
text
stringlengths 454
608k
| url
stringlengths 17
896
| dump
stringlengths 9
15
⌀ | source
stringclasses 1
value | word_count
int64 101
114k
| flesch_reading_ease
float64 50
104
|
|---|---|---|---|---|---|
or view source
First, let's create a authentication token and pass that to the
getFile function, together with the file key we want to retrieve.
import Http import Figma as F F.getFile ( F.personalToken "your-token" ) "your-file-key" |> Http.send.
import Http import Figma as F F.exportNodesAsPng ( F.personalToken "your-token" ) "your-file-key" [ "1:6" ] |> Http.send ExportFinished
Once finished the
ExportFinished message will contain a list of
ExportedImage, with the URL's for the rendered images.
Http.Requestvalue instead of
Cmd, so you can chain calls together. See
getFiledocumentation for an example.
BooleanGroupand
BooleanOperation.
If you need any of these features please open an issue.
|
https://package.frelm.org/repo/1373/2.0.0
|
CC-MAIN-2019-09
|
refinedweb
| 111 | 52.26 |
Hi! I need to run some code through my school's Cyber GIS Jupyter portal to analyze a raster dataset over time. I'm hoping to use the tools from the space-time pattern mining toolset I used in ArcPro to analyze changes across multiple years of raster data. (Moving to Python because the Pro interface is ridiculously slow using these tools) I know ideally I would be using an Image Server through Portal, but it will apparently take several months for the school to finish building it.
I am able to import the arcgis python package, but I don't see the pattern mining tools anywhere. I'm wondering if there are either:
1) pattern mining tools compatible with the arcgis python package. If there are, could someone direct me to them, because I've been searching and can't find them.
-OR-
2) If anyone could share how to install arcpy to Jupyter via Jupyter? I've uploaded arcpy (which I downloaded here:) and unzipped it, but nothing seems to be working. The following errors occur when I try to install using conda. If I could get it installed I could potentially use virtualenv to build an environment with compatible packages, but am hopeful that someone has a simpler solution. (Aside from not using Arc, which is what my CS prof is voting for, but I have a whole workflow in ArcPro that I'd love to be able to use.)
A little Windows Explorer will lead you to the toolbox location
C:\..your_install_folder..\Resources\ArcToolBox\toolboxes\Space Time Pattern Mining Tools.tbx
import arcpy
is common, and when you import arcpy a valid license for arcgis pro is checked on the local machine (in the case of local machine install... principle is the same for other situations)
The scripts are located in the...
C:\..your_install_folder..\Resources\ArcToolBox\Scripts
So arcpy is needed.. just have a look at SSCube.py
Arcpy can be installed but it has python requirements and environment requirements, which you can explore on your local machine. So skipping arcpy is not in the plan at least which narrows your possible options.
resolved?
|
https://community.esri.com/t5/python-questions/is-it-possible-to-use-the-space-time-pattern/m-p/1082868
|
CC-MAIN-2021-39
|
refinedweb
| 358 | 61.87 |
Re: Performance counters and logs - inadvertent wipeout?
From: Almali del Benian (adbenian_at_islandnet.com)
Date: 03/08/04
- Next message: Michael W. Ryder: "Re: self connect"
- Previous message: anonymous_at_discussions.microsoft.com: "computer not responding"
- In reply to: Carey Frisch [MVP]: "Re: Performance counters and logs - inadvertent wipeout?"
- Messages sorted by: [ date ] [ thread ]
Date: Mon, 08 Mar 2004 03:31:40 GMT
Update: Carey, I went to the sites you mentioned. They got me started
- in a way. I didn't really understand very well, though, and don't
know how I might best set things up.
I played with it just a little, and at least got some idea of how the
setups work. But there's no way I'd attempt to make a proper
selection.
I noticed that you can import settings from a specified location; how
lovely! Of course, I had wiped all traces out, including Registry
keys, with my little Wizard operation. But my dealer might have
settings he uses regularly; he sells quite a few of these systems, or
some a fair bit fancier.
So what I will do is find out from my dealer if he has a standard
setup. I see that it's possible, if you have settings in place
somewhere, you can import them from that location.
I'd guess he'd set them all up fairly similarly.
So I'll ask him if he might put settings on a CD, and perhaps I could
import them from there, rather than taking my machine on a long trek.
Do you have any thoughts about that?
If there's a moral to this story, it's that a person with my skills
and lack of them, knowledge and lack of it, does very well to buy from
a really good local dealer. Which mine is <g>.
Luckily, I had just completed getting my CD-burning software in place,
so, for the first time, I have a reliable CD-writer working for me. (I
won't tell the horror stories about my previous CD-Writer; only say,
it was a dud.)
Thanks very much for the steer, Carey. It does strike me quite funny
that I hadn't a hope of comprehending how I might actually use the
information you steered me to, but there is this very crucial feature
of your steer: your.giving me that information helped me see how to
ask my dealer about it, and might have saved me that long trek with my
machine.
Almali del Benian
On Sun, 7 Mar 2004 12:22:25 -0600, "Carey Frisch [MVP]"
<[email protected]> wrote:
>HOW TO: Set Up Administrative Alerts in Windows XP
>;en-us;310490&Product=winxp
>
>HOW TO: Manage System Monitor Counters in Windows XP
>;en-us;305610&Product=winxp
>
>--
>Carey Frisch
>Microsoft MVP
>Windows XP - Shell/User
>
>Be Smart! Protect your PC!
>
>
>-------------------------------------------------------------------------------------
>
>"Almali del Benian" <[email protected]> wrote in message:
> news:[email protected]...
>
>|I posted this question to WindowsXPnewusers, but had no replies.
>|
>| Maybe somebody here can help me out.
>|
>| I'm new to WindowsXP. My dealer set up my machine with great care and
>| attention; he also updated Windows to the minute, installed and
>| updated my Microsoft Office 2000 as well, before letting the machine
>| out of his shop into my hands.
>|
>| The other night, seeing references to Hotfixes on the newuser group, I
>| went to Control Panel, Add/Remove, but then instead of staying in the
>| main Add/Remove screen where I should have stayed, I went to Windows
>| Components. (Silly me; thinking of "Windows.")
>|
>| I'm not sure what I did (it was wrong, whatever it was), but a Wizard
>| popped up. I was so disoriented then that perhaps I clicked on a Next;
>| if so, I thought, surely I could cancel. But then there appeared a
>| message saying that my Performance counters and logs had been removed,
>| and/or at least, two (if I remember the numbers right) Registry keys
>| had been removed.
>|
>| Obviously, this occurred at my ignorant clicking, when I should have
>| kept my hands off.
>|
>| Hey! I didn't want to do that!
>|
>| Can I get these counters and logs back, or start them again? I have
>| begun to look at the Help and Support screens, and find them totally
>| daunting; I don't understand them. Yet. It will probably take me weeks
>| to understand them. I will pursue it.
>|
>| In the meantime, though, can somebody here:
>|
>| 1) Suggest to me what I might have done, and what happened as a
>| result, and what my losses probably are?
>|
>| 2) Suggest to me how I can go about restoring the Performance logs and
>| counters capability, so they will at least start up again, if I have
>| lost previous ones?
>|
>| Further information, in case it applies:
>|
>| I'm running XP Home
>| My machine is network-capable, but it is not networked; I'm using it
>| as a single-user machine.
>| I use ZoneAlarm (free), AdSubtract, AVG antivirus (v. 7,paid),
>| AdAware, Spybot.
>| I have run chkdsk /r a few times, and defragged twice or three times,
>| since receiving the machine just over three weeks ago.
>|
>| I have purposely not run chkdksk/ r nor defragged since I made this
>| terrible error two evenings ago.
>|
>| I had already installed NTBackup from the Windows (OEM) CD, and run it
>| twice, on 27 Feb. and 29 Feb, backing up only the System State, to my
>| second hard drive, D. I stopped doing that when a friend told me
>| (likely erroneously) that NTBackup doesn't work with XP Home; he said
>| you can back up, but you can't restore (perhaps especially, not the
>| System State, and he might be right about that part).
>|
>| I probably wouldn't want to restore the System State, anyway; I just
>| did the backups to learn something.
>|
>| I have set Restore Points a couple of times, but also have no
>| intention of using those if I can possibly help it; I gather you use
>| one of those only if your system won't work at all.
>|
>| I am in the process of setting up backup procedures, backing up to
>| CD-Rs and CDRWs. My crucial backups, for now, consist of redundant
>| files and folders on the two physical hard drives. If one has to
>| choose to back up Performance Counters and Logs, to back them up, then
>| I have no backups of those.
>|
>| Likely I wouldn't need old Performance Counters and Logs anyway,
>| provided I could start them up again.
>|
>| It was the removal of two Registry keys that really scared me.
>|
>| I hope somebody can step me through at least re-starting Performance
>| Logs and Counters?
>|
>| Thanks in advance!
>|
>|
>| Almali del Benian
- Next message: Michael W. Ryder: "Re: self connect"
- Previous message: anonymous_at_discussions.microsoft.com: "computer not responding"
- In reply to: Carey Frisch [MVP]: "Re: Performance counters and logs - inadvertent wipeout?"
- Messages sorted by: [ date ] [ thread ]
|
http://www.tech-archive.net/Archive/WinXP/microsoft.public.windowsxp.perform_maintain/2004-03/1153.html
|
crawl-002
|
refinedweb
| 1,151 | 72.16 |
:Matt, I think this one should fix your NFS problem, can you test this change? : :Best Regards, :sephe Hmm. I would have thought it would have, but it doesn't. My UDP mount still locks up with rxcsum turned on. I experimented a bit with the code around line 887. With rxcsum and txcsum both turned on: * With both the IP and UDP/TCP checks removed my UDP mount works. * With the IP check removed and the UDP/TCP check retained, the UDP mount does not work. * With the IP check retained and the UDP/TCP check removed, the UDP mount works. Something must be getting set wrong or processed wrong in m_pkthdr in the UDP/TCP check. I've enclosed my test patch with comments. -Matt Matthew Dillon <[email protected]> Index: if_nfe.c =================================================================== RCS file: /cvs/src/sys/dev/netif/nfe/if_nfe.c,v retrieving revision 1.15 diff -u -p -r1.15 if_nfe.c --- if_nfe.c 10 Aug 2007 15:29:25 -0000 1.15 +++ if_nfe.c 10 Aug 2007 17:25:13 -0000 @@ -886,17 +886,23 @@ m->m_pkthdr.rcvif = ifp; if ((ifp->if_capenable & IFCAP_RXCSUM) && (flags & NFE_RX_CSUMOK)) { +#if 1 + /* this works */ if (flags & NFE_RX_IP_CSUMOK_V2) { m->m_pkthdr.csum_flags |= CSUM_IP_CHECKED | CSUM_IP_VALID; } +#endif +#if 0 + /* this doesn't work */ if (flags & (NFE_RX_UDP_CSUMOK_V2 | NFE_RX_TCP_CSUMOK_V2)) { m->m_pkthdr.csum_flags |= CSUM_DATA_VALID | CSUM_PSEUDO_HDR; m->m_pkthdr.csum_data = 0xffff; } +#endif } ifp->if_ipackets++;
|
https://www.dragonflybsd.org/mailarchive/commits/2007-08/msg00135.html
|
CC-MAIN-2017-43
|
refinedweb
| 226 | 79.36 |
$ cnpm install @liberdevelopers/sucrase
Sucrase is an alternative to Babel that allows super-fast development builds.. Because of this smaller scope, Sucrase can get away with an architecture that is much more performant but less extensible and maintainable. Sucrase's parser is forked from Babel's parser (so Sucrase is indebted to Babel and wouldn't be possible without it) and trims it down to a focused subset of what Babel solves. If it fits your use case, hopefully Sucrase can speed up your development experience!
Sucrase has been extensively tested. It can successfully build the Benchling frontend code, Babel, React, TSLint, Apollo client, and decaffeinate with all tests passing, about 1 million lines of code total.
Sucrase is about 20x faster than Babel. Here's one measurement of how Sucrase compares with other tools on a large TypeScript codebase with 4045 files and 661081 lines of code:
Time Speed Sucrase 2.928s 225752 lines per second swc 13.782s 47966 lines per second TypeScript 39.603s 16693 lines per second Babel 52.598s 12569 lines per second
The main configuration option in Sucrase is an array of transform names. These transforms are available:
React.createElement, e.g.
<div a={b} />becomes
React.createElement('div', {a: b}). Behaves like Babel 7's React preset, including adding
createReactClassdisplay names and JSX context information.
isolatedModulesTypeScript flag so that the typechecker will disallow the few features like
const enums that need cross-file compilation.
import/
export) to CommonJS (
require/
module.exports) using the same approach as Babel and TypeScript with
--esModuleInterop. Also includes dynamic
import.
react-hot-loader/babeltransform in the react-hot-loader project. This enables advanced hot reloading use cases such as editing of bound methods.
These proposed JS features are built-in and always transformed:
class C { x = 1; }. This includes static fields but not the
#xprivate field syntax.
export * as a from 'a';
const n = 1_234;
try { doThing(); } catch { }.
All JS syntax not mentioned above will "pass through" and needs to be supported by your JS runtime. For example:
throwexpressions, optional chaining, generator arrow functions, and
doexpressions are all unsupported in browsers and Node (as of this writing), and Sucrase doesn't make an attempt to transpile them.
Like Babel, Sucrase compiles JSX to React functions by default, but can be configured for any JSX use case.
React.createElement.
React.Fragment.
Two legacy modes can be used with the
import transform:
--esModuleInteropflag is enabled. For example, if a CJS module exports a function, legacy TypeScript interop requires you to write
import * as add from './add';, while Babel, Webpack, Node.js, and TypeScript with
--esModuleInteroprequire you to write
import add from './add';. As mentioned in the docs, the TypeScript team recommends you always use
--esModuleInterop.
require('./MyModule')instead of
require('./MyModule').default. Analogous to babel-plugin-add-module-exports.
Installation:
yarn add --dev sucrase # Or npm install --save-dev sucrase
Often, you'll want to use one of the build tool integrations: Webpack, Gulp, Jest, Rollup, Broccoli.
Compile on-the-fly via a require hook with some reasonable defaults:
// Register just one extension. require("sucrase/register/ts"); // Or register all at once. require("sucrase/register");
Compile on-the-fly via a drop-in replacement for node:
sucrase-node index.ts
Run on a directory:
sucrase ./srcDir -d ./outDir --transforms typescript,imports
Call from JS directly:
import {transform} from "sucrase"; const compiledCode = transform(code, {transforms: ["typescript", "imports"]}).code;
Sucrase is intended to be useful for the most common cases, but it does not aim to have nearly the scope and versatility of Babel. Some specific examples:
const enums are treated as regular
enums rather than inlining across files.
See the Project Vision document for more details on the philosophy behind Sucrase.
As JavaScript implementations mature, it becomes more and more reasonable to disable Babel transforms, especially in development when you know that you're targeting a modern runtime. You might hope that you could simplify and speed up the build step by eventually disabling Babel entirely, but this isn't possible if you're using a non-standard language extension like JSX, TypeScript, or Flow. Unfortunately, disabling most transforms in Babel doesn't speed it up as much as you might expect. To understand, let's take a look at how Babel works:
Only step 4 gets faster when disabling plugins, so there's always a fixed cost to running Babel regardless of how many transforms are enabled.
Sucrase bypasses most of these steps, and works like this:
<Foowith
React.createElement(Foo.
Because Sucrase works on a lower level and uses a custom parser for its use case, it is much faster than Babel.
Contributions are welcome, whether they be bug reports, PRs, docs, tests, or anything else! Please take a look through the Contributing Guide to learn how to get started.
Sucrase is MIT-licensed. A large part of Sucrase is based on a fork of the Babel parser, which is also MIT-licensed.
Sucrase is an enzyme that processes sugar. Get it?
|
https://developer.aliyun.com/mirror/npm/package/@liberdevelopers/sucrase
|
CC-MAIN-2020-24
|
refinedweb
| 833 | 57.27 |
Preface
Tip: Here you can add a general description of what this article will record:
For example: With the continuous development of artificial intelligence, machine learning is becoming more and more important. Many people have started learning machine learning. This paper introduces the basic content of machine learning.
Tip: The following is the main body of this article. The following cases can be used as reference.
1. C++ Keyword
Up to now, there are several major versions of C++98, C++11 and C++17. There are 63 keywords in C++98, of which 32 are inherited from C.
In the following C++11 and C++17, a few more keywords were added, which I learned to add.
2. Namespaces
1.std space
namespace std library standard namespace, including all representations in the C++ standard library
#include<iostream> using namespace std; int main() { cout << "hello world" << endl; } //For example, the cout and endl used in this library belong to the std library. If you do not declare using the std library, you need to use the std Library //Scope qualifier (:) declaration introduced. #include<iostream> int main() { std::cout << "hello world" << std::endl; }
2. Other self-defined spaces
You can also define your own namespace to accomplish the functions you need
#include<iostream> namespace myspace { int a = 100; int b = 300; int Add(int a, int b) { return a + b; } void print() { std::cout <<"Add(a, b) "<< Add(a, b) << std::endl; } } using namespace myspace; int main() { myspace::print(); //Use field qualifier to indicate that the print function in myspace space was called print(); //Introduced directly with the using namespace keyword return 0; }
A new scope is equivalent to a new namespace in that it separates functions and variables you define from others.
3. C++ Input and Output
C has its own input and output, and C++ has its own input and output.
#include<stdio.h> int main() { printf("hello world\n"); return 0; } #include<stdio.h> int main() { char s[13]; scanf("%s", s); printf("%s\n",s); return 0; }
C has a high format output requirement for output input, that is, you must declare the output format when you output, otherwise he will make an error or think you need to input a string on your screen.
C++ overrides input and output in the case of inheriting input and output from C. There is no requirement for output input format. When entering custom types, you need to overload input and output operators.
#include<iostream> using namespace std; int main() { int a; float b; cin >> a >> b; cout << "a = " << a << endl; cout << "b = " << b << endl; }
4. Default parameters in C++.
Significance of 1.C++ default parameters
The default parameter is also known as the spare parameter, which means that when you don't give him parameters, you set him an arbitrary parameter so that he doesn't have to output out-of-order or out-of-line values.
#include<iostream> using namespace std; void test(int a = 0) { cout << "a = " << a << endl; } int main() { test();//Without passing, he will use the default parameters test(10);//When passing a parameter, use the specified argument return 0; }
Classification of 2.C++ default parameters
All default parameters are given from left to right
#include<iostream> using namespace std; void test(int a = 0,int b = 0,int c =0) { cout << "a = " << a << endl; cout << "b = " << b << endl; cout << "c = " << c << endl; } int main() { test(); test(10,20,30); return 0; }
By semi-default, only a few parameters are given in turn from right to left. When you pass in a parameter, it is important to note that the parameters for which you do not have a default parameter are given constants.
#include<iostream> using namespace std; void test(int a ,int b = 0,int c =0) { cout << "a = " << a << endl; cout << "b = " << b << endl; cout << "c = " << c << endl; } int main() { test(1);//You have given default parameters to both b and c, but a has no default parameters and you need to pass in the value of a test(10,20,30);//If you pass in three values, the default parameters you give are not used. return 0; }
Default parameters cannot occur in both definitions and declarations, and if they occur at the same time, the compiler cannot determine which parameter is being used and an error will occur. The default parameter must be a constant or a global variable.
5. Function overloading in C++.
1. Definition of function overload
Function overload: Declare several functions with the same name under the same scope, and the list of parameters (parameter type, number of parameters, parameter order) of these functions with the same name must be different to handle problems with similar functions but different data types. (You can do this with a template class)
Call the same function to sum different data types.
2. Implementation of Function Overload
6. References in C++.
1. Implementation of References
A reference is not a new definition of a variable, but an alias for an existing variable. The compiler does not open up a new space for the pointer. It uses the same memory space as his reference variable.
Usage characteristics of references:
1. References must be initialized when they are defined.
2. A variable can have multiple references, but a reference can only refer to one entity and is his entire life cycle.
#include<iostream> using namespace std; int main() { int a = 10; int& b = a; //The lifetime of b is the entire function and can only be a reference to entity a cout << b << endl; }
References can be used as return values, or as parameters, because when you pass a reference, the constructor is not called to produce new variables, and when you pass a value, you need to open up space to construct variables, which greatly reduces function execution time, saves space to some extent, and meets the requirements of C++ language efficiency.
2. Comparison of reference and pointer
#include<iostream> using namespace std; int main() { int a = 10; int& b = a; int* c; c = &a; cout << b << endl; cout <<*c << endl; return 0; }
In C++, the bottom level of references is achieved by pointers. References are aliased entities. This is achieved by opening up the bottom space to store the address of the variable being pointed to when defining references.
Comparison of references and pointers:
1. References need to be initialized when they are defined. The pointer does not require initialization, that is, you can either point to null or not, or to an object.
2. After the reference is initialized, he can no longer reference other objects. The pointer can point to objects of the same type.
3. There is a null pointer, but there is no null reference
4. When measuring length, the size of the reference is the size it points to the entity, and the size of the pointer is always the size of the addressing range (4 bytes under 32 bits, 8 bytes under 64 bits).
5. There are multilevel pointers, but only one level of references.
6. Accessing the entity space, the quotation is handled directly by the compiler, and the pointer requires you to dereference it.
7. References are safer than pointers. There are wild pointers for pointers, but there are no wild references for references.
6. Inline Functions
Functions decorated with inline are called inline functions, which expand where the C++ compiler calls them at compile time, without the overhead of the function stack, and improve the efficiency of the program.
summary
That's what you learned today.
|
https://programmer.ink/think/c-getting-started-beginning.html
|
CC-MAIN-2022-21
|
refinedweb
| 1,262 | 58.21 |
[
]
Darryl L. Pierce closed QPID-4954.
----------------------------------
Resolution: Invalid
The bindings generated by Swig don't require a special layer on top of them.
> Create a layer on top of the Swig bindings that more closely matches the C++ APIs
> ---------------------------------------------------------------------------------
>
> Key: QPID-4954
> URL:
> Project: Qpid
> Issue Type: Improvement
> Components: Python Client
> Reporter: Darryl L. Pierce
> Assignee: Darryl L. Pierce
>
> The APIs generated by Swig do not provide documentation usable by Python developers,
and are not in namespaces corresponding to those in C++. A simple layer on top of Python that
matches C++ would be more intuitive for a developer to use.
--
|
http://mail-archives.us.apache.org/mod_mbox/qpid-dev/201309.mbox/%3CJIRA.12654957.1372261967321.157059.1379534753011@arcas%3E
|
CC-MAIN-2019-30
|
refinedweb
| 101 | 63.39 |
README
vue-snipvue-snip
Vue.js directive that clamps the content of a text element if it exceeds the specified number of lines.
Key features:Key features:
- two snipping approaches (CSS / JavaScript) picked on a per-element basis
- no need to specify line heights
- re-snipping on element resize and reactive data change
- no dependencies (small and fast)
To get a hands-on experience try the Interactive Demo.
InstallationInstallation
# install with npm npm install vue-snip # or with yarn yarn add vue-snip
Vue 2Vue 2
import Vue from 'vue' import VueSnip from 'vue-snip' import App from './App' Vue.use(VueSnip) new Vue({ render: h => h(App) }).$mount('#app')
Vue 3Vue 3
import { createApp } from 'vue' import VueSnip from 'vue-snip' import App from './App' createApp(App).use(VueSnip).mount('#app')
UsageUsage
The most basic usage looks like this:
<template> <p v-snip> ... </p> </template>
Most of the time, you probably need to pass in the
maxLines value:
<template> <p v- ... </p> </template>
You can also pass in the snipping
method argument:
<template> <p v-snip: ... </p> </template>
Both of these are reactive so you can do even this:
<template> <p v-snip:[method]="maxLines"> ... </p> </template> <script> export default { data () { return { method: 'js', maxLines: 3 } } } </script>
Elements are automatically re-snipped when they get resized or when reactive data changes. If you need to re-snip an element in some different case, you can expose the snipping function to your Vue instances via the
exposeSnipFunction options property and snip the element manually as needed:
<template> <p v-snip: ... </p> </template> <script> export default { data () { return { bigFontSize: false, } } mounted () { setTimeout(() => { this.bigFontSize = true this.$nextTick(() => this.$snipText(this.$refs.paragraph)) }, 2000) } } </script>
OptionsOptions
Your options will get merged with the defaults, so just define what you want to change (no need to redefine all properties).
import Vue from 'vue' import VueSnip from 'vue-snip' const options = { // your setup } Vue.use(VueSnip, options)
The options object:The options object:
How it worksHow it works
- CSS approach is based on the
-webkit-line-clamp.
- JavaScript approach is based on the progressive cutting of the element's
innerTextin a loop.
Note: CSS approach is faster (preferred), but does not work in older browsers / in all situations (f.e. does not work in IE11, when you need the text to flow around a floated element, or when you want a custom ellipsis). The idea is to allow you to freely pick the approach on a per-element basis.
CaveatsCaveats
For the directive.
IE11 SupportIE11 Support
IE11 does not support
-webkit-line-clamp (falls back to the JS method), and the
ResizeObserver API. This API needs to be polyfilled if you want to re-snip the elements on the resize in IE11 (they would still get snipped when inserted / on data change without the polyfill). Recommended: @juggle/resize-observer
import { ResizeObserver as Polyfill } from '@juggle/resize-observer'; window.ResizeObserver = window.ResizeObserver || Polyfill;
Change LogChange Log
All changes are documented in the change log.
|
https://www.skypack.dev/view/vue-snip
|
CC-MAIN-2022-27
|
refinedweb
| 499 | 54.02 |
Transparency problemPosted Thursday, 20 February, 2014 - 01:24 by virabhadra in
Hallo together!
I expect the problem is known and solution is known too.
May be someone can give me a link or quick solution of the problem.
I'm coding in the enveronment
using OpenTK.Graphics.OpenGL4; just to not use deprecated functions.
My OpenGL initialization looks standard:
GL.ClearColor(Color.White); GL.Enable(EnableCap.DepthTest); GL.DepthFunc(DepthFunction.Lequal); GL.Enable(EnableCap.Blend); GL.BlendFunc(BlendingFactorSrc.SrcAlpha, BlendingFactorDest.OneMinusSrcAlpha);
Rendering with
GL.Clear(ClearBufferMask.ColorBufferBit | ClearBufferMask.DepthBufferBit);
Fragment shader (diffuse/specular lighting + transparency for some parts) looks this way:
#version 400 in VS_OUT { vec3 N, L, V; vec2 tex; } fs_in; // Material properties uniform vec4 Ka, Kd, Ks; uniform float Ns; // Lighting properties uniform vec4 La, Ld, Ls; uniform vec3 Lpos; uniform sampler2D texture1; uniform int texture_id; // if texture_id is -1, object is not textured out vec4 frag_color; void main() { vec3 N = normalize(fs_in.N); vec3 L = normalize(fs_in.L); vec3 V = normalize(fs_in.V); vec4 Ia = La * Ka; vec4 Id = Ld * Kd * max(dot(N, L), 0); vec4 Is = Ls * Ks * pow(max(dot(reflect(-L, N), V), 0.0), Ns); vec4 texcolor = texture2D(texture1, fs_in.tex); if (texture_id == -1) frag_color = vec4((Ia + Id + Is).xyz, Kd.a); else frag_color = Ia + Id * vec4(texcolor.rgb, 0) + Is * texcolor.a; }
The result on a test model looks terrible (see a sample image in the attachment).
I have investigated only that transparency is depended on the order rendering.
A sphere and a cube on the picture are semi transparent, but another sphere inside is absolutely invisible and rendering of visible objects is not correct.
I tried to apply to apply some solutions from the Internet, but they always play with BlendFunc and without Depth Test.
I want to keep transparency and depth at the same time. I saw it work in software like "Deep Exploration".
May be I haven't found anything useful.
Thank you!
Re: Transparency problem
As you found out, transparency depends on the order of rendering. See here for some suggestions:
|
http://www.opentk.com/node/3567
|
CC-MAIN-2015-32
|
refinedweb
| 344 | 50.43 |
I had written a source code of C++ and complied it with the same name using the following command line.
For example:
c++ source-code.cpp -o source-code.cpp
Now my source code has been replaced by the executable program.Is there any way to retrieve my source-code.
I'm new to Linux so I'm not sure if there is any way to undo what I've done.
This question came from our site for professional and enthusiast programmers.
You might be lucky enough to have an editor open or a terminal window with scrollback.
And in the locking-the-barn-door-after-the-horse-has-bolted department, a good development practice even when working on toy programs is to use source code control.
Using either git or hg, you can do
$ hg init
$ hg add source.cpp
$ hg commit -m 'change' source.cpp
$ # edit here, and you can optionally revert to the original
$ hg commit -m 'change' source.cpp
$ # now if you clobber it you can go back to one of the previous revisions
The option -o specifies the output file, that is why the source code was overwritten.
-o
You should have used
c++ source-code.cpp -o executable-name
As for retrieving the original source from the compiled file: no you cannot. You could disassemble it (so get an assembly version of your program) and I'm sure there is some little program out there that will rewrite some "C++ style" code from it, but that will never be like your original code as more than one instruction in C++ may correspond to the same machine code.
a.out
Which editor did you use. Most probably there might be source-code.cpp~ backup file if you are using Vim or something.
oops ... you are out of!
more here:
Try some disk recovering tool maybe the new file wasn't written on the same blocks as the original one. I am just thinking out loud here, but its better that you gave this a shot. Btw which editor are you using? Have you checked if your editor creates an automatic backup of every file?
In the highly unlikely event that you haven't closed your vi session yet, open a new terminal and look for a .source-code.cpp.swp file in the same folder. Remember that files starting with a period are not listed by ls command by default; use ls -A to see them.
.source-code.cpp.swp
ls
ls -A
The last line of the .swp file would have the text from your original file before being corrupted by mal-compilation.
.swp
My original file test.cpp
test.cpp
#include <iostream>
using namespace std;
int main()
{
cout << "Hello World!" << endl;
cout << "Let us C";
}
The last part of my .test.cpp.swp (in this case, it contained a single huge line).
.test.cpp.swp
@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@
@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@
@^@^@^cout << "Let us C";^@ cout << "Hello World!" << endl;^@{^@int main()^@^@using namespace std;^@#i nclude <iostream>^@
The .swp file get deleted once you close the vi session; so if you've already closed it, you're out of luck.
no, unless you can undo your action through Linux, your source code is lost. You probably should have compiled it to a different name.
You cannot reverse-compile your source code.
I won't say it's impossible. The FBI can probably get some portion of it back with a huge heaping helping of luck. But since your executable is certainly larger than your source, you've overwritten all of it.
This is one reason why you should use a version control system.
As @jase21 mentioned, if you'd used vim or gedit, there'll be a source.cpp~ file which contains a backup.
vim
gedit
source.cpp~
emacs will have a #source.cpp# file.
emacs
#source.cpp#
What text editor did you use? On a lighter note, how many lines of code lost?
By posting your answer, you agree to the privacy policy and terms of service.
asked
5 years ago
viewed
2410 times
active
3 years ago
|
http://superuser.com/questions/195569/how-can-i-recover-source-overwritten-by-a-bad-compile-command/195572
|
CC-MAIN-2016-07
|
refinedweb
| 680 | 76.01 |
Patrick Decat wrote:
The problem, apparently, raises it's head in the 3rd line of the traceback. The code there reads:The problem, apparently, raises it's head in the 3rd line of the traceback. The code there reads:Traceback (innermost last): Module ZPublisher.Publish, line 101, in publish Module ZPublisher.mapply, line 88, in mapply Module ZPublisher.Publish, line 39, in call_object Module App.Management, line 85, in manage_workspace Redirect:
Advertising
def call_object(object, args, request): result=apply(object,args) # Type s<cr> to step into published object. return resultSo, I'm not sending the correct arguments to Zope. This is my first External Script in years (and I'd only written a couple before). So, please help me with this. The script is below in its (short) entirety. It works just fine from the command prompt. The idea is explained in the comments. Please help me understand how to pass it arguments.
TIA, beno """This function is to be used as a wrapper before passing to VirtualHostMonster so that I can convert URLs such as this: into choose to use the former for purposes of getting my pages ranked by Google (since they dislike deep directory structures), but prefer the d
eep dir structure for my use in my Zope instance. """ import re from urlparse import urlparse def URL_Rewrite(old_url): item6 = '' item4 = '' testPound = re.compile('[a-z_A-Z0-9:\/\.]*[#][a-zA-Z0-9:\/\.]*') testQuestion = re.compile('[a-z_A-Z0-9:\/\.]*[\?][a-zA-Z0-9:\/\.]*') testEnding = re.compile('[a-zA-Z_0-9:\/\.#\?]*[p][t]') if re.match(testPound,old_url): item6 = '#' elif re.match(testQuestion,old_url): item6 = '?' if re.match(testEnding,old_url): item4 = '.pt' parts = urlparse(old_url) item0 = parts[0] # The next rule is required because urlparse() deletes the '://' item0 = item0 + '://' item1 = parts[1] item2 = '/x/c/s/j/en-us' subPartsOf2 = re.split('.pt',parts[2]) item3 = re.sub('\.','/',subPartsOf2[0]) # The other sub-part is an empty string# The next rule is required because for some reason a ';' gets added by urlparse()
item3 = re.sub(';','',item3) item5 = parts[3] item7 = parts[4] item8 = parts[5]new_url = item0 + item1 + item2 + item3 + item4 + item5 + item6 + item7 + item8
return new_url _______________________________________________ Zope maillist - [email protected] ** No cross posts or HTML encoding! **(Related lists - )
|
https://www.mail-archive.com/[email protected]/msg24918.html
|
CC-MAIN-2016-44
|
refinedweb
| 373 | 58.28 |
Django OAuth Toolkit
OAuth2 goodies for the Djangonauts!
.. image:: :target:
.. image:: :alt: Build Status :target:
.. image:: :alt: Coverage Status :target:
If you are facing one or more of the following: *, 3.4
- Django 1.4, 1.5, 1.6, 1.7, 1.8
Installation
Install with pip::
pip install django-oauth-toolkit
Add
oauth2_provider to your
INSTALLED_APPS
.. code-block:: python
INSTALLED_APPS = ( ... 'oauth2_provider', )
If you need an OAuth2 provider you’ll want to add the following to your urls.py.
Notice that
oauth2_provider namespace is mandatory.
.. code-block:: python / Todo list (help wanted)
- OAuth1 support
- OpenID connector
- Nonrel storages support
Changelog
master
* #273: Generic read write scope by resource]
* Fix the migrations to be two-step and allow upgrade from 0.7.2 0
0.7.1 [2014-04-27]
* Added database indexes to the OAuth2 related models to improve performances. **Warning: schema migration does not work for sqlite3 database, migration should be performed manually**)parameter `{'scope_name': 'scope_description'}` * Namespace 'oauthparameter
|
https://devhub.io/repos/davidfischer-ch-django-oauth-toolkit
|
CC-MAIN-2020-24
|
refinedweb
| 159 | 51.24 |
This is an updated release of Don Kackman's excellent UxTheme control, ported to VC 8.0. The theme explorer has been updated to add theme color detail to the explorer interface. The code has been scrubbed to remove old syntax. Class names have been modified slightly to fit my naming conventions. (Class names begin with C, and structure names begin with S.) I removed references to vcclr.h. String handling is performed with Marshal::StringToHGlobalAuto. Appropriate macros for accessing managed strings are located in stdafx.h. At the urging of Don, I changed the name space from System::Windows::Froms::Themes to UxThemeTool.
Marshal::StringToHGlobalAuto
System::Windows::Froms::Themes
UxThemeTool
I became interested in Don's original work while I developed a custom button in managed C++ using .NET 2.0. The tool allowed me to add theme elements to my button control. However, I really wanted to use it without having to use the /clr:oldSyntax setting. So, I became sidetracked for a couple of days while I ported this code to VS 2005.
/clr:oldSyntax
There really is nothing difficult about using this code. Simply add a reference to the UxThemeTool.dll to your C# or VB.NET project. You will need to be familiar with the Theme API included in the platform SDK for Windows XP or Windows Server 2003.
Initializing the control is simple. In your application's form, place the following code in the form_load method:
form_load
// Call IsAppThemed first. This checks for theming before loading the UxTheme.dll.
// You do not want to access any theme methods if this property returns false.
if ( CUxTheme.IsAppThemed )
{
// Do something with themes here
}
else
{
MessageBox.Show( "Themes are not enabled" );
this.Close();
}
I was able to add additional documentation using the XML comment nomenclature outlined by Microsoft. However, the documentation process for managed C++ is much more labor intensive than for C#.
I was surprised at how lax the VS 2003 C++ compiler is. While porting the VS 2003 project code, I found a class that inherited (implemented) an interface, yet one of the functions was not implemented in the derived class. VS 2003 (VC 7.1) did not complain, but VS 2005 (VC 8.0) issued an error. Most of the porting work had to do with changes in syntax (removing _gc constructs and changing or adding abstract and override qualifiers). I also wanted to get rid of all dependencies on vcclr.h. (I just don't like dragging in gcroot.h everywhere, even if it's not used.)
_gc
I added a default color parameter to CUxTheme::GetColor. I also removed a throw from this method. It turns out that most theme colors do not exist (are not used). Rather than throw an exception, I decided it would be better to simply return a default color. The method treeView1_AfterSelect_1 in file Form1.cs illustrates the coding style you can use to retrieve colors.
CUxTheme::GetColor
treeView1_AfterSelect_1
If you want to compile this in Visual Studio 2008, be aware that Microsoft has introduced a bug in tmschema.h and schemadef.h distributed with the Platform SDK. There is #pragma once included at the beginning of these files. Since tmschema.def is meant for inclusion twice in your source code, the #pragma once statement prevents the second pass from parsing correctly. Please see the post in my blog for further explanation. The simplest way to fix the problem is to comment out the #pragma once statements at the top of tmschema.h and schemadef.h. You should be aware that these files do not include updates for Vista. Microsoft has changed the internal structure for access Windows Vista themes. I am working on updating the code to handle Vista themes.
#pragma once
This article, along with any associated source code and files, is licensed under The Code Project Open License (CPOL)
#if ((NTDDI_VERSION >= NTDDI_LONGHORN || defined(__VSSYM32_H__)) && !defined(SCHEMA_VERIFY_VSSYM32))
#pragma message ("TmSchema.h is obsolete. Please include vssym32.h instead.")
#include "vssym32.h"
#else
...
General News Suggestion Question Bug Answer Joke Rant Admin
Use Ctrl+Left/Right to switch messages, Ctrl+Up/Down to switch threads, Ctrl+Shift+Left/Right to switch pages.
|
http://www.codeproject.com/Articles/25132/A-Managed-C-Wrapper-Around-the-Windows-XP-Theme-AP?fid=1203279&df=10000&mpp=10&sort=Position&spc=Relaxed&tid=2553541
|
CC-MAIN-2015-32
|
refinedweb
| 696 | 68.16 |
I am working on very simple slender man game. The problem is my location change code works really weird.
Here is the code:
#pragma strict
var Spawn1 : Transform;
var Spawn2 : Transform;
var Spawn3 : Transform;
var Spawn4 : Transform;
function Update ()
{
spawn();
}
function spawn ()
{
yield WaitForSeconds (3);
this.transform.position = Spawn1.position;
yield WaitForSeconds (3);
this.transform.position = Spawn2.position;
}
i'm not sure what really weird means. Perhaps you can explain exactly what is happening or what you find weird about your currently solution.
idk how to explain that but it is really weird. If you are avaliable to test that on your own unity you will see that somethings are really wrong at this script.
I am really sorry but my english isnt enough to explain that. Actually I am not sure about I can explain this even in my native language.
okay, hows this, what is this script attached to? Now also remember, the code above will execute once per frame, stacking 3 second calls and yielding during the entire game play.
It can be attached to any obect. My goal with this script is;
It will change the location of object every 3 seconds with this line:
Spawn1
wait 3 seconds
Spawn2
Spawn 3
Wait 3 seconds
Spawn 4
and then again spawn 1, spawn 2, spawn 3, spawn 4.
Actually I tried to make a loop.
Answer by Landern
·
Aug 19, 2014 at 08:16 PM
Try this(it was not tested), assign the Transforms in the inspector.
import System.Collections.Generic; // To use list
#pragma strict
var spawnPositions : List.<Transform> = new List.<Transform>(); // Add as many as you want in the inspector
var spawnIndex : int = 0;
function Update ()
{
// If not invoking, invoke the spawn method.
if (!IsInvoking("spawn"))
Invoke("spawn", 3); // Invoke every 3 seconds if not invoking already
}
function spawn ()
{
this.transform.position = spawnPositions[spawnIndex].position; // Set this gameobjects transform to the spawnIndex of spawnPositions
spawnIndex++; // Increment the currentIndex
// The index is 0 based when accessing items in the list, we need to compare the count minus 1 to see if we need to reset the spawnIndex.
if (spawnIndex > spawnPositions.Count - 1)
spawnIndex = 0;
}
Here is the error that I am getting ^
Sorry, i made a mistake on the list declaration.
Answer by Cherno
·
Aug 20, 2014 at 03:33 PM
var t : float;
var threshold : float = 3.0f;
var newPos : Vector3;
function Update() {
t += Timer.deltaTime;
if(t >= threshold) {
t = 0.0f;
transform.position = newPos;
}
}
How you determing the next position is up to you; you could use
newPos = new Vector3(Random.Range(0,100), 0, Random.Range(0,100));
so it randomly pikcs a ground position between 0 and 100 and the x.
Locating Position of Object not Working?
2
Answers
Transform Checking on all Array Objects (JS)
3
Answers
Transform.position can't be changed smoothly.
2
Answers
Vector3 Transform.Position Not Working
2
Answers
Getting an Objects position once
2
Answers
|
https://answers.unity.com/questions/774299/changing-object-location-everry-3-second.html
|
CC-MAIN-2020-29
|
refinedweb
| 490 | 66.33 |
CVSROOT: /sources/emacs Module name: emacs Changes by: Stefan Monnier <monnier> 08/10/28 01:02:48 Index: emacs.c =================================================================== RCS file: /sources/emacs/emacs/src/emacs.c,v retrieving revision 1.451 retrieving revision 1.452 diff -u -b -r1.451 -r1.452 --- emacs.c 27 Oct 2008 07:02:36 -0000 1.451 +++ emacs.c 28 Oct 2008 01:02:46 -0000 1.452 @@ -235,8 +235,6 @@ int noninteractive1; -/* Nonzero means Emacs was started as a daemon. */ -int is_daemon = 0; /* Name for the server started by the daemon.*/ static char *daemon_name; @@ -244,6 +242,8 @@ startup. */ static int daemon_pipe[2]; +#define IS_DAEMON (daemon_pipe[1] != 0) + /* Save argv and argc. */ char **initial_argv; int initial_argc; @@ -1086,6 +1086,20 @@ /* Start as a daemon: fork a new child process which will run the rest of the initialization code, then exit. + Detaching a daemon requires the following steps: + - fork + - setsid + - exit the parent + - close the tty file-descriptors + + We only want to do the last 2 steps once the daemon is ready to + serve requests, i.e. after loading .emacs (initialization). + OTOH initialization may start subprocesses (e.g. ispell) and these + should be run from the proper process (the one that will end up + running as daemon) and with the proper "session id" in order for + them to keep working after detaching, so fork and setsid need to be + performed before initialization. + We want to avoid exiting before the server socket is ready, so use a pipe for synchronization. The parent waits for the child to close its end of the pipe (using `daemon-initialized') @@ -1131,7 +1145,6 @@ daemon_name = xstrdup (dname_arg); /* Close unused reading end of the pipe. */ close (daemon_pipe[0]); - is_daemon = 1; #ifdef HAVE_SETSID setsid(); #endif @@ -2429,7 +2442,7 @@ If the daemon was given a name argument, return that name. */) () { - if (is_daemon) + if (IS_DAEMON) if (daemon_name) return build_string (daemon_name); else @@ -2439,12 +2452,14 @@ } DEFUN ("daemon-initialized", Fdaemon_initialized, Sdaemon_initialized, 0, 0, 0, - doc: /* Mark the Emacs daemon as being initialized. */) + doc: /* Mark the Emacs daemon as being initialized. +This finishes the daemonization process by doing the other half of detaching +from the parent process and its tty file descriptors. */) () { int nfd; - if (!is_daemon) + if (!IS_DAEMON) error ("This function can only be called if emacs is run as a daemon"); if (daemon_pipe[1] < 0) @@ -2460,7 +2475,14 @@ dup2 (nfd, 2); close (nfd); - /* Closing the pipe will notify the parent that it can exit. */ + /* Closing the pipe will notify the parent that it can exit. + FIXME: In case some other process inherited the pipe, closing it here + won't notify the parent because it's still open elsewhere, so we + additionally send a byte, just to make sure the parent really exits. + Instead, we should probably close the pipe in start-process and + call-process to make sure the pipe is never inherited by + subprocesses. */ + write (daemon_pipe[1], "\n", 1); close (daemon_pipe[1]); /* Set it to an invalid value so we know we've already run this function. */ daemon_pipe[1] = -1; @@ -2584,6 +2606,9 @@ doc: /* Value of `current-time' after loading the init files. This is nil during initialization. */); Vafter_init_time = Qnil; + + /* Make sure IS_DAEMON starts up as false. */ + daemon_pipe[1] = 0; } /* arch-tag: 7bfd356a-c720-4612-8ab6-aa4222931c2e
|
http://lists.gnu.org/archive/html/emacs-diffs/2008-10/msg00991.html
|
CC-MAIN-2015-22
|
refinedweb
| 540 | 64.81 |
We pay for user submitted tutorials and articles that we publish. Anyone can send in a contributionLearn More
The fourteenth post of the series of programming job interview challenge is out, 83 readers provided an answer:
Those are other blog entries where you can find answers to the brackets question:
Those are the readers who provided correct answers in the form of a comment: sirrocco, Omar, Jason Kikel, Trinity, Justin Etheredge, Michael Mrozek, Nate, Kevin Hjelden, Jeremy Weiskotten, Alex, S Javeed, Steven Baker, leppie, Morgan Cheng, Hello world, herval, Samuel Williams, dextar, macmariman, Darrell Wright, Ryan, Shams Mahmood, Kimmen, Terje Myklebust, Jelle Hissink, Matt Howells, Dave Amphlett, Mark Brackett, configurator, Tim Kington, valera, Christof Jans, Michael, Richard Vasquez, Gerhard Balthasar, Daniel Jimenez, ilitirit, Sayre, Dejan Dimitrovski, Phi, Arni Hermann, Carl Anderson, bartek szabat, Klemen K., Petar Petrov, Niranjan Viswakarma, Michael Dikman, Alessio Spadaro, Santa, Marcos Silva Pereira and Joost Morsink.
This Week Question:
Your input:
You need to determine whether the given point is inside or outside the given polygon. Here is an example of a point which is outside the polygon:
Provide the most efficient and simple algorithm. Please don’t provide Code snippets alone (without explanation), I don’t know each and every programming language…
words will be enough.
Get updates by RSS to catch up with the next posts in this series and to get the correct answer for today’s question. As always you may post the solution in your blog or comment. Comments with answers will be approved only next week.
Tags :.Net2D spacebracketsC#challengeconcaveconvexgeometryjob interviewpointpolygonprogrammingquestionSoftware
Breeze : Designed by Amit Raz and Nitzan Kupererd
Omar
Said on August 5, 2008 :.
David
Said on August 5, 2008 :
1) Find all line segments that intersect the horizontal line that the point is on (same y value).
2) For each of those segments, interpolate the x value for the point where it crosses the horizontal line that the point is on then add that value to a list.
3) Sort the list.
4) For each pair of values in the list, check if the x value of the point is at or between those 2 values. If it is the point is inside the polygon.
Tristan
Said on August 5, 2008 :
It has been a while since i have done a line fill algorithm, but as I remember you create a list/ table of edges(sorted by low y, low x), you can then discard (or not add) all edges that begin and end below the point in question, same for above.
so now we could have a shape such as
\//\\||||//\\ .
the first step is to check and make sure the point is to the right of the first line in the table. the second step is that it is to the left of the last edge in the table.
if it isnt, it is outside the table and we end.
if it is we introduce a state variable, inOrOut.
we then use simple math (y=mx+b) to find the relevant points on each entry in the table.
initial state is out. we cross the first entry in the table at {(y[point]-b)/m,y[point]} and switch the state (inOrOut = !inOrOut) we then calculate the x,y position of the next intercept. since we are at the same level of y, we compare the values of x to the point. if it is less than or equal to the intercept point, than the point is in. if it is greater than we switch the state to out and we repeat this step until the point is found giving the point the state held in inOrOut.
Joost Morsink
Said on August 5, 2008 :
A point is never in a shape of zero, one or two points.
If the shape is convex it is easy:
1. map the points to line segments
2. map the line segments to lines
3. the given point needs to be on the same side of the line for every given line for it to be in the convex shape.
For concave shapes, the shape needs to be split up into convex shapes, and the given point must lie in one of the convex shapes, calculated as follows:
1. Start with the first three points in the list.
2. Keep the first point as a fixed point
3. If the angle between 1st-2nd < angle between 1st-3rd, don’t include the triangle, otherwise do.
4. If the traingle was included, repeat.
4b. Otherwise, make the current second point the new fixed point and take the next two from the list for the second and third and repeat.
5. When the list has no more points, take the first point once more and repeat, then stop.
6. Repeat for a list of all the points that have been the fixed point in the previous iteration.
That’s about it, I think.
Michael Mrozek
Said on August 5, 2008 :
Find the minimum and maximum X and Y for the polygon (that is, the bounding rectangle that encloses the polygon). If the point is outside that rectangle (x maxX || y maxY), the point is outside the polygon. Otherwise, draw lines from the point to points outside the bounding box on each side. Count the number of times each line crosses a vertex of the polygon. If any line crosses an odd number of vertices, the point is inside the polygon; if they all cross an even number, the point is outside
Jonathan Starr
Said on August 5, 2008 :
I will post a more rigorous solution on my web site, but this is my most efficient solution (should be sufficient I think).
1. Get any random point that is not collinear with the point in question (the one you do not know is inside or outside the shape) and any one of the vertices of the shape. Create a ray from the point in question through this arbitrary point.
2. Check for intersection between this ray and all of the line segments that make up the shape.
3. If the number of intersections is an even number, then the point in question is outside the shape. Otherwise it is inside.
Voila! I hope that is satisfactory (it was for me).
Thanks for the sweet!!!! problem.
Jonathan Starr
Mark R
Said on August 5, 2008 :
Hey, thanks for the quote! And now you follow it up with a question I first solved 30 years ago…
Go through each segment of the polygon and determine if it intersects the point on the y axis, excluding the higher of the two endpoints (min(Y0,Y1) <= Yp < max(Y0,Y1)). If it intersects, calculate the X coordinate of the intersection; if it is equal to the X coordinate of the point, the point lies on the boundary of the polygon and should be considered inside. If it isn’t equal, increment a counter if it is less than the X coordinate of the point. When you are finished with all of the segments, the point is inside if the count is odd, and outside if the count is even.
Excluding the maximum Y coordinate of each segment avoids some special cases, when the segment is horizontal or the point is at the intersection of two segments.
A small optimization can be made when comparing the X coordinates – if both endpoints of the segment are greater than the point, the segment can be ignored, and if both are less than the point, you can increment the count without calculating the intersection.
Chris Marisic
Said on August 5, 2008 :.
Michael Russell
Said on August 5, 2008 :
Well, your description misses the corner case of if the point is on one of the lines, but I would first check to see if the point is outside of (minX, minY)-(maxX, maxY) to fail fast.
I would then create a line segment from (minX, pointY) to (pointX, pointY) and count the number of line segments that intersect with it.
If the count is even, the point is outside. If the count is odd, the point is inside.
Dejan Dimitrovski
Said on August 5, 2008 :
For now I only now half of the solution, which would only work IF all of the angles of the final polygon do not exceed 180 degrees. In that case the solution is to find if the XY coordinates of the testing point are within the range Xmin < X < Xmax and Ymin < Y < Ymax, where XYmin/max are the smallest/largest values in the list of the provided polygon coordinates.
Looking forward to seeing the full solution
redge
Said on August 5, 2008 :
There’s a simple and quite elegant solution for this problem. I can’t say that it is was my idea, though — I read about it a while ago.
Starting at the single point, create a very long line segment. A useful approach could be a segment parallel to the x-Axis, starting at the single point and reaching far to the right.
Now calculate the intersections between this line segment and all the line segments that form the shape. When you are finished, just count the intersections: when there is an even number of intersections, you are outside the shape — an odd number signifies that you are inside.
That’s it!
buzzard
Said on August 5, 2008 :
Computational Geometry in an interview?
Jon von Gillern
Said on August 5, 2008 :
Tim Kington
Said on August 5, 2008 :
Draw a line from the point to the outside of the polygon, and count how many lines you cross. If the number is even, it’s on the outside.
Gabriele Cannata
Said on August 5, 2008 :
A simple way is to “draw” a line from the point and intersecting at least an edge of the polygon (for example taking a median point of two vertex). Then we could count how many edges this line will cross (with simple line-segment intersection algorithm). If the number of intersection is even, the point is outside. If it’s odd it’s inside.
Alex
Said on August 5, 2008 :
If the point is well and truly within a polygon, than a line drawn from that point in any direction will cross the borders of that polygon an odd number of times- For example, it will either leave the polygon once, or leave, re-enter due to some funky polygon angle, but eventually leave again. If the point is NOT in the polygon, it will either cross 0 borders, or enter and leave again, or enter,leave,enter again, and leave again. You get the idea.
Run through the list once, and get an xmax, ymax, xmin, and ymin (So we’re not drawing this line all the way out into infinite).
Then, “draw” 4 lines from the point being evaluated.
point.x,point.y -> point.x,ymax + 1
point.x,point.y -> xmax + 1,point.y
point.x,point.y -> point.x, ymin – 1
point.x,point.y -> xmin – 1,point.y
(I added those +1 and -1’s just to make sure there’s no confusion if the line ends directly on one of those listed points.
Now, for each of these 4 lines, check if they intersect any of the lines provided in the list of points which make up the polygon. Determining whether two lines intersect or not can be done in constant time.
Keep a counter for the number of times each of these 4 test lines crosses a polygon boundary. If that number odd for every test line, the point in question is inside a polygon.
Of course, this all depends on what you mean by “efficiency”. If the question is how fast you can write the code, it’s an entirely different solution:
Programatically draw a white box. Draw the polygon inside it using those coordinates. Use the programmatic equivalent of the bucket tool to fill the area near pixel 0,0 (top left in programming terms) green.
Then check the pixel in question. If the area at those coordinates are green, return false, since the bucket can’t cross line boundaries:D
steven
Said on August 5, 2008 :
this is a simple collision detection algorithm.
you really need to come up with original questions.
Morgan Cheng
Said on August 6, 2008 :
The easiest way is to sum up all angles of given point and neighboring vertex points. If given point is inside the polygon, the sum of the angles should be 360 degrees (2*Pi); if it is out of the polygon, the sum is supposed to be zero. The time complexity is O(n), assuming Math.Atan2 is O(1). The space complexity is O(1).
Below is the code. Since the sum may be inaccurate for large of double numbers, the angleSum might not be 2*Math.PI or 0 exactly, so I just check compare it with Math.PI.
public static bool CheckPolygon(Point[] polygonPoints, Point point)
{
double angleSum = 0.0;
for (int i = 0; i Math.PI)
{
angle -= 2 * Math.PI;
}
while (angle < -Math.PI)
{
angle += 2 * Math.PI;
}
angleSum += angle;
}
Console.WriteLine(angleSum);
return (Math.Abs(angleSum) < Math.PI);
}
Shahar Y
Said on August 6, 2008 :
@ buzzard
You are not required to provide the equations needed to solve the question, just describe it in words. It is a “thinking” problem.
Carl Anderson
Said on August 6, 2008 :
Moving clockwise around the polygon, we extend each line infinitely and think of it as [a vector] pointing in the direction from the first point of the line to second point. Then we take the point and determine whether it is to the left or to the right of our line, with respect to the line’s direction. If the point is to the right of all the lines, it is within the polygon.
Code-wise here is the relevant method:
//
inline int
isLeft( Point P0, Point P1, Point P2 )
{
return ( (P1.x – P0.x) * (P2.y – P0.y)
– (P2.x – P0.x) * (P1.y – P0.y) );
}
Stefan M
Said on August 6, 2008 :
Fire a beam from the single point into any direction. Calculate the number of intersections with the sides of the polygon.
#intersections=even => point is outside
#intersections=odd => point is inside
0 intersections count as even.
Special case: the beam hits a corner of the polygon.
In this case do not count the hit when the corner point is a local minimum or maximum, i.e. the neighbour points of the hit polygon corner point are on the same side of the beam.
Ahmad
Said on August 6, 2008 :
A “theoretical” solution.
)
-Take a point A known to be inside the polygon.
-Connect this point A with the given poiint
– if the line intersects the polygon edge, the given point is outside otherwise inside.
(The problem with this solution is how to determine the first point is inside the polygon..recursive problem
Jon von Gillern
Said on August 6, 2008 :
Shahar, I bet you’d get more traffic if you added a “kick it” button from dotnetkicks.com
Andrew
Said on August 6, 2008 :
Course grain the 2D space and determine the maximal/minimal values on each axis to provide a simple mapping from the problem space to a finite canvas of pixels; include at least one pixel padding in the canvas so the edges are less than and greater than the minimal and maximal values respectively. Initialize the canvas’ pixels with color0, then plot the lines using color1. Next flood fill the canvas, using color2, staring from the pixel that maps to the single point given in part 2 of the problem statement. Now, just test any edge pixel: if any edge pixel is color2 then the point is exterior; otherwise it is interior.
Any decent line plotting and flood fill algorithms will work.
An algorithm is required to determine a suitable course graining. If the point maps to a pixel colored with color1 (the color of the lines) then finer course graining is required; otherwise the current course graining is fine enough. An iterative approach of re-attempting the solution, with finer course graining on each iteration until a suitable one is found, would work.
If the 2D points are given as integer values then there is an obvious mapping to a canvas, but with large values it would still make sense to find a suitable course graining.
The above algorithm has terrible worse case behavior. But, if the point is not very close to any line then it should work in a reasonable time.
I’m sure that this is not the ‘correct’ solution the author has in mind, but I’m stuck on trying to reduce the problem to simpler parts.
Shahar Y
Said on August 6, 2008 :
@ Jon von Gillern
We (Dev102 team) will discuss about it tomorrow, thanks for your advice and involvement
Niki
Said on August 6, 2008 :
If you test only one point, I don’t think you can get better than O(n), where n is the number of lines. An algorithm could look like this:
Iterate through each line in the polygon
Let the line go from points P1-P2:
Test if the point Q in question is inside the triangle 0-P1-P2, where 0 is the origin (0,0).
Count the number of triangles that contain Q. If Q is contained in an even number of triangles, it’s outside the polygon, otherwise it’s inside.
(Triangle hit-testing is a lot easier, because triangles are always convex. I leave it as an exercise to the reader
)
If you test many points with respect to the same polygon, sorting the points and using a plane-sweep algorithm might be more efficient.
Erik
Said on August 6, 2008 :
What I would do is to create an array of triangles using the array of points as input; then for each triangle, determine if the reference point is inside the triangle geometrically; if none of these triangles contain the reference point, then the point lies outside the polygon; otherwise, if one of the triangles does contain the point, then the polygon contains the point.
References:
– for cutting a polygon up into triangles:
– for determining if a point lies inside an individual triangle:
Marc Melvin
Said on August 6, 2008 :
I don’t have time to get into the math involved while I’m at work (snicker), but I’m sure someone else will do that sooner or later. Conceptually, however, starting at the point specified, you need to calculate a vector in any direction and determine the number of lines that the vector intersects. If the number of intersections is odd, then you are inside the polygon. If it is even, you are outside the polygon.
Kevin Pang
Said on August 6, 2008 :
My answer:
Ian Qvist
Said on August 6, 2008 :
This could be done by ray testing.
By using ray testing, you make a line that goes from the point (x,y) and in any direction to the outside of the boundary of the polygon. as an example, we could just let this line go straight down.
Then we count the number of times the line passes a side of the polygon. If the number of times it crosses a line is an odd number, then the point is outside the polygon. An even number means it’s inside the polygon.
This kind of testing would have problems if the point we test for is on the edge of the polygon.
There is also other solutions to this problem. Some needs the polygon to be convex, some sums up the angles relative to the point, but the ray testing is the simplest by far.
Ian Qvist
Said on August 6, 2008 :
Oh, I’m not sure if it is a requirement to post source code, but there is some that works in XNA 3.0 and .NET 3.5 written in C#:
[CODE-START]
public static bool Inside(Vector2 point, Vector2[] polygons)
{
Vector2 tempP1, tempP2;
bool inside = false;
if (polygons.Length < 3)
{
return false;
}
Vector2 lastPoint = new Vector2(polygons[polygons.Length – 1].X, polygons[polygons.Length – 1].Y);
for (int i = 0; i lastPoint.X)
{
tempP1 = lastPoint;
tempP2 = currentPoint;
}
else
{
tempP1 = currentPoint;
tempP2 = lastPoint;
}
if ((currentPoint.X < point.X) == (point.X <= lastPoint.X)
&& ((long)point.Y – (long)tempP1.Y) * (long)(tempP2.X – tempP1.X)
< ((long)tempP2.Y – (long)tempP1.Y) * (long)(point.X – tempP1.X))
{
inside = !inside;
}
lastPoint = currentPoint;
}
return inside;
}
[CODE-END]
The code could be optimized by not using the expensive multiplications, but it works relative fast.
And as an added bonus, I’ve uploaded a picture of the good old red (outside) versus blue (inside) test of the algorithm:
Catalin
Said on August 6, 2008 :
Hello
I describe the solution in my (newbie) blog
The core of the algorithm is: count the intersections of a ray originating in the input point with the polygon
Andy
Said on August 7, 2008 :
You haven’t specified whether the polygon can be re-entrant (i.e. the edges can intersect, forming a ‘loop’). A point inside the loop is outside the polygon’s boundary, but inside the closed region.
Kimmen
Said on August 7, 2008 :
The first solution I remembered was for convex polygons, but I didn’t remember the solution which works for concave polygons as well. It ended up with me cheating using google =P. Then it struck me that the solution I learned in school was the ray-casting solution. You cast a ray from the point through the polygon. If the ray crosses even number of edges, the point is outside otherwise it’s inside.
Shahar Y
Said on August 7, 2008 :
@ Andy
The polygon edges can not intersect.
leppie
Said on August 7, 2008 :
The simplest solution is just to use GraphicsPath and Region in .NET
I will think of a real solution during the day ;p
Valera KOlupaev
Said on August 7, 2008 :
The solution:
Draw imaginative beam from target point, for example to the left, and count number of intersections with polygon edges.
If counted number is even – target point is outside of the polygon and vice versa.
This algorithm have some problems in joints, but we can skip joints which formed by lines that all placed below or above target point.
Ruby:
def assert
raise “Assert Error” unless yield
end
class Point
attr_accessor :x, :y
def initialize(x, y)
@x = x;
@y = y;
end
def sub(pt)
return Point.new(pt.x – @x, pt.y – @y)
end
def to_s()
return @x.to_s + “, ” + @y.to_s + “; ”
end
end
class Poly
attr_accessor :points
def initialize(points)
@points = points;
end
def self.isCross(pt1, pt2, pt0)
swapped = false
if pt1.x > pt2.x
t = pt1
pt1 = pt2
pt2 = t
swapped = true
end
return :corner if (pt0.x < pt2.x and pt2.y == pt0.y and not swapped) or (pt0.x < pt1.x and pt1.y == pt0.y and swapped)
return :false if (pt0.x < pt2.x and pt2.y == pt0.y and swapped) or (pt0.x < pt1.x and pt1.y == pt0.y and not swapped)
return :true if pt0.x [pt1.y, pt2.y].min and pt0.y pt2.x or pt0.y [pt1.y, pt2.y].max
# actually corner, but it was checked before
return :false if pt2.y == pt1.y
dx = (pt2.x – pt1.x) * (pt0.y – pt1.y) / (pt2.y – pt1.y)
return :true if dx + pt1.x > pt0.x and dx + pt1.x pt.y and npt.y < pt.y) or (ppt.y pt.y)
count = count + 1
end
else
print “Error”
end
}
print count , “\n”
return true if count.modulo(2) == 1
return false
end
end
poly = Poly.new([Point.new(3, 5),
Point.new(9, 9),
Point.new(15, 9),
Point.new(12, 5),
Point.new(12, 3),
Point.new(9, 2)])
inPoly = [Point.new(7, 6),
Point.new(10, 5),
Point.new(12, 7)]
outOfPoly = [Point.new(1, 2),
Point.new(1, 5),
Point.new(1, 6)]
inPoly.each {|pt| assert {poly.inPoly(pt) == true}}
outOfPoly.each {|pt| assert {poly.inPoly(pt) == false}}
Maneesh Chaturvedi
Said on August 7, 2008 :
Hi
One simple way would be to perform the following checks
1) Check that the x co-ordinate of the given point(p) lies within the maximum and minimum x co-ordinates of the list of points. If it does not then return false.
2) Similarly perform a check for the y co-ordinate. If it does not lie between the minimum and maximum values, return false.
3) If the point(p) equals any given point(x=x1 and y=y1) within the list of points return true.
4) Take the point(p1) in the list with the minimum value of y. Calculate the slope from this point to the given point(p) using s=y2-y1/x2-x1. Also calculate the slope of the adjacent points lets say p2 and p3. If the slopes are s1 and s2 and s lies between s1 and s2, then the point lies within the polygon, else it lies outside the polygon.
Kivanc Ozuolmez
Said on August 7, 2008 :
Hi all,
Here is my solution :
I didn’t mind about the points which are exactly on the edges (It is not mentioned in the question though) but, for the others my code seems working.
Shams Mahmood
Said on August 7, 2008 :
We need to breakdown the polygon into triangles by creating appropriate diagonals. Need to handle the vertex having a concave angle specially while forming these triangles.
Once we have the set of triangles we can use line equations of the sides of the triangles and the center point of the triangle (average of the vertices of the triangle) to determine whether the given point is inside this triangle or not.
leppie
Said on August 8, 2008 :
OK, serious attempt
1. Create a function of each line in order, iow f(x) = ax + b.
2. Create a function of each line from the start point to the single point, say g(x).
3. Compare each function (in 1) gradient to the gradient of the function (in 2). Normalize the gradient, multiply the sign of f(x)’s gradient with both gradients.
4. If all comparisons are f(x)’s gradient < g(x)’s gradient, the point will be inside, else outside.
I think that will work, too lazy to test
Ngu Soon Hui
Said on August 8, 2008 :
I’ve come up with a solution for this:
Xerxes
Said on August 10, 2008 :
Hi,
I’ve submitted a solution to the 14th Challenge on my website.
thanks
Xerxes.
|
http://www.dev102.com/2008/08/05/a-programming-job-interview-challenge-14-2d-geometry/
|
CC-MAIN-2015-40
|
refinedweb
| 4,450 | 71.04 |
Working Incrementally
Now let’s address our real problem, which is that our design only allows for one global list. In this chapter I’ll demonstrate a critical TDD technique: how to adapt existing code using an incremental, step-by-step process which takes you from working state to working state. Testing Goat, not Refactoring Cat.
Small Design When Necessary
Let’s have a think about how we want support for multiple lists to work. Currently the FT (which is the closest we have to a design document) says this:
# Edith wonders whether the site will remember her list. Then she sees # that the site has generated a unique URL for her -- there is some # explanatory text to that effect. self.fail('Finish the test!') # She visits that URL - her to-do list is still there. # Satisfied, she goes back to sleep
But really we want to expand on this, by saying that different users don’t see each other’s lists, and each get their own URL as a way of going back to their saved lists. What might a new design look like?
Not Big Design Up Front
TDD is closely associated with the agile movement in software development, which includes a reaction against Big Design Up Front, the traditional software engineering practice whereby, after a lengthy requirements gathering exercise, there is an equally lengthy design stage where the software is planned out on paper. The agile philosophy is that you learn more from solving problems in practice than in theory, especially when you confront your application with real users as soon as possible. Instead of a long up-front design phase, we try to put a minimum viable application out there early, and let the design evolve gradually based on feedback from real-world usage.
But that doesn’t mean that thinking about design is outright banned! In the last big chapter we saw how just blundering ahead without thinking can eventually get us to the right answer, but often a little thinking about design can help us get there faster. So, let’s think about our minimum viable lists app, and what kind of design we’ll need to deliver it:
We want each user to be able to store their own list—at least one, for now.
A list is made up of several items, whose primary attribute is a bit of descriptive text.
We need to save lists from one visit to the next. For now, we can give each user a unique URL for their list. Later on we may want some way of automatically recognising users and showing them their lists.
To deliver the "for now" items, it sounds like we’re going to store lists and their items in a database. Each list will have a unique URL, and each list item will be a bit of descriptive text, associated with a particular list.
YAGNI!
Once you start thinking about design, it can be hard to stop. All sorts of other thoughts are occurring to us—we might want to give each list a name or title, we might want to recognise users using usernames and passwords, we might want to add a longer notes field as well as short descriptions to our list, we might want to store some kind of ordering, and so on. But we obey another tenet of the agile gospel: "YAGNI" (pronounced yag-knee), which stands for "You ain’t gonna need it!" As software developers, we have fun creating things, and sometimes it’s hard to resist the urge to build things just because an idea occurred to us and we might need it. The trouble is that more often than not, no matter how cool the idea was, you won’t end up using it. Instead you have a load of unused code, adding to the complexity of your application. YAGNI is the mantra we use to resist our overenthusiastic creative urges.
REST (ish)
We
have an idea of the data structure we want—the Model part of
Model-View-Controller (MVC). What about the View and Controller parts?
How should the user interact with
Lists and their
Items using a web browser?
Representational State Transfer (REST) is an approach to web design that’s usually used to guide the design of web-based APIs. When designing a user-facing site, it’s not possible to stick strictly to the REST rules, but they still provide some useful inspiration (skip ahead to [appendix_rest_api] if you want to see a real REST API).
REST suggests that we have a URL structure that matches our data structure, in this case lists and list items. Each list can have its own URL:
/lists/<list identifier>/
That will fulfill the requirement we’ve specified in our FT. To view a list, we use a GET request (a normal browser visit to the page).
To create a brand new list, we’ll have a special URL that accepts POST requests:
/lists/new
To add a new item to an existing list, we’ll have a separate URL, to which we can send POST requests:
/lists/<list identifier>/add_item
(Again, we’re not trying to perfectly follow the rules of REST, which would use a PUT request here—we’re just using REST for inspiration. Apart from anything else, you can’t use PUT in a standard HTML form.)
In summary, our scratchpad for this chapter looks something like this:
Implementing the New Design Incrementally Using TDD
How do we use TDD to implement the new design? Let’s take another look at the flowchart for the TDD process in The TDD process with functional and unit tests.
At the top level, we’re going to use a combination of adding new functionality (by adding a new FT and writing new application code), and refactoring our application—that is, rewriting some of the existing implementation so that it delivers the same functionality to the user but using aspects of our new design. We’ll be able to use the existing functional test to verify we don’t break what already works, and the new functional test to drive the new features.
At the unit test level, we’ll be adding new tests or modifying existing ones to test for the changes we want, and we’ll be able to similarly use the unit tests we don’t touch to help make sure we don’t break anything in the process.
Ensuring We Have a Regression Test
Let’s translate our scratchpad into a new functional test method, which introduces a second user and checks that their to-do list is separate from Edith’s.
We’ll start out very similarly to the first. Edith adds a first item to create a to-do list, but we introduce our first new assertion—Edith’s list should live at its own, unique URL:
def test_can_start_a_list_for_one_user(self): # Edith has heard about a cool new online to-do app. She goes [...] # The page updates again, and now shows both items on her list self.wait_for_row_in_list_table('2: Use peacock feathers to make a fly') self.wait_for_row_in_list_table('1: Buy peacock feathers') # Satisfied, she goes back to sleep def test_multiple_users_can_start_lists_at_different_urls(self): # Edith starts a new to-do list self.browser.get(self.live_server_url) inputbox = self.browser.find_element_by_id('id_new_item') inputbox.send_keys('Buy peacock feathers') inputbox.send_keys(Keys.ENTER) self.wait_for_row_in_list_table('1: Buy peacock feathers') # She notices that her list has a unique URL edith_list_url = self.browser.current_url self.assertRegex(edith_list_url, '/lists/.+') (1)
Next we imagine a new user coming along. We want to check that they don’t see any of Edith’s items when they visit the home page, and that they get their own unique URL for their list:
[...] self.assertRegex(edith_list_url, '/lists/.+') (1) # Now a new user, Francis, comes along to the site. ## We use a new browser session to make sure that no information ## of Edith's is coming through from cookies etc self.browser.quit() self.browser = webdriver.Firefox() # Francis visits the home page. There is no sign of Edith's # list self.browser.get(self.live_server_url) page_text = self.browser.find_element_by_tag_name('body').text self.assertNotIn('Buy peacock feathers', page_text) self.assertNotIn('make a fly', page_text) # Francis starts a new list by entering a new item. He # is less interesting than Edith... inputbox = self.browser.find_element_by_id('id_new_item') inputbox.send_keys('Buy milk') inputbox.send_keys(Keys.ENTER) self.wait_for_row_in_list_table('1: Buy milk') # Francis gets his own unique URL francis_list_url = self.browser.current_url self.assertRegex(francis_list_url, '/lists/.+') self.assertNotEqual(francis_list_url, edith_list_url) # Again, there is no trace of Edith's list page_text = self.browser.find_element_by_tag_name('body').text self.assertNotIn('Buy peacock feathers', page_text) self.assertIn('Buy milk', page_text) # Satisfied, they both go back to sleep
Other than that, the new test is fairly self-explanatory. Let’s see how we do when we run our FTs:
$ python manage.py test functional_tests [...] .F ====================================================================== FAIL: test_multiple_users_can_start_lists_at_different_urls (functional_tests.tests.NewVisitorTest) --------------------------------------------------------------------- Traceback (most recent call last): File "...python-tdd-book/functional_tests/tests.py", line 83, in test_multiple_users_can_start_lists_at_different_urls self.assertRegex(edith_list_url, '/lists/.+') AssertionError: Regex didn't match: '/lists/.+' not found in '' --------------------------------------------------------------------- Ran 2 tests in 5.786s FAILED (failures=1)
Good, our first test still passes, and the second one fails where we might expect. Let’s do a commit, and then go and build some new models and views:
$ git commit -a
Iterating Towards the New Design
Being all excited about our new design, I had an overwhelming urge to dive in at this point and start changing models.py, which would have broken half the unit tests, and then pile in and change almost every single line of code, all in one go. That’s a natural urge, and TDD, as a discipline, is a constant fight against it. Obey the Testing Goat, not Refactoring Cat! We don’t need to implement our new, shiny design in a single big bang. Let’s make small changes that take us from a working state to a working state, with our design guiding us gently at each stage.
There are four items on our to-do list. The FT, with its
Regexp didn't
match, is telling us that the second item—giving lists their own URL and
identifier—is the one we should work on next. Let’s have a go at fixing
that, and only that.
The URL comes from the redirect after POST. In lists/tests.py, find
test_redirects_after_POST, and change the expected redirect
location:
self.assertEqual(response.status_code, 302) self.assertEqual(response['location'], '/lists/the-only-list-in-the-world/')
Does that seem slightly strange? Clearly, /lists/the-only-list-in-the-world isn’t a URL that’s going to feature in the final design of our application. But we’re committed to changing one thing at a time. While our application only supports one list, this is the only URL that makes sense. We’re still moving forwards, in that we’ll have a different URL for our list and our home page, which is a step along the way to a more REST-ful design. Later, when we have multiple lists, it will be easy to change.
Running the unit tests gives us an expected fail:
$ python manage.py test lists [...] AssertionError: '/' != '/lists/the-only-list-in-the-world/'
We can go adjust our
home_page view in lists/views.py:
def home_page(request): if request.method == 'POST': Item.objects.create(text=request.POST['item_text']) return redirect('/lists/the-only-list-in-the-world/') items = Item.objects.all() return render(request, 'home.html', {'items': items})
Of course, that will now totally break the functional tests, because there is no such URL on our site yet. Sure enough, if you run them, you’ll find they fail just after trying to submit the first item, saying that they can’t find the list table; it’s because the URL /the-only-list-in-the-world/ doesn’t exist yet!
File "...python-tdd-book/functional_tests/tests.py", line 57, in test_can_start_a_list_for_one_user [...] selenium.common.exceptions.NoSuchElementException: Message: Unable to locate element: [id="id_list_table"] [...]"]
Not only is our new test failing, but the old one is too. That tells us we’ve introduced a regression. Let’s try to get back to a working state as quickly as possible by building a URL for our one and only list.
