
Commit
·
f93e49c
1
Parent(s):
0042e78
Now local OCR outputs can be saved to file and reloaded to save preparation time. Bug fixing in logs and tabular data redaction. Update to documentation
Browse files- README.md +40 -4
- app.py +91 -50
- tools/aws_textract.py +205 -20
- tools/config.py +19 -16
- tools/custom_csvlogger.py +26 -5
- tools/custom_image_analyser_engine.py +142 -38
- tools/data_anonymise.py +62 -42
- tools/file_conversion.py +62 -6
- tools/file_redaction.py +140 -36
- tools/helper_functions.py +24 -7
README.md
CHANGED
|
@@ -39,6 +39,7 @@ You can now [speak with a chat bot about this user guide](https://huggingface.co
|
|
| 39 |
- [Redacting only specific pages](#redacting-only-specific-pages)
|
| 40 |
- [Handwriting and signature redaction](#handwriting-and-signature-redaction)
|
| 41 |
- [Reviewing and modifying suggested redactions](#reviewing-and-modifying-suggested-redactions)
|
|
|
|
| 42 |
|
| 43 |
See the [advanced user guide here](#advanced-user-guide):
|
| 44 |
- [Merging redaction review files](#merging-redaction-review-files)
|
|
@@ -119,12 +120,14 @@ Click 'Redact document'. After loading in the document, the app should be able t
|
|
| 119 |
- **'...ocr_results.csv'** files contain the line-by-line text outputs from the entire document. This file can be useful for later searching through for any terms of interest in the document (e.g. using Excel or a similar program).
|
| 120 |
- **'...review_file.csv'** files are the review files that contain details and locations of all of the suggested redactions in the document. This file is key to the [review process](#reviewing-and-modifying-suggested-redactions), and should be downloaded to use later for this.
|
| 121 |
|
| 122 |
-
### Additional AWS Textract outputs
|
| 123 |
|
| 124 |
If you have used the AWS Textract option for extracting text, you may also see a '..._textract.json' file. This file contains all the relevant extracted text information that comes from the AWS Textract service. You can keep this file and upload it at a later date alongside your input document, which will enable you to skip calling AWS Textract every single time you want to do a redaction task, as follows:
|
| 125 |
|
| 126 |

|
| 127 |
|
|
|
|
|
|
|
| 128 |
### Downloading output files from previous redaction tasks
|
| 129 |
|
| 130 |
If you are logged in via AWS Cognito and you lose your app page for some reason (e.g. from a crash, reloading), it is possible recover your previous output files, provided the server has not been shut down since you redacted the document. Go to 'Redaction settings', then scroll to the bottom to see 'View all output files from this session'.
|
|
@@ -307,7 +310,7 @@ To filter the 'Search suggested redactions' table you can:
|
|
| 307 |
Once you have filtered the table, you have a few options underneath on what you can do with the filtered rows:
|
| 308 |
|
| 309 |
- Click the 'Exclude specific row from redactions' button to remove only the redaction from the last row you clicked on from the document.
|
| 310 |
-
- Click the 'Exclude all items in table from redactions' button to remove all redactions visible in the table from the document.
|
| 311 |
|
| 312 |
**NOTE**: After excluding redactions using either of the above options, click the 'Reset filters' button below to ensure that the dropdowns and table return to seeing all remaining redactions in the document.
|
| 313 |
|
|
@@ -325,6 +328,40 @@ You can search through the extracted text by using the search bar just above the
|
|
| 325 |
|
| 326 |

|
| 327 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 328 |
# ADVANCED USER GUIDE
|
| 329 |
|
| 330 |
This advanced user guide will go over some of the features recently added to the app, including: modifying and merging redaction review files, identifying and redacting duplicate pages across multiple PDFs, 'fuzzy' search and redact, and exporting redactions to Adobe Acrobat.
|
|
@@ -469,13 +506,12 @@ The app should then pick up these keys when trying to access the AWS Textract an
|
|
| 469 |
|
| 470 |
Again, a lot can potentially go wrong with AWS solutions that are insecure, so before trying the above please consult with your AWS and data security teams.
|
| 471 |
|
| 472 |
-
## Modifying
|
| 473 |
|
| 474 |
You can find the folder containing the files discussed in this section [here](https://github.com/seanpedrick-case/document_redaction_examples/blob/main/merge_review_files/).
|
| 475 |
|
| 476 |
As well as serving as inputs to the document redaction app's review function, the 'review_file.csv' output can be modified outside of the app, and also merged with others from multiple redaction attempts on the same file. This gives you the flexibility to change redaction details outside of the app.
|
| 477 |
|
| 478 |
-
### Modifying existing redaction review files
|
| 479 |
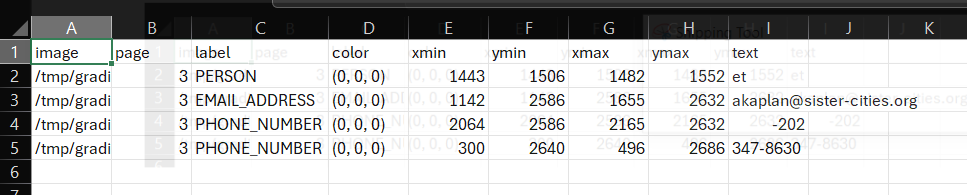
If you open up a 'review_file' csv output using a spreadsheet software program such as Microsoft Excel you can easily modify redaction properties. Open the file '[Partnership-Agreement-Toolkit_0_0_redacted.pdf_review_file_local.csv](https://github.com/seanpedrick-case/document_redaction_examples/blob/main/merge_review_files/Partnership-Agreement-Toolkit_0_0.pdf_review_file_local.csv)', and you should see a spreadshet with just four suggested redactions (see below). The following instructions are for using Excel.
|
| 480 |
|
| 481 |
|
|
|
|
| 39 |
- [Redacting only specific pages](#redacting-only-specific-pages)
|
| 40 |
- [Handwriting and signature redaction](#handwriting-and-signature-redaction)
|
| 41 |
- [Reviewing and modifying suggested redactions](#reviewing-and-modifying-suggested-redactions)
|
| 42 |
+
- [Redacting tabular data files (CSV/XLSX) or copy and pasted text](#redacting-tabular-data-files-xlsxcsv-or-copy-and-pasted-text)
|
| 43 |
|
| 44 |
See the [advanced user guide here](#advanced-user-guide):
|
| 45 |
- [Merging redaction review files](#merging-redaction-review-files)
|
|
|
|
| 120 |
- **'...ocr_results.csv'** files contain the line-by-line text outputs from the entire document. This file can be useful for later searching through for any terms of interest in the document (e.g. using Excel or a similar program).
|
| 121 |
- **'...review_file.csv'** files are the review files that contain details and locations of all of the suggested redactions in the document. This file is key to the [review process](#reviewing-and-modifying-suggested-redactions), and should be downloaded to use later for this.
|
| 122 |
|
| 123 |
+
### Additional AWS Textract / local OCR outputs
|
| 124 |
|
| 125 |
If you have used the AWS Textract option for extracting text, you may also see a '..._textract.json' file. This file contains all the relevant extracted text information that comes from the AWS Textract service. You can keep this file and upload it at a later date alongside your input document, which will enable you to skip calling AWS Textract every single time you want to do a redaction task, as follows:
|
| 126 |
|
| 127 |

|
| 128 |
|
| 129 |
+
Similarly, if you have used the 'Local OCR method' to extract text, you may see a '..._ocr_results_with_words.json' file. This file works in the same way as the AWS Textract .json results described above, and can be uploaded alongside an input document to save time on text extraction in future in the same way.
|
| 130 |
+
|
| 131 |
### Downloading output files from previous redaction tasks
|
| 132 |
|
| 133 |
If you are logged in via AWS Cognito and you lose your app page for some reason (e.g. from a crash, reloading), it is possible recover your previous output files, provided the server has not been shut down since you redacted the document. Go to 'Redaction settings', then scroll to the bottom to see 'View all output files from this session'.
|
|
|
|
| 310 |
Once you have filtered the table, you have a few options underneath on what you can do with the filtered rows:
|
| 311 |
|
| 312 |
- Click the 'Exclude specific row from redactions' button to remove only the redaction from the last row you clicked on from the document.
|
| 313 |
+
- Click the 'Exclude all items in table from redactions' button to remove all redactions visible in the table from the document. **Important:** ensure that you have clicked the blue tick icon next to the search box before doing this, or you will remove all redactions from the document. If you do end up doing this, click the 'Undo last element removal' button below to restore the redactions.
