
File size: 1,884 Bytes
15dc177 0e8b08c 15dc177 df7120d 15dc177 df7120d 15dc177 df7120d 15dc177 0e8b08c |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 |
---
license: apache-2.0
datasets:
- SetFit/amazon_reviews_multi_en
language:
- en
metrics:
- accuracy
base_model:
- distilbert/distilbert-base-uncased
pipeline_tag: text-classification
library_name: transformers
---
This repository contains a fine-tuned DistilBERT model for sentiment classification of Amazon product reviews The model classifies a given review into two classes: Positive and Negative
---
## **Model Overview**
- **Base Model**: [distilbert/distilbert-base-uncased](https://huggingface.co/distilbert/distilbert-base-uncased)
- **Dataset**: [SetFit/amazon_reviews_multi_en](https://huggingface.co/datasets/SetFit/amazon_reviews_multi_en),
- **Classes**: Binary classification (`Positive`, `Negative`)
- **Performance**:
- **Test Accuracy**: 90%
- **Validation Accuracy**: 90%
*Figure 1: Confusion matrix for test data*
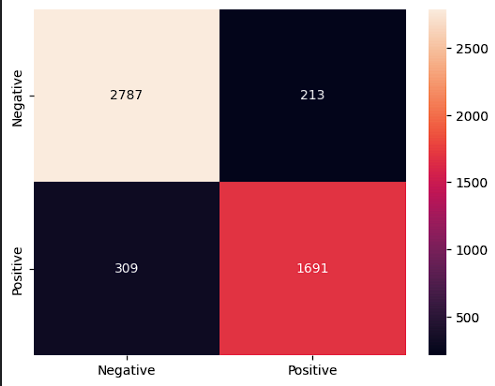
*Figure 2: Confusion matrix for validation data*

### How to Use the Model
Below is an example of how to load and use the model for sentiment classification:
```python
from transformers import DistilBertTokenizer,DistilBertForSequenceClassification
import torch
# Load the tokenizer and model
model = DistilBertForSequenceClassification.from_pretrained(
"ashish-001/DistilBert-Amazon-review-sentiment-classifier")
tokenizer = DistilBertTokenizer.from_pretrained(
"ashish-001/DistilBert-Amazon-review-sentiment-classifier")
# Example usage
text = "This product is amazing!"
inputs = tokenizer(text, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
sentiment = torch.argmax(logits, dim=1).item()
print(f"Predicted sentiment: {'Positive' if sentiment else 'Negative'}") |