Taking a First, Self-Contained Step: One New URL
Open
up lists/tests.py, and add a new test class called
ListViewTest. Then
copy the method called
test_displays_all_list_items across from
HomePageTest into our new class, rename it, and adapt it slightly:
class ListViewTest(TestCase): def test_displays_all_items(self): Item.objects.create(text='itemey 1') Item.objects.create(text='itemey 2') response = self.client.get('/lists/the-only-list-in-the-world/') self.assertContains(response, 'itemey 1') (1) self.assertContains(response, 'itemey 2') (1)
Let’s try running this test now:
self.assertContains(response, 'itemey 1') [...] AssertionError: 404 != 200 : Couldn't retrieve content: Response code was 404
Here’s a nice side effect of using
assertContains: it tells us straight
away that the test is failing because our new URL doesn’t exist yet, and
is returning a 404.
A New URL
Our singleton list URL doesn’t exist yet. We fix that in superlists/urls.py.
urlpatterns = [ url(r'^$', views.home_page, name='home'), url(r'^lists/the-only-list-in-the-world/$', views.view_list, name='view_list'), ]
Running the tests again, we get:
AttributeError: module 'lists.views' has no attribute 'view_list'
A New View Function
Nicely self-explanatory. Let’s create a dummy view function in lists/views.py:
def view_list(request): pass
Now we get:
ValueError: The view lists.views.view_list didn't return an HttpResponse object. It returned None instead. [...] FAILED (errors=1)
Down to just one failure, and it’s pointing us in the right direction. Let’s
copy the two last lines from the
home_page view and see if they’ll do the
trick:
def view_list(request): items = Item.objects.all() return render(request, 'home.html', {'items': items})
Rerun the unit tests and they should pass:
Ran 7 tests in 0.016s OK
Now let’s try the FTs again and see what they tell us:
FAIL: test_can_start_a_list_for_one_user [...] File "...python-tdd-book/functional_tests/tests.py", line 67, in test_can_start_a_list_for_one_user [...] AssertionError: '2: Use peacock feathers to make a fly' not found in ['1: Buy peacock feathers'] FAIL: test_multiple_users_can_start_lists_at_different_urls [...] AssertionError: 'Buy peacock feathers' unexpectedly found in 'Your To-Do list\n1: Buy peacock feathers' [...]
Both of them are getting a little further than they were before, but they’re still failing. It would be nice to get back to a working state and get that first one passing again. What’s it trying to tell us?
It’s failing when we try to add the second item. We have to put our debugging hats on here. We know the home page is working, because the test has got all the way down to line 67 in the FT, so we’ve at least added a first item. And our unit tests are all passing, so we’re pretty sure the URLs and views are doing what they should—the home page displays the right template, and can handle POST requests, and the only-list-in-the-world view knows how to display all items…but it doesn’t know how to handle POST requests. Ah, that gives us a clue.
A second clue is the rule of thumb that, when all the unit tests are passing but the functional tests aren’t, it’s often pointing at a problem that’s not covered by the unit tests, and in our case, that’s often a template problem.
The answer is that our home.html input form currently doesn’t specify an explicit URL to POST to:
<form method="POST">
By default the browser sends the POST data back to the same URL it’s currently on. When we’re on the home page that works fine, but when we’re on our only-list-in-the-world page, it doesn’t.
Now we could dive in and add POST request handling to our new view, but that would involve writing a bunch more tests and code, and at this point we’d like to get back to a working state as quickly as possible. Actually the quickest thing we can do to get things fixed is to just use the existing home page view, which already works, for all POST requests:
<form method="POST" action="/">
Try that, and we’ll see our FTs get back to a happier place:
FAIL: test_multiple_users_can_start_lists_at_different_urls [...] AssertionError: 'Buy peacock feathers' unexpectedly found in 'Your To-Do list\n1: Buy peacock feathers' Ran 2 tests in 8.541s FAILED (failures=1)
Our original test passes once again, so we know we’re back to a working state. The new functionality may not be working yet, but at least the old stuff works as well as it used to.
Green? Refactor
Time for a little tidying up.
In the Red/Green/Refactor dance, we’ve arrived at green, so we should see what needs a refactor. We now have two views, one for the home page, and one for an individual list. Both are currently using the same template, and passing it all the list items currently in the database. If we look through our unit test methods, we can see some stuff we probably want to change:
$ grep -E "class|def" lists/tests.py class HomePageTest(TestCase): def test_uses_home_template(self): def test_displays_all_list_items(self): def test_can_save_a_POST_request(self): def test_redirects_after_POST(self): def test_only_saves_items_when_necessary(self): class ListViewTest(TestCase): def test_displays_all_items(self): class ItemModelTest(TestCase): def test_saving_and_retrieving_items(self):
We can definitely delete the
test_displays_all_list_items method from
HomePageTest; it’s no longer needed. If you run
manage.py test lists
now, it should say it ran 6 tests instead of 7:
Ran 6 tests in 0.016s OK
Next, since we don’t actually need the home page template to display all list items any more, it should just show a single input box inviting you to start a new list.
Another Small Step: A Separate Template for Viewing Lists
Since the home page and the list view are now quite distinct pages, they should be using different HTML templates; home.html can have the single input box, whereas a new template, list.html, can take care of showing the table of existing items.
Let’s add a new test to check that it’s using a different template:
class ListViewTest(TestCase): def test_uses_list_template(self): response = self.client.get('/lists/the-only-list-in-the-world/') self.assertTemplateUsed(response, 'list.html') def test_displays_all_items(self): [...]
assertTemplateUsed is one of the more useful functions that the Django Test
Client gives us. Let’s see what it says:
AssertionError: False is not true : Template 'list.html' was not a template used to render the response. Actual template(s) used: home.html
Great! Let’s change the view:
def view_list(request): items = Item.objects.all() return render(request, 'list.html', {'items': items})
But, obviously, that template doesn’t exist yet. If we run the unit tests, we get:
django.template.exceptions.TemplateDoesNotExist: list.html
Let’s create a new file at lists/templates/list.html:
$ touch lists/templates/list.html
A blank template, which gives us this error—good to know the tests are there to make sure we fill it in:
AssertionError: False is not true : Couldn't find 'itemey 1' in response
The template for an individual list will reuse quite a lot of the stuff we currently have in home.html, so we can start by just copying that:
$ cp lists/templates/home.html lists/templates/list.html
That gets the tests back to passing (green). Now let’s do a little more
tidying up (refactoring). We said the home page doesn’t need to list items, it
only needs the new list input field, so we can remove some lines from
lists/templates/home.html, and maybe slightly tweak the
h1 to say "Start a
new To-Do list":
<body> <h1>Start a new To-Do list</h1> <form method="POST"> <input name="item_text" id="id_new_item" placeholder="Enter a to-do item" /> {% csrf_token %} </form> </body>
We rerun the unit tests to check that hasn’t broken anything—good…
There’s actually no need to pass all the items to the home.html template in
our
home_page view, so we can simplify that:
def home_page(request): if request.method == 'POST': Item.objects.create(text=request.POST['item_text']) return redirect('/lists/the-only-list-in-the-world/') return render(request, 'home.html')
Rerun the unit tests once more; they still pass. Time to run the functional tests:
AssertionError: '1: Buy milk' not found in ['1: Buy peacock feathers', '2: Buy milk']
Not bad! Our regression test (the first FT) is passing, and our new test is now getting slightly further forwards—it’s telling us that Francis isn’t getting his own list page (because he still sees some of Edith’s list items).
It may feel like we haven’t made much headway since, functionally, the site still behaves almost exactly like it did when we started the chapter, but this really is progress. We’ve started on the road to our new design, and we’ve implemented a number of stepping stones without making anything worse than it was before. Let’s commit our progress so far:
$ git status # should show 4 changed files and 1 new file, list.html $ git add lists/templates/list.html $ git diff # should show we've simplified home.html, # moved one test to a new class in lists/tests.py added a new view # in views.py, and simplified home_page and made one addition to # urls.py $ git commit -a # add a message summarising the above, maybe something like # "new URL, view and template to display lists"
A Third Small Step: A URL for Adding List Items
Where are we with our own to-do list?
We’ve sort of made progress on the second item, even if there’s still only one list in the world. The first item is a bit scary. Can we do something about items 3 or 4?
Let’s have a new URL for adding new list items. If nothing else, it’ll simplify the home page view.
A Test Class for New List Creation
Open up lists/tests.py, and move the
test_can_save_a_POST_request and
test_redirects_after_POST methods into a
new class, then change the URL they POST to:
class NewListTest(TestCase): def test_can_save_a_POST_request(self): self.client.post('/lists/new', data={'item_text': 'A new list item'}) self.assertEqual(Item.objects.count(), 1) new_item = Item.objects.first() self.assertEqual(new_item.text, 'A new list item') def test_redirects_after_POST(self): response = self.client.post('/lists/new', data={'item_text': 'A new list item'}) self.assertEqual(response.status_code, 302) self.assertEqual(response['location'], '/lists/the-only-list-in-the-world/')
While we’re at it, let’s learn a new Django Test Client method,
assertRedirects:
def test_redirects_after_POST(self): response = self.client.post('/lists/new', data={'item_text': 'A new list item'}) self.assertRedirects(response, '/lists/the-only-list-in-the-world/')
There’s not much to it, but it just nicely replaces two asserts with a single one…
Try running that:
self.assertEqual(Item.objects.count(), 1) AssertionError: 0 != 1 [...] self.assertRedirects(response, '/lists/the-only-list-in-the-world/') [...] AssertionError: 404 != 302 : Response didn't redirect as expected: Response code was 404 (expected 302)
The first failure tells us we’re not saving a new item to the database, and the
second says that, instead of returning a 302 redirect, our view is returning
a 404. That’s because we haven’t built a URL for /lists/new, so the
client.post is just getting a "not found" response.
A URL and View for New List Creation
Let’s build our new URL now:
urlpatterns = [ url(r'^$', views.home_page, name='home'), url(r'^lists/new$', views.new_list, name='new_list'), url(r'^lists/the-only-list-in-the-world/$', views.view_list, name='view_list'), ]
Next we get a
no attribute 'new_list', so let’s fix that, in
lists/views.py:
def new_list(request): pass
Then we get "The view lists.views.new_list didn’t return an HttpResponse
object". (This is getting rather familiar!) We could return a raw
HttpResponse, but since we know we’ll need a redirect, let’s borrow a line
from
def new_list(request): return redirect('/lists/the-only-list-in-the-world/')
That gives:
self.assertEqual(Item.objects.count(), 1) AssertionError: 0 != 1
Seems reasonably straightforward. We borrow another line from
def new_list(request): Item.objects.create(text=request.POST['item_text']) return redirect('/lists/the-only-list-in-the-world/')
And everything now passes:
Ran 7 tests in 0.030s OK
And the FTs show me that I’m back to the working state:
[...] AssertionError: '1: Buy milk' not found in ['1: Buy peacock feathers', '2: Buy milk'] Ran 2 tests in 8.972s FAILED (failures=1)
Removing Now-Redundant Code and Tests
We’re looking good. Since our new views are now doing most of the work that
home_page used to do, we should be able to massively simplify it. Can we
remove the whole
if request.method == 'POST' section, for example?
def home_page(request): return render(request, 'home.html')
Yep!
OK
And while we’re at it, we can remove the now-redundant
test_only_saves_items_when_necessary test too!
Doesn’t that feel good? The view functions are looking much simpler. We rerun the tests to make sure…
Ran 6 tests in 0.016s OK
and the FTs?
A Regression! Pointing Our Forms at the New URL
Oops:
ERROR: test_can_start_a_list_for_one_user [...] File "...python-tdd-book/functional_tests/tests.py", line 57, in test_can_start_a_list_for_one_user self.wait_for_row_in_list_table('1: Buy peacock feathers') File "...python-tdd-book/functional_tests/tests.py", line 23, in wait_for_row_in_list_table table = self.browser.find_element_by_id('id_list_table') selenium.common.exceptions.NoSuchElementException: Message: Unable to locate element: [id="id_list_table"] ERROR: test_multiple_users_can_start_lists_at_different_urls [...]"] [...] Ran 2 tests in 11.592s FAILED (errors=2)
It’s because our forms are still pointing to the old URL. In both home.html and lists.html, let’s change them to:
<form method="POST" action="/lists/new">
And that should get us back to working again:
AssertionError: '1: Buy milk' not found in ['1: Buy peacock feathers', '2: Buy milk'] [...] FAILED (failures=1)
That’s another nicely self-contained commit, in that we’ve made a bunch of changes to our URLs, our views.py is looking much neater and tidier, and we’re sure the application is still working as well as it did before. We’re getting good at this working-state-to-working-state malarkey!
$ git status # 5 changed files $ git diff # URLs for forms x2, moved code in views + tests, new URL $ git commit -a
And we can cross out an item on the to-do list:
Biting the Bullet: Adjusting Our Models
Enough housekeeping with our URLs. It’s time to bite the bullet and change our models. Let’s adjust the model unit test. Just for a change, I’ll present the changes in the form of a diff:
@@ -1,5 +1,5 @@ from django.test import TestCase -from lists.models import Item +from lists.models import Item, List class HomePageTest(TestCase): @@ -44,22 +44,32 @@ class ListViewTest(TestCase): -class ItemModelTest(TestCase): +class ListAndItemModelsTest(TestCase): def test_saving_and_retrieving_items(self): + list_ = List() + list_.save() + first_item = Item() first_item.text = 'The first (ever) list item' + first_item.list = list_ first_item.save() second_item = Item() second_item.text = 'Item the second' + second_item.list = list_ second_item.save() + saved_list = List.objects.first() + self.assertEqual(saved_list, list_) + saved_items = Item.objects.all() self.assertEqual(saved_items.count(), 2) first_saved_item = saved_items[0] second_saved_item = saved_items[1] self.assertEqual(first_saved_item.text, 'The first (ever) list item') + self.assertEqual(first_saved_item.list, list_) self.assertEqual(second_saved_item.text, 'Item the second') + self.assertEqual(second_saved_item.list, list_)
We create a new
List object, and then we assign each item to it
by assigning it as its
.list property. We check that the list is properly
saved, and we check that the two items have also saved their relationship
to the list. You’ll also notice that we can compare list objects with each
other directly (
saved_list and
list_)—behind the scenes, these
will compare themselves by checking that their primary key (the
.id attribute)
is the same.
Time for another unit-test/code cycle.
For the first couple of iterations, rather than explicitly showing you what code to enter in between every test run, I’m only going to show you the expected error messages from running the tests. I’ll let you figure out what each minimal code change should be on your own.
Your first error should be:
ImportError: cannot import name 'List' from 'lists.models'
Fix that, and then you should see:
AttributeError: 'List' object has no attribute 'save'
Next you should see:
django.db.utils.OperationalError: no such table: lists_list
So we run a
makemigrations:
$ python manage.py makemigrations Migrations for 'lists': lists/migrations/0003_list.py - Create model List
And then you should see:
self.assertEqual(first_saved_item.list, list_) AttributeError: 'Item' object has no attribute 'list'
A Foreign Key Relationship
How do we give our
Item a list attribute? Let’s just try naively making it
like the
text attribute (and here’s your chance to see whether your
solution so far looks like mine by the way):
from django.db import models class List(models.Model): pass class Item(models.Model): text = models.TextField(default='') list = models.TextField(default='')
As usual, the tests tell us we need a migration:
$ python manage.py test lists [...] django.db.utils.OperationalError: no such column: lists_item.list $ python manage.py makemigrations Migrations for 'lists': lists/migrations/0004_item_list.py - Add field list to item
Let’s see what that gives us:
AssertionError: 'List object' != <List: List object>
We’re not quite there. Look closely at each side of the
!=. Django has only
saved the string representation of the
List object. To save the relationship
to the object itself, we tell Django about the relationship between the two
classes using a
ForeignKey:
from django.db import models class List(models.Model): pass class Item(models.Model): text = models.TextField(default='') list = models.ForeignKey(List, default=None)
That’ll need a migration too. Since the last one was a red herring, let’s delete it and replace it with a new one:
$ rm lists/migrations/0004_item_list.py $ python manage.py makemigrations Migrations for 'lists': lists/migrations/0004_item_list.py - Add field list to item
Adjusting the Rest of the World to Our New Models
Back in our tests, now what happens?
$ python manage.py test lists [...] ERROR: test_displays_all_items (lists.tests.ListViewTest) django.db.utils.IntegrityError: NOT NULL constraint failed: lists_item.list_id [...] ERROR: test_redirects_after_POST (lists.tests.NewListTest) django.db.utils.IntegrityError: NOT NULL constraint failed: lists_item.list_id [...] ERROR: test_can_save_a_POST_request (lists.tests.NewListTest) django.db.utils.IntegrityError: NOT NULL constraint failed: lists_item.list_id Ran 6 tests in 0.021s FAILED (errors=3)
Oh dear!
There is some good news. Although it’s hard to see, our model tests are passing. But three of our view tests are failing nastily.
The reason is because of the new relationship we’ve introduced between
Items and
Lists, which requires each item to have a parent list, which
our old tests and code aren’t prepared for.
Still, this is exactly why we have tests! Let’s get them working again. The
easiest is the
ListViewTest; we just create a parent list for our two test
items:
class ListViewTest(TestCase): def test_displays_all_items(self): list_ = List.objects.create() Item.objects.create(text='itemey 1', list=list_) Item.objects.create(text='itemey 2', list=list_)
That gets us down to two failing tests, both on tests that try to POST to our
new_list view. Decoding the tracebacks using our usual technique, working
back from error to line of test code to, buried in there somewhere, the line
of our own code that caused the failure:
File "...python-tdd-book/lists/views.py", line 9, in new_list Item.objects.create(text=request.POST['item_text'])
It’s when we try to create an item without a parent list. So we make a similar change in the view:
from lists.models import Item, List [...] def new_list(request): list_ = List.objects.create() Item.objects.create(text=request.POST['item_text'], list=list_) return redirect('/lists/the-only-list-in-the-world/')
And that gets our tests passing again:
Ran 6 tests in 0.030s OK
Are you cringing internally at this point? Arg! This feels so wrong; we create a new list for every single new item submission, and we’re still just displaying all items as if they belong to the same list! I know, I feel the same. The step-by-step approach, in which you go from working code to working code, is counterintuitive. I always feel like just diving in and trying to fix everything all in one go, instead of going from one weird half-finished state to another. But remember the Testing Goat! When you’re up a mountain, you want to think very carefully about where you put each foot, and take one step at a time, checking at each stage that the place you’ve put it hasn’t caused you to fall off a cliff.
So just to reassure ourselves that things have worked, we rerun the FT:
AssertionError: '1: Buy milk' not found in ['1: Buy peacock feathers', '2: Buy milk'] [...]
Sure enough, it gets all the way through to where we were before. We haven’t broken anything, and we’ve made a change to the database. That’s something to be pleased with! Let’s commit:
$ git status # 3 changed files, plus 2 migrations $ git add lists $ git diff --staged $ git commit
And we can cross out another item on the to-do list:
Each List Should Have Its Own URL
What
shall we use as the unique identifier for our lists? Probably the
simplest thing, for now, is just to use the auto-generated
id field from the
database. Let’s change
ListViewTest so that the two tests point at new
URLs.
We’ll also change the old
test_displays_all_items test and call it
test_displays_only_items_for_that_list instead, and make it check that
only the items for a specific list are displayed:
class ListViewTest(TestCase): def test_uses_list_template(self): list_ = List.objects.create() response = self.client.get(f'/lists/{list_.id}/') self.assertTemplateUsed(response, 'list.html') def test_displays_only_items_for_that_list(self): correct_list = List.objects.create() Item.objects.create(text='itemey 1', list=correct_list) Item.objects.create(text='itemey 2', list=correct_list) other_list = List.objects.create() Item.objects.create(text='other list item 1', list=other_list) Item.objects.create(text='other list item 2', list=other_list) response = self.client.get(f'/lists/{correct_list.id}/') self.assertContains(response, 'itemey 1') self.assertContains(response, 'itemey 2') self.assertNotContains(response, 'other list item 1') self.assertNotContains(response, 'other list item 2')
Running the unit tests gives an expected 404, and another related error:
FAIL: test_displays_only_items_for_that_list (lists.tests.ListViewTest) AssertionError: 404 != 200 : Couldn't retrieve content: Response code was 404 (expected 200) [...] FAIL: test_uses_list_template (lists.tests.ListViewTest) AssertionError: No templates used to render the response
Capturing Parameters from URLs
It’s time to learn how we can pass parameters from URLs to views:
urlpatterns = [ url(r'^$', views.home_page, name='home'), url(r'^lists/new$', views.new_list, name='new_list'), url(r'^lists/(.+)/$', views.view_list, name='view_list'), ]
We adjust the regular expression for our URL to include a capture group,
(.+), which will match any characters, up to the following
/. The captured
text will get passed to the view as an argument.
In other words, if we go to the URL /lists/1/,
view_list will get a second
argument after the normal
request argument, namely the string
"1".
If we go to /lists/foo/, we get
view_list(request, "foo").
But our view doesn’t expect an argument yet! Sure enough, this causes problems:
ERROR: test_displays_only_items_for_that_list (lists.tests.ListViewTest) [...] TypeError: view_list() takes 1 positional argument but 2 were given [...] ERROR: test_uses_list_template (lists.tests.ListViewTest) [...] TypeError: view_list() takes 1 positional argument but 2 were given [...] ERROR: test_redirects_after_POST (lists.tests.NewListTest) [...] TypeError: view_list() takes 1 positional argument but 2 were given FAILED (errors=3)
We can fix that easily with a dummy parameter in views.py:
def view_list(request, list_id): [...]
Now we’re down to our expected failure:
FAIL: test_displays_only_items_for_that_list (lists.tests.ListViewTest) [...] AssertionError: 1 != 0 : Response should not contain 'other list item 1'
Let’s make our view discriminate over which items it sends to the template:
def view_list(request, list_id): list_ = List.objects.get(id=list_id) items = Item.objects.filter(list=list_) return render(request, 'list.html', {'items': items})
Adjusting new_list to the New World
Oops, now we get errors in another test:
ERROR: test_redirects_after_POST (lists.tests.NewListTest) ValueError: invalid literal for int() with base 10: 'the-only-list-in-the-world'
Let’s take a look at this test then, since it’s moaning:
class NewListTest(TestCase): [...] def test_redirects_after_POST(self): response = self.client.post('/lists/new', data={'item_text': 'A new list item'}) self.assertRedirects(response, '/lists/the-only-list-in-the-world/')
It looks like it hasn’t been adjusted to the new world of
Lists and
Items.
The test should be saying that this view redirects to the URL of the specific
new list it just created:
def test_redirects_after_POST(self): response = self.client.post('/lists/new', data={'item_text': 'A new list item'}) new_list = List.objects.first() self.assertRedirects(response, f'/lists/{new_list.id}/')
That still gives us the invalid literal error. We take a look at the view itself, and change it so it redirects to a valid place:
def new_list(request): list_ = List.objects.create() Item.objects.create(text=request.POST['item_text'], list=list_) return redirect(f'/lists/{list_.id}/')
That gets us back to passing unit tests:
$ python3 manage.py test lists [...] ...... --------------------------------------------------------------------- Ran 6 tests in 0.033s OK
What about the functional tests? We must be almost there?
The Functional Tests Detect Another Regression
Well, almost:
F. ====================================================================== FAIL: test_can_start_a_list_for_one_user (functional_tests.tests.NewVisitorTest) --------------------------------------------------------------------- Traceback (most recent call last): File "...python-tdd-book/functional_tests/tests.py", line 67, in test_can_start_a_list_for_one_user self.wait_for_row_in_list_table('2: Use peacock feathers to make a fly') [...] AssertionError: '2: Use peacock feathers to make a fly' not found in ['1: Use peacock feathers to make a fly'] --------------------------------------------------------------------- Ran 2 tests in 8.617s FAILED (failures=1)
Our new test is actually passing, and different users can get different lists, but the old test is warning us of a regression. It looks like you can’t add a second item to a list any more. It’s because of our quick-and-dirty hack where we create a new list for every single POST submission. This is exactly what we have functional tests for!
And it correlates nicely with the last item on our to-do list:
One More View to Handle Adding Items to an Existing List
We need a URL and view to handle adding a new item to an existing list (/lists/<list_id>/add_item). We’re getting pretty good at these now, so let’s knock one together quickly:
class NewItemTest(TestCase): def test_can_save_a_POST_request_to_an_existing_list(self): other_list = List.objects.create() correct_list = List.objects.create() self.client.post( f'/lists/{correct_list.id}/add_item', data={'item_text': 'A new item for an existing list'} ) self.assertEqual(Item.objects.count(), 1) new_item = Item.objects.first() self.assertEqual(new_item.text, 'A new item for an existing list') self.assertEqual(new_item.list, correct_list) def test_redirects_to_list_view(self): other_list = List.objects.create() correct_list = List.objects.create() response = self.client.post( f'/lists/{correct_list.id}/add_item', data={'item_text': 'A new item for an existing list'} ) self.assertRedirects(response, f'/lists/{correct_list.id}/')
We get:
AssertionError: 0 != 1 [...] AssertionError: 301 != 302 : Response didn't redirect as expected: Response code was 301 (expected 302)
Beware of Greedy Regular Expressions!
That’s
a little strange. We haven’t actually specified a URL for
/lists/1/add_item yet, so our expected failure is
404 != 302. Why are we
getting a 301?
This was a bit of a puzzler! It’s because we’ve used a very "greedy" regular expression in our URL:
url(r'^lists/(.+)/$', views.view_list, name='view_list'),
Django
has some built-in code to issue a permanent redirect (301) whenever
someone asks for a URL which is almost right, except for a missing slash.
In this case, /lists/1/add_item/ would be a match for
lists/(.+)/, with the
(.+) capturing
1/add_item. So Django "helpfully"
guesses that we actually wanted the URL with a trailing slash.
We can fix that by making our URL pattern explicitly capture only numerical
digits, by using the regular expression
\d:
url(r'^lists/(\d+)/$', views.view_list, name='view_list'),
That gives us the failure we expected:
AssertionError: 0 != 1 [...] AssertionError: 404 != 302 : Response didn't redirect as expected: Response code was 404 (expected 302)
The Last New URL
Now we’ve got our expected 404, let’s add a new URL for adding new items to existing lists:
urlpatterns = [ url(r'^$', views.home_page, name='home'), url(r'^lists/new$', views.new_list, name='new_list'), url(r'^lists/(\d+)/$', views.view_list, name='view_list'), url(r'^lists/(\d+)/add_item$', views.add_item, name='add_item'), ]
Three very similar-looking URLs there. Let’s make a note on our to-do list; they look like good candidates for a refactoring:
Back to the tests, we get the usual missing module view objects:
AttributeError: module 'lists.views' has no attribute 'add_item'
The Last New View
Let’s try:
def add_item(request): pass
Aha:
TypeError: add_item() takes 1 positional argument but 2 were given
def add_item(request, list_id): pass
And then:
ValueError: The view lists.views.add_item didn't return an HttpResponse object. It returned None instead.
We can copy the
redirect from
new_list and the
List.objects.get from
view_list:
def add_item(request, list_id): list_ = List.objects.get(id=list_id) return redirect(f'/lists/{list_.id}/')
That takes us to:
self.assertEqual(Item.objects.count(), 1) AssertionError: 0 != 1
Finally we make it save our new list item:
def add_item(request, list_id): list_ = List.objects.get(id=list_id) Item.objects.create(text=request.POST['item_text'], list=list_) return redirect(f'/lists/{list_.id}/')
And we’re back to passing tests.
Ran 8 tests in 0.050s OK
Testing the Response Context Objects Directly
We’ve got our new view and URL for adding items to existing lists; now we just need to actually use it in our list.html template. So we open it up to adjust the form tag…
<form method="POST" action="but what should we put here?">
…oh. To get the URL for adding to the current list, the template needs to know what list it’s rendering, as well as what the items are. We want to be able to do something like this:
<form method="POST" action="/lists/{{ list.id }}/add_item">
For that to work, the view will have to pass the list to the template.
Let’s create a new unit test in
ListViewTest:
def test_passes_correct_list_to_template(self): other_list = List.objects.create() correct_list = List.objects.create() response = self.client.get(f'/lists/{correct_list.id}/') self.assertEqual(response.context['list'], correct_list) (1)
That gives us:
KeyError: 'list'
because we’re not passing
list into the template. It actually gives us an
opportunity to simplify a little:
def view_list(request, list_id): list_ = List.objects.get(id=list_id) return render(request, 'list.html', {'list': list_})
That, of course, will break one of our old tests, because the template
needed
items:
FAIL: test_displays_only_items_for_that_list (lists.tests.ListViewTest) [...] AssertionError: False is not true : Couldn't find 'itemey 1' in response
But we can fix it in list.html, as well as adjusting the form’s POST action:
<form method="POST" action="/lists/{{ list.id }}/add_item"> (1) [...] {% for item in list.item_set.all %} (2) <tr><td>{{ forloop.counter }}: {{ item.text }}</td></tr> {% endfor %}
So that gets the unit tests to pass:
Ran 9 tests in 0.040s OK
How about the FTs?
$ python manage.py test functional_tests [...] .. --------------------------------------------------------------------- Ran 2 tests in 9.771s OK
HOORAY! Oh, and a quick check on our to-do list:
Irritatingly, the Testing Goat is a stickler for tying up loose ends too, so we’ve got to do this one final thing.
Before we start, we’ll do a commit—always make sure you’ve got a commit of a working state before embarking on a refactor:
$ git diff $ git commit -am "new URL + view for adding to existing lists. FT passes :-)"
A Final Refactor Using URL includes
superlists/urls.py is really
meant for URLs that apply to your
entire site. For URLs that only apply to the
lists app, Django encourages us
to use a separate lists/urls.py, to make the app more self-contained. The
simplest way to make one is to use a copy of the existing urls.py:
$ cp superlists/urls.py lists/
Then we replace three lines in superlists/urls.py with an
include:
from django.conf.urls import include, url from lists import views as list_views (1) from lists import urls as list_urls (1) urlpatterns = [ url(r'^$', list_views.home_page, name='home'), url(r'^lists/', include(list_urls)), (2) ]
Back in lists/urls.py we can trim down to only include the latter part of our three URLs, and none of the other stuff from the parent urls.py:
from django.conf.urls import url from lists import views urlpatterns = [ url(r'^new$', views.new_list, name='new_list'), url(r'^(\d+)/$', views.view_list, name='view_list'), url(r'^(\d+)/add_item$', views.add_item, name='add_item'), ]
Rerun the unit tests to check that everything worked.
When I did it, I couldn’t quite believe I did it correctly on the first go. It always pays to be skeptical of your own abilities, so I deliberately changed one of the URLs slightly, just to check if it broke a test. It did. We’re covered.
Feel free to try it yourself! Remember to change it back, check that the tests all pass again, and then do a final commit:
$ git status $ git add lists/urls.py $ git add superlists/urls.py $ git diff --staged $ git commit
Phew. A marathon chapter. But we covered a number of important topics, starting with test isolation, and then some thinking about design. We covered some rules of thumb like "YAGNI" and "three strikes then refactor". But, most importantly, we saw how to adapt an existing site step by step, going from working state to working state, in order to iterate towards a new design.
I’d say we’re pretty close to being able to ship this site, as the very first beta of the superlists website that’s going to take over the world. Maybe it needs a little prettification first…let’s look at what we need to do to deploy it in the next couple of chapters.
|
https://www.obeythetestinggoat.com/book/chapter_working_incrementally.html
|
CC-MAIN-2021-17
|
refinedweb
| 7,814 | 66.54 |
On 07/06/07, Jan Engelhardt <[email protected]> wrote:>> On Jun 6 2007 11:05, Jesper Juhl wrote:> >> > - Source files should be 7bit ASCII>> Nah. Think of....>> MODULE_AUTHOR("J. Ørsted <[email protected]>");>That's true. I wrote that comment shortly after reading , but you are right, 7bit ASCII canbe too limiting at times... Hmmm...> > - Maybe warn about usage of float/double in source files?>> Generally yes, maybe, but see arch/i386/kernel/cpu/bugs.c,> arch/i386/math-emu/. Generally there is nothing to it. I think the> feature to allow the kernel to use [i387] FP without manually> saving/restoring the FP stack has been added some time ago.>I know there are places where floats and doubles can be used safely,but for those rare occasions wouldn't it make sense to have the scriptwarn and require the submitter to justify the use? After all, thegeneral rule is to not use floating point in the kernel, so such apatch is suspicious.> > - 'return' is not a function, so warn about patches that think it is> > and use 'return(expr);' (this one is tricky since 'return (expr);' can> > be OK in some cases.>> Now, if we could detect superfluous parentheses and branches,> that'd be cool ;-) there are too many if ((a < 5) || (b > 6)) around.>Yeah wouldn't it be cool :-) It might require a bit too much perlmagic to actually implement something sane, but I just threw everyidea that came into my mind into the mail, assuming Andy could sortout the ones that were a little too crazy ;)--
|
http://lkml.org/lkml/2007/6/7/194
|
CC-MAIN-2016-07
|
refinedweb
| 262 | 68.5 |
#include <deal.II/base/patterns.h>
Test for the string being an integer. integer is allowed.
Giving bounds may be useful if for example a value can only be positive and less than a reasonable upper bound (for example the number of refinement steps to be performed), or in many other cases.
Definition at line 189 integers is implied. The default values are chosen such that no bounds are enforced on parameters.
Note that the range implied by an object of the current type is inclusive of both bounds values, i.e., the
upper_bound is an allowed value, rather than indicating a half-open value as is often done in other contexts.
Definition at line 213 of file patterns.cc.
Return
true if the string is an integer and its value is within the specified range.
Implements Patterns::PatternBase.
Definition at line 221 of file patterns.cc.
Return a description of the pattern that valid strings are expected to match. If bounds were specified to the constructor, then include them into this description.
Implements Patterns::PatternBase.
Definition at line 243 of file patterns.cc.
Return a copy of the present object, which is newly allocated on the heap. Ownership of that object is transferred to the caller of this function.
Implements Patterns::PatternBase.
Definition at line 304 of file patterns.cc.
Create a new object if the start of description matches description_init. Ownership of that object is transferred to the caller of this function.
Definition at line 312 integer value. If the numeric_limits class is available use this information to obtain the extremal values, otherwise set it so that this class understands that all values are allowed.
Definition at line 197 of file patterns.h.
Maximal integer value. If the numeric_limits class is available use this information to obtain the extremal values, otherwise set it so that this class understands that all values are allowed.
Definition at line 204 of file patterns.h.
Value of the lower bound. A number that satisfies the match operation of this class must be equal to this value or larger, if the bounds of the interval for a valid range.
Definition at line 259 of file patterns.h.
Value of the upper bound. A number that satisfies the match operation of this class must be equal to this value or less, if the bounds of the interval for a valid range.
Definition at line 267 of file patterns.h.
Initial part of description
Definition at line 272 of file patterns.h.
|
https://dealii.org/developer/doxygen/deal.II/classPatterns_1_1Integer.html
|
CC-MAIN-2020-45
|
refinedweb
| 417 | 58.38 |
Spring Dependencies - Opposite Direction, Please?
Here we'll see how to manage dependencies between beans in Spring framework context using "opposite direction" of such dependencies.
Spring is great in providing inversion of control container, instantiating beans, wiring them as well as managing their lifecycle. But can it be improved there?
Yes, Spring Framework is great. No doubts. I remember that excitement when I played with it first time (that's was several years ago). That's was great to see that after providing proper configuration the magic happened - all beans were instantiated and more importantly, they were wired together by container...
At that moment inversion of control was pretty new concept and things that were handled by Spring impressed us too much. Right at that time we've completed pretty large product that required sophisticated setup of components and dependencies between them and so we were totally disappointed that Spring appeared late..
Ok, Spring is great. But definitely one can be improved in some areas. Let's leave warious holy wars related to Spring alone and take a look to it's basic functionality - the IoC container. After all, that's one of the basic concept of Spring - so probably we'll be able to polish it a little there?
Let's imagine that we have two beans in our Spring context - BeanA and BeanB. And BeanA has property to which BeanB should be wired. If we'll omit autowiring issues there, such a dependency will be described in Spring context XML as follows:
<bean class="..." id="BeanA">
<property name="propertyThatRefersToB" ref="BeanB"/>
</bean>
<bean id="BeanB" class="..."/>
or, it could be even shorter if p: namespace from Spring 2.x is used:
<bean class="..." id="BeanA"
p:
In general, this way to instruct the Spring how to inject BeanB to BeanA is pretty fine and is more than enough in most situation.Unfortunately, not in all.
The overall concept of Spring framework assumes that context is assembled when all beans are known (and that's pretty natural). However, that approach does not work well if application should be built using not solid, but rather plugin based architecture.Recently, in one of projects we develop here in SoftAMIS we've got the same issue - the overall system should support dynamically loaded plugins (actually, the entire application could be considered as set of plugins) and, what is more important, generally speaking, that set of plugins is unknown so new plugins may be added later as well as existing ones may be disabled.
That's was the case were Spring container simply may fail...Fortunately, in our application, plugins are assembled only during application startup, so we got different challenge - how to compose final Spring context from several configuration files. Since Spring initially supported dividing entire application context by several configuration files, that's was not to hard.
However, here we still had little trouble - in Spring, to make reference to bean, you need to know name of that bean. That's was obviously not acceptable for plugins - and what we needed there is ability to specify that reference not on parent bean (BeanA), but on bean that is referred - (BeanB).Thus, instead of having top-to-bottom direction of references, we needed opposite one, that assumes that directly on the bean we may specify where one should be injected. The following picture illustrates such a difference between these approaches:
We've tried to find ready solution for that, but didn't find any that can satisfy our needs (please thing that actually there more complex types of references between beans exists - via list, map and set, for example).
So, necessity is mother of progress - and we've created small library that allows to have such opposite injections in Spring.
Thanks to support of custom namespaces in Spring 2.x, resulting markup was pretty simple. Like that:
<bean class="..." id="BeanA"/>
<bean class="..." id="BeanB">
<inject:to-ref
</bean>
Pretty simple, right? Please note tag from custom namespace (supported by Spring 2.x):
<inject:to-ref
Using it now we've just inverted direction in which we declare references between beans in Spring context - BeanA just could be considered as extension point which underlying BeanB may be plugged into. And think about having such ability to dynamically plug bean into list or map (yes, we have them already too) ....
Well, that's was description of generic idea. One of these days I'll post more detailed entry about that technology as well as provide complete source code for it - so stay tuned!
UPDATE:
I've added another entry to my blog that describes this issue more. And, from there the Inject4Spring library is available - it provides support for concepts I've described there.
Please use the following link to get it:Introducing Inject4Spring
(Note: Opinions expressed in this article and its replies are the opinions of their respective authors and not those of DZone, Inc.)
Ronald Miura replied on Tue, 2008/06/03 - 10:17am
Have you tried this?
or maybe
Andrew Sazonov replied on Tue, 2008/06/03 - 10:57am
in response to:
Ronald Miura
Hi Roland,
Yes, sure, that will work... But it requires more coding (that's not an issues if there are only couple beans that should be wired, but that additional coding may require significant time if there are many such cases within application). Also, it hides details of registrations within code (for example, if I'd like to register bean in other' bean map under some key), that by my opinion, not too good.
And, in addition, it ties beans to Spring framework (since in your approach it's necessary to implement InitializingBean - that may be not good for some applications.
That's why we've created that small injection library that allows to wire such beans pretty similar to standard Spring way. I suppose I'll make it available one of these days - just need to polish it a little at the moment.
Regards,
Andrew
Ronald Miura replied on Tue, 2008/06/03 - 11:49am
It's 'Ronald'.
Well, the second option doesn't require you to implement any interface. Yet another option is to just query the context for beans that implement you 'Plugin' interface.
But nice work! I sometimes also feel that Spring is quite powerful when dealing with static structures, but is somewhat limited when it comes to dynamic discovery/configuration. Maybe OSGi (the latest and greatest silver bullet :)) will help in this.
Anyway, the fact that you were able to code such feature as an extension namespace just shows how the Spring component model is flexible :)
Bruno Borges replied on Tue, 2008/06/03 - 1:01pm
Ronald Miura replied on Tue, 2008/06/03 - 1:50pm
@Bruno: if the property to be injected is a list, the container won't automatically add all the compatible references (and I don't think it would always be desirable), and this would be a pretty common scenario in a plugin architecture.
And, autowire (the XML one, @Autowired is far less error-prone, because of its usage pattern) may cause strange bugs sometimes... For example, I was using the SchedulerFactoryBean for Quartz support. Everything was working fine, I was using the default jobStore in memory, but for some reason I turned the autowiring on, and suddenly the scheduler started to throw JDBC-related errors. But I didn't set up LocalDataSourceJobStore! Only after much research, I found the answer in the LocalDataSourceJobStore javadoc:
<cite>This JobStore will be used if SchedulerFactoryBean's "dataSource" property is set.<cite>
This is not mentioned in the SchedulerFactoryBean javadoc, and was triggered by the application's dataSource being 'autowired' into the scheduler. Solution: turn the autowiring off, either globally and wire everything by hand, or only for the scheduler and any other conflicting bean...
So, autowiring is nice, but use with caution! :)
Bruno Borges replied on Tue, 2008/06/03 - 2:13pm
Yeah, I know the risks when using autowiring. But even for your plugin concept, I see no difference between the normal direction and the opposite one. Either way, one bean must know of other's existence. From my point of view, you went from this: "BeanA, set this BeanB into your setBeanBProperty" to this --> "BeanB, set yourself at BeanA's setBeanBProperty".
Is these ways really that different between them? BeanB must know the id of BeanA anyway. And vice-versa using the usual way Spring suggests. What if BeanA would behave in a different way if the developer coded for an optional BeanB property? There are lots of beans like that, inclusive within Spring itself. If one bean property is set, the bean will behave as it supposed to work with that dependency; if not it will figure out how to do their stuff without the dependency.
So imagine a BeanA provided from someone with an optional dependency injection. Then you put a BeanB and configure it with an opposite injection. Wow! Wasn't you that configured BeanA, sou you don't know how it works! Even worse: depending on the context, you should have never injected BeanB into BeanA because of some very weird BeanA's behaviour.
Your plugin concept is a little bit wrong IMHO. Your plugin should register itself somehow and just let others decide if they are going to be used or not. You register a plugin to Eclipse this way, and they work this way when they have any other dependency.
"I depend on you. Are you registered? If yes, give me a hand. If not, I have two options: quit my job, or figure out how to do other's."
m2c
Ronald Miura replied on Tue, 2008/06/03 - 3:37pm
The difference between 'A knows B' and 'B knows A' is, suppose A is a 'PluginRegistry' class. If every time a new plugin is added, you have to change the definition of the registry. It'd be a kind of 'Open-Close Principle' violation. You don't go changing any XML file when installing new plugins in Eclipse, do you? But the plugin surely knows how to register itself. Thus, 'B knows A' is less coupled than the 'A knows B'.
Sure, you could design a plugin architecture with extreme low-coupling between components (general-purpose APIs like OSGi probably are like that), but this adds complexity to the solution. Many times, it just isn't worth it. And when you do need something like that, just use the solutions available instead of rolling your own...
Bruno Borges replied on Tue, 2008/06/03 - 3:59pm
Hitesh Lad replied on Tue, 2008/06/03 - 5:50pm
Ales Justin replied on Wed, 2008/06/04 - 3:18am
Have a look at what we do in our Microcontainer (MC) project:
Since we're doing exactly what you need. :-)
And we already support Spring beans xml files, handling them via MC (no need for Spring lib in classpath, since we understand its schema):
So no need to rewrite those config files.
OK, perhaps a small change in namespace si required. ;-)
|
http://java.dzone.com/news/spring-dependencies-opposite-d
|
CC-MAIN-2013-20
|
refinedweb
| 1,847 | 62.27 |
(X,Y) coordinate using python openCV
Dear all,
It is my first time to work on openCV; in fact, I just heard of it two months ago.I need to get the position point value using (x,y) coordinate system so I can program motors to pick the dices. My question, can you please help to find the location of each dice and return (x,y) values for each one of them? I attached an example of what I really want.
Thank you.
what have you tried, so far ? (we won't write your program)
Just a suggestion - If you always have an image of the scene you could simply take the image coordinate system in openCV: Top-left corner is 0,0; x-axis is horizontal, y-axis is vertical.
I think one way is to look for white color (thresholding or masks), draw contours on the new image (only the dice should be visible) and take the center of the contours.
|
https://answers.opencv.org/question/199275/xy-coordinate-using-python-opencv/
|
CC-MAIN-2019-35
|
refinedweb
| 163 | 74.53 |
Hello All,
Reporting in avamar always in my nightmares. I usually use avamar cli mccli and some other tools on avamar. But an automated emaling always has been problem for me . Today i tried somtehing else and wolla it worked perfectly .Now i want to share this with you.
First we need some tools for this . I belive that almost all of us familiar with them.
Here we go ,
First i connect avamar with winscp. Then ,
I save the session information ,
Warning : This action may have security issues. So do it with your own risk.
After that i create some scripts . I will try to explain them below. Basically i create 3 windows batch you can merge them or split whatever you want.
In first line i am changing folder to be able to run winscp commands,
cd "c:\Program Files (x86)\WinSCP"
winscp /console /command "open avamar" "call /usr/local/avamar/bin/./replcnt.sh > /home/Reports/replication_log.txt"
In above line winscp conencts the avamar with saved user name and password. After connected it runs “call”command and the replication report script.
winscp /console /command "open avamar" "call capacity.sh > /home/Reports/capacity_log.txt" "exit"
I added the the what ever i need.
winscp /console /command "open avamar" "call status.dpn > /home/Reports/status_dpn.txt" "exit"
winscp /console /command "open avamar" "call dpnctl status > /home/Reports/dpnctl_status.txt" "exit"
winscp /console /command "open avamar" "cd /home/Reports" "get *.txt E:\Reports\ " "exit"
and the last line is connecting avamar and goes to my report folder and copying all txt files to my windows server.
And here is the output files
Ok good now we have our reports on our windows server what is next ?
I need to keep them with date format so here is second batch . It renames our files with date format.
set HR=%time:~0,2%
set HR=%Hr: =0%
set HR=%HR: =%
rename e:\Reports\capacity_log.txt capacity_log_results_%date:~10,4%-%date:~4,2%-%date:~7,2%_%HR%%time:~3,2%.txt
rename e:\Reports\dpnctl_status.txt dpnctl_results_%date:~10,4%-%date:~4,2%-%date:~7,2%_%HR%%time:~3,2%.txt
rename e:\Reports\status_dpn.txt status_results_%date:~10,4%-%date:~4,2%-%date:~7,2%_%HR%%time:~3,2%.txt
rename e:\Reports\replication_log.txt replication_log_results_%date:~10,4%-%date:~4,2%-%date:~7,2%_%HR%%time:~3,2%.txt
And here is the output.
Now we have reports that renamed with dates.
And this time i need to zipped these files. This time i use winrar. This is the third batch file.
First i set home env. For winrar then change the directory to my reports directory
set path="C:\Program Files\WinRAR\";%path%
cd e:\Reports
rar a -r e:\Reports\reports.rar E:\reports\*.txt e:\Reports\Reports.rar
Its all done . Now we just need to schedule these batch files with windows task scheduler.
And email them again with task scheduler.
And it works .
I hope it is usefull for everybody who uses Avamar. Have nice works.
Ahmet Keçeciler
This is great info. appreciate the detail.
However, why could you not have performed these various commands and renaming etc. on the Utility node then email them directly from it?
The process could be scheduled using the Linux CRON.
This would eliminate the need to interact with a Windows host but if for some reason they are actually needed on Windows a single winscp could be used to retrieve it.
Interesting thread for sure, as reports ARE a nightmare as soon as you need something a little custom.
The way I do it is, I wrote a script that interrogate the postgress database (you'll need to be creative with SQL queries here), and email the results to the concerned administrators.
Here is a prototype in python that fetch MSSQL plugin backups exceptions. Warning, this is very ALPHA, non-optimized and ugly code, but hopefully you'll get the idea:
#!/usr/bin/python
import pdb
import psycopg2
from smtplib import SMTP
import datetime
#pdb.set_trace()
def sendreport(message_text):
smtp = SMTP()
smtp.connect('smtp.server.local', 25)
from_addr = "Avamar grid <[email protected]>"
to_addr = "[email protected]"
subj = "Avamar SQL Backup Exceptions"
date = datetime.datetime.now().strftime( "%d/%m/%Y %H:%M" )
msg = "From: %s\nTo: %s\nSubject: %s\nDate: %s\n\n%s" % ( from_addr, to_addr, subj, date, message_text )
smtp.sendmail(from_addr, to_addr, msg)
smtp.quit()
try:
conn = psycopg2.connect('host=avamar_utility_node_ip port=5555 dbname=mcdb user=viewuser password=viewuser1')
print "Connected to Database"
except:
print "No Connection"
#cur = conn.cursor(cursor_factory=psycopg2.extras.DictCursor)
cur = conn.cursor()
#pdb.set_trace()
try:
cur.execute("select client_name,domain,recorded_date,plugin_name,status_code FROM v_activities WHERE recorded_date_time > current_timestamp - interval '24 hours' AND plugin_name='Windows SQL'")
rows = cur.fetchall()
message_text = '\nServeur\t\t\t\tResultat'
message_text += '\n--------\t\t\t\t\t--------'
for row in rows:
if (row[4] == 30000):
result='Completed with succes.'
elif (row[4] == 30005):
result='Completed with exceptions.'
elif (row[4] == 30999):
result='Backup in error!'
print "Serveur: " + row[0] + " Resultat: " + result
message_text += "\n" + row[0] + "\t\t" + result
print "msg: \n" + message_text
except:
print "Not Working"
sendreport(message_text)
As an intermediate option, have you looked into "plink" or its more GUI-friendly cousin TortoisePlink.exe? The plink utility can be used to run SSH commands on remote hosts and it's a lot more lightweight than WinSCP.
For the security conscious, I would recommend setting up passwordless authentication from the Windows host to the utility node. While this is not officially supported, it does work and it's far more secure than saving login credentials. This does require you to keep the private key secured.
Hello,
First off all thank you for your replies .
I actually did this for my customers who are not familiar with linux systems. And all af them want to control this system without trying to use avamar cli or linux bash. So why i did it with using windows instead of linux. Also Other comments are absuletly true about saving connection credantials. Our customers in my country are needs diffirent things, they want to some reports with email but but dont want struggle and learn new things. So this is my easiest way to do this. With this way they can control scripts schedules without interacting with avamar. Because of that i renamed the article " Different Way ..."
I know there is a alot of way to accomplish that what we want ... Also my best concept is K.I.S ( Keep It Simple)
|
https://www.dell.com/community/Avamar/A-different-way-to-create-and-email-avamar-reports/td-p/7022643
|
CC-MAIN-2019-26
|
refinedweb
| 1,089 | 60.61 |
This is a discussion on Format text(ifstream, ofstream) within the C++ Programming forums, part of the General Programming Boards category; Originally Posted by R.Stiltskin Why are you writing the entire buffer? If you read a 5 letter word into a ...
Code:#include <iostream> #include <fstream> #include <cstring> using namespace std; int main () { ifstream input("input.txt"); // ofstream output("output.txt"); const int MAX = 70; // instead of 100 char buff[MAX]; int i; for(i = 0; i<5; ++i ) buff[i] = 98+i; cout << "I did not terminate my string with a 0 so strlen\n"; cout << "will give the length from buff[0] to the first 0 it happens\n"; cout << "to find.\nThis prints every byte from buff[0] up to and\n"; cout << "including the first \"random\" zero as a 1-byte unsigned number:\n"; for(i = 0; i <= strlen(buff); ++i ) cout << (int)(unsigned char)*(buff+i) << "\n"; cout << endl; cout << "Some of the \"garbage\" characters may be unprintable, or line\n"; cout << "feed or backspace or carriage return or extended ascii chars.\n"; cout << "Here's the same thing when cout tries to show it as text:\n"; cout << buff << endl; cout << "Now see what happens if I properly terminate the string.\n"; buff[5] = '\0'; cout << "As numbers:\n"; for(i = 0; i <= strlen(buff); ++i ) cout << (int)(unsigned char)*(buff+i) << " "; cout << endl <<endl; cout << "and as letters:\n"; cout << buff <<endl; }
What I don't understand is why, when I run the code that I posted in #32, cout prints a garbage character at the beginning of the line "Now see what happens if I ...".
This happens even if I put "cout.flush()" before that line. The only way to avoid that seems to be to print any non-printable ascii char before that line.
This problem does not occur when I send the output to a file rather than the console.
It's probably simply that you've got garbage characters at the end of buff - there is no good way of predicting what they will do or what effect they will have, since it's "random" characters - and they may well mean just about anything including "move down a row" or "move up a row" or anything else that you can't tell what it means.
[Note, they are not as random as the result of rand(), but they are random in the sense that they are not defined by the program as such - they will have whatever value happens to be in the memory at that location - which if you have the same calling sequence for multiple runs will possibly be similar or even the same].
--
Mats
Compilers can produce warnings - make the compiler programmers happy: Use them!
Please don't PM me for help - and no, I don't do help over instant messengers.
i used name.c_str() because the compiler was having problem when i tried to Prompt for the source file name. And i didn't have to enter two \\ as i would with cin.i used name.c_str() because the compiler was having problem when i tried to Prompt for the source file name. And i didn't have to enter two \\ as i would with cin.Code:#include <fstream> using std::ofstream; using std::ifstream; #include <iostream> using std::cin; using std::cout; using std::cerr; #include <sstream> #include <iomanip> #include <cstring> using std::string; using namespace std; #include <cstdlib> using std::exit; #include <stdio.h> #include <iterator> int main (void) { int width; //width of output line text string name; //input string for location of text file cout << "Enter name of input text file(location on disk): "<<endl; getline (cin, name); //Prompts user to input source text ifstream input; //create stream object homework input.open ( name.c_str() ); //reads source text file cout << "\n\nEnter name of the output text file: " <<endl; getline (cin, name); //Promt user to input output text ofstream output; //create stream object homework2 output.open (name.c_str() ); if (!input) { cerr << "Unable to open file hw6.txt"; exit(1); } // call system to stop if(!output){ cerr << "Unable to create text file\n"; exit(1);} //call system to stop // create reader objects cout << "Enter the width for the output of the text (40 - 70): " ; //Prompts for range for output text cin >> width; if ( width < 40 || width > 70 ) //set range for output line text cout << "error...width can't be smaller than 40 or larger than 70...Re-Enter range: "; //re-prompts if width exceeds range cin >> width; const int MAX = 100; char buff[MAX]; int word_length, line_length = 0; //declare variables for length of word and line respectively if( input >> buff ) { line_length += strlen( buff ); // set line length cout << buff; while( input >> buff ) { word_length = strlen( buff ); //set word legnth line_length += word_length + 1; if( line_length > width ) { cout << "\n" << buff; //prints newline if line length exceeds desired width line_length = word_length; } else { cout << ' ' << buff; } } cout << "\n"; } output << buff; //stores buff into created text file output.close(); //close ofstream input.close(); return 0; }
but whatever that was, you seem to have worked it out.
Code:cout << buff; output << buff;
thanks man, I had to use a conditional structure in case the person using the program input a width that was out of range.
on the cout, output question. shouldnt cout also be usable when dealing with ofstream?
hay i have been having the same problem my compiler is not read it properly
do you have more methods of doing this "ofstream fileOut(P)" taking user input and using it as a file address....
here is my program i could not get to work!!!!
Code:int main() { string P = ""; cout << "Input Directery Example: \" C:\\Users\\mugen\\Desktop\\data.txt \" " << endl; getline(cin, P); ofstream fileOut(P); //does not seem to read string "P" how do i get it to work system("pause"); }
i don't have to overload "ofstream.open()" do it if so what is the definition for it...i haven't learned more then operation overload yet!!!
The ofstream constructor takes a c-string (char array) as its argument, not a std::string.
TryCode:ofstream fileOut( P.c_str() );
|
http://cboard.cprogramming.com/cplusplus-programming/114194-format-text-ifstream-ofstream-3.html
|
CC-MAIN-2014-10
|
refinedweb
| 1,021 | 67.18 |
NAME
ulimit - get and set user limits
SYNOPSIS
#include <ulimit.h> long ulimit(int cmd, long newlimit);
DESCRIPTION
Warning: This routine is obsolete. Use getrlimit(2), setrlimit(2), and sysconf(3) instead. For the shell command ulimit(), see bash(1). The ulimit() call will get or set some limit for the calling-negative value. On error, -1 is returned, and errno is set appropriately.
ERRORS
EPERM A non-root process tried to increase a limit.
CONFORMING TO
SVr4, POSIX.1-2001.
SEE ALSO
bash(1), getrlimit(2), setrlimit(2), sysconf(3)
COLOPHON
This page is part of release 3.01 of the Linux man-pages project. A description of the project, and information about reporting bugs, can be found at.
|
http://manpages.ubuntu.com/manpages/intrepid/man3/ulimit.3.html
|
CC-MAIN-2015-06
|
refinedweb
| 120 | 61.83 |
XML has become one of the major technologies used today for
business integration software evolution. Lots of object models are
being used today to manipulate XML in various ways. AXIOM will
improve XML manipulation by providing a new lightweight object
model built around pull parsing, enabling efficient and easy
manipulation of XML. AXIOM is the object model for
Apache Axis 2, the next
generation of the Apache web services engine. AXIOM is different
from existing XML object models in various ways, the major one
being the way it incrementally builds the memory model of an
incoming XML source.
AXIOM itself does not contain a parser and it depends on
StAX for
input and output.
This tutorial will first show you how to obtain AXIOM and it
will then go through the fundamental features of the AXIOM
architecture. You will learn how to create XML documents from
scratch, using elements, attributes, element content ("texts"), and
namespaces. You will see how to read and write XML files from and
to disk.
AXIOM comes bundled with the
Axis2 M1
release. The lib directory contains the
axis-om-m1.jar file. However, more adventurous users can
download the latest source, via Subversion, from the
Apache Axis2 project and build the sources using
Maven. AXIOM is maintained
under the xml module of Apache Axis2. One can find
more information at the
Axis2 Subversion
site.
xml
AXIOM uses StAX reader and writer interfaces to interact with
the external world, as shown in Figure 1. However, you can still
use SAX and DOM to interact with AXIOM. Use of the standard StAX
interfaces will enable AXIOM to interact with any kind of input
source, be it an input stream, file, standard data binding tool,
etc.
Figure 1. AXIOM interaction
Now let's take a deeper look at AXIOM architecture.
AXIOM uses a "builder" that will build the XML object model in
memory, according to the events pulled from the underlying StAX
parser, but will not create the entire object model at once.
Instead, it only builds when the relevant information is
absolutely required. This builder concept is the key to the most
promising feature, the deferred building support for AXIOM. The
builder comes into the picture when you are building an object
model from an existing resource. If you build the object model
programmatically, then you don't have to use builders.
This builder can optionally provide the events generated by the
StAX parser to the user directly, while building the object model
or not. This feature is called caching in AXIOM. This enables one
to work at the event level, minimizing the memory requirement, or
to work with the object model, improving performance.
If one opts to set the cache on (i.e., to build the
object model by pulling events), then he can later retrieve the infoset through the AXIOM API. At any particular time, the XML object
model will be either "partially" built or fully built. This concept
is new to the XML processing world. AXIOM builder builds the object
model only to the extent required by the ultimate user, but will
not build the whole model at once. For example, take the following
XML fragment.
>
Say the user wants to get the project of the first employee. This
will make the builder build the object structure representing only
up to the fourth line of the XML fragment. The rest will be kept
"untouched" in the stream and the object structure contains only up
to line 4. Then, if the user wants to know the project of the
second employee, the builder builds only up to line 9. All of these things
will happen transparently to the user, simply providing better
performance.
The relationship of the builder to the XML data and the object
model is shown in Figure 2.
Figure 2. AXIOM architecture
One of the most interesting things about AXIOM is that the model
discussed so far is not by any means dependent on a particular
programming language. Therefore, the AXIOM architecture can be
implemented using any programming language that has an
implementation of StAX. Moreover, this concept does not talk about
the memory representation of the object model. The Axis2 project
contains an implementation of the concept with a linked list object
model, which has proven to be lightweight, fast, and efficient
compared to other object models. There was another parallel effort
made to implement this concept using a table model as well, which
is now in the scratch area of the Apache Axis2 project. Even though
the current major implementation of AXIOM uses a linked list model,
one can implement the same concept using any other suitable memory
model, as well.
AXIOM comes bundled with several builders:
StAXOMBuilder
StAXSOAPModelBuilder
SOAPEnvelope
getHeaders()
getBody()
MTOMBuilder
Please note that the current AXIOM implementation lags support
for processing instructions and DTD information items of the XML
infoset. But there is an ongoing effort within the Axis2 team to
provide these features as well.
You can create an AXIOM using different methods. Let's try to do
it programmatically this time.");
}
}
The first line sets up the OMFactory (remember, the
"OM" in AXIOM stands for "object model"). This
OMFactory will enable to switch between different Java
implementations of AXIOM. For example, I mentioned earlier that the
current implementation is based on a linked list model. But if
someone needed to use her own implementation of the AXIOM API, she
could do that without touching a single line that uses those
classes. The OMFactory.newInstance() method is smart
enough to pick up the first implementation of AXIOM from the
classpath. For this reason, it is highly recommended that you create new
OM objects using the OMFactory.
OMFactory
OMFactory.newInstance()
Note that we have passed three parameters to create an
OMElement. AXIOM is very much aware of namespaces and
encourages the use of them. So the method signature is
createOMElement(String localName, String namespaceURI, String
namespacePrefix). If this namespace is already defined in
the scope, AXIOM will assign that to this element, without
declaring a new one.
OMElement
createOMElement(String localName, String namespaceURI, String
namespacePrefix)
Texts are also considered as nodes in AXIOM. You can either
create an OMText and add that to
OMElement, or you can simply use the
element.setValue() method.
OMText
element.setValue()
First, let's create a namespace that can be used later, and then
we'll use it to create the documentElement. Since we are
using the factory for object creation, let's assign that to a new
variable, omFactory, as well.
documentElement
omFactory")
Adding an attribute to an element is as easy as saying
element.insertAttribute(String attrName, String attrValue,
OMNamespace ns). Here you have the option of passing
null to the namespace. The addChild() method
allows you to add either an OMElement or an
OMText.
element.insertAttribute(String attrName, String attrValue,
OMNamespace ns)
null
addChild()
You can use the declareNamespace() method to add a
new namespace method to the element.
declareNamespace()
I've mentioned in the first segment of this article that AXIOM
depends on the StAX interface to interact with external world. For
serializing, AXIOM uses the StAX writer interface.
try {
XMLStreamWriter writer =
XMLOutputFactory.newInstance().createXMLStreamWriter(
System.out);
documentElement.serialize(writer, false);
writer.flush();
} catch (XMLStreamException e) {
e.printStackTrace();
}
try {
XMLStreamWriter writer =
XMLOutputFactory.newInstance().createXMLStreamWriter(
System.out);
documentElement.serialize(writer, false);
writer.flush();
} catch (XMLStreamException e) {
e.printStackTrace();
}
Create a writer to any output stream and call the
serialize() method of an OMElement.
Notice the Boolean flag in the serialize method. It has no meaning
in this instance, but would be important if you were building the
object model from an existing resource, like a file, using a
builder. At any given point, you may have not built the whole XML
representation, but you want to serialize the whole thing.
Serializing will go through the whole input stream and will print
it to an output stream. Once accessed, the input stream cannot be
accessed again. So you must have the option to build the object
model while accessing the incoming stream. The true
Boolean flag will ask the builder to build the object model while
serializing, and a false flag will just flush the XML
to the outgoing stream from the incoming stream. This "caching"
concept was introduced earlier.
serialize()
true
false
This is what you will get as the output:
<myPrefix:MyDocumentElement
xmlns:
<myPrefix:SecondElement
myPrefix:Sample Text
</myPrefix:SecondElement>
</myPrefix:MyDocumentElement>
<myPrefix:MyDocumentElement
xmlns:
<myPrefix:SecondElement
myPrefix:Sample Text
</myPrefix:SecondElement>
</myPrefix:MyDocumentElement>
Editor's note: Line breaks and indentation have been added to
the XML to suit the java.net page layout.
You can build AXIOM from any input stream corresponding to
XML. Here, the advantage is that you can start building as soon as
you receive the first bit, without waiting to finish the whole
stream.();
You have to create a StAX reader from the XML file and then pass
that to the StAXOMBuilder with a reference to the
preferred OMFactory. Then you can get the document
element from that.
The best thing here in AXIOM is that you can mix elements that
are partially built with programmatically built elements. AXIOM
will take care of both types of elements.
Let's see how we can retrieve children of an element, providing
specific information like QName. You can use a
OMElement method to retrieve its children, given a
QName. This will provide you with an iterator.
QName
For example, let's say you want to find a children with the
local name "project" and namespace URI.
QName elementQName = new QName("project", "");
Iterator infoIter =
documentElement.getChildrenWithName(elementQName);
while (infoIter.hasNext()) {
OMElement element = (OMElement) infoIter.next();
System.out.println("Matching Element Name = " +
element.getFirstElement().getText());
}
QName elementQName = new QName("project", "");
Iterator infoIter =
documentElement.getChildrenWithName(elementQName);
while (infoIter.hasNext()) {
OMElement element = (OMElement) infoIter.next();
System.out.println("Matching Element Name = " +
element.getFirstElement().getText());
}
Note here that AXIOM is very much concerned about namespaces, so
one has to provide a QName to retrieve a child.
getChildWithName(QName) will return the first matching
node, while getChildrenWithName(QName) will return an
iterator.
getChildWithName(QName)
getChildrenWithName(QName)
The beauty of the parser here is that the iterator returned does
not have information until it is asked for it. The iterator asks the
builder to build if and only if the iterator needs information.
There are lots of enhancements like this within AXIOM, to make it
as lightweight as possible without compromising performance.
One more thing here to note is that we have called
contributor.getFirstElement() to get the first
element. But the method contributor.getFirstChild()
may return a node of type text if there are leading
spaces before the children of contributor element. The
getText() method returns all of the texts that are
direct children of an element, irrespective of location. Those two
features were purposely introduced to preserve the full infoset, as
is required by most security implementations.
contributor.getFirstElement()
contributor.getFirstChild()
text
getText()
Let's say that you want to work on the events level and want to
get events of a particular element.
XMLStreamReader streamReader =
documentElement.getPullParser(true);
XMLStreamReader streamReader =
documentElement.getPullParser(true);
You will be provided with an instance of the StAX stream reader,
which is internally implemented in AXIOM. The Boolean flag is used
to set the cache on or off.
Let's look at how smart AXIOM is when handling a complex
scenario. If the documentElement() is half-built,
AXIOM will generate the StAX events from the in-memory object
model, for the built parts. For the rest, it will get the events
directly from the builder and pass them to the user. In this
process, if the user wants the cache on, the builder will build the
object structure while handing over the events to the user.
documentElement()
If one needs to get SAX events from AXIOM, its just a matter of
writing a converter from StAX events to SAX events, which is very
easy.
This article introduced you to the AXIOM concept for XML
handling and explained the implementation of it found in the Apache
Axis2 project. The AXIOM API was designed to keep convenience and
developer-friendliness in mind. I introduced only some of the
methods in AXIOM, and AXIOM is continuously being improved to
provide a better and better implementation. I strongly recommend
that curious users to have a peek at the current sources found
under the Apache Axis2 project. That said, note that the current
AXIOM implementation will not provide full infoset support--though our community has made progress in making AXIOM a full
infoset-supported object model.
S. W. Eran Chinthaka is a pioneering member of Apache Axis2, AXIOM and
Synapse projects, working fulltime with WSO2 Inc..
View all java.net Articles.
|
http://today.java.net/pub/a/today/2005/05/10/axiom.html
|
crawl-002
|
refinedweb
| 2,121 | 55.84 |
Macros are dangerous because their use resembles that of real functions, but they have different semantics. The inline function-specifier was introduced to the C programming language in the C99 standard. Inline functions should be preferred over macros when they can be used interchangeably. Making a function an inline function suggests that calls to the function be as fast as possible by using, for example, an alternative to the usual function call mechanism, such as inline substitution. (See also PRE31-C. Avoid side effects in arguments to unsafe macros, PRE01-C. Use parentheses within macros around parameter names, and PRE02-C. Macro replacement lists should be parenthesized.)
Inline substitution is not textual substitution, nor does it create a new function. For example, the expansion of a macro used within the body of the function uses the definition it had at the point the function body appeared, not where the function is called; and identifiers refer to the declarations in scope where the body occurs.
Arguably, a decision to inline a function is a low-level optimization detail that the compiler should make without programmer input. The use of inline functions should be evaluated on the basis of (a) how well they are supported by targeted compilers, (b) what (if any) impact they have on the performance characteristics of your system, and (c) portability concerns. Static functions are often as good as inline functions and are supported in C.
Noncompliant Code Example
In this noncompliant code example, the macro
CUBE() has undefined behavior when passed an expression that contains side effects:
#define CUBE(X) ((X) * (X) * (X)) void func(void) { int i = 2; int a = 81 / CUBE(++i); /* ... */ }
For this example, the initialization for
a expands to
int a = 81 / ((++i) * (++i) * (++i));
which is undefined (see EXP30-C. Do not depend on the order of evaluation for side effects).
Compliant Solution
When the macro definition is replaced by an inline function, the side effect is executed only once before the function is called:
inline int cube(int i) { return i * i * i; } void func(void) { int i = 2; int a = 81 / cube(++i); /* ... */ }
Noncompliant Code Example
In this noncompliant code example, the programmer has written a macro called
EXEC_BUMP() to call a specified function and increment a global counter [Dewhurst 2002]. When the expansion of a macro is used within the body of a function, as in this example, identifiers refer to the declarations in scope where the body occurs. As a result, when the macro is called in the
aFunc() function, it inadvertently increments a local counter with the same name as the global variable. Note that this example also violates DCL01-C. Do not reuse variable names in subscopes.
size_t count = 0; #define EXEC_BUMP(func) (func(), ++count) void g(void) { printf("Called g, count = %zu.\n", count); } void aFunc(void) { size_t count = 0; while (count++ < 10) { EXEC_BUMP(g); } }
The result is that invoking
aFunc() (incorrectly) prints out the following line five times:
Called g, count = 0.
Compliant Solution
In this compliant solution, the
EXEC_BUMP() macro is replaced by the inline function
exec_bump(). Invoking
aFunc() now (correctly) prints the value of
count ranging from 0 to 9:
size_t count = 0; void g(void) { printf("Called g, count = %zu.\n", count); } typedef void (*exec_func)(void); inline void exec_bump(exec_func f) { f(); ++count; } void aFunc(void) { size_t count = 0; while (count++ < 10) { exec_bump(g); } }
The use of the inline function binds the identifier
count to the global variable when the function body is compiled. The name cannot be re-bound to a different variable (with the same name) when the function is called.
Noncompliant Code Example
Unlike functions, the execution of macros can interleave. Consequently, two macros that are harmless in isolation can cause undefined behavior when combined in the same expression. In this example,
F() and
G() both increment the global variable
operations, which causes problems when the two macros are used together:
int operations = 0, calls_to_F = 0, calls_to_G = 0; #define F(x) (++operations, ++calls_to_F, 2 * x) #define G(x) (++operations, ++calls_to_G, x + 1) void func(int x) { int y = F(x) + G(x); }
The variable
operations is both read and modified twice in the same expression, so it can receive the wrong value if, for example, the following ordering occurs:
read operations into register 0 read operations into register 1 increment register 0 increment register 1 store register 0 into operations store register 1 into operations
This noncompliant code example also violates EXP30-C. Do not depend on the order of evaluation for side effects.
Compliant Solution
The execution of functions, including inline functions, cannot be interleaved, so problematic orderings are not possible:
int operations = 0, calls_to_F = 0, calls_to_G = 0; inline int f(int x) { ++operations; ++calls_to_F; return 2 * x; } inline int g(int x) { ++operations; ++calls_to_G; return x + 1; } void func(int x) { int y = f(x) + g(x); }
Platform-Specific Details
GNU C (and some other compilers) supported inline functions before they were added to the C Standard and, as a result, have significantly different semantics. Richard Kettlewell provides a good explanation of differences between the C99 and GNU C rules [Kettlewell 2003].
Exceptions
PRE00-C-EX1: Macros can be used to implement local functions (repetitive blocks of code that have access to automatic variables from the enclosing scope) that cannot be achieved with inline functions.
PRE00-C-EX2: Macros can be used for concatenating tokens or performing stringification. For example,
enum Color { Color_Red, Color_Green, Color_Blue }; static const struct { enum Color color; const char *name; } colors[] = { #define COLOR(color) { Color_ ## color, #color } COLOR(Red), COLOR(Green), COLOR(Blue) };
calculates only one of the two expressions depending on the selector's value. See PRE05-C. Understand macro replacement when concatenating tokens or performing stringification for more information.
PRE00-C-EX3: Macros can be used to yield a compile-time constant. This is not always possible using inline functions, as shown by the following example:
#define ADD_M(a, b) ((a) + (b)) static inline int add_f(int a, int b) { return a + b; }
In this example, the
ADD_M(3,4) macro invocation yields a constant expression, but the
add_f(3,4) function invocation does not.
PRE00-C-EX4: Macros can be used to implement type-generic functions that cannot be implemented in the C language without the aid of a mechanism such as C++ templates.
An example of the use of function-like macros to create type-generic functions is shown in MEM02-C. Immediately cast the result of a memory allocation function call into a pointer to the allocated type.
Type-generic macros may also be used, for example, to swap two variables of any type, provided they are of the same type.
PRE00-C-EX5: Macro parameters exhibit call-by-name semantics, whereas functions are call by value. Macros must be used in cases where call-by-name semantics are required.
Risk Assessment
Improper use of macros may result in undefined behavior.
Automated Detection
Related Vulnerabilities
Search for vulnerabilities resulting from the violation of this rule on the CERT website.
14 Comments
David Svoboda
C99, section 6.5.15 "The Conditional Operator", says:
That seems to suggest that PRE00-EX2 is unnecessary, since you don't need a macro to use 'lazy evaluation' with the conditional operator.
Martin Sebor
I'm also not sure I understand the point of PRE00-EX2. Is there a better example?
In my experience, the two most compelling use cases in favor of macros are:
__FILE__,
__LINE__, and
__func__
Robert Seacord (Manager)
I replaced the existing exception with your token concatenation and/or stringification example.
I hesitated for your second example which uses implicit expansion of _FILE, __LINE, and __func_ but also defines a function like macro TRACE().
Doesn't this represent yet another exception to this guideline?
David Svoboda
Yes. Specifically the _FILE_ and _LINE_ macros (and others?) provide info you can't get properly from embedding them in a function.
Martin Sebor
I missed your and Robert's responses to my comment.
Yes, my goal behind showing the
TRACE()macro was to illustrate an exception to this guideline. However, I'm not sure I see the relationship between __FILE__, __LINE__ and this guideline since it focuses on function-like macros. That said, I think a guideline advising against defining macros in general, i.e., including object-like macros, would be appropriate, but I cannot find one. If no one objects I'd like to go ahead and add one. Or rather, extend this one to both kinds of macros.
David Svoboda
If you have a good 'avoid writing object-like macros' go ahead & suggest it. This rule is big enough and covers the function-like- macro space; I'd ranter not complicate it further.
Dhruv Mohindra
The return type in PRE00-EX3 appears to be missing.
Martin Sebor
Are there any objections to extending this guideline to recommend against all macros, not just function-like macros, and renaming it to: Prefer typed constants and functions to macros?
The rationale should be obvious: object-like macros are subject to type safety problems, cause namespace pollution, and may cause code bloat (due to duplication of string literals, for example).
Robert Seacord (Manager)
We have a number of guidelines which when taken together say this.
DCL06-C isn't as strong as "don't use object-like macros" and in fact contains a compliant solution using object-like macros.
I'm a little worried that such a guideline might be too strong for C language. Tom frequently comments at WG14 meetings that "we're not C+, we like macros" which I think may represent a slightly different mindset among C programmers than C+ programmers. If someone would to write a checker for such a guideline it would definitely find alot of true positives (as would a checker for finding function-like macros). It might be that you could just strengthen DCL06-C to suggest a preference order among the various mechanisms defining symbolic constants and clearly identify the problems with object-like macros. I think there are good arguments for using enum constants over const-qualified Objects for integer constants as well (don't consume memory, you can't take their address).
Martin Sebor
I'm actually with Tom on this one. Despite everyone's best efforts, the unfortunate reality is that writing portable programs in C and especially in C++ would be virtually impossible without macros and I suspect a checker would have plenty of macros of both kinds to complain about. (Google Code Search returns about 41,000 records of object-like macros in C code and 30,000 occurrences of function-like macros).
