
repo
stringlengths 26
115
| file
stringlengths 54
212
| language
stringclasses 2
values | license
stringclasses 16
values | content
stringlengths 19
1.07M
|
|---|---|---|---|---|
https://github.com/bqdong/typst-drawing
|
https://raw.githubusercontent.com/bqdong/typst-drawing/main/blackboard.typ
|
typst
|
// Inspired by https://github.com/kmaed/kmbeamer
#let colors = (
gray33: rgb("#333333"),
midnightblue: rgb("#00152D"),
navyblue: rgb("#1F2F54"),
ultramarine: rgb("#4B64A1"),
water: rgb("#A9CEEC"),
sepia: rgb("#4A3B2A"),
brown: rgb("#763900"),
goldbrown: rgb("#C47600"),
satsuma: rgb("#FA8000"),
snow: rgb("#F1F1F1"),
whiteee: rgb("#EEEEEC"),
midyellow: rgb("#FAD43A"),
lemonchiffon: rgb("#FFFACD"),
gold: rgb("#FFD700"),
concrete: rgb("#F3F3F3"),
denim: rgb("#1776C7"),
tamarillo: rgb("#A31515"),
jellybean: rgb("#247690"),
deepgreen: rgb("#005731"),
bottlegreen: rgb("#264435"),
tokiwa: rgb("#357C4C"),
indigo: rgb("#234794"),
chartreuse: rgb("#7FFF00"),
kerria: rgb("#FFA500"),
vermilion: rgb("#ED514E"),
madder: rgb("#B22D35"),
maroon: rgb("#682A2B"),
tomato: rgb("#FF6347")
)
#set page(
width: 128mm,
height: 96mm,
margin: 0pt,
background: [
#grid(
rows: (2mm,) * 48,
columns: (2mm,) * 64,
fill: colors.at("bottlegreen"),
stroke: (paint: colors.at("bottlegreen").darken(10%), thickness: 0.2mm)
)
]
)
// outer
#let outer-tl = (0mm, 0mm)
#let outer-tr = (128mm, 0mm)
#let outer-bl = (0mm, 96mm)
#let outer-br = (128mm, 96mm)
// middle
#let mid-tl-1 = (1mm, 1mm)
#let mid-tr-1 = (127mm, 1mm)
#let mid-bl-1 = (1mm, 95mm)
#let mid-br-1 = (127mm, 95mm)
// middle
#let mid-tl-2 = (3mm, 3mm)
#let mid-tr-2 = (125mm, 3mm)
#let mid-bl-2 = (3mm, 93mm)
#let mid-br-2 = (125mm, 93mm)
// inner
#let inner-tl = (4mm, 4mm)
#let inner-tr = (124mm, 4mm)
#let inner-bl = (4mm, 92mm)
#let inner-br = (124mm, 92mm)
// outer
#path(
fill: colors.at("kerria"),
outer-tl,
outer-tr,
mid-tr-1,
mid-tl-1,
mid-bl-1,
outer-bl
)
#place(
top + left,
dx: 0mm,
dy: 0mm
)[
#path(
fill: colors.at("brown"),
outer-bl,
mid-bl-1,
mid-br-1,
mid-tr-1,
outer-tr,
outer-br
)
]
// middle
#place(
top + left,
)[
#path(
fill: colors.at("goldbrown"),
mid-tl-1,
mid-tr-1,
mid-tr-2,
mid-tl-2,
mid-bl-2,
mid-bl-1
)
]
#place(
top + left,
)[
#path(
fill: colors.at("goldbrown"),
mid-bl-1,
mid-bl-2,
mid-br-2,
mid-tr-2,
mid-tr-1,
mid-br-1
)
]
// outer
#place(
top + left
)[
#path(
fill: colors.at("brown"),
mid-tl-2,
mid-tr-2,
inner-tr,
inner-tl,
inner-bl,
mid-bl-2
)
]
#place(
top + left,
)[
#path(
fill: colors.at("kerria"),
mid-bl-2,
inner-bl,
inner-br,
inner-tr,
mid-tr-2,
mid-br-2
)
]
|
|
https://github.com/Shadow-Song/CV
|
https://raw.githubusercontent.com/Shadow-Song/CV/main/CV%20-%20ch_CN/resume.typ
|
typst
|
#import "template.typ": *
// 设置图标, 来源: https://fontawesome.com/icons/
// 如果要修改图标颜色, 请手动修改 svg 文件中的 fill="rgb(38, 38, 125)" 属性
// 例如可以使用 VS Code 的全局文本替换功能
#let faAward = icon("icons/fa-award.svg")
#let faBuildingColumns = icon("icons/fa-building-columns.svg")
#let faCode = icon("icons/fa-code.svg")
#let faEnvelope = icon("icons/fa-envelope.svg")
#let faGithub = icon("icons/fa-github.svg")
#let faGraduationCap = icon("icons/fa-graduation-cap.svg")
#let faLinux = icon("icons/fa-linux.svg")
#let faPhone = icon("icons/fa-phone.svg")
#let faWindows = icon("icons/fa-windows.svg")
#let faWrench = icon("icons/fa-wrench.svg")
#let faWork = icon("icons/fa-work.svg")
// 主题颜色
#let themeColor = rgb(38, 38, 125)
// 设置简历选项与头部
#show: resume.with(
// 字体基准大小
size: 10pt,
// 标题颜色
themeColor: themeColor,
// 控制纸张的边距
top: 1.5cm,
bottom: 2cm,
left: 2cm,
right: 2cm,
// 如果需要姓名及联系信息居中,请删除下面关于头像的三行参数,并取消headerCenter的注释
//headerCenter : true,
// 如果不需要头像,则将下面三行的参数注释或删除
photograph: "Avatar.jpg",
photographWidth: 8em,
gutterWidth: 2em,
)[
= 鹿逸远
#info(
color: themeColor,
(
// 其实 icon 也可以直接填字符串, 如 "fa-phone.svg"
icon: faPhone,
content: "(+86) 151-6950-7851"
),
(
icon: faBuildingColumns,
content: "中国海洋大学",
),
(
icon: faGraduationCap,
content: "计算机科学与技术",
),
(
icon: faEnvelope,
content: "<EMAIL>",
link: "mailto:<EMAIL>"
),
(
icon: faGithub,
content: "github.com/Shadow-Song",
link: "https://github.com/Shadow-Song",
),
)
][
#h(2em) // 手动顶行, 2em 代表两个字的宽度
本人是一名2021级的本科生,目前就读于中国海洋大学计算机科学与技术专业。我最擅长的技术栈是iOS原生开发,能够熟练地使用SwiftUI、Moya与SwiftyJSON等框架。因此我希望能够在贵公司的iOS开发部门实习,提升自己的技术水平,同时为公司的发展贡献力量。
]
== #faGraduationCap 教育背景
#sidebar(withLine: true, sideWidth: 12%)[
21.09 - 24.06
24.09 - 25.06
][
*中国海洋大学* · 计算机技术学院 · 计算机科学与技术(中外合作办学)
*赫瑞-瓦特大学* · 数学与计算机科学学院 · 机器人工程学
]
== #faWrench 专业技能
#sidebar(withLine: false, sideWidth: 12%)[
*操作系统*
*掌握*
*熟悉*
*了解*
*英语*
][
Linux, MacOS
Swift, Python, C, Java, ARM汇编
SwiftUI, FastAPI, Flask, MySQL, Linux
OpenCV, 深度学习
IELTS 6.0 (听力5.5,口语6.0,阅读5.5,写作6.0)
]
== #faAward 获奖情况
#item(
[ *2023全国大学生挑战者杯* ],
[ *全国三等奖* ],
date[ 2023 年 12 月 ]
)
#item(
[ *2024美国大学生数学建模竞赛* ],
[ *S奖* ],
date[ 2024 年 05 月 ]
)
#item(
[ *2023中国海洋大学奖学金* ],
[ *创新创业奖学金* ],
date[ 2023 年 10 月 ]
)
== #faCode 项目经历
#item(
link(
"https://github.com/Shadow-Song/Canvas",
[ *Ocean BB Lite* ]
),
[ *个人项目* ],
date[ 2023年 12 月 - 2024 年 6 月 ]
)
#tech[ _iOS原生开发, SwiftUI, FastAPI, MySQL_ ]
为中国海洋大学本科生设计,对接学校Blackboard平台,提供作业查询,待办事项,提交作业等功能。
- 使用Moya和SwiftyJSON对Blackboard API进行封装,实现了对学校Blackboard平台的访问
- 使用SwiftUI构建页面
- 使用FastAPI与MySQL搭建后端,实现作业提醒功能。
- 从前后端实现到备案、上架App Store,完全由个人完成。
#item(
link(
"https://github.com/Shadow-Song/RoboFinalProject",
[ *基于树莓派4B的机器小车* ]
),
[ *课程项目* ],
date[ 2023 年 09 月 – 2024 年 1 月 ]
)
#tech[ _Python, Linux, OpenCV, GPIO_ ]
基于树莓派4B的机器小车,实现了自动寻迹,避障,遥控等功能。
- 使用OpenCV进行图像处理,实现了自动寻迹功能
- 使用Python控制GPIO以及连接的传感器与电机,实现了避障功能
- 使用蓝牙与PyGame库连接DualShock 4手柄,实现了遥控功能
#item(
link(
"https://github.com/Shadow-Song/VisionRobot",
[ *基于Jetson Nano的机械臂* ]
),
[ *课程项目* ],
date[ 2024 年 02 月 – 2024 年 06 月 ]
)
#tech[ _Python, Linux, YoloV5, Dji-RoboMaster_ ]
基于Jetson Nano的机械臂,实现了自动抓取,识别不同颜色的易拉罐等功能。
- 使用自己的数据集训练YoloV5模型,实现了识别不同颜色的易拉罐
- 使用Python控制机械臂,实现了自动抓取并放置在不同位置的功能
- 使用Python控制Dji-RoboMaster,实现了定点移动的功能
== #faBuildingColumns 校园经历
#item(
[ *iOS Club 技术负责人* ],
[],
date[ 2022 年 09 月 – 2024 年 09 月 ]
)
在没有老师教授相关知识的情况下,自学iOS开发与SwiftUI,组织了多次线上活动,帮助同学学习iOS开发。帮助社团构建了iOS的知识体系,为新成立的iOS Club产出了第一个项目。
#item(
[ *班长* ],
[],
date[ 2022 年 09 月 – 至今 ]
)
负责班级日常事务,组织班级活动,维护班级风气。
|
|
https://github.com/NathanBurgessDev/tabletop-war-game-helper
|
https://raw.githubusercontent.com/NathanBurgessDev/tabletop-war-game-helper/main/Dissertation/20363169_dissertation.typ
|
typst
|
#import "interimTemplate.typ": *
#show: diss-title.with(
title: "Tabletop War Game Assistant",
author: "<NAME>",
ID: "20363169",
email: "psynb7",
programme: "BSc Hons Computer Science",
module: "COMP3003",
)
#let todo(body) = [
#let rblock = block.with(stroke: red, radius: 0.5em, fill: red.lighten(80%))
#let top-left = place.with(top + left, dx: 1em, dy: -0.35em)
#block(inset: (top: 0.35em), {
rblock(width: 100%, inset: 1em, body)
top-left(rblock(fill: white, outset: 0.25em, text(fill: red)[*TODO*]))
})
<todo>
]
#pagebreak()
#outline(title: "Table of Contents",depth: 3, indent: auto)
#set page(numbering: "1",number-align: center)
#counter(page).update(1)
// Number all headings
#set heading(numbering: "1.1.")
// Tweak space above and below headings
#show heading: set block(above: 2em, below: 1.3em)
// Justified paragraphs
#set par(justify: true)
#pagebreak()
#import "@preview/wordometer:0.1.1": word-count, total-words
#show: word-count
= Abstract
This project aims to create a computer vision based tracking system for physical tabletop miniatures for an example wargaming system. As wargaming rules are quite complex, the system will also aim to create a viable representation of certain rules to aid the players. This involves the creation of custom tags to track miniatures aimed to handle occlusion, provide accurate information whilst also not requiring external hardware.
= Introduction and Project Intention
Tabletop war-gaming is a popular hobby which has recently seen a surge in popularity during the COVID-19 pandemic, however, with a high barrier to entry, it remains niche and inaccessible to many. The rules to tabletop war-games can be complex and difficult to learn. This can be daunting for new players, putting them off the hobby as well as causing disagreement between seasoned players over rules interpretations.
Some of the most popular war-gaming systems are produced by Games Workshop @gw-size. One of their more popular systems, Warhammer 40k, has a core rule-book of 60 pages @40k-rules and the simplified version of another game system, Kill Team, is a rather dense three page spread @kt-lite-rules. This complexity can be off putting to new players. Many tabletop / board games suffer from a player's first few games taking significantly longer than is advertised due to needing to constantly check the rules.
As well as this, new players are likely to take longer to make decisions as they are not familiar with the game's mechanics of what constitutes a "good" move #footnote("sometimes referred to as 'analysis paralysis'") . This can be exacerbated by the game's reliance on dice rolls to determine the outcome of actions. Meaning that seemingly "optimal" moves do not always result in favourable outcomes, causing an extended learning period for an already complex game.
Kill Team is a miniature war-game known as a "skirmish" game. This means the game is played on a smaller scale with only \~20 miniatures on the table at one time. The aim of the game is to compete over objectives on the board for points. Each player takes turns activating a miniature and performing actions with it. The game uses dice to determine the results of your models engaging in combat with each other with the required rolls being determined by the statistics of each "operative" (a miniature) involved and the terrain.
#figure(
image("images/gallowdark.jpg", width:80%),
caption:([An example of the Kill Team tabletop game using the Gallowdark terrain. The terrain we will focus on here are the flat walls and pillars. @gallowdark-image])
) <gallowdark-terrain>
Video games help on-board new players by having the rules enforced by the game itself. For example, a digital chess game will tell you when you are in check. A physical chess game requires players to recognise when they are in check themselves. This project aims to bring a similar methodology to tabletop war-gaming, specifically the Kill Team Lite @kt-lite-rules system using the Gallowdark setting. The Kill Team Lite rules are publicly available from Games Workshop's website and are designed to be played on a smaller scale to other war games, making it a good candidate for a proof of concept. As well as this, the Gallowdark @gallowdark setting streamlines the terrain used and removes verticality from the game, making implementation much simpler.
Developing a system that can digitally represent a physical Kill Team board would allow for the creation of tools to assist players. For example, a digital game helper would remove the burden of rules enforcement from the players and onto the system, allowing players to focus on the game itself or allow players to make more informed game decisions by being able to preview the options available to them. This could also be utilised to record a game and view a replay or be used for content creation to make accurate board representations to viewers with digital effects.
This project will focus on the development of a system that can track the position of miniature models and terrain pieces on a Kill Team board which can subsequently be displayed digitally. From here, we aim to implement proof of concept visualisation of a few select game rules on the digital board to demonstrate that the tracking system provides the necessary information to process said rules.
= Background
To determine the specific goals for this project, it is important to provide some more context on the gameplay and community surrounding Kill Team. As this is a very complex game, we will be omitting a large percentage of the rules, focusing on the topics that will have an impact on the overall design or provide unique challenges.
== game board Components
Before looking at the game rules, we will first break down the physical components of the game board to determine what needs to be tracked and problems that may arise from this.
A game of Kill Team is composed of two players, each with a group of "operatives" (miniatures) referred to as a "Kill Team". Each Kill Team has its own unique rules, with each operative having its own set of unique statistics and special abilities. A miniature is composed of a circular base with a model placed on top. The diameter of the base is either 25mm, 28.5mm, 32mm, 40mm or occasionally 50mm.
#figure(
image("images/kasrkinExample.jpg", width:50%),
caption:[An example of a Kasrkin Kill Team operative on a 28.5mm base @kasrkin-image. The height of the operative is \~35mm excluding the base. This project will focus on getting the system functional with the Kasrkin models on 28.5mm bases.]
) <Kasrkin-Example-Figure>
It is worth noting that it is common for models to extend past the edge of their base as seen in @Kasrkin-Example-Figure. Whilst the example above is somewhat minor in its overlap, different models can be more extreme in their extension. As a result of this the system will need to be able to locate and identify an operative from only a partial view of the base, or its surroundings, from a bird's eye view. The detection system will either need to be above the board if using visual detection methods or below the board if using, for example, an RFID method. This is due to the terrain potentially surrounding an operative, so having a camera on each side of the board will not guarantee it is visible as can be seen in @gallowdark-terrain.
The game is played on a 30" by 22" board, referred to as a "Killzone". The Gallowdark ruleset instead uses a 27" by 24" board with the specialised terrain shown in @gallowdark-terrain. As stated previously, the terrain we are focusing on here are the thin walls with pillars connecting them. The terrain is all at the same height, but the operatives are shorter than the terrain. As a result, the system will need to find a solution to detect operatives behind terrain. From a birds eye view, the terrain will block part of the operative due to parallax. For this project, we will focus on using a half sized board to simplify this problem.
#figure(
image("images/parallaxDiagram.svg", width:40%),
caption:[An example of the problem introduced by parallax. The camera is placed above the board offset from the operative. The operative is partially obstructed by terrain. The green triangle represents the parts visible to the camera. The red lines demonstrate the areas blocked by the terrain.]
)<parallax-diagram>
The further away the camera is from the operative on the x axis, the more the terrain will block the operative. However, as the camera travels away on the y axis, the terrain will block less of the operative. For a camera implementation this would also mean we lose quality in the image. As a result, a camera based system would need to find an ideal distance from the board which provides enough quality in the image, whilst also being able to see enough of an operative if it is obscured by terrain.
== Gameplay
The gameplay of Kill Team focuses around a turn based system with a full game consisting of 4 rounds - called "turning points". Each player takes turns "activating" a single operative and performing actions with it. The number of actions available to an operative is defined by it's statistics #footnote("There are a lot of exceptions to this with abilities being able to modify the stats of themselves or other operatives, but for the sake of simplicity we are going to ignore this and assume stats are set."). Once an operative has performed it's maximum number of actions, play is handed to the other player. That same operative may not be "activated" until every other operative, still in play, on their team has been activated. Once every operative on both teams has been activated the next turning point begins resetting the activation of each operative still in play. Once all 4 turning points have been completed the game ends and a winner is decided.
This project is focussed on creating a digital representation of the board, and then implementing a few select rules from the game to demonstrate the system's capabilities. The rules for "movement" and "shooting" present themselves as good candidates for this due to both their complexity and frequency within the game.
Please note that the explanations for these rules are abstracted from the Kill Team Lite rules published publicly by Games Workshop @kt-lite-rules.
// ==== Movement
// There are two types of movement available: "normal move" and "dash". A normal move allows an operative to move a set distance as defined in it's statistics (typically this is 6"). A dash allows an operative to only move 3". Movement has several restrictions attatched.
// #set enum(numbering: "1.a.")
// + Movement must not exceed the operative's movement characteristic.
// + Movement must be made in straight line increments. This means no curves but diagonals are fine.
// + Increments can be less than 1" but are still treated as 1" for the purpose of total movement.
// + An operative cannot move through terrain unless it is a "small obstacle" (such as a barricade) #footnote("We will not be encountering small obstacles in this implementation.")
// + An operative may not move over the edge of the board or through any part of another operative's base.
// + An operative CAN perform a normal move and dash in the same turn.
// + An operative CAN perform a normal move OR dash and then perform a "shoot" action.
// This is quite a complex set of rules to enforce, making movement a good candidate for the system to assist with.
=== Shooting and Line of Sight
Operatives can be set to two states: "concealed" or "engaged". These states are used to determine whether an operative is a valid target or whether it is able to make offensive actions, such as shooting. An operative's state is denoted by a small triangle of orange card pointing to the model. The system will need a way to track the state of an operative, whether this be through detecting the orange markers or manually updating the state.
Anecdotally, the Kill Team line of sight rules tend to be the most complex part of the game and are constructed in such a way that experienced players can abuse them to gain an advantage such as one way shooting#footnote("This is a technique used to allow an attacker to be able to select a valid target but the defender is unable to fire back.").
#figure(
image("images/orders.jpg",width:35%),
caption: [An example of the markers used to denote the state of an operative @order-image. The board will need to be able to mark operatives as appropriate and display this to the user.]
)
There are a set of requirements that must be met to determine whether an operative is able to be targeted by a shooting attack.
We will use *attacker* to refer to the operative making the attack and *defender* to refer to the intended target.
For a defender in the engaged state:
+ The defender must be *visible*.
+ The defender must be not *obscured*.
For a defender in the concealed state:
+ The defender must be *visible*.
+ The defender must be not *obscured*.
+ The defender must be not *in cover*.
Kill Team defines *visible*, *obscured* and *in cover* very strictly. This is done using *cover / visibility lines* which are straight lines 1mm wide drawn from one point on an operative to another operative.
*Visible* is used to simulate whether a defender can be physically seen by an attacker
For a defender to be (visible) the following must be true:
+ A visibility line can be drawn from the head of the attacker to any part of the defender's *model*, not including the base.
*Obscured* is used to simulate whether a defender is blocked by large terrain, such as a wall, while also containing edge cases for operatives peeking round said terrain or attempting to use it directly as cover.
When drawing cover lines the attacker picks one point on their base and draws two cover lines from that point to every point on the defenders base, to create a cone. In practice this means drawing two cover lines to the extremes of the defender's base.
#figure(
image("images/killTeamCover.png", width:60%),
caption: [An example of cover lines @kt-lite-rules.]
)
For a defender to be *obscured* the following must be true:
+ The defender is >2" from a point where a cover line crosses a terrain feature which is considered obscuring#footnote("For our use case the terrain walls in Gallowdark are all considered obscuring terrain.").
+ If the attacker is \<1" from a point in which a cover line crosses a terrain feature, then that part of the feature is not obscuring.
*In cover* simulates whether an operative is attempting to intentionally take cover behind a piece of terrain. A concealed operative is hiding behind the terrain whereas an engaged operative is poking around / over it.
For a defender to be *in cover* the following must be true:
+ The defender is >2" from the attacker
+ The defender is \<1" from a point where a cover line crosses a terrain feature.
=== Key Takeaways
The above rules outline what information the system will need to be able to track and display to the user. It also highlights the complexity of the rules to justify the reasonings behind this project.
+ It is important to know the positions of operatives and terrain.
+ The system will need to be able to know the size of an operative's base.
+ Rotation of operatives is not needed to be tracked (except for visiblity when determining *visible*).
+ Operatives need to be marked as concealed or engaged.
+ Accuracy is important to the system. Visibility / cover lines being 1mm wide and distances measured in inches will require accurate measurements.
+ The system will need to abstract the above rules whilst also being able to display the reasoning behind the application. For example, if a defender is obscured the system should show what is obscuring and from what point the firing cone was drawn.
== Community
Tabletop wargames require you to build and paint your own miniatures, because of this the target audience tends to be more of the creative type. Using this information we can allow some liberty in what they might need to do to utilise this system. For example, creating homemade tags is something that creatives might be more inclined to do as opposed to something more technical using RFID or infrared sensors. The whole system should be designed to be as accessible as possible to the target audience, requiring little to no specialised equipment.
The miniatures are also not defined in their appearance. They can be painted in any scheme, be customised to have completely different looks or use entirely different models than what is intended#footnote("Known as proxying."). This means the tracking system needs to be ambivalent of what the model looks like, both in colour and silhouette.
Since miniatures are highly customisable players tend to be very attached to them. So one important requirement is to not be invasive to the miniature. This rules out requiring a certain paint job, placing stickers on heads or putting QR codes above operatives. The system should aim to obscure models as little as possible and cause no damage.
= Related Work
== Previous Mixed Reality Tabletop Systems
Some companies, such as The Last Game Board @last-game-board and Teburu @teburu, sell specialist game boards to provide a mixed reality experience.
The Last Game Board achieves this through utilising the touch screen to recognise specific shapes on the bottom of miniatures to determine location and identity. The Last game board is 17" x 17", as a result the number of game systems which are compatible is limited. However, you can connect multiple systems together. The drawback of this is the price point for the system is rather high, with boards starting at \~\$350. It is also worth noting that this system has not received great reviews, with alpha users reporting: long load times, low FPS, graphical and sound glitches, lack of updates and even screens refusing to display half the screen for certain applications.
#figure(
image("images/theLastGameBoard.png", width:70%),
caption: [The Last Game Board touchscreen tabletop system @last-game-board])
Teburu @teburu instead takes an RFID based approach, providing a base mat that allows you to connect squares containing RFID receivers and game pieces containing an RFID chip. Teburu connects to a tablet device to provide the digital experience as well as to multiple devices for individual player information. Teburu games allow for game pieces to either be in predetermined positions or within a vague area i.e. within a room.
#figure(
image("images/teburu.jpg", width:80%),
caption:([The Teburu Game System @teburu-video showcasing The Bad Karmas board game. The black board is the main game board. The squares above connect to the board below to transmit the RFID reader information back to the system for display.])
)
An RFID based approach is also used in "An RFID-based Infrastructure for Automatically Deter-
mining the Position and Orientation of Game Objects in Tabletop Games" (#cite(<rfid-based>,form:"prose")) which places an antenna grid below the game board to detect RFID chips within models. This allowed them to find what chip is in range of what antenna, allowing them to find the general location of a game piece. This worked particularly well for larger models where you could put RFID chips far away from each-other on the model. Using the known positions of the chips and dimensions of the model combined with which antenna said chips are in range of, allows you to determine an accurate position of each model. They also go into alternate RFID approaches which will be discussed later when outlining the chosen methodology.
// INSERT IMAGE
#figure(
grid(
columns: 2,
image("images/rfid-plane.png",width:80%),
image("images/rfid-software.png",width:80%)),
caption: "An example of <NAME> and <NAME>'s approach depicting the antenna grid, RFID tags and physical model alongside the computer's prediction of the model's position"
)
Surfacescapes @surfacescapes is a system developed in 2009 by a group of masters students at Carnegie Mellon as a university project. Surfacescapes uses a Microsoft Surface Tabletop (the product line was rebranded to PixelSense in 2011). This uses a rear projection display, and 5 near IR cameras behind the screen @pixelsense-specs. This allows the PixelSense to identify fingers, tags, and blobs touching the screen using the near IR image. Surfacescapes utilises this tag sensing technology to track game pieces using identifiable tags on the bases of miniatures.
#figure(
image("images/surfacescapes.jpg",width:80%),
caption:([An example of surfacescapes' in use on the Microsoft Surface Tabletop @surfacescapes-images. The position of the models have been tracked by the system and outlined with a green circle.])
)
Foundry Virtual Tabletop @foundry is an application used to create fully digital Dungeons and Dragons tabletops. These can either be used for remote play or in person play using a horizontal TV as a game board. Foundry VTT allows for the creation of modules to add new functionality to your virtual tabletop. One such module is the Material Plane @material-plane module which allows the tracking of physical miniatures on a TV game board. This functions by placing each miniature on a base containing an IR LED with an IR sensor then placed above the board. This can be configured to either move the closest "virtual" model to where the IR LED is or (with some internal electronics in the bases) can be set up to flash the IR LED in a pattern to attach different bases to specific models. An indicator LED is present to show when the IR LED is active.
#figure(
image("images/foundry.jpg",width:40%),
caption:([An example of one of the Material Plane bases. A miniature would be attached to the top. @material-plane-github.])
)
== Object Detection and Tracking Technologies
Finding a method to detect and find the positions of miniatures on a game board, whilst not obstructing the game, is the main focus of this project. This section will outline the different technological approaches that could be taken to achieve this.
=== RFID
An RFID based approach appeared to be a good solution initially. This would involve embedding RFID chips underneath the bases of the miniatures. Then some method of reading these chips would then need to be embedded either within or underneath the game board. There are a number of different approaches that could be taken to locating RFID chips which have been outlined by <NAME> and <NAME> @rfid-based in their work on a similar project.
RFID solutions would require either an antenna grid underneath the game board or multiple individual RFID readers. This would be a viable option as hiding an antenna grid below a board is a relatively simple and unobstructive task. The same goes for hiding RFID readers beneath a table.
The main drawback of RFID is that a reader (at its core) can only detect if a chip is in range or not (referred to as "absence and presence" results). Due to this, some extra methodology would need to be implemented to determine the position of a chip.
One approach utilises increasing the range of an RFID reader to its maximum and then subsequently reducing the range repeatedly. Using the known ranges of the readers it would be possible to deduce which tags are within range of which reader - and subsequently deduce from which ranges it is detectable in the position of the RFID chip. This approach could in theory provide a reasonably accurate position of the RFID chip. However, this approach would take a longtime to update as each RFID reader would need to perform several read cycles. Combined with problems caused from interference between the chips / readers, the fact that being able to vary the signal strength of an RFID reader is not a common feature and the need for multiple RFID readers, this approach does not meet the requirements for this project.
Another approach utilises measuring the signal strength received from an RFID chip and estimating the distance from the reader to the chip, known as received signal strength indication (RSSI) . This approach is much quicker than the previous method needing only a single read cycle to determine distance. Most modern day RFID readers can report RF phase upon tag reading. However, current RSSI methods have an error range of \~60cm caused by noise data, false positives / negatives and NLOS (non-line of sight) @RSSI. This won't work for this project given than the board size is 70 x 60 cm.
Trilateration is a process in which multiple receivers use the time of arrival signal from a tag to determine its position. This suffers from similar problems to other RFID methods in that it produces an area in which the tag could exist within - as opposed to its exact position. Combined with the need for 3 RFID readers, this approach fails to be accessible to the target audience.
The approach previously mentioned in <NAME> and <NAME>'s paper, which utilised an antenna grid below the game board, seemed promising.
#figure(
image("images/rfidCircle.png",width:60%),
caption:([An example from <NAME> and <NAME>'s paper @rfid-based describing their overlapping approach. The black square represents the RFID tag whilst the grey circles show the read area of each RFID reader. The intent is to use which readers are in range of the tag to determine an "area of uncertainty" of the tag's location.])
)
They were attempting to do this for Warhammer 40k, a game played on a much bigger board typically with larger models. As a result they were able to put RFID tags across larger models, such as vehicles, and utilise the known position of each tag relative to the model and the estimated position from the RFID readers to determine not only an accurate position but also orientation. Unfortunately for this project the size of the miniatures in Kill Team would require the use of one tag or two in very close proximity.
A potentially valid method utilising RFID could be to use the approach outlined by <NAME>, <NAME>, <NAME>, <NAME>, and <NAME> in their paper @rfid-tracking using first-order taylor series approximation to achieve mm level accuracy called TrackT. However, this approach is highly complex and can only track a small amount of tags at a time.
// READ THIS AND EXPLAIN
=== Machine / Deep Learning
Modern object tracking systems are often based on a machine learning or deep learning approach. In this case a classifier model would be used to identify each unique miniature on a team, and then subsequently locate it within the game board. The biggest drawback to this approach is the amount of training data needed for each class in a classifier. According to Darknet's documentation (a framework for neural-networks such as YOLO) @yolo each class should have ~2000 training images.
Since each user will use their own miniatures, posed and painted in their own way, they would have to create their own dataset for their miniatures and train the model on them each time. As a user's miniatures are likely to follow a similar paint scheme, ML classification could potentially struggle to identify between miniatures from top down and far away if not enough training data is supplied.
=== ARKit
Apple's ARKit supports the scanning and detection of 3D objects @ARKit by finding 3D spatial features on a target. Currently any phone running IOS 12 or above is capable of utilising the ARKit. In this system, you could scan in your models, then use the ARKit to detect them from above. This information could then be conveyed to the main system. This could also allow for the system to be expanded in the future to use a side-on camera as opposed to just top down detection, allowing for verticality within other Kill Team game systems. Combined with certain Apple products having an inbuilt LIDAR sensor (such as the iPhone 12+ Pro and iPad Pro 2020 - 2022), which further enhances the ARKit's detection, this could be a viable approach.
#figure(
image("images/LIDAR.png", width:80%),
caption:([Registering an an object in ARKit @ARKit])
)
After some testing utilising an iPad Pro with a LIDAR scanner, some drawbacks were found with this approach. The object detection required you to be too close to the models to detect them, and when being removed and re-added ARKit either took a long time to relocate a model or failed to do so at all.
As a result I won't be using this approach for the project. Although, for future work, this could be an interesting option to explore allowing you to implement AR features such as highlighting models on your phone or tablet or displaying information above the model.
=== Computer Vision
After considering all the options above, the best method found was using computer vision techniques.
One technique is blob detection. A blob is defined as a group of bright or dark pixels contrasting against a background. In this case the miniatures would be the blobs.
Utilising blob analysis would be good for locating the general position of miniatures (as they would very clearly stick out from the background) but getting their exact centre may then prove difficult (which would be needed for calculating movement and line of sight). Combined with the addition of terrain adding clutter to the image and the miniatures potentially being any colour, this approach could prove difficult to implement in the given time frame.
The computer vision method explored the most was utilising coloured tags to identify miniatures.
The use of coloured tags would also mean there would be access to specific measurements allowing for an accurate location to be discerned. However, some external modification to the game board or miniatures would need to be made. The challenge here is finding a way to do this without obstructing the flow of the game or the models themselves.
== Fiducial Markers and Tag Detection
A promising approach appears to be using fiducial markers. Aruco tags @arucoTags are a type of fiducial marker commonly used in robotics and computer vision. These tags are black and white squares with unique patterns in the centre. The tags are designed to be easily segmentable from the background and easily identifiable. The tags allow for pose estimation, which is the process of determining the rotation and translation of the marker in relation to the camera.
#figure(
image("images/arucoExample.jpg", width:80%),
caption: [An example of aruco tags @arucoTags.]
)
= Project Description
This project aims to create a system that can track tabletop miniatures, in a game of Kill Team Gallowdark, using only materials easily accessible to the average miniature war-gamer. Then, utilise this system to create a digital representation of the game board. This digital representation will then be used to implement a few select game rules to demonstrate the system's capabilities and show that the tracking system provides the necessary information to process said rules.
The project can be broken down into two main goals.
#set enum(numbering: "1.a.")
+ Detection of the models and terrain to create a virtual representation of the game board.
+ The position of the miniature must be tracked accurately.
+ Be able to identify between different miniatures.
+ Aim to be non-invasive to the miniatures.
+ Be ambivalent to a model's shape and colour.
+ Be able to complete this task whilst being accessible to the average miniature war-gamer. Not utilising any equipment the average wargamer would not have access to in their own home.
+ Implementing the game logic in the virtual board to guide players through the game.
+ Allow users to select a model and which action they wish to preview.
+ Calculate the distance a model can move and display this on the virtual board.
+ Account for terrain that blocks movement.
+ Calculate the line of sight between the selected model and opposing models then display this on the virtual board.
+ Account for terrain that blocks line of sight.
+ Display the reasoning behind the line of sight calculation.
+ Display whether the target is obscured or in cover.
+ Display information about the selected model's odds to hit a target.
The methodology chosen to achieve these goals must meet the takeaways from the project background section. These requirements are not included here as they are more implementation specific instead of outlining the functionality of the project.
#pagebreak()
= Methodology and Design
== Tracking Methodology
We settled on using a computer vision and tag based approach to detect the models and terrain. This would utilise placing a camera above the centre of the game board on an adjustable stand and using tags to locate the models and terrain.
This approach was chosen for a few key reasons. Firstly, it is the most accessible option to the target audience. The only components needed are a camera, a computer, a printer and some method to position a camera above a board. Unlike RFID, IR or custom table methods, the average war-gamer would have access to these components. One intention for this project is to prove this is a viable method utilising only a phone camera and a stand.
Secondly, it is the most flexible option. A tag based system does not care about the shape or colour of the models, only the tags. This requirement meant that machine learning approaches would not be as viable as the potential variation in models used is too high. If we stuck to only supporting specific, unmodified models this may potentially work, but this would place a restriction on the target audience and in a subject such as miniature wargaming where customisation is so heavily valued, this would not be a good approach. As well as this given the unique paint schemes each player may use this would mean an ML model would need to be either trained specifically for each player's kill team or be able to use a model's silhouette to identify it. Both of these approaches either require users to make their own datasets and train the model themselves, a time consuming and technical task, or require a model that can identify a model from its silhouette, a complex task that would require a lot of training data and wouldn't be that accurate due to potential model customisations.
Building on this, maintaining a unique identification for an object is a key requirement but is difficult to implement using a machine learning approach. Kill Teams can utilise multiple of the same type of operative, as a result the system would need to be able to track each "unique" operative despite having the same appearance. This becomes problematic when occlusion is introduced. If we were to move an operative and at the same time cover or move another operative of the same type, it would be difficult to differentiate which one was which. A potential solution would be to utilise similar technology to facial recognition models, particularly looking at research into identifying the differences between identical twins.
In contrast, a tag based system is ambivalent to the appearance of the model. This means the system is functional with any model, regardless of customisation which meets one of the main requirements of the project.
Finally, a tag based system will assist with accuracy. Getting the location and rotation of an aurco tag using pose estimation is a well documented process. This methodology can be applied to a tag design that will function well with miniatures and terrain.
=== Camera Setup
A camera will be placed above the centre of the game board looking downwards providing a view of the entire game board. The image will be distorted by two factors: Camera distortion and image distortion.
Camera distortion is caused by different camera designs having slightly different distortion in the images they produce due to the different lenses. This can be corrected by using a camera calibration method to produce a camera matrix and distortion coefficients which can be used to undistort resultant images. Radial distortions result in the image having straight lines appear curved. Tangential distortions result in the image appearing tilted along an axis. OpenCV provides a simple method to calibrate a camera using a chessboard pattern. This produces the camera matrix and distortion coefficients which can be saved and used to un-distort images. It is important to note that each different camera will have a different distortion so will need to be calibrated separately.
Image distortion is caused by the location of the camera relative to the board. To correct this we can perform perspective correction. Taking a top down view of the board will not guarantee that the board will be rectangular in the image. For example, it is likely for the camera to not be perfectly level resulting in parts of the board appearing closer or longer than they actually are. To remedy this we can identify the four corners of the board and perform a perspective correction algorithm to produce a flattened version of the board. At the same time this will give us the boundaries of the board and crop the image.
#figure(
grid(
columns: 2,
image("images/perspectiveCorrection1.png",width:80%),
image("images/perspectiveCorrection0.png",width:80%),
),
caption: [An example of perspective correction in #cite(<whiteboard-scanning>,form: "prose")]
)
=== Terrain Detection
Terrain detection utilises a straightforward approach. As the shape of terrain is limited in Kill Team Gallowdark to different constructions of pillars and walls. We can define a 2D model in the program to draw the terrain on the board. This means to detect terrain we only need to find a reference point to draw the model from, as opposed to needing to find the exact shape of the terrain.
This is achieved using aruco tags. As previously mentioned these allow us to perform pose estimation to find the location and rotation of the tag relative to the camera. Each type of terrain is defined by a unique aruco tag in a range. For example, a pillar with one wall can sit in the id range 1-10, a pillar with two walls in the id range 11-20 etc. Once we have identified the rotation, translation and scale of the tag we can apply these transformations to the model to draw the terrain on the board at the correct location.
The terrain detection system returns a list of terrain objects with:
+ The position of the four tag corners
+ The rotation of the tag as an angle
+ The id of the tag
=== Operative Detection and Identification
Operative detection is more complicated. Unlike terrain we can't place aruco tags on top of models as this is obstructive to the game and would appear significantly out of place. Instead we will design a tag to be placed around the base of the model.
The tag must be able to provide two pieces of information: the position of the operative and which operative it is.
==== Position
As the models are placed on top of circular bases the position of the operative can be defined by the centre point of the circle and the radius of it's base. As the base size of a model is set, and the board size is also known, we do not have to worry about finding the radius of the base.
The requirements for the tag to provide the position are as such:
+ Be unobstructive to the model.
+ Be easily producible.
+ Be easily findable by the camera.
+ Provide the centre point of the operatives base.
+ Achieve all of the above whilst also being able to be occluded by both terrain and the model itself.
+ Ideally the centre point should be able to be found even with a quarter of the tag being visible.
These requirements resulted in this tag design:
#figure(
image("images/circleYellow.jpg",width:50%,),
caption: ([An example of the basic contrasting rim design.])
)
To achieve this a high contrast rim will be placed around the base of the model. In this implemention we have chosen to use a bright yellow #footnote("Although this could be changed to any colour which strongly contrasts the game board provided the correct thresholds were provided.").
Utilising Hough Circle transforms @hough-circles in openCV we can easily find the centre point of a provided circle. The "completeness" of the curve required to be determined as a full circle can be easily adjusted to allow for occlusion.
#figure(
image("images/detection.png",width:80%),
caption: ([Circle detection on a game board with example terrain.])
)
In extreme cases where the rim is heavily blocked by terrain the system will be unable to locate the model. However due to the nature of this project being aimed at following the Kill Team Gallowdark rule set, the terrain pieces used are placed along a grid. This prevents a situation where a terrain piece is very close to the edge of a board with a miniature placed behind resulting in the miniature being blocked from view.
==== Identification
The tag must also be able to provide a unique identifier for each model. The virtual game board will know which tag ID corresponds to which operative.
The method of identification on the tag must need to be functional whilst being occluded by terrain and the model itself. Ideally the tag should be able to be identified even if only a quarter of the tag is visible.
Kill Teams are typically made up of 7 - 14 operatives. This means our tag must be able to represent at least 28 different options.
To do this the following design was chosen:
It is important to note that the encoding is read right to left and uses little-endian#footnote("This is a little bit unconventional. Whilst this would appear to be big-endian, unlike binary, the encoding starts at the left and reads right so we encounter the smallest bit first, making this little endian.") encoding. When reading clockwise the first bit we encounter is the smallest. When reading anticlockwise the first bit we encounter is the largest.
#figure(
image("images/crunched10.png",width:60%),
caption: ([A tag representing the ID: 10. The outer ring is split into quarters with five sections within. The first section is a high contrast colour to indicate the start of the encoding. The four proceeding sections are split into black and white to represent the binary ID of the model. This pattern then repeats around the rim of the tag so only a portion of the tag needs to be visible to determine the ID.])
)
Using 4 bits for identification allows for 16 different options. The first high contrast section colour can be changed to represent which team the model is on. This allows for 32 different options, more than enough for most Kill Team games.
The tag can be scaled to fit the size of the base of the model which is placed over the white circle. For this implementation we will use paper printed tags. This is a simple and cheap solution that is easy to get consistent colouring with. A tag of a similar design could be 3D printed with indents to paint in the colours.
Having an outer rim provides two benefits. Firstly, it allows for the identification bits to be placed further away from the model, making it less likely to be obscured. Secondly, it acts as a barrier to prevent the yellow rims from touching each other. This is important as Hough Circle detection can easily mistake two close but separate circles as one, larger circle or multiple smaller circles.
The high contrasting starting bit (shown here in magenta) is used to determine the starting point of the encoding. From here the system can then read clockwise and anti-clockwise to determine the binary ID.
== Game Board Representation
The interface is created using Pygame. This is a simple to use library that allows for the creation of 2D games. It is relatively lightweight and quick to develop with.
The digital game board represents a 22" x 15" board. Which is half the size of a standard board.
=== Terrain and Operative Placement
The size of the image will likely be different to the size of the digital game board. Due to this we need to scale the terrain and operative positions, provided by the tracking system, to match the scale of the game board.
Operative positions are provided as a list of operative objects containing: the centre point and the ID.
The centre point of the circle is scaled and translated to match the game board scale. As the base size of the model is known, we draw a circle of the correct size at the scaled centre point. This keeps our digital representation accurate to the rules representation.
A list of operative ID's in use is stored. When an operative is detected, the ID is checked to see if it is in use. If it is in use, we update the position of that ID. If it is not in use, we ignore the detection as it was likely an error.
Terrain positions are provided as a list of terrain objects containing: the four corners of the tag, the rotation around the z axis relative to the camera and the id.
To draw the terrain we apply a scale to the model to match the game board scale. We then apply the rotation to the model before finally finding the translation between the tag corners and the corresponding points on the model. We then apply this translation to all the vertices of the model to then draw the terrain.
=== GUI design
The GUI is made up of a main game board window and the surrounding area. The surrounding area is used to display information not directly affecting the game board. Such as an explanation of what the board is representing, the controls for the system and a button to remove an operative from play.
The game board will display several things:
+ The operatives on the board, with their ID's and team colours.
+ Terrain coloured to represent whether it is light or heavy terrain.
+ Highlight the selected operative.
+ Once an operative is selected.
+ The line of sight status of the opposing operatives.
+ Opposing operatives who are in cover or obscured will be displayed in a different colour.
+ The firing cones of the selected operative to these obscured / covered operatives are also displayed.
+ Inside the firing cones the points providing cover and obscurement are also displayed.
#figure(
image("images/board-suggestion.png",width:60%),
caption: ([An example of what the GUI could look like #footnote("The final GUI can be seen in the video and evaluation section.").])
)
=== Line of Sight
In this implementation we handle the two complex parts of line of sight - obscured and in cover.
==== Cover Lines
Both of these line of sight rules are based on the existence of terrain between the two models. The first thing we need to do is determine the sightline of a chosen operative to the opposing operatives. This is represented by two cover lines from a point on the attackers base to the extremes of the defenders base.
#figure(
grid(
columns: 2,
image("images/singleCoverLine.png",width:60%),
image("images/coverLines.png",width:60%),
),
caption: ([An example of cover lines being drawn. The left image shows the attacker (in blue) drawing a firing cone from one point on it's base, to the extremes of the defender's base. The right image shows how this has been done from both sides of the attacker to get the two widest possible valid firing cones.])
)
==== Obscuring and Covering Terrain
Once we have the firing cones we can determine whether an operative is obscured or in cover. This is done by producing a list of terrain lines that fall within the firing cones. We then check if any of the points on the terrain lines satisfy the distance requirements from the attacker and / or the defender. If they do, the obscuring points / cover points are drawn onto the board to provide an explanation to the user.
// Parallax is a problem that still needs to be addressed. Through testing it was found that using a standard game board size, the parallax was too great to expect to locate a rim. As a result, we have settled on using a two camera solution. This solves the parallax problem by having each camera watch a different half of the game board.
// However, one problem with this approach is that calibration will be needed to ensure that the overlap between the cameras does not cause issues. This could be achieved by either calibrating the cameras to the game board, as it will be of a known size, by placing tags on each corner of the board. Alternatively the middle of the board could be marked with a piece of tape, or tags on the edges. This should then allow for the two images to be stitched together accurately.
// PROVIDE SOME IMAGE TO DESCRIBE THIS. CITE OPEN CV AND MATLAB
// MinDist - min distanceb etween the centres of two circles,
// param1 - sensitivity of the canny edge detection -
// param2 - how close to a full circle is needed for it to be detected - number of edge points needed to declare a circle.
// minRadius + maxRadius - pretty self explanitory - closer or further to camera
// - One potential tracking approach is explored by this video:
// https://www.youtube.com/watch?v=RaCwLrKuS1w
// - Looks at a circle in the newest frame that is closest in position and size to the tracked circle in the last frame.
// - We can exploit the fact that _Kill Team_ is turn based such that only one model can move at a time. Due to this we can compare the differences between the previous image of the game state and the current game state to indentify which model has been moved.
// - This can assist in making up for shortcomings in the identifcation methods.
// Once we have located a model we need to identify it. In our implementation of _Kill Team_ we will assume that each player will have up to 14 models on their team (known as "operatives"). As a result we will need to create an encoding capable of representing at least 28 different options.
// Another rim will be placed around the bright contrast rim from before. This rim will be split into 6 sections. The first section will indicate the starting of the encoding and will use a unique colour. The other 5 sections will use 2 different colours to represent 1 or 0. Once a rim has been located, the system will then determine the orientation of the encoding circle. As the size is known, we can then rotate around the image of the encoding circle reading each section to eventually get a binary number. Each binary number will then represent a unique model on the board.
// #figure(
// image("images/circle.png",width:60%),
// caption: ([An example of what the encoding circle could look like. The red section indicates the start of the encoding. The system would be able to determine which direction to read in based on the start encoding section being in the bottom or top half of the image.])
// )
// Another encoding method that was considered was to use one rim for both detection and identification. By using one rim of known colours, the image could be split into 3 images each containing only the colour of each segment. Each image would then be converted to black and white and recombined to create a singular image with the segments connected to create a full circle. After circle detection has been performed the system could then do the normal encoding reading. This approach would allow the rims of the miniatures to be significantly smaller and only require three contrasting colours.
// One problem faced by this approach is that vision of the entire circle is needed to read the encoding, as a result if it is partially obscured then the system will be unable to identify the model.
// This could be counteracted by splitting the encoding into quarters around the rim, so that as long as 1/4 of the encoding is visible, the system can correctly identify it. We can also exploit _Kill Team_ being a turn based game and simply compare the current game state with the previous game state to identify which pieces have been moved. A combination of active tracking and being able to determine which piece has moved, should allow for a robust system.
// Terrain detection will be performed using two possible solutions, the user can either select predetermined terrain set ups or the system can detect the terrain pieces.
// The current approach for terrain detection is to use QR codes on the top of each terrain piece. In _Gallowdark_ the size and shape of each terrain "module" is already known. As a result, the QR code can be used to determine the type of terrain and orientation. Then, since the terrain type has been established we already know the size and shape. So we can then fill it in on the virtual board.
// Once the system has correctly identified and located each model and the terrain, a digital representation of the game board can be created.
// #figure(
// image("images/board-suggestion.png"),
// caption: ([A proposed GUI for the game helper.])
// ) <GUI>
// In @GUI the red semi-circle represents the valid area of movement for a selected operative. This can be calculated by splitting the game board into a very small grid, we can then apply a path finding algorithm (Dijkstra's, A\* etc) to the grid from the operative's starting point. We can then calculate all grid positions reachable by using a movement value less than or equal to the current operatives available movement characteristic.
// Red circles around opposing operatives show they are in line of sight. This would be calculated using simple ray casting. A white and red circle indicates a selected opposing operative. This is to calculate the statistics on the right hand side of the screen to be specific to the opposing operative.
// The information for the selected operative is displayed below the game board. A user can select the action they have performed / want to perform on the right hand side.
// The GUI will be built in _PyQt_ @pyqt which is a Python wrapper for the _Qt_ framework. One potential stretch goal is for the GUI and the detection system to be separate entities. For example, the detection system should be able to detect and track pieces without input needed from the virtual game board i.e. which model is selected. This would allow for other detection systems to be swapped out in the future or for other applications to be developed using the detection system.
= Implementation
This project will use openCV @openCV to process the video feed from the camera. This library contains great support for computer vision tasks and is available for both Python and C++. An alternative image processing suite would be MATLAB but this is not directly compatible with other languages so would require a lot of extra work to integrate with a GUI.
Python was chosen as the language for this project due to both prior knowledge and Python's loose type system contributing to the ability to produce quick working prototypes separate from the main project. C++ on the other hand would produce a more robust final product but would take longer to develop. As this project aims to serve as a proof of concept for the idea, Python fits the role better.
== Model Tracking
=== Design
A full sized kill team board is 22" x 30". This is too large for a single camera to capture the entire board and still be able to see miniaturesres behind terrain.
#figure(
grid(
columns: 2,
grid.cell(figure(image("images/newCloseParallax.jpg",width:95%,), caption:([The board from up close.]))),
grid.cell(figure(image("images/farParallax.jpg",width:95%),caption:([The board from afar.]))),
),
caption: ([An example of parallax.])
) <parallax>
As seen in @parallax, to get an image of the entire board, the camera needs to be >1m away. Behind the wall, a yellow rim representing the model base is present.
This introduces three problems:
+ Having an arm long enough to hold the camera this high above the board is impractical and sometimes impossible given a small room.
+ The quality of the board in the image will decrease.
+ The colour of the board changes, as is visible in @parallax, this would make our colour thresholding less effective and require more complex solutions to colour correct the image.
+ The image distortion will have a greater effect on the image. A small deviation from being level will have a greater effect on the image the further away the camera is.
The solution to this is to utilise two cameras.
One camera would cover the left half of the board and the other the right. This would allow for each camera to be closer to the board, whilst minimising the parallax effect. The two images can then be stitched together to create a single image of the entire board.
Whilst this was in the original plan, the project ended up focusing on creating a functional system for a half sized board so that, if there was time, a two camera solution could be implemented.
The camera design we ended up with was a single camera on a cheap phone holder stand pointed straight down at the centre of the board.
=== Video feed
To make the system as accessible as possible, we want to use a phone camera as the video input device. This would allow for the system to be used by the average war-gamer without needing to purchase any additional equipment.
To do this, we used a program called DroidCam @droidcam. This allows for a phone to connect either via USB or over wifi to a computer on the same network. The phone then acts as a webcam. The downside here is that droidcam is limited to 480p in the free version. Although, for the paid version the quality is increased to 1080p or even 4k if utilising the OBS plugin which you can then use to produce a virtual webcam.
For this use case, 1080p is more than enough.
This project was developed on an Arch linux with the 6.8.2 kernel. The phone used was an iPhone 13. As a result, when loading video input the system will use the linux method of video input. The camera is represented as a file found in /dev/videoX where X is the number of the camera. 0 is usually the built-in camera and 2 is our external camera, though this can change depending on whether the external camera was connected on startup. This is easily changeable in the code in the _Camera_ object to instead take an int instead of a "/dev/videoX" string for use on a windows system.
Getting video input from droidcam had two main issues.
The first was that the Arch package was broken. DroidCam makes use of the v4l2loopback kernel module to create a virtual webcam. As the video is not being produced by a physical card a virtual device has to be used. When kernel 6.8 was released vl42loopback was broken. This left a few options to fix the issue. Either downgrade the kernel or compile the module from source with a community fix applied. Whilst the fix has been applied to the main branch it has not yet been released. Neither of these options were ideal.
Upon further examination it would appear that the default version for Arch is: v4l2loopback-dkms 0.13.1-1 whereas droidcam makes use of a slightly different version: v4l2loopback-dc-dkms 1:2.1.2-1. According to the github page for DroidCam ,their version of v4l2loopback-dc-dkms has not been updated since 26/03/24. Arch kernel 6.8 was released on 29/03/24. It would also appear that DroidCam uses its own branch of v4l2loopback as indicated by the "dc" in the package name.
One user suggested installing the default branch of v4l2loopback instead. This still produced the same error, however after some further research it was found that running _sudo modprobe v4l2loopback_ would fix the issue as the module was not being loaded on startup.
Once this was complete, the video feed was outputting in 1080p with low latency over wireless connection on Eduroam.
=== Calibration
To solve the camera distortion problem we need to calibrate the camera. This involves applying a camera calibration matrix to resultant images to account for the intrinsic properties of that specific camera design. There are two potential methods we could use. Most modern cameras have publically available lens profiles that can be used to correct the distortion @lensFun. Although these are aimed at use for photography or editing software, as a result they do not fit the format that OpenCV requires. The second method is to calibrate the camera ourselves.
OpenCV provides a simple method to calibrate a camera using a chessboard pattern @openCV-calibration.
#figure(
grid(
columns: 2,
image("images/chessboard.jpg",width:80%),
image("images/chessboard2.jpg",width:80%),
),
caption: ([Some of the images used in calibration.])
)
#figure(
image("images/calibrationWithLines.jpg",width:80%),
caption: ([An example of the image points found in calibration.])
)
A chessboard pattern is used as it is easy to find specific points of which the relative positions are known. In this case, the corners between black and white squares are used. As we know the position of these points in the real world and also the points at the image, we can use this to calculate the camera matrix and distortion coefficients.
In the case of the camera matrix the points are used to calculate the focal length and optical centres of the camera. These values are then stored in a camera matrix.
The matrix and distortion coefficents are used later as they are required for the perspective-n-point pose computation utilised in the aruco tag detection.
Getting the calibration working took longer than expected. It is suggested to use around 15 images for calibration and when calibrating, each image was taking 3 - 5 minutes each and then not returning a calibration matrix. It was later found that this was due to the length and width of the chessboard pattern being passed as the wrong size. This was fixed and calibration now took \<5 seconds in total. The length of calibration was due to OpenCV attempting to find a correctly size chessboard that was not present in the image.