|
| 314 |
|
| 315 |
**NOTE**: After excluding redactions using either of the above options, click the 'Reset filters' button below to ensure that the dropdowns and table return to seeing all remaining redactions in the document.
|
| 316 |
|
|
|
|
| 328 |
|
| 329 |

|
| 330 |
|
| 331 |
+
## Redacting tabular data files (XLSX/CSV) or copy and pasted text
|
| 332 |
+
|
| 333 |
+
### Tabular data files (XLSX/CSV)
|
| 334 |
+
|
| 335 |
+
The app can be used to redact tabular data files such as xlsx or csv files. For this to work properly, your data file needs to be in a simple table format, with a single table starting from the first cell (A1), and no other information in the sheet. Similarly for .xlsx files, each sheet in the file that you want to redact should be in this simple format.
|
| 336 |
+
|
| 337 |
+
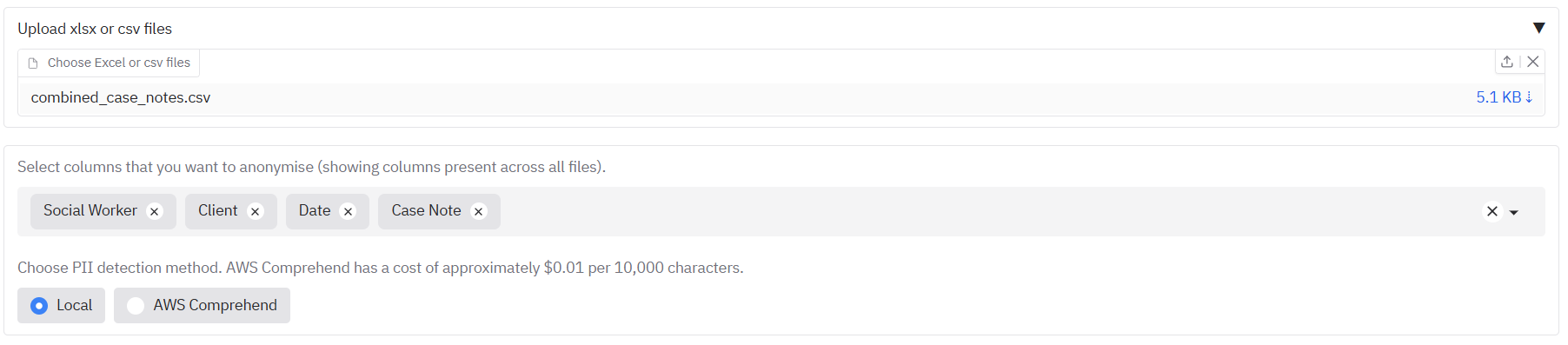
To demonstrate this, we can use [the example csv file 'combined_case_notes.csv'](https://github.com/seanpedrick-case/document_redaction_examples/blob/main/combined_case_notes.csv), which is a small dataset of dummy social care case notes. Go to the 'Open text or Excel/csv files' tab. Drop the file into the upload area. After the file is loaded, you should see the suggested columns for redaction in the box underneath. You can select and deselect columns to redact as you wish from this list.
|
| 338 |
+
|
| 339 |
+
|
| 340 |
+
|
| 341 |
+
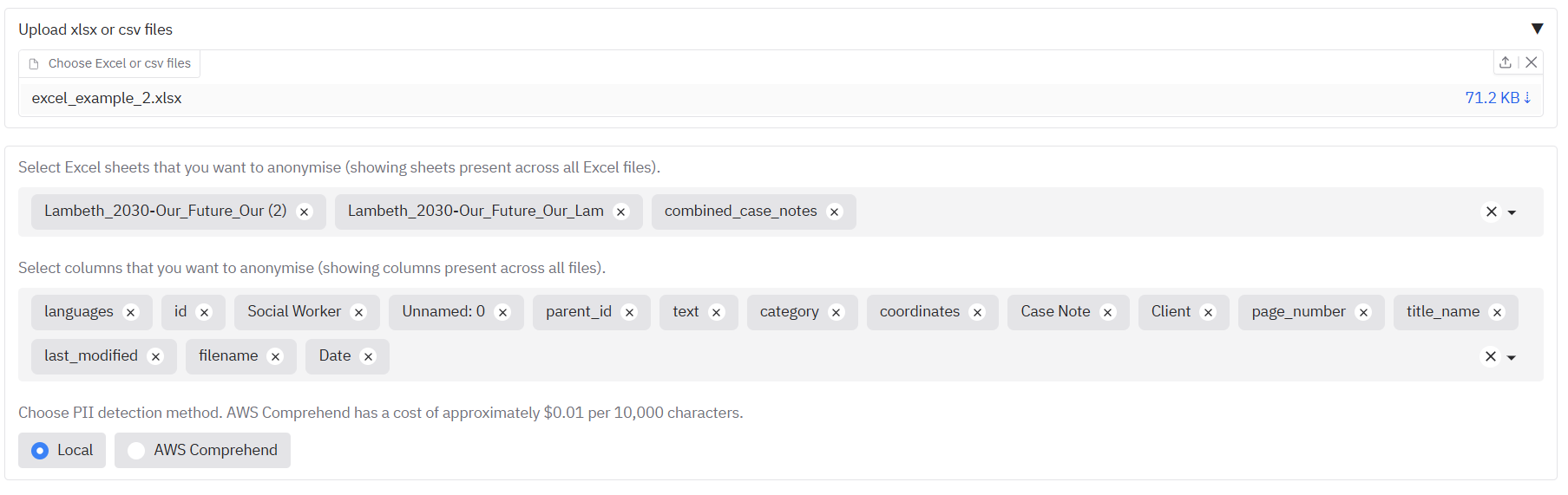
If you were instead to upload an xlsx file, you would see also a list of all the sheets in the xlsx file that can be redacted. The 'Select columns' area underneath will suggest a list of all columns in the file across all sheets.
|
| 342 |
+
|
| 343 |
+
|
| 344 |
+
|
| 345 |
+
Once you have chosen your input file and sheets/columns to redact, you can choose the redaction method. 'Local' will use the same local model as used for documents on the first tab. 'AWS Comprehend' will give better results, at a slight cost.
|
| 346 |
+
|
| 347 |
+
When you click Redact text/data files, you will see the progress of the redaction task by file and sheet, and you will receive a csv output with the redacted data.
|
| 348 |
+
|
| 349 |
+
### Choosing output anonymisation format
|
| 350 |
+
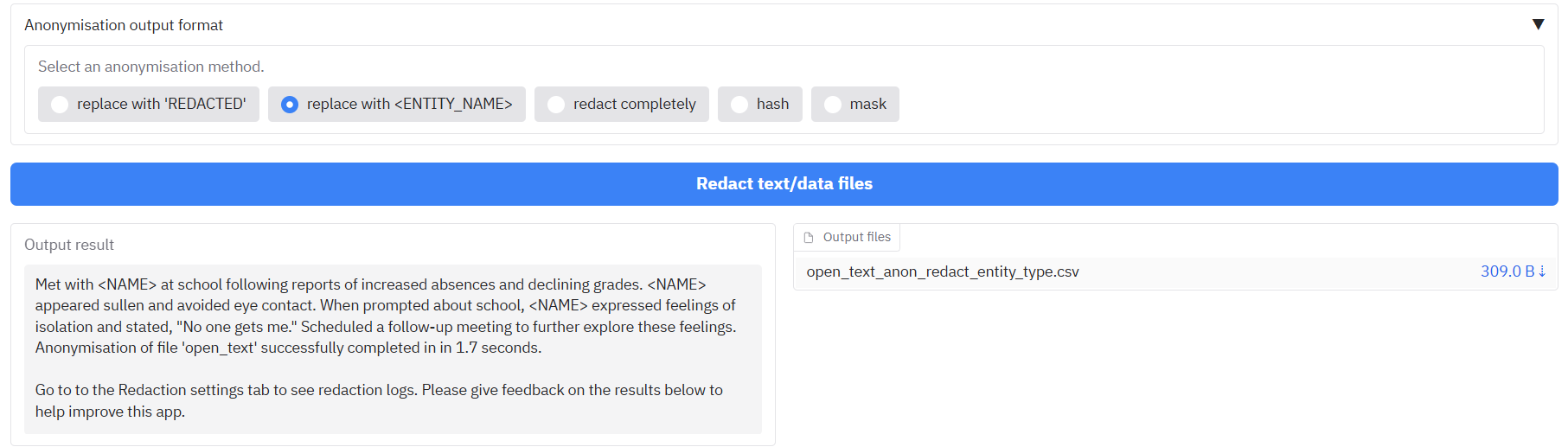
You can also choose the anonymisation format of your output results. Open the tab 'Anonymisation output format' to see the options. By default, any detected PII will be replaced with the word 'REDACTED' in the cell. You can choose one of the following options as the form of replacement for the redacted text:
|
| 351 |
+
- replace with 'REDACTED': Replaced by the word 'REDACTED' (default)
|
| 352 |
+
- replace with <ENTITY_NAME>: Replaced by e.g. 'PERSON' for people, 'EMAIL_ADDRESS' for emails etc.
