
url
stringlengths 61
61
| repository_url
stringclasses 1
value | labels_url
stringlengths 75
75
| comments_url
stringlengths 70
70
| events_url
stringlengths 68
68
| html_url
stringlengths 49
51
| id
int64 1.12B
1.61B
| node_id
stringlengths 18
19
| number
int64 3.68k
5.61k
| title
stringlengths 1
290
| user
dict | labels
list | state
stringclasses 2
values | locked
bool 1
class | assignee
dict | assignees
list | milestone
dict | comments
list | created_at
timestamp[s] | updated_at
timestamp[s] | closed_at
timestamp[s] | author_association
stringclasses 3
values | active_lock_reason
null | draft
bool 2
classes | pull_request
dict | body
stringlengths 2
33.9k
⌀ | reactions
dict | timeline_url
stringlengths 70
70
| performed_via_github_app
null | state_reason
stringclasses 3
values | is_pull_request
bool 2
classes |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/datasets/issues/5100
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5100/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5100/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5100/events
|
https://github.com/huggingface/datasets/issues/5100
| 1,404,458,586 |
I_kwDODunzps5TtlZa
| 5,100 |
datasets[s3] sagemaker can't run a model - datasets issue with Value and ClassLabel and cast() method
|
{
"login": "jagochi",
"id": 115545475,
"node_id": "U_kgDOBuMVgw",
"avatar_url": "https://avatars.githubusercontent.com/u/115545475?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jagochi",
"html_url": "https://github.com/jagochi",
"followers_url": "https://api.github.com/users/jagochi/followers",
"following_url": "https://api.github.com/users/jagochi/following{/other_user}",
"gists_url": "https://api.github.com/users/jagochi/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jagochi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jagochi/subscriptions",
"organizations_url": "https://api.github.com/users/jagochi/orgs",
"repos_url": "https://api.github.com/users/jagochi/repos",
"events_url": "https://api.github.com/users/jagochi/events{/privacy}",
"received_events_url": "https://api.github.com/users/jagochi/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[] | 2022-10-11T11:16:31 | 2022-10-11T13:48:26 | 2022-10-11T13:48:26 |
NONE
| null | null | null | null |
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/5100/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/5100/timeline
| null |
completed
| false |
https://api.github.com/repos/huggingface/datasets/issues/5099
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5099/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5099/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5099/events
|
https://github.com/huggingface/datasets/issues/5099
| 1,404,370,191 |
I_kwDODunzps5TtP0P
| 5,099 |
datasets doesn't support # in data paths
|
{
"login": "loubnabnl",
"id": 44069155,
"node_id": "MDQ6VXNlcjQ0MDY5MTU1",
"avatar_url": "https://avatars.githubusercontent.com/u/44069155?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/loubnabnl",
"html_url": "https://github.com/loubnabnl",
"followers_url": "https://api.github.com/users/loubnabnl/followers",
"following_url": "https://api.github.com/users/loubnabnl/following{/other_user}",
"gists_url": "https://api.github.com/users/loubnabnl/gists{/gist_id}",
"starred_url": "https://api.github.com/users/loubnabnl/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/loubnabnl/subscriptions",
"organizations_url": "https://api.github.com/users/loubnabnl/orgs",
"repos_url": "https://api.github.com/users/loubnabnl/repos",
"events_url": "https://api.github.com/users/loubnabnl/events{/privacy}",
"received_events_url": "https://api.github.com/users/loubnabnl/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
},
{
"id": 1935892877,
"node_id": "MDU6TGFiZWwxOTM1ODkyODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/good%20first%20issue",
"name": "good first issue",
"color": "7057ff",
"default": true,
"description": "Good for newcomers"
},
{
"id": 4614514401,
"node_id": "LA_kwDODunzps8AAAABEwvm4Q",
"url": "https://api.github.com/repos/huggingface/datasets/labels/hacktoberfest",
"name": "hacktoberfest",
"color": "DF8D62",
"default": false,
"description": ""
}
] |
closed
| false |
{
"login": "riccardobucco",
"id": 9295277,
"node_id": "MDQ6VXNlcjkyOTUyNzc=",
"avatar_url": "https://avatars.githubusercontent.com/u/9295277?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/riccardobucco",
"html_url": "https://github.com/riccardobucco",
"followers_url": "https://api.github.com/users/riccardobucco/followers",
"following_url": "https://api.github.com/users/riccardobucco/following{/other_user}",
"gists_url": "https://api.github.com/users/riccardobucco/gists{/gist_id}",
"starred_url": "https://api.github.com/users/riccardobucco/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/riccardobucco/subscriptions",
"organizations_url": "https://api.github.com/users/riccardobucco/orgs",
"repos_url": "https://api.github.com/users/riccardobucco/repos",
"events_url": "https://api.github.com/users/riccardobucco/events{/privacy}",
"received_events_url": "https://api.github.com/users/riccardobucco/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"login": "riccardobucco",
"id": 9295277,
"node_id": "MDQ6VXNlcjkyOTUyNzc=",
"avatar_url": "https://avatars.githubusercontent.com/u/9295277?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/riccardobucco",
"html_url": "https://github.com/riccardobucco",
"followers_url": "https://api.github.com/users/riccardobucco/followers",
"following_url": "https://api.github.com/users/riccardobucco/following{/other_user}",
"gists_url": "https://api.github.com/users/riccardobucco/gists{/gist_id}",
"starred_url": "https://api.github.com/users/riccardobucco/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/riccardobucco/subscriptions",
"organizations_url": "https://api.github.com/users/riccardobucco/orgs",
"repos_url": "https://api.github.com/users/riccardobucco/repos",
"events_url": "https://api.github.com/users/riccardobucco/events{/privacy}",
"received_events_url": "https://api.github.com/users/riccardobucco/received_events",
"type": "User",
"site_admin": false
}
] | null |
[
"`datasets` doesn't seem to urlencode the directory names here\r\n\r\nhttps://github.com/huggingface/datasets/blob/7feeb5648a63b6135a8259dedc3b1e19185ee4c7/src/datasets/utils/file_utils.py#L109-L111\r\n\r\nfor example we should have\r\n```python\r\nfrom datasets.utils.file_utils import hf_hub_url\r\n\r\nurl = hf_hub_url(\"loubnabnl/bigcode_csharp\", \"data/c#/data_0003.jsonl\")\r\nprint(url)\r\n# Currently returns\r\n# https://huggingface.co/datasets/loubnabnl/bigcode_csharp/resolve/main/data/c#/data_0003.jsonl\r\n# while it should be \r\n# https://huggingface.co/datasets/loubnabnl/bigcode_csharp/resolve/main/data/c%23/data_0003.jsonl\r\n```",
"I'll work on this :)",
"@loubnabnl The dataset you linked in the description of the bug does not work and returns a 404. Where can I find the dataset to reproduce the bug?",
"I think you can create a dataset repository on the Hub with a dummy file containing a `#`",
"Ah sorry it was private I just made it public, I can also help with this if needed",
"@lhoestq Should I url encode also repo_id and revision parameters? I'm not sure what are the valid characters there.\r\n\r\nPersonally, I would be cautious and only url encode the path parameter.",
"These are possible solutions (assuming `from urllib.parse import quote`):\r\n\r\n1) url encode only the path parameter:\r\n```\r\n# src/datasets/utils/file_utils.py\r\ndef hf_hub_url(repo_id: str, path: str, revision: Optional[str] = None) -> str:\r\n revision = revision or config.HUB_DEFAULT_VERSION\r\n return config.HUB_DATASETS_URL.format(repo_id=repo_id, path=quote(path), revision=revision)\r\n```\r\n2) url encode all parameters:\r\n```\r\n# src/datasets/utils/file_utils.py\r\ndef hf_hub_url(repo_id: str, path: str, revision: Optional[str] = None) -> str:\r\n revision = revision or config.HUB_DEFAULT_VERSION\r\n return config.HUB_DATASETS_URL.format(repo_id=quote(repo_id), path=quote(path), revision=quote(revision))\r\n```\r\n3) url encode the whole url:\r\n```\r\n# src/datasets/config.py\r\nHUB_DATASETS_PATH = \"/datasets/{repo_id}/resolve/{revision}/{path}\"\r\nHUB_DATASETS_URL = HF_ENDPOINT + HUB_DATASETS_PATH\r\n```\r\n```\r\n# src/datasets/utils/file_utils.py\r\ndef hf_hub_url(repo_id: str, path: str, revision: Optional[str] = None) -> str:\r\n revision = revision or config.HUB_DEFAULT_VERSION\r\n return config.HF_ENDPOINT + quote(config.HUB_DATASETS_PATH.format(repo_id=repo_id, path=path, revision=revision))\r\n```",
"repo_id can only contain alphanumeric characters and _- so it doesn't need to be encoded.\r\n\r\nHowever I agree it's a good idea to also apply `quote` to the revision as well as in 2. !",
"Should be fixed by https://github.com/huggingface/datasets/issues/5099 - we'll do a release later today"
] | 2022-10-11T10:05:32 | 2022-10-13T13:14:20 | 2022-10-13T13:14:20 |
NONE
| null | null | null |
## Describe the bug
dataset files with `#` symbol their paths aren't read correctly.
## Steps to reproduce the bug
The data in folder `c#`of this [dataset](https://huggingface.co/datasets/loubnabnl/bigcode_csharp) can't be loaded. While the folder `c_sharp` with the same data is loaded properly
```python
ds = load_dataset('loubnabnl/bigcode_csharp', split="train", data_files=["data/c#/*"])
```
```
FileNotFoundError: Couldn't find file at https://huggingface.co/datasets/loubnabnl/bigcode_csharp/resolve/27a3166cff4bb18e11919cafa6f169c0f57483de/data/c#/data_0003.jsonl
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 2.5.2
- Platform: macOS-12.2.1-arm64-arm-64bit
- Python version: 3.9.13
- PyArrow version: 9.0.0
- Pandas version: 1.4.3
cc @lhoestq
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/5099/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/5099/timeline
| null |
completed
| false |
https://api.github.com/repos/huggingface/datasets/issues/5098
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5098/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5098/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5098/events
|
https://github.com/huggingface/datasets/issues/5098
| 1,404,058,518 |
I_kwDODunzps5TsDuW
| 5,098 |
Classes label error when loading symbolic links using imagefolder
|
{
"login": "horizon86",
"id": 49552732,
"node_id": "MDQ6VXNlcjQ5NTUyNzMy",
"avatar_url": "https://avatars.githubusercontent.com/u/49552732?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/horizon86",
"html_url": "https://github.com/horizon86",
"followers_url": "https://api.github.com/users/horizon86/followers",
"following_url": "https://api.github.com/users/horizon86/following{/other_user}",
"gists_url": "https://api.github.com/users/horizon86/gists{/gist_id}",
"starred_url": "https://api.github.com/users/horizon86/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/horizon86/subscriptions",
"organizations_url": "https://api.github.com/users/horizon86/orgs",
"repos_url": "https://api.github.com/users/horizon86/repos",
"events_url": "https://api.github.com/users/horizon86/events{/privacy}",
"received_events_url": "https://api.github.com/users/horizon86/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
},
{
"id": 1935892877,
"node_id": "MDU6TGFiZWwxOTM1ODkyODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/good%20first%20issue",
"name": "good first issue",
"color": "7057ff",
"default": true,
"description": "Good for newcomers"
},
{
"id": 4614514401,
"node_id": "LA_kwDODunzps8AAAABEwvm4Q",
"url": "https://api.github.com/repos/huggingface/datasets/labels/hacktoberfest",
"name": "hacktoberfest",
"color": "DF8D62",
"default": false,
"description": ""
}
] |
closed
| false |
{
"login": "riccardobucco",
"id": 9295277,
"node_id": "MDQ6VXNlcjkyOTUyNzc=",
"avatar_url": "https://avatars.githubusercontent.com/u/9295277?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/riccardobucco",
"html_url": "https://github.com/riccardobucco",
"followers_url": "https://api.github.com/users/riccardobucco/followers",
"following_url": "https://api.github.com/users/riccardobucco/following{/other_user}",
"gists_url": "https://api.github.com/users/riccardobucco/gists{/gist_id}",
"starred_url": "https://api.github.com/users/riccardobucco/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/riccardobucco/subscriptions",
"organizations_url": "https://api.github.com/users/riccardobucco/orgs",
"repos_url": "https://api.github.com/users/riccardobucco/repos",
"events_url": "https://api.github.com/users/riccardobucco/events{/privacy}",
"received_events_url": "https://api.github.com/users/riccardobucco/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"login": "riccardobucco",
"id": 9295277,
"node_id": "MDQ6VXNlcjkyOTUyNzc=",
"avatar_url": "https://avatars.githubusercontent.com/u/9295277?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/riccardobucco",
"html_url": "https://github.com/riccardobucco",
"followers_url": "https://api.github.com/users/riccardobucco/followers",
"following_url": "https://api.github.com/users/riccardobucco/following{/other_user}",
"gists_url": "https://api.github.com/users/riccardobucco/gists{/gist_id}",
"starred_url": "https://api.github.com/users/riccardobucco/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/riccardobucco/subscriptions",
"organizations_url": "https://api.github.com/users/riccardobucco/orgs",
"repos_url": "https://api.github.com/users/riccardobucco/repos",
"events_url": "https://api.github.com/users/riccardobucco/events{/privacy}",
"received_events_url": "https://api.github.com/users/riccardobucco/received_events",
"type": "User",
"site_admin": false
}
] | null |
[
"It can be solved temporarily by remove `resolve` in \r\nhttps://github.com/huggingface/datasets/blob/bef23be3d9543b1ca2da87ab2f05070201044ddc/src/datasets/data_files.py#L278",
"Hi, thanks for reporting and suggesting a fix! We still need to account for `.`/`..` in the file path, so a more robust fix would be `Path(os.path.abspath(filepath))`.",
"> Hi, thanks for reporting and suggesting a fix! We still need to account for `.`/`..` in the file path, so a more robust fix would be `Path(os.path.abspath(filepath))`.\r\n\r\nThanks for your reply!"
] | 2022-10-11T06:10:58 | 2022-11-14T14:40:20 | 2022-11-14T14:40:20 |
NONE
| null | null | null |
**Is your feature request related to a problem? Please describe.**
Like this: #4015
When there are **symbolic links** to pictures in the data folder, the parent folder name of the **real file** will be used as the class name instead of the parent folder of the symbolic link itself. Can you give an option to decide whether to enable symbolic link tracking?
This is inconsistent with the `torchvision.datasets.ImageFolder` behavior.
For example:
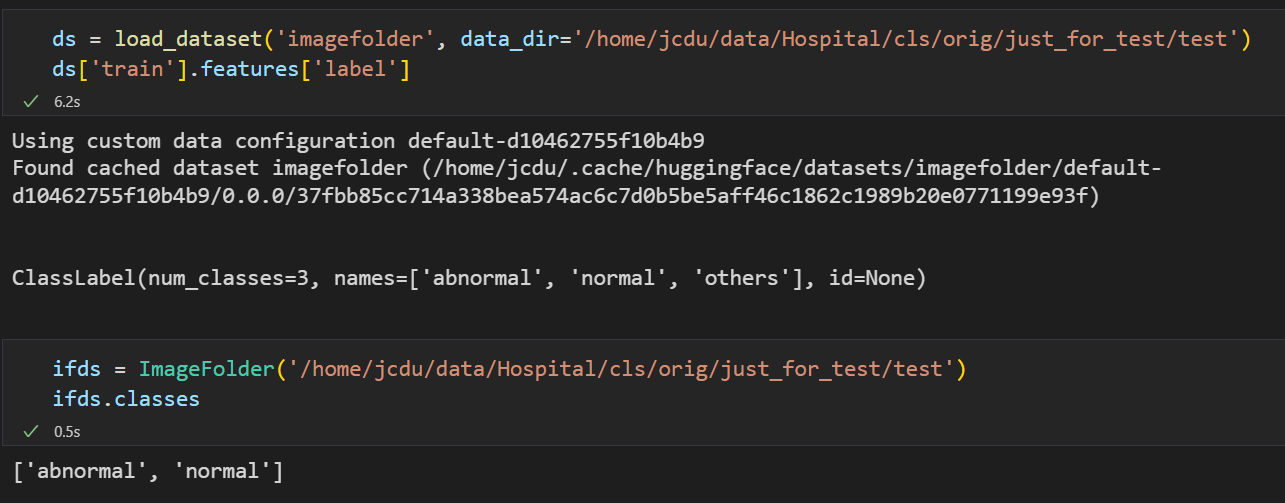

It use `others` in green circle as class label but not `abnormal`, I wish `load_dataset` not use the real file parent as label.
**Describe the solution you'd like**
A clear and concise description of what you want to happen.
**Describe alternatives you've considered**
A clear and concise description of any alternative solutions or features you've considered.
**Additional context**
Add any other context about the feature request here.
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/5098/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/5098/timeline
| null |
completed
| false |
https://api.github.com/repos/huggingface/datasets/issues/5097
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5097/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5097/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5097/events
|
https://github.com/huggingface/datasets/issues/5097
| 1,403,679,353 |
I_kwDODunzps5TqnJ5
| 5,097 |
Fatal error with pyarrow/libarrow.so
|
{
"login": "catalys1",
"id": 11340846,
"node_id": "MDQ6VXNlcjExMzQwODQ2",
"avatar_url": "https://avatars.githubusercontent.com/u/11340846?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/catalys1",
"html_url": "https://github.com/catalys1",
"followers_url": "https://api.github.com/users/catalys1/followers",
"following_url": "https://api.github.com/users/catalys1/following{/other_user}",
"gists_url": "https://api.github.com/users/catalys1/gists{/gist_id}",
"starred_url": "https://api.github.com/users/catalys1/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/catalys1/subscriptions",
"organizations_url": "https://api.github.com/users/catalys1/orgs",
"repos_url": "https://api.github.com/users/catalys1/repos",
"events_url": "https://api.github.com/users/catalys1/events{/privacy}",
"received_events_url": "https://api.github.com/users/catalys1/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] |
closed
| false | null |
[] | null |
[
"Thanks for reporting, @catalys1.\r\n\r\nThis seems a duplicate of:\r\n- #3310 \r\n\r\nThe source of the problem is in PyArrow:\r\n- [ARROW-15141: [C++] Fatal error condition occurred in aws_thread_launch](https://issues.apache.org/jira/browse/ARROW-15141)\r\n- [ARROW-17501: [C++] Fatal error condition occurred in aws_thread_launch](https://issues.apache.org/jira/browse/ARROW-17501)\r\n\r\nThe bug in their dependency is still unresolved:\r\n- https://github.com/aws/aws-sdk-cpp/issues/1809\r\n\r\nApparently, the `aws-sdk-cpp` PyArrow dependency needs to be pinned at version `1.8.186` if using conda. Have you updated it after installing PyArrow?\r\n```shell\r\nconda list aws-sdk-cpp\r\n```\r\n\r\nMaybe you should try to downgrade it to that version:\r\n```shell\r\nconda install -c conda-forge aws-sdk-cpp=1.8.186\r\n```"
] | 2022-10-10T20:29:04 | 2022-10-11T06:56:01 | 2022-10-11T06:56:00 |
NONE
| null | null | null |
## Describe the bug
When using datasets, at the very end of my jobs the program crashes (see trace below).
It doesn't seem to affect anything, as it appears to happen as the program is closing down. Just importing `datasets` is enough to cause the error.
## Steps to reproduce the bug
This is sufficient to reproduce the problem:
```bash
python -c "import datasets"
```
## Expected results
Program should run to completion without an error.
## Actual results
```bash
Fatal error condition occurred in /opt/vcpkg/buildtrees/aws-c-io/src/9e6648842a-364b708815.clean/source/event_loop.c:72: aws_thread_launch(&cleanup_thread, s_event_loop_destroy_async_thread_fn, el_group, &thread_options) == AWS_OP_SUCCESS
Exiting Application
################################################################################
Stack trace:
################################################################################
/u/user/miniconda3/envs/env/lib/python3.10/site-packages/pyarrow/libarrow.so.900(+0x200af06) [0x150dff547f06]
/u/user/miniconda3/envs/env/lib/python3.10/site-packages/pyarrow/libarrow.so.900(+0x20028e5) [0x150dff53f8e5]
/u/user/miniconda3/envs/env/lib/python3.10/site-packages/pyarrow/libarrow.so.900(+0x1f27e09) [0x150dff464e09]
/u/user/miniconda3/envs/env/lib/python3.10/site-packages/pyarrow/libarrow.so.900(+0x200ba3d) [0x150dff548a3d]
/u/user/miniconda3/envs/env/lib/python3.10/site-packages/pyarrow/libarrow.so.900(+0x1f25948) [0x150dff462948]
/u/user/miniconda3/envs/env/lib/python3.10/site-packages/pyarrow/libarrow.so.900(+0x200ba3d) [0x150dff548a3d]
/u/user/miniconda3/envs/env/lib/python3.10/site-packages/pyarrow/libarrow.so.900(+0x1ee0b46) [0x150dff41db46]
/u/user/miniconda3/envs/env/lib/python3.10/site-packages/pyarrow/libarrow.so.900(+0x194546a) [0x150dfee8246a]
/lib64/libc.so.6(+0x39b0c) [0x150e15eadb0c]
/lib64/libc.so.6(on_exit+0) [0x150e15eadc40]
/u/user/miniconda3/envs/env/bin/python(+0x28db18) [0x560ae370eb18]
/u/user/miniconda3/envs/env/bin/python(+0x28db4b) [0x560ae370eb4b]
/u/user/miniconda3/envs/env/bin/python(+0x28db90) [0x560ae370eb90]
/u/user/miniconda3/envs/env/bin/python(_PyRun_SimpleFileObject+0x1e6) [0x560ae37123e6]
/u/user/miniconda3/envs/env/bin/python(_PyRun_AnyFileObject+0x44) [0x560ae37124c4]
/u/user/miniconda3/envs/env/bin/python(Py_RunMain+0x35d) [0x560ae37135bd]
/u/user/miniconda3/envs/env/bin/python(Py_BytesMain+0x39) [0x560ae37137d9]
/lib64/libc.so.6(__libc_start_main+0xf3) [0x150e15e97493]
/u/user/miniconda3/envs/env/bin/python(+0x2125d4) [0x560ae36935d4]
Aborted (core dumped)
```
## Environment info
- `datasets` version: 2.5.1
- Platform: Linux-4.18.0-348.23.1.el8_5.x86_64-x86_64-with-glibc2.28
- Python version: 3.10.4
- PyArrow version: 9.0.0
- Pandas version: 1.4.3
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/5097/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/5097/timeline
| null |
completed
| false |
https://api.github.com/repos/huggingface/datasets/issues/5096
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5096/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5096/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5096/events
|
https://github.com/huggingface/datasets/issues/5096
| 1,403,379,816 |
I_kwDODunzps5TpeBo
| 5,096 |
Transfer some canonical datasets under an organization namespace
|
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 4564477500,
"node_id": "LA_kwDODunzps8AAAABEBBmPA",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20contribution",
"name": "dataset contribution",
"color": "0e8a16",
"default": false,
"description": "Contribution to a dataset script"
}
] |
open
| false |
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
}
] | null |
[
"The transfer of the dummy dataset to the dummy org works as expected:\r\n```python\r\nIn [1]: from datasets import load_dataset; ds = load_dataset(\"dummy_canonical_dataset\", download_mode=\"force_redownload\"); ds\r\nDownloading builder script: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2.98k/2.98k [00:00<00:00, 2.01MB/s]\r\nDownloading and preparing dataset dummy_canonical_dataset/default (download: 411 bytes, generated: 385 bytes, post-processed: Unknown size, total: 796 bytes) to .../.cache/huggingface/datasets/dummy_canonical_dataset/default/1.0.0/100870c358637e269fee140585e61e1472d5075a9bf6f866719934c725e55fb4...\r\nDownloading data: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 411/411 [00:00<00:00, 293kB/s]\r\nDataset dummy_canonical_dataset downloaded and prepared to .../.cache/huggingface/datasets/dummy_canonical_dataset/default/1.0.0/100870c358637e269fee140585e61e1472d5075a9bf6f866719934c725e55fb4. Subsequent calls will reuse this data.\r\n100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 304.16it/s]\r\nOut[1]: \r\nDatasetDict({\r\n train: Dataset({\r\n features: ['langs', 'ner_tags', 'tokens'],\r\n num_rows: 3\r\n })\r\n})\r\n\r\nIn [2]: from datasets import load_dataset; ds = load_dataset(\"dummy-canonical-org/dummy_canonical_dataset\"); ds\r\nDownloading builder script: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2.98k/2.98k [00:00<00:00, 1.57MB/s]\r\nDownloading and preparing dataset dummy_canonical_dataset/default to .../.cache/huggingface/datasets/dummy-canonical-org___dummy_canonical_dataset/default/1.0.0/100870c358637e269fee140585e61e1472d5075a9bf6f866719934c725e55fb4...\r\nDataset dummy_canonical_dataset downloaded and prepared to .../.cache/huggingface/datasets/dummy-canonical-org___dummy_canonical_dataset/default/1.0.0/100870c358637e269fee140585e61e1472d5075a9bf6f866719934c725e55fb4. Subsequent calls will reuse this data.\r\n100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 362.48it/s]\r\nOut[2]: \r\nDatasetDict({\r\n train: Dataset({\r\n features: ['langs', 'ner_tags', 'tokens'],\r\n num_rows: 3\r\n })\r\n})\r\n```",
"Cool ! 🚀 "
] | 2022-10-10T15:44:31 | 2023-02-17T15:33:18 | null |
MEMBER
| null | null | null |
As discussed during our @huggingface/datasets meeting, we are planning to move some "canonical" dataset scripts under their corresponding organization namespace (if this does not exist).
On the contrary, if the dataset already exists under the organization namespace, we are deprecating the canonical one (and eventually delete it).
First, we should test it using a dummy dataset/organization.
TODO:
- [x] Test with a dummy dataset
- [x] Create dummy canonical dataset: https://huggingface.co/datasets/dummy_canonical_dataset
- [x] Create dummy organization: https://huggingface.co/dummy-canonical-org
- [x] Transfer dummy canonical dataset to dummy organization
- [ ] Transfer datasets
- [x] cord19 => allenai
- [x] emotion => dair-ai
- [ ] gem => GEM
- [x] indonlu => indonlp
- [ ] multilingual_librispeech => facebook
- It already exists "facebook/multilingual_librispeech"
- [ ] oscar => oscar-corpus
- [x] peer_read => allenai
- [x] qasper => allenai
- [x] s2orc => allenai
- [x] scicite => allenai
- [x] scifact => allenai
- [x] scitldr => allenai
- [x] swiss_judgment_prediction => rcds
- [ ] wmt14, wmt15, wmt16, wmt17, wmt18, wmt19,... => wmt
- ...
EDIT: the list above is continuously being updated
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/5096/reactions",
"total_count": 2,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 2,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/5096/timeline
| null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5095
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5095/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5095/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5095/events
|
https://github.com/huggingface/datasets/pull/5095
| 1,403,221,408 |
PR_kwDODunzps5Afzsq
| 5,095 |
Fix tutorial (#5093)
|
{
"login": "riccardobucco",
"id": 9295277,
"node_id": "MDQ6VXNlcjkyOTUyNzc=",
"avatar_url": "https://avatars.githubusercontent.com/u/9295277?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/riccardobucco",
"html_url": "https://github.com/riccardobucco",
"followers_url": "https://api.github.com/users/riccardobucco/followers",
"following_url": "https://api.github.com/users/riccardobucco/following{/other_user}",
"gists_url": "https://api.github.com/users/riccardobucco/gists{/gist_id}",
"starred_url": "https://api.github.com/users/riccardobucco/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/riccardobucco/subscriptions",
"organizations_url": "https://api.github.com/users/riccardobucco/orgs",
"repos_url": "https://api.github.com/users/riccardobucco/repos",
"events_url": "https://api.github.com/users/riccardobucco/events{/privacy}",
"received_events_url": "https://api.github.com/users/riccardobucco/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"Oops I merged without linking to the hacktoberfest issue - not sure if it counts in this case\r\n\r\nsorry about that..\r\n\r\nNext time you can just mention \"Close #XXXX\" in your issue to link it",
"It should :) (the `hacktoberfest` repo topic is all that matters)"
] | 2022-10-10T13:55:15 | 2022-10-10T17:50:52 | 2022-10-10T15:32:20 |
CONTRIBUTOR
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5095",
"html_url": "https://github.com/huggingface/datasets/pull/5095",
"diff_url": "https://github.com/huggingface/datasets/pull/5095.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5095.patch",
"merged_at": "2022-10-10T15:32:20"
}
|
Close #5093
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/5095/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/5095/timeline
| null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5094
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5094/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5094/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5094/events
|
https://github.com/huggingface/datasets/issues/5094
| 1,403,214,950 |
I_kwDODunzps5To1xm
| 5,094 |
Multiprocessing with `Dataset.map` and `PyTorch` results in deadlock
|
{
"login": "RR-28023",
"id": 36822895,
"node_id": "MDQ6VXNlcjM2ODIyODk1",
"avatar_url": "https://avatars.githubusercontent.com/u/36822895?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/RR-28023",
"html_url": "https://github.com/RR-28023",
"followers_url": "https://api.github.com/users/RR-28023/followers",
"following_url": "https://api.github.com/users/RR-28023/following{/other_user}",
"gists_url": "https://api.github.com/users/RR-28023/gists{/gist_id}",
"starred_url": "https://api.github.com/users/RR-28023/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/RR-28023/subscriptions",
"organizations_url": "https://api.github.com/users/RR-28023/orgs",
"repos_url": "https://api.github.com/users/RR-28023/repos",
"events_url": "https://api.github.com/users/RR-28023/events{/privacy}",
"received_events_url": "https://api.github.com/users/RR-28023/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] |
open
| false | null |
[] | null |
[
"Hi ! Could it be an Out of Memory issue that could have killed one of the processes ? can you check your memory ?",
"Hi! I don't think it is a memory issue. I'm monitoring the main and spawn python processes and threads with `htop` and the memory does not peak. Besides, the example I've posted above should not be that demanding in terms of memory, right? (I have 32GB of RAM). ",
"Indeed it should be fine. I couldn't reproduce the error though - I ran your script on my side and it works fine. What version of pytorch are you using ?",
"Interesting.. I'm using `torch 1.12.1`",
"I also tried on colab and it works fine 🤔 \r\nMaybe something is wrong with your installation of pytorch ?",
"Oh actually I just saw that you're using python 3.9\r\n\r\nThis could be related to https://github.com/huggingface/datasets/issues/4113\r\n\r\nWe'll fix that as soon as we can, in the meantime you can try to use use single process, or use an older version of python maybe ?",
"I tried with python 3.7 and the issue persists. In collab, which also uses 3.7 I don't get the issue, so yes I guess is something on mu side... will post it here if I manage to fix it",
"Hi! Which version of transformers are you using? I test the code on Colab (so python 3.7) with transformers 4.23.1, torch 1.12.1 and pyarrow 9.0.0 (also 6.x), it worked without stuck."
] | 2022-10-10T13:50:56 | 2022-10-18T16:18:53 | null |
NONE
| null | null | null |
## Describe the bug
There seems to be an issue with using multiprocessing with `datasets.Dataset.map` (i.e. setting `num_proc` to a value greater than one) combined with a function that uses `torch` under the hood. The subprocesses that `datasets.Dataset.map` spawns [a this step](https://github.com/huggingface/datasets/blob/1b935dab9d2f171a8c6294269421fe967eb55e34/src/datasets/arrow_dataset.py#L2663) go into wait mode forever.
## Steps to reproduce the bug
The below code goes into deadlock when `NUMBER_OF_PROCESSES` is greater than one.
```python
NUMBER_OF_PROCESSES = 2
from transformers import AutoTokenizer, AutoModel
from datasets import load_dataset
dataset = load_dataset("glue", "mrpc", split="train")
tokenizer = AutoTokenizer.from_pretrained("sentence-transformers/all-MiniLM-L6-v2")
model = AutoModel.from_pretrained("sentence-transformers/all-MiniLM-L6-v2")
model.to("cpu")
def cls_pooling(model_output):
return model_output.last_hidden_state[:, 0]
def generate_embeddings_batched(examples):
sentences_batch = list(examples['sentence1'])
encoded_input = tokenizer(
sentences_batch, padding=True, truncation=True, return_tensors="pt"
)
encoded_input = {k: v.to("cpu") for k, v in encoded_input.items()}
model_output = model(**encoded_input)
embeddings = cls_pooling(model_output)
examples['embeddings'] = embeddings.detach().cpu().numpy() # 64, 384
return examples
embeddings_dataset = dataset.map(
generate_embeddings_batched,
batched=True,
batch_size=10,
num_proc=NUMBER_OF_PROCESSES
)
```
While debugging it I've seen that it gets "stuck" when calling `torch.nn.Embedding.forward` but some testing shows that the same happens with other functions from `torch.nn`.
## Environment info
- Platform: Linux-5.14.0-1052-oem-x86_64-with-glibc2.31
- Python version: 3.9.14
- PyArrow version: 9.0.0
- Pandas version: 1.5.0
Not sure if this is a HF problem, a PyTorch problem or something I'm doing wrong..
Thanks!
