to 1.
draw z1..z2..z3..z4--z1;
```
*/
// TODO: METAFONT syntax highlight
```
% 定义一支以 30 度角握住的宽头笔
pen mypen;
mypen := pensquare xscaled 0.05w yscaled 0.01w rotated 30;
% 点1位于基线上,宽度1/4 em的位置
x1 = 0.25 * w; y1 = 0;
% 点2位于半宽、3/4高的位置
x2 = 0.5 * w; y2 = h * 0.75;
% 点3在点2下方,和点1同高
x3 = x2; y3 = y1;
% 点4的横坐标位于点1、3的中点,纵坐标位于点1、2的1/4处
x4 = (x1 + x3) / 2; y4 = y1 + (y2-y1) * 0.25;
% 使用定义的书法笔
pickup mypen;
% 以光滑曲线连结点1、2、3、4,再用直线连回点1
draw z1..z2..z3..z4--z1;"
```
// The glyph generated by this program looks like so:
此程序生成的#tr[glyph]如下:
#figure(caption: [
// A METAFONT snail.
用 METAFONT 绘制的涡形。
], placement: none)[#image("metafont.png")]<figure:metafont-snail>
// The idea behind METAFONT was that, by specifying the shapes as equations, fonts then could be *parameterized*. For example, above we declared `mypen` to be a broad-nibbed pen. If we change this one line to be `mypen := pencircle xscaled 0.05w yscaled 0.05w;`, the glyph will instead be drawn with a circular pen, giving a low-contrast effect. Better, we can place the parameters (such as the pen shape, serif length, x-height) into a separate file, create multiple such parameter files and generate many different fonts from the same equations.
METAFONT 的理念是,通过方程的形式指定形状,字体就可以被*参数化*。例如,上面我们把`mypen`声明为一支宽头笔。如果我们把这一行代码改为```metafont mypen := pencircle xscaled 0.05w yscaled 0.05w;```,就可以获得低对比度的效果,类似于使用圆珠笔绘制。更好的方法是,我们可以把参数(例如笔的形状、衬线长度、#tr[x-height])等放进单独的文件;一旦创建了多个这样的参数文件,就可以从同一组方程生成许多不同的字体。
// However, METAFONT never really caught on, for two reasons. The first is that it required type designers to approach their work from a *mathematical* perspective. As Knuth himself admitted, "asking an artist to become enough of a mathematician to understand how to write a font with 60 parameters is too much." Another reason was that, according to <NAME>, METAFONT's assumption that letters are based around skeletal forms filled out by the strokes of a pen was "flawed";[^5] and while METAFONT does allow for defining outlines and filling them, the interface to this is even clunkier than the `draw` command shown above. However, Knuth's essay on "the concept of a meta-font"[^6] can be seen as sowing the seeds for today's variable font technology.
然而,METAFONT从未真正流行起来,原因有二。首先,它要求字体设计师用*数学*的方法来工作。Knuth 自己也承认,“要求一个艺术家像数学家那样用60个参数来绘制字体实在是太过分了。”其次,根据 <NAME> 的说法,METAFONT 中字母由笔画沿着骨架而构建起来的假设其实是“有缺陷的”@Hoefler.JonathanHoefler.2015;尽管METAFONT确实允许定义#tr[outline]并进行填充,但其接口比上面所示的`draw`命令更加繁琐。不过无论如何,Knuth关于Meta-Font的论文#[@Knuth.ConceptMetaFont.1982]依然可以被认为是为如今的可变字体技术埋下了种子。
// As a sort of bridge between the bitmap and vector worlds, the Linotron 202 phototypesetter, introduced in 1978, stored its character designs digitally as a set of straight line segments. A design was first scanned into a bitmap format and then turned into outlines. Linotype-Paul's "non-Latin department" almost immediately began working with the Linotron 202 to develop some of the first Bengali outline fonts; Fiona Ross' PhD thesis describes some of the difficulties faced in this process and how they were overcome.[^10]
作为#tr[bitmap]和矢量世界之间的一座桥梁,Linotron 202照排机于1978年推出,它通过一组直线段来储存#tr[character]的设计。设计稿首先被扫描成#tr[bitmap]格式,然后再被转换成#tr[outline]。Linotype-Paul的非拉丁部门几乎立即就开始用Linotron 202开发首批孟加拉文字体;Fiona Ross的博士论文@Ross.EvolutionPrinted.1988 描述了这一过程中所面临的一些困难,以及他们是如何解决的。#footnote[另外,#cite(form: "prose", <Condon.ExperienceMergenthaler.1980>) 是对202照排机内部技术的极为精彩的研究。]
|
https://github.com/monashcoding/typst-polylux-theme
|
https://raw.githubusercontent.com/monashcoding/typst-polylux-theme/main/README.md
|
markdown
|
# MAC Typst Polylux Theme
MAC theme for [Polylux](https://polylux.dev/book/), a slides package for [Typst](https://typst.app/).
|
|
https://github.com/NMD03/typst-uds
|
https://raw.githubusercontent.com/NMD03/typst-uds/main/chapters/01-Introduction.typ
|
typst
|
#import "../template.typ": *
Fist, in the `thesis.typ` file, adapt the configuration to match your requirements.
For further configuration, look in the upper part of the `template.typ` file,
e.g. to learn how to change the company name and logo.
Of cause, you may change other parts of the template to adapt it to your preferences.
Also, make sure to read the #link("https://typst.app/docs/")[Typst documentation].
This template is for english documents only (for now),
but one could translate it...
To configure your the language of your thesis,
set the `language` parameter to either `en` (default) or `de`.
*Note* that the template needs to know your first chapter,
you can supply it if it is not "Introduction" using the `first_chapter_title` parameter.
#figure(```typ
#show: thesis.with(
...
first_chapter_title = "Introduction but with another title",
language: "en",
)
```, kind: "code", supplement: "Code example",
caption: [Code example explaining how to configure language and a different first chapter]
)
// By default, the template will *not* apply a pagebreak
// on non-top-level headings to avoid headings without content
// on the same page but can be enabled.
// The threshold percentage on the page can be configured
// by providing the `heading_pagebreak_percentage` propery like `0.7` or `none`.
// Top-level headings will always have a (weak) pagebreak.
== Bibliography
As for bibliography / reference listing,
you may decide whether to use "Hayagriva", a yaml-based format format designed for Typst
or BibTeX (`.bib`) format, which is _well supported by other platforms and tooling_
since it is commonly used by LaTeX.
You may use the Zotero `zotero-better-bibtex` extension
for automatic synchronization.
To switch between bibliography formats, change the above to the following:
#figure(```typ
#show: thesis.with(
...
bibliography_path = "literature.bib", // or literature.yml for Hayagriva
customized_ieee_citations = true, // default
)
```, kind: "code", supplement: "Code example",
caption: [Code example on how to use different bibliography formats with this template]
)
By default, this template displayes ISBNs in the Bibliography.
If no DOI is known, the ISBN is shown instead, and as a fallback the URL if available.
This deviates from the normal/usual IEEE citation style.
Do disable this behaiviour and use the normal IEEE,
set ```typ customized_ieee_citations = false```.
== Proposed Structure
But of cause, you can do it as you like.
Put each chapter in the `chapter/` directory,
prefixed i.e. with `01-` if it is the first chapter.
I'd recommend using CamelCase or snake_case but not spaces.
Also, I would recommend deciding if to put the heading `= Introduction`
in these files or to the parent file.
You can include files using the following e.g:
```typ
#include ./chapters/01-example.typ
```
If your chapter gets too large for one file, create a subdirectory
in `chapters` with the chapters name,
and create files for the different sections.
== Acronyms
These are implemented provided by this template, not typst itself.
You can use them like:
```typ
#acro("HPE")
#acro("HPE", pref: true) // To prefer the long version
#acro("JSON", append: "-schemata")
```
+ #acro("HPE")
+ #acro("HPE", pref: true) // To prefer the long version
+ #acro("JSON", append: "-schemata")
== TODO marker
Well, if you are too lazy to write now,
just add a todo-marker.
```typ
#todo([Your #strike[excuse] notes on what change here])
```
For example:
#todo([I could probably write more on how to use this template and Typst in general, if I wouldn't be too lazy...])
And the template makes sure it is well readable in the PDF and not forgotten.
== Once you are done
Add a signature to your thesis.
Use the `signature` property.
Set it to `hide`, to leave some blank space for you to sign manually,
e.g. in a printed version.
Or put in the path to your signature image or svg.
|
|
https://github.com/xsro/xsro.github.io
|
https://raw.githubusercontent.com/xsro/xsro.github.io/zola/typst/nlct/math/ode_numerical.typ
|
typst
|
== Numerical methods for ode
The closed-loop control system is usually written as
$
dot(x)=f(t,x).
$
To verify the control performance, several numerical method is important.
- https://www.math.hkust.edu.hk/~machas/numerical-methods-for-engineers.pdf
=== Euler method -- First Order
$
x_(n+1)=x_n+Delta t f(t_n,x_n)
$
For small enough $Delta t$,
the numerical solution should converge to the exact solution of the ode,
when such a solution exists.
The Euler Method has a local error, that is, the error incurred over a single time step,
of $O(Delta t^2)$.
The global error, however,
comes from integrating out to a time $T$.
If this integration takes $N$ time steps,
then the global error is the sum of $N$ local errors.
Since $N = T/(∆t)$, the global error is given by $O(∆t)$,
and it is customary to call the Euler Method a first-order method.
=== Modified Euler,Heun’s method,predictor-corrector method -- Second Order
$
k_1=Delta t f(t_n,x_(n)) quad
k_2=Delta t f(t_n+Delta t, x_n+k_1)\
x_(n+1)=x_n+1/2 (k_1+k_2)
$
=== Runge-Kutta methods
First, we compute the Taylor series for $x_(n+1)$ directly:
$
x_(n+1)=x(t_n+Delta t)=x(t_n)+Delta t dot(x)(t_n)+1/2 (Delta t)^2 dot.double(x)(t_n)+O(Delta t^3)
$
Now, $dot(x)(t_n)=f(t_n,x_n)$.
The second derivative is more tricky and requires partial derivatives.
We have
$
dot.double(x)(t_n)
=lr(d/(d t)f(t,x(t))|)_(t=t_n)
=f_t (t_n,x_n)+dot(x)(t_n) f_x (t_n,x_n)
=f_t (t_n,x_n)+f(t_n,x_n) f_x (t_n,x_n)
$
Putting all the terms together, we obtain
$
x_(n+1)=x_n+Delta t f(t_n,x_n)
+1/2(Delta t)^2(f_t (t_n,x_n)+f(t_n,x_n)+f(t_n,x_n)f_x(t_n,x_n))+O(Delta t^3)
$<talyor>
Second, we compute the Taylor series for $x_(n+1)$ from the Runge-Kutta formula.
We start with
$
x_(n+1)=x_n+a Delta t f(t_n,x_n)+b Delta t f(t_n + alpha Delta t, x_n + beta Delta t f(t_n,x_n))+O(Delta t^3)
$
and the Taylor series that we need is
$
f(t_n+ alpha Delta t, x_n + beta Delta t f(t_n,x_n))\
=f(t_n,x_n)
+ alpha Delta t f_t(t_n,x_n)
+ beta Delta t f(t_n,x_n) f_x(t_n,x_n)
+ O(Delta t^2)
$
The Taylor-series for $x_(n+1)$ from the Runge-Kutta method is therefore given by
$
x_(n+1)=x_n + (a+b) Delta t f(t_n, x_n)
+ (Delta t)^2 (alpha b f_t(t_n,x_n)+beta b f(t_n,x_n)f_x(t_n,x_n))+O(Delta t^3)
$<rk>
Comparing @talyor and @rk, we find three constraints for the four constants.
$
a+b=1,
alpha b =1\/2,
beta b = 1\/2
$
=== Second-order Runge-Kutta methods
The family of second-order Runge-Kutta methods that solve $dot(x)=f(t,x)$ is given by
$
k_1=Delta t f(t_n,x_n),quad
k_2=Delta t (f_n+ alpha Delta t,x_n+beta k_1),\
x_(n+1)=x_n+a k_1 + b k_2
$
where we have derived three constraints for the four constants $alpha$,$beta$,$a$ and $b$:
$
a+b =1 , alpha b =1/2, beta b=1/2
$
The modified Euler method corresponds to $alpha=beta=1$ and $a=b=1/2$.
The function $f(t,x)$ is evaluated at the times $t=t_n$ and $t=t_n+Delta t$.
The midpoint method corresponds to $alpha=beta=1/2$, $a=0$ and $b=1$.
In this method, the function $f(t,x)$ is evaluated at the times $t=t_n$
and $t=t_n+Delta t \/2 $ and we have
$
k_1=Delta t f(t_n,x_n) quad
k_2=Delta t f(t_n+1/2 Delta t, x_n+1/2 k_1),\
x_(n+1)=x_n+k_2
$
=== Higher Order Runge-Kutta methods
Higher-order Runge-Kutta methods can also be derived,
but require substantially more algebra.
For example, the general form of the third-order method is given by
$
k_1&=Delta t f(t_n,x_n),\
k_2&=Delta t f(t_n+alpha Delta t, x_n+beta k_1),\
k_3&=Delta t f(t_n + gamma Delta t, x_n+delta k_1+epsilon k_2),\
x_(n+1)&=x_n+ a k_1+b k_2+c k_3
$
with constraints $alpha$,$beta$,$gamma$,$delta$,$epsilon.alt$,$a$,$b$ and $c$.
The foutth-order method has stages $k_1$,$k_2$,$k_3$ and $k_4$.
The fifth-order methood requires at least six stages.
The table below gives the order of the method and the minimum number of stages required.
#align(center)[
#table(columns:8,[order],..(2,3,4,5,6,7,8).map(i=>[#i]),
[minimum \#stage],..(2,3,4,6,7,9,11).map(i=>[#i]))
]
Because the fifth-order method requires two more stages than the fourth-order method,
the fourth-order method has found some popularity.
The general fouth-order method with four stages has 13 constants and 11 constraints.
A particularly simple fourth-order method that has been widely used in the past by physicsts ig given by
$
k_1&=Delta t f(t_n,x_n),quad
&k_2&=Delta t f(t_n+1/2 Delta t, x_n+1/2 k_1),\
k_3&=Delta t f(t_n+1/2 Delta t, x_n+1/2 k_2),
&k_4&=Delta t f(t_n+Delta t,x_n+k_3);\
$
$
x_(n+1)=x_n+1/6(k_1+2k_2+2k_3+k_4)
$
=== Adaptive Runge-Kutta methods
An adaptive ode solver automatically finds the best integration step-size $Delta t$ at each time step.
The Dormand-Prince method, which is implemented in #smallcaps("MATLAB")'s most widely used solver, #link("https://ww2.mathworks.cn/help/matlab/ref/ode45.html?lang=en")[`[t,y,te,ye,ie] = ode45(odefun,tspan,y0,options)`],
determines the step size by comparing the results of fourth- and fifth- order Runge-Kutta methods.
This solver requires six function evaluations per time step,
and saves computational time by constructing both fourth- and fifth-order methods using the same function evaluation's.
=== stiff ODE
- https://ww2.mathworks.cn/help/matlab/math/solve-stiff-odes.html?lang=en
For some ODE problems, the step size taken by the solver is forced down to an unreasonably small level in comparison to the interval of integration, even in a region where the solution curve is smooth. *These step sizes can be so small that traversing a short time interval might require millions of evaluations*. This can lead to the solver failing the integration, but even if it succeeds it will take a very long time to do so.
Equations that cause this behavior in ODE solvers are said to be stiff. The problem that stiff ODEs pose is that explicit solvers (such as ode45) are untenably slow in achieving a solution. This is why ode45 is classified as a nonstiff solver along with ode23, ode78, ode89, and ode113.
Solvers that are designed for stiff ODEs, known as stiff solvers, typically do more work per step. The pay-off is that they are able to take much larger steps, and have improved numerical stability compared to the nonstiff solvers.
|
|
https://github.com/glambrechts/slydst
|
https://raw.githubusercontent.com/glambrechts/slydst/main/lib.typ
|
typst
|
MIT License
|
#import "slydst.typ": slides, frame, definition, theorem, lemma, corollary, algorithm
|
https://github.com/vEnhance/1802
|
https://raw.githubusercontent.com/vEnhance/1802/main/src/minmax.typ
|
typst
|
MIT License
|
#import "@local/evan:1.0.0":*
= Critical points
== [TEXT] Critical points in 18.01
First, a comparison to 18.01.
Way back when you had a differentiable single-variable function $f : RR -> RR$,
and you were trying to minimize it, you used the following terms:
#figure(
table(
columns: 2,
align: left,
table.header([18.01 term], [Meaning]),
[Global minimum], [Minimum of the function $f$ across the entire region you're considering],
[Local minimum], [A point at which $f$ is smaller than any nearby points in a small neighborhood],
[Critical point], [A point where $f'(x) = 0$],
),
kind: table,
caption: [18.01 terminology for critical points]
)
Each row includes all the ones above it, but not vice-versa.
Here's a picture of an example showing these for
a random function $f(x) = -1/5 x^6 - 2/7 x^5 + 2/3 x^4 + x^3$.
From left to right in @fig-1801-critical-points, there are four critical points:
- A local maximum (that isn't a global maximum), drawn in blue.
- A local minimum (that isn't a global minimum), draw in green.
- An critical inflection point --- neither a local minimum _nor_ a local maximum. Drawn in orange.
- A global maximum, drawn in purple.
Note there's no global minimum at all, since the function $f$ goes to $-oo$ in both directions
as $x -> -oo$ or $x -> +oo$.
#figure(
image("figures/minmax-1801graph.png", width: auto),
caption: [Some examples of critical points in an 18.01 graph of a single variable function.],
) <fig-1801-critical-points>
== [TEXT] Critical points in 18.02 <sec-critical-points>
In 18.02, when we consider $f : RR^n -> RR$ the only change we make is:
#definition[
For 18.02, we generalize the definition of *critical point* to be a point $P$
for which $nabla f (P) = bf(0)$ is the zero vector.
(The other two definitions don't change.)
]
As soon as I say this I need to carry over the analogous warnings from 18.01:
#warning[
- Keep in mind that each of the implications
$ "Global minimum" ==> "Local minimum" ==> "Critical point, i.e. " nabla f = bf(0) $
is true only one way, not conversely.
So a local minimum may not be a global minimum;
and a point with gradient zero might not be a minimum, even locally.
You should still find all the critical points,
just be aware a lot of them may not actually be min's or max's.
- There may not be _any_ global minimum or maximum at all, like we just saw.
]
#definition[
In 18.02, a critical point that isn't a local minimum or maximum is called a *saddle point*.
]
#example[
The best example of a saddle point to keep in your head is the origin for the function
$ f(x,y) = x^2 - y^2. $
Why is this a saddle point? We have $f(0,0) = 0$, and the gradient is zero too, since
$ nabla f = vec(2x, 2y) ==> nabla f (0,0) = vec(2 dot 0, 2 dot 0) = vec(0, 0). $
The problem is that the small changes in $x$ and $y$ clash in sign.
Specifically, if we go a little bit to either the left or right in the $x$-direction,
then $f$ will _increase_ a little bit, e.g.
$ f(0.1, 0) = f(-0.1, 0) = 0.01 > 0. $
But the $-y^2$ term does the opposite: if we go a little bit up or down in the $y$-direction,
then $f$ will _decrease_ a little bit.
$ f(0, 0.1) = f(0, -0.1) = -0.01 < 0. $
So the issue is the clashing signs of small changes in $x$ and $y$ directions.
This causes $f$ to neither be a local minimum nor local maximum.
There's actually nothing special about $pm x$ and $pm y$ in particular;
I only used those to make arithmetic easier.
You can see @fig-hyperbola-saddle for values of $f$ at other nearby points.
]
#figure(
image("figures/minmax-hyperbola-saddle.png", width: auto),
caption: [Values of $f(x,y) = x^2-y^2$ at a distance of $0.1$ from the saddle point $(0,0)$.
Green values are positive and red ones are negative.
It's a saddle point because there are both.
],
) <fig-hyperbola-saddle>
#remark[
The name "saddle point" comes from the following picture: if one looks at the surface
$ z = x^2 - y^2 $
then near $(0,0)$ you have something that looks like a horse saddle.
It curves upwards along the $x$-direction, but downwards along the $y$-direction.
]
We'll get to the recipe for distinguishing
between saddle points and local minimums and maximums in a moment;
like in 18.01, there is something called the second derivative test.
First, one digression and a few examples of finding critical points.
== [SIDENOTE] Saddle points are way more common than critical inflection points <sec-saddle-sim>
At first glance, you might be tempted to think that a saddle point
is the 18.02 version of the critical inflection point.
However, that analogy is actually not so good for your instincts,
and *saddle points feel quite different from 18.01 critical inflection points*.
Let me explain why.
In 18.01, it was _possible_ for a critical point to be neither a local minimum or maximum,
and we called these critical inflection points.
However, in 18.01 this was actually really rare.
To put this in perspective, suppose we considered a random 18.01 function of the form
$ f(x) = square x^3 + square x^2 + square x + square $
where each square was a random integer between $-1000000$ and $1000000$ inclusive.
Of the approximately $10^(25)$ functions of this shape,
you will find that while there are plenty of critical points,
the chance of finding a critical inflection point is something like $10^(-15)$ ---
far worse than the lottery.
(Of course, if you _know_ where to look, you can find them:
$f(x) = x^3$ has a critical inflection point at the origin, for example.)
In 18.02 this is no longer true.
If we picked a random function of a similar form
$ f(x) = square x^3 + square x^2 + square x + square y^3 + square y^2 + square y + square $
where we fill each square with a number from $-1000000$ to $1000000$
then you'll suddenly see saddle points everywhere.
For example, when I ran this simulation $10000$ times,
among the critical points that showed up, I ended up with about
- 24.6% local minimums
- 25.3% local maximums
- 50.1% saddle points.
And the true limits (if one replaces $10^6$ with $N$ and takes the limit as $N -> oo$)
are what you would guess from the above: 25%, 25%, 50%.
(If you want to see the code, it's in the Appendix, @appendix-saddle-sim.)
Why is the 18.02 situation so different?
It comes down to this: in 18.02, you can have two clashing directions.
For the two experiments I've run here, consider the picture in @fig-whysaddle.
Here $P$ is a critical point,
and we consider walking away from it in one of two directions.
I'll draw a blue $+$ arrow if $f$ increases, and a red $-$ arrow if $f$ decreases.
#figure(
image("figures/minmax-whysaddle.png", width: auto),
caption: [Why the 18.01 and 18.02 polynomial experiments have totally different outcomes.],
) <fig-whysaddle>
In the 18.01 experiment, we saw that two arrows pointing _opposite_ directions
almost always have the same color.
So in 18.01, when we could only walk in one direction,
that meant almost every point was either a local minimum or a local maximum.
But the picture for 18.02 is totally different because there's nothing that forces
the north/south pair to have the same sign as the east/west pair.
For a "random" function, if you believe the colors are equally likely,
then half the time the arrows don't match colors and you end up with a saddle point.
This whole section was for two-variable functions $P(x) + Q(y)$, so it's already a simplification.
If you ran an analogous three-variable experiment defined similarly for
polynomials $f(x,y,z) = P(x) + Q(y) + R(z)$:
- 12.5% local minimums
- 12.5% local maximums
- 75.0% saddle points.
If we return to the world of _any_ two-variable function, the truth is even more complicated than this.
In this sidenote I only talked about functions $f(x,y)$
that looked like $P(x) + Q(y)$ where $P$ and $Q$ were polynomials.
The $x$ and $y$ parts of the function were completely unconnected,
so we only looked in the four directions north/south/east/west.
But most two-variable functions have some more dependence between $x$ and $y$,
like $f(x,y) = x^2y^3$ or $f(x) = e^x sin(y)$ or similar.
Then you actually need to think about more directions than just north/south/east/west.
#digression[
For example, Poonen's lecture notes (see question 9.22) show a weird _monkey saddle_:
the point $(0,0)$ is a critical point of
$ f(x,y) = x y (x-y) $
where the values of $f$ nearby split into six regions, alternating negative and positive,
in contrast to @fig-hyperbola-saddle where there were only four zones on the circle.
(See also #link("https://w.wiki/6LLG")[Wikipedia for monkey saddle].)
Poonen also invites the reader to come up with an _octopus saddle_
(which sounds like it needs sixteen regions, eight down ones for each leg of the octopus).
]
== [RECIPE] Finding critical points
For finding critical points, on paper you can just follow the definition:
#recipe(title: [Recipe for finding critical points])[
To find the critical points of $f : RR^n -> RR$
1. Compute the gradient $nabla f$.
2. Set it equal to the zero vector and solve the resulting system of $n$ equations in $n$ variables.
]
The thing that might be tricky is that you have to solve a system of equations.
Depending on how difficult your function is to work with, that might require some
creativity in order to get the algebra right.
We'll show some examples where the algebra is really simple,
and examples where the algebra is much more involved.
#sample[
Find the critical points of $f(x,y,z) = x^2 + 2 y^2 + 3 z^2$.
]
#soln[
The gradient is
$ nabla f (x,y,z) = vec(2x, 4y, 6z). $
In order for this to equal $vec(0,0,0)$, we need to solve the three-variable system of equations
$
2x &= 0 \
4y &= 0 \
6z &= 0 \
$
which is so easy that it's almost insulting: $x=y=z=0$.
The only critical point is $(0,0,0)$.
]
#sample[
Find the critical points of $f(x,y) = x y (6 - x - y)$.
]
#soln[
This example is a lot more annoying than the previous one, despite having fewer variables,
because casework is forced upon you.
You need to solve four systems of linear equations, not just one, as you'll see.
We expand $ f(x,y) = 6 x y - x^2 y - x y^2. $
So $ nabla f = vec(6 y - 2 x y - y^2, 6 x - x^2 - 2 x y). $
Hence, the resulting system of equations to solve is
$
y (6 - 2 x - y) &= 0 \
x (6 - 2 y - x) &= 0.
$
The bad news is that these are quadratic equations.
Fortunately, they come in factored form, so we can rewrite them as OR statements:
$
y (6 - 2 x - y) &= 0 ==> (y = 0 " OR " 2x + y = 6) \
x (6 - 2 y - x) &= 0 ==> (x = 0 " OR " x + 2y = 6).
$
So actually there are $2^2 = 4$ cases to consider, and we have to manually tackle all four.
These cases fit into the following $2 times 2$ table; we solve all four systems of equations.
#align(center)[
#block(breakable: false)[
#table(
columns: 3,
align: left + horizon,
stroke: 0.5pt,
[], [Top eqn.~gives $y=0$], [Top eqn.~gives $2x+y=6$],
[Bottom eqn.~gives $x=0$], [$cases(y=0, x=0) ==> (x,y) = (0,0)$], [$cases(2x+y=6 \ x=0) ==> (x,y) = (0,6)$],
[Bottom eqn.~gives $x+2y=6$], [$cases(y=0, x+2y=6) ==> (x,y)=(6,0)$], [$cases(2x+y=6, x+2y=6) ==> (x,y) = (2,2)$]
),
]
]
So we get there are four critical points, one for each case: $(0,0)$, $(0,6)$, $(6,0)$ and $(2,2)$.
]
== [TEXT] General advice for solving systems of equations <sec-system-advice>
In the last example with $f(x,y) = x y(6 - x - y)$,
we saw the solving a system of equations is not necessarily an easy task.
In general, solving a system of generic equations,
even when the number of variables equals the number of unknowns,
can be disproportionately difficult in the number of variables.
#digression(title: [Digression: Even simple-looking systems can be challenging])[
It's easy to generate examples of systems that can't be solved by hand.
But it's also possible to generate examples of systems that look innocent,
_and_ can be solved by hand in a nice way,
_but_ for which finding that nice way is extremely challenging.
One example of such a system of equations is
$
x^3 &= 3 x - 12 y + 50 \
y^3 &= 12 y + 3 z - 2 \
z^3 &= 27 z + 27 x.
$
There is a way to solve it by hand, but it's quite hard to come up with,
even for the best high school students in the world.
(The source of the problem is the
#link("https://aops.com/community/p1566057")[USA Team Selection Test 2009].)
]
This means that you need to put away your chef hat for a moment
and put on your problem-solving cap:
The good news is that it's all high-school algebra: no calculus involved, no derivatives, etc.
The bad news is that it's tricky. You really have to think.
#tip(title: [Tips on systems of equations])[
- When solving a system of equations, *treat it like a self-contained algebra puzzle*.
That means you cannot just blindly follow a recipe, but need to actually think.
- Possible strategy in some situations: try to isolate one variable in terms of others.
For example, if you see $x^2 + x + 2 y = 7$,
one strategy is to rewrite it as $y = 1/2 (7 - (x^2 + x))$
and then use that substitution to kill all the $x$'s for your system.
This reduces the number of variables by $1$, at the cost of some work.
- If there's symmetry in the system of equations, see if you can exploit it to save work.
- Try to factor things when you spot factors.
For example, if you see $x y - x = 0$, write it as $x (y-1) = 0$,
then either $x=0$ or $y=1$.
- If you are taking square roots of both sides,
That is, if $a^2 = b^2$, you conclude $a = pm b$, not $a = b$.
- Be careful in making sure you don't miss cases if you start getting OR statements.
In the last example, there were $2^2 = 4$ cases.
You can easily imagine careless students accidentally forgetting a case.
- See if you can "guess" some obvious solutions to start (e.g. all-zero).
If so, note them down so you know that they should show up later.
]
I also need one warning: be really careful about *division by zero*.
For example, in the example from last section,
careless students might try to divide by $y$ and $x$ to get
$
6 y - 2 x y - y^2 &= 0 ==> 2x + y = 6 \
6 x - 2 x y - x^2 &= 0 ==> x + 2y = 6.
$
But this is wrong, because $x$ and $y$ could be zero too!
If you make this mistake you're only getting to one of the four critical points.
This is important enough I'll box it:
#warning(title: [Warning: Watch for division by zero])[
*Any time you divide both sides of an equation*,
ask yourself if you the expression you're dividing by could be $0$ as well.
If so, that case needs to be handled separately.
]
I'm going to give two examples, each with three variables,
to show these ideas in the tip I just mentioned.
Fair warning: these are deliberately a bit trickier, to give some space to show ideas.
Don't worry if you can't do these two yourself.
The exam ones will probably tone down this algebra step a bit.
#sample[
Find all the critical points of the function
$ f(x, y, z) = x^3 + y^3 + z^3 - 3 x y z. $
]
#soln[
We first compute the gradient:
$ nabla f = vec(3 x^2 - 3 y z, 3 y^2 - 3 z x, 3 z ^2 - 3 x y). $
The critical points occur when $nabla f = bf(0)$,
which gives us the system of equations (after dividing by $3$):
$
x^2 &= y z \
y^2 &= z x \
z^2 &= x y.
$
We'd like to divide out by the variables, but this would be division by zero.
Indeed, note $(0,0,0)$ is a solution!
- If $x = 0$, then it follows $z = 0$ from the last equation, then $y = 0$ from the second.
- By symmetry, if _any_ of the three variables is zero, then all three are.
Now let's suppose all the variables are nonzero.
Then we can write the first equation safely as $ z = x^2 / y$
and use that to get rid of $z$ in the second equation:
$ y^2 = (x^2 / y) x => x^3 = y^3. $
Similarly, we get $y^3 = z^3$ and $z^3 = x^3$.
So in fact $x = y = z$, because we can safely take cube roots of real numbers.
And any triple with $x = y = z$ works fine.
In conclusion, every point of the form $(t,t,t)$ is a critical point ---
an infinite family of critical points!
]
#sample[
Find all the critical points of the function
$ f(x, y, z) = z(x-y)(y-z) - 2 x z. $
]
#soln[
The gradient is given by
$ nabla f = vec(z(y - z) - 2 z, z(-2y+x-z), y(x-y) -2z(x-y) -2x). $
That looks scary, but it turns out the first two equations factor.
Cleaning things up, we get:
$
z(y-z-2) &= 0 \
z(-2y+x+z) &= 0 \
y(x-y) -2(x-y)z -2x &= 0.
$
In the first equation, we have cases on $z = 0$ and $y = z+2$.
- First case: If $z = 0$, then both the first and second equation are true and give no further information.
So we turn to the last equation, which for $z = 0$ says
$ y(x-y) - 2x = 0. $
This is a linear equation in $x$ that we can isolate:
$ (y-2) x - y^2 = 0 ==> (y-2) x = y^2. $
Again, before dividing by $y-2$, we check the cases:
- If $y = 2$, we get an obvious contradiction $0 = 4$.
- So we can assume $y != 2$ and $x = y^2/(y-2)$.
Hence, for _any_ real number $y != 2$, we get a critical point
$ (y^2/(y-2), y, 0). $
- Now assume $z != 0$.
Then we can safely divide by $z$ in the first two equations to get
$ y &= z + 2 \ x &= 2 y - z. $
Our strategy now is to write everything in terms of $z$.
The first equation tells us $y = z+2$, so the second equation says
$ x = 2(z+2) + z = z + 4. $
We have one more equation, so we make the two substitutions everywhere and expand:
$ 0 &= (z+2)((z+4)-(z+2)) -2((z+4)-(z+2))z -2(z+4) \
&= 2(z+2) - 4z - 2(z+4) = -4z - 4 \
&==> z = -1. $
Hence, we get one more critical point $(3, 1, -1)$.
In conclusion, the answer is
$ (y^2/(y-2), y, 0) " for every " y != 2 ", plus one extra point" (3, 1, -1). #qedhere $
]
== [RECIPE] The second derivative test for two-variable functions
Earlier we classified critical points by looking at nearby points.
Technically speaking, we did not give a precise definition of "nearby", just using
small numbers like $0.01$ or $0.1$ to make a point.
So in 18.02, the exam will want a more systematic theorem for classifying
critical points as local minimum, local maximum, or saddle point.
I thought for a bit about trying to explain why the second derivative test works,
but ultimately I decided to not include it in these notes.
Here's some excuses why:
#digression[
The issue is that getting the "right" understanding of this would require
me to talk about _quadratic forms_.
However, in the prerequisite parts Alfa and Bravo of these notes,
we only did linear algebra, and didn't cover quadratic forms in this context at all.
I hesitate to introduce an entire chapter on quadratic forms
(which are much less intuitive than linear functions) and _then_ tie that to eigenvalues
of a $2 times 2$ matrix just to justify a single result not reused later.
(Poonen has some hints on quadratic forms in section 9 of his notes
if you want to look there though.)
The other downside is that even if quadratic forms are done correctly,
the second derivative test doesn't work in all cases anyway,
if the changes of the function near the critical point are sub-quadratic (e.g. degree three).
And multivariable Taylor series are not on-syllabus for 18.02.
]
So to get this section over with quickly, I'll just give the result.
I'm sorry this will seem to come out of nowhere.
#recipe(title: [Recipe: The second derivative test])[
Suppose $f(x,y)$ has a critical point at $P$.
We want to tell whether it's a local minimum, local maximum, or saddle point.
Assume $f$ has a continuous second derivative near $P$.
1. Let $A = f_(x x) (P)$, $B = f_(x y) (P) = f_(y x) (P)$, $C = f_(y y) (P)$.
These are the partial derivatives of the partial derivatives of $f$ (yes, I'm sorry),
evaluated at $P$.
If you prefer gradients, you could write this instead as
$ nabla f_x (P) = vec(A,B), #h(1em) nabla f_y (P) = vec(B,C). $
2. If $A C - B^2 != 0$, output the answer based on the following chart:
- If $A C - B^2 < 0$, output "saddle point".
- If $A C - B^2 > 0$ and $A, C >= 0$, output "local minimum".
- If $A C - B^2 > 0$ and $A, C <= 0$, output "local maximum".
3. If $A C - B^2 = 0$, the second derivative test is inconclusive.
Any of the above answers are possible, including weird/rare saddle points like the monkey saddle.
You have to use a different method instead.
]
The quantity $A C - B^2$ is sometimes called the _Hessian determinant_;
it's the determinant of the matrix $mat(A, B; B, C)$.
#tip[
It is indeed a theorem that if $f$ is differentiable twice continuously, then $f_(x y) = f_(y x)$.
That is, if you take a well-behaved function $f$ and differentiate with respect to $x$
then differentiate with respect to $y$,
you get the same answer as if you differentiate with respect to $y$ and respect to $x$.
You'll see this in the literature written sometimes as
$ (partial)/(partial x) (partial)/(partial y) f = (partial)/(partial y) (partial)/(partial x) f. $
]
#sample[
Use the second derivative test to classify the critical point $(0,0)$ of
the function $ f(x,y) = x^3 + x^2 + y^3 - y^2. $
]
#soln[
Start by computing the partial derivatives:
$ nabla f = vec(3x^2 + 2x, 3y^2 - 2y) ==> cases(f_x = 3x^2 + 2x, f_y = 3y^2 - 2y). $
We now do partial differentiation a second time on each of these.
Depending on your notation, you can write this as either
$ nabla f_x = vec(6x+2,0) #h(1em) nabla f_y = vec(0,6y-2) $
or
$ f_(x x) = 6x+2, #h(1em) f_(x y) = f_(y x) = 0, #h(1em) f_(y y) = 6y-2. $
Again, the repeated $f_(x y) = f_(y x)$ is either $(partial) / (partial y) (6x+2) = 0$
or $(partial) / (partial x) (6y-2) = 0$;
for well-behaved functions, you always get the same answer for $f_(x y)$ and $f_(y x)$.
At the origin, we get
$
A &= 6 dot 0 + 2 = 2 \
B &= 0 \
C &= 6 dot 0 - 2 = -2.
$
Since $A C - B^2 = -4 < 0$, we output the answer "saddle point".
]
#sample[
Find the critical points of $f(x,y) = x y + y^2 + 2 y$
and classify them using the second derivative test.
]
#soln[
Start by computing the gradient:
$ nabla f = vec(y, x + 2 y + 2). $
Solve the system of equations $y = 0$ and $x + 2y + 2 = 0$ to get just $(x,y) = (-2,0)$.
Hence this is the only critical point.
We now compute the second derivatives:
$
f_(x x) &= (partial)/(partial x) (y) = 0 \
f_(x y) = f_(y x) &= (partial)/(partial y) (y) = (partial)/(partial x)(x + 2 y + 2) = 1 \
f_(y y) &= (partial)/(partial y) (x + 2 y + 2) = 2.
$
These are all constant functions in this example;
anyway, we have $A = 0$, $B = 1$, $C = 2$, and $A C - B^2 = -1 < 0$,
so output "saddle point".
]
== [EXER] Exercises
#exer[
Find the critical points of $f(x,y,z) = x^2 + y^3 + z^4$ and classify them
as local minimums, local maximums, or saddle points.
]
#exer[
Show that
$ f(x,y) = (x+y)^(100) - (x-y)^(100) $
has exactly one critical point, and that critical point is a saddle point.
]
#exerstar[
Give an example of a differentiable function $f : RR^2 -> RR$ with the following property:
every lattice point $(x,y)$ (i.e. a point where both $x$ and $y$ are integers)
is a saddle point, and there are no other saddle points.
For example, $(2, -7)$, $(100, 100)$, and $(-42, -13)$ should be saddle points,
but $(1/2, 0)$, $(pi, -sqrt(2))$, and $(sqrt(7), sqrt(11))$ should not be.
]
#exerstar[
Does there exist a differentiable function $f : RR^2 -> RR$
such that _every_ point in $RR^2$ is a saddle point?
]
#pagebreak()
= Regions
In 18.02, you'll be asked to find global minimums or maximums over a *constraint region* $cal(R)$,
which is only a subregion of $RR^n$.
For example, if you have a three-variable function $f(x,y,z)$ given to you,
you may be asked questions like
- What is the global maximum of $f$ (if any) across all of $RR^3$?
- What is the global maximum of $f$ (if any) across the octant#footnote[
Like "quadrant" with $x y$-graphs. If you've never seen this word before, ignore it.
] $x,y,z > 0$?
- What is the global maximum of $f$ (if any) across the cube given by $-1 <= x,y,z <= 1$?
- What is the global maximum of $f$ (if any) across the sphere $x^2+y^2+z^2 = 1$?
- ... and so on.
It turns out that thinking about constraint regions is actually half the problem.
In 18.01 you usually didn't have to think much about it,
because the regions you got were always intervals, and that made things easy.
But in 18.02, you will need to pay much more attention.
#warning(title: [Warning: if you are proof-capable, read the grown-up version])[
This entire section is going to be a lot of wishy-washy terms
that I don't actually give definitions for.
If you are a high-school student preparing for a math olympiad,
or you are someone who can read proofs,
read the version at #url("https://web.evanchen.cc/handouts/LM/LM.pdf") instead.
We use open/closed sets and compactness there to do things correctly.
]
== [TEXT] Constraint regions
#digression(title: [Digression: An English lesson on circle vs disk, sphere vs ball])[
To be careful about some words that are confused in English,
I will use the following conventions:
- The word *circle* refers to a one-dimensional object with no inside, like $x^2+y^2=1$.
It has no area.
- The word *open disk* refers to points strictly inside a circle, like $x^2+y^2 < 1$
- The word *closed disk* refers to a circle and all the points inside it, like $x^2+y^2=1$ or $x^2+y^2<1$.
- The word *disk* refers to either an open disk or a closed disk.
Similarly, a *sphere* refers only to the surface, not the volume, like $x^2+y^2+z^2=1$.
Then we have *open ball*, *closed ball*, and *ball* defined in the analogous way.
]
In 18.02, all the constraint regions we encounter will be made out of some number
(possibly zero) of equalities and inequalities.
We provide several examples.
#example(title: [Examples of regions in $RR$])[
In $RR$:
- All of $RR$, with no further conditions.
- An open interval like $-1 < x < 1$ in $RR$.
- A closed interval like $-1 <= x <= 1$ in $RR$.
]
#example(title: [Examples of two-dimensional regions in $RR^2$])[
In $RR^2$, some two-dimensional regions:
- All of $RR^2$, with no further conditions.
- The first quadrant $x, y > 0$, not including the axes
- The first quadrant $x, y >= 0$, including the positive $x$ and $y$ axes.
- The square $-1 < x < 1$ and $-1 < y < 1$, not including the four sides of the square.
- The square $-1 <= x <= 1$ and $-1 <= y <= 1$, including the four sides.
- The open disk $x^2 + y^2 < 1$, filled-in unit disk without its circumference.
- The closed disk $x^2 + y^2 <= 1$, filled-in unit disk including its circumference.
]
#example(title: [Examples of one-dimensional regions in $RR^2$])[
In $RR^2$, some one-dimensional regions:
- The unit circle $x^2 + y^2 = 1$, which is a circle of radius $1$, not filled.
- Both $x^2+y^2=1$ and $x,y > 0$, a quarter-arc, not including $(1,0)$ and $(0,1)$.
- Both $x^2+y^2=1$ and $x,y >= 0$, a quarter-arc, including $(1,0)$ and $(0,1$).
- The equation $x + y = 1$ is a line.
- Both $x + y = 1$ and $x,y > 0$: a line segment not containing the endpoints $(1,0)$ and $(0,1)$.
- Both $x + y = 1$ and $x,y >= 0$: a line segment containing the endpoints $(1,0)$ and $(0,1)$.
]
I could have generated plenty more examples for $RR^2$,
and I haven't even gotten to $RR^3$ yet.
That's why the situation of constraint regions requires more thought in 18.02 than 18.01,
(whereas in 18.01 there were pretty much only a few examples that happened).
In order to talk about the regions further, I have to introduce some new words.
The three that you should care about for this class are the following:
"boundary", "limit cases", and "dimension".
#warning(title: [Warning: This is all going to be waving hands furiously])[
As far as I know, in 18.02 it's not possible to give precise definitions for these words.
So you have to play it by ear.
All the items below are rules of thumb that work okay for 18.02,
but won't hold up in 18.100/18.900.
]
- The *boundary* is usually the points you get when you choose any one of the $<=$ and $>=$
constraints and turn it into and $=$ constraint.
For example, the boundary of the region cut out by $-1 <= x <= 1$ and $-1 <= y <= 1$
(which is a square of side length $2$)
are the four sides of the square, where either $x = pm 1$ or $y = pm 1$.
- The *limit cases* come in two forms:
- If any of the variables can go to $pm oo$, all those cases are usually limit cases.
- If you have any $<$ and $>$ inequalities,
the cases where the variables approach those strict bounds are usually limit cases.
- The *dimension* of $cal(R)$ is the hardest to define in words but easiest to guess.
I'll give you two ways to guess it:
- Geometric guess:
pick a point $P$ in $cal(R)$ that's not on the boundary.
Look at all the points of $cal(R)$ that are close to $P$, i.e.~a small neighborhood.
- Say $cal(R)$ is one-dimensional if the small neighborhood could be given a _length_.
- Say $cal(R)$ is two-dimensional if the small neighborhood could be given an _area_.
- Say $cal(R)$ is three-dimensional if the small neighborhood could be given a _volume_.
- Algebraic guess:
the dimension of a region in $RR^n$ is usually equal to $n$ minus the number of $=$ in constraints.
Overall, trust your instinct on dimension; you'll usually be right.
The table below summarizes how each constraint affects each of the three words above.
#figure(
table(
columns: 4,
align: left,
table.header([Constraint], [Boundary], [Limit case], [Dimension]),
[$<=$ or $>=$], [Change to $=$ to get boundary], [No effect], [No effect],
[$<$ or $>$], [No effect], [Approach for limit case], [No effect],
[$=$], [No effect], [No effect], [Reduces dim by one],
),
kind: table,
caption: [Effects of the rules of thumb.]
) <table-rule-thumb>
Let's use some examples.
#example(title: [Example: the circle, open disk, and closed disk])[
- The circle $x^2 + y^2 = 1$ is a *one-dimensional* shape.
Again, we consider this region to be _one-dimensional_
even though the points live in $RR^2$.
The rule of thumb is that with $2$ variables and $1$ equality, the dimension should be $2-1=1$.
Because there are no inequality constraints at all,
and because $x$ and $y$ can't be larger than $1$ in absolute value,
there is no *boundary* and there are no *limit cases*.
- The open disk $x^2 + y^2 < 1$ is *two-dimensional* now,
since it's something that makes sense to assign an area.
(Or the rule of thumb that with $2$ variables and $0$ equalities,
the dimension should be $2-0=2$.)
There is one family of *limit cases: when $x^2+y^2$ approaches $1^-$*.
But there is no boundary.
- The closed disk $x^2 + y^2 <= 1$ is also *two-dimensional*.
Because $x$ and $y$ can't be larger than $1$ in absolute value,
and there were no $<$ or $>$ constraints, there are no limit cases to consider.
But there is a *boundary of $x^2 + y^2 = 1$*.
]
#todo[Draw a figure for this]
In compensation for the fact that I'm not giving you true definitions,
I will instead give you a pile of examples, their dimensions, boundaries, and limit cases.
See @table-1d-regions, @table-2d-regions, @table-3d-regions.
#figure(
table(
columns: 4,
align: center + horizon,
table.header([Region], [Dim.], [Boundary], [Limit cases]),
[All of $RR$], [1-D], [No boundary], [$x -> pm oo$],
[$-1 < x < 1$], [1-D], [No boundary], [$x -> pm 1$],
[$-1 <= x <= 1$], [1-D], [$x = pm 1$], [No limit cases],
),
kind: table,
caption: [Examples of regions inside $RR$ and their properties.]
) <table-1d-regions>
#figure(
table(
columns: 4,
align: center + horizon,
table.header([Region], [Dim.], [Boundary], [Limit cases]),
[All of $RR^2$], [2-D], [No boundary], [$x -> pm oo$ or $y -> pm oo$],
[$x,y > 0$], [2-D], [No boundary], [$x -> 0^+$ or $y -> 0^+$ \ or $x -> +oo$ or $y -> +oo$],
[$x,y >= 0$], [2-D], [$x=0$ or $y=0$], [$x -> +oo$ or $y -> +oo$],
[$-1 < x < 1 \ -1 < y < 1$], [2-D], [No boundary], [$x,y -> pm 1$],
[$-1 <= x <= 1 \ -1 <= y <= 1$], [2-D], [$x=pm 1$ or $y=pm 1$], [No limit cases],
[$x^2 + y^2 < 1$], [2-D], [No boundary], [$x^2+y^2 -> 1^-$],
[$x^2 + y^2 <= 1$], [2-D], [$x^2 + y^2 = 1$], [No limit cases],
[$x^2 + y^2 = 1$], [1-D], [No boundary], [No limit cases],
[$x^2 + y^2 = 1 \ x,y > 0$], [1-D], [No boundary], [$x -> 0^+$ or $y -> 0^+$],
[$x^2 + y^2 = 1 \ x,y >= 0$], [1-D], [$(1,0)$ and $(0,1)$], [No limit cases],
[$x + y = 1$], [1-D], [No boundary], [$x -> pm oo$ or $y -> pm oo$],
[$x + y = 1 \ x, y > 0$], [1-D], [No boundary], [$x -> 0^+$ or $y -> 0^+$],
[$x + y = 1 \ x, y >= 0$], [1-D], [$(1,0)$ and $(0,1)$], [No limit cases]
),
kind: table,
caption: [Examples of regions inside $RR^2$ and their properties],
) <table-2d-regions>
#figure(
table(
columns: 4,
align: center + horizon,
table.header([Region], [Dim.], [Boundary], [Limit cases]),
[All of $RR^3$], [3-D], [No boundary], [Any var to $pm oo$],
[$x,y,z > 0$], [3-D], [No boundary], [Any var to $0$ or $oo$],
[$x,y,z >= 0$], [3-D], [$x=0$ or $y=0$ or $z=0$], [Any var to $oo$],
[$x^2 + y^2 + z^2 < 1$], [3-D], [No boundary], [$x^2 + y^2 + z^2 -> 1^-$],
[$x^2 + y^2 + z^2 <= 1$], [3-D], [$x^2 + y^2 + z^2 = 1$], [No limit cases],
[$x^2 + y^2 + z^2 = 1$], [2-D], [No boundary], [No limit cases],
[$x^2 + y^2 + z^2 = 1 \ x,y,z > 0$], [2-D], [No boundary], [$(1,0)$ and $(0,1)$],
[$x^2 + y^2 + z^2 = 1 \ x,y,z >= 0$], [2-D], [Three quarter-circle arcs#footnote[
To be explicit, the first quarter circle is $x^2+y^2=1$, $x,y >=0$ and $z = 0$.
The other two quarter-circle arcs are similar.
]], [No limit cases],
[$x + y + z = 1$], [2-D], [No boundary], [Any var to $pm oo$],
[$x + y + z = 1 \ x, y, z > 0$], [2-D], [No boundary], [Any var to $0^+$],
[$x + y + z = 1 \ x, y, z >= 0$], [2-D], [$x=0$ or $y=0$ or $z=0$], [No limit cases],
),
kind: table,
caption: [Examples of regions inside $RR^3$ and their properties],
) <table-3d-regions>
#digression(title: [Digression on intentionally misleading constraints that break the rule of thumb])[
I hesitate to show these, but here are some examples where the rules of thumb fail:
- An unusually cruel exam-writer might rewrite the unit circle as
$ x^2 + y^2 <= 1 " and " x^2 + y^2 >= 1 $
instead of the more natural $x^2 + y^2 = 1$.
Then if you were blindly following the rules of thumb, you'd get the wrong answer.
- In $RR^3$ the region cut out by the single equation
$ x^2 + y^2 + z^2 = 0 $
is actually $0$-dimensional, because there's only one point in it: $(0,0,0)$.
That said, intentionally misleading constraints like this are likely off-syllabus for 18.02.
]
== [RECIPE] Working with regions
This is going to be an unsatisfying recipe, because it's just the rules of thumb.
But again, for 18.02, the rules of thumb should work on all the exam questions.
#recipe(title: [Recipe: The rule of thumb for regions defined by equations and inequalities])[
Given a region $cal(R)$ contained in $RR^n$, to guess its dimension, limit cases, and boundary:
- The dimension is probably $n$ minus the number of $=$ constraints.
- The limit cases are obtained by turning $<$ and $>$ into limits,
and considering when any of the variables can go to $pm oo$.
- The boundary is obtained when any $<=$ and $>=$ becomes $=$.
See @table-rule-thumb.
]
#todo[Add some more examples here]
== [TEXT] Examples of regions described in words rather than equations
#todo[Add examples that aren't triangles]
|
https://github.com/Pavanato/ALN_A2
|
https://raw.githubusercontent.com/Pavanato/ALN_A2/main/provas.typ
|
typst
|
#import "theorems.typ": *
#show: thmrules.with(qed-symbol: $square$)
#set page(numbering: "1")
// #set page(margin: 1.5cm)
#set text(font: "Linux Libertine", lang: "pt")
#set heading(numbering: "1.")
#let theorem = thmbox("teorema", "Teorema", fill: rgb("#eeffee"))
#let corollary = thmbox(
"Corolário",
"Corolário",
base: "teorema",
fill: rgb("#f8e8e8"),
titlefmt: strong
)
#let definition = thmbox(
"definição",
"Definição",
// inset: (x: 1.2em, top: 1em),
fill: rgb("#e7e7e7")
)
#let example = thmplain("exemplo", "Exemplo").with(numbering: none)
#let proof = thmproof("prova", "Prova", titlefmt: strong)
#set heading(numbering: "1.")
// resumo algebra linear numerica
= Método da Potência
Dado um vetor inicial $x_0$, o método da potência itera a multiplicação da matriz $A$ pelo vetor $x_(k-1)$, normaliza o resultado e repete o processo até que a sequência $x_k$ convirja para um vetor próprio de $A$. O algoritmo é dado por:
+ Escolha um vetor inicial $x_0$.
+ Para $k = 1, 2, 3, ...$ faça:
+ $y_k = A x_(k-1)$
+ $x_k = y_k / (max(y_k))$
Por fim, o autovalor é dado por $lambda = max(y_k)$. Onde $max(y_k)$ é o maior valor absoluto de $y_k$.
== Exemplo
Dada a matriz $A = mat(1, 2; 2,1)$, calcule a segunda iteração do método da potência para o vetor inicial $x_0 = vec(1, 0)$.
*Solução:*
- $y_1 = A x_0 = mat(1, 2; 2, 1) vec(1, 0) = vec(1, 2)$
- $x_1 = y_1 / (max(y_1)) = vec(1/2, 1)$
- $y_2 = A x_1 = mat(1, 2; 2, 1) vec(1/2, 1) = vec(5/2, 2)$
Portanto, a aproximação do autovalor é $lambda = 5/2$.
= Discos de Gerschgorin
Dada uma matriz $A$, os discos de Gerschgorin são regiões circulares no plano complexo que contêm todos os autovalores de $A$. Cada disco é centrado no elemento $a_(i i)$ da diagonal principal e tem raio igual à soma dos módulos dos elementos da linha $i$ que não pertencem à diagonal principal.
== Exemplo
Dada a matriz $A = mat(1, 1, -1; 1, 3, 2; 3, 2, 5)$, calcule os discos de Gerschgorin. Imagem:
#figure(image("gersh1.png", width: 40%), caption: [
Discos de Gerschgorin para a matriz $A$
])
#figure(image("gersh2.png", width: 40%), caption: [
Discos de Gerschgorin para a matriz $A^T$
])
= Mínimos Quadrados
Dado um sistema linear $A x = b$, o problema dos mínimos quadrados consiste em encontrar o vetor $hat(x)$ que minimiza a norma do resíduo $r = b - A x$. A solução é dada por $(A^T A)hat(x) = A^T b$.
== Exemplo
Dado o sistema linear $A x = b$, onde $A = mat(1, 1; 1, 2; 1, 3)$ e $b = vec(2, 3, 3)$, calcule a solução do problema dos mínimos quadrados.
*Solução:*
$ A^T A = mat(1, 1, 1; 1, 2, 3) mat(1, 1; 1, 2; 1, 3) = mat(3, 6; 6, 14) $
$ A^T b = mat(1, 1, 1; 1, 2, 3) vec(2, 3, 3) = vec(8, 16) $
$ (A^T A)hat(x) = A^T b ==> mat(3, 6; 6, 14)hat(x) = vec(8, 16) $
$ hat(x) = mat(3, 6; 6, 14)^(-1) vec(8, 16) = 1/6 mat(14, -6; -6, 3) vec(8, 16) = vec(8/3, 0) $
Testando a solução:
$ A hat(x) = mat(1, 1; 1, 2; 1, 3) vec(8/3, 0) = vec(8/3, 8/3, 8/3) $
= Decomposição QR
Dada uma matriz $A$, a decomposição QR consiste em encontrar uma matriz ortogonal $Q$ e uma matriz triangular superior $R$ tal que $A = Q R$. A matriz $Q$ é obtida a partir da ortogonalização de Gram-Schmidt e a matriz $R$ é obtida a partir da multiplicação de $Q^T A$.
== Exemplo
Dada a matriz $A = mat(1, 1; 1, 2; 1, 3)$, calcule a decomposição QR.
*Solução:*
Vetor $a_1 = vec(1, 1, 1)$
$ q_1 = a_1 / (||a_1||) = vec(1/sqrt(3), 1/sqrt(3), 1/sqrt(3)) $
$ a_2 = vec(1, 2, 3) - <q_1, a_2> q_1 = vec(1, 2, 3) - (6/sqrt(3))(1/sqrt(3)) vec(1, 1, 1) = vec(-1, 0, 1) $
$ q_2 = a_2 / (||a_2||) = vec(-1/sqrt(2), 0, 1/sqrt(2)) $
$ a_3 = q_1 times q_2 = vec(1/sqrt(3), 1/sqrt(3), 1/sqrt(3)) times vec(-1/sqrt(2), 0, 1/sqrt(2)) = vec(1/sqrt(6), -2/sqrt(6), 1/sqrt(6)) $
Portanto, a matriz $Q$ é dada por:
$ Q = mat(1/sqrt(3), -1/sqrt(2), 1/sqrt(6); 1/sqrt(3), 0, -2/sqrt(6); 1/sqrt(3), 1/sqrt(2), 1/sqrt(6)) $
A matriz $R$ é obtida a partir da multiplicação $Q^T A$:
$ R = Q^T A = mat(1/sqrt(3), 1/sqrt(3), 1/sqrt(3); -1/sqrt(2), 0, 1/sqrt(2); 1/sqrt(6), -2/sqrt(6), 1/sqrt(6)) mat(1, 1; 1, 2; 1, 3) = mat(sqrt(3), 2 sqrt(3); 0, sqrt(2); 0, 0) $
= Decomposição em Valores Singulares
Dada uma matriz $A$, a decomposição em valores singulares consiste em encontrar três matrizes $U$, $Sigma$ e $V$ tais que $A = U Sigma V^T$, onde $U$ e $V$ são ortogonais e $Sigma$ é uma matriz diagonal com os autovalores de $A$.
== Exemplo
Dada a matriz $A = mat(1, 0; 1, 1; -1, 1)$, calcule a decomposição em valores singulares.
*Solução:*
A matriz $A^T A$ é dada por:
$ A^T A = mat(1, 1, -1; 0, 1, 1) mat(1, 0; 1, 1; -1, 1) = mat(3, 0; 0, 2) $
Os autovalores de $A^T A$ são $lambda_1 = 3$ e $lambda_2 = 2$. Os autovetores correspondentes são $v_1 = vec(1, 0)$ e $v_2 = vec(0, 1)$.
A matriz $V$ é dada por:
$ V = mat(1, 0; 0, 1) $
A matriz $A A^T$ é dada por:
$ A A^T = mat(1, 0; 1, 1; -1, 1) mat(1, 1, -1; 0, 1, 1) = mat(1, 1, -1; 1, 2, 0; -1, 0, 2) $
Os autovalores de $A A^T$ são $lambda_1 = 3$, $lambda_2 = 2$ e $lambda_3 = 0$. Os autovetores correspondentes são:
$ u_1 = vec(-1, -1, 1)", " u_2 = vec(0, 1, 1) "e " u_3 = vec(2, -1, 1) $
Normalizando os autovetores, obtemos:
$ u_1 = vec(-1/sqrt(3), -1/sqrt(3), 1/sqrt(3)) ", " u_2 = vec(0, 1/sqrt(2), 1/sqrt(2)) "e " u_3 = vec(2/sqrt(6), -1/sqrt(6), 1/sqrt(6)) $
Portanto, a matriz $U$ é dada por:
$ U = mat(-1/sqrt(3), 0, 2/sqrt(6); -1/sqrt(3), 1/sqrt(2), -1/sqrt(6); 1/sqrt(3), 1/sqrt(2), 1/sqrt(6)) $
A matriz $Sigma$ é dada por:
$ Sigma = mat(sqrt(3), 0; 0, sqrt(2);0,0) $
Portanto, a decomposição em valores singulares de $A$ é dada por:
$ A = mat(1/sqrt(3), 0, 2/sqrt(6); -1/sqrt(3), 1/sqrt(2), -1/sqrt(6); 1/sqrt(3), 1/sqrt(2), 1/sqrt(6)) mat(sqrt(3), 0; 0, sqrt(2);0,0) mat(1, 0; 0, 1)^T $
= Pseudo-Inversa
Dada uma matriz $A$, a pseudo-inversa $A^+$ é uma generalização da inversa de $A$ para matrizes não quadradas. A pseudo-inversa é dada por $A^+ = V Sigma^+ U^T$, onde $U$, $Sigma$ e $V$ são as matrizes da decomposição em valores singulares de $A$.
