
relative_path
stringclasses 812
values | section
stringclasses 339
values | filename
stringlengths 2
61
| text
stringlengths 6
1.76M
|
|---|---|---|---|
PyTorch/Classification/ConvNets/triton/scripts | scripts | setup_environment | #!/usr/bin/env bash
# Copyright (c) 2021 NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
WORKDIR="${WORKDIR:=$(pwd)}"
export WORKSPACE_DIR=${WORKDIR}/workspace
export DATASETS_DIR=${WORKSPACE_DIR}/datasets_dir
export CHECKPOINT_DIR=${WORKSPACE_DIR}/checkpoint_dir
export MODEL_REPOSITORY_PATH=${WORKSPACE_DIR}/model_store
export SHARED_DIR=${WORKSPACE_DIR}/shared_dir
echo "Preparing directories"
mkdir -p ${WORKSPACE_DIR}
mkdir -p ${DATASETS_DIR}
mkdir -p ${CHECKPOINT_DIR}
mkdir -p ${MODEL_REPOSITORY_PATH}
mkdir -p ${SHARED_DIR}
echo "Setting up environment"
export MODEL_NAME=resnet50
export TRITON_LOAD_MODEL_METHOD=explicit
export TRITON_INSTANCES=1
|
Tools/PyTorch/TimeSeriesPredictionPlatform/models/tft_pyt/triton/runner | runner | experiment | # Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import dataclasses
import pathlib
from datetime import datetime
from typing import Any, Dict, Optional
# method from PEP-366 to support relative import in executed modules
if __name__ == "__main__" and __package__ is None:
__package__ = pathlib.Path(__file__).parent.name
from .core import DataObject
class ExperimentStatus(object):
"""
Experiment status flags object
"""
SUCCEED = "Succeed"
FAILED = "Failed"
class StageStatus:
"""
Stages status flags object
"""
SUCCEED = "Succeed"
FAILED = "Failed"
class Stage(DataObject):
"""
Stage data object
"""
name: str
status: str
started_at: Optional[int]
ended_at: Optional[int]
result_path: Optional[str]
result_type: Optional[str]
def __init__(
self,
name: str,
result_path: Optional[str],
result_type: Optional[str],
status: str = StageStatus.FAILED,
started_at: Optional[int] = None,
ended_at: Optional[int] = None,
):
"""
Args:
name: name of stage
result_path: path where results file is stored
result_type: type of results
status: success/fail status
started_at: time when stage has started
ended_at: time when stage has ended
"""
self.name = name
self.status = status
self.started_at = started_at
self.ended_at = ended_at
self.result_path = result_path
self.result_type = result_type
def start(self) -> None:
"""
Update stage execution info at start
Returns:
None
"""
self.started_at = int(datetime.utcnow().timestamp())
def end(self) -> None:
"""
Update stage execution info at end
Returns:
None
"""
self.status = StageStatus.SUCCEED
self.ended_at = int(datetime.utcnow().timestamp())
class Experiment(DataObject):
"""
Experiment data object
"""
experiment_id: int
parameters: Dict
stages: Dict[str, Stage]
results: Dict[str, str]
status: str
started_at: Optional[int]
ended_at: Optional[int]
def __init__(
self,
experiment_id: int,
parameters: Dict,
stages: Dict[str, Stage],
results: Dict[str, str],
started_at: Optional[int] = None,
ended_at: Optional[int] = None,
status: str = ExperimentStatus.FAILED,
):
"""
Args:
experiment_id: experiment identifier
parameters: dictionary with experiment configuration
stages: dictionary with stages run in experiment
results: mapping between results types and location where are stored
started_at: time when experiment has started
ended_at: time when experiment has ended
status: experiment success/fail information
"""
self.experiment_id = experiment_id
self.started_at = started_at
self.ended_at = ended_at
self.parameters = parameters
self.stages = stages
self.status = status
self.results = results
self.results_dir = f"experiment_{experiment_id}"
def start(self) -> None:
"""
Update experiment execution info at start
Returns:
None
"""
self.started_at = int(datetime.utcnow().timestamp())
def end(self) -> None:
"""
Update experiment execution info at end
Returns:
None
"""
self.status = ExperimentStatus.SUCCEED
self.ended_at = int(datetime.utcnow().timestamp())
@dataclasses.dataclass
class Status:
state: ExperimentStatus
message: str
@dataclasses.dataclass
class ExperimentResult:
"""
Experiment result object
"""
status: Status
experiment: Experiment
results: Dict[str, pathlib.Path]
payload: Dict[str, Any] = dataclasses.field(default_factory=dict)
|
PyTorch/SpeechSynthesis/Tacotron2/trtis_cpp/src/trt/tacotron2 | tacotron2 | postNetInstance | /*
* Copyright (c) 2019-2020, NVIDIA CORPORATION. All rights reserved.
*
* Redistribution and use in source and binary forms, with or without
* modification, are permitted provided that the following conditions are met:
* * Redistributions of source code must retain the above copyright
* notice, this list of conditions and the following disclaimer.
* * Redistributions in binary form must reproduce the above copyright
* notice, this list of conditions and the following disclaimer in the
* documentation and/or other materials provided with the distribution.
* * Neither the name of the NVIDIA CORPORATION nor the
* names of its contributors may be used to endorse or promote products
* derived from this software without specific prior written permission.
*
* THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND
* ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED
* WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
* DISCLAIMED. IN NO EVENT SHALL NVIDIA CORPORATION BE LIABLE FOR ANY
* DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES
* (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES;
* LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND
* ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
* (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS
* SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
*/
#ifndef TT2I_POSTNETINSTANCE_H
#define TT2I_POSTNETINSTANCE_H
#include "binding.h"
#include "engineDriver.h"
#include "timedObject.h"
#include "trtPtr.h"
#include "NvInfer.h"
#include "cuda_runtime.h"
#include <string>
namespace tts
{
class PostNetInstance : public TimedObject, public EngineDriver
{
public:
/**
* @brief Tensor of shape {1 x NUM_CHANNELS x NUM_FRAMES x 1 }
*/
static constexpr const char* const INPUT_NAME = "input_postnet";
/**
* @brief Tensor of s hape {1 x NUM_FRAMES x NUM_CHANNELS x 1}
*/
static constexpr const char* const OUTPUT_NAME = "output_postnet";
static constexpr const char* const ENGINE_NAME = "tacotron2_postnet";
/**
* @brief Create a new PostNetInstance.
*
* @param engine The ICudaEngine containing the built network.
*/
PostNetInstance(TRTPtr<nvinfer1::ICudaEngine> engine);
// disable copying
PostNetInstance(const PostNetInstance& other) = delete;
PostNetInstance& operator=(const PostNetInstance& other) = delete;
/**
* @brief Perform inference through this network (apply the postnet).
*
* @param stream The cuda stream.
* @param batchSize The size of the batch to run.
* @param inputDevice The input tensor on the GPU.
* @param outputDevice The output tensor on the GPU.
*/
void infer(cudaStream_t stream, int batchSize, const void* inputDevice, void* outputDevice);
/**
* @brief Get the number of mel-scale spectrograms the postnet processes at
* once.
*
* @return The number mels that will be processed at once.
*/
int getMelChunkSize() const;
/**
* @brief Get the number of mel-scale spectrograms channels the postnet is
* configured for.
*
* @return The number of mel channels.
*/
int getNumMelChannels() const;
/**
* @brief Get the total size of the output tensor.
*
* @return The total size.
*/
int getOutputSize() const;
private:
Binding mBinding;
TRTPtr<nvinfer1::IExecutionContext> mContext;
};
} // namespace tts
#endif
|
TensorFlow2/LanguageModeling/BERT/scripts | scripts | finetune_inference_benchmark | #!/bin/bash
# Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ==============================================================================
LOGFILE="/results/squad_inference_benchmark_bert.log"
tmp_file="/tmp/squad_inference_benchmark.log"
for s in base large; do
for precision in fp16 fp32; do
for slen in 128 384; do
len=""
if [ "$slen" = 128 ] ; then
len="_seq128"
fi
for i in 1 2 4 8; do
scripts/run_inference_benchmark$len.sh $s $i $precision true |& tee $tmp_file
perf=`cat $tmp_file | grep -F 'Throughput Average (sentences/sec) =' | tail -1 | awk -F'= ' '{print $2}'`
la=`cat $tmp_file | grep -F 'Latency Average (ms)' | awk -F'= ' '{print $2}'`
l50=`cat $tmp_file | grep -F 'Latency Confidence Level 50 (ms)' | awk -F'= ' '{print $2}'`
l90=`cat $tmp_file | grep -F 'Latency Confidence Level 90 (ms)' | awk -F'= ' '{print $2}'`
l95=`cat $tmp_file | grep -F 'Latency Confidence Level 95 (ms)' | awk -F'= ' '{print $2}'`
l99=`cat $tmp_file | grep -F 'Latency Confidence Level 99 (ms)' | awk -F'= ' '{print $2}'`
l100=`cat $tmp_file | grep -F 'Latency Confidence Level 100 (ms)' | awk -F'= ' '{print $2}'`
echo "$s $slen $i $precision $perf $la $l50 $l90 $l95 $l99 $l100" >> $LOGFILE
done
done
done
done
|
PyTorch/LanguageModeling/BERT | BERT | run_glue | # coding=utf-8
# Copyright 2018 The Google AI Language Team Authors and The HugginFace Inc. team.
# Copyright (c) 2018-2021, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""BERT finetuning runner."""
from __future__ import absolute_import, division, print_function
import pickle
import argparse
import logging
import os
import random
import wget
import json
import time
import dllogger
import numpy as np
import torch
from torch.utils.data import (DataLoader, RandomSampler, SequentialSampler,
TensorDataset)
from torch.utils.data.distributed import DistributedSampler
from tqdm import tqdm, trange
from file_utils import PYTORCH_PRETRAINED_BERT_CACHE
import modeling
from tokenization import BertTokenizer
from optimization import BertAdam, warmup_linear
from schedulers import LinearWarmUpScheduler
from apex import amp
from sklearn.metrics import matthews_corrcoef, f1_score
from utils import (is_main_process, mkdir_by_main_process, format_step,
get_world_size)
from processors.glue import PROCESSORS, convert_examples_to_features
torch._C._jit_set_profiling_mode(False)
torch._C._jit_set_profiling_executor(False)
logging.basicConfig(
format='%(asctime)s - %(levelname)s - %(name)s - %(message)s',
datefmt='%m/%d/%Y %H:%M:%S',
level=logging.INFO,
)
logger = logging.getLogger(__name__)
def compute_metrics(task_name, preds, labels):
assert len(preds) == len(labels)
if task_name == "cola":
return {"mcc": matthews_corrcoef(labels, preds)}
elif task_name == "sst-2":
return {"acc": simple_accuracy(preds, labels)}
elif task_name == "mrpc":
return acc_and_f1(preds, labels)
elif task_name == "sts-b":
return pearson_and_spearman(preds, labels)
elif task_name == "qqp":
return acc_and_f1(preds, labels)
elif task_name == "mnli":
return {"acc": simple_accuracy(preds, labels)}
elif task_name == "mnli-mm":
return {"acc": simple_accuracy(preds, labels)}
elif task_name == "qnli":
return {"acc": simple_accuracy(preds, labels)}
elif task_name == "rte":
return {"acc": simple_accuracy(preds, labels)}
elif task_name == "wnli":
return {"acc": simple_accuracy(preds, labels)}
else:
raise KeyError(task_name)
def simple_accuracy(preds, labels):
return (preds == labels).mean()
def acc_and_f1(preds, labels):
acc = simple_accuracy(preds, labels)
f1 = f1_score(y_true=labels, y_pred=preds)
return {
"acc": acc,
"f1": f1,
"acc_and_f1": (acc + f1) / 2,
}
def accuracy(out, labels):
outputs = np.argmax(out, axis=1)
return np.sum(outputs == labels)
from apex.multi_tensor_apply import multi_tensor_applier
class GradientClipper:
"""
Clips gradient norm of an iterable of parameters.
"""
def __init__(self, max_grad_norm):
self.max_norm = max_grad_norm
if multi_tensor_applier.available:
import amp_C
self._overflow_buf = torch.cuda.IntTensor([0])
self.multi_tensor_l2norm = amp_C.multi_tensor_l2norm
self.multi_tensor_scale = amp_C.multi_tensor_scale
else:
raise RuntimeError('Gradient clipping requires cuda extensions')
def step(self, parameters):
l = [p.grad for p in parameters if p.grad is not None]
total_norm, _ = multi_tensor_applier(
self.multi_tensor_l2norm,
self._overflow_buf,
[l],
False,
)
total_norm = total_norm.item()
if (total_norm == float('inf')): return
clip_coef = self.max_norm / (total_norm + 1e-6)
if clip_coef < 1:
multi_tensor_applier(
self.multi_tensor_scale,
self._overflow_buf,
[l, l],
clip_coef,
)
def parse_args(parser=argparse.ArgumentParser()):
## Required parameters
parser.add_argument(
"--data_dir",
default=None,
type=str,
required=True,
help="The input data dir. Should contain the .tsv files (or other data "
"files) for the task.",
)
parser.add_argument(
"--bert_model",
default=None,
type=str,
required=True,
help="Bert pre-trained model selected in the list: bert-base-uncased, "
"bert-large-uncased, bert-base-cased, bert-large-cased, "
"bert-base-multilingual-uncased, bert-base-multilingual-cased, "
"bert-base-chinese.",
)
parser.add_argument(
"--task_name",
default=None,
type=str,
required=True,
choices=PROCESSORS.keys(),
help="The name of the task to train.",
)
parser.add_argument(
"--output_dir",
default=None,
type=str,
required=True,
help="The output directory where the model predictions and checkpoints "
"will be written.",
)
parser.add_argument(
"--init_checkpoint",
default=None,
type=str,
required=True,
help="The checkpoint file from pretraining",
)
## Other parameters
parser.add_argument(
"--max_seq_length",
default=128,
type=int,
help="The maximum total input sequence length after WordPiece "
"tokenization. \n"
"Sequences longer than this will be truncated, and sequences shorter \n"
"than this will be padded.",
)
parser.add_argument("--do_train",
action='store_true',
help="Whether to run training.")
parser.add_argument("--do_eval",
action='store_true',
help="Whether to get model-task performance on the dev"
" set by running eval.")
parser.add_argument("--do_predict",
action='store_true',
help="Whether to output prediction results on the dev "
"set by running eval.")
parser.add_argument("--do_lower_case",
action='store_true',
help="Set this flag if you are using an uncased model.")
parser.add_argument("--train_batch_size",
default=32,
type=int,
help="Batch size per GPU for training.")
parser.add_argument("--eval_batch_size",
default=8,
type=int,
help="Batch size per GPU for eval.")
parser.add_argument("--learning_rate",
default=5e-5,
type=float,
help="The initial learning rate for Adam.")
parser.add_argument("--num_train_epochs",
default=3.0,
type=float,
help="Total number of training epochs to perform.")
parser.add_argument("--max_steps",
default=-1.0,
type=float,
help="Total number of training steps to perform.")
parser.add_argument(
"--warmup_proportion",
default=0.1,
type=float,
help="Proportion of training to perform linear learning rate warmup "
"for. E.g., 0.1 = 10%% of training.",
)
parser.add_argument("--no_cuda",
action='store_true',
help="Whether not to use CUDA when available")
parser.add_argument("--local_rank",
type=int,
default=os.getenv('LOCAL_RANK', -1),
help="local_rank for distributed training on gpus")
parser.add_argument('--seed',
type=int,
default=1,
help="random seed for initialization")
parser.add_argument(
'--gradient_accumulation_steps',
type=int,
default=1,
help="Number of updates steps to accumulate before performing a "
"backward/update pass.")
parser.add_argument(
'--fp16',
action='store_true',
help="Mixed precision training",
)
parser.add_argument(
'--amp',
action='store_true',
help="Mixed precision training",
)
parser.add_argument(
'--loss_scale',
type=float,
default=0,
help="Loss scaling to improve fp16 numeric stability. Only used when "
"fp16 set to True.\n"
"0 (default value): dynamic loss scaling.\n"
"Positive power of 2: static loss scaling value.\n",
)
parser.add_argument('--server_ip',
type=str,
default='',
help="Can be used for distant debugging.")
parser.add_argument('--server_port',
type=str,
default='',
help="Can be used for distant debugging.")
parser.add_argument('--vocab_file',
type=str,
default=None,
required=True,
help="Vocabulary mapping/file BERT was pretrainined on")
parser.add_argument("--config_file",
default=None,
type=str,
required=True,
help="The BERT model config")
parser.add_argument('--skip_checkpoint',
default=False,
action='store_true',
help="Whether to save checkpoints")
return parser.parse_args()
def init_optimizer_and_amp(model, learning_rate, loss_scale, warmup_proportion,
num_train_optimization_steps, use_fp16):
param_optimizer = list(model.named_parameters())
no_decay = ['bias', 'LayerNorm.bias', 'LayerNorm.weight']
optimizer_grouped_parameters = [
{
'params': [
p for n, p in param_optimizer
if not any(nd in n for nd in no_decay)
],
'weight_decay': 0.01
},
{
'params': [
p for n, p in param_optimizer if any(nd in n for nd in no_decay)
],
'weight_decay': 0.0
},
]
optimizer, scheduler = None, None
if use_fp16:
logger.info("using fp16")
try:
from apex.optimizers import FusedAdam
except ImportError:
raise ImportError("Please install apex from "
"https://www.github.com/nvidia/apex to use "
"distributed and fp16 training.")
if num_train_optimization_steps is not None:
optimizer = FusedAdam(
optimizer_grouped_parameters,
lr=learning_rate,
bias_correction=False,
)
amp_inits = amp.initialize(
model,
optimizers=optimizer,
opt_level="O2",
keep_batchnorm_fp32=False,
loss_scale="dynamic" if loss_scale == 0 else loss_scale,
)
model, optimizer = (amp_inits
if num_train_optimization_steps is not None else
(amp_inits, None))
if num_train_optimization_steps is not None:
scheduler = LinearWarmUpScheduler(
optimizer,
warmup=warmup_proportion,
total_steps=num_train_optimization_steps,
)
else:
logger.info("using fp32")
if num_train_optimization_steps is not None:
optimizer = BertAdam(
optimizer_grouped_parameters,
lr=learning_rate,
warmup=warmup_proportion,
t_total=num_train_optimization_steps,
)
return model, optimizer, scheduler
def gen_tensor_dataset(features):
all_input_ids = torch.tensor(
[f.input_ids for f in features],
dtype=torch.long,
)
all_input_mask = torch.tensor(
[f.input_mask for f in features],
dtype=torch.long,
)
all_segment_ids = torch.tensor(
[f.segment_ids for f in features],
dtype=torch.long,
)
all_label_ids = torch.tensor(
[f.label_id for f in features],
dtype=torch.long,
)
return TensorDataset(
all_input_ids,
all_input_mask,
all_segment_ids,
all_label_ids,
)
def get_train_features(data_dir, bert_model, max_seq_length, do_lower_case,
local_rank, train_batch_size,
gradient_accumulation_steps, num_train_epochs, tokenizer,
processor):
cached_train_features_file = os.path.join(
data_dir,
'{0}_{1}_{2}'.format(
list(filter(None, bert_model.split('/'))).pop(),
str(max_seq_length),
str(do_lower_case),
),
)
train_features = None
try:
with open(cached_train_features_file, "rb") as reader:
train_features = pickle.load(reader)
logger.info("Loaded pre-processed features from {}".format(
cached_train_features_file))
except:
logger.info("Did not find pre-processed features from {}".format(
cached_train_features_file))
train_examples = processor.get_train_examples(data_dir)
train_features, _ = convert_examples_to_features(
train_examples,
processor.get_labels(),
max_seq_length,
tokenizer,
)
if is_main_process():
logger.info(" Saving train features into cached file %s",
cached_train_features_file)
with open(cached_train_features_file, "wb") as writer:
pickle.dump(train_features, writer)
return train_features
def dump_predictions(path, label_map, preds, examples):
label_rmap = {label_idx: label for label, label_idx in label_map.items()}
predictions = {
example.guid: label_rmap[preds[i]] for i, example in enumerate(examples)
}
with open(path, "w") as writer:
json.dump(predictions, writer)
def main(args):
args.fp16 = args.fp16 or args.amp
if args.server_ip and args.server_port:
# Distant debugging - see
# https://code.visualstudio.com/docs/python/debugging#_attach-to-a-local-script
import ptvsd
logger.info("Waiting for debugger attach")
ptvsd.enable_attach(
address=(args.server_ip, args.server_port),
redirect_output=True,
)
ptvsd.wait_for_attach()
if args.local_rank == -1 or args.no_cuda:
device = torch.device(
"cuda" if torch.cuda.is_available() and not args.no_cuda else "cpu")
n_gpu = torch.cuda.device_count()
else:
torch.cuda.set_device(args.local_rank)
device = torch.device("cuda", args.local_rank)
n_gpu = 1
# Initializes the distributed backend which will take care of
# sychronizing nodes/GPUs.
if not torch.distributed.is_initialized():
torch.distributed.init_process_group(backend='nccl')
logger.info("device: {} n_gpu: {}, distributed training: {}, "
"16-bits training: {}".format(
device,
n_gpu,
bool(args.local_rank != -1),
args.fp16,
))
if not args.do_train and not args.do_eval and not args.do_predict:
raise ValueError("At least one of `do_train`, `do_eval` or "
"`do_predict` must be True.")
if is_main_process():
if (os.path.exists(args.output_dir) and os.listdir(args.output_dir) and
args.do_train):
logger.warning("Output directory ({}) already exists and is not "
"empty.".format(args.output_dir))
mkdir_by_main_process(args.output_dir)
if is_main_process():
dllogger.init(backends=[
dllogger.JSONStreamBackend(
verbosity=dllogger.Verbosity.VERBOSE,
filename=os.path.join(args.output_dir, 'dllogger.json'),
),
dllogger.StdOutBackend(
verbosity=dllogger.Verbosity.VERBOSE,
step_format=format_step,
),
])
else:
dllogger.init(backends=[])
dllogger.metadata("e2e_train_time", {"unit": "s"})
dllogger.metadata("training_sequences_per_second", {"unit": "sequences/s"})
dllogger.metadata("e2e_inference_time", {"unit": "s"})
dllogger.metadata("inference_sequences_per_second", {"unit": "sequences/s"})
dllogger.metadata("exact_match", {"unit": None})
dllogger.metadata("F1", {"unit": None})
dllogger.log(step="PARAMETER", data={"Config": [str(args)]})
if args.gradient_accumulation_steps < 1:
raise ValueError("Invalid gradient_accumulation_steps parameter: {}, "
"should be >= 1".format(
args.gradient_accumulation_steps))
if args.gradient_accumulation_steps > args.train_batch_size:
raise ValueError("gradient_accumulation_steps ({}) cannot be larger "
"train_batch_size ({}) - there cannot be a fraction "
"of one sample.".format(
args.gradient_accumulation_steps,
args.train_batch_size,
))
args.train_batch_size = (args.train_batch_size //
args.gradient_accumulation_steps)
random.seed(args.seed)
np.random.seed(args.seed)
torch.manual_seed(args.seed)
if n_gpu > 0:
torch.cuda.manual_seed_all(args.seed)
dllogger.log(step="PARAMETER", data={"SEED": args.seed})
processor = PROCESSORS[args.task_name]()
num_labels = len(processor.get_labels())
#tokenizer = BertTokenizer.from_pretrained(args.bert_model, do_lower_case=args.do_lower_case)
tokenizer = BertTokenizer(
args.vocab_file,
do_lower_case=args.do_lower_case,
max_len=512,
) # for bert large
num_train_optimization_steps = None
if args.do_train:
train_features = get_train_features(
args.data_dir,
args.bert_model,
args.max_seq_length,
args.do_lower_case,
args.local_rank,
args.train_batch_size,
args.gradient_accumulation_steps,
args.num_train_epochs,
tokenizer,
processor,
)
num_train_optimization_steps = int(
len(train_features) / args.train_batch_size /
args.gradient_accumulation_steps) * args.num_train_epochs
if args.local_rank != -1:
num_train_optimization_steps = (num_train_optimization_steps //
torch.distributed.get_world_size())
# Prepare model
config = modeling.BertConfig.from_json_file(args.config_file)
# Padding for divisibility by 8
if config.vocab_size % 8 != 0:
config.vocab_size += 8 - (config.vocab_size % 8)
# modeling.ACT2FN["bias_gelu"] = modeling.bias_gelu_training
model = modeling.BertForSequenceClassification(
config,
num_labels=num_labels,
)
logger.info("USING CHECKPOINT from {}".format(args.init_checkpoint))
checkpoint = torch.load(args.init_checkpoint, map_location='cpu')
checkpoint = checkpoint["model"] if "model" in checkpoint.keys() else checkpoint
model.load_state_dict(checkpoint, strict=False)
logger.info("USED CHECKPOINT from {}".format(args.init_checkpoint))
dllogger.log(
step="PARAMETER",
data={
"num_parameters":
sum([p.numel() for p in model.parameters() if p.requires_grad]),
},
)
model.to(device)
# Prepare optimizer
model, optimizer, scheduler = init_optimizer_and_amp(
model,
args.learning_rate,
args.loss_scale,
args.warmup_proportion,
num_train_optimization_steps,
args.fp16,
)
if args.local_rank != -1:
try:
from apex.parallel import DistributedDataParallel as DDP
except ImportError:
raise ImportError("Please install apex from "
"https://www.github.com/nvidia/apex to use "
"distributed and fp16 training.")
model = DDP(model)
elif n_gpu > 1:
model = torch.nn.DataParallel(model)
loss_fct = torch.nn.CrossEntropyLoss()
results = {}
if args.do_train:
logger.info("***** Running training *****")
logger.info(" Num examples = %d", len(train_features))
logger.info(" Batch size = %d", args.train_batch_size)
logger.info(" Num steps = %d", num_train_optimization_steps)
train_data = gen_tensor_dataset(train_features)
if args.local_rank == -1:
train_sampler = RandomSampler(train_data)
else:
train_sampler = DistributedSampler(train_data)
train_dataloader = DataLoader(
train_data,
sampler=train_sampler,
batch_size=args.train_batch_size,
)
global_step = 0
nb_tr_steps = 0
tr_loss = 0
latency_train = 0.0
nb_tr_examples = 0
model.train()
tic_train = time.perf_counter()
for _ in trange(int(args.num_train_epochs), desc="Epoch"):
tr_loss, nb_tr_steps = 0, 0
for step, batch in enumerate(
tqdm(train_dataloader, desc="Iteration")):
if args.max_steps > 0 and global_step > args.max_steps:
break
batch = tuple(t.to(device) for t in batch)
input_ids, input_mask, segment_ids, label_ids = batch
logits = model(input_ids, segment_ids, input_mask)
loss = loss_fct(
logits.view(-1, num_labels),
label_ids.view(-1),
)
if n_gpu > 1:
loss = loss.mean() # mean() to average on multi-gpu.
if args.gradient_accumulation_steps > 1:
loss = loss / args.gradient_accumulation_steps
if args.fp16:
with amp.scale_loss(loss, optimizer) as scaled_loss:
scaled_loss.backward()
else:
loss.backward()
tr_loss += loss.item()
nb_tr_examples += input_ids.size(0)
nb_tr_steps += 1
if (step + 1) % args.gradient_accumulation_steps == 0:
if args.fp16:
# modify learning rate with special warm up for BERT
# which FusedAdam doesn't do
scheduler.step()
optimizer.step()
optimizer.zero_grad()
global_step += 1
latency_train = time.perf_counter() - tic_train
tr_loss = tr_loss / nb_tr_steps
results.update({
'global_step':
global_step,
'train:loss':
tr_loss,
'train:latency':
latency_train,
'train:num_samples_per_gpu':
nb_tr_examples,
'train:num_steps':
nb_tr_steps,
'train:throughput':
get_world_size() * nb_tr_examples / latency_train,
})
if is_main_process() and not args.skip_checkpoint:
model_to_save = model.module if hasattr(model, 'module') else model
torch.save(
{"model": model_to_save.state_dict()},
os.path.join(args.output_dir, modeling.WEIGHTS_NAME),
)
with open(
os.path.join(args.output_dir, modeling.CONFIG_NAME),
'w',
) as f:
f.write(model_to_save.config.to_json_string())
if (args.do_eval or args.do_predict) and is_main_process():
eval_examples = processor.get_dev_examples(args.data_dir)
eval_features, label_map = convert_examples_to_features(
eval_examples,
processor.get_labels(),
args.max_seq_length,
tokenizer,
)
logger.info("***** Running evaluation *****")
logger.info(" Num examples = %d", len(eval_examples))
logger.info(" Batch size = %d", args.eval_batch_size)
eval_data = gen_tensor_dataset(eval_features)
# Run prediction for full data
eval_sampler = SequentialSampler(eval_data)
eval_dataloader = DataLoader(
eval_data,
sampler=eval_sampler,
batch_size=args.eval_batch_size,
)
model.eval()
preds = None
out_label_ids = None
eval_loss = 0
nb_eval_steps, nb_eval_examples = 0, 0
cuda_events = [(torch.cuda.Event(enable_timing=True),
torch.cuda.Event(enable_timing=True))
for _ in range(len(eval_dataloader))]
for i, (input_ids, input_mask, segment_ids, label_ids) in tqdm(
enumerate(eval_dataloader),
desc="Evaluating",
):
input_ids = input_ids.to(device)
input_mask = input_mask.to(device)
segment_ids = segment_ids.to(device)
label_ids = label_ids.to(device)
with torch.no_grad():
cuda_events[i][0].record()
logits = model(input_ids, segment_ids, input_mask)
cuda_events[i][1].record()
if args.do_eval:
eval_loss += loss_fct(
logits.view(-1, num_labels),
label_ids.view(-1),
).mean().item()
nb_eval_steps += 1
nb_eval_examples += input_ids.size(0)
if preds is None:
preds = logits.detach().cpu().numpy()
out_label_ids = label_ids.detach().cpu().numpy()
else:
preds = np.append(preds, logits.detach().cpu().numpy(), axis=0)
out_label_ids = np.append(
out_label_ids,
label_ids.detach().cpu().numpy(),
axis=0,
)
torch.cuda.synchronize()
eval_latencies = [
event_start.elapsed_time(event_end)
for event_start, event_end in cuda_events
]
eval_latencies = list(sorted(eval_latencies))
def infer_latency_sli(threshold):
index = int(len(eval_latencies) * threshold) - 1
index = min(max(index, 0), len(eval_latencies) - 1)
return eval_latencies[index]
eval_throughput = (args.eval_batch_size /
(np.mean(eval_latencies) / 1000))
results.update({
'eval:num_samples_per_gpu': nb_eval_examples,
'eval:num_steps': nb_eval_steps,
'infer:latency(ms):50%': infer_latency_sli(0.5),
'infer:latency(ms):90%': infer_latency_sli(0.9),
'infer:latency(ms):95%': infer_latency_sli(0.95),
'infer:latency(ms):99%': infer_latency_sli(0.99),
'infer:latency(ms):100%': infer_latency_sli(1.0),
'infer:latency(ms):avg': np.mean(eval_latencies),
'infer:latency(ms):std': np.std(eval_latencies),
'infer:latency(ms):sum': np.sum(eval_latencies),
'infer:throughput(samples/s):avg': eval_throughput,
})
preds = np.argmax(preds, axis=1)
if args.do_predict:
dump_predictions(
os.path.join(args.output_dir, 'predictions.json'),
label_map,
preds,
eval_examples,
)
if args.do_eval:
results['eval:loss'] = eval_loss / nb_eval_steps
eval_result = compute_metrics(args.task_name, preds, out_label_ids)
results.update(eval_result)
if is_main_process():
logger.info("***** Results *****")
for key in sorted(results.keys()):
logger.info(" %s = %s", key, str(results[key]))
with open(os.path.join(args.output_dir, "results.txt"), "w") as writer:
json.dump(results, writer)
dllogger_queries_from_results = {
'exact_match': 'acc',
'F1': 'f1',
'e2e_train_time': 'train:latency',
'training_sequences_per_second': 'train:throughput',
'e2e_inference_time': ('infer:latency(ms):sum', lambda x: x / 1000),
'inference_sequences_per_second': 'infer:throughput(samples/s):avg',
}
for key, query in dllogger_queries_from_results.items():
results_key, convert = (query if isinstance(query, tuple) else
(query, lambda x: x))
if results_key not in results:
continue
dllogger.log(
step=tuple(),
data={key: convert(results[results_key])},
)
dllogger.flush()
return results
if __name__ == "__main__":
main(parse_args())
|
PyTorch/SpeechSynthesis/HiFiGAN/common/text | text | letters_and_numbers | import re
_letters_and_numbers_re = re.compile(
r"((?:[a-zA-Z]+[0-9]|[0-9]+[a-zA-Z])[a-zA-Z0-9']*)", re.IGNORECASE)
_hardware_re = re.compile(
'([0-9]+(?:[.,][0-9]+)?)(?:\s?)(tb|gb|mb|kb|ghz|mhz|khz|hz|mm)', re.IGNORECASE)
_hardware_key = {'tb': 'terabyte',
'gb': 'gigabyte',
'mb': 'megabyte',
'kb': 'kilobyte',
'ghz': 'gigahertz',
'mhz': 'megahertz',
'khz': 'kilohertz',
'hz': 'hertz',
'mm': 'millimeter',
'cm': 'centimeter',
'km': 'kilometer'}
_dimension_re = re.compile(
r'\b(\d+(?:[,.]\d+)?\s*[xX]\s*\d+(?:[,.]\d+)?\s*[xX]\s*\d+(?:[,.]\d+)?(?:in|inch|m)?)\b|\b(\d+(?:[,.]\d+)?\s*[xX]\s*\d+(?:[,.]\d+)?(?:in|inch|m)?)\b')
_dimension_key = {'m': 'meter',
'in': 'inch',
'inch': 'inch'}
def _expand_letters_and_numbers(m):
text = re.split(r'(\d+)', m.group(0))
# remove trailing space
if text[-1] == '':
text = text[:-1]
elif text[0] == '':
text = text[1:]
# if not like 1920s, or AK47's , 20th, 1st, 2nd, 3rd, etc...
if text[-1] in ("'s", "s", "th", "nd", "st", "rd") and text[-2].isdigit():
text[-2] = text[-2] + text[-1]
text = text[:-1]
# for combining digits 2 by 2
new_text = []
for i in range(len(text)):
string = text[i]
if string.isdigit() and len(string) < 5:
# heuristics
if len(string) > 2 and string[-2] == '0':
if string[-1] == '0':
string = [string]
else:
string = [string[:-2], string[-2], string[-1]]
elif len(string) % 2 == 0:
string = [string[i:i+2] for i in range(0, len(string), 2)]
elif len(string) > 2:
string = [string[0]] + [string[i:i+2] for i in range(1, len(string), 2)]
new_text.extend(string)
else:
new_text.append(string)
text = new_text
text = " ".join(text)
return text
def _expand_hardware(m):
quantity, measure = m.groups(0)
measure = _hardware_key[measure.lower()]
if measure[-1] != 'z' and float(quantity.replace(',', '')) > 1:
return "{} {}s".format(quantity, measure)
return "{} {}".format(quantity, measure)
def _expand_dimension(m):
text = "".join([x for x in m.groups(0) if x != 0])
text = text.replace(' x ', ' by ')
text = text.replace('x', ' by ')
if text.endswith(tuple(_dimension_key.keys())):
if text[-2].isdigit():
text = "{} {}".format(text[:-1], _dimension_key[text[-1:]])
elif text[-3].isdigit():
text = "{} {}".format(text[:-2], _dimension_key[text[-2:]])
return text
def normalize_letters_and_numbers(text):
text = re.sub(_hardware_re, _expand_hardware, text)
text = re.sub(_dimension_re, _expand_dimension, text)
text = re.sub(_letters_and_numbers_re, _expand_letters_and_numbers, text)
return text
|
TensorFlow2/Classification/ConvNets/efficientnet_v1/B4/training/AMP | AMP | train_benchmark_8xV100-32G | # Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
horovodrun -np 8 bash ./scripts/bind.sh --cpu=exclusive --ib=single -- python3 main.py \
--cfg config/efficientnet_v1/b4_cfg.py \
--mode train_and_eval \
--use_amp \
--use_xla \
--model_dir ./output \
--data_dir /data \
--log_steps 100 \
--max_epochs 2 \
--save_checkpoint_freq 5 \
--train_batch_size 64 \
--eval_batch_size 64 \
--train_img_size 380 \
--eval_img_size 380 \
--augmenter_name autoaugment \
--lr_decay cosine \
--mixup_alpha 0.2 \
--defer_img_mixing \
--moving_average_decay 0.9999 \
--lr_init 0.005
|
TensorFlow2/Recommendation/WideAndDeep/triton/runner | runner | utils | # Copyright (c) 2021-2022, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import os
import pathlib
import shutil
import subprocess
from enum import Enum
from typing import Any
# method from PEP-366 to support relative import in executed modules
if __name__ == "__main__" and __package__ is None:
__package__ = pathlib.Path(__file__).parent.name
from .core import Command
from .exceptions import RunnerException
from .logger import LOGGER
def format_env_key(s: str):
"""
Format environmental variable key
Args:
s: String to format
Returns:
Upper cased string
"""
return s.upper()
def format_env_value(value: Any) -> str:
"""
Format environment variable value
Args:
value: value to be formatted
Returns:
Formatted value as a string
"""
value = value if not isinstance(value, Enum) else value.value
value = value if type(value) not in [list, tuple] else ",".join(map(str, value))
value = str(value)
return value
def get_result_path(result_path: str) -> str:
"""
Map result path when different variants passed ex. with env variable in path
Args:
result_path: Path to result file
Returns:
str
"""
for env_var, val in os.environ.items():
result_path = result_path.replace(f"${{{env_var}}}", val)
if result_path.startswith("/"):
return result_path
if result_path.startswith("./"):
result_path = result_path[2:]
return result_path
def clean_directory(directory: pathlib.Path) -> None:
"""
Remove all files and directories from directory
Args:
directory: Path to directory which should be cleaned
Returns:
None
"""
LOGGER.debug(f"Cleaning {directory.as_posix()}")
if not directory.is_dir():
LOGGER.warning(f"{directory.name} is not a directory.")
return
for item in os.listdir(directory):
item_path = directory / item
if item_path.is_dir():
LOGGER.debug(f"Remove dir {item_path.as_posix()}")
shutil.rmtree(item_path.as_posix())
elif item_path.is_file():
LOGGER.debug(f"Remove file: {item_path.as_posix()}")
item_path.unlink()
else:
LOGGER.warning(f"Cannot remove item {item_path.name}. Not a file or directory.")
def exec_command(command: Command) -> None:
"""
Execute command
Args:
command: Command to run
"""
try:
process = subprocess.Popen(
[str(command)],
shell=True,
start_new_session=True,
stdout=subprocess.PIPE,
stderr=subprocess.STDOUT,
encoding="utf-8",
)
while True:
output = process.stdout.readline()
if output == "" and process.poll() is not None:
break
if output:
print(output.rstrip())
LOGGER.write(output)
result = process.poll()
if result != 0:
raise RunnerException(f"Command {command} failed with exit status: {result}")
except subprocess.CalledProcessError as e:
raise RunnerException(f"Running command {e.cmd} failed with exit status {e.returncode} : {e.output}")
def measurement_env_params(measurement):
params = {}
for key, value in measurement.__dict__.items():
param = f"{measurement.__class__.__name__.upper()}_{key.upper()}"
params[param] = " ".join(list(map(lambda val: str(val), value))) if isinstance(value, list) else int(value)
return params
def offline_performance_configuration(steps, max_batch_size):
step = int(max_batch_size) // steps
batch_sizes = [step * idx for idx in range(1, steps + 1)]
concurrency = [1]
return batch_sizes, concurrency
def online_performance_configuration(steps, max_batch_size, number_of_model_instances):
max_total_requests = 2 * int(max_batch_size) * int(number_of_model_instances)
max_concurrency = min(128, max_total_requests)
step = max(1, max_concurrency // steps)
min_concurrency = step
batch_sizes = [max(1, max_total_requests // max_concurrency)]
concurrency = list(range(min_concurrency, max_concurrency + 1, step))
return batch_sizes, concurrency
|
TensorFlow/Detection/SSD/models/research/slim/nets/nasnet | nasnet | nasnet_utils_test | # Copyright 2017 The TensorFlow Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ==============================================================================
"""Tests for slim.nets.nasnet.nasnet_utils."""
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import tensorflow as tf
from nets.nasnet import nasnet_utils
class NasnetUtilsTest(tf.test.TestCase):
def testCalcReductionLayers(self):
num_cells = 18
num_reduction_layers = 2
reduction_layers = nasnet_utils.calc_reduction_layers(
num_cells, num_reduction_layers)
self.assertEqual(len(reduction_layers), 2)
self.assertEqual(reduction_layers[0], 6)
self.assertEqual(reduction_layers[1], 12)
def testGetChannelIndex(self):
data_formats = ['NHWC', 'NCHW']
for data_format in data_formats:
index = nasnet_utils.get_channel_index(data_format)
correct_index = 3 if data_format == 'NHWC' else 1
self.assertEqual(index, correct_index)
def testGetChannelDim(self):
data_formats = ['NHWC', 'NCHW']
shape = [10, 20, 30, 40]
for data_format in data_formats:
dim = nasnet_utils.get_channel_dim(shape, data_format)
correct_dim = shape[3] if data_format == 'NHWC' else shape[1]
self.assertEqual(dim, correct_dim)
def testGlobalAvgPool(self):
data_formats = ['NHWC', 'NCHW']
inputs = tf.placeholder(tf.float32, (5, 10, 20, 10))
for data_format in data_formats:
output = nasnet_utils.global_avg_pool(
inputs, data_format)
self.assertEqual(output.shape, [5, 10])
if __name__ == '__main__':
tf.test.main()
|
Tools/DGLPyTorch/SyntheticGraphGeneration/syngen/benchmark/models/layers | layers | gat_layers | # Copyright (c) 2023, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import dgl
import torch
import torch.nn as nn
import torch.nn.functional as F
from dgl.nn.pytorch import GATConv
"""
GAT: Graph Attention Network
Graph Attention Networks (Veličković et al., ICLR 2018)
https://arxiv.org/abs/1710.10903
"""
class GATLayer(nn.Module):
"""
Parameters
----------
in_dim :
Number of input features.
out_dim :
Number of output features.
num_heads : int
Number of heads in Multi-Head Attention.
dropout :
Required for dropout of attn and feat in GATConv
batch_norm :
boolean flag for batch_norm layer.
residual :
If True, use residual connection inside this layer. Default: ``False``.
activation : callable activation function/layer or None, optional.
If not None, applies an activation function to the updated node features.
Using dgl builtin GATConv by default:
https://github.com/graphdeeplearning/benchmarking-gnns/commit/206e888ecc0f8d941c54e061d5dffcc7ae2142fc
"""
def __init__(
self,
in_dim,
out_dim,
num_heads,
dropout,
batch_norm,
residual=False,
activation=F.elu,
):
super().__init__()
self.residual = residual
self.activation = activation
self.batch_norm = batch_norm
if in_dim != (out_dim * num_heads):
self.residual = False
if dgl.__version__ < "0.5":
self.gatconv = GATConv(
in_dim, out_dim, num_heads, dropout, dropout
)
else:
self.gatconv = GATConv(
in_dim,
out_dim,
num_heads,
dropout,
dropout,
allow_zero_in_degree=True,
)
if self.batch_norm:
self.batchnorm_h = nn.BatchNorm1d(out_dim * num_heads)
def forward(self, g, h):
h_in = h # for residual connection
h = self.gatconv(g, h).flatten(1)
if self.batch_norm:
h = self.batchnorm_h(h)
if self.activation:
h = self.activation(h)
if self.residual:
h = h_in + h # residual connection
return h
##############################################################
#
# Additional layers for edge feature/representation analysis
#
##############################################################
class CustomGATHeadLayer(nn.Module):
def __init__(self, in_dim, out_dim, dropout, batch_norm):
super().__init__()
self.dropout = dropout
self.batch_norm = batch_norm
self.fc = nn.Linear(in_dim, out_dim, bias=False)
self.attn_fc = nn.Linear(2 * out_dim, 1, bias=False)
self.batchnorm_h = nn.BatchNorm1d(out_dim)
def edge_attention(self, edges):
z2 = torch.cat([edges.src["z"], edges.dst["z"]], dim=1)
a = self.attn_fc(z2)
return {"e": F.leaky_relu(a)}
def message_func(self, edges):
return {"z": edges.src["z"], "e": edges.data["e"]}
def reduce_func(self, nodes):
alpha = F.softmax(nodes.mailbox["e"], dim=1)
alpha = F.dropout(alpha, self.dropout, training=self.training)
h = torch.sum(alpha * nodes.mailbox["z"], dim=1)
return {"h": h}
def forward(self, g, h):
z = self.fc(h)
g.ndata["z"] = z
g.apply_edges(self.edge_attention)
g.update_all(self.message_func, self.reduce_func)
h = g.ndata["h"]
if self.batch_norm:
h = self.batchnorm_h(h)
h = F.elu(h)
h = F.dropout(h, self.dropout, training=self.training)
return h
class CustomGATLayer(nn.Module):
"""
Param: [in_dim, out_dim, n_heads]
"""
def __init__(
self, in_dim, out_dim, num_heads, dropout, batch_norm, residual=True
):
super().__init__()
self.in_channels = in_dim
self.out_channels = out_dim
self.num_heads = num_heads
self.residual = residual
if in_dim != (out_dim * num_heads):
self.residual = False
self.heads = nn.ModuleList()
for i in range(num_heads):
self.heads.append(
CustomGATHeadLayer(in_dim, out_dim, dropout, batch_norm)
)
self.merge = "cat"
def forward(self, g, h, e):
h_in = h # for residual connection
head_outs = [attn_head(g, h) for attn_head in self.heads]
if self.merge == "cat":
h = torch.cat(head_outs, dim=1)
else:
h = torch.mean(torch.stack(head_outs))
if self.residual:
h = h_in + h # residual connection
return h, e
def __repr__(self):
return "{}(in_channels={}, out_channels={}, heads={}, residual={})".format(
self.__class__.__name__,
self.in_channels,
self.out_channels,
self.num_heads,
self.residual,
)
##############################################################
class CustomGATHeadLayerEdgeReprFeat(nn.Module):
def __init__(self, in_dim, out_dim, dropout, batch_norm):
super().__init__()
self.dropout = dropout
self.batch_norm = batch_norm
self.fc_h = nn.Linear(in_dim, out_dim, bias=False)
self.fc_e = nn.Linear(in_dim, out_dim, bias=False)
self.fc_proj = nn.Linear(3 * out_dim, out_dim)
self.attn_fc = nn.Linear(3 * out_dim, 1, bias=False)
self.batchnorm_h = nn.BatchNorm1d(out_dim)
self.batchnorm_e = nn.BatchNorm1d(out_dim)
def edge_attention(self, edges):
z = torch.cat(
[edges.data["z_e"], edges.src["z_h"], edges.dst["z_h"]], dim=1
)
e_proj = self.fc_proj(z)
attn = F.leaky_relu(self.attn_fc(z))
return {"attn": attn, "e_proj": e_proj}
def message_func(self, edges):
return {"z": edges.src["z_h"], "attn": edges.data["attn"]}
def reduce_func(self, nodes):
alpha = F.softmax(nodes.mailbox["attn"], dim=1)
h = torch.sum(alpha * nodes.mailbox["z"], dim=1)
return {"h": h}
def forward(self, g, h, e):
import pdb
pdb.set_trace()
z_h = self.fc_h(h)
z_e = self.fc_e(e)
g.ndata["z_h"] = z_h
g.edata["z_e"] = z_e
g.apply_edges(self.edge_attention)
g.update_all(self.message_func, self.reduce_func)
h = g.ndata["h"]
e = g.edata["e_proj"]
if self.batch_norm:
h = self.batchnorm_h(h)
e = self.batchnorm_e(e)
h = F.elu(h)
e = F.elu(e)
h = F.dropout(h, self.dropout, training=self.training)
e = F.dropout(e, self.dropout, training=self.training)
return h, e
class CustomGATLayerEdgeReprFeat(nn.Module):
"""
Param: [in_dim, out_dim, n_heads]
"""
def __init__(
self, in_dim, out_dim, num_heads, dropout, batch_norm, residual=True
):
super().__init__()
self.in_channels = in_dim
self.out_channels = out_dim
self.num_heads = num_heads
self.residual = residual
if in_dim != (out_dim * num_heads):
self.residual = False
self.heads = nn.ModuleList()
for i in range(num_heads):
self.heads.append(
CustomGATHeadLayerEdgeReprFeat(
in_dim, out_dim, dropout, batch_norm
)
)
self.merge = "cat"
def forward(self, g, h, e):
h_in = h # for residual connection
e_in = e
head_outs_h = []
head_outs_e = []
for attn_head in self.heads:
h_temp, e_temp = attn_head(g, h, e)
head_outs_h.append(h_temp)
head_outs_e.append(e_temp)
if self.merge == "cat":
h = torch.cat(head_outs_h, dim=1)
e = torch.cat(head_outs_e, dim=1)
else:
raise NotImplementedError
if self.residual:
h = h_in + h # residual connection
e = e_in + e
return h, e
def __repr__(self):
return "{}(in_channels={}, out_channels={}, heads={}, residual={})".format(
self.__class__.__name__,
self.in_channels,
self.out_channels,
self.num_heads,
self.residual,
)
##############################################################
class CustomGATHeadLayerIsotropic(nn.Module):
def __init__(self, in_dim, out_dim, dropout, batch_norm):
super().__init__()
self.dropout = dropout
self.batch_norm = batch_norm
self.fc = nn.Linear(in_dim, out_dim, bias=False)
self.batchnorm_h = nn.BatchNorm1d(out_dim)
def message_func(self, edges):
return {"z": edges.src["z"]}
def reduce_func(self, nodes):
h = torch.sum(nodes.mailbox["z"], dim=1)
return {"h": h}
def forward(self, g, h):
z = self.fc(h)
g.ndata["z"] = z
g.update_all(self.message_func, self.reduce_func)
h = g.ndata["h"]
if self.batch_norm:
h = self.batchnorm_h(h)
h = F.elu(h)
h = F.dropout(h, self.dropout, training=self.training)
return h
class CustomGATLayerIsotropic(nn.Module):
"""
Param: [in_dim, out_dim, n_heads]
"""
def __init__(
self, in_dim, out_dim, num_heads, dropout, batch_norm, residual=True
):
super().__init__()
self.in_channels = in_dim
self.out_channels = out_dim
self.num_heads = num_heads
self.residual = residual
if in_dim != (out_dim * num_heads):
self.residual = False
self.heads = nn.ModuleList()
for i in range(num_heads):
self.heads.append(
CustomGATHeadLayerIsotropic(
in_dim, out_dim, dropout, batch_norm
)
)
self.merge = "cat"
def forward(self, g, h, e):
h_in = h # for residual connection
head_outs = [attn_head(g, h) for attn_head in self.heads]
if self.merge == "cat":
h = torch.cat(head_outs, dim=1)
else:
h = torch.mean(torch.stack(head_outs))
if self.residual:
h = h_in + h # residual connection
return h, e
def __repr__(self):
return "{}(in_channels={}, out_channels={}, heads={}, residual={})".format(
self.__class__.__name__,
self.in_channels,
self.out_channels,
self.num_heads,
self.residual,
)
|
TensorFlow/Detection/SSD/models/research/object_detection/utils | utils | visualization_utils | # Copyright 2017 The TensorFlow Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ==============================================================================
"""A set of functions that are used for visualization.
These functions often receive an image, perform some visualization on the image.
The functions do not return a value, instead they modify the image itself.
"""
import abc
import collections
import functools
# Set headless-friendly backend.
import matplotlib; matplotlib.use('Agg') # pylint: disable=multiple-statements
import matplotlib.pyplot as plt # pylint: disable=g-import-not-at-top
import numpy as np
import PIL.Image as Image
import PIL.ImageColor as ImageColor
import PIL.ImageDraw as ImageDraw
import PIL.ImageFont as ImageFont
import six
import tensorflow as tf
from object_detection.core import standard_fields as fields
from object_detection.utils import shape_utils
_TITLE_LEFT_MARGIN = 10
_TITLE_TOP_MARGIN = 10
STANDARD_COLORS = [
'AliceBlue', 'Chartreuse', 'Aqua', 'Aquamarine', 'Azure', 'Beige', 'Bisque',
'BlanchedAlmond', 'BlueViolet', 'BurlyWood', 'CadetBlue', 'AntiqueWhite',
'Chocolate', 'Coral', 'CornflowerBlue', 'Cornsilk', 'Crimson', 'Cyan',
'DarkCyan', 'DarkGoldenRod', 'DarkGrey', 'DarkKhaki', 'DarkOrange',
'DarkOrchid', 'DarkSalmon', 'DarkSeaGreen', 'DarkTurquoise', 'DarkViolet',
'DeepPink', 'DeepSkyBlue', 'DodgerBlue', 'FireBrick', 'FloralWhite',
'ForestGreen', 'Fuchsia', 'Gainsboro', 'GhostWhite', 'Gold', 'GoldenRod',
'Salmon', 'Tan', 'HoneyDew', 'HotPink', 'IndianRed', 'Ivory', 'Khaki',
'Lavender', 'LavenderBlush', 'LawnGreen', 'LemonChiffon', 'LightBlue',
'LightCoral', 'LightCyan', 'LightGoldenRodYellow', 'LightGray', 'LightGrey',
'LightGreen', 'LightPink', 'LightSalmon', 'LightSeaGreen', 'LightSkyBlue',
'LightSlateGray', 'LightSlateGrey', 'LightSteelBlue', 'LightYellow', 'Lime',
'LimeGreen', 'Linen', 'Magenta', 'MediumAquaMarine', 'MediumOrchid',
'MediumPurple', 'MediumSeaGreen', 'MediumSlateBlue', 'MediumSpringGreen',
'MediumTurquoise', 'MediumVioletRed', 'MintCream', 'MistyRose', 'Moccasin',
'NavajoWhite', 'OldLace', 'Olive', 'OliveDrab', 'Orange', 'OrangeRed',
'Orchid', 'PaleGoldenRod', 'PaleGreen', 'PaleTurquoise', 'PaleVioletRed',
'PapayaWhip', 'PeachPuff', 'Peru', 'Pink', 'Plum', 'PowderBlue', 'Purple',
'Red', 'RosyBrown', 'RoyalBlue', 'SaddleBrown', 'Green', 'SandyBrown',
'SeaGreen', 'SeaShell', 'Sienna', 'Silver', 'SkyBlue', 'SlateBlue',
'SlateGray', 'SlateGrey', 'Snow', 'SpringGreen', 'SteelBlue', 'GreenYellow',
'Teal', 'Thistle', 'Tomato', 'Turquoise', 'Violet', 'Wheat', 'White',
'WhiteSmoke', 'Yellow', 'YellowGreen'
]
def save_image_array_as_png(image, output_path):
"""Saves an image (represented as a numpy array) to PNG.
Args:
image: a numpy array with shape [height, width, 3].
output_path: path to which image should be written.
"""
image_pil = Image.fromarray(np.uint8(image)).convert('RGB')
with tf.gfile.Open(output_path, 'w') as fid:
image_pil.save(fid, 'PNG')
def encode_image_array_as_png_str(image):
"""Encodes a numpy array into a PNG string.
Args:
image: a numpy array with shape [height, width, 3].
Returns:
PNG encoded image string.
"""
image_pil = Image.fromarray(np.uint8(image))
output = six.BytesIO()
image_pil.save(output, format='PNG')
png_string = output.getvalue()
output.close()
return png_string
def draw_bounding_box_on_image_array(image,
ymin,
xmin,
ymax,
xmax,
color='red',
thickness=4,
display_str_list=(),
use_normalized_coordinates=True):
"""Adds a bounding box to an image (numpy array).
Bounding box coordinates can be specified in either absolute (pixel) or
normalized coordinates by setting the use_normalized_coordinates argument.
Args:
image: a numpy array with shape [height, width, 3].
ymin: ymin of bounding box.
xmin: xmin of bounding box.
ymax: ymax of bounding box.
xmax: xmax of bounding box.
color: color to draw bounding box. Default is red.
thickness: line thickness. Default value is 4.
display_str_list: list of strings to display in box
(each to be shown on its own line).
use_normalized_coordinates: If True (default), treat coordinates
ymin, xmin, ymax, xmax as relative to the image. Otherwise treat
coordinates as absolute.
"""
image_pil = Image.fromarray(np.uint8(image)).convert('RGB')
draw_bounding_box_on_image(image_pil, ymin, xmin, ymax, xmax, color,
thickness, display_str_list,
use_normalized_coordinates)
np.copyto(image, np.array(image_pil))
def draw_bounding_box_on_image(image,
ymin,
xmin,
ymax,
xmax,
color='red',
thickness=4,
display_str_list=(),
use_normalized_coordinates=True):
"""Adds a bounding box to an image.
Bounding box coordinates can be specified in either absolute (pixel) or
normalized coordinates by setting the use_normalized_coordinates argument.
Each string in display_str_list is displayed on a separate line above the
bounding box in black text on a rectangle filled with the input 'color'.
If the top of the bounding box extends to the edge of the image, the strings
are displayed below the bounding box.
Args:
image: a PIL.Image object.
ymin: ymin of bounding box.
xmin: xmin of bounding box.
ymax: ymax of bounding box.
xmax: xmax of bounding box.
color: color to draw bounding box. Default is red.
thickness: line thickness. Default value is 4.
display_str_list: list of strings to display in box
(each to be shown on its own line).
use_normalized_coordinates: If True (default), treat coordinates
ymin, xmin, ymax, xmax as relative to the image. Otherwise treat
coordinates as absolute.
"""
draw = ImageDraw.Draw(image)
im_width, im_height = image.size
if use_normalized_coordinates:
(left, right, top, bottom) = (xmin * im_width, xmax * im_width,
ymin * im_height, ymax * im_height)
else:
(left, right, top, bottom) = (xmin, xmax, ymin, ymax)
draw.line([(left, top), (left, bottom), (right, bottom),
(right, top), (left, top)], width=thickness, fill=color)
try:
font = ImageFont.truetype('arial.ttf', 24)
except IOError:
font = ImageFont.load_default()
# If the total height of the display strings added to the top of the bounding
# box exceeds the top of the image, stack the strings below the bounding box
# instead of above.
display_str_heights = [font.getsize(ds)[1] for ds in display_str_list]
# Each display_str has a top and bottom margin of 0.05x.
total_display_str_height = (1 + 2 * 0.05) * sum(display_str_heights)
if top > total_display_str_height:
text_bottom = top
else:
text_bottom = bottom + total_display_str_height
# Reverse list and print from bottom to top.
for display_str in display_str_list[::-1]:
text_width, text_height = font.getsize(display_str)
margin = np.ceil(0.05 * text_height)
draw.rectangle(
[(left, text_bottom - text_height - 2 * margin), (left + text_width,
text_bottom)],
fill=color)
draw.text(
(left + margin, text_bottom - text_height - margin),
display_str,
fill='black',
font=font)
text_bottom -= text_height - 2 * margin
def draw_bounding_boxes_on_image_array(image,
boxes,
color='red',
thickness=4,
display_str_list_list=()):
"""Draws bounding boxes on image (numpy array).
Args:
image: a numpy array object.
boxes: a 2 dimensional numpy array of [N, 4]: (ymin, xmin, ymax, xmax).
The coordinates are in normalized format between [0, 1].
color: color to draw bounding box. Default is red.
thickness: line thickness. Default value is 4.
display_str_list_list: list of list of strings.
a list of strings for each bounding box.
The reason to pass a list of strings for a
bounding box is that it might contain
multiple labels.
Raises:
ValueError: if boxes is not a [N, 4] array
"""
image_pil = Image.fromarray(image)
draw_bounding_boxes_on_image(image_pil, boxes, color, thickness,
display_str_list_list)
np.copyto(image, np.array(image_pil))
def draw_bounding_boxes_on_image(image,
boxes,
color='red',
thickness=4,
display_str_list_list=()):
"""Draws bounding boxes on image.
Args:
image: a PIL.Image object.
boxes: a 2 dimensional numpy array of [N, 4]: (ymin, xmin, ymax, xmax).
The coordinates are in normalized format between [0, 1].
color: color to draw bounding box. Default is red.
thickness: line thickness. Default value is 4.
display_str_list_list: list of list of strings.
a list of strings for each bounding box.
The reason to pass a list of strings for a
bounding box is that it might contain
multiple labels.
Raises:
ValueError: if boxes is not a [N, 4] array
"""
boxes_shape = boxes.shape
if not boxes_shape:
return
if len(boxes_shape) != 2 or boxes_shape[1] != 4:
raise ValueError('Input must be of size [N, 4]')
for i in range(boxes_shape[0]):
display_str_list = ()
if display_str_list_list:
display_str_list = display_str_list_list[i]
draw_bounding_box_on_image(image, boxes[i, 0], boxes[i, 1], boxes[i, 2],
boxes[i, 3], color, thickness, display_str_list)
def _visualize_boxes(image, boxes, classes, scores, category_index, **kwargs):
return visualize_boxes_and_labels_on_image_array(
image, boxes, classes, scores, category_index=category_index, **kwargs)
def _visualize_boxes_and_masks(image, boxes, classes, scores, masks,
category_index, **kwargs):
return visualize_boxes_and_labels_on_image_array(
image,
boxes,
classes,
scores,
category_index=category_index,
instance_masks=masks,
**kwargs)
def _visualize_boxes_and_keypoints(image, boxes, classes, scores, keypoints,
category_index, **kwargs):
return visualize_boxes_and_labels_on_image_array(
image,
boxes,
classes,
scores,
category_index=category_index,
keypoints=keypoints,
**kwargs)
def _visualize_boxes_and_masks_and_keypoints(
image, boxes, classes, scores, masks, keypoints, category_index, **kwargs):
return visualize_boxes_and_labels_on_image_array(
image,
boxes,
classes,
scores,
category_index=category_index,
instance_masks=masks,
keypoints=keypoints,
**kwargs)
def _resize_original_image(image, image_shape):
image = tf.expand_dims(image, 0)
image = tf.image.resize_images(
image,
image_shape,
method=tf.image.ResizeMethod.NEAREST_NEIGHBOR,
align_corners=True)
return tf.cast(tf.squeeze(image, 0), tf.uint8)
def draw_bounding_boxes_on_image_tensors(images,
boxes,
classes,
scores,
category_index,
original_image_spatial_shape=None,
true_image_shape=None,
instance_masks=None,
keypoints=None,
max_boxes_to_draw=20,
min_score_thresh=0.2,
use_normalized_coordinates=True):
"""Draws bounding boxes, masks, and keypoints on batch of image tensors.
Args:
images: A 4D uint8 image tensor of shape [N, H, W, C]. If C > 3, additional
channels will be ignored. If C = 1, then we convert the images to RGB
images.
boxes: [N, max_detections, 4] float32 tensor of detection boxes.
classes: [N, max_detections] int tensor of detection classes. Note that
classes are 1-indexed.
scores: [N, max_detections] float32 tensor of detection scores.
category_index: a dict that maps integer ids to category dicts. e.g.
{1: {1: 'dog'}, 2: {2: 'cat'}, ...}
original_image_spatial_shape: [N, 2] tensor containing the spatial size of
the original image.
true_image_shape: [N, 3] tensor containing the spatial size of unpadded
original_image.
instance_masks: A 4D uint8 tensor of shape [N, max_detection, H, W] with
instance masks.
keypoints: A 4D float32 tensor of shape [N, max_detection, num_keypoints, 2]
with keypoints.
max_boxes_to_draw: Maximum number of boxes to draw on an image. Default 20.
min_score_thresh: Minimum score threshold for visualization. Default 0.2.
use_normalized_coordinates: Whether to assume boxes and kepoints are in
normalized coordinates (as opposed to absolute coordiantes).
Default is True.
Returns:
4D image tensor of type uint8, with boxes drawn on top.
"""
# Additional channels are being ignored.
if images.shape[3] > 3:
images = images[:, :, :, 0:3]
elif images.shape[3] == 1:
images = tf.image.grayscale_to_rgb(images)
visualization_keyword_args = {
'use_normalized_coordinates': use_normalized_coordinates,
'max_boxes_to_draw': max_boxes_to_draw,
'min_score_thresh': min_score_thresh,
'agnostic_mode': False,
'line_thickness': 4
}
if true_image_shape is None:
true_shapes = tf.constant(-1, shape=[images.shape.as_list()[0], 3])
else:
true_shapes = true_image_shape
if original_image_spatial_shape is None:
original_shapes = tf.constant(-1, shape=[images.shape.as_list()[0], 2])
else:
original_shapes = original_image_spatial_shape
if instance_masks is not None and keypoints is None:
visualize_boxes_fn = functools.partial(
_visualize_boxes_and_masks,
category_index=category_index,
**visualization_keyword_args)
elems = [
true_shapes, original_shapes, images, boxes, classes, scores,
instance_masks
]
elif instance_masks is None and keypoints is not None:
visualize_boxes_fn = functools.partial(
_visualize_boxes_and_keypoints,
category_index=category_index,
**visualization_keyword_args)
elems = [
true_shapes, original_shapes, images, boxes, classes, scores, keypoints
]
elif instance_masks is not None and keypoints is not None:
visualize_boxes_fn = functools.partial(
_visualize_boxes_and_masks_and_keypoints,
category_index=category_index,
**visualization_keyword_args)
elems = [
true_shapes, original_shapes, images, boxes, classes, scores,
instance_masks, keypoints
]
else:
visualize_boxes_fn = functools.partial(
_visualize_boxes,
category_index=category_index,
**visualization_keyword_args)
elems = [
true_shapes, original_shapes, images, boxes, classes, scores
]
def draw_boxes(image_and_detections):
"""Draws boxes on image."""
true_shape = image_and_detections[0]
original_shape = image_and_detections[1]
if true_image_shape is not None:
image = shape_utils.pad_or_clip_nd(image_and_detections[2],
[true_shape[0], true_shape[1], 3])
if original_image_spatial_shape is not None:
image_and_detections[2] = _resize_original_image(image, original_shape)
image_with_boxes = tf.py_func(visualize_boxes_fn, image_and_detections[2:],
tf.uint8)
return image_with_boxes
images = tf.map_fn(draw_boxes, elems, dtype=tf.uint8, back_prop=False)
return images
def draw_side_by_side_evaluation_image(eval_dict,
category_index,
max_boxes_to_draw=20,
min_score_thresh=0.2,
use_normalized_coordinates=True):
"""Creates a side-by-side image with detections and groundtruth.
Bounding boxes (and instance masks, if available) are visualized on both
subimages.
Args:
eval_dict: The evaluation dictionary returned by
eval_util.result_dict_for_batched_example() or
eval_util.result_dict_for_single_example().
category_index: A category index (dictionary) produced from a labelmap.
max_boxes_to_draw: The maximum number of boxes to draw for detections.
min_score_thresh: The minimum score threshold for showing detections.
use_normalized_coordinates: Whether to assume boxes and kepoints are in
normalized coordinates (as opposed to absolute coordiantes).
Default is True.
Returns:
A list of [1, H, 2 * W, C] uint8 tensor. The subimage on the left
corresponds to detections, while the subimage on the right corresponds to
groundtruth.
"""
detection_fields = fields.DetectionResultFields()
input_data_fields = fields.InputDataFields()
images_with_detections_list = []
# Add the batch dimension if the eval_dict is for single example.
if len(eval_dict[detection_fields.detection_classes].shape) == 1:
for key in eval_dict:
if key != input_data_fields.original_image:
eval_dict[key] = tf.expand_dims(eval_dict[key], 0)
for indx in range(eval_dict[input_data_fields.original_image].shape[0]):
instance_masks = None
if detection_fields.detection_masks in eval_dict:
instance_masks = tf.cast(
tf.expand_dims(
eval_dict[detection_fields.detection_masks][indx], axis=0),
tf.uint8)
keypoints = None
if detection_fields.detection_keypoints in eval_dict:
keypoints = tf.expand_dims(
eval_dict[detection_fields.detection_keypoints][indx], axis=0)
groundtruth_instance_masks = None
if input_data_fields.groundtruth_instance_masks in eval_dict:
groundtruth_instance_masks = tf.cast(
tf.expand_dims(
eval_dict[input_data_fields.groundtruth_instance_masks][indx],
axis=0), tf.uint8)
images_with_detections = draw_bounding_boxes_on_image_tensors(
tf.expand_dims(
eval_dict[input_data_fields.original_image][indx], axis=0),
tf.expand_dims(
eval_dict[detection_fields.detection_boxes][indx], axis=0),
tf.expand_dims(
eval_dict[detection_fields.detection_classes][indx], axis=0),
tf.expand_dims(
eval_dict[detection_fields.detection_scores][indx], axis=0),
category_index,
original_image_spatial_shape=tf.expand_dims(
eval_dict[input_data_fields.original_image_spatial_shape][indx],
axis=0),
true_image_shape=tf.expand_dims(
eval_dict[input_data_fields.true_image_shape][indx], axis=0),
instance_masks=instance_masks,
keypoints=keypoints,
max_boxes_to_draw=max_boxes_to_draw,
min_score_thresh=min_score_thresh,
use_normalized_coordinates=use_normalized_coordinates)
images_with_groundtruth = draw_bounding_boxes_on_image_tensors(
tf.expand_dims(
eval_dict[input_data_fields.original_image][indx], axis=0),
tf.expand_dims(
eval_dict[input_data_fields.groundtruth_boxes][indx], axis=0),
tf.expand_dims(
eval_dict[input_data_fields.groundtruth_classes][indx], axis=0),
tf.expand_dims(
tf.ones_like(
eval_dict[input_data_fields.groundtruth_classes][indx],
dtype=tf.float32),
axis=0),
category_index,
original_image_spatial_shape=tf.expand_dims(
eval_dict[input_data_fields.original_image_spatial_shape][indx],
axis=0),
true_image_shape=tf.expand_dims(
eval_dict[input_data_fields.true_image_shape][indx], axis=0),
instance_masks=groundtruth_instance_masks,
keypoints=None,
max_boxes_to_draw=None,
min_score_thresh=0.0,
use_normalized_coordinates=use_normalized_coordinates)
images_with_detections_list.append(
tf.concat([images_with_detections, images_with_groundtruth], axis=2))
return images_with_detections_list
def draw_keypoints_on_image_array(image,
keypoints,
color='red',
radius=2,
use_normalized_coordinates=True):
"""Draws keypoints on an image (numpy array).
Args:
image: a numpy array with shape [height, width, 3].
keypoints: a numpy array with shape [num_keypoints, 2].
color: color to draw the keypoints with. Default is red.
radius: keypoint radius. Default value is 2.
use_normalized_coordinates: if True (default), treat keypoint values as
relative to the image. Otherwise treat them as absolute.
"""
image_pil = Image.fromarray(np.uint8(image)).convert('RGB')
draw_keypoints_on_image(image_pil, keypoints, color, radius,
use_normalized_coordinates)
np.copyto(image, np.array(image_pil))
def draw_keypoints_on_image(image,
keypoints,
color='red',
radius=2,
use_normalized_coordinates=True):
"""Draws keypoints on an image.