That being said, it seems to me that a function-like macro that avoids the common pitfalls (i.e., PRE01-C, PRE02-C, PRE31-C, etc.) is no more dangerous than an object-like macro. Both run the risk of colliding with names in other scopes, but with care, both can be used safely. Given that, the rationale for having a guideline advising against writing one kind seems just as good for having a guideline against the other.
Furthermore, as evidenced by the number of exceptions to this guideline, there are a good number of use cases involving function-like macros that cannot be adequately handled by other means (inline functions). On the other hand, outside of
#ifdirectives I cannot think of any use cases involving object-like macros that could not be equivalently handled by using static constants of the appropriate type instead. In my view, this makes the argument against object-like macros even more compelling than the one against function-like ones.
Konrad Borowski
inlineis actually wrong. It's the C99 keyword that actually means the definition in header file is provided for inlining (but the compiler doesn't have to inline it, in fact some compilers ignore this keyword entirely). Inline functions are relatively tricky in C99 - the
inlinekeyword should be specified in the header, but the actual code also should have definition of it without the keyword (code duplication, but I doubt anyone cares). Or use
static inlineto actually make function inline (without actually compiling it to object code).
This is not some random issue, forgetting that
inlineused by itself doesn't actually define the function causes problems in non-gcc compilers (like clang).
Aaron Ballman
The usage of
inlinein this recommendation is acceptable because the examples place the inline on the function definition, not the function prototype. All of the examples show functions with external linkage due to being at file scope, but also demonstrate usages within the same translation unit. As such, they are a valid inline definition. I am not certain what problems you are seeing with compilers such as Clang, but my testing of these examples demonstrated correct behavior (so perhaps it's a version-specific bug with the compiler, or perhaps your tests differ from mine).
Konrad Borowski
sharingli
inline always misused
|
https://wiki.sei.cmu.edu/confluence/display/c/PRE00-C.+Prefer+inline+or+static+functions+to+function-like+macros?focusedCommentId=88035505
|
CC-MAIN-2020-10
|
refinedweb
| 2,154 | 50.46 |
A question I’ve seen come up from time to time is “Why doesn’t Lazy<T> support asynchronous initialization?” It’s a fair question. After all, if you’re using Lazy<T> because you have an expensive resource you want to delay the creation of until it’s absolutely needed, it’s fair to reason that the creation of that resource could also be time-consuming, and thus you don’t necessarily want to block the requesting thread while the resource is being initialized (of course, a Lazy<T> may also be used not because the T takes a long time to create, but because its hefty from a resource consumption perspective). This would be particularly true if the value factory for the Lazy<T> does I/O in order to initialize the data, such as downloading from a remote web site.
The answer as to why Lazy<T> doesn’t have built-in asynchronous support iis that Lazy<T> is all about caching a value and synchronizing multiple threads attempting to get at that cached value, whereas we have another type in the .NET Framework focused on representing an asynchronous operation and making its result available in the future: Task<T>. Rather than building asynchronous semantics into Lazy<T>, you can instead combine the power of Lazy<T> and Task<T> to get the best of both types!
Let’s take just a few lines of code to put the two together:
public class AsyncLazy<T> : Lazy<Task<T>>
{
public AsyncLazy(Func<T> valueFactory) :
base(() => Task.Factory.StartNew(valueFactory)) { }
public AsyncLazy(Func<Task<T>> taskFactory) :
base(() => Task.Factory.StartNew(() => taskFactory()).Unwrap()) { }
}
Here we have a new AsyncLazy<T> that derives from Lazy<Task<T>> and provides two constructors. Each of the constructors takes a function from the caller, just as does Lazy<T>. The first constructor, in fact, takes the same Func<T> that Lazy<T>. Instead of passing that Func<T> directly down to the base constructor, however, we instead pass down a new Func<Task<T>> which simply uses StartNew to run the user-provided Func<T>. The second constructor is a bit more fancy. Rather than taking a Func<T>, it takes a Func<Task<T>>. With this function, we have two good options for how to deal with it. The first is simply to pass the function straight down to the base constructor, e.g.
public AsyncLazy(Func<Task<T>> taskFactory) : base(taskFactory) { }
That option works, but it means that when a user accesses the Value property of this instance, the taskFactory delegate will be invoked synchronously. That could be perfectly reasonable if the taskFactory delegate does very little work before returning the task instance. If, however, the taskFactory delegate does any non-negligable work, a call to Value would block until the call to taskFactory completes. To cover that case, the second approach is to run the taskFactory using Task.Factory.StartNew, i.e. to run the delegate itself asynchronously, just as with the first constructor, even though this delegate already returns a Task<T>. Of course, now StartNew will be returning a Task<Task<T>>, so we use the Unwrap method in .NET 4 to convert the Task<Task<T>> into a Task<T>, and that’s what’s passed down the base type.
With the implementation out of the way, we can now observe the power this holds, especially when mixed with the new language support in C# and Visual Basic for working with tasks asynchronously. As a reminder, Lazy<T> exposes a Value property of type T. The first time Value is accesses, the valueFactory delegate is invoked to get that T value, which is returned from Value on this and all subsequent calls to Value. By default, if multiple threads access Value concurrently, the first thread to get to Value will cause the delegate to be invoked, and all other threads will block until the T value has been computed. In the case of AsyncLazy, the T is actually a Task<T>.
Let’s say in our program we have one of these AsyncLazy instances:
static string LoadString() { … }
static AsyncLazy<string> m_data = new AsyncLazy<string>(LoadString);
Now elsewhere in my code I need the result of accessing LoadString. The work to load the string could take some time, and I don’t want to block the accessing thread waiting until the data has been loaded. We can thus access m_data.Value to get the Task<string> which will complete with the loaded string data when it’s available. Since this is a standard Task<string>, I have all of the facilities available to me that Task<string> provides, including the ability to synchronously wait for the data (e.g. Wait, Result), or to asynchronously be notified when the data is available (e.g. ContinueWith). With the new language support, we also have “await”. Thus, we can write an asynchronous method that does:
string data = await m_data.Value;
A few interesting things to note about this. First, the Value property will return very quickly, as all the first access to Value does is run the delegate which just launches a task and returns it, and all subsequent accesses will just return that cached task. Thus, we quickly get back a Task<string> which we can await, allowing the current thread to be used for other work while the data is being loaded. Second, and subtle, this operation is very efficient once the data has been loaded. Task<string> stores the result once it’s available, and accessing its Result property (which Task<T>’s support for await does) just returns that stored value. Further, the code generated by await makes a call into the task’s TaskAwaiter as returned by the task’s GetAwaiter method. The TaskAwaiter value returned by GetAwaiter has a BeginAwait method on it, which is called by the compiler-generated code for the await expression. BeginAwait first checks whether the task has already completed, and if it is, it simply returns false from BeginAwait, which tells the compiler-generated code that there’s no need to do anything fancy for asynchronicity, and rather than the code can just continue executing. In other words, once the lazy value is available, the “await” in effect just goes away.
With our second constructor on the AsyncLazy<T> type, we can also pass an asynchronous method as the taskFactory delegate. Remember that a method marked with the new async keyword can return either void, Task, or Task<T>, and just as an anonymous method that returns T can be treated as a Func<T>, so too can an anonymous method that returns Task<T> be treated as a Func<Task<T>>, which just so happens to be the same type as taskFactory. Thus, we can write code like the following:
static AsyncLazy<string> m_data = new AsyncLazy<string>(async delegate
{
WebClient client = new WebClient();
return (await client.DownloadStringTaskAsync(someUrl)).ToUpper();
});
Here, not only is a consumer of the m_data instance not going to block a thread when they “await m_data.Value”, but the initialization routine will also not block any threads while waiting for the data to be asynchronously downloaded from the Web site.
One last thought on the subject. In a previous post, we talked about how the C# and Visual Basic compilers allow you to await anything that exposes the right pattern of methods. If you don’t like the thought of having to type “.Value” every time you access your AsyncLazy<T> instance, well then you can simply augment AsyncLazy<T> with a one-line GetAwaiter method:
public class AsyncLazy<T> : Lazy<Task<T>>
{
public AsyncLazy(Func<T> valueFactory) :
base(() => Task.Factory.StartNew(valueFactory)) { }
public AsyncLazy(Func<Task<T>> taskFactory) :
base(() => Task.Factory.StartNew(() => taskFactory()).Unwrap()) { }
public TaskAwaiter<T> GetAwaiter() { return Value.GetAwaiter(); }
}
Now, for the previous m_data example, instead of writing:
string result = await m_data.Value;
we can simply write:
string result = await m_data;
and it’ll have the same effect.
Enjoy!
Join the conversationAdd Comment
I think plastering everything with GetAwaiter is not very clean. It is like ruby "5.times { |i| puts i }". The times method does not logically belong to Int32 at all.
This thought actually came to mind in the last article "await anything". Does it seem right to you to await … a TimeSpan? This would only be appropriate in a very specific scenario where you have to await a TimeSpan 100th of times all over your code. The disadvantage is that it is one additional concept that people have to learn, but unnecessarily so. What is wrong with await Task.Delay()? It is like operator overloading, but misused.
Hi Tobi-
I'm not advocating that everything have a GetAwaiter method. I'm just highlighting that and how it can be done. It's very similar to how you can add a GetEnumerator method to anything, and there, too, it shouldn't be done willy nilly. As I state at the end of the "await anything;" post, just because you can doesn't mean you should: "Just keep in mind that while there are plenty of 'cool' things you can do, code readability and maintainability is really important, so make sure that the coolness isn’t trumped by lack of clarity about the code’s meaning."
I was going to make an F# version of this class, but then I realized that language features make it unnecessary. "AsyncLazy<T> foo = new AsyncLazy<T>(() => my code)" is actually more typing than simply, "let foo = lazy(async{ my code })"
Hi Joel-
Thanks. The definition of the class was simply to help explore the topic. The same thing is of course possible in other languages, such as using C# and Visual Basic's new async functionality:
var foo = new Lazy<Task<T>>(async delegate { /* my code */ });
Then you're just dealing with small differences in typing due to syntax.
Here is another implementation of async lazy
16handles.wordpress.com/…/asynchronous-lazy-initialization
I'm just wandering why the second constructor overload is:
base(() => Task.Factory.StartNew(() => taskFactory()).Unwrap())
Instead of:
base(taskFactory)
@Michael: That's discussed in the post… search the text for "With this function, we have two good options for how to deal with it", as that begins the explanation. I hope that helps.
Hi,
shouldn't the line
public TaskAwaiter GetAwaiter() { return Value.GetAwaiter(); }
be
public TaskAwaiter<T> GetAwaiter() { return Value.GetAwaiter(); }
?
@Takeshi: Yup, thanks for pointing out the typo… fixed.
Is there a big reason why Task.Factory.StartNew is used vs. Task.Run ? Is it due to scheduler stuff?
@Eric: Simply that this post was written before Task.Run existed. 😉
Two questions:
1) What if I'm using a Lazy in ASP.NET and want to have an asynchronous initialization method that is guaranteed to run on the same thread?
2) AsyncLazy won't work with LazyThreadSafetyMode.PublicationOnly, right? MSDN:
"If the initialization method throws an exception on any thread, the exception is propagated out of the Lazy<T>.Value property on that thread. The exception is not cached. The value of the IsValueCreated property remains false, and subsequent calls to the Value property, either by the thread where the exception was thrown or by other threads, cause the initialization method to run again."
But in the cast of AsyncLazy, and exception isn't thrown, just captured by the returned Task, so the initialization method is never re-run.
@Eric Johnson:
#1. I'm not quite sure what you're asking… you want the operation to be asynchronous, presumably because it's doing async I/O somewhere, but you want it to run on a particular thread? You mean you want the CPU-bound portions of the operation to run on a particular thread? How come? Regardless, this would be pretty difficult to achieve; if you're running on a thread pool, the whole idea is that any thread from the pool can be used to satisfy the need for a thread.
#2. "so the initialization method is never re-run"… right.
|
https://blogs.msdn.microsoft.com/pfxteam/2011/01/15/asynclazyt/
|
CC-MAIN-2016-40
|
refinedweb
| 2,011 | 61.56 |
Introduction: Pi - the News Reader
This is a project based on Raspberry Pi. It is a 'bot' which goes to the internet to fetch news headlines and reads them for you. It also uses a voice recognition system to interact with you.
Step 1: See the Project in Action
Step 2: Complete Tutorial
News Site -
Voicecommand Tutorials:...
news.py (for indentation of the for loops, look at my code in the video)
*******************************************************************************************
import subprocess
import requests
from bs4 import BeautifulSoup
import textwrap
head = 'mpg123 -q ' tail = ' &'
url = ""
r = requests.get(url)
soup = BeautifulSoup(r.content)
g_data = soup.find_all("div",{"class":"nstory_intro"})
for item in g_data:
shorts = textwrap.wrap(item.text, 100)
for sentence in shorts:
sendthis = sentence.join(['"', '"'])
print(head + sendthis + tail)
print subprocess.check_output (head + sendthis + tail, shell=True)
Recommendations
We have a be nice policy.
Please be positive and constructive.
|
http://www.instructables.com/id/Pi-The-news-reader/
|
CC-MAIN-2018-09
|
refinedweb
| 142 | 60.82 |
note jimt <p>I'm coming in a bit late to the party, but I think I've come up with an elegant and fast solution. I was tinkering around with the w() function from [id://580083] to see about different approaches. (that function, in case you all are curious will determine for a set of natural numbers N and a sum S, is there any subset of numbers in N that will add up to S). It's highly recursive and extremely golfed and really powerful, so be careful if you try to read it.</p> <p>Anyway, my original approach to it was to generate powersets and sum them, but that gets out of control ridiculously fast with memory requirements. Yesterday, [node://Limbic~Region] msg'ed me and said he may monkey around with optimizing it, and I, hypercompetitive asshole that I am, started investigating it as well. While in process, I came up with a nifty powerset generator (that I'll probably put over in snippets), and modified it to solve this problem here.</p> <p>Constraints on my version - it's all bitwise and binary, so it only handles sets up to 32 elements (or 64 if you're lucky), so it would require modification to handle larger sets. Also, it doesn't try to guess in advance which powersets it should and should not produce. It's based upon an iterator that generates sets as it goes along. If a set matches the condition, you should flag it so it knows not to bother generating any of the powersets of that subset.</p> <p>It uses the simple concept of counting in binary to generate powersets, and this one starts at the high set (all elements in) and counts its way down. This way it should hit most (all?) "big" sets before hitting smaller subsets. I don't know if I can actually prove that's the case, but I <i>think</i> it is.</p> <p>Since we're just counting, each set has a numeric index between 0 and 2<sup>n</sup> - 1. The assumption is, as we're going along, you can flag a set's as matching the condition. Then, any subsets of that set will not be generated.</p> <p>First, the code.</p> <code> # returns _2_ closures to generate certain powersets sub limbic_power_generator { my $set = shift; #we start with the original set and count down to the null set my $set_idx = 2 ** @$set; #these are the set indexes we should skip my %skippers = (); # our first closure generates subsets my $generator = sub { --; #boolean to see if we should break out of this loop my $should_skip = 0; # here's the slick binary logic. Iterate over each superset we # should skip. if our current set_idx & (binary and) the skip set is equal # to the set_idx we're at, then we know that we have a subset of that # skip set. So we skip this set. $should_skip is set to 1, which means # we'll stay in our while loop and decrement down to the next set. foreach my $skip (keys %skippers) { if (($skip & $set_idx) == $set_idx) { $should_skip = 1; last; } } #bow out if this set is NOT a subset of any set we're skipping last unless $should_skip; #bow out of the function completely with the null set if we've hit 0. return () unless $set_idx; } # Now we convert our set_idx to binary. Each bit stores whether the element # is in this subset. For example, set_idx 11 would be 1011, so we keep # elements 0, 2, and 3. my @in_set = reverse split //, unpack("B*", pack("N", $set_idx)); # now we return a list. The first element is an arrayref which is the actual # subset we generated, the second is our set_idx. # we reverse it to make our lives easier, so don't be surprised when the # counting gets out of order. Order is irrelevant in this case, anyway. return ([map { $set->[$_] } grep { $in_set[$_] } (0..$#$set)], $set_idx); }; # our second closure allows you to add sets to skip my $skipper = sub { $skippers{$_[0]}++ }; # return both of our closures. return ($generator, $skipper) } #we'll use Limbic~Region's example set. my $limbic_set = [qw(A B C D)]; #create our iterator and skipper my ($limbic_iterator, $limbic_skipper) = limbic_power_generator($limbic_set); #and start cruising over our powersets. while ( my ($set, $idx) = $limbic_iterator->() ) { #fancy crap to get it to print out properly. my $display = {map {$_ => 1} @$set}; printf("%2s%2s%2s%2s (%d)\n", (map {$display->{$_} ? $_ : ' '} @$limbic_set), $idx); # now here's the trick, something here will determine a condition whether or # not this subset matches the search parameters. Let's say, for sake of # argument, that set_idx 7 (ABC) matches. We'll just set it here. $limbic_skipper->(7); # that will prevent sets (AB, AC, A, BC, B, C) from printing out. } </code> <p>The slick binary logic deserves explanation. let's assume that set ABC (1110) is a valid set that meets the condition. Set BC (0110) may meet it. To see if BC is a subset of ABC, just binary and them together. You should end up with the set you're testing (1110 & 0110 = 0110). If you do, it's a subset and you can skip. If not, it's not a subset, so continue with it.</p> <p>To try and help illustrate, here's a graphical representation of the order in which the powersets get generated. Each row is the order in which the sets are generated (ABCD first, ABC second, ABD third,etc). Each column represents a subset (excepting that everything shoul be under ABCD). So you can see that ABC is generated (idx 14), and if it matches the condition, then it will skip over everything else in that column (AB, AC, A, BC, B, C).</p> <p>Note that the sets are repeated under each bucket in which they would match. Technically, there would be additional columns off to set side for (AB), which A and B underneath it, but the diagram was getting busy as is. Note that each subset is only generated once (A) is not created 4x, it's just repeated in each column that has it as a subset.</p> <p><b>Whoops-</b> These subsets are actually backwards relative to how they're actually generated (its ABCD, BCD; not ABC, ABC) because of the reversal of the binary digits. I didn't realize that until after I'd spent the time building up the spiffy diagram and didn't want to re-create it with the proper order. The concept is the same, just the sets are produced in a slightly different order.</p> <code> ABCD| ABC |ABC | AB D| |AB D AB |AB |AB A CD| | |A CD A C |A C | |A C A D| |A D| A |A |A |A BCD| | | | BCD BC | BC | | | BC B D| | B D| | B D B | B | B | | B CD| | | CD| CD C | C | | C | C D| | D| D| D () </code> <p>And there you have it. It's lightning fast, and memory efficient. For each subset that matches, you only need to store a single integer to skip over generation of its powerset. I guess the algorithm is O(n<sup>2</sup>) (or is it O(n log n)? I always goof those up), but that makes it sound scarier than it is - you need to iterate over each set index to see if you should skip it, but at each spot you're doing m bitwise ands for each set you've already determined you should skip. So say you know you're skipping 5 sets, that's at most 5 bitwise ands for each possible set index. Should be pretty cheap.</p> 576101 576101
|
http://www.perlmonks.org/?displaytype=xml;node_id=580599
|
CC-MAIN-2016-30
|
refinedweb
| 1,293 | 70.23 |
Closed Bug 783958 Opened 7 years ago Closed 6 years ago
b2g email client needs its HTML security implementation reviewed
Categories
(Firefox OS Graveyard :: General, defect)
Tracking
(Not tracked)
People
(Reporter: asuth, Assigned: freddyb)
References
Details
Attachments
(1 file)
The e-mail client may receive HTML e-mails that are full of nefarious badness. We have implemented a defense-in-depth strategy that is believed to be safe. It needs to be reviewed. Our strategy is derived from this discussion on the webapi list: With particular focus on Henri Sivonen's response: The key ideas are that: sandboxed iframes are great but insufficient because they currently have no means of preventing information leakage from displaying images, fetching external resources, or prefetching external resources. (Content policies protect Thunderbird from this.) We could push for a standardized thing along these lines. The pipeline is generally: 1) HTML is sanitized using bleach.js by using document.implementation.createHTMLDocumet to create a document "loaded as data" and then crammed in using innerHTML and traversing the DOM tree and removing everything that's not covered by a whitelist covering tags, attributes (both global and per-tag), and CSS style rules (based on whitelisted properties.) Notes: - Our whitelist does not include <script> tags or any on* attributes. - href's are not whitelisted, but instead a helper function transfers the values (iff they are http/https currently) onto an inert attribute we made up. - src's are not whitelisted, but instead a helper function transfers: a) http/https protocol references onto an external image attribute we made up, b) cid protocol references onto an embedded image attribute we made up, c) discards everything else. - We currently don't whitelist any CSS stuff that could include a url() reference (including shortcuts like 'background'), although we'd want to support this along similar lines to our handling of sources. 2) The sanitized HTML is inserted into an iframe with sandbox="allow-same-origin" set on it. We specify "allow-same-origin" because we need to be able to reach into the DOM tree to perform fix-ups. Since "allow-scripts" is not set, this is believed safe. Sandbox flags are being implemented on Bug 341604 and have not yet landed. We are currently populating the iframe using iframe.contentDocument.open/write/close after setting the sandbox attribute. The spec is clear that a navigation event must take place after the sandbox flag is set for the protection to take place. It's not 100% clear that this covers our current mechanism. Additionally, our app should be protected by CSP that prevents all scripts except from 'self' which should carry over to our same-origin iframe. If we end up implementing the CSP sandbox directive on Bug 671389 that should also constrain the iframe (and potentially avoid any navigation semantics issues). Note that I do not believe the CSP stuff has happened for our app yet. 3) If the user requests embedded images or external images to be displayed, we traverse the DOM tree and transfer the contents of our inert made-up attributes onto the "src" attributes of images as appropriate. For the embedded image case, we map the cid reference to the Blob we stored the image and then use window.URL.createObjectURL. The tentative plan for clicking on links is to add an event listener for clicks and see if the user clicked on an 'a' and then consult the inert place we stashed the href on and then prompt the user with a "do you want to browse to [the actual link you clicked on]". This has not been UX approved yet, but I think is a reasonable way to a) help deal with potential phishing issues and our lack of a display-the-URL-on-hover implementation, and b) provide confirmation the user actually wants to both trigger the browser and for the specific URL, especially since it is easy to mis-interpret a scroll or just fat-finger the wrong link. ## Implementation Details / Source ## - bleach.js fork used: - bleach.js' actual JS logic: - bleach.js' unit tests (which use a different whitelist): - our HTML sanitization whitelist and logic with lots of comments: - our email lib tests related to HTML and sanitization: - our iframe creation logic, also with lots of comments:
Note: This implementation has already landed in gaia and is hooked-up to IMAP accounts, but not ActiveSync accounts. Because MozTCPSocket has not landed, a custom b2g build is currently required in order to be exposed to the implementation or any risks it might have.
Assignee: nobody → ptheriault
Thanks for heaps of info Andrew. I'll digest and get back to you asap.? For example "allow-same-origin-in" and "allow-same-origin-out", or an up/down or inner/outer suffix to the same effect.
. Do you know if we are giving anything up by using "allow-same-origin" (but not allowing script)? Given the inert nature of the document, it seems like the primary risk would be that the HTTP requests related to (remote) image fetches could leak some type of information, such as the referrer. (Link clicks are not currently implemented, but may be dispatched to the browser in such a way that no referrer is generated.) And indeed, when I just ran b2g-desktop with gaia built with DEBUG=1 (so served off of http:// instead of as a packaged zip), the referrer did show up in the logs. However, when I ran without DEBUG and therefore as a packaged app, no referrer goes over the wire to the webserver. It's not clear if the latter behavior is intended or a side effect of the different protocol causing it to be filtered out..
(In reply to Andrew Sutherland (:asuth) from comment #4) > . Yes this was the intention. Apps will be on the web and there is often a need for them to be more privileged than content they frame. Perhaps some future enhancements to <iframe mozbrowser> would make it usable by the email app. It seems that <iframe mozbrowser> may support injection by the parent in future as this would be handy for other apps. All of the restrictions the email client needs would be useful options to the iframe mozbrowser or sandbox so perhaps someday this could be used and simplify the email client. > Do you know if we are giving anything up by using "allow-same-origin" (but > not allowing script)? It seems ok because the HTML has been sanitized so well. ... >. It would seem more appropriate for the User-Agent to indicate the application rather than for it to be exposed in the 'referer', if this is even an issue. There is a need for an app and/or mozbrowser to be able to change the user-agent string, to limit fingerprinting, and perhaps there is a case to be made for the email client app to modify the default user agent too.
Apologies for the delay in getting through this, Andrew. I am working on this as a priority at the moment.
Should have commented on this bug a long time ago: I finished reviewing this code, and didn't find any issues. I performed limited testing by using a modified version of the email app, and injecting malicious content but didn't find any issues. Given the complexity of the problem I think it would be good to develop a custom fuzzer to exercise the sanitization list thoroughly, but I havent had a chance to do this.?
Flags: needinfo?(ptheriault)
Mozilla's Thimble uses slowparse by Atul:
Thanks, Josh! slowparse looks pretty sweet in terms of implementation simplicity, being webby as opposed to requiring a bunch of node shims, having tests, etc. Atul, is there any reason we would want to not use slowparse?
(In reply to Andrew Sutherland (:asuth) from comment #8) >? I'm not aware of any pre-existing solutions. What is the timeline for this change?
Flags: needinfo?(ptheriault)
(In reply to Paul Theriault [:pauljt] from comment #11) > I'm not aware of any pre-existing solutions. What is the timeline for this > change? Migrating the e-mail back-end to live in a worker (bug 814257) is part of the push to make the e-mail app be more responsive/appear faster/etc. I think the dream is that we would uplift all of this stuff to v1.0.1 in the extremely short term (this week/ASAP/unreasonably soon/etc.), but a v1.1 uplift may be more realistic depending on what release management thinks of the risk profile over the various massive changes going on. My sincere apologies for creating this situation by not realizing when I implemented the sanitizer that it was going to be a potentially major problem/change for migrating to a worker instead of a background page. I was betting pretty hard on the background page thing being an option or our workers drastically improving.
Is there any way we could keep the sanitizer in main thread, in addition to the worker ( can you still get the performance increase)? I am concerned about using a new parser - any differences in behavior between the worker parser and the parser in the browser are potential security vulnerabilities. As an aside, I am aware of at least a few security issues on webmaker, not sure if they relate specifically to the parser or not though.
Hi Asuth and b2g folks! So, while I would be totally flattered if you used slowparse, there are a number of things that might not be awesome for your needs, as the parser was created primarily to make HTML easier to learn and manipulate--not to sanitize. Among the potential drawbacks are: * Slowparse uses the DOM API to create an actual DOM tree as it parses through the document. This part of the code is abstracted away into something called a "DOM Builder" [1], so it's possible to make an alternative implementation that doesn't use a page's DOM API directly (e.g. for use in a web worker). Currently, the direct use of the DOM API results in a few bugs [2], although none of them are security vulnerabilities. * Slowparse has never been security reviewed; it also doesn't actually sanitize HTML. A separate extension to Slowparse called "forbidJS" [3] can be used to report errors for the most common uses of JS via script tags, javascript URLs, and event-handling attributes, but these errors are only intended to let users know as early as possible that their JS won't work when published: the JS isn't actually stripped from the HTML--that's done on the server-side, via Bleach. * Slowparse isn't actually a fully-featured HTML5 parser. There are a number of HTML5 "shortcuts" that it's oblivious to [4]. All that said, patches are welcome. I also think that the Popcorn team has been investigating ways to sanitize HTML using JavaScript, at the very least via nodejs, so you might want to consult with them too. [1] [2] [3] [4]
As a status update, Vivien (:vingtetun) has been been porting a worker-thread SAX parser and adapting our bleach.js implementation to use that.
As an update, we had an off-thread discussion where many people thought we should surface a WebAPI for this stuff, but not pure JS implementations were immediately available. Accordingly, Vivien went with using John Resig's "Pure Javascript HTML Parser" available at ejohn.org/blog/pure-javascript-html-parser/. It was only labeled MPL licensed (although was derived from a tri-licensed-including-Apache 2.0 upstream), but I asked John and he kindly has allowed us to use it under Apache 2.0 which is our preferred license for Gaia. There were some potential security bugs in the implementation that I believe I've resolved: - The HTML parser seemed to be under the incorrect impression that you could escape double-quotes with backslashes inside attributes. This was a problem because the sanitizer was up-converting single-quoted attributes and unquoted attributes to become double-quoted attributes. The up-conversion seems reasonable to me, although I don't strongly care, so I've fixed the code to properly escape attributes and added some unit tests to our bleach.js. - Greedy .* match was used for script and style tags so if there was more than one script/style tag in a document, its characters would include everything in between. - The dynamically built regexp for script/style was unsafely case sensitive, so the same thing could happen. I've also made the parser/sanitizer strip and ignore namespace prefixes on tags for the time being. This was done for consistency with the DOM-based implementation (which ignored 'prefix' and 'namespaceURI') rather than out of any security concern. Since we operate on a white-list, namespacing would just cause valid things to become invalid. Although if you white-list 'xmlns' as an attribute, things would become more exciting, including causing CDATA parsing to start needing to happen, which the parser does not support. I still have a bit more to do on cleaning up the parser/sanitizer. I'll ping here again when I am done hacking on it and review/audit can begin. I have created a pull request at which will be what people get pointed at.
Okay, the HTML sanitizer passes both its bleach.js tests and our gaia-email-libs-and-more tests. Paul, the pull request is here if you could take a look or find someone who can take a look: Barring major complications, this will likely land on gaia/master early next week where it will bake for a little before being uplifted to v1.0.1 and v1.1.
Flags: needinfo?(ptheriault)
Thanks for the update Andrew. I'll take a look. I am concerned about the parser quirks, but I will have a look at in the context of other mitigating controls.
Flags: needinfo?(ptheriault)
I've been able to focus more on the CSS parsing side of the house now, and we are going to need to do something more sophisticated than the naive '}', '{', ';' splitting Vivien did as an initial stop-gap implementation. (Which is not really a surprise; I should have called that out in my previous statement that I did not think we were good to go with CSS.) Specifically, this CSS string is able to cause us to pass-through background-image which is undesirable for information leakage purposes: body { /* } */ background-image: url(); /* { color: red; */ } Given that CSS explicitly calls for error recovery that involves parsing matched characters and escapes, I think continuing with the regexp implementation is a bad idea. It looks like the best option is Tab Atkins' "Standards-Based CSS Parser" at and which he introduces in a blog post at. Tab is the editor of the CSS3 spec, and the parser is designed to match the spec at the potential cost of speed/performance. Since Gecko ideally conforms to the spec, this seems like the best way to ensure that what the sanitizer sees is what the Gecko CSS parser would see if it read the same thing. Note that the implementation is currently very limited in terms of unit tests, so we would be relying on the correctness of its translation of the spec at the current time. Because the parser does not include integrated stringification, we would likely want to run the lexer in location-storing mode and slightly modify the parser to operate in a somewhat streaming fashion that allows us to emit or not emit the verbatim text provided as appropriate. The long-term performance plan would be to build up some serious nefarious test coverage before we would consider moving to a parser that might in fact deviate from spec. The other best option would appear to be the caja CSS parser: caja is intended to do things like this, and even has a unit test case for error recovery, but does not have overwhelming coverage at the unit level, at least: There are a number of other pure JS parsers out there too. I have done a brief skim of the readme's and the unit test directories and none of them jump out at me as advertising any specific levels of spec compliance or having specific error recovery unit tests, but it was indeed a very brief skim!
As an update, we went with with the CSS3 syntax spec derived implementation at. This was landed very late on 4/3 in bug 814257. As per previous discussion with :pauljt where I believe consensus was reached on this, we believe the protection provided by CSP and the iframe sandbox that both prevent the execution of JS in the iframe context are keeping us safe from malicious code. The fallout of a failure of the sanitizer is expected to be limited to information leakage that a message is being displayed, namely from URI references that would be actively fetched (images) or pre-fetched (appropriately marked links, DNS?). We continue to err on the side of removing HTML attributes and CSS declarations that *might* contain such references. Bug 857914 has been filed on not erring so much about that.
Assignee: ptheriault → fbraun
The current setup is very cumbersome to setup. htmlchew.js doesn't really work as well in a browser as it's supposed to..where would I get define() for example? :/
This part of the review is done. Please address bug 899070 for a secreview+ :)
I am attaching the test files I produced during my tests. Feel free to play with. :)
Status: NEW → RESOLVED
Closed: 6 years ago
Resolution: --- → FIXED
|
https://bugzilla.mozilla.org/show_bug.cgi?id=783958
|
CC-MAIN-2019-39
|
refinedweb
| 2,951 | 59.23 |
I am going to tell you a story about an issue that brought me a rather painful debugging session, and the lessons that can be learned from it.
A few years back I was restructuring the libraries of a larger project. Restructuring means I shoved around some compilation units that were in different libs before and put them in the same lib, because they belonged together. Compilation and linking worked without problems, and since I had not touched any code, I was very sure that everything should work as before. A basic functionality test suite did not show any failures, so I checked everything in and went home.
The end.
Not quite.
The next morning I started the application and it almost immediately crashed. I started the debugger to find out where the crash originated from, in order to tell the developer who was responsible for that part.
Hours of debugging and swearing later, I had found the source of the crash. A pointer that could not possibly be touched by anything legal got altered and accessing it resulted in the crash. A data breakpoint told me it was a
std::string constructor that altered the pointer. More precisely it was the construction of the third string member of an object that had only two strings and nothing else. What the…?
Examining where that constructor call originated from, I got to a code location that looked like this:
//SomeFooBarClass.cpp class NamingHelper { string name_; string suffix_; string info_; public: NamingHelper(string const& name, string const& suffix) : name_(name), suffix_(suffix), info_("default-info") //<======!!!==== {} //... }; void SomeFooBarClass::doSomeNaming() { NamingHelper helper("meow", "-fix"); //... }
In the initialization list, the construction of
info_ was what seemed to wreak havoc with some memory that did belong to another object. When I looked one call back in the stack trace, I got this:
//SomeFooBazClass.cpp class NamingHelper { string name_; string suffix_; public: NamingHelper(string const& name, string const& suffix) : name_(name), suffix_(suffix) {} //... }; void SomeFooBazClass::doSomeNaming() { NamingHelper helper("meow", "-fix"); //<======!!!==== //... }
See the difference?
NamingHelper had only two members. Seconds before it had three. It took me a while to realize that I was in a different source file. The surrounding code was almost identical, as were the class names.
Cause of the Problem
Sometime in the past, there had been only
SomeFooBarClass, with a two-element
NamingHelper. When the very similar
SomeFooBazClass was needed, someone just copy-pasted the whole class, made some minor changes and checked in, violating several rules of clean coding, like the DRY principle. He should have factored out the common behavior or generalize the existing class by adding a parametrization for the differing behavior.
Months later, someone else made a minor change to
SomeFooBarClass, adding the
info_ member to the
NamingHelper of that class’ implementation. The two classes were in different libraries at that time, otherwise, the crash or a similar problem should have occurred back then already.
When I put both compilation units into the same lib, I unknowingly violated the One Definition Rule: I had two differing class definitions with the same name, in the same namespace, in two different compilation units. The linker does not need to warn about that, it simply can assume the class definitions are the same. Having the same class definition in different translation units happens all the time if you include the same header in more than one source file.
Having two instances of the constructor
NamingHelper::NamingHelper(string const&, string const&) is not an issue for the linker, either. Both constructors have been defined inside the class definition, making them implicitly
inline, and having the same
inline function defined in several translation units is a linker’s daily business. It can assume that each definition is the same because the ODR says they have to be, and then picks whichever definition it wants.
In this case, it picked the constructor definition of the three-element
NamingHelper. The compiler on the other hand, while compiling
SomeFooBazClass.cpp did know only a two-element
NamingHelper and therefore reserved only enough space for the two strings on the stack. When the three-element constructor was executed, the third string got constructed in another object’s memory, a typical case of undefined behavior.
Lessons Learned
The first thing to notice is that this error can not only occur because someone carelessly copy-pastes some code that should be refactored instead.
NamingHelper is a very generic name for a helper class, and it is not very unlikely that two developers come up with the same names for their helper classes. That is not necessarily bad, although too generic names or poor names, in general, tend to obfuscate the meaning of code.
Take care when naming things. When using short, generic names make sure they don’t reach too far.
In other words,
i may be OK for a loop variable, but it certainly is not for something that can be accessed globally. In this case, the generic helper class names reached out of their respective translation units, which should have been prevented. This can be achieved easily by using anonymous namespaces, which I used to solve the problem in the end.
Consider giving internal linkage to helper classes and functions, e.g. by putting them in an unnamed namespace.
In hindsight, I should have done what the copy-paste guy hadn’t done: Refactoring the two classes. Of course, one should approach refactoring in a pragmatic way, not in a dogmatic way, i.e. don’t start a huge refactoring session after you changed just two or three lines of code. But in this case, a very ugly code smell had caused me several hours of debugging, so I should have spent an hour or two to set things right. I just had not read about “Clean Code” and heard of the “Boy Scout Rule” yet.
Instead of just fixing bad code, improve it.
Last but not least there was another error I had made: I had made false assumptions. By only running a basic test suite before checking in I exposed others to an error I could have found running all unit tests.
Don’t just think that nothing can go wrong, prove it. Run all unit tests before checking in.
Yes, I mean all unit tests. But I mean only real unit tests, not integration tests or full system tests that are labeled as “unit tests”. There is a huge difference between the two, which I will write about in a future post.
6 Comments
Permalink
If you’re running on a recent enough version of gcc then compiler warning -Wodr, in conjunction with -flto, can find this sort of problem at link time.
Permalink
Ouch… That’s so annoying!
Thanks for the lesson.
By the way, I have a question for the paragraph if “Cause of the Problem”
You said, the copy-paste programmer should have parametized the existing class.
In you own suggestion, which option would have been best? And can you please comment on these options/scenerio.
I have thought of few options including:
(1) Simply Inheriting from the NamingHelper and do his Addition. //Note: No need for vtables here since there arent virtual functions and the NamingHelper2 wouldn’t ever be manipulated from base class. Either at compiletime or runtime
(2) Liase with the maintainer of NameHelper to add an additional std::string member to his class. So that I can use it. This of cause is, far as the performance/usage requirements of NameHelper permits it.
(3) If NameHelper was a class I just use as a client (i.e I don’t care about a bulk of its implementation details, I am only sticking to contracts). Should I wrap NameHelper in another ‘light’ class that just adds the behaviour I need?
regards,
Timothy
Permalink
Forgive my typos please….
Permalink
By parametrizing the class I meant the original
SomeFooBarClass, i.e. a class that, depending on some parameter would either behave the “Bar” way or the “Baz” way. I don’t remember what the two classes did exactly and what the difference was, so I have to be a bit vague. However, code duplication never is a good sign.
As for your options: The
NameHelperclasses were very lightweight classes, not much more than data structures. The author was right to put it in the source file of
SomeFooBarClassand not make it a full grown class with its own header and source, because it was only a little implementation detail. So the inheritance option is not applicable. The same applies for your option 3, putting a wrapper around it would have made it just a fat little class without much benefits.
I would kind of go with option 2: If you don’t plainly copy
SomeFooBarClassbut parametrize/generalize it, then there is only one
doSomeNamingmethod and only one
NameHelperis needed. In order to deal with the Bar/Baz parametrization the
doSomeNamingand the
NameHelperwould have been generalized a bit for the two possible options, and there would have been only one
NameHelper, capable of dealing with both cases.
Permalink
Ohh. Ok I get, Thanks for clarifying.
With respect to your post,
Originaly,
NameHelper
should be as simple as it was. Fine.
Now that we needed same interface but slightly different behaviour, can we then adopt a design pattern? 🙂
(i.e A minimal Policy-based design? Optionally supply an to change the behaviour? )
Thanks.
Permalink
It depends. As far as I remember the difference in this case was only the info attribute, so it probably could be just made an empty string for the original case.
would usually think twice (at least) before considering a design pattern for helper classes. helper classes usually provide only a small part of a functionality. using a design pattern usually implies having several classes providing a complete functionality, i.e. more than just a helper class.
|
https://arne-mertz.de/2015/01/helper-classes-deserve-some-care-too/
|
CC-MAIN-2022-05
|
refinedweb
| 1,648 | 63.19 |
!
We.
In our static assets directory, we have the following directories:
public/images public/javascripts public/stylesheets
We want to namespace our application (my_app). We could type the following:
mkdir public/images/my_app mkdir public/javascripts/my_app mkdir public/stylesheets/my_app
Or to save time, we could type:
mkdir public/{images,javascripts,stylesheets}/my_app
This will create the three directories with one command.
I recently had the opportunity to visit Boulder, CO (Wiki, Map). The reason for my visit was to visit the Pivotal Labs office and spend a day pairing with them.
One of the cool/interesting features of the Pivotal office is that the company provides breakfast in the morning. I walked into the office to find two quiches, pears, strawberries, Orange Juice, Milk, Coffee and several choices of breakfast cereal.
|
http://pivotallabs.com/users/jnoble/blog
|
crawl-003
|
refinedweb
| 133 | 51.38 |
Adjust Numbers in an expression by a set amount
Re: Replacing number with another Incrementing #
I am trying to adjust some subtitle files, so I have about 60 files that all need the same adjustments. The problem is that it’s not all the same numbers.
For example,
00:00:36.250 line:77% 00:00:36.250 line:84% 00:00:42.333 line:85% 00:00:47.458 line:84%
I need to move everything down by 5% so all the 84% should be 89%, all the 85% should be 90%, all the 77% should be 82%, etc. The 84, 85, 76, & 77 are common enough that I could do a general search for all of them, but every subtitle is just slightly off of where it should be. the ones that are a problem are the random ones at 13% or 24% or 35%. I saw another post that had a somewhat similar issue that was a bit different, so I figured I would see if someone knows something that’d help.
I don’t know exactly what you are going to do now.
Do you want to increase all percentages by 5 or not?
What if values are greater than or equal to 96%, do you want to set them to 100%? Or is there an upper limit?
So I’m trying to increase the values by 5%. 100% is the upper limit, but 87% is the highest I’ve seen. The ones at the bottom 84, 85, with a couple at 86 & 87 I’m completely removing the line:84% value entirely because I want those to be at the bottom. So I’m not worried about it hitting the upper limit. Oh, yeah, so It does % by % down from the top, so when i say down that’s a higher number, sorry about that.
I want every “line:??%” value to increase by +5% of whatever is there. if there happens to be something that goes over 100% it will be ignored by VTT anyways. I’ve done for 1 folder doing a [Find In Files] starting at 99% & going down increasing everything by 5%, but it took a lot of time & I have to repeat the process for other shows when I find the appropriate % I need to shift. I figure there has to be a simpler way to do it.
Thanks for the help
I assume that this python script will do what you want to do
from Npp import editor def increase(m): current_value = int(m.group(0)) current_value = current_value+5 if current_value < 96 else 100 return current_value editor.rereplace('(?<=line:)\d+(?=%)', increase)
@Ekopalypse said in Adjust Numbers in an expression by a set amount:
def increase(m):
current_value = int(m.group(0))
current_value = current_value+5 if current_value < 96 else 100
return current_value
editor.rereplace(’(?<=line:)\d+(?=%)’, increase)
Awesome, it shifts the lines perfectly. But is there a way to make it work on more than 1 file at a time? I have folders of from 12 to 300 files that I need to do the same thing on. It’s a great tool to have on hand that I can adjust to whatever I need, but having to be doing it 60 times is still a problem. If it’s not possible it’s not possible, but I figured there has to be a way
- Ekopalypse last edited by Ekopalypse
One solution could be to use something like this
import os from Npp import editor def increase(m): # As long as only one value in a line is changed # one can set the default bookmark symbol to see where the changes took place # start, end = m.span(0) # start_line = editor.lineFromPosition(start) # end_line = editor.lineFromPosition(end) # for i in range(start_line, end_line+1): # editor.markerAdd(i, 24) current_value = int(m.group(0)) current_value = current_value+5 if current_value < 96 else 100 return current_value for currrent_directory, _, files in os.walk(r'PATH_WITHOUT_TRAILING_BAKSLASH'): for _file in files: if _file.endswith('.txt'): notepad.open(os.path.join(currrent_directory, _file)) editor.rereplace('(?<=line:)\d+(?=%)', increase) # notepad.save() # automatically save changes # notepad.close() # close active buffer
It walks down from a given directory and loads the file with the txt extension and changes its contents if it matches something.
@Ekopalypse Would this work if the extension is VTT? It’s set to open as a text document but I don’t think that counts
- Alan Kilborn last edited by
@Leon-Bob-Noël said in Adjust Numbers in an expression by a set amount:
Would this work if the extension is VTT?
Not as it is. But, really, is it that hard to see it?
I mean, the relevant line in the code reads almost like English:
if _file.endswith('.txt'):
Exercise left to the reader to figure out what to change it to. :-)
@Alan-Kilborn oh yeah, cool. So do I not run this whithin Notepad ++ then?
I’ve tried running it in Notepad ++ python scripts but no matter how I do it it does not work. With a file open in the directory it does nothing, with the directory open as workspace it does nothing, I didn’t try it with those setting with TXT files, assuming that changing it to “if _file.endswith(’.vtt’)::” didn’t work because Notepad++ wasn’t recognizing them because it doesn’t recognize the extension by default & doesn’t have the language in it’s database
- Ekopalypse last edited by Ekopalypse
@Leon-Bob-Noël
It must run from within Npp but there is no need to load the file,
this is done by the script.
You just have to adjust the file ending and the root path.
os.walk(r'PATH_WITHOUT_TRAILING_BAKSLASH'):
example
os.walk(r'C:\Documents\whatever\directory\it\is'):
- Leon Bob Noël last edited by Leon Bob Noël
@Ekopalypse Ah, thanks. Will is do recursive directories or just the root specified?
@Leon-Bob-Noël - it walks the tree recursively.
- Alan Kilborn last edited by
You could just experiment with it to find out these answers, instead of asking and then waiting to have a response.
@Alan-Kilborn if I was receiving answers while I was able to actually do it sure, but then if not I’d have to then ask if there was a way to do it. That seems much less efficient. I know when I’m helping someone I’d much rather have them ask questions right away. The longer they wait the less likely I’ll be looking at the forum to know they need a response. Maybe that’s just me, but having a question & waiting to ask it because it might not be necessary is just rude to the person giving help, while asking questions that are unnecessary right away is only really harmful to the ego of the asker, I’d rather look like I don’t know something I actually don’t know, than go to do something & have to come back & ask for more information because I was afraid of looking like an idiot, & thereby actually being an idiot
|
https://community.notepad-plus-plus.org/topic/21252/adjust-numbers-in-an-expression-by-a-set-amount/2?lang=en-US
|
CC-MAIN-2021-39
|
refinedweb
| 1,181 | 71.44 |
This article is based on documentation from and
The reason I started to use Pexepect was because I was looking for a module that can take care of some of the automation needs I have (mostly with ssh and ftp).
You can use other modules such as subprocess, but I find this module easier to use.
Note, this post is not for a Python beginner, but hey it’s always fun to learn new things
What is Pexpect?
Pexpect is a pure Python module that makes Python a better tool for controlling
and automating other programs.
Pexpect is basically a pattern matching system. It runs program and watches
output.
When output matches a given pattern Pexpect can respond as if a human were
typing responses.
What can Pexpect be used for?.
Installing Pexpect
The latest version of Pexpect can be found here
wget tar xzf pexpect-2.3.tar.gz cd pexpect-2.3 sudo python ./setup.py install # If your systems support yum or apt-get, you might be able to use the # commands below to install the pexpect package. sudo yum install pexpect.noarch # or sudo apt-get install python-pexpect
Pexpect.
emember that any time you try to match a pattern that needs look-ahead that
you will always get a minimal match.
Recommended Python Training
For Python training, our top recommendation is DataCamp.
The following will always return just one character:
child.expect (‘.+’)
Specify correctly the text you expect back, you can add ‘.*’ to the beginning
or to the end of the text you’re expecting to make sure you’re catching
unexpected characters
This example will match successfully, but will always return no characters:
child.expect (‘.*’)
Generally any star * expression will match as little as possible.
The pattern given to expect() may also be a list of regular expressions,
this allows you to match multiple optional responses.
(example if you get various responses from the server)
The send() method
Writes a string to the child application.
From the child’s point of view it looks just like someone typed the text from
a terminal.
The before and after properties
After each call to expect() the before and after properties will be set to the
text printed by child application.
The before property will contain all text up to the expected string pattern.
You can use child.before to print the output from the other side of the connection
The after string will contain the text that was matched by the expected pattern.
The match property is set to the re MatchObject.
Connect and download a file from a remote FTP Server
This connects to the openbsd ftp site and downloads the recursive directory
listing.
You can use this technique with any application.
This is especially handy if you are writing automated test tools.
Again, this example is copied from here
import pexpect child = pexpect.spawn ('ftp') child.expect ('Name .*: ') child.sendline ('anonymous') child.expect ('Password:') child.sendline ('[email protected]') child.expect ('ftp> ') child.sendline ('cd pub') child.expect('ftp> ') child.sendline ('get ls-lR.gz') child.expect('ftp> ') child.sendline ('bye')
In the second example, we can see how to get back the control from Pexpect
Connect to a remote FTP Server and get control
This example uses ftp to login to the OpenBSD site (just as above),
list files in a directory and then pass interactive control of the ftp session
to the human user.
import pexpect child = pexpect.spawn ('ftp') child.expect ('Name .*: ') child.sendline ('anonymous') child.expect ('Password:') child.sendline ('[email protected]') child.expect ('ftp> ') child.sendline ('ls /pub/OpenBSD/') child.expect ('ftp> ') print child.before # Print the result of the ls command. child.interact() # Give control of the child to the user.
EOF, Timeout and End Of Line
There are special patters to match the End Of File or a Timeout condition.
I will not write about it in this article, but refer to the official documentation
because it is good to know how it works.
Recommended Python Training
For Python training, our top recommendation is DataCamp.
|
https://www.pythonforbeginners.com/systems-programming/how-to-use-the-pexpect-module-in-python
|
CC-MAIN-2021-31
|
refinedweb
| 676 | 67.86 |
in reply to
This could have DWIM better
If you're worried about polluting other's namespaces, why don't you just override the function locally? I started with japhy's modification and produced this:
BEGIN {
use subs 'length';
sub length(;$) {
my $arg = @_ ? $_[0] : $_;
defined($arg) ? CORE::length($arg) : undef;
}
}
[download]
You could even modularize this pretty easily:
package Func::Smarter;
require Exporter;
use vars qw'@ISA @EXPORT @EXPORT_OK';
use subs qw 'length'
@ISA = 'Exporter';
@EXPORT_OK = qw'length';
sub length (;$) {
my $arg = @_ ? $_[0] : $_;
defined($arg) ? CORE::length($arg) : undef;
}
1;
[download]
Then you could just use Func::Smarter 'length';,
|
http://www.perlmonks.org/index.pl?node_id=533766
|
CC-MAIN-2015-06
|
refinedweb
| 105 | 64.91 |
04 June 2009 11:01 [Source: ICIS news]
SINGAPORE (ICIS news)--India’s Reliance Industries (RIL) expects to achieve full production at its newly started polypropylene (PP) line at Jamnagar, in Gujarat state, by mid-June, a source close to the project said on Thursday.
“The newly started PP line is operating at 80% capacity currently, and securing propylene feedstock from Reliance’s new fluid catalytic cracker (FCC) at ?xml:namespace>
The company plans to start up its second new PP line at the same site by early July, the source added. Both PP lines have a capacity of 450,000 tonnes/year each.
The new FCC unit was running at reduced operating rates and was expected to stabilise in the next two weeks, he added.
The source could not give details on the present operating rate of the unit or the amount of propylene being produced.
Reliance also operates an older 1m tonne/year PP plant and FCC unit at
Under the EOU label, the company was required to export 50% of the output from the complex. The new PP lines at
“Therefore the company would prefer to use the output from the older plant for domestic sales and direct product from the new lines into export markets,” the source said.
Domestic demand for PP was currently quite strong, the source added. However, Indian producers reduced PP prices by Indian rupees (Rs) 9,000/tonne ($190.84/tonne) last week to Rs57,000-58,000/tonne in a bid to compete better against lower priced imports.
The rupee has strengthened by more than 5% in the past two weeks on the back of improving sentiments in the wake of a decisive mandate following the recent Indian federal elections.
The only other Indian PP producer besides Reliance is Haldia Petrochemicals.
($1 = Rs47.16)
For more
|
http://www.icis.com/Articles/2009/06/04/9222134/reliance-to-achieve-full-output-at-new-pp-line-by-mid-june.html
|
CC-MAIN-2015-06
|
refinedweb
| 305 | 59.13 |
Join the Nasdaq Community today and get free, instant access to portfolios, stock ratings, real-time alerts, and more!
(San Francisco)
With all the news of Amazon's 20th anniversary return ($100 of shares at IPO would be worth almost $64,000 now), many might be looking for the next big IPO to buy. However, caution is demanded during the IPO process, as historically speaking, things do not usually go very well for those who buy right near an IPO. However, if you are keen to do so, this piece gives three tips for how to go about it. Firstly, be clear about why you are buying, and why now. Secondly, be very clear about your risk tolerance. And thirdly, stick to your plan, buying and selling at pre-determined prices and suiting the investment to your overall financial goals.
FINSUM : Buying at IPO can be dangerous, especially in the short-term, but over the long haul it can immensely profitable.
Source: Wall Street.
|
https://www.nasdaq.com/article/how-to-pick-the-next-amazon-cm792383?utm_source=feedburner&utm_medium=feed&utm_campaign=Feed%3A+nasdaq%2Fcategories+%28Articles+by+Category%29
|
CC-MAIN-2018-39
|
refinedweb
| 164 | 70.43 |
Second/last screenshot.
Sorry, but I should offer the following version which prevents anything happening if you are not in a View; that is, if you are in the Find dialog, or anywhere else.
import sublime, sublime_plugin
def adjustEdits(view):
edited = view.get_regions("edited_rgns") or ]
edited_last = view.get_regions("edited_rgn") or ]
if not edited and not edited_last:
return False
new_edits = ]
edited.extend(edited_last)
for i, r in enumerate(edited):
if i > 0 and r.begin() == prev_end:
new_edits.append(sublime.Region(prev_begin, r.end()))
else:
new_edits.append(r)
prev_begin, prev_end = (r.begin(), r.end())
view.add_regions("edited_rgns", new_edits, "keyword", \
sublime.HIDDEN | sublime.PERSISTENT)
view.erase_regions("edited_rgn")
return view.get_regions("edited_rgns") or ]
def showRegion(view, reg):
view.sel().clear()
view.show(reg)
view.sel().add(reg)
class ToggleEditsCommand(sublime_plugin.TextCommand):
def run(self, edit):
window = sublime.active_window()
view = window.active_view() if window != None else None
if view is None or view.id() != self.view.id():
sublime.status_message('Click into the view/tab first.')
return
edited = adjustEdits(self.view)
if not edited:
sublime.status_message('No edits to show or hide.')
return
toggled = self.view.get_regions("toggled_edits") or ]
if toggled:
self.view.erase_regions("toggled_edits")
else:
self.view.add_regions("toggled_edits", edited, \
"keyword", sublime.DRAW_OUTLINED)
class PrevEdit reversed(edited) if r.begin() < currA]:
showRegion(self.view, reg)
break
else:
sublime.status_message('No edits further up.')
class NextEdit edited if r.begin() > currA]:
showRegion(self.view, reg)
break
else:
sublime.status_message('No edits further down.')
class QuickEditsCommand(sublime_plugin.TextCommand):
def run(self, edit):
window = sublime.active_window()
view = window.active_view() if window != None else None
if view is None or view.id() != self.view.id():
sublime.status_message('Click into the view/tab first.')
return
self.vid = self.view.id()
edited = adjustEdits(self.view)
if not edited:
sublime.status_message('No edits to list.')
return
the_edits = ]
for i, r in enumerate(edited):
curr_line, _ = self.view.rowcol(r.begin())
curr_text = self.view.substr(r).strip():40]
if not len(curr_text):
curr_text = self.view.substr(self.view.line(r)).strip():40] \
+ " (line)"
the_edits.append("Line: %03d %s" % ( curr_line + 1, curr_text ))
window.show_quick_panel(the_edits, self.on_chosen)
def on_chosen(self, index):
if index == -1: return
window = sublime.active_window()
view = window.active_view() if window != None else None
if view is None or view.id() != self.vid:
sublime.status_message('You are in a different view.')
return
edited = self.view.get_regions("edited_rgns") or ]
for reg in [r for i, r in enumerate(edited) if i == index]:
showRegion(self.view, reg)
break
class CaptureEditing(sublime_plugin.EventListener):
def on_modified(self, view):
# create hidden regions that mirror the edited regions
window = sublime.active_window()
curr_view = window.active_view() if window != None else None
if curr_view is None or curr_view.id() != view.id():
return
sel = view.sel()[0]
currA, currB = (sel.begin(), sel.end())
self.curr_line, _ = view.rowcol(currA)
if not hasattr(self, 'prev_line'):
self.prev_line = self.curr_line
if currA > 0 and sel.empty():
currA -= 1
self.lastx, self.lasty = (currA, currB)
self.curr_edit = sublime.Region(self.lastx, self.lasty)
view.add_regions("edited_rgn",[self.curr_edit], \
"keyword", sublime.HIDDEN | sublime.PERSISTENT)
return
if self.curr_line == self.prev_line:
self.lastx = min(currA, self.lastx)
self.lasty = max(currB, self.lasty)
self.curr_edit = sublime.Region(self.lastx, self.lasty)
view.add_regions("edited_rgn",[self.curr_edit], \
"keyword", sublime.HIDDEN | sublime.PERSISTENT)
else:
self.prev_line = self.curr_line
if currA > 0 and sel.empty():
currA -= 1
self.lastx, self.lasty = (currA, currB)
_ = adjustEdits(view)
My GitHub includes an icon
Different icon - it's a pencil .
I shall stop now! But, of course, feedback is encouraged. Andy.
@SimFox3I've replied to your email but my responses are just sitting in my Outbox?!
You enquired about my **LastEditLine **command and I did copy this file initially to work on - but I got side-tracked and this revision doesn't have the same feature-set. That is, it's completely different .
LastEditLine cycles through the last edit positions similar to the behaviour of Word (when pressing Shift F5). This was my intention, but I might revisit it once I've completed my AndyEdits
*LastEditLine.zip (1.12 KB)*
Someone has raised the following two issues:
I shall investigate these. If someone has experience with the Undo actions I will appreciate advice. I suspect it cannot be worked around; at least, not without substantial coding?
Actually, this sounds like the same issue, so if I fix the first one..
I've fixed the first issue at my GitHub. I won't post the code here, as it is now part of a package (including the icon) unless someone requests me to. This will also make the Undo behave slightly better, but I think the previously mentioned issue persists to some extent. I doubt that this can be fully overcome.
There is now an option to remove the edit history for a region (via a quick panel). This could be useful if you are performing a lot of edits on the same file and don't wish to lose all the edit history by closing the file.
This new remove option enables you to use this package as a kind of workflow. Start different areas with a comment, so that this comment will appear as a title in the quick-panel list of edits. The continuous lines following the comment will be treated as a single edit-item. When completed, using Ctrl+Alt+D (or other shortcut) to *complete *the task. Added: Hint - you can also cut and paste the same line and it will be added as a new edit-item
I can confirm it's fixed.
For the undo issue, I suppose only jps can give an answer...
Undo seems to behave a little better now, as a result of the other fix. I think cutting and pasting the same content will be one way to correct edited regions, or even over-writing an area with a space or character, and then using Undo.
It just occurred to me that it *might *be useful to have another shortcut to specifically add the currently highlighted text as an edit-region. I might play with this. However, cutting and pasting achieves the same (or similar) result.
Didn't change anything for my test case but maybe it's better for other test case.Strangely, soft undo works without any issue for me.
So it looks more and more like a ST2 bug.As jps not very active in this forum since a few weeks, anyone has it's phone number
I believe Undo (and other features - Duplicate, Cut, Paste) can be problematic with any plug-in. But for this simple plug-in it shouldn't be a major concern, and most of these features seem to behave well. I find if I highlight an area, press Space and then Undo (Ctrl-Z) the whole area becomes a single edit-region. This process also removes any smaller edit regions within this larger area. In view of this, I don't think it's necessary for me to create a shortcut to do this (as mentioned in my previous post).
If anyone can think of something useful that might be added to this, please let me know - I might consider it . Otherwise, I think it's complete - and I'm very pleased with it
IMHO, it's a major issue. I had the same issue with another plugin (Edit History).If every time I trigger an undo (which is fairly often for me ) it remove a line that don't have to be removed, and keep a line that have to be removed, it quickly become a mess.
I really like this plugin, but without this issue resolved I don't think I will use it since I've no confidence in it.
I shall investigate! Is it just Undo that causes you concern/issues?
Trying a few things with this Undo issue, including doing nothing :
def doNothing(view):
view.add_regions("doh", [sublime.Region(0, 0)], "nothing", sublime.HIDDEN)
It's kind-of a catch-22: writing code to correct Undo, the code we write becomes the *thing *that is undone. I recall others discussing this before; hopefully someone might offer some advice based on their experience .
I've edited my GitHub so that the region for the currently edited line doesn't extend beyond the end of the line. So, for example, pressing Backspace doesn't cause the region to extend to the next line. This means that we can use, for example, Ctrl-Backspace to delete the previous word, in preference to Ctrl-Z.
Actually yes.I don't have any other issue with your plugin, and this undo issue is not an issue from your plugin.
Do you mind if I try to open a new [BUG] topic about this subject ? Maybe jps will give us more info about this issue.
That's fine. I shall still pursue this Undo issue myself: if I can trace the "sequence of events" then there might be a way around it.
I was thinking if I store variables x, y that represent the *previous *edit position (perhaps as globals), then I can check for "undo" being pressed once so that "on the next update" - re-instate the region x,y. The difference here is that x,y would be integers, rather than reflecting part of the buffer; and this change would occur on the next update, rather than happening straight-away (and being undone!). But it would help if I fully understood the sequence of events.
Andy.
I tried briefly to create a test case but actually found that the problem is not where I thought it was Not sure if it's really a bug or simply a limitation of the current API.
What I've found so far:-the problem, as you probably already found, is that an undo command trigger an on_modified event that recreate the region.-it looks like when entering the on_modified event after an undo, the region is correct (last region is removed).-undo command trigger an on_modified event, but soft_undo not (???)-multi-selection edition doesn't work ?
I wrote a plugin last week () that have to deal with on_modified/on_selection_modified and found this about events sequence:When you type a char or paste from clipboard:
When you trigger undo:
So, maybe storing the actual view.sel() in the on_selection_modified event and compare it with the one in on_modified event could be used to identify an undo command.If they are the same, it's an undo, otherwise it's an edition.
While conceding that this is *imperfect * (flawed?) while the undo issue remains, in the meantime I've detoured to enable jumping to any edit in any file.
It doesn't store multi-select edited regions currently; that is, it will only store the first region. This feature could be added at some point.
@bizoo Please gave my latest update on GitHub a trial run, thank you
Well there remains an issue with Undo or Soft Undo in that it might consider an area as being edited when you have undone all edits for that area. I can only suggest that others give this a trial and see whether its behaviour is acceptable to you. Bear in mind that you have the option to create or remove edit regions as you progress, although you cannot remove the most recent (the current!) edit region. (Type a character in any other region and you can then remove the previous edit region.)
I will be using this a lot myself I suspect - I like the pencil that follows along and easily jumping between, and highlighting, edits will be very useful. (I don't overuse Undo, as I dint moke mistusks!)
|
https://forum.sublimetext.com/t/split-iterate-regions/7509/36
|
CC-MAIN-2017-22
|
refinedweb
| 1,939 | 60.01 |
On Tue, Jul 21, 2015 at 12:12:03PM -0400, Cole Robinson wrote: > On 07/17/2015 10:15 AM, Daniel P. Berrange wrote: > > On Tue, Jul 14, 2015 at 02:44:59PM -0400, Cole Robinson wrote: > >> As of fedora polkit-0.113-2, polkit-devel only pulls in polkit-libs, not > >> full polkit, but we need the latter for pkcheck otherwise our configure > >> test fails. > >> --- > >> libvirt.spec.in | 2 ++ > >> 1 file changed, 2 insertions(+) > >> > >> diff --git a/libvirt.spec.in b/libvirt.spec.in > >> index 0adf55e..40d2ccb 100644 > >> --- a/libvirt.spec.in > >> +++ b/libvirt.spec.in > >> @@ -531,6 +531,8 @@ BuildRequires: cyrus-sasl-devel > >> %endif > >> %if %{with_polkit} > >> %if 0%{?fedora} >= 20 || 0%{?rhel} >= 7 > >> +# F22 polkit-devel doesn't pull in polkit anymore, which we need for pkcheck > >> +BuildRequires: polkit >= 0.112 > >> BuildRequires: polkit-devel >= 0.112 > >> %else > >> %if 0%{?fedora} || 0%{?rhel} >= 6 > > > > NACK. > > > > We don't actually use pkcheck anymore, since we switched to using > > dbus API calls. So we should kill the binary check in configure.ac > > instead. > > > > My autotools-fu is weak and I can't really spare time for this at the moment, > so I'd appreciate it if someone else could pick it up Ok, I've looked at this and due to the way we detect polkit-0 and prefer polkit-1 when both are installed, we need to keep the check for pkcheck. So on that basis ACK to your original patch. I'll also send a followup to clarify this rationale in configure.ac. Regards, Daniel -- |: -o- :| |: -o- :| |: -o- :| |: -o- :|
|
https://listman.redhat.com/archives/libvir-list/2015-July/msg00826.html
|
CC-MAIN-2022-21
|
refinedweb
| 260 | 68.06 |
How to Test If a Class Is Thread-Safe in Java
How to Test If a Class Is Thread-Safe in Java
Learn how to test if a class is thread-safe in Java.
Join the DZone community and get the full member experience.Join For Free
Tests for thread safety differ from typical single-threaded tests. To test if a method is thread-safe we need to call the method in parallel from multiple threads. We need to do this for all potential thread interleavings. And afterward, we need to check if the result is correct.
Those three requirements for our test lead to a special type of tests for thread safety which differ from typical single-threaded tests. Since we want to test all thread interleavings our test must be repeatable and run automatically. And since the methods run in parallel the potential result is a combination of different outcomes.
You may also like: What Does Thread-Safety Mean in Java?
Let us look at an example to see how this looks in practice.
Testing for Thread Safety
Suppose we want to test if the following class representing an Address is thread-safe. It offers one method to update the street and city, the method update and one method to read the complete Address, the method
toString:
public class MutableAddress {
private volatile String street;
private volatile String city;
private volatile String phoneNumber;
public MutableAddress(String street, String city,
String phoneNumber) {
this.street = street;
this.city = city;
this.phoneNumber = phoneNumber;
}
public void update(String street ,String city ) {
this.street = street;
this.city = city;
}
public String toString() {
return "street=" + street + ",city=" + city + ",
phoneNumber=" + phoneNumber;
}
}
String phoneNumber) {
I use volatile fields, line 2 through 4, to make sure that the threads always see the current values, as explained in greater detail here. You can download the source code of all examples from GitHub here.
Now, let us first see if the combination of
toString and update is thread-safe. Here is the test:
xxxxxxxxxx
import com.vmlens.api.AllInterleavings;
public class TestToStringAndUpdate {
public void testMutableAddress() throws InterruptedException {
try (AllInterleavings allInterleavings =
new AllInterleavings("TestToStringAndUpdate_Not_Thread_Safe");) {
while (allInterleavings.hasNext()) {
MutableAddress address = new MutableAddress("E. Bonanza St.",
"South Park", "456 77 99");
String readAddress = null;
Thread first = new Thread(() -> {
address.update("Evergreen Terrace", "Springfield");
});
first.start();
readAddress = address.toString();
first.join();
assertTrue("readAddress:" + readAddress,readAddress.equals(
"street=E. Bonanza St.,city=South Park,phoneNumber=456 77 99")
|| readAddress.equals(
"street=Evergreen Terrace,city=Springfield,phoneNumber=456 77 99"));
}
}
}
}
The test executes the two methods in parallel from two threads. To test all thread interleavings, we put the complete test in a while loop iterating over all thread interleavings using the class AllInterleavings from vmlens, line 7. To see if the class is thread-safe, we compare the result against the to potential outcomes, the value before the update and after the update, lines 17 through 20.
Running the test leads to the following error:
xxxxxxxxxx
java.lang.AssertionError: readAddress:street=Evergreen Terrace
,city=South Park,phoneNumber=456 77 99
at com.vmlens.tutorialCopyOnWrite.TestToStringAndUpdate.
testMutableAddress(TestToStringAndUpdate.java:22)
To see what went wrong, we look at the report vmlens generated:
The problem is that for one thread interleaving the thread with Thread id 30 first updates the street name and then the main thread, thread id 1, reads the street and city name. So, the main thread reads a partial updated address which leads to the error.
To make the address class thread-safe, we copy the address value every time we update the address. Here is a thread-safe implementation using this technique. It consists of two classes, an immutable value, and a mutable container.
First, the immutable value class:
xxxxxxxxxx
public class AddressValue {
private final String street;
private final String city;
private final String phoneNumber;
public AddressValue(String street, String city,
String phoneNumber) {
super();
this.street = street;
this.city = city;
this.phoneNumber = phoneNumber;
}
public String getStreet() {
return street;
}
public String getCity() {
return city;
}
public String getPhoneNumber() {
return phoneNumber;
}
}
Second is the mutable container class:
xxxxxxxxxx
public class AddressUsingCopyOnWrite {
private volatile AddressValue addressValue;
private final Object LOCK = new Object();
public AddressUsingCopyOnWrite(String street,
String city, String phone) {
this.addressValue = new AddressValue( street,
city, phone);
}
public void update(String street ,String city ) {
synchronized(LOCK){
addressValue = new AddressValue( street, city,
addressValue.getPhoneNumber() );
}
}
public String toString() {
AddressValue local = addressValue;
return "street=" + local.getStreet()
+ ",city=" + local.getCity() +
",phoneNumber=" + local.getPhoneNumber();
}
}
The class
AddressUsingCopyOnWrite creates a new address value every time it updates the variable
addressValue. This makes sure that we always read a consistent address, either the value before or after the update.
If we run the test with those two classes, the test succeeds.
What Do We Need to Test?
So far, we tested the combination of
toString and
update for thread safety. To test if a class is thread-safe, we need to test all combinations of modifying methods and all combinations of read-only methods together with modifying methods. So, for our example class, we need to test the following two combinations:
updateand
update
toStringand
update
Since the combinations of read-only methods are automatically thread-safe, we do not need to test the combination of the method toString with itself.
Data Races
So far, we used volatile fields to avoid data races. Let us see what happens when we use normal fields instead. So, in our thread-safe class
AddressUsingCopyOnWrite, we remove the volatile modifier and re-run our test. Now, vmlens reports a data race in the file target/interleave/issues.html
A data race is an access to a field where a thread might read a stale value. If the thread, indeed, reads a stale value depends on external factors like which optimizations the compiler is using or on which hardware architecture the JVM is running and on which cores the threads are running. To make it possible to always detect such a data race independent of those external factors, vmlens searches for data races in the execution trace of the test run. And if vmlens have found one as in the example, it reports them in the issue report.
Summary
Tests for thread safety differ from typical single-threaded tests. To test if the combination of two methods, a and b, is thread-safe, call them from two different threads. Put the complete test in a while loop iterating over all thread interleavings with the help from the class
AllInterleavings from vmlens. Test if the result is either an after b or b after a. And to test if a class is a thread-safe, test all combinations of modifying methods and all combinations of read-only methods together with modifying methods.
Further Reading
7 Techniques for Thread-Safe Classes
What Does Thread-Safety Mean in Java?
5 Tips to Make Your Classes Thread-Safe
Published at DZone with permission of Thomas Krieger , DZone MVB. See the original article here.
Opinions expressed by DZone contributors are their own.
{{ parent.title || parent.header.title}}
{{ parent.tldr }}
{{ parent.linkDescription }}{{ parent.urlSource.name }}
|
https://dzone.com/articles/how-to-test-if-a-class-is-thread-safe-in-java
|
CC-MAIN-2020-05
|
refinedweb
| 1,169 | 55.84 |
3. Library calls (functions within program libraries)
TTYNAMESection: Linux Programmer's Manual (3)
Updated: 2017-05-03
Index | Return to Main Contents
NAMEttyname, ttyname_r - return name of a terminal
SYNOPSIS
#include <unistd.h> char *ttyname(int fd); int ttyname_r(int fd, char *buf, size_t buflen);
DESCRIPTIONThe function ttyname() returns a pointer to the null-terminated pathname of the terminal device that is open on the file descriptor fd, or NULL on error (for example, if fd is not connected to a terminal). The return value may point to static data, possibly overwritten by the next call. The function ttyname_r() stores this pathname in the buffer buf of length buflen.
RETURN VALUEThe function ttyname() returns a pointer to a pathname on success. On error, NULL is returned, and errno is set appropriately. The function ttyname_r() returns 0 on success, and an error number upon error.
ERRORS
-).
ATTRIBUTESFor an explanation of the terms used in this section, see attributes(7).
CONFORMING TOPOSIX.1-2001, POSIX.1-2008, 4.2BSD.
NOTESA process that keeps a file descriptor that refers to a pts(4) device open when switching to another mount namespace that uses a different /dev/ptmx instance may still accidentally find that a device path of the same name for that file descriptor exists. However, this device path refers to a different device and thus can't be used to access the device that the file descriptor refers to. Calling ttyname() or ttyname_r() on the file descriptor in the new mount namespace will cause these functions to return NULL and set errno to ENODEV.
SEE ALSOtty(1), fstat(2), ctermid(3), isatty(3), pts(4)
COLOPHONThis page is part of release 4.15 of the Linux man-pages project. A description of the project, information about reporting bugs, and the latest version of this page, can be found at.
Index
Return to Main Contents
|
https://eandata.com/linux/?chap=3&cmd=ttyname
|
CC-MAIN-2020-34
|
refinedweb
| 312 | 51.89 |
Last week I ran a poll (that maxed out at 400 responses on twtpoll) asking how developers recommend using regions in C# (or not). You can see the results here:
About 15% of the respondents chose Other and/or chose to leave a comment. The comments are useful because they often highlight answer categories that I overlooked when I set up the poll. In this case, there were a lot of comments, I think because there are a lot of different opinions about regions in general, some of them rather heated.
Clearly the largest number of respondents simply never use Regions. A number of comments went on to say things like “Regions aren’t evil I just don’t know a situation where they’re useful.” The most popular use of regions from the ones I provided was for wrapping interface implementations, which isn’t too surprising since these regions are often automatically added when an interface is implemented automatically. Similarly, a large number of comments referenced “generated code” as a use case for regions, which I probably should have included in the original listing.
I added a couple of the options above, F and G, as items that I would consider obvious wrong answers on a standardized test. Surprisingly, both got a reasonable number of votes, with 13% of respondents recommending the use of regions with long functions. Now, some of these votes probably belong to commenters like this one: “Hiding long methods as I refactor it”. If you’re temporarily collapsing sections of a long function during your refactoring exercise, that seems quite reasonable to me. But if you’re putting regions into your function as a recommended, long-term approach, then I probably don’t want to work on that codebase with you. I would much rather functions be small enough that (without regions) they fit on one screen, and if they get too big for that, fix the problem by extracting out well-named and well-composed methods, as opposed to hiding the problem behind regions. And regions with regions. Wow.
My personal opinion is that regions had some great and common use cases in the early versions of .NET and C#. For instance, the first version of ASP.NET used regions appropriately to hide auto-generated wire-up code in the codebehind. A large number of comments continue to suggest that regions be used for generated code. Today, two things make this less of an issue. The first is partial classes. Generated code today is almost always in its own class, or could be, and as such rather than wrapping it with a region, I find it is better to simply use a partial class to keep the generated code in a separate file from the custom code. The second feature is more of an IDE feature. A lot of users find regions helpful as a code navigation tool, or as a way to limit what they are looking at on the screen. VS2010 provides great support for expanding and collapsing methods and other areas of code that you don’t wish to see, and tools like ReSharper make it trivial to navigate to a type or member anywhere in your solution (ctrl-T, then type a substring of the type, then enter and you’re there. For a member, the default keymap is the not-quite-as-easy-to-type ctrl-F12). A number of comments also suggested using regions for using statements. These don’t tend to bother me because I can quickly scroll down and not have to see them on my screen, and my using statements are usually quite small since ReSharper will clean up the ones I don’t need and will auto-add any that I do need, and my classes are small so they aren’t generally using more than a handful of other namespaces. And of course, VS2010 supports collapsing using statements as well, like so:
Why Consider Them Harmful, Smelly, or even “Evil”?