|
| 353 |
+
- redact completely: Text is removed completely and replaced by nothing.
|
| 354 |
+
- hash: Replaced by a unique long ID code that is consistent with entity text. I.e. a particular name will always have the same ID code.
|
| 355 |
+
- mask: Replace with stars '*'.
|
| 356 |
+
|
| 357 |
+
### Redacting copy and pasted text
|
| 358 |
+
You can also write open text into an input box and redact that using the same methods as described above. To do this, write or paste text into the 'Enter open text' box that appears when you open the 'Redact open text' tab. Then select a redaction method, and an anonymisation output format as described above. The redacted text will be printed in the output textbox, and will also be saved to a simple csv file in the output file box.
|
| 359 |
+
|
| 360 |
+
|
| 361 |
+
|
| 362 |
+
### Redaction log outputs
|
| 363 |
+
A list of the suggested redaction outputs from the tabular data / open text data redaction is available on the Redaction settings page under 'Log file outputs'.
|
| 364 |
+
|
| 365 |
# ADVANCED USER GUIDE
|
| 366 |
|
| 367 |
This advanced user guide will go over some of the features recently added to the app, including: modifying and merging redaction review files, identifying and redacting duplicate pages across multiple PDFs, 'fuzzy' search and redact, and exporting redactions to Adobe Acrobat.
|
|
|
|
| 506 |
|
| 507 |
Again, a lot can potentially go wrong with AWS solutions that are insecure, so before trying the above please consult with your AWS and data security teams.
|
| 508 |
|
| 509 |
+
## Modifying existing redaction review files
|
| 510 |
|
| 511 |
You can find the folder containing the files discussed in this section [here](https://github.com/seanpedrick-case/document_redaction_examples/blob/main/merge_review_files/).
|
| 512 |
|
| 513 |
As well as serving as inputs to the document redaction app's review function, the 'review_file.csv' output can be modified outside of the app, and also merged with others from multiple redaction attempts on the same file. This gives you the flexibility to change redaction details outside of the app.
|
| 514 |
|
|
|
|
| 515 |
If you open up a 'review_file' csv output using a spreadsheet software program such as Microsoft Excel you can easily modify redaction properties. Open the file '[Partnership-Agreement-Toolkit_0_0_redacted.pdf_review_file_local.csv](https://github.com/seanpedrick-case/document_redaction_examples/blob/main/merge_review_files/Partnership-Agreement-Toolkit_0_0.pdf_review_file_local.csv)', and you should see a spreadshet with just four suggested redactions (see below). The following instructions are for using Excel.
|
| 516 |
|
| 517 |

|
app.py
CHANGED
|
@@ -5,7 +5,7 @@ import gradio as gr
|
|
| 5 |
from gradio_image_annotation import image_annotator
|
| 6 |
|
| 7 |
from tools.config import OUTPUT_FOLDER, INPUT_FOLDER, RUN_DIRECT_MODE, MAX_QUEUE_SIZE, DEFAULT_CONCURRENCY_LIMIT, MAX_FILE_SIZE, GRADIO_SERVER_PORT, ROOT_PATH, GET_DEFAULT_ALLOW_LIST, ALLOW_LIST_PATH, S3_ALLOW_LIST_PATH, FEEDBACK_LOGS_FOLDER, ACCESS_LOGS_FOLDER, USAGE_LOGS_FOLDER, TESSERACT_FOLDER, POPPLER_FOLDER, REDACTION_LANGUAGE, GET_COST_CODES, COST_CODES_PATH, S3_COST_CODES_PATH, ENFORCE_COST_CODES, DISPLAY_FILE_NAMES_IN_LOGS, SHOW_COSTS, RUN_AWS_FUNCTIONS, DOCUMENT_REDACTION_BUCKET, SHOW_WHOLE_DOCUMENT_TEXTRACT_CALL_OPTIONS, TEXTRACT_WHOLE_DOCUMENT_ANALYSIS_BUCKET, TEXTRACT_WHOLE_DOCUMENT_ANALYSIS_INPUT_SUBFOLDER, TEXTRACT_WHOLE_DOCUMENT_ANALYSIS_OUTPUT_SUBFOLDER, SESSION_OUTPUT_FOLDER, LOAD_PREVIOUS_TEXTRACT_JOBS_S3, TEXTRACT_JOBS_S3_LOC, TEXTRACT_JOBS_LOCAL_LOC, HOST_NAME, DEFAULT_COST_CODE, OUTPUT_COST_CODES_PATH, OUTPUT_ALLOW_LIST_PATH, COGNITO_AUTH, SAVE_LOGS_TO_CSV, SAVE_LOGS_TO_DYNAMODB, ACCESS_LOG_DYNAMODB_TABLE_NAME, DYNAMODB_ACCESS_LOG_HEADERS, CSV_ACCESS_LOG_HEADERS, FEEDBACK_LOG_DYNAMODB_TABLE_NAME, DYNAMODB_FEEDBACK_LOG_HEADERS, CSV_FEEDBACK_LOG_HEADERS, USAGE_LOG_DYNAMODB_TABLE_NAME, DYNAMODB_USAGE_LOG_HEADERS, CSV_USAGE_LOG_HEADERS
|
| 8 |
-
from tools.helper_functions import put_columns_in_df, get_connection_params, reveal_feedback_buttons, custom_regex_load, reset_state_vars, load_in_default_allow_list, tesseract_ocr_option, text_ocr_option, textract_option, local_pii_detector, aws_pii_detector, no_redaction_option, reset_review_vars, merge_csv_files, load_all_output_files, update_dataframe, check_for_existing_textract_file, load_in_default_cost_codes, enforce_cost_codes, calculate_aws_costs, calculate_time_taken, reset_base_dataframe, reset_ocr_base_dataframe, update_cost_code_dataframe_from_dropdown_select
|
| 9 |
from tools.aws_functions import upload_file_to_s3, download_file_from_s3, upload_log_file_to_s3
|
| 10 |
from tools.file_redaction import choose_and_run_redactor
|
| 11 |
from tools.file_conversion import prepare_image_or_pdf, get_input_file_names
|
|
@@ -47,9 +47,6 @@ else:
|
|
| 47 |
SAVE_LOGS_TO_CSV = eval(SAVE_LOGS_TO_CSV)
|
| 48 |
SAVE_LOGS_TO_DYNAMODB = eval(SAVE_LOGS_TO_DYNAMODB)
|
| 49 |
|
| 50 |
-
print("SAVE_LOGS_TO_CSV:", SAVE_LOGS_TO_CSV)
|
| 51 |
-
print("SAVE_LOGS_TO_DYNAMODB:", SAVE_LOGS_TO_DYNAMODB)
|
| 52 |
-
|
| 53 |
if CSV_ACCESS_LOG_HEADERS: CSV_ACCESS_LOG_HEADERS = eval(CSV_ACCESS_LOG_HEADERS)
|
| 54 |
if CSV_FEEDBACK_LOG_HEADERS: CSV_FEEDBACK_LOG_HEADERS = eval(CSV_FEEDBACK_LOG_HEADERS)
|
| 55 |
if CSV_USAGE_LOG_HEADERS: CSV_USAGE_LOG_HEADERS = eval(CSV_USAGE_LOG_HEADERS)
|
|
@@ -77,6 +74,9 @@ with app:
|
|
| 77 |
all_decision_process_table_state = gr.Dataframe(value=pd.DataFrame(), headers=None, col_count=0, row_count = (0, "dynamic"), label="all_decision_process_table", visible=False, type="pandas", wrap=True)
|
| 78 |
review_file_state = gr.Dataframe(value=pd.DataFrame(), headers=None, col_count=0, row_count = (0, "dynamic"), label="review_file_df", visible=False, type="pandas", wrap=True)
|
| 79 |
|
|
|
|
|
|
|
|
|
|
| 80 |
session_hash_state = gr.Textbox(label= "session_hash_state", value="", visible=False)
|
| 81 |
host_name_textbox = gr.Textbox(label= "host_name_textbox", value=HOST_NAME, visible=False)
|
| 82 |
s3_output_folder_state = gr.Textbox(label= "s3_output_folder_state", value="", visible=False)
|
|
@@ -121,7 +121,12 @@ with app:
|
|
| 121 |
|
| 122 |
doc_full_file_name_textbox = gr.Textbox(label = "doc_full_file_name_textbox", value="", visible=False)
|
| 123 |
doc_file_name_no_extension_textbox = gr.Textbox(label = "doc_full_file_name_textbox", value="", visible=False)
|
| 124 |
-
blank_doc_file_name_no_extension_textbox_for_logs = gr.Textbox(label = "doc_full_file_name_textbox", value="", visible=False)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 125 |
doc_file_name_with_extension_textbox = gr.Textbox(label = "doc_file_name_with_extension_textbox", value="", visible=False)
|
| 126 |
doc_file_name_textbox_list = gr.Dropdown(label = "doc_file_name_textbox_list", value="", allow_custom_value=True,visible=False)
|
| 127 |
latest_review_file_path = gr.Textbox(label = "latest_review_file_path", value="", visible=False) # Latest review file path output from redaction
|
|
@@ -200,6 +205,7 @@ with app:
|
|