Args:
image: a PIL.Image object.
keypoints: a numpy array with shape [num_keypoints, 2].
color: color to draw the keypoints with. Default is red.
radius: keypoint radius. Default value is 2.
use_normalized_coordinates: if True (default), treat keypoint values as
relative to the image. Otherwise treat them as absolute.
"""
draw = ImageDraw.Draw(image)
im_width, im_height = image.size
keypoints_x = [k[1] for k in keypoints]
keypoints_y = [k[0] for k in keypoints]
if use_normalized_coordinates:
keypoints_x = tuple([im_width * x for x in keypoints_x])
keypoints_y = tuple([im_height * y for y in keypoints_y])
for keypoint_x, keypoint_y in zip(keypoints_x, keypoints_y):
draw.ellipse([(keypoint_x - radius, keypoint_y - radius),
(keypoint_x + radius, keypoint_y + radius)],
outline=color, fill=color)
def draw_mask_on_image_array(image, mask, color='red', alpha=0.4):
"""Draws mask on an image.
Args:
image: uint8 numpy array with shape (img_height, img_height, 3)
mask: a uint8 numpy array of shape (img_height, img_height) with
values between either 0 or 1.
color: color to draw the keypoints with. Default is red.
alpha: transparency value between 0 and 1. (default: 0.4)
Raises:
ValueError: On incorrect data type for image or masks.
"""
if image.dtype != np.uint8:
raise ValueError('`image` not of type np.uint8')
if mask.dtype != np.uint8:
raise ValueError('`mask` not of type np.uint8')
if np.any(np.logical_and(mask != 1, mask != 0)):
raise ValueError('`mask` elements should be in [0, 1]')
if image.shape[:2] != mask.shape:
raise ValueError('The image has spatial dimensions %s but the mask has '
'dimensions %s' % (image.shape[:2], mask.shape))
rgb = ImageColor.getrgb(color)
pil_image = Image.fromarray(image)
solid_color = np.expand_dims(
np.ones_like(mask), axis=2) * np.reshape(list(rgb), [1, 1, 3])
pil_solid_color = Image.fromarray(np.uint8(solid_color)).convert('RGBA')
pil_mask = Image.fromarray(np.uint8(255.0*alpha*mask)).convert('L')
pil_image = Image.composite(pil_solid_color, pil_image, pil_mask)
np.copyto(image, np.array(pil_image.convert('RGB')))
def visualize_boxes_and_labels_on_image_array(
image,
boxes,
classes,
scores,
category_index,
instance_masks=None,
instance_boundaries=None,
keypoints=None,
use_normalized_coordinates=False,
max_boxes_to_draw=20,
min_score_thresh=.5,
agnostic_mode=False,
line_thickness=4,
groundtruth_box_visualization_color='black',
skip_scores=False,
skip_labels=False):
"""Overlay labeled boxes on an image with formatted scores and label names.
This function groups boxes that correspond to the same location
and creates a display string for each detection and overlays these
on the image. Note that this function modifies the image in place, and returns
that same image.
Args:
image: uint8 numpy array with shape (img_height, img_width, 3)
boxes: a numpy array of shape [N, 4]
classes: a numpy array of shape [N]. Note that class indices are 1-based,
and match the keys in the label map.
scores: a numpy array of shape [N] or None. If scores=None, then
this function assumes that the boxes to be plotted are groundtruth
boxes and plot all boxes as black with no classes or scores.
category_index: a dict containing category dictionaries (each holding
category index `id` and category name `name`) keyed by category indices.
instance_masks: a numpy array of shape [N, image_height, image_width] with
values ranging between 0 and 1, can be None.
instance_boundaries: a numpy array of shape [N, image_height, image_width]
with values ranging between 0 and 1, can be None.
keypoints: a numpy array of shape [N, num_keypoints, 2], can
be None
use_normalized_coordinates: whether boxes is to be interpreted as
normalized coordinates or not.
max_boxes_to_draw: maximum number of boxes to visualize. If None, draw
all boxes.
min_score_thresh: minimum score threshold for a box to be visualized
agnostic_mode: boolean (default: False) controlling whether to evaluate in
class-agnostic mode or not. This mode will display scores but ignore
classes.
line_thickness: integer (default: 4) controlling line width of the boxes.
groundtruth_box_visualization_color: box color for visualizing groundtruth
boxes
skip_scores: whether to skip score when drawing a single detection
skip_labels: whether to skip label when drawing a single detection
Returns:
uint8 numpy array with shape (img_height, img_width, 3) with overlaid boxes.
"""
# Create a display string (and color) for every box location, group any boxes
# that correspond to the same location.
box_to_display_str_map = collections.defaultdict(list)
box_to_color_map = collections.defaultdict(str)
box_to_instance_masks_map = {}
box_to_instance_boundaries_map = {}
box_to_keypoints_map = collections.defaultdict(list)
if not max_boxes_to_draw:
max_boxes_to_draw = boxes.shape[0]
for i in range(min(max_boxes_to_draw, boxes.shape[0])):
if scores is None or scores[i] > min_score_thresh:
box = tuple(boxes[i].tolist())
if instance_masks is not None:
box_to_instance_masks_map[box] = instance_masks[i]
if instance_boundaries is not None:
box_to_instance_boundaries_map[box] = instance_boundaries[i]
if keypoints is not None:
box_to_keypoints_map[box].extend(keypoints[i])
if scores is None:
box_to_color_map[box] = groundtruth_box_visualization_color
else:
display_str = ''
if not skip_labels:
if not agnostic_mode:
if classes[i] in category_index.keys():
class_name = category_index[classes[i]]['name']
else:
class_name = 'N/A'
display_str = str(class_name)
if not skip_scores:
if not display_str:
display_str = '{}%'.format(int(100*scores[i]))
else:
display_str = '{}: {}%'.format(display_str, int(100*scores[i]))
box_to_display_str_map[box].append(display_str)
if agnostic_mode:
box_to_color_map[box] = 'DarkOrange'
else:
box_to_color_map[box] = STANDARD_COLORS[
classes[i] % len(STANDARD_COLORS)]
# Draw all boxes onto image.
for box, color in box_to_color_map.items():
ymin, xmin, ymax, xmax = box
if instance_masks is not None:
draw_mask_on_image_array(
image,
box_to_instance_masks_map[box],
color=color
)
if instance_boundaries is not None:
draw_mask_on_image_array(
image,
box_to_instance_boundaries_map[box],
color='red',
alpha=1.0
)
draw_bounding_box_on_image_array(
image,
ymin,
xmin,
ymax,
xmax,
color=color,
thickness=line_thickness,
display_str_list=box_to_display_str_map[box],
use_normalized_coordinates=use_normalized_coordinates)
if keypoints is not None:
draw_keypoints_on_image_array(
image,
box_to_keypoints_map[box],
color=color,
radius=line_thickness / 2,
use_normalized_coordinates=use_normalized_coordinates)
return image
def add_cdf_image_summary(values, name):
"""Adds a tf.summary.image for a CDF plot of the values.
Normalizes `values` such that they sum to 1, plots the cumulative distribution
function and creates a tf image summary.
Args:
values: a 1-D float32 tensor containing the values.
name: name for the image summary.
"""
def cdf_plot(values):
"""Numpy function to plot CDF."""
normalized_values = values / np.sum(values)
sorted_values = np.sort(normalized_values)
cumulative_values = np.cumsum(sorted_values)
fraction_of_examples = (np.arange(cumulative_values.size, dtype=np.float32)
/ cumulative_values.size)
fig = plt.figure(frameon=False)
ax = fig.add_subplot('111')
ax.plot(fraction_of_examples, cumulative_values)
ax.set_ylabel('cumulative normalized values')
ax.set_xlabel('fraction of examples')
fig.canvas.draw()
width, height = fig.get_size_inches() * fig.get_dpi()
image = np.fromstring(fig.canvas.tostring_rgb(), dtype='uint8').reshape(
1, int(height), int(width), 3)
return image
cdf_plot = tf.py_func(cdf_plot, [values], tf.uint8)
tf.summary.image(name, cdf_plot)
def add_hist_image_summary(values, bins, name):
"""Adds a tf.summary.image for a histogram plot of the values.
Plots the histogram of values and creates a tf image summary.
Args:
values: a 1-D float32 tensor containing the values.
bins: bin edges which will be directly passed to np.histogram.
name: name for the image summary.
"""
def hist_plot(values, bins):
"""Numpy function to plot hist."""
fig = plt.figure(frameon=False)
ax = fig.add_subplot('111')
y, x = np.histogram(values, bins=bins)
ax.plot(x[:-1], y)
ax.set_ylabel('count')
ax.set_xlabel('value')
fig.canvas.draw()
width, height = fig.get_size_inches() * fig.get_dpi()
image = np.fromstring(
fig.canvas.tostring_rgb(), dtype='uint8').reshape(
1, int(height), int(width), 3)
return image
hist_plot = tf.py_func(hist_plot, [values, bins], tf.uint8)
tf.summary.image(name, hist_plot)
class EvalMetricOpsVisualization(object):
"""Abstract base class responsible for visualizations during evaluation.
Currently, summary images are not run during evaluation. One way to produce
evaluation images in Tensorboard is to provide tf.summary.image strings as
`value_ops` in tf.estimator.EstimatorSpec's `eval_metric_ops`. This class is
responsible for accruing images (with overlaid detections and groundtruth)
and returning a dictionary that can be passed to `eval_metric_ops`.
"""
__metaclass__ = abc.ABCMeta
def __init__(self,
category_index,
max_examples_to_draw=5,
max_boxes_to_draw=20,
min_score_thresh=0.2,
use_normalized_coordinates=True,
summary_name_prefix='evaluation_image'):
"""Creates an EvalMetricOpsVisualization.
Args:
category_index: A category index (dictionary) produced from a labelmap.
max_examples_to_draw: The maximum number of example summaries to produce.
max_boxes_to_draw: The maximum number of boxes to draw for detections.
min_score_thresh: The minimum score threshold for showing detections.
use_normalized_coordinates: Whether to assume boxes and kepoints are in
normalized coordinates (as opposed to absolute coordiantes).
Default is True.
summary_name_prefix: A string prefix for each image summary.
"""
self._category_index = category_index
self._max_examples_to_draw = max_examples_to_draw
self._max_boxes_to_draw = max_boxes_to_draw
self._min_score_thresh = min_score_thresh
self._use_normalized_coordinates = use_normalized_coordinates
self._summary_name_prefix = summary_name_prefix
self._images = []
def clear(self):
self._images = []
def add_images(self, images):
"""Store a list of images, each with shape [1, H, W, C]."""
if len(self._images) >= self._max_examples_to_draw:
return
# Store images and clip list if necessary.
self._images.extend(images)
if len(self._images) > self._max_examples_to_draw:
self._images[self._max_examples_to_draw:] = []
def get_estimator_eval_metric_ops(self, eval_dict):
"""Returns metric ops for use in tf.estimator.EstimatorSpec.
Args:
eval_dict: A dictionary that holds an image, groundtruth, and detections
for a batched example. Note that, we use only the first example for
visualization. See eval_util.result_dict_for_batched_example() for a
convenient method for constructing such a dictionary. The dictionary
contains
fields.InputDataFields.original_image: [batch_size, H, W, 3] image.
fields.InputDataFields.original_image_spatial_shape: [batch_size, 2]
tensor containing the size of the original image.
fields.InputDataFields.true_image_shape: [batch_size, 3]
tensor containing the spatial size of the upadded original image.
fields.InputDataFields.groundtruth_boxes - [batch_size, num_boxes, 4]
float32 tensor with groundtruth boxes in range [0.0, 1.0].
fields.InputDataFields.groundtruth_classes - [batch_size, num_boxes]
int64 tensor with 1-indexed groundtruth classes.
fields.InputDataFields.groundtruth_instance_masks - (optional)
[batch_size, num_boxes, H, W] int64 tensor with instance masks.
fields.DetectionResultFields.detection_boxes - [batch_size,
max_num_boxes, 4] float32 tensor with detection boxes in range [0.0,
1.0].
fields.DetectionResultFields.detection_classes - [batch_size,
max_num_boxes] int64 tensor with 1-indexed detection classes.
fields.DetectionResultFields.detection_scores - [batch_size,
max_num_boxes] float32 tensor with detection scores.
fields.DetectionResultFields.detection_masks - (optional) [batch_size,
max_num_boxes, H, W] float32 tensor of binarized masks.
fields.DetectionResultFields.detection_keypoints - (optional)
[batch_size, max_num_boxes, num_keypoints, 2] float32 tensor with
keypoints.
Returns:
A dictionary of image summary names to tuple of (value_op, update_op). The
`update_op` is the same for all items in the dictionary, and is
responsible for saving a single side-by-side image with detections and
groundtruth. Each `value_op` holds the tf.summary.image string for a given
image.
"""
if self._max_examples_to_draw == 0:
return {}
images = self.images_from_evaluation_dict(eval_dict)
def get_images():
"""Returns a list of images, padded to self._max_images_to_draw."""
images = self._images
while len(images) < self._max_examples_to_draw:
images.append(np.array(0, dtype=np.uint8))
self.clear()
return images
def image_summary_or_default_string(summary_name, image):
"""Returns image summaries for non-padded elements."""
return tf.cond(
tf.equal(tf.size(tf.shape(image)), 4),
lambda: tf.summary.image(summary_name, image),
lambda: tf.constant(''))
update_op = tf.py_func(self.add_images, [[images[0]]], [])
image_tensors = tf.py_func(
get_images, [], [tf.uint8] * self._max_examples_to_draw)
eval_metric_ops = {}
for i, image in enumerate(image_tensors):
summary_name = self._summary_name_prefix + '/' + str(i)
value_op = image_summary_or_default_string(summary_name, image)
eval_metric_ops[summary_name] = (value_op, update_op)
return eval_metric_ops
@abc.abstractmethod
def images_from_evaluation_dict(self, eval_dict):
"""Converts evaluation dictionary into a list of image tensors.
To be overridden by implementations.
Args:
eval_dict: A dictionary with all the necessary information for producing
visualizations.
Returns:
A list of [1, H, W, C] uint8 tensors.
"""
raise NotImplementedError
class VisualizeSingleFrameDetections(EvalMetricOpsVisualization):
"""Class responsible for single-frame object detection visualizations."""
def __init__(self,
category_index,
max_examples_to_draw=5,
max_boxes_to_draw=20,
min_score_thresh=0.2,
use_normalized_coordinates=True,
summary_name_prefix='Detections_Left_Groundtruth_Right'):
super(VisualizeSingleFrameDetections, self).__init__(
category_index=category_index,
max_examples_to_draw=max_examples_to_draw,
max_boxes_to_draw=max_boxes_to_draw,
min_score_thresh=min_score_thresh,
use_normalized_coordinates=use_normalized_coordinates,
summary_name_prefix=summary_name_prefix)
def images_from_evaluation_dict(self, eval_dict):
return draw_side_by_side_evaluation_image(
eval_dict, self._category_index, self._max_boxes_to_draw,
self._min_score_thresh, self._use_normalized_coordinates)
|
PyTorch/Detection/Efficientdet/effdet/csrc/nms/cuda | cuda | vision | // Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
#pragma once
#include <torch/extension.h>
at::Tensor nms_cuda(const at::Tensor boxes, float nms_overlap_thresh); |
TensorFlow/Detection/SSD/models/research/object_detection/utils | utils | dataset_util | # Copyright 2017 The TensorFlow Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ==============================================================================
"""Utility functions for creating TFRecord data sets."""
import tensorflow as tf
def int64_feature(value):
return tf.train.Feature(int64_list=tf.train.Int64List(value=[value]))
def int64_list_feature(value):
return tf.train.Feature(int64_list=tf.train.Int64List(value=value))
def bytes_feature(value):
return tf.train.Feature(bytes_list=tf.train.BytesList(value=[value]))
def bytes_list_feature(value):
return tf.train.Feature(bytes_list=tf.train.BytesList(value=value))
def float_list_feature(value):
return tf.train.Feature(float_list=tf.train.FloatList(value=value))
def read_examples_list(path):
"""Read list of training or validation examples.
The file is assumed to contain a single example per line where the first
token in the line is an identifier that allows us to find the image and
annotation xml for that example.
For example, the line:
xyz 3
would allow us to find files xyz.jpg and xyz.xml (the 3 would be ignored).
Args:
path: absolute path to examples list file.
Returns:
list of example identifiers (strings).
"""
with tf.gfile.GFile(path) as fid:
lines = fid.readlines()
return [line.strip().split(' ')[0] for line in lines]
def recursive_parse_xml_to_dict(xml):
"""Recursively parses XML contents to python dict.
We assume that `object` tags are the only ones that can appear
multiple times at the same level of a tree.
Args:
xml: xml tree obtained by parsing XML file contents using lxml.etree
Returns:
Python dictionary holding XML contents.
"""
if not xml:
return {xml.tag: xml.text}
result = {}
for child in xml:
child_result = recursive_parse_xml_to_dict(child)
if child.tag != 'object':
result[child.tag] = child_result[child.tag]
else:
if child.tag not in result:
result[child.tag] = []
result[child.tag].append(child_result[child.tag])
return {xml.tag: result}
|
TensorFlow2/LanguageModeling/BERT/data | data | README | Steps to reproduce datasets from web
1) Build the container
* docker build -t bert_tf2 .
2) Run the container interactively
* nvidia-docker run -it --ipc=host bert_tf2
* Optional: Mount data volumes
* -v yourpath:/workspace/bert_tf2/data/wikipedia_corpus/download
* -v yourpath:/workspace/bert_tf2/data/wikipedia_corpus/extracted_articles
* -v yourpath:/workspace/bert_tf2/data/wikipedia_corpus/raw_data
* -v yourpath:/workspace/bert_tf2/data/wikipedia_corpus/intermediate_files
* -v yourpath:/workspace/bert_tf2/data/wikipedia_corpus/final_text_file_single
* -v yourpath:/workspace/bert_tf2/data/wikipedia_corpus/final_text_files_sharded
* -v yourpath:/workspace/bert_tf2/data/wikipedia_corpus/final_tfrecords_sharded
* -v yourpath:/workspace/bert_tf2/data/bookcorpus/download
* -v yourpath:/workspace/bert_tf2/data/bookcorpus/final_text_file_single
* -v yourpath:/workspace/bert_tf2/data/bookcorpus/final_text_files_sharded
* -v yourpath:/workspace/bert_tf2/data/bookcorpus/final_tfrecords_sharded
* Optional: Select visible GPUs
* -e CUDA_VISIBLE_DEVICES=0
** Inside of the container starting here**
3) Download pretrained weights (they contain vocab files for preprocessing) and SQuAD
* bash data/create_datasets_from_start.sh squad
5) "One-click" Wikipedia data download and prep (provides tfrecords)
* bash data/create_datasets_from_start.sh pretrained wiki_only
6) "One-click" Wikipedia and BookCorpus data download and prep (provided tfrecords)
* bash data/create_datasets_from_start.sh pretrained wiki_books
|
TensorFlow2/Recommendation/SIM/sim/data | data | defaults | # Copyright (c) 2022 NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
REMAINDER_FILENAME = 'remainder.tfrecord'
USER_FEATURES_CHANNEL = 'user_features'
TARGET_ITEM_FEATURES_CHANNEL = 'target_item_features'
POSITIVE_HISTORY_CHANNEL = 'positive_history'
NEGATIVE_HISTORY_CHANNEL = 'negative_history'
LABEL_CHANNEL = 'label'
TRAIN_MAPPING = "train"
TEST_MAPPING = "test"
FILES_SELECTOR = "files"
DTYPE_SELECTOR = "dtype"
CARDINALITY_SELECTOR = "cardinality"
DIMENSIONS_SELECTOR = 'dimensions'
|
TensorFlow/Segmentation/UNet_Medical/examples | examples | unet_TRAIN_TF-AMP_8GPU | # Copyright (c) 2020, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# This script launches U-Net run in TF-AMP on 8 GPUs and runs 5-fold cross-validation training for 6400 iterations.
# Usage:
# bash unet_TRAIN_TF-AMP_8GPU.sh <path to dataset> <path to results directory> <batch size>
horovodrun -np 8 python main.py --data_dir $1 --model_dir $2 --log_every 100 --max_steps 6400 --batch_size $3 --exec_mode train_and_evaluate --crossvalidation_idx 0 --augment --xla --amp > $2/log_TF-AMP_8GPU_fold0.txt
horovodrun -np 8 python main.py --data_dir $1 --model_dir $2 --log_every 100 --max_steps 6400 --batch_size $3 --exec_mode train_and_evaluate --crossvalidation_idx 1 --augment --xla --amp > $2/log_TF-AMP_8GPU_fold1.txt
horovodrun -np 8 python main.py --data_dir $1 --model_dir $2 --log_every 100 --max_steps 6400 --batch_size $3 --exec_mode train_and_evaluate --crossvalidation_idx 2 --augment --xla --amp > $2/log_TF-AMP_8GPU_fold2.txt
horovodrun -np 8 python main.py --data_dir $1 --model_dir $2 --log_every 100 --max_steps 6400 --batch_size $3 --exec_mode train_and_evaluate --crossvalidation_idx 3 --augment --xla --amp > $2/log_TF-AMP_8GPU_fold3.txt
horovodrun -np 8 python main.py --data_dir $1 --model_dir $2 --log_every 100 --max_steps 6400 --batch_size $3 --exec_mode train_and_evaluate --crossvalidation_idx 4 --augment --xla --amp > $2/log_TF-AMP_8GPU_fold4.txt
python utils/parse_results.py --model_dir $2 --exec_mode convergence --env TF-AMP_8GPU |
PyTorch/Segmentation/MaskRCNN/pytorch/configs | configs | e2e_faster_rcnn_R_101_FPN_1x | MODEL:
META_ARCHITECTURE: "GeneralizedRCNN"
WEIGHT: "catalog://ImageNetPretrained/MSRA/R-101"
BACKBONE:
CONV_BODY: "R-101-FPN"
OUT_CHANNELS: 256
RPN:
USE_FPN: True
ANCHOR_STRIDE: (4, 8, 16, 32, 64)
PRE_NMS_TOP_N_TRAIN: 2000
PRE_NMS_TOP_N_TEST: 1000
POST_NMS_TOP_N_TEST: 1000
FPN_POST_NMS_TOP_N_TEST: 1000
ROI_HEADS:
USE_FPN: True
ROI_BOX_HEAD:
POOLER_RESOLUTION: 7
POOLER_SCALES: (0.25, 0.125, 0.0625, 0.03125)
POOLER_SAMPLING_RATIO: 2
FEATURE_EXTRACTOR: "FPN2MLPFeatureExtractor"
PREDICTOR: "FPNPredictor"
DATASETS:
TRAIN: ("coco_2014_train", "coco_2014_valminusminival")
TEST: ("coco_2014_minival",)
DATALOADER:
SIZE_DIVISIBILITY: 32
SOLVER:
BASE_LR: 0.02
WEIGHT_DECAY: 0.0001
STEPS: (60000, 80000)
MAX_ITER: 90000
|
TensorFlow/Classification/ConvNets/resnext101-32x4d/training | training | DGX2_RNxt101-32x4d_AMP_90E | #!/bin/bash
# Copyright (c) 2019 NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
WORKSPACE=${1:-"/workspace/rn50v15_tf"}
DATA_DIR=${2:-"/data"}
OTHER=${@:3}
if [[ ! -z "${BIND_TO_SOCKET}" ]]; then
BIND_TO_SOCKET="--bind-to socket"
fi
mpiexec --allow-run-as-root ${BIND_TO_SOCKET} -np 16 python3 main.py --arch=resnext101-32x4d \
--mode=train_and_evaluate --iter_unit=epoch --num_iter=90 \
--batch_size=128 --warmup_steps=100 --cosine_lr --label_smoothing 0.1 \
--lr_init=0.256 --lr_warmup_epochs=8 --momentum=0.875 --weight_decay=6.103515625e-05 \
--amp --static_loss_scale 128 \
--data_dir=${DATA_DIR}/tfrecords --data_idx_dir=${DATA_DIR}/dali_idx \
--results_dir=${WORKSPACE}/results --weight_init=fan_in ${OTHER}
|
TensorFlow/Segmentation/UNet_3D_Medical | UNet_3D_Medical | main | # Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
""" Entry point of the application.
This file serves as entry point to the implementation of UNet3D for
medical image segmentation.
Example usage:
$ python main.py --exec_mode train --data_dir ./data --batch_size 2
--max_steps 1600 --amp
All arguments are listed under `python main.py -h`.
Full argument definition can be found in `arguments.py`.
"""
import os
import numpy as np
import horovod.tensorflow as hvd
from model.model_fn import unet_3d
from dataset.data_loader import Dataset, CLASSES
from runtime.hooks import get_hooks
from runtime.arguments import PARSER
from runtime.setup import build_estimator, set_flags, get_logger
def parse_evaluation_results(result, logger, step=()):
"""
Parse DICE scores from the evaluation results
:param result: Dictionary with metrics collected by the optimizer
:param logger: Logger object
:return:
"""
data = {CLASSES[i]: float(result[CLASSES[i]]) for i in range(len(CLASSES))}
data['mean_dice'] = sum([result[CLASSES[i]] for i in range(len(CLASSES))]) / len(CLASSES)
data['whole_tumor'] = float(result['whole_tumor'])
if hvd.rank() == 0:
logger.log(step=step, data=data)
return data
def main():
""" Starting point of the application """
hvd.init()
set_flags()
params = PARSER.parse_args()
logger = get_logger(params)
dataset = Dataset(data_dir=params.data_dir,
batch_size=params.batch_size,
fold_idx=params.fold,
n_folds=params.num_folds,
input_shape=params.input_shape,
params=params)
estimator = build_estimator(params=params, model_fn=unet_3d)
hooks = get_hooks(params, logger)
if 'train' in params.exec_mode:
max_steps = params.max_steps // (1 if params.benchmark else hvd.size())
estimator.train(
input_fn=dataset.train_fn,
steps=max_steps,
hooks=hooks)
if 'evaluate' in params.exec_mode:
result = estimator.evaluate(input_fn=dataset.eval_fn, steps=dataset.eval_size)
_ = parse_evaluation_results(result, logger)
if params.exec_mode == 'predict':
if hvd.rank() == 0:
predictions = estimator.predict(
input_fn=dataset.test_fn, hooks=hooks)
for idx, pred in enumerate(predictions):
volume = pred['predictions']
if not params.benchmark:
np.save(os.path.join(params.model_dir, "vol_{}.npy".format(idx)), volume)
if __name__ == '__main__':
main()
|
PyTorch/SpeechSynthesis/HiFiGAN/fastpitch | fastpitch | __init__ | from .entrypoints import nvidia_fastpitch, nvidia_textprocessing_utils |
TensorFlow/Segmentation/UNet_Industrial/scripts | scripts | UNet_1GPU | #!/usr/bin/env bash
# Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# This script launches UNet training in FP32 on 1 GPU using 16 batch size (16 per GPU)
# Usage ./UNet_FP32_1GPU_XLA.sh <path to result repository> <path to dataset> <dagm classID (1-10)>
BASEDIR="$( cd "$( dirname "${BASH_SOURCE[0]}" )" >/dev/null 2>&1 && pwd )"
export TF_CPP_MIN_LOG_LEVEL=3
python "${BASEDIR}/../main.py" \
--unet_variant='tinyUNet' \
--activation_fn='relu' \
--exec_mode='train_and_evaluate' \
--iter_unit='batch' \
--num_iter=2500 \
--batch_size=16 \
--warmup_step=10 \
--results_dir="${1}" \
--data_dir="${2}" \
--dataset_name='DAGM2007' \
--dataset_classID="${3}" \
--data_format='NCHW' \
--use_auto_loss_scaling \
--noamp \
--xla \
--learning_rate=1e-4 \
--learning_rate_decay_factor=0.8 \
--learning_rate_decay_steps=500 \
--rmsprop_decay=0.9 \
--rmsprop_momentum=0.8 \
--loss_fn_name='adaptive_loss' \
--weight_decay=1e-5 \
--weight_init_method='he_uniform' \
--augment_data \
--display_every=250 \
--debug_verbosity=0
|
TensorFlow2/LanguageModeling/ELECTRA | ELECTRA | .gitignore | # Initially taken from Github's Python gitignore file
# Byte-compiled / optimized / DLL files
__pycache__/
*.py[cod]
*$py.class
# C extensions
*.so
#Data checkpoints and results
data/*/*/
data/*/*.zip
checkpoints/
results/*
#Editor
.idea
.idea/*
# Distribution / packaging
.Python
build/
develop-eggs/
dist/
downloads/
eggs/
.eggs/
lib/
lib64/
parts/
sdist/
var/
wheels/
*.egg-info/
.installed.cfg
*.egg
MANIFEST
# PyInstaller
# Usually these files are written by a python script from a template
# before PyInstaller builds the exe, so as to inject date/other infos into it.
*.manifest
*.spec
# Installer logs
pip-log.txt
pip-delete-this-directory.txt
# Unit test / coverage reports
htmlcov/
.tox/
.nox/
.coverage
.coverage.*
.cache
nosetests.xml
coverage.xml
*.cover
.hypothesis/
.pytest_cache/
# Translations
*.mo
*.pot
# Django stuff:
*.log
local_settings.py
db.sqlite3
# Flask stuff:
instance/
.webassets-cache
# Scrapy stuff:
.scrapy
# Sphinx documentation
docs/_build/
# PyBuilder
target/
# Jupyter Notebook
.ipynb_checkpoints
# IPython
profile_default/
ipython_config.py
# pyenv
.python-version
# celery beat schedule file
celerybeat-schedule
# SageMath parsed files
*.sage.py
# Environments
.env
.venv
env/
venv/
ENV/
env.bak/
venv.bak/
# Spyder project settings
.spyderproject
.spyproject
# Rope project settings
.ropeproject
# mkdocs documentation
/site
# mypy
.mypy_cache/
.dmypy.json
dmypy.json
# Pyre type checker
.pyre/
# vscode
.vscode
|
Tools/DGLPyTorch/SyntheticGraphGeneration/syngen/analyzer/tabular | tabular | utils | # Copyright (c) 2023, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from typing import Any, Dict, List, Tuple, Union
import pandas as pd
try:
import ipywidgets as widgets
from IPython import get_ipython
from IPython.core.display import HTML, Markdown, display
except ImportError:
print("IPython not installed.")
from typing import Dict
def load_data(
path_real: str,
path_fake: str,
real_sep: str = ",",
fake_sep: str = ",",
drop_columns: List = None,
) -> Tuple[pd.DataFrame, pd.DataFrame]:
"""
Load data from a real and synthetic data csv. This function makes sure that the loaded data has the same columns
with the same data types.
Args:
path_real: string path to csv with real data
path_fake: string path to csv with real data
real_sep: separator of the real csv
fake_sep: separator of the fake csv
drop_columns: names of columns to drop.
Return: Tuple with DataFrame containing the real data and DataFrame containing the synthetic data.
"""
real = pd.read_csv(path_real, sep=real_sep, low_memory=False)
fake = pd.read_csv(path_fake, sep=fake_sep, low_memory=False)
if set(fake.columns.tolist()).issubset(set(real.columns.tolist())):
real = real[fake.columns]
elif drop_columns is not None:
real = real.drop(drop_columns, axis=1)
try:
fake = fake.drop(drop_columns, axis=1)
except:
print(f"Some of {drop_columns} were not found on fake.index.")
assert len(fake.columns.tolist()) == len(
real.columns.tolist()
), f"Real and fake do not have same nr of columns: {len(fake.columns)} and {len(real.columns)}"
fake.columns = real.columns
else:
fake.columns = real.columns
for col in fake.columns:
fake[col] = fake[col].astype(real[col].dtype)
return real, fake
def dict_to_df(data: Dict[str, Any]):
return pd.DataFrame(
{"result": list(data.values())}, index=list(data.keys())
)
class EvaluationResult(object):
def __init__(
self, name, content, prefix=None, appendix=None, notebook=False
):
self.name = name
self.prefix = prefix
self.content = content
self.appendix = appendix
self.notebook = notebook
def show(self):
if self.notebook:
output = widgets.Output()
with output:
display(Markdown(f"## {self.name}"))
if self.prefix:
display(Markdown(self.prefix))
display(self.content)
if self.appendix:
display(Markdown(self.appendix))
return output
else:
print(f"\n{self.name}")
if self.prefix:
print(self.prefix)
print(self.content)
if self.appendix:
print(self.appendix)
|
PyTorch/Segmentation/MaskRCNN/pytorch/tools | tools | train_net | # Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved.
# Copyright (c) 2022, NVIDIA CORPORATION. All rights reserved.
r"""
Basic training script for PyTorch
"""
# Set up custom environment before nearly anything else is imported
# NOTE: this should be the first import (no not reorder)
from maskrcnn_benchmark.utils.env import setup_environment # noqa F401 isort:skip
import argparse
import os
import logging
import functools
import torch
from maskrcnn_benchmark.config import cfg
from maskrcnn_benchmark.data import make_data_loader
from maskrcnn_benchmark.solver import make_lr_scheduler
from maskrcnn_benchmark.solver import make_optimizer
from maskrcnn_benchmark.engine.inference import inference
from maskrcnn_benchmark.engine.trainer import do_train
from maskrcnn_benchmark.modeling.detector import build_detection_model
from maskrcnn_benchmark.utils.checkpoint import DetectronCheckpointer
from maskrcnn_benchmark.utils.collect_env import collect_env_info
from maskrcnn_benchmark.utils.comm import synchronize, get_rank, is_main_process
from maskrcnn_benchmark.utils.imports import import_file
from maskrcnn_benchmark.utils.logger import setup_logger
from maskrcnn_benchmark.utils.miscellaneous import mkdir
from maskrcnn_benchmark.engine.tester import test
from maskrcnn_benchmark.utils.logger import format_step
#from dllogger import Logger, StdOutBackend, JSONStreamBackend, Verbosity
#import dllogger as DLLogger
import dllogger
import torch.utils.tensorboard as tbx
from maskrcnn_benchmark.utils.logger import format_step
# See if we can use apex.DistributedDataParallel instead of the torch default,
# and enable mixed-precision via apex.amp
try:
from apex.parallel import DistributedDataParallel as DDP
use_apex_ddp = True
except ImportError:
print('Use APEX for better performance')
use_apex_ddp = False
def test_and_exchange_map(tester, model, distributed):
results = tester(model=model, distributed=distributed)
# main process only
if is_main_process():
# Note: one indirection due to possibility of multiple test datasets, we only care about the first
# tester returns (parsed results, raw results). In our case, don't care about the latter
map_results, raw_results = results[0]
bbox_map = map_results.results["bbox"]['AP']
segm_map = map_results.results["segm"]['AP']
else:
bbox_map = 0.
segm_map = 0.
if distributed:
map_tensor = torch.tensor([bbox_map, segm_map], dtype=torch.float32, device=torch.device("cuda"))
torch.distributed.broadcast(map_tensor, 0)
bbox_map = map_tensor[0].item()
segm_map = map_tensor[1].item()
return bbox_map, segm_map
def mlperf_test_early_exit(iteration, iters_per_epoch, tester, model, distributed, min_bbox_map, min_segm_map):
if iteration > 0 and iteration % iters_per_epoch == 0:
epoch = iteration // iters_per_epoch
dllogger.log(step="PARAMETER", data={"eval_start": True})
bbox_map, segm_map = test_and_exchange_map(tester, model, distributed)
# necessary for correctness
model.train()
dllogger.log(step=(iteration, epoch, ), data={"BBOX_mAP": bbox_map, "MASK_mAP": segm_map})
# terminating condition
if bbox_map >= min_bbox_map and segm_map >= min_segm_map:
dllogger.log(step="PARAMETER", data={"target_accuracy_reached": True})
return True
return False
def train(cfg, local_rank, distributed, fp16, dllogger):
model = build_detection_model(cfg)
device = torch.device(cfg.MODEL.DEVICE)
model.to(device)
optimizer = make_optimizer(cfg, model)
scheduler = make_lr_scheduler(cfg, optimizer)
use_amp = False
if fp16:
use_amp = True
else:
use_amp = cfg.DTYPE == "float16"
if distributed:
if cfg.USE_TORCH_DDP or not use_apex_ddp:
model = torch.nn.parallel.DistributedDataParallel(
model, device_ids=[local_rank], output_device=local_rank,
# this should be removed if we update BatchNorm stats
broadcast_buffers=False,
)
else:
model = DDP(model, delay_allreduce=True)
arguments = {}
arguments["iteration"] = 0
output_dir = cfg.OUTPUT_DIR
save_to_disk = get_rank() == 0
checkpointer = DetectronCheckpointer(
cfg, model, optimizer, scheduler, output_dir, save_to_disk
)
extra_checkpoint_data = checkpointer.load(cfg.MODEL.WEIGHT)
arguments.update(extra_checkpoint_data)
data_loader, iters_per_epoch = make_data_loader(
cfg,
is_train=True,
is_distributed=distributed,
start_iter=arguments["iteration"],
)
checkpoint_period = cfg.SOLVER.CHECKPOINT_PERIOD
# set the callback function to evaluate and potentially
# early exit each epoch
if cfg.PER_EPOCH_EVAL:
per_iter_callback_fn = functools.partial(
mlperf_test_early_exit,
iters_per_epoch=iters_per_epoch,
tester=functools.partial(test, cfg=cfg, dllogger=dllogger),
model=model,
distributed=distributed,
min_bbox_map=cfg.MIN_BBOX_MAP,
min_segm_map=cfg.MIN_MASK_MAP)
else:
per_iter_callback_fn = None
do_train(
model,
data_loader,
optimizer,
scheduler,
checkpointer,
device,
checkpoint_period,
arguments,
use_amp,
cfg,
dllogger,
per_iter_end_callback_fn=per_iter_callback_fn,
nhwc=cfg.NHWC
)
return model, iters_per_epoch
def test_model(cfg, model, distributed, iters_per_epoch, dllogger):
if distributed:
model = model.module
torch.cuda.empty_cache() # TODO check if it helps
iou_types = ("bbox",)
if cfg.MODEL.MASK_ON:
iou_types = iou_types + ("segm",)
output_folders = [None] * len(cfg.DATASETS.TEST)
dataset_names = cfg.DATASETS.TEST
if cfg.OUTPUT_DIR:
for idx, dataset_name in enumerate(dataset_names):
output_folder = os.path.join(cfg.OUTPUT_DIR, "inference", dataset_name)
mkdir(output_folder)
output_folders[idx] = output_folder
data_loaders_val = make_data_loader(cfg, is_train=False, is_distributed=distributed)
results = []
for output_folder, dataset_name, data_loader_val in zip(output_folders, dataset_names, data_loaders_val):
result = inference(
model,
data_loader_val,
dataset_name=dataset_name,
iou_types=iou_types,
box_only=cfg.MODEL.RPN_ONLY,
device=cfg.MODEL.DEVICE,
expected_results=cfg.TEST.EXPECTED_RESULTS,
expected_results_sigma_tol=cfg.TEST.EXPECTED_RESULTS_SIGMA_TOL,
output_folder=output_folder,
dllogger=dllogger,
)
synchronize()
results.append(result)
if is_main_process():
map_results, raw_results = results[0]
bbox_map = map_results.results["bbox"]['AP']
segm_map = map_results.results["segm"]['AP']
dllogger.log(step=(cfg.SOLVER.MAX_ITER, cfg.SOLVER.MAX_ITER / iters_per_epoch,), data={"BBOX_mAP": bbox_map, "MASK_mAP": segm_map})
dllogger.log(step=tuple(), data={"BBOX_mAP": bbox_map, "MASK_mAP": segm_map})
def main():
parser = argparse.ArgumentParser(description="PyTorch Object Detection Training")
parser.add_argument(
"--config-file",
default="",
metavar="FILE",
help="path to config file",
type=str,
)
parser.add_argument("--local_rank", type=int, default=os.getenv('LOCAL_RANK', 0))
parser.add_argument("--max_steps", type=int, default=0, help="Override number of training steps in the config")
parser.add_argument("--skip-test", dest="skip_test", help="Do not test the final model",
action="store_true",)
parser.add_argument("--fp16", help="Mixed precision training", action="store_true")
parser.add_argument("--amp", help="Mixed precision training", action="store_true")
parser.add_argument('--skip_checkpoint', default=False, action='store_true', help="Whether to save checkpoints")
parser.add_argument("--json-summary", help="Out file for DLLogger", default="dllogger.out",
type=str,
)
parser.add_argument(
"opts",
help="Modify config options using the command-line",
default=None,
nargs=argparse.REMAINDER,
)
args = parser.parse_args()
args.fp16 = args.fp16 or args.amp
num_gpus = int(os.environ["WORLD_SIZE"]) if "WORLD_SIZE" in os.environ else 1
args.distributed = num_gpus > 1
if args.distributed:
torch.cuda.set_device(args.local_rank)
torch.distributed.init_process_group(
backend="nccl", init_method="env://"
)
synchronize()
cfg.merge_from_file(args.config_file)
cfg.merge_from_list(args.opts)
# Redundant option - Override config parameter with command line input
if args.max_steps > 0:
cfg.SOLVER.MAX_ITER = args.max_steps
if args.skip_checkpoint:
cfg.SAVE_CHECKPOINT = False
cfg.freeze()
output_dir = cfg.OUTPUT_DIR
if output_dir:
mkdir(output_dir)
logger = setup_logger("maskrcnn_benchmark", output_dir, get_rank())
if is_main_process():
dllogger.init(backends=[dllogger.JSONStreamBackend(verbosity=dllogger.Verbosity.VERBOSE,
filename=args.json_summary),
dllogger.StdOutBackend(verbosity=dllogger.Verbosity.VERBOSE, step_format=format_step)])
else:
dllogger.init(backends=[])
dllogger.metadata("BBOX_mAP", {"unit": None})
dllogger.metadata("MASK_mAP", {"unit": None})
dllogger.metadata("e2e_train_time", {"unit": "s"})
dllogger.metadata("train_perf_fps", {"unit": "images/s"})
dllogger.log(step="PARAMETER", data={"gpu_count":num_gpus})
# dllogger.log(step="PARAMETER", data={"environment_info": collect_env_info()})
dllogger.log(step="PARAMETER", data={"config_file": args.config_file})
with open(args.config_file, "r") as cf:
config_str = "\n" + cf.read()
dllogger.log(step="PARAMETER", data={"config":cfg})
if args.fp16:
fp16 = True
else:
fp16 = False
model, iters_per_epoch = train(cfg, args.local_rank, args.distributed, fp16, dllogger)
if not args.skip_test:
if not cfg.PER_EPOCH_EVAL:
test_model(cfg, model, args.distributed, iters_per_epoch, dllogger)
if __name__ == "__main__":
main()
dllogger.log(step=tuple(), data={})
dllogger.flush()
|
PyTorch/LanguageModeling/BERT/triton/dist4l/runner | runner | start_NVIDIA-DGX-1-(1x-V100-32GB) | # Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#!/bin/bash
# Install Docker
. /etc/os-release && \
curl -fsSL https://download.docker.com/linux/debian/gpg | apt-key add - && \
echo "deb [arch=amd64] https://download.docker.com/linux/debian buster stable" > /etc/apt/sources.list.d/docker.list && \
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey| apt-key add - && \
curl -s -L https://nvidia.github.io/nvidia-docker/$ID$VERSION_ID/nvidia-docker.list > /etc/apt/sources.list.d/nvidia-docker.list && \
apt-get update && \
apt-get install -y docker-ce docker-ce-cli containerd.io nvidia-docker2
# Install packages
pip install -r triton/runner/requirements.txt
# Evaluate Runner
python3 -m "triton.dist4l.runner.__main__" \
--config-path "triton/dist4l/runner/config_NVIDIA-DGX-1-(1x-V100-32GB).yaml" \
--device 0 |
PyTorch/SpeechSynthesis/FastPitch/phrases | phrases | phrase_8_256 | The forms of printed letters should be beautiful, and that their arrangement on the page should be reasonable and a help to the shapeliness of the letters themselves and the form of printed letters should be beautiful, and that their arrangement on pages.
The forms of printed letters should be beautiful, and that their arrangement on the page should be reasonable and a help to the shapeliness of the letters themselves and the form of printed letters should be beautiful, and that their arrangement on pages.
The forms of printed letters should be beautiful, and that their arrangement on the page should be reasonable and a help to the shapeliness of the letters themselves and the form of printed letters should be beautiful, and that their arrangement on pages.
The forms of printed letters should be beautiful, and that their arrangement on the page should be reasonable and a help to the shapeliness of the letters themselves and the form of printed letters should be beautiful, and that their arrangement on pages.
The forms of printed letters should be beautiful, and that their arrangement on the page should be reasonable and a help to the shapeliness of the letters themselves and the form of printed letters should be beautiful, and that their arrangement on pages.
The forms of printed letters should be beautiful, and that their arrangement on the page should be reasonable and a help to the shapeliness of the letters themselves and the form of printed letters should be beautiful, and that their arrangement on pages.
The forms of printed letters should be beautiful, and that their arrangement on the page should be reasonable and a help to the shapeliness of the letters themselves and the form of printed letters should be beautiful, and that their arrangement on pages.
The forms of printed letters should be beautiful, and that their arrangement on the page should be reasonable and a help to the shapeliness of the letters themselves and the form of printed letters should be beautiful, and that their arrangement on pages.
|
PyTorch/LanguageModeling/BERT/triton/deployment_toolkit | deployment_toolkit | utils | # Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import logging
from typing import Tuple
LOGGER = logging.getLogger(__name__)
def parse_server_url(server_url: str) -> Tuple[str, str, int]:
DEFAULT_PORTS = {"http": 8000, "grpc": 8001}
# extract protocol
server_url_items = server_url.split("://")
if len(server_url_items) != 2:
raise ValueError("Prefix server_url with protocol ex.: grpc://127.0.0.1:8001")
requested_protocol, server_url = server_url_items
requested_protocol = requested_protocol.lower()
if requested_protocol not in DEFAULT_PORTS:
raise ValueError(f"Unsupported protocol: {requested_protocol}")
# extract host and port
default_port = DEFAULT_PORTS[requested_protocol]
server_url_items = server_url.split(":")
if len(server_url_items) == 1:
host, port = server_url, default_port
elif len(server_url_items) == 2:
host, port = server_url_items
port = int(port)
if port != default_port:
LOGGER.warning(
f"Current server URL is {server_url} while default {requested_protocol} port is {default_port}"
)
else:
raise ValueError(f"Could not parse {server_url}. Example of correct server URL: grpc://127.0.0.1:8001")
return requested_protocol, host, port
|
CUDA-Optimized/FastSpeech/fastspeech | fastspeech | __init__ | # Copyright (c) 2020, NVIDIA CORPORATION. All rights reserved.
# Redistribution and use in source and binary forms, with or without
# modification, are permitted provided that the following conditions are met:
# * Redistributions of source code must retain the above copyright
# notice, this list of conditions and the following disclaimer.
# * Redistributions in binary form must reproduce the above copyright
# notice, this list of conditions and the following disclaimer in the
# documentation and/or other materials provided with the distribution.
# * Neither the name of the NVIDIA CORPORATION nor the
# names of its contributors may be used to endorse or promote products
# derived from this software without specific prior written permission.
# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND
# ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED
# WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
# DISCLAIMED. IN NO EVENT SHALL NVIDIA CORPORATION BE LIABLE FOR ANY
# DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES
# (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES;
# LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND
# ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
# (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS
# SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
import os
from fastspeech.utils.hparam import Hparam
import torch
# hyperparamter
HP_ROOT_PATH = os.path.join(os.path.dirname(__file__), 'hparams')
hparam = Hparam(HP_ROOT_PATH)
# device
DEFAULT_DEVICE = torch.device('cuda' if torch.cuda.is_available() else 'cpu') |
TensorFlow2/Recommendation/WideAndDeep/triton/deployment_toolkit | deployment_toolkit | extensions | # Copyright (c) 2021-2022, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import importlib
import logging
import os
import re
from pathlib import Path
from typing import List
LOGGER = logging.getLogger(__name__)
class ExtensionManager:
def __init__(self, name: str):
self._name = name
self._registry = {}
def register_extension(self, extension: str, clazz):
already_registered_class = self._registry.get(extension, None)
if already_registered_class and already_registered_class.__module__ != clazz.__module__:
raise RuntimeError(
f"Conflicting extension {self._name}/{extension}; "
f"{already_registered_class.__module__}.{already_registered_class.__name} "
f"and "
f"{clazz.__module__}.{clazz.__name__}"
)
elif already_registered_class is None:
clazz_full_name = f"{clazz.__module__}.{clazz.__name__}" if clazz is not None else "None"
LOGGER.debug(f"Registering extension {self._name}/{extension}: {clazz_full_name}")
self._registry[extension] = clazz
def get(self, extension):
if extension not in self._registry:
raise RuntimeError(f"Missing extension {self._name}/{extension}")
return self._registry[extension]
@property
def supported_extensions(self):
return list(self._registry)
@staticmethod
def scan_for_extensions(extension_dirs: List[Path]):
register_pattern = r".*\.register_extension\(.*"
for extension_dir in extension_dirs:
for python_path in extension_dir.rglob("*.py"):
if not python_path.is_file():
continue
payload = python_path.read_text()
if re.findall(register_pattern, payload):
import_path = python_path.relative_to(toolkit_root_dir.parent)
package = import_path.parent.as_posix().replace(os.sep, ".")
package_with_module = f"{package}.{import_path.stem}"
spec = importlib.util.spec_from_file_location(name=package_with_module, location=python_path)
my_module = importlib.util.module_from_spec(spec)
my_module.__package__ = package
try:
spec.loader.exec_module(my_module) # pytype: disable=attribute-error
except ModuleNotFoundError as e:
LOGGER.error(
f"Could not load extensions from {import_path} due to missing python packages; {e}"
)
runners = ExtensionManager("runners")
loaders = ExtensionManager("loaders")
savers = ExtensionManager("savers")
toolkit_root_dir = (Path(__file__).parent / "..").resolve()
ExtensionManager.scan_for_extensions([toolkit_root_dir])
|
TensorFlow/Detection/SSD/models/research/object_detection/models | models | ssd_mobilenet_v2_feature_extractor | # Copyright 2018 The TensorFlow Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ==============================================================================
"""SSDFeatureExtractor for MobilenetV2 features."""
import tensorflow as tf
from object_detection.meta_architectures import ssd_meta_arch
from object_detection.models import feature_map_generators
from object_detection.utils import context_manager
from object_detection.utils import ops
from object_detection.utils import shape_utils
from nets.mobilenet import mobilenet
from nets.mobilenet import mobilenet_v2
slim = tf.contrib.slim
class SSDMobileNetV2FeatureExtractor(ssd_meta_arch.SSDFeatureExtractor):
"""SSD Feature Extractor using MobilenetV2 features."""
def __init__(self,
is_training,
depth_multiplier,
min_depth,
pad_to_multiple,
conv_hyperparams_fn,
reuse_weights=None,
use_explicit_padding=False,
use_depthwise=False,
override_base_feature_extractor_hyperparams=False):
"""MobileNetV2 Feature Extractor for SSD Models.
Mobilenet v2 (experimental), designed by sandler@. More details can be found
in //knowledge/cerebra/brain/compression/mobilenet/mobilenet_experimental.py
Args:
is_training: whether the network is in training mode.
depth_multiplier: float depth multiplier for feature extractor.
min_depth: minimum feature extractor depth.
pad_to_multiple: the nearest multiple to zero pad the input height and
width dimensions to.
conv_hyperparams_fn: A function to construct tf slim arg_scope for conv2d
and separable_conv2d ops in the layers that are added on top of the
base feature extractor.
reuse_weights: Whether to reuse variables. Default is None.
use_explicit_padding: Whether to use explicit padding when extracting
features. Default is False.
use_depthwise: Whether to use depthwise convolutions. Default is False.
override_base_feature_extractor_hyperparams: Whether to override
hyperparameters of the base feature extractor with the one from
`conv_hyperparams_fn`.
"""
super(SSDMobileNetV2FeatureExtractor, self).__init__(
is_training=is_training,
depth_multiplier=depth_multiplier,
min_depth=min_depth,
pad_to_multiple=pad_to_multiple,
conv_hyperparams_fn=conv_hyperparams_fn,
reuse_weights=reuse_weights,
use_explicit_padding=use_explicit_padding,
use_depthwise=use_depthwise,
override_base_feature_extractor_hyperparams=
override_base_feature_extractor_hyperparams)
def preprocess(self, resized_inputs):
"""SSD preprocessing.
Maps pixel values to the range [-1, 1].
Args:
resized_inputs: a [batch, height, width, channels] float tensor
representing a batch of images.
Returns:
preprocessed_inputs: a [batch, height, width, channels] float tensor
representing a batch of images.
"""
return (2.0 / 255.0) * resized_inputs - 1.0
def extract_features(self, preprocessed_inputs):
"""Extract features from preprocessed inputs.
Args:
preprocessed_inputs: a [batch, height, width, channels] float tensor
representing a batch of images.
Returns:
feature_maps: a list of tensors where the ith tensor has shape
[batch, height_i, width_i, depth_i]
"""
preprocessed_inputs = shape_utils.check_min_image_dim(
33, preprocessed_inputs)
feature_map_layout = {
'from_layer': ['layer_15/expansion_output', 'layer_19', '', '', '', ''],
'layer_depth': [-1, -1, 512, 256, 256, 128],
'use_depthwise': self._use_depthwise,
'use_explicit_padding': self._use_explicit_padding,
}
with tf.variable_scope('MobilenetV2', reuse=self._reuse_weights) as scope:
with slim.arg_scope(
mobilenet_v2.training_scope(is_training=None, bn_decay=0.9997)), \
slim.arg_scope(
[mobilenet.depth_multiplier], min_depth=self._min_depth):
with (slim.arg_scope(self._conv_hyperparams_fn())
if self._override_base_feature_extractor_hyperparams else
context_manager.IdentityContextManager()):
_, image_features = mobilenet_v2.mobilenet_base(
ops.pad_to_multiple(preprocessed_inputs, self._pad_to_multiple),
final_endpoint='layer_19',
depth_multiplier=self._depth_multiplier,
use_explicit_padding=self._use_explicit_padding,
scope=scope)
with slim.arg_scope(self._conv_hyperparams_fn()):
feature_maps = feature_map_generators.multi_resolution_feature_maps(
feature_map_layout=feature_map_layout,
depth_multiplier=self._depth_multiplier,
min_depth=self._min_depth,
insert_1x1_conv=True,
image_features=image_features)
return feature_maps.values()
|
PyTorch/Detection/Efficientdet/effdet/layers | layers | __init__ | # Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from .activations import *
from .cond_conv2d import CondConv2d, get_condconv_initializer
from .config import is_exportable, is_scriptable, is_no_jit, set_exportable, set_scriptable, set_no_jit,\
set_layer_config
from .conv2d_same import Conv2dSame
from .create_act import create_act_layer, get_act_layer, get_act_fn
from .create_conv2d import create_conv2d
from .drop import DropBlock2d, DropPath, drop_block_2d, drop_path
from .mixed_conv2d import MixedConv2d
from .padding import get_padding
from .pool2d_same import AvgPool2dSame, create_pool2d
from .nms_layer import batched_soft_nms, batched_nms |
TensorFlow2/Recommendation/WideAndDeep/triton | triton | run_inference_on_triton | #!/usr/bin/env python3
# Copyright (c) 2021-2022, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
r"""
To infer the model deployed on Triton, you can use `run_inference_on_triton.py` script.
It sends a request with data obtained from pointed data loader and dumps received data into dump files.
Those files are stored in directory pointed by `--output-dir` argument.
Currently, the client communicates with the Triton server asynchronously using GRPC protocol.
Example call:
```shell script
python ./triton/run_inference_on_triton.py \
--server-url localhost:8001 \
--model-name ResNet50 \
--model-version 1 \
--dump-labels \
--output-dir /results/dump_triton
```
"""
import argparse
import logging
import time
import traceback
from pathlib import Path
from tqdm import tqdm
# method from PEP-366 to support relative import in executed modules
if __package__ is None:
__package__ = Path(__file__).parent.name
from .deployment_toolkit.args import ArgParserGenerator
from .deployment_toolkit.core import DATALOADER_FN_NAME, load_from_file
from .deployment_toolkit.dump import JsonDumpWriter
from .deployment_toolkit.triton_inference_runner import TritonInferenceRunner
LOGGER = logging.getLogger("run_inference_on_triton")
def _parse_args():
parser = argparse.ArgumentParser(description="Infer model on Triton server", allow_abbrev=False)
parser.add_argument(
"--server-url", type=str, default="localhost:8001", help="Inference server URL (default localhost:8001)"
)
parser.add_argument("--model-name", help="The name of the model used for inference.", required=True)
parser.add_argument("--model-version", help="The version of the model used for inference.", required=True)
parser.add_argument("--dataloader", help="Path to python file containing dataloader.", required=True)
parser.add_argument("--dump-labels", help="Dump labels to output dir", action="store_true", default=False)
parser.add_argument("--dump-inputs", help="Dump inputs to output dir", action="store_true", default=False)
parser.add_argument("-v", "--verbose", help="Verbose logs", action="store_true", default=True)
parser.add_argument("--output-dir", required=True, help="Path to directory where outputs will be saved")
parser.add_argument(
"--response-wait-time", required=False, help="Maximal time to wait for response", default=120, type=float
)
parser.add_argument(
"--max-unresponded-requests",
required=False,
help="Maximal number of unresponded requests",
default=128,
type=int,
)
parser.add_argument(
"--synchronous", help="Enable synchronous calls to Triton Server", action="store_true", default=False
)
args, *_ = parser.parse_known_args()
get_dataloader_fn = load_from_file(args.dataloader, label="dataloader", target=DATALOADER_FN_NAME)
ArgParserGenerator(get_dataloader_fn).update_argparser(parser)
args = parser.parse_args()
return args
def main():
args = _parse_args()
log_format = "%(asctime)s %(levelname)s %(name)s %(message)s"
log_level = logging.INFO if not args.verbose else logging.DEBUG
logging.basicConfig(level=log_level, format=log_format)
LOGGER.info("args:")
for key, value in vars(args).items():
LOGGER.info(f" {key} = {value}")
get_dataloader_fn = load_from_file(args.dataloader, label="dataloader", target=DATALOADER_FN_NAME)
dataloader_fn = ArgParserGenerator(get_dataloader_fn).from_args(args)
try:
runner = TritonInferenceRunner(
server_url=args.server_url,
model_name=args.model_name,
model_version=args.model_version,
dataloader_fn=dataloader_fn,
verbose=False,
response_wait_time=args.response_wait_time,
max_unresponded_requests=args.max_unresponded_requests,
synchronous=args.synchronous,
)
except Exception as e:
message = traceback.format_exc()
LOGGER.error(f"Encountered exception \n{message}")
raise e
with JsonDumpWriter(output_dir=args.output_dir) as writer:
start = time.time()
for ids, x, y_pred, y_real in tqdm(runner, unit="batch", mininterval=10):
data = _verify_and_format_dump(args, ids, x, y_pred, y_real)
writer.write(**data)
stop = time.time()
LOGGER.info(f"\nThe inference took {stop - start:0.3f}s")
def _verify_and_format_dump(args, ids, x, y_pred, y_real):
data = {"outputs": y_pred, "ids": {"ids": ids}}
if args.dump_inputs:
data["inputs"] = x
if args.dump_labels:
if not y_real:
raise ValueError(
"Found empty label values. Please provide labels in dataloader_fn or do not use --dump-labels argument"
)
data["labels"] = y_real
return data
if __name__ == "__main__":
main()
|
PyTorch/SpeechRecognition/wav2vec2/common/fairseq/modules | modules | grad_multiply | # Copyright (c) Facebook, Inc. and its affiliates.
#
# This source code is licensed under the MIT license found in the
# LICENSE file in the root directory of this source tree.
# Copyright (c) 2023, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import torch
class GradMultiply(torch.autograd.Function):
@staticmethod
def forward(ctx, x, scale):
ctx.scale = scale
res = x.new(x)
return res
@staticmethod
def backward(ctx, grad):
return grad * ctx.scale, None
|
TensorFlow/Segmentation/VNet/hooks | hooks | profiling_hook | # Copyright (c) 2019, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import time
import numpy as np
import tensorflow as tf
import dllogger as DLLogger
class ProfilingHook(tf.estimator.SessionRunHook):
def __init__(self, warmup_steps, global_batch_size, logger, training=True):
self._warmup_steps = warmup_steps
self._global_batch_size = global_batch_size
self._step = 0
self._timestamps = []
self._logger = logger
self._training = training
def before_run(self, run_context):
self._step += 1
if self._step >= self._warmup_steps:
self._timestamps.append(time.time())
def end(self, session):
deltas = np.array([self._timestamps[i + 1] - self._timestamps[i] for i in range(len(self._timestamps) - 1)])
stats = process_performance_stats(np.array(deltas),
self._global_batch_size)
self._logger.log(step=(), data={metric: value for (metric, value) in stats})
self._logger.flush()
def process_performance_stats(timestamps, batch_size):
timestamps_ms = 1000 * timestamps
latency_ms = timestamps_ms.mean()
std = timestamps_ms.std()
n = np.sqrt(len(timestamps_ms))
throughput_imgps = (1000.0 * batch_size / timestamps_ms).mean()
stats = [("Throughput Avg", str(throughput_imgps)),
('Latency Avg:', str(latency_ms))]
for ci, lvl in zip(["90%:", "95%:", "99%:"],
[1.645, 1.960, 2.576]):
stats.append(("Latency_"+ci, str(latency_ms + lvl * std / n)))
return stats |
PaddlePaddle/Classification/RN50v1.5 | RN50v1.5 | lr_scheduler | # Copyright (c) 2022 NVIDIA Corporation. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import sys
import logging
import paddle
class Cosine:
"""
Cosine learning rate decay.
lr = eta_min + 0.5 * (learning_rate - eta_min) * (cos(epoch * (PI / epochs)) + 1)
Args:
args(Namespace): Arguments obtained from ArgumentParser.
step_each_epoch(int): The number of steps in each epoch.
last_epoch (int, optional): The index of last epoch. Can be set to restart training.
Default: -1, meaning initial learning rate.
"""
def __init__(self, args, step_each_epoch, last_epoch=-1):
super().__init__()
if args.warmup_epochs >= args.epochs:
args.warmup_epochs = args.epochs
self.learning_rate = args.lr
self.T_max = (args.epochs - args.warmup_epochs) * step_each_epoch
self.eta_min = 0.0
self.last_epoch = last_epoch
self.warmup_steps = round(args.warmup_epochs * step_each_epoch)
self.warmup_start_lr = args.warmup_start_lr
def __call__(self):
learning_rate = paddle.optimizer.lr.CosineAnnealingDecay(
learning_rate=self.learning_rate,
T_max=self.T_max,
eta_min=self.eta_min,
last_epoch=self.
last_epoch) if self.T_max > 0 else self.learning_rate
if self.warmup_steps > 0:
learning_rate = paddle.optimizer.lr.LinearWarmup(
learning_rate=learning_rate,
warmup_steps=self.warmup_steps,
start_lr=self.warmup_start_lr,
end_lr=self.learning_rate,
last_epoch=self.last_epoch)
return learning_rate
def build_lr_scheduler(args, step_each_epoch):
"""
Build a learning rate scheduler.
Args:
args(Namespace): Arguments obtained from ArgumentParser.
step_each_epoch(int): The number of steps in each epoch.
return:
lr(paddle.optimizer.lr.LRScheduler): A learning rate scheduler.
"""
# Turn last_epoch to last_step, since we update lr each step instead of each epoch.
last_step = args.start_epoch * step_each_epoch - 1
learning_rate_mod = sys.modules[__name__]
lr = getattr(learning_rate_mod, args.lr_scheduler)(args, step_each_epoch,
last_step)
if not isinstance(lr, paddle.optimizer.lr.LRScheduler):
lr = lr()
logging.info("build lr %s success..", lr)
return lr
|
PyTorch/Segmentation/MaskRCNN/pytorch/maskrcnn_benchmark/modeling/roi_heads/box_head | box_head | inference | # Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved.
import torch
import torch.nn.functional as F
from torch import nn
from maskrcnn_benchmark.structures.bounding_box import BoxList
from maskrcnn_benchmark.structures.boxlist_ops import boxlist_nms
from maskrcnn_benchmark.structures.boxlist_ops import cat_boxlist
from maskrcnn_benchmark.modeling.box_coder import BoxCoder
class PostProcessor(nn.Module):
"""
From a set of classification scores, box regression and proposals,
computes the post-processed boxes, and applies NMS to obtain the
final results
"""
def __init__(
self, score_thresh=0.05, nms=0.5, detections_per_img=100, box_coder=None
):
"""
Arguments:
score_thresh (float)
nms (float)
detections_per_img (int)
box_coder (BoxCoder)
"""
super(PostProcessor, self).__init__()
self.score_thresh = score_thresh
self.nms = nms
self.detections_per_img = detections_per_img
if box_coder is None:
box_coder = BoxCoder(weights=(10., 10., 5., 5.))
self.box_coder = box_coder
def forward(self, x, boxes):
"""
Arguments:
x (tuple[tensor, tensor]): x contains the class logits
and the box_regression from the model.
boxes (list[BoxList]): bounding boxes that are used as
reference, one for ech image
Returns:
results (list[BoxList]): one BoxList for each image, containing
the extra fields labels and scores
"""
class_logits, box_regression = x
class_prob = F.softmax(class_logits, -1)
# TODO think about a representation of batch of boxes
image_shapes = [box.size for box in boxes]
boxes_per_image = [len(box) for box in boxes]
concat_boxes = torch.cat([a.bbox for a in boxes], dim=0)
proposals = self.box_coder.decode(
box_regression.view(sum(boxes_per_image), -1), concat_boxes
)
num_classes = class_prob.shape[1]
proposals = proposals.split(boxes_per_image, dim=0)
class_prob = class_prob.split(boxes_per_image, dim=0)
results = []
for prob, boxes_per_img, image_shape in zip(
class_prob, proposals, image_shapes
):
boxlist = self.prepare_boxlist(boxes_per_img, prob, image_shape)
boxlist = boxlist.clip_to_image(remove_empty=False)
boxlist = self.filter_results(boxlist, num_classes)
results.append(boxlist)
return results
def prepare_boxlist(self, boxes, scores, image_shape):
"""
Returns BoxList from `boxes` and adds probability scores information
as an extra field
`boxes` has shape (#detections, 4 * #classes), where each row represents
a list of predicted bounding boxes for each of the object classes in the
dataset (including the background class). The detections in each row
originate from the same object proposal.
`scores` has shape (#detection, #classes), where each row represents a list
of object detection confidence scores for each of the object classes in the
dataset (including the background class). `scores[i, j]`` corresponds to the
box at `boxes[i, j * 4:(j + 1) * 4]`.
"""
boxes = boxes.reshape(-1, 4)
scores = scores.reshape(-1)
boxlist = BoxList(boxes, image_shape, mode="xyxy")
boxlist.add_field("scores", scores)
return boxlist
def filter_results(self, boxlist, num_classes):
"""Returns bounding-box detection results by thresholding on scores and
applying non-maximum suppression (NMS).