Evil is obviously a strong word, and of course since regions have no effect on compiled code, they can’t directly have any impact on the software you’re creating. However, I do think it is at least fair to say that regions often represent “code smells.” That is, areas of your code that may be worth investigating to see if there is rotten code that needs to be cleaned up. Why do some, including me, tend to feel this way? Because regions are often a symptom of underlying problems with the code itself. Regions do two things:
- Provide a single-line comment
- Wrap some number of lines of code and allow it to be hidden on demand
When might you need these features?
- The intent of the code is unclear
- The code is too long to quickly understand at a glance
- Both of the above
- You prefer an “outline view” of classes so you can drill into each category of member when you dig into a class
In the case of items 1 through 3, regions are covering up problems.
If the intent of a block of code is unclear, fix the code. Extract a method. Rename the variables. Refactor. Simplify. Don’t add a comment or a region (glorified comment) to try and cover up the problem. If you spill something in the kitchen, should you clean up the floor, or just throw a rug over it or put out an orange cone to warn people about the spill? Which option is going to keep the kitchen optimally usable? The same goes for your code. Keep it clean. Regions are rugs under which to sweep smelly code.
If the code is simply too long, fix it. Eliminate duplication. Refactor. Abstract details into larger-grained operations. If you’re spending 10 lines of plumbing code talking to a database or service, move that into its own method or class that is only responsible for that work. If you’re spending lots of lines of code copying values from one object to another, use a tool like Automapper to map the values with one line of code. Keep your code concise and at the appropriate level of abstraction for the method you’re in, and don’t mix plumbing code with application code if you can help it.
In the case of 4, regions are being used to do something that your IDE should be able to easily do for you. I won’t say regions are being mis-used in this context, but I do think that if a large number of people use them for this purpose, then Visual Studio or one of the add-in providers should provide this kind of view such that you don’t have to implement yourself in the source code with region statements. I definitely think it’s valid that some developers prefer this view of their classes, I just don’t think they should have to clutter up everybody’s codebase in order to do so. Let the IDE do that work. And of course, if the classes and methods are small, the need for a high-level view is significantly lessened. If you prefer to have all of your public properties in one section, public methods in another, private members in another, etc. then wouldn’t you prefer to have an IDE that would simply let you specify the organization you prefer, and automatically have it in every file you open?
Summary
Almost half of the developers polled would never recommend using regions. Yet nearly 15% of those polled would recommend using them to organize long methods. A great many use them to organize code into categories (public, private, methods, properties), though this could probably be better done automatically by a tool. When .NET was young, regions provided a useful way to hide generated code within classes or to provide expand/collapse capabilities within the IDE. Today, partial classes and improvements to the IDE and various plug-ins make these uses unnecessary for many developers. Clearly, there are still some opportunities for IDE/plug-in vendors to build in code organization support that will further erode the legitimate use cases for regions. If you’re not using them for such organizational purposes today, think about the underlying reason you’re using a region the next time you add one, and consider if you wouldn’t be better off correcting the underlying code deficiency rather than hiding it under the region rug.
|
http://ardalis.com/regional-differences
|
CC-MAIN-2015-14
|
refinedweb
| 1,418 | 58.62 |
3000 miles on a triplet
By user12625760 on Nov 09, 2007
On a whim I asked if my daughter if she wanted a lift to school today so that we could have an extra 45 minutes in the morning rather than have to rush out to get the bus. She accepted and then just after the point of no return (ie she had missed her bus) someone calls me to arrange a 9am phone meeting. I had to put them back to 9:30 to be sure of getting back in time.
As
I cycled back I noticed the milage on my trip computer was moving
towards the 3000 mile mark and when I got home it was.
In 3000 miles the furthest it has been from home would either be Richmond or Thorpe Park. The vast majority of those miles have been the school runs.
It is on it's second set of tyres and second rear chain and cassette. I expect to have to replace the other two chains when the rear needs to be replaced again.
Has it been a success? Absolutely. I sold a car we no longer needed thanks to the triplet. I have the option of taking my daughter to school, you would not do that in a car unless you enjoy sitting in traffic jams.
The only thing that has not turned out as I expected is that I always planned using it as a way to pursuade my daughters to do what I wanted. Something like, “Tidy your room or I will take you to school on the trilpet”, on the basis that I thought that arriving at school on a triplet when you are a teenager would be so uncool that they would rather tidy the room. Alas not. Travelling by triplet is seen by their peers as just about the coolest way to travel, so I need another method to get my way. Do Fathers ever get their daughters to do what they want? Well I suppose I have in that they ride the triplet mostly without complaint.
|
https://blogs.oracle.com/chrisg/entry/3000_miles_on_a_triplet
|
CC-MAIN-2016-22
|
refinedweb
| 348 | 83.39 |
Tell us what you think of the site.
It seems that “Mirroring” a layer completely destroys the base level geometry’s UVs on one side.
This puzzled me for 3 days until i realized what was happening.
This breaks the whole import layer geometry work flow. If u have mirrored a layer then export the base geo and high geo…
then do:
import low res geo
import as layer (vertex position) high res geo.
The mesh explodes on half of the model.
However if you were to export level 2 rather than level 1(base level)… it will import fine.
Mirror seems to be destroying the base level uvs on half the object. BUT its not just the UVs. I even tried pasting good uv’s back over the bad UVs in softimage… The result was that it just would not take the good UVs without exploding half of it. So something gets screwed with the geometry that I could not figure out. I just know the “explosive evidence” is noticeable in the UVs on half the model because each polygon will no longer be welded on half the model.
This may be because I had some triangles on the base… but i’m not sure.
Anyone else notice this?
Anyways… All in all, 2011 seems much more stable and nicer than previous versions I beta tested (2009 and 2010)… Its a huge improvement I feel. Good job guys.
yeah I ma having the same problem i think.... except i have done no mirroring of the geometry in my model.
MY geo is symmetrical, as are my UVs.
After workingo on my model in higher resolutions when i go to my lowest res half of it totally gets messed up. but when i go to subdivision 1 everything seems to be fine.
this is the second time this happens to me, and theonly thing in common is that i was using the “send to maya” button back and forth quite a bit.
In maya, the half that is destroyed behaves very interesting. i can select indiviual UVs from the uv view like there was northing wrong with my mesh, but in the 3d view i seem to be selecting multiple uvs (even though i am only selecting one in the Uv view)
very bizarre! i am restricted to working with my subdivision 1 as my lowest res now, i can’t send subd 0 back to maya and back again because then my sculpt get really messed up. as long as i don’t go as low as that subd level i seem to be fine… i hope.
never had such issue… are you sure your geo is clean.?
have you tried the mudbox base head..?
if its possible capture a vid and send it to autodesk for bug tracking…
in the help menue --> report a problem
The geo was fine from i could tell.
I just tried to reproduce it with new geometry…
First i tried with all quads
Then i tried na object with mostly quad but 2 tris
Both symmed ok and imported back in ok.
I swear there is nothing wrong with the geometry i tried. Theres no double faces, etc. Its all very clean geo.
Again after symming a level then exporting etc… the uv’s get exploded (each poly uv unwelds)
This si the only sign of anything odd on the geometry and it only happened after symming a layer in mudbox.
I have had quite a few instances of uv poly’s unwelding and spinning around. I have no idea why it happens but its possibly an obj import/export issue. Trouble is i constantly use max,topogun and mud so don’t know which one it is. plus it seams to be random.
some weird settings in the maya import export..?
maybe send the mesh to autodesk for a closer look…
x_rintintin:
I use topogun as well. I was a beta tester for a while on it, and I’ve never had it blow up UVs etc when working with Zbrush.
I think this is mudbox’s doing somehow.
I actually just came to post about another oddity with the Mirror X function on layers. Its mirroring artifacts (sometimes)
I use Smart Rsym in Zbrush quite a bit, and have never had errors with it like this. Mirroring is a key function I would need.
Also slightly related to symmetry.. although a different symmetry.
I noticed that zooming really close to an object while having Mirror X on your brush… it doesnt mirror over. You can actually see the “mirrored brush dot” right next to your brush on the part your zoomed all the way into.
You have to zoom in real close for this to happen.
When you paint, when its like this, its not mirrored over the actual X at all.
Strange behavior.
A.Baroody 06 May 2010 10:49 PM
I think this is mudbox’s doing somehow.
Mirroring in Mudbox is just moving vertices on one side to match up with corresponding vertices on the other side. So it’s not touching UVs or doing anything complex with the geometry. But if you post the mesh or a section of the mesh, I’d be happy to examine your issue.
I noticed that zooming really close to an object while having Mirror X on your brush… it doesnt mirror over.
I noticed that zooming really close to an object while having Mirror X on your brush… it doesnt mirror over.
I’m not able to reproduce this. Can you post a video or series of screen grabs?
I wonder if this might be related to an issue I have with X symmetry when I have the camera between the two sides of the model. Say I’m sculpting the palm of the base human mesh and the camera is in close looking at one palm. The second side is off the screen behind the clip plane. In this case the display doesn’t seem to update properly leaving the box around the active area (the bit you’ve sculpted) visible as you sculpt. In addition to this and worse, the sculpting isn’t smooth, it’s all lumpy and irregular and the frame rate goes through the floor.
it doesn’t do this in tangent symmetry mode (although you can’t use that on unconnected geometry like a pair of gloves).
it’s been the same since Mud2009.
I just posted my problem with the uv’s exploding on one half of my model, and I bet it’s from the exact same thing. I mirrored the geometry from one eye over to the other before redoing my uv’s. Now, after doing my uv’s and re-importing, my mesh explodes on one half of my model once I go up one level. I would say this is definitely a mudbox issue. Did anyone come up with a solution?
If you want to see a pic, I added one to my other post.
Matt Dragovits
3D Modeler - Maya/Mudbox
I just did a little more testing and I think I know what’s causing it a little more…
I did have two triangles on my model. (one on each side on the bottom of the boots. In order to active symmetry in mudbox it told me I had to set the topological axis on level two for symmetry to work. I believe this is why when you re-import your uv’s it looks fine on level one, but once you step up to level two they start to explode. I don’t know technically why it does this, but this does seem to be a big part of the equation.
Furthermore, if you lay out your uv’s and re-import them, then mirror the symmetry with the new uv’s it won’t explode. It definitely has something to do with setting the topological axis on level two for a model that has triangles.
please send this info also to the dev team…
help --> report a problem
I submitted the error to Autodesk
|
http://area.autodesk.com/forum/autodesk-mudbox/community-help/mudbox-2011-symmetry-bug/
|
crawl-003
|
refinedweb
| 1,358 | 80.11 |
You want to authenticate users but you’re unsure how. The documentation isn’t the most helpful thing in the world. You think, “wow… this documentation assumes I know all this other stuff…”
What are the things you need to authenticate users? There are 3 things you need and I’m going to show you what each looks like.
First: You need some routes
You need authentication routes. I think it makes the most sense to create a separate app for this purpose. (Separate all your login logic from all your other logic)
Let’s look at some login routes:
_loginapp/urls.py
from django.conf.urls import url from django.conf import settings from django.conf.urls.static import static from . import views urlpatterns = [ # Session Login url(r'^login/$', views.login_user, name='login'), url(r'^logout/$', views.logout_user, name='logout'), url(r'^auth/$', views.login_form, name='login_form'), ]
Second: You’ll need some templates
Templates are important. Templates are the HTML representation of your application. For example, at the bare minimum, you’ll need a way to let your users login. How do you do it? It doesn’t have to be pretty because this is JUST HTML.
loginapp/templates/loginapp/login.html
<form method='post' action="{% url 'loginapp:login' %}"> <label for="username">Username:</label> <input type="text" name="username" /> <br> <label for="password">Password:</label> <input type="password" name="password" /> <br> <input type="submit" value="Login" /> </form>
Third: You’ll need some views
The views you’ll need for login will be:
- The login form view (shows the login form)
- The POST view that will authenticate a user that is active / exists
- A view that will log the user out
Let’s start with the login form view (loginapp/auth):
def login_form(request): return render(request, 'accounts/login.html', {})
This view simply renders our
login.html template that we created above. It’s also possible to make only 2 routes (1 that will detect a POST request and 1 that will detect a GET request) however, I (personally) really like have separate views for each request method.
Here is an example of a view that will detect a username and password and use those credentials to authenticate a user and login the user thus creating a session specifically for that user.
def login_user(request): username = request.POST.get('username') password = request.POST.get('password') user = authenticate(username=username, password=password) if user is not None: # the password verified for the user if user.is_active: login(request, user) return redirect('/polls/') return redirect(settings.LOGIN_URL, request)
This method will get the
username and
password from the POST request data. Then, we will use the
username and
password to try to authenticate a user that exists in our database.
If a user exists, we will try to login our user and redirect to our
polls application. If the user does not exist we will redirect back to the login form.
How do you logout an authenticated user?
def logout_user(request): logout(request) return redirect('/polls/')
This method will take the request object and user it to logout the logged in user. Once the user logs out, the application will redirect the user to our
polls application.
This is the 3 things that you need to authenticate users in your Django application. (If you want to use Session Authentication with Django REST Framework) this is how you would accomplish this.
I hope that helps you when need to authenticate users in your future web
|
https://chrisbartos.com/articles/3-things-you-need-to-authenticate-users-in-django/
|
CC-MAIN-2018-13
|
refinedweb
| 582 | 57.87 |
Do a dynamic graph with ui and pyplot
Hello!
I am new to pythonista but found very interesting this approach of turning an ipad into a programmable device...
I would love to be able to use it for some teaching activities, but I would need to be able to plot a curve that is changed dynamically by moving sliders.
I can plot the curve in pythonsta
I can do sliders in pythonista
I can plot the dynamic curve with other python interfaces (jupyter notebook, using interact from ipywidgets)
but I wasn't able to find any indication if that would be possible with pythonista.
So is it possible and if yes, is there an example somewhere?
Thanks for any help
@chjl07 , hey. I am way out of my depth on this question. The math too much for me. But I think I can see a solution even i cant wok it out. If you save the pic to a file, you could create a ui that has the sliders, each time the sliders are changed you rewrite and reload the image into a ui.Image control. There may be a direct way to do this, but this is a my dumb simple idea to do it. Could be a little slow, maybe not. I had problems understanding the arr param to plt.imsave. So i could not go further. I am guessing this is the worse way to approach this problem. But sometimes the worse way, can shine some light to the real answer.
import matplotlib.pyplot as plt x = np.arange(0, 5, 0.1); y = np.sin(x) plt.plot(x, y) plt.show() plt.imsave(fname='crap', arr=(0,0,0))
@chjl07 , I found a few entries on the forum about pyplot. So i did something extra that shows my simple approach. It's slow and I dont eve understand what its doing, plotting wise. Is not important, I am sure you do. Not sure how much speed is an issue for you, but i think you can see from the basic example below, you could add multiple sliders to control different variables.
Again, i dont understand they math or the matplotlib. But the pattern I am using here is to do a live update as the slider moves. Another approach could be set all your sliders, then have a button you click that does the drawing using the values of the sliders.
Again, sorry, i dont really know this, just wanted to try to help. I think other guys on the forum will have a smarter approach.
import ui import numpy as np import matplotlib.pyplot as plt from io import BytesIO class MyClass(ui.View): def __init__(self, p1=1, p2=2, p3=3, *args, **kwargs): super().__init__(*args, **kwargs) self.p1 = p1 self.p2 = p2 self.p3 = p3 self.img = None self.make_view() def make_view(self): slider1 = ui.Slider(x=0, y=self.height-32 , width=self.bounds.width, value=self.y, action=self.slider_action) self.add_subview(slider1) self.img = ui.ImageView(frame=self.bounds.inset(30, 30)) self.add_subview(self.img) self.set_needs_display() def draw(self): # called by ui Module when set_needs_display() is called. # as per the docs you should not call this method yourself. plt.plot([self.p1, self.p2, self.p3]) b = BytesIO() plt.savefig(b) img = ui.Image.from_data(b.getvalue()) self.img.image = img def slider_action(self, sender): self.p1 *= sender.value+1 self.p2 *= sender.value+2 self.p3 *= sender.value+3 self.set_needs_display() if __name__ == '__main__': f = (0, 0, 400, 400) mc= MyClass(frame=f, name='*** WTF ***') mc.present('sheet')
Hi Phuket2
Thanks a lot. your example works on my ipad and I think this approach could work. I have been using the approach of designing the ui with pyui, right now I am still trying to figure out how to pass the image to the ui...
x = np.linspace(0,9,100) plt.show() img=plt.plot(x,np.sin(x)) v['imageview1'].img=img
doesnt deliver any error, but doesnt do the job either...
Sorry, I was too fast typing my last message. I meant :
x = np.linspace(0,9,100) img=plt.plot(x,np.sin(x)) plot.show() v['imageview1'].img=img
the plot.show shows the curve in the background. But I have no curve in the user interface
Thanks again. So finally it worked. Here the total code. This plots the parabolic trajectory as a function of angle and initial velocity. I just need to figure out how to delete the previous image and not have them superimposed when the sliders are used.
import matplotlib.pyplot as plt import numpy as np import ui from io import BytesIO g=9.81 def plotparabole(alpha,v_0): #Le programme calcule en radians, mais un input en degres est plus intuitif alpharad=alpha*np.pi/180 #le graphe sera de 100 points, pour un temps entre 0 et 9 secondes, #mais suivant les conditions, le temps de vol réel peut être plus court t = np.linspace(0,9,100) #représentation du vecteur vitesse à t=0 vit=[0,0,v_0*np.cos(alpharad),v_0*np.sin(alpharad)] ax = plt.gca() ax.quiver(0,0,v_0*np.cos(alpharad),v_0*np.sin(alpharad),color='red',angles='xy', scale_units='xy', scale=1) plt.axis([0, 170, 0, 100]) #tracé de la trajectoire, grâce à des coordonnées parametrées en fonction du temps plt.plot(v_0*np.cos(alpharad)*t, -0.5*g*t**2+v_0*np.sin(alpharad)*t) plt.axes().set_aspect('equal') b = BytesIO() plt.savefig(b) img = ui.Image.from_data(b.getvalue()) return(img) ######################################################### def slider_action(sender): # Get the root view: v = sender.superview # Get the sliders: v0 = v['slider1'].value*40 alpha = v['slider2'].value*90 v['alpha'].text = 'alpha=%f degres' % (alpha) v['v0'].text = 'vitesse=%f m/s' % (v0) img=plotparabole(alpha,v0) v['imageview1'].image=img v = ui.load_view('Balistique') slider_action(v['imageview1']) if ui.get_screen_size()[1] >= 768: # iPad v.present('sheet') else: # iPhone v.present()
and here the pyui file:
[ { "selected" : false, "frame" : "{{0, 0}, {560, 427}}", "class" : "View", "nodes" : [ { "selected" : false, "frame" : "{{15, 380}, {242, 34}}", "class" : "Slider", "nodes" : [ ], "attributes" : { "flex" : "W", "border_width" : 1, "action" : "slider_action", "frame" : "{{180, 168}, {200, 34}}", "border_color" : "RGBA(1.000000,0.200000,0.200000,1.000000)", "class" : "Slider", "value" : 0.5, "uuid" : "0EBE87B6-3527-4D66-B9D6-F1361D7BB24F", "corner_radius" : 2, "name" : "slider1" } }, { "selected" : false, "frame" : "{{295, 387}, {232, 34}}", "class" : "Slider", "nodes" : [ ], "attributes" : { "action" : "slider_action", "flex" : "W", "frame" : "{{180, 168}, {200, 34}}", "uuid" : "6D51E0F1-9BE3-4486-8962-D365342746A5", "class" : "Slider", "value" : 0.5, "name" : "slider2" } }, { "selected" : false, "frame" : "{{295, 340}, {198, 32}}", "class" : "Label", "nodes" : [ ], "attributes" : { "font_name" : "<System>", "frame" : "{{205, 169}, {150, 32}}", "uuid" : "733AE3FF-A92D-41CD-B37D-66EF27B4DD3A", "class" : "Label", "alignment" : "left", "text" : "alpha", "font_size" : 18, "name" : "alpha" } }, { "selected" : false, "frame" : "{{15, 340}, {178, 32}}", "class" : "Label", "nodes" : [ ], "attributes" : { "font_name" : "<System>", "frame" : "{{205, 169}, {150, 32}}", "uuid" : "733AE3FF-A92D-41CD-B37D-66EF27B4DD3A", "class" : "Label", "alignment" : "left", "text" : "v0", "name" : "v0", "font_size" : 18 } }, { "selected" : true, "frame" : "{{15, 28}, {524, 304}}", "class" : "ImageView", "nodes" : [ ], "attributes" : { "alpha" : 1, "frame" : "{{230, 164}, {100, 100}}", "class" : "ImageView", "background_color" : "RGBA(0.956522,1.000000,0.869565,1.000000)", "uuid" : "60FC8613-07A2-4229-ACFE-B8DD87CC03FE", "name" : "imageview1", "image_name" : "iob:alert_256" } } ], "attributes" : { "enabled" : true, "background_color" : "RGBA(1.000000,1.000000,1.000000,1.000000)", "tint_color" : "RGBA(0.000000,0.478000,1.000000,1.000000)", "border_color" : "RGBA(0.000000,0.000000,0.000000,1.000000)", "flex" : "" } } ]
I just need to figure out how to delete the previous image and not have them superimposed when the sliders are used.
Use this to close the previous plot.
plt.close()
--
JJW
@chjl07 , thats great. Glad you got it working. As I said I didn't know what I was doing, but could sort of imagine how it could be solved.
Look if you are happy with what you have thats fine. But there is a way to load a UIFile into a regular Custom View Class. Can make working with your pyui so much easier. I have put the code below. If you search the forum you will see where this code came from , essentially @JonB.
But its a pretty nice way to handle views created in the ui designer.
You have to do things.
- pass the filename of your pyui file to MyClass (pretty evident)
- Can not show here, but you have to set the 'Custom View Class' property in the ui Designer of of your form to the name of the class name you are using. In this example, the class I want to bring the pyui file into is called MyClass. So, eg, if you decided to call you class MYPlotClass, you would but that in the 'Custom View Class' property into your form.
Hope I have not made it sound complicated because its not.
Look again, this may not be important to you. But for me its great to be able to get a UIFile loaded into a class the same as if you had created a CustomView.
It's worth a look.
import ui def pyui_bindings(obj): # JonB def WrapInstance(obj): class Wrapper(obj.__class__): def __new__(cls): return obj return Wrapper bindings = globals().copy() bindings[obj.__class__.__name__] = WrapInstance(obj) return bindings class MyClass(ui.View): def __init__(self, ui_file, *args, **kwargs): ui.load_view(ui_file, pyui_bindings(self)) super().__init__(*args, **kwargs) if __name__ == '__main__': ui_file = 'MyPYUIForm.pyui' mc = MyClass(ui_file, name='MyForm') mc.present('sheet')
|
https://forum.omz-software.com/topic/4518/do-a-dynamic-graph-with-ui-and-pyplot
|
CC-MAIN-2021-39
|
refinedweb
| 1,575 | 68.26 |
Following logic is used in the solution:-
Traverse through every element of the left side of the root.
If both p and q are found, move left. If none are found, move right. If only one of them is found, root is the answer.
Assuming that tree is sufficiently balanced, traversing takes n/2 time and we repeat this logn time.
A good catch is to compare the TreeNode reference and not their values, since multiple nodes can have same value and we may get false positive! Below is the code :-
public class Solution { boolean foundP = false; boolean foundQ = false; public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) { if(root == p || root == q) return root; prefix(root.left, p, q); if(foundP && foundQ) { foundP = foundQ = false; return lowestCommonAncestor(root.left, p, q); } else if(!foundP && !foundQ) return lowestCommonAncestor(root.right, p, q); return root; } void prefix(TreeNode root, TreeNode p, TreeNode q) { if(root == null) return; if(root == p) foundP = true; else if(root == q) foundQ = true; prefix(root.left, p, q); prefix(root.right, p , q); } }
if(root == p || root == q)
return root;
This is an important part of your solution that you don't address in your summary. Without it,
[[p],[1,q]] will not return correctly.
One average you are good, but your worst case is
O(n^2): each node has left only and p and q are at the lowest levels. I think it's possible
O(n) worst/avg time.
@TWiStErRob: I am not very sure regarding the runtime complexity of this problem. But let's see. If we consider the tree to be balanced, we could traverse n/2 nodes in the 1st pass, then n/4, n/8, .., so on. So, summing up, n(1 + 1/2 + 1/4 + ... 1/(2^lgn) ) which is less than 2n (using GP). This gives us O(n).
However, if the tree is totally unbalanced (one node on each level), we could be looking (n -1) + (n - 2) + ... 1 nodes, which gives us O(n^2)
You actually visit each node only once regardless of input in
lowestCommonAncestor recursion, only the
prefix method skews your runtime a lot. I suggest you try to work those into a single method and a single left-right recursion. Btw, what's the runtime score (in ms) you were given? link
Looks like your connection to LeetCode Discuss was lost, please wait while we try to reconnect.
|
https://discuss.leetcode.com/topic/18955/java-solution-o-nlgn
|
CC-MAIN-2017-43
|
refinedweb
| 408 | 74.59 |
Groovy 1.5.7 contains mainly bug fixes (61 bug fixes), but also some minor API improvements (20 improvements) backported from the1.6 branch, whereas Groovy 1.6-beta-2 brings a wealth of novelty (68 bug fixes and 38 improvements and new features). Here, we'll mainly cover the new features of beta-2.
Following up on our major compile-time and runtime performance improvements in beta-1, we continued our efforts in that area for beta-2. But you'll also be interested in discovering the changes and new features brought by this new release.
Multiple Assignments
In beta-1, we introduced the possibility to define multiple assignments. However, we faced some issues and ambiguities with the subscript notation, so we adapted the syntax slightly by using parentheses instead of square brackets. We also now cover all the assignment use cases, which wasn't the case previously.
You can define and assign several variables at once:
def (a, b) = [1,2]
assert a == 1
assert b == 2
And you can also define the types of the variables in one shot as follows:
def (int i, String j) = [1, 'Groovy']
For the assignment (without priori definition of the variables), just don't use the 'def' keyword:
def a, b
(a, b) = functionReturningAList()
Otherwise, apart from the syntax change, the behavior is the same as in beta-1: if the list on the right-hand side contains more elements than the number of variables on the left-hand side, only the first elements will be assigned in order into the variables. Also, when there are less elements than variables, the extra variables will be assigned null.
Optional return for if/else and try/catch/finally blocks
Although not a syntax change, but at least a new behavior: it is now possible for if/else and try/catch/finally blocks to return a value. No need to explicitly use the 'return' keyword inside these constructs, as long as they are the latest statement in the block of code.
As an example, the following method will return 1, although the 'return' keyword was omitted.
def method() {
if (true) 1 else 0
}
You can have a look at our test case to have an overview of this new behavior. initiated and introduced in beta-1, we are able to tackle new and innovative ideas without necessary grammar changes.
With AST Transformations, people can hook into the compiler to make some changes to the AST in order to change the program that is being compiled. AST Transformations provides Groovy with improved compile-time metaprogramming capabilities allowing powerful flexibility at the language level, without a runtime performance penalty.
In beta-1, two AST Transformations found their way in the release, pioneered by our talented Groovy Swing team. With the @Bindable transformation marker annotation, property listeners are transparently added to the class for the property that is being annotated. Sames goes for the @Vetoable annotation for vetoing property changes.
In beta-2, new transformations have been created:
- @Singleton to transform a class into a singleton (example)
- @Immutable to forbid changes to an instance once it's been created (example)
- @Delegate transparently implement the delegation pattern (example :)
- @Lazy for lazily initializing properties (example)
- @Category / @Mixin helps mixin category methods at compile-time (example)
- @Newify allows to omit using the 'new' keyword for creating instances, simply doing Integer(5) will create an instance, and also gives you the ability to use a Ruby-esque syntax with Integer.new(5)
Swing builder
The swing builder which pioneered AST transformations added support for binding to simple closures, i.e. bean(property: bind { otherBean.property } ) is the same as bind(source: otherBean, target: property). It is also a closure so you can do more complex expressions like bean(location: bind {pos.x + ',' + pos.y} ) -- but the expression needs to stay simple enough: no loops or branching, for instance.
Grape, the adaptable / advanced packaging engine
Also leveraging AST Transformations, Groovy 1.6-beta-2 provides a preview of the Groovy Advanced or Adaptable Packaging Engine..
For more information on Grape, please read the documentation.
Per instance metaclass even for POJOs
So far, Groovy classes could have a per-instance metaclass, but POJOs could only have on metaclass for all instances (ie. a per-class metaclass). This is now not the case anymore, as POJOs can have per-instance metaclass too. Also, setting the metaclass property to null will restore the default metaclass.
ExpandoMetaClass DSL
A new DSL for EMC was created to allow chaining the addition of new methods through EMC without the usual object.metaClass repetition. You can find some examples in our test cases again: here and there.
Runtime mixins
One last feature I'll mention today is runtime mixins. Unlike the @Category/@Mixin combo, or even the @Delegate transformation, as their name imply, mixin behavior at runtime. You can find examples here, which also combine the use of the EMC DSL
Useful links
You can download both versions here, and the JARs will be available shortly on the central Maven repository.
And you can read the release notes from JIRA for 1.5.7 and the release notes for 1.6-beta-2.
Further down the road
We adapted the Groovy roadmap a little: as features which were supposed to be in 1.7 have already been implemented in 1.6, the scope of 1.7 is reduced and 1.8 is made useless, so after 1.6, we'll focus on 1.7 which will mainly bring one new major feature (the ability to define anonymous inner classes in Groovy, to bridge the small difference gap with Java), and afterwards, we'll be able to focus our energy on Groovy 2.0 improving and rewriting parts of the Groovy core to bring in even more performance and to pave the way for even more power features in future versions.
We're looking forward to hearing about your feedback on those two releases.
Thanks a lot to everybody for their help and respective contributions.
Enjoy!
--
Guillaume Laforge
Groovy Project Manager
G2One, Inc. Vice-President Technology
Otengi Miloskov replied on Thu, 2008/10/09 - 11:24pm
Andres Almiray replied on Fri, 2008/10/10 - 12:46am
in response to:
Otengi Miloskov
Yes, they are quite similar. Here are some useful links on the matter
Otengi Miloskov replied on Fri, 2008/10/10 - 1:40am
in response to:
Andres Almiray
This is great, Thanks.
So Just need to use Scenegraph and make a builder with it and we can use Groovy for RIA as JavaFX.
Jacek Furmankiewicz replied on Fri, 2008/10/10 - 7:58am
Andres Almiray replied on Fri, 2008/10/10 - 10:55am
in response to:
Otengi Miloskov
Actually no, we don't need SceneGraph, we have our own GraphicsBuilder built with the same philosophy as SwingBuilder
There is plenty of info on GraphicsBuilder at my blog () and a couple of tutorials here at Groovy Zone ;-)
Guillaume Laforge replied on Sat, 2008/10/11 - 5:23am
in response to:
Jacek Furmankiewicz
|
http://groovy.dzone.com/news/groovy-157-and-16-beta2-releas
|
CC-MAIN-2014-41
|
refinedweb
| 1,172 | 60.24 |
It's not the same without you
Join the community to find out what other Atlassian users are discussing, debating and creating.
Hi.
i want to build something equal like the SEN field in support.atlassian.com
my goal is..
if a user enters a number in a field...some queries should be done on an external server using this number.
the results should be displayed below this field...
i think something like this is used to verify a customers SEN.
You should use the script runner plugin.
The code would look like
import groovy.sql.Sql; import groovy.sql.GroovyRowResult; import java.sql.SQLException; Sql connection; try { connection = Sql.newInstance( 'jdbc:postgresql://localhost:5432/database','user','password', 'org.postgresql.Driver' ); } catch (SQLException e) { return "Unknown (Issue connecting to the database: ${e.getMessage()})"; } GroovyRowResult result = null; try { result = connection.firstRow("select name from customers where id = ${customerid} "); } catch (SQLException e) { return "Issue retrieving data from the database: " + e.getMessage();; } if (result == null) { // no value given return "Customer not known"; } return "The customer is " + result.get("name");
hmm
i get some result like:
javax.script.ScriptException: groovy.lang.MissingPropertyException: No such property: username for class: Script24 A stacktrace has been logged.
in my case i've set up a field "username"
by entering a user name a query should be performed to show me the users email_address
running the query in the local db works fine. am i missing something here?
Its hard to tell without code
Propably you use something like $username without declaring it.
You need to retrieve the value from the customfield. The script runner wiki has many examples how to do this.
Francis
You'll need to do a bit of coding to get this. I've not seen a plugin that will do this off-the-shelf.
yeah that's what i expected. but could you share any idea?
i mean i don't think it is done by some jelly scripts doesn.
|
https://community.atlassian.com/t5/Questions/how-can-i-run-background-queries-using-customfield-values/qaq-p/245511
|
CC-MAIN-2018-13
|
refinedweb
| 327 | 69.79 |
On Thursday, September 7, 2017 3:54:15 AM EDT Greg Ewing wrote: > This problem would also not arise if context vars > simply had names instead of being magic key objects: > > def foo(): > contextvars.set("mymodule.myvar", 1) > > That's another thing I think would be an improvement, > but it's orthogonal to what we're talking about here > and would be best discussed separately. On the contrary, using simple names (PEP 550 V1 was actually doing that) is a regression. It opens up namespace clashing issues. Imagine you have a variable named "foo", and then some library you import also decides to use the name "foo", what then? That's one of the reasons why we do `local = threading.local()` instead of `threading.set_local("foo", 1)`. Elvis
|
https://mail.python.org/pipermail/python-dev/2017-September/149291.html
|
CC-MAIN-2017-47
|
refinedweb
| 128 | 63.09 |
§Play 2.5 Migration Guide
This is a guide for migrating from Play 2.4 to Play 2.5. If you need to migrate from an earlier version of Play then you must first follow the Play 2.4 Migration Guide.
As well as the information contained on this page, there is more detailed migration information for some topics:
- Streams Migration Guide – Migrating to Akka Streams, now used in place of iteratees in many Play APIs
- Java Migration Guide - Migrating Java applications. Play now uses native Java types for functional types and offers several new customizable components in Java.
Lucidchart has also put together an informative blog post on upgrading from Play 2.3.x to Play 2.5.x..5.x")
Where the “x” in
2.5.x is the minor version of Play you want to use, per instance
2.5.0.
§sbt upgrade to 0.13.11
Although Play 2.5 will still work with sbt 0.13.8, we recommend upgrading to the latest sbt version, 0.13.11. The 0.13.11 release of sbt has a number of improvements and bug fixes.
Update your
project/build.properties so that it reads:
sbt.version=0.13.11
§Play Slick upgrade
If your project is using Play Slick, you need to upgrade it:
libraryDependencies += "com.typesafe.play" %% "play-slick" % "2.0.0"
Or:
libraryDependencies ++= Seq( "com.typesafe.play" %% "play-slick" % "2.0.0", "com.typesafe.play" %% "play-slick-evolutions" % "2.0.0" )
§Play Ebean upgrade
If your project is using Play Ebean, you need to upgrade it:
addSbtPlugin("com.typesafe.sbt" % "sbt-play-ebean" % "3.0.0")
§ScalaTest + Plus upgrade
If your project is using ScalaTest + Play, you need to upgrade it:
libraryDependencies ++= Seq( "org.scalatestplus.play" %% "scalatestplus-play" % "1.5.1" % "test" )
§Scala 2.10 support discontinued
Play 2.3 and 2.4 supported both Scala 2.10 and 2.11. Play 2.5 has dropped support for Scala 2.10 and now only supports Scala 2.11. There are a couple of reasons for this:
Play 2.5’s internal code makes extensive use of the scala-java8-compat library, which only supports Scala 2.11. The scala-java8-compat has conversions between many Scala and Java 8 types, such as Scala
Futures and Java
CompletionStages. (You might find this library useful for your code too.)
The next version of Play will probably add support for Scala 2.12. It’s time for Play to move to Scala 2.11 so that the upcoming transition to 2.12 will be easier.
§How to migrate
Both Scala and Java users must configure sbt to use Scala 2.11. Even if you have no Scala code in your project, Play itself uses Scala and must be configured to use the right Scala libraries.
To set the Scala version in sbt, simply set the
scalaVersion key, eg:
scalaVersion := "2.11.8"
If you have a single project build, then this setting can just be placed on its own line in
build.sbt. However, if you have a multi project build, then the scala version setting must be set on each project. Typically, in a multi project build, you will have some common settings shared by every project, this is the best place to put the setting, eg:
def common = Seq( scalaVersion := "2.11.8" ) lazy val projectA = (project in file("projectA")) .enablePlugins(PlayJava) .settings(common: _*) lazy val projectB = (project in file("projectB")) .enablePlugins(PlayJava) .settings(common: _*)
§Change to Logback configuration
As part of the change to remove Play’s hardcoded dependency on Logback (see Highlights), one of the classes used by Logback configuration had to be moved to another package.
§How to migrate
You will need to update your Logback configuration files (
logback*.xml) and change any references to the old
play.api.Logger$ColoredLevel to the new
play.api.libs.logback.ColoredLevel class.
The new configuration after the change will look something like this:
<conversionRule conversionWord="coloredLevel" converterClass="play.api.libs.logback.ColoredLevel" />
If you use compile time dependency injection, you will need to change your application loader from using
Logger.configure(...) to the following:
LoggerConfigurator(context.environment.classLoader).foreach { _.configure(context.environment) }
You can find more details on how to set up Play with different logging frameworks are in Configuring logging section of the documentation.
§Play WS upgrades to AsyncHttpClient 2
Play WS has been upgraded to use AsyncHttpClient 2. This is a major upgrade that uses Netty 4.0. Most of the changes in AHC 2.0 are under the hood, but AHC has some significant refactorings which require breaking changes to the WS API:
AsyncHttpClientConfigreplaced by
DefaultAsyncHttpClientConfig.
allowPoolingConnectionand
allowSslConnectionPoolare combined in AsyncHttpClient into a single
keepAlivevariable. As such,
play.ws.ning.allowPoolingConnectionand
play.ws.ning.allowSslConnectionPoolare not valid and will throw an exception if configured.
webSocketIdleTimeouthas been removed, so is no longer available in
AhcWSClientConfig.
ioThreadMultiplierhas been removed, so is no longer available in
AhcWSClientConfig.
FluentCaseInsensitiveStringsMapclass is removed and replaced by Netty’s
HttpHeaderclass.
Realm.AuthScheme.Nonehas been removed, so is no longer available in
WSAuthScheme.
In addition, there are number of small changes:
- In order to reflect the proper AsyncHttpClient library name, package
play.api.libs.ws.ningwas renamed into
play.api.libs.ws.ahcand
Ning*classes were renamed into
Ahc*. In addition, the AHC configuration settings have been changed to
play.ws.ahcprefix, i.e.
play.ws.ning.maxConnectionsPerHostis now
play.ws.ahc.maxConnectionsPerHost.
- The deprecated interface
play.libs.ws.WSRequestHolderhas been removed.
- The
play.libs.ws.play.WSRequestinterface now returns
java.util.concurrent.CompletionStageinstead of
F.Promise.
- Static methods that rely on
Play.currentor
Play.applicationhave been deprecated.
- Play WS would infer a charset from the content type and append a charset to the
Content-Typeheader of the request if one was not already set. This caused some confusion and bugs, and so in 2.5.x the
Content-Typeheader does not automatically include an inferred charset. If you explicitly set a
Content-Typeheader, the setting is honored as is.
§Deprecated
GlobalSettings
As part of the on going efforts to move away from global state in Play,
GlobalSettings and the application
Global object have been deprecated. For more details, see the Play 2.4 migration guide for how to migrate away from using
GlobalSettings.
§Removed Plugins API
The Plugins API was deprecated in Play 2.4 and has been removed in Play 2.5. The Plugins API has been superseded by Play’s dependency injection and module system which provides a cleaner and more flexible way to build reusable components. For details on how to migrate from plugins to dependency injection see the Play 2.4 migration guide.
§Routes generated with InjectedRoutesGenerator
Routes are now generated using the dependency injection aware
InjectedRoutesGenerator, rather than the previous
StaticRoutesGenerator which assumed controllers were singleton objects.
To revert back to the earlier behavior (if you have “object MyController” in your code, for example), please add the following line to your
build.sbt file:
routesGenerator := StaticRoutesGenerator
If you’re using
Build.scala instead of
build.sbt you will need to import the
routesGenerator settings key:
import play.sbt.routes.RoutesCompiler.autoImport._
Using static controllers with the static routes generator is not deprecated, but it is recommended that you migrate to using classes with dependency injection.
§Replaced static controllers with dependency injection
controllers.ExternalAssets is now a class, and has no static equivalent.
controllers.Assets and
controllers.Default are also classes, and while static equivalents exist, it is recommended that you use the class version.
§How to migrate
The recommended solution is to use classes for all your controllers. The
InjectedRoutesGenerator is now the default, so the controllers in the routes file are assumed to be classes instead of objects.
If you still have static controllers, you can use
StaticRoutesGenerator (described above) and add the
@ symbol in front of the route in the
routes file, e.g.
GET /assets/*file @controllers.ExternalAssets.at(path = "/public", file)
§Deprecated play.Play and play.api.Play methods
The following methods have been deprecated in
play.Play:
public static Application application()
public static Mode mode()
public static boolean isDev()
public static boolean isProd()
public static boolean isTest()
Likewise, methods in
play.api.Play that take an implicit
Application and delegate to Application, such as
def classloader(implicit app: Application) are now deprecated.
§How to migrate
These methods delegate to either
play.Application or
play.Environment – code that uses them should use dependency injection to inject the relevant class.
You should refer to the list of dependency injected components in the Play 2.4 Migration Guide to migrate built-in Play components.
For example, the following code injects an environment and configuration into a Controller in Scala:
class HomeController @Inject() (environment: play.api.Environment, configuration: play.api.Configuration) extends Controller { def index = Action { Ok(views.html.index("Your new application is ready.")) } def config = Action { Ok(configuration.underlying.getString("some.config")) } def count = Action { val num = environment.resource("application.conf").toSeq.size Ok(num.toString) } }
§Handling legacy components
Generally the components you use should not need to depend on the entire application, but sometimes you have to deal with legacy components that require one. You can handle this by injecting the application into one of your components:
class FooController @Inject() (appProvider: Provider[Application]) extends Controller { implicit lazy val app = appProvider.get() def bar = Action { Ok(Foo.bar(app)) } }
Note that you usually want to use a
Provider[Application] in this case to avoid circular dependencies.
Even better, you can make your own
*Api class that turns the static methods into instance methods:
class FooApi @Inject() (appProvider: Provider[Application]) { implicit lazy val app = appProvider.get() def bar = Foo.bar(app) def baz = Foo.baz(app) }
This allows you to benefit from the testability you get with DI and still use your library that uses global state.
§Content-Type charset changes
Prior to Play 2.5, Play would add a
charset parameter to certain content types that do not define a charset parameter, specifically
application/json and
application/x-www-form-urlencoded. Now the
Content-Type is sent without a charset by default. This applies both to sending requests with
WS and returning responses from Play actions. If you have a non-spec-compliant client or server that requires you to send a charset parameter, you can explicitly set the
Content-Type header.
§Guice injector and Guice builder changes
By default, Guice can resolve your circular dependency by proxying an interface in the cycle. Since circular dependencies are generally a code smell, and you can also inject Providers to break the cycle, we have chosen to disable this feature on the default Guice injector. Other DI frameworks also are not likely to have this feature, so it can lead to problems when writing Play modules.
Now there are four new methods on the Guice builders (
GuiceInjectorBuilder and
GuiceApplicationBuilder) for customizing how Guice injects your classes:
*
disableCircularProxies: disables the above-mentioned behaviour of proxying interfaces to resolve circular dependencies. To allow proxying use
disableCircularProxies(false).
*
requireExplicitBindings: instructs the injector to only inject classes that are explicitly bound in a module. Can be useful in testing for verifying bindings.
*
requireAtInjectOnConstructors: requires a constructor annotated with @Inject to instantiate a class.
*
requireExactBindingAnnotations: disables the error-prone feature in Guice where it can substitute a binding for @Named Foo when injecting @Named(“foo”) Foo.
§CSRF changes
In order to make Play’s CSRF filter more resilient to browser plugin vulnerabilities and new extensions, the default configuration for the CSRF filter has been made far more conservative. The changes include:
- Instead of blacklisting
POSTrequests, now only
GET,
HEADand
OPTIONSrequests are whitelisted, and all other requests require a CSRF check. This means
DELETEand
PUTrequests are now checked.
- Instead of blacklisting
application/x-www-form-urlencoded,
multipart/form-dataand
text/plainrequests, requests of all content types, including no content type, require a CSRF check. One consequence of this is that AJAX requests that use
application/jsonnow need to include a valid CSRF token in the
Csrf-Tokenheader.
- Stateless header-based bypasses, such as the
X-Requested-With, are disabled by default.
There’s a new config option to bypass the new CSRF protection for requests with certain headers. This config option is turned on by default for the Cookie and Authorization headers, so that REST clients, which typically don’t use session authentication, will still work without having to send a CSRF token.
However, since the config option allows through all requests without those headers, applications that use other authentication schemes (NTLM, TLS client certificates) will be vulnerable to CSRF. These applications should disable the config option so that their authenticated (cookieless) requests are protected by the CSRF filter.
Finally, an additional option has been added to disable the CSRF check for origins trusted by the CORS filter. Please note that the CORS filter must come before the CSRF filter in your filter chain for this to work!
Play’s old default behaviour can be restored by adding the following configuration to
application.conf:
play.filters.csrf { header { bypassHeaders { X-Requested-With = "*" Csrf-Token = "nocheck" } protectHeaders = null } bypassCorsTrustedOrigins = false method { whiteList = [] blackList = ["POST"] } contentType.blackList = ["application/x-www-form-urlencoded", "multipart/form-data", "text/plain"] }
§Getting the CSRF token
Previously, a CSRF token could be retrieved from the HTTP request in any action. Now you must have either a CSRF filter or a CSRF action for
CSRF.getToken to work. If you’re not using a filter, you can use the
CSRFAddToken action in Scala or
AddCSRFToken Java annotation to ensure a token is in the session.
Also, a minor bug was fixed in this release in which the CSRF token would be empty (throwing an exception in the template helper) if its signature was invalid. Now it will be regenerated on the same request so a token is still available from the template helpers and
CSRF.getToken.
For more details, please read the CSRF documentation for Java and Scala.
§Crypto Deprecated
From Play 1.x, Play has come with a
Crypto object that provides some cryptographic operations. This used internally by Play. The
Crypto object is not mentioned in the documentation, but is mentioned as “cryptographic utilities” in the scaladoc..
§How to Migrate
Cryptographic migration will depend on your use case, especially if there is unsafe construction of the cryptographic primitives. The short version is to use Kalium if possible, otherwise use KeyCzar or straight JCA.
Please see Crypto Migration for more details.
§Netty 4 upgrade
Netty has been upgraded from 3.10 to 4.0. One consequence of this is the configuration options for configuring Netty channel options have changed. The full list options can be seen here.
§How to Migrate
Modify any
play.server.netty.option keys to use the new keys defined in ChannelOption. A mapping of some of the more popularly used ones is:
§Changes to
sendFile,
sendPath and
sendResource methods
Java (
play.mvc.StatusHeader) and Scala (
play.api.mvc.Results.Status) APIs had the following behavior before:
In other words, they were mixing
inline and
attachment modes when delivering files. Now, when delivering files, paths and resources uses
inline as the default behavior. Of course, you can alternate between these two modes using the parameters present in these methods.
Next: Streams Migration Guide
|
https://www.playframework.com/documentation/2.7.0-M1/Migration25
|
CC-MAIN-2019-47
|
refinedweb
| 2,544 | 50.43 |
2.10. Statements and Expressions¶
A statement is an instruction that the Python interpreter can execute. You have only seen the assignment
statement so far. Some other kinds of statements that you’ll see in future chapters are
while statements,
for statements,
if statements, and
import statements. (There are other kinds too!)
An expression is a combination of literals, variable names, operators, and calls to functions. Expressions need to be evaluated. The result of evaluating an expression is a value or object.
If you ask Python to
In this example
len is a built-in Python function that returns the number of characters in a string.
The evaluation of an expression produces a value, which is why expressions can appear on the right hand side of assignment statements. A literal all by itself is a simple expression, and so is a variable.
In a program, anywhere that a literal value (a string or a number) is acceptable, a more complicated expression is also acceptable. Here are all the kinds of expressions we’ve seen so far:
- literal
e.g., “Hello” or 3.14
- variable name
e.g., x or len
- operator expression
<expression> operator-name <expression>
- function call expressions
<expression>(<expressions separated by commas>)
Notice that operator expressions (like
+ and
*) have sub-expressions before and after the operator. Each of these can themselves be simple or complex expressions. In that way, you can build up to having pretty complicated expressions.
Similarly, when calling a function, instead of putting a literal inside the parentheses, a complex expression can be placed inside the parentheses. (Again, we provide some hidden code that defines the functions
square and
sub).
With a function call, it’s even possible to have a complex expression before the left parenthesis, as long as that expression evaluates to a function object. For now, though, we will just use variable names (like square, sub, and len) that are directly bound to function objects.
It is important to start learning to read code that contains complex expressions. The Python interpreter examines any line of code and parses it into components. For example, if it sees an
= symbol, it will try to treat the whole line as an assignment statement. It will expect to see a valid variable name to the left of the =, and will parse everything to the right of the = as an expression. It will try to figure out whether the right side is a literal, a variable name, an operator expression, or a function call expression. If it’s an operator expression, it will further try to parse the sub-expressions before and after the operator. And so on. You should learn to parse lines of code in the same way.
In order to evaluate an operator expression, the Python interpreter first completely evaluates the expression before the operator, then the one after, then combines the two resulting values using the operator. In order to evaluate a function call expression, the interpreter evaluates the expression before the parentheses (i.e., it looks up the name of the function). Then it tries to evaluate each of the expressions inside the parentheses. There may be more than one, separated by commas. The values of those expressions are passed as inputs to the function when the function is called.
If a function call expression is a sub-expression of some more complicated expression, as
square(x) is in
sub(square(y), square(x)), then the return value from
square(x) is passed as an input to the
sub function. This is one of the tricky things that you will have to get used to working out when you read (or write) code. In this example, the
square function is called (twice) before the
sub function is called, even though the
sub function comes first when reading the code from left to right. In the following example we will use the notation of -add- to indicate that Python has looked up the name add and determined that it is a function object.
y = 7
add(square(y), square(x))
To start giving you some practice in reading and understanding complicated expressions, try doing the Parsons problem below. Be careful not to indent any of the lines of code; that’s something that will come later in the course.
Please order the code fragments in the order in which the Python interpreter would evaluate them. x is 2 and y is 3. Now the interpreter is executing square(x + sub(square(y), 2 *x)).
|
https://runestone.academy/runestone/books/published/fopp/SimplePythonData/StatementsandExpressions.html
|
CC-MAIN-2021-43
|
refinedweb
| 751 | 63.19 |
#include <FXToolBar.h>
#include <FXToolBar.h>
Inheritance diagram for FX::FXToolBar:
LAYOUT_TOP|LAYOUT_LEFT|LAYOUT_FILL_X
0
3
2
DEFAULT_SPACING
Construct a floatable toolbar Normally, the toolbar is docked under window p.
When floated, the toolbar can be docked under window q, which is typically an FXToolBarShell window.
Construct a non-floatable toolbar.
The toolbar can not be undocked.
[virtual]
Destroy.
Set parent when docked.
If it was docked, reparent under the new docking window.
Set parent when floating.
If it was undocked, then reparent under the new floating window.
[inline]
Return parent when docked.
Return parent when floating.
Return true if toolbar is docked.
LAYOUT_SIDE_TOP
(FXWindow *)-1L
Dock the bar against the given side, after some other widget.
However, if after is -1, it will be docked as the innermost bar just before the work-area, while if after is 0, if will be docked as the outermost bar.
Undock or float the bar.
The initial position of the wet dock is a few pixels below and to the right of the original docked position.
Return default width.
Reimplemented from FX::FXPacker.
Return default height.
Perform layout.
Return width for given height.
Reimplemented from FX::FXWindow.
Return height for given width.
Set docking side.
Return docking side.
Save toolbar to a stream.
Load toolbar from a stream.
|
http://fox-toolkit.org/ref12/classFX_1_1FXToolBar.html
|
CC-MAIN-2021-17
|
refinedweb
| 216 | 63.36 |
Hi,
In DSS recipe, is it possible to add a column to a dataframe with an ID indicating the row number ?
I am using R at the moment with the command
data <- tibble::rowid_to_column(data, "ID")
but it would be great to have this function build in in DSS prepare recipe.
Thanks
Hi,
In a prepare recipe, you could do that with a Python formula step, provided that your data is not parallelized when processed. If your input dataset is filesystem, try checking the "Preserve ordering" option in your input dataset's Advanced settings, then adding a Python step (in "cell" mode) to your Prepare recipe, with for instance this kind of code:
count = 0
def process(row):
global count
count = count + 1
return count
You can find more info on Data ordering here.
Since Dataiku V.7, it can be done visually with the prepare recipe: “output file record column” with "enrich record with context" processor
|
https://community.dataiku.com/t5/Using-Dataiku-DSS/Add-ID-for-row-number-in-DSS-dataframe/td-p/2133
|
CC-MAIN-2021-31
|
refinedweb
| 157 | 62.72 |
Hi.
I am wondering if someone knows a way to get the Plugin~/Plugout~ data from one track into a M4L device on another track.
this is not possible.
it is a crippling made by ableton and threading issues.
it is still crippled in Live9 and it is infuriating.
global send~ / receive~ do not work. workaround is to use a buffered global namespace buffer~ setup, but it is dangerous and does not really do what we want.
Sure this is a waste… Can’t you use the routing capabilities of Live ofr that ? Say you want the data fro mtrack 1 in track 2, select ‘track 1’ as audio source for track 2 and set monitoring on ?
The only problem with your solution Stephane is, if you did that, track 2 would not be able to have its own audio.
Thank you for your help.
I know. That was an hypothesis.
Log in to reply
Let us tell you about notable Max projects, obscure facts, and creative media artists of all kinds.
|
https://cycling74.com/forums/topic/getting-plugin-data-on-a-different-track/
|
CC-MAIN-2016-44
|
refinedweb
| 172 | 82.44 |
Do you know how to check if two strings are anagrams of each other in Python? It’s a common problem and there are multiple ways to solve it.
Two strings are anagrams of each other if they both contain the same characters and each character is present in each string the same number of times. Two ways to check if two strings are anagrams in Python is by using the sorted() function or the collections.Counter() function.
Technically anagrams should have a meaning but in this scenario we will consider as anagrams also permutations of characters without meaning.
Let the anagrams begin!
What is an Anagram in Python?
The anagram is not a concept specific to Python, it’s a more generic concept. If two words contain the same letters and each letter is present the same number of times they are anagrams of each other.
For example, the following strings are anagrams of each other:
'elle' and 'leel'
Other examples of anagrams are:
'hello' and 'olleh' 'hello' and 'lleoh'
And the following strings are not anagrams…
'elle' and 'leele'
So, how can we verify anagrams in Python?
One way is by using the sorted built-in function.
Let’s see what output does the sorted function return…
>>> sorted('elle') ['e', 'e', 'l', 'l'] >>> sorted('leel') ['e', 'e', 'l', 'l']
The sorted function takes an iterable as argument and returns a sorted list that contains the items in the iterable.
In this specific case we have passed a string to the sorted function (yes, a string is an iterable) and we get back a list of characters.
Have a look at the output of the sorted function.
How do you think you can use this function to check if two strings are anagrams of each other?
We can simply compare the two lists returned by the sorted function. If the two lists are equal then the two strings are anagrams.
Here is the logic we can use:
>>> sorted('leel') == sorted('leel') True >>> sorted('leel') == sorted('leele') False
Example of Program to Check if Two Strings are Anagrams of Each Other
Let’s write a simple Python program that read two string from the user by calling the input function and checks if the two strings are anagrams.
first_string = input("Provide the first string: ") second_string = input("Provide the second string: ") if sorted(first_string) == sorted(second_string): print("The two strings are anagrams of each other.") else: print("The two strings are not anagrams of each other.")
After reading the two strings from the user input we verify, using a Python if else statement, if the lists returned by the sorted function are the same.
Verify if the program does what it’s expected to do…
$ python anagrams.py Provide the first string: hello Provide the second string: olelh The two strings are anagrams of each other. $ python anagrams.py Provide the first string: hello Provide the second string: ollleh The two strings are not anagrams of each other.
Looks good!
We have created a simple program that performs an anagram test between two strings.
Perform Anagram Check in a Python Function
Before making our algorithm to check for anagrams more complex I want to refactor the previous code and move all the logic into a function.
The function takes the two strings as arguments and prints the messages we have seen before.
def anagram_checker(first_value, second_value): if sorted(first_string) == sorted(second_string): print("The two strings are anagrams of each other.") else: print("The two strings are not anagrams of each other.")
And here is how we can call it from the main of our Python program.
first_string = input("Provide the first string: ") second_string = input("Provide the second string: ") anagram_checker(first_string, second_string)
Before continuing with this tutorial verify that the new code works as expected.
In the next section we will see how to enhance our code.
How to Find Anagrams For a String in a List of Strings
It’s time to learn how to look for anagrams for a string in a list of strings.
Let’s assume we have the following list:
words = ['enif', 'ollhe', 'aivrre', 'gdo', 'atc', 'neif']
We want to take one string as user input and find any anagrams for it inside the list of words.
You already know how to get the user input so for now let’s focus on updating the anagram_checker function.
This function will now:
- Take as arguments the string we are searching anagrams for and the list of words.
- Return a list that contains any anagrams found.
- If no anagrams are found the list returned is empty.
def anagram_checker(value, words): anagrams = [] for word in words: if sorted(word) == sorted(value): anagrams.append(word) return anagrams
We use a for loop to go through each word in the list to verify which one is an anagram for the first value passed to the function.
Let’s test this function to see if it returns the expected results…
words = ['enif', 'ollhe', 'aivrre', 'gdo', 'atc', 'neif'] # Test 1 print(anagram_checker('hello', words)) [output] ['ollhe'] # Test 2 print(anagram_checker('fine', words)) [output] ['enif', 'neif'] # Test 3 print(anagram_checker('python', words)) [output] []
The three tests executed against our function return the correct results.
How to Generate Anagrams For a Word Using Python
Now we will solve a slightly different problem.
Given a string we want to generate all the words made of the possible permutations of the letters in the word.
So, for the word ‘cat’ we want the following output:
['cat', 'cta', 'atc', 'act', 'tac', 'tca']
The Python itertools module provides the permurations() function that can help us with this.
Let’s see what the permutations() function returns when we pass our string to it.
>>> from itertools import permutations >>> permutations('cat') <itertools.permutations object at 0x7fa2d8079d60>
We get back an itertools.permutations object. Let’s see if we can cast it to a list…
>>> list(permutations('cat')) [('c', 'a', 't'), ('c', 't', 'a'), ('a', 'c', 't'), ('a', 't', 'c'), ('t', 'c', 'a'), ('t', 'a', 'c')]
This time we get back a list of tuples. The elements of each tuple are characters in the original string.
I would like to see a list of strings, how can we generate it?
We can use a list comprehension and the Python string join method:
>>> [''.join(element) for element in list(permutations('cat'))] ['cat', 'cta', 'act', 'atc', 'tca', 'tac']
It looks better!
The join method transforms each tuple into a string.
How to Find Anagrams in a Python List Using a Dictionary
Now, let’s find out how we can use a Python dictionary to store all the anagrams starting from a list of strings.
['cat', 'hello', 'tiger', 'olleh', 'tac', 'atc', 'regit', 'elephant']
The algorithm to store anagrams will work as follows:
- Go through each string in the list and firstly sort its characters.
- Check if any anagram of this string is already a dictionary key.
- If not add this word as dictionary key otherwise add this word to the value (of type list) mapped to the existing dictionary key.
For example, if we take the first string ‘cat’, we expect something like this:
{'cat': ['tac', 'atc'], .... }
So, ‘cat’ is encountered and it’s set as dictionary key. Then when ‘tac’ and ‘atc’ are processed they are added to the list mapped to the ‘cat’ key because they are anagrams of ‘cat’.
Makes sense?
Let’s write the code to do this…
Firstly we need a function that takes a word and a list of dictionary keys and checks if an anagram of the word is present in the dictionary keys.
If present it returns the key otherwise it returns None.
def get_anagram_from_dictionary_keys(word, keys): for key in keys: if sorted(word) == sorted(key): return key return None
Test this function first…
Scenario in which an anagram for the word is one of the dictionary keys
keys = ['cat', 'hello', 'tiger'] print(get_anagram_from_dictionary_keys('tac', keys)) [output] cat
Scenario in which there is no anagram for the word in the list of dictionary keys
print(get_anagram_from_dictionary_keys('elephant', keys)) [output] None
Make sure you understand this function before continuing considering that we will call this function when generating our dictionary of anagrams.
Writing a Function That Creates a Dictionary of Anagrams
And now we will write the function that generates the dictionary of anagrams starting from a list of words.
The function does the following:
- Go through each word in the list of words.
- Convert the word to lowercase.
- Call the previous function get_anagram_from_dictionary_keys().
- If a key is returned by the previous function this word is simply added to the list mapped to the existing dictionary key. Otherwise this word becomes a new dictionary key.
def create_anagrams_dictionary(words): anagrams = {} for word in words: word = word.lower() dict_key_for_word = get_anagram_from_dictionary_keys(word, anagrams.keys()) if dict_key_for_word: anagrams[dict_key_for_word].append(word) else: anagrams[word] = [] return anagrams
It’s time to test our code.
words = ['cat', 'hello', 'tiger', 'olleh', 'tac', 'atc', 'regit', 'elephant'] print(create_anagrams_dictionary(words))
And the output is…
{'cat': ['tac', 'atc'], 'hello': ['olleh'], 'tiger': ['regit'], 'elephant': []}
It works as we expected!
Using collections.Counter() to Search for Anagrams
Another way to check if two strings are anagrams of each other is by using the Counter() function of the collections module.
Given a string the Counter() function returns a dictionary-like object in which the keys are the characters of the string and the values are the number of times each character appears in the string.
Here is an example:
>>> from collections import Counter >>> Counter('cat') Counter({'c': 1, 'a': 1, 't': 1})
Now, let’s apply the Counter function to the string ‘tac’.
>>> Counter('tac') Counter({'t': 1, 'a': 1, 'c': 1})
We can simply compare the two objects returned to verify if the two strings are anagrams of each other.
>>> Counter('cat') == Counter('tac') True >>> Counter('cat') == Counter('hrt') False
Another trick you can use in your Python programs! 🙂
Conclusion
In this tutorial we went through multiple ways of verifying if two strings are anagrams of each others.
We have also seen how to find anagrams of a word in a list of words and how to generate words made of permutations of all the characters in a single word.
I know it’s quite a lot, I hope you have found it useful! 😉
I’m a Tech Lead, Software Engineer and Programming Coach. I want to help you in your journey to become a Super Developer!
|
https://codefather.tech/blog/anagrams-python/
|
CC-MAIN-2021-31
|
refinedweb
| 1,735 | 68.5 |
#include "C:\Programs\arduino-1.5.1r2\hardware\arduino\sam\libraries\Pwm01\pwm01.h"void setup() { uint32_t pwm_duty = 32767; uint32_t pwm_freq1 = 2; uint32_t pwm_freq2 = 5000; // Set PWM Resolution pwm_set_resolution(16); // Setup PWM Once (Up to two unique frequencies allowed //----------------------------------------------------- pwm_setup( 6, pwm_freq1, 1); // Pin 6 freq set to "pwm_freq1" on clock A pwm_setup( 7, pwm_freq2, 2); // Pin 7 freq set to "pwm_freq2" on clock B pwm_setup( 8, pwm_freq2, 2); // Pin 8 freq set to "pwm_freq2" on clock B pwm_setup( 9, pwm_freq2, 2); // Pin 9 freq set to "pwm_freq2" on clock B // Write PWM Duty Cycle Anytime After PWM Setup //----------------------------------------------------- pwm_write_duty( 6, pwm_duty ); // 50% duty cycle on Pin 6 pwm_write_duty( 7, pwm_duty ); // 50% duty cycle on Pin 7 pwm_write_duty( 8, pwm_duty ); // 50% duty cycle on Pin 8 pwm_write_duty( 9, pwm_duty ); // 50% duty cycle on Pin 9 delay(30000); // 30sec Delay; PWM signal will still stream // Force PWM Stop On All Pins //----------------------------- pwm_stop( 6 ); pwm_stop( 7 ); pwm_stop( 8 ); pwm_stop( 9 );}void loop() { }
Hi!As i like libraries, i have done one for Timers on the Arduino DUE.You can check it out here: 6 timers are fully implemented, and ready to play with...
The Time library has been updated for compatibility with Arduino Due. Due-specific example was added, using Markus Lange's rtc_clock library to access the Due's on-chip RTC.
What on-chip RTC?
Please enter a valid email to subscribe
We need to confirm your email address.
To complete the subscription, please click the link in the
Thank you for subscribing!
Arduino
via Egeo 16
Torino, 10131
Italy
|
http://forum.arduino.cc/index.php?topic=144446.msg1190733
|
CC-MAIN-2017-13
|
refinedweb
| 260 | 53.14 |
Java Exercises: Convert a given string into lowercase
Java Basic: Exercise-59 with Solution
Write a Java program to convert a given string into lowercase.
Pictorial Presentation: String to Lowercase
Sample Solution:
Java Code:
import java.util.*; public class Exercise59 { public static void main(String[] args){ Scanner in = new Scanner(System.in); System.out.print("Input a String: "); String line = in.nextLine(); line = line.toLowerCase(); System.out.println(line); } }
Sample Output:
Input a String: THE QUICK BROWN FOX JUMPS OVER THE LAZY DOG. the quick brown fox jumps over the lazy dog.
Flowchart:
Java Code Editor:
Contribute your code and comments through Disqus.
Previous: Write a Java program to capitalize the first letter of each word in a sentence.
Next: Write a Java program to find the penultimate (next to last) word of a sentence.
What is the difficulty level of this exercise?
New Content: Composer: Dependency manager for PHP, R Programming
|
https://www.w3resource.com/java-exercises/basic/java-basic-exercise-59.php
|
CC-MAIN-2019-18
|
refinedweb
| 152 | 51.24 |
Automating the world one-liner at a time…
The\FileSystem::C:\Temp\testMode LastWriteTime Length Name---- ------------- ------ ----d---- 6/19/2007 6:12 AM subdir-a--- 6/19/2007 6:12 AM 47 Invoke-Test.ps1-a--- 6/19/2007 6:12 AM 47 LibraryTest.ps1PS> Get-Content Invoke-Test.ps1. .\LibraryTest.ps1echo "I Love PowerShell"PS>PS> Get-Content LibraryTest.ps1function echo ($msg){ write-host $msg}PS>PS> C:\temp\test\Invoke-Test.ps1I Love PowerShellPS>PS> Set-Location subdirPS> C:\temp\test\Invoke-Test.ps1The term '.\LibraryTest.ps1' is not recognized as a cmdlet, function, operable program, or script file. Verify the term and try again.At C:\temp\test\Invoke-Test.ps1:1 char:2+ . <<<< .\LibraryTest.ps1The term 'echo' is not recognized as a cmdlet, function, operable program,or script file. Verify the term and try again.At C:\temp\test\Invoke-Test.ps1:2 char:5+ echo <<<< "I Love PowerShell"PS>72PS> function t { (Get-Variable -Scope 0).Count }PS> t17PS> # That tells us that the function has access to 72 variables but 17 are in its scope.PS> # PowerShell populates these for each scope automatically.PS> PS> function t { Get-Variable -Scope 0 |sort Name}PS> tName Value---- -----? Trueargs {}ConsoleFileNameCulture en-USExecutionContext System.Management.Automation.EngineIntrin...false FalseHOME E:\Users\jsnover.NTDEVHost System.Management.Automation.Internal.Hos...input System.Array+SZArrayEnumeratorMaximumVariableCount 4096MyInvocation System.Management.Automation.InvocationInfonullPID 960PSHOME E:\Windows\system32\WindowsPowerShell\v1.0\ShellId Microsoft.PowerShelltrue TrueUMyCommand : t1.ps1ScriptLineNumber : 1OffsetInLine : 9ScriptName :Line : .\t1.ps1PositionMessage : At line:1 char:9 + .\t1.ps1 <<<<InvocationName : .\t1.ps1PipelineLength : 1PipelinePosition : 1PS> # Note the LACK of a PATH. Let's explore the structure of MyInvocationPS> # to see if we can find one.PS> $MyInvocation |Get-Member -type Property TypeName: System.Management.Automation.InvocationInfoNameInfoNamePath : C:\Temp\test\subdir\t2.ps1Definition : C:\Temp\test\subdir\t2.ps1Name : t2.ps1CommandType : ExternalScriptPS>
#function Get-ScriptDirectory{ $Invocation = (Get-Variable MyInvocation -Scope 1).Value Split-Path $Invocation.MyCommand.Path}$path = Join-Path (Get-ScriptDirectory) LibraryTest.ps1. $pathecho "I Love PowerShell"PS>PS> C:\Temp\test\Invoke-Test.ps1I Love PowerShellPS>PS> Set-Location subdirPS>PS> C:\Temp\test\Invoke-Test.ps1I Love PowerShellPS>PS>
# If it can work there, it can work anywhere!
I just love this stuff!!!!
Jeffrey Snover [MSFT]Windows Management Partner ArchitectVisit the Windows PowerShell Team blog at: the Windows PowerShell ScriptCenter at:
So being a team member doesn't make one know everything.
I put that in my startup script a long time ago. Never thought that it needed to be noted. Your blog made me realize that many things in PS are not clearly documented (It took me a bit of time to discover MyInvocation.Path.)
It just proves, once again, that everything is there. It just tazkes a bit of time and thought to uncover how to do it.
Hurray for PowerShell! Hooray for .NET!
Great stuff Jeffrey / PS Team.
Discussed in the newsgroup a few weeks ago:
> Discussed in the newsgroup a few weeks ago:
Doh!!!!
Well I guess it proves this point:
... you can always just post a question to our newsgroup Microsoft.Public.Windows.PowerShell and the community will help.
Jeffrey Snover [MSFT]
Windows Management Partner Architect
Visit the Windows PowerShell Team blog at:
Visit the Windows PowerShell ScriptCenter at:
It is very nice to know the trick about using the -scope on get-variable. Thanks for pointing that out. What we tend to do in our scripts (and we use a number of dot sourced PowerShell libraries) is this:
$ScriptDir = split-path -parent $MyInvocation.MyCommand.Path
. "$ScriptDir\TestUtils.ps1"
at the top of each script.
Another simple solution could be:
push-location myScriptPath
...
pop-location
Thanks! That tip saved the day for me. I needed to run a powershell script from a UNC path which was loading an assembly from the same UNC path as the script. It worked flawlessly!
You need to "Dot source" the file. Basically, its ". <filename>". Check "Get-ScriptDirectory
Going to the parent scope for the script-level $MyInvocation variable does not always work. I just had this situation:
function Test()
{
$inv = (Get-Variable MyInvocation -Scope 1).Value
$inv.MyCommand | Format-List *
}
function Test2()
Test
Test2
Where the parent scope is actually the Test2 function not the script scope. You can always get the script scope $MyInvocation variable by using the $script namespace prefix:
$scriptInvocation = $script:MyInvocation
This works when called from any function scope no matter how deeply nested.
Let me start by saying I really, really appreciate the information in this post - but I did run into the same problem as Hristo.
I think it was a disservice to make a function for this trick. A function suggests it can be referenced from numerous places, but clearly it will only work if called from the main script. Also, I don't see much point in calling this repeatedly - the answer doesn't change no matter how often you call it.
I think it makes much more sense to just put these two lines at the beginning of a script and leave the variable available for the duration of its execution:
$Invocation = (Get-Variable MyInvocation -Scope 0).Value
$ScriptPath = Split-Path $Invocation.MyCommand.Path
Then later on you just make reference to it like so:
$ReportPath = Join-Path $ScriptPath $ReportFile
Not only is this much simpler, it will also work reliably from anywhere within the program.
How do you get your input text to be yellow and your output to be white????
And I thought that %0.. and %~dp0 were CMD.exe voodoo.
The script directory is so often used, I would argue that the lack of an automatic variable is an over site. Now that Version 2 is out, is there an easier way or is it just as convoluted?
Based on this article I now just use this one line to grab the script directory:
# Get the directory that this script is in.
$ScriptDirectory = Split-Path $MyInvocation.MyCommand.Path -Parent
Nice and easy :)
Hi there
I am fairly new to powershell so my actions are quite basic.
I have made a powershell script as below:
get-service ‘Netback*’ -computername SERVER1 > server1.txt
get-service ‘Netback*’ -computername SERVER2 > server2.txt
Now, thats fine for a couple of machines, but when I have a whole list its obviously harder.
If I copy the files to a txt file, and then run this command:
Get-Content server.txt | ForEach-object {get-service ‘Netback*’}, I get the following display:
Status Name Displayname
Running NetBackup… Netbackup Client Service
So to my question:
How am I able to list any one of the machines in my server.txt file so that I know which server it’s referring to? It’s probably simple, but I can’t work it out.
server.txt would consist of:
SERVER1
SERVER2
Thanks
Justin
"I just love this stuff!!!!"
Give us a break.
Powershell should use C# syntax.
Here is a puzzle for you:
################################################################
#$connectionString = "........"
function Get-ScriptDirectory
Split-Path $script:MyInvocation.MyCommand.Path
$dir = Get-ScriptDirectory
Add-PSSnapin SqlServerCmdletSnapin100
Add-PSSnapin SqlServerProviderSnapin100
$connection = New-Object -TypeName System.Data.SqlClient.SqlConnection($connectionString)
foreach ($f in Get-ChildItem -path $dir | ?{ $_.PSIsContainer } | sort-object )
$path = $dir + "\" + $f.Name + "\" + "update.sql";
$path
Invoke-sqlcmd -InputFile $path
#$query = Get-Content $path
$connection.Close()
This returns :
Invoke-sqlcmd :)
1) Remote connectios are active.
2) Connection string is correct.
|
http://blogs.msdn.com/b/powershell/archive/2007/06/19/get-scriptdirectory.aspx?PageIndex=1
|
CC-MAIN-2015-06
|
refinedweb
| 1,222 | 51.44 |
52058/what-is-a-resource-quota-in-kubernetes:
Different teams work in different namespaces. Currently this is voluntary, but support for making this mandatory via ACLs is planned.
The administrator creates one or more ResourceQuotas with a message explaining the constraint that would have been violated.
If quota is enabled in a namespace for compute resources like cpu and memory, users must specify requests or limits for those values; otherwise, the quota system may reject pod creation.
Hint: Use the LimitRanger admission controller to force defaults for pods that make no compute resource requirements.
I think your Legacy Authorisation has been ...READ MORE
Out of the box is a work ...READ MORE
Config maps ideally stores application configuration in ...READ MORE
On Google Compute Engine (GCE) and Google Container Engine (GKE) is an abstraction for pods. ...READ MORE
Kubernetes is a combination of multiple parts ...READ MORE
OR
Already have an account? Sign in.
|
https://www.edureka.co/community/52058/what-is-a-resource-quota-in-kubernetes
|
CC-MAIN-2020-16
|
refinedweb
| 154 | 57.87 |
Managing COM Object Lifetime in a Garbage-Collected Environment
COM objects are responsible for managing their own lifetimes using a standard reference counting scheme. .NET objects, on the other hand, don't need to perform this mundane and error-prone task. The same is true for COM components written or used in Visual Basic, but the difference with .NET is that the Common Language Runtime (CLR) uses garbage collection to manage object lifetime. In a garbage-collected environment, objects are not freed as soon as the last client is finished using it, but at some undetermined point afterward.
To make the use of COM components in managed code as seamless as possible, the CLR encapsulates them in wrapper objects known as Runtime-Callable Wrappers (RCWs). RCWs are responsible for handling all transitions between COM and .NET, such as data marshaling, exception handling, and the subject of this articleobject lifetime. To prevent managed clients of a COM object from engaging in reference counting, an RCW's lifetime is controlled by garbage collection (just like any other managed object). Each RCW caches interface pointers for the COM object it wraps, and internally maintains its own reference count on these interface pointers. When an RCW is garbage-collected, its finalizer releases all of its cached interface pointers. Thus, a COM object is guaranteed to be alive as long as its RCW is alive.