Onde $Sigma^+$ é a pseudo-inversa de $Sigma$, obtida substituindo os elementos não nulos de $Sigma$ por seus inversos e transpondo a matriz resultante.
== Exemplo
Usando o exemplo anterior, calcule a pseudo-inversa da matriz $A = mat(1, 0; 1, 1; -1, 1)$.
Já calculamos a decomposição em valores singulares de $A$, então basta calcular a pseudo-inversa:
$ Sigma^+ = mat(1/sqrt(3), 0; 0, 1/sqrt(2);0,0)^T = mat(1/sqrt(3), 0,0; 0, 1/sqrt(2),0) $
Portanto, a pseudo-inversa de $A$ é dada por:
$ A^+ &= mat(1, 0; 0, 1) mat(1/sqrt(3), 0,0; 0, 1/sqrt(2),0) mat(1/sqrt(3), 0, 2/sqrt(6); -1/sqrt(3), 1/sqrt(2), -1/sqrt(6); 1/sqrt(3), 1/sqrt(2), 1/sqrt(6))^T \
&= mat(1/3, 1/3, -1/3; 0, 1/2, 1/2) $
Podemos checar que a pseudo-inversa de $A$ é correta verificando que $A^+ A = I$:
$ A^+ A = mat(1/3, 1/3, -1/3; 0, 1/2, 1/2) mat(1, 0; 1, 1; -1, 1) = mat(1, 0; 0, 1) $
= Householder
A transformação de Householder é uma transformação ortogonal que zera todos os elementos de um vetor, exceto o primeiro. Dada uma matriz $A$ e um vetor $x$, a transformação de Householder é dada por:
$ H = I - 2 u u^T $
Onde $u = (x + ||x|| e_1)/(||x + ||x|| e_1||)$, $e_1$ é o primeiro vetor da base canônica e $||x||$ é a norma de $x$.
== Exemplo
Dada a matriz $A$, calcule a transformação de Householder que zera os elementos da primeira coluna, exceto o primeiro.
*Solução:*
Seja $a_1$ a primeira coluna de $A$. O vetor $u$ é dado por $u = (a_1 + ||a_1|| e_1)/(||a_1 + ||a_1|| e_1||)$. A matriz $H$ é dada por:
$ H_1 = I - 2 u u^T $
Onde aplicamos a transformação de Householder em $A$:
$ H_1 dot A = Q_1 dot A $
Caso quisessemos pegar a segunda coluna, bastaria fazer $H_2 = I - 2 u_2 u_2^T$ e aplicar $Q_2 dot Q_1 dot A$. Onde para construir $u_2$ pegamos a segunda coluna de $Q_1 dot A$ a partir do segundo elemento. E construímos $Q_2$ da seguinte forma:
$ Q_2 = mat(1, dots ,0; dots.v,H_2,;0) $
(ficou meio paia, mas é tipo você criar uma linha de zeros e uma coluna de zeros e colocar a matriz $H_2$ no lugar certo, onde tem um "1" no $a_(11)$)
Se quiser ver isso com uma matriz $A$ verdade, faça a questão $4)b)$ da prova de $2022$
E a questão $5)$ de $2023$.
|
|
https://github.com/jgm/typst-hs
|
https://raw.githubusercontent.com/jgm/typst-hs/main/test/typ/compiler/break-continue-08.typ
|
typst
|
Other
|
// Ref: true
// Should output `Hello World 🌎`.
#for _ in range(10) {
[Hello ]
[World #{
[🌎]
break
}]
}
|
https://github.com/herbhuang/utdallas-thesis-template-typst
|
https://raw.githubusercontent.com/herbhuang/utdallas-thesis-template-typst/main/layout/cover.typ
|
typst
|
MIT License
|
#let cover(
title: "",
degree: "",
program: "",
author: "",
) = {
set page(
margin: (left: 30mm, right: 30mm, top: 40mm, bottom: 40mm),
numbering: none,
number-align: center,
)
let body-font = "New Computer Modern"
let sans-font = "New Computer Modern Sans"
set text(
font: body-font,
size: 12pt,
lang: "en"
)
set par(leading: 1em)
// --- Cover ---
v(1cm)
align(center, image("../figures/logo.png", width: 26%))
v(5mm)
align(center, text(font: sans-font, 2em, weight: 700, "Technical University of Munich"))
v(5mm)
align(center, text(font: sans-font, 1.5em, weight: 100, "School of Computation, Information and Technology \n -- Informatics --"))
v(15mm)
align(center, text(font: sans-font, 1.3em, weight: 100, degree + "’s Thesis in " + program))
v(15mm)
align(center, text(font: sans-font, 2em, weight: 700, title))
v(10mm)
align(center, text(font: sans-font, 2em, weight: 500, author))
}
|
https://github.com/DawnEver/typst-academic-cv
|
https://raw.githubusercontent.com/DawnEver/typst-academic-cv/main/template.typ
|
typst
|
//http://zhongguose.com/
#let background = rgb(255, 250, 250)
#let gray = rgb(82, 97, 106)
#let heading_color =rgb(23, 114, 180)
#let body_color = rgb(34, 32, 36)
// black-white
// #let background = rgb(255, 250, 250)
// #let gray = rgb(169, 168, 169)
// #let heading_color = rgb(82,97,106) //52616a
// #let body_color = rgb(30,32,34) //1e2022
// red
...
#let font_cn = "Microsoft Yahei"
#let font_en = "Times"
#let font_title = 30pt
#let font_2p = 22pt
#let font_s2p = 18pt
#let font_3p = 16pt
#let font_s3p = 15pt
#let font_4p = 14pt
#let font_s4p = 12pt
#let font_5p = 10.5pt
#let font_s5p = 9pt
#let project(body) = {
// margin
set page(
paper: "a4",
numbering: "1",
margin: (top: 2cm, bottom: 2cm, left: 2cm, right: 2cm),
// background: image("img/background.png"),
fill:background,
header: grid(columns: (1fr,1fr,1fr),
align(left)[],
align(center+top)[#v(0.2em)#image("img/hust.svg",width: 90%)],
align(right)[],
)
)
set text(font: (font_en,font_cn),size: font_s4p);
set list(body-indent:6pt)
set par(justify: true)
show heading: it => {
show: smallcaps
v(-0.4em)
text(weight: "black",size:font_3p,fill:heading_color)[#it]
v(-1em)
line(length: 100%,stroke:0.05em+heading_color)
v(0em)
}
body
// bibliography(("publications.bib","patents.bib"),style: "ieee",title: "Publications and Patents",full:true)
}
// personal information
#let info_en(name: "", phone: "", email: "", github: "", youtube:"", orcid:"", blog: "") = {
v(-2em)
grid(
columns: (20fr,2fr,5fr),
align(left+horizon)[
// Contact information
#v(1em)
#text([#name], weight: "black", size:font_title,fill:body_color)
#set text(size:font_s4p,fill:body_color,)
#set box(height: 1em,baseline: 20%)
#v(-1.5em)
#grid(columns: (6em, 1fr),
column-gutter: 1.6em,
row-gutter: 0.5em,
[#box[#image("img/envelope-solid.svg")]
#text(weight: "bold")[Email:]],
link("mailto:" + email),
[#box[#image("img/phone-solid.svg")]
#text(weight: "bold")[Phone:]],
link("tel:" + phone)[#phone],
// [#box[#image("img/youtube.svg")]
// #text(weight: "bold")[Youtube:]],
// link("https://" + youtube)[#youtube],
[#box[#image("img/orcid.svg")]
#text(weight: "bold")[ORCID:]],
link("https://orcid.org/" + orcid)[#orcid],
[#box[#image("img/github.svg")]
#text(weight: "bold")[Github:]],
link("https://github.com/" + github)[#github],
[#box[#image("img/blog.svg")]
#text(weight: "bold")[Blog:]],
link("https://" + blog)[#blog],
)
],
"",
align(horizon)[#image("img/photo.png")],
)
}
#let info_zh(name: "", phone: "", email: "", github: "", blog: "") = {
v(-2em)
grid(
columns: (20fr,2fr,5fr),
align(left+horizon)[
// Contact information
#v(1em)
#text([#name], weight: "black", size:font_title,fill:body_color)
#set text(size:font_s4p,fill:body_color,)
#set box(height: 1em,baseline: 20%)
#v(-1.5em)
#grid(columns: (5em, 1fr),
column-gutter: 1.6em,
row-gutter: 0.5em,
[#box[#image("img/envelope-solid.svg")]
#text(weight: "bold")[邮箱:]],
link("mailto:" + email),
[#box[#image("img/phone-solid.svg")]
#text(weight: "bold")[电话:]],
link("tel:" + phone)[#phone],
[#box[#image("img/github.svg")]
#text(weight: "bold")[Github:]],
link("https://github.com/" + github)[#github],
[#box[#image("img/blog.svg")]
#text(weight: "bold")[博客:]],
link("https://" + blog)[#blog],
)
],
"",
align(horizon)[#image("img/photo.png")],
)
}
#let skills()={
set text(font:"Noto Serif CJK SC",size:font_s4p,fill:body_color,)
set box(height: 1em,baseline: 20%)
let h_pad = 1em
grid(columns:(1fr, 1fr, 1fr, 1fr, 1fr, ),
column-gutter: 2em,
row-gutter: 1em,
[#box[#image("img/python.svg")]#h(h_pad)Python],
[#box[#image("img/nodejs.svg")]#h(h_pad)Nodejs],
[#box[#image("img/rust.svg")]#h(h_pad)Rust],
[#box[#image("img/go.svg")]#h(h_pad)Golang],
[#box[#image("img/cpp.svg")]#h(h_pad)C/C++],
[#box[#image("img/matlab.jpg")]#h(h_pad)Matlab],
[#box[#image("img/femm.svg")]#h(h_pad)Femm],
[#box[#image("img/ansys.svg")]#h(h_pad)Ansys],
// "",
// "",
[#box[#image("img/photoshop.svg")]#h(h_pad)Photoshop],
[#box[#image("img/illustrator.svg")]#h(h_pad)Illustrator],
)
}
// date
#let dateFn(body) = {
set text(font: (font_en,font_cn), fill: gray, size: font_s4p)
place(end, body)
}
// event
#let event(date:"",title:"",event:"",body) ={
v(-0.2em)
grid(
columns: (1fr, 9em),
box()[#text(weight: "bold", size: font_4p, fill: body_color)[#title]],
align(right+horizon)[#dateFn[#date]],
)
set text(size: font_s4p, fill: body_color)
v(-0.4em)
h(1em)
box()[
#box(baseline: -20%)[#sym.triangle.filled]
#strong[#event]
#h(2em)
#body
]
v(-0.3em)
}
// publication
#let publication(authors:(),title:"",booktitle:"",location:"",number:"",page:"",date:"",doi:"",type:"",addtion:"") ={
v(-0.2em)
grid(columns: (1.5em,1em, 10fr),
align()[
#if type == "patent"{
box[#image("img/patent.svg")]
}
#if type == "software"{
box[#image("img/software.svg")]
}
#if type == "journal"{
box[#image("img/journal.svg")]
}
#if type == "conference"{
box[#image("img/conference.svg")]
}
],
"",
{let auth_n = authors.len()
if auth_n > 4 {
[#authors.at(0), #authors.at(1), #authors.at(2), #authors.at(3) _et. al._]
}else{
authors.join(", ", last: " and ")
}
// authors.join(", ", last: " and ")
if title != ""{
[, "#title"]
}
if booktitle != ""{
[, #emph(booktitle)]
}
if location !=""{
[, #location]
}
if number != ""{
[, No. #number]
}
if page != ""{
[, pp. #page]
}
if date != ""{
[, #date]
}
if doi!= ""{
[, doi: #link("https://doi.org/"+doi)[#doi]]
}
if addtion != ""{
[, #addtion]
}
}
)
v(-0.2em)
}
#let publication_legend() ={
let pad_size = 0.2em
let icon_size = 1em
// v(-0.3em)
grid(
columns: (pad_size, icon_size, 1fr, icon_size, 1fr, icon_size, 1fr, icon_size, 1fr, pad_size),
gutter: 0.1em,
"",
image("img/journal.svg"),
align(left+horizon)[Journal],
image("img/conference.svg"),
align(left+horizon)[Conference],
image("img/patent.svg"),
align(left+horizon)[Patent],
image("img/software.svg"),
align(left+horizon)[Software Copyright],
"",
)
v(-0.2em)
}
|
|
https://github.com/frectonz/the-pg-book
|
https://raw.githubusercontent.com/frectonz/the-pg-book/main/book/200.%20real.html.typ
|
typst
|
real.html
The Real Reason to End the Death Penalty
April 2021When intellectuals talk about the death penalty, they talk about
things like whether it's permissible for the state to take someone's
life, whether the death penalty acts as a deterrent, and whether
more death sentences are given to some groups than others. But in
practice the debate about the death penalty is not about whether
it's ok to kill murderers. It's about whether it's ok to kill
innocent people, because at least 4% of people on death row are
innocent.When I was a kid I imagined that it was unusual for people to be
convicted of crimes they hadn't committed, and that in murder cases
especially this must be very rare. Far from it. Now, thanks to
organizations like the
Innocence Project,
we see a constant stream
of stories about murder convictions being overturned after new
evidence emerges. Sometimes the police and prosecutors were just
very sloppy. Sometimes they were crooked, and knew full well they
were convicting an innocent person.<NAME> and three other men spent 18 years in prison on a
murder conviction. They were exonerated after DNA testing implicated
three different men, two of whom later confessed. The police had
been told about the other men early in the investigation, but never
followed up the lead.<NAME> spent 33 years in prison on a murder conviction. He
was convicted because "experts" said his teeth matched photos of
bite marks on one victim. He was exonerated after DNA testing showed
the murder had been committed by another man, <NAME>.<NAME> and two other men spent 39 years in prison after being
convicted of murder on the testimony of a 12 year old boy, who later
recanted and said he'd been coerced by police. Multiple people have
confirmed the boy was elsewhere at the time. The three men were
exonerated after the county prosecutor dropped the charges, saying
"The state is conceding the obvious."<NAME> spent 12 years in prison on a murder conviction,
including 10 years on death row. He was exonerated after it was
discovered that the assistant district attorney had concealed phone
records proving he could not have committed the crimes.<NAME> spent 29 years on death row after having been convicted
of murder. He was exonerated after new evidence proved he was not
even at the scene when the murder occurred. The attorneys assigned
to represent him had never tried a jury case before.<NAME> was actually executed in 2004 by lethal injection.
The "expert" who testified that he deliberately set fire to his
house has since been discredited. A re-examination of the case
ordered by the state of Texas in 2009 concluded that "a finding of
arson could not be sustained."<NAME>
has spent 20 years on death row after being convicted
of murder on the testimony of the actual killer, who escaped with
a life sentence in return for implicating him. In 2015 he came
within minutes of execution before it emerged that Oklahoma had
been planning to kill him with an illegal combination of drugs.
They still plan to go ahead with the execution, perhaps as soon as
this summer, despite
new
evidence exonerating him.I could go on. There are hundreds of similar cases. In Florida
alone, 29 death row prisoners have been exonerated so far.Far from being rare, wrongful murder convictions are
very common.
Police are under pressure to solve a crime that has gotten a lot
of attention. When they find a suspect, they want to believe he's
guilty, and ignore or even destroy evidence suggesting otherwise.
District attorneys want to be seen as effective and tough on crime,
and in order to win convictions are willing to manipulate witnesses
and withhold evidence. Court-appointed defense attorneys are
overworked and often incompetent. There's a ready supply of criminals
willing to give false testimony in return for a lighter sentence,
suggestible witnesses who can be made to say whatever police want,
and bogus "experts" eager to claim that science proves the defendant
is guilty. And juries want to believe them, since otherwise some
terrible crime remains unsolved.This circus of incompetence and dishonesty is the real issue with
the death penalty. We don't even reach the point where theoretical
questions about the moral justification or effectiveness of capital
punishment start to matter, because so many of the people sentenced
to death are actually innocent. Whatever it means in theory, in
practice capital punishment means killing innocent people.
Thanks to <NAME>, <NAME>, and <NAME> for
reading drafts of this.Related:Will Florida Kill an Innocent Man?Was <NAME> Framed for Murder?Did Texas execute an innocent man?
|
|
https://github.com/v-shenoy/vitae
|
https://raw.githubusercontent.com/v-shenoy/vitae/main/vitae.typ
|
typst
|
MIT License
|
#let hsep() = {
line(length: 100%, stroke: rgb(0, 0, 0, 75))
}
#let vsep() = {
set text(fill: rgb(0, 0, 0, 200), size: 12pt, weight: "bold")
[ | ]
}
#let iconify_link(l) = {
grid(
columns: 2,
gutter: 5pt,
image("assets/icons/" + l.icon + ".svg", width: 12pt),
[ #v(2pt); #link(l.url, l.display); ],
)
}
#let render_links(links) = {
show link: underline
grid(
columns: links.len(),
gutter: 7pt,
..links.map(iconify_link),
)
}
#let section_heading(name) = {
grid(
columns: 2,
gutter: 1fr,
[ = #name #h(5pt) ],
[ #v(5pt) #line(length: 100%, stroke: 1.5pt) ]
)
}
#let render_header(name, links) = {
set align(center)
[
#set text(font: "LibreBaskerville", size: 13pt)
= #name
]
render_links(links)
}
#let render_summary(summary) = {
section_heading("Summary")
par(summary)
}
#let render_experience(ex) = {
section_heading("Experience")
for job in ex {
[ == #job.company ]
for pos in job.positions {
grid(
columns: 2,
gutter: 1fr,
[
#strong(emph(pos.role)) #vsep() #emph(pos.team)
],
[
#set align(right)
#pos.location
#vsep()
#strong(pos.start) -- #strong(pos.end)
]
)
for point in pos.info {
[ - #eval(point, mode: "markup") ]
}
}
}
}
#let render_education(education) = {
section_heading("Education")
for school in education {
grid(
columns: 2,
gutter: 1fr,
[
== #school.name
#eval(school.degree, mode: "markup") #vsep() #eval(school.grade, mode: "markup")
],
[
#set align(right)
=== #school.start -- #school.end
#school.location
]
)
// for point in school.info {
// [ - #eval(point, mode: "markup") ]
// }
}
}
#let render_skills(skills) = {
section_heading("Skills")
for (section, values) in skills.pairs() {
strong(section + ": ")
values.join(" " + sym.circle.filled.tiny + " ")
linebreak()
}
}
#let render_cv(data) = {
render_header(data.name, data.links)
render_summary(data.summary)
render_experience(data.experience)
render_education(data.education)
render_skills(data.skills)
}
#let data = yaml("data.yaml")
#set document(
title: data.name + " -- CV",
author: data.name
)
#set page(
paper: "a4",
margin: (
x: 1cm,
y: 0.8cm
),
// footer: [
// #set align(right)
// #set text(size: 9pt, fill: rgb(0, 0, 0, 150))
// Updated on -- #datetime.today().display("[day] [month repr:long], [year]")
// ],
)
#set text(font: "Calibri", size: 10.5pt)
#render_cv(data)
|
https://github.com/yhtq/Notes
|
https://raw.githubusercontent.com/yhtq/Notes/main/计算方法B/code/hw3/上机报告.typ
|
typst
|
#import "../../../template.typ": *
#show: note.with(
title: "上机报告",
author: "YHTQ",
date: datetime.today().display(),
logo: none,
withOutlined : false,
withTitle : false,
withHeadingNumbering: false
)
#let output = read("output.txt")
本次作业主要是利用 Householder 变换实现 QR 分解,并且利用 QR 分解求解线性方程组,并与上次作业的结果进行比较。下面是程序的输出结果:\
#box[
#output
]
可以看到 QR 分解具有较高的数值精度,然而效率较低。不过这里的效率差距明显高于理论值,这里很可能是因为本次编写 QR 分解的程序时,为了实现方便在生成 Householder 矩阵时造成了额外的内存分配和复制。可见代码的简洁和运行效率往往不能兼得。
\
|
|
https://github.com/Nrosa01/TFG-2023-2024-UCM
|
https://raw.githubusercontent.com/Nrosa01/TFG-2023-2024-UCM/main/Memoria%20Typst/capitulos/2.2.SimuladoresDeArena.typ
|
typst
|
#import "../utilities/gridfunc.typ": *
#import "../data/gridexamples.typ": *
#import "../data/data.typ": *
== Simuladores de arena <simuladoresArena>
En esta sección, se hablará de manera resumida acerca de qué son los simuladores de arena y su funcionamiento. Más tarde, se presentan una serie de antecedentes que se han tomado de base para el desarrollo del proyecto.
=== Introducción
Los simuladores de arena son simuladores cuyo
objetivo es representar con precisión interacciones dinámicas entre elementos físicos como granos de arena u otros materiales granulares presentes en el mundo real. Estos comparten muchas similitudes estructurales y conceptuales con los autómatas celulares.
El "mapa" de la simulación está formado por un conjunto de celdas dentro de un número finito de dimensiones, representado como una matriz. Cada una de estas celdas se encuentra, en cada paso discreto de la simulación, en un estado concreto dentro de un número finito de estados en los que puede encontrarse. Cada uno de estos estados representa el tipo de la partícula que se encuentra en la celda.
Sin embargo, a diferencia de los autómatas celulares, donde la evolución de cada celda está estrictamente determinada por reglas locales con sus celdas vecinas y pueden procesarse todas las partículas sin seguir un orden específico, un simulador de arena funciona de manera secuencial y no determinista. El estado futuro de una celda no solo es influenciado por el estado de sus celdas vecinas, sino también por el orden en que las partículas son procesadas. Además, el procesar una celda, no necesariamente se limita a afectar solo a esa celda. Por ejemplo, el simular fenómenos físicos como la gravedad, implica mover partículas por la matriz de celdas, fenómeno no contemplado en los autómatas celulares. En este sistema, "mover" una partícula consiste en cambiar el estado de una celda a otra.
Sin embargo, existen casos en los que este comportamiento no es deseado. Es posible simular el comportamiento de un autómata celular en un simulador de arena aún procesando de forma secuencial mediante una técnica conocida como "doble buffer". En esta técnica, se tienen dos matrices, una que representa el estado actual de la simulación y otra que representa el estado futuro. En cada paso de la simulación, se procesa el estado actual y se guarda el resultado en el estado futuro. Una vez se ha procesado toda la matriz, se intercambian los estados de las matrices. De esta forma, se consigue que el estado futuro de una celda no se vea afectado por el estado futuro de otra celda, es decir, que una celda cambie su estado o el de su vecina no afecta a dicha celda en el mismo paso de simulación.
En un simulador de arena, pueden existir multitud de tipos de partículas, cada una con unas reglas distintas de evolución e interacción con otras celdas de la matriz, lo que puede dar lugar a ejecuciones con dinámicas muy complejas. Para explicar el funcionamiento de los simuladores de arena, se tomará un ejemplo básico de un simulador que contenga solo un tipo de partícula, la de arena. Esta partícula tiene el siguiente comportamiento:
- Si la celda de abajo esta vacía, me muevo a ella.
- En caso de que la celda de abajo esté ocupada por otra partícula, intento moverme en dirección abajo izquierda y abajo derecha, si las celdas están vacías.
- En caso de que no se cumpla ninguna de estas condiciones, la partícula no se mueve.
#grid_example("Ejemplo de simulador de arena", (sand_simulator_01, sand_simulator_02, sand_simulator_03, sand_simulator_04), vinit: 1pt)
Esta ejecución toma como base un orden de ejecución de abajo a arriba y de derecha a izquierda. Para un orden de ejecución de arriba a abajo y de izquierda a derecha el resultado sería el siguiente.
#grid_example("Ejemplo de simulador de arena, diferente orden", (sand_simulator_lr_01, sand_simulator_lr_02, sand_simulator_lr_03, sand_simulator_lr_04), vinit: 1pt)
Como puede verse, el orden en el que se procesan las celdas de la matriz afecta al resultado final.
=== Simuladores de arena dentro de los videojuegos
Dentro de la industria de los videojuegos, se han utilizado simuladores de arena con diferentes fines, como pueden ser mejorar la calidad visual o aportarle variabilidad al diseño y jugabilidad del propio videojuego.
Este proyecto toma como principal referencia a "Noita", un videojuego indie roguelike que utiliza la simulación de partículas como núcleo principal de su jugabilidad. En "Noita", cada píxel en pantalla representa un material y está simulado siguiendo unas reglas físicas y químicas específicas de ese material. Esto permite que los diferentes materiales sólidos, líquidos y gaseosos se comporten de manera realista de acuerdo a sus propiedades. El jugador tiene la capacidad de provocar reacciones en este entorno, por ejemplo destruyéndolo o haciendo que interactúen entre sí.
#figure(
image("../images/Noita.png", width: 50%),
caption: [
Imagen gameplay de Noita
],
)
Noita no es el primer videojuego que hace uso de los simuladores de partículas. A continuación, se enumeran algunos de los títulos, tanto videojuegos como sandbox, más notables de simuladores de los cuales el proyecto ha tomado inspiración durante el desarrollo.
- Falling Sand Game @falling_sand_game
Probablemente el primer videojuego comercial de este subgénero. A diferencia de Noita, este videojuego busca proporcionarle al jugador la capacidad de experimentar con diferentes partículas físicas así como fluidos y gases, ofreciendo la posibilidad de ver como interaccionan tanto en un apartado físico como químicas. Este videojuego estableció una base que luego tomaron otros videojuegos más adelante.
- Powder Toy @powder_toy
Actualmente el sandbox basado en partículas más completo y complejo del mercado. Este no solo proporciona interacciones ya existentes en sus predecesores, como Falling Sand Game, sino que añade otros elementos físicos de gran complejidad como pueden ser temperatura, presión, gravedad, fricción, conductividad, densidad, viento etc.
- Sandspiel @sandspiel
Este proyecto utiliza la misma base que sus predecesores, proporcionando al jugador libertad de hacer interaccionar partículas a su gusto. Además, añade elementos presentes en Powder Toy como el viento, aunque la escala de este proyecto es más limitada que la de proyectos anteriores. De Sandspiel, nace otro proyecto llamado Sandspiel Club @sandspiel_club, el cual utiliza como base Sandspiel, pero, en esta versión, el creador porporciona a cualquier usuario de este proyecto la capacidad de crear partículas propias mediante un sistema de scripting visual haciendo uso de la librería Blockly @blockly de Google. Además, similar a otros títulos menos relevantes como Powder Game (no confundir con Powder Toy), es posible guardar el estado de la simulación y compartirla con otros usuarios.
|
|
https://github.com/HPDell/typst-slides-uob
|
https://raw.githubusercontent.com/HPDell/typst-slides-uob/main/slides-uob.typ
|
typst
|
// Slides template for the University of Bristol
// Author: <NAME>
#let red = rgb(171, 31, 45)
#let document-title = state("title", "")
#let in-slide = state("in-slide", false)
#let slides(
title: "",
authors: (),
date: datetime.today(),
short-title: "",
body
) = {
set document(
title: title,
author: authors
)
set page(
width: 320mm,
height: 200mm,
margin: 0mm
)
document-title.update(title)
set par(leading: 0.8em)
set text(font: "Fira Sans", size: 20pt)
show math.equation: set text(font: "Libertinus Math")
show math.equation.where(block: true): set par(leading: 0.5em)
set heading(numbering: "1.1")
show heading.where(level: 1): it => {
locate(loc => {
if in-slide.at(loc) {
none
} else {
pagebreak(weak: true)
v(32%)
align(center, [
#block(
text(size: 36pt, [Section #counter(heading).display()])
)
#block(
fill: red,
width: 80%,
inset: 28pt,
radius: 8pt,
above: 1em,
text(fill: white, size: 42pt, it.body)
)
])
}
})
}
show heading.where(level: 2): it => {
locate(loc => {
if in-slide.at(loc) {
none
} else {
pagebreak(weak: true)
v(32%)
align(center, [
#block(
text(size: 36pt, [Section #locate(
loc => query(heading.where(level: 1), loc).last().numbering
)])
)
#block(
fill: red,
width: 80%,
inset: 28pt,
radius: 8pt,
above: 1em,
text(fill: white, size: 42pt, locate(
loc => query(
selector(heading.where(level: 1)).before(loc),
loc
).last().body
))
)
#block(
width: 80%,
align(center, text(fill: red, size: 36pt, it.body))
)
])
}
})
}
show heading.where(level: 3): none
show heading.where(level: 4): it => text(
size: 1.1em,
fill: red,
weight: "bold",
stack(
dir: ltr,
spacing: 0.2em,
image("UoB_Bullet.svg", height: 0.8em),
it.body)
)
set list(marker: text(fill: red, size: 1.2em, baseline: -4pt, sym.triangle.filled.r))
set enum(numbering: n => text(fill: red, weight: "bold", [#n.]))
set table(
inset: 0.64em,
stroke: red,
fill: (_, row) => if row == 0 { red.lighten(10%) } else {white}
)
// Title Page
grid(
rows: (1fr, 128pt, 1fr),
columns: 100%,
block(
height: 100%,
width: 100%,
inset: (top: 24pt, right: 48pt)
)[
#align(right, image("UoB_Logo.svg", height: 48pt))
],
block(
inset: (left: 48pt, right: 48pt)
)[
#align(left + horizon)[
#set par(leading: 0.6em)
#set text(fill: red, size: 40pt, weight: "extrabold")
#title
]
],
block(
height: 100%,
inset: (left: 48pt, right: 48pt)
)[
#text(size: 24pt, authors.join(", "))
#text(size: 20pt, style: "italic", date.display("[day] [month repr:short] [year]"))
]
)
body
}
#let slide(body, subtitle: []) = {
in-slide.update(true)
locate( loc => {
if counter(page).at(loc).first() > 1 {
pagebreak(weak: true)
}
})
grid(
rows: (64pt, 1fr, 28pt),
columns: (100%),
gutter: 4pt,
block(
height: 100%,
width: 100%,
stroke: 0pt,
fill: red,
inset: (top: 16pt, bottom: 8pt, left: 48pt, right: 48pt)
)[
#if subtitle == [] {
block(height: 100%, [
#text(
size: 36pt,
weight: "extrabold",
fill: white,
locate(loc => query(
selector(heading.where(level: 3)).before(loc),
loc
).last().body)
)
])
} else {
grid(
columns: (auto, 1fr),
column-gutter: 16pt,
block(height: 100%, [
#text(
size: 36pt,
weight: "extrabold",
fill: white,
locate(loc => query(
selector(heading.where(level: 3)).before(loc),
loc
).last().body)
)
]),
block(height: 100%, inset: (top: 4pt), [
#text(size: 28pt, fill: white, subtitle)
])
)
}
],
block(
height: 100%,
width: 100%,
inset: (top: 16pt, left: 48pt, right: 48pt, bottom: 16pt)
)[
#align(horizon, body)
],
block(
height: 100%,
width: 100%,
stroke: (top: 2pt + red),
inset: (top: 10pt, left: 48pt, right: 48pt)
)[
#set text(size: 12pt, font: "Fira Sans")
#text(style: "italic", document-title.display())
#h(1fr) #counter(page).display()
]
)
in-slide.update(false)
}
#let empty(content) = {
in-slide.update(true)
pagebreak(weak: true)
block(width: 100%, height: 100%, inset: 48pt, align(horizon, [
#set text(size: 20pt)
#content
]))
in-slide.update(false)
}
#let leaflet(content, title: []) = {
grid(
rows: (auto, auto),
columns: (auto,),
block(
width: 100%,
fill: red,
stroke: red,
inset: 12pt,
radius: (top-left: 8pt, top-right: 8pt),
text(fill: white, size: 24pt, weight: "bold", title)
),
block(
width: 100%,
stroke: red,
inset: 12pt,
radius: (bottom-right: 8pt, bottom-left: 8pt),
text(content)
)
)
}
#let th(content) = text(fill: white, content)
|
|
https://github.com/typst/packages
|
https://raw.githubusercontent.com/typst/packages/main/packages/preview/unichar/0.1.0/ucd/block-1AFF0.typ
|
typst
|
Apache License 2.0
|
#let data = (
("KATAKANA LETTER MINNAN TONE-2", "Lm", 0),
("KATAKANA LETTER MINNAN TONE-3", "Lm", 0),
("KATAKANA LETTER MINNAN TONE-4", "Lm", 0),
("KATAKANA LETTER MINNAN TONE-5", "Lm", 0),
(),
("KATAKANA LETTER MINNAN TONE-7", "Lm", 0),
("KATAKANA LETTER MINNAN TONE-8", "Lm", 0),
("KATAKANA LETTER MINNAN NASALIZED TONE-1", "Lm", 0),
("KATAKANA LETTER MINNAN NASALIZED TONE-2", "Lm", 0),
("KATAKANA LETTER MINNAN NASALIZED TONE-3", "Lm", 0),
("KATAKANA LETTER MINNAN NASALIZED TONE-4", "Lm", 0),
("KATAKANA LETTER MINNAN NASALIZED TONE-5", "Lm", 0),
(),
("KATAKANA LETTER MINNAN NASALIZED TONE-7", "Lm", 0),
("KATAKANA LETTER MINNAN NASALIZED TONE-8", "Lm", 0),
)
|
https://github.com/0xPARC/0xparc-intro-book
|
https://raw.githubusercontent.com/0xPARC/0xparc-intro-book/main/src/zkintro.typ
|
typst
|
#import "preamble.typ":*
= Introduction to SNARKs
Peggy has done some very difficult calculation.
She wants to prove to Victor that she did it.
Victor wants to check that Peggy did it, but he
is too lazy to redo the whole calculation himself.
- Maybe Peggy wants to keep part of the calculation secret.
Maybe her calculation was "find a solution to this puzzle,"
and she wants to prove that she found a solution
without saying what the solution is.
- Maybe it's just a really long, annoying calculation,
and Victor does not have the energy to check it all line-by-line.
A _SNARK_#h(0.05em) lets Peggy (the "prover")
send Victor (the "verifier") a short proof
that she has indeed done the calculation correctly.
The proof will be much shorter than the original calculation,
and Victor's verification is much faster.
(As a tradeoff, writing a SNARK proof of a calculation is much slower
than just doing the calculation.)
The name stands for:
- _Succinct_: the proof length is short (in fact, it's a constant length,
independent of how long the problem is).
- _Non-interactive_: the protocol does not require back-and-forth communication.
- _Argument_: basically a proof.
There's a technical difference, but we won't worry about it.
- _of Knowledge_: the proof doesn't just show the system of equations has a solution;
it also shows that the prover knows one.
We won't discuss it here, but it is also possible and frequently useful to make a _zero knowledge (zk)_ SNARK. These are typically called "zkSNARKs." This gives Peggy a guarantee
that Victor will not learn anything about the intermediate steps
in her calculation, aside from any particular steps Peggy chooses to reveal.
== What can you do with a SNARK?
One answer: You can prove that you have a solution to a system of equations.
Sounds pretty boring, unless you're an algebra student.
Slightly better answer: You can prove that you have executed a program correctly,
revealing some or all of the inputs and outputs, as you please.
For example: You know a message $M$ such that
$op("sha")(M) = "0xa91af3ac..."$, but you don't want to reveal $M$.
Or: You only want to reveal the first 30 bytes of $M$.
Or: You know a message $M$, and a digital signature proving that $M$ was signed by
[trusted authority], such that a certain neural network, run on the input $M$, outputs "Good."
One recent application along these lines is
#cite("https://tlsnotary.org", "TLSNotary").
TLSNotary lets you certify a transcript of communications with a server
in a privacy-preserving way: you only reveal the parts you want to.
|
|
https://github.com/noriHanda/undergrad_paper
|
https://raw.githubusercontent.com/noriHanda/undergrad_paper/main/template.typ
|
typst
|
#let titleL = 1.8em
#let titleM = 1.6em
#let titleS = 1.2em
#let university = "北海道大学"
#let fontSerif = ("Noto Serif", "Noto Serif CJK JP")
#let fontSan = ("Noto Sans", "Noto Sans CJK JP")
#let bibliographyTitleJa = "参考文献"
#let project(title: "", englishTitle: "", author: "", university: university, affiliation: "", lab: "", grade: "", supervisor: none, year: none, body) = {
set document(author: author, title: title)
// Font
set text(font: fontSerif, lang: "ja", size: 12pt)
// Heading
set heading(numbering: (..nums) => {
if nums.pos().len() > 1 {
nums.pos().map(str).join(".") + " "
} else {
text(cjk-latin-spacing: none)[第 #str(nums.pos().first()) 章]
h(1em)
}
})
show heading: set text(font: fontSan, weight: "medium", lang: "ja")
show heading.where(level: 1): it => {
pagebreak()
set text(size: 1.4em)
pad(top: 3em, bottom: 2.5em)[
#it
]
}
show heading.where(level: 2): it => pad(top: 1em, bottom: 0.6em, it)
// Figure
show figure: it => pad(y: 1em, it)
show figure.caption: it => pad(top: 0.6em, it)
// Outline
show outline.entry: set text(font: fontSan, lang: "ja")
show outline.entry.where(
level: 1
): it => {
v(0.2em)
set text(weight: "semibold")
it
}
align(center)[
#v(6em)
#block(text(titleS)[#year 年度 卒業論文])
#v(8em)
#block(text(titleL, title))
#v(2em)
#pad(x: 4em, block(text(titleS, englishTitle)))
#v(8em)
// Author information.
#block(text(titleS)[#university])
#block(text(titleS)[#affiliation])
#block(text(titleS)[#lab #grade])
#v(2em)
#block(text(titleS)[#author])
#if supervisor != none [
#v(0.6em)
#block(text(titleS)[指導教員 #supervisor])
]
]
pagebreak(weak: true)
set par(justify: true, first-line-indent: 1pt, leading: 1em)
body
}
#let abstract(body) = {
v(180pt)
align(center)[
#text(font: fontSan, size: titleM, tracking: 2em, weight: "medium")[要旨]
]
v(2em)
set par(first-line-indent: 1em)
body
pagebreak(weak: true)
}
|
|
https://github.com/Myriad-Dreamin/typst.ts
|
https://raw.githubusercontent.com/Myriad-Dreamin/typst.ts/main/fuzzers/corpora/text/features_10.typ
|
typst
|
Apache License 2.0
|
#import "/contrib/templates/std-tests/preset.typ": *
#show: test-page
//
// // Error: 24-25 expected "lining", "old-style", or auto, found integer
// #set text(number-type: 2)
|
https://github.com/SkiFire13/master-thesis
|
https://raw.githubusercontent.com/SkiFire13/master-thesis/master/preface/copyright.typ
|
typst
|
#import "../config/translated.typ": degree
#let no-linebreak(body) = {
show linebreak: none
body
}
#let copyright(name, title, date) = page(align(bottom)[
#name:
_ #no-linebreak(title) _,
#degree,
#(sym.copyright)
#(date.year()).
])
|
|
https://github.com/RandomcodeDev/FalseKing-Design
|
https://raw.githubusercontent.com/RandomcodeDev/FalseKing-Design/main/game/story.typ
|
typst
|
= Story
The player (Shadow) is a rogue who is displeased with the current state of the five kingdoms. They wish to take over and become the King of Aether, the most powerful element.
== Introduction
The game's world is introduced with a cutscene explaining each kingdom, and who Shadow is. Then, it shifts to Shadow in their underground home, which is inside the Kingdom of Aether. Shadow lives alone with two cats. When the King of Aether declares that cats are no longer allowed in the kingdom, Shadow finally decides to rebel after years of being a common criminal.
Note: the kingdoms are not in any particular order
== #text(teal)[Air kingdom]
|
|
https://github.com/tingerrr/anti-matter
|
https://raw.githubusercontent.com/tingerrr/anti-matter/main/example/back-matter.typ
|
typst
|
MIT License
|
#set heading(numbering: none)
= Glossary
Content
= Appendix
Content
= Acknowledgement
Content
|
https://github.com/polarkac/MTG-Stories
|
https://raw.githubusercontent.com/polarkac/MTG-Stories/master/stories/015_Commander%20(2014%20Edition).typ
|
typst
|
#import "@local/mtgset:0.1.0": conf
#show: doc => conf("Commander (2014 Edition)", doc)
#include "./015 - Commander (2014 Edition)/001_Loran's Smile.typ"
#include "./015 - Commander (2014 Edition)/002_The Lithomancer.typ"
#include "./015 - Commander (2014 Edition)/003_The First World Is the Hardest.typ"
|
|
https://github.com/nikhilweee/nikipedia-typst
|
https://raw.githubusercontent.com/nikhilweee/nikipedia-typst/main/template/shorthands.typ
|
typst
|
// Math Helpers
#let bx = math.bold("x")
#let bz = math.bold("z")
#let bw = math.bold("w")
#let cL = math.cal("L")
#let DKL = $D_"KL"$
// Equation Helpers
// #let eqnum = math.equation.with(block: true, numbering: "(1)")
#let eqlab(eq, lab) = {
[
#math.equation(eq, block: true, numbering: "(1)")
#label(lab)
]
}
// Citation Helpers
#let prose = cite.with(form: "prose")
// #let prose = (citation) => {
// set cite(form: "prose")
// citation
// }
|
|
https://github.com/jgm/typst-hs
|
https://raw.githubusercontent.com/jgm/typst-hs/main/test/typ/math/vec-01.typ
|
typst
|
Other
|
// Test alternative delimiter.
#set math.vec(delim: "[")
$ vec(1, 2) $
|
https://github.com/jfrydell/fpga-gpu
|
https://raw.githubusercontent.com/jfrydell/fpga-gpu/main/report/report.typ
|
typst
|
#import "template.typ": *
#show: project.with(
title: "ECE 350 Final Project - GPU",
authors: (
"<NAME>",
),
)
= Overall Design and Specifications
My project's goal was to augment the baseline ECE 350 CPU with a special-purpose graphics unit, with the ability to render semi-realistic 3D scenes as well as realtime graphics. To do this, I created a separate "GPU"#footnote[It's arguably more similar to an array processor employing predicated SIMD and one SIMT-like feature than a real GPU with multiple independent processors, but it is a Unit for Processing Graphics, so...] core for the ECE 350 CPU.
== Goals and Non-goals
Because the above is fairly broad, I target two more specific goals for the GPU:
- Render a scene in real time (>20fps) with some interactive component. This will be referred to as the "game," although enjoyable gameplay is not a major focus of the project.
- Render a somewhat realistic 3D scene, including specular and diffuse lighting as well as reflections. The focus here is on render quality rather than latency, so real time animation is an explicit nongoal
While additional scenes are possible to showcase specific functionality, these two serve as the benchmark for what can be considered a "useful" GPU.
== Project Components
The overall design can be isolated into 4 separate components. For simplicity, data flows linearly through these components in one direction, and they are listed here in this dataflow order:
1. *Input unit*: this is the simplest component, buffering input from the PS2-interface keyboard and exposing it to the CPU through a MMIO interface.
2. *CPU core*: this is the CPU core as designed throughout the course. It processes input for interactive demos and sets parameters (via registers, see @regfile) for the GPU to control the render. The program run by the CPU is hard-coded to a ROM during synthesis/implementation.
3. *GPU core*: this is a 16-wide half-precision SIMD core that does the graphics processing (as the name implies). Its program (also hard-coded at synthesis/implementation) is referred to as a "shader," and runs once per pixel, writing resulting RGB colors to the framebuffer.
4. *Framebuffer/Output*: this generates the required VGA sync signals (as done in Lab 6) and sends the color data for each pixel over the built-in VGA port at the correct time. Color data is stored in a large RAM (12 bits per pixel), exposing a write port for the GPU to set pixel colors after computing them.
In terms of overall inputs and outputs, the project receives keyboard input via the built-in PS2 interface and outputs via the built-in VGA port. The on-board LEDs and switches are used for debugging, but are not considered part of the overall project interface.#pagebreak()
= GPU Core Architecture #footnote[The rubric asks for processor modifications. Here, CPU modifications are limited to the MMIO interface for input and GPU registers, so we instead discuss the GPU's architecture, which technically could be considered an extreme modification to the processor.]
The main component of this project is a 16-wide half-precision-float vector-based Graphics Processing Unit accompanying the CPU. This section details its unique architecture, scheduling, and integration with the rest of the system.
== ISA <isa>
The ISA for our GPU core is described in the table below. All instructions are 20-bit, and most are "simple" (R-type) instructions with the following format:
#table(columns: (auto, auto, auto, auto, auto), [Opcode], [Destination], [Source 1], [Source 2], [Unused], [`insn[19:16]`], [`insn[15:12]`], [`insn[11:7]`], [`insn[6:2]`], [`insn[1:0]`])
There are 4 exceptions, each of which has a unique format described in the table below. The table lists all currently-supported instructions, along with a brief description of their functionality:
#table(columns: (auto,auto,auto), [Opcode], [Instruction], [Description],
[`0000`], [`add DEST, SRC1, SRC2`], [Adds two registers, setting DEST = SRC1 + SRC2],
[`0001`], [`sub DEST, SRC1, SRC2`], [Subtracts two registers, setting DEST = SRC1 - SRC2],
[`0010`], [`mul DEST, SRC1, SRC2`], [Multiplies two registers, setting DEST = SRC1 \* SRC2],
[`0011`], [`div DEST, SRC1, SRC2`], [Divides two registers, setting DEST = SRC1 / SRC2],
[`0100`], [`floor DEST, SRC1`], [Floors a register to the nearest integer, ignoring the second source. Inputs in the range [-0.00048828125, -0] are incorrectly floored to -0 rather than -1.],
[`0101`], [`abs DEST, SRC1`], [Takes the absolute value of a register, ignoring the second source],
[`0110`], [`sqrt DEST, SRC1`], [Takes the square root of a register, ignoring the second source],
[`0111`], [`atan DEST, SRC1`], [Computes $1/pi tan^(-1)("SRC1")$, ignoring the second source. Uses a 2048-entry lookup table, so the last 4 bits of mantissa are truncated (table entries correspond to the average of the 16 values mapping to the entry).],
[`1000`], [`cmov DEST, SRC1, SRC2`], [Sets DEST = SRC1 if SRC2 < 0, otherwise does nothing],
[`1010`], [`done`], [Signals that the output pixel color is set in registers 17, 18, and 19, stopping the program. This logically may occur as early as fetch in the 4-stage pipeline, so 3 no-ops should be added after the last write to one of these registers.],
[`1101`], [`bltz SRC1, DESTPC`], [Branches to PC = DESTPC if SRC1 < 0. There are several restrictions, described in @control. The value of DESTPC is only 11 bits, the first 4 of which are `insn[15:12]` and the latter 7 are `insn[6:0]`.],
[`1110`], [`setx COUNT`], [Sets the X register (for looping) to COUNT, so an upcoming loop repeats COUNT times (for COUNT+1 total executions).],
[`1111`], [`loop DESTPC`], [Decrements the X register and sets PC = DESTPC if the original value is at least 1. Together with `setx`, this allows constant-iteration loops to be easily implemented.],
)
== Pipeline
The GPU's pipeline is somewhat similar to the standard 5-stage pipeline, but with the memory stage omitted because the GPU _does not_ have any ability to access memory (due to 16-ported global memory being hard to synthesize). This consists of the following stages:
- Fetch: load the instruction from the current PC. Unlike the traditional pipeline, a few instructions are actually completed in this stage: `setx`, `loop`, and `done`. These instructions do not interact with registers in the standard way, so they complete in Fetch to avoid unnecessary stalling (note that this allows loops to be done with no stalls). The only non-scalar (i.e. scaling with SIMD width) part of this stage is the quasi-SIMT branching optimization described in @control.
- Decode: load the two inputs from the register file. The MSB of the source determines which register file is loaded from (see @regfile). Bypassing also occurs at this stage, with bypassed operands being latched into execute to avoid adding additional overhead to the compute-heavy execute stage.
- Execute: computes the result from the input operands. Most simple instructions use Vivado's provided floating point IP, with the exception of `abs`, `floor`, `atan`, and `cmov`. The `cmov` and `bltz` instructions simply check an input sign bit, either setting the destination register to \$16 or setting the minimum executed PC as described in @control, respectively. This stage is entirely vector, with all logic being duplicated for each SIMD vector element.
- Writeback: writes the result from execute to the destination register as long as it is nonzero. Note that, as described in @regfile, only registers \$17-31 are writeable by the GPU core, so the MSB of the destination register name is always asserted.
== Scheduling
The GPU continuously renders the image, scanning through 16 pixels at a time. Each execution of the shader program on 16 pixels is referred to as a "dispatch." Each dispatch consists of a horizontal line of 16 pixels, and the x- and y- coordinates of the dispatch are considered to be those of the leftmost pixel in the dispatch. The x-coordinate ranges from -320 to +319 left-to-right, and the y-coordinate ranges from -240 to 239 top-to-bottom.
When the `done` instruction is seen, the scheduling logic extracts the color values from the output registers 17-19 and writes them to the framebuffer as described in @color_output. On the next clock cycle, the GPU is reset to PC 0 and the next dispatch begins. Registers are not reset, so programs cannot take advantage of any initial register value without setting it on the previous dispatch.
== Regfile <regfile>
The GPU register file logically includes 32 registers divided into 2 groups: register 0-15 are scalar register and 16-31 are vector registers. Because all GPU instructions act on vectors, only the latter are writable by the GPU (with the exception of 16, see next paragraph). The scalar registers are instead exposed through the GPU interface to be written by the CPU, allowing parameters of the render (time, positions, colors) to be controlled.
Registers 0, 1, 2, and 16 contain special values and are non-writable. Register \$0 is the constant 0, \$1 holds the current dispatch's y-coordinate, and \$2 holds the current dispatch's leftmost x-coordinate. (Vector) register \$16 holds the index of the vector for each element (i.e. the numbers 0 through 15). This allows the expression `add $rd, $2, $16` to compute each pixel's x-coordinate in `$rd`.
The 16 scalar registers are stored in a central register file to allow writes from the CPU. The 16 vector registers, on the other hand, are distributed element-wise, with each execution core holding its own register file.
== Control, Predication, and SIMT <control>
My GPU supports 3 types of control: static looping, conditional moves, and "quasi-SIMT" forward conditional branches. Static looping support is supported by the `setx` and `loop` instructions described in @isa.
Conditional branching is more complex, as the vector nature of the core prevents traditional register-based branching due to the possibility of different elements in a dispatch diverging. This would traditionally be handled with predication (an "associative processor" in Flynn's taxonomy), but I implement a weaker form using conditional moves only. Rather than conditionally skipping a basic block or predicating away all instructions within it, shaders must use scratch registers for potentially-unwanted computation, conditionally moving results back into the desired location with `cmov`. Most conditional computing in my shaders utilizes this primitive.
My GPU does implement one conditional branch: `bltz` or branch less than zero. When an element conditionally branches based on this, it sets a "minimum executed PC" register local to its execute stage to the new program counter. Future instructions are then ignored until this program counter is reached, emulating a forward conditional branch.
As an optimization, the fetch stage looks at the minimum executed PC registers for each element and finds the minimum among them. If this value is greater than the current PC, we skip forward to this value, as no instructions prior to it are executed. This speeds up execution in two very common cases: if every element in a dispatch branches past a block, the whole dispatch "executes" (stalls) only a few instructions before skipping past as a whole, and if a branch is used to break out of a loop, the whole dispatch breaks out once all individual elements have done so.
Because this conditional branch logically causes each element to execute a different series of instructions, I call it "quasi-SIMT (Single Instruction Multiple Thread)," inspired by modern GPUs' approach toward branches of allowing each data value to logically follow an independent thread while using masking to resolve intra-dispatch conflicts. My implementation has several restrictions due to its simplicity:
- It only works on forward branches, more formally with the restriction that the control flow must satisfy the following constraints for any combination of taken/not-taken branches:
- Control flow must at some point reach the destination PC
- All instructions after reaching the destination PC must statically appear later than the destination (i.e. must have a higher PC)
- All instructions executed prior to reaching the destination PC must statically appear earlier than the destination (i.e. must have a lower PC)
- No `done` or `setx` instructions may be skipped by such a branch. `loop` instructions may be skipped, but the previous restriction ensures skipping and executing such loops are equivalent when the branch occurs (as all instructions "inside" the loop will be predicated away).
- The `bltz` instruction only has 11 bits for the destination PC. A smart microarchitect would make the branch relative, but I didn't bother to while implementing it, so conditional branches become useless for long programs. Users should resolve this by writing shorter programs (if you choose to write a >2,000 instruction for this thing, conditional branch limitations are the _least_ of your problems).
== Color conversion / Dithering <color_output>
Once the shader program executes the `done` instruction, the 16-bit half-precision floating point values in registers 17, 18, and 19 are converted to three 4-bit VGA channels for compatibility with the Nexys A7 interface. To avoid color banding due to the lack of depth, randomized dithering is used, producing a smoother color gradient.
Color conversion begins with using Vivado IP blocks to convert each half-precision float value into an 8-bit signed integer. Then, the lower 3 bits are compared to a pseudo-random 3-bit number, and if they are greater, 1 is added to the upper 4 bits before outputting; otherwise, the upper 4 bits are taken as output. There are two exceptions to this algorithm: if the number is negative, 0 is output, and if it is greater than `01111000`#sub[2], the maximum is output (ignoring the comparison to avoid oveflow).
The pseudo-random numbers are generated with a 144-bit LSFR (for 16 pixels in a dispatch each containing 3 channels needing 3 bits of randomness). Bits 143, 141, 139, and 136 (zero-indexed) are XORed to create a new LSB each cycle, in accordance with Ward and Molteno's table of maximum-cycle LSFRs.#footnote[#text(blue)[#link("https://datacipy.cz/lfsr_table.pdf")]#linebreak()Archived Version: #text(blue)[#link("https://web.archive.org/web/20231031092924/https://datacipy.cz/lfsr_table.pdf")]]
A comparison of non-dithered and dithered renderings is shown below:
#figure[#grid(columns: (auto, auto), column-gutter: 2%, image("noditherbad.png"), image("dithergood.png"))]
= Other Components and Integration
While the GPU core is the main component of this project, there are a few others, in both hardware and software, I wanted to document here.
== Keyboard Interface
The only user input device is a PS/2-interface keyboard connected to the Nexys A7's onboard USB port. The PS/2 protocol is handled with the provided code from Lab 7, which presents 8-bit data words and a ready signal.
Some basic sequential logic translates these signals into a single register containing the currently-held key code. On a keypress, this register is set to the corresponding scancode. On release, keycode `0xF0` indicates that the following key was released, so our logic simply sets the register to 0 and ignores the subsequent word. This fails to correctly handle overlapping or simultaneous keypresses, but is sufficient for our purposes.
== CPU MMIO
The CPU reads input and writes to GPU scalar registers through a basic MMIO interface. Since the standard ECE 350 CPU only uses 4096 words of RAM, addresses above `0x1000` are used to communicate with the rest of the system.
GPU registers 3-15 are mapped to addresses `0x1003` through `0x100f`. When a write is performed to this location, it is converted from a 32-bit integer assumed to be made up of 16 integer bits and 16 fraction bits to a half-precision float.#footnote[Technically, values are converted to single-precision floats and then half-precision floats. This is because the Vivado IP Catalog fixed-to-float converter doesn't allow conversion to half-precision floats. I know, I'm as upset about it as you! That's _dozens_ of LUTs I'll never get back!] From the CPU side, this offers a reasonable compromise, with values from $0.015625$ to $32768$ representable at least as well as half-precision floats, smaller values being limited to $1.5 dot 10^(-5)$ absolute precision (greater than the 10 bits of _relative_ floating point precision), and larger values being unrepresentable.
Memory address `0x1000` is mapped to the keyboard interface described above. Loads from this address get the currently held key (with 24 leading `0`s), and any store to this address clears the key, allowing an already-processed keypress to be subsequently ignored.
== Output Module
The output module generates VGA sync and data signals to display the data in the framebuffer onscreen. Because the GPU processes 16 pixels simultaneously, the framebuffer also stores colors for 16 pixels in each word (for more details on the framebuffer, see @bram). This enables all results from the dispatch to be written to the framebuffer in one cycle.
This design slightly complicates the VGA output module's logic. The provided VGA interface from Lab 6 produces x and y coordinates of the current pixel, as well as the necessary horizontal and vertical sync signals. Using these coordinates, the formula `(y << 5) + (y << 3) + (x >> 4) + 1` gives the address of the next upcoming block of 16 pixels in the framebuffer. Once the leftmost pixel in a dispatch is reached, the data at this location is stored into a shift register, which shifts 12 bits with each 25 MHz pixel clock cycle. The current pixel color is therefore always in the last 12 bits of this shift register, which are sent to the built-in VGA port.
== Assembler
To support the new GPU ISA, I wrote a basic assembler in Python. It deals with the strange format of simple instructions (i.e. 4-bit destinations and 5-bit sources), but does not handle branches and jumps.#footnote[Let's pretend it's for performance reasons: I can't afford a _second pass_ when assemblying these 30-100 instruction files! That's _dozens_ of microseconds I'll never get back!]
Instead, the assembler outputs labels along with the generated binary, along with annotations at each branch and jump. This makes it fairly easily to manually set branch targets. Not ideal, and I've planning on fixing it for weeks, but nothing's more permanant than a temporary fix!
= Challenges
As with any project, there were dozens of medium-to-large challenges I faced in this project. Unfortunately, most were small typos or similarly silly screw-ups that aren't worth describing here. I instead describe two of my more interesting challenges and solutions.
== BRAM Limitations <bram>
The Artix-7 FPGA includes 4,860 Kbits of block RAM.#footnote[See #text(blue)[#link("https://digilent.com/reference/programmable-logic/nexys-a7/reference-manual")]] Because my framebuffer is made up of $640 dot 480 dot 12 = 3,686,400$ bits of data, I initially assumed RAM usage would not be a problem.
Unfortunately, the FPGA BRAM is divided into 135 36K BRAM blocks, each containing 32768 bits of data (the 36K advertised capacity includes parity disabled here) addressable in several configurations: 1x32K, 2x16K, 4x8K, and so on, where $N$x$M$K means a depth of $M$K and a word size of $N$ bits. We needed a framebuffer with $(640 dot 480)/16 = 19200$ words each of size $16 dot 12 = 192$ bits.
Because the depth of this RAM is greater than 16K, the synthesized configuration uses the 32K configuration with each bit taking a full BRAM block. This requires 192 BRAM blocks in total, more than our chip has.
With this understanding of the BRAM allocation mechanism, I realized that the framebuffer could be divided into two parts: a 16384-entry main buffer and a 2816-entry secondary one. This requires only 96 BRAM blocks for the main buffer (each 2x16K), and 24 for the secondary (each 8x4K). The only downside (and reason this isn't synthesized automatically) is the extra mux for reads and combinational write-enable logic it requires.
With this change, 120 BRAM blocks are used for the framebuffer. With the addition of `atan` lookup tables and the CPU and GPU register files, a total of 130.5 BRAM blocks are utilized, about 97% of the FPGA capacity.
== Debugging
Testing methodology is discussed more in @testing, but this challenge concerns bugs that escaped testing and were not apparent until flashing the design onto the FPGA. This happened fairly often, as even 10 frames of rendering represents millions of GPU instructions to step through, and glitches with user input occur at the 0.1-1.0 second level, not in a 0.00001 second simulation.
Because there was is so much state to keep track of, and re-implementing a design with different debug probes or outputted signals on LEDs takes about 10 minutes, my debugging logic gradually developed into the following:
```
assign LED[15:0] = SW[4:0] == 5'd0 ?
SW[15] == 0 ? regfile_scalar[SW[8:5]] : {8'd0, kb_data}
: SW[15] == 0 ?
cpu_rs1 == SW[4:0] ? cpu_regA[15:0]
: cpu_rs2 == SW[4:0] ? cpu_regB[15:0]
: 16'd0
: cpu_rs1 == SW[4:0] ?
cpu_regA[31:16]
: cpu_rs2 == SW[4:0] ? cpu_regB[31:16]
: 16'd0;
```
Beautiful, isn't it? Scalar GPU registers are easily accessed by the last 5 switches, and viewing the contents of the CPU register file (which only has 2 read ports due to the structural Verilog implementation for Checkpoint 2) is accomplished with persistance-of-vision!
= Testing <testing>
Testing this project mostly consisted of rigorous testing of each component part, as outlined in the following subsections.
== GPU Core Testing
The main issue with testing the GPU core is that Icarus Verilog does not support the specialized Vivado Floating Point IP blocks. So, I wrote a "stub" floating point unit (execute stage) that writes all inputs to a file and reads outputs from another. By repeatedly running a test in Icarus and using a basic C program to compute the correct floating point unit outputs, the correct inputs and outputs would eventually stabilize (with number of runs bounded by the number of executed instructions). While not ideal, this served as a good way to validate the overall structure of the GPU core itself.
== Output and Scheduling Testing
After the basic GPU core was complete, I integrated it with the output/framebuffer module and wrote the scheduling logic. Testing this involved Vivado Behavioral Simulation of a basic program generating a gradient. Once the output was correct, the gradient appeared on the VGA monitor, validating scheduling logic.
== CPU Integration Tests
Once the CPU was integrated, simulating one end-to-end test became very difficult. Luckily, a basic test program displaying different GPU scalar registers made it clear that all registers were correctly writable through the MMIO interface.
== GPU Program Emulation
For individual shader programs for demos, I wrote an emulator (in Python, with numpy providing passable performance) of the GPU ISA, allowing programs to be tested without synthesizing/implementing a new design. This allowed programming to happen before the GPU was complete, sped up iterations when tweaking programs, and provided a playground to try out and measure performance improvements (such as forward branching).