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/5094/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/5094/timeline
| null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5093
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5093/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5093/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5093/events
|
https://github.com/huggingface/datasets/issues/5093
| 1,402,939,660 |
I_kwDODunzps5TnykM
| 5,093 |
Mismatch between tutoriel and doc
|
{
"login": "clefourrier",
"id": 22726840,
"node_id": "MDQ6VXNlcjIyNzI2ODQw",
"avatar_url": "https://avatars.githubusercontent.com/u/22726840?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/clefourrier",
"html_url": "https://github.com/clefourrier",
"followers_url": "https://api.github.com/users/clefourrier/followers",
"following_url": "https://api.github.com/users/clefourrier/following{/other_user}",
"gists_url": "https://api.github.com/users/clefourrier/gists{/gist_id}",
"starred_url": "https://api.github.com/users/clefourrier/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/clefourrier/subscriptions",
"organizations_url": "https://api.github.com/users/clefourrier/orgs",
"repos_url": "https://api.github.com/users/clefourrier/repos",
"events_url": "https://api.github.com/users/clefourrier/events{/privacy}",
"received_events_url": "https://api.github.com/users/clefourrier/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
},
{
"id": 1935892877,
"node_id": "MDU6TGFiZWwxOTM1ODkyODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/good%20first%20issue",
"name": "good first issue",
"color": "7057ff",
"default": true,
"description": "Good for newcomers"
},
{
"id": 4614514401,
"node_id": "LA_kwDODunzps8AAAABEwvm4Q",
"url": "https://api.github.com/repos/huggingface/datasets/labels/hacktoberfest",
"name": "hacktoberfest",
"color": "DF8D62",
"default": false,
"description": ""
}
] |
closed
| false |
{
"login": "riccardobucco",
"id": 9295277,
"node_id": "MDQ6VXNlcjkyOTUyNzc=",
"avatar_url": "https://avatars.githubusercontent.com/u/9295277?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/riccardobucco",
"html_url": "https://github.com/riccardobucco",
"followers_url": "https://api.github.com/users/riccardobucco/followers",
"following_url": "https://api.github.com/users/riccardobucco/following{/other_user}",
"gists_url": "https://api.github.com/users/riccardobucco/gists{/gist_id}",
"starred_url": "https://api.github.com/users/riccardobucco/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/riccardobucco/subscriptions",
"organizations_url": "https://api.github.com/users/riccardobucco/orgs",
"repos_url": "https://api.github.com/users/riccardobucco/repos",
"events_url": "https://api.github.com/users/riccardobucco/events{/privacy}",
"received_events_url": "https://api.github.com/users/riccardobucco/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"login": "riccardobucco",
"id": 9295277,
"node_id": "MDQ6VXNlcjkyOTUyNzc=",
"avatar_url": "https://avatars.githubusercontent.com/u/9295277?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/riccardobucco",
"html_url": "https://github.com/riccardobucco",
"followers_url": "https://api.github.com/users/riccardobucco/followers",
"following_url": "https://api.github.com/users/riccardobucco/following{/other_user}",
"gists_url": "https://api.github.com/users/riccardobucco/gists{/gist_id}",
"starred_url": "https://api.github.com/users/riccardobucco/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/riccardobucco/subscriptions",
"organizations_url": "https://api.github.com/users/riccardobucco/orgs",
"repos_url": "https://api.github.com/users/riccardobucco/repos",
"events_url": "https://api.github.com/users/riccardobucco/events{/privacy}",
"received_events_url": "https://api.github.com/users/riccardobucco/received_events",
"type": "User",
"site_admin": false
}
] | null |
[
"Hi, thanks for reporting! This line should be replaced with \r\n```python\r\ndataset = dataset.map(lambda examples: tokenizer(examples[\"text\"], return_tensors=\"np\"), batched=True)\r\n```\r\nfor it to work (the `return_tensors` part inside the `tokenizer` call).",
"Can I work on this?",
"Fixed in https://github.com/huggingface/datasets/pull/5095"
] | 2022-10-10T10:23:53 | 2022-10-10T17:51:15 | 2022-10-10T17:51:14 |
CONTRIBUTOR
| null | null | null |
## Describe the bug
In the "Process text data" tutorial, [`map` has `return_tensors` as kwarg](https://huggingface.co/docs/datasets/main/en/nlp_process#map). It does not seem to appear in the [function documentation](https://huggingface.co/docs/datasets/main/en/package_reference/main_classes#datasets.Dataset.map), nor to work.
## Steps to reproduce the bug
MWE:
```python
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
from datasets import load_dataset
dataset = load_dataset("lhoestq/demo1", split="train")
dataset = dataset.map(lambda examples: tokenizer(examples["review"]), batched=True, return_tensors="pt")
```
## Expected results
return_tensors to be a valid kwarg :smiley:
## Actual results
```python
>> TypeError: map() got an unexpected keyword argument 'return_tensors'
```
## Environment info
- `datasets` version: 2.3.2
- Platform: Linux-5.14.0-1052-oem-x86_64-with-glibc2.29
- Python version: 3.8.10
- PyArrow version: 8.0.0
- Pandas version: 1.4.3
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/5093/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/5093/timeline
| null |
completed
| false |
https://api.github.com/repos/huggingface/datasets/issues/5092
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5092/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5092/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5092/events
|
https://github.com/huggingface/datasets/pull/5092
| 1,402,713,517 |
PR_kwDODunzps5AeIsS
| 5,092 |
Use HTML relative paths for tiles in the docs
|
{
"login": "lewtun",
"id": 26859204,
"node_id": "MDQ6VXNlcjI2ODU5MjA0",
"avatar_url": "https://avatars.githubusercontent.com/u/26859204?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lewtun",
"html_url": "https://github.com/lewtun",
"followers_url": "https://api.github.com/users/lewtun/followers",
"following_url": "https://api.github.com/users/lewtun/following{/other_user}",
"gists_url": "https://api.github.com/users/lewtun/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lewtun/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lewtun/subscriptions",
"organizations_url": "https://api.github.com/users/lewtun/orgs",
"repos_url": "https://api.github.com/users/lewtun/repos",
"events_url": "https://api.github.com/users/lewtun/events{/privacy}",
"received_events_url": "https://api.github.com/users/lewtun/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"> Good catch, @lewtun. Thanks for the fix.\r\n> \r\n> Do you know if there are other absolute paths in the docs that should be fixed as well?\r\n\r\nI found a few more in [0d4796b](https://github.com/huggingface/datasets/pull/5092/commits/0d4796b747e6620d9fcc17a8f74acc5cf4bba7be).\r\n\r\nHowever, I noticed that none of the cross-references (e.g. to API classes / methods) work locally, but that is probably just a limitation of the local build",
"Thanks."
] | 2022-10-10T07:24:27 | 2022-10-11T13:25:45 | 2022-10-11T13:23:23 |
MEMBER
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5092",
"html_url": "https://github.com/huggingface/datasets/pull/5092",
"diff_url": "https://github.com/huggingface/datasets/pull/5092.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5092.patch",
"merged_at": "2022-10-11T13:23:23"
}
|
This PR replaces the absolute paths in the landing page tiles with relative ones so that one can test navigation both locally in and in future PRs (see [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5084/en/index) for an example PR where the links don't work).
I encountered this while working on the `optimum` docs and figured I'd fix it elsewhere too :)
Internal Slack thread: https://huggingface.slack.com/archives/C02GLJ5S0E9/p1665129710176619
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/5092/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/5092/timeline
| null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5091
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5091/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5091/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5091/events
|
https://github.com/huggingface/datasets/pull/5091
| 1,401,112,552 |
PR_kwDODunzps5AZCm9
| 5,091 |
Allow connection objects in `from_sql` + small doc improvement
|
{
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-10-07T12:39:44 | 2022-10-09T13:19:15 | 2022-10-09T13:16:57 |
CONTRIBUTOR
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5091",
"html_url": "https://github.com/huggingface/datasets/pull/5091",
"diff_url": "https://github.com/huggingface/datasets/pull/5091.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5091.patch",
"merged_at": "2022-10-09T13:16:57"
}
|
Allow connection objects in `from_sql` (emit a warning that they are cachable) and add a tip that explains the format of the con parameter when provided as a URI string.
PS: ~~This PR contains a parameter link, so https://github.com/huggingface/doc-builder/pull/311 needs to be merged before it's "ready for review".~~ Done!
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/5091/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/5091/timeline
| null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5090
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5090/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5090/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5090/events
|
https://github.com/huggingface/datasets/issues/5090
| 1,401,102,407 |
I_kwDODunzps5TgyBH
| 5,090 |
Review sync issues from GitHub to Hub
|
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] |
closed
| false |
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
}
] | null |
[
"Nice!!"
] | 2022-10-07T12:31:56 | 2022-10-08T07:07:36 | 2022-10-08T07:07:36 |
MEMBER
| null | null | null |
## Describe the bug
We have discovered that sometimes there were sync issues between GitHub and Hub datasets, after a merge commit to main branch.
For example:
- this merge commit: https://github.com/huggingface/datasets/commit/d74a9e8e4bfff1fed03a4cab99180a841d7caf4b
- was not properly synced with the Hub: https://github.com/huggingface/datasets/actions/runs/3002495269/jobs/4819769684
```
[main 9e641de] Add Papers with Code ID to scifact dataset (#4941)
Author: Albert Villanova del Moral <[email protected]>
1 file changed, 42 insertions(+), 14 deletions(-)
push failed !
GitCommandError(['git', 'push'], 1, b'remote: ---------------------------------------------------------- \nremote: Sorry, your push was rejected during YAML metadata verification: \nremote: - Error: "license" does not match any of the allowed types \nremote: ---------------------------------------------------------- \nremote: Please find the documentation at: \nremote: https://huggingface.co/docs/hub/models-cards#model-card-metadata \nremote: ---------------------------------------------------------- \nTo [https://huggingface.co/datasets/scifact.git\n](https://huggingface.co/datasets/scifact.git/n) ! [remote rejected] main -> main (pre-receive hook declined)\nerror: failed to push some refs to \'[https://huggingface.co/datasets/scifact.git\](https://huggingface.co/datasets/scifact.git/)'', b'')
```
We are reviewing sync issues in previous commits to recover them and repushing to the Hub.
TODO: Review
- [x] #4941
- scifact
- [x] #4931
- scifact
- [x] #4753
- wikipedia
- [x] #4554
- wmt17, wmt19, wmt_t2t
- Fixed with "Release 2.4.0" commit: https://github.com/huggingface/datasets/commit/401d4c4f9b9594cb6527c599c0e7a72ce1a0ea49
- https://huggingface.co/datasets/wmt17/commit/5c0afa83fbbd3508ff7627c07f1b27756d1379ea
- https://huggingface.co/datasets/wmt19/commit/b8ad5bf1960208a376a0ab20bc8eac9638f7b400
- https://huggingface.co/datasets/wmt_t2t/commit/b6d67191804dd0933476fede36754a436b48d1fc
- [x] #4607
- [x] #4416
- lccc
- Fixed with "Release 2.3.0" commit: https://huggingface.co/datasets/lccc/commit/8b1f8cf425b5653a0a4357a53205aac82ce038d1
- [x] #4367
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/5090/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/5090/timeline
| null |
completed
| false |
https://api.github.com/repos/huggingface/datasets/issues/5089
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5089/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5089/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5089/events
|
https://github.com/huggingface/datasets/issues/5089
| 1,400,788,486 |
I_kwDODunzps5TflYG
| 5,089 |
Resume failed process
|
{
"login": "felix-schneider",
"id": 208336,
"node_id": "MDQ6VXNlcjIwODMzNg==",
"avatar_url": "https://avatars.githubusercontent.com/u/208336?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/felix-schneider",
"html_url": "https://github.com/felix-schneider",
"followers_url": "https://api.github.com/users/felix-schneider/followers",
"following_url": "https://api.github.com/users/felix-schneider/following{/other_user}",
"gists_url": "https://api.github.com/users/felix-schneider/gists{/gist_id}",
"starred_url": "https://api.github.com/users/felix-schneider/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/felix-schneider/subscriptions",
"organizations_url": "https://api.github.com/users/felix-schneider/orgs",
"repos_url": "https://api.github.com/users/felix-schneider/repos",
"events_url": "https://api.github.com/users/felix-schneider/events{/privacy}",
"received_events_url": "https://api.github.com/users/felix-schneider/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] |
open
| false | null |
[] | null |
[] | 2022-10-07T08:07:03 | 2022-10-07T08:07:03 | null |
NONE
| null | null | null |
**Is your feature request related to a problem? Please describe.**
When a process (`map`, `filter`, etc.) crashes part-way through, you lose all progress.
**Describe the solution you'd like**
It would be good if the cache reflected the partial progress, so that after we restart the script, the process can restart where it left off.
**Describe alternatives you've considered**
Doing processing outside of `datasets`, by writing the dataset to json files and building a restart mechanism myself.
**Additional context**
N/A
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/5089/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/5089/timeline
| null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5088
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5088/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5088/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5088/events
|
https://github.com/huggingface/datasets/issues/5088
| 1,400,530,412 |
I_kwDODunzps5TemXs
| 5,088 |
load_datasets("json", ...) don't read local .json.gz properly
|
{
"login": "junwang-wish",
"id": 112650299,
"node_id": "U_kgDOBrboOw",
"avatar_url": "https://avatars.githubusercontent.com/u/112650299?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/junwang-wish",
"html_url": "https://github.com/junwang-wish",
"followers_url": "https://api.github.com/users/junwang-wish/followers",
"following_url": "https://api.github.com/users/junwang-wish/following{/other_user}",
"gists_url": "https://api.github.com/users/junwang-wish/gists{/gist_id}",
"starred_url": "https://api.github.com/users/junwang-wish/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/junwang-wish/subscriptions",
"organizations_url": "https://api.github.com/users/junwang-wish/orgs",
"repos_url": "https://api.github.com/users/junwang-wish/repos",
"events_url": "https://api.github.com/users/junwang-wish/events{/privacy}",
"received_events_url": "https://api.github.com/users/junwang-wish/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] |
open
| false | null |
[] | null |
[
"Hi @junwang-wish, thanks for reporting.\r\n\r\nUnfortunately, I'm not able to reproduce the bug. Which version of `datasets` are you using? Does the problem persist if you update `datasets`?\r\n```shell\r\npip install -U datasets\r\n``` ",
"Thanks @albertvillanova I updated `datasets` from `2.5.1` to `2.5.2` and tested copying the `json.gz` to a different directory and my mind was blown:\r\n\r\n```python\r\nfpath = '/data/junwang/.cache/general/57b6f2314cbe0bc45dda5b78f0871df2/test.json.gz'\r\nds_panda = DatasetDict(\r\n test=Dataset.from_pandas(\r\n pd.read_json(fpath, lines=True)\r\n )\r\n)\r\nds_direct = load_dataset(\r\n 'json', data_files={\r\n 'test': fpath\r\n }, features=Features(\r\n text_input=Value(dtype=\"string\", id=None),\r\n text_output=Value(dtype=\"string\", id=None)\r\n )\r\n)\r\nlen(ds_panda['test']), len(ds_direct['test'])\r\n```\r\nproduces \r\n```python\r\nUsing custom data configuration default-0e6cf24134163e8b\r\nFound cached dataset json (/data/junwang/.cache/huggingface/datasets/json/default-0e6cf24134163e8b/0.0.0/e6070c77f18f01a5ad4551a8b7edfba20b8438b7cad4d94e6ad9378022ce4aab)\r\n(1, 0)\r\n```\r\nbut then I ran below command to see if the same file in a different directory leads to same discrepancy\r\n```shell\r\ncp /data/junwang/.cache/general/57b6f2314cbe0bc45dda5b78f0871df2/test.json.gz tmp_test.json.gz\r\n```\r\nand so I ran\r\n```python\r\nfpath = 'tmp_test.json.gz'\r\nds_panda = DatasetDict(\r\n test=Dataset.from_pandas(\r\n pd.read_json(fpath, lines=True)\r\n )\r\n)\r\nds_direct = load_dataset(\r\n 'json', data_files={\r\n 'test': fpath\r\n }, features=Features(\r\n text_input=Value(dtype=\"string\", id=None),\r\n text_output=Value(dtype=\"string\", id=None)\r\n )\r\n)\r\nlen(ds_panda['test']), len(ds_direct['test'])\r\n```\r\nand behold, I get \r\n```python\r\nUsing custom data configuration default-f679b32ab0008520\r\nDownloading and preparing dataset json/default to /data/junwang/.cache/huggingface/datasets/json/default-f679b32ab0008520/0.0.0/e6070c77f18f01a5ad4551a8b7edfba20b8438b7cad4d94e6ad9378022ce4aab...\r\nDataset json downloaded and prepared to /data/junwang/.cache/huggingface/datasets/json/default-f679b32ab0008520/0.0.0/e6070c77f18f01a5ad4551a8b7edfba20b8438b7cad4d94e6ad9378022ce4aab. Subsequent calls will reuse this data.\r\n(1, 1)\r\n```\r\nThey match now !\r\n\r\nThis problem happens regardless of the shell I use (VScode jupyter extension or plain old Python REPL). \r\n\r\nI attached the `json.gz` here for reference: [test.json.gz](https://github.com/huggingface/datasets/files/9734843/test.json.gz)\r\n\r\n"
] | 2022-10-07T02:16:58 | 2022-10-07T14:43:16 | null |
NONE
| null | null | null |
## Describe the bug
I have a local file `*.json.gz` and it can be read by `pandas.read_json(lines=True)`, but cannot be read by `load_datasets("json")` (resulting in 0 lines)
## Steps to reproduce the bug
```python
fpath = '/data/junwang/.cache/general/57b6f2314cbe0bc45dda5b78f0871df2/test.json.gz'
ds_panda = DatasetDict(
test=Dataset.from_pandas(
pd.read_json(fpath, lines=True)
)
)
ds_direct = load_dataset(
'json', data_files={
'test': fpath
}, features=Features(
text_input=Value(dtype="string", id=None),
text_output=Value(dtype="string", id=None)
)
)
len(ds_panda['test']), len(ds_direct['test'])
```
## Expected results
Lines of `ds_panda['test']` and `ds_direct['test']` should match.
## Actual results
```
Using custom data configuration default-c0ef2598760968aa
Downloading and preparing dataset json/default to /data/junwang/.cache/huggingface/datasets/json/default-c0ef2598760968aa/0.0.0/e6070c77f18f01a5ad4551a8b7edfba20b8438b7cad4d94e6ad9378022ce4aab...
Dataset json downloaded and prepared to /data/junwang/.cache/huggingface/datasets/json/default-c0ef2598760968aa/0.0.0/e6070c77f18f01a5ad4551a8b7edfba20b8438b7cad4d94e6ad9378022ce4aab. Subsequent calls will reuse this data.
(62087, 0)
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version:
- Platform: Ubuntu 18.04.4 LTS
- Python version: 3.8.13
- PyArrow version: 9.0.0
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/5088/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/5088/timeline
| null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5087
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5087/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5087/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5087/events
|
https://github.com/huggingface/datasets/pull/5087
| 1,400,487,967 |
PR_kwDODunzps5AW-N9
| 5,087 |
Fix filter with empty indices
|
{
"login": "Mouhanedg56",
"id": 23029765,
"node_id": "MDQ6VXNlcjIzMDI5NzY1",
"avatar_url": "https://avatars.githubusercontent.com/u/23029765?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Mouhanedg56",
"html_url": "https://github.com/Mouhanedg56",
"followers_url": "https://api.github.com/users/Mouhanedg56/followers",
"following_url": "https://api.github.com/users/Mouhanedg56/following{/other_user}",
"gists_url": "https://api.github.com/users/Mouhanedg56/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Mouhanedg56/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Mouhanedg56/subscriptions",
"organizations_url": "https://api.github.com/users/Mouhanedg56/orgs",
"repos_url": "https://api.github.com/users/Mouhanedg56/repos",
"events_url": "https://api.github.com/users/Mouhanedg56/events{/privacy}",
"received_events_url": "https://api.github.com/users/Mouhanedg56/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-10-07T01:07:00 | 2022-10-07T18:43:03 | 2022-10-07T18:40:26 |
CONTRIBUTOR
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5087",
"html_url": "https://github.com/huggingface/datasets/pull/5087",
"diff_url": "https://github.com/huggingface/datasets/pull/5087.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5087.patch",
"merged_at": "2022-10-07T18:40:26"
}
|
Fix #5085
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/5087/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/5087/timeline
| null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5086
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5086/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5086/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5086/events
|
https://github.com/huggingface/datasets/issues/5086
| 1,400,216,975 |
I_kwDODunzps5TdZ2P
| 5,086 |
HTTPError: 404 Client Error: Not Found for url
|
{
"login": "km5ar",
"id": 54015474,
"node_id": "MDQ6VXNlcjU0MDE1NDc0",
"avatar_url": "https://avatars.githubusercontent.com/u/54015474?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/km5ar",
"html_url": "https://github.com/km5ar",
"followers_url": "https://api.github.com/users/km5ar/followers",
"following_url": "https://api.github.com/users/km5ar/following{/other_user}",
"gists_url": "https://api.github.com/users/km5ar/gists{/gist_id}",
"starred_url": "https://api.github.com/users/km5ar/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/km5ar/subscriptions",
"organizations_url": "https://api.github.com/users/km5ar/orgs",
"repos_url": "https://api.github.com/users/km5ar/repos",
"events_url": "https://api.github.com/users/km5ar/events{/privacy}",
"received_events_url": "https://api.github.com/users/km5ar/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] |
closed
| false | null |
[] | null |
[
"FYI @lewtun ",
"Hi @km5ar, thanks for reporting.\r\n\r\nThis should be fixed in the notebook:\r\n- the filename `datasets-issues-with-hf-doc-builder.jsonl` no longer exists on the repo; instead, current filename is `datasets-issues-with-comments.jsonl`\r\n- see: https://huggingface.co/datasets/lewtun/github-issues/tree/main\r\n\r\nAnyway, depending on your version of `datasets`, you can now use:\r\n```python\r\nfrom datasets import load_dataset\r\n\r\nissues_dataset = load_dataset(\"lewtun/github-issues\")\r\nissues_dataset\r\n```\r\ninstead of:\r\n```python\r\nfrom huggingface_hub import hf_hub_url\r\n\r\ndata_files = hf_hub_url(\r\n repo_id=\"lewtun/github-issues\",\r\n filename=\"datasets-issues-with-hf-doc-builder.jsonl\",\r\n repo_type=\"dataset\",\r\n)\r\nfrom datasets import load_dataset\r\n\r\nissues_dataset = load_dataset(\"json\", data_files=data_files, split=\"train\")\r\nissues_dataset\r\n```\r\n\r\nOutput:\r\n```python\r\nIn [25]: ds = load_dataset(\"lewtun/github-issues\")\r\nDownloading: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 10.5k/10.5k [00:00<00:00, 5.75MB/s]\r\nUsing custom data configuration lewtun--github-issues-cff5093ecc410ea2\r\nDownloading and preparing dataset json/lewtun--github-issues to .../.cache/huggingface/datasets/lewtun___json/lewtun--github-issues-cff5093ecc410ea2/0.0.0/e6070c77f18f01a5ad4551a8b7edfba20b8438b7cad4d94e6ad9378022ce4aab...\r\nDownloading data: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 12.2M/12.2M [00:00<00:00, 26.5MB/s]\r\nDownloading data files: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:02<00:00, 2.70s/it]\r\nExtracting data files: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 1589.96it/s]\r\nDataset json downloaded and prepared to .../.cache/huggingface/datasets/lewtun___json/lewtun--github-issues-cff5093ecc410ea2/0.0.0/e6070c77f18f01a5ad4551a8b7edfba20b8438b7cad4d94e6ad9378022ce4aab. Subsequent calls will reuse this data.\r\n100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 133.95it/s]\r\n\r\nIn [26]: ds\r\nOut[26]: \r\nDatasetDict({\r\n train: Dataset({\r\n features: ['url', 'repository_url', 'labels_url', 'comments_url', 'events_url', 'html_url', 'id', 'node_id', 'number', 'title', 'user', 'labels', 'state', 'locked', 'assignee', 'assignees', 'milestone', 'comments', 'created_at', 'updated_at', 'closed_at', 'author_association', 'active_lock_reason', 'pull_request', 'body', 'timeline_url', 'performed_via_github_app', 'is_pull_request'],\r\n num_rows: 3019\r\n })\r\n})\r\n```",
"Thanks for reporting @km5ar and thank you @albertvillanova for the quick solution! I'll post a fix on the source too"
] | 2022-10-06T19:48:58 | 2022-10-07T15:12:01 | 2022-10-07T15:12:01 |
NONE
| null | null | null |
## Describe the bug
I was following chap 5 from huggingface course: https://huggingface.co/course/chapter5/6?fw=tf
However, I'm not able to download the datasets, with a 404 erros
<img width="1160" alt="iShot2022-10-06_15 54 50" src="https://user-images.githubusercontent.com/54015474/194406327-ae62c2f3-1da5-4686-8631-13d879a0edee.png">
## Steps to reproduce the bug
```python
from huggingface_hub import hf_hub_url
data_files = hf_hub_url(
repo_id="lewtun/github-issues",
filename="datasets-issues-with-hf-doc-builder.jsonl",
repo_type="dataset",
)
from datasets import load_dataset
issues_dataset = load_dataset("json", data_files=data_files, split="train")
issues_dataset
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 2.5.2
- Platform: macOS-10.16-x86_64-i386-64bit
- Python version: 3.9.12
- PyArrow version: 9.0.0
- Pandas version: 1.4.4
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/5086/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/5086/timeline
| null |
completed
| false |
https://api.github.com/repos/huggingface/datasets/issues/5085
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5085/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5085/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5085/events
|
https://github.com/huggingface/datasets/issues/5085
| 1,400,113,569 |
I_kwDODunzps5TdAmh
| 5,085 |
Filtering on an empty dataset returns a corrupted dataset.
|
{
"login": "gabegma",
"id": 36087158,
"node_id": "MDQ6VXNlcjM2MDg3MTU4",
"avatar_url": "https://avatars.githubusercontent.com/u/36087158?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gabegma",
"html_url": "https://github.com/gabegma",
"followers_url": "https://api.github.com/users/gabegma/followers",
"following_url": "https://api.github.com/users/gabegma/following{/other_user}",
"gists_url": "https://api.github.com/users/gabegma/gists{/gist_id}",
"starred_url": "https://api.github.com/users/gabegma/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gabegma/subscriptions",
"organizations_url": "https://api.github.com/users/gabegma/orgs",
"repos_url": "https://api.github.com/users/gabegma/repos",
"events_url": "https://api.github.com/users/gabegma/events{/privacy}",
"received_events_url": "https://api.github.com/users/gabegma/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
},
{
"id": 4614514401,
"node_id": "LA_kwDODunzps8AAAABEwvm4Q",
"url": "https://api.github.com/repos/huggingface/datasets/labels/hacktoberfest",
"name": "hacktoberfest",
"color": "DF8D62",
"default": false,
"description": ""
}
] |
closed
| false |
{
"login": "Mouhanedg56",
"id": 23029765,
"node_id": "MDQ6VXNlcjIzMDI5NzY1",
"avatar_url": "https://avatars.githubusercontent.com/u/23029765?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Mouhanedg56",
"html_url": "https://github.com/Mouhanedg56",
"followers_url": "https://api.github.com/users/Mouhanedg56/followers",
"following_url": "https://api.github.com/users/Mouhanedg56/following{/other_user}",
"gists_url": "https://api.github.com/users/Mouhanedg56/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Mouhanedg56/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Mouhanedg56/subscriptions",
"organizations_url": "https://api.github.com/users/Mouhanedg56/orgs",
"repos_url": "https://api.github.com/users/Mouhanedg56/repos",
"events_url": "https://api.github.com/users/Mouhanedg56/events{/privacy}",
"received_events_url": "https://api.github.com/users/Mouhanedg56/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"login": "Mouhanedg56",
"id": 23029765,
"node_id": "MDQ6VXNlcjIzMDI5NzY1",
"avatar_url": "https://avatars.githubusercontent.com/u/23029765?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Mouhanedg56",
"html_url": "https://github.com/Mouhanedg56",
"followers_url": "https://api.github.com/users/Mouhanedg56/followers",
"following_url": "https://api.github.com/users/Mouhanedg56/following{/other_user}",
"gists_url": "https://api.github.com/users/Mouhanedg56/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Mouhanedg56/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Mouhanedg56/subscriptions",
"organizations_url": "https://api.github.com/users/Mouhanedg56/orgs",
"repos_url": "https://api.github.com/users/Mouhanedg56/repos",
"events_url": "https://api.github.com/users/Mouhanedg56/events{/privacy}",
"received_events_url": "https://api.github.com/users/Mouhanedg56/received_events",
"type": "User",
"site_admin": false
}
] | null |
[
"~~It seems like #5043 fix (merged recently) is the root cause of such behaviour. When we empty indices mapping (because the dataset length equals to zero), we can no longer get column item like: `ds_filter_2['sentence']` which uses\r\n`ds_filter_1._indices.column(0)`~~\r\n\r\n**UPDATE:**\r\nEmpty datasets are returned without going through partial function on `map` method, which will not work to get indices for `filter`: we need to run `get_indices_from_mask_function` partial function on the dataset to get output = `{\"indices\": []}`. But this is complicated since functions used in args, in particular `get_indices_from_mask_function`, do not support empty datasets.\r\nWe can just handle empty datasets aside on filter method.",
"#self-assign",
"Thank you for solving this amazingly quickly!"
] | 2022-10-06T18:18:49 | 2022-10-07T19:06:02 | 2022-10-07T18:40:26 |
NONE
| null | null | null |
## Describe the bug
When filtering a dataset twice, where the first result is an empty dataset, the second dataset seems corrupted.
## Steps to reproduce the bug
```python
datasets = load_dataset("glue", "sst2")
dataset_split = datasets['validation']
ds_filter_1 = dataset_split.filter(lambda x: False) # Some filtering condition that leads to an empty dataset
assert ds_filter_1.num_rows == 0
sentences = ds_filter_1['sentence']
assert len(sentences) == 0
ds_filter_2 = ds_filter_1.filter(lambda x: False) # Some other filtering condition
assert ds_filter_2.num_rows == 0
assert 'sentence' in ds_filter_2.column_names
sentences = ds_filter_2['sentence']
```
## Expected results
The last line should be returning an empty list, same as 4 lines above.
## Actual results
The last line currently raises `IndexError: index out of bounds`.
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 2.5.2
- Platform: macOS-11.6.6-x86_64-i386-64bit
- Python version: 3.9.11
- PyArrow version: 7.0.0
- Pandas version: 1.4.1
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/5085/reactions",
"total_count": 3,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 3,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/5085/timeline
| null |
completed
| false |
https://api.github.com/repos/huggingface/datasets/issues/5084
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5084/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5084/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5084/events
|
https://github.com/huggingface/datasets/pull/5084
| 1,400,016,229 |
PR_kwDODunzps5AVXwm
| 5,084 |
IterableDataset formatting in numpy/torch/tf/jax
|
{
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5084). All of your documentation changes will be reflected on that endpoint.",
"Actually I'm not happy with this implementation. It always require the iterable dataset to have definite `features`, which removes a lot of flexibility. So I think we need an actual formatting from python objects, not from arrow data.",
"Closing this one since it has too many conflicts and still require some work - it will be easier to open a new PR"
] | 2022-10-06T16:53:38 | 2022-12-20T17:19:52 | 2022-12-20T17:19:52 |
MEMBER
| null | true |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5084",
"html_url": "https://github.com/huggingface/datasets/pull/5084",
"diff_url": "https://github.com/huggingface/datasets/pull/5084.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5084.patch",
"merged_at": null
}
|
This code now returns a numpy array:
```python
from datasets import load_dataset
ds = load_dataset("imagenet-1k", split="train", streaming=True).with_format("np")
print(next(iter(ds))["image"])
```
It also works with "arrow", "pandas", "torch", "tf" and "jax"
### Implementation details:
I'm using the existing code to format an Arrow Table to the right output format for simplicity.
Therefore it's probbaly not the most optimized approach.
For example to output PyTorch tensors it does this for every example:
python data -> arrow table -> numpy extracted data -> pytorch formatted data
### Releasing this feature
Even though I consider this as a bug/inconsistency, this change is a breaking change.
And I'm sure some users were relying on the torch iterable dataset to return PIL Image and used data collators to convert to pytorch.
So I guess this is `datasets` 3.0 ?
### TODO
- [x] merge https://github.com/huggingface/datasets/pull/5072
- [ ] docs
- [ ] tests
Close https://github.com/huggingface/datasets/issues/5083
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/5084/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/5084/timeline
| null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5083
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5083/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5083/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5083/events
|
https://github.com/huggingface/datasets/issues/5083
| 1,399,842,514 |
I_kwDODunzps5Tb-bS
| 5,083 |
Support numpy/torch/tf/jax formatting for IterableDataset
|
{
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
},
{
"id": 3287858981,
"node_id": "MDU6TGFiZWwzMjg3ODU4OTgx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/streaming",
"name": "streaming",
"color": "fef2c0",
"default": false,
"description": ""
},
{
"id": 3761482852,
"node_id": "LA_kwDODunzps7gM6xk",
"url": "https://api.github.com/repos/huggingface/datasets/labels/good%20second%20issue",
"name": "good second issue",
"color": "BDE59C",
"default": false,
"description": "Issues a bit more difficult than \"Good First\" issues"
}
] |
open
| false |
{
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
}
] | null |
[] | 2022-10-06T15:14:58 | 2023-02-17T14:10:01 | null |
MEMBER
| null | null | null |
Right now `IterableDataset` doesn't do any formatting.
In particular this code should return a numpy array:
```python
from datasets import load_dataset
ds = load_dataset("imagenet-1k", split="train", streaming=True).with_format("np")
print(next(iter(ds))["image"])
```
Right now it returns a PIL.Image.