Because COM objects are often designed to be destroyed as soon as clients are finished using them, it can be problematic to keep COM objects alive until garbage collection releases them at some undetermined time. An example of a troublesome COM object is one that holds onto a limited resource, such as a database connection, and doesn't release it until it is destroyed.
In Visual Basic 6, a COM object could be immediately released by setting the object reference to Nothing (null). In managed code, however, setting an object to null only makes the original instance eligible for garbage collection; the object is not immediately released. One way to force the early release of a COM object wrapped by an RCW is to force the early garbage collection of the RCW. Once an RCW is eligible for collection, calling System.GC.Collect followed by System.GC.WaitForPendingFinalizers will do the trick.
Forcing garbage collection is not a quick operation, however, so a special API exists in the System.Runtime.InteropServices namespace for forcing an RCW to release its inner COM object before the RCW is collected: Marshal.ReleaseComObject. This static (Shared in VB .NET) method must be passed an RCW, and returns an integer representing the RCW's reference count on the wrapped COM object. For an RCW called obj, this method can be called in Visual Basic .NET as follows:
Marshal.ReleaseComObject(obj)
ReleaseComObject decrements the reference counts of any interface pointers cached once by the RCW, similar to what would happen if the RCW were collected. Because interface pointers inside RCWs are not reference-counted based on the number of .NET clients, calling ReleaseComObject once per RCW is usually enough. However, an interface pointer's reference count is incremented every time it crosses the boundary from unmanaged to managed code. It's rare that this occurs more than once, but to be absolutely sure that calling ReleaseComObject releases the underlying COM object, youshould call ReleaseComObject in a loop until the returned reference count reaches zero, as follows in C#:
while (Marshal.ReleaseComObject(obj) > 0) {}
Once the returned count reaches zero, the CLR is guaranteed to release all of the COM object's interface pointers that the RCW holds onto. (Whether the COM object's own reference count reaches zero is dependent on whether additional COM objects are holding onto its interface pointers.) Although the RCW remains alive until the next collection, it's just an empty wrapper unusable to any .NET clients. Attempting to call any member on an RCW after passing it to ReleaseComObject raises a NullReferenceException.
ReleaseComObject is only meant to be used if absolutely necessary. In many cases, you should be able to let the garbage collector take care of everything rather than complicating your code with explicit releasing.
|
http://www.informit.com/articles/article.aspx?p=26993
|
CC-MAIN-2017-13
|
refinedweb
| 695 | 53.1 |
Pemi - Python Extract Modify Integrate
Project description
Welcome to Pemi’s documentation!
Pemi is a framework for building testable ETL processes and workflows. Users define pipes that define how to collect, transform, and deliver data. Pipes can be combined with other pipes to build out complex and modular data pipelines. Testing is a first-class feature of Pemi and comes with a testing API to allow for describing test coverage in a manner that is natural for data transformations.
Full documentation on readthedocs
Install Pemi
Pemi can be installed from pip:
pip install pemi
Concepts and Features
Pipes
The principal abstraction in Pemi is the Pipe. A pipe can be composed of Data Sources, Data Targets, and other Pipes. When a pipe is executed, it collects data form the data sources, manipulates that data, and loads the results into the data targets. For example, here’s a simple “Hello World” pipe. It takes a list of names in the form of a Pandas DataFrame and returns a Pandas DataFrame saying hello to each of them.
import pandas as pd import pemi from pemi.fields import * class HelloNamePipe(pemi.Pipe): # Override the constructor to configure the pipe def __init__(self): # Make sure to call the parent constructor super().__init__() # Add a data source to our pipe - a pandas dataframe called 'input' self.source( pemi.PdDataSubject, name='input', schema = pemi.Schema( name=StringField() ) ) # Add a data target to our pipe - a pandas dataframe called 'output' self.target( pemi.PdDataSubject, name='output' ) # All pipes must define a 'flow' method that is called to execute the pipe def flow(self): self.targets['output'].df = self.sources['input'].df.copy() self.targets['output'].df['salutation'] = self.sources['input'].df['name'].apply( lambda v: 'Hello ' + v )
To use the pipe, we have to create an instance of it:
pipe = HelloNamePipe()
and give some data to the source named “input”:
pipe.sources['input'].df = pd.DataFrame({ 'name': ['Buffy', 'Xander', 'Willow', 'Dawn'] })
The pipe performs the data transformation when the flow method is called:
pipe.flow()
The data target named “output” is then populated:
pipe.targets['output'].df
Data Subjects
Data Sources and Data Targets are both types of Data Subjects. A data subject is mostly just a reference to an object that can be used to manipulate data. In the [Pipes](#pipes) example above, we defined the data source called “input” as using the pemi.PdDataSubject class. This means that this data subject refers to a Pandas DataFrame object. Calling the df method on this data subject simply returns the Pandas DataFrame, which can be manipulated in all the ways that Pandas DataFrames can be manipulated.
Pemi supports 3 data subjects natively, but can easily be extended to support others. The 3 supported data subjects are
- pemi.PdDataSubject - Pandas DataFrames
- pemi.SaDataSubject - SQLAlchemy Engines
- pemi.SparkDataSubject - Apache Spark DataFrames
Schemas
A data subject can optionally be associated with a Schema. Schemas can be used to validate that the data object of the data subject conforms to the schema. This is useful when data is passed from the target of one pipe to the source of another because it ensures that downstream pipes get the data they are expecting.
For example, suppose we wanted to ensure that our data had fields called id and name. We would define a data subject like:
from pemi.fields import * ds = pemi.PdDataSubject( schema=pemi.Schema( id=IntegerField(), name=StringField() ) )
If we provide the data subject with a dataframe that does not have a field:
df = pd.DataFrame({ 'name': ['Buffy', 'Xander', 'Willow'] }) ds.df = df
Then an error will be raised when the schema is validated (which happens automatically when data is passed between pipes, as we’ll see below):
ds.validate_schema() #=> MissingFieldsError: DataFrame missing expected fields: {'id'}
We’ll also see later that defining a data subject with a schema also aids with writing tests. So while optional, defining data subjects with an associated schema is highly recommended.
Referencing data subjects in pipes
Data subjects are rarely defined outside the scope of a pipe as done in [Schemas](#schemas). Instead, they are usually defined in the constructor of a pipe as in [Pipes](#pipes). Two methods of the pemi.Pipe class are used to define data subjects: source and target. These methods allow one to specify the data subject class that the data subject will use, give it a name, assign a schema, and pass on any other arguments to the specific data subject class.
For example, if we were to define a pipe that was meant to use an Apache Spark dataframe as a source:
spark_session = ... class MyPipe(pemi.Pipe): def __init__(self): super().__init__() self.source( pemi.SparkDataSubject, name='my_spark_source', schema=pemi.Schema( id=IntegerField(), name=StringField() ), spark=spark_session )
When self.source is called, it builds the data subject from the options provided and puts it in a dictionary that is associated with the pipe. The spark data frame can then be accessed from within the flow method as:
def flow(self): self.sources['my_spark_source'].df
Types of Pipes
Most user pipes will typically inherit from the main pemi.Pipe class. However, the topology of the pipe can classify it according to how it might be used. While the following definitions can be bent in some ways, they are useful for describing the purpose of a given pipe.
- A Source Pipe is a pipe that is used to extract data from some external system and convert it into a Pemi data subject. This data subject is the target of the source pipe.
- A Target Pipe is a pipe that is used to take a data subject and convert it into a form that can be loaded into some external system. This data subject is the source of the target pipe.
- A Transformation Pipe is a pipe that takes one or more data sources, transforms them, and delivers one more target sources.
- A Job Pipe is a pipe that is self-contained and does not specify any source or target data subjects. Instead, it is usually composed of other pipes that are connected to each other.
Pipe Connections
A pipe can be composed of other pipes that are each connected to each other. These connections for a directed acyclic graph (DAG). When then connections between all pipes are executed, the pipes that form the nodes of the DAG are executed in the order specified by the DAG (in parallel, when possible – parallel execution is made possible under the hood via Dask graphs). The data objects referenced by the node pipes’ data subjects are passed between the pipes according.
As a minimal example showing how connections work, let’s define a dummy source pipe that just generates a Pandas dataframe with some data in it:
class MySourcePipe(pemi.Pipe): def __init__(self): super().__init__() self.target( pemi.PdDataSubject, name='main' ) def flow(self): self.targets['main'].df = pd.DataFrame({ 'id': [1,2,3], 'name': ['Buffy', 'Xander', 'Willow'] })
And a target pipe that just prints the “salutation” field:
class MyTargetPipe(pemi.Pipe): def __init__(self): super().__init__() self.source( pemi.PdDataSubject, name='main' ) def flow(self): for idx, row in self.sources['main'].df.iterrows(): print(row['salutation'])
Now we define a job pipe that will connect the dummy source pipe to our hello world pipe and connect that to our dummy target pipe:
class MyJob(pemi.Pipe): def __init__(self): super().__init__() self.pipe( name='my_source_pipe', pipe=MySourcePipe() ) self.connect('my_source_pipe', 'main').to('hello_pipe', 'input') self.pipe( name='hello_pipe', pipe=HelloNamePipe() ) self.connect('hello_pipe', 'output').to('my_target_pipe', 'main') self.pipe( name='my_target_pipe', pipe=MyTargetPipe() ) def flow(self): self.connections.flow()
In the flow method we call self.connections.flow(). This calls the flow method of each pipe defined in the connections graph and transfers data between them, in the order specified by the DAG.
The job pipe can be executed by calling its flow method:
MyJob().flow() # => Hello Buffy # => Hello Xander # => Hello Willow
Furthermore, if you’re running this in a Jupyter notebook, you can see a graph of the connections by running:
MyJob().connections.graph()
Referencing pipes in pipes
Referencing pipes within pipes works the same way as for data sources and targets. For example, if we wanted to run the MyJob job pipe and then look at the source of the “hello_pipe”:
job = MyJob() job.flow() job.pipes['hello_pipe'].sources['input'].df
Where to go from here
Full documentation on readthedocs
Project details
Release history Release notifications
Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
|
https://pypi.org/project/pemi/
|
CC-MAIN-2018-26
|
refinedweb
| 1,429 | 56.35 |
Dan Foreman-Mackey
Python modules in C
August 03, 2012
Writing your own C extensions to Python can seem like a pretty daunting task when you first get started. If you take a look at the Python/C API docs the details of reference counting and compilation are enough to make you go crazy. This is the main reason why so many options exist for wrapping or compiling C code into Python without ever directly interacting with the API. That being said, I often find that all that I need to do is wrap a single C function that accepts a few doubles and returns another double. In this case, it seems crazy to generate the thousands of lines of C code required by automatic methods like Cython and SWIG. You might argue that these aesthetic issues don't provide sufficient reason for diving into the rabbit hole that the C API seems to be—and maybe you'd be right—but I'm a stubborn coder and I don't mind getting my hands a little dirty so I went for it. This was a few years ago and since then, I've developed a template module that suits my needs perfectly and it seems to make the extension writing process relatively painless so I thought that I'd share what I've learned here.
I'm not going to claim that what I say here is a general introduction to writing C extensions because I don't feel qualified to do that but it should be a sufficient tutorial for a scientific programmer (read: grad student) to get started and write a fully functional module for their research. In particular, this tutorial will be most useful for someone who already has a chunk of code written in C and just wants to be able to call a few of those functions directly from within Python. Several people have specifically asked me about how to do this when they have legacy data analysis code that they would like to use with my Markov chain Monte Carlo package emcee. In that context, the C code is expected to return the likelihood of some data given some model parameters passed as doubles to the C function. This is the same format that would be needed if you just wanted to find the minimum chi-squared (or maximum likelihood) solution to a problem using something like scipy.optimize.
The Objective
To be concrete, let's consider a specific example: fitting a line (parameterized by a slope m and y intercept b) to some N noisy data points \( \{ x_n, y_n, \sigma_n \} \). In this case, the chi-squared function is given by:
$$ \chi^2 (m, b) = \sum_{n = 1} ^N \frac{[y_n - (m \, x_n + b)]^2}{\sigma_n^2} \quad . $$
It's probably overkill to write this function in C but it'll do for our
purposes today. In C, the file
chi2.c containing our function should look
something like:
#include "chi2.h" double chi2(double m, double b, double *x, double *y, double *yerr, int N) { int n; double result = 0.0, diff; for (n = 0; n < N; n++) { diff = (y[n] - (m * x[n] + b)) / yerr[n]; result += diff * diff; } return result; }
And the corresponding header file
chi2.h is simply:
double chi2(double m, double b, double *x, double *y, double *yerr, int N);
Now, our goal is to wrap this function so that we can call it from directly within Python.
The Wrapper).
In order to be able to access the C functions and types in the Python API,
the first thing that we need to do is import the Python header. I also
expect that we'll want to interact with
numpy arrays and our
chi2
function as well so let's import those headers too:
#include <Python.h> #include <numpy/arrayobject.h> #include "chi2.h"
Next, we should write the docstrings for our module and the function that we're wrapping:
static char module_docstring[] = "This module provides an interface for calculating chi-squared using C."; static char chi2_docstring[] = "Calculate the chi-squared of some data given a model.";
and declare the function:
static PyObject *chi2_chi2(PyObject *self, PyObject *args);
This is the first time that we're seeing anything Python-specific. The
type
PyObject refers to all Python types. Any communication between the
Python interpreter and your C code will be done by passing
PyObjects so
any function that you want to be able to call from Python must return one.
Under the hood,
PyObject is just a
struct with a reference count and a
pointer to the data contained within the object. This can be as simple as
a
double or
int or as complicated as a fully functional Python class.
Remember: everything is an object.
The name that I've given to the function (
chi2_chi2) is also a matter of
convention. From Python, we're going to call the function with the command
_chi2.chi2 where
_chi2 is the name of the module and
chi2 is the name
of the function. Since C doesn't have any concept of namespaces, the
convention is to name your C functions with the form
{module_name}_{function_name} and my preference is to leave out the
leading underscore but it doesn't really matter either way.
The arguments for the function are pretty standard fare. In our case the
self object points to the module and the
args object is a Python tuple
of input arguments—we'll see how to parse them soon. It is also possible
to accept keyword arguments by including a third
PyObject in the calling
specification but let's not get into that here.
Now, we'll specify what the members of this module will be. In this case
there is only going to be one function (called
chi2) so the "method
definition" looks like:
static PyMethodDef module_methods[] = { {"chi2", chi2_chi2, METH_VARARGS, chi2_docstring}, {NULL, NULL, 0, NULL} };
More functions can be added by adding more lines like the second one. This
second line contains all the info that the interpreter needs to link a Python
call to the correct C function and call it in the right way. The
first string is the name of the function as it will be called from Python,
the second object is the C function to link to and the last argument is the
docstring for the function. The third argument
METH_VARARGS means that the
function only accepts positional arguments. If you wanted to support
keyword arguments, you would need to change this to
METH_VARARGS |
METH_KEYWORDS.
The final step in initializing your new C module is to write an
init{name}
function. This function must be called
init_chi2 where
_chi2 is
(of course) the name of the module.
PyMODINIT_FUNC init_chi2(void) { PyObject *m = Py_InitModule3("_chi2", module_methods, module_docstring); if (m == NULL) return; /* Load `numpy` functionality. */ import_array(); }
Everything that's going on here should be fairly self explanatory by this
point but it's important to note that if you want to use any of the
functionality defined by
numpy, you need to include the call to
import_array() (a function defined in the
numpy/arrayobject.h header).
The Interface
Up to this point, we've written only about 25 lines of C code to set up a C extension module. All of these steps will be common between any modules that you write but as we continue, the details become somewhat less general because I will focus on building a wrapper for scientific code.
Now, it's time to write the
chi2_chi2 function that we declared above.
In this example, the
args tuple will contain two
doubles (the slope
and y-intercept of our model) and three
numpy arrays for the x, y
and uncertainties that constitute the "data" that we're trying to model.
Let's just throw down the whole function here and then dissect it line-by-line
below:
static PyObject *chi2_chi2(PyObject *self, PyObject *args) { double m, b; PyObject *x_obj, *y_obj, *yerr_obj; /* Parse the input tuple */ if (!PyArg_ParseTuple(args, "ddOOO", &m, &b, &x_obj, &y_obj, &yerr_obj)) return NULL; /* Interpret the input objects as numpy arrays. */ PyObject *x_array = PyArray_FROM_OTF(x_obj, NPY_DOUBLE, NPY_IN_ARRAY); PyObject *y_array = PyArray_FROM_OTF(y_obj, NPY_DOUBLE, NPY_IN_ARRAY); PyObject *yerr_array = PyArray_FROM_OTF(yerr_obj, NPY_DOUBLE, NPY_IN_ARRAY); /* If that didn't work, throw an exception. */ if (x_array == NULL || y_array == NULL || yerr_array == NULL) { Py_XDECREF(x_array); Py_XDECREF(y_array); Py_XDECREF(yerr_array); return NULL; } /* How many data points are there? */ int N = (int)PyArray_DIM(x_array, 0); /* Get pointers to the data as C-types. */ double *x = (double*)PyArray_DATA(x_array); double *y = (double*)PyArray_DATA(y_array); double *yerr = (double*)PyArray_DATA(yerr_array); /* Call the external C function to compute the chi-squared. */ double value = chi2(m, b, x, y, yerr, N); /* Clean up. */ Py_DECREF(x_array); Py_DECREF(y_array); Py_DECREF(yerr_array); if (value < 0.0) { PyErr_SetString(PyExc_RuntimeError, "Chi-squared returned an impossible value."); return NULL; } /* Build the output tuple */ PyObject *ret = Py_BuildValue("d", value); return ret; }
I know that that was a lot in one go so let's break things down a little bit.
The first thing that we did was parse the input tuple using the
PyArg_ParseTuple function. This function takes the tuple, a format and
the list of pointers to the objects that you want to take the input values.
This format should be familiar if you've ever used something like the
sscanf function in C but the format characters are a little
different. In our example,
d
indicates that the argument should be cast as a C
double and
O is
just a catchall for
PyObjects. There isn't a specific format character
for
numpy arrays so we have to parse them as raw
PyObjects and then
interpret them afterwards. If
PyArg_ParseTuple fails, it will return
NULL which is the C-API technique for propagating exceptions. That means
that we should also return
NULL immediately if parsing the tuple fails.
The next few lines (12-25) show how to load
numpy arrays from the raw
objects. The
PyArray_FROM_OTF
function is a fairly general method for converting an arbitrary Python
object into a well-behaved
numpy array that can be used in a standard
C function. It is important to note that this creation mechanism only
returns a copy of the object if necessary. Instead, the function normally
only returns a pointer to the input object if it was already a
numpy
array satisfying various requirements that we won't discuss in detail here.
The flags
NPY_DOUBLE and
NPY_IN_ARRAY ensure that the returned array
object will be represented as contiguous arrays of C
doubles. There are
some other options available for different types, orderings and permissions
but most of the time, this is probably what you'll need and the other
options are described in the
documentation.
Reference Counting: Memory management in Python works by keeping track of the number of "references" to a particular object and then deallocating the memory of that object when that count reaches zero. You can read more about the details of this system elsewhere but for now, you need to keep in mind that when you return a
PyObjectfrom a function you might want to run
Py_INCREFon it to increment the reference count and when you create a new object within you function that you don't want to return, you should run
Py_DECREFon it before the function returns (even if the execution failed) so that you don't end up with a memory leak. The documentation explaining this system makes the important comment that it is part of each function's "interface specification" whether or not it increases the reference count of an object before it returns or not. With this in mind, you need to keep careful track of which functions do what or the memory usage can become a little ugly.
In our example, the objects returned by
PyArg_ParseTuple do not have
their reference count incremented (the calling function still "owns" them)
so you don't need to decrement the reference count of the
*_obj objects
before returning. Conversely,
PyArray_FROM_OTF does return an object with
a +1 reference count. This means that you must call
Py_DECREF with
the
*_array objects as the first argument before returning from this
function. If
PyArray_FROM_OTF can't coerce the input object into a
form digestible as a
numpy array, it will return
NULL so that's why
on lines 19-21, I actually use
Py_XDECREF.
Py_XDECREF checks
to make sure that the object isn't a
NULL pointer before trying to
decrease the reference count whereas
Py_DECREF
will explode if you try to call it on
NULL.
If we successfully reach line 25 then all of the input arguments were
as expected and we have the input
numpy arrays arranged the way we want
them to be. Now we can get on to the fun stuff. For simplicity,
on line 26, I'm assuming that we received a 1D array (but I could check this
using the
PyArray_NDIM
function) and getting the length of the array. Then, I'm getting pointers
to the actual C array (which will be formatted properly as an array of
doubles because of the flags that we used in
PyArray_FROM_OTF above).
Then, on line 34, we can finally call the C function that we wanted to wrap
in the first place.
The conditional on line 41 in the example is probably unnecessary because
the
chi2 function (by definition) will always return a non-negative value
but I wanted to include it anyways because it demonstrates how you would
throw an exception if something went wrong in the execution of the C code.
The Python interpreter has a global variable that contains a pointer to the
most recent exception that has been thrown. Then if a function returns
NULL
it starts an upwards cascade where each function either catches the exception
using a
try-except statement or also returns
NULL. When the interpreter
receives a
NULL return value, it stops execution of the current code and
shows a representation of the value of the global
Exception variable and
the traceback. On line 42, if
chi2 returned a number less than zero,
the global
Exception is being set to have the type
RuntimeError and
the description: "Chi-squared returned an impossible value." Then, by
returning
NULL we're indicating that something went wrong.
Finally, if
value was non-negative (it'd better be), we can use
Py_BuildValue to
create the output tuple. If
Py_ParseTuple has a syntax similar to
sscanf then
Py_BuildValue is the analog of
sprintf with the same
format characters as
Py_ParseTuple. Here, we don't need to
Py_INCREF
the return object because
Py_BuildValue does that for us but if you
generated the output in a different way, you might have to.
That's it for the code required for our module. It might seem like a lot of work but you'll notice that we've only written about 120 lines of code and the vast majority of these lines will be exactly the same in every module that you need to write.
Building
The last thing that we need to talk about is how you might compile and
link this module so that it can actually be called from Python. The best
way to do this is to use the built-in Python distribution
utilities. Traditionally,
the build script is called
setup.py and for our example, the file
is actually extremely simple:
from distutils.core import setup, Extension import numpy.distutils.misc_util setup( ext_modules=[Extension("_chi2", ["_chi2.c", "chi2.c"])], include_dirs=numpy.distutils.misc_util.get_numpy_include_dirs(), )
and you can call it using the command:
python setup.py build_ext --inplace
which will compile and link you source code and create a shared object
called
_chi2.so in the same directory. Then, from Python, you can do
the following:
>>> import _chi2 >>> print _chi2.chi2(2.0, 1.0, [-1.0, 4.2, 30.6], ... [-1.5, 8.0, 63.0], ... [1.0, 1.5, 0.6]) 2.89888888889
Summary
Hopefully, after going through this tutorial, you should be able to write your own C-extension module especially if it is just a single C function that you want to wrap. In general, I find that most of my time is spent copy-and-pasting when I'm writing a C extension and once you get the hang of it it shouldn't take too much effort to incorporate code like this into projects that you're working on. Since so much of this structure is the same across projects, it would be awesome if someone wanted to make an interactive tool for auto-generating skeleton code but I haven't seen anything like this yet.
To see all the source code for this tutorial in one place, you can
repository using
git:
git clone git://gist.github.com/3247796.git c_ext cd c_ext python setup.py build_ext --inplace
If you have any comments, suggestions or questions, fork this page or tweet at me.
|
http://dan.iel.fm/posts/python-c-extensions/
|
CC-MAIN-2017-39
|
refinedweb
| 2,825 | 56.89 |
Advanced blurring techniques
Today we will try to dig a bit deeper into blurring techniques available for Android developers. I read couple of articles and SO posts describing different ways to do this, so I want to summarize what I learned.
Why?
More and more developers now try to add different kinds of blurry backgrounds for their custom views. Take a look at awesome Muzei app by +RomanNurik or Yahoo Weather app. I really like what they did with the design there.
I was inspired to write this article by set of blog posts from here (by Mark Allison). So the first part of this post will be really similar to Mark's post. But I will try to go even further.
Basically what we will try to accomplish today is the following:
Prerequisites
Let me describe what I will be working with. I have 1 activity which hosts different fragments in a
ViewPager. Every fragment represent 1 blurring technique.
Here is what my
layout_main.xml looks like:
<android.support.v4.view.ViewPager xmlns:
And here is my
fragment_layout.xml:
<?xml version="1.0" encoding="utf-8"?> <FrameLayout xmlns: <ImageView android: <TextView android: <LinearLayout android: </FrameLayout>
As you can see this is just an
ImageView with
TextView centered and some debug layout (
@+id/controls) I will use to display performance measurements and add some more tweaks.
The general blurring technique looks like:
- Cut that part of background which is behind my
TextView
- Blur it
- Set this blurred part as background to my
TextView
Renderscript
The most popular answer to questions like "how do I implement blur in Android" is - Renderscript. This is very powerful and optimized "engine" to work with graphics. I will not try to explain how it works under the hood (since I don't know either :) and this is definitely out of scope for this post).
public class RSBlurFragment extends Fragment { private ImageView image; private TextView text; private TextView statusText; @Override public View onCreateView(LayoutInflater inflater, ViewGroup container, Bundle savedInstanceState) { View view = inflater.inflate(R.layout.fragment_layout, container, false); image = (ImageView) view.findViewById(R.id.picture); text = (TextView) view.findViewById(R.id.text); statusText = addStatusText((ViewGroup) view.findViewById(R.id.controls)); applyBlur(); return view; } private void applyBlur() { image.getViewTreeObserver().addOnPreDrawListener(new ViewTreeObserver.OnPreDrawListener() { @Override public boolean onPreDraw() { image.getViewTreeObserver().removeOnPreDrawListener(this); image.buildDrawingCache(); Bitmap bmp = image.getDrawingCache(); blur(bmp, text); return true; } }); } @TargetApi(Build.VERSION_CODES.JELLY_BEAN_MR1)); RenderScript rs = RenderScript.create(getActivity()); Allocation overlayAlloc = Allocation.createFromBitmap( rs, overlay); ScriptIntrinsicBlur blur = ScriptIntrinsicBlur.create( rs, overlayAlloc.getElement()); blur.setInput(overlayAlloc); blur.setRadius(radius); blur.forEach(overlayAlloc); overlayAlloc.copyTo(overlay); view.setBackground(new BitmapDrawable( getResources(), overlay)); rs.destroy(); statusText.setText(System.currentTimeMillis() - startMs + "ms"); } @Override public String toString() { return "RenderScript"; } private TextView addStatusText(ViewGroup container) { TextView result = new TextView(getActivity()); result.setLayoutParams(new ViewGroup.LayoutParams(ViewGroup.LayoutParams.WRAP_CONTENT, ViewGroup.LayoutParams.WRAP_CONTENT)); result.setTextColor(0xFFFFFFFF); container.addView(result); return result; } }
- When fragment gets created - I inflate my layout, add
TextViewto my debug panel (I will use it to display blurring performance) and apply blur to the image
- Inside
applyBlur()I register
onPreDrawListener(). I need this because at the moment my
applyBlur()is called nothing is laid out yet, so there is nothing to blur. I need to wait until my layout is measured, laid out and is ready to be displayed.
- In
onPreDraw()callback first thing I usually do is change generated
falsereturn value to
true. It is really important to understand that if you return
false- the frame which is about to be drawn will be skipped. I am actually interested in the first frame, so I return
true.
- Then I remove my callback because I don't want to listen to pre-draw events anymore.
- Now I want to get
Bitmapout of my
ImageView. I build drawing cache and retrieve it by calling
getDrawingCache()
- And eventually blur. Let's discuss this step more precisely.
I want to say here that I realize that my code doesn't cover couple of very important moments:
- It doesn't re-blur when layout changes. For this you need to register
onGlobalLayoutListenerand repeat blurring whenever layout changes
- It does blurring in the main thread. Obviously is not the way you do it in production, but for the sake of simplicity, I will do that for now :)
So, let's go back to my
blur():
- At first I create an empty bitmap to copy part of my background into. This bitmap I will blur later and set as a background to my
TextView
- Create
Canvasbacked up by this bitmap
- Translate canvas to the position of my
TextViewwithin parent layout
- Draw part of my
ImageViewto bitmap
- At this point I have a bitmap equals to my
TextViewsize and containing that part of my
ImageViewwhich is behind the
TextView
- Create Renderscript instance
- Copy my bitmap to Renderscript-friendly piece of data
- Create Renderscript blur instance
- Set input, radius and apply blur
- Copy result back to my bitmap
- Great! Now we have blurred bitmap. Let's set it as a background to my
TextView
Here is what I got:
As we can see, result is pretty good and it took 57ms. Since one frame in Android should render no more than ~16ms (60fps) we can see that doing that on UI thread will drop our frame rate down to 17fps for the period of blurring. Obviously is not acceptable, so we need to offload this to
AsyncTask or something similar.
Also it worth mentioning that
ScriptIntrinsicBlur is available from API 17 only, but you can use renderscript support lib to lower required API a bit.
But still, a lot of us still have to support older APIs which don't have this fancy renderscript support. Let's find out what we can do here.
FastBlur
Since blur process is nothing more than just pixel manipulation, obvious solution would be to try do blurring manually. Luckily, there are plenty examples of Java implementation of blur. The only thing we need to do is to find relatively quick implementation.
Thanks to this post on SO, I picked fast blur implementation. Let's see what does it look like.
I will describe only blur function since the rest of the code is the same:); overlay = FastBlur.doBlur(overlay, (int)radius, true); view.setBackground(new BitmapDrawable(getResources(), overlay)); statusText.setText(System.currentTimeMillis() - startMs + "ms"); }
And here is result:
As we can see, quality of blur is pretty much the same.
So, the benefit of using
FastBlur is that we eliminated renderscript dependency (and removed min API constraint).
But damn! It takes hell a lot of time! We spent 147ms doing blur! And this is far not the slowest SW blurring algorithm. I don't event want to try Gaussian blur...
Going beyond
Now let's think what can we do better. Blurring process itself is all about "losing" pixels. You know what else is all about losing pixels? Right! Downscaling!
What if we try to downscale our bitmap first, do blur and then upscale it again. I tried to implement this technique and here is what I got:
Well, look at that! 13ms for renderscript and 2ms for FastBlur. Not bad at all!
Let's look at the code. I describe only fastblur approach since it the same for renderscript. Full code you can check in my GitHub repo.
private void blur(Bitmap bkg, View view) { long startMs = System.currentTimeMillis(); float scaleFactor = 1; float radius = 20; if (downScale.isChecked()) { scaleFactor = 8; radius = 2; } Bitmap overlay = Bitmap.createBitmap((int) (view.getMeasuredWidth()/scaleFactor), (int) (view.getMeasuredHeight()/scaleFactor), Bitmap.Config.ARGB_8888); Canvas canvas = new Canvas(overlay); canvas.translate(-view.getLeft()/scaleFactor, -view.getTop()/scaleFactor); canvas.scale(1 / scaleFactor, 1 / scaleFactor); Paint paint = new Paint(); paint.setFlags(Paint.FILTER_BITMAP_FLAG); canvas.drawBitmap(bkg, 0, 0, paint); overlay = FastBlur.doBlur(overlay, (int)radius, true); view.setBackground(new BitmapDrawable(getResources(), overlay)); statusText.setText(System.currentTimeMillis() - startMs + "ms"); }
Let's go through the code:
scaleFactortells what level of downscale we want to apply. In my case I will downscale my bitmap to 1/8 of its original size. Also since my bitmap will be blurred by downscaling/upscaling process, I don't need that big radius for my blurring algo. I decided to go with
2.
- Now I need to create bitmap. This bitmap will be 8 times smaller than I finally need for my background.
- Also please note that I provided
Paintwith
FILTER_BITMAP_FLAG. In this way I will get bilinear filtering applied to my bitmap during scaling. It will give me even smoother blurring.
- As before, apply blur. In this case image is smaller and radius is lower, so blur is really fast.
- Set blurred image as a background. This will automatically upscale it back again.
It is interesting that fastblur did blurring even faster than renderscript. That's because we don't waste time copying our bitmap to
Allocation and back.
With these simple manipulations I managed to get relatively fast blurring mechanism w/o renderscript dependency.
WARNING! Please note that FastBlur uses hell a lot of additional memory (it is copying entire bitmap into temp buffers), so even if it works perfect for small bitmaps, I would not recommend using it for blurring entire screen since you can easily get OutOfMemoryException on low-end devices. Use your best judjement
Source code for this article is available on GitHub
|
https://trickyandroid.com/advanced-blurring-techniques/
|
CC-MAIN-2018-30
|
refinedweb
| 1,551 | 57.77 |
The client will be making an array and adding numbers to it. Its my job/objective to make sure that when the client passes it into the array - it is sorted in non-decreasing order.
Note - i just finally learned about binary search and still trying to toy around with it. Have to utilize it - can't use sequential search as its resource consuming.
So i'm basically just starting off with the client program VAGUELY - (you get the jist) - doing basic things like,
basically just shoving value 10,9,11 into my program.basically just shoving value 10,9,11 into my program.PHP Code:
list.add(10);
list.add(9);
list.add(11);
So, ideally - i want it the array to sort itself out. (without using array.sort)
array - [9.10.11]
Though i'm running into issues - i think my logic/thoughts/code in the ADD method (below) is messed. But i've hit a stump.. and honestly can't get around it... I called indexOf to use binary search to locate the index for the value, and so found that.
Simply insert into that index? But it doesn't seem to comply.
Might have been misunderstanding something. I got the idea.. just can't think of the right code to put it into performance.
Took 2 quarter break from java, and decided to jump back into it for the next level class as it was a minor requirement -so my coding IS indeed flakey most definetly, so any assistance small or large would be greatly appreciated.
PHP Code:
import java.util.*;
public class SortArrayList {
private int[] elementData;
private int size;
public static final int MAX_CAP = 100;
public SortArrayList() {
this(MAX_CAP);
}
public SortArrayList(int capacity) {
elementData = new int[capacity];
size = 0;
}
// Use binary search to look for a requested value.
public int indexOf(int value) {
int index = Arrays.binarySearch(elementData,0,size, value);
return index;
}
public void add(int value) {
int indexLocation = indexOf(value); // look for index of value wanted to be inserted.
if(indexLocation > 0) {
size++;
elementData[indexLocation] = value;
}else{
size++;
elementData[-(indexLocation-1)] = value;
}
}
|
http://www.javaprogrammingforums.com/collections-generics/1066-having-trouble-insert-sorting-array-values-w-binary-searching.html
|
CC-MAIN-2014-10
|
refinedweb
| 349 | 58.99 |
Writing tests for your app is necessary, but it is not productive to spend much time on trivial tests. An often underestimated Dart keyword is assert, which can be used to test conditions in your code.
Look at the code file
microtest.dart, where
microtest is an internal package as seen in the previous recipe:
import 'package:microtest/microtest.dart'; void main() { Person p1 = new Person("Jim Greenfield", 178, 86.0); print('${p1.name} weighs ${p1.weight}' ); // lots of other code and method calls // p1 = null; // working again with p1: assert(p1 is Person); p1.weight = 100.0; print('${p1.name} now weighs ${p1.weight}' ); }
We import the
microtest library, which contains the definition of the ...
No credit card required
|
https://www.oreilly.com/library/view/dart-scalable-application/9781787288027/ch24s06.html
|
CC-MAIN-2019-43
|
refinedweb
| 120 | 69.28 |
A small Django package allowing a dictionary to be passed to contrib.messages. The dictionary is then pre-rendered and passed to the real contrib.message function.
A recent version of Django is required, but there are no third-party dependencies for this package.
Use your favorite Python installer to install it from PyPI:
$ pip install django-dictmessages
Or get the source from the application site:
$ hg clone $ cd django-dictmessages $ python setup.py install
Add 'dictmessages' to your INSTALLED_APPS setting like this:
INSTALLED_APPS = { ... 'dictmessages', }
Wherever you would normally make use of the django.contrib.messages API you can use this package instead:
# Before... from django.contrib import messages # After... from dictmessages import messages
Since dictmessages is a simply a wrapper around the original functionality, you can continue to use it in the same way:
from dictmessages import messages ... ... # This still works the same... messages.success(request, 'Awesome! You totally nailed that, dude.')
But, if you’d like to something a little more fancy…:
from dictmessages import messages ... ... message_dictionary = dict( object='Awesome!', activity='You totally nailed that, dude.') messages.success(requestion, message_dictionary).
|
https://pypi.org/project/django-dictmessages/
|
CC-MAIN-2016-50
|
refinedweb
| 182 | 51.04 |
Earlier.
Hey Scott,
Don't let Bill see this, you put him second!!! LOL.
Great stuff! Thanks!
.NET 3.5 extension methods
Wouldn't the .NET Framework Design Guidelines suggest .ToJson() as the correct capitalisation of the extension method's name? (And for that matter, .Json for the namespace?)
;)
Good stuff though Scott, don't know how you find the time to write these up so clearly.
I've found the new JSON generation mechanisms in .NET 3.5 to be quite useful indeed. I wrote a similar extension method that uses the XmlJsonWriter directly, with reflection. This enables me to easily translate anonymous objects to JSON. In the rather common case that you want to push only part of an object graph down to your script layer, it's a great strategy. It also enables you to create more JavaScript-friendly property names on the fly.
var jsonString = users.Select(u => new { id = u.Id, name = u.FullName }).ToJsonString();
Hi,
One extension method I've found useful in web development is an EnsureIdSet() method. By adding this to Controls, you can ensure that either an ID has been specifically set or the ID is set to the auto-generated 'ctlXX' ID. (Without this, the ID may not be set until much later in the page lifecycle.)
Cheers,
Geoff
Too cool! Can't wait to mess with this. Have been waiting for ages for this kinda thing :-)
Keep up the good work guys!
/M
Looking a bit closer at this class, it appears that it's less strict than the DataContractJsonSerializer, and works well even with anonymous types ... very handy indeed. I'd been looking for a class like this, but never bothered to inspect the System.Web.Extensions assembly. Such is the joy of working with undocumented frameworks, I suppose.
I'm getting an obsoletion warning though, which is somewhat concerning. Is this class on the chopping block?
'System.Web.Script.Serialization.JavaScriptSerializer.JavaScriptSerializer()' is obsolete: 'The recommended alternative is System.Runtime.Serialization.DataContractJsonSerializer.'
How about a ".ToJavaScript()" on Expression?
Then you could write validation logic in C# and send it to the client as JavaScript!
I have done it in a different way while using the service factory
When implementing the webservice as in the following code you have the following
1) Difference between the business objects and the objects that you want to send to the browser. Not all data you have got from the database might be needed to be sent to the browser.
2) Use of Ajax to serialise.
3) Use of translate function to convert data from Business Object to DataType that you are sending the data down to the client.
using System;
using System.Collections.Generic;
using System.Text;
using ProjectName.BusinessLogic;
using ProjectName.BusinessEntities;
// AJax and serialisation namespaces
using System.Web.Services;
using System.Web.Script.Services;
using System.Web.Script.Serialization;
namespace ProjectName.ServiceImplementation
{
[System.Web.Services.WebService(Namespace = "", Name = "EntityPriceSet")]
[System.Web.Services.WebServiceBindingAttribute(ConformsTo = System.Web.Services.WsiProfiles.BasicProfile1_1, EmitConformanceClaims = true)]
// Definition for ajax webservice
[ScriptService]
public class EntityPriceSetWS : ProjectName.ServiceContracts.IEntityPriceSet
{
#region IEntityPriceSet Members
// definition for ajax web method
[WebMethod]
// Define response serialisation method.
[ScriptMethod(UseHttpGet = false, ResponseFormat = ResponseFormat.Json)]
public List<ProjectName.DataTypes.EntityPriceSetAvailabilityResponse> /*string*/ GetMainPricingByEntityVersionIDAgencyAndDates(ProjectName.DataTypes.EntityPriceSetAvailabilityRequest request)
{
List<ProjectName.DataTypes.EntityPriceSetAvailabilityResponse> ret = new List<ProjectName.DataTypes.EntityPriceSetAvailabilityResponse>();
EntityPriceSetMgr mgr = new EntityPriceSetMgr();
List<ProjectName.BusinessEntities.EntityPriceSet> epss = mgr.GetMainPricingByEntityVersionIDAgencyAndDates(request.AgencyID,
request.EntityVersionIDs, request.FromDate, request.ToDate);
foreach (ProjectName.BusinessEntities.EntityPriceSet eps in epss)
{
ProjectName.DataTypes.EntityPriceSetAvailabilityResponse r = Translators.TranslateBetweenEntityPriceSetAvailabilityResponseAndEntityPriceSet.TranslateEntityPriceSetToEntityPriceSetAvailabilityResponse(eps);
ret.Add(r);
}
return ret; // This gets serialised on its way
}
#endregion
}
}
That's a beautiful class. I just had to write my own the other day for a 2.0 project. I plan on porting that project over to 3.5, but we're a little busy right now (and it's 30k lines of code, so I'm in no rush).
I have to say that I'm somewhat torn in my feelings about 3.5 and VS2008. I've been using it in a production environment for a couple of months now, and I'm loving it for the most part, but there still is that 25% that's missing.
From the small things: (public static T FindControl<T>(this Control ctrl)) to the large things (Entity framework fitting into a proper architecture with proper seperation for DAL, BLL and other layers).
All in all (and yes, this is the end of my rant)... great job, great product. Ooh, another 'beef' I have with 2008... right-click on a MasterPage and click "Add Content Page"... and it spits out "WebForm1.aspx" <-- nasty... Why not prompt for a name?
Again, to bust your chops: ToJSON should be ToJson :)
Scott, tell me - why do you use deprecated method to serialize? Only for simplicity?
Sweet! I also built my own JSON serializer for 2.0 (and 1.1). I don't recall the size; however, it may be even bigger than 30k. I've seen integers (numbers in js) both wrapped and unwrapped in double quotes and I have not found the 'standard' anyware online. Can you point me to the defacto? One other thing: I agree with Nullable: I perfer ToJson over ToJSON. Thanks Scott...
Sorry I must be missing something, I don't understand how the person class or people list knows to use the extension class. There isn't any code other than the using statment that links the class is that all that is required ?
Trivial - I think you mean magnifying glass rather than hour-glass. I should not point things like that out but it is a friendly point.
Please can you do a demo of disconnected Linq to sql. I am almost busting to see how you recommend using linq to sql via say WCF to a smart client type app be it an xbap or silverlight app.
This May I came up with a set of extension method that exposes a IEnumerable<T> interface that returns items back in a random order.
I provided two extension methods:
public static T NextRandom<T>(this IEnumerable<T> source)
Returns a random back every time it is call without regard to whether its been return before.
public static IEnumerable<T> Radomized<T>(this IEnumerable<T> source)
Returns every item of a IEnumerable back exactly once in a random order. Uses a list to track remaining items, NextRemaining to return from that list, and a custom iterator using yield to return the interface.
Sample Solution is here:
foreachdev.net/.../linq-part-2how-to-be-random-with-linq-to-objects
This is GREAT! I am a .NET developer, but was always interested in a more Open Microsoft. I donated the domain OpenAjax.Org to foster greater collaboration, and I am VERY excited that Microsoft has joined the OpenAjax Alliance. I am also created a project on JSON.Com to promote JavaScript Object Notation, and I thank you for putting this into .Net as well.
I recently created a custom JavaScript serializer based off of the JavaScriptSerializer that uses the XmlAttributes, so there was a more consistent serialization between XML and JavaScript. Plus the XmlAttributes offered better control over the serialization of the object.
I hope there is some plans to expand the control of sterilization in JavaScript because just having the ScriptIgnoreAttribute is not enough. My sample is here.
coderjournal.com/.../creating-a-more-accurate-json-net-serializer
You've been kicked (a good thing) - Trackback from DotNetKicks.com
Hi Derek,
>>>>>> I'm getting an obsoletion warning though, which is somewhat concerning. Is this class on the chopping block?
The JavaScriptSerializer is currently marked obsolete - although I'm not sure why (was going to ask someone about this today). It is very handy. Note that obsolete doesn't mean removal in .NET 3.5 - it will be supported at least another version or two (or longer if I can convince them <g>).
Thanks,
Scott,?
ps Thanks for another great tip!!!
Hi Ariel,
>>>>>> Sorry I must be missing something, I don't understand how the person class or people list knows to use the extension class. There isn't any code other than the using statment that links the class is that all that is required ?
If you add a using statement for a namespace with an extension method, the compiler will automatically enable the extension methods for those types that the extension method extends. In the example above I was extending "object" - which is why it worked on everything.
>>>>>>> Trivial - I think you mean magnifying glass rather than hour-glass. I should not point things like that out but it is a friendly point.
Good catch!
>>>>>>>> Please can you do a demo of disconnected Linq to sql. I am almost busting to see how you recommend using linq to sql via say WCF to a smart client type app be it an xbap or silverlight app.
Yep - this is definitely on my list todo. I'll get to it later this month I hope.
Hi Marc,
>>>>>>?
Extension methods themselves only allow you to work against public members. If you wanted to access private members you'd need to-do it via internal reflection inside the extension method.
It's been a while since I got time to read up on some blog posts and I stumbled on some interesting
Yeah, why would JavaScriptSerializer be marked obsolete? The DataContractJsonSerializer requires you to put DataMember on all the fields/properties you want to serialize. If you have a 3rd pary class that's not marked serialize or implements iseralizable I believe it fails. +1 Vote for saving JavaScriptSerializer! :)
no words, just cool.
tnk
Hi Scott,
It's a cool idea to collect all these useful extension methods in a central location. I'll contribute the following one that extends the Redirect method of the Response object, allowing you to use string formatting directly in the Redirect call:
public static void Redirect(this System.Web.HttpResponse response,
string newUrl, params object[] args)
HttpContext.Current.Response.Redirect(string.Format(newUrl, args));
This allows you to do stuff like:
Response.Redirect("SomePage.aspx?CatId={0}", categoryId.ToString());
Fore more details about this, see: imar.spaanjaars.com/QuickDocId.aspx
Imar
I have a requirement where I need to pull only selected columns based on user selection from the database instead of pulling all the columns and then making them invisible. Can this be done in LINQ to SQL? Is it possible to dynamically (based on user selected variable list) return variables in LINQ?
For example, if I have 100 columns for an order in my orderdetails table and in the application preference the user can check the columns he/she interested in and then pull on those from the database or say all the columns are retrieved for some other reason, but when the user filters or does any querying operation on the orderdetails table (LINQ to SQL) I should return only the interested columns (dim a = from a1 in OrderDetails Select a1) in the select clause. Is this possible in LINQ?
Ram
Hey Scott, great post.
Here is a handy extension method that applies some action to every element in an enumrable:
void ForEach<T>(this IEnumerable<T> elements, Action action);
FWIW, I've used extension methods to simply code quite a bit. I wrote a little WinForms app here that scans a forum I moderate for spam and deletes the spam posts automatically. I used extension methods on System.Windows.Forms.HtmlElement for determining whether an HTML element contained spammy text. The resulting code is quite clean and extension methods are largely to thank for that.
>>>>>>>Extension methods themselves only allow you to work against public members. If you wanted to access private members you'd need to-do it via internal reflection inside the extension method.
Can you please provide and example of how can I use the internal extension to work with the private members of the class. Thanks in advance
Nice example. But shouldn't your ToJSON method be written ToJson in order to follow the framework naming guidelines? Acronyms with more than two letters should be cased just like names (first letter upper case, rest lower case).
I feel a little bit pedantic, but I think following these guidelines can only help the community to have more coherent naming across the different code pieces.
Pierre, author of
Pingback from ThemePassion - Best stuff about design! » Tip/Trick: Building a ToJSON() Extension Method using .NET 3.5
Pingback from To and FromJson Extension Methods « Ramblings of the Sleepy…
I always enjoy reading ScottGu's Blog. A recent post about Json and extension methods grabbed my attention,
Hi all:
You can read this post in spanish here:
thinkingindotnet.wordpress.com/.../trucos-creando-un-metodo-de-extension-tojson-con-net-35
Thanks to Scottgu’s blog ( weblogs.asp.net/.../tip-trick-building-a-tojson-extension-method-using-net-3-5.aspx
Pingback from Techy News Blog » Converting Data to JSON in .NET Framework 3.5
ASP.NET: Uno extension method per trovare i controlli
Pingback from Development in a Blink » Blog Archive » Building a ToPoSH() Extension Method using .Net 3.5
C# Extensions and Casting
Welcome to the thirty-third edition of Community Convergence. This week we have a new video called Programming
Thank you for your fantastic articles.
I'm playing with LINQ and WFC to build a little DB-driven AJAX app. I've hit a wall wrt sending LINQ objects from my WFC services -- they don't serialize automatically to JSON. The approach you outlined above does the trick, but then I need to handle deserialization myself on the client-side.
Is there a way to allow WFC services to pass back unadulterated LINQ objects and collections, without decorating each LINQ class with [Serializable] or using this trick?
Best,
Mike
The question that I have regarding the Extension Methods is not related to JSON rather on the conflict resolving with same extension method on different assemblies. My question is as follows:
I have checked the IL generated by the extension methods and it seems that it uses the .CompilerServices.ExtensionAttribute::.ctor() attribute. So this is not explicitly calling the static method at compile time rather calling the function at the runtime.
It is very likely that many people will have their own implementation of the custom methods on classes like string, int, StringBuilder etc and it is likely that when you add third party dlls then same method may have the same signature in different assemblies. If they are used in code then this error is caught at compile time and easily resolved by explicitly calling the static method from the static class. But if the code is already compiled then adding such a dll in the same private dll path would create runtime ambiguous method error. But if we had pointed the IL to point to the static class then we would able to avoid such an issue since Namespace and class name combination would be very hard match.
So a piece of code that uses one assembly and name import directive in header could run into such a problem where a assembly added later on with same namespace has same extended method. This is likely to happen on common classes like string.
So my question is was this scenario taken into account when designing the IL generation for extension methods? How do we resolve this?
Nice one!
I'm trying to use DataContractJsonSerializer. How can I serialize an object to a string instead of a FileStream though?
Is it possible to use linq with vs2005 today? Or is it just a feature of Oracs?
Hi Michael,
>>>>>> Is it possible to use linq with vs2005 today? Or is it just a feature of Oracs?
Unfortunately LINQ is a VS 2008/.NET 3.5 feature only.
Sorry!
So I just tried doing my first extension method and I guess I have a talent for picking out some exception. I would like to add a "ToHexString" to a type of byte[]. When I tried this out, I get the following message:
'System.Array' does not contain a definition for 'ToHexString' and no extension method 'ToHexString' accepting a first argument of type 'System.Array' could be found (are you missing a using directive or an assembly reference?)
So then I tried to make my extension take an argument of (this System.Array byteArray). But I don't know what do with the System.Array to test if it is a Byte Array or some other array or how to get to the individual members... any help would be appreciated.
Hi Jeff,
The problem you have is that you are trying to add the extension method to array. Instead you'd want to add it to byte array like so:
public static string ToHexString(this byte[] byteArray) {
I just tried this out and confirmed it works.
Now I dont have to use Newtonsoft.Json. =)
that sounds cool, well with Extension methods you will be able to do all sort of crazy things you dont have to stop with Json, any kind of object serialization can be added.
ps.: like the way you have put Bill is next to you.
Nice tip - thanks.
As others have said you can do it with other serializations as well, so I had to try...
using System.Xml.Serialization;
using System.IO;
using System.Windows.Markup;
//Here's one for XML.
public static string ToXML( this object obj )
XmlSerializer x = new XmlSerializer(obj.GetType());
StringBuilder b = new StringBuilder();
using (StringWriter wr = new StringWriter( b ))
x.Serialize(wr, obj);
return b.ToString();
//Heres a simple one for Xaml
public static string ToXaml( this object obj )
return XamlWriter.Save(obj);
I really like C#.
that is cool, but i like to know if you could put constraints on extension methods so if a class is marked as non-serializable the method wont be availabled for that class. is it possible?
----------
A Generic JSON Serialization Extension Method Starring DataContractJsonSerializer
Pingback from Building a ToJSON() Extension Method using .NET 3.5 « vincenthome’s Software Development
I finally subscribed to Rick Strahl's blog because an inordinate number of my Googling ends up there
Very recently I wrote an application where I had to deal with DataSet from a Web Service. Please note
I always thought that was true until I talked to my brother. He has a different opinion.
More adventures in JSON serialization. I'm tellin' ya, it's like a Saturday morning cartoon
|
http://weblogs.asp.net/scottgu/archive/2007/10/01/tip-trick-building-a-tojson-extension-method-using-net-3-5.aspx
|
crawl-001
|
refinedweb
| 3,091 | 58.08 |
I). The directory looks like this: Eggs\ \archetypes.kss-1.2.3-py2.4.egg \five.customerize-0.2-py2.4.egg \plone.app.content-1.0.1-py2.4.egg \plone.app.contentmenu-1.0.3-py2.4.egg \plone.app.contentrules-1.0.2-py2.4.egg \and so on... Now, if I add the "eggs\plone.app.content-1.0.1-py2.4.egg" dir to my PYTHONPATH, Source Analysis seems to properly process *all* the files as it should, however, if I then add "eggs\plone.app.contentmenu-1.0.3-py2.4.egg" it *only* processes the first one. This seems to be the case for *all* files where the namespace is "duplicated" at the top level. To fix this, I wrote a little script that "flattens" the entire egg dir (not optimum, but it works) and I confirmed that that solves the issue. Now I am to a new problem. For existing code, it isn't a big deal to run the script every once in a while to "flatten" the eggs dir, but for code I am *developing* it is a real pain. Currently, I have 3 dirs labeled as follows: sfb.theme, sfb.policy, sfb.cmis - they are all in my "src-custom" folder which is included using my buildout into the pythonpath of plone/zope. Problem is, I get the same results as above; if I include "sfb.theme" first, that is *all* that shows up in the Source Analysis. My only solution would be to "flatten" my code, which of course is not possible during *development*.). Thoughts? --- Best Regards, Andrew D. Fields American Village Corp. Andrew at AVCorp.biz V: 503.362.0005 x102 F: 503.362.0007 7585 State St. - Salem, OR - 97317 -------------- next part -------------- An HTML attachment was scrubbed... URL: /pipermail/wingide-users/attachments/20071210/0c48fabc/attachment.html
|
http://wingware.com/pipermail/wingide-users/2007-December/004922.html
|
CC-MAIN-2018-05
|
refinedweb
| 310 | 68.57 |
- Ian Gillespie
- Sep 14, 2016
- Tested on Splunk Version: N/A
In a previous blog series, I covered how to create and CRUD a KV Store using Splunk’s SPL (Search Processing Language). In this blog post I am going to cover how to do the same thing using Python.
In a previous blog series, I covered how to create and CRUD a KV Store using Splunk’s SPL (Search Processing Language). Feel free to check out the various pieces and parts of that tutorial here: Creating and CRUDing a KV Store in Splunk: Part 1 and Part 2.
In this blog post I'm going to cover how to do the same thing using Python. The blog post is available, as well as the subsequent screencasts. So, feel free to read, watch or do both.
In order to follow along with this you should download the Splunk Python SDK.
You can place the Splunk SDK folder where you want, but you will need to add the folder to your Python path in order to run the examples:
export PYTHONPATH=~/splunk-sdk-python
In this example, I’m going to use a .splunkrc file to store my credentials. The .splunkrc file is a handy way for us to store our credentials when we connect to Splunk through our Python script.
You don’t have to use a .splunkrc file, but its easier than having to write this every time we want to execute a file, see below:
<python_script>.py --username=”<username>” --password=”<password>”
# Splunk host (default: localhost) host=localhost # Splunk admin port (default: 8089) port=8089 # Splunk username username=admin # Splunk password password=changeme # Access scheme (default: https) scheme=https # Your version of Splunk (default: 5.0) version=6.4.2 #only needed for the JavaScript SDK
The location of the .splunkrc file will depend on whether or not you’re following along using Windows.
On Windows, you will put the .splunkrc in C:\Users\currenusername\.splunkrc
If you are on Linux or OSX place it in ~/.splunkrc
When we run our Python file, Splunk is going to check and see if user credentials have been passed into the command line. If not, it will then check if a .splunkrc file exists.
Inside of your Splunk SDK folder, there is an examples folder. This is where we will add our task_collection.py and add the following:
import sys, json from splunklib.client import connect
Importing connect will allow us to actually connect to Splunk. We will pass our credentials to it shortly. Next, we will try to import parse, which will be used to pull out our credentials from command line arguments or the .splunkrc file. If it cannot be imported that means you did not successfully export the SDK to your PYTHONPATH, as described above.
try: from utils import parse except ImportError: raise Exception("Add the SDK repository to your PYTHONPATH to run the examples " "(e.g., export PYTHONPATH=~/splunk-sdk-python.")
We then define the main() function where we will set up an opts variable from which we will pull out our user credentials. We will also set the owner to nobody and the app context to search. We will then connect to Splunk using our opts.kwargs.
def main(): #in this example, i’m using a .splunkrc file to pull credentials opts = parse(sys.argv[1:], {}, ".splunkrc") opts.kwargs["owner"] = "nobody" opts.kwargs["app"] = "search" service = connect(**opts.kwargs)
Next, in the main() function, we will set up our collection name and set the collection using service.kvstore.
collection_name = "task_collection" collection = service.kvstore[collection_name]
We will also check if the collection exists and if it does not, then we will create it:
#if the collection is found, print it out #if not, then create the collection if collection_name in service.kvstore: print "Collection %s found!" % collection_name else: service.kvstore.create(collection_name)
You can then read the data from KV Store collection, using the query() function:
#print out the data from the collection print "Collection data: %s" % json.dumps(collection.data.query(), indent=1)
Finally, you will want to run the following, in order to execute the main() function, when you run the Python script from the command line:
if __name__ == "__main__": main()
Once you’ve added everything, save the file.
To create, or insert, new data in your collection add the following to the Python script inside of the main() function above where we are printing out the collection data using the query() function:
collection.data.insert(json.dumps({"Task_Name":"Python Task","Task_Description":"This task was created in python.","Status":"In Progress","Estimated_Completion_Date":"October 20th", "Notes":"No notes at this time."}))
All we are doing is inserting JSON to add a new value to KV Store.
Save the script and then run it on the command line. You should get back something like this:
Collection task_collection found! Collection data: [ { "Status": "In Progress", "_key": "57a6a49067174ac5cf6ec013", "Notes": "No notes at this time.", "Task_Description": "This task was created in python.", "Task_Name": "Python Task", "Estimated_Completion_Date": "October 20th", "_user": "nobody" } ]
As described above, we can use query() to read the data from our KV Store. In our example we are specifically running this (see below) to print out the results:
print "Collection data: %s" % json.dumps(collection.data.query(), indent=1)
Currently, we don’t have an update in our file. Go ahead and comment out the collection.data.insert that currently exists and then add:
collection.data.update(str(“<_key_id>”), json.dumps({"Task_Name":"Python Task 2.0","Task_Description":"This task was updated in Python.","Status":"Delayed","Estimated_Completion_Date":"November 2nd","Notes":"This project has been somewhat delayed...whoops."}))
The key to updating is to first provide a string version of the _key you want to update and then as the second parameter include all the fields you want to update from your KV Store.
Save your file and rerun it, and you should see the updated values in the output.
We can either delete a specific row based on the _key:
collection.data.delete(json.dumps({"_key":"<_key_id>"}))
Or we can delete the entire collection:
collection.data.delete()
So, what can we do with this information? We could CRUD our KV Store from outside of Splunk using the Python SDK, or we could create a custom REST endpoint, modify our data and the CRUD the collection in some way.
With all of this information, you should have a pretty solid understand of how to create a new KV store collection, as well as a lookup definition that allows us to communicate with our collection through the Splunk query language. We also covered how to CRUD our KV store collection through the Splunk query language as well as doing the same through Python. If you have any questions, feel free to leave them below in the comments section.
If you're looking for something different than the typical "one-size-fits-all" security mentality, you've come to the right place.
|
https://www.hurricanelabs.com/splunk-tutorials/splunk-tutorial-cruding-a-kv-store-in-splunk-using-python
|
CC-MAIN-2019-18
|
refinedweb
| 1,158 | 64.71 |
how to shuffle a word's letters randomly in python? for example, we have the word "cat". change that randomly to, act, tac or tca and ex.. to be exact,The scrambling process must be implemented manually. Built-in functions or string methods that “automate” this process are prohibited from use. thanks
views:222
answers:7
shuffling a word
import random word = "cat" shuffled = list(word) random.shuffle(shuffled) shuffled = ''.join(shuffled) print shuffled
...or done in a different way, inspired by Dominic's answer...
import random shuffled = ''.join(random.sample(word, len(word)))
return "".join(random.sample(word, len(word)))
Used like:
word = "Pocketknife" print "".join(random.sample(word, len(word))) >>> teenockpkfi
Take a look at the Fisher-Yates shuffle. It's extremely space and time-efficient, and easy to implement.
To be very slightly more low level, this just swaps the current letter with a random letter which comes after it.
from random import randint word = "helloworld" def shuffle(word): wordlen = len(word) word = list(word) for i in range(0,wordlen-1): pos = randint(i+1,wordlen-1) word[i], word[pos] = word[pos], word[i] word = "".join(word) return word print shuffle(word)
This won't create all possible permutations with equal probability, but still might be alright for what you want
Here is a way that doesn't use
random.shuffle. Hopefully
random.choice is ok. You should add any restrictions to the question
>>> from random import choice >>> from itertools import permutations >>> "".join(choice(list(permutations("cat")))) 'atc'
This method is not as efficient as random.shuffle, so will be slow for long words
This cookbook recipe has a simple implementation of Fisher-Yates shuffling in Python. Of course, since you have a string argument and must return a string, you'll need a first statement (say the argument name is
s) like
ary = list(s), and in the
return statement you'll use
''.join to put the array of characters
ary back into a single string.
from random import random def shuffle(x): for i in reversed(xrange(1, len(x))): j = int(random() * (i+1)) x[i], x[j] = x[j], x[i]
|
http://ansaurus.com/question/3182964-shuffling-a-word
|
CC-MAIN-2017-34
|
refinedweb
| 360 | 58.38 |
9.3. Transformer¶
The Transformer model is also based on the encoder-decoder architecture. It, however, differs to the seq2seq model that the transformer replaces the recurrent layers in seq2seq with attention layers. To deal with sequential inputs, each item in the sequential is copied as the query, the key and the value as illustrated in Fig. 9.3.1. It therefore outputs a same length sequential output. We call such an attention layer as a self-attention layer.
The transformer architecture, with a comparison to the seq2seq model with attention, is shown in Fig. 9.3.2. These two models are similar to each other in.
It can also be seen that the transformer differs to the seq2seq with attention model in three major places:
A recurrent layer in seq2seq is replaced with a transformer block. This block contains a self-attention layer (muti-head attention) and a network with two dense layers (position-wise FFN) for the encoder. For the decoder, another mut-head attention layer is used to take the encoder state.
The encoder state is passed to every transformer block in the decoder, instead of using as an additional input of the first recurrent layer in seq2seq.
Since the self-attention layer does not distinguish the item order in a sequence, a positional encoding layer is used to add sequential information into each sequence item.
In the rest of this section, we will explain every new layer introduced by the transformer, and construct a model to train on the machine translation dataset.
import math import d2l from mxnet import nd, autograd from mxnet.gluon import nn
9.3.1. Multi-Head Attention¶
A multi-head attention layer consists of \(h\) parallel attention layers, each one is called a head. For each head, we use three dense layers with hidden sizes \(p_q\), \(p_k\) and \(p_v\) to project the queries, keys and values, respectively, before feeding into the attention layer. The outputs of these \(h\) heads are concatenated and then projected by another dense layer.
To be more specific, assume we have the learnable parameters \(\mathbf W_q^{(i)}\in\mathbb R^{p_q\times d_q}\), \(\mathbf W_k^{(i)}\in\mathbb R^{p_k\times d_k}\), and \(\mathbf W_v^{(i)}\in\mathbb R^{p_v\times d_v}\), for \(i=1,\ldots,h\), and \(\mathbf W_o\in\mathbb R^{d_o\times h p_v}\). Then the output for each head can be obtained by
where \(\text{attention}\) can be any attention layer introduced before. Since we already have learnable parameters, the simple dot product attention is used.
Then we concatenate all outputs and project them to obtain the multi-head attention output
In practice, we often use \(p_q=p_k=p_v=d_o/h\). The hyper-parameters for a multi-head attention, therefore, contain the number heads \(h\), and output feature size \(d_o\).
class MultiHeadAttention(nn.Block): def __init__(self, units, num_heads, dropout, **kwargs): # units = d_o super(MultiHeadAttention, self).__init__(**kwargs) assert units % num_heads == 0 self.num_heads = num_heads self.attention = d2l.DotProductAttention(dropout) self.W_q = nn.Dense(units, use_bias=False, flatten=False) self.W_k = nn.Dense(units, use_bias=False, flatten=False) self.W_v = nn.Dense(units, use_bias=False, flatten=False) # query, key, and value shape: (batch_size, num_items, dim) # valid_length shape is either (bathc_size, ) or (batch_size, num_items) def forward(self, query, key, value, valid_length): # Project and transpose from (batch_size, num_items, units) to # (batch_size * num_heads, num_items, p), where units = p * num_heads. query, key, value = [transpose_qkv(X, self.num_heads) for X in ( self.W_q(query), self.W_k(key), self.W_v(value))] if valid_length is not None: # Copy valid_length by num_heads times if valid_length.ndim == 1: valid_length = valid_length.tile(self.num_heads) else: valid_length = valid_length.tile((self.num_heads, 1)) output = self.attention(query, key, value, valid_length) # Transpose from (batch_size * num_heads, num_items, p) back to # (batch_size, num_items, units) return transpose_output(output, self.num_heads)
Here are the definitions of the transpose functions.
def transpose_qkv(X, num_heads): # Shape after reshape: (batch_size, num_items, num_heads, p) # 0 means copying the shape element, -1 means inferring its value X = X.reshape((0, 0, num_heads, -1)) # Swap the num_items and the num_heads dimensions X = X.transpose((0, 2, 1, 3)) # Merge the first two dimensions. Use reverse=True to infer # shape from right to left return X.reshape((-1, 0, 0), reverse=True) def transpose_output(X, num_heads): # A reversed version of transpose_qkv X = X.reshape((-1, num_heads, 0, 0), reverse=True) X = X.transpose((0, 2, 1, 3)) return X.reshape((0, 0, -1))
Create a multi-head attention with the output size \(d_o\) equals to 100, the output will share the same batch size and sequence length as the input, but the last dimension will be equal to \(d_o\).
cell = MultiHeadAttention(100, 10, 0.5) cell.initialize() X = nd.ones((2, 4, 5)) valid_length = nd.array([2,3]) cell(X, X, X, valid_length).shape
(2, 4, 100)
9.3.2. Position-wise Feed-Forward Networks¶
The position-wise feed-forward network accepts a 3-dim input with shape (batch size, sequence length, feature size). It consists of two dense layers that applies to the last dimension, which means the same dense layers are used for each position item in the sequence, so called position-wise.
class PositionWiseFFN(nn.Block): def __init__(self, units, hidden_size, **kwargs): super(PositionWiseFFN, self).__init__(**kwargs) self.ffn_1 = nn.Dense(hidden_size, flatten=False, activation='relu') self.ffn_2 = nn.Dense(units, flatten=False) def forward(self, X): return self.ffn_2(self.ffn_1(X))
Similar to the muti-head attention, the position-wise feed-forward network will only change the last dimension size of the input. In addition, if two items in the input sequence are identical, the according outputs will be identical as well.
ffn = PositionWiseFFN(4, 8) ffn.initialize() ffn(nd.ones((2, 3, 4)))[0]
[[ 0.00752072 0.00865059 0.01013744 -0.00906538] [ 0.00752072 0.00865059 0.01013744 -0.00906538] [ 0.00752072 0.00865059 0.01013744 -0.00906538]] <NDArray 3x4 @cpu(0)>
9.3.3. Add and Norm¶
The input and the output of a multi-head attention layer or a position-wise feed-forward network are combined by a block that contains a residual structure and a layer normalization layer.
Layer normalization is similar batch normalization, but the mean and
variances are calculated along the last dimension, e.g
X.mean(axis=-1) instead of the first batch dimension, e.g.
X.mean(axis=0).
layer = nn.LayerNorm() layer.initialize() batch = nn.BatchNorm() batch.initialize() X = nd.array([[1,2],[2,3]]) # compute mean and variance from X in the training mode. with autograd.record(): print('layer norm:',layer(X), '\nbatch norm:', batch(X))
layer norm: [[-0.99998 0.99998] [-0.99998 0.99998]] <NDArray 2x2 @cpu(0)> batch norm: [[-0.99998 -0.99998] [ 0.99998 0.99998]] <NDArray 2x2 @cpu(0)>
The connection block accepts two inputs \(X\) and \(Y\), the input and output of an other block. Within this connection block, we apply dropout on \(Y\).(nd.ones((2,3,4)), nd.ones((2,3,4))).shape
(2, 3, 4)
9.3.4. Positional Encoding¶
Unlike the recurrent layer, both the multi-head attention layer and the position-wise feed-forward network compute the output of each item in the sequence independently. This property allows us to parallel the computation but is inefficient to model the sequence information. The transformer model therefore adds positional information into the input sequence.
Assume \(X\in\mathbb R^{l\times d}\) is the embedding of an example, where \(l\) is the sequence length and \(d\) is the embedding size. This layer will create a positional encoding \(P\in\mathbb R^{l\times d}\) and output \(P+X\), with \(P\) defined as following:
for \(i=0,\ldots,l-1\) and \(j=0,\ldots,\lfloor(d-1)/2\rfloor\).
class PositionalEncoding(nn.Block): def __init__(self, units, dropout, max_len=1000): super(PositionalEncoding, self).__init__() self.dropout = nn.Dropout(dropout) # Create a long enough P self.P = nd.zeros((1, max_len, units)) X = nd.arange(0, max_len).reshape((-1,1)) / nd.power( 10000, nd.arange(0, units, 2)/units) self.P[:, :, 0::2] = nd.sin(X) self.P[:, :, 1::2] = nd.cos(X) def forward(self, X): X = X + self.P[:, :X.shape[1], :].as_in_context(X.context) return self.dropout(X)
Now we visualize the position values for 4 dimensions. As can be seen, the 4th dimension has the same frequency as the 5th but with different offset. The 5th and 6th dimension have a lower frequency.
pe = PositionalEncoding(20, 0) pe.initialize() Y = pe(nd.zeros((1, 100, 20 ))) d2l.plot(nd.arange(100), Y[0, :,4:8].T, figsize=(6, 2.5), legend=["dim %d"%p for p in [4,5,6,7]])
9.3.5. Encoder¶
Now we define the transformer block for the encoder, which contains a multi-head attention layer, a position-wise feed-forward network, and two connection blocks.
class EncoderBlock(nn.Block): def __init__(self, units, hidden_size, num_heads, dropout, **kwargs): super(EncoderBlock, self).__init__(**kwargs) self.attention = MultiHeadAttention(units, num_heads, dropout) self.add_1 = AddNorm(dropout) self.ffn = PositionWiseFFN(units, hidden_size) self.add_2 = AddNorm(dropout) def forward(self, X, valid_length): Y = self.add_1(X, self.attention(X, X, X, valid_length)) return self.add_2(Y, self.ffn(Y))
Due to the residual connections, this block will not change the input
shape. It means the
units argument should be equal to the input’s
last dimension size.
encoder_blk = EncoderBlock(24, 48, 8, 0.5) encoder_blk.initialize() encoder_blk(nd.ones((2, 100, 24)), valid_length).shape
(2, 100, 24)
The encoder stacks \(n\) blocks. Due to the residual connection again,, units, hidden_size, num_heads, num_layers, dropout, **kwargs): super(TransformerEncoder, self).__init__(**kwargs) self.units = units self.embed = nn.Embedding(vocab_size, units) self.pos_encoding = PositionalEncoding(units, dropout) self.blks = nn.Sequential() for i in range(num_layers): self.blks.add( EncoderBlock(units, hidden_size, num_heads, dropout)) def forward(self, X, valid_length, *args): X = self.pos_encoding(self.embed(X) * math.sqrt(self.units)) for blk in self.blks: X = blk(X, valid_length) return X
Create an encoder with two transformer blocks, whose hyper-parameters are same as before.
encoder = TransformerEncoder(200, 24, 48, 8, 2, 0.5) encoder.initialize() encoder(nd.ones((2, 100)), valid_length).shape
(2, 100, 24)
9.3.6. Decoder¶
Let first look at how a decoder behaviors during predicting. Similar to the seq2seq model, we call \(T\) forwards to generate a \(T\) length sequence. At time step \(t\), assume \(\mathbf x_t\) is the current input, i.e. the query. Then keys and values of the self-attention layer consist of the current query with all past queries \(\mathbf x_1, \ldots, \mathbf x_{t-1}\).
During training, because the output for the \(t\)-query could depend all \(T\) key-value pairs, which results in an inconsistent behavior than prediction. We can eliminate it by specifying the valid length to be \(t\) for the \(t\)-th query.
Another difference compared to the encoder transformer block is that the decoder block has an additional multi-head attention layer that accepts the encoder outputs as keys and values.
class DecoderBlock(nn.Block): # i means it's the i-th block in the decoder def __init__(self, units, hidden_size, num_heads, dropout, i, **kwargs): super(DecoderBlock, self).__init__(**kwargs) self.i = i self.attention_1 = MultiHeadAttention(units, num_heads, dropout) self.add_1 = AddNorm(dropout) self.attention_2 = MultiHeadAttention(units, num_heads, dropout) self.add_2 = AddNorm(dropout) self.ffn = PositionWiseFFN(units, hidden_size) self.add_3 = AddNorm(dropout) def forward(self, X, state): enc_outputs, enc_valid_lengh = state[0], state[1] # state[2][i] contains the past queries for this block if state[2][self.i] is None: key_values = X else: key_values = nd.concat(state[2][self.i], X, dim=1) state[2][self.i] = key_values if autograd.is_training(): batch_size, seq_len, _ = X.shape # shape: (batch_size, seq_len), the values in the j-th column # are j+1 valid_length = nd.arange( 1, seq_len+1, ctx=X.context).tile((batch_size, 1)) else: valid_length = None X2 = self.attention_1(X, key_values, key_values, valid_length) Y = self.add_1(X, X2) Y2 = self.attention_2(Y, enc_outputs, enc_outputs, enc_valid_lengh) Z = self.add_2(Y, Y2) return self.add_3(Z, self.ffn(Z)), state
Similar to the encoder block,
units should be equal to the last
dimension size of \(X\).
decoder_blk = DecoderBlock(24, 48, 8, 0.5, 0) decoder_blk.initialize() X = nd.ones((2, 100, 24)) state = [encoder_blk(X, valid_length), valid_length, [None]] decoder_blk(X, state)[0].shape
(2, 100, 24)
The construction of the decoder is identical to the encoder except for the additional last dense layer to obtain confident scores.
class TransformerDecoder(d2l.Decoder): def __init__(self, vocab_size, units, hidden_size, num_heads, num_layers, dropout, **kwargs): super(TransformerDecoder, self).__init__(**kwargs) self.units = units self.num_layers = num_layers self.embed = nn.Embedding(vocab_size, units) self.pos_encoding = PositionalEncoding(units, dropout) self.blks = nn.Sequential() for i in range(num_layers): self.blks.add( DecoderBlock(units,.units)) for blk in self.blks: X, state = blk(X, state) return self.dense(X), state
9.3.7. Training¶
We use similar hyper-parameters as for the seq2seq with attention model: two transformer blocks with both the embedding size and the block output size to be 32. The additional hyper-parameters are chosen as 4 heads with the hidden size to be 2 times larger than output size.
embed_size, units,), units, num_hiddens, num_heads, num_layers, dropout) decoder = TransformerDecoder( len(src_vocab), units, num_hiddens, num_heads, num_layers, dropout) model = d2l.EncoderDecoder(encoder, decoder) d2l.train_s2s_ch8(model, train_iter, lr, num_epochs, ctx)
loss 0.031, 4690 tokens/sec on gpu(0)
Compared to the seq2seq model with attention model, the transformer runs faster per epoch, and converges faster at the beginning.
Finally, we translate three sentences.
for sentence in ['Go .', 'Wow !', "I'm OK .", 'I won !']: print(sentence + ' => ' + d2l.predict_s2s_ch8( model, sentence, src_vocab, tgt_vocab, num_steps, ctx))
Go . => va ! Wow ! => <unk> ! I'm OK . => je vais bien ça . equals to apply 2 \(Conv(1,1)\) layers.
Layer normalization differs from batch normalization by normalizaing along the last dimension (the feature dimension) instead of the first (batchsize) dimension.