=== Homography
Solving image distortion requires the use of homography. We want an image of the game board to be from a perfect top down view. But as the camera is not directly above the centre of the board, along with the camera not being perfectly level and distortion from the distance of the camera to the board, the board in the image will appear to be distorted. To correct this we need to find the transformation from the plane in the image to the plane as it should appear. This is known as performing a perspective transform, or perspective correction.
#figure(
image("images/openCVHomography.jpg",width:60%),
caption: ([An example of perspective removal / correction from the OpenCV documentation @openCV-perspective.])
)
To perform this transform to our game board we first need to find the four corners of the board. Ideally this would be done either through the use of aruco tags or through segmenting the board from the background. Board detection will be covered in section 7.1.5.
From these four corners we can form a trapezoid. Using this trapezoid, we can then find the height and width of the final rectangle #footnote("This will be the largest height and width of the rectangle"). With the new height and width we can then find the perspective transform with OpenCV's getPerspectiveTransform function that correctly maps the trapezoid to the rectangle with minimal distortion. We can then apply this transform using OpenCV's warpPerspective function to get a top down view of the board. This can be seen in @homography and @homography-extreme
#figure(
grid(
columns: 2,
image("images/homographyFlat.png",width:95%),
image("images/homographyFlatTransform.png",width:95%),
),
caption: ([An example of perspective correction.])
) <homography>
#figure(
grid(
columns: 2,
image("images/homographyTestCurve.png",width:95%),
image("images/homographyTestCurvedResult.png",width:95%),
),
caption: ([A more extreme example of perspective correction.])
)<homography-extreme>
=== Board Detection
An attempt was made at segmenting the board from the background as can be seen in @boardDetection.
This approach utilised canny edge detection to find the separation between the board and the background and then HoughLines to find lines in the image. We then attempt to find a large rectangle from the provided lines. The image also has to be scaled down significantly for this to run in a reasonable time. Alternative approaches were taken using both contour detection and harris corner detection. However, these were not successful.
Contour detection appeared promising though the detailing on the board meant contours were incomplete. Attempts to fill the contours were made but unsuccessful. Automatic board detection was abandoned in favour of manually selecting the corners of the board on startup. The easiest solution would be to use aruco tags, but due to time constraints this was not implemented.
#figure(
grid(
columns: 2,
image("images/boardDetection.png",width:80%),
image("images/boardDetectionOrig.png",width:80%),
),
caption: ([An attempt at segmenting the board from the background.]
)) <boardDetection>
=== Tag Detection
Before we can attempt to locate the centre point of the circle we need to clear the image of noise. This is done by blurring the image#footnote("This is done to help reduce other noise from the image and soften edges."), converting to HSV and then applying a threshold to only show the yellow colour space in the image. This leaves us with a binary image with white pixels representing yellow and black for everything else.
From here, we perform edge detection on the image to find the edges of the circles in the image. This helps speed up the circle detection. This leaves us with a wireframe of the circles. We can then apply Hough Circle detection to the image to find the centre points of the circles and their radii. OpenCV provides a simple function to do this.
This leaves our processing pipeline as such:
+ Apply a gaussian blur to the image
+ Convert the image to HSV
+ Apply a threshold to only show the yellow colour space
+ Apply edge detection to the image
+ Apply Hough Circle detection to the image giving us a list of detected circle centre points and their radii.
It is important to note that Hough Circle transform can easily mistake two close but separate circles as one circle.
==== Hough Circles
OpenCV's implementation of Hough Circle transform makes up the backbone of the model tracking system, giving us the bases of each model.
The Hough Circle transform works by taking in a radius and drawing circles of that radius around each edge detected in the image. The result is an accumulator array where the highest values are where the most circles drawn by the transform intersect. This position is taken as the centre of the circle.
#figure(
image("images/HoughCircles.png",width:60%),
caption: ([An example of Hough Circle detection and the accumulator produced. @hough-circles-explained.])
)
In OpenCV, this functionality is expanded to allow for both a range of radii, a minimum distance between the centres of circles and the minimum accumulator value needed to declare a circle centre. This minimum value allows for the transform to find incomplete circles. This is useful for our implementation as the yellow rims around the bases of the models are not always visible.
There is a problem with the use of Hough Circle detection. The perspective transform applied to the image can cause the circles to appear more like ellipses as they move away from the centre. This change is quite minor but in an ideal system we would utilise an ellipse or oval detection method instead. However, these implementations are not as readily available and would require more work to implement.
A large portion of this project was spent on finding and testing different approaches to detect the circles that was: robust, fast and allowed for identification to be done easily. Attempts were made using blob and contour detection, but these were not successful. Contour detection was not able to deal with occlusion well and blob detection struggled when the circles came close together.
=== Model Identification
The process to get the encoding is as follows:
+ Take the circle centres and radii from the Hough Circle detection.
+ Using the same transformed image as before, but unblurred and un-thresholded:
+ Convert the image to HSV.
+ Apply a gaussian blur.
+ Apply a threshold to only show the magenta colour space.
+ Perform an image dilation to ensure the magenta is a solid block.
+ Find the contours of the magenta.
+ Compute the centroids of the magenta.
+ Find the four closest centroids to each circle centre that are within the radius + a constant.
This will give us the starting positions of each visible encoding quarter for each circle.
From here we need to get the binary encoding.
The process to get the binary encoding is as follows:
+ For each circle:
+ For each starting position provided (magenta centroid):
+ Rotate the coordinates of the magenta centroid around the circle centre to get the coordinates of each encoding bit.
+ This is done both clockwise and anti-clockwise.
+ Get the colour of the pixel at each encoding bit coordinate.
+ If the resultant colour is within the threshold values for white, the bit is 1. If it is within the threshold values for black, the bit is 0. Anything else returns a NaN value.
This will give us a circle centre, the associated magenta centroids and the clockwise and anticlockwise binary encoding associated with each magenta centroid.
Now that we have the colour values for each encoding bit in each quarter. We need to determine the final ID.
+ For each circle:
+ Reverse the anti-clockwise readings.
+ Group the associated encodings bits lists by their positions in the encoding to create 4 lists (position 0, position 1, etc)#footnote(" for example 1 2 3 4 , 1 2 3 4, 1 2 2 3, 1 2 3 4 would become: [1,1,1,1] [2,2,2,2] [3,3,2,3] [4,4,3,4]").
+ For each list:
+ The final encoding bit for that position is the majority bit present.
+ The final ID is the binary number created by the final encoding bits for each position.
+ Create an object containing the circle centre and the final ID.
+ Add this object to a list of all the found circles
+ Return the list of all the found circles and their encodings.
=== Optimisations
At this point in the project the detection system was running, but it was exceptionally slow. Each detection (including image loading) was taking nearly 3 seconds as can be seen in @optimisation-rotate. This was not acceptable for real time or even turn based system. The issue was found to be rotating the image to find the encoding bits. Instead of finding the coordinates of the encoding bits of each circle, the entire image was being rotated and the same coordinates check. This was a very expensive operation. Changing this to rotate the coordinates and not the image made significant time saves.
#figure(
table(
columns: (auto, auto, auto,auto),
inset: 10pt,
align: horizon,
table.header(
[],[*Real* (s)],[*User* (s)], [*Sys* (s)],
),
[Before],[2.290],[3.089],[1.195],
[After],[0.678],[1.374],[1.293],
),
caption: ([The time taken for a single detection before and after rotation optimisation.])
) <optimisation-rotate>
After chasing down several other instances of entire image operations, the time taken for a single detection was reduced to be mostly un-noticable. Providing the Python runtime would unfortunately not provide much information here as at this point, the program was just running the detection so a majority of the time was spent on overhead and image loading.
== Terrain Detection
As mentioned previously, terrain detection is done using aruco tags. The aruco tags are placed on top of the pillars of the terrain so that the corners of the pillar align with the black corners of the tag.
OpenCV provides methods for performing pose estimation on aruco tags.
#figure(
image("images/poseEstimation.png",width:60%),
caption: ([An example of pose estimation on an aruco tag.])
)
Pose estimation will give us a matrix which tells us the rotation and translation of the tag in reference to the location of the camera.
The rotation of the aruco tag is provided in the form of a rodrigues rotation vector. However, our model library requires an angle to perform a rotation. To convert between the two, we convert the rotation vector to a rotation matrix and then to euler angles. From here we can extract the z axis rotation (as we are working in a 2D plane from top down) and take the negative to get the correct angle for our model.
Terrain is slightly more complicated as it is defined as a series of 2D points to form a polygon. The terrain model is represented in mm sizes. The game board uses 3 pixels to represent 1mm. So we scale the terrain by 3x to match. We then rotate the terrain model to match the rotation of the tag. Finally we need to find the translation to move our model from model space into world space. This is done using the top left corner of the tag and the point which matches this on the model.
We scale the tag corner position into world space from the image space and then subtract the model corner position from the tag corner position to find the translation. From here, we can apply this translation to the terrain model to find the correct vertices to draw the terrain on the game board.
A terrain's ID is stored when it is detected originally. When that same ID is detected again, the position of the terrain is updated. If a new ID is detected, a new terrain object is created and added to the list of terrain objects.
Terrain detection caused more issues than expected. The main issue came from getting the rotation of the terrain. Converting from a rotation vector to euler angles was a process that ended up taking a long time to get right. However, the main problem came from doing the pose estimation.
Semi recently, OpenCV was updated to include a new method for pose estimation, deprecating the old method. This new method was not as well documented as a result. The new method also added some levels of complexity. Previously, OpenCV had a dedicated function for pose estimation. Now, this functionality has been moved into solvePnP. This made the research done prior on implementing pose estimation redundant. Eventually, a workaround was produced that allowed for the correct rotation to be found.
== Game Board Representation
Originally, the plan was to use Qt for the GUI. However, this was abandoned for several reasons. Firstly, running Qt in a virtual environment on Arch caused issues for a while. Despite being installed, it simply would crash on startup. This was run into when trying to display images in OpenCV as it uses Qt for the GUI. This was solved by updating to Qt6 and then reverting to Qt5.
Secondly, when attempting to use Qt for the GUI, it would not display as desired. Qt is a very complex library and as a result getting simple GUI elements to display as desired was incredibly difficult. One of the main issues was trying to display the circles for the operatives. When placing a circle button in Qt it would place as desired, but adding multiple circles at the top of the screen would cause everything to shift. This is likely due to Qt being aimed at more generic user interfaces, rather than the specific use case of displaying a game board.
At the realisation that this project was closer to building a game than a general interface, the decision was made to switch to Pygame. Though a few other options were considered, such as Pyglet, Pygame was chosen due to its simplicity and abundance of documentation.
=== Linking of detected models and terrain to the virtual board
When a model is detected, its ID is checked against a list of IDs in use. If the ID is in use, the position of the operative in the list is updated. Before the position is updated, the coordinates from the image are translated to fit the board. This involves finding the scale between the virtual board and the board in the image as well as moving the coordinates to treat 0,0 as the top left corner of the virtual board and not the top left hand corner of the window.
If the ID is not in use, the tag is ignored. This is to prevent false positives from being added to the board.
As the game board is meant to be a strict representation of the rules, the base size of the model is defined within the program. This helps to ensure consistency between base sizes that would otherwise be difficult to maintain.
Operatives are also drawn with their team colours, state (concealed or engaged) and names.
#figure(
image("images/stateExample.png",width:60%),
caption: ([An example of the operatives and their state on the game board.])
)
The relationship between models on the physical and virtual game board will be covered more in depth in section 8.1.
One issue that was encountered was that OpenCV uses y,x coordinates when indexing an image or getting the length and width. This caused some significant confusion when trying to find the required scaling between the image and the board.
Terrain functions in a similar way to operatives. Although, terrain does not need to be declared beforehand. When a new terrain ID is detected, a new terrain object is created and added to the list of terrain objects. If a terrain ID is detected that is already in use, the position and rotation of the terrain is updated.
The position of the terrain is based off of the top left hand corner of the aruco tag.
The terrain positioning ended up being broken for a while due to the terrain model being defined upside down. This meant that the top left hand corner of the tag was being matched to the bottom left hand corner of the terrain model.
=== Line of Sight
===W Firing Cones
#figure(
image("images/findingCoverLines.svg",width:40%),
caption: ([The process for finding the cover line positions.])
) <coverLines>
As shown in @coverLines, the process for finding the cover lines is as follows:
+ Find the line equation between the two centre points of the bases.
+ Find the perpendicular line to this line through each of the centre points.
+ Find the intersection points of the perpendicular lines with the edges of the bases.
This gives us enough information to form the two firing cones we need.
Getting the firing cones is a simple process in theory but getting a functional implementation took significantly longer than expected.
Finding the line equation between the two centre points is a simple process. Getting the perpendicular gradient had some issues. Python had some problems with taking the reciprocal of a float.
Finding the intersection points on the bases proved problematic. Quite a few mistakes were made in the process of converting the algebra to Python code which took several days to notice.
A separate methodology was used based on a wolfram alpha solution. Although it was overlooked that the solution was specific to the circle being at 0,0 so this solution could not be used.
==== Terrain Within Firing Cones
Originally the plan was to use a ray-casting method to find the line of sight. This had two main problems. Firstly, it made getting the information required for obscured and in cover more difficult than it needed to be. As we are concerned with the distances of many points within the firing cones, a raycasting implementation would need to be done past terrain after contact with the firing cone. Secondly, it would require a 2D array representation of the game board to be created. This would require some kind of rasterization of terrain and operatives to build. This would be very computationally intensive for a suboptimal solution.
The rules for obscured and in cover are very specific in their requirements as covered earlier. This allows us to exploit the specifics of the problem to simplify the process. As the line of sight rules are more complicated than simply whether an operative is visible to another operative, we need a unique solution to this problem.
We can break the problem down into several parts:
+ Building the firing cone.
+ Determining what terrain is within the firing cone
+ Creating a list of lines within the firing cone.
+ For each line finding the closest point to the operative.
+ Determining whether the point meets the obscured or in cover requirements.
Both obscured and in cover are determined by the distance between the attacker / defender and a point at which terrain is within the firing cone.
We can determine whether a terrain line is within the firing cone if it satisfies any combination of the following two conditions:
+ The start or end of the line falls within the firing cone.
+ The line intersects with the firing cone.
Using this we can rebuild a list of terrain lines that fall within the firing cones.
The lines are determined as follows:
+ If a line satisfies none of these then it can be ignored.
+ If it satisfies both points within the firing cone then we take both the start and end points.
+ If a line satisfies only one point within the firing cone then the line must also intersect with the firing cone. We then take the point within the firing cone and the point of intersection.
+ If a line intersects the firing cone at two points then we take both points of intersection.
This leaves us with a list of lines that fall within the firing cone.
Finding whether a point falls within the firing cone is done by calculating the barycentric coordinates of the point in relation to the triangle formed between the two points on the defender and the single point on the attacker. If alpha, beta, and gamma are all between 0 and 1, then that point falls within the triangle.
Finding whether a line intersects with the firing cone is a bit trickier. Finding the intersection of a line and another line is easy. However, finding the intersection between two line segments is more complicated. This is because the intersection point of two lines can be outside of the line segments. Whilst an algorithm existed to solve this, it had several bugs that needed to be fixed.
Now that we have a list of lines that fall within the firing cone we can find the closest point on each line to an operative. If the point meets the obscured or in cover requirements then we check if the requirements are also met for the attacker / defender. If they are, then we set the defender to be obscured or in cover.
Finding the closest point on a line to another point is a deceptively difficult problem. The solution ended up using some vector algebra to project the point onto the line using a pre-existing algorithm.
= Evaluation
This section will discuss the results and limitations of the project. Section 7.1 will discuss how well the system performs in tracking models and terrain. Section 7.2 will discuss the overall outcome of the project in relation to the initial goals set out in section 4.
== Tracking System
The first test involves comparing the position of the detected models on the board to the actual position of the models.
The second test involves checking how well the system can track multiple models at once.
As this is a live system, the tests will be performed in real time. This is difficult to demonstrate in a report so screenshots will be provided to show the results of the tests along with a description of observations. These observations can be better seen in the supplied demonstration video.
=== Accuracy
#figure(
grid(
columns: 2,
image("images/unDistorted.png",width:95%),
image("images/distorted.png",width:95%),
),
caption: ([The actual board and the transformed board #footnote("It is important to note that the binary decoding for these tests was reversed - this has since been fixed. But the encodings on the rings are swapped as they're symmetrical.").])
) <evaluation-tracking>
#figure(
image("images/trackingEvaluation.png",width:60%),
caption: ([The digital game board of @evaluation-tracking])
) <gameboard-evaluation-tracking>
The tracking system provided the coordinates of (754,771) for "Ten Team Two" (pictured in blue) and (1642,581) for "Five Team One" (pictured in red) as seen in @gameboard-evaluation-tracking. These values are including the translation to fit the Pygame window, which is 279 pixels in the x direction and 50 in the y. Each pixel representing 3mm. (0,0) is considered to be at the top left corner of the board with y increasing downwards.
The equation to convert from the Pygame coordinates to the real world is as follows:
Let $a$ and $b$ be the game board coordinates for x and y respectively. Let $x$ and $y$ be the actual, real world coordinates for x and y respectively.
$ x = ( a - 279) / 3$
$ y = (b - 50) / 3$
These values represent the position in mm from the top left corner of the board in the x and y directions respectively.
#figure(
table(
columns: (auto,auto, auto, auto,auto,auto),
inset: 10pt,
align: horizon,
table.header(
[*Operative Name*],[*Pygame*], [*game board*], [*Real World*],[*Actual*],[*Difference*],
),
[
ID: Ten, Team Two (blue)
],
[(754,771)],
[(475,721)],
[(158,240)],
[(160,235)],
[(2,5)],
[
ID: Five, Team One (red)
],
[(1642,581)],
[(1363,531)],
[(454,177)],
[(459,181)],
[(5,4)],
),
caption: [Results of the tracking system from @evaluation-tracking]
)
#figure(
grid(
columns: 2,
image("images/trackingCorners.png",width:95%),
image("images/trackingCornersGameBoard.png",width:95%),
),
caption: ([Tracking at the corners of the board to see how distance affects detection.])
)<evaluation-tracking-corners>
#figure(
table(
columns: (auto,auto, auto, auto,auto,auto),
inset: 10pt,
align: horizon,
table.header(
[*Operative Name*],[*Pygame*], [*game board*], [*Real World*],[*Actual*],[*Difference*],
),
[ID: Ten, Team Two (blue)],
[(352,1113)],
[(73,1063)],
[(24,354)],
[(27,349)],
[(3,5)],
[ID: Five, Team One (red)],
[(1886,118)],
[(1607,68)],
[(536,23)],
[(535,24)],
[(1,1)],
),
caption: [Results of the tracking system from @evaluation-tracking-corners #footnote("The small blue circle in the right image is the board centre point.")]
)
These results are very promising. The tracking system seems to be able to accurately determine the position of the models on the board down to 5mm. This is a very good result. The tags were marked on the centre of the base when taking the real world measurements. Although, these were not perfectly centreed. A visualisation of the accuracy can be better seen in @six-real-overlay.
The next test will look at how well the system can track operatives with the models present.
#figure(
grid(
columns: 2,
image("images/trackingWithModels.png",width:95%),
image("images/tracingWithModelsBoard.png",width:95%),
),
caption: ([Tracking with models present.])
)<evaluation-tracking-models>
In @evaluation-tracking-models the system correctly identified the red team model but failed to identify the blue team model. The tracking system determined that the blue team model was ID: 0 or ID: 4.This is likely due to the blue team model being partially cropped out of the image and containing black on the model. As a result when checking for the binary parts of the model are interfering.
However, as seen in @five-frames the system was able to eventually identify the blue team model. This presents a limitation of the current system. As the system does not have a confidence value for the identification, it will simply return any valid identification it can find. This will result in problems when more models are present as the system will be likely to move a model into another when mis-identifications are present. A potential fix for this would be to utilise a system using hamming distance to better identify models with partial data. This will be expanded upon in Section 8.2. A temporary fix was applied that would prevent the system from placing a model in the same position as a model that was already present. Whilst this isn't a particularly robust solution, it does prevent the system from placing two models in the same position.
// or to implement a "smart" method based on the previous game state. This method would exploit the fact that only one model can move at a time and that the system can compare the current game state to the previous game state to determine which model has moved. This could utilise image segmentation to remove the terrain and game board from the previous image and then compare the remaining data with the current image to help determine which model has moved. This would still require an tag based system to assist but would be a more robust solution.
#figure(
image("images/trackingWithModelsFrameFive.png",width:60%),
caption: ([The same setup as @evaluation-tracking-models but 5 frames later.])
) <five-frames>
#pagebreak()
=== Multiple Tag Tracking
#figure(
grid(
columns: 2,
image("images/sixModelTest.png",width:95%),
image("images/sixModelScreen.png",width:95%),
),
caption: ([The game board with 6 models present.])
)<six-real>
#figure(
image("images/sixModelScreenOverlay.png",width: 60%),
caption: ([The images in @six-real overlaid on each other.])
)<six-real-overlay>
As seen in @six-real-overlay, the system was able to track all six models present. The system is able to track multiple tags, with the correct identification, at the same time with high levels of accuracy. Although, it would appear that as the tags move further up, the accuracy dwindles slightly, this can be seen in "Nine Team One" in @six-real-overlay.
=== Tracking With Terrain
#figure(
grid(
columns: 2,
image("images/sixModelTerrain.png",width: 95%),
image("images/sixModelTerrainBoard.png",width: 95%),
),
caption: ([The game board with 6 models and terrain present.])
) <six-terrain>
#figure(
image("images/sixModelTerrainOverlay.png",width: 60%),
caption: ([The images in @six-terrain overlaid on each other.])
)<six-terrain-overlay>
As seen in @six-terrain-overlay, the system is able to track both models and terrain simultaneously. However, the terrain appears to be slightly tilted to the right. This is likely due to the position of the aruco tag on the terrain being slightly offset. As well as this, you can see that the top left corner of the aruco tag and the top left hand corner of the terrain pillar are not well lined up. This will contribute to the mis-positioning of the terrain. Although in relation to the models and the centre of the board, the terrain is in a good position.
#figure(
image("images/terrainObscured.png",width: 60%),
caption: ([The game board with a model obscured by terrain.])
) <terrain-obscured>
#figure(
image("images/terrainObscuredBoard.png",width: 60%),
caption: ([The digital game board with a model obscured by terrain.])
) <terrain-obscured-board>
In @terrain-obscured-board the system was unable to find the obscured model. The use of black terrain is likely causing the system to find 0s in the binary encoding, making identification difficult when combined with the blocking of the starting bits. However, as seen in @terrain-obscured-roated when rotating the model the system is able to find a correct identification.
#figure(
image("images/terrainObscuredRotated.png",width: 60%),
caption: ([The digital game board after the model was rotated.])
) <terrain-obscured-roated>
Another problem is present which is visible in @terrain-obscured-roated. The roll of the terrain is not being accounted for, resulting in an incorrect positioning. A potential fix for this will be discussed in section 8.2.
#figure(
image("images/terrainProblem.png",width:60%),
caption: ([ @terrain-obscured overlayed with @terrain-obscured-board ])
)
=== Summary
Some testing was done to compare the usefulness of the visualisation of the game board This involved playing a solo round of kill team with the system with four operatives. Overall, the system was able to track and identify miniatures to a satisfactory level. There were a few times where the system would take a while to find a model but this was usually fixable with some rotating and slight shifting. However, terrain ended up being problematic. The system could get the rough area of terrain but struggled to get the exact position, combined with the terrain shifting slightly whilst stationary, this made the experience less enjoyable. The terrain shifting is likely caused by a lack of distance checking when updating terrain. Whilst the terrain rotation must be greater than a constant value to be updated, this was overlooked for the position. Some different approaches to remedy this will be discussed in section 8.2.
The line of sight visualisation was satisfactory, displaying in cover or obscured to a degree that appeared realistic.
= Summary and Reflections
== Project Management
The first and second gannt charts show the original and interim gannt charts for the project#footnote("These have been submitted in the appendix."). The final gannt chart shows the updated gannt chart with the actual timeline of the project.
Previously, I stated that tackling the ring detection first was a good choice. This allowed for me to encounter larger issues and provide solutions to them whilst still in the research stages on the project. However, in hindsight tackling terrain would have been a better decision. As the terrain detection system was using pre-existing methods, it would have taught me about how fiducial marker systems work. This would have been useful when building the model detection system.
On the other hand the model detection system took a long time to get right. Leaving this until later would have likely caused significant stress as it is the main focus of the project. It was a part of the project which was very important to get right, so leaving plenty of time was the sensible choice to make.
// As per the initial Project Proposal the original goal for the first semester was to have ring detection and terrain detection completed. Currently, simple ring detection has been completed. This still needs to be expanded to include identification, though work has begun on this. Terrain detection has been moved backwards to allow for more time to make a good detection system for the miniatures.
// Choosing to tackle the ring detection first was a good choice. This allowed for me to encounter larger issues and provide solutions to them whilst still in the research stages on the project. This has allowed for me to develop my computer vision skills and take approaches I would not have otherwise considered. For example, using a singular rim of multiple colours and combining the images to create a full circle for identification.
Supervisor meetings were held every week to check for blockers or advice on reports. Uniquely, our supervisor meetings were conducted as a group with the other two dissertation students my supervisor had. As all three of us were working on tabletop game based projects we were all knowledgeable in the area. This meant we could provide feedback or ideas for each other's projects from a student perspective.
Previously I mentioned that gannt charts were unhelpful in managing the project and that I would instead take a kanban based approach from my previous successes in the methodology in the second year group project. In reality, past the first week this was left behind. Instead, I opted for leaving myself a comment block about what I had achieved that day and what I needed to do next. This came in useful when writing the report as I had a breakdown of what was completed and the difficulties faced that I would otherwise not have remembered. This was a much more effective method of tracking progress than the gantt chart.
I also previously mentioned that this project was taken as a 70 / 50 split. This made the second half of the project significantly more manageable. Although this project did make use of extension time, that time fell within the easter break. I find that development work is much more effective when done in long, uninterrupted sessions. being able to have only 50 credits of work to do with a long break at the end of the project was very helpful.
I achieved the majority of what I wanted to get done in this project with the only missing part being movement preview. This was not a priority as the technical interest of this project is the development of the tracking system.
// I found the Gantt chart to be unhelpful in managing the project. Gantt charts work well in well structured work environments. However, due to the nature of this semester having a large amount of other courseworks and commitments that needed to be balanced. An agile approach was much more effective, doing work when time was available. The nature of development work being much more effective when done in long, uninterrupted sessions meant that, with this semester's courseworks and lectures being very demanding at 70 credits, being able to find long swathes of uninterrupted time was very difficult between lectures, courseworks, tutorials etc. As a result, development was done in smaller, more frequent chunks which were not as effective as longer, less frequent chunks. I expect this to change next semester when the workload decreases down to 50 credits.
// A much preferred method, that I will likely go ahead with, is Kanban. I personally found most use from the Gantt chart in that the project is naturally broken up into sub tasks. This approach of sub-tasking when, combined with a less structured agile approach, is something that Kanban works really well at and have found effective in the past in GRP (COMP2002).
// In the interests of being able to show current progress in comparison to previous I have included an updated Gantt chart (@firstGantt) along with the previous one (@secondGantt).
// Looking at the time remaining I will focus on getting the main parts of the system functional. These are: model detection and tracking, terrain detection, virtual game board representation, movement preview and line of sight preview. If there is time available then I will aim to also implement the flow of the game (breaking it down into each phase, providing guidance of what to do in each phase, statistics etc). The most technically interesting part of this is the virtual game board and tracking technology. So placing a focus on having them work fluidly is more important to the dissertation.
== Future Work and Reflections
Something I underestimated was the amount of time needed to research and determine which method should be used for model detection. A large amount of time was spent determining the viability of different approaches that may make the system more robust and easier to produce. As a result of this, development started later and took longer than was expected.
The biggest impact on this project was needing to get an extension on other coursework deadlines. This extension had a knock on effect of other courseworks which took priority over this project. The timings allotted in the Gantt chart did not take into account extensions being needed.
The reflection above was written at the time of interim report submission. It has been left in as I believe it is important to evaluate how I handled the project in the past compared to now.
I started development by attempting to produce a tag detection system for the operatives and then move onto terrain afterwards. In hindsight, it would have been better to start with terrain detection. I utilised aruco markers to find the position of terrain. The process of implementing aruco markers ended up teaching a lot about fiducial markers that I wish I had known before building the model tags. I'll cover the specifics of this when discussing upgrades to the detection system.
=== Order Tokens
Order tokens are a key part of the game that are not currently implemented. These are usually small pieces of orange triangular card pointing at an operative with an image denoting the state. A future system might be able to segment these tokens out and use the direction of the triangle to determine the state of an operative without needing manual input.
=== Odds to Hit
As Kill Team is mostly based on dice rolls modified by the statistics of the operatives, a future system could implement a way to calculate the odds of hitting a target. A problem with this would be needing to then store and update health values manually. This could be done by moving the dice roll calculation to being digital. Although, I don't think this is a good idea. An important part of tabletop boardgames is actually physically rolling the dice.
There are plenty of pre-existing systems to see the values of physical dice. These typically either utilise computer vision to detect the sides of the dice or use specific dice that are aware of their orientation. A "smart dice" system would prevent the need for manual interaction with the system. This would be a good place to start for a next addition to the system as it opens up a lot more game mechanics to be streamlines.
=== Increasing total number of operatives
The current system only supports 16 operatives total on a half-size board. The colours of the encodings can be changed to allow for more but this requires thresholding for different colour values to be re-done. A better approach may be to use more than 4 bits for the encoding and utilise hamming distance to deal with partial data
=== Server Client Architecture For Game Board and Detection
The current system is run on a single thread. This is fine as it currently is but there are a few problems. One such problem is that the GUI is running on the same thread as the detection meaning responsiveness is likely to be a problem on slower machines. A solution to this would be to have the detection system function as a server that can serve data to the game boards.
This also opens up the avenue for alternative detection systems to be used as a server based architecture would allow for the creation of an API that is agnostic to the type of detection used.
Alternatively this could be expanded to allow two players to play against each other on different game boards by transmitting their model positions to each other.
=== Solo Play
If the system were to receive more rules integrations it may be possible to make an AI that can play against a human. This would require a huge amount of work to implement the rules of the game but it would be very interesting to see.
=== Detection Upgrades
One of the biggest changes that could be made would be to make the operative tags utilise hamming distance. Hamming distance is a method that lets us maximise the difference between our marker patterns. If we design markers that are maximally different from each other then when errors are present we can use the information we do have to determine which marker is most likely to be the correct one. For example. if we're using a 4 bit encoding but we only have two tags 0,1,1,1 and 1,0,0,0 we can determine the ID of the tag based on only one bit of information. This method can be applied in a more complex way to develop a tagset. This is a system that is used by aruco tags.
Another problem is with the positioning of terrain. The terrain is only rotated in the Z axis from the aruco markers which is resulting in the terrain being slightly off. In future a different model library should be used to allow for more complex rotations to increase the accuracy of the terrain.
The same pose estimation approach should also likely be taken to the operative tags. This system would greatly benefit from a more robust method of moving models. Currently everything is done by x,y coordinate movement but it would be much more streamlined to use a proper matrix transformation system to move models. This would also make the system much more maintainable as the current system does a lot of calculations between different spaces all over the place and having a streamlined pipeline would make this much easier to manage.
== LSEPI
The main LSEPI issue you could see here is copyright issues as Kill Team is a copyrighted entity owned by Games Workshop. The way this project will handle this is by having the system implement the Kill Team Lite rule set previously mentioned. This is publicly available published by Games Workshop. One issue is that different Kill Teams will have different and unique rules as well as their own statistics pages. These are copyrighted and won't be able to be directly implemented. As a result of this, this project will implement basic operatives with fake statistic pages based off of the publicly published Kill Team information. If this proves to be problematic then the game rules will be based on a very similar system Firefight @one-page. This is published by One Page Rules, who produce free to use, public miniature war-game systems. Though as this is based off of the published, free to use Kill Team Lite rules, I don't expect this to be a problem.
=== Accessibility
A key focus of this project was on accessibility to the average-miniature wargamer. This led to a focus on not using specialist hardware. I believe the system achieved this goal with the main potential issues being technical setup and camera setup. Being a Python project, Python needs to be installed with the libraries. The process of doing this to a non-technical individual can appear quite daunting. The camera setup is also a potential issue. Droidcam ended up being a harder to use piece of software than I first anticipated. This could be a potential issue for the average user.
=== Open Source
I intend to open source the code for this project using a copyleft licence. When performing the background research for this project I found that there were very few closely linked projects. As a result of this I want the code and the takeaways I gathered from this project to be available to the public to assist anyone undertaking a similar project in the future.
= Final Reflections
Overall, I believe this project has met the goals of digitising a physical game board. The accuracy of the model tracking is very good and the terrain tracking is satisfactory but needs some improvements. The line of sight system provides enough information to the user to know whether a model is obscured / in cover as well as what is causing the obstruction.
A problem I ran into quite frequently was the OpenCV documentation was quite lacking. Documentation for versions >4.7 tended to only support C++. OpenCV claims to have support for 5 different languages but only provides in-depth documentation on C++. From the work I have done, it appears that a lot of questions that get asked about OpenCV are asked in the context of Python. This is a problem I have run into in several open source projects. Whilst the functionality is amazing the documentation tends to go out of date quickly as contributions are made. This is a shame as the OpenCV documentation which is of good quality is incredibly well done. It explains the concepts at both a low and high level with examples. A big takeaway from this project will be in contributing to the documentation of open source projects I use if I can. OpenCV does have a documentation repository that I will likely contribute to in the future to provide more Python examples.
= Bibliography
#bibliography(title: none, style: "ieee", "interim.yml")
|
|
https://github.com/Myriad-Dreamin/typst.ts
|
https://raw.githubusercontent.com/Myriad-Dreamin/typst.ts/main/fuzzers/corpora/text/lang_01.typ
|
typst
|
Apache License 2.0
|
#import "/contrib/templates/std-tests/preset.typ": *
#show: test-page
// Test that the language passed to the shaper has an effect.
#set text(font: "Ubuntu")
// Some lowercase letters are different in Serbian Cyrillic compared to other
// Cyrillic languages. Since there is only one set of Unicode codepoints for
// Cyrillic, these can only be seen when setting the language to Serbian and
// selecting one of the few fonts that support these letterforms.
Бб
#text(lang: "uk")[Бб]
#text(lang: "sr")[Бб]
|
https://github.com/vEnhance/1802
|
https://raw.githubusercontent.com/vEnhance/1802/main/src/dotprod.typ
|
typst
|
MIT License
|
#import "@local/evan:1.0.0":*
= The dot product
The dot product is the first surprising result you'll see in this class,
because it has _two_ definitions that look nothing alike,
one algebraic and one geometric.
Because of that, we'll be able to get a ton of mileage out of it.
This will be a general theme across the course:
almost every new concept we define will have some sort "algebraic" side
(like the coordinates for vector addition)
and some "geometric" side (the parallelogram in @fig-parallelogram).
This is the bar a concept has to pass for us to study it in this class:
in order for us to deem a concept worthy of our attention in 18.02,
it must have both an interpretation with algebra and an interpretation in geometry.
== [TEXT] Two different definitions of the dot product
I promised you two definitions right? So here they are.
#definition[
Suppose $bf(v) = vec(a_1, dots.v, a_n)$ and $bf(w) = vec(b_1, dots.v, b_n)$ are two vectors in $RR^n$.
The _algebraic definition_ is to take the sum of the component-wise products:
$
vec(a_1, dots.v, a_n)
dot
vec(b_1, dots.v, b_n)
:= a_1 b_1 + ... + a_n b_n.
$
The _geometric definition_ is that if $theta$ is the angle between the two vectors
when we draw them as arrows with a common starting point, then
$ bf(v) dot bf(w) := |bf(v)| |bf(w)| cos theta. $
That is, the dot product equals the product of the lengths
times the cosine of the included angle.
]
It's totally not obvious that these two definitions are the same?
The standard proof uses the law of cosines;
I'll say a bit more about this once I've done a few examples.
I also found a proof without trigonometry that I typed in @appendix-dotpf.
I won't dwell on this proof too much in the interest of moving these notes forward.
#typesig[
Remember, the dot product takes two vectors _of equal dimensions_ as inputs
and outputs a _scalar_ (i.e. a real number).
*It does not output a vector!*
This is the mistake every calculus or linear algebra
instructor dreads for the first few weeks of class.
Repeat: dot product output type is *number*! Not a vector!
]
#example[
Let's find the dot product of $bf(v) = vec(-5, 5 sqrt(3))$
and $bf(w) = vec(7sqrt(3), -7)$, both ways.
- The algebraic definition is easy:
$ bf(v) dot bf(w) = - 5 dot 7 sqrt(3) + 5 sqrt(3) dot (-7) = -70 sqrt(3). $
- The geometric definition is a bit more work, see @fig-vectors-example.
In this picture, you can see there are two $30 degree$ angles between the axes,
and the lengths of the vectors are $10$ and $14$.
Hence, the angle $theta$ between them is $theta = 90 degree + (30 degree + 30 degree) = 150 degree$.
So the geometric definition gives that
$ bf(v) dot bf(w) = |bf(v)| |bf(w)| cos theta = 10 dot 14 dot cos(150 degree)
= 140 dot - sqrt(3)/2 = -70sqrt(3). $
]
#todo[an example of perpendicular in 2D]
This example shows something new:
#memo[Two nonzero vectors have perpendicular directions
if and only if their dot product is $0$.]
#todo[an example of perpendicular in 3D]
#todo[an example of lengths]
#memo[The dot product of a vector with itself is the squared length.]
#tip[
You can see from this example that computing the dot product
of two given vectors with coordinates is
way easier to do with the algebraic definition.
This will be true in general throughout this class:
- Use the algebraic definition when you need to do practical calculation.
- Use the geometric definition to interpret the result in some way.
]
#figure(
[TODO],
// image("<+Path+>", width: auto),
caption: [Some pictures of dot product.],
) <fig-vectors-example>
== [SIDENOTE] The proof of the equivalence of the dot product properties
== [RECIPE] Checking whether two vectors are perpendicular
== [TEXT] Projection
== [RECIPE] Projection of one vector along the direction along another
#recipe(title: [Recipe for projecting one vector along another])[
Suppose $bf(v)$ and $bf(w)$ are given vectors in $RR^n$.
To find the length of the projection of $bf(v)$ along $bf(w)$:
1. Output the absolute value of $(bf(v) dot bf(w)) / (|bf(w)|)$.
To find the actual vector $bf(v)$ along $bf(w)$:
1. Output $(bf(v) dot bf(w)) / (|bf(w)|) (bf(w)) / (|bf(w)|)$.
]
#todo[define it]
#pagebreak()
= Planes and their normal vectors
== [TEXT] Planes in $RR^3$
== [TEXT] Normal vectors to lines in $RR^2$
Before we get to normal vectors to planes in $RR^3$, I want to do everything in $RR^2$ first.
If you are confused about normal vectors in the plane, it might help to first do the $RR^2$ case,
which is easier to draw and for which you might have better intuition from eighth or ninth
grade algebra.
Here's a question: which vectors in $RR^2$ are perpendicular to $vec(1,2)$?
They're the vectors lying on a line of slope $-1/2$ through the origin, namely
$ 0 = vec(x,y) dot vec(1, 2) <==> 0 = x + 2 y. $
#figure(
image("figures/r02-x-plus-2y.png", width: 12cm),
caption: [Plots of $x+2y=0$ and $x+2y=pi$.],
)
Okay, in that case what does the line
$ x + 2 y = pi $
look like? Well, it's a parallel line, the slope is still the same.
Equivalently, you could also imagine it as the points $vec(x,y)$ such that
$ vec(x,y) - vec(pi,0) " is perpendicular to " (1,2) $
or do the same thing for any point on the line, like
$ vec(x,y) - vec(0, pi slash 2) " is perpendicular to " (1,2) $
or even
$ vec(x,y) - vec(0.218 pi, 0.564 pi) " is perpendicular to " (1,2) $
But that's silly. Most of the time you don't care about base points.
All you care is the line has slope $-1/2$,
and for that the LHS just needs to be $x + 2y$ (or even $100 x + 200 y$).
The RHS can be whatever you want.
In $RR^3$, the exact same thing is true for the expression $a x + b y + c z = d$.
The only difference is that the word "slope" is banned (or at least needs a new type;
it won't be a single number).
Nevertheless, even if we can't talk about slope, we can still talk about parallel planes,
and now the whole discussion carries over wholesale.
== [RECIPE] Normal vectors to a plane
#idea[
Everything we used slope for in 18.01,
we should rephrase in terms of normal vectors for 18.02.
]
#recipe(title: [Recipe for calculating normal vector to a plane])[
To find the normal vector of a plane given in the form $a x + b y + c z = d$:
1. Output $vec(a,b,c)$ (or any other multiple of $vec(a,b,c)$).
]
== [RECIPE] Finding a plane through a point with a direction <recipe-plane-known-dir>
#recipe(title: [Recipe for finding a plane given a normal vector and a point on it])[
Suppose the given normal vector is $vec(a,b,c)$, and $P in RR^3$ is a given point.
1. Write $a x + b y + c z$ for the left-hand side.
2. Evaluate the left-hand side at $P$ to get a number $d$.
3. Output $a x + b y + c z = d$.
]
#sample[
Find the equation of the plane parallel to $x + 2 y + 3 z = 100$
which passes through the point $(1, 4, 9)$.
]
#solution[
Planes are parallel when they have the same normal vector,
so we know the normal vector is $vec(1,2,3)$ for both.
Hence the answer should take the form $x + 2 y + 3 z = d$ for some $d$.
In order to pass through $(1, 4, 9)$ we should choose $d = 1 + 2 dot 4 + 3 dot 9 = 36$.
So output $ x + 2 y + 3 z = 36$.
]
== [TEXT] Calculating distance to a plane
== [RECIPE] Distance to a plane <sec-distance-plane>
== [EXER] Exercises
#exer[
Find all possible values of $a x + b y + c z$
over real numbers $a$, $b$, $c$, $x$, $y$, $z$
satisfying $a^2 + b^2 + c^2 = 2$ and $x^2 + y^2 + z^2 = 5$.
]
#pagebreak()
|
https://github.com/dismint/docmint
|
https://raw.githubusercontent.com/dismint/docmint/main/religion/essay2.typ
|
typst
|
#import "template.typ": *
#show: template.with(
title: "24.05 Essay 2",
subtitle: "<NAME>",
pset: true,
)
#note(
title: "Prompt #2"
)[
Develop an argument against the following claim: the same body of total evidence cannot both justify theism and agnosticism.
]
= Argument
#twocol(
[
/ P1.1: In the presence of faith, it is often required to have external beliefs that may not be rooted in evidence.
/ P1.2: If it is often required to have external beliefs that may not be rooted in evidence, then a total body of evidence can lead to different conclusions.
/ P1.3: In the presence of faith, a total body of evidence can lead to different conclusions.
/ P2.1: Theism exists in the presence of faith.
/ P2.2: Agnosticism exists in the presence of faith.
/ P2.3: In both Theism and Agnosticism, a total body of evidence can lead to different conclusions.
/ P3: If in both Theism and Agnosticism, a total body of evidence can lead to different conclusions, then the same body of total evidence can justify both Theism and Agnosticism.
/ C: The same body of total evidence can justify both Theism and Agnosticism.
Note that the arrows are slightly off from what we have seen in the class, for example if I had full control over this graphic, the arrows from `1.1` and `1.2` would join at a center point before continuing onward to `1.3`
],
bimg("img/essay2.png")
)
In this essay, I will argue that a total body of evidence can in fact, justify both Theism and Agnosticism. At the core of this argument is the idea of belief and faith. Both belief and faith are sensitive words in the context of human emotions, and finding the _true_ definition of either is extremely subjective. I will instead attempt to clearly define what I believe them to be, as well as other key terminologies that will be used throughout this essay.
= Essay
In *`P1.1`*, I define a core part of what I believe it means to be faithful. I actually believe that this trait can be attributed to *trust* as well, but I will not be attempting to motivate that claim here.
I claim that in the presence of faith, it is often required to have external beliefs that may not be rooted in evidence. This is a core part of what it means to have faith - I would go as far to say that without this mindset of faith, we are not actually looking at faith, but rather logic.
This is not to say that faith and logic live on opposite sides of the spectrum. It of course can be the case that you have faith in something that is logically sound as well. If your favorite sports team has been doing well the entire season, having faith in them that they will also win the finals is equally logical. However, I mean to distinguish when faith becomes its own unique construct, which is when not all parts of it are rooted in evidence. When I say that I have faith in something, I usually mean that I believe in some intangible that I cannot show or prove through evidence. This is what I believe it means to have faith - that even if your sports team is doing poorly, you will have *faith* that they can perform in the finals.
I believe this interpretation of faith is reasonable and is consistent with what most people have as the sentiment when they have faith in something. The following parts of my argument relies on this definition of faith, and I will be using it throughout the rest of this essay. If one is to disagree with this definition, then my argument holds no weight to that person.
Then, I now believe in *`P1.2`* that if it is often required to have external beliefs that may not be rooted in evidence, then a total body of evidence can lead to different conclusions. This is a direct result of the definition of faith that I have provided. If faith is the belief in something that is not rooted in evidence, then it is reasonable to say that a total body of evidence can lead to different conclusions. Different parties can have different faiths not rooted in evidence, and thus can arrive at different conclusions. I want to note here that both of these conclusions are *correct*. Of course, people can always come to their own conclusions, but what differentiates them is whether they hold any weight. It is not of interest if there merely exist two conclusions, as long as only one is correct and the rest of somehow flawed. However, having multiple correct conclusions should be considered a point of interest. That is the claim I make here - that faith leads to equally correct interpretations of the data. You cannot say a sports team who is not in the finals is going to win, but you can have faith and conclude that one of the two teams in the finals is going to win.
This leads to counterpoint that this faith cannot be translated into a conclusion or a concrete belief. If you acknowledge that you have faith, you acknowledge that there is some illogical part of your reasoning, and thus it should compel you to conclude that although you might believe a certain way, any other party should view you as being unable to come to any definitive conclusion. I disagree with this point, as I hold the idea that the strength of the idea of faith is that it allows you to do exactly this - come to conclusions that are not rooted in evidence. Thinking about my time with religious friends and family, I have seen this absolute conviction of certainty that faith can provide in the face of insurmountable evidence or lack thereof. This is why I say that faith can lead to different conclusions, and that these conclusions can be equally correct.
*`P1.3`* simply connects these two points together. If faith is the belief in something that is not rooted in evidence, and if it is often required to have external beliefs that may not be rooted in evidence, then a total body of evidence can lead to different conclusions.
I then say in both parts of *`P2`* that Theism and Agnosticism exist in the presence of faith. I don't mean to say that both require faith, although I do believe that Theism does, but rather that they both exist in a reality where faith is a construct that must be considered. I make this point because it is necessary for any conversation about faith. Otherwise there simply exist two frames of reference for different people where Theism and Agnosticism can be reached as a conclusion. I believe it is acceptable to say this because of whether or not you believe in someone's faith, I believe that everyone should conclude the idea of faith should be respected. Again, denying the existence of faith is denying the existence of a construct that is very real to many people.
Therefore, both people who are Theists and Agnostics can have faith in their beliefs. This is not to say that they must have faith, but rather that they can, and both parties should respect that.
*`P2.3`* then concludes that in both Theism and Agnosticism, a total body of evidence can lead to different conclusions. This is a direct result of the previous points I have made. If faith is a construct that is necessary to consider, and if faith can lead to different conclusions, then it is reasonable to say that in both Theism and Agnosticism, a total body of evidence can lead to different conclusions.
Therefore, it must be the case that the same body of total evidence can justify both Theism and Agnosticism. This is the claim I make in *`C`*. If in both Theism and Agnosticism, a total body of evidence can lead to different conclusions, then the same body of total evidence can justify both Theism and Agnosticism.
|
|
https://github.com/Az-21/typst-components
|
https://raw.githubusercontent.com/Az-21/typst-components/main/style/1.0.0/Components/_components.typ
|
typst
|
Creative Commons Zero v1.0 Universal
|
#import "checklist.typ": *
#import "code.typ": *
#import "hyperlink.typ": *
#import "showybox-presets.typ": *
|
https://github.com/ukihot/igonna
|
https://raw.githubusercontent.com/ukihot/igonna/main/articles/computer/pc.typ
|
typst
|
== PCの内容
=== マザーボード
マザーボードは、コンピューターの中核となる基板であり、他のコンポーネントが相互に通信し、協調して動作するための接続ポイントを提供する。
CPU、RAM、ストレージ、グラフィックボードなどのコンポーネントがマザーボードに接続され、それらの間でデータや電力がやり取りされる。
マザーボード上には、CPUソケット、RAMスロット、拡張カードスロット(PCI ExpressやPCI)、ストレージ接続ポート(SATAやM.2)、USBポート、ネットワークポートなどが備わっている。
=== CPU
CPU(Central Processing Unit)は、コンピューターの中央処理装置であり、プログラムの実行やデータの処理を担当する。
命令を解釈して実行し、算術演算や論理演算を行います。コンピューターの性能や処理速度は、CPUの種類やクロック周波数、コア数などによって決まる。
一般的なCPUには、インテルやAMDなどのメーカーから製造されたものがある。
=== グラフィックボード
グラフィックボードは、コンピューターにおいてグラフィック処理を担当する拡張カードである。
高解像度のビデオや3Dグラフィックスを処理するために使用されます。
グラフィックボードには、GPU(Graphics Processing Unit)が搭載されており、画像の描画や処理を高速かつ効率的に行う。
ゲーミングPCやデザインワークステーションなどで高性能なグラフィックボードが利用される。
=== GPU
GPU(Graphics Processing Unit)は、グラフィック処理を担当するプロセッサであり、主に3Dグラフィックスの描画や処理に使用される。
大量の計算を並列処理することが得意であり、グラフィックスだけでなく、科学計算や機械学習などの分野でも利用されます。
NVIDIAやAMDなどのメーカーから、様々な用途に合わせたGPUが提供されている。
=== ストレージ
ストレージは、コンピューター内にデータを保持するための装置である。
一般的なストレージには、HDD(Hard Disk Drive)やSSD(Solid State Drive)がある。
HDDは磁気ディスクを使用してデータを保存し、大容量のデータを格納することができる。
一方、SSDはフラッシュメモリを使用してデータを保存し、高速でアクセスが可能ある。
OSやアプリケーション、ユーザーデータなどを永続的に保存する。
=== RAM
RAM(Random Access Memory)は、コンピューターが実行中のプログラムやデータを一時的に保持するためのメモリである。
CPUがアクセスしやすい高速なメモリであり、データの読み書きが速く行える。
コンピューターの処理速度や多重タスク処理能力に直接影響を与えるため、十分な容量と高速なアクセス速度が要求される。
|
|
https://github.com/yhtq/Notes
|
https://raw.githubusercontent.com/yhtq/Notes/main/常微分方程/作业/2100012990 郭子荀 常微分方程 5.typ
|
typst
|
#import "../../template.typ": proof, note, corollary, lemma, theorem, definition, example, remark, proposition,der, partialDer, Spec
#import "../../template.typ": *
// Take a look at the file `template.typ` in the file panel
// to customize this template and discover how it works.
#show: note.with(
title: "作业4",
author: "YHTQ",
date: none,
logo: none,
withOutlined : false,
withTitle :false,
)
应交时间为 5月6日
#set heading(numbering: none)
= 162
== 3
记初值 $x(0), x'(0)$ 下的解为:
$
phi(t, x(0), x'(0))
$
代入微分方程有:
$
(partial^2 phi)/(partial t^2) + C partialDer(phi, t) + g(phi) = p(t)
$
上式关于 $x(0), x'(0)$ 求偏导,将得到相同形式的方程:
$
u'' + C u' + g'(phi) u = 0
$
其中 $u_1 = partialDer(phi, x(0))$ 或 $u_2 = partialDer(phi, x'(0))$\
此外,显然将有 $u'_1 = partialDer(phi', x(0))$ 或 $u'_2 = partialDer(phi', x'(0))$\
以上两式意味着:
$
Phi'_t &= partialDer((phi(t), phi'(t)), (x(0), x'(0)))\
&= mat(u_1, u_2;u'_1, u'_2)\
det Phi'_t& = u_1 u'_2 - u_2 u'_1 \
(det Phi'_t)' &= u'_1 u'_2 + u_1 u''_2 - u'_1 u'_2 - u_2 u''_1 = u_1 u''_2 - u_2 u''_1\
&= - u_1 (C u'_2 + g'(phi) u_2) + u_2 (C u'_1 + g'(phi) u_1) \
&= - C (u_1 u'_2 - u_2 u'_1) = - C det Phi'_t\
$
上式表明:
$
det Phi'_t = A e^(-C t)
$
其中 $A$ 与 $t$ 无关,代入 $t = 0$ 立得 $A = 1$,因此:
$
det Phi'_t = e^(-C t)
$
将 $t = 2 pi$ 代入立得结论
== 4
== 1
设解为 $phi(x, mu)$,将有:
$
partialDer(partialDer(phi, mu), x) = phi^2 + 2 phi partialDer(phi, mu)\
partialDer(phi, mu) (0, mu) = 1
$
此外,$phi(x, 0)$ 是方程:
$
cases(
y' = 2 x,
y(0) = -1
)
$
的解,因此:
$
phi(x, 0) = x^2 - 1
$
综上,所求 $partialDer(y, mu)|_(mu = 1)$ 是微分方程:
$
cases(
u' = (x^2 - 1)^2 + 2 (x^2 - 1) u,
u(0) = 1
)
$
的解,求解得:
$
u = e^(2/3 x(x^2-3)) (1 + integral_(0)^(x) e^(2/3 t(t^2-3)) (t^2 - 1)^2 dif t )
$
== 2
设 $u = partialDer(y, mu)$ 将有:
$
u'' = 2/y^2 u
$
将 $mu = 1$ 代入原方程,变成:
$
cases(
y'' = 2/x - 2/y,
y(1) = 1,y'(1) = 1
)
$
观察发现 $y = x$ 是方程的一个解。同时,可以将原方程转化成二维的一阶微分方程,进而证明该初值下解是唯一的。\
因此只需解:
$
cases(
u'' = 2/x^2 u,
u(1) = 0,
u'(1) = 1
)
$
解得 $u = (x^3-1)/(3 x)$
= 172
== 1
设 $y(x)$ 满足题中等式,有:
$
y = Phi(x)(Inv(Phi)(x_0) y_0+ integral_(x_0)^(x) Inv(Phi)(s) f(s, y(s)) dif s)\
y' = Phi'(x) (Inv(Phi)(x_0) y_0+ integral_(x_0)^(x) Inv(Phi)(s) f(s, y(s)) dif s) + Phi(x) Inv(Phi)(x) f(x, y(x))\
= Phi'(x) (Inv(Phi)(x_0) y_0+ integral_(x_0)^(x) Inv(Phi)(s) f(s, y(s)) dif s) + f(x, y(x))\
= Phi'(x) Inv(Phi)(x) y + f(x, y(x))\
= A(x) Phi(x) Inv(Phi)(x) y + f(x, y(x))\
= A(x) y + f(x, y(x))
$
因此积分方程的解也是微分方程的解,另一方面设 $y$ 是微分方程的解,则有:
$
(Inv(Phi)(x) y)' = Inv(Phi)'(x) y + Inv(Phi)(x) y' = Inv(Phi)'(x) y + Inv(Phi)(x) (A(x) y + f(x, y))\
= Inv(Phi)'(x) y + Inv(Phi)(x) (Phi'(x) Inv(Phi)(x) y + f(x, y))\
= Inv(Phi)(x) + f(x, y)
$
两边积分即可
== 3
注意到齐次线性微分方程的解应当两两不交,因此当然不能同时为解
== 4
先解 $x$ 将有:
$
x' = 2/t x + 1
$
这是一阶线性微分方程,其解为:
$
x = C_1 t^2 - t
$
因此:
$
y' = 1/t (C_1 t^2 - t) + y\
y' = C_1 t + y - 1
$
其解为:
$
y = C_2 e^t + C_1 (-1-t) e^(-t) + e^(-t)
$
|
|
https://github.com/shiki-01/typst
|
https://raw.githubusercontent.com/shiki-01/typst/main/school/industry/1st_term_1/1_1.typ
|
typst
|
#import "../../../lib/conf.typ": conf, come, desc, light
#import "@preview/codelst:2.0.1": sourcecode
#show: doc => conf(
title: [情報産業と社会 1学期中間],
date: [2024年4月11日],
doc,
)
= 情報産業と社会
== 4章 1節「コンピュータの仕組み」
*ハードウェア*
#image("1_1_1.drawio.svg")
#table(
columns: 2,
table.header(
[名前],[説明]
),
[プログラムカウンタ], [次に実行する命令が入ってくる番地を記憶しておく#light[レジスタ]],
[命令レジスタ],[主記憶装置から取り出した命令とデータを一時的に記憶しておくレジスタ],
[命令デコーダ],[命令を解読する装置],
[汎用レジスタ],[一時的な値の保存を自由に行うことができるレジスタ]
)
#desc("レジスタ")[
CPU内のプログラムやデータを一時的に保存する記憶装置を言う
]
#pagebreak()
#come("時間の単位","info")[
- $"1秒"$ = $"1,000ms"$ = $10^(-3)s$
- $"1ms"$ = $"1,000μs"$ = $10^(-6)s$
- $"1μs"$ = $"1,000ns"$ = $10^(-9)s$
- $"1ns"$ = $"1,000ps"$ = $10^(-12)s$
- $"1ps"$ = $"1,000fs"$ = $10^(-15)s$
- $"1fs"$ = $10^(-18)s$
]
#come("バイトの単位","info")[
- $"1B"$ = $"8bit"$
- $"1KB"$ = $"1,024B"$
- $"1MB"$ = $"1,024KB"$
- $"1GB"$ = $"1,024MB"$
- $"1TB"$ = $"1,024GB"$
- $"1PB"$ = $"1,024TB"$
]
#come("単位一覧","info")[
- $"8bit"$ = $"1B"$
- $"1GHz"$($10^9$) = $"1ns"$
- $"1MIPS"$ = $"1,000,000回/秒"$ = $"1μs"$
]
*メモリの種類*
- メモリ
- RAM - 揮発性
- DRAM (主記憶) - リフレッシュ必要
- SRAM (キャッシュメモリ) - リフレッシュ不要
- ROM - 不揮発性
- マスクROM - 書き換え不可
- PROM - 書き換え可能
- EPROM - 紫外線で消去
- EEPROM - 電気で消去
*色*
RGB(#light("光の三原色"))
0 〜 255 => 255^3 = 16,777,216色
0 〜 f の16進数で色を指定することができる
加法混色
CMY(#light("色の三原色"))
減法混色
#come("三属性","comment")[
#light("色相")・#light("明度")・#light("彩度")
]
色相環で対の位置にある色→補色
無彩色→白・黒・灰のみ
画素(ドット、ピクセル)
1インチ ≒ 2.5cm
*dpiとppm*
#desc("dpi")[
1インチ(≒ 2.5cm)あたりのドット数を表す単位\
プリンターやスキャナーの性能を表す際に使われる\
性能の尺度を#light("解像度")という
]
#desc("ppm")[
プリンターが1分間に印刷できるページ数を表す単位
]
*入出力インターフェース*
#desc("インターフェース")[
異なる種類のものを結びつける際の規格
]
#desc("USB")[
コンピュータに周辺機器を接続する規格\
キーボードやマウス、ディスクドライブ、プリンタ、デジタルカメラなど
]
#desc("HDMI")[
デジタル家電向けんインターフェース\
コンピュータではディスプレイに利用されている\
非圧縮デジタル形式で音声と映像を伝送するため、品質劣化がない
]
#desc("イーサネット")[
LANの有線接続で使用される
]
#desc("Bluetooth")[
短距離無線通信の規格で、2.4GHzの周波数を利用して10m以内で通信を行う
]
#desc("RFID")[
電波を用いることで直接触れることなく情報をやり取りする技術
]
#desc("デバイスドライバ")[
PCから周辺機器を操作するためのソフトウェア
]
#desc("プラグアンドプレイ")[
周辺機器をPCに接続した際に、自動的にデバイスドライバのインストールと設定を行う機能
]
*ソフトウェア*
- システムソフトウェア
- 基本ソフトウェア( OS )
- ミドルウェア
- アプリケーションソフトウェア
#desc("基本ソフトウェア( OS )")[
機械を動かすためのシステム。\
ユーザー個々の識別や権限を管理する。\
周辺機器を操作する#light("ドライバ")を導入することで各種周辺機器を利用する。\
例) Android, iOS, Windows, MacOS, iPadOS, Linux, Unix etc...