Setting `streaming=False` does return a numpy array after #5072
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/5083/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/5083/timeline
| null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5082
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5082/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5082/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5082/events
|
https://github.com/huggingface/datasets/pull/5082
| 1,399,379,777 |
PR_kwDODunzps5ATJv-
| 5,082 |
adding keep in memory
|
{
"login": "Mustapha-AJEGHRIR",
"id": 66799406,
"node_id": "MDQ6VXNlcjY2Nzk5NDA2",
"avatar_url": "https://avatars.githubusercontent.com/u/66799406?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Mustapha-AJEGHRIR",
"html_url": "https://github.com/Mustapha-AJEGHRIR",
"followers_url": "https://api.github.com/users/Mustapha-AJEGHRIR/followers",
"following_url": "https://api.github.com/users/Mustapha-AJEGHRIR/following{/other_user}",
"gists_url": "https://api.github.com/users/Mustapha-AJEGHRIR/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Mustapha-AJEGHRIR/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Mustapha-AJEGHRIR/subscriptions",
"organizations_url": "https://api.github.com/users/Mustapha-AJEGHRIR/orgs",
"repos_url": "https://api.github.com/users/Mustapha-AJEGHRIR/repos",
"events_url": "https://api.github.com/users/Mustapha-AJEGHRIR/events{/privacy}",
"received_events_url": "https://api.github.com/users/Mustapha-AJEGHRIR/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"Hi @mariosasko , I have added a test for the `keep_in_memory` version. I have also removed the `Compatible with temp_seed` part in the scope of `dset_shuffled`, please verify if that makes sense."
] | 2022-10-06T11:10:46 | 2022-10-07T14:35:34 | 2022-10-07T14:32:54 |
CONTRIBUTOR
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5082",
"html_url": "https://github.com/huggingface/datasets/pull/5082",
"diff_url": "https://github.com/huggingface/datasets/pull/5082.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5082.patch",
"merged_at": "2022-10-07T14:32:54"
}
|
Fixing #514 .
Hello @mariosasko 👋, I have implemented what you have recommanded to fix the keep in memory problem for shuffle on the issue #514 .
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/5082/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/5082/timeline
| null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5081
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5081/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5081/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5081/events
|
https://github.com/huggingface/datasets/issues/5081
| 1,399,340,050 |
I_kwDODunzps5TaDwS
| 5,081 |
Bug loading `sentence-transformers/parallel-sentences`
|
{
"login": "PhilipMay",
"id": 229382,
"node_id": "MDQ6VXNlcjIyOTM4Mg==",
"avatar_url": "https://avatars.githubusercontent.com/u/229382?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/PhilipMay",
"html_url": "https://github.com/PhilipMay",
"followers_url": "https://api.github.com/users/PhilipMay/followers",
"following_url": "https://api.github.com/users/PhilipMay/following{/other_user}",
"gists_url": "https://api.github.com/users/PhilipMay/gists{/gist_id}",
"starred_url": "https://api.github.com/users/PhilipMay/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/PhilipMay/subscriptions",
"organizations_url": "https://api.github.com/users/PhilipMay/orgs",
"repos_url": "https://api.github.com/users/PhilipMay/repos",
"events_url": "https://api.github.com/users/PhilipMay/events{/privacy}",
"received_events_url": "https://api.github.com/users/PhilipMay/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] |
open
| false | null |
[] | null |
[
"tagging @nreimers ",
"The dataset is sadly not really compatible to be loaded with `load_dataset`. So far it is better to git clone it and to use the files directly.\r\n\r\nA data loading script would be needed to be added to this dataset. But this was too much overhead / not really intuitive how to create it.",
"Since the dataset is a bunch of TSVs we should not need a dataset script I think.\r\n\r\nBy default it tries to load all the TSVs at once, which fails here because they don't all have the same columns (pd.read_csv uses the first line as header by default). But those files have no header ! So, to properly load any TSV file in this repo, one has to pass `names=[...]` for pd.read_csv to know which column names to use.\r\n\r\nTo fix this situation, we can either do\r\n1. replace the TSVs by TSV with column names\r\n2. OR specify the pd.read_csv kwargs as YAML in the dataset card - and `datasets` would use that by default\r\n\r\nWDTY ?",
"There are more issues in the dataset.\r\nTo load OpenSubtitles I have to provide this (see `skiprows`):\r\n\r\n```python\r\ndf_os = pd.read_csv(\r\n \"./parallel-sentences/OpenSubtitles/OpenSubtitles-en-de-train.tsv.gz\", \r\n sep=\"\\t\", \r\n quoting=csv.QUOTE_NONE,\r\n header=None,\r\n names=[\"en\", \"de\"],\r\n skiprows=[540344, 9151700, 10040173, 10040199, 11314673, 11338258, 11869223, 12159297, 12251078, 12303334],\r\n)\r\n```",
"What's wrong with those lines exactly ?\r\nMaybe passing `error_bad_lines=False` (and maybe `warn_bad_lines=True`) can be helpful",
"> What's wrong with those lines exactly ? \r\n\r\nStuff like this: `ParserError: Error tokenizing data. C error: Expected 2 fields in line 540345, saw 3`\r\n\r\n",
"> Maybe passing error_bad_lines=False (and maybe warn_bad_lines=True) can be helpful\r\n\r\nYes. That would hide the issue but not solve it.",
"@nreimers WDYT about the two options mentioned above ?"
] | 2022-10-06T10:47:51 | 2022-10-11T10:00:48 | null |
CONTRIBUTOR
| null | null | null |
## Steps to reproduce the bug
```python
from datasets import load_dataset
dataset = load_dataset("sentence-transformers/parallel-sentences")
```
raises this:
```
/home/phmay/miniconda3/envs/paraphrase-mining/lib/python3.9/site-packages/datasets/download/streaming_download_manager.py:697: FutureWarning: the 'mangle_dupe_cols' keyword is deprecated and will be removed in a future version. Please take steps to stop the use of 'mangle_dupe_cols'
return pd.read_csv(xopen(filepath_or_buffer, "rb", use_auth_token=use_auth_token), **kwargs)
/home/phmay/miniconda3/envs/paraphrase-mining/lib/python3.9/site-packages/datasets/download/streaming_download_manager.py:697: FutureWarning: the 'mangle_dupe_cols' keyword is deprecated and will be removed in a future version. Please take steps to stop the use of 'mangle_dupe_cols'
return pd.read_csv(xopen(filepath_or_buffer, "rb", use_auth_token=use_auth_token), **kwargs)
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
Cell In [4], line 1
----> 1 dataset = load_dataset("sentence-transformers/parallel-sentences", split="train")
File ~/miniconda3/envs/paraphrase-mining/lib/python3.9/site-packages/datasets/load.py:1693, in load_dataset(path, name, data_dir, data_files, split, cache_dir, features, download_config, download_mode, ignore_verifications, keep_in_memory, save_infos, revision, use_auth_token, task, streaming, **config_kwargs)
1690 try_from_hf_gcs = path not in _PACKAGED_DATASETS_MODULES
1692 # Download and prepare data
-> 1693 builder_instance.download_and_prepare(
1694 download_config=download_config,
1695 download_mode=download_mode,
1696 ignore_verifications=ignore_verifications,
1697 try_from_hf_gcs=try_from_hf_gcs,
1698 use_auth_token=use_auth_token,
1699 )
1701 # Build dataset for splits
1702 keep_in_memory = (
1703 keep_in_memory if keep_in_memory is not None else is_small_dataset(builder_instance.info.dataset_size)
1704 )
File ~/miniconda3/envs/paraphrase-mining/lib/python3.9/site-packages/datasets/builder.py:807, in DatasetBuilder.download_and_prepare(self, output_dir, download_config, download_mode, ignore_verifications, try_from_hf_gcs, dl_manager, base_path, use_auth_token, file_format, max_shard_size, storage_options, **download_and_prepare_kwargs)
801 if not downloaded_from_gcs:
802 prepare_split_kwargs = {
803 "file_format": file_format,
804 "max_shard_size": max_shard_size,
805 **download_and_prepare_kwargs,
806 }
--> 807 self._download_and_prepare(
808 dl_manager=dl_manager,
809 verify_infos=verify_infos,
810 **prepare_split_kwargs,
811 **download_and_prepare_kwargs,
812 )
813 # Sync info
814 self.info.dataset_size = sum(split.num_bytes for split in self.info.splits.values())
File ~/miniconda3/envs/paraphrase-mining/lib/python3.9/site-packages/datasets/builder.py:898, in DatasetBuilder._download_and_prepare(self, dl_manager, verify_infos, **prepare_split_kwargs)
894 split_dict.add(split_generator.split_info)
896 try:
897 # Prepare split will record examples associated to the split
--> 898 self._prepare_split(split_generator, **prepare_split_kwargs)
899 except OSError as e:
900 raise OSError(
901 "Cannot find data file. "
902 + (self.manual_download_instructions or "")
903 + "\nOriginal error:\n"
904 + str(e)
905 ) from None
File ~/miniconda3/envs/paraphrase-mining/lib/python3.9/site-packages/datasets/builder.py:1513, in ArrowBasedBuilder._prepare_split(self, split_generator, file_format, max_shard_size)
1506 shard_id += 1
1507 writer = writer_class(
1508 features=writer._features,
1509 path=fpath.replace("SSSSS", f"{shard_id:05d}"),
1510 storage_options=self._fs.storage_options,
1511 embed_local_files=embed_local_files,
1512 )
-> 1513 writer.write_table(table)
1514 finally:
1515 num_shards = shard_id + 1
File ~/miniconda3/envs/paraphrase-mining/lib/python3.9/site-packages/datasets/arrow_writer.py:540, in ArrowWriter.write_table(self, pa_table, writer_batch_size)
538 if self.pa_writer is None:
539 self._build_writer(inferred_schema=pa_table.schema)
--> 540 pa_table = table_cast(pa_table, self._schema)
541 if self.embed_local_files:
542 pa_table = embed_table_storage(pa_table)
File ~/miniconda3/envs/paraphrase-mining/lib/python3.9/site-packages/datasets/table.py:2044, in table_cast(table, schema)
2032 """Improved version of pa.Table.cast.
2033
2034 It supports casting to feature types stored in the schema metadata.
(...)
2041 table (:obj:`pyarrow.Table`): the casted table
2042 """
2043 if table.schema != schema:
-> 2044 return cast_table_to_schema(table, schema)
2045 elif table.schema.metadata != schema.metadata:
2046 return table.replace_schema_metadata(schema.metadata)
File ~/miniconda3/envs/paraphrase-mining/lib/python3.9/site-packages/datasets/table.py:2005, in cast_table_to_schema(table, schema)
2003 features = Features.from_arrow_schema(schema)
2004 if sorted(table.column_names) != sorted(features):
-> 2005 raise ValueError(f"Couldn't cast\n{table.schema}\nto\n{features}\nbecause column names don't match")
2006 arrays = [cast_array_to_feature(table[name], feature) for name, feature in features.items()]
2007 return pa.Table.from_arrays(arrays, schema=schema)
ValueError: Couldn't cast
Action taken on Parliament's resolutions: see Minutes: string
Následný postup na základě usnesení Parlamentu: viz zápis: string
-- schema metadata --
pandas: '{"index_columns": [{"kind": "range", "name": null, "start": 0, "' + 742
to
{'Membership of Parliament: see Minutes': Value(dtype='string', id=None), 'Състав на Парламента: вж. протоколи': Value(dtype='string', id=None)}
because column names don't match
```
## Expected results
no error
## Actual results
error
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version:
- Platform: Linux
- Python version: Python 3.9.13
- PyArrow version: pyarrow 9.0.0
- transformers 4.22.2
- datasets 2.5.2
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/5081/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/5081/timeline
| null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5080
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5080/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5080/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5080/events
|
https://github.com/huggingface/datasets/issues/5080
| 1,398,849,565 |
I_kwDODunzps5TYMAd
| 5,080 |
Use hfh for caching
|
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] |
open
| false |
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
}
] | null |
[
"There is some discussion in https://github.com/huggingface/huggingface_hub/pull/1088 if it can help :)"
] | 2022-10-06T05:51:58 | 2022-10-06T14:26:05 | null |
MEMBER
| null | null | null |
## Is your feature request related to a problem?
As previously discussed in our meeting with @Wauplin and agreed on our last datasets team sync meeting, I'm investigating how `datasets` can use `hfh` for caching.
## Describe the solution you'd like
Due to the peculiarities of the `datasets` cache, I would propose adopting `hfh` caching system in stages.
First, we could easily start using `hfh` caching for:
- dataset Python scripts
- dataset READMEs
- dataset infos JSON files (now deprecated)
Second, we could also use `hfh` caching for data files downloaded from the Hub.
Further investigation is needed for:
- files downloaded from non-Hub hosts
- extracted files from downloaded archive/compressed files
- generated Arrow files
## Additional context
Docs about the `hfh` caching system:
- [Manage huggingface_hub cache-system](https://huggingface.co/docs/huggingface_hub/main/en/how-to-cache)
- [Cache-system reference](https://huggingface.co/docs/huggingface_hub/main/en/package_reference/cache)
The `transformers` library has already adopted `hfh` for caching. See:
- huggingface/transformers#18438
- huggingface/transformers#18857
- huggingface/transformers#18966
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/5080/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/5080/timeline
| null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5079
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5079/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5079/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5079/events
|
https://github.com/huggingface/datasets/pull/5079
| 1,398,609,305 |
PR_kwDODunzps5AQemi
| 5,079 |
refactor: replace AssertionError with more meaningful exceptions (#5074)
|
{
"login": "galbwe",
"id": 20004072,
"node_id": "MDQ6VXNlcjIwMDA0MDcy",
"avatar_url": "https://avatars.githubusercontent.com/u/20004072?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/galbwe",
"html_url": "https://github.com/galbwe",
"followers_url": "https://api.github.com/users/galbwe/followers",
"following_url": "https://api.github.com/users/galbwe/following{/other_user}",
"gists_url": "https://api.github.com/users/galbwe/gists{/gist_id}",
"starred_url": "https://api.github.com/users/galbwe/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/galbwe/subscriptions",
"organizations_url": "https://api.github.com/users/galbwe/orgs",
"repos_url": "https://api.github.com/users/galbwe/repos",
"events_url": "https://api.github.com/users/galbwe/events{/privacy}",
"received_events_url": "https://api.github.com/users/galbwe/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-10-06T01:39:35 | 2022-10-07T14:35:43 | 2022-10-07T14:33:10 |
CONTRIBUTOR
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5079",
"html_url": "https://github.com/huggingface/datasets/pull/5079",
"diff_url": "https://github.com/huggingface/datasets/pull/5079.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5079.patch",
"merged_at": "2022-10-07T14:33:10"
}
|
Closes #5074
Replaces `AssertionError` in the following files with more descriptive exceptions:
- `src/datasets/arrow_reader.py`
- `src/datasets/builder.py`
- `src/datasets/utils/version.py`
The issue listed more files that needed to be fixed, but the rest of them were contained in the top-level `datasets` directory, which was removed when #4974 was merged
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/5079/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/5079/timeline
| null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5078
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5078/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5078/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5078/events
|
https://github.com/huggingface/datasets/pull/5078
| 1,398,335,148 |
PR_kwDODunzps5APjkH
| 5,078 |
Fix header level in Audio docs
|
{
"login": "stevhliu",
"id": 59462357,
"node_id": "MDQ6VXNlcjU5NDYyMzU3",
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stevhliu",
"html_url": "https://github.com/stevhliu",
"followers_url": "https://api.github.com/users/stevhliu/followers",
"following_url": "https://api.github.com/users/stevhliu/following{/other_user}",
"gists_url": "https://api.github.com/users/stevhliu/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stevhliu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stevhliu/subscriptions",
"organizations_url": "https://api.github.com/users/stevhliu/orgs",
"repos_url": "https://api.github.com/users/stevhliu/repos",
"events_url": "https://api.github.com/users/stevhliu/events{/privacy}",
"received_events_url": "https://api.github.com/users/stevhliu/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-10-05T20:22:44 | 2022-10-06T08:12:23 | 2022-10-06T08:09:41 |
MEMBER
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5078",
"html_url": "https://github.com/huggingface/datasets/pull/5078",
"diff_url": "https://github.com/huggingface/datasets/pull/5078.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5078.patch",
"merged_at": "2022-10-06T08:09:41"
}
|
Fixes header level so `Dataset features` is the doc title instead of `The Audio type`:

|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/5078/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/5078/timeline
| null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5077
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5077/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5077/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5077/events
|
https://github.com/huggingface/datasets/pull/5077
| 1,398,080,859 |
PR_kwDODunzps5AOs9L
| 5,077 |
Fix passed download_config in HubDatasetModuleFactoryWithoutScript
|
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-10-05T16:42:36 | 2022-10-06T05:31:22 | 2022-10-06T05:29:06 |
MEMBER
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5077",
"html_url": "https://github.com/huggingface/datasets/pull/5077",
"diff_url": "https://github.com/huggingface/datasets/pull/5077.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5077.patch",
"merged_at": "2022-10-06T05:29:06"
}
|
Fix passed `download_config` in `HubDatasetModuleFactoryWithoutScript`.
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/5077/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/5077/timeline
| null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5076
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5076/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5076/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5076/events
|
https://github.com/huggingface/datasets/pull/5076
| 1,397,918,092 |
PR_kwDODunzps5AOJp7
| 5,076 |
fix: update exception throw from OSError to EnvironmentError in `push…
|
{
"login": "rahulXs",
"id": 29496999,
"node_id": "MDQ6VXNlcjI5NDk2OTk5",
"avatar_url": "https://avatars.githubusercontent.com/u/29496999?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/rahulXs",
"html_url": "https://github.com/rahulXs",
"followers_url": "https://api.github.com/users/rahulXs/followers",
"following_url": "https://api.github.com/users/rahulXs/following{/other_user}",
"gists_url": "https://api.github.com/users/rahulXs/gists{/gist_id}",
"starred_url": "https://api.github.com/users/rahulXs/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rahulXs/subscriptions",
"organizations_url": "https://api.github.com/users/rahulXs/orgs",
"repos_url": "https://api.github.com/users/rahulXs/repos",
"events_url": "https://api.github.com/users/rahulXs/events{/privacy}",
"received_events_url": "https://api.github.com/users/rahulXs/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-10-05T14:46:29 | 2022-10-07T14:35:57 | 2022-10-07T14:33:27 |
CONTRIBUTOR
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5076",
"html_url": "https://github.com/huggingface/datasets/pull/5076",
"diff_url": "https://github.com/huggingface/datasets/pull/5076.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5076.patch",
"merged_at": "2022-10-07T14:33:27"
}
|
Status:
Ready for review
Description of Changes:
Fixes #5075
Changes proposed in this pull request:
- Throw EnvironmentError instead of OSError in `push_to_hub` when the Hub token is not present.
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/5076/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/5076/timeline
| null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5075
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5075/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5075/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5075/events
|
https://github.com/huggingface/datasets/issues/5075
| 1,397,865,501 |
I_kwDODunzps5TUbwd
| 5,075 |
Throw EnvironmentError when token is not present
|
{
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1935892877,
"node_id": "MDU6TGFiZWwxOTM1ODkyODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/good%20first%20issue",
"name": "good first issue",
"color": "7057ff",
"default": true,
"description": "Good for newcomers"
},
{
"id": 4614514401,
"node_id": "LA_kwDODunzps8AAAABEwvm4Q",
"url": "https://api.github.com/repos/huggingface/datasets/labels/hacktoberfest",
"name": "hacktoberfest",
"color": "DF8D62",
"default": false,
"description": ""
}
] |
closed
| false | null |
[] | null |
[
"@mariosasko I've raised a PR #5076 against this issue. Please help to review. Thanks."
] | 2022-10-05T14:14:18 | 2022-10-07T14:33:28 | 2022-10-07T14:33:28 |
CONTRIBUTOR
| null | null | null |
Throw EnvironmentError instead of OSError ([link](https://github.com/huggingface/datasets/blob/6ad430ba0cdeeb601170f732d4bd977f5c04594d/src/datasets/arrow_dataset.py#L4306) to the line) in `push_to_hub` when the Hub token is not present.
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/5075/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/5075/timeline
| null |
completed
| false |
https://api.github.com/repos/huggingface/datasets/issues/5074
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5074/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5074/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5074/events
|
https://github.com/huggingface/datasets/issues/5074
| 1,397,850,352 |
I_kwDODunzps5TUYDw
| 5,074 |
Replace AssertionErrors with more meaningful errors
|
{
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1935892877,
"node_id": "MDU6TGFiZWwxOTM1ODkyODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/good%20first%20issue",
"name": "good first issue",
"color": "7057ff",
"default": true,
"description": "Good for newcomers"
},
{
"id": 4614514401,
"node_id": "LA_kwDODunzps8AAAABEwvm4Q",
"url": "https://api.github.com/repos/huggingface/datasets/labels/hacktoberfest",
"name": "hacktoberfest",
"color": "DF8D62",
"default": false,
"description": ""
}
] |
closed
| false |
{
"login": "galbwe",
"id": 20004072,
"node_id": "MDQ6VXNlcjIwMDA0MDcy",
"avatar_url": "https://avatars.githubusercontent.com/u/20004072?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/galbwe",
"html_url": "https://github.com/galbwe",
"followers_url": "https://api.github.com/users/galbwe/followers",
"following_url": "https://api.github.com/users/galbwe/following{/other_user}",
"gists_url": "https://api.github.com/users/galbwe/gists{/gist_id}",
"starred_url": "https://api.github.com/users/galbwe/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/galbwe/subscriptions",
"organizations_url": "https://api.github.com/users/galbwe/orgs",
"repos_url": "https://api.github.com/users/galbwe/repos",
"events_url": "https://api.github.com/users/galbwe/events{/privacy}",
"received_events_url": "https://api.github.com/users/galbwe/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"login": "galbwe",
"id": 20004072,
"node_id": "MDQ6VXNlcjIwMDA0MDcy",
"avatar_url": "https://avatars.githubusercontent.com/u/20004072?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/galbwe",
"html_url": "https://github.com/galbwe",
"followers_url": "https://api.github.com/users/galbwe/followers",
"following_url": "https://api.github.com/users/galbwe/following{/other_user}",
"gists_url": "https://api.github.com/users/galbwe/gists{/gist_id}",
"starred_url": "https://api.github.com/users/galbwe/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/galbwe/subscriptions",
"organizations_url": "https://api.github.com/users/galbwe/orgs",
"repos_url": "https://api.github.com/users/galbwe/repos",
"events_url": "https://api.github.com/users/galbwe/events{/privacy}",
"received_events_url": "https://api.github.com/users/galbwe/received_events",
"type": "User",
"site_admin": false
}
] | null |
[
"Hi, can I pick up this issue?",
"#self-assign",
"Looks like the top-level `datasource` directory was removed when https://github.com/huggingface/datasets/pull/4974 was merged, so there are 3 source files to fix."
] | 2022-10-05T14:03:55 | 2022-10-07T14:33:11 | 2022-10-07T14:33:11 |
CONTRIBUTOR
| null | null | null |
Replace the AssertionErrors with more meaningful errors such as ValueError, TypeError, etc.
The files with AssertionErrors that need to be replaced:
```
src/datasets/arrow_reader.py
src/datasets/builder.py
src/datasets/utils/version.py
```
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/5074/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/5074/timeline
| null |
completed
| false |
https://api.github.com/repos/huggingface/datasets/issues/5073
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5073/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5073/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5073/events
|
https://github.com/huggingface/datasets/pull/5073
| 1,397,832,183 |
PR_kwDODunzps5AN3Gn
| 5,073 |
Restore saved format state in `load_from_disk`
|
{
"login": "asofiaoliveira",
"id": 74454835,
"node_id": "MDQ6VXNlcjc0NDU0ODM1",
"avatar_url": "https://avatars.githubusercontent.com/u/74454835?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/asofiaoliveira",
"html_url": "https://github.com/asofiaoliveira",
"followers_url": "https://api.github.com/users/asofiaoliveira/followers",
"following_url": "https://api.github.com/users/asofiaoliveira/following{/other_user}",
"gists_url": "https://api.github.com/users/asofiaoliveira/gists{/gist_id}",
"starred_url": "https://api.github.com/users/asofiaoliveira/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/asofiaoliveira/subscriptions",
"organizations_url": "https://api.github.com/users/asofiaoliveira/orgs",
"repos_url": "https://api.github.com/users/asofiaoliveira/repos",
"events_url": "https://api.github.com/users/asofiaoliveira/events{/privacy}",
"received_events_url": "https://api.github.com/users/asofiaoliveira/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-10-05T13:51:47 | 2022-10-11T16:55:07 | 2022-10-11T16:49:23 |
CONTRIBUTOR
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5073",
"html_url": "https://github.com/huggingface/datasets/pull/5073",
"diff_url": "https://github.com/huggingface/datasets/pull/5073.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5073.patch",
"merged_at": "2022-10-11T16:49:23"
}
|
Hello! @mariosasko
This pull request relates to issue #5050 and intends to add the format to datasets loaded from disk.
All I did was add a set_format in the Dataset.load_from_disk, as DatasetDict.load_from_disk relies on the first.
I don't know if I should add a test and where, so let me know if I should and I can work on that as well!
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/5073/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/5073/timeline
| null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5072
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5072/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5072/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5072/events
|
https://github.com/huggingface/datasets/pull/5072
| 1,397,765,531 |
PR_kwDODunzps5ANoo5
| 5,072 |
Image & Audio formatting for numpy/torch/tf/jax
|
{
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"I just added a consolidation step so that numpy arrays or tensors of images are stacked together if the shapes match, instead of having lists of tensors\r\n\r\nFeel free to review @mariosasko :)",
"I added a few lines in the docs and reverted the ragged numpy array change :)\r\n\r\nready for another review @mariosasko !"
] | 2022-10-05T13:07:03 | 2022-10-10T13:24:10 | 2022-10-10T13:21:32 |
MEMBER
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5072",
"html_url": "https://github.com/huggingface/datasets/pull/5072",
"diff_url": "https://github.com/huggingface/datasets/pull/5072.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5072.patch",
"merged_at": "2022-10-10T13:21:32"
}
|
Added support for image and audio formatting for numpy, torch, tf and jax.
For images, the dtype used is the one of the image (the one returned by PIL.Image), e.g. uint8
I also added support for string, binary and None types. In particular for torch and jax, strings are kept unchanged (previously it was returning an error because you can't create a tensor of strings)
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/5072/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/5072/timeline
| null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5071
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5071/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5071/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5071/events
|
https://github.com/huggingface/datasets/pull/5071
| 1,397,301,270 |
PR_kwDODunzps5AMG3g
| 5,071 |
Support DEFAULT_CONFIG_NAME when no BUILDER_CONFIGS
|
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"Super, thanks a lot for adding this support, Albert!"
] | 2022-10-05T06:28:39 | 2022-10-06T14:43:12 | 2022-10-06T14:40:26 |
MEMBER
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5071",
"html_url": "https://github.com/huggingface/datasets/pull/5071",
"diff_url": "https://github.com/huggingface/datasets/pull/5071.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5071.patch",
"merged_at": "2022-10-06T14:40:25"
}
|
This PR supports defining a default config name, even if no predefined allowed config names are set.
Fix #5070.
CC: @stas00
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/5071/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 1,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/5071/timeline
| null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5070
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5070/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5070/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5070/events
|
https://github.com/huggingface/datasets/issues/5070
| 1,396,765,647 |
I_kwDODunzps5TQPPP
| 5,070 |
Support default config name when no builder configs
|
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] |
closed
| false |
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
}
] | null |
[
"Thank you for creating this feature request, Albert.\r\n\r\nFor context this is the datatest where Albert has been helping me to switch to on-the-fly split config https://huggingface.co/datasets/HuggingFaceM4/cm4-synthetic-testing\r\n\r\nand the attempt to switch on-the-fly splits was here: https://huggingface.co/datasets/HuggingFaceM4/cm4-synthetic-testing/discussions/2/files\r\n\r\nbut which I had to revert since providing no split breaks at run time.\r\n"
] | 2022-10-04T19:49:35 | 2022-10-06T14:40:26 | 2022-10-06T14:40:26 |
MEMBER
| null | null | null |
**Is your feature request related to a problem? Please describe.**
As discussed with @stas00, we could support defining a default config name, even if no predefined allowed config names are set. That is, support `DEFAULT_CONFIG_NAME`, even when `BUILDER_CONFIGS` is not defined.
**Additional context**
In order to support creating configs on the fly **by name** (not using kwargs), the list of allowed builder configs `BUILDER_CONFIGS` must not be set.
However, if so, then `DEFAULT_CONFIG_NAME` is not supported.
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/5070/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 1,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/5070/timeline
| null |
completed
| false |
https://api.github.com/repos/huggingface/datasets/issues/5067
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5067/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5067/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5067/events
|
https://github.com/huggingface/datasets/pull/5067
| 1,396,361,768 |
PR_kwDODunzps5AI86d
| 5,067 |
Fix CONTRIBUTING once dataset scripts transferred to Hub
|
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-10-04T14:16:05 | 2022-10-06T06:14:43 | 2022-10-06T06:12:12 |
MEMBER
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5067",
"html_url": "https://github.com/huggingface/datasets/pull/5067",
"diff_url": "https://github.com/huggingface/datasets/pull/5067.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5067.patch",
"merged_at": "2022-10-06T06:12:12"
}
|
This PR updates the `CONTRIBUTING.md` guide, once the all dataset scripts have been removed from the GitHub repo and transferred to the HF Hub:
- #4974
See diff here: https://github.com/huggingface/datasets/commit/e3291ecff9e54f09fcee3f313f051a03fdc3d94b
Additionally, this PR fixes the line separator that by some previous mistake was CRLF instead of LF.
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/5067/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/5067/timeline
| null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5066
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5066/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5066/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5066/events
|
https://github.com/huggingface/datasets/pull/5066
| 1,396,086,745 |
PR_kwDODunzps5AIDWj
| 5,066 |
Support streaming gzip.open
|
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-10-04T11:20:05 | 2022-10-06T15:13:51 | 2022-10-06T15:11:29 |
MEMBER
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5066",
"html_url": "https://github.com/huggingface/datasets/pull/5066",
"diff_url": "https://github.com/huggingface/datasets/pull/5066.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5066.patch",
"merged_at": "2022-10-06T15:11:29"
}
|
This PR implements support for streaming out-of-the-box dataset scripts containing `gzip.open`.
This has been a recurring issue. See, e.g.:
- #5060
- #3191
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/5066/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/5066/timeline
| null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5065
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5065/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5065/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5065/events
|
https://github.com/huggingface/datasets/pull/5065
| 1,396,003,362 |
PR_kwDODunzps5AHxlQ
| 5,065 |
Ci py3.10
|
{
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"Does it sound good to you @albertvillanova ?"
] | 2022-10-04T10:13:51 | 2022-11-29T15:28:05 | 2022-11-29T15:25:26 |
MEMBER
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5065",
"html_url": "https://github.com/huggingface/datasets/pull/5065",
"diff_url": "https://github.com/huggingface/datasets/pull/5065.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5065.patch",
"merged_at": "2022-11-29T15:25:26"
}
|
Added a CI job for python 3.10
Some dependencies don't work on 3.10 like apache beam, so I remove them from the extras in this case.
I also removed some s3 fixtures that we don't use anymore (and that don't work on 3.10 anyway)
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/5065/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/5065/timeline
| null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5064
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5064/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5064/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5064/events
|
https://github.com/huggingface/datasets/pull/5064
| 1,395,978,143 |
PR_kwDODunzps5AHsP0
| 5,064 |
Align signature of create/delete_repo with latest hfh
|
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-10-04T09:54:53 | 2022-10-07T17:02:11 | 2022-10-07T16:59:30 |
MEMBER
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5064",
"html_url": "https://github.com/huggingface/datasets/pull/5064",
"diff_url": "https://github.com/huggingface/datasets/pull/5064.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5064.patch",
"merged_at": "2022-10-07T16:59:30"
}
|
This PR aligns the signature of `create_repo`/`delete_repo` with the current one in hfh, by removing deprecated `name` and `organization`, and using `repo_id` instead.
Related to:
- #5063
CC: @lhoestq
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/5064/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/5064/timeline
| null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5063
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5063/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5063/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5063/events
|
https://github.com/huggingface/datasets/pull/5063
| 1,395,895,463 |
PR_kwDODunzps5AHasG
| 5,063 |
Align signature of list_repo_files with latest hfh
|
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-10-04T08:51:46 | 2022-10-07T16:42:57 | 2022-10-07T16:40:16 |
MEMBER
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5063",
"html_url": "https://github.com/huggingface/datasets/pull/5063",
"diff_url": "https://github.com/huggingface/datasets/pull/5063.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5063.patch",
"merged_at": "2022-10-07T16:40:16"
}
|
This PR aligns the signature of `list_repo_files` with the current one in `hfh`, by renaming deprecated `token` to `use_auth_token`.
This is already the case for `dataset_info`.
CC: @lhoestq
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/5063/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/5063/timeline
| null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5062
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5062/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5062/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5062/events
|
https://github.com/huggingface/datasets/pull/5062
| 1,395,739,417 |
PR_kwDODunzps5AG6SA
| 5,062 |
Fix CI hfh token warning
|
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"good catch !"
] | 2022-10-04T06:36:54 | 2022-10-04T08:58:15 | 2022-10-04T08:42:31 |
MEMBER
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5062",
"html_url": "https://github.com/huggingface/datasets/pull/5062",
"diff_url": "https://github.com/huggingface/datasets/pull/5062.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5062.patch",
"merged_at": "2022-10-04T08:42:31"
}
|
In our CI, we get warnings from `hfh` about using deprecated `token`: https://github.com/huggingface/datasets/actions/runs/3174626525/jobs/5171672431
```
tests/test_upstream_hub.py::TestPushToHub::test_push_dataset_dict_to_hub_private
tests/test_upstream_hub.py::TestPushToHub::test_push_dataset_dict_to_hub
tests/test_upstream_hub.py::TestPushToHub::test_push_dataset_dict_to_hub_multiple_files
tests/test_upstream_hub.py::TestPushToHub::test_push_dataset_dict_to_hub_multiple_files_with_max_shard_size
tests/test_upstream_hub.py::TestPushToHub::test_push_dataset_dict_to_hub_overwrite_files
C:\hostedtoolcache\windows\Python\3.7.9\x64\lib\site-packages\huggingface_hub\utils\_deprecation.py:97: FutureWarning: Deprecated argument(s) used in 'dataset_info': token. Will not be supported from version '0.12'.
warnings.warn(message, FutureWarning)
```
This PR fixes the tests in `TestPushToHub` so that we fix these warnings.
