
hexsha
stringlengths 40
40
| size
int64 5
1.04M
| ext
stringclasses 6
values | lang
stringclasses 1
value | max_stars_repo_path
stringlengths 3
344
| max_stars_repo_name
stringlengths 5
125
| max_stars_repo_head_hexsha
stringlengths 40
78
| max_stars_repo_licenses
sequencelengths 1
11
| max_stars_count
int64 1
368k
⌀ | max_stars_repo_stars_event_min_datetime
stringlengths 24
24
⌀ | max_stars_repo_stars_event_max_datetime
stringlengths 24
24
⌀ | max_issues_repo_path
stringlengths 3
344
| max_issues_repo_name
stringlengths 5
125
| max_issues_repo_head_hexsha
stringlengths 40
78
| max_issues_repo_licenses
sequencelengths 1
11
| max_issues_count
int64 1
116k
⌀ | max_issues_repo_issues_event_min_datetime
stringlengths 24
24
⌀ | max_issues_repo_issues_event_max_datetime
stringlengths 24
24
⌀ | max_forks_repo_path
stringlengths 3
344
| max_forks_repo_name
stringlengths 5
125
| max_forks_repo_head_hexsha
stringlengths 40
78
| max_forks_repo_licenses
sequencelengths 1
11
| max_forks_count
int64 1
105k
⌀ | max_forks_repo_forks_event_min_datetime
stringlengths 24
24
⌀ | max_forks_repo_forks_event_max_datetime
stringlengths 24
24
⌀ | content
stringlengths 5
1.04M
| avg_line_length
float64 1.14
851k
| max_line_length
int64 1
1.03M
| alphanum_fraction
float64 0
1
| lid
stringclasses 191
values | lid_prob
float64 0.01
1
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
8b15b7848b7a92827669631c3894a5e9c2e96a44 | 6,490 | md | Markdown | includes/azure-stack-edge-iot-troubleshoot-compute.md | changeworld/azure-docs.it- | 34f70ff6964ec4f6f1a08527526e214fdefbe12a | [
"CC-BY-4.0",
"MIT"
] | 1 | 2017-06-06T22:50:05.000Z | 2017-06-06T22:50:05.000Z | includes/azure-stack-edge-iot-troubleshoot-compute.md | changeworld/azure-docs.it- | 34f70ff6964ec4f6f1a08527526e214fdefbe12a | [
"CC-BY-4.0",
"MIT"
] | 41 | 2016-11-21T14:37:50.000Z | 2017-06-14T20:46:01.000Z | includes/azure-stack-edge-iot-troubleshoot-compute.md | changeworld/azure-docs.it- | 34f70ff6964ec4f6f1a08527526e214fdefbe12a | [
"CC-BY-4.0",
"MIT"
] | 7 | 2016-11-16T18:13:16.000Z | 2017-06-26T10:37:55.000Z | ---
author: v-dalc
ms.service: databox
ms.author: alkohli
ms.topic: include
ms.date: 03/23/2021
ms.openlocfilehash: 0d912d0ac3f0fcf4c52116e67909038a1973304b
ms.sourcegitcommit: 32e0fedb80b5a5ed0d2336cea18c3ec3b5015ca1
ms.translationtype: MT
ms.contentlocale: it-IT
ms.lasthandoff: 03/30/2021
ms.locfileid: "105105444"
---
Usare le risposte di runtime dell'agente IoT Edge per risolvere gli errori correlati al calcolo. Ecco un elenco di risposte possibili:
* 200 - OK
* 400 - La configurazione della distribuzione è in formato non corretto o non valida.
* 417: il dispositivo non ha un set di configurazione della distribuzione.
* 412 - La versione dello schema nella configurazione della distribuzione non è valida.
* 406 - Il dispositivo è offline o non invia segnalazioni sullo stato.
* 500 - Si è verificato un errore nel runtime di IoT Edge.
Per ulteriori informazioni, vedere [IOT Edge Agent](../articles/iot-edge/iot-edge-runtime.md?preserve-view=true&view=iotedge-2018-06#iot-edge-agent).
Il seguente errore è correlato al servizio IoT Edge sul dispositivo Azure Stack Edge Pro.
### <a name="compute-modules-have-unknown-status-and-cant-be-used"></a>I moduli di calcolo presentano uno stato sconosciuto e non possono essere usati
#### <a name="error-description"></a>Descrizione errore
Tutti i moduli del dispositivo mostrano lo stato sconosciuto e non possono essere usati. Lo stato sconosciuto viene mantenuto in un riavvio.<!--Original Support ticket relates to trying to deploy a container app on a Hub. Based on the work item, I assume the error description should not be that specific, and that the error applies to Azure Stack Edge Devices, which is the focus of this troubleshooting.-->
#### <a name="suggested-solution"></a>Soluzione suggerita
Eliminare il servizio IoT Edge e quindi ridistribuire i moduli. Per ulteriori informazioni, vedere [Remove IOT Edge service](../articles/databox-online/azure-stack-edge-gpu-manage-compute.md#remove-iot-edge-service).
### <a name="modules-show-as-running-but-are-not-working"></a>I moduli vengono mostrati come in esecuzione, ma non funzionano
#### <a name="error-description"></a>Descrizione errore
Lo stato di runtime del modulo viene visualizzato come in esecuzione, ma i risultati previsti non vengono visualizzati.
Questa condizione può essere dovuta a un problema relativo alla configurazione della route del modulo che non funziona o `edgehub` non esegue il routing dei messaggi come previsto. È possibile controllare i `edgehub` log. Se si verificano errori, ad esempio la mancata connessione al servizio hub Internet delle cose, il motivo più comune è che i problemi di connettività. È possibile che si verifichino problemi di connettività perché la porta AMPQ utilizzata come porta predefinita dal servizio hub Internet per la comunicazione è bloccata o il server proxy Web blocca tali messaggi.
#### <a name="suggested-solution"></a>Soluzione suggerita
Seguire questa procedura:
1. Per risolvere l'errore, passare alla risorsa hub Internet delle cose per il dispositivo e quindi selezionare il dispositivo perimetrale.
1. Passare a **impostare i moduli > impostazioni di runtime**.
1. Aggiungere la `Upstream protocol` variabile di ambiente e assegnarle un valore `AMQPWS` . I messaggi configurati in questo caso vengono inviati tramite WebSocket tramite la porta 443.
### <a name="modules-show-as-running-but-do-not-have-an-ip-assigned"></a>I moduli vengono visualizzati come in esecuzione, ma non è stato assegnato un indirizzo IP
#### <a name="error-description"></a>Descrizione errore
Lo stato di runtime del modulo viene visualizzato come in esecuzione, ma l'app in contenitori non dispone di un indirizzo IP assegnato.
Questa condizione è dovuta al fatto che l'intervallo di indirizzi IP forniti per gli indirizzi IP del servizio esterno Kubernetes non è sufficiente. È necessario estendere questo intervallo per assicurarsi che vengano analizzati tutti i contenitori o le macchine virtuali distribuite.
#### <a name="suggested-solution"></a>Soluzione suggerita
Nell'interfaccia utente Web locale del dispositivo, seguire questa procedura:
1. Passare alla pagina **calcolo** . Selezionare la porta per cui è stata abilitata la rete di calcolo.
1. Immettere un intervallo statico e contiguo di indirizzi IP per gli **indirizzi IP del servizio esterno Kubernetes**. È necessario 1 IP per il `edgehub` servizio. Inoltre, è necessario un IP per ogni modulo di IoT Edge e per ogni macchina virtuale che verrà distribuita.
1. Selezionare **Applica**. L'intervallo di indirizzi IP modificati dovrebbe essere applicato immediatamente.
Per altre informazioni, vedere [modificare gli IP del servizio esterno per i contenitori](../articles/databox-online/azure-stack-edge-gpu-manage-compute.md#change-external-service-ips-for-containers).
### <a name="configure-static-ips-for-iot-edge-modules"></a>Configurare gli indirizzi IP statici per i moduli IoT Edge
#### <a name="problem-description"></a>Descrizione del problema
Kubernetes assegna indirizzi IP dinamici a ogni modulo IoT Edge sul dispositivo GPU di Azure Stack Edge Pro. È necessario un metodo per configurare gli indirizzi IP statici per i moduli.
#### <a name="suggested-solution"></a>Soluzione suggerita
È possibile specificare indirizzi IP fissi per i moduli di IoT Edge tramite la sezione K8s-experimental, come descritto di seguito:
```yaml
{
"k8s-experimental": {
"serviceOptions" : {
"loadBalancerIP" : "100.23.201.78",
"type" : "LoadBalancer"
}
}
}
```
### <a name="expose-kubernetes-service-as-cluster-ip-service-for-internal-communication"></a>Esporre il servizio Kubernetes come servizio IP del cluster per la comunicazione interna
#### <a name="problem-description"></a>Descrizione del problema
Per impostazione predefinita, il tipo di servizio Internet delle cose è di tipo Load Balancer ed è stato assegnato un indirizzo IP esterno. Potrebbe non essere necessario un indirizzo IP esterno per l'applicazione. Potrebbe essere necessario esporre i pod all'interno del cluster KUbernetes per l'accesso come altri pod e non come servizio di bilanciamento del carico esposto esternamente.
#### <a name="suggested-solution"></a>Soluzione suggerita
È possibile usare le opzioni create tramite la sezione K8s-experimental. L'opzione di servizio seguente dovrebbe funzionare con i binding di porta.
```yaml
{
"k8s-experimental": {
"serviceOptions" : {
"type" : "ClusterIP"
}
}
}
``` | 60.092593 | 585 | 0.782435 | ita_Latn | 0.997419 |
8b16bca99bdb7e395666cff3b2d3710b8e0aaba3 | 181 | md | Markdown | manifest/development/foruns.md | MUHammadUmerHayat/Informatinal-Links | 6f911c2e852b7eb19456a9bab37083fbdfd9e59b | [
"MIT"
] | 1 | 2020-09-05T11:23:10.000Z | 2020-09-05T11:23:10.000Z | manifest/development/foruns.md | MUHammadUmerHayat/Informatinal-Links | 6f911c2e852b7eb19456a9bab37083fbdfd9e59b | [
"MIT"
] | null | null | null | manifest/development/foruns.md | MUHammadUmerHayat/Informatinal-Links | 6f911c2e852b7eb19456a9bab37083fbdfd9e59b | [
"MIT"
] | null | null | null | ## Fóruns
* [Devnaestrada](https://devnaestrada.com.br/)
* [Guj](https://www.guj.com.br/)
* [Imasters](https://forum.imasters.com.br/)
* [Tableless](http://forum.tableless.com.br/) | 30.166667 | 46 | 0.674033 | yue_Hant | 0.220587 |
8b175366f7dd916d957e0542ecb04e0f9215d231 | 2,606 | md | Markdown | witcher/README.md | daelsepara/zil-experiment | 1e9be391a5fae766dace210a074be5fea172ef31 | [
"MIT"
] | null | null | null | witcher/README.md | daelsepara/zil-experiment | 1e9be391a5fae766dace210a074be5fea172ef31 | [
"MIT"
] | null | null | null | witcher/README.md | daelsepara/zil-experiment | 1e9be391a5fae766dace210a074be5fea172ef31 | [
"MIT"
] | null | null | null | # Witcher ZIL
## Design Goals
With our increasing understanding of ZIL, it is time to create a more sophisticated game. Here, we try to create an interactive fiction game set in the Witcher game universe by CD Projekt Red.
Our goals are to implement these features
- [X] combat! (14 June 2020)
- [X] silver and steel swords that can be enhanced by the application of certain oils (11 June 2020)
- [X] swords with oil should also confer bonuses when combatting specific monsters (14 June 2020)
- [X] witcher medallion that can detect invisible objects (12 June 2020)
- [X] travelling with or without Roach (12 June 2020)
- [X] eating/drinking food and/or potions and decoctions (13 June 2020, eating, 22 June 2020 cat's eye potion)
- [X] monster bounties (19 June 2020)
- [X] mechanisms for generic NPCs (blacksmith, alchemist, merchant) (20 June 2020)
### Phase 2 goals (Starting 22 June 2020)
- [X] random money drops/pickups (23 June 2020)
- [ ] armorer NPC
- [X] non-monster-killing quests (22 June 2020 search quest, 24 June 2020 Recover item(s) quest and connected quests)
- [ ] superior versions of oils
- [ ] non-bounty related NPC dialogs
- [X] other interesting objects (24 JUNE 2020 border posts, allow fast travel between locations)
### Phase 3 (TBD)
- [ ] other types of silver/steel swords
- [ ] overall story or plot arc
## Compiling and running
You need a ZIL compiler or assembler, or something like [ZILF](https://bitbucket.org/jmcgrew/zilf/wiki/Home) installed to convert the .zil file into a format usable by a z-machine interpreter such as [Frotz](https://davidgriffith.gitlab.io/frotz/).
Once installed, you can compile and convert it to a z-machine file using *zilf* and *zapf*
```
./zilf witcher.zil
./zapf witcher.zap
```
To play the game, run it with a Z-machine interpreter like *Frotz*
```
frotz witcher.z5
```
Where you are greeted by the following screen:
```
ZIL Witcher
Experiments with ZIL
By SD Separa (2020)
Inspired by the Witcher Games by CD Projekt Red
Release 0 / Serial number 200612 / ZILF 0.9 lib J5
------------------------------------------------------
Once you were many. Now you are few. Hunters. Killers of the world's filth. Witchers. The ultimate killing machines. Among you, a legend, the one they call Geralt of
Rivia, the White Wolf.
That legend is you.
------------------------------------------------------
Campsite
A small campfire is burning underneath a tree. All is quiet except for the crackling sounds of burning wood. The fire keeps the wolves and other would-be predators at
bay.
Roach is here.
>
```
(work in progress)
| 33.410256 | 248 | 0.712203 | eng_Latn | 0.994937 |
8b1798b7c60c70854c997a61a6a9b87ee18399e5 | 766 | md | Markdown | reference/concepts/implicit_self.md | gsilvapt/python | d675468b2437d4c09c358d023ef998a05a781f58 | [
"MIT"
] | 1,177 | 2017-06-21T20:24:06.000Z | 2022-03-29T02:30:55.000Z | reference/concepts/implicit_self.md | gsilvapt/python | d675468b2437d4c09c358d023ef998a05a781f58 | [
"MIT"
] | 1,938 | 2019-12-12T08:07:10.000Z | 2021-01-29T12:56:13.000Z | reference/concepts/implicit_self.md | gsilvapt/python | d675468b2437d4c09c358d023ef998a05a781f58 | [
"MIT"
] | 1,095 | 2017-06-26T23:06:19.000Z | 2022-03-29T03:25:38.000Z | # Implicit self
TODO: ADD MORE
- the example uses the `self` implicit argument for methods and properties linked to a specific instance of the class [matrix](../exercise-concepts/matrix.md)
- the example uses `self` for methods and properties linked to a specific instance of the class. [robot-simulator](../exercise-concepts/robot-simulator.md)
- the exercise relies on the implied passing of `self` as the first parameter of bound methods [allergies](../exercise-concepts/allergies.md)
- student needs to know how to use statement `self` in a class [binary-search-tree](../exercise-concepts/binary-search-tree.md)
- within the class definition, methods and properties can be accessed via the `self.` notation [phone-number](../exercise-concepts/phone-number.md)
| 76.6 | 158 | 0.774151 | eng_Latn | 0.993035 |
8b1806724b6dbc8c12ffaa82ddb1c95a80235b5b | 177 | md | Markdown | README.md | ajmwagar/oxy | c835355aab6eed3c2c9f73d672c175b8dc30e0fe | [
"MIT"
] | 4 | 2019-08-17T02:14:55.000Z | 2022-03-20T03:09:58.000Z | README.md | ajmwagar/oxy | c835355aab6eed3c2c9f73d672c175b8dc30e0fe | [
"MIT"
] | null | null | null | README.md | ajmwagar/oxy | c835355aab6eed3c2c9f73d672c175b8dc30e0fe | [
"MIT"
] | null | null | null | # oxy
A Wayland window manager...
See this [blog post](https://averywagar.com/posts/2019/06/oxidizing-my-workflow-writing-a-wayland-window-manager-in-rust-part-1-setting-up/).
| 35.4 | 141 | 0.762712 | eng_Latn | 0.420695 |
8b18496843ff6140edb340fee62271115c246bcc | 376 | md | Markdown | README.md | syucream/elastiquic | 9a351840b23fb1426aa2795a55e05ddb3b88f8bf | [
"MIT"
] | 1 | 2017-08-01T14:28:22.000Z | 2017-08-01T14:28:22.000Z | README.md | syucream/elastiquic | 9a351840b23fb1426aa2795a55e05ddb3b88f8bf | [
"MIT"
] | null | null | null | README.md | syucream/elastiquic | 9a351840b23fb1426aa2795a55e05ddb3b88f8bf | [
"MIT"
] | null | null | null | # elastiquic
An elastic QUIC client and benchmark tool written in golang.
## quickstart
* Prepare goquic
```
$ go get -u -d github.com/devsisters/goquic
$ cd $GOPATH/src/github.com/devsisters/goquic/
$ ./build_libs.sh
```
* Write definitions
```
$ vim definitions.json
```
* run elastiquic
```
$ go run elastiquic.go
..
Total requests: 2, successed: 2, failed: 0
```
| 12.965517 | 60 | 0.68617 | eng_Latn | 0.420552 |
8b1a433d6b369e5d1c7327f50b705338227d9f6b | 19,454 | md | Markdown | articles/hdinsight/hdinsight-apache-kafka-connect-vpn-gateway.md | DarryStonem/azure-docs.es-es | aa59a5fa09188f4cd2ae772e7818b708e064b1c0 | [
"CC-BY-4.0",
"MIT"
] | 1 | 2017-05-20T17:31:12.000Z | 2017-05-20T17:31:12.000Z | articles/hdinsight/hdinsight-apache-kafka-connect-vpn-gateway.md | DarryStonem/azure-docs.es-es | aa59a5fa09188f4cd2ae772e7818b708e064b1c0 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | articles/hdinsight/hdinsight-apache-kafka-connect-vpn-gateway.md | DarryStonem/azure-docs.es-es | aa59a5fa09188f4cd2ae772e7818b708e064b1c0 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ---
title: "Conexión a Kafka en HDInsight mediante redes virtuales - Azure | Microsoft Docs"
description: "Obtenga información sobre cómo conectarse a Kafka de manera remota en HDInsight mediante el cliente kafka-python. La configuración que se indica en este documento usa HDInsight dentro de una instancia de Azure Virtual Network. El cliente remoto se conecta a la red virtual mediante una puerta de enlace de VPN de punto a sitio."
services: hdinsight
documentationCenter:
author: Blackmist
manager: jhubbard
editor: cgronlun
tags: azure-portal
ms.service: hdinsight
ms.devlang:
ms.custom: hdinsightactive
ms.topic: article
ms.tgt_pltfrm: na
ms.workload: big-data
ms.date: 04/18/2017
ms.author: larryfr
translationtype: Human Translation
ms.sourcegitcommit: aaf97d26c982c1592230096588e0b0c3ee516a73
ms.openlocfilehash: 9ddf19c008c35525419a357436b1a969a4b19205
ms.lasthandoff: 04/27/2017
---
# <a name="connect-to-kafka-on-hdinsight-preview-through-an-azure-virtual-network"></a>Conexión a Kafka en HDInsight (versión preliminar) mediante una instancia de Azure Virtual Network
Obtenga información sobre cómo conectarse a Kafka en HDInsight mediante redes virtuales de Azure. Los clientes de Kafka (productores y consumidores) pueden ejecutarse directamente en HDInsight o en sistemas remotos. Los clientes remotos deben conectarse a Kafka en HDInsight mediante una instancia de Azure Virtual Network. Use la información que se entrega en este documento para entender cómo los clientes remotos se pueden conectar a HDInsight mediante las redes virtuales de Azure.
> [!IMPORTANT]
> Varias de las configuraciones que se describen en este documento se pueden usar con clientes Windows, macOS o Linux. Sin embargo, el ejemplo de punto a sitio que se incluye solo proporciona un cliente VPN para Windows.
>
> El ejemplo también usa un cliente Python ([kafka-python](http://kafka-python.readthedocs.io/en/master/)) para comprobar la comunicación con Kafka en HDInsight.
## <a name="architecture-and-planning"></a>Arquitectura y planeación
Los clústeres de HDInsight están protegidos dentro de una instancia de Azure Virtual Network y solo permiten el tráfico SSH y HTTPS entrante. El tráfico llega a través de una puerta de enlace pública que no enruta el tráfico desde los clientes Kafka. Para tener acceso a Kafka desde un cliente remoto, debe crear una instancia de Azure Virtual Network que proporcione una puerta de enlace de red privada virtual (VPN). Una vez que haya configurado la puerta de enlace y la red virtual, instale HDInsight en la red virtual y conéctelo a ella a través de la puerta de enlace de VPN.

En la lista siguiente se muestra información sobre el proceso de usar Kafka en HDInsight con una red virtual:
1. Cree una red virtual. Para información específica sobre cómo usar HDInsight con redes virtuales de Azure, consulte el documento sobre la [extensión de HDInsight mediante una instancia de Azure Virtual Network](hdinsight-extend-hadoop-virtual-network.md).
2. (Opcional) Cree una máquina virtual de Azure dentro de la red virtual e instale ahí un servidor DNS personalizado. Este servidor DNS se usa para habilitar la resolución de nombres para clientes remotos en una configuración de sitio a sitio o de red virtual a red virtual. Para más información, consulte el documento sobre [resolución de nombres para máquinas virtuales y servicios en la nube](../virtual-network/virtual-networks-name-resolution-for-vms-and-role-instances.md).
3. Cree una puerta de enlace de VPN para la red virtual. Para más información sobre las configuraciones de puerta de enlace de VPN, consulte el documento de [información sobre VPN Gateway](../vpn-gateway/vpn-gateway-about-vpngateways.md).
4. Cree HDInsight dentro de la red virtual. Si configuró un servidor DNS personalizado para la red, HDInsight se configura automáticamente para usarlo.
5. (Opcional) Si no usó un servidor DNS personalizado y no tiene resolución de nombres entre los clientes y la red virtual, debe configurar Kafka para publicidad de direcciones IP. Para más información, consulte la sección [Configuración de Kafka para anunciar direcciones IP](#configure-kafka-for-ip-advertising) de este documento.
## <a name="create-using-powershell"></a>Creación mediante PowerShell
Los pasos de esta sección crean la configuración siguiente con [Azure PowerShell](/powershell/azure/overview):
* Red virtual
* Puerta de enlace de VPN de punto a sitio
* Cuenta de Azure Storage (usada por HDInsight)
* Kafka en HDInsight
1. Siga los pasos que aparecen en el documento [Funcionamiento de los certificados autofirmados para conexiones de punto a sitio](../vpn-gateway/vpn-gateway-certificates-point-to-site.md) para crear los certificados que se necesitan para la puerta de enlace.
2. Abra un símbolo del sistema de PowerShell y use el código siguiente para iniciar sesión en la suscripción de Azure:
```powershell
Add-AzureRmAccount
# If you have multiple subscriptions, uncomment to set the subscription
#Select-AzureRmSubscription -SubscriptionName "name of your subscription"
```
3. Use el código siguiente para crear variables que contengan la información de configuración:
```powershell
# Prompt for generic information
$resourceGroupName = Read-Host "What is the resource group name?"
$baseName = Read-Host "What is the base name? It is used to create names for resources, such as 'net-basename' and 'kafka-basename':"
$location = Read-Host "What Azure Region do you want to create the resources in?"
$rootCert = Read-Host "What is the file path to the root certificate? It is used to secure the VPN gateway."
# Prompt for HDInsight credentials
$adminCreds = Get-Credential -Message "Enter the HTTPS user name and password for the HDInsight cluster" -UserName "admin"
$sshCreds = Get-Credential -Message "Enter the SSH user name and password for the HDInsight cluster" -UserName "sshuser"
# Names for Azure resources
$networkName = "net-$baseName"
$clusterName = "kafka-$baseName"
$storageName = "store$baseName" # Can't use dashes in storage names
$defaultContainerName = $clusterName
$defaultSubnetName = "default"
$gatewaySubnetName = "GatewaySubnet"
$gatewayPublicIpName = "GatewayIp"
$gatewayIpConfigName = "GatewayConfig"
$vpnRootCertName = "rootcert"
$vpnName = "VPNGateway"
# Network settings
$networkAddressPrefix = "10.0.0.0/16"
$defaultSubnetPrefix = "10.0.0.0/24"
$gatewaySubnetPrefix = "10.0.1.0/24"
$vpnClientAddressPool = "172.16.201.0/24"
# HDInsight settings
$HdiWorkerNodes = 4
$hdiVersion = "3.5"
$hdiType = "Kafka"
```
4. Use el código siguiente para crear la red virtual y el grupo de recursos de Azure:
```powershell
# Create the resource group that contains everything
New-AzureRmResourceGroup -Name $resourceGroupName -Location $location
# Create the subnet configuration
$defaultSubnetConfig = New-AzureRmVirtualNetworkSubnetConfig -Name $defaultSubnetName `
-AddressPrefix $defaultSubnetPrefix
$gatewaySubnetConfig = New-AzureRmVirtualNetworkSubnetConfig -Name $gatewaySubnetName `
-AddressPrefix $gatewaySubnetPrefix
# Create the subnet
New-AzureRmVirtualNetwork -Name $networkName `
-ResourceGroupName $resourceGroupName `
-Location $location `
-AddressPrefix $networkAddressPrefix `
-Subnet $defaultSubnetConfig, $gatewaySubnetConfig
# Get the network & subnet that were created
$network = Get-AzureRmVirtualNetwork -Name $networkName `
-ResourceGroupName $resourceGroupName
$gatewaySubnet = Get-AzureRmVirtualNetworkSubnetConfig -Name $gatewaySubnetName `
-VirtualNetwork $network
$defaultSubnet = Get-AzureRmVirtualNetworkSubnetConfig -Name $defaultSubnetName `
-VirtualNetwork $network
# Set a dynamic public IP address for the gateway subnet
$gatewayPublicIp = New-AzureRmPublicIpAddress -Name $gatewayPublicIpName `
-ResourceGroupName $resourceGroupName `
-Location $location `
-AllocationMethod Dynamic
$gatewayIpConfig = New-AzureRmVirtualNetworkGatewayIpConfig -Name $gatewayIpConfigName `
-Subnet $gatewaySubnet `
-PublicIpAddress $gatewayPublicIp
# Get the certificate info
# Get the full path in case a relative path was passed
$rootCertFile = Get-ChildItem $rootCert
$cert = New-Object System.Security.Cryptography.X509Certificates.X509Certificate2($rootCertFile)
$certBase64 = [System.Convert]::ToBase64String($cert.RawData)
$p2sRootCert = New-AzureRmVpnClientRootCertificate -Name $vpnRootCertName `
-PublicCertData $certBase64
# Create the VPN gateway
New-AzureRmVirtualNetworkGateway -Name $vpnName `
-ResourceGroupName $resourceGroupName `
-Location $location `
-IpConfigurations $gatewayIpConfig `
-GatewayType Vpn `
-VpnType RouteBased `
-EnableBgp $false `
-GatewaySku Standard `
-VpnClientAddressPool $vpnClientAddressPool `
-VpnClientRootCertificates $p2sRootCert
```
> [!WARNING]
> Este proceso puede tardar varios minutos en completarse.
5. Use el código siguiente para crear el contenedor de blobs y la cuenta de Azure Storage:
```powershell
# Create the storage account
New-AzureRmStorageAccount `
-ResourceGroupName $resourceGroupName `
-Name $storageName `
-Type Standard_GRS `
-Location $location
# Get the storage account keys and create a context
$defaultStorageKey = (Get-AzureRmStorageAccountKey -ResourceGroupName $resourceGroupName `
-Name $storageName)[0].Value
$storageContext = New-AzureStorageContext -StorageAccountName $storageName `
-StorageAccountKey $defaultStorageKey
# Create the default storage container
New-AzureStorageContainer -Name $defaultContainerName `
-Context $storageContext
```
6. Use el código siguiente para crear el clúster de HDInsight:
```powershell
# Create the HDInsight cluster
New-AzureRmHDInsightCluster `
-ResourceGroupName $resourceGroupName `
-ClusterName $clusterName `
-Location $location `
-ClusterSizeInNodes $hdiWorkerNodes `
-ClusterType $hdiType `
-OSType Linux `
-Version $hdiVersion `
-HttpCredential $adminCreds `
-SshCredential $sshCreds `
-DefaultStorageAccountName "$storageName.blob.core.windows.net" `
-DefaultStorageAccountKey $defaultStorageKey `
-DefaultStorageContainer $defaultContainerName `
-VirtualNetworkId $network.Id `
-SubnetName $defaultSubnet.Id
```
> [!WARNING]
> Este proceso tarda unos 20 minutos en completarse.
8. Use el cmdlet siguiente para recuperar la dirección URL del cliente de VPN de Windows para la red virtual:
```powershell
Get-AzureRmVpnClientPackage -ResourceGroupName $resourceGroupName `
-VirtualNetworkGatewayName $vpnName `
-ProcessorArchitecture Amd64
```
Para descargar el cliente de VPN de Windows, use el identificador URI devuelto en el explorador web.
## <a name="configure-kafka-for-ip-advertising"></a>Configuración de Kafka para anunciar direcciones IP
De manera predeterminada, Zookeeper devuelve el nombre de dominio de los agentes de Kafka a los clientes. Esta configuración no funciona para el cliente de VPN, por lo que no puede usar la resolución de nombres para entidades de la red virtual. Use los pasos siguientes para configurar Kafka en HDInsight y anunciar direcciones IP en lugar de nombres de dominio:
1. En el explorador web, vaya a https://CLUSTERNAME.azurehdinsight.net. Reemplace __CLUSTERNAME__ por el nombre del clúster de Kafka en HDInsight.
Cuando se le solicite, use el nombre de usuario y la contraseña HTTPS para el clúster. Aparece la interfaz de usuario web de Ambari para el clúster.
2. Para ver información sobre Kafka, seleccione __Kafka__ en la lista de la izquierda.

3. Para ver la configuración de Kafka, seleccione __Configs__ (Configuraciones) en la parte superior central.

4. Para encontrar la configuración __kafka-env__, escriba `kafka-env` en el campo __Filtrar__ que se encuentra en la esquina superior derecha.

5. Para configurar Kafka y anunciar direcciones IP, agregue el texto siguiente en la parte inferior del campo __kafka-env-template__:
```
# Configure Kafka to advertise IP addresses instead of FQDN
IP_ADDRESS=$(hostname -i)
echo advertised.listeners=$IP_ADDRESS
sed -i.bak -e '/advertised/{/advertised@/!d;}' /usr/hdp/current/kafka-broker/conf/server.properties
echo "advertised.listeners=PLAINTEXT://$IP_ADDRESS:9092" >> /usr/hdp/current/kafka-broker/conf/server.properties
```
6. Para configurar la interfaz en que escucha Kafka, escriba `listeners` en el campo __Filtrar__ que se encuentra en la esquina superior derecha.
7. Para configurar Kafka para que escuche en todas las interfaces de red, cambie el valor del campo __listeners__ (agentes de escucha) a `PLAINTEXT://0.0.0.0:92092`.
8. Use el botón __Guardar__ para guardar los cambios en la configuración. Escriba un mensaje de texto para describir los cambios. Seleccione __Aceptar__ una vez que se guarden los cambios.

9. Para evitar errores al reiniciar Kafka, use el botón __Acciones de servicio__ y seleccione __Activar el modo de mantenimiento__. Seleccione Aceptar para completar esta operación.

10. Para reiniciar Kafka, use el botón __Reiniciar__ y seleccione __Restart All Affected__ (Reiniciar todos los elementos afectados). Confirme el reinicio y use el botón __Aceptar__ una vez que se complete la operación.

11. Para deshabilitar el modo de mantenimiento, use el botón __Acciones de servicio__ y seleccione __Desactivar el modo de mantenimiento__. Seleccione **Aceptar** para completar esta operación.
## <a name="connect-to-the-vpn-gateway"></a>Conexión a la puerta de enlace de VPN
Para conectarse a la puerta de enlace de VPN desde un __cliente Windows__, use la sección __Conexión a Azure__ del documento [Configuración de una conexión de punto a sitio](../vpn-gateway/vpn-gateway-howto-point-to-site-rm-ps.md#a-nameconnectapart-7---connect-to-azure).
## <a name="remote-kafka-client"></a>Cliente Kafka remoto
Para conectarse a Kafka desde el equipo cliente, debe usar la dirección IP de los agentes de Kafka o los nodos de Zookeeper (cualquiera sea la opción que requiere el cliente). Use los pasos siguientes para recuperar la dirección IP de los agentes de Kafka y, luego, úselos desde una aplicación Python
1. Use el script siguiente para recuperar las direcciones IP de los nodos del clúster:
```powershell
# Get the NICs for the HDInsight workernodes (names contain 'workernode').
$nodes = Get-AzureRmNetworkInterface `
-ResourceGroupName $resourceGroupName `
| where-object {$_.Name -like "*workernode*"}
# Loop through each node and get the IP address
foreach($node in $nodes) {
$node.IpConfigurations.PrivateIpAddress
}
```
En este script se supone que `$resourceGroupName` es el nombre del grupo de recursos de Azure que contiene la red virtual. La salida del script es similar al texto siguiente:
10.0.0.12
10.0.0.6
10.0.0.13
10.0.0.5
> [!NOTE]
> Si el cliente Kafka usa nodos de Zookeeper en lugar de agentes de Kafka, reemplace `*workernode*` por `*zookeepernode*` en el script de PowerShell.
> [!WARNING]
> Si escala el clúster o los nodos presentan un error y es necesario reemplazarlos, es posible que las direcciones IP cambien. Actualmente, no hay direcciones IP específicas asignadas previamente para los nodos de un clúster de HDInsight.
2. Use el código siguiente para instalar el cliente [kafka-python](http://kafka-python.readthedocs.io/):
pip install kafka-python
3. Para enviar datos a Kafka, use el código Python siguiente:
```python
from kafka import KafkaProducer
# Replace the `ip_address` entries with the IP address of your worker nodes
producer = KafkaProducer(bootstrap_servers=['ip_address1','ip_address2','ip_adderess3','ip_address4'])
for _ in range(50):
producer.send('testtopic', b'test message')
```
Reemplace las entradas `'ip_address'` por las direcciones devueltas del paso 1 de esta sección.
> [!NOTE]
> Este código envía la cadena `test message` al tema `testtopic`. La configuración predeterminada de Kafka en HDInsight es crear el tema si no existe.
4. Para recuperar los mensajes de Kafka, use el código Python siguiente:
```python
from kafka import KafkaConsumer
# Replace the `ip_address` entries with the IP address of your worker nodes
# Note: auto_offset_reset='earliest' resets the starting offset to the beginning
# of the topic
consumer = KafkaConsumer(bootstrap_servers=['ip_address1','ip_address2','ip_adderess3','ip_address4'],auto_offset_reset='earliest')
consumer.subscribe(['testtopic'])
for msg in consumer:
print (msg)
```
Reemplace las entradas `'ip_address'` por las direcciones devueltas del paso 1 de esta sección. La salida contiene el mensaje de prueba que se envió al productor en el paso anterior.
## <a name="troubleshooting"></a>Solución de problemas
Si tiene problemas para conectarse a la red virtual o para conectarse a HDInsight a través de la red, consulte el documento [Solución de problemas de las conexiones y la puerta de enlace de Virtual Network](../network-watcher/network-watcher-troubleshoot-manage-powershell.md) para instrucciones.
## <a name="next-steps"></a>Pasos siguientes
Para más información sobre cómo crear una instancia de Azure Virtual Network con puerta de enlace de VPN de punto a sitio, consulte los documentos siguientes:
* [Configuración de una conexión de punto a sitio mediante Azure Portal](../vpn-gateway/vpn-gateway-howto-point-to-site-resource-manager-portal.md)
* [Configuración de una conexión de punto a sitio mediante Azure PowerShell](../vpn-gateway/vpn-gateway-howto-point-to-site-rm-ps.md)
Para más información sobre cómo trabajar con Kafka en HDInsight, consulte los documentos siguientes:
* [Introducción a Kafka en HDInsight](hdinsight-apache-kafka-get-started.md)
* [Uso de creación de reflejos con Kafka en HDInsight](hdinsight-apache-kafka-mirroring.md)
| 54.340782 | 580 | 0.758404 | spa_Latn | 0.876105 |
8b1ae860f41424099ff34f1ab52513eb65ff0ec5 | 921 | md | Markdown | csharp/destinations/snowflake/README.md | raaij/quix-library | d286e6bcad194d40adf261a85ecccec3e32bccd4 | [
"Apache-2.0"
] | null | null | null | csharp/destinations/snowflake/README.md | raaij/quix-library | d286e6bcad194d40adf261a85ecccec3e32bccd4 | [
"Apache-2.0"
] | null | null | null | csharp/destinations/snowflake/README.md | raaij/quix-library | d286e6bcad194d40adf261a85ecccec3e32bccd4 | [
"Apache-2.0"
] | null | null | null | # C# Snowflake Sink
The sample contained in this folder gives an example on how to stream data from Quix to Snowflake, it handles both parameter and event data.
## Requirements / Prerequisites
- A Snowflake account.
## Environment variables
The code sample uses the following environment variables:
- **Broker__TopicName**: Name of the input topic to read from.
- **Snowflake__ConnectionString**: The Snowflake database connection string.
- e.g. account=xxx.north-europe.azure;user=xxx;password=xxx;db=xxx
## Known limitations
- Binary parameters are not supported in this version
- Stream metadata is not persisted in this version
## Docs
Check out the [SDK docs](https://quix.ai/docs/sdk/introduction.html) for detailed usage guidance
## How to run
Create an account on [Quix](https://portal.platform.quix.ai/self-sign-up?xlink=github) to edit or deploy this application without a local environment setup.
| 36.84 | 156 | 0.774159 | eng_Latn | 0.984952 |
8b1b73481af267bfd9ce4cac3f0311ef294c1aa4 | 6,808 | md | Markdown | articles/governance/resource-graph/overview.md | Nike1016/azure-docs.hu-hu | eaca0faf37d4e64d5d6222ae8fd9c90222634341 | [
"CC-BY-4.0",
"MIT"
] | 1 | 2019-09-29T16:59:33.000Z | 2019-09-29T16:59:33.000Z | articles/governance/resource-graph/overview.md | Nike1016/azure-docs.hu-hu | eaca0faf37d4e64d5d6222ae8fd9c90222634341 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | articles/governance/resource-graph/overview.md | Nike1016/azure-docs.hu-hu | eaca0faf37d4e64d5d6222ae8fd9c90222634341 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ---
title: Az Azure Resource Graph áttekintése
description: Ismerje meg, hogyan az Azure-erőforrás Graph szolgáltatás lehetővé teszi, hogy nagy mennyiségű erőforrást összetett lekérdezés.
author: DCtheGeek
ms.author: dacoulte
ms.date: 05/06/2019
ms.topic: overview
ms.service: resource-graph
manager: carmonm
ms.openlocfilehash: d78c640f4269c799d3d371e6dd9db477faf96694
ms.sourcegitcommit: 47ce9ac1eb1561810b8e4242c45127f7b4a4aa1a
ms.translationtype: MT
ms.contentlocale: hu-HU
ms.lasthandoff: 07/11/2019
ms.locfileid: "67807414"
---
# <a name="overview-of-the-azure-resource-graph-service"></a>Az Azure-erőforrás Graph szolgáltatás áttekintése
Az Azure Erőforrás-grafikon egy olyan szolgáltatás, az Azure-ban, amely való kiterjesztésére szolgál Azure Resource Management azáltal, hogy hatékony és nagy teljesítményű erőforrások feltárási és ipari méretekben lekérdezés lehetővé teszi egy adott halmazát az előfizetések között, hogy hatékonyan szabályozhatja a környezet. Ezek a lekérdezések a következő funkciókat biztosítják:
- Erőforrások lekérdezése az erőforrás-tulajdonságok alapján végzett összetett szűréssel, csoportosítással és rendezéssel.
- Azon képessége, iteratív a források a cégirányítási követelmények alapján.
- Szabályzatok alkalmazásából adódó következmények felmérése kiterjedt felhőkörnyezetben.
- Lehetővé teszi [erőforrás-tulajdonságok módosításait részletezik](./how-to/get-resource-changes.md) (előzetes verzió).
Ez a dokumentáció mindegyik funkciót részletesen tárgyalja.
> [!NOTE]
> Az Azure Erőforrás-grafikon működteti az Azure portál keresősávjában, az új tallózási "Minden erőforrás" élményt és az Azure Policy [módosítási előzmények](../policy/how-to/determine-non-compliance.md#change-history-preview)
> _diff vizuális_. Úgy van kialakítva, hogy az ügyfelek kezelése nagyméretű környezetekben.
[!INCLUDE [service-provider-management-toolkit](../../../includes/azure-lighthouse-supported-service.md)]
## <a name="how-does-resource-graph-complement-azure-resource-manager"></a>Hogyan egészíti ki a Resource Graph az Azure Resource Managert
Az Azure Resource Manager jelenleg támogatja lekérdezések keresztül alapvető erőforrás mezők, kifejezetten - erőforrás nevét, Azonosítóját, típus, erőforráscsoport, előfizetés és hely. Erőforrás-kezelő szolgáltatásokat egyéni erőforrás-szolgáltató hívása egy erőforrás részletes tulajdonságok egyszerre is tartalmazza.
Az Azure Resource Graph segítségével az erőforrás-szolgáltatók egyenkénti hívása nélkül is hozzáférhet az általuk visszaadott tulajdonságokhoz. Támogatott erőforrástípusait listáját, keressen egy **Igen** a a [erőforrások teljes üzemmód telepítéseit](../../azure-resource-manager/complete-mode-deletion.md) tábla.
Az Azure Erőforrás-grafikon a következőket teheti:
- Hozzáférés a anélkül, hogy az egyes hívásokat mindegyik erőforrás-szolgáltató erőforrás-szolgáltató által visszaadott tulajdonságait.
- Az elmúlt 14 napban tulajdonságok változott az erőforrás végzett módosítási előzmények megtekintése és mikor. (előzetes verzió)
## <a name="how-resource-graph-is-kept-current"></a>Hogyan tárolódik aktuális erőforrás-grafikon
Egy Azure-erőforrás frissítésekor az Erőforrás-grafikon Resource Manager által a változás értesítést kap.
Erőforrás-grafikon majd frissíti az adatbázist. Erőforrás-grafikon is elvégzi a szokványos _teljes vizsgálat_. Ez a vizsgálat biztosítja, hogy erőforrás gráfadatok aktuális kihagyott értesítések esetén, vagy egy erőforrás-en kívül a Resource Manager frissítésekor.
## <a name="the-query-language"></a>A lekérdezőnyelv
Most, hogy már jobban érti az Azure Resource Graph lényegét, ismerkedjünk meg közelebbről a lekérdezések összeállításával.
Fontos megérteni, hogy az Azure Resource Graph lekérdezési nyelv alapul a [Kusto-lekérdezés nyelvi](../../data-explorer/data-explorer-overview.md) Azure Data Explorer által használt.
Első lépésként olvassa el az Azure Resource Graphfal használható műveleteket és funkciókat ismertető, [a Resource Graph lekérdezőnyelve](./concepts/query-language.md) című cikket.
Az erőforrások tallózását az [erőforrások kezeléséről](./concepts/explore-resources.md) szóló cikk írja le.
## <a name="permissions-in-azure-resource-graph"></a>Engedélyek az Azure Resource Graphban
A Resource Graph használatához megfelelő jogosultságokkal kell rendelkeznie a [szerepköralapú hozzáférés-vezérlésben](../../role-based-access-control/overview.md) (RBAC), és legalább olvasási jogosultsággal kell rendelkeznie a lekérdezni kívánt erőforrásokon. Ha nem rendelkezik legalább `read` engedélyekkel az Azure-objektumhoz vagy -objektumcsoporthoz, a rendszer nem ad vissza eredményeket.
> [!NOTE]
> Erőforrás-grafikon egy egyszerű elérhető előfizetések használja a bejelentkezés során. Aktív munkamenet során hozzáadott új előfizetés erőforrások megtekintéséhez az egyszerű frissítenie kell a környezetben. Ez a művelet automatikusan megtörténik, amikor kijelentkezik, majd újból.
## <a name="throttling"></a>Throttling
Ingyenes szolgáltatás erőforrás-grafikon a lekérdezések szabályozott a legjobb felhasználói élményt és válasz ideje biztosít minden ügyfél számára. Ha a szervezet által támogatni kívánt nagy méretű és gyakori lekérdezések a erőforrás Graph API használatával, használja a portál "Visszajelzés" a [erőforrás Graph portáloldalán](https://portal.azure.com/#blade/Microsoft_Azure_Policy/PolicyMenuBlade/ResourceGraph).
Adja meg az üzleti esetekhez, és jelölje be a "Microsoft e-mail üzeneteket küldhet Önnek a Visszajelzésével kapcsolatban" jelölőnégyzetet ahhoz, hogy a csapat Önnel a kapcsolatot.
Erőforrás-grafikon felhasználói szinten lekérdezések szabályozza. A szolgáltatás válasza a következő HTTP-fejléceket tartalmazza:
- `x-ms-user-quota-remaining` (int): A felhasználó többi erőforrás kvótáját. Ez az érték lekérdezés száma képezi le.
- `x-ms-user-quota-resets-after` (ÓÓ:) Az időtartamot, amíg a felhasználó kvóta fogyasztás alaphelyzetbe állítása
További információkért lásd: [szabályozott kérelmeinek útmutatást](./concepts/guidance-for-throttled-requests.md).
## <a name="running-your-first-query"></a>Az első lekérdezés futtatása
Erőforrás-grafikon támogatja a .NET-hez készült Azure CLI-vel, az Azure PowerShell és az Azure SDK-t. A lekérdezés szerkezete ugyanaz az egyes nyelvekhez. Útmutató a Resource Graph engedélyezéséhez az [Azure CLI-ben](first-query-azurecli.md#add-the-resource-graph-extension) és az [Azure PowerShellben](first-query-powershell.md#add-the-resource-graph-module).
## <a name="next-steps"></a>További lépések
- Az első lekérdezés futtatása [Azure CLI-vel](first-query-azurecli.md).
- Az első lekérdezés futtatása [Azure PowerShell-lel](first-query-powershell.md).
- Kezdje [alapszintű lekérdezéseket](./samples/starter.md).
- A elmélyítse [speciális lekérdezések](./samples/advanced.md). | 78.252874 | 413 | 0.821974 | hun_Latn | 1.000009 |
8b1bf1750bb5ef0ee84e75d4783761bcff3d3987 | 3,241 | md | Markdown | exampleSite/content/english/blog/how-to-make-use-of-the-description-meta-tag.md | sanderwollaert/educenter-hugo | 947664b8a98e5703fef71080030a76c29c88aa41 | [
"MIT"
] | null | null | null | exampleSite/content/english/blog/how-to-make-use-of-the-description-meta-tag.md | sanderwollaert/educenter-hugo | 947664b8a98e5703fef71080030a76c29c88aa41 | [
"MIT"
] | null | null | null | exampleSite/content/english/blog/how-to-make-use-of-the-description-meta-tag.md | sanderwollaert/educenter-hugo | 947664b8a98e5703fef71080030a76c29c88aa41 | [
"MIT"
] | null | null | null | ---
title: How to make use of the "description" meta tag
date: 2020-11-15T09:45:17.000+00:00
bg_image: images/backgrounds/page-title.jpg
description: The description tag should accurately summarize the page content and
should be unique
image: images/blog/post-3.jpg
author: Sander Wollaert
categories:
- SEO
tags: []
type: post
---
### Summaries can be defined for each page
A page's description meta tag gives Google and other search engines a summary of what the page is about. Whereas a page's title may be a few words or a phrase, a page's description meta tag might be a sentence or two or a short paragraph. Google Webmaster Tools provides a handy [content analysis section](http://googlewebmastercentral.blogspot.com/2007/12/new-content-analysis-and-sitemap.html) that'll tell you about any description meta tags that are either too short, long, or duplicated too many times (the same information is also shown for `<title>` tags). Like the `<title>` tag, the description meta tag is placed within the tag of your HTML document.
### What are the merits of description meta tags?
Description meta tags are important because **Google might use them as snippets for your pages**. Note that we say "might" because Google may choose to use a relevant section of your page's visible text if it does a good job of matching up with a user's query. Alternatively, Google might use your site's description in the Open Directory Project if your site is listed there (learn how to [prevent search engines from displaying ODP data](http://www.google.com/support/webmasters/bin/answer.py?answer=35264)). Adding description meta tags to each of your pages is always a good practice in case Google cannot find a good selection of text to use in the snippet. The Webmaster Central Blog has an informative post on [improving snippets with better description meta tags. ](http://googlewebmastercentral.blogspot.com/2007/09/improve-snippets-with-meta-description.html)
Words in the snippet are bolded when they appear in the user's query. This gives the user clues about whether the content on the page matches with what he or she is looking for.
### Best Practices
#### Accurately summarize the page's content
Write a description that would both inform and interest users if they saw your description meta tag as a snippet in a search result.
* **Avoid** writing a description meta tag that has no relation to the content on the page
* **Avoid** using generic descriptions like "This is a web page" or "Page about baseball cards" filling the description with only keywords
* **Avoid** copying and pasting the entire content of the document into the description meta tag
#### Use unique descriptions for each page
Having a different description meta tag for each page helps both users and Google, especially in searches where users may bring up multiple pages on your domain (e.g. searches using the [site: operator]()). If your site has thousands or even millions of pages, hand-crafting description meta tags probably isn't feasible. In this case, you could automatically generate description meta tags based on each page's content.
* **Avoid** using a single description meta tag across all of your site's pages or a large group of pages | 83.102564 | 869 | 0.784943 | eng_Latn | 0.996722 |
8b1e41b69844a807c1a8922d9c00ff27ced2bc4f | 587 | md | Markdown | _posts/2019-11-19-pyneng-online-jan-apr-2019.md | rubmu/natenka | 2ecd8f4bdc4974ff10e84cdb637a0cefecf9c88e | [
"MIT"
] | 18 | 2017-02-19T15:58:54.000Z | 2022-02-13T22:15:19.000Z | _posts/2019-11-19-pyneng-online-jan-apr-2019.md | rubmu/natenka | 2ecd8f4bdc4974ff10e84cdb637a0cefecf9c88e | [
"MIT"
] | 3 | 2020-02-26T14:42:54.000Z | 2021-09-28T00:32:23.000Z | _posts/2019-11-19-pyneng-online-jan-apr-2019.md | rubmu/natenka | 2ecd8f4bdc4974ff10e84cdb637a0cefecf9c88e | [
"MIT"
] | 27 | 2017-05-03T15:38:41.000Z | 2022-02-08T02:53:38.000Z | ---
title: "PyNEng Online: 11.01.20 - 11.04.20"
date: 2019-11-19
tags:
- pyneng-online
- pyneng
category:
- pyneng
---
## Объявляется набор на курс "Python для сетевых инженеров"
Курс начинается 11.01.20 и идет до 11.04.20.
14 недель, 20 лекций, 60 часов теории, 100 домашних заданий, Python 3.7.
Курс достаточно интенсивный, несмотря на то, что он идет 14 недель.
Поэтому приготовьтесь много работать и делать домашние задания.
Подробнее на [странице курса](https://natenka.github.io/pyneng-online/)
> Для записи на курс пишите мне на email, который указан на странице курса.
| 24.458333 | 75 | 0.74276 | rus_Cyrl | 0.850127 |
8b1f6465dfeb29380b5328c91bded4f4cf774f91 | 579 | md | Markdown | README.md | jeti182/big_M_toj_models | f22a99e4f6ef55f4c33a42c8e949da26d5045070 | [
"MIT"
] | null | null | null | README.md | jeti182/big_M_toj_models | f22a99e4f6ef55f4c33a42c8e949da26d5045070 | [
"MIT"
] | null | null | null | README.md | jeti182/big_M_toj_models | f22a99e4f6ef55f4c33a42c8e949da26d5045070 | [
"MIT"
] | null | null | null | # big_M_toj_models
TOJ models and anylsis scripts to a company the Tünnermann & Scharlau (2021) TOJ data set paper.
## Dendencies
* [PyMC3](https://github.com/pymc-devs/pymc3)
* [ArviZ](https://github.com/arviz-devs/arviz)
## Installation
* Install the dependencies listed above, e.g.: `conda install -c conda-forge pymc3 arviz`
* Clone the repositories: `git clone https://github.com/jeti182/big_M_toj_models.git`
## Data set
Download the data set at https://osf.io/e4stu/ and copy it into the same folder as the scripts
## Usage
Run with `python big_M_toj_models`
| 32.166667 | 100 | 0.746114 | eng_Latn | 0.345264 |
8b2289e47d39c3f750fa3fdfce32baed78f2f5c9 | 918 | md | Markdown | _posts/_queue/2011-07-17-tsql-random-rows.md | groundh0g/ososoft.net | 7e2a1baee9cdb7ebdedbd1da6d7ce5869324d665 | [
"MIT"
] | null | null | null | _posts/_queue/2011-07-17-tsql-random-rows.md | groundh0g/ososoft.net | 7e2a1baee9cdb7ebdedbd1da6d7ce5869324d665 | [
"MIT"
] | null | null | null | _posts/_queue/2011-07-17-tsql-random-rows.md | groundh0g/ososoft.net | 7e2a1baee9cdb7ebdedbd1da6d7ce5869324d665 | [
"MIT"
] | null | null | null | ---
layout: post
category : code
tagline:
tags : [ tsql, code, tips, tricks ]
---
{% include JB/setup %}
Sometimes it can be useful to randomly select a value (or row) from a table. One easy way to do this is to sort the table using a column that contains random values, and then select the first row. The following query illustrates this concept.
~~~
-- initialize example data
DECLARE @Data TABLE (Id int IDENTITY(1,1), Caption varchar(25))
INSERT INTO @Data (Caption)
SELECT 'Apple'
UNION SELECT 'Orange'
UNION SELECT 'Banana'
UNION SELECT 'Pear'
UNION SELECT 'Mango'
UNION SELECT 'Kiwi'
-- query
SELECT TOP 1
Caption
FROM @Data
ORDER BY NEWID()
~~~
Every time you run this query, you’ll be presented with a random fruit from the list.
It’s worth noting that this isn’t the fastest code in the world. While it’s fine for rarely-run data samples, I wouldn’t use it in an oft-called production routine.
-- Joe | 27 | 242 | 0.737473 | eng_Latn | 0.966465 |
8b22c563640d5799f7979b8b88ff23ad39a0d424 | 3,178 | md | Markdown | _posts/2019-04-11-Docker-install-ubuntu.md | mdchao2010/mdchao2010.github.io | a2a7c127b1a243927205fb66454cf48657d9cac4 | [
"MIT"
] | null | null | null | _posts/2019-04-11-Docker-install-ubuntu.md | mdchao2010/mdchao2010.github.io | a2a7c127b1a243927205fb66454cf48657d9cac4 | [
"MIT"
] | null | null | null | _posts/2019-04-11-Docker-install-ubuntu.md | mdchao2010/mdchao2010.github.io | a2a7c127b1a243927205fb66454cf48657d9cac4 | [
"MIT"
] | null | null | null | ---
layout: post
title: "ubuntu 16 安装 Docker"
date: 2019-04-11
categories: docker
tags: docker ubuntu 16
---
* content
{:toc}
## 前言
Docker 要求 Ubuntu 系统的内核版本高于 3.10,通过下面的命令查看内核版本:
```bash
uname -r
```
### 卸载老版本
Docker老版本(例如1.13),叫做docker-engine。Docker进入17.x版本后,名称发生了变化,叫做docker-ce或者docker-ee。
因此,如果有安装老版本的Docker,必须先删除老版本的Docker。
1.确认安装了docker
```bash
dpkg -l | grep -i docker
```
2.删除旧docker版本:
```bash
sudo apt-get purge -y docker-engine docker docker.io docker-ce
sudo apt-get autoremove -y --purge docker-engine docker docker.io docker-ce
```
需要注意的是,执行该命令只会卸载Docker本身,而不会删除Docker内容,例如镜像、容器、卷以及网络。这些文件保
存在`/var/lib/docker` 目录中,需要手动删除。
```bash
sudo rm -rf /var/lib/docker
sudo rm /etc/apparmor.d/docker
sudo groupdel docker
sudo rm -rf /var/run/docker.sock
```
### 安装步骤
由于docker安装需要使用https,所以需要使 apt 支持 https 的拉取方式。
1.安装https。
```bash
sudo apt-get update # 先更新一下软件源库信息
sudo apt-get install \
apt-transport-https \
ca-certificates \
curl \
software-properties-common
```
2.添加Docker软件包源,设置apt仓库地址
鉴于国内网络问题,强烈建议使用国内地址,添加 阿里云 的apt仓库(使用国内源)
```bash
$ curl -fsSL https://mirrors.aliyun.com/docker-ce/linux/ubuntu/gpg | sudo apt-key add -
$ sudo add-apt-repository \
"deb [arch=amd64] https://mirrors.aliyun.com/docker-ce/linux/ubuntu \
$(lsb_release -cs) \
stable"
```
**TIPS**: Docker有两种构建方式,Stable(稳定)构建一般是一个季度发布一次;Edge(边缘)构建一般是一个月发布一次。
### 安装Docker
1.执行以下命令更新apt的包索引
```bash
$ sudo apt-get update
$ sudo apt-get install docker-ce # 安装最新版的docker
```
2.安装你想要的Docker版本(CE/EE)
```bash
$ apt-cache policy docker-ce # 查看可供安装的所有docker版本
$ sudo apt-get install docker-ce=18.03.0~ce-0~ubuntu # 安装指定版本的docker
```
3.验证安装是否正确
```bash
docker info
```
### docker 配置http_proxy
docker deamon不会读取系统代理,需要手动配置
根据经验需要修改/etc/default/docker这个配置文件,文件中也确实提供了配置代理的注释和参考,此配置方法适
用于低于Ubuntu16版本系统,Ubuntu 16配置方法如下:
1.创建目录`/etc/systemd/system/docker.service.d`
```bash
sudo mkdir docker.service.d
```
2.在该目录下创建文件`http-proxy.conf`,在文件中添加配置:
```bash
[Service]
Environment="HTTP_PROXY=http://[proxy-addr]:[proxy-port]/"
Environment="HTTPS_PROXY=http://[proxy-addr]:[proxy-port]/"
```
或者执行
```bash
sh -c "cat << EOF > /etc/systemd/system/docker.service.d/http-proxy.conf
[Service]
Environment="HTTP_PROXY=http://192.168.199.62:808"
Environment="HTTP_PROXY=http://192.168.199.62:808"
EOF"
```
3.刷新配置
```
sudo systemctl daemon-reload
```
4.重启docker服务
```bash
sudo systemctl restart docker
```
### 采坑指南
按照docker官方安装教程在执行以下命令的时候:`sudo apt-get install docker-ce`会出现如下的报错:
```bash
The following packages have unmet dependencies:
docker-ce : Depends: libltdl7 (>= 2.4.6) but it is not going to be installed
Recommends: aufs-tools but it is not going to be installed
Recommends: cgroupfs-mount but it is not installable or
cgroup-lite but it is not going to be installed
E: Unable to correct problems, you have held broken packages.
```
此问题源于libltdl7版本过低,ubuntu16.04默认无更高版本。
解决方案:
搜索到libltdl7 2.4.6的包,下载:
```
wget http://launchpadlibrarian.net/236916213/libltdl7_2.4.6-0.1_amd64.deb
```
要先安装`libltdl7`,否则安装`docker-ce`会报错
```
sudo dpkg -i libltdl7_2.4.6-0.1_amd64.deb
```
然后再安装 `docker-ce-17.03.2.ce`,就能正常安装
```bash
sudo apt-get install docker-ce
```
| 20.771242 | 87 | 0.731278 | yue_Hant | 0.500866 |
8b22cedd7d195d4afc47e7ff26b88aff6311ad7a | 1,808 | md | Markdown | articles/api-management/policies/cache-response.md | Nike1016/azure-docs.hu-hu | eaca0faf37d4e64d5d6222ae8fd9c90222634341 | [
"CC-BY-4.0",
"MIT"
] | 1 | 2019-09-29T16:59:33.000Z | 2019-09-29T16:59:33.000Z | articles/api-management/policies/cache-response.md | Nike1016/azure-docs.hu-hu | eaca0faf37d4e64d5d6222ae8fd9c90222634341 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | articles/api-management/policies/cache-response.md | Nike1016/azure-docs.hu-hu | eaca0faf37d4e64d5d6222ae8fd9c90222634341 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ---
title: Az Azure API management policy – képességek háttérszolgáltatás hozzáadása |} A Microsoft Docs
description: Az Azure API management házirend-minta - képességeket adhat a háttérszolgáltatás mutatja be. Lehetővé teheti például, hogy egy időjárás-előrejelző API-ban a szélesség és hosszúság helyett elég legyen egy hely nevét megadni.
services: api-management
documentationcenter: ''
author: vladvino
manager: cfowler
editor: ''
ms.service: api-management
ms.workload: mobile
ms.tgt_pltfrm: na
ms.devlang: na
ms.topic: article
ms.date: 10/13/2017
ms.author: apimpm
ms.openlocfilehash: 7c9edbf4b2d231453cd336521a04ba6b7714b696
ms.sourcegitcommit: d4dfbc34a1f03488e1b7bc5e711a11b72c717ada
ms.translationtype: MT
ms.contentlocale: hu-HU
ms.lasthandoff: 06/13/2019
ms.locfileid: "61062207"
---
# <a name="add-capabilities-to-a-backend-service"></a>Képességek hozzáadása a háttérszolgáltatáshoz
Ez a cikk bemutatja egy Azure API management házirend minta, amely bemutatja, hogyan adhat hozzá funkciókat háttérszolgáltatás. Lehetővé teheti például, hogy egy időjárás-előrejelző API-ban a szélesség és hosszúság helyett elég legyen egy hely nevét megadni. Az ismertetett lépéseket követve beállíthatja, vagy szerkesztheti egy szabályzat-kódot, [Set meg vagy szerkessze a szabályzat](../set-edit-policies.md). További példák megtekintéséhez lásd: [házirend minták](../policy-samples.md).
## <a name="policy"></a>Szabályzat
Illessze be a kódot a **bejövő** letiltása.
[!code-xml[Main](../../../api-management-policy-samples/examples/Call out to an HTTP endpoint and cache the response.policy.xml)]
## <a name="next-steps"></a>További lépések
További információ az APIM-szabályzatokat:
+ [Átalakítási házirendek](../api-management-transformation-policies.md)
+ [A házirend-minták](../policy-samples.md)
| 45.2 | 489 | 0.795354 | hun_Latn | 0.999872 |
8b2308094b4c0ffefdb962f6552d1633beaab247 | 1,159 | md | Markdown | README.md | syyongx/ii18n | 03d063505fc9f2c037c22a9000b7ff5e7571e2e6 | [
"MIT"
] | 23 | 2018-06-21T06:04:39.000Z | 2022-02-10T08:06:29.000Z | README.md | syyongx/ii18n | 03d063505fc9f2c037c22a9000b7ff5e7571e2e6 | [
"MIT"
] | null | null | null | README.md | syyongx/ii18n | 03d063505fc9f2c037c22a9000b7ff5e7571e2e6 | [
"MIT"
] | 1 | 2019-02-19T06:48:53.000Z | 2019-02-19T06:48:53.000Z | # II18N
[](https://godoc.org/github.com/syyongx/ii18n)
[](https://goreportcard.com/report/github.com/syyongx/ii18n)
[![MIT licensed][3]][4]
[3]: https://img.shields.io/badge/license-MIT-blue.svg
[4]: LICENSE
Go i18n library.
## Download & Install
```shell
go get github.com/syyongx/ii18n
```
## Quick Start
```go
import github.com/syyongx/ii18n
func main() {
config := map[string]Config{
"app": Config{
SourceNewFunc: NewJSONSource,
OriginalLang: "en-US",
BasePath: "./testdata",
FileMap: map[string]string{
"app": "app.json",
"error": "error.json",
},
},
}
NewI18N(config)
message := T("app", "hello", nil, "zh-CN")
}
```
## Apis
```go
NewI18N(config map[string]Config) *I18N
T(category string, message string, params map[string]string, lang string) string
```
## LICENSE
II18N source code is licensed under the [MIT](https://github.com/syyongx/ii18n/blob/master/LICENSE) Licence.
| 25.195652 | 134 | 0.625539 | yue_Hant | 0.316422 |
8b230b60eeced7e8ff1a9ec3ca1c74040ac60d22 | 109 | md | Markdown | README.md | tys404/edxNodeJs | c8be772194dcbcd3251aeb7ffccc87cf340c3fa5 | [
"MIT"
] | null | null | null | README.md | tys404/edxNodeJs | c8be772194dcbcd3251aeb7ffccc87cf340c3fa5 | [
"MIT"
] | null | null | null | README.md | tys404/edxNodeJs | c8be772194dcbcd3251aeb7ffccc87cf340c3fa5 | [
"MIT"
] | null | null | null | # edxNodeJs
node.js exercises for edx course Microsoft: DEV280x Building Functional Prototypes using Node.js
| 36.333333 | 96 | 0.834862 | eng_Latn | 0.471912 |
8b25b1da69aa6432505b8c1456c833af2156679b | 40 | md | Markdown | README.md | Edilaine100/VMT | b1b652bc01a307f5446a952c1aaf6ef50c433555 | [
"MIT"
] | null | null | null | README.md | Edilaine100/VMT | b1b652bc01a307f5446a952c1aaf6ef50c433555 | [
"MIT"
] | null | null | null | README.md | Edilaine100/VMT | b1b652bc01a307f5446a952c1aaf6ef50c433555 | [
"MIT"
] | null | null | null | # VMT
2 trabalho da Equipe de Inovação
| 13.333333 | 33 | 0.75 | por_Latn | 1.000009 |
8b2625e0dbaec1387b50c94f19430a6ff4c872af | 25,510 | md | Markdown | README.md | kdoroschak/PyPore | fa4c662ae84aadffca69a0d731b0b1483aef0ea5 | [
"MIT"
] | 24 | 2015-01-28T14:17:53.000Z | 2021-12-21T05:56:01.000Z | README.md | jmschrei/PyPore | fa4c662ae84aadffca69a0d731b0b1483aef0ea5 | [
"MIT"
] | 1 | 2021-01-11T02:47:40.000Z | 2021-01-11T03:57:41.000Z | README.md | kdoroschak/PyPore | fa4c662ae84aadffca69a0d731b0b1483aef0ea5 | [
"MIT"
] | 10 | 2015-01-31T04:43:01.000Z | 2021-01-11T02:13:45.000Z | # PyPore
## _Analysis of Nanopore Data_
The PyPore package is based off of a few core data analysis packages in order to provide a consistent and easy framework for handling nanopore data in the UCSC nanopore lab. The packages it requires are:
* numpy
* scipy
* matplotlib
* sklearn
Packages which are not required, but can be used, are:
* mySQLdb
* cython
* PyQt4
Let's get started!
# DataTypes
There are several core datatypes implemented in order to speed up analysis. These are currently File, Event, and Segment. Each of these is a way to store a full, or parts of, a .abf file and perform common tasks.
### Files
* **Attributes**: duration, mean, std, min, max, n *(# events)*, second, current, sample, events, event_parser, filename
* **Instance Methods**: parse( parser ), delete(), to\_meta(), to\_json( filename ), to\_dict(), to\_database( database, host, user, password ), plot( color_events )
* **Class Methods**: from\_json( filename ), from\_database( ... )
Nanopore data files consist primarily of current levels corresponding to ions passing freely through the nanopore ("open channel"), and a blockages as something passes through the pore, such as a DNA strand ("events"). Data from nanopore experiments are stored in Axon Binary Files (extension .abf), as a sequence 32 bit floats, and supporting information about the hardware. They can be opened and loaded with the following:
```
from PyPore.DataTypes import *
file = File( "My_File.abf" )
```
The File class contains many methods to simplify the analysis of these files. The simplest analysis to do is to pull the events, or blockages of current, from the file, while ignoring open channel. Let's say that we are looking for any blockage of current which causes the current to dip from an open channel of ~120 pA. To be conservative, we set the threshold the current has to dip before being significant to 110 pA. This can be done simply with the file's parse method, which requires a parser class which will perform the parsing. The simplest event detector is the *lambda_event_parser*, which has a keyword *threshold*, indicating the raw current that serves as the threshold.
```
from PyPore.DataTypes import *
file = File( "My_File.abf" )
file.parse( parser=lambda_event_parser( threshold=50 ) )
```
The events are now stored as Event objects in file.events. The only other important file methods involve loading and saving them to a cache, which we'll cover later. Files also have the properties mean, std, and n (number of events). If we wanted to look at what it thought were events, we could use the plot method. By default, this method will plot detected events in a different color.
```
from PyPore.DataTypes import *
file = File( "My_File.abf" )
file.parse( parser=lambda_event_parser( threshold=50 ) )
file.plot()
```