== Timing Validation
Beginning with the initial GPU core and continuing through full integration, I ran Vivado timing simulations after major changes to ensure clock constraints were met. Unfortunately, the use of a single-cycle execute stage limited the clock speed to 25 MHz. The Vivado IP floating-point division was the limiting factor.
#pagebreak()
= Assembly Programs / Demos
I wrote 3 demos to showcase the generality and functionality of my GPU. The first is a basic game, the second a properly-lit raymarched 3D scene, and the third a basic Mandelbrot set fractal explorer. A photo of the 3D scene can be found in @color_output, and the other two are shown below.
== Tunnel Running Game
In this demo, a 3D-looking red/green spiral tunnel is rendered by the GPU, with blue rings periodically advancing along the z-axis. The player is represented with a gray circle, and the goal is to jump over each blue ring. The CPU assembly program runs a basic startup animation, randomly generates ring locations with a Linear Congruential Generator with ZX11 parameters, detects keyboard input to trigger player jump, simulates gravity while the player is in the air, and checks if the player fails to jump over a ring and resets the game on a loss. The GPU renders the tunnel with basic trigonometry and overlays the player on top.
== Raymarching Sphere Demo
In this demo, the GPU uses a basic raymarching loop to render a sphere sitting on a checkerboard floor. While the intersection of a ray with the sphere could be evaluated with a closed-form expression, raymarching was used to provide an extensible template for more complex shapes. Once the raymarching is complete, a ray hitting the sphere calculates the reflected ray to add Phong lighting along with basic diffuse lighting based on the sphere normal. The reflected ray is then cast to the floor to reflect the checkerboard floor onto the sphere. If the ray misses the sphere, the reflection is skipped with a forward branch, so the floor/sky color is computed for the original ray. Unfortunately, this method causes inconsistent rounding in the checkerboard floor, as rays missing the sphere use their new position to calculate the floor color, which will vary as the sphere moves. The CPU program just initializes GPU registers and moves the sphere's vertical position gradually up and down.
== Fractal Explorer
To showcase the maximum floating-point throughput of the GPU as well as better use of color, I wrote a basic Mandelbrot set renderer for the GPU. Iteration count is interpolated with a linear function of distance of the escaping point from the origin, somewhat reducing banding (a log function is needed for a smooth iteration count). This iteration count is translated to a color along a white to blue gradient and output to the screen. Additionally, the corresponding CPU program allows for navigation and zooming with the keyboard.
#figure[#grid(columns: (auto, auto), column-gutter: 2%, image("tunnel.png"), image("fractal.png"))]
= Possible Improvements
Given that this was a one-person 3–4 week project, there are several improvements I would like to have made but simply did not have time for (both due to time constraints and significant wastes of time). This section details several of the most tempting improvements, from broad architecture changes to small incremental improvements.
== Width
The total project uses only 35% of the available LUTs on the Nexys A7 FPGA. Increasing from 16-wide to 32-wide should therefore be feasible, which would provide a 100% speedup. Unfortunately, the `atan` lookup table currently is implemented in BRAM for each element, so increasing width would be limited by BRAM limitations. Switching the lookup table to distributed ROM and/or multi-porting it would allow for this optimization to be done fairly easily.
== Execute Pipelining
I used asynchronous floating point operations to make the GPU pipeline easier to implement. Using clocked floating point operations would significantly increase possible clock frequency. Additionally, Vivado's Floating Point IP includes pipelined units, which would allow such frequency increases without changes to throughput. While this would significantly complicate the GPU pipeline, it would unlock significant performance improvements, as well as allowing more complex instructions (such as non-lookup-based trig).
== Framebuffer Retrieval
Currently, data flows strictly one way through this system: from CPU to GPU to framebuffer. Enabling the framebuffer to be read by the GPU would allow for several interesting possibilities. At its most basic, cellular automata and/or sand games could be run. With some scheduling logic changes, a course-grained render could be followed up by a higher-resolution refinement pass. This would be a fairly simple way to add many new capabilities to the project without the complexity of full memory access.
== Precision
In both the raymarching and fractal demos, floating point imprecision limited detail/zoom sooner than performance. This indicates that increasing to (or separately supporting) single-precision floating point could be worth the latency increase.
== Left Edge
Currently, the first dispatch of each row of pixels does not render properly. I didn't notice this bug until the last few days of work, as the VGA monitor adapts to this and crops off the left edge. However, this would be an interesting (or painful) bug to investigate.
== Assembler Improvements
My assembler is mostly human-powered, with no branch, label, or even `setx` suppport. This should have been fixed during the project (it would have saved far more time than it took), but it's easy to ignore infrastructure with a deadline approaching.
== Memory
This is the largest difference between my project and any serious processor—wide memory access is one of the hardest problems in any vector processor or GPU, and I sidestepped it completely with my split register file and simple demos. At the very least, implementing per-element scratchpad memory would be fairly easy to do and greatly beneficial (the raymarching demo was severely bottlenecked by the number of registers). More general memory would be difficult, but interesting. Alas, doing so would be more akin to starting again than improving this GPU; after all, it's hard to access memory when you don't even have integer instructions/memory!
|
|
https://github.com/haxibami/haxipst
|
https://raw.githubusercontent.com/haxibami/haxipst/main/test/resume.typ
|
typst
|
#import "../src/main.typ": *
#import "@preview/roremu:0.1.0": roremu
#show: resume.with(
pdf-author: "著者",
pdf-keywords: (
"キーワード1",
"キーワード2",
),
title: [#text(size: 1.5em)[*タイトル*]],
author: [著者],
header: [ヘッダー #h(1fr) #datetime.today().display()],
)
#set heading(numbering: "1.a.")
= 見出し1
== 見出し2
=== 見出し3
= ショーケース
== 段落のインデント
デフォルトで段落はインデントされる。
#roremu(128)…
#macro.no-indent[
もちろん、インデントさせないこともできる。
]
```Typst
#macro.no-indent[
もちろん、インデントさせないこともできる。
]
```
しかし、たいていの場合、インデントしたほうがよいだろう #emoji.face.stars
=== 実装
#link("https://github.com/typst/typst/issues/311")[\#311] がまだ解決されていないので、力技
#let code = read("../src/lib/better-indent.typ")
#raw(
code,
lang: "Typst",
block: true,
)
== 引用
#quote(
attribution: [Кино],
block: true,
)[
... Они говорят им нельзя рисковать, потому что у них есть дом.
]
|
|
https://github.com/SWATEngineering/Docs
|
https://raw.githubusercontent.com/SWATEngineering/Docs/main/src/3_PB/AnalisiDeiRequisiti/content.typ
|
typst
|
MIT License
|
#import "meta.typ" : title
#import "functions.typ" : glossary, team, modulo, requirements_table, generate_requirements_array
#show link: underline
#set list(marker: ([•], [--]))
#set enum(numbering: "1.a.")
= Introduzione
== Scopo del documento
Il presente documento ha lo scopo di fornire una descrizione dettagliata dei casi d'uso e dei requisiti del progetto "InnovaCity". Questi risultano dall'analisi del capitolato C6 presentato dalla Proponente Sync Lab e dalla successiva interazione diretta con essa attraverso gli incontri svolti.
== Scopo del prodotto
Lo scopo del prodotto è la realizzazione di un #glossary("sistema") di persistenza dati e successiva visualizzazione di questi, provenienti da sensori dislocati geograficamente. Tale piattaforma consentirà all'#glossary("amministratore pubblico") di acquisire una panoramica completa delle condizioni della città, facilitando così la presa di decisioni informate e tempestive riguardo alla gestione delle risorse e all'implementazione di servizi.
== Glossario
Al fine di evitare possibili ambiguità relative al linguaggio utilizzato nei
documenti, viene fornito il _Glossario v2.0_, nel quale sono presenti tutte le
definizioni di termini aventi uno specifico significato che vuole essere
disambiguato. Tali termini, sono scritti in corsivo e marcati con una G a pedice.
== Riferimenti
=== Riferimenti normativi
- Capitolato C6 - InnovaCity: Smart city monitoring platform:
#link("https://www.math.unipd.it/~tullio/IS-1/2023/Progetto/C6.pdf") (22-02-2024)\
#link("https://www.math.unipd.it/~tullio/IS-1/2023/Progetto/C6p.pdf") (22-02-2024)
- _Norme di Progetto v2.0_
- _Verbale Esterno 10-11-2023_
- _Verbale Esterno 24-11-2023_
- _Verbale Esterno 06-12-2023_
- Regolamento progetto didattico:
#link("https://www.math.unipd.it/~tullio/IS-1/2023/Dispense/PD2.pdf") (22-02-2024)
=== Riferimenti informativi
Analisi dei requisiti - corso di Ingegneria del Software a.a. 2023/2024: \
#link("https://www.math.unipd.it/~tullio/IS-1/2023/Dispense/T5.pdf") (22-02-2024) \
Professor <NAME> e descrizione delle funzionalità: Use Case e relativi diagrammi (UML) - corso di Ingegneria del Software a.a. 2023/2024: \
#link("https://www.math.unipd.it/~rcardin/swea/2022/Diagrammi%20di%20Attivit%C3%A0.pdf") (22-02-2024)
= Descrizione
== Obiettivi del prodotto
L'obiettivo consiste nella creazione di una piattaforma di monitoraggio e gestione di una #glossary("Smart City"). L'utente, individuato nell'#glossary("amministratore pubblico"), potrà farne impiego per migliorare la qualità generale della vita e l'efficienza dei servizi nel contesto di un'area urbana. L'utente sarà in grado di monitorare, attraverso la consultazione di una #glossary("dashboard"), lo stato della città, esaminando aspetti ambientali, logistici e di sicurezza. Questo cruscotto includerà rappresentazioni grafiche basate su dati provenienti da sensori installati all'interno dell'area geografica della città.
== Funzionalità del prodotto
Il prodotto si compone di due parti principali:
- Una *#glossary("data pipeline")* in grado di raccogliere, persistere e processare dati provenienti da più sorgenti (ovvero i sensori) in #glossary("real-time")\;
- Una *#glossary("dashboard")* che permette di visualizzare i dati raccolti.
La piattaforma prevede fondamentalmente una tipologia di utente: l'#glossary("amministratore pubblico"). Questo utente avrà accesso alla #glossary("dashboard") e prenderà visione di diverse metriche e indicatori sullo stato della città, mediante diversi strumenti di visualizzazione.
== Utenti e caratteristiche
Il prodotto, destinato ad amministratori pubblici, consente loro di ottenere una panoramica sulle condizioni della città. Ciò fornisce loro una base solida per prendere decisioni ponderate riguardo la gestione delle risorse e sull'implementazione dei servizi, risultando cruciale per il miglioramento dell'efficienza complessiva della gestione urbana. Si presuppone che l'#glossary("amministratore pubblico") abbia conoscenze di analisi e di interpretazione dei dati, tali da poter trarre un beneficio concreto dal controllo della #glossary("dashboard").
= Casi d'uso
== Scopo
In questa sezione si vogliono elencare e descrivere tutti i casi d'uso individuati dall'analisi del capitolato e dalle interazioni avute con la Proponente. In particolare, si individuano gli #glossary("attori") e le funzionalità di cui questi possono usufruire. Ogni caso d'uso possiede un codice, la cui struttura è descritta nelle _Norme di Progetto v2.0_.
== Attori
Il #glossary("sistema") si interfaccerà con due attori diversi:
- *#glossary("Amministratore pubblico")*: è un utente che ha accesso alla #glossary("dashboard") in tutte le sue funzionalità e può visualizzare i dati raccolti dai sensori, mediante quest'ultima;
- *#glossary("Sensore")*: è un dispositivo in grado di effettuare misurazioni relative al proprio dominio di interesse. Questi dati possono essere letti ed utilizzati dal #glossary("sistema").
Relativamente all'utilizzo della #glossary("dashboard"), viene definito un unico attore con accesso completo alle funzionalità, in quanto per sua natura l'#glossary("amministratore pubblico") possiede le competenze tecniche necessarie per poter interagire con essa in tutte le sue parti.
#figure(
image("assets/attori.png", width: 40%),
caption: [Gerarchia degli attori]
)
#pagebreak()
== Elenco dei casi d'uso
#set heading(numbering: none)
=== UC0: Visualizzazione menù #glossary("dashboard")
- *Attore Principale*: #glossary("amministratore pubblico")\;
- *Precondizioni*: il #glossary("sistema") è operativo e accessibile;
- *Postcondizioni*: l'#glossary("amministratore pubblico") visualizza un menù di selezione da cui può scegliere in che #glossary("dashboard") spostarsi tra: Dati grezzi, Ambientale, Urbanistica e Superamento soglie;
- *Scenario Principale*:
+ L'#glossary("amministratore pubblico") accede alla piattaforma di visualizzazione.
#figure(
image("assets/UML/UC0_Visualizzazione-menù-dashboard.png",width:70%),
caption: [UC0 Visualizzazione menù #glossary("dashboard")]
)
=== UC1: Visualizzazione #glossary[dashboard] dati grezzi
- *Attore Principale*: #glossary("amministratore pubblico")\;
- *Precondizioni*: il #glossary("sistema") è operativo e accessibile;
- *Postcondizioni*: l'#glossary("amministratore pubblico") visualizza un #glossary("pannello") contenente i dati grezzi inviati dai sensori, all'interno di un'unica #glossary[dashboard]\;
- *Scenario Principale*:
+ L'#glossary("amministratore pubblico") accede alla piattaforma di visualizzazione;
+ L'#glossary("amministratore pubblico") seleziona la visualizzazione della #glossary("dashboard") relativa ai dati grezzi.
#figure(
image("assets/UML/UC1_Visualizzazione-dashboard-dati-grezzi.png",width:70%),
caption: [UC1 Visualizzazione #glossary("dashboard") dati grezzi]
)
=== UC1.1: Visualizzazione #glossary("pannello") dati grezzi
- *Attore Principale*: #glossary("amministratore pubblico")\;
- *Precondizioni*: l'#glossary("amministratore pubblico") ha selezionato la visualizzazione relativa al dominio dei dati grezzi;
- *Postcondizioni*: l'#glossary("amministratore pubblico") visualizza il #glossary("pannello") relativo ai dati grezzi, che riporta il nome del #glossary[sensore], la tipologia del #glossary[sensore], il timestamp della rilevazione e il valore della misurazione, in forma tabellare, per ogni tipo di #glossary[sensore]\; nel caso in cui la misurazione sia composta da più dati, tutti i valori sono elencati ed etichettati opportunamente all'interno della stessa entrata in tale colonna;
- *Scenario Principale*:
+ L'#glossary("amministratore pubblico") accede alla piattaforma di visualizzazione;
+ L'#glossary("amministratore pubblico") seleziona la visualizzazione della #glossary("dashboard") generale relativa ai dati grezzi.
- *Estensioni*: [UC9].
#figure(
image("assets/UML/UC1.1_Visualizzazione-pannello-dati-grezzi.png",width:100%),
caption: [UC1.1 Visualizzazione #glossary("pannello") dati grezzi]
)
=== UC2: Visualizzazione #glossary("dashboard") dati ambientali
- *Attore Principale*: #glossary("amministratore pubblico")\;
- *Precondizioni*: il #glossary("sistema") è operativo e accessibile;
- *Postcondizioni*: l'#glossary("amministratore pubblico") visualizza una lista di #glossary("pannelli") contenenti dati relativi al dominio ambientale;
- *Scenario Principale*:
+ L'#glossary("amministratore pubblico") accede alla piattaforma di visualizzazione;
+ L'#glossary("amministratore pubblico") seleziona la visualizzazione del dominio ambientale.
#figure(
image("assets/UML/UC2_Visualizzazione-dashboard-dati-ambientali.png",width:70%),
caption: [UC2 Visualizzazione #glossary("dashboard") dati ambientali]
)
=== UC2.1: Visualizzazione #glossary("pannello") dati ambientali
- *Attore Principale*: #glossary("amministratore pubblico")\;
- *Precondizioni*: l'#glossary("amministratore pubblico") ha selezionato la visualizzazione relativa al dominio dei dati ambientali;
- *Postcondizioni*: l'#glossary("amministratore pubblico") visualizza un #glossary("pannello") contenente dati relativi al dominio ambientale;
- *Scenario Principale*:
+ L'#glossary("amministratore pubblico") accede alla piattaforma di visualizzazione;
+ L'#glossary("amministratore pubblico") seleziona la visualizzazione del dominio ambientale.
- *Specializzazioni*: [UC2.2], [UC2.3], [UC2.4], [UC2.5], [UC2.6], [UC2.7], [UC2.8], [UC2.9], [UC2.10], [UC2.11], [UC2.12], [UC2.13];
- *Estensioni*: [UC9].
#figure(
image("assets/UML/UC2.1_Visualizzazione-pannello-dati-ambientali.png",width:100%),
caption: [UC2.1 Visualizzazione #glossary("pannello") dati ambientali]
)
#pagebreak()
=== UC2.2: Visualizzazione #glossary("pannello") #glossary("time series") per temperatura
- *Attore Principale*: #glossary("amministratore pubblico")\;
- *Precondizioni*: l'#glossary("amministratore pubblico") ha selezionato la visualizzazione relativa al dominio dei dati ambientali;
- *Postcondizioni*: l'#glossary("amministratore pubblico") visualizza un #glossary("pannello") contenente un grafico relativo alla temperatura, espressa in gradi Celsius (°C), in formato #glossary("time series") che ne mostra l'andamento in media aritmetica distinto per #glossary("sensore"), aggregando i dati per intervalli di 1 minuto. Il grafico mostra anche l'andamento in media aritmetica di tutti i sensori, aggregando i dati per intervalli di 5 minuti;
- *Scenario Principale*:
+ L'#glossary("amministratore pubblico") accede alla piattaforma di visualizzazione;
+ L'#glossary("amministratore pubblico") seleziona la visualizzazione del dominio ambientale.
#figure(
image("assets/UML/UC2.2_Visualizzazion-pannello-time-series-per-temperatura.png",width:100%),
caption: [UC2.2 Visualizzazione #glossary("pannello") #glossary[time series] per temperatura]
)
=== UC2.3: Visualizzazione #glossary("pannello") #glossary[time series] per umidità
- *Attore Principale*: #glossary("amministratore pubblico")\;
- *Precondizioni*: l'#glossary("amministratore pubblico") ha selezionato la visualizzazione relativa al dominio dei dati ambientali;
- *Postcondizioni*: l'#glossary("amministratore pubblico") visualizza un #glossary("pannello") contenente un grafico relativo all'umidità, espressa in percentuale, in formato #glossary("time series") che ne mostra l'andamento in media aritmetica distinto per #glossary("sensore"), aggregando i dati per intervalli di 1 minuto. Il grafico mostra anche l'andamento in media aritmetica di tutti i sensori, aggregando i dati per intervalli di 5 minuti;
- *Scenario Principale*:
+ L'#glossary("amministratore pubblico") accede alla piattaforma di visualizzazione;
+ L'#glossary("amministratore pubblico") seleziona la visualizzazione del dominio ambientale.
#figure(
image("assets/UML/UC2.3_Visualizzazione-pannello-time-series-umidità.png",width:100%),
caption: [UC2.3 Visualizzazione #glossary("pannello") #glossary[time series] per umidità]
)
=== UC2.4: Visualizzazione grafico a mappa direzione del vento
- *Attore Principale*: #glossary("amministratore pubblico")\;
- *Precondizioni*: l'#glossary("amministratore pubblico") ha selezionato la visualizzazione relativa al dominio dei dati ambientali;
- *Postcondizioni*: l'#glossary("amministratore pubblico") visualizza un #glossary("pannello") contenente una mappa che esprime, mediante frecce aventi origine nelle coordinate geografiche del #glossary("sensore"), la direzione del vento rilevata da ciascun #glossary("sensore")\;
- *Scenario Principale*:
+ L'#glossary("amministratore pubblico") accede alla piattaforma di visualizzazione;
+ L'#glossary("amministratore pubblico") seleziona la visualizzazione del dominio ambientale.
#figure(
image("assets/UML/UC2.4_Visualizzazione-grafico-a-mappa-direzione-del-vento.png",width:100%),
caption: [UC2.4 Visualizzazione grafico a mappa direzione del vento]
)
=== UC2.5: Visualizzazione tabella velocità del vento
- *Attore Principale*: #glossary("amministratore pubblico")\;
- *Precondizioni*: l'#glossary("amministratore pubblico") ha selezionato la visualizzazione relativa al dominio dei dati ambientali;
- *Postcondizioni*: l'#glossary("amministratore pubblico") visualizza un #glossary("pannello") contenente gli ultimi dati relativi alla velocità del vento, espressa in chilometri all'ora (km/h), e alla sua direzione, espressa in gradi (con gli 0° a Est e i 180° a Ovest), registrate da ciascun #glossary("sensore") (di cui viene riportato il nome), sotto forma tabellare;
- *Scenario Principale*:
+ L'#glossary("amministratore pubblico") accede alla piattaforma di visualizzazione;
+ L'#glossary("amministratore pubblico") seleziona la visualizzazione del dominio ambientale.
#figure(
image("assets/UML/UC2.5_Visualizzazione-tabella-velocità-del-vento.png",width:100%),
caption: [UC2.5 Visualizzazione tabella velocità del vento]
)
=== UC2.6: Visualizzazione #glossary("pannello") #glossary[time series] per precipitazioni
- *Attore Principale*: #glossary("amministratore pubblico")\;
- *Precondizioni*: l'#glossary("amministratore pubblico") ha selezionato la visualizzazione relativa al dominio dei dati ambientali;
- *Postcondizioni*: l'#glossary("amministratore pubblico") visualizza un #glossary("pannello") contenente un grafico relativo all'intensità delle precipitazioni, espressa in millimetri orari (mm/h), in formato #glossary("time series") che ne mostra l'andamento in media aritmetica distinto per #glossary("sensore"), aggregando i dati per intervalli di 1 minuto. Il grafico mostra anche l'andamento in media aritmetica di tutti i sensori, aggregando i dati per intervalli di 5 minuti;
- *Scenario Principale*:
+ L'#glossary("amministratore pubblico") accede alla piattaforma di visualizzazione;
+ L'#glossary("amministratore pubblico") seleziona la visualizzazione del dominio ambientale.
#figure(
image("assets/UML/UC2.6_Visualizzazione-pannello-time-series-per-precipitazioni.png",width:100%),
caption: [UC2.6 Visualizzazione #glossary("pannello") #glossary[time series] per precipitazioni]
)
#pagebreak()
=== UC2.7: Visualizzazione #glossary("pannello") precipitazioni medie
- *Attore Principale*: #glossary("amministratore pubblico")\;
- *Precondizioni*: l'#glossary("amministratore pubblico") ha selezionato la visualizzazione relativa al dominio dei dati ambientali;
- *Postcondizioni*: l'#glossary("amministratore pubblico") visualizza un #glossary("pannello") contenente un indice numerico relativo alle precipitazioni, espresse millimetri di pioggia all'ora (mm/h), indicante la media dell'intensità delle precipitazioni tra tutti i dati raccolti dai sensori nell'intervallo di tempo impostato all'interno della #glossary[dashboard] [UC6.4];
- *Scenario Principale*:
+ L'#glossary("amministratore pubblico") accede alla piattaforma di visualizzazione;
+ L'#glossary("amministratore pubblico") seleziona la visualizzazione del dominio ambientale.
#figure(
image("assets/UML/UC2.7_Visualizzazione-pannello-precipitazioni-medie.png",width:100%),
caption: [UC2.7 Visualizzazione #glossary("pannello") precipitazioni medie]
)
=== UC2.8: Visualizzazione #glossary("pannello") #glossary[time series] per inquinamento dell'aria
- *Attore Principale*: #glossary("amministratore pubblico")\;
- *Precondizioni*: l'#glossary("amministratore pubblico") ha selezionato la visualizzazione relativa al dominio dei dati ambientali;
- *Postcondizioni*: l'#glossary("amministratore pubblico") visualizza un #glossary("pannello") contenente un grafico relativo al livello di polveri sottili nell'aria, espresso in $#sym.mu g\/m^3$ (#glossary("PM10")), in formato #glossary("time series"), che ne mostra l'andamento in media aritmetica distinto per #glossary("sensore"), aggregando i dati per intervalli di 1 minuto. Il grafico mostra anche l'andamento in media aritmetica di tutti i sensori, aggregando i dati per intervalli di 5 minuti;
- *Scenario Principale*:
+ L'#glossary("amministratore pubblico") accede alla piattaforma di visualizzazione;
+ L'#glossary("amministratore pubblico") seleziona la visualizzazione del dominio ambientale.
#figure(
image("assets/UML/UC2.8_Visualizzazione-pannello-time-series-per-inquinamento-dell-aria.png",width:100%),
caption: [UC2.8 Visualizzazione #glossary("pannello") #glossary[time series] per inquinamento dell'aria]
)
=== UC2.9: Visualizzazione #glossary("pannello") inquinamento dell'aria medio
- *Attore Principale*: #glossary("amministratore pubblico")\;
- *Precondizioni*: l'#glossary("amministratore pubblico") ha selezionato la visualizzazione relativa al dominio dei dati ambientali;
- *Postcondizioni*: l'#glossary("amministratore pubblico") visualizza un #glossary("pannello") contenente la media della concentrazione di inquinanti dell'aria, espressa in $#sym.mu g\/m^3$ (#glossary("PM10")), considerando tutti i sensori attivi nell'ultimo minuto, e presentata in formato numerico;
- *Scenario Principale*:
+ L'#glossary("amministratore pubblico") accede alla piattaforma di visualizzazione;
+ L'#glossary("amministratore pubblico") seleziona la visualizzazione del dominio ambientale.
#figure(
image("assets/UML/UC2.9_Visualizzazione-pannello-inquinamento-dell-aria-medio.png",width:100%),
caption: [UC2.9 Visualizzazione #glossary("pannello") inquinamento dell'aria medio]
)
=== UC2.10: Visualizzazione #glossary("pannello") #glossary[time series] per livello dei bacini idrici
- *Attore Principale*: #glossary("amministratore pubblico")\;
- *Precondizioni*: l'#glossary("amministratore pubblico") ha selezionato la visualizzazione relativa al dominio dei dati ambientali;
- *Postcondizioni*: l'#glossary("amministratore pubblico") visualizza un #glossary("pannello") contenente un grafico relativo alla percentuale di riempimento dei bacini idrici, in formato #glossary("time series"), che ne mostra l'andamento in media aritmetica distinto per #glossary("sensore"), aggregando i dati per intervalli di 1 minuto. Il grafico mostra anche l'andamento in media aritmetica di tutti i sensori, aggregando i dati per intervalli di 5 minuti;
- *Scenario Principale*:
+ L'#glossary("amministratore pubblico") accede alla piattaforma di visualizzazione;
+ L'#glossary("amministratore pubblico") seleziona la visualizzazione del dominio ambientale.
#figure(
image("assets/UML/UC2.10_Visualizzazione-pannello-time-series-per-livello-dei-bacini-idrici.png",width:100%),
caption: [UC2.10 Visualizzazione #glossary("pannello") #glossary[time series] per livello dei bacini idrici]
)
=== UC2.11: Visualizzazione #glossary("pannello") temperatura media
- *Attore Principale*: #glossary("amministratore pubblico")\;
- *Precondizioni*: l'#glossary("amministratore pubblico") ha selezionato la visualizzazione relativa al dominio dei dati ambientali;
- *Postcondizioni*: l'#glossary("amministratore pubblico") visualizza un #glossary("pannello") contenente la media della temperatura, espressa in gradi Celsius (°C), considerando tutti i sensori attivi nell'intervallo di tempo impostato all'interno della #glossary[dashboard] [UC6.4], e presentata in formato numerico;
- *Scenario Principale*:
+ L'#glossary("amministratore pubblico") accede alla piattaforma di visualizzazione;
+ L'#glossary("amministratore pubblico") seleziona la visualizzazione del dominio ambientale.
#figure(
image("assets/UML/UC2.11_Visualizzazione-pannello-temperatura-media.png",width:100%),
caption: [UC2.11 Visualizzazione #glossary("pannello") temperatura media]
)
#pagebreak()
=== UC2.12: Visualizzazione #glossary("pannello") inquinamento dell'aria massimo
- *Attore Principale*: #glossary("amministratore pubblico")\;
- *Precondizioni*: l'#glossary("amministratore pubblico") ha selezionato la visualizzazione relativa al dominio dei dati ambientali;
- *Postcondizioni*: l'#glossary("amministratore pubblico") visualizza un #glossary("pannello") contenente il massimo coefficiente di inquinamento dell'aria registrato tra tutti i sensori, espresso in $#sym.mu g\/m^3$, negli ultimi 5 minuti, presentato in formato numerico;
- *Scenario Principale*:
+ L'#glossary("amministratore pubblico") accede alla piattaforma di visualizzazione;
+ L'#glossary("amministratore pubblico") seleziona la visualizzazione del dominio ambientale.
#figure(
image("assets/UML/UC2.12_Visualizzazione-pannello-inquinamento-dell-aria-massimo.png",width:100%),
caption: [UC2.12 Visualizzazione #glossary("pannello") inquinamento dell'aria massimo]
)
=== UC2.13: Visualizzazione posizione sensori su mappa
- *Attore Principale*: #glossary("amministratore pubblico")\;
- *Precondizioni*: il #glossary("sistema") è operativo e accessibile;
- *Postcondizioni*: l'#glossary("amministratore pubblico") visualizza un #glossary("pannello") contenente una mappa che mostra le posizioni dei sensori, visualizzati tramite icone collocate nelle corrispondenti coordinate geografiche, su di essa. Le icone dei sensori sono colorate in base al tipo di #glossary("sensore") e riportano una label che ne esplicita il nome;
- *Scenario Principale*:
+ L'#glossary("amministratore pubblico") accede alla piattaforma di visualizzazione;
+ L'#glossary("amministratore pubblico") seleziona la visualizzazione del dominio ambientale.
#figure(
image("assets/UML/UC2.13_Visualizzazione-posizione-sensori-su-mappa.png",width:100%),
caption: [UC2.13 Visualizzazione posizione sensori su mappa]
)
=== UC3: Visualizzazione #glossary("dashboard") dati urbanistici
- *Attore Principale*: #glossary("amministratore pubblico")\;
- *Precondizioni*: il #glossary("sistema") è operativo e accessibile;
- *Postcondizioni*: l'#glossary("amministratore pubblico") visualizza una lista di #glossary("pannelli") contenenti dati relativi al dominio urbanistico;
- *Scenario Principale*:
+ L'#glossary("amministratore pubblico") accede alla piattaforma di visualizzazione;
+ L'#glossary("amministratore pubblico") seleziona la visualizzazione del dominio urbanistico.
#figure(
image("assets/UML/UC3_Visualizzazione-dashboard-dati-urbanistici.png",width:60%),
caption: [UC3 Visualizzazione #glossary("dashboard") dati urbanistici]
)
=== UC3.1: Visualizzazione #glossary("pannello") dati urbanistici
- *Attore Principale*: #glossary("amministratore pubblico")\;
- *Precondizioni*: l'#glossary("amministratore pubblico") ha selezionato la visualizzazione relativa al dominio dei dati urbanistici;
- *Postcondizioni*: l'#glossary("amministratore pubblico") visualizza un #glossary("pannello") contenente dati relativi al dominio urbanistico;
- *Scenario Principale*:
+ L'#glossary("amministratore pubblico") accede alla piattaforma di visualizzazione;
+ L'#glossary("amministratore pubblico") seleziona la visualizzazione del dominio urbanistico.
- *Specializzazioni*: [UC3.2], [UC3.3], [UC3.4], [UC3.5], [UC3.6], [UC3.7];
- *Estensioni*: [UC9].
#figure(
image("assets/UML/UC3.1_Visualizzazione-pannello-dati-urbanistici.png",width:100%),
caption: [UC3.1 Visualizzazione #glossary("pannello") dati urbanistici]
)
=== UC3.2: Visualizzazione mappa disponibilità parcheggi
- *Attore Principale*: #glossary("amministratore pubblico")\;
- *Precondizioni*: l'#glossary("amministratore pubblico") ha selezionato la visualizzazione relativa al dominio dei dati urbanistici;
- *Postcondizioni*: l'#glossary("amministratore pubblico") visualizza un #glossary("pannello") contenente una mappa per indicare la disponibilità dei parcheggi, espressa in numero di posti auto liberi, registrata da ciascun #glossary("sensore"), attraverso un indicatore numerico posto nelle coordinate geografiche del corrispondente #glossary("sensore")\;
- *Scenario Principale*:
+ L'#glossary("amministratore pubblico") accede alla piattaforma di visualizzazione;
+ L'#glossary("amministratore pubblico") seleziona la visualizzazione del dominio urbanistico.
#figure(
image("assets/UML/UC3.2_Visualizzazione-grafico-a-mappa-disponibilità-parcheggi.png",width:100%),
caption: [UC3.2 Visualizzazione mappa disponibilità parcheggi]
)
#pagebreak()
=== UC3.3: Visualizzazione grafico a mappa disponibilità delle colonne di ricarica
- *Attore Principale*: #glossary[amministratore pubblico]\;
- *Precondizioni*: l'#glossary[amministratore pubblico] ha selezionato la visualizzazione relativa al dominio dei dati urbanistici;
- *Postcondizioni*: l'#glossary("amministratore pubblico") visualizza un #glossary("pannello") contenente una mappa indicante la disponibilità delle colonne di ricarica per auto, mediante icone colorate in base alla disponibilità, posizionate in corrispondenza della posizione stessa del #glossary("sensore")\;
- *Scenario Principale*:
+ L'#glossary[amministratore pubblico] accede alla piattaforma di visualizzazione;
+ L'#glossary[amministratore pubblico] seleziona la visualizzazione del dominio urbanistico.
#figure(
image("assets/UML/UC3.3_Visualizzazione-mappa-delle-colonne-di-ricarica.png",width:100%),
caption: [UC3.3 Visualizzazione grafico a mappa disponibilità delle colonne di ricarica]
)
=== UC3.4: Visualizzazione tabella descrittiva delle colonne di ricarica
- *Attore Principale*: #glossary("amministratore pubblico")\;
- *Precondizioni*: l'#glossary("amministratore pubblico") ha selezionato la visualizzazione relativa al dominio dei dati urbanistici;
- *Postcondizioni*: l'#glossary("amministratore pubblico") visualizza un #glossary("pannello") contenente una tabella, la quale riporta dati relativi all'erogazione in chiloWatt per ora (kWh) attuale registrata da ciascun #glossary("sensore") (di cui viene riportato il nome);
- *Scenario Principale*:
+ L'#glossary("amministratore pubblico") accede alla piattaforma di visualizzazione;
+ L'#glossary("amministratore pubblico") seleziona la visualizzazione del dominio urbanistico.
#figure(
image("assets/UML/UC3.4_Visualizzazione-tabella-descrittiva-delle-colonne-di-ricarica.png",width:100%),
caption: [UC3.4 Visualizzazione tabella descrittiva delle colonne di ricarica]
)
=== UC3.5: Visualizzazione grafico a mappa congestione stradale
*Attore Principale*: #glossary("amministratore pubblico")\;
- *Precondizioni*: l'#glossary("amministratore pubblico") ha selezionato la visualizzazione relativa al dominio dei dati urbanistici;
- *Postcondizioni*: l'#glossary("amministratore pubblico") visualizza un #glossary("pannello") contenente una mappa indicante lo stato di congestione delle strade; ciascuna strada monitorata da un #glossary[sensore] riporta uno stato tra "LOW", "MEDIUM", "HIGH" e "BLOCKED", in base al livello di congestione;
- *Scenario Principale*:
+ L'#glossary("amministratore pubblico") accede alla piattaforma di visualizzazione;
+ L'#glossary("amministratore pubblico") seleziona la visualizzazione del dominio urbanistico.
#figure(
image("assets/UML/UC3.5_Visualizzazione-grafico-a-mappa-intensità-traffico.png",width:100%),
caption: [UC3.5 Visualizzazione grafico a mappa congestione stradale]
)
=== UC3.6: Visualizzazione grafico a mappa delle biciclette elettriche
*Attore Principale*: #glossary("amministratore pubblico")\;
- *Precondizioni*: l'#glossary("amministratore pubblico") ha selezionato la visualizzazione relativa al dominio dei dati urbanistici;
- *Postcondizioni*: l'#glossary("amministratore pubblico") visualizza un #glossary("pannello") contenente una mappa indicante la posizione in tempo reale delle biciclette elettriche, mediante degli indicatori numerici indicanti la percentuale della batteria posizionati in corrispondenza delle coordinate geografiche del #glossary[sensore] monitorante il mezzo;
- *Scenario Principale*:
+ L'#glossary("amministratore pubblico") accede alla piattaforma di visualizzazione;
+ L'#glossary("amministratore pubblico") seleziona la visualizzazione del dominio urbanistico.
#figure(
image("assets/UML/UC3.6_Visualizzazione-posizione-real-time-delle-biciclette-elettriche-e-relativa-percentuale-batteria.png",width:100%),
caption: [UC3.6 Visualizzazione grafico a mappa delle biciclette elettriche]
)
=== UC3.7: Visualizzazione grafico a mappa delle zone ecologiche
*Attore Principale*: #glossary("amministratore pubblico")\;
- *Precondizioni*: l'#glossary("amministratore pubblico") ha selezionato la visualizzazione relativa al dominio dei dati urbanistici;
- *Postcondizioni*: l'#glossary("amministratore pubblico") visualizza un #glossary("pannello") contenente una mappa indicante lo stato di riempimento delle zone ecologiche, espresso in valori percentuali posizionati in corrispondenza delle coordinate geografiche delle zone ecologiche;
- *Scenario Principale*:
+ L'#glossary("amministratore pubblico") accede alla piattaforma di visualizzazione;
+ L'#glossary("amministratore pubblico") seleziona la visualizzazione del dominio urbanistico.
#figure(
image("assets/UML/UC3.7_Visualizzazione-indicatore-percentuale-su-mappa-riempimento-zone-rifiuti.png",width:100%),
caption: [UC3.7 Visualizzazione grafico a mappa delle zone ecologiche]
)
#pagebreak()
=== UC4: Visualizzazione #glossary("dashboard") superamento soglie
- *Attore Principale*: #glossary("amministratore pubblico")\;
- *Precondizioni*: il #glossary("sistema") è operativo e accessibile;
- *Postcondizioni*: l'#glossary("amministratore pubblico") visualizza una lista di #glossary("pannelli") contenenti dati relativi al superamento delle soglie;
- *Scenario Principale*:
+ L'#glossary("amministratore pubblico") seleziona la visualizzazione della #glossary[dashboard] superamento soglie.
#figure(
image("assets/UML/UC4_Visualizzazione-dashboard-dati-anomali-e-superamento-soglie.png",width:60%),
caption: [UC4 Visualizzazione #glossary("dashboard") superamento soglie]
)
=== UC4.1: Visualizzazione tabella #glossary("dati anomali")
- *Attore Principale*: #glossary("amministratore pubblico")\;
- *Precondizioni*: il #glossary("sistema") è operativo e accessibile;
- *Postcondizioni*: l'#glossary("amministratore pubblico") visualizza un #glossary("pannello") contenente una tabella ordinata, che mostra tutti i #glossary("dati anomali") rilevati dal #glossary("sistema"). La tabella include il valore dell'anomalia, il nome del #glossary("sensore") che l'ha rilevata e il timestamp relativo;
- *Scenario Principale*:
+ L'#glossary("amministratore pubblico") seleziona la visualizzazione della #glossary[dashboard] superamento soglie.
#figure(
image("assets/UML/UC4.1_Visualizzazione-tabella-dati-anomali.png",width:70%),
caption: [UC4.1 Visualizzazione tabella #glossary("dati anomali")]
)
=== UC4.2: Visualizzazione #glossary[pannello] superamento soglie
- *Attore Principale*: #glossary("amministratore pubblico")\;
- *Precondizioni*: il #glossary("sistema") è operativo e accessibile;
- *Postcondizioni*: l'#glossary("amministratore pubblico") visualizza un #glossary("pannello") contenente una tabella, la quale mostra tutti i dati di un determinato tipo superanti la soglia impostata nel #glossary("sistema")\;
- *Scenario Principale*:
+ L'#glossary("amministratore pubblico") seleziona la visualizzazione della #glossary[dashboard] superamento soglie;
- *Specializzazioni*: [UC4.3], [UC4.4], [UC4.5], [UC4.6], [UC4.7].
- *Estensioni*: [UC9].
#figure(
image("assets/UML/UC4.2_Visualizzazione-tabella-superamento-soglie.png",width:100%),
caption: [UC4.2 Visualizzazione #glossary[pannello] superamento soglie]
)
=== UC4.3: Visualizzazione tabella superamento soglia di temperatura
- *Attore Principale*: #glossary("amministratore pubblico")\;
- *Precondizioni*: il #glossary("sistema") è operativo e accessibile;
- *Postcondizioni*: l'#glossary("amministratore pubblico") visualizza un #glossary("pannello") contenente una tabella, la quale mostra tutti i dati superanti la soglia dei 40° Celsius (40°C), mostrando il valore superante la soglia, il #glossary("sensore") che ha rilevato tale valore e il timestamp relativo;
- *Scenario Principale*:
+ L'#glossary("amministratore pubblico") seleziona la visualizzazione della #glossary[dashboard] superamento soglie.
#figure(
image("assets/UML/UC4.3_Visualizzazione-tabella-superamento-soglia-temperatura.png",width:100%),
caption: [UC4.3 Visualizzazione tabella superamento soglia di temperatura]
)
=== UC4.4: Visualizzazione tabella superamento soglia di precipitazioni
- *Attore Principale*: #glossary("amministratore pubblico")\;
- *Precondizioni*: il #glossary("sistema") è operativo e accessibile;
- *Postcondizioni*: l'#glossary("amministratore pubblico") visualizza un #glossary("pannello") contenente una tabella, la quale mostra tutti i dati superanti la soglia dei 50 millimetri di pioggia all'ora (50 mm/h), mostrando il valore superante la soglia, il #glossary("sensore") che ha rilevato tale valore e il timestamp relativo;
- *Scenario Principale*:
+ L'#glossary("amministratore pubblico") seleziona la visualizzazione della #glossary[dashboard] superamento soglie.
#figure(
image("assets/UML/UC4.4_Visualizzazione-tabella-superamento-soglia-precipitazioni.png",width:100%),
caption: [UC4.4 Visualizzazione tabella superamento soglia di precipitazioni]
)
=== UC4.5: Visualizzazione tabella superamento soglia di inquinamento dell'aria
- *Attore Principale*: #glossary("amministratore pubblico")\;
- *Precondizioni*: il #glossary("sistema") è operativo e accessibile;
- *Postcondizioni*: l'#glossary("amministratore pubblico") visualizza un #glossary("pannello") contenente una tabella, la quale mostra tutti i dati superanti la soglia di 80#[#sym.mu]g su metro cubo ($80#sym.mu g\/m^3$), mostrando il valore superante la soglia, il #glossary("sensore") che ha rilevato tale valore e il timestamp relativo;
- *Scenario Principale*:
+ L'#glossary("amministratore pubblico") seleziona la visualizzazione della #glossary[dashboard] superamento soglie.
#figure(
image("assets/UML/UC4.5_Visualizzazione-tabella-superamento-soglia-inquinamento.png",width:100%),
caption: [UC4.5 Visualizzazione tabella superamento soglia di inquinamento dell'aria]
)
=== UC4.6: Visualizzazione tabella superamento soglia dei bacini idrici
- *Attore Principale*: #glossary("amministratore pubblico")\;
- *Precondizioni*: il #glossary("sistema") è operativo e accessibile;
- *Postcondizioni*: l'#glossary("amministratore pubblico") visualizza un #glossary("pannello") contenente una tabella, la quale mostra tutti i dati superanti la soglia del 70% di capienza, mostrando il valore superante la soglia, il #glossary("sensore") che ha rilevato tale valore e il timestamp relativo;
- *Scenario Principale*:
+ L'#glossary("amministratore pubblico") seleziona la visualizzazione della #glossary[dashboard] superamento soglie.
#figure(
image("assets/UML/UC4.6_Visualizzazione-tabella-superamento-soglia-bacini.png",width:100%),
caption: [UC4.6 Visualizzazione tabella superamento soglia dei bacini idrici]
)
=== UC4.7: Visualizzazione tabella superamento soglia delle zone ecologiche
- *Attore Principale*: #glossary("amministratore pubblico")\;
- *Precondizioni*: il #glossary("sistema") è operativo e accessibile;
- *Postcondizioni*: l'#glossary("amministratore pubblico") visualizza un #glossary("pannello") contenente una tabella, la quale mostra tutti i dati superanti la soglia del 80% di capienza, mostrando il valore superante la soglia, il #glossary("sensore") che ha rilevato tale valore e il timestamp relativo;
- *Scenario Principale*:
+ L'#glossary("amministratore pubblico") seleziona la visualizzazione della #glossary[dashboard] superamento soglie.
#figure(
image("assets/UML/UC4.7_Visualizzazione-tabella-superamento-soglia-cassonetti.png",width:100%),
caption: [UC4.7 Visualizzazione tabella superamento soglia delle zone ecologiche]
)
#pagebreak()
=== UC5: Visualizzazione notifiche di superamento soglia
- *Attore Principale*: #glossary("amministratore pubblico")\;
- *Precondizioni*: il #glossary("sistema") è operativo e accessibile;
- *Postcondizioni*: l'#glossary("amministratore pubblico") visualizza una lista di notifiche che denotano il superamento di una soglia impostata;
- *Scenario Principale*:
+ Il #glossary("sistema") rileva condizioni che richiedono l'invio di notifiche per segnalare il superamento di una soglia impostata.
#figure(
image("assets/UML/UC5_Ricezione-notifiche-superamento-soglie.png",width:70%),
caption: [UC5 Visualizzazione notifiche di superamento soglia]
)
=== UC5.1: Visualizzazione singola notifica di superamento soglia
- *Attore Principale*: #glossary("amministratore pubblico")\;
- *Precondizioni*: il #glossary("sistema") è operativo e accessibile;
- *Postcondizioni*: l'#glossary("amministratore pubblico") visualizza una notifica che denota il superamento di una soglia impostata;
- *Scenario Principale*:
+ Il #glossary("sistema") rileva condizioni che richiedono l'invio di una notifica per segnalare il superamento di una soglia impostata.
- *Specializzazioni*: [UC5.2], [UC5.3], [UC5.4], [UC5.5], [UC5.6].
#figure(
image("assets/UML/UC5.1_Visualizzazione-singola-notifica-di-superamento-soglia.png",width:70%),
caption: [UC5.1 Visualizzazione singola notifica di superamento soglia]
)
=== UC5.2: Visualizzazione notifica di superamento soglia temperatura
- *Attore Principale*: #glossary("amministratore pubblico")\;
- *Precondizioni*: il #glossary("sistema") è operativo e accessibile;
- *Postcondizioni*: l'#glossary("amministratore pubblico") visualizza una notifica relativa alla temperatura che denota il superamento dei 40° Celsius (40°C); la notifica riporta il nome del #glossary[sensore] che ha effettuato la misurazione il cui valore supera la soglia e il valore esatto della temperatura;
- *Scenario Principale*:
+ Il #glossary("sistema") rileva una temperatura superiore ai 40° Celsius (40°C) negli ultimi 5 minuti.
#figure(
image("assets/UML/UC5.2_Visualizzazione-allerte-superamento-soglia-temperatura.png",width:70%),
caption: [UC5.2 Visualizzazione notifica di superamento soglia temperatura]
)
#pagebreak()
=== UC5.3: Visualizzazione notifica di superamento soglia precipitazioni
- *Attore Principale*: #glossary("amministratore pubblico")\;
- *Precondizioni*: il #glossary("sistema") è operativo e accessibile;
- *Postcondizioni*: l'#glossary("amministratore pubblico") visualizza una notifica relativa alle precipitazioni che denota il superamento dei 50 millimetri di pioggia all'ora (50 mm/h); la notifica riporta il nome del #glossary[sensore] che ha effettuato la misurazione il cui valore supera la soglia e il valore esatto dell'intensità delle precipitazioni;
- *Scenario Principale*:
+ Il #glossary("sistema") rileva un livello di precipitazioni superiore ai 50 millimetri di pioggia all'ora (50 mm/h) negli ultimi 5 minuti.
#figure(
image("assets/UML/UC5.3_Visualizzazione-allerte-superamento-soglia-precipitazioni.png",width:70%),
caption: [UC5.3 Visualizzazione notifica di superamento soglia precipitazioni]
)
=== UC5.4: Visualizzazione notifica di superamento soglia inquinamento dell'aria
- *Attore Principale*: #glossary("amministratore pubblico")\;
- *Precondizioni*: il #glossary("sistema") è operativo e accessibile;
- *Postcondizioni*: l'#glossary("amministratore pubblico") visualizza una notifica relativa all'inquinamento dell'aria che denota il superamento di 80#[#sym.mu]g su metro cubo ($80#sym.mu g\/m^3$); la notifica riporta il nome del #glossary[sensore] che ha effettuato la misurazione il cui valore supera la soglia e il valore esatto dell'inquinamento dell'aria;
- *Scenario Principale*:
+ Il #glossary("sistema") rileva un coefficiente di inquinamento dell'aria (#glossary("PM10")) superiore ai 80#[#sym.mu]g su metro cubo ($80#sym.mu g\/m^3$) negli ultimi 5 minuti.
#figure(
image("assets/UML/UC5.4_Visualizzazione-allerte-superamento-soglia-inquinamento-dell'aria.png",width:70%),
caption: [UC5.4 Visualizzazione notifica di superamento soglia inquinamento dell'aria]
)
=== UC5.5: Visualizzazione notifica di superamento soglia bacini idrici
- *Attore Principale*: #glossary("amministratore pubblico")\;
- *Precondizioni*: il #glossary("sistema") è operativo e accessibile;
- *Postcondizioni*: l'#glossary("amministratore pubblico") visualizza una notifica relativa ai bacini idrici che denota il superamento del 70% della capienza di un particolare bacino; la notifica riporta il nome del #glossary[sensore] che ha effettuato la misurazione il cui valore supera la soglia e il valore esatto del riempimento del bacino idrico;
- *Scenario Principale*:
+ Il #glossary("sistema") rileva che il livello di un particolare bacino idrico è superiore al 70% della sua capienza negli ultimi 5 minuti.
#figure(
image("assets/UML/UC5.5_Visualizzazione-allerte-superamento-soglia-bacini-idrici.png",width:70%),
caption: [UC5.5 Visualizzazione notifica di superamento soglia bacini idrici]
)
=== UC5.6: Visualizzazione notifica di superamento soglia zone ecologiche
- *Attore Principale*: #glossary("amministratore pubblico")\;
- *Precondizioni*: il #glossary("sistema") è operativo e accessibile;
- *Postcondizioni*: l'#glossary("amministratore pubblico") visualizza una notifica relativa alle zone ecologiche che denota il superamento dell'80% della capienza di una particolare zona ecologica; la notifica riporta il nome del #glossary[sensore] che ha effettuato la misurazione il cui valore supera la soglia e il valore esatto del riempimento della zona ecologica;
- *Scenario Principale*:
+ Il #glossary("sistema") rileva che il livello di una particolare zona ecologica è superiore all'80% della sua capienza negli ultimi 5 minuti.
#figure(
image("assets/UML/UC5.6_Visualizzazione-allerte-superamento-soglia-zone-ecologiche.png",width:70%),
caption: [UC5.6 Visualizzazione notifica di superamento soglia zone ecologiche]
)
=== UC6: Applicazione filtri
- *Attore Principale*: #glossary("amministratore pubblico")\;
- *Precondizioni*: l'#glossary("amministratore pubblico") sta visualizzando uno o più #glossary("pannelli") con i dati;
- *Postcondizioni*: l'#glossary("amministratore pubblico") visualizza solamente i dati relativi al filtro applicato (oppure ai filtri applicati);
- *Scenario Principale*:
+ L'#glossary("amministratore pubblico") seleziona l'icona o il pulsante relativo al filtro dei dati;
+ L'#glossary("amministratore pubblico") seleziona secondo quali valori filtrare il #glossary("pannello") (o i #glossary("pannelli")).
#figure(
image("assets/UML/UC6_Applicazione-filtri.png",width:70%),
caption: [UC6 Applicazione filtri]
)
=== UC6.1: Filtro sotto-insieme di sensori su grafici #glossary[time series]
- *Attore Principale*: #glossary("amministratore pubblico")\;
- *Precondizioni*:
+ L'#glossary("amministratore pubblico") sta visualizzando uno o più #glossary("pannelli") #glossary[time series] con i dati;
+ Il #glossary("pannello") offre la funzionalità di filtro dei dati tramite selezione di uno o più sensori.
- *Postcondizioni*: l'#glossary("amministratore pubblico") visualizza solamente i dati relativi ai sensori selezionati, all'interno di tale #glossary("pannello")\;
- *Scenario Principale*:
+ L'#glossary("amministratore pubblico") seleziona il #glossary("sensore") (o i sensori) da visualizzare tramite la legenda.
#figure(
image("assets/UML/UC6.1_Filtro-sotto-insieme-di-sensori-su-grafici-time-series.png",width:70%),
caption: [UC6.1 Filtro sotto-insieme di sensori su grafici #glossary[time series]]
)
/*Cambiare il numero nell'immagine*/
=== UC6.2: Filtro per tipologia #glossary("sensore") su tabella
- *Attore Principale*: #glossary("amministratore pubblico")\;
- *Precondizioni*:
+ L'#glossary("amministratore pubblico") sta visualizzando uno o più #glossary("pannelli") tabellari con i dati;
+ Il #glossary("pannello") offre la funzionalità di filtro dei dati tramite apposita icona o pulsante.
- *Postcondizioni*: l'#glossary("amministratore pubblico") visualizza solamente i dati relativi alle tipologie di #glossary("sensore") selezionate, all'interno di tale #glossary("pannello")\;
- *Scenario Principale*:
+ L'#glossary("amministratore pubblico") seleziona la funzionalità relativa al filtro dei dati;
+ L'#glossary("amministratore pubblico") seleziona i valori delle tipologie di #glossary("sensore") desiderati.
#figure(
image("assets/UML/UC6.2_Filtro-per-tipologia-sensore-su-tabella.png",width:70%),
caption: [UC6.2 Filtro per tipologia #glossary("sensore") su tabella]
)
=== UC6.3: Filtro per nome #glossary("sensore") su tabella
- *Attore Principale*: #glossary("amministratore pubblico")\;
- *Precondizioni*:
+ L'#glossary("amministratore pubblico") ha scelto un #glossary("pannello") su cui effettuare l'operazione di filtro;
+ Il #glossary("pannello") offre la funzionalità di filtro dei dati.
- *Postcondizioni*: l'#glossary("amministratore pubblico") visualizza solamente i dati relativi ai sensori selezionati, all'interno di tale #glossary("pannello")\;
- *Scenario Principale*:
+ L'#glossary("amministratore pubblico") seleziona la funzionalità relativa al filtro dei dati;
+ L'#glossary("amministratore pubblico") seleziona i valori dei nomi dei sensori desiderati.
#figure(
image("assets/UML/UC6.3_Filtro-per-nome-sensore-su-tabella.png",width:70%),
caption: [UC6.3 Filtro per nome #glossary("sensore") su tabella]
)
#pagebreak()
=== UC6.4: Filtro per intervallo temporale
- *Attore Principale*: #glossary("amministratore pubblico")\;
- *Precondizioni*: l'#glossary("amministratore pubblico") sta visualizzando uno o più #glossary("pannelli")\;
- *Postcondizioni*: l'#glossary("amministratore pubblico") visualizza solamente i dati relativi all'intervallo temporale selezionato, in tutti i #glossary("pannelli") della #glossary("dashboard") dove è stato applicato il filtro;
- *Scenario Principale*:
+ L'#glossary("amministratore pubblico") seleziona la funzionalità relativa al filtro dei dati per intervallo temporale;
+ L'#glossary("amministratore pubblico") seleziona l'intervallo temporale desiderato.
#figure(
image("assets/UML/UC6.4_Filtro-per-intervallo-temporale.png",width:70%),
caption: [UC6.4 Filtro per intervallo temporale]
)
=== UC7: Ordinamento #glossary("pannelli") tabellari
- *Attore Principale*: #glossary("amministratore pubblico")\;
- *Precondizioni*: l'#glossary("amministratore pubblico") sta visualizzando un #glossary("pannello"), con all'interno una tabella;
- *Postcondizioni*: l'#glossary("amministratore pubblico") visualizza i dati ordinati nella tabella, secondo il campo selezionato;
- *Scenario Principale*:
+ L'#glossary("amministratore pubblico") seleziona un campo della tabella, secondo cui ordinare i dati (le informazioni sono ordinabili rispetto a tutte le colonne della tabella);
+ Per tale campo l'#glossary("amministratore pubblico") sceglie tra l'ordinamento crescente e decrescente.
#figure(
image("assets/UML/UC7_Ordinamento-pannelli-tabellari.png",width:70%),
caption: [UC7 Ordinamento #glossary("pannelli") tabellari]
)
=== UC8: Modifica layout #glossary("pannelli")
- *Attore Principale*: #glossary("amministratore pubblico")\;
- *Precondizioni*: l'#glossary("amministratore pubblico") sta visualizzando almeno un #glossary("pannello")\;
- *Postcondizioni*: l'#glossary("amministratore pubblico") visualizza il nuovo layout;
- *Scenario Principale*:
+ L'#glossary("amministratore pubblico") modifica la dimensione e la posizione dei #glossary("pannelli") contenuti all'interno della #glossary("dashboard").
- *Specializzazioni*: [UC8.1], [UC8.2].
#figure(
image("assets/UML/UC8_Modifica-layout-pannelli.png",width:70%),
caption: [UC8 Modifica layout #glossary("pannelli")]
)
=== UC8.1: Spostamento #glossary("pannelli")
- *Attore Principale*: #glossary("amministratore pubblico")\;
- *Precondizioni*: l'#glossary("amministratore pubblico") sta visualizzando almeno un #glossary("pannello")\;
- *Postcondizioni*: l'#glossary("amministratore pubblico") visualizza il nuovo layout;
- *Scenario Principale*:
+ L'#glossary("amministratore pubblico") sposta i #glossary("pannelli") all'interno della #glossary[dashboard] a suo piacimento.
#figure(
image("assets/UML/UC8.1_Spostamento-pannelli.png",width:100%),
caption: [UC8.1 Spostamento #glossary("pannelli")]
)
=== UC8.2: Ridimensionamento #glossary("pannelli")
- *Attore Principale*: #glossary("amministratore pubblico")\;
- *Precondizioni*: l'#glossary("amministratore pubblico") sta visualizzando almeno un #glossary("pannello")\;
- *Postcondizioni*: l'#glossary("amministratore pubblico") visualizza il nuovo layout;
- *Scenario Principale*:
+ L'#glossary("amministratore pubblico") ridimensiona i #glossary("pannelli") a suo piacimento all'interno della #glossary[dashboard].
#figure(
image("assets/UML/UC8.2_Ridimensionamento-pannelli.png",width:100%),
caption: [UC8.2 Ridimensionamento #glossary("pannelli")]
)
/*Cambiare il numero nell'immagine*/
=== UC9: Visualizzazione errore nessun dato
- *Attore Principale*: #glossary("amministratore pubblico")\;
- *Precondizioni*: il #glossary("sistema") di visualizzazione non ottiene alcun dato da mostrare all'interno di un #glossary("pannello")\;
- *Postcondizioni*: l'#glossary("amministratore pubblico") visualizza un messaggio di errore segnalante l'assenza di dati da mostrare;
- *Scenario Principale*:
+ L'#glossary("amministratore pubblico") vuole visualizzare qualche #glossary("pannello") [UC1.1], [UC2.1], [UC3.1], [UC4.2];
+ Il #glossary("sistema") non ha i dati con cui popolare tale pannello.
#pagebreak()
=== UC10: Inserimento dati temperatura
- *Attore Principale*: #glossary("sensore")\;
- *Precondizioni*: il #glossary("sensore") è acceso e collegato al #glossary("sistema")\;
- *Postcondizioni*: il #glossary("sistema") ha persistito i dati inviati dal #glossary("sensore")\;
- *Scenario Principale*:
+ Il #glossary("sensore") effettua una rilevazione della temperatura;
+ Il #glossary("sensore") formatta il messaggio da inviare al #glossary("sistema"), di modo da mandare la temperatura, espressa in gradi Celsius (°C), il timestamp di rilevazione e le proprie coordinate geografiche;
+ Il #glossary("sensore") invia il messaggio al #glossary("sistema").
#figure(
image("assets/UML/UC10_Inserimento-dati-temperatura.png",width:70%),
caption: [UC10 Inserimento dati temperatura]
)
/*Cambiare il numero nell'immagine*/
=== UC11: Inserimento dati umidità
- *Attore Principale*: #glossary("sensore")\;
- *Precondizioni*: il #glossary("sensore") è acceso e collegato al #glossary("sistema")\;
- *Postcondizioni*: il #glossary("sistema") ha persistito i dati inviati dal #glossary("sensore")\;
- *Scenario Principale*:
+ Il #glossary("sensore") effettua una rilevazione dell'umidità relativa;
+ Il #glossary("sensore") formatta il messaggio da inviare al #glossary("sistema"), di modo da mandare la percentuale di umidità relativa, il timestamp di rilevazione e le proprie coordinate geografiche;
+ Il #glossary("sensore") invia il messaggio al #glossary("sistema").