]
OS
- CUI(グラフィカル・ユーザー・インターフェース)...グラフィックがあってそれを操作する
- GUI(キャラクター・ユーザー・インターフェース)...コマンド入力で文字で操作する
#desc("マルチタスク")[
複数のプロセスを頻繁に素早く切り替えてそれらのプロセスがあたかも同時に行われているように見せる機能
]
#desc("ミドルウェア")[
基本ソフトウェアアプリケーションソフトウェアの中間に位置する。共通する機能を除いて開発できるので効率的に開発できる。
]
#table(
columns: 2,
table.header[種類][機能],
[DBMS],[データベースのデータの共用やデータの独立性などを管理するシステム],
[TPモニタ],[オンライントランザクション処理などを管理するシステム],
[CASE],[コンピュータによるソフトウェア開発のためのツール]
)
#desc("アプリケーションソフトウェア")[
]
#table(
columns: 2,
table.header[種類][用途],
[ワープロ],[文章の編集や作成を行うソフトウェア],
[表計算],[シートと呼ばれる2次元の表に、数値や文字を入力し、データの収集や分析ができるソフトウェア],
[データベース],[多くのデータを蓄積し、必要に応じてデータの検索、抽出及び加工ができるソフトウェア],
[グラフィックス],[図形や画像を編集したり作成したりするためのソフトウェア。用途によってペイント系(画素単位)、ドロー系(数式)などの種類がある],
[プレゼンテーション],[プレゼンテーション用の資料や企画書などを作成するソフトウェア。簡単な表やグラフを作成する機能を持っている],
[Webブラウザ],[ Webページを閲覧するためのソフトウェア],
)
*フォルダ*
#desc("ルートフォルダ")[一番上にあるフォルダ]
#desc("サブフォルダ")[ルートフォルダの下にあるフォルダ]
#desc("カレントフォルダ")[現在作業しているフォルダ]
#desc("絶対パス")[ルートフォルダから目的とするファイルまでの経路]
#desc("相対パス")[カレントフォルダから目的とするフォルダまでの経路]
- ルートフォルダは表記の始まりに「 / 」または「 ¥ 」で表す
- フォルダの次のフォルダやファイルとの間は「 / 」または「 ¥ 」で区切って表す
- カレントフォルダは「 . 」で表す
- 1階層上のフォルダは「 .. 」で表す
*ファイルの種類*
- 静止画ファイル
- BMP
- JPEG - 非可逆圧縮
- jpg
- jpeg
- PNG - Webでよく使われる - 可逆圧縮
- GIF - 圧縮されるので256色まで - 可逆圧縮
- 動画ファイル
- MPEG - 非可逆圧縮
- 音声ファイル
- MIDI
- MP3 - 非可逆圧縮
バックアップ
it 415
|
|
https://github.com/desid-ms/desid_playground
|
https://raw.githubusercontent.com/desid-ms/desid_playground/main/_extensions/desid/typst-show.typ
|
typst
|
MIT License
|
#show: doc => article(
$if(title)$
title: [$title$],
$if(subtitle)$
subtitle: [$subtitle$],
$endif$
$endif$
$if(by-author)$
authors: (
$for(by-author)$
$if(it.name.literal)$
( name: [$it.name.literal$],
affiliation: [$for(it.affiliations)$$it.name$$sep$, $endfor$],
location: [$it.location$],
role: [$for(it.roles)$$it.role$$sep$, $endfor$],
email: [$it.email$] ),
$endif$
$endfor$
),
$endif$
$if(product)$
product: (
name: [$if(product.name)$$product.name$$else$none$endif$],
project:[$if(product.project)$$product.project$$else$none$endif$],
contract:[$if(product.contract)$$product.contract$$else$none$endif$],
),
$endif$
$if(date)$
date: "$date$",
$endif$
$if(lang)$
lang: "$lang$",
$endif$
$if(region)$
region: "$region$",
$endif$
$if(abstract)$
abstract: [$abstract$],
abstracttitle: "$labels.abstract$",
$endif$
$if(margin)$
margin: ($for(margin/pairs)$$margin.key$: $margin.value$,$endfor$),
$endif$
$if(papersize)$
paper: "$papersize$",
$endif$
$if(mainfont)$
font: ("$mainfont$",),
$endif$
$if(fontsize)$
fontsize: $fontsize$,
$endif$
$if(section-numbering)$
sectionnumbering: "$section-numbering$",
$endif$
$if(toc)$
toc: $toc$,
$endif$
$if(version)$
version: [$version$],
$endif$
$if(first-page-footer)$
first-page-footer: [$first-page-footer$],
$endif$
publisher: $if(publisher)$$publisher$$else$"DESID"$endif$,
documenttype: $if(documenttype)$$documenttype$$else$"Relatório"$endif$,
$if(toc-title)$
toc_title: [$toc-title$],
$endif$
// $if(toc-indent)$
// toc_indent: $toc-indent$,
// $endif$
// toc_depth: $toc-depth$,
// cols: $if(columns)$$columns$$else$1$endif$,
doc,
)
|
https://github.com/lucannez64/Notes
|
https://raw.githubusercontent.com/lucannez64/Notes/master/future.typ
|
typst
|
#import "@preview/bubble:0.1.0": *
#import "@preview/fletcher:0.4.3" as fletcher: diagram, node, edge
#import "@preview/cetz:0.2.2": canvas, draw, tree
#import "@preview/cheq:0.1.0": checklist
#import "@preview/typpuccino:0.1.0": macchiato
#import "@preview/wordometer:0.1.1": *
#import "@preview/tablem:0.1.0": tablem
#show: bubble.with(
title: "future",
subtitle: "12/08/2024",
author: "<NAME>",
affiliation: "EPFL",
year: "2024/2025",
class: "Génie Mécanique",
logo: image("JOJO_magazine_Spring_2022_cover-min-modified.png"),
)
#set page(footer: context [
#set text(8pt)
#set align(center)
#text("page "+ counter(page).display())
]
)
#set heading(numbering: "1.1")
#show: checklist.with(fill: luma(95%), stroke: blue, radius: .2em)
|
|
https://github.com/typst/packages
|
https://raw.githubusercontent.com/typst/packages/main/packages/preview/vercanard/1.0.0/template.typ
|
typst
|
Apache License 2.0
|
#let entry(title, body, details) = [
#heading(level: 2, title)
#body
#text(fill: gray, details)
]
#let resume(name: "", title: "", accent-color: rgb("db9df8"), margin: 100pt, aside: [], body) = {
set page(margin: 0pt, background: place(top + right, rect(fill: accent-color.lighten(80%), width: 33.33333%, height: 100%)))
set text(font: "Inria Sans", size: 12pt)
set block(above: 0pt, below: 0pt)
set par(justify: true)
{
show heading.where(level: 1): set text(size: 40pt)
show heading.where(level: 2): set text(size: 18pt)
box(
fill: accent-color,
width: 100%,
outset: 0pt,
inset: (rest: margin, bottom: 0.4 * margin),
stack(
spacing: 10pt,
heading(level: 1, upper(name)), heading(level: 2, upper(title)))
)
}
show heading: set text(fill: accent-color)
grid(
columns: (2fr, 1fr),
block(outset: 0pt, inset: (top: 0.4 * margin, right: 0pt, rest: margin), stroke: none, width: 100%, {
set block(above: 10pt)
show heading.where(level: 1): it => style(s => {
let h = text(size: 18pt, upper(it))
let dim = measure(h, s)
stack(
dir: ltr,
h,
place(
dy: 7pt,
dx: 10pt,
horizon + left,
line(stroke: accent-color, length: 100% - dim.width - 10pt)
),
)
})
body
}),
{
v(20pt)
set block(inset: (left: 0.4 * margin, right: 0.4 * margin))
show heading: it => align(right, upper(it))
set list(marker: "")
show list: it => {
set par(justify: false)
align(right, block(it))
}
aside
}
)
}
|
https://github.com/timjs/borrow-calculus
|
https://raw.githubusercontent.com/timjs/borrow-calculus/main/calculus.typ
|
typst
|
#let setup = (
font-family: "Lucida", //"Libertinus",
coloured: true,
)
#let setup = if setup.font-family == "Lucida" {
setup + (
body-font: "Lucida Bright OT",
sans-font: "Lucida Sans OT",
math-font: "Lucida Bright Math OT",
font-size: 10pt,
font-leading: 0.85em, //FIXME: change?
)
} else {
setup + (
body-font: "Libertinus Serif",
sans-font: "Libertinus Sans",
math-font: "Libertinus Math",
font-size: 11pt,
font-leading: 0.65em,
)
}
#show math.equation: set text(font: setup.math-font)
#set text(font: setup.body-font, size: setup.font-size)
#set par(leading: setup.font-leading)
#set table(stroke: none)
#let identity(it) = it
#let framed(it) = box(stroke: 1pt, inset: 4pt, it)
#let grayed(it) = {
set text(fill: color.gray)
it
}
#let grammar(name, symbol, ..rules) = align(center, table(
columns: 4,
align: (right, center, left, left),
symbol, $::=$, [], name + ":",
..rules
.pos()
.chunks(2)
.map( ((rule, desc)) => ([], $|$, rule, "– " + desc) )
.flatten()
))
#let constants(name, symbol, ..rules) = align(center, table(
columns: 2,
align: (right, left),
..rules
))
#let rule(name, ..premises, conclusion, condition: []) = {
let premises = premises.pos().join($wide$)
$ #text(smallcaps(name)) space frac(premises, conclusion) space #condition $
}
#let colour(colour, it) = if setup.coloured { text(fill: colour, it) } else { it }
#let input(it) = colour(blue, it)
#let output(it) = colour(red, it)
#let quantities = $cal(Q)$
#let owned(it) = $ceil(it)$
#let borrowed(it) = $floor(it)$
#let synthesize(contextIn, expression, quantity , type, contextOut) = $
input(contextIn) tack.r input(expression) :^input(quantity) output(type) ~> output(contextOut)
$
#let lookup(env, elem, type) = $input(env) forces input(elem) : output(type)$
#let keyword(it) = $sans(bold(#it))$
// #let many(item, amount) = {
// let end = if amount == "" {$thin$} else {$thick$}
// $overline(thin item thin)^amount$
// }
#let more(item) = $overline(thin item thin)$
#let many(item, amount) = $more(item)^amount$
// #let many(item, "n") = $item_1, ..., item_amount$
#let each(it) = $forall_(it)$
#let each(it) = $"for each" it$
#let borrow(args, body) = $""^args {body}$
#let funtion(fvars, pvars, body) = $keyword("fn")^fvars\(pvars\) space body$
#let apply(func, args) = $func\(args\)$
#let tuple(..items) = {
let items = items.pos().join([,])
$\(items\)$
}
#let variant(ctor, num, args) = $ctor^num \(args\)$
#let list(items) = $\[items\]$
#let bind(quant, names, expr, body) = $keyword("let")^quant space \(names\) = expr; space body$
#let match(quant, scrut, arms) = $keyword("match")^quant space scrut space \{arms\}$
//arms.pos().chunks(2).map(((pat, exp)) => pat |-> exp)$
// #let fold(quant, list, accum, var1, var2, body) = $keyword("fold")^quant space list keyword("from") accum keyword("with") var1, var2 |-> body$
#let fold(quant, list, accum, var1, var2, body) = $keyword("fold")^quant space list, accum, {var1, var2 |-> body}$
#let arrow(..from, to) = {
let from = from.pos().join($, space$)
$\(from\) -> to$
// let from = from.pos().join($times$)
// $\(from -> to\)$
}
#let List(type) = $"List"(type)$
#let variants(..items) = {
let items = items.pos().join([,])
$angle.l items angle.r$
}
#let arg(name, quant, type) = $name attach(tr: quant, ":") type$
#let qt(quant, it) = $attach(tl: quant, it)$
= Borrowing calculus
== Metavariables
#stack(
dir: ltr,
spacing: 1fr,
table(
columns: 2,
align: (right, left),
$a$, [],
$b$, [basic values],
$c$, [constants],
$d$, [declarations],
$e$, [expressions],
$f$, [],
$g$, [],
$h$, [],
$i$, [],
$j$, [],
$k$, [],
$l$, [],
$m$, [modules],
$n$, [],
$o$, [],
$p$, [patterns],
$q$, [quantities],
$r$, [],
$s$, [],
$t$, [],
$u$, [],
$v$, [values],
$w$, [],
$x$, [variables],
$y$, [],
$z$, [],
),
table(
columns: 2,
align: (right, left),
$alpha$, [],
$beta$, [],
$gamma$, [],
$delta$, [],
$epsilon$, [()],
$zeta$, [],
$eta$, [],
$theta$, [],
$iota$, [],
$kappa$, [],
$lambda$, [],
$mu$, [],
$nu$, [],
$xi$, [],
$omicron$, [],
$pi$, [],
$rho$, [rows],
$sigma$, [schemas],
$tau$, [types],
$upsilon$, [],
$phi$, [],
$chi$, [],
$psi$, [],
$omega$, [],
)
)
\ We write:
- $many(x, n)$ for an _ordered_ set of $x$es of length $n$, so $x_1, ..., x_n$.
- $more(x)$ for an _unordered_ set of $x$es.
#pagebreak()
== Syntax
#grammar("Expressions", $e$,
$x, y, z$, "variable",
$borrow(many(x, ""), e)$, "borrow",
$funtion(many(z, ""), many(arg(x, q, tau), n), e_0)$, "abstraction",
$apply(e_0, many(e, n))$, "application",
$tuple(many(e, n))$, "tuple",
$bind(q_0, many(x, n), e_0, e)$, "split",
$variant(C, n, many(e, n))$, "variant",
$match(q_0, e_0, many(C^n \(many(x, n)\) |-> e, m))$, "match",
)
#grammar("Values", $v$,
$funtion(many(z, ""), many(arg(x, q, tau), n), e_0)$, "abstraction",
$tuple(many(v, n))$, "tuple",
$variant(C, n, many(v, n))$, "variant",
)
#grammar("Basic values", $b$,
$tuple(many(b, n))$, "tuple",
$variant(C, n, many(b, n))$, "variant",
)
#grammar("Types", $tau$,
$arrow(many(tau^q, n), tau_0)$, "abstraction",
$tuple(many(tau, n))$, "tuple",
$variants(many(C^n (many(tau, n)), m))$, "variant",
$List(tau)$, "list",
)
#grammar("Quantities", $q$,
$epsilon$, "borrowed",
$1$, "linear",
$omega$, "unrestricted",
)
#let shorthands(relation, ..rules) = align(center, table(
columns: 4,
align: (right, center, left, left),
..rules
.pos()
.chunks(3)
.map( ((short, long, description)) => (short, relation, long, "– " + description) )
.flatten()
))
#shorthands($in$,
$mu$, ${epsilon, omega}$, "multiple",
$nu$, ${1, omega}$, "owned",
$pi$, ${epsilon, 1}$, "parameter",
)
#pagebreak()
== Typing
The algorithmic typing rules of $lambda^"borrow"$ are given in @fig-rules.
The typing relation $synthesize(Gamma, e, q, tau, Gamma')$ can be read as
#quote[using expression $e$ with quantity $q$ can make use of all the bindings in context $Gamma$, which yields type $tau$ and a modifed context $Gamma'$.]
#figure(caption: [Typing rules])[$
framed(synthesize(Gamma^+, e^+, q^+, tau^-, Gamma^-))
\
\
bold("Variables")
\
rule("Var"_1,
space,
synthesize(Gamma\, arg(x, 1, tau), x, 1, tau, Gamma),
) quad
rule("Var"_mu,
space,
synthesize(Gamma\, arg(x, mu, tau), x, mu, tau, Gamma\, arg(x, mu, tau)),
condition: mu in {epsilon, omega}
)\
// rule("Weak",
// synthesize(Gamma, x, omega, tau, Gamma),
// synthesize(Gamma, x, 1, tau, Gamma),
// ) quad
rule("Var"_"weak",
space,
synthesize(Gamma\, arg(x, omega, tau) , x, 1, tau, Gamma\, arg(x, omega, tau)),
) quad
rule("Borrow",
synthesize(Gamma_0\, more(arg(x, epsilon, tau) ), e, q, tau, Gamma_1\, more(arg(x, epsilon, tau))),
synthesize(Gamma_0\, more(arg(x, nu, tau)), borrow(more(x), e), q, tau, Gamma_1\, more(arg(x, nu, tau))),
condition: nu in {1, omega}
)\
\
bold("Introduction")
\
rule("Abs",
synthesize(Gamma_0^nu\, many(arg(x, q, tau), n), e_0, owned(q), tau_0, Gamma_1),
synthesize(Gamma_0^epsilon union Gamma_0^nu, funtion("", many(arg(x, q, tau), n), e_0), q,
arrow(many(tau^q, n), tau_0), Gamma_0^epsilon union Gamma_1 without many(x, n)),
condition: exists z in "fv"(e_0) without many(x, n). space arg(z, 1, tau_z) in Gamma_0 => q = 1,
)\
grayed(
rule("Abs",
synthesize(Gamma_0^nu\, arg(x_1, q_1, tau_1), e_0, owned(q), tau_0, Gamma_1),
synthesize(Gamma_0^epsilon union Gamma_0^nu, funtion("", arg(x_1, q_1, tau_1), e_0), q,
arrow(tau_1^(q_1), tau_0), Gamma_0^epsilon union Gamma_1 without x),
condition: exists z in "fv"(e_0) without x_1. space arg(z, 1, tau_z) in Gamma_0 => q = 1,
)\
)
rule("Pair",
each(i in 1..n),
synthesize(Gamma_i, e_i, owned(q), tau_i, Gamma_(i+1)),
synthesize(Gamma_1, tuple(many(e, n)), q, tuple(many(tau, n)), Gamma_(n+1)),
)\
grayed(
rule("Pair",
synthesize(Gamma_1, e_1, owned(q), tau_1, Gamma_2),
synthesize(Gamma_2, e_2, owned(q), tau_2, Gamma_3),
synthesize(Gamma_1, tuple(e_1, e_2), q, tuple(tau_1, tau_2), Gamma_3),
)\
)
rule("Con",
lookup(Delta, C^n, arrow(many(tau, n), tau_0)),
each(i in 1..n),
synthesize(Gamma_i, e_i, owned(q), tau_i, Gamma_(i+1)),
synthesize(Gamma_1, variant(C, n, many(e, n)), q, tau_0, Gamma_(n+1)),
)\
grayed(
rule("Inj",
lookup(Delta, C, arrow(tau_1, tau_0)),
synthesize(Gamma_1, e_1, owned(q), tau_1, Gamma_2),
synthesize(Gamma_1, variant(C, "", e_1), q, tau_0, Gamma_2),
)\
)
\
bold("Elimination")
\
rule("App",
synthesize(Gamma_0, e_0, q, arrow(many(tau^q, n), tau_0), Gamma_1),
each(i in 1..n),
synthesize(Gamma_i, e_i, q_i, tau_i, Gamma_(i+1)),
synthesize(Gamma_0, apply(e_0, many(e, n)), q, tau_0, Gamma_(n+1)),
)\
grayed(
rule("App",
synthesize(Gamma_0, e_0, q, arrow(tau_1^(q_1), tau_0), Gamma_1),
synthesize(Gamma_1, e_1, q_1, tau_1, Gamma_2),
synthesize(Gamma_0, apply(e_0, e_1), q, tau_0, Gamma_2),
)\
)
rule("Let",
synthesize(Gamma_0, e_0, q_0, tuple(many(tau, n)), Gamma_1),
synthesize(Gamma_1\, many(arg(x, q_0, tau), n), e, q, tau, Gamma_2),
synthesize(Gamma_0, bind(q_0, many(x, n), e_0, e), q, tau, Gamma_2 without many(x, n)),
)\
grayed(
rule("Let",
synthesize(Gamma_0, e_0, q_0, tuple(tau_1, tau_2), Gamma_1),
synthesize(Gamma_1\, arg(x_1, q_1, tau_1)\, arg(x_2, q_2, tau_2), e, q, tau, Gamma_2),
synthesize(Gamma_0, bind(q_0, x_1\, x_2, e_0, e), q, tau, Gamma_2 without x_1\, x_2),
)\
)
rule("Match",
synthesize(Gamma_0, e_0, q_0, tau_0, Gamma_1),
each(i in 1..m),
lookup(Delta, C_i^(n_i), arrow(many(tau, n_i), tau_0)),
synthesize(Gamma_1\, many(arg(x, q_0, tau), n_i), e_i, q, tau, Gamma_2 union many(arg(x, q_0, tau), n_i)),
synthesize(Gamma_0, match(q_0, e_0, many(variant(C, n, many(x, n)) |-> e, m)), q, tau, Gamma_2),
)\
grayed(
rule("Match",
synthesize(Gamma_0, e_0, q_0, tau_0, Gamma_1),
each(i in 1..2),
lookup(Delta, C_i, arrow(tau_i, tau_0)),
synthesize(Gamma_1\, arg(x_i, q_0, tau_i), e_i, q, tau, Gamma_2 union arg(x_i, q_0, tau_i)),
synthesize(Gamma_0, match(q_0, e_0, many(variant(C, "", x) |-> e, 2)), q, tau, Gamma_2),
)\
)
// rule("Fold",
// synthesize(Gamma_1, e_1, q_1, list(tau_1), Gamma_2),
// synthesize(Gamma_2, e_2, 1, tau_2, Gamma_3),
// synthesize(Gamma_3\, arg(x_1, q, tau_1)\, arg(x_2, 1, tau_2), e_3, 1, tau, Gamma_4),
// synthesize(Gamma_1, fold(q_1, e_1, e_2, x_1, x_2, e_3), "", tau, Gamma_4),
// )\
$]<fig-rules>
#pagebreak()
=== Helpers
#let function(signature, ..rules) = table(
columns: 3,
align: (left, center, left),
table.cell(colspan: 3, signature),
..rules
.pos()
.chunks(2)
.map( ((pattern, definition)) => (pattern, $=$, definition) )
.flatten()
)
#function($owned(.) : "Quantity" -> "Quantity"$,
$owned(epsilon)$, $1$,
$owned(q)$, $q$,
)
#function($borrowed(.) : "Quantity" -> "Quantity"$,
$borrowed(\_)$, $epsilon$,
)
=== Constants
#let constants(..rules) = table(
columns: 3,
align: (right, center, left),
..rules
.pos()
.chunks(2)
.map( ((name, type)) => (name, $:$, type) )
.flatten()
)
#shorthands(":",
$"fold"_q$, $forall_q. arrow(qt(q, List(tau_1)), qt(1, tau_2), qt(epsilon, arrow(qt(q, tau_1), qt(1, tau_2), tau_2)), tau_2)$, "fold list",
$"Nil"^0_tau$, $List(tau)$, "nil list",
$"Cons"^2$, $arrow(tau, List(tau), List(tau))$, "cons list",
)
#shorthands(":=",
$"Bool"$, $variants("False"^0: (), "True"^0: ())$, "boolean type",
$"Option"(tau)$, $variants("None"^0: (), "Some"^1: tau)$, "option type",
$"Result"(tau_1, tau_2)$, $variants("Wrong"^1: tau_1, "Right"^1: tau_2)$, "either type",
)
#pagebreak()
== Tests
#lorem(250)
$|space.med|space.hair|space.thin|space.sixth|space.quarter|space.third|space.en|space.quad|$
$\
|space| \
|space.quad| 1\
|space.en space.en| 2\
|space.third space.third space.third| 3\
|space.quarter space.quarter space.quarter space.quarter| 4\
|space.sixth space.sixth space.sixth space.sixth space.sixth space.sixth| 6\
$
$\
|thin|med|thick|quad|wide| \
|wide| "wide = 2 quad"\
|quad| "quad"\
|thick thick thick| "3 thick"\
|med med med med| "4 med"\
|thin thin thin thin thin thin| "6 thin"\
|quad| "quad"\
$
$
Gamma_0 union Gamma_1 without Gamma_2 \
Gamma_0 union.double Gamma_1 backslash Gamma_2 \
Gamma_0 union.double Gamma_1 slash.double Gamma_2 \
Gamma_0 union.plus Gamma_1 union.minus Gamma_2 \
Gamma_0 plus Gamma_1 minus Gamma_2 \
Gamma_0 plus.circle Gamma_1 minus.circle Gamma_2 \
Gamma_0 plus.circle Gamma_1 backslash.circle Gamma_2 \
Gamma_0 compose Gamma_1 div Gamma_2 \
$
|
|
https://github.com/francescoo22/kt-uniqueness-system
|
https://raw.githubusercontent.com/francescoo22/kt-uniqueness-system/main/src/annotation-system/rules/base.typ
|
typst
|
#import "../../proof-tree.typ": *
#import "../../vars.typ": *
// ****************** General ******************
#let M-Type = prooftree(
axiom($m(alpha_0 beta_0 x_0, ..., alpha_n beta_n x_n): alpha {begin_m; overline(s); ret_m e}$),
rule(label: "M-Type", $mtype(m) = alpha_0 beta_0, ..., alpha_n beta_n -> alpha$),
)
#let M-Args = prooftree(
axiom($m(alpha_0 beta_0 x_0, ..., alpha_n beta_n x_n): alpha {begin_m; overline(s); ret_m e}$),
rule(label: "M-Args", $args(m) = x_0, ..., x_n$),
)
// ****************** Context ******************
#let Not-In-Base = prooftree(
axiom(""),
rule(label: "Not-In-Base", $p in.not dot$),
)
#let Not-In-Rec = prooftree(
axiom($p != p'$),
axiom($p in.not Delta$),
rule(n:2, label: "Not-In-Rec", $p in.not (p' : alpha beta, Delta)$),
)
#let Root-Base = prooftree(
axiom(""),
rule(label: "Root-Base", $root(x) = x$),
)
#let Root-Rec = prooftree(
axiom($root(p) = x$),
rule(label: "Root-Rec", $root(p.f) = x$),
)
#let Ctx-Base = prooftree(
axiom(""),
rule(label: "Ctx-Base", $dot ctx$),
)
#let Ctx-Rec = prooftree(
axiom($Delta ctx$),
axiom($p in.not Delta$),
rule(n:2, label: "Ctx-Rec", $p: alpha beta, Delta ctx$),
)
#let Lookup-Base = prooftree(
axiom($(p: alpha beta, Delta) ctx$),
rule(label: "Lookup-Base", $(p: alpha beta, Delta) inangle(p) = alpha beta$),
)
#let Lookup-Rec = prooftree(
axiom($(p: alpha beta, Delta) ctx$),
axiom($p != p'$),
axiom($Delta inangle(p') = alpha' beta'$),
rule(n:3, label: "Lookup-Rec", $(p: alpha beta, Delta) inangle(p') = alpha' beta'$),
)
#let Lookup-Default = prooftree(
axiom($type(p) = C$),
axiom($class C(overline(f': alpha'_f), f: alpha, overline(f'': alpha''_f))$),
rule(n:2, label: "Lookup-Default", $dot inangle(p.f) = alpha$),
)
// #let In = prooftree(
// axiom($root(p) = x$),
// axiom($Delta inangle(x) = alpha beta$),
// rule(n:2, label: "In", $p in Delta$),
// )
#let Remove-Empty = prooftree(
axiom(""),
rule(label: "Remove-Empty", $dot without p = dot$),
)
#let Remove-Base = prooftree(
axiom(""),
rule(label: "Remove-Base", $(p: alpha beta, Delta) without p = Delta$),
)
#let Remove-Rec = prooftree(
axiom($Delta without p = Delta'$),
axiom($p != p'$),
rule(n:2, label: "Remove-Rec", $(p': alpha beta, Delta) without p = p': alpha beta, Delta'$),
)
#let SubPath-Base = prooftree(
axiom(""),
rule(label: "SubPath-Base", $p subset.sq p.f$),
)
#let SubPath-Rec = prooftree(
axiom($p subset.sq p'$),
rule(label: "SubPath-Rec", $p subset.sq p'.f$),
)
#let SubPath-Eq-1 = prooftree(
axiom($p = p'$),
rule(label: "SubPath-Eq-1", $p subset.sq.eq p'$),
)
#let SubPath-Eq-2 = prooftree(
axiom($p subset.sq p'$),
rule(label: "SubPath-Eq-2", $p subset.sq.eq p'$),
)
#let Remove-SupPathsEq-Empty = prooftree(
axiom(""),
rule(label: "Remove-SupPathsEq-Empty", $dot minus.circle p = dot$),
)
#let Remove-SupPathsEq-Discard = prooftree(
axiom($p subset.sq.eq p'$),
axiom($Delta minus.circle p = Delta'$),
rule(n:2, label: "Remove-SupPathsEq-Discard", $(p': alpha beta, Delta) minus.circle p = Delta'$),
)
#let Remove-SupPathsEq-Keep = prooftree(
axiom($p subset.not.sq.eq p'$),
axiom($Delta minus.circle p = Delta'$),
rule(n:2, label: "Remove-SupPathsEq-Keep", $(p': alpha beta, Delta) minus.circle p = (p': alpha beta, Delta')$),
)
#let Replace = prooftree(
axiom($Delta minus.circle p = Delta'$),
rule(label: "Replace", $Delta[p |-> alpha beta] = Delta', p: alpha beta$),
)
#let Get-SupPaths-Empty = prooftree(
axiom(""),
rule(label: "Get-SupPaths-Empty", $dot tr sp(p) = dot$),
)
#let Get-SupPaths-Discard = prooftree(
axiom($not (p subset.sq p')$),
axiom($Delta tr sp(p) = p_0 : alpha_0 beta_0, ..., p_n : alpha_n beta_n$),
rule(n: 2, label: "Get-SupPaths-Discard", $p': alpha beta, Delta tr sp(p) = p_0 : alpha_0 beta_0, ..., p_n : alpha_n beta_n$),
)
#let Get-SupPaths-Keep = prooftree(
axiom($p subset.sq p'$),
axiom($Delta tr sp(p) = p_0 : alpha_0 beta_0, ..., p_n : alpha_n beta_n$),
rule(n: 2, label: "Get-SupPaths-Keep", $p': alpha beta, Delta tr sp(p) = p': alpha beta, p_0 : alpha_0 beta_0, ..., p_n : alpha_n beta_n$),
)
// ************ Get ************
#let Get-Var = prooftree(
axiom($Delta inangle(x) = alpha beta$),
rule(label: "Get-Var", $Delta(x) = alpha beta$)
)
#let Get-Path = prooftree(
axiom($Delta(p) = alpha beta$),
axiom($Delta inangle(p.f) = alpha'$),
rule(n: 2, label: "Get-Path", $Delta(p.f) = Lub{alpha beta, alpha'}$)
)
#let Std-Empty = prooftree(
axiom(""),
rule(label: "Std-Empty", $dot tr std(p, alpha beta)$),
)
#let Std-Rec-1 = prooftree(
axiom($not (p subset.sq p')$),
axiom($Delta tr std(p, alpha beta)$),
rule(n:2, label: "Std-Rec-1", $p' : alpha beta, Delta tr std(p, alpha beta)$),
)
#let Std-Rec-2 = prooftree(
axiom($p subset.sq p'$),
axiom($root(p) = x$),
axiom($(x : alpha beta) (p') = alpha'' beta''$),
axiom($alpha' beta' rel alpha'' beta''$),
axiom($Delta tr std(p, alpha beta)$),
rule(n:5, label: "Std-Rec-2", $p' : alpha' beta', Delta tr std(p, alpha beta)$),
)
|
|
https://github.com/Myriad-Dreamin/shiroa
|
https://raw.githubusercontent.com/Myriad-Dreamin/shiroa/main/github-pages/docs/format/supports.typ
|
typst
|
Apache License 2.0
|
#import "/github-pages/docs/book.typ": book-page
#show: book-page.with(title: "Typst Supports")
In this section you will learn how to:
- Make a cross reference in the same page or to other pages.
- Embed HTML elements into the pages:
- `html-ext.iframe` corresponds to a ```html <iframe/>``` element
- Specifically, embed multimedia elements:
- `html-ext.video` corresponds to a ```html <video/>``` element
- `html-ext.audio` corresponds to a ```html <audio/>``` element
|
https://github.com/jamesrswift/pixel-pipeline
|
https://raw.githubusercontent.com/jamesrswift/pixel-pipeline/main/src/layers/drawing/layer.typ
|
typst
|
The Unlicense
|
#let _validate(input, output, next, enabled: false) = {
next(input, output)
}
#let _vertex(input, output, next) = {
if "draw" not in input.tags {return next(input, output)}
// Polygon
if "polygon" in input.tags {
return next(input, output)
}
}
#let _render(input, output, next) = {
if "draw" not in input.tags {return next(input, output)}
if "polygon" in input.tags {
return input + (:
content: polygon(
..input.positions.pos().map(pos=>pos.position),
fill: input.at("fill", default: none),
stroke: input.at("stroke", default: auto)
)
)
}
}
#let _layout(input, output, next) = {
if "draw" not in input.tags {return next(input, output)}
return input
}
#let layer(
validation: false
) = (:
validation: _validate.with(enabled: validation),
// input-assembler: input-assembler,
// compute: compute,
vertex: _vertex,
render: _render,
layout: _layout,
)
|
https://github.com/remigerme/typst-polytechnique
|
https://raw.githubusercontent.com/remigerme/typst-polytechnique/main/template/report.typ
|
typst
|
MIT License
|
#import "@preview/typographix-polytechnique-reports:0.1.4" as template
// Defining variables for the cover page and PDF metadata
// Main title on cover page
#let title = [Rapport de stage en entreprise
#linebreak()
sur plusieurs lignes]
// Subtitle on cover page
#let subtitle = "Un sous-titre pour expliquer ce titre"
// Logo on cover page
#let logo = none // instead of none set to image("path/to/my-logo.png")
#let logo-horizontal = true // set to true if the logo is squared or horizontal, set to false if not
// Short title on headers
#let short-title = "Rapport de stage"
#let author = "<NAME>"
#let date-start = datetime(year: 2024, month: 06, day: 05)
#let date-end = datetime(year: 2024, month: 09, day: 05)
// Set to true for bigger margins and so on (good luck with your report)
#let despair-mode = false
#set text(lang: "fr")
// Set document metadata
#set document(title: title, author: author, date: datetime.today())
#show: template.apply.with(despair-mode: despair-mode)
// Cover page
#template.cover.cover(title, author, date-start, date-end, subtitle: subtitle, logo: logo, logo-horizontal: logo-horizontal)
#pagebreak()
// Acknowledgements
#heading(level: 1, numbering: none, outlined: false)[Remerciements]
#lorem(250)
#pagebreak()
// Executive summary
#heading(level: 1, numbering: none, outlined: false)[Executive summary]
#lorem(300)
#pagebreak()
// Table of contents
#outline(title: [Template contents], indent: 1em, depth: 2)
// Defining header and page numbering (will pagebreak)
#show: template.page.apply-header-footer.with(short-title: short-title)
// Introduction
#heading(level: 1, numbering: none)[Introduction]
#lorem(400)
#pagebreak()
// Here goes the main content
= Premier titre
== Un sous-titre
#lorem(30)
=== Un détail pas si inutile
==== Halte au sketch
#lorem(20)
=== Encore un autre décidément
#lorem(120)
==== Il en faut toujours plus
#lorem(80)
== L'inspiration se fait rare
Ne pas oublier d'expirer surtout. #lorem(20)
#lorem(35)
#pagebreak()
= Deuxième partie
#lorem(300)
#pagebreak()
= Troisième axe
Parce qu'on a beaucoup de choses à dire et qu'on en a gros.
#pagebreak()
// Conclusion
#heading(level: 1, numbering: none)[Conclusion]
#lorem(200)
// Bibliography (if necessary)
// #pagebreak()
// #bibliography("path-to-file.bib")
|
https://github.com/Error-418-SWE/Documenti
|
https://raw.githubusercontent.com/Error-418-SWE/Documenti/src/1%20-%20Candidatura/Lettera%20di%20presentazione/Lettera%20di%20presentazione.typ
|
typst
|
#block[
ERROR\_418 \
DOCUMENTAZIONE PROGETTO \
#block[
#figure(
align(center)[#table(
columns: 2,
align: (col, row) => (left,left,).at(col),
inset: 6pt,
[Mail:],
[<EMAIL>],
[Redattori:],
[<NAME>, <NAME>],
[Verificatori:],
[<NAME>, <NAME>, <NAME>],
[Amministratori:],
[<NAME>, <NAME>],
[Destinatari:],
[<NAME>, <NAME>],
)]
)
]
]
Con la presente, il gruppo Error\_418 intende comunicarVi la volontà di
candidarsi e impegnarsi nello sviluppo e realizzazione del capitolato
denominato:
#block[
#strong[WMS3: warehouse management 3D]
]
proposto dall’azienda Sanmarco Informatica. La documentazione relativa
ai verbali interni ed esterni redatti e all’analisi e valutazione
complessiva di tutti i capitolati è reperibile al link:
#block[
#link("https://github.com/Error-418-SWE/Documenti/tree/main")
]
All’interno della repository sarà possibile trovare:
- Analisi e valutazione dei capitolati con motivazioni che hanno portato
alla scelta corrente;
- Preventivo dei costi con annessa suddivisione degli impegni totali e
individuali;
- Verbali interni:
- 17-10-2023;
- 18-10-2023;
- 21-10-2023;
- 25-10-2023;
- 26-10-2023;
- 29-10-2023;
- 30-10-2023.
- Verbali esterni con l’azienda:
- 26-10-2023.
All’interno del documento dedicato, è preventivato il costo stimato alla
realizzazione del prodotto, valore individuato a 13.580,00 € con data di
consegna prevista entro il 20-03-2023.
#figure(
align(center)[#table(
columns: 3,
align: (col, row) => (left,left,left,).at(col),
inset: 6pt,
[Nome], [Matricola], [Ruolo],
[<NAME>],
[2042381],
[Validatore],
[<NAME>],
[2042346],
[Redattore],
[<NAME>],
[2010003],
[Validatore],
[<NAME>],
[1222011],
[Redattore],
[<NAME>],
[1226325],
[Validatore],
[<NAME>],
[1193375],
[Validatore],
[<NAME>],
[2043680],
[Validatore],
)]
, caption: [Membri del gruppo]
)
Cordiali saluti, \
#emph[Error\_418] - Gruppo 7 di Ingegneria del Software
|
|
https://github.com/ralphmb/typst-template-stats-dissertation
|
https://raw.githubusercontent.com/ralphmb/typst-template-stats-dissertation/main/presentation/pres.typ
|
typst
|
Apache License 2.0
|
#import "@preview/polylux:0.3.1": *
#set page(paper: "presentation-16-9")
#set text(size: 25pt)
#import themes.clean: *
#set text(font: "Inria Sans")
#show table: set text(20pt)
#set table(align:right)
#show: clean-theme.with(
footer: [<NAME>, Coventry University],
)
#title-slide(
title: [Project Title],
authors:[<NAME>],
date:[Jan 1 1970]
)
#new-section-slide("Introduction")
#slide(title:[Project Aims])[
- The quick brown fox
- jumped over the
- lazy dog
]
#slide()[
#side-by-side[
== Here's a plot
- Check it out
][
#figure(
image("./assets/contourplot_logistic.png", fit:"contain")
)
]
]
|
https://github.com/ice1000/website
|
https://raw.githubusercontent.com/ice1000/website/main/index.typ
|
typst
|
#import "/book.typ": book-page
#show: book-page.with(title: "<NAME>")
= Tesla (<NAME>
I am a second-year Ph.D. student in the #link("https://www.csd.cs.cmu.edu")[Computer Science Department] at CMU,
advised by Professor #link("https://www.cs.cmu.edu/~balzers")[<NAME>].
My personal interests include implementing type checkers for dependent type theories,
making fancy programming language tools, programming language design,
and thinking about type theories from a category theoretical point of view.
Some links: #link("https://orcid.org/0000-0002-9050-846X")[ORCiD], #link("https://github.com/ice1000")[GitHub],
#link("https://arxiv.org/a/zhang_t_4")[arXiv], #link("https://www.aya-prover.org")[Aya Prover].
== Coordinates
- My email is teslaz [at] cmu [dot] edu.
- My office is in the Gates--Hillman Center, floor 5, 5103 (need ID access outside business hours).
== Collaborators
- My advisor: logical relations for session type theories.
- #link("https://chasenorman.com")[Chase Norman]: automated theorem proving for dependent type theories (#link("https://chasenorman.com/demo.html")[online demo]).
This website is under construction, stay tuned!
|
|
https://github.com/Ttajika/class
|
https://raw.githubusercontent.com/Ttajika/class/main/seminar2024/quiz_bank.typ
|
typst
|
#import "functions.typ": *
#import "@preview/cetz:0.2.2"
#import "@preview/codly:1.0.0": *
#set text(font: "<NAME>",lang:"jp")
#show strong: set text(font: "<NAME>", lang:"jp")
#show raw: set text(font:"<NAME>")
//see https://typst.app/docs/reference/foundations/calc
Quiz_createで問題のリストを作成する. Quiz = Quiz_createとするとQuizが問題のリストを格納する変数
- quiz関数で,形式に合った問題を作成する. 以下その各種引数の説明
- 最初の引数はid: これがラベルにもなるので,問題を引用するときは @Q2 のようにできる.回答のラベルはAをつけて @Q2A
- なので別のidにAをつけたものをidにするとラベルが重複しエラーが出るので注意.
- question: 問題文. [] の中に入力する
- answer: 解答. [] の中に入力する
- commentary: 解説. [] の中に入力する
- point: 配点. 整数を入力する. 合計点を計算するシステムは未実装.
#let Quiz = Quiz_create(
// quiz("Q1", question:[
// 各プレイヤーが,5つの戦略を持つゲームを書きなさい.
// ], answer:[
// ], point:3, show-answer:true, category:"Term1"),
// quiz("Q2", question:[
// 3人のプレイヤーがいるゲームの利得表を書きなさい.
// ], answer:[
// ], point:3, show-answer:true, category:"Term1"),
quiz("Q3", question:[
次のゲームの弱支配戦略・強支配戦略を見つけなさい.
+ #Ngame(("A","B"),
(("U","D"),("L","R")),
(([1,3],[2,6]),
([3,2],[2,3])
)
)
+ #Ngame(("A","B"),
(("U","D"),("L","R")),
(([3,6],[2,6]),
([3,4],[2,4])
)
)
+ #Ngame(("A","B"),
(("U","M", "D"),("L","C","R")),
(([1,3],[2,6],[2,3]),
([3,2],[1,3],[2,3]),
([2,1],[2,3],[3,2])
)
)
], answer:[
], point:5, show-answer:true, category:"Term1"),
quiz("Q4", question:[
次のゲームの支配される戦略の逐次的消去によって残る戦略の組をすべてみつけなさい.
+ #Ngame(("A","B"),
(("U","D"),("L","R")),
(([1,3],[2,6]),
([3,2],[2,3])
)
)
+ #Ngame(("A","B"),
(("U","M", "D"),("L","C","R")),
(([1,3],[2,6],[2,3]),
([3,2],[1,3],[2,3]),
([2,1],[2,3],[3,2])
)
)
+ #Ngame(("A","B"),
(("A1","A2", "A3", "A4", "A5", "A6"),("B1","B2","B3","B4","B5", "B6","B7")),
(([5,3],[2,3],[2,6],[3,5],[2,6],[1,1],[2,2]),
([3,2],[3,4],[5,3],[4,1],[3,2],[3,2],[3,3]),
([5,3],[2,5],[5,4],[2,3],[3,9],[2,3],[3,10]),
([3,2],[4,4],[4,3],[5,2],[4,3],[9,5],[5,3]),
([1,2],[5,5],[3,3],[2,4],[3,4],[4,6],[6,4]),
([3,1],[2,3],[4,2],[6,1],[1,1],[2,5],[3,4])
)
)
], answer:[
], point:5, show-answer:true, category:"Term1"),
quiz("Q5", question:[
次のゲームの純粋戦略ナッシュ均衡の組をすべてみつけなさい.
+ #Ngame(("A","B"),
(("U","D"),("L","R")),
(([1,3],[2,6]),
([3,2],[2,3])
)
)
+ #Ngame(("A","B"),
(("U","D"),("L","R")),
(([3,6],[2,6]),
([3,4],[2,4])
)
)
+ #Ngame(("A","B"),
(("U","M", "D"),("L","C","R")),
(([1,3],[2,6],[2,3]),
([3,2],[1,3],[2,3]),
([2,1],[2,3],[3,2])
)
)
+ #Ngame(("A","B"),
(("A1","A2", "A3", "A4", "A5", "A6"),("B1","B2","B3","B4","B5", "B6","B7")),
(([5,3],[2,3],[2,6],[3,5],[2,6],[1,1],[2,2]),
([3,2],[3,4],[5,3],[4,1],[3,2],[3,2],[3,3]),
([5,3],[2,5],[5,4],[2,3],[3,9],[2,3],[3,10]),
([3,2],[4,4],[4,3],[5,2],[4,3],[9,5],[5,3]),
([1,2],[5,5],[3,3],[2,4],[3,4],[4,6],[6,4]),
([3,1],[2,3],[4,2],[6,1],[1,1],[2,5],[3,4])
)
)
], answer:[
], point:5, show-answer:true, category:"Term1"),
quiz("Q5.5", question:[
@Q5 で求めたナッシュ均衡がパレート効率的かどうかそれぞれ調べなさい.
], point:6, show-answer:true, category:"Term1"),
quiz("Q6", question:[
N人鹿狩りゲームの変形版として,次のゲームを考える.
- 参加者が$k$人以上であれば, 参加者は 利得$10$を得る.不参加者は利得$0$を得る.
- 参加者が$k$人より少なければ,参加者も不参加者も利得は0である.
+ このゲームのナッシュ均衡を全て求めなさい.
+ どのような状況がこのゲームに当てはまるだろうか?考えなさい.
], commentary:[
参加者が$ell$人のとき,次の2点を確かめる.(1) 参加していないプレイヤーが参加したがるか (2) 参加しているプレイヤーが参加したがらないか
], point:8, show-answer:true, category:"Term1"),
quiz("Q7", question:[
N人鹿狩りゲームの変形版として,次のゲームを考える.
- 参加者が$k$人以上であれば, 参加者は利得$10$を得る.不参加者は利得$20$を得る.
- 参加者が$k$人より少なければ,参加者も不参加者も利得は0である.
+ このゲームのナッシュ均衡を全て求めなさい.
+ どのような状況がこのゲームに当てはまるだろうか?考えなさい.
], commentary:[
参加者が$ell$人のとき,次の2点を確かめる.(1) 参加していないプレイヤーが参加したがるか (2) 参加しているプレイヤーが参加したがらないか
], point:8, show-answer:true, category:"Term1"),
quiz("Q7.5", question:[
2プレイヤー・2戦略のゲームを Rgamer を用いて1000個作成し,純粋戦略ナッシュ均衡の存在する割合を計算しなさい.ただし,利得はランダムにすること.
], commentary:[
- ループを使う.例えば次のようにすると,1から1000まで, {}の中身を繰り返す.{}の中身にゲームを生成し,ナッシュ均衡を求めるコードを入れる.
```R
N <- 1000 #Nは繰り返しの数である.
for (i in 1:N){
...
game <- ...
game_sol <- ...
...
}
```
...のところには適切なコードが入るものとする(この部分を自身で考える).
- ランダムな4つの成分を持つベクトルを出力するには例えば以下のようにする.
```R
payoff1 <- runif(4, min = 1, max = 100)
```
これにより,1から100までのランダムな実数を4つ生成するベクトルをpayoff1に代入できる.
- ナッシュ均衡が存在しない場合,それを出力するコードはNULLを出力する.その場合は
```R
if (is.null(game_sol$psNE) {
x <- x + 1
}
```
このようにすれば,NULLが発生するたびに,xという変数に1を足していくというコードになる.つまり,ナッシュ均衡が存在しないゲームの数を数え上げることになる.
], point:8, show-answer:true, category:"Term1"),
quiz("Q7.8", question:[
2プレイヤー・2戦略のゲームを Rgamer を用いて1000個作成し,パレート効率的な純粋戦略ナッシュ均衡が存在する割合を計算しなさい.
ただし,利得はランダムにすること.
], commentary:[
パレート最適かどうかをチェックするには以下の関数を定義する.このコードでは,与えられたナッシュ均衡がパレート効率的であればTRUEを,そうでなければFALSEを出力する関数(`isPareto`)を作成している.
```R
#引数はゲームとナッシュ均衡. これはrgamerを用いて求める.
isPareto <- function(game, NE) {
m <- length(game$df$s1) #mは戦略の組み合わせの総数
Num <- NULL
# NEのインデックスを探す
for (i in 1:m) {
g <- paste0("[", game$df[i, 3], ", ", game$df[i, 4], "]")
if (g == NE) {
Num <- i
break #breakはループを打ち切る命令
}
}
# Numが見つからない場合のエラーハンドリング
if (is.null(Num)) {
stop("NEが見つかりません")
}
#NEpayoffはナッシュ均衡における利得
#NEpayoff[1]がプレイヤー1の,NEpayoff[2]がプレイヤー2の利得
NEpayoff <- c(game$df$payoff1[Num], game$df$payoff2[Num])
# パレート最適性のチェック
# jは戦略組の番号
for (j in 1:m) {
cond1 <- all(game$df$payoff1[j] >= NEpayoff[1], game$df$payoff2[j] >= NEpayoff[2])
cond2 <- any(game$df$payoff1[j] > NEpayoff[1], game$df$payoff2[j] > NEpayoff[2])
# 両方の条件が満たされた場合
if (cond1 && cond2) {
print("is Not Pareto")
return(TRUE)
break #breakはループを打ち切る命令
}
}
print("is Pareto")
return(FALSE)
}
```
], point:10, show-answer:true, category:"Term1"),
quiz("Q7.4", question:[
2プレイヤー・2戦略のゲームを Rgamer を用いて1000個作成し,強支配戦略均衡の存在する割合を計算しなさい.ただし,利得はランダムにすること.], point:8),
quiz("Q8", question:[
次のゲームの混合戦略ナッシュ均衡を求めなさい.
#Ngame(("A","B"),
(("U","D"),("L","R")),
(([4,6],[2,1]),
([3,2],[4,4])))
], answer:[
], point:7, show-answer:true, category:"Term1"),
quiz("Q9", question:[
次のゲームの混合戦略ナッシュ均衡を求めなさい.
#Ngame(("A","B"),
(("U","D"),("L","R")),
(([$a,e$],[$d,f$]),
([$b,h$],[$c,g$])))
ただし,$a>b$, $c>d$, $e>f$, $g>h$ であるとする.
], answer:[
], point:9, show-answer:true, category:"Term1"),
quiz("Q11", question:[
次のゲームは査察ゲームという.
#Ngame(("査察官","旅行者"),
(("調査する","調査しない"),("危険物を持ち込む","持ち込まない")),
(([$-c,-z$],[$-c,0$]),
([$-d,a$],[$0,0$])))
ただし,$a,d,c,z>0$ かつ $d>c$であるとする.つまり,$a$は持ち込みの利益,$z$は罰則の重さ,$d$は持ち込まれたことによる被害,$c$は調査の費用である.
+ $a,d,c,z$に適当な数字を入れ,混合戦略ナッシュ均衡を求めなさい.
+ 1で入れた数字について,$a$の値を増やしたとき,危険物を持ち込む確率はどう変化するか? ほかの$d,c,z$についてもそれぞれ同じことを考えなさい.
], answer:[
], point:10, show-answer:true, category:"Term1"),
quiz("Q9.5", question:[
次のゲームの混合戦略ナッシュ均衡をすべて求めなさい.