"""
# unwrap the boxlist to avoid additional overhead.
# if we had multi-class NMS, we could perform this directly on the boxlist
boxes = boxlist.bbox.reshape(-1, num_classes * 4)
scores = boxlist.get_field("scores").reshape(-1, num_classes)
device = scores.device
result = []
# Apply threshold on detection probabilities and apply NMS
# Skip j = 0, because it's the background class
inds_all = scores > self.score_thresh
for j in range(1, num_classes):
inds = inds_all[:, j].nonzero().squeeze(1)
scores_j = scores[inds, j]
boxes_j = boxes[inds, j * 4 : (j + 1) * 4]
boxlist_for_class = BoxList(boxes_j, boxlist.size, mode="xyxy")
boxlist_for_class.add_field("scores", scores_j)
boxlist_for_class = boxlist_nms(
boxlist_for_class, self.nms, score_field="scores"
)
num_labels = len(boxlist_for_class)
boxlist_for_class.add_field(
"labels", torch.full((num_labels,), j, dtype=torch.int64, device=device)
)
result.append(boxlist_for_class)
result = cat_boxlist(result)
number_of_detections = len(result)
# Limit to max_per_image detections **over all classes**
if number_of_detections > self.detections_per_img > 0:
cls_scores = result.get_field("scores")
image_thresh, _ = torch.kthvalue(
cls_scores.cpu(), number_of_detections - self.detections_per_img + 1
)
keep = cls_scores >= image_thresh.item()
keep = torch.nonzero(keep).squeeze(1)
result = result[keep]
return result
def make_roi_box_post_processor(cfg):
use_fpn = cfg.MODEL.ROI_HEADS.USE_FPN
bbox_reg_weights = cfg.MODEL.ROI_HEADS.BBOX_REG_WEIGHTS
box_coder = BoxCoder(weights=bbox_reg_weights)
score_thresh = cfg.MODEL.ROI_HEADS.SCORE_THRESH
nms_thresh = cfg.MODEL.ROI_HEADS.NMS
detections_per_img = cfg.MODEL.ROI_HEADS.DETECTIONS_PER_IMG
postprocessor = PostProcessor(
score_thresh, nms_thresh, detections_per_img, box_coder
)
return postprocessor
|
TensorFlow2/Segmentation/nnUNet/runtime | runtime | args | import argparse
from argparse import ArgumentDefaultsHelpFormatter, ArgumentParser
from pathlib import Path
def positive_int(value):
ivalue = int(value)
if ivalue <= 0:
raise argparse.ArgumentTypeError(f"Argparse error. Expected a positive integer but got {value}")
return ivalue
def non_negative_int(value):
ivalue = int(value)
if ivalue < 0:
raise argparse.ArgumentTypeError(f"Argparse error. Expected a non-negative integer but got {value}")
return ivalue
def float_0_1(value):
fvalue = float(value)
if not (0 <= fvalue <= 1):
raise argparse.ArgumentTypeError(f"Argparse error. Expected a float from range (0, 1), but got {value}")
return fvalue
def str2bool(v):
if isinstance(v, bool):
return v
if v.lower() in ("yes", "true", "t", "y", "1"):
return True
elif v.lower() in ("no", "false", "f", "n", "0"):
return False
else:
raise argparse.ArgumentTypeError("Boolean value expected.")
class ArgParser(ArgumentParser):
def arg(self, *args, **kwargs):
return super().add_argument(*args, **kwargs)
def flag(self, *args, **kwargs):
return super().add_argument(*args, action="store_true", **kwargs)
def boolean_flag(self, *args, **kwargs):
return super().add_argument(*args, type=str2bool, nargs="?", const=True, metavar="BOOLEAN", **kwargs)
def get_main_args():
p = ArgParser(formatter_class=ArgumentDefaultsHelpFormatter)
# Runtime
p.arg(
"--exec-mode",
"--exec_mode",
type=str,
choices=["train", "evaluate", "predict", "export"],
default="train",
help="Execution mode to run the model",
)
p.arg("--gpus", type=non_negative_int, default=1)
p.arg("--data", type=Path, default=Path("/data"), help="Path to data directory")
p.arg("--task", type=str, default="01", help="Task number, MSD uses numbers 01-10")
p.arg("--dim", type=int, choices=[2, 3], default=3, help="UNet dimension")
p.arg("--seed", type=non_negative_int, default=None, help="Random seed")
p.flag("--benchmark", help="Run model benchmarking")
p.boolean_flag("--tta", default=False, help="Enable test time augmentation")
p.boolean_flag("--save-preds", "--save_preds", default=False, help="Save predictions")
# Logging
p.arg("--results", type=Path, default=Path("/results"), help="Path to results directory")
p.arg("--logname", type=str, default="dllogger.json", help="DLLogger output filename")
p.flag("--quiet", help="Minimalize stdout/stderr output")
p.boolean_flag("--use-dllogger", "--use_dllogger", default=True, help="Use DLLogger logging")
# Performance optimization
p.boolean_flag("--amp", default=False, help="Enable automatic mixed precision")
p.boolean_flag("--xla", default=False, help="Enable XLA compiling")
# Training hyperparameters and loss fn customization
p.arg("--batch-size", "--batch_size", type=positive_int, default=2, help="Batch size")
p.arg("--learning-rate", "--learning_rate", type=float, default=0.0003, help="Learning rate")
p.arg("--momentum", type=float, default=0.99, help="Momentum factor (SGD only)")
p.arg(
"--scheduler",
type=str,
default="cosine_annealing",
choices=["none", "poly", "cosine", "cosine_annealing"],
help="Learning rate scheduler",
)
p.arg("--end-learning-rate", type=float, default=0.00001, help="End learning rate for poly scheduler")
p.arg(
"--cosine-annealing-first-cycle-steps",
type=positive_int,
default=4096,
help="Length of a cosine decay cycle in steps, only with 'cosine_annealing' scheduler",
)
p.arg(
"--cosine-annealing-peak-decay", type=float_0_1, default=0.95, help="Multiplier reducing initial learning rate"
)
p.arg("--optimizer", type=str, default="adam", choices=["sgd", "adam", "radam"], help="Optimizer")
p.boolean_flag("--deep-supervision", "--deep_supervision", default=False, help="Use deep supervision.")
p.boolean_flag("--lookahead", default=False, help="Use Lookahead with the optimizer")
p.arg("--weight-decay", "--weight_decay", type=float, default=0.0001, help="Weight decay (L2 penalty)")
p.boolean_flag(
"--loss-batch-reduction",
dest="reduce_batch",
default=True,
help="Reduce batch dimension first during loss calculation",
)
p.boolean_flag(
"--loss-include-background",
dest="include_background",
default=False,
help="Include background class to loss calculation",
)
# UNet architecture
p.arg("--negative-slope", type=float, default=0.01, help="Negative slope for LeakyReLU")
p.arg(
"--norm",
type=str,
choices=["instance", "batch", "group", "none"],
default="instance",
help="Type of normalization layers",
)
# Checkpoints
p.arg(
"--ckpt-strategy",
type=str,
default="last_and_best",
choices=["last_and_best", "last_only", "none"],
help="Strategy how to save checkpoints",
)
p.arg("--ckpt-dir", type=Path, default=Path("/results/ckpt/"), help="Path to checkpoint directory")
p.arg("--saved-model-dir", type=Path, help="Path to saved model directory (for evaluation and prediction)")
p.flag("--resume-training", "--resume_training", help="Resume training from the last checkpoint")
p.boolean_flag("--load_sm", default=False, help="Load exported savedmodel")
p.boolean_flag("--validate", default=False, help="Validate exported savedmodel")
# Data loading and processing
p.arg(
"--nvol",
type=positive_int,
default=2,
help="Number of volumes which come into single batch size for 2D model",
)
p.arg(
"--oversampling",
type=float_0_1,
default=0.33,
help="Probability of crop to have some region with positive label",
)
p.arg(
"--num-workers",
type=non_negative_int,
default=8,
help="Number of subprocesses to use for data loading",
)
# Sliding window inference
p.arg(
"--overlap",
type=float_0_1,
default=0.25,
help="Amount of overlap between scans during sliding window inference",
)
p.arg(
"--blend",
"--blend-mode",
dest="blend_mode",
type=str,
choices=["gaussian", "constant"],
default="constant",
help="How to blend output of overlapping windows",
)
# Validation
p.arg("--nfolds", type=positive_int, default=5, help="Number of cross-validation folds")
p.arg("--fold", type=non_negative_int, default=0, help="Fold number")
p.arg("--epochs", type=positive_int, default=1000, help="Number of epochs")
p.arg("--skip-eval", type=non_negative_int, default=0, help="Skip evaluation for the first N epochs.")
p.arg(
"--steps-per-epoch",
type=positive_int,
help="Steps per epoch. By default ceil(training_dataset_size / batch_size / gpus)",
)
# Benchmarking
p.arg(
"--bench-steps",
type=non_negative_int,
default=200,
help="Number of benchmarked steps in total",
)
p.arg(
"--warmup-steps",
type=non_negative_int,
default=100,
help="Number of warmup steps before collecting benchmarking statistics",
)
args = p.parse_args()
return args
|
PyTorch/SpeechRecognition/Jasper/common | common | audio | # Copyright (c) 2019, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import random
import soundfile as sf
import librosa
import torch
import numpy as np
import sox
def audio_from_file(file_path, offset=0, duration=0, trim=False, target_sr=16000):
audio = AudioSegment(file_path, target_sr=target_sr, int_values=False,
offset=offset, duration=duration, trim=trim)
samples = torch.tensor(audio.samples, dtype=torch.float).cuda()
num_samples = torch.tensor(samples.shape[0]).int().cuda()
return (samples.unsqueeze(0), num_samples.unsqueeze(0))
class AudioSegment(object):
"""Monaural audio segment abstraction.
:param samples: Audio samples [num_samples x num_channels].
:type samples: ndarray.float32
:param sample_rate: Audio sample rate.
:type sample_rate: int
:raises TypeError: If the sample data type is not float or int.
"""
def __init__(self, filename, target_sr=None, int_values=False, offset=0,
duration=0, trim=False, trim_db=60):
"""Create audio segment from samples.
Samples are converted to float32 internally, with int scaled to [-1, 1].
Load a file supported by librosa and return as an AudioSegment.
:param filename: path of file to load
:param target_sr: the desired sample rate
:param int_values: if true, load samples as 32-bit integers
:param offset: offset in seconds when loading audio
:param duration: duration in seconds when loading audio
:return: numpy array of samples
"""
with sf.SoundFile(filename, 'r') as f:
dtype = 'int32' if int_values else 'float32'
sample_rate = f.samplerate
if offset > 0:
f.seek(int(offset * sample_rate))
if duration > 0:
samples = f.read(int(duration * sample_rate), dtype=dtype)
else:
samples = f.read(dtype=dtype)
samples = samples.transpose()
samples = self._convert_samples_to_float32(samples)
if target_sr is not None and target_sr != sample_rate:
samples = librosa.resample(samples, orig_sr=sample_rate,
target_sr=target_sr)
sample_rate = target_sr
if trim:
samples, _ = librosa.effects.trim(samples, top_db=trim_db)
self._samples = samples
self._sample_rate = sample_rate
if self._samples.ndim >= 2:
self._samples = np.mean(self._samples, 1)
def __eq__(self, other):
"""Return whether two objects are equal."""
if type(other) is not type(self):
return False
if self._sample_rate != other._sample_rate:
return False
if self._samples.shape != other._samples.shape:
return False
if np.any(self.samples != other._samples):
return False
return True
def __ne__(self, other):
"""Return whether two objects are unequal."""
return not self.__eq__(other)
def __str__(self):
"""Return human-readable representation of segment."""
return ("%s: num_samples=%d, sample_rate=%d, duration=%.2fsec, "
"rms=%.2fdB" % (type(self), self.num_samples, self.sample_rate,
self.duration, self.rms_db))
@staticmethod
def _convert_samples_to_float32(samples):
"""Convert sample type to float32.
Audio sample type is usually integer or float-point.
Integers will be scaled to [-1, 1] in float32.
"""
float32_samples = samples.astype('float32')
if samples.dtype in np.sctypes['int']:
bits = np.iinfo(samples.dtype).bits
float32_samples *= (1. / 2 ** (bits - 1))
elif samples.dtype in np.sctypes['float']:
pass
else:
raise TypeError("Unsupported sample type: %s." % samples.dtype)
return float32_samples
@property
def samples(self):
return self._samples.copy()
@property
def sample_rate(self):
return self._sample_rate
@property
def num_samples(self):
return self._samples.shape[0]
@property
def duration(self):
return self._samples.shape[0] / float(self._sample_rate)
@property
def rms_db(self):
mean_square = np.mean(self._samples ** 2)
return 10 * np.log10(mean_square)
def gain_db(self, gain):
self._samples *= 10. ** (gain / 20.)
def pad(self, pad_size, symmetric=False):
"""Add zero padding to the sample.
The pad size is given in number of samples. If symmetric=True,
`pad_size` will be added to both sides. If false, `pad_size` zeros
will be added only to the end.
"""
self._samples = np.pad(self._samples,
(pad_size if symmetric else 0, pad_size),
mode='constant')
def subsegment(self, start_time=None, end_time=None):
"""Cut the AudioSegment between given boundaries.
Note that this is an in-place transformation.
:param start_time: Beginning of subsegment in seconds.
:type start_time: float
:param end_time: End of subsegment in seconds.
:type end_time: float
:raise ValueError: If start_time or end_time is incorrectly set, e.g. out
of bounds in time.
"""
start_time = 0.0 if start_time is None else start_time
end_time = self.duration if end_time is None else end_time
if start_time < 0.0:
start_time = self.duration + start_time
if end_time < 0.0:
end_time = self.duration + end_time
if start_time < 0.0:
raise ValueError("The slice start position (%f s) is out of "
"bounds." % start_time)
if end_time < 0.0:
raise ValueError("The slice end position (%f s) is out of bounds." %
end_time)
if start_time > end_time:
raise ValueError("The slice start position (%f s) is later than "
"the end position (%f s)." % (start_time, end_time))
if end_time > self.duration:
raise ValueError("The slice end position (%f s) is out of bounds "
"(> %f s)" % (end_time, self.duration))
start_sample = int(round(start_time * self._sample_rate))
end_sample = int(round(end_time * self._sample_rate))
self._samples = self._samples[start_sample:end_sample]
class Perturbation:
def __init__(self, p=0.1, rng=None):
self.p = p
self._rng = random.Random() if rng is None else rng
def maybe_apply(self, segment, sample_rate=None):
if self._rng.random() < self.p:
self(segment, sample_rate)
class SpeedPerturbation(Perturbation):
def __init__(self, min_rate=0.85, max_rate=1.15, discrete=False, p=0.1, rng=None):
super(SpeedPerturbation, self).__init__(p, rng)
assert 0 < min_rate < max_rate
self.min_rate = min_rate
self.max_rate = max_rate
self.discrete = discrete
def __call__(self, data, sample_rate):
if self.discrete:
rate = np.random.choice([self.min_rate, None, self.max_rate])
else:
rate = self._rng.uniform(self.min_rate, self.max_rate)
if rate is not None:
data._samples = sox.Transformer().speed(factor=rate).build_array(
input_array=data._samples, sample_rate_in=sample_rate)
class GainPerturbation(Perturbation):
def __init__(self, min_gain_dbfs=-10, max_gain_dbfs=10, p=0.1, rng=None):
super(GainPerturbation, self).__init__(p, rng)
self._rng = random.Random() if rng is None else rng
self._min_gain_dbfs = min_gain_dbfs
self._max_gain_dbfs = max_gain_dbfs
def __call__(self, data, sample_rate=None):
del sample_rate
gain = self._rng.uniform(self._min_gain_dbfs, self._max_gain_dbfs)
data._samples = data._samples * (10. ** (gain / 20.))
class ShiftPerturbation(Perturbation):
def __init__(self, min_shift_ms=-5.0, max_shift_ms=5.0, p=0.1, rng=None):
super(ShiftPerturbation, self).__init__(p, rng)
self._min_shift_ms = min_shift_ms
self._max_shift_ms = max_shift_ms
def __call__(self, data, sample_rate):
shift_ms = self._rng.uniform(self._min_shift_ms, self._max_shift_ms)
if abs(shift_ms) / 1000 > data.duration:
# TODO: do something smarter than just ignore this condition
return
shift_samples = int(shift_ms * data.sample_rate // 1000)
# print("DEBUG: shift:", shift_samples)
if shift_samples < 0:
data._samples[-shift_samples:] = data._samples[:shift_samples]
data._samples[:-shift_samples] = 0
elif shift_samples > 0:
data._samples[:-shift_samples] = data._samples[shift_samples:]
data._samples[-shift_samples:] = 0
|
TensorFlow/Detection/SSD/models/research/slim/nets | nets | s3dg_test | # Copyright 2018 The TensorFlow Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ==============================================================================
"""Tests for networks.s3dg."""
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import tensorflow as tf
from nets import s3dg
class S3DGTest(tf.test.TestCase):
def testBuildClassificationNetwork(self):
batch_size = 5
num_frames = 64
height, width = 224, 224
num_classes = 1000
inputs = tf.random_uniform((batch_size, num_frames, height, width, 3))
logits, end_points = s3dg.s3dg(inputs, num_classes)
self.assertTrue(logits.op.name.startswith('InceptionV1/Logits'))
self.assertListEqual(logits.get_shape().as_list(),
[batch_size, num_classes])
self.assertTrue('Predictions' in end_points)
self.assertListEqual(end_points['Predictions'].get_shape().as_list(),
[batch_size, num_classes])
def testBuildBaseNetwork(self):
batch_size = 5
num_frames = 64
height, width = 224, 224
inputs = tf.random_uniform((batch_size, num_frames, height, width, 3))
mixed_6c, end_points = s3dg.s3dg_base(inputs)
self.assertTrue(mixed_6c.op.name.startswith('InceptionV1/Mixed_5c'))
self.assertListEqual(mixed_6c.get_shape().as_list(),
[batch_size, 8, 7, 7, 1024])
expected_endpoints = ['Conv2d_1a_7x7', 'MaxPool_2a_3x3', 'Conv2d_2b_1x1',
'Conv2d_2c_3x3', 'MaxPool_3a_3x3', 'Mixed_3b',
'Mixed_3c', 'MaxPool_4a_3x3', 'Mixed_4b', 'Mixed_4c',
'Mixed_4d', 'Mixed_4e', 'Mixed_4f', 'MaxPool_5a_2x2',
'Mixed_5b', 'Mixed_5c']
self.assertItemsEqual(end_points.keys(), expected_endpoints)
def testBuildOnlyUptoFinalEndpointNoGating(self):
batch_size = 5
num_frames = 64
height, width = 224, 224
endpoints = ['Conv2d_1a_7x7', 'MaxPool_2a_3x3', 'Conv2d_2b_1x1',
'Conv2d_2c_3x3', 'MaxPool_3a_3x3', 'Mixed_3b', 'Mixed_3c',
'MaxPool_4a_3x3', 'Mixed_4b', 'Mixed_4c', 'Mixed_4d',
'Mixed_4e', 'Mixed_4f', 'MaxPool_5a_2x2', 'Mixed_5b',
'Mixed_5c']
for index, endpoint in enumerate(endpoints):
with tf.Graph().as_default():
inputs = tf.random_uniform((batch_size, num_frames, height, width, 3))
out_tensor, end_points = s3dg.s3dg_base(
inputs, final_endpoint=endpoint, gating_startat=None)
print(endpoint, out_tensor.op.name)
self.assertTrue(out_tensor.op.name.startswith(
'InceptionV1/' + endpoint))
self.assertItemsEqual(endpoints[:index+1], end_points)
def testBuildAndCheckAllEndPointsUptoMixed5c(self):
batch_size = 5
num_frames = 64
height, width = 224, 224
inputs = tf.random_uniform((batch_size, num_frames, height, width, 3))
_, end_points = s3dg.s3dg_base(inputs,
final_endpoint='Mixed_5c')
endpoints_shapes = {'Conv2d_1a_7x7': [5, 32, 112, 112, 64],
'MaxPool_2a_3x3': [5, 32, 56, 56, 64],
'Conv2d_2b_1x1': [5, 32, 56, 56, 64],
'Conv2d_2c_3x3': [5, 32, 56, 56, 192],
'MaxPool_3a_3x3': [5, 32, 28, 28, 192],
'Mixed_3b': [5, 32, 28, 28, 256],
'Mixed_3c': [5, 32, 28, 28, 480],
'MaxPool_4a_3x3': [5, 16, 14, 14, 480],
'Mixed_4b': [5, 16, 14, 14, 512],
'Mixed_4c': [5, 16, 14, 14, 512],
'Mixed_4d': [5, 16, 14, 14, 512],
'Mixed_4e': [5, 16, 14, 14, 528],
'Mixed_4f': [5, 16, 14, 14, 832],
'MaxPool_5a_2x2': [5, 8, 7, 7, 832],
'Mixed_5b': [5, 8, 7, 7, 832],
'Mixed_5c': [5, 8, 7, 7, 1024]}
self.assertItemsEqual(endpoints_shapes.keys(), end_points.keys())
for endpoint_name, expected_shape in endpoints_shapes.iteritems():
self.assertTrue(endpoint_name in end_points)
self.assertListEqual(end_points[endpoint_name].get_shape().as_list(),
expected_shape)
def testHalfSizeImages(self):
batch_size = 5
num_frames = 64
height, width = 112, 112
inputs = tf.random_uniform((batch_size, num_frames, height, width, 3))
mixed_5c, _ = s3dg.s3dg_base(inputs)
self.assertTrue(mixed_5c.op.name.startswith('InceptionV1/Mixed_5c'))
self.assertListEqual(mixed_5c.get_shape().as_list(),
[batch_size, 8, 4, 4, 1024])
def testTenFrames(self):
batch_size = 5
num_frames = 10
height, width = 224, 224
inputs = tf.random_uniform((batch_size, num_frames, height, width, 3))
mixed_5c, _ = s3dg.s3dg_base(inputs)
self.assertTrue(mixed_5c.op.name.startswith('InceptionV1/Mixed_5c'))
self.assertListEqual(mixed_5c.get_shape().as_list(),
[batch_size, 2, 7, 7, 1024])
def testEvaluation(self):
batch_size = 2
num_frames = 64
height, width = 224, 224
num_classes = 1000
eval_inputs = tf.random_uniform((batch_size, num_frames, height, width, 3))
logits, _ = s3dg.s3dg(eval_inputs, num_classes,
is_training=False)
predictions = tf.argmax(logits, 1)
with self.test_session() as sess:
sess.run(tf.global_variables_initializer())
output = sess.run(predictions)
self.assertEquals(output.shape, (batch_size,))
if __name__ == '__main__':
tf.test.main()
|
TensorFlow2/LanguageModeling/BERT/data | data | create_datasets_from_start | #!/bin/bash
# Copyright (c) 2019 NVIDIA CORPORATION. All rights reserved.
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
export BERT_PREP_WORKING_DIR=/workspace/bert_tf2/data
to_download=${1:-"all"}
pretrained_to_download=${2:-"wiki_only"} # By default, we don't download BooksCorpus dataset due to recent issues with the host server
if [ "$to_download" = "all" ] || [ "$to_download" = "squad" ] ; then
#SQUAD
python3 ${BERT_PREP_WORKING_DIR}/bertPrep.py --action download --dataset google_pretrained_weights # Includes vocab
python3 ${BERT_PREP_WORKING_DIR}/bertPrep.py --action download --dataset squad
export BERT_DIR=${BERT_PREP_WORKING_DIR}/download/google_pretrained_weights/uncased_L-24_H-1024_A-16
export SQUAD_DIR=${BERT_PREP_WORKING_DIR}/download/squad
python create_finetuning_data.py \
--squad_data_file=${SQUAD_DIR}/v1.1/train-v1.1.json \
--vocab_file=${BERT_DIR}/vocab.txt \
--train_data_output_path=${SQUAD_DIR}/v1.1/squad_v1.1_train.tf_record \
--meta_data_file_path=${SQUAD_DIR}/v1.1/squad_v1.1_meta_data \
--fine_tuning_task_type=squad --max_seq_length=384
python create_finetuning_data.py \
--squad_data_file=${SQUAD_DIR}/v2.0/train-v2.0.json \
--vocab_file=${BERT_DIR}/vocab.txt \
--train_data_output_path=${SQUAD_DIR}/v2.0/squad_v2.0_train.tf_record \
--meta_data_file_path=${SQUAD_DIR}/v2.0/squad_v2.0_meta_data \
--fine_tuning_task_type=squad --max_seq_length=384 --version_2_with_negative=True
fi
if [ "$to_download" = "all" ] || [ "$to_download" = "pretrained" ] ; then
#Pretrained
if [ "$pretrained_to_download" = "wiki_books" ] ; then
python3 ${BERT_PREP_WORKING_DIR}/bertPrep.py --action download --dataset bookscorpus
fi
python3 ${BERT_PREP_WORKING_DIR}/bertPrep.py --action download --dataset wikicorpus_en
DATASET="wikicorpus_en"
# Properly format the text files
if [ "$pretrained_to_download" = "wiki_books" ] ; then
python3 ${BERT_PREP_WORKING_DIR}/bertPrep.py --action text_formatting --dataset bookscorpus
DATASET="books_wiki_en_corpus"
fi
python3 ${BERT_PREP_WORKING_DIR}/bertPrep.py --action text_formatting --dataset wikicorpus_en
# Shard the text files
python3 ${BERT_PREP_WORKING_DIR}/bertPrep.py --action sharding --dataset $DATASET
# Create TFRecord files Phase 1
python3 ${BERT_PREP_WORKING_DIR}/bertPrep.py --action create_tfrecord_files --dataset ${DATASET} --max_seq_length 128 \
--max_predictions_per_seq 20 --vocab_file ${BERT_PREP_WORKING_DIR}/download/google_pretrained_weights/uncased_L-24_H-1024_A-16/vocab.txt
# Create TFRecord files Phase 2
python3 ${BERT_PREP_WORKING_DIR}/bertPrep.py --action create_tfrecord_files --dataset ${DATASET} --max_seq_length 512 \
--max_predictions_per_seq 80 --vocab_file ${BERT_PREP_WORKING_DIR}/download/google_pretrained_weights/uncased_L-24_H-1024_A-16/vocab.txt
fi |
MxNet/Classification/RN50v1.5 | RN50v1.5 | imagenet_classes | classes = {
0: 'tench, Tinca tinca',
1: 'goldfish, Carassius auratus',
2: 'great white shark, white shark, man-eater, man-eating shark, Carcharodon carcharias',
3: 'tiger shark, Galeocerdo cuvieri',
4: 'hammerhead, hammerhead shark',
5: 'electric ray, crampfish, numbfish, torpedo',
6: 'stingray',
7: 'cock',
8: 'hen',
9: 'ostrich, Struthio camelus',
10: 'brambling, Fringilla montifringilla',
11: 'goldfinch, Carduelis carduelis',
12: 'house finch, linnet, Carpodacus mexicanus',
13: 'junco, snowbird',
14: 'indigo bunting, indigo finch, indigo bird, Passerina cyanea',
15: 'robin, American robin, Turdus migratorius',
16: 'bulbul',
17: 'jay',
18: 'magpie',
19: 'chickadee',
20: 'water ouzel, dipper',
21: 'kite',
22: 'bald eagle, American eagle, Haliaeetus leucocephalus',
23: 'vulture',
24: 'great grey owl, great gray owl, Strix nebulosa',
25: 'European fire salamander, Salamandra salamandra',
26: 'common newt, Triturus vulgaris',
27: 'eft',
28: 'spotted salamander, Ambystoma maculatum',
29: 'axolotl, mud puppy, Ambystoma mexicanum',
30: 'bullfrog, Rana catesbeiana',
31: 'tree frog, tree-frog',
32: 'tailed frog, bell toad, ribbed toad, tailed toad, Ascaphus trui',
33: 'loggerhead, loggerhead turtle, Caretta caretta',
34: 'leatherback turtle, leatherback, leathery turtle, Dermochelys coriacea',
35: 'mud turtle',
36: 'terrapin',
37: 'box turtle, box tortoise',
38: 'banded gecko',
39: 'common iguana, iguana, Iguana iguana',
40: 'American chameleon, anole, Anolis carolinensis',
41: 'whiptail, whiptail lizard',
42: 'agama',
43: 'frilled lizard, Chlamydosaurus kingi',
44: 'alligator lizard',
45: 'Gila monster, Heloderma suspectum',
46: 'green lizard, Lacerta viridis',
47: 'African chameleon, Chamaeleo chamaeleon',
48: 'Komodo dragon, Komodo lizard, dragon lizard, giant lizard, Varanus komodoensis',
49: 'African crocodile, Nile crocodile, Crocodylus niloticus',
50: 'American alligator, Alligator mississipiensis',
51: 'triceratops',
52: 'thunder snake, worm snake, Carphophis amoenus',
53: 'ringneck snake, ring-necked snake, ring snake',
54: 'hognose snake, puff adder, sand viper',
55: 'green snake, grass snake',
56: 'king snake, kingsnake',
57: 'garter snake, grass snake',
58: 'water snake',
59: 'vine snake',
60: 'night snake, Hypsiglena torquata',
61: 'boa constrictor, Constrictor constrictor',
62: 'rock python, rock snake, Python sebae',
63: 'Indian cobra, Naja naja',
64: 'green mamba',
65: 'sea snake',
66: 'horned viper, cerastes, sand viper, horned asp, Cerastes cornutus',
67: 'diamondback, diamondback rattlesnake, Crotalus adamanteus',
68: 'sidewinder, horned rattlesnake, Crotalus cerastes',
69: 'trilobite',
70: 'harvestman, daddy longlegs, Phalangium opilio',
71: 'scorpion',
72: 'black and gold garden spider, Argiope aurantia',
73: 'barn spider, Araneus cavaticus',
74: 'garden spider, Aranea diademata',
75: 'black widow, Latrodectus mactans',
76: 'tarantula',
77: 'wolf spider, hunting spider',
78: 'tick',
79: 'centipede',
80: 'black grouse',
81: 'ptarmigan',
82: 'ruffed grouse, partridge, Bonasa umbellus',
83: 'prairie chicken, prairie grouse, prairie fowl',
84: 'peacock',
85: 'quail',
86: 'partridge',
87: 'African grey, African gray, Psittacus erithacus',
88: 'macaw',
89: 'sulphur-crested cockatoo, Kakatoe galerita, Cacatua galerita',
90: 'lorikeet',
91: 'coucal',
92: 'bee eater',
93: 'hornbill',
94: 'hummingbird',
95: 'jacamar',
96: 'toucan',
97: 'drake',
98: 'red-breasted merganser, Mergus serrator',
99: 'goose',
100: 'black swan, Cygnus atratus',
101: 'tusker',
102: 'echidna, spiny anteater, anteater',
103: 'platypus, duckbill, duckbilled platypus, duck-billed platypus, Ornithorhynchus anatinus',
104: 'wallaby, brush kangaroo',
105: 'koala, koala bear, kangaroo bear, native bear, Phascolarctos cinereus',
106: 'wombat',
107: 'jellyfish',
108: 'sea anemone, anemone',
109: 'brain coral',
110: 'flatworm, platyhelminth',
111: 'nematode, nematode worm, roundworm',
112: 'conch',
113: 'snail',
114: 'slug',
115: 'sea slug, nudibranch',
116: 'chiton, coat-of-mail shell, sea cradle, polyplacophore',
117: 'chambered nautilus, pearly nautilus, nautilus',
118: 'Dungeness crab, Cancer magister',
119: 'rock crab, Cancer irroratus',
120: 'fiddler crab',
121: 'king crab, Alaska crab, Alaskan king crab, Alaska king crab, Paralithodes camtschatica',
122: 'American lobster, Northern lobster, Maine lobster, Homarus americanus',
123: 'spiny lobster, langouste, rock lobster, crawfish, crayfish, sea crawfish',
124: 'crayfish, crawfish, crawdad, crawdaddy',
125: 'hermit crab',
126: 'isopod',
127: 'white stork, Ciconia ciconia',
128: 'black stork, Ciconia nigra',
129: 'spoonbill',
130: 'flamingo',
131: 'little blue heron, Egretta caerulea',
132: 'American egret, great white heron, Egretta albus',
133: 'bittern',
134: 'crane',
135: 'limpkin, Aramus pictus',
136: 'European gallinule, Porphyrio porphyrio',
137: 'American coot, marsh hen, mud hen, water hen, Fulica americana',
138: 'bustard',
139: 'ruddy turnstone, Arenaria interpres',
140: 'red-backed sandpiper, dunlin, Erolia alpina',
141: 'redshank, Tringa totanus',
142: 'dowitcher',
143: 'oystercatcher, oyster catcher',
144: 'pelican',
145: 'king penguin, Aptenodytes patagonica',
146: 'albatross, mollymawk',
147: 'grey whale, gray whale, devilfish, Eschrichtius gibbosus, Eschrichtius robustus',
148: 'killer whale, killer, orca, grampus, sea wolf, Orcinus orca',
149: 'dugong, Dugong dugon',
150: 'sea lion',
151: 'Chihuahua',
152: 'Japanese spaniel',
153: 'Maltese dog, Maltese terrier, Maltese',
154: 'Pekinese, Pekingese, Peke',
155: 'Shih-Tzu',
156: 'Blenheim spaniel',
157: 'papillon',
158: 'toy terrier',
159: 'Rhodesian ridgeback',
160: 'Afghan hound, Afghan',
161: 'basset, basset hound',
162: 'beagle',
163: 'bloodhound, sleuthhound',
164: 'bluetick',
165: 'black-and-tan coonhound',
166: 'Walker hound, Walker foxhound',
167: 'English foxhound',
168: 'redbone',
169: 'borzoi, Russian wolfhound',
170: 'Irish wolfhound',
171: 'Italian greyhound',
172: 'whippet',
173: 'Ibizan hound, Ibizan Podenco',
174: 'Norwegian elkhound, elkhound',
175: 'otterhound, otter hound',
176: 'Saluki, gazelle hound',
177: 'Scottish deerhound, deerhound',
178: 'Weimaraner',
179: 'Staffordshire bullterrier, Staffordshire bull terrier',
180: 'American Staffordshire terrier, Staffordshire terrier, American pit bull terrier, pit bull terrier',
181: 'Bedlington terrier',
182: 'Border terrier',
183: 'Kerry blue terrier',
184: 'Irish terrier',
185: 'Norfolk terrier',
186: 'Norwich terrier',
187: 'Yorkshire terrier',
188: 'wire-haired fox terrier',
189: 'Lakeland terrier',
190: 'Sealyham terrier, Sealyham',
191: 'Airedale, Airedale terrier',
192: 'cairn, cairn terrier',
193: 'Australian terrier',
194: 'Dandie Dinmont, Dandie Dinmont terrier',
195: 'Boston bull, Boston terrier',
196: 'miniature schnauzer',
197: 'giant schnauzer',
198: 'standard schnauzer',
199: 'Scotch terrier, Scottish terrier, Scottie',
200: 'Tibetan terrier, chrysanthemum dog',
201: 'silky terrier, Sydney silky',
202: 'soft-coated wheaten terrier',
203: 'West Highland white terrier',
204: 'Lhasa, Lhasa apso',
205: 'flat-coated retriever',
206: 'curly-coated retriever',
207: 'golden retriever',
208: 'Labrador retriever',
209: 'Chesapeake Bay retriever',
210: 'German short-haired pointer',
211: 'vizsla, Hungarian pointer',
212: 'English setter',
213: 'Irish setter, red setter',
214: 'Gordon setter',
215: 'Brittany spaniel',
216: 'clumber, clumber spaniel',
217: 'English springer, English springer spaniel',
218: 'Welsh springer spaniel',
219: 'cocker spaniel, English cocker spaniel, cocker',
220: 'Sussex spaniel',
221: 'Irish water spaniel',
222: 'kuvasz',
223: 'schipperke',
224: 'groenendael',
225: 'malinois',
226: 'briard',
227: 'kelpie',
228: 'komondor',
229: 'Old English sheepdog, bobtail',
230: 'Shetland sheepdog, Shetland sheep dog, Shetland',
231: 'collie',
232: 'Border collie',
233: 'Bouvier des Flandres, Bouviers des Flandres',
234: 'Rottweiler',
235: 'German shepherd, German shepherd dog, German police dog, alsatian',
236: 'Doberman, Doberman pinscher',
237: 'miniature pinscher',
238: 'Greater Swiss Mountain dog',
239: 'Bernese mountain dog',
240: 'Appenzeller',
241: 'EntleBucher',
242: 'boxer',
243: 'bull mastiff',
244: 'Tibetan mastiff',
245: 'French bulldog',
246: 'Great Dane',
247: 'Saint Bernard, St Bernard',
248: 'Eskimo dog, husky',
249: 'malamute, malemute, Alaskan malamute',
250: 'Siberian husky',
251: 'dalmatian, coach dog, carriage dog',
252: 'affenpinscher, monkey pinscher, monkey dog',
253: 'basenji',
254: 'pug, pug-dog',
255: 'Leonberg',
256: 'Newfoundland, Newfoundland dog',
257: 'Great Pyrenees',
258: 'Samoyed, Samoyede',
259: 'Pomeranian',
260: 'chow, chow chow',
261: 'keeshond',
262: 'Brabancon griffon',
263: 'Pembroke, Pembroke Welsh corgi',
264: 'Cardigan, Cardigan Welsh corgi',
265: 'toy poodle',
266: 'miniature poodle',
267: 'standard poodle',
268: 'Mexican hairless',
269: 'timber wolf, grey wolf, gray wolf, Canis lupus',
270: 'white wolf, Arctic wolf, Canis lupus tundrarum',
271: 'red wolf, maned wolf, Canis rufus, Canis niger',
272: 'coyote, prairie wolf, brush wolf, Canis latrans',
273: 'dingo, warrigal, warragal, Canis dingo',
274: 'dhole, Cuon alpinus',
275: 'African hunting dog, hyena dog, Cape hunting dog, Lycaon pictus',
276: 'hyena, hyaena',
277: 'red fox, Vulpes vulpes',
278: 'kit fox, Vulpes macrotis',
279: 'Arctic fox, white fox, Alopex lagopus',
280: 'grey fox, gray fox, Urocyon cinereoargenteus',
281: 'tabby, tabby cat',
282: 'tiger cat',
283: 'Persian cat',
284: 'Siamese cat, Siamese',
285: 'Egyptian cat',
286: 'cougar, puma, catamount, mountain lion, painter, panther, Felis concolor',
287: 'lynx, catamount',
288: 'leopard, Panthera pardus',
289: 'snow leopard, ounce, Panthera uncia',
290: 'jaguar, panther, Panthera onca, Felis onca',
291: 'lion, king of beasts, Panthera leo',
292: 'tiger, Panthera tigris',
293: 'cheetah, chetah, Acinonyx jubatus',
294: 'brown bear, bruin, Ursus arctos',
295: 'American black bear, black bear, Ursus americanus, Euarctos americanus',
296: 'ice bear, polar bear, Ursus Maritimus, Thalarctos maritimus',
297: 'sloth bear, Melursus ursinus, Ursus ursinus',
298: 'mongoose',
299: 'meerkat, mierkat',
300: 'tiger beetle',
301: 'ladybug, ladybeetle, lady beetle, ladybird, ladybird beetle',
302: 'ground beetle, carabid beetle',
303: 'long-horned beetle, longicorn, longicorn beetle',
304: 'leaf beetle, chrysomelid',
305: 'dung beetle',
306: 'rhinoceros beetle',
307: 'weevil',
308: 'fly',
309: 'bee',
310: 'ant, emmet, pismire',
311: 'grasshopper, hopper',
312: 'cricket',
313: 'walking stick, walkingstick, stick insect',
314: 'cockroach, roach',
315: 'mantis, mantid',
316: 'cicada, cicala',
317: 'leafhopper',
318: 'lacewing, lacewing fly',
319: "dragonfly, darning needle, devil's darning needle, sewing needle, snake feeder, snake doctor, mosquito hawk, skeeter hawk",
320: 'damselfly',
321: 'admiral',
322: 'ringlet, ringlet butterfly',
323: 'monarch, monarch butterfly, milkweed butterfly, Danaus plexippus',
324: 'cabbage butterfly',
325: 'sulphur butterfly, sulfur butterfly',
326: 'lycaenid, lycaenid butterfly',
327: 'starfish, sea star',
328: 'sea urchin',
329: 'sea cucumber, holothurian',
330: 'wood rabbit, cottontail, cottontail rabbit',
331: 'hare',
332: 'Angora, Angora rabbit',
333: 'hamster',
334: 'porcupine, hedgehog',
335: 'fox squirrel, eastern fox squirrel, Sciurus niger',
336: 'marmot',
337: 'beaver',
338: 'guinea pig, Cavia cobaya',
339: 'sorrel',
340: 'zebra',
341: 'hog, pig, grunter, squealer, Sus scrofa',
342: 'wild boar, boar, Sus scrofa',
343: 'warthog',
344: 'hippopotamus, hippo, river horse, Hippopotamus amphibius',
345: 'ox',
346: 'water buffalo, water ox, Asiatic buffalo, Bubalus bubalis',
347: 'bison',
348: 'ram, tup',
349: 'bighorn, bighorn sheep, cimarron, Rocky Mountain bighorn, Rocky Mountain sheep, Ovis canadensis',
350: 'ibex, Capra ibex',
351: 'hartebeest',
352: 'impala, Aepyceros melampus',
353: 'gazelle',
354: 'Arabian camel, dromedary, Camelus dromedarius',
355: 'llama',
356: 'weasel',
357: 'mink',
358: 'polecat, fitch, foulmart, foumart, Mustela putorius',
359: 'black-footed ferret, ferret, Mustela nigripes',
360: 'otter',
361: 'skunk, polecat, wood pussy',
362: 'badger',
363: 'armadillo',
364: 'three-toed sloth, ai, Bradypus tridactylus',
365: 'orangutan, orang, orangutang, Pongo pygmaeus',
366: 'gorilla, Gorilla gorilla',
367: 'chimpanzee, chimp, Pan troglodytes',
368: 'gibbon, Hylobates lar',
369: 'siamang, Hylobates syndactylus, Symphalangus syndactylus',
370: 'guenon, guenon monkey',
371: 'patas, hussar monkey, Erythrocebus patas',
372: 'baboon',
373: 'macaque',
374: 'langur',
375: 'colobus, colobus monkey',
376: 'proboscis monkey, Nasalis larvatus',
377: 'marmoset',
378: 'capuchin, ringtail, Cebus capucinus',
379: 'howler monkey, howler',
380: 'titi, titi monkey',
381: 'spider monkey, Ateles geoffroyi',
382: 'squirrel monkey, Saimiri sciureus',
383: 'Madagascar cat, ring-tailed lemur, Lemur catta',
384: 'indri, indris, Indri indri, Indri brevicaudatus',
385: 'Indian elephant, Elephas maximus',
386: 'African elephant, Loxodonta africana',
387: 'lesser panda, red panda, panda, bear cat, cat bear, Ailurus fulgens',
388: 'giant panda, panda, panda bear, coon bear, Ailuropoda melanoleuca',
389: 'barracouta, snoek',
390: 'eel',
391: 'coho, cohoe, coho salmon, blue jack, silver salmon, Oncorhynchus kisutch',
392: 'rock beauty, Holocanthus tricolor',
393: 'anemone fish',
394: 'sturgeon',
395: 'gar, garfish, garpike, billfish, Lepisosteus osseus',
396: 'lionfish',
397: 'puffer, pufferfish, blowfish, globefish',
398: 'abacus',
399: 'abaya',
400: "academic gown, academic robe, judge's robe",
401: 'accordion, piano accordion, squeeze box',
402: 'acoustic guitar',
403: 'aircraft carrier, carrier, flattop, attack aircraft carrier',
404: 'airliner',
405: 'airship, dirigible',
406: 'altar',
407: 'ambulance',
408: 'amphibian, amphibious vehicle',
409: 'analog clock',
410: 'apiary, bee house',
411: 'apron',
412: 'ashcan, trash can, garbage can, wastebin, ash bin, ash-bin, ashbin, dustbin, trash barrel, trash bin',
413: 'assault rifle, assault gun',
414: 'backpack, back pack, knapsack, packsack, rucksack, haversack',
415: 'bakery, bakeshop, bakehouse',
416: 'balance beam, beam',
417: 'balloon',
418: 'ballpoint, ballpoint pen, ballpen, Biro',
419: 'Band Aid',
420: 'banjo',
421: 'bannister, banister, balustrade, balusters, handrail',
422: 'barbell',
423: 'barber chair',
424: 'barbershop',
425: 'barn',
426: 'barometer',
427: 'barrel, cask',
428: 'barrow, garden cart, lawn cart, wheelbarrow',
429: 'baseball',
430: 'basketball',
431: 'bassinet',
432: 'bassoon',
433: 'bathing cap, swimming cap',
434: 'bath towel',
435: 'bathtub, bathing tub, bath, tub',
436: 'beach wagon, station wagon, wagon, estate car, beach waggon, station waggon, waggon',
437: 'beacon, lighthouse, beacon light, pharos',
438: 'beaker',
439: 'bearskin, busby, shako',
440: 'beer bottle',
441: 'beer glass',
442: 'bell cote, bell cot',
443: 'bib',
444: 'bicycle-built-for-two, tandem bicycle, tandem',
445: 'bikini, two-piece',
446: 'binder, ring-binder',
447: 'binoculars, field glasses, opera glasses',
448: 'birdhouse',
449: 'boathouse',
450: 'bobsled, bobsleigh, bob',
451: 'bolo tie, bolo, bola tie, bola',
452: 'bonnet, poke bonnet',
453: 'bookcase',
454: 'bookshop, bookstore, bookstall',
455: 'bottlecap',
456: 'bow',
457: 'bow tie, bow-tie, bowtie',
458: 'brass, memorial tablet, plaque',
459: 'brassiere, bra, bandeau',
460: 'breakwater, groin, groyne, mole, bulwark, seawall, jetty',
461: 'breastplate, aegis, egis',
462: 'broom',
463: 'bucket, pail',
464: 'buckle',
465: 'bulletproof vest',
466: 'bullet train, bullet',
467: 'butcher shop, meat market',
468: 'cab, hack, taxi, taxicab',
469: 'caldron, cauldron',
470: 'candle, taper, wax light',
471: 'cannon',
472: 'canoe',
473: 'can opener, tin opener',
474: 'cardigan',
475: 'car mirror',
476: 'carousel, carrousel, merry-go-round, roundabout, whirligig',
477: "carpenter's kit, tool kit",
478: 'carton',
479: 'car wheel',
480: 'cash machine, cash dispenser, automated teller machine, automatic teller machine, automated teller, automatic teller, ATM',
481: 'cassette',
482: 'cassette player',
483: 'castle',
484: 'catamaran',
485: 'CD player',
486: 'cello, violoncello',
487: 'cellular telephone, cellular phone, cellphone, cell, mobile phone',
488: 'chain',
489: 'chainlink fence',
490: 'chain mail, ring mail, mail, chain armor, chain armour, ring armor, ring armour',
491: 'chain saw, chainsaw',
492: 'chest',
493: 'chiffonier, commode',
494: 'chime, bell, gong',
495: 'china cabinet, china closet',
496: 'Christmas stocking',
497: 'church, church building',
498: 'cinema, movie theater, movie theatre, movie house, picture palace',
499: 'cleaver, meat cleaver, chopper',
500: 'cliff dwelling',
501: 'cloak',
502: 'clog, geta, patten, sabot',
503: 'cocktail shaker',
504: 'coffee mug',
505: 'coffeepot',
506: 'coil, spiral, volute, whorl, helix',
507: 'combination lock',
508: 'computer keyboard, keypad',
509: 'confectionery, confectionary, candy store',
510: 'container ship, containership, container vessel',
511: 'convertible',
512: 'corkscrew, bottle screw',
513: 'cornet, horn, trumpet, trump',
514: 'cowboy boot',
515: 'cowboy hat, ten-gallon hat',
516: 'cradle',
517: 'crane',
518: 'crash helmet',
519: 'crate',
520: 'crib, cot',
521: 'Crock Pot',
522: 'croquet ball',
523: 'crutch',
524: 'cuirass',
525: 'dam, dike, dyke',
526: 'desk',
527: 'desktop computer',
528: 'dial telephone, dial phone',
529: 'diaper, nappy, napkin',
530: 'digital clock',
531: 'digital watch',
532: 'dining table, board',
533: 'dishrag, dishcloth',
534: 'dishwasher, dish washer, dishwashing machine',
535: 'disk brake, disc brake',
536: 'dock, dockage, docking facility',
537: 'dogsled, dog sled, dog sleigh',
538: 'dome',
539: 'doormat, welcome mat',
540: 'drilling platform, offshore rig',
541: 'drum, membranophone, tympan',
542: 'drumstick',
543: 'dumbbell',
544: 'Dutch oven',
545: 'electric fan, blower',
546: 'electric guitar',
547: 'electric locomotive',
548: 'entertainment center',
549: 'envelope',
550: 'espresso maker',
551: 'face powder',
552: 'feather boa, boa',
553: 'file, file cabinet, filing cabinet',
554: 'fireboat',
555: 'fire engine, fire truck',
556: 'fire screen, fireguard',
557: 'flagpole, flagstaff',
558: 'flute, transverse flute',
559: 'folding chair',
560: 'football helmet',
561: 'forklift',
562: 'fountain',
563: 'fountain pen',
564: 'four-poster',
565: 'freight car',
566: 'French horn, horn',
567: 'frying pan, frypan, skillet',
568: 'fur coat',
569: 'garbage truck, dustcart',
570: 'gasmask, respirator, gas helmet',
571: 'gas pump, gasoline pump, petrol pump, island dispenser',
572: 'goblet',
573: 'go-kart',
574: 'golf ball',
575: 'golfcart, golf cart',
576: 'gondola',
577: 'gong, tam-tam',
578: 'gown',
579: 'grand piano, grand',
580: 'greenhouse, nursery, glasshouse',
581: 'grille, radiator grille',
582: 'grocery store, grocery, food market, market',
583: 'guillotine',
584: 'hair slide',
585: 'hair spray',
586: 'half track',
587: 'hammer',
588: 'hamper',
589: 'hand blower, blow dryer, blow drier, hair dryer, hair drier',
590: 'hand-held computer, hand-held microcomputer',
591: 'handkerchief, hankie, hanky, hankey',
592: 'hard disc, hard disk, fixed disk',
593: 'harmonica, mouth organ, harp, mouth harp',
594: 'harp',
595: 'harvester, reaper',
596: 'hatchet',
597: 'holster',
598: 'home theater, home theatre',
599: 'honeycomb',
600: 'hook, claw',
601: 'hoopskirt, crinoline',
602: 'horizontal bar, high bar',
603: 'horse cart, horse-cart',
604: 'hourglass',
605: 'iPod',
606: 'iron, smoothing iron',
607: "jack-o'-lantern",
608: 'jean, blue jean, denim',
609: 'jeep, landrover',
610: 'jersey, T-shirt, tee shirt',
611: 'jigsaw puzzle',
612: 'jinrikisha, ricksha, rickshaw',
613: 'joystick',
614: 'kimono',
615: 'knee pad',
616: 'knot',
617: 'lab coat, laboratory coat',
618: 'ladle',
619: 'lampshade, lamp shade',
620: 'laptop, laptop computer',
621: 'lawn mower, mower',
622: 'lens cap, lens cover',
623: 'letter opener, paper knife, paperknife',
624: 'library',
625: 'lifeboat',
626: 'lighter, light, igniter, ignitor',
627: 'limousine, limo',
628: 'liner, ocean liner',
629: 'lipstick, lip rouge',
630: 'Loafer',
631: 'lotion',
632: 'loudspeaker, speaker, speaker unit, loudspeaker system, speaker system',
633: "loupe, jeweler's loupe",
634: 'lumbermill, sawmill',
635: 'magnetic compass',
636: 'mailbag, postbag',
637: 'mailbox, letter box',
638: 'maillot',
639: 'maillot, tank suit',
640: 'manhole cover',
641: 'maraca',
642: 'marimba, xylophone',
643: 'mask',
644: 'matchstick',
645: 'maypole',
646: 'maze, labyrinth',
647: 'measuring cup',
648: 'medicine chest, medicine cabinet',
649: 'megalith, megalithic structure',
650: 'microphone, mike',
651: 'microwave, microwave oven',
652: 'military uniform',
653: 'milk can',
654: 'minibus',
655: 'miniskirt, mini',
656: 'minivan',
657: 'missile',
658: 'mitten',
659: 'mixing bowl',
660: 'mobile home, manufactured home',
661: 'Model T',
662: 'modem',
663: 'monastery',
664: 'monitor',
665: 'moped',
666: 'mortar',
667: 'mortarboard',
668: 'mosque',
669: 'mosquito net',
670: 'motor scooter, scooter',
671: 'mountain bike, all-terrain bike, off-roader',
672: 'mountain tent',
673: 'mouse, computer mouse',
674: 'mousetrap',
675: 'moving van',
676: 'muzzle',
677: 'nail',
678: 'neck brace',
679: 'necklace',
680: 'nipple',
681: 'notebook, notebook computer',
682: 'obelisk',
683: 'oboe, hautboy, hautbois',
684: 'ocarina, sweet potato',
685: 'odometer, hodometer, mileometer, milometer',
686: 'oil filter',
687: 'organ, pipe organ',
688: 'oscilloscope, scope, cathode-ray oscilloscope, CRO',
689: 'overskirt',
690: 'oxcart',
691: 'oxygen mask',
692: 'packet',
693: 'paddle, boat paddle',
694: 'paddlewheel, paddle wheel',
695: 'padlock',
696: 'paintbrush',
697: "pajama, pyjama, pj's, jammies",
698: 'palace',
699: 'panpipe, pandean pipe, syrinx',
700: 'paper towel',
701: 'parachute, chute',
702: 'parallel bars, bars',
703: 'park bench',
704: 'parking meter',
705: 'passenger car, coach, carriage',
706: 'patio, terrace',
707: 'pay-phone, pay-station',
708: 'pedestal, plinth, footstall',
709: 'pencil box, pencil case',
710: 'pencil sharpener',
711: 'perfume, essence',
712: 'Petri dish',
713: 'photocopier',
714: 'pick, plectrum, plectron',
715: 'pickelhaube',
716: 'picket fence, paling',
717: 'pickup, pickup truck',
718: 'pier',
719: 'piggy bank, penny bank',
720: 'pill bottle',
721: 'pillow',
722: 'ping-pong ball',
723: 'pinwheel',
724: 'pirate, pirate ship',
725: 'pitcher, ewer',
726: "plane, carpenter's plane, woodworking plane",
727: 'planetarium',
728: 'plastic bag',
729: 'plate rack',
730: 'plow, plough',
731: "plunger, plumber's helper",
732: 'Polaroid camera, Polaroid Land camera',
733: 'pole',
734: 'police van, police wagon, paddy wagon, patrol wagon, wagon, black Maria',
735: 'poncho',
736: 'pool table, billiard table, snooker table',
737: 'pop bottle, soda bottle',
738: 'pot, flowerpot',
739: "potter's wheel",
740: 'power drill',
741: 'prayer rug, prayer mat',
742: 'printer',
743: 'prison, prison house',
744: 'projectile, missile',
745: 'projector',
746: 'puck, hockey puck',
747: 'punching bag, punch bag, punching ball, punchball',
748: 'purse',
749: 'quill, quill pen',
750: 'quilt, comforter, comfort, puff',
751: 'racer, race car, racing car',
752: 'racket, racquet',
753: 'radiator',
754: 'radio, wireless',
755: 'radio telescope, radio reflector',
756: 'rain barrel',
757: 'recreational vehicle, RV, R.V.',
758: 'reel',
759: 'reflex camera',
760: 'refrigerator, icebox',
761: 'remote control, remote',
762: 'restaurant, eating house, eating place, eatery',
763: 'revolver, six-gun, six-shooter',
764: 'rifle',
765: 'rocking chair, rocker',
766: 'rotisserie',
767: 'rubber eraser, rubber, pencil eraser',
768: 'rugby ball',
769: 'rule, ruler',
770: 'running shoe',
771: 'safe',
772: 'safety pin',
773: 'saltshaker, salt shaker',
774: 'sandal',
775: 'sarong',
776: 'sax, saxophone',
777: 'scabbard',
778: 'scale, weighing machine',
779: 'school bus',
780: 'schooner',
781: 'scoreboard',
782: 'screen, CRT screen',
783: 'screw',
784: 'screwdriver',
785: 'seat belt, seatbelt',
786: 'sewing machine',
787: 'shield, buckler',
788: 'shoe shop, shoe-shop, shoe store',
789: 'shoji',
790: 'shopping basket',
791: 'shopping cart',
792: 'shovel',
793: 'shower cap',
794: 'shower curtain',
795: 'ski',
796: 'ski mask',
797: 'sleeping bag',
798: 'slide rule, slipstick',
799: 'sliding door',
800: 'slot, one-armed bandit',
801: 'snorkel',
802: 'snowmobile',
803: 'snowplow, snowplough',
804: 'soap dispenser',
805: 'soccer ball',
806: 'sock',
807: 'solar dish, solar collector, solar furnace',
808: 'sombrero',
809: 'soup bowl',
810: 'space bar',
811: 'space heater',
812: 'space shuttle',
813: 'spatula',
814: 'speedboat',
815: "spider web, spider's web",
816: 'spindle',
817: 'sports car, sport car',
818: 'spotlight, spot',
819: 'stage',
820: 'steam locomotive',
821: 'steel arch bridge',
822: 'steel drum',
823: 'stethoscope',
824: 'stole',
825: 'stone wall',
826: 'stopwatch, stop watch',
827: 'stove',
828: 'strainer',
829: 'streetcar, tram, tramcar, trolley, trolley car',
830: 'stretcher',
831: 'studio couch, day bed',
832: 'stupa, tope',
833: 'submarine, pigboat, sub, U-boat',
834: 'suit, suit of clothes',
835: 'sundial',
836: 'sunglass',
837: 'sunglasses, dark glasses, shades',
838: 'sunscreen, sunblock, sun blocker',
839: 'suspension bridge',
840: 'swab, swob, mop',
841: 'sweatshirt',
842: 'swimming trunks, bathing trunks',
843: 'swing',
844: 'switch, electric switch, electrical switch',
845: 'syringe',
846: 'table lamp',
847: 'tank, army tank, armored combat vehicle, armoured combat vehicle',
848: 'tape player',
849: 'teapot',
850: 'teddy, teddy bear',
851: 'television, television system',
852: 'tennis ball',
853: 'thatch, thatched roof',
854: 'theater curtain, theatre curtain',
855: 'thimble',
856: 'thresher, thrasher, threshing machine',
857: 'throne',
858: 'tile roof',
859: 'toaster',
860: 'tobacco shop, tobacconist shop, tobacconist',
861: 'toilet seat',
862: 'torch',
863: 'totem pole',
864: 'tow truck, tow car, wrecker',
865: 'toyshop',
866: 'tractor',
867: 'trailer truck, tractor trailer, trucking rig, rig, articulated lorry, semi',
868: 'tray',
869: 'trench coat',
870: 'tricycle, trike, velocipede',
871: 'trimaran',
872: 'tripod',
873: 'triumphal arch',
874: 'trolleybus, trolley coach, trackless trolley',
875: 'trombone',
876: 'tub, vat',
877: 'turnstile',
878: 'typewriter keyboard',
879: 'umbrella',
880: 'unicycle, monocycle',
881: 'upright, upright piano',
882: 'vacuum, vacuum cleaner',
883: 'vase',
884: 'vault',
885: 'velvet',
886: 'vending machine',
887: 'vestment',
888: 'viaduct',
889: 'violin, fiddle',
890: 'volleyball',
891: 'waffle iron',
892: 'wall clock',
893: 'wallet, billfold, notecase, pocketbook',
894: 'wardrobe, closet, press',
895: 'warplane, military plane',
896: 'washbasin, handbasin, washbowl, lavabo, wash-hand basin',
897: 'washer, automatic washer, washing machine',
898: 'water bottle',
899: 'water jug',
900: 'water tower',
901: 'whiskey jug',
902: 'whistle',
903: 'wig',
904: 'window screen',
905: 'window shade',
906: 'Windsor tie',
907: 'wine bottle',
908: 'wing',
909: 'wok',
910: 'wooden spoon',
911: 'wool, woolen, woollen',
912: 'worm fence, snake fence, snake-rail fence, Virginia fence',
913: 'wreck',
914: 'yawl',
915: 'yurt',
916: 'web site, website, internet site, site',
917: 'comic book',
918: 'crossword puzzle, crossword',
919: 'street sign',
920: 'traffic light, traffic signal, stoplight',
921: 'book jacket, dust cover, dust jacket, dust wrapper',
922: 'menu',
923: 'plate',
924: 'guacamole',
925: 'consomme',
926: 'hot pot, hotpot',
927: 'trifle',
928: 'ice cream, icecream',
929: 'ice lolly, lolly, lollipop, popsicle',
930: 'French loaf',
931: 'bagel, beigel',
932: 'pretzel',
933: 'cheeseburger',
934: 'hotdog, hot dog, red hot',
935: 'mashed potato',
936: 'head cabbage',
937: 'broccoli',
938: 'cauliflower',
939: 'zucchini, courgette',
940: 'spaghetti squash',
941: 'acorn squash',
942: 'butternut squash',
943: 'cucumber, cuke',
944: 'artichoke, globe artichoke',
945: 'bell pepper',
946: 'cardoon',
947: 'mushroom',
948: 'Granny Smith',
949: 'strawberry',
950: 'orange',
951: 'lemon',
952: 'fig',
953: 'pineapple, ananas',
954: 'banana',
955: 'jackfruit, jak, jack',
956: 'custard apple',
957: 'pomegranate',
958: 'hay',
959: 'carbonara',
960: 'chocolate sauce, chocolate syrup',
961: 'dough',
962: 'meat loaf, meatloaf',
963: 'pizza, pizza pie',
964: 'potpie',
965: 'burrito',
966: 'red wine',
967: 'espresso',
968: 'cup',
969: 'eggnog',
970: 'alp',
971: 'bubble',
972: 'cliff, drop, drop-off',
973: 'coral reef',
974: 'geyser',
975: 'lakeside, lakeshore',
976: 'promontory, headland, head, foreland',
977: 'sandbar, sand bar',
978: 'seashore, coast, seacoast, sea-coast',
979: 'valley, vale',
980: 'volcano',
981: 'ballplayer, baseball player',
982: 'groom, bridegroom',
983: 'scuba diver',
984: 'rapeseed',
985: 'daisy',
986: "yellow lady's slipper, yellow lady-slipper, Cypripedium calceolus, Cypripedium parviflorum",
987: 'corn',
988: 'acorn',
989: 'hip, rose hip, rosehip',
990: 'buckeye, horse chestnut, conker',
991: 'coral fungus',
992: 'agaric',
993: 'gyromitra',
994: 'stinkhorn, carrion fungus',
995: 'earthstar',
996: 'hen-of-the-woods, hen of the woods, Polyporus frondosus, Grifola frondosa',
997: 'bolete',
998: 'ear, spike, capitulum',
999: 'toilet tissue, toilet paper, bathroom tissue'
}
|
PyTorch/Detection/SSD/examples | examples | run_notebook | PYTHONPATH=$PYTHONPATH:/mlperf/ jupyter-notebook --ip 0.0.0.0 --no-browser --allow-root
|
PyTorch/SpeechSynthesis/Tacotron2/tacotron2/text | text | cleaners | """ from https://github.com/keithito/tacotron """
'''
Cleaners are transformations that run over the input text at both training and eval time.
Cleaners can be selected by passing a comma-delimited list of cleaner names as the "cleaners"
hyperparameter. Some cleaners are English-specific. You'll typically want to use:
1. "english_cleaners" for English text
2. "transliteration_cleaners" for non-English text that can be transliterated to ASCII using
the Unidecode library (https://pypi.python.org/pypi/Unidecode)
3. "basic_cleaners" if you do not want to transliterate (in this case, you should also update
the symbols in symbols.py to match your data).
'''
import re
from .numbers import normalize_numbers
from .unidecoder import unidecoder
# Regular expression matching whitespace:
_whitespace_re = re.compile(r'\s+')
# List of (regular expression, replacement) pairs for abbreviations:
_abbreviations = [(re.compile('\\b%s\\.' % x[0], re.IGNORECASE), x[1]) for x in [
('mrs', 'misess'),
('mr', 'mister'),
('dr', 'doctor'),
('st', 'saint'),
('co', 'company'),
('jr', 'junior'),
('maj', 'major'),
('gen', 'general'),
('drs', 'doctors'),
('rev', 'reverend'),
('lt', 'lieutenant'),
('hon', 'honorable'),
('sgt', 'sergeant'),
('capt', 'captain'),
('esq', 'esquire'),
('ltd', 'limited'),
('col', 'colonel'),
('ft', 'fort'),
]]
def expand_abbreviations(text):
for regex, replacement in _abbreviations:
text = re.sub(regex, replacement, text)
return text
def expand_numbers(text):
return normalize_numbers(text)
def lowercase(text):
return text.lower()
def collapse_whitespace(text):
return re.sub(_whitespace_re, ' ', text)
def convert_to_ascii(text):
return unidecoder(text)
def basic_cleaners(text):
'''Basic pipeline that lowercases and collapses whitespace without transliteration.'''
text = lowercase(text)
text = collapse_whitespace(text)
return text
def transliteration_cleaners(text):
'''Pipeline for non-English text that transliterates to ASCII.'''
text = convert_to_ascii(text)
text = lowercase(text)
text = collapse_whitespace(text)
return text
def english_cleaners(text):
'''Pipeline for English text, including number and abbreviation expansion.'''
text = convert_to_ascii(text)
text = lowercase(text)
text = expand_numbers(text)
text = expand_abbreviations(text)
text = collapse_whitespace(text)
return text
|
PyTorch/Segmentation/MaskRCNN/pytorch/maskrcnn_benchmark/modeling | modeling | make_layers | # Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved.
"""
Miscellaneous utility functions
"""
import torch
from torch import nn
from torch.nn import functional as F
from maskrcnn_benchmark.config import cfg
from maskrcnn_benchmark.layers import Conv2d
from maskrcnn_benchmark.modeling.poolers import Pooler
def get_group_gn(dim, dim_per_gp, num_groups):
"""get number of groups used by GroupNorm, based on number of channels."""
assert dim_per_gp == -1 or num_groups == -1, \
"GroupNorm: can only specify G or C/G."
if dim_per_gp > 0:
assert dim % dim_per_gp == 0, \
"dim: {}, dim_per_gp: {}".format(dim, dim_per_gp)
group_gn = dim // dim_per_gp
else:
assert dim % num_groups == 0, \
"dim: {}, num_groups: {}".format(dim, num_groups)
group_gn = num_groups
return group_gn
def group_norm(out_channels, affine=True, divisor=1):
out_channels = out_channels // divisor
dim_per_gp = cfg.MODEL.GROUP_NORM.DIM_PER_GP // divisor
num_groups = cfg.MODEL.GROUP_NORM.NUM_GROUPS // divisor
eps = cfg.MODEL.GROUP_NORM.EPSILON # default: 1e-5
return torch.nn.GroupNorm(
get_group_gn(out_channels, dim_per_gp, num_groups),
out_channels,
eps,
affine
)
def make_conv3x3(
in_channels,
out_channels,
dilation=1,
stride=1,
use_gn=False,
use_relu=False,
kaiming_init=True
):
conv = Conv2d(
in_channels,
out_channels,
kernel_size=3,
stride=stride,
padding=dilation,
dilation=dilation,
bias=False if use_gn else True
)
if kaiming_init:
nn.init.kaiming_normal_(
conv.weight, mode="fan_out", nonlinearity="relu"
)
else:
torch.nn.init.normal_(conv.weight, std=0.01)
if not use_gn:
nn.init.constant_(conv.bias, 0)
module = [conv,]
if use_gn:
module.append(group_norm(out_channels))
if use_relu:
module.append(nn.ReLU(inplace=True))
if len(module) > 1:
return nn.Sequential(*module)
return conv
def make_fc(dim_in, hidden_dim, use_gn=False):
'''
Caffe2 implementation uses XavierFill, which in fact
corresponds to kaiming_uniform_ in PyTorch
'''
if use_gn:
fc = nn.Linear(dim_in, hidden_dim, bias=False)
nn.init.kaiming_uniform_(fc.weight, a=1)
return nn.Sequential(fc, group_norm(hidden_dim))
fc = nn.Linear(dim_in, hidden_dim)
nn.init.kaiming_uniform_(fc.weight, a=1)
nn.init.constant_(fc.bias, 0)
return fc
def conv_with_kaiming_uniform(use_gn=False, use_relu=False):
def make_conv(
in_channels, out_channels, kernel_size, stride=1, dilation=1
):
conv = Conv2d(
in_channels,
out_channels,
kernel_size=kernel_size,
stride=stride,
padding=dilation * (kernel_size - 1) // 2,
dilation=dilation,
bias=False if use_gn else True
)
# Caffe2 implementation uses XavierFill, which in fact
# corresponds to kaiming_uniform_ in PyTorch
nn.init.kaiming_uniform_(conv.weight, a=1)
if not use_gn:
nn.init.constant_(conv.bias, 0)
module = [conv,]
if use_gn:
module.append(group_norm(out_channels))
if use_relu:
module.append(nn.ReLU(inplace=True))
if len(module) > 1:
return nn.Sequential(*module)
return conv
return make_conv
|
TensorFlow/Detection/SSD/models/research/object_detection/samples/configs | configs | ssd_mobilenet_v1_coco | # SSD with Mobilenet v1 configuration for MSCOCO Dataset.
# Users should configure the fine_tune_checkpoint field in the train config as
# well as the label_map_path and input_path fields in the train_input_reader and
# eval_input_reader. Search for "PATH_TO_BE_CONFIGURED" to find the fields that
# should be configured.
model {
ssd {
num_classes: 90
box_coder {
faster_rcnn_box_coder {
y_scale: 10.0
x_scale: 10.0
height_scale: 5.0
width_scale: 5.0
}
}
matcher {
argmax_matcher {
matched_threshold: 0.5
unmatched_threshold: 0.5
ignore_thresholds: false
negatives_lower_than_unmatched: true
force_match_for_each_row: true
}
}
similarity_calculator {
iou_similarity {
}
}
anchor_generator {
ssd_anchor_generator {
num_layers: 6
min_scale: 0.2
max_scale: 0.95
aspect_ratios: 1.0
aspect_ratios: 2.0
aspect_ratios: 0.5
aspect_ratios: 3.0
aspect_ratios: 0.3333
}
}
image_resizer {
fixed_shape_resizer {
height: 300
width: 300
}
}
box_predictor {
convolutional_box_predictor {
min_depth: 0
max_depth: 0
num_layers_before_predictor: 0
use_dropout: false
dropout_keep_probability: 0.8
kernel_size: 1
box_code_size: 4
apply_sigmoid_to_scores: false
conv_hyperparams {
activation: RELU_6,
regularizer {
l2_regularizer {
weight: 0.00004
}
}
initializer {
truncated_normal_initializer {
stddev: 0.03
mean: 0.0
}
}
batch_norm {
train: true,
scale: true,
center: true,
decay: 0.9997,
epsilon: 0.001,
}
}
}
}
feature_extractor {
type: 'ssd_mobilenet_v1'
min_depth: 16
depth_multiplier: 1.0
conv_hyperparams {
activation: RELU_6,
regularizer {
l2_regularizer {
weight: 0.00004
}
}
initializer {
truncated_normal_initializer {
stddev: 0.03
mean: 0.0
}
}
batch_norm {
train: true,
scale: true,
center: true,
decay: 0.9997,
epsilon: 0.001,
}
}
}
loss {
classification_loss {
weighted_sigmoid {
}
}
localization_loss {
weighted_smooth_l1 {
}
}
hard_example_miner {
num_hard_examples: 3000
iou_threshold: 0.99
loss_type: CLASSIFICATION
max_negatives_per_positive: 3
min_negatives_per_image: 0
}
classification_weight: 1.0
localization_weight: 1.0
}
normalize_loss_by_num_matches: true
post_processing {
batch_non_max_suppression {
score_threshold: 1e-8
iou_threshold: 0.6
max_detections_per_class: 100
max_total_detections: 100
}
score_converter: SIGMOID
}
}
}
train_config: {
batch_size: 24
optimizer {
rms_prop_optimizer: {
learning_rate: {
exponential_decay_learning_rate {
initial_learning_rate: 0.004
decay_steps: 800720
decay_factor: 0.95
}
}
momentum_optimizer_value: 0.9
decay: 0.9
epsilon: 1.0
}
}
fine_tune_checkpoint: "PATH_TO_BE_CONFIGURED/model.ckpt"
from_detection_checkpoint: true
# Note: The below line limits the training process to 200K steps, which we
# empirically found to be sufficient enough to train the pets dataset. This
# effectively bypasses the learning rate schedule (the learning rate will
# never decay). Remove the below line to train indefinitely.
num_steps: 200000
data_augmentation_options {
random_horizontal_flip {
}
}
data_augmentation_options {
ssd_random_crop {
}
}
}
train_input_reader: {
tf_record_input_reader {
input_path: "PATH_TO_BE_CONFIGURED/mscoco_train.record-?????-of-00100"
}
label_map_path: "PATH_TO_BE_CONFIGURED/mscoco_label_map.pbtxt"
}
eval_config: {
num_examples: 8000
# Note: The below line limits the evaluation process to 10 evaluations.
# Remove the below line to evaluate indefinitely.
max_evals: 10
}
eval_input_reader: {
tf_record_input_reader {
input_path: "PATH_TO_BE_CONFIGURED/mscoco_val.record-?????-of-00010"
}
label_map_path: "PATH_TO_BE_CONFIGURED/mscoco_label_map.pbtxt"
shuffle: false
num_readers: 1
}
|
TensorFlow2/Segmentation/MaskRCNN/mrcnn_tf2/model/models/resnet50 | resnet50 | resnet | import tensorflow as tf
from mrcnn_tf2.model.models.resnet50 import BottleneckGroup, Conv2DBlock
class ResNet50(tf.keras.Model):
def __init__(self, name='resnet50', *args, **kwargs):
super().__init__(name=name, *args, **kwargs)
self.conv2d = Conv2DBlock(
filters=64,
kernel_size=7,
strides=2,
use_batch_norm=True,
use_relu=True,
trainable=False
)
self.maxpool2d = tf.keras.layers.MaxPool2D(
pool_size=3,
strides=2,
padding='SAME'
)
self.group_1 = BottleneckGroup(
blocks=3,
filters=64,
strides=1,
trainable=False
)
self.group_2 = BottleneckGroup(
blocks=4,
filters=128,
strides=2
)
self.group_3 = BottleneckGroup(
blocks=6,
filters=256,
strides=2
)
self.group_4 = BottleneckGroup(
blocks=3,
filters=512,
strides=2
)
def call(self, inputs, training=None, mask=None):
net = self.conv2d(inputs, training=training)
net = self.maxpool2d(net)
c2 = self.group_1(net, training=training)
c3 = self.group_2(c2, training=training)
c4 = self.group_3(c3, training=training)
c5 = self.group_4(c4, training=training)
return {2: c2, 3: c3, 4: c4, 5: c5}
def get_config(self):
pass
|
PyTorch/SpeechSynthesis/HiFiGAN | HiFiGAN | README | # HiFi-GAN 1.0 For PyTorch
This repository provides a script and recipe to train the HiFi-GAN model to achieve state-of-the-art accuracy. The content of this repository is tested and maintained by NVIDIA.