Continuation of:
- #5031
CC: @lhoestq
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/5062/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/5062/timeline
| null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5061
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5061/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5061/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5061/events
|
https://github.com/huggingface/datasets/issues/5061
| 1,395,476,770 |
I_kwDODunzps5TLUki
| 5,061 |
`_pickle.PicklingError: logger cannot be pickled` in multiprocessing `map`
|
{
"login": "ZhaofengWu",
"id": 11954789,
"node_id": "MDQ6VXNlcjExOTU0Nzg5",
"avatar_url": "https://avatars.githubusercontent.com/u/11954789?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ZhaofengWu",
"html_url": "https://github.com/ZhaofengWu",
"followers_url": "https://api.github.com/users/ZhaofengWu/followers",
"following_url": "https://api.github.com/users/ZhaofengWu/following{/other_user}",
"gists_url": "https://api.github.com/users/ZhaofengWu/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ZhaofengWu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ZhaofengWu/subscriptions",
"organizations_url": "https://api.github.com/users/ZhaofengWu/orgs",
"repos_url": "https://api.github.com/users/ZhaofengWu/repos",
"events_url": "https://api.github.com/users/ZhaofengWu/events{/privacy}",
"received_events_url": "https://api.github.com/users/ZhaofengWu/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] |
open
| false | null |
[] | null |
[
"This is maybe related to python 3.10, do you think you could try on 3.8 ?\r\n\r\nIn the meantime we'll keep improving the support for 3.10. Let me add a dedicated CI",
"I did some binary search and seems like the root cause is either `multiprocess` or `dill`. python 3.10 is fine. Specifically:\r\n- `multiprocess==0.70.12.2, dill==0.3.4`: works\r\n- `multiprocess==0.70.12.2, dill==0.3.5.1`: doesn't work\r\n- `multiprocess==0.70.13, dill==0.3.5.1`: doesn't work\r\n- `multiprocess==0.70.13, dill==0.3.4`: can't test, `multiprocess==0.70.13` requires `dill>=0.3.5.1`\r\n\r\nI will pin their versions on my end. I don't have enough knowledge of how python multiprocessing works to debug this, but ideally there could be a fix. It's also possible that I'm doing something wrong in my code, but again the `.name` of the logger that failed to pickle is `datasets.fingerprint`, which I'm not using directly.",
"Do you know which logger fails at being pickled ?",
"I'm not 100% sure how to figure it out -- the stack trace above doesn't clearly give me a place where I can print out who owns the logger, etc. I only found out its `.name` is `datasets.fingerprint` by printing right before\r\n```\r\n File \".../logging/__init__.py\", line 1774, in __reduce__\r\n raise pickle.PicklingError('logger cannot be pickled')\r\n```\r\nIf you have any idea on how to find it out, please let me know.",
"Ok I see, not sure why it triggers this error though, in `logging.py` the code is\r\n\r\nhttps://github.com/python/cpython/blob/c9da063e32725a66495e4047b8a5ed13e72d9e8e/Lib/logging/__init__.py#L1769-L1775\r\n\r\nand on my side it works on 3.10 with dill 0.3.5.1 and multiprocess 0.70.13\r\n```python\r\n>>> datasets.fingerprint.logger.__reduce__() \r\n(<function logging.getLogger(name=None)>, ('datasets.fingerprint',))\r\n```\r\nCould you try to run this code ?\r\n\r\nAre you in an environment where the loggers are instantiated differently ? Can you check the source code of `logging.Logger.__reduce__` in `\".../logging/__init__.py\", line 1774` ?"
] | 2022-10-03T23:51:38 | 2022-10-14T16:44:54 | null |
NONE
| null | null | null |
## Describe the bug
When I `map` with multiple processes, this error occurs. The `.name` of the `logger` that fails to pickle in the final line is `datasets.fingerprint`.
```
File "~/project/dataset.py", line 204, in <dictcomp>
split: dataset.map(
File ".../site-packages/datasets/arrow_dataset.py", line 2489, in map
transformed_shards[index] = async_result.get()
File ".../site-packages/multiprocess/pool.py", line 771, in get
raise self._value
File ".../site-packages/multiprocess/pool.py", line 537, in _handle_tasks
put(task)
File ".../site-packages/multiprocess/connection.py", line 214, in send
self._send_bytes(_ForkingPickler.dumps(obj))
File ".../site-packages/multiprocess/reduction.py", line 54, in dumps
cls(buf, protocol, *args, **kwds).dump(obj)
File ".../site-packages/dill/_dill.py", line 620, in dump
StockPickler.dump(self, obj)
File ".../pickle.py", line 487, in dump
self.save(obj)
File ".../pickle.py", line 560, in save
f(self, obj) # Call unbound method with explicit self
File ".../pickle.py", line 902, in save_tuple
save(element)
File ".../pickle.py", line 560, in save
f(self, obj) # Call unbound method with explicit self
File ".../site-packages/dill/_dill.py", line 1963, in save_function
_save_with_postproc(pickler, (_create_function, (
File ".../site-packages/dill/_dill.py", line 1140, in _save_with_postproc
pickler.save_reduce(*reduction, obj=obj)
File ".../pickle.py", line 717, in save_reduce
save(state)
File ".../pickle.py", line 560, in save
f(self, obj) # Call unbound method with explicit self
File ".../pickle.py", line 887, in save_tuple
save(element)
File ".../pickle.py", line 560, in save
f(self, obj) # Call unbound method with explicit self
File ".../site-packages/dill/_dill.py", line 1251, in save_module_dict
StockPickler.save_dict(pickler, obj)
File ".../pickle.py", line 972, in save_dict
self._batch_setitems(obj.items())
File ".../pickle.py", line 998, in _batch_setitems
save(v)
File ".../pickle.py", line 560, in save
f(self, obj) # Call unbound method with explicit self
File ".../site-packages/dill/_dill.py", line 1963, in save_function
_save_with_postproc(pickler, (_create_function, (
File ".../site-packages/dill/_dill.py", line 1140, in _save_with_postproc
pickler.save_reduce(*reduction, obj=obj)
File ".../pickle.py", line 717, in save_reduce
save(state)
File ".../pickle.py", line 560, in save
f(self, obj) # Call unbound method with explicit self
File ".../pickle.py", line 887, in save_tuple
save(element)
File ".../pickle.py", line 560, in save
f(self, obj) # Call unbound method with explicit self
File ".../site-packages/dill/_dill.py", line 1251, in save_module_dict
StockPickler.save_dict(pickler, obj)
File ".../pickle.py", line 972, in save_dict
self._batch_setitems(obj.items())
File ".../pickle.py", line 998, in _batch_setitems
save(v)
File ".../pickle.py", line 560, in save
f(self, obj) # Call unbound method with explicit self
File ".../site-packages/dill/_dill.py", line 1963, in save_function
_save_with_postproc(pickler, (_create_function, (
File ".../site-packages/dill/_dill.py", line 1154, in _save_with_postproc
pickler._batch_setitems(iter(source.items()))
File ".../pickle.py", line 998, in _batch_setitems
save(v)
File ".../pickle.py", line 578, in save
rv = reduce(self.proto)
File ".../logging/__init__.py", line 1774, in __reduce__
raise pickle.PicklingError('logger cannot be pickled')
_pickle.PicklingError: logger cannot be pickled
```
## Steps to reproduce the bug
Sorry I failed to have a minimal reproducible example, but the offending line on my end is
```python
dataset.map(
lambda examples: self.tokenize(examples), # this doesn't matter, lambda e: [1] * len(...) also breaks. In fact I'm pretty sure it breaks before executing this lambda
batched=True,
num_proc=4,
)
```
This does work when `num_proc=1`, so it's likely a multiprocessing thing.
## Expected results
`map` succeeds
## Actual results
The error trace above.
## Environment info
- `datasets` version: 1.16.1 and 2.5.1 both failed
- Platform: Ubuntu 20.04.4 LTS
- Python version: 3.10.4
- PyArrow version: 9.0.0
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/5061/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/5061/timeline
| null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5060
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5060/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5060/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5060/events
|
https://github.com/huggingface/datasets/issues/5060
| 1,395,382,940 |
I_kwDODunzps5TK9qc
| 5,060 |
Unable to Use Custom Dataset Locally
|
{
"login": "zanussbaum",
"id": 33707069,
"node_id": "MDQ6VXNlcjMzNzA3MDY5",
"avatar_url": "https://avatars.githubusercontent.com/u/33707069?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/zanussbaum",
"html_url": "https://github.com/zanussbaum",
"followers_url": "https://api.github.com/users/zanussbaum/followers",
"following_url": "https://api.github.com/users/zanussbaum/following{/other_user}",
"gists_url": "https://api.github.com/users/zanussbaum/gists{/gist_id}",
"starred_url": "https://api.github.com/users/zanussbaum/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/zanussbaum/subscriptions",
"organizations_url": "https://api.github.com/users/zanussbaum/orgs",
"repos_url": "https://api.github.com/users/zanussbaum/repos",
"events_url": "https://api.github.com/users/zanussbaum/events{/privacy}",
"received_events_url": "https://api.github.com/users/zanussbaum/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] |
closed
| false | null |
[] | null |
[
"Hi ! I opened a PR in your repo to fix this :)\r\nhttps://huggingface.co/datasets/zpn/pubchem_selfies/discussions/7\r\n\r\nbasically you need to use `open` for streaming to work properly",
"Thank you so much for this! Naive question, is this a feature of `open` or have you all overloaded it to be able to read from a URL? Any links to code/documentation would be greatly appreciated, I'd love to learn more",
"`datasets` extends `open` in dataset scripts to work with URLs. The builtin `open` from python only works with local files.\r\n\r\nYou can find the extension here: https://github.com/huggingface/datasets/blob/6ad430ba0cdeeb601170f732d4bd977f5c04594d/src/datasets/download/streaming_download_manager.py#L435-L451\r\n\r\nI think we can create a docs section dedicated to streaming to explain how this works",
"Closing this one - feel free to reopen if you have more questions"
] | 2022-10-03T21:55:16 | 2022-10-06T14:29:18 | 2022-10-06T14:29:17 |
CONTRIBUTOR
| null | null | null |
## Describe the bug
I have uploaded a [dataset](https://huggingface.co/datasets/zpn/pubchem_selfies) and followed the instructions from the [dataset_loader](https://huggingface.co/docs/datasets/dataset_script#download-data-files-and-organize-splits) tutorial. In that tutorial, it says
```
If the data files live in the same folder or repository of the dataset script,
you can just pass the relative paths to the files instead of URLs.
```
Accordingly, I put the [relative path](https://huggingface.co/datasets/zpn/pubchem_selfies/blob/main/pubchem_selfies.py#L76) to the data to be used. I was able to test the dataset and generate the metadata locally with `datasets-cli test path/to/<your-dataset-loading-script> --save_infos --all_configs`
However, if I try to load the data using `load_dataset`, I get the following error
```
with gzip.open(filepath, mode="rt") as f:
File "/usr/local/Cellar/[email protected]/3.9.7_1/Frameworks/Python.framework/Versions/3.9/lib/python3.9/gzip.py", line 58, in open
binary_file = GzipFile(filename, gz_mode, compresslevel)
File "/usr/local/Cellar/[email protected]/3.9.7_1/Frameworks/Python.framework/Versions/3.9/lib/python3.9/gzip.py", line 173, in __init__
fileobj = self.myfileobj = builtins.open(filename, mode or 'rb')
FileNotFoundError: [Errno 2] No such file or directory: 'https://huggingface.co/datasets/zpn/pubchem_selfies/resolve/main/data/Compound_021000001_021500000/Compound_021000001_021500000_SELFIES.jsonl.gz'
```
## Steps to reproduce the bug
```python
>>> from datasets import load_dataset
>>> dataset = load_dataset("zpn/pubchem_selfies", streaming=True)
>>> t = dataset["train"]
>>> for item in t:
...... print(item)
...... break
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/Users/zachnussbaum/env/lib/python3.9/site-packages/datasets/iterable_dataset.py", line 723, in __iter__
for key, example in self._iter():
File "/Users/zachnussbaum/env/lib/python3.9/site-packages/datasets/iterable_dataset.py", line 713, in _iter
yield from ex_iterable
File "/Users/zachnussbaum/env/lib/python3.9/site-packages/datasets/iterable_dataset.py", line 113, in __iter__
yield from self.generate_examples_fn(**self.kwargs)
File "/Users/zachnussbaum/.cache/huggingface/modules/datasets_modules/datasets/zpn--pubchem_selfies/d2571f35996765aea70fd3f3f8e3882d59c401fb738615c79282e2eb1d9f7a25/pubchem_selfies.py", line 475, in _generate_examples
with gzip.open(filepath, mode="rt") as f:
File "/usr/local/Cellar/[email protected]/3.9.7_1/Frameworks/Python.framework/Versions/3.9/lib/python3.9/gzip.py", line 58, in open
binary_file = GzipFile(filename, gz_mode, compresslevel)
File "/usr/local/Cellar/[email protected]/3.9.7_1/Frameworks/Python.framework/Versions/3.9/lib/python3.9/gzip.py", line 173, in __init__
fileobj = self.myfileobj = builtins.open(filename, mode or 'rb')
FileNotFoundError: [Errno 2] No such file or directory: 'https://huggingface.co/datasets/zpn/pubchem_selfies/resolve/main/data/Compound_021000001_021500000/Compound_021000001_021500000_SELFIES.jsonl.gz'
````
```
## Expected results
A clear and concise description of the expected results.
## Actual results
Specify the actual results or traceback.
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 2.5.1
- Platform: macOS-12.5.1-x86_64-i386-64bit
- Python version: 3.9.7
- PyArrow version: 9.0.0
- Pandas version: 1.5.0
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/5060/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/5060/timeline
| null |
completed
| false |
https://api.github.com/repos/huggingface/datasets/issues/5059
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5059/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5059/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5059/events
|
https://github.com/huggingface/datasets/pull/5059
| 1,395,050,876 |
PR_kwDODunzps5AEoX7
| 5,059 |
Fix typo
|
{
"login": "stevhliu",
"id": 59462357,
"node_id": "MDQ6VXNlcjU5NDYyMzU3",
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stevhliu",
"html_url": "https://github.com/stevhliu",
"followers_url": "https://api.github.com/users/stevhliu/followers",
"following_url": "https://api.github.com/users/stevhliu/following{/other_user}",
"gists_url": "https://api.github.com/users/stevhliu/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stevhliu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stevhliu/subscriptions",
"organizations_url": "https://api.github.com/users/stevhliu/orgs",
"repos_url": "https://api.github.com/users/stevhliu/repos",
"events_url": "https://api.github.com/users/stevhliu/events{/privacy}",
"received_events_url": "https://api.github.com/users/stevhliu/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-10-03T17:05:25 | 2022-10-03T17:34:40 | 2022-10-03T17:32:27 |
MEMBER
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5059",
"html_url": "https://github.com/huggingface/datasets/pull/5059",
"diff_url": "https://github.com/huggingface/datasets/pull/5059.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5059.patch",
"merged_at": "2022-10-03T17:32:27"
}
|
Fixes a small typo :)
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/5059/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/5059/timeline
| null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5058
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5058/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5058/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5058/events
|
https://github.com/huggingface/datasets/pull/5058
| 1,394,962,424 |
PR_kwDODunzps5AEVWn
| 5,058 |
Mark CI tests as xfail when 502 error
|
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-10-03T15:53:55 | 2022-10-04T10:03:23 | 2022-10-04T10:01:23 |
MEMBER
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5058",
"html_url": "https://github.com/huggingface/datasets/pull/5058",
"diff_url": "https://github.com/huggingface/datasets/pull/5058.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5058.patch",
"merged_at": "2022-10-04T10:01:23"
}
|
To make CI more robust, we could mark as xfail when the Hub raises a 502 error (besides 500 error):
- FAILED tests/test_upstream_hub.py::TestPushToHub::test_push_dataset_to_hub_skip_identical_files
- https://github.com/huggingface/datasets/actions/runs/3174626525/jobs/5171672431
```
> raise HTTPError(http_error_msg, response=self)
E requests.exceptions.HTTPError: 502 Server Error: Bad Gateway for url: https://hub-ci.huggingface.co/datasets/__DUMMY_TRANSFORMERS_USER__/test-16648055339047.git/info/lfs/objects/batch
```
- FAILED tests/test_upstream_hub.py::TestPushToHub::test_push_dataset_dict_to_hub_overwrite_files
- https://github.com/huggingface/datasets/actions/runs/3145587033/jobs/5113074889
```
> raise HTTPError(http_error_msg, response=self)
E requests.exceptions.HTTPError: 502 Server Error: Bad Gateway for url: https://hub-ci.huggingface.co/datasets/__DUMMY_TRANSFORMERS_USER__/test-16643866807322.git/info/lfs/objects/verify
```
Currently, we mark as xfail when 500 error:
- #4845
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/5058/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/5058/timeline
| null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5057
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5057/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5057/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5057/events
|
https://github.com/huggingface/datasets/pull/5057
| 1,394,827,216 |
PR_kwDODunzps5AD4c6
| 5,057 |
Support `converters` in `CsvBuilder`
|
{
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-10-03T14:23:21 | 2022-10-04T11:19:28 | 2022-10-04T11:17:32 |
CONTRIBUTOR
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5057",
"html_url": "https://github.com/huggingface/datasets/pull/5057",
"diff_url": "https://github.com/huggingface/datasets/pull/5057.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5057.patch",
"merged_at": "2022-10-04T11:17:32"
}
|
Add the `converters` param to `CsvBuilder`, to help in situations like [this one](https://discuss.huggingface.co/t/typeerror-in-load-dataset-related-to-a-sequence-of-strings/23545).
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/5057/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/5057/timeline
| null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5056
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5056/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5056/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5056/events
|
https://github.com/huggingface/datasets/pull/5056
| 1,394,713,173 |
PR_kwDODunzps5ADfxN
| 5,056 |
Fix broken URL's (GEM)
|
{
"login": "manandey",
"id": 6687858,
"node_id": "MDQ6VXNlcjY2ODc4NTg=",
"avatar_url": "https://avatars.githubusercontent.com/u/6687858?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/manandey",
"html_url": "https://github.com/manandey",
"followers_url": "https://api.github.com/users/manandey/followers",
"following_url": "https://api.github.com/users/manandey/following{/other_user}",
"gists_url": "https://api.github.com/users/manandey/gists{/gist_id}",
"starred_url": "https://api.github.com/users/manandey/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/manandey/subscriptions",
"organizations_url": "https://api.github.com/users/manandey/orgs",
"repos_url": "https://api.github.com/users/manandey/repos",
"events_url": "https://api.github.com/users/manandey/events{/privacy}",
"received_events_url": "https://api.github.com/users/manandey/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5056). All of your documentation changes will be reflected on that endpoint.",
"Thanks, @manandey. We have removed all dataset scripts from this repo. Subsequent PRs should be opened directly on the Hugging Face Hub."
] | 2022-10-03T13:13:22 | 2022-10-04T13:49:00 | 2022-10-04T13:48:59 |
CONTRIBUTOR
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5056",
"html_url": "https://github.com/huggingface/datasets/pull/5056",
"diff_url": "https://github.com/huggingface/datasets/pull/5056.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5056.patch",
"merged_at": null
}
|
This PR fixes the broken URL's in GEM. cc. @lhoestq, @albertvillanova
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/5056/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/5056/timeline
| null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5055
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5055/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5055/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5055/events
|
https://github.com/huggingface/datasets/pull/5055
| 1,394,503,844 |
PR_kwDODunzps5ACyVU
| 5,055 |
Fix backward compatibility for dataset_infos.json
|
{
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-10-03T10:30:14 | 2022-10-03T13:43:55 | 2022-10-03T13:41:32 |
MEMBER
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5055",
"html_url": "https://github.com/huggingface/datasets/pull/5055",
"diff_url": "https://github.com/huggingface/datasets/pull/5055.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5055.patch",
"merged_at": "2022-10-03T13:41:32"
}
|
While working on https://github.com/huggingface/datasets/pull/5018 I noticed a small bug introduced in #4926 regarding backward compatibility for dataset_infos.json
Indeed, when a dataset repo had both dataset_infos.json and README.md, the JSON file was ignored. This is unexpected: in practice it should be ignored only if the README.md has a dataset_info field, which has precedence over the data in the JSON file.
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/5055/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/5055/timeline
| null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5054
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5054/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5054/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5054/events
|
https://github.com/huggingface/datasets/pull/5054
| 1,394,152,728 |
PR_kwDODunzps5ABnd3
| 5,054 |
Fix license/citation information of squadshifts dataset card
|
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 4564477500,
"node_id": "LA_kwDODunzps8AAAABEBBmPA",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20contribution",
"name": "dataset contribution",
"color": "0e8a16",
"default": false,
"description": "Contribution to a dataset script"
}
] |
closed
| false | null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-10-03T05:19:13 | 2022-10-03T09:26:49 | 2022-10-03T09:24:30 |
MEMBER
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5054",
"html_url": "https://github.com/huggingface/datasets/pull/5054",
"diff_url": "https://github.com/huggingface/datasets/pull/5054.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5054.patch",
"merged_at": "2022-10-03T09:24:30"
}
|
This PR fixes the license/citation information of squadshifts dataset card, once the dataset owners have responded to our request for information:
- https://github.com/modestyachts/squadshifts-website/issues/1
Additionally, we have updated the mention in their website to our `datasets` library (they were referring old name `nlp`):
- https://github.com/modestyachts/squadshifts-website/pull/2#event-7500953009
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/5054/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/5054/timeline
| null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5053
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5053/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5053/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5053/events
|
https://github.com/huggingface/datasets/issues/5053
| 1,393,739,882 |
I_kwDODunzps5TEshq
| 5,053 |
Intermittent JSON parse error when streaming the Pile
|
{
"login": "neelnanda-io",
"id": 77788841,
"node_id": "MDQ6VXNlcjc3Nzg4ODQx",
"avatar_url": "https://avatars.githubusercontent.com/u/77788841?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/neelnanda-io",
"html_url": "https://github.com/neelnanda-io",
"followers_url": "https://api.github.com/users/neelnanda-io/followers",
"following_url": "https://api.github.com/users/neelnanda-io/following{/other_user}",
"gists_url": "https://api.github.com/users/neelnanda-io/gists{/gist_id}",
"starred_url": "https://api.github.com/users/neelnanda-io/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/neelnanda-io/subscriptions",
"organizations_url": "https://api.github.com/users/neelnanda-io/orgs",
"repos_url": "https://api.github.com/users/neelnanda-io/repos",
"events_url": "https://api.github.com/users/neelnanda-io/events{/privacy}",
"received_events_url": "https://api.github.com/users/neelnanda-io/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] |
open
| false | null |
[] | null |
[
"Maybe #2838 can help. In this PR we allow to skip bad chunks of JSON data to not crash the training\r\n\r\nDid you have warning messages before the error ?\r\n\r\nsomething like this maybe ?\r\n```\r\n03/24/2022 02:19:46 - WARNING - datasets.utils.streaming_download_manager - Got disconnected from remote data host. Retrying in 5sec [1/20]\r\n03/24/2022 02:20:01 - WARNING - datasets.utils.streaming_download_manager - Got disconnected from remote data host. Retrying in 5sec [2/20]\r\n03/24/2022 02:20:09 - ERROR - datasets.packaged_modules.json.json - Failed to read file 'gzip://file-000000000007.json::https://huggingface.co/datasets/lvwerra/codeparrot-clean-train/resolve/1d740acb9d09cf7a3307553323e2c677a6535407/file-000000000007.json.gz' with error <class 'pyarrow.lib.ArrowInvalid'>: JSON parse error: Invalid value. in row 0\r\n```",
"Ah, thanks! I did get errors like that. Sad that PR wasn't merged in! \r\n\r\nI'm currently just downloading 200GB of the Pile locally to avoid streaming (I have space and it's faster anyway), but that's really useful! I can probably apply the dumb patch of just commenting out the bits that raise the JSON Parse Error lol, based on your code - if I continue the loop should it be fine?",
"Yup you can get some inspiration from this PR. It simply ignores the bad chunks (a chunk is ~a few MBs of data).\r\nWe'll try to merge this PR soon"
] | 2022-10-02T11:56:46 | 2022-10-04T17:59:03 | null |
NONE
| null | null | null |
## Describe the bug
I have an intermittent error when streaming the Pile, where I get a JSON parse error which causes my program to crash.
This is intermittent - when I rerun the program with the same random seed it does not crash in the same way. The exact point this happens also varied - it happened to me 11B tokens and 4 days into a training run, and now just happened 2 minutes into one, but I can't reliably reproduce it.
I'm using a remote machine with 8 A6000 GPUs via runpod.io
## Expected results
I have a DataLoader which can iterate through the whole Pile
## Actual results
Stack trace:
```
Failed to read file 'zstd://12.jsonl::https://the-eye.eu/public/AI/pile/train/12.jsonl.zst' with error <class 'pyarrow.lib.ArrowInvalid'>: JSON parse error: Invalid value. in row 0
```
I'm currently using HuggingFace accelerate, which also gave me the following stack trace, but I've also experienced this problem intermittently when using DataParallel, so I don't think it's to do with parallelisation
```
Traceback (most recent call last):
File "ddp_script.py", line 1258, in <module>
main()
File "ddp_script.py", line 1143, in main
for c, batch in tqdm.tqdm(enumerate(data_iter)):
File "/opt/conda/lib/python3.7/site-packages/tqdm/std.py", line 1195, in __iter__
for obj in iterable:
File "/opt/conda/lib/python3.7/site-packages/accelerate/data_loader.py", line 503, in __iter__
next_batch, next_batch_info, next_skip = self._fetch_batches(main_iterator)
File "/opt/conda/lib/python3.7/site-packages/accelerate/data_loader.py", line 454, in _fetch_batches
broadcast_object_list(batch_info)
File "/opt/conda/lib/python3.7/site-packages/accelerate/utils/operations.py", line 333, in broadcast_object_list
torch.distributed.broadcast_object_list(object_list, src=from_process)
File "/opt/conda/lib/python3.7/site-packages/torch/distributed/distributed_c10d.py", line 1900, in broadcast_object_list
object_list[i] = _tensor_to_object(obj_view, obj_size)
File "/opt/conda/lib/python3.7/site-packages/torch/distributed/distributed_c10d.py", line 1571, in _tensor_to_object
return _unpickler(io.BytesIO(buf)).load()
_pickle.UnpicklingError: invalid load key, '@'.
```
## Steps to reproduce the bug
```python
from datasets import load_dataset
dataset = load_dataset(
cfg["dataset_name"], streaming=True, split="train")
dataset = dataset.remove_columns("meta")
dataset = dataset.map(tokenize_and_concatenate, batched=True)
dataset = dataset.with_format(type="torch")
train_data_loader = DataLoader(
dataset, batch_size=cfg["batch_size"], num_workers=3)
for batch in train_data_loader:
continue
```
`tokenize_and_concatenate` is a custom tokenization function I defined on the GPT-NeoX tokenizer to tokenize the text, separated by endoftext tokens, and reshape to have length batch_size, I don't think this is related to tokenization:
```
import numpy as np
import einops
import torch
def tokenize_and_concatenate(examples):
texts = examples["text"]
full_text = tokenizer.eos_token.join(texts)
div = 20
length = len(full_text) // div
text_list = [full_text[i * length: (i + 1) * length]
for i in range(div)]
tokens = tokenizer(text_list, return_tensors="np", padding=True)[
"input_ids"
].flatten()
tokens = tokens[tokens != tokenizer.pad_token_id]
n = len(tokens)
curr_batch_size = n // (seq_len - 1)
tokens = tokens[: (seq_len - 1) * curr_batch_size]
tokens = einops.rearrange(
tokens,
"(batch_size seq) -> batch_size seq",
batch_size=curr_batch_size,
seq=seq_len - 1,
)
prefix = np.ones((curr_batch_size, 1), dtype=np.int64) * \
tokenizer.bos_token_id
return {
"text": np.concatenate([prefix, tokens], axis=1)
}
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 2.4.0
- Platform: Linux-5.4.0-105-generic-x86_64-with-debian-buster-sid
- Python version: 3.7.13
- PyArrow version: 9.0.0
- Pandas version: 1.3.5
ZStandard data:
Version: 0.18.0
Summary: Zstandard bindings for Python
Home-page: https://github.com/indygreg/python-zstandard
Author: Gregory Szorc
Author-email: [email protected]
License: BSD
Location: /opt/conda/lib/python3.7/site-packages
Requires:
Required-by:
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/5053/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/5053/timeline
| null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5052
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5052/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5052/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5052/events
|
https://github.com/huggingface/datasets/pull/5052
| 1,393,076,765 |
PR_kwDODunzps4_-PZw
| 5,052 |
added from_generator method to IterableDataset class.
|
{
"login": "hamid-vakilzadeh",
"id": 56002455,
"node_id": "MDQ6VXNlcjU2MDAyNDU1",
"avatar_url": "https://avatars.githubusercontent.com/u/56002455?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/hamid-vakilzadeh",
"html_url": "https://github.com/hamid-vakilzadeh",
"followers_url": "https://api.github.com/users/hamid-vakilzadeh/followers",
"following_url": "https://api.github.com/users/hamid-vakilzadeh/following{/other_user}",
"gists_url": "https://api.github.com/users/hamid-vakilzadeh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/hamid-vakilzadeh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/hamid-vakilzadeh/subscriptions",
"organizations_url": "https://api.github.com/users/hamid-vakilzadeh/orgs",
"repos_url": "https://api.github.com/users/hamid-vakilzadeh/repos",
"events_url": "https://api.github.com/users/hamid-vakilzadeh/events{/privacy}",
"received_events_url": "https://api.github.com/users/hamid-vakilzadeh/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"I added a test and moved the `streaming` param from `read` to `__init_`. Then, I also decided to update the `read` method of the rest of the packaged modules to account for this param. \r\n\r\n@hamid-vakilzadeh Are you OK with these changes? ",
"@mariosasko these all look great! Thanks for the updates."
] | 2022-09-30T22:14:05 | 2022-10-05T12:51:48 | 2022-10-05T12:10:48 |
CONTRIBUTOR
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5052",
"html_url": "https://github.com/huggingface/datasets/pull/5052",
"diff_url": "https://github.com/huggingface/datasets/pull/5052.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5052.patch",
"merged_at": "2022-10-05T12:10:48"
}
|
Hello,
This resolves issues #4988.
I added a method `from_generator` to class `IterableDataset`.
I modified the `read` method of input stream generator to also return Iterable_dataset.
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/5052/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/5052/timeline
| null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5051
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5051/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5051/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5051/events
|
https://github.com/huggingface/datasets/pull/5051
| 1,392,559,503 |
PR_kwDODunzps4_8drw
| 5,051 |
Revert task removal in folder-based builders
|
{
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-09-30T14:50:03 | 2022-10-03T12:23:35 | 2022-10-03T12:21:31 |
CONTRIBUTOR
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5051",
"html_url": "https://github.com/huggingface/datasets/pull/5051",
"diff_url": "https://github.com/huggingface/datasets/pull/5051.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5051.patch",
"merged_at": "2022-10-03T12:21:31"
}
|
Reverts the removal of `task_templates` in the folder-based builders. I also added the `AudioClassifaction` task for consistency.
This is needed to fix https://github.com/huggingface/transformers/issues/19177.
I think we should soon deprecate and remove the current task API (and investigate if it's possible to integrate the `train eval index` API), but we need to update the Transformers examples before that so we don't break them.
cc @NielsRogge
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/5051/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/5051/timeline
| null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5050
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5050/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5050/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5050/events
|
https://github.com/huggingface/datasets/issues/5050
| 1,392,381,882 |
I_kwDODunzps5S_g-6
| 5,050 |
Restore saved format state in `load_from_disk`
|
{
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
},
{
"id": 1935892877,
"node_id": "MDU6TGFiZWwxOTM1ODkyODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/good%20first%20issue",
"name": "good first issue",
"color": "7057ff",
"default": true,
"description": "Good for newcomers"
}
] |
closed
| false |
{
"login": "asofiaoliveira",
"id": 74454835,
"node_id": "MDQ6VXNlcjc0NDU0ODM1",
"avatar_url": "https://avatars.githubusercontent.com/u/74454835?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/asofiaoliveira",
"html_url": "https://github.com/asofiaoliveira",
"followers_url": "https://api.github.com/users/asofiaoliveira/followers",
"following_url": "https://api.github.com/users/asofiaoliveira/following{/other_user}",
"gists_url": "https://api.github.com/users/asofiaoliveira/gists{/gist_id}",
"starred_url": "https://api.github.com/users/asofiaoliveira/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/asofiaoliveira/subscriptions",
"organizations_url": "https://api.github.com/users/asofiaoliveira/orgs",
"repos_url": "https://api.github.com/users/asofiaoliveira/repos",
"events_url": "https://api.github.com/users/asofiaoliveira/events{/privacy}",
"received_events_url": "https://api.github.com/users/asofiaoliveira/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"login": "asofiaoliveira",
"id": 74454835,
"node_id": "MDQ6VXNlcjc0NDU0ODM1",
"avatar_url": "https://avatars.githubusercontent.com/u/74454835?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/asofiaoliveira",
"html_url": "https://github.com/asofiaoliveira",
"followers_url": "https://api.github.com/users/asofiaoliveira/followers",
"following_url": "https://api.github.com/users/asofiaoliveira/following{/other_user}",
"gists_url": "https://api.github.com/users/asofiaoliveira/gists{/gist_id}",
"starred_url": "https://api.github.com/users/asofiaoliveira/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/asofiaoliveira/subscriptions",
"organizations_url": "https://api.github.com/users/asofiaoliveira/orgs",
"repos_url": "https://api.github.com/users/asofiaoliveira/repos",
"events_url": "https://api.github.com/users/asofiaoliveira/events{/privacy}",
"received_events_url": "https://api.github.com/users/asofiaoliveira/received_events",
"type": "User",
"site_admin": false
}
] | null |
[
"Hi, can I work on this?",
"Hi, sure! Let us know if you need some pointers/help."