#figure(
image("assets/UML/UC11_Inserimento-dati-umidità.png",width:70%),
caption: [UC11 Inserimento dati umidità]
)
=== UC12: Inserimento dati velocità e direzione del vento
- *Attore Principale*: #glossary("sensore")\;
- *Precondizioni*: il #glossary("sensore") è acceso e collegato al #glossary("sistema")\;
- *Postcondizioni*: il #glossary("sistema") ha persistito i dati inviati dal #glossary("sensore")\;
- *Scenario Principale*:
+ Il #glossary("sensore") effettua una rilevazione della velocità (km/h) e della direzione del vento;
+ Il #glossary("sensore") formatta il messaggio da inviare al #glossary("sistema"), di modo da mandare la direzione del vento, espressa in gradi (con gli 0° a Est e i 180° a Ovest), la velocità del vento, espressa in chilometri all'ora (km/h), il timestamp di rilevazione e le proprie coordinate geografiche;
+ Il #glossary("sensore") invia il messaggio al #glossary("sistema").
#figure(
image("assets/UML/UC12_Inserimento-dati-velocità-e-direzione-del-vento.png",width:70%),
caption: [UC12 Inserimento dati velocità e direzione del vento]
)
/*Cambiare il numero nell'immagine*/
=== UC13: Inserimento dati precipitazioni
- *Attore Principale*: #glossary("sensore")\;
- *Precondizioni*: il #glossary("sensore") è acceso e collegato al #glossary("sistema")\;
- *Postcondizioni*: il #glossary("sistema") ha persistito i dati inviati dal #glossary("sensore")\;
- *Scenario Principale*:
+ Il #glossary("sensore") effettua una rilevazione quantitativa delle precipitazioni;
+ Il #glossary("sensore") formatta il messaggio da inviare al #glossary("sistema"), di modo da mandare la quantità di precipitazioni rilevate, espresse in millimetri all'ora (mm/h), il timestamp di rilevazione e le proprie coordinate geografiche;
+ Il #glossary("sensore") invia il messaggio al #glossary("sistema").
#figure(
image("assets/UML/UC13_Inserimento-dati-precipitazioni.png",width:70%),
caption: [UC13 Inserimento dati precipitazioni]
)
=== UC14: Inserimento dati inquinamento dell'aria
- *Attore Principale*: #glossary("sensore")\;
- *Precondizioni*: il #glossary("sensore") è acceso e collegato al #glossary("sistema")\;
- *Postcondizioni*: il #glossary("sistema") ha persistito i dati inviati dal #glossary("sensore")\;
- *Scenario Principale*:
+ Il #glossary("sensore") effettua una rilevazione quantitativa dell'inquinamento dell'aria;
+ Il #glossary("sensore") formatta il messaggio da inviare al #glossary("sistema"), di modo da mandare rilevazioni #glossary("PM10") relative all'inquinamento dell'aria, espresse in $#sym.mu g\/m^3$, il timestamp di rilevazione e le proprie coordinate geografiche;
+ Il #glossary("sensore") invia il messaggio al #glossary("sistema").
#figure(
image("assets/UML/UC14_Inserimento-dati-inquinamento-dell-aria.png",width:70%),
caption: [UC14 Inserimento dati inquinamento dell'aria]
)
#pagebreak()
=== UC15: Inserimento dati livello bacini idrici
- *Attore Principale*: #glossary("sensore")\;
- *Precondizioni*: il #glossary("sensore") è acceso e collegato al #glossary("sistema")\;
- *Postcondizioni*: il #glossary("sistema") ha persistito i dati inviati dal #glossary("sensore")\;
- *Scenario Principale*:
+ Il #glossary("sensore") effettua una rilevazione del livello del bacino idrico in cui è installato;
+ Il #glossary("sensore") formatta il messaggio da inviare al #glossary("sistema"), di modo da mandare la percentuale di riempimento del bacino idrico controllato, il timestamp di rilevazione e le proprie coordinate geografiche;
+ Il #glossary("sensore") invia il messaggio al #glossary("sistema").
#figure(
image("assets/UML/UC15_Inserimento-dati-livello-bacini-idrici.png",width:70%),
caption: [UC15 Inserimento dati livello bacini idrici]
)
=== UC16: Inserimento dati disponibilità parcheggi
- *Attore Principale*: #glossary("sensore")\;
- *Precondizioni*: il #glossary("sensore") è acceso e collegato al #glossary("sistema")\;
- *Postcondizioni*: il #glossary("sistema") ha persistito i dati inviati dal #glossary("sensore")\;
- *Scenario Principale*:
+ Il #glossary("sensore") rileva gli ingressi e le uscite del parcheggio in cui è installato;
+ Il #glossary("sensore") formatta il messaggio da inviare al #glossary("sistema"), di modo da mandare il numero di auto presenti all'interno del parcheggio controllato e il numero di posti auto totali a disposizione, il timestamp di rilevazione e le proprie coordinate geografiche;
+ Il #glossary("sensore") invia il messaggio al #glossary("sistema").
#figure(
image("assets/UML/UC16_Inserimento-dati-disponibilità-parcheggi.png",width:70%),
caption: [UC16 Inserimento dati disponibilità parcheggi]
)
/*Cambiare il numero nell'immagine*/
=== UC17: Inserimento dati colonne di ricarica
- *Attore Principale*: #glossary("sensore")\;
- *Precondizioni*: il #glossary("sensore") è acceso e collegato al #glossary("sistema")\;
- *Postcondizioni*: il #glossary("sistema") ha persistito i dati inviati dal #glossary("sensore")\;
- *Scenario Principale*:
+ Il #glossary("sensore") effettua una rilevazione del wattaggio erogato dalla colonna di ricarica;
+ Il #glossary("sensore") formatta il messaggio da inviare al #glossary("sistema"), di modo da mandare un indicatore booleano che rende nota la disponibilità della colonna, la quantità di energia erogata, espressa in chilowatt all'ora (kWh), il timestamp di rilevazione e le proprie coordinate geografiche;
+ Il #glossary("sensore") invia il messaggio al #glossary("sistema").
#figure(
image("assets/UML/UC17_Inserimento-dati-colonne-di-ricarica.png",width:70%),
caption: [UC17 Inserimento dati colonne di ricarica]
)
=== UC18: Inserimento dati biciclette elettriche
- *Attore Principale*: #glossary("sensore")\;
- *Precondizioni*: il #glossary("sensore") è acceso e collegato al #glossary("sistema")\;
- *Postcondizioni*: il #glossary("sistema") ha persistito i dati inviati dal #glossary("sensore")\;
- *Scenario Principale*:
+ Il #glossary("sensore") effettua una rilevazione della posizione e della percentuale della batteria della bicicletta elettrica su cui è installato;
+ Il #glossary("sensore") formatta il messaggio da inviare al #glossary("sistema"), di modo da mandare il timestamp di rilevazione, la percentuale di batteria e le coordinate geografiche della bicicletta;
+ Il #glossary("sensore") invia il messaggio al #glossary("sistema").
#figure(
image("assets/UML/UC18_Inserimento-dati-biciclette-elettriche.png",width:70%),
caption: [UC18 Inserimento dati biciclette elettriche]
)
=== UC19: Inserimento dati riempimento zone ecologiche
- *Attore Principale*: #glossary("sensore")\;
- *Precondizioni*: il #glossary("sensore") è acceso e collegato al #glossary("sistema")\;
- *Postcondizioni*: il #glossary("sistema") ha persistito i dati inviati dal #glossary("sensore")\;
- *Scenario Principale*:
+ Il #glossary("sensore") effettua una rilevazione del livello di riempimento del contenitore ecologico associato;
+ Il #glossary("sensore") formatta il messaggio da inviare al #glossary("sistema"), di modo da mandare la percentuale di riempimento della zona ecologica controllata, il timestamp di rilevazione e le proprie coordinate geografiche;
+ Il #glossary("sensore") invia il messaggio al #glossary("sistema").
#figure(
image("assets/UML/UC19_Inserimento-dati-riempimento-zone-ecologiche.png",width:70%),
caption: [UC19 Inserimento dati riempimento zone ecologiche]
)
#pagebreak()
=== UC20: Inserimento dati congestione stradale
- *Attore Principale*: #glossary("sensore")\;
- *Precondizioni*: il #glossary("sensore") è acceso e collegato al #glossary("sistema")\;
- *Postcondizioni*: il #glossary("sistema") ha persistito i dati inviati dal #glossary("sensore")\;
- *Scenario Principale*:
+ Il #glossary("sensore") effettua una rilevazione del livello di congestione della strada su cui è installato;
+ Il #glossary("sensore") formatta il messaggio da inviare al #glossary("sistema"), di modo da mandare il numero di auto circolanti nella strada controllata, lo stato della congestione stradale, espresso nei seguenti stati (ordinati per ordine di congestione crescente) "LOW", "MEDIUM", "HIGH", "BLOCKED", il tempo medio necessario per percorrere la strada, il timestamp di rilevazione e le proprie coordinate geografiche;
+ Il #glossary("sensore") invia il messaggio al #glossary("sistema").
#figure(
image("assets/UML/UC20_Inserimento-dati-congestione-stradale.png",width:70%),
caption: [UC20 Inserimento dati congestione stradale]
)
#set heading(numbering: "1.1")
#pagebreak()
= Requisiti
#show figure: set block(breakable: true)
== Requisiti funzionali
#let C = counter("UC_counter_req")
#let requisiti_funzionali = (
(
"Obbligatorio", "L'utente deve poter accedere all'applicazione senza dover effettuare l'autenticazione.", "Capitolato"
),
(
"Obbligatorio", [L'utente deve poter visualizzare un menù di selezione delle #glossary("dashboard"), che permetta di selezionare tra Dati grezzi, Ambientale, Urbanistica e Superamento soglie.], [UC#C.display()]
),
(
"Obbligatorio", [L'utente deve poter visualizzare una #glossary("dashboard") generale relativa ai dati grezzi.], [UC#C.step()#C.display()]
),
(
"Obbligatorio", [L'utente deve poter visualizzare, in forma tabellare, i dati grezzi inviati da tutti i sensori con il nome del #glossary[sensore], la tipologia del #glossary[sensore], il timestamp della rilevazione e il valore della misurazione (se composta da più dati, tutti i valori sono elencati nella colonna corrispondente), all'interno della #glossary("dashboard") relativa ai dati grezzi.], [#C.step(level:2)UC#C.display()]
),
(
"Obbligatorio", [L'utente deve poter monitorare i dati provenienti dai sensori relativi ai dati ambientali in una #glossary("dashboard") apposita.], [#C.step()UC#C.display()]
),
(
"Obbligatorio", [L'utente deve poter visualizzare un #glossary("pannello") contenente un grafico in formato #glossary("time series") rappresentante l'andamento in media aritmetica della temperatura, espressa in gradi Celsius, per ciascun #glossary("sensore"), aggregando i dati per intervalli di 1 minuto, nella #glossary("dashboard") relativa ai dati ambientali.], [#C.step(level:2)#C.step(level:2)UC#C.display()]
),
(
"Obbligatorio", [L'utente deve poter visualizzare un #glossary("pannello") contenente un grafico in formato #glossary("time series") rappresentante l'andamento in media aritmetica della temperatura, espressa in gradi Celsius, di tutti i sensori, aggregando i dati per intervalli di 5 minuti, nella #glossary("dashboard") relativa ai dati ambientali.], [UC#C.display()]
),
(
"Obbligatorio", [L'utente deve poter visualizzare un #glossary("pannello") contenente un grafico in formato #glossary("time series") rappresentante l'andamento in media aritmetica della percentuale d'umidità, per ciascun #glossary("sensore"), aggregando i dati per intervalli di 1 minuto, nella #glossary("dashboard") relativa ai dati ambientali.], [#C.step(level:2)UC#C.display()]
),
(
"Obbligatorio", [L'utente deve poter visualizzare un #glossary("pannello") contenente un grafico in formato #glossary("time series") rappresentante l'andamento in media aritmetica della percentuale d'umidità, di tutti i sensori, aggregando i dati per intervalli di 5 minuti, nella #glossary("dashboard") relativa ai dati ambientali.], [UC#C.display()]
),
(
"Desiderabile", [L'utente deve poter visualizzare un #glossary("pannello") contenente una mappa che evidenzi la direzione del vento, mediante frecce collocate nelle coordinate geografiche del #glossary("sensore"), nella #glossary("dashboard") relativa ai dati ambientali.], [#C.step(level:2)UC#C.display()]
),
(
"Obbligatorio", [L'utente deve poter visualizzare un #glossary("pannello") contenente una tabella la quale riporta l'ultima velocità del vento, espressa in chilometri all'ora (km/h), e la sua direzione, espressa in gradi (con gli 0° a Est e i 180° a Ovest), per ciascun #glossary("sensore"), nella #glossary("dashboard") relativa ai dati ambientali.], [#C.step(level:2)UC#C.display()]
),
(
"Obbligatorio", [L'utente deve poter visualizzare un #glossary("pannello") contenente un grafico in formato #glossary("time series") rappresentante l'andamento in media aritmetica dell'intensità delle precipitazioni, espresse in millimetri all'ora (mm/h), per ciascun #glossary("sensore"), aggregando i dati per intervalli di 1 minuto, nella #glossary("dashboard") relativa ai dati ambientali.], [#C.step(level:2)UC#C.display()]
),
(
"Obbligatorio", [L'utente deve poter visualizzare un #glossary("pannello") contenente un grafico in formato #glossary("time series") rappresentante l'andamento in media aritmetica dell'intensità delle precipitazioni, espresse in millimetri all'ora (mm/h), di tutti i sensori, aggregando i dati per intervalli di 5 minuti, nella #glossary("dashboard") relativa ai dati ambientali.], [UC#C.display()]
),
(
"Desiderabile", [L'utente deve poter visualizzare un #glossary("pannello") contenente un indice numerico rappresentante l'intensità media delle precipitazioni, espressa in millimetri all'ora (mm/h), nell'intervallo di tempo impostato all'interno della #glossary[dashboard], facendo la media dei dati raccolti tra tutti i sensori, nella #glossary("dashboard") relativa ai dati ambientali.], [#C.step(level:2)UC#C.display()]
),
(
"Obbligatorio", [L'utente deve poter visualizzare un #glossary("pannello") contenente un grafico in formato #glossary("time series") rappresentante l'andamento in media aritmetica del livello di polveri sottili nell'aria, espressi in $#sym.mu g\/m^3$ (#glossary("PM10")), per ciascun #glossary("sensore"), aggregando i dati per intervalli di 1 minuto, nella #glossary("dashboard") relativa ai dati ambientali.], [#C.step(level:2)UC#C.display()]
),
(
"Obbligatorio", [L'utente deve poter visualizzare un #glossary("pannello") contenente un grafico in formato #glossary("time series") rappresentante l'andamento in media aritmetica del livello di polveri sottili nell'aria, espressi in $#sym.mu g\/m^3$ (#glossary("PM10")), di tutti i sensori, aggregando i dati per intervalli di 5 minuti, nella #glossary("dashboard") relativa ai dati ambientali.], [UC#C.display()]
),
(
"Desiderabile", [L'utente deve poter visualizzare un #glossary("pannello") contenente un indice numerico, che esprime il livello medio di polveri sottili nell'aria, espresso in $#sym.mu g\/m^3$ (#glossary("PM10")), nell'ultimo minuto, facendo la media dei dati raccolti tra tutti i sensori, nella #glossary("dashboard") relativa ai dati ambientali.], [#C.step(level:2)UC#C.display()]
),
(
"Obbligatorio", [L'utente deve poter visualizzare un #glossary("pannello") contenente un grafico in formato #glossary("time series") rappresentante l'andamento in media aritmetica della percentuale di riempimento dei bacini idrici, per ciascun #glossary("sensore"), aggregando i dati per intervalli di 1 minuto, nella #glossary("dashboard") relativa ai dati ambientali.], [#C.step(level:2)UC#C.display()]
),
(
"Obbligatorio", [L'utente deve poter visualizzare un #glossary("pannello") contenente un grafico in formato #glossary("time series") rappresentante l'andamento in media aritmetica della percentuale di riempimento dei bacini idrici, di tutti i sensori, aggregando i dati per intervalli di 5 minuti, nella #glossary("dashboard") relativa ai dati ambientali.], [UC#C.display()]
),
(
"Desiderabile", [L'utente deve poter visualizzare un #glossary("pannello") contenente un indice numerico, che esprime la temperatura media, espressa in gradi Celsius, nell'intervallo di tempo impostato all'interno della #glossary[dashboard], facendo la media dei dati raccolti tra tutti i sensori, nella #glossary("dashboard") relativa ai dati ambientali.], [#C.step(level:2)UC#C.display()]
),
(
"Desiderabile", [L'utente deve poter visualizzare un #glossary("pannello") contenente un indice numerico, che esprime il livello massimo di polveri sottili nell'aria, espresso in $#sym.mu g\/m^3$ (#glossary("PM10")), negli ultimi 5 minuti, tra i dati registrati da tutti i sensori, nella #glossary("dashboard") relativa ai dati ambientali.], [#C.step(level:2)UC#C.display()]
),
(
"Obbligatorio", [L'utente deve poter visualizzare un #glossary("pannello") contenente una mappa che mostri le posizioni dei sensori che monitorano i dati ambientali, mediante icone colorate in base al tipo di #glossary[sensore], nella #glossary("dashboard") relativa ai dati ambientali.], [#C.step(level:2)UC#C.display()]
),
(
"Obbligatorio", [L'utente deve poter monitorare i dati provenienti dai sensori relativi ai dati urbanistici in una #glossary("dashboard") apposita.], [#C.step()UC#C.display()]
),
(
"Obbligatorio", [L'utente deve poter visualizzare un #glossary("pannello") contenente una mappa che evidenzi il numero di posti liberi nei vari parcheggi, mediante indicatori numerici posti nelle coordinate geografiche del #glossary("sensore"), nella #glossary("dashboard") relativa ai dati urbanistici.], [#C.step(level: 2)#C.step(level: 2)UC#C.display()]
),
("Obbligatorio",[L'utente deve poter visualizzare un #glossary("pannello") contenente icone poste nelle coordinate geografiche dei sensori che indichino la disponibilità delle colonne di ricarica, nella #glossary("dashboard") relativa ai dati urbanistici.],[#C.step(level:2) #C.step(level:3)UC#C.display()]),
(
"Desiderabile", [L'utente deve poter visualizzare un #glossary("pannello") contenente una tabella la quale riporta l'erogazione delle colonne di ricarica per auto, espressa in chiloWatt all'ora (kWh), controllata da ciascun #glossary("sensore"), nella #glossary("dashboard") relativa ai dati urbanistici.], [#C.step(level:3)UC#C.display()]
),
(
"Obbligatorio", [L'utente deve poter visualizzare un #glossary("pannello") contenente una mappa che evidenzi lo stato di congestione delle strade, mediante gli stati "LOW", "MEDIUM", "HIGH", "BLOCKED", posti nelle coordinate geografiche dei sensori che le monitorano, nella #glossary("dashboard") relativa ai dati urbanistici.], [#C.step(level:2)UC#C.display()]
),
(
"Obbligatorio", [L'utente deve poter visualizzare un #glossary("pannello") contenente una mappa che mostri la posizione delle biciclette elettriche controllate, in tempo reale, mediante degli indicatori numerici, indicanti la percentuale della batteria, posizionati nelle coordinate geografiche del mezzo, nella #glossary("dashboard") relativa ai dati urbanistici.], [#C.step(level:2)UC#C.display()]
),
(
"Obbligatorio", [L'utente deve poter visualizzare un #glossary("pannello") contenente una mappa che mostri la percentuale di riempimento delle zone ecologiche, mediante degli indicatori percentuali, posizionati nelle coordinate geografiche della zona, nella #glossary("dashboard") relativa ai dati urbanistici.], [#C.step(level:2)UC#C.display()]
),
(
"Desiderabile", [L'utente deve poter monitorare i dati superanti le soglie impostate nel #glossary[sistema], in una #glossary("dashboard") apposita.], [#C.step()UC#C.display()]
),
(
"Opzionale", [L'utente deve poter visualizzare un #glossary("pannello") contenente una tabella che mostri i #glossary("dati anomali"), il #glossary("sensore") che li ha rilevati e il timestamp del rilevamento, nella #glossary("dashboard") relativa ai dati superanti le soglie.], [#C.step(level:2)UC#C.display()]
),
(
"Desiderabile", [L'utente deve poter visualizzare un #glossary("pannello") contenente una tabella che mostri i dati i cui valori superano la soglia dei 40° Celsius (40°C) di temperatura, il #glossary("sensore") che li ha rilevati e il timestamp del rilevamento, nella #glossary("dashboard") relativa ai dati superanti le soglie.], [#C.step(level:2)#C.step(level:2)UC#C.display()]
),
(
"Desiderabile", [L'utente deve poter visualizzare un #glossary("pannello") contenente una tabella che mostri i dati i cui valori superano la soglia dei 50 millimetri di pioggia all'ora (50 mm/h), il #glossary("sensore") che li ha rilevati e il timestamp del rilevamento, nella #glossary("dashboard") relativa ai dati superanti le soglie.], [#C.step(level:2)UC#C.display()]
),
(
"Desiderabile", [L'utente deve poter visualizzare un #glossary("pannello") contenente una tabella che mostri i dati i cui valori superano la soglia di 80#[#sym.mu]g su metro cubo ($80#sym.mu g\/m^3$) di inquinamento dell'aria, il #glossary("sensore") che li ha rilevati e il timestamp del rilevamento, nella #glossary("dashboard") relativa ai dati superanti le soglie.], [#C.step(level:2)UC#C.display()]
),
(
"Desiderabile", [L'utente deve poter visualizzare un #glossary("pannello") contenente una tabella che mostri i dati i cui valori superano la soglia del 70% di capienza di un bacino idrico, il #glossary("sensore") che li ha rilevati e il timestamp del rilevamento, nella #glossary("dashboard") relativa ai dati superanti le soglie.], [#C.step(level:2)UC#C.display()]
),
(
"Desiderabile", [L'utente deve poter visualizzare un #glossary("pannello") contenente una tabella che mostri i dati i cui valori superano la soglia dell'80% di capienza di una zona ecologica, il #glossary("sensore") che li ha rilevati e il timestamp del rilevamento, nella #glossary("dashboard") relativa ai dati superanti le soglie.], [#C.step(level:2)UC#C.display()]
),
(
"Desiderabile", "L'utente deve poter visualizzare delle notifiche che denotano il superamento di una soglia impostata.", [#C.step()UC#C.display()]
),
(
"Desiderabile", "L'utente deve poter visualizzare una notifica relativa alla temperatura che denota il superamento dei 40° Celsius (40°C).", [#C.step(level:2)UC#C.step(level:2)#C.display()]
),
(
"Desiderabile", "L'utente deve poter visualizzare una notifica relativa alle precipitazioni che denota il superamento dei 50 millimetri di pioggia all'ora (50 mm/h).", [#C.step(level:2)UC#C.display()]
),
(
"Desiderabile", [L'utente deve poter visualizzare una notifica relativa all'inquinamento dell'aria che denota il superamento di 80#[#sym.mu]g su metro cubo ($80#sym.mu g\/m^3$).], [#C.step(level:2)UC#C.display()]
),
(
"Desiderabile", "L'utente deve poter visualizzare una notifica relativa ai bacini idrici che denota il superamento del 70% della capienza di un particolare bacino.", [#C.step(level:2)UC#C.display()]
),
(
"Desiderabile", "L'utente deve poter visualizzare una notifica relativa alle zone ecologiche che denota il superamento dell'80% della capienza di una particolare zona ecologica.", [#C.step(level:2)UC#C.display()]
),
(
"Obbligatorio", [L'utente deve poter filtrare i dati, visualizzati all'interno di un grafico di tipo #glossary("time series"), in base ad un sottoinsieme selezionato di sensori.], [#C.step()#C.step(level:2)UC#C.display()]
),
(
"Obbligatorio", [L'utente deve poter filtrare i dati, visualizzati all'interno di una tabella, in base ad un sotto-insieme di sensori, selezionandone la tipologia di interesse.], [#C.step(level:2)UC#C.display()]
),
(
"Obbligatorio", [L'utente deve poter filtrare i dati, visualizzati all'interno di una tabella, in base ad un sotto-insieme di sensori, selezionando i nomi dei sensori di interesse.], [#C.step(level:2)UC#C.display()]
),
(
"Obbligatorio", [L'utente deve poter filtrare i dati in base ad un intervallo temporale, mostrando quindi nella #glossary("dashboard") d'interesse, solamente i dati aventi un timestamp in tale intervallo.], [#C.step(level:2)UC#C.display()]
),
(
"Desiderabile", [Nei #glossary("pannelli") con tabelle, l'utente deve poter ordinare i dati in base a tutti i campi presenti, sia in ordine crescente che decrescente.], [#C.step()UC#C.display()]
),
(
"Desiderabile", [L'utente deve poter modificare il layout della #glossary("dashboard") visualizzata, agendo sullo spostamento dei #glossary("pannelli").], [#C.step()#C.step(level:2)UC#C.display()]
),
(
"Desiderabile", [L'utente deve poter modificare il layout della #glossary("dashboard") visualizzata, agendo sul ridimensionamento dei #glossary("pannelli").], [#C.step(level:2)UC#C.display()]
),
(
"Obbligatorio", [L'utente deve poter visualizzare un messaggio di errore, qualora il #glossary("sistema") di visualizzazione non sia in grado di reperire o non abbia dati da mostrare all'utente per un determinato #glossary("pannello").], [#C.step()UC#C.display()]
),
(
"Obbligatorio", [Il #glossary("sensore") deve poter mandare e far persistere dati relativi alla temperatura, espressa in gradi Celsius, il timestamp di rilevazione e le proprie coordinate geografiche.], [#C.step()UC#C.display()]
),
(
"Obbligatorio", [Il #glossary("sensore") deve poter mandare e far persistere dati relativi all'umidità, espressa in percentuale, il timestamp di rilevazione e le proprie coordinate geografiche.], [#C.step()UC#C.display()]
),
(
"Obbligatorio", [Il #glossary("sensore") deve poter mandare e far persistere dati relativi alla velocità del vento, espressa in chilometri all'ora (km/h), alla direzione del vento, espressa in gradi (con gli 0° a Est e i 180° a Ovest), il timestamp di rilevazione e le proprie coordinate geografiche.], [#C.step()UC#C.display()]
),
(
"Obbligatorio", [Il #glossary("sensore") deve poter mandare e far persistere dati relativi alle precipitazioni, espresse in millimetri all'ora (mm/h), il timestamp di rilevazione e le proprie coordinate geografiche.], [#C.step()UC#C.display()]
),
(
"Obbligatorio", [Il #glossary("sensore") deve poter mandare e far persistere dati relativi all'inquinamento dell'aria, espresso in microgrammi al metro cubo (#glossary("PM10")), il timestamp di rilevazione e le proprie coordinate geografiche.], [#C.step()UC#C.display()]
),
(
"Obbligatorio", [Il #glossary("sensore") deve poter mandare e far persistere dati relativi alla percentuale di riempimento del bacino idrico controllato, il timestamp di rilevazione e le proprie coordinate geografiche.], [#C.step()UC#C.display()]
),
(
"Obbligatorio", [Il #glossary("sensore") deve poter mandare e far persistere dati relativi al numero di auto presenti all'interno del parcheggio controllato e il numero di posti auto totali a disposizione, il timestamp di rilevazione e le proprie coordinate geografiche.], [#C.step()UC#C.display()]
),
(
"Obbligatorio", [Il #glossary("sensore") deve poter mandare e far persistere dati relativi alla disponibilità della colonna di ricarica controllata, alla quantità di energia erogata dalla colonna, espresse in chilowatt all'ora (kWh), il timestamp di rilevazione e le proprie coordinate geografiche.], [#C.step()UC#C.display()]
),
(
"Obbligatorio", [Il #glossary("sensore") deve poter mandare e far persistere dati relativi alle coordinate geografiche della bicicletta elettrica controllata, la percentuale di batteria della stessa e il timestamp di rilevazione.], [#C.step()UC#C.display()]
),
(
"Obbligatorio", [Il #glossary("sensore") deve poter mandare e far persistere dati relativi alla percentuale di riempimento della zona ecologica controllata, il timestamp di rilevazione e le proprie coordinate geografiche.], [#C.step()UC#C.display()]
),
(
"Obbligatorio", [Il #glossary("sensore") deve poter mandare e far persistere dati relativi al numero di auto circolanti nella strada controllata, allo stato di congestione nella strada, espresso in stati (in ordine di congestione crescente sono: "LOW", "MEDIUM", "HIGH", "BLOCKED"), il tempo medio necessario per percorrere la strada, il timestamp di rilevazione e le proprie coordinate geografiche.], [#C.step()UC#C.display()]
),
/*questi qui sotto sono gli ex requisiti di vincolo
<NAME>, ne ho commentato qualcuno perchè credo siano inglobati nei precedenti*/
/*TODO: crearci le specifiche di test*/ (
"Obbligatorio",[Dev'essere realizzato un simulatore per almeno una tipologia di #glossary("sensore").],"Capitolato",
),
(
"Obbligatorio","La simulazione deve produrre dati realistici, ovvero deve emulare il comportamento reale dell'entità che viene simulata.","Capitolato",
),
/*
(
"Obbligatorio",[Deve esistere una #glossary("dashboard") che riporti almeno i dati di un #glossary("sensore").],"Capitolato",
),
(
"Desiderabile","La simulazione deve realizzare più di una sorgente dati.","Capitolato",
),*/
(
"Opzionale","Il sistema deve rendere possibile la rilevazione di relazioni tra dati provenienti da sorgenti diverse.","Capitolato",
),
/*
(
"Opzionale",[Un #glossary("sistema") di allerta che notifichi l'utente in caso di anomalie o eventi critici.],"Verbale esterno",
),
*/
(
"Opzionale","Il sistema deve rendere possibile la previsione di eventi futuri, basata su dati storici e attuali.","Capitolato",
),
/*
(
"Desiderabile",[Deve esistere una #glossary("dashboard") avanzata contenente: una mappa della città, widget e informazioni sui sensori (ad esempio il tipo di #glossary("sensore"), il modello, ecc.).],"Capitolato"
)
*/
)
#let requisiti_funzionali_con_codice = generate_requirements_array("F", requisiti_funzionali)
#figure(
requirements_table(requisiti_funzionali_con_codice),
caption: "Requisiti funzionali")
#pagebreak()
== Requisiti di qualità
#let requisiti_qualita = (
(
"Obbligatorio","Il superamento di test che dimostrino il corretto funzionamento dei servizi utilizzati e delle funzionalità implementate. La copertura di test deve essere almeno dell'80% e deve essere dimostrata tramite report.","Capitolato",
), /*
(
"Obbligatorio",[Il #glossary("sistema") deve essere testato nella sua interezza tramite #glossary("test end-to-end")],"Capitolato",
),*/
(
"Obbligatorio", [Viene richiesta una #glossary("documentazione") sulle scelte implementative e progettuali, che dovranno essere accompagnate da motivazioni.],"Capitolato",
),
("Obbligatorio",[Viene richiesto il _Manuale Utente_.],"Capitolato"),
("Obbligatorio",[Viene richiesto il documento _Specifica Tecnica_.],"Capitolato"),
(
"Desiderabile","La documentazione dovrà riguardare anche problemi aperti ed eventuali possibili soluzioni da approfondire in futuro.","Capitolato"
),
("Desiderabile",[L'#glossary("amministratore pubblico") deve poter imparare a padroneggiare il #glossary("sistema") in breve tempo.],"Norme di Progetto"),
("Obbligatorio",[La #glossary[repository] di github del codice sorgente "InnovaCity" deve essere accessibile a tutti.],"Verbale esterno"),
("Obbligatorio",[Devono essere rispettati i vincoli e le metriche definite nel _Piano di Qualifica v2.0_.],"Norme di Progetto")
)
#let requisiti_qualita_con_codice = generate_requirements_array("Q", requisiti_qualita)
#figure(
requirements_table(requisiti_qualita_con_codice),
caption: "Requisiti di qualità")
#pagebreak()
== Requisiti di vincolo
#let requisiti_vincolo = (
(
"Obbligatorio","I dati vanno raccolti in un database OLAP, per esempio ClickHouse.","Capitolato",
),
("Obbligatorio","I dati devono poter essere visualizzati su una piattaforma di data-visualization, per esempio Grafana.","Capitolato"),
("Obbligatorio",[Deve essere utilizzato #glossary[Docker Compose] versione 3.8 per l'installazione del software.],"Verbale esterno"),
("Obbligatorio","I dati in ingresso nel database OLAP devono avere formato pseudo-tabellare, si deve utilizzare il formato Json.", "Verbale esterno"),
("Obbligatorio","Deve essere utilizzato un message broker per lo streaming dei dati, per esempio Apache Kafka.","Capitolato"),
("Obbligatorio","Il sistema deve essere compatibile con Google Chrome v122, Mozilla Firefox v123 o Microsoft Edge v122.","Verbale interno"),
("Obbligatorio","Il sistema deve poter essere installato su sistema operativo Windows (10 o 11), con RAM minimale di 6GB, processore 64 bit e compatibilità con WSL 2.","Verbale interno"),
("Obbligatorio","Il sistema deve poter essere installato su sistema operativo MACOS (versione minima 10.14 Mojave) con RAM minimale di 6GB.","Verbale interno"),
("Obbligatorio","Il sistema deve poter essere installato su sistema operativo Linux Ubuntu (22.04 o superiori) con RAM minimale di 6GB.","Verbale interno")
)
#let requisiti_vincolo_con_codice = generate_requirements_array("V", requisiti_vincolo)
#figure(
requirements_table(requisiti_vincolo_con_codice),
caption: "Requisiti di vincolo")
#pagebreak()
/*
Ho spostato i contenuti nei requisiti di vincolo. pero non so bene se è la sezione giusta.
== Requisiti sistema operativo
L'applicazione viene eseguita sul browser e l'unico software che deve essere installato sul sistema operativo è Docker.\
Docker viene fornito in quasi tutte le distro Linux, tramite il gestore di pacchetti specifico per la distribuzione, per cui l'installazione è molto semplice.
Su Windows si richiede la versione Windows 10 o superiori, con processore 64 bit, una RAM minima di 4GB, e WSL 2 (compatibilità con il kernel di Linux fornita da Microsoft che consente agli utenti di eseguire applicazioni Linux direttamente su Windows senza la necessità di una macchina virtuale separata) versione 1.1.3.0 per utilizzare Container Linux; alternativamente, si può usare la funzionalità di Hyper-v (tecnologia di virtualizzazione fornita da Microsoft come parte dei sistemi operativi Windows) e Container Windows. Inoltre deve essere abilitata la virtualizzazione dell'hardware all'interno del BIOS.
Per MAC, si richiede la versione minima 10.14 Mojave e una RAM minimale di 4GB.
Fonte:
- *Docker*: #link("https://docs.docker.com/get-docker/") (22-02-2024);
- *WSL*: #link("https://learn.microsoft.com/it-it/windows/wsl/install") (22-02-2024);
- *Hyper-v*: #link("https://learn.microsoft.com/it-it/virtualization/hyper-v-on-windows/quick-start/enable-hyper-v") (22-02-2024).
#pagebreak()
*/
== Requisiti prestazionali
#let requisiti_prestazioni = (
(
"Obbligatorio",[Il #glossary("sistema") deve gestire un carico di #glossary("dati in entrata") superiore ai 40 dati al secondo per un sistema con processore multicore con almeno 2.5GHz di clock, 6 GB di RAM.],"Verbale esterno"
),
("Desiderabile",[Il #glossary("sistema") deve avere un tempo di elaborazione inferiore ai 5 secondi, dal momento in cui la #glossary[dashboard] viene aperta a quello in cui i dati vengono visualizzati al suo interno.],"Norme di Progetto"),
)
#let requisiti_prestazioni_con_codice = generate_requirements_array("P", requisiti_prestazioni)
#figure(
requirements_table(requisiti_prestazioni_con_codice),
caption: "Requisiti di prestazioni")
#pagebreak()
== Tracciamento Fonti - Requisiti
=== Fonti - Requisiti funzionali
#C.update(0)
#figure(
table(
columns: (auto, auto),
inset: 10pt,
align: horizon,
[*Fonti*], [*Requisiti*],
..requisiti_funzionali_con_codice.map(content => (content.at(3),content.at(0))).flatten().map(content => [#content])
),
caption: "Fonti - Requisiti funzionali")
=== Fonti - Requisiti qualità
#figure(
table(
columns: (auto, auto),
inset: 10pt,
align: horizon,
[*Fonti*], [*Requisiti*],
..requisiti_qualita_con_codice.map(content => (content.at(3),content.at(0))).flatten().map(content => [#content])
),
caption: "Fonti - Requisiti qualità")
=== Fonti - Requisiti vincolo
#figure(
table(
columns: (auto, auto),
inset: 10pt,
align: horizon,
[*Fonti*], [*Requisiti*],
..requisiti_vincolo_con_codice.map(content => (content.at(3),content.at(0))).flatten().map(content => [#content])
),
caption: "Fonti - Requisiti vincolo")
=== Fonti - Requisiti prestazioni
#figure(
table(
columns: (auto, auto),
inset: 10pt,
align: horizon,
[*Fonti*], [*Requisiti*],
..requisiti_prestazioni_con_codice.map(content => (content.at(3),content.at(0))).flatten().map(content => [#content])
),
caption: "Fonti - Requisiti prestazioni")
== Tracciamento Requisiti - Fonti
=== Requisiti funzionali - Fonti
#C.update(0)
#figure(
table(
columns: (auto, auto),
inset: 10pt,
align: horizon,
[*Requisiti*],[*Fonti*],
..requisiti_funzionali_con_codice.map(content => (content.at(0),content.at(3))).flatten().map(content => [#content])
),
caption: "Fonti - Requisiti funzionali")
=== Requisiti qualità - Fonti
#figure(
table(
columns: (auto, auto),
inset: 10pt,
align: horizon,
[*Requisiti*],[*Fonti*],
..requisiti_qualita_con_codice.map(content => (content.at(0),content.at(3))).flatten().map(content => [#content])
),
caption: "Fonti - Requisiti qualità")
=== Requisiti vincolo - Fonti
#figure(
table(
columns: (auto, auto),
inset: 10pt,
align: horizon,
[*Requisiti*],[*Fonti*],
..requisiti_vincolo_con_codice.map(content => (content.at(0),content.at(3))).flatten().map(content => [#content])
),
caption: "Fonti - Requisiti vincolo")
=== Requisiti prestazioni - Fonti
#figure(
table(
columns: (auto, auto),
inset: 10pt,
align: horizon,
[*Requisiti*],[*Fonti*],
..requisiti_prestazioni_con_codice.map(content => (content.at(0),content.at(3))).flatten().map(content => [#content])
),
caption: "Fonti - Requisiti prestazioni")
#pagebreak()
== Riepilogo
#let funzionale_obb = requisiti_funzionali.filter(content => content.at(0) == "Obbligatorio").len()
#let funzionale_des = requisiti_funzionali.filter(content => content.at(0) == "Desiderabile").len()
#let funzionale_opz = requisiti_funzionali.filter(content => content.at(0) == "Opzionale").len()
#let funzionale_tot = funzionale_des + funzionale_obb + funzionale_opz
#let qualità_obb = requisiti_qualita.filter(content => content.at(0) == "Obbligatorio").len()
#let qualità_des = requisiti_qualita.filter(content => content.at(0) == "Desiderabile").len()
#let qualità_opz = requisiti_qualita.filter(content => content.at(0) == "Opzionale").len()
#let qualità_tot = qualità_des + qualità_obb + qualità_opz
#let vincolo_obb = requisiti_vincolo.filter(content => content.at(0) == "Obbligatorio").len()
#let vincolo_des = requisiti_vincolo.filter(content => content.at(0) == "Desiderabile").len()
#let vincolo_opz = requisiti_vincolo.filter(content => content.at(0) == "Opzionale").len()
#let vincolo_tot = vincolo_des + vincolo_obb + vincolo_opz
#let prestazioni_obb = requisiti_prestazioni.filter(content => content.at(0) == "Obbligatorio").len()
#let prestazioni_des = requisiti_prestazioni.filter(content => content.at(0) == "Desiderabile").len()
#let prestazioni_opz = requisiti_prestazioni.filter(content => content.at(0) == "Opzionale").len()
#let prestazioni_tot = prestazioni_des + prestazioni_obb + prestazioni_opz
#figure(
table(
columns: (auto, auto, auto, auto, auto),
inset: 10pt,
align: horizon,
[*Tipologia*], [*Obbligatori*], [*Desiderabili*], [*Opzionali*], [*Totale*],
[funzionali], [#funzionale_obb], [#funzionale_des], [#funzionale_opz], [#funzionale_tot],
[di qualità], [#qualità_obb], [#qualità_des], [#qualità_opz], [#qualità_tot],
[di vincolo], [#vincolo_obb], [#vincolo_des], [#vincolo_opz], [#vincolo_tot],
[di prestazioni], [#prestazioni_obb],[#prestazioni_des],[#prestazioni_opz],[#prestazioni_tot]
),
caption: "Tabella di riepilogo dei vincoli")
|
https://github.com/SkiFire13/master-thesis-presentation
|
https://raw.githubusercontent.com/SkiFire13/master-thesis-presentation/master/touying-diagrams.typ
|
typst
|
#import "@preview/cetz:0.2.2"
#import "@preview/fletcher:0.5.1" as fletcher
#import "@preview/touying:0.3.1": touying-reducer
#let _canvas-reducer(..args) = cetz.canvas({
cetz.draw.group(name: "inner", ..args)
cetz.draw.on-layer(-99, cetz.draw.rect((rel: (-1pt, -1pt), to: "inner.south-west"), (rel: (1pt, 1pt), to: "inner.north-east"), fill: white.transparentize(10%), stroke: none))
})
#let _cetz-cover(object) = cetz.draw.on-layer(-100, object)
#let _diagram-reducer(..args) = text(fill: black, fletcher.diagram(
..args,
render: (grid, nodes, edges, options) => {
_canvas-reducer(fletcher.draw-diagram(grid, nodes, edges, debug: options.debug))
}
))
#let _fletcher-cover(objects) = {
if type(objects) == array { objects = objects.join() }
let seq = objects + []
seq.children.map(child => {
if child.func() == metadata {
let value = child.value
if value.layer == auto {
value.layer = 0
}
value.layer = value.layer - 100
metadata(value)
} else {
child
}
}).join()
}
#let diagram = touying-reducer.with(reduce: _diagram-reducer, cover: _fletcher-cover)
|
|
https://github.com/TheLukeGuy/backtrack
|
https://raw.githubusercontent.com/TheLukeGuy/backtrack/main/src/lib.typ
|
typst
|
Apache License 2.0
|
// Copyright © 2023 <NAME>
// This file is part of Backtrack.
//
// Licensed under the Apache License, Version 2.0 (the "License"); you may not
// use this file except in compliance with the License. You may obtain a copy of
// the License at <http://www.apache.org/licenses/LICENSE-2.0>.
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS, WITHOUT
// WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the
// License for the specific language governing permissions and limitations under
// the License.
#import "versions.typ"
#let current-version = {
import "checks.typ": *
// Versions before 2023-03-21 can't run most modern version checks, so we need
// to check for it first.
if v2023-03-21-supported {
if v0-9-0-supported {
versions.from-v0-9-0-version(sys.version)
} else if v0-8-0-supported() {
versions.v0-8-0
} else if v0-7-0-supported() {
versions.v0-7-0
} else if v0-6-0-supported() {
versions.v0-6-0
} else if v0-5-0-supported() {
versions.v0-5-0
} else if v0-4-0-supported() {
versions.v0-4-0
} else if v0-3-0-supported() {
versions.v0-3-0
} else if v0-2-0-supported() {
versions.v0-2-0
} else if v0-1-0-supported() {
versions.v0-1-0
} else if v2023-03-28-supported() {
versions.v2023-03-28
} else {
versions.v2023-03-21
}
} else if v2023-02-15-supported() {
versions.v2023-02-15
} else if v2023-02-12-supported() {
versions.v2023-02-12
} else {
versions.v2023-01-30
}
}
|
https://github.com/TypstApp-team/typst
|
https://raw.githubusercontent.com/TypstApp-team/typst/master/tests/typ/bugs/footnote-keep-multiple.typ
|
typst
|
Apache License 2.0
|
// Test that the logic that keeps footnote entry together with
// their markers also works for multiple footnotes in a single
// line or frame (here, there are two lines, but they are one
// unit due to orphan prevention).
---
#set page(height: 100pt)
#v(40pt)
A #footnote[a] \
B #footnote[b]
|
https://github.com/FkHiroki/ex-E5
|
https://raw.githubusercontent.com/FkHiroki/ex-E5/main/sections/section1.typ
|
typst
|
MIT No Attribution
|
= 1. 目的
本稿では、本大学の理工学部計算センターのワークステーションを用いてUNIX系OSの操作に慣れ、プログラムの作成、コンパイル、実行を行うことを目的とする。ここでは、C言語を用いてプログラムの作成法学びながら、モンテカルロ法のシミュレーションを行う。
|
https://github.com/pta2002/typst-timeliney
|
https://raw.githubusercontent.com/pta2002/typst-timeliney/main/manual.typ
|
typst
|
MIT License
|
#import "@preview/mantys:0.1.4": *
#import "timeliney.typ": *
#show: mantys.with(
..toml("typst.toml").package,
examples-scope: (
group: group,
headerline: headerline,
milestone: milestone,
task: task,
taskgroup: taskgroup,
timeline: timeline,
)
)
#command(
"timeline",
arg[body],
arg(spacing: 5pt),
arg(show-grid: false),
arg(grid-style: (stroke: (dash: "dashed", thickness: .5pt, paint: gray))),
arg(task-vline: true),
arg(line-style: (stroke: 3pt)),
arg(milestone-overhang: 5pt),
arg(milestone-layout: "in-place"),
arg(box-milestones: true),
arg(milestone-line-style: ()),
arg(offset: 0),
)[
#argument("spacing", types: ("length",), default: 5pt)[
Spacing between lines
]
#argument("show-grid", types: ("boolean",), default: true)[
Show a grid behind the timeline
]
#argument(
"grid-style",
types: ("dictionary",),
default: (stroke: (dash: "dashed", thickness: .5pt, paint: gray)),
)[
The style to use for the grid (has no effect if `show-grid` is false)
]
#argument("task-vline", types: ("boolean",), default: true)[
Show a vertical line next to the task names
]
#argument("line-style", types: ("dictionary",), default: (stroke: 3pt))[
The style to use for the lines in the timelines
]
#argument(
"milestone-overhang",
types: ("length",),
default: 5pt,
)[
How far the milestone lines should extend past the end of the timeline (only has
an effect if `milestone-layout` is `in-place`)
]
#argument(
"milestone-layout",
types: ("string",),
default: "in-place",
)[
How to lay out the milestone lines. Can be `in-place` or `aligned`.
`in-place` displays the milestones directly below the timeline, and tries to lay
them out as well as possible to avoid colisions.
`aligned` displays the milestones in a separate box, aligned with the task
titles.
]
#argument("box-milestones", types: ("boolean",), default: true)[
Whether to draw a box around the milestones (only has an effect if
`milestone-layout` is `aligned`)
]
#argument("milestone-line-style", types: ("dictionary",), default: ())[
The style to use for the milestone lines
]
#argument("offset", types: ("float",), default: 0)[
Offset to be automatically added to all the timespans
]
#example[```
#timeline(
show-grid: true,
{
headerline(group(([*2023*], 4)), group(([*2024*], 4)))
headerline(
group(..range(4).map(n => strong("Q" + str(n + 1)))),
group(..range(4).map(n => strong("Q" + str(n + 1)))),
)
taskgroup(title: [*Research*], {
task("Research the market", (0, 2), style: (stroke: 2pt + gray))
task("Conduct user surveys", (1, 3), style: (stroke: 2pt + gray))
})
taskgroup(title: [*Development*], {
task("Create mock-ups", (2, 3), style: (stroke: 2pt + gray))
task("Develop application", (3, 5), style: (stroke: 2pt + gray))
task("QA", (3.5, 6), style: (stroke: 2pt + gray))
})
taskgroup(title: [*Marketing*], {
task("Press demos", (3.5, 7), style: (stroke: 2pt + gray))
task("Social media advertising", (6, 7.5), style: (stroke: 2pt + gray))
})
milestone(
at: 3.75,
style: (stroke: (dash: "dashed")),
align(center, [
*Conference demo*\
Dec 2023
])
)
milestone(
at: 6.5,
style: (stroke: (dash: "dashed")),
align(center, [
*App store launch*\
Aug 2024
])
)
}
)
```]
]
#command("headerline", arg("..titles", is-sink: true))[
#argument("titles", types: ("array",), is-sink: true)[
The titles to display in the header line.
Can be specified in several different formats:
#example[```
// One column per title
#headerline("Title 1", "Title 2", "Title 3")
```]
#example[```
// Each title occupies 2 columns
#headerline(("Title 1", 2), ("Title 2", 2))
```]
#example[```
// Two groups of titles
#headerline(
group("Q1", "Q2", "Q3", "Q4"),
group("Q1", "Q2", "Q3", "Q4"),
)
```]
#example[```
// Two lines of headers
#headerline(
group(("2023", 4), ("2024", 4))
)
#headerline(
group("Q1", "Q2", "Q3", "Q4"),
group("Q1", "Q2", "Q3", "Q4"),
)
```]
]
]
#command("group", arg("..titles", is-sink: true))[
Defines a group of titles in a header line.
Takes the same options as `#headerline`.
]
#command(
"task",
arg([name]),
arg([style], default: none),
arg("..lines", is-sink: true),
)[
Defines a task
#argument("name", types: ("content",))[
The name of the task
]
#argument(
"style",
types: ("dictionary",),
default: none,
)[
The style to use for the task line. If not specified, the default style will be
used.
]
#argument(
"..lines",
types: ("array",)
)[
The lines to display in the task. Can be specified in several different formats:
#example[```
// Spans 1 month, starting at the first month of the timeline
#task("Task", (0, 1))
```]
#example[```
// One red line at month 1, and a line spanning 2 months starting at month 4
#task("Task", (from: 0, to: 1, style: (stroke: red)), (3, 5))
```]
]
]
#command("taskgroup", arg("title", default: none), arg("tasks"))[
Groups tasks together in a box. If `title` is specified, a title will be
displayed, with a line spanning all the inner tasks.
#argument("title", types: ("content",), default: none)[
The title of the task group
]
#argument("tasks", types: ("content",))[
The tasks to display in the group
]
#example[```
#taskgroup(title: "Research", {
task("Task 1", (0, 1))
task("Task 2", (3, 5))
})
```]
]
#command(
"milestone",
arg("body"),
arg("at"),
arg("style"),
arg("overhang"),
arg("spacing"),
arg(anchor: "top"),
)[
Defines a milestone. The way it's displayed depends on the `milestone-layout`
option of the `#timeline` command.
#argument(
"at",
types: ("float",),
)[
The month at which the milestone should be displayed. Can be fractional.
]
#argument("style", types: ("dictionary",), default: ())[
Style for the milestone line. Defaults to `milestone-line-style`.
]
#argument(
"overhang",
types: ("length",),
default: 5pt,
)[
How far the milestone line should extend past the end of the timeline. Defaults
to `milestone-overhang`.
]
#argument("spacing", types: ("length",), default: 5pt)[
Spacing between the milestone line and the text. Defaults to `spacing`.
]
#argument(
"anchor",
types: ("string",),
default: "top",
)[
The anchor point for the milestone text. Can be `top`, `bottom`, `left`,
`right`, `top-left`, `top-right`, `bottom-left`, `bottom-right`, `center`,
`center-left`, `center-right`, `center-top`, `center-bottom`. Defaults to `top`.
]
#argument("body", types: ("content",))[
The text to display next to the milestone line
]
]
|
https://github.com/Myriad-Dreamin/typst.ts
|
https://raw.githubusercontent.com/Myriad-Dreamin/typst.ts/main/fuzzers/corpora/text/deco_02.typ
|
typst
|
Apache License 2.0
|
#import "/contrib/templates/std-tests/preset.typ": *
#show: test-page
// Test stroke folding.
#set underline(stroke: 2pt, offset: 2pt)
#underline(text(red, [DANGER!]))
|
https://github.com/ClassicConor/UoKCSYear1ExamNotes2024
|
https://raw.githubusercontent.com/ClassicConor/UoKCSYear1ExamNotes2024/master/Databases%20(With%20Exam%20Answers)/Databases%202022%20Paper/Databases%202022%20Answers.typ
|
typst
|
= 2022 Databases and the Web Exam
<databases-and-the-web-exam>
== Question 1
<question-1>
#quote(block: true)[
#block[
#set enum(numbering: "(a)", start: 1)
+ Inspect the following code:
]
```html
<html>
<head>
<title>First Attempt</title>
<style>
td th table { border: solid 1px }
</style>
</head>
<body>
<p style="colour:green">CO323 Coursework</p>
<table>
<tr><th>Question<th></th>Solution</th></tr>
<tr><td>How to calculate width?</td><td>Try code()</td></tr>
</table>
<caption>Notes</caption>
</body>
</html>
```
Identify four problems with the above code by stating the corresponding
line number and show how you fix those errors.
]
- Line 5: include commas between td, th, table to make sure that all are referenced.
- Line 9: Change `colour` to `color`
- Line 11: For the second table header, use an opening tag instead of a closing tag (currently, it’s `</th>Solution</th>`, but this needs to change to `<th>Solution</th>`)
- Line 14 - The <caption> tag should be placed within the <table> tag for it to be valid HTML.
#quote(block: true)[
#block[
#set enum(numbering: "(a)", start: 2)
+ Consider the following HTML with associated CSS:
]
```html
<div id="container"><div id="inner"></div></div>
```
```css
#container {
width: 400px;
}
#inner {
padding: 5px;
margin: 2px;
border: solid 1px grey;
width: calc(50% - 4px);
}
```
What is the entire width of the inner element, in pixels? Show your
calculation.
]
Container width = 400px \
Total padding = 5px \* 2 = 10px \
Total margin = 1px \* 2 = 2px
(400px / 2) - 4 = 196px \
196px + 10px + 2px = 208px
#quote(block: true)[
#block[
#set enum(numbering: "(a)", start: 3)
+ Provide the complete HTML and CSS code that produces the following
table:
]
#figure(image("./DatabasesQuestion1CTable.png"),
caption: [
Question 1c
]
)
]
```html
<html>
<style>
<!-- Optional styling to make the borders 1px solid black, as well as collapsed into a single line -->
table, td {
border-collapse: collapse;
border: 1px solid black;
}
</style>
<body>
<table>
<tr>
<td></td>
<td><b>A</b></td> <!-- Add bold text with <b> tag -->
<td><b>B</b></td> <!-- Add bold text with <b> tag -->
</tr>
<tr>
<td><b>C</b></td> <!-- Add bold text with <b> tag -->
<td>1</td>
<td>2</td>
</tr>
</table>
</body>
</html>
```
#pagebreak()
== Question 2
<question-2>
#quote(block: true)[
#block[
#set enum(numbering: "(1)", start: 2)
+ Inspect the following HTML code for displaying the marks of a student.
]
```html
<html>
<head>
<title>Marks</title>
<script>
function calculateMarks() {}
</script>
</head>
<body onload="calculateMarks()">
<div id="marks">
<p><span>Module</span><span>CW1</span><span>%</span><span>CW2<
/span><span>%</span><span>Exam</span><span>%</span></p>
<p><span>Networks</span><span>60</span><span>25</span><span>80
</span><span>25</span><span>70</span><span>50</span></p>
<p><span>Programming</span><span>90</span><span>30</span><span
>90</span><span>30</span><span>60</span><span>40</span></p>
<p><span>AI</span><span>50</span><span>20</span><span>60</span
><span>30</span><span>80</span><span>50</span></p>
</div>
<table>
<tr><th>Module</th><th>Final Mark</th></tr>
<tr id="Programming"><th>Programming</th><td>?</td></tr>
<tr id="Networks"><th>Networks</th><td>?</td></tr>
<tr id="AI"><th>AI</th><td>?</td></tr>
</table>
</body>
</html>
```
Complete the JavaScript function calculateMarks() to calculate the final
mark for each module, where two coursework marks and an exam mark are
provided with their corresponding percentage weights. The function
should then print the final marks onto the corresponding table cells (?
within the `<td>` tags). The final mark of a module is the weighted
average of the provided coursework and exam marks. Provide brief
comments within the code to describe your solution. Note that your code
should work for any number of modules displayed in this way (not only
for the above three modules). \[20 marks\]
]
HTML Code formatted normally:
```html
<!DOCTYPE html>
<html>
<head>
<title>Marks</title>
<script>
function calculateMarks() {}
</script>
</head>
<body onload="calculateMarks()">
<div id="marks">
<p>
<span>Module</span>
<span>CW1</span>
<span>%</span>
<span>CW2</span>
<span>%</span>
<span>Exam</span>
<span>%</span>
</p>
<p>
<span>Networks</span>
<span>60</span>
<span>25</span>
<span>80</span>
<span>25</span>
<span>70</span>
<span>50</span>
</p>
<p>
<span>Programming</span>
<span>90</span>
<span>30</span>
<span>90</span>
<span>30</span>
<span>60</span>
<span>40</span>
</p>
<p>
<span>AI</span>
<span>50</span>
<span>20</span>
<span>60</span>
<span>30</span>
<span>80</span>
<span>50</span>
</p>
</div>
<table>
<tr>
<th>Module</th>
<th>Final Mark</th>
</tr>
<tr id="Programming">
<th>Programming</th>
<td>?</td>
</tr>
<tr id="Networks">
<th>Networks</th>
<td>?</td>
</tr>
<tr id="AI">
<th>AI</th>
<td>?</td>
</tr>
</table>
</body>
</html>
```
Corresponding initial output:
#figure(image("DatabasesQuestion2InitialHTMLOutput.png"),
caption: [
Question 2 HTML output
]
)
Correct JavaScript code, with appropriate comments:
```html
<script>
function calculateMarks() {
// Get all the paragraphs <p> in the marks <div>
let paragraphs = document.getElementById("marks").getElementsByTagName("p");
// Create an array of all the average marks for each module and set to empty
let allAverageMarks = []
// Loop through each paragraph module
for (let i = 1; i < paragraphs.length; i++) {
// Get all the spans <span> in the paragraph <p>
let spans = paragraphs[i].getElementsByTagName("span");
// Calculate the average mark for the module
let averageMark = 0;
// Loop through each <span> in the paragraph
for (let j = 1; j < spans.length; j++) {
// Add the mark to the average mark, and save to an integer value
averageMark += parseInt(spans[j].innerHTML);
}
// Divide the average mark by the number of spans <span> to get the average mark, then save it to an integer value
averageMark = parseInt(averageMark / spans.length);
// Add the average mark to the allAverageMarks array
allAverageMarks.push(averageMark);
}
// Grab all the table data <td> in the table <table>
let tableData = document.getElementsByTagName("table")[0].getElementsByTagName("td");
// Loop through each table data <td> and set the innerHTML to the average mark
for (let i = 0; i < tableData.length; i++) {
tableData[i].innerHTML = allAverageMarks[i];
}
}
</script>
```
Corresponding final output:
#figure(image("DatabasesQuestion2FinalHTMLOutput.png"),
caption: [
Question 2 HTML output
]
)
#pagebreak()
== Question 3
<question-3>
=== (a) A PHP function is defined as follows
<a-a-php-function-is-defined-as-follows>
```php
function planets($arr) {
if ($arr[1]) {
print "Mercury";
}
else {
for ($i=0; $i <= $arr[2]; $i++)
{ print $arr[3][$i];
}
}
print count($arr);
}
```
Recall that array \$arr can be defined using a statement of the form:
`$arr = array(…);`
#quote(block: true)[
#block[
#set enum(numbering: "(i)", start: 1)
+ Give an array \$arr such that
]
```php
planets($arr)
```
prints `Mercury`. \[2 marks\]
]
It wants to make sure that there’s a value at index two. Therefore, we
can simply create an array with two values like this:
```php
$arr = array("planet1", "planet2");
```
#quote(block: true)[
For this case, what is the output of the instruction:
```php
print count($arry);
```
]
The output will be: `2`
#quote(block: true)[
Give an array \$arr such that
```php
planets($arr)
```
prints `Venus`.
]
This works because first of all, it checks if the item at index 1 is
true, which we negate by explicitly making it false. Next, it gets to
index 3, and begins to go through each item in this position, therefore
requiring another array. It goes through the first three items, which it
prints out to the screen. Because of this, we can then simply organise
the letters of `Venus` to come out in any order we’d like.
```php
$arr = array(
0,
false,
2,
array("Ven", "u", "s")
);
```
#quote(block: true)[
For this case, what is the output of the instruction:
```php
print(count($arr));
```
]
The output will be: `4`
#quote(block: true)[
#block[
#set enum(numbering: "(i)", start: 3)
+ Give an array \$arr such that
]
```php
planets($arr)
```
prints `Earth Jupiter Saturn`
Note: the for loop must do three iterations in case (iii).