#Ngame(("A","B"),
(("U","D"),("L","M","R")),
(([$1,3$],[$0,2$],[$1,1$]),
([$0,1$],[$1,2$],[0,3])))
], answer:[
], point:15, show-answer:true, category:"Term1"),
quiz("Q10", question:[
次のゲームを考える.
- 参加者が $k$ 人以上であれば, 参加者は利得$10$を得る.不参加者は利得$20$を得る.
- 参加者が $k$ 人より少なければ,参加者も不参加者も利得は0である.
- 人の数は $n$ である.
このゲームの混合戦略ナッシュ均衡を考えるために次に答えなさい.
+ 参加者が $k-2$ 人以下であることが予想されるとき,ある一人が参加することで利益が増えるかどうか答えなさい.
+ 参加者が $k$ 人以上であることが予想されるとき,ある一人が参加することで利益が増えるかどうか答えなさい.
+ ある一人が参加する確率が $r$ であるとき,参加者が $k-1$ 人である確率を求めなさい.
+ ある一人が参加する確率が $r$ であるとき,参加することと参加しないことが無差別になるような $r$ の値を求めなさい.
+ 混合戦略ナッシュ均衡における,一人が参加する確率 $r$ を求めなさい.
], answer:[
], point:9, show-answer:true, category:"Term1", commentary:[$n$ 人中 $k$ 人が参加する確率は $attach(C,bl:n,br:k) = (n!)/((n-k)!k!)$である.]),
quiz("Q12", question:[
クールノー競争を考える.逆需要曲線が $P(x)=100-x$ であるとし,企業1の費用が$10$, 企業2の費用が $c$ であるとする.
+ $c=10$のときのナッシュ均衡を求めなさい.
+ $c$を増加させていったとき,ナッシュ均衡における企業2の生産量が$0$になるような最小の値を求めなさい.
], answer:[
], point:8, show-answer:true, category:"Term1"),
quiz("Q13", question:[
次のゲームは差別化ベルトラン競争と呼ばれるものの一種である.
$
pi_1(p_1,p_2)= (D-p_1+1/2 p_2) times (p_1-c_1)\
pi_2(p_1,p_2)= (D+1/2 p_1- p_2)times (p_2-c_2)
$
+ $D, c_1,c_2$に適当な数値を代入し,このゲームのナッシュ均衡を求めなさい.
+ $D$の値が増えたとき,ナッシュ均衡はどう変化するか答えなさい.$c_1,c_2$がそれぞれ増えたときについてもそれぞれ答えなさい.
], answer:[
], point:8, show-answer:true, category:"Term1"),
quiz("Q14", question:[
後出しジャンケンのゲームの木を描きなさい
], answer:[
], point:6, show-answer:true, category:"Term1"),
quiz("Q14.1", question:[
二目並べのゲームの木を描きなさい.ただし,以下のマスの上で行われるとする.
#align(center)[
#cetz.canvas({
import cetz.draw: *
rect((0,0),(2,2))
rect((0,0),(1,1))
rect((1,1),(1,2))
rect((1,2),(2,1))
content((.5,.5),[a])
content((.5,1.5),[b])
content((1.5,.5),[d])
content((1.5,1.5),[c])
})]
], answer:[
], point:6, show-answer:true, category:"Term1"),
quiz("Q14.2", question:[
三目並べ (tick-tack-toe) のゲームの木を答えなさい.ただし,以下のマスの上で行われるとする.
#align(center)[
#cetz.canvas({
import cetz.draw: *
rect((0,0),(3,3))
for j in (0,1,2) {
for i in (0,1,2){
rect((0+j,0+i),(1+j,1+i))
content((0.5+j,0.5+i),[#numbering("a",i+3*j+1)])
}
}
})]
], answer:[
], point:12, show-answer:true, category:"Term1"),
quiz("Q15", question:[
次のゲームの木で表されるゲーム(*ムカデゲーム*)のバックワードインダクションによる解を求めなさい.
#align(center)[
#cetz.canvas({
import cetz.draw: *
line((0,0),(10,0), mark:(end:"straight"))
for i in range(5){
line((2*i,0),(2*i,-1.5), mark:(end:"straight"))
circle((2*i,0),radius: 1mm, fill:white)
let name = {
if calc.odd(i+1) {1} else {2} }
let payoff1 = {
i+2 - 2*name
}
let payoff2 = {
i + 3- 4/name
}
content((2*i,0),[P#name],padding:(y:4mm), anchor:"south")
content((2*i+1,-0.2),[C],padding:(y:4mm), anchor:"south")
content((2*i +.2,-1.2),[D],padding:(y:4mm), anchor:"south")
content((2*i,-2.5),[$(#payoff1, #payoff2)$],padding:(y:4mm), anchor:"south")
}
content( (10,0), [$(3,5)$], anchor:"west",padding:(x:2mm))
}
)]
], answer:[
], point:8, show-answer:true, category:"Term1"),
quiz("Q16", question:[
2人鹿狩りゲームの変形版として,次のゲームを考える.
- 寄付額が20になったら全員が利得11を獲る.
- 寄付額が20未満なら,寄付額分のお金を失う.
プレイヤー1,プレイヤー2の順番に寄付額を決定する場合のバックワードインダクションの解をひとつ求めなさい.ただし,各プレイヤーは無差別であれば寄付することを選ぶとする.
], answer:[
], point:12, show-answer:true, category:"Term1"),
quiz("Q17", question:[
@Q16 のゲームを考える.
プレイヤー1,2が同時に寄付額を決めるステージが2回あるとき,次のようなサブゲーム完全均衡を求めなさい.
+ 均衡経路上の寄付額は0
+ 均衡経路上の合計寄付額は20
ただし,各プレイヤーは無差別であれば寄付することを選ぶとする.
], answer:[
], point:14, show-answer:true, category:"Term1"),
quiz("Q18", question:[
@Q16 のゲームを考える.
プレイヤー1,2が同時に寄付額を決めるステージが2回あるとき,サブゲーム完全均衡を求めなさい.ただし各プレイヤーはステージ1,2のどちらか一度しか寄付できないとする.
ただし,各プレイヤーは無差別であれば寄付することを選ぶとする.
], answer:[
], point:14, show-answer:true, category:"Term1"),
quiz("Q19", question:[
自分の利得が $x$, 相手の利得が $y$ のとき,主観的な利得 $pi(x,y)$ が次のように定義されるとする.
$
pi(x,y)= x-alpha y
$
これをシャーデンフロイデのモデルと呼ぶ.$alpha$の値を適当に設定し,最後通牒ゲームを分析しなさい.その上で,不平等回避のモデルでの結果とどのような違いがあるか答えなさい.
], answer:[
], point:8, show-answer:true, category:"Term1"),
quiz("Q20", question:[
提案者が利得10の分前を提案し,応答者は何をしようと提案者が提案する通りに利得が実現する.このゲームを*独裁者ゲーム*と呼ぶ.
@Q19 のシャーデンフロイデのモデルと不平等回避のモデルで独裁者ゲームの結果にどのような違いが起きるか,答えなさい.
], answer:[
], point:10, show-answer:true, category:"Term1"),
quiz("Q15.1", question:[
(記憶力のないプレイヤーたちによるムカデゲーム)次のゲームの木で表されるゲームの純粋戦略サブゲーム完全均衡をすべて求めなさい.ただし,同じ曲線で囲まれたノードは同じ情報集合に属するとする.
#align(center)[
#cetz.canvas({
import cetz.draw: *
//情報集合
hobby((2-0.2, 0.1), (5, -.8), (6.2, 0.2), omega: 0, stroke: (paint: red.lighten(20%), thickness: 14pt, cap: "round"))
hobby((2-0.2, 0.1), (5., -.8), (6.2, 0.2), omega: 0, stroke:(paint: red.lighten(100%), thickness: 8pt, cap: "round"))
hobby((-0.1, -0.1), (1, 1), (4, -0.), (5.2, 1), (8.1, -0.1), omega: 0, stroke: (paint: blue.lighten(20%), thickness: 14pt, cap: "round"))
hobby((-0.1, -0.1), (1, 1), (4.0, -0.), (5.2, 1), (8.1, -.1), omega: 0, stroke: (paint: blue.lighten(100%), thickness: 8pt, cap: "round"))
line((0,0),(10,0), mark:(end:"straight"))
for i in range(5){
line((2*i,0),(2*i,-1.5), mark:(end:"straight"))
circle((2*i,0),radius: 1mm, fill:white)
let name = {
if calc.odd(i+1) {1} else {2} }
let payoff1 = {
i+2 - 2*name
}
let payoff2 = {
i + 3- 4/name
}
content((2*i,0),[#box(fill:white.transparentize(10%))[P#name]],padding:(y:4mm), anchor:"south")
content((2*i+1,-0.2),[#box(fill:white.transparentize(10%))[C]],padding:(y:4mm), anchor:"south")
content((2*i +.2,-1.2),[D],padding:(y:4mm), anchor:"south")
content((2*i,-2.5),[$(#payoff1, #payoff2)$],padding:(y:4mm), anchor:"south")
}
content( (10,0), [$(3,5)$], anchor:"west",padding:(x:2mm))
}
)]
], commentary:[同じ情報集合に含まれるノードでは同じ行動をする事に注意をする.情報集合がいくつあるかを考える.
], point:9, show-answer:true, category:"Term1"),
quiz("QM", question:[以下のCSVファイルをダウンロードし,ボストン方式とDA方式によるマッチング結果をそれぞれ出力しなさい. \
- #link("https://www.dropbox.com/scl/fi/kh8s2k4wkdnb29865e61c/Male_pref.csv?rlkey=<KEY>&st=84hzjkyb&dl=0")[男性の選好の名簿]
- #link("https://www.dropbox.com/scl/fi/68y9v7hqxvppyovyhfo4p/Female_pref.csv?rlkey=<KEY>&st=6ezzhg2c&dl=0")[女性の選好の名簿]
], point: 8),
quiz("QM2", question:[次の選好をもつ人々を考える.
/ M1: W1 W2
/ M2: W2 W1
/ W1: M2 M1
/ W2: M1 M2
+ 男性側提案DA方式によるマッチングを求めなさい
+ 1で求めたマッチングについて,W2が M1 という選好を提示する(つまりM2は受け入れ不能と詐称する)ときの男性側提案DA方式によるマッチングを計算することで,男性側提案DA方式が女性にとって耐戦略的でないことを示しなさい.
+ 女性側提案DA方式によるマッチングを求めなさい
+ 1で求めたマッチングについて,女性側提案DA方式が男性にとって耐戦略的でないことを示しなさい.
],point:5),
quiz("Q21", question:[
人とモノのマッチングモデルを考える.つまり,人にモノを一つづつ割り当てることを考える.
次のようなアルゴリズムを*逐次独裁者アルゴリズム*と呼ぶ.
+ 人の優先順位を決める
+ 最初に決めた順位の順に人がモノをひとつづつ選んでいく.
このアルゴリズムが耐戦略的かつ効率的であることを説明しなさい.
], answer:[
], point:10, show-answer:true, category:"Term1"),
quiz("Q21.5", question:[人と各個人の物についてのリストが与えられたとき,逐次独裁者アルゴリズムによって配分を出力する関数を作りなさい.
], answer:[
], point:10, show-answer:true, category:"Term1"),
quiz("Q22", question:[
人とモノのマッチングモデルを考える.つまり,$n$ 人に $n$ 種類のものを割り当てる.
次のような方式を*最良交換サイクル方式*と呼ぶ.
+ 人に適当にモノを割り当てる
+ 各個人は自分が最も欲しいモノを持っている人を指差す
+ 指さしのサイクルができれば,そのサイクルを使ってモノを交換する.サイクルの外の人はそのまま自分に割り当てられたモノをもつ
+ サイクルで交換した人を除外し,残りの人たちで同じことを繰り返す.
この方式が耐戦略的であることを説明しなさい.
], answer:[
], point:10, show-answer:true, category:"Term1", commentary:[
- 最良交換サイクル方式を例によって説明する.人が4人(M1, M2, M3, N4), モノが三つあるとする(O1, O2, O3, O4).人の好みは次のようになっている.
/ M1: O2 O1 O3 O4
/ M2: O3 O2 O1 O4
/ M3: O1 O4 O2 O3
/ M4: O1 O3 O2 O4
+ まず最初に人にモノをランダムに割り当てる.ここではM1にO1, M2にO2, M3にO3, M4にO4を割り当てたことにしよう.
+ 次に,各個人が一番欲しいモノを持っている人を指差す.M1はO2が一番欲しいのでM2を,M2はO3が一番欲しいのでM3をM3はO1が一番欲しいのでM1を指差す.ここで,M1がM2を,M2がM3を,M3がM1を指差しているのでサイクルができている.M4はM1を指差すが,ここではサイクルができていない.
+ M1 $->$ M2 $->$ M3 $->$ M1というサイクルができたので彼らの中でモノを交換する.つまりM1はM2の持っているO2を,M2はM3の持っているO3を,M3はM1のもっているO1を得る.
+ 残ったM4は残っているのが彼自身しかいないので,自分自身を指差し(これがサイクルになる) O4を得る.
+ 全員の交換が終われば方式は終了する.
- 耐戦略的かどうかは自分が嘘をついてどうなるかを考えれば良い.例えば本来1回目でサイクルが作れる人は自分が一番欲しいモノを得ているので嘘をついても仕方ない.2回目でサイクルが作れる人は二番目に欲しいモノを得ているが,仮に1回目で嘘をついても,サイクルには入れないので今より良いモノは得られない.3回目以降も同じである.
]),
quiz("Q22.5", question:[人と各個人の物についてのリストが与えられたとき,最良交換サイクルアルゴリズムによって配分を出力する関数を作りなさい.
], answer:[
], point:10, show-answer:true, category:"Term1"),
)
|
|
https://github.com/Meisenheimer/Notes
|
https://raw.githubusercontent.com/Meisenheimer/Notes/main/src/StochasticProcess.typ
|
typst
|
MIT License
|
#import "@local/math:1.0.0": *
= Stochastic Process
== Poisson process
== Markov chain
|
https://github.com/Myriad-Dreamin/shiroa
|
https://raw.githubusercontent.com/Myriad-Dreamin/shiroa/main/github-pages/docs/format/theme.typ
|
typst
|
Apache License 2.0
|
#import "/github-pages/docs/book.typ": book-page, cross-link
#show: book-page.with(title: "Theme")
= Theme
The default renderer uses a #link("https://handlebarsjs.com")[handlebars] template to
render your typst source files and comes with a default theme included in the `shiroa`
binary.
Currently we have no much design on theme's html part. But you can still configure your book project like a regular typst project.
== Things to note
#let t = cross-link("/guide/get-started.typ")[Get Started]
Your `book.typ` should at least provides a `book-meta`, as #t shown.
```typ
#import "@preview/shiroa:0.1.1": *
#show: book
#book-meta(
title: "My Book"
summary: [
= My Book
]
)
```
// todo: update it
What is arguable, your `template.typ` must import and respect the `page-width` and `target` variable from `@preview/typst-ts-variables:0.1.1` to this time.
```typ
#import "@preview/typst-ts-variables:0.1.1": page-width, target
#let project(body) = {
// set web/pdf page properties
set page(
width: page-width,
// for a website, we don't need pagination.
height: auto,
)
// remove margins for web target
set page(margin: (
// reserved beautiful top margin
top: 20pt,
// Typst is setting the page's bottom to the baseline of the last line of text. So bad :(.
bottom: 0.5em,
// remove rest margins.
rest: 0pt,
)) if target.starts-with("web");
body
}
```
// The theme is totally customizable, you can selectively replace every file from
// the theme by your own by adding a `theme` directory next to `src` folder in your
// project root. Create a new file with the name of the file you want to override
// and now that file will be used instead of the default file.
// Here are the files you can override:
// - **_index.hbs_** is the handlebars template.
// - **_head.hbs_** is appended to the HTML `<head>` section.
// - **_header.hbs_** content is appended on top of every book page.
// - **_css/_** contains the CSS files for styling the book.
// - **_css/chrome.css_** is for UI elements.
// - **_css/general.css_** is the base styles.
// - **_css/print.css_** is the style for printer output.
// - **_css/variables.css_** contains variables used in other CSS files.
// - **_book.js_** is mostly used to add client side functionality, like hiding /
// un-hiding the sidebar, changing the theme, ...
// - **_highlight.js_** is the JavaScript that is used to highlight code snippets,
// you should not need to modify this.
// - **_highlight.css_** is the theme used for the code highlighting.
// - **_favicon.svg_** and **_favicon.png_** the favicon that will be used. The SVG
// version is used by [newer browsers].
// - **fonts/fonts.css** contains the definition of which fonts to load.
// Custom fonts can be included in the `fonts` directory.
// Generally, when you want to tweak the theme, you don't need to override all the
// files. If you only need changes in the stylesheet, there is no point in
// overriding all the other files. Because custom files take precedence over
// built-in ones, they will not get updated with new fixes / features.
// **Note:** When you override a file, it is possible that you break some
// functionality. Therefore I recommend to use the file from the default theme as
// template and only add / modify what you need. You can copy the default theme
// into your source directory automatically by using `shiroa init --theme` and just
// remove the files you don't want to override.
// `shiroa init --theme` will not create every file listed above.
// Some files, such as `head.hbs`, do not have built-in equivalents.
// Just create the file if you need it.
// If you completely replace all built-in themes, be sure to also set
// [`output.html.preferred-dark-theme`] in the config, which defaults to the
// built-in `navy` theme.
// [`output.html.preferred-dark-theme`]: ../configuration/renderers.md#html-renderer-options
// [newer browsers]: https://caniuse.com/#feat=link-icon-svg
|
https://github.com/typst/packages
|
https://raw.githubusercontent.com/typst/packages/main/packages/preview/songb/0.1.0/README.md
|
markdown
|
Apache License 2.0
|
<!--
SPDX-FileCopyrightText: 2024 <NAME> <<EMAIL>>
SPDX-License-Identifier: CC0-1.0 -->
# songb: Songbook package for [Typst](https://typst.app)
Attempt at creating a songbook package to replace [patacrep](https://github.com/patacrep/patacrep) (which is based on LaTeX + [Songs](https://songs.sourceforge.net/)).
## Quickstart
First, create a `main.typ` file, like the following:
```typ
#set page(paper: "a6",margin: (inside: 14mm, outside: 6mm, y: 10mm))
#import "@preview/songb:0.1.0": autobreak, index-by-letter
// helper function, to include you own songs (feel free to customize)
#let song(path) = {
// WARNING: autobreak is currently broken (does not converge)
// see https://github.com/typst/typst/discussions/4530
autobreak(include path)
v(-1.19em)
}
// indexes (put them wherever you want, or comment them out)
= Song Index
#index-by-letter(<song>)
= Singer Index
#index-by-letter(<singer>)
#pagebreak()
// include all you songs, in the right order
#song("./songs/first_song.typ")
#song("./songs/other_song.typ")
// ...
```
Then, create your song files, like `songs/first_song.typ`:
```typ
#import "@preview/songb:0.1.0": song, chorus, verse, chord
#show: doc => song(
title: "First Song",
singer: "Sing",
doc,
)
#chorus[
#chord[Am]First line,#chord[G][ ]of the chorus\
#chord[Am]Second line,#chord[G][ ]of the chorus.
]
#verse[
#chord[Em]First verse\
With multiple\
#chord[C]Lines
]
If there is #chord[D][a] bridge\
you can write it directly
```
## Writing a song
### song
```typ
#let song(
title: none,
title-index: none,
singer: none,
singer-index: none,
references: (),
line-color: rgb(0xd0, 0xd0, 0xd0),
header-display: (number, title, singer) => (...),
doc
)
```
### chord
```typ
// first argument: chord name
// optional second argument: text below the chord (useful for whitespace for instance)
#let chord(..content)
```
### verse
```typ
#let verse(body)
```
### chorus
```typ
#let chorus(body)
```
## Organizing songs
### autobreak
> [!WARNING]
> Currently broken (lack of convergence for bigger documents)
> See https://github.com/typst/typst/discussions/4530
This function aims at putting the content on a single page (or on facing pages), by introducing pagebreaks when needed.
```typ
#let autobreak(content)
```
### index-by-letter
```typ
#let index-by-letter(label, letter-highlight: (letter) => (...))
```
label: `<song>` or `<singer>` are provided by the `song` function.
|
https://github.com/Myriad-Dreamin/typst.ts
|
https://raw.githubusercontent.com/Myriad-Dreamin/typst.ts/main/docs/proposals/bytefield.typ
|
typst
|
Apache License 2.0
|
// Bytefield - generate protocol headers and more
// Feel free to contribute with any features you think are missing.
// Still a WIP - alpha stage and a bit hacky at the moment
#import "@preview/tablex:0.0.4": tablex, cellx, gridx
#set text(font: "IBM Plex Mono")
#let bfcell(
len, // lenght of the fields in bits
content,
fill: none, // color to fill the field
height: auto // height of the field
) = cellx(colspan: len, fill: fill, inset: 0pt)[#box(height: height, width: 100%, stroke: 1pt + black)[#content]]
#let bytefield(bits: 32, rowheight: 2.5em, bitheader: auto, ..fields) = {
// state variables
let col_count = 0
let cells = ()
// calculate cells
for (idx, field) in fields.pos().enumerate() {
let (size, content, fill, ..) = field;
let remaining_cols = bits - col_count;
col_count = calc.rem(col_count + size, bits);
// if no size was specified
if size == none {
size = remaining_cols
content = content + sym.star
}
if size > bits and remaining_cols == bits and calc.rem(size, bits) == 0 {
content = content + " (" + str(size) + " Bit)"
cells.push(bfcell(int(bits),fill:fill, height: rowheight * size/bits)[#content])
size = 0
}
while size > 0 {
let width = calc.min(size, remaining_cols);
size -= remaining_cols
remaining_cols = bits
cells.push(bfcell(int(width),fill:fill, height: rowheight,)[#content])
}
}
bitheader = if bitheader == auto {
range(bits).map(i => if calc.rem(i,8) == 0 or i == (bits - 1) { text(9pt)[#i] } else { none })
} else if bitheader != none {
assert(type(bitheader) == "array", message: "header must be an array or none")
range(bits).map(i => if i in bitheader { text(9pt)[#i] } else {none})
}
box(width: 100%)[
//#show grid: set block(below: 0pt)
#gridx(
columns: range(bits).map(i => 1fr),
align: center + horizon,
//inset:0pt,
..bitheader,
..cells,
)
]
}
// Low level API
#let bitbox(length_in_bits, content, fill: none) = (
type: "bitbox",
size: length_in_bits, // length of the field
fill: fill,
content: content,
var: false,
show_size: false,
)
// High level API
#let bit(..args) = bitbox(1, ..args)
#let bits(len, ..args) = bitbox(len, ..args)
#let byte(..args) = bitbox(8, ..args)
#let bytes(len, ..args) = bitbox(len * 8, ..args)
#let padding(..args) = bitbox(none, ..args)
// Rotating text for flags
#let flagtext(text) = align(end,pad(-3pt,rotate(270deg,text)))
// Common network protocols
#let ipv4 = bytefield(
bits(4)[Version], bits(4)[TTL], bytes(1)[TOS], bytes(2)[Total Length],
bytes(2)[Identification], bits(3)[Flags], bits(13)[Fragment Offset],
bytes(1)[TTL], bytes(1)[Protocol], bytes(2)[Header Checksum],
bytes(4)[Source Address],
bytes(4)[Destination Address],
bytes(3)[Options], bytes(1)[Padding]
)
#let ipv6 = bytefield(
bits(4)[Version], bytes(1)[Traffic Class], bits(20)[Flowlabel],
bytes(2)[Payload Length], bytes(1)[Next Header], bytes(1)[Hop Limit],
bytes(128/8)[Source Address],
bytes(128/8)[Destination Address],
)
#let icmp = bytefield(
header: (0,8,16,31),
byte[Type], byte[Code], bytes(2)[Checksum],
bytes(2)[Identifier], bytes(2)[Sequence Number],
padding[Optional Data ]
)
#let icmpv6 = bytefield(
header: (0,8,16,31),
byte[Type], byte[Code], bytes(2)[Checksum],
padding[Internet Header + 64 bits of Original Data Datagram ]
)
#let dns = bytefield(
bytes(2)[Identification], bytes(2)[Flags],
bytes(2)[Number of Questions], bytes(2)[Number of answer RRs],
bytes(2)[Number of authority RRs], bytes(2)[Number of additional RRs],
bytes(8)[Questions],
bytes(8)[Answers (variable number of resource records) ],
bytes(8)[Authority (variable number of resource records) ],
bytes(8)[Additional information (variable number of resource records) ],
)
#let tcp = bytefield(
bytes(2)[Source Port], bytes(2)[ Destinatino Port],
bytes(4)[Sequence Number],
bytes(4)[Acknowledgment Number],
bits(4)[Data Offset],bits(6)[Reserved], bits(6)[Flags], bytes(2)[Window],
bytes(2)[Checksum], bytes(2)[Urgent Pointer],
bytes(3)[Options], byte[Padding],
padding[...DATA...]
)
#let tcp_detailed = bytefield(
bytes(2)[Source Port], bytes(2)[ Destinatino Port],
bytes(4)[Sequence Number],
bytes(4)[Acknowledgment Number],
bits(4)[Data Offset],bits(6)[Reserved], bit[#flagtext("URG")], bit[#flagtext("ACK")], bit[#flagtext("PSH")], bit[#flagtext("RST")], bit[#flagtext("SYN")], bit[#flagtext("FIN")], bytes(2)[Window],
bytes(2)[Checksum], bytes(2)[Urgent Pointer],
bytes(3)[Options], byte[Padding],
padding[...DATA...]
)
#let udp = bytefield(
bitheader: (0,16,31),
bytes(2)[Source Port], bytes(2)[ Destinatino Port],
bytes(2)[Length], bytes(2)[Checksum],
padding[...DATA...]
)
|
https://github.com/LDemetrios/Typst4k
|
https://raw.githubusercontent.com/LDemetrios/Typst4k/master/src/test/resources/suite/visualize/image.typ
|
typst
|
// Test the `image` function.
--- image-png ---
// Load an RGBA PNG image.
#image("/assets/images/rhino.png")
--- image-jpg ---
// Load an RGB JPEG image.
#set page(height: 60pt)
#image("/assets/images/tiger.jpg")
--- image-sizing ---
// Test configuring the size and fitting behaviour of images.
// Set width and height explicitly.
#box(image("/assets/images/rhino.png", width: 30pt))
#box(image("/assets/images/rhino.png", height: 30pt))
// Set width and height explicitly and force stretching.
#image("/assets/images/monkey.svg", width: 100%, height: 20pt, fit: "stretch")
// Make sure the bounding-box of the image is correct.
#align(bottom + right, image("/assets/images/tiger.jpg", width: 40pt, alt: "A tiger"))
--- image-fit ---
// Test all three fit modes.
#set page(height: 50pt, margin: 0pt)
#grid(
columns: (1fr, 1fr, 1fr),
rows: 100%,
gutter: 3pt,
image("/assets/images/tiger.jpg", width: 100%, height: 100%, fit: "contain"),
image("/assets/images/tiger.jpg", width: 100%, height: 100%, fit: "cover"),
image("/assets/images/monkey.svg", width: 100%, height: 100%, fit: "stretch"),
)
--- image-jump-to-next-page ---
// Does not fit to remaining height of page.
#set page(height: 60pt)
Stuff
#image("/assets/images/rhino.png")
--- image-baseline-with-box ---
// Test baseline.
A #box(image("/assets/images/tiger.jpg", height: 1cm, width: 80%)) B
--- image-svg-complex ---
// Test advanced SVG features.
#image("/assets/images/pattern.svg")
--- image-svg-text ---
#set page(width: 250pt)
#figure(
image("/assets/images/diagram.svg"),
caption: [A textful diagram],
)
--- image-svg-text-font ---
#set page(width: 250pt)
#show image: set text(font: ("Roboto", "Noto Serif CJK SC"))
#figure(
image("/assets/images/chinese.svg"),
caption: [Bilingual text]
)
--- image-natural-dpi-sizing ---
// Test that images aren't upscaled.
// Image is just 48x80 at 220dpi. It should not be scaled to fit the page
// width, but rather max out at its natural size.
#image("/assets/images/f2t.jpg")
--- image-file-not-found ---
// Error: 8-29 file not found (searched at tests/suite/visualize/path/does/not/exist)
#image("path/does/not/exist")
--- image-bad-format ---
// Error: 2-22 unknown image format
#image("./image.typ")
--- image-bad-svg ---
// Error: 2-33 failed to parse SVG (found closing tag 'g' instead of 'style' in line 4)
#image("/assets/images/bad.svg")
--- image-decode-svg ---
// Test parsing from svg data
#image.decode(`<svg xmlns="http://www.w3.org/2000/svg" height="140" width="500"><ellipse cx="200" cy="80" rx="100" ry="50" style="fill:yellow;stroke:purple;stroke-width:2" /></svg>`.text, format: "svg")
--- image-decode-bad-svg ---
// Error: 2-168 failed to parse SVG (missing root node)
#image.decode(`<svg height="140" width="500"><ellipse cx="200" cy="80" rx="100" ry="50" style="fill:yellow;stroke:purple;stroke-width:2" /></svg>`.text, format: "svg")
--- image-decode-detect-format ---
// Test format auto detect
#image.decode(read("/assets/images/tiger.jpg", encoding: none), width: 80%)
--- image-decode-specify-format ---
// Test format manual
#image.decode(read("/assets/images/tiger.jpg", encoding: none), format: "jpg", width: 80%)
--- image-decode-specify-wrong-format ---
// Error: 2-91 failed to decode image (Format error decoding Png: Invalid PNG signature.)
#image.decode(read("/assets/images/tiger.jpg", encoding: none), format: "png", width: 80%)
--- issue-870-image-rotation ---
// Ensure that EXIF rotation is applied.
// https://github.com/image-rs/image/issues/1045
// File is from https://magnushoff.com/articles/jpeg-orientation/
#image("/assets/images/f2t.jpg", width: 10pt)
--- issue-measure-image ---
// Test that image measurement doesn't turn `inf / some-value` into 0pt.
#context {
let size = measure(image("/assets/images/tiger.jpg"))
test(size, (width: 1024pt, height: 670pt))
}
--- issue-2051-new-cm-svg ---
#set text(font: "New Computer Modern")
#image("/assets/images/diagram.svg")
--- issue-3733-dpi-svg ---
#set page(width: 200pt, height: 200pt, margin: 0pt)
#image("/assets/images/relative.svg")
|
|
https://github.com/j1nxie/resume
|
https://raw.githubusercontent.com/j1nxie/resume/main/cv.typ
|
typst
|
Do What The F*ck You Want To Public License
|
#import "template.typ": *
#import "data.typ": *
#show: project.with(title: name, author: author)
#chiline()
#self
#show heading.where(level: 1): it => [
#set text(font: sans, weight: "regular")
#smallcaps(it.body)
]
/* = #experiencetitle
#experience */
#group((
leftsection[ Experience ],
experience,
leftsection[ Technical \ Skills ],
tech,
leftsection(edutitle),
edu,
leftsection[ Hobbies \ and \ Interests ],
hobbies,
))
|
https://github.com/FrightenedFoxCN/typst-langpack
|
https://raw.githubusercontent.com/FrightenedFoxCN/typst-langpack/main/test-annot.typ
|
typst
|
#import "annotation.typ": *
#show: doc => annotated(doc)
This is a test for an #annot(annot: "With some reminder.")[annotated] paragraph. #lorem(50) #annot(annot: "Latin.")[Lorem ipsum] is used as the example in the previous paragraph.
|
|
https://github.com/jgm/typst-hs
|
https://raw.githubusercontent.com/jgm/typst-hs/main/test/typ/compute/calc-09.typ
|
typst
|
Other
|
// Test the `rem` function.
#test(calc.rem(1, 1), 0)
#test(calc.rem(5, 3), 2)
#test(calc.rem(5, -3), 2)
#test(calc.rem(22.5, 10), 2.5)
#test(calc.rem(9, 4.5), 0)
|
https://github.com/dankelley/typst_templates
|
https://raw.githubusercontent.com/dankelley/typst_templates/main/memo/README.md
|
markdown
|
MIT License
|
# Instructions
## Installing typst
On a macOS machine, type
```sh
brew install typst
```
to install typst. This assumes that you have 'homebrew' installed. If not,
please consult the typst webpage for other ways to install typst.
## Setting up the memo template
Do as follows (for version 0.0.2; change that sequence for later versions).
```sh
mkdir -p ~/Library/Application\ Support/typst/packages/local/memo/0.0.1
cp 0.0.1/* ~/Library/Application\ Support/typst/packages/local/memo/0.0.1
```
## A sample file
To see how this works, take a look at the included sample file,
named `sample_memo.typ`. Then try compiling it, by typing
```sh
typst compile sample_memo.typ
```
and you'll get a PDF file, as is included in this subdirectory
of this repository.
|
https://github.com/typst/packages
|
https://raw.githubusercontent.com/typst/packages/main/packages/preview/cetz/0.3.0/src/process.typ
|
typst
|
Apache License 2.0
|
#import "util.typ"
#import "path-util.typ"
#import "aabb.typ"
#import "drawable.typ"
#import "vector.typ"
/// Processes an element's function to get its drawables and bounds. Returns a {{dictionary}} with the key-values: `ctx` The modified context object, `bounds` The {{aabb}} of the element's drawables, `drawables` An {{array}} of the element's {{drawable}}s.
///
/// - ctx (ctx): The current context object.
/// - element-func (function): A function that when passed {{ctx}}, it should return an element dictionary.
#let element(ctx, element-func) = {
let bounds = none
let element
let anchors = (:)
(ctx, ..element,) = element-func(ctx)
if "drawables" in element {
if type(element.drawables) == dictionary {
element.drawables = (element.drawables,)
}
for drawable in element.drawables {
if drawable.bounds {
bounds = aabb.aabb(
if drawable.type == "path" {
path-util.bounds(drawable.segments)
} else if drawable.type == "content" {
let (x, y, _, w, h,) = drawable.pos + (drawable.width, drawable.height)
((x + w / 2, y - h / 2, 0), (x - w / 2, y + h / 2, 0))
},
init: bounds
)
}
}
}
let name = element.at("name", default: none)
if name != none {
assert.eq(type(name), str,
message: "Element name must be a string")
assert(not name.contains("."),
message: "Invalid name for element '" + element.name + "'; name must not contain '.'")
if "anchors" in element {
ctx.nodes.insert(name, element)
if ctx.groups.len() > 0 {
ctx.groups.last().push(name)
}
}
}
if ctx.debug and bounds != none {
element.drawables.push(drawable.path(
path-util.line-segment((
bounds.low,
(bounds.high.at(0), bounds.low.at(1), 0),
bounds.high,
(bounds.low.at(0), bounds.high.at(1), 0)
)),
stroke: red,
close: true
))
}
return (
ctx: ctx,
bounds: bounds,
drawables: element.at("drawables", default: ()),
)
}
/// Runs the `element` function for a list of element functions and aggregates the results.
/// - ctx (ctx): The current context object.
/// - body (array): The array of element functions to process.
/// -> dictionary
#let many(ctx, body) = {
let drawables = ()
let bounds = none
for el in body {
let r = element(ctx, el)
if r != none {
if r.bounds != none {
bounds = aabb.aabb(r.bounds, init: bounds)
}
ctx = r.ctx
drawables += r.drawables
}
}
return (ctx: ctx, bounds: bounds, drawables: drawables)
}
|
https://github.com/ShapeLayer/ucpc-solutions__typst
|
https://raw.githubusercontent.com/ShapeLayer/ucpc-solutions__typst/main/lib/i18n/en-us.typ
|
typst
|
Other
|
#let make-prob-meta = (
difficulty_prefix: "Difficulty — ",
difficulty_postfix: "",
author: "Author",
authors: "Authors",
submitted_prefix: "",
submitted_postfix: " Submitted",
passed_prefix: "",
passed_postfix: " Passed",
ac-ratio_prefix: "AC Ratio: ",
ac-ratio_postfix: "%",
first-solver_prefix: "First Solver: ",
first-solver_postfix: "",
online-open-contest: "Online Open Contet",
offline-onsite-contest: "Offline Onsite Contest",
first_solved_at_prefix: "+",
first_solved_at_postfix: "min",
)
#let make-prob-overview = (
problem: "Problem",
difficulty: "Difficulty",
author: "Author",
)
#let make-problem = (
make-prob-meta: make-prob-meta
)
#let problem = make-problem
|
https://github.com/dashuai009/dashuai009.github.io
|
https://raw.githubusercontent.com/dashuai009/dashuai009.github.io/main/src/content/blog/006/006.typ
|
typst
|
#let date = datetime(
year: 2022,
month: 9,
day: 9,
)
#metadata((
"title": "linux缺页中断次数统计",
"author": "dashuai009",
description: "",
pubDate: date.display(),
subtitle: [linux,缺页中断],
))<frontmatter>
#import "../../__template/style.typ": conf
#show: conf
#date.display();
#outline()
= 描述
修改内核源代码,使得内核自启动以后,统计发生缺页的次数。
编写程序,输出内核启动时间,和内核统计到的缺页中断次数。
= 实验环境
`openeuler20.03LTS qemu x86_64`
= 统计次数
== 声明计数变量
在内核文件arch/x86/mm/fault.c中定义了`do_page_fault()`函数,这是操作系统处理缺页中断的入口。
只需要在这里添加一个计数变量`unsigned long pfcount`,并在每次执行`do_page_fault()`时,使计数变量加一。
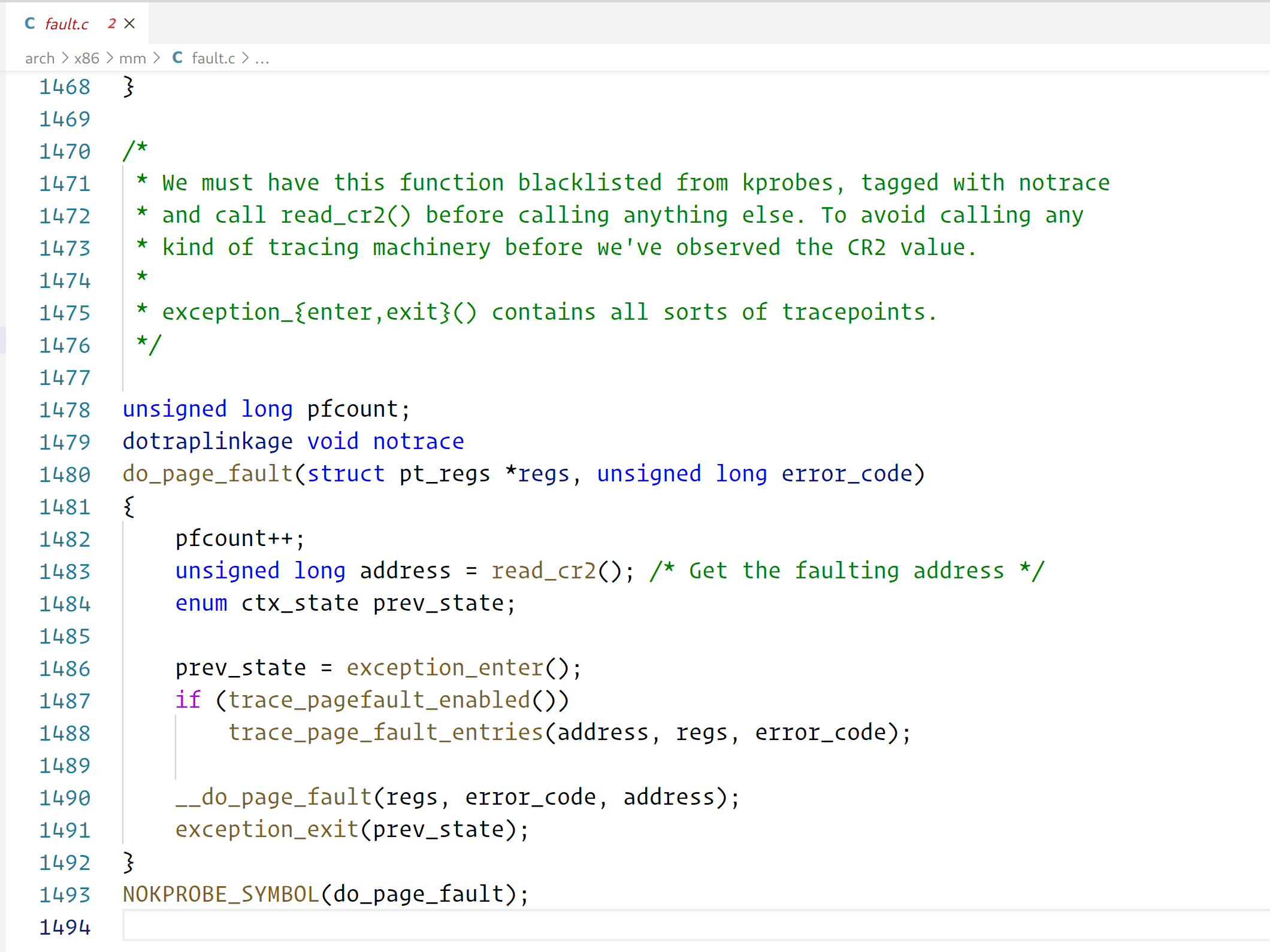
== 声明为全局变量
在内核文件include/linux/mm.h中,将`pfcount`声明为全局变量。
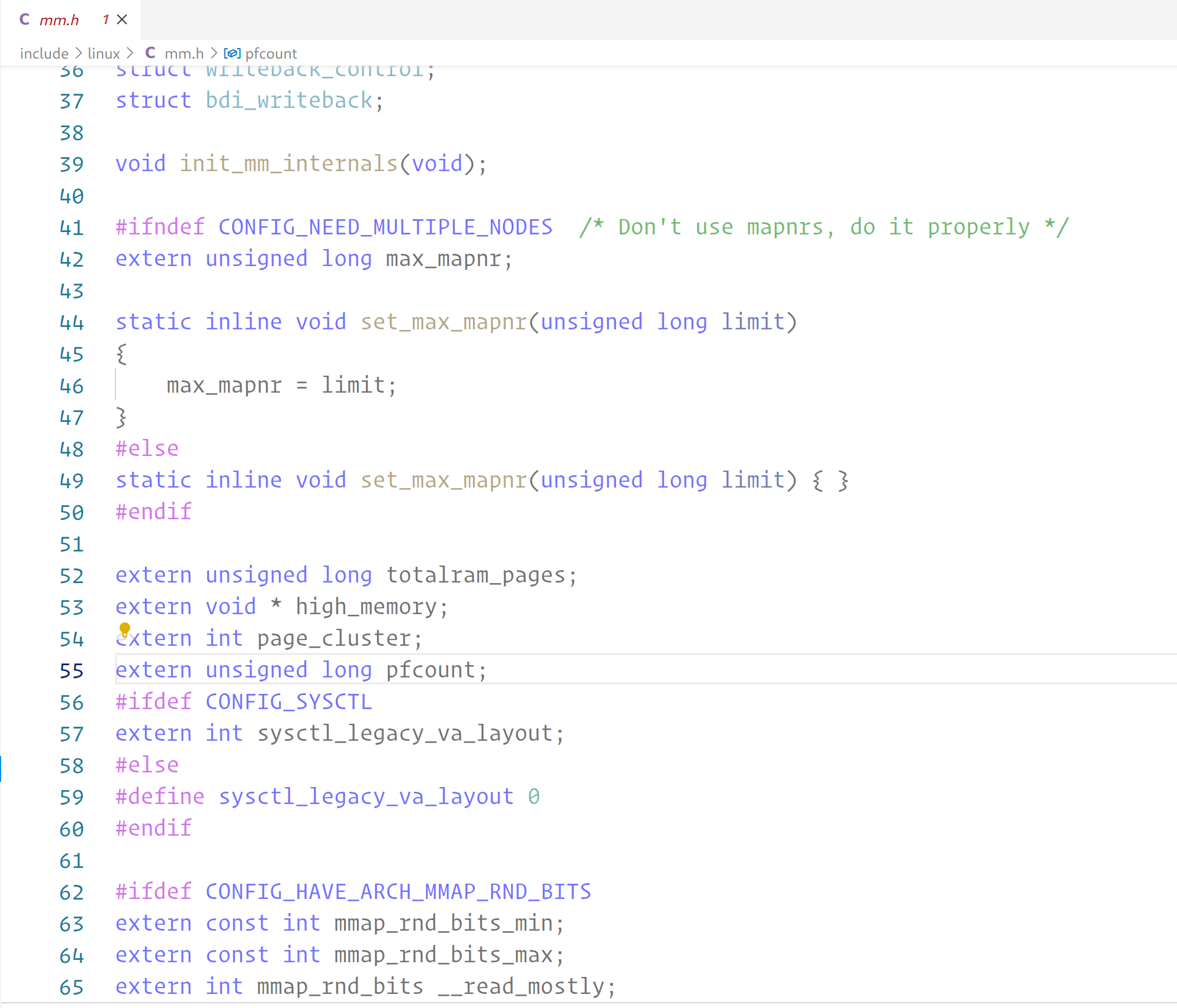
== 导出到内核变量全局符号表中
在内核文件kernel/kallsyms.c中,最后一行添加`EXPORT_SYMBOL_GPL(pfcount)`
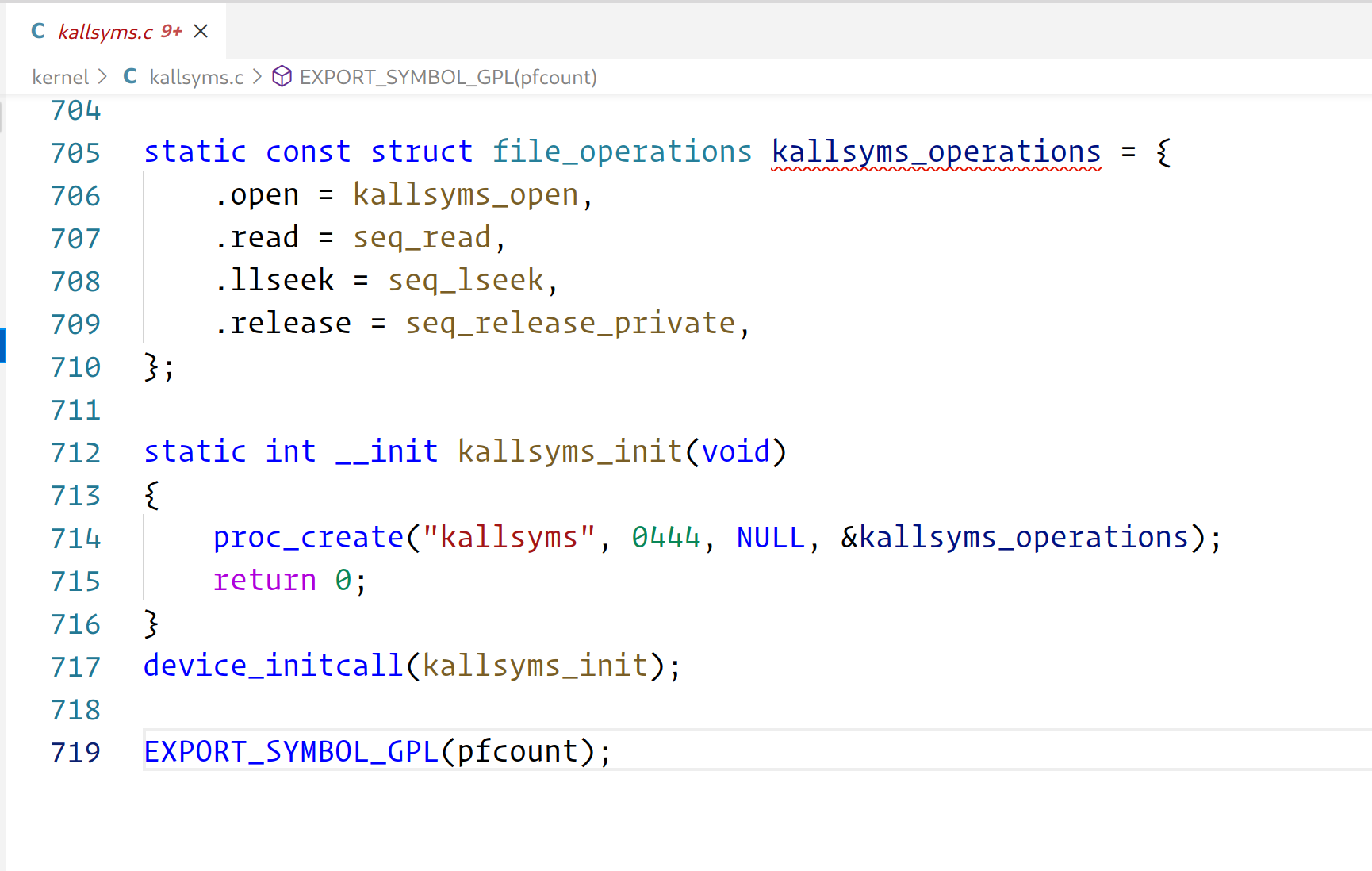
EXPORT_SYMBOL_GPL 导出的符号只能被GPL协议的模块读取。
= 重新编译内核
`make & make modules_install & make install`
这一步真是一言难尽~~之前三步的修改会导致*整个内核几乎重新编译一遍。*(修改的内容太底层,不是模块方式加载进去)
= 编写模块输出统计变量
编写如下pf.c文件
这里将当前日期和缺页次数,输出到了/proc/pfcount。这里用到了/proc文件系统。之后可以直接通过`cat /proc/pfcount`直接查看当前的信息。
```c
#include <linux/fs.h>
#include <linux/mm.h>
#include <linux/proc_fs.h>
#include <linux/rtc.h>
#include <linux/time.h>
#include <linux/module.h>
#define BUFSIZE 512
MODULE_LICENSE("GPL");
struct timeval tv;
struct rtc_time tm;
static struct proc_dir_entry *pf;
static ssize_t read_pfcount(struct file *f, char __user *ubuf, size_t count,
loff_t *ppos) {
char buf[BUFSIZE];
int len=0;
int year, mon, day, hour, min, sec;
//printk( KERN_DEBUG "read handler\n");
if(*ppos > 0 || count < BUFSIZE)
return 0;
do_gettimeofday(&tv);
rtc_time_to_tm(tv.tv_sec, &tm);
year = tm.tm_year + 1900;
mon = tm.tm_mon + 1;
day = tm.tm_mday;
hour = tm.tm_hour + 8;
min = tm.tm_min;
sec = tm.tm_sec;
len=sprintf(buf,"Current time: %d-%02d-%02d %02d:%02d:%02d pfcount = %ld\n", year,
mon, day, hour, min, sec, pfcount);
if(copy_to_user(ubuf,buf,len))
return -EFAULT;
*ppos = len;
return len;
}
static ssize_t write_pfcount(struct file *f, const char __user *buf, size_t len,
loff_t *off) {
printk(KERN_DEBUG "test\n");
return -1;
}
static const struct file_operations myProc = {
.owner = THIS_MODULE,
.write = write_pfcount,
.read = read_pfcount,
};
static int __init myproc_init(void) {
printk("Start pf modules...\n");
pf = proc_create("pfcount", 0660, NULL, &myProc);
if (pf == NULL)
return -ENOMEM;
return 0;
}
static void __exit myproc_exit(void) {
printk("Exit pf module...\n");
proc_remove(pf);
}
module_init(myproc_init);
module_exit(myproc_exit);
```
= 加载并执行模块
执行结果
可以看到系统在09:22:17~09:31:13的536秒中,缺页中断发生了2826616-1693154=1133462次。
= 本次实验的缺点
== volatile
有地方这样写声明全局变量
`extern unsigned long volatile pfcount;`
[volatile 的作用](https://www.runoob.com/w3cnote/c-volatile-keyword.html)
我这里没有加volatile关键字,不知道有没有影响。~~(编译一次太费劲了)~~
|
|
https://github.com/7sDream/fonts-and-layout-zhCN
|
https://raw.githubusercontent.com/7sDream/fonts-and-layout-zhCN/master/template/consts.typ
|
typst
|
Other
|
#import "@preview/book:0.2.5": get-page-width
#import "util.typ"
#let upstream-version = "72e96c3"
#let title = "全球文种的字体与布局"
#let author = "<NAME>"
#let translators = ("7sDream", "<NAME>")
#let font = (
chinese-normal: ("Noto Sans SC",),
chinese-emph: ("LXGW WenKai GB",),
chinese-mono: ("Noto Sans SC",),
western-normal: ("Noto Sans",),
western-emph: ("Linux Libertine",),
western-mono: ("Cascadia Mono", "Noto Sans Mono"),
// No color in PDF, we use svg directly for now
emoji: (/*"Twitter Color Emoji", */),
)
#let font-group = (
normal: (..font.western-normal, ..font.chinese-normal, ..font.emoji),
emph: (..font.western-emph, ..font.chinese-emph, ..font.emoji),
mono: (..font.western-mono, ..font.chinese-mono, ..font.emoji),
)
#let _font-size-scale = if util.is-web-target() { 1.4 } else { 1.0 }
#let size = (
pdf-page:(
paper: "a4",
margin: (top: 2.5cm, bottom: 2cm, left: 2cm, right: 2cm),
numbering: "1",
),
web-page: (
width: get-page-width(),
height: auto,
margin: (top: 20pt, bottom: 0.5em, rest: 0pt),
numbering: none,
),
tiny: 6pt * _font-size-scale,
script: 8pt * _font-size-scale,
footnote: 10pt * _font-size-scale,
small: 11pt * _font-size-scale,
text: 12pt * _font-size-scale,
large: 14pt * _font-size-scale,
Large: 17pt * _font-size-scale,
LARGE: 20pt * _font-size-scale,
huge: 25pt * _font-size-scale,
Huge: 25pt * _font-size-scale,
chapter-spacing: 30pt * _font-size-scale,
section-above: 20pt * _font-size-scale,
subsection-above: 10pt * _font-size-scale,
subsubsection-above: 8pt * _font-size-scale,
par-spacing: 15pt * _font-size-scale,
)
|
https://github.com/KrisjanisP/lu-icpc-notebook
|
https://raw.githubusercontent.com/KrisjanisP/lu-icpc-notebook/main/1-cpplang.typ
|
typst
|
= C++ programming language
== Input/Output disable sync
```cpp
ios_base::sync_with_stdio(false);
cin.tie(NULL); cout.tie(NULL);
```
== Optimization pragmas
```cpp
// change to O3 to disable fast-math for geometry problems
#pragma GCC optimize("Ofast,unroll-loops")
#pragma GCC target("avx2,bmi,bmi2,lzcnt,popcnt,tune=native")
```
== Printing structs
```cpp
ostream& operator<<(ostream& os, const pair<int, int>& p) {
return os << "(" << p.first << ", " << p.second << ")";
}
```
== Lambda func for sorting
```cpp
using ii = pair<int,int>;
vector<ii> fracs = {{1, 2}, {3, 4}, {1, 3}};
// sort positive rational numbers
sort(fracs.begin(), fracs.end(),
[](const ii& a, const ii& b) {
return a.fi*b.se < b.fi*a.se;
});
```
|
|
https://github.com/vEnhance/1802
|
https://raw.githubusercontent.com/vEnhance/1802/main/src/polar.typ
|
typst
|
MIT License
|
#import "@local/evan:1.0.0":*
= Polar coordinates
== [TEXT] Polar coordinate is a special case of change of variables
Last section one of the transition maps we used was
$ bf(T)_"polar" (r, theta) = (r cos theta, r sin theta). $
This map is so common that you should actually memorize its area scaling factor.
Remember from last section we computed
$ J_(bf(T)) &= mat(
partial / (partial r) cos theta,
partial / (partial r) sin theta;
partial / (partial theta) (r cos theta),
partial / (partial theta) (r sin theta))
= mat(cos theta, sin theta; -r sin theta, r cos theta). \
|det J_(bf(T))| &=
det mat(cos theta, sin theta; -r sin theta, r cos theta)
= r cos^2 theta - (-r sin^2 theta) = r(cos^2 theta + sin^2 theta) = r. $
You should actually just remember the final result of this calculation
so you don't have to work it out again.
