
Improving Video Generation with Human Feedback
📃 [Paper] • 🌐 [Project Page] • [Github] • 🤗[VideoGen-RewardBench]• 🏆[ Leaderboard]
Introduction
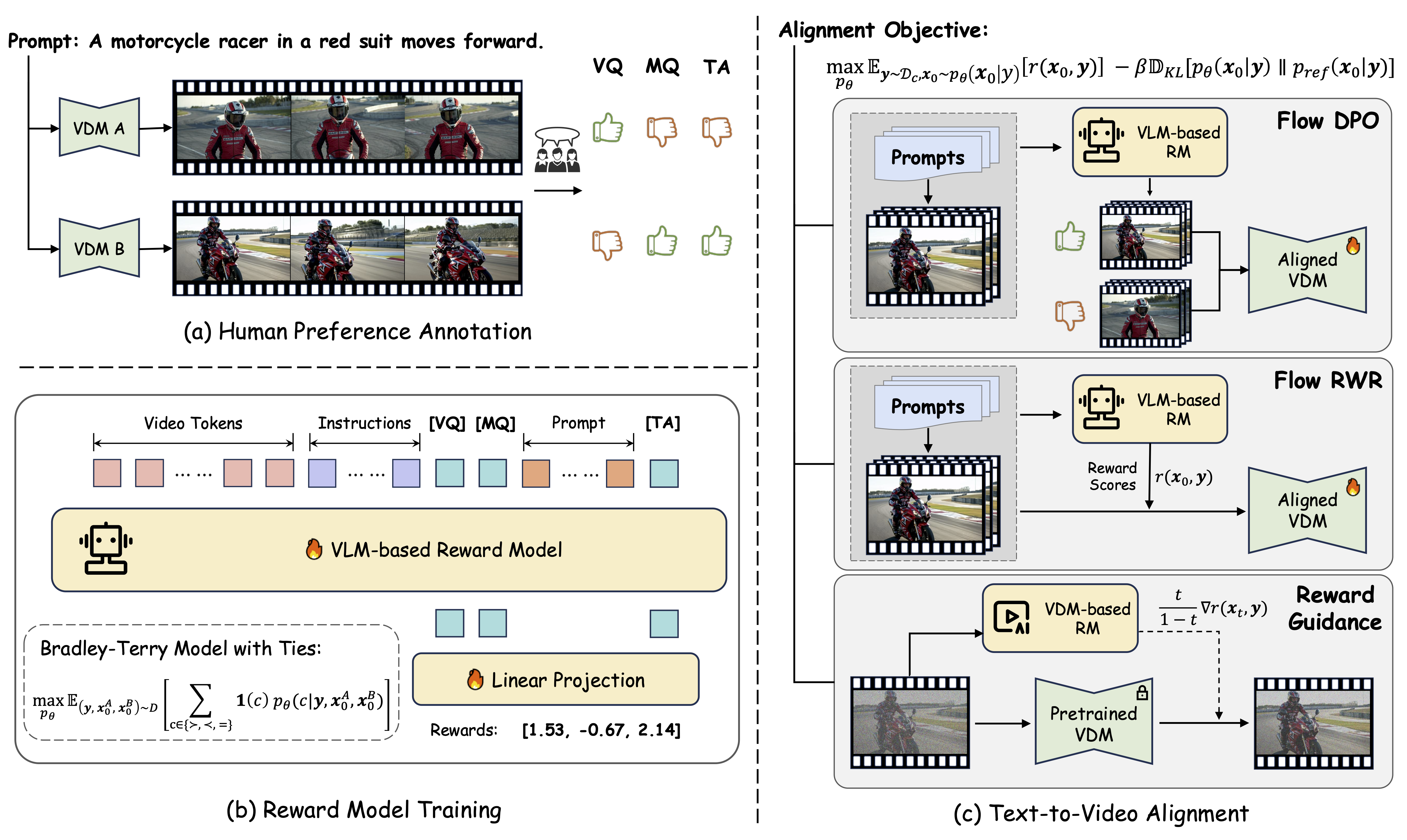
Welcome to VideoReward, a VLM-based reward model introduced in our paper Improving Video Generation with Human Feedback. VideoReward is a multi-dimensional reward model that evaluates generated videos on three critical aspects:
- Visual Quality (VQ): The clarity, aesthetics, and single-frame reasonableness.
- Motion Quality (MQ): The dynamic stability, dynamic reasonableness, naturalness, and dynamic degress.
- Text Alignment (TA): The relevance between the generated video and the text prompt.
This versatile reward model can be used for data filtering, guidance, reject sampling, DPO, and other RL methods.
Usage
Please refer to our github for details on usage.
Citation
If you find this project useful, please consider citing:
@article{liu2025improving,
title={Improving Video Generation with Human Feedback},
author={Jie Liu and Gongye Liu and Jiajun Liang and Ziyang Yuan and Xiaokun Liu and Mingwu Zheng and Xiele Wu and Qiulin Wang and Wenyu Qin and Menghan Xia and Xintao Wang and Xiaohong Liu and Fei Yang and Pengfei Wan and Di Zhang and Kun Gai and Yujiu Yang and Wanli Ouyang},
journal={arXiv preprint arXiv:2501.13918},
year={2025}
}
Inference Providers
NEW
This model is not currently available via any of the supported Inference Providers.
The model cannot be deployed to the HF Inference API:
The model has no library tag.