]
```php
$arr = array(
0,
false,
2,
array("Earth ", "Jupiter ", "Saturn "));
```
#quote(block: true)[
#block[
#set enum(numbering: "(i)", start: 4)
+ For this case, what is the output of the instruction:
]
```php
print count($arr);
```
]
The output will be: `4`
=== (b)The following is the body of a web document titled index.html
<bthe-following-is-the-body-of-a-web-document-titled-index.html>
```html
<h2>Write a city:</h2>
<form action="search.php" method="POST">
<input type="text" city="cityName" />
<input type="submit" value="Submit" />
</form>
```
#quote(block: true)[
#block[
#set enum(numbering: "(i)", start: 1)
+ Create a drawing of what will appear on the web page when it is opened
in a web browser.
]
]
#figure(image("DatabasesQuestion4a.png"),
caption: [
Databases Question 4a
]
)
#quote(block: true)[
#block[
#set enum(numbering: "(i)", start: 2)
+ Describe what would happen after a user submits the form with the city
name and write an example.
]
]
A HTTP POST request is sent to "search.php". In addition, the data from the form, specifically the "cityName" input text box, is made available to "search.php" using the \$\_POST superglobal array.
#quote(block: true)[
#block[
#set enum(numbering: "(i)", start: 3)
+ Write a PHP statement in the document `search.php` to display the city
submitted in (ii).
]
]
```php
// Check if the form has been submitted
if ($_SERVER["REQUEST_METHOD"] == "POST") {
// Check if the city name is provided
if (!empty($_POST["cityName"])) {
// Retrieve the city name from the form data
$cityName = $_POST["cityName"];
// Display the submitted city name
echo "You submitted the city: " . $cityName;
}
}
```
Alternative solution:
```php
<?php
// Start the session if needed (not strictly necessary for this task, but often used)
session_start();
// Retrieve the submitted city name from the POST data
$cityName = $_POST['cityName'];
// Display the city name. htmlspecialchars is used to prevent XSS attacks by converting special characters to HTML entities so that they are displayed as text
echo 'You searched for the city: ' . htmlspecialchars($cityName);
?>
```
#quote(block: true)[
#block[
#set enum(numbering: "(i)", start: 4)
+ Describe what would happen after a user submits the form with the city
name if the method used is `GET` (replacing the `POST` method in
`search.php` ) with an example.
]
]
If the user uses `GET` instead of `POST` in their HTML and PHP code,
although the output onto the browser will be exactly the same, the URL
for that specific website will be different. If the user inputs Paris,
then the url that will be displayed will look like this:
`http://example.com/search.php?cityName=Paris`
It will have `search.php`, then `?`, then `cityName=Paris`.
#pagebreak()
== Question 4
<question-4>
A database is built in the library to catalogue books and handle book
lending. Each book in the library is catalogued by author. Any number of
books can be associated to an author. Each user is allowed to borrow one
and only one book. The database stores information about the following
entities and their relationships:
- User: unique reference number, name, and phone number,
- Author: unique reference number, name
- Book: unique title, category (e.g.~Physics, Science,..), publication
year, the user (reference) borrowing the book, the author (reference)
of the book
#quote(block: true)[
#block[
#set enum(numbering: "(a)", start: 1)
+ Write SQL CREATE TABLE statements for these three tables. Justify your
choices of keys used.
]
]
User Table:
```sql
CREATE TABLE User (
UserID INT PRIMARY KEY,
Name VARCHAR(255),
PhoneNumber VARCHAR(20)
);
```
`UserID`: This is chosen as the primary key for the User table because
it uniquely identifies each user. It is set to be of type INT for
efficiency and scalability. Additionally, it is declared as PRIMARY KEY
to ensure its uniqueness and to allow for efficient indexing and
retrieval of user records.
Author Table:
```sql
CREATE TABLE Author (
AuthorID INT PRIMARY KEY,
Name VARCHAR(255)
);
```
`AuthorID`: This is chosen as the primary key for the Author table
because it uniquely identifies each author. It is set to be of type INT
for efficiency and scalability. Additionally, it is declared as PRIMARY
KEY to ensure its uniqueness and to allow for efficient indexing and
retrieval of author records.
Book Table:
```sql
CREATE TABLE Book (
BookID INT PRIMARY KEY,
Title VARCHAR(255),
Category VARCHAR(50),
PublicationYear INT,
BorrowerID INT,
AuthorID INT,
FOREIGN KEY (BorrowerID) REFERENCES User(UserID),
FOREIGN KEY (AuthorID) REFERENCES Author(AuthorID)
);
```
Alternative solution for the Book table:
```sql
CREATE TABLE Book (
BookID INT PRIMARY KEY,
Title VARCHAR(255),
Category VARCHAR(50),
PublicationYear INT,
BorrowerID INT REFERENCES User(UserID),
AuthorID INT REFERENCES Author(AuthorID)
);
```
`BookID`: This is chosen as the primary key for the Book table because
it uniquely identifies each book. It is set to be of type INT for
efficiency and scalability. Additionally, it is declared as PRIMARY KEY
to ensure its uniqueness and to allow for efficient indexing and
retrieval of book records. Although its not referenced within the
details for the Book table, it has the same benefits for the primary key
as mentioned for UserID and AuthorID in the User and Author tables
respectively.
=== (b) Write SQL statements to perform the following tasks
<b-write-sql-statements-to-perform-the-following-tasks>
#quote(block: true)[
#block[
#set enum(numbering: "(i)", start: 1)
+ Insert a new entry in the user table (for a set of values at your
choice).
]
]
```sql
INSERT INTO User (Name, PhoneNumber)
VALUES ('<NAME>', '01227-223990');
```
#quote(block: true)[
#block[
#set enum(numbering: "(i)", start: 2)
+ List the title for all books with author "<NAME>".
]
]
```sql
SELECT Book.Title
FROM Book
JOIN Author ON Book.AuthorID = Author.AuthorID
WHERE Author.Name = '<NAME>';
```
#quote(block: true)[
#block[
#set enum(numbering: "(i)", start: 3)
+ List the names of all the authors in the database, and beside each
name give the number of books published on or after 2017
]
]
```sql
SELECT a.Name, COUNT(b.BookID) AS BooksPublishedSince2017
FROM Author a
LEFT JOIN Book b ON a.AuthorID = b.AuthorID AND b.PublicationYear >= 2017
GROUP BY a.Name;
```
|
|
https://github.com/Myriad-Dreamin/typst.ts
|
https://raw.githubusercontent.com/Myriad-Dreamin/typst.ts/main/fuzzers/corpora/visualize/gradient-stroke_01.typ
|
typst
|
Apache License 2.0
|
#import "/contrib/templates/std-tests/preset.typ": *
#show: test-page
#align(
center + bottom,
square(
size: 50pt,
fill: gradient.radial(red, blue, radius: 70.7%, focal-center: (10%, 10%)),
stroke: 10pt + gradient.radial(red, blue, radius: 70.7%, focal-center: (10%, 10%))
)
)
|
https://github.com/fenjalien/metro
|
https://raw.githubusercontent.com/fenjalien/metro/main/tests/unit/bracket-unit-denominator/test.typ
|
typst
|
Apache License 2.0
|
#import "/src/lib.typ": unit, metro-setup
#set page(width: auto, height: auto)
#unit("joule per mole per kelvin", per-mode: "symbol", bracket-unit-denominator: false)
|
https://github.com/remigerme/typst-polytechnique
|
https://raw.githubusercontent.com/remigerme/typst-polytechnique/main/heading.typ
|
typst
|
MIT License
|
/***********************/
/* TEMPLATE DEFINITION */
/***********************/
#let apply(doc) = {
// Numbering parameters
set heading(numbering: "1.1 - ")
// H1 styling
show heading.where(level:1): he => {
set align(center)
box(width: 85%)[#{
set par(justify: false)
set text(
size: 20pt,
weight: "black",
fill: rgb("CE0037"),
font: "New Computer Modern Sans",
hyphenate: false
)
if he.numbering != none {
counter(heading).display(he.numbering.slice(0, -3))
linebreak()
}
upper(he.body)
image("assets/filet-long.svg", width: 30%)
v(0.5em)
}]
}
// H2 styling
show heading.where(level:2): he => {
box[#{
set text(
size:20pt,
weight: "medium",
fill: rgb("00677F"),
)
smallcaps(he)
v(-0.5em)
image("assets/filet-court.svg")
v(0.3em)
}]
}
// H3 styling
show heading.where(level: 3): he => {
set text(
size: 16pt,
weight: "regular",
fill: rgb("01426A")
)
if he.numbering != none {
counter(heading).display(he.numbering.slice(0, -3))
[ • ]
}
smallcaps(he.body)
}
// H4 styling
show heading.where(level: 4): he => {
he
v(0.2em)
}
// Quick fix for paragraph indentation...
// Any superior entity who might be reading, please forgive me
show heading: he => {
{
set par(first-line-indent: 0pt)
he
}
par()[#text(size: 0em)[#h(0em)]]
}
// Don't forget to return doc cause
// we're in a template
doc
}
/********************/
/* TESTING TEMPLATE */
/********************/
#show: apply
#outline()
= My first section
== A sub-section
#heading(level: 2, numbering: none)[Sub-section without numbering]
#lorem(60)
=== No more ideas
==== Sometimes dummy text is
===== Really important
really ?
==== Back again
#heading(level: 3, numbering: none)[Sub-sub-section without numbering]
=== Guess who's back ?
#lorem(40)
= My second section
#lorem(30)
== Another one
|
https://github.com/SiyangShao/resume
|
https://raw.githubusercontent.com/SiyangShao/resume/main/main_work.typ
|
typst
|
#show heading: set text(font: "Linux Biolinum")
#show link: underline
// Uncomment the following lines to adjust the size of text
// The recommend resume text size is from `10pt` to `12pt`
#set text(
size: 11pt,
)
// Feel free to change the margin below to best fit your own CV
#set page(
margin: (x: 0.9cm, y: 1.3cm),
)
// For more customizable options, please refer to official reference: https://typst.app/docs/reference/
#set par(justify: true)
#let chiline() = {v(-3pt); line(length: 100%); v(-5pt)}
= SHAO Siyang
<EMAIL> |
+65-98602734 | #link("https://github.com/SiyangShao")[github.com/SiyangShao]
== Education
#chiline()
#link("https://www.ntu.edu.sg/")[*Nanyang Technological University*] #h(1fr) Aug 2021 -- Jun 2025 \
Bachelor of Engineering (Computer Engineering) #h(1fr) Singapore\
- Expected: Honours (Highest Distinction); GPA: 4.60 / 5.0
- Relevant Modules: Operating Systems (A+), Computer Network (A+), Computer Architecture and Organisation (A+), Advanced Computer Architecture (A)
== Skills Summary
#chiline()
- *Languages*: Golang, C++, Python, CUDA, ROCm
- *Tools*: Docker, Kubernetes, Knative, Kafka, Clickhouse, Grpc, Ray
== Work Experience
#chiline()
*TikTok Pte. Ltd.* #h(1fr) Singapore \
Backend Engineer Intern (Video Infrastructure) #h(1fr) Jan 2024 -- May 2024
- Co-Designed and implemented metrics metadata discover and manage system, bridged the gap between development teams and SRE teams concerning the monitoring metrics
- Implemented persistent global SLI monitor and manage system, monitored and managed the compliance of SLI metrics across all global regions, contributing to improvements in full-link stability
== Open Source Projects
#chiline()
*ServerlessLLM* #h(1fr) #link("https://github.com/ServerlessLLM/ServerlessLLM") \
Core Contributor #h(1fr) Jun 2024 -- Current \
- Supported ROCm for `sllm-store`, the internal library of ServerlessLLM which provides high-performance model loading
- Integrated vLLM backend, enabling ServerlessLLM project to perform inference through vLLM
- Explored methods to enable vLLM backend to benefit from high-performance model loading via `sllm-store`
- Maintained the controller of the ServerlessLLM project, which manages the lifecycle of the inference backends
== Co-Curricular Activities
#chiline()
*NTU ICPC Team* #h(1fr) #link("https://icpc.global/ICPCID/B15T259WIX3C") \
Team Member / Captain #h(1fr) Dec 2021 -- Mar 2024\
- Represented the school in ICPC (International Collegiate Programming Contest) and solved complex algorithm problems
== Awards
#chiline()
- 2022 ICPC Asia Manila Regional Ranked 2 #h(1fr) Dec 2022
- 2023 ICPC Asia Jakarta Regional Ranked 13 #h(1fr) Dec 2023
- 2024 ICPC Asia Pacific Championship Ranked 22 #h(1fr) Mar 2024
- Dean's List in Academic Year 2022-23 (Top 5% of cohort) #h(1fr) Aug 2023
- NTU President Research Scholar in Academic Year 2023-24 #h(1fr) Aug 2024
// - Shopee Code League Finalist #h(1fr) Mar 2022
// - ICPC Trainning Camp Powered by Huawei (Top 10 in South East Asia and Asia Pacific) #h(1fr) Feb 2022
== Research Experience
#chiline()
*LLM Inference in Serverless Systems* #h(1fr) \
Supervised by <NAME> #h(1fr) Mar 2024 -- Current \
- Investigated cluster-level scheduling for large language model inference in serverless systems
- Explored optimal scaling policies and mechanisms for serverless LLM environments
- Utilized GPU memory usage for a memory-centric scheduling LLM inference system
// - Optimized overall throughput and reduced request queueing latency
*MIG-based GPU Partitioning and Performance Analysis* #h(1fr) \
Supervised by <NAME> #h(1fr) Jun 2023 -- Nov 2023 \
- Explored the use of MIG (Multi-Instance GPU) to physically partition a single GPU
// - Investigated the performance overhead associated with achieving physical isolation across multiple instances
// - Compared performance gains and trade-offs of using MIG for multi-model scenarios on a single GPU
- Analyzed memory and PCIe bandwidth utilization across multiple MIG instances
|
|
https://github.com/OJII3/tuat-typst
|
https://raw.githubusercontent.com/OJII3/tuat-typst/main/CONTRIBUTING.md
|
markdown
|
# CONTRIBUTING.md
## Formatting
- Use `typstyle`.
|
|
https://github.com/rxt1077/it610
|
https://raw.githubusercontent.com/rxt1077/it610/master/markup/slides/runtimes.typ
|
typst
|
#import "/templates/slides.typ": *
#show: university-theme.with(
short-title: [Runtimes],
)
#title-slide(
title: [Container Runtimes],
)
#slide(title: [Background], side-by-side[
#v(1fr)
- Recall that containers are largely just #link("https://en.wikipedia.org/wiki/Linux_namespaces")[namespaces] and #link("https://en.wikipedia.org/wiki/Cgroups")[cgroups]
- A container runtime is the software that is used to support the containerization of software
#v(1fr)
][
#v(1fr)
#image("/images/cgroups.jpg")
#v(1fr)
])
#slide(title: [What specifically does a runtime do?], side-by-side[
#align(center, [
#v(1fr)
#image("/images/runtimes.png")
#text(12pt, link("https://landscape.cncf.io/guide#runtime")[Source: Cloud Native Landscape])
#v(1fr)
])
][
#v(1fr)
- image management
- lifecycle management
- creation
- resource management
#v(1fr)
])
#slide(title: [Docker (original)])[
- One of the first runtimes, and as such many things strive to be Docker compatible.
- Runs on many platforms and is easy to use
- Extremely popular _not just for the runtime_ but also for the tools that work with it such as their container registry Docker Hub.
- Supports app containers
- Requires a daemon to be running as root
- Losing ground in the production environment, but still common on dev machines
]
#slide(title: [Old Docker], align(center, image("/images/old-docker.png")))
#slide(title: [containerd])[
#align(center, image("/images/containerd.png", height: 30%))
- Born from the Open Container Initiative (OCI) which was created to make open standards for containers
- Daemon that runs in the background and supports app containers (sound familiar?)
- Relies on a lower-level tool called runc (written by Docker)
- Current versions of Docker run on containerd
]
#slide(title: [runc])[
#align(center, image("/images/runc.png", height: 30%))
- Universal, lightweight container runtime
- Designed for security
- No Docker dependencies
- Supports a very simple model of container execution
]
#slide(title: [New Docker], align(center, image("/images/new-docker.png")))
#slide(title: [CRI-O], side-by-side[
#v(1fr)
- Implements Kubernetes Container Runtime Interface (CRI) with OCI standards
- Runs as a daemon
- Support app containers
- Bridges the gap between K8s and containers, no need to run a `docker` command in-between
- Not meant for use by devs
#v(1fr)
][
#image("/images/cri-o.png")
])
#slide(title: [Podman], side-by-side[
#v(1fr)
#image("/images/podman.png", width: 100%)
#v(1fr)
][
#v(1fr)
- daemonless tool to use OCI containers
- has a similar CLI to `docker`
- supports similar features as `docker`
- Linux only
#v(1fr)
])
#slide(title: [LXC], side-by-side[
#v(1fr)
- Container engine designed for _system_ containers
- Rootless, daemonless, and fast
- Keep this in mind if you encounter a _tough_ virtualization feature
- Works with tools Linux admins are already familiar with
- Linux only
#v(1fr)
][
#v(1fr)
#image("/images/lxc.svg")
#v(1fr)
])
#slide(title: [Just for fun: #link("https://github.com/p8952/bocker")[Bocker]], side-by-side[
#v(1fr)
#image(width: 100%, "/images/container-funny.png")
#v(1fr)
][
#v(1fr)
- A lot of what Docker does can be implemented in around 100 lines of BASH!
- Remember these are things that are _already_ built in to the Linux kernel
- Obviously Linux only
#v(1fr)
])
#slide(title: [What does this mean?], side-by-side[
#v(1fr)
- As a sysadmin, you have options
- Almost all Linux-based
- A few kernel features can spawn a massive shift in software deployment
#v(1fr)
][
#v(1fr)
#image(width: 100%, "/images/docker-funny.png")
#v(1fr)
])
#slide(title: [Don't forget to demo...], side-by-side[
#v(1fr)
#image("/images/terminal.png")
#v(1fr)
][
#v(1fr)
- the Docker daemon running
- a `docker save` to show the structure of the filesystem
#v(1fr)
])
|
|
https://github.com/simon-epfl/notes-ba3-simon
|
https://raw.githubusercontent.com/simon-epfl/notes-ba3-simon/main/electromag/notes.typ
|
typst
|
== Cours 1
- +- force attraction, -- ou ++ force de répulsion
- on peut diviser +- mais pas créer => conservation de la charge
- la force est inversement proportionnelle à la distance $F=k/(r^alpha)$
- ...elle dépend aussi des charges des deux corps $F = k (q_1q_2)/(r^alpha)$
- induction : ex de la balle neutre, quand on approche la barre - ou +, les charges dans la balle se séparent (mais celles qui sont plus près de la barre, donc celles attirées conduisent à une force plus forte (car $F = k/(r^alpha)$) donc la balle est attirée)
La charge est quantifiée :
$ Q = N e $
$N $ le nombre de charges, $e = + (-) 1.6 dot 10^(-19) C$
$ arrow(F_c) = 1/(4pi epsilon_0) (q_1 q_2)/(r^2) hat(r) $
Principe de superposition :
$ arrow(F_z) = sum_(j = 1)^s (q_j q_z)/(r_(j z)^2) hat(r_(j z)), "si continue" arrow integral $
== Cours 2
On définit le champ électrique (au lieu de parler d'une force d'une charge $Q$ sur une petite charge $q$, on enlève $q$ de l'équation).
Ainsi: $ arrow(F_(Q arrow q)) = q E_Q hat(r) $
$ arrow(E) = 1/(4 pi epsilon_0) Q/r^2 hat(r) $
$ arrow(E_"tot") = sum_(1)^n arrow(E_j) = sum 1/(4 pi epsilon_0) Q/r_(j x)^2 hat(r_(j x)), "si continue" arrow integral $
On peut dessiner pour chaque point dans l'espace le vecteur $arrow(E)$. Pour simplifier on dessine des lignes de champ.
Electrostatique : les charges ne bougent pas. Donc $arrow(E) = 0$.
#pagebreak()
=== La polarisation
ça tourne
$ sum tau = sum |arrow(r) times F| = d q E sin(theta) $
($arrow(r)$ du centre de masse à l'application de la force donc distance $d$)
#image("rot.png")
=== Dipôles
Si on a deux dipôles séparés par une distnce $d$, on a $arrow(p) = q arrow(d)$
$ arrow(F) = (arrow(p) dot arrow(nabla)) arrow(E) $
$ F = q d (d E)/(d x) + ... + q d (d E)/(d n) $
=== Flux
$ "volume" = v dot d t dot A $
Produit scalaire entre la quantité et la surface?
$ Phi_E = arrow(E) dot arrow(S) = E dot S = 1/(4 pi epsilon_0) q/r^2 4 pi r^2 = q/(epsilon_0) $
==== Loi de Gauss
$ Phi_E |_S = q_"intérieure"/(epsilon_0) $
on peut utiliser Gauss au lieu d'intégrer
== 1ère équation de Maxwell
$ integral.cont arrow(E) d arrow(S) = Q_"intérieure"/epsilon_0 = integral.cont rho/epsilon_0 d V $
== Energie potentielle electrique
Le travail est lié à cette énergie potentielle par le fait que, pour déplacer une charge q dans un champ électrique créé par Q, il faut fournir ou récupérer une certaine quantité d'énergie. Ce travail est directement relié à la variation de l'énergie potentielle.
$ U = (q Q)/(4 pi epsilon_0 r) $
$ W = U(r_1) - U(r_2) $
comme en méca, au lieu de calculer l'intégrale pour le travail on peut clculer la différence de potentiel electrique
deux sujets (deux charges) => en découle le potentiel électrique, qui ne dépend que d'une des deux
à cause de la conservation de l'énergie comme en méca on peut faire la différence pour retrouver le champ électrique (E = dV/dr)
|
|
https://github.com/bamboovir/typst-resume-template
|
https://raw.githubusercontent.com/bamboovir/typst-resume-template/main/template.typ
|
typst
|
MIT License
|
// const color
#let color_darknight = rgb("#131A28")
#let color_darkgray = rgb("333333")
// layout utility
#let justify_align(left_body, right_body) = {
block[
#left_body
#box(width: 1fr)[
#align(right)[
#right_body
]
]
]
}
#let justify_align_3(left_body, mid_body, right_body) = {
block[
#box(width: 1fr)[
#align(left)[
#left_body
]
]
#box(width: 1fr)[
#align(center)[
#mid_body
]
]
#box(width: 1fr)[
#align(right)[
#right_body
]
]
]
}
#let resume(author: (), date: "", body) = {
set document(
author: author.firstname + " " + author.lastname,
title: "resume",
)
set text(
font: ("Source Sans Pro"),
lang: "en",
size: 11pt,
fill: color_darknight,
fallback: false
)
set page(
paper: "a4",
margin: (left: 15mm, right: 15mm, top: 10mm, bottom: 10mm),
footer: [
#set text(fill: gray, size: 8pt)
#justify_align_3[
#smallcaps[#date]
][
#smallcaps[
#author.firstname
#author.lastname
#sym.dot.c
#"Résumé"
]
][
#counter(page).display()
]
],
footer-descent: 0pt,
)
// set paragraph spacing
show par: set block(above: 0.75em, below: 0.75em)
set par(justify: true)
set heading(
numbering: none,
outlined: false,
)
let name = {
align(center)[
#pad(bottom: 5pt)[
#block[
#set text(size: 32pt, style: "normal", font: ("Roboto"))
#text(weight: "thin")[#author.firstname]
#text(weight: "bold")[#author.lastname]
]
]
]
}
let positions = {
set text(
size: 9pt,
weight: "regular"
)
align(center)[
#smallcaps[
#author.positions.join(
text[#" "#sym.dot.c#" "]
)
]
]
}
let contacts = {
set box(height: 11pt)
let linkedin_icon = box(image("assets/icons/linkedin.svg"))
let github_icon = box(image("assets/icons/square-github.svg"))
let email_icon = box(image("assets/icons/square-envelope-solid.svg"))
let phone_icon = box(image("assets/icons/square-phone-solid.svg"))
let separator = box(width: 5pt)
align(center)[
#block[
#align(horizon)[
#phone_icon
#box[#text(author.phone)]
#separator
#email_icon
#box[#link("mailto:" + author.email)[#author.email]]
#separator
#github_icon
#box[#link("https://github.com/" + author.github)[#author.github]]
#separator
#linkedin_icon
#box[
#link("https://www.linkedin.com/in/" + author.linkedin)[#author.linkedin]
]
]
]
]
}
name
positions
contacts
body
}
// general style
#let resume_section(title) = {
set text(
size: 16pt,
weight: "regular"
)
align(left)[
#smallcaps[
// #text[#title.slice(0, 3)]#strong[#text[#title.slice(3)]]
#strong[#text[#title]]
]
#box(width: 1fr, line(length: 100%))
]
}
#let resume_item(body) = {
set text(size: 10pt, style: "normal", weight: "light")
set par(leading: 0.65em)
body
}
#let resume_time(body) = {
set text(weight: "light", style: "italic", size: 9pt)
body
}
#let resume_degree(body) = {
set text(size: 10pt, weight: "light")
smallcaps[#body]
}
#let resume_organization(body) = {
set text(size: 12pt, style: "normal", weight: "bold")
body
}
#let resume_location(body) = {
set text(size: 12pt, style: "italic", weight: "light")
body
}
#let resume_position(body) = {
set text(size: 10pt, weight: "regular")
smallcaps[#body]
}
#let resume_category(body) = {
set text(size: 11pt, weight: "bold")
body
}
#let resume_gpa(numerator, denominator) = {
set text(size: 12pt, style: "italic", weight: "light")
text[Cumulative GPA: #box[#strong[#numerator] / #denominator]]
}
// sections specific components
#let education_item(organization, degree, gpa, time_frame) = {
set block(above: 0.7em, below: 0.7em)
set pad(top: 5pt)
pad[
#justify_align[
#resume_organization[#organization]
][
#gpa
]
#justify_align[
#resume_degree[#degree]
][
#resume_time[#time_frame]
]
]
}
#let work_experience_item_header(
company,
location,
position,
time_frame
) = {
set block(above: 0.7em, below: 0.7em)
set pad(top: 5pt)
pad[
#justify_align[
#resume_organization[#company]
][
#resume_location[#location]
]
#justify_align[
#resume_position[#position]
][
#resume_time[#time_frame]
]
]
}
#let personal_project_item_header(
name,
location,
position,
start_time,
) = {
set block(above: 0.7em, below: 0.7em)
set pad(top: 5pt)
pad[
#justify_align[
#resume_organization[#name]
][
#resume_location[#location]
]
#justify_align[
#resume_position[#position]
][
#resume_time[#start_time]
]
]
}
#let skill_item(category, items) = {
set block(above: 1.0em, below: 1.0em)
grid(
columns: (18fr, 80fr),
gutter: 10pt,
align(right)[
#resume_category[#category]
],
align(left)[
#set text(size: 11pt, style: "normal", weight: "light")
#items.join(", ")
],
)
}
|
https://github.com/typst-doc-cn/tutorial
|
https://raw.githubusercontent.com/typst-doc-cn/tutorial/main/src/basic/reference-typebase.typ
|
typst
|
Apache License 2.0
|
#import "mod.typ": *
#show: book.ref-page.with(title: [参考:基本类型])
#let glue-block = block.with(breakable: false)
// === 空字面量 <grammar-none-literal>
// 空字面量是纯粹抽象的概念,这意味着你在现实中很难找到对应的实体。就像是数学中的零与负数,空字面量自然产生于运算过程中。
// #code(```typ
// #repr((0, 1).find((_) => false)),
// #repr(if false [啊?])
// ```)
// 上例第一行,当在「数组」中查找一个不存在的元素时,“没有”就是```typc none```。
// 上例第二行,当条件不满足,且没有`false`分支时,“没有内容”就是```typc none```。
// 这些例子都蕴含较复杂的脚本逻辑,会在下一节详细介绍。
// #pro-tip[
// 空字面量自然产生于运算过程中。以下是所有会产生```typc none```的自然场景:
// - 当变量未初始化时。
// #code(```typ
// #let x; #type(x)
// ```)
// - 当`if`语句条件不满足,且没有`false`(`else`)分支时,`if`语句的值为```typc none```。
// #code(```typ
// #type(if false {})
// ```)
// - 当`for`语句、`while`语句、函数没有产生任何值时,函数返回值为```typc none```。
// #code(```typ
// #let f() = {}; #type(f())
// ```)
// - 当函数显式`return`且未写明返回值时,函数返回值为```typc none```。
// #code(```typ
// #let f() = return; #type(f())
// ```)
// ]
// `none`不产生任何内容:
// #code(```typ
// #none
// ```)
// `none`的类型是`none`类型:
// #code(```typ
// #type(none)
// ```)
// `none`值不等于`none`类型,因为一个是值而另一个是类型:
// #code(```typ
// #(type(none) == none), #type(none), #type(type(none))
// ```)
// // 使用以下方法将`none`转化为布尔类型:
// // #code(```typ
// // #let some-x = none
// // #(some-x == none)
// // #((some-x != none) and (1 < 2))
// // ```)
// === 布尔字面量
// 一个布尔字面量表示逻辑的确否。它要么为`false`(真)<grammar-true-literal>要么为`true`(假)<grammar-false-literal>。
// #code(```typ
// 两个值 #false 和 #true 偷偷混入了我们内容之中。
// ```)
// 一般来说,我们不直接使用布尔值。当代码做逻辑判断的时候,会自然产生布尔值。
// #code(```typ
// $1 < 2$的结果为:#(1 < 2) \
// $1 > 2$的结果为:#(1 > 2)
// ```)
// 布尔值的类型是布尔类型:
// #code(```typ
// #type(false), #type(true)
// ```)
// === 整数字面量 <grammar-integer-literal>
// 一个整数字面量代表一个整数。相信你一定知道整数的含义。Typst中的整数默认为十进制:
// #code(```typ
// 三个值 #(-1)、#0 和 #1 偷偷混入了我们内容之中。
// ```)
// #pro-tip[
// 有的时候Typst不支持在#mark("#")后直接跟一个值。这个时候无论值有多么复杂,都可以将值用一对圆括号包裹起来,从而允许Typst轻松解析该值。例如,Typst无法处理#mark("#")后直接跟随一个#mark("hyphen")的情况:
// #code(```typ
// #(-1), #(0), #(1)
// ```)
// ]
// Typst允许十进制数存在前导零:
// #code(```typ
// #009009
// ```)
// 有些数字使用其他进制表示更为方便。你可以分别使用`0x`、`0o`和`0b`前缀加上进制内容表示十六进制数、八进制数和二进制数:<grammar-n-adecimal-literal>
// #code(```typ
// 十六进制数:#(0xdeadbeef)、#(-0xdeadbeef) \
// 八进制数:#(0o755)、#(-0o644) \
// 二进制数:#(0b1001)、#(-0b1001)
// ```)
// 上例中,当数字被输出到文档时,Typst将数字都转换成了十进制表示。
// 以十六进制数为例介绍其与十进制数之间的关系。将一个十六进制数转换成一个十进制数,计算方式是:从十六进制数的低位(右边)开始,逐步向高位(左边),取每位的字符对应十进制数值,与 $16$ 的 $n$ 次幂相乘(这里的 $n$ 不是固定的,它等于该字符所在的位序 $-1$ ,位序指从低位到高位的排序),最后将每位的计算结果相加,即可获得对应十进制的值。
// 十六进制数字与十进制数字对应关系如下:
// #{
// set align(center)
// table(
// columns: 10,
// [十六进制],[...],[8],[9],[a/A],[b/B],[c/C],[d/D],[e/E],[f/F],
// [十进制],[...],[8],[9],[10],[11],[12],[13],[14],[15]
// )
// }
// 举个例子:十进制的1324相当于十六进制的0x52C。
// + 计算“C”:
// 因为“C”对应的十进制值是12,它所在的位序是1,即它是右边第1位,所以它的值为:$12 dot (16^(1-1)) = 12$
// + 计算“2”:
// 因为“2”对应的十进制值是2,它所在的位序是2,即它是右边第2位,所以它的值为:$2 dot (16^(2-1)) = 32$
// + 计算“5”:
// 因为“5”对应的十进制值是5,它所在的位序是3,即它是右边第3位,所以它的值为:$5 dot (16^(3-1)) = 1280$
// + 将每位结果相加:
// $ 12 + 32 + 1280 = 1324 $
// 检验:
// #code(```typ
// #1324, #0x52c, #(0x52c == 1324)
// ```)
// 整数的类型是整数类型:
// #code(```typ
// #type(0), #type(0x0), #type(0o0), #type(0b0)
// ```)
// 整数的有效取值范围是$[-2^63,2^63)$,其中$2^63=9223372036854775808$。
// === 浮点数字面量 <grammar-float-literal>
// 浮点数与整数非常类似。最常见的浮点数由至少一个整数部分或小数部分组成:
// #code(```typ
// 三个值 #(0.001)、#(.1) 和 #(2.) 偷偷混入了我们内容之中。
// ```)
// 浮点数的类型是浮点数类型:
// #code(```typ
// #type(2.)
// ```)
// 可见```typc 2.```与```typc 2```类型并不相同。
// 当数字过大时,其会被隐式转换为浮点数存储:
// #code(```typ
// #type(9000000000000000000000000000000)
// ```)
// 整数相除时会被转换为浮点数:
// #code(```typ
// #(10 / 4), #type(10 / 4) \
// #(12 / 4), #type(12 / 4) \
// ```)
// 为了转换类型,可以使用`int`,但有可能产生精度损失(就近取整):
// #code(```typ
// #int(10 / 4),
// #int(12 / 4),
// #int(9000000000000000000000000000000)
// ```)
// 有些数字使用#term("exponential notation")更为方便。你可以使用标准的#term("exponential notation")创建浮点数:<grammar-exp-repr-float>
// #code(```typ
// #(1e2)、#(1.926e3)、#(-1e-3)
// ```)
// Typst还为你内置了一些特殊的数值,它们都是浮点数:
// #code(```typ
// $pi$=#calc.pi \
// $tau$=#calc.tau \
// $inf$=#calc.inf \
// NaN=#calc.nan \
// ```)
// === 字符串字面量 <grammar-string-literal>
// Typst中所有字符串都是`utf-8`编码的,因此使用时不存在编码问题。字符串由一对「英文双引号」定界:
// #code(```typ
// #"Hello world!!"
// ```)
// 字符串的类型是字符串类型:
// #code(```typ
// #type("Hello world!!")
// ```)
// 有些字符无法置于双引号之内,例如双引号本身。这时候你需要嵌入字符的转义序列:
// #code(```typ
// #"Hello \"world\"!!"
// ```)
// 字符串中的转义序列与「标记模式」中的转义序列语法相同,但内容不同。Typst允许的字符串中的转义序列如下:
// #{
// set align(center)
// table(
// columns: 7,
// [代码], [`\\`],[`\"`],[`\n`],[`\r`],[`\t`],[`\u{2665}`],
// [效果], "\\", "\"", [(换行)], [(回车)], [(制表)], "\u{2665}",
// )
// }
// 与《基础文档》中的转义序列相同,你可以使用`\u{unicode}`格式直接嵌入Unicode字符。
// #code(```typ
// #"香辣牛肉粉好吃\u{2665}"
// ```)
// 除了使用简单字面量构造,可以使用以下方法从代码块获得字符串:
// #code(```typ
// #repr(`包含换行符和双引号的
// "内容"`.text)
// ```)
== 类型转换
整数转浮点数:<grammar-int-to-float>
#code(```typ
#float(1), #(type(float(1)))
```)
布尔值转整数:<grammar-bool-to-int>
#code(```typ
#int(false), #(type(int(false))) \
#int(true), #(type(int(true)))
```)
浮点数转整数:<grammar-float-to-int>
#code(```typ
#int(1), #(type(int(1)))
```)
该方法是就近取整,并有精度损失(根据规范,超出精度范围时,如何选择较近的值舍入是「与实现相关」):
#code(```typ
#int(1.5), #int(1.99),
// 超出浮点精度范围会就近舍入再转换成整数
#int(1.9999999999999999)
```)
为了向下或向上取整,你可以同时使用`calc.floor`或`calc.ceil`函数(有精度损失):
#code(```typ
#int(calc.floor(1.9)), #int(calc.ceil(1.9))
```)
十进制字符串转整数:<grammar-dec-str-to-int>
#code(```typ
#int("1"), #(type(int("1")))
```)
十六进制/八进制/二进制字符串转整数:<grammar-nadec-str-to-int>
#code(```typ
#let safe-to-int(x) = {
let res = eval(x)
assert(type(res) == int, message: "should be integer")
res
}
#safe-to-int("0xf"), #(type(safe-to-int("0xf"))) \
#safe-to-int("0o755"), #(type(safe-to-int("0o755"))) \
#safe-to-int("0b1011"), #(type(safe-to-int("0b1011"))) \
```)
注意:`assert(type(res) == int)`是必须的,否则是不安全的。
数字转字符串:<grammar-num-to-str>
#code(```typ
#repr(str(1)), #(type(str(1)))
#repr(str(.5)), #(type(str(.5)))
```)
整数转 $N$ 进制字符串:<grammar-int-to-nadec-str>
#code(```typ
#str(501, base:16), #str(0xdeadbeef, base:36)
```)
布尔值转字符串:<grammar-bool-to-str>
#code(```typ
#repr(false), #(type(repr(false)))
```)
数字转布尔值:<grammar-int-to-bool>
#code(```typ
#let to-bool(x) = x != 0
#repr(to-bool(0)), #(type(to-bool(0))) \
#repr(to-bool(1)), #(type(to-bool(1)))
```)
Typst的基本类型设计大量参考Python和Rust。Typst基本类型的特点是半纯的API设计。其基本类型的方法倾向于保持纯度,但如果影响到了使用的方便性,Typst会适当牺牲纯度。
如下所示,`array.push`就是带有副作用的:
#code(```typ
#let t = (1, 2)
#t.push(3)
#t
```)
== 布尔类型 <reference-type-bool>
Typst的布尔值是只有两个实例的类型。#ref-bookmark[`type:bool`]
#code(```
#false, #true
```)
布尔值一般用来表示逻辑的确否。
#code(```
#(1 < 2), #(1 > 2)
```)
== 整数 <reference-type-int>
Typst的整数是64位宽度的有符号整数。#ref-bookmark[`type:int`]
*有符号*整数的意思是,你可以使用正整数、负整数或零作为整数对象的内容。
#code(```typ
正数:#1;负数:#(-1);零:#0。
```)
*64位宽度*整数的意思是,Typst允许你使用的整数是有限大的。正数、负数与整数均分$2^64$个数字。因此:
- 最大的正整数是$2^63-1$。
#code(```typ
#int(9223372036854775807)
```)
- 最小的负整数是$-2^63$。
#code(```typ
#int(-9223372036854775808)
```)
Typst还允许你使用其他#term("representation")表示整数。借鉴了其他编程语言,使用`0x`、`0o`和`0b`分别可以指定十六进制、八进制和二进制整数:
#code(```typ
#0xffff, #0o755, #0b101010
```)
#ref-cons-signature("int")
除了#term("literal")构造整数,#ref-bookmark[`func:int`]你还能使用构造器#typst-func("int")将其他值转换为整数。
- 将布尔值转换为$0$或$1$:
#code(```typ
#int(false), #int(true)
```)
- 将浮点数向零取整为整数:
#code(```typ
#int(-1.1), #int(1.1), #int(-0.1), #int(-1.9)
```)
- 将字符串依照十进制表示转换为整数:
#code(```typ
#int("42"), #int("0"), #int("-17")
```)
你可以使用各种操作符进行整数运算:
#code(```typ
#(1 + 2) \
#(2 - 5) \
#(3 + 4 < 8)
```)
详见#(refs.scripting-base)[《基本字面量、变量和简单函数》]中的表达式类型。
整数类型上没有任何方法,但是Typst正计划将`calc`上的方法移动到整数类型和浮点数类型上。
== 浮点数 <reference-type-float>
Typst的浮点数是64位宽度的有符号浮点数。#ref-bookmark[`type:float`]
*有符号*浮点数的意思是,你可以使用正数、负数或零作为浮点数数对象的内容。*64位宽度*浮点数的意思是,Typst允许你使用的浮点数是有限大的。正数、负数与浮点数均分$2^64$个浮点数。
Typst的浮点数遵守#link("https://standards.ieee.org/ieee/754/6210/")[IEEE-754浮点数标准]。因此:
- 最大的正数为 $f_max = 2^1023 dot (2 - 2^(-52))$。
- 最小的正数为 $f_min = 2^(-1022) dot 2^(-52)$。
- 最大的负数为 $-f_min$。
- 最小的负数为 $-f_max$。
Typst还允许你使用#term("exponential notation")表示浮点数。Typst允许你使用`{x}e{y}`格式表示$x dot 10^y$的浮点数:
#code(```typ
#1e1, #1e-1, #(-1e1), #(-1e-1), #(1.1e1)
```)
#ref-cons-signature("float")
除了#term("literal")构造浮点数,#ref-bookmark[`func:float`]你还能使用构造器#typst-func("float")将其他值转换为浮点数。
- 将布尔值转换为$0.0$或$1.0$:
#code(```typ
#float(false), #float(true)
```)
- 将整数转换成#term("nearest")的浮点数:
#code(```typ
#float(0), #float(-0), #float(10000000000)
```)
- 将百分比数字转换成#term("nearest")的浮点数:
#code(```typ
#float(100%), #float(1150%), #float(1%)
```)
- 将字符串依照十进制或#term("exponential notation")表示转换为浮点数:
#code(```typ
#float("42.2"), #float("0"), #float("-17"), #float("1e5")
```)
你可以使用各种操作符进行浮点数运算,且浮点数允许与整数混合运算:
#code(```typ
#(10 / 4) \
#(3.5 + 4.6 < 8)
```)
详见#(refs.scripting-base)[《基本字面量、变量和简单函数》]中的表达式类型。
浮点数类型上没有任何方法,但是Typst正计划将`calc`上的方法移动到整数类型和浮点数类型上。
== 字符串 <reference-type-str>
Typst的字符串是#term("utf-8 encoding")的字节序列。#ref-bookmark[`type:str`]
#link("https://en.wikipedia.org/wiki/UTF-8", "UTF-8编码")是一个广泛使用的变长编码规范。这意味着当你使用“abc123”字符串时,实际存储了这样的字节数据:
#code(```typ
#let f(x) = range(x.len()).map(
i => x.at(i))
#f(bytes("abc123"))
```)
这意味着当你使用“ふ店”字符串时,实际存储了这样的字节数据:
#code(```typ
#let f(x) = range(x.len()).map(
i => x.at(i))
#f(bytes("ふ店"))
```)
在绝大部分情况下,你不需要关心字符串的编码问题,因为在Typst脚本中只有#term("utf-8 encoding")的字符串。
但是这不意味着你不需要了解#term("utf-8 encoding")。Typst的字符串API与底层编码息息相关,因此你需要尽可能多地掌握与#term("utf-8 encoding")有关的知识。
在编码体系中,与Typst相关的主要有三层,它们在原始字节数据视角下的边界并不一样:
+ 字节表示:按字节寻址时,每个偏移量都索引到一个字节。
+ #term("codepoint")表示:#term("utf-8 encoding")是变长编码。在#term("utf-8 encoding")中,很多#term("codepoint")都由多个字节组成。UTF-8字符串中#term("codepoint")数据按照顺序存放,自然有些字节偏移量在#term("codepoint")寻址中不是合法的。
+ #term("grapheme cluster")表示:#term("grapheme cluster")就是人类视觉效果上的“最小字符单位”。在码位之上,Unicode规范还规定了多个码位组成一个#term("grapheme cluster")的情况。在这种情况下,自然有些码位(字节)偏移量在#term("grapheme cluster")寻址中不是合法的。
下表说明了\u{0061}\u{0303}在字节表示下的合法偏移量。
#let to-bytes-array(x) = range(x.len()).map(i => x.at(i))
#{
set align(center)
let i = text(red, [非法])
table(
columns: (50pt, 95pt, 130pt, 80pt),
..(
[数据],
..to-bytes-array(bytes("\u{0061}\u{0303}")).map(it => [0x#str(it, base: 16)]),
[字节],
[第1个字节],
[第2个字节],
[第3个字节],
).map(it => align(center, it)),
[码位],
[英文字母a],
[#term("tilde diacritical marks")],
i,
[字素簇],
[波浪变音的英文字母a],
i,
i,
)
}
#pro-tip[
关于#term("grapheme cluster")的定义,请参考#link("https://unicode.org/reports/tr29/")[《Unicode规范:文本分段》]。
]
字符串的字面量由双引号包裹。你可以在字符串字面量中使用与字符串相关的转义序列。
#code(```typ
#"hello world!" \
#"\"hello\n world\"!" \
```)
详见#(refs.scripting-base)[《基本字面量、变量和简单函数》]中关于字符串类型的描述。
你可以使用`in`关键字检查一个字符串是否是另一个字符串的子串:#ref-bookmark[`operator:in`\ of `str`]
#code(```typ
#("fox" in "lazy fox"),
#(" fox" in "lazy fox"),
#("fox " in "lazy fox"),
#("dog" in "lazy fox")
```)
`in`关键字左侧值还可以是一个正则表达式类型,以检查#term("pattern")是否匹配字符串:
#code(```typ
#(regex("\d+") in "ten euros") \
#(regex("\d+") in "10 euros")
```)
`in`关键字是以#term("codepoint")为粒度检查文本的:
#code(```typ
#("\u{0303}" in "ã")
```)
#ref-cons-signature("str")
除了#term("literal")构造字符串,#ref-bookmark[`func:str`]你还能使用构造器#typst-func("str")将其他值转换为字符串。
- 将整数和浮点数转换为十进制格式字符串:
#code(```typ
#str(0), #str(199),
#str(0.1), #str(9.1)
```)
- 将标签转换为其名称:
#code(```typ
#str(<owo:this-label>)
```)
- 将字节数组依照#term("utf-8 encoding")编码:
#code(```typ
#str(bytes((72, 0x69, 33)))
```)
特别地,你可以使用`base`参数,#ref-bookmark[`param:base`\ of `str`]将整数依照$N (2 lt.slant N lt.slant 36)$进制格式转换为字符串:
#code(```typ
#str(15, base: 16),
#str(14, base: 14),
#str(0xdeadbeef, base: 36)
```)
借鉴Python和JavaScript,Typst不提供字符类型。相应的,仅具备单个#term("codepoint")的字符串就被视作一个#term("character")。也就是说,Typst认定#term("character")与#term("codepoint")等同。这是符合主流观念的。
- “a”、“我”是字符。
- “ã”不是字符。
#glue-block[
#ref-method-signature("str.to-unicode")
你可以使用#typst-func("str.to-unicode")#ref-bookmark[`method:to-unicode`\ `of str`]函数获得一个字符的#term("codepoint")表示:
#code(```typ
#"a".to-unicode(),
#"我".to-unicode()
```)
#pro-tip[
显然,不是所有的“字符”都可以应用`to-unicode`方法。
#```typ
#"ã".to-unicode() /* 不能编译 */
```
这是因为视觉上为单个字符的ã是一个#term("grapheme cluster"),包含多个码位。
]
]
#ref-method-signature("str.from-unicode")
你可以使用#typst-func("str.from-unicode")#ref-bookmark[`method:from-unicode`\ `of str`]函数将一个数字的#term("codepoint")表示转换成字符(串):
#code(```typ
#str.from-unicode(97),
#str.from-unicode(25105)
```)
#ref-method-signature("str.len")
你可以使用#typst-func("str.len")#ref-bookmark[`method:len`\ `of str`]函数获得一个字符串的*字节表示的长度*:
#code(```typ
#"abc".len(),
#"香風とうふ店".len(),
#"ã".len()
```)
你可能希望得到一个字符串的#term("codepoint width"),这时你可以组合以下方法:
#code(```typ
#"abc".codepoints().len(),
#"香風とうふ店".codepoints().len(),
#"ã".codepoints().len()
```)
你可能希望得到一个字符串的#term("grapheme cluster width"),这时你可以组合以下方法:
#code(```typ
#"abc".clusters().len(),
#"香風とうふ店".clusters().len(),
#"ã".clusters().len()
```)
#glue-block[
#ref-method-signature("str.first")
你可以使用#typst-func("str.first")#ref-bookmark[`method:first`\ `of str`]函数获得一个字符串的第一个#term("grapheme cluster"):
#code(```typ
#"Wee".first(),
#"<NAME>".first(),
#"\u{0061}\u{0303}\u{0061}".first()
```)
]
#ref-method-signature("str.last")
你可以使用#typst-func("str.last")#ref-bookmark[`method:last`\ `of str`]函数获得一个字符串的最后一个#term("grapheme cluster"):
#code(```typ
#"Wee".last(),
#"我 们 俩".last(),
#"\u{0061}\u{0303}\u{0061}".last(),
#"\u{0061}\u{0061}\u{0303}".last()
```)
#ref-method-signature("str.at")
你可以使用#typst-func("str.at")#ref-bookmark[`method:at`\ `of str`]函数获得一个字符串位于*字节偏移量*为`offset`的#term("grapheme cluster"):
#code(```typ
#"我 们 俩".at(0),
#"我 们 俩".at(3),
#"我 们 俩".at(4),
#"我 们 俩".at(8)
```)
上例中,第一个空格的字节偏移量为 $3$,“俩”的字节偏移量为 $8$ 。
#ref-method-signature("str.slice")
你可以使用#typst-func("str.slice")#ref-bookmark[`method:slice`\ `of str`]函数截取字节偏移量从`start`到`end`的子串:
#code(```typ
#repr("我 们 俩".slice(0, 11)),
#repr("我 们 俩".slice(4, 8)),
```)
`end`参数可以省略:#ref-bookmark[`param:end`\ of `str.slice`]
#code(```typ
#repr("我 们 俩".slice(0)),
#repr("我 们 俩".slice(4)),
```)
#ref-method-signature("str.trim")
你可以使用#typst-func("str.trim")#ref-bookmark[`method:trim`\ `of str`]去除字符串的首尾空白字符:
#code(```typ
#repr(" A ".trim())
```)
#typst-func("str.trim")可以指定`pattern`参数。#ref-bookmark[`param:pattern`\ of `str.trim`]
#code(```typ
#repr("wwAww".trim("w"))
```)
`pattern`可以是`none`、字符串或正则表达式。当不指定`pattern`时,Typst会指定一个模式*贪婪地*去除首尾空格。
#code(```typ
#repr(" A ".trim()),
#repr(" A ".trim(none)),
#repr("wwAww".trim("w")),
#repr("abAde".trim(regex("[a-z]+"))),
```)
#pro-tip[
当`pattern`参数为`none`时,Typst直接调用Rust的`trim_start`或`trim_end`方法,以默认获得更高的性能。
]
`at`参数可以为`start`或`end`,#ref-bookmark[`param:at`\ of `str.trim`]分别指定则只清除起始位置或结束位置的字符。
#code(```typ
#repr(" A ".trim(" ", at: start)),
#repr(" A ".trim(" ", at: end))
```)
`repeat`参数为false时,#ref-bookmark[`param:repeat`\ of `str.trim`]不会重复运行`pattern`;否则会重复运行。默认`repeat`为`true`。
#code(```typ
#repr(" A ".trim(" ")),
#repr(" A ".trim(" ", repeat: false))
```)
`pattern`会在起始位置或结束位置执行至少一次。
#code(```typ
#repr(" A ".trim(" ", at: start, repeat: false)),
#repr("abAde".trim(
regex("[a-z]"), repeat: false)),
#repr("abAde".trim(
regex("[a-z]+"), repeat: false))
```)
#ref-method-signature("str.split")
你可以使用#typst-func("str.split")#ref-bookmark[`method:split`\ `of str`]函数将一个字符串依照空白字符拆分:
#code(```typ
#"我 们仨".split(),
```)
#glue-block[
#ref-method-signature("str.rev")
你可以使用#typst-func("str.rev")#ref-bookmark[`method:rev`\ `of str`]函数将一个字符串逆转:
#code(```typ
#"abcdedfg".rev()
```)
逆转时Typst会为你考虑#term("grapheme cluster")。
#code(```typ
#"ãb".rev()
```)
]
str.clusters, str.codepoints
str.contains, str.starts-with, str.ends-with
str.find, str.position, str.match, str.matches, str.replace
== 字典
#code(```typ
#let dict = (
name: "Typst",
born: 2019,
)
#dict.name \
#(dict.launch = 20)
#dict.len() \
#dict.keys() \
#dict.values() \
#dict.at("born") \
#dict.insert("city", "Berlin ")
#("name" in dict)
```)
dict.len, dict.at
dict.insert, dict.remove
dict.keys, dict.values, dict.pairs
== 数组
#code(```typ
#let values = (1, 7, 4, -3, 2)
#values.at(0) \
#(values.at(0) = 3)
#values.at(-1) \
#values.find(calc.even) \
#values.filter(calc.odd) \
#values.map(calc.abs) \
#values.rev() \
#(1, (2, 3)).flatten() \
#(("A", "B", "C")
.join(", ", last: " and "))
```)
array.range
array.len
array.first, array.last, array.slice
array.push, array.pop, array.insert, array.remove
array.contains, array.find, array.position, array.filter
array.map, array.enumerate, array.zip, array.fold, array.sum, array.product, array.any, array.all, array.flatten, array.rev, array.split, array.join, array.intersperse, array.sorted, array.dedup
|
https://github.com/jgm/typst-hs
|
https://raw.githubusercontent.com/jgm/typst-hs/main/test/typ/math/delimited-05.typ
|
typst
|
Other
|
// Test half LRs.
$ lr(a/b\]) = a = lr(\{a/b) $
|
https://github.com/TypstApp-team/typst
|
https://raw.githubusercontent.com/TypstApp-team/typst/master/tests/typ/text/symbol.typ
|
typst
|
Apache License 2.0
|
// Test symbols.
---
#emoji.face
#emoji.woman.old
#emoji.turtle
#set text(font: "New Computer Modern Math")
#sym.arrow
#sym.arrow.l
#sym.arrow.r.squiggly
#sym.arrow.tr.hook
#sym.arrow.r;this and this#sym.arrow.l;
---
// Error: 13-20 unknown symbol modifier
#emoji.face.garbage
|
https://github.com/eliapasquali/typst-thesis-template
|
https://raw.githubusercontent.com/eliapasquali/typst-thesis-template/main/chapters/requirements.typ
|
typst
|
Other
|
#import "../config/thesis-config.typ": useCase
#pagebreak(to:"odd")
= Analisi dei requisiti
<cap:analisi-requisiti>
#v(1em)
#text(style: "italic", [
Breve introduzione al capitolo
])
#v(1em)
== Casi d'uso
Per lo studio dei casi di utilizzo del prodotto sono stati creati dei diagrammi.
I diagrammi dei casi d'uso (in inglese _Use Case Diagram_) sono diagrammi di tipo _UML_ (*TODO* AGGIUNGI GLOSSARIO in qualche modo) dedicati alla descrizione delle funzioni o servizi offerti da un sistema, così come sono percepiti e utilizzati dagli attori che interagiscono col sistema stesso.
Essendo il progetto finalizzato alla creazione di un tool per l'automazione di un processo, le interazioni da parte dell'utilizzatore devono essere ovviamente ridotte allo stretto necessario. Per questi motivi i diagrammi dei casi d'uso risultano semplici e in numero ridotto.
#figure(
image("../images/usecase/scenario-principale.png", width: 100%),
caption: "Use Case - UC0: Scenario principale"
) <uc:scenario-principale>
// L'ordine e i nomi delle chiavi sono arbitrari, vedere la funzione nel file ..config/thesis-config.typ
#useCase(
(
number: 0,
name: "Apertura plugin",
"Attore principale": "Sviluppatore applicativi",
"Precondizioni": "Lo sviluppatore è entrato nel plug-in di simulazione all'interno dell'IDE",
"Postcondizioni": "Il sistema è pronto per permettere una nuova interazione",
"Scenario principale": "La finestra di simulazione mette a disposizione i comandi per configurare, registrare o eseguire un test"
)
)
<uc:0>
== Tracciamento dei requisiti
Da un'attenta analisi dei requisiti e degli use case effettuata sul progetto è stata stilata la tabella che traccia i requisiti in rapporto agli use case.
Sono stati individuati diversi tipi di requisiti e si è quindi fatto utilizzo di un codice identificativo per distinguerli.
Il codice dei requisiti è così strutturato R(F/Q/V)(N/D/O) dove:
#set list(marker: none)
- R = requisito
- F = funzionale
- Q = qualitativo
- V = di vincolo
- N = obbligatorio (necessario)
- D = desiderabile
- Z = opzionale
Nelle tabelle @tab:requisiti-funzionali, @tab:requisiti-qualitativi e @tab:requisiti-vincolo sono riassunti i requisiti e il loro tracciamento con gli use case delineati in fase di analisi.
#figure(
table(
columns: (auto, auto, auto),
align: (center, left, center),
[*Requisito*], [*Descrizione*], [*Use Case*],
[RFN-1], [L'interfaccia permette di configurare il tipo di sonde del test], [UC1],
),
caption: "Tabella del tracciamento dei requisti funzionali",
)
<tab:requisiti-funzionali>
#figure(
table(
columns: (auto, auto, auto),
align: (center, left, center),
[*Requisito*], [*Descrizione*], [*Use Case*],
[RQD-1], [Le prestazioni del simulatore hardware deve garantire la giusta esecuzione dei test e non la generazione di falsi negativi], [#sym.dash],
),
caption: "Tabella del tracciamento dei requisti funzionali",
)
<tab:requisiti-qualitativi>
#figure(
table(
columns: (auto, auto, auto),
align: (center, left, center),
[*Requisito*], [*Descrizione*], [*Use Case*],
[RVQ-1], [La libreria per l'esecuzione dei test automatici deve essere riutilizzabil], [#sym.dash],
),
caption: "Tabella del tracciamento dei requisti funzionali",
)
<tab:requisiti-vincolo>
|
https://github.com/duskmoon314/thu-polylux
|
https://raw.githubusercontent.com/duskmoon314/thu-polylux/main/README.md
|
markdown
|
MIT License
|
# THU-Polylux
一个 THU 风格的 Typst/Polylux 主题,仿照 THU 风格的 Beamer 主题制作。
|
https://github.com/LuminolT/SHU-Bachelor-Thesis-Typst
|
https://raw.githubusercontent.com/LuminolT/SHU-Bachelor-Thesis-Typst/main/README.md
|
markdown
|
# SHU-Bachelor-Thesis-Typst (开发ing)
上海大学本科毕业论文[_typst_](https://typst.app/)模板
## 为什么要使用typst
typst相较Latex具有较为简洁的[语法](https://typst.app/docs/reference/syntax/),更加用户友好的[教程及文档](https://typst.app/docs/tutorial/)。除去其用于支持用户自定样式的语法,typst具有与markdown高度相似的语法,使非模板编辑者能更好的聚焦文档编写本身。而且,typst具有快速的编译速度,搭配[vscode typst lsp](https://marketplace.visualstudio.com/items?itemName=nvarner.typst-lsp)的监听修改自动编译的功能,可以即时预览编译出的pdf文件。
## 使用
### 安装typst
[typst Github主页](https://github.com/typst/typst)提供了详细的安装教程
for Archlinux
``` shell
$ pacman -S typst
```
### 编写
修改body目录下各文件即可
### 编译
``` shell
# for linux and macos
$ make
```
## TODO
由于没有找到学校最新的本科毕业论文格式要求,所以上述格式是参照学校提供的word文档格式编写,其中难免会有细节的疏漏,欢迎PR
以下是尚未完成功能
- [ ] 图片插入格式
- [ ] 表格插入格式
- [ ] 参考文献格式
- [ ] 公式插入格式
- [ ] 页首及页尾格式(未找到明确要求)
- [x] 模块划分
- [ ] windows 编译脚本
- [ ] ...
|
|
https://github.com/VadimYarovoy/CourseWork
|
https://raw.githubusercontent.com/VadimYarovoy/CourseWork/main/typ/stage_3.typ
|
typst
|
#import "@preview/timeliney:0.0.1"
== Представить общий вид жизненного цикла программного проекта в графическом виде
Длина одного спринта 1 неделя
Обоснование длины спринта: Короткие сроки и наличие паралельной работы требуют
высокой частоты синхронизации планирования, и следовательно коротких спринтов.
Из исходных данных длительность проекта не должна превышать *8 недель*. Также известно, что добавление нового функционала предварительно оценивается в *7 недель*.