Colloquially, it can be written like so:
#memo(title: [Memorize: The Jacobian for polar coordinates])[
When converting from Cartesian coordinates $(x,y)$ to polar coordinates $(r,theta)$
you should replace $dif x dif y$ to $r dif r dif theta$.
Colloquially, we write
$ dif x dif y = r dif r dif theta. $
]
Many other sources will write $dif A$ as a shorthand for _both_:
so if you have $(x,y)$ coordinates then $dif A = dif x dif y$,
while if you have polar coordinates then $dif A = r dif r dif theta$.
(They're equal, after all.)
Again, this can be made more precise later on in life once you have access
to a new object called a _differential form_,
but for now just treat it as a mnemonic for one very common change of variables,
rather than a formal statement.
The upshot is that in practice:
#idea[
Once you remember that $dif x dif y$ turns into $1 dif r dif theta$,
you can jump into problems directly in polar coordinates,
skipping the $x$ and $y$ altogether.
]
For example, if you want to find the area of the unit disk,
you know in polar coordinates the unit disk is $0 <= r <= 1$ and $0 <= theta <= 2pi$,
so you can just directly think via the integral
$ int_(r=0)^1 int_(theta=0)^(2 pi) r dif r dif theta $
and not even bother writing the $x y$-version $iint_(x^2+y^2<=1) dif x dif y$.
Compared to back in @sec-chvar-polar, it's the same thing;
it's just a shift in mindset where you go from
"take an $x y$-picture and translate into polar coordinates"
to "take a picture and write it directly in polar coordinates".
|
https://github.com/DieracDelta/presentations
|
https://raw.githubusercontent.com/DieracDelta/presentations/master/polylux/book/src/dynamic/enum-one-by-one.typ
|
typst
|
#import "../../../polylux.typ": *
#set page(paper: "presentation-16-9")
#set text(size: 50pt)
#polylux-slide[
#enum-one-by-one(numbering: "i)", number-align: start)[first][second][third]
]
|
|
https://github.com/typst/packages
|
https://raw.githubusercontent.com/typst/packages/main/packages/preview/quill/0.4.0/src/tequila-impl.typ
|
typst
|
Apache License 2.0
|
#import "gates.typ"
#let bgate(qubit, constructor, nq: 1, end: none, ..args) = ((
qubit: qubit,
n: nq,
end: end,
constructor: constructor,
args: args
),)
#let generate-single-qubit-gate(qubit, constructor: gates.gate, ..args) = {
if qubit.named().len() != 0 {
assert(false, message: "Unexpected argument `" + qubit.named().pairs().first().first() + "`")
}
qubit = qubit.pos()
if qubit.len() == 1 { qubit = qubit.first() }
if type(qubit) == int { return bgate(qubit, constructor, ..args) }
qubit.map(qubit => bgate(qubit, constructor, ..args))
}
#let generate-two-qubit-gate(control, target, start, end) = {
if type(control) == int and type(target) == int {
return bgate(control, start, nq: target - control + 1, end: end, target - control)
}
let gates = ()
if type(control) == int { control = (control,) }
if type(target) == int { target = (target,) }
for i in range(calc.max(control.len(), target.len())) {
let c = control.at(i, default: control.last())
let t = target.at(i, default: target.last())
assert.ne(t, c, message: "Target and control qubit cannot be the same")
gates.push(bgate(c, start, nq: t - c + 1, end: end, t - c) )
}
gates
}
#let gate(qubit, ..args) = bgate(qubit, gates.gate, ..args)
#let mqgate(qubit, n: 1, ..args) = {
bgate(qubit, nq: n, gates.mqgate, ..args.pos(), ..args.named() + (n: n))
}
#let barrier() = bgate(0, barrier)
#let x(..qubit) = generate-single-qubit-gate(qubit, $X$)
#let y(..qubit) = generate-single-qubit-gate(qubit, $Y$)
#let z(..qubit) = generate-single-qubit-gate(qubit, $Z$)
#let h(..qubit) = generate-single-qubit-gate(qubit, $H$)
#let s(..qubit) = generate-single-qubit-gate(qubit, $S$)
#let sdg(..qubit) = generate-single-qubit-gate(qubit, $S^dagger$)
#let sx(..qubit) = generate-single-qubit-gate(qubit, $sqrt(X)$)
#let sxdg(..qubit) = generate-single-qubit-gate(qubit, $sqrt(X)^dagger$)
#let t(..qubit) = generate-single-qubit-gate(qubit, $T$)
#let tdg(..qubit) = generate-single-qubit-gate(qubit, $T^dagger$)
#let p(theta, ..qubit) = generate-single-qubit-gate(qubit, $P (#theta)$)
#let rx(theta, ..qubit) = generate-single-qubit-gate(qubit, $R_x (#theta)$)
#let ry(theta, ..qubit) = generate-single-qubit-gate(qubit, $R_y (#theta)$)
#let rz(theta, ..qubit) = generate-single-qubit-gate(qubit, $R_z (#theta)$)
#let u(theta, phi, lambda, ..qubit) = generate-single-qubit-gate(
qubit, $U (#theta, #phi, #lambda)$
)
#let meter(..qubit) = generate-single-qubit-gate(qubit, constructor: gates.meter)
#let cx(control, target) = generate-two-qubit-gate(
control, target, gates.ctrl, gates.targ
)
#let cz(control, target) = generate-two-qubit-gate(
control, target, gates.ctrl, gates.ctrl.with(0)
)
#let swap(control, target) = generate-two-qubit-gate(
control, target, gates.swap, gates.swap.with(0)
)
#let ca(control, target, content) = generate-two-qubit-gate(
control, target, gates.ctrl, gates.gate.with(content)
)
/// Constructs a circuit from operation instructions.
///
/// - n (auto, int): Number of qubits. Can be inferred automatically.
/// - x (int): Determines at which column the subcircuit will be put in the circuit.
/// - y (int): Determines at which row the subcircuit will be put in the circuit.
/// - append-wire (boolean): If set to `true`, the a last column of outgoing wires will be added.
/// - ..children (any): Sequence of instructions.
#let build(
n: auto,
x: 1,
y: 0,
append-wire: true,
..children
) = {
let operations = children.pos().flatten()
let num-qubits = n
if num-qubits == auto {
num-qubits = calc.max(..operations.map(x => x.qubit + calc.max(0, x.n - 1))) + 1
}
let tracks = ((),) * num-qubits
for op in operations {
let start = op.qubit
// if start < 0 { start = num-qubits + start }
let end = start + op.n - 1
assert(start >= 0 and start < num-qubits, message: "The qubit `" + str(start) + "` is out of range. Leave `n` at `auto` if you want to automatically resize the circuit. ")
assert(end >= 0 and end < num-qubits, message: "The qubit `" + str(end) + "` is out of range. Leave `n` at `auto` if you want to automatically resize the circuit. ")
let (q1, q2) = (start, end).sorted()
if op.constructor == barrier {
(q1, q2) = (0, num-qubits - 1)
}
let max-track-len = calc.max(..tracks.slice(q1, q2 + 1).map(array.len))
for q in range(q1, q2 + 1) {
let dif = max-track-len - tracks.at(q).len()
if op.constructor != barrier and q not in (q1, q2) {
dif += 1
}
tracks.at(q) += (1,) * dif
}
if op.constructor != barrier {
tracks.at(start).push((op.constructor)(..op.args, x: x + tracks.at(start).len(), y: y + start))
if op.end != none {
tracks.at(end).push((op.end)(x: x + tracks.at(end).len(), y: y + end))
}
}
}
let max-track-len = calc.max(..tracks.map(array.len)) + 1
for q in range(tracks.len()) {
tracks.at(q) += (1,) * (max-track-len - tracks.at(q).len())
}
let num-cols = x + calc.max(..tracks.map(array.len)) - 2
if append-wire { num-cols += 1 }
let placeholder = gates.gate(
none,
x: num-cols, y: y + num-qubits - 1,
data: "placeholder", box: false, floating: true,
size-hint: (it, i) => (width: 0pt, height: 0pt)
)
(placeholder,) + tracks.flatten().filter(x => type(x) != int)
}
/// Constructs a graph state preparation circuit.
///
/// - n (auto, int): Number of qubits. Can be inferred automatically.
/// - x (int): Determines at which column the subcircuit will be put in the circuit.
/// - y (int): Determines at which row the subcircuit will be put in the circuit.
/// - invert (boolean): If set to `true`, the circuit will be inverted, i.e., a circuit for
/// "uncomputing" the corresponding graph state.
/// ..edges (array):
#let graph-state(
n: auto,
x: 1,
y: 0,
invert: false,
..edges
) = {
edges = edges.pos()
let max-qubit = 0
for edge in edges {
assert(type(edge) == array, message: "Edges need to be pairs of vertices")
assert(edge.len() == 2, message: "Every edge needs to have exactly two vertices")
max-qubit = calc.max(max-qubit, ..edge)
}
let num-qubits = max-qubit + 1
if n != auto {
num-qubits = n
assert(n > max-qubit, message: "")
}
let gates = (
h(range(num-qubits)),
barrier(),
edges.map(edge => cz(..edge))
)
if invert {
gates = gates.rev()
}
build(
x: x, y: y,
..gates
)
}
/// Template for the quantum fourier transform (QFT).
/// - n (auto, int): Number of qubits.
/// - x (int): Determines at which column the QFT routine will be placed in the circuit.
/// - y (int): Determines at which row the QFT routine will be placed in the circuit.
#let qft(
n,
x: 1,
y: 0
) = {
let gates = ()
for i in range(n - 1) {
gates.push(h(i))
for j in range(2, n - i + 1) {
gates.push(ca(i + j - 1, i, $R_#j$))
gates.push(p(i + j - 1))
}
gates.push(barrier())
}
gates.push(h(n - 1))
build(n: n, x: x, y: y, ..gates)
}
|
https://github.com/imkochelorov/ITMO
|
https://raw.githubusercontent.com/imkochelorov/ITMO/main/src/linear-algebra/s2/practice/main.typ
|
typst
|
#import "../../../template.typ": *
#show par: set block(spacing: 0.55em)
#set page(margin: 0.45in, height: auto)
#set par(leading: 0.75em, first-line-indent: 0em, justify: false)
#set text(font: "New Computer Modern")
#set heading(numbering: "1.1.")
#show raw: set text(font: "New Computer Modern Mono")
#show heading: set block(above: 1.4em, below: 1em)
#show heading.where(level: 1): set align(center)
#show heading.where(level: 1): set text(1.44em)
#set quote(block: true, attribution: "<NAME>")
#show outline.entry.where(
level: 1
): it => {
v(15pt, weak: true)
text(weight: "bold", size: 1.35em, it)
}
#show: project.with(
title: "Линейная алгебра\nII семестр",
authors: (
"_scarleteagle",
"imkochelorov",
"AberKadaber"
),
date: "весна 2024",
subtitle: "Практик:
<NAME>"
)
#let make = sym.supset.sq
#let see = $angle.spheric quad$
#let proof=par(strong("Доказательство:"))
#let sum=$limits(sum)$
#let product=$limits(product)$
#let dp(first, second)=$angle.l #first, #second angle.r$
#let def=strong("Определение:")
#let nb=par(strong("Замечание: "))
#let ex=strong("Пример: ")
#let exs=par(strong("Примеры: "))
#let dp(first, second)=$angle.l #first, #second angle.r$
#let th=strong("Теорема:")
#let proof=par(strong("Доказательство:"))
#let qed = $space qed$
#let lm=par(strong("Лемма:"))
#let apply=$op(circle.small)$
#let tens=$op(times.circle)$
// #show linebreak: v(0.2cm)
#let hla(body) = text(fill: red)[#body]
#let hlb(body) = text(fill: purple)[#body]
#let hlc(body) = text(fill: eastern)[#body]
#outline(title: "Оглавление", indent: auto)
#pagebreak()
//#quote("Давайте поиграем в решение задач", attribution: "<NAME>", block: true)
= Тензоры
Тензор - значение ПЛФ на всех наборах базисных векторов\ \
_Зачем нам тензоры?_\
Тензоры инвариантны _(константны)_\
Фактически, тензор --- матричное представление полилинейной формы\
// Например в криволинейных координатах
\
*Пример тензора:*\ \
$Epsilon = display(mat(augment: #(vline: (3, 6)),
0, 0, 0, 0, 0, -1, 0, 1, 0;
0, 0, 1, 0, 0, 0, -1, 0, 0;
0, -1, 0, 1, 0, 0, 0, 0, 0))
$ \ \
Ранг тензора _определён строго_ -- он равен 3\
Валентность тензора _однозначно определить нельзя_:
(3, 0), (2, 1), (1, 2), (0, 3) --- возможные её значения\ \
Обозначение $epsilon_(i j k): i - "строка", space j - "столбец" space k - "слой"$\ #v(0.4cm)
$(3, space 0) <--> epsilon_(i j k)$\ #v(0.4cm)
$(2, space 1) <--> epsilon_(i j)^k$\ #v(0.4cm)
$(1, space 2) <--> epsilon_(i)^(j k)$\ #v(0.4cm)
$(0, space 3) <--> epsilon^(i j k)$\
// а что это мы нащли? что такое B&
// Ну это сы взяли один тензор и умножили на как я понял
// Типа свертку сдалли
\
$make a = (0 space 1 space 1)^T$\ \
$b_(j k) = epsilon_(i j k) a^i$ -- внутри происходит немое суммирование Эйнштейна\ \
$b_11 = epsilon_(1 1 1)a^1 + epsilon_(2 1 1) a^2 + epsilon_(3 1 1) a^3$
\ \
$B = display(mat(
0, 1, -1;
-1, 0, 0;
1, 0, 0))
$
\ \
== Свёртка индексов:
$ A = display(mat(augment: #(hline: 2, vline: 2),
1, 2, 3, 4;
-4, -3, -2, -1;
-4, -3, -2, -1;
5, 6, 7, 8)) = ||a^(i j)_(k l)|| $
#align(center)[_i --- локальная строка, j --- локальный столбец, k --- глобальная строка, l --- глобальный стобец_] // я понял по 3 дефиса
\
Будем считать что это тензор четвертого ранга, валентности (2, 2)\ #v(0.4cm)
$a_(h l)^(h j) = b_(l)^(j)$\ #v(0.4cm)
$b_l^j = sum_h a^(h j) _ (h l) = a ^(1 j)_(1 l)+ a^(2 j)_(2 l)$ \ #v(0.4cm)
$b_1^1 = a^(1 1)_(1 1) + a^(2 1) _ (2 1) = 6$\ #v(0.4cm)
$b_1^2 = a^(1 2)_(1 1) + a^(2 2) _ (2 1) = 10$\ #v(0.4cm)
$dots$ \ #v(0.4cm)
$B = display(mat(
6, 10;
8, 12))$
\ \
*Тензорное произведение:*
\ #v(0.4cm)
$A - "ПЛФ валентности" (1, 0) <--> a=(1, -1, 0)$\ #v(0.4cm)
$B - "ПЛФ валентности" (2, 0) <--> b = display(mat(
1, 2, 3;
4, 5, 6;
7, 8, 9))
$
\ #v(0.4cm)
// я хз как буквы над буквами писать
$limits(a)^alpha times.circle limits(b)^beta = limits(c)^gamma$\ \
$(alpha_i) times.circle (beta_(j k)) = gamma_(i j k)$ \ \
$gamma_231 = alpha_2 dot beta_31$\ \
$C = display(mat(augment: #(vline: (3, 6)),
1, 4, 7, 2, 5, 8, 3, 6, 9;
0, 0, -7, -2, -5, -8, -1, 0, 0;
0, -1, 0, 1, 0, 0, 0, 0, 0))
$ \ \
*Другой пример:*
\ #v(0.4cm)
$A(2, 0) <--> a = display(mat(
1, -1;
-1, 1)) $\ #v(0.4cm)
$A(1, 1) <--> b = display(mat(
1, 1;
1, 2)) $\ #v(0.4cm)
$c = a times.circle b $
$ (alpha_(i j)) times.circle (beta_l^k) = gamma_(i j l)^k $
#align(center)[_Нумерация сверху вниз, слева направо: \ k --- локальная строка, i --- локальный столбец, j --- глобальная строка, l --- глобальный стобец_]
\
// нахера
// кажется так лучше
// нуууу хзхз
$C = display(mat(augment: #(hline: 2, vline: 2),
1, -1, 1, -1;
1, -1, 2, -2;
dots, dots, dots, dots;
dots, dots, dots, dots)) $ \ \
*Следующий пример:*
\ #v(0.4cm)
Индекс сферху = форма = горизонтальные координаты\ #v(0.4cm)
Индекс снизу = вектор = вертикальные координаты\ #v(0.4cm)
$a^1 = (1, 0, 0)$\
$a_2 = (0, 1, 0)^T = display(vec(0, 1, 0))$\ \
$a_3 = (0, 0, 1)^T = display(vec(0, 0, 1))$\ #v(0.4cm)
$b = a^1 times.circle a_2 times.circle a_3$\ #v(0.4cm)
$beta_(i k) ^ j = (psi^j) times.circle (zeta_i) times.circle (eta_k)$
\ #v(0.4cm) $b = display(mat(augment: #(vline: (3, 6)),
0, 0, 0, 0, 0, 0, 0, 1, 0;
0, 0, 0, 0, 0, 0, 0, 0, 0;
0, 0, 0, 0, 0, 0, 0, 0, 0))
$\ \ // имба // полезно
== Транспонирование тензора:
#v(0.4cm)
_Двумерное сечение --- двумерная матрица, в которой зафиксированы все индексы, кроме 2 конкретных_\ #v(0.4cm)
Транспонирование тензора --- операция, результатом которой
\ #v(0.4cm)
$A_(i k l) ^ (T (k l)) = A_(i l k)$\ #v(0.4cm)
$A$ --- валентность (3, 0) $<--> a = display(mat(augment: #(vline: (3, 6)),
#text(fill: red)[1], #text(fill: purple)[3], #text(fill: eastern)[2], #text(fill: red)[7], #text(fill: purple)[8], #text(fill: eastern)[9], #text(fill: red)[4], #text(fill: purple)[6], #text(fill: eastern)[5] ; // 00%
9, 7, 8, 3, 1, 2, 6, 4, 5;
4, 2, 3, 8, 6, 7, 1, 9, 5)) $\ #v(0.4cm)
$b_(i j k) = a_(i k l)$\ #v(0.4cm)
$make i = 1 => b_(j k) = a_(1 j k) = display(mat(
#text(fill: red)[1], #text(fill: red)[7], #text(fill: red)[4] ;
#text(fill: purple)[3], #text(fill: purple)[8], #text(fill: purple)[6] ;
#text(fill: eastern)[2], #text(fill: eastern)[9], #text(fill: eastern)[5]))
=> a_(1 k j) = display(mat(
#text(fill: red)[1], #text(fill: purple)[3], #text(fill: eastern)[2] ;
#text(fill: red)[7], #text(fill: purple)[8], #text(fill: eastern)[9] ;
#text(fill: red)[4], #text(fill: purple)[6], #text(fill: eastern)[5])) $\ #v(0.4cm)
$make i = 2 => b_(j k) = dots$\ #v(0.4cm)
$B_(i j k) = A_(i k j) = display(mat(augment: #(vline: (3, 6)),
#text(fill: red)[1], #text(fill: red)[7], #text(fill: red)[4], #text(fill: purple)[3], #text(fill: purple)[8], #text(fill: purple)[6], #text(fill: eastern)[2], #text(fill: eastern)[9], #text(fill: eastern)[5] ;
9, 3, 6, 7, 1, 4, 8, 2, 5;
4, 8, 1, 2, 6, 9, 3, 7, 5))$\ \
== Проверка тензора на симметричность и антисимметричность
#v(0.4cm)
$a = display(mat(augment: #(vline: (3, 6)),
0, 0, 0, -1, 2, -1, 1, -2, 1;
1, -2, 1, 0, 0, -0, -1, 2, 1;
-1, 2, -1, 1, -2, -1, 0, 0, 0))
$\ \
_Является ли он симметричным или антисимметричным?_\ \
$a_223 = 2$ --- не антисимметричный по $[i j k]$\ \
$a_123 = -2, space a_213 = -1 =>$ не симметрично по $(i j k)$, по $(i j)$, не антисиметрично по $[i j]$\ \
$a_133 = 1$ не антисимметрично по $[j k]$\ \
$a_221 = -2, space a_212 = 0 =>$ не симметрично по $(j k)$\ \
$a_221 = -2, space a_122 = 2 =>$ не симметрично по $(i|j|k)$, но симметрично по $[i|j|k]$\ \
// если надо будет сократить функцию "красный текст", в принципе можно
// можно и для зеленого и синего вдруг понадобятся
// чтобы бло просто red(), greeen(), blue()
//#rect(fill: purple)
//#rect(fill: maroon)
// норм цвета, заполни просто пж
// ?
// да посмотри в таблицу, я начал дальше заполнять, просто цвета пж раскидай, Тимур
// ебать сочетаются цвета конечно
// сарказм или не? я дальтоник
// сарказм
#align(right)[_Квадратные скобки - наличие свойства антисимметричности по данному набору_]\
#align(right)[_Круглые скобки - наличие свойства симметричности по данному набору индексов_]\ \
== Симметризация и антисимметризация тензоров
=== Симметризация
#v(0.4cm)
$W in Omega^p_0(KK)$\ \
$U(x_1, dots, x_p) = 1/p! sum_sigma W(x_sigma(1), dots, x_sigma(p)), quad U in Sigma^p (KK), quad U = "Sym"(W)$\ \
$A = display(mat(
1, 2, 3;
2, 3, 4;
1, 1, 1))$\ \
$B = "Sym"(A) quad$
$b_ (i, j) = a_ (i j) ^ (s) = 1/2! (a_(i j) + a_ ( j i))$ \ \
$b_11 = 1/2(1 + 1) = 1 quad b_13 = 1/2(3 + 1) = 2$//что делаешь
\ \
$b_12 = 1/2(2 + 2) = 2 quad b_23 = 1/2(4+1) = 5/2$\ \
$B = display(mat(
1, 2, 2;
2, 3, 5/2;
2, 5/2, 1)) = "Sym"A$\ \
=== Антисимметризация
\ $V(x_1, dots x_p) = 1/p! sum_sigma (-1)^([sigma])W(x_(sigma(1)), dots, x_sigma(p))\, V in Lambda^p (KK)$\ \ // ебать как догадаться что KK это mathbb(K) //:)
$V = "ASym"(W) = "Alt"(W)$\ \
$v_(i j) = 1/2((-1)^{i j} a_(i j) + (-1)^{j i} a_(j i))$\ \
$v_(1 3) = 1/2(a_13 - a_31) = 1$\ \
$V = display(mat(
0, 0, 1;
0, 0, 3/2;
-1, -3/2, 0)) = "ASym"A$\ \
== Разложение на тензорное произведение одновалентных форм
#v(0.4cm)
$a^(i j)_k = alpha f^i times.circle f^j times.circle e_k$\ \
$(a^(i j)_k) = display(mat(augment: #(vline: (2)),
1, 1, 2, 2 ;
1, 2, 2, 2)) &= 1 dot f^1 times.circle f^1 times.circle e_1 + 1 dot f^1 times.circle f^2 times.circle e_1 + 1 dot f^2 times.circle f^1 times.circle e_1 + 1 dot f^2 times.circle f^2 times.circle e_1 + \ & + space 2(f^1 times.circle f^1 times.circle e_2 + f^1 times.circle f^2 times.circle e_2 + f^2 times.circle f^1 times.circle e_2 + f^2 times.circle f^1 times.circle e_2) =\ \ &= (f^1 times.circle f^1 + f^1 times.circle f^2 +f^2 times.circle f^1 + f^2 times.circle f^2) times.circle(e_1 + 2e_2) = \ \ & = (f^1+f^2) times.circle (f^1 + f^2) times.circle (e_1 + 2e_2)$ // тут a^(2 2)_2 не 1 случаем?
// чуваки это я для дзшки техаю не стирайте пж
/*$-72 dot f^1 times.circle f^1 times.circle f^1 times.circle f^1 -24 dot f^1 times.circle f^2 times.circle f^1 times.circle f^1 +48 dot f^1 times.circle f^1 times.circle f^1 times.circle f^2 +16 dot f^1 times.circle f^2 times.circle f^1 times.circle f^2 +\ \
+108 dot f^1 times.circle f^1 times.circle f^2 times.circle f^1 +36 dot f^1 times.circle f^2 times.circle f^2 times.circle f^1 -72 dot f^1 times.circle f^1 times.circle f^2 times.circle f^2 -24 dot f^1 times.circle f^2 times.circle f^2 times.circle f^2 = \ \
4f^1 times.circle (-18 dot f^1 times.circle f^1 times.circle f^1 -6 dot f^2 times.circle f^1 times.circle f^1 +12 dot f^1 times.circle f^1 times.circle f^2 +4 dot f^2 times.circle f^1 times.circle f^2 +\ \
+27 dot f^1 times.circle f^2 times.circle f^1 +9 dot f^2 times.circle f^2 times.circle f^1 -18 dot f^1 times.circle f^2 times.circle f^2 -6 dot f^2 times.circle f^2 times.circle f^2) = \ \
= 4 dot f^1 times.circle (3dot f^1 times.circle (-6 dot f^1 times.circle f^1 +4 dot f^1 times.circle f^2 + 9 dot f^2 times.circle f^1 - 6 dot f^2 times.circle f^2 ) + \ \ + f^2 times.circle ( -6 dot f^1 times.circle f^1 +4 dot f^1 times.circle f^2+ 9 dot f^2 times.circle f^1 - 6 dot f^2 times.circle f^2 )) = \ \
=4 dot f^1 times.circle (3dot f^1 times.circle f^2) times.circle(-6 dot f^1 times.circle f^1 +4 dot f^1 times.circle f^2 + 9 dot f^2 times.circle f^1 - 6 dot f^2 times.circle f^2 ) = \ \
=4 dot f^1 times.circle (3dot f^1 times.circle f^2) times.circle(2 dot f^1 times.circle( -3 dot f^1 +2 dot f^2) - 3 dot f^2 times.circle (-3 dot f^1 + 2 dot f^2 )) = \ \
= 4 dot f^1 times.circle (3dot f^1 times.circle f^2) times.circle(2 dot f^1 - 3 dot f^2) times.circle( -3 dot f^1 +2 dot f^2)$
\ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \
$-18 dot e_1 times.circle e_1 times.circle e_1 -36 dot e_2 times.circle e_1 times.circle e_1 -18 dot e_3 times.circle e_1 times.circle e_1 - \ \
-12 dot e_1 times.circle e_2 times.circle e_1 -24 dot e_2 times.circle e_2 times.circle e_1 -12 dot e_3 times.circle e_2 times.circle e_1 + \ \
+12 dot e_1 times.circle e_1 times.circle e_2 +24 dot e_2 times.circle e_1 times.circle e_2 +12 dot e_3 times.circle e_1 times.circle e_2 + \ \
+8 dot e_1 times.circle e_2 times.circle e_2 +16 dot e_2 times.circle e_2 times.circle e_2 +8 dot e_3 times.circle e_2 times.circle e_2 - \ \
-6 dot e_1 times.circle e_1 times.circle e_3 -12 dot e_2 times.circle e_1 times.circle e_3 -6 dot e_3 times.circle e_1 times.circle e_3 - \ \
-4 dot e_1 times.circle e_2 times.circle e_3 -8 dot e_2 times.circle e_2 times.circle e_3 -4 dot e_3 times.circle e_2 times.circle e_3 = \ \ =
(e_1 times.circle e_1 + 2 dot e_2 times.circle e_1 + e_3 times.circle e_1 ) times.circle (-18dot e_1 + 12 dot e_2 - 6 dot e_3) + \ \ +
(e_1 times.circle e_2 + 2 dot e_2 times.circle e_2 + e_3 times.circle e_2 ) times.circle (-12dot e_1 + 8 dot e_2 - 4 dot e_3) = \ \ =
3 dot (e_1 + 2dot e_2 + e_3) times.circle e_1 times.circle(-6dot e_1 + 4 dot e_2 - 2 dot e_3) + \ \ + 2 dot (e_1 + 2dot e_2 + e_3) times.circle e_2 times.circle(-6dot e_1 + 4 dot e_2 - 2 dot e_3) = \ \ =
(e_1 + 2dot e_2 + e_3) times.circle (3dot e_1 + 2 dot e_2) times.circle (-6dot e_1 + 4 dot e_2 - 2 dot e_3)$
\ \ \ \
Заметим что тензор антисимметричен по всем четырем индексам:\ \
$A(f^(i_1), f^(i_2), f^(i_3), f^(i_4)) = cases(0\, "какие нибудь" i "совпади", 1452 dot (-1)^([i])\, "иначе (т.к. в этом случае" i - "перестановака можно подсчитать ее четность)")$
\ \
Отсюда можно сделать вывод что $A = "const" dot f^1 and f^2 and f^3 and f^4$, а т.к. ненулевые значения равны 1452 при четных перестановках $i$, const = 1452*/
#pagebreak()
//#quote("Всякое в жизни бывает")
== Смена базиса ПЛФ
Хочется понимать, что будет при смене базиса
\ #v(0.4cm)
$X$ --- ЛП (пространство контрвекторов)\ #v(0.4cm)
${e_i}$ --- базис $X$\ #v(0.4cm)
$x in X, space x_e = sum xi^i e_i$\ #v(0.4cm)
${tilde(e)_i}$ --- новый базис $X$\ #v(0.4cm)
Базис $e$ связан с базисом $tilde(e)$ матрицей перехода $T$:\
$ tilde(E) = T_(e -> tilde(e)) E $#align(center)[$E$ --- матрица базиса $e, space tilde(E)$ --- матрица базиса $tilde(e)$] \
$tilde(e)_i = display(sum_(k=1)^n tau_i^k e_k)$\ #v(0.4cm)
$x_(tilde(e)) = S_(tilde(e) -> e) x_e, quad S_(tilde(e)-> e) = T_(e->tilde(e))^(-1)$\
\
$X^*$:\ #v(0.4cm)
${f^j}, space {tilde(f)^j}$ --- базисы, cопряжённые ${e_i}$ и ${tilde(e)_i}$ соответственно\ #v(0.4cm)
$y_f = sum g_j f^j$\ #v(0.4cm)
$tilde(f)^j = f^j S$\ #v(0.4cm)
$y_tilde(f) = y_f T$
\ \
$T = norm(tau_j^i)$ _(верхний индекс отвечает за строку, нижний за столбец)_\ #v(0.4cm)
$S = norm(sigma_j^i)$\ #v(0.4cm)
$tau_i^k dot sigma_k^j = delta_i^j<=> T S = I$ - единичная матрица\ #v(0.4cm)
$display(omega_(i_1 dots i_p)^(j_1 dots j_q))$: $quad {e}, space{f}$ --- $p$ _раз контрвариантен и $q$ раз ковариантен ($p$ векторов из $X$, $q$ векторов из $X^\*$)_\ #v(0.4cm)
$tilde(omega)_(i'_1 dots i'_p)^(j'_1 dots j'_q)$: $quad {tilde(e)}, space {tilde(f)}$\ #v(0.4cm)
$display(tilde(omega)_(i'_1 dots i'_p)^(j'_1 dots j'_q) = omega_(i_1 dots i_p)^(j_1 dots j_q) dot underbrace(sigma_(i'_1)^(i_1) dot dots dot sigma_(i'_p)^(i_p), p "раз") dot underbrace(tau_(j_1)^(j'_1) dot dots dot tau_(j_q)^(j'_q), q "раз"))$\ #v(0.4cm)
_$p$ раз контрвариантен $=> p$ раз преобразовывается по контрвариантному закону (домножение на $sigma$)_\
_$q$ раз ковариантен $=>$ q раз преобразовывается по ковариантному закону (домножение на $tau$)_\
// кста я тут понял что один момнт я не понял
// 293 строка, почему там когда тильду выражаем не через тильду, домножаем на переход из тильды в нетильду а не наоборот
// ну да, x умножаем на обратную
// Вань, ты про cetz читал? //может быть, но скорее нет // я тебе скидывал, package для рисования
// ааааааа, не читал
\ #ex\ #v(0.4cm)
Тензор валентности (2, 1), задан стандартный базис ${e}: e_1 = (1,0, 0) space e_2 = (0, 1, 0), space e_3 = (0, 0, 1)$\ #v(0.4cm)
$tilde(e)_1 = e_1$\ #v(0.4cm)
$tilde(e)_2 = e_3$\ #v(0.4cm)
$tilde(e)_3 = e_2$\ #v(0.4cm)
$A_e = display(mat(augment: #(vline: (3, 6)),
1, 2, 3, 4, 5, 8, 7, 8, 9;
1, 3, 2, 1, 5, 9, 8, 7, 6;
9, 8, 7, 6, 5, 4, 3, 2, 1
))$\ \
$T = display(mat(
1, 0, 0;
0, 0, 1;
0, 1, 0
)) = S$\ \
$tilde(a)_(j'k')^(i') = a^i_(j k) dot sigma_(j')^j dot sigma_(k')^k dot tau_i^(i') limits(=)_("свертка индексов по" i) sigma_(j')^j dot sigma_(k')^k dot (a_(j k)^1 dot tau_1^(j') + a_(j k) ^ 2 dot tau_(2)^(j') + a_(j k)^3 dot tau_3^(i'))\ \
limits(=)_("свертка индексов по" j)sigma_(k')^k (sigma_j'^1 (a_(1k)^1 tau_1^(i') + a_(1k)^2 tau_2^(i') + a_(1 k)^3 tau_3^(i')) + sigma_(j')^2(a_(2k)^1 tau_1^(i') + a_(2k)^2 tau_2^(i') + a_(2 k)^3 tau_3^(i')) + sigma_(j')^3(a_(3k)^1 tau_1^(j') + a_(3k)^2 tau_2^(j') + a_(3 k)^3 tau_3^(j'))\ \ limits(=)_("свертка индексов по" k) italic(text("предлагается оставить непосчитанным"))$\ \
_Вместо расписывания свёртки, можно использовать #math.cancel("голову") матричные произведения_
= Определитель матрицы
По честному, определитель матрицы не умеет считать никто. Не существует _нормального_ алгоритма, позволяющего посчитать определитель матрицы произвольного порядка
\ \
(запись матрицы внутри | $$ | подразумевает определитель матрицы)\
== Метод приведения матрицы к треугольному виду
#ex
$ D = display(mat(delim: "|",
a_1, x, x, dots, x;
x, a_2, x, dots, x;
x, x, a_3, dots, x;
dots.v, dots.v, dots.v, dots.down, dots.v;
x, x, x, dots, a_n
))//_(#pad(top: -50pt, $-(1)\ -(1)\ space space space space dots.v \ -(1)$))
limits(=)^((1))
display(mat(delim: "|",
a_1, x, x, dots, x;
x-a_1, a_2 - x, 0, dots, 0;
x-a_1, 0, a_3 - x, dots, 0;
dots.v, dots.v, dots.v, dots.down, dots.v;
x-a_1, 0,0, dots, a_n-x
)) limits(=)^((2)) product_(i=1)^n (a_i-x) display(mat(delim: "|",
a_1/(a_1-x), x/(a_2-x), x/(a_3-x), dots, x/(a_n-x);
-1, 1, 0, dots, 0;
-1, 0, 1, dots, 0;
dots.v, dots.v, dots.v, dots.down, dots.v;
-1, 0,0, dots, 1
)) limits(=)^((3)) $
$ limits(=)^((3))product_(i=1)^n (a_i - x) display(mat(delim: "|",
A, x/(a_2-x), x/(a_3-x), dots, x/(a_n-x);
0, 1, 0, dots, 0;
0, 0, 1, dots, 0;
dots.v, dots.v, dots.v, dots.down, dots.v;
0, 0,0, dots, 1
)) limits(=)^((4))product_(i=1)^n (a_i - x)(1 + x/(a_1-x) + x/(a_2-x) + dots + x/(a_n-x))limits(=)^((5)) $$ limits(=)^((5))-x product_(i=1)^n (a_i - x)(1/x + 1/(a_1-x) + 1/(a_2-x) + dots + 1/(a_n-x)) $
В (1) равенстве мы вычли из всех строчек первую.\ #v(0.2cm)
В (2) равенстве поделили каждый столбец на $(a_i-x)$.\ #v(0.2cm)
В (3) равенстве мы прибавили к первому столбцу все остальные столбцы\ #v(0.2cm)
В (4) равенстве мы сказали что определитель равен произведению элементов на главной диагонали (т.к. есть треугольник из нулей), а также расписали $A$\ #v(0.2cm)
//что значит расписали A
В (5) равенстве вынесли $x$ за скобку
== Метод выделения множителей
#ex
$ D = display(mat(delim: "|",
1,2,3,dots,n;
1,x+1,3,dots,n;
1,2,x+1,dots,n;
dots.v,dots.v,dots.v,dots.down,dots.v;
1,2,3,dots,x+1
))=P_(n-1) (x)
$\
$D = P_(n-1) (x)=(x-1) P_(n-2) (x) = (x-1) (x-2) P_(n-3) (x) = dots = (x-1)(x-2)dots(x-n+1) P_0 (x)$\ #v(0.4cm)
$x=1: P_(n-1) (1) = 0$\
$x=2: P_(n-2) (2) = 0$\ #v(0.4cm)
$P_0 (x)=1$ (_приведённый многочлен_) т.к. наибольшая степень достигается только при перемножении $n-1$ скобки стоящей на главной диагонали. У всех них коэффициент 1, поэтому и итоговый коэффициент будет 1 \ $=> $ _(для этой конкретной матрицы)_ $D = (x-1)(x-2)dots(x-n+1)$
== Метод разложения на линейные множители
#ex\
$ D = display(mat(delim: "|",
0,x,y,z;
x,0,z,y;
y,z,0,x;
z,y,x,0
)) limits(=)^((1)) display(mat(delim: "|",
x-y-z,x,y,z;
x-y-z,0,z,y;
y+z-x,z,0,x;
z+y-x,y,x,0
)) $
$ (x - y - z), quad (x+z-y), quad (x + y + z) quad (x+y-z) $
$ D = alpha(x-y-z)(x+z-y)(x+y+z)(x+y-z), quad alpha = plus.minus 1 $
#align(center)[_При $z^4$ должен быть +, поэтому $alpha =+1$_]
\
В (1) равенстве прибавим к первом столбцу второй и вычтем 3-ий и 4-ый\
Аналогично можем:
+ Прибавить 3-ий, вычесть 2-ой и 4-ый
+ Прибавить 4-ый, вычесть 2-ой и 3-ий
+ Прибавить 2-ой, 3-ий и 4-ый
При каждом из действий из первого столбца будет выделяться скобка, причем все они взаимнопросты, а т.к. суммарная степень многочлена 4, больше скобок не будет
#quote("Вроде определитель всего лишь 4x4, а уже душно")
== Метод рекуррентных соотношений
#ex\
$ D_n =display(mat(delim: "|",
a_1, x, dots, x, x;
x, a_2, dots, x, x;
dots.v, dots.v, dots.down, dots.v, dots.v;
x, x, dots, a_(n-1), x;
x, x, dots,x, a_n
)) =^((1)) display(mat(delim: "|",
a_1, x, dots, x, x;
x, a_2, dots, x, x;
dots.v, dots.v, dots.down, dots.v, dots.v;
x, x, dots, a_(n-1), x;
x, x, dots,x, x
)) + display(mat(delim: "|",
a_1, x, dots, x, 0;
x, a_2, dots, x, 0;
dots.v, dots.v, dots.down, dots.v, dots.v;
x, x, dots, a_(n-1), 0;
x, x, dots,x, a_n-x
)) = x product_(i=1)^(n-1)(a_i-x) + (a_n-x)D_(n-1)=\
=x product_(i=1)^(n-1)(a_i-x) + x product_(i=1)^(n-2) (a_i-x)(a_n-x) + (a_n-x)(a_(n-1)-x)D_(n-2) $
$ D_1 = x + (a_1 - x) $
В (1) равенстве мы разложили последний столбец по следующему правилу:
$ display(vec(x, x, dots.v, a_n + x - x) = vec(x, x, dots.v, x) + vec(0, 0, dots.v, a_n - x)) $
//распишите, что мы ещё здесь делали...
// тыгыдын на x
#ex\
$ D_n =display(mat(delim: "|",
7, 5, 0, dots, 0;
2, 7, 5, dots, 0;
0,2,7,dots,0;
dots.v, dots.v, dots.v, dots.down, dots.v;
0, 0, 0, dots, 7
)) display(=)^((1)) 7 dot display(mat(delim: "|",
7, 5, 0, dots, 0;
2, 7, 5, dots, 0;
0,2,7,dots,0;
dots.v, dots.v, dots.v, dots.down, dots.v;
0, 0, 0, dots, 7
)) - 5 dot display(mat(delim: "|",
2, 5, dots, 0;
0,7, dots,0;
dots.v, dots.v, dots.down, dots.v;
0, 0, dots, 7
)) =^((2)) 7 D_(n-1) - 5dot 2 dot D_(n-2) $ $ D_n = 7 dot D_(n-1) - 10D_(n - 2) limits(<->)^((3)) x^2 - 7x + 10 = 0 - "характеристическое уравнение" $ $ D_n = C_1(x_1)^n + C_2(x_2)^n, quad C_1 = (D_2 - x_2D_1)/(x_1(x_1 - x_2)), quad C_2 = -(D_2 - x_1D_1)/(x_2(x_1 - x_2)) $
В равенстве (1) найдем определитель при помощи разложения по первой строке\
В равенстве (2) найдем вторую матрицу при помощи разложения по первому столбцу\
//#quote("Метод подбора интегрирующего множителя - либо подобрал либо нет)")
\
/*
$ x^2 - 7x + 10 = 0\
D_n = c_1 (x_1)^n + c_2 (x_2)^n\
c_1 = (D_2 - x_2 D_1)/(x_1 (x_1-x_2))\
c_2 = -(D_2 - x_1 D_1)/(x_2 (x_1-x_2))$
*/
#pagebreak()
= Линейные операторы
#align(center)[_Преподаватель: <NAME>_]\
*Пример:*
+ $x |-> x + a, quad x, a in E^3$
+ $f(x) |-> f(x+1) - f(x), quad f in RR[x]$
+ $display(vec(x_1, x_2) |-> vec(2 x_2, x_1 + 3)\, quad x_i in F)$
+ $x |-> (x, a)dot a quad x, a in E_3$
Проверим, являются ли эти операторы линейными:
// ваня ты комп зарядил?
// +
#columns(2)[
1. $phi(lambda x + mu y) = lambda phi(x) + mu phi(y)$\
$(x+y) |-> (x+y)+a$\
$x |-> x+a$\
$y |-> y + a$\
Если $a = 0$, то $phi = cal(I)$ (тождественный)\
Если $a != 0$, то $phi$ не линейный оператор.
#colbreak()
2. $f(x) |-> f(x)$ --- $cal(I)$\
$f(x) |-> f(x+1)$\
$(f+g)(x) |-> (f+g)(x+1) = f(x+1) + g(x+1)$\
Сумма линейных операторов --- линейный оператор
]
#columns(2)[
// #set enum(start: 3)
3. Нет, линейности по второй координате не будет
#colbreak()
// #set enum(start: 4)
4. Да, скалярное произведение линейно
]
#v(0.4cm)
== Матрицы линейного оператора
#v(0.4cm)
#align(center)[$phi(x) = [phi]dot x$] #v(0.4cm)
*Пример:*
$E^3: (i, j, k)$\
+ $display(x |->^phi a times x)$
+ $B:$ поворот на $(2pi)/3$ вокруг прямой $x=y=z$
Матрица линейного оператора хранит образы базисных векторов.\ \
#table(columns: (20fr, 11fr),
inset: 0pt,
stroke: none,
align: top,
[
$[phi] :$\
$a = a_1 i + a_2 j + a_3 k$\
$phi(i) = a times i = (a_1 i + a_2 j + a_3 k) times i = 0 i-a_2 k + a_3 j$\
$phi(j) = a times j = (a_1 i + a_2 j + a_3 k) times j = a_1 k + 0 j - a_3 i$\
$phi(k) = a times k = (a_1 i + a_2 j + a_3 k) times k = -a_1 j + a_2 i + 0 k$\ \
],
[
$[phi] = display(mat(
0, -a_3, a_2;
-a_2, 0, -a_1;
a_3, a_1, 0
))$
\ \
$[B] = display(mat(
0, 0, 1;
1, 0, 0;
0, 1, 0
))$
])
//$alpha(x, x) = 0$\
//$0 = alpha(x + y, x + y) = alpha(x, x) + alpha(y, y)$\
//$alpha(x, y) = -alpha(y, x)$
//блять куда
//я не увидел нихрена там, потому что он загораживал. и он тут же стёр
*Характеристика поля:*\ #v(0.4cm)
$underbracket(1 + 1 + dots + 1, p) = 0, space p - min /* min? */ > 0 <=> "char" KK = p$\ #v(0.4cm)
$exists.not p <=> "char" KK = 0$\ #v(0.4cm)
$CC, RR, QQ: "char" = 0$\ #v(0.4cm)
$ZZ_p, space p$ --- простое: $"char" = p$
\ \
*Пример:* _пространство квадратных матриц размера 2_ #v(0.4cm)
$M_2 (F) quad E_11, E_12, E_21, E_22 $ -- базис\ #v(0.4cm)
$phi: X |-> display(mat(a, b; c, d) dot X)$\ #v(0.4cm)
$[phi]=display(mat(a, 0, b,0 ;0, a, 0, b ;c, 0, d, 0;0, c, 0, d))$\ #v(0.4cm)
$phi(E_11) = display(mat(a, b; c, d) times mat(1, 0; 0, 0) = mat(a, 0; c, 0)) = a dot E_11 + c dot E_21 = a E_11 + 0 E_12 + c E_21 + 0 E_22$\
\
*Пример:* _пространство многочленов не выше третьей степени_\ #v(0.4cm)
#table(columns: (5fr, 10fr),
inset: 0pt,
stroke: none,
align: left,
[
$RR[x]_3 quad (1, x, x^2, x^3)$\ #v(0.4cm)
$cal(A): f |-> display(1/x) display(limits(integral))_0^x f(t) dif t$\ \
$cal(A)(1) = display(1/x) display(limits(integral))_0^x 1 dif t = 1$\ \
$cal(A)(x) = display(1/x) display(limits(integral))_0^x x dif t = x/2$\ \
$cal(A)(x^2) = display(1/x) display(limits(integral))_0^x x^2 dif t = x^2/3$\ \
$cal(A)(x^3) = display(1/x) display(limits(integral))_0^x x^3 dif t = x^3/4$\ \
],
[
$[cal(A)]=display(mat(1,0,0,0;0,1/2,0,0;0,0,1/3,0;0,0,0,1/4))$\ #v(0.4cm)
$limits(lim)_(n->+infinity) cal(A)^n = cal(P)_(<1>)^(<x,x^2,x^3>)$ --- проектор на 1 паралленльно $x, x^2, x^3$\ #v(0.4cm)
$limits(lim)_(n->+infinity) cal(A)^n = display(mat(augment: #(hline: 1, vline: 1),1,0,0,0;0,0,0,0;0,0,0,0;0,0,0,0))$
])
== Переход в новый базис
#v(0.4cm)
$e = (e_1,e_2,e_3,e_4)$\ #v(0.4cm)
$[phi]_e = display(mat(0,1,2,3;5,4,0,-1;3,2,0,3;6,1,-1,7))$\ #v(0.4cm)
$tilde(e) = \(limits(e_2)_(tilde(e_1)),limits(e_1)_tilde(e_2),limits(e_3)_tilde(e_3),limits(e_4)_tilde(e_4)\)$\ #v(0.4cm)
$[phi]_(tilde(e)) = (e arrow.squiggly.long tilde(e))^(-1) dot [phi]_e dot (e arrow.squiggly.long tilde(e))$\ #v(0.4cm)
$(e arrow.squiggly.long tilde(e)) = display(mat(0, 1, 0, 0; 1, 0, 0, 0; 0, 0, 1, 0; 0,0,0,1)) = (e arrow.squiggly.long tilde(e))^(-1)$, обратная матрица такая же, потому что _потому_\ #v(0.5cm) // squiggly arrow //struggling arrow // there is only struggle
$[phi]_tilde(e) = display(mat(0, 1, 0, 0; 1, 0, 0, 0; 0, 0, 1, 0; 0,0,0,1)) times display(mat(0,1,2,3;5,4,0,-1;3,2,0,3;6,1,-1,7)) times display(mat(0, 1, 0, 0; 1, 0, 0, 0; 0, 0, 1, 0; 0,0,0,1)) = display(mat(4,5,0,-1;1,0,2,3;2,3,0,3;1,6,-1,7))$
// #image("image.png", width: 100%)
// Мое погоняло ебись оно все конем
\ #v(0.2cm)
*_Домашняя работа:_*\
Найти матрицу $phi_tilde(e),$ если
$tilde(e) = (e_1, e_1 + e_2, e_1 + e_2 + e_3, e_1 + e_2 + e_3 + e_4)$
#quote("Не нужно гадать. Нужно взять и умножить", attribution: "<NAME>")
*_Решение:_*\ #v(0.4cm)
$e = (e_1,e_2,e_3,e_4)$\ #v(0.4cm)
$[phi]_e = display(mat(0,1,2,3;5,4,0,-1;3,2,0,3;6,1,-1,7))$\ #v(0.4cm)
$tilde(e) = (e_1, e_1 + e_2, e_1 + e_2 + e_3, e_1 + e_2 + e_3 + e_4)$\ #v(0.4cm)
#align(center)[$[phi]_(tilde(e)) = (e arrow.squiggly.long tilde(e))^(-1) dot [phi]_e dot (e arrow.squiggly.long tilde(e))$] #v(0.4cm)
#columns(2)[
#align(center)[$(e arrow.squiggly.long tilde(e)) = display(mat(1, 1, 1, 1; 0, 1, 1, 1; 0, 0, 1, 1; 0,0,0,1))$]
#colbreak()
#align(center)[$(e arrow.squiggly.long tilde(e))^(-1) = display(mat(1, -1, 0, 0; 0, 1, -1, 0; 0, 0, 1, -1; 0,0,0,1))$
]]
#v(0.4cm)
#align(center)[$[phi]_(tilde(e)) = display(mat(1, -1, 0, 0; 0, 1, -1, 0; 0, 0, 1, -1; 0,0,0,1)) dot display(mat(0,1,2,3;5,4,0,-1;3,2,0,3;6,1,-1,7)) dot display(mat(1, 1, 1, 1; 0, 1, 1, 1; 0, 0, 1, 1; 0,0,0,1)) = display(mat(-5,-8,-6,-2;2,4,4,0;-3,-2,-1,-5;6,7,6,13))$]
\ \
== Базис и ядро линейного оператора
#v(0.4cm)
#columns(2)[
#align(center)[$"Ker"phi = {x in X | phi(x) = 0}$]
#colbreak()
#align(center)[$"Im"phi = {y in Y | y = phi(x)}$]
]#v(0.4cm)
*Пример:*\ #v(0.4cm)
$[phi] = display(mat(1,0,2,3;2,1,1,-1;3,2,0,-7;6,3,3,-5))$\ \
*Задание:* \
Найти базисы $"Ker"phi$ и $"Im"phi$\ #v(0.4cm)
//$x in "Ker"phi <=> phi(x) = 0 quad [phi] dot x = 0$\ \
//Я правильно понял, что мы щас сидим домашку решаем?
// кажись
//Как найти ядро --- решить однородную систему с матрицей\
//Как найти базис ядра --- найти фундаментальную систему решений
// как решать слау
*Решение:*\ #v(0.4cm)
$[phi] = display(mat(1,0,2,3;2,1,1,-1;3,2,0,-7;6,3,3,-5)) tilde display(mat(1,0,2,3;0,1,-3,-7;0,2,-6,-16;0,0,0,0)) tilde display(mat(1,0,2,3;0,1,-3,-7;0,0,0,-2))$\ #v(0.4cm)
#table(columns: (3fr, 20fr),
inset: 0pt,
stroke: none,
align: top,
[
$x_4 = 0$\
$x_1 = -2 x_3$\
$x_2 = 3 x_3$
],
[
$display(vec(x_1,x_2,x_3,x_4)) = x_3 display(vec(-2,3,1,0)) => dim "Im"phi = 3$
])
// нахера это вот нижнее, мы справа просто ставим столбец нулей и т.к. любая комбинация нулей ноль можно столбц даже не писать
// я не помню как слау решать
// не уважаемо
//так стоп. в дз написан какой-то новый базис. что делать в дз то
// то же что и чуть чуть выше
//а от какой матрицы
//а где есть матрица. нету же
// мне кажется та из задания которая сразу под этим
//так это ведь уже другое задание оказывается было, которое мы щас решили
// в плане, утебя есть матрица линейного оператора, а также координаты в старом базисе, ну теперь находим матрицу перехода, обратную и пое
\ \
$RR[x]_n, quad n > 2$\
+ $cal(A): f(x) |-> f(x+1)$\ #v(0.2cm)
$"Ker" cal(A) = {0}, quad "Im"(cal(A))= RR[x]_n$
+ $cal(B): f(x) |-> f(-x)$\ #v(0.2cm)
$"Ker" cal(B) = {0}, quad "Im"(cal(B))= RR[x]_n$
+ $cal(C): f(x) |-> x f''(x)$\ #v(0.2cm)
$"Ker" cal(C) = RR[x]_1, quad "Im"(cal(C))= x dot RR[x]_(n-2)$
+ $cal(D): f(x) |-> f(0) x$\ #v(0.2cm)
$"Ker" cal(D) = x RR[x]_(n-1), quad "Im"(cal(D)) = {a x | a in RR}$
#v(0.4cm)
== Сопряженный оператор (Сопряженное отображение)
#v(0.4cm)
// тема которую мы не дотехали
// упс упс упс, ну да и хрен с ним
// почему ctrl+D не работает
// alt f4 попробуй
#table(columns: (5fr, 5fr, 10fr),
inset: 0pt,
stroke: none,
align: left,
[
$phi: V -> V$\ #v(0.4cm)
$phi^*: V^* -> V^*$\ #v(0.4cm)
$(underbracket(phi^* underbracket(omega, in V^*), in V^*), x\):= (omega, phi x)$\ #v(0.4cm)
$[phi]_e = A$\ #v(0.4cm)
$[phi^*]_(e^*) = space ?$
],
[
$e_1, dots, e_n$ --- базис $V$\ #v(0.4cm)
$e_1^*, dots, e_n^*$ --- базис $V^*$\ #v(0.4cm)
$(e_1^*, e_j) = delta_(i j)$\ #v(0.4cm)
$e_i^* (x) = x_i$\ #v(0.4cm)
$e_i (x^*)= x_i^*$
],
[
$A = (a_(i j))$\ #v(0.4cm)
$a_(i j)$ --- $i$-я координата $j$-ого базисного вектора\ #v(0.4cm)
$a_(i j) = (e_i^*, phi(e_j)) = (phi^* e_i^*, e_j)$ ---\ #v(0.4cm)$j$-я координата $i$-ого базисного ковектора при действии сопряжённого оператора\ #v(0.4cm)
$[phi^*]_(e^*) = A^T$
])
\
*_Домашная работа:_* #v(0.4cm)
Выразить $"Ker"(phi^*)$ и $"Im"(phi^*)$ через $"Ker"(phi)$ и $"Im"(phi)$
//1. Найти $"Ker"(phi^*)$\
//2. Найти $"Im"(phi^*)$\
\
*_Решение:_*
#align(center)[$[phi]_e = A, quad [phi^*]_(e^*) = A^T quad quad quad quad quad [phi]_e = A quad [phi^*]_(e^*) = A^T$] #v(0.4cm)
1. $"Ker"(phi^*)$
$"Ker"(phi) space = {x in X #h(0.32cm)| phi(x) = 0 <=> [phi] dot x = 0}$\ #v(0.4cm)
$"Ker"(phi^*) = {f in X^* | phi^*(f) = 0 <=> f dot [phi]^* = 0}$\ #v(0.4cm)
$phi(x) #h(0.25cm)= 0 <=> A dot x #h(0.35cm)= 0 <=> forall i in [1, n]: sum_(j = 1)^m A_(i j) dot x_j = 0$\ #v(0.4cm)
$phi^*(f) = 0 <=> f dot A^T = 0 <=> forall j in [1, n] : sum_(i = 1)^m f_i dot A^T_(i j) = 0 <=> forall j in [1, n] : sum_(i = 1)^m A_(j i) dot f_i = 0$
#line(angle: 0deg, length: 14.5cm)
#align(left)[$"Ker"(phi^*) = {f in X^* | nu_f = xi_x, space x in "Ker"(phi)}$]
#v(0.4cm)
2. $"Im"(phi^*)$
$"Im"(phi) space = {y in Y #h(0.32cm)| y = phi(x) <=> [phi] dot x = y}$\ #v(0.4cm)
$"Im"(phi^*) = {g in Y^* | g = phi^*(f) <=> f dot [phi]^* = g}$\ #v(0.4cm)
$phi(x) #h(0.25cm)= y <=> A dot x #h(0.35cm)= y <=> forall i in [1, n]:sum_(j = 1)^m A_(i j) dot x_j = y_i$\ #v(0.4cm)
$phi^*(g) = 0 <=> f dot A^T = f <=> forall j in [1, n]: sum_(i = 1)^m g_i dot A^T_(i j) = y_j <=> forall j in [1, n]: sum_(i = 1)^m A_(j i) dot g_i = y_j$
#line(angle: 0deg, length: 14.5cm)
#align(left)[$"Im"(phi^*) = {f in X^* | nu_f = xi_x, space x in "Im"(phi)}$]
#v(0.4cm)
\
*Задание:*\ #v(0.4cm)
$phi in "End"V quad V = "Ker"phi plus.circle "Im"phi quad quad <=> quad quad "Ker"phi^2 = "Ker"phi$\ #v(0.4cm)
То есть, доказать, что пространство раскладывается в прямую сумму ядра и образа тогда и только тогда, когда $"Ker"(phi) = "Ker"(phi^2)$ \ #v(0.4cm)
Мы знаем что для любого оператора $"Ker"(phi^2) >=
"Ker"(phi)$\
Теперь пусть $"Ker"(phi^2) <= "Ker"(phi)$\
Рассмотрим некоторый $x in "Ker"(phi) sect "Im"(phi) => phi(x) = 0$\ #v(0.4cm)
$x = phi(y) => phi(x) = phi^2(y) = 0 => y in "Ker"(phi^2) => y in "Ker"(phi) => phi(y) = 0 = x => x = 0 => \ "Ker"(phi) sect "Im"(phi)={0} $ \ #v(0.4cm)
В обратную сторону: пусть $"Ker"(phi) sect
"Im"(phi) = {0}$\
Найдем ядро квадрата: $phi(phi(x)) = 0 => phi(x) in "Ker"(phi) $ дописать
\ \
*_Домашняя работа:_*\
+ Доказать, что ранг проектора равен его следу\
+ Доказать, что След(AB) = След(BA)
#v(0.4cm)
/*_*Решение:*_ #v(0.4cm)
1. _"Ранг проектора равен его следу"_
$ X = L_1 plus.circle L_2 $
#table(columns: (2.5fr, 10fr),
inset: 0pt,
stroke: none,
//align: horizon,
align(left)[
Базис $L_1 = display(vec(e_1, dots, e_k))$\ #v(0.6cm)
Базис $L_2 = display(vec(e_(k+1), dots, e_n))$
], [
$P_L_1$
])*/
#pagebreak()
= Повторение теории
$phi in "End"(x) <=> phi: X -> X$#v(0.2cm)
Собственный вектор:\
$x$ --- собственный вектор оператора $phi$, если $phi x = lambda x, lambda in K, lambda$ --- собственное значение\
$sigma_phi = {lambda_1, lambda_2, dots, lambda_k}$ --- спектр линейного оператора $phi$ --- множество всех собственных значений.