] | 2022-09-30T12:40:07 | 2022-10-11T16:49:24 | 2022-10-11T16:49:24 |
CONTRIBUTOR
| null | null | null |
Even though we save the `format` state in `save_to_disk`, we don't restore it in `load_from_disk`. We should fix that.
Reported here: https://discuss.huggingface.co/t/save-to-disk-loses-formatting-information/23815
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/5050/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/5050/timeline
| null |
completed
| false |
https://api.github.com/repos/huggingface/datasets/issues/5049
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5049/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5049/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5049/events
|
https://github.com/huggingface/datasets/pull/5049
| 1,392,361,381 |
PR_kwDODunzps4_7zOY
| 5,049 |
Add `kwargs` to `Dataset.from_generator`
|
{
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-09-30T12:24:27 | 2022-10-03T11:00:11 | 2022-10-03T10:58:15 |
CONTRIBUTOR
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5049",
"html_url": "https://github.com/huggingface/datasets/pull/5049",
"diff_url": "https://github.com/huggingface/datasets/pull/5049.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5049.patch",
"merged_at": "2022-10-03T10:58:15"
}
|
Add the `kwargs` param to `from_generator` to align it with the rest of the `from_` methods (this param allows passing custom `writer_batch_size` for instance).
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/5049/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/5049/timeline
| null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5048
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5048/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5048/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5048/events
|
https://github.com/huggingface/datasets/pull/5048
| 1,392,170,680 |
PR_kwDODunzps4_7KI2
| 5,048 |
Fix bug with labels of eurlex config of lex_glue dataset
|
{
"login": "iliaschalkidis",
"id": 1626984,
"node_id": "MDQ6VXNlcjE2MjY5ODQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/1626984?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/iliaschalkidis",
"html_url": "https://github.com/iliaschalkidis",
"followers_url": "https://api.github.com/users/iliaschalkidis/followers",
"following_url": "https://api.github.com/users/iliaschalkidis/following{/other_user}",
"gists_url": "https://api.github.com/users/iliaschalkidis/gists{/gist_id}",
"starred_url": "https://api.github.com/users/iliaschalkidis/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/iliaschalkidis/subscriptions",
"organizations_url": "https://api.github.com/users/iliaschalkidis/orgs",
"repos_url": "https://api.github.com/users/iliaschalkidis/repos",
"events_url": "https://api.github.com/users/iliaschalkidis/events{/privacy}",
"received_events_url": "https://api.github.com/users/iliaschalkidis/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 4564477500,
"node_id": "LA_kwDODunzps8AAAABEBBmPA",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20contribution",
"name": "dataset contribution",
"color": "0e8a16",
"default": false,
"description": "Contribution to a dataset script"
}
] |
closed
| false | null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"@JamesLYC88 here is the fix! Thanks again!",
"Thanks, @albertvillanova. When do you expect that this change will take effect when someone downloads the dataset?",
"The change is immediately available now, since this change we made to our library:\r\n- #4059"
] | 2022-09-30T09:47:12 | 2022-09-30T16:30:25 | 2022-09-30T16:21:41 |
CONTRIBUTOR
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5048",
"html_url": "https://github.com/huggingface/datasets/pull/5048",
"diff_url": "https://github.com/huggingface/datasets/pull/5048.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5048.patch",
"merged_at": "2022-09-30T16:21:41"
}
|
Fix for a critical bug in the EURLEX dataset label list to make LexGLUE EURLEX results replicable.
In LexGLUE (Chalkidis et al., 2022), the following is mentioned w.r.t. EUR-LEX: _"It supports four different label granularities, comprising 21, 127, 567, 7390 EuroVoc concepts, respectively. We use the 100 most frequent concepts from level 2 [...]”._ The current label list has all 127 labels, which leads to different (lower) results, as communicated by users.
Thanks!
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/5048/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/5048/timeline
| null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5047
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5047/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5047/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5047/events
|
https://github.com/huggingface/datasets/pull/5047
| 1,392,088,398 |
PR_kwDODunzps4_64bS
| 5,047 |
Fix cats_vs_dogs
|
{
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 4564477500,
"node_id": "LA_kwDODunzps8AAAABEBBmPA",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20contribution",
"name": "dataset contribution",
"color": "0e8a16",
"default": false,
"description": "Contribution to a dataset script"
}
] |
closed
| false | null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-09-30T08:47:29 | 2022-09-30T10:23:22 | 2022-09-30T09:34:28 |
MEMBER
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5047",
"html_url": "https://github.com/huggingface/datasets/pull/5047",
"diff_url": "https://github.com/huggingface/datasets/pull/5047.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5047.patch",
"merged_at": "2022-09-30T09:34:28"
}
|
Reported in https://github.com/huggingface/datasets/pull/3878
I updated the number of examples
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/5047/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/5047/timeline
| null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5046
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5046/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5046/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5046/events
|
https://github.com/huggingface/datasets/issues/5046
| 1,391,372,519 |
I_kwDODunzps5S7qjn
| 5,046 |
Audiofolder creates empty Dataset if files same level as metadata
|
{
"login": "msis",
"id": 577139,
"node_id": "MDQ6VXNlcjU3NzEzOQ==",
"avatar_url": "https://avatars.githubusercontent.com/u/577139?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/msis",
"html_url": "https://github.com/msis",
"followers_url": "https://api.github.com/users/msis/followers",
"following_url": "https://api.github.com/users/msis/following{/other_user}",
"gists_url": "https://api.github.com/users/msis/gists{/gist_id}",
"starred_url": "https://api.github.com/users/msis/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/msis/subscriptions",
"organizations_url": "https://api.github.com/users/msis/orgs",
"repos_url": "https://api.github.com/users/msis/repos",
"events_url": "https://api.github.com/users/msis/events{/privacy}",
"received_events_url": "https://api.github.com/users/msis/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
},
{
"id": 1935892877,
"node_id": "MDU6TGFiZWwxOTM1ODkyODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/good%20first%20issue",
"name": "good first issue",
"color": "7057ff",
"default": true,
"description": "Good for newcomers"
},
{
"id": 4614514401,
"node_id": "LA_kwDODunzps8AAAABEwvm4Q",
"url": "https://api.github.com/repos/huggingface/datasets/labels/hacktoberfest",
"name": "hacktoberfest",
"color": "DF8D62",
"default": false,
"description": ""
}
] |
closed
| false |
{
"login": "riccardobucco",
"id": 9295277,
"node_id": "MDQ6VXNlcjkyOTUyNzc=",
"avatar_url": "https://avatars.githubusercontent.com/u/9295277?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/riccardobucco",
"html_url": "https://github.com/riccardobucco",
"followers_url": "https://api.github.com/users/riccardobucco/followers",
"following_url": "https://api.github.com/users/riccardobucco/following{/other_user}",
"gists_url": "https://api.github.com/users/riccardobucco/gists{/gist_id}",
"starred_url": "https://api.github.com/users/riccardobucco/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/riccardobucco/subscriptions",
"organizations_url": "https://api.github.com/users/riccardobucco/orgs",
"repos_url": "https://api.github.com/users/riccardobucco/repos",
"events_url": "https://api.github.com/users/riccardobucco/events{/privacy}",
"received_events_url": "https://api.github.com/users/riccardobucco/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"login": "riccardobucco",
"id": 9295277,
"node_id": "MDQ6VXNlcjkyOTUyNzc=",
"avatar_url": "https://avatars.githubusercontent.com/u/9295277?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/riccardobucco",
"html_url": "https://github.com/riccardobucco",
"followers_url": "https://api.github.com/users/riccardobucco/followers",
"following_url": "https://api.github.com/users/riccardobucco/following{/other_user}",
"gists_url": "https://api.github.com/users/riccardobucco/gists{/gist_id}",
"starred_url": "https://api.github.com/users/riccardobucco/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/riccardobucco/subscriptions",
"organizations_url": "https://api.github.com/users/riccardobucco/orgs",
"repos_url": "https://api.github.com/users/riccardobucco/repos",
"events_url": "https://api.github.com/users/riccardobucco/events{/privacy}",
"received_events_url": "https://api.github.com/users/riccardobucco/received_events",
"type": "User",
"site_admin": false
}
] | null |
[
"Hi! Unfortunately, I can't reproduce this behavior. Instead, I get `ValueError: audio at 2063_fe9936e7-62b2-4e62-a276-acbd344480ce_1.wav doesn't have metadata in /audio-data/metadata.csv`, which can be fixed by removing the `./` from the file name.\r\n\r\n(Link to a Colab that tries to reproduce this behavior: https://colab.research.google.com/drive/1IhQzULYi0Van1xLrN_SddBX1JF7mLZZK?usp=sharing)",
"I think we can make the file name matching part more robust by replacing `file_name` with `os.path.normpath(file_name)`, to ignore \"./\" among other things, in these two places:\r\n* https://github.com/huggingface/datasets/blob/85cd129bde605cd9acacdff0d065fc02e39e09b1/src/datasets/packaged_modules/folder_based_builder/folder_based_builder.py#L319\r\n* https://github.com/huggingface/datasets/blob/85cd129bde605cd9acacdff0d065fc02e39e09b1/src/datasets/packaged_modules/folder_based_builder/folder_based_builder.py#L388",
"@mariosasko Some tests failed (see my PR). Any thoughts on that?",
"Yes, I mentioned the solution in my review.",
"I realized what I was doing wrong.\r\n\r\nThe documentation puts the files in a subfolder.\r\nOnce I have done that, it worked.\r\n\r\nBut l agree that this should be handled better if possible."
] | 2022-09-29T19:17:23 | 2022-10-28T13:05:07 | 2022-10-28T13:05:07 |
NONE
| null | null | null |
## Describe the bug
When audio files are at the same level as the metadata (`metadata.csv` or `metadata.jsonl` ), the `load_dataset` returns a `DatasetDict` with no rows but the correct columns.
https://github.com/huggingface/datasets/blob/1ea4d091b7a4b83a85b2eeb8df65115d39af3766/docs/source/audio_dataset.mdx?plain=1#L88
## Steps to reproduce the bug
`metadata.csv`:
```csv
file_name,duration,transcription
./2063_fe9936e7-62b2-4e62-a276-acbd344480ce_1.wav,10.768,hello
```
```python
>>> audio_dataset = load_dataset("audiofolder", data_dir="/audio-data/")
>>> audio_dataset
DatasetDict({
train: Dataset({
features: ['audio', 'duration', 'transcription'],
num_rows: 0
})
validation: Dataset({
features: ['audio', 'duration', 'transcription'],
num_rows: 0
})
})
```
I've tried, with no success,:
- setting `split` to something else so I don't get a `DatasetDict`,
- removing the `./`,
- using `.jsonl`.
## Expected results
```
Dataset({
features: ['audio', 'duration', 'transcription'],
num_rows: 1
})
```
## Actual results
```
DatasetDict({
train: Dataset({
features: ['audio', 'duration', 'transcription'],
num_rows: 0
})
validation: Dataset({
features: ['audio', 'duration', 'transcription'],
num_rows: 0
})
})
```
## Environment info
- `datasets` version: 2.5.1
- Platform: Linux-5.13.0-1025-aws-x86_64-with-glibc2.29
- Python version: 3.8.10
- PyArrow version: 9.0.0
- Pandas version: 1.5.0
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/5046/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/5046/timeline
| null |
completed
| false |
https://api.github.com/repos/huggingface/datasets/issues/5045
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5045/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5045/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5045/events
|
https://github.com/huggingface/datasets/issues/5045
| 1,391,287,609 |
I_kwDODunzps5S7V05
| 5,045 |
Automatically revert to last successful commit to hub when a push_to_hub is interrupted
|
{
"login": "jorahn",
"id": 13120204,
"node_id": "MDQ6VXNlcjEzMTIwMjA0",
"avatar_url": "https://avatars.githubusercontent.com/u/13120204?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jorahn",
"html_url": "https://github.com/jorahn",
"followers_url": "https://api.github.com/users/jorahn/followers",
"following_url": "https://api.github.com/users/jorahn/following{/other_user}",
"gists_url": "https://api.github.com/users/jorahn/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jorahn/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jorahn/subscriptions",
"organizations_url": "https://api.github.com/users/jorahn/orgs",
"repos_url": "https://api.github.com/users/jorahn/repos",
"events_url": "https://api.github.com/users/jorahn/events{/privacy}",
"received_events_url": "https://api.github.com/users/jorahn/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] |
open
| false | null |
[] | null |
[
"Could you share the error you got please ? Maybe the full stack trace if you have it ?\r\n\r\nMaybe `push_to_hub` be implemented as a single commit @Wauplin ? This way if it fails, the repo is still at the previous (valid) state instead of ending-up in an invalid/incimplete state.",
"> Maybe push_to_hub be implemented as a single commit ? \r\n\r\nI think that would definitely be the way to go. Do you know the reasons why not implementing it like this in the first place ? I guess it is because of not been able to upload all at once with `huggingface_hub` but if there was another reason, please let me know.\r\nAbout pushing all at once, it seems to be a more and more requested feature. I have created this issue https://github.com/huggingface/huggingface_hub/issues/1085 recently but other discussions already happened in the past. The `moon-landing` team is working on it (cc @coyotte508). The `huggingface_hub` integration will come afterwards.\r\n\r\nFor now, maybe it's best to wait for a proper implementation instead of creating a temporary workaround :)\r\n",
"> I think that would definitely be the way to go. Do you know the reasons why not implementing it like this in the first place ? I guess it is because of not been able to upload all at once with huggingface_hub but if there was another reason, please let me know.\r\n\r\nIdeally we would want to upload the files iteratively - and then once everything is uploaded we proceed to commit. When we implemented `push_to_hub`, using `upload_file` for each shard was the only option.\r\n\r\nFor more context: for each shard to upload we do:\r\n1. load the arrow shard in memory\r\n2. convert to parquet\r\n3. upload\r\n\r\nSo to avoid OOM we need to upload the files iteratively.\r\n\r\n> For now, maybe it's best to wait for a proper implementation instead of creating a temporary workaround :)\r\n\r\nLet us know if we can help !",
"> Ideally we would want to upload the files iteratively - and then once everything is uploaded we proceed to commit. \r\n\r\nOh I see. So maybe this has to be done in an implementation specific to `datasets/` as it is not a very common case (upload a bunch of files on the fly).\r\n\r\nYou can maybe have a look at how `huggingface_hub` is implemented for LFS files (arrow shards are LFS anyway, right?).\r\nIn [`upload_lfs_files`](https://github.com/huggingface/huggingface_hub/blob/e28646c977fc9304a4c3576ce61ff07f9778950b/src/huggingface_hub/_commit_api.py#L164) LFS files are uploaded 1 by 1 (multithreaded) and then [the commit is pushed](https://github.com/huggingface/huggingface_hub/blob/e28646c977fc9304a4c3576ce61ff07f9778950b/src/huggingface_hub/hf_api.py#L1926) to the Hub once all files have been uploaded. This is pretty much what you need, right ?\r\n\r\nI can help you if you have questions how to do it in `datasets`. If that makes sense we could then move the implementation from `datasets` to `huggingface_hub` once it's mature. Next week I'm on holidays but feel free to start without my input.\r\n\r\n(also cc @coyotte508 and @SBrandeis who implemented LFS upload in `hfh`)",
"> Could you share the error you got please ? Maybe the full stack trace if you have it ?\r\n\r\nHere’s part of the stack trace, that I can reproduce at the moment from a photo I took (potential typos from OCR):\r\n```\r\nValueError\r\nTraceback (most recent call last)\r\n<ipython-input-4-274613b7d3f5> in <module>\r\nfrom datasets import load dataset\r\nds = load_dataset('jrahn/chessv6', use_auth_token-True)\r\n\r\n/us/local/1ib/python3.7/dist-packages/datasets/table.py in cast_table _to_schema (table, schema)\r\nLine 2005 raise ValueError()\r\n\r\nValueError: Couldn't cast \r\nfen: string \r\nmove: string \r\nres: string \r\neco: string \r\nmove_id: int64\r\nres_num: int64 to\r\n{ 'fen': Value(dtype='string', id=None), \r\n'move': Value(dtype=' string', id=None),\r\n'res': Value(dtype='string', id=None),\r\n'eco': Value(dtype='string', id=None), \r\n'hc': Value(dtype='string', id=None), \r\n'move_ id': Value(dtype='int64', id=None),\r\n'res_num': Value(dtype= 'int64' , id=None) }\r\nbecause column names don't match \r\n```\r\n\r\nThe column 'hc' was removed before the interrupted push_to_hub(). It appears in the column list in curly brackets but not in the column list above.\r\n\r\nLet me know, if I can be of any help."
] | 2022-09-29T18:08:12 | 2022-09-30T16:49:21 | null |
NONE
| null | null | null |
**Is your feature request related to a problem? Please describe.**
I pushed a modification of a large dataset (remove a column) to the hub. The push was interrupted after some files were committed to the repo. This left the dataset to raise an error on load_dataset() (ValueError couldn’t cast … because column names don’t match). Only by specifying the previous (complete) commit as revision=commit_hash in load_data(), I was able to repair this and after a successful, complete push, the dataset loads without error again.
**Describe the solution you'd like**
Would it make sense to detect an incomplete push_to_hub() and automatically revert to the previous commit/revision?
**Describe alternatives you've considered**
Leave everything as is, the revision parameter in load_dataset() allows to manually fix this problem.
**Additional context**
Provide useful defaults
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/5045/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/5045/timeline
| null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5044
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5044/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5044/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5044/events
|
https://github.com/huggingface/datasets/issues/5044
| 1,391,242,908 |
I_kwDODunzps5S7K6c
| 5,044 |
integrate `load_from_disk` into `load_dataset`
|
{
"login": "stas00",
"id": 10676103,
"node_id": "MDQ6VXNlcjEwNjc2MTAz",
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stas00",
"html_url": "https://github.com/stas00",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://api.github.com/users/stas00/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stas00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stas00/subscriptions",
"organizations_url": "https://api.github.com/users/stas00/orgs",
"repos_url": "https://api.github.com/users/stas00/repos",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"received_events_url": "https://api.github.com/users/stas00/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] |
open
| false | null |
[] | null |
[
"I agree the situation is not ideal and it would be awesome to use `load_dataset` to reload a dataset saved locally !\r\n\r\nFor context:\r\n\r\n- `load_dataset` works in three steps: download the dataset, then prepare it as an arrow dataset, and finally return a memory mapped arrow dataset. In particular it creates a cache directory to store the arrow data and the subsequent cache files for `map`.\r\n\r\n- `load_from_disk` directly returns a memory mapped dataset from the arrow file (similar to `Dataset.from_file`). It doesn't create a cache diretory, instead all the subsequent `map` calls write in the same directory as the original data. \r\n\r\nIf we want to keep the download_and_prepare step for consistency, it would unnecessarily copy the arrow data into the datasets cache. On the other hand if we don't do this step, the cache directory doesn't exist which is inconsistent.\r\n\r\nI'm curious, what would you expect to happen in this situation ?",
"Thank you for the detailed breakdown, @lhoestq \r\n\r\n> I'm curious, what would you expect to happen in this situation ?\r\n\r\n1. the simplest solution is to add a flag to the dataset saved by `save_to_disk` and have `load_dataset` check that flag - if it's set simply switch control to `load_from_disk` behind the scenes. So `load_dataset` detects it's a local filesystem, looks inside to see whether it's something it can cache or whether it should use it directly as is and continues accordingly with one of the 2 dataset-type specific APIs.\r\n\r\n2. the more evolved solution is to look at a dataset produced by `save_to_disk` as a remote resource like hub. So the first time `load_dataset` sees it, it'll take a fingerprint and create a normal cached dataset. On subsequent uses it'll again discover it as a remote resource, validate that it has it cached via the fingerprint and serve as a normal dataset. \r\n\r\nAs you said the cons of approach 2 is that if the dataset is huge it'll make 2 copies on the same machine. So it's possible that both approaches can be integrated. Say if `save_to_disc(do_not_cache=True)` is passed it'll use solution 1, otherwise solution 2. or could even symlink the huge arrow files to the cache instead? or perhaps it's more intuitive to use `load_dataset(do_not_cache=True)` instead. So that one can choose whether to make a cached copy or not for the locally saved dataset. i.e. a simple at use point user control.\r\n\r\nSurely there are other ways to handle it, this is just one possibility.\r\n",
"I think the simplest is to always memory map the local file without copy, but still have a cached directory in the cache at `~/.cache/huggingface` instead of saving `map` results next to the original data.\r\n\r\nIn practice we can even use symlinks if it makes the implementation simpler",
"Yes, so that you always have the cached entry for any dataset, but the \"payload\" doesn't have to be physically in the cache if it's already on the local filesystem. As you said a symlink will do. "
] | 2022-09-29T17:37:12 | 2022-09-30T16:59:19 | null |
MEMBER
| null | null | null |
**Is your feature request related to a problem? Please describe.**
Is it possible to make `load_dataset` more universal similar to `from_pretrained` in `transformers` so that it can handle the hub, and the local path datasets of all supported types?
Currently one has to choose a different loader depending on how the dataset has been created.
e.g. this won't work:
```
$ git clone https://huggingface.co/datasets/severo/test-parquet
$ python -c 'from datasets import load_dataset; ds=load_dataset("test-parquet"); \
ds.save_to_disk("my_dataset"); load_dataset("my_dataset")'
[...]
Traceback (most recent call last):
File "<string>", line 1, in <module>
File "/home/stas/anaconda3/envs/py38-pt112/lib/python3.8/site-packages/datasets/load.py", line 1746, in load_dataset
builder_instance.download_and_prepare(
File "/home/stas/anaconda3/envs/py38-pt112/lib/python3.8/site-packages/datasets/builder.py", line 704, in download_and_prepare
self._download_and_prepare(
File "/home/stas/anaconda3/envs/py38-pt112/lib/python3.8/site-packages/datasets/builder.py", line 793, in _download_and_prepare
self._prepare_split(split_generator, **prepare_split_kwargs)
File "/home/stas/anaconda3/envs/py38-pt112/lib/python3.8/site-packages/datasets/builder.py", line 1277, in _prepare_split
writer.write_table(table)
File "/home/stas/anaconda3/envs/py38-pt112/lib/python3.8/site-packages/datasets/arrow_writer.py", line 524, in write_table
pa_table = table_cast(pa_table, self._schema)
File "/home/stas/anaconda3/envs/py38-pt112/lib/python3.8/site-packages/datasets/table.py", line 2005, in table_cast
return cast_table_to_schema(table, schema)
File "/home/stas/anaconda3/envs/py38-pt112/lib/python3.8/site-packages/datasets/table.py", line 1968, in cast_table_to_schema
raise ValueError(f"Couldn't cast\n{table.schema}\nto\n{features}\nbecause column names don't match")
ValueError: Couldn't cast
_data_files: list<item: struct<filename: string>>
child 0, item: struct<filename: string>
child 0, filename: string
```
both times the dataset is being loaded from disk. Why does it fail the second time?
Why can't `save_to_disk` generate a dataset that can be immediately loaded by `load_dataset`?
e.g. the simplest hack would be to have `save_to_disk` add some flag to the saved dataset, that tells `load_dataset` to internally call `load_from_disk`. like having `save_to_disk` create a `load_me_with_load_from_disk.txt` file ;) and `load_dataset` will support that feature from saved datasets from new `datasets` versions. The old ones will still need to use `load_from_disk` explicitly. Unless the flag is not needed and one can immediately tell by looking at the saved dataset that it was saved via `save_to_disk` and thus use `load_from_disk` internally.
The use-case is defining a simple API where the user only ever needs to pass a `dataset_name_or_path` and it will always just work. Currently one needs to manually add additional switches telling the system whether to use one loading method or the other which works but it's not smooth.
Thank you!
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/5044/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/5044/timeline
| null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5043
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5043/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5043/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5043/events
|
https://github.com/huggingface/datasets/pull/5043
| 1,391,141,773 |
PR_kwDODunzps4_3uzy
| 5,043 |
Fix `flatten_indices` with empty indices mapping
|
{
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-09-29T16:17:28 | 2022-09-30T15:46:39 | 2022-09-30T15:44:25 |
CONTRIBUTOR
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5043",
"html_url": "https://github.com/huggingface/datasets/pull/5043",
"diff_url": "https://github.com/huggingface/datasets/pull/5043.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5043.patch",
"merged_at": "2022-09-30T15:44:25"
}
|
Fix #5038
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/5043/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/5043/timeline
| null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5042
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5042/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5042/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5042/events
|
https://github.com/huggingface/datasets/pull/5042
| 1,390,762,877 |
PR_kwDODunzps4_2eqa
| 5,042 |
Update swiss judgment prediction
|
{
"login": "JoelNiklaus",
"id": 3775944,
"node_id": "MDQ6VXNlcjM3NzU5NDQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/3775944?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/JoelNiklaus",
"html_url": "https://github.com/JoelNiklaus",
"followers_url": "https://api.github.com/users/JoelNiklaus/followers",
"following_url": "https://api.github.com/users/JoelNiklaus/following{/other_user}",
"gists_url": "https://api.github.com/users/JoelNiklaus/gists{/gist_id}",
"starred_url": "https://api.github.com/users/JoelNiklaus/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/JoelNiklaus/subscriptions",
"organizations_url": "https://api.github.com/users/JoelNiklaus/orgs",
"repos_url": "https://api.github.com/users/JoelNiklaus/repos",
"events_url": "https://api.github.com/users/JoelNiklaus/events{/privacy}",
"received_events_url": "https://api.github.com/users/JoelNiklaus/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 4564477500,
"node_id": "LA_kwDODunzps8AAAABEBBmPA",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20contribution",
"name": "dataset contribution",
"color": "0e8a16",
"default": false,
"description": "Contribution to a dataset script"
}
] |
closed
| false | null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-09-29T12:10:02 | 2022-09-30T07:14:00 | 2022-09-29T14:32:02 |
CONTRIBUTOR
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5042",
"html_url": "https://github.com/huggingface/datasets/pull/5042",
"diff_url": "https://github.com/huggingface/datasets/pull/5042.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5042.patch",
"merged_at": "2022-09-29T14:32:02"
}
|
I forgot to add the new citation.
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/5042/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/5042/timeline
| null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5041
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5041/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5041/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5041/events
|
https://github.com/huggingface/datasets/pull/5041
| 1,390,722,230 |
PR_kwDODunzps4_2WES
| 5,041 |
Support streaming hendrycks_test dataset.
|
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 4564477500,
"node_id": "LA_kwDODunzps8AAAABEBBmPA",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20contribution",
"name": "dataset contribution",
"color": "0e8a16",
"default": false,
"description": "Contribution to a dataset script"
}
] |
closed
| false | null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-09-29T11:37:58 | 2022-09-30T07:13:38 | 2022-09-29T12:07:29 |
MEMBER
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5041",
"html_url": "https://github.com/huggingface/datasets/pull/5041",
"diff_url": "https://github.com/huggingface/datasets/pull/5041.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5041.patch",
"merged_at": "2022-09-29T12:07:29"
}
|
This PR:
- supports streaming
- fixes the description section of the dataset card
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/5041/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/5041/timeline
| null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5040
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5040/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5040/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5040/events
|
https://github.com/huggingface/datasets/pull/5040
| 1,390,566,428 |
PR_kwDODunzps4_11O2
| 5,040 |
Fix NonMatchingChecksumError in hendrycks_test dataset
|
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 4564477500,
"node_id": "LA_kwDODunzps8AAAABEBBmPA",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20contribution",
"name": "dataset contribution",
"color": "0e8a16",
"default": false,
"description": "Contribution to a dataset script"
}
] |
closed
| false | null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-09-29T09:37:43 | 2022-09-29T10:06:22 | 2022-09-29T10:04:19 |
MEMBER
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5040",
"html_url": "https://github.com/huggingface/datasets/pull/5040",
"diff_url": "https://github.com/huggingface/datasets/pull/5040.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5040.patch",
"merged_at": "2022-09-29T10:04:19"
}
|
Update metadata JSON.
Fix #5039.
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/5040/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/5040/timeline
| null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5039
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5039/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5039/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5039/events
|
https://github.com/huggingface/datasets/issues/5039
| 1,390,353,315 |
I_kwDODunzps5S3xuj
| 5,039 |
Hendrycks Checksum
|
{
"login": "DanielHesslow",
"id": 9974388,
"node_id": "MDQ6VXNlcjk5NzQzODg=",
"avatar_url": "https://avatars.githubusercontent.com/u/9974388?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/DanielHesslow",
"html_url": "https://github.com/DanielHesslow",
"followers_url": "https://api.github.com/users/DanielHesslow/followers",
"following_url": "https://api.github.com/users/DanielHesslow/following{/other_user}",
"gists_url": "https://api.github.com/users/DanielHesslow/gists{/gist_id}",
"starred_url": "https://api.github.com/users/DanielHesslow/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/DanielHesslow/subscriptions",
"organizations_url": "https://api.github.com/users/DanielHesslow/orgs",
"repos_url": "https://api.github.com/users/DanielHesslow/repos",
"events_url": "https://api.github.com/users/DanielHesslow/events{/privacy}",
"received_events_url": "https://api.github.com/users/DanielHesslow/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 2067388877,
"node_id": "MDU6TGFiZWwyMDY3Mzg4ODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20bug",
"name": "dataset bug",
"color": "2edb81",
"default": false,
"description": "A bug in a dataset script provided in the library"
}
] |
closed
| false |
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
}
] | null |
[
"Thanks for reporting, @DanielHesslow. We are fixing it. ",
"@albertvillanova thanks for taking care of this so quickly!",
"The dataset metadata is fixed. You can download it normally."
] | 2022-09-29T06:56:20 | 2022-09-29T10:23:30 | 2022-09-29T10:04:20 |
NONE
| null | null | null |
Hi,
The checksum for [hendrycks_test](https://huggingface.co/datasets/hendrycks_test) does not compare correctly, I guess it has been updated on the remote.
```
datasets.utils.info_utils.NonMatchingChecksumError: Checksums didn't match for dataset source files:
['https://people.eecs.berkeley.edu/~hendrycks/data.tar']
```
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/5039/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/5039/timeline
| null |
completed
| false |
https://api.github.com/repos/huggingface/datasets/issues/5038
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5038/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5038/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5038/events
|
https://github.com/huggingface/datasets/issues/5038
| 1,389,631,122 |
I_kwDODunzps5S1BaS
| 5,038 |
`Dataset.unique` showing wrong output after filtering
|
{
"login": "mxschmdt",
"id": 4904985,
"node_id": "MDQ6VXNlcjQ5MDQ5ODU=",
"avatar_url": "https://avatars.githubusercontent.com/u/4904985?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mxschmdt",
"html_url": "https://github.com/mxschmdt",
"followers_url": "https://api.github.com/users/mxschmdt/followers",
"following_url": "https://api.github.com/users/mxschmdt/following{/other_user}",
"gists_url": "https://api.github.com/users/mxschmdt/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mxschmdt/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mxschmdt/subscriptions",
"organizations_url": "https://api.github.com/users/mxschmdt/orgs",
"repos_url": "https://api.github.com/users/mxschmdt/repos",
"events_url": "https://api.github.com/users/mxschmdt/events{/privacy}",
"received_events_url": "https://api.github.com/users/mxschmdt/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] |
closed
| false | null |
[] | null |
[
"Hi! It seems like `flatten_indices` (called in `unique`) doesn't know how to handle empty indices mappings. I'm working on the fix.",
"Thanks, that was fast!"
] | 2022-09-28T16:20:35 | 2022-09-30T15:44:25 | 2022-09-30T15:44:25 |
CONTRIBUTOR
| null | null | null |
## Describe the bug
After filtering a dataset, and if no samples remain, `Dataset.unique` will return the unique values of the unfiltered dataset.
## Steps to reproduce the bug
```python
from datasets import Dataset
dataset = Dataset.from_dict({'id': [0]})
dataset = dataset.filter(lambda _: False)
print(dataset.unique('id'))
```
## Expected results
The above code should return an empty list since the dataset is empty.
## Actual results
```bash
[0]
```
## Environment info
- `datasets` version: 2.5.1
- Platform: Linux-5.18.19-100.fc35.x86_64-x86_64-with-glibc2.34
- Python version: 3.9.14
- PyArrow version: 7.0.0
- Pandas version: 1.3.5
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/5038/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/5038/timeline
| null |
completed
| false |
https://api.github.com/repos/huggingface/datasets/issues/5037
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5037/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5037/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5037/events
|
https://github.com/huggingface/datasets/pull/5037
| 1,389,244,722 |
PR_kwDODunzps4_xcp0
| 5,037 |
Improve CI performance speed of PackagedDatasetTest
|
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"There was a CI error which seemed unrelated: https://github.com/huggingface/datasets/actions/runs/3143581330/jobs/5111807056\r\n```\r\nFAILED tests/test_load.py::test_load_dataset_private_zipped_images[True] - FileNotFoundError: https://hub-ci.huggingface.co/datasets/__DUMMY_TRANSFORMERS_USER__/repo_zipped_img_data-16643808721979/resolve/75c3fc424a3b898a828b2b3fd84d96da4703228a/data.zip\r\n```\r\nIt disappeared after merging the main branch."
] | 2022-09-28T12:08:16 | 2022-09-30T16:05:42 | 2022-09-30T16:03:24 |
MEMBER
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5037",
"html_url": "https://github.com/huggingface/datasets/pull/5037",
"diff_url": "https://github.com/huggingface/datasets/pull/5037.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5037.patch",
"merged_at": "2022-09-30T16:03:24"
}
|
This PR improves PackagedDatasetTest CI performance speed. For Ubuntu (latest):
- Duration (without parallelism) before: 334.78s (5.58m)
- Duration (without parallelism) afterwards: 0.48s
The approach is passing a dummy `data_files` argument to load the builder, so that it avoids the slow inferring of it over the entire root directory of the repo.