#timeliney.timeline(
show-grid: true,
{
import timeliney: *
headerline(
group(..range(8).map(n => strong("" + str(n + 1)))),
)
taskgroup(title: [*Подготовка*], {
task("Планирование задач", (0, 1), style: (stroke: 2pt + yellow))
})
taskgroup(title: [*MVP*], {
task("Разработка", (1, 3), style: (stroke: 2pt + red))
task("Тестирование", (3, 5), style: (stroke: 2pt + blue))
})
taskgroup(title: [*Основное движение*], {
task("Доработка продукта", (3, 7), style: (stroke: 2pt + red))
task("Приемочное тестирование", (5, 7), style: (stroke: 2pt + blue))
})
taskgroup({
task([*Запасная неделя*], (7, 8), style: (stroke: 2pt + green))
})
milestone(
at: 3,
style: (stroke: (dash: "dashed")),
align(center, [
*MVP ready*
])
)
milestone(
at: 7,
style: (stroke: (dash: "dashed")),
align(center, [
*App ready*
])
)
}
)
|
|
https://github.com/kilpkonn/CV
|
https://raw.githubusercontent.com/kilpkonn/CV/master/modules_en/professional.typ
|
typst
|
// Imports
#import "@preview/brilliant-cv:2.0.3": cvSection, cvEntry
#let metadata = toml("../metadata.toml")
#let cvSection = cvSection.with(metadata: metadata)
#let cvEntry = cvEntry.with(metadata: metadata)
#cvSection("Professional Experience")
#cvEntry(
title: [Senior Software Developer],
society: [Milrem Robotics],
logo: image("../src/logos/milrem.jpg"),
date: [2020 - Present],
location: [Tallinn, Estonia],
description: list(
[In charge of THeMIS UGV platform software, mainly generator and motor control],
[One of the main contributors to design of external interface],
[In charge of 8x8 UGV platform high-level systems and CI/CD]
),
tags: ("C++", "Rust", "ROS2", "Zenoh"),
)
#cvEntry(
title: [Teaching Assistant],
society: [TalTech - Tallinn University of Technology],
logo: image("../src/logos/taltech.jpg"),
date: [2019 - 2023],
location: [Tallinn, Estonia],
description: list(
[Designed some tasks and mentored students in Python, Java and Algorithms courses],
[Mentored students in Game/Web Development and Robotics courses],
),
tags: ("Python", "Java", "SpringBoot", "CI/CD"),
)
|
|
https://github.com/Amelia-Mowers/typst-tabut
|
https://raw.githubusercontent.com/Amelia-Mowers/typst-tabut/main/doc/example-snippets/usd.typ
|
typst
|
MIT License
|
#let usd(input) = {
set align(right);
let dollars-int = int(input);
let cents-int = int((input - dollars-int) * 100);
let dollars-str = str(dollars-int);
let cents-str = str(cents-int);
if cents-str.len() < 2 {
cents-str = "0" + cents-str;
}
let dollars-chunks = ();
let dollars-to-chunk = dollars-str.rev();
while dollars-to-chunk.len() > 3 {
dollars-chunks.push(
dollars-to-chunk.slice(0, 3).rev()
);
dollars-to-chunk = dollars-to-chunk.slice(3);
}
dollars-chunks.push(dollars-to-chunk.rev());
[\$#{dollars-chunks.rev().join(",")}.#cents-str]
}
|
https://github.com/BoneDocument/BoneDocument
|
https://raw.githubusercontent.com/BoneDocument/BoneDocument/main/lib.typ
|
typst
|
#let bone-document(
title: "Document Title",
author: (),
body,
) = {
set document(author: author, title: title)
set page(
margin: (
x: 6em,
y: 6em,
),
footer: [
Powered By
#link(
"https://github.com/zrr1999/BoneDocument")[BoneDocument]
#h(1fr)
#counter(page).display(
"1")
],
)
set heading(level: 2, numbering: "1.1.1")
set par(
// first-line-indent: 2em,
justify: true)
set text(
font: (
"Hack Nerd Font",
// "Source Han Sans CN",
"Source Han Serif SC",
),
lang: "zh",
)
show emph: it => {
text(
it.body,
font: (
"Hack Nerd Font",
"Source Han Serif SC",
),
style: "italic",
)
}
show link: it => {
set text(
blue,
font: (
"Hack Nerd Font",
"Source Han Serif SC",
),
weight: "bold",
)
it// h(-0.5em)// TODO: typst will add space before link
}
show heading.where(
level: 1): it =>{
set text(
rgb("#448"),
size: 16pt,
font: "Source Han Sans CN",
)
set par(first-line-indent: 0pt)
counter(heading).display("一、")
it.body
v(14pt, weak: true)
}
show heading.where(
level: 2): it =>{
it
v(12pt, weak: true)
}
show heading.where(
level: 3): it =>{
it
v(10pt, weak: true)
}
align(
center)[
#block(
text(
font: "Source Han Sans CN",
weight: 700,
2em,
title,
))
]
body
}
|
|
https://github.com/Myriad-Dreamin/typst.ts
|
https://raw.githubusercontent.com/Myriad-Dreamin/typst.ts/main/fuzzers/corpora/text/shaping_02.typ
|
typst
|
Apache License 2.0
|
#import "/contrib/templates/std-tests/preset.typ": *
#show: test-page
// A forced `deva` script enables Devanagari font features.
#set text(script: "deva")
ABCअपार्टमेंट
|
https://github.com/paugarcia32/CV
|
https://raw.githubusercontent.com/paugarcia32/CV/main/modules_es/professional.typ
|
typst
|
Apache License 2.0
|
#import "../brilliant-CV/template.typ": *
#cvSection("Experiencia Profesional")
#cvEntry(
title: [Internino de Ciberseguridad],
society: [Mar<NAME>],
logo: "../src/logos/marsh.png",
date: [2024 - Present],
location: [Barcelona, ES],
description: list(
[Evaluar la madurez de la ciberseguridad, mediante el uso de marcos de referencia como ISO 27001 o NIST, identificando áreas de mejora y proponiendo soluciones para alcanzar un nivel adecuado de seguridad.],
[Análisis de riesgos para evaluar las amenazas y vulnerabilidades que enfrentan los sistemas y procesos críticos de las empresas.],
[Análisis de vulnerabilidades en sistemas y aplicaciones, con el objetivo de identificar posibles debilidades y brechas de seguridad que podrían ser explotadas por atacantes.],
),
//tags: ("Tags Example here", "Dataiku", "Snowflake", "SparkSQL")
)
#cvEntry(
title: [Profesor particular],
society: [Freelance],
logo: "../src/logos/professor.png",
date: [2018 - 2021],
location: [Barcelona, ES],
description: list(
[Clases particulares a alumnos de la ESO y bachillerato de asignaturas principalmente de la rama científica y técnica.],
),
//tags: ("Tags Example here", "Dataiku", "Snowflake", "SparkSQL")
)
|
https://github.com/Dav1com/minerva-report-fcfm
|
https://raw.githubusercontent.com/Dav1com/minerva-report-fcfm/master/template/meta.typ
|
typst
|
MIT No Attribution
|
#import "@preview/minerva-report-fcfm:0.3.0" as minerva
#let titulo = "Informe Minerva"
#let subtitulo = "Typst"
#let tema = "Aprendiendo a usar el template"
#let departamento = minerva.departamentos.dcc
#let curso = "CC4034 - Composición de Documentos"
#let fechas = ( // diccionario de fechas
realización: "14 de Abril de 2024",
entrega: minerva.util.formato-fecha(datetime.today())
)
#let lugar = "Santiago, Chile"
#let autores = ("Integrante1", "Integrante2")
#let equipo-docente = (
Profesores: ("Profesor1", "Profesor2"),
Auxiliar: "ÚnicoAuxiliar",
Ayudante: [
Ayudante1 \
Ayudante $1+1$
],
)
|
https://github.com/posit-dev/bcorp-report
|
https://raw.githubusercontent.com/posit-dev/bcorp-report/main/typst-show.typ
|
typst
|
#show: doc => posit(
$if(title)$
title: [$title$],
$endif$
$if(subtitle)$
subtitle: [$subtitle$],
$endif$
$if(lang)$
lang: "$lang$",
$endif$
$if(region)$
region: "$region$",
$endif$
$if(margin)$
margin: ($for(margin/pairs)$$margin.key$: $margin.value$,$endfor$),
$endif$
$if(papersize)$
paper: "$papersize$",
$endif$
$if(mainfont)$
font: ("$mainfont$",),
$endif$
$if(fontsize)$
fontsize: $fontsize$,
$endif$
doc,
)
|
|
https://github.com/kdog3682/2024-typst
|
https://raw.githubusercontent.com/kdog3682/2024-typst/main/src/strokes.typ
|
typst
|
#let dashes = ("solid", "dotted", "densely-dotted", "loosely-dotted", "dashed", "densely-dashed", "loosely-dashed", "dash-dotted", "densely-dash-dotted", "loosely-dash-dotted")
#let caps = ("butt", "round", "square")
#let ref = (
soft: (dash: "loosely-dotted", thickness: 0.5pt, paint: black),
gentle: (dash: "loosely-dotted", thickness: 0.45pt, paint: blue),
fierce: (dash: "loosely-dotted", thickness: 0.45pt, paint: blue),
thin: (dash: "loosely-dotted", thickness: 0.5pt, paint: black),
dashed: (dash: "loosely-dash-dotted", thickness: 0.5pt, paint: black),
hard: (dash: "solid", thickness: 0.5pt, paint: black),
thick: (dash: "solid", thickness: 2.5pt, paint: black),
)
#let soft = ref.soft
#let get(key, paint: none, cap: none) = {
let value = ref.at(key)
if paint != none {
value.insert("paint", paint)
}
if cap != none {
value.insert("cap", cap)
}
return value
}
// #panic(get("thin", paint: blue))
|
|
https://github.com/touying-typ/touying
|
https://raw.githubusercontent.com/touying-typ/touying/main/themes/simple.typ
|
typst
|
MIT License
|
// This theme is from https://github.com/andreasKroepelin/polylux/blob/main/themes/simple.typ
// Author: <NAME>
#import "../src/exports.typ": *
/// Default slide function for the presentation.
///
/// - `config` is the configuration of the slide. You can use `config-xxx` to set the configuration of the slide. For more several configurations, you can use `utils.merge-dicts` to merge them.
///
/// - `repeat` is the number of subslides. Default is `auto`,which means touying will automatically calculate the number of subslides.
///
/// The `repeat` argument is necessary when you use `#slide(repeat: 3, self => [ .. ])` style code to create a slide. The callback-style `uncover` and `only` cannot be detected by touying automatically.
///
/// - `setting` is the setting of the slide. You can use it to add some set/show rules for the slide.
///
/// - `composer` is the composer of the slide. You can use it to set the layout of the slide.
///
/// For example, `#slide(composer: (1fr, 2fr, 1fr))[A][B][C]` to split the slide into three parts. The first and the last parts will take 1/4 of the slide, and the second part will take 1/2 of the slide.
///
/// If you pass a non-function value like `(1fr, 2fr, 1fr)`, it will be assumed to be the first argument of the `components.side-by-side` function.
///
/// The `components.side-by-side` function is a simple wrapper of the `grid` function. It means you can use the `grid.cell(colspan: 2, ..)` to make the cell take 2 columns.
///
/// For example, `#slide(composer: 2)[A][B][#grid.cell(colspan: 2)[Footer]]` will make the `Footer` cell take 2 columns.
///
/// If you want to customize the composer, you can pass a function to the `composer` argument. The function should receive the contents of the slide and return the content of the slide, like `#slide(composer: grid.with(columns: 2))[A][B]`.
///
/// - `..bodies` is the contents of the slide. You can call the `slide` function with syntax like `#slide[A][B][C]` to create a slide.
#let slide(
config: (:),
repeat: auto,
setting: body => body,
composer: auto,
..bodies,
) = touying-slide-wrapper(self => {
let deco-format(it) = text(size: .6em, fill: gray, it)
let header(self) = deco-format(
components.left-and-right(
utils.call-or-display(self, self.store.header),
utils.call-or-display(self, self.store.header-right),
),
)
let footer(self) = {
v(.5em)
deco-format(
components.left-and-right(
utils.call-or-display(self, self.store.footer),
utils.call-or-display(self, self.store.footer-right),
),
)
}
let self = utils.merge-dicts(
self,
config-page(
header: header,
footer: footer,
fill: self.colors.neutral-lightest,
),
config-common(subslide-preamble: self.store.subslide-preamble),
)
touying-slide(self: self, config: config, repeat: repeat, setting: setting, composer: composer, ..bodies)
})
/// Centered slide for the presentation.
#let centered-slide(..args) = touying-slide-wrapper(self => {
touying-slide(self: self, ..args.named(), align(center + horizon, args.pos().sum(default: none)))
})
/// Title slide for the presentation.
///
/// Example: `#title-slide[Hello, World!]`
#let title-slide(body) = centered-slide(
config: config-common(freeze-slide-counter: true),
body,
)
/// New section slide for the presentation. You can update it by updating the `new-section-slide-fn` argument for `config-common` function.
#let new-section-slide(body) = centered-slide([
#text(1.2em, weight: "bold", utils.display-current-heading(level: 1))
#body
])
/// Focus on some content.
///
/// Example: `#focus-slide[Wake up!]`
#let focus-slide(background: auto, foreground: white, body) = touying-slide-wrapper(self => {
self = utils.merge-dicts(
self,
config-common(freeze-slide-counter: true),
config-page(fill: if background == auto {
self.colors.primary
} else {
background
}),
)
set text(fill: foreground, size: 1.5em)
touying-slide(self: self, align(center + horizon, body))
})
/// Touying simple theme.
///
/// Example:
///
/// ```typst
/// #show: simple-theme.with(aspect-ratio: "16-9", config-colors(primary: blue))`
/// ```
///
/// - `aspect-ratio` is the aspect ratio of the slides. Default is `16-9`.
///
/// - `header` is the header of the slides. Default is `self => utils.display-current-heading(setting: utils.fit-to-width.with(grow: false, 100%), depth: self.slide-level)`.
///
/// - `header-right` is the right part of the header. Default is `self.info.logo`.
///
/// - `footer` is the footer of the slides. Default is `none`.
///
/// - `footer-right` is the right part of the footer. Default is `context utils.slide-counter.display() + " / " + utils.last-slide-number`.
///
/// - `primary` is the primary color of the slides. Default is `aqua.darken(50%)`.
///
/// - `subslide-preamble` is the preamble of the subslides. Default is `block(below: 1.5em, text(1.2em, weight: "bold", utils.display-current-heading(level: 2)))`.
///
/// ----------------------------------------
///
/// The default colors:
///
/// ```typ
/// config-colors(
/// neutral-light: gray,
/// neutral-lightest: rgb("#ffffff"),
/// neutral-darkest: rgb("#000000"),
/// primary: aqua.darken(50%),
/// )
/// ```
#let simple-theme(
aspect-ratio: "16-9",
header: self => utils.display-current-heading(
setting: utils.fit-to-width.with(grow: false, 100%),
level: 1,
depth: self.slide-level,
),
header-right: self => self.info.logo,
footer: none,
footer-right: context utils.slide-counter.display() + " / " + utils.last-slide-number,
primary: aqua.darken(50%),
subslide-preamble: block(
below: 1.5em,
text(1.2em, weight: "bold", utils.display-current-heading(level: 2)),
),
..args,
body,
) = {
show: touying-slides.with(
config-page(
paper: "presentation-" + aspect-ratio,
margin: 2em,
footer-descent: 0em,
),
config-common(
slide-fn: slide,
new-section-slide-fn: new-section-slide,
zero-margin-header: false,
zero-margin-footer: false,
),
config-methods(
init: (self: none, body) => {
set text(fill: self.colors.neutral-darkest, size: 25pt)
show footnote.entry: set text(size: .6em)
show heading.where(level: 1): set text(1.4em)
body
},
alert: utils.alert-with-primary-color,
),
config-colors(
neutral-light: gray,
neutral-lightest: rgb("#ffffff"),
neutral-darkest: rgb("#000000"),
primary: primary,
),
// save the variables for later use
config-store(
header: header,
header-right: header-right,
footer: footer,
footer-right: footer-right,
subslide-preamble: subslide-preamble,
),
..args,
)
body
}
|
https://github.com/AU-Master-Thesis/thesis
|
https://raw.githubusercontent.com/AU-Master-Thesis/thesis/main/sections/4-results/study-1.typ
|
typst
|
MIT License
|
#import "../../lib/mod.typ": *
// #jonas[Alright you can stop reading now. No more content at all.]
// == Overskrift
#pagebreak(weak: true)
== #study.H-1.full.n <s.r.study-1>
// #jonas[all these results are new since last. We are working towards measuring ours and their code and then comparing their paper vs our code vs their code. Does that make sense? It will be obvious where we are still missing results]
// #todo[create an experiment where we measure the effect of number of internal iterations. Should give a lower error the higher it is.]
This section presents all results pertaining to the first contribution, that is the #acr("MAGICS") simulator, along with its capabilities to reproduce the results of the #acr("GBP") Planner@gbpplanner. Sections #numref(<s.r.results.circle-obstacles>)-#numref(<s.r.results.failure>) present the results of the experiments conducted in scenarios #boxed[*S-1*] to #boxed[*S-5*] respectively. For a description of these scenarios see the previous section #nameref(<s.r.scenarios>, "Scenarios").
=== Circle & Environment Obstacles <s.r.results.circle-obstacles>
For this scenario, similar to @gbpplanner, the _#acr("LDJ")_ and _distance travelled_ metrics are presented, see @f.circle-experiment-ldj and @f.circle-experiment-distance-travelled respectively. By comparing both figures to the corresponding ones of @gbpplanner, Figure 4 and 5, it is evident that #acr("MAGICS") is unable to reproduce the results of the #acr("GBP") Planner for lookahead multiple, $l_m=3$, and time horizon, $t_(K-1)=13.33s$.
#let handles = (
(
label: [C: $l_m=3,t_(K-1)=5s$],
color: theme.lavender,
alpha: 0%,
space: 1em,
),
(
label: [C: $l_m=1,t_(K-1)=13.33s$],
color: theme.teal,
alpha: 70%,
space: 1em,
),
(
label: [C: $l_m=3,t_(K-1)=13.33s$],
color: theme.green,
alpha: 70%,
space: 1em,
),
(
label: [EB: $l_m=3,t_(K-1)=5s$],
color: theme.mauve,
alpha: 50%,
space: 0em,
)
)
// #let value-swatches = [#sl#swatch(theme.yellow.lighten(45%))#swatch(theme.peach.lighten(45%))]
#let value-swatches = {
for s in handles.map(handle => swatch(handle.color.lighten(handle.alpha))) {
s
}
}
#figure(
grid(
columns: 2,
align: horizon,
block(
clip: true,
pad(
top: -2mm,
right: -2mm,
rest: -3mm,
image("../../figures/plots/circle-experiment-ldj.svg"),
)
),
{
v(-1.75em)
legend(handles, direction: ttb, fill: theme.base)
}
),
caption: [
#acr("LDJ") metric for the _Circle_ scenario as the number of robots $N_R$ increases. Each value#value-swatches is averaged over five different seeds; $#equation.as-set(params.seeds)$. Corresponds with Figure 5 in @gbpplanner. C = Circle Scenario, EB = Environment Obstacles Scenario.
]
)<f.circle-experiment-ldj>
The results on both figures #numref(<f.circle-experiment-ldj>) and #numref(<f.circle-experiment-distance-travelled>), show that lowering the lookahead multiple to $l_m=1$, or lowering the time horizon to $t_(K-1)=5s$ individually obtain results that are closer to those of @gbpplanner. The best possible results for are achieved with #text(theme.lavender, $l_m=3,t_(K-1)=5s$).
#figure(
grid(
columns: 2,
align: horizon,
block(
clip: true,
pad(
top: -2mm,
right: -2mm,
rest: -3mm,
image("../../figures/plots/circle-experiment-distance-travelled.svg"),
)
),
{
v(-1.75em)
legend(handles, direction: ttb, fill: theme.base)
}
),
caption: [
Distribution of distances travelled, as the number of robots $N_R$ increases. Each value#value-swatches is averaged over five different seeds; $#equation.as-set(params.seeds)$. Corresponds with Figure 4 in @gbpplanner. C = Circle Scenario, EB = Environment Obstacles Scenario.
]
)<f.circle-experiment-distance-travelled>
#pagebreak(weak: true)
The results for the Environment Obstacles scenario are shown with purple and a tag of EB in all three figures; #numref(<f.circle-experiment-ldj>), #numref(<f.circle-experiment-distance-travelled>), and #numref(<f.obstacle-experiment-makespan>). It can be seen how these results are consistently worse-
#v(-0.55em)
#let fig = [
#v(1em)
#figure(
z-stack(
pad(
x: -4mm,
y: -4mm,
image("../../figures/plots/circle-experiment-makespan.svg")
),
{
set text(size: 1.1em)
place(right + top, dy: 0.2em, dx: 0.1em, legend(handles, direction: ttb, fill: white.transparentize(40%)))
}
),
caption: [
Comparison of makespan for the _Circle_ and _Environment Obstacles_ scenarios, as the number of robots $N_R$ increases. Each value #sl is averaged over five different seeds; $#equation.as-set(params.seeds)$. Corresponds with Figure 6 in @gbpplanner. C = Circle Scenario, EB = Environment Obstacles Scenario.
]
)<f.obstacle-experiment-makespan>
]
#let body = [
performing than the Circle scenario, and are comparable to @gbpplanner, with only a small expected descrepency.
@f.obstacle-experiment-makespan presents the makespan results for both the Circle and Environment Obstacles scenarios. The figure shows that the makespan for #lm3-th5.n is significantly lower than for the two runs with $t_(K-1)=13.33s$. Furthermore, the makespan values for #lm3-th5.s are much closer to the corresponding values of @gbpplanner. Hence, it was deemed unnecessary to have validative results from the `gbpplanner` code itself.
]
#grid(
columns: (1fr, 85mm),
column-gutter: 1em,
body,
fig
)
=== Varying Network Connectivity <s.r.results.network>
#let gbpplanner-results = (
rc: (20, 40, 60, 80),
makespan: (12.0, 12.3, 12.7, 14.8),
mean-dist: (104.0, 104.5, 104.0, 103.8),
ldj: (-9.02, -8.76, -8.38, -8.47),
)
#let ours = (
lm3-th13: (
rc: (20, 40, 60, 80),
makespan: (46.012491607666014, 64.58217391967773, 65.34115142822266, 64.63148651123046),
mean-dist: (236.89510927868324, 285.9908325030257, 295.2933289314799, 283.24733969761115),
ldj: (-14.479386124124115, -15.966531007631174, -16.334361227393277, -16.105878378955726),
)
)
#let tablify(dictionaries) = dictionaries.map(dict => dict.values()).flatten().map(it => [#it])
// #let colors = (
// theirs: theme.peach.lighten(20%),
// ours: theme.lavender
// )
#let vc = table.cell.with(inset: 0.75em)
#let tc = vc
#let tc2 = table.cell.with(fill: colors.theirs.lighten(70%), stroke: none)
#let oc = table.cell.with(fill: colors.ours.lighten(80%), stroke: none)
#let oc2 = table.cell.with(fill: colors.ours.lighten(80%), stroke: none)
#let theirs = boxed.with(color: colors.theirs)
#let ours = boxed.with(color: colors.ours)
#let T1 = theirs[*T-1*]
#let T2 = theirs[*T-2*]
#let O1 = ours[*O-1*]
#let O2 = ours[*O-2*]
The _makespan_, _distance travelled_, and _LDJ_ metrics are presented in @t.network-experiment. From these numbers, the experiment with communication range of 20 meters, $r_C=20"m"$, did much worse than the other three $r_C in {40, 60, 80}m$, where the change is very minimal in all three metrics.//#note.j[Discussion: #sym.dash.en _if not negligible_.] In @t.network-experiment, results of four experiments are shown:
#term-table(
colors: (colors.theirs, colors.theirs, colors.ours, colors.ours),
boxed(color: colors.theirs, [*Theirs-1*]), [The results from the #gbpplanner paper@gbpplanner],
boxed(color: colors.theirs, [*Theirs-2*]), [The results of the provided code by #gbpplanner, with the same parameters as the #gbpplanner paper; #lm3-th13.n.],
boxed(color: colors.ours, [*Ours-1*]), [The results of #acr("MAGICS"), with the same parameters as the #gbpplanner paper; #lm3-th13.n.],
boxed(color: colors.ours, [*Ours-2*]), [The results of #acr("MAGICS"), with tuned parameters; #lm3-th5.n.],
)
// #[
// #set list(marker: boxed(color: theme.peach, [*Theirs-1*]))
// - The results from the #gbpplanner paper@gbpplanner
// #set list(marker: boxed(color: theme.lavender, [*Ours-1*]))
// - The results of #acr("MAGICS"), with the same parameters as the #gbpplanner paper; #lm3-th13.n.
// #set list(marker: boxed(color: theme.lavender, [*Ours-2*]))
// - The results of #acr("MAGICS"), with tuned parameters; #lm3-th5.n.
// #set list(marker: boxed(color: theme.peach, [*Theirs-3*]))
// - The results of the provided code by #gbpplanner, with the same parameters as the #gbpplanner paper; #lm3-th13.n.
// ]
// O1
// makespan: {20: 110.84, 40: 169.78, 60: 178.6, 80: 176.23999999999998}
// distance: {20: 295.5999750811273, 40: 469.9587116164673, 60: 499.84999164026755, 80: 514.5135772497284}
// ldj: {20: -17.5307399430643, 40: -19.511392192446536, 60: -19.940552192799846, 80: -20.232993297885482}
#figure(
tablec(
columns: (auto,) + range(12).map(_ => 1fr),
alignment: center + horizon,
header-color: (fill: theme.base, text: theme.text),
header: table.header(
tc(rowspan: 2, [$bold(r_C)$\ \[$bold(m)$\]]), tc(colspan: 4, [Makespan \[$bold(s)$\]]), tc(colspan: 4, [Distance Travelled \[$bold(m)$\]]), tc(colspan: 4, [LDJ \[$bold(m"/"s^3)$\]]), table.hline(), T1, T2, O1, O2, T1, T2, O1, O2, T1, T2, O1, O2
),
// vc[20], table.vline(), vc[$12.0$], vc[$110.8$], vc[$46.0$], vc[$199.50$], table.vline(), vc[$104$], vc[$295.6$], vc[$236.9$], vc[$519.5$], table.vline(), vc[$-9.02$], vc[$-17.5$], vc[$-14.5$], vc[$-22.9$],
vc[20], table.vline(), vc[$12.0$], vc[$199.50$], vc[$110.8$], vc[$46.0$], table.vline(), vc[$104$], vc[$519.5$], vc[$295.6$], vc[$236.9$], table.vline(), vc[$-9.02$], vc[$-22.9$], vc[$-17.5$], vc[$-14.5$],
vc[40], vc[$12.3$], vc[$260.9$], vc[$169.8$], vc[$64.6$], vc[$104.5$], vc[$751.1$], vc[$470.0$], vc[$286.0$], vc[$-8.76$], vc[$-23.7$], vc[$-19.5$], vc[$-16.0$],
vc[60], vc[$12.7$], vc[$443.3$], vc[$178.6$], vc[$65.3$], vc[$104.0$], vc[$1551.7$], vc[$499.8$], vc[$295.3$], vc[$-8.38$], vc[$-25.3$], vc[$-19.9$], vc[$-16.3$],
vc[80], vc[$14.8$], vc[$379.0$], vc[$176.2$], vc[$64.6$], vc[$103$], vc[$1069.4$], vc[$514.5$], vc[$283.2$], vc[$-8.47$], vc[$-24.9$], vc[$-20.2$], vc[$-16.1$],
),
caption: [Results for the Varying Network Connectivity scenario. Shows the effect of varying communication range $r_C$ in the same environment as the Environment Obstacles scenario. Values in the #T1 column is taken from Table 1 in @gbpplanner. Column #T2 are results obtained by running the experiment in `gbpplanner`@gbpplanner-code, where #O1 and #O2 are results from #acr("MAGICS"). #O1 is with lookahead multiple $l_m=3$ and time horizon $t_(K-1)=13.33s$, where #O2 is with #lm3-th5.n. Performed over 5 different seeds; $#equation.as-set(params.seeds)$. Corresponds with Table 1 in @gbpplanner.],
)<t.network-experiment>
=== Junction <s.r.results.junction>
#let body = [
The results of the Junction experiment are presented on a plot in @f.qin-vs-qout, similarly to how it was done in @gbpplanner. The plot shows that the input flowrate $Q_"in"$ is very close to the output flowrate $Q_"out"$ for $Q_"in" in [0, 6.5]$, where it starts deviating from the optimal flowrate at $Q_"in" = 7.5$, decreasing to an output flowrate of $Q_"out" approx 6.6$. This result is consistent with both the presented numbers in @gbpplanner and the provided `gbpplanner` code. In @t.qin-vs-qout, the raw data is presented. Here it becomes clear that the output flowrate follows the input flowrate perfectly up until $Q_"in" = 4$, where $Q_"out" = 3.98$ #sym.dash.en _and from here on $Q_"out"$ consistently deviates more and more_. These results are comparable to the results of @gbpplanner, looking at their Figure 7.
]
#let handles = (
(
patch: inline-line(stroke: (thickness: 2pt, paint: theme.overlay2, dash: "dotted")),
label: [$Q_"in" = Q_"out"$],
color: theme.overlay2,
alpha: 0%,
space: 1em,
),
(
label: [$60s$ Mean Flowrate],
color: theme.lavender,
alpha: 0%,
space: 0em,
),
)
#let fig = [
#figure(
block(
clip: true,
z-stack(
pad(
top: -2mm,
right: -2mm,
rest: -3mm,
image("../../figures/plots/qin-vs-qout.svg"),
),
{
set text(size: 1.1em)
place(right + bottom, dy: -2.4em, dx: -0.9em, legend(handles, direction: ttb, fill: white.transparentize(40%)))
}
)
),
caption: [
This plot illustrates the relationship between the input flowrate $Q_"in"$ the output flowrate $Q_"out"$ robots for the Junction scenario, @s.r.scenarios.junction. The dashed dark-gray line #inline-line(stroke: (thickness: 2pt, paint: theme.overlay2, dash: "dotted")) represents the ideal scenario where $Q_"in" = Q_"out"$. The solid blue colored line with circle markers#sl indicates the average flowrate measured over a 50-second steady-state period. The results demonstrate a close approximation to the ideal flowrate, with slight deviations observed at higher flowrates. Performed over 5 different seeds; $#equation.as-set(params.seeds)$. Corresponds with Figure 7 in @gbpplanner.
]
)<f.qin-vs-qout>
]
#grid(
columns: (1fr, 80mm),
column-gutter: 1em,
body,
fig
)
#let qins = (0.0, 0.5, 1.0, 1.5, 2.0, 2.5, 3.0, 3.5, 4.0, 4.5, 5.0, 5.5, 6.0, 6.5, 7.0)
#let qouts = (0.0, 0.508, 1.0, 1.5199999999999998, 2.0, 2.5, 3.0, 3.5, 3.9760000000000004, 4.476, 4.948, 5.452, 5.964, 6.408000000000001, 6.555999999999999)
#figure(
{
let header-columns = (0,)
show table.cell : it => {
if it.x == 0 {
set text(white)
it
} else {
it
}
}
tablec(
columns: (auto,) + range(qins.len()).map(_ => 1fr),
alignment: center + horizon,
fill: (x, y) => if x in header-columns { theme.lavender } else if calc.even(x) { theme.base } else { theme.mantle },
$bold(Q_"in")$,
..qins.map(qin => [$#qin$]),
$bold(Q_"out")$,
..qouts.map(qout => [$#strfmt("{0:.2}", qout)$]),
)
},
caption: [The relationship between the input flowrate $Q_"in"$ and the output flowrate $Q_"out"$ for the Junction scenario.]
)<t.qin-vs-qout>
=== Communications Failure <s.r.results.failure>
// #jens[results from ours and their code.]
// Circle experiment: distribution of distances travelled as number of robots in the formation NR is varied. The GBP planner creates shorter paths and a smaller spread of distances than ORCA; robots collaborate to achieve their goals.
// Circle experiment: distribution of the LDJ metric as NR increases, with smoother trajectories shown by more positive values. The worst performing GBP planning robots had smoother paths than the best robots for ORCA.
Results for communications failure rates $gamma in {0, 10, 20, 30, 40, 50, 60, 70, 80, 90}%$ are shown in @t.comms-failure-experiment. Results from the #gbpplanner paper are marked #T1 and #T2, where #O1 and #O2 are results from #acr("MAGICS"). #O1 is with lookahead multiple $l_m=3$ and time horizon $t_(K-1)=13.33s$, where #O2 is with #lm3-th5.n. For $gamma in {80, 90}%$ it was deemed impossible to gather results for #acr("MAGICS"), as the rate of convergence almost without any communication resulted in exceedingly long simulation times. That fact in itself should speak to the missing numbers.
#pagebreak(weak: true)
#let gbpplanner-results = (
rc: (0, 10, 20, 30, 40, 50, 60, 70, 80, 90),
makespan_10: (19.5, 20.3, 22.9, 25.7, 30.8, 35.6, 42.0, 51.3, 87.4, 146.9),
mean_collisions_10: (0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.6),
makespan_15: (14.9, 17.1, 18.9, 22.5, 26.5, 30.6, 38.8, 44.6, 63.4, 12.6),
mean_collisions_15: (0.0, 0.0, 0.0, 0.0, 0.0, 0.2, 0.8, 0.8, 0.8, 4.6),
)
// │ target_speed ┆ failure_rate ┆ makespan │
// │ 10.0 ┆ 0.0 ┆ 86.300003 │
// │ 10.0 ┆ 0.1 ┆ 146.300003 │
// │ 10.0 ┆ 0.2 ┆ 140.199997 │
// │ 10.0 ┆ 0.3 ┆ 163.699997 │
// │ 10.0 ┆ 0.4 ┆ 157.400009 │
// │ 10.0 ┆ 0.5 ┆ 231.400009 │
// │ 10.0 ┆ 0.6 ┆ 257.200012 │
// │ 10.0 ┆ 0.7 ┆ 260.899994 │
// │ 10.0 ┆ 0.8 ┆ 362.100006 │
// │ 10.0 ┆ 0.9 ┆ 938.900024 │
// │ 15.0 ┆ 0.0 ┆ 238.600006 │
// │ 15.0 ┆ 0.1 ┆ 203.199997 │
// │ 15.0 ┆ 0.2 ┆ 329.800018 │
// │ 15.0 ┆ 0.3 ┆ 231.100006 │
// │ 15.0 ┆ 0.4 ┆ 220.800003 │
// │ 15.0 ┆ 0.5 ┆ 221.5 │
// │ 15.0 ┆ 0.6 ┆ 328.700012 │
// │ 15.0 ┆ 0.7 ┆ 505.600006 │
// │ 15.0 ┆ 0.8 ┆ 799.600037 │
// │ 15.0 ┆ 0.9 ┆ 864.600037 │
// OURS 10 lm3 th5
// │ 0.0 ┆ 21.125 │
// │ 0.1 ┆ 24.24 │
// │ 0.2 ┆ 27.1 │
// │ 0.3 ┆ 29.06 │
// │ 0.4 ┆ 33.16 │
// │ 0.5 ┆ 39.84 │
// │ 0.6 ┆ 48.4 │
// │ 0.7 ┆ 60.82 │
// OURS 15 lm3 th5
// │ 0.0 ┆ 20.3 │
// │ 0.1 ┆ 23.8 │
// │ 0.2 ┆ 26.9 │
// │ 0.3 ┆ 29.6 │
// │ 0.4 ┆ 33.5 │
// │ 0.5 ┆ 40.2 │
// │ 0.6 ┆ 48.78 │
// │ 0.7 ┆ 68.2 │
// │ 0.0 ┆ 1.2 │
// │ 0.1 ┆ 1.8 │
// │ 0.2 ┆ 6.2 │
// │ 0.3 ┆ 11.2 │
// │ 0.4 ┆ 18.2 │
// │ 0.5 ┆ 36.0 │
// │ 0.6 ┆ 41.6 │
// │ 0.7 ┆ 55.6 │
// OURS 10 lm3 th13.33
// │ 0.0 ┆ 139.06 │
// │ 0.1 ┆ 160.36 │
// │ 0.2 ┆ 179.12 │
// │ 0.3 ┆ 194.74 │
// │ 0.4 ┆ 211.86 │
// │ 0.5 ┆ 211.58 │
// │ 0.6 ┆ 222.12 │
// │ 0.7 ┆ 276.76 │
// │ 0.0 ┆ 6.0 │
// │ 0.1 ┆ 11.6 │
// │ 0.2 ┆ 27.6 │
// │ 0.3 ┆ 50.2 │
// │ 0.4 ┆ 84.6 │
// │ 0.5 ┆ 89.0 │
// │ 0.6 ┆ 111.4 │
// │ 0.7 ┆ 121.4 │
// OURS 15 lm3 th13.33
// │ 0.0 ┆ 165.26 │
// │ 0.1 ┆ 190.64 │
// │ 0.2 ┆ 207.22 │
// │ 0.3 ┆ 189.68 │
// │ 0.4 ┆ 215.98 │
// │ 0.5 ┆ 235.92 │
// │ 0.6 ┆ 251.62 │
// │ 0.7 ┆ 363.22 │
// │ 0.0 ┆ 7.4 │
// │ 0.1 ┆ 12.0 │
// │ 0.2 ┆ 33.6 │
// │ 0.3 ┆ 47.8 │
// │ 0.4 ┆ 68.0 │
// │ 0.5 ┆ 107.2 │
// │ 0.6 ┆ 118.8 │
// │ 0.7 ┆ 136.8 │
#let d = sym.dash.en
#figure(
tablec(
columns: range(15).map(_ => 1fr),
alignment: center + horizon,
// stroke: gray,
header-color: (fill: theme.base, text: theme.text),
header: table.header(
tc(colspan: 1, [$bold(|v_0|)$]), tc(colspan: 7, $bold(10m"/"s)$), tc(colspan: 7, $bold(15m"/"s)$), table.hline(),
tc(rowspan: 2, $bold(gamma)$), tc(colspan: 4, [MS $s$]), tc(colspan: 3, [C]), tc(colspan: 4, [MS $s$]), tc(colspan: 3, [C]), table.hline(),
..range(2).map(_ => (T1, T2, O1, O2, T1, O1, O2)).flatten(),
),
// $0$, table.vline(), $19.5$, oc[], vc[$21.1$], vc[$86.3$], table.vline(), $0$, oc[], vc[$0.5$], table.vline(), $14.9$, oc[], vc[$20.3$], vc[$238.6$], table.vline(), $0$, oc[], vc[$1.2$],
$0$, table.vline(), $19.5$, vc[$86.3$], vc[$139.1$], vc[$21.1$], table.vline(), $0$, vc[$6.0$], vc[$0.5$], table.vline(), $14.9$, vc[$238.6$], vc[$165.3$], vc[$20.3$], table.vline(), $0$, vc[$7.4$], vc[$1.2$],
$10$, $20.3$, vc[$146.3$], vc[$160.4$], vc[$24.2$], $0$, vc[$11.6$], vc[$1.8$], $17.1$, vc[$203.2$], vc[$190.6$], vc[$23.8$], $0$, vc[$12.0$], vc[$1,8$],
$20$, $22.9$, vc[$140.2$], vc[$179.1$], vc[$27.1$], $0$, vc[$27.6$], vc[$6.8$], $18.9$, vc[$329.8$], vc[$207.2$], vc[$26.9$], $0$, vc[$33.6$], vc[$6.2$],
$30$, $25.7$, vc[$163.7$], vc[$194.7$], vc[$29.1$], $0$, vc[$50.2$], vc[$11.0$], $22.5$, vc[$231.1$], vc[$189.7$], vc[$29.6$], $0$, vc[$47.8$], vc[$11.2$],
$40$, $30.8$, vc[$157.4$], vc[$211.9$], vc[$33.2$], $0$, vc[$84.6$], vc[$18.4$], $26.5$, vc[$220.8$], vc[$216.0$], vc[$33.5$], $0$, vc[$68.0$], vc[$18.2$],
$50$, $35.6$, vc[$231.4$], vc[$211.6$], vc[$39.8$], $0$, vc[$89.0$], vc[$33.0$], $30.6$, vc[$221.5$], vc[$235.9$], vc[$40.2$], $0.2$, vc[$107.2$], vc[$36.0$],
$60$, $42$, vc[$257.2$], vc[$222.1$], vc[$48.4$], $0$, vc[$11.4$], vc[$39.6$], $38.8$, vc[$328.7$], vc[$251.6$], vc[$48.8$], $0.8$, vc[$118.8$], vc[$41.6$],
$70$, $51.3$, vc[$260.9$], vc[$276.8$], vc[$60.8$], $0$, vc[$121.4$], vc[$51.8$], $44.6$, vc[$505.6$], vc[$363.2$], vc[$68.2$], $0.8$, vc[$136.8$], vc[$55.6$],
$80$, $87.4$, vc[$362.1$], vc[#d], vc[#d], $0$, vc[#d], vc[#d], $63.4$, vc[$799.6$], vc[#d], vc[#d], $0.8$, vc[#d], vc[#d],
$90$, $146.9$, vc[$938.9$], vc[#d], vc[#d], $1.6$, vc[#d], vc[#d], $12.6$, vc[$864.6$], vc[#d], vc[#d], $4.6$, vc[#d], vc[#d],
),
caption: [
Communications Failure experiment results. Results pertaining to #acr("MAGICS") are marked #O1 and #O2. #O1 is with lookahead multiple $l_m=3$, and time horizon $t_(K-1)=13.33s$, where #O2 is with #lm3-th5.n. Values in column #T1 is taken from Table 2 in @gbpplanner, where #T2 columns are results obtained from the `gbpplanner`@gbpplanner-code with #lm3-th13.n. Cells marked with a dash, #sym.dash.en, had a very low rate of convergence as so few interrobot messages were shared, and thus were not measurable. Corresponds with Table 2 in @gbpplanner.
]
)<t.comms-failure-experiment>
// THEIR CAPTION
// shows that as γ increases, it takes longer for all robots to reach their goals. However, trajectories for the 10 m/s case are completely collision free up to γ = 80%. As the initial speed increases, collisions happen at lower values of γ as robots have less time to react to faster moving neighbours who they may not be receiving messages from. This experiment shows one of the benefits of GBP — safe trajectories can still be planned even with possible communication failures, which is likely in any realistic settings.
|
https://github.com/DieracDelta/presentations
|
https://raw.githubusercontent.com/DieracDelta/presentations/master/05_23_24/main.typ
|
typst
|
#import "polylux/polylux.typ": *
#import themes.metropolis: *
#show: metropolis-theme.with(
footer: [#logic.logical-slide.display() / #utils.last-slide-number]
)
#let codeblock(body, caption: none, lineNum:true) = {
if lineNum {
show raw.where(block:true): it =>{
set par(justify: false)
block(fill: luma(240),inset: 0.3em,radius: 0.3em,
// grid size: N*2
grid(
columns: 2,
align: left+top,
column-gutter: 0.5em,
stroke: (x,y) => if x==0 {( right: (paint:gray, dash:"densely-dashed") )},
inset: 0.3em,
..it.lines.map((line) => (str(line.number), line.body)).flatten()
)
)
}
figure(body, caption: caption, kind: "code", supplement: "Code")
}
else{
figure(body, caption: caption, kind: "code", supplement: "Code")
}
}
#let font = "Fira Code Regular Nerd Font Complete"
#let wt = "light"
#set text(font: font, weight: wt, size: 25pt)
#show math.equation: set text(font: "Fira Math")
#set strong(delta: 100)
#set par(justify: true)
#title-slide(
author: [<NAME>],
title: "Slides - 5/23",
)
#slide(title: "Table of contents")[
#metropolis-outline
]
#new-section-slide([High Level Idea])
#slide(title: "Pitch")[
- Compile C to a #alert[unsafe subset] of Rust (“RustLight”)
#uncover((2, 3, 4))[- Run RustLight through the Rust compiler]
#uncover((3, 4))[- RustLight operational semantics serve as a "Rust Spec"]
#uncover(4)[- Improve on C2Rust]
]
#new-section-slide([Translation Intuition (C2Rust)])
#slide(title: "Translation Intuition")[
- Run through examples from C2Rust
]
#let side-by-side_dup(columns: none, gutter: 1em, ..bodies) = {
let bodies = bodies.pos()
let columns = if columns == none { (1fr,) * bodies.len() } else { columns }
if columns.len() != bodies.len() {
panic("number of columns must match number of content arguments")
}
grid(columns: columns, gutter: gutter, align: top, ..bodies)
}
#slide(title: "Types")[
- Types match using glibc types
- Some UB like addition overflow match Compcert C
- For pointers only use `*mut`
]
#slide(title: "Calling convention")[
Calling convention: `extern "C"` or `extern "sysv64"`
]
#slide(title: "Globals + Statics")[
#set text(font: font, weight: wt, size: 15pt)
#side-by-side_dup[
#underline("C Lang")
#codeblock(
```C
static int global_counter = 0;
const int data = 0;
void increment_counter() {
static int inner = 2;
global_counter += data + inner;
}
```
)
][
#underline("Rust Lang")
#codeblock(
```rust
static mut global_counter: c_int = 0;
#[no_mangle]
pub static mut data: c_int = 0;
#[no_mangle]
pub unsafe extern "C" fn increment_counter() {
static mut inner: c_int = 2 as c_int;
global_counter += data + inner;
}
```
)
]
]
#slide(title: "Struct")[
#set text(font: font, weight: wt, size: 15pt)
#side-by-side_dup[
#underline("C Lang")
#codeblock(
```C
struct LinkedList {
int size;
struct LinkedList* next;
int data[];
};
```
)
][
#underline("Rust Lang")
#codeblock(
```rust
#[derive(Copy, Clone)]
#[repr(C)]
pub struct LinkedList {
pub size: c_int,
pub next: *mut LinkedList,
pub data: [c_int; 0],
}
```
)
]
]
#slide(title: "Union")[
#set text(font: font, weight: wt, size: 15pt)
#side-by-side_dup[
#underline("C Lang")
#codeblock(
```C
union Data {
int i;
float f;
};
```
)
][
#underline("Rust Lang")
#codeblock(
```rust
#[derive(Copy, Clone)]
#[repr(C)]
pub union Data {
pub i: c_int,
pub f: c_float,
}
```
)
]
]
#slide(title: "Loops")[
#set text(font: font, weight: wt, size: 15pt)
#side-by-side_dup[
#underline("C Lang")
#codeblock(
```C
int main() {
int i = 1;
while (i <= 10) {
i++;
}
return 0;
}
```
)
][
#underline("Rust Lang")
#codeblock(
```rust
unsafe fn main_0() -> c_int {
let mut i: c_int = 1 as c_int;
i = 0 as c_int;
while i < 5 as c_int {
i += 1;
i;
i += 1;
i;
}
return 0 as c_int;
}
```
)
]
]
#slide(title: "Switch")[
#set text(font: font, weight: wt, size: 9pt)
#side-by-side_dup[
#underline("C Lang")
#codeblock(
```C
void copy_mod(char *to, const char *from, int count) {
int n = (count + 2) / 3;
switch (count % 3) {
case 0: *to++ = *from++;
case 2: *to++ = *from++;
case 1: *to++ = *from++;
}
}
```
)
][
#underline("Rust Lang")
```rust
#[no_mangle]
pub unsafe extern "C" fn copy_mod(
mut to: *mut c_char,
mut from: *const c_char,
mut count: c_int,
) {
let mut n: c_int = (count + 2 as c_int) / 3 as c_int;
let mut current_block_2: u64;
match count % 3 as c_int {
0 => {
let fresh0 = from;
from = from.offset(1);
let fresh1 = to;
to = to.offset(1);
*fresh1 = *fresh0;
current_block_2 = 3977108684013665309;
}
2 => {
current_block_2 = 3977108684013665309;
}
1 => {
current_block_2 = 12446396083632624885;
}
_ => {
current_block_2 = 715039052867723359;
}
}
match current_block_2 {
3977108684013665309 => {
let fresh2 = from;
from = from.offset(1);
let fresh3 = to;
to = to.offset(1);
*fresh3 = *fresh2;
current_block_2 = 12446396083632624885;
}
_ => {}
}
match current_block_2 {
12446396083632624885 => {
let fresh4 = from;
from = from.offset(1);
let fresh5 = to;
to = to.offset(1);
*fresh5 = *fresh4;
}
_ => {}
};
}
```
]
]
#slide(title: "Goto")[
#set text(font: font, weight: wt, size: 10pt)
#side-by-side_dup[
#underline("C Lang")
#codeblock(
```C
int sample(int a) {
int result = 0;
if (a == 1) {
goto answer_1;
} else if (a == 2) {
goto answer_2;
}
answer_1:
result = 1;
goto end;
answer_2:
result = 2;
goto end;
end:
return result;
}
```
)
][
#underline("Rust Lang")
#codeblock(
```rust
#[no_mangle]
pub unsafe extern "C" fn sample(mut a: c_int) -> c_int {
let mut current_block: u64;
let mut result: c_int = 0 as c_int;
if a == 1 as c_int {
current_block = 710105030588991595;
} else if a == 2 as c_int {
result = 2 as c_int;
current_block = 2013428324500076459;
} else {
current_block = 710105030588991595;
}
match current_block {
710105030588991595 => {
result = 1 as c_int;
}
_ => {}
}
return result;
}
```
)
]
]
#slide(title: "Duff's Device")[
#set text(font: font, weight: wt, size: 8pt)
#side-by-side_dup[
#underline("C Lang")
#codeblock(
```C
void duffsDevice(char *to, const char *from, int count) {
int n = (count + 2) / 3;
switch (count % 3) {
case 0: do { *to++ = *from++;
case 2: *to++ = *from++;
case 1: *to++ = *from++;
} while (--n > 0);
}
}
```
)
][
#underline("Rust Lang")
```rust
#[no_mangle]
pub unsafe extern "C" fn duffsDevice( mut to: *mut c_char, mut from: *const c_char, mut count: c_int) {
let mut n: c_int = (count + 2 as c_int) / 3 as c_int;
let mut current_block_2: u64;
match count % 3 as c_int {
0 => {
current_block_2 = 12237857397564741460;
}
2 => {
current_block_2 = 11244789108393354615;
}
1 => {
current_block_2 = 6256153909998011048;
}
_ => {
current_block_2 = 11875828834189669668;
}
}
loop {
match current_block_2 {
11875828834189669668 => {
return;
}
12237857397564741460 => {
let fresh0 = from;
from = from.offset(1);
let fresh1 = to;
to = to.offset(1);
*fresh1 = *fresh0;
current_block_2 = 11244789108393354615;
}
11244789108393354615 => {
let fresh2 = from;
from = from.offset(1);
let fresh3 = to;
to = to.offset(1);
*fresh3 = *fresh2;
current_block_2 = 6256153909998011048;
}
_ => {
let fresh4 = from;
from = from.offset(1);
let fresh5 = to;
to = to.offset(1);
*fresh5 = *fresh4;
n -= 1;
if n > 0 as c_int {
current_block_2 = 12237857397564741460;
} else {
current_block_2 = 11875828834189669668;
}
}
}
};
}
```
]
]
#new-section-slide([Lifetimes & Existing Work])
#slide(title: "Lifetimes")[
- Claim: Use one pointer type `*mut`
- Need to prove RustLight lifetime semantics matches with Rust
]
#slide(title: "Non-lexical Lifetimes")[
#codeblock(
```Rust
fn main() {
let mut scores = vec![1, 2, 3];
let score = &scores[0];
scores.push(4);
}
```
)
(Credit: SO)
// https://stackoverflow.com/questions/50251487/what-are-non-lexical-lifetimes
]
#slide(title: "Existing Work")[
#set text(font: font, weight: wt, size: 15pt)
#table(
columns: 6,
[*Work*], [*Supports NLL*], [*Supports TPB*], [*Is Source Level*], [*Strictness wrt BC*], [*Models Unsafe*],
[RustBelt], [Mostly], [No], [No], [Not Strict Enough], [Yes],
[Oxide], [No], [No], [Yes], [Too strict], [No],
[K], [No], [No], [Yes], [Too strict], [No],
[Stack Borrows], [Yes], [Yes], [Yes], [Too Strict], [Yes],
[Tree Borrows], [Yes], [Yes], [Yes], [Slightly Too Strict], [Yes],
)
]
#slide(title: "Two-phase borrow")[
```rust
// pub fn push(&mut self, value: T)
fn main() {
let mut v = Vec::new();
v.push(v.len());
let r = &mut Vec::new();
Vec::push(r, r.len());
}
```
(Credit: Rustc dev)
// https://rustc-dev-guide.rust-lang.org/borrow_check/two_phase_borrows.html
]
#slide(title: "Tree Borrows")[
Each pointer is a state machine that is either:
- Reserved
- Active
- Disabled
- Frozen
]
//
|
|
https://github.com/Mc-Zen/tidy
|
https://raw.githubusercontent.com/Mc-Zen/tidy/main/examples/repeater.typ
|
typst
|
MIT License
|
/// Repeats content a specified number of times.
/// - body (content): The content to repeat.
/// - num (int): Number of times to repeat the content.
/// - separator (content): Optional separator between repetitions
/// of the content.
/// -> content
#let repeat(body, num, separator: []) = ((body,)*num).join(separator)
/// An awfully bad approximation of pi.
/// -> float
#let awful-pi = 3.14
|
https://github.com/Myriad-Dreamin/typst.ts
|
https://raw.githubusercontent.com/Myriad-Dreamin/typst.ts/main/fuzzers/corpora/layout/place-float-auto_03.typ
|
typst
|
Apache License 2.0
|
#import "/contrib/templates/std-tests/preset.typ": *
#show: test-page
//
// // Error: 2-36 floating placement must be `auto`, `top`, or `bottom`
// #place(horizon, float: true)[Hello]
|
https://github.com/Myriad-Dreamin/typst.ts
|
https://raw.githubusercontent.com/Myriad-Dreamin/typst.ts/main/fuzzers/corpora/meta/document_01.typ
|
typst
|
Apache License 2.0
|
#import "/contrib/templates/std-tests/preset.typ": *
#show: test-page
// This, too.
// Ref: false
#set document(author: ("A", "B"), date: datetime.today())
|
https://github.com/Isaac-Fate/booxtyp
|
https://raw.githubusercontent.com/Isaac-Fate/booxtyp/master/src/theorems/lemma.typ
|
typst
|
Apache License 2.0
|
#import "./new-theorem-template.typ": new-theorem-template
#let lemma = new-theorem-template("Lemma")
|
https://github.com/Error-418-SWE/Documenti
|
https://raw.githubusercontent.com/Error-418-SWE/Documenti/src/3%20-%20PB/Documentazione%20esterna/Piano%20di%20Qualifica/Piano%20di%20Qualifica.typ
|
typst
|
#import "/template.typ": *
#import "@preview/cetz:0.2.0"
#show: project.with(
title: "Piano di Qualifica",
subTitle: "Metriche, qualità e valutazione",
authors: (
"<NAME>",
"<NAME>",
),
showLog: true,
isExternalUse: true,
showTablesIndex: false,
showIndex: false,
showImagesIndex: false,
);
#outline(
title: "Indice dei contenuti",
depth: 4,
indent: true
)
#pagebreak()
#outline(
title: "Indice delle tabelle",
target: figure.where(kind: table)
)
#pagebreak()
#outline(
title: "Indice dei grafici",
target: figure.where(kind: "chart")
)
#pagebreak()
#let evalScope = (
json_ndp_v : ndp_v,
json_pdp_v : pdp_v,
json_pdq_v : pdq_v,
json_adr_v : adr_v,
json_glo_v : glo_v,
json_st_v : st_v,
json_man_v : man_v
)
#set table(align: center + horizon)
#let singleTable(data) = {
return figure(
table(
align: center + horizon,
columns: (0.5fr, 0.5fr, 1.5fr, 0.75fr, 1fr),
rows: (auto, 45pt),
[Codice], [Metrica], [Formula], [Soglia ottimale], [Soglia accettabile],
data.codice, data.sigla, eval(data.formula, mode: "markup", scope: evalScope), eval(data.sogliaOttimale, mode: "markup"), eval(data.sogliaAccettabile, mode: "markup")
),
caption: "Tabella metrica " + data.sigla + " (" + data.nome + ")"
)
}
#let nameAndDescriptionList(params) = {
let result = "";
result += "\nDati: \n";
for param in params {
let delimiter = ";"
if(param == params.last()){ delimiter = "."}
result += eval("- " + param.nome + ": " + param.descrizione + delimiter , mode: "markup", scope: evalScope);
}
return result;
}
#let extensionStructure(data) = {
let result = "";
result += eval("*" + data.codice + " - " + data.sigla + " " + data.nome + "*\\", mode: "markup");
result += eval(data.descrizione, mode: "markup", scope: evalScope);
if data.parametri.len() > 0 {
result += nameAndDescriptionList(data.parametri);
}
result += singleTable(data);
result += "\n";
return result;
}
#let metricsTablesGenerator(allJsonData, titleDepth : 3) = {
let result = "";
for data in allJsonData {
let titleHeader = "";
for i in range(titleDepth){
titleHeader += "="
}
titleHeader += " " + data.codice + " - " + data.sigla + " " + data.nome;
result += eval(titleHeader, mode: "markup")
result += eval("*Descrizione*: \\ " + data.descrizione, mode: "markup", scope: evalScope)
result += eval("\\ \\ *Note aggiuntive:* \\ " + data.noteAggiuntive + " \\ \\", mode: "markup")
if(data.estensioni.len() == 0){
if(data.parametri.len() > 0){
result += nameAndDescriptionList(data.parametri);
}
result += singleTable(data);
}else{
for extension in data.estensioni{
result += extensionStructure(extension)
}
}
result += "\n"
}
return result;
}
= Introduzione
== Scopo del documento
Il presente documento viene redatto con lo scopo di definire gli standard di qualità e di valutazione del prodotto. Essi saranno definiti conformemente ai requisiti e alle richieste del Proponente.
Definire la qualità di un prodotto consiste nell'attuazione di un insieme di processi che vadano a definire una base con cui misurare efficienza ed efficacia del lavoro svolto.
== Approccio al documento
Il presente documento viene redatto in modo incrementale per assicurare la coerenza delle informazioni al suo interno con gli sviluppi in corso e le esigenze evolutive del progetto. I valori identificati come accettabili per le metriche riportate possono subire variazioni con l'avanzamento dello sviluppo.
== Dashboard di monitoraggio
Il gruppo si dota di una dashboard di monitoraggio per tenere traccia delle metriche di processo e di prodotto. La dashboard è accessibile a tutti i membri del gruppo. Essa è accessibile al seguente link:
#align(center, link(grafana))
== Glossario
#glo_paragrafo
== Riferimenti <riferimenti>
=== Riferimenti a documentazione interna <riferimenti-interni>
- Documento #glo_v: \
_#link("https://github.com/Error-418-SWE/Documenti/blob/main/3%20-%20PB/Glossario_v" + glo_vo + ".pdf")_
#lastVisitedOn(25, 02, 2024)
- Documento #ndp_v: \
_#link("https://github.com/Error-418-SWE/Documenti/tree/main/3%20-%20PB/Documentazione%20interna/Norme%20di%20Progetto_v" + ndp_vo + ".pdf")_
#lastVisitedOn(25, 02, 2024)
- Documento #pdp_v: \
_#link("https://github.com/Error-418-SWE/Documenti/tree/main/3%20-%20PB/Documentazione%20esterna/Piano%20di%20Progetto_v" + pdp_vo + ".pdf")_
#lastVisitedOn(25, 02, 2024)
=== Riferimenti normativi <riferimenti-normativi>
- ISO/IEC 9126 1:2001: \
_#link("https://www.iso.org/standard/22749.html")_
#lastVisitedOn(13, 02, 2024)
- Capitolato "Warehouse Management 3D" (C5) di _Sanmarco Informatica S.p.A._: \
_#link("https://www.math.unipd.it/~tullio/IS-1/2023/Progetto/C5.pdf")_
#lastVisitedOn(13, 02, 2024)
=== Riferimenti informativi <riferimenti-informativi>
- Dispense T7 (Qualità del software): \
_#link("https://www.math.unipd.it/~tullio/IS-1/2023/Dispense/T7.pdf")_
#lastVisitedOn(13, 02, 2024)
- Dispense T8 (Qualità di processo): \
_#link("https://www.math.unipd.it/~tullio/IS-1/2023/Dispense/T8.pdf")_
#lastVisitedOn(13, 02, 2024)
- _Clean Code: A Handbook of Agile Software Craftsmanship_ di _<NAME>_: \
_#link("https://www.ibs.it/clean-code-handbook-of-agile-libro-inglese-robert-martin/e/9780132350884")_
#lastVisitedOn(24, 02, 2024)
= Qualità di processo
La qualità di processo rappresenta un aspetto fondamentale per garantire l'efficacia e l'efficienza del lavoro svolto. Per garantire la qualità di processo, il gruppo si impegna a seguire le norme e le procedure definite nel documento #ndp_v.
#let metricheProcessi = json("./metriche/processi.json")
== Processi primari
=== Fornitura
#metricsTablesGenerator(metricheProcessi.fornitura, titleDepth : 4)
== Processi di supporto
=== Documentazione
#metricsTablesGenerator(metricheProcessi.documentazione, titleDepth : 4)
=== Miglioramento
#metricsTablesGenerator(metricheProcessi.miglioramento, titleDepth : 4)
= Qualità di prodotto
La qualità di prodotto mira a garantire non solo che il prodotto soddisfi i requisiti definiti nel documento #adr_v, ma anche che sia conforme agli standard di qualità definiti che il gruppo si impone, perseguendo obiettivi di efficienza, efficacia, usabilità, manutenibilità, affidabilità e portabilità.
#let metricheProdotto = json("./metriche/prodotto.json")
== Efficacia
#metricsTablesGenerator(metricheProdotto.efficacia)
== Efficienza
#metricsTablesGenerator(metricheProdotto.efficienza)
== Usabilità
#metricsTablesGenerator(metricheProdotto.usabilita)
== Manutenibilità
#metricsTablesGenerator(metricheProdotto.manutenibilita)
== Affidabilità
#metricsTablesGenerator(metricheProdotto.affidabilita)
== Portabilità
#metricsTablesGenerator(metricheProdotto.portabilita)
= Test
In questa sezione sono elencati i test eseguiti sul prodotto che, come riportato in #ndp_v, possono essere:
- *test di unità*: per testare una singola unità software;
- *test di integrazione*: per verificare la corretta integrazione delle parti del sistema.