| 200 |
cost_code_choice_drop = gr.Dropdown(value=DEFAULT_COST_CODE, label="Choose cost code for analysis. Please contact Finance if you can't find your cost code in the given list.", choices=[DEFAULT_COST_CODE], allow_custom_value=False, visible=False)
|
| 201 |
|
| 202 |
textract_output_found_checkbox = gr.Checkbox(value= False, label="Existing Textract output file found", interactive=False, visible=False)
|
|
|
|
| 203 |
total_pdf_page_count = gr.Number(label = "Total page count", value=0, visible=False)
|
| 204 |
estimated_aws_costs_number = gr.Number(label = "Approximate AWS Textract and/or Comprehend cost ($)", value=0, visible=False, precision=2)
|
| 205 |
estimated_time_taken_number = gr.Number(label = "Approximate time taken to extract text/redact (minutes)", value=0, visible=False, precision=2)
|
|
@@ -256,10 +262,14 @@ with app:
|
|
| 256 |
if SHOW_COSTS == "True":
|
| 257 |
with gr.Accordion("Estimated costs and time taken", open = True, visible=True):
|
| 258 |
with gr.Row(equal_height=True):
|
| 259 |
-
|
| 260 |
-
|
| 261 |
-
|
| 262 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
| 263 |
|
| 264 |
if GET_COST_CODES == "True" or ENFORCE_COST_CODES == "True":
|
| 265 |
with gr.Accordion("Apply cost code", open = True, visible=True):
|
|
@@ -397,7 +407,7 @@ with app:
|
|
| 397 |
###
|
| 398 |
with gr.Tab(label="Open text or Excel/csv files"):
|
| 399 |
gr.Markdown("""### Choose open text or a tabular data file (xlsx or csv) to redact.""")
|
| 400 |
-
with gr.Accordion("
|
| 401 |
in_text = gr.Textbox(label="Enter open text", lines=10)
|
| 402 |
with gr.Accordion("Upload xlsx or csv files", open = True):
|
| 403 |
in_data_files = gr.File(label="Choose Excel or csv files", file_count= "multiple", file_types=['.xlsx', '.xls', '.csv', '.parquet', '.csv.gz'], height=file_input_height)
|
|
@@ -407,6 +417,9 @@ with app:
|
|
| 407 |
in_colnames = gr.Dropdown(choices=["Choose columns to anonymise"], multiselect = True, label="Select columns that you want to anonymise (showing columns present across all files).")
|
| 408 |
|
| 409 |
pii_identification_method_drop_tabular = gr.Radio(label = "Choose PII detection method. AWS Comprehend has a cost of approximately $0.01 per 10,000 characters.", value = default_pii_detector, choices=[local_pii_detector, aws_pii_detector])
|
|
|
|
|
|
|
|
|
|
| 410 |
|
| 411 |
tabular_data_redact_btn = gr.Button("Redact text/data files", variant="primary")
|
| 412 |
|
|
@@ -464,10 +477,10 @@ with app:
|
|
| 464 |
aws_access_key_textbox = gr.Textbox(value='', label="AWS access key for account with permissions for AWS Textract and Comprehend", visible=True, type="password")
|
| 465 |
aws_secret_key_textbox = gr.Textbox(value='', label="AWS secret key for account with permissions for AWS Textract and Comprehend", visible=True, type="password")
|
| 466 |
|
| 467 |
-
|
| 468 |
-
anon_strat = gr.Radio(choices=["replace with 'REDACTED'", "replace with <ENTITY_NAME>", "redact completely", "hash", "mask", "encrypt", "fake_first_name"], label="Select an anonymisation method.", value = "replace with 'REDACTED'")
|
| 469 |
|
| 470 |
-
|
|
|
|
| 471 |
|
| 472 |
with gr.Accordion("Combine multiple review files", open = False):
|
| 473 |
multiple_review_files_in_out = gr.File(label="Combine multiple review_file.csv files together here.", file_count='multiple', file_types=['.csv'])
|
|
@@ -493,14 +506,17 @@ with app:
|
|
| 493 |
handwrite_signature_checkbox.change(calculate_aws_costs, inputs=[total_pdf_page_count, text_extract_method_radio, handwrite_signature_checkbox, pii_identification_method_drop, textract_output_found_checkbox, only_extract_text_radio], outputs=[estimated_aws_costs_number])
|
| 494 |
textract_output_found_checkbox.change(calculate_aws_costs, inputs=[total_pdf_page_count, text_extract_method_radio, handwrite_signature_checkbox, pii_identification_method_drop, textract_output_found_checkbox, only_extract_text_radio], outputs=[estimated_aws_costs_number])
|
| 495 |
only_extract_text_radio.change(calculate_aws_costs, inputs=[total_pdf_page_count, text_extract_method_radio, handwrite_signature_checkbox, pii_identification_method_drop, textract_output_found_checkbox, only_extract_text_radio], outputs=[estimated_aws_costs_number])
|
|
|
|
| 496 |
|
| 497 |
# Calculate time taken
|
| 498 |
-
total_pdf_page_count.change(calculate_time_taken, inputs=[total_pdf_page_count, text_extract_method_radio, pii_identification_method_drop, textract_output_found_checkbox, only_extract_text_radio], outputs=[estimated_time_taken_number])
|
| 499 |
-
text_extract_method_radio.change(calculate_time_taken, inputs=[total_pdf_page_count, text_extract_method_radio, pii_identification_method_drop, textract_output_found_checkbox, only_extract_text_radio], outputs=[estimated_time_taken_number])
|
| 500 |
-
pii_identification_method_drop.change(calculate_time_taken, inputs=[total_pdf_page_count, text_extract_method_radio, pii_identification_method_drop, textract_output_found_checkbox, only_extract_text_radio], outputs=[estimated_time_taken_number])
|
| 501 |
-
handwrite_signature_checkbox.change(calculate_time_taken, inputs=[total_pdf_page_count, text_extract_method_radio, pii_identification_method_drop, textract_output_found_checkbox, only_extract_text_radio], outputs=[estimated_time_taken_number])
|
| 502 |
-
textract_output_found_checkbox.change(calculate_time_taken, inputs=[total_pdf_page_count, text_extract_method_radio, handwrite_signature_checkbox, pii_identification_method_drop, textract_output_found_checkbox, only_extract_text_radio], outputs=[estimated_time_taken_number])
|
| 503 |
-
only_extract_text_radio.change(calculate_time_taken, inputs=[total_pdf_page_count, text_extract_method_radio, pii_identification_method_drop, textract_output_found_checkbox, only_extract_text_radio], outputs=[estimated_time_taken_number])
|
|
|
|
|
|
|
| 504 |
|
| 505 |
# Allow user to select items from cost code dataframe for cost code
|
| 506 |
if SHOW_COSTS=="True" and (GET_COST_CODES == "True" or ENFORCE_COST_CODES == "True"):
|
|
@@ -510,27 +526,30 @@ with app:
|
|
| 510 |
cost_code_choice_drop.select(update_cost_code_dataframe_from_dropdown_select, inputs=[cost_code_choice_drop, cost_code_dataframe_base], outputs=[cost_code_dataframe])
|
| 511 |
|
| 512 |
in_doc_files.upload(fn=get_input_file_names, inputs=[in_doc_files], outputs=[doc_file_name_no_extension_textbox, doc_file_name_with_extension_textbox, doc_full_file_name_textbox, doc_file_name_textbox_list, total_pdf_page_count]).\
|
| 513 |
-
success(fn = prepare_image_or_pdf, inputs=[in_doc_files, text_extract_method_radio, latest_file_completed_text, redaction_output_summary_textbox, first_loop_state, annotate_max_pages, all_image_annotations_state, prepare_for_review_bool_false, in_fully_redacted_list_state, output_folder_textbox, input_folder_textbox, prepare_images_bool_false], outputs=[redaction_output_summary_textbox, prepared_pdf_state, images_pdf_state, annotate_max_pages, annotate_max_pages_bottom, pdf_doc_state, all_image_annotations_state, review_file_state, document_cropboxes, page_sizes, textract_output_found_checkbox, all_img_details_state, all_line_level_ocr_results_df_base]).\