## Total duration of PackagedDatasetTest
| | Before | Afterwards | Improvement
|---|---:|---:|---:|
| Linux | 334.78s | 0.48s | x700
| Windows | 513.02s | 1.09s | x500
## Durations by each individual sub-test
More accurate durations, running them on GitHub, for Linux (latest).
Before this PR, the total test time (without parallelism) for `tests/test_dataset_common.py::PackagedDatasetTest` is 334.78s (5.58m)
```
39.07s call tests/test_dataset_common.py::PackagedDatasetTest::test_load_dataset_offline_imagefolder
38.94s call tests/test_dataset_common.py::PackagedDatasetTest::test_load_dataset_offline_audiofolder
34.18s call tests/test_dataset_common.py::PackagedDatasetTest::test_load_dataset_offline_parquet
34.12s call tests/test_dataset_common.py::PackagedDatasetTest::test_load_dataset_offline_csv
34.00s call tests/test_dataset_common.py::PackagedDatasetTest::test_load_dataset_offline_pandas
34.00s call tests/test_dataset_common.py::PackagedDatasetTest::test_load_dataset_offline_text
33.86s call tests/test_dataset_common.py::PackagedDatasetTest::test_load_dataset_offline_json
10.39s call tests/test_dataset_common.py::PackagedDatasetTest::test_builder_class_audiofolder
6.50s call tests/test_dataset_common.py::PackagedDatasetTest::test_builder_configs_audiofolder
6.46s call tests/test_dataset_common.py::PackagedDatasetTest::test_builder_configs_imagefolder
6.40s call tests/test_dataset_common.py::PackagedDatasetTest::test_builder_class_imagefolder
5.77s call tests/test_dataset_common.py::PackagedDatasetTest::test_builder_class_csv
5.77s call tests/test_dataset_common.py::PackagedDatasetTest::test_builder_class_text
5.74s call tests/test_dataset_common.py::PackagedDatasetTest::test_builder_configs_parquet
5.69s call tests/test_dataset_common.py::PackagedDatasetTest::test_builder_class_json
5.68s call tests/test_dataset_common.py::PackagedDatasetTest::test_builder_configs_pandas
5.67s call tests/test_dataset_common.py::PackagedDatasetTest::test_builder_class_parquet
5.67s call tests/test_dataset_common.py::PackagedDatasetTest::test_builder_class_pandas
5.66s call tests/test_dataset_common.py::PackagedDatasetTest::test_builder_configs_json
5.66s call tests/test_dataset_common.py::PackagedDatasetTest::test_builder_configs_csv
5.55s call tests/test_dataset_common.py::PackagedDatasetTest::test_builder_configs_text
(42 durations < 0.005s hidden.)
```
With this PR: 0.48s
```
0.09s call tests/test_dataset_common.py::PackagedDatasetTest::test_load_dataset_offline_audiofolder
0.08s call tests/test_dataset_common.py::PackagedDatasetTest::test_load_dataset_offline_csv
0.08s call tests/test_dataset_common.py::PackagedDatasetTest::test_load_dataset_offline_imagefolder
0.06s call tests/test_dataset_common.py::PackagedDatasetTest::test_load_dataset_offline_json
0.05s call tests/test_dataset_common.py::PackagedDatasetTest::test_builder_class_audiofolder
0.05s call tests/test_dataset_common.py::PackagedDatasetTest::test_load_dataset_offline_parquet
0.04s call tests/test_dataset_common.py::PackagedDatasetTest::test_load_dataset_offline_pandas
0.03s call tests/test_dataset_common.py::PackagedDatasetTest::test_load_dataset_offline_text
(55 durations < 0.005s hidden.)
```
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/5037/reactions",
"total_count": 2,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 1,
"eyes": 1
}
|
https://api.github.com/repos/huggingface/datasets/issues/5037/timeline
| null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5036
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5036/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5036/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5036/events
|
https://github.com/huggingface/datasets/pull/5036
| 1,389,094,075 |
PR_kwDODunzps4_w8Bs
| 5,036 |
Add oversampling strategy iterable datasets interleave
|
{
"login": "ylacombe",
"id": 52246514,
"node_id": "MDQ6VXNlcjUyMjQ2NTE0",
"avatar_url": "https://avatars.githubusercontent.com/u/52246514?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ylacombe",
"html_url": "https://github.com/ylacombe",
"followers_url": "https://api.github.com/users/ylacombe/followers",
"following_url": "https://api.github.com/users/ylacombe/following{/other_user}",
"gists_url": "https://api.github.com/users/ylacombe/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ylacombe/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ylacombe/subscriptions",
"organizations_url": "https://api.github.com/users/ylacombe/orgs",
"repos_url": "https://api.github.com/users/ylacombe/repos",
"events_url": "https://api.github.com/users/ylacombe/events{/privacy}",
"received_events_url": "https://api.github.com/users/ylacombe/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-09-28T10:10:23 | 2022-09-30T12:30:48 | 2022-09-30T12:28:23 |
CONTRIBUTOR
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5036",
"html_url": "https://github.com/huggingface/datasets/pull/5036",
"diff_url": "https://github.com/huggingface/datasets/pull/5036.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5036.patch",
"merged_at": "2022-09-30T12:28:23"
}
|
Hello everyone,
Following the issue #4893 and the PR #4831, I propose here an oversampling strategy for a `IterableDataset` list.
The `all_exhausted` strategy stops building the new dataset as soon as all samples in each dataset have been added at least once.
It follows roughly the same logic behind #4831, namely:
- if ``probabilities`` is `None` and the strategy is `all_exhausted`, it simply performs a round robin interleaving that stops when the longest dataset is out of samples. Here the new dataset length will be $maxLengthDataset*nbDataset$.
- if ``probabilities`` is not `None` and the strategy is `all_exhausted`, it keeps trace of the datasets which were out of samples but continues to add them to the new dataset, and stops as soons as every dataset runs out of samples at least once.
In order to be consistent and also to align with the `Dataset` behavior, please note that the behavior of the default strategy (`first_exhausted`) has been changed. Namely, it really stops when a dataset is out of samples whereas it used to stop when receiving the `StopIteration` error.
To give an example of the last note, with the following snippet:
```
>>> from tests.test_iterable_dataset import *
>>> d1 = IterableDataset(ExamplesIterable((lambda: (yield from [(i, {"a": i}) for i in [0, 1, 2]])), {}))
>>> d2 = IterableDataset(ExamplesIterable((lambda: (yield from [(i, {"a": i}) for i in [10, 11, 12, 13]])), {}))
>>> d3 = IterableDataset(ExamplesIterable((lambda: (yield from [(i, {"a": i}) for i in [20, 21, 22, 23, 24]])), {}))
>>> dataset = interleave_datasets([d1, d2, d3])
>>> [x["a"] for x in dataset]
```
The result here will then be `[10, 0, 11, 1, 2]` instead of `[10, 0, 11, 1, 2, 20, 12, 13]`.
I modified the behavior because I found it to be consistent with the under/oversampling approach and because it unified the undersampling and oversampling code, but I stay open to any suggestions.
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/5036/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/5036/timeline
| null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5035
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5035/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5035/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5035/events
|
https://github.com/huggingface/datasets/pull/5035
| 1,388,914,476 |
PR_kwDODunzps4_wVie
| 5,035 |
Fix typos in load docstrings and comments
|
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-09-28T08:05:07 | 2022-09-28T17:28:40 | 2022-09-28T17:26:15 |
MEMBER
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5035",
"html_url": "https://github.com/huggingface/datasets/pull/5035",
"diff_url": "https://github.com/huggingface/datasets/pull/5035.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5035.patch",
"merged_at": "2022-09-28T17:26:14"
}
|
Minor fix of typos in load docstrings and comments
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/5035/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/5035/timeline
| null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5034
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5034/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5034/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5034/events
|
https://github.com/huggingface/datasets/pull/5034
| 1,388,855,136 |
PR_kwDODunzps4_wJCu
| 5,034 |
Update README.md of yahoo_answers_topics dataset
|
{
"login": "borgr",
"id": 6416600,
"node_id": "MDQ6VXNlcjY0MTY2MDA=",
"avatar_url": "https://avatars.githubusercontent.com/u/6416600?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/borgr",
"html_url": "https://github.com/borgr",
"followers_url": "https://api.github.com/users/borgr/followers",
"following_url": "https://api.github.com/users/borgr/following{/other_user}",
"gists_url": "https://api.github.com/users/borgr/gists{/gist_id}",
"starred_url": "https://api.github.com/users/borgr/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/borgr/subscriptions",
"organizations_url": "https://api.github.com/users/borgr/orgs",
"repos_url": "https://api.github.com/users/borgr/repos",
"events_url": "https://api.github.com/users/borgr/events{/privacy}",
"received_events_url": "https://api.github.com/users/borgr/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5034). All of your documentation changes will be reflected on that endpoint.",
"Thanks, @borgr. We have removed all dataset scripts from this repo. Subsequent PRs should be opened directly on the Hugging Face Hub.",
"Do you mean to edit through \"edit dataset card\" button? because it just leads to a broken page...\r\nhttps://huggingface.co/datasets/yahoo_answers_topics\r\n\r\nhttps://github.com/huggingface/datasets/tree/main/datasets/yahoo_answers_topics",
"Hi @borgr, good catch! I'm going to report the button leading to a broken link.\r\n\r\nIn the meantime, you can propose a PR to the `README.md` file using this link: https://huggingface.co/datasets/yahoo_answers_topics/blob/main/README.md"
] | 2022-09-28T07:17:33 | 2022-10-06T15:56:05 | 2022-10-04T13:49:25 |
CONTRIBUTOR
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5034",
"html_url": "https://github.com/huggingface/datasets/pull/5034",
"diff_url": "https://github.com/huggingface/datasets/pull/5034.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5034.patch",
"merged_at": null
}
| null |
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/5034/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/5034/timeline
| null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5033
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5033/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5033/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5033/events
|
https://github.com/huggingface/datasets/pull/5033
| 1,388,842,236 |
PR_kwDODunzps4_wGSE
| 5,033 |
Remove redundant code from some dataset module factories
|
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-09-28T07:06:26 | 2022-09-28T16:57:51 | 2022-09-28T16:55:12 |
MEMBER
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5033",
"html_url": "https://github.com/huggingface/datasets/pull/5033",
"diff_url": "https://github.com/huggingface/datasets/pull/5033.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5033.patch",
"merged_at": "2022-09-28T16:55:12"
}
|
This PR removes some redundant code introduced by mistake after a refactoring in:
- #4576
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/5033/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/5033/timeline
| null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5032
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5032/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5032/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5032/events
|
https://github.com/huggingface/datasets/issues/5032
| 1,388,270,935 |
I_kwDODunzps5Sv1VX
| 5,032 |
new dataset type: single-label and multi-label video classification
|
{
"login": "fcakyon",
"id": 34196005,
"node_id": "MDQ6VXNlcjM0MTk2MDA1",
"avatar_url": "https://avatars.githubusercontent.com/u/34196005?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/fcakyon",
"html_url": "https://github.com/fcakyon",
"followers_url": "https://api.github.com/users/fcakyon/followers",
"following_url": "https://api.github.com/users/fcakyon/following{/other_user}",
"gists_url": "https://api.github.com/users/fcakyon/gists{/gist_id}",
"starred_url": "https://api.github.com/users/fcakyon/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/fcakyon/subscriptions",
"organizations_url": "https://api.github.com/users/fcakyon/orgs",
"repos_url": "https://api.github.com/users/fcakyon/repos",
"events_url": "https://api.github.com/users/fcakyon/events{/privacy}",
"received_events_url": "https://api.github.com/users/fcakyon/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] |
open
| false | null |
[] | null |
[
"Hi ! You can in the `features` folder how we implemented the audio and image feature types.\r\n\r\nWe can have something similar to videos. What we need to decide:\r\n- the video loading library to use\r\n- the output format when a user accesses a video type object\r\n- what parameters a `Video()` feature type needs\r\n\r\nalso cc @nateraw who also took a look at what we can do for video",
"@lhoestq @nateraw is there any progress on adding video classification datasets? ",
"Hi ! I think we just missing which lib we're going to use to decode the videos + which parameters must go in the `Video` type",
"Hmm. `decord` could be nice but it's no longer maintained [it seems](https://github.com/dmlc/decord/issues/214). ",
"pytorchvideo uses [pyav](https://github.com/PyAV-Org/PyAV) as the default decoder: https://github.com/facebookresearch/pytorchvideo/blob/c8d23d8b7e597586a9e2d18f6ed31ad8aa379a7a/pytorchvideo/data/labeled_video_dataset.py#L37\r\n\r\nAlso it would be great if `optionally` audio can also be decoded from the video as in pytorchvideo: https://github.com/facebookresearch/pytorchvideo/blob/c8d23d8b7e597586a9e2d18f6ed31ad8aa379a7a/pytorchvideo/data/labeled_video_dataset.py#L35\r\n\r\nHere are the other decoders supported in pytorchvideo: https://github.com/facebookresearch/pytorchvideo/blob/c8d23d8b7e597586a9e2d18f6ed31ad8aa379a7a/pytorchvideo/data/encoded_video.py#L17\r\n",
"@sayakpaul I did do quite a bit of work on [this PR](https://github.com/huggingface/datasets/pull/4532) a while back to add a video feature. It's outdated, but uses my `encoded_video` [package](https://github.com/nateraw/encoded-video) under the hood, which is basically a wrapper around PyAV stolen from [pytorchvideo](https://github.com/facebookresearch/pytorchvideo/) that gets rid of the `torch` dependency. \r\n\r\nwould be really great to get something like this in...it's just a really tricky and time consuming feature to add. "
] | 2022-09-27T19:40:11 | 2022-11-02T19:10:13 | null |
NONE
| null | null | null |
**Is your feature request related to a problem? Please describe.**
In my research, I am dealing with multi-modal (audio+text+frame sequence) video classification. It would be great if the datasets library supported generating multi-modal batches from a video dataset.
**Describe the solution you'd like**
Assume I have video files having single/multiple labels. I want to train a single/multi-label video classification model. I want datasets to support generating multi-modal batches (audio+frame sequence) from video files. Audio waveform and frame sequence can be extracted from each video clip then I can use any audio, image and video model from transformers library to extract features which will be fed into my model.
**Describe alternatives you've considered**
Currently, I am using https://github.com/facebookresearch/pytorchvideo dataloaders. There seems to be not much alternative.
**Additional context**
I am wiling to open a PR but don't know where to start.
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/5032/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 1
}
|
https://api.github.com/repos/huggingface/datasets/issues/5032/timeline
| null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5031
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5031/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5031/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5031/events
|
https://github.com/huggingface/datasets/pull/5031
| 1,388,201,146 |
PR_kwDODunzps4_t82_
| 5,031 |
Support hfh 0.10 implicit auth
|
{
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"@lhoestq it is now released so you can move forward with it :) ",
"I took your comments into account @Wauplin :)\r\nI also bumped the requirement to 0.2.0 because we're using `set_access_token`\r\n\r\ncc @albertvillanova WDYT ? I edited the CI job to also check for our minimum supported version of hfh at the same time as the minimum pyarrow version",
"@lhoestq great, thanks ! :)"
] | 2022-09-27T18:37:49 | 2022-09-30T09:18:24 | 2022-09-30T09:15:59 |
MEMBER
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5031",
"html_url": "https://github.com/huggingface/datasets/pull/5031",
"diff_url": "https://github.com/huggingface/datasets/pull/5031.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5031.patch",
"merged_at": "2022-09-30T09:15:59"
}
|
In huggingface-hub 0.10 the `token` parameter is deprecated for dataset_info and list_repo_files in favor of use_auth_token.
Moreover if use_auth_token=None then the user's token is used implicitly.
I took those two changes into account
Close https://github.com/huggingface/datasets/issues/4990
TODO:
- [x] fix tests
We should wait hfh 0.10 to be relased first to make sure it works correctly before merging
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/5031/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/5031/timeline
| null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5030
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5030/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5030/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5030/events
|
https://github.com/huggingface/datasets/pull/5030
| 1,388,061,340 |
PR_kwDODunzps4_tfBO
| 5,030 |
Fast dataset iter
|
{
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"I ran some benchmarks (focused on the data fetching part of `__iter__`) and it seems like the combination `table.to_reader(batch_size)` + `RecordBatch.slice` performs the best ([script](https://gist.github.com/mariosasko/0248288a2e3a7556873969717c1fe52b) with the results). I think we can choose (implicit) `batch_size=10` in the final implementation to avoid having problems with fetching large examples."
] | 2022-09-27T16:44:51 | 2022-09-29T15:50:44 | 2022-09-29T15:48:17 |
CONTRIBUTOR
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5030",
"html_url": "https://github.com/huggingface/datasets/pull/5030",
"diff_url": "https://github.com/huggingface/datasets/pull/5030.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5030.patch",
"merged_at": "2022-09-29T15:48:17"
}
|
Use `pa.Table.to_reader` to make iteration over examples/batches faster in `Dataset.{__iter__, map}`
TODO:
* [x] benchmarking (the only benchmark for now - iterating over (single) examples of `bookcorpus` (75 mil examples) in Colab is approx. 2.3x faster)
* [x] check if iterating over bigger chunks + slicing to fetch individual examples in `_iter` yields better performance
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/5030/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/5030/timeline
| null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5029
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5029/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5029/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5029/events
|
https://github.com/huggingface/datasets/pull/5029
| 1,387,600,960 |
PR_kwDODunzps4_r8-j
| 5,029 |
Fix import in `ClassLabel` docstring example
|
{
"login": "alvarobartt",
"id": 36760800,
"node_id": "MDQ6VXNlcjM2NzYwODAw",
"avatar_url": "https://avatars.githubusercontent.com/u/36760800?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/alvarobartt",
"html_url": "https://github.com/alvarobartt",
"followers_url": "https://api.github.com/users/alvarobartt/followers",
"following_url": "https://api.github.com/users/alvarobartt/following{/other_user}",
"gists_url": "https://api.github.com/users/alvarobartt/gists{/gist_id}",
"starred_url": "https://api.github.com/users/alvarobartt/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/alvarobartt/subscriptions",
"organizations_url": "https://api.github.com/users/alvarobartt/orgs",
"repos_url": "https://api.github.com/users/alvarobartt/repos",
"events_url": "https://api.github.com/users/alvarobartt/events{/privacy}",
"received_events_url": "https://api.github.com/users/alvarobartt/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-09-27T11:35:29 | 2022-09-27T14:03:24 | 2022-09-27T12:27:50 |
CONTRIBUTOR
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5029",
"html_url": "https://github.com/huggingface/datasets/pull/5029",
"diff_url": "https://github.com/huggingface/datasets/pull/5029.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5029.patch",
"merged_at": "2022-09-27T12:27:50"
}
|
This PR addresses a super-simple fix: adding a missing `import` to the `ClassLabel` docstring example, as it was formatted as `from datasets Features`, so it's been fixed to `from datasets import Features`.
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/5029/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/5029/timeline
| null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5028
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5028/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5028/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5028/events
|
https://github.com/huggingface/datasets/issues/5028
| 1,386,272,533 |
I_kwDODunzps5SoNcV
| 5,028 |
passing parameters to the method passed to Dataset.from_generator()
|
{
"login": "Basir-mahmood",
"id": 64276129,
"node_id": "MDQ6VXNlcjY0Mjc2MTI5",
"avatar_url": "https://avatars.githubusercontent.com/u/64276129?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Basir-mahmood",
"html_url": "https://github.com/Basir-mahmood",
"followers_url": "https://api.github.com/users/Basir-mahmood/followers",
"following_url": "https://api.github.com/users/Basir-mahmood/following{/other_user}",
"gists_url": "https://api.github.com/users/Basir-mahmood/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Basir-mahmood/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Basir-mahmood/subscriptions",
"organizations_url": "https://api.github.com/users/Basir-mahmood/orgs",
"repos_url": "https://api.github.com/users/Basir-mahmood/repos",
"events_url": "https://api.github.com/users/Basir-mahmood/events{/privacy}",
"received_events_url": "https://api.github.com/users/Basir-mahmood/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] |
closed
| false | null |
[] | null |
[
"Hi! Yes, you can either use the `gen_kwargs` param in `Dataset.from_generator` (`ds = Dataset.from_generator(gen, gen_kwargs={\"param1\": val})`) or wrap the generator function with `functools.partial`\r\n(`ds = Dataset.from_generator(functools.partial(gen, param1=\"val\"))`) to pass custom parameters to it.\r\n"
] | 2022-09-26T15:20:06 | 2022-10-03T13:00:00 | 2022-10-03T13:00:00 |
NONE
| null | null | null |
Big thanks for providing dataset creation via a generator.
I want to ask whether there is any way that parameters can be passed to the method Dataset.from_generator() method, like as follows.
```
from datasets import Dataset
def gen(param1):
for idx in len(custom_dataset):
yield custom_dataset[idx] + param1
ds = Dataset.from_generator(gen(param1))
```
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/5028/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/5028/timeline
| null |
completed
| false |
https://api.github.com/repos/huggingface/datasets/issues/5027
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5027/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5027/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5027/events
|
https://github.com/huggingface/datasets/pull/5027
| 1,386,153,072 |
PR_kwDODunzps4_nFUE
| 5,027 |
Fix typo in error message
|
{
"login": "severo",
"id": 1676121,
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/severo",
"html_url": "https://github.com/severo",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"organizations_url": "https://api.github.com/users/severo/orgs",
"repos_url": "https://api.github.com/users/severo/repos",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"received_events_url": "https://api.github.com/users/severo/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-09-26T14:10:09 | 2022-09-27T12:28:03 | 2022-09-27T12:26:02 |
CONTRIBUTOR
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5027",
"html_url": "https://github.com/huggingface/datasets/pull/5027",
"diff_url": "https://github.com/huggingface/datasets/pull/5027.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5027.patch",
"merged_at": "2022-09-27T12:26:02"
}
| null |
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/5027/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/5027/timeline
| null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5026
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5026/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5026/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5026/events
|
https://github.com/huggingface/datasets/pull/5026
| 1,386,071,154 |
PR_kwDODunzps4_mz1w
| 5,026 |
patch CI_HUB_TOKEN_PATH with Path instead of str
|
{
"login": "Wauplin",
"id": 11801849,
"node_id": "MDQ6VXNlcjExODAxODQ5",
"avatar_url": "https://avatars.githubusercontent.com/u/11801849?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Wauplin",
"html_url": "https://github.com/Wauplin",
"followers_url": "https://api.github.com/users/Wauplin/followers",
"following_url": "https://api.github.com/users/Wauplin/following{/other_user}",
"gists_url": "https://api.github.com/users/Wauplin/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Wauplin/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Wauplin/subscriptions",
"organizations_url": "https://api.github.com/users/Wauplin/orgs",
"repos_url": "https://api.github.com/users/Wauplin/repos",
"events_url": "https://api.github.com/users/Wauplin/events{/privacy}",
"received_events_url": "https://api.github.com/users/Wauplin/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-09-26T13:19:01 | 2022-09-26T14:30:55 | 2022-09-26T14:28:45 |
CONTRIBUTOR
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5026",
"html_url": "https://github.com/huggingface/datasets/pull/5026",
"diff_url": "https://github.com/huggingface/datasets/pull/5026.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5026.patch",
"merged_at": "2022-09-26T14:28:45"
}
|
Should fix the tests for `huggingface_hub==0.10.0rc0` prerelease (see [failed CI](https://github.com/huggingface/datasets/actions/runs/3127805250/jobs/5074879144)).
Related to [this thread](https://huggingface.slack.com/archives/C02V5EA0A95/p1664195165294559) (internal link).
Note: this should be a backward compatible fix (e.g. works also with previous versions of `huggingface_hub`)
I am not sure where to put the changes so feel free to cherry-pick the commit and close this one without merging.
cc @lhoestq
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/5026/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/5026/timeline
| null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5025
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5025/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5025/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5025/events
|
https://github.com/huggingface/datasets/issues/5025
| 1,386,011,239 |
I_kwDODunzps5SnNpn
| 5,025 |
Custom Json Dataset Throwing Error when batch is False
|
{
"login": "jmandivarapu1",
"id": 21245519,
"node_id": "MDQ6VXNlcjIxMjQ1NTE5",
"avatar_url": "https://avatars.githubusercontent.com/u/21245519?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jmandivarapu1",
"html_url": "https://github.com/jmandivarapu1",
"followers_url": "https://api.github.com/users/jmandivarapu1/followers",
"following_url": "https://api.github.com/users/jmandivarapu1/following{/other_user}",
"gists_url": "https://api.github.com/users/jmandivarapu1/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jmandivarapu1/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jmandivarapu1/subscriptions",
"organizations_url": "https://api.github.com/users/jmandivarapu1/orgs",
"repos_url": "https://api.github.com/users/jmandivarapu1/repos",
"events_url": "https://api.github.com/users/jmandivarapu1/events{/privacy}",
"received_events_url": "https://api.github.com/users/jmandivarapu1/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] |
closed
| false | null |
[] | null |
[
"Hi! Our processors are meant to be used in `batched` mode, so if `batched` is `False`, you need to drop the batch dimension (the error message warns you that the array has an extra dimension meaning it's 4D instead of 3D) to avoid the error:\r\n```python\r\ndef prepare_examples(examples):\r\n #Some preporcessing for each image and text as all my data saved in cloud\r\n #For this reason I couldn't set the batch to True. \r\n encoding = processor(img_as_tensor, words, boxes=boxes, word_labels=labels,\r\n truncation=True, padding=\"max_length\", return_tensors=\"np\")\r\n # drop extra dim\r\n for k in encoding.items():\r\n encoding[k]=encoding[k][0]\r\n return encoding\r\n```",
"> Hi! Our processors are meant to be used in `batched` mode, so if `batched` is `False`, you need to drop the batch dimension (the error message warns you that the array has an extra dimension meaning it's 4D instead of 3D) to avoid the error:\r\n> \r\n> ```python\r\n> def prepare_examples(examples):\r\n> #Some preporcessing for each image and text as all my data saved in cloud\r\n> #For this reason I couldn't set the batch to True. \r\n> encoding = processor(img_as_tensor, words, boxes=boxes, word_labels=labels,\r\n> truncation=True, padding=\"max_length\", return_tensors=\"np\")\r\n> # drop extra dim\r\n> for k in encoding.items():\r\n> encoding[k]=encoding[k][0]\r\n> return encoding\r\n> ```\r\n\r\nThank you it did work\r\n\r\n```\r\nfor k,v in encoding.items():\r\n encoding[k]=encoding[k][0]\r\n```"
] | 2022-09-26T12:38:39 | 2022-09-27T19:50:00 | 2022-09-27T19:50:00 |
NONE
| null | null | null |
## Describe the bug
A clear and concise description of what the bug is.
I tried to create my custom dataset using below code
```
from datasets import Features, Sequence, ClassLabel, Value, Array2D, Array3D
from torchvision import transforms
from transformers import AutoProcessor
# we'll use the Auto API here - it will load LayoutLMv3Processor behind the scenes,
# based on the checkpoint we provide from the hub
from datasets import load_dataset
def prepare_examples(examples):
#Some preporcessing for each image and text as all my data saved in cloud
#For this reason I couldn't set the batch to True.
encoding = processor(img_as_tensor, words, boxes=boxes, word_labels=labels,
truncation=True, padding="max_length")
# encoding['pixel_values']=np.array(encoding['pixel_values'])
return encoding
dataset = load_dataset("json", data_files='issues.jsonl')
processor = AutoProcessor.from_pretrained("microsoft/layoutlmv3-base", apply_ocr=False)
features = dataset["train"].features
column_names = dataset["train"].column_names
# we need to define custom features for `set_format` (used later on) to work properly
features = Features({
'pixel_values': Array3D(dtype="float32", shape=(3, 224, 224)),
'input_ids': Sequence(feature=Value(dtype='int64')),
'attention_mask': Sequence(Value(dtype='int64')),
'bbox': Array2D(dtype="int64", shape=(512, 4)),
'labels': Sequence(feature=Value(dtype='int64')),
})
train_dataset = dataset["train"].map(
prepare_examples,
batched=False,
remove_columns=column_names,
features=features
)
```
It throws below error.
```
/opt/conda/lib/python3.7/site-packages/datasets/arrow_writer.py in __arrow_array__(self, type)
172 storage = to_pyarrow_listarray(data, pa_type)
--> 173 return pa.ExtensionArray.from_storage(pa_type, storage)
174
/opt/conda/lib/python3.7/site-packages/pyarrow/array.pxi in pyarrow.lib.ExtensionArray.from_storage()
TypeError: Incompatible storage type list<item: list<item: list<item: list<item: float>>>> for extension type extension<arrow.py_extension_type<Array3DExtensionType>>
```
## Steps to reproduce the bug
```python
# Sample code to reproduce the bug
```
rom datasets import Features, Sequence, ClassLabel, Value, Array2D, Array3D
from torchvision import transforms
from transformers import AutoProcessor
# we'll use the Auto API here - it will load LayoutLMv3Processor behind the scenes,
# based on the checkpoint we provide from the hub
from datasets import load_dataset
def prepare_examples(examples):
#Some preporcessing for each image and text as all my data saved in cloud
encoding = processor(img_as_tensor, words, boxes=boxes, word_labels=labels,
truncation=True, padding="max_length")
# encoding['pixel_values']=np.array(encoding['pixel_values'])
return encoding
dataset = load_dataset("json", data_files='issues.jsonl')
processor = AutoProcessor.from_pretrained("microsoft/layoutlmv3-base", apply_ocr=False)
features = dataset["train"].features
column_names = dataset["train"].column_names
# we need to define custom features for `set_format` (used later on) to work properly
features = Features({
'pixel_values': Array3D(dtype="float32", shape=(3, 224, 224)),
'input_ids': Sequence(feature=Value(dtype='int64')),
'attention_mask': Sequence(Value(dtype='int64')),
'bbox': Array2D(dtype="int64", shape=(512, 4)),
'labels': Sequence(feature=Value(dtype='int64')),
})
train_dataset = dataset["train"].map(
prepare_examples,
batched=False,
remove_columns=column_names,
features=features
)
## Expected results
A clear and concise description of the expected results.
Expected would be similar to all the otherdatasets with no error.
## Actual results
Specify the actual results or traceback.
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version:
- Platform: Unix
- Python version: 3.9
- PyArrow version: 9.0.0
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/5025/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/5025/timeline
| null |
completed
| false |
https://api.github.com/repos/huggingface/datasets/issues/5024
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5024/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5024/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5024/events
|
https://github.com/huggingface/datasets/pull/5024
| 1,385,947,624 |
PR_kwDODunzps4_mZ3J
| 5,024 |
Fix string features of xcsr dataset
|
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 4564477500,
"node_id": "LA_kwDODunzps8AAAABEBBmPA",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20contribution",
"name": "dataset contribution",
"color": "0e8a16",
"default": false,
"description": "Contribution to a dataset script"
}
] |
closed
| false | null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-09-26T11:55:36 | 2022-09-28T07:56:18 | 2022-09-28T07:54:19 |
MEMBER
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5024",
"html_url": "https://github.com/huggingface/datasets/pull/5024",
"diff_url": "https://github.com/huggingface/datasets/pull/5024.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5024.patch",
"merged_at": "2022-09-28T07:54:19"
}
|
This PR fixes string features of `xcsr` dataset to avoid character splitting.
Fix #5023.
CC: @yangxqiao, @yuchenlin
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/5024/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/5024/timeline
| null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5023
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5023/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5023/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5023/events
|
https://github.com/huggingface/datasets/issues/5023
| 1,385,881,112 |
I_kwDODunzps5Smt4Y
| 5,023 |
Text strings are split into lists of characters in xcsr dataset
|
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 2067388877,
"node_id": "MDU6TGFiZWwyMDY3Mzg4ODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20bug",
"name": "dataset bug",
"color": "2edb81",
"default": false,
"description": "A bug in a dataset script provided in the library"
}
] |
closed
| false |
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
}
] | null |
[] | 2022-09-26T11:11:50 | 2022-09-28T07:54:20 | 2022-09-28T07:54:20 |
MEMBER
| null | null | null |
## Describe the bug
Text strings are split into lists of characters.