Positional encoding is the only place that adds positional information to the transformer model.
|
http://classic.d2l.ai/chapter_attention-mechanism/transformer.html
|
CC-MAIN-2020-16
|
refinedweb
| 2,327 | 52.05 |
The shmem_alloc function allocates a region of shared memory of the given size, using the given name to avoid conflicts between multiple regions in the program. The size of the region will not be automatically increased if its boundaries are overrun. Use the shmem_realloc function for that automatic increases.
This function must be called before any daemon workers are spawned in order for the handle to the shared region to be inherited by the children.
Because the region must be inherited by the children, the region cannot be reallocated with a larger size when necessary.
#include <base/shmem.h> shmem_s *shmem_alloc(char *name, int size, int expose);
A pointer to a new shared memory region.
char *name is the name for the region of shared memory being created. The value of name must be unique to the program that calls the shmem_alloc() function or conflicts will occur.
int size is the number of characters of memory to be allocated for the shared memory.
int expose is either zero or nonzero. If nonzero, then on systems that support it, the file that is used to create the shared memory becomes visible to other processes running on the system.
|
http://docs.oracle.com/cd/E19575-01/821-0049/aecil/index.html
|
CC-MAIN-2014-15
|
refinedweb
| 197 | 53.61 |
How I got a residency appointment thanks to Python, Selenium and Telegram
Hello everyone!
As some of you might know, I’m a Venezuelan 🇻🇪 living in Montevideo, Uruguay 🇺🇾. I’ve been living here for almost a year, but because of the pandemic my residency appointments have slowed down to a crawl, and in the middle of the quarantine they added a new appointment system. Before, there were no appointments, you just had to get there early and wait for the secretary to review your files and assign someone to attend you. But now, they had implemented an appointment system that you could do from the comfort of your own home/office. There was just one issue: there were never appointments available.
That was a little stressful. I was developing a small tick by checking the site multiple times a day, with no luck. But then, I decided I wanted to do a bot that checks the site for me, that way I could just forget about it and let the computers do it for me.
Tech
Selenium
I had some experience with Selenium in the past because I had to run automated tests on an Android application, but I had never used it for the web. I knew it supported Firefox and had an extensive API to interact with websites. In the end, I just had to inspect the HTML and search for the “No appointments available” error message. If the message wasn’t there, I needed a way to be notified so I can set my appointment as fast as possible.
Telegram Bot API
Telegram was my goto because I have a lot of experience with it. It has a stupidly easy API that allows for superb bot management. I just needed the bot to send me a message whenever the “No appointments available” message wasn’t found on the site.
The plan
Here comes the juicy part: How is everything going to work together?
I divided the work into four parts:
- Inspecting the site
- Finding the error message on the site
- Sending the message if nothing was found
- Deploy the job with a cronjob on my VPS
Inspecting the site
Here is the site I needed to inspect:
- On the first site, I need to click the bottom button. By inspecting the HTML, I found out that its name is
form:botonElegirHora
- When the button is clicked, it loads a second page that has an error message if no appointments are found. The ID of that message is
form:warnSinCupos.
Using Selenium to find the error message
First, I needed to define the browser session and its settings. I wanted to run it in headless mode so no X session is needed:
from selenium import webdriver from selenium.webdriver.firefox.options import Options options = Options() options.headless = True d = webdriver.Firefox(options=options)
Then, I opened the site, looked for the button (
form:botonElegirHora) and
clicked it
# This is the website I wanted to scrape d.get('') elem = d.find_element_by_name('form:botonElegirHora') elem.click()
And on the new page, I looked for the error message (
form:warnSinCupos)
try: warning_message = d.find_element_by_id('form:warnSinCupos') except Exception: pass
This was working exactly how I wanted: It opened a new browser session, opened the site, clicked the button, and then looked for the message. For now, if the message wasn’t found, it does nothing. Now, the script needs to send me a message if the warning message wasn’t found on the page.
Using Telegram to send a message if the warning message wasn’t found
The Telegram bot API has a very simple way to send messages. If you want to read more about their API, you can check it here.
There are a few steps you need to follow to get a Telegram bot:
- First, you need to “talk” to the Botfather to create the bot.
- Then, you need to find your Telegram Chat ID. There are a few bots that can help you with that, I personally use
@get_id_bot.
- Once you have the ID, you should read the
sendMessageAPI, since that’s the only one we need now. You can check it here.
So, by using the Telegram documentation, I came up with the following code:
import requests chat_id = # Insert your chat ID here telegram_bot_id = # Insert your Telegram bot ID here telegram_data = { "chat_id": chat_id "parse_mode": "HTML", "text": ("<b>Hay citas!</b>\nHay citas en el registro civil, para " f"entrar ve a {SAE_URL}") } requests.post('{telegram_bot_id}/sendmessage', data=telegram_data)
The complete script
I added a few loggers and environment variables and voilá! Here is the complete code:
#!/usr/bin/env python3 import os import requests from datetime import datetime from selenium import webdriver from selenium.webdriver.firefox.options import Options from dotenv import load_dotenv load_dotenv() # This loads the environmental variables from the .env file in the root folder TELEGRAM_BOT_ID = os.environ.get('TELEGRAM_BOT_ID') TELEGRAM_CHAT_ID = os.environ.get('TELEGRAM_CHAT_ID') SAE_URL = '' options = Options() options.headless = True d = webdriver.Firefox(options=options) d.get(SAE_URL) print(f'Headless Firefox Initialized {datetime.now()}') elem = d.find_element_by_name('form:botonElegirHora') elem.click() try: warning_message = d.find_element_by_id('form:warnSinCupos') print('No dates yet') print('------------------------------') except Exception: telegram_data = { "chat_id": TELEGRAM_CHAT_ID, "parse_mode": "HTML", "text": ("<b>Hay citas!</b>\nHay citas en el registro civil, para " f"entrar ve a {SAE_URL}") } requests.post('' f'{TELEGRAM_BOT_ID}/sendmessage', data=telegram_data) print('Dates found!') d.close() # To close the browser connection
Only one more thing to do, to deploy everything to my VPS
Deploy and testing on the VPS
This was very easy. I just needed to pull my git repo, install the
requirements.txt and set a new cron to run every 10 minutes and check the
site. The cron settings I used where:
*/10 * * * * /usr/bin/python3 /my/script/location/registro-civil-scraper/app.py >> /my/script/location/registro-civil-scraper/log.txt
The
>> /my/script/location/registro-civil-scraper/log.txt part is to keep the logs on a new file.
Did it work?
Yes! And it worked perfectly. I got a message the following day at 21:00
(weirdly enough, that’s 0:00GMT, so maybe they have their servers at GMT time
and it opens new appointments at 0:00).
Conclusion
I always loved to use programming to solve simple problems. With this script, I didn’t need to check the site every couple of hours to get an appointment, and sincerely, I wasn’t going to check past 19:00, so I would’ve never found it by my own.
My brother is having similar issues in Argentina, and when I showed him this, he said one of the funniest phrases I’ve heard about my profession:
“Programmers could take over the world, but they are too lazy”
I lol’d way too hard at that.
I loved Selenium and how it worked. Recently I created a crawler using Selenium, Redis, peewee, and Postgres, so stay tuned if you want to know more about that.
In the meantime, if you want to check the complete script, you can see it on my Git instance: or Gitlab, if you prefer:
|
https://rogs.me/2020/08/how-i-got-a-residency-appointment-thanks-to-python-selenium-and-telegram/
|
CC-MAIN-2021-21
|
refinedweb
| 1,185 | 63.9 |
In part one, we also performed a review of the Internet Explorer history and cached files on the system used by Joe Schmo, the primary suspect of the intrusion. Analysis of the web browsing history revealed Internet searches for license cracks and hacking books; however, all this malicious activity appeared to have been performed while Joe was on vacation with his family in Florida.
In part two we now set out to determine who used Joe's machine while he was on vacation. We will proceed by examining further investigative leads that involve performing an in-depth review of the web activity of all other browsers installed on Joe's hard drive.
Let's begin the investigation by reviewing the Firefox cache on Joe Schmo's system. The directory is located at the following path:
\Documents and Settings\<user name>\Application Data
\Mozilla\Firefox\Profiles\<random text>\Cache
Within the Cache directory, there are a number of files relevant to our investigation. Joe's cache directory is available below in Figure 1.
Cache
There are three types of files in this directory:
We will examine each of these files in order to reconstruct Firefox's cached data.
There are 32 buckets in this file. Within each bucket, there are 256 records inside each bucket. That means we have 8,192 records in the Cache Map file.
Each record contains the information for one instance of cache data. A record contains four 32-bit integers:
There are two methods Firefox uses to save the cache data. Firefox either saves the information inside a Cache Block File or creates a separate file. The hash number is used to name the separate file if that is how a specific cache instance was saved. The other two fields we will use to reconstruct the cache data are the "data location" and the "metadata location." Each instance of cache data has metadata information and the cache content.
If you take the "metadata location" field and "bitwise AND" it with 0x30000000 and then left shift the result 28 bits, you will have a number between zero and three. If the result is a zero, the cache metadata is saved in a separate file. If the result is one, two, or three, the cache metadata is embedded in a cache block file. The same algorithm using the data location as the input will identify similar information for the cache content.
After the Cache Block File has been identified using the methodology presented above, we only need to know where the data is located in which appropriate Cache Block File. The start block is calculated by "bitwise ANDing" the metadata location/data location with 0x00FFFFFF. Next, we must calculate the number of contiguous blocks comprising the cache metadata/data. The size is calculated by "bitwise ANDing" the metadata location/data location with 0x03000000 and right shifting the result 24 bits. Now, we need to know how large the blocks are for a particular cache block file. Mozilla browsers define the block size by left shifting the number 256 by the following number of bits: subtract one from the cache block file number and then multiply the result by two. Therefore, when N=1 the block size is 256 bytes. When N=2, the block size is 512 bytes. When N=3, the block size is 1,024 bytes.
Lastly, we have to account for a bitmap header in the cache block file. The bitmap header is defined as 4,096 bytes long. The blocks in the cache block files begin immediately after the bitmap header. Using the algorithms presented above, we are able to extract the metadata and cache content for each record found in the cache map file.
<HASH NUMBER><TYPE><GENERATION NUMBER>
The hash number is available from the Cache Map file. The "Type" is either 'd', for cache content, or 'm' for cache metadata. The "Generation Number" is an integer that is identified by "bitwise ANDing" the metadata location/data location with 0x000000FF.
By default, Cache View presents the files from the browser caches of the system on which it is running. In our case, as is the case with most forensics investigations, all investigative activity is performed on a forensics workstation, which is separate from the actual evidence media. Thus, we need to import the cached files of the browsers from a copy of the evidence medium onto the forensics workstation. In the case of Firefox, it means importing the following folder:
Once the folder is stored at a known location on the forensics workstation, Cache View can be instructed to retrieve files from it, rather than the browser caches of the forensics workstation. This is shown below in Figure 4.
A zipped version of the Firefox Cache folder from Joe Schmo's system, used for example purposes in this article, can be downloaded from this link.
After importing the cache folder into Cache View you should be presented with a view similar to that shown in Figure 5, below.
As seen in Figure 5, the files are categorized by the domain names from which they were retrieved. By clicking the by14fd.bay14.hotmail.msn.com folder in the left pane of Cache View, we observe a number of links to visited pages within this domain in the right pane of Cache View. These web pages may provide insight into additional Hotmail activity recorded on Joe Schmo's machine -- this piques our interest! We decide to embark on a journey to view these files. This process entails the following:
by14fd.bay14.hotmail.msn.com
This operation is achieved by selecting all the links in the right-pane, right-clicking the mouse and selecting the Copy to.. option as shown below in Figure 6.
Following step 1, the files were saved in a folder called by14fd.bay14.hotmail.msn.com on the forensics workstation's desktop. We then ran the Unix "file" command (in a Cygwin environment) against all the files in this folder.
Figure 7 indicates that the files are gzip compressed. In order to decompress the files, we created copies of the files, named them 1.gz, 2.gz and 3.gz respectively, and then ran the "gunzip" utility against them.
We then proceeded to opening 1.gz using Firefox. The following screenshot, Figure 9, shows the actual visited page that was re-constructed by this process.
The extracted web page shown in Figure 9, displays an email viewed on Joe Schmo's machine. Careful examination of the page reveals that the e-mail resides in the Hotmail inbox of [email protected] content of the email is extremely pertinent to this case. It indicates that Ted Wilson, the owner of the [email protected] email account, sent Mike Green an email providing him Joe Schmo's credentials for the victim Docustodian server, discussed in part one. Ted also indicated in the email to Mike Green that the client software for Docustodian may need a license crack that he would send shortly. Furthermore, the email was sent on March 10, 2005 at 10:05PM, while Joe was on vacation with his family. So the cat is now out of the bag! Ted Wilson is guilty of master-minding the unacceptable use of the Docustodian server.
[email protected]
So who is Ted Wilson and how did he gain access to Joe Schmo's system?
Conversations with personnel at the law firm indicated that Ted was the intern employed to cover for Joe Schmo when he was on vacation.
licensecrack.java
C:\windows\system32\temp\temp\temp\
This file presented a last access time stamp of 07:32PM on March 11, 2005. An excerpt from licensecrack.java is listed below:
/*
* This program should be run on the same LAN
* as the Docustodian client machine.
* Modify the hosts file on the client machine accordingly.
* It tricks the client in believing that it has a valid license
* to access the server
* Author: Ted Wilson
*/
import java.net.*;
import java.io.*;
import java.io.ByteArrayOutputStream;
public class License
{
static DatagramSocket sock; // socket
static DatagramPacket opkt; // communications packet
static DatagramPacket ipkt; // communications packet
static InetAddress clientIP; // IP address of client
static String msg; // message sent and received
static byte[] inbuf; // input message buffer
static final int port = 4760; // port number to use
static byte[] temp;
static String[] hex ;
static int port1;
public static void main (String[] args)
{
// create the input packet
hex = new String[3];
hex[0] = "e3e875cd5a946d78cbb3e3e3e3e3e3e3e3e3e3e3e3e3e3e3e3e3e3e
3ea4213";
hex[1] = "d2d719c58e69159f46fad2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2d2
d6022a";
hex[2] = "c1c0fc1b57c5bffcaa45c1c1c1c1c1c1c1c1c1c1c1c1c1c1c1c1c1
c";
A brief review of the file shown above provides further incriminating evidence against Ted Wilson. The comments preceding the actual logic indicate the author of the program and provide insight into the malicious intent of the code. A detailed review of the source code indicated that the Docustodian licensing service was susceptible to a replay attack. Every time a new instance of a licensed client was executed, the Docustodian client and the licensing server exchanged the same set of six packets. Further, the Docustodian client, rather than the licensing server, provided final approval on the legitimacy of the connection. The suspect took advantage of this fact by tricking the Docustodian client into believing that licensecrack.java was the true licensing server that responded appropriately to their client's license verification requests. This software flaw, in conjunction with Joe Schmo's valid credentials resulted in the transformation of the law firm's document management system into a teenage hacker group's private "warez" site!
All of the evidence examined in this two part series existed in web history and cache files. By simply examining the evidence associated with web browser caches, we were able to solve the mystery of unauthorized access to the Docustodian server.
|
http://www.securityfocus.com/print/infocus/1832
|
crawl-002
|
refinedweb
| 1,624 | 53.71 |
# Locks in PostgreSQL: 4. Locks in memory
To remind you, we've already talked about [relation-level locks](https://habr.com/en/company/postgrespro/blog/500714/), [row-level locks](https://habr.com/en/company/postgrespro/blog/503008/), [locks on other objects](https://habr.com/en/company/postgrespro/blog/504498/) (including predicate locks) and interrelationships of different types of locks.
The following discussion of **locks in RAM** finishes this series of articles. We will consider spinlocks, lightweight locks and buffer pins, as well as events monitoring tools and sampling.
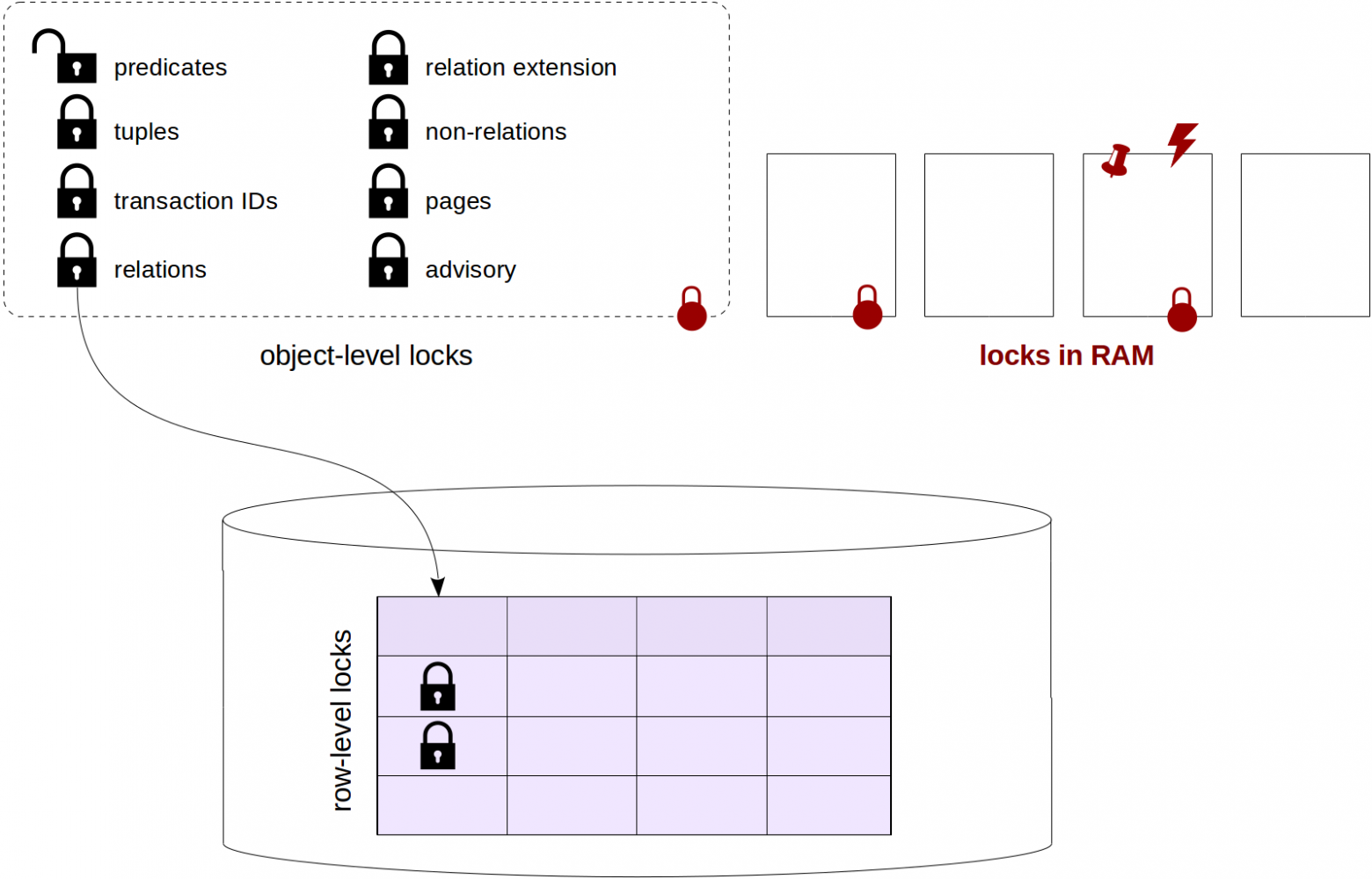
Spinlocks
=========
Unlike normal, «heavy-weight», locks, to protect structures in the shared memory, more lightweight and less expensive (in overhead costs) locks are used.
The simplest of them are *spinlocks*. They are meant to be acquired for very short time intervals (a few processor instructions), and they protect separate memory areas from simultaneous changes.
Spinlocks are implemented based on atomic processor instructions, such as compare-and-swap. They support the only, exclusive, mode. If a lock is acquired, a waiting process performs busy waiting — the command is repeated («spins» in a loop, hence the name) until it is a success. This makes sense since spinlocks are used in the cases where the probability of a conflict is estimated as very low.
Spinlocks do not enable detection of deadlocks (PostgreSQL developers take care of this) and provide no monitoring tools. Essentially, the only thing we can do with spinlocks is to be aware of their existence.
Lightweight locks
=================
So-called *lightweight locks* (lwlocks) come next.
They get acquired for a short time that is needed to work with the data structure (such as a hash table or a list of pointers). As a rule, a lightweight lock is held briefly, but sometimes lightweight locks protect input/output operations, so in general, the time might also be considerable.
Two modes are supported: exclusive (for data modifications) and shared (only for reading). There is actually no wait queue: if a few processes wait for release of a lock, one of them will get the access in a more or less random fashion. In high-concurrency and large-load systems, this can be troublesome (for example, see this [discussion](https://postgrespro.com/list/thread-id/2400193)).
There are no techniques to check for deadlocks, so this is left to the responsibility of developers of the core. However, lightweight locks have monitoring tools, so, unlike spinlocks, we can «see» them (I will show a bit later how to do this).
Buffer pin
==========
Yet another type of locks, which we already touched upon in the article on the [buffer cache](https://habr.com/en/company/postgrespro/blog/491730/), is a *buffer pin*.
Different operations, including data modifications, can be performed with a pinned buffer, but under the condition that the changes are not visible to other processes due to multiversion concurrency control. That is, we can, for instance, add a new row to the page, but cannot replace a page in the buffer with another one.
If a buffer pin hinders a process, as a rule, the latter just skips this buffer and chooses a different one. But in some cases, where exactly this buffer is needed, the process queues and «falls asleep»; the system will wake it up when the buffer is unpinned.
Monitoring can access waits related to buffer pins.
Example: buffer cache
=====================

Now, in order to get some (although incomplete!) insight into how and where locks are used, let's consider the buffer cache as an example.
To access a hash table that contains links to buffers, a process must acquire a lightweight *buffer mapping lock* in a shared mode, and if the table needs to be updated, in an exclusive mode. To reduce the granularity, this lock is structured as a *tranche* that consists of 128 separate locks, each protecting its own part of the hash table.
The process gets access to the buffer header using a spinlock. Certain operations (such as a counter increment) can also be performed without explicit locking, by means of atomic processor instructions.
In order to read the contents of a buffer, a *buffer content lock* is needed. It is usually acquired only for the time needed to read pointers to tuples, and after that, a buffer pin provides sufficient protection. To change the contents of a buffer, this lock must be acquired in an exclusive mode.
When a buffer is read from disk (or written to disk), an *IO in progress* lock is also acquired, which indicates to other processes that the page is being read (or written) — they can queue up if they need to do something with this page.
Pointers to free buffers and to the next victim are protected by one *buffer strategy lock* spinlock.
Example: WAL buffers
====================
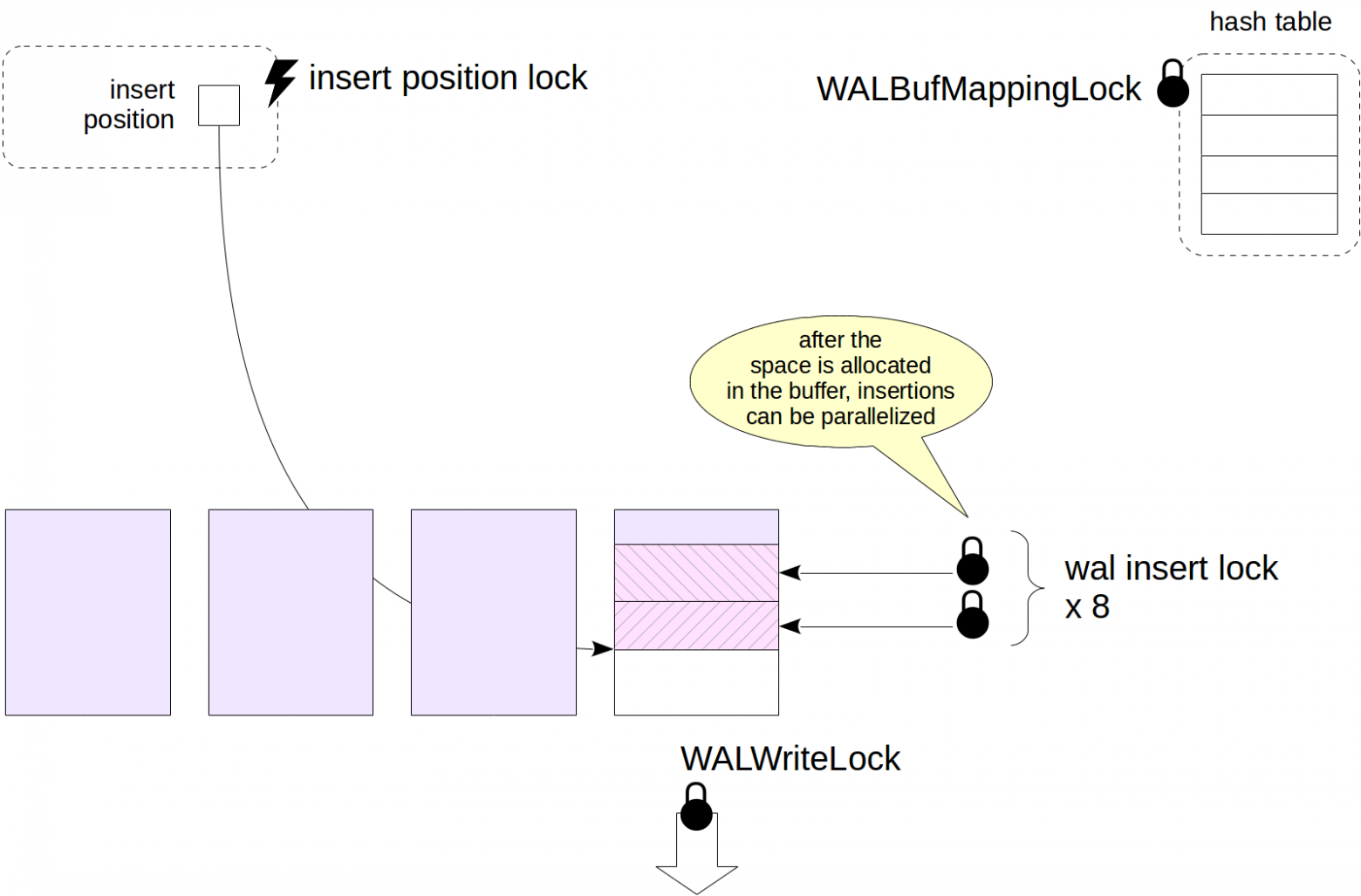
WAL buffers provide another example.
The WAL cache also uses a hash table that contains mapping of pages to buffers. Unlike for the buffer cache, this hash table is protected by the only lightweight `WALBufMappingLock` lock since the size of the WAL cache is smaller (usually 1/32 of the buffer cache) and access to the buffers is more regular.
Writes of pages to disk are protected by the `WALWriteLock` lock, so that only one process can perform this operation at a time.
To create a WAL record, the process must first allocate space in a WAL page. To do this, it acquires an *insert position lock* spinlock. When the space is allocated, the process copies the contents of its record to the space allocated. Copying can be performed by several processes simultaneously, therefore, the record is protected by a tranche of 8 lightweight *wal insert lock* locks (the process must acquire *any* of them).
The figure does not show all WAL-related locks, but this and previous examples must give an idea of how locks in RAM are used.
Wait events monitoring
======================
Starting with PostgreSQL 9.6, the `pg_stat_activity` view has built-in events monitoring tools. When a process (system or backend) cannot do its job and waits for something, we can see this wait in the view: the `wait_event_type` column shows the wait type and the `wait_event` column shows the name of a specific wait.
Note that the view shows only waits that are properly handled in the source code. If the view does not show a wait, in general, this does not mean with 100 percent probability that the process really waits for nothing.
Unfortunately, the only available information on waits is the *current* information. No accumulated statistics are maintained. The only way to get the picture of waits in time is *sampling* the state of the view at a certain interval. No built-in tools are provided to this end, but we can use extensions, such as [pg\_wait\_sampling](https://github.com/postgrespro/pg_wait_sampling).
We need to take into account the probabilistic nature of sampling. To get a more or less credible picture, the number of measurements must be pretty large. Low-frequency sampling may fail to provide a credible picture, while use of higher frequencies will increase overhead costs. For the same reason, sampling is useless to analyze short-lived sessions.
All the waits can be divided into several types.
Waits for the locks discussed make up a large category:
* Waits for locks on objects (the value of `Lock` in the `wait_event_type` column).
* Waits for lightweight locks (`LWLock`).
* Waits for a buffer pin (`BufferPin`).
But processes can also await other events:
* Waits for input/output (`IO`) occur when a process needs to read or write data.
* A process can wait for the data needed from a client (`Client`) or another process (`IPC`).
* Extensions can register their specific waits (`Extension`).
Sometimes situations arise when a process just doesn't do any productive work. This category includes:
* Waits of a background process in its main loop (`Activity`).
* Waits for a timer (`Timeout`).
Usually, waits like these are treated as «normal» and do not indicate any problems.
The wait type is followed by the name of a specific wait. For the complete table, see the [documentation](https://postgrespro.com/docs/postgresql/11/monitoring-stats#WAIT-EVENT-TABLE).
If the name of a wait is not defined, the process is not in the waiting state. We need to treat this point in time as *unaccounted for* since we are actually unaware of what exactly is happening at that moment.
However, let's watch this for ourselves.
```
=> SELECT pid, backend_type, wait_event_type, wait_event
FROM pg_stat_activity;
```
```
pid | backend_type | wait_event_type | wait_event
-------+------------------------------+-----------------+---------------------
28739 | logical replication launcher | Activity | LogicalLauncherMain
28736 | autovacuum launcher | Activity | AutoVacuumMain
28963 | client backend | |
28734 | background writer | Activity | BgWriterMain
28733 | checkpointer | Activity | CheckpointerMain
28735 | walwriter | Activity | WalWriterMain
(6 rows)
```
It's clear that all background backend processes are idle. Empty values of `wait_event_type` and `wait_event` tell us that the process is waiting for nothing; in our example, the backend process is busy executing the query.
Sampling
--------
To get a more or less complete picture of waits by means of sampling, we will use the [pg\_wait\_sampling](https://github.com/postgrespro/pg_wait_sampling) extension. We need to build it from source codes, but I will omit this part. Then we add the library name to the *shared\_preload\_libraries* parameter and restart the server.
```
=> ALTER SYSTEM SET shared_preload_libraries = 'pg_wait_sampling';
```
```
student$ sudo pg_ctlcluster 11 main restart
```
Now we install the extension in the database.
```
=> CREATE EXTENSION pg_wait_sampling;
```
The extension allows us to look through the history of waits, which is stored in a circular buffer. But what's mostly interesting to us is the waits profile, that is, the statistics accumulated since the server start.
This is roughly what we will see a few seconds later:
```
=> SELECT * FROM pg_wait_sampling_profile;
```
```
pid | event_type | event | queryid | count
-------+------------+---------------------+---------+-------
29074 | Activity | LogicalLauncherMain | 0 | 220
29070 | Activity | WalWriterMain | 0 | 220
29071 | Activity | AutoVacuumMain | 0 | 219
29069 | Activity | BgWriterMain | 0 | 220
29111 | Client | ClientRead | 0 | 3
29068 | Activity | CheckpointerMain | 0 | 220
(6 rows)
```
Because nothing happened since the server start, most waits refer to the types `Activity` (backend processes wait until there is some work for them) and `Client` (`psql` waits until a user sends a request).
With the default settings (of the *pg\_wait\_sampling.profile\_period* parameter), the sampling period equals 10 milliseconds, which means that values are saved 100 times a second. Therefore, to evaluate the duration of waits in seconds, we need to divide the value of `count` by 100.
To figure out which process the waits pertain to, let's add the `pg_stat_activity` view to the query:
```
=> SELECT p.pid, a.backend_type, a.application_name AS app,
p.event_type, p.event, p.count
FROM pg_wait_sampling_profile p
LEFT JOIN pg_stat_activity a ON p.pid = a.pid
ORDER BY p.pid, p.count DESC;
```
```
pid | backend_type | app | event_type | event | count
-------+------------------------------+------+------------+----------------------+-------
29068 | checkpointer | | Activity | CheckpointerMain | 222
29069 | background writer | | Activity | BgWriterMain | 222
29070 | walwriter | | Activity | WalWriterMain | 222
29071 | autovacuum launcher | | Activity | AutoVacuumMain | 221
29074 | logical replication launcher | | Activity | LogicalLauncherMain | 222
29111 | client backend | psql | Client | ClientRead | 4
29111 | client backend | psql | IPC | MessageQueueInternal | 1
(7 rows)
```
Let's produce some workload using `pgbench` and see how the picture changes.
```
student$ pgbench -i test
```
We reset the accumulated profile to zero and run the test for 30 seconds in a separate process.
```
=> SELECT pg_wait_sampling_reset_profile();
```
```
student$ pgbench -T 30 test
```
We need to execute the query while the `pgbench` process is not finished yet:
```
=> SELECT p.pid, a.backend_type, a.application_name AS app,
p.event_type, p.event, p.count
FROM pg_wait_sampling_profile p
LEFT JOIN pg_stat_activity a ON p.pid = a.pid
WHERE a.application_name = 'pgbench'
ORDER BY p.pid, p.count DESC;
```
```
pid | backend_type | app | event_type | event | count
-------+----------------+---------+------------+------------+-------
29148 | client backend | pgbench | IO | WALWrite | 8
29148 | client backend | pgbench | Client | ClientRead | 1
(2 rows)
```
The waits of the `pgbench` process will certainly differ slightly depending on a particular system. In our situation, a wait for WAL writing (`IO`/`WALWrite`) is highly likely to be presented, however, most of the time the process was doing something presumably productive rather than being idle.
Lightweight locks
-----------------
We always need to keep in mind that if a wait is missing when sampling, this does not mean that there was really no wait. If the wait was shorter than the sampling period (a hundredth of a second in our example), it could just fail to get into the sample.
That's why lightweight locks did not occur in the profile, but they will if the data is collected for a long time. To be able to see them for sure, we can intentionally slow down the file system, for example, by using the [slowfs](https://github.com/nirs/slowfs) project, built on top of the [FUSE](https://github.com/libfuse/libfuse) file system.
This is what we can see on the same test if any input/output operation takes 1/10 of a second.
```
=> SELECT pg_wait_sampling_reset_profile();
```
```
student$ pgbench -T 30 test
```
```
=> SELECT p.pid, a.backend_type, a.application_name AS app,
p.event_type, p.event, p.count
FROM pg_wait_sampling_profile p
LEFT JOIN pg_stat_activity a ON p.pid = a.pid
WHERE a.application_name = 'pgbench'
ORDER BY p.pid, p.count DESC;
```
```
pid | backend_type | app | event_type | event | count
-------+----------------+---------+------------+----------------+-------
29240 | client backend | pgbench | IO | WALWrite | 1445
29240 | client backend | pgbench | LWLock | WALWriteLock | 803
29240 | client backend | pgbench | IO | DataFileExtend | 20
(3 rows)
```
Now the major wait of the `pgbench` process relates to input/output, more exactly, to WAL writes, which synchronously occur for every commit. Because (as shown in one of the above examples) a WAL write is protected by a lightweight `WALWriteLock` lock, this lock is also present in the profile — and it's just what we wanted to look at.
Buffer pin
----------
To see a buffer pin, let's make use of the fact that open cursors hold the pin to faster read the next row.
Let's start a transaction, open a cursor and select one row.
```
=> BEGIN;
=> DECLARE c CURSOR FOR SELECT * FROM pgbench_history;
=> FETCH c;
```
```
tid | bid | aid | delta | mtime | filler
-----+-----+-------+-------+----------------------------+--------
9 | 1 | 35092 | 477 | 2019-09-04 16:16:18.596564 |
(1 row)
```
Let's check that the buffer is pinned (`pinning_backends`):
```
=> SELECT * FROM pg_buffercache
WHERE relfilenode = pg_relation_filenode('pgbench_history')
AND relforknumber = 0 \gx
```
```
-[ RECORD 1 ]----+------
bufferid | 190
relfilenode | 47050
reltablespace | 1663
reldatabase | 16386
relforknumber | 0
relblocknumber | 0
isdirty | t
usagecount | 1
pinning_backends | 1 <-- buffer is pinned 1 time
```
Now let's [vacuum](https://habr.com/en/company/postgrespro/blog/484106/) the table:
```
| => SELECT pg_backend_pid();
```
```
| pg_backend_pid
| ----------------
| 29367
| (1 row)
```
```
| => VACUUM VERBOSE pgbench_history;
```
```
| INFO: vacuuming "public.pgbench_history"
| INFO: "pgbench_history": found 0 removable, 0 nonremovable row versions in 1 out of 1 pages
| DETAIL: 0 dead row versions cannot be removed yet, oldest xmin: 732651
| There were 0 unused item pointers.
```
```
| Skipped 1 page due to buffer pins, 0 frozen pages.
```
```
| 0 pages are entirely empty.
| CPU: user: 0.00 s, system: 0.00 s, elapsed: 0.00 s.
| VACUUM
```
As we can see, the page was skipped (`Skipped 1 page due to buffer pins`). Indeed, VACUUM cannot process it because physical deletion of tuples from a page in a pinned buffer is forbidden. But vacuuming will not wait either, and the page will be processed next time.
And now let's perform [vacuuming with freezing](https://habr.com/en/company/postgrespro/blog/487590/):
```
| => VACUUM FREEZE VERBOSE pgbench_history;
```
If freezing is explicitly requested, none of the pages tracked in the all-frozen bit can be skipped; otherwise, it is impossible to reduce the maximum age of non-frozen transactions in `pg_class.relfrozenxid`. So, vacuuming hangs until the cursor is closed.
```
=> SELECT age(relfrozenxid) FROM pg_class WHERE oid = 'pgbench_history'::regclass;
```
```
age
-----
27
(1 row)
```
```
=> COMMIT; -- cursor closes automatically
```
```
| INFO: aggressively vacuuming "public.pgbench_history"
| INFO: "pgbench_history": found 0 removable, 26 nonremovable row versions in 1 out of 1 pages
| DETAIL: 0 dead row versions cannot be removed yet, oldest xmin: 732651
| There were 0 unused item pointers.
```
```
| Skipped 0 pages due to buffer pins, 0 frozen pages.
```
```
| 0 pages are entirely empty.
| CPU: user: 0.00 s, system: 0.00 s, elapsed: 3.01 s.
| VACUUM
```
```
=> SELECT age(relfrozenxid) FROM pg_class WHERE oid = 'pgbench_history'::regclass;
```
```
age
-----
0
(1 row)
```
And let's look into the waits profile of the second `psql` session, where the VACUUM commands were executed:
```
=> SELECT p.pid, a.backend_type, a.application_name AS app,
p.event_type, p.event, p.count
FROM pg_wait_sampling_profile p
LEFT JOIN pg_stat_activity a ON p.pid = a.pid
WHERE p.pid = 29367
ORDER BY p.pid, p.count DESC;
```
```
pid | backend_type | app | event_type | event | count
-------+----------------+------+------------+------------+-------
29367 | client backend | psql | BufferPin | BufferPin | 294
29367 | client backend | psql | Client | ClientRead | 10
(2 rows)
```
The `BufferPin` wait tells us that VACUUM was waiting for the buffer to get free.
And this is where we will consider discussing locks as finished. Thank you all for attentive reading and comments!
|
https://habr.com/ru/post/507036/
| null | null | 2,820 | 54.32 |
One :-).
Outline
This article describes how to enable a bare-metal (no RTOS) in RAW/native (no sockets, TCP only) lwip application running the MQTT protocol with TLS.
The project used in this article is available on GitHub:
The project runs a MQTT client application which initiates TLS handshaking and then communicates securely with a Mosquitto broker.
Prerequisites: Software/Tools
In this article I have used the following software and tools:
- MQTT broker running with TLS on port 8883, e.g. see Enable Secure Communication with TLS and the Mosquitto Broker
- MCUXpresso IDE v10.0.0 b344:
- MCUXpresso SDK for FRDM-K64F: which includes
- lwip 2.0.0
- mbed TLS 2.3.0
- MQTT lwip stub from lwip 2.0.2:
- mbed TLS 2.4.2 (Apache):
- Optional: Processor Expert v3.2.0 (see “MCUXpresso IDE: Installing Processor Expert into Eclipse Neon“)
- TCP based (raw) example, e.g. the lwip tcp ping application (or the project from MQTT with lwip and NXP FRDM-K64F Board).
But any other software/tool combination should do it too :-).
mbed TLS
As outlined in “Introduction to Security and TLS (Transport Layer Security)“, I have selected mbed TLS because its licensing terms are very permissive (Apache).
Get mbed TLS from (I recommend the Apache version as it is permissive).
Another way is to get it from the NXP MCUXpresso SDK for the FRDM-K64F. Use the ‘import SDK examples’ function from the quickstart panel and import the mbedtls_selftest example. The advantage of this method is that it comes with the random number generator drivers (RNG):
Adding mbedTLS
From the mbed TLS distribution, add the ‘mbedtls’ folder to the project. You need
- mbedtls\include\mbedtls
- mbedtls\library
The mbed TLS implementation uses a ‘port’ which takes advantage of the hardware encryption unit of the on the NXP Kinetis K64F device. That ‘port’ is part of the MCUXpresso SDK, place it inside mbedtls\port.
And finally I need the driver for the mmCAU (Memory-Mapped Cryptographic Acceleration Unit) of the NXP Kinetis device:
- mmcau_common: common mmCAU files and interface
- \libs\lib_mmcau.a: library with cryptographic routines
The mbed configuration file is included with a preprocessor symbol. Add the following to compiler Preprocessor defined symbols:
MBEDTLS_CONFIG_FILE='"ksdk_mbedtls_config.h"'
Next, add the following to compiler include path settings so it can find all the needed header files:
"${workspace_loc:/${ProjName}/mbedtls/port/ksdk}" "${workspace_loc:/${ProjName}/mbedtls/include/mbedtls}" "${workspace_loc:/${ProjName}/mbedtls/include}" "${workspace_loc:/${ProjName}/mmcau_common}"
And add the mmCAU library to the linker options so it gets linked with the application (see “Creating and using Libraries with ARM gcc and Eclipse“):
Last but not least, make sure that the random number generator (RNG) source files of the MCUXpresso SDK are part of the project:
- drivers/fsl_rnga.c
- drivers/fsl_rnga.h
This completes the files and settings to add mbed TLS to the project :-).
MQTT without TLS
In an application with MQTT, the MQTT communication protocol is handled between the application and the stack:
The block diagram below shows the general flow of the MQTT application interacting with lwip in RAW (tcp) mode. With lwip the application has basically two call backs:
- recv_cb(): callback called when we receive a packet from the network
- sent_cb(): callback called *after* a packet has been sent
💡 There is yet another call back, the error callback. To keep things simple, I ignore that callback here.s
In raw/bare metal mode, the application calls ethernet_input() which calls the ‘received’ callback. With using MQTT, the MQTT parses the incoming data and passes it to the application (e.g. CONNACK message).
If the application is e.g. sending a PUBLISH request, that TCP message is constructed by the MQTT layer and put into a buffer (actually a ring buffer). That data is only sent if the mqtt_output_send() is called (which is not available to the application). mqtt_output_send() is called for ‘sending’ functions like mqtt_publish() or as a side effect of the mqtt_tcp_sent_cb() callback which is called after a successful tcp_write(). The MQTT sent_cb() is forwarded to the application sent_cb() callback.
MQTT with TLS
The TLS encryption is happening between the application/MQTT part and the TCP/IP (lwip) layers. That way it is transparent between the protocol and the physical layer:
While things look easy from the above block diagram, it is much more complex to get the cryptographic library working between MQTT and lwip:
- mbed TLS needs to be initialized properly
- The application needs to first start the TLS handshaking, adding an extra state to the application state handling
- All calls to the lwip TCP layer needs to be replaced with calls to the mbedtls_ssl layer
- The communication flow is not any more ‘send one message, receive one sent_cb() callback). Because the TLS layer is doing the handshaking, multiple messages will be transmitted and received, so the call backs need to be separated too.
- Without the TLS layer, the communication flow is more synchronous, and received messages are directly passed up to the application layer. With the TLS between, there is the need for an extra buffering of the incoming messages.
- Messages to be sent from the MQTT layer are already buffered in the non-TLS version. To ensure that they are sent, an extra function mqtt_output.send() has been added.
💡 I’m not very happy with that mqtt_output_send() method, but that’s the best I was able to come up to get things working. I might need to refactor this.
To make the above working, I had the tweak the existing MQTT implementation with comes with lwip. Several things should be considered for a general refactoring or done with extra callbacks. I might be able to implement and improve it over the next weeks.
All the needed changes in the application to support TLS are enabled with the following macro inside mqtt_opts.h:
#ifndef MQTT_USE_TLS #define MQTT_USE_TLS 1 /*!< 1: enable TLS/SLL support; 0: do not use TLS/SSL */ #endif
The following sections explain the implementation in more details.
Random Number Generator
Before using the random number generator, it needs to be initialized:
#if MQTT_USE_TLS /* initialize random number generator */ RNGA_Init(RNG); /* init random number generator */ RNGA_Seed(RNG, SIM->UIDL); /* use device unique ID as seed for the RNG */ if (TLS_Init()!=0) { /* failed? */ printf("ERROR: failed to initialize for TLS!\r\n"); for(;;) {} /* stay here in case of error */ } #endif
TLS Initialization
To use the mbed TLS library, several objects have to be initialized at application startup:
static mbedtls_entropy_context entropy; static mbedtls_ctr_drbg_context ctr_drbg; static mbedtls_ssl_context ssl; static mbedtls_ssl_config conf; static mbedtls_x509_crt cacert; static mbedtls_ctr_drbg_context ctr_drbg; static int TLS_Init(void) { /* inspired by */ int ret; const char *pers = "ErichStyger-PC"; /* initialize the different descriptors */ mbedtls_ssl_init( &ssl ); mbedtls_ssl_config_init( &conf ); mbedtls_x509_crt_init( &cacert ); mbedtls_ctr_drbg_init( &ctr_drbg ); mbedtls_entropy_init( &entropy ); if( ( ret = mbedtls_ctr_drbg_seed( &ctr_drbg, mbedtls_entropy_func, &entropy, (const unsigned char *) pers, strlen(pers ) ) ) != 0 ) { printf( " failed\n ! mbedtls_ctr_drbg_seed returned %d\n", ret ); return -1; } /* * First prepare the SSL configuration by setting the endpoint and transport type, and loading reasonable * defaults for security parameters. The endpoint determines if the SSL/TLS layer will act as a server (MBEDTLS_SSL_IS_SERVER) * or a client (MBEDTLS_SSL_IS_CLIENT). The transport type determines if we are using TLS (MBEDTLS_SSL_TRANSPORT_STREAM) * or DTLS (MBEDTLS_SSL_TRANSPORT_DATAGRAM). */ if( ( ret = mbedtls_ssl_config_defaults( &conf, MBEDTLS_SSL_IS_CLIENT, MBEDTLS_SSL_TRANSPORT_STREAM, MBEDTLS_SSL_PRESET_DEFAULT ) ) != 0 ) { printf( " failed\n ! mbedtls_ssl_config_defaults returned %d\n\n", ret ); return -1; } /* The authentication mode determines how strict the certificates that are presented are checked. */ mbedtls_ssl_conf_authmode(&conf, MBEDTLS_SSL_VERIFY_NONE ); /* \todo change verification mode! */ /* The library needs to know which random engine to use and which debug function to use as callback. */ mbedtls_ssl_conf_rng( &conf, mbedtls_ctr_drbg_random, &ctr_drbg ); mbedtls_ssl_conf_dbg( &conf, my_debug, stdout ); mbedtls_ssl_setup(&ssl, &conf); if( ( ret = mbedtls_ssl_set_hostname( &ssl, "ErichStyger-PC" ) ) != 0 ) { printf( " failed\n ! mbedtls_ssl_set_hostname returned %d\n\n", ret ); return -1; } /* the SSL context needs to know the input and output functions it needs to use for sending out network traffic. */ mbedtls_ssl_set_bio(&ssl, &mqtt_client, mbedtls_net_send, mbedtls_net_recv, NULL); return 0; /* no error */ }
💡 Notice that with I’m using MBEDTLS_SSL_VERIFY_NONE. I need to change this in a next iteration, see “Tuturial: mbedTLS SLL Certificate Verification with Mosquitto, lwip and MQTT“.
Application Main Loop
The application runs in an endless loop. To keep things simple, it uses a timer/timestamp to connect and then periodically publish MQTT data:
static void DoMQTT(struct netif *netifp) { uint32_t timeStampMs, diffTimeMs; #define CONNECT_DELAY_MS 1000 /* delay in seconds for connect */ #define PUBLISH_PERIOD_MS 10000 /* publish period in seconds */ MQTT_state = MQTT_STATE_IDLE; timeStampMs = sys_now(); /* get time in milli seconds */ for(;;) { LED1_On(); diffTimeMs = sys_now()-timeStampMs; if (MQTT_state==MQTT_STATE_IDLE && diffTimeMs>CONNECT_DELAY_MS) { MQTT_state = MQTT_STATE_DO_CONNECT; /* connect after 1 second */ timeStampMs = sys_now(); /* get time in milli seconds */ } if (MQTT_state==MQTT_STATE_CONNECTED && diffTimeMs>=PUBLISH_PERIOD_MS) { MQTT_state = MQTT_STATE_DO_PUBLISH; /* publish */ timeStampMs = sys_now(); /* get time in milli seconds */ } MqttDoStateMachine(&mqtt_client); /* process state machine */ /* Poll the driver, get any outstanding frames */ LED1_Off(); ethernetif_input(netifp); sys_check_timeouts(); /* Handle all system timeouts for all core protocols */ } }
With ethernetif_input() it polls for any incoming TCP packets. With sys_check_timeouts() it checks for any timeout and for example sends periodic PINGREQ messages to the MQTT broker.
Application State Machine
The application state machine goes through init, connect and TLS handshake sequence, follwed by a periodic PUBLISH:
static void MqttDoStateMachine(mqtt_client_t *mqtt_client) { switch(MQTT_state) { case MQTT_STATE_INIT: case MQTT_STATE_IDLE: break; case MQTT_STATE_DO_CONNECT: printf("Connecting to Mosquito broker\r\n"); if (mqtt_do_connect(mqtt_client)==0) { #if MQTT_USE_TLS MQTT_state = MQTT_STATE_DO_TLS_HANDSHAKE; #else MQTT_state = MQTT_STATE_WAIT_FOR_CONNECTION; #endif } else { printf("Failed to connect to broker\r\n"); } break; #if MQTT_USE_TLS case MQTT_STATE_DO_TLS_HANDSHAKE: if (mqtt_do_tls_handshake(mqtt_client)==0) { printf("TLS handshake completed\r\n"); mqtt_start_mqtt(mqtt_client); MQTT_state = MQTT_STATE_WAIT_FOR_CONNECTION; } break; #endif case MQTT_STATE_WAIT_FOR_CONNECTION: if (mqtt_client_is_connected(mqtt_client)) { printf("Client is connected\r\n"); MQTT_state = MQTT_STATE_CONNECTED; } else { #if MQTT_USE_TLS mqtt_recv_from_tls(mqtt_client); #endif } break; case MQTT_STATE_CONNECTED: if (!mqtt_client_is_connected(mqtt_client)) { printf("Client got disconnected?!?\r\n"); MQTT_state = MQTT_STATE_DO_CONNECT; } #if MQTT_USE_TLS else { mqtt_tls_output_send(mqtt_client); /* send (if any) */ mqtt_recv_from_tls(mqtt_client); /* poll if we have incoming packets */ } #endif break; case MQTT_STATE_DO_PUBLISH: printf("Publish to broker\r\n"); my_mqtt_publish(mqtt_client, NULL); MQTT_state = MQTT_STATE_CONNECTED; break; case MQTT_STATE_DO_DISCONNECT: printf("Disconnect from broker\r\n"); mqtt_disconnect(mqtt_client); MQTT_state = MQTT_STATE_IDLE; break; default: break; } }
In the MQTT_STATE_CONNECTED it calls mqtt_tls_output_send() to send any outstanding MQTT packets. It uses mqqt_recv_from_tls() to poll any incoming TCP packets.
Connecting to the Broker
The following is the connection code to the broker:
static int); memset(client, 0, sizeof(mqtt_client_t)); /* initialize all fields */ /*; ci.keep_alive = 60; /* timeout */ /* Initiate client and connect to server, if this fails immediately an error code is returned otherwise mqtt_connection_cb will be called with connection result after attempting to establish a connection with the server. For now MQTT version 3.1.1 is always used */ #if MQTT_USE_TLS client->ssl_context = &ssl; err = mqtt_client_connect(client, &broker_ipaddr, MQTT_PORT_TLS, mqtt_connection_cb, 0, &ci); #else err = mqtt_client_connect(client, &broker_ipaddr, MQTT_PORT, mqtt_connection_cb, 0, &ci); #endif /* For now just print the result code if something goes wrong */ if(err != ERR_OK) { printf("mqtt_connect return %d\n", err); return -1; /* error */ } return 0; /* ok */ }
At this state, the only difference between TLS and unencrypted communication is that it uses uses a different port (8883 instead of 1883) and that it stores the SSL context in the client descriptor. Inside mqtt_client_connect(), it will directly call the tcp_connect() function.
Connection Callback
If the TCP connection succeeds, it calls the connection callback:
/** * TCP connect callback function. @see tcp_connected_fn * @param arg MQTT client * @param err Always ERR_OK, mqtt_tcp_err_cb is called in case of error * @return ERR_OK */ static err_t mqtt_tcp_connect_cb(void *arg, struct tcp_pcb *tpcb, err_t err) { mqtt_client_t* client = (mqtt_client_t *)arg; if (err != ERR_OK) { LWIP_DEBUGF(MQTT_DEBUG_WARN,("mqtt_tcp_connect_cb: TCP connect error %d\n", err)); return err; } /* Initiate receiver state */ client->msg_idx = 0; #if MQTT_USE_TLS /* Setup TCP callbacks */ tcp_recv(tpcb, tls_tcp_recv_cb); tcp_sent(tpcb, tls_tcp_sent_cb); tcp_poll(tpcb, NULL, 0); LWIP_DEBUGF(MQTT_DEBUG_TRACE,("mqtt_tcp_connect_cb: TCP connection established to server, starting TLS handshake\n")); /* Enter MQTT connect state */ client->conn_state = TLS_HANDSHAKING; /* Start cyclic timer */ sys_timeout(MQTT_CYCLIC_TIMER_INTERVAL*1000, mqtt_cyclic_timer, client); client->cyclic_tick = 0; #else /* Setup TCP callbacks */ tcp_recv(tpcb, mqtt_tcp_recv_cb); tcp_sent(tpcb, mqtt_tcp_sent_cb); tcp_poll(tpcb, mqtt_tcp_poll_cb, 2); LWIP_DEBUGF(MQTT_DEBUG_TRACE,("mqtt_tcp_connect_cb: TCP connection established to server\n")); /* Enter MQTT connect state */ client->conn_state = MQTT_CONNECTING; /* Start cyclic timer */ sys_timeout(MQTT_CYCLIC_TIMER_INTERVAL*1000, mqtt_cyclic_timer, client); client->cyclic_tick = 0; /* Start transmission from output queue, connect message is the first one out*/ mqtt_output_send(client, &client->output, client->conn); #endif return ERR_OK; }
In TLS mode, it configures the special call backs for tls handling (tls_rcp_recv_cb() and tls_tcp_sent_cb()) and moves the connection state into TLS_HANDSHAKING mode.
Receiver Callback
Because the normal receiver callback mqtt_tcp_recv_cb() does not work with the TLS layer, I have implemented a function which reads from the TLS layer:
💡 Note that the error handling is not completed yet!
err_t mqtt_recv_from_tls(mqtt_client_t *client) { int nof; mqtt_connection_status_t status; struct pbuf p; /*! \todo check if can we really use rx_buffer here? */ nof = mbedtls_ssl_read(client->ssl_context, client->rx_buffer, sizeof(client->rx_buffer)); if (nof>0) { printf("mqtt_recv_from_tls: recv %d\r\n", nof); memset(&p, 0, sizeof(struct pbuf)); /* initialize */ p.len = nof; p.tot_len = p.len; p.payload = client->rx_buffer; status = mqtt_parse_incoming(client, &p); if (status!=MQTT_CONNECT_ACCEPTED) { return ERR_CONN; /* connection error */ /*! \todo In case of communication error, have to close connection! */ } } return ERR_OK; }
TLS Sent Callback
For every packet sent, the callback tsl_tcp_sent_cb() gets called:
#if MQTT_USE_TLS /** * TCP data sent callback function. @see tcp_sent_fn * @param arg MQTT client * @param tpcb TCP connection handle * @param len Number of bytes sent * @return ERR_OK */ static err_t tls_tcp_sent_cb(void *arg, struct tcp_pcb *tpcb, u16_t len) { printf("tls_tcp_sent_cb\r\n"); return mqtt_tcp_sent_cb(arg, tpcb, 0); /* call normal (non-tls) callback */ } #endif /*MQTT_USE_TLS */
It call the corresponding callback in the MQTT layer:
/** * TCP data sent callback function. @see tcp_sent_fn * @param arg MQTT client * @param tpcb TCP connection handle * @param len Number of bytes sent * @return ERR_OK */ static err_t mqtt_tcp_sent_cb(void *arg, struct tcp_pcb *tpcb, u16_t len) { mqtt_client_t *client = (mqtt_client_t *)arg; LWIP_UNUSED_ARG(tpcb); LWIP_UNUSED_ARG(len); if (client->conn_state == MQTT_CONNECTED) { struct mqtt_request_t *r; printf("mqtt_tcp_sent_cb: and MQTT_CONNECTED\r\n"); /* Reset keep-alive send timer and server watchdog */ client->cyclic_tick = 0; client->server_watchdog = 0; /* QoS 0 publish has no response from server, so call its callbacks here */ while ((r = mqtt_take_request(&client->pend_req_queue, 0)) != NULL) { LWIP_DEBUGF(MQTT_DEBUG_TRACE,("mqtt_tcp_sent_cb: Calling QoS 0 publish complete callback\n")); if (r->cb != NULL) { r->cb(r->arg, ERR_OK); } mqtt_delete_request(r); } /* Try send any remaining buffers from output queue */ mqtt_output_send(client, &client->output, client->conn); } return ERR_OK; }
Net.c Functions
The interface to the network/lwip layer for mbed TLS is implemented in net.c.
The receiving function puts the incoming data into a ring buffer and returns the number of bytes received
/* * Read at most 'len' characters */ int mbedtls_net_recv( void *ctx, unsigned char *buf, size_t len ) { struct mqtt_client_t *context; context = (struct mqtt_client_t *)ctx; if(context->conn == NULL) { return( MBEDTLS_ERR_NET_INVALID_CONTEXT ); } if (RNG1_NofElements()>=len) { printf("mbedtls_net_recv: requested nof: %d, available %d\r\n", len, (int)RNG1_NofElements()); if (RNG1_Getn(buf, len)==ERR_OK) { return len; /* ok */ } } return 0; /* nothing read */ }
The sending function writes the data with tcp_write():
/* * Write at most 'len' characters */ int mbedtls_net_send( void *ctx, const unsigned char *buf, size_t len ) { struct mqtt_client_t *context; context = (struct mqtt_client_t *)ctx; int err; if(context->conn == NULL) { return( MBEDTLS_ERR_NET_INVALID_CONTEXT ); } printf("mbedtls_net_send: len: %d\r\n", len); err = tcp_write(context->conn, buf, len, TCP_WRITE_FLAG_COPY /*| (wrap ? TCP_WRITE_FLAG_MORE : 0)*/); if (err!=0) { return MBEDTLS_ERR_SSL_WANT_WRITE; } return len; /* >0: no error */ }
Sending MQTT Messages
With TLS, sending MQTT messages is using mbedtls_ssl_write() instead of tcp_write():
/** * Try send as many bytes as possible from output ring buffer * @param rb Output ring buffer * @param tpcb TCP connection handle */ static void mqtt_output_send(mqtt_client_t *client, struct mqtt_ringbuf_t *rb, struct tcp_pcb *tpcb) { err_t err; int nof; u8_t wrap = 0; u16_t ringbuf_lin_len = mqtt_ringbuf_linear_read_length(rb); u16_t send_len = tcp_sndbuf(tpcb); LWIP_ASSERT("mqtt_output_send: tpcb != NULL", tpcb != NULL); if (send_len == 0 || ringbuf_lin_len == 0) { return; } LWIP_DEBUGF(MQTT_DEBUG_TRACE,("mqtt_output_send: tcp_sndbuf: %d bytes, ringbuf_linear_available: %d, get %d, put %d\n", send_len, ringbuf_lin_len, ((rb)->get & MQTT_RINGBUF_IDX_MASK), ((rb)->put & MQTT_RINGBUF_IDX_MASK))); if (send_len > ringbuf_lin_len) { /* Space in TCP output buffer is larger than available in ring buffer linear portion */ send_len = ringbuf_lin_len; /* Wrap around if more data in ring buffer after linear portion */ wrap = (mqtt_ringbuf_len(rb) > ringbuf_lin_len); } #if MQTT_USE_TLS printf("mqtt_output_send: | (wrap ? TCP_WRITE_FLAG_MORE : 0)); #endif if ((err == ERR_OK) && wrap) { mqtt_ringbuf_advance_get_idx(rb, send_len); /* Use the lesser one of ring buffer linear length and TCP send buffer size */ send_len = LWIP_MIN(tcp_sndbuf(tpcb), mqtt_ringbuf_linear_read_length(rb)); #if MQTT_USE_TLS printf(); #endif } if (err == ERR_OK) { mqtt_ringbuf_advance_get_idx(rb, send_len); /* Flush */ tcp_output(tpcb); } else { LWIP_DEBUGF(MQTT_DEBUG_WARN, ("mqtt_output_send: Send failed with err %d (\"%s\")\n", err, lwip_strerr(err))); } }
Summary
In order to get MQTT working with TLS/SLL and lwip, I had to deep dive into how TLS and lwip works. I have to admit that things were not as easy as I thought as both MQTT and TLS are new to me, and I only had used lwip as a ‘black box’. The current implementation is very likely not ideal, not that clean and lacks some error handling. But it ‘works’ fine so far with a local Mosquitto broker. Plus I have learned a lot new things. I plan to clean it up more, add better error handling, plus to add FreeRTOS in a next step. Will see how it goes :-).
I hope this is useful for you. I have pushed the application for the NXP FRDM-K64F board on GitHub (). I plan to update/improve/extend the implementation, so make sure you check the latest version on GitHub.
I hope you find this useful to add TLS to your MQTT application with lwip.
💡 There is an alterative lwip API which should be easier to use with TLS. I have found that one after writing this article:
How to add server certificate verification, see my next article: “Tuturial: mbedTLS SLL Certificate Verification with Mosquitto, lwip and MQTT“.
Happy Encrypting 🙂
Links
- MQTT:
- lwip:
- mbed TLS library:
- mbed TLS tutorial:
- TLS/SSL:
- MQTT on NXP FRDM-K64F: MQTT with lwip and NXP FRDM-K64F Board
- Introduction to TLS: Introduction to Security and TLS (Transport Layer Security)
- Enable TLS in Mosquitto Broker: Enable Secure Communication with TLS and the Mosquitto Broker
- Project used in this article on GitHub:
- Tuturial: mbedTLS SLL Certificate Verification with Mosquitto, lwip and MQTT
- TLS Security:
- TLS and web certificates explained:
- Understanding security in IoT:
- Understanding Transport Layer Security:
Thanks, Erich. Will have to give it ago. Have you played with FNET at all? Found that a while ago when looking for lwip alternatives. looks like that has mbed tls built in too.
Hi Carl,
yes, I’m aware of FNET. But as it (currently?) only supports NXP devices, I have not used it. lwip on the other side is much more broadly used and supported.
Erich
Hi Erich,
Compliments for gettin it running !
I expect that my implementation ( MQX based ) should be a little bit simpler since RTCS give socket support with asyncronous receive and sending of the TCP/IP packets.
Anyway, thank very much for all these article about MQTT and SSL : they are really inspiring and offer also a list of useful links.
Luca
Thanks :-). Yes, I could have used sockets as well with lwip, but I wanted to start on the very low level, as it is easier to add a sockets layer later then to go the other way round.
Pingback: Tuturial: mbedTLS SLL Certificate Verification with Mosquitto, lwip and MQTT | MCU on Eclipse
Hi Erich,
Great introduction! It’s very useful.
I have one question about the reduce RAM usage part.
The size of MBEDTLS_MPI_MAX_SIZE is reduced from 1024(default) to 512. I dont know what is MPI. How can you decide the 512 is enough? Can you give me some clues? 🙂
Thanks!
Hi Amanda,
see.
MPI stands for Message Passing Interface, and that define is used in many places for buffers. It basically describes the maxiumum number of bytes which can be passed in a single message.
Basically it means that the keys exchanged should not be larger than 512 bytes.
I hope this helps,
Erich
It is possible to use MQTT mbedTLS with ESP8266 ?
You mean connecting from a NXP FRDM board (e.g. FRDM-K64F) with an MQTT client using mbedTLS to a MQTT server running on a ESP8266? Not done that, but I don’t see a reason why this would not work if the software on the ESP8266 is properly running the protocol.
I meant connect the NXP FRDM board to a ESP8266 (over UART) and send to a MQTT broker ( AWS ) values or strings.
I didn’t find any exemples in the internet using AT command that’s why I was wondering if it was possible ?
I don’t see a reason why this should not work. I have done similar things (see).
Where are the certificates loaded? I didnt found where the CA, certificate and private key are passed.
– Richmond
Hi Richmond,
see
Erich
FYI, LWIP now supports MQTT over TLS via ALTCP_TLS. It now supports loading of CA certificate, client certificate and private key. Tested it working with Amazon AWS IoT cloud.
Hi Erich,
I’m trying since months to follow your amazing tutorial step by step. I bought all materials and installed all tools on Linux, and I’m trying to connect the board with a local mosquitto broker (in my PC).
My two Questions:
1- How to configure the board (client-publisher) with the local mosquitto broker?
Note:
In “config.h” I made in /* broker settings */ CONFIG_USE_BROKER_LOCAL (1) and CONFIG_USE_BROKER_HSLU (0), and for /* client configuration settings */ I gave my PC settings in not WORK_NETZWORK. And in /* connection settings to broker */ I set again my PC settings (HOST_NAME, HOST_IP) in CONFIG_USE_BROKER_LOCAL. Unfortunatly I could not see the result becuse it was a problem in the debugging.
2- How to make a correct debug, every time I make debug I get this message in the “Debugger Console” of MCUXpresso:
“GNU gdb (GNU Tools for Arm Embedded Processors 7-2017-q4-major) 8.0.50.20171128”.
Program stopped.
ResetISR () at ../startup/startup_mk64f12.c:460
460 void ResetISR(void) {
Temporary breakpoint 1, main () at ../source/lwip_mqtt.c:844
844 SYSMPU_Type *base = SYSMPU;”
And before I ge this message in the Console “[MCUXpresso Semihosting Telnet console for ‘FRDM-K64F_lwip_mqtt_bm LinkServer Debug’ started on port 52358 @ 127.0.0.1]”
The Console writes this:
“MCUXpresso IDE RedlinkMulti Driver v10.2 (Jul 25 2018 11:28:11 – crt_emu_cm_redlink build 555)
Reconnected to existing link server
Connecting to probe 1 core 0:0 (using server started externally) gave ‘OK’
============= SCRIPT: kinetisconnect.scp =============
Kinetis Connect Script
DpID = 2BA01477
Assert NRESET
Reset pin state: 00
Power up Debug
MDM-AP APID: 0x001C0000
MDM-AP System Reset/Hold Reset/Debug Request
MDM-AP Control: 0x0000001C
MDM-AP Status (Flash Ready) : 0x00000032
Part is not secured
MDM-AP Control: 0x00000014
Release NRESET
Reset pin state: 01
MDM-AP Control (Debug Request): 0x00000004
MDM-AP Status: 0x0001003A
MDM-AP Core Halted
============= END SCRIPT =============================
Probe Firmware: MBED CMSIS-DAP (MBED)
Serial Number: 024002014D87DE5BB07923E3
VID:PID: 0D28:0204
USB Path: /dev/hidraw0
Using memory from core 0:0 after searching for a good core
debug interface type = Cortex-M3/4 (DAP DP ID 2BA01477) over SWD TAP 0
processor type = Cortex-M4 (CPU ID 00000C24) on DAP AP 0
number of h/w breakpoints = 6
number of flash patches = 2
number of h/w watchpoints = 4
Probe(0): Connected&Reset. DpID: 2BA01477. CpuID: 00000C24. Info:
Debug protocol: SWD. RTCK: Disabled. Vector catch: Disabled.
Content of CoreSight Debug ROM(s):
RBASE E00FF000: CID B105100D PID 04000BB4C4 ROM dev (type 0x1)
ROM 1 E000E000: CID B105E00D PID 04000BB00C ChipIP dev SCS (type 0x0)
ROM 1 E0001000: CID B105E00D PID 04003BB002 ChipIP dev DWT (type 0x0)
ROM 1 E0002000: CID B105E00D PID 04002BB003 ChipIP dev FPB (type 0x0)
ROM 1 E0000000: CID B105E00D PID 04003BB001 ChipIP dev ITM (type 0x0)
ROM 1 E0040000: CID B105900D PID 04000BB9A1 CoreSight dev TPIU type 0x11 Trace Sink – TPIU
ROM 1 E0041000: CID B105900D PID 04000BB925 CoreSight dev ETM type 0x13 Trace Source – core
ROM 1 E0042000: CID B105900D PID 04003BB907 CoreSight dev ETB type 0x21 Trace Sink – ETB
ROM 1 E0043000: CID B105900D PID 04001BB908 CoreSight dev CSTF type 0x12 Trace Link – Trace funnel/router
Inspected v.2 On chip Kinetis Flash memory module FTFE_4K.cfx
Image ‘Kinetis SemiGeneric Feb 17 2017 17:24:02’
Opening flash driver FTFE_4K.cfx
Sending VECTRESET to run flash driver
Flash variant ‘K 64 FTFE Generic 4K’ detected (1MB = 256*4K at 0x0)
Closing flash driver FTFE_4K.cfx
NXP: MK64FN1M0xxx12
( 65) Chip Setup Complete
Connected: was_reset=true. was_stopped=true
Awaiting telnet connection to port 3330 …
GDB nonstop mode enabled
Opening flash driver FTFE_4K.cfx (already resident)
Sending VECTRESET to run flash driver
Flash variant ‘K 64 FTFE Generic 4K’ detected (1MB = 256*4K at 0x0)
Writing 142880 bytes to address 0x00000000 in Flash”
I hope you can help.
1) in lwip_app.c you can onfigure the IP address of the broker (I have not used DHCP for this)
2) I recommend you use the SEGGER J-Link firmware instead
I hope this helps,
Erich
Hi Erich,
thanks for your reply.
I didn’t find any file with the name lwip_app.c!
Hi Erich,
1- I’m not working on mqtt-FreeRTOS without mbedtls but with mbedtls “FRDM-K64F_lwip_lwip_mqtt_bm”. I think, I can configure the IP address in /source/config.h file.
2- When MCUXpresso searches for a propes then it findes only LinkServer type. So I have no chance to make with SEGGER J-Link.
Hi Ahmed,
you can use the OpenSDA as a Segger J-Link or P&E Multilink, see
Erich
Hello Erich,
first, thank you very much for such a good job. Do you think is it possible not to use the RNG1 Module? how should I modify the mbedtls_net_recv?
Thank you,
To be more precise, I see that, porting this example in another microcontroller, the mbedtls_net_recv always has no data in the RNG1 Ringbuffer. Could you explain how it is used?
Thank you,
Mattia
In that case it means that you are not receiving the data. Have you tried to run it on a K64F as well?
I’m waiting for the MCUXpresso to be available to download, then I will test on my K64F.
However, I can’t understand very well the firmware.
if (RNG1_Getn(buf, len)==ERR_OK)
{
return len; /* ok */
}
But who writes on buf?
The strange thing is that with no TLS the program is perfect, so it seems that some union between TLS and TCP is missing.
I found what the problem was: it seems that tcp_write didn’t send data. I put a tcp_output, now it works!
Thanks,
Mattia
You can use whatever you like. The RNG1 is a simple implementation of a ring buffer, but you can replace it with your own implementation too.
Hi Erich,
I’m working on a project to use the device shadow service from AWS IoT. Some of the libraries that i’m using could only working properly in the environment with OS so I’m trying to port MQTT Client with TLS in bare metal way.
The project mentoned in the article on github needs FreeRTOS currently. Is there any old working versions without FreeRTOS? That would be very helpful for the project I’m working on.
I think I started that project in bare metal mode, so you might go back in the history of git to get that version.
But I believe using anything like this does not make any sense without an RTOS. It makes it so much more complicated without an RTOS, so I recommend you use one.
|
https://mcuoneclipse.com/2017/04/17/tutorial-secure-tls-communication-with-mqtt-using-mbedtls-on-top-of-lwip/?like_comment=90039&_wpnonce=fd4bb3e0f4
|
CC-MAIN-2020-29
|
refinedweb
| 4,526 | 50.57 |
|
++
>
STL
STL
1-20 of 87
Using the Standard Library Algorithms with Arrays
by Kevin Spiteri
Pointers may be used as iterators when using the standard library algorithms found in
<algorithm>
..
Returning from
main()
by Mohan Bisht
This tip describes the exceptions and their workarounds for returning from
main()
.
Generate Permutations for a Given Set of Numbers
by Karthik Kumar
Use the STL Library function
next_permutation
to generate permutations for s given set of numbers.
Include Templates
by Danny Kalev
Unlike ordinary classes and functions, which you declare in a header file and define in a separate .cpp file, a template
Serializing a Polymorphic Object
by Danny Kalev
A polymorphic object has one or more virtual functions. When you serialize such an object to a file so that it can be reconstituted later, the deserialization might rewrite its vptr and cause ...
Parenthesize Macro Arguments
by Danny Kalev
It's a good idea to parenthesize every macro argument. For ...
Namespaces and the C Standard Library
by Danny Kalev
The C++ Standard requires that the C standard library be declared in namespace std, just as the C++ Standard Library. Thus, if you #include <cstdio> and call printf(), you should use a ...
Where are std::min() and std::max()?
by Danny Kalev
The Standard Library defines the two template functions std::min() and std::max() in the <algorithm> header. In general, you should use these template functions for calculating the min and ...
<iostream.h> or <iostream>?
by Danny Kalev
Although the <iostream.h> library was deprecated for several years, many C++ users still use it in new code instead of using the newer, standard compliant <iostream> library. What are the ...
std::vector Iterators
by Danny Kalev
To create an iterator of a vector, you have to use a vector specialization. In the following examples, I create two vector iterators: one for the specialization vector <int> and another for ...
The remove_if() algorithm
by Danny Kalev
The remove_if() algorithms (defined in the standard header <algorithm>) has the following ...
Function Object Bases
by Danny Kalev
To simplify the process of writing custom function objects, the Standard Library provides two classes that serve as base classes of such objects: std::unary_function and std::binary_function. ...
The remove() Algorithm
by Danny Kalev
The Standard Library defines the std::remove() algorithm, which moves desired elements to the front of a container and returns an iterator pointing to the end of the sequence of the desired ...
Generating a Unique Filename
by Danny Kalev
To generate a unique filename that won't conflict with any other files that exist in the current directory, use the tmpnam() function declared in <stdio.h> as ...
1-20 of 87
Thanks for your registration, follow us on our social networks to keep up-to-date
|
http://www.devx.com/tips/cpp/stl
|
CC-MAIN-2016-40
|
refinedweb
| 459 | 51.99 |
Development Team/Almanac
Contents
- 1 How do I get additional help beyond this almanac?
- 2 Where can I see the components of Sugar and their relationships?
- 3 Where can I see API changes?
- 4 Getting Started
- 5 Package: sugar
- 6 Package: sugar.activity
- 7 Package: sugar.datastore
- 8 Package: sugar.graphics
- 9 Package: sugar.presence
- 10 Clipboard
- 11 Logging
- 12 Internationalization
- 13 Text and Graphics for Sugar Activities
- 14 Audio & Video
- 15 Mouse
- 16 Miscellaneous
- 16.1 How do I know when my activity is "active" or not?
- 16.2 How do I get the amount of free space available on disk under the /home directory tree?
- 16.3 How do I know whether my activity is running on a physical XO?
- 16.4 How do I know the current language setting on my XO?
- 16.5 How do I repeatedly call a specific method after N number of seconds?