Given that a file is huge, only every 100th point is used in the black regions, and every 5th point is used in events. This may lead to some problems, such as there are two regions which seem like they should be called events, but are colored black and not cyan. This is because in reality, there are spikes below 0 in each of these segments, and the parsing method filtered out any events which went below 0 pA at any point. However, the downsampling removed this spike (because it was less than 100 points long).
### Events
* **Attributes**: duration, start, end, mean, std, min, max, n, current, sample, segments, state\_parser, filtered, filter\_order, filter\_cutoff
* **Instance Methods**: filter( order, cutoff ), parse( parser ), delete(), apply\_hmm( hmm ), plot( [hmm, kwargs), to\_meta(), to\_dict(), to\_json()
* **Class Methods**: from\_json( filename ), from\_database( ... ), from\_segments( segments )
Events are segments of current which correspond to something passing through the nanopore. We hope that it is something which we are interested in, such as DNA or protein. An event is usually made up of a sequence of discrete segments of current, which should correspond to reading some region of whatever is passing through. In the best case, each discrete segment in an event corresponds to a single nucleotide of DNA, or a single amino acid of a protein passing through.
Events are often noisy, and transitions between them are quick, making filtering a good option for trying to see the underlying signal. Currently only [bessel filters](http://en.wikipedia.org/wiki/Bessel_filter) are supported for filtering tasks, as they've been shown to perform very well.
Let's continue with our example, and imagine that now we want to filter each event, and look at it! The filter method has two parameters, order and cutoff, defaulting to order=1 and cutoff=2000. (Note that we now import pyplot as well.)
```
from PyPore.DataTypes import *
from matplotlib import pyplot as plt
file = File( "My_File.abf" )
file.parse( parser=lambda_event_parser( threshold=50 ) )
for event in file.events:
event.filter( order=1, cutoff=2000 )
event.plot()
plt.show()
```

The first event plotted in this loop is shown.
Currently, *lambda_event_parser* and *MemoryParse* are the most used File parsers. MemoryParse takes in two lists, one of starts of events, and one of ends of events, and will cut a file into it's respective events. This is useful if you've done an analysis before and remember where the split points are.
The plot command will draw the event on whatever canvas you have, allowing you to make subplots with the events or add them into GUIs (such as Abada!), with the downside being that you need to use plt.show() after calling the plot command. The plot command wraps the pyplot.plot command, allowing you pass in any argument that could be used by pyplot.plot, for example:
```
event.plot( alpha=0.5, marker='o' )
```

This plot doesn't look terrible good, and takes longer to plot, but it is possible to do!
Subplot handling is extremely easy. All of the plotting commands plot to whichever canvas is currently open, allowing for you to do something like this:
```
from PyPore.DataTypes import *
from matplotlib import pyplot as plt
file = File( "My_File.abf" )
file.parse( parser=lambda_event_parser( threshold=50 ) )
for event in file.events:
plt.subplot(211)
event.plot()
plt.subplot(212)
event.filter()
event.plot()
plt.show()
```
This plot shows how easy it is to show a comparison between an event which is not filtered versus one which is filtered.
The next step is usually to try to segment this event into it's discrete states. There are several segmenters which have been written to do this, of which currently *StatSplit is the best, written by Dr. Kevin Karplus and based on a recursive maximum likelihood algorithm. This algorithm was sped up by rewritting it in Cython, leading to *SpeedyStatSplit, which is a python wrapper for the cython code. Segmenting an event is the same process as detecting events in a file, by using the parse method on an event and passing in a parser.
Let's say that now we want to segment an event and view it. Using the same plot command for the event, we can specify to color by 'cycle', which colors the segments in a four-color cycle for easy viewing. SpeedyStatSplit takes in several parameters, of which *min_gain_per_sample is the most important, and 0.50 to 1.50 usually provide an adequate level to parse at, with higher numbers leading to less segments.
```
from PyPore.DataTypes import *
from matplotlib import pyplot as plt
file = File( "My_File.abf" )
file.parse( parser=lambda_event_parser( threshold=50 ) )
for event in file.events:
event.filter( order=1, cutoff=2000 )
event.parse( parser=SpeedyStatSplit( min_gain_per_sample=0.50 ) )
event.plot( color='cycle' )
plt.show()
```

The color cycle goes blue-red-green-cyan.
The most reliable segmenter currently is *SpeedyStatSplit*. For more documentation on the parsers, see the parsers segment of this documentation. Both Files and Events inherit from the Segment class, described below. This means that any of the parsers will work on either files or events.
The last core functionality is the ability to apply an hidden markov model (HMM) to an event, and see which segments correspond to which hidden states. HMM functionality is made possible through the use of the yahmm class, which has a Model class and a viterbi method, which is called to find the best path through the HMM. A good example of one of these HMMs is tRNAbasic or tRNAbasic2, which were both made for this purpose. Lets say we want to compare the two HMMs to see which one we agree with more.
```
from PyPore.DataTypes import *
from PyPore.hmm import tRNAbasic
from matplotlib import pyplot as plt
file = File( "My_File.abf" )
file.parse( lambda_event_parser( threshold=50 ) )
for i, event in enumerate( file.events ):
event.filter()
event.parse( SpeedyStatSplit( min_gain_per_sample=.2 ) )
plt.subplot( 411 )
event.plot( color='cycle' )
plt.subplot( 412 )
event.plot( color='hmm', hmm=tRNAbasic() )
plt.subplot( 413 )
event.plot( color='hmm', hmm=tRNAbasic2() )
plt.subplot( 414 )
plt.imshow( [ np.arange(11) ], interpolation='nearest', cmap="Set1" )
plt.grid( False )
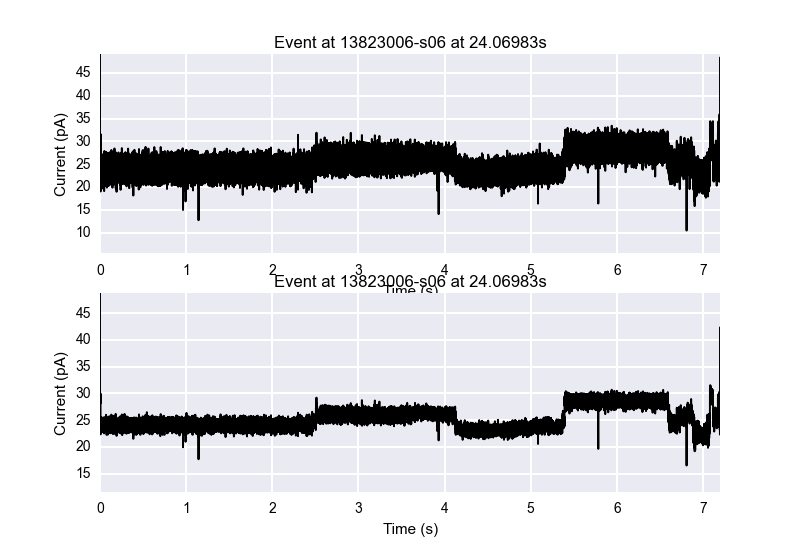
means = [ 33, 29.1, 24.01, 26.04, 24.4, 29.17, 27.1, 25.7, 22.77, 30.06, 24.9 ]
for i, mean in enumerate( means ):
plt.text( i-0.2, 0.1, str(mean), fontsize=16 )
plt.show()
```
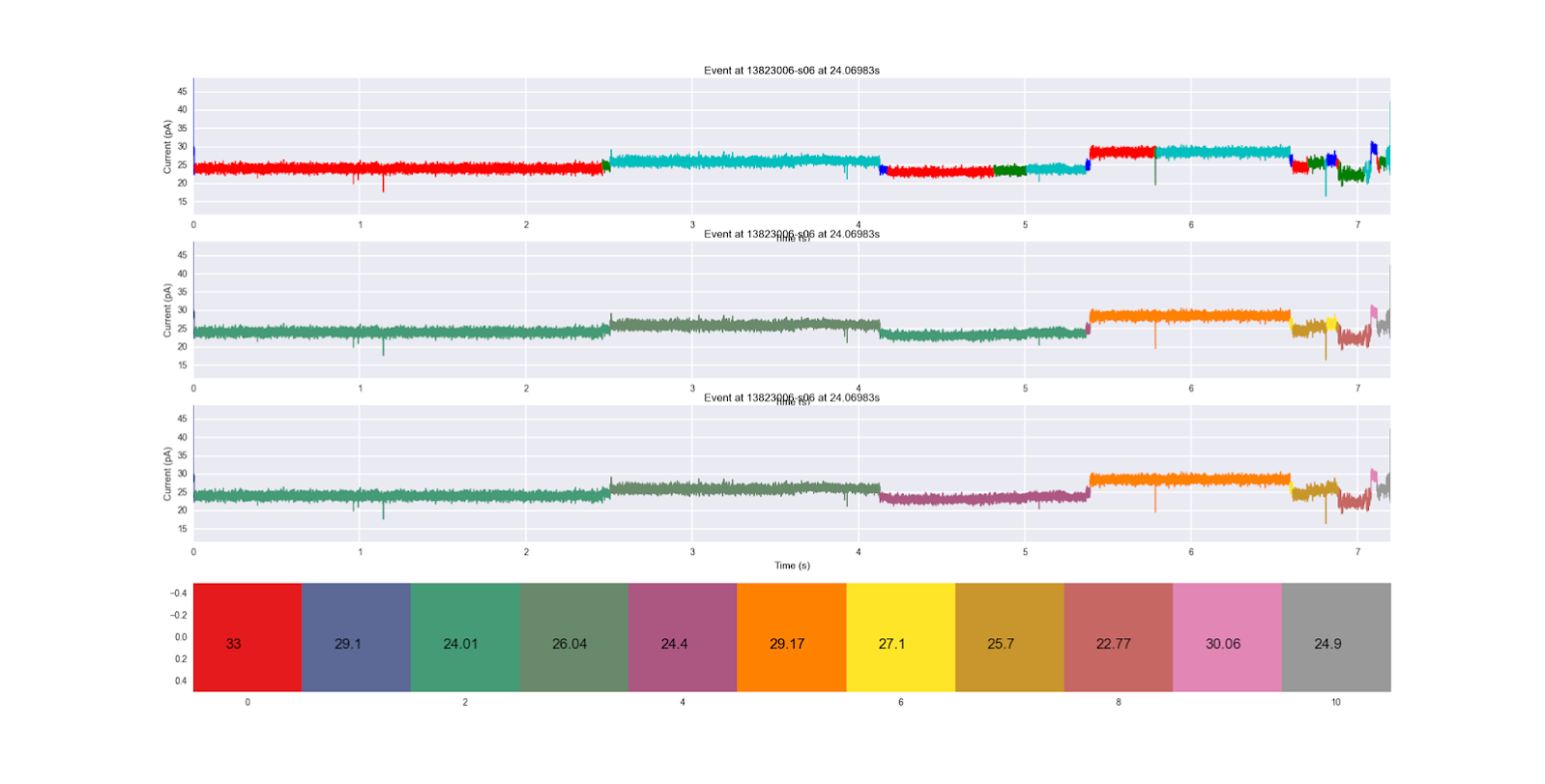
You'll notice that the title of an image and the xlabel of the image above it will always conflict. This is unfortunate, but an acceptable consequence in my opinion. If you're making more professional grade images, you may need to go in and manually fix this conflict. We see the original segmentation on the top, the first HMM applied next, and the second HMM on the bottom. The color coding of each HMM hidden state (sequentially) along with the mean ionic current of their emission distribution are shown at the very bottom. We see that the bottom HMM seems to progress more sequentially, progressing to the purple state instead of regressing back to the blue-green state in the middle of the trace. It also does not go backwards to the yellow state once it's in the gold state later on in the trace. It seems like a more robust HMM, and this way of comparing them is super easy to do.
Event objects also have the properties start, end, duration, mean, std, and n (number of segments after segmentation has been performed).
### Segments
* **Attributes**: duration, start, end, mean, std, min, max, current
* **Instance Methods**: to\_json( filename ), to\_dict(), to\_meta(), delete()
* **Class Methods**: from\_json( filename )
A segment stores the series of floats in a given range of ionic current. This abstract notion allows for both Event and File to inherit from it, as both a file and an event are a range of floats. The context in which you will most likely interact with a Segment is in representing a discrete step of the biopolymer through the pore, with points usually coming from the same distribution.
Segments are short sequences of current samples, usually which appear to be from the same distribution. They are the core place where data are stored, as usually an event is analyzed by the metadata stored in each state. Segments have the attributes current, which stores the raw current samples, in addition to mean, std, duration, start, end, min, and max.
### Metadata
If storing the raw sequence of current samples is too memory intensive, there are two ways to get rid of lists of floats representing the current, which take up the vast majority of the memory ( >~99% ).
1) Initialize a MetaSegment object, instead of a Segment one, and feed in whatever statistics you'd like to save. This will prevent the current from ever being saved to a second object. For this example, lets assume you have a list of starts and ends of segments in an event, such as loading them from a cache.
```
event = Event( current=[...], start=..., file=... )
event.segments = [ MetaSegment( mean=np.mean( event.current[start:end] ),
std=np.std( event.current[start:end] ),
duration=(end-start)/100000 ) for start, end in zip( starts, ends ) ]
```
In this example, references to the current are not stored in both the event and the segment, which may save memory if you wish to not store the raw current after analyzing a file. The duration here is divided by 100,000 because abf files store 100,000 samples per second, and we wished to convert from the integer index of the start and end to the second index of the start and end.
2) If you have the memory to store the references, but don't want to accumulate them past a single event, you can parse a file normally, and produce normal segments, then call the function to_meta() to turn them into MetaSegments. This does not require any calculation on the user part, but does require the segment have contained all current samples at one point.
```
event = Event( current=[...], start=..., file=... )
event.parse( parser=SpeedyStatSplit() )
for segment in event.segments:
segment.to_meta()
```
You may have noticed that every datatype implements a to\_meta() method, which removes simply retypes the object to "Meta...", and removes the current attribute, and all references to that list. Remember that in python, if any references exist to a list, the list still exists. This means that your file contains the list of ionic current, and all events or segments simply contain pointers to that list, so meta-izing a list or segment by itself probably won't help that much in terms of memory. However, you can meta-ize the File, which will meta-ize everything in the file tree. This means that calling to\_meta() on a file will cause to\_meta() to be called on each event, which will cause to\_meta() to be called on every segment, removing every reference to that list, and tagging that list for garbage collection.
# Parsers
Given that both Events and Files inherit from the Segment class, any parser can be used on both Events and Files. However, some were written for the express purpose of event detection or segmentation, and are better suited for that task.
### Event Detector Intended Parsers
These parsers were intended to be use for event detection. They include:
* *lambda_event_parser( threshold )* : This parser will define an event to be any consecutive points of ionic current between a drop below threshold to a jump above the threshold. This is a very simplistic parser, built on the idea that the difference between open channel current and the highest biopolymer related state in ~30-40% of open channel, meaning that setting this threshold anywhere in that range will quickly yield the events.
### Segmenter Intended Parsers
* *SpeedyStatSplit( min_gain_per_sample, min_width, max_width, window_width, use_log )* : This parser uses maximum likelihood in order to split segments. This is the current best segmenter, as it can handle segments which have different variances but the same mean, and segments with very similar means. It is the cython implementation of StatSplit, speeding up the implementation ~40x. The min gain per sample attribute is the most important one, with ~0.5 being a good default, and higher numbers producing less segments, smaller numbers producing more segments. The min width and max width parameters are in points, and their default values are usually good.
* *StatSplit( ... )* : The same as SpeedyStatSplit, except slower. Use if masochistic.
* *novakker_parser( low_thresh, high_thresh )* : This is an implementation of the derivative part of a filter-derivative method to segmentation. It has two thresholds on the derivative, of which the high thresh must be reached before a segmentation is made. However, before the next segmentation is made, the derivative must go below the low threshold. This ensures that a region of rapid change does not get overly segmented.
* *snakebase_parser( threshold )* : This parser takes the attitude that transitions between segments occurs when the peak-to-peak amplitude between two consecutive waves is higher than threshold. This method seems to work decently when segments have significantly different means, especially when over-segmenting is not a problem.
### Misc.
* *MemoryParser( starts, ends )* : This parser is mostly used internally in order to load up saved analyses, however it is available for all to use. The starts of segments, and the ends, are provided in a list with the *i*-th element of starts and ends correspond to the *i*-th segment you wish to make. This can be used for event detection or segmentation.
# HMMs
### Making Hidden Markov Models
PyPore is set up to accept <a href="https://www.github.com/jmschrei/yahmm">YAHMM</a> hidden Markov models by default. The YAHMM package is a general HMM package, which is written in Cython for speed. The original yahmm package was written by Adam Novak, but has been converted to Cython and expanded upon by myself. Here is an example of making a model:
```
from yahmm import *
model = Model( "happy model" )
a = State( NormalDistribution( 3, 4 ), 'a' )
b = State( NormalDistribution( 10, 1 ), 'b' )
model.add_transition( model.start, a, 0.50 )
model.add_transition( model.start, b, 0.50 )
model.add_transition( a, b, 0.50 )
model.add_transition( b, a, 0.50 )
model.add_transition( a, model.end, 0.50 )
model.add_transition( b, model.end, 0.50 )
model.bake()
```
In order to use cython modules, you must import them properly using the pyximport package. The next step is to create a Model object, then various State objects, then connect the beginning of the model to the states, the states to each other, and the states to the end of the model in the appropriate manner! Then you can call forward, backward, and viterbi as needed on any sequence of observations. It is important to bake the model in the end, as that solidifies the internals of the HMM.
I usually create a function with the name of the HMM, and have the code to build that HMM inside the function, and return a baked model.
### Using HMMs
There are three ways to use HMMs on event objects.
1) The first is to simply use event.apply_hmm( hmm, algorithm ). Algorithm can be forward, backward, or viterbi, depending on what you want. Forward gives the log probability of the event given the model going forward, backward is the same but using the backwards algorithm, and viterbi returns a tuple of the log probability, and most likely path. This defaults to viterbi.
```
print event.apply_hmm( tRNAbasic(), algorithm='forward' )
print event.apply_hmm( tRNAbasic(), algorithm='backward' )
print event.apply_hmm( tRNAbasic() )
```
1) The second is in the parse class, to create HMM-assisted segmentation. This will concatenate states of the same hidden state which are next to each other, allowing you to add prior information to your segmentation.
```
event.parse( parser=SpeedyStatSplit( min_gain_per_sample=.2 ), hmm=tRNAbasic() )
```
2) Lastly, you can pass it in in the plot function. This does not change the underlying event at all, but will simply color it differently when it plots. An example is similar to what we did earlier when comparing different HMM models on an event. Here are two examples of HMM usage for plotting. cmap allows you to define the colormap you use on the serial ID of sequential HMM matching states, and defaults to Set1 due to its wide range of colors.
```
event.plot( color='hmm', hmm=tRNAbasic(), cmap='Reds' )
event.plot( color='hmm', hmm=tRNAbasic2(), cmap='Greens' )
```
# Saving Analyses
If you perform an analysis and wish to save the results, there are multiple ways for you to do such. These operation seems common, for applications such as testing a HMM. If you write a HMM and want to make modifications to it, it would be useful to not have to redo the segmentation, but instead simply load up the same segmentation from the last time you did it. Alternatively, you may have a large batch of files you wish to analyze, and want to grab the metadata for each file to easily read after you go eat lunch, so you don't need to deal with the whole files.
### MySQL Database:
The first is to store it to a MySQL database. The tables must be properly made for this-- see database.py if you want to see how to set up your own database to store PyPore results. If you are connected to the UCSC SoE secure network, there is a MySQL database, named chenoo, which will allow you to store an analysis. This is done on the file level, in order to preserve RDBMS format.
```
from PyPore.DataTypes import *
file = File( "My_File.abf" )
file.parse( parser=lambda_event_parser( threshold=110 ) )
for event in file.events:
event.filter( order=1, cutoff=2000 )
event.parse( parser=SpeedyStatSplit( min_gain_per_sample=0.50 ) )
event.plot( color='cycle' )
plt.show()
file.to_database( database="chenoo", host="...", password="...", user="..." )
```
Host, password, and user must be set for your specific database. These files can then be read back by the following code.
```
from PyPore.DataTypes import *
file = File.from_database( database="chenoo", host="...", password="...", user="...", AnalysisID, filename, eventDetector, eventDetectorParams, segmenter, segmenterParams, filterCutoff, filterOrder )
```
This will load the file back, with the previous segmentations. This will be anywhere from 10x to 1000x faster than performing the segmentation again. The time depends on how stable your connection with the database is, and how complex the analysis you did was.
Now, it seems like there are a lot of parameters after user! You need to fill in as many of these as you can, to help identify which analysis you meant. AnalysisID is a primary key, but is also assigned by the database automatically when you stored it, so it is possible you do not know it. If you connect to MySQL independently and look up that ID, you can use it solely to identify which file you meant. If you do not provide enough information to uniquely identify a file, you may get an incorrect analysis.
### JSON File
A more portable and simple way to store analyses is to save the file to a json. This can be done simply with the following code.
```
from PyPore.DataTypes import *
file = File( "My_File.abf" )
file.parse( parser=lambda_event_parser( threshold=110 ) )
for event in file.events:
event.filter( order=1, cutoff=2000 )
event.parse( parser=SpeedyStatSplit( min_gain_per_sample=0.50 ) )
event.plot( color='cycle' )
plt.show()
file.to_json( filename="My_File.json" )
```
The representation of your analysis will then be available as a human-readable json format. It may not be particularly fun to look at, but you will be able to read the metadata from the file. A snippet from an example file looks like the following:
```
{
"name" : "File",
"n" : 16,
"event_parser" : {
"threshold" : 50.0,
"name" : "lambda_event_parser"
},
"duration" : 750.0,
"filename" : "13823006-s06",
"events" : [
{
"std" : 1.9335278997265508,
"end" : 31.26803,
"state_parser" : {
"min_gain_per_sample" : 0.5,
"min_width" : 1000,
"window_width" : 10000,
"max_width" : 1000000,
"name" : "SpeedyStatSplit"
},
"name" : "Event",
"min" : 16.508111959669066,
"max" : 48.73997069621818,
"segments" : [
{
"std" : 2.8403093295527646,
"end" : 0.01,
"name" : "Segment",
"min" : 22.330505378907066,
"max" : 48.73997069621818,
"start" : 0.0,
"duration" : 0.01,
"mean" : 27.341223956001969
},
{
"std" : 0.5643329015609988,
"end" : 2.5060499999999997,
"name" : "Segment",
"min" : 17.67660726490438,
"max" : 26.554361458946911,
"start" : 0.01,
"duration" : 2.49605,
"mean" : 24.084380592526145
....
```
The file continues to list every event, and every segment in every event. The code to reconstruct an analysis from a json file is just as long as the code to reconstruct from the database.
```
from PyPore.DataTypes import *
file = File.from_json( "My_File.json" )
```
This is usually faster than loading from a database, solely due to not having to connect across a network and stream data, and instead reading locally.
| 63.61596 | 888 | 0.737279 | eng_Latn | 0.998691 |
8b267363de03be666dbe10c8a4bdf5c02e3bdad7 | 1,896 | md | Markdown | docs/NewConfirmedTokensTransactionsRData.md | Crypto-APIs/Crypto_APIs_2.0_SDK_Golang | be835146c51ba871da4b6e7a3f0cfa19298cc9c0 | [
"MIT"
] | 4 | 2021-07-10T13:19:17.000Z | 2022-03-05T22:21:52.000Z | docs/NewConfirmedTokensTransactionsRData.md | Crypto-APIs/Crypto_APIs_2.0_SDK_Golang | be835146c51ba871da4b6e7a3f0cfa19298cc9c0 | [
"MIT"
] | null | null | null | docs/NewConfirmedTokensTransactionsRData.md | Crypto-APIs/Crypto_APIs_2.0_SDK_Golang | be835146c51ba871da4b6e7a3f0cfa19298cc9c0 | [
"MIT"
] | 1 | 2021-07-25T04:05:22.000Z | 2021-07-25T04:05:22.000Z | # NewConfirmedTokensTransactionsRData
## Properties
Name | Type | Description | Notes
------------ | ------------- | ------------- | -------------
**Item** | [**NewConfirmedTokensTransactionsRI**](NewConfirmedTokensTransactionsRI.md) | |
## Methods
### NewNewConfirmedTokensTransactionsRData
`func NewNewConfirmedTokensTransactionsRData(item NewConfirmedTokensTransactionsRI, ) *NewConfirmedTokensTransactionsRData`
NewNewConfirmedTokensTransactionsRData instantiates a new NewConfirmedTokensTransactionsRData object
This constructor will assign default values to properties that have it defined,
and makes sure properties required by API are set, but the set of arguments
will change when the set of required properties is changed
### NewNewConfirmedTokensTransactionsRDataWithDefaults
`func NewNewConfirmedTokensTransactionsRDataWithDefaults() *NewConfirmedTokensTransactionsRData`
NewNewConfirmedTokensTransactionsRDataWithDefaults instantiates a new NewConfirmedTokensTransactionsRData object
This constructor will only assign default values to properties that have it defined,
but it doesn't guarantee that properties required by API are set
### GetItem
`func (o *NewConfirmedTokensTransactionsRData) GetItem() NewConfirmedTokensTransactionsRI`
GetItem returns the Item field if non-nil, zero value otherwise.
### GetItemOk
`func (o *NewConfirmedTokensTransactionsRData) GetItemOk() (*NewConfirmedTokensTransactionsRI, bool)`
GetItemOk returns a tuple with the Item field if it's non-nil, zero value otherwise
and a boolean to check if the value has been set.
### SetItem
`func (o *NewConfirmedTokensTransactionsRData) SetItem(v NewConfirmedTokensTransactionsRI)`
SetItem sets Item field to given value.
[[Back to Model list]](../README.md#documentation-for-models) [[Back to API list]](../README.md#documentation-for-api-endpoints) [[Back to README]](../README.md)
| 36.461538 | 161 | 0.795886 | yue_Hant | 0.91902 |
8b27e217d4ed1c41a6217d3eab1513622f16b1e4 | 2,291 | md | Markdown | sdk-api-src/content/rpcndr/nf-rpcndr-ndrasyncclientcall.md | amorilio/sdk-api | 54ef418912715bd7df39c2561fbc3d1dcef37d7e | [
"CC-BY-4.0",
"MIT"
] | null | null | null | sdk-api-src/content/rpcndr/nf-rpcndr-ndrasyncclientcall.md | amorilio/sdk-api | 54ef418912715bd7df39c2561fbc3d1dcef37d7e | [
"CC-BY-4.0",
"MIT"
] | null | null | null | sdk-api-src/content/rpcndr/nf-rpcndr-ndrasyncclientcall.md | amorilio/sdk-api | 54ef418912715bd7df39c2561fbc3d1dcef37d7e | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ---
UID: NF:rpcndr.NdrAsyncClientCall
title: NdrAsyncClientCall function (rpcndr.h)
description: The NdrAsyncClientCall function is the asynchronous client-side entry point for the /Oi and /Oic mode stub.
helpviewer_keywords: ["NdrAsyncClientCall","NdrAsyncClientCall function [RPC]","rpc.ndrasyncclientcall","rpcndr/NdrAsyncClientCall"]
old-location: rpc\ndrasyncclientcall.htm
tech.root: Rpc
ms.assetid: 591f56de-6ceb-46d7-9720-cd2213605ef2
ms.date: 12/05/2018
ms.keywords: NdrAsyncClientCall, NdrAsyncClientCall function [RPC], rpc.ndrasyncclientcall, rpcndr/NdrAsyncClientCall
req.header: rpcndr.h
req.include-header: Rpc.h
req.target-type: Windows
req.target-min-winverclnt: Windows 2000 Professional [desktop apps \| UWP apps]
req.target-min-winversvr: Windows 2000 Server [desktop apps \| UWP apps]
req.kmdf-ver:
req.umdf-ver:
req.ddi-compliance:
req.unicode-ansi:
req.idl:
req.max-support:
req.namespace:
req.assembly:
req.type-library:
req.lib: RpcRT4.lib
req.dll: RpcRT4.dll
req.irql:
targetos: Windows
req.typenames:
req.redist:
ms.custom: 19H1
f1_keywords:
- NdrAsyncClientCall
- rpcndr/NdrAsyncClientCall
dev_langs:
- c++
topic_type:
- APIRef
- kbSyntax
api_type:
- DllExport
api_location:
- RpcRT4.dll
api_name:
- NdrAsyncClientCall
---
# NdrAsyncClientCall function
## -description
The <b>NdrAsyncClientCall</b> function is the asynchronous client-side entry point for the <a href="/windows/desktop/Midl/-oi">/Oi</a> and <b>/Oic</b> mode stub.
## -parameters
### -param pStubDescriptor [in]
Pointer to the MIDL-generated <a href="/windows/desktop/api/rpcndr/ns-rpcndr-midl_stub_desc">MIDL_STUB_DESC</a> structure that contains information about the description of the remote interface.
### -param pFormat [in]
Pointer to the MIDL-generated procedure format string that describes the method and parameters.
### -param ...
Pointer to the client-side calling stack.
## -returns
Return value of the remote call. The maximum size of a return value is equivalent to the register size of the system. MIDL switches to the <a href="/windows/desktop/Midl/-os">/Os</a> mode stub if the return value size is larger than the register size.
Depending on the method definition, this function can throw an exception if there is a network or server failure.
| 30.546667 | 251 | 0.773898 | eng_Latn | 0.68771 |
8b27e9a6891bc76e5fa6d09948f897ac032f1390 | 81 | md | Markdown | README.md | JulioTsutsui/react-component-challenge | 22329601740cdedb94eafcae542266e1ee06c058 | [
"MIT"
] | null | null | null | README.md | JulioTsutsui/react-component-challenge | 22329601740cdedb94eafcae542266e1ee06c058 | [
"MIT"
] | null | null | null | README.md | JulioTsutsui/react-component-challenge | 22329601740cdedb94eafcae542266e1ee06c058 | [
"MIT"
] | null | null | null | # Conteúdos aprendidos durante o desafio
1. Componentização
1. Interfaces em TS
| 16.2 | 40 | 0.802469 | por_Latn | 0.999717 |
8b28e1796aa8f973e868abab6431317e4c441e8e | 6,040 | md | Markdown | introduction/diff-frwd-invrrtd-index/README.md | bhatman-r/inverted-index-series | c858e06a00bc0a8c69e1654af716dfd3e4601321 | [
"Apache-2.0"
] | 1 | 2021-09-04T23:39:30.000Z | 2021-09-04T23:39:30.000Z | introduction/diff-frwd-invrrtd-index/README.md | im-bhatman/inverted-index-series | c858e06a00bc0a8c69e1654af716dfd3e4601321 | [
"Apache-2.0"
] | null | null | null | introduction/diff-frwd-invrrtd-index/README.md | im-bhatman/inverted-index-series | c858e06a00bc0a8c69e1654af716dfd3e4601321 | [
"Apache-2.0"
] | null | null | null | # Forward and Inverted Indexes - Requirement based differences
So this is my first post in the series of #explainlikeimfive on Dev.to. You can read the original post [here](https://dev.to/bhatman/forward-and-inverted-indexes-requirement-based-differences-1m3e). I hope you guys find this useful.
In this article, we try to understand the use of Forward and Inverted Indexes based on different requirements. The article is not about why the forward indexes are better than inverted, or vice-versa. Because both of them serve different purposes/requirements as explained in the post.
### **Topics to be covered**
* Definitions
* Requirement 1 and using Forward Indexes
* Requirement 2 and using Inverted Indexes
Note: Forward Indexes are heavily used in traditional SQL databases like B-tree, Hash Indexes etc. So if you have ever heard of "indexes" in databases then chances are it was referring to _forward indexes_. Whereas Inverted Index articles and documentation specifically mention _inverted index_.
So now moving to the question of the hour, what is the main difference between Traditional forward indexes and inverted indexes?
> Inverted Index stores the words as index and document name(s) as mapped reference(s).
Forward Index stores the document name as index and word(s) as mapped reference(s).
But Ritesh you told me that you will explain it like I am five ? Stop this gibberish now..
Okay, let me give you real-world examples of forward and Inverted Index which we all see in our daily lives.
So I have this book with me "Team of Rivals", a great book written by Doris Kearns Goodwin about the political genius of Abraham Lincoln. Let's use this book to explain the difference between forward and reverse indexes.

**Requirement 1**: I know that I want to read the section "Show Down in Chicago" of the book, but I don't know which page it is on.
So What how can I do this? How can I reach the "Show Down in Chicago" section of this 880 pages book?
**Approach 1 (Grepping)**: I will turn every page of the book from the beginning and check if it is the desired section. The technique is called _grepping_. But the section "Show Down in Chicago" is on page 237. So the number of checks required to reach the section will be ~237, and this is not acceptable because of the time and effort required in this.
**Approach 2 (Forward Indexes)**: Let's use Forward Indexes to solve this issue. You must have seen the first few pages which tell you about the exact location of the chapter/section, like this image.

This is the actual idea of the working of forward indexes. Use a key(here chapter/section name) name to point to the specific record in the db (here starting of the content of the chapter int he book). So now the number of checks to reach the "Show Down in Chicago" gets reduced down to 1. Hence reducing the time and effort of our search. (It's not exactly 1 comparison but yes comparisons and time required in this approach are wayyyyyyyyy less than that of our approach 1 i.e grepping).
***
Now look at the next requirement related to a term search.
**Requirement 2**: I want to search for all the documents which have mentioned the term "Baltimore" in the book. And let me remind you there are 880 pages in the book. And more than 300,000 words. Therefore grepping(aka scanning) in this case will require you to make 300,000 comparisons. This is enough to make any sane man go crazy.
So how do we do this? How do we find all the pages which have mentioned "Baltimore"?
**Approach 1(grepping)**: You know the run, check each and every term of the book from start to end, and note down the page which has mentioned "Baltimore". Again very time consuming as already seen for the Requirement 1 too.
**Approach 2 (Inverted Indexes)**: Since we are talking about searching a term in a large collection of documents(aka collection of chapters in this case) we can use Inverted Indexes to solve this issue, and yes almost all books use these Inverted Indexes to make your life easier. Just like many other books "Team of Rivals" has inverted indexes at the end of the book as shown in this image.