- *test di sistema*: per verificare che il sistema soddisfi i requisiti definiti nel documento #adr_v;
- *test di accettazione*: svolti assieme al Proponente, per verificare che il prodotto soddisfi quanto atteso.
Ad ogni test viene associato un codice definito come segue:
#align(`[Tipologia]-[Identificativo numerico]`, center)
*Tipologia* indica il tipo di test:
- `UT`: Unit test;
- `IT`: Integration test;
- `ST`: System test;
- `AT`: Acceptance test.
*Identificativo numerico* indica la sequenza numerica identificativa del test:
- *Test di unità* e *Test di integrazione*: l'identificativo numerico è così composto:
- [`Numero suite`].[`Numero test`].
- *Test di sistema* e *Test di accettazione*: l'identificativo numerico è così composto:
- [`Numero test`] è il codice del requisito associato al test.
Ad ogni test è associato uno stato che può essere:
- `P`: positivo, il test ha dato esito positivo;
- `N`: negativo, il test ha dato esito negativo;
- `NI`: non implementato.
#let table-json(data) = {
let keys = data.at(0).keys()
table(
columns: keys.len(),
..keys,
..data.map(
row => keys.map(
key => {
return eval(row.at(key, default: [n/a]), mode: "markup")}
)
).flatten()
)
}
\
== Test di unità
La suite di test di unità ha lo scopo di verificare il corretto funzionamento delle singole unità software. Il termine "unità" si riferisce al più piccolo componente dotato di comportamento autonomo, che può dunque essere singolarmente testato.
I test di unità sono stati implementati mediante l'utilizzo del framework Jest.
#show figure: set block(breakable: true)
#figure(
table-json(json("./test/unitTest.json")),
caption: "Tabella unit test"
)
\
== Test di integrazione
La suite di test di integrazione ha lo scopo di verificare che i diversi componenti del sistema si integrino correttamente, mirando ad individuare eventuali errori durante l'interazione tra le diverse unità software.
I test di integrazione sono stati implementati mediante l'utilizzo del framework Jest.
#figure(
table-json(json("./test/integrationTest.json")),
caption: "Tabella integration test"
)
\
== Test di sistema
La suite di test di sistema ha lo scopo di verificare che il sistema soddisfi i requisiti definiti nel documento #adr_v. L'implementazione di test automatici per la parte interattiva del prodotto e per l'ambiente tridimensionale è stata ritenuta eccessivamente complessa in termini di tempo e risorse valutando l'inesperienza del gruppo. Non risultava però ragionevole rinunciare a questa tipologia di test, pertanto si è deciso di svolgerli manualmente.
#figure(
table-json(json("./test/systemTest.json")),
caption: "Tabella test di sistema"
)
\
== Test di accettazione
La suite di test di accettazione ha lo scopo di verificare che il prodotto soddisfi quanto atteso dal Proponente. Tali test sono stati svolti manualmente in occasione dei regolari meeting esterni tenuti con il Proponente aziendale.
#figure(
table-json(json("./test/acceptanceTest.json")),
caption: "Tabella test di accettazione"
)
\
= Cruscotto di valutazione della qualità
== Premessa
Come stabilito dal #pdp_v e dalle #ndp_v, il gruppo ha imposto Sprint della durata settimanale. Nel primo Sprint si è confermato l'utilizzo dell'ITS Jira come strumento di tracciamento, ma per comprenderne a fondo le meccaniche e il corretto utilizzo, sono stati necessari i seguenti 4 Sprint. Nel corso di questo periodo, sono state apportate modifiche di configurazione, anche consapevolmente non retrocompatibili, che hanno introdotto eterogeneità nei dati riportati dall'ITS.
Per questo motivo, i dati utili al corretto calcolo delle metriche sono disponibili dal quinto Sprint, iniziato il 04/12/2023.
== Qualità di processo - Fornitura
#let arrayToPointCoordinate(array) = {
let i = 0;
let result = ();
for value in array {
result.insert(i, (i + 4, value));
i += 1;
}
return result.map(((x,y)) => {(x,y)})
}
#let graphFromJson(jsonGraphParams) = {
return figure(
cetz.canvas({
import cetz.plot
plot.plot(size: (12, 7), {
for line in jsonGraphParams.lines{
plot.add(arrayToPointCoordinate(line.valori), line: line.type, label: line.label, mark: line.marker, style: (stroke: (paint: eval(line.color))));
}
for hline in jsonGraphParams.hlines{
plot.add-hline(hline.valore, label: hline.label, style: (stroke: (paint: eval(hline.color, mode: "code"), dash: "dotted")));
}
for vline in jsonGraphParams.vlines{
plot.add-vline(vline.valore, label: vline.label, style: (stroke: (paint: eval(vline.color, mode: "code"), dash: "dotted")));
}
plot.add-vline(13, label: "RTB", style: (stroke: (paint: black, dash: "dotted")))
plot.add-vline(24, label: "PB" , style: (stroke: (paint: red, dash: "dotted")))
},
y-max: jsonGraphParams.y-max,
y-min: jsonGraphParams.y-min,
x-max: 25,
x-min: 4,
x-tick-step: 1,
y-tick-step: jsonGraphParams.y-tick-step,
x-label: "Sprint",
y-label: jsonGraphParams.y-label,
)
}),
caption: jsonGraphParams.caption,
supplement: "Grafico",
kind : "chart"
)
}
#let cruscotto = json("./cruscotto/cruscotto.json");
=== Rapporto tra PPV, PAC e PEV
#graphFromJson(cruscotto.PPV-PAC-PEV)
*RTB*: #eval(cruscotto.PPV-PAC-PEV.RTB, mode: "markup", scope: evalScope)
*PB*: #eval(cruscotto.PPV-PAC-PEV.PB, mode: "markup", scope: evalScope)
\
\
=== Cost Performance Index CPI
#graphFromJson(cruscotto.CPI)
*RTB*: #eval(cruscotto.CPI.RTB, mode: "markup", scope: evalScope);
*PB*: #eval(cruscotto.CPI.PB, mode: "markup", scope: evalScope);
\
\
=== Rapporto tra BAC e EAC
#graphFromJson(cruscotto.BAC-EAC)
*RTB*: #eval(cruscotto.BAC-EAC.RTB, mode: "markup", scope: evalScope);
*PB*: #eval(cruscotto.BAC-EAC.PB, mode: "markup", scope: evalScope);
\
\
== Qualità di processo - Documentazione
=== Errori ortografici
*Documentazione esterna*
#graphFromJson(cruscotto.EO-Esterna)
*Documentazione interna*
#graphFromJson(cruscotto.EO-Interna)
*RTB*: #eval(cruscotto.EO-Interna.RTB, mode: "markup", scope: evalScope);
*PB*: #eval(cruscotto.EO-Interna.PB, mode: "markup", scope: evalScope);
\
\
== Qualità di processo - Miglioramento
=== Metriche soddisfatte
#graphFromJson(cruscotto.MS)
*RTB*: #eval(cruscotto.MS.RTB, mode: "markup", scope: evalScope);
*PB*: #eval(cruscotto.MS.PB, mode: "markup", scope: evalScope);
\
\
== Qualità di prodotto - Efficacia
=== Copertura requisiti obbligatori
#graphFromJson(cruscotto.MRC)
*PB*: #eval(cruscotto.MRC.PB, mode: "markup", scope: evalScope);
\
\
=== Copertura requisiti desiderabili
#graphFromJson(cruscotto.DRC)
*PB*: #eval(cruscotto.DRC.PB, mode: "markup", scope: evalScope);
\
\
=== Copertura requisiti opzionali
#graphFromJson(cruscotto.ORC)
*PB*: #eval(cruscotto.ORC.PB, mode: "markup", scope: evalScope);
\
\
== Qualità di prodotto - Affidabilità
=== Code coverage
#graphFromJson(cruscotto.CCV)
*PB*: #eval(cruscotto.CCV.PB, mode: "markup", scope: evalScope);
\
\
=== Branch coverage
#graphFromJson(cruscotto.BCV)
*PB*: #eval(cruscotto.BCV.PB, mode: "markup", scope: evalScope);
\
\
=== Failure definisce
#graphFromJson(cruscotto.FD)
*PB*: #eval(cruscotto.FD.PB, mode: "markup", scope: evalScope);
|
|
https://github.com/frectonz/the-pg-book
|
https://raw.githubusercontent.com/frectonz/the-pg-book/main/book/150.%20invtrend.html.typ
|
typst
|
invtrend.html
Startup Investing Trends
June 2013(This talk was written for an audience of investors.)Y Combinator has now funded 564 startups including the current
batch, which has 53. The total valuation of the 287 that have
valuations (either by raising an equity round, getting acquired,
or dying) is about $11.7 billion, and the 511 prior to the current
batch have collectively raised about $1.7 billion.
[1]As usual those numbers are dominated by a few big winners. The top
10 startups account for 8.6 of that 11.7 billion. But there is a
peloton of younger startups behind them. There are about 40 more
that have a shot at being really big.Things got a little out of hand last summer when we had 84 companies
in the batch, so we tightened up our filter to decrease the batch
size.
[2]
Several journalists have tried to interpret that as
evidence for some macro story they were telling, but the reason had
nothing to do with any external trend. The reason was that we
discovered we were using an n² algorithm, and we needed to buy
time to fix it. Fortunately we've come up with several techniques
for sharding YC, and the problem now seems to be fixed. With a new
more scaleable model and only 53 companies, the current batch feels
like a walk in the park. I'd guess we can grow another 2 or 3x
before hitting the next bottleneck.
[3]One consequence of funding such a large number of startups is that
we see trends early. And since fundraising is one of the main
things we help startups with, we're in a good position to notice
trends in investing.I'm going to take a shot at describing where these trends are
leading. Let's start with the most basic question: will the future
be better or worse than the past? Will investors, in the aggregate,
make more money or less?I think more. There are multiple forces at work, some of which
will decrease returns, and some of which will increase them. I
can't predict for sure which forces will prevail, but I'll describe
them and you can decide for yourself.There are two big forces driving change in startup funding: it's
becoming cheaper to start a startup, and startups are becoming a
more normal thing to do.When I graduated from college in 1986, there were essentially two
options: get a job or go to grad school. Now there's a third: start
your own company.
That's a big change. In principle it was possible to start your
own company in 1986 too, but it didn't seem like a real possibility.
It seemed possible to start a consulting company, or a niche product
company, but it didn't seem possible to start a company that would
become big.
[4]That kind of change, from 2 paths to 3, is the sort of big social
shift that only happens once every few generations. I think we're
still at the beginning of this one. It's hard to predict how big
a deal it will be. As big a deal as the Industrial Revolution?
Maybe. Probably not. But it will be a big enough deal that it
takes almost everyone by surprise, because those big social shifts
always do.One thing we can say for sure is that there will be a lot more
startups. The monolithic, hierarchical companies of the mid 20th
century are being replaced by networks
of smaller companies. This process is not just something happening
now in Silicon Valley. It started decades ago, and it's happening
as far afield as the car industry. It has a long way to run.
[5]
The other big driver of change is that startups are becoming cheaper
to start. And in fact the two forces are related: the decreasing
cost of starting a startup is one of the reasons startups are
becoming a more normal thing to do.The fact that startups need less money means founders will increasingly
have the upper hand over investors. You still need just as much
of their energy and imagination, but they don't need as much of
your money. Because founders have the upper hand, they'll retain
an increasingly large share of the stock in, and control of, their
companies. Which means investors will get less stock and less
control.Does that mean investors will make less money? Not necessarily,
because there will be more good startups. The total amount of
desirable startup stock available to investors will probably increase,
because the number of desirable startups will probably grow faster
than the percentage they sell to investors shrinks.There's a rule of thumb in the VC business that there are about 15
companies a year that will be really successful. Although a lot
of investors unconsciously treat this number as if it were some
sort of cosmological constant, I'm certain it isn't. There are
probably limits on the rate at which technology can develop, but
that's not the limiting factor now. If it were, each successful
startup would be founded the month it became possible, and that is
not the case. Right now the limiting factor on the number of big
hits is the number of sufficiently good founders starting companies,
and that number can and will increase. There are still a lot of
people who'd make great founders who never end up starting a company.
You can see that from how randomly some of the most successful
startups got started. So many of the biggest startups almost didn't
happen that there must be a lot of equally good startups that
actually didn't happen.There might be 10x or even 50x more good founders out there. As
more of them go ahead and start startups, those 15 big hits a year
could easily become 50 or even 100.
[6]What about returns, though? Are we heading for a world in which
returns will be pinched by increasingly high valuations? I think
the top firms will actually make more money than they have in the
past. High returns don't come from investing at low valuations.
They come from investing in the companies that do really well. So
if there are more of those to be had each year, the best pickers
should have more hits.This means there should be more variability in the VC business.
The firms that can recognize and attract the best startups will do
even better, because there will be more of them to recognize and
attract. Whereas the bad firms will get the leftovers, as they do
now, and yet pay a higher price for them.Nor do I think it will be a problem that founders keep control of
their companies for longer. The empirical evidence on that is
already clear: investors make more money as founders' bitches than
their bosses. Though somewhat humiliating, this is actually good
news for investors, because it takes less time to serve founders
than to micromanage them.What about angels? I think there is a lot of opportunity there.
It used to suck to be an angel investor. You couldn't get access
to the best deals, unless you got lucky like <NAME>, and
when you did invest in a startup, VCs might try to strip you of
your stock when they arrived later. Now an angel can go to something
like Demo Day or AngelList and have access to the same deals VCs
do. And the days when VCs could wash angels out of the cap table
are long gone.I think one of the biggest unexploited opportunities in startup
investing right now is angel-sized investments made quickly. Few
investors understand the cost that raising money from them imposes
on startups. When the company consists only of the founders,
everything grinds to a halt during fundraising, which can easily
take 6 weeks. The current high cost of fundraising means there is
room for low-cost investors to undercut the rest. And in this
context, low-cost means deciding quickly. If there were a reputable
investor who invested $100k on good terms and promised to decide
yes or no within 24 hours, they'd get access to almost all the best
deals, because every good startup would approach them first. It
would be up to them to pick, because every bad startup would approach
them first too, but at least they'd see everything. Whereas if an
investor is notorious for taking a long time to make up their mind
or negotiating a lot about valuation, founders will save them for
last. And in the case of the most promising startups, which tend
to have an easy time raising money, last can easily become never.Will the number of big hits grow linearly with the total number of
new startups? Probably not, for two reasons. One is that the
scariness of starting a startup in the old days was a pretty effective
filter. Now that the cost of failing is becoming lower, we should
expect founders to do it more. That's not a bad thing. It's common
in technology for an innovation that decreases the cost of failure
to increase the number of failures and yet leave you net ahead.The other reason the number of big hits won't grow proportionately
to the number of startups is that there will start to be an increasing
number of idea clashes. Although the finiteness of the number of
good ideas is not the reason there are only 15 big hits a year, the
number has to be finite, and the more startups there are, the more
we'll see multiple companies doing the same thing at the same time.
It will be interesting, in a bad way, if idea clashes become a lot
more common.
[7]Mostly because of the increasing number of early failures, the startup
business of the future won't simply be the same shape, scaled up.
What used to be an obelisk will become a pyramid. It will be a
little wider at the top, but a lot wider at the bottom.What does that mean for investors? One thing it means is that there
will be more opportunities for investors at the earliest stage,
because that's where the volume of our imaginary solid is growing
fastest. Imagine the obelisk of investors that corresponds to
the obelisk of startups. As it widens out into a pyramid to match
the startup pyramid, all the contents are adhering to the top,
leaving a vacuum at the bottom.That opportunity for investors mostly means an opportunity for new
investors, because the degree of risk an existing investor or firm
is comfortable taking is one of the hardest things for them to
change. Different types of investors are adapted to different
degrees of risk, but each has its specific degree of risk deeply
imprinted on it, not just in the procedures they follow but in the
personalities of the people who work there.I think the biggest danger for VCs, and also the biggest opportunity,
is at the series A stage. Or rather, what used to be the series A
stage before series As turned into de facto series B rounds.Right now, VCs often knowingly invest too much money at the series
A stage. They do it because they feel they need to get a big chunk
of each series A company to compensate for the opportunity cost of
the board seat it consumes. Which means when there is a lot of
competition for a deal, the number that moves is the valuation (and
thus amount invested) rather than the percentage of the company
being sold. Which means, especially in the case of more promising
startups, that series A investors often make companies take more
money than they want.Some VCs lie and claim the company really needs that much. Others
are more candid, and admit their financial models require them to
own a certain percentage of each company. But we all know the
amounts being raised in series A rounds are not determined by asking
what would be best for the companies. They're determined by VCs
starting from the amount of the company they want to own, and the
market setting the valuation and thus the amount invested.Like a lot of bad things, this didn't happen intentionally. The
VC business backed into it as their initial assumptions gradually
became obsolete. The traditions and financial models of the VC
business were established when founders needed investors more. In
those days it was natural for founders to sell VCs a big chunk of
their company in the series A round. Now founders would prefer to
sell less, and VCs are digging in their heels because they're not
sure if they can make money buying less than 20% of each series A
company.The reason I describe this as a danger is that series A investors
are increasingly at odds with the startups they supposedly serve,
and that tends to come back to bite you eventually. The reason I
describe it as an opportunity is that there is now a lot of potential
energy built up, as the market has moved away from VCs' traditional
business model. Which means the first VC to break ranks and start
to do series A rounds for as much equity as founders want to sell
(and with no "option pool" that comes only from the founders' shares)
stands to reap huge benefits.What will happen to the VC business when that happens? Hell if I
know. But I bet that particular firm will end up ahead. If one
top-tier VC firm started to do series A rounds that started from
the amount the company needed to raise and let the percentage
acquired vary with the market, instead of the other way around,
they'd instantly get almost all the best startups. And that's where
the money is.You can't fight market forces forever. Over the last decade we've
seen the percentage of the company sold in series A rounds creep
inexorably downward. 40% used to be common. Now VCs are fighting
to hold the line at 20%. But I am daily waiting for the line to
collapse. It's going to happen. You may as well anticipate it,
and look bold.Who knows, maybe VCs will make more money by doing the right thing.
It wouldn't be the first time that happened. Venture capital is a
business where occasional big successes generate hundredfold returns.
How much confidence can you really have in financial models for
something like that anyway? The
big successes only have to get a tiny bit less occasional to
compensate for a 2x decrease in the stock sold in series A rounds.If you want to find new opportunities for investing, look for things
founders complain about. Founders are your customers, and the
things they complain about are unsatisfied demand. I've given two
examples of things founders complain about most—investors who
take too long to make up their minds, and excessive dilution in
series A rounds—so those are good places to look now. But
the more general recipe is: do something founders want.
Notes[1]
I realize revenue and not fundraising is the proper test of
success for a startup. The reason we quote statistics about
fundraising is because those are the numbers we have. We couldn't
talk meaningfully about revenues without including the numbers from
the most successful startups, and we don't have those. We often
discuss revenue growth with the earlier stage startups, because
that's how we gauge their progress, but when companies reach a
certain size it gets presumptuous for a seed investor to do that.In any case, companies' market caps do eventually become a function
of revenues, and post-money valuations of funding rounds are at
least guesses by pros about where those market caps will end up.The reason only 287 have valuations is that the rest have mostly
raised money on convertible notes, and although convertible notes
often have valuation caps, a valuation cap is merely an upper bound
on a valuation.[2]
We didn't try to accept a particular number. We have no way
of doing that even if we wanted to. We just tried to be significantly
pickier.[3]
Though you never know with bottlenecks, I'm guessing the next
one will be coordinating efforts among partners.[4]
I realize starting a company doesn't have to mean starting a
startup. There will be lots of people starting normal companies
too. But that's not relevant to an audience of investors.<NAME> reports that in Silicon Valley it seemed thinkable
to start a startup in the mid 1980s. It would have started there.
But I know it didn't to undergraduates on the East Coast.[5]
This trend is one of the main causes of the increase in
economic inequality in the US since the mid twentieth century. The
person who would in 1950 have been the general manager of the x
division of Megacorp is now the founder of the x company, and owns
significant equity in it.[6]
If Congress passes the founder
visa in a non-broken form, that alone could in principle get
us up to 20x, since 95% of the world's population lives outside the
US.[7]
If idea clashes got bad enough, it could change what it means
to be a startup. We currently advise startups mostly to ignore
competitors. We tell them startups are competitive like running,
not like soccer; you don't have to go and steal the ball away from
the other team. But if idea clashes became common enough, maybe
you'd start to have to. That would be unfortunate.Thanks to <NAME>, <NAME>, <NAME>,
<NAME>, <NAME>, <NAME>, <NAME>, and <NAME> for reading
drafts of this.
|
|
https://github.com/vEnhance/1802
|
https://raw.githubusercontent.com/vEnhance/1802/main/src/level.typ
|
typst
|
MIT License
|
#import "@local/evan:1.0.0":*
= Level curves (aka contour plots) <sec-level-curve>
== [TEXT] Level curves replace $x y$-graphs
In high school and 18.01, you were usually taught to plot single-variable functions
in two dimensions, so $f(x) = x^2$ would be drawn as a parabola $y = x^2$, and so on.
You may have drilled into your head that $x$ is an input and $y$ is an output.
However, for 18.02 we'll typically want to draw pictures of functions
like $f(x,y) = x^2+y^2$ in a different way#footnote[
This is a lot like how we drew planes in a symmetric form earlier.
In high school algebra, you drew 2D graphs of one-variable functions
like $y = 2 x + 5$ or $y = x^2 + 7$.
So it might have seemed a bit weird to you that we wrote
planes instead like $2 x + 5 y + 3 z = 7$ rather than, say, $z = (7 - 2 x - 5 y) / 3$.
But this form turned out to be better, because it let us easily access the normal vector
(which here is $angle.l 2, 5, 3 angle.r$).
The analogy carries over here.
], using what's known as a _level curve_.
#definition[
For any number $c$ and function $f(x,y)$
the level curve for the value $c$ is the plot of points for which $f(x, y) = c$.
]
The contrast to what you're used to is that:
- In high school and 18.01, the variables $x$ and $y$ play different roles,
with $x$ representing the input and $y = f(X)$ representing output.
- In 18.02, when we draw a function $f(x,y)$
both $x$ and $y$ are inputs; we treat them all with equal respect.
Meanwhile, the _output_ of the function does _not_ have a variable name.
If we really want to refer to it, we might sometimes write $f = 2$ as a shorthand
for "the level curve for output $2$".
To repeat that in table format:
#figure(
table(
columns: 2,
align: left,
table.header([18.01 $x y$-graphs], [18.02 level curves]),
[$x$ is input], [Both variables are inputs],
[$y$ is output], [No variable name for output],
),
kind: table
)
We give some examples.
#example(title: [Example: the level curves of $f(x,y) = y - x^2$])[
To draw the level curves of the function $f(x, y) = y - x^2$,
we begin by recalling that a level curve corresponds to the points $(x, y)$
such that the function takes on a constant value, say $c$.
For our function, this becomes:
$ y - x^2 = c $
which rearranges to
$ y = x^2 + c. $
Let's talk through some values of $c$.
- As an example, if $c = 0$, then some points on the level curve would be
$(-3,9)$, $(-2,4)$, $(-1,1)$, $(0,0)$, $(1,1)$, $(2,4)$, $(3,9)$,
or even $(sqrt(5), 6)$ and $(sqrt(11), 12)$.
You probably already recognize what's happening: $y = x^2$ happens to be an equation
you met before in 18.01 form, so you get a parabola.
(More generally, if you get an equation in 18.01 form where $y$ is a function of $x$,
you can sketch it like you did before).
- If we change the value of $c = 2$, this equation represents a family of parabolas.
For example, the level curve for $2$ will be the parabola with points like
$(-2,6)$, $(-1,3)$, $(0,2)$, $(1,3)$, $(2,6)$.
In general, as $c$ varies, the level curves are parabolas
that shift upward or downward along the $y$-axis.
The shape of these curves is determined by the quadratic term $x^2$,
which indicates that all level curves will have the same basic "U" shape.
#figure(
image("figures/level-curve1.png"),
caption: [The level curves of $f(x,y) = y-x^2$.],
)
]
#example(title: [Example: the level curves of $f(x,y) = x - y^2$])[
Let's draw level curves for $f(x,y) = x-y^2$.
This example is exactly like the previous one, except the roles of $x$ and $y$ are flipped.
#figure(
image("figures/level-curve2.png"),
caption: [The level curves of $f(x,y) = x-y^2$.],
)
]
#example(title: [Example: the level curves of $f(x,y) = x^2+y^2$])[
Let's draw level curves of $f(x,y) = x^2+y^2$
For each $c$ we want to sketch the curve
$ x^2 + y^2 = c. $
When $c < 0$, no points at all appear on this curve, and when $c = 0$
the only point is the origin $(0,0)$.
For $c > 0$ this equation represents a family of circles centered at the origin $(0, 0)$,
with radius $sqrt(c)$.
For example:
- No points work for $c < 0$.
- For $c = 0$, the level curve is the single point $(0,0)$.
- For $c = 1$, the level curve is a circle with radius $1$.
- For $c = 4$, the level curve is a circle with radius $2$.
- For $c = 9$, the level curve is a circle with radius $3$.
As $c$ increases, the circles expand outward from the origin.
These concentric circles represent the level curves of the function $f(x, y) = x^2 + y^2$.
#figure(
image("figures/level-curve3.png"),
caption: [Four of the level curves for $f(x,y) = x^2+y^2$.],
)
]
#example(title: [Example: the level curves of $f(x,y) = |x| + |y|$])[
Let's draw level curves of $f(x,y) = |x| + |y|$.
To draw the level curve for $c$, we are looking at
$ |x| + |y| = c. $
Like before, if $c < 0$ there are no pairs $(x,y)$ at all and for $c = 0$ there is only a single point.
This equation represents a family of polygons.
Specifically, for a given value of $c$,
the points that satisfy this equation form a diamond shape centered at the origin.
Indeed, in the first quadrant (where the absolute values don't do anything)
it represents the line segment joining $(0,c)$ to $(c,0)$.
So for example,
- When $c < 0$, there are no points.
- For $c = 0$, the level curve is just the point $(0,0)$.
- For $c = 1$, the level curve is a diamond with vertices at $(1, 0)$, $(-1, 0)$, $(0, 1)$, and $(0, -1)$.
- For $c = 2$, the level curve is a larger diamond with vertices at $(2, 0)$, $(-2, 0)$, $(0, 2)$, and $(0, -2)$.
- For $c = 3$, the diamond expands further, with vertices at $(3, 0)$, $(-3, 0)$, $(0, 3)$, and $(0, -3)$.
As $c$ increases, the diamonds expand outward, maintaining their shape but increasing in size.
Each level curve is a square rotated by 45 degrees.
#figure(
image("figures/level-curve4.png"),
caption: [Four of the level curves for $f(x,y) = |x|+|y|$.],
)
]
== [RECIPE] Drawing level curves
Despite the fact this section is labeled "recipe", there isn't an
easy method that works for every function.
*You have to do it in an ad-hoc way depending on the exact function you're given*.
For many functions you'll see on an exam, it'll be pretty easy.
To summarize the procedure,
given an explicit function like $f(x,y)$ and the value of $c$,
one tries to plot all the points $(x,y)$ in space with $f(x,y) = c$.
We gave three examples right above, where:
- The level curves of $f(x,y) = y-x^2$ were easy to plot because
for any given $c$, the equation just became an $x y$-plot like in 18.01.
- The level curves of $f(x,y) = x-y^2$ were similar to the previous example,
but the roles of $x$ and $y$ were flipped.
- To draw the level curves of $f(x,y) = x^2+y^2$,
you needed to know that $x^2 + y^2 = r^2$ represents a circle of radius $r$
centered at $(0,0)$.
- To draw the level curves of $f(x,y) = |x| + |y|$,
we had to think about it an ad-hoc manner where we worked in each quadrant;
in Quadrant I we figured out that we got a line,
and then we applied the same image to the other quadrants
to get diamond shapes.
So you can see it really depends on the exact $f$ you are given.
If you wrote a really nasty function like $f(x,y) = e^(sin x y) + cos(x + y)$,
there's probably no easy way to draw the level curve by hand.
== [TEXT] Level surfaces are exactly the same thing, with three variables instead of two
Nothing above really depends on having exactly two variables.
If we had a three-variable function $f(x,y,z)$,
we could draw _level surfaces_ for a value of $c$
by plotting all the points in $RR^3$ for which $f(x,y,z) = c$.
#example(title: [Example: Level surface of $f(x,y,z) = x^2+y^2+z^2$])[
If $f(x,y,z) = x^2 + y^2 + z^2$,
then the level surface for the value $c$ will be a sphere with radius $sqrt(c)$ if $c >= 0$.
(When $c < 0$, the level surface is empty.)
]
#example(title: [Example: Level surface of $f(x,y,z) = x + 2 y + 3 z$])[
If $f(x,y,z) = x + 2 y + 3 z$,
all the level surfaces of $f$ are planes in $RR^3$,
which are parallel to each other with normal vector $vec(1,2,3)$.
]
== [EXER] Exercises
#exer[
Draw 2-D level curves for some values for the following functions:
- $f(x,y) = 5 x + y$
- $f(x,y) = x y$
- $f(x,y) = sin(x^2 + y^2)$
- $f(x,y) = e^(y - x^2)$
- $f(x,y) = max(x,y)$ (i.e.~$f$ outputs the larger of its two inputs,
so $f(3,5)=5$ and $f(2,-9)=2$, for example).
]
#exerstar[
Give an example of a polynomial function $f(x,y)$
for which the level curve for the value $100$ consists of exactly seven points.
]
|
https://github.com/xhalo32/math-camp
|
https://raw.githubusercontent.com/xhalo32/math-camp/main/equal-sets/treasure-hunt-equal-sets.typ
|
typst
|
MIT License
|
#import "@preview/cetz:0.2.2"
#show page: it => align(center, it)
#[
#set text(size: 36pt)
= 3. Set puzzle
]
Use lines to connect those sets which have *exactly the same* elements. The line intersections indicate the coordinates of the next checkpoint.
#v(2em)
#set text(size: 16pt)
#cetz.canvas({
import cetz.draw: *
import calc: *
// Your drawing code goes here
import cetz.plot
let ngon = 10
let points = range(ngon).map(n => (n, (8 + 7 * cos(n/ngon * 2 * pi), 8 + 7 * sin(n/ngon * 2 * pi))))
for (i, coord) in points {
circle(name: "point" + str(i), coord, radius: 0.1, fill: black)
}
content("point0", move(dx: 15pt, $NN$))
content("point1", move(dy: -15pt, $ZZ$))
content("point2", move(dy: -15pt, ${n in NN | n < 4}$))
content("point3", move(dy: -15pt, $NN without {0}$))
content("point4", move(dx: -40pt, $NN without ZZ$))
content("point5", move(dy: 15pt, ${n in NN | n <= 4}$))
content("point6", move(dx: -40pt, ${0, 1, 2, 3}$))
content("point7", move(dx: -40pt, $NN sect ZZ$))
content("point8", move(dx: 15pt, $ emptyset $))
content("point9", move(dx: 40pt, ${1, 2, 3, 4}$))
// line("point0", "point7")
// line("point4", "point8")
// line("point2", "point6")
// Sample lines which are incorrect
// line("point0", "point3", stroke: red)
// line("point5", "point9", stroke: red)
// line("point7", "point1", stroke: red)
// line("point0", "point4", stroke: red)
let marker(coords, label) = {
// circle(coords, radius: 0.1, fill: black)
let length = 0.15
line((coords.at(0) - length, coords.at(1) - length), (coords.at(0) + length, coords.at(1) + length), thickness: 0.1)
line((coords.at(0) + length, coords.at(1) - length), (coords.at(0) - length, coords.at(1) + length), thickness: 0.1)
content(coords, move(dy: 12pt, label))
}
// Correct points
marker((5.3, 8), $x = 6$)
marker((8.6, 3.4), $y = 6$)
// Fake points
marker((8.6, 16 - 3.4), $y = 0.5$)
marker((4.5, 6.8), $y = 0.5$)
marker((10.7, 4.8), $x = 12$)
marker((8, 4.3), $y = 3.4$)
marker((12.2, 10), $x = 3.5$)
marker((7.2, 10.5), $x = 8$)
marker((9, 8), $x = 9.5$)
marker((6, 5), $y = 6.5$)
marker((12.2, 6), $x = 7$)
})
#v(4em)
#set text(size: 12pt)
Hints
- Look up "set-builder notation" using a search engine
|
https://github.com/EpicEricEE/typst-based
|
https://raw.githubusercontent.com/EpicEricEE/typst-based/master/tests/encode/test.typ
|
typst
|
MIT License
|
#import "/src/lib.typ": *
#set page(width: auto, height: auto, margin: 0pt)
// Test cases from: https://www.rfc-editor.org/rfc/rfc4648#section-10
#{
// Test Base64
assert.eq(encode64(""), "")
assert.eq(encode64("f"), "Zg==")
assert.eq(encode64("fo"), "Zm8=")
assert.eq(encode64("foo"), "Zm9v")
assert.eq(encode64("foob"), "Zm9vYg==")
assert.eq(encode64("fooba"), "Zm9vYmE=")
assert.eq(encode64("foobar"), "Zm9vYmFy")
// Test Base32
assert.eq(encode32(""), "")
assert.eq(encode32("f"), "MY======")
assert.eq(encode32("fo"), "MZXQ====")
assert.eq(encode32("foo"), "MZXW6===")
assert.eq(encode32("foob"), "MZXW6YQ=")
assert.eq(encode32("fooba"), "MZXW6YTB")
assert.eq(encode32("foobar"), "MZXW6YTBOI======")
// Test Base64 with extended hex alphabet
assert.eq(encode32(hex: true, ""), "")
assert.eq(encode32(hex: true, "f"), "CO======")
assert.eq(encode32(hex: true, "fo"), "CPNG====")
assert.eq(encode32(hex: true, "foo"), "CPNMU===")
assert.eq(encode32(hex: true, "foob"), "CPNMUOG=")
assert.eq(encode32(hex: true, "fooba"), "CPNMUOJ1")
assert.eq(encode32(hex: true, "foobar"), "CPNMUOJ1E8======")
// Test Base16
assert.eq(encode16(""), "")
assert.eq(encode16("f"), "66")
assert.eq(encode16("fo"), "666f")
assert.eq(encode16("foo"), "666f6f")
assert.eq(encode16("foob"), "666f6f62")
assert.eq(encode16("fooba"), "666f6f6261")
assert.eq(encode16("foobar"), "666f6f626172")
}
|
https://github.com/Shedward/dnd-charbook
|
https://raw.githubusercontent.com/Shedward/dnd-charbook/main/dnd/page/page.typ
|
typst
|
#import "cover.typ": *
#import "attacks.typ": *
#import "charlist.typ": *
#import "inventory.typ": *
#import "spells.typ": *
#import "abilities.typ": *
#import "proficiencies.typ": *
#import "biography.typ": *
#import "quests.typ": *
|
|
https://github.com/jgm/typst-hs
|
https://raw.githubusercontent.com/jgm/typst-hs/main/test/typ/math/root-00.typ
|
typst
|
Other
|
// Test root with more than one character.
$A = sqrt(x + y) = c$
|
https://github.com/Myriad-Dreamin/typst.ts
|
https://raw.githubusercontent.com/Myriad-Dreamin/typst.ts/main/docs/cookery/guide/compilers.typ
|
typst
|
Apache License 2.0
|
#import "/docs/cookery/book.typ": *
#show: book-page.with(title: "Compilers")
= Compilers
See:
+ #cross-link("/guide/compiler/ts-cli.typ")[Command Line Interface]
+ #cross-link("/guide/compiler/service.typ")[Compiler in Rust]
+ #cross-link("/guide/compiler/node.typ")[Compiler in Node.js]
+ #cross-link("/guide/compiler/bindings.typ")[Compiler in Wasm (Web)]
|
https://github.com/lmenjoulet/CV
|
https://raw.githubusercontent.com/lmenjoulet/CV/master/resume.typ
|
typst
|
#let config = toml("./config.toml")
#let content = toml("./locales/"+ config.locale + ".toml")
// styling
#set page(
margin: 2em
)
#set text(
font: config.style.font,
size: 10pt
)
#set par(justify: true)
#set list(
indent: 1em
)
#show heading: it => [
#if it.level == 2 {
line(length: 100%, stroke: 1pt)
}
*#it*
]
#show link: set text(blue)
// content
#set document(
title: content.title,
author: content.author,
)
#let sidebar = {[
#if config.style.visibleProfile [
#pad(1em)[#image(config.profile)]
#line(length: 100%)
]
#for contact in content.contacts [
#contact.category: #h(1fr) #link(contact.link)[#contact.display] \
]
#line(length: 100%)
=== #content.languages.title
#for language in content.languages.items [
- *#language.lang*: #language.level #language.proof
]
#line(length: 100%)
=== #content.skills.title
#for category in content.skills.categories [
==== #category.title
#for skill in category.items [ #highlight(fill: aqua)[#skill]]
]
#line(length: 100%)
=== #content.aboutme.title
#content.aboutme.content
#line(length: 100%)
https://github.com/lmenjoulet/CV
]}
#let main = {[
= #content.author
_#content.degree _
== #content.jobs.title
#for job in content.jobs.items [
=== #job.position
_#job.company, #job.location #h(1fr) #job.date _
#for keypoint in job.description [
- #keypoint
]
]
== #content.trainings.title
#for training in content.trainings.items [
=== #training.title
_#training.school, #training.location #h(1fr) #training.date _
#for keypoint in training.description [
- #keypoint
]
]
]}
// Body
#align(center)[
#set text(size: 1.5em)
#underline[*Curriculum Vitae*]
]
#grid(
columns: (2fr, 5.5fr),
column-gutter: 2em,
sidebar,
main
)
|
|
https://github.com/typst/packages
|
https://raw.githubusercontent.com/typst/packages/main/packages/preview/fh-joanneum-iit-thesis/1.2.0/template/chapters/1-acknowledgements.typ
|
typst
|
Apache License 2.0
|
#import "global.typ": *
#todo([ Optionally, you might add an *Acknowledgements* section (in German *Danksagung*) to say thank you or give credits to someone. ])
|
https://github.com/AxiomOfChoices/Typst
|
https://raw.githubusercontent.com/AxiomOfChoices/Typst/master/Templates/math.typ
|
typst
|
#import "@preview/ctheorems:1.1.1": *
// Various symbols
#let Frob = math.op("Frob")
#let adj = math.op("adj")
#let Gal = math.op("Gal")
#let rank = math.op("rank")
#let supp = $op("supp")$
#let Mat = $op("Mat")$
#let Top = $bold(op("Top"))$
#let Ab = $bold(op("Ab"))$
#let Gp = $bold(op("Gp"))$
#let pair(x, y) = $lr(angle.l #x mid(|) #y angle.r)$
#let sl = $frak(op("sl"))$
#let Sl = $op("SL")$
#let gl = $frak(op("gl"))$
#let Gl = $op("GL")$
#let ve = $epsilon$
#let seq = $subset.eq$
#let Mink = math.op("Mink")
#let qd = math.op("qd")
#let fu = $frak(U)$
#let pb() = {
pagebreak(weak: true)
}
#let sat = $tack.r.double$
#let satn = $tack.r.double.not$
#let proves = $tack.r$
#let elm = $prec$
#let Th = math.op("Th")
#let mM = $cal(M)$
#let mN = $cal(N)$
#let ov(el) = math.overline(el)
#let quo = math.op("/")
#let subs(a, b) = $#a quo #b$
#let uproduct = $product mM_i slash.big cal(U)$
#let Def = math.op("Def")
#let cf = math.op("cf")
#let Cn = math.op("Cn")
#let ip(x, y) = $lr(angle.l #x, #y angle.r)$
#let suc = math.op("suc")
#let Area = math.op("Area")
#let Volume = math.op("Volume")
#let Hess = math.op("Hess")
#let Rm = math.op("Rm")
#let Ric = math.op("Ric")
#let lie = $cal(L)$
#let Sym = math.op("Sym")
#let AntiSym = math.op("ASym")
#let div = math.op("div")
#let tp = math.op("tp")
#let heis = math.op("heis")
#let char = math.op("char")
#let ad = math.op("ad")
#let Cl = math.op("Cl")
#let Lie = math.bold(math.op("Lie"))
#let iso = math.tilde.equiv
#let diam = math.op("Diam")
#let Lip = math.op("Lip")
#let Aut = math.op("Aut")
#let rng = math.op("rng")
#let dom = math.op("dom")
#let rad = math.op("rad")
#let acl = math.op("acl")
#let dcl = math.op("dcl")
#let Rad = math.op("Rad")
#let CB = math.op("CB")
#let Ord = math.op("Ord")
#let Clop = math.op("Clop")
#let conv = math.op("Conv")
#let RM = math.op("RM")
#let Age = math.op("Age")
#let SH = math.op("SH")
#let Sc = math.op("Sc")
#let span = math.op("Span")
#let ZFC = math.op("ZFC")
#let DLO = math.op("DLO")
#let ACF = math.op("ACF")
#let GaussArea = math.op("GaussArea")
#let flat = $♭$
#let gen(x) = $lr(angle.l #x angle.r)$
#let into = $arrow.hook$
#let col(x, color) = text(fill: color, $#x$)
#let col(x, color) = text(fill: color, $#x$)
#let symbol_replacing(doc) = {
show math.equation: set text(features: ("cv01",))
doc
}
#let theorem = thmbox(
"theorem",
"Theorem",
padding: (top: 0em, bottom: 0em),
fill: rgb("#e8e8f8"),
)
#let lemma = thmbox(
"theorem", // Lemmas use the same counter as Theorems
"Lemma",
padding: (top: 0em, bottom: 0em),
fill: rgb("#efe6ff")
)
#let conjecture = thmbox(
"theorem", // Lemmas use the same counter as Theorems
"Conjecture",
padding: (top: 0em, bottom: 0em),
fill: rgb("#FFBE98")
)
#let claim = thmbox(
"theorem", // Lemmas use the same counter as Theorems
"Claim",
padding: (top: 0em, bottom: 0em),
fill: rgb("#ffefe6")
)
#let technique = thmplain(
"technique", // Lemmas use the same counter as Theorems
"Technique",
padding: (top: 0em, bottom: 0em),
)
#let proposition = thmbox(
"theorem", // Lemmas use the same counter as Theorems
"Proposition",
padding: (top: 0em, bottom: 0em),
fill: rgb("#efe6ff")
)
#let corollary = thmbox(
"corollary",
"Corollary",
padding: (top: 0em, bottom: 0em),
base: "theorem", // Corollaries are 'attached' to Theorems
fill: rgb("#f8e8e8")
)
#let definition = thmbox(
"definition", // Definitions use their own counter
"Definition",
padding: (top: 0em, bottom: 0em),
fill: rgb("#e8f8e8")
)
#let exercise = thmbox(
"exercise",
"Exercise",
padding: (top: 0em, bottom: 0em),
stroke: rgb("#ffaaaa") + 1pt,
)
// Examples and remarks are not numbered
#let example = thmplain(
"example",
"Example",
inset: (x: 0.0em),
).with(numbering: none)
#let remark = thmplain(
"remark",
"Remark",
padding: (top: 0em, bottom: 0em),
//stroke: rgb("#ffaaaa") + 1pt,
).with(numbering: none)
// Proofs are attached to theorems, although they are not numbered
#let proof = thmplain(
"proof",
"Proof",
base: "theorem",
bodyfmt: body => [
#body #h(1fr) $square$ // Insert QED symbol
],
).with(numbering: none)
#let solution = thmplain(
"solution",
"Solution",
base: "exercise",
).with(numbering: none)
#let assumptions = thmplain(
"assumptions",
"Assumptions",
)
#let conditions = thmplain(
"conditions",
"Conditions",
)
// #let equation_references(doc) = {
// // set math.equation(numbering: "(1)")
// show ref: it => {
// let eq = math.equation
// let el = it.element
// if el != none and el.func() == eq{
// // el.fields()
// numbering("(1)",
// ..counter(eq)
// .at(el.location()))
// }
// else {
// it
// }
// }
// doc
// }
//
#let equation_references(doc) = {
show ref: it => {
let el = it.element
if el != none and el.func() == math.equation {
link(
el.location(),
numbering(
section_based_equation_numbering,
counter(math.equation).at(el.location()).at(0) + 1,
),
)
} else {
it
}
}
doc
}
#let section_based_equation_numbering(number, el) = {
locate(loc => {
let count = counter(heading.where(level: 1)).at(loc).last()
numbering("(1.1)", count, number)
})
}
#let equation_numbering(doc) = {
show heading.where(level: 1): it => {
counter(math.equation).update(0)
it
}
show math.equation: it => {
if it.has("label") {
math.equation(
block: true,
numbering: section_based_equation_numbering,
it,
)
} else {
it
}
}
doc
}
|
|
https://github.com/RhenzoHideki/desenvolvimento-em-fpga
|
https://raw.githubusercontent.com/RhenzoHideki/desenvolvimento-em-fpga/main/AE4/relatório.typ
|
typst
|
#import "../typst-ifsc/templates/article.typ":*
#show: doc => article(
title: "Relatório Atividade extra-classe 4
Conversor de binário para BCD",
subtitle: "Dispositivos lógicos programaveis",
// Se apenas um autor colocar , no final para indicar que é um array
authors: ("<NAME>",),
date: "26 de Setembro de 2023",
doc,
)
#show raw.where(block: false): box.with(
fill: luma(240),
inset: (x: 3pt, y: 0pt),
outset: (y: 3pt),
radius: 2pt,
)
= Resolução da Atividade extra-classe 4 (AE4)
Seguindo as orientações da atividade , foi feito um código conversor de binário para BCD (bin2bcd) com entrada binária variando entre 0 a 9999. A familia utilizada foi Cyclone IV E e a placa escolhida foi a EP4CE115F29C8 , estando de acordo com as orientações anteriores.
== Código utilizado
o código feito foi este:
`
library ieee;
use ieee.std_logic_1164.all;
use ieee.numeric_std.all;
entity bin2bcd is
port (
A : in std_logic_vector(14 downto 0);
sm : out std_logic_vector( 4 downto 0 );
sc : out std_logic_vector( 4 downto 0 );
sd : out std_logic_vector( 4 downto 0 );
su: out std_logic_vector( 4 downto 0 )
);
end entity;
architecture ae4 of bin2bcd is
signal A_uns : unsigned(14 downto 0);
signal slice_mil: unsigned(14 downto 0);
signal slice_cem: unsigned(14 downto 0);
signal slice_dez: unsigned(14 downto 0);
signal slice_uni: unsigned(14 downto 0);
begin
A_uns <= unsigned(A);
sm <= std_logic_vector(resize(slice_mil,5));
sc <= std_logic_vector(resize(slice_cem,5));
sd <= std_logic_vector(resize(slice_dez,5));
su <= std_logic_vector(resize(slice_uni,5));
-- Convert each binary digit to BCD
slice_mil <= A_uns/1000;
slice_cem <= (A_uns/100) rem 10;
slice_dez <= (A_uns/10) rem 10 ;
slice_uni <= A_uns rem 10;
end architecture;
`
\
O código foi baseado nos código feitos em aula junto com o conhecimento adquirido. Utilizando 4 saídas std_logic_vector sm (Sinal milhar), sc (Sinal centena), sd (Sinal dezena), su (Sinal unidade), e utilizando uma entrada A . slice_mil , slice_cem , slice_dez , slice_uni são os intermediários para trocar de sinal não sinalizado (unsigned).
== Simulação funcional
Utilizando esse código , foi possível obter a Simulação funcional usando o ModelSim de acordo com o comando da questão , desta forma foi feito alguns testes para testar o código , este foi o resultado obtido :
#align(center)[
#figure(
image(
"./Figuras/Simulação_Ae4.png",width: 110%,
),
caption: [
simulação funcional \ Fonte: Elaborada pelo autor
],
supplement: "Figura AE4"
)
]
Foi analisado 3 valores nessa simulação com A sendo 4578, 9998, 0003, é possível ver que os valores de sm, sc, sd, su foram alterados nos momentos que A recebeu os valores de entrada. Os resultados satisfazem o objetivo do código e da atividade extra-classe 4.
== Número de elementos lógicos
Com a simulação funcional feita , é possível ter certeza ver que foi alçado o objetivo em código , mas é necessária a analise de quãao custoso o código está sendo e se é aceitável o número de recursos.
As figuras a seguir mostram o número de recursos utilizados para que o código seja implementado:
#align(center)[
#figure(
image(
"./Figuras/Screenshot from 2023-09-30 20-02-13.png",width: 110%,
),
caption: [
simulação funcional \ Fonte: Elaborada pelo autor
],
supplement: "Figura AE4"
)
]
#align(center)[
#figure(
image(
"./Figuras/Screenshot from 2023-09-30 20-05-02.png",width: 110%,
),
caption: [
simulação funcional \ Fonte: Elaborada pelo autor
],
supplement: "Figura AE4"
)
]
Esses são os registros da quantidade de recurso utilizada para funcionamento se baseando no código anterior. o valor representa 1% do total de elementos lógicos da placa , porém utiliza 1272 elementos lógicos. Após algumas tentativas tentando otimizar o uso dos elementos lógicos , foi concluído que com os recursos aprendidos até a AE4 não foi observado maneira melhor ou mais intuitiva de executar um código que atendesse as requisições sem alterar outras partes além do código.
#pagebreak()
== Tempo de propagação
Para essa atividade também foi requisitado que fosse estudado o quão rápido era a execução do código e o tempo de propagação na placa. Esse resultado é mostrado na figura a seguir:
#align(center)[
#figure(
image(
"./Figuras/Screenshot from 2023-09-29 18-46-20.png",width: 100%,
),
caption: [
simulação funcional \ Fonte: Elaborada pelo autor
],
supplement: "Figura AE4"
)
]
Pode-se ver na figura 8 que o tempo de propagação é de 57.4 ns , essa é a pior situação simulada possível com o modelo utilizando sua forma de operação mais lenta , dessa forma pode-se fazer a analise e decidir se é aceitável ou não a propagação . O que é possível fazer para alterar esses valores é alterar o valor de seed das simulações , alterar a placa utilizada mantendo-se dentro da familia Cyclone IV E , e procurar por outras otimizações no código e distribuição dos elementos lógicos na placa e diminuir suas distancias.
#pagebreak()
== RTL Viewer
A seguir uma imagem do RTL viewer após a compilação do código.
#align(center)[
#figure(
image(
"./Figuras/Screenshot from 2023-10-01 11-27-02.png",width: 100%,
),
caption: [
RTL viewer \ Fonte: Elaborada pelo autor
],
supplement: "Figura AE4"
)
]
É possível ver no RTL Viewer os circuitos utilizados para satisfazer o código. Utilizando 3 circuitos de divisão e mais 3 circuitos de Mod (Resto da divisão inteira) .
#pagebreak()
== Technology Map
A seguir os prints dos Technology Maps tirados da atividade.
#align(center)[
#figure(
image(
"./Figuras/Screenshot from 2023-10-01 11-29-32.png",width: 110%,
),
caption: [
Technology Map Viewer (Post-Fitting) \ Fonte: Elaborada pelo autor
],
supplement: "Figura AE4"
)
]
#align(center)[
#figure(
image(
"./Figuras/Screenshot from 2023-10-01 11-30-06.png",width: 110%,
),
caption: [
Technology Map Viewer (Post Mapping) \ Fonte: Elaborada pelo autor
],
supplement: "Figura AE4"
)
]
= Conclusão
Observando os resultados obtidos , é crível que eles são aceitáveis com os recursos aprendidos até o momento. Porém é bem possível diversas possíveis otimizações como mencionando anteriormente , alterando tanto o tempo de propagação quanto o número de elementos. Ou também é possível que diminuir o tempo de propagação leve um uso maior de elementos lógicos.
|
|
https://github.com/mrtz-j/typst-thesis-template
|
https://raw.githubusercontent.com/mrtz-j/typst-thesis-template/main/template/thesis.typ
|
typst
|
MIT License
|
// A central place where libraries are imported (or macros are defined)
// which are used within all the chapters:
#import "chapters/global.typ": *
#let epigraph = [
"The problem with object-oriented languages is they’ve got all this implicit \
environment that they carry around with them. You wanted a banana but \
what you got was a gorilla holding the banana and the entire jungle." \
--- <NAME>
]
#let abstract = [#lorem(150)]
#let acknowledgements = [#lorem(50)]
// Put your abbreviations/acronyms here.
// 'key' is what you will reference in the typst code
// 'short' is the abbreviation (what will be shown in the pdf on all references except the first)
// 'long' is the full acronym expansion (what will be shown in the first reference of the document)
#let abbreviations = (
(
key: "gc",
short: "GC",
long: "Garbage Collection",
),
(
key: "uit",
short: "UiT",
long: "University of Tromsø – The Arctic University of Norway",
),
(
key: "cow",
short: "COW",
long: "Copy on Write",
),
(
key: "cpu",
short: "CPU",
long: "Central Processing Unit",
),
)
#show: thesis.with(
author: "<author>",
title: "<title>",
degree: "<degree>",
faculty: "<faculty>",
department: "<department>",
major: "<major>",
supervisors: (
(
title: "Main Supervisor",
name: "<NAME>",
affiliation: [UiT The Arctic University of Norway, \
Faculty of Science and Technology, \
Department of Computer Science
],
),
(
title: "External Supervisor",
name: "<NAME>",
affiliation: [External Company A/S],
),
),
epigraph: epigraph,
abstract: abstract,
acknowledgements: acknowledgements,
preface: none,
figure-index: true,
table-index: true,
listing-index: true,
abbreviations: abbreviations,
submission-date: datetime.today(),
bibliography: bibliography("refs.bib", title: "Bibliography", style: "ieee"),
)
// Code blocks
#codly(languages: (
rust: (
name: "Rust",
color: rgb("#CE412B"),
),
// NOTE: Hacky, but 'fs' doesn't syntax highlight
fsi: (
name: "F#",
color: rgb("#6a0dad"),
),
))
// Include as many chapters as you like.
= Introduction <chp:introduction>
#include "./chapters/introduction.typ"
// NOTE:
// It's important to have explicit pagebreaks between each chapter,
// otherwise header stylings from the template might break
#pagebreak()
= Basic Usage <chp:basic_usage>
#include "./chapters/basic-usage.typ"
#pagebreak()
= Figures <chp:figures>
#include "./chapters/figures.typ"
#pagebreak()
= Typst Basics <chp:typst_basics>
#include "./chapters/typst-basics.typ"
#pagebreak()
= Utilities <chp:utilities>
#include "./chapters/utilities.typ"
|
https://github.com/Vanille-N/mpri2-edt
|
https://raw.githubusercontent.com/Vanille-N/mpri2-edt/master/classes.typ
|
typst
|
#import "typtyp.typ"
#let tt = typtyp
#import "time.typ"
#let Room = tt.typedef("Room", tt.content)
#let Class = tt.typedef("Class", tt.struct(
name: tt.content,
color: tt.color,
uid: tt.option(tt.content),
teacher: tt.content,
fmt: tt.any,
))
#let new(col, fmt, name, uid, teacher) = {
tt.is(tt.color, col)
tt.is(tt.content, name)
tt.is(tt.option(tt.content), uid)
tt.is(tt.content, teacher)
tt.ret(Class, ( name: name, color: col, uid: uid, teacher: teacher, fmt: fmt ))
}
#let SemDescr = tt.typedef("SemDescr", tt.array(tt.int))
#let TimeClass = tt.typedef("TimeClass", tt.struct(
descr: Class,
room: Room,
start: time.Time,
len: time.Time,
sem: SemDescr,
ects: tt.int,
))
#let slot(descr, room, sem: none, start: none, len: none, ects: none) = {
tt.is(Class, descr)
tt.is(Room, room)
tt.is(time.Time, start)
tt.is(time.Time, len)
tt.is(SemDescr, sem)
tt.is(tt.int, ects)
tt.ret(TimeClass, (
descr: descr,
room: room,
sem: sem,
ects: ects,
start: start,
len: len,
))
}
#let Day = tt.typedef("Day", tt.array(TimeClass))
#let Week = tt.typedef("Week", tt.struct(mon: Day, tue: Day, wed: Day, thu: Day, fri: Day))
#let merge(w1, w2) = {
tt.is(Week, w1)
tt.is(Week, w2)
tt.ret(Week, (
mon: w1.mon + w2.mon,
tue: w1.tue + w2.tue,
wed: w1.wed + w2.wed,
thu: w1.thu + w2.thu,
fri: w1.fri + w2.fri,
))
}
|
|
https://github.com/IdoWinter/UnitedDumplingsLegislatureArchive
|
https://raw.githubusercontent.com/IdoWinter/UnitedDumplingsLegislatureArchive/main/legislature/constitution/israeli-laws-adoption.typ
|
typst
|
MIT License
|
#import "../templates.typ": *
#eng_heb(
eng: [
#show: doc => constitutional_amendement_en("Adoption of Israeli Laws for Legal Completeness in the United Dumplings", preamble: [
Acknowledging the challenges posed by the limited capacity of the United Dumplings Parliament to comprehensively legislate across all domains, and recognizing the robustness of the Israeli legal system, this amendment aims to fortify the legal framework of the United Dumplings by selectively adopting Israeli laws, thus minimizing loopholes and ensuring a comprehensive legal system.
], doc)
== Selective Adoption of Israeli Laws
===
The United Dumplings shall selectively adopt Israeli statutes, regulations, and legal precedents to address gaps within its own legal framework, ensuring a comprehensive coverage of legislative matters and minimizing loopholes.
===
This adoption shall be confined to areas where the United Dumplings Parliament identifies a need for enhanced legal clarity or completeness, excluding sensitive areas such as national security, foreign relations, and cultural specifics.
== Parliamentary Authority and Discretion
===
The United Dumplings Parliament holds the sole authority to review, select, and adopt Israeli laws deemed beneficial for the legal completeness of the United Dumplings.
===
The Parliament may, at its discretion, modify, adapt, or exclude any part of the Israeli laws to ensure alignment with the United Dumplings' constitutional values, societal norms, and legal principles.
== Implementation and Harmonization
===
Adopted Israeli laws shall undergo necessary modifications to ensure full integration into the United Dumplings' legal system, respecting the unique cultural, societal, and legal context of the United Dumplings.
===
In case of any legal conflict or ambiguity arising from the adopted laws, the judiciary of the United Dumplings shall interpret these laws in a manner that best aligns with the country's constitutional principles and legal framework.
== Amendment and Review
===
This constitutional provision may be amended or repealed solely by the United Dumplings Parliament through its standard legislative process, ensuring the sovereign right of the United Dumplings to control its legal framework.
== Commencement
===
This amendment becomes effective immediately upon its ratification, marking a step towards legislative completeness and coherence within the United Dumplings.
], heb: [
])
|
https://github.com/jgm/typst-hs
|
https://raw.githubusercontent.com/jgm/typst-hs/main/test/typ/compiler/let-16.typ
|
typst
|
Other
|
// Ref: false
// Simple destructuring.
#let (a: a, b, x: c) = (a: 1, b: 2, x: 3)
#test(a, 1)
#test(b, 2)
#test(c, 3)
|
https://github.com/Skimmeroni/Appunti
|
https://raw.githubusercontent.com/Skimmeroni/Appunti/main/Metodi%20Algebrici/Strutture/Resto.typ
|
typst
|
Creative Commons Zero v1.0 Universal
|
#import "../Metodi_defs.typ": *
Il @Congruence-mod-is-equivalence stabilisce che la congruenza
modulo $n$ é una relazione di equivalenza su $ZZ$. Pertanto,
deve essere possibile identificare delle classi di equivalenza
per la congruenza modulo $n$.
Preso $n$ intero con $n > 0$ ed un certo $a in ZZ$, la classe di
equivalenza di $a$ rispetto alla congruenza modulo $n$ viene indicata
con $[a]_(n)$. Tale classe di equivalenza corrisponde all'insieme ${b:
b in ZZ and a equiv b mod n}$, ovvero all'insieme che contiene tutti i
numeri interi che, divisi per $n$, restituiscono lo stesso resto della
divisione fra $n$ e $a$.
#example[
$[19]_(7)$ é la classe di equivalenza per la congruenza modulo
$7$ che contiene tutti e soli i numeri interi che, divisi per
$7$, restituiscono il medesimo resto della divisione fra $19$
e $7$. Come da definizione di classe di equivalenza, qualsiasi
numero che rispetti tale caratteristica puó essere scelto come
rappresentante. Pertanto, $[19]_(7)$ é equivalente, ad esempio,
a $[-2]_(7)$, perché $19 equiv -2 mod 7$.
]
Le classi di equivalenza indotte dalla congruenza modulo $n$ vengono
anche chiamate *classi di resto*. L'insieme quoziente di $ZZ$ rispetto
alla relazione di congruenza modulo $n$ con $n > 0$ si dice *insieme
delle classi di resto modulo* $n$ e si denota con $ZZ_(n)$.
#lemma[
Sia $n$ un numero intero. Ogni elemento $a$ della classe di resto
$[a]_(n)$ puó essere scritto in maniera univoca nella forma $[r]_(n)$,
dove $r$ é il resto della divisione fra $a$ ed $n$.
] <Residue-class-is-unique>
#proof[
Se $r$ é il resto della divisione di $a$ per $n$, allora vale
$a = n k + r$ per un certo $k in ZZ$, da cui si ha $a - r = n k$,
che é la definizione di congruenza modulo $n$.