\ \
== Решение задач
#set math.mat(delim: "[")
#set math.vec(delim: "[")
+ $tau: RR_2^2 -> RR_2^2, quad tau A = A^T$\ #v(0.2cm)
Хотим найти собственные значения и собственные вектора:\
Введем базис в пространстве $RR_2^2$ #v(0.4cm)
$M_1 = mat(1, 0;0, 0), quad M_2 = mat(0, 1;0, 0), quad M_3 = display(mat(0, 0;1, 0)), quad M_4 = display(mat(0, 0;0, 1))$\ #v(0.4cm)
$tau M_1 = M_1 quad tau M_2 = M_3 quad tau M_3 = M_2 quad tau M_4 = M_4$\ #v(0.2cm)
В пространсве матриц работать неудобно, поэтому построим изоморфизм из $RR_2^2 " в " RR^4$:\ #v(0.4cm)
$display(mat(a, b;c, d)) /*~*/ <-> (a, b, c, d)^T$\ #v(0.4cm)
$A_tau = display(mat(1, 0, 0, 0;0, 0, 1, 0;0, 1, 0, 0;0, 0, 0, 1))$\ \
$cal(X)_tau (lambda) = display(mat(1-lambda, 0, 0, 0;0, -lambda, 1, 0;0, 1, -lambda, 0;0, 0, 0, 1-lambda)) = (1-lambda)^2 (lambda^2-1 ) = -(1-lambda)^3 (1+lambda)$#v(0.2cm)
$sigma_tau = {-1^((1)), 1^((3))}$#v(0.4cm)
Найдем собственные вектора:\ #v(0.4cm)
$phi x = lambda x <=> A x = lambda x <=> (A-lambda E)x = 0$\
- $lambda_1 = -1$\ #v(0.4cm)
$(A - lambda_1 E) = mat(2, 0, 0, 0; 0, 1, 1, 0; 0, 1, 1, 0; 0, 0, 0, 2) tilde display(mat(2, 0, 0, 0; 0, 1, 1, 0; 0, 0, 0, 2; 0, 0, 0, 0))$\ #v(0.4cm)
$make x_3$ --- параметр, возьмем $x_3 = 1$:#v(0.4cm)
$x_4 = 0, x_2 = -1, x_1 = 0 => v_1 = display(mat(0; -1; 1; 0)) tilde display(mat(0, -1;1, 0))$
- $lambda_2 = 1^((3))$#v(0.2cm)
#table(columns: (7fr, 10fr),
inset: 0pt,
stroke: none,
align: horizon,
align(left)[
$(A - lambda_2 E) = display(mat(0, 0, 0, 0; 0, -1, 1, 0; 0, 1, -1, 0; 0, 0, 0, 0)) tilde display(mat(0, 1, -1, 0; 0, 0, 0, 0; 0, 0, 0, 0; 0, 0, 0, 0))$
],[
$make x_1, x_3, x_4$ --- параметры#v(0.2cm)
$make x_1 = 1, x_3 = x_4 = 0 => x_2 = 0$\
$make x_3 = 1, x_1 = x_4 = 0 => x_2 = 1$\
$make x_4 = 1, x_1 = x_3 = 0 => x_2 = 0$\
])\
$display(mat(delim: "(", 1, 0, 0, 0))^T = display(mat(1, 0; 0, 0)) = v_2$#v(0.6cm)
$display(mat(delim: "(", 0, 1, 0, 1))^T = display(mat(0, 1; 0, 1)) = v_3$#v(0.6cm)
$display(mat(delim: "(", 0, 0, 0, 1))^T = display(mat(0, 0; 0, 1)) = v_4$#v(0.4cm)
Собственный базис: ${v_1, v_2, v_3, v_4}$\ \
$tau$ --- оператор скалярного типа $=> A_tau$ может быть диаганализована\ \
#table(columns: (2fr, 10fr),
inset: 0pt,
stroke: none,
align: horizon,
align(left)[$tilde(A)_tau = display(mat(augment: #(vline: (1), hline: (1)), -1, 0, 0, 0; 0,1, 0, 0; 0, 0, 1, 0; 0, 0, 0, 1))$],[ --- значения на диагоналях такие, т.к. это собственные значения. Порядок мог быть \ #h(0.4cm)каким угодно, но нельзя -1 ставить в любое место между 1, т.к. значения должны \ #h(0.4cm) записываться по порядку ])\ #v(0.4cm)
$tilde(A)'_tau = display(mat(1,0,0,0;0,1,0,0;0,0,1,0;0,0,0,-1))$ --- тоже вариант, но в базисе: ${v_2, v_3, v_4, v_1}$
\
2. #table(columns: (1.6fr, 10fr),
inset: 0pt,
stroke: none,
align: horizon,
align(left)[
$A = display(mat(0, 1, 0; 0, 0, 1; 1, 0, 0))$],[
${x, y, z}$\
$phi x = z, quad phi y = x, quad phi z = y $
])#v(0.4cm)
$chi_phi (lambda) = det (A - lambda E) = display(mat(delim: "|", -lambda, 1, 0; 0, -lambda, 1; 1, 0, -lambda)) = lambda^3 - 1$ \ \
$make KK = RR => lambda^3 = 1 => lambda = 1 => sigma_A = {1}$ (тут первая кратность и ее можно не писать)\ #v(0.4cm)
$lambda = 1 => (A - lambda E) = display(mat(-1, 1, 0; 0, -1, 1; 1, 0, -1)) tilde display(mat(-1, 1, 0; 0, -1, 1; 0, 0, 0)) => v = display(vec(1,1,1))$#v(0.2cm)
$tilde(A) = display(mat(augment: #(vline: (1), hline: (1)) ,1, 0, 0; 0; 0)) =>$
в $RR$ диагонализовать нельзя
\ \
$make KK = CC$\
$lambda^3 = 1 => lambda = cos (2 pi k)/3 + i sin (2 pi k)/3$\ #v(0.2cm)
$k = 0 quad lambda_1 = 1$\ #v(0.3cm)
$k = 1 quad lambda_2 = -1/2 + i 1/2 = e^((2 pi)/3) i$\ #v(0.3cm)
$k = 2 quad lambda_3 = -1/2 - i 1/2 = e^((-2pi)/3 i)$\ #v(0.4cm)
$tilde(A) = display(mat(1,0,0;0,e^((2pi)/3 i),0;0,0,e^(-(2pi)/3 i)))$#v(0.4cm)
Над $CC$ матрица диагонализуема всегда, а над $RR$ --- не всегда.\
+ $cal(P)_2$ --- пространство однородных полиномов от двух переменных #v(0.2cm)
$phi(p)(x, y) = x (diff p) / (diff y) + y (diff p) / (diff x)$ #v(0.2cm)
Найти матрицу $A phi, $ собственные значения и собственные функции #v(0.2cm)
$make {x^2, x y, y^2} $ --- базис $cal(P)_2(x, y)$\ #v(0.2cm)
$phi(x^2) = 2 x y$\ #v(0.2cm)
$phi(x y) = x^2 + y^2$\ #v(0.2cm)
$phi(y^2) = 2 x y$ #v(0.4cm)
$A_phi = display(mat(0,1,0;2,0,2;0,1,0))$ #v(0.4cm)
$chi_phi (lambda) = abs(A - lambda E) = display(mat(-lambda,1,0;2,-lambda,2;0,1,-lambda)) = - lambda^3 + 4lambda = -lambda (lambda - 2) (lambda + 2)$ #v(0.4cm)
$sigma_phi = {-2, 0, 2}$ #v(0.4cm)
$lambda = -2 => display(mat(2,1,0;2,2,2;0,1,2)) tilde display(mat(2,1,0;0,1,2;0,0,0)) => x_3 = 1 => x_2 = -2, x_1 = 1 => v_1 = vec(1, -2, 1) => p(x, y) = x^2 - 2 x y + y^2$ #v(0.6cm)
$lambda = 0 => display(mat(0,1,0;2,0,2;0,1,0)) tilde display(mat(2,0,2;0,1,0;0,0,0)) => $
$x_3=1 => x_2 = 0, x_1 = -1 => $
$v_2 = vec(-1, 0, 1) => p_2 (x, y) = y^2 - x^2$ #v(0.6cm)
$lambda = 2 => display(mat(-2,1,0;2,-2,2;0,1,-2)) tilde display(mat(-2,1,0;0,1,-2;0,0,0)) => x_3 = 1 => x_2 = 2, x_1 = 1 => v_3 = vec(1,2,1) => p_3 (x, y) = x^2 + 2x y + y^2$ #v(0.6cm)
$tilde(A)_phi = display(mat(-2,0,0;0,0,0;0,0,2))$\ #v(0.4cm)
Проверим, что $v_3$ --- собственный вектор\ #v(0.4cm)
$A v_3 = display(mat(0,1,0;2,0,2;0,1,0)) display(vec(1,2,1)) = display(vec(2,4,2)) = 2 display(vec(1,2,1)) = lambda_3 v_3$\ #v(0.4cm)
$tilde(A)_phi = S A T, quad S = T^(-1), space T = display(mat(1, -1, 1; -2, 0, 2; 1, 1, 1))$
+ $X = L_1 plus.dot L_2 plus.dot L_3 => forall x in X quad x =^! x_1 = x_1 + x_2 + x_3, quad x_j in L_j$\ #v(0.4cm)
$phi in "End"(RR^3), A = display(mat(4,0,0;0,5,-1;0,-1,5)), tau_phi = {4^((2)), 6}$ #v(0.6cm)
$v_1 = display(vec(0,1,1)), v_2 = display(vec(1,0,0)), v_3 = display(vec(0,-1,1))$\ #v(0.4cm)
${xi_i}_(i=1)^3$ и ${eta^j}_(j=1)^3$ --- сопряжённые базисы $=> forall x quad x = eta^1 (x) xi_1 + eta^2 (x) xi_2 + eta^3 (x) xi_3$\ #v(0.2cm)
$x_j = eta^j (x) xi_j => cal(P)_L_1 (*) = xi_1 eta^1 (*)$ #v(0.4cm)
$T = display(mat(0,1,0;1,0,-1;1,0,1)), quad S = T^(-1) = display(1/2 mat(0,1,1;1,0,0;0,-1,1))$\ #v(0.4cm)
$phi = 4 cal(P)_(lambda = 4) + 6 cal(P)_(lambda = 6)$\ #v(0.2cm)
$cal(P)_(lambda = 1) = cal(P)_v_1 + cal(P)_v_2$\ #v(0.2cm)
$cal(P)_v_1 e_1 = (u^1, e_1) v_1 = display([1/2 mat(delim: "(", 0,1,1) vec(delim: "(", 1,0,0)]) dot display(vec(0,1,1)) = display(vec(0,0,0))$\ #v(0.6cm)
$cal(P)_v_1 e_2 = (u^1, e_2) v_1 = display([1/2 mat(delim: "(", 0,1,1) vec(delim: "(", 0,1,0)]) dot display(vec(0,1,1)) = display(1/2vec(0,1,1))$#v(0.6cm)
$cal(P)_v_1 e_3 = (u^1, e_3) v_1 = display([1/2 mat(delim: "(", 0,1,1) vec(delim: "(", 0,0,1)]) dot display(vec(0,1,1)) = display(1/2vec(0,1,1))$\ #v(0.4cm)
$cal(P)_v_1 = display(1/2 mat(0,0,0;0,1,1;0,1,1))$\ #v(0.4cm)
$cal(P)_v_2 e_j = (u^2, e_j) v_2 => cal(P)_v_2 = display(mat(1,0,0;0,0,0;0,0,0))$ #v(0.4cm)
$cal(P)_(lambda=4) = cal(P)_v_1 + cal(P)_v_2 = display(1/2 mat(2,0,0;0,1,1;0,1,1))$\
$cal(P)_(lambda=6) = display(1/2 mat(0,0,0;0,1,-1;0,-1, 1))$\
$display(sum_(j=1)^3) cal(P)_L_j = cal(I), quad phi = limits(sum, inline: #false)^i lambda_j cal(P)_lambda_j $\
$display(4 dot 1/2 dot mat(2,0,0;0,1,1;0,1,1) + 6 dot 1/2 mat(0,0,0;0,1,-1;0,-1,1) = mat(4,0,0;0,5,-1;0,-1,5)=A)$
|
|
https://github.com/Myriad-Dreamin/typst.ts
|
https://raw.githubusercontent.com/Myriad-Dreamin/typst.ts/main/fuzzers/corpora/layout/par-bidi_03.typ
|
typst
|
Apache License 2.0
|
#import "/contrib/templates/std-tests/preset.typ": *
#show: test-page
// Test embedding up to level 4 with isolates.
#set text(dir: rtl)
א\u{2066}A\u{2067}Bב\u{2069}?
|
https://github.com/typst/packages
|
https://raw.githubusercontent.com/typst/packages/main/packages/preview/unichar/0.1.0/ucd/block-1E290.typ
|
typst
|
Apache License 2.0
|
#let data = (
("TOTO LETTER PA", "Lo", 0),
("TOTO LETTER BA", "Lo", 0),
("TOTO LETTER TA", "Lo", 0),
("TOTO LETTER DA", "Lo", 0),
("TOTO LETTER KA", "Lo", 0),
("TOTO LETTER GA", "Lo", 0),
("TOTO LETTER MA", "Lo", 0),
("TOTO LETTER NA", "Lo", 0),
("TOTO LETTER NGA", "Lo", 0),
("TOTO LETTER SA", "Lo", 0),
("TOTO LETTER CHA", "Lo", 0),
("TOTO LETTER YA", "Lo", 0),
("TOTO LETTER WA", "Lo", 0),
("TOTO LETTER JA", "Lo", 0),
("TOTO LETTER HA", "Lo", 0),
("TOTO LETTER RA", "Lo", 0),
("TOTO LETTER LA", "Lo", 0),
("TOTO LETTER I", "Lo", 0),
("TOTO LETTER BREATHY I", "Lo", 0),
("TOTO LETTER IU", "Lo", 0),
("TOTO LETTER BREATHY IU", "Lo", 0),
("TOTO LETTER U", "Lo", 0),
("TOTO LETTER E", "Lo", 0),
("TOTO LETTER BREATHY E", "Lo", 0),
("TOTO LETTER EO", "Lo", 0),
("TOTO LETTER BREATHY EO", "Lo", 0),
("TOTO LETTER O", "Lo", 0),
("TOTO LETTER AE", "Lo", 0),
("TOTO LETTER BREATHY AE", "Lo", 0),
("TOTO LETTER A", "Lo", 0),
("TOTO SIGN RISING TONE", "Mn", 230),
)
|
https://github.com/typst/packages
|
https://raw.githubusercontent.com/typst/packages/main/packages/preview/babel/0.1.1/src/alphabets.typ
|
typst
|
Apache License 2.0
|
#import "@preview/mantys:0.1.4": *
#let maze(alphabet, width: 20, height: 4) = {
import "baffle.typ": baffle
par(leading: 0.50em, {
for y in range(height) {
for x in range(width) {
[#baffle(alphabet: alphabet, [X])]
}
[\ ]
}
})
}
#let alphabets = yaml("alphabets.yaml")
|
https://github.com/nafkhanzam/typst-common
|
https://raw.githubusercontent.com/nafkhanzam/typst-common/main/lib.typ
|
typst
|
#import "src/common/answer.typ": *
#import "src/common/binary.typ": *
#import "src/common/currency.typ": *
#import "src/common/data.typ": *
#import "src/common/dates.typ": *
#import "src/common/gray.typ": *
#import "src/common/kode.typ": *
#import "src/common/style.typ": *
#import "src/common/truth-table-legacy.typ" as tt-legacy
#import "src/common/truth-table-reimp.typ" as tt
#import "src/common/utils.typ": *
#import "src/km/lib.typ": *
#import "src/touying-themes/touying.typ"
#import "src/touying-themes/university.typ" as st-university //? st = Slide Theme
#import "src/touying-themes/its.typ" as st-its //? st = Slide Theme
#import "src/touying-themes/its-mooc.typ" as st-its-mooc //? st = Slide Theme
#import "src/templates/formal.typ" as t-formal //? t = Template
#import "src/templates/general.typ" as t-general //? t = Template
#import "src/templates/drpm/lib.typ" as t-drpm //? t = Template
|
|
https://github.com/iceghost/typst-at-hcmut
|
https://raw.githubusercontent.com/iceghost/typst-at-hcmut/main/README.md
|
markdown
|
Apache License 2.0
|
# Typst at HCMUT
Template của mình dành cho những bạn muốn thử
sử dụng Typst làm báo cáo trong trường.
Mặc dù mình năm 4, không viết báo cáo nhiều nữa rồi,
nhưng mình mong thế hệ sau sẽ hiểu rõ hơn những tài liệu họ soạn thảo,
không phải mù quáng xài mấy cái template LaTeX rồi không biết
customize kiểu gì :^)
Mục tiêu của template là trở thành một template mà bạn thực sự hiểu
và có thể làm những thứ bạn muốn, không cần phải copy-paste code trên mạng.
Template này được viết với nội dung như một bài hướng dẫn,
các bạn có thể mở file [main.pdf](main.pdf) để đọc.
## Contribute
Để báo lỗi, hoặc đóng góp thêm cách mình có thể cải thiện template này,
các bạn sử dụng tính năng [Discussion](https://github.com/iceghost/typst-at-hcmut/discussions)
để tạo nguyện vọng nhé.
## I used Typst in my report!
Nếu bạn có báo cáo nào xài Typst và public được cho mọi người tham khảo,
bạn có thể nhắn mình ghi vào đây nhé :)
- https://github.com/dadn-dream-home/documents: Đồ án đa ngành của mình/iceghost.
Đồ án này mình là project đầu tiên mình viết bằng Typst,
nên có thể nó sẽ hơi khác template chút.
|
https://github.com/typst/packages
|
https://raw.githubusercontent.com/typst/packages/main/packages/preview/nth/0.2.0/README.md
|
markdown
|
Apache License 2.0
|
# Nth
Provides a function `#nth()` which takes a number and returns it suffixed by an english ordinal.
This package is named after the nth [LaTeX macro](https://ctan.org/pkg/nth) by <NAME>.
## Usage
Include this line in your document to import the package.
```typst
#import "@preview/nth:0.2.0": nth
```
Then, you can use `#nth()` to markup ordinal numbers in your document.
For example, writing `#nth(1)` shows 1<sup>st</sup>,
`#nth(2)` shows 2<sup>nd</sup>,
`#nth(3)` shows 3<sup>rd</sup>,
`#nth(4)` shows 4<sup>th</sup>,
and `#nth(11)` shows 11<sup>th</sup>.
_Please use version 0.2.0 as version 0.1.0 is broken!_
See issue [here](https://github.com/typst/packages/pull/162) (thanks to jeffa5)._
## TODO
* Pass argument to choose whether or not to put ordinals in superscript.
|
https://github.com/Myriad-Dreamin/typst.ts
|
https://raw.githubusercontent.com/Myriad-Dreamin/typst.ts/main/fuzzers/corpora/meta/cite-group_00.typ
|
typst
|
Apache License 2.0
|
#import "/contrib/templates/std-tests/preset.typ": *
#show: test-page
A#[@netwok@arrgh]B \
A@netwok@arrgh B \
A@netwok @arrgh B \
A@netwok @arrgh. B \
A @netwok#[@arrgh]B \
A @netwok@arrgh, B \
A @netwok @arrgh, B \
A @netwok @arrgh. B \
A#[@netwok @arrgh @quark]B. \
A @netwok @arrgh @quark B. \
A @netwok @arrgh @quark, B.
#set text(0pt)
#bibliography("/assets/files/works.bib")
|
https://github.com/akrantz01/resume
|
https://raw.githubusercontent.com/akrantz01/resume/main/template/sections.typ
|
typst
|
MIT License
|
#import "awards.typ": awards
#import "education.typ": education
#import "experience.typ": experience
#import "projects.typ": projects
#import "skills.typ": skills
#let types = (
"awards": awards,
"education": education,
"experience": experience,
"projects": projects,
"skills": skills,
)
#let sections(layout, data) = {
let settings = layout.at("settings", default: (:))
for (id, section) in layout.sections {
let renderer = types.at(section.type)
let title = section.at("title", default: none)
if title == none {
title = upper(id.slice(0, count: 1)) + id.slice(1)
}
renderer(
title: title,
settings: settings,
omit: section.at("omit", default: ()),
..data.at(id, default: ()),
)
}
}
|
https://github.com/jgm/typst-hs
|
https://raw.githubusercontent.com/jgm/typst-hs/main/test/typ/compiler/ops-invalid-02.typ
|
typst
|
Other
|
// Error: 10 expected expression
#test({2*}, 2)
|
https://github.com/AxiomOfChoices/Typst
|
https://raw.githubusercontent.com/AxiomOfChoices/Typst/master/Courses/Math%20591%20-%20Mathematical%20Logic/Assignments/Assignment%206.typ
|
typst
|
#import "/Templates/generic.typ": latex, header
#import "@preview/ctheorems:1.1.0": *
#import "/Templates/math.typ": *
#import "/Templates/assignment.typ": *
#import "@preview/commute:0.2.0": node, arr, commutative-diagram
#import "@preview/cetz:0.2.0"
#let head(doc) = header(doc, title: "Assignment 6")
#show: head
#show: latex
#show: NumberingAfter
#show: thmrules
#show: symbol_replacing
#set page(margin: (x: 1.6cm, top: 2.5cm, bottom: 1.9cm))
#show math.equation: it => {
if it.has("label") {
return math.equation(block: true, numbering: "(1)", it)
} else {
it
}
}
#show ref: it => {
let el = it.element
if el != none and el.func() == math.equation {
link(
el.location(),
numbering(
"(1)",
counter(math.equation).at(el.location()).at(0) + 1,
),
)
} else {
it
}
}
#let lemma = lemma.with(numbering: none)
#set enum(numbering: "(a)")
#let claim = claim.with(base_level: 1)
= Question
<question-1>
== Statement
Show that the computation of the Morley rank of a formula with parameters in a model $mM$ does not depend on the choice of an $aleph_0$-saturated extension of $mM$.
== Solution
Let us formalize the statement of the question.
#claim[
If $mN_1,mN_2 succ mM$ and $mN_1,mN_2$ are $aleph_0$-saturated then for any formula $phi$ with parameters in $mM$ we have
$
RM_mN_1 (phi) = RM_mN_2 (phi).
$
]
To show this is true we first show that it is enough to prove the claim
#claim[
If $mM elm frak(C)$ and $phi$ is a formula with parameters in $mM$ then
$
RM_mM (phi) = RM_frak(C) (phi)
$
]
Assume that this claim is true, then since every model embeds in the monster model we get that
$
RM_mN_1 (phi) = RM_frak(C) (phi) = RM_mN_2 (phi)
$
and so knowing the second claim proves the first claim.
Now let us prove the second claim, we denote $mN := frak(C)$ and note that $mN$ is $aleph_0$-strongly homogeneous.
We now prove
$
RM_mM (phi) >= alpha <=> RM_mN (phi) >= alpha
$
through induction on $alpha$.
The base case, $alpha = 0$, is trivial since
$
RM_mM (phi) >= 0 <=> phi(mM) != nothing
$
and since $phi(mM)$ being empty can be written as an $L$-sentence we have
$
RM_mM (phi) >= 0 <=> phi(mM) != nothing
<=>
phi(mN) != nothing <=> RM_mN (phi) >= 0
$
The limit case is also trivial by inductive hypothesis.
For the successor case assume that $RM_mM (phi) >= alpha + 1$, then there is an infinite sequence of $L(mM)$ formulas $phi_i$ that are pairwise inconsistent, imply $phi$, and have $RM_mM (phi_i) >= alpha$. The $phi_i$ are also $L(mN)$ formulas and hence by inductive hypothesis we have $RM_mN (phi_i) >= alpha$, so we also have $RM_mN (phi) >= alpha + 1$.
On the other hand assume that $RM_mN (phi) >= alpha + 1$, then for any $n$ there are $L$-formulas $phi_i (ov(x), ov(y))$ and parameters $ov(a)_i$ for $1 <= i <= n$ such that $phi_i (ov(x), ov(a)_i)$ are pairwise inconsistent, imply $phi(ov(x))$, and have $RM_mN (phi_i (ov(x), ov(a)_i)) >= alpha$. Now let $ov(c)$ be the parameters of $phi$ in $mM$ and consider
$
tp_mN (ov(a)_1 ... ov(a)_n quo ov(c))
$
since this is a type over $ov(c)$ and since $mM$ is $aleph_0$-saturated we get that there is a realization of this type in $mM$. That is there are tuples $ov(b)_i in mM$ with
$
tp_mN (ov(a)_1 ... ov(a)_n quo ov(c))
= tp_mM (ov(b)_1 ... ov(b)_n quo ov(c))
= tp_mN (ov(b)_1 ... ov(b)_n quo ov(c)).
$
Next consider the $L(mM)$-formulas $psi_i (ov(x)) := phi_i (ov(x), ov(b)_i)$, since $mN$ is $aleph_0$-strongly homogeneous there is an automorphism $f$ of $mN$ that fixes $ov(c)$ and such that $f(ov(a)_i) = ov(b)_i$. Under this automorphism the formulas $phi_i (ov(x), ov(a)_i)$ map to $phi_i (ov(x), ov(b)_i) = psi_i$. Using this we get that since $phi_i (ov(x), ov(a)_i)$ are pairwise inconsistent so are $psi_i$, since this automorphism fixes $ov(c)$ it also fixes $phi$, so since $phi_i (ov(x), ov(a)_i)$ imply $phi$ so do $psi_i$. Since we have this decomposition of $phi$ into $psi_i$'s it is enough to show that $psi_i$'s have $RM_mM (psi_i) >= alpha$.
But now Morley rank is a model theoretic property and so it is preserved under automorphisms and thus
$
RM_(mN) (psi_i) = RM_(mN) (phi_i (ov(x), ov(a)_i)) >= alpha,
$
which finishes the proof.
= Question
<question-2>
== Statement
Suppose that $tp(ov(a)) = tp(ov(b))$ and let $phi(ov(x), ov(y))$ be a formula. Show that $RM(phi(ov(x), ov(a))) = RM(phi(ov(x), ov(b)))$.
== Solution
Using @question-1 we know that we can embed $mM$ into a monster model $frak(C)$ and have
$
RM_mM (phi(ov(x), ov(a))) = RM_frak(C) (phi(ov(x), ov(a)))
"and"
RM_mM (phi(ov(x), ov(b))) = RM_frak(C) (phi(ov(x), ov(b)))
$
We now note that there is an automorphism of $frak(C)$ that maps $ov(a)$ to $ov(b)$ since it is $aleph_0$-strongly homogeneous, we thus get
$
RM_frak(C) (phi(ov(x), ov(a))) = RM_frak(C) (phi(ov(x), ov(b))),
$
and so we also get
$
RM_mM (phi(ov(x), ov(a)))
= RM_frak(C) (phi(ov(x), ov(a)))
= RM_frak(C) (phi(ov(x), ov(b)))
= RM_mM (phi(ov(x), ov(b))).
$
= Question
== Statement
Given an algebra $cal(A)$ of definable subsets of a model $mM$ we define the Morley rank over $cal(A)$ as follows. For a set $A in cal(A)$ we define
#[
#set enum(numbering: "(i)", indent: 1em)
+ $RM_cal(A) (A) >= 0$ if $A$ is non-empty.
+ $RM_cal(A) (A) >= alpha + 1$ if there exists a sequence $B_n$ of disjoint subsets of $A$, with each $B_n in cal(A)$ and $RM_cal(A) (B_n) >= alpha$ for each $n$.
+ $RM_cal(A) (A) >= gamma$ for a limit $gamma$ if for every $beta < gamma$, $RM_cal(A) (A) >= beta$.
]
Suppose that $T$ is totally transcendental and let $frak(C) sat T$ be the monster model.
+ Find a countable set $C$ of tuples of elements of $frak(C)$ such that for every $ov(a) in C$ and every $ov(b) in frak(C)$ there exists $ov(b') in C$ such that $tp(ov(b) quo ov(a)) = tp(ov(b') quo ov(a))$.
+ Let $cal(A)$ be the algebra of sets definable over $C$. Show that for every set $A in cal(A)$ we have $RM(A) = RM_cal(A) (A)$.
+ Show that if $A in cal(A)$, then $RM_(cal(A)) (A)$ is equal to the $CB([A])$ computed in the stone space of $cal(A)$. Conclude that $RM_cal(A) (A) < omega_1$.
Conclude that $RM(x = x) < omega_1$.
== Solution
=== (a)
To find this countable set we will construct via induction a sequence of countable sets $C_n$ such that for every $ov(a) in C_n$ and every $ov(b) in frak(C)$ there exists $ov(b') in C_(n+1)$ such that
$
tp(ov(b) quo ov(a)) = tp(ov(b') quo ov(a)).
$
After constructing such a sequence, setting $C = union.big_(n) C_n$ we get a countable union of countable sets which also clearly satisfies the requirements of the question.
To construct such a sequence we start with $C_0 = { () }$, the set containing the empty tuple. Then assuming we constructed $C_n$, fix some positive natural number $m$, and consider the partition of $frak(C)^m$ given by the equivalence classes of the equivalence relation
$
ov(v) tilde ov(w) <=> tp(ov(v) quo C_n) = tp(ov(w) quo C_n).
$
Now since $T$ is totally transcendental and since $C_n$ is countable by inductive hypothesis we get that there are at most countable many equivalence classes of this relation, hence let $D_m$ be a countable set of representatives for each equivalence class. We now set
$
C_(n+1) := C_n union.big_(m) D_m.
$
Clearly $C_(n+1)$ remains countable and for any tuples $ov(a) in C_n$, $ov(b) in frak(C)^m$ we have that there is some element $ov(b') in C_(n+1)$ such that
$
tp(ov(b) quo C_n) = tp(ov(b') quo C_n),
$
and hence
$
tp(ov(b) quo ov(a)) = tp(ov(b') quo ov(a)),
$
=== (b)
Let $phi(ov(x), ov(a))$ be the formula defining $A in cal(A)$, we prove the statement by proving
$
RM(phi) >= alpha <=> RM_cal(A) (phi) >= alpha
$
through induction on $alpha$.
#remark[
I am going to use $RM(phi), RM(A)$ as well as $RM_cal(A) (phi), RM_cal(A) (A)$ interchangeably wherever it is convenient.
]
Base case is simple, since $RM(phi) >= 0$ and $RM_cal(A) (phi) >= 0$ are both equivalent to $A$ being non-empty. The limit case is also simple by inductive hypothesis.
Now assume that $RM_cal(A) (A) >= alpha + 1$, then we have an infinite sequence of sets $A_n in cal(A)$ that are disjoint, contained in $A$ and have $RM_cal(A) (A_n) >= alpha + 1$. Since they are in $cal(A)$ they are definable over $C$ and thus also over $frak(C)$, but by inductive hypothesis we have
$
RM(A_n) = RM_cal(A) (A_n) >= alpha
$
and thus we have that $RM(A) >= alpha + 1$.
Next assume that $RM(A) >= alpha + 1$, then we have infinitely many disjoint definable sets $A_n$ contained in $A$ such that $RM(A_n) >= alpha$. Now let $phi_n (ov(x), ov(b)_n)$ be the formulas that define $A_n$, for each $ov(b)_n$ we can can, by part (a), find $ov(b'_n)$ such that for any $n$ we have
$
tp(ov(b)_n quo ov(a)) = tp(ov(b'_n) quo ov(a)).
$
Since $frak(C)$ is $kappa$-strongly homogeneous for very large enough $kappa$, we have that there exists an automorphism $f: frak(C) -> frak(C)$ such that $f$ fixes $ov(a)$, and $f(ov(b)_n) = ov(b'_n)$, since this automorphism preserves Morley rank we get that
$
alpha <= RM(phi_n (ov(x), ov(b)_n)) = RM(phi_n (ov(x), ov(b'_n)))
$
and since $ov(b'_n)$ are all in $C$, then $B_n := phi_n (ov(frak(C)), ov(b'_n))$ are all elements of $cal(A)$, so we also get by inductive hypothesis
$
RM(B_n) >= alpha <==> RM_cal(A) (B_n) >= alpha
$
and so we conclude $RM_cal(A) (B_n) >= alpha$.
Now since $f$ maps the formulas $phi_n (ov(x), ov(b)_n)$ to the formula $phi_n (ov(x), ov(b'_n))$ we get that it also maps $A_n$ onto $B_n$. We hence know that $B_n$'s are disjoint since $A_n$'s are disjoint, then since $f$ fixes $ov(a)$ we get that the set $A$ is invariant under $f$ and so $B_n = f(A_n) seq f(A) = A$.
We now know that we have a sequence of subsets $B_n$ of $A$, which are disjoint and each have $RM_cal(A) (B_n) >= alpha$, so we get that $RM_cal(A) (A) >= alpha + 1$.
=== (c)
First note that the stone space $S(cal(A))$ is indeed a $0$-dimensional topological space, since the open sets $[A]$ forming its basis are closed since $[A]^c = [A^c]$. From here the definition given in the question is identical to the Cantor-Bendixson rank we defined in class for clopen subsets of a $0$-dimensional topological space.
Then since $T$ is totally transcendental and $S(cal(A))$ is in correspondence with $S_n (C)$ then we know that $|S(cal(A))| <= aleph_0$. Next since $T$ is totally transcendental we saw in class that
$
CB([frak(C)]) = RM_cal(A) (frak(C)) = RM (frak(C)) = RM (x = x) < infinity.
$
and so the Cantor-Bendixson derivatives of $S(cal(A))$ never stabilize and so every step removes at least one point. Now since the Cantor-Bendixson rank's image always contains an initial segment of ordinals we get that
$
CB : S(cal(A)) -> {alpha : alpha <= RM(x = x)}
$
is surjective. Hence we have
$
|{alpha : alpha <= RM(x = x)}| <= |S(cal(A))| <= aleph_0
$
and this is only possible if $RM(x = x) < omega_1$.
= Question
== Statement
Let $K$ be an algebraically closed field and $k$ its subfield. Describe the spaces $S_n (k)$ in terms of the spectrum (the set of all prime ideals) of polynomial rings. Which types in $S_1(k)$ are algebraic?
== Solution
Consider a complete type $p in S_n (k)$, for every polynomial $f$ in $n$ we know that either
$
f(ov(x)) = 0 in p "or" not (f(ov(x)) = 0) in p.
$
Since we want to connect these to prime ideals we would hope that the set of vanishing polynomials on the type are a prime ideal of polynomials, which is exactly the case. Set
$
Z(p) = {f "polynomial over" k : f(ov(x)) in p}
$
then for any $f,g in k[ov(x)]$ we have
$
K sat (f(ov(x)) = 0) and (g(ov(x)) = 0) => (f(ov(x)) + g(ov(x)) = 0)
$
so $V(p)$ is is additive. Additionally we have
$
K sat (f(ov(x)) = 0) or (g(ov(x)) = 0) <=> f(ov(x)) g(ov(x)) = 0
$
and so $V(p)$ is either an ideal or empty, and if it is an ideal it is a prime ideal in $k[ov(x)]$.
Now the converse is also true, every prime ideal also corresponds to a type. Let $I$ be a prime ideal of $k[ov(x)]$, then consider the type
$
W(I) = {f(ov(x)) = 0 : f in I}
$
this is not yet a complete type but we can take all the conclusions of this type to complete it. This is because $A C F_p$ has quantifier elimination so every formula is equivalent to boolean combination of polynomials, so the truth value of every formula can be derived from just the formulas in the set above. We also map the 'empty' ideal to the complete type of a transcendental number over $k$.
We can see that these two operations are inverses of each other, and so complete types in $S_n (k)$ are in correspondence with prime ideals of $k[ov(x)]$.
Now let us specifically consider $S_1 (k)$, take an algebraic type $p$ and consider its corresponding prime ideal $Z(p)$. Since this is an ideal in $k[x]$, which is a PID, then there is a polynomial $f$ such that $Z(p) = (f)$. Now since $Z(p)$ is a prime ideal we also know that $f$ is irreducible and thus is either linear has no roots of $k$. If it is linear then its only root is just an element of $k$ which is trivially algebraic, hence we can assume that $f$ is at least quadratic and has no roots in $k$. Now $K$ is algebraically closed so $f$ factors as
$
f = product_i (x - alpha_i)
$
for some $alpha_i in K backslash k$, since $f$ is irreducible over $k$ then the polynomials $f$ are minimal polynomials for $alpha_i$ and so all $alpha_i$ are in the algebraic closure $ov(k)$. Conversely for any element $ov(x)$ in the algebraic closure, its minimal polynomial is irreducible and thus generates a prime ideal. We thus have that the algebraic types in $S_1 (k)$ are exactly the types of elements of the algebraic closure of $k$.
= Question
<question-5>
== Statement
Show that any algebraic type is isolated.
== Solution
Let $p$ be an algebraic type, from class then we know that there is an algebraic formula $phi$ such that $phi in p$.
Now take some model $mM sat T$ and consider the sets $A := phi(mM)$ and $B := p(mM)$. Both of these sets are finite, and we also have
$
B = A sect.big_(psi in p) psi(mM).
$
Now since $A$ is finite then $A backslash B$ is finite so enumerate it as ${ov(x)_1,...,ov(x)_n}$, then by the equation above, for each $ov(x)_i$, there is a formula $psi_i in p$ such that $mM tack.r.double.not psi_i (ov(x)_i)$.
Now this means that
$
(phi and.big_(i <= n) psi_i)(mM) seq B,
$
but also we know that anything in $B$ satisfies all of these formulas so we get
$
B seq (phi and.big_(i <= n) psi_i)(mM)
$
and so $phi and.big_(i <= n) psi_i$ isolates $p$.
= Question
== Statement
Find an example of a minimal but not strongly minimal structure.
== Solution
Consider the structure $(S, <)$ where $S = omega_0 union.sq omega_0^-$ where $omega_0$ has the standard well order, $omega_0^-$ has the reverse order, and every element of $omega_0^-$ is larger than every element of $omega_0$. I am certain the formula $x = x$ in this model is a minimal formula, but I am not entirely sure how to prove it.
Now consider the collection of formulas
$
q(ov(x)) = {n < x : x in omega_0} union {x < m : m in omega_0^-},
$
this is clearly finitely satisfiable in $(S, <)$ and thus constitutes a type. Let $(S', <)$ denote any elementary extension which implements this type, let $y$ be the realization of this type. We now show that the formula $x = x$ is not minimal in this structure. Consider the formula $phi(z) = z < y$, we know that $phi(S')$ contains $omega_0$ while its complement contains $omega_0^-$ so neither are finite. This finishes the proof.
= Question
<question-7>
== Statement
Given a tuple $ov(a)$ and a set of parameters $A$ we write $RM(ov(a) quo A)$ for the Morley rank of $tp(ov(a)quo A)$.
Suppose $b$ is algebraic over $A ov(a)$. Show that $RM(ov(a)b quo A) = RM(ov(a) quo A)$.
== Solution
First recall that by @question-5 since $b$ is algebraic over $A ov(a)$ it is also isolated over $A ov(a)$ and thus there is a formula $phi(x, ov(a), ov(c))$ where $ov(c) in A$ that isolates $tp(b quo A ov(a))$.
We now show that $RM(ov(a) quo A) <= RM(ov(a) b quo A)$, to see this, for any formula $psi(ov(y), ov(x))$ we define the following operation
$
pi(psi)(ov(y)) = exists x (phi(x, ov(y), ov(c)) and psi(ov(y), x)).
$
#claim[
As long as $psi_i$ each imply $exists x phi(x, ov(y), ov(c))$, $pi$ does not increase $RM$.
]
#proof[
We prove by induction that
$
RM(pi(psi)) >= alpha => RM(psi) >= alpha,
$
this is clear for when $alpha = 0$, if $pi(psi)(ov(a)')$ for some $ov(a)'$ then there exists an $x$ such that $psi(ov(y), x)$. The limit step is also clear.
Now assume that $RM(pi(psi)) >= alpha + 1$, then there are formulas $psi_i$ that are pairwise inconsistent, all imply $pi(psi)$, and have $RM(psi_i) >= alpha$. Then consider the formulas $psi_i'$ defined by
$
psi_i' (ov(y), x) = phi(x, ov(y), ov(c)) and psi_i (ov(y)),
$
these are clearly also pairwise inconsistent and imply $psi$. Furthermore we have
$
pi(psi_i') (ov(y))
&= exists x (phi(x, ov(y), ov(c)) and psi_i'(ov(y), x))
= exists x (phi(x, ov(y), ov(c)) and phi(x, ov(y), ov(c)) and psi_i (ov(y)))
\ &<=> psi_i (ov(y)) and (exists x phi(x, ov(y), ov(c)))
=> psi_i (ov(y))
$
and thus by inductive hypothesis we have that $alpha <= RM(psi_i) <= RM(psi_i')$ and thus we get $RM(psi) >= alpha + 1$.
]
Now from class we know that there is a formula $psi(x, ov(y), ov(c))$ such that $RM(psi) = RM(ov(a) b quo A)$. Since $exists x phi(x, ov(y), ov(c))$ is true for $ov(a)b$ we can replace $psi$ with $psi and (exists x phi(x, ov(y), ov(c)))$ and thus assume WLOG that $psi => exists x phi(x, ov(y), ov(c))$. Then applying the above claim to it we get that
$
RM(pi(psi)) <= RM(ov(a) b quo A),
$
but now $pi(psi)$ is in $tp(ov(a) quo A)$ almost directly by definition, so we get
$
RM(ov(a) quo A) = min {
RM(sigma) : sigma in tp (ov(a) quo A)
} <= RM(pi(psi)) <= RM(ov(a) b quo A).
$
Next we need to show that $RM(ov(a) b quo A) <= RM(ov(a) quo A)$. By an inductive argument similar to the above we may assume that $RM(ov(a) quo A) = alpha$ and $RM(ov(a) b quo A) >= alpha + 1$. Now let us pick a formula $theta$ which matches the rank of $ov(a)$, and we then work with the formula
$
psi(ov(y), x) := theta(ov(y)) and phi(x, ov(y), ov(c)) and |{
x : phi(x, ov(y), ov(c))
}| = n.
$
Since $psi in tp(ov(a) b quo A)$ we have that $RM(psi) >= RM(ov(a) b quo A)$ so we let $psi_i$ be formulas that are pairwise inconsistent, imply $psi$ and have $RM(psi_i) >= alpha$.
Now from class we know that there exist elements $ov(a)_i b_i$ such that $RM(psi_i) = RM(ov(a)_i b_i quo A)$, then by induction we know that $RM(ov(a)_i b_i) = RM(ov(a)_i)$ and so since $pi(psi_i)$ is satisfied by $ov(a)_i$ then
$
RM(pi(psi_i)) >= RM(psi_i) >= alpha
$
#claim[
There is a sequence $psi_n_i$ such that $and.big_(i <= m) pi(psi_n_i)$ is non empty in $S_n (A)$ for all $m in NN$.
]
#proof[
Assume this is not the case, then form a graph $G$ with vertices $psi_i$ and an edge between $psi_i$ and $psi_j$ if their images under $pi$ intersect. By Ramsey's theorem for infinite graphs this graph either contains an infinite clique or an infinite independent set. An infinite clique corresponds to exactly the sequence we want so assume for a contradiction that we have an infinite independent set.
Such an infinite independent set then corresponds to pairwise inconsistent formulas $pi(psi_n_j)$ that imply $theta(ov(y))$. Then since $RM(pi(psi_n_i)) >= alpha$ we have $RM(theta) >= alpha + 1$ which contradicts our assumption that $RM(theta) = alpha$.
]
Since $S_n (A)$ is compact this intersection of closed sets is non-empty and thus there is a type $p$ with $pi(psi_n_i) in p$ for all $i$. But then we are working in the Monster model so this type is realized by an element $ov(g)$. Then by construction there are elements $d_i$ such that $psi_n_i (ov(g), d_i)$ is satisfied for all $i$, but since $psi_n_i$ are pairwise inconsistent the $d_i$ are all distinct, but since $psi_n_i (ov(g), d_i)$ all imply $|{ x : phi(x, ov(g), ov(c))}| = n$ this is a contradiction, which proves that $RM(theta) >= alpha + 1$.
= Question
== Statement
Show that in strongly minimal structures we have $dim(ov(a) quo A) = RM(ov(a) quo A)$.
== Solution
We prove by induction that
$
dim(ov(a) quo A) = n <=> RM(ov(a) quo A) = n
$
for all ordinals $n$.
For $n = 0$ this is trivial since $RM(ov(a) quo A) = 0$ is equivalent to $ov(a)$ being algebraic over $A$ which is equivalent to $dim(ov(a) quo A) = 0$.
We now prove this for $n$ assuming it holds for $n-1$, by @question-7 we may WLOG assume that the $a_i$ are all independent since removing the non-independent ones does not change rank or dimension. Then we have that the dimension of $ov(a)$ is just its length, which we will assume to be $n$.
We now prove that $RM(ov(a) quo A) >= n$, then let $phi(ov(x))$ be a formula that matches this rank, set $ov(a)'$ to be all the elements of $ov(a)$ besides the first one, and let $b_i$ such that $tp(b_i quo ov(a)' A) = tp(ov(a) quo A)$, then consider the formulas $psi_i = phi(ov(x)) and x_1 = b_i$, then by @question-2 we know that
$
RM(psi_i) >= RM(b_i, ov(a)' quo A) = RM(ov(a)' quo A).
$
Now $RM(ov(a)' quo A)$ is $n - 1$ by induction and clearly $psi_i$ are pairwise inconsistent and imply $phi$ so $RM(phi)>= n$.
Next we prove that $RM(ov(a) quo A) <= n$, we again let $phi(ov(x))$ be a formula that matches this rank and we assume for a contradiction that $RM(phi) >= n+1$, then there is a formula $psi$ which is false for $ov(a)$, implies $phi$ and has $RM(psi) >= n$. Let $ov(b)$ realize $psi$ then since $tp(ov(a)) != tp(ov(b))$ we have that $ov(b)$ is dependent so we have $dim(ov(b) quo A) <= n - 1$ and thus by induction we know that $RM(ov(b)) <= n - 1$. But now this is true for all realizations, so since $RM(psi)$ is the maximum of the ranks of its realizations we get that $RM(psi) <= n - 1$ which contradicts its construction.
|
|
https://github.com/ojas-chaturvedi/typst-templates
|
https://raw.githubusercontent.com/ojas-chaturvedi/typst-templates/master/resume/README.md
|
markdown
|
MIT License
|
# Resume
Template taken from: <https://github.com/tzx/NNJR>
## Usage
There are two `.typ` files that you can choose to compile:
1. `resume_yaml.typ` allows you to configure just a `yaml` file for your
resume. See `example.yml` for an example.
2. `resume.typ` allows you to have finer control. An example of possible
behavior is to have some words bold for your bullet points (I can probably
add this to `yaml` by doing something with `eval`, but that's another day)
### [Typst.app](https://typst.app)
Upload all `*.typ` and `*.yaml` files to your Typst project. Change what you want and voila!
A shared project demo is [here](https://typst.app/project/rdCXm00mYQiDPpLtSCK4xs).
### Typst CLI
```sh
# Replace resume.typ with resume_yaml.typ if desired
# Compile to resume.pdf
typst compile resume.typ
# Compile to other path and name
typst compile resume.typ your/path/here.pdf
# Watch
typst watch resume.pdf
```
|
https://github.com/jgm/typst-hs
|
https://raw.githubusercontent.com/jgm/typst-hs/main/test/typ/compute/calc-00.typ
|
typst
|
Other
|
// Test conversion to numbers.