So after checking the Inverted indexes at the end of the book we know that "Baltimore" is mentioned on pages 629 and 630. So there are two parts in this _searching_ for "Baltimore" in the lexicographically ordered Inverted Index list and _fetching_ the pages based on the value of the index (here 629 and 630). The search time is very less for the term in the inverted index since in computing we actually use dictionaries(hash-based or search trees) to keep track of these terms and hence reduces down the search complexity from **O(n)** to **O(log n)** theoretically* when using the binary search or using a search tree, where **n** is the numbers of words/terms in our index.
***
GIST: Forward Indexes are used to map a column's value to a row or group of records. Whereas Inverted Indexes are usually used to maps the words/terms/content of a large document to a list of articles.
There are many other differences but I don't want to go into too many jargon words/topics since this post is part of the #explainmelikeiamfive section. If you are interested in reading a lot more about the Inverted Index, you can follow this series [Inverted Index - The Story begins](https://dev.to/bhatman/inverted-index-the-story-begins-4l60) and the corresponding posts where the topics discussed will be more at intermediate and advanced levels.
You can read the same article on Gihub to on this link: [Forward Indexes and Inverted Indexes - Requirement based differences]()
***
Your feedbacks are most welcome and if you think something can be improved about this post please feel free to write that out in at [email protected] or leave a PR.
| 91.515152 | 679 | 0.779305 | eng_Latn | 0.99961 |
8b2951481e92db0f5f492c3ca77ac29d851db75f | 15,222 | md | Markdown | README.md | nkansal96/aurora-java | 665b5f5a77263b4bb2c7763f32b4b63d642a40d0 | [
"MIT"
] | null | null | null | README.md | nkansal96/aurora-java | 665b5f5a77263b4bb2c7763f32b4b63d642a40d0 | [
"MIT"
] | 14 | 2018-04-30T21:45:47.000Z | 2018-06-08T06:51:08.000Z | README.md | nkansal96/aurora-java | 665b5f5a77263b4bb2c7763f32b4b63d642a40d0 | [
"MIT"
] | null | null | null | # Aurora Java SDK
## Overview
Aurora is the enterprise end-to-end speech solution. This Java SDK will allow you to quickly and easily use the Aurora service to integrate voice capabilities into your application.
The SDK is currently in a pre-alpha release phase. Bugs and limited functionality should be expected.
## Installation
**The Recommended Java version is 8+**
### Maven users
Add this dependency to your project's POM:
```xml
<dependency>
<groupId>com.auroraapi</groupId>
<artifactId>aurora-java</artifactId>
<version>0.1.2</version>
<type>pom</type>
</dependency>
```
### Gradle users
Add this dependency to your project's build file:
```groovy
implementation 'com.auroraapi:aurora-java:0.1.2'
```
### JAR Download
Download the JAR file directly from [here](https://bintray.com/auroraapi/maven/download_file?file_path=com%2Fauroraapi%2Faurora-java%2F0.1.2%2Faurora-java-0.1.2.jar)
## Basic Usage
First, make sure you have an account with [Aurora](http://dashboard.auroraapi.com) and have created an Application.
### Text to Speech (TTS)
```Java
package main;
import com.auroraapi.Aurora;
import com.auroraapi.models.Audio;
import com.auroraapi.models.AuroraException;
import com.auroraapi.models.Speech;
import com.auroraapi.models.Text;
import javax.sound.sampled.LineUnavailableException;
import java.io.IOException;
public class TextToSpeech {
public static void main(String[] args) {
String appId = "<put your appId here>";
String appToken = "<put your appToken here>";
Aurora.init(appId, appToken);
Text text = new Text("Hello World!");
System.out.println("Example tts usage for: " + text.toString());
try {
Speech speech = Aurora.getSpeech(text);
Audio audio = speech.getAudio();
audio.play();
} catch (AuroraException e) {
e.printStackTrace();
} catch (LineUnavailableException | InterruptedException | IOException e) {
e.printStackTrace();
}
}
}
```
### Speech to Text (STT)
#### Convert a WAV file to Speech
```Java
package main;
import com.auroraapi.Aurora;
import com.auroraapi.models.*;
import javax.sound.sampled.LineUnavailableException;
import java.io.IOException;
public class SpeechToText {
public static void main(String[] args) {
String appId = "<put your appId here>";
String appToken = "<put your appToken here>";
Aurora.init(appId, appToken);
try {
Audio audio = Audio.fromFile("text.wav");
Speech speech = new Speech(audio);
Transcript transcript = Aurora.getTranscript(speech);
System.out.println("Transcript: " + transcript.toString());
} catch (AuroraException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
```
#### Convert a previous Text API call to Speech
```Java
package main;
import com.auroraapi.Aurora;
import com.auroraapi.models.AuroraException;
import com.auroraapi.models.Speech;
import com.auroraapi.models.Text;
import com.auroraapi.models.Transcript;
import java.io.IOException;
public class TextAPICallToSpeech {
public static void main(String[] args) {
String appId = "<put your appId here>";
String appToken = "<put your appToken here>";
Aurora.init(appId, appToken);
Text text = new Text("Hello World!");
System.out.println("Example tts usage for: " + text.toString());
try {
Speech speech = Aurora.getSpeech(text);
Transcript transcript = Aurora.getTranscript(speech);
System.out.println("Transcription: " + transcript.toString());
} catch (AuroraException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
```
#### Listen for a specified amount of time
```Java
package main;
import com.auroraapi.Aurora;
import com.auroraapi.models.*;
import javax.sound.sampled.LineUnavailableException;
import java.io.IOException;
public class ListenSpecifiedTime {
public static void main(String[] args) {
String appId = "<put your appId here>";
String appToken = "<put your appToken here>";
Aurora.init(appId, appToken);
Audio.Params params = new Audio.Params(3L, Audio.Params.DEFAULT_SILENCE_LENGTH);
try {
Speech speech = Speech.listen(params);
Transcript transcript = Aurora.getTranscript(speech);
System.out.println("Transcription: " + transcript.getTranscript());
} catch (AuroraException e) {
e.printStackTrace();
} catch (LineUnavailableException | IOException e) {
e.printStackTrace();
}
}
}
```
#### Listen for an unspecified amount of time
Calling this API will start listening and will automatically stop listening after a certain amount of silence (default is 1.0 seconds).
```Java
package main;
import com.auroraapi.Aurora;
import com.auroraapi.models.*;
import javax.sound.sampled.LineUnavailableException;
import java.io.IOException;
public class ListenUnspecifiedTime {
public static void main(String[] args) {
String appId = "<put your appId here>";
String appToken = "<put your appToken here>";
Aurora.init(appId, appToken);
Audio.Params params = new Audio.Params(Audio.Params.DEFAULT_LISTEN_LENGTH, 1L);
try {
Speech speech = Speech.listen(params);
Transcript transcript = Aurora.getTranscript(speech);
System.out.println("Transcription: " + transcript.getTranscript());
} catch (AuroraException e) {
e.printStackTrace();
} catch (LineUnavailableException | IOException e) {
e.printStackTrace();
}
}
}
```
#### Continuously listen
Continuously listen and retrieve speech segments. Note: you can do anything with these speech segments, but here we'll convert them to text. Just like the previous example, these segments are demarcated by silence (1.0 second by default) and can be changed by passing the `silenceLength` parameter. Additionally, you can make these segments fixed length (as in the example before the previous) by setting the `length` parameter.
```Java
package main;
import com.auroraapi.Aurora;
import com.auroraapi.callbacks.SpeechCallback;
import com.auroraapi.models.*;
public class ContinuouslyListen {
public static void main(String[] args) {
String appId = "<put your appId here>";
String appToken = "<put your appToken here>";
Aurora.init(appId, appToken);
SpeechCallback callback = new SpeechCallback() {
@Override
public boolean onSpeech(Speech speech) {
System.out.println("Speech: " + speech.toString());
return false;
}
@Override
public boolean onError(Throwable throwable) {
throwable.printStackTrace();
return false;
}
};
// Params are optional
Aurora.continuouslyListen(callback);
}
}
```
#### Listen and Transcribe
If you already know that you wanted the recorded speech to be converted to text, you can do it in one step, reducing the amount of code you need to write and also reducing latency. Using the `continuouslyListenAndTranscribe` method, the audio that is recorded automatically starts uploading as soon as you call the method and transcription begins. When the audio recording ends, you get back the final transcription.
```Java
package main;
import com.auroraapi.Aurora;
import com.auroraapi.callbacks.TranscriptCallback;
import com.auroraapi.models.*;
public class ListenAndTranscribe {
public static void main(String[] args) {
String appId = "<put your appId here>";
String appToken = "<put your appToken here>";
Aurora.init(appId, appToken);
TranscriptCallback callback = new TranscriptCallback() {
@Override
public boolean onTranscript(Transcript transcript) {
System.out.println("Transcription: " + transcript.getTranscript());
return true;
}
@Override
public boolean onError(Throwable throwable) {
throwable.printStackTrace();
return false;
}
};
// NOTE: Params are optional and the silence and listen lengths are customizable.
Aurora.continuouslyListenAndTranscribe(callback);
}
}
```
#### Listen and echo example
```Java
package main;
import com.auroraapi.Aurora;
import com.auroraapi.callbacks.TranscriptCallback;
import com.auroraapi.models.*;
import javax.sound.sampled.LineUnavailableException;
import java.io.IOException;
public class ListenAndTranscribe {
public static void main(String[] args) {
String appId = "<put your appId here>";
String appToken = "<put your appToken here>";
Aurora.init(appId, appToken);
TranscriptCallback callback = new TranscriptCallback() {
@Override
public boolean onTranscript(Transcript transcript) {
Text text = new Text(transcript.getTranscript());
try {
Speech speech = Aurora.getSpeech(text);
Audio audio = speech.getAudio();
audio.play();
return true;
} catch (AuroraException e) {
e.printStackTrace();
return false;
} catch (LineUnavailableException | InterruptedException | IOException e) {
e.printStackTrace();
return false;
}
}
@Override
public boolean onError(Throwable throwable) {
throwable.printStackTrace();
return false;
}
};
// NOTE: Params are optional and the silence and listen lengths are customizable.
Aurora.continuouslyListenAndTranscribe(callback);
}
}
```
### Interpret (Language Understanding)
The interpret service allows you to take any Aurora `Text` object and understand the user's intent and extract additional query information. Interpret can only be called on `Text` objects and return `Interpret` objects after completion. To convert a user's speech into and `Interpret` object, it must be converted to text first.
#### Basic example
```Java
package main;
import com.auroraapi.Aurora;
import com.auroraapi.models.*;
import java.io.IOException;
import java.util.Map;
public class TextToInterpret {
public static void main(String[] args) {
String appId = "<put your appId here>";
String appToken = "<put your appToken here>";
Aurora.init(appId, appToken);
try {
String str = "what is the weather in los angeles";
Text text = new Text(str);
Interpret interpret = Aurora.getInterpretation(text);
String interpretation = "Interpretation:\n";
interpretation += String.format("Intent: %s\n", interpret.getIntent());
Map<String, String> entities = interpret.getEntities();
for (String key : entities.keySet()) {
String value = entities.get(key);
interpretation += String.format("Entity key: %s, value: %s", key, value);
}
System.out.println(interpretation);
} catch (IOException e) {
e.printStackTrace();
} catch (AuroraException e) {
e.printStackTrace();
}
}
}
```
#### User query example
```Java
package main;
import com.auroraapi.Aurora;
import com.auroraapi.models.*;
import java.io.IOException;
import java.util.Map;
import java.util.Scanner;
public class UserQuery {
public static void main(String[] args) {
String appId = "<put your appId here>";
String appToken = "<put your appToken here>";
Aurora.init(appId, appToken);
while (true) {
try {
Scanner scanner = new Scanner(System.in);
// Assume string input
Text text = new Text(scanner.nextLine());
Interpret interpret = Aurora.getInterpretation(text);
String interpretation = "Interpretation:\n";
interpretation += String.format("Intent: %s\n", interpret.getIntent());
Map<String, String> entities = interpret.getEntities();
for (String key : entities.keySet()) {
String value = entities.get(key);
interpretation += String.format("Entity key: %s, value: %s", key, value);
}
System.out.println(interpretation);
} catch (IOException e) {
e.printStackTrace();
} catch (AuroraException e) {
e.printStackTrace();
}
}
}
}
```
#### Smart Lamp
This example shows how easy it is to voice-enable a smart lamp. It responds to queries in the form of "turn on the lights" or "turn off the lamp". You define what `object` you're listening for (so that you can ignore queries like "turn on the music").
```Java
package main;
import com.auroraapi.Aurora;
import com.auroraapi.callbacks.TranscriptCallback;
import com.auroraapi.models.*;
import java.io.IOException;
public class LampExample {
public static void main(String[] args) {
String appId = "<put your appId here>";
String appToken = "<put your appToken here>";
Aurora.init(appId, appToken);
TranscriptCallback callback = new TranscriptCallback() {
@Override
public boolean onTranscript(Transcript transcript) {
Text text = new Text(transcript.getTranscript());
String[] validWords = {"light", "lights", "lamp"};
try {
Interpret interpret = Aurora.getInterpretation(text);
String intent = interpret.getIntent();
String object = interpret.getEntities().get("object");
for (String word : validWords) {
if (object.equals(word)) {
if (intent.equals("turn_on")) {
// turn on the lamp
} else if (intent.equals("turn_off")) {
// turn off the lamp
}
break;
}
}
return true;
} catch (AuroraException | IOException e) {
e.printStackTrace();
return false;
}
}
@Override
public boolean onError(Throwable throwable) {
throwable.printStackTrace();
return false;
}
};
Audio.Params params = Audio.Params.getDefaultParams();
Aurora.continuouslyListenAndTranscribe(callback, params);
}
}
```
| 30.383234 | 428 | 0.620746 | eng_Latn | 0.577352 |
8b2a23ba4957737836197e412e7da27de3470b04 | 504 | md | Markdown | readme.md | NoxCraft/NoxCraft-Master-Repo | 5564f776435609fea82042a36530bfd8607d120b | [
"RSA-MD"
] | null | null | null | readme.md | NoxCraft/NoxCraft-Master-Repo | 5564f776435609fea82042a36530bfd8607d120b | [
"RSA-MD"
] | null | null | null | readme.md | NoxCraft/NoxCraft-Master-Repo | 5564f776435609fea82042a36530bfd8607d120b | [
"RSA-MD"
] | null | null | null | NoxCraft
====
This project is the master holder of all our project files.
It contains all our plugins and code.
For Changelogs of each plugin visit the src/main/resources folders in any plugin and view changelogs.txt
Some plugins may not have one yet due to no releases
Please read the [License](LICENSE.MD)
Credits
----
Christopher Krier ([AKA Coaster3000](https://github.com/coaster3000)) - Head Developer
Connor Stone ([AKA BBCSTO13](https://github.com/ConnorStone)) - Developer | 29.647059 | 105 | 0.744048 | eng_Latn | 0.944595 |
8b2a59e84c2506f15e379d53a53199eb8dc90b4f | 477 | md | Markdown | docs/adr/0001-config-file-decision.md | phodal/dilay | fbcec5c526d83591d25ddaf9c79e35aa0cda7afc | [
"MIT"
] | 26 | 2019-09-16T03:53:15.000Z | 2020-10-30T05:17:21.000Z | docs/adr/0001-config-file-decision.md | phodal/dilay | fbcec5c526d83591d25ddaf9c79e35aa0cda7afc | [
"MIT"
] | null | null | null | docs/adr/0001-config-file-decision.md | phodal/dilay | fbcec5c526d83591d25ddaf9c79e35aa0cda7afc | [
"MIT"
] | 5 | 2019-10-17T01:57:53.000Z | 2021-06-11T19:36:28.000Z | # 1. Config File Decision
Date: 2019-08-23
## Status
2019-08-23 proposed
## Context
As a Architecture Guard, we need to setup a rule for file place directory
## Decision
Example Config:
```
language: TypeScript
suffix: [ts, js, dart]
FileNamingStyle: camel | dash | underline
fileTree:
- src
- types: ['*.model.ts', '*.d.ts]
- components: '*.component.*'
- shared:
```
tree Rule:
- directory - fileName - fileClass
## Consequences
Consequences here...
| 13.628571 | 73 | 0.666667 | eng_Latn | 0.694279 |
8b2c67e10a787f2d84ea6e75a4e96d8e8d099a6d | 80 | md | Markdown | README.md | solymdev/swiftUIToDoList | 582f7ea6171a12c832c441f5aeece2dd1b839511 | [
"MIT"
] | null | null | null | README.md | solymdev/swiftUIToDoList | 582f7ea6171a12c832c441f5aeece2dd1b839511 | [
"MIT"
] | null | null | null | README.md | solymdev/swiftUIToDoList | 582f7ea6171a12c832c441f5aeece2dd1b839511 | [
"MIT"
] | null | null | null | # SwiftUI Todo List
SwiftUI Simple Todo List using ObservableObject and toggle.
| 26.666667 | 59 | 0.825 | eng_Latn | 0.675619 |
8b2cd61aeec13392ad025c5b43a8307078bbdcda | 2,217 | md | Markdown | docs/Neo4J/docs/cypher_lan.md | doitanyway/notes-everything | f62d28a67696f04c331a40c6ea8d67e1a0e0ebe2 | [
"MIT"
] | 18 | 2018-09-21T01:31:12.000Z | 2021-11-07T04:56:04.000Z | docs/Neo4J/docs/cypher_lan.md | doitanyway/notes-everything | f62d28a67696f04c331a40c6ea8d67e1a0e0ebe2 | [
"MIT"
] | null | null | null | docs/Neo4J/docs/cypher_lan.md | doitanyway/notes-everything | f62d28a67696f04c331a40c6ea8d67e1a0e0ebe2 | [
"MIT"
] | 7 | 2018-09-27T07:08:03.000Z | 2021-03-05T03:40:44.000Z | # cypher基础-cypher语句
## 简介
cypher语句主要包含如下类型;
* 读语句,MATCH,OPTIONAL MATCH,WHERE,START,Aggregation和LOAD CSV
* 写语句,CREATE,MERGE,SET,DELET,REMOVE,FOREACH,CREATE UNIQUE
* 通用语句,RETURN,ORDER BY,LIMIT,SKIP,WITH,UNWIND,UNION,CALL
> 因为内容多,本文只记录一些关键信息,更多信息请查看[官方文档](https://neo4j.com/docs/cypher-manual/4.2/clauses/)
## 详细介绍
### MATCH
模式检验数据库
* 基础查询
```bash
# 简单查询
MATCH (n)
RETURN n
# 查询带某类节点
MATCH (movie:Movie)
RETURN movie.title
# 查询相关的节点
MATCH (director {name: 'Oliver Stone'})--(movie)
RETURN movie.title
# 使用label和属性一起查找
MATCH (:Person {name: 'Oliver Stone'})--(movie:Movie)
RETURN movie.title
```
* 关系查询
```bash
# 找到有关系的2个节点
MATCH (:Person {name: 'Oliver Stone'})-->(movie)
RETURN movie.title
# 查看关系
MATCH (:Person {name: 'Oliver Stone'})-[r]->(movie)
RETURN type(r)
# 指明关系
MATCH (wallstreet:Movie {title: 'Wall Street'})<-[:ACTED_IN]-(actor)
RETURN actor.name
# 匹配多种关系的节点
MATCH (wallstreet {title: 'Wall Street'})<-[:ACTED_IN|:DIRECTED]-(person)
RETURN person.name
# 使用变量来匹配关系
MATCH (wallstreet {title: 'Wall Street'})<-[r:ACTED_IN]-(actor)
RETURN r.role
```
* 关系深度查询
```bash
# 在Person {name: 'Charlie Sheen'} 节点和Person {name: 'Rob Reiner'}节点上创建一个关系
MATCH
(charlie:Person {name: 'Charlie Sheen'}),
(rob:Person {name: 'Rob Reiner'})
CREATE (rob)-[:`TYPE INCLUDING A SPACE`]->(charlie)
MATCH (n {name: 'Rob Reiner'})-[r:`TYPE INCLUDING A SPACE`]->()
RETURN type(r)
```
* 多关系的查询
```bash
MATCH (charlie {name: 'Charlie Sheen'})-[:ACTED_IN]->(movie)<-[:DIRECTED]-(director)
RETURN movie.title, director.name
```
* 关系层级
```bash
MATCH (charlie {name: 'Charlie Sheen'})-[:ACTED_IN*1..3]-(movie:Movie)
RETURN movie.title
```
* 关系层级使用多种类型
```bash
MATCH (charlie {name: 'Charlie Sheen'})-[:ACTED_IN|DIRECTED*2]-(person:Person)
RETURN person.name
```
* 统计次数,采购人名称,供应商名称,以及该采购人和该供应商达成交易次数,只返回其中次数最大的三个,且降序排列返回
```bash
match
(p:Purchaser) --()<-[:WBID] - (s:Supplier) return p.name ,s.name,count(*) as times ORDER BY times DESC SKIP 0 LIMIT 3
```
### OPTIONAL MATCH
### WHERE
### START
### Aggregation
### LOAD CSV
### CREATE
### MERGE
### SET
### DELET
### REMOVE
### FOREACH
### CREATE UNIQUE
### RETURN
### ORDER BY
### LIMIT
### SKIP
### WITH
### UNWIND
### UNION
### CALL | 17.736 | 120 | 0.669373 | yue_Hant | 0.831482 |
8b2e5c4ce0702de7fecc1d7dce6e0dcdf7d86ecf | 31 | md | Markdown | README.md | Milad-Rashidi/invisible-men | 0d19f87d6e2dbcbd6738a9f9117d2c21a8cccd26 | [
"Unlicense"
] | null | null | null | README.md | Milad-Rashidi/invisible-men | 0d19f87d6e2dbcbd6738a9f9117d2c21a8cccd26 | [
"Unlicense"
] | null | null | null | README.md | Milad-Rashidi/invisible-men | 0d19f87d6e2dbcbd6738a9f9117d2c21a8cccd26 | [
"Unlicense"
] | null | null | null | # invisible-men
HTML & CSS
| 10.333333 | 15 | 0.709677 | spa_Latn | 0.217075 |
8b2e80e2b183d7516efab6f641765093d11dc3c4 | 10,355 | md | Markdown | drafts/bad_day.md | lmc2179/lmc2179.github.io | 45b835cebf43935206f313fdf0e1bdce7ad2716b | [
"MIT"
] | null | null | null | drafts/bad_day.md | lmc2179/lmc2179.github.io | 45b835cebf43935206f313fdf0e1bdce7ad2716b | [
"MIT"
] | 1 | 2020-11-01T05:35:06.000Z | 2020-11-01T05:35:06.000Z | drafts/bad_day.md | lmc2179/lmc2179.github.io | 45b835cebf43935206f313fdf0e1bdce7ad2716b | [
"MIT"
] | null | null | null | ---
layout: post
title: "What range of outcomes can I expect? What's the worst day I need to plan for? And other quantile-y questions"
author: "Louis Cialdella"
categories: posts
tags: [datascience]
image: quantile_friend.png
---
*Analytics teams are often confronted with a wide variety of metrics that change every day, week, and month. In order to stay on top of the business, we'd like to know what the "normal range" of a metric is, so we can understand when something unexpected is happening. Additionally, this will let you understand the upper and lower boundaries of your metric - it will help you understand what kinds of "worst cases" you might need to plan for. All of these are instances of quantile estimation - we'll introduce the statistics of quantile estimates and quantile regression.*
What will my "real bad day" look like? How much do I need to keep in reserve to stay safe in that case? Looking forward, what observations are unusually bad? What is the size of the bottom - top difference? How can I establish "normal bounds" so I can know when things are not normal?
# An example: What does a "normal day" of web traffic look like?
If you run a website, you've probably spent time thinking about how many people actually saw your website - that's the point of having one, after all. Let's imagine that you are the supernaturally gifted CEO of the greatest tech company in history, [Zombo.com](http://zombo.com/). You've collected the number of daily visitors over 100 days of traffic to your website, and you want to use it to do some planning.
[Picture of traffic]
Specifically, you want to know: On an "ordinary" day, what's the lowest or highest number of visitors I might expect? This sort of information is a valuable planning tool as you monitor your web traffic. For example, you might want to know the highest total amount of traffic you might get, so you can ensure you have enough bandwidth for all your visitors on your highest-traffic days. Or you might keep this range in mind as you look over each days traffic report, in order to see whether or not you had an abnormally high or low amount of traffic, indicating something has changed and you need to re-evaluate your strategy.
# Upper and lower bounds for the "ordinary" range - Quantiles
## The Population and Sample Quantiles
Let's take our main question, and be a little more specific with it. We want to know:
> On an "ordinary" day, what's the lowest or highest number of visitors I might expect?
One way we could translate this question into more quantitative language is to reframe it as:
> Can we define a range of values, so that almost all (say, 95%) of of daily observations will fall within this range?
Let's start by thinking about the **lower side** of the range, the lowest number of visitors we might expect on a day. We'd like to know a value such that 97.5% of future observations will be above it (we'll do the same on upper end, so overall 2.5 × 2=5% of observations will be outside this range). This value has a name - it is called the 0.025-quantile. More generally, the $q$-quantile is the value such that $q$% of observations are less than it. So, for example, the 0.5-quantile is the median, and the 0.25-quantile is the first quartile.
As usual, we want the population quantile, but we only have a sample to estimate from. We can compute the sample quantile using [the appropriate numpy method](https://numpy.org/devdocs/reference/generated/numpy.quantile.html). Plotting these on our chart from before, we see they look the way we expect:
[Plot of data with lower and upper sample quantiles marked]
That is, the sample 0.025- and 0.975-quantiles cover the central 95% of the data.
## A Simple CI for a quantile
Just now we did two inferences, computing the sample quantiles of our dataset. As good students of statistics we should try to understand how much uncertainty there is around these estimates - we want to compute a standard error or a confidence interval.
1. Sort the observations.
2. l =
3. u =
## Our model assumes every day has the same distribution, which is probably not true
So far, we've put together a method that tells us: What is the
Howver, the range may change depending on some covariates
For example spend
Unsurprisingly the quickest way to do this is with linear regression, though there are other methods too
# Including covariates - Quantile Regression
# Appendix: Imports and data generation
```python
import numpy as np
from matplotlib import pyplot as plt
import seaborn as sns
import datetime
import pandas as pd
dates = [datetime.datetime(year=2020, month=1, day=1) + datetime.timedelta(days=i) for i in range(365)]
spend = np.abs(np.random.normal(0, 1, len(dates)))
visitors = np.random.poisson(5 + 5*spend)
traffic_df = pd.DataFrame({'date': dates, 'spend': spend, 'visitors': visitors})
```
# Appendix: Comparison of Quantile CIs
------------------------------------------------------------------
# Estimating quantiles
https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.mstats.mquantiles.html
I. Quantiles of a sample
1. Jackknife and many flavors of Bootstrap
Noted as an example for the bootstrap in Shalizi's article
https://www.americanscientist.org/article/the-bootstrap
Which bootstrap works best? Is there a pretty way of writing the jackknife estimate
Bootstrap diagnostic - https://www.cs.cmu.edu/~atalwalk/boot_diag_kdd_final.pdf
```
from scipy.stats import norm, sem, skew, t, lognorm
import numpy as np
from matplotlib import pyplot as plt
import seaborn as sns
import pandas as pd
from tqdm import tqdm
from scipy.stats.mstats import mquantiles
TRUE_VALUE = lognorm(s=1).ppf(.01)
def gen_data(n):
return lognorm(s=1).rvs(n)
datasets = [gen_data(1000) for _ in range(1000)] # what happens to each of these methods as we vary the sample size
def percentile_bootstrap_estimate(x, alpha, n_sim=2000):
s = np.percentile(x, 1)
boot_samples = [np.percentile(np.random.choice(x, len(x)), 1) for _ in range(n_sim)]
q = 100* (alpha/2.)
return x, np.percentile(boot_samples, q),np.percentile(boot_samples, 100.-q)
percentile_bootstrap_simulation_results = pd.DataFrame([percentile_bootstrap_estimate(x, .05) for x in tqdm(datasets)], columns=['point', 'lower', 'upper'])
percentile_bootstrap_simulation_results['covered'] = (percentile_bootstrap_simulation_results['lower'] < TRUE_VALUE) & (percentile_bootstrap_simulation_results['upper'] > TRUE_VALUE)
print(percentile_bootstrap_simulation_results.covered.mean())
def standard_bootstrap_estimate(x, alpha, n_sim=2000):
s = np.percentile(x, 1)
k = len(x)
boot_samples = [np.percentile(np.random.choice(x, len(x)), 1) for _ in range(n_sim)]
se = np.std(boot_samples)
t_val = t(k-1).interval(1.-alpha)[1]
return s, s - t_val * se, s + t_val * se
standard_bootstrap_simulation_results = pd.DataFrame([standard_bootstrap_estimate(x, .05) for x in tqdm(datasets)], columns=['point', 'lower', 'upper'])
standard_bootstrap_simulation_results['covered'] = (standard_bootstrap_simulation_results['lower'] < TRUE_VALUE) & (standard_bootstrap_simulation_results['upper'] > TRUE_VALUE)
print(standard_bootstrap_simulation_results.covered.mean())
def bca_bootstrap_estimate(x, alpha, n_sim=2000):
k = len(x)
r = np.percentile(x, 1)
r_i = (np.sum(x) - x)/(k-1)
d_i = r_i - np.mean(r_i)
boot_samples = [np.percentile(np.random.choice(x, len(x)), 1) for _ in range(n_sim)]
p0 = np.sum(boot_samples < r) / n_sim
z0 = norm.ppf(p0)
a = (1./6) * (np.sum(d_i**3) / (np.sum(d_i**2))**(3./2.))
alpha_half = (alpha/2.)
p_low = norm.cdf(z0 + ((z0 + norm.ppf(alpha_half)) / (1. - a*(z0 + norm.ppf(alpha_half)))))
p_high = norm.cdf(z0 + ((z0 + norm.ppf(1.-alpha_half)) / (1. - a*(z0 + norm.ppf(1.-alpha_half)))))
return r, np.percentile(boot_samples, p_low*100.), np.percentile(boot_samples, p_high*100.)
bca_bootstrap_simulation_results = pd.DataFrame([bca_bootstrap_estimate(x, .05) for x in tqdm(datasets)], columns=['point', 'lower', 'upper'])
bca_bootstrap_simulation_results['covered'] = (bca_bootstrap_simulation_results['lower'] < TRUE_VALUE) & (bca_bootstrap_simulation_results['upper'] > TRUE_VALUE)
print(bca_bootstrap_simulation_results.covered.mean())
```
2. Exact methods ("Binomial idea")
https://staff.math.su.se/hoehle/blog/2016/10/23/quantileCI.html
https://stats.stackexchange.com/questions/99829/how-to-obtain-a-confidence-interval-for-a-percentile
```
from scipy.stats import norm, binom, pareto
import numpy as np
MU = 100
S = 1100
#gen_dist = norm(MU, S)
gen_dist = pareto(2)
n = 100
q = 0.95
alpha = .05
TRUE_QUANTILE = gen_dist.ppf(q)
l = int(binom(n, p=q).ppf(alpha/2))
u = int(binom(n, p=q).ppf(1.-alpha/2) ) # ???? Check against R's qbinom
n_sim = 10000
results = 0
lower_dist = []
upper_dist = []
for _ in range(n_sim):
data = sorted(gen_dist.rvs(n))
if data[l] <= TRUE_QUANTILE <= data[u]:
results += 1
lower_dist.append(data[l])
upper_dist.append(data[u])
lower_dist = np.array(lower_dist)
upper_dist = np.array(upper_dist)
print(results / n_sim)
```
3. Easy mode - Asymptotic estimate
Cookbook estimate: http://www.tqmp.org/RegularArticles/vol10-2/p107/p107.pdf
Looks like https://stats.stackexchange.com/a/99833/29694 where we assume the data is normally distributed
Eq 25
4. Methods from Wasserman's all of nonparametric statistics
https://web.stanford.edu/class/ee378a/books/book2.pdf
Use ebook p. 25 to estimate upper and lower bounds on the CDF, then invert them at `q`.
Example 2.17 -
3.7 Theorem
# For when you want to relate covariates to quantiles - Conditional quantiles
5. Quantile regression
https://www.statsmodels.org/dev/examples/notebooks/generated/quantile_regression.html - Linear models of quantiles by picking a different loss function
https://jmlr.org/papers/volume7/meinshausen06a/meinshausen06a.pdf - An ML approach
We can check these using cross-validation on the probability of being greater than q, which is cool
https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.GradientBoostingRegressor.html#sklearn.ensemble.GradientBoostingRegressor
Other approaches: Conditional variance - Section 5 - https://www.stat.cmu.edu/~cshalizi/mreg/15/lectures/24/lecture-24--25.pdf
III. This isn't magic
look out for small samples and edge cases
| 44.252137 | 626 | 0.749493 | eng_Latn | 0.966726 |
8b30144eb45c43806260e8c5ea3dfd2dd86cb8c3 | 18,411 | md | Markdown | security-updates/securityadvisories/2009/960715.md | MicrosoftDocs/security-updates.pl-pl | ad52b460685eaa36a358ff49046c8c8b4e67d2e9 | [
"CC-BY-4.0",
"MIT"
] | 1 | 2020-05-19T20:16:36.000Z | 2020-05-19T20:16:36.000Z | security-updates/securityadvisories/2009/960715.md | MicrosoftDocs/security-updates.pl-pl | ad52b460685eaa36a358ff49046c8c8b4e67d2e9 | [
"CC-BY-4.0",
"MIT"
] | 48 | 2018-01-19T14:59:44.000Z | 2018-11-23T23:17:20.000Z | security-updates/securityadvisories/2009/960715.md | MicrosoftDocs/security-updates.pl-pl | ad52b460685eaa36a358ff49046c8c8b4e67d2e9 | [
"CC-BY-4.0",
"MIT"
] | 2 | 2019-01-05T13:13:25.000Z | 2021-11-18T13:13:10.000Z | ---
TOCTitle: 960715
Title: Poradnik zabezpieczeń firmy Microsoft 960715
ms:assetid: 960715
ms:contentKeyID: 61232263
ms:mtpsurl: 'https://technet.microsoft.com/pl-PL/library/960715(v=Security.10)'
---
Poradnik zabezpieczeń firmy Microsoft 960715
============================================
Pakiet zbiorczy aktualizacji bitów „zabicia” dla formantów ActiveX
------------------------------------------------------------------
Opublikowano: 10 lutego 2009 | Zaktualizowano: 17 czerwca 2009
**Wersja:** 1.2
Firma Microsoft udostępnia w niniejszym poradniku nowy zestaw bitów „zabicia” dla formantów ActiveX.
Aktualizacja zawiera bity „zabicia” dla publikowanych wcześniej biuletynów zabezpieczeń firmy Microsoft:
- [MS08-070](http://go.microsoft.com/fwlink/?linkid=130478), Luki w zabezpieczeniach plików Visual Basic 6.0 Runtime Extended Files (formantów ActiveX) umożliwiają zdalne wykonanie kodu (932349)
Aktualizacja zawiera także bity „zabicia” dla następującego oprogramowania innych firm:
- **Download Manager firmy Akamai**. Niniejsza aktualizacja zabezpieczeń ustawia [bit „zabicia”](http://support.microsoft.com/kb/240797) dla formantu ActiveX opracowanego przez firmę Akamai Technologies. Firma Akamai Technologies opublikowała aktualizację zabezpieczeń, która usuwa lukę w zabezpieczeniach zagrożonego składnika. Aby uzyskać więcej informacji na ten temat oraz adresy lokalizacji z plikami do pobrania, zobacz publikację zabezpieczeń firmy Akamai Technologies. Bit „zabicia” jest ustawiany na żądanie właściciela formantów ActiveX. Identyfikatory klas (CLSID) dla tego formantu ActiveX zostały wymienione w sekcji **Często zadawane pytania** w niniejszym poradniku.
- **AxLoader firmy Research in Motion (RIM)**. Niniejsza aktualizacja zabezpieczeń ustawia [bit „zabicia”](http://support.microsoft.com/kb/240797) dla formantu ActiveX opracowanego przez firmę Research In Motion (RIM). Firma RIM opublikowała aktualizację zabezpieczeń, która usuwa lukę w zabezpieczeniach zagrożonego składnika. Aby uzyskać więcej informacji na ten temat oraz adresy lokalizacji z plikami do pobrania, zobacz publikację zabezpieczeń firmy Research in Motion. Bit „zabicia” jest ustawiany na żądanie właściciela formantów ActiveX. Identyfikatory klas (CLSID) dla tego formantu ActiveX zostały wymienione w sekcji **Często zadawane pytania** w niniejszym poradniku.
Więcej informacji na temat instalacji tej aktualizacji można znaleźć w [artykule 960715 bazy wiedzy Microsoft Knowledge Base](http://support.microsoft.com/kb/960715).
### Informacje ogólne
Przegląd
--------
**Cel poradnika:** Powiadomienie o dostępności bitów „zabicia” dla formantów ActiveX.
**Status poradnika:** Opublikowano artykuł w bazie wiedzy Microsoft Knowledge Base oraz odpowiednią aktualizację.
**Zalecenie:** Przeczytać wymieniony artykuł bazy wiedzy Knowledge Base i zainstalować odpowiedni pakiet aktualizacyjny.
| Materiały pomocnicze | Identyfikacja |
|-----------------------------------------------------|--------------------------------------------------|
| **Artykuł w bazie wiedzy Microsoft Knowledge Base** | [960715](http://support.microsoft.com/kb/960715) |
Niniejszy poradnik dotyczy następującego oprogramowania.
| |
|---------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Programy, których dotyczy poradnik |
| Microsoft Windows 2000 z dodatkiem Service Pack 4 |
| Windows XP z dodatkiem Service Pack 2 i dodatkiem Service Pack 3 |
| Windows XP Professional x64 Edition oraz Microsoft Windows XP Professional x64 Edition z dodatkiem Service Pack 2 |
| Windows Server 2003 z dodatkiem Service Pack 1 i Windows Server 2003 z dodatkiem Service Pack 2 |
| Windows Server 2003 x64 Edition i Windows Server 2003 x64 Edition z dodatkiem Service Pack 2 |
| Systemy operacyjne Windows Server 2003 z dodatkiem SP1 dla systemów z procesorem Itanium oraz Windows Server 2003 z dodatkiem SP2 dla systemów z procesorem Itanium |
| Windows Vista i Windows Vista z dodatkiem Service Pack 1 |
| Windows Vista x64 Edition i Windows Vista x64 Edition z dodatkiem Service Pack 1 |
| Windows Server 2008 dla systemów 32-bitowych |
| Windows Server 2008 dla systemów opartych na procesorach X64 |
| Windows Server 2008 dla systemów z procesorem Itanium |
Często zadawane pytania
-----------------------
**Czy użytkownicy posiadający instalację Server Core systemu Windows Server 2008 muszą zainstalować tę aktualizację?**
Użytkownicy posiadający instalację Server Core systemu Windows Server 2008 nie muszą instalować tej aktualizacji. Aby uzyskać więcej informacji na temat opcji instalacji Server Core, zobacz [Server Core](http://msdn.microsoft.com/en-us/library/ms723891(vs.85).aspx). Należy pamiętać, że opcja instalacji Server Core nie dotyczy niektórych wersji systemu Windows Server 2008; zobacz [Porównanie opcji instalacji Server Core](http://www.microsoft.com/windowsserver2008/en/us/compare-core-installation.aspx).
**Dlaczego z tym poradnikiem nie jest powiązany wskaźnik bezpieczeństwa?**
Ta aktualizacja zawiera bity „zabicia” dla formantów innych firm, które nie należą do firmy Microsoft. Firma Microsoft nie określa wskaźnika bezpieczeństwa dla zagrożonych formantów innych firm.
**Czy niniejsza aktualizacja zastępuje zbiorczą aktualizację zabezpieczeń bitów „zabicia” dla formantów ActiveX (950760)?**
Nie, dla celów aktualizowania automatycznego niniejsza aktualizacja nie zastępuje zbiorczej aktualizacji zabezpieczeń bitów „zabicia” dla formantów ActiveX (950760), którą opisano w biuletynie zabezpieczeń firmy Microsoft [MS08-032](http://go.microsoft.com/fwlink/?linkid=116368). Funkcje aktualizowania automatycznego będą nadal oferować aktualizację MS08-032 klientom bez względu na to, czy zainstalowali oni niniejszą aktualizację (960715). Klienci, którzy zainstalowali niniejszą aktualizację (960715), nie muszą jednak instalować aktualizacji MS08-032, aby zapewnić sobie ochronę przy użyciu wszystkich bitów „zabicia” ustawionych w aktualizacji MS08-032.
**Dlaczego firma Microsoft udostępnia ten pakiet zbiorczy aktualizacji bitów „zabicia” dla formantów ActiveX w ramach poradnika zabezpieczeń, skoro wcześniejsze aktualizacje bitów „zabicia” były udostępniane w biuletynie zabezpieczeń?**
Firma Microsoft udostępnia ten Pakiet zbiorczy aktualizacji bitów „zabicia” dla formantów ActiveX w ramach poradnika zabezpieczeń, ponieważ nowe bity „zabicia” nie wpływają na oprogramowanie firmy Microsoft lub zostały wcześniej ustawione przez biuletyn zabezpieczeń firmy Microsoft.
**Czy ta aktualizacja zawiera bity „zabicia”, które zostały wcześniej udostępnione w pakiecie zbiorczym aktualizacji bitów „zabicia” dla formantów ActiveX?**
Tak, ta aktualizacja zawiera także bity „zabicia”, które zostały wcześniej ustawione w ramach [poradnika zabezpieczeń firmy Microsoft 956391](http://technet.microsoft.com/security/advisory/956391).
**Czy aktualizacja ta zawiera bity „zabicia” opublikowane wcześniej w aktualizacji zabezpieczeń programu Internet Explorer?**
Nie, aktualizacja ta nie zawiera bitów „zabicia” opublikowanych wcześniej w aktualizacji zabezpieczeń programu Internet Explorer. Zalecamy instalację najnowszej zbiorczej aktualizacji zabezpieczeń dla programu Internet Explorer.
**Co to jest bit „zabicia”?**
Funkcja zabezpieczeń w programie Microsoft Internet Explorer umożliwia zapobieżenie załadowaniu formantu ActiveX przez aparat renderowania kodu HTML. Polega to na dokonaniu ustawienia w rejestrze, które określa się mianem ustawienia bitu „zabicia”. Po ustawieniu bitu „zabicia” formantu nie można załadować, nawet jeśli jest on w pełni zainstalowany. Ustawienie bitu „zabicia” gwarantuje, że nawet w przypadku wprowadzenia lub ponownego wprowadzenia do systemu składnika zagrożonego luką pozostaje on nieaktywny i niegroźny.
Więcej informacji na ten temat można znaleźć w [artykule 240797 bazy wiedzy Microsoft Knowledge Base](http://support.microsoft.com/kb/240797). Zakończenie uruchamiania formantu ActiveX w programie Internet Explorer.
**Co to jest aktualizacja zabezpieczeń bitów „zabicia” dla formantów ActiveX?**
Niniejsza aktualizacja zabezpieczeń zawiera identyfikatory klasy tylko tych formantów ActiveX, których dotyczy.
**Dlaczego ta aktualizacja nie zawiera żadnych plików binarnych?**
Aktualizacja polega tylko na wprowadzeniu do rejestru zmiany wyłączającej uruchamianie formantu w programie Internet Explorer.
**Czy należy zainstalować tę aktualizację, jeśli w systemie nie jest zainstalowany zagrożony luką składnik lub nie jest używana zagrożona platforma?**
Tak. Zainstalowanie tej aktualizacji zapobiega uruchamianiu zagrożonego luką formantu w programie Internet Explorer.
**Czy należy zainstalować ponownie tę aktualizację, jeśli omawiany w tej aktualizacji zabezpieczeń formant ActiveX zostanie zainstalowany w późniejszym czasie?**
Nie, ponowna instalacja tej aktualizacji nie jest wymagana. Bit „zabicia” uniemożliwi uruchamianie tego formantu w programie Internet Explorer, nawet jeśli zostanie on zainstalowany w późniejszym czasie.
**W jaki sposób działa aktualizacja?**
Ta aktualizacja ustawia bit „zabicia” dla listy identyfikatorów klasy (CLSID).
Następujący identyfikator klasy odnosi się do żądania firmy [Akamai](http://www.akamai.com/) dotyczącego ustawienia bitu „zabicia” dla identyfikatora klasy, który jest zagrożony przez lukę w zabezpieczeniach. Więcej informacji znajduje się w [publikacji zabezpieczeń](http://go.microsoft.com/fwlink/?linkid=139453) wydanej przez firmę Akamai:
| |
|----------------------------------------|
| Identyfikator klasy |
| {FFBB3F3B-0A5A-4106-BE53-DFE1E2340CB1} |
Następujący identyfikator klasy odnosi się do żądania firmy [Research In Motion (RIM)](http://www.rim.com/) dotyczącego ustawienia bitu „zabicia” dla identyfikatora klasy, który jest zagrożony przez lukę w zabezpieczeniach. Więcej informacji znajduje się w [publikacji zabezpieczeń](http://go.microsoft.com/fwlink/?linkid=139451) wydanej przez firmę (RIM):
| |
|----------------------------------------|
| Identyfikator klasy |
| {4788DE08-3552-49EA-AC8C-233DA52523B9} |
Następujące identyfikatory klas odnoszą się do formatu CAPICOM, którego dotyczył biuletyn zabezpieczeń firmy Microsoft [MS08-070](http://go.microsoft.com/fwlink/?linkid=130478), MS08-070, „Luki w zabezpieczeniach plików Visual Basic 6.0 Runtime Extended Files (formantów ActiveX) umożliwiają zdalne wykonanie kodu (932349)”:
| |
|----------------------------------------|
| Identyfikator klasy |
| {1E216240-1B7D-11CF-9D53-00AA003C9CB6} |
| {3A2B370C-BA0A-11d1-B137-0000F8753F5D} |
| {B09DE715-87C1-11d1-8BE3-0000F8754DA1} |
| {cde57a43-8b86-11d0-b3c6-00a0c90aea82} |
| {6262d3a0-531b-11cf-91f6-c2863c385e30} |
| {0ECD9B64-23AA-11d0-B351-00A0C9055D8E} |
| {C932BA85-4374-101B-A56C-00AA003668DC} |
| {248dd896-bb45-11cf-9abc-0080c7e7b78d} |
Zalecane czynności
------------------
**Zapoznanie się z artykułem bazy wiedzy Microsoft Knowledge Base związanym z niniejszym poradnikiem.**
Firma Microsoft zachęca użytkowników do zainstalowania tej aktualizacji. Dodatkowe informacje o tej aktualizacji można znaleźć w [artykule 960715 bazy wiedzy Microsoft Knowledge Base.](http://support.microsoft.com/kb/960715)
#### Obejścia
Obejście oznacza wprowadzenie zmiany ustawienia lub konfiguracji, która nie powoduje wyeliminowania samej luki, lecz może pomóc w zablokowaniu znanych kierunków ataku przed zastosowaniem aktualizacji Firma Microsoft przetestowała następujące obejścia i przedstawią swoją opinię w kwestii ograniczania przez nie funkcjonalności:
- **Uniemożliwienie uruchamiania obiektów COM w programie Internet Explorer**
Uruchamianie obiektu COM w programie Internet Explorer można wyłączyć, ustawiając dla danego formantu bit „zabicia” w rejestrze.
**Ostrzeżenie** Nieprawidłowe korzystanie z Edytora rejestru może spowodować poważne problemy wymagające ponownego zainstalowania systemu operacyjnego. Firma Microsoft nie gwarantuje możliwości rozwiązania problemów, wynikających z nieprawidłowego użycia edytora rejestru. Zmian w rejestrze można dokonywać wyłącznie na własne ryzyko.
Szczegółowy opis działań, które można przeprowadzić, aby uniemożliwić uruchamianie formantu w programie Internet Explorer można znaleźć w [artykule 240797 bazy wiedzy Microsoft Knowledge Base](http://support.microsoft.com/kb/240797). Wykonaj te czynności, aby utworzyć w rejestrze wartość znaczników kompatybilności i uniemożliwić uruchamianie obiektów COM w programie Internet Explorer.
**Uwaga** Identyfikatory klasy i odpowiadające im pliki z obiektami ActiveX zostały udokumentowane we wpisie „W jaki sposób działa aktualizacja?” w sekcji „Często zadawane pytania” powyżej. Poniższe ciągi {XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX} należy zastąpić identyfikatorami klasy, które znajdują się w tej sekcji.
Aby ustawić bit „zabicia” dla formantu o identyfikatorze CLSID {XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX}, w edytorze tekstu, takim jak Notatnik, wklej tekst przedstawiony poniżej. Następnie zapisz plik z rozszerzeniem .reg.
Edytor rejestru systemu Windows 5.00
\[HKEY\_LOCAL\_MACHINE\\SOFTWARE\\Microsoft\\Internet Explorer\\ActiveX Compatibility\\{ XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX }\]
"Compatibility Flags"=dword:00000400
Taki plik .reg można zastosować w pojedynczych systemach, klikając go dwukrotnie. Wykorzystując Zasady grupy, można go również zastosować na poziomie całej domeny. Więcej informacji na temat zasad grupy można znaleźć w następujących witrynach sieci Web firmy Microsoft:
- [Zbiór zasad grupy](http://technet2.microsoft.com/windowsserver/en/library/6d7cb788-b31d-4d17-9f1e-b5ddaa6deecd1033.mspx?mfr=true)
- [Co to jest Edytor obiektu Zasady grupy?](http://technet2.microsoft.com/windowsserver/en/library/47ba1311-6cca-414f-98c9-2d7f99fca8a31033.mspx?mfr=true)
- [Podstawowe narzędzia i ustawienia Zasad grupy](http://technet2.microsoft.com/windowsserver/en/library/e926577a-5619-4912-b5d9-e73d4bdc94911033.mspx?mfr=true)
**Uwaga** Aby zmiany zostały uwzględnione, należy ponownie uruchomić program Internet Explorer.
**Wpływ obejścia**: Brak wpływu, o ile obiekt nie będzie wykorzystywany w programie Internet Explorer.
### Other Information
**Zasoby:**
- Aby przekazać własne uwagi, należy wypełnić formularz na stronie [Pomoc i obsługa techniczna firmy Microsoft: Kontakt](https://support.microsoft.com/common/survey.aspx?scid=sw;en;1257&showpage=1&ws=technet&sd=tech).
- Klienci mogą uzyskać pomoc techniczną w [Biurze Obsługi Klienta Microsoft](http://go.microsoft.com/fwlink/?linkid=21131) pod numerem 0 801 802 000 (Opłata według stawek Twojego operatora) lub (0-22) 594 19 99 w godzinach od 9:00 do 17:00, od poniedziałku do piątku. Dodatkowe informacje dotyczące możliwości skorzystania z pomocy technicznej można znaleźć w witrynie [Pomoc i obsługa techniczna firmy Microsoft](http://support.microsoft.com/?ln=pl).
- Klienci międzynarodowi mogą uzyskać pomoc w lokalnych przedstawicielstwach firmy Microsoft. Więcej informacji o sposobie kontaktowania się z międzynarodową pomocą techniczną firmy Microsoft znajduje się w witrynie [Obsługa międzynarodowa](http://go.microsoft.com/fwlink/?linkid=21155).
- Witryna [Microsoft TechNet Security](http://go.microsoft.com/fwlink/?linkid=21132) zawiera dodatkowe informacje na temat zabezpieczeń w produktach firmy Microsoft.
**Zrzeczenie odpowiedzialności:**
Informacje zawarte w tym poradniku są dostarczane „tak jak są”, bez jakiejkolwiek gwarancji. Firma Microsoft odrzuca wszelkie gwarancje, wyraźne i dorozumiane, w tym gwarancje dotyczące wartości handlowej i przydatności do określonego celu. Firma Microsoft Corporation ani jej dostawcy w żadnym wypadku nie ponoszą odpowiedzialności za jakiekolwiek szkody, w tym bezpośrednie, pośrednie, przypadkowe, wynikowe, utratę zysków handlowych lub szkody specjalne, nawet jeżeli firmę Microsoft Corporation lub jej dostawców powiadomiono o możliwości zaistnienia takich szkód. W niektórych stanach wyłączenie lub ograniczenie odpowiedzialności za straty wynikowe lub przypadkowe, a więc i powyższe ograniczenia, nie mają zastosowania.
**Wersje:**
- Wersja 1.0 (10 lutego 2009 r.): Data publikacji poradnika
- Wersja 1.1 (29 kwietnia 2009 r.): Do sekcji „**Często zadawane pytania**” dodano wpis informujący, że użytkownicy instalacji Server Core systemu Windows Server 2008 nie muszą instalować tej aktualizacji.
- Wersja 1.2 (17 czerwca 2009 r.): Dodano wpis do sekcji **Często zadawane pytania** w celu poinformowania, że dla celów aktualizowania automatycznego niniejsza aktualizacja nie zastępuje zbiorczej aktualizacji zabezpieczeń bitów „zabicia” dla formantów ActiveX (950760), którą opisano w biuletynie zabezpieczeń firmy Microsoft MS08-032.
*Built at 2014-04-18T01:50:00Z-07:00*
| 96.9 | 726 | 0.723263 | pol_Latn | 0.999908 |
8b310e24e0a4056691b26feb86366635be494dd9 | 3,027 | md | Markdown | src/pages/articles/2019-10-20-on-taxing-the-rich.md | joeljackson/whereisjoel | 97e471aec5b4d80fbffdc196d834b8c61f50d760 | [
"MIT"
] | null | null | null | src/pages/articles/2019-10-20-on-taxing-the-rich.md | joeljackson/whereisjoel | 97e471aec5b4d80fbffdc196d834b8c61f50d760 | [
"MIT"
] | null | null | null | src/pages/articles/2019-10-20-on-taxing-the-rich.md | joeljackson/whereisjoel | 97e471aec5b4d80fbffdc196d834b8c61f50d760 | [
"MIT"
] | null | null | null | ---
title: On Taxing The Rich
date: '2019-10-20T00:00:00.000Z'
layout: post
draft: false
path: '/posts/on-taxing-the-rich/'
category: Post Scarcity Economics
tags:
- 'Post Scarcity'
- ''
description: 'Can we fund our social programs by taxing the rich?'
---
The last few weeks have been very interesting. The Canadian election is underway and the American democratic primaries are underway. The idea of universal basic income has been thrown around by Andrew Yang and Single Payer Healthcare is on the tip of every democrat's tongue. (Disclaimer: I'm very pro universal healthcare and making sure every person has enough to live a fulfilled life.)
Every time this comes up a dialogue that sounds kind of like this ensues.
_Person 1_: "That all sounds great, but how are you going to pay for it?"\
_Person 2_: "Well, that's easy, we'll tax rich people. Did you know Jeff Bezos has a net worth of over 100 billion dollars?"
Maybe that works, I don't know. What am I, an economist? But here's a concern.
The thing about the "ultra-rich" is that most of their money doesn't ever make it's way into the economy. Jeff Bezos may be worth 120 billion, but in terms of purchasing behavior it's doubtful Jeff Bezos ever spends more than a million dollars or so in a year. So that means maybe 119.9 billion dollars of his net worth is effectively not part of the economy. It's not being spent on iPhones, it's not getting spent on kumquats, it's not getting spent on cars, rent or lunches. Say we somehow managed to tax that wealth and put that money back into the economy, there wouldn't be more kumquats, iPhones, cars or rental units. Presumably everyone in America is already doing something that created economic value, and they're not just going to be able to do more because more dollars are floating around.
So, somehow taxing half of Jeff Bezos' net worth and then re-injecting it into the economy would be a net cash injection into the economy. Is that any different than just making money?
So what are we to do? In America we live in the richest country at the richest point in human history. Step 1 is agreeing that everyone deserves to not live in fear of losing their job and being out on the street. People seem to paint this as a rejection of free market capitalism. But I think it should be clear that communism and a social safety net are not actually the same thing. If the american government decided to print enough money to give the poorest 5% of the population in the United States $1,000 per month that would work out to $192 billion dollars per year. There is over 10 trillion dollars in cash and money in the United States (M2 monetary supply), so the total monetary supply would be boosted by about 2% per year. These people aren't buying luxury goods most of this would go towards basics, and be re-injected into the economy. It would be a very minor tax that no one would actually notice since it doesn't come out of their bank accounts.
I should reiterate, I'm not an economist. Just my 3 cents.
| 100.9 | 965 | 0.778659 | eng_Latn | 0.999713 |
8b336d60feb83929a72a14dd60c48f6ea592349c | 3,468 | md | Markdown | site/content/blog/2015-09-03-vintage-railroad-speeders-to-return-to-oregons-south-coast-september-12th-26th.md | echopdx/coosbay | 3af551fa62805a9500d48a51d72fa061d4f8c4d0 | [
"MIT"
] | 1 | 2020-07-28T21:27:23.000Z | 2020-07-28T21:27:23.000Z | site/content/blog/2015-09-03-vintage-railroad-speeders-to-return-to-oregons-south-coast-september-12th-26th.md | echopdx/coosbay | 3af551fa62805a9500d48a51d72fa061d4f8c4d0 | [
"MIT"
] | 1 | 2021-05-07T22:54:34.000Z | 2021-05-07T22:54:34.000Z | site/content/blog/2015-09-03-vintage-railroad-speeders-to-return-to-oregons-south-coast-september-12th-26th.md | echopdx/coosbay | 3af551fa62805a9500d48a51d72fa061d4f8c4d0 | [
"MIT"
] | 4 | 2019-01-09T15:52:15.000Z | 2019-05-01T19:00:24.000Z | ---
title: >-
Vintage Railroad ‘Speeders’ to Return to Oregon's South Coast September 12th &
26th
date: 2015-09-03T22:01:52.000Z
description: >-
Fans of the tricked-out vintage railroad maintenance cars known as “speeders”
should be on the lookout for their return to South Coast communities on
Saturday, Sept. 12 and again on Saturday, Sept.26. Weekend trips by members of
the Pacific Railcar Operators will include stops at Sturdivant Park in
Coquille and at the Oregon Coast Historical Railway museum and display area in
Coos Bay, where fans can get a closer look and talk to crew members.
tags:
- Oregon Coast Historical Railway Museum
- Pacific Railcar Operators
- Pacific Railroad Operators
- Railroad
- Railroad museum
- speeders
- vintage rail cars
categories:
- Culture & Museums
image: ''
---
###### Press release generated by the Oregon Coast Historical Railway in Coos Bay
Fans of the tricked-out vintage railroad maintenance cars known as “speeders” should be on the lookout for their return to South Coast communities on Saturday, Sept. 12 and again on Saturday, Sept.26. Weekend trips by members of the Pacific Railcar Operators will include stops at Sturdivant Park in Coquille and at the Oregon Coast Historical Railway museum and display area in Coos Bay, where fans can get a closer look and talk to crew members.
The railroad museum will be open for extended hours during both visits, and offer cookies and refreshments.
Also known as putt-putts, motor cars, and jiggers, the little maintenance vehicles were a fixture on railroads worldwide, eventually to be replaced by trucks that could run on both rails and pavement.
<img class="aligncenter size-large wp-image-67442" src="/wp-content/uploads/2015/09/IMG_0126-e1441317438302-674x506.jpg" alt="IMG_0126" width="674" height="506" srcset="/wp-content/uploads/2015/09/IMG_0126-e1441317438302-674x506.jpg 674w, /wp-content/uploads/2015/09/IMG_0126-e1441317438302-177x133.jpg 177w" sizes="(max-width: 674px) 100vw, 674px" />
The vintage vehicles are meticulously restored by fans and often feature careful reproductions of paint schemes and logos, as well as the proverbial “all the bells and whistles.” On many runs, one of the speeders pulls a communal portable toilet, while another – staffed by a trained medical crew member – has emergency-vehicle markings.
According to Bill Andrews of the Pacific Railroad Operators, both trips will begin in Vaughn, near Veneta, on Friday, Sept. 12 and Friday, Sept. 26 respectively, and head to an overnight stop at Coos Bay’s Red Lion Inn. The groups will proceed to Coquille at about 9 a.m. the next morning, with a lunch break at Sturdivant Park at about noon. The public is welcome to view the speeders and visit with their crews.
The group will return to Coos Bay, stopping at the OCHR museum at about 2:30 p.m. This is another opportunity to look over the vehicles and visit with their crews. The group will conclude the day’s journey adjacent to the Red Lion Inn in Coos Bay. They’ll depart the next day at about 8 a.m., with a return to Vaughn at approximately 6 p.m.
See website and contact information at www.pro-online.org, or check out the site of the North American Railcar Operators Association at www.narcoa.org. For direct information contact Bill Andrews at 541-472-5153.
This press release has been generated by the Oregon Coast Historical Railway in Coos Bay. Contact Dick Jamsgard (541)297-6130.
| 78.818182 | 447 | 0.784602 | eng_Latn | 0.997894 |
8b33e937c4da3e65e43b4be8f389f79b085c2e9d | 604 | md | Markdown | README.md | thiagomva/Bitcoin4Photos | dfc4674120ee3d05273e406c470b2dd3a206d105 | [
"MIT"
] | 2 | 2019-07-02T16:16:25.000Z | 2019-12-03T01:13:35.000Z | README.md | thiagomva/Bitcoin4Photos | dfc4674120ee3d05273e406c470b2dd3a206d105 | [
"MIT"
] | 8 | 2019-11-26T15:37:34.000Z | 2022-02-18T04:00:13.000Z | README.md | thiagomva/Bitcoin4Photos | dfc4674120ee3d05273e406c470b2dd3a206d105 | [
"MIT"
] | 2 | 2019-07-03T00:36:54.000Z | 2020-06-24T06:18:32.000Z | # Bitcoin4Photos
Bitcoin Lightning Network marketplace to buy and sell stock photos and illustrations
## Inspiration
Currently, I find stock sites charge 25%-60% commission on the sale of each photo. In other words, if you sell a photograph on a stock site for a dollar, your reward is 50 cents
## What it does
Bitcoin Lightning Network marketplace to buy and sell stock photos and illustrations
## How I built it
React + Blockstack
## What's next for Bitcoin4Photos
- Payment integration
- Automated withdrawal
- Social Sharing buttons
## Check it out
https://bitcoin4photos.net
| 30.2 | 178 | 0.759934 | eng_Latn | 0.984635 |
8b3443a9883ed3fa27fa47fed3eabe0fd8385c1d | 1,426 | md | Markdown | 2020/10/27/2020-10-27 22:10.md | zhzhzhy/WeiBoHot_history | 32ce4800e63f26384abb17d43e308452c537c902 | [
"MIT"
] | 3 | 2020-07-14T14:54:15.000Z | 2020-08-21T06:48:24.000Z | 2020/10/27/2020-10-27 22:10.md | zhzhzhy/WeiBoHot_history | 32ce4800e63f26384abb17d43e308452c537c902 | [
"MIT"
] | null | null | null | 2020/10/27/2020-10-27 22:10.md | zhzhzhy/WeiBoHot_history | 32ce4800e63f26384abb17d43e308452c537c902 | [
"MIT"
] | null | null | null | 2020年10月27日22时数据
Status: 200
1.吴京早期微博太好笑了
微博热度:2581863
2.蓬佩奥因涉嫌违反联邦法律被调查
微博热度:2248119
3.京东11.11直播超级夜
微博热度:2150533
4.江君怀孕
微博热度:2060452
5.林彦俊道歉
微博热度:1846874
6.谢楠 女性独立的不是钱是心
微博热度:1289992
7.斗罗大陆预告好燃
微博热度:987946
8.火神山雷神山医院今昔航拍对比
微博热度:874796
9.小学生上丰收课挖红薯500斤
微博热度:856154
10.欢乐颂将拍三四五季
微博热度:853377
11.应采儿二胎剖腹产过程
微博热度:796609
12.心动的信号
微博热度:699325
13.有翡少年逐浪预告片
微博热度:596428
14.女孩穿露背装在有轨电车拍照遭斥责
微博热度:553394
15.半是蜜糖半是伤大结局
微博热度:519348
16.斛珠夫人预告片质感
微博热度:488989
17.女孩考第一奖励太丰盛惊出表情包
微博热度:488747
18.花1288元报班学跳绳
微博热度:488177
19.全聚德三个季度亏掉三年利润
微博热度:487790
20.张子凡丁钰琼结婚
微博热度:487191
21.肖战原声台词
微博热度:486806
22.有翡配音
微博热度:486182
23.我国每年乳腺癌新发病例约30万
微博热度:485582
24.深秋的奶汁炖菜
微博热度:485118
25.我凭本事单身
微博热度:484208
26.蔡徐坤张钧甯8年后同框
微博热度:483876
27.公交车上拍写真有错吗
微博热度:483272
28.赵睿被驱逐
微博热度:482590
29.外交部回应美再批对台24亿美元军售
微博热度:482116
30.黑人男子当众抱走卢浮宫展品
微博热度:481919
31.李佳琦直播
微博热度:474701
32.邓超创造营2021发起人
微博热度:460558
33.美绝人寰的皇后造型
微博热度:372168
34.新加坡暂停使用两款流感疫苗
微博热度:359375
35.陶虹穿着礼服打麻将
微博热度:358306
36.使徒行者3
微博热度:352804
37.宝宝的演技可以有多好
微博热度:346864
38.戚薇薇娅搞怪连拍
微博热度:313506
39.上海地铁车厢12月起禁手机外放
微博热度:306774
40.明星细节见人品的动作
微博热度:272015
41.鞠婧祎工作室声明
微博热度:264048
42.本人的日常生活主题曲
微博热度:263671
43.曹赟定冲裁判爆粗口
微博热度:262544
44.申花战胜当代
微博热度:262014
45.喀什新增5例确诊病例
微博热度:261167
46.抗美援朝老兵回忆当年吃树皮
微博热度:260029
47.北京新发地疫情病毒来自冷链进口食品
微博热度:259784
48.罗云熙发博告别袁帅
微博热度:259180
49.世界恋爱日
微博热度:255427
50.警方悬赏通缉3名在逃人员
微博热度:254768
| 6.990196 | 20 | 0.784712 | yue_Hant | 0.362308 |
8b3459b6639c03b5d3ab4b0fc74ef68d5d363fe7 | 1,133 | md | Markdown | README.md | nsoeltan/Project3_User_Authentication | 90ad1f10a2ff32e9b22b0c2e1bca3a525608b9ea | [
"MIT"
] | null | null | null | README.md | nsoeltan/Project3_User_Authentication | 90ad1f10a2ff32e9b22b0c2e1bca3a525608b9ea | [
"MIT"
] | null | null | null | README.md | nsoeltan/Project3_User_Authentication | 90ad1f10a2ff32e9b22b0c2e1bca3a525608b9ea | [
"MIT"
] | null | null | null | # Project3_User_Authentication
This application is a prerequisite application for the Incomplete "Meeting_Minutes_Project3" CinaFlix Meeting Minutes app (Heroku: https://dry-spire-11344.herokuapp.com/).
This notes application can be used to record, review and delete meeting minutes in one place for future releases of the existing CinaFlix Project 2 Application (Heroku: https://enigmatic-basin-95816.herokuapp.com/).
This meeting minutes application allows users to collaboratively capture meeting minutes in one place. Users will have the ability to do the following:
1. Login to the application with the credentials provided by the Admin User
2. Access the Meeting Minutes page for the specified release
3. Logout from the application.
The following technologies, frameworks and libraries are used:
1. Express.js
2. Node.js
3. React
4. Mongod
5. MongoLab add-on
5. Bootstrap
6. Heroku
7. Okta User Authentication
##Deployed Project3_User_Authentication app on Heroku:
https://obscure-dusk-50431.herokuapp.com/
##Credentials to Access the Application:
Username: [email protected]
Password: Testing123
| 34.333333 | 216 | 0.804943 | eng_Latn | 0.960811 |
8b35f4d6359eb6e7130a5e53d7e6ac2b74acd5ca | 69 | md | Markdown | README.md | eduardogc/pokemon-react-adventure | 3f1ada0b05486ba6949805ddae711e71d4bfdaae | [
"MIT"
] | 2 | 2019-06-29T22:19:12.000Z | 2019-07-20T23:33:26.000Z | README.md | eduardogc/pokemon-react-adventure | 3f1ada0b05486ba6949805ddae711e71d4bfdaae | [
"MIT"
] | 9 | 2020-09-05T22:35:38.000Z | 2022-02-26T13:46:19.000Z | README.md | eduardogc/pokemon-react-adventure | 3f1ada0b05486ba6949805ddae711e71d4bfdaae | [
"MIT"
] | 1 | 2019-12-19T19:01:34.000Z | 2019-12-19T19:01:34.000Z | # pokemon-react-adventure
A pokedex desined with React, just for fun
| 23 | 42 | 0.797101 | eng_Latn | 0.990812 |
8b35faffcd57a4a67153672787796aefe5bdca66 | 2,164 | md | Markdown | _indicators/16-3-0.md | MonikaGorzelak/sdg-indicators-pl | 4691d9967a08df3b5fd46a748c15f0f861799983 | [
"CC0-1.0"
] | null | null | null | _indicators/16-3-0.md | MonikaGorzelak/sdg-indicators-pl | 4691d9967a08df3b5fd46a748c15f0f861799983 | [
"CC0-1.0"
] | null | null | null | _indicators/16-3-0.md | MonikaGorzelak/sdg-indicators-pl | 4691d9967a08df3b5fd46a748c15f0f861799983 | [
"CC0-1.0"
] | null | null | null | ---
layout: indicator
indicator_variable_1: ogółem
kategorie: null
zmienne: null
jednostka: punkty
pre: 2
graph: longitudinal
source_url: 'www.stat.gov.pl'
title: >-
Wskaźnik efektywności rządzenia
permalink: /statistics_nat/16-3/
sdg_goal: 16
indicator: 16.3.0
target_id: '16.3'
graph_title: Wskaźnik efektywności rządzenia
nazwa_wskaznika: >-
16.3 Wskaźnik efektywności rządzenia
cel: >-
cel 16. Pokój, sprawiedliwość i silne instytucje
zadanie: null
definicja: >-
Ocena jakości świadczenia usług publicznych, jakości biurokracji, kompetencji urzędników państwowych, niezależności administracji państwowej (służby cywilnej) od politycznych nacisków, społecznej wiarygodności władzy w zakresie prowadzonej polityki.
jednostka_prezentacji: punkty [pkt]
dostepne_wymiary: ogółem
wyjasnienia_metodologiczne: >-
Wskaźnik jest średnią ważoną szeregu (od 7 do 13) innych indeksów odzwierciedlających opinie ekspertów, przedsiębiorców i gospodarstw domowych na temat różnych aspektów funkcjonowania sfery publicznej. Ocenie podlegają w szczególności następujące zjawiska:- jakość usług publicznych - jakość administracji publicznej i stopień jej niezależności od wpływów politycznych - jakość formułowanych i wdrażanych polityk - jakość struktury publicznej: transportowej, sanitarnej, informatycznej, etc.Wartość wskaźnika efektywności rządzenia jest wystandaryzowana w przedziale < -2,5 2,5> , przy czym im wyższa nota, tym wyższa oceny jakości rządzenia w danym kraju.Wskaźnik efektywnego rządzenia lub inaczej efektywność administracji publicznej (Government Effectiveness) jest jednym z 6 Wskaźników jakości rządzenia (Worldwide Governance Indicators) opracownych przez Bank Światowy. Pozostałe wskażniki to: Prawo wyrażania opinii i wpływ obywateli (Voice and Accountability), Polityczna stabilność i brak przemocy (Political Stability and Absence of Violence), Jakość stanowionego prawa (Regulatory Quality), Rządy prawa (Rule of Law), Kontrola korupcji (Corruption Control). Skala wszystkich wskaźników wynosi od -2,5 do +2,5.
zrodlo_danych: Bank Światowy
czestotliwosc_dostępnosc_danych: Dane roczne od 2010 r.
---
| 69.806452 | 1,227 | 0.814233 | pol_Latn | 0.999923 |
8b38bb57e5d158fcef3e93226c8c10769c355ebf | 1,563 | md | Markdown | _posts/2018-03-06-House-of-Mooshki-Felicity.md | queenosestyle/queenosestyle.github.io | 7b095a591cefe4e42cdeb7de71cfa87293a95b5c | [
"MIT"
] | null | null | null | _posts/2018-03-06-House-of-Mooshki-Felicity.md | queenosestyle/queenosestyle.github.io | 7b095a591cefe4e42cdeb7de71cfa87293a95b5c | [
"MIT"
] | null | null | null | _posts/2018-03-06-House-of-Mooshki-Felicity.md | queenosestyle/queenosestyle.github.io | 7b095a591cefe4e42cdeb7de71cfa87293a95b5c | [
"MIT"
] | null | null | null | ---
layout: post
date: 2018-03-06
title: "House of Mooshki Felicity"
category: House of Mooshki
tags: [House of Mooshki]
---
### House of Mooshki Felicity
Just **$309.99**
###
<table><tr><td>BRANDS</td><td>House of Mooshki</td></tr></table>
<a href="https://www.readybrides.com/en/house-of-mooshki/73750-house-of-mooshki-felicity.html"><img src="//img.readybrides.com/173517/house-of-mooshki-felicity.jpg" alt="House of Mooshki Felicity" style="width:100%;" /></a>
<!-- break --><a href="https://www.readybrides.com/en/house-of-mooshki/73750-house-of-mooshki-felicity.html"><img src="//img.readybrides.com/173518/house-of-mooshki-felicity.jpg" alt="House of Mooshki Felicity" style="width:100%;" /></a>
<a href="https://www.readybrides.com/en/house-of-mooshki/73750-house-of-mooshki-felicity.html"><img src="//img.readybrides.com/173519/house-of-mooshki-felicity.jpg" alt="House of Mooshki Felicity" style="width:100%;" /></a>
<a href="https://www.readybrides.com/en/house-of-mooshki/73750-house-of-mooshki-felicity.html"><img src="//img.readybrides.com/173520/house-of-mooshki-felicity.jpg" alt="House of Mooshki Felicity" style="width:100%;" /></a>
<a href="https://www.readybrides.com/en/house-of-mooshki/73750-house-of-mooshki-felicity.html"><img src="//img.readybrides.com/173516/house-of-mooshki-felicity.jpg" alt="House of Mooshki Felicity" style="width:100%;" /></a>
Buy it: [https://www.readybrides.com/en/house-of-mooshki/73750-house-of-mooshki-felicity.html](https://www.readybrides.com/en/house-of-mooshki/73750-house-of-mooshki-felicity.html)
| 82.263158 | 237 | 0.732566 | yue_Hant | 0.749595 |
8b38e1b9c3ef2f3613eb5943ed2e269bdb708124 | 746 | md | Markdown | src/posts/2020-03-17-diary.md | makenowjust/diary | 83a09435b6dec23eadf876c016ec65be55117215 | [
"MIT"
] | 8 | 2017-10-25T12:40:39.000Z | 2021-11-24T00:11:53.000Z | src/posts/2020-03-17-diary.md | makenowjust/diary | 83a09435b6dec23eadf876c016ec65be55117215 | [
"MIT"
] | 24 | 2017-11-06T09:59:14.000Z | 2021-08-25T04:52:23.000Z | src/posts/2020-03-17-diary.md | makenowjust/diary | 83a09435b6dec23eadf876c016ec65be55117215 | [
"MIT"
] | 3 | 2017-11-22T10:14:00.000Z | 2018-04-01T15:53:28.000Z | ---
title: 線形マッチの実装してる(無理)
---
# やったこと
## グラブル
30連でなんか引いた。
水着だしきっとつよい。多分。
<https://mobile.twitter.com/make_now_just/status/1239811173521866752>
## ReRE.js
線形マッチできるVMをひたすら考察していた。
現状の課題は2つ。
- 後読み中のキャプチャの扱い
* 例えば `/^.*(?<=(a*)(a*))$/` を `aa'` にマッチさせたら、後読み部分は本来は後ろから読むので、結果は `['aa', '', 'aa']`になる。だけど通常と同じようにマッチを行なったら `['aa', 'aa', '']` となって、左の `(a*)` に入力が吸われてしまう。
* 上手くやれそうでやれそうにない‥‥。Tagged NFAとかの理論をちゃんと学ぶべきかも
- 否定先読み・後読みの扱い
* キャプチャが意味を持つ可能性がある肯定先読み・後読みと統一的に扱おうとすると複雑になりすぎる
* 諦めてこの部分は論理式に落とし込んでしまった方が良さそう
* BDD(二分決定図)を使う
後者はどうにかなりそうだけど、前者が難しすぎる。
BDDの実装はこれを参考にする。
<https://ipsj.ixsq.nii.ac.jp/ej/?action=pages_view_main&active_action=repository_view_main_item_detail&item_id=4290&item_no=1&page_id=13&block_id=8>
| 21.941176 | 160 | 0.72118 | yue_Hant | 0.44034 |
8b38fb84ecae9873a09108611427f19a1ce2d743 | 645 | md | Markdown | sites/website/versioned_docs/version-legacy/api/fast-colors.colorlch.equalvalue.md | Microsoft/fast-dna | ab05c42ea643940606f9dd2ec5e96b0eda76acc7 | [
"MIT"
] | 340 | 2018-03-24T00:10:41.000Z | 2019-05-03T17:14:05.000Z | sites/website/versioned_docs/version-legacy/api/fast-colors.colorlch.equalvalue.md | Microsoft/fast-dna | ab05c42ea643940606f9dd2ec5e96b0eda76acc7 | [
"MIT"
] | 1,314 | 2018-03-14T19:04:47.000Z | 2019-05-06T20:30:39.000Z | sites/website/versioned_docs/version-legacy/api/fast-colors.colorlch.equalvalue.md | Microsoft/fast-dna | ab05c42ea643940606f9dd2ec5e96b0eda76acc7 | [
"MIT"
] | 50 | 2018-03-27T02:35:41.000Z | 2019-04-16T17:14:02.000Z | ---
id: fast-colors.colorlch.equalvalue
title: ColorLCH.equalValue() method
hide_title: true
---
<!-- Do not edit this file. It is automatically generated by API Documenter. -->
[@microsoft/fast-colors](./fast-colors.md) > [ColorLCH](./fast-colors.colorlch.md) > [equalValue](./fast-colors.colorlch.equalvalue.md)
## ColorLCH.equalValue() method
Determines if one color is equal to another.
<b>Signature:</b>
```typescript
equalValue(rhs: ColorLCH): boolean;
```
## Parameters
| Parameter | Type | Description |
| --- | --- | --- |
| rhs | [ColorLCH](./fast-colors.colorlch.md) | the color to compare |
<b>Returns:</b>
boolean
| 22.241379 | 141 | 0.683721 | eng_Latn | 0.742512 |
8b390cb4e638c98b139dba79b86d88b325285409 | 946 | md | Markdown | docusaurus/website/i18n/fr/docusaurus-plugin-content-docs/current/tests/meantest.md | isle-project/isle-editor | 45a041571f723923fdab4eea2efe2df211323655 | [
"Apache-2.0"
] | 9 | 2019-08-30T20:50:27.000Z | 2021-12-09T19:53:16.000Z | docusaurus/website/i18n/fr/docusaurus-plugin-content-docs/current/tests/meantest.md | isle-project/isle-editor | 45a041571f723923fdab4eea2efe2df211323655 | [
"Apache-2.0"
] | 1,261 | 2019-02-09T07:43:45.000Z | 2022-03-31T15:46:44.000Z | docusaurus/website/i18n/fr/docusaurus-plugin-content-docs/current/tests/meantest.md | isle-project/isle-editor | 45a041571f723923fdab4eea2efe2df211323655 | [
"Apache-2.0"
] | 3 | 2019-10-04T19:22:02.000Z | 2022-01-31T06:12:56.000Z | ---
id: meantest
title: One-Sample Mean Test
sidebar_label: One-Sample Mean Test
---
Test de la moyenne sur un seul échantillon.
## Options
* __data__ | `object (required)`: les tableaux d'objets de valeur. Default: `none`.
* __variable__ | `string (required)`: nom de la variable. Default: `none`.
* __type__ | `string`: le type de test ("Test Z" ou "Test T"). Default: `'T Test'`.
* __stdev__ | `number`: l'écart type (pour le "Test Z"). Default: `none`.
* __alpha__ | `number`: niveau de signification. Default: `0.05`.
* __direction__ | `string`: la direction du test (soit `less`, `greater` ou `two-sided`). Default: `'two-sided'`.
* __mu0__ | `number`: moyenne sous l'hypothèse nulle. Default: `0`.
* __showDecision__ | `boolean`: contrôle s'il faut afficher si l'hypothèse nulle est rejetée au niveau de signification spécifié. Default: `false`.
## Exemples
```jsx live
<MeanTest
data={heartdisease}
variable="Drugs"
/>
```
| 32.62069 | 147 | 0.686047 | fra_Latn | 0.568221 |
8b391447acacb020e2a27587c276bccc8d7c8a1d | 91 | md | Markdown | README.md | SaPhyoThuHtet/machine-learning-from-scratch | 200b89b9282bd5edd52b30b9d2710c50dc14358a | [
"MIT"
] | 1 | 2021-09-14T06:53:14.000Z | 2021-09-14T06:53:14.000Z | README.md | SaPhyoThuHtet/machine-learning-from-scratch | 200b89b9282bd5edd52b30b9d2710c50dc14358a | [
"MIT"
] | null | null | null | README.md | SaPhyoThuHtet/machine-learning-from-scratch | 200b89b9282bd5edd52b30b9d2710c50dc14358a | [
"MIT"
] | null | null | null | # machine-learning-from-scratch
Machine Learning and Deep Learning Algorithms from Scratch
| 30.333333 | 58 | 0.846154 | eng_Latn | 0.894309 |
8b3a27c11a77c880df0f113c9f84c77d7e3a259f | 746 | md | Markdown | README.md | soreana/JSMTProxy | b5bb0936051cef160892e68d99d3a646d872400c | [
"MIT"
] | null | null | null | README.md | soreana/JSMTProxy | b5bb0936051cef160892e68d99d3a646d872400c | [
"MIT"
] | null | null | null | README.md | soreana/JSMTProxy | b5bb0936051cef160892e68d99d3a646d872400c | [
"MIT"
] | null | null | null | # JSMTProxy
High Performance NodeJS MTProto Proxy
### Configuration
Change port and secret field in config.json.
### Build and run docker image
Clone this repository and change your directory to JSMTProxy and run below commands.
```
$ docker build -t mtproto .
$ docker run -it -p <your public port>:<config.json port> mtproto
```
### Connect from telegram
Modify and send below link to yourself in telegram, and then click on it.
`https://t.me/proxy?server=<your public IP>&port=<your public port>&secret=<your secret>`
### Use docker compose
```
$ docker-compose up -d
```
### Use docker service
```
$ docker swarm init
$ docker stack deploy -c docker-compose.yml mtprotohub
```
Check service status:
```
$ docker service ls
```
| 17.761905 | 89 | 0.713137 | eng_Latn | 0.915525 |
8b3ae8bef47fe22528e895776bccad24b22bfa39 | 5 | md | Markdown | README.md | Dasguan/- | 00c822772f42d1388b1a924d332694c390775b16 | [
"MIT"
] | null | null | null | README.md | Dasguan/- | 00c822772f42d1388b1a924d332694c390775b16 | [
"MIT"
] | null | null | null | README.md | Dasguan/- | 00c822772f42d1388b1a924d332694c390775b16 | [
"MIT"
] | null | null | null | # -1
| 2.5 | 4 | 0.2 | bod_Tibt | 0.52344 |
8b3ddaca0a52933630d2b8890d6a34d120484983 | 1,324 | md | Markdown | README.md | spu-bigdataanalytics/welcome-to-the-class-Sakshi09wal | 82ce6f2ae2e887358e25ef08d155be1d028e548d | [
"MIT"
] | null | null | null | README.md | spu-bigdataanalytics/welcome-to-the-class-Sakshi09wal | 82ce6f2ae2e887358e25ef08d155be1d028e548d | [
"MIT"
] | null | null | null | README.md | spu-bigdataanalytics/welcome-to-the-class-Sakshi09wal | 82ce6f2ae2e887358e25ef08d155be1d028e548d | [
"MIT"
] | null | null | null | # :trophy: Instruction to run Welcome Assignment code for Sakshi Jaiswal!:girl::icecream:
## Introduction
This is our first assigment for Big Data Analytics. We were asked to create a function that would print our name in python.
First we were asked to change the name of the README.md file to instructions.md and create a new README.file ,this file will explain the work .
### Instruction for setting up the enviornment and executing the program
For writing the program I decided to use Jupyter Notebook with python 3.6 with kernel
- First we will visit official anaconda site where we can dowload latest anaconda for python 3.6 after downloading latest version of anaconda we will start installer.Here is the link
https://www.anaconda.com/distribution/#windows
After that anaconda installer will open and we click on launch button of jupyter notebook.
Then We will start jupyter notebook for writing program.
- Click on New then python 3 kernel will open.
- I created a class called print_name and under this class the function name 'info' displays user's name.
- When we execute this program it will ask for user input "Enter Your First name " then "enter your last name".
- Afterthat the program will print greeting message also.
Later I uploaded my assigment with the file called Welcome Sakshi.ipynb
| 49.037037 | 183 | 0.787764 | eng_Latn | 0.998964 |
8b3ebeb046aa817a41969cf4dd79fd11ce7f43a3 | 2,410 | md | Markdown | mdop/appv-v4/how-to-add-a-server.md | MicrosoftDocs/mdop-docs-pr.de-de | 2c2dc8dbac77a389cbaa09dc05c11d2f24ecd31c | [
"CC-BY-4.0",
"MIT"
] | 1 | 2021-04-20T21:13:51.000Z | 2021-04-20T21:13:51.000Z | mdop/appv-v4/how-to-add-a-server.md | MicrosoftDocs/mdop-docs-pr.de-de | 2c2dc8dbac77a389cbaa09dc05c11d2f24ecd31c | [
"CC-BY-4.0",
"MIT"
] | 2 | 2020-07-08T05:12:12.000Z | 2020-07-08T15:38:40.000Z | mdop/appv-v4/how-to-add-a-server.md | MicrosoftDocs/mdop-docs-pr.de-de | 2c2dc8dbac77a389cbaa09dc05c11d2f24ecd31c | [
"CC-BY-4.0",
"MIT"
] | 1 | 2021-11-04T12:31:43.000Z | 2021-11-04T12:31:43.000Z | ---
title: So fügen Sie einen Server hinzu
description: So fügen Sie einen Server hinzu
author: dansimp
ms.assetid: 1f31678a-8edf-4d35-a812-e4a2abfd979b
ms.reviewer: ''
manager: dansimp
ms.author: dansimp
ms.pagetype: mdop, appcompat, virtualization
ms.mktglfcycl: deploy
ms.sitesec: library
ms.prod: w10
ms.date: 06/16/2016
ms.openlocfilehash: 7d08b79bcbf34910ce357f39635431d11e3e99bd
ms.sourcegitcommit: 354664bc527d93f80687cd2eba70d1eea024c7c3
ms.translationtype: MT
ms.contentlocale: de-DE
ms.lasthandoff: 06/26/2020
ms.locfileid: "10808725"
---
# So fügen Sie einen Server hinzu
Damit Sie Ihre Application Virtualization-Verwaltungsserver effizienter verwalten können, sollten Sie Sie in Servergruppen organisieren. Nachdem Sie in der Application Virtualization Server-Verwaltungskonsole eine Servergruppe erstellt haben, können Sie die folgende Vorgehensweise verwenden, um der Gruppe einen Server hinzuzufügen.
**Hinweis** Alle Server in einer Servergruppe müssen mit demselben Datenspeicher verbunden sein.
**So fügen Sie einen Server zu einer Gruppe hinzu**
1. Klicken Sie im linken Bereich auf den Knoten **Servergruppen** , um die Liste der Servergruppen zu erweitern.
2. Klicken Sie mit der rechten Maustaste auf die gewünschte Servergruppe, und wählen Sie **neuer Application Virtualization Management Server**aus.
3. Geben Sie im **Assistenten für neue Server Gruppe**den **Anzeigenamen** und den **Namen des DNS-Hosts**ein.
4. Übernehmen Sie die Standardwerte im Feld **Maximale Speicherzuteilung** für den Server Cache und das Feld Warnungs **Speicherzuteilung** , um die Warnstufe für den Schwellenwert anzugeben.
5. Klicken Sie auf **Weiter**.
6. Aktivieren Sie im Dialogfeld **Verbindungssicherheitsmodus** das Kontrollkästchen **Erweiterte Sicherheit verwenden** , um bei Bedarf den erweiterten Sicherheitsmodus auszuwählen. Falls erforderlich, führen Sie den **Zertifikat-Assistenten** aus, oder zeigen Sie vorhandene Zertifikate an.
7. Klicken Sie auf **Weiter**.
8. Aktivieren Sie im Dialogfeld **App virt-Porteinstellungen** das Optionsfeld **Standard Port verwenden** oder **benutzerdefinierter** Port, und geben Sie die benutzerdefinierte Portnummer ein.
9. Klicken Sie auf **Fertig stellen**.
## Verwandte Themen
[So erstellen Sie eine Servergruppe](how-to-create-a-server-group.md)
[So entfernen Sie einen Server](how-to-remove-a-server.md)
| 37.076923 | 333 | 0.792116 | deu_Latn | 0.991996 |
8b3ec22d4bd5b118f26afc81c0fd64ef19ddb70e | 17 | md | Markdown | 2017/11/12/commit.md | xxagere/sims | eb881e50fc1332b30e93407f1c899a8a52d57592 | [
"MIT"
] | null | null | null | 2017/11/12/commit.md | xxagere/sims | eb881e50fc1332b30e93407f1c899a8a52d57592 | [
"MIT"
] | null | null | null | 2017/11/12/commit.md | xxagere/sims | eb881e50fc1332b30e93407f1c899a8a52d57592 | [
"MIT"
] | null | null | null | 12 on 11/12/2017
| 8.5 | 16 | 0.705882 | fin_Latn | 0.836503 |
8b3ee5b886a12783cfca54ac57c64b16399dc98e | 3,216 | md | Markdown | README.md | kzykhys/CoroutineIO | b4cc8ed0e1dbaf70d365fb8ccea7d90f08fc9858 | [
"MIT"
] | 4 | 2015-09-17T05:56:32.000Z | 2018-06-12T03:06:11.000Z | README.md | kzykhys/CoroutineIO | b4cc8ed0e1dbaf70d365fb8ccea7d90f08fc9858 | [
"MIT"
] | null | null | null | README.md | kzykhys/CoroutineIO | b4cc8ed0e1dbaf70d365fb8ccea7d90f08fc9858 | [
"MIT"
] | null | null | null | CoroutineIO
===========
[](https://packagist.org/packages/kzykhys/coroutine-io)
[](https://travis-ci.org/kzykhys/CoroutineIO)
Fast socket server implementation using *Generator*.
This project is heavily inspired by @nikic's [great post][1].
Following project shows the possibility of CoroutineIO.
* [kzykhys/coupe][2] - Coupé - A Handy HTTP/HTTPS Server written in *PURE* PHP
Requirements
------------
* PHP5.5+
Installation
------------
Create or update your composer.json and run `composer update`
``` json
{
"require": {
"kzykhys/coroutine-io": "~0.1.0"
}
}
```
Example (HTTP Server)
---------------------
1. Run `php example.php`
2. Open `http://localhost:8000` in browser and hold down the F5 key
3. Watch the console output
```
php example.php
```
```
::1:50531
GET / HTTP/1.1
Host: localhost:8000
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.9; rv:25.0) Gecko/20100101 Firefox/25.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: ja,en-us;q=0.7,en;q=0.3
Accept-Encoding: gzip, deflate
DNT: 1
Connection: keep-alive
```
### example.php
``` php
<?php
use CoroutineIO\Example\HttpHandler;
use CoroutineIO\Example\HttpServer;
require __DIR__ . '/vendor/autoload.php';
$server = new HttpServer(new HttpHandler());
$server->run();
```
### Class HttpServer
``` php
<?php
namespace CoroutineIO\Example;
use CoroutineIO\Exception\Exception;
use CoroutineIO\Server\Server;
/**
* Simple HTTP Server Implementation
*/
class HttpServer extends Server
{
/**
* {@inheritdoc}
*/
public function createSocket($address = 'localhost:8000')
{
$socket = @stream_socket_server('tcp://' . $address, $no, $str);
if (!$socket) {
throw new Exception("$str ($no)");
}
return $socket;
}
}
```
### Class HttpHandler
``` php
<?php
namespace CoroutineIO\Example;
use CoroutineIO\Server\HandlerInterface;
use CoroutineIO\Socket\ProtectedStreamSocket;
use CoroutineIO\Socket\StreamSocket;
/**
* Simple HTTP Server Implementation
*/
class HttpHandler implements HandlerInterface
{
/**
* {@inheritdoc}
*/
public function handleClient(StreamSocket $socket)
{
$socket->block(false);
$data = (yield $socket->read(8048));
$response = $this->handleRequest($data, new ProtectedStreamSocket($socket));
yield $socket->write($response);
yield $socket->close();
}
/**
* {@inheritdoc}
*/
public function handleRequest($input, ProtectedStreamSocket $socket)
{
// Displays request information
echo $socket->getRemoteName() . "\n";
echo $input;
return "HTTP/1.1 200 OK\nContent-Type: text/plain\nContent-Length: 5\n\nHello";
}
}
```
License
-------
The MIT License
Author
------
Kazuyuki Hayashi (@kzykhys)
[1]: http://nikic.github.io/2012/12/22/Cooperative-multitasking-using-coroutines-in-PHP.html "Cooperative multitasking using coroutines (in PHP!)"
[2]: https://github.com/kzykhys/coupe
| 19.975155 | 146 | 0.659515 | eng_Latn | 0.250684 |
8b3f7e42565987c3ef9a8c17808e8a51c25ceb16 | 16,180 | md | Markdown | notes/3_Physics/Unit-8.md | euankho/note-service | a5298d983c3c288747fdc0ea78c31aa9f553f418 | [
"MIT"
] | null | null | null | notes/3_Physics/Unit-8.md | euankho/note-service | a5298d983c3c288747fdc0ea78c31aa9f553f418 | [
"MIT"
] | null | null | null | notes/3_Physics/Unit-8.md | euankho/note-service | a5298d983c3c288747fdc0ea78c31aa9f553f418 | [
"MIT"
] | 1 | 2021-03-04T15:18:56.000Z | 2021-03-04T15:18:56.000Z | # Physics - Unit 8
## Primary and secondary sources
- **A primary source** is one that *has not been transformed or converted before use by the consumer*, so a fossil fuel – coal.
- **The definition of a secondary source** of energy is one that results from the transformation of a primary source. Ie. electric energy
- Electricity is the most important secondary energy
- Hydrogen is another useful secondary energy
## Renewable and non renewable sources
- Primary sources can be divided into two, renewable and non-renewable
- Renewable sources: can be replenished in relatively short time
- Non renewable: Finite sources, which are being depleted much faster than they can be produced, and so will run out
- A good way to classify renewable and non-renewable resources is by the rates at which they are being consumed and replaced
## Types of energy sources