|
| 514 |
-
success(fn=check_for_existing_textract_file, inputs=[doc_file_name_no_extension_textbox, output_folder_textbox], outputs=[textract_output_found_checkbox])
|
|
|
|
| 515 |
|
| 516 |
# Run redaction function
|
| 517 |
document_redact_btn.click(fn = reset_state_vars, outputs=[all_image_annotations_state, all_line_level_ocr_results_df_base, all_decision_process_table_state, comprehend_query_number, textract_metadata_textbox, annotator, output_file_list_state, log_files_output_list_state, recogniser_entity_dataframe, recogniser_entity_dataframe_base, pdf_doc_state, duplication_file_path_outputs_list_state, redaction_output_summary_textbox, is_a_textract_api_call, textract_query_number]).\
|
| 518 |
success(fn= enforce_cost_codes, inputs=[enforce_cost_code_textbox, cost_code_choice_drop, cost_code_dataframe_base]).\
|
| 519 |
-
success(fn= choose_and_run_redactor, inputs=[in_doc_files, prepared_pdf_state, images_pdf_state, in_redact_language, in_redact_entities, in_redact_comprehend_entities, text_extract_method_radio, in_allow_list_state, in_deny_list_state, in_fully_redacted_list_state, latest_file_completed_text, redaction_output_summary_textbox, output_file_list_state, log_files_output_list_state, first_loop_state, page_min, page_max, actual_time_taken_number, handwrite_signature_checkbox, textract_metadata_textbox, all_image_annotations_state, all_line_level_ocr_results_df_base, all_decision_process_table_state, pdf_doc_state, current_loop_page_number, page_break_return, pii_identification_method_drop, comprehend_query_number, max_fuzzy_spelling_mistakes_num, match_fuzzy_whole_phrase_bool, aws_access_key_textbox, aws_secret_key_textbox, annotate_max_pages, review_file_state, output_folder_textbox, document_cropboxes, page_sizes, textract_output_found_checkbox, only_extract_text_radio, duplication_file_path_outputs_list_state, latest_review_file_path, input_folder_textbox, textract_query_number, latest_ocr_file_path],
|
| 520 |
-
outputs=[redaction_output_summary_textbox, output_file, output_file_list_state, latest_file_completed_text, log_files_output, log_files_output_list_state, actual_time_taken_number, textract_metadata_textbox, pdf_doc_state, all_image_annotations_state, current_loop_page_number, page_break_return, all_line_level_ocr_results_df_base, all_decision_process_table_state, comprehend_query_number, output_review_files, annotate_max_pages, annotate_max_pages_bottom, prepared_pdf_state, images_pdf_state, review_file_state, page_sizes, duplication_file_path_outputs_list_state, in_duplicate_pages, latest_review_file_path, textract_query_number, latest_ocr_file_path], api_name="redact_doc").\
|
| 521 |
success(fn=update_annotator_object_and_filter_df, inputs=[all_image_annotations_state, page_min, recogniser_entity_dropdown, page_entity_dropdown, text_entity_dropdown, recogniser_entity_dataframe_base, annotator_zoom_number, review_file_state, page_sizes, doc_full_file_name_textbox, input_folder_textbox], outputs=[annotator, annotate_current_page, annotate_current_page_bottom, annotate_previous_page, recogniser_entity_dropdown, recogniser_entity_dataframe, recogniser_entity_dataframe_base, text_entity_dropdown, page_entity_dropdown, page_sizes, all_image_annotations_state])
|
| 522 |
|
| 523 |
# If the app has completed a batch of pages, it will rerun the redaction process until the end of all pages in the document
|
| 524 |
-
current_loop_page_number.change(fn = choose_and_run_redactor, inputs=[in_doc_files, prepared_pdf_state, images_pdf_state, in_redact_language, in_redact_entities, in_redact_comprehend_entities, text_extract_method_radio, in_allow_list_state, in_deny_list_state, in_fully_redacted_list_state, latest_file_completed_text, redaction_output_summary_textbox, output_file_list_state, log_files_output_list_state, second_loop_state, page_min, page_max, actual_time_taken_number, handwrite_signature_checkbox, textract_metadata_textbox, all_image_annotations_state, all_line_level_ocr_results_df_base, all_decision_process_table_state, pdf_doc_state, current_loop_page_number, page_break_return, pii_identification_method_drop, comprehend_query_number, max_fuzzy_spelling_mistakes_num, match_fuzzy_whole_phrase_bool, aws_access_key_textbox, aws_secret_key_textbox, annotate_max_pages, review_file_state, output_folder_textbox, document_cropboxes, page_sizes, textract_output_found_checkbox, only_extract_text_radio, duplication_file_path_outputs_list_state, latest_review_file_path, input_folder_textbox, textract_query_number, latest_ocr_file_path],
|
| 525 |
-
outputs=[redaction_output_summary_textbox, output_file, output_file_list_state, latest_file_completed_text, log_files_output, log_files_output_list_state, actual_time_taken_number, textract_metadata_textbox, pdf_doc_state, all_image_annotations_state, current_loop_page_number, page_break_return, all_line_level_ocr_results_df_base, all_decision_process_table_state, comprehend_query_number, output_review_files, annotate_max_pages, annotate_max_pages_bottom, prepared_pdf_state, images_pdf_state, review_file_state, page_sizes, duplication_file_path_outputs_list_state, in_duplicate_pages, latest_review_file_path, textract_query_number, latest_ocr_file_path]).\
|
| 526 |
success(fn=update_annotator_object_and_filter_df, inputs=[all_image_annotations_state, page_min, recogniser_entity_dropdown, page_entity_dropdown, text_entity_dropdown, recogniser_entity_dataframe_base, annotator_zoom_number, review_file_state, page_sizes, doc_full_file_name_textbox, input_folder_textbox], outputs=[annotator, annotate_current_page, annotate_current_page_bottom, annotate_previous_page, recogniser_entity_dropdown, recogniser_entity_dataframe, recogniser_entity_dataframe_base, text_entity_dropdown, page_entity_dropdown, page_sizes, all_image_annotations_state])
|
| 527 |
|
| 528 |
# If a file has been completed, the function will continue onto the next document
|
| 529 |
-
latest_file_completed_text.change(fn = choose_and_run_redactor, inputs=[in_doc_files, prepared_pdf_state, images_pdf_state, in_redact_language, in_redact_entities, in_redact_comprehend_entities, text_extract_method_radio, in_allow_list_state, in_deny_list_state, in_fully_redacted_list_state, latest_file_completed_text, redaction_output_summary_textbox, output_file_list_state, log_files_output_list_state, second_loop_state, page_min, page_max, actual_time_taken_number, handwrite_signature_checkbox, textract_metadata_textbox, all_image_annotations_state, all_line_level_ocr_results_df_base, all_decision_process_table_state, pdf_doc_state, current_loop_page_number, page_break_return, pii_identification_method_drop, comprehend_query_number, max_fuzzy_spelling_mistakes_num, match_fuzzy_whole_phrase_bool, aws_access_key_textbox, aws_secret_key_textbox, annotate_max_pages, review_file_state, output_folder_textbox, document_cropboxes, page_sizes, textract_output_found_checkbox, only_extract_text_radio, duplication_file_path_outputs_list_state, latest_review_file_path, input_folder_textbox, textract_query_number, latest_ocr_file_path],