- 16.6 How do I update the current build version of code that is running on my XO?
- 16.7 I am developing on an XO laptop, but my keyboard and language settings are not ideal. How can I change them?
- 16.8 My Python activity wants to use threads; how do I do that?
- 16.9 How do I customize the title that is displayed for each instance of my activity?
- 16.10 What packages are available on sugar to support game development?
- 16.11 How do I detect when one of the game buttons on the laptop have been pressed?
- 17 How do I know if the screen has been rotated?
- 18 Notes
How do I get additional help beyond this almanac?
- Looking to get started with the basics of Sugar development? Check out OLPC Austria's Activity Handbook (Please note that this handbook was last updated in May 2008 so the screenshots still show pre-8.2 design. In terms of the code itself things should still work as described. If you run into any issues please contact ChristophD.)
- See also Development Team/Almanac/Code Snippets
Now, on to the actual almanac ...
Where can I see the components of Sugar and their relationships? Icons
Package: sugar
Package: sugar.activity
Package: sugar.datastore
Package: sugar.graphics
- sugar.graphics.alert
- sugar.graphics.icon
- sugar.graphics.notebook
- sugar.graphics.toolbutton
- sugar.graphics.toolbox
- sugar.graphics.style
Package: sugar.presence
Clipboard
- Notes on using GTK's Clipboard Module
Logging
- sugar.logger
- Notes on using Python Standard Logging
Internationalization
Text and Graphics for Sugar Activities
How do I create a text box for code editing?
You can use gtksourceview2
import gtk import gtksourceview2 from sugar.graphics import style ... # set up the buffer buffer = gtksourceview2.Buffer() if hasattr(buffer, 'set_highlight'): # handle different API versions buffer.set_highlight(True) else: buffer.set_highlight_syntax(True) # set mime type for the buffer lang_manager = gtksourceview2.language_manager_get_default() if hasattr(lang_manager, 'list_languages'): # again, handle different APIs langs = lang_manager.list_languages() else: lang_ids = lang_manager.get_language_ids() langs = [lang_manager.get_language(lang_id) for lang_id in lang_ids] for lang in langs: for m in lang.get_mime_types(): if m == mime_type: # <-- this is the mime type you want buffer.set_language(lang) # set up the view object, use it like gtk.TextView view = gtksourceview2.View(buffer) view.set_size_request(300, 450) view.set_editable(True) view.set_cursor_visible(True) view.set_show_line_numbers(True) view.set_wrap_mode(gtk.WRAP_CHAR) view.set_right_margin_position(80) #view.set_highlight_current_line(True) #FIXME: Ugly color view.set_auto_indent(True) view.modify_font(pango.FontDescription("Monospace " + str(style.FONT_SIZE))) ...
To set the text in the buffer:
buffer.set_text(text)
To get all the text:
text = buffer.get_text(buffer.get_start_iter(), buffer.get_end_iter())
You will probably want to put the view in a gtk.ScrolledWindow
sw = gtk.ScrolledWindow() sw.add(view) sw.set_policy(gtk.POLICY_AUTOMATIC, gtk.POLICY_AUTOMATIC)
and add the sw object instead of the view.
You can find more in the Pippy source and in jarabe.view.sourceview. code demonstrates how to get the total amount of free space under /home.
#### Method: getFreespaceKb, returns the available freespace in kilobytes. def getFreespaceKb(self): stat = os.statvfs("/home") freebytes = stat.f_bsize * stat:olpc-update.
- If that doesn't work, you can look at instructions for an olpc olpc:Sugar Control Panel
Keyboard settings on internationalized laptops[3] can also be suboptimal, especially as characters like "-" and "/" are in unfamiliar positions. You can use the setxkbmap command in the olpc know if the screen has been rotated?
When the screen is rotated, GTK issues a CONFIGURE event. Test for this event and grab the screen dimensions in the event handler.
self.window.add_events(gtk.gdk.CONFIGURE) self.window.connect('configure-event', self._configure_cb)
def _configure_cb(self, win, event): width = gtk.gdk.screen_width() height = gtk.gdk.screen_height()
This does not tell you the orientation, however. Allegedly on the XO hardware, you can use olpc-kbdshim (currently undocumented).
This is an example of the share button is removed:
activity_toolbar = toolbox.get_activity_toolbar() activity_toolbar.remove(activity_toolbar.share) activity_toolbar.share = None
|
http://wiki.sugarlabs.org/go/Development_Team/Almanac
|
CC-MAIN-2016-40
|
refinedweb
| 806 | 52.87 |
I am tired of all those "upload to S3" examples and tutorial that does not seem to work , can you just show me something that simply work the super easy way ?
well here are the instruction that you have to follow to get a fully working demo program ,at the end of my answer you will find the demo program to download...
1-Download and install the Amazon web services SDK for .NET which you can find in (). because I have visual studio 2010 I choose to install the 3.5 .NET SDK.
2- open visual studio and make a new project , I have visual studio 2010 and I am using a console application project.
3- add reference to AWSSDK.dll , it is installed with the Amazon web service SDK mentioned above , in my system the dll is located in "C:\Program Files (x86)\AWS SDK for .NET\bin\Net35\AWSSDK.dll".
4- make a new class file ,call it "AmazonUploader" here the complete code of the class:
using System; using System.Collections.Generic; using System.Linq; using System.Text; using Amazon; using Amazon.S3; using Amazon.S3.Transfer; namespace IAmazonS3 client = Amazon.AWSClientFactory.CreateAmazonS3Client(RegionEndpoint.EUWest } } }
5- add a configuration file : right click on your project in the solution explorer and choose "add" -> "new item" then from the list choose the type "Application configuration file" and click the "add" button. a file called "App.config" is added to the solution.
6- edit the app.config file : double click the "app.config" file in the solution explorer the edit menu will appear . replace all the text with the following text :
<?xml version="1.0" encoding="utf-8" ?> <configuration> <appSettings> <add key="AWSProfileName" value="profile1"/> <add key="AWSAccessKey" value="your Access Key goes here"/> <add key="AWSSecretKey" value="your Secret Key goes here"/> </appSettings> </configuration>
you have to modify the above text to reflect your Amazon Access Key Id and Secret Access Key.
7- now in the program.cs file (remember this is a console application) write the following code :
using System; using System.Collections.Generic; using System.Linq; using System.Text; namespace UploadToS3Demo { class Program { static void Main(string[] args) { // preparing our file and directory names string fileToBackup = @"d:\mybackupFile.zip" ; // test file string myBucketName = "mys3bucketname"; //your s3 bucket name goes here string s3DirectoryName = "justdemodirectory"; string s3FileName = @"mybackupFile uploaded in 12-9-2014.zip"; AmazonUploader myUploader = new AmazonUploader(); myUploader.sendMyFileToS3(fileToBackup, myBucketName, s3DirectoryName, s3FileName); } } }
8- replace the strings in the code above with your own data
9- add error correction and your program is ready ,here is the download link
|
https://codedump.io/share/4Sd77Mh7jw7G/1/how-to-upload-a-file-to-amazon-s3-super-easy-using-c
|
CC-MAIN-2018-09
|
refinedweb
| 430 | 50.02 |
>From [email protected] Wed Jan 7 23:39:56 2004 > > This allows to use cdrtools on NT without the need to install ASPI in > > case you are administrator when yu run a program. >I'm using NT4preSP7. Adaptec Aspi 4.60 is running. Normally I use >Adaptec ASPI layer without administator rights to burn a CD. If you call the last cdrecord with no admin rights, then it should use ASPI because it is unable to open a SPTI file. > > Please note that the use of SPTI is default. >ASPI was default for several years. You changed this behavior. ASPI was the only way to go before. If things work as expected, then the change should not cause problems, but this is why there is a test phase before a "final" release is published. > > If you like to force using ASPI, use dev=ASPI:b,t,l or dev=ASPI > > (in the -scanbus case). >Now I'm using administrator rights and cygwin1.dll 1.5.5-cr-0x9b. If you have administrator rights, then the code should first try SPTI. >D:\>cdrecord -v dev=ASPI:1,1,0 blank=fast >Ok, works. >D:\>cdrecord dev=ASPI -scanbus >Cdrecord-Clone 2.01a24 (i586-pc-cygwin) Copyright (C) 1995-2004 Jörg >Schilling >scsidev: 'ASPI' >devname: 'ASPI' >scsibus: -2 target: -2 lun: -2 >cdrecord: Invalid argument. Devname 'ASPI' unknown.. Cannot open SCSI >driver. >cdrecord: For possible targets try 'cdrecord -scanbus'. Make sure you >are root. >cdrecord: For possible transport specifiers try 'cdrecord dev=help'. A bug, the code has not been completely written by me, I did only check for the most obvious problems and reformatted acording to usual indentation rules. Did you try: cdrecord dev=ASPI: -scanbus Please test the patch below.... >D:\>cdrecord -scanbus >Blue screen of death; well, broken OS. I got the same result on three >different computers with NT4. OK, you already mentioned it: if the OS dies, this is a OS bug. But as other authors have been able to hack similar things, there should be a way to prevent this from happening. Anybody has an idea or can help? >W2k with SPTI works without problems (cdrecord -scanbus and cd burning). OK, thank you for the report. I did check it on Win98 and it works out of fhe box with cdrecord -scanbus it prints an error message if you call: cdrecord -scanbus dev=SPTI /*--------------------------------------------------------------------------*/ ------- scsi-wnt.c ------- *** /tmp/sccs.TNaGVX Do Jan 8 15:01:43 2004 --- scsi-wnt.c Do Jan 8 15:01:29 2004 *************** *** 688,700 **** return (-1); } ! if ((device != NULL && *device != '\0' && strcmp(device, "SPTI") != 0 && strcmp(device, "ASPI") != 0) || (busno == -2 && tgt == -2)) { errno = EINVAL; if (scgp->errstr) js_snprintf(scgp->errstr, SCSI_ERRSTR_SIZE, ! "Devname '%s' unknown.", device); return (-1); } if (AspiLoaded <= 0) { /* do not change access method on open driver */ bForceAccess = FALSE; #ifdef PREFER_SPTI --- 688,706 ---- return (-1); } ! if (device != NULL && ! (strcmp(device, "SPTI") == 0 || strcmp(device, "ASPI") == 0) && ! (busno < 0 && tgt < 0 && lun < 0)) ! goto devok; ! ! if ((device != NULL && *device != '\0') || (busno == -2 && tgt == -2)) { errno = EINVAL; if (scgp->errstr) js_snprintf(scgp->errstr, SCSI_ERRSTR_SIZE, ! "Open by 'devname' not supported on this OS"); return (-1); } + devok: if (AspiLoaded <= 0) { /* do not change access method on open driver */ bForceAccess = FALSE; #ifdef PREFER_SPTI:
|
https://lists.debian.org/cdwrite/2004/01/msg00074.html
|
CC-MAIN-2014-15
|
refinedweb
| 540 | 68.47 |
[solved] Manage ISI in fixed duration
edited October 2015 in OpenSesame
Hi
I want to present picture stimuli with different ISI. I used an inline script to have the stimuli presented exactly at 1000, 1500, 2000, and 2500 ms. Yet it seems not working correctly.
The used script is as follows and the Sequence contents is presented in the following link.
Please could you kindly advice what to do on this case.
Thanks,
Masoud
import random
minimum = 1000
maximum = 2500
ISI = random.randint(minimum, maximum)
exp.set("ISI", ISI)
ISI_options = [1000,1500,2000,2500]
ISI = random.choice(ISI_options)
Hi Masoud,
Based on the script you posted there, ISI would be a random number between 1000 and 2500. Note that you're doing nothing with the
ISI_optionsvariable, since the new value for ISI (random.choice(ISI_options)) isn't set with exp.set('ISI', ISI).
You may want to delete the line
ISI = random.randint(minimum,maximum)and move
exp.set("ISI", ISI)to after the line
ISI = random.choice(ISI_options).
Cheers,
Josh
Many Thanks Josh
I made necessary changes in line with your comment. In addition, a keyboard_response is added to the program to collect the responses and to give a Correct or Incorrect feedback to the participant. The thing is that the the Correct feedback will be given to the space bar after the red squares stimuli and the Incorrect feedback will be given after no key response.
I have added the "SPACE" to correct_response in the keyboard and "Unknown" for the allowed responses.
In addition I have added to skectchpads, one is conditioned for correct and the the one for the incorrect responses but the feedback is not presented yet.
Please could you kindly advice more to sort the feedback issue out. I can send the file in the case you can have a look on it.
Thanks,
Masoud
Hi Masoud,
For the two feedback sketchpads, what run-if statement did you use? (When you click on the sequence item that they are in, you can see that items are run 'always' by default). In any case, the keyboard_response item automatically creates a variable
correct, which is set to 1 in case the response was correct, and 0 in case it was incorrect. Thus, for the positive feedback you could use run-if
[correct] = 1, and for the negative feedback run-if
[correct] = 0. Of course the sketchpads need to be placed after the keyboard_response item.
Let me know if this helps. Good luck!
Josh
Dear Josh
Thanks a lot.
Please could you kindly have a look at the file attached with the following link:
I have done what you have said but it is not working yet.
Masoud
Hi Masoud, you didn't copy what I said correctly. I said
[correct] = 1, you used the line
[correct = 1]. Can you see the difference?
Cheers,
Josh
Great and thank you. It works well. You know when I have done that it gives feedback to keypress only. Is there any option to have a correct feedback for no keypress to distractors?
Masoud
Hi Masoud, yes that would be possible.
Right now you have set
spaceas correct response in the keyboard item. What you have to do, is go to the loop item, and create a new variable named
correct_response. Then, you have to indicate the correct response for each condition, i.e., conditions with a distractor to which
correct_responseshould be
none, and conditions without a distractor to which it should be
space. So in the first column there is 'var1', and in the second column there is correct_response, and on each row the response should correspond to the var1.
Lastly, in the keyboard_response item, you can delete
spacefrom correct_response; just leave it empty.
Let me know if it works!
Josh
That does not work. I have made changes in the "run if" for correct and incorrect sketcpads as follows:
run stim "always"
run ISI "always"
run _keyboard_response "always"
run correct "[correct_response]=space and [response]=space or [correct_response]=none and [response]=none"
run incorrect "[correct_response]=none and [response]=space or [correct_response]=space and [response]=none"
run _logger "always"
But still no works.
Any more advice is much appreciated.
Masoud
Hi Masoud,
try changing
"[correct_response]=spaceinto
"[correct_response]='space'(note the quotation marks around the space).
Also, I think you should change
[response]=noneinto
[response]=None. Although, I am not sure about this one.
Do that for each of their occurrences and I think you should be good.
Let us know, if it doesn't work.
good luck,
Eduard
Thousands of thanks Eduard.
Adding the quotation marks and capitalising the first letter of "None" worked eventually.
Cheers,
Masoud
|
https://forum.cogsci.nl/discussion/comment/5998
|
CC-MAIN-2022-33
|
refinedweb
| 775 | 66.13 |
Difference between revisions of "ECE597 Lab 1 Wiring and Running the Beagle"
Latest revision as of 20:48, 27 October 2011
Here's what you need to do to get your Beagle running for the first time.
- Wire your Beagle as shown
- Insert the SD card
- Plug in the 5V power
- Login and look around. Left-click on the background to get a menu.
- Try starting an XTerm.
- Try some basic Linux commands
ls, cd, less mplayer ls /proc ls /sys
<code?/proc</code> and
/sys are files that map to the hardware.
- Try
cd /sys/class/leds ls cd beagleboard::usr0 ls cat trigger echo none > trigger echo 1 > brightness
cat trigger tells you what options you can set trigger to. Try some of them. Explore
/sys and
/proc is see what else you can find.
Homework
There are many interesting programs already compiled for the Beagle that aren't on the SD card we gave you. New applications can be easily installed using the
opkg package manager. When you are back home and connected to the network try:
opkg list | less opkg install gcc
The first command lists the packages you can install. The second command installs the gcc C compiler. With a compiler installed you can take your favorite C program and compile and run it on the Beagle. Here is the embedded version of Hello World as presented in The Embedded Linux Primer.
#include <stdio.h> int bss_var; /* Uninitialized global variable */ int data_var = 1; /* Initialized global variable */ int main(int argc, char **argv) { void *stack_var; /* Local variable on the stack */ stack_var = (void *)main; /* Don't let the compiler */ /* optimize it out */ printf("Hello, World! Main is executing at %p\n", stack_var); printf("This address (%p) is in our stack frame\n", &stack_var); /* bss section contains uninitialized data */ printf("This address (%p) is in our bss section\n", &bss_var); /* data section contains initializated data */ printf("This address (%p) is in our data section\n", &data_var); return 0; } Compile and run it <pre> yoder@beagleboard:~$ gcc helloBeagle.c yoder@beagleboard:~$ ./a.out Hello, World! Main is executing at 0x8380 This address (0xbefa1cf4) is in our stack frame This address (0x10670) is in our bss section This address (0x10668) is in our data section
This is a program I use what talking about the address spaces on the Beagle and virtual memory.
Try some of your own C programs. See how well they run. If you come up with something interesting, add them to the wiki.
|
http://elinux.org/index.php?title=ECE597_Lab_1_Wiring_and_Running_the_Beagle&diff=71497&oldid=18360
|
CC-MAIN-2014-10
|
refinedweb
| 417 | 61.77 |
Realtime Testing Best Practices
Contents
- 1 Introduction
- 2 Test programs
- 3 Test Hardware
- 4 Issues and Techniques
- 5 Tests results taxonomy
- 6 Test presentations and documents
- 7 Uncategorized stuff
Introduction
This page is intended to serve as a collecting point for presentations, documents, results, links and descriptions about testing Realtime performance of Linux systems. In the first section, please upload or place links to presentations or documentsion on the subject of RT testing for linux.
Terminology
This document uses the definitions for real time terminology found in: Real Time Terms
Test programs
RT Measurement programs
Here is a list of programs that have been used for realtime testing:
lpptest
- lpptest - included in the RT-preempt patch
- It consists of a
- 1. driver in the linux kernel, to toggle a bit on the parallel port, and watch for a response toggle back
- 2. a user program to cause the measurement to happen
- 3. a driver to respond to this toggling
- with the RT-preempt patch applied, see:
- drivers/char/lpptest.c
- scripts/testlpp.c
- For some other modifications, see
- remove dependency on TSC
This requires a separate machine to send the signal on the parallel port and receive the response. (Can this be run with a loopback cable? It seems like this would disturb the findings).
Are there any writeups of use of this test?
RealFeel
- RealFeel -
This program is a very simple test of how well a periodic interrupt is processed. The program programs a periodic interrupt using /dev/rtc to fire at a fixed interval. The program measures the time duration from interrupt to interrupt, and compares this to the expected value for the duration. This simple program just prints a list of variances from the expected value, forever.
This program uses the TSC in user space for timestamps.
RealFeel (ETRI version rf-etri)
This program (latency.c) extends realfeel in several ways:
- it adds command line arguments to allow runtime control of most parameters
- it adds a histogram feature to dump the results to a histogram
- it can do both linear and logarithmic histograms
- it locks the process pages in memory (very important)
- it changes the scheduling priority to SCHED_FIFO, at highest priority (very important)
- it adds conditional code to trigger output to a parallel port pin (for capture to an external probe or logic analyzer)
- it abstracts the routine to get the timestamp, with the function: getticks()
- it handles the interrupt signal and does a clean exit of the main loop (on user break?)
- it tracks min, max and average latency for whole run, and for every 1000 cycles of the loop
- it adds a timestamp to the /dev/rtc driver, and reads this as part of the rtc data
- how is rtc timestamp used??
Cyclictest
- Cyclictest - See
LRTB
- Linux Real-Time Benchmarking Framework - See
- quickie overview at:
Hourglass
- Hourglass is a synthetic real-time application that can be used to learn how CPU scheduling in a general-purpose operating system works at microsecond and millisecond granularities
Woerner test
Trevor Woerner wrote an interesting test which received an interrupt on the serial port, and pushed data through several processes, before sending back out the serial port. This test requires an external machine for triggering the test and measuring the results.
See Trevor Woerner's latency tests
Senoner test
Benno Senoner has a latency test that simulates and audio workload. See
Used (and extended??) by Takahashi Iwai - see
Test Features Table
Benchmarking programs
- see Benchmark Programs
- some to look into:
- hackbench
- lmbench
- unixbench
Stress programs
- Ingo Molnar has a shell script which he calls dohell
- good candidates seem to be:
- find
- du
- ping
- Cache Calibrator - see RT-Preempt howto
Stress actions
Here are some things that will kill your RT performance:
- write the time of day to the CMOS of your RTC (see drivers/char/rtc.c - only by code inspection, no test yet)
- have a bus-master device do a long DMA on the bus
- get a page fault on your RT process (can be prevented with mlockall)
- get multiple TLB flushes on your RT code path (how to cause this??)
- get lots of instruction and data cache misses on your RT code path
- how to cause this?
- go down error paths in the RT case?
- be ON a big error case when the RT event happens?
- push your main RT code path and data sets out of cache with other work (in your RT process), prior to the next RT event?
- access data in a very non-localized way on your RT code path
Test Hardware
- LRTB uses a 3-machine system:
Issues and Techniques
This is a list of issues and techniques for dealing with them, having to do with testing realtime performance in Linux.
ping flood isn't good as stress test
At one of the sessions at ELC 2007, Nicholas McGuire stated that a pingflood test is actually a poor test of RT performance, since it causes locality in the networking code rather than stressing the system.
Here is a list of issues that have to be dealt with:
- what tests are available on all platforms?
- is special clock hardware or registers required for a test (e.g. realfeel, which only supports i386?)
- does the program cross-compile?
- Does generation of the test conditions perturb the test results?
- Is special external hardware required?
- How is the system stressed?
- How to stress memory (cause cache-flushes and swapping)
- How to stress bad code paths (long error paths, fault injection?)
- How is performance measured?
Using the LATENCY_TRACE option
Quote about latency-test from Ingo:
I'm seeing roughly half of that worst-case IRQ latency on similar hardware (2GHz Athlon64), so i believe your system has some hardware latency that masks the capabilities of the underlying RTOS. It would be interesting to see IRQSOFF_TIMING + LATENCY_TRACE critical path information from the -RT tree. Just enable those two options in the .config (on the host side), and do: echo 0 > /proc/sys/kernel/preempt_max_latency and the kernel will begin measuring and tracing worst-case latency paths. Then put some load on the host when you see a 50+ usec latency reported to the syslog, send me the /proc/latency_trace. It should be a matter of a few minutes to capture this information.
Number of samples recommended
Ingo wrote:
also, i'm wondering why you tested with only 1,000,000 samples. I routinely do 100,000,000 sample tests, and i did one overnight test with more than 1 billion samples, and the latency difference is quite significant between say 1,000,000 samples and 100,000,000 samples. All you need to do is to increase the rate of interrupts generated by the logger - e.g. my testbox can handle 80,000 irqs/sec with only 15% CPU overhead.
Things to watch for in testing
Another note from Ingo - see here
- Note the bit about IRQ 7 - what's up with that?
> First things first, we want to report back that our setup is validated > before we go onto this one. So we've modified LRTBF to do the > busy-wait thing. here's another bug in the way you are testing PREEMPT_RT irq latencies. Right now you are doing this in lrtbf-0.1a/drivers/par-test.c: if (request_irq ( PAR_TEST_IRQ, &par_test_irq_handler, #if CONFIG_PREEMPT_RT SA_NODELAY, #else //!CONFIG_PREEMPT_RT SA_INTERRUPT, #endif //PREEMPT_RT you should set the SA_INTERRUPT flag in the PREEMPT_RT case too! I.e. the relevant line above should be: SA_NODELAY | SA_INTERRUPT, otherwise par_test_irq_handler will run with interrupts enabled, opening the window for other interrupts to be injected and increasing the worst-case latency! Take a look at drivers/char/lpptest.c how to do this properly. Also, double-check that there is no IRQ 7 thread running on the PREEMPT_RT kernel, to make sure you are measuring irq latencies.
Tests results taxonomy
Test Table
Test presentations and documents
Presentations
[Add links here, most recent at top]
- [TBD Linux Kernel's performance comparison] by HyoJun Im of LG at RTWG 2nd Face-to-Face Meeting in Korea
- Tested Linux Kernel's performance by using opensource benchmarks
- Test Target : Intel Pentium 4 2GHz, 1GB Memory
- compared among linux kernel 2.4.22, 2.6.18 with preemption patch, 2.6.23-rc
- used opensource benchmark test programs
- Realfeel : measure interrupt latency time
- 2.6(preemption) - 3.3ms, 2.6(rc3) - 3.5ms, 2.4 - 258.9ms
- Hackbench Test : measure the scalability of scheduler
- TBD
- InterBench Test : measure the latency time of interactive task under load
- He has good result table to see
- LMbench Test : measure context switching latency time
- TBD
- Analysis of Interrupt Entry Latency in Linux 2.4 vs 2.6 by !SangBae Lee of Samsung for ELC 2007
- Analyzed MV 3.1 (2.4.20) and MV 4.0 (2.6.10), using LTT, on OSK board (OMAP 5920 ARM 192 MHZ)
- This is not a realtime-preempt patch applied test. Only tested between 2.4.20 and 2.6.10 kernel
- Initial results were that linux.2.4.20 was 3X fast for best-case interrupt latency by using LTT
- This test's problem was to use LTT, LTT had really high overhead for this test's comparing
- After reviewing code and finding that the interrupt code path was almost identical, a different, more lightweight tracer was used (Zoom-in tracer) showing latencies were almost the same between 2.4 kernel and 2.6 kernel
- This ZI instrumentation has low overhead, so it is suitable for interrupt reponse time measurement. It was written by SangBae Lee
- Also measured on MIPS 264 MHZ (for real TV system), but following data was measured on OSK board
- Interrupt response time measured:
- with LTT instrumentation:
- 2.6.10 - min = 30 us, max = 400 us
- 2.4.20 - min = 10 us, max = 30 us
- with ZI instrumentation:
- 2.6.10 - min = 3 us, max = 30~35 us
- 2.4.20 - min = 3 us, max = 30~35 us
- Basic result = Don't use LTT for measuring RT performance
- Porting and Evaluating the Linux Realtime Preemption on Embedded Platform by Katsuya Matsubara of Igel at ELC 2007
- Realtime Preempt Patch Adaptation Experience (and Real Time BOF notes) - !YungJoon Jung of ETRI at ELC 2007
- This is the presentation of Realtime BoF in ELC 2007. It includes realtime preempt patch adaptation kernel's test
- Test on VIA Nehemiah board, 1GHZ, 256M memory
- See (need to make this public)
- has good charts comparing vanilla, voluntary preempt, preemptible kernel and RT-preempt
- min = 5.6 us, max = 41.1 us
- showed RT-preempt has throughput problems (reported by hackbench)
- Performance Measurement of PPC64 RT patch (update) (english text) - by Tsutomu Owa of Toshiba at CELF Jamboree 13
- Porting pre-empt RT patch on SuperH (english text) - by Katsuya Matsubara (IGEL) at CELF Jamboree 13
- Performance Measurement of PPC64 RT Patch (english text) - by Tsutomu Owa of Toshiba at CELF Jamboree 12
- Linux Realtime Preemption and Its Impact on ULDD by Katsuya Matsubara & Hitomi Takahashi of IGEL, for CELF Jamboree 11
- very good summary of RT-preempt patch. Also good description of work done on SH4 and work on User Level device drivers.
- Describes basic steps to do a new port of RT-preempt
- Experience with Realtime Performance - by Shinichi Ochiai of Mitsubishi Electric Corporation at CELF ELC 2006
- This describes RT features and how they evolved from 2.4.20 to 2.6.16. Test results are shown for preemptible kernel (2.4.20), voluntary preemption, RT-preempt, and hybrid kernel approach (RTAI). The platforms tested were an SH4 board and an EDEN board, with a VIA processor (i386 clone). RT-preempt is shown to have good RT characteristics, for later kernel versions.
- PREEMPT-RT vs I-PIPE: the numbers, take 3 - by Kristian Benoit, LKML message, 2005
- about extensive testing by Kristian Benoit and Karim Yaghmour
- See also PREEMPT RT vs ADEOS: the numbers, part 1
- and PREEMPT_RT vs I-PIPE: the numbers, take 2
- Trevor Woerner's latency tests
- Interesting host/target test of latency via transmission and reception of strings over serial port
- Real-Time Preemption Patchset - by Manas Saksena, CELF tech conference 2005
- Good paper with overview of RT-preempt patch features
- Audio Latency on Linux Kernels - Takahashi Awai, SUSE, 2003
- Linux Scheduler Latency - by Clark Williams, Red Hat, March 2002
- Realfeel Test of the Preemptible Kernel Patch - article in Linux Journal, 2002 by Andrew Webber
- This is a test of the preemptible kernel feature in 2.4.19, on i386 hardware.
- Real Time and Linux, Part 3: Sub-Kernels and Benchmarks - article in Embedded Linux Journal, online, 2002 by Kevin Dankwardt
- [attachment:p-a03_wilshire.pdf Real Time Linux: Testing and Evaluation] - By Phil Wilshire of Lineo at the Second Real Time Linux Workshop, 2000
- This paper discusses the different benchmarking tools used to evaluate the performance of Linux and their suitability for evaluating Real Time system Performance. It is focused on RTAI.
OLS papers
[FIXTHIS - need to scan for past papers]
- OLS 2006 BOF - Steven Rostedt, RedHat and Klaas Van Gend, MontaVista - See The State of RT and Common Mistakes (OLS 2006 BOF)
- OLS 2007 - Paper by Steven Rostedt - see
Darren Hart wrote:
I have contributed some testing results to Steven Rostedt's OLS RT Internals paper. That will be available to link to after the conference sometime.
Real Time Linux Foundation RTL Workshops
Nicholas said:
There are a number of publications related to both benchmarking and analysis of hardware related artifacts (cache,BTB,TLB,etc.) which were published at the real-time Linux Workshops.
Here is a link to the RTLF events page:
So far, I've scanned 1999-2000 for interesting links.
Uncategorized stuff
This section has random stuff I haven't organized yet:
- - scheduler statistics
- maybe this can be used to analyze process wakeup latency?? Need to see what stats are kept.
- Low-latency HowTo (for audio) -
Notes on ineffective tests
Nicholas McGuire wrote:
The tests noted in the LKML post on this page are very problematic, ping - -f is not testing RT at all, it keeps the kernel in a very small active page set thus reducing page related penalties, the while loop using dd is also not too helpfull as it will de-facto run only in memory and cause absolutely no disk/mass-storage related interaction (try the same with mount -o remount,sync / first and it will be devastating ! (limited to ext2/ext3/ufs))
Notes on test requirements - need to test kernel error paths
Nicholas McGuire wrote:
The big problem with RT tests published is that they are all looking at the good case, they are loading the system but assuming successfull operations. The worst cases pop up when you run in the error paths of the kernel - then a trivial application can induce very large jitter in the system (run crashme in the background and rerun the tests...)
Notes on test requirements - need for usage profile
Also lmbench can give a statistic view of things (and not even that very precisely in some case i.e. context switch measurements are flawed) so this is not of much help for descision makers which variant to use - it does not help if the average performance is good but the mobile phone or mp3 klicks at 1s intervals "deterministically" - so I guess RT benchmarks need a notion of usage-profile to be of value.
|
http://elinux.org/index.php?title=Realtime_Testing_Best_Practices&oldid=4832
|
CC-MAIN-2015-35
|
refinedweb
| 2,560 | 57.2 |
Optimize Namespace Polling
Published: October 22, 2009
Updated: October 16, 2013
Applies To: Windows Server 2008 R2, Windows Server 2012, Windows Server 2012 R2
To maintain a consistent domain-based namespace across namespace servers, it is necessary for namespace servers to periodically poll Active Directory Domain Services (AD DS) to obtain the most current namespace data. You can use this procedure to optimize how this polling occurs.
To optimize namespace polling
Click Start , point to Administrative Tools , and then click DFS Management .
In the console tree, under the Namespaces node, right-click a domain-based namespace, and then click Properties .
On the Advanced tab, select whether the namespace will be optimized for consistency or scalability.
- Choose Optimize for consistency if there are 16 or fewer namespace servers hosting the namespace.
- Choose Optimize for scalability if there are more than 16 namespace servers. This reduces the load on the Primary Domain Controller (PDC) Emulator, but increases the time it requires for changes to the namespace to replicate to all namespace servers. Until changes replicate to all servers, users might have an inconsistent view of the namespace.
Additional references
|
https://technet.microsoft.com/en-us/library/cc732193.aspx
|
CC-MAIN-2015-11
|
refinedweb
| 187 | 50.77 |
I came accross something strange when trying to create friendly URLs.
I have an item model which has:
def to_param "#{id}-#{name}".parameterize end
This makes my item URLs contain the "ID" and "name" just fine:
I also have a category model (item belongs to category and user models) where I have the same def to_param as above but the category URLs stay "unfriendly" no "name" included:
domain.com/categories/ID
I have name column in category table and it has values. I also use ancestry for the category model. Maybe has_ancestry is causing the issue?
I tried below but no luck:
def to_param [id, name.parameterize].join("-") end
Thanks for any advice!
|
http://www.howtobuildsoftware.com/index.php/how-do/4ft/ruby-on-rails-url-ruby-on-rails-4-url-rewriting-rails-4-def-to-param-with-2-models
|
CC-MAIN-2018-39
|
refinedweb
| 113 | 57.98 |
We've made basic examples that show you how to use the PDFmyURL API in all major programming languages. These examples are specifically intended to get you coding in a few minutes without the need to install anything.
If you would rather install a library to code with, we offer a professional PHP library and a .NET component. We can offer libraries in other languages on request.
Our API is very easy to use. It takes a license and either a URL or raw HTML as input and returns a PDF.
You just send a request similar to this, which we will be using in all our examples and which converts to PDF:
You can use a lot of additional parameters in the API call, which give you access to all the features for conversion. These are all specified in the documentation.
NB: You can use both GET as well as POST requests as long as you properly URL encode the data that you pass.
You can implement the PDFmyURL API with the file_get_contents function in PHP. Sending the example request and storing the PDF in a local file thus becomes the following code.
$license = 'yourlicensekey'; $url = urlencode(''); $result = file_get_contents(""); file_put_contents('/tmp/mypdf.pdf',$result);
Of course you can use many options, by referring to the documentation. Also we offer a complete PHP library based on our API.
You can use the following code in Java to send the basic example and get the PDF stored as 'mypdf.pdf':();
Of course you can use many options, by referring to the documentation.
It is very easy to convert a URL to PDF in Ruby with the PDFmyURL API. Just get the result of our URL with the Ruby class Net::HTTP.
Of course you can use many options, by referring to the documentation.
Converting a URL to PDF in C# is easy with the PDFmyURL API. Just use the C# WebClient method as in the example below. Of course you can also use our professional .NET component.
string license = "yourlicensekey"; string url = System.Net.WebUtility.UrlEncode(""); using (var client = new WebClient()) { client.QueryString.Add("license", license); client.QueryString.Add("url", url); client.DownloadFile("", @"c:\temp\mypdf.pdf"); }
Of course you can use many options, by referring to the documentation.
It is easy to convert a URL into PDF in VB.net with our API. Just use the VB.net WebClient. Of course you can also use our custom made .NET component.
Dim license As String = "yourlicensekey" Dim url As String = System.Net.WebUtility.UrlEncode("") Using client As New WebClient client.QueryString.Add("license", license) client.QueryString.Add("url", Url) client.DownloadFile("", "c:\temp\mypdf.pdf") End Using
Of course you can use many options, by referring to the documentation.
You can use the Python function urllib2.urlopen to make use of our API and convert URLs or HTML to PDF.
import urllib2 data = { 'license': 'yourlicensekey', 'url': '' } requesturl = '{license}&url={url}'.format(**data) result = urllib2.urlopen(requesturl) localFile = open('mypdf.pdf', 'w') localFile.write(result.read()) localFile.close()
Of course you can use many options, by referring to the documentation.
You can use several modules in Perl to use our API, such as the File::Fetch or the LWP::Simple module.
The following example takes a webpage and saves it as PDF in the /tmp directory under the filename stored in $where.
use File::Fetch; use URI::Escape; my $license = 'yourlicensekey'; my $url = uri_escape(""); my $ff = File::Fetch->new(uri => ""); my $where = $ff->fetch( to => '/tmp');
Of course you can use many options, by referring to the documentation.
When you use JavaScript you should realize that your license key will be visible to everyone. In the members area we have a setting that enables you to use the API with the domain instead so that this doesn't happen. This setting is activated by default when you sign up and we'll assume that you've set the domain in the below example.
The below example opens a PDF created from a URL in a new tab. We also have another more detailed example that shows how you can use JavaScript to convert pages in protected members areas or on your intranet.
function pdfmyurl (url, savepdf) { var self = this; self.save = savepdf; self.req = new XMLHttpRequest(); // you can add other parameters here - otherwise the defaults from the members area are used var data = "url=" + encodeURIComponent(url); self.req.onload = function(event) { self.reader = new FileReader(); self.reader.addEventListener("loadend", function() { window.open(self.reader.result, "_blank"); return self.reader.result; }); self.reader.readAsDataURL(self.req.response); }; self.req.open("POST", "", true); self.req.setRequestHeader('Content-type', 'application/x-www-form-urlencoded'); self.req.responseType = "blob"; self.req.send(data); }
Of course you can use many options, by referring to the documentation.
The API can also be used in any other programming language or from the command line. If you'd like to see examples in other languages please contact us about this.
|
http://staging.pdfmyurl.com/html-to-pdf-api-examples
|
CC-MAIN-2020-10
|
refinedweb
| 830 | 59.8 |
#include <rte_compat.h>
#include <rte_ethdev.h>
#include <rte_ether.h>
Go to the source code of this file.
i40e PMD specific functions.
EXPERIMENTAL: this API may change, or be removed, without prior notice
Definition in file rte_pmd_i40e.h.
ptype mapping table only accept RTE_PTYPE_XXX or "user defined" ptype. A ptype with MSB set will be regarded as a user defined ptype. Below macro help to create a user defined ptype.
Definition at line 176 of file rte_pmd_i40e.h.
Response sent back to i40e driver from user app after callback
Definition at line 28 of file rte_pmd_i40e.h.
Option of package processing.
Definition at line 49 of file rte_pmd_i40e.h.
Types of package information.
Definition at line 60 of file rte_pmd_i40e.h.
Option types of queue region.
Definition at line 81 of file rte_pmd_i40e.h.
Behavior will be taken if raw packet template is matched.
Definition at line 234 of file rte_pmd_i40e.h.
Flow director report status It defines what will be reported if raw packet template is matched.
Definition at line 244 of file rte_pmd_i40e.h.
Add or remove raw packet template filter to Flow Director.
Notify VF when PF link status changes.
Enable/Disable VF MAC anti spoofing.
Enable/Disable VF VLAN anti spoofing.
Enable/Disable TX loopback on all the PF and VFs.
Enable/Disable VF unicast promiscuous mode.
Enable/Disable VF multicast promiscuous mode.
Set the VF MAC address.
PF should set MAC address before VF initialized, if PF sets the MAC address after VF initialized, new MAC address won't be effective until VF reinitialize.
This will remove all existing MAC filters.
Remove the VF MAC address.
Enable/Disable vf vlan strip for all queues in a pool
Enable/Disable vf vlan insert
Enable/Disable vf broadcast mode
Enable/Disable vf vlan tag
Enable/Disable VF VLAN filter
Get VF's statistics
Clear VF's statistics
Set VF's max bandwidth.
Per VF bandwidth limitation and per TC bandwidth limitation cannot be enabled in parallel. If per TC bandwidth is enabled, this function will disable it.
Set all the TCs' bandwidth weight on a specific VF.
The bw_weight means the percentage occupied by the TC. It can be taken as the relative min bandwidth setting.
Set a specific TC's max bandwidth on a specific VF.
Set some TCs to strict priority mode on a physical port.
Load/Unload a ddp package
rte_pmd_i40e_get_ddp_info - Get profile's info
rte_pmd_i40e_get_ddp_list - Get loaded profile list
Update hardware defined ptype to software defined packet type mapping table.
Reset hardware defined ptype to software defined ptype mapping table to default.
Get hardware defined ptype to software defined ptype mapping items.
Replace a specific or a group of software defined ptypes with a new one
Add a VF MAC address.
Add more MAC address for VF. The existing MAC addresses are still effective.
Update hardware defined pctype to software defined flow type mapping table.
Get software defined flow type to hardware defined pctype mapping items.
Reset hardware defined pctype to software defined flow type mapping table to default.
On the PF, find VF index based on VF MAC address
Do RSS queue region configuration for that port as the command option type
Get input set
Set input set
Get bit value for some field index
Definition at line 1006 of file rte_pmd_i40e.h.
Set bit value for some field index
Definition at line 1032 of file rte_pmd_i40e.h.
Clear bit value for some field index
Definition at line 1057 of file rte_pmd_i40e.h.
Get port fdir info
Get port fdir status
Set GRE key length
For ipn3ke, i40e works with FPGA. In this situation, i40e get link status from fpga, fpga works as switch_dev for i40e. This function set switch_dev for i40e.
|
https://doc.dpdk.org/api-20.11/rte__pmd__i40e_8h.html
|
CC-MAIN-2021-39
|
refinedweb
| 619 | 68.87 |
Ever wondered what computer algorithm gets employed when using Ctrl-F to search for specific words in a page of text?
A number of potential string searching techniques exist. One possible candidate implementation is Nigel Horspool’s Boyer-Moore-Horspol algorithm – an exceptionally fast technique for finding a ‘needle’ substring within a larger ‘haystack’ string.
Here is an example of it’s usage: you simply feed it the needle/haystack strings/lengths so that it returns a pointer to the first occurence of the ‘needle’ string, or null if it is not found. Use the difference between the
result and
haystack pointers to determine the numerical position of the needle substring within the haystack string.
Code listing below:
#include <stdio.h> #include <string.h> #include <limits.h> /* Returns a pointer to the first occurrence of "needle" * within "haystack", or NULL if not found. Works like * memmem(). */ /* Note: In this example needle is a Cstring. The ending * 0x00 will be cut off, so you could call this example with * boyermoore_horspool_memmem(haystack, hlen, "abc", sizeof("abc")) */ const unsigned char* boyermoore_horspool_memmem(const unsigned char* haystack, size_t hlen, const unsigned char* needle, size_t nlen) { size_t scan = 0; size_t bad_char_skip[UCHAR_MAX + 1]; /* Officially called: * bad character shift */ /* Sanity checks on the parameters */ if (nlen <= 0 || !haystack || !needle) return NULL; /* ---- Preprocess ---- */ /* Initialize the table to default value */ /* When a character is encountered that does not occur * in the needle, we can safely skip ahead for the whole * length of the needle. */ for (scan = 0; scan <= UCHAR_MAX; scan = scan + 1) bad_char_skip[scan] = nlen; /* C arrays have the first byte at [0], therefore: * [nlen - 1] is the last byte of the array. */ size_t last = nlen - 1; /* Then populate it with the analysis of the needle */ for (scan = 0; scan < last; scan = scan + 1) bad_char_skip[needle[scan]] = last - scan; /* ---- Do the matching ---- */ /* Search the haystack, while the needle can still be within it. */ while (hlen >= nlen) { /* scan from the end of the needle */ for (scan = last; haystack[scan] == needle[scan]; scan = scan - 1) { /* If the first byte matches, we've found it. */ if (scan == 0) { return haystack; } } /* otherwise, we need to skip some bytes and start again. Note that here we are getting the skip value based on the last byte of needle, no matter where we didn't match. So if needle is: "abcd" then we are skipping based on 'd' and that value will be 4, and for "abcdd" we again skip on 'd' but the value will be only 1. The alternative of pretending that the mismatched character was the last character is slower in the normal case (Eg. finding "abcd" in "...azcd..." gives 4 by using 'd' but only 4-2==2 using 'z'. */ hlen -= bad_char_skip[haystack[last]]; haystack += bad_char_skip[haystack[last]]; } return NULL; } int main() { unsigned char needle[] = "needle"; unsigned char haystack[] = "try to find needle in a haystack"; int needle_length = 6; int haystack_length = 34; const unsigned char* result = boyermoore_horspool_memmem( haystack, 50, needle, 6 ); int pos = result - haystack ; }
|
http://www.technical-recipes.com/2012/finding-substrings-within-strings-using-the-boyer-moore-horspol-algorithm-in-c/
|
CC-MAIN-2017-47
|
refinedweb
| 494 | 67.79 |
This blog post is effectively a log of my experience with the preview of the C# 8 nullable reference types feature.
There are lots of caveats here: it’s mostly “as I go along” so there may well be backtracking. I’m not advising the right thing to do, as I’m still investigating that myself. And of course the feature is still changing. Oh, and this blog post is inconsistent about its tense. Sometimes I write in the present tense as I go along, sometimes I wrote in the past tense afterwards without worrying about it. I hope this isn’t/wasn’t/won’t be too annoying.
I decided that the best way of exploring the feature would be to try to use it with Noda Time. In particular:
- Does it find any existing bugs?
- Do my existing attributes match what Roslyn expects?
- Does the feature get in the way, or improve my productivity?
Installation
I started at the preview page on GitHub. There are two really important points to note:
- Do this on a non-production machine. I used an old laptop, but presumably you can use a VM instead.
- Uninstall all versions of Visual Studio other than VS2017 first
I ended up getting my installation into a bad state, and had to reinstall VS2017 (and then the preview) before it would work again. Fortunately that takes a lot less time than it used to.
Check it works
The preview does not work with .NET Core projects or the command-line csc
It’s only for old-style MSBuild projects targeting the .NET framework, and only from Visual Studio.
So to test your installation:
- Create a new .NET Framework desktop console app
- Edit
Program.csto include:
string? x = null;
- Build
If you get an error CS0453 (“The type ‘string’ must be a non-nullable value type…”) then it’s not working. If it builds with maybe a warning about the variable not being used, you’re good to go.
First steps with Noda Time
The first thing I needed to do was convert Noda Time to a desktop project. This didn’t require the preview to be installed, so I was able to do it on my main machine.
I created a new solution with three desktop projects (NodaTime, NodaTime.Test and NodaTime.Testing), and added the dependencies between the projects and external ones. I then copied these project files over the regular Noda Time ones.
Handy tip: if you add
<Compile Include="**\*.cs" /> in an MSBuild file and open it in Visual Studio, VS will replace it with all the C# files it finds. No need for tedious “Add existing” all over the place.
A small amount of fiddling was required for signing and resources, and then I had a working copy of Noda Time targeting just .NET 4.5. All tests passed :)
For anyone wanting to follow my progress, the code is in a branch of my fork of Noda Time although I don’t know how long I’ll keep it for.
Building with the preview
After fetching that branch onto my older laptop, it built first time – with 228 warnings, most of which were “CS8600: Cannot convert null to non-nullable reference.” Hooray – this is exactly what we want. Bear in mind that this is before I’ve made any changes to the code.
The warnings were split between the three projects like this:
- NodaTime: 94
- NodaTime.Testing: 0
- NodaTime.Test: 134
Follow the annotations
Noda Time already uses
[CanBeNull] and
[NotNull] attributes for both parameters and return types to indicate expectations. The first obvious step is to visit each application of
[CanBeNull] and use a nullable reference type there.
To make it easier to see what’s going on, I first unloaded the NodaTime.Test project. This was so that I could concentrate on making NodaTime self-consistent to start with.
Just doing that actually raised the number of warnings from 94 to 110. Clearly I’m not as consistent as I’d like to be. I suspect I’ve got plenty of parameters which can actually be null but which I didn’t apply the annotation to. It’s time to start actually looking at the warnings.
Actually fix things
I did this in a completely haphazard fashion: fix one warning, go onto another.
I’ve noticed a pattern that was already feasible before, but has extra benefits in the nullable reference type world. Instead of this:
// Old code string id = SomeMethodThatCanReturnNull(); if (id == null) { throw new SomeException(); } // Use id knowing it's not null
… I can use the
?? operator with the C# 7 feature of
throw expressions:
// Old code string id = SomeMethodThatCanReturnNull() ?? throw new SomeException(); // Use id knowing it's not null
That avoids having a separate local variable of type
string?, which can be very handy.
I did find a few places where the compiler could do better at working out nullity. For example:
// This is fine string? x = SomeExpressionThatCanReturnNull(); if (x == null) { return; } string y = x; // This creates a warning: the compiler doesn't know that x // can't be null on the last line string? x = SomeExpressionThatCanReturnNull(); if (ReferenceEquals(x, null)) { return; } string y = x;
The preview doc talks about this in the context of
string.IsNullOrEmpty; the
ReferenceEquals version is a little more subtle as we can’t determine nullity just from the output – it’s only relevant if the other argument is a constant null. On the other hand, that’s such a fundamental method that I’m hopeful it’ll get fixed.
Fixing these warnings didn’t take very long, but it was definitely like playing Whackamole. You fix one warning, and that causes another. For example, you might make a return type nullable to make
a
return null; statement work – and that affects all the callers.
I found that rebuilding would sometimes find more warnings, too. At one point I thought I was done (for the time being) – after rebuilding, I had 26 warnings.
I ran into one very common problem: implementing
IEquatable<T> (for a concrete reference type
T). In every case, I ended up making it implement
IEquatable<T?>. I think that’s the right thing to do… (I didn’t do it consistently though, as I found out later on. And
IEqualityComparer<T> is trickier, as I’ll talk about later.)
Reload the test project
So, after about an hour of fixing warnings in the main project, what would happen when I reload the test project? We previously had 134 warnings in the test project. After reloading… I was down to 123.
Fixing the test project involved fixing a lot more of the production code, interestingly enough. And that led me to find a limitation not mentioned on the preview page:
public static NodaFormatInfo GetInstance(IFormatProvider? provider) { switch (provider) { case null: return ...; case CultureInfo cultureInfo: return ...; case DateTimeFormatInfo dateTimeFormatInfo; return ...; default: throw new ArgumentException($"Cannot use provider of type {provider.GetType()}"); } }
This causes a warning of a possible dereference in the
default case – despite the fact that
provider clearly can’t be null, as otherwise it would match the
null case. Will try to provide a full example in a bug report.
The more repetitive part is fixing all the tests that ensure a method throws an
ArgumentNullException if called with a null argument. As there’s no compile-time checking as well, the argument
needs to be
null!, meaning “I know it’s really null, but pretend it isn’t.” It makes me chuckle in terms of syntax, but it’s tedious to fix every occurrence.
IEqualityComparer<T>
I have discovered an interesting problem. It’s hard to implement
IEqualityComparer<T> properly. The signatures on the interface are pretty trivial:
public interface IEqualityComparer<in T> { bool Equals(T x, T y); int GetHashCode(T obj); }
But problems lurk beneath the surface. The documentation for the
Equals() method doesn’t state what should happen if
x or
y is null. I’ve typically treated this as valid, and just used the normal equality rules (two null references are equal to each other, but nothing else is equal to a null reference.) Compare that with
GetHashCode(), where it’s explicitly documented that the method should throw
ArgumentNullException if
obj is null.
Now think about a type I’d like to implement an equality comparer for –
Period for example. Should I write:
public class PeriodComparer : IEqualityComparer<Period?>
This allows
x and
y to be null – but also allows
obj to be null, causing an
ArgumentNullException, which this language feature is trying to eradicate as far as possible.
I could implement the non-nullable version instead:
public class PeriodComparer : IEqualityComparer<Period>
Now the compiler will check that you’re not passing a possibly-null value to
GetHashCode(), but will also check that for
Equals, despite it being okay.
This feels like it’s a natural but somewhat unwelcome result of the feature arriving so much later than the rest of the type system. I’ve chosen to implement the nullable form, but still throw the
exception in
GetHashCode(). I’m not sure that’s the right solution, but I’d be interested to hear what others think.
Found bugs in Noda Time!
One of the things I was interested in finding out with all of this was how consistent Noda Time is in terms of its nullity handling. Until you have a tool like this, it’s hard to tell. I’m very pleased to say that most of it hangs together nicely – although so far that’s only the result of getting down to no warnings, rather than a file-by-file check through the code, which I suspect I’ll want to do eventually.
I did find two bugs, however. Noda Time tries to handle the case where
TimeZoneInfo.Local returns a null reference, because we’ve seen that happen in the wild. (Hopefully that’s been fixed now in Mono, but even so it’s nice to know we can cope.) It turns out that we have code to cope with it in one place, but there are two places where we don’t… and the C# 8 tooling found that. Yay!
Found a bug in the preview!
To be clear, I didn’t expect the preview code to be perfect. As noted earlier, there are a few places I think it can be smarter. But I found a nasty bug that would hang Visual Studio and cause
csc.exe to fail when building. It turns out that if you have a type parameter
T with a constraint of
T : class, IEquatable<T?>, that causes a stack overflow. I’ve reported the bug (now filed on GitHub thanks to diligent Microsoft folks) so hopefully it’ll be fixed long before the final version.
Admittedly the constraint is interesting in itself – it’s not necessarily clear what it means, if
T is already a nullable reference type. I’ll let smarter people than myself work that out.
Conclusion
Well, that was a jolly exercise. My first impressions are:
- We really need class library authors to embrace this as soon as C# 8 comes out, in order to make it as useful as possible early. Noda Time has no further dependencies, fortunately.
- It didn’t take as long as I feared it might to do a first pass at annotating Noda Time, although I’m sure I missed some things while doing it.
- A few bugs aside, the tooling is generally in very good shape; the warnings it produced were relevant and easy to understand.
- It’s going to take me a while to get used to things like
IList<string?>?for a nullable list of nullable strings.
Overall I’m very excited by all of this – I’m really looking forward to the final release. I suspect more blog posts will come over time…
44
|
https://codeblog.jonskeet.uk/2018/04/21/first-steps-with-nullable-reference-types/?like_comment=31178&_wpnonce=f73a39822c
|
CC-MAIN-2022-40
|
refinedweb
| 1,984 | 64.71 |
ASP.NET MVC Routing: Play Traffic Cop with Your Routes
As an ASP.NET MVC request is received, the routing sends the request to the proper controller. Today, we talk about how to use routing, some tips on using them effectively, and how to debug them easily.
Routing in ASP.NET MVC is one of the basic steps in the MVC Application Processing Pipeline. Since most developers don't see a need to adjust their routing, they leave it alone and carry on with their application.
But what happens when you need to make some adjustments to your MVC page structure? As Google has mentioned, you want to make sure you have SEO-friendly URLs. This means you may need to fix up your site so that Google, Bing, and/or Yahoo! can find your breadcrumb trail through your URL site structure.
NOTE: Download and Review the Lifecycle of an ASP.NET MVC 5 Application to understand what happens when routing occurs (PDF).
Routing Basics
I know I mentioned that I consider UrlHelpers as a table of contents for your application, but routing is also a way to find out how the application is structured. If you are just getting into an ASP.NET MVC application for the first time with a client, I would definitely recommend that you ask them where the UrlHelpers and Routing are located in the application.
If you get a blank stare or they say they just use ActionLinks throughout their application, I would start to worry.
Ok, now I'm referring to that lifecycle document you should've downloaded from above.
When a web request first comes in to your application, it reads the Global.asax.cs class to setup the routes for your application, then heads to the App_Start\RouteConfig.cs file, and registers the routes defined in the static class. It only happens once.
If you don't have a need to modify your routes, you can leave them alone.
Here is the default route with an explanation below:
Default Route
routes.MapRoute( name: "Default", url: "{controller}/{action}/{id}", defaults: new { controller = "Home", action = "Index", id = UrlParameter.Optional } );
The MapRoute method defines the following:
- Name - The Name of the Route (call it anything you want...within reason for fear of your fellow developers yelling at you) ;-)
- URL - The format of your URL
- Defaults - Sets the default controller, action, and id if nothing was passed in. If just a the controller was passed in, the default action would be Index on that controller name.
- Namespaces (optional) - If you are using areas or more than one namespace, you would add the namespace as a fourth parameter like this:
namespaces: new string[] { "DanylkoWeb.Controllers"}
- Constraints (optional) - You can define only certain criteria to come through your routes using constraints. As an example, you could write your own constraint to allow only Chrome users (check the user-agent) when they come to your site and send other browser users away (Yeaahhh...that would be bad).
Once the {controller}, {action}, and {id} are identified, those values are matched to the signature of the controller, action, and other parameters.
Notice I didn't say 'id'? Id can be optional. Heck, it can even be a different parameter signature in the controller.
So if we had the following URL:
The route would breakdown the URL into the following route values:
- 'Blog' is the controller name
- 'Detail' is the name of the method in the controller
- '15' would be the id passed into the method name, Detail.
The general rule is that the route defaults MUST match the action's parameters exactly. It is case sensitive.
"But I want easy-to-read URLs!"
Let's look at a harder example. How about DanylkoWeb, to be more specific?
Notice the URL at the top:
But how do you know which action it goes to? It sure doesn't go to the "aspnet-mvc-routing-play-traffic-cop-with-your-routes-90" method, does it?
No, it doesn't. Here the trick and the route to pull it off:
routes.MapRoute( name: "BlogDetail", url: "Blog/{title}-{id}", defaults: new { controller = "Blog", action = "Detail", title = String.Empty, id = UrlParameter.Optional }, namespaces: new string[] { "DanylkoWeb.Controllers" } );
Let's take it step by step.
Everything looks the same regarding the controller name (Blog), but we have a different parameter type in the URL. Remember when I said you can have different parameters in your URL? This is what I'm talking about when I mentioned it above.
The key here is the last dashed word in the URL. The ID is the last number after the last dash, which is 90. That "id" is passed into the detail method in your Blog controller:
public ActionResult Detail(string id) { // LoadById(id) - load post id 90 .
. }
If you want to include the title in the method signature along with the id, just add "string title," in the method and act on it.
Using Large URLs
One project I worked on in the past was a link directory structure. It was a recursive database table with a lot of locations. A sample URL looked like this:
So how would you break this down to a route?
You would create a route like this:
routes.MapRoute( "LinkData", // Route name "LinkDirectory/{*data}", // URL with parameters new { controller = "LinkDirectory", action = "Category" } );
Ok, see the *data?
The asterisk is a catch-all parameter. It will match and pass /NorthAmerica/UnitedStates/Ohio/Columbus to the LinkDirectory.Category method. As before, make sure the category action method has a parameter (data) that matches the MapRoute parameter name (data).
The method would look like this:
public ActionResult Category(string data, int? page) { // data = "/NorthAmerica/UnitedStates/Ohio/Columbus" }
At this point, you can now parse the URL and load the data.
Debugging Routes
If you have a large application that contains many routes, it may be difficult to track down each and every route coming in to your application. It can be quite maddening!
Here are a few tips to make debugging your routes easier so you don't lose your sanity. ;-)
- If you have a large number of routes registered in your RouteConfig.cs, you may want to take a step back and make a REAL table of contents for your application. How should your site be structured?
// /Blog // /Blog/title-name-A9 // /About/ // /Contact/ // /FAQ/ // . // . // .At first glance, I see only two routes for these URLs...and they were covered in this post: The one route named "Default" and the other one named "BlogDetail."
I have seen others create Routes for each and every request coming in. This table-of-contents method provides an at-a-glance look at how your application is structured and shows you all available URLs for your site. If you don't have any goofy URL structures, I would keep to the Default route.
- While I've never hit the maximum number of routes, I've heard that the more routes you add to your application, the slower it will perform. Try to keep your routes to a minimum and make sure you know that every route is being used.
- Another tip has to do with adding more band-aids on top of more band-aids. As I mentioned in Getting Started With CSS, instead of adding more routes configs on top of each other to figure out the issue, strip every route out (or comment them out) to the very essentials (maybe one "Default" route) and start adding one route at a time to determine your culprit.
- Route Debugging Tools
- Glimpse - One great tool made especially for ASP.NET MVC applications. It has a lot of data to help you diagnose and test sections of your code (just don't put it on your production box, ok?)
- MVC Route Visualizer - Exactly what it says: it displays a route based on a URL you enter.
- Route Debugger Tool (NuGet) - Since Phil Haack created this a while back, someone packaged it up on NuGet making it easier to install and use.
Conclusion
ASP.NET MVC Routing becomes extremely important when you expect a URL to go to a certain controller and it diverts the request to another page altogether.
If you understand the basics and keep your routes simple, you may still be able to keep your sanity (for now) ;-)
References:
Do you have any other Route Debugging tips? Post them below!
|
https://www.danylkoweb.com/Blog/aspnet-mvc-routing-play-traffic-cop-with-your-routes-90
|
CC-MAIN-2021-49
|
refinedweb
| 1,402 | 73.47 |
This article is part of a series of blog posts. We recommend that you start at the beginning. Alternatively, scroll to the bottom of this article to navigate through the whole series.
This article is meant to provide a summary of some key functionality for dlmalloc-2.8.x and introduce a debugging plugin called libdlmalloc [1] that is designed to aid analysis of dlmalloc-2.8.x heap structures and associated chunks. Analysis and development was primarily done using dlmalloc-2.8.3, as that was the version found on the specific Cisco ASA systems under which analysis was carried out.
Introduction
The Doug Lea allocator, better known as dlmalloc [2], is a fairly popular and well-researched heap. dlmalloc-2.7.x is the original heap from which ptmalloc2 [3] was forked, which is likely the most well-known version. ptmalloc2 (or most precisely, a modification of it) is widely used nowadays as it is what served as a base for the GNU Libc heap. dlmalloc-2.8.x used to be the default heap provided in libbionic [4] (Android’s libc), before switching to jemalloc. Various versions of dlmalloc are found in many embedded devices. You can find a list of historical dlmalloc versions on the official server [5]. dlmalloc-2.8.x also used to be the default heap allocator on Cisco ASA firewalls, before switching to the glibc one based on ptmalloc2.
To obtain a copy of dlmalloc-2.8.x for reference, see the listing [5]. To follow along exactly with what we describe, you can grab malloc-2.8.3.[ch] from [5], which is the version we specifically analysed. To see the changelog of the history of dlmalloc, and especially the changes introduced in the 2.8.x branch, see the History: in the latest dlmalloc release [6].
The Doug Lea allocator
In this section we go into some of the more interesting details about dlmalloc-2.8.x, as well as the history of dlmalloc versions and their relationship to ptmalloc. If you are already familiar with dlmalloc-2.8.x feel free to skip on to the libdlmalloc tool section.
dlmalloc vs ptmalloc vs glibc
The ptmalloc allocator, which is part of glibc, was regularly forked from dlmalloc. In the case of ptmalloc2, glibc makes its own modifications to the allocator in its own fork. We did not investigate if this was also the case for ptmalloc, but it presumably was. A quick note about the table below, for those that may be unfamiliar: a bin is a linked list used to track free chunks. The following table demonstrates the relationship of versions:
Often when people refer to dlmalloc they don’t explicitly mention the version. However, these versions can make a notable difference from a functionality and exploitation perspective. For example, dlmalloc 2.6.x lacks fastbins, 2.7.x adds fastbins, 2.8.x drops fasftbins again and introduces a tree-based structure for tracking large free chunks. Fastbins, for instance, are the source of some exploit techniques described by Phantasmal Phantasmagoria [7] and others, which means they don’t directly apply to any dlmalloc version outside of 2.7.x.
With that noted, it’s important to reiterate that in this article we are explicitly talking about dlmalloc-2.8.x and not ptmalloc2 (forked from dlmalloc-2.7.x). Nor are we talking about ptmalloc3 (forked from dlmalloc-2.8.x). Although they share many similarities, we did not analyse ptmalloc3. The tool will be unable to accurately analyse a ptmalloc3 heap without additional functionality being added.
These are critical distinctions because often when people casually refer to dlmalloc, they are referring to ptmalloc2 or sometimes even glibc’s custom modified version of ptmalloc2. Or they are talking about some other specific branch of dlmalloc without the per-thread enhancements, but the version of which they don’t specify. Although these heaps all share the same roots, when you’re doing heap exploitation, the minor differences often become of major significance and thus we feel it is important to highlight. As with the article, the libdlmalloc tool we discuss in this document is specifically designed to analyse dlmalloc-2.8.x.
Historical analysis of dlmalloc-2.8.x / ptmalloc3
Over the past couple of decades there have been quite a few fantastic heap articles that focus on some older versions of dlmalloc (2.7.x or earlier), ptmalloc, or the glibc allocator specifically. However, very few of the well known heap articles focus on dlmalloc-2.8.x or ptmalloc3 specifically. The following is an (incomplete) look at some papers or exploits that discuss dlmalloc-2.8.x or ptmalloc3 directly in some capacity.
blackngel’s Phrack 66 paper MALLOC DES-MALEFICARUM [8] briefly notes that the HOUSE OF SPIRIT can work on ptmalloc3.
blackngel’s Phrack 67 paper The House Of Lore: Reloaded [9] specifically talks about the details of ptmalloc3 and compares it to ptmalloc2. It discusses porting the House of Lore technique directly to ptmalloc3, with a wargames-style example. This appears to be the most comprehensive analysis of ptmalloc3 (and thus dlmalloc-2.8.x) from an exploitation perspective.
Ian Beer’s summary of Pinkie Pie’s Pwn2Own 2013 exploit [10] specifically mentions dlmalloc on Android, which was presumably dlmalloc 2.8.5 or 2.8.6 (versions [11] used by libbionic prior to the jemalloc move). The paper describes his (Pinkie’s) approach to target dlmalloc, as well as an overview of dlmalloc-2.8.x.
Exodus Intelligence’s CVE-2016-1287 exploit paper [12] targeted dlmalloc-2.8.x, although didn’t go into much detail about any nuances of 2.8.x itself.
That appears to be most of the good references. Other passing references to Android’s dlmalloc are made in numerous papers, but little to no actual implementation details about the algorithm are provided.
Note that it’s entirely possible we’re missing some important references, so if you are aware of any we would appreciate hearing about them and will update this section as necessary.
High level differences between dlmalloc-2.8.x & dlmalloc-2.7.x
Although The House Of Lore: Reloaded touched on a bunch of the changes between ptmalloc2 and ptmalloc3, and is well worth reading, we have decided to (re)summarise some of the notable differences between the dlmalloc 2.7.x and 2.8.x changes in more detail.
We don’t go into exhaustive detail about all the differences in this article, but we do touch on some areas of specific interest with regards to what we were looking at. For now, the best place to find additional details about anything you’re interested in is the dlmalloc source code as most things are described in the source code comments.
mstates & arenas
In dlmalloc 2.7.x (and thus ptmalloc2) there is the concept of an arena, which is effectively a structure used to manage the range of memory used to service non-mmapped-based allocations. In dlmalloc 2.7.x, terminology leans towards the
mstate or
malloc_state and isn’t typedef’ed to an arena-related structure. Instead a single global
malloc_state called
_av is used and looked up using the
get_malloc_state() macro. Of note is that the
malloc_state structure tracks a single region of memory that can be extended and this region of memory is used to service the allocations. The dlmalloc-2.7.x comments refer to the memory managed by an
mstate as an arena, and sometimes the well-known ‘main arena’.
In ptmalloc2 this becomes somewhat more complicated in that it allows threads to have their own associated arenas for servicing allocations, which can help reduce lock contention on the heap. In these scenarios the default arena for use is called the
main_arena. ptmalloc2 uses the arena terminology much more, which a lot of past exploit-related research uses.
In dlmalloc-2.8.x the terminology arena seems to be minimised even more and things are now talked about using the concept of
mstates and
mspaces. In relation to
mstates the concept of a memory segment was introduced. Instead of an
mstate only being able to track a single region of memory, it now tracks a list of
malloc_segment structures (aka
msegment), each of which can be allocated independently from different regions of memory.
Although this isn’t particularly important to a lot of exploit scenarios, it’s important to have the correct mental model and the tool we release specifically shows some information about the segments.
smallbin (2.8.x) vs fastbin (2.7.x)
The smallbins in dlmalloc-2.8.x are used to track free chunks in doubly linked list and are most similar to what you’d traditionally imagine when thinking of largebins in something like a ptmalloc2/dlmalloc 2.7.x.
The chunk structure for small chunks looks like this:
struct malloc_chunk {
size_t prev_foot; /* Size of previous chunk (if free). */
size_t head; /* Size and inuse bits. */
struct malloc_chunk* fd; /* double links -- used only if free. */
struct malloc_chunk* bk;
};
The use of only smallbins and treebins in dlmalloc-2.8.x differs significantly from dlmalloc-2.7.x, as the latter used singly linked lists called fastbins to manage especially small chunks, smallbins to track small chunks, and largebins to track bigger chunks below the
mmap threshold.
treebin (2.8.x) vs largebin (2.7.x)
Unlike its predecessors, dlmalloc-2.8.x moves away from a purely doubly linked list for tracking large chunks and moves towards a tree structure, a bitwise trie [17]. The head of each such tree is tracked in what is referred to as a treebin. This leads to significantly more metadata stored for large free chunks and in some situations can complicate corruption scenarios as there is more logic to work around. Conversely, more code paths can lead to additional paths of logic that can also aid in exploitation.
These large chunks are now referred to as
malloc_tree_chunk structures and look like the following:;
};
As mentioned above, these additional fields can both complicate and aid in some exploitation scenarios. In the more traditional approach of abusing a coalescing scenario to achieve a mirror write (a controlled overwrite that occurs when a double linked list entry is unlinked), you can imagine that if you corrupted the
fd and
bk pointers you’d have to be careful what values you place into the additional entries.
Generally the easiest way to simplify exploitation in this scenario is to set
parent to
NULL, as this will prevent the additional fields from being parsed.
For example, when unlinking a large chunk, the
unlink_large_chunk() macro is called. It is);
}
}
else {
[...]
}
This will unlink the chunk from the double linked list, if the list is not empty. Afterwards, which we show below, it checks to see if the parent (
XP) is
NULL. If it is not
NULL you can see it does a bunch of additional actions, including manipulating the child nodes. However, if
parent is
NULL this whole portion of the unlink logic is skipped. In the event you are just wanting to leverage this logic for a traditional mirror write, then ensuring the parent is
NULL will mean you’re safe.
if (XP != 0) {
tbinptr* H = treebin_at(M, X->index);
if (X == *H) {
if ((*H = R) == 0)
clear_treemap(M, X->index);
}
else if (RTCHECK(ok_address(M, XP))) {
if (XP->child[0] == X)
XP->child[0] = R;
else
XP->child[1] = R;
}
else
CORRUPTION_ERROR_ACTION(M);
if (R != 0) {
if (RTCHECK(ok_address(M, R))) {
tchunkptr C0, C1;
R->parent = XP;
if ((C0 = X->child[0]) != 0) {
if (RTCHECK(ok_address(M, C0))) {
R->child[0] = C0;
C0->parent = R;
}
else
CORRUPTION_ERROR_ACTION(M);
}
if ((C1 = X->child[1]) != 0) {
if (RTCHECK(ok_address(M, C1))) {
R->child[1] = C1;
C1->parent = R;
}
else
CORRUPTION_ERROR_ACTION(M);
}
}
else
CORRUPTION_ERROR_ACTION(M);
}
}
}
This is something we do in our CVE-2016-1287 IKEv1 exploit that we will detail in a future blog post.
mspaces
dlmalloc-2.8.x introduced the concept of an
mspace, which is enabled when using the
MSPACES constant. This seems, at least in part, to try to provide something analogous to per-thread arenas, but also serves other purposes. Ostensibly, an
mspace is just an opaque structure that refers to a heap. Most generally, an
mspace structure is simply cast directly to an
mstate, which is then used to manage that heap. The point of using the
MSPACES constant is to facilitate the creation and management of multiple discrete heaps, rather than using the more traditional single global
mstate structure (called
_gm_) to track a single heap.
A few compile-time constants are introduced that are of interest related to
mspaces. First, the
MSPACES and
ONLY_MSPACES constants. By defining
MSPACES you enable the use of allocate wrappers called
mspace_xxx(), such as
mspace_malloc(),
mspace_free(), etc. The point of this is to allow a developer to create a dedicated space, by using
create_mspace(), which can then be passed to these functions. The
ONLY_MSPACES constant is significant because if you don’t define
ONLY_MSPACES then dlmalloc library will provide both the
malloc,
free,
calloc, and
realloc functions that will become your default allocator and the
mspace_xxx functions that can be used for dedicated heaps. In some cases, developers would only want the
mspace versions and
ONLY_MSPACES allows that. This is noteworthy because you might run into dlmalloc-2.8.x on a system and it won’t be the default allocator, but only used for some specific functionality with a dedicated
mspace.
When you call
create_mspace(), the allocator maps a memory segment of the requested size capacity and inserts an
mstate into it as the first chunk.
MSPACES brings with it some important functionality related to another constant called
FOOTERS, which we’ll look at shortly.
2.8.x security mechanisms
dlmalloc-2.8.x has a dedicated section in its comments about security. The main points it raises are the
FOOTERS,
PROCEED_ON_ERROR, and
INSECURE constants. We would like to include the
DEBUG and
USE_DEV_RANDOM constants here, as they can provide some significant security enhancements.
INSECURE
In general, setting the
INSECURE constant will disable almost all of the validation that the heap does. This includes disabling sanity checks of chunk header flags, and disabling sanity checks on addresses, found in chunks, that normally ensure the addresses fall within expected memory ranges associated with the heap. The constant also dictates whether or not any error conditions that are encountered will abort execution.
PROCEED_ON_ERROR
This constant simply dictates the assignment for the
CORRUPTION_ERROR_ACTION and
USAGE_ERROR_ACTION macros, which control what happens when an error is encountered. If
PROCEED_ON_ERROR is set, a detected corrupted state will simply reset the state of the heap and reinitialise the entire
mstate rather than failing. It also unsets
USAGE_ERROR_ACTION so nothing occurs on error.
The default behavior when
PROCEED_ON_ERROR is unset is to abort the program when errors are encountered.
FOOTERS, MSPACES & magic
One interesting security mechanism of dlmalloc-2.8.x is the features that come from the use of combination of the
MSPACES and
FOOTERS constants and how they relate to the use of
malloc_param (aka
mparam)
magic member.
The FOOTERS constant tells dlmalloc to, when creating an in-use chunk, store a
size_t value into the adjacent chunk header. This differs from other heap behavior that will often re-use the first member of the adjacent header as spillover area to save space and simplify alignment. The dlmalloc comment describes the
FOOTERS constant as follows:
If FOOTERS is defined nonzero, then each allocated chunk
carries an additional check word to verify that it was malloced
from its space. These check words are the same within each
execution of a program using malloc, but differ across
executions, so externally crafted fake chunks cannot be
freed. This improves security by rejecting frees/reallocs that
could corrupt heap memory, in addition to the checks preventing
writes to statics that are always on. This may further improve
security at the expense of time and space overhead. (Note that
FOOTERS may also be worth using with MSPACES.)
In dlmalloc-2.8.x the first member of a
malloc_chunk header is not called
prev_size anymore but instead called
prev_foot. The name foot is used because, when
FOOTERS is specified, it is a dedicated field used to hold a specially calculated value to identify the associated heap space. Alternatively, when a chunk is free, the chunk adjacent to it will have a
prev_foot value holding the size of the previous chunk, more like what you would expect from dlmalloc-2.7.x and ptmalloc2. Note that this dedicated footer field differs from other configurations where the analogous field can serve as spillover data for a previous in-use chunk.
The value stored in the footer for an allocated chunk, as described in the quoted paragraph above, is used to verify that the chunk is correctly associated with a specific space. This space can either be the default global
mstate referenced by
_gm_ or if
MSPACES is used, then whatever
mspace the chunk is associated with.
Note that the quoted text says the footer value is the same for any given space in any given execution, but differs across multiple executions. This is as you’d expect for any sort of global cookie value. Let’s look at how the footer value is calculated. The macro is
mark_inuse_foot():
/* Set foot of inuse chunk to be xor of mstate and seed */
#define mark_inuse_foot(M,p,s)
(((mchunkptr)((char*)(p) + (s)))->prev_foot = ((size_t)(M) ^ mparams.magic))
The parameter
M will point to the
mstate associated with this chunk,
p points to the in-use chunk whose foot is being marked and
s is the size of the in-use chunk. This effectively results in the
prev_foot of the adjacent chunks header being set to the address of
M XORed against
mparams.magic.
The effectiveness of this as a security mechanism thus relies on the inability to predict whatever
M and
mparams.magic are used.
M is largely dependent on both ASLR and if you can predict what
mstate is being used. We will touch on the implications of a predictable
M later.
For now, let’s understand what this
mparams.magic value is. The
magic value here is calculated and stored both in the
malloc_params (aka
mparams) structure and the
malloc_state (aka
mstate) structure. We can see the initialisation of this value in
ensure_initialization().
/* Ensure mparams initialized */
#define ensure_initialization()
(void)(mparams.magic != 0 || init_mparams())
The
init_param() function initialises this
magic member when the heap is first being initialised and sets it to one of two values. If
USE_DEV_RANDOM is set it will read
sizeof(size_t) bytes from
/dev/urandom. Otherwise it uses
time(0).