- chemical potential, energy stored in the bonds and the energy released during chemical reactions
## Specific energy and energy density
- **specific energy:** the number of joules that can be released by each kilogram of the fuel
- **Energy density:** the number of joules that can be released from 1 m3 of a fuel.

**Tip:** You do not need to memorize this
## Thermal power station

- **Internal energy:** the energy associated with the random, disordered motion of molecules (kinetic energy and potential energy of the molecules).
- Water, is heated (with primary source / chemical energy) to point where there no bubbles during boiling.
- The steam then spins a turbine which converts the internal energy of the water to kinetic energy
- The blades of the fan spins a coil which produces alternating current (c)
- There are really three energy transfers going on in this process: primary energy to the internal energy of water, this internal energy to the kinetic energy of the turbine, and kinetic energy of the turbine to electrical energy in the generator.
## Sankey Diagram
- **Sankey Diagram:** A visual representation of energy flow in a system
- There are some rules to remember about the Sankey diagram:
- Each energy source and loss in the process is represented by an arrow.
- The diagram is drawn to scale with the width of an arrow being proportional to the amount of energy it represents.
- The energy flow is drawn from left to right.
- When energy is lost from the system it moves to the top or bottom of
the diagram.
- Power transfers as well as energy flows can be represented.
- **Degraded energy:** Energy lost in a process of getting "useful" energy
## Primary sources used in power stations
- **Baseload station:** A station which run 24 hours a day, 7 days a week converting energy all the time. However, the demand that consumers make for energy is variable and cannot always be predicted. From time to time the demand exceeds the output of the baseload stations.
### Fossil fuels
- Advantages:
- Modern fossil-fuel power stations can be very large and can convert significant amounts of power.
- Fossil fuels have significant uses in the chemical industry for the production of plastics, medicines, and other important products.
- Disadvantages:
- The materials have taken a very large time to accumulate and will not be replaced for equally long times.
- The burning of the fuels releases into the atmosphere large quantities of carbon dioxide that have been locked in the coal, oil, and gas for millions of years. This has a major impact on the response of the atmospheric system to the radiation incident on it from the Sun (the greenhouse and enhanced greenhouse effects).
- It makes sense to locate power stations as close as possible to places where fossil fuels are recovered; however, this is not always possible and, in some locations, large-scale transportation of the fuels is still required. A need for transport leads to an overall reduction in the efficiency of the process because energy has to be expended in moving the fuels to the power stations.
### Nuclear fuel
- A baseload station
- A particularly common variety of the thermal reactors is the pressurized water reactor (PWR). Uranium-235 is the nuclide used in these reactor

- While about 99% of uranium ore is U-238, U-235 is needed in a fission process.
- An initial extraction needs to be done to boost the ratio of U-235
- The fuel needs to contain at least 3% U-235
- Too much U-238 will make the fission process not self-sustaining as it is **a good asorber**
- Fuel with boosted proportions of U-235 is called **enriched**
- The enriched material is then formed into **fuel rods**
- Energy released by the fuel rods are very fast neutrons yet we need neutrons which have similar speed with matter at room temperature
- Neutrons with speed that neutrons have when equilibrium with matter at around room temperature is called **thermal neutrons**
- The removal of energy is achieved through the use of a **moderator** (because it moderates (slows down) the speeds of the neutrons)
- Typical moderators for the PWR type include water and carbon in the form of graphite
- The moderator are inelastic
- its function is to receives collision from the neutrons and asorbs the energy from the collision causing the neutron to move slower. It may take multiple collisions to bring the speed of the neutron down to a thermal neutron or ~10 km/s
- The moderator is not part of the fuel rods but are close together. This is because U-238 is very effective at absorbing high-speed neutrons.
- Criterias for a moderator
- should not be a good asorber of neutrons (if it does asorb, it will lower the reaction rate or might stop the reaction completely)
- being inert (does not react with other atoms/molecules) in the extreme conditions of the reactor.
- **control rods:** used to regulate the power output from the reactor and to shut down its operation
- has to be good at asorbing neutrons (very well)
- function: to asorb the neutrons in the reaction to stop more fission reacts
- **heat exchanger:** a mechanism used for conveying the internal energy from inside the reactor to the turbines.
#### Safety issues with nuclear power plants
- Safety measures that are needed to be put in place
- The reactor vessel is made of thick steel to withstand the high temperatures and pressures present in the reactor. This has the benefit of also absorbing alpha and beta radiations together with some of the gamma rays and stray neutron
- The vessel itself is encased in layers of very thick reinforced concrete that also absorb neutrons and gamma rays.
- There are emergency safety mechanisms that operate quickly to shut the reactor down in the event of an accident.
- The fuel rods are inserted into and removed from the core using robots so that human operators do not come into contact with the spent fuel rods, which become highly radioactive during their time in the reactor.
- At the end of the life of a nuclear power plant (20-25 years)
- reactor plant has to be decommisioned
- removing all the fuel rods and other high-activity waste products
- enclosing the reactor vessel and its concrete shield in a larger shell of concrete
- leave the structure alone for up to a century to allow the activity of the structure to drop to a level similar to that of the local background
### Wind Generators
- A baseload station
- The rotor is rotated by the wind and, through a gearbox, this turns an electrical generator. The electrical energy is fed either to a storage system (but this increases the expense) or to the electrical grid.
- There are two principle types:
- horizontal-axis
- can be steered into the wind
- veritcal-axis
- does not have to be steered into the wind and therefore its generator can be placed off-axis.

#### Maximum theoretical value of the available power
- $$\frac{1}{2}\rho\pi r^2v^2$$
- $$\rho$$: density of the air
- A: area of the blade
- v: velocity of the air
- assumes that all kinetic energy from the air can be used
- While a long blade (large A or r) will give the best energy yields, increasing the radius of the blade also increases its mass and this means that the rotors will not rotate at low wind speeds.
- Ideal places where wind farms are placed
- off-shore
- wind speeds are higher than over land because the shore tends to be more smooth
- on top of a hill
- due to the shape of the land
| Advantages | Disadvantages |
| ------------------------------------------------------------ | -------------------------------------------------- |
| No energy costs | Variable output on a daily or seasonal basis |
| No chemical pollution | Site availability can be limited in some countries |
| Capital costs can be high but reduce with economies of scale | Noise pollution |
| Easy to maintain on land; not so easy off-shore | Visual pollution |
| | Ecological impact |
### Pumped storage
- Not a baseload station, output can be increased or decreased
- There are multiple ways which water can be used as a primary energy source:
- pumped storage plants (potential)
- hydroelectric plants (potential)
- tidal barrage (potential)
- tidal flow systems (kinetic)
- wave energy (kinetic)
- All the sources above use one of two methods:
- The GPE (gravitational potential energy) of water held at a level above a reservoir is converted to electrical energy as the water is allowed to fall to the lower level
- The kinetic energy of moving water is transferred to electrical energy as the water flows or as waves move
- A pumped storage system (Figure 10) involves the use of two water reservoirs
- These reservoirs are connected by pipes
- The ammount of water that can flow through the pipes are dependant on the demand of electricity. if high, more water flows and when low, less water flows.
- They can go from 0 to 100 output in a few seconds
- when demand is low, they pump the water back up
#### Maximum theoretical rate of power from water
$$P = \frac{m}{t}g\Delta h = (\frac{V}{t}\rho)g\Delta h$$
- t: time
- m: mass
- V: volume
- $$\rho$$: density of the water
$$m = \rho * V$$
$$m = \frac{m}{V} * V$$
$$m = m$$
### Solar energy
#### Solar heating panels

- solar heating panel contains a pipe, embedded in a black plate, through which a glycol–water mixture is circulated by a pump (glycol has a low freezing point, necessary in cold countries)
- when sunlight, infrared radiation, falls on the blackplate, it heats ups
- the heated gycol is heated through the pipes to the boiler
- through the internal energy, the boiler runs and heats up water
- A solar heating cell absorbs radiant energy and converts it to the internal energy of the working fluid.
#### Solar photovoltaic panels
- The **photovoltaic cell** consists of a single crystal of semiconductor
that has been doped so that one face is p-type semiconductor and the opposite face is n-type.
- electrons in n-type, positive “holes”
- an absence of electrons – in p-type
- The photovoltaic materials in the panel convert electromagnetic radiation from the Sun into electrical energy
- they are used in both series and parralel
- Advantages:
- low maintenance cost
- no fuel cost
- disadvantage
- high initial cost
- relatively low efficiency
#### Math of Solar energy
$$P = \eta IA$$
- P: Power (W)
- $$\eta$$: efficiency or fraction of the energy arriving that is converted into internal energy
- I: itensity of radiation (from the sun per square meter) (W/m<sup>2</sup>)
- A: area of the solar panel (m<sup>2</sup>)
## Thermal energy transfer
- Any object with **a temperature above absolute zero** (0 K) possesses internal energy due to the motion of its atoms and molecules
- Conduction
- **Atomic vibration** occurs in all solids, metal and non-metal alike. At all temperatures above 0 K, the ions in the solid have an internal energy. So they are vibrating about their average fixed position in the solid. The higher the temperature, the greater is the average energy, and therefore the higher their mean speed.
- Can take place in solid, liquid and gases (yet convection is more applicible to liquids and gases)
- The moving electrons collide with neighbouring molecules, transferring energy to them and so increasing their average kinetic energy
- Convection
- the movement of groups of atoms or molecules within fluids (liquids and gases) that arises through variations in density
- cannot take place in solids
- **convection currents** are cycles of currents that occur when hot, dense air heated from a heat source rises due to lowered density through upthrust. A lower pressure is created in the system because of this, so denser and cold air sinks to replace the hot air.
- Thermal radiation
- Thermal radiation is the transfer of energy by means of electromagnetic radiation
- Electromagnetic radiation is unique as a wave in that it does not need a medium in order to move (propagate)
- Atoms contain charged particles and when these charges are accelerated they emit photons. It is these photons that are the thermal radiation.
- Black surfaces
- good at radiating
- good at asorbing energy
- poor reflector of thermal energy
- Black Body Radiation
- A black body is one that absorbs all the wavelengths of electromagnetic radiation that fall on it
### Emission spectrum from a blackbody
$$I = \frac{P}{A}$$
- **I:** Intensity
- **P:** Power
- **A:** Area