## Table Of Contents
- [Model overview](#model-overview)
* [Model architecture](#model-architecture)
* [Default configuration](#default-configuration)
* [Feature support matrix](#feature-support-matrix)
* [Features](#features)
* [Mixed precision training](#mixed-precision-training)
* [Enabling mixed precision](#enabling-mixed-precision)
* [Enabling TF32](#enabling-tf32)
* [Glossary](#glossary)
- [Setup](#setup)
* [Requirements](#requirements)
- [Quick Start Guide](#quick-start-guide)
- [Advanced](#advanced)
* [Scripts and sample code](#scripts-and-sample-code)
* [Parameters](#parameters)
* [Command-line options](#command-line-options)
* [Getting the data](#getting-the-data)
* [Dataset guidelines](#dataset-guidelines)
* [Multi-dataset](#multi-dataset)
* [Training process](#training-process)
* [Inference process](#inference-process)
- [Performance](#performance)
* [Benchmarking](#benchmarking)
* [Training performance benchmark](#training-performance-benchmark)
* [Inference performance benchmark](#inference-performance-benchmark)
* [Results](#results)
* [Training accuracy results](#training-accuracy-results)
* [Training accuracy: NVIDIA DGX A100 (8x A100 80GB)](#training-accuracy-nvidia-dgx-a100-8x-a100-80gb)
* [Training accuracy: NVIDIA DGX-1 (8x V100 16GB)](#training-accuracy-nvidia-dgx-1-8x-v100-16gb)
* [Training stability test](#training-stability-test)
* [Training performance results](#training-performance-results)
* [Training performance: NVIDIA DGX A100 (8x A100 80GB)](#training-performance-nvidia-dgx-a100-8x-a100-80gb)
* [Training performance: NVIDIA DGX-1 (8x V100 16GB)](#training-performance-nvidia-dgx-1-8x-v100-16gb)
* [Inference performance results](#inference-performance-results)
* [Inference performance: NVIDIA DGX A100 (1x A100 80GB)](#inference-performance-nvidia-dgx-a100-1x-a100-80gb)
* [Inference performance: NVIDIA DGX-1 (1x V100 16GB)](#inference-performance-nvidia-dgx-1-1x-v100-16gb)
* [Inference performance: NVIDIA T4](#inference-performance-nvidia-t4)
- [Release notes](#release-notes)
* [Changelog](#changelog)
* [Known issues](#known-issues)
## Model overview
This repository provides a PyTorch implementation of the HiFi-GAN model described in the paper [HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis](https://arxiv.org/abs/2010.05646).
The HiFi-GAN model implements a spectrogram inversion model that allows to synthesize speech waveforms from mel-spectrograms. It follows the generative adversarial network (GAN) paradigm, and is composed of a generator and a discriminator. After training, the generator is used for synthesis, and the discriminator is discarded.
Our implementation is based on the one [published by the authors of the paper](https://github.com/jik876/hifi-gan). We modify the original hyperparameters and provide an alternative training recipe, which enables training on larger batches and faster convergence. HiFi-GAN is trained on a publicly available [LJ Speech dataset](https://keithito.com/LJ-Speech-Dataset/). The <a href="audio/">samples</a> demonstrate speech synthesized with our publicly available FastPitch and HiFi-GAN checkpoints.
This model is trained with mixed precision using Tensor Cores on NVIDIA Volta and the NVIDIA Ampere GPU architectures and evaluated on Volta, Turing and the NVIDIA Ampere GPU architectures. Therefore, researchers can get results up to 2.5x faster than training without Tensor Cores while experiencing the benefits of mixed-precision training. This model is tested against each NGC monthly container release to ensure consistent accuracy and performance over time.
### Model architecture
The entire model is composed of a generator and two discriminators. Both discriminators can be further divided into smaller sub-networks, that work at different resolutions.
The loss functions take as inputs intermediate feature maps and outputs of those sub-networks.
After training, the generator is used for synthesis, and the discriminators are discarded.
All three components are convolutional networks with different architectures.
<p align="center">
<img src="./img/hifigan_model.png" alt="HiFi-GAN model architecture" />
</p>
<p align="center">
<em>Figure 1. The architecture of HiFi-GAN</em>
</p>
### Default configuration
The following features were implemented in this model:
* data-parallel multi-GPU training,
* training and inference with mixed precision using Tensor Cores,
* gradient accumulation for reproducible results regardless of the number of GPUs.
The training recipe we provide for the model, recreates the `v1` model from the HiFi-GAN paper,
which is the largest and has the highest quality of all models described in the paper.
Mixed precision training and memory optimizations allowed us to increase batch size and throughput significantly.
In effect, we modify some hyperparameters of the `v1` recipe.
### Feature support matrix
The following features are supported by this model.
| Feature | HiFi-GAN |
| :-------------------------------|:--------:|
| Automatic mixed precision (AMP) | Yes |
| Distributed data parallel (DDP) | Yes |
#### Features
**Automatic Mixed Precision (AMP)**
This implementation uses native PyTorch AMP
implementation of mixed precision training. It allows us to use FP16 training
with FP32 master weights by modifying just a few lines of code.
**DistributedDataParallel (DDP)**
The model uses PyTorch Lightning implementation
of distributed data parallelism at the module level which can run across
multiple machines.
### Mixed precision training
Mixed precision is the combined use of different numerical precisions in a computational method. [Mixed precision](https://arxiv.org/abs/1710.03740) training offers significant computational speedup by performing operations in half-precision format while storing minimal information in single-precision to retain as much information as possible in critical parts of the network. Since the introduction of [Tensor Cores](https://developer.nvidia.com/tensor-cores) in Volta, and following with both the Turing and Ampere architectures, significant training speedups are experienced by switching to mixed precision -- up to 3x overall speedup on the most arithmetically intense model architectures. Using [mixed precision training](https://docs.nvidia.com/deeplearning/performance/mixed-precision-training/index.html) previously required two steps:
1. Porting the model to use the FP16 data type where appropriate.
2. Adding loss scaling to preserve small gradient values.
For information about:
- How to train using mixed precision, refer to the [Mixed Precision Training](https://arxiv.org/abs/1710.03740) paper and [Training With Mixed Precision](https://docs.nvidia.com/deeplearning/performance/mixed-precision-training/index.html) documentation.
- Techniques used for mixed precision training, refer to the [Mixed-Precision Training of Deep Neural Networks](https://devblogs.nvidia.com/mixed-precision-training-deep-neural-networks/) blog.
#### Enabling mixed precision
For training and inference, mixed precision can be enabled by adding the `--amp` flag.
Mixed precision is using [native PyTorch implementation](https://pytorch.org/blog/accelerating-training-on-nvidia-gpus-with-pytorch-automatic-mixed-precision/).
#### Enabling TF32
TensorFloat-32 (TF32) is the new math mode in [NVIDIA A100](https://www.nvidia.com/en-us/data-center/a100/) GPUs for handling the matrix math also called tensor operations. TF32 running on Tensor Cores in A100 GPUs can provide up to 10x speedups compared to single-precision floating-point math (FP32) on Volta GPUs.
TF32 Tensor Cores can speed up networks using FP32, typically with no loss of accuracy. It is more robust than FP16 for models that require a high dynamic range for weights or activations.
For more information, refer to the [TensorFloat-32 in the A100 GPU Accelerates AI Training, HPC up to 20x](https://blogs.nvidia.com/blog/2020/05/14/tensorfloat-32-precision-format/) blog post.
TF32 is supported in the NVIDIA Ampere GPU architecture and is enabled by default.
### Glossary
**Multi-Period Discriminator**
A sub-network that extracts patterns from the data that occur periodically (for example, every *N* time steps).
**Multi-Scale Discriminator**
A sub-network that extracts patterns from the data at different resolutions of the input signal. Lower resolutions are obtained by average-pooling of the signal.
**Fine-tuning**
Training an already pretrained model further using a task specific dataset for subject-specific refinements, by adding task-specific layers on top if required.
## Setup
The following section lists the requirements you need to meet in order to start training the HiFi-GAN model.
### Requirements
This repository contains a Dockerfile that extends the PyTorch 21.12-py3 NGC container and encapsulates some dependencies. Aside from these dependencies, ensure you have the following components:
- [NVIDIA Docker](https://github.com/NVIDIA/nvidia-docker)
- [PyTorch 21.12-py3 NGC container](https://ngc.nvidia.com/registry/nvidia-pytorch) or newer
- Supported GPUs:
- [NVIDIA Volta architecture](https://www.nvidia.com/en-us/data-center/volta-gpu-architecture/)
- [NVIDIA Turing architecture](https://www.nvidia.com/en-us/design-visualization/technologies/turing-architecture/)
- [NVIDIA Ampere architecture](https://www.nvidia.com/en-us/data-center/nvidia-ampere-gpu-architecture/)
For more information about how to get started with NGC containers, refer to the following sections from the NVIDIA GPU Cloud Documentation and the Deep Learning Documentation:
- [Getting Started Using NVIDIA GPU Cloud](https://docs.nvidia.com/ngc/ngc-getting-started-guide/index.html)
- [Accessing And Pulling From The NGC Container Registry](https://docs.nvidia.com/deeplearning/frameworks/user-guide/index.html#accessing_registry)
- [Running PyTorch](https://docs.nvidia.com/deeplearning/frameworks/pytorch-release-notes/running.html#running)
For those unable to use the PyTorch NGC container, to set up the required environment or create your own container, refer to the versioned [NVIDIA Container Support Matrix](https://docs.nvidia.com/deeplearning/frameworks/support-matrix/index.html).
## Quick Start Guide
To train your model using mixed or TF32 precision with Tensor Cores or using FP32, perform the following steps using the default parameters of the HiFi-GAN model on the LJSpeech 1.1 dataset. For the specifics concerning training and inference, refer to the [Advanced](#advanced) section. Pre-trained HiFi-GAN models are available for download on [NGC](https://ngc.nvidia.com/catalog/models?query=HiFi-GAN&quickFilter=models).
1. Clone the repository.
```bash
git clone https://github.com/NVIDIA/DeepLearningExamples.git
cd DeepLearningExamples/PyTorch/SpeechSynthesis/HiFiGAN
```
2. Build and run the HiFi-GAN PyTorch NGC container.
By default the container uses all available GPUs.
```bash
bash scripts/docker/build.sh
bash scripts/docker/interactive.sh
```
3. Download and preprocess the dataset.
```bash
bash scripts/download_dataset.sh
bash scripts/prepare_dataset.sh
```
The data is downloaded to the `./data/LJSpeech-1.1` directory (on the host). The
`./data/LJSpeech-1.1` directory is mounted under the `/workspace/hifigan/data/LJSpeech-1.1`
location in the NGC container. The complete dataset has the following structure:
```bash
./data/LJSpeech-1.1
├── mels # Mel-spectrograms generated with the `prepare_dataset.sh` script
├── metadata.csv # Mapping of waveforms to utterances
├── README
└── wavs # Raw waveforms
```
Apart from generating mel-spectrograms in `data/LJSpeech-1.1/mels` directory, the `scripts/prepare_dataset.sh` script additionally generates LJSpeech-1.1 relevant split metadata files in `data/filelists` directory.
4. Start training.
```bash
NUM_GPUS=8 BATCH_SIZE=16 GRAD_ACCUMULATION=1 bash scripts/train_lj22khz.sh
```
The training produces a HiFi-GAN model capable of generating waveforms from mel-spectrograms.
It is serialized as a single `.pt` checkpoint file, along with a series of intermediate checkpoints.
The script is configured for 8x GPU with at least 16GB of memory.
To train with 1x GPU, run:
```
NUM_GPUS=1 BATCH_SIZE=16 GRAD_ACCUMULATION=8 bash scripts/train_lj22khz.sh
```
When training with AMP on Ampere GPU architectures, use an additional `--no_amp_grouped_conv` flag to speed up the training:
```bash
AMP=true NUM_GPUS=8 BATCH_SIZE=16 GRAD_ACCUMULATION=1 bash scripts/train_lj22khz.sh --no_amp_grouped_conv
```
The flag will disable mixed-precision training on selected layers. For more details refer to [Known issues](#known-issues).
Consult [Training process](#training-process) and [example configs](#training-performance-benchmark) to adjust to a different configuration or enable Automatic Mixed Precision.
5. (optionally) Fine-tune the model.
Some mel-spectrogram generators are prone to model bias. As the spectrograms differ from the true data on which HiFi-GAN was trained, the quality of the generated audio might suffer. In order to overcome this problem, a HiFi-GAN model can be fine-tuned on the outputs of a particular mel-spectrogram generator in order to adapt to this bias.
In this section we discuss fine-tuning to [FastPitch](https://github.com/NVIDIA/DeepLearningExamples/tree/master/PyTorch/SpeechSynthesis/FastPitch) outputs.
Obtain a model for which HiFi-GAN will be fine-tuned. If the FastPitch model was trained using phonemes, additionally download the CMU Dictionary.
```bash
bash scripts/download_models.sh fastpitch
bash scripts/download_cmudict.sh
```
Generate mel-spectrograms for all utterances in the dataset with the FastPitch model:
```bash
bash scripts/extract_fine_tune_mels.sh
```
Mel-spectrograms should now be prepared in the `data/mels-fastpitch-ljs22khz` directory. The fine-tuning script will load an existing HiFi-GAN model and run several epochs of training using spectrograms generated in the last step.
```bash
bash scripts/fine_tune.sh
```
This step will produce another `.pt` HiFi-GAN model checkpoint file fine-tuned to the particular FastPitch model.
5. Start validation/evaluation.
Ensure your training loss values are comparable to those listed in the table in the
[Results](#results) section. Note the validation loss is evaluated with ground truth durations for letters (not the predicted ones). The loss values are stored in the `./output/nvlog.json` log file, `./output/{train,val,test}` as TensorBoard logs, and printed to the standard output (`stdout`) during training.
The main reported loss is a weighted sum of losses for mel-, pitch-, and duration- predicting modules.
7. Start inference.
The audio can be synthesized either:
- from ground truth mel-spectrograms, as a means of assessing the quality of HiFi-GAN, or
- from an output of a mel-spectrogram generator model like FastPitch or Tacotron 2, as a full text-to-speech pipeline.
We descibe both scenarios.
**Sythesizing audio from ground truth mel-spectrograms**
In order to perform inference, pass a `.pt` checkpoint with the `--hifigan` argument to the inference script:
```bash
python inference.py --cuda \
--hifigan pretrained_models/hifigan/<HiFi-GAN checkpoint> \
-i phrases/devset10.tsv \
-o output/wavs_devset10
```
The speech is generated from a file passed with the `-i` argument, with one utterance per line:
```bash
`<output wav file name>|<utterance>`
```
**Synthesizing audio from raw text with mel-spectrogram generator**
The current implementation allows for convenient inference with the FastPitch model. A pre-trained FastPitch model can be downloaded with the `scripts/download_model.sh fastpitch` script. Alternatively, to train FastPitch or Tacotron 2 from scratch, follow the instructions in [NVIDIA/DeepLearningExamples/FastPitch](https://github.com/NVIDIA/DeepLearningExamples/tree/master/PyTorch/SpeechSynthesis/FastPitch) or [NVIDIA/DeepLearningExamples/Tacotron2](https://github.com/NVIDIA/DeepLearningExamples/tree/master/PyTorch/SpeechSynthesis/Tacotron2).
Begin with downloading the model and the pronunciation dictionary:
```bash
bash scripts/download_models.sh fastpitch
bash scripts/download_cmudict.sh
```
To run inference on FastPitch outputs, pass an additional `.pt` checkpoint with the `--fastpitch` flag:
```bash
python inference.py --cuda \
--hifigan pretrained_models/hifigan/<HiFi-GAN checkpoint> \
--fastpitch pretrained_models/fastpitch/<FastPitch checkpoint> \
-i phrases/devset10.tsv \
-o output/wavs_devset10
```
To run inference in mixed precision, use the `--amp` flag. The output audio will
be stored in the path specified by the `-o` argument. Consult the `inference.py` to learn more options, such as setting the batch size.
Now that you have your model trained and evaluated, you can choose to compare your training results with our [Training accuracy results](#training-accuracy-results). You can also choose to benchmark your performance to the [Training performance benchmark](#training-performance-results), or the [Inference performance benchmark](#inference-performance-results). Following the steps in these sections ensures you achieve the same accuracy and performance results as stated in the [Results](#results) section.
The audio can be generated by following the [Inference process](#inference-process) section below.
The synthesized audio should be similar to the samples in the `./audio` directory.
## Advanced
The following sections provide greater details of the dataset, running training and inference, and the training results.
### Parameters
In this section, we list the most important hyperparameters and command-line arguments,
together with their default values that are used to train HiFi-GAN.
| Flag | Description |
|:----------------------|:------------------------------------------------------------------------------------|
| `--epochs` | number of epochs (default: 1000) |
| `--learning_rate` | learning rate (default: 0.1) |
| `--batch_size` | actual batch size for a single forward-backward step (default: 16) |
| `--grad_accumulation` | number of forward-backward steps over which gradients are accumulated (default: 1) |
| `--amp` | use mixed precision training (default: disabled) |
### Command-line options
To see the full list of available options and their descriptions, use the `-h` or `--help` command-line option, for example:
`python train.py -h`.
### Getting the data
The `./scripts/download_dataset.sh` script will automatically download and extract the dataset to the `./data/LJSpeech-1.1` directory.
The `./scripts/prepare_dataset.sh` script will preprocess the dataset by generating split filelists in `./data/filelists` directory and extracting mel-spectrograms into the `./data/LJSpeech-1.1/mels` directory. Data preparation for LJSpeech-1.1 takes around 3 hours on a CPU.
#### Dataset guidelines
The LJSpeech dataset has 13,100 clips that amount to about 24 hours of speech of a single, female speaker. Since the original dataset does not define a train/dev/test split of the data, we provide a split in the form of three file lists:
```bash
./data/filelists
├── ljs_audio_train_v3.txt
├── ljs_audio_test.txt
└── ljs_audio_val.txt
```
These files are generated during `./scripts/prepare_dataset.sh` script execution.
#### Multi-dataset
Follow these steps to use datasets different from the default LJSpeech dataset.
1. Prepare a directory with .wav files.
```bash
./data/my_dataset
└── wavs
```
2. Prepare filelists with paths to .wav files. They define training/validation split of the data (test is currently unused, but it's a good practice to create it for the final evaluation):
```bash
./data/filelists
├── my-dataset_audio_train.txt
└── my-dataset_audio_val.txt
```
Those filelists should list a single wavefile per line as:
```bash
path/to/file001.wav
path/to/file002.wav
...
```
Those paths should be relative to the path provided by the `--dataset-path` option of `train.py`.
3. (Optional) Prepare file lists with paths to pre-calculated pitch when doing fine-tuning:
```bash
./data/filelists
├── my-dataset_audio_pitch_text_train.txt
└── my-dataset_audio_pitch_text_val.txt
```
In order to use the prepared dataset, pass the following to the `train.py` script:
```bash
--dataset-path ./data/my_dataset` \
--training-files ./data/filelists/my-dataset_audio_text_train.txt \
--validation files ./data/filelists/my-dataset_audio_text_val.txt
```
### Training process
HiFi-GAN is trained to generate waveforms from input mel-spectrograms. During training and validation, the network processes small, random chunks of the input of fixed length.
The training can be started with `scripts/train.sh` script. Output models, DLLogger logs and TensorBoard logs will be saved in the `output/` directory.
The following example output is printed when running the model:
```bash
DLL 2021-06-30 10:58:05.828323 - epoch 1 | iter 1/24 | d loss 7.966 | g loss 95.839 | mel loss 87.291 | 3092.31 frames/s | took 13.25 s | g lr 3.00e-04 | d lr 3.00e-04
DLL 2021-06-30 10:58:06.999175 - epoch 1 | iter 2/24 | d loss 7.957 | g loss 96.151 | mel loss 87.627 | 35109.29 frames/s | took 1.17 s | g lr 3.00e-04 | d lr 3.00e-04
DLL 2021-06-30 10:58:07.945764 - epoch 1 | iter 3/24 | d loss 7.956 | g loss 93.872 | mel loss 88.154 | 43443.33 frames/s | took 0.94 s | g lr 3.00e-04 | d lr 3.00e-04
```
Performance is reported in total input mel-spectrogram frames per second and recorded as `train_frames/s` (after each iteration) and `avg_train_frames/s` (averaged over epoch) in the output log file `./output/nvlog.json`.
The result is averaged over an entire training epoch and summed over all GPUs that were
included in the training. The metrics are averaged in such a way, that gradient accumulation steps would be transparent to the user.
The `scripts/train.sh` script is configured for 8x GPU with at least 16GB of memory.
In a single accumulated step, there are `batch_size x grad_accumulation x GPUs = 16 x 1 x 8 = 128` examples being processed in parallel. With a smaller number of GPUs, increase gradient accumulation steps to keep the relation satisfied, e.g., through env variables
```bash
NUM_GPUS=1 GRAD_ACCUMULATION=8 BATCH_SIZE=16 bash scripts/train.sh
```
The script also enables automatic mixed precision training. To train with mixed precision, specify the `AMP` variable
```bash
AMP=true bash scripts/train.sh
```
### Inference process
You can run inference using the `./inference.py` script. This script takes
mel-spectrograms as input and runs HiFi-GAN inference to produce audio files.
Pre-trained HiFi-GAN models are available for download on [NGC](https://ngc.nvidia.com/catalog/models?query=HiFi-GAN&quickFilter=models).
The latest model can be downloaded with:
```bash
scripts/download_model.sh hifigan
```
Having pre-trained models in place, extract validation mel-spectrograms from the LJSpeech-1.1 test-set, and run inference with:
```bash
bash scripts/inference_example.sh
```
Examine the `inference_example.sh` script to adjust paths to pre-trained models,
and call `python inference.py --help` to learn all available options.
By default, synthesized audio samples are saved in `./output/audio_*` folders.
## Performance
### Benchmarking
The following section shows how to run benchmarks measuring the model
performance in training and inference mode.
#### Training performance benchmark
To benchmark the training performance on a specific batch size, run:
* NVIDIA DGX A100 (8x A100 80GB)
```bash
AMP=true NUM_GPUS=1 BS=64 GRAD_ACCUMULATION=8 EPOCHS=10 bash scripts/train.sh
AMP=true NUM_GPUS=8 BS=64 GRAD_ACCUMULATION=1 EPOCHS=10 bash scripts/train.sh
NUM_GPUS=1 BS=64 GRAD_ACCUMULATION=8 EPOCHS=10 bash scripts/train.sh
NUM_GPUS=8 BS=64 GRAD_ACCUMULATION=1 EPOCHS=10 bash scripts/train.sh
```
* NVIDIA DGX-1 (8x V100 16GB)
```bash
AMP=true NUM_GPUS=1 BS=64 GRAD_ACCUMULATION=8 EPOCHS=10 bash scripts/train.sh
AMP=true NUM_GPUS=8 BS=64 GRAD_ACCUMULATION=1 EPOCHS=10 bash scripts/train.sh
NUM_GPUS=1 BS=64 GRAD_ACCUMULATION=8 EPOCHS=10 bash scripts/train.sh
NUM_GPUS=8 BS=64 GRAD_ACCUMULATION=1 EPOCHS=10 bash scripts/train.sh
```
Each of these scripts runs for 10 epochs and measures the
average number of items per second for each epoch. The performance results can be read from
the `nvlog.json` files produced by the commands.
#### Inference performance benchmark
To benchmark the inference performance on a specific batch size, run:
* For FP16
```bash
AMP=true BATCH_SIZE=1 REPEATS=100 bash scripts/inference_benchmark.sh
```
* For FP32 or TF32
```bash
BATCH_SIZE=1 REPEATS=100 bash scripts/inference_benchmark.sh
```
The output log files will contain performance numbers for the HiFi-GAN model
(number of input mel-spectrogram frames per second, reported as `hifigan_frames/s`)
and FastPitch (number of output mel-spectrogram frames per second as `mel_gen_frames/s`).
The `inference.py` script will run a few warm-up iterations before running the benchmark. Inference will be averaged over 100 runs, as set by the `REPEATS` env variable.
### Results
The following sections provide details on how we achieved our performance and accuracy in training and inference.
#### Training accuracy results
##### Training accuracy: NVIDIA DGX A100 (8x A100 80GB)
Our results were obtained by running the `./platform/DGXA100_HiFi-GAN_{AMP,TF32}_8GPU.sh` training script in the 21.12-py3 NGC container on NVIDIA DGX A100 (8x A100 80GB) GPUs.
We present median mel loss values calculated on the validation subset at the end of the training.
| Dataset | Batch size / GPU | Grad accumulation | GPUs | Val mel loss - FP32 | Val mel loss - mixed precision | Time to train - FP32 | Time to train - mixed precision | Time to train speedup (FP32 to mixed precision) |
|---------|------------------|-------------------|------|-----------------|----------------------------|----------------------|---------------------------------|-------------------------------------------------|
| LJSpeech-1.1 | 128 | 1 | 1 | 9.65 | 9.68 | 151.4 h | 117.1 h | 1.29x |
| LJSpeech-1.1 | 16 | 1 | 8 | 9.65 | 9.68 | 32.9 h | 32.8 h | 1.00x |
##### Training accuracy: NVIDIA DGX-1 (8x V100 16GB)
Our results were obtained by running the `./platform/DGX1_HiFi-GAN_{AMP,FP32}_8GPU.sh` training script in the 21.12-py3 NGC container on NVIDIA DGX-1 (8x V100 16GB) GPUs.
We present median mel loss values calculated on the validation subset at the end of the training.
| Dataset | Batch size / GPU | Grad accumulation | GPUs | Val mel loss - FP32 | Val mel loss - mixed precision | Time to train - FP32 | Time to train - mixed precision | Time to train speedup (FP32 to mixed precision) |
|---------|------------------|-------------------|------|-----------------|----------------------------|----------------------|---------------------------------|-------------------------------------------------|
| LJSpeech-1.1 | 32 | 4 | 1 | 9.65 | 9.73 | 604.6 h | 279.7 h | 2.16x |
| LJSpeech-1.1 | 64 | 2 | 1 | 9.65 | 9.73 | - | 240.2 h | 2.52x |
| LJSpeech-1.1 | 16 | 1 | 8 | 9.65 | 9.73 | 88.3 h | 56.7 h | 1.56x |
Fine tuning of the model on FastPitch outputs makes about half of the steps of the base model and will prolong the training by 50%.
##### Training stability test
The training is stable when different random seeds are used. Below we compare loss curves obtained by training HiFi-GAN with different seeds.
<div style="text-align:center" align="center">
<img src="./img/loss_seeds.png" alt="Loss curves for different random seeds" />
</div>
The training is also stable with respect to different platforms:
<div style="text-align:center" align="center">
<img src="./img/loss.png" alt="Loss curves for different platforms" />
</div>
#### Training performance results
##### Training performance: NVIDIA DGX A100 (8x A100 80GB)
Our results were obtained by running the `./platform/DGXA100_HiFi-GAN_{AMP,TF32}_8GPU.sh` training script in the 21.12-py3 NGC container on NVIDIA DGX A100 (8x A100 80GB) GPUs. Performance numbers, in input mel-scale spectrogram frames per second, were averaged over an entire training epoch.
| Batch size / GPU | Grad accumulation | GPUs | Throughput - TF32 | Throughput - mixed precision | Throughput speedup (TF32 to mixed precision) | Strong scaling - TF32 | Strong scaling - mixed precision |
|-----:|-----:|-------:|---------:|----------:|--------:|-----:|------:|
| 128 | 1 | 1 | 12055.44 | 15578.65 | 1.29 | 1.00 | 1.00 |
| 32 | 1 | 4 | 36766.63 | 40949.55 | 1.11 | 3.05 | 2.63 |
| 16 | 1 | 8 | 55372.63 | 55634.66 | 1.00 | 4.59 | 3.57 |
##### Training performance: NVIDIA DGX-1 (8x V100 16GB)
Our results were obtained by running the `./platform/DGX1_HiFi-GAN_{AMP,FP32}_8GPU.sh`
training script in the PyTorch 21.12-py3 NGC container on NVIDIA DGX-1 with
8x V100 16GB GPUs. Performance numbers, in output mel-scale spectrogram frames per second, were averaged over
an entire training epoch.
| Batch size / GPU | Grad accumulation | GPUs | Throughput - FP32 | Throughput - mixed precision | Throughput speedup (FP32 to mixed precision) | Strong scaling - FP32 | Strong scaling - mixed precision |
|-----:|-----:|-------:|----------:|---------:|--------:|-----:|------:|
| 32 | 4 | 1 | 3017.57 | 6522.37 | 2.16 | 1.00 | 1.00 |
| 64 | 2 | 1 | - | 7596.32 | 2.52 | - | 1.00 |
| 32 | 1 | 4 | 12135.04 | 23660.14 | 1.95 | 4.02 | 3.11 |
| 16 | 1 | 8 | 20659.86 | 32175.41 | 1.56 | 6.85 | 4.24 |
#### Inference performance results
The following tables show inference statistics for the FastPitch and HiFi-GAN
text-to-speech system, gathered from 100 inference runs. Latency is measured from the start of FastPitch inference to
the end of HiFi-GAN inference. Throughput is measured
as the number of generated audio samples per second at 22KHz. RTF is the real-time factor that denotes the number of seconds of speech generated in a second of wall-clock time per input utterance.
Our results were obtained by running the `./scripts/inference_benchmark.sh` script in
the PyTorch 21.12-py3 NGC container. The input utterance has 128 characters, synthesized audio has 8.05 s.
##### Inference performance: NVIDIA DGX A100 (1x A100 80GB)
TorchScript + denoising:
|Batch size|Precision|Avg latency (s)|Latency tolerance interval 90% (s)|Latency tolerance interval 95% (s)|Latency tolerance interval 99% (s)|Throughput (samples/sec)|Speed-up with mixed precision|Avg RTF|
|------|--------|-----------|---------|---------|---------|--------------|-----------|--------|
| 1 | FP16 | 0.019 | 0.021 | 0.021 | 0.022 | 8906958 | 1.29 | 403.94 |
| 2 | FP16 | 0.029 | 0.029 | 0.029 | 0.03 | 11780358 | 1.97 | 267.13 |
| 4 | FP16 | 0.044 | 0.045 | 0.045 | 0.046 | 15248417 | 1.57 | 172.88 |
| 8 | FP16 | 0.082 | 0.082 | 0.082 | 0.082 | 16597793 | 1.57 | 94.09 |
| 1 | TF32 | 0.025 | 0.025 | 0.025 | 0.025 | 6915487 | - | 313.63 |
| 2 | TF32 | 0.057 | 0.057 | 0.057 | 0.057 | 5966172 | - | 135.29 |
| 4 | TF32 | 0.07 | 0.071 | 0.071 | 0.072 | 9710162 | - | 110.09 |
| 8 | TF32 | 0.128 | 0.129 | 0.129 | 0.129 | 10578539 | - | 59.97 |
TorchScript, no denoising:
|Batch size|Precision|Avg latency (s)|Latency tolerance interval 90% (s)|Latency tolerance interval 95% (s)|Latency tolerance interval 99% (s)|Throughput (samples/sec)|Speed-up with mixed precision|Avg RTF|
|------|--------|-----------|---------|---------|---------|--------------|-----------|--------|
| 1 | FP16 | 0.018 | 0.019 | 0.019 | 0.020 | 9480432 | 1.32 | 429.95 |
| 2 | FP16 | 0.027 | 0.028 | 0.028 | 0.028 | 12430026 | 2.02 | 281.86 |
| 4 | FP16 | 0.042 | 0.044 | 0.044 | 0.045 | 15952396 | 1.60 | 180.87 |
| 8 | FP16 | 0.082 | 0.083 | 0.083 | 0.084 | 16461910 | 1.52 | 93.32 |
| 1 | TF32 | 0.024 | 0.025 | 0.025 | 0.025 | 7194880 | - | 326.3 |
| 2 | TF32 | 0.055 | 0.056 | 0.056 | 0.056 | 6141659 | - | 139.27 |
| 4 | TF32 | 0.068 | 0.068 | 0.069 | 0.069 | 9977333 | - | 113.12 |
| 8 | TF32 | 0.125 | 0.126 | 0.126 | 0.127 | 10813904 | - | 61.3 |
##### Inference performance: NVIDIA DGX-1 (1x V100 16GB)
TorchScript + denoising:
|Batch size|Precision|Avg latency (s)|Latency tolerance interval 90% (s)|Latency tolerance interval 95% (s)|Latency tolerance interval 99% (s)|Throughput (samples/sec)|Speed-up with mixed precision|Avg RTF|
|------|--------|-----------|---------|---------|---------|--------------|-----------|--------|
| 1 | FP16 | 0.033 | 0.034 | 0.035 | 0.035 | 5062222 | 1.82 | 229.58 |
| 4 | FP16 | 0.083 | 0.085 | 0.085 | 0.085 | 8106313 | 2.29 | 91.91 |
| 8 | FP16 | 0.142 | 0.144 | 0.144 | 0.145 | 9501139 | 2.54 | 53.86 |
| 1 | FP32 | 0.061 | 0.062 | 0.062 | 0.062 | 2783145 | - | 126.22 |
| 4 | FP32 | 0.192 | 0.194 | 0.194 | 0.195 | 3534640 | - | 40.08 |
| 8 | FP32 | 0.362 | 0.364 | 0.364 | 0.365 | 3747958 | - | 21.25 |
TorchScript, no denoising:
|Batch size|Precision|Avg latency (s)|Latency tolerance interval 90% (s)|Latency tolerance interval 95% (s)|Latency tolerance interval 99% (s)|Throughput (samples/sec)|Speed-up with mixed precision|Avg RTF|
|------|--------|-----------|---------|---------|---------|--------------|-----------|--------|
| 1 | FP16 | 0.030 | 0.031 | 0.031 | 0.031 | 5673639 | 2.02 | 257.31 |
| 4 | FP16 | 0.080 | 0.081 | 0.081 | 0.082 | 8472603 | 2.37 | 96.06 |
| 8 | FP16 | 0.139 | 0.140 | 0.141 | 0.141 | 9737865 | 2.57 | 55.20 |
| 1 | FP32 | 0.060 | 0.061 | 0.061 | 0.062 | 2806620 | - | 127.28 |
| 4 | FP32 | 0.190 | 0.192 | 0.192 | 0.193 | 3571308 | - | 40.49 |
| 8 | FP32 | 0.358 | 0.360 | 0.361 | 0.361 | 3788591 | - | 21.48 |
##### Inference performance: NVIDIA T4
TorchScript, denoising:
|Batch size|Precision|Avg latency (s)|Latency tolerance interval 90% (s)|Latency tolerance interval 95% (s)|Latency tolerance interval 99% (s)|Throughput (samples/sec)|Speed-up with mixed precision|Avg RTF|
|------|--------|-----------|---------|---------|---------|--------------|-----------|--------|
| 1 | FP16 | 0.060 | 0.061 | 0.061 | 0.061 | 2835064 | 2.42 | 128.57 |
| 4 | FP16 | 0.211 | 0.213 | 0.213 | 0.214 | 3205667 | 2.42 | 36.35 |
| 8 | FP16 | 0.410 | 0.413 | 0.413 | 0.414 | 3304070 | 2.45 | 18.73 |
| 1 | FP32 | 0.145 | 0.146 | 0.147 | 0.147 | 1171258 | - | 53.12 |
| 4 | FP32 | 0.512 | 0.515 | 0.515 | 0.516 | 1324952 | - | 15.02 |
| 8 | FP32 | 1.006 | 1.011 | 1.012 | 1.013 | 1347688 | - | 7.64 |
TorchScript, no denoising:
|Batch size|Precision|Avg latency (s)|Latency tolerance interval 90% (s)|Latency tolerance interval 95% (s)|Latency tolerance interval 99% (s)|Throughput (samples/sec)|Speed-up with mixed precision|Avg RTF|
|------|--------|-----------|---------|---------|---------|--------------|-----------|--------|
| 1 | FP16 | 0.057 | 0.058 | 0.058 | 0.059 | 2969398 | 2.48 | 134.67 |
| 4 | FP16 | 0.205 | 0.207 | 0.207 | 0.208 | 3299130 | 2.45 | 37.41 |
| 8 | FP16 | 0.399 | 0.402 | 0.403 | 0.404 | 3389001 | 2.48 | 19.21 |
| 1 | FP32 | 0.142 | 0.143 | 0.143 | 0.144 | 1195309 | - | 54.21 |
| 4 | FP32 | 0.504 | 0.507 | 0.507 | 0.509 | 1345995 | - | 15.26 |
| 8 | FP32 | 0.993 | 0.997 | 0.998 | 0.999 | 1365273 | - | 7.74 |
## Release notes
The performance measurements in this document were conducted at the time of publication and may not reflect the performance achieved from NVIDIA’s latest software release. For the most up-to-date performance measurements, go to https://developer.nvidia.com/deep-learning-performance-training-inference.
### Changelog
February 2022
- Initial release
### Known issues
- With mixed-precision training on Ampere GPUs, the model might suffer from slower training. Be sure to use the scripts provided in the <a href="platform/">platform/</a> directory, and a PyTorch NGC container not older than 21.12-py3.
- For some mel-spectrogram generator models, the best results require fine-tuning of HiFi-GAN on outputs from those models.
For more details, refer to the fine-tuning step of the [Quick Start Guide](#quick-start-guide) section.
|
PyTorch/Segmentation/MaskRCNN/pytorch/maskrcnn_benchmark/modeling | modeling | box_coder | # Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved.
# Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.
import math
from maskrcnn_benchmark import _C
import torch
class BoxCoder(object):
"""
This class encodes and decodes a set of bounding boxes into
the representation used for training the regressors.
"""
def __init__(self, weights, bbox_xform_clip=math.log(1000. / 16)):
"""
Arguments:
weights (4-element tuple)
bbox_xform_clip (float)
"""
self.weights = weights
self.bbox_xform_clip = bbox_xform_clip
def encode(self, reference_boxes, proposals):
"""
Encode a set of proposals with respect to some
reference boxes
Arguments:
reference_boxes (Tensor): reference boxes
proposals (Tensor): boxes to be encoded
"""
wx, wy, ww, wh = self.weights
if reference_boxes.is_cuda and proposals.is_cuda:
targets = torch.stack(_C.box_encode(reference_boxes, proposals, wx, wy, ww, wh), dim=1)
else:
TO_REMOVE = 1 # TODO remove
ex_widths = proposals[:, 2] - proposals[:, 0] + TO_REMOVE
ex_heights = proposals[:, 3] - proposals[:, 1] + TO_REMOVE
ex_ctr_x = proposals[:, 0] + 0.5 * ex_widths
ex_ctr_y = proposals[:, 1] + 0.5 * ex_heights
gt_widths = reference_boxes[:, 2] - reference_boxes[:, 0] + TO_REMOVE
gt_heights = reference_boxes[:, 3] - reference_boxes[:, 1] + TO_REMOVE
gt_ctr_x = reference_boxes[:, 0] + 0.5 * gt_widths
gt_ctr_y = reference_boxes[:, 1] + 0.5 * gt_heights
wx, wy, ww, wh = self.weights
targets_dx = wx * (gt_ctr_x - ex_ctr_x) / ex_widths
targets_dy = wy * (gt_ctr_y - ex_ctr_y) / ex_heights
targets_dw = ww * torch.log(gt_widths / ex_widths)
targets_dh = wh * torch.log(gt_heights / ex_heights)
targets = torch.stack((targets_dx, targets_dy, targets_dw, targets_dh), dim=1)
return targets
def decode(self, rel_codes, boxes):
"""
From a set of original boxes and encoded relative box offsets,
get the decoded boxes.
Arguments:
rel_codes (Tensor): encoded boxes
boxes (Tensor): reference boxes.
"""
boxes = boxes.to(rel_codes.dtype)
TO_REMOVE = 1 # TODO remove
widths = boxes[:, 2] - boxes[:, 0] + TO_REMOVE
heights = boxes[:, 3] - boxes[:, 1] + TO_REMOVE
ctr_x = boxes[:, 0] + 0.5 * widths
ctr_y = boxes[:, 1] + 0.5 * heights
wx, wy, ww, wh = self.weights
dx = rel_codes[:, 0::4] / wx
dy = rel_codes[:, 1::4] / wy
dw = rel_codes[:, 2::4] / ww
dh = rel_codes[:, 3::4] / wh
# Prevent sending too large values into torch.exp()
dw = torch.clamp(dw, max=self.bbox_xform_clip)
dh = torch.clamp(dh, max=self.bbox_xform_clip)
pred_ctr_x = dx * widths[:, None] + ctr_x[:, None]
pred_ctr_y = dy * heights[:, None] + ctr_y[:, None]
pred_w = torch.exp(dw) * widths[:, None]
pred_h = torch.exp(dh) * heights[:, None]
pred_boxes = torch.zeros_like(rel_codes)
# x1
pred_boxes[:, 0::4] = pred_ctr_x - 0.5 * pred_w
# y1
pred_boxes[:, 1::4] = pred_ctr_y - 0.5 * pred_h
# x2 (note: "- 1" is correct; don't be fooled by the asymmetry)
pred_boxes[:, 2::4] = pred_ctr_x + 0.5 * pred_w - 1
# y2 (note: "- 1" is correct; don't be fooled by the asymmetry)
pred_boxes[:, 3::4] = pred_ctr_y + 0.5 * pred_h - 1
return pred_boxes
|
TensorFlow/Detection/SSD/models/research/slim/preprocessing | preprocessing | cifarnet_preprocessing | # Copyright 2016 The TensorFlow Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ==============================================================================
"""Provides utilities to preprocess images in CIFAR-10.
"""
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import tensorflow as tf
_PADDING = 4
slim = tf.contrib.slim
def preprocess_for_train(image,
output_height,
output_width,
padding=_PADDING,
add_image_summaries=True):
"""Preprocesses the given image for training.
Note that the actual resizing scale is sampled from
[`resize_size_min`, `resize_size_max`].
Args:
image: A `Tensor` representing an image of arbitrary size.
output_height: The height of the image after preprocessing.
output_width: The width of the image after preprocessing.
padding: The amound of padding before and after each dimension of the image.
add_image_summaries: Enable image summaries.
Returns:
A preprocessed image.
"""
if add_image_summaries:
tf.summary.image('image', tf.expand_dims(image, 0))
# Transform the image to floats.
image = tf.to_float(image)
if padding > 0:
image = tf.pad(image, [[padding, padding], [padding, padding], [0, 0]])
# Randomly crop a [height, width] section of the image.
distorted_image = tf.random_crop(image,
[output_height, output_width, 3])
# Randomly flip the image horizontally.
distorted_image = tf.image.random_flip_left_right(distorted_image)
if add_image_summaries:
tf.summary.image('distorted_image', tf.expand_dims(distorted_image, 0))
# Because these operations are not commutative, consider randomizing
# the order their operation.
distorted_image = tf.image.random_brightness(distorted_image,
max_delta=63)
distorted_image = tf.image.random_contrast(distorted_image,
lower=0.2, upper=1.8)
# Subtract off the mean and divide by the variance of the pixels.
return tf.image.per_image_standardization(distorted_image)
def preprocess_for_eval(image, output_height, output_width,
add_image_summaries=True):
"""Preprocesses the given image for evaluation.
Args:
image: A `Tensor` representing an image of arbitrary size.
output_height: The height of the image after preprocessing.
output_width: The width of the image after preprocessing.
add_image_summaries: Enable image summaries.
Returns:
A preprocessed image.
"""
if add_image_summaries:
tf.summary.image('image', tf.expand_dims(image, 0))
# Transform the image to floats.
image = tf.to_float(image)
# Resize and crop if needed.
resized_image = tf.image.resize_image_with_crop_or_pad(image,
output_width,
output_height)
if add_image_summaries:
tf.summary.image('resized_image', tf.expand_dims(resized_image, 0))
# Subtract off the mean and divide by the variance of the pixels.
return tf.image.per_image_standardization(resized_image)
def preprocess_image(image, output_height, output_width, is_training=False,
add_image_summaries=True):
"""Preprocesses the given image.
Args:
image: A `Tensor` representing an image of arbitrary size.
output_height: The height of the image after preprocessing.
output_width: The width of the image after preprocessing.
is_training: `True` if we're preprocessing the image for training and
`False` otherwise.
add_image_summaries: Enable image summaries.
Returns:
A preprocessed image.
"""
if is_training:
return preprocess_for_train(
image, output_height, output_width,
add_image_summaries=add_image_summaries)
else:
return preprocess_for_eval(
image, output_height, output_width,
add_image_summaries=add_image_summaries)
|
TensorFlow/Detection/SSD/models/research/slim/nets | nets | inception_v2_test | # Copyright 2016 The TensorFlow Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ==============================================================================
"""Tests for nets.inception_v2."""
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import numpy as np
import tensorflow as tf
from nets import inception
slim = tf.contrib.slim
class InceptionV2Test(tf.test.TestCase):
def testBuildClassificationNetwork(self):
batch_size = 5
height, width = 224, 224
num_classes = 1000
inputs = tf.random_uniform((batch_size, height, width, 3))
logits, end_points = inception.inception_v2(inputs, num_classes)
self.assertTrue(logits.op.name.startswith(
'InceptionV2/Logits/SpatialSqueeze'))
self.assertListEqual(logits.get_shape().as_list(),
[batch_size, num_classes])
self.assertTrue('Predictions' in end_points)
self.assertListEqual(end_points['Predictions'].get_shape().as_list(),
[batch_size, num_classes])
def testBuildPreLogitsNetwork(self):
batch_size = 5
height, width = 224, 224
num_classes = None
inputs = tf.random_uniform((batch_size, height, width, 3))
net, end_points = inception.inception_v2(inputs, num_classes)
self.assertTrue(net.op.name.startswith('InceptionV2/Logits/AvgPool'))
self.assertListEqual(net.get_shape().as_list(), [batch_size, 1, 1, 1024])
self.assertFalse('Logits' in end_points)
self.assertFalse('Predictions' in end_points)
def testBuildBaseNetwork(self):
batch_size = 5
height, width = 224, 224
inputs = tf.random_uniform((batch_size, height, width, 3))
mixed_5c, end_points = inception.inception_v2_base(inputs)
self.assertTrue(mixed_5c.op.name.startswith('InceptionV2/Mixed_5c'))
self.assertListEqual(mixed_5c.get_shape().as_list(),
[batch_size, 7, 7, 1024])
expected_endpoints = ['Mixed_3b', 'Mixed_3c', 'Mixed_4a', 'Mixed_4b',
'Mixed_4c', 'Mixed_4d', 'Mixed_4e', 'Mixed_5a',
'Mixed_5b', 'Mixed_5c', 'Conv2d_1a_7x7',
'MaxPool_2a_3x3', 'Conv2d_2b_1x1', 'Conv2d_2c_3x3',
'MaxPool_3a_3x3']
self.assertItemsEqual(end_points.keys(), expected_endpoints)
def testBuildOnlyUptoFinalEndpoint(self):
batch_size = 5
height, width = 224, 224
endpoints = ['Conv2d_1a_7x7', 'MaxPool_2a_3x3', 'Conv2d_2b_1x1',
'Conv2d_2c_3x3', 'MaxPool_3a_3x3', 'Mixed_3b', 'Mixed_3c',
'Mixed_4a', 'Mixed_4b', 'Mixed_4c', 'Mixed_4d', 'Mixed_4e',
'Mixed_5a', 'Mixed_5b', 'Mixed_5c']
for index, endpoint in enumerate(endpoints):
with tf.Graph().as_default():
inputs = tf.random_uniform((batch_size, height, width, 3))
out_tensor, end_points = inception.inception_v2_base(
inputs, final_endpoint=endpoint)
self.assertTrue(out_tensor.op.name.startswith(
'InceptionV2/' + endpoint))
self.assertItemsEqual(endpoints[:index+1], end_points.keys())
def testBuildAndCheckAllEndPointsUptoMixed5c(self):
batch_size = 5
height, width = 224, 224
inputs = tf.random_uniform((batch_size, height, width, 3))
_, end_points = inception.inception_v2_base(inputs,
final_endpoint='Mixed_5c')
endpoints_shapes = {'Mixed_3b': [batch_size, 28, 28, 256],
'Mixed_3c': [batch_size, 28, 28, 320],
'Mixed_4a': [batch_size, 14, 14, 576],
'Mixed_4b': [batch_size, 14, 14, 576],
'Mixed_4c': [batch_size, 14, 14, 576],
'Mixed_4d': [batch_size, 14, 14, 576],
'Mixed_4e': [batch_size, 14, 14, 576],
'Mixed_5a': [batch_size, 7, 7, 1024],
'Mixed_5b': [batch_size, 7, 7, 1024],
'Mixed_5c': [batch_size, 7, 7, 1024],
'Conv2d_1a_7x7': [batch_size, 112, 112, 64],
'MaxPool_2a_3x3': [batch_size, 56, 56, 64],
'Conv2d_2b_1x1': [batch_size, 56, 56, 64],
'Conv2d_2c_3x3': [batch_size, 56, 56, 192],
'MaxPool_3a_3x3': [batch_size, 28, 28, 192]}
self.assertItemsEqual(endpoints_shapes.keys(), end_points.keys())
for endpoint_name in endpoints_shapes:
expected_shape = endpoints_shapes[endpoint_name]
self.assertTrue(endpoint_name in end_points)
self.assertListEqual(end_points[endpoint_name].get_shape().as_list(),
expected_shape)
def testModelHasExpectedNumberOfParameters(self):
batch_size = 5
height, width = 224, 224
inputs = tf.random_uniform((batch_size, height, width, 3))
with slim.arg_scope(inception.inception_v2_arg_scope()):
inception.inception_v2_base(inputs)
total_params, _ = slim.model_analyzer.analyze_vars(
slim.get_model_variables())
self.assertAlmostEqual(10173112, total_params)
def testBuildEndPointsWithDepthMultiplierLessThanOne(self):
batch_size = 5
height, width = 224, 224
num_classes = 1000
inputs = tf.random_uniform((batch_size, height, width, 3))
_, end_points = inception.inception_v2(inputs, num_classes)
endpoint_keys = [key for key in end_points.keys()
if key.startswith('Mixed') or key.startswith('Conv')]
_, end_points_with_multiplier = inception.inception_v2(
inputs, num_classes, scope='depth_multiplied_net',
depth_multiplier=0.5)
for key in endpoint_keys:
original_depth = end_points[key].get_shape().as_list()[3]
new_depth = end_points_with_multiplier[key].get_shape().as_list()[3]
self.assertEqual(0.5 * original_depth, new_depth)
def testBuildEndPointsWithDepthMultiplierGreaterThanOne(self):
batch_size = 5
height, width = 224, 224
num_classes = 1000
inputs = tf.random_uniform((batch_size, height, width, 3))
_, end_points = inception.inception_v2(inputs, num_classes)
endpoint_keys = [key for key in end_points.keys()
if key.startswith('Mixed') or key.startswith('Conv')]
_, end_points_with_multiplier = inception.inception_v2(
inputs, num_classes, scope='depth_multiplied_net',
depth_multiplier=2.0)
for key in endpoint_keys:
original_depth = end_points[key].get_shape().as_list()[3]
new_depth = end_points_with_multiplier[key].get_shape().as_list()[3]
self.assertEqual(2.0 * original_depth, new_depth)
def testRaiseValueErrorWithInvalidDepthMultiplier(self):
batch_size = 5
height, width = 224, 224
num_classes = 1000
inputs = tf.random_uniform((batch_size, height, width, 3))
with self.assertRaises(ValueError):
_ = inception.inception_v2(inputs, num_classes, depth_multiplier=-0.1)
with self.assertRaises(ValueError):
_ = inception.inception_v2(inputs, num_classes, depth_multiplier=0.0)
def testBuildEndPointsWithUseSeparableConvolutionFalse(self):
batch_size = 5
height, width = 224, 224
inputs = tf.random_uniform((batch_size, height, width, 3))
_, end_points = inception.inception_v2_base(inputs)
endpoint_keys = [
key for key in end_points.keys()
if key.startswith('Mixed') or key.startswith('Conv')
]
_, end_points_with_replacement = inception.inception_v2_base(
inputs, use_separable_conv=False)
# The endpoint shapes must be equal to the original shape even when the
# separable convolution is replaced with a normal convolution.
for key in endpoint_keys:
original_shape = end_points[key].get_shape().as_list()
self.assertTrue(key in end_points_with_replacement)
new_shape = end_points_with_replacement[key].get_shape().as_list()
self.assertListEqual(original_shape, new_shape)
def testBuildEndPointsNCHWDataFormat(self):
batch_size = 5
height, width = 224, 224
inputs = tf.random_uniform((batch_size, height, width, 3))
_, end_points = inception.inception_v2_base(inputs)
endpoint_keys = [
key for key in end_points.keys()
if key.startswith('Mixed') or key.startswith('Conv')
]
inputs_in_nchw = tf.random_uniform((batch_size, 3, height, width))
_, end_points_with_replacement = inception.inception_v2_base(
inputs_in_nchw, use_separable_conv=False, data_format='NCHW')
# With the 'NCHW' data format, all endpoint activations have a transposed
# shape from the original shape with the 'NHWC' layout.
for key in endpoint_keys:
transposed_original_shape = tf.transpose(
end_points[key], [0, 3, 1, 2]).get_shape().as_list()
self.assertTrue(key in end_points_with_replacement)
new_shape = end_points_with_replacement[key].get_shape().as_list()
self.assertListEqual(transposed_original_shape, new_shape)
def testBuildErrorsForDataFormats(self):
batch_size = 5
height, width = 224, 224
inputs = tf.random_uniform((batch_size, height, width, 3))
# 'NCWH' data format is not supported.
with self.assertRaises(ValueError):
_ = inception.inception_v2_base(inputs, data_format='NCWH')
# 'NCHW' data format is not supported for separable convolution.
with self.assertRaises(ValueError):
_ = inception.inception_v2_base(inputs, data_format='NCHW')
def testHalfSizeImages(self):
batch_size = 5
height, width = 112, 112
num_classes = 1000
inputs = tf.random_uniform((batch_size, height, width, 3))
logits, end_points = inception.inception_v2(inputs, num_classes)
self.assertTrue(logits.op.name.startswith('InceptionV2/Logits'))
self.assertListEqual(logits.get_shape().as_list(),
[batch_size, num_classes])
pre_pool = end_points['Mixed_5c']
self.assertListEqual(pre_pool.get_shape().as_list(),
[batch_size, 4, 4, 1024])
def testUnknownImageShape(self):
tf.reset_default_graph()
batch_size = 2
height, width = 224, 224
num_classes = 1000
input_np = np.random.uniform(0, 1, (batch_size, height, width, 3))
with self.test_session() as sess:
inputs = tf.placeholder(tf.float32, shape=(batch_size, None, None, 3))
logits, end_points = inception.inception_v2(inputs, num_classes)
self.assertTrue(logits.op.name.startswith('InceptionV2/Logits'))
self.assertListEqual(logits.get_shape().as_list(),
[batch_size, num_classes])
pre_pool = end_points['Mixed_5c']
feed_dict = {inputs: input_np}
tf.global_variables_initializer().run()
pre_pool_out = sess.run(pre_pool, feed_dict=feed_dict)
self.assertListEqual(list(pre_pool_out.shape), [batch_size, 7, 7, 1024])
def testGlobalPoolUnknownImageShape(self):
tf.reset_default_graph()
batch_size = 1
height, width = 250, 300
num_classes = 1000
input_np = np.random.uniform(0, 1, (batch_size, height, width, 3))
with self.test_session() as sess:
inputs = tf.placeholder(tf.float32, shape=(batch_size, None, None, 3))
logits, end_points = inception.inception_v2(inputs, num_classes,
global_pool=True)
self.assertTrue(logits.op.name.startswith('InceptionV2/Logits'))
self.assertListEqual(logits.get_shape().as_list(),
[batch_size, num_classes])
pre_pool = end_points['Mixed_5c']
feed_dict = {inputs: input_np}
tf.global_variables_initializer().run()
pre_pool_out = sess.run(pre_pool, feed_dict=feed_dict)
self.assertListEqual(list(pre_pool_out.shape), [batch_size, 8, 10, 1024])
def testUnknowBatchSize(self):
batch_size = 1
height, width = 224, 224
num_classes = 1000
inputs = tf.placeholder(tf.float32, (None, height, width, 3))
logits, _ = inception.inception_v2(inputs, num_classes)
self.assertTrue(logits.op.name.startswith('InceptionV2/Logits'))
self.assertListEqual(logits.get_shape().as_list(),
[None, num_classes])
images = tf.random_uniform((batch_size, height, width, 3))
with self.test_session() as sess:
sess.run(tf.global_variables_initializer())
output = sess.run(logits, {inputs: images.eval()})
self.assertEquals(output.shape, (batch_size, num_classes))
def testEvaluation(self):
batch_size = 2
height, width = 224, 224
num_classes = 1000
eval_inputs = tf.random_uniform((batch_size, height, width, 3))
logits, _ = inception.inception_v2(eval_inputs, num_classes,
is_training=False)
predictions = tf.argmax(logits, 1)
with self.test_session() as sess:
sess.run(tf.global_variables_initializer())
output = sess.run(predictions)
self.assertEquals(output.shape, (batch_size,))
def testTrainEvalWithReuse(self):
train_batch_size = 5
eval_batch_size = 2
height, width = 150, 150
num_classes = 1000
train_inputs = tf.random_uniform((train_batch_size, height, width, 3))
inception.inception_v2(train_inputs, num_classes)
eval_inputs = tf.random_uniform((eval_batch_size, height, width, 3))
logits, _ = inception.inception_v2(eval_inputs, num_classes, reuse=True)
predictions = tf.argmax(logits, 1)
with self.test_session() as sess:
sess.run(tf.global_variables_initializer())
output = sess.run(predictions)
self.assertEquals(output.shape, (eval_batch_size,))
def testLogitsNotSqueezed(self):
num_classes = 25
images = tf.random_uniform([1, 224, 224, 3])
logits, _ = inception.inception_v2(images,
num_classes=num_classes,
spatial_squeeze=False)
with self.test_session() as sess:
tf.global_variables_initializer().run()
logits_out = sess.run(logits)
self.assertListEqual(list(logits_out.shape), [1, 1, 1, num_classes])
def testNoBatchNormScaleByDefault(self):
height, width = 224, 224
num_classes = 1000
inputs = tf.placeholder(tf.float32, (1, height, width, 3))
with slim.arg_scope(inception.inception_v2_arg_scope()):
inception.inception_v2(inputs, num_classes, is_training=False)
self.assertEqual(tf.global_variables('.*/BatchNorm/gamma:0$'), [])
def testBatchNormScale(self):
height, width = 224, 224
num_classes = 1000
inputs = tf.placeholder(tf.float32, (1, height, width, 3))
with slim.arg_scope(
inception.inception_v2_arg_scope(batch_norm_scale=True)):
inception.inception_v2(inputs, num_classes, is_training=False)
gamma_names = set(
v.op.name for v in tf.global_variables('.*/BatchNorm/gamma:0$'))
self.assertGreater(len(gamma_names), 0)
for v in tf.global_variables('.*/BatchNorm/moving_mean:0$'):
self.assertIn(v.op.name[:-len('moving_mean')] + 'gamma', gamma_names)
if __name__ == '__main__':
tf.test.main()
|
PyTorch/SpeechSynthesis/Tacotron2/trtis_cpp | trtis_cpp | .gitignore | *.swp
*.swo
*.swn
*.swm
*.pyc
*.csv
*.wav
test.json
__pycache__
build
models
engines
logs
audio
mels
Makefile
trtis_sdk
sampleTacotron2WaveGlow
|
TensorFlow/Classification/ConvNets/triton/scripts | scripts | download_data | #!/usr/bin/env bash
# Copyright (c) 2021 NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# Download checkpoint
if [ -f "${CHECKPOINT_DIR}/checkpoint" ]; then
echo "Checkpoint already downloaded."
else
echo "Downloading checkpoint ..."
wget --content-disposition https://api.ngc.nvidia.com/v2/models/nvidia/rn50_tf_amp_ckpt/versions/20.06.0/zip -O \
rn50_tf_amp_ckpt_20.06.0.zip || {
echo "ERROR: Failed to download checkpoint from NGC"
exit 1
}
unzip rn50_tf_amp_ckpt_20.06.0.zip -d ${CHECKPOINT_DIR}
rm rn50_tf_amp_ckpt_20.06.0.zip
echo "ok"
fi
|
MxNet/Classification/RN50v1.5 | RN50v1.5 | models | # Copyright 2017-2018 The Apache Software Foundation
#
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
# regarding copyright ownership. The ASF licenses this file
# to you under the Apache License, Version 2.0 (the
# "License"); you may not use this file except in compliance
# with the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing,
# software distributed under the License is distributed on an
# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
# KIND, either express or implied. See the License for the
# specific language governing permissions and limitations
# under the License.
#
# -----------------------------------------------------------------------
#
# Copyright (c) 2019, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import copy
import mxnet as mx
from mxnet.gluon.block import HybridBlock
from mxnet.gluon import nn
def add_model_args(parser):
model = parser.add_argument_group('Model')
model.add_argument('--arch', default='resnetv15',
choices=['resnetv1', 'resnetv15',
'resnextv1', 'resnextv15',
'xception'],
help='model architecture')
model.add_argument('--num-layers', type=int, default=50,
help='number of layers in the neural network, \
required by some networks such as resnet')
model.add_argument('--num-groups', type=int, default=32,
help='number of groups for grouped convolutions, \
required by some networks such as resnext')
model.add_argument('--num-classes', type=int, default=1000,
help='the number of classes')
model.add_argument('--batchnorm-eps', type=float, default=1e-5,
help='the amount added to the batchnorm variance to prevent output explosion.')
model.add_argument('--batchnorm-mom', type=float, default=0.9,
help='the leaky-integrator factor controling the batchnorm mean and variance.')
model.add_argument('--fuse-bn-relu', type=int, default=0,
help='have batchnorm kernel perform activation relu')
model.add_argument('--fuse-bn-add-relu', type=int, default=0,
help='have batchnorm kernel perform add followed by activation relu')
return model
class Builder:
def __init__(self, dtype, input_layout, conv_layout, bn_layout,
pooling_layout, bn_eps, bn_mom, fuse_bn_relu, fuse_bn_add_relu):
self.dtype = dtype
self.input_layout = input_layout
self.conv_layout = conv_layout
self.bn_layout = bn_layout
self.pooling_layout = pooling_layout
self.bn_eps = bn_eps
self.bn_mom = bn_mom
self.fuse_bn_relu = fuse_bn_relu
self.fuse_bn_add_relu = fuse_bn_add_relu
self.act_type = 'relu'
self.bn_gamma_initializer = lambda last: 'zeros' if last else 'ones'
self.linear_initializer = lambda groups=1: mx.init.Xavier(rnd_type='gaussian', factor_type="in",
magnitude=2 * (groups ** 0.5))
self.last_layout = self.input_layout
def copy(self):
return copy.copy(self)
def batchnorm(self, last=False):
gamma_initializer = self.bn_gamma_initializer(last)
bn_axis = 3 if self.bn_layout == 'NHWC' else 1
return self.sequence(
self.transpose(self.bn_layout),
nn.BatchNorm(axis=bn_axis, momentum=self.bn_mom, epsilon=self.bn_eps,
gamma_initializer=gamma_initializer,
running_variance_initializer=gamma_initializer)
)
def batchnorm_add_relu(self, last=False):
gamma_initializer = self.bn_gamma_initializer(last)
if self.fuse_bn_add_relu:
bn_axis = 3 if self.bn_layout == 'NHWC' else 1
return self.sequence(
self.transpose(self.bn_layout),
BatchNormAddRelu(axis=bn_axis, momentum=self.bn_mom,
epsilon=self.bn_eps, act_type=self.act_type,
gamma_initializer=gamma_initializer,
running_variance_initializer=gamma_initializer)
)
return NonFusedBatchNormAddRelu(self, last=last)
def batchnorm_relu(self, last=False):
gamma_initializer = self.bn_gamma_initializer(last)
if self.fuse_bn_relu:
bn_axis = 3 if self.bn_layout == 'NHWC' else 1
return self.sequence(
self.transpose(self.bn_layout),
nn.BatchNorm(axis=bn_axis, momentum=self.bn_mom,
epsilon=self.bn_eps, act_type=self.act_type,
gamma_initializer=gamma_initializer,
running_variance_initializer=gamma_initializer)
)
return self.sequence(self.batchnorm(last=last), self.activation())
def activation(self):
return nn.Activation(self.act_type)
def global_avg_pool(self):
return self.sequence(
self.transpose(self.pooling_layout),
nn.GlobalAvgPool2D(layout=self.pooling_layout)
)
def max_pool(self, pool_size, strides=1, padding=True):
padding = pool_size // 2 if padding is True else int(padding)
return self.sequence(
self.transpose(self.pooling_layout),
nn.MaxPool2D(pool_size, strides=strides, padding=padding,
layout=self.pooling_layout)
)
def conv(self, channels, kernel_size, padding=True, strides=1, groups=1, in_channels=0):
padding = kernel_size // 2 if padding is True else int(padding)
initializer = self.linear_initializer(groups=groups)
return self.sequence(
self.transpose(self.conv_layout),
nn.Conv2D(channels, kernel_size=kernel_size, strides=strides,
padding=padding, use_bias=False, groups=groups,
in_channels=in_channels, layout=self.conv_layout,
weight_initializer=initializer)
)
def separable_conv(self, channels, kernel_size, in_channels, padding=True, strides=1):
return self.sequence(
self.conv(in_channels, kernel_size, padding=padding,
strides=strides, groups=in_channels, in_channels=in_channels),
self.conv(channels, 1, in_channels=in_channels)
)
def dense(self, units, in_units=0):
return nn.Dense(units, in_units=in_units,
weight_initializer=self.linear_initializer())
def transpose(self, to_layout):
if self.last_layout == to_layout:
return None
ret = Transpose(self.last_layout, to_layout)
self.last_layout = to_layout
return ret
def sequence(self, *seq):
seq = list(filter(lambda x: x is not None, seq))
if len(seq) == 1:
return seq[0]
ret = nn.HybridSequential()
ret.add(*seq)
return ret
class Transpose(HybridBlock):
def __init__(self, from_layout, to_layout):
super().__init__()
supported_layouts = ['NCHW', 'NHWC']
if from_layout not in supported_layouts:
raise ValueError('Not prepared to handle layout: {}'.format(from_layout))
if to_layout not in supported_layouts:
raise ValueError('Not prepared to handle layout: {}'.format(to_layout))
self.from_layout = from_layout
self.to_layout = to_layout
def hybrid_forward(self, F, x):
# Insert transpose if from_layout and to_layout don't match
if self.from_layout == 'NCHW' and self.to_layout == 'NHWC':
return F.transpose(x, axes=(0, 2, 3, 1))
elif self.from_layout == 'NHWC' and self.to_layout == 'NCHW':
return F.transpose(x, axes=(0, 3, 1, 2))
else:
return x
def __repr__(self):
s = '{name}({content})'
if self.from_layout == self.to_layout:
content = 'passthrough ' + self.from_layout
else:
content = self.from_layout + ' -> ' + self.to_layout
return s.format(name=self.__class__.__name__,
content=content)
class LayoutWrapper(HybridBlock):
def __init__(self, op, io_layout, op_layout, **kwargs):
super(LayoutWrapper, self).__init__(**kwargs)
with self.name_scope():
self.layout1 = Transpose(io_layout, op_layout)
self.op = op
self.layout2 = Transpose(op_layout, io_layout)
def hybrid_forward(self, F, *x):
return self.layout2(self.op(*(self.layout1(y) for y in x)))
class BatchNormAddRelu(nn.BatchNorm):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
if self._kwargs.pop('act_type') != 'relu':
raise ValueError('BatchNormAddRelu can be used only with ReLU as activation')
def hybrid_forward(self, F, x, y, gamma, beta, running_mean, running_var):
return F.BatchNormAddRelu(data=x, addend=y, gamma=gamma, beta=beta,
moving_mean=running_mean, moving_var=running_var, name='fwd', **self._kwargs)
class NonFusedBatchNormAddRelu(HybridBlock):
def __init__(self, builder, **kwargs):
super().__init__()
self.bn = builder.batchnorm(**kwargs)
self.act = builder.activation()
def hybrid_forward(self, F, x, y):
return self.act(self.bn(x) + y)
# Blocks
class ResNetBasicBlock(HybridBlock):
def __init__(self, builder, channels, stride, downsample=False, in_channels=0,
version='1', resnext_groups=None, **kwargs):
super().__init__()
assert not resnext_groups
self.transpose = builder.transpose(builder.conv_layout)
builder_copy = builder.copy()
body = [
builder.conv(channels, 3, strides=stride, in_channels=in_channels),
builder.batchnorm_relu(),
builder.conv(channels, 3),
]
self.body = builder.sequence(*body)
self.bn_add_relu = builder.batchnorm_add_relu(last=True)
builder = builder_copy
if downsample:
self.downsample = builder.sequence(
builder.conv(channels, 1, strides=stride, in_channels=in_channels),
builder.batchnorm()
)
else:
self.downsample = None
def hybrid_forward(self, F, x):
if self.transpose is not None:
x = self.transpose(x)
residual = x
x = self.body(x)
if self.downsample:
residual = self.downsample(residual)
x = self.bn_add_relu(x, residual)
return x
class ResNetBottleNeck(HybridBlock):
def __init__(self, builder, channels, stride, downsample=False, in_channels=0,
version='1', resnext_groups=None):
super().__init__()
stride1 = stride if version == '1' else 1
stride2 = 1 if version == '1' else stride
mult = 2 if resnext_groups else 1
groups = resnext_groups or 1
self.transpose = builder.transpose(builder.conv_layout)
builder_copy = builder.copy()
body = [
builder.conv(channels * mult // 4, 1, strides=stride1, in_channels=in_channels),
builder.batchnorm_relu(),
builder.conv(channels * mult // 4, 3, strides=stride2),
builder.batchnorm_relu(),
builder.conv(channels, 1)
]
self.body = builder.sequence(*body)
self.bn_add_relu = builder.batchnorm_add_relu(last=True)
builder = builder_copy
if downsample:
self.downsample = builder.sequence(
builder.conv(channels, 1, strides=stride, in_channels=in_channels),
builder.batchnorm()
)
else:
self.downsample = None
def hybrid_forward(self, F, x):
if self.transpose is not None:
x = self.transpose(x)
residual = x
x = self.body(x)
if self.downsample:
residual = self.downsample(residual)
x = self.bn_add_relu(x, residual)
return x
class XceptionBlock(HybridBlock):
def __init__(self, builder, definition, in_channels, relu_at_beginning=True):
super().__init__()
self.transpose = builder.transpose(builder.conv_layout)
builder_copy = builder.copy()
body = []
if relu_at_beginning:
body.append(builder.activation())
last_channels = in_channels
for channels1, channels2 in zip(definition, definition[1:] + [0]):
if channels1 > 0:
body.append(builder.separable_conv(channels1, 3, in_channels=last_channels))
if channels2 > 0:
body.append(builder.batchnorm_relu())
else:
body.append(builder.batchnorm(last=True))
last_channels = channels1
else:
body.append(builder.max_pool(3, 2))
self.body = builder.sequence(*body)
builder = builder_copy
if any(map(lambda x: x <= 0, definition)):
self.shortcut = builder.sequence(
builder.conv(last_channels, 1, strides=2, in_channels=in_channels),
builder.batchnorm(),
)
else:
self.shortcut = builder.sequence()
def hybrid_forward(self, F, x):
return self.shortcut(x) + self.body(x)
# Nets
class ResNet(HybridBlock):
def __init__(self, builder, block, layers, channels, classes=1000,
version='1', resnext_groups=None):
super().__init__()
assert len(layers) == len(channels) - 1
self.version = version
with self.name_scope():
features = [
builder.conv(channels[0], 7, strides=2),
builder.batchnorm_relu(),
builder.max_pool(3, 2),
]
for i, num_layer in enumerate(layers):
stride = 1 if i == 0 else 2
features.append(self.make_layer(builder, block, num_layer, channels[i+1],
stride, in_channels=channels[i],
resnext_groups=resnext_groups))
features.append(builder.global_avg_pool())
self.features = builder.sequence(*features)
self.output = builder.dense(classes, in_units=channels[-1])
def make_layer(self, builder, block, layers, channels, stride,
in_channels=0, resnext_groups=None):
layer = []
layer.append(block(builder, channels, stride, channels != in_channels,
in_channels=in_channels, version=self.version,
resnext_groups=resnext_groups))
for _ in range(layers-1):
layer.append(block(builder, channels, 1, False, in_channels=channels,
version=self.version, resnext_groups=resnext_groups))
return builder.sequence(*layer)
def hybrid_forward(self, F, x):
x = self.features(x)
x = self.output(x)
return x
class Xception(HybridBlock):
def __init__(self, builder,
definition=([32, 64],
[[128, 128, 0], [256, 256, 0], [728, 728, 0],
*([[728, 728, 728]] * 8), [728, 1024, 0]],
[1536, 2048]),
classes=1000):
super().__init__()
definition1, definition2, definition3 = definition
with self.name_scope():
features = []
last_channels = 0
for i, channels in enumerate(definition1):
features += [
builder.conv(channels, 3, strides=(2 if i == 0 else 1), in_channels=last_channels),
builder.batchnorm_relu(),
]
last_channels = channels
for i, block_definition in enumerate(definition2):
features.append(XceptionBlock(builder, block_definition, in_channels=last_channels,
relu_at_beginning=False if i == 0 else True))
last_channels = list(filter(lambda x: x > 0, block_definition))[-1]
for i, channels in enumerate(definition3):
features += [
builder.separable_conv(channels, 3, in_channels=last_channels),
builder.batchnorm_relu(),
]
last_channels = channels
features.append(builder.global_avg_pool())
self.features = builder.sequence(*features)
self.output = builder.dense(classes, in_units=last_channels)
def hybrid_forward(self, F, x):
x = self.features(x)
x = self.output(x)
return x
resnet_spec = {18: (ResNetBasicBlock, [2, 2, 2, 2], [64, 64, 128, 256, 512]),
34: (ResNetBasicBlock, [3, 4, 6, 3], [64, 64, 128, 256, 512]),
50: (ResNetBottleNeck, [3, 4, 6, 3], [64, 256, 512, 1024, 2048]),
101: (ResNetBottleNeck, [3, 4, 23, 3], [64, 256, 512, 1024, 2048]),
152: (ResNetBottleNeck, [3, 8, 36, 3], [64, 256, 512, 1024, 2048])}
def create_resnet(builder, version, num_layers=50, resnext=False, classes=1000):
assert num_layers in resnet_spec, \
"Invalid number of layers: {}. Options are {}".format(
num_layers, str(resnet_spec.keys()))
block_class, layers, channels = resnet_spec[num_layers]
assert not resnext or num_layers >= 50, \
"Cannot create resnext with less then 50 layers"
net = ResNet(builder, block_class, layers, channels, version=version,
resnext_groups=args.num_groups if resnext else None)
return net
class fp16_model(mx.gluon.block.HybridBlock):
def __init__(self, net, **kwargs):
super(fp16_model, self).__init__(**kwargs)
with self.name_scope():
self._net = net
def hybrid_forward(self, F, x):
y = self._net(x)
y = F.cast(y, dtype='float32')
return y
def get_model(arch, num_classes, num_layers, image_shape, dtype, amp,
input_layout, conv_layout, batchnorm_layout, pooling_layout,
batchnorm_eps, batchnorm_mom, fuse_bn_relu, fuse_bn_add_relu, **kwargs):
builder = Builder(
dtype = dtype,
input_layout = input_layout,
conv_layout = conv_layout,
bn_layout = batchnorm_layout,
pooling_layout = pooling_layout,
bn_eps = batchnorm_eps,
bn_mom = batchnorm_mom,
fuse_bn_relu = fuse_bn_relu,
fuse_bn_add_relu = fuse_bn_add_relu,
)
if arch.startswith('resnet') or arch.startswith('resnext'):
version = '1' if arch in {'resnetv1', 'resnextv1'} else '1.5'
net = create_resnet(
builder = builder,
version = version,
resnext = arch.startswith('resnext'),
num_layers = num_layers,
classes = num_classes,
)
elif arch == 'xception':
net = Xception(builder, classes=num_classes)
else:
raise ValueError('Wrong model architecture')
net.hybridize(static_shape=True, static_alloc=True)
if not amp:
net.cast(dtype)
if dtype == 'float16':
net = fp16_model(net)
return net
|
PyTorch/DrugDiscovery/MoFlow/moflow/model | model | model | # Copyright (c) 2022, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# Copyright 2020 Chengxi Zang
#
# Permission is hereby granted, free of charge, to any person obtaining a
# copy of this software and associated documentation files (the "Software"),
# to deal in the Software without restriction, including without limitation
# the rights to use, copy, modify, merge, publish, distribute, sublicense,
# and/or sell copies of the Software, and to permit persons to whom the
# Software is furnished to do so, subject to the following conditions:
#
# The above copyright notice and this permission notice shall be included
# in all copies or substantial portions of the Software.
#
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
# FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS
# IN THE SOFTWARE.
import math
import torch
import torch.nn as nn
from moflow.config import Config
from moflow.model.glow import Glow, GlowOnGraph
def gaussian_nll(x, mean, ln_var):
"""Computes the negative log-likelihood of a Gaussian distribution.