|
| 530 |
-
outputs=[redaction_output_summary_textbox, output_file, output_file_list_state, latest_file_completed_text, log_files_output, log_files_output_list_state, actual_time_taken_number, textract_metadata_textbox, pdf_doc_state, all_image_annotations_state, current_loop_page_number, page_break_return, all_line_level_ocr_results_df_base, all_decision_process_table_state, comprehend_query_number, output_review_files, annotate_max_pages, annotate_max_pages_bottom, prepared_pdf_state, images_pdf_state, review_file_state, page_sizes, duplication_file_path_outputs_list_state, in_duplicate_pages, latest_review_file_path, textract_query_number, latest_ocr_file_path]).\
|
| 531 |
success(fn=update_annotator_object_and_filter_df, inputs=[all_image_annotations_state, page_min, recogniser_entity_dropdown, page_entity_dropdown, text_entity_dropdown, recogniser_entity_dataframe_base, annotator_zoom_number, review_file_state, page_sizes, doc_full_file_name_textbox, input_folder_textbox], outputs=[annotator, annotate_current_page, annotate_current_page_bottom, annotate_previous_page, recogniser_entity_dropdown, recogniser_entity_dataframe, recogniser_entity_dataframe_base, text_entity_dropdown, page_entity_dropdown, page_sizes, all_image_annotations_state]).\
|
| 532 |
success(fn=check_for_existing_textract_file, inputs=[doc_file_name_no_extension_textbox, output_folder_textbox], outputs=[textract_output_found_checkbox]).\
|
| 533 |
-
success(fn=
|
|
|
|
|
|
|
| 534 |
|
| 535 |
# If the line level ocr results are changed by load in by user or by a new redaction task, replace the ocr results displayed in the table
|
| 536 |
all_line_level_ocr_results_df_base.change(reset_ocr_base_dataframe, inputs=[all_line_level_ocr_results_df_base], outputs=[all_line_level_ocr_results_df])
|
|
@@ -548,8 +567,8 @@ with app:
|
|
| 548 |
convert_textract_outputs_to_ocr_results.click(fn=check_for_existing_textract_file, inputs=[doc_file_name_no_extension_textbox, output_folder_textbox], outputs=[textract_output_found_checkbox]).\
|
| 549 |
success(fn= check_textract_outputs_exist, inputs=[textract_output_found_checkbox]).\
|
| 550 |
success(fn = reset_state_vars, outputs=[all_image_annotations_state, all_line_level_ocr_results_df_base, all_decision_process_table_state, comprehend_query_number, textract_metadata_textbox, annotator, output_file_list_state, log_files_output_list_state, recogniser_entity_dataframe, recogniser_entity_dataframe_base, pdf_doc_state, duplication_file_path_outputs_list_state, redaction_output_summary_textbox, is_a_textract_api_call]).\
|
| 551 |
-
success(fn= choose_and_run_redactor, inputs=[in_doc_files, prepared_pdf_state, images_pdf_state, in_redact_language, in_redact_entities, in_redact_comprehend_entities, textract_only_method_drop, in_allow_list_state, in_deny_list_state, in_fully_redacted_list_state, latest_file_completed_text, redaction_output_summary_textbox, output_file_list_state, log_files_output_list_state, first_loop_state, page_min, page_max, actual_time_taken_number, handwrite_signature_checkbox, textract_metadata_textbox, all_image_annotations_state, all_line_level_ocr_results_df_base, all_decision_process_table_state, pdf_doc_state, current_loop_page_number, page_break_return, no_redaction_method_drop, comprehend_query_number, max_fuzzy_spelling_mistakes_num, match_fuzzy_whole_phrase_bool, aws_access_key_textbox, aws_secret_key_textbox, annotate_max_pages, review_file_state, output_folder_textbox, document_cropboxes, page_sizes, textract_output_found_checkbox, only_extract_text_radio, duplication_file_path_outputs_list_state, latest_review_file_path, input_folder_textbox, textract_query_number, latest_ocr_file_path],
|
| 552 |
-
outputs=[redaction_output_summary_textbox, output_file, output_file_list_state, latest_file_completed_text, log_files_output, log_files_output_list_state, actual_time_taken_number, textract_metadata_textbox, pdf_doc_state, all_image_annotations_state, current_loop_page_number, page_break_return, all_line_level_ocr_results_df_base, all_decision_process_table_state, comprehend_query_number, output_review_files, annotate_max_pages, annotate_max_pages_bottom, prepared_pdf_state, images_pdf_state, review_file_state, page_sizes, duplication_file_path_outputs_list_state, in_duplicate_pages, latest_review_file_path, textract_query_number, latest_ocr_file_path])
|
| 553 |
|
| 554 |
###
|
| 555 |
# REVIEW PDF REDACTIONS
|
|
@@ -558,7 +577,7 @@ with app:
|
|
| 558 |
# Upload previous files for modifying redactions
|
| 559 |
upload_previous_review_file_btn.click(fn=reset_review_vars, inputs=None, outputs=[recogniser_entity_dataframe, recogniser_entity_dataframe_base]).\
|
| 560 |
success(fn=get_input_file_names, inputs=[output_review_files], outputs=[doc_file_name_no_extension_textbox, doc_file_name_with_extension_textbox, doc_full_file_name_textbox, doc_file_name_textbox_list, total_pdf_page_count]).\
|
| 561 |
-
success(fn = prepare_image_or_pdf, inputs=[output_review_files, text_extract_method_radio, latest_file_completed_text, redaction_output_summary_textbox, second_loop_state, annotate_max_pages, all_image_annotations_state, prepare_for_review_bool, in_fully_redacted_list_state, output_folder_textbox, input_folder_textbox, prepare_images_bool_false], outputs=[redaction_output_summary_textbox, prepared_pdf_state, images_pdf_state, annotate_max_pages, annotate_max_pages_bottom, pdf_doc_state, all_image_annotations_state, review_file_state, document_cropboxes, page_sizes, textract_output_found_checkbox, all_img_details_state, all_line_level_ocr_results_df_base], api_name="prepare_doc").\
|
| 562 |
success(update_annotator_object_and_filter_df, inputs=[all_image_annotations_state, annotate_current_page, recogniser_entity_dropdown, page_entity_dropdown, text_entity_dropdown, recogniser_entity_dataframe_base, annotator_zoom_number, review_file_state, page_sizes, doc_full_file_name_textbox, input_folder_textbox], outputs = [annotator, annotate_current_page, annotate_current_page_bottom, annotate_previous_page, recogniser_entity_dropdown, recogniser_entity_dataframe, recogniser_entity_dataframe_base, text_entity_dropdown, page_entity_dropdown, page_sizes, all_image_annotations_state])
|
| 563 |
|
| 564 |
# Page number controls
|
|
@@ -620,12 +639,12 @@ with app:
|
|
| 620 |
|
| 621 |
# Convert review file to xfdf Adobe format
|
| 622 |
convert_review_file_to_adobe_btn.click(fn=get_input_file_names, inputs=[output_review_files], outputs=[doc_file_name_no_extension_textbox, doc_file_name_with_extension_textbox, doc_full_file_name_textbox, doc_file_name_textbox_list, total_pdf_page_count]).\
|
| 623 |
-
success(fn = prepare_image_or_pdf, inputs=[output_review_files, text_extract_method_radio, latest_file_completed_text, redaction_output_summary_textbox, second_loop_state, annotate_max_pages, all_image_annotations_state, prepare_for_review_bool, in_fully_redacted_list_state, output_folder_textbox, input_folder_textbox, prepare_images_bool_false], outputs=[redaction_output_summary_textbox, prepared_pdf_state, images_pdf_state, annotate_max_pages, annotate_max_pages_bottom, pdf_doc_state, all_image_annotations_state, review_file_state, document_cropboxes, page_sizes, textract_output_found_checkbox, all_img_details_state, all_line_level_ocr_results_df_placeholder]).\