### Albedo
- The proportion of the incident radiation that is reflected by a surface
$$\alpha = \frac{\text{radiation asorbed}}{\text{total incident radiation}}$$
### Black body
- asorbs 100% of the incident radiation (at lowest temperature)
- emits 100% of the wavelengths (if body is hotter than the enviroment)
- the sun is a black body as it emits all the wavelenghts
- Carbon black asorbs 99.9% radiation
### Wien's displacement law
- that a wavelength at which the intensity is a maximum λ<sub>max</sub> in meters is related to the absolute temperature of the black body T by
$$\lambda_{max} = \frac{b}{T}$$
- $$\lambda_{max}$$: maximum intensity at a certain temperature
- b: wien's displacement constant, 2.9 x 10<sup>-3</sup> m K
- **T:** temperature
### Stefan blotzmann
- the power radiated by the object, but this is the same as the energy radiated per second.
$$P = \sigma AT^4$$
- **P:** total power radiated
- $$\sigma$$: stefan-blotzmann equation, 5.7 x 10<sup>8</sup> W m<sup>-2</sup> K<sup>-4</sup>
- **A:** total surface area
- **T:** temperature
### Emissivity
$$e = \frac{\text{power emitted by a radiating object}}{\text{power emitted by a blackbody with the same dimensions at the same temperature}}$$
$$P = e\sigma AT^4$$
### Solar Constant
- **The solar constant** is the amount of solar radiation across all wavelengths that is incident in one second on one square metre at the mean distance of the Earth from the Sun on a plane perpendicular to the line joining the centre of the Sun and the center of the Earth.
### Greenhouse effect
- The sun's warmth is trapped in a planet's lower atmosphere due to the greater transparency of the atmosphere to visible radiation from the sun than to infrared radiation emitted from the planet's surface.
- **Climate change:** a change in global or regional climate patterns
- **Greenhouse gases:**
- Carbon dioxide
- Methane
- Nitrous oxide
- Water vapor
- ozone
- **Enhanced greenhouse effect:** the additional warming produced by increased levels of gases that absorb infrared radiation | 60.827068 | 389 | 0.735723 | eng_Latn | 0.999658 |
8b3fdb5909e53e79407e0d548be1c7c964c83813 | 215 | md | Markdown | articles/dotnet-create-account.md | guyburstein/azure-content | 78ab6ef86246e33a553a1c22655b27a9b7c49412 | [
"CC-BY-3.0"
] | 2 | 2017-03-06T13:38:05.000Z | 2021-06-11T09:22:56.000Z | articles/dotnet-create-account.md | guyburstein/azure-content | 78ab6ef86246e33a553a1c22655b27a9b7c49412 | [
"CC-BY-3.0"
] | null | null | null | articles/dotnet-create-account.md | guyburstein/azure-content | 78ab6ef86246e33a553a1c22655b27a9b7c49412 | [
"CC-BY-3.0"
] | null | null | null | <properties title="Create an Azure account" pageTitle="Create an Azure account" description="Create an account" authors="waltpo" />
[WACOM.INCLUDE [create-an-azure-account](../includes/create-an-azure-account.md)]
| 53.75 | 131 | 0.767442 | eng_Latn | 0.829444 |
8b404cf4e92e8374ef70879d415aabfaabe6af88 | 2,123 | md | Markdown | README.md | yisyang/eos | 01daf11cfdc2b42a4155778f4031f7081013ce5d | [
"MIT"
] | 4 | 2016-08-08T14:23:46.000Z | 2016-12-31T03:42:10.000Z | README.md | yisyang/eos | 01daf11cfdc2b42a4155778f4031f7081013ce5d | [
"MIT"
] | 1 | 2016-12-07T13:13:50.000Z | 2017-04-17T02:19:03.000Z | README.md | yisyang/eos | 01daf11cfdc2b42a4155778f4031f7081013ce5d | [
"MIT"
] | 6 | 2016-04-23T20:45:58.000Z | 2021-03-07T20:25:39.000Z | # Economies of Scale
Dedicated to the devoted fans of the game who have played this game for years and have requested for the source code to be made public.
If you are here because you are interested in programming, DO NOT DIRECTLY USE THE SOURCE CODE HERE, instead, start by using any of the following frameworks or languages depending on your target audience:
Cross-Platform: Unity / Godot / Cocos / NativeScript
Native iOS: Swift
Native Android: Kotlin / Java
Web: Typescript / Javascript
On the database side you can start with MariaDB but may have to move to something on top of Hadoop in time.
Build a minimally viable product, and slowly add to it. It may sound tough, but once you have a solid start the momentum will keep you going, and you will learn a lot more.
The primary reasons to start anew are:
- For security reasons (also because of outdated security practices), the actual database connection and user login scripts have not been included. So the code here does not give you a turnkey server.
- A lot of technology used back at the creation of this game have long been deprecated. Even if you spend time to get it working... it may stop working with a future OS/browser update.
- Trends have shifted and there's a growing number of players who play on mobile only.
## I'm sorry, I'm sorry, I'm sorry.
This is the game I wrote near the start of my programming career. The code is procedural, unscalable (supports only <5k active players even with a decent server), and you can feel the stench from a mile away. Much of the design was done with copy-and-paste. Since first writing the game, many functions used are now considered deprecated. It is possible that the game may stop working at any point in the future when a new OS/browser update comes out.
The game is currently still available to play at https://capitalism-online.com.
# License
The PHP code here is licensed under MIT license, you may use them however you like.
All images/icons under /images are free for personal use and possibly free for commercial use as well, but the licenses are not clear. Use them at your own risk.
| 62.441176 | 451 | 0.781441 | eng_Latn | 0.999883 |
8b4186368a861914002192a3f1d62b9e5b7b1fbd | 5,464 | md | Markdown | _posts/2021-09-23-20210923-RNA-DNA-extractions-from-E5-project.md | Kterpis/Putnam_Lab_Notebook | db66fa864018654d5dd2946f41fdf439f1cfaca8 | [
"MIT"
] | null | null | null | _posts/2021-09-23-20210923-RNA-DNA-extractions-from-E5-project.md | Kterpis/Putnam_Lab_Notebook | db66fa864018654d5dd2946f41fdf439f1cfaca8 | [
"MIT"
] | null | null | null | _posts/2021-09-23-20210923-RNA-DNA-extractions-from-E5-project.md | Kterpis/Putnam_Lab_Notebook | db66fa864018654d5dd2946f41fdf439f1cfaca8 | [
"MIT"
] | null | null | null | ---
layout: post
title: 20210923 RNA DNA extractions from E5 project
date: '2021-09-23'
categories: Processing
tags: DNA RNA
---
## DNA/RNA extractions from E5 project
Extractions from the three coral species from each of the four timepoints
---
#### Extraction Date: September 23, 2021
**Samples**
| Tube number | Timepoint | Species | Colony ID | Coll date | Site |
|------------- |------------ |------------- |------------- |------------- |------------- |
| 41 | January | *Acropora* | ACR-225 | 20200103 | 2 |
| 77 | January | *Pocillopora* | POC-205 | 20200103 | 2 |
| 97 | January | *Porites* | POR-367 | 20200106 | 3 |
| 303 | March | *Acropora* | ACR-244 | 20200303 | 2 |
| 305 | March | *Pocillopora* | POC-222 | 20200303 | 2 |
| 319 | March | *Porites* | POR-236 | 20200303 | 2 |
| 605 | Sept | *Porites* | POR-340 | 20200908 | 3 |
| 611 | Sept | *Pocillopora* | POC-369 | 20200908 | 3 |
| 631 | Sept | *Pocillopora* | POC-42 | 20200911 | 1 |
| 741 | November | *Porites* | POR-72 | 20201101 | 1 |
| 757 | November | *Pocillopora* | POC-52 | 20201101 | 1 |
| 765 | November | *Porites* | POR-76 | 20201101 | 1 |
**Extraction notes**
- ACR and POC samples: pulled out 300ul of shield
- POR samples: pulled out 150ul of shield and added to 150ul of new shield
- Spun down samples for 3 minutes at 9000 rcf and then transfer the supernatant to new tube without disturbing the pellet
- 300ul of shield, 15ul of ProK, and 30ul of ProK digestion buffer, let sit for 2 minutes
- All spins were done for 1 minute or 2.30 minutes
- Did two washes with 700ul of wash buffer for both the DNA and RNA
- Then followed the protocol as described in [protocol](https://github.com/emmastrand/EmmaStrand_Notebook/blob/master/_posts/2019-05-31-Zymo-Duet-RNA-DNA-Extraction-Protocol.md)
**Qubit**
- Used Broad range dsDNA and RNA Qubit [Protocol](https://meschedl.github.io/MESPutnam_Open_Lab_Notebook/Qubit-Protocol/)
- All samples read twice, standard only read once
**DNA**
| Tube number | RFU | DNA 1 (ng/uL) | DNA 2 (ng/uL) | Average |
|------------- |------------ |------------- |------------- |------------- |
| Standard 1 | 196.76 | | | |
| Standard 2 | 21813.55 | | | |
| 41 | | 25.8 | 25.8 | 25.8 |
| 77 | | 20.6 | 20.6 | 20.6 |
| 97 | | nd | nd | nd |
| 303 | | 49.6 | 49.2 | 49.4 |
| 305 | | 84.8 | 84.8 | 84.8 |
| 319 | | 3.50 | 3.50 | 3.50 |
| 605 | | 3.46 | 3.40 | 3.43 |
| 611 | | 3.92 | 3.84 | 3.88 |
| 631 | | 96.8 | 97.0 | 96.9 |
| 741 | | 2.64 | 2.60 | 2.62 |
| 757 | | 50.2 | 50.2 | 50.2 |
| 765 | | 5.34 | 5.34 | 5.34 |
**RNA**
| Tube number | RFU | RNA 1 (ng/uL) | RNA 2 (ng/uL) | Average |
|------------- |------------ |------------- |------------- |------------- |
| Standard 1 | 358.25 | | | |
| Standard 2 | 6841.70 | | | |
| 41 | | 11.8 | 12.6 | 12.2 |
| 77 | | 23.8 | 23.4 | 23.6 |
| 97 | | nd | nd | nd |
| 303 | | 12.4 | 12.8 | 12.6 |
| 305 | | 33.8 | 34.4 | 34.1 |
| 319 | | 26.6 | 27.6 | 27.1 |
| 605 | | 24.6 | 24.4 | 24.5 |
| 611 | | 46.8 | 46.0 | 46.4 |
| 631 | | 62.4 | 62.6 | 62.5 |
| 741 | | 27.6 | 28.4 | 28.0 |
| 757 | | 33.6 | 33.6 | 33.6 |
| 765 | | 30.4 | 31.0 | 30.7 |
**Tape Station**
- Used to check RNA quality [Protocol](https://meschedl.github.io/MESPutnam_Open_Lab_Notebook/RNA-TapeStation-Protocol/)
- Did not tape station #97
- [Results Link](https://github.com/Kterpis/Putnam_Lab_Notebook/blob/8d530709b89313d8db4a82a94058b689f55fdbbe/images/tape_station/2021-09-23%20-%2014.48.25.pdf)
**Gel**
- Modified from this [protocol](https://meschedl.github.io/MESPutnam_Open_Lab_Notebook/Gel-Protocol/)
- Added 0.75g of agarose and 50ml of 1x TAE to flask and microwaved for 45 seconds. This makes a 1.5% gel
- Once cool enough to touch added 2ul of gel green stain
- Swirled and poured into gel mould with comb
- Once solidified, covered with 1X TAE as a running buffer
- Added 1ul of purple loading dye to each of my QC strip tube samples. I had ~9ul of DNA leftover from QC and ~8ul of RNA
- Loaded my gel with the DNA first, then skipped a well and then the RNA
- Ran the gel for 60 minutes at 60 volts

**Addtional Notes**
- Even though qubit did not detect any gDNA in 97 or RNA in 97 there are bands on the gel | 52.038095 | 178 | 0.482064 | eng_Latn | 0.635062 |
8b41cf9b3733c87a36afbb2a9c8327ccce9e5a90 | 15,493 | md | Markdown | content/retrospectives/2020/06/index.md | Rishabh570/mtlynch.io | f90b52fb286563b455933b5f9d47e93bd70020b2 | [
"CC-BY-4.0"
] | null | null | null | content/retrospectives/2020/06/index.md | Rishabh570/mtlynch.io | f90b52fb286563b455933b5f9d47e93bd70020b2 | [
"CC-BY-4.0"
] | null | null | null | content/retrospectives/2020/06/index.md | Rishabh570/mtlynch.io | f90b52fb286563b455933b5f9d47e93bd70020b2 | [
"CC-BY-4.0"
] | null | null | null | ---
title: "Is It Keto: Month 12"
date: 2020-06-01T00:00:00-04:00
description: 50k monthly visitors is more valuable than I'm giving it credit for.
images:
- /retrospectives/2020/06/cover.png
---
## Highlights
* I added 88 new programmatically-generated articles to Is It Keto.
* With 100k monthly pageviews, it's time to explore new ways of working with Is It Keto's audience.
* I created a KVM over IP device that requires <$100 in hardware.
## Goal Grades
At the start of each month, I declare what I'd like to accomplish. Here's how I did against those goals:
### Add 100 new articles to Is It Keto
* **Result**: Added 88 new articles to Is It Keto
* **Grade**: B
Programmatically generating content is harder than I expected. It's easy to generate the score and nutrition data, but it's tough to templatize lots of text that fits a wide range of products.
I'm going to continue building up templates and adding new foods, but I'll explore other options for growing the site's revenues as well.
### Publish one new blog post
* **Result**: I published ["My Eight-Year Quest to Digitize 45 Videotapes."](/digitizing-1/)
* **Grade**: A
I've been working on this article in some form or another for the last two years, so I'm happy to have finally published it. I'm pleased with the result, and it's been nice hearing people say it gave them useful ideas their own digitization projects.
The post [got a good response on Reddit](https://redd.it/gqxvxb) but [failed to gain traction on Hacker News](https://news.ycombinator.com/item?id=23311096). I still think it has a chance on Hacker News, so I'll try again in a week or so.
## Stats
### [Is It Keto](https://isitketo.org)
{{<revenue-graph project="isitketo">}}
| Metric | April 2020 | May 2020 | Change |
| ------------------------- | ----------- | ----------- | ------------------------------------------- |
| Unique Visitors | 35,451 | 50,352 | <font color="green">+14,901 (+42%)</font> |
| Total Pageviews | 72,894 | 99,391 | <font color="green">+26,497 (+36%)</font> |
| Domain Rating (Ahrefs) | 27.0 | 27.0 | 0 |
| AdSense Earnings | $92.09 | $109.92 | <font color="green">+$17.83 (+19%)</font> |
| Amazon Affiliate Earnings | $128.39 | $111.61 | <font color="red">-$16.78 (-13%)</font> |
| **Total Revenue** | **$220.48** | **$221.53** | **<font color="green">+$1.05 (+0%)</font>** |
Is It Keto continued growing in visitors. It seems to have recovered to its normal level of activity pre-COVID. Worryingly, AdSense earnings failed to keep pace, and Amazon Affiliate earnings actually dropped.
Checking the stats more closely, Is It Keto generated 25% more revenue for Amazon in May than it did in April, but Amazon [slashed their affiliate payout rates](https://www.cnbc.com/2020/04/14/amazon-slashes-commission-rates-for-affiliate-program.html), substantially reducing Is It Keto's revenues.
## Doing more with Is It Keto's audience
A few weeks ago, [Justin Vincent](https://nugget.one/jv) reached out to me. He's a serial entrepreneur and founder of [The Nugget Startup Academy](https://nugget.one). He'd been enjoying my blog and wanted to know if I'd be open to a Zoom call to brainstorm ideas for monetizing Is It Keto. I agreed, and it led to several useful insights about the business.
The first thing that surprised me was how highly Justin viewed Is It Keto's visitor stats.
>**Justin**: How many uniques do you get per week?<br>
**Me**: Around ten thousand.<br>
**Justin**: Wow. You're sitting on a goldmine.<br>
Top keto recipe blogs get ~3M unique visitors per month, so my 40-50k felt like nothing. Justin argued that one of the hardest parts of launching a product is finding interested customers, but if I have access to 10,000 people each week interested in keto, that's a huge leg up.
>**Justin**: When you look at existing keto communities, what do you notice people struggling with? What issues come up a lot?<br>
>**Me**: I don't know. I feel like most of the discussion revolves around people sharing progress and other members congratulating them.<br>
>**Justin**: Congratulating each other... That's interesting. Have you seen [wip.chat](https://wip.chat/)?
{{< img src="wip.chat.png" alt="Screenshot of wip.chat" hasBorder="true" maxWidth="650px" caption="[wip.chat](https://wip.chat/), a popular social network for independent software developers" >}}
[wip.chat](https://wip.chat/) is a popular social network for indie developers. Non-members can view some of the content, but you need to be a member to post anything, and that costs $20/month. Their pitch is that the wip.chat community helps you build your product by holding you accountable to your project's milestones.
The more we talked about a wip.chat for keto, the more I liked the idea. All the social networks I've seen for keto use generic tools: Facebook groups, subreddits, Discord channels. What if there was a tool specifically for keto dieters? Over the next week, I brainstormed 25 more ideas, but the wip.chat clone remained at the top of my list.
This week, I'm going to create a landing page for this theoretical keto social network and advertise it on Is It Keto. I'll include a signup button, but when the user tries to pay, they'll see a message saying something like, "I'm still building this site, but you can sign up for this mailing list to find out when it's ready."
Another great insight that came out of the conversation was around partnerships:
>**Justin**: Once you create your membership product, you can make direct partnerships and affiliate deals with other keto businesses.<br>
**Me**: But I already have visitors. Why wouldn't I do that now?<br>
**Justin**: Good question. Why **wouldn't** you do that now?
This is why it's valuable to have an outsider's perspective. I tried approaching other keto companies for affiliate deals early in Is It Keto's life, but I was too small, so most of them ignored me. With 100k monthly pageviews, Is It Keto is significant enough that partnerships are viable. I just forgot to revisit the idea because it had been infeasible for so long. But what's stopping me from contacting keto businesses advertising on my site via AdSense to ask if they want to set up a deal with me directly?
{{< img src="keto-advertiser.png" alt="Screenshot of wip.chat" hasBorder="true" maxWidth="400px" caption="Maybe I can just make a direct deal with this advertiser instead of working through Google AdSense." >}}
## Improving Is It Keto's browser performance
Through most of Is It Keto's life, performance has been an afterthought. Occasionally, I've fixed components that were causing noticeable slowdowns, but I rarely design for speed.
Given that Google drives 90% of the site's visitors, and [Google uses performance as a metric in ranking search results](https://developers.google.com/web/updates/2018/07/search-ads-speed), I spent a few days identifying bottlenecks on Is It Keto. I use the [Gridsome](https://gridsome.org) framework for generating Is It Keto's contents, so [this article](https://www.codegram.com/blog/improving-a-gridsome-website-performance/) helped me achieve a few performance gains.
| Change | Performance impact |
|--------|--------------------|
| Load Bootstrap-Vue components [a la carte](https://bootstrap-vue.org/docs#individual-components-and-directives) instead of importing all of Bootstrap-Vue and Bootstrap-Vue-Icons | High |
| Filter my Gridsome data [at the graphql layer](https://gridsome.org/docs/filtering-data/) rather than at the Vue layer to reduce the size of static JSON files | High |
| Undid [this hack](https://dev.to/jeremyjackson89/gridsome-g-images-with-dynamic-paths-1mgn) for loading images in Gridsome with dynamic paths | Medium |
| Import Google Fonts using a `<link rel>` tag instead of a CSS `@import` | Low |
| Tune the Google Fonts URL to download only the fonts I need | Low |
| Add [`preconnect` and `dns-prefetch` for Google Fonts](https://www.smashingmagazine.com/2019/06/optimizing-google-fonts-performance/) in the HTML `<head>` | Low |
| [Add `?display=swap`](https://fontsplugin.com/google-fonts-font-display-swap/) to my Google Fonts import URL to prevent "Flash of Invisible Text" | Low |
Everyone talks about using [webpack-bundle-analyzer](https://www.npmjs.com/package/webpack-bundle-analyzer) to look for large components in your JS bundle. I felt crazy because I couldn't find any instructions on how to actually use it. All the instructions basically say:
1. `npm install webpack-bundle-analyzer`
1. ???
1. Look at the useful visualization in your browser.
But they never explain **how** you actually generate the visualization. I finally figured out that the missing step 2 is to plug webpack-bundle-analyzer into your build (varies by stack, but [here](https://www.codegram.com/blog/improving-a-gridsome-website-performance/#avoid-enormous-network-payloads-and-minimize-main-thread-work) is how to do it on Gridsome). Then the next time you build your app, you'll see a line like this:
```
Webpack Bundle Analyzer saved report to /home/user/isitketo/dist/report.html
```
And then if you open `report.html`, you'll see the visualization everyone's talking about.
## Web performance is harder than I thought
Is It Keto originally ran on App Engine under Python 2. Given my renewed focus on the site, coupled with Google's plans to [end support for Python 2](https://cloud.google.com/appengine/docs/standard/python/migrate-to-python3/), Back in April, I decided to rewrite the site. I chose [Gridsome](https://gridsome.org), a Vue-based static site generator.
It seemed like I'd get the best of both worlds: the performance of a pre-rendered website and the flexible developer experience of Vue. It turns out that web performance is a bit more complicated than I realized.
I *thought* that the browser would just render all the pre-generated HTML and then evaluate the JavaScript in the background. It turns out that browsers *really* want to evaluate JavaScript before doing anything else. Even though on Is It Keto, my `<script>` tags are at the very bottom of my HTML and they have the `defer` attribute, they still tank my performance metrics:
{{< gallery caption="If I delete the `<script>` tags on Is It Keto, its [Lighthouse score](https://developers.google.com/web/tools/lighthouse) jumps 40 points, but then the site becomes non-functional." >}}
{{< img src="with-scripts.png" alt="Lighthouse score of 47 with scripts enabled" hasBorder="true" >}}
{{< img src="without-scripts.png" alt="Lighthouse score of 87 with scripts deleted" hasBorder="true" >}}
{{</ gallery >}}
Vue 3, due out in the next few months, is supposed to improve performance due to [tree shaking](https://vueschool.io/articles/vuejs-tutorials/faster-web-applications-with-vue-3/). That means it will be able to reduce the size of your JavaScript payload by eliminating unused framework code. Gridsome claims that [their 1.0 release will be Vue 3 compatible](https://twitter.com/gridsome/status/1265742280805285896), but they seem so constrained by developer resources that I'm worried that it could be years before they ever get there.
## Raspberry Pi as a virtual keyboard and monitor
I've been working on a hobby project for the past few weeks that I don't think will turn into a business, but maybe there's a market for it.
My [current server](/building-a-vm-homelab/) is headless, so there's no keyboard or monitor attached. I just interact with it over SSH. The problem is that if the OS fails to load or I want to change BIOS settings, I'm stuck — I have to drag the whole server over to my desk and attach my desktop monitor and keyboard to access the server.
For my next server, I've dreamed about getting some sort of virtual console. There are enterprise solutions like [Dell's iDRAC](https://en.wikipedia.org/wiki/Dell_DRAC) and [HP's iLO](https://en.wikipedia.org/wiki/HP_Integrated_Lights-Out), but they add several hundred dollars to a server's cost. There are also [KVM over IP devices](https://smile.amazon.com/Lantronix-1PORT-Remote-Spider-SLS200USB0-01/dp/B000OH5MDO/), but they also cost $400+ and require bloated client software.
For the past few weeks, I've been trying to build the poor-man's remote console with a [Raspberry Pi 4](https://www.raspberrypi.org/products/raspberry-pi-4-model-b/). The keyboard part works great over the network:
{{< video src="keyboard-demo_2020-05-28.mp4" caption="I got a Raspberry Pi to work as a browser-controlled keyboard" >}}
Displaying video from the target machine is trickier, but I have it working now with about 1 second of latency. Here's what that looks like:
{{< video src="kvmpi-demo.mp4" caption="I got a Raspberry Pi to work as a browser-controlled keyboard" >}}
Right now, the video appears in a separate window, but I'm working on embedding it directly in the webpage.
I'm writing a blog post that will explain everything in more detail, but if you want to peek at the source code, it's public though not fully documented yet:
* [key-mime-pi](https://github.com/mtlynch/key-mime-pi.git): Web server for forwarding keystrokes to the Raspberry Pi's virtual keyboard device.
* [ansible-role-key-mime-pi](https://github.com/mtlynch/ansible-role-key-mime-pi): An Ansible role for configuring the Pi's USB gadget functionality (so it can mimic a keyboard) and for installing the web server as a systemd service.
I'm considering selling pre-configured kits for around $180. If you'd be interested in purchasing one, visit:
* [Tiny Pilot KVM](https://tinypilotkvm.com/?ref=mtlynch.io)
## Legacy projects
Here are some brief updates on projects that I still maintain but are not the primary focus of my development:
### [Zestful](https://zestfuldata.com)
{{<revenue-graph project="zestful">}}
| Metric | April 2020 | May 2020 | Change |
| ------------------ | ---------- | --------- | ------------------------------------------- |
| Unique Visitors | 1,142 | 467 | <font color="red">-675 (-59%)</font> |
| Total Pageviews | 2,960 | 1,258 | <font color="red">-1,702 (-57%)</font> |
| RapidAPI Earnings | $32.19 | $6.48 | <font color="red">-$25.71 (-80%)</font> |
| **Total Revenue** | **$32.19** | **$6.48** | **<font color="red">-$25.71 (-80%)</font>** |
For some reason, Zestful got a burst of interest in May. Three customers requested Enterprise pricing. Two of them seem like dead leads, but I might have something that works well for the third. I should know what's going to happen by the end of this week.
## Wrap up
### What got done?
* Increased the number of articles on Is It Keto by 40%.
* Improved Is It Keto's Lighthouse performance by 43 points (from 4 to 47).
* Presented a talk called ["How to be a Sort of Successful Blogger"](https://decks.mtlynch.io/show-and-tell-2020-05/#/) to my peer mentorship group.
### Lessons learned
* Pre-rendered Vue sites still pay a significant performance penalty.
* Talking to a new person about your business helps you reassess your assumptions.
### Goals for next month
* Validate ideas for a sister product to Is It Keto.
* Add 30 new articles to Is It Keto.
* Create a working Pi-based KVM over IP, controllable through the web browser.
| 78.64467 | 534 | 0.72678 | eng_Latn | 0.991812 |
8b42322e8a739db8cda595eada8a3c5d53d9a4d7 | 334 | md | Markdown | README.md | mak001/silverstripe-data-to-arraylist | a5aa94271be2198d37ecffeec94bf9458700b03f | [
"BSD-3-Clause"
] | 2 | 2016-08-02T20:24:04.000Z | 2016-08-02T20:25:18.000Z | README.md | mak001/silverstripe-data-to-arraylist | a5aa94271be2198d37ecffeec94bf9458700b03f | [
"BSD-3-Clause"
] | 2 | 2017-01-25T21:59:47.000Z | 2019-09-21T18:11:13.000Z | README.md | mak001/silverstripe-data-to-arraylist | a5aa94271be2198d37ecffeec94bf9458700b03f | [
"BSD-3-Clause"
] | 6 | 2016-10-01T07:13:16.000Z | 2019-03-19T03:28:09.000Z | # data-to-arraylist
A helper class that converts DataList to ArrayList and allows adding of additional sort options
## Requirements
- SilverStripe 3.2
## Installation
This is how you install data-to-arraylist.
## Example usage
You use data-to-arraylist like this.
## Documentation
See the [docs/en](docs/en/index.md) folder.
| 16.7 | 95 | 0.757485 | eng_Latn | 0.984348 |
8b445c6c5d5b0de468e7546158e3eb32fcbf4b91 | 688 | md | Markdown | README.md | YusufSuleman/cutelog | 3cbbfaadf6311262074b3f8e1e08e54b75011354 | [
"MIT"
] | 3 | 2021-08-02T12:46:48.000Z | 2021-08-02T12:52:44.000Z | README.md | YusufSuleman/cutelog | 3cbbfaadf6311262074b3f8e1e08e54b75011354 | [
"MIT"
] | 1 | 2021-08-06T11:27:46.000Z | 2021-08-06T11:27:46.000Z | README.md | YusufSuleman/cutelog | 3cbbfaadf6311262074b3f8e1e08e54b75011354 | [
"MIT"
] | null | null | null | # Cute Log
Cute Log is a C++ Library that competes to be a unique logging tool.
Version: 2
# Installation
1. Click "Code" on the main repo page (This one.).
2. Open your project in your IDE.
3. Make a folder called "include" or anything else.
4. Extract everything there.
5.
a. Check if you have to add an include directory in your IDE.
b. If yes, then add the folder you created.
6. In the C++ file you are adding it to, write `#include "cutelog.h"` on the top.
7. Write the function `cuteLogExample()` in the `int main` function.
8. Run it!
9. See the console for coloured text that says "ERROR".
10. If you succeded the last step it is done.
11. Read the wiki of this repo.
| 34.4 | 81 | 0.713663 | eng_Latn | 0.999245 |
8b4602e128260b3796b88574ffcb94ab86d3e8a5 | 33 | md | Markdown | README.md | r-edamame/haskell-clean-architecture | e9414742d6c95796b3cff51ffccdb60d6da6b134 | [
"BSD-3-Clause"
] | 3 | 2019-10-26T12:42:42.000Z | 2019-10-26T14:12:34.000Z | README.md | r-edamame/haskell-clean-architecture | e9414742d6c95796b3cff51ffccdb60d6da6b134 | [
"BSD-3-Clause"
] | null | null | null | README.md | r-edamame/haskell-clean-architecture | e9414742d6c95796b3cff51ffccdb60d6da6b134 | [
"BSD-3-Clause"
] | null | null | null | # Clean Architecture in Haskell
| 11 | 31 | 0.787879 | eng_Latn | 0.90343 |
8b4666d2fb2da0b70a137bc96b00a2d5d78b3b64 | 128 | md | Markdown | ru/_includes/iam/roles/short-descriptions/alb.viewer.md | OlesyaAkimova28/docs | 08b8e09d3346ec669daa886a8eda836c3f14a0b0 | [
"CC-BY-4.0"
] | 117 | 2018-12-29T10:20:17.000Z | 2022-03-30T12:30:13.000Z | ru/_includes/iam/roles/short-descriptions/alb.viewer.md | OlesyaAkimova28/docs | 08b8e09d3346ec669daa886a8eda836c3f14a0b0 | [
"CC-BY-4.0"
] | 205 | 2018-12-29T14:58:45.000Z | 2022-03-30T21:47:12.000Z | ru/_includes/iam/roles/short-descriptions/alb.viewer.md | OlesyaAkimova28/docs | 08b8e09d3346ec669daa886a8eda836c3f14a0b0 | [
"CC-BY-4.0"
] | 393 | 2018-12-26T16:53:47.000Z | 2022-03-31T17:33:48.000Z | [`alb.viewer`](../../../../iam/concepts/access-control/roles.md#alb-viewer) — позволяет просматривать объекты ресурсной модели.
| 64 | 127 | 0.726563 | rus_Cyrl | 0.466997 |
8b470d907a91354edea430239e68e82761ff5efc | 5,224 | md | Markdown | _posts/2016-10-05-HOLIDAY-2015-Shailk-FALL-Style-3618-MINT.md | promsome/promsome.github.io | 69236f5c8f4d9591eec55dafa47ce21914b51851 | [
"MIT"
] | null | null | null | _posts/2016-10-05-HOLIDAY-2015-Shailk-FALL-Style-3618-MINT.md | promsome/promsome.github.io | 69236f5c8f4d9591eec55dafa47ce21914b51851 | [
"MIT"
] | null | null | null | _posts/2016-10-05-HOLIDAY-2015-Shailk-FALL-Style-3618-MINT.md | promsome/promsome.github.io | 69236f5c8f4d9591eec55dafa47ce21914b51851 | [
"MIT"
] | null | null | null | ---
layout: post
date: 2016-10-05
title: "HOLIDAY 2015 Shailk FALL Style 3618 MINT"
category: HOLIDAY 2015
tags: [HOLIDAY 2015]
---
### HOLIDAY 2015 Shailk FALL Style 3618 MINT
Just **$639.99**
###
<a href="https://www.readybrides.com/en/holiday-2015/81788-shailk-fall-holiday-2015-style-3618-mint.html"><img src="//img.readybrides.com/206535/shailk-fall-holiday-2015-style-3618-mint.jpg" alt="Shailk FALL HOLIDAY 2015 Style 3618 MINT" style="width:100%;" /></a>
<!-- break --><a href="https://www.readybrides.com/en/holiday-2015/81788-shailk-fall-holiday-2015-style-3618-mint.html"><img src="//img.readybrides.com/206536/shailk-fall-holiday-2015-style-3618-mint.jpg" alt="Shailk FALL HOLIDAY 2015 Style 3618 MINT" style="width:100%;" /></a>
<a href="https://www.readybrides.com/en/holiday-2015/81788-shailk-fall-holiday-2015-style-3618-mint.html"><img src="//img.readybrides.com/206537/shailk-fall-holiday-2015-style-3618-mint.jpg" alt="Shailk FALL HOLIDAY 2015 Style 3618 MINT" style="width:100%;" /></a>
<a href="https://www.readybrides.com/en/holiday-2015/81788-shailk-fall-holiday-2015-style-3618-mint.html"><img src="//img.readybrides.com/206538/shailk-fall-holiday-2015-style-3618-mint.jpg" alt="Shailk FALL HOLIDAY 2015 Style 3618 MINT" style="width:100%;" /></a>
<a href="https://www.readybrides.com/en/holiday-2015/81788-shailk-fall-holiday-2015-style-3618-mint.html"><img src="//img.readybrides.com/206539/shailk-fall-holiday-2015-style-3618-mint.jpg" alt="Shailk FALL HOLIDAY 2015 Style 3618 MINT" style="width:100%;" /></a>
<a href="https://www.readybrides.com/en/holiday-2015/81788-shailk-fall-holiday-2015-style-3618-mint.html"><img src="//img.readybrides.com/206540/shailk-fall-holiday-2015-style-3618-mint.jpg" alt="Shailk FALL HOLIDAY 2015 Style 3618 MINT" style="width:100%;" /></a>
<a href="https://www.readybrides.com/en/holiday-2015/81788-shailk-fall-holiday-2015-style-3618-mint.html"><img src="//img.readybrides.com/206541/shailk-fall-holiday-2015-style-3618-mint.jpg" alt="Shailk FALL HOLIDAY 2015 Style 3618 MINT" style="width:100%;" /></a>
<a href="https://www.readybrides.com/en/holiday-2015/81788-shailk-fall-holiday-2015-style-3618-mint.html"><img src="//img.readybrides.com/206542/shailk-fall-holiday-2015-style-3618-mint.jpg" alt="Shailk FALL HOLIDAY 2015 Style 3618 MINT" style="width:100%;" /></a>
<a href="https://www.readybrides.com/en/holiday-2015/81788-shailk-fall-holiday-2015-style-3618-mint.html"><img src="//img.readybrides.com/206543/shailk-fall-holiday-2015-style-3618-mint.jpg" alt="Shailk FALL HOLIDAY 2015 Style 3618 MINT" style="width:100%;" /></a>
<a href="https://www.readybrides.com/en/holiday-2015/81788-shailk-fall-holiday-2015-style-3618-mint.html"><img src="//img.readybrides.com/206544/shailk-fall-holiday-2015-style-3618-mint.jpg" alt="Shailk FALL HOLIDAY 2015 Style 3618 MINT" style="width:100%;" /></a>
<a href="https://www.readybrides.com/en/holiday-2015/81788-shailk-fall-holiday-2015-style-3618-mint.html"><img src="//img.readybrides.com/206545/shailk-fall-holiday-2015-style-3618-mint.jpg" alt="Shailk FALL HOLIDAY 2015 Style 3618 MINT" style="width:100%;" /></a>
<a href="https://www.readybrides.com/en/holiday-2015/81788-shailk-fall-holiday-2015-style-3618-mint.html"><img src="//img.readybrides.com/206546/shailk-fall-holiday-2015-style-3618-mint.jpg" alt="Shailk FALL HOLIDAY 2015 Style 3618 MINT" style="width:100%;" /></a>
<a href="https://www.readybrides.com/en/holiday-2015/81788-shailk-fall-holiday-2015-style-3618-mint.html"><img src="//img.readybrides.com/206547/shailk-fall-holiday-2015-style-3618-mint.jpg" alt="Shailk FALL HOLIDAY 2015 Style 3618 MINT" style="width:100%;" /></a>
<a href="https://www.readybrides.com/en/holiday-2015/81788-shailk-fall-holiday-2015-style-3618-mint.html"><img src="//img.readybrides.com/206548/shailk-fall-holiday-2015-style-3618-mint.jpg" alt="Shailk FALL HOLIDAY 2015 Style 3618 MINT" style="width:100%;" /></a>
<a href="https://www.readybrides.com/en/holiday-2015/81788-shailk-fall-holiday-2015-style-3618-mint.html"><img src="//img.readybrides.com/206549/shailk-fall-holiday-2015-style-3618-mint.jpg" alt="Shailk FALL HOLIDAY 2015 Style 3618 MINT" style="width:100%;" /></a>
<a href="https://www.readybrides.com/en/holiday-2015/81788-shailk-fall-holiday-2015-style-3618-mint.html"><img src="//img.readybrides.com/206550/shailk-fall-holiday-2015-style-3618-mint.jpg" alt="Shailk FALL HOLIDAY 2015 Style 3618 MINT" style="width:100%;" /></a>
<a href="https://www.readybrides.com/en/holiday-2015/81788-shailk-fall-holiday-2015-style-3618-mint.html"><img src="//img.readybrides.com/206551/shailk-fall-holiday-2015-style-3618-mint.jpg" alt="Shailk FALL HOLIDAY 2015 Style 3618 MINT" style="width:100%;" /></a>
<a href="https://www.readybrides.com/en/holiday-2015/81788-shailk-fall-holiday-2015-style-3618-mint.html"><img src="//img.readybrides.com/206534/shailk-fall-holiday-2015-style-3618-mint.jpg" alt="Shailk FALL HOLIDAY 2015 Style 3618 MINT" style="width:100%;" /></a>
Buy it: [https://www.readybrides.com/en/holiday-2015/81788-shailk-fall-holiday-2015-style-3618-mint.html](https://www.readybrides.com/en/holiday-2015/81788-shailk-fall-holiday-2015-style-3618-mint.html)
| 163.25 | 280 | 0.74732 | yue_Hant | 0.357759 |
8b48232e3e69a546ae2f43ef3d89c660437c6b7c | 335 | md | Markdown | _project/25-amazing-platform-beds-for-your-inspiration.md | rumnamanya/rumnamanya.github.io | 2deadeff04c8a48cf683b885b7fa6ab9acc1d9d9 | [
"MIT"
] | null | null | null | _project/25-amazing-platform-beds-for-your-inspiration.md | rumnamanya/rumnamanya.github.io | 2deadeff04c8a48cf683b885b7fa6ab9acc1d9d9 | [
"MIT"
] | null | null | null | _project/25-amazing-platform-beds-for-your-inspiration.md | rumnamanya/rumnamanya.github.io | 2deadeff04c8a48cf683b885b7fa6ab9acc1d9d9 | [
"MIT"
] | null | null | null | ---
layout: project_single
title: "25 Amazing Platform Beds For Your Inspiration"
slug: "25-amazing-platform-beds-for-your-inspiration"
parent: "diy-bedroom-furniture-ideas"
---
Here is a collection of 25 Amazing Platform Beds For Your Inspiration. Not all of these options may be what you need or looking for but perhaps they'll give | 47.857143 | 156 | 0.785075 | eng_Latn | 0.989348 |
8b483f9611a32bc82c5f91f5242749ec89d5dde4 | 29 | md | Markdown | java/episim-webapp/src/main/frontend/README.md | krevelen/rivm-vacsim | 73b7910ecba030b4e1d5870a2f550f71941e5a76 | [
"Apache-2.0"
] | 1 | 2019-02-28T11:06:52.000Z | 2019-02-28T11:06:52.000Z | java/episim-webapp/src/main/frontend/README.md | krevelen/rivm-vacsim | 73b7910ecba030b4e1d5870a2f550f71941e5a76 | [
"Apache-2.0"
] | 2 | 2020-05-15T20:28:35.000Z | 2021-01-20T22:33:23.000Z | java/episim-webapp/src/main/frontend/README.md | krevelen/rivm-vacsim | 73b7910ecba030b4e1d5870a2f550f71941e5a76 | [
"Apache-2.0"
] | 1 | 2021-01-08T12:17:29.000Z | 2021-01-08T12:17:29.000Z | Episim Mobile
=============
| 7.25 | 13 | 0.413793 | oci_Latn | 0.661092 |
8b49387c38d644db85e72563df746491f4df902d | 2,519 | md | Markdown | _posts/2018-08-07-sholat-khouf-karena-gempa.md | mdroyyan/mdroyyan.github.io | 3fc219fb693b0296c540c1462c4dcae46b1eee6f | [
"MIT"
] | null | null | null | _posts/2018-08-07-sholat-khouf-karena-gempa.md | mdroyyan/mdroyyan.github.io | 3fc219fb693b0296c540c1462c4dcae46b1eee6f | [
"MIT"
] | null | null | null | _posts/2018-08-07-sholat-khouf-karena-gempa.md | mdroyyan/mdroyyan.github.io | 3fc219fb693b0296c540c1462c4dcae46b1eee6f | [
"MIT"
] | null | null | null | ---
title: "Sholat Khouf Karena Gempa"
excerpt: "Shalat fardhu saat gempa? Sebuah solusi ketika keadaan darurat!"
categories:
- Keislaman
tags:
- Ied
- Budaya
- Tradisi
---
_Oleh: Mohammad Danial Royyan_
### I. Pertanyaan
Pak Kiai mau tanya... kalau seumpama seseorang lagi jalankan sholat fardlu terus ada gempa yang dahsyat sehingga ada rasa takut kalau melanjutkan sholat, maka apakah dia harus melanjutkan sholat atau dibolehkan membatalkan sholat untuk mencari tempat lain yang aman ? Matur nuwun...
### II. Jawaban
Sholat fardlu itu kalau sudah dijalankan maka wajib diselesaikan dan hukum membatalkannya adalah haram, sebagaimana hukum membatalkan sholat sunnah adalah makruh. Oleh karena itu, kalau ada orang sedang jalankan sholat fardlu kemudian terjadi gempa bumi yang dahsyat sehingga jiwa musholli terancam keselamatannya, maka diperbolehkan melanjutkan sambil jalan untuk menghidari reruntuhan yang akan menimpa musholli, dan itu namanya **Sholat Syiddatil Khouf** bukan sekedar sholat khouf.
Sholat syiddatil khouf adalah sholat yang dilakukan dalam keadaan darurat dan gawat sehingga musholli bisa melakukan shalat sebisa-bisanya, dalam keadaan berjalan kaki, berlari atau mengendarai kendaraan, dengan menghadap atau tidak menghadap kiblat. Yang penting shalat itu harus dilakukan meskipun dengan cara yang bebas tanpa ikatan. Allah berfirman:
فَإِنْ خِفْتُمْ فَرِجَالاً أَوْ رُكْبَانًا – البقرة ٢٣٩
{: .text-right}
Artinya: *“Jika kamu dalam keadaan takut (bahaya), maka salatlah sambil berjalan atau berkendaraan.”* (Q.S Al-Baqarah ayat: 239)
### III. Referensi
من صور صلاة الخوف صلاة شدة الخوف وذلك عند التحام القتال وعدم التمكن من تركه لاحد، أو اشتد الخوف وإن لم يلتحم القتال، فلم يأمنوا أن يهجموا عليهم لو ولوا عنهم أو انقسموا، فيصلون رجالا ومشاة على الاقدام وركبانا مستقبلي القبلة واجبا مع التمكن، وغير مستقبليها مع عدمه على حسب الامكان. فإن تمكنوا من استيفاء الركوع والسجود، وجب، وإلا أو مأوا لركوعهم وسجودهم، ويكون السجود أخفض من الركوع. ولو تمكنوا من أحدهما، وجب، ويتقدمون ويتأخرون، لقوله تعالى: فَإِنْ خِفْتُمْ فَرِجَالًا أَوْ رُكْبَانًا - البقرة: 239.وعن النبي صلى الله عليه وآله، قال: مستقبلي القبلة وغير مستقبليها
{: .text-right}
ومن طريق الخاصة: قول الباقر رضي الله عنه في صلاة الخوف عند المطاردة والمناوشة وتلاحم القتال: يصلي كل إنسان منهم بالإيماء حيث كان وجهه .إذا عرفت هذا، فإن هذه الصلاة صحيحة لا يجب قضاؤها عند علمائنا أجمع - وبه قال الشافعي - لاقتضاء الامر الاجزاء.
{: .text-right}
ولأنه يجوز ذلك في النافلة اختيارا، فجاز في الفريضة اضطرارا.
{: .text-right}
| 61.439024 | 562 | 0.780468 | ind_Latn | 0.5484 |
8b4a3018b422dae46220d6b9a819e5e56344ea5c | 2,938 | md | Markdown | src/af/2021-03/01/07.md | Pmarva/sabbath-school-lessons | 0e1564557be444c2fee51ddfd6f74a14fd1c45fa | [
"MIT"
] | 68 | 2016-10-30T23:17:56.000Z | 2022-03-27T11:58:16.000Z | src/af/2021-03/01/07.md | Pmarva/sabbath-school-lessons | 0e1564557be444c2fee51ddfd6f74a14fd1c45fa | [
"MIT"
] | 367 | 2016-10-21T03:50:22.000Z | 2022-03-28T23:35:25.000Z | src/af/2021-03/01/07.md | Pmarva/sabbath-school-lessons | 0e1564557be444c2fee51ddfd6f74a14fd1c45fa | [
"MIT"
] | 109 | 2016-08-02T14:32:13.000Z | 2022-03-31T10:18:41.000Z | ---
title: Stof tot Nadenke
date: 02/07/2021
---
“Volgens die destydse rabbi’s was ’n lewe gevul met ’n magdom werke die somtotaal van ’n opregte geloofslewe. Die vertoon van korrekte handeling was die groot bewys vir hul superieure vroomheid. [So het] die rabbi’s dan hulself van God geskei. Eiegeregtigheid is gekoester. Tog loop ons vandag steeds dieselfde gevaar. Gelowiges raak vreeslik besig en behaal sukses in hul onderskeie bedienings. Dit kan egter uitloop op ’n vertroue in die mens en sy [of haar] planne en metodes. Die neiging om minder te bid en minder geloof aan die dag te lê, steek kop uit. Soos die dissipels van ouds loop ons die gevaar om ons afhanklikheid aan God uit die oog te verloor, en so begin ons om ons aktiwiteite ons verlosser te maak. Ons behoort [eerder] voortdurend die oog op Jesus gerig te hou, met die besef dat die werk van God deur sý mag verrig word. Hoewel ons ons aktief en opreg vir sieleredding moet beywer, moet ons ook tyd vir bepeinsing, gebed en die bestudering van Gods Woord inruim. Slegs die werk van God wat met vele gebed verrig word en wat deur die verdienste van Christus geheilig word, sal uiteindelik as doeltreffend en heilsaam bewys word” (Ellen G. White, The Desire of Ages, bl. 362).
**Besprekingspunte**
`Die konstante druk van voor bly in ’n aktiwiteit-gevulde lewe, om altyd beskikbaar te wees (hetsy liggaamlik of aanlyn), en om ideale na te streef wat onrealisties en mensgemaak is – hierdie dinge kan ’n mens se gesondheid aantas – en kan jou emosioneel, liggaamlik of geestelik siek maak. Hoe kan die gemeente ’n meer verwelkomende tuiste word vir diegene wat afgemat is, vir al die moeë siele wat smag na ware rus?`
`Is ons as gelowiges dalk te bedrywig, selfs met die werk van die Here? Dink ’n bietjie aan die verhaal van Jesus en sy dissipels in Markus 6:30-32. Hoe kan ’n mens dit toepas? Bespreek dit tydens Sabbatskool in klasverband.`
`In 1899 is ’n spoedrekord gebreek. Iemand het dit reggekry om 63.15 kilometer per uur in ’n motorkar te haal – en boonop sonder om te verongeluk! Vandag se motors ry natuurlik heelwat vinniger as dit. Insgelyks is die spoed van die prosessors in ons selfone aansienlik vinniger as die vorige generasie se vinnigste groot rekenaars. Lugvaart is ook vinnig as wat dit eens op ’n tyd was, en daardie spoed neem boonop toe. Die punt is dat bykans alles wat ons deesdae doen vinniger as in die verlede is. Beteken dit egter veel? Ons bly gejaagd en kry steeds nie genoeg rus nie. Wat sê dit vir ’n mens oor die aard van die mens en hoekom die Here rus so belangrik geag het dat Hy dit by die tien gebooie ingesluit het?`
`Die Sabbatsrus is reeds in Eden, voor die sondeval, ingestel. Bedink dit ’n bietjie. Dié bybelwaarheid het natuurlik interessante teologiese implikasies. Watter belangrike punt bring dit egter tuis aangaande die mens se behoefte aan rus, en dit toe die wêreld nog ’n volmaakte en sondelose plek was?` | 183.625 | 1,196 | 0.786249 | afr_Latn | 0.999993 |
8b4a326f8091d3a7bd52c2d21f8aea275910acab | 7,791 | markdown | Markdown | _posts/posts/2016-04-26-in-quest-of-a-better-coffee.markdown | miharekar/mrfoto.github.io | 0aea7543f4a068ae134ed28c01d09fa506419714 | [
"MIT"
] | 1 | 2015-04-29T10:26:59.000Z | 2015-04-29T10:26:59.000Z | _posts/posts/2016-04-26-in-quest-of-a-better-coffee.markdown | mrfoto/mrfoto.github.io | 0aea7543f4a068ae134ed28c01d09fa506419714 | [
"MIT"
] | 6 | 2020-09-16T06:36:08.000Z | 2021-12-29T18:04:54.000Z | _posts/posts/2016-04-26-in-quest-of-a-better-coffee.markdown | mrfoto/mrfoto.github.io | 0aea7543f4a068ae134ed28c01d09fa506419714 | [
"MIT"
] | null | null | null | ---
layout: post
category: posts
title: In Quest of a Better Coffee
excerpt: My coffee story - from Portland to Aeropress and eventually home espresso
tags: [coffee, aeropress, portland, espresso, baratza]
comments: true
---
Today when I opened up *On This Day*[^1] I saw a memory of a life-changing event from 3 years ago. Before that time I was getting my caffeine high from Chinese teas[^2] but on 26th of April 2013 *everything changed*.
I was meandering around Portland and I still vividly remember walking into [Courier Coffee](http://www.couriercoffeeroasters.com/). It was a *hole in a wall* kind of coffee shop, but it had a great rating on Foursquare. I ordered a double shot latte.
After the first sip my mind was blown - *this is what coffee is supposed to taste like*? I've never experienced flavors like that. Coffee is **bitter** and **dark** - not **sweet** and **flavorful**.
**WHAT IS THIS SORCERY**?
<figure>
<a href="https://www.instagram.com/p/YlQmuJrC4A/">
<img src="/images/posts/2016-04-26-courier-coffee.jpg">
</a>
</figure>
Ever since that moment I've been going from one coffee place to another. And no matter where I went I couldn't believe all the flavors my tongue was being bombarded with. Citrusy, nutty, berrylike, chocolaty,…the list went on and on.
I got so used to ordering espresso that when I was waiting for my flight home at the Schiphol airport I ordered one. That was a blast back to reality.
Back home I went from one café to another, but no matter where I went - bitter and dark was there. So called *3rd wave coffee* was nowhere to be found. Mind you - **Slovenia** is #4 country on coffee consumption per capita in the world[^3]. You'd think we'd know how to make our coffee. Unfortunately that is not the case.
The majority of people buy pre-ground coffee blends of questionable origins. The drink is usually made with džezva[^4] where they add coffee to boiling water and let it boil over 3 times. Now you know why it's so bitter.
And don't think that you can get anything better in cafés. They use Italian roasted[^5] blends of questionable origins. If you're in luck they're by *famous* brands like Illy, Julius Meinl, or Lavazza. It's rarely ground on-demand and espresso machine hygiene is non-existent. Consequently the resulting cup of joe is bitter and has burnt, almost ashy taste. Of course you can't drink that as an espresso, which is why by far the most popular drink here is "z mlekom"[^6].
I slowly forgot about the amazing experience until I went to [ArrrrCamp](http://arrrrcamp.be) in 2014. There I walked into [Or Espresso Bar](https://www.orcoffee.be/) by accident. And what a happy accident it was - with the first sip I was back in Portland. Damn, I missed this.
<figure>
<a href="https://www.instagram.com/p/trkZUcLC8O/">
<img src="/images/posts/2016-04-26-or-espresso-bar.jpg">
</a>
</figure>
This time I wouldn't give up so easy. I wanted to experience this taste at home. The first step to great coffee at home is a good coffee maker. After lots of research I settled for [Aeropress](http://www.aerobie.com/product/aeropress/). Immediately the dark liquid tasted **much better**. Even with the questionable origins pre-ground coffee.
By now I've experienced almost all pour-over and full-immersion coffee preparations and Aeropress is still my favorite way to make filter coffee. It's cheap, it's simple, it's fast, it's easy to cleanup, and you can experiment with all the variables[^7].
Next gizmo was the grinder. All I knew about grinders back then was that they should have a burr, not a blade. I got the cheapest one I could find - De'Longhi KG79. It made **all the difference** to have freshly ground coffee.
The final step in preparing good coffee are good beans. Around that time I discovered we have a micro roastery in Slovenia - [Escobar](http://www.escobar.si/). I started purchasing their beans and home coffee quality went through the roof[^8].
Soon thereafter I became aware of the grind inconsistencies so I've upgraded to [Baratza Encore](http://www.baratza.com/grinder/encore/). I loved that grinder but when I got a great deal on [Baratza Virtuoso](http://www.baratza.com/grinder/virtuoso/) I couldn't resist. After a while I also got [Brewista](http://brewista.eu/) Smart Scale and Smart Kettle. Not because I *needed* to, but because I *wanted* to.
<figure>
<a href="https://www.instagram.com/p/96Fek9LC92/">
<img src="/images/posts/2016-04-26-brewista-baratza-setup.jpg">
</a>
</figure>
That was and is more or less my setup for producing excellent coffee at home. It's also my recommendation for anyone that wants to experience better coffee. Aeropress, Baratza Encore, and ideally a variable temperature kettle. Along with some high quality coffee beans this will produce the best coffee you ever had.
As far as the coffee beans go 3rd wave is slowly hitting Slovenia as well. Besides aforementioned Escobar we have [moderna](https://www.facebook.com/kavarnamoderna/), [Buna](http://www.buna.si/), [Iconic](http://www.coffeeiconic.com/), and [Coronini](https://www.facebook.com/Coroninicafe). But the best way to get truly high quality beans is still to order from abroad. My preferred way to do that is [The Coffee Roasters](https://thecoffeeroasters.co.uk/?ref=miha.rekar) coffee subscription. It's completely personalized and the flavors coffee can deliver blow me away almost every month.
You know how above I said that I have "more or less" the same setup today? There was one notable addition to the setup lately and it changed everything. *Again*. Here's a hint:
<figure>
<a href="https://www.instagram.com/p/BB4_X-9rC0k/">
<img src="/images/posts/2016-04-26-alex-duetto-iii.jpg">
</a>
</figure>
Yup, I got an espresso machine. I wanted to get one ever since I had that first sip of coffee in Portland and was unable to get similar coffee in Slovenia. I've read countless forum posts, watched way too many YouTube videos[^9], and finally settled on [Izzo Alex Duetto](http://www.alexduetto.com/). Main reasons being dual boiler system, PID, rotary pump, E61 group, and relative affordability. If these words don't mean anything to you, don't worry. I've been living in a coffee forum bubble where this is all that matters.
Making an espresso is **much harder** than Aeropress or any other method. So many things can go wrong, so many variables must be *just right*. I've spent a lot of time on YouTube again, and I have to thank [European Coffee Trip](http://europeancoffeetrip.com/) for the fantastic [Learn Coffee with Gwilym](https://youtu.be/DdGKesjMMxg?list=PLtil0MLa0-7vNg_ovLcSHDT1O0pbCPuPM) series.
Anyway I now make a decent espresso and a good latte and I still have much to learn. It's not yet at Portland level, but I'm way beyond anything I can get in any local cafe. I love it.
With all that said I would **not recommend** anyone to get into home espresso. Unless you're a lunatic. Like me. But you should **totally** have an Aeropress at home. No doubt.
[^1]: One of the rare features I still use on Facebook
[^2]: Mainly high quality ones from [Daoli](http://daoli.eu/). They're the best!
[^3]: According to [2013 Euromonitor data](http://www.caffeineinformer.com/caffeine-what-the-world-drinks)
[^4]: AKA [Cezve, Ibrik,…](https://en.wikipedia.org/wiki/Cezve)
[^5]: Very dark, almost black, way past the second crack - just before the bean would turn to ash
[^6]: Something like Cortado or Gibraltar - basically a small cup single shot latte
[^7]: Temperature, grind size, time, and coffee to water ratio
[^8]: Compared to anything I had before
[^9]: Damn you, [Prima Coffee Equipment](https://www.youtube.com/user/primacoffeeequipment) and [Seattle Coffee Gear](https://www.youtube.com/user/SeattleCoffeeGear)
| 89.551724 | 590 | 0.756514 | eng_Latn | 0.997256 |
8b4a8737a773ed8e3703741f46cc930bde673500 | 588 | md | Markdown | README.md | Bam-lak/Car-shoow-room-Website | 766cdf3d45b3994482d14b0446c58284a4ce8f71 | [
"MIT"
] | 1 | 2021-04-26T16:18:39.000Z | 2021-04-26T16:18:39.000Z | README.md | Bam-lak/Car-shoow-room-Website | 766cdf3d45b3994482d14b0446c58284a4ce8f71 | [
"MIT"
] | null | null | null | README.md | Bam-lak/Car-shoow-room-Website | 766cdf3d45b3994482d14b0446c58284a4ce8f71 | [
"MIT"
] | null | null | null | # Car-shoow-room-Website
The web-app I have developed is car show room and booking.
=> To make the system functional, you have to import the database from the database file (NB please use the name specified in the database) in mysql
=> The system has two independent logins i.e Admin and Customer
=> To enter to admin all you have to do is register first
=> To enter to the the admin you have to specify the location(localhost/car-showroom/Car_show_room_and_booking/admin/admin/adminlogin.php)
=> The username and password to login to the admin page is admin and admin respectively.
| 45.230769 | 148 | 0.782313 | eng_Latn | 0.999051 |
8b4ae2642abaf185c21f09a4bb09293d22452c02 | 134 | md | Markdown | CHANGELOG.md | Dimimo/textsnippet | ee5219e61aea1b200627952c7def2a22fc971c25 | [
"MIT"
] | 10 | 2017-07-29T11:10:13.000Z | 2020-09-29T12:16:21.000Z | CHANGELOG.md | Dimimo/textsnippet | ee5219e61aea1b200627952c7def2a22fc971c25 | [
"MIT"
] | 3 | 2020-04-22T07:38:07.000Z | 2020-09-12T08:37:25.000Z | CHANGELOG.md | Dimimo/textsnippet | ee5219e61aea1b200627952c7def2a22fc971c25 | [
"MIT"
] | 3 | 2017-07-29T23:30:06.000Z | 2020-09-12T08:28:55.000Z | # 1.0.0
* Initial release.
# 3.0.0
* Add codestyle checks and modernize code to use proper new PHP features. (thanks @janbarasek)
| 14.888889 | 94 | 0.708955 | eng_Latn | 0.986343 |
8b4b39710811640b75f5979faeccf8c2a036e31a | 77 | md | Markdown | README.md | daanheikens/TaskManager | 0681f5c46b8a340de8f018e6ced472b196fcd583 | [
"MIT"
] | null | null | null | README.md | daanheikens/TaskManager | 0681f5c46b8a340de8f018e6ced472b196fcd583 | [
"MIT"
] | null | null | null | README.md | daanheikens/TaskManager | 0681f5c46b8a340de8f018e6ced472b196fcd583 | [
"MIT"
] | null | null | null | # TaskManager
A PHP taskmanager to structure complex and/or linear processes
| 25.666667 | 62 | 0.831169 | eng_Latn | 0.863543 |
8b4b5deaffda7fe11487d72e956cae07c6746f78 | 38 | md | Markdown | README.md | recerca/cinemaandtheatre | 665df77df86a49a7dbebe8cc661c5972b89f100e | [
"CC0-1.0"
] | null | null | null | README.md | recerca/cinemaandtheatre | 665df77df86a49a7dbebe8cc661c5972b89f100e | [
"CC0-1.0"
] | null | null | null | README.md | recerca/cinemaandtheatre | 665df77df86a49a7dbebe8cc661c5972b89f100e | [
"CC0-1.0"
] | null | null | null | # cinemaandtheatre
Cinema and Theatre
| 12.666667 | 18 | 0.842105 | eng_Latn | 0.884529 |
8b4d0cd07faa41eed2e9df4271f1a8414dd0eb90 | 1,068 | md | Markdown | docusaurus/website/i18n/lt/docusaurus-plugin-content-docs/current/draggable-list.md | isle-project/isle-editor | 45a041571f723923fdab4eea2efe2df211323655 | [
"Apache-2.0"
] | 9 | 2019-08-30T20:50:27.000Z | 2021-12-09T19:53:16.000Z | docusaurus/website/i18n/lt/docusaurus-plugin-content-docs/current/draggable-list.md | isle-project/isle-editor | 45a041571f723923fdab4eea2efe2df211323655 | [
"Apache-2.0"
] | 1,261 | 2019-02-09T07:43:45.000Z | 2022-03-31T15:46:44.000Z | docusaurus/website/i18n/lt/docusaurus-plugin-content-docs/current/draggable-list.md | isle-project/isle-editor | 45a041571f723923fdab4eea2efe2df211323655 | [
"Apache-2.0"
] | 3 | 2019-10-04T19:22:02.000Z | 2022-01-31T06:12:56.000Z | ---
id: draggable-list
title: Draggable List
sidebar_label: Draggable List
---
Vilktinų elementų sąrašas, kurį mokiniai gali pertvarkyti.
## Parinktys
* __data__ | `array (required)`: objektų su `id` ir `text` raktais masyvas. Default: `none`.
* __onChange__ | `function`: grįžtamasis skambutis su naujai sutvarkytu duomenų masyvu, iškviečiamas kiekvieno pakeitimo metu.. Default: `onChange(){}`.
* __onInit__ | `function`: grįžtamojo ryšio funkcija, iškviečiama sumontavus komponentą. Default: `onInit(){}`.
* __shuffle__ | `boolean`: kontroliuoja, ar pradinio rodymo metu duomenų elementai turėtų būti permaišyti.. Default: `false`.
* __disabled__ | `boolean`: kontroliuoja, ar elementus galima vilkti, ar ne.. Default: `false`.
* __className__ | `string`: klasės pavadinimas. Default: `''`.
* __style__ | `object`: CSS eilutės stiliai. Default: `{}`.
## Pavyzdžiai
```jsx live
<DraggableList
data={[
{ id: 0, text: "Compact" },
{ id: 1, text: "Large" },
{ id: 2, text: "Midsize" },
{ id: 3, text: "Small" }
]}
/>
```
| 32.363636 | 152 | 0.67603 | lit_Latn | 0.989163 |
8b4d0f05fc483cc28d29540192990c84d41de51e | 1,868 | md | Markdown | projects/pets.md | devdinu/devdinu.github.io | a84c582f4427efb8c8797f5b44456100a2844414 | [
"MIT"
] | null | null | null | projects/pets.md | devdinu/devdinu.github.io | a84c582f4427efb8c8797f5b44456100a2844414 | [
"MIT"
] | 2 | 2022-02-22T14:24:23.000Z | 2022-02-22T14:24:24.000Z | projects/pets.md | devdinu/devdinu.github.io | a84c582f4427efb8c8797f5b44456100a2844414 | [
"MIT"
] | null | null | null | # Pet Projects
purely for fun, and my use :P
## Gcloud-Client
Utility cmd application wrapper around gcloud compute to add `ssh keys` to compute machines with filter. (golang)
[code](https://github.com/devdinu/gcloud-client)
## Mirror
An echo server you could run locally to view the request data. You could add filter on methods, url (body, regex yet to do) and see it. (golang)
[code](https://github.com/devdinu/mirror)
## Dum-E
Helper shell scripts - which is of use at times, and at times needed the most. Just like stark's [dum-e](http://ironman.wikia.com/wiki/Dum-E_and_U)
<br/>
## Chiru
Flying [crazyflie](https://www.bitcraze.io/crazyflie-2/) quadcopter without controller, and using laptop
like we do in game was absolute fun. seeing both hardware and software play together and seeing action, we should do it often.
[code](https://github.com/devdinu/ElateCopter) [video](https://www.youtube.com/embed/DudSDsl3rOU) presented in pycon 2016
## DevMacSetup
Everytime i had to setup laptop fresh, it was a big task, with ansible automated the requirements, mostly for me :)
[code](https://github.com/devdinu/Dev-Mac-Setup)
## Sublime packages
Wrote few sublime packages, obviously starting for my need.
- [Share File](https://github.com/devdinu/ShareFile) : To share files across different sublime users
- [Preference Sync](https://github.com/devdinu/PreferenceSync) : sync my preferences and make sublime customized to me, across all machines, as in fresh/others sublime editors in other machine you could download and make it look/work like yours,
This was really nice, wish i had/have time to maintain and add more documentation to reach more users.
There were projects over time to learn languages, concepts. Fun projects stands out, and when there's a need and users we tend to build and maintain it. Its really hard to market it than building.
| 50.486486 | 245 | 0.767666 | eng_Latn | 0.992268 |
8b4d583595355de8db889715003f5a03fdb1d6b7 | 1,611 | md | Markdown | README.md | giantpanpan/open-wc | e8c54951d26e55ee6b93ccc03110e8710e2814aa | [
"MIT"
] | null | null | null | README.md | giantpanpan/open-wc | e8c54951d26e55ee6b93ccc03110e8710e2814aa | [
"MIT"
] | null | null | null | README.md | giantpanpan/open-wc | e8c54951d26e55ee6b93ccc03110e8710e2814aa | [
"MIT"
] | null | null | null | > ## 🛠 Status: In Development
> open-wc is still in an early stage - pls review our recommendations and test our tools! we are eager to get feedback
# Open Web Component Recommendations
We want to provide a good set of default on how to facilitate your web component.
[](https://circleci.com/gh/open-wc/open-wc)
[](https://www.browserstack.com/automate/public-build/M2UrSFVRang2OWNuZXlWSlhVc3FUVlJtTDkxMnp6eGFDb2pNakl4bGxnbz0tLUE5RjhCU0NUT1ZWa0NuQ3MySFFWWnc9PQ==--86f7fac07cdbd01dd2b26ae84dc6c8ca49e45b50)
[](https://renovatebot.com/)
## Usage
```bash
mkdir my-element
cd my-element
# Default recommendation
npx -p yo -p generator-open-wc -c 'yo open-wc:vanilla'
```
## Homepage
For all further details pls visit [open-wc.org](https://www.open-wc.org).
## We proudly use
<a href="http://browserstack.com/" style="border: none;"><img src="https://github.com/open-wc/open-wc/blob/master/assets/images/Browserstack-logo.svg" width="200" alt="Browserstack Logo" /></a>
## Working on it
```bash
# bootstrap/setup
npm run bootstrap
# linting
npm run lint
# local testing
npm run test
# testing via browserstack
npm run test:bs
# run commands only for a specific scope
lerna run <command> --scope @open-wc/<package-name> --stream
```
| 35.8 | 413 | 0.775295 | eng_Latn | 0.229647 |
8b4da2a6f5397ac2f0afd30ba70e0e3fe5a3d8d4 | 122 | md | Markdown | README.md | VolkmarR/AdventOfCode2020 | 7684806db7a5dba7934f2f35784b05f86df0c4c5 | [
"MIT"
] | null | null | null | README.md | VolkmarR/AdventOfCode2020 | 7684806db7a5dba7934f2f35784b05f86df0c4c5 | [
"MIT"
] | null | null | null | README.md | VolkmarR/AdventOfCode2020 | 7684806db7a5dba7934f2f35784b05f86df0c4c5 | [
"MIT"
] | null | null | null | # Advent of Code CSharp Solutions 2020
Solutions to the [Advent of Code 2020 event](https://adventofcode.com/2020) in C#
| 30.5 | 81 | 0.762295 | eng_Latn | 0.580848 |
8b4db12c6a24e65829ba6d4f07b1f221457628f1 | 1,554 | md | Markdown | README.md | NoelChew/android-dev-challenge-compose-week-3 | 636f7d879414f49e406165b143159b7082113c8f | [
"Apache-2.0"
] | null | null | null | README.md | NoelChew/android-dev-challenge-compose-week-3 | 636f7d879414f49e406165b143159b7082113c8f | [
"Apache-2.0"
] | null | null | null | README.md | NoelChew/android-dev-challenge-compose-week-3 | 636f7d879414f49e406165b143159b7082113c8f | [
"Apache-2.0"
] | null | null | null | # Android Dev Challenge Compose - Bloom App