Given two variable ``mean`` representing :math:`\\mu` and ``ln_var``
representing :math:`\\log(\\sigma^2)`, this function computes in
elementwise manner the negative log-likelihood of :math:`x` on a
Gaussian distribution :math:`N(\\mu, S)`,
.. math::
-\\log N(x; \\mu, \\sigma^2) =
\\log\\left(\\sqrt{(2\\pi)^D |S|}\\right) +
\\frac{1}{2}(x - \\mu)^\\top S^{-1}(x - \\mu),
where :math:`D` is a dimension of :math:`x` and :math:`S` is a diagonal
matrix where :math:`S_{ii} = \\sigma_i^2`.
Args:
x: Input variable.
mean: Mean of a Gaussian distribution, :math:`\\mu`.
ln_var: Logarithm of variance of a Gaussian distribution,
:math:`\\log(\\sigma^2)`.
Returns:
torch.Tensor:
Negative log-likelihood.
"""
x_prec = torch.exp(-ln_var)
x_diff = x - mean
x_power = (x_diff * x_diff) * x_prec * -0.5
loss = (ln_var + math.log(2 * (math.pi))) / 2 - x_power
return loss
class MoFlowLoss(nn.Module):
def __init__(self, config: Config) -> None:
super().__init__()
self.b_n_type = config.num_edge_features
self.a_n_node = config.max_num_nodes
self.a_n_type = config.num_node_features
self.b_size = self.a_n_node * self.a_n_node * self.b_n_type
self.a_size = self.a_n_node * self.a_n_type
if config.model_config.learn_dist:
self.ln_var = nn.Parameter(torch.zeros(1))
else:
self.register_buffer('ln_var', torch.zeros(1))
def forward(self, h, adj_h, sum_log_det_jacs_x, sum_log_det_jacs_adj):
z = [h, adj_h]
logdet = [sum_log_det_jacs_x, sum_log_det_jacs_adj]
device = z[0].device
dtype = z[0].dtype
z[0] = z[0].reshape(z[0].shape[0],-1)
z[1] = z[1].reshape(z[1].shape[0], -1)
logdet[0] = logdet[0] - self.a_size * math.log(2.)
logdet[1] = logdet[1] - self.b_size * math.log(2.)
ln_var_adj = self.ln_var * torch.ones([self.b_size], device=device, dtype=dtype)
ln_var_x = self.ln_var * torch.ones([self.a_size], device=device, dtype=dtype)
nll_adj = torch.mean(
torch.sum(gaussian_nll(z[1], torch.zeros(self.b_size, device=device, dtype=dtype), ln_var_adj), dim=1)
- logdet[1])
nll_adj = nll_adj / (self.b_size * math.log(2.)) # the negative log likelihood per dim with log base 2
nll_x = torch.mean(torch.sum(
gaussian_nll(z[0], torch.zeros(self.a_size, device=device, dtype=dtype), ln_var_x),
dim=1) - logdet[0])
nll_x = nll_x / (self.a_size * math.log(2.)) # the negative log likelihood per dim with log base 2
return nll_x, nll_adj
class MoFlow(nn.Module):
def __init__(self, config: Config):
super(MoFlow, self).__init__()
self.config = config
self.b_n_type = config.num_edge_features
self.a_n_node = config.max_num_nodes
self.a_n_type = config.num_node_features
self.b_size = self.a_n_node * self.a_n_node * self.b_n_type
self.a_size = self.a_n_node * self.a_n_type
self.noise_scale = config.model_config.noise_scale
self.bond_model = Glow(
in_channel=self.b_n_type,
n_flow=config.model_config.bond_config.n_flow,
n_block=config.model_config.bond_config.n_block,
squeeze_fold=config.model_config.bond_config.n_squeeze,
hidden_channel=config.model_config.bond_config.hidden_ch,
conv_lu=config.model_config.bond_config.conv_lu
)
self.atom_model = GlowOnGraph(
n_node=self.a_n_node,
in_dim=self.a_n_type,
hidden_dim_dict={
'gnn': config.model_config.atom_config.hidden_gnn,
'linear': config.model_config.atom_config.hidden_lin
},
n_flow=config.model_config.atom_config.n_flow,
n_block=config.model_config.atom_config.n_block,
mask_row_size_list=config.model_config.atom_config.mask_row_size_list,
mask_row_stride_list=config.model_config.atom_config.mask_row_stride_list,
)
self._cuda_graphs = dict()
self.atom_stream = None
self.bond_stream = None
@torch.jit.ignore
def forward(self, adj: torch.Tensor, x: torch.Tensor, with_cuda_graph: bool = False):
"""
:param adj: (256,4,9,9)
:param x: (256,9,5)
:return:
"""
if with_cuda_graph and self.atom_stream is None:
self.atom_stream = torch.cuda.Stream()
self.bond_stream = torch.cuda.Stream()
h = x
# add uniform noise to node feature matrices
if self.training:
if self.noise_scale == 0:
h = h/2.0 - 0.5 + torch.rand_like(x) * 0.4
else:
h = h + torch.rand_like(x) * self.noise_scale
if with_cuda_graph:
if self.atom_model not in self._cuda_graphs:
h, sum_log_det_jacs_x = self._forward_graph(self.atom_model, adj, h)
else:
self.atom_stream.wait_stream(torch.cuda.current_stream())
with torch.cuda.stream(self.atom_stream):
h, sum_log_det_jacs_x = self._forward_graph(self.atom_model, adj, h)
else:
h, sum_log_det_jacs_x = self.atom_model(adj, h)
# add uniform noise to adjacency tensors
if self.training:
if self.noise_scale == 0:
adj_bond = adj/2.0 - 0.5 + torch.rand_like(adj) * 0.4
else:
adj_bond = adj + torch.rand_like(adj) * self.noise_scale
else:
adj_bond = adj
if with_cuda_graph:
if self.bond_model not in self._cuda_graphs:
adj_h, sum_log_det_jacs_adj = self._forward_graph(self.bond_model, adj_bond)
else:
self.bond_stream.wait_stream(torch.cuda.current_stream())
with torch.cuda.stream(self.bond_stream):
adj_h, sum_log_det_jacs_adj = self._forward_graph(self.bond_model, adj_bond)
else:
adj_h, sum_log_det_jacs_adj = self.bond_model(adj_bond)
if with_cuda_graph:
torch.cuda.current_stream().wait_stream(self.atom_stream)
torch.cuda.current_stream().wait_stream(self.bond_stream)
return h, adj_h, sum_log_det_jacs_x, sum_log_det_jacs_adj
@torch.jit.export
def reverse(self, z):
"""
Returns a molecule, given its latent vector.
:param z: latent vector. Shape: [B, N*N*M + N*T]
B = Batch size, N = number of atoms, M = number of bond types,
T = number of atom types (Carbon, Oxygen etc.)
:return: adjacency matrix and feature matrix of a molecule
"""
batch_size = z.shape[0]
z_x = z[:, :self.a_size]
z_adj = z[:, self.a_size:]
h_adj = z_adj.reshape(batch_size, self.b_n_type, self.a_n_node, self.a_n_node)
h_adj = h_adj.to(memory_format=torch.channels_last)
h_adj = self.bond_model.reverse(h_adj)
if self.noise_scale == 0:
h_adj = (h_adj + 0.5) * 2
adj = h_adj
adj = adj + adj.permute(0, 1, 3, 2)
adj = adj / 2
adj = adj.softmax(dim=1)
max_bond = adj.max(dim=1).values.reshape(batch_size, -1, self.a_n_node, self.a_n_node)
adj = torch.floor(adj / max_bond)
adj = adj.to(memory_format=torch.channels_last)
h_x = z_x.reshape(batch_size, self.a_n_node, self.a_n_type)
h_x = self.atom_model.reverse((adj, h_x))
if self.noise_scale == 0:
h_x = (h_x + 0.5) * 2
return adj, h_x
@torch.jit.ignore
def _forward_graph(self, model, *args):
if model not in self._cuda_graphs:
if torch.distributed.is_initialized():
torch.distributed.barrier()
torch.cuda.synchronize()
self._cuda_graphs[model] = torch.cuda.make_graphed_callables(
model,
args,
)
torch.cuda.synchronize()
if torch.distributed.is_initialized():
torch.distributed.barrier()
return self._cuda_graphs[model](*args)
|
TensorFlow/LanguageModeling/BERT/notebooks | notebooks | bert_squad_tf_inference | #!/usr/bin/env python
# coding: utf-8
# In[ ]:
# Copyright 2021 NVIDIA Corporation. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ==============================================================================
# <img src="http://developer.download.nvidia.com/compute/machine-learning/frameworks/nvidia_logo.png" style="width: 90px; float: right;">
#
# # BERT Question Answering Inference with Mixed Precision
#
# ## 1. Overview
#
# Bidirectional Embedding Representations from Transformers (BERT), is a method of pre-training language representations which obtains state-of-the-art results on a wide array of Natural Language Processing (NLP) tasks.
#
# The original paper can be found here: https://arxiv.org/abs/1810.04805.
#
# NVIDIA's BERT 19.10 is an optimized version of Google's official implementation, leveraging mixed precision arithmetic and tensor cores on V100 GPUS for faster training times while maintaining target accuracy.
# ### 1.a Learning objectives
#
# This notebook demonstrates:
# - Inference on QA task with BERT Large model
# - The use/download of fine-tuned NVIDIA BERT models
# - Use of Mixed Precision for Inference
# ## 2. Requirements
#
# Please refer to the ReadMe file
# ## 3. BERT Inference: Question Answering
#
# We can run inference on a fine-tuned BERT model for tasks like Question Answering.
#
# Here we use a BERT model fine-tuned on a [SQuaD 2.0 Dataset](https://rajpurkar.github.io/SQuAD-explorer/) which contains 100,000+ question-answer pairs on 500+ articles combined with over 50,000 new, unanswerable questions.
# ### 3.a Paragraph and Queries
#
# In this example we will ask our BERT model questions related to the following paragraph:
#
# **The Apollo Program**
# _"The Apollo program, also known as Project Apollo, was the third United States human spaceflight program carried out by the National Aeronautics and Space Administration (NASA), which accomplished landing the first humans on the Moon from 1969 to 1972. First conceived during Dwight D. Eisenhower's administration as a three-man spacecraft to follow the one-man Project Mercury which put the first Americans in space, Apollo was later dedicated to President John F. Kennedy's national goal of landing a man on the Moon and returning him safely to the Earth by the end of the 1960s, which he proposed in a May 25, 1961, address to Congress. Project Mercury was followed by the two-man Project Gemini. The first manned flight of Apollo was in 1968. Apollo ran from 1961 to 1972, and was supported by the two-man Gemini program which ran concurrently with it from 1962 to 1966. Gemini missions developed some of the space travel techniques that were necessary for the success of the Apollo missions. Apollo used Saturn family rockets as launch vehicles. Apollo/Saturn vehicles were also used for an Apollo Applications Program, which consisted of Skylab, a space station that supported three manned missions in 1973-74, and the Apollo-Soyuz Test Project, a joint Earth orbit mission with the Soviet Union in 1975."_
#
# The questions and relative answers expected are shown below:
#
# - **Q1:** "What project put the first Americans into space?"
# - **A1:** "Project Mercury"
# - **Q2:** "What program was created to carry out these projects and missions?"
# - **A2:** "The Apollo program"
# - **Q3:** "What year did the first manned Apollo flight occur?"
# - **A3:** "1968"
# - **Q4:** "What President is credited with the original notion of putting Americans in space?"
# - **A4:** "John F. Kennedy"
# - **Q5:** "Who did the U.S. collaborate with on an Earth orbit mission in 1975?"
# - **A5:** "Soviet Union"
# - **Q6:** "How long did Project Apollo run?"
# - **A6:** "1961 to 1972"
# - **Q7:** "What program helped develop space travel techniques that Project Apollo used?"
# - **A7:** "Gemini Mission"
# - **Q8:** "What space station supported three manned missions in 1973-1974?"
# - **A8:** "Skylab"
#
# ---
#
# The paragraph and the questions can be easily customized by changing the code below:
#
# ---
# In[ ]:
get_ipython().run_cell_magic('writefile', 'input.json', '{"data": \n [\n {"title": "Project Apollo",\n "paragraphs": [\n {"context":"The Apollo program, also known as Project Apollo, was the third United States human spaceflight program carried out by the National Aeronautics and Space Administration (NASA), which accomplished landing the first humans on the Moon from 1969 to 1972. First conceived during Dwight D. Eisenhower\'s administration as a three-man spacecraft to follow the one-man Project Mercury which put the first Americans in space, Apollo was later dedicated to President John F. Kennedy\'s national goal of landing a man on the Moon and returning him safely to the Earth by the end of the 1960s, which he proposed in a May 25, 1961, address to Congress. Project Mercury was followed by the two-man Project Gemini. The first manned flight of Apollo was in 1968. Apollo ran from 1961 to 1972, and was supported by the two man Gemini program which ran concurrently with it from 1962 to 1966. Gemini missions developed some of the space travel techniques that were necessary for the success of the Apollo missions. Apollo used Saturn family rockets as launch vehicles. Apollo/Saturn vehicles were also used for an Apollo Applications Program, which consisted of Skylab, a space station that supported three manned missions in 1973-74, and the Apollo-Soyuz Test Project, a joint Earth orbit mission with the Soviet Union in 1975.", \n "qas": [\n { "question": "What project put the first Americans into space?", \n "id": "Q1"\n },\n { "question": "What program was created to carry out these projects and missions?",\n "id": "Q2"\n },\n { "question": "What year did the first manned Apollo flight occur?",\n "id": "Q3"\n }, \n { "question": "What President is credited with the original notion of putting Americans in space?",\n "id": "Q4"\n },\n { "question": "Who did the U.S. collaborate with on an Earth orbit mission in 1975?",\n "id": "Q5"\n },\n { "question": "How long did Project Apollo run?",\n "id": "Q6"\n }, \n { "question": "What program helped develop space travel techniques that Project Apollo used?",\n "id": "Q7"\n }, \n {"question": "What space station supported three manned missions in 1973-1974?",\n "id": "Q8"\n } \n]}]}]}\n')
# In[ ]:
import os
import sys
notebooks_dir = '../notebooks'
data_dir = '../data/download'
working_dir = '../'
if working_dir not in sys.path:
sys.path.append(working_dir)
# In[ ]:
input_file = os.path.join(notebooks_dir, 'input.json')
# ### 3.b Mixed Precision
#
# Mixed precision training offers significant computational speedup by performing operations in half-precision format, while storing minimal information in single-precision to retain as much information as possible in critical parts of the network. Since the introduction of tensor cores in the Volta and Turing architectures, significant training speedups are experienced by switching to mixed precision -- up to 3x overall speedup on the most arithmetically intense model architectures.
#
# For information about:
# - How to train using mixed precision, see the [Mixed Precision Training](https://arxiv.org/abs/1710.03740) paper and [Training With Mixed Precision](https://docs.nvidia.com/deeplearning/sdk/mixed-precision-training/index.html) documentation.
# - How to access and enable AMP for TensorFlow, see [Using TF-AMP](https://docs.nvidia.com/deeplearning/dgx/tensorflow-user-guide/index.html#tfamp) from the TensorFlow User Guide.
# - Techniques used for mixed precision training, see the [Mixed-Precision Training of Deep Neural Networks](https://devblogs.nvidia.com/mixed-precision-training-deep-neural-networks/) blog.
# In this notebook we control mixed precision execution with the environmental variable:
# In[ ]:
import os
os.environ["TF_ENABLE_AUTO_MIXED_PRECISION"] = "1"
# To effectively evaluate the speedup of mixed precision try a bigger workload by uncommenting the following line:
# In[ ]:
#input_file = '../data/download/squad/v2.0/dev-v2.0.json'
# ## 4. Fine-Tuned NVIDIA BERT TF Models
#
# Based on the model size, we have the following two default configurations of BERT.
#
# | **Model** | **Hidden layers** | **Hidden unit size** | **Attention heads** | **Feedforward filter size** | **Max sequence length** | **Parameters** |
# |:---------:|:----------:|:----:|:---:|:--------:|:---:|:----:|
# |BERTBASE |12 encoder| 768| 12|4 x 768|512|110M|
# |BERTLARGE|24 encoder|1024| 16|4 x 1024|512|330M|
#
# We will take advantage of the fine-tuned models available on NGC (NVIDIA GPU Cluster, https://ngc.nvidia.com).
# Among the many configurations available we will download these two:
#
# - **bert_tf_ckpt_large_qa_squad2_amp_384**
#
# Which are trained on the SQuaD 2.0 Dataset.
# In[ ]:
# bert_tf_ckpt_large_qa_squad2_amp_384
DATA_DIR_FT = data_dir + '/finetuned_large_model_SQUAD2.0'
get_ipython().system('mkdir -p $DATA_DIR_FT')
get_ipython().system('wget --content-disposition -O $DATA_DIR_FT/bert_tf_ckpt_large_qa_squad2_amp_384_19.03.1.zip https://api.ngc.nvidia.com/v2/models/nvidia/bert_tf_ckpt_large_qa_squad2_amp_384/versions/19.03.1/zip && unzip -n -d $DATA_DIR_FT/ $DATA_DIR_FT/bert_tf_ckpt_large_qa_squad2_amp_384_19.03.1.zip && rm -rf $DATA_DIR_FT/bert_tf_ckpt_large_qa_squad2_amp_384_19.03.1.zip')
# In the code that follows we will refer to these models.
# ## 5. Running QA task inference
#
# In order to run QA inference we will follow step-by-step the flow implemented in run_squad.py.
#
# Configuration:
# In[ ]:
import run_squad
import json
import tensorflow as tf
import modeling
import tokenization
import time
import random
tf.logging.set_verbosity(tf.logging.INFO)
# Create the output directory where all the results are saved.
output_dir = os.path.join(working_dir, 'results')
tf.gfile.MakeDirs(output_dir)
# The config json file corresponding to the pre-trained BERT model.
# This specifies the model architecture.
bert_config_file = os.path.join(data_dir, 'finetuned_large_model_SQUAD2.0/bert_config.json')
# The vocabulary file that the BERT model was trained on.
vocab_file = os.path.join(data_dir, 'finetuned_large_model_SQUAD2.0/vocab.txt')
# Initiate checkpoint to the fine-tuned BERT Large model
init_checkpoint = os.path.join(data_dir, 'finetuned_large_model_SQUAD2.0/model.ckpt')
# Whether to lower case the input text.
# Should be True for uncased models and False for cased models.
do_lower_case = True
# Total batch size for predictions
predict_batch_size = 1
params = dict([('batch_size', predict_batch_size)])
# The maximum total input sequence length after WordPiece tokenization.
# Sequences longer than this will be truncated, and sequences shorter than this will be padded.
max_seq_length = 384
# When splitting up a long document into chunks, how much stride to take between chunks.
doc_stride = 128
# The maximum number of tokens for the question.
# Questions longer than this will be truncated to this length.
max_query_length = 64
# This is a WA to use flags from here:
flags = tf.flags
if 'f' not in tf.flags.FLAGS:
tf.app.flags.DEFINE_string('f', '', 'kernel')
FLAGS = flags.FLAGS
verbose_logging = True
# Set to True if the dataset has samples with no answers. For SQuAD 1.1, this is set to False
version_2_with_negative = False
# The total number of n-best predictions to generate in the nbest_predictions.json output file.
n_best_size = 20
# The maximum length of an answer that can be generated.
# This is needed because the start and end predictions are not conditioned on one another.
max_answer_length = 30
# Let's define the tokenizer and create the model for the estimator:
# In[ ]:
# Validate the casing config consistency with the checkpoint name.
tokenization.validate_case_matches_checkpoint(do_lower_case, init_checkpoint)
# Create the tokenizer.
tokenizer = tokenization.FullTokenizer(vocab_file=vocab_file, do_lower_case=do_lower_case)
# Load the configuration from file
bert_config = modeling.BertConfig.from_json_file(bert_config_file)
def model_fn(features, labels, mode, params): # pylint: disable=unused-argument
unique_ids = features["unique_ids"]
input_ids = features["input_ids"]
input_mask = features["input_mask"]
segment_ids = features["segment_ids"]
(start_logits, end_logits) = run_squad.create_model(
bert_config=bert_config,
is_training=False,
input_ids=input_ids,
input_mask=input_mask,
segment_ids=segment_ids,
use_one_hot_embeddings=False)
tvars = tf.trainable_variables()
initialized_variable_names = {}
(assignment_map, initialized_variable_names) = modeling.get_assignment_map_from_checkpoint(tvars, init_checkpoint)
tf.train.init_from_checkpoint(init_checkpoint, assignment_map)
output_spec = None
predictions = {"unique_ids": unique_ids,
"start_logits": start_logits,
"end_logits": end_logits}
output_spec = tf.estimator.EstimatorSpec(mode=mode, predictions=predictions)
return output_spec
config = tf.ConfigProto(log_device_placement=True)
run_config = tf.estimator.RunConfig(
model_dir=None,
session_config=config,
save_checkpoints_steps=1000,
keep_checkpoint_max=1)
estimator = tf.estimator.Estimator(
model_fn=model_fn,
config=run_config,
params=params)
# ### 5.a Inference
# In[ ]:
eval_examples = run_squad.read_squad_examples(
input_file=input_file, is_training=False)
eval_writer = run_squad.FeatureWriter(
filename=os.path.join(output_dir, "eval.tf_record"),
is_training=False)
eval_features = []
def append_feature(feature):
eval_features.append(feature)
eval_writer.process_feature(feature)
# Loads a data file into a list of InputBatch's
run_squad.convert_examples_to_features(
examples=eval_examples,
tokenizer=tokenizer,
max_seq_length=max_seq_length,
doc_stride=doc_stride,
max_query_length=max_query_length,
is_training=False,
output_fn=append_feature)
eval_writer.close()
tf.logging.info("***** Running predictions *****")
tf.logging.info(" Num orig examples = %d", len(eval_examples))
tf.logging.info(" Num split examples = %d", len(eval_features))
tf.logging.info(" Batch size = %d", predict_batch_size)
predict_input_fn = run_squad.input_fn_builder(
input_file=eval_writer.filename,
batch_size=predict_batch_size,
seq_length=max_seq_length,
is_training=False,
drop_remainder=False)
all_results = []
eval_hooks = [run_squad.LogEvalRunHook(predict_batch_size)]
eval_start_time = time.time()
for result in estimator.predict(
predict_input_fn, yield_single_examples=True, hooks=eval_hooks, checkpoint_path=init_checkpoint):
unique_id = int(result["unique_ids"])
start_logits = [float(x) for x in result["start_logits"].flat]
end_logits = [float(x) for x in result["end_logits"].flat]
all_results.append(
run_squad.RawResult(
unique_id=unique_id,
start_logits=start_logits,
end_logits=end_logits))
eval_time_elapsed = time.time() - eval_start_time
time_list = eval_hooks[-1].time_list
time_list.sort()
eval_time_wo_startup = sum(time_list[:int(len(time_list) * 0.99)])
num_sentences = eval_hooks[-1].count * predict_batch_size
avg_sentences_per_second = num_sentences * 1.0 / eval_time_wo_startup
tf.logging.info("-----------------------------")
tf.logging.info("Total Inference Time = %0.2f Inference Time W/O start up overhead = %0.2f "
"Sentences processed = %d", eval_time_elapsed, eval_time_wo_startup,
num_sentences)
tf.logging.info("Inference Performance = %0.4f sentences/sec", avg_sentences_per_second)
tf.logging.info("-----------------------------")
output_prediction_file = os.path.join(output_dir, "predictions.json")
output_nbest_file = os.path.join(output_dir, "nbest_predictions.json")
output_null_log_odds_file = os.path.join(output_dir, "null_odds.json")
run_squad.write_predictions(eval_examples, eval_features, all_results,
n_best_size, max_answer_length,
do_lower_case, output_prediction_file,
output_nbest_file, output_null_log_odds_file,
version_2_with_negative, verbose_logging)
tf.logging.info("Inference Results:")
# Here we show only the prediction results, nbest prediction is also available in the output directory
results = ""
with open(output_prediction_file, 'r') as json_file:
data = json.load(json_file)
for question in eval_examples:
results += "<tr><td>{}</td><td>{}</td><td>{}</td></tr>".format(question.qas_id, question.question_text, data[question.qas_id])
from IPython.display import display, HTML
display(HTML("<table><tr><th>Id</th><th>Question</th><th>Answer</th></tr>{}</table>".format(results)))
# ## 6. What's next
# Now that you are familiar with running QA Inference on BERT, using mixed precision, you may want to try
# your own paragraphs and queries.
#
# You may also want to take a look to the notebook __bert_squad_tf_finetuning.ipynb__ on how to run fine-tuning on BERT, available in the same directory.
|
PyTorch/Segmentation/MaskRCNN/pytorch/configs/quick_schedules | quick_schedules | e2e_faster_rcnn_X_101_32x8d_FPN_quick | MODEL:
META_ARCHITECTURE: "GeneralizedRCNN"
WEIGHT: "catalog://ImageNetPretrained/FAIR/20171220/X-101-32x8d"
BACKBONE:
CONV_BODY: "R-101-FPN"
OUT_CHANNELS: 256
RPN:
USE_FPN: True
ANCHOR_STRIDE: (4, 8, 16, 32, 64)
PRE_NMS_TOP_N_TRAIN: 2000
PRE_NMS_TOP_N_TEST: 1000
POST_NMS_TOP_N_TEST: 1000
FPN_POST_NMS_TOP_N_TEST: 1000
ROI_HEADS:
USE_FPN: True
BATCH_SIZE_PER_IMAGE: 256
ROI_BOX_HEAD:
POOLER_RESOLUTION: 7
POOLER_SCALES: (0.25, 0.125, 0.0625, 0.03125)
POOLER_SAMPLING_RATIO: 2
FEATURE_EXTRACTOR: "FPN2MLPFeatureExtractor"
PREDICTOR: "FPNPredictor"
RESNETS:
STRIDE_IN_1X1: False
NUM_GROUPS: 32
WIDTH_PER_GROUP: 8
DATASETS:
TRAIN: ("coco_2014_minival",)
TEST: ("coco_2014_minival",)
INPUT:
MIN_SIZE_TRAIN: 600
MAX_SIZE_TRAIN: 1000
MIN_SIZE_TEST: 800
MAX_SIZE_TEST: 1000
DATALOADER:
SIZE_DIVISIBILITY: 32
SOLVER:
BASE_LR: 0.005
WEIGHT_DECAY: 0.0001
STEPS: (1500,)
MAX_ITER: 2000
IMS_PER_BATCH: 2
TEST:
IMS_PER_BATCH: 2
|
PyTorch/Segmentation/nnUNet/utils | utils | args | # Copyright (c) 2021-2022, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import json
from argparse import ArgumentDefaultsHelpFormatter, ArgumentParser, Namespace
def positive_int(value):
ivalue = int(value)
assert ivalue > 0, f"Argparse error. Expected positive integer but got {value}"
return ivalue
def non_negative_int(value):
ivalue = int(value)
assert ivalue >= 0, f"Argparse error. Expected non-negative integer but got {value}"
return ivalue
def float_0_1(value):
fvalue = float(value)
assert 0 <= fvalue <= 1, f"Argparse error. Expected float value to be in range (0, 1), but got {value}"
return fvalue
def get_main_args(strings=None):
parser = ArgumentParser(formatter_class=ArgumentDefaultsHelpFormatter)
arg = parser.add_argument
arg(
"--exec_mode",
type=str,
choices=["train", "evaluate", "predict"],
default="train",
help="Execution mode to run the model",
)
arg("--data", type=str, default="/data", help="Path to data directory")
arg("--results", type=str, default="/results", help="Path to results directory")
arg("--config", type=str, default=None, help="Config file with arguments")
arg("--logname", type=str, default="logs.json", help="Name of dlloger output")
arg("--task", type=str, default="01", help="Task number. MSD uses numbers 01-10")
arg("--gpus", type=non_negative_int, default=1, help="Number of gpus")
arg("--nodes", type=non_negative_int, default=1, help="Number of nodes")
arg("--learning_rate", type=float, default=0.0008, help="Learning rate")
arg("--gradient_clip_val", type=float, default=0, help="Gradient clipping norm value")
arg("--negative_slope", type=float, default=0.01, help="Negative slope for LeakyReLU")
arg("--tta", action="store_true", help="Enable test time augmentation")
arg("--brats", action="store_true", help="Enable BraTS specific training and inference")
arg("--deep_supervision", action="store_true", help="Enable deep supervision")
arg("--invert_resampled_y", action="store_true", help="Resize predictions to match label size before resampling")
arg("--amp", action="store_true", help="Enable automatic mixed precision")
arg("--benchmark", action="store_true", help="Run model benchmarking")
arg("--focal", action="store_true", help="Use focal loss instead of cross entropy")
arg("--save_ckpt", action="store_true", help="Enable saving checkpoint")
arg("--nfolds", type=positive_int, default=5, help="Number of cross-validation folds")
arg("--seed", type=non_negative_int, default=None, help="Random seed")
arg("--skip_first_n_eval", type=non_negative_int, default=0, help="Skip the evaluation for the first n epochs.")
arg("--ckpt_path", type=str, default=None, help="Path for loading checkpoint")
arg("--ckpt_store_dir", type=str, default="/results", help="Path for saving checkpoint")
arg("--fold", type=non_negative_int, default=0, help="Fold number")
arg("--patience", type=positive_int, default=100, help="Early stopping patience")
arg("--batch_size", type=positive_int, default=2, help="Batch size")
arg("--val_batch_size", type=positive_int, default=4, help="Validation batch size")
arg("--momentum", type=float, default=0.99, help="Momentum factor")
arg("--weight_decay", type=float, default=0.0001, help="Weight decay (L2 penalty)")
arg("--save_preds", action="store_true", help="Enable prediction saving")
arg("--dim", type=int, choices=[2, 3], default=3, help="UNet dimension")
arg("--resume_training", action="store_true", help="Resume training from the last checkpoint")
arg("--num_workers", type=non_negative_int, default=8, help="Number of subprocesses to use for data loading")
arg("--epochs", type=non_negative_int, default=1000, help="Number of training epochs.")
arg("--warmup", type=non_negative_int, default=5, help="Warmup iterations before collecting statistics")
arg("--nvol", type=positive_int, default=4, help="Number of volumes which come into single batch size for 2D model")
arg("--depth", type=non_negative_int, default=5, help="The depth of the encoder")
arg("--min_fmap", type=non_negative_int, default=4, help="Minimal dimension of feature map in the bottleneck")
arg("--deep_supr_num", type=non_negative_int, default=2, help="Number of deep supervision heads")
arg("--res_block", action="store_true", help="Enable residual blocks")
arg("--filters", nargs="+", help="[Optional] Set U-Net filters", default=None, type=int)
arg("--layout", type=str, default="NCDHW")
arg("--brats22_model", action="store_true", help="Use BraTS22 model")
arg(
"--norm",
type=str,
choices=["instance", "instance_nvfuser", "batch", "group"],
default="instance",
help="Normalization layer",
)
arg(
"--data2d_dim",
choices=[2, 3],
type=int,
default=3,
help="Input data dimension for 2d model",
)
arg(
"--oversampling",
type=float_0_1,
default=0.4,
help="Probability of crop to have some region with positive label",
)
arg(
"--overlap",
type=float_0_1,
default=0.25,
help="Amount of overlap between scans during sliding window inference",
)
arg(
"--scheduler",
action="store_true",
help="Enable cosine rate scheduler with warmup",
)
arg(
"--optimizer",
type=str,
default="adam",
choices=["sgd", "adam"],
help="Optimizer",
)
arg(
"--blend",
type=str,
choices=["gaussian", "constant"],
default="constant",
help="How to blend output of overlapping windows",
)
arg(
"--train_batches",
type=non_negative_int,
default=0,
help="Limit number of batches for training (used for benchmarking mode only)",
)
arg(
"--test_batches",
type=non_negative_int,
default=0,
help="Limit number of batches for inference (used for benchmarking mode only)",
)
if strings is not None:
arg(
"strings",
metavar="STRING",
nargs="*",
help="String for searching",
)
args = parser.parse_args(strings.split())
else:
args = parser.parse_args()
if args.config is not None:
config = json.load(open(args.config, "r"))
args = vars(args)
args.update(config)
args = Namespace(**args)
with open(f"{args.results}/params.json", "w") as f:
json.dump(vars(args), f)
return args
|
PyTorch/SpeechRecognition/Jasper/triton/model_repo_configs/fp32/jasper-onnx-ensemble | jasper-onnx-ensemble | config | name: "jasper-onnx-ensemble"
platform: "ensemble"
max_batch_size: 8#MAX_BATCH
input {
name: "AUDIO_SIGNAL"
data_type: TYPE_FP32
dims: -1#AUDIO_LENGTH
}
input {
name: "NUM_SAMPLES"
data_type: TYPE_INT32
dims: [ 1 ]
}
output {
name: "TRANSCRIPT"
data_type: TYPE_INT32
dims: [-1]
}
ensemble_scheduling {
step {
model_name: "feature-extractor-ts-trace"
model_version: -1
input_map {
key: "input__0"
value: "AUDIO_SIGNAL"
}
input_map {
key: "input__1"
value: "NUM_SAMPLES"
}
output_map {
key: "output__0"
value: "AUDIO_FEATURES"
}
}
step {
model_name: "jasper-onnx"
model_version: -1
input_map {
key: "input__0"
value: "AUDIO_FEATURES"
}
output_map {
key: "output__0"
value: "CHARACTER_PROBABILITIES"
}
}
step {
model_name: "decoder-ts-script"
model_version: -1
input_map {
key: "input__0"
value: "CHARACTER_PROBABILITIES"
}
output_map {
key: "output__0"
value: "TRANSCRIPT"
}
}
}
|
PyTorch/SpeechSynthesis/Tacotron2/trtis_cpp/src/trt/util | util | speechDataBuffer | /*
* Copyright (c) 2019-2020, NVIDIA CORPORATION. All rights reserved.
*
* Redistribution and use in source and binary forms, with or without
* modification, are permitted provided that the following conditions are met:
* * Redistributions of source code must retain the above copyright
* notice, this list of conditions and the following disclaimer.
* * Redistributions in binary form must reproduce the above copyright
* notice, this list of conditions and the following disclaimer in the
* documentation and/or other materials provided with the distribution.
* * Neither the name of the NVIDIA CORPORATION nor the
* names of its contributors may be used to endorse or promote products
* derived from this software without specific prior written permission.
*
* THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND
* ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED
* WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
* DISCLAIMED. IN NO EVENT SHALL NVIDIA CORPORATION BE LIABLE FOR ANY
* DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES
* (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES;
* LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND
* ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
* (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS
* SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
*/
#ifndef TT2I_SPEECHDATABUFFER_H
#define TT2I_SPEECHDATABUFFER_H
#include "cudaMemory.h"
#include "timedObject.h"
namespace tts
{
class SpeechDataBuffer : public TimedObject
{
public:
/**
* @brief Create a new SpeechDataBuffer.
*
* @param inputSpacing The maximum spacing between the start of inputs
* (sequences) in a batch.
* @param melSpacing The spacing between the start of mel-spectrograms in a
* batch.
* @param samplesSpacing The spacing between the start of outputs (samples)
* in a batch.
* @param maxBatchSize The maximum batch size.
*/
SpeechDataBuffer(const int inputSpacing, const int melSpacing, const int samplesSpacing, const int maxBatchSize);
/**
* @brief Copy input sequence data from the host to the device.
*
* @param inputHost The input on the host.
* @param size The number of elements to copy. Must be a multiple of
* inputSpacing.
*/
void copyToDevice(const int32_t* inputHost, size_t size);
/**
* @brief Copy input sequence data from the host to the device.
*
* @param batchSize The number of items in the batch.
* @param inputHost The batch items on the host.
* @param spacing The spacing between the start of batch items on the GPU
* (output).
*/
void copyToDevice(int batchSize, const std::vector<int32_t>* inputHost, int& spacing);
/**
* @brief Copy output from the device to the host.
*
* @param melsHost The location on the host to copy mel spectrograms to.
* @param melsSize The number of mel-spectrograms copied.
* @param samplesHost The location on the host to copy waveform samples to.
* @param samplesSize The number of samples copied.
*/
void copyFromDevice(float* melsHost, size_t melsSize, float* samplesHost, size_t samplesSize);
/**
* @brief Copy output from the device to the host.
*
* @param batchSize The number of items in the batch.
* @param samplesHost The vectors on the host to fill with waveform audio.
* @param sampleSpacing The spacing start of each item in the batch on the
* device.
* @param samplesLengths The length of each item in the batch.
*/
void copyFromDevice(int batchSize, std::vector<float>* samplesHost, int sampleSpacing, const int* samplesLengths);
/**
* @brief Get the input sequences on the device.
*
* @return The input sequences.
*/
const int32_t* getInputOnDevice() const;
/**
* @brief Get the mel-spectrograms on the device.
*
* @return The mel-spectrograms.
*/
float* getMelsOnDevice();
/**
* @brief The waveform audio samples on the device.
*
* @return The audio samples.
*/
float* getSamplesOnDevice();
private:
CudaMemory<int32_t> mInputDevice;
CudaMemory<float> mMelsDevice;
CudaMemory<float> mSamplesDevice;
};
} // namespace tts
#endif
|
PyTorch/SpeechRecognition/Jasper/notebooks | notebooks | Colab_Jasper_TRT_inference_demo | #!/usr/bin/env python
# coding: utf-8
<a href="https://colab.research.google.com/github/NVIDIA/DeepLearningExamples/blob/master/PyTorch/SpeechRecognition/Jasper/notebooks/Colab_Jasper_TRT_inference_demo.ipynb" target="_parent"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/></a>
# In[ ]:
# Copyright 2019 NVIDIA Corporation. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ==============================================================================
# <img src="http://developer.download.nvidia.com/compute/machine-learning/frameworks/nvidia_logo.png" style="width: 90px; float: right;">
#
# # Jasper Inference Demo with NVIDIA TensorRT on Google Colab
# ## Overview
#
#
# In this notebook, we will demo the process of carrying out inference on new audio segment using a pre-trained Pytorch Jasper model downloaded from the NVIDIA NGC Model registry with TensorRT (TRT). NVIDIA TensorRT is a platform for high-performance deep learning inference. It includes a deep learning inference optimizer and runtime that delivers low latency and high-throughput for deep learning inference applications. After optimizing the compute-intensive acoustic model with NVIDIA TensorRT, inference throughput increased by up to 1.8x over native PyTorch.
#
# The Jasper model is an end-to-end neural acoustic model for automatic speech recognition (ASR) that provides near state-of-the-art results on LibriSpeech among end-to-end ASR models without any external data. The Jasper architecture of convolutional layers was designed to facilitate fast GPU inference, by allowing whole sub-blocks to be fused into a single GPU kernel. This is important for meeting strict real-time requirements of ASR systems in deployment.The results of the acoustic model are combined with the results of external language models to get the top-ranked word sequences corresponding to a given audio segment. This post-processing step is called decoding.
#
# The original paper is Jasper: An End-to-End Convolutional Neural Acoustic Model https://arxiv.org/pdf/1904.03288.pdf.
#
# ### Model architecture
# By default the model configuration is Jasper 10x5 with dense residuals. A Jasper BxR model has B blocks, each consisting of R repeating sub-blocks.
# Each sub-block applies the following operations in sequence: 1D-Convolution, Batch Normalization, ReLU activation, and Dropout.
# In the original paper Jasper is trained with masked convolutions, which masks out the padded part of an input sequence in a batch before the 1D-Convolution.
# For inference masking is not used. The reason for this is that in inference, the original mask operation does not achieve better accuracy than without the mask operation on the test and development dataset. However, no masking achieves better inference performance especially after TensorRT optimization.
# More information on the model architecture can be found in the [root folder](https://github.com/NVIDIA/DeepLearningExamples/tree/master/PyTorch/SpeechRecognition/Jasper)
#
# ### TensorRT Inference pipeline
# The Jasper inference pipeline consists of 3 components: data preprocessor, acoustic model and greedy decoder. The acoustic model is the most compute intensive, taking more than 90% of the entire end-to-end pipeline. The acoustic model is the only component with learnable parameters and also what differentiates Jasper from the competition. So, we focus on the acoustic model for the most part.
# For the non-TRT Jasper inference pipeline, all 3 components are implemented and run with native PyTorch. For the TensorRT inference pipeline, we show the speedup of running the acoustic model with TensorRT, while preprocessing and decoding are reused from the native PyTorch pipeline.
# To run a model with TensorRT, we first construct the model in PyTorch, which is then exported into an ONNX file. Finally, a TensorRT engine is constructed from the ONNX file, serialized to TRT plan file, and also launched to do inference.
# Note that TensorRT engine is being runtime optimized before serialization. TRT tries a vast set of options to find the strategy that performs best on user’s GPU - so it takes a few minutes. After the TRT plan file is created, it can be reused.
#
#
# ### Requirement
# 1. Before running this notebook, please set the Colab runtime environment to GPU via the menu *Runtime => Change runtime type => GPU*.
#
# For TRT FP16 and INT8 inference, an NVIDIA Volta, Turing or newer GPU generations is required. On Google Colab, this normally means a T4 GPU.
# In[3]:
get_ipython().system('nvidia-smi')
# The below code check whether a Tensor core GPU is present.
# In[4]:
from tensorflow.python.client import device_lib
def check_tensor_core_gpu_present():
local_device_protos = device_lib.list_local_devices()
for line in local_device_protos:
if "compute capability" in str(line):
compute_capability = float(line.physical_device_desc.split("compute capability: ")[-1])
if compute_capability>=7.0:
return True
print("Tensor Core GPU Present:", check_tensor_core_gpu_present())
tensor_core_gpu = check_tensor_core_gpu_present()
# 2. Next, we clone the NVIDIA Github Deep Learning Example repository and set up the workspace.
# In[5]:
get_ipython().system('git clone https://github.com/NVIDIA/DeepLearningExamples')
# In[7]:
import os
WORKSPACE_DIR='/content/DeepLearningExamples/PyTorch/SpeechRecognition/Jasper/notebooks'
os.chdir(WORKSPACE_DIR)
print (os.getcwd())
# ## Install NVIDIA TensorRT
#
# We will need to install NVIDIA TensorRT 6.0 runtime environment on Colab. First, check the Colab CUDA installed version. As of 2nd Oct 2019, `cuda-10.0` is the CUDA version on Google Colab.
# In[8]:
get_ipython().system('ls /usr/local/')
# Next, we will need to install the NVIDIA TensorRT version that match the current Colab CUDA version, following the instruction at https://docs.nvidia.com/deeplearning/sdk/tensorrt-install-guide/index.html#maclearn-net-repo-install.
# In[ ]:
get_ipython().run_cell_magic('bash', '', 'wget https://developer.download.nvidia.com/compute/machine-learning/repos/ubuntu1804/x86_64/nvidia-machine-learning-repo-ubuntu1804_1.0.0-1_amd64.deb\n\ndpkg -i nvidia-machine-learning-repo-*.deb\napt-get update\n')
# When using the NVIDIA Machine Learning network repository, Ubuntu will be default install TensorRT for the latest CUDA version. The following commands will install libnvinfer6 for an older CUDA version and hold the libnvinfer6 package at this version. Replace 6.0.1 with your version of TensorRT and cuda10.0 with your CUDA version for your Colab environment.
# In[ ]:
get_ipython().run_cell_magic('bash', '', 'version="6.0.1-1+cuda10.0"\nsudo apt-get install libnvinfer6=${version} libnvonnxparsers6=${version} libnvparsers6=${version} libnvinfer-plugin6=${version} libnvinfer-dev=${version} libnvonnxparsers-dev=${version} libnvparsers-dev=${version} libnvinfer-plugin-dev=${version} python-libnvinfer=${version} python3-libnvinfer=${version}\n\n')
# In[11]:
get_ipython().system('sudo apt-mark hold libnvinfer6 libnvonnxparsers6 libnvparsers6 libnvinfer-plugin6 libnvinfer-dev libnvonnxparsers-dev libnvparsers-dev libnvinfer-plugin-dev python-libnvinfer python3-libnvinfer')
# In[12]:
get_ipython().system('dpkg -l | grep TensorRT')
# A successful TensorRT installation should look like:
#
# ```
# hi libnvinfer-dev 6.0.1-1+cuda10.0 amd64 TensorRT development libraries and headers
# hi libnvinfer-plugin-dev 6.0.1-1+cuda10.0 amd64 TensorRT plugin libraries
# hi libnvinfer-plugin6 6.0.1-1+cuda10.0 amd64 TensorRT plugin libraries
# hi libnvinfer6 6.0.1-1+cuda10.0 amd64 TensorRT runtime libraries
# hi libnvonnxparsers-dev 6.0.1-1+cuda10.0 amd64 TensorRT ONNX libraries
# hi libnvonnxparsers6 6.0.1-1+cuda10.0 amd64 TensorRT ONNX libraries
# hi libnvparsers-dev 6.0.1-1+cuda10.0 amd64 TensorRT parsers libraries
# hi libnvparsers6 6.0.1-1+cuda10.0 amd64 TensorRT parsers libraries
# hi python-libnvinfer 6.0.1-1+cuda10.0 amd64 Python bindings for TensorRT
# hi python3-libnvinfer 6.0.1-1+cuda10.0 amd64 Python 3 bindings for TensorRT
# ```
# ## Download pretrained Jasper model from NVIDIA GPU Cloud model repository
#
# NVIDIA provides pretrained Jasper models along with many other deep learning models such as ResNet, BERT, Transformer, SSD... at https://ngc.nvidia.com/catalog/models. Here, we will download and unzip pretrained Jasper Pytorch models.
# In[13]:
get_ipython().run_cell_magic('bash', '', 'wget -nc -q --show-progress -O jasper_model.zip \\\nhttps://api.ngc.nvidia.com/v2/models/nvidia/jasperpyt_fp16/versions/1/zip\n')
# In[14]:
get_ipython().system('unzip -o ./jasper_model.zip')
# After a successful download, a Pytorch checkpoint named ` jasper_fp16.pt` should exist in the current notebooks directory.
# In[16]:
get_ipython().system('ls -l jasper_fp16.pt')
# ## Install extra dependencies
#
# Before proceeding to creating the TensorRT execution engine from the Pytorch checkpoint, we shall install some extra dependency to load and convert the Pytorch model and process input audio files.
#
# - [Apex](https://nvidia.github.io/apex/): this is NVIDIA libraries for automatic mixed precision training in Pytorch
# - [Onnx](https://github.com/onnx/onnx): for processing ONNX model.
# - unidecode, soundfile, toml, pycuda: miscellaneous helper libraries
#
#
# In[ ]:
get_ipython().run_cell_magic('bash', '', 'pip uninstall -y apex\ngit clone https://www.github.com/nvidia/apex\ncd apex\npython setup.py install\n')
# In[ ]:
get_ipython().system('pip install unidecode soundfile toml pycuda')
# In[22]:
get_ipython().system('pip install onnx')
# ## Play with audio examples
#
# You can perform inference using pre-trained checkpoints which takes audio file (in .wav format) as input, and produces the corresponding text file. You can customize the content of the input .wav file. For example, there are several examples of input files at "notebooks" dirctory and we can listen to example1.wav:
# In[19]:
import IPython.display as ipd
ipd.Audio('./example1.wav', rate=22050)
# You can also download your own audio sample to Colab with
#
# ```!wget <link-to-.wav-file>```
# ## FP32 Inference with TensorRT
#
#
# ### Creating TensorRT FP32 execution plan
#
# You can run inference using the trt/perf.py script:
# * the checkpoint is passed as `--ckpt` argument
# * `--model_toml` specifies the path to network configuration file (see examples in "config" directory)
# * `--make_onnx` exports to ONNX file at the path if set
# * `--engine_path` saves the engine file (*.plan)
#
# To create a new engine file (jasper.plan) for TensorRT and run it using fp32 (building the engine for the first time can take several minutes):
# In[23]:
get_ipython().run_cell_magic('bash', '', 'PYTHONPATH=/content/DeepLearningExamples/PyTorch/SpeechRecognition/Jasper \npython ../trt/perf.py \\\n--ckpt_path ./jasper_fp16.pt --wav=example1.wav \\\n--model_toml=../configs/jasper10x5dr_nomask.toml \\\n--make_onnx --onnx_path jasper.onnx \\\n--engine_path jasper.plan\n')
# ### Inference from existing TensorRT FP32 plan
# Inference with an existing plan can be launch with the `--use_existing_engine` flag.
# In[26]:
get_ipython().run_cell_magic('bash', '', 'PYTHONPATH=/content/DeepLearningExamples/PyTorch/SpeechRecognition/Jasper \npython ../trt/perf.py \\\n--wav=./example1.wav \\\n--model_toml=../configs/jasper10x5dr_nomask.toml \\\n--use_existing_engine --engine_path jasper.plan\n')
# ## FP16 Inference with TensorRT
# ### Creating TensorRT FP16 execution plan
#
# We will next create an FP16 TRT inference plan.
#
# To run inference of the input audio file using automatic mixed precision, add the argument `--trt_fp16`. Using automatic mixed precision, the inference time can be reduced efficiently compared to that of using fp32 (building the engine for the first time can take several minutes).
#
# **Important Note:** Efficient FP16 inference requires a Volta, Turing or newer generation GPUs. On Google Colab, this normally means a T4 GPU. On the older K80 GPUs, FP16 performance might actually degrade from an FP32 TRT model.
# In[27]:
get_ipython().run_cell_magic('bash', '', 'PYTHONPATH=/content/DeepLearningExamples/PyTorch/SpeechRecognition/Jasper \npython ../trt/perf.py \\\n--ckpt_path ./jasper_fp16.pt --wav=example1.wav \\\n--model_toml=../configs/jasper10x5dr_nomask.toml \\\n--make_onnx --onnx_path jasper.onnx \\\n--engine_path jasper_fp16.plan \\\n--trt_fp16\n')
# ### Inference from existing TensorRT FP16 plan
# Inference with an existing plan can be launched with the `--use_existing_engine` flag.
# In[29]:
get_ipython().run_cell_magic('bash', '', 'PYTHONPATH=/content/DeepLearningExamples/PyTorch/SpeechRecognition/Jasper \npython ../trt/perf.py \\\n--wav=./example1.wav \\\n--model_toml=../configs/jasper10x5dr_nomask.toml \\\n--use_existing_engine --engine_path jasper_fp16.plan \\\n--trt_fp16\n')
# ## Conclusion
#
# In this notebook, we have walked through the complete process of carrying out inference using a pretrained Jasper Pytorch model using NVIDIA TensorRT on Google Colab.
# ### What's next
# Now that you are familiar with running Jasper inference with TensorRT using full and automatic mixed precision, you may want to play with your own audio samples.
#
# For information on training a Jasper model using your own data, please check out our Github repo: https://github.com/NVIDIA/DeepLearningExamples/tree/master/PyTorch/SpeechRecognition/Jasper
# In[ ]:
|
TensorFlow2/Detection/Efficientdet/scripts/D0 | D0 | training-benchmark-TF32-1xA100-80G | #!/bin/bash
# Copyright (c) 2022, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
bs=104
ep=1
lr=1.1
wu=25
ema=0.999
momentum=0.93
mkdir -p /tmp/training-benchmark-1xTF32-A100-80G
rm -rf /tmp/training-benchmark-1xTF32-A100-80G/*
mpirun -np 1 --allow-run-as-root --bind-to none \
-map-by slot -x LD_LIBRARY_PATH -x PATH \
-mca pml ob1 -mca btl ^openib \
-x CUDA_VISIBLE_DEVICES=0 \
python3 train.py \
--training_file_pattern=/workspace/coco/train-* \
--val_file_pattern=/workspace/coco/val-* \
--val_json_file=/workspace/coco/annotations/instances_val2017.json \
--model_name=efficientdet-d0 \
--model_dir=/tmp/training-benchmark-1xTF32-A100-80G \
--backbone_init=/workspace/checkpoints/efficientnet-b0-joc \
--batch_size=$bs \
--num_epochs=$ep \
--use_xla=True \
--amp=False \
--lr=$lr \
--warmup_epochs=$wu \
--benchmark=True \
--benchmark_steps=500 \
--enable_map_parallelization=False \
--hparams="moving_average_decay=$ema,momentum=$momentum" \
2>&1 | tee /tmp/training-benchmark-1xTF32-A100-80G/train-benchmark.log |
PyTorch/Translation/GNMT/seq2seq/train | train | fp_optimizers | # Copyright (c) 2018-2020, NVIDIA CORPORATION. All rights reserved.
#
# Permission is hereby granted, free of charge, to any person obtaining a copy
# of this software and associated documentation files (the "Software"), to deal
# in the Software without restriction, including without limitation the rights
# to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
# copies of the Software, and to permit persons to whom the Software is
# furnished to do so, subject to the following conditions:
#
# The above copyright notice and this permission notice shall be included in all
# copies or substantial portions of the Software.
#
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
# SOFTWARE.
import logging
import math
import torch
from torch.nn.utils import clip_grad_norm_
import apex.amp._amp_state
from apex import amp
class FP16Optimizer:
"""
Mixed precision optimizer with dynamic loss scaling and backoff.
https://docs.nvidia.com/deeplearning/sdk/mixed-precision-training/index.html#scalefactor
"""
@staticmethod
def set_grads(params, params_with_grad):
"""
Copies gradients from param_with_grad to params
:param params: dst parameters
:param params_with_grad: src parameters
"""
for param, param_w_grad in zip(params, params_with_grad):
if param.grad is None:
param.grad = torch.nn.Parameter(torch.empty_like(param))
param.grad.data.copy_(param_w_grad.grad.data)
@staticmethod
def set_weights(params, new_params):
"""
Copies parameters from new_params to params
:param params: dst parameters
:param new_params: src parameters
"""
for param, new_param in zip(params, new_params):
param.data.copy_(new_param.data)
def __init__(self, model, grad_clip=float('inf'), loss_scale=8192,
dls_downscale=2, dls_upscale=2, dls_upscale_interval=128):
"""
Constructor for the Fp16Optimizer.
:param model: model
:param grad_clip: coefficient for gradient clipping, max L2 norm of the
gradients
:param loss_scale: initial loss scale
:param dls_downscale: loss downscale factor, loss scale is divided by
this factor when NaN/INF occurs in the gradients
:param dls_upscale: loss upscale factor, loss scale is multiplied by
this factor if previous dls_upscale_interval batches finished
successfully
:param dls_upscale_interval: interval for loss scale upscaling
"""
logging.info('Initializing fp16 optimizer')
self.initialize_model(model)
self.since_last_invalid = 0
self.loss_scale = loss_scale
self.dls_downscale = dls_downscale
self.dls_upscale = dls_upscale
self.dls_upscale_interval = dls_upscale_interval
self.grad_clip = grad_clip
def initialize_model(self, model):
"""
Initializes internal state and build fp32 master copy of weights.
:param model: fp16 model
"""
logging.info('Converting model to half precision')
model.half()
logging.info('Initializing fp32 clone weights')
self.model = model
self.model.zero_grad()
self.fp32_params = [param.to(torch.float32).detach()
for param in model.parameters()]
for param in self.fp32_params:
param.requires_grad = True
def step(self, loss, optimizer, scheduler, update=True):
"""
Performs one step of the optimizer.
Applies loss scaling, computes gradients in fp16, converts gradients to
fp32, inverts scaling and applies optional gradient norm clipping.
If gradients are finite, it applies update to fp32 master weights and
copies updated parameters to fp16 model for the next iteration. If
gradients are not finite, it skips the batch and adjusts scaling factor
for the next iteration.
:param loss: value of loss function
:param optimizer: optimizer
:param update: if True executes weight update
"""
loss *= self.loss_scale
loss.backward()
if update:
self.set_grads(self.fp32_params, self.model.parameters())
if self.loss_scale != 1.0:
for param in self.fp32_params:
param.grad.data /= self.loss_scale
norm = clip_grad_norm_(self.fp32_params, self.grad_clip)
if math.isfinite(norm):
scheduler.step()
optimizer.step()
self.set_weights(self.model.parameters(),
self.fp32_params)
self.since_last_invalid += 1
else:
self.loss_scale /= self.dls_downscale
self.since_last_invalid = 0
logging.info(f'Gradient norm: {norm}')
logging.info(f'Skipped batch, new scale: {self.loss_scale}')
if self.since_last_invalid >= self.dls_upscale_interval:
self.loss_scale *= self.dls_upscale
self.loss_scale = min(self.loss_scale, 8192.0)
logging.info(f'Upscaling, new scale: {self.loss_scale}')
self.since_last_invalid = 0
self.model.zero_grad()
class FP32Optimizer:
"""
Standard optimizer, computes backward and applies weight update.
"""
def __init__(self, model, grad_clip=None):
"""
Constructor for the Fp32Optimizer
:param model: model
:param grad_clip: coefficient for gradient clipping, max L2 norm of the
gradients
"""
logging.info('Initializing fp32 optimizer')
self.initialize_model(model)
self.grad_clip = grad_clip
def initialize_model(self, model):
"""
Initializes state of the model.
:param model: model
"""
self.model = model
self.model.zero_grad()
def step(self, loss, optimizer, scheduler, update=True):
"""
Performs one step of the optimizer.
:param loss: value of loss function
:param optimizer: optimizer
:param update: if True executes weight update
"""
loss.backward()
if update:
if self.grad_clip != float('inf'):
clip_grad_norm_(self.model.parameters(), self.grad_clip)
scheduler.step()
optimizer.step()
self.model.zero_grad()
class AMPOptimizer:
"""
Optimizer compatible with AMP.
Uses AMP to apply loss scaling, computes backward and applies weight
update.
"""
def __init__(self, model, grad_clip=None, loss_scale=8192,
dls_upscale_interval=128):
"""
Constructor for the AMPOptimizer
:param model: model
:param grad_clip: coefficient for gradient clipping, max L2 norm of the
gradients
"""
logging.info('Initializing amp optimizer')
self.initialize_model(model)
self.grad_clip = grad_clip
loss_scaler = apex.amp._amp_state.loss_scalers[0]
loss_scaler._loss_scale = loss_scale
loss_scaler._scale_seq_len = dls_upscale_interval
def initialize_model(self, model):
"""
Initializes state of the model.
:param model: model
"""
self.model = model
self.model.zero_grad()
def step(self, loss, optimizer, scheduler, update=True):
"""
Performs one step of the optimizer.
:param loss: value of loss function
:param optimizer: optimizer
:param update: if True executes weight update
"""
with amp.scale_loss(loss, optimizer) as scaled_loss:
scaled_loss.backward()
if update:
if self.grad_clip != float('inf'):
clip_grad_norm_(amp.master_params(optimizer), self.grad_clip)
scheduler.step()
optimizer.step()
self.model.zero_grad()
|
TensorFlow/Segmentation/UNet_Industrial/scripts | scripts | UNet_4GPU_XLA | #!/usr/bin/env bash
# Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# This script launches UNet training in FP32 on 4 GPUs using 16 batch size (4 per GPU)
# Usage ./UNet_FP32_4GPU_XLA.sh <path to result repository> <path to dataset> <dagm classID (1-10)>
BASEDIR="$( cd "$( dirname "${BASH_SOURCE[0]}" )" >/dev/null 2>&1 && pwd )"
export TF_CPP_MIN_LOG_LEVEL=3
mpirun \
-np 4 \
-H localhost:4 \
-bind-to none \
-map-by slot \
-x NCCL_DEBUG=VERSION \
-x LD_LIBRARY_PATH \
-x PATH \
-mca pml ob1 -mca btl ^openib \
--allow-run-as-root \
python "${BASEDIR}/../main.py" \
--unet_variant='tinyUNet' \
--activation_fn='relu' \
--exec_mode='train_and_evaluate' \
--iter_unit='batch' \
--num_iter=2500 \
--batch_size=4 \
--warmup_step=10 \
--results_dir="${1}" \
--data_dir="${2}" \
--dataset_name='DAGM2007' \
--dataset_classID="${3}" \
--data_format='NCHW' \
--use_auto_loss_scaling \
--noamp \
--xla \
--learning_rate=1e-4 \
--learning_rate_decay_factor=0.8 \
--learning_rate_decay_steps=500 \
--rmsprop_decay=0.9 \
--rmsprop_momentum=0.8 \
--loss_fn_name='adaptive_loss' \
--weight_decay=1e-5 \
--weight_init_method='he_uniform' \
--augment_data \
--display_every=250 \
--debug_verbosity=0
|
PyTorch/SpeechSynthesis/Tacotron2/trtis_cpp/src/trt | trt | requirements | torch==1.3.0
onnx==1.5.0
scipy==1.3.1
librosa==0.7.0
|
TensorFlow2/Segmentation/MaskRCNN/mrcnn_tf2/object_detection | object_detection | box_list | # Copyright 2017 The TensorFlow Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Bounding Box List definition.
BoxList represents a list of bounding boxes as tensorflow
tensors, where each bounding box is represented as a row of 4 numbers,
[y_min, x_min, y_max, x_max]. It is assumed that all bounding boxes
within a given list correspond to a single image. See also
box_list_ops.py for common box related operations (such as area, iou, etc).
Optionally, users can add additional related fields (such as weights).
We assume the following things to be true about fields:
* they correspond to boxes in the box_list along the 0th dimension
* they have inferrable rank at graph construction time
* all dimensions except for possibly the 0th can be inferred
(i.e., not None) at graph construction time.
Some other notes:
* Following tensorflow conventions, we use height, width ordering,
and correspondingly, y,x (or ymin, xmin, ymax, xmax) ordering
* Tensors are always provided as (flat) [N, 4] tensors.
"""
import tensorflow as tf
class BoxList(object):
"""Box collection."""
def __init__(self, boxes):
"""Constructs box collection.
Args:
boxes: a tensor of shape [N, 4] representing box corners
Raises:
ValueError: if invalid dimensions for bbox data or if bbox data is not in
float32 format.
"""
if len(boxes.get_shape()) != 2 or boxes.get_shape()[-1] != 4:
raise ValueError('Invalid dimensions for box data.')
if boxes.dtype != tf.float32:
raise ValueError('Invalid tensor type: should be tf.float32')
self.data = {'boxes': boxes}
def num_boxes(self):
"""Returns number of boxes held in collection.
Returns:
a tensor representing the number of boxes held in the collection.
"""
return tf.shape(input=self.data['boxes'])[0]
def num_boxes_static(self):
"""Returns number of boxes held in collection.
This number is inferred at graph construction time rather than run-time.
Returns:
Number of boxes held in collection (integer) or None if this is not
inferrable at graph construction time.
"""
try:
return self.data['boxes'].get_shape()[0].value
except AttributeError:
return self.data['boxes'].get_shape()[0]
def get_all_fields(self):
"""Returns all fields."""
return self.data.keys()
def get_extra_fields(self):
"""Returns all non-box fields (i.e., everything not named 'boxes')."""
return [k for k in self.data if k != 'boxes']
def add_field(self, field, field_data):
"""Add field to box list.
This method can be used to add related box data such as
weights/labels, etc.
Args:
field: a string key to access the data via `get`
field_data: a tensor containing the data to store in the BoxList
"""
self.data[field] = field_data
def has_field(self, field):
return field in self.data
def get(self):
"""Convenience function for accessing box coordinates.
Returns:
a tensor with shape [N, 4] representing box coordinates.
"""
return self.get_field('boxes')
def set(self, boxes):
"""Convenience function for setting box coordinates.
Args:
boxes: a tensor of shape [N, 4] representing box corners
Raises:
ValueError: if invalid dimensions for bbox data
"""
if len(boxes.get_shape()) != 2 or boxes.get_shape()[-1] != 4:
raise ValueError('Invalid dimensions for box data.')
self.data['boxes'] = boxes
def get_field(self, field):
"""Accesses a box collection and associated fields.
This function returns specified field with object; if no field is specified,
it returns the box coordinates.
Args:
field: this optional string parameter can be used to specify
a related field to be accessed.
Returns:
a tensor representing the box collection or an associated field.
Raises:
ValueError: if invalid field
"""
if not self.has_field(field):
raise ValueError('field ' + str(field) + ' does not exist')
return self.data[field]
def set_field(self, field, value):
"""Sets the value of a field.
Updates the field of a box_list with a given value.
Args:
field: (string) name of the field to set value.
value: the value to assign to the field.
Raises:
ValueError: if the box_list does not have specified field.
"""
if not self.has_field(field):
raise ValueError('field %s does not exist' % field)
self.data[field] = value
def get_center_coordinates_and_sizes(self, scope=None):
"""Computes the center coordinates, height and width of the boxes.
Args:
scope: name scope of the function.
Returns:
a list of 4 1-D tensors [ycenter, xcenter, height, width].
"""
box_corners = self.get()
ymin, xmin, ymax, xmax = tf.unstack(tf.transpose(a=box_corners))
width = xmax - xmin
height = ymax - ymin
ycenter = ymin + height / 2.
xcenter = xmin + width / 2.
return [ycenter, xcenter, height, width]
def transpose_coordinates(self, scope=None):
"""Transpose the coordinate representation in a boxlist.
Args:
scope: name scope of the function.
"""
y_min, x_min, y_max, x_max = tf.split(
value=self.get(), num_or_size_splits=4, axis=1)
self.set(tf.concat([x_min, y_min, x_max, y_max], 1))
def as_tensor_dict(self, fields=None):
"""Retrieves specified fields as a dictionary of tensors.
Args:
fields: (optional) list of fields to return in the dictionary.
If None (default), all fields are returned.
Returns:
tensor_dict: A dictionary of tensors specified by fields.