#test(int(false), 0)
#test(int(true), 1)
#test(int(10), 10)
#test(int("150"), 150)
#test(int(10 / 3), 3)
#test(float(10), 10.0)
#test(float(50% * 30%), 0.15)
#test(float("31.4e-1"), 3.14)
#test(type(float(10)), "float")
|
https://github.com/soul667/typst
|
https://raw.githubusercontent.com/soul667/typst/main/PPT/MATLAB/touying/lib.typ
|
typst
|
#import "slide.typ": s, pause, meanwhile, slides-end, touying-equation, touying-reducer
#import "utils/utils.typ"
#import "utils/states.typ"
#import "utils/pdfpc.typ"
#import "utils/components.typ"
#import "themes/themes.typ"
|
|
https://github.com/jgm/typst-hs
|
https://raw.githubusercontent.com/jgm/typst-hs/main/test/typ/compute/foundations-00.typ
|
typst
|
Other
|
#test(type(1), "integer")
#test(type(ltr), "direction")
#test(type(10 / 3), "float")
|
https://github.com/shiki-01/typst
|
https://raw.githubusercontent.com/shiki-01/typst/main/school/chemical/1st_term_1/1_1.typ
|
typst
|
#import "../../../lib/conf.typ": conf, come, desc, ce, light
#import "@preview/codelst:2.0.1": sourcecode
#show: doc => conf(
title: [化学基礎 1学期中間],
date: [2024年4月11日],
doc,
)
= 中学校の復習
#grid(
columns: (2fr, 1fr),
column-gutter: 10pt,
[
*元素名⇄元素記号*
#table(
columns: 3,
table.header(
[元素名],[元素記号],[注意]
),
[塩素],[#ce("Cl")],[$"Cl"$ ※$"cl"$、$"C1"$と間違えない],
[ナトリウム],[#ce("Na")],[],
[マグネシウム],[#ce("Mg")],[],
[カルシウム],[#ce("Ca")],[],
[鉄],[#ce("Fe")],[],
[亜鉛],[#ce("Mg")],[],
[銀],[#ce("Ag")],[],
[水素],[#ce("H")],[],
[酸素],[#ce("O")],[],
[窒素],[#ce("N")],[],
[炭素],[#ce("C")],[],
[硫黄],[#ce("S")],[],
[アルミニウム],[#ce("Al")],[$"Al"$ ※$"A1"$と間違えない],
[カリウム],[#ce("K")],[],
[銅],[#ce("Cu")],[],
[ナトリウムイオン],[#ce("Na+")],[],
[銅(Ⅱ)イオン],[#ce("Cu^2+")],[],
[水酸化物イオン],[#ce("OH-")],[],
[塩化物イオン],[#ce("Cl-")],[],
[水素イオン],[#ce("H+")],[],
)
],
[
*物質名⇄化学式*
#table(
columns: 2,
table.header(
[元素名],[元素記号],
),
[塩素],[#ce("Cl2")],
[水素],[#ce("H2")],
[二酸化炭素],[#ce("CO2")],
[アンモニア],[#ce("NH3")],
[塩化ナトリウム],[#ce("NaCl")],
[酸素],[#ce("O2")],
[硫化鉄(Ⅱ)],[#ce("FeS")],
[水酸化ナトリウム],[#ce("NaHO")],
[窒素],[#ce("N2")],
[硫化銅(Ⅱ)],[#ce("CuS")],
[酸化マグネシウム],[#ce("MgO")],
[酸化銅(Ⅱ)],[#ce("CuO")],
[塩化銅(Ⅱ)],[#ce("CuCl2")],
[水],[#ce("H2O")],
[塩化水素],[#ce("HCl")],
)
]
)
#counter(heading).update( 0 )
= 元素記号
- 元素
物質を構成している基本的な成分。
現在約120種類が知られている
- 元素の周期表
元素を原子番号順(陽子の数)に並べ、似た性質の元素が同じ縦の列に並ぶように配列した表
= 化学と人間生活
== 人間生活の中の化学
- #desc("金属")[
自然に産出していたのものをそのまま使うもの(例:金・銀)と、化合物から金属を単体として取り出す技術#light[(製錬)]を使うものがある
]
- #desc("銅 Cu")[
金属の中では銀に次いで2番目に電気をよく通す\
銅にスズを混ぜた合金の#light[青銅]が得られるようになる\
※ #light[合金] … 金属にほかの金属などを融かし合わせて作られたもの
]
- #desc("鉄 Fe")[
天然で産出することが極めてすくない\
技術の発達により製錬が可能となった金属で、炭素の含有量を調整することで硬く強い#light[真ちゅう]が得られる\
例:#light[ステンレス鋼](クロムとニッケルとの合金)・#light[トタン](表面を亜鉛で覆ったもの)
]
- #desc("アルミニウム Al")[
非常に軽く、電気をよく伝える\
合金としても多く用いられる\
例:#light[ジュラルミン](銅、マグネシウムなどとの合金)
]
#table(
columns: 2,
table.header(
[合金],[主な成分]
),
[青銅(ブロンズ)],[銅、スズ],
[黄銅(真ちゅう、ブラス],[銅、亜鉛],
[白銅],[銅、ニッケル],
[ステンレス鋼],[鉄、クロム、ニッケル],
[ニクロム],[ニッケル、クロム],
[ジュラルミン],[アルミニウム、銅、マグネシウム],
[はんだ],[スズ、鉛],
[無鉛はんだ],[スズ、銀、銅],
)
#desc("セラミックス")[
天然の無機物を高温で処理して得られる非金属材料\
例:陶磁器・ガラス・ファインセラミックス
]
- プラスチック
…#light[石油]や石炭を原料として人工的に作られる物質。加工しやすい。
- #desc("熱可塑性樹脂")[
熱を加えると軟らかくなって融け、冷えると再び固まる樹脂\
例:ポリスチレン(PS)・ポリプロピレン(PP)・ポリエチレンテレフタレート(PET)
]
- #desc("熱硬化性樹脂")[
原材料に熱を加えて成形し、固まった後に加熱しても柔らかくならない樹脂。変形すると困るところに使われる
]
- 繊維
- #desc("天然繊維")[
生物が作った繊維\
例:植物繊維(木綿:コットン・麻:リネン)・動物繊維(絹:シルク・羊毛:ウール)\
#desc("レーヨン")[
天然繊維の成分と同じ物質を取り出し、科学的に処理して再生した繊維
]
]
- #desc("合成繊維")[
人間が石油などから合成した繊維\
#desc("ナイロン")[
天然繊維を全く利用せずに合成された世界初の繊維。カロザースが初めて合成に成功した
]
]
#pagebreak()
== 科学とその役割
*食料、食品*
#desc("化学肥料")[
作物の育成に不足しやすい成分である#light[窒素(N)・リン(P)・カリウム(K)]を補うための、化学薬品を主成分とする肥料
]
#desc("農薬")[
農作物の収穫率を上げるために用いる薬品
]
#desc("食品添加物")[
味や色をよくしたり、日持ちさせたりするために食品に添加されている物質\
例:保存料・調味料・着色料・着香料・酸化防止剤など
]
*洗剤*
#desc("界面")[
水と油の境目に当たるところ
]
#desc("界面活性剤")[
水になじみやすい#light[親水性]と、油になじみやすい #light[親油性 / 疎水性] を併せ持っている
]
#desc("ミセル")[
洗剤を水に溶かしてある濃度いじょうになったときに生じる球の塊のこと
]
*物質のメリットとデメリット*
#desc("有害性")[
環境中に排出された物質が、生物の生息や生育に害を及ぼす性質
]
#desc("物質の有害性")[
物質による有害性の可能性。#light[有害性 × 摂取量 = 環境リスク]の関係で決められる
]
= 物質の成分と構成元素
== 純物質と混合物
#desc("純物質")[
ほかの物質が混ざっていない単一の物質。化学式で書いたときに1個だけになるもの \
例:鉄・ダイヤモンド・水素・水
]
- 融点・沸点・密度などが一定
- ろ過や蒸留などの方法でそれ以上分けられない
#desc("混合物")[
何種類かの物質が混じり合った \
例:お茶・海水・しょう油・空気・#light[塩酸(塩化水素+水)]
]
- 融点・沸点・密度などはその組成によって分けられる
- ろ過や蒸留などの方法で各成分を分けられる
#come("","comment")[
塩酸 = 塩化水素( #ce("HCl") )+ 水( #ce("H2O") )
]
== 物理変化と化学変化
#desc("物理変化")[
その物質の状態だけが変わり、性質は変わらない変化
]
#desc("化学変化")[
反応の前後で性質が異なる物質になる変化
]
== 混合物の分離
#desc("ろ過")[
ろ紙などを用いて個体が混じっている液体を#light[個体と液体]に分離する操作\
例:泥水を泥と水に分ける\
ポイント:ガラス棒を伝わせる・ビーカーの側面にろうとを添わせる
]
#desc("蒸留")[
物質の沸点の差を利用して混合物である溶液と溶媒に分離する操作\
例:赤ワインを水とエタノールに分ける
]
#desc("分留")[
蒸留の一種、2種類以上の液体の混合物を沸点の違いを利用して蒸留によって各成分に分離する操作\
例:
]
#desc("昇華法")[
個体が直接期待になる変化を利用して、分離・精製する方法\
例:
]
#desc("抽出")[
混合物に特定の溶媒を加えて、目的物質だけを溶かして分離する操作\
例:
]
#desc("再結晶")[
物質が溶媒に溶ける量が温度により異なることを利用して、少量の不純物を取り除く方法\
例:
]
#desc("ペーパークロマトグラフィー")[
混合物が溶媒とともに、ろ紙上を移動する速度の違いを利用して分離する操作\
例:
]
|
|
https://github.com/SWATEngineering/Docs
|
https://raw.githubusercontent.com/SWATEngineering/Docs/main/src/2_RTB/VerbaliEsterni/VerbaleEsterno_231124/meta.typ
|
typst
|
MIT License
|
#let data_incontro = "24-11-2023"
#let inizio_incontro = "9:40 "
#let fine_incontro = "10:40"
#let luogo_incontro = "Chiamata Google Meet"
#let company = "Sync Lab"
|
https://github.com/kdog3682/2024-typst
|
https://raw.githubusercontent.com/kdog3682/2024-typst/main/src/piecharts.typ
|
typst
|
#import "very-base-utils.typ": *
#import "strokes.typ"
#let base = (
value-key: "value",
label-key: "label",
outset-key: "outset",
radius: 2,
slice-style: alternating-white,
inner-radius: 0,
outer-label: (
content: (value, label) => {
return bold(label)
},
radius: 125%,
),
inner-label: (
content: (value, label) => {
return resolve-content(value)
},
radius: 110%,
),
)
#let canola = (
stroke: strokes.at("thin", fill: blue),
radius: 2,
inner-radius: 0,
gap: 0,
inner-label: (content: (value, label) => {
align(center, block({
text(weight: "bold", size: 10pt, label)
text(weight: "bold", size: 10pt, value)
}))
} , radius: 120%)
)
#let soft = (
stroke: strokes.get("soft"),
inner-label: (
content: (value, label) => {
return text(red, [*#label*: #value])
},
radius: 110%,
),
)
|
|
https://github.com/LDemetrios/Programnomicon
|
https://raw.githubusercontent.com/LDemetrios/Programnomicon/main/common/escape.typ
|
typst
|
#let try-catch(lbl, key, try, catch) = locate(loc => {
let path-label = label(lbl)
let first-time = query(locate(_ => { }).func(), loc).len() == key
if first-time or query(path-label, loc).len() > 0 {
[#try()#path-label]
} else {
catch()
}
})
#let escape-keys = state("escape-keys", 0)
#let escape(
current: none,
setup: (:),
..commands,
output-file: auto,
handler: it => [#it],
replacement: [`Missing information`],
) = {
assert(current != none or output-file != auto)
escape-keys.display(key => {
let file = if output-file == auto {
current + str(key) + ".typesc"
} else {
output-file
}
[
#metadata((
setup: setup,
commands: commands.pos(),
output: file,
)) #label("typst-key-" + str(key))
]
if sys.inputs.at("typst-escape-working", default: "false") == "true" {
[]
} else {
handler(eval(read(file)))
}
})
escape-keys.update(it => it + 1)
}
#let command(..entries, output: none, error: none) = (
command: entries.pos(),
output-spec: output,
error-spec: error,
)
#let file-format(format, color: "000000") = (
format: format,
color: color,
)
#let finish-escape() = escape-keys.display(it => [
#metadata(
range(it).map(jt => "typst-key-" + str(jt)),
) <typst-escape-keys>
])
//// Example:
//
//#escape(
// setup: (
// "build.gradle.kts": build.text,
// "settings.gradle.kts": settings.text,
// "src/main/kotlin/Main.kt": code.text,
// ),
// command("gradle", "assemble"),
// command(
// ..("java", "-jar", "build/libs/untitled-1.0-SNAPSHOT.jar"),
// output: file-format("conjoined-raw"),
// error: file-format("conjoined-raw", color: "ff0000"),
// ),
// handler: it => it.at(1).output
//)
//
//#finish-escape()
|
|
https://github.com/cidremt/QFT_memo
|
https://raw.githubusercontent.com/cidremt/QFT_memo/main/.config.typ
|
typst
|
/* set a new counter for thms*/
#let s = state("thm", (heading: str(0), counter: 0, style: ()))
/* initialize a document */
/* ---------------------------------------------------------------------------------*/
#let init(doc) = {
set enum(numbering: "i)")
set text(
font: "IPAMincho",
lang: "ja",
)
set par(first-line-indent: 1em)
set page(
paper: "a4",
numbering: " 1 ",
header: locate(loc => [
#set text(size: 10pt)
#let elems = query(selector(heading).before(loc),loc,)
#let default = "QFT memo"
#if elems == (){
align(right, default)
}else{
let body = elems.last().body
default + h(1fr) + body
}
#line(length: 100%, stroke: 0.5pt + black)
]),
)
set heading(numbering: "1.1")
show heading: it =>[
#counter(math.equation).update(0)
#locate(loc => {
s.update(arg => {
arg.at("counter") = 0
arg.at("heading") = counter(heading).at(loc)
arg.at("style") = ()
return arg
})
})
#set text(font: "IPAPGothic")
#if (it.level == 1){
set align(center)
block[
#counter(heading).display() #h(1em)*#it.body*
]
v(1em)
}else{
block[
#counter(heading).display() #h(0.5em) *#it.body*
]
v(0.5em)
}
]
set math.equation(
numbering: {num => locate(loc => "(" + counter(heading).at(loc).map(str).join(".") + "." + str(num) + ")")},
supplement: [式],
)
doc
}
/* ---------------------------------------------------------------------------------*/
/* some funcs*/
/* ---------------------------------------------------------------------------------*/
#let braket(arg1, arg2) = $ angle.l #arg1|#arg2 angle.r $
#let bra(arg) = $ angle.l #arg| #h(0pt) $
#let ket(arg) = $ #h(0pt) |#arg angle.r $
#let ketbra(arg1, arg2) = $#h(0pt) |#arg1 angle.r #h(-1.5pt) angle.l #arg2| #h(0pt)$
#let definition(title, body) = {
s.update(arg => {arg.at("style") = "定義"; arg.at("counter") += 1; return arg})
locate(loc => {
let num = s.at(loc).at("heading").map(str).join(".") + "." + str(s.at(loc).at("counter") )
block(width: 100%, fill: luma(230), radius: 4pt, inset: 8pt)[#text(weight: "bold")[* 定義 #num. *] (#title) \ #body]
})
}
#let theorem(title, body) = {
s.update(arg => {arg.at("style") = "定理"; arg.at("counter") += 1; return arg})
locate(loc => {
let num = s.at(loc).at("heading").map(str).join(".") + "." + str(s.at(loc).at("counter") )
block(width: 100%, fill: luma(230), radius: 4pt, inset: 8pt)[#text(weight: "bold")[* 定理 #num. *] (#title) \ #body]
})
}
#let hypothesis(title, body) = {
s.update(arg => {arg.at("style") = "仮定"; arg.at("counter") += 1; return arg})
locate(loc => {
let num = s.at(loc).at("heading").map(str).join(".") + "." + str(s.at(loc).at("counter") )
block(width: 100%, fill: luma(230), radius: 4pt, inset: 8pt)[#text(weight: "bold")[* 仮定 #num. *] (#title) \ #body]
})
}
#let consequence(title, body) = {
s.update(arg => {arg.at("style") = "結果"; arg.at("counter") += 1; return arg})
locate(loc => {
let num = s.at(loc).at("heading").map(str).join(".") + "." + str(s.at(loc).at("counter") )
block(width: 100%, fill: luma(230), radius: 4pt, inset: 8pt)[#text(weight: "bold")[* 結果 #num. *] (#title) \ #body]
})
}
#let corollary(title, body) = {
s.update(arg => {arg.at("style") = "系"; arg.at("counter") += 1; return arg})
locate(loc => {
let num = s.at(loc).at("heading").map(str).join(".") + "." + str(s.at(loc).at("counter") )
block(width: 100%, fill: luma(230), radius: 4pt, inset: 8pt)[#text(weight: "semibold")[* 系 #num. *] (#title) \ #body]
})
}
/* when you use thmref, you should put a label like #definition[hoge<here>][hoge]*/
#let thmref(label, supplement: none) = {
locate(loc => {
let elems = query(label, loc)
if elems != (){
let dict = s.at(elems.first().location())
if supplement == none{
dict.at("style") + " " + dict.at("heading").map(str).join(".") + "." + str(dict.at("counter"))
}else{
supplement + " " + dict.at("heading").map(str).join(".") + "." + str(dict.at("counter"))
}
}else{
text(fill: red)[*???*]
}
})
}
/* ---------------------------------------------------------------------------------*/
|
|
https://github.com/Duolei-Wang/modern-sustech-thesis
|
https://raw.githubusercontent.com/Duolei-Wang/modern-sustech-thesis/main/template/configs/outline.typ
|
typst
|
MIT License
|
#import "font.typ" as fonts
#let toc(
isCN: true,
toc-title: [Table of Content]
) = {
set outline(
fill: box(
width: 1fr,
repeat(h(5pt) + "." + h(5pt))) + h(5pt)
)
show outline: it => {
show heading: title => {
set align(center)
if(isCN){
set text(
font: fonts.HeiTi,
size: fonts.No2-Small,
)
title
v(1em)
}else{
set text(
font: fonts.HeiTi,
size: fonts.No2-Small,
weight: "bold",
)
title
v(1em)
}
}
it
}
show outline.entry: it => {
v(0.5em, weak: false)
set text(
font: fonts.SongTi,
size: fonts.No4,
)
if(it.level == 1){
set text(
weight: 700,
)
it
}else{
it
}
}
if(isCN){
pagebreak()
outline(
title: [目录]
)
}else{
pagebreak()
outline(
title: toc-title
)
}
}
|
https://github.com/not-matthias/typst-jku
|
https://raw.githubusercontent.com/not-matthias/typst-jku/main/README.md
|
markdown
|
# typst-jku
An attempt to develope a Typst template for JKU thesis'.
It is compatible with Typst's context system and other features introduced in version 0.11.
## Acknowledge
This template is based on the groundlaying work by [<NAME>](https://github.com/dmorawetz/).
It was further adapted, especially to remove deprecated functions, by [<NAME>](https://github.com/Stern1710/).
|
|
https://github.com/gyarab/2023-4e-ruzicka-jako_pavouk
|
https://raw.githubusercontent.com/gyarab/2023-4e-ruzicka-jako_pavouk/main/src-docs/main.typ
|
typst
|
#set page(
paper: "a4",
margin: 3cm,
numbering: "1"
)
#set text(
lang: "cs",
region: "cz",
size: 12pt,
)
#show heading.where(level: 1): it => text(
size: 18pt,
it
)
#show heading.where(level: 2): it => text(
size: 16pt,
it
)
#show heading.where(level: 3): it => text(
size: 14pt,
it
)
#show raw.where(block: true): it => align(block( // nastavení code bloku
stroke: rgb("#ddd"),
fill: rgb("#fafafa"),
inset: 10pt,
radius: 0.5em,
above: 2em,
below: 2em,
it
), center)
#set raw(syntaxes: "custom_highlighting.yaml")
#show par: set block(spacing: 0.65em)
#set par(justify: true, first-line-indent: 2em) // hezky rádoby do bloku
#show figure: it => {it; v(0.4em)} // trošku větsí mezera za obrázkem
#set heading(numbering: "1.")
// ------------- Blbosti -------------
#let LaTeX = {
let A = (
offset: (
x: -0.33em,
y: -0.3em,
),
size: 0.7em,
)
let T = (
x_offset: -0.12em
)
let E = (
x_offset: -0.2em,
y_offset: 0.23em,
size: 1em
)
let X = (
x_offset: -0.1em
)
[L#h(A.offset.x)#text(size: A.size, baseline: A.offset.y)[A]#h(T.x_offset)T#h(E.x_offset)#text(size: E.size, baseline: E.y_offset)[E]#h(X.x_offset)X]
}
#show "LaTeX": name => LaTeX // hahahaha
// ------------- Dokument -------------
#include "titulnistrany.typ"
#include "obsah.typ"
#counter(page).update(1)
#include "kapitoly/uvod.typ"
#pagebreak()
#include "kapitoly/psani.typ"
#include "kapitoly/problemy.typ"
#include "kapitoly/design.typ"
#pagebreak()
#include "kapitoly/do-budoucna.typ"
#include "kapitoly/zaver.typ"
#pagebreak()
#block()[
#set par(justify: false) // citace aby se neroztahovaly
#bibliography(
"citace.yaml",
title: "Odkazy",
style: "the-lancet") // 1 = "the-lancet", [1] = "angewandte-chemie", i pod čarou = "gb-7714-2015-note"
]
|
|
https://github.com/typst/packages
|
https://raw.githubusercontent.com/typst/packages/main/packages/preview/unichar/0.1.0/ucd/block-DC00.typ
|
typst
|
Apache License 2.0
|
#let data = (
"0": ("<Low Surrogate, First>", "Cs", 0),
"3ff": ("<Low Surrogate, Last>", "Cs", 0),
)
|
https://github.com/Myriad-Dreamin/typst.ts
|
https://raw.githubusercontent.com/Myriad-Dreamin/typst.ts/main/fuzzers/corpora/visualize/svg-text_01.typ
|
typst
|
Apache License 2.0
|
#import "/contrib/templates/std-tests/preset.typ": *
#show: test-page
#set page(width: 250pt)
#show image: set text(font: ("Roboto", "Noto Serif CJK SC"))
#figure(
image("/assets/files/chinese.svg"),
caption: [Bilingual text]
)
|
https://github.com/DannySeidel/typst-dhbw-template
|
https://raw.githubusercontent.com/DannySeidel/typst-dhbw-template/main/confidentiality-statement.typ
|
typst
|
MIT License
|
#import "locale.typ": *
#let confidentiality-statement(
authors,
title,
confidentiality-statement-content,
university,
university-location,
date,
language,
many-authors,
date-format,
) = {
let authors-by-city = authors.map(author => author.company.city).dedup()
v(2em)
text(size: 20pt, weight: "bold", CONFIDENTIALITY_STATEMENT_TITLE.at(language))
v(1em)
if (confidentiality-statement-content != none) {
confidentiality-statement-content
} else {
let authors-by-company = authors.map(author => author.company.name).dedup()
let authors-by-study = authors.map(author => author.course-of-studies).dedup()
let companies = authors-by-company.join(", ", last: AND.at(language))
let institution = if (authors-by-company.len() == 1) {
INSTITUTION_SINGLE.at(language)
} else {
INSTITUTION_PLURAL.at(language)
}
text(CONFIDENTIALITY_STATEMENT_SECTION_A.at(language))
v(1em)
align(
center,
text(weight: "bold", title),
)
v(1em)
par(
justify: true,
CONFIDENTIALITY_STATEMENT_SECTION_B.at(language) + [ ] + companies + CONFIDENTIALITY_STATEMENT_SECTION_C.at(language) + [ ] + authors-by-study.join(" | ") + CONFIDENTIALITY_STATEMENT_SECTION_D.at(language) + university + [ ] + university-location + CONFIDENTIALITY_STATEMENT_SECTION_E.at(language) + institution + [ (#companies)] + CONFIDENTIALITY_STATEMENT_SECTION_F.at(language),
)
}
let end-date = if (type(date) == datetime) {
date
} else {
date.at(1)
}
v(2em)
text(authors-by-city.dedup().join(", ", last: AND.at(language)) + [ ] + end-date.display(date-format))
v(0.5em)
if (many-authors) {
grid(
columns: (1fr, 1fr),
gutter: 20pt,
..authors.map(author => {
v(3.5em)
line(length: 80%)
author.name
})
)
} else {
for author in authors {
v(4em)
line(length: 40%)
author.name
}
}
}
|
https://github.com/iceghost/resume
|
https://raw.githubusercontent.com/iceghost/resume/main/1-profile.typ
|
typst
|
== Profile
I am a third-year Computer Science student at HCMUT - Ho Chi Minh University
of Technology and I am interested in pursuing a Software Engineer career,
with a particular focus on Backend Engineering.
In my free time, I keep up-to-date with the latest technology news and work
on side projects. I have a keen interest in programming language designs and
creating products that people will enjoy using.
|
|
https://github.com/typst/packages
|
https://raw.githubusercontent.com/typst/packages/main/packages/preview/ttt-exam/0.1.0/README.md
|
markdown
|
Apache License 2.0
|
# ttt-exam
`ttt-exam` is a *template* to create exams and belongs to the [typst-teacher-tools-collection](https://github.com/jomaway/typst-teacher-templates).
## Usage
Run this command inside your terminal to init a new exam.
```sh
typst init @preview/ttt-exams my-exam
```
This will scaffold the following folder structure.
```ascii
my-exam/
├─ meta.toml
├─ exam.typ
├─ justfile
└─ logo.jpg
```
Replace the `logo.jpg` with your schools, university, ... logo or remove it. Then edit the `meta.toml`.
Edit the `exam.typ` and replace the questions with your own. If you like you can also remove the `meta.toml` file and specify the values directly inside `exam.typ`
If you have installed [just]() you can use it to build a *student* and *teacher* version of your exam by running `just build`.
Here you can see an example with both versions. On the left the student version and on the right the teachers version.

## Features
You can pass the following arguments to `exam`
```typ
#let exam(
// metadata
logo: none, // an image
title: "exam", // shoes the title of the exam -> 1. Schulaufgabe | Stegreifaufgabe | Kurzarbeit
subtitle: none, // Shown below the title
date: none, // date of the exam, preferred type of datetime.
class: "",
subject: "" ,
authors: "",
// config
solutions: false, // if solutions are displayed can also be specified with `--input solution=true` on the cli.
header: "block", // "block" or "page" -> if the header is only a block like in the screenshot or a whole page.
point-field: "sum", // "sum" or "table" // which point-field is show if header is page.
body
)
```
|
https://github.com/tingerrr/hydra
|
https://raw.githubusercontent.com/tingerrr/hydra/main/doc/examples/template.typ
|
typst
|
MIT License
|
#import "/src/lib.typ": hydra
#let example(..args, body) = {
set page(paper: "a8", header: context hydra(..args))
show heading.where(level: 1): it => pagebreak(weak: true) + it
set par(justify: true)
body
}
|
https://github.com/Julien-cpsn/typst-chromo
|
https://raw.githubusercontent.com/Julien-cpsn/typst-chromo/main/examples/example.typ
|
typst
|
MIT License
|
#import "../lib.typ": square-printer-test, gradient-printer-test, circular-printer-test, crosshair-printer-test
#set text(
font: "Arial"
)
= #underline[All together]
#raw("#square-printer-test()", lang: "typst")
#square-printer-test()
#raw("#gradient-printer-test()", lang: "typst")
#gradient-printer-test()
#raw("#circular-printer-test()", lang: "typst")
#circular-printer-test()
#raw("#crosshair-printer-test()", lang: "typst")
#crosshair-printer-test()
#pagebreak()
== #underline[Square test]
#raw("#square-printer-test(dir: rtl)", lang: "typst")
#square-printer-test(dir: rtl)
#raw("#square-printer-test(dir: ttb)", lang: "typst")
#square-printer-test(dir: ttb)
#raw("#square-printer-test(size: 50pt)", lang: "typst")
#square-printer-test(size: 50pt)
#raw("#square-printer-test(dir: ttb, size: 5pt)", lang: "typst")
#square-printer-test(dir: ttb, size: 5pt)
#pagebreak()
== #underline[Gradient test]
#raw("#gradient-printer-test(dir: rtl)", lang: "typst")
#gradient-printer-test(dir: rtl)
#raw("#gradient-printer-test(dir: btt)", lang: "typst")
#gradient-printer-test(dir: btt)
#raw("#gradient-printer-test(width: 50pt)", lang: "typst")
#gradient-printer-test(width: 50pt)
#raw("#gradient-printer-test(height: 40pt)", lang: "typst")
#gradient-printer-test(height: 40pt)
#raw("#gradient-printer-test(width: 400pt, height: 10pt)", lang: "typst")
#gradient-printer-test(width: 400pt, height: 10pt)
#pagebreak()
== #underline[Circular test]
#raw("#circular-printer-test(size: 15pt)", lang: "typst")
#circular-printer-test(size: 15pt)
#raw("#circular-printer-test(size: 200pt)", lang: "typst")
#circular-printer-test(size: 200pt)
#pagebreak()
== #underline[Crosshair test]
#raw("#crosshair-printer-test(dir: rtl)", lang: "typst")
#crosshair-printer-test(dir: rtl)
#raw("#crosshair-printer-test(dir: ttb)", lang: "typst")
#crosshair-printer-test(dir: ttb)
#raw("#crosshair-printer-test(size: 75pt)", lang: "typst")
#crosshair-printer-test(size: 75pt)
|
https://github.com/Jollywatt/typst-fletcher
|
https://raw.githubusercontent.com/Jollywatt/typst-fletcher/master/tests/node-size-inset-outset/test.typ
|
typst
|
MIT License
|
#set page(width: auto, height: auto, margin: 1em)
#import "/src/exports.typ" as fletcher: diagram, node, edge
#let cm-square = box(width: 5mm, height: 5mm, fill: black)
What `5mm` inset should look like:
#rect(fill: green, inset: 5mm, cm-square)
A diagram node with `5mm` inset:
#diagram(node((0,0), cm-square, shape: rect, inset: 5mm, fill: green))
A diagram node with `5mm` outset:
#diagram(
spacing: 1cm,
node((0,0), cm-square, shape: rect, inset: 0pt, outset: 5mm, fill: blue),
edge("->"),
)
#pagebreak()
Circular insets:
#diagram(
node-stroke: 1pt,
node((0,0), $A$, inset: 0pt, shape: rect),
node((1,0), $A$, inset: 0pt),
node((0,1), $A$, shape: rect),
node((1,1), $A$),
node((0,2), $A B C D E$, shape: rect),
node((1,2), $A B C D E$, shape: circle),
)
#pagebreak()
Explicit node size:
#circle(radius: 1cm, align(center + horizon, `1cm`))
#diagram(
node((0,0), `1cm`, stroke: 1pt, radius: 1cm, inset: 1cm, shape: "circle"),
node((0,1), [width], stroke: 1pt, width: 2cm),
node((1,1), [height], height: 4em, inset: 0pt, fill: blue.lighten(50%)),
node((2,1), [both], width: 5em, height: 5em, stroke: 2pt),
)
|
https://github.com/TGM-HIT/typst-protocol
|
https://raw.githubusercontent.com/TGM-HIT/typst-protocol/main/README.md
|
markdown
|
MIT License
|
# TGM HIT protocol template
This is a port of the [LaTeX protocol template](https://github.com/TGM-HIT/latex-protocol/) available for students of the information technology department at the TGM technical secondary school in Vienna.
## Getting Started
Using the Typst web app, you can create a project by e.g. using this link: https://typst.app/?template=tgm-hit-protocol&version=latest.
To work locally, use the following command:
```bash
typst init @preview/tgm-hit-protocol
```
## Usage
The template ([rendered PDF](main.pdf)) contains thesis writing advice (in German) as example content. If you are looking for the details of this template package's function, take a look at the [manual](docs/manual.pdf).
|
https://github.com/AsiSkarp/grotesk-cv
|
https://raw.githubusercontent.com/AsiSkarp/grotesk-cv/main/src/template/content/skills.typ
|
typst
|
The Unlicense
|
#let meta = toml("../info.toml")
#import meta.import.path: skill-entry
#import "@preview/fontawesome:0.4.0": *
#let icon = meta.section.icon.skills
#let language = meta.personal.language
#let include-icon = meta.personal.include_icons
#let accent-color = meta.layout.accent_color
= #if include-icon [#fa-icon(icon) #h(5pt)] #if language == "en" [Skills] else if language == "es" [Habilidades]
#v(0pt)
#if language == "en" [
=== Programming languages
#skill-entry(
accent-color,
skills: (
[C++],
[Python],
[Java],
),
)
=== AI/ML
#skill-entry(
accent-color,
skills: (
[TensorFlow],
[PyTorch],
[OpenAI],
),
)
=== DevOPS
#skill-entry(
accent-color,
skills: (
[Docker],
[Kubernetes],
[Jenkins],
[Cloud Deployment],
),
)
=== Robotics
#skill-entry(
accent-color,
skills: (
[ROS],
[Gazebo],
[URDF],
),
)
=== Databases
#skill-entry(
accent-color,
skills: (
[SQL],
[NoSQL],
[MongoDB],
),
)
=== Tools
#skill-entry(
accent-color,
skills: (
[Git],
[Jira],
[Confluence],
[Slack],
),
)
] else if language == "es" [
=== Lenguajes de programación
#skill-entry(
accent-color,
skills: (
[C++],
[Python],
[Java],
),
)
=== IA/Aprendizaje automático
#skill-entry(
accent-color,
skills: (
[TensorFlow],
[PyTorch],
[OpenAI],
),
)
=== DevOPS
#skill-entry(
accent-color,
skills: (
[Docker],
[Kubernetes],
[Jenkins],
[Despliegue en la nube],
),
)
=== Robótica
#skill-entry(
accent-color,
skills: (
[ROS],
[Gazebo],
[URDF],
),
)
=== Bases de datos
#skill-entry(
accent-color,
skills: (
[SQL],
[NoSQL],
[MongoDB],
),
)
=== Herramientas
#skill-entry(
accent-color,
skills: (
[Git],
[Jira],
[Confluence],
[Slack],
),
)
]
|
https://github.com/0x1B05/nju_os
|
https://raw.githubusercontent.com/0x1B05/nju_os/main/lecture_notes/content/21_可执行文件和加载.typ
|
typst
|
#import "../template.typ": *
#pagebreak()
= 可执行文件和加载
== 可执行文件
=== 什么是可执行文件?
学习操作系统前: 那个 “双击可以弹出窗口的东西”
学习操作系统后:
- 一个操作系统中的对象 (文件)
- 一个字节序列 (我们可以把它当文本编辑)
- 一个描述了状态机初始状态的数据结构
- 哦,打扰了
=== 作为 “数据结构” 的可执行文件
状态机初始状态的描述
- 内存中的各段的位置和权限
- 初始的 PC 在 ELF Header 的 entry
- 寄存器和栈由操作系统决定
- 上节课的 env.c
状态迁移的描述: 代码
RTFM: #link("https://jyywiki.cn/pages/OS/manuals/sysv-abi.pdf")[ System V ABI ]
- binutils 中的工具可以让我们查看其中的重要信息
- ChatGPT 可以帮我们解释不明白的概念
=== 加载最小可执行文件
最小可执行文件
- 代码在内存中
- PC 指向第一条指令
- 除此之外,任何初始状态都行
直接把代码 mmap 到内存
- 然后跳转过去即可
- (你可以想象 execve 里就做了这件事)
|
|
https://github.com/sitandr/typst-examples-book
|
https://raw.githubusercontent.com/sitandr/typst-examples-book/main/src/basics/states/metadata.md
|
markdown
|
MIT License
|
# Metadata
Metadata is invisible content that can be extracted using query or other content.
This may be very useful with `typst query` to pass values to external tools.
```typ
// Put metadata somewhere.
#metadata("This is a note") <note>
// And find it from anywhere else.
#context {
query(<note>).first().value
}
```
|
https://github.com/dyc3/senior-design
|
https://raw.githubusercontent.com/dyc3/senior-design/main/testing.typ
|
typst
|
= Testing
This section contains diagrams for miscellaneous tests.
== Smoke test: Make sure `ott-vis-datasource` makes an outbound HTTP request
#figure(
image("figures/vis/visualization-datasource-smoketest-sequence.svg", width: 80%),
caption: [Sequence diagram showing the smoke test for `ott-vis-datasource`]
) <Figure::visualization-datasource-smoketest-sequence>
|
|
https://github.com/mumblingdrunkard/mscs-thesis
|
https://raw.githubusercontent.com/mumblingdrunkard/mscs-thesis/master/src/frontmatter/acknowledgements.typ
|
typst
|
= Acknowledgements
Thank you to my supervisors <NAME> and <NAME>.
You have both provided valuable input to this project.
Amund has contributed especially towards the practical execution of the project with valuable knowledge about the development process of the BOOM project and various tooling around it.
Magnus is always an interesting sparring partner when discussing various concepts and reasoning about them and has been willing to listen to ideas and always has something valuable to contribute at the end.
Thank you both for keeping me on track to finish this project with something deliverable.
Thanks to the NTNU IDUN computer cluster for providing the countless CPU-hours spent on this project.
Sorry for running compilations and simulations on the login node by mistake even though I never received a complaint by email.
Finally, thank you to myself, for seeing it through despite plenty of personal challenges and blockers this semester.
You are not really used to life being this rough, but you steeled yourself and actually delivered something.
I am proud of you.
|
|
https://github.com/VisualFP/docs
|
https://raw.githubusercontent.com/VisualFP/docs/main/SA/project_documentation/content/personal_report_lukas.typ
|
typst
|
= <NAME>
Outside of the FP lecture, I didn't have many opportunities to look at functional programming in more detail or build an actual application with a functional programming language.
So, I was very happy to be able to broaden my knowledge in functional programming with such an interesting project.
The project itself proved to be a challenge.
Finding a good visual representation for functions was more difficult than I expected.
Not having a satisfying visual concept at about half-time caused some anxiety on my part about whether would be able to build a good PoC application in time.
But thanks to the valuable input from Prof. Dr. <NAME> we were able to create a concept, that has the potential to help beginners get started with functional programming.
Since I've never done a project like this before, I underestimated how much you can achieve in just a few weeks.
In the PoC application, we were able to include a lot more features than I first expected.
So, given the time we had available to build the PoC application, I'm very happy with the result.
However, I'm a bit disappointed that I couldn't build the UI using FRP.
The cooperation with Jann went very well.
I think we found a good balance of communication, so that everyone knows what to do, without discussing every detail.
Overall, I'm happy with both the result of the project and how we got there.
I think we don't have to make any fundamental changes in the way we work for our bachelor thesis.
|
|
https://github.com/kotfind/hse-se-2-notes
|
https://raw.githubusercontent.com/kotfind/hse-se-2-notes/master/os/lectures/2024-10-14.typ
|
typst
|
=== О долгосрочном и краткосрочном планировании
Вытесняющие алгоритмы могут применяться только в краткосрочном планировании
=== Round Robin (вытесняющий FCFS)
От "круглая лента"
Процессы "сидят на карусели", внизу карусели расположен процессор. Когда
процесс находится около процессора, он запускается. Карусель крутится
равномерно.
Более формально:
- процессы в FIFO
- берется процесс из головы
- работает квант времени
- кладется в хвост
Если CPU burst $<=$ кванта времени, то завершаемся заранее, следующему процессу
даем полный квант.
Важен размер кванта времени:
- Если устремить к бесконечности: получаем FCFS
- Если устремить к нулю: теоретически получаем параллельную систему с
производительностью в N раз меньше. На практике накладные расходы из-за переключения
контекста превысят полезную работу.
=== SJF (Shortest Job First)
Из "кучи" процессов выбираем тот, у кого самый короткий CPU Burst
Если две версии:
- Вытесняющая и не вытесняющая
==== Не вытесняющий вариант
Выбрали нужный процессор, не отбираем процессор до конца его CPU burst.
Среднее время ожидания является минимальным возможным
==== Вытесняющий вариант
Допускаем возможность возникновения новых процессов.
Временно прекращаем работу исполнявшегося процесса, если CPU burst нового
меньше, то переключаем на него.
==== Проблема SJF
На практике не реализуем т.к. не знаем время очередного CPU burst
Используют приближение:
$tau(n)$ --- величина $n$-ого CPU burst
$T(n + 1)$ --- предсказания для $(n + 1)$-ого CPU burst
$T(0)$ --- выбираем случайно
$alpha in [0, 1]$ --- параметр
Предсказание:
$ T(n + 1) = alpha t(n) + (1 - alpha)T(n) $
Выбор $alpha$:
- $a = 0: T(n + 1) = T(n) = ... = T(0)$ не учета последнего поведения
- $a = 1: T(n + 1) = tau(n)$ не учета предыстории
- Обычно берут $a = 1/2$ т.к. середина и делить на два легко
==== Для долгосрочного планирования
Программист пытается указать, сколько времени нужно:
- Если указать мало, то начнет считаться быстро, но может не досчитаться и быть
выкинутым из системы
- Если указать много, то точно досчитается, но начнет считаться нескоро
=== Гарантированное планирование
Для многопользовательских систем
Если $N$ пользователей
$T_i$ --- время нахождения $i$-ого пользователя в системе
$tau_i$ --- суммарное процессорное время процессов i-ого времения
- $tau_i << T_i / N$ --- пользователь обделен
- $tau_i >> T_i / N$ --- пользователю благоволят
Введем _коэффициент справедливости_ $= (tau_i N) / T_i$
На исполнение выбираются процессы пользователя с наименьшим коэффициентом
справедливости.
=== Приоритетное планирования
У каждого процесса есть приоритет. Выбирается процесс с минимальным приоритетом.
Гарантированное планирование и SJF --- частные случаи.
Параметры для назначения приоритета:
- Внешние (информация извне; например, "важность" пользователя)
- Внутренние (свойства процесса в системе)
Политика изменения приоритета:
- Статический приоритет
- Динамический приоритет
Процесс с приоритетом $0$ --- самый важный
Приоритетное планирование бывает вытесняющее и не вытесняющее
При долгосрочном загружаем процессы в порядке приоритета. Даже если можно начать
исполнять другие процессы с более низким приоритетом.
= Простые схемы управления памятью
== Иерархия памяти
- Регистры
- Кэш
- Оперативная память
- Вторичная память (swap)
Сверху вниз увеличивается объем и время доступа, падает стоимость
== Принцип локальности
Большинство реальных программ за небольшой промежуток времени работает с
небольшим набором адресов памяти. Принцип связан с принципами мышления человека:
за единицу времени человек может оперировать 5--10 понятиями.
Благодаря этому принципу иерархия памяти работает хорошо.
== Проблема разрешения адресов
Оперативная память может быть представлена в виде массива ячеек с линейными
адресами.
Байт --- минимальная адресуемая ячейка памяти.
Совокупность всех доступных физических адресов ячеек в системе --- это её адресное пространство.
Человеку свойственно мыслить словами (символами), а не числами. Поэтому
имена переменных описываются идентификаторами, образуя символьное адресное
пространство.
Когда делать преобразование из символьного адресного пространства в физическое?
- Компиляция(использовалось в MS DOS)
- Загрузчиком или linker-ом
- Окончательное связывание
=== Логическое адресное пространство
Виртуальная память.
Совокупность адресов, которые используются процессором.
Промежуточный уровень между символьным и физическим адресными пространствами.
Иногда совпадает с физическим адресным пространстве.
|
|
https://github.com/veilkev/jvvslead
|
https://raw.githubusercontent.com/veilkev/jvvslead/Typst/files/1_evacuation.typ
|
typst
|
#import "../sys/packages.typ": *
#import "../sys/sys.typ": *
#import "../sys/header.typ": *
#move(dx: 0pt, dy: -10pt,
title
)
#move(dx: 0pt, dy: -10pt,
desc
)
// Spacing between title/header and content
#v(70pt)
#caution[
This document contains _internal_ company information and should *not* be read by any unauthorized personnel without the expressed approval of H-E-B.
]
= The Essentials
#note("Refunds cannot be done if cashier mode is presently active on a terminal")
#box(height: 68pt,
columns(2, gutter: 11pt)[
#subhead(head: true, "Emergency Evacuation")
#menu("MANAGER", "PAGE DOWN", "2", "F3")
#colbreak()
#subhead(head: true, "Remote Evacuation") \
#menu("PSID", "PASS", "MANAGER")
#colbreak()
])
#v(-20pt, weak: true)
#set text(8pt)
#move(dx: 435pt, dy: -75pt,
box(inset: 20pt, height: 100pt,
stickybox(
rotation: 20deg,
width: 3cm
)[
Instead of pressing [ENTER] after PASS,
Press [MANAGER]
]
))
// Moves content upwards
#v(-100pt)
#set text(12pt)
#stack(dir: ltr,
empha("Cashier Mode", 1), "and", empha("Manager Mode", 2),
"are two of the available options when accessing the ", pin(1), empha("POS", 3), pin(2)
)
#move(dx: 5pt, dy: -5pt,
stack(dir: ltr,
"Cashier Mode is for transactions only. All other ",
" activity should be done under Manager."
))
#set text(8pt)
// #let pinit-point-from(
// pin-dx: 5pt,
// pin-dy: 5pt,
// body-dx: 5pt,
// body-dy: 5pt,
// offset-dx: 35pt,
// offset-dy: 35pt,
// double: false,
// pin-name,
// body,
// ..args,
// ) = { ... }
#pinit-point-from(
offset-dx: 13pt,
offset-dy: 50pt,
pin-dy: 20pt,
(1, 2))[
Point of Sale (transactions)
]
|
|
https://github.com/tfachada/thesist
|
https://raw.githubusercontent.com/tfachada/thesist/main/template/Beginning/Glossary.typ
|
typst
|
MIT License
|
#import "@preview/glossarium:0.5.0": make-glossary, register-glossary, print-glossary
#show: make-glossary
/*
Add your glossary terms below!
- They will always be shown alphabetically;
- If you don't specify a plural/longplural form, #gspl() will just add an s in case you call it;
- Terms with a long form will be shown just as their short form from the second time on.
For any doubts, check the page of the imported package:
https://github.com/typst-community/glossarium
*/
#let main-glossary = (
// Terms you add in glossaries need to be referenced to show up, unless you uncomment this line:
// show-all: true,
(
(
key: "potato",
short: "potato",
plural: "potatoes",
description: "An edible tuber"
),
)
)
#let acronyms-glossary = (
(
(
key: "ist",
short: "IST",
long: "Instituto Superior Técnico"
),
(
key: "dm",
short: "DM",
long: "Diagonal Matrix",
longplural: "diagonal matrices"
),
)
)
#let symbols-glossary = (
(
(
key: "mu_0",
short: $mu_0$,
description: "Standard magnetic permeability"
),
)
)
= Glossary
#register-glossary(main-glossary)
#print-glossary(main-glossary)
== Acronyms
#register-glossary(acronyms-glossary)
#print-glossary(acronyms-glossary)
== Symbols
#register-glossary(symbols-glossary)
#print-glossary(symbols-glossary)
|
https://github.com/Myriad-Dreamin/typst.ts
|
https://raw.githubusercontent.com/Myriad-Dreamin/typst.ts/main/projects/rehype-typst/equation.typ
|
typst
|
Apache License 2.0
|
#set page(height: auto, width: auto, margin: 0pt)
#let s = state("t", (:))
#let pin(t) = locate(loc => {
style(styles => s.update(it => it.insert(t, measure(line(length: loc.position().y + 0.25em), styles).width) + it))
})
#show math.equation: it => {
box(it, inset: (top: 0.5em, bottom: 0.5em))
}
$pin("l1")1+e/sqrt(sqrt(a/c)/(e + c +a/b))$
#locate(loc => [
#metadata(s.final(loc).at("l1")) <label>
])
// #s.display()
// #locate(loc => {
// let s = s.final(loc)
// place(left+top, dx: 0pt, dy: s.l1, line(length: 100pt, stroke: red + 0.1pt))
// })
|
https://github.com/jassielof/typst-templates
|
https://raw.githubusercontent.com/jassielof/typst-templates/main/upsa-bo/estudio-de-factibilidad/template/capítulos/7.estudio de ingeniería.typ
|
typst
|
MIT License
|
= Estudio de Ingeniería
== Descripción Técnica del Producto
== Plan y Programa de Producción
== Selección de la Tecnología
== Descripción de los Procesos Productivos y Administrativos
== Cuantificación de los Recursos de la Producción
=== Diseño de la Línea de Producción Balanceada
==== Tiempo Estándar
==== Números de Puestos de Trabajo en Jornada Normal
==== Número de Horas Extras
==== Cantidad de Maquinaria
==== Cantidad de Equipos
==== Medios de Transporte
==== Muebles Enseres
==== Equipos Informáticos
==== Herramientas
==== Construcciones
==== Instalaciones Eléctricas
==== Instalaciones Hidrosanitarias
==== Instalaciones y Equipos de Seguridad
==== Instalaciones para el Tratamiento de Residuos Sólidos Líquidos y Gaseosos
=== Materia Prima e Insumos
==== Balance de Masa
==== Cantidad de Materia Prima
==== Cantidad de Insumos
=== Balance de Energía
==== Energía Eléctrica
==== Combustibles
=== Vehículos
=== Grasas Lubricantes Filtros y Otros
=== Uniformes y Equipos de Protección Personal
=== Material de Escritorio
=== Material de Limpieza
=== Telecomunicaciones
=== Agua
== Sistema de Gestión de Calidad Total
== Sistema de Información Administrativa
== Cronograma de Implementación
|
https://github.com/typst/packages
|
https://raw.githubusercontent.com/typst/packages/main/packages/preview/unichar/0.1.0/ucd/block-A8E0.typ
|
typst
|
Apache License 2.0
|
#let data = (
("COMBINING DEVANAGARI DIGIT ZERO", "Mn", 230),
("COMBINING DEVANAGARI DIGIT ONE", "Mn", 230),
("COMBINING DEVANAGARI DIGIT TWO", "Mn", 230),
("COMBINING DEVANAGARI DIGIT THREE", "Mn", 230),
("COMBINING DEVANAGARI DIGIT FOUR", "Mn", 230),
("COMBINING DEVANAGARI DIGIT FIVE", "Mn", 230),
("COMBINING DEVANAGARI DIGIT SIX", "Mn", 230),
("COMBINING DEVANAGARI DIGIT SEVEN", "Mn", 230),
("COMBINING DEVANAGARI DIGIT EIGHT", "Mn", 230),
("COMBINING DEVANAGARI DIGIT NINE", "Mn", 230),
("COMBINING DEVANAGARI LETTER A", "Mn", 230),
("COMBINING DEVANAGARI LETTER U", "Mn", 230),
("COMBINING DEVANAGARI LETTER KA", "Mn", 230),
("COMBINING DEVANAGARI LETTER NA", "Mn", 230),
("COMBINING DEVANAGARI LETTER PA", "Mn", 230),
("COMBINING DEVANAGARI LETTER RA", "Mn", 230),
("COMBINING DEVANAGARI LETTER VI", "Mn", 230),
("COMBINING DEVANAGARI SIGN AVAGRAHA", "Mn", 230),
("DEVANAGARI SIGN SPACING CANDRABINDU", "Lo", 0),
("DEVANAGARI SIGN CANDRABINDU VIRAMA", "Lo", 0),
("DEVANAGARI SIGN DOUBLE CANDRABINDU VIRAMA", "Lo", 0),
("DEVANAGARI SIGN CANDRABINDU TWO", "Lo", 0),
("DEVANAGARI SIGN CANDRABINDU THREE", "Lo", 0),
("DEVANAGARI SIGN CANDRABINDU AVAGRAHA", "Lo", 0),
("DEVANAGARI SIGN PUSHPIKA", "Po", 0),
("<NAME>", "Po", 0),
("<NAME>", "Po", 0),
("<NAME>", "Lo", 0),
("<NAME>", "Po", 0),
("<NAME>", "Lo", 0),
("DEVANAGARI LETTER AY", "Lo", 0),
("DEVANAGARI VOWEL SIGN AY", "Mn", 0),
)
|
https://github.com/pride7/Typst-callout
|
https://raw.githubusercontent.com/pride7/Typst-callout/main/lib.typ
|
typst
|
#import "callout.typ": *
#let c1 = callout.with(type:"note")
#let c2 = callout.with(type:"warning")
#let c3 = callout.with(type:"check")
#let c4 = callout.with(type:"summary")
#let c5 = callout.with(type:"question")
#let c6 = callout.with(type:"example")
#let c7 = callout.with(type:"quote")
#let nc1 = callout.with(type:"note", icon:false)
#let nc2 = callout.with(type:"warning", icon:false)
#let nc3 = callout.with(type:"check", icon:false)
#let nc4 = callout.with(type:"summary", icon:false)
#let nc5 = callout.with(type:"question", icon:false)
#let nc6 = callout.with(type:"example", icon:false)
#let nc7 = callout.with(type:"quote", icon:false)
|
|
https://github.com/saYmd-moe/note-for-statistical-mechanics
|
https://raw.githubusercontent.com/saYmd-moe/note-for-statistical-mechanics/main/template.typ
|
typst
|
#import "@preview/i-figured:0.2.3"
#import "@preview/physica:0.8.1": *
#import "@preview/pinit:0.1.2": *
#import "@preview/cetz:0.1.2"
#import "@preview/colorful-boxes:1.2.0": *
#import "./utils/custom-numbering.typ": custom-numbering
#import "./utils/custom-counter.typ": custom-counter
#let conf(
// 文章基础信息设置
title: "Paper Title",
subtitle: none,
shortitle: none,
author: none,
email: none,
date: datetime.today(),
body
) = {
// 字体信息设置,这里可以随意修改为自己想要使用的字体
let song = "FZShuSong-Z01"
let hei = "FZHei-B01"
let kai = "FZKai-Z03"
let xbsong = "FZXiaoBiaoSong-B05"
let code = "DejaVu Sans Mono"
let title-font = hei
let author-font = kai
let body-font = song
let heading-font = xbsong
let caption-font = kai
let header-font = kai
let strong-font = hei
let emph-font = kai
let raw-font = code
// 设置文档元数据
if {author != none} {
set document(author: author, title: title)
}
// 在第一页的页眉添加标题
set page(numbering: "1/1", number-align: center, header: align(left)[
#set text(font: header-font)
#shortitle
])
// 设置英文、中文字体
set text(font: ("Times New Roman", body-font))
// 设置标题样式
show heading.where(level:1): it => box(width: 100%)[
#set align(center)
#v(0.50em)
#set text(font: heading-font, size: 1.75em)
#custom-counter(it)
#h(.5em)
#it.body
]
show heading.where(level:2): it => box(width: 100%)[
#set align(left)
#v(0.50em)
#set text(font: heading-font, size: 1.5em)
#custom-counter(it)
#h(.5em)
#it.body
]
show heading.where(level:3): it => box(width: 100%)[
#set align(left)
#set text(font: heading-font, size: 1.5em)
#custom-counter(it)
#h(.5em)
#it.body
]
show heading.where(level:4): it => box(width: 100%)[
#set align(left)
#set text(font: heading-font, size: 1.25em)
#custom-counter(it)
#h(.5em)
#it.body
]
show heading.where(level:5): it => box(width: 100%)[
#set align(left)
#set text(font: heading-font, size: 1.05em)
#custom-counter(it)
#h(.5em)
#it.body
]
// 设置目录样式
show outline.entry: it => {
strong(custom-counter(it))
it
}
// Title
align(center)[
#block(text(font: title-font, weight: 700, 1.75em, title))
#v(0.5em)
#block(text(font: title-font, weight: 700, 1.25em, shortitle))
]
// Author information.