## :scroll: Description
Bloom as a practice project to learn Jetpack Compose.
## :bulb: Motivation and Context
Have been using Android Views for many years. Apart from a brief experiment with Facebook Litho, this is the first time I am building native UI without using xml code. Looking forward to a stable version of Jetpack Compose.
## :camera_flash: Screenshots
<img src="/results/screenshot_1.png" width="260"> <img src="/results/screenshot_1_dark.png" width="260">
<img src="/results/screenshot_2.png" width="260"> <img src="/results/screenshot_2_dark.png" width="260">
<img src="/results/screenshot_3.png" width="260"> <img src="/results/screenshot_3_dark.png" width="260">
[Video](https://github.com/NoelChew/android-dev-challenge-compose-week-3/blob/main/results/video.mp4)
## License
```
Copyright 2020 The Android Open Source Project
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
https://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
``` | 40.894737 | 223 | 0.772201 | eng_Latn | 0.910197 |
8b4e270df701ce37b6335d8ec69f907117c2bab9 | 341 | md | Markdown | cogs/assistance-cmds/dump.wiiu.md | Xbox-360-1063/Kurisu | b6047ca02709a4b83c7ed429d1f08806243d6c86 | [
"Apache-2.0"
] | 51 | 2018-05-01T19:32:53.000Z | 2022-01-24T23:02:01.000Z | cogs/assistance-cmds/dump.wiiu.md | Xbox-360-1063/Kurisu | b6047ca02709a4b83c7ed429d1f08806243d6c86 | [
"Apache-2.0"
] | 235 | 2018-04-06T15:52:46.000Z | 2022-03-19T15:52:07.000Z | cogs/assistance-cmds/dump.wiiu.md | Xbox-360-1063/Kurisu | b6047ca02709a4b83c7ed429d1f08806243d6c86 | [
"Apache-2.0"
] | 275 | 2018-04-06T14:54:42.000Z | 2022-02-02T20:20:38.000Z | ---
title: Wii U dump/install Guide
url: https://wiiu.hacks.guide/#/dump-games
author.name: NH Discord Server
author.url: https://wiiu.hacks.guide/#/dump-games
thumbnail-url: https://i.imgur.com/CVSu1zc.png
help-desc: How to dump games and data for CFW consoles
---
How to dump/install Wii U game discs using disc2app and WUP Installer GX2
| 31 | 73 | 0.753666 | eng_Latn | 0.340674 |
8b4ea115d83dd671e4e99b86be2fd3ccd3df398a | 20 | md | Markdown | index.md | deadshot465/BurstBotNET | 5255408c89ba7897637e6ddbb652ca2bfec6a621 | [
"BSD-3-Clause"
] | null | null | null | index.md | deadshot465/BurstBotNET | 5255408c89ba7897637e6ddbb652ca2bfec6a621 | [
"BSD-3-Clause"
] | 1 | 2022-01-03T05:48:31.000Z | 2022-01-03T08:31:18.000Z | index.md | AllBurst/BurstBotNET | 5255408c89ba7897637e6ddbb652ca2bfec6a621 | [
"BSD-3-Clause"
] | null | null | null | # Jack of All Trades | 20 | 20 | 0.75 | kor_Hang | 0.47045 |
8b53e8d8a6cfa79104139e59d4b0746b8c37f41b | 3,118 | md | Markdown | src/fr/2021-03/01/07.md | Pmarva/sabbath-school-lessons | 0e1564557be444c2fee51ddfd6f74a14fd1c45fa | [
"MIT"
] | 68 | 2016-10-30T23:17:56.000Z | 2022-03-27T11:58:16.000Z | src/fr/2021-03/01/07.md | Pmarva/sabbath-school-lessons | 0e1564557be444c2fee51ddfd6f74a14fd1c45fa | [
"MIT"
] | 367 | 2016-10-21T03:50:22.000Z | 2022-03-28T23:35:25.000Z | src/fr/2021-03/01/07.md | Pmarva/sabbath-school-lessons | 0e1564557be444c2fee51ddfd6f74a14fd1c45fa | [
"MIT"
] | 109 | 2016-08-02T14:32:13.000Z | 2022-03-31T10:18:41.000Z | ---
title: 'Réflexion avancée'
date: 02/07/2021
---
« Les rabbins estimaient une activité tumultueuse comme la plus haute expression de la piété. Celle-ci devait se montrer par des actes extérieurs. Ils s’éloignaient donc de Dieu et se drapaient dans leur propre suffisance. Les mêmes dangers existent aujourd’hui. Dans la mesure où l’activité s’accroit et où l’on réussit dans ce que l’on fait pour Dieu, on risque de mettre sa confiance dans des méthodes et des plans humains. On est enclin à prier moins, à avoir moins de foi. On risque, ainsi que les disciples, de ne plus sentir sa dépendance à l’égard de Dieu et de chercher un moyen de salut dans sa propre activité. Il nous faut toujours regarder à Jésus et comprendre que c’est sa puissance qui agit. Tout en travaillant avec zèle en vue de sauver ceux qui sont perdus, prenons le temps de prier, de méditer la Parole de Dieu. Seuls, les efforts accompagnés de beaucoup de prières et sanctifiés par les mérites du Christ, serviront, d’une manière durable, la bonne cause. » – Ellen G. White, Jésus-Christ, p. 353, 354.
**Discussion**:
`La pression constante d’être au-dessus des choses, d’être disponible (physiquement ou virtuellement) tout le temps, et d’essayer d’être à la hauteur d’idéaux qui ne sont ni réalistes ni donnés par Dieu peut rendre les gens malades émotionnellement, physiquement et spirituellement. Comment votre église peut-elle devenir un lieu accueillant pour des personnes épuisées et fatiguées qui aspirent au repos?`
`Est-il possible que nous soyons trop occupés, même à faire de bonnes choses pour Dieu? Réfléchissez à l’histoire de Jésus et de Ses disciples dans Marc 6:30-32 et discutez de ses applications dans votre groupe de l’école du sabbat.`
`En 1899, un record de vitesse avait été battu. Quelqu’un avait fait 63,15 Km/h à voiture, et a vécu pour le raconter! Aujourd’hui, bien sûr, les voitures vont beaucoup plus vite que cela. Et la vitesse des processeurs de nos téléphones portables est bien plus rapide que celle des gros ordinateurs les plus rapides de la génération précédente. Et les voyages en avion sont plus rapides qu’autrefois, et le sont encore plus. Le fait est que presque tout ce que nous faisons aujourd’hui est fait plus vite que par le passé, et pourtant, quoi? Nous nous sentons toujours pressés et sans assez de repos. Qu’est-ce que cela devrait nous apprendre sur la nature humaine fondamentale et sur la raison pour laquelle Dieu aurait fait du repos un élément si important au point d’être l’un de Ses commandements?`
`Penchons-nous sur l’idée que même en Éden, avant le péché, le repos du sabbat avait été institué. Outre l’intéressante implication théologique de cette vérité, qu’est-ce que cela devrait nous apprendre sur le fait que le repos était nécessaire même dans un monde parfait et sans péché?`
---
### Citations d’Ellen White en complément à l’étude de la Bible par l’École du Sabbat
Nous nous excusons que les citations quotidiennes d'Ellen White soient temporairement indisponibles. Nous travaillons à fournir à nouveau des citations supplémentaires dans un avenir très proche! | 141.727273 | 1,023 | 0.791533 | fra_Latn | 0.995996 |
8b547aeb7f105ba2c7a3da5b83099816635e8dda | 1,609 | md | Markdown | _projects/promptly.md | rcackerman/portfolio | bb232554e0a981a59b7f947ea376e6431ac80abb | [
"MIT"
] | null | null | null | _projects/promptly.md | rcackerman/portfolio | bb232554e0a981a59b7f947ea376e6431ac80abb | [
"MIT"
] | null | null | null | _projects/promptly.md | rcackerman/portfolio | bb232554e0a981a59b7f947ea376e6431ac80abb | [
"MIT"
] | null | null | null | ---
layout: project
title: Promptly
workplace: Code for America/City and County of San Francisco
description_less: Reducing churn among CalFresh clients.
tags: [qualitative, implementation]
splash_img_source:
splash_img_caption:
---
### Overview
The City and County of San Francisco Human Services Agency (HSA) wanted help addressing churn – lapsed coverage because of missing paperwork – in their CalFresh client population.
### Research
To better empathize with CalFresh (SNAP) recipients, I worked with HSA leadership to apply for and enroll in CalFresh, dropping out of the program in different ways to see how HSA communicated with clients. (You can see most of the letters here!) Our team also performed almost two months of in-depth qualitative research, including unstructured interviews to understand the goals and needs of CalFresh clients and eligibility staff, as well as workshops with eligibility staff to help design more client-friendly services.
### Findings
Our team found that much of the problem was due to paperwork getting lost in the CalFresh office, with no way for clients to know that they were about to lose benefits. In consultation with clients, staff, and non-profit advocates, we determined that a text message alert to clients would be a straightforward way of reducing churn.
Promptly, our text messaging service, was rolled out to San Francisco’s CalFresh clients in 2013, and was found to reduce churn. I served as the main point person on the team for implementation planning: working with county legal staff to draft consent forms and training eligibility staff.
| 73.136364 | 524 | 0.805469 | eng_Latn | 0.999709 |
8b5658a8aca4a67e614b359ba41ac833ef37436c | 613 | md | Markdown | examples/grpc-client-bearer-token-auth/grpc_client_bearer_token_auth.md | TharmiganK/ballerina-distribution | 8916a301aac3fe75772f346780aa3eb2aaf1593e | [
"Apache-2.0"
] | null | null | null | examples/grpc-client-bearer-token-auth/grpc_client_bearer_token_auth.md | TharmiganK/ballerina-distribution | 8916a301aac3fe75772f346780aa3eb2aaf1593e | [
"Apache-2.0"
] | null | null | null | examples/grpc-client-bearer-token-auth/grpc_client_bearer_token_auth.md | TharmiganK/ballerina-distribution | 8916a301aac3fe75772f346780aa3eb2aaf1593e | [
"Apache-2.0"
] | null | null | null | # Client - Bearer Token Auth
A client, which is secured with Bearer token auth can be used to connect to
a secured service.<br/>
The client metadata is enriched with the `Authorization: Bearer <token>`
header by passing the `grpc:BearerTokenConfig` for the `auth` configuration
of the client.
::: code ./examples/grpc-client-bearer-token-auth/grpc_client.proto :::
::: out ./examples/grpc-client-bearer-token-auth/grpc_client.out :::
::: code ./examples/grpc-client-bearer-token-auth/grpc_client_bearer_token_auth.bal :::
::: out ./examples/grpc-client-bearer-token-auth/grpc_client_bearer_token_auth.out ::: | 40.866667 | 87 | 0.76509 | eng_Latn | 0.926668 |
8b5780d1abb76f5851d0a3ed06344c7814ff9c82 | 1,516 | md | Markdown | README.md | Andertaker/django-oauth-tokens | 02de3de078361ca12a004979ab647aa5d745c555 | [
"BSD-3-Clause"
] | null | null | null | README.md | Andertaker/django-oauth-tokens | 02de3de078361ca12a004979ab647aa5d745c555 | [
"BSD-3-Clause"
] | null | null | null | README.md | Andertaker/django-oauth-tokens | 02de3de078361ca12a004979ab647aa5d745c555 | [
"BSD-3-Clause"
] | null | null | null | # Introduction
Application for getting, storing and refreshing OAuth access_tokens for Django standalone applications without user manipulations.
Applications also can imitate authorized requests on behalf of user
# Providers
## Vkontakte
OAUTH_TOKENS_VKONTAKTE_CLIENT_ID = '' # application ID
OAUTH_TOKENS_VKONTAKTE_CLIENT_SECRET = '' # application secret key
OAUTH_TOKENS_VKONTAKTE_SCOPE = ['wall', 'friends'] # application scope
OAUTH_TOKENS_VKONTAKTE_USERNAME = '' # user login
OAUTH_TOKENS_VKONTAKTE_PASSWORD = '' # user password
OAUTH_TOKENS_VKONTAKTE_PHONE_END = '' # last 4 digits of user mobile phone
## Facebook
OAUTH_TOKENS_FACEBOOK_CLIENT_ID = '' # application ID
OAUTH_TOKENS_FACEBOOK_CLIENT_SECRET = '' # application secret key
OAUTH_TOKENS_FACEBOOK_SCOPE = ['offline_access'] # application scope
OAUTH_TOKENS_FACEBOOK_USERNAME = '' # user login
OAUTH_TOKENS_FACEBOOK_PASSWORD = '' # user password
# Settings
OAUTH_TOKENS_HISTORY = True # to keep in DB expired access tokens
# Dependencies
* django
* requests
* requests_oauthlib
* django-taggit
* beautifulsoup4
In order to test with quicktest.py, you also need:
* mock
* factory_boy
| 36.095238 | 130 | 0.613456 | kor_Hang | 0.735455 |
8b57d9448976f63fd512e86dbea3f69ef31699be | 3,898 | md | Markdown | README.md | jduckett/duck_map | c510acfa95e8ad4afb1501366058ae88a73704df | [
"MIT"
] | 1 | 2015-02-25T09:56:04.000Z | 2015-02-25T09:56:04.000Z | README.md | jduckett/duck_map | c510acfa95e8ad4afb1501366058ae88a73704df | [
"MIT"
] | null | null | null | README.md | jduckett/duck_map | c510acfa95e8ad4afb1501366058ae88a73704df | [
"MIT"
] | null | null | null | [](http://travis-ci.org/jduckett/duck_map)
# Duck Map
**Homepage**: [http://jeffduckett.com](http://jeffduckett.com)
**Git**: [http://github.com/jduckett/duck_map](http://github.com/jduckett/duck_map)
**Documentation**: [http://rubydoc.info/github/jduckett/duck_map/frames](http://rubydoc.info/github/jduckett/duck_map/frames)
**Author**: Jeff Duckett
**Copyright**: 2013
**License**: MIT License
## Synopsis
Duck Map is a Rails 4.x compliant gem providing support for dynamically generating sitemaps and meta tags in HTML page headers.
# Support
I am officially dropping support for this repo as I am moving away from Rails. Anybody want it?
## Full Guide
<span class="note">For an in depth discussion see: {file:GUIDE.md Full guide (GUIDE.md)}</span>
## Feature List
- Sitemaps are baked into the standard Rails Routing Code base and are defined directly in config/routes.rb.
- Default sitemap at the root of the application named: /sitemap.xml
- No code needed. Default sitemap.xml content is based on standard Rails controller actions: edit, index, new and show.
- Designed to grab volitale elements such as last modified date directly from a model.
- Automagically finds the first model on a controller and uses model attributes in sitemap and page headers.
- Support for namespaces.
- Support for nested resources.
- Define as many sitemaps as you need.
- Ability to sychronize static last modified dates directly from the rails view files or a .git repository.
- Meta tags for HTML page headers such as title, last modified, canonical url, etc. that match data contained in sitemap.
- Generate static sitemap files with compression.
- Define global attributes and values and fine tune them down to the controller/model levels.
- Support for mongoid
## Quick Start
Follow these steps to create a Rails app with a sitemap.
# open a shell and navigate to a work directory.
# create a Rails app
rails new test.com --skip-bundle
# add the following to your Rails app test.com/Gemfile
gem 'duck_map'
# depending on your Rails version, you may have to add the following lines as well.
gem 'execjs'
gem 'therubyracer'
# make sure you have all the gems, etc.
bundle install
# create a controller
rails g controller home
# create a route in config/routes.rb
root :to => 'home#index'
# start the server
rails s
# view the sitemap
http://localhost:3000/sitemap.xml
# if you view the HTML source of: http://localhost:3000/sitemap.xml
# you should see something similar to the following:
<?xml version="1.0" encoding="UTF-8"?>
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9">
<url>
<loc>http://localhost:3000/</loc>
<lastmod>2011-10-27T13:02:15+00:00</lastmod>
<changefreq>monthly</changefreq>
<priority>0.5</priority>
</url>
</urlset>
## Demo applications
You can find articles and demo apps at: http://jeffduckett.com/blogs.html
## Why use the name Duck Map?
Having "Duck" built into the name? This stems from a habit I picked up years ago back in the days when I was doing DBase and Clipper programming for DOS.
I picked up the idea from one of my favorite authors at the time (Rick Spence - or at least I think it was Rick). Anyway, the idea is to basically sign
your code by incorporating your initials into library names or method calls. That way, you know the origin of a piece of code at a glance. The downside
is that you definitely own it and can't blame it on that guy that keeps beating you to the good doughnuts. I hate that guy!!
The second reason is that there was a pretty good chance I wouldn't run into naming conflicts.
## Copyright
Copyright (c) 2013 Jeff Duckett. See license for details.
| 40.185567 | 154 | 0.72627 | eng_Latn | 0.981996 |
8b5904c8d8730a2f839fb1e9647c68e87b719cc7 | 576 | md | Markdown | packages/components/wc-wiz-breadcrumb/src/components/wiz-breadcrumb/breadcrumb.story.md | wizsolucoes/syz | c6154441656a27ac4879a79467fa15482b7ffb07 | [
"MIT"
] | 2 | 2021-12-10T14:23:49.000Z | 2021-12-14T12:52:51.000Z | packages/components/wc-wiz-breadcrumb/src/components/wiz-breadcrumb/breadcrumb.story.md | wizsolucoes/syz | c6154441656a27ac4879a79467fa15482b7ffb07 | [
"MIT"
] | 9 | 2020-09-04T10:31:07.000Z | 2021-11-22T13:16:50.000Z | packages/components/wc-wiz-breadcrumb/src/components/wiz-breadcrumb/breadcrumb.story.md | wizsolucoes/syz | c6154441656a27ac4879a79467fa15482b7ffb07 | [
"MIT"
] | null | null | null | # Breadcrumb
Breadcrumb é o nosso componente de navegação, também conhecido como trilha de navegação, é um padrão de navegação secundário que representa a hierarquia entre conteúdo ou a trilha do cominho percorrido por um usuário. Em um breadcrumb todos os links são clicáveis, sempre com destaque maior para o caminho presente do usuário.
## Comportamento
O componente breadcrumb conta com um comportamento padrão que proporciona maior usabilidade e adequação a diferentes tipos de produtos e projetos.
<wiz-code-demo>
<wiz-breadcrumb> </wiz-breadcrumb>
</wiz-code-demo> | 57.6 | 326 | 0.809028 | por_Latn | 0.999997 |
8b59192339aa22fe8759766d2b523f0b64bb8c62 | 1,566 | md | Markdown | README.md | teo-luc/planet | f5d9fbdc97a0139321746a241dc204656d5eb2a5 | [
"MIT"
] | 73 | 2016-07-18T13:37:21.000Z | 2021-06-14T09:13:01.000Z | README.md | teo-luc/planet | f5d9fbdc97a0139321746a241dc204656d5eb2a5 | [
"MIT"
] | 11 | 2016-08-25T07:16:12.000Z | 2019-07-21T11:36:11.000Z | README.md | teo-luc/planet | f5d9fbdc97a0139321746a241dc204656d5eb2a5 | [
"MIT"
] | 33 | 2016-07-18T14:03:43.000Z | 2021-09-16T12:55:21.000Z | # Planet
A country picker view controller for iOS.
<img src="https://s3.amazonaws.com/f.cl.ly/items/1z3M1J061d013C1i0H0f/planet.png" width="200">
## Installation
#### CocoaPods
You can use [CocoaPods](http://cocoapods.org/) to install `Planet` by adding it to your `Podfile`:
```ruby
platform :ios, '10.0'
use_frameworks!
pod 'Planet'
```
#### Manually
1. Download and drop `/Planet` folder in your project.
2. Congratulations!
## Example
First, import the library:
```swift
import Planet
```
Then, create the view controller:
```swift
let viewController = CountryPickerViewController()
viewController.delegate = self
```
after you present it and the user selects a country you will get a callback with the country name, ISO code, and calling code.
```swift
func countryPickerViewController(countryPickerViewController: CountryPickerViewController, didSelectCountry country: Country)
```
## Customization
- You can hide the calling codes by toggling `showsCallingCodes`.
- And you can remove the cancel button, for example if you want to present the view controller by pushing it or in a popover by setting `showsCancelButton` to `false`.
- You can show a custom list of countries instead of all countries by supplying a list of ISO codes in the `countryCodes` property. See the comment in the example project
## Contributing
1. Fork it
2. Create your feature branch (`git checkout -b my-new-feature`)
3. Commit your changes (`git commit -am 'Add some feature'`)
4. Push to the branch (`git push origin my-new-feature`)
5. Create new Pull Request
| 28.472727 | 170 | 0.754789 | eng_Latn | 0.957829 |
8b59e10187cb741c563c9c679fef71de86e7e3ad | 491 | md | Markdown | README.md | ligarnes/database-installer | 46688ceb7f87a02bcd40daa01c5440ebfaa14cdc | [
"MIT"
] | null | null | null | README.md | ligarnes/database-installer | 46688ceb7f87a02bcd40daa01c5440ebfaa14cdc | [
"MIT"
] | null | null | null | README.md | ligarnes/database-installer | 46688ceb7f87a02bcd40daa01c5440ebfaa14cdc | [
"MIT"
] | null | null | null | # database-installer
This project provide a simple framework to make database installer with pure sql script.
This framework allow multi-module installation and upgrade easily.
## Builds
Master [](https://travis-ci.org/ligarnes/database-installer)
Develop [](https://travis-ci.org/ligarnes/database-installer)
# Documentation
TODO | 35.071429 | 146 | 0.792261 | eng_Latn | 0.188394 |
543d5b0baed8dd16da9c75108b34d201b9d090de | 1,049 | md | Markdown | _reference/docs.md | n3s0/n3s0.github.io | a304b455f2688158d17d032a794d5d508cdce4a9 | [
"MIT"
] | null | null | null | _reference/docs.md | n3s0/n3s0.github.io | a304b455f2688158d17d032a794d5d508cdce4a9 | [
"MIT"
] | null | null | null | _reference/docs.md | n3s0/n3s0.github.io | a304b455f2688158d17d032a794d5d508cdce4a9 | [
"MIT"
] | null | null | null | ---
layout: single
title: Reference Documentation
permalink: /reference/
classes: wide
---
## Overview
This is documentation for an application I've been working on for a
while. This is a web application that provides reference tables and
lists regarding various topics. Those topics could include anything.
Reference will be available for anyone to use. In the following sections
of this documentation you can treat them as categories. Links to the
documentation will provide the information.
## General
Provides the usual documentation needed to provide a good overview of
the application.
- [README](#)
- [Changelog](#)
- [Requirements](#)
## User
Operational documentation from a user standpoint.
## Development
Provides environment setup, application structure, and code
documentation.
- [Development Environment Setup](#)
- [File & Folder Structure](#)
- [Routes](#)
- [Functions](#)
## Install & Configure
Documentation on how to install and configure the application.
- [Installing Reference](#)
- [Configuring Reference](#)
| 21.854167 | 72 | 0.759771 | eng_Latn | 0.992615 |
543dc26ec1cb09e0a478916cb125e155e0984a18 | 11,094 | md | Markdown | articles/virtual-machines/virtual-machines-azure-slave-plugin-for-jenkins.md | OpenLocalizationTestOrg/azure-docs-pr15_hu-HU | ac1600ab65c96c83848e8b2445ac60e910561a25 | [
"CC-BY-3.0",
"CC-BY-4.0",
"MIT"
] | null | null | null | articles/virtual-machines/virtual-machines-azure-slave-plugin-for-jenkins.md | OpenLocalizationTestOrg/azure-docs-pr15_hu-HU | ac1600ab65c96c83848e8b2445ac60e910561a25 | [
"CC-BY-3.0",
"CC-BY-4.0",
"MIT"
] | null | null | null | articles/virtual-machines/virtual-machines-azure-slave-plugin-for-jenkins.md | OpenLocalizationTestOrg/azure-docs-pr15_hu-HU | ac1600ab65c96c83848e8b2445ac60e910561a25 | [
"CC-BY-3.0",
"CC-BY-4.0",
"MIT"
] | null | null | null | <properties
pageTitle="A beépülő modul Azure kisegítő használata Jenkins folyamatos integrációval |} Microsoft Azure"
description="A beépülő modul Azure kisegítő használatát Jenkins folyamatos integrációval ismerteti."
services="virtual-machines-linux"
documentationCenter=""
authors="rmcmurray"
manager="wpickett"
editor="" />
<tags
ms.service="virtual-machines-linux"
ms.workload="infrastructure-services"
ms.tgt_pltfrm="vm-multiple"
ms.devlang="java"
ms.topic="article"
ms.date="09/20/2016"
ms.author="robmcm"/>
# <a name="how-to-use-the-azure-slave-plug-in-with-jenkins-continuous-integration"></a>A beépülő modul Azure kisegítő használatáról a folyamatos Jenkins-integrációval
Is használhatja a beépülő modul Azure kisegítő Jenkins az Azure rendelkezést kisegítő csomópontok amikor futó elosztott hoz létre.
## <a name="install-the-azure-slave-plug-in"></a>Az Azure kisegítő beépülő modul telepítése
1. Kattintson a Jenkins irányítópult **Jenkins kezelése**.
1. A **Jenkins kezelése** lapon kattintson a **Bővítmények kezelése**lehetőséget.
1. Kattintson a **rendelkezésre álló** fülre.
1. A szűrő mezőben a rendelkezésre álló bővítmények listája felett írja be az **Azure** korlátozhatja a megfelelő bővítmények listában.
Ha úgy dönt, görgesse végig a rendelkezésre álló bővítmények találja az Azure kisegítő beépülő modul **kezelő és elosztott összeállítása** csoportjában.
1. Jelölje be az **Azure kisegítő beépülő modul** jelölőnégyzetet.
1. Kattintson a **telepítés újraindítása nélkül** , vagy **letöltése és telepítése után indítsa újra az**.
Most, hogy a beépülő modul telepítve van, a következő lépésekkel a beépülő modul állítható be az Azure előfizetés profilját, és létrehozásához használt sablon létrehozása a kisegítő csomópontot a virtuális gép.
## <a name="configure-the-azure-slave-plug-in-with-your-subscription-profile"></a>A beépülő modul Azure kisegítő előfizetés profilját konfigurálása
Előfizetés profil is hivatkoznak, mivel közzétételi beállításokat, az XML-fájlban, amely tartalmazza a biztonságos hitelesítő adatait, és néhány további információt a fejlesztői környezet Azure munkához kell. A beépülő modul Azure kisegítő konfigurálásához van szükség:
* Az előfizetés azonosítója
* Előfizetéshez tartozó adatkezelési tanúsítvány
Ezek a [előfizetés profil]találhatók. Az alábbi képen egy előfizetés profil.
<?xml version="1.0" encoding="utf-8"?>
<PublishData>
<PublishProfile SchemaVersion="2.0" PublishMethod="AzureServiceManagementAPI">
<Subscription
ServiceManagementUrl="https://management.core.windows.net"
Id="<Subscription ID value>"
Name="Pay-As-You-Go"
ManagementCertificate="<Management certificate value>" />
</PublishProfile>
</PublishData>
Után előfizetés profilját, kövesse az alábbi lépéseket a beépülő modul Azure kisegítő konfigurálása:
1. Kattintson a Jenkins irányítópult **Jenkins kezelése**.
1. Kattintson a **rendszer konfigurálása**.
1. Görgessen lefelé a **felhőben** szakaszának lapra.
1. Kattintson a **Új felhő hozzáadása > a Microsoft Azure**.
![felhőalapú szakasz][cloud section]
Ez jelennek meg a mezőket, ahol hozzá kell adni a az előfizetés részletei.
![előfizetés konfigurálása][subscription configuration]
1. Másolja a vágólapra az előfizetés azonosító és a kezelés tanúsítvány értékeket előfizetés profilját, és illessze be őket a megfelelő mezőket.
Az előfizetés azonosító és a kezelés tanúsítvány másolásakor ne kerüljön bele az árajánlatok, hogy az érték.
1. Kattintson a **konfigurációjának ellenőrzése**gombra.
1. A konfiguráció helyes ellenőrzését követően kattintson a **Mentés**gombra.
## <a name="set-up-a-virtual-machine-template-for-the-azure-slave-plug-in"></a>Virtuális gép sablon beállítása az Azure kisegítő a beépülő modul
Virtuális gép sablon, amelyekkel a beépülő modul kisegítő csomópont létrehozása az Azure a paraméterek határozza meg. Az alábbi lépéseket a azt fogja sablont hozhat létre egy Ubuntu virtuális gépen.
1. Kattintson a Jenkins irányítópult **Jenkins kezelése**.
1. Kattintson a **rendszer konfigurálása**.
1. Görgessen lefelé a **felhőben** szakaszának lapra.
1. A **felhő** csoportban **Hozzáadása Azure virtuális gép sablon**keresése, és kattintson a **Hozzáadás**gombra.
![virtuális sablon hozzáadása][add vm template]
Ez a mezők, amelyekben meg a sablon hoz létre részleteket jelennek meg.
![üres általános konfigurálása][blank general configuration]
1. A **név** mezőbe írja be az Azure felhőalapú szolgáltatás neve. Ha egy meglévő felhőalapú szolgáltatást a megadott név utal, a kiépítéstől a szolgáltatás a virtuális gépen kell. Egyéb esetben az Azure hoz létre egy újat.
1. A **Leírás** mezőben adja meg a sablon hoz létre leíró szöveget. Csak az a rekordot, és nem szerepel a kiépítési virtuális géphez.
1. **A lista** azonosítja a sablon hoz létre, és ezt követően használják a Jenkins feladat létrehozása a sablon hivatkozni. A célra írja be a **linux** ebbe a mezőbe.
1. A **terület** listában kattintson a régió, ahol a virtuális gép létrejön.
1. **Virtuális gép méret** listában kattintson a megfelelő méretet.
1. A **Tárterület-fiók neve** mezőbe adjon meg egy tárterület-fiókot, ahol hozható létre a virtuális gép. Győződjön meg arról, hogy az ugyanabban a régióban, mint a felhőbeli szolgáltatástól el. Ha azt szeretné, hogy új tároló létrehozni, akkor hagyja ebbe a mezőbe üres.
1. Adatmegőrzési időt adja meg, hogy hány perc, mielőtt Jenkins törli az üresjárati kisegítő. Hagyja üresen ezt a 60 az alapértelmezett értéket. Választhatja állítsa le a kisegítő törlés helyett inkább tétlen állapotában is. Ehhez jelölje be a **Leállítás csak (nem törli) után adatmegőrzési idő** jelölőnégyzetet.
1. **Használatát** listájában válassza a megfelelő feltétel, amikor a kisegítő csomópont szolgálnak. Most kattintson a **Utilize a lehető csomópontot**.
Az űrlap ezen a ponton a némileg hasonlóan kell kinéznie:
![ellenőrzés általános sablon config][checkpoint general template config]
A következő lépésként adja meg a részleteket az operációs rendszer képe, amelyet a kisegítő, létre kell hozni.
1. A **kép család vagy az azonosító** mezőbe meg kell adnia a rendszer képet telepíti a virtuális gépen. Jelölje ki a kép családok listájából, vagy adjon meg egy egyéni képe.
Ha azt szeretné, jelölje be a kép családok listájából, írja be az első karakter (kis-és nagybetűket) a kép család nevét. Például **U** gépelés fog jelenítse meg Ubuntu kiszolgáló családok listáját. Miután kiválasztotta a listából, Jenkins kiépítésekor a virtuális gép az adott rendszer képet, hogy a család legújabb verzióját használja.
![Operációs rendszer kép lista minta][OS Image list sample]
Ha egyéni használni kívánt képet, írja be a saját kép nevével. Egyéni kép nevek nem jelenik a listában, így Önnek nem kell ahhoz, hogy a nevének megfelelően van-e megadva.
Ebben az oktatóanyagban írja be a **U** Ubuntu képek listájának megjelenítéséhez, és válassza a **Ubuntu kiszolgáló 14.04 LTS**.
1. Az **Indítási mód** listában kattintson a **SSH**.
1. Másolja az alábbi parancsfájl, és illessze be a **Init parancsfájl** mezőbe.
# Install Java
sudo apt-get -y update
sudo apt-get install -y openjdk-7-jdk
sudo apt-get -y update --fix-missing
sudo apt-get install -y openjdk-7-jdk
# Install git
sudo apt-get install -y git
#Install ant
sudo apt-get install -y ant
sudo apt-get -y update --fix-missing
sudo apt-get install -y ant
A init parancsfájl végrehajtása után a virtuális gép jön létre. Ebben a példában a parancsfájl telepíti az Java, mely számjegy és telepítsenek.
1. A **felhasználónév** és **jelszó** mezőjébe írja be a használni kívánt értékeket a rendszergazdai fiók a virtuális gépen létrehozott.
1. Kattintson a **Sablon ellenőrzése** ellenőrzéséhez, ha a megadott paramétereket érvényesek.
1. Kattintson a **Mentés**gombra.
## <a name="create-a-jenkins-job-that-runs-on-a-slave-node-on-azure"></a>Azure kisegítő csomópontjait futó Jenkins feladat létrehozása
Ebben a részben létre Azure kisegítő csomópontjait fog futni Jenkins feladatot. A saját project GitHub követheti, hogy telepítve kell.
1. A Jenkins irányítópulton **Új elem**gombra.
1. Írja be egy nevet a tevékenység hoz létre.
1. Kattintson a projekt típusa **Freestyle projekt**.
1. Kattintson az **OK gombra**.
1. Tevékenység beállítása lapon válassza a **korlátozás, ahol a projekt futtatását is lehetővé teszi**.
1. A **Címke-kifejezést** mezőben adja meg a **Linux rendszerhez**. Az előző részben létrehozott, hogy nevű **linux**, amely olyan, mi megadjuk itt kisegítő sablon.
1. A **Szerkesztés** csoportban kattintson a **Hozzáadás összeállítása a lépést** , és válassza a **végrehajtás rendszerhéj**.
1. A következőt lecserélve **(a GitHub fióknév)**, **(a projekt neve)**és **(a project könyvtár)** megfelelő értékek, szerkesztése, és illessze be a szerkesztett parancsfájl a megjelenő területre.
# Clone from git repo
currentDir="$PWD"
if [ -e (your project directory) ]; then
cd (your project directory)
git pull origin master
else
git clone https://github.com/(your GitHub account name)/(your project name).git
fi
# change directory to project
cd $currentDir/(your project directory)
#Execute build task
ant
1. Kattintson a **Mentés**gombra.
1. A Jenkins irányítópulton mutasson a az imént létrehozott feladatot, és kattintson a lefelé mutató nyílra a tevékenység lap beállításainak megjelenítéséhez.
1. Kattintson a **Létrehozás most**gombra.
Jenkins ezután kisegítő csomópont létrehozása a sablon az előző részben létrehozott használatával, és hajtsa végre a parancsfájlt, a feladat végrehajtásához az összeállítás lépésben megadott.
## <a name="next-steps"></a>Következő lépések
Java Azure használatával kapcsolatos további tudnivalókért olvassa el a az [Azure Java Developer Center]című témakört.
<!-- URL List -->
[Azure Java Developer Center]: https://azure.microsoft.com/develop/java/
[előfizetés-profil]: http://go.microsoft.com/fwlink/?LinkID=396395
<!-- IMG List -->
[cloud section]: ./media/virtual-machines-azure-slave-plugin-for-jenkins/jenkins-cloud-section.png
[subscription configuration]: ./media/virtual-machines-azure-slave-plugin-for-jenkins/jenkins-account-configuration-fields.png
[add vm template]: ./media/virtual-machines-azure-slave-plugin-for-jenkins/jenkins-add-vm-template.png
[blank general configuration]: ./media/virtual-machines-azure-slave-plugin-for-jenkins/jenkins-slave-template-general-configuration-blank.png
[checkpoint general template config]: ./media/virtual-machines-azure-slave-plugin-for-jenkins/jenkins-slave-template-general-configuration.png
[OS Image list sample]: ./media/virtual-machines-azure-slave-plugin-for-jenkins/jenkins-os-family-list-sample.png | 44.91498 | 340 | 0.758518 | hun_Latn | 1.000004 |
543dd6c1d7200fa8a9c6a5345e37ec1f5a7b5f9e | 215 | markdown | Markdown | README.markdown | lazyrunner/Truth-or-Drink | 980d9e6e68b5cbe39c825e4648d7576b7666096c | [
"MIT"
] | null | null | null | README.markdown | lazyrunner/Truth-or-Drink | 980d9e6e68b5cbe39c825e4648d7576b7666096c | [
"MIT"
] | null | null | null | README.markdown | lazyrunner/Truth-or-Drink | 980d9e6e68b5cbe39c825e4648d7576b7666096c | [
"MIT"
] | null | null | null | # Truth or Drink
A tinder style truth or drink game.
## Startup
Just open up the index.html file
## Custumization
in the script.js file add questions to the question array and players names to the player array.
| 19.545455 | 96 | 0.762791 | eng_Latn | 0.995793 |
54400a593e4e7d91380462be4553f3293f8a15f7 | 4,118 | md | Markdown | README.md | thepushkarp/rathilang | bf8efb3fbae5a6aa08ad24ffa4c8e44d8c18d15d | [
"MIT"
] | 17 | 2019-11-13T06:24:17.000Z | 2020-07-04T15:50:18.000Z | README.md | thepushkarp/rathilang | bf8efb3fbae5a6aa08ad24ffa4c8e44d8c18d15d | [
"MIT"
] | 19 | 2019-11-14T13:46:34.000Z | 2021-01-28T05:06:57.000Z | README.md | thepushkarp/rathilang | bf8efb3fbae5a6aa08ad24ffa4c8e44d8c18d15d | [
"MIT"
] | 2 | 2019-11-13T06:26:49.000Z | 2019-11-13T06:32:14.000Z | <p align="center"><a href="https://aashutosh.dev/"><img style="margin-bottom:-14px" src="https://user-images.githubusercontent.com/42088801/68935859-4c642180-07bf-11ea-9c2b-98559ff94f32.png" width="175"></a></p>
<h1 align="center">RATHILANG - The Allstack Programming Language</h1>
<p align="center">
<p align="center">
<a href="https://pypi.org/project/rathilang/"><img alt="PyPI" src="https://img.shields.io/pypi/v/rathilang?style=for-the-badge"></a>
<a href="https://travis-ci.com/thepushkarp/rathilang"><img alt="Travis (.com)" src="https://img.shields.io/travis/com/thepushkarp/rathilang?style=for-the-badge"></a>
<a href="https://github.com/thepushkarp/rathilang/issues"><img src="https://img.shields.io/github/issues/thepushkarp/rathilang?style=for-the-badge"></a>
</p>
<hr>
<p align="center"><a href="http://en.wikipedia.org/wiki/Brainfuck">A brainfuck</a> derivative based on the the characteristics of <a href="https://aashutosh.dev/">Aashutosh Rathi</a></p>
## Syntax
| rathilang | brainfuck | description |
| ----------- | --------- | -------------------------------------------------- |
| `jiren` | + | increment the byte at pointer |
| `bakar` | - | decrement the byte at pointer |
| `allstack` | [ | if pointer is zero, jump to matching `developer` |
| `developer` | ] | if pointer is nonzero, jump to matching `allstack` |
| `rathi` | > | increment the data pointer |
| `aashutosh` | < | decrement the data pointer |
| `abeteri` | , | input of one byte into pointer |
| `pitega` | . | output the byte at pointer |
## Installation
stable:
```shell
pip install rathilang
```
or bleeding edge...
```shell
git clone https://github.com/thepushkarp/rathilang.git
cd rathilang
python setup.py install
```
## Usage
```shell
rathilang path/to/file.baka
```
## File Extention
A rathilang program must be stored in a file with a `.baka` extention because `rathilang` doesn't considers any other file worthy enough.
## API Usage
```python
import rathilang
sourcecode = """
jiren jiren jiren jiren jiren jiren jiren jiren jiren jiren allstack rathi jiren rathi jiren jiren jiren
rathi jiren jiren jiren jiren jiren jiren jiren rathi jiren jiren jiren jiren jiren jiren jiren jiren jiren
jiren aashutosh aashutosh aashutosh aashutosh bakar developer rathi rathi rathi jiren jiren pitega rathi
jiren pitega jiren jiren jiren jiren jiren jiren jiren pitega pitega jiren jiren jiren pitega aashutosh
aashutosh jiren jiren pitega rathi bakar bakar bakar bakar pitega rathi bakar bakar bakar bakar bakar bakar
bakar bakar bakar bakar pitega jiren jiren jiren jiren jiren jiren jiren jiren jiren jiren jiren jiren jiren
jiren jiren jiren jiren pitega bakar bakar bakar pitega aashutosh aashutosh jiren pitega aashutosh jiren
jiren jiren jiren jiren jiren jiren jiren jiren jiren pitega"""
# or use sourcecode = rathilang.load_source("FILENAME.allstack") to load from file
rathilang.evaluate(sourcecode)
```
## Development
When developing, use `pipenv` to install needed tools.
```sh
pipenv install
pipenv run black .
pipenv run python -m rathilang tests/hello-devs.baka
```
## Thanks
Special thanks to [Elliot Chance][4] for providing the base implementation of this and [Pikalang][1] for providing the implementation on top of which this repo is made.
## Disclaimer
This is a small gift for [Aashutosh Rathi][3] who did big things for the institute and me. The [pikalang][1] repository served as an inspiration for me. This repository is protected under fair use.
[1]: https://github.com/groteworld/pikalang "Pikalang"
[2]: http://en.wikipedia.org/wiki/Brainfuck "Brainfuck"
[3]: https://aashutosh.dev/ "Aashutosh Rathi"
[4]: http://elliot.land/post/write-your-own-brainfuck-interpreter "Elliot Chance"
<p align="center"> Made with ❤️ by <a href="https://github.com/thepushkarp">Pushkar Patel</a> </p>
| 42.020408 | 211 | 0.678485 | eng_Latn | 0.181033 |
5440280554e0c547dabf76b6026eed9a1726b8b0 | 65,467 | md | Markdown | doc/std/D2006R1.md | Chlorie/libunifex | 9869196338016939265964b82c7244915de6a12f | [
"Apache-2.0"
] | 1 | 2021-11-23T11:30:39.000Z | 2021-11-23T11:30:39.000Z | doc/std/D2006R1.md | Chlorie/libunifex | 9869196338016939265964b82c7244915de6a12f | [
"Apache-2.0"
] | null | null | null | doc/std/D2006R1.md | Chlorie/libunifex | 9869196338016939265964b82c7244915de6a12f | [
"Apache-2.0"
] | 1 | 2021-07-29T13:33:13.000Z | 2021-07-29T13:33:13.000Z | ---
title: "Eliminating heap-allocations in sender/receiver with connect()/start() as basis operations"
document: D2006R1
date: 2020-01-17
audience:
- SG1
- LEWG
author:
- name: Lewis Baker
email: <[email protected]>
- name: Eric Niebler
email: <[email protected]>
- name: Kirk Shoop
email: <[email protected]>
- name: Lee Howes
email: <[email protected]>
toc: false
---
# Abstract
The "Unified executors" paper, [@P0443R11], was recently updated to incorporate the
sender/receiver concepts as the basis for representing composable asynchronous operations
in the standard library.
The basis operation for a sender as specified in [@P0443R11] is `execution::submit()`,
which accepts a sender and a receiver, binds the receiver to the sender and launches the
operation. Once the operation is launched, the sender is responsible for sending the
result of the operation to the receiver by calling one of the completion-signalling
operations (`set_value()`, `set_error()` or `set_done()`) when the operation eventually
completes.
In order to satisfy this contract the `submit()` function needs to ensure that the
receiver, or a move-constructed copy of the receiver, remains alive until the operation
completes so that the result can be delivered to it. This generally means that a sender
that completes asynchronously will need to heap-allocate some storage to hold a copy of
the receiver, along with any other state needed from the sender, so that it will remain
valid until the operation completes.
While many composed operations can avoid additional allocations by bundling their state
into a new receiver passed to a child operation and delegating the responsibility for
keeping it alive to the child operation, there will still generally be a need for a
heap-allocation for each leaf operation.
However, the same is not true with the design of coroutines and awaitables. An awaitable
type is able to inline the storage for its operation-state into the coroutine-frame of the
awaiting coroutine by returning a temporary object from its `operator co_await()`,
avoiding the need to heap-allocate this object internally.
We found that, by taking a similar approach with sender/receiver and defining a basis
operation that lets the sender return its operation-state as an object to the caller, the
sender is able to delegate the responsibility for deciding where the operation-state
object should be allocated to the caller instead of having to heap-allocate it itself
internally.
This allows the caller to choose the most appropriate location for the operation-state of
an operation it's invoking. For example, an algorithm like `sync_wait()` might choose to
store it on the stack, an `operator co_await()` algorithm might choose to store it as a
local variable within the coroutine frame, while a sender algorithm like `via()` might
choose to store it inline in the parent operation-state as a data-member.
**The core change that this paper proposes is refining the sender concept to be defined in
terms of two new basis operations:**
* `connect(sender auto&&, receiver auto&&) -> operation_state` \
Connects a sender to a receiver and returns the operation-state object that stores the
state of that operation.
* `start(operation_state auto&) noexcept -> void` \
Starts the operation (if not already started). An operation is not allowed to signal
completion until it has been started.
There are several other related changes in support of this:
* Retain and redefine the `submit()` operation as a customizable algorithm that has a
default implementation in terms of `connect()` and `start()`.
* Add an `operation_state` concept.
* Add two new type-traits queries: \
`connect_result_t<S, R>` \
`is_nothrow_receiver_of_v<R, An...>`
In addition to these changes, this paper also incorporates a number of bug fixes to
wording in [@P0443R11] discovered while drafting these changes.
# Motivation
This paper proposes a refinement of the sender/receiver design to split out the `submit()`
operation into two more fundamental basis operations; `connect()`, which takes a sender
and a receiver and returns an object that contains the state of that async operation, and
`start()`, which is used to launch the operation.
There are a number of motivations for doing this, each of which will be explored in more
detail below:
* It eliminates the need for additional heap-allocations when awaiting senders within a
coroutine, allowing the operation-state to be allocated as a local variable in the
coroutine frame.
* It allows composed operations to be defined that do not require any heap allocations.
This should allow usage of a reasonable subset of async algorithms in contexts that do
not normally allow heap-allocations, such as embedded or real-time systems.
* It allows separating the preparation of a sender for execution from the actual
invocation of that operation, satisfying one of the desires expressed in [@P1658R0].
* It makes it easier and more efficient to satisfy the sender/receiver contract in the
presence of exceptions during operation launch.
## Lifetime impedance mismatch with coroutines
The paper "Unifying asynchronous APIs in the C++ standard library" [@P1341R0] looked at
the interoperability of sender/receiver with coroutines and showed how senders could be
adapted to become awaitables and how awaitables could be adapted to become senders.
However, as [@P1341R0] identified, adapting between sender/awaitable (in either direction)
typically incurs an additional heap-allocation. This is due to senders and awaitables
generally having inverted ownership models.
### The existing sender/receiver ownership model
With the `submit()`-based asynchronous model of sender/receiver, the `submit()`
implementation cannot typically assume that either the sender or the receiver passed to it
will live beyond the call to `submit()`. This means for senders that complete
asynchronously the implementation of `submit()` will typically need to allocate storage to
hold the receiver (so it can deliver the result) as well as any additional state needed by
the sender for the duration of the operation. This state is often referred to as the
"operation state".
See Example 2 in Appendix A.
Note that some senders may be able to delegate the allocation of the operation-state to a
child operation's `submit()` implementation by wrapping up the the receiver and other
state into a new receiver wrapper and passing this wrapper to the `submit()` call of the
child operation.
See Example 1 in Appendix A.
This delegation can be recursively composed, potentially allowing the state of an entire
chain of operations to be aggregated into a single receiver object passed to the leaf
operation. However, leaf-operations will typically still need to allocate as, by
definition of being a leaf operation, they won't have any other senders they can delegate
to.
In this model, the leaf operation allocates and owns storage required to store the
operation state and the leaf operation is responsible for ensuring that this storage
remains alive until the operation completes.
So in the sender/receiver model we can coalesce allocations for a chain of operations and
have the the allocation performed only by the leaf-operation. Note that for an operation
that is composed of multiple leaf operations, however, it will still typically require
multiple heap-allocations over the lifetime of the operation.
### The coroutine ownership model
With coroutines the ownership model is reversed.
An asynchronous operation is represented using an awaitable object when using coroutines
instead of a sender. The user passes the awaitable object to a `co_await` expression which
the compiler translates into a sequence of calls to various customization points.
The compiler translates the expression '`co_await`\ _`expr`_' expression into something
roughly equivalent to the following (some casts omitted for brevity):
> ```c++
> // 'co_await expr' becomes (roughly)
> decltype(auto) __value = @_expr_@;
> decltype(auto) __awaitable = promise.await_transform(__value);
> decltype(auto) __awaiter = __awaitable.operator co_await();
> if (!__awaiter.await_ready()) {
> // <suspend-coroutine>
> __awaiter.await_suspend(coroutine_handle<promise_type>::from_promise(promise));
> // <return-to-caller-or-resumer>
> }
> // <resume-point>
> __awaiter.await_resume(); // This produces the result of the co_await expression
> ```
When a coroutine is suspended at a suspension point, the compiler is required to maintain
the lifetime of any objects currently in-scope - execution returns to the caller/resumer
without exiting any scopes of the coroutine). The compiler achieves this by placing any
objects whose lifetime spans a suspension point into the coroutine-frame, which is
typically allocated on the heap instead of on the stack, and thus can persist beyond the
coroutine suspending and returning execution to its caller/resumer.
The important thing to note in the expansion of a `co_await` expression above is that the
awaitable object has the opportunity to return an object from its `operator co_await()`
method and this return-value becomes a temporary object whose lifetime extends until the
end of the full-expression (ie. at the next semicolon). By construction this object will
span the suspend-point (`await_ready()` is called before the suspend-point and
`await_resume()` is called after the suspend-point) and so the compiler will ensure that
storage for the awaiter object is reserved in the coroutine frame of the awaiting
coroutine.
Implementations of awaitable types that represent async operations can use this behaviour
to their advantage to externalize the allocation of the operation-state by storing the
operation-state inline in the awaiting coroutine's coroutine-frame, thus avoiding the need
for an additional heap-allocation to store it.
See Example 4 in Appendix A which shows an implementation of
a simple allocation-free executor that uses this technique.
This same strategy of inlining storage of child operation's state into the storage for
parent operation also occurs when the compiler applies the coroutine heap-allocation
elision optimization (see [@P0981R0]). This optimization works by allowing the compiler to
elide heap-allocations for child coroutine-frames whose lifetimes are strictly nested
within the lifetime of the caller by inlining the allocation into storage space reserved
for it in the parent coroutine-frame.
**Taken to its limit, this strategy tends towards a single allocation per high-level
operation that contains enough storage for the entire tree of child operations** (assuming
the storage requirements of the child operations can be statically calculated by the
compiler).
### Comparing Sender/Receiver and Coroutine Lifetime Models
Taking a step-back we can make some comparisons of the differences of ownership/lifetime
models in `submit()`-based sender/receiver and coroutines/awaitables:
|Sender/Receiver|Coroutines/Awaitables|
|--- |--- |
|Coalesces allocations/state into child operations by wrapping receivers.|Coalesces allocations into parent operations by returning state from operator co_await() and by HALO inlining child coroutine-frames. |
| | |
|Tends towards a single allocation for each leaf-level operation.|Tends towards a single allocation per top-level operation.|
| | |
|Type of operation-state is hidden from consumer - an internal implementation detail.|Type of operation-state is exposed to caller allowing its storage to be composed/inlined into parent operation-state.|
| | |
|Producer is responsible for keeping operation-state alive until the operation completes and destroying the operation-state after it completes.|Consumer is responsible for keeping the operation-state alive until the operation completes and destroying the operation-state after it completes.|
| | |
|Often requires moving state of higher-level operations between operation-states of different leaf operations many times as different leaf operations come and go.|Allows storing state of higher-level operations in a stable location (the higher-level operation-state) and passing references to that operation-state into child operations (eg. via the coroutine_handle)|
| | |
|Higher-level operations will often need a number of separate heap-allocations over its lifetime as different leaf operations come and go. Allows dynamically adjusting memory usage over time, potentially reducing overall memory pressure.|Higher-level operations tend to allocate a single larger allocation, reducing the overall number of allocations, but some of this storage may go unused during some parts of the operation, potentially leading to higher memory pressure in some cases.|
### Adapting between sender/receiver and coroutines
One of the goals for the sender/receiver design has been to integrate well with
coroutines, allowing applications to write asynchronous code in a synchronous style, using
the co_await keyword to suspend the coroutine until the asynchronous operation completes.
The paper [@P1341R0] showed that it is possible to adapt typed-senders to be awaitable and
that it's possible to adapt awaitables to become senders. It also discussed how the
inverted ownership model resulted in the overhead of an extra heap-allocation whenever we
do this.
When we adapt an awaitable to become a sender we need to heap-allocate a new
coroutine-frame that can co_await the awaitable, get the result and then pass the result
to a receiver. This coroutine-frame is not generally eligible for the heap-allocation
elision optimization (HALO) as the lifetime of the coroutine is not nested within the
lifetime of the caller.
When we adapt a sender to become an awaitable, the sender will generally need to
heap-allocate the operation-state at the leaf-operation as the sender does not know that
the coroutine will implicitly keep the sender and receiver passed to `submit()` alive
beyond the call to `submit()`.
The paper [@P1341R0] thus proposed to make the core concept for representing asynchronous
operations a Task, which required implementations to provide both the sender and awaitable
interfaces so that tasks could be used either in code that used senders or in code that
used coroutines interchangeably. Implementations could provide one of the implementations
and the other would have a default implementation provided, albeit with some overhead, or
it could provide native implementations of both sender and awaitable interfaces to achieve
better performance.
There were a few downsides to this approach, however.
* It forced a dependency of the core concepts on coroutines (`operator co_await()` and
`coroutine_handle` type) and this meant that implementers that may not be able to
initially implement coroutines for their platforms would be unable to implement the
core asynchronous concepts.
* To achieve the best performance for both sender/receiver and coroutines would require
implementing every algorithm twice - once under sender/receiver using its ownership
model and once under coroutines for its ownership model. \
This would not only be required for your algorithm but for the entire closure of
algorithms that your algorithm is built on. \
Having to implement two versions of each algorithm places a high burden on
implementers of these algorithms.
Thus, we no longer recommend pursuing the Task concept that requires both coroutines and
sender/receiver interfaces to be implemented.
The changes proposed by this paper change the ownership model of sender/receiver to be the
same as that of coroutines. This allows us to instead build a generic implementation of
`operator co_await()` that can work with any `typed_sender` and that does not require any
additional heap-allocations.
This eliminates the need to implement async algorithms twice to be able to get efficient
usage with both coroutines and senders. An async algorithm can just implement the
sender-interface and can rely on the default `operator co_await()` implementation for
senders to allow it to be efficiently used in `co_await` expressions.
Note that a particular type that implements the sender concept can still choose to provide
a custom implementation of `operator co_await()` if desired.
## Simplifying exception-safe implementations of sender algorithms
The semantics of the `submit()` method as described in [@P0443R11] required that the
implementation of `submit()` would eventually call one of the receiver methods that
indicates completion of the operation if `submit()` returns normally.
While the specification was silent on the semantics if `submit()` were to exit with an
exception, the intent was that `submit()` would not subsequently invoke (or have
successfully invoked) any of the completion-signalling functions on the receiver.
This allows the caller to catch the exception thrown out of `submit()` if desired and
either handle the error or pass the error onto the caller's receiver by calling
`set_error()`.
However, implementations of algorithms that are themselves senders must be careful when
implementing this logic to ensure that they are able to correctly handle an exception
propagating from the call to `submit()`. If it naively moves its receiver into the
receiver wrapper it passes to a child operation's `submit()` function then if that
`submit()` function invocation throws then the caller may be left with its receiver now
being in a moved-from state and thus not being able to deliver a result to its receiver.
A good demonstration of the problem is in the implementation of a `sequence()` algorithm
that takes two senders and launches the two operations in sequence - only calling
`submit()` on the second sender once the first sender has completed with `set_value()`.
Example 1 in Appendix B highlights the problem with a naive implementation of this
algorithm.
One strategy for implementing a correct, exception-safe implementation is for the caller
to store its receiver in a stable location and then only pass a pointer or reference to
that receiver to the receiver-wrapper passed to the child operation's `submit()` function.
However, under the sender/receiver design described in [@P0443R11], getting access to a
stable location for the receiver would typically require a heap-allocation.
Example 2 in Appendix B shows a solution that makes use of a `shared_ptr` to to allow
correctly handling exceptions that might be thrown from the second sender's submit().
The changes to the sender/receiver design proposed by this paper provides a solution to
this that does not require a heap-allocation to store the receiver. The receiver can be
stored in the operation-state object returned from `connect()`, which the caller is
required to store in a stable location until the operation completes. Then we can pass a
receiver-wrapper into the child operation that just holds a pointer to this
operation-state and can get access to the receiver via that pointer.
Example 3 in Appendix B shows the alternative `connect()`/`start()`-based implementation
of the `sequence()` algorithm for comparison.
This allows some algorithms to further reduce the number of heap-allocations required to
implement them compared to the `submit()`-based implementation.
## Ability to separate resource allocation for operation from launch
The paper [@P1658R0] "Suggestions for Consensus on Executors" suggested factoring
`submit()` into more basic operations - a `finalize()` and a `start()`.
[@P1658R0] makes the observation that the `submit()` operation signals that the sender is
1. ready for execution and 2. may be executed immediately, and suggests that it would be
valuable to be able to decouple the cost of readying a sender from its launch.
Examples of expensive finalization mentioned in [@P1658R0] include:
* Memory allocation of temporary objects required during execution
* Just-in-time compilation of heterogeneous compute kernels
* Instantiation of task graphs
* Serialization of descriptions of work to be executed remotely
Being able to control where the expensive parts of launching an operation occurs is
important for performance-conscious code.
Splitting the `submit()` operation up into a `connect()` and `start()` operations should
make this possible.
# Proposed Wording
This wording change is described as a delta to [@P0443R11].
[Update subsection "Header `<execution>` synopsis" as follows:]{.ednote}
> ```
> // Customization points
> inline namespace @_unspecified_@ {
> inline constexpr @_unspecified_@ set_value = @_unspecified_@;
> inline constexpr @_unspecified_@ set_done = @_unspecified_@;
> inline constexpr @_unspecified_@ set_error = @_unspecified_@;
> inline constexpr @_unspecified_@ execute = @_unspecified_@;
> @@[`inline constexpr @_unspecified_@ connect = @_unspecified_@;`]{.add}@@
> @@[`inline constexpr @_unspecified_@ start = @_unspecified_@;`]{.add}@@
> inline constexpr @_unspecified_@ submit = @_unspecified_@;
> inline constexpr @_unspecified_@ schedule = @_unspecified_@;
> inline constexpr @_unspecified_@ bulk_execute = @_unspecified_@;
> }
>
> @[`template<class S, class R>`]{.add}@
> @[`using connect_result_t = invoke_result_t<decltype(connect), S, R>;`]{.add}@
>
> @@[`template<class, class> struct @_as-receiver_@; @_// exposition only_@`]{.add}@@
> @@[`template<class, class> struct @_as-invocable_@; @_// exposition only_@`]{.add}@@
>
> // Concepts:
> template<class T, class E = exception_ptr>
> concept receiver = @_see-below_@;
>
> template<class T, class... An>
> concept receiver_of = @_see-below_@;
>
> @[`template<class R, class... An>`]{.add}@
> @[`inline constexpr bool is_nothrow_receiver_of_v =`]{.add}@
> @[`receiver_of<R, An...> &&`]{.add}@
> @[`is_nothrow_invocable_v<decltype(set_value), R, An...>;`]{.add}@
>
> @[`template<class O>`]{.add}@
> @@[`concept operation_state = @_see-below_@;`]{.add}@@
>
> template<class S>
> concept sender = @_see-below_@;
>
> template<class S>
> concept typed_sender = @_see-below_@;
>
> @_... as before_@
>
> @_`// Sender and receiver utilities type`_@
> @[class sink_receiver;]{.rm}@
>
> @@[`namespace @_unspecified_@ { struct sender_base {}; }`]{.add}@@
> @@[`using @_unspecified_@::sender_base;`]{.add}@@
>
> template<class S> struct sender_traits;
> ```
[Change 1.2.2 "Invocable archetype" as follows:]{.ednote}
> The name `execution::invocable_archetype` is an implementation-defined type [that, along
> with any argument pack, models `invocable`]{.rm}[such that
> `invocable<execution::invocable_archetype&>` is `true`]{.add}.
>
> A program that creates an instance of `execution::invocable_archetype` is ill-formed.
[Change 1.2.3.4 `execution::execute`, bullet 3 as follows:]{.ednote}
> Otherwise, [if `F` is not an instance of `@_as-invocable_@<@_R_@, E>` for some type
> _`R`_, and `invocable<remove_cvref_t<F>&>` `&& ` `sender_to<E,`
> `@_as-receiver_@<remove_cvref_t<F>, E>>` is `true`]{.add}, `execution::submit(e,`
> `@_as-receiver_@<`
> [`remove_cvref_t<`]{.add}`F`[`>, E`]{.add}`>`[`(`]{.rm}
> [`{std::`]{.add}`forward<F>(f)`[`)`]{.rm}[`}`]{.add}`)` [if `E` and
> `@_as-receiver_@<F>` model `sender_to`]{.rm}, where _`as-receiver`_ is some
> implementation-defined class template equivalent to:
>
> > ```
> > template<@[invocable]{.rm}[class]{.add}@ F@[, class]{.add}@>
> > struct @_as-receiver_@ {
> > @[private:]{.rm}@
> > @[using invocable_type = std::remove_cvref_t<F>;]{.rm}@
> > @[invocable_type]{.rm}[F]{.add}@ f_;
> > @[public:]{.rm}@
> > @@[`explicit @_as-receiver_@(invocable_type&& f)`]{.rm}@@
> > @[`: f_(move_if_noexcept(f)) {}`]{.rm}@
> > @@[`explicit @_as-receiver_@(const invocable_type& f) : f_(f) {}`]{.rm}@@
> > @@[`@_as-receiver_@(@_as-receiver_@&& other) = default;`]{.rm}@@
> > void set_value() @[`noexcept(is_nothrow_invocable_v<F&>)`]{.add}@ {
> > invoke(f_);
> > }
> > @[`[[noreturn]]`]{.add}@ void set_error(std::exception_ptr) @[`noexcept`]{.add}@ {
> > terminate();
> > }
> > void set_done() noexcept {}
> > };
> > ```
[Before subsection 1.2.3.5 "`execution::submit`", add the following two subsections, and
renumber the subsequent subsections.]{.ednote}
:::add
> **1.2.3.x `execution::connect`**
>
> The name `execution::connect` denotes a customization point object. The expression
> `execution::connect(S, R) ` for some subexpressions `S` and `R` is
> expression-equivalent to:
>
> > * `S.connect(R)`, if that expression is valid, if its type satisfies
> > `operation_state`, and if the type of `S` satisfies `sender`.
> > * Otherwise, `connect(S, R)`, if that expression is valid, if its type satisfies
> > `operation_state`, and if the type of `S` satisfies `sender`, with overload
> > resolution performed in a context that includes the declaration
> >
> > ```
> > void connect();
> > ```
> >
> > and that does not include a declaration of `execution::connect`.
> >
> > * Otherwise, `@_as-operation_@{S, R}`, if `R` is not an instance of
> > `@_as-receiver_@<@_F_@, S>` for some type _`F`_, and if `receiver_of<T> &&`
> > `@_executor-of-impl_@<U, @_as-invocable_@<T, S>>` is `true` where `T` is the type of
> > `R` without _cv_-qualification and `U` is the type of `S` without
> > _cv_-qualification, and where _`as-operation`_ is an implementation-defined class
> > equivalent to
> >
> > ```
> > struct @_as-operation_@ {
> > U e_;
> > T r_;
> > void start() noexcept try {
> > execution::execute(std::move(e_), @_as-invocable_@<T, S>{r_});
> > } catch(...) {
> > execution::set_error(std::move(r_), current_exception());
> > }
> > };
> > ```
> >
> > and _`as-invocable`_ is a class template equivalent to the following:
> >
> > ```
> > template<class R, class>
> > struct @_as-invocable_@ {
> > R* r_ ;
> > explicit @_as-invocable_@(R& r) noexcept
> > : r_(std::addressof(r)) {}
> > @_as-invocable_@(@_as-invocable_@&& other) noexcept
> > : r_(std::exchange(other.r_, nullptr)) {}
> > ~@_as-invocable_@() {
> > if(r_)
> > execution::set_done(std::move(*r_));
> > }
> > void operator()() & noexcept try {
> > execution::set_value(std::move(*r_));
> > r_ = nullptr;
> > } catch(...) {
> > execution::set_error(std::move(*r_), current_exception());
> > r_ = nullptr;
> > }
> > };
> > ```
> >
> > * Otherwise, `execution::connect(S, R)` is ill-formed.
>
> **1.2.3.x `execution::start`**
>
> The name `execution::start` denotes a customization point object. The expression
> `execution::start(O)` for some lvalue subexpression `O` is expression-equivalent to:
>
> > * `O.start()`, if that expression is valid.
> > * Otherwise, `start(O)`, if that expression is valid, with overload resolution
> > performed in a context that includes the declaration
> >
> > ```
> > void start();
> > ```
> >
> > and that does not include a declaration of `execution::start`.
> >
> > * Otherwise, `execution::start(O)` is ill-formed.
:::
[Change 1.2.3.5 "`execution::submit`" in recognition of the fact that `submit` is a
customizable algorithm that has a default implementation in terms of `connect`/`start` as
follows:]{.ednote}
> The name `execution::submit` denotes a customization point object.
>
> [A receiver object is _submitted for execution via a sender_ by scheduling the eventual
> evaluation of one of the receiver's value, error, or done channels.]{.rm}
>
> For some subexpressions `s` and `r`, let `S` be a type such that `decltype((s))` is `S`
> and let `R` be a type such that `decltype((r))` is `R`. The expression
> `execution::submit(s, r)` is ill-formed if [`R` does not model receiver, or if `S` does
> not model either `sender` or `executor`]{.rm}[`sender_to<S, R>` is not `true`]{.add}.
> Otherwise, it is expression-equivalent to:
>
> > * `s.submit(r)`, if that expression is valid and `S` models `sender`. If the function
> > selected does not submit the receiver object `r` via the sender `s`, the program is
> > ill-formed with no diagnostic required.
> > * Otherwise, `submit(s, r)`, if that expression is valid and `S` models `sender`, with
> > overload resolution performed in a context that includes the declaration
> >
> > ```
> > void submit();
> > ```
> >
> > and that does not include a declaration of `execution::submit`. If the function
> > selected by overload resolution does not submit the receiver object `r` via the
> > sender `s`, the program is ill-formed with no diagnostic required.
> >
> > :::rm
> > * Otherwise, `execution::execute(s, @_as-invocable_@<R>(forward<R>(r)))` if `S`
> > and `@_as-invocable_@<R>` model `executor`, where _`as-invocable`_ is some
> > implementation-defined class template equivalent to:
> >
> > ```
> > template<receiver R>
> > struct @_as-invocable_@ {
> > private:
> > using receiver_type = std::remove_cvref_t<R>;
> > std::optional<receiver_type> r_ {};
> > void try_init_(auto&& r) {
> > try {
> > r_.emplace((decltype(r)&&) r);
> > } catch(...) {
> > execution::set_error(r, current_exception());
> > }
> > }
> > public:
> > explicit @_as-invocable_@(receiver_type&& r) {
> > try_init_(move_if_noexcept(r));
> > }
> > explicit @_as-invocable_@(const receiver_type& r) {
> > try_init_(r);
> > }
> > @_as-invocable_@(@_as-invocable_@&& other) {
> > if(other.r_) {
> > try_init_(move_if_noexcept(*other.r_));
> > other.r_.reset();
> > }
> > }
> > ~@_as-invocable_@() {
> > if(r_)
> > execution::set_done(*r_);
> > }
> > void operator()() {
> > try {
> > execution::set_value(*r_);
> > } catch(...) {