Example for "X-CSQA-en":
```
{'id': 'd3845adc08414fda',
'lang': 'en',
'question': {'stem': ['T',
'h',
'e',
' ',
'd',
'e',
'n',
't',
'a',
'l',
' ',
'o',
'f',
'f',
'i',
'c',
'e',
' ',
'h',
'a',
'n',
'd',
'l',
'e',
'd',
' ',
'a',
' ',
'l',
'o',
't',
' ',
'o',
'f',
' ',
'p',
'a',
't',
'i',
'e',
'n',
't',
's',
' ',
'w',
'h',
'o',
' ',
'e',
'x',
'p',
'e',
'r',
'i',
'e',
'n',
'c',
'e',
'd',
' ',
't',
'r',
'a',
'u',
'm',
'a',
't',
'i',
'c',
' ',
'm',
'o',
'u',
't',
'h',
' ',
'i',
'n',
'j',
'u',
'r',
'y',
',',
' ',
'w',
'h',
'e',
'r',
'e',
' ',
'w',
'e',
'r',
'e',
' ',
't',
'h',
'e',
's',
'e',
' ',
'p',
'a',
't',
'i',
'e',
'n',
't',
's',
' ',
'c',
'o',
'm',
'i',
'n',
'g',
' ',
'f',
'r',
'o',
'm',
'?'],
'choices': [{'label': ['A'], 'text': ['t', 'o', 'w', 'n']},
{'label': ['B'], 'text': ['m', 'i', 'c', 'h', 'i', 'g', 'a', 'n']},
{'label': ['C'], 'text': ['h', 'o', 's', 'p', 'i', 't', 'a', 'l']},
{'label': ['D'], 'text': ['s', 'c', 'h', 'o', 'o', 'l', 's']},
{'label': ['E'],
'text': ['o',
'f',
'f',
'i',
'c',
'e',
' ',
'b',
'u',
'i',
'l',
'd',
'i',
'n',
'g']}]},
'answerKey': 'C'}
## Steps to reproduce the bug
```python
ds = load_dataset("datasets/xcsr", "X-CSQA-en", split="validation", streaming=True)
item = next(iter(ds))
item
```
## Expected results
```
{'id': 'd3845adc08414fda',
'lang': 'en',
'question': {'stem': 'The dental office handled a lot of patients who experienced traumatic mouth injury, where were these patients coming from?',
'choices': {'label': ['A', 'B', 'C', 'D', 'E'],
'text': ['town', 'michigan', 'hospital', 'schools', 'office building']}},
'answerKey': 'C'}
```
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/5023/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/5023/timeline
| null |
completed
| false |
https://api.github.com/repos/huggingface/datasets/issues/5022
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5022/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5022/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5022/events
|
https://github.com/huggingface/datasets/pull/5022
| 1,385,432,859 |
PR_kwDODunzps4_kxYe
| 5,022 |
Fix languages of X-CSQA configs in xcsr dataset
|
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 4564477500,
"node_id": "LA_kwDODunzps8AAAABEBBmPA",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20contribution",
"name": "dataset contribution",
"color": "0e8a16",
"default": false,
"description": "Contribution to a dataset script"
}
] |
closed
| false | null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"Thanks @lhoestq, I had missed that... ",
"thx for the super fast work @albertvillanova ! any estimate for when the relevant release will happen?\r\n\r\nThanks again ",
"@thesofakillers after a recent change in our library (see #4059), now fixes in all datasets are immediately accessible. You can try it:\r\n```python\r\nfrench = datasets.load_dataset(\"xcsr\", \"X-CSQA-fr\")\r\n```\r\n\r\nPlease note there is an additional fix to that dataset in progress (to be merged today):\r\n- #5024"
] | 2022-09-26T05:13:39 | 2022-09-26T12:27:20 | 2022-09-26T10:57:30 |
MEMBER
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5022",
"html_url": "https://github.com/huggingface/datasets/pull/5022",
"diff_url": "https://github.com/huggingface/datasets/pull/5022.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5022.patch",
"merged_at": "2022-09-26T10:57:30"
}
|
Fix #5017.
CC: @yangxqiao, @yuchenlin
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/5022/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/5022/timeline
| null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5021
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5021/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5021/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5021/events
|
https://github.com/huggingface/datasets/issues/5021
| 1,385,351,250 |
I_kwDODunzps5SkshS
| 5,021 |
Split is inferred from filename and overrides metadata.jsonl
|
{
"login": "float-trip",
"id": 102226344,
"node_id": "U_kgDOBhfZqA",
"avatar_url": "https://avatars.githubusercontent.com/u/102226344?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/float-trip",
"html_url": "https://github.com/float-trip",
"followers_url": "https://api.github.com/users/float-trip/followers",
"following_url": "https://api.github.com/users/float-trip/following{/other_user}",
"gists_url": "https://api.github.com/users/float-trip/gists{/gist_id}",
"starred_url": "https://api.github.com/users/float-trip/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/float-trip/subscriptions",
"organizations_url": "https://api.github.com/users/float-trip/orgs",
"repos_url": "https://api.github.com/users/float-trip/repos",
"events_url": "https://api.github.com/users/float-trip/events{/privacy}",
"received_events_url": "https://api.github.com/users/float-trip/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
},
{
"id": 1935892865,
"node_id": "MDU6TGFiZWwxOTM1ODkyODY1",
"url": "https://api.github.com/repos/huggingface/datasets/labels/duplicate",
"name": "duplicate",
"color": "cfd3d7",
"default": true,
"description": "This issue or pull request already exists"
}
] |
closed
| false | null |
[] | null |
[
"Hi! What's the structure of your image folder? `datasets` by default tries to infer to what split each file belongs based on directory/file names. If it's OK to load all the images inside the `dataset` folder in the `train` split, you can do the following:\r\n```python\r\ndataset = load_dataset(\"imagefolder\", data_files=\"dataset/**\")\r\n```",
"Thanks! Specifying `data_files` worked for that case.\r\n\r\nI'm new to the library, so let me try rephrasing the issue. If there's no actual bug here, sorry for the trouble.\r\n\r\nI've uploaded an example [here](https://files.catbox.moe/nfj2pd.zip) with the following files: \r\n\r\n```\r\n.\r\n├── bug.py\r\n└── imagefolder\r\n ├── test\r\n │ ├── metadata.jsonl\r\n │ ├── dog.jpg\r\n │ └── personal trainer.jpg\r\n └── train\r\n ├── metadata.jsonl\r\n ├── cat.jpg\r\n └── testing center.jpg\r\n```\r\n\r\n`bug.py`\r\n```\r\nfrom datasets import load_dataset\r\n\r\ndataset = load_dataset(\"imagefolder\")\r\n\r\nprint(dataset)\r\n# DatasetDict({\r\n# test: Dataset({\r\n# features: ['image', 'text'],\r\n# num_rows: 1\r\n# })\r\n# })\r\n\r\nfor split in dataset:\r\n print(\"Split:\", split)\r\n for n in dataset[split]:\r\n print(n['text'])\r\n\r\n\r\n# Split: test\r\n# testing center\r\n```\r\n\r\nAs far as I can tell, this conforms with the example given here: https://huggingface.co/docs/datasets/image_dataset#imagefolder. It appears to me that, even though `metadata.jsonl` is present, the inferred labels from the path are taking precedent. Does this sound like a bug/undocumented behavior?",
"This looks like a duplicate of https://github.com/huggingface/datasets/issues/4895 (the problem is explained in this comment: https://github.com/huggingface/datasets/issues/4895#issuecomment-1248269550).\r\n\r\nIn the meantime, you can do the following to fetch all the splits:\r\n```python\r\ndataset = load_dataset(\"imagefolder\", data_files={\"train\": \"imagefolder/train/**\", \"test\": \"imagefolder/test/**\"})\r\n```\r\n"
] | 2022-09-26T03:22:14 | 2022-09-29T08:07:50 | 2022-09-29T08:07:50 |
NONE
| null | null | null |
## Describe the bug
Including the strings "test" or "train" anywhere in a filename causes `datasets` to infer the split and silently ignore all other files.
This behavior is documented for directory names but not filenames: https://huggingface.co/docs/datasets/image_dataset#imagefolder
## Steps to reproduce the bug
`metadata.jsonl`
```json
{"file_name": "photo of a cat.jpg", "text": "a photo of a cat"}
{"file_name": "photo of a dog.jpg", "text": "a photo of a dog"}
{"file_name": "photo of a train.jpg", "text": "a photo of a train"}
{"file_name": "photo of test tubes.jpg", "text": "a photo of test tubes"}
```
`bug.py`
```python
from datasets import load_dataset
dataset = load_dataset("dataset")
print(dataset)
# DatasetDict({
# train: Dataset({
# features: ['image', 'text'],
# num_rows: 1
# })
# test: Dataset({
# features: ['image', 'text'],
# num_rows: 1
# })
# })
for split in dataset:
for n in dataset[split]:
print(n['text'])
# a photo of a train
# a photo of test tubes
```
## Expected results
One single dataset with all four images / a warning for unused files / documentation of this behavior
## Actual results
Only the images with "test" or "train" in the name are loaded
## Environment info
- `datasets` version: 2.5.1
- Platform: macOS-12.5.1-x86_64-i386-64bit
- Python version: 3.10.4
- PyArrow version: 9.0.0
- Pandas version: 1.5.0
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/5021/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/5021/timeline
| null |
completed
| false |
https://api.github.com/repos/huggingface/datasets/issues/5020
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5020/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5020/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5020/events
|
https://github.com/huggingface/datasets/pull/5020
| 1,384,684,078 |
PR_kwDODunzps4_istJ
| 5,020 |
Fix URLs of sbu_captions dataset
|
{
"login": "donglixp",
"id": 1070872,
"node_id": "MDQ6VXNlcjEwNzA4NzI=",
"avatar_url": "https://avatars.githubusercontent.com/u/1070872?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/donglixp",
"html_url": "https://github.com/donglixp",
"followers_url": "https://api.github.com/users/donglixp/followers",
"following_url": "https://api.github.com/users/donglixp/following{/other_user}",
"gists_url": "https://api.github.com/users/donglixp/gists{/gist_id}",
"starred_url": "https://api.github.com/users/donglixp/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/donglixp/subscriptions",
"organizations_url": "https://api.github.com/users/donglixp/orgs",
"repos_url": "https://api.github.com/users/donglixp/repos",
"events_url": "https://api.github.com/users/donglixp/events{/privacy}",
"received_events_url": "https://api.github.com/users/donglixp/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 4564477500,
"node_id": "LA_kwDODunzps8AAAABEBBmPA",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20contribution",
"name": "dataset contribution",
"color": "0e8a16",
"default": false,
"description": "Contribution to a dataset script"
}
] |
closed
| false | null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-09-24T14:00:33 | 2022-09-28T07:20:20 | 2022-09-28T07:18:23 |
CONTRIBUTOR
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5020",
"html_url": "https://github.com/huggingface/datasets/pull/5020",
"diff_url": "https://github.com/huggingface/datasets/pull/5020.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5020.patch",
"merged_at": "2022-09-28T07:18:23"
}
|
Forbidden
You don't have permission to access /~vicente/sbucaptions/sbu-captions-all.tar.gz on this server.
Additionally, a 403 Forbidden error was encountered while trying to use an ErrorDocument to handle the request.
Apache/2.4.6 (Red Hat Enterprise Linux) OpenSSL/1.0.2k-fips PHP/5.4.16 mod_fcgid/2.3.9 mod_wsgi/3.4 Python/2.7.5 mod_perl/2.0.11 Perl/v5.16.3 Server at [www.cs.virginia.edu](mailto:[email protected]) Port 443
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/5020/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/5020/timeline
| null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5019
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5019/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5019/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5019/events
|
https://github.com/huggingface/datasets/pull/5019
| 1,384,673,718 |
PR_kwDODunzps4_iq9b
| 5,019 |
Update swiss judgment prediction
|
{
"login": "JoelNiklaus",
"id": 3775944,
"node_id": "MDQ6VXNlcjM3NzU5NDQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/3775944?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/JoelNiklaus",
"html_url": "https://github.com/JoelNiklaus",
"followers_url": "https://api.github.com/users/JoelNiklaus/followers",
"following_url": "https://api.github.com/users/JoelNiklaus/following{/other_user}",
"gists_url": "https://api.github.com/users/JoelNiklaus/gists{/gist_id}",
"starred_url": "https://api.github.com/users/JoelNiklaus/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/JoelNiklaus/subscriptions",
"organizations_url": "https://api.github.com/users/JoelNiklaus/orgs",
"repos_url": "https://api.github.com/users/JoelNiklaus/repos",
"events_url": "https://api.github.com/users/JoelNiklaus/events{/privacy}",
"received_events_url": "https://api.github.com/users/JoelNiklaus/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 4564477500,
"node_id": "LA_kwDODunzps8AAAABEBBmPA",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20contribution",
"name": "dataset contribution",
"color": "0e8a16",
"default": false,
"description": "Contribution to a dataset script"
}
] |
closed
| false | null |
[] | null |
[
"Thank you very much for the detailed review @albertvillanova!\r\n\r\nI updated the PR with the requested changes. ",
"At the end, I had to manually fix the conflict, so that CI tests are launched.\r\n\r\nPLEASE NOTE: you should first pull to incorporate the previous commit\r\n```shell\r\ngit pull\r\n```",
"_The documentation is not available anymore as the PR was closed or merged._",
"Thank you very much for the detailed feedback and your time @albertvillanova! \r\nYes, thanks. My other datasets are already on the hub: https://huggingface.co/joelito\r\n"
] | 2022-09-24T13:28:57 | 2022-09-28T07:13:39 | 2022-09-28T05:48:50 |
CONTRIBUTOR
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5019",
"html_url": "https://github.com/huggingface/datasets/pull/5019",
"diff_url": "https://github.com/huggingface/datasets/pull/5019.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5019.patch",
"merged_at": "2022-09-28T05:48:50"
}
|
Hi,
I updated the dataset to include additional data made available recently. When I test it locally, it seems to work. However, I get the following error with the dummy data creation:
`Dummy data generation done but dummy data test failed since splits ['train', 'validation', 'test'] have 0 examples for config 'fr'`. Do you know why this could be the case?
Cheers,
Joel
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/5019/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/5019/timeline
| null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5018
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5018/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5018/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5018/events
|
https://github.com/huggingface/datasets/pull/5018
| 1,384,146,585 |
PR_kwDODunzps4_hA0V
| 5,018 |
Create all YAML dataset_info
|
{
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 4564477500,
"node_id": "LA_kwDODunzps8AAAABEBBmPA",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20contribution",
"name": "dataset contribution",
"color": "0e8a16",
"default": false,
"description": "Contribution to a dataset script"
}
] |
closed
| false | null |
[] | null |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5018). All of your documentation changes will be reflected on that endpoint.",
"Closing since https://github.com/huggingface/datasets/pull/4974 removed all the datasets scripts.\r\n\r\nIndividual PRs must be opened on the Hugging face Hub to add the YAML metadata"
] | 2022-09-23T18:08:15 | 2022-10-03T17:08:05 | 2022-10-03T17:08:05 |
MEMBER
| null | true |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5018",
"html_url": "https://github.com/huggingface/datasets/pull/5018",
"diff_url": "https://github.com/huggingface/datasets/pull/5018.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5018.patch",
"merged_at": null
}
|
Following https://github.com/huggingface/datasets/pull/4926
Creates all the `dataset_info` YAML fields in the dataset cards
The JSON are also updated using the simplified backward compatible format added in https://github.com/huggingface/datasets/pull/4926
Needs https://github.com/huggingface/datasets/pull/4926 to be merged first
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/5018/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/5018/timeline
| null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5017
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5017/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5017/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5017/events
|
https://github.com/huggingface/datasets/issues/5017
| 1,384,022,463 |
I_kwDODunzps5SfoG_
| 5,017 |
xcsr: X-CSQA simply uses english for all alleged non-english data
|
{
"login": "thesofakillers",
"id": 26286291,
"node_id": "MDQ6VXNlcjI2Mjg2Mjkx",
"avatar_url": "https://avatars.githubusercontent.com/u/26286291?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thesofakillers",
"html_url": "https://github.com/thesofakillers",
"followers_url": "https://api.github.com/users/thesofakillers/followers",
"following_url": "https://api.github.com/users/thesofakillers/following{/other_user}",
"gists_url": "https://api.github.com/users/thesofakillers/gists{/gist_id}",
"starred_url": "https://api.github.com/users/thesofakillers/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thesofakillers/subscriptions",
"organizations_url": "https://api.github.com/users/thesofakillers/orgs",
"repos_url": "https://api.github.com/users/thesofakillers/repos",
"events_url": "https://api.github.com/users/thesofakillers/events{/privacy}",
"received_events_url": "https://api.github.com/users/thesofakillers/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 2067388877,
"node_id": "MDU6TGFiZWwyMDY3Mzg4ODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20bug",
"name": "dataset bug",
"color": "2edb81",
"default": false,
"description": "A bug in a dataset script provided in the library"
}
] |
closed
| false |
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
}
] | null |
[
"Thanks for reporting, @thesofakillers. Good catch. We are fixing this. "
] | 2022-09-23T16:11:54 | 2022-09-26T10:57:31 | 2022-09-26T10:57:31 |
NONE
| null | null | null |
## Describe the bug
All the alleged non-english subcollections for the X-CSQA task in the [xcsr benchmark dataset ](https://huggingface.co/datasets/xcsr) seem to be copies of the english subcollection, rather than translations. This is in contrast to the data description:
> we automatically translate the original CSQA and CODAH datasets, which only have English versions, to 15 other languages, forming development and test sets for studying X-CSR
## Steps to reproduce the bug
```python
# let's say you want to load the french X-CSQA subcollection
french = datasets.load_dataset("xcsr", "X-CSQA-fr")
# for good measure, let's load english too
english = datasets.load_dataset("xcsr", "X-CSQA-en")
# let's inspect
"".join(english['test'][0]['question']['stem'])
# output: 'The people wanted to stop the parade, so what did they set up to thwart it?'
"".join(french['test'][0]['question']['stem'])
# output: 'The people wanted to stop the parade, so what did they set up to thwart it?'
# what? Why are they both in english?
# I've checked this for validation and train splits too, across many datapoints. It's all the same english dataset
# maybe i need to look better?
french['test'].unique('lang')
# output: ['en']
# no, it's all english
```
## Expected results
Accessing a subcollection in language X should return a subcollection containg samples in language X
## Actual results
Accessing a subcollection in language X returns a subcollection containing samples in English.
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 2.5.1
- Platform: macOS-10.15.7-x86_64-i386-64bit
- Python version: 3.8.13
- PyArrow version: 9.0.0
- Pandas version: 1.4.3
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/5017/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/5017/timeline
| null |
completed
| false |
https://api.github.com/repos/huggingface/datasets/issues/5016
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5016/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5016/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5016/events
|
https://github.com/huggingface/datasets/pull/5016
| 1,383,883,058 |
PR_kwDODunzps4_gKny
| 5,016 |
Fix tar extraction vuln
|
{
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-09-23T14:22:21 | 2022-09-29T12:42:26 | 2022-09-29T12:40:28 |
MEMBER
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5016",
"html_url": "https://github.com/huggingface/datasets/pull/5016",
"diff_url": "https://github.com/huggingface/datasets/pull/5016.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5016.patch",
"merged_at": "2022-09-29T12:40:28"
}
|
Fix for CVE-2007-4559
Description:
Directory traversal vulnerability in the (1) extract and (2) extractall functions in the tarfile
module in Python allows user-assisted remote attackers to overwrite arbitrary files via a .. (dot dot)
sequence in filenames in a TAR archive, a related issue to CVE-2001-1267.
I fixed it by using the solution proposed in https://stackoverflow.com/questions/10060069/safely-extract-zip-or-tar-using-python
It blocks extraction of files with an absolute path or double dots and symlinks.
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/5016/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/5016/timeline
| null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5015
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5015/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5015/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5015/events
|
https://github.com/huggingface/datasets/issues/5015
| 1,383,485,558 |
I_kwDODunzps5SdlB2
| 5,015 |
Transfer dataset scripts to Hub
|
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false |
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
}
] | null |
[
"Sounds good ! Can I help with anything ?"
] | 2022-09-23T08:48:10 | 2022-10-05T07:15:57 | 2022-10-05T07:15:57 |
MEMBER
| null | null | null |
Before merging:
- #4974
TODO:
- [x] Create label: ["dataset contribution"](https://github.com/huggingface/datasets/pulls?q=label%3A%22dataset+contribution%22)
- [x] Create project: [Datasets: Transfer datasets to Hub](https://github.com/orgs/huggingface/projects/22/)
- [x] PRs:
- [x] Add dataset: we should recommend transfer all additions of datasets to the Hub, under the appropriate namespace; no more additions of datasets on GitHub
- [x] Update dataset: in general, we should merge bug fixes; enhancements should be considered on a case-by-case basis, depending on whether there is a more suitable namespace on the Hub
- [ ] Issues
Finally:
- [x] #4974
Let me know what you think! :hugs:
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/5015/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 1,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/5015/timeline
| null |
completed
| false |
https://api.github.com/repos/huggingface/datasets/issues/5014
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5014/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5014/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5014/events
|
https://github.com/huggingface/datasets/issues/5014
| 1,383,422,639 |
I_kwDODunzps5SdVqv
| 5,014 |
I need to read the custom dataset in conll format
|
{
"login": "506610466",
"id": 39985245,
"node_id": "MDQ6VXNlcjM5OTg1MjQ1",
"avatar_url": "https://avatars.githubusercontent.com/u/39985245?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/506610466",
"html_url": "https://github.com/506610466",
"followers_url": "https://api.github.com/users/506610466/followers",
"following_url": "https://api.github.com/users/506610466/following{/other_user}",
"gists_url": "https://api.github.com/users/506610466/gists{/gist_id}",
"starred_url": "https://api.github.com/users/506610466/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/506610466/subscriptions",
"organizations_url": "https://api.github.com/users/506610466/orgs",
"repos_url": "https://api.github.com/users/506610466/repos",
"events_url": "https://api.github.com/users/506610466/events{/privacy}",
"received_events_url": "https://api.github.com/users/506610466/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] |
open
| false | null |
[] | null |
[
"Hi! We don't currently have a builder for parsing custom `conll` datasets, but I guess we could add one as a packaged module (similarly to what [TFDS](https://github.com/tensorflow/datasets/blob/master/tensorflow_datasets/core/dataset_builders/conll/conll_dataset_builder.py) did). @lhoestq @albertvillanova WDYT?\r\n\r\nIn the meantime, you can use `Dataset.from_generator` to create a dataset as follows:\r\n```python\r\nfrom datasets import Dataset\r\n\r\n# 2009 version\r\nINPUT_COLUMNS = \"ID FORM LEMMA PLEMMA POS PPOS FEAT PFEAT HEAD PHEAD DEPREL PDEPREL\".split()\r\n\r\ndef read_conll(file):\r\n example = {col: [] for col in INPUT_COLUMNS}\r\n idx = 0\r\n with open(file) as f:\r\n for line in f:\r\n if line.startswith(\"-DOCSTART-\") or line == \"\\n\" or not line:\r\n if example[next(iter(example))]:\r\n yield idx, example\r\n idx += 1\r\n example = {col: [] for col in INPUT_COLUMNS}\r\n else:\r\n row_cols = line.split()\r\n for i, col in enumerate(example):\r\n example[col] = row_cols[i].rstrip()\r\n\r\n# (optional) pass custom features with `features=Features(...)`\r\ndset = Dataset.from_generator(read_conll, gen_kwargs={\"file\": \"path/to/conll/file\"}) \r\n``` ",
"I think we could add a dedicated builder if you think this format is general enough.",
"\r\n\r\n\r\n> I think we could add a dedicated builder if you think this format is general enough.\r\n\r\nI think its functions are incomplete. It should have to_ Conll and from_ There are two methods of conll."
] | 2022-09-23T07:49:42 | 2022-11-02T11:57:15 | null |
NONE
| null | null | null |
I need to read the custom dataset in conll format
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/5014/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/5014/timeline
| null |
reopened
| false |
https://api.github.com/repos/huggingface/datasets/issues/5013
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5013/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5013/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5013/events
|
https://github.com/huggingface/datasets/issues/5013
| 1,383,415,971 |
I_kwDODunzps5SdUCj
| 5,013 |
would huggingface like publish cpp binding for datasets package ?
|
{
"login": "mullerhai",
"id": 6143404,
"node_id": "MDQ6VXNlcjYxNDM0MDQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/6143404?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mullerhai",
"html_url": "https://github.com/mullerhai",
"followers_url": "https://api.github.com/users/mullerhai/followers",
"following_url": "https://api.github.com/users/mullerhai/following{/other_user}",
"gists_url": "https://api.github.com/users/mullerhai/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mullerhai/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mullerhai/subscriptions",
"organizations_url": "https://api.github.com/users/mullerhai/orgs",
"repos_url": "https://api.github.com/users/mullerhai/repos",
"events_url": "https://api.github.com/users/mullerhai/events{/privacy}",
"received_events_url": "https://api.github.com/users/mullerhai/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1935892913,
"node_id": "MDU6TGFiZWwxOTM1ODkyOTEz",
"url": "https://api.github.com/repos/huggingface/datasets/labels/wontfix",
"name": "wontfix",
"color": "ffffff",
"default": true,
"description": "This will not be worked on"
}
] |
closed
| false | null |
[] | null |
[
"Hi ! Can you share more information about your use case ? How could it help you to have cpp bindings versus using the python libraries ?",
"> Hi ! Can you share more information about your use case ? How could it help you to have cpp bindings versus using the python libraries ?\r\n\r\nfor example ,the huggingface load_model() and load_dataset() can execute in cpp env",
"If it's a viable option for you, you can check [tch-rs](https://github.com/LaurentMazare/tch-rs) to load models in Rust. Regarding datasets, you can first download them in python and then use Arrow C++ or Rust to load them",
"If you are more adventurous, another option is to embed python calls inside c++ e.g. with `pybind11`.",
"> pybind11\r\n\r\nI think it is not the best solution"
] | 2022-09-23T07:42:49 | 2023-02-24T16:20:57 | 2023-02-24T16:20:57 |
NONE
| null | null | null |
HI:
I use cpp env libtorch, I like use hugggingface ,but huggingface not cpp binding, would you like publish cpp binding for it.
thanks
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/5013/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/5013/timeline
| null |
completed
| false |
https://api.github.com/repos/huggingface/datasets/issues/5012
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5012/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5012/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5012/events
|
https://github.com/huggingface/datasets/issues/5012
| 1,382,851,096 |
I_kwDODunzps5SbKIY
| 5,012 |
Force JSON format regardless of file naming on S3
|
{
"login": "junwang-wish",
"id": 112650299,
"node_id": "U_kgDOBrboOw",
"avatar_url": "https://avatars.githubusercontent.com/u/112650299?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/junwang-wish",
"html_url": "https://github.com/junwang-wish",
"followers_url": "https://api.github.com/users/junwang-wish/followers",
"following_url": "https://api.github.com/users/junwang-wish/following{/other_user}",
"gists_url": "https://api.github.com/users/junwang-wish/gists{/gist_id}",
"starred_url": "https://api.github.com/users/junwang-wish/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/junwang-wish/subscriptions",
"organizations_url": "https://api.github.com/users/junwang-wish/orgs",
"repos_url": "https://api.github.com/users/junwang-wish/repos",
"events_url": "https://api.github.com/users/junwang-wish/events{/privacy}",
"received_events_url": "https://api.github.com/users/junwang-wish/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] |
open
| false | null |
[] | null |
[
"Hi ! Support for URIs like `s3://...` is not implemented yet in `data_files=`. You can use the HTTP URL instead if your data is public in the meantime"
] | 2022-09-22T18:28:15 | 2022-09-26T09:31:38 | null |
NONE
| null | null | null |
I have a file on S3 created by Data Version Control, it looks like `s3://dvc/ac/badff5b134382a0f25248f1b45d7b2` but contains a json file. If I run
```python
dataset = load_dataset(
"json",
data_files='s3://dvc/ac/badff5b134382a0f25248f1b45d7b2'
)
```
It gives me
```
InvalidSchema: No connection adapters were found for 's3://dvc/ac/badff5b134382a0f25248f1b45d7b2'
```
However, I cannot go ahead and change the names of the s3 file. Is there a way to "force" load a S3 url with certain decoder (JSON, CSV, etc.) regardless of s3 URL naming?
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/5012/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/5012/timeline
| null | null | false |
https://api.github.com/repos/huggingface/datasets/issues/5011
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5011/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5011/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5011/events
|
https://github.com/huggingface/datasets/issues/5011
| 1,382,609,587 |
I_kwDODunzps5SaPKz
| 5,011 |
Audio: `encode_example` fails with IndexError
|
{
"login": "sanchit-gandhi",
"id": 93869735,
"node_id": "U_kgDOBZhWpw",
"avatar_url": "https://avatars.githubusercontent.com/u/93869735?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sanchit-gandhi",
"html_url": "https://github.com/sanchit-gandhi",
"followers_url": "https://api.github.com/users/sanchit-gandhi/followers",
"following_url": "https://api.github.com/users/sanchit-gandhi/following{/other_user}",
"gists_url": "https://api.github.com/users/sanchit-gandhi/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sanchit-gandhi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sanchit-gandhi/subscriptions",
"organizations_url": "https://api.github.com/users/sanchit-gandhi/orgs",
"repos_url": "https://api.github.com/users/sanchit-gandhi/repos",
"events_url": "https://api.github.com/users/sanchit-gandhi/events{/privacy}",
"received_events_url": "https://api.github.com/users/sanchit-gandhi/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] |
closed
| false | null |
[] | null |
[
"Sorry bug on my part 😅 Closing "
] | 2022-09-22T15:07:27 | 2022-09-23T09:05:18 | 2022-09-23T09:05:18 |
CONTRIBUTOR
| null | null | null |
## Describe the bug
Loading the dataset [earnings-22](https://huggingface.co/datasets/sanchit-gandhi/earnings22_split) from the Hub yields an Index Error. I created this dataset locally and then pushed to hub at the specified URL. Thus, I expect the dataset should work out-of-the-box! Indeed, the dataset viewer functions correctly, and there were no issues when I had the dataset locally.
Don't think it's a sound file bug as the version matches what worked previously.
Update: the bug appeared for me on a GPU, mysteriously on a TPU I can't repro and it downloads correctly...
## Steps to reproduce the bug
```python
from datasets import load_dataset
earnings22 = load_dataset("sanchit-gandhi/earnings22_split")
```
## Expected results
```
>>> earnings22
DatasetDict({
validation: Dataset({
features: ['source_id', 'audio', 'segment_id', 'sentence', 'start_ts', 'end_ts', 'id'],
num_rows: 2650
})
train: Dataset({
features: ['source_id', 'audio', 'segment_id', 'sentence', 'start_ts', 'end_ts', 'id'],
num_rows: 52006
})
test: Dataset({
features: ['source_id', 'audio', 'segment_id', 'sentence', 'start_ts', 'end_ts', 'id'],
num_rows: 2735
})
})
```
## Actual results
```
Traceback (most recent call last):
File "/opt/conda/envs/hf/lib/python3.8/site-packages/datasets/arrow_dataset.py", line 2764, in _map_single
writer.write(example)
File "/opt/conda/envs/hf/lib/python3.8/site-packages/datasets/arrow_writer.py", line 451, in write
self.write_examples_on_file()
File "/opt/conda/envs/hf/lib/python3.8/site-packages/datasets/arrow_writer.py", line 409, in write_examples_on_file
self.write_batch(batch_examples=batch_examples)
File "/opt/conda/envs/hf/lib/python3.8/site-packages/datasets/arrow_writer.py", line 508, in write_batch
arrays.append(pa.array(typed_sequence))
File "pyarrow/array.pxi", line 231, in pyarrow.lib.array
File "pyarrow/array.pxi", line 110, in pyarrow.lib._handle_arrow_array_protocol
File "/opt/conda/envs/hf/lib/python3.8/site-packages/datasets/arrow_writer.py", line 197, in __arrow_array__
out = cast_array_to_feature(out, type, allow_number_to_str=not self.trying_type)
File "/opt/conda/envs/hf/lib/python3.8/site-packages/datasets/table.py", line 1683, in wrapper
return func(array, *args, **kwargs)
File "/opt/conda/envs/hf/lib/python3.8/site-packages/datasets/table.py", line 1795, in cast_array_to_feature
return feature.cast_storage(array)
File "/opt/conda/envs/hf/lib/python3.8/site-packages/datasets/features/audio.py", line 190, in cast_storage
storage = pa.array([Audio().encode_example(x) if x is not None else None for x in storage.to_pylist()])
File "/opt/conda/envs/hf/lib/python3.8/site-packages/datasets/features/audio.py", line 190, in <listcomp>
storage = pa.array([Audio().encode_example(x) if x is not None else None for x in storage.to_pylist()])
File "/opt/conda/envs/hf/lib/python3.8/site-packages/datasets/features/audio.py", line 92, in encode_example
sf.write(buffer, value["array"], value["sampling_rate"], format="wav")
File "/opt/conda/envs/hf/lib/python3.8/site-packages/soundfile.py", line 313, in write
channels = data.shape[1]
IndexError: tuple index out of range
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 2.4.0
- Platform: Linux-4.19.0-21-cloud-amd64-x86_64-with-glibc2.10
- Python version: 3.8.13
- PyArrow version: 9.0.0
- Pandas version: 1.4.3
Plus:
- SoundFile version: 0.10.3.post1
cc @lhoestq @polinaeterna
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/5011/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/5011/timeline
| null |
completed
| false |
https://api.github.com/repos/huggingface/datasets/issues/5010
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5010/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5010/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5010/events
|
https://github.com/huggingface/datasets/pull/5010
| 1,382,308,799 |
PR_kwDODunzps4_bB3q
| 5,010 |
Add deprecation warning to multilingual_librispeech dataset card
|
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 4564477500,
"node_id": "LA_kwDODunzps8AAAABEBBmPA",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20contribution",
"name": "dataset contribution",
"color": "0e8a16",
"default": false,
"description": "Contribution to a dataset script"
}
] |
closed
| false | null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-09-22T11:41:59 | 2022-09-23T12:04:37 | 2022-09-23T12:02:45 |
MEMBER
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5010",
"html_url": "https://github.com/huggingface/datasets/pull/5010",
"diff_url": "https://github.com/huggingface/datasets/pull/5010.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5010.patch",
"merged_at": "2022-09-23T12:02:45"
}
|
Besides the current deprecation warning in the script of `multilingual_librispeech`, this PR adds a deprecation warning to its dataset card as well.
The format of the deprecation warning is aligned with the one in the library documentation when docstrings contain the `<Deprecated/>` tag.