align(center)[
#pad(
top: 0.25em,
bottom: 0.25em,
x: 0.25em,
)[
#set text(font: ("Times New Roman", author-font),size: 1.5em)
#author
#par()[#email]
]
]
// Main body
set par(first-line-indent: 2em)
set list(indent: 3em)
set enum(indent: 3em)
//set figure(gap: 0.8cm)
set math.equation(numbering: "(1)")
set math.equation(supplement: [式])
set math.cases(gap: 1em)
set figure(supplement: [图])
set highlight(fill:rgb("39c5bb"))
show figure: it => [
//#v(12pt)
#set text(font: caption-font)
#it
#par()[#text(size: 0.0em)[#h(0.0em)]]
//#v(12pt)
]
show image: it => [
#it
#par()[#text(size: 0.0em)[#h(0.0em)]]
]
show table: it => [
#set text(font: body-font)
#it
]
show strong: set text(font: strong-font)
show emph: set text(font: emph-font)
show ref: set text(blue)
show footnote: set text(blue)
show raw.where(block: true): block.with(
width: 100%,
fill: luma(240),
inset: 10pt,
)
show raw: set text(font: (raw-font, hei), size: 10pt)
show link: underline
show link: set text(blue)
// 使用 i-figure 包添加章节编号
//show heading: i-figured.reset-counters
//show figure: i-figured.show-figure
//show math.equation: it => i-figured.show-equation(
// it,
// level: 1,
// leading-zero: false,
// numbering: "(1-1)",
//)
set bibliography(style: "mla")
[
#show heading: it => box(width: 100%)[
#it.body
]
#outline(
title: "目录",
indent: .75em,
depth: 4
)
]
counter(heading.where(level:1)).update(0)
counter(heading.where(level:2)).update(0)
pagebreak()
body
}
// 方程标注函数
#let pinit-highlight-equation-from(height: 2em, pos: bottom, fill: rgb(0, 180, 255), highlight-pins, point-pin, body) = {
pinit-highlight(..highlight-pins, dy: -0.6em, fill: rgb(..fill.components().slice(0, -1), 40))
pinit-point-from(
fill: fill, pin-dx: -0.6em, pin-dy: if pos == bottom { 0.8em } else { -0.6em }, body-dx: 0pt, body-dy: if pos == bottom { -1.7em } else { -1.6em }, offset-dx: -0.6em, offset-dy: if pos == bottom { 0.8em + height } else { -0.6em - height },
point-pin,
rect(
inset: 0.5em,
stroke: (bottom: 0.12em + fill),
{
set text(fill: fill)
body
}
)
)
}
// 定义几个标注函数
#let note(body) = {
outlinebox(
body,
title: [#text(size: 1em)[✎ Note]],
radius: 5pt,
width: auto
)
}
#let example(body) = {
outlinebox(
body,
title: [#text(size: 1em)[ Example]],
color: "green",
radius: 5pt,
width: auto
)
}
|
|
https://github.com/Le-foucheur/dotfile
|
https://raw.githubusercontent.com/Le-foucheur/dotfile/main/.config/Code/User/History/620b997c/6awA.typ
|
typst
|
#import "../template.typ": *
#import "../../../transposition.typ" : *
#set heading(numbering: (..numbers) => {
let n=numbers.pos().len();
if n==1 {question.update(1); }
else if n==2 { [Partie ]; numbering("I",numbers.pos().at(1)) ;"."}
else if n==3 {"N=° ";question.step(); question.display(na);"."}
else if n==4 {numbering("a.",numbers.pos().at(3)+1)}
else if n==5 {numbering("i.",numbers.pos().at(4)+1)}
})
#set underline(stroke: red + 1pt)
#set par(leading: 0.7em)
#set page(numbering: (..nums) => nums.pos().map(na).join("/"), number-align: right)
<NAME>
#align(center, text(20pt)[Maths : DM #na(18)])
#t(1) Il est important avant de commencer lire ce DM\
#t(1) d'avoir bien compris le tableau et les exemples suivants
#grid(
columns: 2,
gutter: 5em,
table(
columns: 3,
align: center,
//chiffre
[symbole usuel],[symbole du DM],[prononciation],
[0],$fe$,[fé],
[1],$ur$,[ur],
[2],$tur$,[tur],
[3],$an$,[an],
[4],$rai$,[rai],
[5],$kau$,[kau],
[6],$geb$,[gèb],
[7],$wun$,[wun],
[8],$hag$,[hag],
[9],$nau$,[nau],
[10],$je$,[je],
[11],$ei$,[ei],
//symbole math
$=$,$ing$,[ing/i ng],
$+$,$ti$,[ti],
$-$,$al$,[al],
$times$,$dag$,[dag],
$div$,$lag$,[lag],
$in$,$so$,[so],
$forall$,$per$,[per],
$exists$,$ber$,[ber],
$exists !$,$uber$,[\\],
$>$,$man$,[man],
$<$,$eh$,[e],
$>=$,$maning$,[maning],
$<=$,$ehwing$,[ehwing],
$!=$,$naing$, [naing],
$subset$,$suz$, [suz],
$supset$,$zus$, [zus],
),
v(16em)+
$ #na(79) ti #na(65) ing #na(144) " ce qui est équivalant à" 79+65=144 $ +
v(6em) +
$ e^inc limits(ing)_(inc -> fe) ur ti inc ti inc^tur /tur! ti dots.c ti inc^v1 / v1! ti o(inc^v1) $ +
align(center)[est équivalant à] +
$ e^x limits(=)_(x -> 0) 1 + x + x^2/2 + dots.c + x^n/x! + o(x^n) $
)
#pagebreak()
= Problème #tur : nombres algébrique et extensions de corps \
== extensions de corps\
=== Premiers exemples a.\
#t(1) il est évidant que $RR$ est un sous-corps de $CC$ et de plus $CC$ est de dimension finis,\
#t(1) donc $CC$ est une extention finie de $RR$\
\
#t(1) de plus soit $com so CC$ alors
$ per inc, v1 so RR, com ing inc ti i v1 <=> com so Vect(ur,i) $
#t(1) Ainsi comme $ur$ et $i$ ne sont pas colinéaire dans $RR$, $Vect(ur,i)$ forme une base de $CC$\
#t(1) #undermath[Ainsi $[CC : RR] ing tur$]\
\
#t(1) soit $ens$ un sous-corps qui contient $RR$\
#t(1) comme $[RR : RR] ing ur$ et que l'on vient de prouver que $[CC : RR] ing tur$\
#t(1) il apparait donc comme condition que, $ur ehwing [ens : RR] ehwing tur $\
#t(1) Ainsi $[ens : RR] ing ur$ ou $[ens : RR] ing tur$\
#t(1) #undermath[Et ansi $ens ing RR$ ou $ens ing CC$]
==== \
#t(1) Soit $inc so QQ(sqrt(tur))$, alors $ber v1, com so QQ, inc ing v1 ti com sqrt(tur)$, alors prenons $com ing fe$\
#t(1) ainsi $inc ing v1 so QQ$, donc $QQ suz QQ(sqrt(tur))$ et comme $QQ$ est un corps \
de $QQ(sqrt(tur))$\
#t(1) de plus, soit $inc so QQ(sqrt(tur))$ alors $ber v1, com so QQ, inc ing ber ti v1 sqrt(tur)$, soit un telle $com, v1$\
#t(1) donc $inc ing com ti v1 sqrt(tur) so Vect(ur, sqrt(tur))$\
#t(1) et supposons par l'absurde $ber inc, v1 so QQ dag QQ^*, inc ti v1 sqrt(tur) ing fe$ \
#t(1) alors $inc/v1 ing al sqrt(tur)$ ce qui est absurde car $inc/v1 so QQ$, donc $inc ing v1 ing fe$ \
#t(1) Ainsi $(ur, sqrt(tur))$ est une base de $QQ(sqrt(tur))$\
#t(1) #undermath[Donc $[QQ(sqrt(tur)):QQ] ing tur$]\
==== i.\
#t(1) Soit $upright(P) so QQ[X] tq P(root(an,tur)) ing fe$\
#t(1) prenons la divisions euclidienne de $X^an al tur$ par $upright(P)$\
#t(1) ce qui nous donne $X^an al tur ing upright(P Q) ti R$ avec $upright(Q) so QQ_ur [X] et upright(R) so QQ[X] tq deg upright(R) eh tur$ \
#t(1) En évaluant notre expression précédente en $root(an,tur)$ on obtient :
$ (root(an,tur))^an al tur ing fe ing underbrace(upright(P(root(an,tur))),ing fe) ti upright(R) $
#t(1) donc $upright(R) ing fe$ et donc $deg upright(R) ing fe$\
#t(1) #undermath[ainsi $upright(P)$ divise $upright(X^an al tur)$]\
\
#t(1) Ainsi Comme $upright(P)$ divise $X^an al tur$ et que $deg upright(P) ing tur$,\
#t(1) alors $upright(P)$ et $X^an al tur$ possède deux racines en commun dont $root(an,tur)$\
#t(1) et comme $X^an al tur ing (X al root(an,tur))(X al root(an,tur)e^( i pi /an))(X al root(an,tur)e^( i (tur pi )/an))$ donc $upright(P)$ à en plus une racine complexe\
#t(1) or un polynôme dans $RR$ qui possède une racine complexe possède sont conjugée\
#t(1) ce qui n'est pas le cas pour $upright(P)$ donc $upright(P) cancel(so) QQ[X]$ ce qui est absurde \
#t(1) #undermath[Donc $cancel(ber) P so QQ[X], P(root(an,tur))ing fe$]\
#let rac = $root(an,tur)$
===== \
#t(1) Par un résonnement annaloge à la question #ur .b on montre que $QQ suz QQ(root(an,tur))$,\
#t(1) De plus soit $inc so QQ(root(an,tur))$ alors soient $v1,com,v2 so QQ, inc ing v1 ti com root(an,tur) ti v2 (rac)^tur$ \
#t(1) donc $inc so Vect(ur, rac, rac^tur)$ \
#t(1) donc $QQ(root(an,tur))$ est une extensions finis et $[Q(rac) : QQ] ing an$\
==== \
#t(1) Soient $v1_ur, dots.c, v1_n so QQ$ tels que $display(sum_(v2 ing ur)^(n) v1_v2 ln(p_v2) ing fe ) $,\
#t(1) alors $ ln(product_(v2 ing ur)^(n) p_v2^v1_v2 ) ing fe " "donc product_(v2 ing ur)^(n) p_v2^v1_v2 ing ur $
#t(1) Or comme $per v2 so [|ur; n|], v1_v2 so QQ$ donc $ber v3, com_ur, dots.c, com _n so NN,per v2 so [|ur; n|], v1_v2 ing com_v2/v3$. Ainsi
$ (product_(v2 ing ur)^(n) p_v2^com_v2)^(1/v3) ing ur <=> product_(v2 ing ur)^(n) p_v2^com_v2 ing ur $\
#t(1) Or comme $per v2 so [|ur;n|], p_v2^com_v2 so NN donc p_ur^v2_ur ing dots.c ing p_n^v2_n ing ur " "donc v2_ur ing dots.c ing v2_n ing fe $\
#t(1) Et donc $v1_ur ing dots.c ing v1_n ing fe$\
#t(1) #undermath[Ainsi $(ln(p_ur), dots.c, ln(p_n))$ est libre]\
#t(1) Et donc la dimmension de $RR$ n'est pas finis, donc $RR$ n'est pas une extention finis de $QQ$
=== \
#t(1) soit $inc so upright(bold(L))$, alors $uber v1_ur, dots.c, v1_n so upright(bold(K))$ tel que, $display(inc ing sum_(com ing ur)^(n))alpha_com v1_com$\
\
#t(1) Or on a $display(per com so [|ur, n|]\,uber v2_ur\, dots.c \, v2_p so k \, v1_com ing sum_(v3 ing ur)^(p) beta_v3 v2_v3 )$\
\
#t(1) Ainsi $uber v1_ur, dots.c, v1_n so upright(bold(K)) so k,uber v2_ur\, dots.c \, v2_p so k, inc ing display(sum_(ur ehwing com ehwing n \ ur ehwing v3 ehwing p) alpha_com beta_v3 v1_com v2_v3)$\
#t(1) Donc $inc$ s'écrit d'une manière unique comme des élément de $k$,\
#t(1) donc la famille $(alpha_i beta_j)_(ur ehwing i ehwing n \ ur ehwing j ehwing p)$ est une base de du $k$-espace vectoriel *L*\
#t(1) De plus la famille $(alpha_i beta_j)_(ur ehwing i ehwing n \ ur ehwing j ehwing p)$ comporte exactement $n p$ éléments\
#t(1) #undermath[Donc *L* est une extensions finis de $k$ et $[upright(bold(L)) : k] ing [upright(bold(L)) : upright(bold(K))] [upright(bold(K)) : k]$]
#pagebreak()
== Éléments algébriques \
=== \
#t(1) pour montrer que $KK[alpha] ing {P(alpha), P so KK[X]}$,\
#t(1) on montre que ${P(alpha), P so KK[X]} ing Vect_KK (alpha^n, n so NN) $\
#t(1) pour cela,
$ pol1 so {P(alpha), P so KK[X]} &<=>ber v2_fe, dots.c, v2_n so KK pol1 ing sum_(v1 ing fe)^(n) v2_v1 alpha^v1 so Vect_KK (alpha^n, n so NN) ing KK[alpha] $
#t(1) Donc ${P(alpha), P so KK[X]} ing KK[alpha]$\
\
#t(1) soient $v1, v2 so KK[alpha]$, alors $ber P,Q so KK[X], P(alpha) ing v1 et Q(alpha) ing v2$, alors: \
- $fe so KK[alpha] $
- $v1 al v2 ing P(alpha) al Q(alpha) ing (P al Q)(alpha) et P al Q so KK[X] $
- $v1 dag v2 ing P(alpha) dag Q(alpha) ing (P dag Q)(alpha) et P Q so KK[X]$
#t(1) #undermath[Donc $KK[alpha]$ est un sous-anneau de $LL$]\
\
#t(1) Et $Vect(alpha^n, n so NN)$ est le plus petit ensemble stable par $ti et dag$,\
#t(1) ce qui fais de luis le plus petit sous-anneau contanant $alpha et KK$
=== \
#t(1) procédons par double inclusion pour prouver que $alpha$ est algébrique sur $KK$ si et seulement si\
#t(1) il existe $n so NN tq (1,alpha, dots.c, alpha^n)$ soit une famille liée\
#t(1) $(=>)$ Supposons que $alpha$ est algébrique sur $KK$, alors
$ ber pol1 so KK[X], pol1(alpha) ing fe &<=> ber n so NN, ber v1_fe, dots.c, v1_n so KK, pol1(alpha) ing sum_(v2 ing fe)^(n) v1_v2 alpha^v2 ing fe \
&donc al sum_(v2 ing ur)^(n) v1_v2 alpha^v2 ing v1_fe\
&#undermath[$donc (1, alpha, dots.c, alpha^n) "est liée"$]
$
#t(1) ($arrow.l.double$) Supposons que $(1, alpha, dots.c, alpha^n)$ soit liée, alors:
$ ber v1_fe, dots.c, v1_n so KK, ber v3 so NN, com alpha^v3 ing sum_(v2 ing fe\ v2 naing v3)^(n)v1_v2 alpha^v2 \
donc sum_(v2 ing fe\ v2 naing v3)^(n)v1_v2 alpha^v2 al com alpha^v3 ing fe
$
#t(1) en posant $al com ing v1_v3$, on obtient
$ sum_(v2 ing fe\ v2 naing v3)^(n)v1_v2 alpha^v2 al com alpha^v3 ing sum_(v2 ing fe)^(n)v1_v2 alpha^v2 ing fe $
#t(1) Or $display(sum_(v2 ing fe)^(n)v1_v2 alpha^v2) so RR[X]$\
#t(1) #undermath[Donc $alpha$ est algébrique]\
\
#t(1) Par le principe de double inclusion\
#t(1) #undermath[$alpha$ est algébrique #ssi il existe $n so NN$ #tq $(1,alpha,dots.c, alpha^n )$ est liée]\
=== \
#t(1) Soit $inc so LL$, alors $inc$ est algébrique de degré #ur sur $KK$ #ssi $(ur, inc)$ est liée\
#t(1) #ssi il existe $v1 so KK, inc ing v1 dag ur ing v1$ #ssi $inc so KK$\
#t(1) Donc on a bien #undermath[$(ur, inc)$ liée $<=> inc so KK$]\
=== \
#t(1) Supposons que $LL$ est une extention finie de $KK$ et soit $inc so LL$\
#t(1) alors $inc$ est algébrique sur $KK$ si:
$ a $
=== a.\
#t(1) On sait par la définitions que $(1,alpha, dots.c, alpha^(d al ur))$ est libre\
#t(1) Et $Vect(alpha^n, n so NN) ing Vect(alpha^n, n so [|ur;d al ur|])$ \
#t(1) #undermath[Ainsi $Vect(alpha^n, n so [|ur;d al ur|])$ est une base de $KK[alpha]$]\
==== \
#t(1) Supposons que $beta naing fe$, alors prouvons que $f_beta$ est linéaire et bijective\
- linéarité:
#t(1) Soient $v1 so KK, inc, com so KK[alpha], f_beta (v1 inc ti com) ing beta v1 inc ti beta com ing v1 f_beta (inc) ti f_beta (com)$ donc $f_beta$ ets linéaire\
- bijectivité:
#t(1) soit $inc so KK[alpha], f_beta (inc) ing fe$\
#t(1) alors $beta inc ing fe$ donc $inc ing fe$ car $beta naing fe$\
#t(1) donc $Ker(f_beta) ing {fe}. donc f_beta$ est injéctive\
#t(1) Et soient $inc, com so KK[alpha], f_beta (inc) ing com$\
#t(1) alors $inc ing com/beta$ car $beta naing fe$, et donc $f_beta$ est surjective\
#t(1) et comme $f_beta$ va de $KK[alpha]$ dans $KK[alpha]$\
#t(1) #undermath[$f_beta$ est un automorphisme]\
#text(fill:white)[====]
#v(-16pt)
==== \
#t(1) On a: $KK suz KK[alpha]$, donc $KK$ est un sous-corps de $KK[alpha]$\
#t(1) De plus comme $(1, alpha, dots.c, alpha^(d al ur))$ est une base de $KK[alpha]$ qui comporte $d$ élément\
#t(1) #undermath[Ainsi $KK[alpha]$ est une extensions finie de $KK$, avec $[KK[alpha]:KK] ing d$]\
==== \
#t(1) Il est évidant que $QQ(rac) suz CC$, et commme $QQ$ est un sous groupe et que $rac so CC$,\
#t(1) alors par les questions précédente:\
#t(1) #undermath[$QQ(rac)$ est un sous-corps de $CC$]
=== \
#t(1) i) $=>$ ii) est évidant car $KK[alpha]$ est un corps et donc stable par $dag$\
#pagebreak()
#t(1) ii) $=>$ iii) Supposons que $alpha^(al ur) suz KK[alpha]$, alors \
#t(1) $ber pol1 suz KK[X], pol1(alpha) ing alpha^(al ur)$, soit $pol1$ un telle polynôme, alors:
$
pol1(alpha) ing alpha^(al ur) &<=> alpha pol1(alpha) ing alpha alpha^(al tur) ing ur\
&<=> alpha pol1(alpha) al alpha ing fe
$
#t(1) Posons $ens ing X pol1(X) al ur so KK[X]$, ainsi $ ens(alpha) ing 0$\
#t(1) #undermath[Et donc $alpha$ est constructible]\
#t(1) iii) $=>$ i) Supposons que $alpha$ est algébrique sur $KK$, alors par la question #na(7).\
#t(1) $KK[alpha]$ est un sous-corps de $LL$\
\
#t(1)Ainsi par un raisonnement cyclique,\
#t(1)#undermath[on a bien que $KK[alpha]$ est un sous-corps de $LL <=> alpha^(al ur) so KK[alpha] <=> alpha$ est algébrique sur $KK$ ]\
== Polynômes minimal d'un élément algébrique\
=== \
#t(1) Si $I_alpha$ na possède pas une polynôme de degré $q$,\
#t(1) alors soit $pol1 so I_alpha$ de degré $q$, alors soit $v1$ sont coefficient dominant\
#t(1) alors le polynome $pol1/v1$ est de degrés $q$ et sont coefficient dominant vaut $ur$\
#t(1) De plus $pol1/v1 (alpha) ing (pol1 (alpha))/v1 ing fe/v1 ing fe donc pol1/v1 so I_alpha$\
#t(1) Donc $I_alpha$ possède un polynôme unitaire de degrés $q$
#t(1) Soient $pol1, pol2 so I_alpha$ deux polynômes unitaire de degrés $q$\
#t(1) Alors $ber v1_fe, dots.c, v1_(q al ur), v2_fe, dots.c, v2_(q al ur) so KK, pol1 ing X^q ti display(sum_(v3 ing fe)^(q al ur))v1_v3 X^v3 et pol2 ing X^q ti display(sum_(v3 ing fe)^(q al ur))v2_v3 X^v3$\
#t(1) Alors $pol1(alpha) al pol2(alpha) ing display(sum_(v3 ing fe)^(q al ur))v1_v3 alpha^v3 al display(sum_(v3 ing fe)^(q al ur))v2_v3 alpha^v3 ing fe$\
#t(1) donc $display(sum_(v3 ing fe)^(q al ur))(v1_v3 al v2_v3) alpha^v3$, et comme $(1, alpha, dots.c, alpha^(q al ur))$ est libre, on a: $per v3 so [|fe;q al ur|], v1_v3 ing v2_v3$\
#t(1) Ainsi on a bien $pol1 ing pol2$\
#t(1) #undermath[Donc il existe un unique polynome unitaire de degré $q$ dans $I_alpha$]\
=== \
#t(1) Supposons par l'absurde que $mu_alpha$ est réductible,\
#t(1) alors $ber pol1, pol2 so KK[X], mu_alpha ing pol1 pol2$, soient de tels polynômes\
#t(1) Ainsi $mu_alpha (alpha) ing pol1(alpha) pol2(alpha) ing fe$ donc $pol1(alpha) ing fe ou pol2(alpha) ing fe$,\
#t(1) donc $alpha$ est algébrique de degrés inférieur stricte à $d$, absurde ! \
#t(1) #undermath[Donc $mu_alpha$ est irréductible]\
\
#t(1) Soit $pol1 so I_alpha$, alors $ber pol2 so KK[X], pol1 ing mu_alpha pol2$ car $pol1(alpha) ing fe$, ainsi $I_alpha suz {mu_alpha pol1, pol1 so KK[X]} $\
#t(1) Et soit $ber pol2 so KK[X], pol1 ing mu_alpha pol2$, alors $pol1(alpha) ing (mu_alpha pol2)(alpha) ing mu_alpha (alpha) pol2(alpha) ing fe$,\
#t(1) donc $pol1 so I_alpha$ et donc ${mu_alpha pol2, pol2 so KK[X]} suz I_alpha$\
#t(1) Ainsi par double inclusion #undermath[${mu_alpha pol2, pol2 so KK[X]} ing I_alpha$]
#pagebreak()
=== \
#t(1) étant donner que $mu_alpha$ est le plus petit polynômes telle que $mu_alpha (alpha) ing fe$\
#t(1) alors $(1,alpha, dots.c, alpha^q)$ est la plus petite famille liée, donc le degrés de alpha vaut $q$ est $d$, si bien que:\
#t(1) #undermath[$deg mu_alpha ing d$]\
=== \
#t(1) il est évidant que le polynôme minimal est $X^an al tur$\
=== \
#let alp = $sqrt(#na(2)) ti sqrt(#na(3))$
#t(1) Posons $pol1 ing v1 X^#na(4) ti v2 X^#na(3) ti v3 X^#na(2) ti inc X ti com so QQ[X]$, avec $v1,v2,v3,inc,com$ non tous nul\
#t(1) Alors cherchons $v1,v2,v3,inc,com$ tel que $pol1(alpha) ing fe$\
#t(1) Ainsi $ pol1(alpha) &ing v1 (alp)^#na(4) ti v2 (alp)^#na(3) ti v3 (alp)^#na(2) ti inc (alp) ti com\
&ing #na(49)v1 ti #na(20) v1 sqrt(#na(6)) ti #na(11) v2 sqrt(#na(2)) ti #na(9) v2 sqrt(#na(3)) ti #na(5) v3 ti #na(2) v3 sqrt(#na(6)) ti inc sqrt(#na(2)) ti inc sqrt(#na(3)) ti com \
&ing (#na(20) v1 ti #na(2) v3)sqrt(#na(6)) ti (#na(9)v2 ti inc)sqrt(#na(3)) ti (#na(11)v2 ti inc)sqrt(#na(2)) ti #na(49) v1 ti #na(5) v3 ti com ing fe
$
#t(1) Alors comme $(1,sqrt(#na(2)),sqrt(#na(3)),sqrt(#na(6)))$ est libre, on obtient:
$
cases(#na(20) v1 ti #na(2) v3 ing fe,
#na(9)v2 ti inc ing fe,
#na(11)v2 ti inc ing fe,
#na(49) v1 ti #na(5) v3 ti com ing fe
) <=> cases(
v2 ing fe,
inc ing fe,
v3 ing al #na(10) v1,
#na(49) v1 ti #na(5) v3 ti com ing fe
) <=> cases(
v2 ing fe,
inc ing fe,
v3 ing al #na(10) v1,
v1 ing com
)
$\
#t(1) #undermath[Ainsi $pol1 ing com X^#na(4) al #na(10) com X^#na(2) ti com$, ainsi on prouve que $alpha$ est algébrique] \
#t(1) #undermath[et que $pol1$ est le polynôme minimal de $alpha$ sur $QQ$ car sinon on aurais $v1 ing fe$]\
== Nombres algébriques (sur $QQ$)\
=== a.\
#t(1) il est évidant que $QQ[alpha,beta]$ est stable par $ti et dag$ \
#t(1) et deplus, soit $inc, com, v3 so QQ[alpha,beta]$ alors $ber v1, v2, v4, v1', v2', v4', v1', v2', v4' so QQ, inc ing v1 ti v2 alpha ti v4 beta$\
#t(1) $et com ing v1' ti v2' alpha ti v4' beta et v3 ing v1' ti v2' alpha ti v4' beta$\
#t(1) alors
$
(com ti inc)v3 &ing (v1 ti v2 alpha ti v4 beta ti v1' ti v2' alpha ti v4' beta) (v1'' ti v2'' alpha ti v4'' beta)\
&ing (v1 ti v2 alpha ti v4 beta)(v1'' ti v2'' alpha ti v4'' beta) ti (v1' ti v2' alpha ti v4' beta)(v1'' ti v2'' alpha ti v4'' beta)\
&ing com v3 ti inc v3
$
#t(1) De même $v3(inc ti com) ing v3 inc ti v3 com$\
#t(1) De plus par la question #na(7) $QQ[alpha, beta]$ est une extention finie de $QQ[alpha]$\
#t(1) Or $QQ[alpha]$ est une extensions finis de $QQ$\
#t(1) #undermath[Donc $QQ[alpha, beta]$ est un corps et est une extention finie de $QQ$]\
#pagebreak()
==== \
#t(1) Pourvons d'abord que $sqrt(#na(3)) cancel(so) QQ(sqrt(#na(2)))$,\
#t(1) Pour cela cherchons $v1, v2 so QQ, v1 ti v2 sqrt(#na(2)) ing sqrt(#na(3))$, alors:
$
&v1^#na(2) ti tur v2^tur ti tur v1 v2 sqrt(tur) ing an\
&donc cases(tur v1 v2 sqrt(tur) ing fe, v1^#na(2) ti tur v2^tur ing an )
<=>
cases(v1 ing fe "ou" v2 ing fe, v1^#na(2) ti tur v2^tur ing an)
$
#t(1) Il est évidant que $v2 naing fe$ car $v2 so QQ et sqrt(#na(3)) cancel(so) QQ$ donc $v1 ing fe$\
#t(1) Ainsi $tur v2^#na(2) ing an <=> v2 ing sqrt(#na(3)/#na(2)) cancel(so )QQ$ absurde, donc $sqrt(an) cancel(so) QQ(sqrt(tur))$\
#t(1) Et donc comme $QQ$ est un sous corps de $QQ(sqrt(#na(2)))$ et que $QQ(sqrt(#na(2)))$ est un sous corps de $QQ[sqrt(#na(2)), sqrt(#na(3))]$, \
#t(1) et comme $(1, sqrt(#na(2)))$ est une base du $QQ$-espace vectoriel $QQ(sqrt(tur))$\
#t(1) et que $(1, sqrt(#na(3)))$ est une base du $QQ(sqrt(tur))$-espace vectoriel $QQ[sqrt(#na(2)), sqrt(#na(3))]$\
#t(1) Ainsi par la question #na(2). $(1,sqrt(tur), sqrt(an), sqrt(geb))$ est une base du $QQ$-espace vectoriel $QQ[sqrt(#na(2)), sqrt(#na(3))]$\
#t(1) #undermath[Et donc $QQ[sqrt(#na(2)), sqrt(#na(3))] ing {v1 ti v2 sqrt(tur) ti com sqrt(an) ti v3 sqrt(geb), v1,v2, com, v3 so QQ}$]\
=== \
#let Qb = $overline(QQ)$
#t(1) Soit $v1, v2 so Qb$. Alors $QQ[v1,v2]$ est un corps,\
#t(1) et en particulier une extension finie de $QQ$. \
#t(1) Donc la somme,l’inverse et le produits sont stables dans $QQ[v1,v2]$,\
#t(1) et donc par la question #na(6). #undermath[$Qb$ est un corps, et est donc un sous-corps de $CC$]
#pagebreak()
#let oui(s,n) = for i in range(s,n+1){
(text(font: "FreeMono")[#str.from-unicode(i)],)
}
#grid(
columns: 25,
gutter: 5pt,
..oui(119808,120831)
)
// ==== \
|
|
https://github.com/rlpundit/typst
|
https://raw.githubusercontent.com/rlpundit/typst/main/Typst/en-Report/chaps/chpt1.typ
|
typst
|
MIT License
|
/* --------------------------------- DO NOT EDIT -------------------------------- */
#import "../Class.typ": *
#show: report.with(isAbstract: false)
#chap(chap1) // Chapter 1
#set page(header: smallcaps(title) + h(1fr) + emph(chap1) + line(length: 100%))
/* ------------------------------------------------------------------------------ */
== Introduction <chp:chap1>
#lorem(32)
== Section 1
#lorem(16)
=== Subsection 1.1
#lorem(64)
=== Subsection 1.2
#lorem(64)
== Section 2
#lorem(16)
=== Subsection 2.1
#lorem(64)
=== Subsection 2.2
#lorem(64)
#figure(
image("images/typst.svg", width: 40%),
caption: "Typst logo",
) <fig:typst-logo>
@fig:typst-logo shows the `Typst` logo.
#figure(
table(
columns: (auto, auto, auto),
[a], [b], [c], [$a$], [$b$], [$c$],
),
caption: "Some table",
) <tab:some-table>
@tab:some-table displays some table.
== Conclusion
#lorem(32)
|
https://github.com/yixiak/sysu-report-typst-template
|
https://raw.githubusercontent.com/yixiak/sysu-report-typst-template/master/template.typ
|
typst
|
MIT License
|
#let report(
title: "实验报告",
subtitle: "Lab 0: 环境准备",
name: "张三",
stdid: "11223344",
classid: "计科一班",
subject:"实验课程",
time: "2022~2023 学年第二学期",
banner: none + "",
body,
) = {
set document(title: title)
set page(paper: "a4", numbering: "1", number-align: center)
set text( lang: "zh", size: 11pt)
set heading(numbering: "1.1.")
let fieldname(name) = [
#set align(right + horizon)
//#set text(font: fonts.text)
#name
]
let fieldvalue(value) = [
#set align(left + horizon)
//#set text(font: fonts.text)
#value
]
align(center)[
#grid(
columns: (200pt, 240pt),
row-gutter: 1em,
fieldname(text("姓") + h(2em) + text("名:") + h(1em)),
fieldvalue(name),
fieldname(text("学") + h(2em) + text("号:") + h(1em)),
fieldvalue(stdid),
fieldname(text("教学班号:") + h(1em)),
fieldvalue(classid),
fieldname(text("课") + h(2em) + text("程:") + h(1em)),
fieldvalue(subject),
)
]
}
|
https://github.com/taylorh140/typst-pintora
|
https://raw.githubusercontent.com/taylorh140/typst-pintora/main/package/pintorita.typ
|
typst
|
#import "@preview/jogs:0.2.3": compile-js, call-js-function
#let pintora-src = read("./pintora.js")
#let pintora-bytecode = compile-js(pintora-src)
#let render(src, ..args) = {
let named-args = args.named()
let factor = named-args.at("factor",default:none)
let style = named-args.at("style",default:"larkLight")
let font = named-args.at("font",default:"Arial")
let svg-output = call-js-function(pintora-bytecode, "PintoraRender", src, style, font)
if (factor != none){
let svg-width = svg-output.find(regex("width=\"(\d+)")).find(regex("\d+"))
let new-width = int(svg-width) * factor * 1pt
named-args.insert("width", new-width)
let junk = named-args.remove("factor")
}
image.decode(svg-output, ..args.pos(), ..named-args)
}
#let render-svg(src, ..args) = {
// style: ["default", "larkLight", "larkDark", "dark"]
let named-args = args.named()
let factor = named-args.at("factor",default:none)
let style = named-args.at("style",default:"larkLight")
let font = named-args.at("font",default:"Arial")
let svg-output = call-js-function(pintora-bytecode, "PintoraRender", src, style, font)
if (factor != none){
let svg-width = svg-output.find(regex("width=\"(\d+)")).find(regex("\d+"))
let new-width = int(svg-width) * factor * 1pt
named-args.insert("width", new-width)
let junk = named-args.remove("factor")
}
svg-output
}
|
|
https://github.com/nathanielknight/tsot
|
https://raw.githubusercontent.com/nathanielknight/tsot/main/src/playbook_joker.typ
|
typst
|
#import("common_moves.typst")
#import("utils_playbook.typst") as upb
#import "theme.typst"
#show: theme.common
#show: theme.playbook
#upb.name[The Joker]
#upb.pitch[
Just my luck: we're out in the black, nobody for parsecs, and I'm stuck with
the biggest bunch of squares in known space. If these tightasses don't lighten
up and learn to have some fun I'm gonna blow us all out the airlock.
]
#upb.nameAndTraits[
- You want to have fun and slack off.
- You must always do the fun, dangerous, or cool thing.
- You must never hesitate or think twice.
]
#upb.moves(
prelude: [
#common_moves.introduce
],
encounter: (
miss: [
- You are killed by the Threat. Put down this playbook. The Encounter phase is over. Begin the Struggle.
- Your constant fooling around and lack of attention causes problems. What happens? Increase tension by 3.
],
partial: [
- Stumble across something important that you don't recognize because you're too busy goofing off. Mark 1 Mission and mark a detail on the Threat Playbook. How does the audience realize what you missed?
],
hit: [
- One of your harebrained diversions ends up actually being useful. How did _that_ happen? Mark 3 Mission.
],
),
struggle: [
- In a moment of dire need, you're suddenly serious and competent. Roll 3d Escape and 1d Calamity.
- Work towards escape with frantic energy or gallows humour. Roll 2d Escape and 3d Calamity. You can make this move as many times as it takes.
],
)
#upb.development[
- Illustrate one of your Traits after you've introduced it
- Let one of your Directives get you in trouble
- Incorporate a trait of the Setting, Mission, or Threat
- Incorporate a trait from one of your comrades
]
|
|
https://github.com/AsiSkarp/grotesk-cv
|
https://raw.githubusercontent.com/AsiSkarp/grotesk-cv/main/src/lib.typ
|
typst
|
The Unlicense
|
#import "@preview/fontawesome:0.4.0": *
#let section-title-style(str, color) = {
text(
size: 12pt,
weight: "bold",
fill: rgb(color),
str,
)
}
#let name-block(
header-name,
color,
) = {
text(
fill: rgb(color),
size: 30pt,
weight: "extrabold",
header-name,
)
}
#let title-block(
title,
color,
) = {
text(
size: 12pt,
style: "italic",
fill: rgb(color),
title,
)
}
#let info-block-style(
icon,
txt,
color,
include-icons,
) = {
text(
size: 10pt,
fill: rgb(color),
weight: "medium",
if include-icons {
fa-icon(icon) + h(10pt) + txt
} else {
txt
},
)
}
#let info-block(
metadata,
) = {
let info = metadata.personal.info
let icons = metadata.personal.icon
let color = metadata.layout.text.color.medium
let include-icons = metadata.personal.include_icons
table(
columns: (1fr, 1fr),
stroke: none,
..info.pairs().map(((key, val)) => info-block-style(icons.at(key), val, color, include-icons))
)
}
#let header-table(
metadata,
) = {
let lang = metadata.personal.language
let subtitle = metadata.language.at(lang).at("subtitle")
table(
columns: 1fr,
inset: 0pt,
stroke: none,
row-gutter: 4mm,
[#name-block(metadata.personal.first_name + " " + metadata.personal.last_name, metadata.layout.text.color.dark)],
[#title-block(
subtitle,
metadata.layout.text.color.dark,
)],
[#info-block(metadata)],
)
}
#let cover-header-table(
metadata,
) = {
let lang = metadata.personal.language
let subtitle = metadata.language.at(lang).at("subtitle")
table(
columns: 1fr,
inset: 0pt,
stroke: none,
row-gutter: 4mm,
[#name-block(metadata.personal.first_name + " " + metadata.personal.last_name, metadata.layout.text.color.dark)],
[#title-block(
subtitle,
metadata.layout.text.color.dark,
)],
)
}
#let make-header-photo(
photo,
profile-photo,
) = {
if profile-photo != false {
box(
clip: true,
radius: 50%,
photo,
)
} else {
box(
clip: true,
stroke: 5pt + yellow,
radius: 50%,
fill: yellow,
)
}
}
#let cv-header(left-comp, right-comp, cols, align) = {
table(
columns: cols,
inset: 0pt,
stroke: none,
column-gutter: 10pt,
align: top,
{
left-comp
},
{
right-comp
}
)
}
#let make-info-table(
metadata,
) = {
let color = metadata.layout.text.color.medium
let info = metadata.personal.info
let icons = metadata.personal.icon
let include-icons = metadata.personal.include_icons
table(
columns: 1fr,
align: right,
stroke: none,
..info.pairs().map(((key, val)) => info-block-style(icons.at(key), val, color, include-icons))
)
}
#let create-header(
metadata,
photo,
use-photo: false,
) = {
cv-header(
header-table(metadata),
make-header-photo(photo, use-photo),
(74%, 20%),
left,
)
}
#let create-cover-header(
metadata,
) = {
cv-header(
cover-header-table(metadata),
make-info-table(metadata),
(65%, 30%),
left,
)
}
#let cv-section(title) = {
section-title-style(title)
h(4pt)
}
#let date-style(date) = (
table.cell(
align: right,
text(
size: 9pt,
weight: "bold",
style: "italic",
date,
),
)
)
#let company-name-style(company) = {
table.cell(
align: right,
text(
size: 9pt,
weight: "bold",
style: "italic",
company,
),
)
}
#let degree-style(degree) = (
text(
weight: "bold",
degree,
)
)
#let reference-name-style(name) = (
text(
weight: "bold",
name,
)
)
#let phonenumber-style(phone) = (
text(
size: 9pt,
style: "italic",
weight: "medium",
phone,
)
)
#let institution-style(institution) = (
table.cell(
text(
style: "italic",
weight: "medium",
institution,
),
)
)
#let location-style(location) = (
table.cell(
text(
style: "italic",
weight: "medium",
location,
),
)
)
#let email-style(email) = (
text(
size: 9pt,
style: "italic",
weight: "medium",
email,
)
)
#let tag-style(str) = {
align(
right,
text(
weight: "regular",
str,
),
)
}
#let tag-list-style(color, tags) = {
for tag in tags {
box(
inset: (x: 0.4em),
outset: (y: 0.3em),
fill: rgb(color),
radius: 3pt,
tag-style(tag),
)
h(5pt)
}
}
#let profile-entry(str) = {
text(
size: text-size,
weight: "medium",
str,
)
}
#let reference-entry(
name: "Name",
title: "Title",
company: "Company",
telephone: "Telephone",
email: "Email",
) = {
table(
columns: (3fr, 2fr),
inset: 0pt,
stroke: none,
row-gutter: 3mm,
[#reference-name-style(name)],
[#company-name-style(company)],
table.cell(colspan: 2)[#phonenumber-style(telephone), #email-style(email)],
)
v(2pt)
}
#let education-entry(
degree: "Degree",
date: "Date",
institution: "Institution",
location: "Location",
description: "",
highlights: (),
) = {
table(
columns: (3fr, 1fr),
inset: 0pt,
stroke: none,
row-gutter: 3mm,
[#degree-style(degree)], [#date-style(date)],
[#institution-style(institution), #location-style(location)],
)
v(2pt)
}
#let experience-entry(
title: "Title",
date: "Date",
company: "Company",
location: "Location",
) = {
table(
columns: (1fr, 1fr),
inset: 0pt,
stroke: none,
row-gutter: 3mm,
[#degree-style(title)] ,
[#date-style(date)],
table.cell(colspan: 2)[#institution-style(company), #location-style(location)],
)
v(5pt)
}
#let skill-style(skill) = {
text(
weight: "bold",
skill,
)
}
#let skill-tag(color, skill) = {
box(
inset: (x: 0.3em),
outset: (y: 0.2em),
fill: rgb(color),
radius: 3pt,
skill-style(skill),
)
}
#let skill-entry(
color,
skills: (),
) = {
table(
columns: 1fr,
inset: 0pt,
stroke: none,
row-gutter: 2mm,
column-gutter: 3mm,
align: center,
for sk in skills {
[#skill-tag(color, sk) #h(4pt)]
},
)
}
#let language-entry(
language: "Language",
proficiency: "Proficiency",
) = {
table(
columns: (1fr, 1fr),
inset: 0pt,
stroke: none,
row-gutter: 3mm,
align: left,
table.cell(
text(
weight: "bold",
language,
),
),
table.cell(
align: right,
text(
weight: "medium",
proficiency,
),
)
)
}
#let recipient-style(str) = {
text(
style: "italic",
str,
)
}
#let recipient-entry(
name: "Name",
title: "Title",
company: "Company",
address: "Address",
city: "City",
) = {
table(
columns: 1fr,
inset: 0pt,
stroke: none,
row-gutter: 3mm,
align: left,
recipient-style(name),
recipient-style(title),
recipient-style(company),
recipient-style(address),
)
}
#let create-panes(left, right, proportion) = {
grid(
columns: (proportion, 96% - proportion),
column-gutter: 20pt,
stack(
spacing: 20pt,
left,
),
stack(
spacing: 20pt,
right,
),
)
}
#let cv(
metadata,
photo: "",
use-photo: false,
left-pane: (),
right-pane: (),
left-pane-proportion: 71%,
doc,
) = {
set text(
fill: rgb(metadata.layout.text.color.dark),
font: metadata.layout.text.font,
size: eval(metadata.layout.text.size),
)
set align(left)
set page(
fill: rgb(metadata.layout.fill_color),
paper: metadata.layout.paper_size,
margin: (
left: 1.2cm,
right: 1.2cm,
top: 1.6cm,
bottom: 1.2cm,
),
)
set list(marker: [‣])
create-header(metadata, photo, use-photo: use-photo)
create-panes(left-pane, right-pane, left-pane-proportion)
doc
}
#let cover-letter(
metadata,
doc,
) = {
set text(
fill: rgb(metadata.layout.text.color.dark),
font: metadata.layout.text.font,
size: eval(metadata.layout.text.size),
)
set align(left)
set page(
fill: rgb(metadata.layout.fill_color),
paper: metadata.layout.paper_size,
margin: (
left: 1.2cm,
right: 1.2cm,
top: 1.6cm,
bottom: 1.2cm,
),
)
set list(marker: [‣])
create-cover-header(metadata)
doc
}
|
https://github.com/Quaternijkon/Typst_Lab_Report
|
https://raw.githubusercontent.com/Quaternijkon/Typst_Lab_Report/main/lib.typ
|
typst
|
#import "@preview/codly:0.2.1": *
#import "@preview/i-figured:0.2.4"
#import "@preview/pintorita:0.1.1"
#import "@preview/gentle-clues:0.8.0": *
#import "@preview/cheq:0.1.0": checklist
#import "@preview/unify:0.6.0": num, qty, numrange, qtyrange
#import "@preview/mitex:0.2.4" : *
#import "@preview/showybox:2.0.1": *
#import "@preview/cuti:0.2.1": show-cn-fakebold
|
|
https://github.com/AlvaroRamirez01/Analisis_de_Algoritmos_2024-1
|
https://raw.githubusercontent.com/AlvaroRamirez01/Analisis_de_Algoritmos_2024-1/master/Tarea_01_Problemas_y_Algoritmos/conf.typ
|
typst
|
#let conf(
materia: none,
tarea: none,
profesor: (nombre: none, sexo: none),
ayudantes: (),
alumnos: (),
fecha: datetime.today(),
encabezado: "Contenidos",
bibliografia: (enable: true, path: "biblio.bib"),
doc,
) = {
set text(font: "Noto Serif")
set heading(numbering: "1.1.")
set page(
margin: (x: 1.56cm,),
header: locate(loc =>
if loc.page() != 1 {
let header = style(styles => {
let header-text = {
materia + h(1fr)
tarea + h(1fr)
datetime.today()
.display("[day]/[month]/[year]")
}
let measures = measure(header-text, styles)
header-text + v(-0.65em)
line(length: 100%)
})
header
}
),
footer: {
set align(center)
line(length: 100%)
v(-0.65em)
counter(page).display(
(n, m) => [ Página #n de #m ],
both: true,
)
},
)
let header = {
line(length: 100%)
grid(
columns: (1fr, 3fr, 1fr),
gutter: 5pt,
rows: 14em,
image("imgs/fc.svg"),
[
#set align(horizon)
#text(20pt)[*#materia*]\
#text(18pt)[*#tarea*]\
#text(14pt)[
#let (nombre, sexo) = profesor
#if sexo == "M" {
[*Profesor:* #nombre]
} else if sexo == "F" {
[*Profesora:* #nombre]
} else {
[*Profesor(a):* #nombre]
}
]\
#text(12pt)[
#if ayudantes.len() == 1 {
[*Ayudante:* #ayudantes.first()]
} else {
let l = (none,) * ayudantes.len()
[
//*Ayudantes:* #ayudantes.join(", ")
#box(
baseline: 100% - 0.65em,
grid(
columns: 2,
gutter: 0.65em,
[*Ayudantes:*],
..l.zip(ayudantes).flatten().slice(1),
)
)
]
}
]\
#text(12pt)[
#alumnos.fold(none, (inc, alumno) => [
#inc
*Nombre*: #alumno.at("nombre")\
*N°. de Cuenta.*: #alumno.at("cuenta")\
*Correo*: #alumno.at("email")\
])
]\
],
image("imgs/unam.svg"),
)
line(length: 100%)
}
v(-2em)
header
set align(left)
// let texto-integrantes = {
// if alumnos.len() == 1 {
// [
// = Alumno
// La Tarea fue realizada por:\
// ]
// } else {
// [
// = Integrantes
// Los integrantes de la tarea son:\
// ]
// }
// }
[
// = #encabezado
#doc
// #pagebreak()
// #texto-integrantes
// #alumnos.fold(none, (inc, alumno) => [
// #inc
// - *Nombre*: #alumno.at("nombre")
// - *Num. de Cta.*: #alumno.at("cuenta")
// - *Correo*: #alumno.at("email")
// ])
]
/* if bibliografia.at("enable") {
show bibliography: set heading(numbering: "1.")
bibliography(
bibliografia.at("path"),
title: "Bibliografía",
)
} */
}
#let pregunta(titulo, body) = {
set heading(
level: 2,
supplement: [Pregunta],
)
heading(titulo)
body
}
#let solucion(color: black, body) = {
set block(
fill: color.lighten(90%),
inset: 5pt,
radius: 5pt,
stroke: 2pt + color,
width: 100%,
)
block[
#move(
dx: -3pt, dy: -3pt,
rect(
fill: color,
radius: (top-left: 3pt, bottom-right: 3pt),
stroke: 3pt + color,
)[
#set text(14pt, white)
*Solución:*
]
)
#body
]
}
|
|
https://github.com/dantevi-other/kththesis-typst
|
https://raw.githubusercontent.com/dantevi-other/kththesis-typst/main/utils/content-stylers.typ
|
typst
|
MIT License
|
/* ---------------------------------------------
This file conatains functions that are meant to
modify the style of content (i.e., that which is
within a `[]`).
Example:
```typ
#import "utils/content-stylers.typ" as cs
#cs.font-size-0[This text will get a font size 0.]
```
--------------------------------------------- */
//-- Font sizers
#import "values.typ" as values
#let font-size-0(it) = [
#set text(
size: values.font-size-0
)
#it
]
#let font-size-1(it) = [
#set text(
size: values.font-size-1
)
#it
]
#let font-size-2(it) = [
#set text(
size: values.font-size-2
)
#it
]
#let font-size-3(it) = [
#set text(
size: values.font-size-3
)
#it
]
|
https://github.com/pedrofp4444/BD
|
https://raw.githubusercontent.com/pedrofp4444/BD/main/report/content/[3] Modelação Concetual/main.typ
|
typst
|
#import "abordagem.typ": abordagem
#import "entidades.typ": entidades
#import "relacionamentos.typ": relacionamentos
#import "caracterização.typ": caracterização
#import "diagrama.typ": diagrama
#let concetual = {
[
= Modelação Concetual
#abordagem
#entidades
#relacionamentos
#caracterização
#diagrama
]
}
|
|
https://github.com/akshaybabloo/CV
|
https://raw.githubusercontent.com/akshaybabloo/CV/master/cv.typ
|
typst
|
MIT License
|
#import "resume.typ": section, data
#include "resume.typ"
#{
set text(font: "Roboto", size: 9pt, fallback: true)
if "languages" in data {
section("Languages")
for language in data.languages {
[ / #language.language: #language.fluency ]
}
}
if "projects" in data {
section("Projects")
for project in data.projects {
[ / #project.name: #project.description ]
}
}
if "publications" in data {
section("Publications")
for publication in data.publications {
[ / #publication.name: #publication.description ]
}
}
if "awards" in data {
section("Awards")
for award in data.awards {
[ / #award.title: #award.awarded ]
}
}
}
|
https://github.com/Myriad-Dreamin/typst.ts
|
https://raw.githubusercontent.com/Myriad-Dreamin/typst.ts/main/fuzzers/corpora/meta/footnote-refs_01.typ
|
typst
|
Apache License 2.0
|
#import "/contrib/templates/std-tests/preset.typ": *
#show: test-page
// Multiple footnotes are refs
First #footnote[A]<fn1> \
Second #footnote[B]<fn2> \
First ref @fn1 \
Third #footnote[C] \
Fourth #footnote[D]<fn4> \
Fourth ref @fn4 \
Second ref @fn2 \
Second ref again @fn2
|
https://github.com/darioglasl/Arbeiten-Vorlage-Typst
|
https://raw.githubusercontent.com/darioglasl/Arbeiten-Vorlage-Typst/main/05_Qualitätssicherung/04_validierung_nfr.typ
|
typst
|
#import "../Helpers/nfr-data.typ": nfrScenarios
== Validierung von NFRs <headingNfrValidation>>
Die Validation der Non Functional Requirements ist durch die Entwickler und den Review Prozess sichergestellt.
Die nicht funktionalen Anforderungen sind in @headingNfrs beschrieben.
Folgende Tabellen beschreiben den abschliessenden Status der NFRs.
#let n = 0
#while n < nfrScenarios.len() {
let number = n + 1
let title = if n < 10 {
[NFR-0#number]
} else {
[NFR-#number]
}
figure(
table(
columns: (16%, 84%),
inset: (x: 5pt, y: 4pt),
align: left,
fill: (_, row) => if calc.odd(row) { luma(225) } else { white },
[*ID*], [*#title* #nfrScenarios.at(n).titel],
[Anforderung], [#nfrScenarios.at(n).anforderung],
[Level], [#nfrScenarios.at(n).level],
[Status], [*#nfrScenarios.at(n).status*],
[Begründung], [#nfrScenarios.at(n).begründung],
),
caption: [Validierung #title #nfrScenarios.at(n).anforderung],
)
n = n + 1
}
|
|
https://github.com/AntoineCorbel/typst
|
https://raw.githubusercontent.com/AntoineCorbel/typst/main/main.typ
|
typst
|
#import "template.typ": *
#import "typst-boxes.typ": *
#import "info-box.typ": *
// Take a look at the file `template.typ` in the file panel
// to customize this template and discover how it works.
#show: project.with(
title: "Semi-conducteur HPGe, diverses informations",
authors: (
(name: "<NAME>", email: "<EMAIL>"),
),
date: "16 juin 2023",
)
#set math.equation(numbering: "(1)")
#set heading(numbering: "1.")
//==================================================================
// Typing MirionLogo will show the logo in the pdf
#show "Logo": name => box[
#box(image(
"Logo.png",
width: 1em,
))
#name // to show the name after the logo, can be disabled.
]
#let GD(body) = {
set text(fill: red)
[
*GD:* #body
]
}
#let MM(body) = {
set text(fill: orange)
[
*MM:* #body
]
}
// We generated the example code below so you can see how
// your document will look. Go ahead and replace it with
// your own content!
= Introduction
Je vais dans cet article parler des différentes propriétés du HPGe, mais plus globalement des semi-conducteurs. En effet, leurs propriétés sont clés dans la spectrométrie gamma, que ce soit en physique nucléaire ou bien en physique des hautes énergies.
== Création d'un cristal de germanium
#figure(
image("hpge_growth.svg", width: 60%),
caption: [Processus de création d'un cristal HPGe à partir de germanium liquide @HPGeGrowth]
) <fig:HPGe>
On utilise pour créer un cristal pur, un petit morceau de cristal dont l'axe $<100>$ du réseau cristallin est orienté comme on le souhaite. On vient plonger ce morceau dans le germanium liquide, puis le retirer très lentement ($~ "mm/h"$). A son contact, le germanium liquide va se solidifier, formant une tige dont le réseau cristallin suit la même orientation que le _Seed Cristal_ visible en @fig:HPGe[Fig.]
== Le fonctionnement des semi-conducteurs
Il est important de passer par cette étape pour bien comprendre comment les semi-conducteurs sont utiles à la physique, et bien plus.
Un semi-conducteur est un matériau qui peut avoir des les propriétés d'un conducteur électrique, ou bien d'un isolant, et ce en fonction de sa température. _Mais comment cela fonctionne ?_ Il s'agit en fait de la structure atomique du matériau directement qui lui apporte ces propriétés.
Pour illustrer un peu ces mots, on peut se référer à la figure @bandes ci-dessous.
#figure(
image("SCBandes.jpg", width: 50%),
caption: [Structure en bandes d'un semi-conducteur @MaxicoursBandes]
) <bandes>
== Le dopage
Cette méthode consiste à ajouter des impuretés dans le matériau dans le but de modifier ses propriétés de conductivité. Par exemple, le HPGe utilisé pour AGATA est de type N.
Voici une rapide description des types de dopage existant.
+ #underline[Le type N]
- Il consiste à ajouter dans le semi-conducteur des atomes donneurs d'électrons. Ces derniers vont ainsi augmenter la densité électronique du matériau, le rendant plus *négativement chargé*. (@dopages, schéma de gauche)
+ #underline[Le type P]
- A l'inverse, ce dernier consiste à ajouter des atomes receveurs d'électrons dans le semi-conducteur. Les impuretés captureront alors des électrons, laissant une densité de trous plus importante, trous *chargés positivement*. (@dopages, schéma de droite)
Il est également possible de réaliser les deux types de dopage simultanément, cela ayant pour but d'augmenter encore plus la conductivité du semi-conducteur.
#figure(
grid(
columns: 2,
column-gutter: 1mm,
image("N-doped_Si.png", width: 70%),
image("P-doped_Si.png", width: 70%),
),
caption: [Représentation d'un réseau cristallin dopé de type N (gauche) et de type P (droite). L'électron que l'on voit libre à gauche étant très peu lié aux atomes, il pourra facilement passer vers la bande de conduction, d'où une conductivité accrue dans le semi-conducteur @dopageWikipedia]
) <dopages>
== Jonction PN
Il s'agit d'une zone du cristal dans laquelle le dopage varie brusquement, passant d'un dopage p à un dopage n. Lorsque la jonction p est mise en contact avec la région n, les électrons et les trous diffusent spontanément de part et d'autre de la jonction, créant ainsi *une zone de déplétion* @Bonnaud2006 (également appelée zone de charge d'espace (ZCE)). La jonction ne laisse quasiment pas passer le courant. La largeur de la zone de déplétion varie avec la tension appliquée de part et d'autre de la jonction @jonctionpnWikipedia.
Cette zone de déplétion ne comporte plus de charges libres, car les paires électron/trou se sont recombinées suite à la diffusion évoquée dans le paragraphe précédent.
== Pourquoi AGATA a des HPGe de type N et pas P ?
Pour la collaboration AGATA, les détecteurs sont faits en germanium ultra-pur (HPGe). Ces derniers sont de type N. Les détecteurs AGATA étant des coaxiaux, on peut calculer le rayon $R_c$ tel que pour l'aire intérieure $cal(A)_("int")$, on ait $cal(A)_("int") = cal(A)_("tot") / 2 = cal(A)_("ext")$ avec $cal(A)_("tot")$ l'aire totale de notre coax pris en vue du haut et $cal(A)_("ext")$ l'aire extérieure, entre $R_c$ et $R_("tot")$.
#figure(
image("coax.png", width: 50%),
caption: [
Représentation schématique d'un détecteur coaxial vu du dessus, avec deux cercles concentriques d'aires $cal(A)_("int")$ et $cal(A)_("ext")$ égales.
],
) <coax>
On peut effectuer un rapide calcul en prenant l'hypothèse d'un coax sans trou central, juste pour avoir une idée approximative de la valeur de $R_c$ par rapport à $R_("tot")$:
On veut $ R_c "tel que" cal(A)_("int") = cal(A)_("ext") = cal(A)_("tot") / 2 = (pi R_("tot")^2) / 2 $
Or $ cal(A)_("int") = pi R_c^2 $
On a donc l'égalité $ cal(A)_("int") = cal(A)_("tot") / 2 <==> pi R_c^2 = (pi R_("tot")^2) / 2 $
D'où $ R_c = R_("tot") / sqrt(2) $
/*Pour $R_("tot") = 8 "cm"$, cela donne $R_c = 5.65 "cm"$, soit 70 % de $R_("tot")$ à l'intérieur de $R_c$ et 30 % de $R_("tot")$ à l'extérieur de $R_c$.*/
#colorbox(
title: "'Rayon d'équilibre' pour un détecteur coaxial",
color: "red",
radius: 1pt,
width: auto
)[
Pour un détecteur coaxial dont on néglige le trou central, le rayon $R_c$ pour lequel il y a autant de surface à l'intérieur qu'à l'extérieur du cercle de rayon $R_c$ est
$ R_c = R_("tot") / sqrt(2) approx 0.707 dot R_("tot") $
avec $R_("tot")$ le rayon total du détecteur coaxial. La distance entre le centre du détecteur et $R_c$ est donc $approx 2.3$ fois plus importante que la distance $abs(R_c - R_("tot"))$
]
Les interactions ayant en moyenne lieu à $R = R_c$, si l'on prend en considération que les trous ont une plus grande probabilité de se faire piéger suite à des dommages neutroniques, il faut limiter au plus leur parcours lors de la collecte des charges, ce qui revient à les collecter sur les bords extérieurs du coax. C'est la raison pour laquelle on a mis sur le trou central un contact (+), créant un champ électrique $arrow(E)$, dirigé vers la terre.
Les électrons vont alors remonter ce champ électrique, et les trous le suivre. *Leur parcours moyen sera donc plus faible que celui des électrons, limitant au maximum leur piégeage.* Pour donner un ordre de grandeur, les détecteurs de type P sont environ 10 fois plus sensibles aux dommages neutrons que les types N (#text(blue, "info Gilbert")).
#bibliography("bibliography.bib")
|
|
https://github.com/soul667/typst
|
https://raw.githubusercontent.com/soul667/typst/main/PPT/typst-slides-fudan/themes/polylux/book/src/dynamic/rule-array.typ
|
typst
|
#import "../../../polylux.typ": *
#set page(paper: "presentation-16-9")
#set text(size: 30pt)
#polylux-slide[
#uncover((1, 2, 4))[uncovered only on subslides 1, 2, and 4]
]
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.