> > execution::set_error(*r_, current_exception());
> > }
> > r_.reset();
> > }
> > };
> > ```
> > :::
> > :::add
> > * Otherwise, `execution::start((new @_submit-receiver_@<S, R>{s,r})->state_)`,
> > where _`submit-receiver`_ is an implementation-defined class template equivalent
> > to
> >
> > ```
> > template<class S, class R>
> > struct @_submit-receiver_@ {
> > struct wrap {
> > @_submit-receiver_@* p_;
> > template<class...As>
> > requires receiver_of<R, As...>
> > void set_value(As&&... as) && noexcept(is_nothrow_receiver_of_v<R, As...>) {
> > execution::set_value(std::move(p_->r_), (As&&) as...);
> > delete p_;
> > }
> > template<class E>
> > requires receiver<R, E>
> > void set_error(E&& e) && noexcept {
> > execution::set_error(std::move(p_->r_), (E&&) e);
> > delete p_;
> > }
> > void set_done() && noexcept {
> > execution::set_done(std::move(p_->r_));
> > delete p_;
> > }
> > };
> > remove_cvref_t<R> r_;
> > connect_result_t<S, wrap> state_;
> > @_submit-receiver_@(S&& s, R&& r)
> > : r_((R&&) r)
> > , state_(execution::connect((S&&) s, wrap{this}))
> > {}
> > };
> > ```
> > :::
[Change 1.2.3.6 `execution::schedule` as follows:]{.ednote}
> The name `execution::schedule` denotes a customization point object. [For some
> subexpression `s`, let `S` be a type such that `decltype((s))` is `S`.]{.add} The
> expression `execution::schedule(`[`S`]{.rm}[`s`]{.add}`)` [for some subexpression
> `S`]{.rm} is expression-equivalent to:
>
> > * [`S`]{.rm}[`s`]{.add}`.schedule()`, if that expression is valid and its type
> > [N]{.rm} models `sender`.
> > * Otherwise, `schedule(`[`S`]{.rm}[`s`]{.add}`)`, if that expression is valid and its
> > type [N]{.rm} models `sender` with overload resolution performed in a context that
> > includes the declaration
> >
> > ```
> > void schedule();
> > ```
> >
> > and that does not include a declaration of `execution::schedule`.
> >
> > * [Otherwise, `@_decay-copy_@(S)` if the type `S` models `sender`.]{.rm}
> >
> > :::add
> > * Otherwise, `@_as-sender_@<remove_cvref_t<S>>{s}` if `S` satisfies `executor`, where
> > _`as-sender`_ is an implementation-defined class template equivalent to
> >
> > ```
> > template<class E>
> > struct @_as-sender_@ {
> > private:
> > E ex_;
> > public:
> > template<template<class...> class Tuple, template<class...> class Variant>
> > using value_types = Variant<Tuple<>>;
> > template<template<class...> class Variant>
> > using error_types = Variant<std::exception_ptr>;
> > static constexpr bool sends_done = true;
> >
> > explicit @_as-sender_@(E e)
> > : ex_((E&&) e) {}
> > template<class R>
> > requires receiver_of<R>
> > connect_result_t<E, R> connect(R&& r) && {
> > return execution::connect((E&&) ex_, (R&&) r);
> > }
> > template<class R>
> > requires receiver_of<R>
> > connect_result_t<const E &, R> connect(R&& r) const & {
> > return execution::connect(ex_, (R&&) r);
> > }
> > };
> > ```
> > :::
> >
> > * Otherwise, `execution::schedule(`[`S`]{.rm}[`s`]{.add}`)` is ill-formed.
[Merge subsections 1.2.4 and 1.2.5 into a new subsection "Concepts `receiver` and
`receiver_of`" and change them as follows:]{.ednote}
> [XXX TODO The receiver concept...]{.rm}[A receiver represents the continuation of an
> asynchronous operation. An asynchronous operation may complete with a (possibly empty)
> set of values, an error, or it may be cancelled. A receiver has three principal
> operations corresponding to the three ways an asynchronous operation may complete:
> `set_value`, `set_error`, and `set_done`. These are collectively known as a receiver’s
> _completion-signal operations_.]{.add}
>
> > ```
> > @[_`// exposition only:`_]{.rm}@
> > @[`template<class T>`]{.rm}@
> > @@[`inline constexpr bool @_is-nothrow-move-or-copy-constructible_@ =`]{.rm}@@
> > @[`is_nothrow_move_constructible<T> ||`]{.rm}@
> > @[`copy_constructible<T>;`]{.rm}@
> >
> > template<class T, class E = exception_ptr>
> > concept receiver =
> > move_constructible<remove_cvref_t<T>> &&
> > @[`constructible_from<remove_cvref_t<T>, T> &&`]{.add}@
> > @@[`(@_is-nothrow-move-or-copy-constructible_@<remove_cvref_t<T>>) &&`]{.rm}@@
> > requires(@[`remove_cvref_t<`]{.add}T[`>`]{.add}@&& t, E&& e) {
> > { execution::set_done(@[(T&&) t]{.rm}[std::move(t)]{.add}@) } noexcept;
> > { execution::set_error(@[(T&&) t]{.rm}[std::move(t)]{.add}@, (E&&) e) } noexcept;
> > };
> >
> > template<class T, class... An>
> > concept receiver_of =
> > receiver<T> &&
> > requires(@[`remove_cvref_t<`]{.add}T[`>`]{.add}@&& t, An&&... an) {
> > execution::set_value(@[(T&&) t]{.rm}[std::move(t)]{.add}@, (An&&) an...);
> > };
> > ```
>
> :::add
>
> The receiver’s completion-signal operations have semantic requirements that are
> collectively known as the _receiver contract_, described below:
>
> > * None of a receiver’s completion-signal operations shall be invoked before
> > `execution::start` has been called on the operation state object that was returned
> > by `execution::connect` to connect that receiver to a sender.
> > * Once `execution::start` has been called on the operation state object, exactly one
> > of the receiver’s completion-signal operations shall complete non-exceptionally
> > before the receiver is destroyed.
> > * If `execution::set_value` exits with an exception, it is still valid to call
> > `execution::set_error` or `execution::set_done` on the receiver.
>
> Once one of a receiver’s completion-signal operations has completed non-exceptionally,
> the receiver contract has been satisfied.
> :::
[Before 1.2.6 "Concepts `sender` and `sender_to`," insert a new section 1.2.x "Concept
`operation_state`" as follows:]{.ednote}
:::add
> 1.2.x Concept `operation_state`
>
> > ```
> > template<class O>
> > concept operation_state =
> > destructible<O> &&
> > is_object_v<O> &&
> > requires (O& o) {
> > { execution::start(o) } noexcept;
> > };
> > ```
>
> An object whose type satisfies `operation_state` represents the state of an asynchronous
> operation. It is the result of calling `execution::connect` with a `sender` and a
> `receiver`.
>
> `execution::start` may be called on an `operation_state` object at most once. Once
> `execution::start` has been called on it, the `operation_state` must not be destroyed
> until one of the receiver’s completion-signal operations has begun executing, provided
> that invocation will not exit with an exception.
>
> The start of the invocation of `execution::start` shall strongly happen before
> [intro.multithread] the invocation of one of the three receiver operations.
>
> `execution::start` may or may not block pending the successful transfer of execution to
> one of the three receiver operations.
:::
[Change 1.2.6 "Concepts `sender` and `sender_to`" as follows:]{.ednote}
> XXX TODO The `sender` and `sender_to` concepts...
>
> [Let _`sender-to-impl`_ be the exposition-only concept]{.rm}
>
> > ```
> > @[`template<class S, class R>`]{.rm}@
> > @@[`concept @_sender-to-impl_@ =`]{.rm}@@
> > @[`requires(S&& s, R&& r) {`]{.rm}@
> > @[`execution::submit((S&&) s, (R&&) r);`]{.rm}@
> > @[`};`]{.rm}@
> > ```
>
> [Then,]{.rm}
>
> > ```
> > template<class S>
> > concept sender =
> > move_constructible<remove_cvref_t<S>> &&
> > @@[`@_sender-to-impl_@<S, sink_receiver>;`]{.rm}@@
> > @[`!requires {`]{.add}@
> > @@[`typename sender_traits<remove_cvref_t<S>>::__unspecialized; @_// exposition only_@`]{.add}@@
> > @[`};`]{.add}@
> >
> > template<class S, class R>
> > concept sender_to =
> > sender<S> &&
> > receiver<R> &&
> > @@[`@_sender-to-impl_@<S, R>;`]{.rm}@@
> > @[`requires (S&& s, R&& r) {`]{.add}@
> > @[`execution::connect((S&&) s, (R&&) r);`]{.add}@
> > @[`};`]{.add}@
> > ```
>
> None of these operations shall introduce data races as a result of concurrent
> invocations of those functions from different threads.
>
> A[n]{.rm} sender type's destructor shall not block pending completion of the submitted
> function objects. [_Note:_ The ability to wait for completion of submitted function
> objects may be provided by the associated execution > context. _--end note_]
>
> :::rm
> In addition to the above requirements, types `S` and `R` model `sender_to` only if
> they satisfy the requirements from the Table below.~~
>
> In the Table below,
>
> * `s` denotes a (possibly `const`) sender object of type `S`,
> * `r` denotes a (possibly `const`) receiver object of type `R`.
>
> |Expression|Return Type|Operational semantics|
> |--- |--- |--- |
> |execution::submit(s, r)|void|If `execution::submit(s, r)` exits without throwing an exception, then the implementation shall invoke exactly one of `execution::set_value(rc, values...)`, `execution::set_error(rc, error)` or `execution::set_done(rc)` where `rc` is either `r` or an object moved from `r`. If any of the invocations of `set_value` or `set_error` exits via an exception then it is valid to call to either `set_done(rc)` or `set_error(rc, E)`, where `E` is an `exception_ptr` pointing to an unspecified exception object.<br/><br/>`submit` may or may not block pending the successful transfer of execution to one of the three receiver operations.<br/><br/>The start of the invocation of `submit` strongly happens before [intro.multithread] the invocation of one of the three receiver operations.|
>
> :::
[In subsection 1.2.7 "Concept `typed_sender`", change the definition of the `typed_sender`
concept as follows:]{.ednote}
> ```
> template<class S>
> concept typed_sender =
> sender<S> &&
> @_`has-sender-types`_@<sender_traits<@[`remove_cvref_t<`]{.add}`S`[`>`]{.add}@>>;
> ```
[Change 1.2.8 "Concept `scheduler`" as follows:]{.ednote}
> XXX TODO The scheduler concept...
>
> > ```
> > template<class S>
> > concept scheduler =
> > copy_constructible<remove_cvref_t<S>> &&
> > equality_comparable<remove_cvref_t<S>> &&
> > requires(E&& e) {
> > execution::schedule((S&&)s);
> > }; @[`// && sender<invoke_result_t<execution::schedule, S>>`]{.rm}@
> > ```
>
> None of a scheduler's copy constructor, destructor _[... as before]_
>
> [...]
>
> [`execution::submit(N, r)`,]{.rm}[`execution::start(o)`, where `o` is the result of a
> call to `execution::connect(N, r)`]{.add} for some receiver object `r`, is required to
> eagerly submit `r` for execution on an execution agent that `s` creates for it. Let `rc`
> be `r` or an object created by copy or move construction from `r`. The semantic
> constraints on the sender `N` returned from a scheduler `s`'s `schedule` function are as
> follows:
>
> > * If `rc`'s `set_error` function is called in response to a submission error,
> > scheduling error, or other internal error, let `E` be an expression that refers to
> > that error if `set_error(rc, E)` is well-formed; otherwise, let `E` be an
> > `exception_ptr` that refers to that error. [ _Note_: `E` could be the result of
> > calling `current_exception` or `make_exception_ptr` — _end note_ ] The scheduler
> > calls `set_error(rc, E)` on an unspecified weakly-parallel execution agent ([
> > _Note_: An invocation of `set_error` on a receiver is required to be `noexcept` —
> > _end note_]), and
> > * If `rc`'s `set_error` function is called in response to an exception that propagates
> > out of the invocation of `set_value` on `rc`, let `E` be
> > `make_exception_ptr(receiver_invocation_error{})` invoked from within a catch clause
> > that has caught the exception. The executor calls `set_error(rc, E)` on an
> > unspecified weakly-parallel execution agent, and
> > * A call to `set_done(rc)` is made on an unspecified weakly-parallel execution agent.
> > [An invocation of a receiver's `set_done` function is required to be
> > `noexcept`]{.note}
>
> [The senders returned from a scheduler's `schedule` function have wide discretion when
> deciding which of the three receiver functions to call upon submission.]{.note}
[Change subsection 1.2.9 Concepts "`executor` and `executor_of`" as follows to reflect the
fact that the operational semantics of `execute` require a copy to be made of the
invocable:]{.ednote}
> XXX TODO The `executor` and `executor_of` concepts...
>
> Let _`executor-of-impl`_ be the exposition-only concept
>
> > ```
> > template<class E, class F>
> > concept @_`executor-of-impl`_@ =
> > invocable<@[`remove_cvref_t<`]{.add}`F`[`>`]{.add}@&> &&
> > @[`constructible_from<remove_cvref_t<F>, F> &&`]{.add}@
> > @[`move_constructible<remove_cvref_t<F>> &&`]{.add}@
> > @[`copy_constructible<E> &&`]{.add}@
> > is_nothrow_copy_constructible_v<E> &&
> > @[`is_nothrow_destructible_v<E> &&`]{.rm}@
> > equality_comparable<E> &&
> > requires(const E& e, F&& f) {
> > execution::execute(e, (F&&) f);
> > };
> > ```
>
> Then,
>
> > ```
> > template<class E>
> > concept executor =
> > @_executor-of-impl_@<E, execution::invocable_archetype>;
> >
> > template<class E, class F>
> > concept executor_of =
> > @[`executor<E> &&`]{.add}@
> > @_executor-of-impl_@<E, F>;
> > ```
[Remove subsection 1.2.10.1 "Class `sink_receiver`".]{.ednote}
[Change subsection 1.2.10.2 "Class template `sender_traits`" as follows:]{.ednote}
> The class template `sender_traits` can be used to query information about a sender; in
> particular, what values and errors it sends through a receiver's value and error
> channel, and whether or not it ever calls `set_done` on a receiver.
>
> > ```
> > @[`template<class S>`]{.rm}@
> > @[`struct sender-traits-base {}; // exposition-only`]{.rm}@
> >
> > @[`template<class S>`]{.rm}@
> > @[`requires (!same_as<S, remove_cvref_t<S>>)`]{.rm}@
> > @[`struct sender-traits-base`]{.rm}@
> > @[`: sender_traits<remove_cvref_t<S>> {};`]{.rm}@
> >
> > @[`template<class S>`]{.rm}@
> > @[`requires same_as<S, remove_cvref_t<S>> &&`]{.rm}@
> > @[`sender<S> && has-sender-traits<S>`]{.rm}@
> > @[`struct sender-traits-base<S> {`]{.rm}@
> > @[`template<template<class...> class Tuple,`]{.rm}@
> > @[`template<class...> class Variant>`]{.rm}@
> > @[`using value_types =`]{.rm}@
> > @[`typename S::template value_types<Tuple, Variant>;`]{.rm}@
> > @[`template<template<class...> class Variant>`]{.rm}@
> > @[`using error_types =`]{.rm}@
> > @[`typename S::template error_types<Variant>;`]{.rm}@
> > @[`static constexpr bool sends_done = S::sends_done;`]{.rm}@
> > @[`};`]{.rm}@
> >
> > @[`template<class S>`]{.rm}@
> > @[`struct sender_traits : sender-traits-base<S> {};`]{.rm}@
> > ```
>
> :::add
> The primary `sender_traits<S>` class template is defined as if inheriting from an
> implementation-defined class template `@_sender-traits-base_@<S>` defined
> as follows:
>
> > * Let _`has-sender-types`_ be an implementation-defined concept equivalent to:
> >
> > ```
> > template<template<template<class...> class, template<class...> class> class>
> > struct @_has-value-types_@; @_// exposition only_@
> >
> > template<template<template<class...> class> class>
> > struct @_has-error-types_@; @_// exposition only_@
> >
> > template<class S>
> > concept @_has-sender-types_@ =
> > requires {
> > typename @_has-value-types_@<S::template value_types>;
> > typename @_has-error-types_@<S::template error_types>;
> > typename bool_constant<S::sends_done>;
> > };
> > ```
> >
> > If `@_has-sender-types_@<S>` is `true`, then _`sender-traits-base`_ is equivalent
> > to:
> >
> > ```
> > template<class S>
> > struct @_sender-traits-base_@ {
> > template<template<class...> class Tuple, template<class...> class Variant>
> > using value_types = typename S::template value_types<Tuple, Variant>;
> > template<template<class...> class Variant>
> > using error_types = typename S::template error_types<Variant>;
> > static constexpr bool sends_done = S::sends_done;
> > };
> > ```
> >
> > * Otherwise, let _`void-receiver`_ be an implementation-defined class
> > type equivalent to
> >
> > ```
> > struct @_void-receiver_@ { @_// exposition only_@
> > void set_value() noexcept;
> > void set_error(exception_ptr) noexcept;
> > void set_done() noexcept;
> > };
> > ```
> >
> > If `@_executor-of-impl_@<S, @_as-invocable_@<@_void-receiver_@, S>>` is `true`,
> > then _`sender-traits-base`_ is equivalent to
> >
> > ```
> > template<class S>
> > struct @_sender-traits-base_@ {
> > template<template<class...> class Tuple, template<class...> class Variant>
> > using value_types = Variant<Tuple<>>;
> > template<template<class...> class Variant>
> > using error_types = Variant<exception_ptr>;
> > static constexpr bool sends_done = true;
> > };
> > ```
> >
> > * Otherwise, if `derived_from<S, sender_base>` is `true`, then
> > _`sender-traits-base`_ is equivalent to
> >
> > ```
> > template<class S>
> > struct @_sender-traits-base_@ {};
> > ```
> >
> > * Otherwise, _`sender-traits-base`_ is equivalent to
> >
> > ```
> > template<class S>
> > struct @_sender-traits-base_@ {
> > using __unspecialized = void; @_// exposition only_@
> > };
> > ```
> :::
[Change 1.5.4.5 "`static_thread_pool` sender execution functions" as follows:]{.ednote}
> In addition to conforming to the above specification, `static_thread_pool`
> [executors]{.rm} [`scheduler`s' senders]{.add} shall conform to the following
> specification.
>
> > ```
> > class C
> > {
> > public:
> > @[`template<template<class...> class Tuple, template<class...> class Variant>`]{.add}@
> > @[`using value_types = Variant<Tuple<>>;`]{.add}@
> > @[`template<template<class...> class Variant>`]{.add}@
> > @[`using error_types = Variant<>;`]{.add}@
> > @[`static constexpr bool sends_done = true;`]{.add}@
> >
> > template<@[`class Receiver`]{.rm}[`receiver_of`]{.add}@ R>
> > @[`void`]{.rm}[_`see-below`_]{.add}@ @[`submit`]{.rm}[`connect`]{.add}([`Receiver`]{.rm}[`R`]{.add}@&& r) const;
> > };
> > ```
>
> `C` is a type satisfying the [`typed_`]{.add}`sender` requirements.
>
> > ```
> > template<@[`class Receiver`]{.rm}[`receiver_of`]{.add}@ R>
> > @[`void`]{.rm}[_`see-below`_]{.add}@ @[`submit`]{.rm}[`connect`]{.add}([`Receiver`]{.rm}[`R`]{.add}@&& r) const;
> > ```
>
> [_Returns_: An object whose type satisfies the `operation_state` concept.]{.add}
>
> _Effects_: [Submits]{.rm} [When `execution::start` is called on the returned operation
> state,]{.add} the receiver `r` [is submitted]{.add} for execution on the
> `static_thread_pool` according to the the properties established for `*this`.
> [l]{.rm}[L]{.add}et `e` be an object of type `exception_ptr`[,]{.rm}[;]{.add} then
> `static_thread_pool` will evaluate one of `set_value(r)`, `set_error(r, e)`, or
> `set_done(r)`.
\pagebreak
# Appendix A - Examples of status quo lifetime/ownership
## Example 1: Delegating responsibility for allocating storage to a child sender
```c++
template<typename Func, typename Inner>
struct transform_sender {
Inner inner_;
Func func_;
template<typename Receiver>
struct transform_receiver {
Func func_;
Receiver receiver_;
template<typename... Values>
void set_value(Values&&... values) {
receiver_.set_value(std::invoke(func_, (Values&&)values...));
}
template<typename Error>
void set_error(Error&& error) {
receiver_.set_error((Error&&)error);
}
void set_done() {
receiver_.set_done();
}
};
template<typename Receiver>
void submit(Receiver r) {
// Here we delegate responsibility for storing the receiver, 'r'
// and a copy of 'func_' to the implementation of inner_.submit() which
// is required to store the transform_receiver we pass to it.
inner_.submit(transform_receiver<Receiver>{func_, std::move(r)});
}
};
```
\pagebreak
## Example 2: A simple execution context that shows the allocation necessary for operation-state for the `schedule()` operation.
```c++
class simple_execution_context {
struct task_base {
virtual void execute() noexcept = 0;
task_base* next;
};
class schedule_sender {
simple_execution_context& ctx;
public:
explicit schedule_sender(simple_execution_context& ctx) noexcept : ctx(ctx) {}
template<std::receiver_of Receiver>
void submit(Receiver&& r) {
class task final : private task_base {
std::remove_cvref_t<Receiver> r;
public:
explicit task(Receiver&& r) : r((Receiver&&)r) {}
void execute() noexcept override {
try {
std::execution::set_value(std::move(r));
} catch (...) {
std::execution::set_error(std::move(r), std::current_exception());
}
delete this;
}
};
// Allocate the "operation-state" needed to hold the receiver
// and other state (like storage of 'next' field of intrusive list,
// vtable-ptr for dispatching type-erased implementation)
task* t = new task{static_cast<Receiver&&>(r));
// Enqueue this task to the executor's linked-list of tasks to execute.
ctx.enqueue(t);
}
};
class scheduler {
simple_execution_context& ctx;
public:
explicit scheduler(simple_execution_context& ctx) noexcept : ctx(ctx) {}
schedule_sender schedule() const noexcept { return schedule_sender{ctx}; }
};
public:
scheduler get_scheduler() noexcept { return scheduler{*this}; }
// Processes all pending tasks until the queue is empty.
void drain() noexcept {
while (head != nullptr) {
task_base* t = std::exchange(head, head->next);
t->execute();
}
}
private:
void enqueue(task_base* t) noexcept {
t->next = std::exchange(head, t);
}
task_base* head = nullptr;
};
```
\pagebreak
## Example 3: The same `simple_execution_context` as above but this time with the `schedule()` operation implemented using coroutines and awaitables.
Note that this does not require any heap allocations.
```c++
class simple_execution_context {
class awaiter {
friend simple_execution_context;
simple_execution_context& ctx;
awaiter* next = nullptr;
std::coroutine_handle<> continuation;
public:
explicit awaiter(simple_execution_context& ctx) noexcept : ctx(ctx) {}
bool await_ready() const noexcept { return false; }
void await_suspend(std::continuation_handle<> h) noexcept {
continuation = h;
ctx.enqueue(this);
}
void await_resume() noexcept {}
};
class schedule_awaitable {
simple_execution_context& ctx;
public:
explicit schedule_awaitable(simple_execution_context& ctx) noexcept : ctx(ctx) {}
// Return an instance of the operation-state from 'operator co_await()'
// This is will be placed as a local variable within the awaiting coroutine's
// coroutine-frame and means that we don't need a separate heap-allocation.
awaiter operator co_await() const noexcept {
return awaiter{ctx};
}
};
class scheduler {
simple_execution_context& ctx;
public:
explicit scheduler(simple_execution_context& ctx) noexcept : ctx(ctx) {}
schedule_awaitable schedule() const noexcept { return schedule_awaitable{ctx}; }
};
public:
scheduler get_scheduler() noexcept { return scheduler{*this}; }
// Processes all pending awaiters until the queue is empty.
void drain() noexcept {
while (head != nullptr) {
awaiter* a = std::exchange(head, head->next);
a->execute();
}
}
private:
void enqueue(awaiter* a) noexcept {
a->next = std::exchange(head, a);
}
awaiter* head = nullptr;
};
```
\pagebreak
## Example 4: The same `simple_execution_context` but this time implemented using the `connect`/`start` refinements to the sender/receiver.
This uses similar techniques to the coroutine version above; _i.e._, returning the
operation-state to the caller and relying on them to keep the operation-state alive until
the operation completes.
```c++
class simple_execution_context {
struct task_base {
virtual void execute() noexcept = 0;
task_base* next;
};
class schedule_sender {
simple_execution_context& ctx;
public:
explicit schedule_sender(simple_execution_context& ctx) noexcept : ctx(ctx) {}
template<typename Receiver>
class operation_state final : private task_base {
simple_execution_context& ctx;
std::remove_cvref_t<Receiver> receiver;
void execute() noexcept override {
try {
std::execution::set_value(std::move(receiver));
} catch (...) {
std::execution::set_error(std::move(receiver), std::current_exception());
}
}
public:
explicit operation_state(simple_execution_context& ctx, Receiver&& r)
: ctx(ctx), receiver((Receiver&&)r) {}
void start() noexcept & {
ctx.enqueue(this);
}
};
// Returns the operation-state object to the caller which is responsible for
// ensuring it remains alive until the operation completes once start() is called.
template<std::receiver_of Receiver>
operation_state<Receiver> connect(Receiver&& r) {
return operation_state<Receiver>{*this, (Receiver&&)r};
}
};
class scheduler {
simple_execution_context& ctx;
public:
explicit scheduler(simple_execution_context& ctx) noexcept : ctx(ctx) {}
schedule_sender schedule() const noexcept { return schedule_sender{ctx}; }
};
public:
scheduler get_scheduler() noexcept { return scheduler{*this}; }
// Processes all pending tasks until the queue is empty.
void drain() noexcept {
while (head != nullptr) {
task_base* t = std::exchange(head, head->next);
t->execute();
}
}
private:
void enqueue(task_base* t) noexcept {
t->next = std::exchange(head, t);
}
task_base* head = nullptr;
};
```
\pagebreak
# Appendix B - Exception-safe sender adapters
## Example 1: A naive sender-adapter that executes two other senders sequentially with `submit()` as the basis
This is difficult to get right because of the potential for the `submit()` method to
throw. This code snippet shows the problem with a naive approach.
```c++
template<typename First, typename Second>
class sequence_sender {
First first;
Second second;
template<typename Receiver>
class first_receiver {
Second second;
Receiver receiever;
public:
explicit first_receiver(Second&& second, Receiver&& recevier)
noexcept(std::is_nothrow_move_constructible_v<Second> &&
std::is_nothrow_move_constructible_v<Receiver>)
: second((Second&&)second), receiver((Receiver&&)receiver) {}
void set_value() && noexcept {
try {
execution::submit(std::move(second), std::move(receiver));
} catch (...) {
// BUG: What do we do here?
//
// We need to signal completion using 'receiver' but now
// 'receiver' might be in a moved-from state and so we
// cannot safely invoke set_error(receiver, err) here.
}
}
template<typename Error>
void set_error(Error&& e) && noexcept {
execution::set_error(std::move(receiver), (E&&)e);
}
void set_done() && noexcept {
execution::set_done(std::move(receiver));
}
};
public:
explicit sequence_sender(First first, Second second)
noexcept(std::is_nothrow_move_constructible_v<First> &&
std::is_nothrow_move_constructible_v<Second>)
: first((First&&)first), second((Second&&)second)
{}
template<typename Receiver>
void submit(Receiver receiver) && {
// If this call to submit() on the first sender throws then
// we let the exception propagate out without calling the
// 'receiver'.
execution::submit(
std::move(first),
first_receiver<Receiver>{std::move(second), std::move(receiver)});
}
};
```
\pagebreak
## Example 2: An improved sender-adaptor for sequencing senders using `submit()` as a basis
This shows a more correct implementation that makes use of `shared_ptr` to allow recovery
in the case that the `submit()` on the second sender throws. We pass a copy of the
`shared_ptr` into `submit()` and also retain a copy that we can use in case `submit()`
throws an exception.
```c++
template<typename Receiver>
class shared_receiver {
std::shared_ptr<Receiver> receiver_;
public:
explicit shared_receiver(Receiver&& r)
: receiver_(std::make_shared<Receiver>((Receiver&&)r))
{}
template<typename... Values>
requires value_receiver<Receiver, Values...>
void set_value(Values&&... values) && noexcept(
is_nothrow_invocable_v<decltype(execution::set_value), Receiver, Values...>) {
execution::set_value(std::move(*receiver_), (Values&&)values...);
}
template<typename Error>
requires error_receiver<Receiver, Error>
void set_error(Error&& error) && noexcept {
exection::set_error(std::move(*receiver_), (Error&&)error);
}
void set_done() && noexcept requires done_receiver<Receiver> {
execution::set_done(std::move(*receiver_));
}
};
template<typename First, typename Second>
class sequence_sender {
First first;
Second second;
template<typename Receiver>
class first_receiver {
Second second;
shared_receiver<Receiver> receiver;
public:
explicit first_receiver(Second&& second, Receiver&& recevier)
noexcept(std::is_nothrow_move_constructible_v<Second> &&
std::is_nothrow_move_constructible_v<Receiver>)
: second((Second&&)second), receiver((Receiver&&)receiver) {}
void set_value() && noexcept {
try {
execution::submit(std::move(second), std::as_const(receiver));
} catch (...) {
// We only copied the receiver into submit() so we still have access
// to the original receiver to deliver the error.
//
// Note that we must assume that if submit() throws then it will not
// have already called any of the completion methods on the receiver.
execution::set_error(std::move(receiver), std::current_exception());
}
}
template<typename Error>
void set_error(Error&& e) && noexcept {
execution::set_error(std::move(receiver), (E&&)e);
}
void set_done() && noexcept {
execution::set_done(std::move(receiver));
}
};
public:
explicit sequence_sender(First first, Second second)
noexcept(std::is_nothrow_move_constructible_v<First> &&
std::is_nothrow_move_constructible_v<Second>)
: first((First&&)first), second((Second&&)second)
{}
template<typename Receiver>
requires std::execution::sender_to<Second, shared_receiver<Receiver>>
void submit(Receiver receiver) && {
// If this call to submit() on the first sender throws then
// we let the exception propagate out without calling the
// 'receiver'.
execution::submit(
std::move(first),
first_receiver<Receiver>{std::move(second), std::move(receiver)});
}
};
```
\pagebreak
## Example 3: Implementation of the `sequence()` algorithm using `connect()`/`start()`-based senders
Notice that this implementation does not require any heap-allocations to
implement correctly.
```c++
// Helper that allows in-place construction of std::variant element
// using the result of a call to a lambda/function. Relies on C++17
// guaranteed copy-elision when returning a prvalue.
template<std::invocable Func>
struct __implicit_convert {
Func func;
operator std::invoke_result_t<Func>() && noexcept(std::is_nothrow_invocable_v<Func>) {
return std::invoke((Func&&)func);
}
};
template<std::invocable Func>
__implicit_convert(Func) -> __implicit_convert<Func>;
template<typename First, typename Second>
class sequence_sender {
template<typename Receiver>
class operation_state {
class second_receiver {
operation_state* state_;
public:
explicit second_receiver(operation_state* state) noexcept : state_(state) {}
template<typename... Values>
requires std::execution::receiver_of<Receiver, Values...>
void set_value(Values&&... values) noexcept(std::is_nothrow_invocable_v<
decltype(std::execution::set_value), Receiver, Values...>) {
std::execution::set_value(std::move(state_->receiver_), (Values&&)values...);
}
template<typename Error>
requires std::execution::receiver<Receiver, Error>
void set_error(Error&& error) noexcept {
std::execution::set_error(std::move(state_->receiver_), (Error&&)error);
}
void set_done() noexcept {
std::execution::set_done(std::move(state_->receiver_));
}
};
class first_receiver {
operation_state* state_;
public:
explicit first_receiver(operation_state* state) noexcept : state_(state) {}
void set_value() noexcept {
auto* state = state_;
try {
auto& secondState = state->secondOp_.template emplace<1>(
__implicit_convert{[state] {
return std::execution::connect(std::move(state->secondSender_),
first_receiver{state});
}});
std::execution::start(secondState);
} catch (...) {
std::execution::set_error(std::move(state->receiver_), std::current_exception());
}
}
template<typename Error>
requires std::execution::receiver<Receiver, Error>
void set_error(Error&& error) noexcept {
std::execution::set_error(std::move(state_->receiver_), (Error&&)error);
}
void set_done() noexcept {
std::execution::set_done(std::move(state_->receiver_));
}
};
explicit operation_state(First&& first, Second&& second, Receiver receiver)
: secondSender_((Second&&)second)
, receiver_((Receiver&&)receiver)
, state_(std::in_place_index<0>, __implicit_convert{[this, &first] {
return std::execution::connect(std::move(first),
first_receiver{this});
}})
{}
void start() & noexcept {
std::execution::start(std::get<0>(state_));
}
private:
Second secondSender_;
Receiver receiver_;
// This operation-state contains storage for the child operation-states of
// the 'first' and 'second' senders. Only one of these is active at a time
// so we use a variant to allow the second sender to reuse storage from the
// first sender's operation-state.
std::variant<std::execution::connect_result_t<First, first_receiver>,
std::execution::connect_result_t<Second, second_receiver>> state_;
};
public:
explicit sequence_sender(First first, Second second)
: firstSender_((First&&)first)
, secondSender_((Second&&)second)
{}
template<typename Receiver>
operation_state<std::remove_cvref_t<Receiver>> connect(Receiver&& r) && {
return operation_state<std::remove_cvref_t<Receiver>>{
std::move(first_), std::move(second_), (Receiver&&)r};
}
private:
First firstSender_;
Second secondSender_;
};
```
| 40.114583 | 809 | 0.685139 | eng_Latn | 0.98801 |
5441665bf182b333507e203a975bba35d784cd30 | 1,540 | md | Markdown | dist/README.md | boringresearch/bioInfograph | 748cac993d54add2441478297ce22b66042a5099 | [
"MIT"
] | 5 | 2021-03-31T12:44:52.000Z | 2022-01-10T03:00:51.000Z | dist/README.md | boringresearch/bioInfograph | 748cac993d54add2441478297ce22b66042a5099 | [
"MIT"
] | 1 | 2022-02-14T20:51:29.000Z | 2022-02-18T10:11:54.000Z | dist/README.md | boringresearch/bioInfograph | 748cac993d54add2441478297ce22b66042a5099 | [
"MIT"
] | 3 | 2021-12-07T20:31:46.000Z | 2022-02-14T20:48:12.000Z | # bootstrap.js v3.2.0
https://github.com/twbs/bootstrap/releases/download/v3.2.0/bootstrap-3.2.0-dist.zip
# jquery.js v1.12.0
https://github.com/jquery/jquery/releases/tag/1.12.0
# jquery-ui.js v1.12.0
https://jqueryui.com/resources/download/jquery-ui-1.12.0.zip
# lodash.js v3.5.0
https://cdnjs.cloudflare.com/ajax/libs/lodash.js/3.5.0/lodash.min.js
# dropzone.js v5.1.1
https://github.com/dropzone/dropzone/releases/tag/v5.1.1
```
Modifications are made to allow emitting "previewReady" status when an image is fully
loaded into memory and displayed in the preview box, see https://bit.ly/3Gup4Zp for details.
```
(https://bit.ly/3Gup4Zp)
# gridstack.js v0.3.0
https://github.com/gridstack/gridstack.js/releases/tag/v0.3.0
```
Modifications are made to preserve inline styles, including positions, size and z-index after moving
grid panel, see https://bit.ly/3CaOg3T for details.
```
(https://bit.ly/3CaOg3T)
## Creating stylesheet definition of 48 grid columns
``` bash
node-sass < gridstack_width.scss > gridstack-extra.css
```
# svg-pan-zoom.js v3.6.1
https://github.com/bumbu/svg-pan-zoom/releases/tag/3.6.1
# svg-inject.js v1.2.3
https://github.com/iconfu/svg-inject/releases/tag/v1.2.3
```
Modifications: added function to set numeric portion of ID; exported functions to be global scope, see
https://bit.ly/3Gus3kz for details.
```
(https://bit.ly/3Gus3kz)
# tinymce.js v4.8.4
https://download.tiny.cloud/tinymce/community/tinymce_4.8.4.zip
# FileSaver.js v1.3.4
https://github.com/eligrey/FileSaver.js/releases/tag/1.3.4
| 31.428571 | 102 | 0.746753 | kor_Hang | 0.284705 |
5442c888c655d37acef2ff78585454ed6667416f | 430 | md | Markdown | content/curation/deusex1goty.md | SanctuaryCrew/scwebsite | a9b759719dd14e30b703c6c971eb268c5ceab0db | [
"MIT"
] | null | null | null | content/curation/deusex1goty.md | SanctuaryCrew/scwebsite | a9b759719dd14e30b703c6c971eb268c5ceab0db | [
"MIT"
] | 3 | 2020-04-09T05:07:51.000Z | 2020-04-11T22:17:31.000Z | content/curation/deusex1goty.md | SanctuaryCrew/scwebsite | a9b759719dd14e30b703c6c971eb268c5ceab0db | [
"MIT"
] | null | null | null | ---
title: "Deus Ex: Game of the Year Edition"
date: 2020-04-10T20:37:19-07:00
author: RetroNutcase
featured_image:
categories:
- Reviews
- Authored by RetroNutcase
tags:
- Review
steamcuration: "Before CyberPunk2077, there was this. Open ended mission design and a variety of weapons and tools mean plenty of ways to tackle the game. An absolute classic FPS/RPG hybrid"
draft: false
---
Full review to come at a later date. | 28.666667 | 190 | 0.760465 | eng_Latn | 0.944202 |
5442f55197910ca6d53b0b69b11feecac2755740 | 15,115 | md | Markdown | content/documents/v1/component-list/database.md | kaysen820/swoft-www-cn | 6eccdcf8f1d1f3b71160bee14c5e6a632c00c824 | [
"MIT"
] | 11 | 2019-09-03T09:55:56.000Z | 2021-04-16T05:48:50.000Z | content/documents/v1/component-list/database.md | kaysen820/swoft-www-cn | 6eccdcf8f1d1f3b71160bee14c5e6a632c00c824 | [
"MIT"
] | 1 | 2019-11-17T06:06:44.000Z | 2019-11-17T06:07:17.000Z | content/documents/v1/component-list/database.md | kaysen820/swoft-www-cn | 6eccdcf8f1d1f3b71160bee14c5e6a632c00c824 | [
"MIT"
] | 28 | 2019-09-03T10:01:56.000Z | 2022-01-19T03:34:25.000Z | +++
title = "数据库"
toc = true
type = "docs"
draft = false
date = "2018-09-19"
lastmod = "2018-09-20"
weight = 307
[menu.v1]
parent = "component-list"
weight = 7
+++
提供ActiveRecord常见的操作方式,方便简单快捷。
开始事务后,之间的所有操作都在同一个事务里面,但是不支持并发操作,因为是同一个连接。
查询器是一套封装面向对象的方法,来实现SQL拼装和操作。
## SQL语句
获取最后执行SQL语句,调用get_last_sql()全局函数。
> 组件版本必须不小于1.1.0,之前版本需要调整升级才能使用当前最新操作,不兼容之前版本。
## 数据库配置
主要是配置数据库主从连接信息,Swoft 提供 `properties` 和 `env` 两种方式配置,且 `env` 会覆盖 `properties` 配置。
> 主从都配置,默认读操作使用从配置,写操作使用主配置. 若**只配置主**,读写操作都会使用主配置
### 一些说明
- 数据库实例: 实例相当于分类,如下面看到的含有默认的两个节点 `master` `slave`, 属于默认实例 `default`
- 数据库节点: 每个实例下的item,都是一个节点,key 是节点名称。 通常我们会用两个节点,分别命名为 `master` `slave`
- 每个节点都会创建一个连接池,池的名称是 `instance.node` 例如下面的 `default.master` `other.master`
- 通过 `\Swoft::getPool('instance.node')` 可以拿到连接池对象
> 您可以自定义实例和节点的名称,不过使用时要注意区分和选择。当然,我们推荐使用通用的命名
### properties
配置 `config/properties/db.php`
```php
return [
'master' => [
'name' => 'master',
'uri' => [
'127.0.0.1:3306/test?user=root&password=123456&charset=utf8',
'127.0.0.1:3306/test?user=root&password=123456&charset=utf8',
],
'minActive' => 8,
'maxActive' => 8,
'maxWait' => 8,
'timeout' => 8,
'maxIdleTime' => 60,
'maxWaitTime' => 3,
],
'slave' => [
'name' => 'slave',
'uri' => [
'127.0.0.1:3306/test?user=root&password=123456&charset=utf8',
'127.0.0.1:3306/test?user=root&password=123456&charset=utf8',
],
'minActive' => 8,
'maxActive' => 8,
'maxWait' => 8,
'timeout' => 8,
'maxIdleTime' => 60,
'maxWaitTime' => 3,
],
];
```
- master/slave 主从配置
- name 连接池节点名称,用于服务发现
- uri 连接地址信息
- minActive 最小活跃链接数
- maxActive 最大活跃连接数
- maxIdleTime 连接最大空闲时间,单位秒
- maxWaitTime 连接最大等待时间,单位秒
- maxWait 最大等待连接
- timeout 超时时间,单位秒
> master,slave 是两个特殊的名称,他们会归纳到 `default` 实例中去。表现为 `default.master`, `default.slave`
- 像上面直接写 master,slave 框架会自动将这两个划分到 `default` 实例中去
- 所以这里实际结构该是下面这样的(_允许上面的配置是为了兼容之前的版本_), 新增实例应当遵循这个结构
```php
'default' => [
'master' => [ // ...],
'slave' => [ // ...],
]
```
### env
配置.env文件
```ini
# the pool of master nodes pool
DB_NAME=dbMaster
DB_URI=127.0.0.1:3306/test?user=root&password=123456&charset=utf8,127.0.0.1:3306/test?user=root&password=123456&charset=utf8
DB_MIN_ACTIVE=6
DB_MAX_ACTIVE=10
DB_MAX_WAIT=20
DB_MAX_IDLE_TIME=60
DB_MAX_WAIT_TIME=3
DB_TIMEOUT=200
# the pool of slave nodes pool
DB_SLAVE_NAME=dbSlave
DB_SLAVE_URI=127.0.0.1:3306/test?user=root&password=123456&charset=utf8,127.0.0.1:3306/test?user=root&password=123456&charset=utf8
DB_SLAVE_MIN_ACTIVE=5
DB_SLAVE_MAX_ACTIVE=10
DB_SLAVE_MAX_WAIT=20
DB_SLAVE_MAX_WAIT_TIME=3
DB_SLAVE_MAX_IDLE_TIME=60
DB_SLAVE_TIMEOUT=200
```
- DB/DB_SLAVE_NAME 连接池节点名称,用于服务发现
- DB/DB_SLAVE_URI 连接地址信息
- DB/DB_SLAVE_MIN_ACTIVE 最小活跃链接数
- DB/DB_SLAVE_MAX_ACTIVE 最大活跃连接数
- DB/DB_SLAVE_MAX_IDLE_TIME 连接最大空闲时间,单位秒
- DB/DB_SLAVE_MAX_WAIT_TIME 连接最大等待时间,单位秒
- DB/DB_SLAVE_MAX_WAIT 最大等待连接
- DB/DB_SLAVE_TIMEOUT 超时时间,单位秒
### 数据库实例
上面的配置都是属于默认实例 `default`, 含有两个节点 `master` `slave`
### 增加实例
增加实例需在 `db.php` 增加新的实例配置,如下:
- 新增实例 `other`
- 它同样含有两个节点 `master` `slave`
```php
return [
// ...
'other' => [
'master' => [
'name' => 'master2',
'uri' => [
'127.0.0.1:3301',
'127.0.0.1:3301',
],
'maxIdel' => 1,
'maxActive' => 1,
'maxWait' => 1,
'timeout' => 1,
],
'slave' => [
'name' => 'slave3',
'uri' => [
'127.0.0.1:3301',
'127.0.0.1:3301',
],
'maxIdel' => 1,
'maxActive' => 1,
'maxWait' => 1,
'timeout' => 1,
],
],
];
```
> 注意: 新增实例除了要添加配置外,还需新增相关的 pool配置类,pool类,请参照 `app/Pool` 和 `swoft/db` 的test示例
## 实体定义
无论是高级查询还是基础查询,都会需要一个表实体。一个表字段和一个类属性是一一映射,对类的操作相当于对表的操作,该类称为一个实体
- 一个实体类对应一张数据库的表结构
- 实体对象代表了表的一行数据记录
> 注意: 实体不能作为属性被注入到任何类, 因为每个实体对象都是不同的数据记录行。实体对象都是在哪用就在哪里创建它。
### @Entity
标记一个类是一个实体,无需多余参数
参数:
- `instance` 定义实体对应实例,默认 `default` 实例 _对,就是前面配置上的那个`default`实例:)_
> 若需使用基础查询,必须继承Model
### @Table
- name 定义该实体映射的数据库表名
### @Column
参数:
- name 定义类属性映射的表字段,没该注解标记的属性,不映射
- type 定义字段数据更新时验证类型,暂时提供常见的数据类型延迟,后续会更多
说明:
- 若定义type,可定义其它验证条件
- 所有字段属性,必须要有`getter`和`setter`方法
> 类属性默认值即是表字段默认值
### @Id
该注解标明当前类属性对应了数据库表中的主键,**必须**有这个注解标记
### 快速生成实体类
swoft 提供了内置命令帮助快速生成实体类。
```bash
php bin/swoft entity:create -d dbname mytable,table2
```
> 更多使用信息请查看 [命令创建实体](create-entity.md) 或者使用 `-h` 查看命令帮助信息
### 示例
```php
/**
* @Entity()
* @Table(name="user")
*/
class User extends Model
{
/**
* 主键ID
*
* @Id()
* @Column(name="id", type=Types::INT)
* @var null|int
*/
private $id;
/**
* 名称
*
* @Column(name="name", type=Types::STRING, length=20)
* @Required()
* @var null|string
*/
private $name;
/**
* 年龄
*
* @Column(name="age", type=Types::INT)
* @var int
*/
private $age = 0;
/**
* 性别
*
* @Column(name="sex", type="int")
* @var int
*/
private $sex = 0;
/**
* 描述
*
* @Column(name="description", type="string")
* @var string
*/
private $desc = "";
/**
* 非数据库字段,未定义映射关系
*
* @var mixed
*/
private $otherProperty;
/**
* @return int|null
*/
public function getId()
{
return $this->id;
}
/**
* @param int|null $id
*/
public function setId($id)
{
$this->id = $id;
}
/**
* @return null|string
*/
public function getName()
{
return $this->name;
}
/**
* @param null|string $name
*/
public function setName($name)
{
$this->name = $name;
}
/**
* @return int
*/
public function getAge(): int
{
return $this->age;
}
/**
* @param int $age
*/
public function setAge(int $age)
{
$this->age = $age;
}
/**
* @return int
*/
public function getSex(): int
{
return $this->sex;
}
/**
* @param int $sex
*/
public function setSex(int $sex)
{
$this->sex = $sex;
}
/**
* @return string
*/
public function getDesc(): string
{
return $this->desc;
}
/**
* @param string $desc
*/
public function setDesc(string $desc)
{
$this->desc = $desc;
}
/**
* @return mixed
*/
public function getOtherProperty()
{
return $this->otherProperty;
}
/**
* @param mixed $otherProperty
*/
public function setOtherProperty($otherProperty)
{
$this->otherProperty = $otherProperty;
}
}
```
## 数据库查询器
查询器,提供可以使用面向对象的方法操作数据库。
### 方法列表
| 方法 | 功能 |
| :--- | :--- |
| insert | 插入数据 |
| batchInsert | 批量插入数据 |
| update | 更新数据 |
| delete | 删除数据 |
| counter | count数据 |
| get | 查询数据 |
| one | 查询一行数据 |
| table | 指定表名及别名 |
| innerJoin | 内连接 |
| leftJoin | 左连接 |
| rightJoin | 右连接 |
| condition | 通过数组结构快速指定条件 |
| where | where 条件语句 |
| andWhere | where and 条件语句 |
| openWhere | where 里面左括号 |
| closeWhere | where 里面右括号 |
| orWhere | where or 条件语句 |
| whereIn | where in语句 |
| whereNotIn | where not in 语句 |
| whereBetween | where between and 语句 |
| whereNotBetween | where not between and语句 |
| having | having语句 |
| andHaving | having and语句 |
| orHaving | having or语句 |
| havingIn | having in语句 |
| havingNotIn | having not in语句 |
| havingBetween | having between and语句 |
| havingNotBetween | havin not between and 语句 |
| openHaving | having括号开始语句 |
| closeHaving | having括号结束语句 |
| groupBy | group by语句 |
| orderBy | order by语句 |
| condition | 条件查询 |
| limit | limit语句 |
| count | count语句 |
| max | max语句 |
| min | min语句 |
| avg | avg语句 |
| sum | sum语句 |
| setParameter | 设置参数 |
| setParameters | 设置多个参数 |
| selectDb | 设置连接的DB |
| selectNode | 选择连接的节点 |
| selectInstance | 选择连接的实例 |
| force | 强制使用 Master 节点 |
| className | 设置数据的实体对象类 |
### 获取最后执行的 SQL
直接通过 `get_last_sql()` 函数从 SQLStack 中获得最后执行的 SQL
### 规则与格式
- 语句中的表名,可以是数据库表名,也可以是表对应的实体类名
- 查询器都是通过getResult\(\)方法获取结果
- 插入操作,成功返回插入ID,如果ID传值,插入数据库返回0,错误返回false
- 更新操作,成功返回影响行数,如果失败返回false
- 删除操作,成功返回影响行数,如果失败返回false
- 查询操作,单条记录成功返回一维数组或一个实体,多条记录返回多维数组或实体数组
## AR快速操作
Model里面提供了常见的数据库操作方式。
### 插入数据
#### 对象方式
```php
$user = new User();
$user->setName('name');
$user->setSex(1);
$user->setDesc('this my desc');
$user->setAge(mt_rand(1, 100));
$id = $user->save()->getResult();
```
#### 数组填充
```php
$data = [
'name' => 'name',
'sex' => 1,
'desc' => 'desc2',
'age' => 100,
];
$user = new User();
$result = $user->fill($data)->save()->getResult();
```
#### 数组方式
```php
$user = new User();
$user['name'] = 'name2';
$user['sex'] = 1;
$user['desc'] = 'this my desc9';
$user['age'] = 99;
$result = $user->save()->getResult();
```
#### 批量插入
```php
$values = [
[
'name' => 'name',
'sex' => 1,
'description' => 'this my desc',
'age' => 99,
],
[
'name' => 'name2',
'sex' => 1,
'description' => 'this my desc2',
'age' => 100,
]
];
$result = User::batchInsert($values)->getResult();
```
### 删除数据
#### 对象删除
```php
/* @var User $user */
$user = User::findById($id)->getResult();
$result = $user->delete()->getResult();
$this->assertEquals(1, $result);
```
#### 主键删除一条数据
```php
$result = User::deleteById(1)->getResult();
```
#### 主键删除多条数据
```php
$result = User::deleteByIds([1,2])->getResult();
```
#### 删除一条数据
```php
// delete from user where name='name2testDeleteOne' and age=99 and id=1 limit 1
$result = User::deleteOne(['name' => 'name2testDeleteOne', 'age' => 99, 'id' => 1])->getResult();
```
#### 删除多条数据
```php
// delete from user where name='name' and id in (1,2)
$result = User::deleteAll(['name' => 'name', 'id' => [1,2])->getResult();
```
### 更新数据
#### 实体更新
```php
/* @var User $user */
$user = User::findById(1)->getResult();
$user->setName('newName');
$updateResult = $user->update()->getResult();
```
#### 更新一条数据
```php
// update user set name='testUpdateOne' where id=1 limit 1
$result = User::updateOne(['name' => 'testUpdateOne'], ['id' => 1])->getResult();
```
#### 更新多条数据
```php
// update user set name='testUpdateOne' where id in (1,2)
$result = User::updateAll(['name' => 'testUpdateAll'], ['id' => [1,2]])->getResult();
```
### 查询数据
使用AR实体查询,返回结果是都是实体对象,不是数组。
#### 查询一条数据
```php
// select id,name from user where id=1 limit 1
$user2 = User::findOne(['id' => 1], ['fields' => ['id', 'name']])->getResult();
```
#### 查询多条数据
```
findAll(array $condition = [], array $options = [])
```
- `$condition` 查找条件,数组
- `$options` 额外选项。 如: `orderby` `limit` `offset`
使用示例:
```php
// select * from user where name='testUpdateAll' and id in (1,2)
$result = User::findAll(['name' => 'testUpdateAll', 'id' => [1,2]])->getResult();
// select * from user where name='tom' and id > 2 order by createAt DESC
$result = User::findAll(['name' => 'tom', ['id', '>', 2]], ['orderby' => ['createAt' => 'DESC'])->getResult();
// select * from user where name like '%swoft%' order by createAt DESC limit 10
$result = User::findAll([['name', 'like', '%swoft%']], ['orderby' => ['createAt' => 'DESC'], 'limit' => 10])->getResult();
```
#### 主键查询一条数据
```php
// selet * from user where id=1
/* @var User $user */
$user = User::findById(1)->getResult();
```
#### 主键查询多条数据
```php
// select id from user where id in(1,2) order by id asc limit 0,2
$users = User::findByIds([1,2], ['fields' => ['id'], 'orderby' => ['id' => 'asc'], 'limit' => 2])->getResult();
```
#### 实体查询器
```php
// select * from user order by id desc limit 0,2
$result = User::query()->orderBy('id', QueryBuilder::ORDER_BY_DESC)->limit(2)->get()->getResult();
```
#### 主键是否存在查询
存在返回true,不存在返回false
```php
User::exist(1)->getResult()
```
#### 计数查询
直接返回满足条件的行数
```php
$count = User::count('id', ['id' => [1,2]])->getResult();
```
## 查询器使用
插入数据
```php
$values = [
'name' => 'name',
'sex' => 1,
'description' => 'this my desc',
'age' => 99,
];
$result = Query::table(User::class)->insert($values)->getResult();
```
删除数据
```php
$result = Query::table(User::class)->where('id', 1)->delete()->getResult();
```
更新数据
```php
$result = Query::table(User::class)->where('id', 1)->update(['name' => 'name666'])->getResult();
```
查询数据
```php
$result = Query::table(User::class)->where('id', 1)->limit(1)->get()->getResult();
```
聚合操作
```php
$count = Query::table(User::class)->count('id', 'userCount')->getResult();
$countNum = $count['userCount'];
$ageNum = Query::table(User::class)->sum('age', 'ageNum')->getResult();
$ageNum = $ageNum['ageNum'];
$maxAge = Query::table(User::class)->max('age', 'maxAge')->getResult();
$maxAge = $maxAge['maxAge'];
$minAge = Query::table(User::class)->min('age', 'minAge')->getResult();
$minAge = $minAge['minAge'];
$avgAge = Query::table(User::class)->avg('age', 'avgAge')->getResult();
$avgAge = $avgAge['avgAge'];
```
切换数据库实例
```php
$data = [
'name' => 'name',
'sex' => 1,
'description' => 'this my desc instance',
'age' => mt_rand(1, 100),
];
$userid = Query::table(User::class)->selectInstance('other')->insert($data)->getResult();
$user2 = Query::table(User::class)->selectInstance('other')->where('id', $userid)->limit(1)->get()->getResult();
```
切换数据库
```php
$data = [
'name' => 'name',
'sex' => 1,
'description' => 'this my desc table',
'age' => mt_rand(1, 100),
];
$userid = Query::table(User::class)->selectDb('test2')->insert($data)->getResult();
$user2 = Query::table(User::class)->selectDb('test2')->where('id', $userid)->limit(1)->get()->getResult();
```
## SQL与事务
### SQL原生语句
```php
// 增删改查操作
$result = Db::query('insert into user(name, sex,description, age) values("' . $name . '", 1, "xxxx", 99)')->getResult();
$result = Db::query('delete from user where id=' . $id)->getResult();
$result = Db::query('update user set name="' . $name . '" where id=' . $id)->getResult();
$result = Db::query('select * from user where id=' . $id)->getResult();
// 参数绑定
$result = Db::query('select * from user where id=:id and name=:name', ['id' => $id, ':name'=>'name'])->getResult();
$result2 = Db::query('select * from user where id=? and name=?', [$id, 'name'])->getResult();
```
### 事务
开启事务后,事务之间的所有操作都是同一个连接,注意不能使用并发操作。
```php
Db::beginTransaction();
$user = new User();
$user->setName('name');
$user->setSex(1);
$user->setDesc('this my desc');
$user->setAge(mt_rand(1, 100));
$userId = $user->save()->getResult();
$count = new Count();
$count->setUid($userId);
$count->setFollows(mt_rand(1, 100));
$count->setFans(mt_rand(1, 100));
$countId = $count->save()->getResult();
Db::commit();
//Db::rollback();
``` | 19.75817 | 130 | 0.56917 | yue_Hant | 0.518467 |
54433309612440fb2ce7f31b8706bd1acd970d08 | 7,637 | md | Markdown | _READMES/RedditSota.state-of-the-art-result-for-machine-learning-problems 21-26-07-272.md | BJBaardse/open-source-words | 18ca0c71e7718a0e2e9b7269b018f77b06f423b4 | [
"Apache-2.0"
] | 17 | 2018-07-13T02:16:22.000Z | 2021-09-16T15:31:49.000Z | _READMES/RedditSota.state-of-the-art-result-for-machine-learning-problems 21-26-07-272.md | letform/open-source-words | 18ca0c71e7718a0e2e9b7269b018f77b06f423b4 | [
"Apache-2.0"
] | null | null | null | _READMES/RedditSota.state-of-the-art-result-for-machine-learning-problems 21-26-07-272.md | letform/open-source-words | 18ca0c71e7718a0e2e9b7269b018f77b06f423b4 | [
"Apache-2.0"
] | 6 | 2018-10-12T09:09:05.000Z | 2021-01-01T15:32:45.000Z | state of the art result for all machine learning problems last update 17th november 2017 news i am looking for a collaborator esp who does research in nlp computer vision and reinforcement learning if you are not a researcher but you are willing contact me email me redditsota gmail com this repository provides state of the art sota results for all machine learning problems we do our best to keep this repository up to date if you do find a problems sota result is out of date or missing please raise this as an issue with this information research paper name dataset metric source code and year we will fix it immediately you can also submit this google form if you are new to github this is an attempt to make one stop for all types of machine learning problems state of the art result i can not do this alone i need help from everyone please submit the google form raise an issue if you find sota result for a dataset please share this on twitter facebook and other social media this summary is categorized into supervised learning speech computer vision nlp semi supervised learning computer vision unsupervised learning speech computer vision nlp transfer learning reinforcement learning supervised learning nlp 1 language modelling research paper datasets metric source code year breaking the softmax bottleneck a high rank rnn language model ptb wikitext 2 perplexity 47 69 perplexity 40 68 pytorch 2017 dynamic evaluation of neural sequence models ptb wikitext 2 perplexity 51 1 perplexity 44 3 pytorch 2017 averaged stochastic gradient descent with weight dropped lstm or qrnn ptb wikitext 2 perplexity 52 8 perplexity 52 0 pytorch 2017 fraternal dropout ptb wikitext 2 perplexity 56 8 perplexity 64 1 pytorch 2017 factorization tricks for lstm networks one billion word benchmark perplexity 23 36 tensorflow 2017 2 machine translation research paper datasets metric source code year weighted transformer network for machine translation wmt 2014 english to french wmt 2014 english to german bleu 41 4 bleu 28 9 not found 2017 attention is all you need wmt 2014 english to french wmt 2014 english to german bleu 41 0 bleu 28 4 pytorch tensorflow 2017 non autoregressive neural machine translation wmt16 ro→en bleu 31 44 not found 2017 improving neural machine translation with conditional sequence generative adversarial nets nist02 nist03 nist04 nist05 38 74 36 01 37 54 33 76 nmtpy 2017 3 text classification research paper datasets metric source code year learning structured text representations yelp accuracy 68 6 not found 2017 attentive convolution yelp accuracy 67 36 not found 2017 4 natural language inference leader board stanford natural language inference snli multinli research paper datasets metric source code year natural language inference over interaction space stanford natural language inference snli accuracy 88 9 tensorflow 2017 5 question answering leader board squad research paper datasets metric source code year qanet ensemble the stanford question answering dataset exact match 83 877 f1 89 737 tensorflow 2018 6 named entity recognition research paper datasets metric source code year named entity recognition in twitter using images and text ritter f measure 0 59 not found 2017 7 abstractive summarization research paper datasets metric source code year cutting off redundant repeating generations for neural abstractive summarization duc 2004gigaword duc 2004 rouge 1 32 28 rouge 2 10 54 rouge l 27 80 gigaword rouge 1 36 30 rouge 2 17 31 rouge l 33 88 not yet available 2017 convolutional sequence to sequence duc 2004gigaword duc 2004 rouge 1 33 44 rouge 2 10 84 rouge l 26 90 gigaword rouge 1 35 88 rouge 2 27 48 rouge l 33 29 pytorch 2017 8 dependency parsing research paper datasets metric source code year globally normalized transition based neural networks final conll 09 dependency parsing 94 08 uas accurancy 92 15 las accurancy syntaxnet 2017 computer vision 1 classification research paper datasets metric source code year dynamic routing between capsules mnist test error 0 25±0 005 official implementation pytorch tensorflow keras chainer list of all implementations 2017 high performance neural networks for visual object classification norb test error 2 53 ± 0 40 not found 2011 shakedrop regularization cifar 10 cifar 100 test error 2 31 test error 12 19 not found 2017 aggregated residual transformations for deep neural networks cifar 10 test error 3 58 pytorch 2017 random erasing data augmentation cifar 10 cifar 100 fashion mnist test error 3 08 test error 17 73 test error 3 65 pytorch 2017 eraserelu a simple way to ease the training of deep convolution neural networks cifar 10 cifar 100 test error 3 56 test error 16 53 pytorch 2017 dynamic routing between capsules multimnist test error 5 pytorch tensorflow keras chainer list of all implementations 2017 learning transferable architectures for scalable image recognition imagenet 1k top 1 error 17 3 tensorflow 2017 squeeze and excitation networks imagenet 1k top 1 error 18 68 caffe 2017 aggregated residual transformations for deep neural networks imagenet 1k top 1 error 20 4 pytorch 2016 2 instance segmentation research paper datasets metric source code year mask r cnn coco average precision 37 1 detectron official version mxnet keras tensorflow 2017 3 visual question answering research paper datasets metric source code year tips and tricks for visual question answering learnings from the 2017 challenge vqa overall score 69 not found 2017 4 person re identification research paper datasets metric source code year random erasing data augmentation market 1501 cuhk03 new protocol dukemtmc reid rank 1 89 13 map 83 93 rank 1 84 02 map 78 28 labeled rank 1 63 93 map 65 05 detected rank 1 64 43 map 64 75 pytorch 2017 speech speech sota 1 asr research paper datasets metric source code year the microsoft 2017 conversational speech recognition system switchboard hub500 wer 5 1 not found 2017 the capio 2017 conversational speech recognition system switchboard hub500 wer 5 0 not found 2017 semi supervised learning computer vision research paper datasets metric source code year distributional smoothingwith virtual adversarial training svhn norb test error 24 63 test error 9 88 theano 2016 virtual adversarial training a regularization method for supervised and semi supervised learning mnist test error 1 27 not found 2017 few shot object detection voc2007 voc2012 map 41 7 map 35 4 not found 2017 unlabeled samples generated by gan improve the person re identification baseline in vitro market 1501 cuhk 03 dukemtmc reid cub 200 2011 rank 1 83 97 map 66 07 rank 1 84 6 map 87 4 rank 1 67 68 map 47 13 test accuracy 84 4 matconvnet 2017 unsupervised learning computer vision 1 generative model research paper datasets metric source code year progressive growing of gans for improved quality stability and variation unsupervised cifar 10 inception score 8 80 theano 2017 nlp machine translation research paper datasets metric source code year unsupervised machine translation using monolingual corpora only multi30k task1 en fr fr en de en en de bleu 32 76 32 07 26 26 22 74 not found 2017 unsupervised neural machine translation with weight sharing wmt14 en fr fr en wmt16 de en en de bleu 16 97 15 58 bleu 14 62 10 86 not found 2018 transfer learning research paper datasets metric source code year one model to learn them all wmt en → de wmt en → fr bleu imagenet top 5 accuracy bleu 21 2 bleu 30 5 86 tensorflow 2017 reinforcement learning research paper datasets metric source code year mastering the game of go without human knowledge the game of go elo rating 5185 c 2017 email redditsota gmail com | 7,637 | 7,637 | 0.832919 | eng_Latn | 0.983938 |
544354d88c6a99c0012cc2d6a135863f2460a814 | 233 | md | Markdown | README.md | Asteria-Sun/Some-Short-Programs | df0b1a0f5fc838efbdb88da91ad653026044e23a | [
"Apache-2.0"
] | null | null | null | README.md | Asteria-Sun/Some-Short-Programs | df0b1a0f5fc838efbdb88da91ad653026044e23a | [
"Apache-2.0"
] | null | null | null | README.md | Asteria-Sun/Some-Short-Programs | df0b1a0f5fc838efbdb88da91ad653026044e23a | [
"Apache-2.0"
] | null | null | null | # Some-Short-Programs
MDD (maximum drawdown) calculation;
Expected updates:
1,Brown Motion (definition, codes)
2,BSM fomula
3,Ito lemma
4,YTM, spot rata, forward rate
5,Macaulay duration, Modified duration, Effective duarion, DV01
| 23.3 | 63 | 0.785408 | yue_Hant | 0.564019 |
54435934240d3a9a51bd012378cedbd20f6d2302 | 28 | md | Markdown | README.md | Handsomevic/handsomevic.github.io | 6737ffb17b0d0dfc28ae98b25375504922ed3aac | [
"CC-BY-3.0"
] | null | null | null | README.md | Handsomevic/handsomevic.github.io | 6737ffb17b0d0dfc28ae98b25375504922ed3aac | [
"CC-BY-3.0"
] | null | null | null | README.md | Handsomevic/handsomevic.github.io | 6737ffb17b0d0dfc28ae98b25375504922ed3aac | [
"CC-BY-3.0"
] | null | null | null | # handsomevic.gitub.io
web
| 7 | 22 | 0.75 | vie_Latn | 0.181711 |
54444c2a9a95bb873c196e0769ee5878b13cc2c0 | 1,901 | md | Markdown | db/shared/README.md | RedTint/serverless-framework-base | cf782c802e2c80233ddb0fe15f76c74319847758 | [
"MIT"
] | null | null | null | db/shared/README.md | RedTint/serverless-framework-base | cf782c802e2c80233ddb0fe15f76c74319847758 | [
"MIT"
] | null | null | null | db/shared/README.md | RedTint/serverless-framework-base | cf782c802e2c80233ddb0fe15f76c74319847758 | [
"MIT"
] | null | null | null | # DB
This README constain details about the data available in our database
## ACCOUNTS
### Create Account
**Required Parameters:**
```
{
"email": "[email protected]",
"username": "SomeUser",
"mobile_number": "639088884306"
}
```
**More Details:**
* **api_code** – **PREFIX** with ACCOUNTS#'. Generated from user email + an API_CODE_MODIFIER.
* Validations:
* Required
* Unique
* **api_key**
* Auto-generated using `generate-password` with 10 characters
* Saved using MD5 - one-way hash.
* Validations:
* None
* **email**
* Validations:
* Required
* Unique
* No limit on characters
* **mobile_number**
* Validations:
* Required
* Valid Mobile Number
* **password**
* Auto-generated using `generate-password` with 10 characters
* Saved using MD5 - one-way hash.
* Validations:
* None
* **account_type**
* Default to `ACCOUNT_TYPE_CREDIT`.
* Validations:
* None
* **status**
* Default to `ACCOUNT_STATUS_ENABLED`.
* Validations:
* None
* **date_created**
* Auto-generated with `(new Date(dateCreated)).toISOString()`
* Validations:
* None
* **date_updated**
* Auto-generated with `(new Date(dateCreated)).toISOString()`
* Validations:
* None
* **first_name**
* Validations:
* None
* **middle_name**
* Validations:
* None
* **last_name**
* Validations:
* None
* **nickname**
* Validations:
* None
**Code Excerpt**
```
"email": email,
"username": username,
"password": password,
"mobile_number": mobileNumber,
"api_code": ACCOUNT_PREFIX + apiCode,
"api_key": apiKey,
"account_type": accountType,
"status": status,
"date_created": (new Date(dateCreated)).toISOString(),
"date_updated": (new Date(dateCreated)).toISOString(),
"first_name": firstName,
"middle_name": middleName,
"last_name": lastName,
"nickname": nickname,
```
| 21.602273 | 94 | 0.637033 | yue_Hant | 0.522471 |
54450b65df8c66d2f8a79ce72982c361dacf4dc8 | 2,093 | md | Markdown | README.md | Tykam993/Mood-Ring-Chat-Room | 9d593451c8677f4b1c7420967c53944148d97193 | [
"Artistic-2.0"
] | null | null | null | README.md | Tykam993/Mood-Ring-Chat-Room | 9d593451c8677f4b1c7420967c53944148d97193 | [
"Artistic-2.0"
] | null | null | null | README.md | Tykam993/Mood-Ring-Chat-Room | 9d593451c8677f4b1c7420967c53944148d97193 | [
"Artistic-2.0"
] | null | null | null | Mood Ring Chatroom - Procjam 2014
===
Team Three Musketeers
=
What
===
As a part of a college class, I participated in the Procedural Content Jam (http://itch.io/jam/procjam).
Our idea is to create a chat room that has procedurally-generated graphics based on what its users type into chat.
Why
===
I like the idea of the environment changing based on unconscious decisions. When we speak, we often don't realize
what kind of language or tone we're using--especially in online chat. I thought it would be fun to objectively (and not-so-objectively) analyze what people are saying, and reflect that visually.
-Inner-workings-
The app is set up with the Model-View-Control pattern (http://en.wikipedia.org/wiki/Model%E2%80%93view%E2%80%93controller).
The chat system represents the view, the user-input as way of interfacing with the Control, and the Model as the "emotional state" of the user.
-as of 11/20/2014-
- When a user inputs something into chat, the controller grabs the input, splits it into a list of single words, and removes duplicates.
- It then checks the MySQL database to see if each word has any related value to it. If not, it then interacts with Big Huge Thesaurus to get a list of synonyms of the input word.
- If any of the synonyms match our criteria for having an "emotional value," we add the input word associated with its "emotional value" to the MySQL database (this saves us costly GET requests to Big Huge Thesaurus' API--we get 1000/day).
- If any emotional value is found, we add it to our model
- The model is represented as a 2D Vector, using this dimensions of emotion as our inner model:
http://en.wikipedia.org/wiki/File:Two_Dimensions_of_Emotion.gif.jpg
- At any point, the View can check the current state of the Model, which is returned as a 2D Vector.
Future
===
(As of 11/20/2014) we are using Big Huge Thesaurus' API and my MySQL server to compare user input to a hand-crafted list of "emotional" words. In future versions, I plan to implement sentiment analysis to really capture what kinds of feeling and emotions users are communicating.
| 63.424242 | 279 | 0.774009 | eng_Latn | 0.998417 |
5446ecdbc4e552f4ee3a62fc90eebab4c03bd5d1 | 1,695 | md | Markdown | docs/msbuild/errors/msb4175.md | MicrosoftDocs/visualstudio-docs.pt-br | b1882dc108a37c4caebbf5a80c274c440b9bbd4a | [
"CC-BY-4.0",
"MIT"
] | 5 | 2019-02-19T20:22:40.000Z | 2022-02-19T14:55:39.000Z | docs/msbuild/errors/msb4175.md | MicrosoftDocs/visualstudio-docs.pt-br | b1882dc108a37c4caebbf5a80c274c440b9bbd4a | [
"CC-BY-4.0",
"MIT"
] | 32 | 2018-08-24T19:12:03.000Z | 2021-03-03T01:30:48.000Z | docs/msbuild/errors/msb4175.md | MicrosoftDocs/visualstudio-docs.pt-br | b1882dc108a37c4caebbf5a80c274c440b9bbd4a | [
"CC-BY-4.0",
"MIT"
] | 25 | 2017-11-02T16:03:15.000Z | 2021-10-02T02:18:00.000Z | ---
title: "MSB4175: A fábrica de tarefas 'task-factory-name' não pôde ser carregada do assembly 'assembly-name'."
description: Esse erro ocorre quando MSBuild encontra um problema durante a criação de uma tarefa usando uma fábrica de tarefas.
ms.date: 07/07/2021
ms.topic: error-reference
f1_keywords:
- MSB4175
- MSBuild.TaskFactoryLoadFailure
dev_langs:
- VB
- CSharp
- C++
- FSharp
author: ghogen
ms.author: ghogen
manager: jmartens
ms.technology: msbuild
ms.workload:
- multiple
ms.openlocfilehash: 451df7942cc652f9b880b5d7fd2fe64f530589b9
ms.sourcegitcommit: 68897da7d74c31ae1ebf5d47c7b5ddc9b108265b
ms.translationtype: MT
ms.contentlocale: pt-BR
ms.lasthandoff: 08/13/2021
ms.locfileid: "122116130"
---
# <a name="msb4175-the-task-factory-task-factory-name-could-not-be-loaded-from-the-assembly-assembly-name"></a>MSB4175: A fábrica de tarefas 'task-factory-name' não pôde ser carregada do assembly 'assembly-name'
Esse erro ocorre quando MSBuild encontra um problema durante a criação de uma tarefa usando uma fábrica de tarefas.
Quando MSBuild processa um UsingTask, uma fábrica de tarefas cria uma instância de uma tarefa que é invocada. Normalmente, um assembly ou DLL é usado, mas a tarefa também pode ser criada dinamicamente do código, como no caso de e ou de `CodeTaskFactory` `RoslynTaskFactory` XAML, como no caso de `XamlTaskFactory` . Um segundo erro pode dar mais informações sobre a causa da falha. Os motivos comuns para esse erro incluem:
- O assembly de tarefas não pôde ser carregado. Verifique o caminho e as permissões no arquivo.
- Há um erro de codificação no código usado para criar dinamicamente a tarefa. O erro do compilador será mostrado em um segundo erro.
| 48.428571 | 423 | 0.79764 | por_Latn | 0.99588 |
5447fe0b4c7677e5d9eb9f5ca3bf459b1da05946 | 4,521 | md | Markdown | README.md | c4arl0s/Collection_Views_Objective-C | 52d1bc3d9bb18905698465a5c79bddfb70480ad5 | [
"MIT"
] | null | null | null | README.md | c4arl0s/Collection_Views_Objective-C | 52d1bc3d9bb18905698465a5c79bddfb70480ad5 | [
"MIT"
] | null | null | null | README.md | c4arl0s/Collection_Views_Objective-C | 52d1bc3d9bb18905698465a5c79bddfb70480ad5 | [
"MIT"
] | null | null | null | # CollectionView - Objective-C
Collection_Views_Objective-C