Raises:
ValueError: if specified field is not contained in boxlist.
"""
tensor_dict = {}
if fields is None:
fields = self.get_all_fields()
for field in fields:
if not self.has_field(field):
raise ValueError('boxlist must contain all specified fields')
tensor_dict[field] = self.get_field(field)
return tensor_dict
|
TensorFlow2/Classification/ConvNets/efficientnet_v2 | efficientnet_v2 | README | # EfficientNet v2-S For TensorFlow 2.6
This repository provides scripts and recipes to train EfficientNet v2-S to achieve state-of-the-art accuracy.
The content of the repository is maintained by NVIDIA and is tested against each NGC monthly released container to ensure consistent accuracy and performance over time.
## Table Of Contents
- [Model overview](#model-overview)
* [Model architecture](#model-architecture)
* [Default configuration](#default-configuration)
* [Feature support matrix](#feature-support-matrix)
* [Features](#features)
* [Mixed precision training](#mixed-precision-training)
* [Enabling mixed precision](#enabling-mixed-precision)
* [Enabling TF32](#enabling-tf32)
- [Setup](#setup)
* [Requirements](#requirements)
- [Quick Start Guide](#quick-start-guide)
- [Advanced](#advanced)
* [Scripts and sample code](#scripts-and-sample-code)
* [Parameters](#parameters)
* [Command-line options](#command-line-options)
* [Getting the data](#getting-the-data)
* [Training process](#training-process)
* [Multi-node](#multi-node)
* [Inference process](#inference-process)
- [Performance](#performance)
* [Benchmarking](#benchmarking)
* [Training performance benchmark](#training-performance-benchmark)
* [Inference performance benchmark](#inference-performance-benchmark)
* [Results](#results)
* [Training results for EfficientNet v2-S](#training-results-for-efficientnet-v2-s)
* [Training accuracy: NVIDIA DGX A100 (8x A100 80GB)](#training-accuracy-nvidia-dgx-a100-8x-a100-80gb)
* [Training accuracy: NVIDIA DGX-1 (8x V100 32GB)](#training-accuracy-nvidia-dgx-1-8x-v100-32gb)
* [Training performance results for EfficientNet v2-S](#training-performance-results-for-efficientnet-v2-s)
* [Training performance: NVIDIA DGX A100 (8x A100 80GB)](#training-performance-nvidia-dgx-a100-8x-a100-80gb)
* [Training performance: NVIDIA DGX-1 (8x V100 32GB)](#training-performance-nvidia-dgx-1-8x-v100-32gb)
* [Training EfficientNet v2-S at scale](#training-efficientnet-v2-s-at-scale)
* [10x NVIDIA DGX-1 V100 (8x V100 32GB)](#10x-nvidia-dgx-1-v100-8x-v100-32gb)
* [10x NVIDIA DGX A100 (8x A100 80GB)](#10x-nvidia-dgx-a100-8x-a100-80gb)
* [Inference performance results for EfficientNet v2-S](#inference-performance-results-for-efficientnet-v2-s)
* [Inference performance: NVIDIA DGX A100 (1x A100 80GB)](#inference-performance-nvidia-dgx-a100-1x-a100-80gb)
* [Inference performance: NVIDIA DGX-1 (1x V100 32GB)](#inference-performance-nvidia-dgx-1-1x-v100-32gb)
- [Release notes](#release-notes)
* [Changelog](#changelog)
* [Known issues](#known-issues)
## Model overview
EfficientNet TensorFlow 2 is a family of image classification models, which achieve state-of-the-art accuracy, yet being an order-of-magnitude smaller and faster than previous models.
Specifically, this readme covers model v2-S as suggested in [EfficientNetV2: Smaller Models and Faster Training](https://arxiv.org/abs/2104.00298).
NVIDIA's implementation of EfficientNet TensorFlow 2 is an optimized version of [TensorFlow Model Garden](https://github.com/tensorflow/models/tree/master/official/vision/image_classification) implementation,
leveraging mixed precision arithmetic on NVIDIA Volta, NVIDIA Turing, and the NVIDIA Ampere GPU architectures for faster training times while maintaining target accuracy.
The major differences between the papers' original implementations and this version of EfficientNet are as follows:
- Automatic mixed precision (AMP) training support
- Cosine LR decay for better accuracy
- Weight initialization using `fan_out` for better accuracy
- Multi-node training support using Horovod
- XLA enabled for better performance
- Gradient accumulation support
- Lightweight logging using [dllogger](https://github.com/NVIDIA/dllogger)
Other publicly available implementations of EfficientNet include:
- [Tensorflow Model Garden](https://github.com/tensorflow/models/tree/master/official/vision/image_classification)
- [Pytorch version](https://github.com/rwightman/pytorch-image-models)
- [Google's implementation for TPU EfficientNet v1](https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet)
- [Google's implementation for TPU EfficientNet v2](https://github.com/google/automl/tree/master/efficientnetv2)
This model is trained with mixed precision Tensor Cores on NVIDIA Volta, NVIDIA Turing, and the NVIDIA Ampere GPU architectures. It provides a push-button solution to pretraining on a corpus of choice. As a result, researchers can get results 1.5--2x faster than training without Tensor Cores, while experiencing the benefits of mixed precision training. This model is tested against each NGC monthly released container to ensure consistent accuracy and performance over time.
### Model architecture
EfficientNet v2 is developed based on AutoML and compound scaling, but with a particular emphasis on faster training. For this purpose, the authors have proposed 3 major changes compared to v1: 1) the objective function of AutoML is revised so that the number of flops is now substituted by training time, because FLOPs is not an accurate surrogate of the actual training time; 2) a multi-stage training is proposed where the early stages of training use low resolution images and weak regularization, but the subsequent stages use larger images and stronger regularization; 3) an additional block called fused MBConv is used in AutoML, which replaces the 1x1 depth-wise convolution of MBConv with a regular 3x3 convolution.
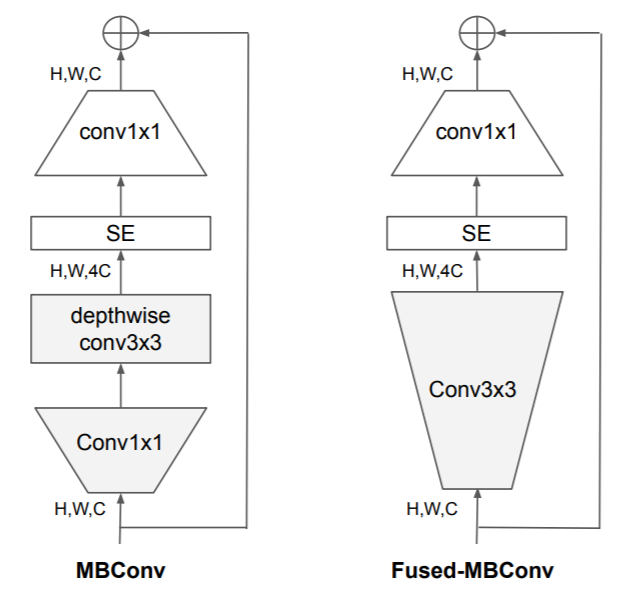
EfficientNet v2 base model is scaled up using a non-uniform compounding scheme, through which the depth and width of blocks are scaled depending on where they are located in the base architecture. With this approach, the authors have identified the base "small" model, EfficientNet v2-S, and then scaled it up to obtain EfficientNet v2-M,L,XL. Below is the detailed overview of EfficientNet v2-S, which is reproduced in this repository.
### Default configuration
Here is the baseline EfficientNet v2-S structure.
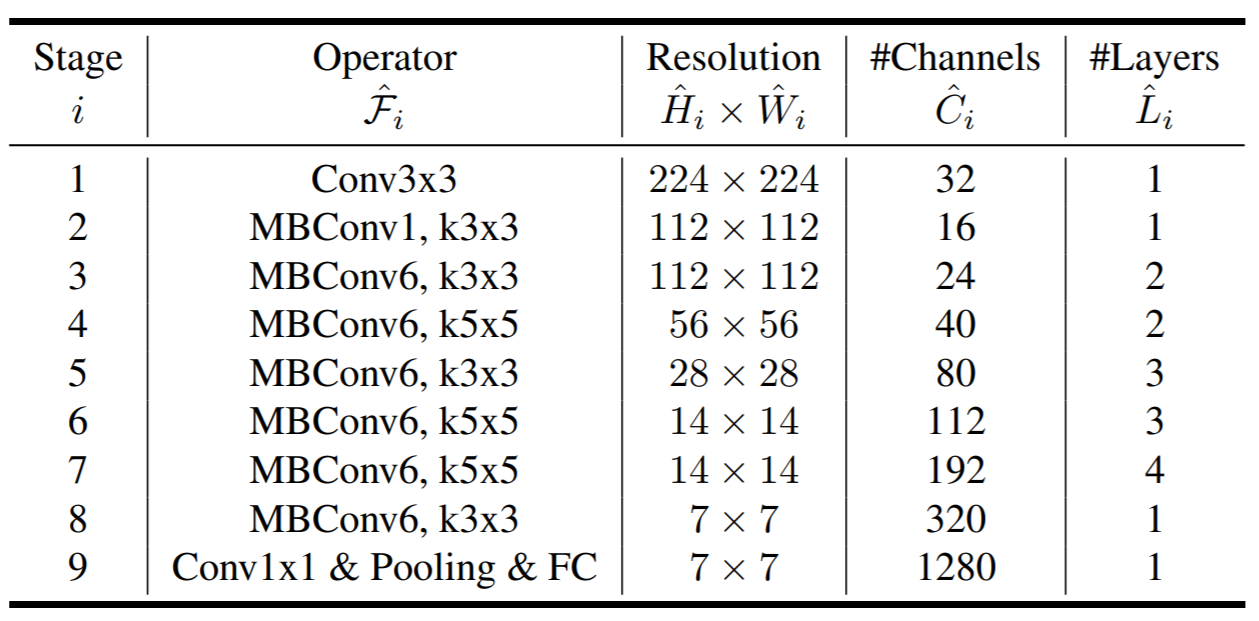
The following features are supported by this implementation:
- General:
- XLA support
- Mixed precision support
- Multi-GPU support using Horovod
- Multi-node support using Horovod
- Cosine LR Decay
- Inference:
- Support for inference on a single image is included
- Support for inference on a batch of images is included
### Feature support matrix
| Feature | EfficientNet
|-----------------------|-------------------------- |
|Horovod Multi-GPU training (NCCL) | Yes |
|Multi-GPU training | Yes |
|Multi-node training | Yes |
|Automatic mixed precision (AMP) | Yes |
|XLA | Yes |
|Gradient Accumulation| Yes |
|Stage-wise Training| Yes |
#### Features
**Multi-GPU training with Horovod**
Our model uses Horovod to implement efficient multi-GPU training with NCCL. For details, refer to example sources in this repository or refer to the [TensorFlow tutorial](https://github.com/horovod/horovod/#usage).
**Multi-node training with Horovod**
Our model also uses Horovod to implement efficient multi-node training.
**Automatic Mixed Precision (AMP)**
Computation graphs can be modified by TensorFlow on runtime to support mixed precision training. A detailed explanation of mixed precision can be found in Appendix.
**Gradient Accumulation**
Gradient Accumulation is supported through a custom train_step function. This feature is enabled only when grad_accum_steps is greater than 1.
**Stage-wise Training**
Stage-wise training was proposed for EfficientNet v2 to further accelerate convergence. In this scheme, the early stages use low resolution images and weak regularization, but the subsequent stages use larger images and stronger regularization. This feature is activated when `--n_stages` is greater than 1. The current codebase allows the user to linearly schedule the following factors in the various stages of training:
| factor | value in the first stage | value in the last stage
|-----------------------|-------------------------- |-------------------------- |
| image resolution | --base_img_size | --img_size |
| strength of mixup | --base_mixup | --mixup_alpha |
| strength of cutmix | --base_cutmix | --cutmix_alpha |
| strength of random aug.| --base_randaug_mag | --raug_magnitude |
Note that if `--n_stages` is set to 1, then the above hyper-parameters beginning with `base_` will have no effect.
### Mixed precision training
Mixed precision is the combined use of different numerical precisions in a computational method. [Mixed precision](https://arxiv.org/abs/1710.03740) training offers significant computational speedup by performing operations in half-precision format while storing minimal information in single-precision to retain as much information as possible in critical parts of the network. Since the introduction of [Tensor Cores](https://developer.nvidia.com/tensor-cores) in NVIDIA Volta, and following with both the NVIDIA Turing and NVIDIA Ampere Architectures, significant training speedups are experienced by switching to mixed precision -- up to 3x overall speedup on the most arithmetically intense model architectures. Using [mixed precision training](https://docs.nvidia.com/deeplearning/performance/mixed-precision-training/index.html) previously required two steps:
1. Porting the model to use the FP16 data type where appropriate.
2. Adding loss scaling to preserve small gradient values.
This can now be achieved using Automatic Mixed Precision (AMP) for TensorFlow to enable the full [mixed precision methodology](https://docs.nvidia.com/deeplearning/sdk/mixed-precision-training/index.html#tensorflow) in your existing TensorFlow model code. AMP enables mixed precision training on NVIDIA Volta, NVIDIA Turing, and NVIDIA Ampere GPU architectures automatically. The TensorFlow framework code makes all necessary model changes internally.
In TF-AMP, the computational graph is optimized to use as few casts as necessary and maximize the use of FP16, and the loss scaling is automatically applied inside of supported optimizers. AMP can be configured to work with the existing tf.contrib loss scaling manager by disabling the AMP scaling with a single environment variable to perform only the automatic mixed-precision optimization. It accomplishes this by automatically rewriting all computation graphs with the necessary operations to enable mixed precision training and automatic loss scaling.
For information about:
- How to train using mixed precision, refer to the [Mixed Precision Training](https://arxiv.org/abs/1710.03740) paper and [Training With Mixed Precision](https://docs.nvidia.com/deeplearning/performance/mixed-precision-training/index.html) documentation.
- Techniques used for mixed precision training, refer to the [Mixed-Precision Training of Deep Neural Networks](https://devblogs.nvidia.com/mixed-precision-training-deep-neural-networks/) blog.
- How to access and enable AMP for TensorFlow, refer to [Using TF-AMP](https://docs.nvidia.com/deeplearning/dgx/tensorflow-user-guide/index.html#tfamp) from the TensorFlow User Guide.
#### Enabling mixed precision
Mixed precision is enabled in TensorFlow by using the Automatic Mixed Precision (TF-AMP) extension which casts variables to half-precision upon retrieval, while storing variables in single-precision format. Furthermore, to preserve small gradient magnitudes in backpropagation, a [loss scaling](https://docs.nvidia.com/deeplearning/sdk/mixed-precision-training/index.html#lossscaling) step must be included when applying gradients. In TensorFlow, loss scaling can be applied statically by using simple multiplication of loss by a constant value or automatically, by TF-AMP. Automatic mixed precision makes all the adjustments internally in TensorFlow, providing two benefits over manual operations. First, programmers need not modify network model code, reducing development and maintenance effort. Second, using AMP maintains forward and backward compatibility with all the APIs for defining and running TensorFlow models.
To enable mixed precision, you can simply add the `--use_amp` to the command-line used to run the model. This will enable the following code:
```
if params.use_amp:
policy = tf.keras.mixed_precision.experimental.Policy('mixed_float16', loss_scale='dynamic')
tf.keras.mixed_precision.experimental.set_policy(policy)
```
#### Enabling TF32
TensorFloat-32 (TF32) is the new math mode in [NVIDIA A100](https://www.nvidia.com/en-us/data-center/a100/) GPUs for handling the matrix math also called tensor operations. TF32 running on Tensor Cores in A100 GPUs can provide up to 10x speedups compared to single-precision floating-point math (FP32) on NVIDIA Volta GPUs.
TF32 Tensor Cores can speed up networks using FP32, typically with no loss of accuracy. It is more robust than FP16 for models which require a high dynamic range for weights or activations.
For more information, refer to the [TensorFloat-32 in the A100 GPU Accelerates AI Training, HPC up to 20x](https://blogs.nvidia.com/blog/2020/05/14/tensorfloat-32-precision-format/) blog post.
TF32 is supported in the NVIDIA Ampere GPU architecture and is enabled by default.
## Setup
The following section lists the requirements that you need to meet in order to start training the EfficientNet model.
### Requirements
This repository contains a Dockerfile that extends the TensorFlow NGC container and encapsulates some dependencies. Aside from these dependencies, ensure you have the following components:
- [NVIDIA Docker](https://github.com/NVIDIA/nvidia-docker)
- [TensorFlow 21.09-py3] NGC container or later
- Supported GPUs:
- [NVIDIA Volta architecture](https://www.nvidia.com/en-us/data-center/volta-gpu-architecture/)
- [NVIDIA Turing architecture](https://www.nvidia.com/en-us/geforce/turing/)
- [NVIDIA Ampere architecture](https://www.nvidia.com/en-us/data-center/nvidia-ampere-gpu-architecture/)
For more information about how to get started with NGC containers, refer to the following sections from the NVIDIA GPU Cloud Documentation and the Deep Learning Documentation:
- [Getting Started Using NVIDIA GPU Cloud](https://docs.nvidia.com/ngc/ngc-getting-started-guide/index.html)
- [Accessing And Pulling From The NGC Container Registry](https://docs.nvidia.com/deeplearning/frameworks/user-guide/index.html#accessing_registry)
- [Running TensorFlow](https://docs.nvidia.com/deeplearning/frameworks/tensorflow-release-notes/running.html#running)
As an alternative to the use of the Tensorflow2 NGC container, to set up the required environment or create your own container, refer to the versioned [NVIDIA Container Support Matrix](https://docs.nvidia.com/deeplearning/frameworks/support-matrix/index.html).
For multi-node, the sample provided in this repository requires [Enroot](https://github.com/NVIDIA/enroot) and [Pyxis](https://github.com/NVIDIA/pyxis) set up on a [SLURM](https://slurm.schedmd.com) cluster.
## Quick Start Guide
To train your model using mixed or TF32 precision with Tensor Cores or using FP32, perform the following steps using the default parameters of the EfficientNet model on the ImageNet dataset. For the specifics concerning training and inference, refer to the [Advanced](#advanced) section.
1. Clone the repository.
```
git clone https://github.com/NVIDIA/DeepLearningExamples.git
cd DeepLearningExamples/TensorFlow2/Classification/ConvNets/efficientnet
```
2. Download and prepare the dataset.
`Runner.py` supports ImageNet with [TensorFlow Datasets (TFDS)](https://www.tensorflow.org/datasets/overview). Refer to the [TFDS ImageNet readme](https://github.com/tensorflow/datasets/blob/master/docs/catalog/imagenet2012.md) for manual download instructions.
3. Build EfficientNet on top of the NGC container.
`bash ./scripts/docker/build.sh YOUR_DESIRED_CONTAINER_NAME`
4. Start an interactive session in the NGC container to run training/inference. **Ensure that `launch.sh` has the correct path to ImageNet on your machine and that this path is mounted onto the `/data` directory, because this is where training and evaluation scripts search for data.**
`bash ./scripts/docker/launch.sh YOUR_DESIRED_CONTAINER_NAME`
5. Start training.
To run training for a standard configuration, **under the container default entry point `/workspace`**, run one of the scripts in the `./efficinetnet_v2/S/training/{AMP,TF32,FP32}/convergence_8x{A100-80G, V100-16G, V100-32G}.sh`. For example:
`bash ./efficinetnet_v2/S/training/AMP/convergence_8xA100-80G.sh`
6. Start validation/evaluation.
To run validation/evaluation for a standard configuration, **under the container default entry point `/workspace`**, run one of the scripts in the `./efficinetnet_v2/S/evaluation/evaluation_{AMP,FP32,TF32}_8x{A100-80G,V100-16G,V100-32G}.sh`. The evaluation script is configured to use the checkpoint specified in the `checkpoint` file for evaluation. The specified checkpoint will be read from the location passed by `--model_dir'.For example:
`bash ./efficinetnet_v2/S/evaluation/evaluation_AMP_A100-80G.sh`
7. Start inference/predictions.
To run inference for a standard configuration, **under the container default entry point `/workspace`**, run one of the scripts in the `./efficinetnet_v2/S/inference/inference_{AMP,FP32,TF32}.sh`.
Ensure your JPEG images used to run inference on are mounted in the `/infer_data` directory with this folder structure :
```
infer_data
| ├── images
| | ├── image1.JPEG
| | ├── image2.JPEG
```
For example:
`bash ./efficinetnet_v2/S/inference/inference_AMP.sh`
Now that you have your model trained and evaluated, you can choose to compare your training results with our [Training accuracy results](#training-accuracy-results). You can also choose to benchmark your performance to [Training performance benchmark](#training-performance-results), or [Inference performance benchmark](#inference-performance-results). Following the steps in these sections will ensure that you achieve the same accuracy and performance results as stated in the [Results](#results) section.
## Advanced
The following sections provide greater details of the dataset, running training and inference, and the training results.
### Scripts and sample code
The repository is structured as follows:
- `scripts/` - shell scripts to build and launch EfficientNet container on top of NGC container,
- `efficientnet_{v1,v2}` scripts to launch training, evaluation and inference
- `model/` - building blocks and EfficientNet model definitions
- `runtime/` - detailed procedure for each running mode
- `utils/` - support util functions for learning rates, optimizers, etc.
- `dataloader/` provides data pipeline utils
- `config/` contains model definitions
### Parameters
The hyper parameters can be grouped into model-specific hyperparameters (e.g., #layers ) and general hyperparameters (e.g., #training epochs).
The model-specific hyperparameters are to be defined in a python module, which must be passed in the command line via --cfg ( `python main.py --cfg config/efficientnet_v2/s_cfg.py`). To override model-specific hyperparameters, you can use a comma separated list of k=v pairs (e.g., `python main.py --cfg config/efficientnet_v2/s_cfg.py --mparams=bn_momentum=0.9,dropout=0.5`).
The general hyperparameters and their default values can be found in `utils/cmdline_helper.py`. The user can override these hyperparameters in the command line (e.g., `python main.py --cfg config/efficientnet_v2/s_cfg.py --data_dir xx --train_batch_size 128`). Here is a list of important hyperparameters:
- `--mode` (`train_and_eval`,`train`,`eval`,`prediction`) - the default is `train_and_eval`.
- `--use_amp` Set to True to enable AMP
- `--use_xla` Set to True to enable XLA
- `--model_dir` The folder where model checkpoints are saved (the default is `/workspace/output`)
- `--data_dir` The folder where data resides (the default is `/data/`)
- `--log_steps` The interval of steps between logging of batch level stats.
- `--augmenter_name` Type of data augmentation
- `--raug_num_layers` Number of layers used in the random data augmentation scheme
- `--raug_magnitude` Strength of transformations applied in the random data augmentation scheme
- `--cutmix_alpha` Cutmix parameter used in the last stage of training.
- `--mixup_alpha` Mixup parameter used in the last stage of training.
- `--defer_img_mixing` Move image mixing ops from the data loader to the model/GPU (faster training)
- `--eval_img_size` Size of images used for evaluation
- `--eval_batch_size` The evaluation batch size per GPU
- `--n_stages` Number of stages used for stage-wise training
- `--train_batch_size` The training batch size per GPU
- `--train_img_size` Size of images used in the last stage of training
- `--base_img_size` Size of images used in the first stage of training
- `--max_epochs` The number of training epochs
- `--warmup_epochs` The number of epochs of warmup
- `--moving_average_decay` The decay weight used for EMA
- `--lr_init` The learning rate for a batch size of 128, effective learning rate will be automatically scaled according to the global training batch size: `lr=lr_init * global_BS/128 where global_BS=train_batch_size*n_GPUs`
- `--lr_decay` Learning rate decay policy
- `--weight_decay` Weight decay coefficient
- `--save_checkpoint_freq` Number of epochs to save checkpoints
**NOTE**: Avoid changing the default values of the general hyperparameters provided in `utils/cmdline_helper.py`. The reason is that some other models supported by this repository may rely on such default values. If you wish to change the values, override them via the command line.
### Command-line options
To display the full list of available options and their descriptions, use the `-h` or `--help` command-line option, for example:
`python main.py --help`
### Getting the data
Refer to the [TFDS ImageNet readme](https://github.com/tensorflow/datasets/blob/master/docs/catalog/imagenet2012.md) for manual download instructions.
To train on the ImageNet dataset, pass `$path_to_ImageNet_tfrecords` to `$data_dir` in the command-line.
Name the TFRecords in the following scheme:
- Training images - `/data/train-*`
- Validation images - `/data/validation-*`
### Training process
The training process can start from scratch, or resume from a checkpoint.
By default, bash script `scripts/S/training/{AMP,FP32,TF32}/convergence_8x{A100-80G,V100-16G,V100-32G}.sh` will start the training process with the following settings.
- Use 8 GPUs by Horovod
- Has XLA enabled
- Saves checkpoints after every 10 epochs to `/workspace/output/` folder
- AMP or FP32 or TF32 based on the folder `scripts/S/training/{AMP, FP32, TF32}`
The training starts from scratch if `--model_dir` has no checkpoints in it. To resume from a checkpoint, place the checkpoint into `--model_dir` and make sure the `checkpoint` file points to it.
#### Multi-node
Multi-node runs can be launched on a Pyxis/enroot Slurm cluster (refer to [Requirements](#requirements)) with the `run_S_multinode.sub` script with the following command for a 4-node NVIDIA DGX A100 example:
```
PARTITION=<partition_name> sbatch N 4 --ntasks-per-node=8 run_S_multinode.sub
```
Checkpoints will be saved after `--save_checkpoint_freq` epochs at `checkpointdir`. The latest checkpoint will be automatically picked up to resume training in case it needs to be resumed. Cluster partition name has to be provided `<partition_name>`.
Note that the `run_S_multinode.sub` script is a starting point that has to be adapted depending on the environment. In particular, pay attention to the variables such as `--container-image`, which handles the container image to train, and `--datadir`, which handles the location of the ImageNet data.
Refer to the scripts to find the full list of variables to adjust for your system.
### Inference process
Validation can be done either during training (when `--mode train_and_eval` is used) or in a post-training setting (`--mode eval`) on a checkpointed model. The evaluation script expects data in the tfrecord format.
`bash ./scripts/S/evaluation/evaluation_{AMP,FP32,TF32}_{A100-80G,V100-16G,V100-32G}.sh`
Metrics gathered through this process are listed below:
```
- eval_loss
- eval_accuracy_top_1
- eval_accuracy_top_5
- avg_exp_per_second_eval
- avg_exp_per_second_eval_per_GPU
- avg_time_per_exp_eval : Average Latency
- latency_90pct : 90% Latency
- latency_95pct : 95% Latency
- latency_99pct : 99% Latency
```
The scripts used for inference expect the inference data in the following directory structure:
```
infer_data
| ├── images
| | ├── image1.JPEG
| | ├── image2.JPEG
```
Run:
`bash ./scripts/S/inference/inference_{AMP,FP32,TF32}.sh`
## Performance
The performance measurements in this document were conducted at the time of publication and may not reflect the performance achieved from NVIDIA’s latest software release. For the most up-to-date performance measurements, go to [NVIDIA Data Center Deep Learning Product Performance](https://developer.nvidia.com/deep-learning-performance-training-inference).
### Benchmarking
The following section shows how to run benchmarks measuring the model performance in training and inference modes.
#### Training performance benchmark
Training benchmark for EfficientNet v2-S was run on NVIDIA DGX A100 80GB and NVIDIA DGX-1 V100 32GB.
`bash ./scripts/S/training/{AMP, FP32, TF32}/train_benchmark_8x{A100-80G, V100-32G}.sh`
#### Inference performance benchmark
Inference benchmark for EfficientNet v2-S was run on NVIDIA DGX A100 80GB and NVIDIA DGX-1 V100 32GB.
### Results
The following sections provide details on how we achieved our performance and accuracy in training and inference.
#### Training results for EfficientNet v2-S
##### Training accuracy: NVIDIA DGX A100 (8x A100 80GB)
Our results were obtained by running the training scripts in the tensorflow:21.09-tf2-py3 NGC container on multi-node NVIDIA DGX A100 (8x A100 80GB) GPUs. We evaluated the models using both the original and EMA weights and selected the higher accuracy to report.
<!---
| 8 | 83.87% | 83.93% | 33hrs | 13.5hrs | 2.44 |
--->
| GPUs | Accuracy - TF32 | Accuracy - mixed precision | Time to train - TF32 | Time to train - mixed precision | Time to train speedup (TF32 to mixed precision) |
|----------|------------------|-----------------------------|-------------------------|----------------------------------|--------------------------------------------------------|
| 8 | 83.87% | 83.93% | 32hrs | 14hrs | 2.28 |# PBR
| 16 | 83.89% | 83.83% | 16hrs | 7hrs | 2.28 |
##### Training accuracy: NVIDIA DGX-1 (8x V100 32GB)
Our results were obtained by running the training scripts in the tensorflow:21.09-tf2-py3 NGC container on multi-node NVIDIA DGX V100 (8x V100 32GB) GPUs. We evaluated the models using both the original and EMA weights and selected the higher accuracy to report.
<!---
[//]: | 8 | 83.86% | 84.0% | 126.5hrs | 59hrs | 2.14 | # RNO
--->
| GPUs | Accuracy - FP32 | Accuracy - mixed precision | Time to train - FP32 | Time to train - mixed precision | Time to train speedup (FP32 to mixed precision) |
|----------|------------------|-----------------------------|-------------------------|----------------------------------|--------------------------------------------------------|
| 8 | 83.86% | 84.0% | 90.3hrs | 55hrs | 1.64 | # PBR
| 16 | 83.75% | 83.87% | 60.5hrs | 28.5hrs | 2.12 | # RNO
| 32 | 83.81% | 83.82% | 30.2hrs | 15.5hrs | 1.95 | # RNO
#### Training performance results for EfficientNet v2-S
##### Training performance: NVIDIA DGX A100 (8x A100 80GB)
EfficientNet v2-S uses images of increasing resolution during training. Since throughput changes depending on the image size, we have measured throughput based on the image size used in the last stage of training (300x300).
<!---
# | 8 | 3100 | 7000 | 2.25 | 7.94 | 7.36 | # without PBR
--->
| GPUs | Throughput - TF32 | Throughput - mixed precision | Throughput speedup (TF32 - mixed precision) | Weak scaling - TF32 | Weak scaling - mixed precision |
|-----|------------------------|---------------------------------|-----------------------------------------------|------------------------|----------------------------------|
| 1 | 390 | 950 | 2.43 | 1 | 1 |
| 8 | 2800 | 6600 | 2.35 | 7.17 | 6.94 | # PBR
| 16 | 5950 | 14517 | 2.43 | 15.25 | 15.28 |
##### Training performance: NVIDIA DGX-1 (8x V100 32GB)
EfficientNet v2-S uses images of increasing resolution during training. Since throughput changes depending on the image size, we have measured throughput based on the image size used in the last stage of training (300x300).
| GPUs | Throughput - FP32 | Throughput - mixed precision | Throughput speedup (FP32 - mixed precision) | Weak scaling - FP32 | Weak scaling - mixed precision |
|-----|------------------------|---------------------------------|-----------------------------------------------|------------------------|----------------------------------|
| 1 | 156 | 380 | 2.43 | 1 | 1 | # DLCLUSTER
| 8 | 952 | 1774 | 1.86 | 6.10 | 4.66 | # PBR
| 16 | 1668 | 3750 | 2.25 | 10.69 | 9.86 | # RNO
| 32 | 3270 | 7250 | 2.2 | 20.96 | 19.07 | # RNO
#### Training EfficientNet v2-S at scale
##### 10x NVIDIA DGX-1 V100 (8x V100 32GB)
We trained EfficientNet v2-S at scale using 10 DGX-1 machines each having 8x V100 32GB GPUs. We used the same set of hyperparameters and NGC container as before. Also, throughput numbers were measured in the last stage of training. The accuracy was selected as the better between that of the original weights and EMA weights.
| # Nodes | GPUs | Optimizer |Accuracy - mixed precision |Time to train - mixed precision | Time to train speedup | Throughput - mixed precision | Throughput scaling |
|----------|----------|-----------|-----------------------------|--------------------------------|------------------------------|---------------------------------|------------------------|
| 1 | 8 | RMSPROP| 84.0% | 55hrs | 1 | 1774 | 1 |
| 10 | 80 | RMSPROP| 83.76% | 6.5hrs | 8.46 | 16039 | 9.04 |
<!---
| 20 | 160 | 83.74% | 3.5hrs | 15.71 | 31260 | 17.62 |
--->
##### 10x NVIDIA DGX A100 (8x A100 80GB)
We trained EfficientNet v2-S at scale using 10 DGX A100 machines each having 8x A100 80GB GPUs. This training setting has an effective batch size of 36800 (460x8x10), which requires advanced optimizers particularly designed for large-batch training. For this purpose, we used the nvLAMB optimizer with the following hyper parameters: lr_warmup_epochs=10, beta_1=0.9, beta_2=0.999, epsilon=0.000001, grad_global_clip_norm=1, lr_init=0.00005, weight_decay=0.00001. As before, we used tensorflow:21.09-tf2-py3 NGC container and measured throughput numbers in the last stage of training. The accuracy was selected as the better between that of the original weights and EMA weights.
| # Nodes | GPUs | Optimizer | Accuracy - mixed precision |Time to train - mixed precision | Time to train speedup | Throughput - mixed precision | Throughput scaling |
|----------|----------|-----------|-----------------------------|--------------------------------|------------------------------|---------------------------------|------------------------|
| 1 | 8 | RMSPROP| 83.93% | 14hrs | 1 | 6600 | 1 | #PBR
| 10 | 80 | nvLAMB | 82.84% | 1.84hrs | 7.60 | 62130 | 9.41 |
#### Inference performance results for EfficientNet v2-S
##### Inference performance: NVIDIA DGX A100 (1x A100 80GB)
Our results were obtained by running the inferencing benchmarking script in the tensorflow:21.09-tf2-py3 NGC container on the NVIDIA DGX A100 (1x A100 80GB) GPU.
FP16 Inference Latency
| Batch size | Resolution | Throughput Avg | Latency Avg (ms) | Latency 90% (ms) |Latency 95% (ms) |Latency 99% (ms) |
|------------|------------------|--------|--------|--------|--------|--------|
| 1 | 384x384 | 29 | 33.99 | 33.49 | 33.69 | 33.89 |
| 8 | 384x384 | 204 | 39.14 | 38.61 | 38.82 | 39.03 |
| 32 | 384x384 | 772 | 41.35 | 40.64 | 40.90 | 41.15 |
| 128 | 384x384 | 1674 | 76.45 | 74.20 | 74.70 | 75.80 |
| 256 | 384x384 | 1960 | 130.57 | 127.34 | 128.74 | 130.27 |
| 512 | 384x384 | 2062 | 248.18 | 226.80 | 232.86 | 248.18 |
| 1024 | 384x384 | 2032 | 503.73 | 461.78 | 481.50 | 503.73 |
TF32 Inference Latency
| Batch size | Resolution | Throughput Avg | Latency Avg (ms) | Latency 90% (ms) | Latency 95% (ms) | Latency 99% (ms) |
|-------------|-----------------|--------|--------|--------|--------|--------|
| 1 | 384x384 | 39 | 25.55 | 25.05 | 25.26 | 25.47 |
| 8 | 384x384 | 244 | 32.75 | 32.16 | 32.40 | 32.64 |
| 32 | 384x384 | 777 | 41.13 | 40.69 | 40.84 | 41.00 |
| 128 | 384x384 | 1000 | 127.94| 126.71 | 127.12 | 127.64 |
| 256 | 384x384 | 1070 | 239.08| 235.45 | 236.79 | 238.39 |
| 512 | 384x384 | 1130 | 452.71 | 444.64 | 448.18 | 452.71 |
### Inference performance: NVIDIA DGX-1 (1x V100 32GB)
Our results were obtained by running the inferencing benchmarking script in the tensorflow:21.09-tf2-py3 NGC container on the NVIDIA DGX V100 (1x V100 32GB) GPU.
FP16 Inference Latency
| Batch size | Resolution | Throughput Avg | Latency Avg (ms) | Latency 90% (ms) |Latency 95% (ms) |Latency 99% (ms) |
|------------|------------------|--------|--------|--------|--------|--------|
| 1 | 384x384 | 29 | 33.99 | 33.49 | 33.69 | 33.89 |
| 8 | 384x384 | 184 | 43.37 | 42.80 | 43.01 | 43.26 |
| 32 | 384x384 | 592 | 52.96 | 53.20 | 53.45 | 53.72 |
| 128 | 384x384 | 933 | 136.98 | 134.44 | 134.79 | 136.05 |
| 256 | 384x384 | 988 | 258.94 | 251.56 | 252.86 | 257.92 |
FP32 Inference Latency
| Batch size | Resolution | Throughput Avg | Latency Avg (ms) | Latency 90% (ms) | Latency 95% (ms) | Latency 99% (ms) |
|-------------|-----------------|--------|--------|--------|--------|--------|
| 1 | 384x384 | 45 | 22.02 | 21.87 | 21.93 | 21.99 |
| 8 | 384x384 | 260 | 30.73 | 30.33 | 30.51 | 30.67 |
| 32 | 384x384 | 416 | 76.89 | 76.57 | 76.65 | 76.74 |
| 128 | 384x384 | 460 | 278.24| 276.56 | 276.93 | 277.74 |
## Release notes
### Changelog
February 2022
- Initial release
### Known issues
- EfficientNet v2 might run into OOM or might exhibit a significant drop in throughput at the onset of the last stage of training. The fix is to resume training from the latest checkpoint.
|
PyTorch/LanguageModeling/Transformer-XL/pytorch | pytorch | run_enwik8_base | #!/bin/bash
export OMP_NUM_THREADS=1
if [[ $1 == 'train' ]]; then
echo 'Run training...'
python train.py \
--cuda \
--data ../data/enwik8/ \
--dataset enwik8 \
--n_layer 12 \
--d_model 512 \
--n_head 8 \
--d_head 64 \
--d_inner 2048 \
--dropout 0.1 \
--dropatt 0.0 \
--optim adam \
--lr 0.00025 \
--warmup_step 0 \
--max_step 400000 \
--tgt_len 512 \
--mem_len 512 \
--eval_tgt_len 128 \
--batch_size 22 \
--multi_gpu \
--gpu0_bsz 4 \
${@:2}
elif [[ $1 == 'eval' ]]; then
echo 'Run evaluation...'
python eval.py \
--cuda \
--data ../data/enwik8/ \
--dataset enwik8 \
--tgt_len 80 \
--mem_len 2100 \
--clamp_len 820 \
--same_length \
--split test \
${@:2}
else
echo 'unknown argment 1'
fi
|
PyTorch/LanguageModeling/BERT/triton/runner | runner | preparer | # Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import abc
import pathlib
from datetime import datetime
from typing import Dict, List
# method from PEP-366 to support relative import in executed modules
if __name__ == "__main__" and __package__ is None:
__package__ = pathlib.Path(__file__).parent.name
from .config import Config
from .configuration import Configuration
from .downloader import download
from .experiment import Experiment, Stage
from .logger import LOGGER
from .maintainer import Maintainer
from .pipeline import Pipeline
from .stages import ResultsType, TritonPerformanceOfflineStage, TritonPerformanceOnlineStage
from .task import Checkpoint, Dataset, SystemInfo, Task
from .triton import Triton
from .utils import clean_directory
class Preparer(abc.ABC):
"""
Runner preparer object.
"""
@abc.abstractmethod
def exec(
self,
workspace: pathlib.Path,
config: Config,
pipeline: Pipeline,
maintainer: Maintainer,
triton: Triton,
logs_dir: pathlib.Path,
):
pass
class ExperimentPreparer(Preparer):
"""
Experiment runner preparer object.
"""
def exec(
self,
workspace: pathlib.Path,
config: Config,
pipeline: Pipeline,
maintainer: Maintainer,
triton: Triton,
logs_dir: pathlib.Path,
):
LOGGER.info("Preparing Triton container image")
triton_container_image = self._prepare_triton_container_image(config, maintainer, triton)
LOGGER.info("Initialize task")
task = self._initialize_task(
workspace=workspace,
config=config,
pipeline=pipeline,
triton_container_image=triton_container_image,
logs_dir=logs_dir,
)
LOGGER.info("Preparing directories")
self._create_dirs(workspace, task)
LOGGER.info("Clean previous run artifacts directories")
self._clean_previous_run_artifacts(workspace, task)
LOGGER.info("Downloading checkpoints")
self._download_checkpoints(task)
return task
def _create_dirs(self, workspace: pathlib.Path, task: Task) -> None:
"""
Create directories used to store artifacts and final results
Returns:
None
"""
for directory in [task.results_dir, task.logs_dir, task.checkpoints_dir]:
directory_path = workspace / directory
directory_path.mkdir(parents=True, exist_ok=True)
LOGGER.info(f"Directory {directory} created.")
def _clean_previous_run_artifacts(self, workspace: pathlib.Path, task: Task) -> None:
"""
Clean logs from previous run
Returns:
None
"""
for directory in [
task.logs_dir,
task.results_dir,
]:
directory_path = workspace / directory
clean_directory(directory_path)
LOGGER.info(f"Location {directory} cleaned.")
def _prepare_triton_container_image(self, config: Config, maintainer: Maintainer, triton: Triton) -> str:
"""
Prepare Triton Container Image based on provided configuration
Returns:
Name of container image to use in process
"""
if not config.triton_dockerfile:
image_name = triton.container_image(config.container_version)
LOGGER.info(f"Using official Triton container image: {image_name}.")
return image_name
if config.triton_container_image:
LOGGER.info(f"Using provided Triton Container Image: {config.triton_container_image}")
return config.triton_container_image
normalized_model_name = config.model_name.lower().replace("_", "-")
image_name = f"tritonserver-{normalized_model_name}:latest"
LOGGER.info(f"Building Triton Container Image: {image_name}")
maintainer.build_image(
image_name=image_name,
image_file_path=pathlib.Path(config.triton_dockerfile),
build_args={"FROM_IMAGE": triton.container_image(container_version=config.container_version)},
)
return image_name
def _download_checkpoints(self, task: Task) -> None:
"""
Download checkpoints
"""
for variant, checkpoint in task.checkpoints.items():
checkpoint_url = checkpoint.url
download_path = checkpoint.path
if download_path.is_dir():
LOGGER.info(f"Checkpoint {download_path.name} already downloaded.")
continue
if not checkpoint_url:
LOGGER.warning(
f"Checkpoint {variant} url is not provided."
"\nIf you want to use that checkpoint please train the model locally"
f"\nand copy to {download_path} directory"
)
continue
download(checkpoint_url, download_path)
def _initialize_task(
self,
workspace: pathlib.Path,
config: Config,
pipeline: Pipeline,
triton_container_image: str,
logs_dir: pathlib.Path,
) -> Task:
"""
Initialize task object
Args:
workspace: Path to workspace where artifacts are stored
config: Config object
pipeline: Pipeline object
triton_container_image: Triton Inference Server container image used for tests
Returns:
Task object
"""
datasets = {}
for dataset in config.datasets:
datasets[dataset.name] = Dataset(name=dataset.name)
checkpoints = {}
for checkpoint in config.checkpoints:
download_path = workspace / Task.checkpoints_dir / checkpoint.name
checkpoints[checkpoint.name] = Checkpoint(name=checkpoint.name, url=checkpoint.url, path=download_path)
results_types = self._task_results_types(pipeline=pipeline)
stages = dict()
for stage in pipeline.stages():
stages[stage.label] = {"result_path": stage.result_path, "result_type": stage.result_type}
experiments = list()
for idx, configuration in enumerate(config.configurations, start=1):
experiment = self._prepare_experiment(
idx=idx,
configuration=configuration,
results_types=results_types,
stages=stages,
)
experiments.append(experiment)
system_info = SystemInfo.from_host()
task = Task(
model_name=config.model_name,
framework=config.framework,
checkpoints=checkpoints,
datasets=datasets,
datasets_dir=config.datasets_dir,
experiments=experiments,
container_version=config.container_version,
system_info=system_info,
triton_container_image=triton_container_image,
triton_custom_operations=config.triton_custom_operations,
triton_load_model_method=config.triton_load_model_method,
started_at=int(datetime.utcnow().timestamp()),
logs_dir=logs_dir,
)
return task
def _task_results_types(self, pipeline: Pipeline) -> List[str]:
"""
Types of results generated as part of task
Returns:
List of result types
"""
results = list()
for stage in pipeline.stages():
if TritonPerformanceOfflineStage.label == stage.label:
results.append(ResultsType.TRITON_PERFORMANCE_OFFLINE)
continue
if TritonPerformanceOnlineStage.label == stage.label:
results.append(ResultsType.TRITON_PERFORMANCE_ONLINE)
continue
return results
def _prepare_experiment(
self,
idx: int,
configuration: Configuration,
results_types: List[str],
stages: Dict,
) -> Experiment:
"""
Prepare experiments data
Args:
idx: Experiment index
configuration: Configuration object
results_types: Results types stored in experiment
stages: Stages executed as part of experiment
Returns:
Experiment object
"""
parameters = {key.lower(): value for key, value in configuration.parameters.items()}
results_mapped = dict()
for result_type in results_types:
results_mapped[result_type] = result_type
stages_mapped = dict()
for name, stage_data in stages.items():
stages_mapped[name] = Stage(name=name, **stage_data)
experiment = Experiment(
experiment_id=idx,
parameters=parameters,
stages=stages_mapped,
results=results_mapped,
)
return experiment
|
PyTorch/Forecasting/TFT | TFT | log_helper | # Copyright (c) 2021-2022, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import os
import subprocess
import sys
import itertools
import atexit
import dllogger
from dllogger import Backend, JSONStreamBackend, StdOutBackend
import torch.distributed as dist
from torch.utils.tensorboard import SummaryWriter
class TensorBoardBackend(Backend):
def __init__(self, verbosity, log_dir):
super().__init__(verbosity=verbosity)
self.summary_writer = SummaryWriter(log_dir=os.path.join(log_dir, 'TB_summary'),
flush_secs=120,
max_queue=200
)
self.hp_cache = None
atexit.register(self.summary_writer.close)
@property
def log_level(self):
return self._log_level
def metadata(self, timestamp, elapsedtime, metric, metadata):
pass
def log(self, timestamp, elapsedtime, step, data):
if step == 'HPARAMS':
parameters = {k: v for k, v in data.items() if not isinstance(v, (list, tuple))}
#Unpack list and tuples
for d in [{k+f'_{i}':v for i,v in enumerate(l)} for k,l in data.items() if isinstance(l, (list, tuple))]:
parameters.update(d)
#Remove custom classes
parameters = {k: v for k, v in data.items() if isinstance(v, (int, float, str, bool))}
parameters.update({k:'None' for k, v in data.items() if v is None})
self.hp_cache = parameters
if step == ():
if self.hp_cache is None:
print('Warning: Cannot save HParameters. Please log HParameters with step=\'HPARAMS\'', file=sys.stderr)
return
self.summary_writer.add_hparams(self.hp_cache, data)
if not isinstance(step, int):
return
for k, v in data.items():
self.summary_writer.add_scalar(k, v, step)
def flush(self):
pass
def setup_logger(args):
os.makedirs(args.results, exist_ok=True)
log_path = os.path.join(args.results, args.log_file)
if os.path.exists(log_path):
for i in itertools.count():
s_fname = args.log_file.split('.')
fname = '.'.join(s_fname[:-1]) + f'_{i}.' + s_fname[-1] if len(s_fname) > 1 else args.stat_file + f'.{i}'
log_path = os.path.join(args.results, fname)
if not os.path.exists(log_path):
break
def metric_format(metric, metadata, value):
return "{}: {}".format(metric, f'{value:.5f}' if isinstance(value, float) else value)
def step_format(step):
if step == ():
return "Finished |"
elif isinstance(step, int):
return "Step {0: <5} |".format(step)
return "Step {} |".format(step)
if not dist.is_initialized() or not args.distributed_world_size > 1 or args.distributed_rank == 0:
dllogger.init(backends=[JSONStreamBackend(verbosity=1, filename=log_path),
TensorBoardBackend(verbosity=1, log_dir=args.results),
StdOutBackend(verbosity=2,
step_format=step_format,
prefix_format=lambda x: "")#,
#metric_format=metric_format)
])
else:
dllogger.init(backends=[])
dllogger.log(step='PARAMETER', data=vars(args), verbosity=0)
container_setup_info = {**get_framework_env_vars(), **get_system_info()}
dllogger.log(step='ENVIRONMENT', data=container_setup_info, verbosity=0)
dllogger.metadata('loss', {'GOAL': 'MINIMIZE', 'STAGE': 'TRAIN', 'format': ':5f', 'unit': None})
dllogger.metadata('P10', {'GOAL': 'MINIMIZE', 'STAGE': 'TRAIN', 'format': ':5f', 'unit': None})
dllogger.metadata('P50', {'GOAL': 'MINIMIZE', 'STAGE': 'TRAIN', 'format': ':5f', 'unit': None})
dllogger.metadata('P90', {'GOAL': 'MINIMIZE', 'STAGE': 'TRAIN', 'format': ':5f', 'unit': None})
dllogger.metadata('items/s', {'GOAL': 'MAXIMIZE', 'STAGE': 'TRAIN', 'format': ':1f', 'unit': 'items/s'})
dllogger.metadata('val_loss', {'GOAL': 'MINIMIZE', 'STAGE': 'VAL', 'format':':5f', 'unit': None})
dllogger.metadata('val_P10', {'GOAL': 'MINIMIZE', 'STAGE': 'VAL', 'format': ':5f', 'unit': None})
dllogger.metadata('val_P50', {'GOAL': 'MINIMIZE', 'STAGE': 'VAL', 'format': ':5f', 'unit': None})
dllogger.metadata('val_P90', {'GOAL': 'MINIMIZE', 'STAGE': 'VAL', 'format': ':5f', 'unit': None})
dllogger.metadata('val_items/s', {'GOAL': 'MAXIMIZE', 'STAGE': 'VAL', 'format': ':1f', 'unit': 'items/s'})
dllogger.metadata('test_P10', {'GOAL': 'MINIMIZE', 'STAGE': 'TEST', 'format': ':5f', 'unit': None})
dllogger.metadata('test_P50', {'GOAL': 'MINIMIZE', 'STAGE': 'TEST', 'format': ':5f', 'unit': None})
dllogger.metadata('test_P90', {'GOAL': 'MINIMIZE', 'STAGE': 'TEST', 'format': ':5f', 'unit': None})
dllogger.metadata('sum', {'GOAL': 'MINIMIZE', 'STAGE': 'TEST', 'format': ':5f', 'unit': None})
dllogger.metadata('throughput', {'GOAL': 'MAXIMIZE', 'STAGE': 'TEST', 'format': ':1f', 'unit': 'items/s'})
dllogger.metadata('latency_avg', {'GOAL': 'MIMIMIZE', 'STAGE': 'TEST', 'format': ':5f', 'unit': 's'})
dllogger.metadata('latency_p90', {'GOAL': 'MIMIMIZE', 'STAGE': 'TEST', 'format': ':5f', 'unit': 's'})
dllogger.metadata('latency_p95', {'GOAL': 'MIMIMIZE', 'STAGE': 'TEST', 'format': ':5f', 'unit': 's'})
dllogger.metadata('latency_p99', {'GOAL': 'MIMIMIZE', 'STAGE': 'TEST', 'format': ':5f', 'unit': 's'})
dllogger.metadata('average_ips', {'GOAL': 'MAXIMIZE', 'STAGE': 'TEST', 'format': ':1f', 'unit': 'items/s'})
def get_framework_env_vars():
return {
'NVIDIA_PYTORCH_VERSION': os.environ.get('NVIDIA_PYTORCH_VERSION'),
'PYTORCH_VERSION': os.environ.get('PYTORCH_VERSION'),
'CUBLAS_VERSION': os.environ.get('CUBLAS_VERSION'),
'NCCL_VERSION': os.environ.get('NCCL_VERSION'),
'CUDA_DRIVER_VERSION': os.environ.get('CUDA_DRIVER_VERSION'),
'CUDNN_VERSION': os.environ.get('CUDNN_VERSION'),
'CUDA_VERSION': os.environ.get('CUDA_VERSION'),
'NVIDIA_PIPELINE_ID': os.environ.get('NVIDIA_PIPELINE_ID'),
'NVIDIA_BUILD_ID': os.environ.get('NVIDIA_BUILD_ID'),
'NVIDIA_TF32_OVERRIDE': os.environ.get('NVIDIA_TF32_OVERRIDE'),
}
def get_system_info():
system_info = subprocess.run('nvidia-smi --query-gpu=gpu_name,memory.total,enforced.power.limit --format=csv'.split(), capture_output=True).stdout
system_info = [i.decode('utf-8') for i in system_info.split(b'\n')]
system_info = [x for x in system_info if x]
return {'system_info': system_info}
|
PyTorch/Segmentation/MaskRCNN/pytorch | pytorch | ABSTRACTIONS | ## Abstractions
The main abstractions introduced by `maskrcnn_benchmark` that are useful to
have in mind are the following:
### ImageList
In PyTorch, the first dimension of the input to the network generally represents
the batch dimension, and thus all elements of the same batch have the same
height / width.
In order to support images with different sizes and aspect ratios in the same
batch, we created the `ImageList` class, which holds internally a batch of
images (os possibly different sizes). The images are padded with zeros such that
they have the same final size and batched over the first dimension. The original
sizes of the images before padding are stored in the `image_sizes` attribute,
and the batched tensor in `tensors`.
We provide a convenience function `to_image_list` that accepts a few different
input types, including a list of tensors, and returns an `ImageList` object.
```python
from maskrcnn_benchmark.structures.image_list import to_image_list
images = [torch.rand(3, 100, 200), torch.rand(3, 150, 170)]
batched_images = to_image_list(images)
# it is also possible to make the final batched image be a multiple of a number
batched_images_32 = to_image_list(images, size_divisible=32)
```
### BoxList
The `BoxList` class holds a set of bounding boxes (represented as a `Nx4` tensor) for
a specific image, as well as the size of the image as a `(width, height)` tuple.
It also contains a set of methods that allow to perform geometric
transformations to the bounding boxes (such as cropping, scaling and flipping).
The class accepts bounding boxes from two different input formats:
- `xyxy`, where each box is encoded as a `x1`, `y1`, `x2` and `y2` coordinates, and
- `xywh`, where each box is encoded as `x1`, `y1`, `w` and `h`.
Additionally, each `BoxList` instance can also hold arbitrary additional information
for each bounding box, such as labels, visibility, probability scores etc.
Here is an example on how to create a `BoxList` from a list of coordinates:
```python
from maskrcnn_benchmark.structures.bounding_box import BoxList, FLIP_LEFT_RIGHT
width = 100
height = 200
boxes = [
[0, 10, 50, 50],
[50, 20, 90, 60],
[10, 10, 50, 50]
]
# create a BoxList with 3 boxes
bbox = BoxList(boxes, image_size=(width, height), mode='xyxy')
# perform some box transformations, has similar API as PIL.Image
bbox_scaled = bbox.resize((width * 2, height * 3))
bbox_flipped = bbox.transpose(FLIP_LEFT_RIGHT)
# add labels for each bbox
labels = torch.tensor([0, 10, 1])
bbox.add_field('labels', labels)
# bbox also support a few operations, like indexing
# here, selects boxes 0 and 2
bbox_subset = bbox[[0, 2]]
```
|
PyTorch/Segmentation/MaskRCNN/pytorch/configs/pascal_voc | pascal_voc | e2e_mask_rcnn_R_50_FPN_1x_cocostyle | MODEL:
META_ARCHITECTURE: "GeneralizedRCNN"
WEIGHT: "catalog://ImageNetPretrained/MSRA/R-50"
BACKBONE:
CONV_BODY: "R-50-FPN"
OUT_CHANNELS: 256
RPN:
USE_FPN: True
ANCHOR_STRIDE: (4, 8, 16, 32, 64)
PRE_NMS_TOP_N_TRAIN: 2000
PRE_NMS_TOP_N_TEST: 1000
POST_NMS_TOP_N_TEST: 1000
FPN_POST_NMS_TOP_N_TEST: 1000
ROI_HEADS:
USE_FPN: True
ROI_BOX_HEAD:
POOLER_RESOLUTION: 7
POOLER_SCALES: (0.25, 0.125, 0.0625, 0.03125)
POOLER_SAMPLING_RATIO: 2
FEATURE_EXTRACTOR: "FPN2MLPFeatureExtractor"
PREDICTOR: "FPNPredictor"
NUM_CLASSES: 21
ROI_MASK_HEAD:
POOLER_SCALES: (0.25, 0.125, 0.0625, 0.03125)
FEATURE_EXTRACTOR: "MaskRCNNFPNFeatureExtractor"
PREDICTOR: "MaskRCNNC4Predictor"
POOLER_RESOLUTION: 14
POOLER_SAMPLING_RATIO: 2
RESOLUTION: 28
SHARE_BOX_FEATURE_EXTRACTOR: False
MASK_ON: True
DATASETS:
TRAIN: ("voc_2012_train_cocostyle",)
TEST: ("voc_2012_val_cocostyle",)
DATALOADER:
SIZE_DIVISIBILITY: 32
SOLVER:
BASE_LR: 0.01
WEIGHT_DECAY: 0.0001
STEPS: (18000,)
MAX_ITER: 24000
|
PyTorch/Recommendation/DLRM/tests/feature_specs | feature_specs | 13_num_30_cat | channel_spec:
categorical:
- cat_0.bin
- cat_1.bin
- cat_2.bin
- cat_3.bin
- cat_4.bin
- cat_5.bin
- cat_6.bin
- cat_7.bin
- cat_8.bin
- cat_9.bin
- cat_10.bin
- cat_11.bin
- cat_12.bin
- cat_13.bin
- cat_14.bin
- cat_15.bin
- cat_16.bin
- cat_17.bin
- cat_18.bin
- cat_19.bin
- cat_20.bin
- cat_21.bin
- cat_22.bin
- cat_23.bin
- cat_24.bin
- cat_25.bin
- cat_26.bin
- cat_27.bin
- cat_28.bin
- cat_29.bin
label:
- label
numerical: &id001
- num_0
- num_1
- num_2
- num_3
- num_4
- num_5
- num_6
- num_7
- num_8
- num_9
- num_10
- num_11
- num_12
feature_spec:
cat_0.bin:
cardinality: 100000
dtype: int32
cat_1.bin:
cardinality: 100001
dtype: int32
cat_10.bin:
cardinality: 100010
dtype: int32
cat_11.bin:
cardinality: 100011
dtype: int32
cat_12.bin:
cardinality: 100012
dtype: int32
cat_13.bin:
cardinality: 100013
dtype: int32
cat_14.bin:
cardinality: 100014
dtype: int32
cat_15.bin:
cardinality: 100015
dtype: int32
cat_16.bin:
cardinality: 100016
dtype: int32
cat_17.bin:
cardinality: 100017
dtype: int32
cat_18.bin:
cardinality: 100018
dtype: int32
cat_19.bin:
cardinality: 100019
dtype: int32
cat_2.bin:
cardinality: 100002
dtype: int32
cat_20.bin:
cardinality: 100020
dtype: int32
cat_21.bin:
cardinality: 100021
dtype: int32
cat_22.bin:
cardinality: 100022
dtype: int32
cat_23.bin:
cardinality: 100023
dtype: int32
cat_24.bin:
cardinality: 100024
dtype: int32
cat_25.bin:
cardinality: 100025
dtype: int32
cat_26.bin:
cardinality: 100026
dtype: int32
cat_27.bin:
cardinality: 100027
dtype: int32
cat_28.bin:
cardinality: 100028
dtype: int32
cat_29.bin:
cardinality: 100029
dtype: int32
cat_3.bin:
cardinality: 100003
dtype: int32
cat_4.bin:
cardinality: 100004
dtype: int32
cat_5.bin:
cardinality: 100005
dtype: int32
cat_6.bin:
cardinality: 100006
dtype: int32
cat_7.bin:
cardinality: 100007
dtype: int32
cat_8.bin:
cardinality: 100008
dtype: int32
cat_9.bin:
cardinality: 100009
dtype: int32
label:
dtype: bool
num_0:
dtype: float16
num_1:
dtype: float16
num_10:
dtype: float16
num_11:
dtype: float16
num_12:
dtype: float16
num_2:
dtype: float16
num_3:
dtype: float16
num_4:
dtype: float16
num_5:
dtype: float16
num_6:
dtype: float16
num_7:
dtype: float16
num_8:
dtype: float16
num_9:
dtype: float16
metadata: {}
source_spec:
test:
- features: *id001
files:
- test/numerical.bin
type: split_binary
- features:
- label
files:
- test/label.bin
type: split_binary
- features:
- cat_0.bin
files:
- test/cat_0.bin
type: split_binary
- features:
- cat_1.bin
files:
- test/cat_1.bin
type: split_binary
- features:
- cat_2.bin
files:
- test/cat_2.bin
type: split_binary
- features:
- cat_3.bin
files:
- test/cat_3.bin
type: split_binary
- features:
- cat_4.bin
files:
- test/cat_4.bin
type: split_binary
- features:
- cat_5.bin
files:
- test/cat_5.bin
type: split_binary
- features:
- cat_6.bin
files:
- test/cat_6.bin
type: split_binary
- features:
- cat_7.bin
files:
- test/cat_7.bin
type: split_binary
- features:
- cat_8.bin
files:
- test/cat_8.bin
type: split_binary
- features:
- cat_9.bin
files:
- test/cat_9.bin
type: split_binary
- features:
- cat_10.bin
files:
- test/cat_10.bin
type: split_binary
- features:
- cat_11.bin
files:
- test/cat_11.bin
type: split_binary
- features:
- cat_12.bin
files:
- test/cat_12.bin
type: split_binary
- features:
- cat_13.bin
files:
- test/cat_13.bin
type: split_binary
- features:
- cat_14.bin
files:
- test/cat_14.bin
type: split_binary
- features:
- cat_15.bin
files:
- test/cat_15.bin
type: split_binary
- features:
- cat_16.bin
files:
- test/cat_16.bin
type: split_binary
- features:
- cat_17.bin
files:
- test/cat_17.bin
type: split_binary
- features:
- cat_18.bin
files:
- test/cat_18.bin
type: split_binary
- features:
- cat_19.bin
files:
- test/cat_19.bin
type: split_binary
- features:
- cat_20.bin
files:
- test/cat_20.bin
type: split_binary
- features:
- cat_21.bin
files:
- test/cat_21.bin
type: split_binary
- features:
- cat_22.bin
files:
- test/cat_22.bin
type: split_binary
- features:
- cat_23.bin
files:
- test/cat_23.bin
type: split_binary
- features:
- cat_24.bin
files:
- test/cat_24.bin
type: split_binary
- features:
- cat_25.bin
files:
- test/cat_25.bin
type: split_binary
- features:
- cat_26.bin
files:
- test/cat_26.bin
type: split_binary
- features:
- cat_27.bin
files:
- test/cat_27.bin
type: split_binary
- features:
- cat_28.bin
files:
- test/cat_28.bin
type: split_binary
- features:
- cat_29.bin
files:
- test/cat_29.bin
type: split_binary
train:
- features: *id001
files:
- train/numerical.bin
type: split_binary
- features:
- label
files:
- train/label.bin
type: split_binary
- features:
- cat_0.bin
files:
- train/cat_0.bin
type: split_binary
- features:
- cat_1.bin
files:
- train/cat_1.bin
type: split_binary
- features:
- cat_2.bin
files:
- train/cat_2.bin
type: split_binary
- features:
- cat_3.bin
files:
- train/cat_3.bin
type: split_binary
- features:
- cat_4.bin
files:
- train/cat_4.bin
type: split_binary
- features:
- cat_5.bin
files:
- train/cat_5.bin
type: split_binary
- features:
- cat_6.bin
files:
- train/cat_6.bin
type: split_binary
- features:
- cat_7.bin
files:
- train/cat_7.bin
type: split_binary
- features:
- cat_8.bin
files:
- train/cat_8.bin
type: split_binary
- features:
- cat_9.bin
files:
- train/cat_9.bin
type: split_binary
- features:
- cat_10.bin
files:
- train/cat_10.bin
type: split_binary
- features:
- cat_11.bin
files:
- train/cat_11.bin
type: split_binary
- features:
- cat_12.bin
files:
- train/cat_12.bin
type: split_binary
- features:
- cat_13.bin
files:
- train/cat_13.bin
type: split_binary
- features:
- cat_14.bin
files:
- train/cat_14.bin
type: split_binary
- features:
- cat_15.bin
files:
- train/cat_15.bin
type: split_binary
- features:
- cat_16.bin
files:
- train/cat_16.bin
type: split_binary
- features:
- cat_17.bin
files:
- train/cat_17.bin
type: split_binary
- features:
- cat_18.bin
files:
- train/cat_18.bin
type: split_binary
- features:
- cat_19.bin
files:
- train/cat_19.bin
type: split_binary
- features:
- cat_20.bin
files:
- train/cat_20.bin
type: split_binary
- features:
- cat_21.bin
files:
- train/cat_21.bin
type: split_binary
- features:
- cat_22.bin
files:
- train/cat_22.bin
type: split_binary
- features:
- cat_23.bin
files:
- train/cat_23.bin
type: split_binary
- features:
- cat_24.bin
files:
- train/cat_24.bin
type: split_binary
- features:
- cat_25.bin
files:
- train/cat_25.bin
type: split_binary
- features:
- cat_26.bin
files:
- train/cat_26.bin
type: split_binary
- features:
- cat_27.bin
files:
- train/cat_27.bin
type: split_binary
- features:
- cat_28.bin
files:
- train/cat_28.bin
type: split_binary
- features:
- cat_29.bin
files:
- train/cat_29.bin
type: split_binary
|
PaddlePaddle/Classification/RN50v1.5 | RN50v1.5 | inference | # Copyright (c) 2022 NVIDIA Corporation. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import os
import time
import glob
import numpy as np
import dllogger
from paddle.fluid import LoDTensor
from paddle.inference import Config, PrecisionType, create_predictor
from dali import dali_dataloader, dali_synthetic_dataloader
from utils.config import parse_args, print_args
from utils.mode import Mode
from utils.logger import setup_dllogger
def init_predictor(args):
infer_dir = args.trt_inference_dir
assert os.path.isdir(
infer_dir), f'inference_dir = "{infer_dir}" is not a directory'
pdiparams_path = glob.glob(os.path.join(infer_dir, '*.pdiparams'))
pdmodel_path = glob.glob(os.path.join(infer_dir, '*.pdmodel'))
assert len(pdiparams_path) == 1, \
f'There should be only 1 pdiparams in {infer_dir}, but there are {len(pdiparams_path)}'
assert len(pdmodel_path) == 1, \
f'There should be only 1 pdmodel in {infer_dir}, but there are {len(pdmodel_path)}'
predictor_config = Config(pdmodel_path[0], pdiparams_path[0])
predictor_config.enable_memory_optim()
predictor_config.enable_use_gpu(0, args.device)
precision = args.trt_precision
max_batch_size = args.batch_size
assert precision in ['FP32', 'FP16', 'INT8'], \
'precision should be FP32/FP16/INT8'
if precision == 'INT8':
precision_mode = PrecisionType.Int8
elif precision == 'FP16':
precision_mode = PrecisionType.Half
elif precision == 'FP32':
precision_mode = PrecisionType.Float32
else:
raise NotImplementedError
predictor_config.enable_tensorrt_engine(
workspace_size=args.trt_workspace_size,
max_batch_size=max_batch_size,
min_subgraph_size=args.trt_min_subgraph_size,
precision_mode=precision_mode,
use_static=args.trt_use_static,
use_calib_mode=args.trt_use_calib_mode)
predictor = create_predictor(predictor_config)
return predictor
def predict(predictor, input_data):
'''
Args:
predictor: Paddle inference predictor
input_data: A list of input
Returns:
output_data: A list of output
'''
# copy image data to input tensor
input_names = predictor.get_input_names()
for i, name in enumerate(input_names):
input_tensor = predictor.get_input_handle(name)
if isinstance(input_data[i], LoDTensor):
input_tensor.share_external_data(input_data[i])
else:
input_tensor.reshape(input_data[i].shape)
input_tensor.copy_from_cpu(input_data[i])
# do the inference
predictor.run()
results = []
# get out data from output tensor
output_names = predictor.get_output_names()
for i, name in enumerate(output_names):
output_tensor = predictor.get_output_handle(name)
output_data = output_tensor.copy_to_cpu()
results.append(output_data)
return results
def benchmark_dataset(args):
"""
Benchmark DALI format dataset, which reflects real the pipeline throughput including
1. Read images
2. Pre-processing
3. Inference
4. H2D, D2H
"""
predictor = init_predictor(args)
dali_iter = dali_dataloader(args, Mode.EVAL, 'gpu:' + str(args.device))
# Warmup some samples for the stable performance number
batch_size = args.batch_size
image_shape = args.image_shape
images = np.zeros((batch_size, *image_shape)).astype(np.float32)
for _ in range(args.benchmark_warmup_steps):
predict(predictor, [images])[0]
total_images = 0
correct_predict = 0
latency = []
start = time.perf_counter()
last_time_step = time.perf_counter()
for dali_data in dali_iter:
for data in dali_data:
label = np.asarray(data['label'])
total_images += label.shape[0]
label = label.flatten()
images = data['data']
predict_label = predict(predictor, [images])[0]
correct_predict += (label == predict_label).sum()
batch_end_time_step = time.perf_counter()
batch_latency = batch_end_time_step - last_time_step
latency.append(batch_latency)
last_time_step = time.perf_counter()
end = time.perf_counter()
latency = np.array(latency) * 1000
quantile = np.quantile(latency, [0.9, 0.95, 0.99])
statistics = {
'precision': args.trt_precision,
'batch_size': batch_size,
'throughput': total_images / (end - start),
'accuracy': correct_predict / total_images,
'eval_latency_avg': np.mean(latency),
'eval_latency_p90': quantile[0],
'eval_latency_p95': quantile[1],
'eval_latency_p99': quantile[2],
}
return statistics
def benchmark_synthetic(args):
"""
Benchmark on the synthetic data and bypass all pre-processing.
The host to device copy is still included.
This used to find the upper throughput bound when tunning the full input pipeline.