|
| 624 |
success(convert_df_to_xfdf, inputs=[output_review_files, pdf_doc_state, images_pdf_state, output_folder_textbox, document_cropboxes, page_sizes], outputs=[adobe_review_files_out])
|
| 625 |
|
| 626 |
# Convert xfdf Adobe file back to review_file.csv
|
| 627 |
convert_adobe_to_review_file_btn.click(fn=get_input_file_names, inputs=[adobe_review_files_out], outputs=[doc_file_name_no_extension_textbox, doc_file_name_with_extension_textbox, doc_full_file_name_textbox, doc_file_name_textbox_list, total_pdf_page_count]).\
|
| 628 |
-
success(fn = prepare_image_or_pdf, inputs=[adobe_review_files_out, text_extract_method_radio, latest_file_completed_text, redaction_output_summary_textbox, second_loop_state, annotate_max_pages, all_image_annotations_state, prepare_for_review_bool, in_fully_redacted_list_state, output_folder_textbox, input_folder_textbox, prepare_images_bool_false], outputs=[redaction_output_summary_textbox, prepared_pdf_state, images_pdf_state, annotate_max_pages, annotate_max_pages_bottom, pdf_doc_state, all_image_annotations_state, review_file_state, document_cropboxes, page_sizes, textract_output_found_checkbox, all_img_details_state, all_line_level_ocr_results_df_placeholder]).\
|
| 629 |
success(fn=convert_xfdf_to_dataframe, inputs=[adobe_review_files_out, pdf_doc_state, images_pdf_state, output_folder_textbox], outputs=[output_review_files], scroll_to_output=True)
|
| 630 |
|
| 631 |
###
|
|
@@ -634,11 +653,14 @@ with app:
|
|
| 634 |
in_data_files.upload(fn=put_columns_in_df, inputs=[in_data_files], outputs=[in_colnames, in_excel_sheets]).\
|
| 635 |
success(fn=get_input_file_names, inputs=[in_data_files], outputs=[data_file_name_no_extension_textbox, data_file_name_with_extension_textbox, data_full_file_name_textbox, data_file_name_textbox_list, total_pdf_page_count])
|
| 636 |
|
| 637 |
-
tabular_data_redact_btn.click(
|
|
|
|
|
|
|
| 638 |
|
|
|
|
| 639 |
# If the output file count text box changes, keep going with redacting each data file until done
|
| 640 |
-
text_tabular_files_done.change(fn=anonymise_data_files, inputs=[in_data_files, in_text, anon_strat, in_colnames, in_redact_language, in_redact_entities, in_allow_list_state, text_tabular_files_done, text_output_summary, text_output_file_list_state, log_files_output_list_state, in_excel_sheets, second_loop_state, output_folder_textbox, in_deny_list_state, max_fuzzy_spelling_mistakes_num, pii_identification_method_drop_tabular, in_redact_comprehend_entities, comprehend_query_number, aws_access_key_textbox, aws_secret_key_textbox], outputs=[text_output_summary, text_output_file, text_output_file_list_state, text_tabular_files_done, log_files_output, log_files_output_list_state]).\
|
| 641 |
-
success(fn = reveal_feedback_buttons, outputs=[data_feedback_radio, data_further_details_text, data_submit_feedback_btn, data_feedback_title])
|
| 642 |
|
| 643 |
###
|
| 644 |
# IDENTIFY DUPLICATE PAGES
|
|
@@ -715,17 +737,30 @@ with app:
|
|
| 715 |
success(fn = upload_log_file_to_s3, inputs=[access_logs_state, access_s3_logs_loc_state], outputs=[s3_logs_output_textbox])
|
| 716 |
|
| 717 |
### FEEDBACK LOGS
|
| 718 |
-
|
| 719 |
-
|
| 720 |
-
|
| 721 |
-
|
| 722 |
-
|
| 723 |
-
|
| 724 |
-
|
| 725 |
-
|
| 726 |
-
|
| 727 |
-
|
| 728 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 729 |
|
| 730 |
### USAGE LOGS
|
| 731 |
# Log processing usage - time taken for redaction queries, and also logs for queries to Textract/Comprehend
|
|
@@ -738,15 +773,21 @@ with app:
|
|
| 738 |
latest_file_completed_text.change(lambda *args: usage_callback.flag(list(args), save_to_csv=SAVE_LOGS_TO_CSV, save_to_dynamodb=SAVE_LOGS_TO_DYNAMODB, dynamodb_table_name=USAGE_LOG_DYNAMODB_TABLE_NAME, dynamodb_headers=DYNAMODB_USAGE_LOG_HEADERS, replacement_headers=CSV_USAGE_LOG_HEADERS), [session_hash_textbox, doc_file_name_no_extension_textbox, data_full_file_name_textbox, total_pdf_page_count, actual_time_taken_number, textract_query_number, pii_identification_method_drop, comprehend_query_number, cost_code_choice_drop, handwrite_signature_checkbox, host_name_textbox, text_extract_method_radio, is_a_textract_api_call], None, preprocess=False).\
|
| 739 |
success(fn = upload_log_file_to_s3, inputs=[usage_logs_state, usage_s3_logs_loc_state], outputs=[s3_logs_output_textbox])
|
| 740 |
|
|
|
|
|
|
|
|
|
|
| 741 |
successful_textract_api_call_number.change(lambda *args: usage_callback.flag(list(args), save_to_csv=SAVE_LOGS_TO_CSV, save_to_dynamodb=SAVE_LOGS_TO_DYNAMODB, dynamodb_table_name=USAGE_LOG_DYNAMODB_TABLE_NAME, dynamodb_headers=DYNAMODB_USAGE_LOG_HEADERS, replacement_headers=CSV_USAGE_LOG_HEADERS), [session_hash_textbox, doc_file_name_no_extension_textbox, data_full_file_name_textbox, total_pdf_page_count, actual_time_taken_number, textract_query_number, pii_identification_method_drop, comprehend_query_number, cost_code_choice_drop, handwrite_signature_checkbox, host_name_textbox, text_extract_method_radio, is_a_textract_api_call], None, preprocess=False).\
|
| 742 |
success(fn = upload_log_file_to_s3, inputs=[usage_logs_state, usage_s3_logs_loc_state], outputs=[s3_logs_output_textbox])
|
| 743 |
else:
|
| 744 |
-
usage_callback.setup([session_hash_textbox, blank_doc_file_name_no_extension_textbox_for_logs,
|
|
|
|
|
|
|
|
|
|
| 745 |
|
| 746 |
-
|
| 747 |
success(fn = upload_log_file_to_s3, inputs=[usage_logs_state, usage_s3_logs_loc_state], outputs=[s3_logs_output_textbox])
|
| 748 |
|
| 749 |
-
successful_textract_api_call_number.change(lambda *args: usage_callback.flag(list(args), save_to_csv=SAVE_LOGS_TO_CSV, save_to_dynamodb=SAVE_LOGS_TO_DYNAMODB, dynamodb_table_name=USAGE_LOG_DYNAMODB_TABLE_NAME, dynamodb_headers=DYNAMODB_USAGE_LOG_HEADERS, replacement_headers=CSV_USAGE_LOG_HEADERS), [session_hash_textbox,
|
| 750 |
success(fn = upload_log_file_to_s3, inputs=[usage_logs_state, usage_s3_logs_loc_state], outputs=[s3_logs_output_textbox])
|
| 751 |
|
| 752 |
if __name__ == "__main__":
|
|
|
|
| 5 |
from gradio_image_annotation import image_annotator
|
| 6 |
|
| 7 |
from tools.config import OUTPUT_FOLDER, INPUT_FOLDER, RUN_DIRECT_MODE, MAX_QUEUE_SIZE, DEFAULT_CONCURRENCY_LIMIT, MAX_FILE_SIZE, GRADIO_SERVER_PORT, ROOT_PATH, GET_DEFAULT_ALLOW_LIST, ALLOW_LIST_PATH, S3_ALLOW_LIST_PATH, FEEDBACK_LOGS_FOLDER, ACCESS_LOGS_FOLDER, USAGE_LOGS_FOLDER, TESSERACT_FOLDER, POPPLER_FOLDER, REDACTION_LANGUAGE, GET_COST_CODES, COST_CODES_PATH, S3_COST_CODES_PATH, ENFORCE_COST_CODES, DISPLAY_FILE_NAMES_IN_LOGS, SHOW_COSTS, RUN_AWS_FUNCTIONS, DOCUMENT_REDACTION_BUCKET, SHOW_WHOLE_DOCUMENT_TEXTRACT_CALL_OPTIONS, TEXTRACT_WHOLE_DOCUMENT_ANALYSIS_BUCKET, TEXTRACT_WHOLE_DOCUMENT_ANALYSIS_INPUT_SUBFOLDER, TEXTRACT_WHOLE_DOCUMENT_ANALYSIS_OUTPUT_SUBFOLDER, SESSION_OUTPUT_FOLDER, LOAD_PREVIOUS_TEXTRACT_JOBS_S3, TEXTRACT_JOBS_S3_LOC, TEXTRACT_JOBS_LOCAL_LOC, HOST_NAME, DEFAULT_COST_CODE, OUTPUT_COST_CODES_PATH, OUTPUT_ALLOW_LIST_PATH, COGNITO_AUTH, SAVE_LOGS_TO_CSV, SAVE_LOGS_TO_DYNAMODB, ACCESS_LOG_DYNAMODB_TABLE_NAME, DYNAMODB_ACCESS_LOG_HEADERS, CSV_ACCESS_LOG_HEADERS, FEEDBACK_LOG_DYNAMODB_TABLE_NAME, DYNAMODB_FEEDBACK_LOG_HEADERS, CSV_FEEDBACK_LOG_HEADERS, USAGE_LOG_DYNAMODB_TABLE_NAME, DYNAMODB_USAGE_LOG_HEADERS, CSV_USAGE_LOG_HEADERS