#if USE_DEV_RANDOM
int fd;
unsigned char buf[sizeof(size_t)];
/* Try to use /dev/urandom, else fall back on using time */
if ((fd = open("/dev/urandom", O_RDONLY)) >= 0 &&
read(fd, buf, sizeof(buf)) == sizeof(buf)) {
s = *((size_t *) buf);
close(fd);
}
else
#endif /* USE_DEV_RANDOM */
s = (size_t)(time(0) ^ (size_t)0x55555555U);
s |= (size_t)8U; /* ensure nonzero */
s &= ~(size_t)7U; /* improve chances of fault for bad values */
}
Obviously
USE_DEV_RANDOM is much better, especially if you have any problems with your time functions (more on that later). The next question is where and when is this
prev_foot validated at runtime. The macro to decode the expected
mstate address is
get_mstate_for():
#define get_mstate_for(p)
((mstate)(((mchunkptr)((char*)(p) +
(chunksize(p))))->prev_foot ^ mparams.magic))
We can see this in use during calls to
dlfree():
#if FOOTERS
mstate fm = get_mstate_for(p);
if (!ok_magic(fm)) {
USAGE_ERROR_ACTION(fm, p);
return;
}
#else /* FOOTERS */
#define fm gm
#endif /* FOOTERS */
and
mspace_free():
#if FOOTERS
mstate fm = get_mstate_for(p);
#else
mstate fm = (mstate)msp;
#endif
if (!ok_magic(fm)) {
USAGE_ERROR_ACTION(fm, p);
return;
}
It’s also checked in the
dlrealloc() and
mspace_realloc() functions.
First this is fetching what it believes to be an
mstate address from a chunk address. In the process it is validating with
ok_magic() that the
magic member of that
mstate matches the global
mparams.magic value that is set. So, in the event that the
prev_foot value is incorrect, the
magic value won’t match.
Whether or not an abort occurs is based on the compile-time constant called
PROCEED_ON_ERROR that we touched on earlier.
#if (FOOTERS && !INSECURE)
/* Check if (alleged) mstate m has expected
magicfield */
#define ok_magic(M) ((M)->magic == mparams.magic)
#else
#define ok_magic(M) (1)
#endif
Safe unlinking
dlmalloc-2.8.5 introduced safe unlinking, something glibc’s ptmalloc2, forked from dlmalloc-2.7.x, has had for some time. This safe unlinking is done for both small chunks and tree chunks.
The
unlink_small_chunk() from
malloc-2.8.4.c and below (F == B)
clear_smallmap(M, I);
else if (RTCHECK((F == smallbin_at(M,I) || ok_address(M, F)) &&
(B == smallbin_at(M,I) || ok_address(M, B)))) {
F->bk = B;
B->fd = F;
}
else {
CORRUPTION_ERROR_ACTION(M);
}
}
Whereas, for
malloc-2.8.5.c, they introduced additional checks
F->bk == P and
B->fd == (RTCHECK(F == smallbin_at(M,I) || (ok_address(M, F) && F->bk == P))) {
if (B == F) {
clear_smallmap(M, I);
}
else if (RTCHECK(B == smallbin_at(M,I) ||
(ok_address(M, B) && B->fd == P))) {
F->bk = B;
B->fd = F;
}
else {
CORRUPTION_ERROR_ACTION(M);
}
}
else {
CORRUPTION_ERROR_ACTION(M);
}
}
Note
RTCHECK() causing an exception immediately is reliant on
INSECURE being unset and a specific version of GNUC. Otherwise it will be based on
CORRUPTION_ERROR_ACTION behavior, which we described earlier.
/* In gcc, use __builtin_expect to minimize impact of checks */
#if !INSECURE
#if defined(__GNUC__) && __GNUC__ >= 3
#define RTCHECK(e) __builtin_expect(e, 1)
...
Similarly,
malloc-2.8.4.c has an
unlink_large_chunk());
}
}
And
malloc-2.8.5.c introduced the more secure version:
#define unlink_large_chunk(M, X) {
tchunkptr XP = X->parent;
tchunkptr R;
if (X->bk != X) {
tchunkptr F = X->fd;
R = X->bk;
if (RTCHECK(ok_address(M, F) && F->bk == X && R->fd == X)) {
F->bk = R;
R->fd = F;
}
else {
CORRUPTION_ERROR_ACTION(M);
}
...
It’s useful to know your version in case you run into a system using an older version.
DEBUG constant
Although it’s not explicitly marked as a security feature, the
DEBUG constant will more aggressively validate handled chunks and therefore does result in more security. This is in part because, in
DEBUG mode,
assert()'s will abort the program, preventing further exploitation if triggered. It’s also because of the introduction of additional functions called at runtime like
check_inuse_chunk():
#if ! DEBUG
#define check_free_chunk(M,P)
#define check_inuse_chunk(M,P)
#define check_malloced_chunk(M,P,N)
#define check_mmapped_chunk(M,P)
#define check_malloc_state(M)
#define check_top_chunk(M,P)
#else
#define check_free_chunk(M,P) do_check_free_chunk(M,P)
#define check_inuse_chunk(M,P) do_check_inuse_chunk(M,P)
#define check_top_chunk(M,P) do_check_top_chunk(M,P)
#define check_malloced_chunk(M,P,N) do_check_malloced_chunk(M,P,N)
#define check_mmapped_chunk(M,P) do_check_mmapped_chunk(M,P)
#define check_malloc_state(M) do_check_malloc_state(M)
By default most allocation routines functions don’t do a lot of validation, but these
DEBUG-specific functions actually do. That said, even though there are a lot defined above, most of them aren’t called during the normal code allocation and free code paths. One that is called is
check_inuse_chunk(), which we can take a closer look at.
/* Check properties of inuse chunks */
static void do_check_inuse_chunk(mstate m, mchunkptr p) {
do_check_any_chunk(m, p);
assert(cinuse(p));
assert(next_pinuse(p));
/* If not pinuse and not mmapped, previous chunk has OK offset */
assert(is_mmapped(p) || pinuse(p) || next_chunk(prev_chunk(p)) == p);
if (is_mmapped(p))
do_check_mmapped_chunk(m, p);
}
We can see that it does some pretty obvious checks. If the current chunk is in use it should have the
CINUSE flag set and the adjacent forward chunk should have the
PINUSE flag set. If the chunk isn’t mmapped and the previous chunk is free, it can work out the previous chunk’s starting location using the size stored in
prev_foot. So it validates that the size of the previous chunk points to the in-use chunk as you’d expect.
In addition to these we see the first call is
do_check_any_chunk(), so let’s take a look at what this does as well.
/* Check properties of any chunk, whether free, inuse, mmapped etc */
static void do_check_any_chunk(mstate m, mchunkptr p) {
assert((is_aligned(chunk2mem(p))) || (p->head == FENCEPOST_HEAD));
assert(ok_address(m, p));
}
This is quite straightforward. It ensures that the chunk is aligned on an expected boundary or that the chunk is a special
FENCEPOST value. It calls a macro
ok_address(). This is defined as follows:
#if !INSECURE
/* Check if address a is at least as high as any from MORECORE or MMAP */
#define ok_address(M, a) ((char*)(a) >= (M)->least_addr)
This check is interesting as it could, for example, prevent a bug where you can free an arbitrary address and try to free a fake chunk located on the stack. This would only be prevented by assuming the stack address was lower than the segment(s) of memory the
mstate is managing.
All in all, these
do_check_inuse_chunk() checks are pretty easy to overcome. Where is
check_inuse_chunk() actually called? Mostly in debug functions that aren’t directly called. But most notably it is called by
dlfree() and
mspace_free() before freeing a chunk:
void mspace_free(mspace msp, void* mem) {
if (mem != 0) {
mchunkptr p = mem2chunk(mem);
#if FOOTERS
mstate fm = get_mstate_for(p);
#else /* FOOTERS */
mstate fm = (mstate)msp;
#endif /* FOOTERS */
if (!ok_magic(fm)) {
USAGE_ERROR_ACTION(fm, p);
return;
}
if (!PREACTION(fm)) {
check_inuse_chunk(fm, p);
It is also checked in
internal_realloc(), which is called by
dlrealloc() and
mspace_realloc(), and a few other places like inside
do_check_malloced_chunk(). This latter function is called quite a bit throughout the allocation routines and means there are even more checks happening regularly. You can see below that it does a few additional checks to validate the size of the chunk in use.
/* Check properties of malloced chunks at the point they are malloced */
static void do_check_malloced_chunk(mstate m, void* mem, size_t s) {
if (mem != 0) {
mchunkptr p = mem2chunk(mem);
size_t sz = p->head & ~(PINUSE_BIT|CINUSE_BIT);
do_check_inuse_chunk(m, p);
assert((sz & CHUNK_ALIGN_MASK) == 0);
assert(sz >= MIN_CHUNK_SIZE);
assert(sz >= s);
/* unless mmapped, size is less than MIN_CHUNK_SIZE more than request */
assert(is_mmapped(p) || sz < (s + MIN_CHUNK_SIZE));
}
}
We mentioned earlier that safe unlinking isn’t on by default <= 2.8.4, so it is interesting to note that
check_free_chunk() function does do a linkage check itself.
/* Check properties of free chunks */
static void do_check_free_chunk(mstate m, mchunkptr p) {
size_t sz = p->head & ~(PINUSE_BIT|CINUSE_BIT);
mchunkptr next = chunk_plus_offset(p, sz);
do_check_any_chunk(m, p);
assert(!cinuse(p));
assert(!next_pinuse(p));
assert (!is_mmapped(p));
if (p != m->dv && p != m->top) {
if (sz >= MIN_CHUNK_SIZE) {
assert((sz & CHUNK_ALIGN_MASK) == 0);
assert(is_aligned(chunk2mem(p)));
assert(next->prev_foot == sz);
assert(pinuse(p));
assert (next == m->top || cinuse(next));
assert(p->fd->bk == p);
assert(p->bk->fd == p);
}
else /* markers are always of size SIZE_T_SIZE */
assert(sz == SIZE_T_SIZE);
}
}
However, unlike the other
DEBUG functions, it turns out
check_free_chunk() is rarely ever called. The only normal code path it is called along is a specific conditional case in
prepend_alloc(), which in turn is only called by very specific cases via
sys_alloc(). Therefore, for typical corruption situations it would never actually touch a corrupted free chunk where you had modified the linkage.
The take away from all of this is that with
DEBUG builds you’ll have to be more careful when modifying heap chunk headers, but you can often still abuse unlinking during coalescing and other common exploit tricks despite the extra checks.
There is an interesting case with
DEBUG builds where some aggressive checking functions, like
traverse_and_check(), are defined and also do these additional
DEBUG-based checks.
/* Traverse each chunk and check it; return total */
static size_t traverse_and_check(mstate m) {
size_t sum = 0;
if (is_initialized(m)) {
msegmentptr s = &m->seg;
sum += m->topsize + TOP_FOOT_SIZE;
while (s != 0) {
mchunkptr q = align_as_chunk(s->base);
mchunkptr lastq = 0;
assert(pinuse(q));
while (segment_holds(s, q) &&
q != m->top && q->head != FENCEPOST_HEAD) {
sum += chunksize(q);
if (cinuse(q)) {
assert(!bin_find(m, q));
do_check_inuse_chunk(m, q);
}
else {
assert(q == m->dv || bin_find(m, q));
assert(lastq == 0 || cinuse(lastq)); /* Not 2 consecutive free */
do_check_free_chunk(m, q);
}
lastq = q;
q = next_chunk(q);
}
s = s->next;
}
}
return sum;
}
These functions are not used by any default heap functions but can be used by some specific modifications of dlmalloc, and is the case for Cisco ASA Checkheaps implementation. We will detail this in a future blog post dedicated to Checkheaps.
libdlmalloc
Before looking at how dlmalloc was built on Cisco ASA devices, it is useful to introduce a new tool that can help with some of the analysis with such things.
libdlmalloc [1] was originally developed to aid in observing the success or failure of heap feng shui attempts and exploit states, but it should provide general purpose value to both developers and exploit writers doing any sort of dlmalloc-related analysis. libdlmalloc was primarily modelled after other similar heap analysis tools such as libtalloc [13], developed by Aaron Adams, and in turn the jemalloc plugin shadow [14], developed by argp and huku at CENSUS labs. In the same vein as these tools, main functionality is provided by a set of discrete debugger commands. Some Python functions are included that replicate various macros and functions inside dlmalloc-2.8.x, as is the approach in cloudburst’s libheap [15], however this wasn’t the primary focus.
It is worth noting that we don’t currently abstract out much of the debugging logic. However, we plan to do it eventually, so in that sense it lags behind the more recent design changes in both shadow [16] and libheap.
Currently we provide a file containing the main logic called
libdlmalloc_28x.py. Although some portions contain gdb-specific functionality, in general it can be used to some capacity without being run inside gdb as well, which is useful for offline analysis of a heap snapshot for instance.
import libdlmalloc_28x as libdlmalloc
When used with our asadbg scripts [19], libdlmalloc is very powerful because it will be automatically loaded and available on whatever firmware version you are debugging. We detailed this in a previous blog post.
Overview of commands
dlhelp
This is the main function to view the available commands. Each of the commands supports the
-h option which allows you to obtain more detailed usage instructions.
(gdb) dlhelp
[libdlmalloc] dlmalloc commands for gdb
[libdlmalloc] dlchunk : show one or more chunks metadata and contents
[libdlmalloc] dlmstate : print mstate structure information. caches address after first use
[libdlmalloc] dlcallback : register a callback or query/modify callback status
[libdlmalloc] dlhelp : this help message
[libdlmalloc] NOTE: Pass -h to any of these commands for more extensive usage. Eg: dlchunk -h
dlmstate
First we’ll show the
dlmstate command. We can use this command to analyse the contents of an
mstate structure at a specified address.
(gdb) dlmstate -h
[libdlmalloc] usage: dlmstate [-v] [-f] [-x] [-c <count>] <addr>
[libdlmalloc] <addr> a mstate struct addr. Optional if mstate cached
[libdlmalloc] -v use verbose output (multiples for more verbosity)
[libdlmalloc] -c print bin counts
[libdlmalloc] --depth how deep to count each bin (default 10)
[libdlmalloc] NOTE: Last defined mstate will be cached for future use
The usage is straightforward. Normally you will simply supply an address or, if you want to use a cached version, no address at all.
For our example we happen to know that the
mstate is at address
0xa8400008:
[SNIP]
smallbin[13] (sz 0x68) = 0xad0297e8, 0xad0297e8 [EMPTY]
smallbin[14] (sz 0x70) = 0xad029420, 0xad029420 [EMPTY]
smallbin[15] (sz 0x78) = 0xad03d688, 0xad03d688
[SNIP]
smallbin[27] (sz 0xd8) = 0xad03d3e0, 0xad03d3e0 [EMPTY]
smallbin[28] (sz 0xe0) = 0xad0370d0, 0xad0370d0 [EMPTY]
smallbin[29] (sz 0xe8) = 0xac4e5760, 0xac4e5760 [EMPTY]]
[SNIP]
treebin[28] (sz 0x600000) = 0x0 [EMPTY]
treebin[29] (sz 0x800000) =
We can see that there is some useful information presented, like the state of the various small and tree bins, including if they contain any chunks. Whether or not a bin is marked as
[EMPTY] is dictated by checking the corresponding
smallmap or
treemap bitmaps and whether or not the bin entry has legitimate pointers. We can also get segment information that tracks the various backing pages used to store actual chunks.
In the case above we happen to know that the
mstate on a 32-bit system we were analysing was at
0xa8400008. We don’t currently support symbol resolution, however if symbols are present it would be possible to find this address by querying the
_gm_ global from dlmalloc similar to how, on ptmalloc2, tools will often look up
main_arena.
It’s worth highlighting that some values shown must be fuzzily inferred, which means they may be prone to error. For instance, we don’t necessarily know the native system’s mutex size, or if mutexes were even compiled into dlmalloc. As such, we try to work it out based on a simple heuristic check.
We will refer back to the originally shown
dlmstate structure in order to further demonstrate other commands.
Another nice feature is related to the fact that sometimes you want an approximate idea of how many chunks live in a specific bin. Perhaps you want to ensure you have only one chunk in a bin. You can use
dlmstate -c to do a count of each bin. By default it only counts maximum ten entries per bin, so that it’s not too sluggish over slow debugging connections.
(gdb) dlmstate -c
[libdlmalloc] Using cached mstate
smallbin[00] (sz 0x0) = 0xa840002c, 0xa840002c [EMPTY]
smallbin[01] (sz 0x8) = 0xa8400034, 0xa8400034 [EMPTY]
smallbin[02] (sz 0x10) = 0xa94f59c0, 0xa88647f0 [10+]
smallbin[03] (sz 0x18) = 0xacb59f70, 0xa9689a30 [10+]
smallbin[04] (sz 0x20) = 0xacff2be0, 0xa87206f8 [10+]
smallbin[05] (sz 0x28) = 0xa883dd48, 0xa948a100 [10+]
smallbin[06] (sz 0x30) = 0xa8a1d6a8, 0xa8a1e230 [10+]
smallbin[07] (sz 0x38) = 0xac787d80, 0xacfe5070 [8]
smallbin[08] (sz 0x40) = 0xa94af598, 0xa94af598 [2]
smallbin[09] (sz 0x48) = 0xac4e5088, 0xac4e5088 [EMPTY]
smallbin[10] (sz 0x50) = 0xac4e5080, 0xac4e5080 [EMPTY]
smallbin[11] (sz 0x58) = 0xa8a1d680, 0xa8a1d680 [EMPTY]
smallbin[12] (sz 0x60) = 0xac782c08, 0xac782c08 [EMPTY]
smallbin[13] (sz 0x68) = 0xac4e5068, 0xac4e5068 [2]
smallbin[14] (sz 0x70) = 0xac4e4fe0, 0xac4e4fe0 [EMPTY]
...
smallbin[31] (sz 0xf8) = 0xacff1e28, 0xacff1e28 [EMPTY]
treebin[00] (sz 0x180) = 0xac799f38 [1]
treebin[01] (sz 0x200) = 0xa883da10 [2]
treebin[02] (sz 0x300) = 0x0 [EMPTY]
...
treebin[31] (sz 0xffffffff) = 0x0 [EMPTY]
dlchunk
The
dlchunk command is used to show information related to a chunk.
(gdb) dlchunk -h
[libdlmalloc] usage: dlchunk [-v] [-f] [-x] [-c <count>] <addr>
[libdlmalloc] <addr> a dlmalloc chunk header
[libdlmalloc] -v use verbose output (multiples for more verbosity)
[libdlmalloc] -f use <addr> explicitly, rather than be smart
[libdlmalloc] -x hexdump the chunk contents
[libdlmalloc] -m max bytes to dump with -x
[libdlmalloc] -c number of chunks to print
[libdlmalloc] -s search pattern when print chunks
[libdlmalloc] --depth depth to search inside chunk
[libdlmalloc] -d debug and force printing stuff
To demonstrate the
dlchunk command we will analyse the chunk that was shown at
smallbin[15] in the first
dlmstate output example (not shown in the
dlmstate -c example). Let’s analyse this chunk at
0xad03d688 that we expect to have a size of
0x78 (the bin size).
(gdb) dlchunk 0xad03d688
0xad03d688 F sz:0x00078 fl:-P
We see that this is a free chunk (
F) of size
0x78 and the
PINUSE flag is set, meaning the previously adjacent chunk is in use. If we want a bit more detail we use the
-v flag:
(gdb) dlchunk -v 0xad03d688
struct malloc_chunk @ 0xad03d688 {
prev_foot = 0x8140d4d0
head = 0x78 (PINUSE)
fd = 0xa84000a4
bk = 0xa84000a4
Here we get some more information, as well as the
fd/
bk pointers which happen to point into the
mstate bin index for this size of free chunk. This is an example where, if you don’t yet know the
mstate address but you’re analysing some heap chunk, you might still be able to find a reference to somewhere inside the
mstate structure and work out the base address.
If we need to, we can dump the contents of the chunk using the additional
-x:
(gdb) dlchunk -v 0xad03d688 -x
struct malloc_chunk @ 0xad03d688 {
prev_foot = 0x8140d4d0
head = 0x78 (PINUSE)
fd = 0xa84000a4
bk = 0xa84000a4
0x68 bytes of chunk data:
0xad03d698: 0xf3ee0123 0x00000000 0xad03d618 0xad03d708
0xad03d6a8: 0x08a7c048 0x096cfb47 0x00000000 0x00000000
0xad03d6b8: 0x00000000 0x00000000 0x00000000 0xffffffff
0xad03d6c8: 0x0000001c 0x0000002e 0x00000007 0x0000001e
0xad03d6d8: 0x00000004 0x00000075 0x00000002 0x00000095
0xad03d6e8: 0x00000000 0x00000000 0x02b0a0c5 0x00000000
0xad03d6f8: 0x5ee33210 0xf3eecdef
Using
–m, the output from
-x can be limited to only show a max number of bytes from the chunk.
If we want to look at a few chunks adjacent to this free chunk we’re analysing, we use
-c:
(gdb) dlchunk -c 10 0xad03d688
0xad03d688 F sz:0x00078 fl:-P
0xad03d700 M sz:0x00078 fl:C-
0xad03d778 F sz:0xed268 fl:-P
0xad12a9e0 M sz:0x10030 fl:C-
0xad13aa10 F sz:0x2eac55c0 fl:-P
0xdbbfffd0 F sz:0x00030 fl:--
<<< end of heap segment >>>
We specify we want to see ten chunks adjacent to the 0x78-byte chunk of interest. What we see above is that there is an adjacent in-use chunk (denoted by the
CINUSE flag
C being set), an adjacent free chunk, another adjacent allocated chunk, and then an extremely large free chunk followed by a special small free chunk (special because a chunk should always have
P or
C flags set).
If you are familiar with dlmalloc, you will recognise that the 0x2eac55c0-byte chunk is the
top chunk which is a free chunk encompassing almost the entire remainder of available heap memory. The final free chunk following it is a special marker indicating the actual end of the segment. Note that the
top chunk is not specific to dlmalloc-2.8.x, but exists in 2.6.x and 2.7.x. This
top chunk is often referred to as the wilderness.
Back to the commands, we can get significantly more details about these chunks by combining the
-v and
-c <count> options:
(gdb) dlchunk -v -c 10 0xad03d688
struct malloc_chunk @ 0xad03d688 {
prev_foot = 0x8140d4d0
head = 0x78 (PINUSE)
fd = 0xa84000a4
bk = 0xa84000a4
--
struct malloc_chunk @ 0xad03d700 {
prev_foot = 0x78
size = 0x78 (CINUSE)
--
struct malloc_tree_chunk @ 0xad03d778 {
prev_foot = 0x8140d4d0
head = 0xed268 (PINUSE)
fd = 0x0
bk = 0x0
left = 0x0
right = 0x0
parent = 0x5ee33210
bindex = 0xa84003a4
--
struct malloc_chunk @ 0xad12a9e0 {
prev_foot = 0xed268
size = 0x10030 (CINUSE)
--
struct malloc_tree_chunk @ 0xad13aa10 {
prev_foot = 0x8140d4d0
head = 0x2eac55c0 (PINUSE)
fd = 0x0
bk = 0x0
left = 0x0
right = 0x0
parent = 0x0
bindex = 0x0
--
struct malloc_chunk @ 0xdbbfffd0 {
prev_foot = 0x0
head = 0x30
fd = 0x0
bk = 0x0
--
<<< end of heap segment >>>
As you can see, the tool will stop parsing if it hits what it determines is the edge of the heap segment.
We support large free chunk analysis which, as we noted earlier, uses a tree-based structure (technically a bitwise trie [17]) rather than the usually doubly linked list seen in small chunks. We can see in the output above that the chunk at
0xad03d778 is both large and free; correspondingly we see that the output additionally shows the
left,
right,
parent, and
bindex values for the tree structure. However, the reader will notice that these values seem wrong. And indeed, they aren’t accurate in this particular case. Why is that? It’s because this chunk happens to be the most recently freed chunk and therefore is currently what is called the ‘designated victim’, meaning it hasn’t yet been inserted into a treebin tree yet. You can validate this by checking against the
dv value shown in the
mstate structure:
[...]
As you can see,
dv and
dvsize match the chunk we were analysing. The ability to correlate this type of information when analysing heap behavior is very useful. There are times during exploitation where you specifically want to rely on the designated victim chunk’s behavior, so this can help realise those scenarios.
Going back to the treebin structure, by analysing a chunk actually on a treebin, we can see that the fields are in fact set correctly:
(gdb) dlchunk -v 0xad029ac0
struct malloc_tree_chunk @ 0xad029ac0 {
prev_foot = 0x8140d4d0
head = 0xc530 (PINUSE)
fd = 0xad029ac0
bk = 0xad029ac0
left = 0x0
right = 0x0
parent = 0xa8400170
bindex = 0xf
Another useful option of
dlchunk is searching:
(gdb) dlchunk -x 0xad03d700
0xad03d700 M sz:0x00078 fl:C- alloc_pc:0x08a7c048,-
0x70 bytes of chunk data:
0xad03d708: 0xa11c0123 0x00000048 0x00000000 0x00000000
0xad03d718: 0xad03d618 0xa84003c4 0x08a7c048 0x096cfb47
0xad03d728: 0x00000000 0x00000000 0x00000000 0x00000000
0xad03d738: 0x00000000 0xffffffff 0x0000001c 0x00000010
0xad03d748: 0x00000008 0x0000001e 0x00000004 0x00000075
0xad03d758: 0x00000002 0x00000095 0x00000000 0x00000000
0xad03d768: 0x02cc1773 0x00000000 0xa11ccdef 0x00000000
(gdb) dlchunk -s 0x02cc1773 0xad03d700
0xad03d700 M sz:0x00078 fl:C- alloc_pc:0x08a7c048,- [MATCH]
We see above that the value
0x02cc1773 is present in the chunk’s hex output, so we search for it and we get a match. This is coupled with the
-c <count> command to search a number of chunks. This would let you see, for example, if a series of adjacent chunks of some recognisable size hold some value you had tried to populate them with, without manually searching through the hexdumps.
We can further augment this using the
--depth argument which lets you specify how deep into the chunk you want to search for the value. This is useful if you know that one of a hundred chunks you are interested in will have some wanted value in the first 16-bytes, but you don’t care about the remaining bytes of the chunk, no matter its size.
dlcallback
Another feature we added, which was specifically to help with some analysis of the Cisco ASA device, is the concept of callbacks that the
dlchunk and
dlmstate libdlmalloc commands can call to provide additional information. The callback we created to test this functionality so far is from a separate heap analysis tool we called libmempool that we detail in a future blog post. But in short it is designed to describe Cisco-specific related structures injected into dlmalloc chunks by special heap wrapping functions.
(gdb) dlcallback -h
[libdlmalloc] usage: dlcallback <option>
[libdlmalloc] disable temporarily disable the registered callback
[libdlmalloc] enable enable the registered callback
[libdlmalloc] status check if a callback is registered
[libdlmalloc] clear forget the registered callback
[libdlmalloc] register <name> <module> use a global function <name> as callback from <module>
[libdlmalloc] ex: register mpcallback libmempool/libmempool
In order to use a callback you need to register a function that will be passed some information about the chunk or
mstate being inspected. In our case we have
libmempool.py specify the
mpcallback function that takes an argument to a dictionary containing a lot of information provided by libdlmalloc. We can then register this function using the command:
(gdb) dlcallback register mpcallback libmempool/libmempool
[libmempool] loaded
[libdlmalloc] mpcallback registered as callback
In the case above, the
libmempool.py package located in the
libmempool/ folder is loaded and the
mpcallback function is dynamically looked up. The code will attempt to either lookup the specified function in the global namespace or load the specified module and look up the function in that module’s namespace.
We can validate that the callback is registered:
(gdb) dlcallback status
[libdlmalloc] a callback is registered and enabled
If we wanted to temporarily disable the callback for whatever reason, we can disable it and re-enable it at a different time as well. We can clear it technically:
(gdb) dlcallback status
[libdlmalloc] a callback is registered and enabled
(gdb) dlcallback disable
[libdlmalloc] callback disabled
(gdb) dlcallback status
[libdlmalloc] a callback is registered and disabled
(gdb) dlcallback enable
[libdlmalloc] callback enabled
(gdb) dlcallback clear
[libdlmalloc] callback cleared
(gdb) dlcallback status
[libdlmalloc] a callback is not registered
For the sake of example, let’s register the
mpcallback function. When run, it’s entirely up to the callback to do whatever it wants to do with the information provided to it by libdlmalloc. In our example case,
mpcallback will look for a Cisco-specific structure inside the chunk and dump out the values.
(gdb) dlcallback register mpcallback libmempool/libmempool
[libmempool] loaded
[libdlmalloc] mpcallback registered as callback
Then we look at some dlmalloc chunks on a Cisco ASA device, where we know they’ve been wrapped by a function that inserts a
mempool header inside:
(gdb) dlcallback disable
[libdlmalloc] callback disabled
(gdb) dlchunk 0xad03d700
0xad03d700 M sz:0x00078 fl:C-
(gdb) dlcallback enable
[libdlmalloc] callback enabled
(gdb) dlchunk 0xad03d700
0xad03d700 M sz:0x00078 fl:C- alloc_pc:0x08a7c048,-
In the example above we compare the output from a non-verbose
dlchunk listing with and without the callback enabled. We see that the callback adds a special
alloc_pc field, which represents the address of the function that was responsible for the allocation, which Cisco helpfully tracks. We can get even more information by using the verbose listing:
(gdb) dlcallback disable
[libdlmalloc] callback disabled
(gdb) dlchunk -v 0xad03d700
struct malloc_chunk @ 0xad03d700 {
prev_foot = 0x78
size = 0x78 (CINUSE)
(gdb) dlcallback enable
[libdlmalloc] callback enabled
(gdb) dlchunk -v 0xad03d700
struct malloc_chunk @ 0xad03d700 {
prev_foot = 0x78
size = 0x78 (CINUSE)
struct mp_header @ 0xad03d708 {
mh_magic = 0xa11c0123
mh_len = 0x48
mh_refcount = 0x0
mh_unused = 0x0
mh_fd_link = 0xad03d618 (OK)
mh_bk_link = 0xa84003c4 (-)
allocator_pc = 0x8a7c048 (-)
free_pc = 0x96cfb47 (-)
We can see all the contents of the internal structure parsed by the callback. You can imagine that this type of information is extremely helpful if, for example, you are corrupting an adjacent heap chunk and these structure values must hold specific values.
A similar use for the callbacks is when analysing an
mstate. Although it’s likely to be rare, in theory an
mstate could be modified to hold additional information. In the case of the Cisco ASA devices we looked at, this is exactly what happens. This
mstate structure contains additional book keeping bins and statistics located after the end of the
mstate‘s segment structure member.
(gdb) dlcallback status
[libdlmalloc] a callback is registered and enabled
(gdb) dlcallback disable
[libdlmalloc] callback disabled
Above, we call
dlmstate with the callback disabled and it shows us the contents of the
mstate structure only. Now we’ll enable the callback and check again:
struct mp_mstate @ 0xa84001e4 {
mp_smallbin[00] - sz: 0x00000000 cnt: 0x0000, mh_fd_link: 0x0
mp_smallbin[01] - sz: 0x00000008 cnt: 0x0000, mh_fd_link: 0x0
mp_smallbin[02] - sz: 0x00000010 cnt: 0x0000, mh_fd_link: 0x0
mp_smallbin[03] - sz: 0x00000018 cnt: 0x0000, mh_fd_link: 0x0
mp_smallbin[04] - sz: 0x00000020 cnt: 0x0000, mh_fd_link: 0x0
mp_smallbin[05] - sz: 0x00000028 cnt: 0x0000, mh_fd_link: 0x0
mp_smallbin[06] - sz: 0x00000030 cnt: 0x0212, mh_fd_link: 0xacff5230
mp_smallbin[07] - sz: 0x00000038 cnt: 0x0cb6, mh_fd_link: 0xa94b2290
mp_smallbin[08] - sz: 0x00000040 cnt: 0x1c8e, mh_fd_link: 0xad01c8d8
mp_smallbin[09] - sz: 0x00000048 cnt: 0x0273, mh_fd_link: 0xad017fb8
mp_smallbin[10] - sz: 0x00000050 cnt: 0x0426, mh_fd_link: 0xacfdd1c8
mp_smallbin[11] - sz: 0x00000058 cnt: 0x0120, mh_fd_link: 0xad03d5c0
mp_smallbin[12] - sz: 0x00000060 cnt: 0x0127, mh_fd_link: 0xad03d560
mp_smallbin[13] - sz: 0x00000068 cnt: 0x09ff, mh_fd_link: 0xacb53fc0
mp_smallbin[14] - sz: 0x00000070 cnt: 0x003f, mh_fd_link: 0xacff6c78
mp_smallbin[15] - sz: 0x00000078 cnt: 0x0074, mh_fd_link: 0xad03d708
...
mp_smallbin[30] - sz: 0x000000f0 cnt: 0x0006, mh_fd_link: 0xacfe83f0
mp_smallbin[31] - sz: 0x000000f8 cnt: 0x0045, mh_fd_link: 0xad0184e8
mp_treebin[00] - sz: 0x00000100 cnt: 0x0191, mh_fd_link: 0xad024698
mp_treebin[01] - sz: 0x00000200 cnt: 0x0134, mh_fd_link: 0xacff5380
mp_treebin[02] - sz: 0x00000300 cnt: 0x016e, mh_fd_link: 0xacffc548
mp_treebin[03] - sz: 0x00000400 cnt: 0x004e, mh_fd_link: 0xad002f08
mp_treebin[04] - sz: 0x00000600 cnt: 0x0071, mh_fd_link: 0xa9506260
mp_treebin[05] - sz: 0x00000800 cnt: 0x0030, mh_fd_link: 0xacb50bf0
mp_treebin[06] - sz: 0x00000c00 cnt: 0x0273, mh_fd_link: 0xacffb828
mp_treebin[07] - sz: 0x00001000 cnt: 0x004f, mh_fd_link: 0xa9506690
mp_treebin[08] - sz: 0x00001800 cnt: 0x003e, mh_fd_link: 0xacb4d448
mp_treebin[09] - sz: 0x00002000 cnt: 0x0010, mh_fd_link: 0xac74f1e8
mp_treebin[10] - sz: 0x00003000 cnt: 0x0024, mh_fd_link: 0xac781f00
mp_treebin[11] - sz: 0x00004000 cnt: 0x0028, mh_fd_link: 0xacf9e618
mp_treebin[12] - sz: 0x00006000 cnt: 0x009b, mh_fd_link: 0xac795fc0
mp_treebin[13] - sz: 0x00008000 cnt: 0x000b, mh_fd_link: 0xacae3998
mp_treebin[14] - sz: 0x0000c000 cnt: 0x0026, mh_fd_link: 0xad003428
mp_treebin[15] - sz: 0x00010000 cnt: 0x000b, mh_fd_link: 0xacab70b8
...
mp_treebin[30] - sz: 0x00c00000 cnt: 0x0001, mh_fd_link: 0xaae411d0
mp_treebin[31] - sz: 0xffffffff cnt: 0x0001, mh_fd_link: 0xab641700 [UNSORTED]
You can see that an
mp_mstate structure is now shown after the
mstate structure, which was populated by the callback implemented in libmempool.
When we used
dlmstate above, we didn’t provide the address that we had originally passed to
dlmstate. This highlights a ‘caching’ feature where libdlmalloc will cache a copy of the
mstate structure and address, and use it on subsequent calls unless an address is explicitly specified. This is good on systems where you’re debugging over serial whereby reading a large amount of data can be cumbersome. The caveat with it is that you can sometimes forget that you’re looking at a stale copy of the
mstate structure which does not take into account the latest allocations.
Future libdlmalloc development
In the future we hope to properly abstract out the gdb-related portions so that the tool could be easily integrated into other debuggers, in a similar vein to what argp did with shadow, his jemalloc analysis tool. We hope to eventually test on more versions of dlmalloc-2.8.x and with additional compile time options, as currently all testing has been on Cisco devices. We would like to implement other commands such as allowing for easy bin walking and searching, as well as linear in-use searching in a given segment or series of segments.
If you want to try play around with
libdlmalloc-28x.py, you can compile one of the
malloc-2.8.x.c files from the official server [5] and give it a try.
Cisco implementation of dlmalloc
As noted many times now, the libdlmalloc tool was developed while researching Cisco ASA devices, and as such it has been specifically tested on this platform. This means that it is currently biased towards dlmalloc-2.8.3 despite supporting 2.8.x in general, so expect some inconsistencies if looking at other versions.
On 32-bit and old 64-bit Cisco ASA devices,
lina uses a version of dlmalloc compiled directly into its ELF binary, rather than relying on an external version provided in something like glibc or some other library.
lina does in fact link to glibc, but due to the way it wraps allocation functions it won’t end up using them. Rather, it calls directly into the dlmalloc functions. We will talk more about the wrappers in another article.
Identifying dlmalloc version used in lina
When reversing
lina, we identified several assertions, such as below:
.text:09BE4DE0 loc_9BE4DE0:
.text:09BE4DE0 mov edx, ebx
.text:09BE4DE2 mov ecx, offset aHeapMemoryCorr ; "Heap memory corrupted"
.text:09BE4DE7 sub edx, [ebx] ; unk
.text:09BE4DE9 mov eax, ebx ; chunk_addr
.text:09BE4DEB call print_checkheaps_failure
.text:09BE4DF0 mov dword ptr [esp+8], 0B0Ah
.text:09BE4DF8 mov dword ptr [esp+4], offset aMalloc_c ; "malloc.c"
.text:09BE4E00 mov dword ptr [esp], offset aNext_pinuseP_0 ; "(next_pinuse(p))"
.text:09BE4E07 call __lina_assert
This can easily be matched to dlmalloc [2] heap allocator source code. It is interesting to match the exact version to get a good idea of what we’re up against and to see if it supports things like safe unlinking.
Looking at
lina, starting from
validate_buffers() and
mspace_malloc() we identify the following functions:
check_free_chunk,
check_inuse_chunk,
check_mmapped_chunk and
check_top_chunk. They can be found by looking at the debugging strings passed to
__lina_assert. After dumping all malloc*.c from the official website [18] into a local directory, we can easily deduce that it is almost definitely version 2.8.3, or a modification of it, based on two debugging strings being used:
dlmalloc$ grep "(next == m->top || cinuse(next))" *
malloc-2.8.0.c: assert (next == m->top || cinuse(next));
malloc-2.8.1.c: assert (next == m->top || cinuse(next));
malloc-2.8.2.c: assert (next == m->top || cinuse(next));
malloc-2.8.3.c: assert (next == m->top || cinuse(next));
dlmalloc$ grep "segment_holds(sp, (char\*)sp)" *
malloc-2.8.3.c: assert(segment_holds(sp, (char*)sp));
malloc-2.8.4.c: assert(segment_holds(sp, (char*)sp));
malloc-2.8.5.c: assert(segment_holds(sp, (char*)sp));
malloc-2.8.6.c: assert(segment_holds(sp, (char*)sp));
This means the dlmalloc version embedded in
lina does not have safe unlinking!
As a side note, you might wonder what this
validate_buffers() function is and why it’s packed with all these asserts. This will be covered in our blog post dedicated to Checkheaps.
Cisco build constants
Given that we know we’re looking at dlmalloc-2.8.3, we still need to try to poke around and work out other configuration details. Based on looking at other asserts and testing we can infer the following configuration constants of interest were used:
MSPACES 1
FOOTERS 1
USE_LOCKS 1
ONLY_MSPACES 1
DEBUG 1
INSECURE 0
USE_DEV_RANDOM 0
PROCEED_ON_ERROR 0
Most notably is that
DEBUG is set, which means a significant number of chunk validation routines will be called, though as we described earlier they’re not always enough to catch corruption.
Working out these types of build-time constant for a target system can help you compile a toy build of dlmalloc for offline testing that you can use to try out some ideas without necessarily having to debug a live device (which can be slow over serial).
Static magic and static mstates
Earlier we described the concepts of
FOOTERS and
MSPACES and how these provide a security mechanism effectively by serving as a form of cookie at the end of a chunk. We showed that
USE_DEV_RANDOM could further improve the random value selected for use as the
magic member. Let’s take a look at how all of these available pieces can still not come together correctly when looking at the implementation of this logic on the Cisco ASA (analysis taken from 9.2.4 32-bit).
If we return to
init_param(), in Cisco’s case they clearly do not use the
USE_DEV_RANDOM constant and therefore instead rely on the usage of a time API as their random value. Specifically a function
__wrap_time(0) is called. This in turn calls
unix_time(), which in turn calls
clock_get_time() and
clock_epoch_to_unix_time().
.text:09BE4AE0 loc_9BE4AE0: ; CODE XREF: create_mspace_with_base+E
.text:09BE4AE0 mov ds:mparams_mmap_threshold, 40000h
.text:09BE4AEA mov ds:mparams_trim_threshold, 200000h
.text:09BE4AF4 mov ds:mparam_default_mflags, 3
.text:09BE4AFE mov dword ptr [esp], 0
.text:09BE4B05 call __wrap_time
.text:09BE4B0A mov edx, ds:mparams_magic
.text:09BE4B10 test edx, edx
.text:09BE4B12 jnz short loc_9BE4B2E
.text:09BE4B14 xor eax, 55555555h
.text:09BE4B19 or eax, 8
.text:09BE4B1C and eax, 0FFFFFFF8h
.text:09BE4B1F mov ds:mparams_magic, eax
.text:09BE4B24 mov eax, ds:mparam_default_mflags
.text:09BE4B29 mov ds:_gm__mflags, eax
The
magic member of
mparams is setup initially when creating a new
mspace via
create_mspace_with_base().
__wrap_time() is defined as follows:
.text:09C00D70 arg_0 = dword ptr 8
.text:09C00D70
.text:09C00D70 push ebp
.text:09C00D71 mov ebp, esp
.text:09C00D73 push ebx
.text:09C00D74 sub esp, 4
.text:09C00D77 mov ebx, [ebp+arg_0]
.text:09C00D7A call unix_time
.text:09C00D7F test ebx, ebx
.text:09C00D81 jz short loc_9C00D85
.text:09C00D83 mov [ebx], eax
.text:09C00D85
.text:09C00D85 loc_9C00D85: ; CODE XREF: __wrap_time+11
.text:09C00D85 add esp, 4
.text:09C00D88 pop ebx
.text:09C00D89 pop ebp
.text:09C00D8A retn
.text:09C00D8A endp
The interesting thing about this is that at the time of
init_param() in
create_mspace_with_base() it is early enough during boot that the
__wrap_time(0) call will always end up return a static value. This value appears to be the NTP timestamp max value of
0x7c558180, corresponding to ‘Wed Feb 6 23:28:16 2036’, which is the rollover to a new epoch. This static value is returned because
clock_get_time() relies on reading from a global variable to read the current system time and the variable isn’t yet initialised early in boot. So
clock_get_time() returns 0. This is then passed to
clock_epoch_to_unix_time(), which tries to convert it by doing the following:
.text:09BC4E70 arg_0 = dword ptr 8
.text:09BC4E70
.text:09BC4E70 push ebp
.text:09BC4E71 mov ebp, esp
.text:09BC4E73 mov eax, [ebp+arg_0]
.text:09BC4E76 pop ebp
.text:09BC4E77 mov eax, [eax]
.text:09BC4E79 add eax, 7C558180h
.text:09BC4E7E retn
.text:09BC4E7E endp
.text:09BC4E7E
This leads to the result of
0x7c558180 being returned. When XORed with
0x55555555 and bit fiddled the resulting
magic value is
0x2900d4d8.
s = (size_t)(time(0) ^ (size_t)0x55555555U);
s |= (size_t)8U; /* ensure nonzero */
s &= ~(size_t)7U; /* improve chances of fault for bad values */
We can confirm that this is in fact the value by looking at the
magic value output from calling the
dlmstate command:
(gdb) dlmstate 0xa8400008
struct dl_mstate @ 0xa8400008 {
...
magic = 0x2900d4d8
...
If you’re playing around with a Cisco ASA device you could confirm that this
magic value never changes across builds or reboots on your system. So, why is this significant?
Imagine a system with no ASLR and that a constant
mparams.magic value is setting these footers. The value of
M should be relatively predictable, and
mparams.magic is entirely predictable. As such, we can predict the value of
prev_foot, which means if we’re abusing a memory corruption bug on a Cisco ASA device, we have a good chance of bypassing the footer checks.
As an example using the addresses and values previously shown in this article, our
mstate is at
0xa8400008 and
mparams.magic is
0x2900d4d8. This means we’d expect the
prev_foot values to be
0xa8400008^0x2900d4d8=0x8140d4d0. Let’s take a look at an in-use chunk:
(gdb) dlchunk -x 0xacfe5430-8
0xacfe5428 M sz:0x00030 fl:CP alloc_pc:0x09bec1ae,-
0x28 bytes of chunk data:
0xacfe5430: 0xa11c0123 0x00000004 0x00000000 0x00000000
0xacfe5440: 0xacfee540 0xa84002a4 0x09bec1ae 0x00000000
0xacfe5450: 0xacfe9ab0 0xa11ccdef
We see that we have a 0x30 byte in-use chunk. We want to see the
prev_foot value of the adjacent chunk to it:
(gdb) dlchunk 0xacfe5458 -v
struct malloc_chunk @ 0xacfe5458 {
prev_foot = 0x8140d4d0
head = 0x10 (PINUSE)
fd = 0xacff2ca0
bk = 0xacff3e58
As we can see, the
prev_foot value is exactly what we expected.
How predictable are the
mstate addresses in practice? On our Cisco ASA 5505 devices we’ve only ever observed two addresses for the most heavily used
mspace. There are, however, multiple
mspaces in use on this device; one for general shared heap allocations and one dedicated to DMA-related allocations. We found that the
mstate for the global shared
mempool that most allocations come from is almost always at
0xa8800008 or
0xa8400008.
However, this variance can reduce the chances of successful exploitation if you were to get it wrong. This isn’t ideal. But it turns out another customisation Cisco made to dlmalloc makes all of what we just described irrelevant for the security of the allocator anyway. As we showed earlier, normally the beginning of a call like
mspace_free() is as follows:
void mspace_free(mspace msp, void* mem) {
if (mem != 0) {
mchunkptr p = mem2chunk(mem);
#if FOOTERS
mstate fm = get_mstate_for(p);
msp = msp; /* placate people compiling -Wunused */
#else /* FOOTERS */
mstate fm = (mstate)msp;
#endif /* FOOTERS */
if (!ok_magic(fm)) {
USAGE_ERROR_ACTION(fm, p);
return;
}
However, upon reversing Cisco’s implementation of
mspace_free(), it turns out they have a custom modification where they assume that the correct
mspace is passed if non-
NULL and don’t rely on using the pointer derived from a footer at all!
/* Approximate implementation on Cisco ASA 9.2.4 */
void mspace_free(mspace msp, void* mem) {
if (mem != 0) {
mchunkptr p = mem2chunk(mem);
if (msp != NULL) {
mstate fm = (mstate)msp;
} else {
mstate fm = get_mstate_for(p);
msp = msp; /* placate people compiling -Wunused */
}
if (!ok_magic(fm)) {
USAGE_ERROR_ACTION(fm, p);
return;
}
A similar lack of checking is present in
mspace_realloc().
This means we don’t have to correctly guess the footer at all! Interestingly, you can confirm this in practice if you’re testing Exodus Intel’s CVE-2016-1287 exploit. They use a static
prev_foot that, when decoded, corresponds to an
mstate located at
0xc8000008, which with an unmodified dlmalloc-2.8.3 should fail on our systems where we’ve been seeing
0xa8400008 and
0xa8800008. But it still succeeds!
A quick look at dlmalloc on 64-bit
In all of our earlier examples we showed 32-bit examples which were taken from a 32-bit Cisco ASA device. One interesting thing to note is that for general heap allocations, 64-bit Cisco ASA devices only use dlmalloc to track a special mempool-bookkeeping structure, which is a custom extension to the dlmalloc
mstate structure and nothing else.
Let’s take a look. In the example below we’ve found the
mstate chunk and it starts at
0x7ffff7ff7000. If we list the chunks from this point we see:
(gdb) dlchunk -c 4 0x7ffff7ff7000
0x7ffff7ff7000 M sz:0x010c0 fl:CP alloc_pc:0x00000000,-
0x7ffff7ff80c0 F sz:0x00ee0 fl:-P free_pc:0x00000000,-
0x7ffff7ff8fa0 F sz:0x00060 fl:-- free_pc:0x00000000,-
<<< end of heap segment >>>
In the example above the
0xee0 is the
top chunk and
0x60 is the special dlmalloc segment footer. If we take a look at the actual
mstate structure we see the following:
(gdb) dlmstate 0x7ffff7ff7010
struct dl_mstate @ 0x7ffff7ff7010 {
smallmap = 0b000000000000000000000000000000
treemap = 0b000000000000000000000000000000
dvsize = 0x0
topsize = 0xee0
least_addr = 0x7ffff7ff7000
dv = 0x0
top = 0x7ffff7ff80c0
trim_check = 0x200000
magic = 0x2900d4d8
smallbin[00] (sz 0x0) = 0x7ffff7ff7050, 0x7ffff7ff7050 [EMPTY]
smallbin[01] (sz 0x8) = 0x7ffff7ff7060, 0x7ffff7ff7060 [EMPTY]
smallbin[02] (sz 0x10) = 0x7ffff7ff7070, 0x7ffff7ff7070 [EMPTY]
smallbin[03] (sz 0x18) = 0x7ffff7ff7080, 0x7ffff7ff7080 [EMPTY]
smallbin[04] (sz 0x20) = 0x7ffff7ff7090, 0x7ffff7ff7090 [EMPTY]
...
smallbin[29] (sz 0xe8) = 0x7ffff7ff7220, 0x7ffff7ff7220 [EMPTY]
smallbin[30] (sz 0xf0) = 0x7ffff7ff7230, 0x7ffff7ff7230 [EMPTY]
smallbin[31] (sz 0xf8) = 0x7ffff7ff7240, 0x7ffff7ff7240 [EMPTY]
treebin[00] (sz 0x180) = 0x0 [EMPTY]
treebin[01] (sz 0x200) = 0x0 [EMPTY]
treebin[02] (sz 0x300) = 0x0 [EMPTY]
treebin[03] (sz 0x400) = 0x0 [EMPTY]
treebin[04] (sz 0x600) = 0x0 [EMPTY]
...
treebin[29] (sz 0x800000) = 0x0 [EMPTY]
treebin[30] (sz 0xc00000) = 0x0 [EMPTY]
treebin[31] (sz 0xffffffff) = 0x0 [EMPTY]
footprint = 0x2000
max_footprint = 0x2000
mflags = 0x7
mutex = 0x0,0x0,0x55555e506260,0x0,0x0,0x7ffff7ff7000,
seg = struct malloc_segment @ 0x7ffff7ff73a0 {
base = 0x7ffff7ff7000
size = 0x2000
next = 0x0
sflags = 0x8
We see that it’s basically empty and the segment for the heap is only
0x2000, corresponding to the chunks we saw before. This is because 64-bit relies on glibc, which is a modified ptmalloc2 for servicing all actual allocations.
Conclusions
We took a look at dlmalloc-2.8.x and noted the important differences between this version and dlmalloc-2.7.x. We revealed a gdb-based Python script called libdlmalloc which is completely integrated with asadbg. libdlmalloc is designed to aid in the analysis of dlmalloc-2.8.x heaps and showed some of its use on a real-world Cisco ASA 5505 system running 9.2.4, as well as giving some examples of interest about how it is configured and customised and how those changes impact the security of the system.
Hopefully this post highlighted the importance of explicit clarification when documenting heap exploitation, as well as heap tools. As time goes on, there will be an increasing number of heap versions, branches, and forks, many of them introducing their own subtle changes. All of this means that the importance of clarifying exactly what versions research pertains to and has been tested on will be of increasing importance.
We would appreciate any feedback or corrections. You can test out the libdl
References
[1]
[2]
[3]
[4]
[5]
[6]
[7]
[8]
[9]
[10]
[11]
[12]
[13]
[14]
[15]
[16]
[17]
[18]
[19]
Published date: 09 October 2017
Written by: Aaron Adams and Cedric Halbronn
|
https://research.nccgroup.com/2017/10/09/cisco-asa-series-part-four-dlmalloc-2-8-x-libdlmalloc-dlmalloc-on-cisco-asa/
|
CC-MAIN-2022-05
|
refinedweb
| 10,468 | 51.48 |
Hello,
I'm running a LPC4357 on a OEM board from embeddedartists.com
I have a LWIP implementation based on LPCOpen where I receive commands from a client computer (LPC is server) and response some data to the client.
My Problem is now, that if my client send one command to the server, the server send the response two or more times.
The Wireshark screenshot shows the bevaviour: Client (@191) requenst some data (No. 86889) and the server (@10) responsed two times (No. 86890 and 86896).
The strange thing is: This behaviour only happens if I'm using the debug mode or if the client is far away. If I build a release programm and the client is my Computer next to the server I have a perfect communication (1 command -> 1 response).
On my main loop i call a function processNetwork() where all the network stuff is done (code below), this is part of the LPCOpen examples.
I tried different call intervalls for this processNetwork() function (as soon as possible, 10ms, 100ms, 250ms) but without any solutions to that problem.
I also call tcp_recved() at the end of my tcp_received() function after I processed the incomming data.
As a reason of the different behaviours between Debug and Release builds I think the problem is any kind of timing issue.
I would be happy if you have any idea what the problem could be or in which direction i have to search for.
Kind regards,
Michael
void processNetwork(void){ /* Handle packets as part of this loop, not in the IRQ handler */ lpc_enetif_input(&lpc_netif); /* lpc_rx_queue will re-qeueu receive buffers. This normally occurs automatically, but in systems were memory is constrained, pbufs may not always be able to get allocated, so this function can be optionally enabled to re-queue receive buffers. */ #if 0 while (lpc_rx_queue(&lpc_netif)) {} #endif /* Free TX buffers that are done sending */ lpc_tx_reclaim(&lpc_netif); /* LWIP timers - ARP, DHCP, TCP, etc. */ sys_check_timeouts(); /* Call the PHY status update state machine once in a while to keep the link status up-to-date */ physts = lpcPHYStsPoll(); /* Only check for connection state when the PHY status has changed */ if (physts & PHY_LINK_CHANGED) networkLinkChanged(); /* Print IP address info */ if (ipPrinted == false) { if (lpc_netif.ip_addr.addr) { static char tmp_buff[16]; ETHERNETDEBUGOUT("IP_ADDR : %s\n", ipaddr_ntoa_r((const ip_addr_t *) &lpc_netif.ip_addr, tmp_buff, 16)); ETHERNETDEBUGOUT("NET_MASK : %s\n", ipaddr_ntoa_r((const ip_addr_t *) &lpc_netif.netmask, tmp_buff, 16)); ETHERNETDEBUGOUT("GATEWAY_IP : %s\n", ipaddr_ntoa_r((const ip_addr_t *) &lpc_netif.gw, tmp_buff, 16)); ETHERNETDEBUGOUT("HOSTNAME : %s\n\n",lpc_netif.hostname); ipPrinted = true; } } }
Solved! Go to Solution.
Hi,
There is important to isolate the issue, could you try using only (without modifications) the webserver example from LPCOpen?
I want to know if there is a software or hardware issue.
Regards
Sol
Hi Sol,
the advice was good. I cross checked my code with the Echo example and found a memory leak.
I didn't free all received pbufs and thereby I received the package twice or more.
Thanks for the help / hint.
Best regards
Michael
Hi,
There is important to isolate the issue, could you try using only (without modifications) the webserver example from LPCOpen?
I want to know if there is a software or hardware issue.
Regards
Sol
|
https://community.nxp.com/t5/LPC-Microcontrollers/LWIP-receive-incomming-packages-multiple-times/m-p/865028/highlight/true
|
CC-MAIN-2020-45
|
refinedweb
| 532 | 63.59 |
Board to PC communication over USB
The Arm Mbed microcontroller on your board can communicate with a host PC over the same USB cable that you use for programming.
If you're working on Windows earlier than Windows 10, you might need to install a serial driver.
This allows you to:
- Print out messages to a host PC terminal (useful for debugging).
- Read input from the host PC keyboard.
- Communicate with applications and programming languages running on the host PC that can communicate with a serial port. Examples are Perl, Python and Java.
Hello, world
This program prints a "Hello World" message that you can view on a terminal application. Communication over the USB serial port uses the standard serial interface. Specify the internal (USBTX, USBRX) pins to connect to the serial port routed over USB:
#include "mbed.h" Serial pc(USBTX, USBRX); // tx, rx int main() { pc.printf("Hello World!\n"); while(1); }
Using terminal applications
Terminal applications run on your host PC. They provide a window where your Mbed board can print and where you can type characters back to your board.
Serial configuration: The standard setup for the USB serial port is 9600 baud, 8 bits, 1 stop bit, no parity (9600-8-N-1)
Installing an application for Windows
There are many terminal applications for Windows, including:
- CoolTerm - this is the application we use in this example. We use it often because it usually "just works".
- Tera Term.
- PuTTY.
- Some Windows PCs come with Hyperterminal installed.
Configuring the connection
- Plug in your Mbed board.
- Open CoolTerm.
- Click Connect. This opens up an 8-n-1 9600 baud connection to the first available serial port. If you have more than one board plugged in, you may need to change the port under Options > Serial Port > Port.
Check your connection parameters:
- Select Options > Serial Port.
- You should see 9600 baud, 8 bits, 1 stop bit, no parity (9600-8-N-1).
- If you do not see your board, click Re-Scan Peripherals.
Your terminal program is now configured and connected.
Using terminal applications on Linux
CoolTerm should work under Linux. If for some reason it doesn't, you can try one of the following:
Additional examples
Use your terminal application to interact with the following examples.
If you're not sure how to build these examples and run them on your board, please see our build tools section.
Echo back characters you type
#include "mbed.h" Serial pc(USBTX, USBRX); int main() { pc.printf("Echoes back to the screen anything you type\n"); while(1) { pc.putc(pc.getc()); } }; } } }
Pass characters in both directions
Tie pins together to see characters echoed back.
; } } }
Using stdin, stdout and stderr
By default, the C
stdin,
stdout and
stderr file handles map to the PC serial connection:
#include "mbed.h" int main() { printf("Hello World!\n"); while(1); }
Read to a buffer
#include "mbed.h" DigitalOut myled(LED1); Serial pc(USBTX, USBRX); int main() { char c; char buffer[128]; pc.gets(buffer, 4); pc.printf("I got '%s'\n", buffer); while(1); }
|
https://os.mbed.com/docs/mbed-os/v5.9/tutorials/serial-comm.html
|
CC-MAIN-2019-30
|
refinedweb
| 510 | 66.33 |
Leverage a JavaFX Application with Nashorn Script
Java-JavaScript interoperability incepted in Java SE 6 and rode Mozilla Rhino until Java SE 7. Oracle Nashorn is the script engine shipped with the latest version of Java SE 8. Observe how the bin folder of your Java SDK getts fatter with each new introduction of tools. This time it is JJS. This tool represents the Nashorn script engine and can be used to run JavaScript from the command line. The command line is the basic way to interact with the engine, or we can embed it inside a Java application. This coupling of Java with JavaScript can be extended to use JavaFX API as well. The integration is seamless although the languages have a very different inherent nature. One is strictly typed and another being dynamic and un-typed. The article shall explore the simplicity of integration between two very different types of languages, especially from the point of view of a JavaFX application.
A JavaFX App vis-à-vis Scripting App
The life-cycle of a JavaFX application is managed by the init(), start(), and stop() methods. In a similar manner, a Nashorn script can be managed. However, it is not compulsory to have these methods in Nashorn. If no start() method is supplied in a script, the entire code written in the global scope is considered to be the start() method. Let us create a simple JavaFX application to draw a pie chart on some hypothetical data on the sales of food items on a restaurant. The application code is as follows:
package application; import javafx.application.Application; import javafx.collections.FXCollections; import javafx.collections.ObservableList; import javafx.scene.Scene; import javafx.scene.chart.PieChart; import javafx.scene.layout.BorderPane; import javafx.scene.layout.GridPane; import javafx.stage.Stage; public class Main extends Application { private GridPane grid = new GridPane(); @Override public void start(Stage primaryStage) { BorderPane root = new BorderPane(); root.setTop(grid); Scene scene = new Scene(root, 400, 400); grid.addRow(0, createPie()); primaryStage.setScene(scene); primaryStage.sizeToScene(); primaryStage.show(); } public PieChart createPie(){ PieChart pie=new PieChart(); pie.getData().clear(); ObservableList<PieChart.Data>; } public static void main(String[] args) { launch(args); } }
It is a simple JavaFX application where we create a PieChart on the basis of given ObservableArrayList of PieChart.Data. As we run the program, it gives an output as follows.
Figure 1: The rendered pie chart
We almost entirely can write the preceding JavaFX application in JavaScript with the help of Nashorn. A replica of the same application in JavaScript is as follows.
load("fx:base.js") load("fx:controls.js") load("fx:graphics.js") function start(primaryStage){ grid=new GridPane() root = new BorderPane(); root.setTop(grid); grid.addRow(0, createPie()); primaryStage.setScene(new Scene(root, 400, 400)); primaryStage.sizeToScene(); primaryStage; }
Observe how we have imported classes and packages into the JavaScript file with the load method. We also can use the complete classified name of the JavaFX classes or import them by using the Java.type() function.
The code snippet for using a complete classified name is:
var pie=new javafx.scene.chart.PieChart();
or, we may use a Java.type() function as follows:
var PieChart=Java.type("javafx.scene.chart.PieChart"); var pie=new PieChart();
However, it is not a very convenient way to write code in this manner, especially as lines of code increase. Fortunately, JavaFX contains several script files that we can load within the script. These files define the JavaFX types as their simple names. We simply can use the load method to import these script files.
The list of some common Nashorn script files we may want to load for creating JavaFX objects are shown in the following table. As a rule of thumb, fx:base.js, fx:graphics.js, and fx:controls.js are the most common.
Executing a Script with the JJS Tool
To run the application, we need to pass the -fx flag to the JJS command-line tool along with the JavaScript file name. This flag introduces to Nashorn that the script is using JavaFX APIs and automatically initiates program setup without the need to write explicit boiler-plate code.
Thus, to run the previous code file, say, with the name script1.js, we may write this line of code.
Figure 2: Writing the JJS script
About the Global $STAGE Object
Try creating an empty JavaScript file (say, test.js) and run the file with JJS command-line tool as follows:
C:\>jjs -fx test.js
Observe that an empty window is displayed as an output even if not a single line of code is written in test.js. This interesting aspect is due to Nashorn's global object name $STAGE, which is created automatically by the engine and references the primary stage. As a result, we easily can refer to this global object and modify the previous JavaScript application as follows:
load("fx:base.js") load("fx:controls.js") load("fx:graphics.js") grid = new GridPane() root = new BorderPane(); root.setTop(grid); grid.addRow(0, createPie()); $STAGE.setScene(new Scene(root, 400, 400)); $STAGE.sizeToScene(); $STAGE; }
Conclusion
Scripting and JavaFX can leverage productivity if they can merge not only the code but also each other's advantage as well. Scripts are evaluated at runtime and can be compiled to Java byte code. The Scripting API allows us to execute scripts written in any scripting language. These features make integration seamless even with major language differences between the two. The advantage of scripting, if fully utilized, especially in JavaFX, is that we may able to say Java is partly (tinge of) un-typed and dynamic as well.
References
-
-
-<<
|
https://www.developer.com/java/data/leverage-a-javafx-application-with-nashorn-script.html
|
CC-MAIN-2018-39
|
refinedweb
| 941 | 58.28 |
I'm doing an assignment that's a separate class for a program called "MadChoosers" and THIS class creates an array of four MadChoosers called chooserList and the four chooserList arrays are chooserList[0]-to hold proper names; chooserList[1]-to hold adjectives; chooserList[2]-for nouns; and chooserList[3]- for verbs. I am new to arrays...still learning them in class and I understand the "idea" behind them and what not...I get the feeling that my code is wrong, I have been looking at the tutorial on here and that helps a little but when I try to use the same codes for Strings, it doesn't work...this is the code I have so far (I'll post both classes so you can see what's going on)
Code Java:
public class MadChooser { //intstance variables String wordlist[]; int firstEmpty; public static void main(String[] args) { } /*default constructor creates a size 20 wordlist(no strings yet) starts firstEmpty = 0*/ public MadChooser() { wordlist = new String[20]; int firstEmpty = 0; } /*parameterized constructor that takes an array of Strings as a parameter. Set wordlist to this array and firstEmpty to the length of the array (it is totally filled). EC+ 10: instead of just setting worldist to the list passed in, make wordlist a new array of the same size and copy all the Strings over from the other wordlist.*/ public MadChooser(String[] b) { wordlist = new String[b.length]; for (int v = 0; v < wordlist.length; v++) { wordlist[v] = b[v]; } firstEmpty = wordlist.length; } /*parameterized constructor that takes integer and makes wordlist that size (no words in it yet so firstEmpty is still 0)*/ public MadChooser(int a) { a = 0; firstEmpty = a; } /*method add(String newWord) which given a string, adds it to wordlist in the first * empty position, unless the array is full (check firstEmpty against the * size of the array); when you add a new string, remember to update firstEmpty*/ public void Add(String newWord) { if (firstEmpty < wordlist.length) { wordlist[firstEmpty] = newWord; firstEmpty++; } } /*Overload Add with a second method add(String[] newWords) which, given an * array of Strings adds all of them to wordlist(until it runs out of room) * Think abt what the loop needs to look like to make sure you don't run off * either array (there are several correct ways to do this)*/ public void Add(String[] newWords) { for (int i = 0; i < newWords.length; i++) { this.Add(newWords[i]); } } /*Method pickWord(), returns a randomly chosen string from wordlist(it is * possible wordlist may not be full, make sure to only use words from that * are filled in (use firstEmpty); if wordlist has no words, return null.*/ public String pickWord() { int w = (int) (Math.random() * firstEmpty); return wordlist[w]; } /*EC+20: add method find, give String parameter, returns true if that string is already in wordlist, false otherwise. (hint == doesn't work with Strings, need something like "firstString.equals(secondString)" Have the add() method use find to check if a word being added is already in the list if so, don't add it*/ public String find(String h) { if (h.equals(wordlist)) { } return h; } }
**THIS IS THE CLASS I'M CONFUSED ON**
Code Java:
public class ChooserList { /*write a program that creates an array of four MadChoosers, chooserList. * chooserList[0] will be used to hold proper names, chooserList[1] will hold * adjectives, chooserList[2] nouns, and chooserList[3] verbs.*/ String[] chooserListNames; //do I even need these? String[] chooserListAdj; String[] chooserListNouns; String[] chooserListVerbs; chooserList = new String [4]; //this isn't working right }
Thx in advance guys!
|
http://www.javaprogrammingforums.com/%20whats-wrong-my-code/27333-class-arrays-printingthethread.html
|
CC-MAIN-2018-09
|
refinedweb
| 591 | 72.09 |
.
Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.2 or any later version published by the Free Software Foundation; with no Invariant Sections, no Front-Cover Texts, and no Back-Cover Texts.
The.
Tcl is built up from commands which act on data, and which accept a number of options which specify how each command is executed. Each command consists of the name of the command followed by one or more words separated by whitespace. Because Tcl is interpreted, it can be run interactively through its shell command, tclsh, or non-interactively as a script. When Tcl is run interactively, the system responds to each command that is entered as illustrated in the following example. You can experiment with tclsh by simply opening a terminal and entering the command tclsh.
The previous example illustrates several aspects of the Tcl language. The first line, set a 35 assigns 35 to the variable a using the set command. The second line evaluates the result of 35 times the value of a using the expr command. Note that Tcl, like Perl and Bash requires the use of the dollar operator to get the value of a variable. The open brackets around the expression [ expr 35 * $a ] instruct the interpreter to perform a command substitution on the expression, adds it to the rest of the string and uses the puts command to print the string to Tcl's default output channel, standard output.
Tcl's windowing shell, Wish, is an interpreter that reads commands from standard input or from file, and interprets them using the Tcl language, and builds graphical components from the Tk toolkit. Like the tclsh, it can be run interactively.
To invoke Wish interactively, start X on your system, open a terminal, and type wish at the command prompt. If your environment is set up properly, this will launch an empty root window and start the windowing shell in your terminal. The following example is a two-line script that is one of the simplest programs that can be created with wish:
Let's break down these two lines of code:
button .submit -text "Click Me" -command { puts "\nHello World" }:
The button command enables you to create and manipulate the Tk button widget. As with all Tk widgets, the syntax is button .name [-option value] [-option value] .... The curly braces surrounding the puts command allow you to nest the text string, "Hello World", inside of the command without performing any variable substitutions. Other basic widgets include the following: label, checkbutton, radiobutton, command, separator, entry, and frame. Click the button a few times to verify that it works.
pack .submit
The pack command tells the Tk packer geometry manager to pack the window name as a slave of the master window . which is always referred to by the character .. As with the other Tk widget commands we will see, the syntax is pack .name [-option value] [-option value].
While the previous example was very simple, more advanced examples are nearly as easy to build. Have a look at the following script which creates a simple graphical front end for apachectl ( please note, this example is intended to be run as a script rather than interactively from the shell. You will need to set the permissions of the script as executable and run this script as a user with privileges to start and stop apache ):
This script introduces a few new concepts. Let's look at some of them line by line:
As we saw earlier, the set command is used to assign a value to a variable. As with the previous examples, the syntax is simple: set variable_name value. In order to make the variable available to the Tcl procedures that we are creating in this program, we need to import the apachectl variable into each procedure. This is accomplished using the global command which adds a named variable to the local namespace of a given procedure. The global command accepts one or more variables as arguments and assigns the named variables to each procedure used in the program. Global is also used to export variables that are declared within a procedure's local namespace.
Procedures in Tcl are created with the proc command. The proc command takes the following form: proc name {args} {body} where name is the name of the procedure. Args are the formal arguments accepted by the procedure, and body is the main code of the procedure. Procedures are executed the same way that any other command is executed in Tcl.
The script we are currently working with consists of 4 procedures. The first 3 ( start, stop, restart ), simply import the apachectl variable into the local namespace and execute the basic apachectl commands as background processes while the 4th procedure, "screen", uses the packer to build the basic screen and call each of the functions.
Let's have a closer look at the screen procedure:
The screen procedure begins by using the frame command to construct the basic frame that will contain the buttons specified further down in the procedure. As this example illustrates, slave widgets are specified by prepending them with the name of their master followed by a ".". The master must already be packed before the slave can use them, so we pack the frame .top before specifying the button command and tell it to fill along the x axis.
Last, we use the button command to create 3 buttons as slaves to .top, passing in the appropriate procedure to execute when the button is pressed, and adding a text label using the -command and -text arguments, respectively.
Providing.
This.
Readers.
|
http://www.ibiblio.org/pub/Linux/docs/HOWTO/other-formats/html_single/Scripting-GUI-TclTk.html
|
CC-MAIN-2015-14
|
refinedweb
| 949 | 60.14 |
Wow, awesome! Regards, Michael Alex Hornung <[email protected]> schrieb: >Hi all, > >heads down if you use master: problems (maybe) and new features are >coming your way! > >Over the past few weeks I've been preparing a major series of commits. >A >few weeks ago I updated opencrypto and also added support for twofish >and serpent ciphers. This was the preliminary work needed for tcplay. > >tcplay is a fully featured BSD-licensed TrueCrypt implementation using >our dm_target_crypt; it is 100% compatible (with recent versions; older >versions using aes-lrw and similar are not). It supports cipher >cascades, hidden volumes, system volumes, etc. I started it as an >experiment to investigate the TrueCrypt header format, but it ended up >as a full implementation written from scratch. It now is divided into >tcplay(8), the tool itself, and libtcplay (tcplay(3)), a very simple >API >to mount and unmount TrueCrypt volumes. tcplay is now fully integrated >into DragonFly, including cryptdisks(8) support and root mount support >(the realroot type is "tcplay", as documented in mkinitrd(8)). > >WARNING: I've done my best in testing it and its compatibility with >TrueCrypt, but it might well be that I missed something. For now I >advise you to treat tcplay as unstable/experimental. If you find out >that some volume is not compatible but works fine in TrueCrypt, it'd be >good if you could provide me with a sample volume that behaves like >that >so I can dig into it. > >While testing tcplay with cipher cascades, I found a bug in >dm_target_crypt which affects interdependent/stacked volumes. If one >crypt volume was dependent on another, a situation could occur where >one >volume would starve the other of memory I/O buffers provided by a >shared >mpipe. To avoid this situation I've changed the mpipes to be >per-instance, to ensure that every instance always has some I/O buffers >available. It uses now at most 0.2% of physical memory for each >instance. Previously it used at most 0.5% of physical memory across all >instances. This is pretty arbitrary, if someone feels it's too >small/big, please let me know. > >Since tcplay was intended to be BSD licensed but depended on >libdevmapper which is GPL-licensed, I decided on Friday to rewrite >libdevmapper under a BSD license; the result of which is libdm. It's a >fairly simple implementation but has (almost) all public features of >libdevmapper. It won't work with stuff like dmsetup and lvm since those >use all sorts of internal pools and trees that libdm doesn't have, but >I >have tested it with both tcplay(8) and cryptsetup(8) and it works like >a >charm. By default both tcplay(8) and cryptsetup(8) now use libdm >instead >of libdevmapper. I also switched over cryptsetup after the testing as >both libtcplay and libcryptsetup are used in cryptdisks(8) and hence >both have to use the same backend dm library as the namespace collides. > >WARNING: A word of warning about libdm: I wrote it in just a few hours >and I bet there are still some minor issues. I've tested the main >functionality of cryptsetup linked against libdm, but there might be >some cases left that will behave erratically. If that's the case, >please >let me know so I can dig into that. > >Just in case someone wonders, I am fully aware of NetBSD's libdm. I did >not use it because it has a different API that is not directly >compatible with linux libdevmapper's and would hence require rewriting >of libdevmapper consumers instead of a plug-in replacement. > >While on it, I also further simplified some of dm(4). I got rid of >excessive locking in the I/O path and concurrency and performance under >heavy use should improve. Previously the I/O strategy path was under >one >exclusive lock which is now gone. This also fixes some other issues >that >could occur when using remove or remove_all, where remove_all would >hold >the same lock as the strategy routine required, and removal would >deadlock. > >I plan to write some proper documentation on the whole dm story (lvm, >cryptsetup, tcplay, etc) but I still haven't found the time to do that. > > >Cheers, >Alex Hornung
|
https://www.dragonflybsd.org/mailarchive/kernel/2011-07/msg00031.html
|
CC-MAIN-2018-13
|
refinedweb
| 710 | 61.56 |
Alter your tracker's
nosyreaction.py detectors script to change the
nosyreaction function to be:
def nosyreaction(db, cl, nodeid, oldvalues): '''. ''' # send a copy of all new messages to the nosy list msgs = determineNewMessages(cl, nodeid, oldvalues) for msgid in msgs: try: cl.nosymessage(nodeid, msgid, oldvalues) except roundupdb.MessageSendError, message: raise roundupdb.DetectorError, message if not msgs: try: cl.nosymessage(nodeid, None, oldvalues) except roundupdb.MessageSendError, message: raise roundupdb.DetectorError, message
But a message for every change may be too much for you. Another route is to just require a message for certain changes. An example is to require a message when changing the
assigned_to field. Put the following code into an auditor to require that the users enters a message when changing the
assigned_to field:
if 'assigned_to' in new_values and 'messages' not in new_values : raise Reject, "Changing assigned_to requires a message"
|
http://www.mechanicalcat.net/tech/roundup/wiki/NosyMessagesAllTheTime
|
crawl-001
|
refinedweb
| 143 | 51.95 |
0
Hi everybody,
I've got a code which returns to a given text an inverse index. From a list of tokens, the function produces a list sorted by the frequency.
Example:
inverted_index(['the', 'house', ',', 'the', 'beer'])
[('the', [0, 3]), ('beer', [4]), ('house', [1]), (',', [2])]
Code:
def outp(txt): ind = {} for word in txt: if word not in ind.keys(): i = txt.index(word) ind[word] = [i] else: i = txt.index(word, ind[word][-1]+1) ind[word].append(i) sorted_ind = sorted(ind.items(), key=lsort, reverse=True) return sorted_ind def lsort(kv): return len(kv[1])
The code works, but it's very slow.
So, my question is: How could it be written s.t. the code is faster?
Thanks for any propositions, Darek
Edited by Darek6
|
https://www.daniweb.com/programming/software-development/threads/424254/performance
|
CC-MAIN-2018-43
|
refinedweb
| 128 | 70.29 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.