"""
predictor = init_predictor(args)
dali_iter = dali_synthetic_dataloader(args, 'gpu:' + str(args.device))
batch_size = args.batch_size
image_shape = args.image_shape
images = np.random.random((batch_size, *image_shape)).astype(np.float32)
latency = []
# warmup
for _ in range(args.benchmark_warmup_steps):
predict(predictor, [images])[0]
# benchmark
start = time.perf_counter()
last_time_step = time.perf_counter()
for dali_data in dali_iter:
for data in dali_data:
images = data['data']
predict(predictor, [images])[0]
batch_end_time_step = time.perf_counter()
batch_latency = batch_end_time_step - last_time_step
latency.append(batch_latency)
last_time_step = time.perf_counter()
end = time.perf_counter()
latency = np.array(latency) * 1000
quantile = np.quantile(latency, [0.9, 0.95, 0.99])
statistics = {
'precision': args.trt_precision,
'batch_size': batch_size,
'throughput': args.benchmark_steps * batch_size / (end - start),
'eval_latency_avg': np.mean(latency),
'eval_latency_p90': quantile[0],
'eval_latency_p95': quantile[1],
'eval_latency_p99': quantile[2],
}
return statistics
def main(args):
setup_dllogger(args.trt_log_path)
if args.show_config:
print_args(args)
if args.trt_use_synthetic:
statistics = benchmark_synthetic(args)
else:
statistics = benchmark_dataset(args)
dllogger.log(step=tuple(), data=statistics)
if __name__ == '__main__':
main(parse_args(including_trt=True))
|
TensorFlow/Segmentation/VNet/examples | examples | vnet_predict | # Copyright (c) 2019, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import argparse
import os
import subprocess
from os.path import dirname
PARSER = argparse.ArgumentParser(description="vnet_predict")
PARSER.add_argument('--data_dir',
required=True,
type=str)
PARSER.add_argument('--model_dir',
required=True,
type=str)
PARSER.add_argument('--batch_size',
required=True,
type=int)
PARSER.add_argument('--amp', dest='use_amp', action='store_true', default=False)
def build_command(FLAGS, path_to_main, use_amp):
return 'python {} --data_dir {} --model_dir {} --exec_mode predict --batch_size {} {}'.format(
path_to_main,
FLAGS.data_dir,
FLAGS.model_dir,
FLAGS.batch_size,
use_amp)
def main():
FLAGS = PARSER.parse_args()
use_amp = '--amp' if FLAGS.use_amp else ''
path_to_main = os.path.join(dirname(dirname(os.path.realpath(__file__))), 'main.py')
cmd = build_command(FLAGS, path_to_main, use_amp)
print('Command to be executed:')
print(cmd)
subprocess.call(cmd, shell=True)
if __name__ == '__main__':
main()
|
PyTorch/Segmentation/MaskRCNN/pytorch/demo | demo | README | ## Webcam and Jupyter notebook demo
This folder contains a simple webcam demo that illustrates how you can use `maskrcnn_benchmark` for inference.
### With your preferred environment
You can start it by running it from this folder, using one of the following commands:
```bash
# by default, it runs on the GPU
# for best results, use min-image-size 800
python webcam.py --min-image-size 800
# can also run it on the CPU
python webcam.py --min-image-size 300 MODEL.DEVICE cpu
# or change the model that you want to use
python webcam.py --config-file ../configs/caffe2/e2e_mask_rcnn_R_101_FPN_1x_caffe2.yaml --min-image-size 300 MODEL.DEVICE cpu
# in order to see the probability heatmaps, pass --show-mask-heatmaps
python webcam.py --min-image-size 300 --show-mask-heatmaps MODEL.DEVICE cpu
```
### With Docker
Build the image with the tag `maskrcnn-benchmark` (check [INSTALL.md](../INSTALL.md) for instructions)
Adjust permissions of the X server host (be careful with this step, refer to
[here](http://wiki.ros.org/docker/Tutorials/GUI) for alternatives)
```bash
xhost +
```
Then run a container with the demo:
```
docker run --rm -it \
-e DISPLAY=${DISPLAY} \
--privileged \
-v /tmp/.X11-unix:/tmp/.X11-unix \
--device=/dev/video0:/dev/video0 \
--ipc=host maskrcnn-benchmark \
python demo/webcam.py --min-image-size 300
```
**DISCLAIMER:** *This was tested for an Ubuntu 16.04 machine,
the volume mapping may vary depending on your platform*
|
PyTorch/Forecasting/TFT/triton/deployment_toolkit | deployment_toolkit | args | # Copyright (c) 2021-2022, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import argparse
import inspect
import logging
from typing import Callable, Dict, Optional, Union
from model_navigator.utils.cli import is_dict_generic, is_list_generic, is_optional_generic
from .core import GET_ARGPARSER_FN_NAME, load_from_file
LOGGER = logging.getLogger(__name__)
def str2bool(v):
if isinstance(v, bool):
return v
if v.lower() in ("yes", "true", "t", "y", "1"):
return True
elif v.lower() in ("no", "false", "f", "n", "0"):
return False
else:
raise argparse.ArgumentTypeError("Boolean value expected.")
def filter_fn_args(args: Union[dict, argparse.Namespace], fn: Callable) -> dict:
signature = inspect.signature(fn)
parameters_names = list(signature.parameters)
if isinstance(args, argparse.Namespace):
args = vars(args)
args = {k: v for k, v in args.items() if k in parameters_names}
return args
def add_args_for_fn_signature(parser, fn) -> argparse.ArgumentParser:
parser.conflict_handler = "resolve"
signature = inspect.signature(fn)
for parameter in signature.parameters.values():
if parameter.name in ["self", "args", "kwargs"]:
continue
argument_kwargs = {}
if parameter.annotation != inspect.Parameter.empty:
is_optional = is_optional_generic(parameter.annotation)
if is_optional:
annotation = parameter.annotation.__args__[0] # Optional[cls] will be changed into Union[cls, None]
else:
annotation = parameter.annotation
is_list = is_list_generic(annotation)
is_dict = is_dict_generic(annotation)
if parameter.annotation == bool:
argument_kwargs["type"] = str2bool
argument_kwargs["choices"] = [0, 1]
elif is_list:
argument_kwargs["type"] = annotation.__args__[0] # List[cls] -> cls
elif is_dict:
raise RuntimeError(
f"Could not prepare argument parser for {parameter.name}: {parameter.annotation} in {fn}"
)
else:
argument_kwargs["type"] = annotation
if parameter.default != inspect.Parameter.empty:
if parameter.annotation == bool:
argument_kwargs["default"] = str2bool(parameter.default)
else:
argument_kwargs["default"] = parameter.default
else:
argument_kwargs["required"] = True
name = parameter.name.replace("_", "-")
LOGGER.debug(f"Adding argument {name} with {argument_kwargs}")
parser.add_argument(f"--{name}", **argument_kwargs)
return parser
class ArgParserGenerator:
def __init__(self, cls_or_fn, module_path: Optional[str] = None):
self._cls_or_fn = cls_or_fn
init_method_name = "__init__"
self._handle = cls_or_fn if inspect.isfunction(cls_or_fn) else getattr(cls_or_fn, init_method_name, None)
input_is_python_file = module_path and module_path.endswith(".py")
self._input_path = module_path if input_is_python_file else None
self._required_fn_name_for_signature_parsing = getattr(
cls_or_fn, "required_fn_name_for_signature_parsing", None
)
def update_argparser(self, parser):
name = self._handle.__name__
group_parser = parser.add_argument_group(name)
add_args_for_fn_signature(group_parser, fn=self._handle)
self._update_argparser(group_parser)
def get_args(self, args: argparse.Namespace):
filtered_args = filter_fn_args(args, fn=self._handle)
tmp_parser = argparse.ArgumentParser(allow_abbrev=False)
self._update_argparser(tmp_parser)
custom_names = [
p.dest.replace("-", "_") for p in tmp_parser._actions if not isinstance(p, argparse._HelpAction)
]
custom_params = {n: getattr(args, n) for n in custom_names}
filtered_args = {**filtered_args, **custom_params}
return filtered_args
def from_args(self, args: Union[argparse.Namespace, Dict]):
args = self.get_args(args)
LOGGER.info(f"Initializing {self._cls_or_fn.__name__}({args})")
return self._cls_or_fn(**args)
def _update_argparser(self, parser):
label = "argparser_update"
if self._input_path:
update_argparser_handle = load_from_file(self._input_path, label=label, target=GET_ARGPARSER_FN_NAME)
if update_argparser_handle:
update_argparser_handle(parser)
elif self._required_fn_name_for_signature_parsing:
fn_handle = load_from_file(
self._input_path, label=label, target=self._required_fn_name_for_signature_parsing
)
if fn_handle:
add_args_for_fn_signature(parser, fn_handle)
|
PyTorch/LanguageModeling/BERT/triton/deployment_toolkit/perf_analyzer | perf_analyzer | perf_analyzer | # Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import logging
import pathlib
from subprocess import PIPE, CalledProcessError, Popen
# method from PEP-366 to support relative import in executed modules
if __package__ is None:
__package__ = pathlib.Path(__file__).parent.name
from .exceptions import PerfAnalyzerException
MAX_INTERVAL_CHANGES = 10
COUNT_INTERVAL_DELTA = 50
TIME_INTERVAL_DELTA = 2000
LOGGER = logging.getLogger(__name__)
class PerfAnalyzer:
"""
This class provides an interface for running workloads
with perf_analyzer.
"""
def __init__(self, config):
"""
Parameters
----------
config : PerfAnalyzerConfig
keys are names of arguments to perf_analyzer,
values are their values.
"""
self.bin_path = "perf_analyzer"
self._config = config
self._output = str()
def run(self):
"""
Runs the perf analyzer with the
initialized configuration
Returns
-------
List of Records
List of the metrics obtained from this
run of perf_analyzer
Raises
------
PerfAnalyzerException
If subprocess throws CalledProcessError
"""
for _ in range(MAX_INTERVAL_CHANGES):
command = [self.bin_path]
command += self._config.to_cli_string().replace("=", " ").split()
LOGGER.debug(f"Perf Analyze command: {command}")
try:
process = Popen(command, start_new_session=True, stdout=PIPE, encoding="utf-8")
streamed_output = ""
while True:
output = process.stdout.readline()
if output == "" and process.poll() is not None:
break
if output:
streamed_output += output
print(output.rstrip())
self._output += streamed_output
result = process.poll()
if result != 0:
raise CalledProcessError(returncode=result, cmd=command, output=streamed_output)
return
except CalledProcessError as e:
if self._faild_with_measruement_inverval(e.output):
if self._config["measurement-mode"] is None or self._config["measurement-mode"] == "count_windows":
self._increase_request_count()
else:
self._increase_time_interval()
else:
raise PerfAnalyzerException(
f"Running perf_analyzer with {e.cmd} failed with" f" exit status {e.returncode} : {e.output}"
)
raise PerfAnalyzerException(f"Ran perf_analyzer {MAX_INTERVAL_CHANGES} times, but no valid requests recorded.")
def output(self):
"""
Returns
-------
The stdout output of the
last perf_analyzer run
"""
if self._output:
return self._output
raise PerfAnalyzerException("Attempted to get perf_analyzer output" "without calling run first.")
def _faild_with_measruement_inverval(self, output: str):
return (
output.find("Failed to obtain stable measurement") or output.find("Please use a larger time window")
) != -1
def _increase_request_count(self):
self._config["measurement-request-count"] += COUNT_INTERVAL_DELTA
LOGGER.debug(
"perf_analyzer's measurement request count is too small, "
f"increased to {self._config['measurement-request-count']}."
)
def _increase_time_interval(self):
self._config["measurement-interval"] += TIME_INTERVAL_DELTA
LOGGER.debug(
"perf_analyzer's measurement window is too small, "
f"increased to {self._config['measurement-interval']} ms."
)
|
TensorFlow2/Segmentation/MaskRCNN/mrcnn_tf2/object_detection | object_detection | preprocessor | # Copyright 2017 The TensorFlow Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Preprocess images and bounding boxes for detection.
We perform two sets of operations in preprocessing stage:
(a) operations that are applied to both training and testing data,
(b) operations that are applied only to training data for the purpose of
data augmentation.
A preprocessing function receives a set of inputs,
e.g. an image and bounding boxes,
performs an operation on them, and returns them.
Some examples are: randomly cropping the image, randomly mirroring the image,
randomly changing the brightness, contrast, hue and
randomly jittering the bounding boxes.
The image is a rank 4 tensor: [1, height, width, channels] with
dtype=tf.float32. The groundtruth_boxes is a rank 2 tensor: [N, 4] where
in each row there is a box with [ymin xmin ymax xmax].
Boxes are in normalized coordinates meaning
their coordinate values range in [0, 1]
Important Note: In tensor_dict, images is a rank 4 tensor, but preprocessing
functions receive a rank 3 tensor for processing the image. Thus, inside the
preprocess function we squeeze the image to become a rank 3 tensor and then
we pass it to the functions. At the end of the preprocess we expand the image
back to rank 4.
"""
import tensorflow as tf
from mrcnn_tf2.object_detection import box_list
def _flip_boxes_left_right(boxes):
"""Left-right flip the boxes.
Args:
boxes: rank 2 float32 tensor containing the bounding boxes -> [N, 4].
Boxes are in normalized form meaning their coordinates vary
between [0, 1].
Each row is in the form of [ymin, xmin, ymax, xmax].
Returns:
Flipped boxes.
"""
ymin, xmin, ymax, xmax = tf.split(value=boxes, num_or_size_splits=4, axis=1)
flipped_xmin = tf.subtract(1.0, xmax)
flipped_xmax = tf.subtract(1.0, xmin)
flipped_boxes = tf.concat([ymin, flipped_xmin, ymax, flipped_xmax], 1)
return flipped_boxes
def _flip_masks_left_right(masks):
"""Left-right flip masks.
Args:
masks: rank 3 float32 tensor with shape
[num_instances, height, width] representing instance masks.
Returns:
flipped masks: rank 3 float32 tensor with shape
[num_instances, height, width] representing instance masks.
"""
return masks[:, :, ::-1]
def keypoint_flip_horizontal(keypoints, flip_point, flip_permutation,
scope=None):
"""Flips the keypoints horizontally around the flip_point.
This operation flips the x coordinate for each keypoint around the flip_point
and also permutes the keypoints in a manner specified by flip_permutation.
Args:
keypoints: a tensor of shape [num_instances, num_keypoints, 2]
flip_point: (float) scalar tensor representing the x coordinate to flip the
keypoints around.
flip_permutation: rank 1 int32 tensor containing the keypoint flip
permutation. This specifies the mapping from original keypoint indices
to the flipped keypoint indices. This is used primarily for keypoints
that are not reflection invariant. E.g. Suppose there are 3 keypoints
representing ['head', 'right_eye', 'left_eye'], then a logical choice for
flip_permutation might be [0, 2, 1] since we want to swap the 'left_eye'
and 'right_eye' after a horizontal flip.
scope: name scope.
Returns:
new_keypoints: a tensor of shape [num_instances, num_keypoints, 2]
"""
keypoints = tf.transpose(a=keypoints, perm=[1, 0, 2])
keypoints = tf.gather(keypoints, flip_permutation)
v, u = tf.split(value=keypoints, num_or_size_splits=2, axis=2)
u = flip_point * 2.0 - u
new_keypoints = tf.concat([v, u], 2)
new_keypoints = tf.transpose(a=new_keypoints, perm=[1, 0, 2])
return new_keypoints
def random_horizontal_flip(image,
boxes=None,
masks=None,
keypoints=None,
keypoint_flip_permutation=None,
seed=None):
"""Randomly flips the image and detections horizontally.
The probability of flipping the image is 50%.
Args:
image: rank 3 float32 tensor with shape [height, width, channels].
boxes: (optional) rank 2 float32 tensor with shape [N, 4]
containing the bounding boxes.
Boxes are in normalized form meaning their coordinates vary
between [0, 1].
Each row is in the form of [ymin, xmin, ymax, xmax].
masks: (optional) rank 3 float32 tensor with shape
[num_instances, height, width] containing instance masks. The masks
are of the same height, width as the input `image`.
keypoints: (optional) rank 3 float32 tensor with shape
[num_instances, num_keypoints, 2]. The keypoints are in y-x
normalized coordinates.
keypoint_flip_permutation: rank 1 int32 tensor containing the keypoint flip
permutation.
seed: random seed
Returns:
image: image which is the same shape as input image.
If boxes, masks, keypoints, and keypoint_flip_permutation are not None,
the function also returns the following tensors.
boxes: rank 2 float32 tensor containing the bounding boxes -> [N, 4].
Boxes are in normalized form meaning their coordinates vary
between [0, 1].
masks: rank 3 float32 tensor with shape [num_instances, height, width]
containing instance masks.
keypoints: rank 3 float32 tensor with shape
[num_instances, num_keypoints, 2]
Raises:
ValueError: if keypoints are provided but keypoint_flip_permutation is not.
"""
def _flip_image(image):
# flip image
image_flipped = tf.image.flip_left_right(image)
return image_flipped
if keypoints is not None and keypoint_flip_permutation is None:
raise ValueError(
'keypoints are provided but keypoints_flip_permutation is not provided')
result = []
# random variable defining whether to do flip or not
do_a_flip_random = tf.greater(tf.random.uniform([], seed=seed), 0.5)
# flip image
image = tf.cond(pred=do_a_flip_random, true_fn=lambda: _flip_image(image), false_fn=lambda: image)
result.append(image)
# flip boxes
if boxes is not None:
boxes = tf.cond(pred=do_a_flip_random, true_fn=lambda: _flip_boxes_left_right(boxes),
false_fn=lambda: boxes)
result.append(boxes)
# flip masks
if masks is not None:
masks = tf.cond(pred=do_a_flip_random, true_fn=lambda: _flip_masks_left_right(masks),
false_fn=lambda: masks)
result.append(masks)
# flip keypoints
if keypoints is not None and keypoint_flip_permutation is not None:
permutation = keypoint_flip_permutation
keypoints = tf.cond(
pred=do_a_flip_random,
true_fn=lambda: keypoint_flip_horizontal(keypoints, 0.5, permutation),
false_fn=lambda: keypoints)
result.append(keypoints)
return tuple(result)
def _compute_new_static_size(image, min_dimension, max_dimension):
"""Compute new static shape for resize_to_range method."""
image_shape = image.get_shape().as_list()
orig_height = image_shape[0]
orig_width = image_shape[1]
num_channels = image_shape[2]
orig_min_dim = min(orig_height, orig_width)
# Calculates the larger of the possible sizes
large_scale_factor = min_dimension / float(orig_min_dim)
# Scaling orig_(height|width) by large_scale_factor will make the smaller
# dimension equal to min_dimension, save for floating point rounding errors.
# For reasonably-sized images, taking the nearest integer will reliably
# eliminate this error.
large_height = int(round(orig_height * large_scale_factor))
large_width = int(round(orig_width * large_scale_factor))
large_size = [large_height, large_width]
if max_dimension:
# Calculates the smaller of the possible sizes, use that if the larger
# is too big.
orig_max_dim = max(orig_height, orig_width)
small_scale_factor = max_dimension / float(orig_max_dim)
# Scaling orig_(height|width) by small_scale_factor will make the larger
# dimension equal to max_dimension, save for floating point rounding
# errors. For reasonably-sized images, taking the nearest integer will
# reliably eliminate this error.
small_height = int(round(orig_height * small_scale_factor))
small_width = int(round(orig_width * small_scale_factor))
small_size = [small_height, small_width]
new_size = large_size
if max(large_size) > max_dimension:
new_size = small_size
else:
new_size = large_size
return tf.constant(new_size + [num_channels])
def _compute_new_dynamic_size(image, min_dimension, max_dimension):
"""Compute new dynamic shape for resize_to_range method."""
image_shape = tf.shape(input=image)
orig_height = tf.cast(image_shape[0], dtype=tf.float32)
orig_width = tf.cast(image_shape[1], dtype=tf.float32)
num_channels = image_shape[2]
orig_min_dim = tf.minimum(orig_height, orig_width)
# Calculates the larger of the possible sizes
min_dimension = tf.constant(min_dimension, dtype=tf.float32)
large_scale_factor = min_dimension / orig_min_dim
# Scaling orig_(height|width) by large_scale_factor will make the smaller
# dimension equal to min_dimension, save for floating point rounding errors.
# For reasonably-sized images, taking the nearest integer will reliably
# eliminate this error.
large_height = tf.cast(tf.round(orig_height * large_scale_factor), dtype=tf.int32)
large_width = tf.cast(tf.round(orig_width * large_scale_factor), dtype=tf.int32)
large_size = tf.stack([large_height, large_width])
if max_dimension:
# Calculates the smaller of the possible sizes, use that if the larger
# is too big.
orig_max_dim = tf.maximum(orig_height, orig_width)
max_dimension = tf.constant(max_dimension, dtype=tf.float32)
small_scale_factor = max_dimension / orig_max_dim
# Scaling orig_(height|width) by small_scale_factor will make the larger
# dimension equal to max_dimension, save for floating point rounding
# errors. For reasonably-sized images, taking the nearest integer will
# reliably eliminate this error.
small_height = tf.cast(tf.round(orig_height * small_scale_factor), dtype=tf.int32)
small_width = tf.cast(tf.round(orig_width * small_scale_factor), dtype=tf.int32)
small_size = tf.stack([small_height, small_width])
new_size = tf.cond(
pred=tf.cast(tf.reduce_max(input_tensor=large_size), dtype=tf.float32) > max_dimension,
true_fn=lambda: small_size, false_fn=lambda: large_size)
else:
new_size = large_size
return tf.stack(tf.unstack(new_size) + [num_channels])
def resize_to_range(image,
masks=None,
min_dimension=None,
max_dimension=None,
method=tf.image.ResizeMethod.BILINEAR,
align_corners=False,
pad_to_max_dimension=False):
"""Resizes an image so its dimensions are within the provided value.
The output size can be described by two cases:
1. If the image can be rescaled so its minimum dimension is equal to the
provided value without the other dimension exceeding max_dimension,
then do so.
2. Otherwise, resize so the largest dimension is equal to max_dimension.
Args:
image: A 3D tensor of shape [height, width, channels]
masks: (optional) rank 3 float32 tensor with shape
[num_instances, height, width] containing instance masks.
min_dimension: (optional) (scalar) desired size of the smaller image
dimension.
max_dimension: (optional) (scalar) maximum allowed size
of the larger image dimension.
method: (optional) interpolation method used in resizing. Defaults to
BILINEAR.
align_corners: bool. If true, exactly align all 4 corners of the input
and output. Defaults to False.
pad_to_max_dimension: Whether to resize the image and pad it with zeros
so the resulting image is of the spatial size
[max_dimension, max_dimension]. If masks are included they are padded
similarly.
Returns:
Note that the position of the resized_image_shape changes based on whether
masks are present.
resized_image: A 3D tensor of shape [new_height, new_width, channels],
where the image has been resized (with bilinear interpolation) so that
min(new_height, new_width) == min_dimension or
max(new_height, new_width) == max_dimension.
resized_masks: If masks is not None, also outputs masks. A 3D tensor of
shape [num_instances, new_height, new_width].
resized_image_shape: A 1D tensor of shape [3] containing shape of the
resized image.
Raises:
ValueError: if the image is not a 3D tensor.
"""
if len(image.get_shape()) != 3:
raise ValueError('Image should be 3D tensor')
if image.get_shape().is_fully_defined():
new_size = _compute_new_static_size(image, min_dimension, max_dimension)
else:
new_size = _compute_new_dynamic_size(image, min_dimension, max_dimension)
new_image = tf.image.resize(
image, new_size[:-1], method=method)
if pad_to_max_dimension:
new_image = tf.image.pad_to_bounding_box(
new_image, 0, 0, max_dimension, max_dimension)
result = [new_image]
if masks is not None:
new_masks = tf.expand_dims(masks, 3)
new_masks = tf.image.resize(
new_masks,
new_size[:-1],
method=tf.image.ResizeMethod.NEAREST_NEIGHBOR)
new_masks = tf.squeeze(new_masks, 3)
if pad_to_max_dimension:
new_masks = tf.image.pad_to_bounding_box(
new_masks, 0, 0, max_dimension, max_dimension)
result.append(new_masks)
result.append(new_size)
return result
def _copy_extra_fields(boxlist_to_copy_to, boxlist_to_copy_from):
"""Copies the extra fields of boxlist_to_copy_from to boxlist_to_copy_to.
Args:
boxlist_to_copy_to: BoxList to which extra fields are copied.
boxlist_to_copy_from: BoxList from which fields are copied.
Returns:
boxlist_to_copy_to with extra fields.
"""
for field in boxlist_to_copy_from.get_extra_fields():
boxlist_to_copy_to.add_field(field, boxlist_to_copy_from.get_field(field))
return boxlist_to_copy_to
def box_list_scale(boxlist, y_scale, x_scale, scope=None):
"""scale box coordinates in x and y dimensions.
Args:
boxlist: BoxList holding N boxes
y_scale: (float) scalar tensor
x_scale: (float) scalar tensor
scope: name scope.
Returns:
boxlist: BoxList holding N boxes
"""
y_scale = tf.cast(y_scale, tf.float32)
x_scale = tf.cast(x_scale, tf.float32)
y_min, x_min, y_max, x_max = tf.split(
value=boxlist.get(), num_or_size_splits=4, axis=1)
y_min = y_scale * y_min
y_max = y_scale * y_max
x_min = x_scale * x_min
x_max = x_scale * x_max
scaled_boxlist = box_list.BoxList(
tf.concat([y_min, x_min, y_max, x_max], 1))
return _copy_extra_fields(scaled_boxlist, boxlist)
def keypoint_scale(keypoints, y_scale, x_scale, scope=None):
"""Scales keypoint coordinates in x and y dimensions.
Args:
keypoints: a tensor of shape [num_instances, num_keypoints, 2]
y_scale: (float) scalar tensor
x_scale: (float) scalar tensor
scope: name scope.
Returns:
new_keypoints: a tensor of shape [num_instances, num_keypoints, 2]
"""
y_scale = tf.cast(y_scale, tf.float32)
x_scale = tf.cast(x_scale, tf.float32)
new_keypoints = keypoints * [[[y_scale, x_scale]]]
return new_keypoints
def scale_boxes_to_pixel_coordinates(image, boxes, keypoints=None):
"""Scales boxes from normalized to pixel coordinates.
Args:
image: A 3D float32 tensor of shape [height, width, channels].
boxes: A 2D float32 tensor of shape [num_boxes, 4] containing the bounding
boxes in normalized coordinates. Each row is of the form
[ymin, xmin, ymax, xmax].
keypoints: (optional) rank 3 float32 tensor with shape
[num_instances, num_keypoints, 2]. The keypoints are in y-x normalized
coordinates.
Returns:
image: unchanged input image.
scaled_boxes: a 2D float32 tensor of shape [num_boxes, 4] containing the
bounding boxes in pixel coordinates.
scaled_keypoints: a 3D float32 tensor with shape
[num_instances, num_keypoints, 2] containing the keypoints in pixel
coordinates.
"""
boxlist = box_list.BoxList(boxes)
image_height = tf.shape(input=image)[0]
image_width = tf.shape(input=image)[1]
scaled_boxes = box_list_scale(boxlist, image_height, image_width).get()
result = [image, scaled_boxes]
if keypoints is not None:
scaled_keypoints = keypoint_scale(keypoints, image_height, image_width)
result.append(scaled_keypoints)
return tuple(result)
|
PyTorch/SpeechSynthesis/HiFiGAN/common | common | filter_warnings | # Copyright (c) 2021-2022, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Mutes known and unrelated PyTorch warnings.
The warnings module keeps a list of filters. Importing it as late as possible
prevents its filters from being overriden.
"""
import warnings
# NGC 22.04-py3 container (PyTorch 1.12.0a0+bd13bc6)
warnings.filterwarnings(
"ignore",
message='positional arguments and argument "destination" are deprecated.'
' nn.Module.state_dict will not accept them in the future.')
# 22.08-py3 container
warnings.filterwarnings(
"ignore",
message="is_namedtuple is deprecated, please use the python checks")
|
PyTorch/Segmentation/MaskRCNN/pytorch/maskrcnn_benchmark/modeling/detector | detector | detectors | # Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved.
from .generalized_rcnn import GeneralizedRCNN
_DETECTION_META_ARCHITECTURES = {"GeneralizedRCNN": GeneralizedRCNN}
def build_detection_model(cfg):
meta_arch = _DETECTION_META_ARCHITECTURES[cfg.MODEL.META_ARCHITECTURE]
return meta_arch(cfg)
|
TensorFlow2/LanguageModeling/BERT/official/modeling/activations | activations | __init__ | # Copyright 2019 The TensorFlow Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ==============================================================================
"""Activations package definition."""
from official.modeling.activations.gelu import gelu
from official.modeling.activations.swish import hard_swish
from official.modeling.activations.swish import identity
from official.modeling.activations.swish import simple_swish
|
TensorFlow2/Detection/Efficientdet/model | model | label_util | # Copyright 2020 Google Research. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ==============================================================================
"""A few predefined label id mapping."""
import tensorflow as tf
import yaml
coco = {
# 0: 'background',
1: 'person',
2: 'bicycle',
3: 'car',
4: 'motorcycle',
5: 'airplane',
6: 'bus',
7: 'train',
8: 'truck',
9: 'boat',
10: 'traffic light',
11: 'fire hydrant',
13: 'stop sign',
14: 'parking meter',
15: 'bench',
16: 'bird',
17: 'cat',
18: 'dog',
19: 'horse',
20: 'sheep',
21: 'cow',
22: 'elephant',
23: 'bear',
24: 'zebra',
25: 'giraffe',
27: 'backpack',
28: 'umbrella',
31: 'handbag',
32: 'tie',
33: 'suitcase',
34: 'frisbee',
35: 'skis',
36: 'snowboard',
37: 'sports ball',
38: 'kite',
39: 'baseball bat',
40: 'baseball glove',
41: 'skateboard',
42: 'surfboard',
43: 'tennis racket',
44: 'bottle',
46: 'wine glass',
47: 'cup',
48: 'fork',
49: 'knife',
50: 'spoon',
51: 'bowl',
52: 'banana',
53: 'apple',
54: 'sandwich',
55: 'orange',
56: 'broccoli',
57: 'carrot',
58: 'hot dog',
59: 'pizza',
60: 'donut',
61: 'cake',
62: 'chair',
63: 'couch',
64: 'potted plant',
65: 'bed',
67: 'dining table',
70: 'toilet',
72: 'tv',
73: 'laptop',
74: 'mouse',
75: 'remote',
76: 'keyboard',
77: 'cell phone',
78: 'microwave',
79: 'oven',
80: 'toaster',
81: 'sink',
82: 'refrigerator',
84: 'book',
85: 'clock',
86: 'vase',
87: 'scissors',
88: 'teddy bear',
89: 'hair drier',
90: 'toothbrush',
}
voc = {
# 0: 'background',
1: 'aeroplane',
2: 'bicycle',
3: 'bird',
4: 'boat',
5: 'bottle',
6: 'bus',
7: 'car',
8: 'cat',
9: 'chair',
10: 'cow',
11: 'diningtable',
12: 'dog',
13: 'horse',
14: 'motorbike',
15: 'person',
16: 'pottedplant',
17: 'sheep',
18: 'sofa',
19: 'train',
20: 'tvmonitor',
}
waymo = {
# 0: 'background',
1: 'vehicle',
2: 'pedestrian',
3: 'cyclist',
}
def get_label_map(mapping):
"""Get label id map based on the name, filename, or dict."""
# case 1: if it is None or dict, just return it.
if not mapping or isinstance(mapping, dict):
return mapping
# case 2: if it is a yaml file, load it to a dict and return the dict.
assert isinstance(mapping, str), 'mapping must be dict or str.'
if mapping.endswith('.yaml'):
with tf.io.gfile.GFile(mapping) as f:
return yaml.load(f, Loader=yaml.FullLoader)
# case 3: it is a name of a predefined dataset.
return {'coco': coco, 'voc': voc, 'waymo': waymo}[mapping]
|
TensorFlow/Detection/SSD/models/research/slim/nets | nets | overfeat_test | # Copyright 2016 The TensorFlow Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ==============================================================================
"""Tests for slim.nets.overfeat."""
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import tensorflow as tf
from nets import overfeat
slim = tf.contrib.slim
class OverFeatTest(tf.test.TestCase):
def testBuild(self):
batch_size = 5
height, width = 231, 231
num_classes = 1000
with self.test_session():
inputs = tf.random_uniform((batch_size, height, width, 3))
logits, _ = overfeat.overfeat(inputs, num_classes)
self.assertEquals(logits.op.name, 'overfeat/fc8/squeezed')
self.assertListEqual(logits.get_shape().as_list(),
[batch_size, num_classes])
def testFullyConvolutional(self):
batch_size = 1
height, width = 281, 281
num_classes = 1000
with self.test_session():
inputs = tf.random_uniform((batch_size, height, width, 3))
logits, _ = overfeat.overfeat(inputs, num_classes, spatial_squeeze=False)
self.assertEquals(logits.op.name, 'overfeat/fc8/BiasAdd')
self.assertListEqual(logits.get_shape().as_list(),
[batch_size, 2, 2, num_classes])
def testGlobalPool(self):
batch_size = 1
height, width = 281, 281
num_classes = 1000
with self.test_session():
inputs = tf.random_uniform((batch_size, height, width, 3))
logits, _ = overfeat.overfeat(inputs, num_classes, spatial_squeeze=False,
global_pool=True)
self.assertEquals(logits.op.name, 'overfeat/fc8/BiasAdd')
self.assertListEqual(logits.get_shape().as_list(),
[batch_size, 1, 1, num_classes])
def testEndPoints(self):
batch_size = 5
height, width = 231, 231
num_classes = 1000
with self.test_session():
inputs = tf.random_uniform((batch_size, height, width, 3))
_, end_points = overfeat.overfeat(inputs, num_classes)
expected_names = ['overfeat/conv1',
'overfeat/pool1',
'overfeat/conv2',
'overfeat/pool2',
'overfeat/conv3',
'overfeat/conv4',
'overfeat/conv5',
'overfeat/pool5',
'overfeat/fc6',
'overfeat/fc7',
'overfeat/fc8'
]
self.assertSetEqual(set(end_points.keys()), set(expected_names))
def testNoClasses(self):
batch_size = 5
height, width = 231, 231
num_classes = None
with self.test_session():
inputs = tf.random_uniform((batch_size, height, width, 3))
net, end_points = overfeat.overfeat(inputs, num_classes)
expected_names = ['overfeat/conv1',
'overfeat/pool1',
'overfeat/conv2',
'overfeat/pool2',
'overfeat/conv3',
'overfeat/conv4',
'overfeat/conv5',
'overfeat/pool5',
'overfeat/fc6',
'overfeat/fc7'
]
self.assertSetEqual(set(end_points.keys()), set(expected_names))
self.assertTrue(net.op.name.startswith('overfeat/fc7'))
def testModelVariables(self):
batch_size = 5
height, width = 231, 231
num_classes = 1000
with self.test_session():
inputs = tf.random_uniform((batch_size, height, width, 3))
overfeat.overfeat(inputs, num_classes)
expected_names = ['overfeat/conv1/weights',
'overfeat/conv1/biases',
'overfeat/conv2/weights',
'overfeat/conv2/biases',
'overfeat/conv3/weights',
'overfeat/conv3/biases',
'overfeat/conv4/weights',
'overfeat/conv4/biases',
'overfeat/conv5/weights',
'overfeat/conv5/biases',
'overfeat/fc6/weights',
'overfeat/fc6/biases',
'overfeat/fc7/weights',
'overfeat/fc7/biases',
'overfeat/fc8/weights',
'overfeat/fc8/biases',
]
model_variables = [v.op.name for v in slim.get_model_variables()]
self.assertSetEqual(set(model_variables), set(expected_names))
def testEvaluation(self):
batch_size = 2
height, width = 231, 231
num_classes = 1000
with self.test_session():
eval_inputs = tf.random_uniform((batch_size, height, width, 3))
logits, _ = overfeat.overfeat(eval_inputs, is_training=False)
self.assertListEqual(logits.get_shape().as_list(),
[batch_size, num_classes])
predictions = tf.argmax(logits, 1)
self.assertListEqual(predictions.get_shape().as_list(), [batch_size])
def testTrainEvalWithReuse(self):
train_batch_size = 2
eval_batch_size = 1
train_height, train_width = 231, 231
eval_height, eval_width = 281, 281
num_classes = 1000
with self.test_session():
train_inputs = tf.random_uniform(
(train_batch_size, train_height, train_width, 3))
logits, _ = overfeat.overfeat(train_inputs)
self.assertListEqual(logits.get_shape().as_list(),
[train_batch_size, num_classes])
tf.get_variable_scope().reuse_variables()
eval_inputs = tf.random_uniform(
(eval_batch_size, eval_height, eval_width, 3))
logits, _ = overfeat.overfeat(eval_inputs, is_training=False,
spatial_squeeze=False)
self.assertListEqual(logits.get_shape().as_list(),
[eval_batch_size, 2, 2, num_classes])
logits = tf.reduce_mean(logits, [1, 2])
predictions = tf.argmax(logits, 1)
self.assertEquals(predictions.get_shape().as_list(), [eval_batch_size])
def testForward(self):
batch_size = 1
height, width = 231, 231
with self.test_session() as sess:
inputs = tf.random_uniform((batch_size, height, width, 3))
logits, _ = overfeat.overfeat(inputs)
sess.run(tf.global_variables_initializer())
output = sess.run(logits)
self.assertTrue(output.any())
if __name__ == '__main__':
tf.test.main()
|
TensorFlow2/Recommendation/WideAndDeep/triton/deployment_toolkit/triton_performance_runner/perf_analyzer | perf_analyzer | perf_analyzer | # Copyright (c) 2021-2022, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import logging
import pathlib
from subprocess import PIPE, CalledProcessError, Popen
# method from PEP-366 to support relative import in executed modules
from typing import List, Optional
if __package__ is None:
__package__ = pathlib.Path(__file__).parent.name
from .exceptions import PerfAnalyzerException
MAX_INTERVAL_CHANGES = 10
COUNT_INTERVAL_DELTA = 50
TIME_INTERVAL_DELTA = 2000
LOGGER = logging.getLogger(__name__)
class PerfAnalyzer:
"""
This class provides an interface for running workloads
with perf_analyzer.
"""
def __init__(self, config, timeout: Optional[int]):
"""
Parameters
----------
config : PerfAnalyzerConfig
keys are names of arguments to perf_analyzer,
values are their values.
"""
self.bin_path = "perf_analyzer"
self._config = config
self._output = ""
self._timeout = timeout
def run(self):
"""
Runs the perf analyzer with the
initialized configuration
Returns
-------
List of Records
List of the metrics obtained from this
run of perf_analyzer
Raises
------
PerfAnalyzerException
If subprocess throws CalledProcessError
"""
self._output = ""
for _ in range(MAX_INTERVAL_CHANGES):
command = [self.bin_path]
command += self._config.to_cli_string().replace("=", " ").split()
LOGGER.debug(f"Perf Analyze command: {command}")
if not self._timeout:
LOGGER.debug("Perf Analyze command timeout not set")
else:
LOGGER.debug(f"Perf Analyze command timeout: {self._timeout} [s]")
try:
self._run_with_stream(command=command)
return
except CalledProcessError as e:
if self._failed_with_measurement_inverval(e.output):
if self._config["measurement-mode"] is None or self._config["measurement-mode"] == "count_windows":
self._increase_request_count()
else:
self._increase_time_interval()
else:
raise PerfAnalyzerException(
f"Running perf_analyzer with {e.cmd} failed with" f" exit status {e.returncode} : {e.output}"
)
raise PerfAnalyzerException(f"Ran perf_analyzer {MAX_INTERVAL_CHANGES} times, but no valid requests recorded.")
def output(self):
"""
Returns
-------
The stdout output of the
last perf_analyzer run
"""
if self._output:
return self._output
raise PerfAnalyzerException("Attempted to get perf_analyzer output" "without calling run first.")
def _run_with_stream(self, command: List[str]):
commands_lst = []
if self._timeout:
commands_lst = ["timeout", str(self._timeout)]
commands_lst.extend(command)
LOGGER.debug(f"Run with stream: {commands_lst}")
process = Popen(commands_lst, start_new_session=True, stdout=PIPE, encoding="utf-8")
streamed_output = ""
while True:
output = process.stdout.readline()
if output == "" and process.poll() is not None:
break
if output:
streamed_output += output
print(output.rstrip())
self._output += streamed_output
result = process.poll()
LOGGER.debug(f"Perf Analyzer process exited with result: {result}")
# WAR for Perf Analyzer exit code 0 when stabilization failed
if result == 0 and self._failed_with_measurement_inverval(streamed_output):
LOGGER.debug("Perf Analyzer finished with exit status 0, however measurement stabilization failed.")
result = 1
if result != 0:
raise CalledProcessError(returncode=result, cmd=commands_lst, output=streamed_output)
def _failed_with_measurement_inverval(self, output: str):
checks = [
output.find("Failed to obtain stable measurement"),
output.find("Please use a larger time window"),
]
result = any([status != -1 for status in checks])
LOGGER.debug(f"Measurement stability message validation: {checks}. Result: {result}.")
return result
def _increase_request_count(self):
self._config["measurement-request-count"] += COUNT_INTERVAL_DELTA
LOGGER.debug(
"perf_analyzer's measurement request count is too small, "
f"increased to {self._config['measurement-request-count']}."
)
def _increase_time_interval(self):
self._config["measurement-interval"] += TIME_INTERVAL_DELTA
LOGGER.debug(
"perf_analyzer's measurement window is too small, "
f"increased to {self._config['measurement-interval']} ms."
)
|
TensorFlow2/LanguageModeling/BERT/official/nlp/modeling/networks | networks | bert_pretrainer_test | # Copyright 2019 The TensorFlow Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ==============================================================================
"""Tests for BERT trainer network."""
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import tensorflow as tf
from tensorflow.python.keras import keras_parameterized # pylint: disable=g-direct-tensorflow-import
from official.nlp.modeling import networks
from official.nlp.modeling.networks import bert_pretrainer
# This decorator runs the test in V1, V2-Eager, and V2-Functional mode. It
# guarantees forward compatibility of this code for the V2 switchover.
@keras_parameterized.run_all_keras_modes
class BertPretrainerTest(keras_parameterized.TestCase):
def test_bert_trainer(self):
"""Validate that the Keras object can be created."""
# Build a transformer network to use within the BERT trainer.
vocab_size = 100
sequence_length = 512
test_network = networks.TransformerEncoder(
vocab_size=vocab_size, num_layers=2, sequence_length=sequence_length)
# Create a BERT trainer with the created network.
num_classes = 3
num_token_predictions = 2
bert_trainer_model = bert_pretrainer.BertPretrainer(
test_network,
num_classes=num_classes,
num_token_predictions=num_token_predictions)
# Create a set of 2-dimensional inputs (the first dimension is implicit).
word_ids = tf.keras.Input(shape=(sequence_length,), dtype=tf.int32)
mask = tf.keras.Input(shape=(sequence_length,), dtype=tf.int32)
type_ids = tf.keras.Input(shape=(sequence_length,), dtype=tf.int32)
lm_mask = tf.keras.Input(shape=(sequence_length,), dtype=tf.int32)
# Invoke the trainer model on the inputs. This causes the layer to be built.
lm_outs, cls_outs = bert_trainer_model([word_ids, mask, type_ids, lm_mask])
# Validate that the outputs are of the expected shape.
expected_lm_shape = [None, num_token_predictions, vocab_size]
expected_classification_shape = [None, num_classes]
self.assertAllEqual(expected_lm_shape, lm_outs.shape.as_list())
self.assertAllEqual(expected_classification_shape, cls_outs.shape.as_list())
def test_bert_trainer_tensor_call(self):
"""Validate that the Keras object can be invoked."""
# Build a transformer network to use within the BERT trainer. (Here, we use
# a short sequence_length for convenience.)
test_network = networks.TransformerEncoder(
vocab_size=100, num_layers=2, sequence_length=2)
# Create a BERT trainer with the created network.
bert_trainer_model = bert_pretrainer.BertPretrainer(
test_network, num_classes=2, num_token_predictions=2)
# Create a set of 2-dimensional data tensors to feed into the model.
word_ids = tf.constant([[1, 1], [2, 2]], dtype=tf.int32)
mask = tf.constant([[1, 1], [1, 0]], dtype=tf.int32)
type_ids = tf.constant([[1, 1], [2, 2]], dtype=tf.int32)
lm_mask = tf.constant([[1, 1], [1, 0]], dtype=tf.int32)
# Invoke the trainer model on the tensors. In Eager mode, this does the
# actual calculation. (We can't validate the outputs, since the network is
# too complex: this simply ensures we're not hitting runtime errors.)
_, _ = bert_trainer_model([word_ids, mask, type_ids, lm_mask])
def test_serialize_deserialize(self):
"""Validate that the BERT trainer can be serialized and deserialized."""
# Build a transformer network to use within the BERT trainer. (Here, we use
# a short sequence_length for convenience.)
test_network = networks.TransformerEncoder(
vocab_size=100, num_layers=2, sequence_length=5)
# Create a BERT trainer with the created network. (Note that all the args
# are different, so we can catch any serialization mismatches.)
bert_trainer_model = bert_pretrainer.BertPretrainer(
test_network, num_classes=4, num_token_predictions=3)
# Create another BERT trainer via serialization and deserialization.
config = bert_trainer_model.get_config()
new_bert_trainer_model = bert_pretrainer.BertPretrainer.from_config(config)
# Validate that the config can be forced to JSON.
_ = new_bert_trainer_model.to_json()
# If the serialization was successful, the new config should match the old.
self.assertAllEqual(bert_trainer_model.get_config(),
new_bert_trainer_model.get_config())
if __name__ == '__main__':
tf.test.main()
|
PyTorch/LanguageModeling/Transformer-XL/pytorch | pytorch | train | # coding: utf-8
# Copyright (c) 2019-2020, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import argparse
import functools
import itertools
import logging
import math
import os
import shutil
import sys
import time
import warnings
import dllogger
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
import yaml
try:
from apex import amp
except ModuleNotFoundError:
warnings.warn('APEX AMP is unavailable')
from torch.nn.parallel import DistributedDataParallel
import lamb
import utils
from data_utils import get_lm_corpus
from mem_transformer import MemTransformerLM
from utils.data_parallel import BalancedDataParallel
from utils.exp_utils import AverageMeter
from utils.exp_utils import TimeoutHandler
from utils.exp_utils import benchmark
from utils.exp_utils import create_exp_dir
from utils.exp_utils import l2_promote
from utils.exp_utils import log_env_info
from utils.exp_utils import register_ignoring_timeout_handler
def parse_args():
parent_parser = argparse.ArgumentParser(
description='PyTorch Transformer-XL Language Model',
formatter_class=argparse.ArgumentDefaultsHelpFormatter,
add_help=False,
)
parser = argparse.ArgumentParser(parents=[parent_parser], add_help=True)
cfg_parser = argparse.ArgumentParser(parents=[parent_parser], add_help=False)
cfg_parser.add_argument('--config', default='default')
cfg_parser.add_argument('--config_file', default=None)
config_args, _ = cfg_parser.parse_known_args()
if config_args.config is not None and config_args.config_file is not None:
with open(config_args.config_file) as f:
config = yaml.load(f, Loader=yaml.FullLoader)[config_args.config]['train']
else:
config = {}
general = parser.add_argument_group('general setup')
general.add_argument('--work_dir', default='LM-TFM', type=str,
help='Directory for the results')
general.add_argument('--append_dataset', action='store_true',
help='Automatically append dataset name to work_dir')
general.add_argument('--append_time', action='store_true',
help='Automatically append current time to work_dir')
general.add_argument('--cuda', action='store_true',
help='Run training on a GPU using CUDA')
general.add_argument('--fp16', action='store_true',
help='Run training in fp16/mixed precision')
general.add_argument('--restart', type=str, default='',
help='Restart training from the saved checkpoint')
general.add_argument('--debug', action='store_true',
help='Run in debug mode (do not create exp dir)')
general.add_argument('--log_all_ranks', action='store_true',
help='Enable logging from all distributed ranks')
general.add_argument('--dllog_file', type=str, default='train_log.json',
help='Name of the DLLogger output file')
general.add_argument('--txtlog_file', type=str, default='train_log.log',
help='Name of the txt log file')
general.add_argument('--save_all', action='store_true',
help='Save all checkpoints')
general.add_argument('--no_env', action='store_true',
help='Do not print info on execution env')
general.add_argument('--no_eval', action='store_true',
help='Disable model evaluation')
general.add_argument('--no_test', action='store_true',
help='Disable model evaluation on test data')
general.add_argument('--log_interval', type=int, default=10,
help='Report interval')
general.add_argument('--target_throughput', type=float, default=None,
help='Target training throughput (for benchmarking)')
general.add_argument('--target_perplexity', type=float, default=None,
help='Target validation perplexity (for benchmarking)')
general.add_argument('--apex_amp_opt_level', type=str, default='O2',
choices=['O0', 'O1', 'O2', 'O3'],
help='Optimization level for apex amp')
general.add_argument('--amp', choices=['apex', 'pytorch'], default='apex',
help='Implementation of automatic mixed precision')
general.add_argument('--affinity', type=str,
default='socket_unique_interleaved',
choices=['socket', 'single', 'single_unique',
'socket_unique_interleaved',
'socket_unique_continuous',
'disabled'],
help='type of CPU affinity')
dataset = parser.add_argument_group('dataset setup')
dataset.add_argument('--data', type=str, default='../data/wikitext-103',
help='Location of the data corpus')
dataset.add_argument('--dataset', type=str, default='wt103',
choices=['wt103', 'lm1b', 'enwik8', 'text8'],
help='Dataset name')
dataset.add_argument('--vocab', type=str, default='word', choices=['word', 'bpe'],
help='Type of vocabulary')
model = parser.add_argument_group('model setup')
model.add_argument('--n_layer', type=int, default=16,
help='Number of total layers')
model.add_argument('--n_head', type=int, default=8,
help='Number of heads')
model.add_argument('--d_head', type=int, default=64,
help='Head dimension')
model.add_argument('--d_embed', type=int, default=-1,
help='Embedding dimension')
model.add_argument('--d_model', type=int, default=512,
help='Model dimension')
model.add_argument('--d_inner', type=int, default=2048,
help='Inner dimension in feedforward layer')
model.add_argument('--dropout', type=float, default=0.1,
help='Global dropout rate')
model.add_argument('--dropatt', type=float, default=0.0,
help='Attention probability dropout rate')
model.add_argument('--pre_lnorm', action='store_true',
help='Apply LayerNorm to the input instead of the output')
model.add_argument('--attn_type', type=int, default=0,
help='Attention type. 0 for ours, 1 for Shaw et al,'
'2 for Vaswani et al, 3 for Al Rfou et al.')
model.add_argument('--not_tied', action='store_true',
help='Do not tie the word embedding and softmax weights')
model.add_argument('--clamp_len', type=int, default=-1,
help='Use the same pos embeddings after clamp_len')
model.add_argument('--adaptive', action='store_true',
help='Use adaptive softmax')
model.add_argument('--div_val', type=int, default=1,
help='Dividend value for adaptive input and softmax')
model.add_argument('--sample_softmax', type=int, default=-1,
help='Number of samples in sampled softmax')
model.add_argument('--init', default='normal', type=str,
help='Parameter initializer to use')
model.add_argument('--emb_init', default='normal', type=str,
help='Parameter initializer to use')
model.add_argument('--init_range', type=float, default=0.1,
help='Parameters initialized by U(-init_range, init_range)')
model.add_argument('--emb_init_range', type=float, default=0.01,
help='Parameters initialized by U(-init_range, init_range)')
model.add_argument('--init_std', type=float, default=0.02,
help='Parameters initialized by N(0, init_std)')
model.add_argument('--proj_init_std', type=float, default=0.01,
help='Parameters initialized by N(0, init_std)')
opt = parser.add_argument_group('optimizer setup')
opt.add_argument('--optim', default='jitlamb', type=str,
choices=['adam', 'sgd', 'adagrad', 'lamb', 'jitlamb'],
help='Optimizer to use')
opt.add_argument('--lr', type=float, default=0.01,
help='Initial learning rate')
opt.add_argument('--mom', type=float, default=0.0,
help='Momentum for sgd')
opt.add_argument('--scheduler', default='cosine', type=str,
choices=['cosine', 'inv_sqrt', 'dev_perf', 'constant'],
help='LR scheduler to use')
opt.add_argument('--max_step_scheduler', type=int, default=None,
help='Max number of training steps for LR scheduler')
opt.add_argument('--warmup_step', type=int, default=1000,
help='Number of iterations for LR warmup')
opt.add_argument('--decay_rate', type=float, default=0.5,
help='Decay factor when ReduceLROnPlateau is used')
opt.add_argument('--lr_min', type=float, default=0.0,
help='Minimum learning rate during annealing')
opt.add_argument('--clip', type=float, default=0.25,
help='Gradient clipping')
opt.add_argument('--weight_decay', type=float, default=0.0,
help='Weight decay for adam|lamb')
opt.add_argument('--clip_nonemb', action='store_true',
help='Only clip the gradient of non-embedding params')
opt.add_argument('--patience', type=int, default=0,
help='Patience')
opt.add_argument('--eta_min', type=float, default=0.001,
help='Min learning rate for cosine scheduler')
training = parser.add_argument_group('training setup')
training.add_argument('--max_step', type=int, default=40000,
help='Max number of training steps')
training.add_argument('--batch_size', type=int, default=256,
help='Global batch size')
training.add_argument('--local_batch_size', type=int, default=None,
help='Local (per-device) batch size, this setting \
overrides global --batch_size and sets batch_size \
to local_batch_size * world_size')
training.add_argument('--batch_chunk', type=int, default=1,
help='Split batch into chunks and train with '
'gradient accumulation')
training.add_argument('--roll', action='store_true',
help='Enable random shifts within each data stream')
training.add_argument('--tgt_len', type=int, default=192,
help='Number of tokens to predict')
training.add_argument('--ext_len', type=int, default=0,
help='Length of the extended context')
training.add_argument('--mem_len', type=int, default=192,
help='Length of the retained previous heads')
training.add_argument('--seed', type=int, default=1111,
help='Random seed')
training.add_argument('--multi_gpu', default=None, type=str,
choices=['ddp', 'dp'],
help='Use multiple GPU')
training.add_argument('--gpu0_bsz', type=int, default=-1,
help='Batch size on gpu 0 (for "dp" backend)')
training.add_argument('--same_length', action='store_true',
help='Use the same attn length for all tokens')
training.add_argument('--varlen', action='store_true',
help='Use variable length')
training.add_argument('--swap_mem', action='store_true',
help='Swap memory tensors to cpu')
val = parser.add_argument_group('validation setup')
val.add_argument('--eval_tgt_len', type=int, default=192,
help='Number of tokens to predict for evaluation')
val.add_argument('--eval_batch_size', type=int, default=16,
help='Eval batch size')
val.add_argument('--eval_max_steps', type=int, default=-1,
help='Max eval steps')
val.add_argument('--eval_interval', type=int, default=5000,
help='Evaluation interval')
dist = parser.add_argument_group('distributed setup')
dist.add_argument('--local_rank', type=int,
default=os.getenv('LOCAL_RANK', 0),
help='Used for multi-process training.')
parser.set_defaults(**config)
args, _ = parser.parse_known_args()
args.tied = not args.not_tied
if args.d_embed < 0:
args.d_embed = args.d_model
if args.ext_len < 0:
raise RuntimeError('Extended context length must be non-negative')
if args.mem_len == 0:
if args.eval_tgt_len > args.ext_len + args.tgt_len:
raise RuntimeError('eval_tgt_len should be <= tgt_len + ext_len; '
f'eval_tgt_len: {args.eval_tgt_len}, '
f'tgt_len: {args.tgt_len}, '
f'ext_len: {args.ext_len}')
else:
if args.eval_tgt_len > args.mem_len + args.tgt_len:
raise RuntimeError('eval_tgt_len should be <= tgt_len + mem_len; '
f'eval_tgt_len: {args.eval_tgt_len}, '
f'tgt_len: {args.tgt_len}, '
f'mem_len: {args.mem_len}')
if args.batch_size % args.batch_chunk != 0:
raise RuntimeError('Batch size needs to be divisible by batch chunk')
if (
args.local_batch_size is not None
and args.local_batch_size % args.batch_chunk != 0
):
raise RuntimeError('Local batch size needs to be divisible by '
'batch chunk')
if args.fp16 and args.amp == 'apex' and 'apex' not in sys.modules:
raise RuntimeError(
'APEX AMP unavailable, install APEX or switch to pytorch AMP'
)
return args
def save_checkpoint(args, model, mems, model_config, optimizer, scheduler,
scaler, vocab, epoch, batch, last_iter, train_step,
best_val_loss, is_best, work_dir, device):
if args.fp16:
if args.amp == 'pytorch':
amp_state = scaler.state_dict()
elif args.amp == 'apex':
amp_state = amp.state_dict()
else:
amp_state = None
memory = [
utils.distributed.all_gather_tensors(mem, device) for mem in mems
]
state = {
'args': args,
'model_config': model_config,
'model_state': model.state_dict(),
'optimizer_state': optimizer.state_dict(),
'scheduler_state': scheduler.state_dict(),
'rng_states': utils.exp_utils.get_default_rng_states(device),
'memory': memory,
'vocab': vocab,
'amp_state': amp_state,
'epoch': epoch,
'batch': batch,
'last_iter': last_iter,
'train_step': train_step,
'best_val_loss': best_val_loss,
}
last_chkpt_fname = 'checkpoint_last.pt'
with utils.distributed.sync_workers() as rank:
last_chkpt_path = os.path.join(work_dir, last_chkpt_fname)
if rank == 0:
# always save last checkpoint
logging.info(f'Saving checkpoint to {last_chkpt_path}')
torch.save(state, last_chkpt_path)
# save best checkpoint if better than previous best
if is_best:
best_chkpt_fname = 'checkpoint_best.pt'
best_chkpt_path = os.path.join(work_dir, best_chkpt_fname)
logging.info(f'Saving checkpoint to {best_chkpt_path}')
shutil.copy(last_chkpt_path, best_chkpt_path)
# save every checkpoint if save_all is true
if args.save_all:
step_chkpt_fname = f'checkpoint_{train_step}.pt'
step_chkpt_path = os.path.join(work_dir, step_chkpt_fname)
logging.info(f'Saving checkpoint to {step_chkpt_path}')
shutil.copy(last_chkpt_path, step_chkpt_path)
def load_checkpoint(path):
if os.path.isdir(path):
path = os.path.join(path, 'checkpoint_last.pt')
dst = f'cuda:{torch.cuda.current_device()}'
logging.info(f'Loading checkpoint from {path}')
checkpoint = torch.load(path, map_location=dst)
return checkpoint
def init_weight(weight, args):
if args.init == 'uniform':
nn.init.uniform_(weight, -args.init_range, args.init_range)
elif args.init == 'normal':
nn.init.normal_(weight, 0.0, args.init_std)
def init_bias(bias):
nn.init.constant_(bias, 0.0)
def weights_init(m, args):
classname = m.__class__.__name__
if classname.find('Linear') != -1:
if hasattr(m, 'weight') and m.weight is not None:
init_weight(m.weight, args)
if hasattr(m, 'bias') and m.bias is not None:
init_bias(m.bias)
elif classname.find('AdaptiveEmbedding') != -1:
if hasattr(m, 'emb_projs'):
for i in range(len(m.emb_projs)):
if m.emb_projs[i] is not None:
nn.init.normal_(m.emb_projs[i], 0.0, args.proj_init_std)
elif classname.find('Embedding') != -1:
if hasattr(m, 'weight'):
init_weight(m.weight, args)
elif classname.find('ProjectedAdaptiveLogSoftmax') != -1:
if hasattr(m, 'cluster_weight') and m.cluster_weight is not None:
init_weight(m.cluster_weight, args)
if hasattr(m, 'cluster_bias') and m.cluster_bias is not None:
init_bias(m.cluster_bias)
if hasattr(m, 'out_projs'):
for i in range(len(m.out_projs)):
if m.out_projs[i] is not None:
nn.init.normal_(m.out_projs[i], 0.0, args.proj_init_std)
if hasattr(m, 'out_layers_weights'):
for i in range(len(m.out_layers_weights)):
if m.out_layers_weights[i] is not None:
init_weight(m.out_layers_weights[i], args)
elif classname.find('LayerNorm') != -1:
if hasattr(m, 'weight'):
nn.init.normal_(m.weight, 1.0, args.init_std)
if hasattr(m, 'bias') and m.bias is not None:
init_bias(m.bias)
elif classname.find('TransformerLM') != -1:
if hasattr(m, 'r_emb'):
init_weight(m.r_emb, args)
if hasattr(m, 'r_w_bias'):
init_weight(m.r_w_bias, args)
if hasattr(m, 'r_r_bias'):
init_weight(m.r_r_bias, args)
if hasattr(m, 'r_bias'):
init_bias(m.r_bias)
def update_dropout(m, args):
classname = m.__class__.__name__
if classname.find('Dropout') != -1:
if hasattr(m, 'p'):
m.p = args.dropout
def update_dropatt(m, args):
if hasattr(m, 'dropatt'):
m.dropatt.p = args.dropatt
def evaluate(eval_iter, model, args):
# Turn on evaluation mode which disables dropout.
model.eval()
# If the model does not use memory at all, make the ext_len longer.
# Otherwise, make the mem_len longer and keep the ext_len the same.
if args.mem_len == 0:
model.reset_length(tgt_len=args.eval_tgt_len,
ext_len=args.ext_len + args.tgt_len - args.eval_tgt_len,
mem_len=args.mem_len
)
else:
model.reset_length(tgt_len=args.eval_tgt_len,
ext_len=args.ext_len,
mem_len=args.mem_len + args.tgt_len - args.eval_tgt_len,
)
# Evaluation
total_len, total_loss = 0, 0.
with torch.no_grad():
mems = None
for i, (data, target, seq_len, warm) in enumerate(eval_iter):
if args.eval_max_steps > 0 and i >= args.eval_max_steps:
break
enable_autocast = args.fp16 and args.amp == 'pytorch'
with torch.cuda.amp.autocast(enable_autocast):
loss, mems = model(data, target, mems)
loss = loss.float().mean().type_as(loss)
if warm:
# assert (mems is None) or mems.size(1) == model.mem_len
total_loss += seq_len * loss.item()
total_len += seq_len
# Switch back to the training mode
model.reset_length(tgt_len=args.tgt_len,
ext_len=args.ext_len,
mem_len=args.mem_len
)
model.train()
return total_loss / total_len
def train_iteration(model, i, mems, data_chunks, target_chunks, scaler,
optimizer, device, delay_unscale, args):
cpu = torch.device('cpu')
data_i = data_chunks[i].contiguous()
target_i = target_chunks[i].contiguous()
if args.swap_mem and mems[i] is not None:
mems[i] = mems[i].to(device, non_blocking=True)
enable_autocast = args.fp16 and args.amp == 'pytorch'
with torch.cuda.amp.autocast(enable_autocast):
loss, mems[i] = model(data_i, target_i, mems[i])
loss = loss.float().mean().type_as(loss) / args.batch_chunk
if args.swap_mem and mems[i] is not None:
mems[i] = mems[i].to(cpu, non_blocking=True)
if args.fp16:
if args.amp == 'pytorch':
scaler.scale(loss).backward()
elif args.amp == 'apex':
with amp.scale_loss(loss, optimizer, delay_unscale=delay_unscale) as scaled_loss:
scaled_loss.backward()
else:
loss.backward()
train_loss = loss.float().item()
return train_loss
def train(tr_iter, va_iter, model, para_model, mems, model_config, optimizer,
optimizer_sparse, scheduler, scheduler_sparse, scaler, vocab, epoch,
last_batch, last_iter, train_step, best_val_loss, meters,
timeout_handler, device, args):
# Turn on training mode which enables dropout.
model.train()
train_loss = 0
cur_loss = float('inf')
target_tokens = 0
log_step = 0
utils.distributed.barrier()
log_start_time = time.time()
if args.varlen:
train_iter = tr_iter.get_varlen_iter(start=last_iter)
else:
train_iter = tr_iter.get_fixlen_iter(start=last_iter)
for batch, (data, target, seq_len, _) in enumerate(train_iter, start=last_batch+1):
log_step += 1
target_tokens += target.numel()
for param in model.parameters():
param.grad = None
data_chunks = torch.chunk(data, args.batch_chunk, 1)
target_chunks = torch.chunk(target, args.batch_chunk, 1)
for i in range(args.batch_chunk):
if i < args.batch_chunk - 1 and isinstance(para_model, DistributedDataParallel):
with para_model.no_sync():
train_loss_chunk = train_iteration(
para_model, i, mems, data_chunks, target_chunks, scaler,
optimizer, device, True, args
)
else:
train_loss_chunk = train_iteration(
para_model, i, mems, data_chunks, target_chunks, scaler,
optimizer, device, False, args
)
train_loss += train_loss_chunk
if args.fp16:
if args.amp == 'pytorch':
scaler.unscale_(optimizer)
torch.nn.utils.clip_grad_norm_(model.parameters(), args.clip)
elif args.amp == 'apex':
torch.nn.utils.clip_grad_norm_(amp.master_params(optimizer), args.clip)
else:
torch.nn.utils.clip_grad_norm_(model.parameters(), args.clip)
if args.fp16 and args.amp == 'pytorch':
scaler.step(optimizer)
scaler.update()
else:
optimizer.step()
if optimizer_sparse:
optimizer_sparse.step()
# step-wise learning rate annealing
train_step += 1
if args.scheduler in ['cosine', 'constant', 'dev_perf']:
# linear warmup stage
if train_step < args.warmup_step:
curr_lr = args.lr * train_step / args.warmup_step
optimizer.param_groups[0]['lr'] = curr_lr
if optimizer_sparse:
optimizer_sparse.param_groups[0]['lr'] = curr_lr * 2
else:
if args.scheduler == 'cosine':
scheduler.step(train_step - args.warmup_step)
if scheduler_sparse:
scheduler_sparse.step(train_step - args.warmup_step)
elif args.scheduler == 'inv_sqrt':
scheduler.step(train_step)
if scheduler_sparse:
scheduler_sparse.step(train_step)
if train_step % args.log_interval == 0:
cur_loss = train_loss / log_step
cur_loss = utils.distributed.all_reduce_item(cur_loss, op='mean')
train_loss = 0
utils.distributed.barrier()
current_time = time.time()
elapsed = current_time - log_start_time
avg_elapsed = elapsed / log_step
avg_elapsed = utils.distributed.all_reduce_item(avg_elapsed, op='max')
log_start_time = current_time
log_step = 0
lr = optimizer.param_groups[0]['lr']
throughput = target_tokens / elapsed
throughput = utils.distributed.all_reduce_item(throughput, op='sum')
meters['train_throughput'].update(throughput, elapsed)
target_tokens = 0
log_str = '| epoch {:3d} step {:>8d} | batches {:>6d} / {:d} | lr {:.3e} ' \
'| ms/batch {:5.1f} | tok/s {:7.0f} | loss {:5.2f}'.format(
epoch,
train_step,
batch,
tr_iter.n_batch,
lr,
avg_elapsed * 1000,
throughput,
cur_loss,
)
dllogger_data = {
'epoch': epoch,
'train_batch': batch+1,
'lr': lr,
'train_time/batch': avg_elapsed * 1000,
'train_throughput': throughput,
'train_loss': cur_loss,
}
if args.dataset in ['enwik8', 'text8']:
log_str += ' | bpc {:9.5f}'.format(cur_loss / math.log(2))
dllogger_data['train_bits_per_character'] = cur_loss / math.log(2)
else:
log_str += ' | ppl {:9.2f}'.format(math.exp(cur_loss))
dllogger_data['train_perplexity'] = math.exp(cur_loss)
logging.info(log_str)
dllogger.log(step=tuple([train_step]), data=dllogger_data)
do_periodic_eval = train_step % args.eval_interval == 0
is_final_step = train_step == args.max_step
interrupted = timeout_handler.interrupted
if (do_periodic_eval or is_final_step or interrupted) and not args.no_eval:
utils.distributed.barrier()
eval_start_time = time.time()
val_loss = evaluate(va_iter, model, args)
val_loss = utils.distributed.all_reduce_item(val_loss, op='mean')
utils.distributed.barrier()
eval_elapsed = time.time() - eval_start_time
logging.info('-' * 100)
log_str = '| Eval {:3d} at step {:>8d} | time: {:5.2f}s ' \
'| valid loss {:5.2f}'.format(
train_step // args.eval_interval,
train_step,
eval_elapsed,
val_loss,
)
dllogger_data = {
'valid_elapsed': eval_elapsed,
'valid_loss': val_loss,
}
if args.dataset in ['enwik8', 'text8']:
log_str += ' | bpc {:9.5f}'.format(val_loss / math.log(2))
dllogger_data['valid_bits_per_character'] = val_loss / math.log(2)
else:
log_str += ' | valid ppl {:9.3f}'.format(math.exp(val_loss))
dllogger_data['valid_perplexity'] = math.exp(val_loss)
logging.info(log_str)
logging.info('-' * 100)
dllogger.log(step=tuple([train_step]), data=dllogger_data)
last_iter = tr_iter.last_iter
# Check if the validation loss is the best we've seen so far.
is_best = False
if not best_val_loss or val_loss < best_val_loss:
best_val_loss = val_loss
is_best = True
if not args.debug:
save_checkpoint(args, model, mems, model_config, optimizer,
scheduler, scaler, vocab, epoch, batch,
last_iter, train_step, best_val_loss, is_best,
args.work_dir, device)
# dev-performance based learning rate annealing
if args.scheduler == 'dev_perf':
scheduler.step(val_loss)
if scheduler_sparse:
scheduler_sparse.step(val_loss)
# subtract eval time from timers for training
utils.distributed.barrier()
log_start_time += time.time() - eval_start_time
if interrupted:
logging.info(f'Received SIGTERM, exiting')
sys.exit(0)
if is_final_step:
break
return train_step, best_val_loss, cur_loss
def main():
args = parse_args()
if args.affinity != 'disabled':
nproc_per_node = torch.cuda.device_count()
affinity = utils.gpu_affinity.set_affinity(
args.local_rank,
nproc_per_node,
args.affinity
)
print(f'{args.local_rank}: thread affinity: {affinity}')
# Initialize device and distributed backend
torch.cuda.set_device(args.local_rank)
l2_promote()
device = torch.device('cuda' if args.cuda else 'cpu')
utils.distributed.init_distributed(args.cuda)
args.work_dir = utils.exp_utils.build_work_dir_name(args.work_dir,
args.dataset,
args.append_dataset,
args.append_time,
)
with utils.distributed.sync_workers() as rank:
if rank == 0:
create_exp_dir(args.work_dir,
scripts_to_save=['train.py', 'mem_transformer.py'],
debug=args.debug)
# Setup logging
if args.log_all_ranks:
log_file = f'train_log_rank_{utils.distributed.get_rank()}.log'
else:
log_file = args.txtlog_file
dllog_file = args.dllog_file
log_file = os.path.join(args.work_dir, log_file)
dllog_file = os.path.join(args.work_dir, dllog_file)
if args.debug:
log_file = os.devnull
dllog_file = os.devnull
utils.exp_utils.setup_logging(log_all_ranks=args.log_all_ranks,
filename=log_file,
)
utils.exp_utils.setup_dllogger(enabled=True, filename=dllog_file)
if args.local_batch_size is not None:
world_size = utils.distributed.get_world_size()
args.batch_size = world_size * args.local_batch_size
logging.info(f'--local_batch_size was set, adjusting global batch size'
f' to {args.batch_size} (local_batch_size * world_size)')
if args.batch_size % args.batch_chunk != 0:
raise RuntimeError('Batch size needs to be divisible by '
'batch chunk')
logging.info(args)
dllogger.log(step='PARAMETER', data=vars(args))
dllogger.metadata('train_throughput', {'unit': 'tokens/s'})
dllogger.metadata('train_elapsed', {'unit': 'min'})
dllogger.metadata('valid_elapsed', {'unit': 'min'})
dllogger.metadata('train_perplexity', {'unit': None})
dllogger.metadata('valid_perplexity', {'unit': None})
dllogger.metadata('train_loss', {'unit': None})
dllogger.metadata('valid_loss', {'unit': None})
logging.info(f'world size: {utils.distributed.get_world_size()}')
if not args.no_env:
log_env_info()
register_ignoring_timeout_handler()
# Set the random seed manually for reproducibility.
np.random.seed(args.seed)
torch.manual_seed(args.seed)
###########################################################################
# Load data
###########################################################################
corpus = get_lm_corpus(args.data, args.dataset, args.vocab)
ntokens = len(corpus.vocab)
vocab = corpus.vocab
args.n_token = ntokens
if args.mem_len == 0:
eval_mem_len = 0
else:
eval_mem_len = args.mem_len + args.tgt_len - args.eval_tgt_len
tr_iter = corpus.get_iterator('train', args.batch_size, args.tgt_len,
device=device, ext_len=args.ext_len)
va_iter = corpus.get_iterator('valid', args.eval_batch_size,
args.eval_tgt_len, device=device,
mem_len=eval_mem_len, ext_len=args.ext_len)
te_iter = corpus.get_iterator('test', args.eval_batch_size,
args.eval_tgt_len, device=device,
mem_len=eval_mem_len, ext_len=args.ext_len)
# adaptive softmax / embedding
cutoffs, tie_projs = [], [False]
if args.adaptive:
assert args.dataset in ['wt103', 'lm1b']
if args.dataset == 'wt103':
cutoffs = [19997, 39997, 199997]
tie_projs += [True] * len(cutoffs)
elif args.dataset == 'lm1b':
cutoffs = [59997, 99997, 639997]
tie_projs += [False] * len(cutoffs)
###########################################################################
# Build the model
###########################################################################
model_config = {
'n_token': ntokens,
'n_layer': args.n_layer,
'n_head': args.n_head,
'd_model': args.d_model,
'd_head': args.d_head,
'd_inner': args.d_inner,
'dropout': args.dropout,
'dropatt': args.dropatt,
'dtype': None,
'tie_weight': args.tied,
'd_embed': args.d_embed,
'div_val': args.div_val,
'tie_projs': tie_projs,
'pre_lnorm': args.pre_lnorm,
'tgt_len': args.tgt_len,
'ext_len': args.ext_len,
'mem_len': args.mem_len,
'cutoffs': cutoffs,
'same_length': args.same_length,
'attn_type': args.attn_type,
'clamp_len': args.clamp_len,
'sample_softmax': args.sample_softmax,
}
model = MemTransformerLM(**model_config)
model.apply(functools.partial(weights_init, args=args))
# ensure embedding init is not overridden by out_layer in case of weight sharing
model.word_emb.apply(functools.partial(weights_init, args=args))
args.n_all_param = sum([p.nelement() for p in model.parameters()])
args.n_nonemb_param = sum([p.nelement() for p in model.layers.parameters()])
# optimizer
if args.optim.lower() == 'sgd':
if args.sample_softmax > 0:
dense_params, sparse_params = [], []
for param in model.parameters():
if param.size() == model.word_emb.weight.size():
sparse_params.append(param)
else:
dense_params.append(param)
optimizer_sparse = optim.SGD(sparse_params, lr=args.lr * 2)
optimizer = optim.SGD(dense_params, lr=args.lr, momentum=args.mom)
else:
optimizer = optim.SGD(model.parameters(), lr=args.lr,
momentum=args.mom)
optimizer_sparse = None
elif args.optim.lower() == 'adam':
if args.sample_softmax > 0:
dense_params, sparse_params = [], []
for param in model.parameters():
if param.size() == model.word_emb.weight.size():
sparse_params.append(param)
else:
dense_params.append(param)
optimizer_sparse = optim.SparseAdam(sparse_params, lr=args.lr)
optimizer = optim.Adam(dense_params, lr=args.lr,
weight_decay=args.weight_decay)
else:
optimizer = optim.Adam(model.parameters(), lr=args.lr,
weight_decay=args.weight_decay)
optimizer_sparse = None
elif args.optim.lower() == 'adagrad':
optimizer = optim.Adagrad(model.parameters(), lr=args.lr)
optimizer_sparse = None
elif args.optim.lower() == 'lamb':
optimizer = lamb.Lamb(model.parameters(), lr=args.lr,
weight_decay=args.weight_decay)
optimizer_sparse = None
elif args.optim.lower() == 'jitlamb':
optimizer = lamb.JITLamb(model.parameters(), lr=args.lr,
weight_decay=args.weight_decay)
optimizer_sparse = None
model = model.to(device)
scaler = None
if args.fp16:
if args.amp == 'pytorch':
scaler = torch.cuda.amp.GradScaler()
elif args.amp == 'apex':
model, optimizer = amp.initialize(
model,
optimizer,
opt_level=args.apex_amp_opt_level,
)
if args.multi_gpu == 'ddp' and torch.distributed.is_initialized():
para_model = DistributedDataParallel(model,
device_ids=[args.local_rank],
output_device=args.local_rank,
broadcast_buffers=False,
find_unused_parameters=True,
)
elif args.multi_gpu == 'dp':
if args.gpu0_bsz >= 0:
para_model = BalancedDataParallel(args.gpu0_bsz // args.batch_chunk,
model, dim=1).to(device)
else:
para_model = nn.DataParallel(model, dim=1).to(device)
else:
para_model = model
# scheduler
if args.scheduler == 'cosine':
if args.max_step_scheduler:
max_step = args.max_step_scheduler
else:
max_step = args.max_step
scheduler = optim.lr_scheduler.CosineAnnealingLR(
optimizer, max_step - args.warmup_step, eta_min=args.eta_min)
if args.sample_softmax > 0 and optimizer_sparse is not None:
scheduler_sparse = optim.lr_scheduler.CosineAnnealingLR(
optimizer_sparse, max_step - args.warmup_step,
eta_min=args.eta_min)
else:
scheduler_sparse = None
elif args.scheduler == 'inv_sqrt':
# originally used for Transformer (in Attention is all you need)
def lr_lambda(step):
# return a multiplier instead of a learning rate
if step == 0 and args.warmup_step == 0:
return 1.