Related to:
- #4060
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/5010/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 1,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/5010/timeline
| null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5009
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5009/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5009/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5009/events
|
https://github.com/huggingface/datasets/issues/5009
| 1,381,194,067 |
I_kwDODunzps5SU1lT
| 5,009 |
Error loading StonyBrookNLP/tellmewhy dataset from hub even though local copy loads correctly
|
{
"login": "ykl7",
"id": 4996184,
"node_id": "MDQ6VXNlcjQ5OTYxODQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/4996184?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ykl7",
"html_url": "https://github.com/ykl7",
"followers_url": "https://api.github.com/users/ykl7/followers",
"following_url": "https://api.github.com/users/ykl7/following{/other_user}",
"gists_url": "https://api.github.com/users/ykl7/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ykl7/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ykl7/subscriptions",
"organizations_url": "https://api.github.com/users/ykl7/orgs",
"repos_url": "https://api.github.com/users/ykl7/repos",
"events_url": "https://api.github.com/users/ykl7/events{/privacy}",
"received_events_url": "https://api.github.com/users/ykl7/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] |
closed
| false | null |
[] | null |
[
"I think this is because some columns are mostly empty lists. In particular the train and validation splits only have empty lists for `val_ann`. Therefore the type inference doesn't know which type is inside (or it would have to scan the other splits first before knowing).\r\n\r\nYou can fix that by specifying the features types explicitly.\r\nThen you can save the feature types inside the dataset repository, so that you won't need to specify the features in subsequent calls:\r\n```python\r\nfrom datasets import load_dataset, Features, Sequence, Value\r\nfrom datasets.info import DatasetInfosDict\r\n\r\nfeatures = Features({\r\n 'narrative': Value('string'),\r\n 'question': Value('string'),\r\n 'original_sentence_for_question': Value('string'),\r\n 'narrative_lexical_overlap': Value('float64'),\r\n 'is_ques_answerable': Value('string'),\r\n 'answer': Value('string'),\r\n 'is_ques_answerable_annotator': Value('string'),\r\n 'original_narrative_form': Sequence(Value('string')),\r\n 'question_meta': Value('string'),\r\n 'helpful_sentences': Sequence(Value('int64')),\r\n 'human_eval': Value('bool'),\r\n 'val_ann': Sequence(Value('int64')),\r\n 'gram_ann': Sequence(Value('int64'))\r\n})\r\nds = load_dataset('StonyBrookNLP/tellmewhy', features=features)\r\nDatasetInfosDict({\"default\": ds[\"train\"].info}).write_to_directory(\"path/to/local/tellmewhy\")\r\n```\r\nand then after pushing the change to the dataset repository on the Hub, `load_dataset(\"StonyBrookNLP/tellmewhy\")` will work directly`",
"(Note that specifying explicit types will be made easier with https://github.com/huggingface/datasets/pull/4926)",
"`gram_ann` and `val_ann` are annotations that only exist for part of the test set. I wanted to keep all the columns consistent across all files, so I added them to train and validation as well. I'll check if removing them from those files is still compliant with this repo. Otherwise, I will do as you suggested. Thanks @lhoestq !",
"@lhoestq I followed the exact steps you described but it seems like I'm getting the same error unfortunately. Any other ideas? Thanks in advance",
"Hi ! If you move `dataset_infos.json` from `data/` to the root of your dataset repository if should work :)",
"I tried that and pushed to the [hub](https://huggingface.co/datasets/StonyBrookNLP/tellmewhy/tree/main). Now, there is a new error.\r\n```\r\n File \"/home/yklal95/tellmewhy/src/prepare_data.py\", line 67, in main\r\n dataset = load_dataset('StonyBrookNLP/tellmewhy')\r\n File \"/home/yklal95/anaconda3/envs/tmw-generalization/lib/python3.9/site-packages/datasets/load.py\", line 1746, in load_dataset\r\n builder_instance.download_and_prepare(\r\n File \"/home/yklal95/anaconda3/envs/tmw-generalization/lib/python3.9/site-packages/datasets/builder.py\", line 704, in download_and_prepare\r\n self._download_and_prepare(\r\n File \"/home/yklal95/anaconda3/envs/tmw-generalization/lib/python3.9/site-packages/datasets/builder.py\", line 775, in _download_and_prepare\r\n verify_checksums(\r\n File \"/home/yklal95/anaconda3/envs/tmw-generalization/lib/python3.9/site-packages/datasets/utils/info_utils.py\", line 33, in verify_checksums\r\n raise ExpectedMoreDownloadedFiles(str(set(expected_checksums) - set(recorded_checksums)))\r\ndatasets.utils.info_utils.ExpectedMoreDownloadedFiles: {'/home/yklal95/tellmewhy/data/test.json', '/home/yklal95/tellmewhy/data/validation.json', '/home/yklal95/tellmewhy/data/train.json'}\r\n```\r\nNo changes were made to any of the other files and they are still on the hub. Let me know if you have any ideas @lhoestq Thanks!",
"Oh I see - the code I gave you returns local paths instead of URLs to store metadata about files to download.\r\nI opened a PR in your repo here to remove this: https://huggingface.co/datasets/StonyBrookNLP/tellmewhy/discussions/1\r\nsorry for the inconvenience !",
"It works now! Thanks a lot @lhoestq "
] | 2022-09-21T16:23:06 | 2022-09-29T13:07:29 | 2022-09-29T13:07:29 |
NONE
| null | null | null |
## Describe the bug
I have added a new dataset with the identifier `StonyBrookNLP/tellmewhy` to the hub. When I load the individual files using my local copy using `dataset = datasets.load_dataset("json", data_files="data/train.jsonl")`, it loads the dataset correctly. However, when I try to load it from the hub, I get an error (pasted below). Additionally, `dataset = datasets.load_dataset("json", data_dir="data/")` throws the same error.
## Steps to reproduce the bug
```python
dataset = datasets.load_dataset('StonyBrookNLP/tellmewhy')
```
## Expected results
Successfully load the `StonyBrookNLP/tellmewhy` dataset.
## Actual results
```
Using custom data configuration StonyBrookNLP--tellmewhy-82712924092694ff
Downloading and preparing dataset json/StonyBrookNLP--tellmewhy to /home/yklal95/.cache/huggingface/datasets/StonyBrookNLP___json/StonyBrookNLP--tellmewhy-82712924092694ff/0.0.0/a3e658c4731e59120d44081ac10bf85dc7e1388126b92338344ce9661907f253...
Downloading data files: 100%|██████████████████████████████| 3/3 [00:00<00:00, 957.46it/s]
Extracting data files: 100%|███████████████████████████████| 3/3 [00:00<00:00, 299.14it/s]
Traceback (most recent call last):
File "/home/yklal95/tmw-generalization/src/load_datasets.py", line 17, in <module>
main(args)
File "/home/yklal95/tmw-generalization/src/load_datasets.py", line 11, in main
dataset = datasets.load_dataset(args.dataset_name)
File "/home/yklal95/anaconda3/envs/tmw-generalization/lib/python3.9/site-packages/datasets/load.py", line 1746, in load_dataset
builder_instance.download_and_prepare(
File "/home/yklal95/anaconda3/envs/tmw-generalization/lib/python3.9/site-packages/datasets/builder.py", line 704, in download_and_prepare
self._download_and_prepare(
File "/home/yklal95/anaconda3/envs/tmw-generalization/lib/python3.9/site-packages/datasets/builder.py", line 793, in _download_and_prepare
self._prepare_split(split_generator, **prepare_split_kwargs)
File "/home/yklal95/anaconda3/envs/tmw-generalization/lib/python3.9/site-packages/datasets/builder.py", line 1277, in _prepare_split
writer.write_table(table)
File "/home/yklal95/anaconda3/envs/tmw-generalization/lib/python3.9/site-packages/datasets/arrow_writer.py", line 524, in write_table
pa_table = table_cast(pa_table, self._schema)
File "/home/yklal95/anaconda3/envs/tmw-generalization/lib/python3.9/site-packages/datasets/table.py", line 2005, in table_cast
return cast_table_to_schema(table, schema)
File "/home/yklal95/anaconda3/envs/tmw-generalization/lib/python3.9/site-packages/datasets/table.py", line 1969, in cast_table_to_schema
arrays = [cast_array_to_feature(table[name], feature) for name, feature in features.items()]
File "/home/yklal95/anaconda3/envs/tmw-generalization/lib/python3.9/site-packages/datasets/table.py", line 1969, in <listcomp>
arrays = [cast_array_to_feature(table[name], feature) for name, feature in features.items()]
File "/home/yklal95/anaconda3/envs/tmw-generalization/lib/python3.9/site-packages/datasets/table.py", line 1681, in wrapper
return pa.chunked_array([func(chunk, *args, **kwargs) for chunk in array.chunks])
File "/home/yklal95/anaconda3/envs/tmw-generalization/lib/python3.9/site-packages/datasets/table.py", line 1681, in <listcomp>
return pa.chunked_array([func(chunk, *args, **kwargs) for chunk in array.chunks])
File "/home/yklal95/anaconda3/envs/tmw-generalization/lib/python3.9/site-packages/datasets/table.py", line 1822, in cast_array_to_feature
casted_values = _c(array.values, feature.feature)
File "/home/yklal95/anaconda3/envs/tmw-generalization/lib/python3.9/site-packages/datasets/table.py", line 1683, in wrapper
return func(array, *args, **kwargs)
File "/home/yklal95/anaconda3/envs/tmw-generalization/lib/python3.9/site-packages/datasets/table.py", line 1853, in cast_array_to_feature
return array_cast(array, feature(), allow_number_to_str=allow_number_to_str)
File "/home/yklal95/anaconda3/envs/tmw-generalization/lib/python3.9/site-packages/datasets/table.py", line 1683, in wrapper
return func(array, *args, **kwargs)
File "/home/yklal95/anaconda3/envs/tmw-generalization/lib/python3.9/site-packages/datasets/table.py", line 1761, in array_cast
raise TypeError(f"Couldn't cast array of type {array.type} to {pa_type}")
TypeError: Couldn't cast array of type int64 to null
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 2.4.0
- Platform: Linux-4.15.0-121-generic-x86_64-with-glibc2.27
- Python version: 3.9.13
- PyArrow version: 9.0.0
- Pandas version: 1.5.0
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/5009/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/5009/timeline
| null |
completed
| false |
https://api.github.com/repos/huggingface/datasets/issues/5008
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5008/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5008/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5008/events
|
https://github.com/huggingface/datasets/pull/5008
| 1,381,090,903 |
PR_kwDODunzps4_XAc5
| 5,008 |
Re-apply input columns change
|
{
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-09-21T15:09:01 | 2022-09-22T13:57:36 | 2022-09-22T13:55:23 |
CONTRIBUTOR
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5008",
"html_url": "https://github.com/huggingface/datasets/pull/5008",
"diff_url": "https://github.com/huggingface/datasets/pull/5008.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5008.patch",
"merged_at": "2022-09-22T13:55:23"
}
|
Fixes the `filter` + `input_columns` combination, which is used in the `transformers` examples for instance.
Revert #5006 (which in turn reverts #4971)
Fix https://github.com/huggingface/datasets/issues/4858
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/5008/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/5008/timeline
| null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5007
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5007/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5007/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5007/events
|
https://github.com/huggingface/datasets/pull/5007
| 1,381,007,607 |
PR_kwDODunzps4_WvFQ
| 5,007 |
Add some note about running the transformers ci before a release
|
{
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-09-21T14:14:25 | 2022-09-22T10:16:14 | 2022-09-22T10:14:06 |
MEMBER
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5007",
"html_url": "https://github.com/huggingface/datasets/pull/5007",
"diff_url": "https://github.com/huggingface/datasets/pull/5007.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5007.patch",
"merged_at": "2022-09-22T10:14:06"
}
| null |
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/5007/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/5007/timeline
| null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5006
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5006/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5006/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5006/events
|
https://github.com/huggingface/datasets/pull/5006
| 1,380,968,395 |
PR_kwDODunzps4_Wm8z
| 5,006 |
Revert input_columns change
|
{
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"Merging this one and I'll check if it fixes the `transformers` CI before doing a patch release"
] | 2022-09-21T13:49:20 | 2022-09-21T14:14:33 | 2022-09-21T14:11:57 |
MEMBER
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5006",
"html_url": "https://github.com/huggingface/datasets/pull/5006",
"diff_url": "https://github.com/huggingface/datasets/pull/5006.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5006.patch",
"merged_at": "2022-09-21T14:11:57"
}
|
Revert https://github.com/huggingface/datasets/pull/4971
Fix https://github.com/huggingface/datasets/issues/5005
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/5006/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/5006/timeline
| null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5005
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5005/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5005/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5005/events
|
https://github.com/huggingface/datasets/issues/5005
| 1,380,952,960 |
I_kwDODunzps5ST6uA
| 5,005 |
Release 2.5.0 breaks transformers CI
|
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] |
closed
| false |
{
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
}
] | null |
[
"Shall we revert https://github.com/huggingface/datasets/pull/4971 @mariosasko ?\r\n\r\nAnd for consistency we can update IterableDataset.map later"
] | 2022-09-21T13:39:19 | 2022-09-21T14:11:57 | 2022-09-21T14:11:57 |
MEMBER
| null | null | null |
## Describe the bug
As reported by @lhoestq:
> see https://app.circleci.com/pipelines/github/huggingface/transformers/47634/workflows/b491886b-e66e-4edb-af96-8b459e72aa25/jobs/564563
this is used here: [https://github.com/huggingface/transformers/blob/3b19c0317b6909e2d7f11b5053895ac55[…]torch/speech-pretraining/run_wav2vec2_pretraining_no_trainer.py](https://github.com/huggingface/transformers/blob/3b19c0317b6909e2d7f11b5053895ac55250e7da/examples/pytorch/speech-pretraining/run_wav2vec2_pretraining_no_trainer.py#L482-L488)
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/5005/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/5005/timeline
| null |
completed
| false |
https://api.github.com/repos/huggingface/datasets/issues/5004
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5004/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5004/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5004/events
|
https://github.com/huggingface/datasets/pull/5004
| 1,380,860,606 |
PR_kwDODunzps4_WQck
| 5,004 |
Remove license tag file and validation
|
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-09-21T12:35:14 | 2022-09-22T11:47:41 | 2022-09-22T11:45:46 |
MEMBER
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5004",
"html_url": "https://github.com/huggingface/datasets/pull/5004",
"diff_url": "https://github.com/huggingface/datasets/pull/5004.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5004.patch",
"merged_at": "2022-09-22T11:45:46"
}
|
As requested, we are removing the validation of the licenses from `datasets` because this is done on the Hub.
Fix #4994.
Related to:
- #4926, which is removing all the validation from `datasets`
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/5004/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/5004/timeline
| null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5003
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5003/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5003/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5003/events
|
https://github.com/huggingface/datasets/pull/5003
| 1,380,617,353 |
PR_kwDODunzps4_Vdko
| 5,003 |
Fix missing use_auth_token in streaming docstrings
|
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-09-21T09:27:03 | 2022-09-21T16:24:01 | 2022-09-21T16:20:59 |
MEMBER
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5003",
"html_url": "https://github.com/huggingface/datasets/pull/5003",
"diff_url": "https://github.com/huggingface/datasets/pull/5003.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5003.patch",
"merged_at": "2022-09-21T16:20:59"
}
|
This PRs fixes docstrings:
- adds the missing `use_auth_token` param
- updates syntax of param types
- adds params to docstrings without them
- fixes return/yield types
- fixes syntax
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/5003/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/5003/timeline
| null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5002
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5002/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5002/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5002/events
|
https://github.com/huggingface/datasets/issues/5002
| 1,380,589,402 |
I_kwDODunzps5SSh9a
| 5,002 |
Dataset Viewer issue for loubnabnl/humaneval-x
|
{
"login": "loubnabnl",
"id": 44069155,
"node_id": "MDQ6VXNlcjQ0MDY5MTU1",
"avatar_url": "https://avatars.githubusercontent.com/u/44069155?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/loubnabnl",
"html_url": "https://github.com/loubnabnl",
"followers_url": "https://api.github.com/users/loubnabnl/followers",
"following_url": "https://api.github.com/users/loubnabnl/following{/other_user}",
"gists_url": "https://api.github.com/users/loubnabnl/gists{/gist_id}",
"starred_url": "https://api.github.com/users/loubnabnl/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/loubnabnl/subscriptions",
"organizations_url": "https://api.github.com/users/loubnabnl/orgs",
"repos_url": "https://api.github.com/users/loubnabnl/repos",
"events_url": "https://api.github.com/users/loubnabnl/events{/privacy}",
"received_events_url": "https://api.github.com/users/loubnabnl/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 3470211881,
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer",
"name": "dataset-viewer",
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co"
}
] |
closed
| false |
{
"login": "severo",
"id": 1676121,
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/severo",
"html_url": "https://github.com/severo",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"organizations_url": "https://api.github.com/users/severo/orgs",
"repos_url": "https://api.github.com/users/severo/repos",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"received_events_url": "https://api.github.com/users/severo/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"login": "severo",
"id": 1676121,
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/severo",
"html_url": "https://github.com/severo",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"organizations_url": "https://api.github.com/users/severo/orgs",
"repos_url": "https://api.github.com/users/severo/repos",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"received_events_url": "https://api.github.com/users/severo/received_events",
"type": "User",
"site_admin": false
}
] | null |
[
"It's a bug! Thanks for reporting, I'm looking at it",
"Fixed."
] | 2022-09-21T09:06:17 | 2022-09-21T11:49:49 | 2022-09-21T11:49:49 |
NONE
| null | null | null |
### Link
https://huggingface.co/datasets/loubnabnl/humaneval-x/viewer/
### Description
The dataset has subsets but the viewer gets stuck in the default subset even when I select another one (the data loading of the subsets works fine)
### Owner
Yes
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/5002/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 1
}
|
https://api.github.com/repos/huggingface/datasets/issues/5002/timeline
| null |
completed
| false |
https://api.github.com/repos/huggingface/datasets/issues/5001
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5001/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5001/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5001/events
|
https://github.com/huggingface/datasets/pull/5001
| 1,379,844,820 |
PR_kwDODunzps4_TBWa
| 5,001 |
Support loading XML datasets
|
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
}
|
[] |
open
| false | null |
[] | null |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/datasets/pr_5001). All of your documentation changes will be reflected on that endpoint.",
"> CC: @davanstrien\r\n\r\nI should have some time to look at this on Friday :) ",
"@albertvillanova I've tried this with a few different XML datasets. One issue I've run into is getting a `KeyError` when the attributes of a field differ from the first parsed row. Unfortunately, this can come up in the ALTO XML format, for example, if you want to parse the 'string' field, which contains the text in the ALTO XML files. \r\n\r\nWhen parsing a file, this instance has no 'STYLE' attribute: \r\n\r\n```xml\r\n<TextLine HEIGHT=\"39\" WIDTH=\"295\" VPOS=\"926\" HPOS=\"247\"><String WC=\"0.4600000083\" CONTENT=\"jufqu’en\" HEIGHT=\"39\" WIDTH=\"117\" VPOS=\"926\" HPOS=\"247\"/><SP WIDTH=\"14\" VPOS=\"928\" HPOS=\"365\"/><String WC=\"0.6075000167\" CONTENT=\"l’an\" HEIGHT=\"26\" WIDTH=\"50\" VPOS=\"928\" HPOS=\"380\"/><SP WIDTH=\"24\" VPOS=\"936\" HPOS=\"431\"/><String WC=\"0.4300000072\" CONTENT=\"1\" HEIGHT=\"16\" WIDTH=\"9\" VPOS=\"936\" HPOS=\"456\"/><String STYLE=\"italics\" WC=\"0.5774999857\" CONTENT=\"361.\" HEIGHT=\"25\" WIDTH=\"68\" VPOS=\"933\" HPOS=\"474\"/></TextLine>\r\n```\r\n\r\nWhereas this one which appears later in the file, does have this field: \r\n\r\n```xml\r\n<TextLine HEIGHT=\"39\" WIDTH=\"712\" VPOS=\"966\" HPOS=\"297\"><String STYLE=\"italics\" WC=\"0.6999999881\" CONTENT=\"I\" HEIGHT=\"17\" WIDTH=\"9\" VPOS=\"977\" HPOS=\"297\"/><String WC=\"0.5\" CONTENT=\"I.\" HEIGHT=\"18\" WIDTH=\"25\" VPOS=\"976\" HPOS=\"318\"/><SP WIDTH=\"24\" VPOS=\"971\" HPOS=\"344\"/><String STYLE=\"italics\" WC=\"0.3359999955\" CONTENT=\"Crade\" HEIGHT=\"26\" WIDTH=\"91\" VPOS=\"967\" HPOS=\"369\"/><SP WIDTH=\"31\" VPOS=\"971\" HPOS=\"461\"/><String STYLE=\"italics\" WC=\"0.6060000062\" CONTENT=\"Pétri\" HEIGHT=\"26\" WIDTH=\"71\" VPOS=\"968\" HPOS=\"493\"/><SP WIDTH=\"23\" VPOS=\"968\" HPOS=\"565\"/><String STYLE=\"italics\" WC=\"0.612857163\" CONTENT=\"Candidi\" HEIGHT=\"27\" WIDTH=\"111\" VPOS=\"967\" HPOS=\"589\"/><SP WIDTH=\"19\" VPOS=\"967\" HPOS=\"701\"/><String STYLE=\"italics\" WC=\"0.4088888764\" CONTENT=\"Decembrii\" HEIGHT=\"28\" WIDTH=\"144\" VPOS=\"966\" HPOS=\"721\"/><SP WIDTH=\"10\" VPOS=\"968\" HPOS=\"866\"/><String STYLE=\"italics\" WC=\"0.4600000083\" CONTENT=\"in\" HEIGHT=\"25\" WIDTH=\"27\" VPOS=\"968\" HPOS=\"877\"/><SP WIDTH=\"9\" VPOS=\"967\" HPOS=\"905\"/><String STYLE=\"italics\" WC=\"0.5099999905\" CONTENT=\"funere\" HEIGHT=\"38\" WIDTH=\"94\" VPOS=\"967\" HPOS=\"915\"/></TextLine>\r\n```\r\n\r\nSince the first-seen fields define what is passed to `arrow_writer`, this causes a KeyError when the version with the extra attributes is encountered because it doesn't expect this column. \r\n\r\nSince it's important to support streaming, I'm not sure there is a nice way to detect attributes for the whole file easily in an automatic way. The two potential ways I can see of doing it.\r\n\r\n- Do an initial pass on a batch of data to have a higher chance of encountering variations in attributes before doing the arrow write. \r\n- Do a full pass on one file (and assume that this won't change across files) \r\n\r\nI think the other way of doing this would be to allow users to define expected/wanted attributes as another loading argument. This could then be used to extract the described attributes (and make them None if not found). This requires a bit more work from the user but could be helpful. For example, in the XML above, likely, most users will only want the `WC` and `CONTENT` attributes. So they could specify this upfront and avoid loading extra data they don't need or want. I suspect this option would make more sense than making this operation automatic for the case where attributes might change. WDYT? \r\n\r\n\r\n\r\n\r\n\r\n\r\n"
] | 2022-09-20T18:42:58 | 2022-11-01T12:44:42 | null |
MEMBER
| null | true |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5001",
"html_url": "https://github.com/huggingface/datasets/pull/5001",
"diff_url": "https://github.com/huggingface/datasets/pull/5001.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/5001.patch",
"merged_at": null
}
|
CC: @davanstrien
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/5001/reactions",
"total_count": 2,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 2
}
|
https://api.github.com/repos/huggingface/datasets/issues/5001/timeline
| null | null | true |
https://api.github.com/repos/huggingface/datasets/issues/5000
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/5000/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/5000/comments
|
https://api.github.com/repos/huggingface/datasets/issues/5000/events
|
https://github.com/huggingface/datasets/issues/5000
| 1,379,709,398 |
I_kwDODunzps5SPLHW
| 5,000 |
Dataset Viewer issue for asapp/slue
|
{
"login": "fwu-asapp",
"id": 56092571,
"node_id": "MDQ6VXNlcjU2MDkyNTcx",
"avatar_url": "https://avatars.githubusercontent.com/u/56092571?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/fwu-asapp",
"html_url": "https://github.com/fwu-asapp",
"followers_url": "https://api.github.com/users/fwu-asapp/followers",
"following_url": "https://api.github.com/users/fwu-asapp/following{/other_user}",
"gists_url": "https://api.github.com/users/fwu-asapp/gists{/gist_id}",
"starred_url": "https://api.github.com/users/fwu-asapp/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/fwu-asapp/subscriptions",
"organizations_url": "https://api.github.com/users/fwu-asapp/orgs",
"repos_url": "https://api.github.com/users/fwu-asapp/repos",
"events_url": "https://api.github.com/users/fwu-asapp/events{/privacy}",
"received_events_url": "https://api.github.com/users/fwu-asapp/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"<img width=\"519\" alt=\"Capture d’écran 2022-09-20 à 22 33 47\" src=\"https://user-images.githubusercontent.com/1676121/191358952-1220cb7d-745a-4203-a66b-3c707b25038f.png\">\r\n\r\n```\r\nNot found.\r\n\r\nError code: SplitsResponseNotFound\r\n```\r\n\r\nhttps://datasets-server.huggingface.co/splits?dataset=asapp/slue\r\n\r\n```json\r\n{\"error\":\"Not found.\"}\r\n```",
"I just launched a refresh. It's weird, I don't see any entry for this dataset in the cache, it's a bug on our side. In order to try to understand what happened, did you change the visibility status from private to public, by any chance?",
"The dataset is being refreshed, please retry later.\r\n\r\n<img width=\"802\" alt=\"Capture d’écran 2022-09-20 à 22 39 46\" src=\"https://user-images.githubusercontent.com/1676121/191360072-7cc86486-4e84-4b47-8f9a-4a69fe84a5ac.png\">\r\n",
"OK. We now have an issue because the dataset cannot be streamed, and the dataset viewer relies on it.\r\n\r\nMaybe @huggingface/datasets can help:\r\n\r\n```\r\nError code: StreamingRowsError\r\nException: NotImplementedError\r\nMessage: Extraction protocol for TAR archives like 'https://public-dataset-model-store.awsdev.asapp.com/users/sshon/public/slue/slue-voxpopuli_v0.2_blind.tar.gz' is not implemented in streaming mode. Please use `dl_manager.iter_archive` instead.\r\nTraceback: Traceback (most recent call last):\r\n File \"/src/services/worker/src/worker/responses/first_rows.py\", line 337, in get_first_rows_response\r\n rows = get_rows(dataset, config, split, streaming=True, rows_max_number=rows_max_number, hf_token=hf_token)\r\n File \"/src/services/worker/src/worker/utils.py\", line 123, in decorator\r\n return func(*args, **kwargs)\r\n File \"/src/services/worker/src/worker/responses/first_rows.py\", line 65, in get_rows\r\n ds = load_dataset(\r\n File \"/src/services/worker/.venv/lib/python3.9/site-packages/datasets/load.py\", line 1739, in load_dataset\r\n return builder_instance.as_streaming_dataset(split=split)\r\n File \"/src/services/worker/.venv/lib/python3.9/site-packages/datasets/builder.py\", line 1025, in as_streaming_dataset\r\n splits_generators = {sg.name: sg for sg in self._split_generators(dl_manager)}\r\n File \"/tmp/modules-cache/datasets_modules/datasets/asapp--slue/adaa0c78233e1a1df9c2f054e690ec5fc3eaf453bd76b80fe5cbe5728e55d9b1/slue.py\", line 189, in _split_generators\r\n dl_dir = dl_manager.download_and_extract(_DL_URLS[config_name])\r\n File \"/src/services/worker/.venv/lib/python3.9/site-packages/datasets/download/streaming_download_manager.py\", line 944, in download_and_extract\r\n return self.extract(self.download(url_or_urls))\r\n File \"/src/services/worker/.venv/lib/python3.9/site-packages/datasets/download/streaming_download_manager.py\", line 907, in extract\r\n urlpaths = map_nested(self._extract, path_or_paths, map_tuple=True)\r\n File \"/src/services/worker/.venv/lib/python3.9/site-packages/datasets/utils/py_utils.py\", line 385, in map_nested\r\n return function(data_struct)\r\n File \"/src/services/worker/.venv/lib/python3.9/site-packages/datasets/download/streaming_download_manager.py\", line 912, in _extract\r\n protocol = _get_extraction_protocol(urlpath, use_auth_token=self.download_config.use_auth_token)\r\n File \"/src/services/worker/.venv/lib/python3.9/site-packages/datasets/download/streaming_download_manager.py\", line 390, in _get_extraction_protocol\r\n raise NotImplementedError(\r\n NotImplementedError: Extraction protocol for TAR archives like 'https://public-dataset-model-store.awsdev.asapp.com/users/sshon/public/slue/slue-voxpopuli_v0.2_blind.tar.gz' is not implemented in streaming mode. Please use `dl_manager.iter_archive` instead.\r\n```",
"Thanks @severo, \r\n\r\nDo I have to modify the python script to support streaming so that it can be previewed?\r\nIs there a document somewhere that I can follow?\r\n",
"Hi @fwu-asapp thanks for reporting, and thanks @severo for the investigation.\r\n\r\nAs explained by @severo, the preview requires that your dataset loading script supports streaming.\r\n\r\nThere are several options here:\r\n- the easiest would be to replace the source files, archived using ZIP instead TAR: the TAR format does not allow random access while streaming, but only sequential access; the ZIP files support streaming out of the box.\r\n- alternatively, to stream TAR archives you can use `dl_manager.iter_archive`: the only prerequisite is that your \"index\" files (.tsv) should have been archived before their corresponding audio files, so while iterating the content of the TAR archive, the metadata files appear first. I think this is the case for voxpopuli tar but not for voxceleb.\r\n- if your .tsv files were not archived before their corresponding audio files (I think this is the case for voxceleb), then you should extract the .tsv files and host them separately (you can host them on the same Hugging Face Hub).\r\n - you can take as example, e.g.: https://huggingface.co/datasets/vivos/blob/main/vivos.py\r\n\r\nAs an advanced approach, you can handle both streaming and non-streaming cases separately.\r\n- as for example: https://huggingface.co/datasets/librispeech_asr/blob/main/librispeech_asr.py or https://huggingface.co/datasets/google/fleurs/blob/main/fleurs.py\r\n\r\nSee related discussion:\r\n- https://github.com/huggingface/datasets/issues/4697#issuecomment-1191502492",
"Thanks @albertvillanova for your clarification. I'll talk to my collaborators to see if we can replace those files. Let me just close this issue for now.",
"FYI, after replacing the source files with the ZIP ones, the dataset viewer works well. Thanks again to @severo and @albertvillanova for your help!",
"Great! And thank you for sharing that interesting dataset!"
] | 2022-09-20T16:45:45 | 2022-09-27T07:04:03 | 2022-09-21T07:24:07 |
NONE
| null | null | null |
### Link
https://huggingface.co/datasets/asapp/slue/viewer/
### Description
Hi,
I wonder how to get the dataset viewer of our slue dataset to work.
Best,
Felix
### Owner
Yes
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/5000/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/5000/timeline
| null |
completed
| false |
https://api.github.com/repos/huggingface/datasets/issues/4999
|
https://api.github.com/repos/huggingface/datasets
|
https://api.github.com/repos/huggingface/datasets/issues/4999/labels{/name}
|
https://api.github.com/repos/huggingface/datasets/issues/4999/comments
|
https://api.github.com/repos/huggingface/datasets/issues/4999/events
|
https://github.com/huggingface/datasets/pull/4999
| 1,379,610,030 |
PR_kwDODunzps4_SQxL
| 4,999 |
Add EmptyDatasetError
|
{
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] | null |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 2022-09-20T15:28:05 | 2022-09-21T12:23:43 | 2022-09-21T12:21:24 |
MEMBER
| null | false |
{
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4999",
"html_url": "https://github.com/huggingface/datasets/pull/4999",
"diff_url": "https://github.com/huggingface/datasets/pull/4999.diff",
"patch_url": "https://github.com/huggingface/datasets/pull/4999.patch",
"merged_at": "2022-09-21T12:21:24"
}
|
examples:
from the hub:
```python
Traceback (most recent call last):
File "playground/ttest.py", line 3, in <module>
print(load_dataset("lhoestq/empty"))
File "/Users/quentinlhoest/Desktop/hf/nlp/src/datasets/load.py", line 1686, in load_dataset
**config_kwargs,
File "/Users/quentinlhoest/Desktop/hf/nlp/src/datasets/load.py", line 1458, in load_dataset_builder
data_files=data_files,
File "/Users/quentinlhoest/Desktop/hf/nlp/src/datasets/load.py", line 1171, in dataset_module_factory
raise e1 from None
File "/Users/quentinlhoest/Desktop/hf/nlp/src/datasets/load.py", line 1162, in dataset_module_factory
download_mode=download_mode,
File "/Users/quentinlhoest/Desktop/hf/nlp/src/datasets/load.py", line 760, in get_module
else get_data_patterns_in_dataset_repository(hfh_dataset_info, self.data_dir)
File "/Users/quentinlhoest/Desktop/hf/nlp/src/datasets/data_files.py", line 678, in get_data_patterns_in_dataset_repository
) from None
datasets.data_files.EmptyDatasetError: The dataset repository at 'lhoestq/empty' doesn't contain any data file.
```
from local directory:
```python
Traceback (most recent call last):
File "playground/ttest.py", line 3, in <module>
print(load_dataset("playground/empty"))
File "/Users/quentinlhoest/Desktop/hf/nlp/src/datasets/load.py", line 1686, in load_dataset
**config_kwargs,
File "/Users/quentinlhoest/Desktop/hf/nlp/src/datasets/load.py", line 1458, in load_dataset_builder
data_files=data_files,
File "/Users/quentinlhoest/Desktop/hf/nlp/src/datasets/load.py", line 1107, in dataset_module_factory
path, data_dir=data_dir, data_files=data_files, download_mode=download_mode
File "/Users/quentinlhoest/Desktop/hf/nlp/src/datasets/load.py", line 625, in get_module
else get_data_patterns_locally(base_path)
File "/Users/quentinlhoest/Desktop/hf/nlp/src/datasets/data_files.py", line 460, in get_data_patterns_locally
raise EmptyDatasetError(f"The directory at {base_path} doesn't contain any data file") from None
datasets.data_files.EmptyDatasetError: The directory at playground/empty doesn't contain any data file
```
Close https://github.com/huggingface/datasets/issues/4995
|
{
"url": "https://api.github.com/repos/huggingface/datasets/issues/4999/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/datasets/issues/4999/timeline
| null | null | true |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.