]
Il @Residue-class-is-unique definisce una "forma standard" per
rappresentare le classi di equivalenza per la congruenza modulo
$n$.
#theorem[
Per ogni numero intero $n > 0$, l'insieme quoziente $ZZ_(n)$ contiene
$n$ classi di resto distinte. Tali classi di resto, scritte in forma
standard, sono
$ ZZ_(n) = {[0]_(n), [1]_(n), ..., [n − 1]_(n)} =
{{n k : k in ZZ},
{1 + n k : k in ZZ},
...,
{n - 1 + n k : k in ZZ}} $
] <Distinct-residue-classes>
#proof[
Sia $a in ZZ$. La divisione con resto fornisce $a = n q + r$ con
$0 lt.eq r < n$. Poichè $a − r = q n$ si ha che $a equiv r mod n$.
Ciò mostra che ogni intero $a$ è congruo, modulo $n$, a uno degli
interi $0, 1, ..., n − 1$. D'altra parte se $i$ e $j$ sono interi,
con $0 lt.eq i < n$ e $0 lt.eq j < n$ si ha, assumendo $i gt.eq j$,
che $0 lt.eq i − j lt.eq n − 1$ e quindi $i − j = k n$ se e solo
se $k = 0$, cioè $i = j$.
]
#example[
#grid(
columns: (0.5fr, 0.5fr),
[
Con $n = 2$, si ha $ZZ_(2) = {[0]_(2), [1]_(2)}$:
$ [0]_(2)&= {..., −6, −4, −2, 0, 2, 4, 6, ...} \
[1]_(2)&= {..., −5, −3, −1, 1, 3, 5, 7, ...} $
],
[
Con $n = 3$, si ha $ZZ_(3) = {[0]_(3), [1]_(3), [2]_(3)}$:
$ [0]_(3)&= {..., −9, −6, −3, 0, 3, 6, 9, ...} \
[1]_(3)&= {..., −8, −5, −2, 1, 4, 7, 10, ...} \
[2]_(3)&= {..., −7, −4, −1, 2, 5, 8, 11, ...} $
]
)
Ad esempio, la classe di resto $[5]_(7)$ rappresenta, oltre al numero $5$,
anche il numero $12$ $(1 times 7 + 5)$, il numero $19$ $(2 times 7 + 5)$,
il numero $2308$ $(329 times 7 + 5)$, il numero $-2$ $(-1 times 7 + 5)$
il numero $-9$ $(-2 times 7 + 5)$, ecc...
]
#lemma[
Sia $[a]_(n)$ con $n in NN$ una classe di resto. Se vale $[a]_(n) =
[0]_(n)$, allora $n | a$.
] <Class-as-divisibility>
#proof[
Per la definizione di classe di resto, l'espressione $[a]_(n) = [0]_(n)$
equivale a dire che la divisione fra $a$ e $n$ ha lo stesso resto della
divisione fra $0$ ed $n$. Dato che la divisione fra $0$ ed un qualsiasi
numero (intero) ha quoziente $0$ e resto $0$, si ha che la divisione fra
$a$ e $n$ ha resto $0$, ovvero che $n | a$.
]
Sull'insieme delle classi di resto modulo $n$ é possibile definire le
operazioni di somma e di prodotto. Siano $[a]_(n)$ e $[b]_(n)$ due classi
di resto modulo $n$. La somma ed il prodotto sono definiti come:
#grid(
columns: (0.5fr, 0.5fr),
[$ [a]_(n) + [b]_(n) = [a + b]_(n) $],
[$ [a]_(n) dot [b]_(n) = [a b]_(n) $]
)
#example[
in $ZZ_(5)$, si ha $[1]_(5) + [3]_(5) = [3 + 1]_(5) = [4]_(5)$ e
$[2]_(5) dot [3]_(5) = [2 dot 3]_(5) = [6]_(5)$
]
#lemma[
Sia $n in ZZ$ con $n > 0$. Siano poi $a, b, c, d in ZZ$,
tali per cui $[a]_(n) = [b]_(n)$ e $[c]_(n) = [d]_(n)$. Allora vale:
#grid(
columns: (0.5fr, 0.5fr),
[$ [a]_(n) + [c]_(n) = [b]_(n) + [d]_(n) $],
[$ [a]_(n) dot [c]_(n) = [b]_(n) dot [d]_(n) $]
)
]
#proof[
Poichè $[a]_(n) = [b]_(n)$ e $[c]_(n) = [d]_(n)$ si ha, per definizione
di classe di equivalenza, $a = b + n k$ e $c = d + n h$ per $k, h in
ZZ$. Sommando e moltiplicando l'una all'altra, si ha:
#set math.mat(delim: none)
$ mat(
a + c = b + n k + d + n h =>
a + c = (b + d) + n(h + k);
a dot c = (b + n k) dot (d + n h) =>
a c = b d + b n h + n k d + n^(2) k h =>
a c = b d + n(b h + d k + n k h)
) $
Essendo $ZZ$ chiuso rispetto alla somma e al prodotto, si ha
$k + h in ZZ$ e $b h + d k + k h n in ZZ$, siano questi
rispettivamente $alpha$ e $beta$. Si ha:
#grid(
columns: (0.5fr, 0.5fr),
[$ (a + c) = (b + d) + n alpha $],
[$ a c = b d + n beta $]
)
Applicando nuovamente la definizione di classe di equivalenza, si ha
che $[a + c]_(n) = [b + d]_(n)$ e $[a c]_(n) = [b d]_(n)$. Per come
sono state definite la somma ed il prodotto rispetto alle classi di
equivalenza, si ha infine $[a]_(n) + [c]_(n) = [b]_(n) + [d]_(n)$ e
$[a]_(n) [c]_(n) = [b]_(n) [d]_(n)$.
]
#theorem[
La struttura algebrica $(ZZ_(n), +)$, formata dalle classi di resto
modulo $n$ e dalla somma su queste definita, é un gruppo abeliano.
] <Residue-classes-sum-group>
#proof[
La struttura algebrica $(ZZ_(n), +)$ é:
- un semigruppo, perché l'operazione $+$ cosí definita gode della
proprietá associativa. Questo é determinato dal fatto che l'usuale
somma in $ZZ$ gode di tale proprietá:
$ ([a]_(n) + [b]_(n)) + [c]_(n) = & [a + b]_(n) + [c]_(n) =
[(a + b) + c]_(n) = [a + (b + c)]_(n) \ = & [a]_(n) + [b + c]_(n) =
[a]_(n) + ([b]_(n) + [c]_(n)) $
- un monoide, perché per l'operazione $+$ cosí definita esiste l'elemento
neutro. Tale elemento é $[0]_(n)$, infatti preso un qualsiasi $[a]_(n)
in ZZ_(n)$:
$ [0]_(n) + [a]_(n) = [a]_(n) + [0]_(n) = [a + 0]_(n) = [0 + a]_(n) =
[a]_(n) $
- un gruppo, perché per l'operazione $+$ cosí definita esiste un elemento
inverso per qualsiasi elemento di $ZZ_(n)$. Preso un qualsiasi $[a]_(n)
in ZZ_(n)$, tale elemento inverso é $[n - a]_(n)$, in quanto:
$ [a]_(n) + [n - a]_(n) = [n - a]_(n) + [a]_(n) = [(n - a) + a]_(n) =
[a + (n - a)]_(n) = [n]_(n) = 0 $
Inoltre, $+$ gode della proprietá commutativa. Infatti:
$ [a]_(n) + [b]_(n) = [a + b]_(n) = [b + a]_(n) = [b]_(n) + [a]_(n) $
Pertanto, $(ZZ_(n), +)$ é un gruppo abeliano.
]
#theorem[
La struttura algebrica $(ZZ_(n), dot)$, formata dalle classi di resto
modulo $n$ e dal prodotto su queste definito, é un monoide abeliano.
] <Residue-classes-product-monoid>
#proof[
La struttura algebrica $(ZZ_(n), dot)$ é:
- un semigruppo, perché l'operazione $dot$ cosí definita gode della
proprietá associativa. Questo é determinato dal fatto che l'usuale
prodotto in $ZZ$ gode di tale proprietá:
$ ([a]_(n) dot [b]_(n)) dot [c]_(n) = & [a dot b]_(n) dot [c]_(n) =
[(a dot b) dot c]_(n) = [a dot (b dot c)]_(n) \ = & [a]_(n) dot
[b dot c]_(n) = [a]_(n) dot ([b]_(n) dot [c]_(n)) $
- un monoide, perché per l'operazione $dot$ cosí definita esiste
l'elemento neutro. Tale elemento é $[1]_(n)$, infatti preso un
qualsiasi $[a]_(n) in ZZ_(n)$:
$ [1]_(n) dot [a]_(n) = [a]_(n) dot [1]_(n) = [a dot 1]_(n) =
[1 dot a]_(n) = [a]_(n) $
Inoltre, $dot$ gode della proprietá commutativa. Infatti:
$ [a]_(n) dot [b]_(n) = [a dot b]_(n) = [b dot a]_(n) =
[b]_(n) dot [a]_(n) $
Pertanto, $(ZZ_(n), dot)$ é un monoide abeliano.
]
Il @Residue-classes-sum-group ed il @Residue-classes-product-monoid
suggeriscono che per qualsiasi classe di resto in $ZZ_(n)$ esista
un inverso per la somma, ma non per tutte esiste un inverso per
il prodotto.
#lemma[
Siano $a, n$ due numeri interi, dove $n > 1$. La classe di resto
$[a]_(n)$ ammette inverso in $ZZ_(n)$ rispetto al prodotto se e
soltanto se $a$ ed $n$ sono coprimi, ovvero se $"MCD"(a, n) = 1$.
]
#proof[
Se la classe di resto $[a]_(n)$ è invertibile, allora esiste $[b]_(n)
in ZZ_(n)$ tale per cui $[a]_(n) [b]_(n) = [1]_(n)$, ovvero $[a b]_(n)
= [1]_(n)$. Per come la somma sulle classi di resto é stata definita,
é possibile sommare $[-1]_(n)$ ad entrambi i membri, ottenendo $[a b]_(n)
+ [-1]_(n) = [1]_(n) + [-1]_(n)$, da cui si ricava $[a b - 1]_(n) =
[0]_(n)$. Per il @Class-as-divisibility, si ha $n | a b - 1$. Deve allora
esistere un $k in ZZ$ tale per cui $a b - 1 = n k$, ovvero $a b - n k =
1$. Dato che sia $b$ sia $k$ sono certamente esistenti, é possibile
applicare il @Coprime-as-Bézout per provare che $a$ ed $n$ sono coprimi.
Viceversa, si assuma che $a$ ed $n$ siano coprimi. Per l'identitá di
Bézout esistono $s, t in ZZ$ tali per cui $a s + n t = 1$, ovvero
$a s = 1 - n t$. Questo equivale a dire che $a s equiv 1 mod n$,
ovvero che $[a s]_(n) = [a]_(n) [s]_(n) = [1]_(n)$. Si ha quindi
che per $[a]_(n)$ esiste l'invertibile.
]
#example[
In $ZZ_(51)$ l'elemento $[13]_(51)$ è invertibile perchè
$"MCD"(13, 51) = 1$. D'altro canto, $[15]_(51)$ non lo é,
perché $"MCD"(15, 51) = 3$.
]
#lemma[
Il numero di classi di resto in $ZZ_(n)$ (con $n > 0$ numero intero)
che ammettono inverso rispetto al prodotto é pari a $phi(n)$.
]
#theorem[
La struttura algebrica $(ZZ_(n) - {[0]_(n)}, dot)$, formata dalle
classi di resto modulo $n$ esclusa $[0]_(n)$ e dal prodotto su queste
definito, é un gruppo abeliano se e soltanto se $n$ é un numero primo.
In altre parole, le classi di resto modulo $n$ (tranne $[0]_(n)$)
ammettono sempre inversa solamente se $n$ é un numero primo.
]
// #proof[
// Dimostrabile, da aggiungere
// ]
Sia $[a]_(n)$ una classe di resto invertibile, e si supponga di
volerne trovarne l'inverso $[a]^(-1)_(n)$. É sufficiente osservare
come l'espressione $[a]_(n) [a]^(-1)_(n) = [1]_(n)$ equivalga a $a
dot a^(-1) equiv 1 mod n$. Pertanto, occorre risolvere tale congruenza
lineare con $a^(-1)$ come incognita e sceglierne una soluzione qualsiasi,
essendo tutte equivalenti.
#example[
In $ZZ_(9)$, la classe di resto $[7]_(9)$ é invertibile, in quanto
$"MCD"(7, 9) = 1$. L'inverso é ricavato dal risolvere la congruenza
lineare $7 x equiv 1 mod 9$, che ha come soluzione $4 + 9 k$ con $k in
ZZ$. Pertanto, l'inverso di $[7]_(9)$ é $[4]_(9)$.
]
|
https://github.com/imtsuki/resume
|
https://raw.githubusercontent.com/imtsuki/resume/master/template.typ
|
typst
|
MIT License
|
#let project(author: (), body) = {
set document(title: "Curriculum Vitae", author: author.name)
set page(
margin: (x: 0.9cm, y: 1.3cm),
footer: [
#set align(right)
#set text(fill: gray)
Last updated: #datetime.today().display("[month repr:short] [day], [year]")
]
)
set text(font: "Linux Libertine", lang: "en")
show par: set block(above: 0.75em, below: 0.75em)
show heading: set text(font: "Linux Biolinum")
show link: underline
set par(leading: 0.58em)
let links = (
email: link("mailto:" + author.email)[#author.email],
github: link(author.github)[#author.github.trim("https://", at: start)],
website: link(author.website)[#author.website.trim("https://", at: start)]
)
[
= #author.name
#links.email | #links.github | #links.website
]
set par(justify: true)
body
}
|
https://github.com/OverflowCat/typecharts
|
https://raw.githubusercontent.com/OverflowCat/typecharts/neko/README.md
|
markdown
|
# typecharts
(WIP) Typst bindings for Apache ECharts using jogs.

## Usage
### `render()`
```typst
#render(config, option, theme: none, actions: none)
```
`actions` is an array containing actions to be dispatched using `chart.dispatchAction()`.
### `evalRender()`
|
|
https://github.com/SkymanOne/ecs-typst-template
|
https://raw.githubusercontent.com/SkymanOne/ecs-typst-template/main/ecsproject.typ
|
typst
|
MIT License
|
#import "@preview/wordometer:0.1.1": word-count, total-words
#let author_linked(
name: "<NAME>",
email: none,
) = {
if email == none {
text(name)
} else {
let email = "mailto:" + email
link(email)[#name]
}
}
#let margins = (inside: 1.4in, outside: 1.0in, top: 1.0in, bottom: 1.0in)
#let body-font = "New Computer Modern"
#let sans-font = "New Computer Modern Sans"
#let page_style(
page_numbering: "1",
title_numbering: "1.",
display_word_count: false,
doc
) = {
let words_label = text(weight: "bold", [Total words: #total-words])
set page(
numbering: page_numbering,
margin: margins,
)
set text(
font: body-font,
size: 12pt,
lang: "en",
)
set align(left)
set par(leading: 0.6em)
set footnote.entry(gap: 0.2em)
show par: it => [
#set par(justify: true)
#pad(top: 0.1em, bottom: 0.1em, it)
]
set heading(numbering: title_numbering)
show heading.where(level: 1): it => {
set text(size: 26pt, weight: "semibold")
let counter_display = if it.numbering != none {
counter(heading).display(it.numbering)
}
pad(top: 1.4em, bottom: 1.4em, left: 0.2em, [
#table(
columns: 2,
stroke: none,
align: left,
[#counter_display], [#it.body]
)
])
}
show heading.where(level: 2): it => {
set text(size: 18pt, weight: "semibold")
let counter_display = if it.numbering != none {
counter(heading).display(it.numbering)
}
pad(top: 0.5em, bottom: 0.5em, [
#counter_display #it.body
])
}
show heading.where(level: 3): it => {
set text(size: 14pt, weight: "semibold")
let counter_display = if it.numbering != none {
counter(heading).display(it.numbering)
}
pad(top: 0.5em, bottom: 0.5em, [
#counter_display #it.body
])
}
set page(header: locate(loc => {
let current_page = counter(page).at(loc).at(0)
let before_elems = query(
heading.where(level: 1).before(loc),
loc,
)
let after_elems = query(
heading.where(level: 1).after(loc),
loc,
)
let heading_present = false;
if after_elems != () {
let h_counter = counter(page).at(after_elems.first().location()).at(0)
if current_page >= h_counter {
heading_present = true
}
}
if not heading_present {
if before_elems != () {
let h_counter = counter(heading.where(level: 1)).display()
let last_header = before_elems.last().body
v(4em)
if last_header == text("Statement of Originality") {
emph(last_header) + h(1fr) + counter(page).display(page_numbering)
} else {
emph(h_counter + " " + last_header) + h(1fr) + counter(page).display(page_numbering)
}
v(-1em)
line(stroke: 0.5pt, length: 100%)
}
}
}), footer: locate(loc => {
let current_page = counter(page).at(loc).at(0)
let before_elems = query(
heading.where(level: 1).before(loc),
loc,
)
let after_elems = query(
heading.where(level: 1).after(loc),
loc,
)
let heading_present = false;
if before_elems != () {
let h_counter = counter(page).at(before_elems.last().location()).at(0)
if current_page == h_counter {
heading_present = true
}
}
if heading_present {
let p_counter = counter(page).display(page_numbering)
align(center, p_counter)
}
if display_word_count {
align(center, words_label)
}
}),
header-ascent: 20%,
footer-descent: 10%)
doc
}
#let cover(
title: "My project",
author: (
name: "<NAME>",
email: none
),
supervisor: (
name: "<NAME>",
email: none
),
examiner: (
name: "<NAME>",
email: none
),
date: "December 22, 2023",
program: "BSc Computer Science",
department: "Electronics and Computer Science",
faculty: "Faculty of Engineering and Physical Sciences",
university: "University of Southampton",
is_progress_report: false,
) = {
set document(title: title, author: author.at("name"))
set page(
numbering: none,
margin: margins,
)
counter(page).update(0)
set text(
font: body-font,
size: 12pt,
lang: "en",
)
set align(center)
v(7em)
par()[
#text(14pt, department) \
#text(14pt, faculty) \
#text(14pt, university)
]
v(6.5em)
let author_content = author_linked(name: author.at("name"), email: author.at("email"))
box(width: 250pt, height: 89pt)[
#grid(
columns: 1,
gutter: 2em,
text(author_content),
text(date),
box(text(14pt, weight: "bold", title))
)
]
let supervisor_content = author_linked(name: supervisor.at("name"), email: supervisor.at("email"))
let examiner_content = author_linked(name: examiner.at("name"), email: examiner.at("email"))
v(15em)
par()[
#text("Project supervisor: ") #supervisor_content \
#text("Second examiner: " ) #examiner_content
]
let award_text = if is_progress_report {
"A project progress report submitted for the award of"
} else {
"A project report submitted for the award of"
}
v(4.3em)
par()[
#text(14pt, award_text) \
#text(14pt, program)
]
}
#let abstract(
author: (
name: "<NAME>",
email: none,
),
program: "Program name",
department: "Electronics and Computer Science",
faculty: "Faculty of Engineering and Physical Sciences",
university: "University of Southampton",
is_progress_report: false,
content: lorem(150),
) = {
set page(
numbering: none,
margin: margins,
)
counter(page).update(0)
set align(center)
set text(
font: body-font,
size: 12pt,
lang: "en",
)
v(8.5em)
text(upper(university))
v(0.5em)
underline(text("ABSTRACT"))
v(0.5em)
par()[
#text(upper(faculty)) \
#text(upper(department))
]
v(0.5em)
let report_text = if is_progress_report {
"A project progress report submitted for the award of"
} else {
"A project report submitted for the award of"
}
let award_text = report_text + " " + program
underline(text(award_text))
v(0.5em)
let author_content = author_linked(name: author.at("name"), email: author.at("email"))
text("By " + author_content)
v(2em)
set align(left)
set par(linebreaks: "optimized", justify: true)
par(text(content))
}
#let originality_statement(
acknowledged: "I have acknowledged all sources, and identified any content taken from elsewhere.",
resources: "I have not used any resources produced by anyone else.",
foreign: "I did all the work myself, or with my allocated group, and have not helped anyone else",
material: "The material in the report is genuine, and I have included all my data/code/designs.",
reuse: "I have not submitted any part of this work for another assessment.",
participants: "My work did not involve human participants, their cells or data, or animals."
) = {
let box(info: none) = block(stroke: 0.5pt + black, width: 100%, pad(4pt, text(weight: "bold", info)))
page_style(
page_numbering: "i",
[
#heading(level: 1, numbering: none, "Statement of Originality")
#set list(tight: false, spacing: 1.5em, indent: 1.5em)
- I have read and understood the #link("http://ecs.gg/ai")[ECS Academic Integrity information] and the University’s #link("https://www.southampton.ac.uk/quality/assessment/academic_integrity.page")[Academic Integrity Guidance for Students].
- I am aware that failure to act in accordance with the #link("http://www.calendar.soton.ac.uk/sectionIV/academic-integrity-regs.html")[Regulations Governing Academic Integrity] may lead to the imposition of penalties which, for the most serious cases, may include termination of programme.
- I consent to the University copying and distributing any or all of my work in any form and using third parties (who may be based outside the EU/EEA) to verify whether my work contains plagiarised material, and for quality assurance purposes.
#v(1em)
*You must change the statements in the boxes if you do not agree with them.*
We expect you to acknowledge all sources of information (e.g. ideas, algorithms, data) using citations. You must also put quotation marks around any sections of text that you have copied without paraphrasing. If any figures or tables have been taken or modified from another source, you must explain this in the caption and cite the original source.
#box(info: acknowledged)
If you have used any code (e.g. open-source code), reference designs, or similar resources
that have been produced by anyone else, you must list them in the box below. In the
report, you must explain what was used and how it relates to the work you have done.
#box(info: resources)
You can consult with module teaching staff/demonstrators, but you should not show
anyone else your work (this includes uploading your work to publicly-accessible repositories
e.g. Github, unless expressly permitted by the module leader), or help them to
do theirs. For individual assignments, we expect you to work on your own. For group
assignments, we expect that you work only with your allocated group. You must get
permission in writing from the module teaching staff before you seek outside assistance,
e.g. a proofreading service, and declare it here.
#box(info: foreign)
We expect that you have not fabricated, modified or distorted any data, evidence,
references, experimental results, or other material used or presented in the report.
You must clearly describe your experiments and how the results were obtained, and include
all data, source code and/or designs (either in the report, or submitted as a separate
file) so that your results could be reproduced.
#box(info: material)
We expect that you have not previously submitted any part of this work for another
assessment. You must get permission in writing from the module teaching staff before
re-using any of your previously submitted work for this assessment.
#box(info: reuse)
If your work involved research/studies (including surveys) on human participants, their
cells or data, or on animals, you must have been granted ethical approval before the
work was carried out, and any experiments must have followed these requirements. You
must give details of this in the report, and list the ethical approval reference number(s)
in the box below.
#box(info: participants)
])
}
#let table_of_contents() = {
page_style(
page_numbering: "i",
{
set page(header: [])
heading(level: 1, "Contents", numbering: none)
show outline.entry.where(level: 1): it => {
v(1.2em, weak: true)
strong(it)
}
outline(title: none, indent: 2em, fill: line(length: 100%, stroke: (thickness: 1pt, dash: "loosely-dotted")))
}
)
}
#let acknowledgments(text: lorem(100)) = {
if text != none {
page_style(
page_numbering: "i",
{
set page(header: [])
heading(level: 1, "Acknowledgments", numbering: none)
text
}
)
}
}
#let use_project(
title: "My project",
author: (
name: "<NAME>",
email: none
),
supervisor: (
name: "<NAME>",
email: none
),
examiner: (
name: "<NAME>",
email: none
),
date: "December 22, 2023",
program: "BSc Computer Science",
department: "Electronics and Computer Science",
faculty: "Faculty of Engineering and Physical Sciences",
university: "University of Southampton",
is_progress_report: false,
originality_statements: (
acknowledged: "I have acknowledged all sources, and identified any content taken from elsewhere.",
resources: "I have not used any resources produced by anyone else.",
foreign: "I did all the work myself, or with my allocated group, and have not helped anyone else",
material: "The material in the report is genuine, and I have included all my data/code/designs.",
reuse: "I have not submitted any part of this work for another assessment.",
participants: "My work did not involve human participants, their cells or data, or animals."
),
abstract_text: lorem(50),
acknowledgments_text: lorem(50),
page_numbering: "1",
title_numbering: "1.",
display_word_count: false,
doc
) = {
cover(
title: title,
supervisor: supervisor,
examiner: examiner,
author: author,
date: date,
program: program,
department: department,
faculty: faculty,
university: university,
is_progress_report: is_progress_report
)
abstract(
author: author,
program: program,
department: department,
faculty: faculty,
university: university,
is_progress_report: is_progress_report,
content: abstract_text
)
originality_statement(
acknowledged: originality_statements.at("acknowledged"),
resources: originality_statements.at("resources"),
foreign: originality_statements.at("foreign"),
material: originality_statements.at("material"),
reuse: originality_statements.at("reuse"),
participants: originality_statements.at("participants")
)
acknowledgments(text: acknowledgments_text)
table_of_contents()
// todo: conifgure to exclude apendix and bibliography
show: word-count
show: doc => page_style(
page_numbering: page_numbering,
title_numbering: title_numbering,
display_word_count: display_word_count,
doc
)
counter(page).update(1)
doc
}
|
https://github.com/TypstApp-team/typst
|
https://raw.githubusercontent.com/TypstApp-team/typst/master/tests/typ/text/raw-theme.typ
|
typst
|
Apache License 2.0
|
// Test code highlighting with custom theme.
---
#set page(width: 180pt)
#set text(6pt)
#set raw(theme: "/files/halcyon.tmTheme")
#show raw: it => {
set text(fill: rgb("a2aabc"))
rect(
width: 100%,
inset: (x: 4pt, y: 5pt),
radius: 4pt,
fill: rgb("1d2433"),
place(right, text(luma(240), it.lang)) + it,
)
}
```typ
= Chapter 1
#lorem(100)
#let hi = "Hello World"
#show heading: emph
```
|
https://github.com/Fr4nk1inCs/typreset
|
https://raw.githubusercontent.com/Fr4nk1inCs/typreset/master/src/bundles/report.typ
|
typst
|
MIT License
|
#import "../styles/report.typ": style
|
https://github.com/OrangeX4/typst-sympy-calculator
|
https://raw.githubusercontent.com/OrangeX4/typst-sympy-calculator/main/README.md
|
markdown
|
MIT License
|
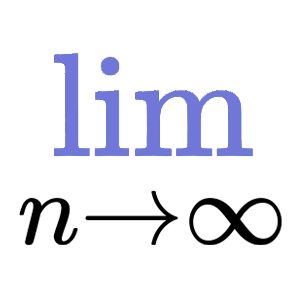
# [Typst Sympy Calculator](https://github.com/OrangeX4/typst-sympy-calculator)
## About
`Typst Sympy Calculator` parses **Typst Math Expressions** and converts it into the equivalent **SymPy form**. Then, **calculate it** and convert to typst math text.
It is designed for providing **people writing in typst** a ability to calculate something when writing math expression. It is based on `Sympy` module in `Python`.
The `typst-sympy-calculator` python package is a backend for a VS Code extension [`Typst Sympy Calculator`](https://github.com/OrangeX4/vscode-typst-sympy-calculator), and you also can use it just for parse typst math expression to sympy form in order to do things for yourself.
## Features
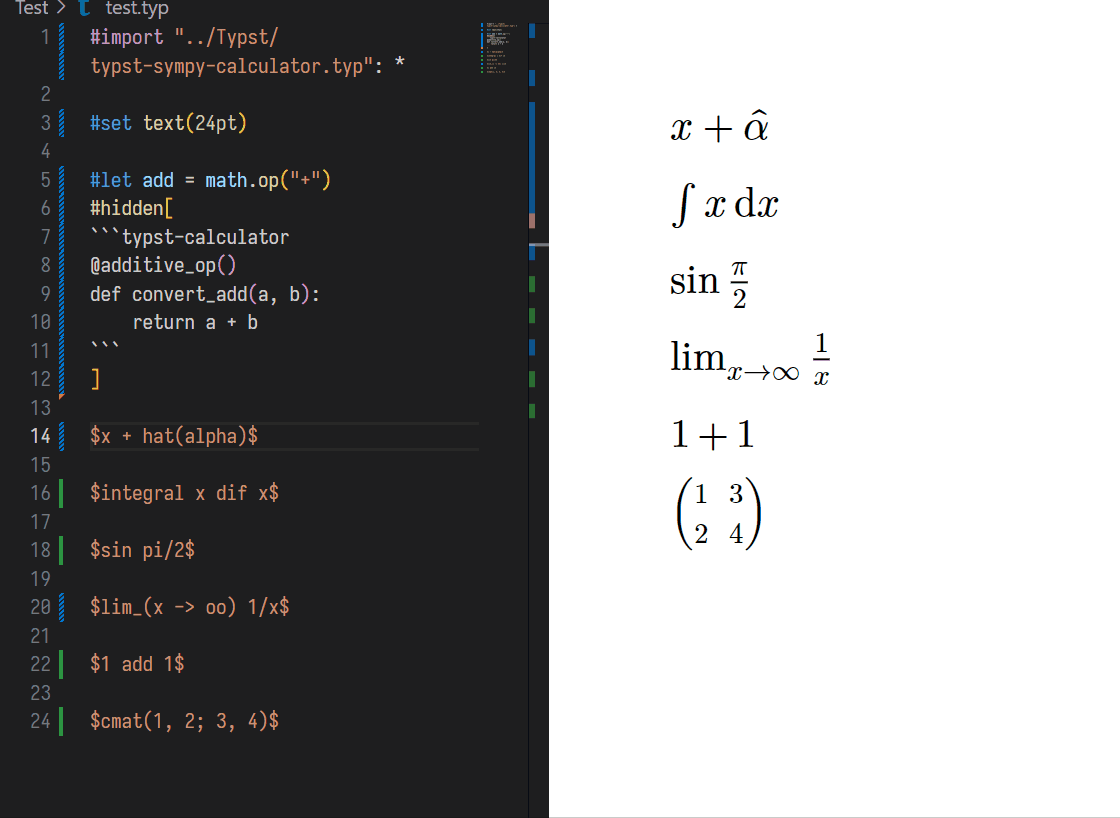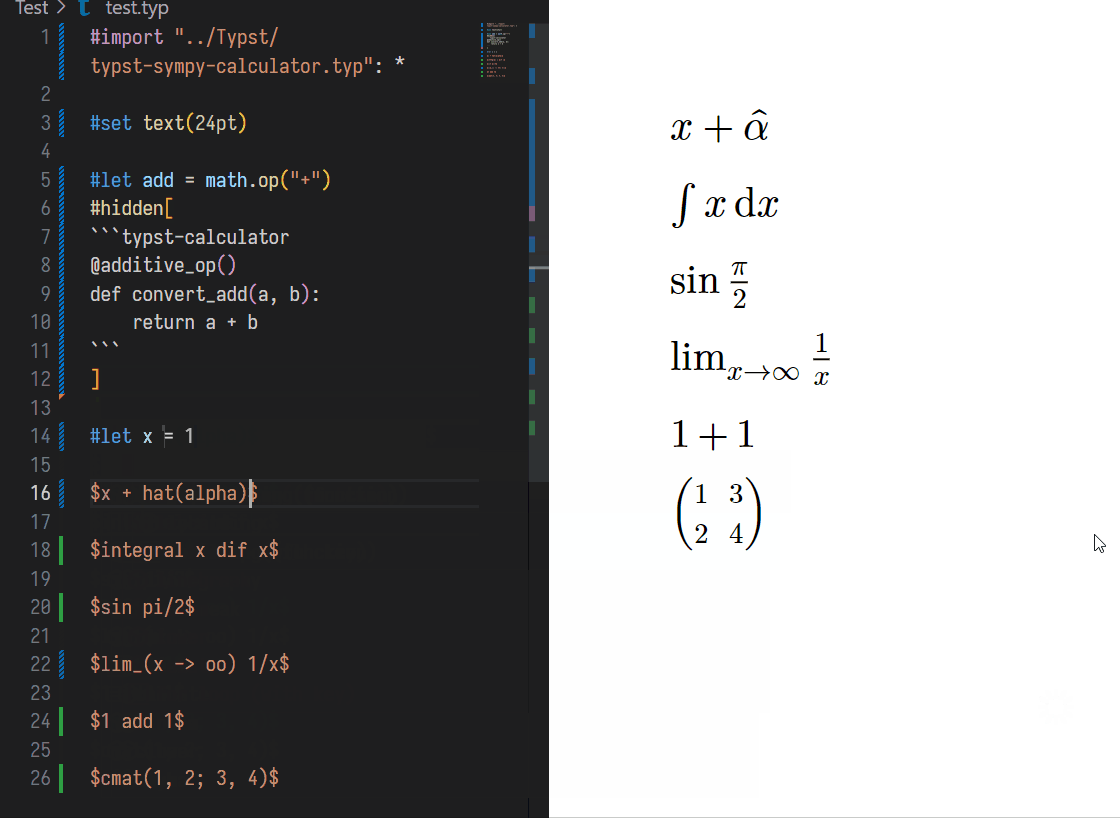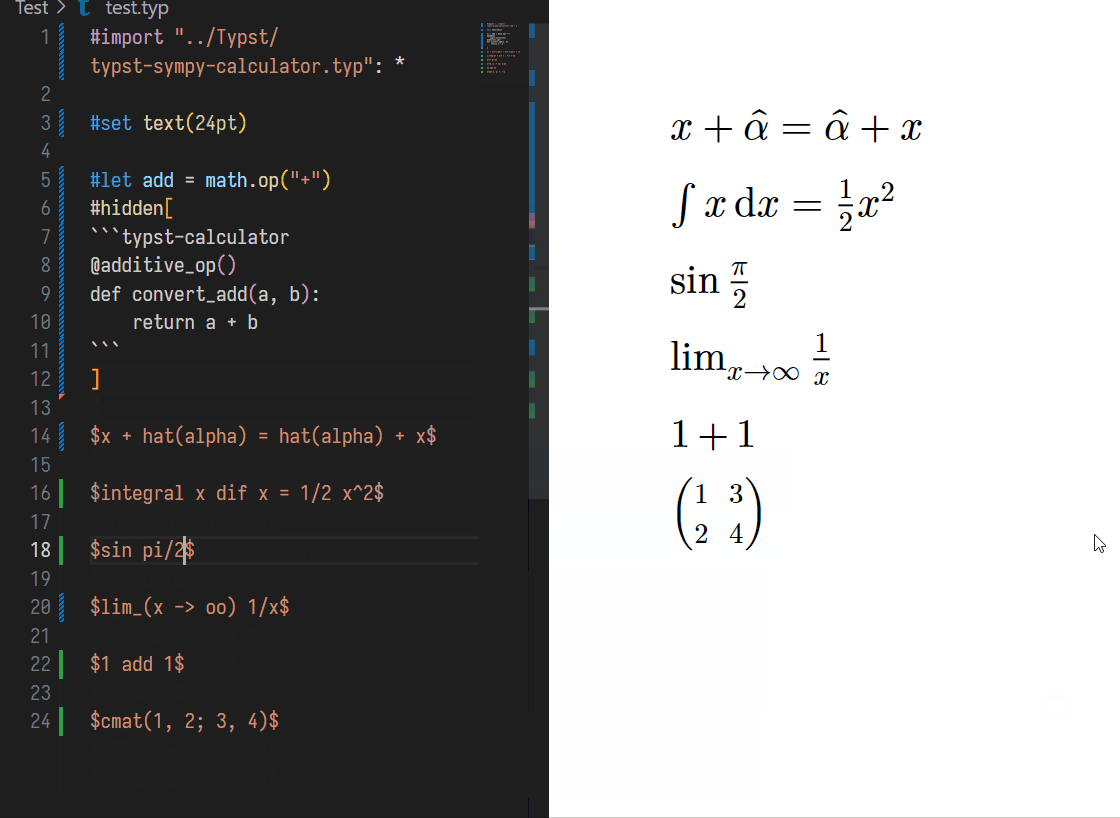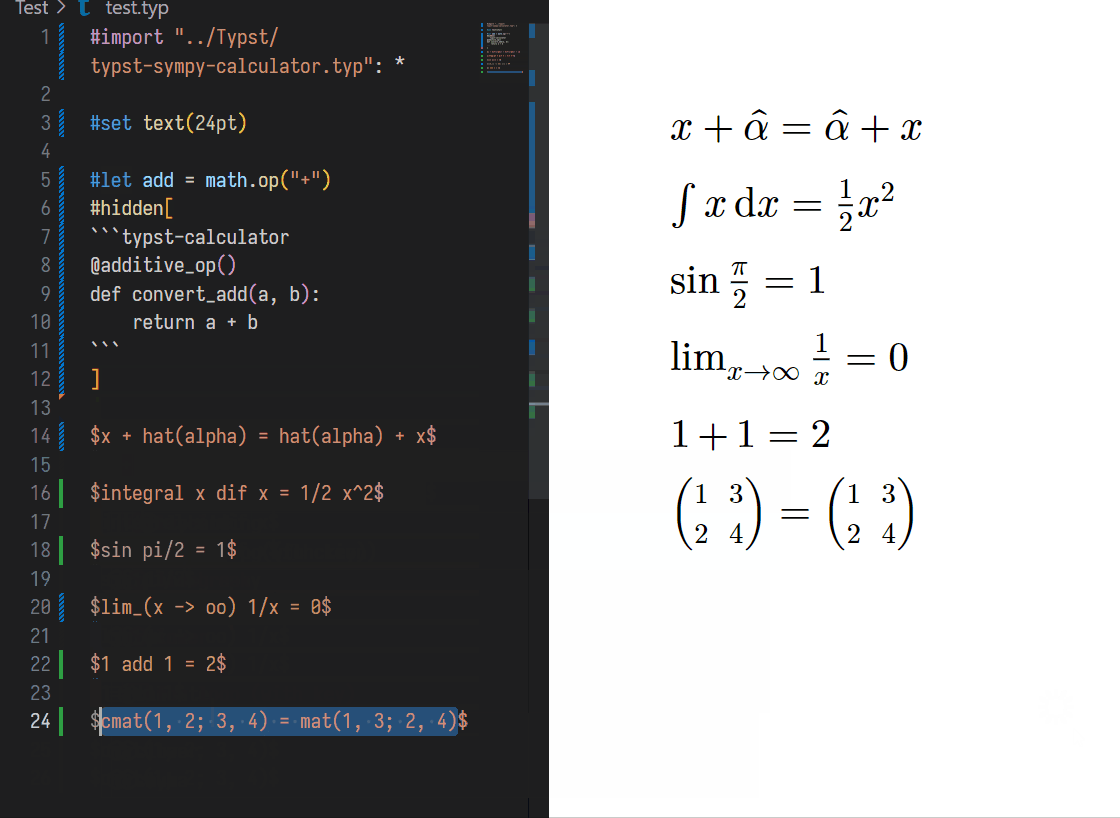
- **Default Math:**
- [x] **Arithmetic:** Add (`+`), Sub (`-`), Dot Mul (`dot`), Cross Mul (`times`), Frac (`/`), Power (`^`), Abs (`|x|`), Sqrt (`sqrt`), etc...
- [x] **Alphabet:** `a - z`, `A - Z`, `alpha - omega`, Subscript (`x_1`), Accent Bar(`hat(x)`), etc...
- [x] **Common Functions:** `gcd`, `lcm`, `floor`, `ceil`, `max`, `min`, `log`, `ln`, `exp`, `sin`, `cos`, `tan`, `csc`, `sec`, `cot`, `arcsin`, `sinh`, `arsinh`, etc...
- [x] **Funcion Symbol:** `f(x)`, `f(x-1,)`, `g(x,y)`, etc...
- [x] **Calculous:** Limit `lim_(x -> oo) 1/x`, Integration `integral_1^2 x dif x`, etc...
- [x] **Calculous:** Derivation (`dif/(dif x) (x^2 + 1)` is not supported, but you can use `derivative(expr, var)` instead), etc...
- [x] **Reduce:** Sum `sum_(k=1)^oo (1/2)^k`, Product `product_(k=1)^oo (1/2)^k`, etc...
- [x] **Eval At:** Evalat `x^2 bar_(x = 2)`, `x^2 "|"_(x = 2)`, etc...
- [x] **Linear Algebra:** Matrix to raw echelon form `rref`, Determinant `det`, Transpose `^T`, Inverse `^(-1)`, etc...
- [x] **Relations:** `==`, `>`, `>=`, `<`, `<=`, etc...
- [x] **Solve Equation:** Single Equation `x + 1 = 2`, Multiple Equations `cases(x + y = 1, x - y = 2)`, etc...
- [ ] **Logical:** `and`, `or`, `not`, etc...
- [ ] **Set Theory:** `in`, `sect`, `union`, `subset`, etc...
- [x] **Other:** Binomial `binom(n, k)` ...
- **Custom Math (in typst file):**
- [x] **Define Accents:** `#let acc(x) = math.accent(x, math.grave)`
- [x] **Define Operators:** `#let add = math.op("add")`
- [x] **Define Symbols:** `#let xy = math.italic("xy")` or `#let mail = symbol("🖂", ("stamped", "🖃"),)`
- [x] **Define Functions:**
```py
# typst-calculator
@func()
def convert_add(a, b):
return a + b
```
- **Typst Math Printer:**
- [x] Complete `TypstMathPrinter` in `TypstConverter.py`
- [ ] Custom Printer for `TypstCalculator.py` and `TypstCalculatorServer.py`
- **VS Code Extension:**
- [x] Develop a VS Code Extension for `Typst Calculator`
## Install
```bash
pip install typst-sympy-calculator
```
## Usage
### Difference Between `parse`, `converter`, `calculator`, `server`
- `TypstParser.py`: parse typst math expression to ANTLR abstract syntax tree with `TypstGrammar.g4`;
- `TypstConverter.py`:
- convert typst math expression to sympy expression via `TypstMathConverter`;
- convert sympy expression to typst math expression via `TypstMathPrinter`;
- has `decorators` for defining custom functions, operators;
- has `define_accent`, `define_symbol_base` and `define_function` for defining custom accents, symbols and functions;
- `TypstCalculator.py`:
- calculate sympy expression and convert to typst math expression;
- has `subs`, `simplify`, `evalf` methods;
- has `set_variance` and `unset_variance` for calculating with variance;
- `DefaultTypstCalculator`: define many useful functions, operators, accents, symbols;
- Accents, Alphabet, Greeks, Arithmetic, Common Functions, Calculous, Linear Algebra, etc...
- `TypstCalculatorServer`:
- has `init` method for initializing `TypstCalculator` with a typst file;
- **can define your custom functions on your typst file**;
- has `simplify`, `subs`, `evalf` methods for calculating with typst file;
It is a top-down design, so you can use `TypstCalculatorServer` directly, or use `TypstCalculator` with `TypstConverter`.
**RECOMMEND: see the usage of decorators like `@func()` in [DefaultTypstCalculator.py](https://github.com/OrangeX4/typst-sympy-calculator/blob/main/DefaultTypstCalculator.py).**
For the usage, you can see the unit test part `if __name__ == '__main__':` in each files.
### Sympy Expressions and Typst Math Text
```python
from TypstCalculatorServer import TypstCalculatorServer
server = TypstCalculatorServer()
typst_math = r'1 + 1'
expr = server.sympy(typst_math)
print(server.typst(expr))
```
```python
from TypstCalculator import TypstCalculator
calculator = TypstCalculator()
typst_math = r'1 + 1'
expr = calculator.sympy(typst_math)
print(calculator.typst(expr))
```
```python
from TypstConverter import TypstMathConverter
converter = TypstMathConverter()
typst_math = r'1 + 1'
expr = converter.sympy(typst_math)
print(converter.typst(expr))
```
### Typst Calculator Server
The simplest way to use it is just like `TypstCalculatorServer.py`:
```python
from TypstCalculatorServer import TypstCalculatorServer
server = TypstCalculatorServer()
typst_file = os.path.abspath(r'./tests/test.typ')
server.init(typst_file)
server.return_text = True # otherwise just return sympy form
expr = server.simplify('1 + 1', typst_file)
print(expr) # 2
server.enable_subs = False
expr = server.simplify('a + 1', typst_file)
print(expr) # a + 1
server.enable_subs = True
expr = server.simplify('a + 1', typst_file)
print(expr) # 2
expr = server.simplify('b + 1', typst_file)
print(expr) # a + 2
expr = server.simplify('cmat(1, 2)', typst_file)
print(expr) # mat(1; 2)
expr = server.simplify('f(1) + f(1)', typst_file)
print(expr) # 2 f(1)
expr = server.simplify('xy + mail + mail.stamped', typst_file)
print(expr) # mail + mail.stamped + xy
expr = server.solve('x + y + z = 1')
print(expr) # y = -x - z + 1, z = -x - y + 1, x = -y - z + 1
expr = server.solve('cases(x + y + z = 1, x = 2)')
print(expr) # cases(x = 2, z = -y - 1), cases(y = -z - 1, x = 2), y = -x - z + 1, z = -x - y + 1
expr = server.solve('cases(x^2 + y = 4, y = 2)')
print(expr) # x = sqrt(4 - y), cases(y = 2, x = sqrt(2)), cases(y = 2, x = -sqrt(2)), x = -sqrt(4 - y)
expr = server.solve('cases(x < 2, x > 1)')
print(expr) # 1 < x and x < 2
```
and the typst files `tests/test.typ`
```typst
#import "cal.typ": *
// set variances
#let a = 1
#let b = $a + 1$
```
and `tests/cal.typ` just like:
```typst
// define accents
#let acc(x) = math.accent(x, math.grave)
// define operators
#let add = math.op("add")
#let f = math.op("f")
// define symbols
#let xy = math.italic("xy")
#let mail = symbol("🖂", ("stamped", "🖃"),)
```
### Default Typst Calculator
If you have not a typst file, you can use `DefaultTypstCalculator.py`, it define many useful functions and symbols just like:
```python
# Symbols
abc = 'abcdefghijklmnopqrstuvwxyz'
for c in abc:
calculator.define_symbol_base(c)
calculator.define_symbol_base(c.upper())
# Functions
@func()
def convert_sin(expr):
return sympy.sin(expr)
```
So you can use it by:
```python
from DefaultTypstCalculator import get_default_calculator
calculator = get_default_calculator(complex_number=True)
calculator.return_text = True
operator, relation_op, additive_op, mp_op, postfix_op, \
reduce_op, func, func_mat, constant = calculator.get_decorators()
expr = calculator.simplify('1 + 1')
assert expr == '2'
expr = calculator.evalf('1/2', n=3)
assert expr == '0.500'
calculator.set_variance('a', '1/2')
expr = calculator.simplify('a + 1')
assert expr == '3/2'
calculator.unset_variance('a')
expr = calculator.simplify('a + 1')
assert expr == 'a + 1' or expr == '1 + a'
expr = calculator.evalf('pi', n=3)
assert expr == '3.14'
expr = calculator.simplify('max(1, 2)')
assert expr == '2'
calculator.define_function('f')
expr = calculator.simplify('f(1) + f(1) - f(1)')
assert expr == 'f(1)'
expr = calculator.simplify('lim_(x -> oo) 1/x')
assert expr == '0'
```
### Variances
You can **ASSIGN** variance a value using same assignment form in typst:
```typst
#let x = 1
// Before
$ x $
// Shift + Ctrl + E
// After
$ x = 1 $
```
PS: You can use grammar like `y == x + 1` to describe the relation of equality.
If you want to see the bonding of variances, you can press `Shift + Ctrl + P`, and input `typst-sympy-calculator: Show Current variances`, then you will get data like:
```typst
y = x + 1
z = 2 x
```
### Functions
You can **DEFINE** a function using same form in typst:
```typst
#let f = math.op("f")
// Before
$ f(1) + f(1) $
// Shift + Ctrl + E
// After
$ f(1) + f(1) = 2 f(1) $
```
### Symbols
You can **DEFINE** a symbol using same form in typst:
```typst
#let xy = math.italic("xy")
#let email = symbol("🖂", ("stamped", "🖃"),)
$ xy + email + email.stamped $
```
### Accents
You can **DEFINE** a accent using same form in typst:
```typst
#let acc(x) = math.accent(x, math.grave)
$ acc(x) $
```
### Decorators for Operators
You can **DEFINE** a operator using same form in typst:
```typst
#let add = math.op("+")
'''typst-calculator
@additive_op()
def convert_add(a, b):
return a + b
'''
// Before
$ 1 add 1 $
// Shift + Ctrl + E
// After
$ 1 add 1 = 2 $
```
Or just use `'''typst-sympy-calculator` or `'''python \n # typst-calculator` to define a operator.
there are some decorators you can use:
- `@operator(type='ADDITIVE_OP', convert_ast=convert_ast, name=name, ast=False)`: Define a common operator;
- `@func()`: Define a function, receive args list;
- `@func_mat()`: Define a matrix function, receive single arg `matrix`;
- `@constant()`: Define a constant, receive no args but only return a constant value;
- `@relation_op()`: Define a relation operator, receive args `a` and `b`;
- `@additive_op()`: Define a additive operator, receive args `a` and `b`;
- `@mp_op()`: Define a multiplicative operator, receive args `a` and `b`;
- `@postfix_op()`: Define a postfix operator, receive args `a`;
- `@reduce_op()`: Define a reduce operator, receive args `expr` and `args = (symbol, sub, sup)`;
It is important that the function name MUST be `def convert_{operator_name}`, or you can use decorator arg `@func(name='operator_name')`, and the substring `_dot_` will be replaced by `.`.
There are some examples (from [DefaultTypstCalculator.py](https://github.com/OrangeX4/typst-sympy-calculator/blob/main/DefaultTypstCalculator.py)):
```python
# Functions
@func()
def convert_binom(n, k):
return sympy.binomial(n, k)
# Matrix
@func_mat()
def convert_mat(mat):
return sympy.Matrix(mat)
# Constants
@constant()
def convert_oo():
return sympy.oo
# Relation Operators
@relation_op()
def convert_eq(a, b):
return sympy.Eq(a, b)
# Additive Operators
@additive_op()
def convert_plus(a, b):
return a + b
# Mp Operators
@mp_op()
def convert_times(a, b):
return a * b
# Postfix Operators
@postfix_op()
def convert_degree(expr):
return expr / 180 * sympy.pi
# Reduces
@reduce_op()
def convert_sum(expr, args):
# symbol, sub, sup = args
return sympy.Sum(expr, args)
```
## Contributing
1. Clone it by `git clone https://github.com/OrangeX4/typst-calculator.git`
2. Install dependencies by `pip install -r requirements.txt`
3. Compile ANTLR grammar by `python ./scripts/compile.py`
4. Debug or add your code with `TypstCalculatorServer.py` or `TypstCalculator.py`, etc...
It is welcome to create an issue or pull request.
## Thanks
- [augustt198 / latex2sympy](https://github.com/augustt198/latex2sympy)
- [purdue-tlt / latex2sympy](https://github.com/purdue-tlt/latex2sympy)
- [ANTLR](https://www.antlr.org/)
- [Sympy](https://www.sympy.org/en/index.html)
## License
This project is licensed under the MIT License.
|
https://github.com/jgm/typst-hs
|
https://raw.githubusercontent.com/jgm/typst-hs/main/test/typ/compiler/label-00.typ
|
typst
|
Other
|
// Test labelled headings.
#show heading: set text(10pt)
#show heading.where(label: <intro>): underline
= Introduction <intro>
The beginning.
= Conclusion
The end.
|
https://github.com/chrischriscris/Tareas-CI5651-EM2024
|
https://raw.githubusercontent.com/chrischriscris/Tareas-CI5651-EM2024/main/tarea06/src/main.typ
|
typst
|
#import "template.typ": conf, question, pseudocode, GITFRONT_REPO
#show: doc => conf("Tarea 6: Árboles", doc)
#question[
// Pregunta 1
Considere un arreglo `A[1..N]`, representando una permutación de los números de
$1$ a $N$ .
Se desea que ejecute $N$ acciones de la forma `multiswap(a, b)`. Esta acción
consiste en:
#enum(numbering: "(a)")[
Intercambiar el valor en la posición `a` con el valor en la posición `b`.
][
Invocar `multiswap(a+1, b+1)`.
][
El proceso termina cuando `b` se sale del rango del arreglo o `a` alcanza el
primer valor de `b` utilizado.
]
A continuación se presenta una implementación en pseudo–Python para
`multiswap(a,b)`:
#pseudocode[
```python
def multiswap(A, a, b):
i, j = a, b
while i < b and j <= N:
swap(A, i, j)
i += 1
j += 1
```
]
Si $A$ inicia como la permutación identidad (números del $1$ al $N$ , de menor
a mayor) y se ejecutan $N$ operaciones `multiswap(ai, bi)` (donde los valores
para $"ai"$ y $"bi"$ vienen dados en una lista de tuplas), se desea que imprima el
arreglo resultado.
Diseñe un algoritmo que pueda ejecutar esta acción en tiempo
#underline[promedio] $O(N log(N))$, usando memoria adicional $O(N)$.
*Pista*:
Una estructura de datos que permita _dividir_ o _reunir_ subarreglos eficientemente con una
_alta probabilidad_, puede llevar al camino del bien.
][
Analizando el problema, notamos que podemos expresar el resultado de
`multiswap(a, b)` según dos casos como:
- Si $b-a <= N+1-b$ (la parada se da porque `a` alcanza el primer valor de `b`):
`multiswap(a, b)` = $A[1..a) + A[b..2b-a) + A[a..b) + A[2b-a..N]$. Es decir,
se intercambia $A[a..b)$ con $A[b..2b-a)$ y se deja el resto igual.
- En caso contrario (la parada se da porque `b` se sale del rango del arreglo):
`multiswap(a, b)` = $A[1..a) + A[b..N] + A(a+N-b..b) + A[a..a+N-b]$. Esta
vez se intercambia $A[a..a+N-b]$ con $A[b..N]$ y se deja el resto igual.
Donde el operador $+$ representa la concatenación de arreglos.
De esta forma, el problema consiste en hallar una forma de intercambiar dos
subarreglos de rangos disjuntos en tiempo promedio $O(log(N))$, con lo cual
lograríamos el objetivo de hacer $N$ operaciones en tiempo promedio $O(N log(N))$.
Así, la idea consiste en construir un treap implícito en base a la
permutación identidad (que en el caso promedio se encontrará aproximadamente
balanceado) y nos permitirá hacer las operaciones de `split` y `merge` en
tiempo promedio $O(log(N))$. Un pseudocódigo para el programa que resuelve el
problema es el siguiente:
#pseudocode[
```python
def multi_multiswap(A: Lista[Entero], swaps: Lista[Tupla[Entero, Entero]]):
t = construir_treap(A)
for swap in swaps:
t = multiswap(t, swap.a, swap.b)
imprimir_inorden(t)
def multiswap(t: Treap, a: Entero, b: Entero) -> Treap:
if t is None:
return
n = t.tamaño()
if b - a <= n - b + 1:
sub1, r1 = t.dividir(a - 1)
sub2, r2 = r1.dividir(b - a)
sub3, sub4 = r2.dividir(b - a)
return t.mezclar(sub1, sub3, sub2, sub4)
sub1, r1 = t.dividir(a - 1)
sub2, r2 = r1.dividir(n - b + 1)
sub3, sub4 = r2.dividir(2 * b - n - a - 1)
return t.mezclar(sub1, sub3, sub2, sub4)
```
]
La construcción de un treap implícito toma memoria adicional $O(N)$, ya que
por cada nodo se almacenan una cantidad constante de campos, y tiempo
$O(N log(N))$ en el caso promedio. Luego, cada operación `multiswap` hace una
cantidad constante de operaciones que en promedio toman tiempo $O(log(N))$,
por lo que el tiempo total de ejecución es $O(N log(N))$ en el caso promedio.
Una implementación de este algoritmo en Lua se puede encontrar
#link(GITFRONT_REPO + "tarea6/ej1/")[aquí].
][
// Pregunta 2
Sea $A = (N, C)$ un árbol (notemos que $|C| = |N| − 1$) y un predicado
$p : C → {"true", "false"}$. Queremos responder consultas que pueden tener una
de dos formas:
- $"forall"(x, y)$, para $x, y in N$, que diga si evaluar $p$ para _todas_ las
conexiones entre entre los nodos $x$ e $y$ resulta en $"true"$.
- $"exists"(x, y)$, para $x, y in N$, que diga si evaluar $p$ para _alguna_ de
las conexiones entre entre los nodos $x$ e $y$ resulta en $"true"$.
Diseñe un algoritmo que pueda responder $Q$ consultas de cualquiera de estas
formas en tiempo $O(|N| + Q log |N|)$, usando memoria adicional $O(|N|)$.
*Pista*:
Realice un precondicionamiento adecuado en $O(|N|)$, que le permita responder
cada consulta en $O(log |N|)$.
][
Podemos resolver el problema aplicando la descomposición Heavy–Light, la idea
es la siguiente:
- Se obtiene una descomposición Heavy–Light del árbol $A$.
- Se construye un árbol de segmentos para las aristas $c$ de cada cadena pesada,
tomando como valores de las aristas el valor de $p(c)$.
- Cada árbol de segmentos contendrá un campo para responder consultas de tipo
$"forall"$ y otro para consultas de tipo $"exists"$, en los que se acumulan los
valores de los hijos con un $and$ y un $or$ respectivamente.
- Por cada consulta se realiza el procedimiento usual: se halla el ancestro
común más bajo de $x$ y $y$, se descompone el camino entre $x$ y el ancestro
común más bajo en cadenas pesadas y se responde la consulta con los valores
acumulados en los árboles de segmentos correspondientes.
Veamos que para el precondicionamiento se obtiene una descomposición Heavy–Light
en tiempo y memoria $O(|N|)$, y otro con el mismo requerimiento asintótico de
tiempo y memoria para hallar el ancestro común más bajo de cualesquiera dos
nodos. Luego, por cada consulta se halla el ancestro común más bajo en tiempo
$O(log |N|)$ y se responde la consulta en tiempo $O(log |N|)$, por lo que el
tiempo total de ejecución para responder $Q$ consultas es $O(|N| + Q log |N|)$.
Una implementación parcial de este algoritmo en Swift se puede encontrar
#link(GITFRONT_REPO + "tarea6/ej2/")[aquí].
][
// Pregunta 3
Considere un arreglo `A[1..N]`, representando una permutación de los números
de $1$ a $N$.
Se desea que responda $Q$ consultas de la forma `seleccion(i, j, k)`. Esta
consulta pide calcular el $k$–ésimo elemento del subarreglo `A[i..j]`, si ese
subarreglo estuviera ordenado.
Tomemos, por ejemplo, `A = [2,6,3,1,8,4,7,9,5]`:
- Al hacer `consulta(2,5,3)`, se refiere al subarreglo comprendido entre las
posiciones $2$ y $5$; es decir: `[6,3,1,4]`. Si ordenáramos este sub–arreglo,
el resultado sería `[1,3,4,6]` y el tercero (3–ésimo elemento) sería 4.
- Al hacer `consulta(3,7,1)`, se refiere al subarreglo comprendido entre las
posiciones $3$ y $7$; es decir: `[3,1,8,4,7]`. Si ordenáramos este sub–arreglo,
el resultado sería `[1,3,4,7,8]` y el primero (1–ésimo elemento) sería 1.
- Al hacer `consulta(1,9,5)`, se refiere al subarreglo comprendido entre las
posiciones $1$ y $9$; es decir: `[2,6,3,1,8,4,7,9,5]`. Si ordenáramos este
sub–arreglo, el resultado sería `[1,2,3,4,5,6,7,8,9]` y el quinto (5–ésimo
elemento) sería 5.
Se desea que diseñe un algoritmo que pueda responder todas las consultas usando
tiempo $O((N + Q) log N)$ y memoria $O(N log N)$.
*Pistas*:
- Consideremos un arreglo de ocurrencias, donde la i–ésima posición representa
la ocurrencia del valor i (1 si está y 0 si no está). Consideremos el mismo
subarreglo del primer ejemplo: `[6,3,1,4]`. Su arreglo de ocurrencias sería
`[1, 0, 1, 1, 0, 1, 0, 0, 0]`.
- En el arreglo de ocurrencias anterior, ¿cuántas veces aparecen los números
del 2 al 5? O, en general, ¿cuántas veces apareces los números del i al j? ¿Hay
alguna estructura que permita responder este tipo de consultas _eficientemente_?
- En algún momento hablamos sobre arreglos cumulativos para resolver consultas
estilo `suma(i, j)`. Una idea en particular, que usamos ahí, podría ser de
utilidad.
- Cuando sientan que el problema se vuelve muy difícil, sean _persistentes_.
- El tiempo y el espacio son uno.
][
501 Not Implemented.
]
|
|
https://github.com/wj461/operating-system-personal
|
https://raw.githubusercontent.com/wj461/operating-system-personal/main/HW4/document.typ
|
typst
|
#align(center, text(17pt)[
*Operating-system homework\#3*
])
#(text(14pt)[
= Programming problems
])
Kernel: 6.8.1-arch1-1\
gcc (GCC) 13.2.1
== 10.44
#image("./img/10.png")
== 11.27
#image("./img/11.png")
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.