else:
return 1. / (step ** 0.5) if step > args.warmup_step \
else step / (args.warmup_step ** 1.5)
scheduler = optim.lr_scheduler.LambdaLR(optimizer, lr_lambda=lr_lambda)
if args.sample_softmax > 0 and optimizer_sparse is not None:
scheduler_sparse = optim.lr_scheduler.LambdaLR(
optimizer_sparse,
lr_lambda=lr_lambda
)
else:
scheduler_sparse = None
elif args.scheduler == 'dev_perf':
scheduler = optim.lr_scheduler.ReduceLROnPlateau(
optimizer, factor=args.decay_rate, patience=args.patience,
min_lr=args.lr_min,
)
if args.sample_softmax > 0 and optimizer_sparse is not None:
scheduler_sparse = optim.lr_scheduler.ReduceLROnPlateau(
optimizer_sparse, factor=args.decay_rate, patience=args.patience,
min_lr=args.lr_min,
)
else:
scheduler_sparse = None
elif args.scheduler == 'constant':
pass
logging.info('=' * 100)
for k, v in args.__dict__.items():
logging.info(' - {} : {}'.format(k, v))
logging.info('=' * 100)
logging.info('#params = {}'.format(args.n_all_param))
logging.info('#non emb params = {}'.format(args.n_nonemb_param))
train_step = 0
start_epoch = 1
last_batch = 0
last_iter = 0
best_val_loss = None
cur_loss = float('inf')
train_mems = [None for _ in range(args.batch_chunk)]
if args.restart:
try:
checkpoint = load_checkpoint(args.restart)
model.load_state_dict(checkpoint['model_state'])
optimizer.load_state_dict(checkpoint['optimizer_state'])
scheduler.load_state_dict(checkpoint['scheduler_state'])
if args.fp16:
if args.amp == 'pytorch':
scaler.load_state_dict(checkpoint['amp_state'])
elif args.amp == 'apex':
amp.load_state_dict(checkpoint['amp_state'])
utils.exp_utils.set_default_rng_states(
checkpoint['rng_states'], device
)
train_mems = [
checkpoint['memory'][i][utils.distributed.get_rank()]
for i in range(args.batch_chunk)
]
train_step = checkpoint['train_step']
start_epoch = checkpoint['epoch']
last_batch = checkpoint['batch']
last_iter = checkpoint['last_iter']
best_val_loss = checkpoint['best_val_loss']
if train_step >= args.max_step:
logging.info(f'Loaded checkpoint after {train_step} steps, but '
f'this run was scheduled for a total of '
f'{args.max_step} steps, exiting')
sys.exit(1)
model.apply(functools.partial(update_dropout, args=args))
model.apply(functools.partial(update_dropatt, args=args))
except FileNotFoundError:
logging.info(f'Could not load checkpoint from {args.restart}, '
f'starting training from random init')
meters = {}
warmup = args.mem_len // args.tgt_len + 2
meters['train_throughput'] = AverageMeter(warmup=warmup)
###########################################################################
# Train
###########################################################################
# Loop over epochs.
# At any point you can hit Ctrl + C to break out of training early.
utils.distributed.barrier()
start_time = time.time()
with TimeoutHandler() as timeout_handler:
try:
for epoch in itertools.count(start=start_epoch):
if args.roll:
tr_iter.roll(seed=args.seed + epoch)
train_step, best_val_loss, cur_loss = train(
tr_iter, va_iter, model, para_model, train_mems,
model_config, optimizer, optimizer_sparse, scheduler,
scheduler_sparse, scaler, vocab, epoch, last_batch,
last_iter, train_step, best_val_loss, meters,
timeout_handler, device, args
)
last_batch = 0
last_iter = 0
if train_step == args.max_step:
logging.info('-' * 100)
logging.info('End of training')
break
except KeyboardInterrupt:
logging.info('-' * 100)
logging.info('Exiting from training early')
utils.distributed.barrier()
elapsed = time.time() - start_time
###########################################################################
# Test
###########################################################################
summary = {}
test_path = os.path.join(args.work_dir, 'checkpoint_best.pt')
if (
not args.debug
and not args.no_test
and not args.no_eval
and os.path.exists(test_path)
):
# Load the best saved model.
checkpoint = load_checkpoint(test_path)
model.load_state_dict(checkpoint['model_state'])
# Run on test data.
utils.distributed.barrier()
test_start_time = time.time()
test_loss = evaluate(te_iter, model, args)
test_loss = utils.distributed.all_reduce_item(test_loss, 'mean')
utils.distributed.barrier()
test_elapsed = time.time() - test_start_time
logging.info('=' * 100)
if args.dataset in ['enwik8', 'text8']:
logging.info('| End of training | test time: {:5.2f}s | test loss {:5.2f} | test bpc {:9.5f}'.format(
test_elapsed, test_loss, test_loss / math.log(2)))
else:
logging.info('| End of training | test time: {:5.2f}s | test loss {:5.2f} | test ppl {:9.3f}'.format(
test_elapsed, test_loss, math.exp(test_loss)))
logging.info('=' * 100)
summary.update({
'test_elapsed': test_elapsed,
'test_loss': test_loss,
})
if args.dataset in ['enwik8', 'text8']:
summary['test_bits_per_character'] = test_loss / math.log(2)
else:
summary['test_perplexity'] = math.exp(test_loss)
logging.info(f'Training time: {(elapsed / 60):.2f} minutes')
logging.info(f'Training throughput: {meters["train_throughput"].avg:.2f} tok/s')
if best_val_loss:
best_val_perplexity = math.exp(best_val_loss)
else:
best_val_perplexity = None
summary.update({
'train_throughput': meters['train_throughput'].avg,
'train_elapsed': elapsed / 60,
'train_loss': cur_loss,
'valid_loss': best_val_loss,
'valid_perplexity': best_val_perplexity,
})
dllogger.log(step=tuple(), data=summary)
passed = benchmark(
target_perplexity=args.target_perplexity,
test_perplexity=best_val_perplexity,
target_throughput=args.target_throughput,
test_throughput=meters['train_throughput'].avg
)
if not passed:
sys.exit(1)
if __name__ == "__main__":
# Disable profiling executor
try:
torch._C._jit_set_profiling_executor(False)
torch._C._jit_set_profiling_mode(False)
except AttributeError:
pass
# Before we do anything with models, we want to ensure that we get fp16
# execution of torch.einsum in APEX AMP.
# Otherwise it'll default to "promote" mode, and we'll get fp32 operations.
# Note that running `--apex_amp_opt_level O2` will remove the need for this
# code, but it is still valid.
if 'apex' in sys.modules:
amp.register_half_function(torch, 'einsum')
main()
|
PyTorch/SpeechRecognition/Jasper/common | common | tb_dllogger | import atexit
import glob
import os
import re
from pathlib import Path
import numpy as np
import torch
from torch.utils.tensorboard import SummaryWriter
import dllogger
from dllogger import StdOutBackend, JSONStreamBackend, Verbosity
tb_loggers = {}
class TBLogger:
"""
xyz_dummies: stretch the screen with empty plots so the legend would
always fit for other plots
"""
def __init__(self, enabled, log_dir, name, interval=1, dummies=True):
self.enabled = enabled
self.interval = interval
self.cache = {}
if self.enabled:
self.summary_writer = SummaryWriter(
log_dir=os.path.join(log_dir, name),
flush_secs=120, max_queue=200)
atexit.register(self.summary_writer.close)
if dummies:
for key in ('aaa', 'zzz'):
self.summary_writer.add_scalar(key, 0.0, 1)
def log(self, step, data):
for k, v in data.items():
self.log_value(step, k, v.item() if type(v) is torch.Tensor else v)
def log_value(self, step, key, val, stat='mean'):
if self.enabled:
if key not in self.cache:
self.cache[key] = []
self.cache[key].append(val)
if len(self.cache[key]) == self.interval:
agg_val = getattr(np, stat)(self.cache[key])
self.summary_writer.add_scalar(key, agg_val, step)
del self.cache[key]
def log_grads(self, step, model):
if self.enabled:
norms = [p.grad.norm().item() for p in model.parameters()
if p.grad is not None]
for stat in ('max', 'min', 'mean'):
self.log_value(step, f'grad_{stat}', getattr(np, stat)(norms),
stat=stat)
def unique_log_fpath(fpath):
"""Have a unique log filename for every separate run"""
log_num = max([0] + [int(re.search("\.(\d+)", Path(f).suffix).group(1))
for f in glob.glob(f"{fpath}.*")])
return f"{fpath}.{log_num + 1}"
def stdout_step_format(step):
if isinstance(step, str):
return step
fields = []
if len(step) > 0:
fields.append("epoch {:>4}".format(step[0]))
if len(step) > 1:
fields.append("iter {:>4}".format(step[1]))
if len(step) > 2:
fields[-1] += "/{}".format(step[2])
return " | ".join(fields)
def stdout_metric_format(metric, metadata, value):
name = metadata.get("name", metric + " : ")
unit = metadata.get("unit", None)
format = f'{{{metadata.get("format", "")}}}'
fields = [name, format.format(value) if value is not None else value, unit]
fields = [f for f in fields if f is not None]
return "| " + " ".join(fields)
def init_log(args):
enabled = (args.local_rank == 0)
if enabled:
fpath = args.log_file or os.path.join(args.output_dir, 'nvlog.json')
backends = [
JSONStreamBackend(Verbosity.DEFAULT, fpath, append=True),
JSONStreamBackend(Verbosity.DEFAULT, unique_log_fpath(fpath)),
StdOutBackend(Verbosity.VERBOSE, step_format=stdout_step_format,
metric_format=stdout_metric_format)
]
else:
backends = []
dllogger.init(backends=backends)
dllogger.metadata("train_lrate", {"name": "lrate", "unit": None, "format": ":>3.2e"})
for id_, pref in [('train', ''), ('train_avg', 'avg train '),
('dev', ' avg dev '), ('dev_ema', ' EMA dev ')]:
dllogger.metadata(f"{id_}_loss",
{"name": f"{pref}loss", "unit": None, "format": ":>7.2f"})
dllogger.metadata(f"{id_}_wer",
{"name": f"{pref}wer", "unit": "%", "format": ":>6.2f"})
dllogger.metadata(f"{id_}_throughput",
{"name": f"{pref}utts/s", "unit": "samples/s", "format": ":>5.0f"})
dllogger.metadata(f"{id_}_took",
{"name": "took", "unit": "s", "format": ":>5.2f"})
tb_subsets = ['train', 'dev', 'dev_ema'] if args.ema else ['train', 'dev']
global tb_loggers
tb_loggers = {s: TBLogger(enabled, args.output_dir, name=s)
for s in tb_subsets}
log_parameters(vars(args), tb_subset='train')
def log(step, tb_total_steps=None, subset='train', data={}):
if tb_total_steps is not None:
tb_loggers[subset].log(tb_total_steps, data)
if subset != '':
data = {f'{subset}_{key}': v for key,v in data.items()}
dllogger.log(step, data=data)
def log_grads_tb(tb_total_steps, grads, tb_subset='train'):
tb_loggers[tb_subset].log_grads(tb_total_steps, grads)
def log_parameters(data, verbosity=0, tb_subset=None):
for k,v in data.items():
dllogger.log(step="PARAMETER", data={k:v}, verbosity=verbosity)
if tb_subset is not None and tb_loggers[tb_subset].enabled:
tb_data = {k:v for k,v in data.items()
if type(v) in (str, bool, int, float)}
tb_loggers[tb_subset].summary_writer.add_hparams(tb_data, {})
def flush_log():
dllogger.flush()
for tbl in tb_loggers.values():
if tbl.enabled:
tbl.summary_writer.flush()
|
TensorFlow2/Recommendation/DLRM_and_DCNv2/deployment/hps | hps | constants | # Copyright (c) 2023, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
# author: Tomasz Grel ([email protected])
key_local_prefix = "KEYS"
numkey_local_prefix = "NUMKEYS"
key_global_prefix = "EMB_KEY"
numkey_global_prefix = "EMB_N_KEY"
emb_output_name = "OUTPUT0"
ens_lookup_tensors_name = "LOOKUP_VECTORS"
dense_input1_name = "args_1"
ens_numerical_features_name = "numerical_features"
dense_numerical_features_name = "args_0"
dense_output_name = "output_1"
ens_output_name = "DENSE_OUTPUT"
hps_model_name = "hps_embedding"
dense_model_name = "tf_reshape_dense_model"
|
Tools/PyTorch/TimeSeriesPredictionPlatform/models/tft_pyt | tft_pyt | inference | # Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import os
import pandas as pd
import numpy as np
import pickle
import argparse
import torch
from torch.utils.data import DataLoader
from torch.cuda import amp
from torch.utils.tensorboard import SummaryWriter
from tqdm import tqdm
from modeling import TemporalFusionTransformer
from configuration import ElectricityConfig
from data_utils import TFTDataset
from utils import PerformanceMeter
from criterions import QuantileLoss
import dllogger
from log_helper import setup_logger
def _unscale_per_id(config, values, ids, scalers):
values = values.cpu().numpy()
num_horizons = config.example_length - config.encoder_length + 1
flat_values = pd.DataFrame(
values,
columns=[f't{j}' for j in range(num_horizons - values.shape[1], num_horizons)]
)
flat_values['id'] = ids
df_list = []
for idx, group in flat_values.groupby('id'):
scaler = scalers[idx]
group_copy = group.copy()
for col in group_copy.columns:
if not 'id' in col:
_col = np.expand_dims(group_copy[col].values, -1)
_t_col = scaler.inverse_transform(_col)[:,-1]
group_copy[col] = _t_col
df_list.append(group_copy)
flat_values = pd.concat(df_list, axis=0)
flat_values = flat_values[[col for col in flat_values if not 'id' in col]]
flat_tensor = torch.from_numpy(flat_values.values)
return flat_tensor
def _unscale(config, values, scaler):
values = values.cpu().numpy()
num_horizons = config.example_length - config.encoder_length + 1
flat_values = pd.DataFrame(
values,
columns=[f't{j}' for j in range(num_horizons - values.shape[1], num_horizons)]
)
for col in flat_values.columns:
if not 'id' in col:
_col = np.expand_dims(flat_values[col].values, -1)
_t_col = scaler.inverse_transform(_col)[:,-1]
flat_values[col] = _t_col
flat_values = flat_values[[col for col in flat_values if not 'id' in col]]
flat_tensor = torch.from_numpy(flat_values.values)
return flat_tensor
def predict(args, config, model, data_loader, scalers, cat_encodings, extend_targets=False):
model.eval()
predictions = []
targets = []
ids = []
perf_meter = PerformanceMeter()
n_workers = args.distributed_world_size if hasattr(args, 'distributed_world_size') else 1
for step, batch in enumerate(data_loader):
perf_meter.reset_current_lap()
with torch.no_grad():
batch = {key: tensor.cuda() if tensor.numel() else None for key, tensor in batch.items()}
ids.append(batch['id'][:,0,:])
targets.append(batch['target'])
predictions.append(model(batch).float())
perf_meter.update(args.batch_size * n_workers,
exclude_from_total=step in [0, len(data_loader)-1])
targets = torch.cat(targets, dim=0)
if not extend_targets:
targets = targets[:,config.encoder_length:,:]
predictions = torch.cat(predictions, dim=0)
if config.scale_per_id:
ids = torch.cat(ids, dim=0).cpu().numpy()
unscaled_predictions = torch.stack(
[_unscale_per_id(config, predictions[:,:,i], ids, scalers) for i in range(len(config.quantiles))],
dim=-1)
unscaled_targets = _unscale_per_id(config, targets[:,:,0], ids, scalers).unsqueeze(-1)
else:
ids = None
unscaled_predictions = torch.stack(
[_unscale(config, predictions[:,:,i], scalers['']) for i in range(len(config.quantiles))],
dim=-1)
unscaled_targets = _unscale(config, targets[:,:,0], scalers['']).unsqueeze(-1)
return unscaled_predictions, unscaled_targets, ids, perf_meter
def visualize_v2(args, config, model, data_loader, scalers, cat_encodings):
unscaled_predictions, unscaled_targets, ids, _ = predict(args, config, model, data_loader, scalers, cat_encodings, extend_targets=True)
num_horizons = config.example_length - config.encoder_length + 1
pad = unscaled_predictions.new_full((unscaled_targets.shape[0], unscaled_targets.shape[1] - unscaled_predictions.shape[1], unscaled_predictions.shape[2]), fill_value=float('nan'))
pad[:,-1,:] = unscaled_targets[:,-num_horizons,:]
unscaled_predictions = torch.cat((pad, unscaled_predictions), dim=1)
ids = torch.from_numpy(ids.squeeze())
joint_graphs = torch.cat([unscaled_targets, unscaled_predictions], dim=2)
graphs = {i:joint_graphs[ids == i, :, :] for i in set(ids.tolist())}
for key, g in graphs.items():
for i, ex in enumerate(g):
df = pd.DataFrame(ex.numpy(),
index=range(num_horizons - ex.shape[0], num_horizons),
columns=['target'] + [f'P{int(q*100)}' for q in config.quantiles])
fig = df.plot().get_figure()
ax = fig.get_axes()[0]
_values = df.values[config.encoder_length-1:,:]
ax.fill_between(range(num_horizons), _values[:,1], _values[:,-1], alpha=0.2, color='green')
os.makedirs(os.path.join(args.results, 'single_example_vis', str(key)), exist_ok=True)
fig.savefig(os.path.join(args.results, 'single_example_vis', str(key), f'{i}.pdf'))
def inference(args, config, model, data_loader, scalers, cat_encodings):
unscaled_predictions, unscaled_targets, ids, perf_meter = predict(args, config, model, data_loader, scalers, cat_encodings)
if args.joint_visualization or args.save_predictions:
ids = torch.from_numpy(ids.squeeze())
#ids = torch.cat([x['id'][0] for x in data_loader.dataset])
joint_graphs = torch.cat([unscaled_targets, unscaled_predictions], dim=2)
graphs = {i:joint_graphs[ids == i, :, :] for i in set(ids.tolist())}
for key, g in graphs.items(): #timeseries id, joint targets and predictions
_g = {'targets': g[:,:,0]}
_g.update({f'P{int(q*100)}':g[:,:,i+1] for i, q in enumerate(config.quantiles)})
if args.joint_visualization:
summary_writer = SummaryWriter(log_dir=os.path.join(args.results, 'predictions_vis', str(key)))
for q, t in _g.items(): # target and quantiles, timehorizon values
if q == 'targets':
targets = torch.cat([t[:,0], t[-1,1:]]) # WIP
# We want to plot targets on the same graph as predictions. Probably could be written better.
for i, val in enumerate(targets):
summary_writer.add_scalars(str(key), {f'{q}':val}, i)
continue
# Tensor t contains different time horizons which are shifted in phase
# Next lines realign them
y = t.new_full((t.shape[0] + t.shape[1] -1, t.shape[1]), float('nan'))
for i in range(y.shape[1]):
y[i:i+t.shape[0], i] = t[:,i]
for i, vals in enumerate(y): # timestep, timehorizon values value
summary_writer.add_scalars(str(key), {f'{q}_t+{j+1}':v for j,v in enumerate(vals) if v == v}, i)
summary_writer.close()
if args.save_predictions:
for q, t in _g.items():
df = pd.DataFrame(t.tolist())
df.columns = [f't+{i+1}' for i in range(len(df.columns))]
os.makedirs(os.path.join(args.results, 'predictions', str(key)), exist_ok=True)
df.to_csv(os.path.join(args.results, 'predictions', str(key), q+'.csv'))
losses = QuantileLoss(config)(unscaled_predictions, unscaled_targets)
normalizer = unscaled_targets.abs().mean()
q_risk = 2 * losses / normalizer
perf_dict = {
'throughput': perf_meter.avg,
'latency_avg': perf_meter.total_time/len(perf_meter.intervals),
'latency_p90': perf_meter.p(90),
'latency_p95': perf_meter.p(95),
'latency_p99': perf_meter.p(99),
'total_infernece_time': perf_meter.total_time,
}
return q_risk, perf_dict
def main(args):
setup_logger(args)
# Set up model
state_dict = torch.load(args.checkpoint)
config = state_dict['config']
model = TemporalFusionTransformer(config).cuda()
model.load_state_dict(state_dict['model'])
model.eval()
model.cuda()
# Set up dataset
test_split = TFTDataset(args.data, config)
data_loader = DataLoader(test_split, batch_size=args.batch_size, num_workers=4)
scalers = pickle.load(open(args.tgt_scalers, 'rb'))
cat_encodings = pickle.load(open(args.cat_encodings, 'rb'))
if args.visualize:
# TODO: abstract away all forms of visualization.
visualize_v2(args, config, model, data_loader, scalers, cat_encodings)
quantiles, perf_dict = inference(args, config, model, data_loader, scalers, cat_encodings)
quantiles = {'test_p10': quantiles[0].item(), 'test_p50': quantiles[1].item(), 'test_p90': quantiles[2].item(), 'sum':sum(quantiles).item()}
finish_log = {**quantiles, **perf_dict}
dllogger.log(step=(), data=finish_log, verbosity=1)
print('Test q-risk: P10 {} | P50 {} | P90 {}'.format(*quantiles))
print('Latency:\n\tAverage {:.3f}s\n\tp90 {:.3f}s\n\tp95 {:.3f}s\n\tp99 {:.3f}s'.format(
perf_dict['latency_avg'], perf_dict['latency_p90'], perf_dict['latency_p95'], perf_dict['latency_p99']))
if __name__=='__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--checkpoint', type=str,
help='Path to the checkpoint')
parser.add_argument('--data', type=str,
help='Path to the test split of the dataset')
parser.add_argument('--tgt_scalers', type=str,
help='Path to the tgt_scalers.bin file produced by the preprocessing')
parser.add_argument('--cat_encodings', type=str,
help='Path to the cat_encodings.bin file produced by the preprocessing')
parser.add_argument('--batch_size', type=int, default=64)
parser.add_argument('--visualize', action='store_true', help='Visualize predictions - each example on the separate plot')
parser.add_argument('--joint_visualization', action='store_true', help='Visualize predictions - each timeseries on separate plot. Projections will be concatenated.')
parser.add_argument('--save_predictions', action='store_true')
parser.add_argument('--results', type=str, default='/results')
parser.add_argument('--log_file', type=str, default='dllogger.json')
ARGS = parser.parse_args()
main(ARGS)
|
PyTorch/Classification/GPUNet/triton/deployment_toolkit/triton_performance_runner/perf_analyzer | perf_analyzer | perf_analyzer | # Copyright (c) 2022, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import logging
import pathlib
from subprocess import PIPE, CalledProcessError, Popen
# method from PEP-366 to support relative import in executed modules
from typing import List, Optional
if __package__ is None:
__package__ = pathlib.Path(__file__).parent.name
from .exceptions import PerfAnalyzerException
MAX_INTERVAL_CHANGES = 10
COUNT_INTERVAL_DELTA = 50
TIME_INTERVAL_DELTA = 2000
LOGGER = logging.getLogger(__name__)
class PerfAnalyzer:
"""
This class provides an interface for running workloads
with perf_analyzer.
"""
def __init__(self, config, timeout: Optional[int]):
"""
Parameters
----------
config : PerfAnalyzerConfig
keys are names of arguments to perf_analyzer,
values are their values.
"""
self.bin_path = "perf_analyzer"
self._config = config
self._output = ""
self._timeout = timeout
def run(self):
"""
Runs the perf analyzer with the
initialized configuration
Returns
-------
List of Records
List of the metrics obtained from this
run of perf_analyzer
Raises
------
PerfAnalyzerException
If subprocess throws CalledProcessError
"""
self._output = ""
for _ in range(MAX_INTERVAL_CHANGES):
command = [self.bin_path]
command += self._config.to_cli_string().replace("=", " ").split()
LOGGER.debug(f"Perf Analyze command: {command}")
if not self._timeout:
LOGGER.debug("Perf Analyze command timeout not set")
else:
LOGGER.debug(f"Perf Analyze command timeout: {self._timeout} [s]")
try:
self._run_with_stream(command=command)
return
except CalledProcessError as e:
if self._failed_with_measurement_inverval(e.output):
if self._config["measurement-mode"] is None or self._config["measurement-mode"] == "count_windows":
self._increase_request_count()
else:
self._increase_time_interval()
else:
raise PerfAnalyzerException(
f"Running perf_analyzer with {e.cmd} failed with" f" exit status {e.returncode} : {e.output}"
)
raise PerfAnalyzerException(f"Ran perf_analyzer {MAX_INTERVAL_CHANGES} times, but no valid requests recorded.")
def output(self):
"""
Returns
-------
The stdout output of the
last perf_analyzer run
"""
if self._output:
return self._output
raise PerfAnalyzerException("Attempted to get perf_analyzer output" "without calling run first.")
def _run_with_stream(self, command: List[str]):
commands_lst = []
if self._timeout:
commands_lst = ["timeout", str(self._timeout)]
commands_lst.extend(command)
LOGGER.debug(f"Run with stream: {commands_lst}")
process = Popen(commands_lst, start_new_session=True, stdout=PIPE, encoding="utf-8")
streamed_output = ""
while True:
output = process.stdout.readline()
if output == "" and process.poll() is not None:
break
if output:
streamed_output += output
print(output.rstrip())
self._output += streamed_output
result = process.poll()
LOGGER.debug(f"Perf Analyzer process exited with result: {result}")
# WAR for Perf Analyzer exit code 0 when stabilization failed
if result == 0 and self._failed_with_measurement_inverval(streamed_output):
LOGGER.debug("Perf Analyzer finished with exit status 0, however measurement stabilization failed.")
result = 1
if result != 0:
raise CalledProcessError(returncode=result, cmd=commands_lst, output=streamed_output)
def _failed_with_measurement_inverval(self, output: str):
checks = [
output.find("Failed to obtain stable measurement"),
output.find("Please use a larger time window"),
]
result = any([status != -1 for status in checks])
LOGGER.debug(f"Measurement stability message validation: {checks}. Result: {result}.")
return result
def _increase_request_count(self):
self._config["measurement-request-count"] += COUNT_INTERVAL_DELTA
LOGGER.debug(
"perf_analyzer's measurement request count is too small, "
f"increased to {self._config['measurement-request-count']}."
)
def _increase_time_interval(self):
self._config["measurement-interval"] += TIME_INTERVAL_DELTA
LOGGER.debug(
"perf_analyzer's measurement window is too small, "
f"increased to {self._config['measurement-interval']} ms."
)
|
PyTorch/Classification/ConvNets/triton | triton | metric | # Copyright (c) 2021-2022, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from typing import Any, Dict, List, NamedTuple, Optional
import numpy as np
from deployment_toolkit.core import BaseMetricsCalculator
class MetricsCalculator(BaseMetricsCalculator):
def __init__(self):
pass
def calc(
self,
*,
ids: List[Any],
y_pred: Dict[str, np.ndarray],
x: Optional[Dict[str, np.ndarray]],
y_real: Optional[Dict[str, np.ndarray]],
) -> Dict[str, float]:
categories = np.argmax(y_pred["OUTPUT__0"], axis=-1)
print(categories.shape)
print(categories[:128], y_pred["OUTPUT__0"] )
print(y_real["OUTPUT__0"][:128])
return {
"accuracy": np.mean(np.argmax(y_pred["OUTPUT__0"], axis=-1) ==
np.argmax(y_real["OUTPUT__0"], axis=-1))
}
|
PyTorch/LanguageModeling/BERT | BERT | file_utils | # Copyright 2018 The Google AI Language Team Authors and The HugginFace Inc. team.
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
Utilities for working with the local dataset cache.
This file is adapted from the AllenNLP library at https://github.com/allenai/allennlp
Copyright by the AllenNLP authors.
"""
from __future__ import (absolute_import, division, print_function, unicode_literals)
import json
import logging
import os
import shutil
import tempfile
from functools import wraps
from hashlib import sha256
import sys
from io import open
import boto3
import requests
from botocore.exceptions import ClientError
from tqdm import tqdm
logger = logging.getLogger(__name__) # pylint: disable=invalid-name
try:
USE_TF = os.environ.get("USE_TF", "AUTO").upper()
USE_TORCH = os.environ.get("USE_TORCH", "AUTO").upper()
if USE_TORCH in ("1", "ON", "YES", "AUTO") and USE_TF not in ("1", "ON", "YES"):
import torch
_torch_available = True # pylint: disable=invalid-name
logger.info("PyTorch version {} available.".format(torch.__version__))
else:
logger.info("Disabling PyTorch because USE_TF is set")
_torch_available = False
except ImportError:
_torch_available = False # pylint: disable=invalid-name
try:
USE_TF = os.environ.get("USE_TF", "AUTO").upper()
USE_TORCH = os.environ.get("USE_TORCH", "AUTO").upper()
if USE_TF in ("1", "ON", "YES", "AUTO") and USE_TORCH not in ("1", "ON", "YES"):
import tensorflow as tf
assert hasattr(tf, "__version__") and int(tf.__version__[0]) >= 2
_tf_available = True # pylint: disable=invalid-name
logger.info("TensorFlow version {} available.".format(tf.__version__))
else:
logger.info("Disabling Tensorflow because USE_TORCH is set")
_tf_available = False
except ImportError:
_tf_available = False # pylint: disable=invalid-name
try:
from urllib.parse import urlparse
except ImportError:
from urlparse import urlparse
try:
from pathlib import Path
PYTORCH_PRETRAINED_BERT_CACHE = Path(os.getenv('PYTORCH_PRETRAINED_BERT_CACHE',
Path.home() / '.pytorch_pretrained_bert'))
except AttributeError:
PYTORCH_PRETRAINED_BERT_CACHE = os.getenv('PYTORCH_PRETRAINED_BERT_CACHE',
os.path.join(os.path.expanduser("~"), '.pytorch_pretrained_bert'))
def is_torch_available():
return _torch_available
def is_tf_available():
return _tf_available
def url_to_filename(url, etag=None):
"""
Convert `url` into a hashed filename in a repeatable way.
If `etag` is specified, append its hash to the url's, delimited
by a period.
"""
url_bytes = url.encode('utf-8')
url_hash = sha256(url_bytes)
filename = url_hash.hexdigest()
if etag:
etag_bytes = etag.encode('utf-8')
etag_hash = sha256(etag_bytes)
filename += '.' + etag_hash.hexdigest()
return filename
def filename_to_url(filename, cache_dir=None):
"""
Return the url and etag (which may be ``None``) stored for `filename`.
Raise ``EnvironmentError`` if `filename` or its stored metadata do not exist.
"""
if cache_dir is None:
cache_dir = PYTORCH_PRETRAINED_BERT_CACHE
if sys.version_info[0] == 3 and isinstance(cache_dir, Path):
cache_dir = str(cache_dir)
cache_path = os.path.join(cache_dir, filename)
if not os.path.exists(cache_path):
raise EnvironmentError("file {} not found".format(cache_path))
meta_path = cache_path + '.json'
if not os.path.exists(meta_path):
raise EnvironmentError("file {} not found".format(meta_path))
with open(meta_path, encoding="utf-8") as meta_file:
metadata = json.load(meta_file)
url = metadata['url']
etag = metadata['etag']
return url, etag
def cached_path(url_or_filename, cache_dir=None):
"""
Given something that might be a URL (or might be a local path),
determine which. If it's a URL, download the file and cache it, and
return the path to the cached file. If it's already a local path,
make sure the file exists and then return the path.
"""
if cache_dir is None:
cache_dir = PYTORCH_PRETRAINED_BERT_CACHE
if sys.version_info[0] == 3 and isinstance(url_or_filename, Path):
url_or_filename = str(url_or_filename)
if sys.version_info[0] == 3 and isinstance(cache_dir, Path):
cache_dir = str(cache_dir)
parsed = urlparse(url_or_filename)
if parsed.scheme in ('http', 'https', 's3'):
# URL, so get it from the cache (downloading if necessary)
return get_from_cache(url_or_filename, cache_dir)
elif os.path.exists(url_or_filename):
# File, and it exists.
return url_or_filename
elif parsed.scheme == '':
# File, but it doesn't exist.
raise EnvironmentError("file {} not found".format(url_or_filename))
else:
# Something unknown
raise ValueError("unable to parse {} as a URL or as a local path".format(url_or_filename))
def split_s3_path(url):
"""Split a full s3 path into the bucket name and path."""
parsed = urlparse(url)
if not parsed.netloc or not parsed.path:
raise ValueError("bad s3 path {}".format(url))
bucket_name = parsed.netloc
s3_path = parsed.path
# Remove '/' at beginning of path.
if s3_path.startswith("/"):
s3_path = s3_path[1:]
return bucket_name, s3_path
def s3_request(func):
"""
Wrapper function for s3 requests in order to create more helpful error
messages.
"""
@wraps(func)
def wrapper(url, *args, **kwargs):
try:
return func(url, *args, **kwargs)
except ClientError as exc:
if int(exc.response["Error"]["Code"]) == 404:
raise EnvironmentError("file {} not found".format(url))
else:
raise
return wrapper
@s3_request
def s3_etag(url):
"""Check ETag on S3 object."""
s3_resource = boto3.resource("s3")
bucket_name, s3_path = split_s3_path(url)
s3_object = s3_resource.Object(bucket_name, s3_path)
return s3_object.e_tag
@s3_request
def s3_get(url, temp_file):
"""Pull a file directly from S3."""
s3_resource = boto3.resource("s3")
bucket_name, s3_path = split_s3_path(url)
s3_resource.Bucket(bucket_name).download_fileobj(s3_path, temp_file)
def http_get(url, temp_file):
req = requests.get(url, stream=True)
content_length = req.headers.get('Content-Length')
total = int(content_length) if content_length is not None else None
progress = tqdm(unit="B", total=total)
for chunk in req.iter_content(chunk_size=1024):
if chunk: # filter out keep-alive new chunks
progress.update(len(chunk))
temp_file.write(chunk)
progress.close()
def get_from_cache(url, cache_dir=None):
"""
Given a URL, look for the corresponding dataset in the local cache.
If it's not there, download it. Then return the path to the cached file.
"""
if cache_dir is None:
cache_dir = PYTORCH_PRETRAINED_BERT_CACHE
if sys.version_info[0] == 3 and isinstance(cache_dir, Path):
cache_dir = str(cache_dir)
if not os.path.exists(cache_dir):
os.makedirs(cache_dir)
# Get eTag to add to filename, if it exists.
if url.startswith("s3://"):
etag = s3_etag(url)
else:
response = requests.head(url, allow_redirects=True)
if response.status_code != 200:
raise IOError("HEAD request failed for url {} with status code {}"
.format(url, response.status_code))
etag = response.headers.get("ETag")
filename = url_to_filename(url, etag)
# get cache path to put the file
cache_path = os.path.join(cache_dir, filename)
if not os.path.exists(cache_path):
# Download to temporary file, then copy to cache dir once finished.
# Otherwise you get corrupt cache entries if the download gets interrupted.
with tempfile.NamedTemporaryFile() as temp_file:
logger.info("%s not found in cache, downloading to %s", url, temp_file.name)
# GET file object
if url.startswith("s3://"):
s3_get(url, temp_file)
else:
http_get_tokenization_utils(url, temp_file)
# we are copying the file before closing it, so flush to avoid truncation
temp_file.flush()
# shutil.copyfileobj() starts at the current position, so go to the start
temp_file.seek(0)
logger.info("copying %s to cache at %s", temp_file.name, cache_path)
with open(cache_path, 'wb') as cache_file:
shutil.copyfileobj(temp_file, cache_file)
logger.info("creating metadata file for %s", cache_path)
meta = {'url': url, 'etag': etag}
meta_path = cache_path + '.json'
with open(meta_path, 'w', encoding="utf-8") as meta_file:
json.dump(meta, meta_file)
logger.info("removing temp file %s", temp_file.name)
return cache_path
def read_set_from_file(filename):
'''
Extract a de-duped collection (set) of text from a file.
Expected file format is one item per line.
'''
collection = set()
with open(filename, 'r', encoding='utf-8') as file_:
for line in file_:
collection.add(line.rstrip())
return collection
def get_file_extension(path, dot=True, lower=True):
ext = os.path.splitext(path)[1]
ext = ext if dot else ext[1:]
return ext.lower() if lower else ext
def hf_bucket_url(model_id: str, filename: str, use_cdn=True) -> str:
"""
Resolve a model identifier, and a file name, to a HF-hosted url
on either S3 or Cloudfront (a Content Delivery Network, or CDN).
Cloudfront is replicated over the globe so downloads are way faster
for the end user (and it also lowers our bandwidth costs). However, it
is more aggressively cached by default, so may not always reflect the
latest changes to the underlying file (default TTL is 24 hours).
In terms of client-side caching from this library, even though
Cloudfront relays the ETags from S3, using one or the other
(or switching from one to the other) will affect caching: cached files
are not shared between the two because the cached file's name contains
a hash of the url.
"""
S3_BUCKET_PREFIX = "https://s3.amazonaws.com/models.huggingface.co/bert"
CLOUDFRONT_DISTRIB_PREFIX = "https://cdn.huggingface.co"
endpoint = CLOUDFRONT_DISTRIB_PREFIX if use_cdn else S3_BUCKET_PREFIX
legacy_format = "/" not in model_id
if legacy_format:
return f"{endpoint}/{model_id}-{filename}"
else:
return f"{endpoint}/{model_id}/{filename}"
def torch_required(func):
# Chose a different decorator name than in tests so it's clear they are not the same.
@wraps(func)
def wrapper(*args, **kwargs):
if is_torch_available():
return func(*args, **kwargs)
else:
raise ImportError(f"Method `{func.__name__}` requires PyTorch.")
return wrapper
def is_remote_url(url_or_filename):
parsed = urlparse(url_or_filename)
return parsed.scheme in ("http", "https")
|
TensorFlow/Recommendation/WideAndDeep | WideAndDeep | __init__ | # Copyright (c) 2020, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
|
CUDA-Optimized/FastSpeech/waveglow | waveglow | __init__ | # Copyright (c) 2020, NVIDIA CORPORATION. All rights reserved.
# Redistribution and use in source and binary forms, with or without
# modification, are permitted provided that the following conditions are met:
# * Redistributions of source code must retain the above copyright
# notice, this list of conditions and the following disclaimer.
# * Redistributions in binary form must reproduce the above copyright
# notice, this list of conditions and the following disclaimer in the
# documentation and/or other materials provided with the distribution.
# * Neither the name of the NVIDIA CORPORATION nor the
# names of its contributors may be used to endorse or promote products
# derived from this software without specific prior written permission.
# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND
# ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED
# WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
# DISCLAIMED. IN NO EVENT SHALL NVIDIA CORPORATION BE LIABLE FOR ANY
# DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES
# (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES;
# LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND
# ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
# (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS
# SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE. |
TensorFlow2/LanguageModeling/BERT | BERT | classifier_data_lib | # Copyright 2019 The TensorFlow Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ==============================================================================
"""BERT library to process data for classification task."""
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import collections
import csv
import os
from absl import logging
import tensorflow as tf
import tokenization
class InputExample(object):
"""A single training/test example for simple sequence classification."""
def __init__(self, guid, text_a, text_b=None, label=None):
"""Constructs a InputExample.
Args:
guid: Unique id for the example.
text_a: string. The untokenized text of the first sequence. For single
sequence tasks, only this sequence must be specified.
text_b: (Optional) string. The untokenized text of the second sequence.
Only must be specified for sequence pair tasks.
label: (Optional) string. The label of the example. This should be
specified for train and dev examples, but not for test examples.
"""
self.guid = guid
self.text_a = text_a
self.text_b = text_b
self.label = label
class InputFeatures(object):
"""A single set of features of data."""
def __init__(self,
input_ids,
input_mask,
segment_ids,
label_id,
is_real_example=True):
self.input_ids = input_ids
self.input_mask = input_mask
self.segment_ids = segment_ids
self.label_id = label_id
self.is_real_example = is_real_example
class DataProcessor(object):
"""Base class for data converters for sequence classification data sets."""
def __init__(self, process_text_fn=tokenization.convert_to_unicode):
self.process_text_fn = process_text_fn
def get_train_examples(self, data_dir):
"""Gets a collection of `InputExample`s for the train set."""
raise NotImplementedError()
def get_dev_examples(self, data_dir):
"""Gets a collection of `InputExample`s for the dev set."""
raise NotImplementedError()
def get_test_examples(self, data_dir):
"""Gets a collection of `InputExample`s for prediction."""
raise NotImplementedError()
def get_labels(self):
"""Gets the list of labels for this data set."""
raise NotImplementedError()
@staticmethod
def get_processor_name():
"""Gets the string identifier of the processor."""
raise NotImplementedError()
@classmethod
def _read_tsv(cls, input_file, quotechar=None):
"""Reads a tab separated value file."""
with tf.io.gfile.GFile(input_file, "r") as f:
reader = csv.reader(f, delimiter="\t", quotechar=quotechar)
lines = []
for line in reader:
lines.append(line)
return lines
class XnliProcessor(DataProcessor):
"""Processor for the XNLI data set."""
def __init__(self, process_text_fn=tokenization.convert_to_unicode):
super(XnliProcessor, self).__init__(process_text_fn)
self.language = "zh"
def get_train_examples(self, data_dir):
"""See base class."""
lines = self._read_tsv(
os.path.join(data_dir, "multinli",
"multinli.train.%s.tsv" % self.language))
examples = []
for (i, line) in enumerate(lines):
if i == 0:
continue
guid = "train-%d" % (i)
text_a = self.process_text_fn(line[0])
text_b = self.process_text_fn(line[1])
label = self.process_text_fn(line[2])
if label == self.process_text_fn("contradictory"):
label = self.process_text_fn("contradiction")
examples.append(
InputExample(guid=guid, text_a=text_a, text_b=text_b, label=label))
return examples
def get_dev_examples(self, data_dir):
"""See base class."""
lines = self._read_tsv(os.path.join(data_dir, "xnli.dev.tsv"))
examples = []
for (i, line) in enumerate(lines):
if i == 0:
continue
guid = "dev-%d" % (i)
language = self.process_text_fn(line[0])
if language != self.process_text_fn(self.language):
continue
text_a = self.process_text_fn(line[6])
text_b = self.process_text_fn(line[7])
label = self.process_text_fn(line[1])
examples.append(
InputExample(guid=guid, text_a=text_a, text_b=text_b, label=label))
return examples
def get_labels(self):
"""See base class."""
return ["contradiction", "entailment", "neutral"]
@staticmethod
def get_processor_name():
"""See base class."""
return "XNLI"
class MnliProcessor(DataProcessor):
"""Processor for the MultiNLI data set (GLUE version)."""
def get_train_examples(self, data_dir):
"""See base class."""
return self._create_examples(
self._read_tsv(os.path.join(data_dir, "train.tsv")), "train")
def get_dev_examples(self, data_dir):
"""See base class."""
return self._create_examples(
self._read_tsv(os.path.join(data_dir, "dev_matched.tsv")),
"dev_matched")
def get_test_examples(self, data_dir):
"""See base class."""
return self._create_examples(
self._read_tsv(os.path.join(data_dir, "test_matched.tsv")), "test")
def get_labels(self):
"""See base class."""
return ["contradiction", "entailment", "neutral"]
@staticmethod
def get_processor_name():
"""See base class."""
return "MNLI"
def _create_examples(self, lines, set_type):
"""Creates examples for the training and dev sets."""
examples = []
for (i, line) in enumerate(lines):
if i == 0:
continue
guid = "%s-%s" % (set_type, self.process_text_fn(line[0]))
text_a = self.process_text_fn(line[8])
text_b = self.process_text_fn(line[9])
if set_type == "test":
label = "contradiction"
else:
label = self.process_text_fn(line[-1])
examples.append(
InputExample(guid=guid, text_a=text_a, text_b=text_b, label=label))
return examples
class MrpcProcessor(DataProcessor):
"""Processor for the MRPC data set (GLUE version)."""
def get_train_examples(self, data_dir):
"""See base class."""
return self._create_examples(
self._read_tsv(os.path.join(data_dir, "train.tsv")), "train")
def get_dev_examples(self, data_dir):
"""See base class."""
return self._create_examples(
self._read_tsv(os.path.join(data_dir, "dev.tsv")), "dev")
def get_test_examples(self, data_dir):
"""See base class."""
return self._create_examples(
self._read_tsv(os.path.join(data_dir, "test.tsv")), "test")
def get_labels(self):
"""See base class."""
return ["0", "1"]
@staticmethod
def get_processor_name():
"""See base class."""
return "MRPC"
def _create_examples(self, lines, set_type):
"""Creates examples for the training and dev sets."""
examples = []
for (i, line) in enumerate(lines):
if i == 0:
continue
guid = "%s-%s" % (set_type, i)
text_a = self.process_text_fn(line[3])
text_b = self.process_text_fn(line[4])
if set_type == "test":
label = "0"
else:
label = self.process_text_fn(line[0])
examples.append(
InputExample(guid=guid, text_a=text_a, text_b=text_b, label=label))
return examples
class ColaProcessor(DataProcessor):
"""Processor for the CoLA data set (GLUE version)."""
def get_train_examples(self, data_dir):
"""See base class."""
return self._create_examples(
self._read_tsv(os.path.join(data_dir, "train.tsv")), "train")
def get_dev_examples(self, data_dir):
"""See base class."""
return self._create_examples(
self._read_tsv(os.path.join(data_dir, "dev.tsv")), "dev")
def get_test_examples(self, data_dir):
"""See base class."""
return self._create_examples(
self._read_tsv(os.path.join(data_dir, "test.tsv")), "test")
def get_labels(self):
"""See base class."""
return ["0", "1"]
@staticmethod
def get_processor_name():
"""See base class."""
return "COLA"
def _create_examples(self, lines, set_type):
"""Creates examples for the training and dev sets."""
examples = []
for (i, line) in enumerate(lines):
# Only the test set has a header
if set_type == "test" and i == 0:
continue
guid = "%s-%s" % (set_type, i)
if set_type == "test":
text_a = self.process_text_fn(line[1])
label = "0"
else:
text_a = self.process_text_fn(line[3])
label = self.process_text_fn(line[1])
examples.append(
InputExample(guid=guid, text_a=text_a, text_b=None, label=label))
return examples
class SstProcessor(DataProcessor):
"""Processor for the SST-2 data set (GLUE version)."""
def get_train_examples(self, data_dir):
"""See base class."""
return self._create_examples(
self._read_tsv(os.path.join(data_dir, "train.tsv")), "train")
def get_dev_examples(self, data_dir):
"""See base class."""
return self._create_examples(
self._read_tsv(os.path.join(data_dir, "dev.tsv")), "dev")
def get_test_examples(self, data_dir):
"""See base class."""
return self._create_examples(
self._read_tsv(os.path.join(data_dir, "test.tsv")), "test")
def get_labels(self):
"""See base class."""
return ["0", "1"]
@staticmethod
def get_processor_name():
"""See base class."""
return "SST-2"
def _create_examples(self, lines, set_type):
"""Creates examples for the training and dev sets."""
examples = []
for (i, line) in enumerate(lines):
if i == 0:
continue
guid = "%s-%s" % (set_type, i)
if set_type == "test":
text_a = tokenization.convert_to_unicode(line[1])
label = "0"
else:
text_a = tokenization.convert_to_unicode(line[0])
label = tokenization.convert_to_unicode(line[1])
examples.append(
InputExample(guid=guid, text_a=text_a, text_b=None, label=label))
return examples
class QnliProcessor(DataProcessor):
"""Processor for the QNLI data set (GLUE version)."""
def get_train_examples(self, data_dir):
"""See base class."""
return self._create_examples(
self._read_tsv(os.path.join(data_dir, "train.tsv")), "train")
def get_dev_examples(self, data_dir):
"""See base class."""
return self._create_examples(
self._read_tsv(os.path.join(data_dir, "dev.tsv")), "dev_matched")
def get_test_examples(self, data_dir):
"""See base class."""
return self._create_examples(
self._read_tsv(os.path.join(data_dir, "test.tsv")), "test")
def get_labels(self):
"""See base class."""
return ["entailment", "not_entailment"]
@staticmethod
def get_processor_name():
"""See base class."""
return "QNLI"
def _create_examples(self, lines, set_type):
"""Creates examples for the training and dev sets."""
examples = []
for (i, line) in enumerate(lines):
if i == 0:
continue
guid = "%s-%s" % (set_type, 1)
if set_type == "test":
text_a = tokenization.convert_to_unicode(line[1])
text_b = tokenization.convert_to_unicode(line[2])
label = "entailment"
else:
text_a = tokenization.convert_to_unicode(line[1])
text_b = tokenization.convert_to_unicode(line[2])
label = tokenization.convert_to_unicode(line[-1])
examples.append(
InputExample(guid=guid, text_a=text_a, text_b=text_b, label=label))
return examples
def convert_single_example(ex_index, example, label_list, max_seq_length,
tokenizer):
"""Converts a single `InputExample` into a single `InputFeatures`."""
label_map = {}
for (i, label) in enumerate(label_list):
label_map[label] = i
tokens_a = tokenizer.tokenize(example.text_a)
tokens_b = None
if example.text_b:
tokens_b = tokenizer.tokenize(example.text_b)
if tokens_b:
# Modifies `tokens_a` and `tokens_b` in place so that the total
# length is less than the specified length.
# Account for [CLS], [SEP], [SEP] with "- 3"
_truncate_seq_pair(tokens_a, tokens_b, max_seq_length - 3)
else:
# Account for [CLS] and [SEP] with "- 2"
if len(tokens_a) > max_seq_length - 2:
tokens_a = tokens_a[0:(max_seq_length - 2)]
# The convention in BERT is:
# (a) For sequence pairs:
# tokens: [CLS] is this jack ##son ##ville ? [SEP] no it is not . [SEP]
# type_ids: 0 0 0 0 0 0 0 0 1 1 1 1 1 1
# (b) For single sequences:
# tokens: [CLS] the dog is hairy . [SEP]
# type_ids: 0 0 0 0 0 0 0
#
# Where "type_ids" are used to indicate whether this is the first
# sequence or the second sequence. The embedding vectors for `type=0` and
# `type=1` were learned during pre-training and are added to the wordpiece
# embedding vector (and position vector). This is not *strictly* necessary
# since the [SEP] token unambiguously separates the sequences, but it makes
# it easier for the model to learn the concept of sequences.
#
# For classification tasks, the first vector (corresponding to [CLS]) is
# used as the "sentence vector". Note that this only makes sense because
# the entire model is fine-tuned.
tokens = []
segment_ids = []
tokens.append("[CLS]")
segment_ids.append(0)
for token in tokens_a:
tokens.append(token)
segment_ids.append(0)
tokens.append("[SEP]")
segment_ids.append(0)
if tokens_b:
for token in tokens_b:
tokens.append(token)
segment_ids.append(1)
tokens.append("[SEP]")
segment_ids.append(1)
input_ids = tokenizer.convert_tokens_to_ids(tokens)
# The mask has 1 for real tokens and 0 for padding tokens. Only real
# tokens are attended to.
input_mask = [1] * len(input_ids)
# Zero-pad up to the sequence length.
while len(input_ids) < max_seq_length:
input_ids.append(0)
input_mask.append(0)
segment_ids.append(0)
assert len(input_ids) == max_seq_length
assert len(input_mask) == max_seq_length
assert len(segment_ids) == max_seq_length
label_id = label_map[example.label]
if ex_index < 5:
logging.info("*** Example ***")
logging.info("guid: %s", (example.guid))
logging.info("tokens: %s",
" ".join([tokenization.printable_text(x) for x in tokens]))
logging.info("input_ids: %s", " ".join([str(x) for x in input_ids]))
logging.info("input_mask: %s", " ".join([str(x) for x in input_mask]))
logging.info("segment_ids: %s", " ".join([str(x) for x in segment_ids]))
logging.info("label: %s (id = %d)", example.label, label_id)
feature = InputFeatures(
input_ids=input_ids,
input_mask=input_mask,
segment_ids=segment_ids,
label_id=label_id,
is_real_example=True)
return feature
def file_based_convert_examples_to_features(examples, label_list,
max_seq_length, tokenizer,
output_file):
"""Convert a set of `InputExample`s to a TFRecord file."""
writer = tf.io.TFRecordWriter(output_file)
for (ex_index, example) in enumerate(examples):
if ex_index % 10000 == 0:
logging.info("Writing example %d of %d", ex_index, len(examples))
feature = convert_single_example(ex_index, example, label_list,
max_seq_length, tokenizer)
def create_int_feature(values):
f = tf.train.Feature(int64_list=tf.train.Int64List(value=list(values)))
return f
features = collections.OrderedDict()
features["input_ids"] = create_int_feature(feature.input_ids)
features["input_mask"] = create_int_feature(feature.input_mask)
features["segment_ids"] = create_int_feature(feature.segment_ids)
features["label_ids"] = create_int_feature([feature.label_id])
features["is_real_example"] = create_int_feature(
[int(feature.is_real_example)])
tf_example = tf.train.Example(features=tf.train.Features(feature=features))
writer.write(tf_example.SerializeToString())
writer.close()
def _truncate_seq_pair(tokens_a, tokens_b, max_length):
"""Truncates a sequence pair in place to the maximum length."""
# This is a simple heuristic which will always truncate the longer sequence
# one token at a time. This makes more sense than truncating an equal percent
# of tokens from each, since if one sequence is very short then each token
# that's truncated likely contains more information than a longer sequence.
while True:
total_length = len(tokens_a) + len(tokens_b)
if total_length <= max_length:
break
if len(tokens_a) > len(tokens_b):
tokens_a.pop()
else:
tokens_b.pop()
def generate_tf_record_from_data_file(processor,
data_dir,
tokenizer,
train_data_output_path=None,
eval_data_output_path=None,
max_seq_length=128):
"""Generates and saves training data into a tf record file.
Arguments:
processor: Input processor object to be used for generating data. Subclass
of `DataProcessor`.
data_dir: Directory that contains train/eval data to process. Data files
should be in from "dev.tsv", "test.tsv", or "train.tsv".
tokenizer: The tokenizer to be applied on the data.
train_data_output_path: Output to which processed tf record for training
will be saved.
eval_data_output_path: Output to which processed tf record for evaluation
will be saved.
max_seq_length: Maximum sequence length of the to be generated
training/eval data.
Returns:
A dictionary containing input meta data.
"""
assert train_data_output_path or eval_data_output_path
label_list = processor.get_labels()
assert train_data_output_path
train_input_data_examples = processor.get_train_examples(data_dir)
file_based_convert_examples_to_features(train_input_data_examples, label_list,
max_seq_length, tokenizer,
train_data_output_path)
num_training_data = len(train_input_data_examples)
if eval_data_output_path:
eval_input_data_examples = processor.get_dev_examples(data_dir)
file_based_convert_examples_to_features(eval_input_data_examples,
label_list, max_seq_length,
tokenizer, eval_data_output_path)
meta_data = {
"task_type": "bert_classification",
"processor_type": processor.get_processor_name(),
"num_labels": len(processor.get_labels()),
"train_data_size": num_training_data,
"max_seq_length": max_seq_length,
}
if eval_data_output_path:
meta_data["eval_data_size"] = len(eval_input_data_examples)
return meta_data
|
PyTorch/SpeechSynthesis/Tacotron2/trtis_cpp/src/trt/util | util | binding | /*
* Copyright (c) 2019-2020, NVIDIA CORPORATION. All rights reserved.
*
* Redistribution and use in source and binary forms, with or without
* modification, are permitted provided that the following conditions are met:
* * Redistributions of source code must retain the above copyright
* notice, this list of conditions and the following disclaimer.
* * Redistributions in binary form must reproduce the above copyright
* notice, this list of conditions and the following disclaimer in the
* documentation and/or other materials provided with the distribution.
* * Neither the name of the NVIDIA CORPORATION nor the
* names of its contributors may be used to endorse or promote products
* derived from this software without specific prior written permission.
*
* THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND
* ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED
* WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
* DISCLAIMED. IN NO EVENT SHALL NVIDIA CORPORATION BE LIABLE FOR ANY
* DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES
* (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES;
* LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND
* ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
* (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS
* SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
*/
#include "binding.h"
#include <cassert>
#include <stdexcept>
#include <string>
using namespace nvinfer1;
namespace tts
{
/******************************************************************************
* CONSTANTS ******************************************************************
*****************************************************************************/
namespace
{
constexpr size_t MIN_SIZE = 64;
}
/******************************************************************************
* CONSTRUCTORS / DESTRUCTOR **************************************************
*****************************************************************************/
Binding::Binding()
: mBindings()
{
mBindings.reserve(MIN_SIZE);
}
/******************************************************************************
* PUBLIC METHODS *************************************************************
*****************************************************************************/
void** Binding::getBindings()
{
return mBindings.data();
}
/******************************************************************************
* PRIVATE METHODS ************************************************************
*****************************************************************************/
void Binding::setVoidBinding(const ICudaEngine& engine, const char* const name, void* const ptr)
{
const int pos = engine.getBindingIndex(name);
if (pos < 0)
{
throw std::runtime_error("Invalid binding index " + std::to_string(pos) + " for '" + name + "'.");
}
if (pos + 1 > static_cast<int>(mBindings.size()))
{
mBindings.resize(pos + 1);
}
mBindings[pos] = ptr;
}
} // namespace tts
|
TensorFlow2/Recommendation/WideAndDeep/tests/feature_specs | feature_specs | more_multihot_moreless_hotness | channel_spec:
label:
- clicked
map: []
multihot_categorical:
- topic_id_list
- entity_id_list
- category_id_list
- additional_1
- additional_2
numerical:
- document_id_document_id_promo_sim_categories
- document_id_document_id_promo_sim_topics
- document_id_document_id_promo_sim_entities
- document_id_promo_ctr
- publisher_id_promo_ctr
- source_id_promo_ctr
- document_id_promo_count
- publish_time_days_since_published
- ad_id_ctr
- advertiser_id_ctr
- campaign_id_ctr
- ad_id_count
- publish_time_promo_days_since_published
onehot_categorical:
- ad_id
- document_id
- platform
- document_id_promo
- campaign_id
- advertiser_id
- source_id
- geo_location
- geo_location_country
- geo_location_state
- publisher_id
- source_id_promo
- publisher_id_promo
feature_spec:
ad_id:
cardinality: 250000
ad_id_count: {}
ad_id_ctr: {}
advertiser_id:
cardinality: 2500
advertiser_id_ctr: {}
campaign_id:
cardinality: 5000
campaign_id_ctr: {}
category_id_list:
cardinality: 100
max_hotness: 3
clicked: {}
document_id:
cardinality: 300000
document_id_document_id_promo_sim_categories: {}
document_id_document_id_promo_sim_entities: {}
document_id_document_id_promo_sim_topics: {}
document_id_promo:
cardinality: 100000
document_id_promo_count: {}
document_id_promo_ctr: {}
entity_id_list:
cardinality: 10000
max_hotness: 3
geo_location:
cardinality: 2500
geo_location_country:
cardinality: 300
geo_location_state:
cardinality: 2000
platform:
cardinality: 4
publish_time_days_since_published: {}
publish_time_promo_days_since_published: {}
publisher_id:
cardinality: 1000
publisher_id_promo:
cardinality: 1000
publisher_id_promo_ctr: {}
source_id:
cardinality: 4000
source_id_promo:
cardinality: 4000
source_id_promo_ctr: {}
topic_id_list:
cardinality: 350
max_hotness: 3
additional_1:
cardinality: 1000
max_hotness: 10
additional_2:
cardinality: 123
max_hotness: 2
metadata: {}
source_spec:
test:
- features:
- clicked
- ad_id
- document_id
- platform
- document_id_promo
- campaign_id
- advertiser_id
- source_id
- geo_location
- geo_location_country
- geo_location_state
- publisher_id
- source_id_promo
- publisher_id_promo
- topic_id_list
- entity_id_list
- category_id_list
- document_id_document_id_promo_sim_categories
- document_id_document_id_promo_sim_topics
- document_id_document_id_promo_sim_entities
- document_id_promo_ctr
- publisher_id_promo_ctr
- source_id_promo_ctr
- document_id_promo_count
- publish_time_days_since_published
- ad_id_ctr
- advertiser_id_ctr
- campaign_id_ctr
- ad_id_count
- publish_time_promo_days_since_published
- additional_1
- additional_2
files:
- valid.csv
type: csv
train:
- features:
- clicked
- ad_id
- document_id
- platform
- document_id_promo
- campaign_id
- advertiser_id
- source_id
- geo_location
- geo_location_country
- geo_location_state
- publisher_id
- source_id_promo
- publisher_id_promo
- topic_id_list
- entity_id_list
- category_id_list
- document_id_document_id_promo_sim_categories
- document_id_document_id_promo_sim_topics
- document_id_document_id_promo_sim_entities
- document_id_promo_ctr
- publisher_id_promo_ctr
- source_id_promo_ctr
- document_id_promo_count
- publish_time_days_since_published
- ad_id_ctr
- advertiser_id_ctr
- campaign_id_ctr
- ad_id_count
- publish_time_promo_days_since_published
- additional_1
- additional_2
files:
- train.csv
type: csv
|
TensorFlow2/Segmentation/UNet_Medical/model | model | tf_trt | import os
from operator import itemgetter
import tensorflow as tf
from tensorflow.python.compiler.tensorrt import trt_convert as trt
from tensorflow.compat.v1.saved_model import tag_constants, signature_constants
def export_model(model_dir, prec, tf_trt_model_dir=None):
model = tf.keras.models.load_model(os.path.join(model_dir, f'saved_model_{prec}'))
input_shape = [1, 572, 572, 1]
dummy_input = tf.constant(tf.zeros(input_shape, dtype=tf.float32 if prec=="fp32" else tf.float16))
_ = model(dummy_input, training=False)
trt_prec = trt.TrtPrecisionMode.FP32 if prec == "fp32" else trt.TrtPrecisionMode.FP16
converter = trt.TrtGraphConverterV2(
input_saved_model_dir=os.path.join(model_dir, f'saved_model_{prec}'),
conversion_params=trt.TrtConversionParams(precision_mode=trt_prec),
)
converter.convert()
tf_trt_model_dir = tf_trt_model_dir or f'/tmp/tf-trt_model_{prec}'
converter.save(tf_trt_model_dir)
print(f"TF-TRT model saved at {tf_trt_model_dir}")
def _force_gpu_resync(func):
p = tf.constant(0.) # Create small tensor to force GPU resync
def wrapper(*args, **kwargs):
rslt = func(*args, **kwargs)
(p + 1.).numpy() # Sync the GPU
return rslt
return wrapper
class TFTRTModel:
def __init__(self, model_dir, precision, output_tensor_name="output_1"):
temp_tftrt_dir = f"/tmp/tf-trt_model_{precision}"
export_model(model_dir, precision, temp_tftrt_dir)
saved_model_loaded = tf.saved_model.load(temp_tftrt_dir, tags=[tag_constants.SERVING])
print(f"TF-TRT model loaded from {temp_tftrt_dir}")
self.graph_func = saved_model_loaded.signatures[signature_constants.DEFAULT_SERVING_SIGNATURE_DEF_KEY]
self.output_tensor_name = output_tensor_name
self.precision = tf.float16 if precision == "amp" else tf.float32
def __call__(self, x, **kwargs):
return self.infer_step(x)
#@_force_gpu_resync
@tf.function(jit_compile=False)
def infer_step(self, batch_x):
if batch_x.dtype != self.precision:
batch_x = tf.cast(batch_x, self.precision)
output = self.graph_func(batch_x)
return itemgetter(self.output_tensor_name)(output)
|
PyTorch/Segmentation/nnUNet/triton/scripts | scripts | download_data | #!/usr/bin/env bash
# Copyright (c) 2021 NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
if [ -f "${CHECKPOINT_DIR}/nnunet_pyt_ckpt_3d_fold2_amp_21.02.0.zip" ]; then
echo "Checkpoint already downloaded."
else
echo "Downloading checkpoint ..."
wget --content-disposition https://api.ngc.nvidia.com/v2/models/nvidia/nnunet_pyt_ckpt_3d_fold2_amp/versions/21.02.0/zip -O nnunet_pyt_ckpt_3d_fold2_amp_21.02.0.zip || {
echo "ERROR: Failed to download checkpoint from NGC"
exit 1
}
unzip nnunet_pyt_ckpt_3d_fold2_amp_21.02.0.zip -d ${CHECKPOINT_DIR}
rm nnunet_pyt_ckpt_3d_fold2_amp_21.02.0.zip
echo "ok"
fi
|
TensorFlow2/Segmentation/UNet_Medical/runtime | runtime | losses | # Copyright (c) 2021, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Training and evaluation losses"""
import tensorflow as tf
# Class Dice coefficient averaged over batch
def dice_coef(predict, target, axis=1, eps=1e-6):
intersection = tf.reduce_sum(input_tensor=predict * target, axis=axis)
union = tf.reduce_sum(input_tensor=predict * predict + target * target, axis=axis)
dice = (2. * intersection + eps) / (union + eps)
return tf.reduce_mean(input_tensor=dice, axis=0) # average over batch
def partial_losses(predict, target):
n_classes = predict.shape[-1]
flat_logits = tf.reshape(tf.cast(predict, tf.float32),
[tf.shape(input=predict)[0], -1, n_classes])
flat_labels = tf.reshape(target,
[tf.shape(input=predict)[0], -1, n_classes])
crossentropy_loss = tf.reduce_mean(input_tensor=tf.nn.softmax_cross_entropy_with_logits(logits=flat_logits,
labels=flat_labels),
name='cross_loss_ref')
dice_loss = tf.reduce_mean(input_tensor=1 - dice_coef(tf.keras.activations.softmax(flat_logits, axis=-1),
flat_labels), name='dice_loss_ref')
return crossentropy_loss, dice_loss
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.