# Collection Views Versus Tables Views
- Unlike tables, collections introduce a Layout - a class that specifies how items are placed onscreens.
- Layouts organize the location of each cell, so items appear exactly where needed.
# Implementation
``` objective-c
UICollectionViewFlowLayout *collectionViewFlowLayout = [[UICollectionViewFlowLayout alloc] init];
collectionViewFlowLayout.scrollDirection = UICollectionViewScrollDirectionHorizontal;
UICollectionView *collectionView = [[UICollectionView alloc] initWithFrame:CGRectZero collectionViewLayout:collectionViewFlowLayout];
collectionView.delegate = self;
collectionView.dataSource = self;
```
**Passing nil produce an exception.**
# Scroll direction
- UICollectionViewScrollDirectionHorizontal
- UICollectionViewScrollDirectionVertical
# Header and Footer Sizing
- headerReferenceSize
- footerReferenceSize
conform to: UICollectionViewDelegateFlowLayout
``` objective-c
- (CGSize)collectionView:(UICollectionView *)collectionView layout:(UICollectionViewLayout *)collectionViewLayout referenceSizeForHeaderInSection:(NSInteger)section
{
return CGSizeMake(60.0f, 30.0f);
}
- (CGSize)collectionView:(UICollectionView *)collectionView layout:(UICollectionViewLayout *)collectionViewLayout referenceSizeForFooterInSection:(NSInteger)section
{
return CGSizeMake(60.0f, 30.0f);
}
```
# Insets (recuadro) (something positioned within a larger object)
Describes how the outer edges of a section add padding, this padding affects how sections relate to their optional headers and footers and how sections move apart from each other in general.
# Recipe: Basic Collection View Flows
- optional headers
- optional footers
# Collection Views
- A collection of views
- Collection views are created the same way as tables.
# Collection View Cell
- They are empty cells that we have to customize as we did before for custom table view cells.
- UICollectionViewCell class creates the cell, and contain three empty views to manage their content:
- a view for the content
- a view for the background
- second background view that is shown when the cell is selected.
### contentView
### backgroundView
### selectedbackgroundView
# Collection View Flow Layout
- The big difference between TableViews and Collection Views is that the position of the cells in a Collection View are not determinated by the view, they are set by a **layout object** that works along with the Collection View to present the cells on the screen. This object is created from a subclass of the **UICollectionViewLayout** class.
- Collection Views include by default a subclass called **UICollectionViewFlowLayout** that provides a very customizable **grid-like** layout that is usually more than enough for our projects. The layout is called **Flow**.
- scrollDirection
- minimumInteritemSpacing
- minimumLineSpacing
- sectionInset
- itemSize
- estimatedItemSize
# Collection View Protocols
- UICollectionViewDelegate
- UICollectionViewDataSource
# Layout Protocol
- The Flow layout can also designate a delegate to get specific values for individual cells.
- The methods are defined in the UICollectionViewDelegate-FlowLayout protocol.
# Implementing Collection Views (process to configure)
- Implement delegate methods to report the number of cells in the section (only one by default), and provide the cells.
- Get the prototype cell calling the dequeueReusableCell() method with the identifier assigned to the cell from the Attributes Inspector panel ("myCell" in this example), cast it as our subclass, and then configure the elements in the cell.
# ¿what is the difference from tableViews ?
- The indexPath structure includes three properties: section, row, and item.
- The section and row properties are used to identify the sections and each cell on a Table View, but Collection views considere a cell to be an item, not an entire row, and therefore they use the section and item properties instead.
# What happened when we add a Collection View (drag and drop) to the storyboard ?
- The system creates an UICollectionViewFlowLayout object and assigns it to the collectionView-Layout property of the collection view's object.
- This layout object is configured by default to position the cells in a grid. The result is shown in the following figure:
# Header and Footer Sizing
| 37.991597 | 344 | 0.803362 | eng_Latn | 0.974148 |
544a2bffdcd11f92ab01020a10e6096a85797308 | 647 | md | Markdown | content/post/pink-ribbon-event.md | thriveweb/glass | 6e66d1882c2c5593ca8000fe8ee2981c2256b6e4 | [
"MIT"
] | null | null | null | content/post/pink-ribbon-event.md | thriveweb/glass | 6e66d1882c2c5593ca8000fe8ee2981c2256b6e4 | [
"MIT"
] | 1 | 2018-05-30T01:17:27.000Z | 2018-05-30T01:17:27.000Z | content/post/pink-ribbon-event.md | thriveweb/glass | 6e66d1882c2c5593ca8000fe8ee2981c2256b6e4 | [
"MIT"
] | 2 | 2019-07-18T02:37:06.000Z | 2020-01-09T13:06:46.000Z | ---
title: Pink Ribbon Event
template: BlogPost
image: https://glassmanagement.imgix.net/images/uploads/breast-cancer-flyer-1.jpg
collection: Events
author: Tegan Glass
date: 9th November 2018
content: >-
On October 30th - 30 Glass kids came together to put on a show to raise money
for Breast Cancer.
Whilst guests enjoyed the delicacies from Greendays, they enjoyed the showcase
from Sun Emporium. 30 gorgeous children of all ages rocked the runway in the
latest Summer 2018 range.
Huge thank you to everyone who attended on the day and made this such a
special day to remember.
videoSource: 'https://vimeo.com/299805862'
---
| 28.130435 | 81 | 0.766615 | eng_Latn | 0.985363 |
544a7779bd2bad8c76fe88329274b8da79943572 | 470 | md | Markdown | _pages/software-service.md | newideas8/newideas8.github.io | df8e476f6a75b8b0ff7f039489cd3a9e2e834544 | [
"MIT"
] | null | null | null | _pages/software-service.md | newideas8/newideas8.github.io | df8e476f6a75b8b0ff7f039489cd3a9e2e834544 | [
"MIT"
] | null | null | null | _pages/software-service.md | newideas8/newideas8.github.io | df8e476f6a75b8b0ff7f039489cd3a9e2e834544 | [
"MIT"
] | null | null | null | ---
permalink: /services/
title: "專業服務"
author_profile: true
redirect_from:
- /md/
- /markdown.html
---
## 資訊系統開發
* 系統分析與規劃
* 系統設計與開發
* 網站應用系統(Web)
* 手機應用程式(App)
* 前端設計開發
* 響應式網站設計(RWD)
* 使用者介面/使用者體驗(UI/UX)
* 後端設計開發
* 後台管理系統
* API設計開發
* 自動化測試程式
* 嵌入式系統開發
## 數位行銷整合
> 搜尋引擎最佳化(SEO)
> 網站流量分析(GA)
> 社群媒體經營
> 行銷機器人
## 創新軟體服務
* 電子書銷售服務平台(EPUB3.0)
* 雲端電子書櫃服務
* 線上電子書閱讀器
* 電子書編輯製作服務(EPUB3.0)
* 電子書編輯製作
* 有聲書編輯製作
* 電子書轉製服務
| 10.444444 | 24 | 0.595745 | yue_Hant | 0.999314 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.