|
| 8 |
+
from tools.helper_functions import put_columns_in_df, get_connection_params, reveal_feedback_buttons, custom_regex_load, reset_state_vars, load_in_default_allow_list, tesseract_ocr_option, text_ocr_option, textract_option, local_pii_detector, aws_pii_detector, no_redaction_option, reset_review_vars, merge_csv_files, load_all_output_files, update_dataframe, check_for_existing_textract_file, load_in_default_cost_codes, enforce_cost_codes, calculate_aws_costs, calculate_time_taken, reset_base_dataframe, reset_ocr_base_dataframe, update_cost_code_dataframe_from_dropdown_select, check_for_existing_local_ocr_file, reset_data_vars, reset_aws_call_vars
|
| 9 |
from tools.aws_functions import upload_file_to_s3, download_file_from_s3, upload_log_file_to_s3
|
| 10 |
from tools.file_redaction import choose_and_run_redactor
|
| 11 |
from tools.file_conversion import prepare_image_or_pdf, get_input_file_names
|
|
|
|
| 47 |
SAVE_LOGS_TO_CSV = eval(SAVE_LOGS_TO_CSV)
|
| 48 |
SAVE_LOGS_TO_DYNAMODB = eval(SAVE_LOGS_TO_DYNAMODB)
|
| 49 |
|
|
|
|
|
|
|
|
|
|
| 50 |
if CSV_ACCESS_LOG_HEADERS: CSV_ACCESS_LOG_HEADERS = eval(CSV_ACCESS_LOG_HEADERS)
|
| 51 |
if CSV_FEEDBACK_LOG_HEADERS: CSV_FEEDBACK_LOG_HEADERS = eval(CSV_FEEDBACK_LOG_HEADERS)
|
| 52 |
if CSV_USAGE_LOG_HEADERS: CSV_USAGE_LOG_HEADERS = eval(CSV_USAGE_LOG_HEADERS)
|
|
|
|
| 74 |
all_decision_process_table_state = gr.Dataframe(value=pd.DataFrame(), headers=None, col_count=0, row_count = (0, "dynamic"), label="all_decision_process_table", visible=False, type="pandas", wrap=True)
|
| 75 |
review_file_state = gr.Dataframe(value=pd.DataFrame(), headers=None, col_count=0, row_count = (0, "dynamic"), label="review_file_df", visible=False, type="pandas", wrap=True)
|
| 76 |
|
| 77 |
+
all_page_line_level_ocr_results = gr.State([])
|
| 78 |
+
all_page_line_level_ocr_results_with_children = gr.State([])
|
| 79 |
+
|
| 80 |
session_hash_state = gr.Textbox(label= "session_hash_state", value="", visible=False)
|
| 81 |
host_name_textbox = gr.Textbox(label= "host_name_textbox", value=HOST_NAME, visible=False)
|
| 82 |
s3_output_folder_state = gr.Textbox(label= "s3_output_folder_state", value="", visible=False)
|
|
|
|
| 121 |
|
| 122 |
doc_full_file_name_textbox = gr.Textbox(label = "doc_full_file_name_textbox", value="", visible=False)
|
| 123 |
doc_file_name_no_extension_textbox = gr.Textbox(label = "doc_full_file_name_textbox", value="", visible=False)
|
| 124 |
+
blank_doc_file_name_no_extension_textbox_for_logs = gr.Textbox(label = "doc_full_file_name_textbox", value="", visible=False)
|
| 125 |
+
blank_data_file_name_no_extension_textbox_for_logs = gr.Textbox(label = "data_full_file_name_textbox", value="", visible=False)
|
| 126 |
+
placeholder_doc_file_name_no_extension_textbox_for_logs = gr.Textbox(label = "doc_full_file_name_textbox", value="document", visible=False)
|
| 127 |
+
placeholder_data_file_name_no_extension_textbox_for_logs = gr.Textbox(label = "data_full_file_name_textbox", value="data_file", visible=False)
|
| 128 |
+
|
| 129 |
+
# Left blank for when user does not want to report file names
|
| 130 |
doc_file_name_with_extension_textbox = gr.Textbox(label = "doc_file_name_with_extension_textbox", value="", visible=False)
|
| 131 |
doc_file_name_textbox_list = gr.Dropdown(label = "doc_file_name_textbox_list", value="", allow_custom_value=True,visible=False)
|
| 132 |
latest_review_file_path = gr.Textbox(label = "latest_review_file_path", value="", visible=False) # Latest review file path output from redaction
|
|
|
|
| 205 |
cost_code_choice_drop = gr.Dropdown(value=DEFAULT_COST_CODE, label="Choose cost code for analysis. Please contact Finance if you can't find your cost code in the given list.", choices=[DEFAULT_COST_CODE], allow_custom_value=False, visible=False)
|
| 206 |
|
| 207 |
textract_output_found_checkbox = gr.Checkbox(value= False, label="Existing Textract output file found", interactive=False, visible=False)
|
| 208 |
+
local_ocr_output_found_checkbox = gr.Checkbox(value= False, label="Existing local OCR output file found", interactive=False, visible=False)
|
| 209 |
total_pdf_page_count = gr.Number(label = "Total page count", value=0, visible=False)
|
| 210 |
estimated_aws_costs_number = gr.Number(label = "Approximate AWS Textract and/or Comprehend cost ($)", value=0, visible=False, precision=2)
|
| 211 |
estimated_time_taken_number = gr.Number(label = "Approximate time taken to extract text/redact (minutes)", value=0, visible=False, precision=2)
|
|
|
|
| 262 |
if SHOW_COSTS == "True":
|
| 263 |
with gr.Accordion("Estimated costs and time taken", open = True, visible=True):
|
| 264 |
with gr.Row(equal_height=True):
|
| 265 |
+
with gr.Column(scale=1):
|
| 266 |
+
textract_output_found_checkbox = gr.Checkbox(value= False, label="Existing Textract output file found", interactive=False, visible=True)
|
| 267 |
+
local_ocr_output_found_checkbox = gr.Checkbox(value= False, label="Existing local OCR output file found", interactive=False, visible=True)
|
| 268 |
+
with gr.Column(scale=4):
|
| 269 |
+
with gr.Row(equal_height=True):
|
| 270 |
+
total_pdf_page_count = gr.Number(label = "Total page count", value=0, visible=True)
|
| 271 |
+
estimated_aws_costs_number = gr.Number(label = "Approximate AWS Textract and/or Comprehend cost (£)", value=0.00, precision=2, visible=True)
|
| 272 |
+
estimated_time_taken_number = gr.Number(label = "Approximate time taken to extract text/redact (minutes)", value=0, visible=True, precision=2)
|
| 273 |
|
| 274 |
if GET_COST_CODES == "True" or ENFORCE_COST_CODES == "True":
|
| 275 |
with gr.Accordion("Apply cost code", open = True, visible=True):
|
|
|
|
| 407 |
###
|
| 408 |
with gr.Tab(label="Open text or Excel/csv files"):
|
| 409 |
gr.Markdown("""### Choose open text or a tabular data file (xlsx or csv) to redact.""")
|
| 410 |
+
with gr.Accordion("Redact open text", open = False):
|
| 411 |
in_text = gr.Textbox(label="Enter open text", lines=10)
|
| 412 |
with gr.Accordion("Upload xlsx or csv files", open = True):
|
| 413 |
in_data_files = gr.File(label="Choose Excel or csv files", file_count= "multiple", file_types=['.xlsx', '.xls', '.csv', '.parquet', '.csv.gz'], height=file_input_height)
|
|
|
|
| 417 |
in_colnames = gr.Dropdown(choices=["Choose columns to anonymise"], multiselect = True, label="Select columns that you want to anonymise (showing columns present across all files).")
|
| 418 |
|
| 419 |
pii_identification_method_drop_tabular = gr.Radio(label = "Choose PII detection method. AWS Comprehend has a cost of approximately $0.01 per 10,000 characters.", value = default_pii_detector, choices=[local_pii_detector, aws_pii_detector])
|
| 420 |
+
|
| 421 |
+
with gr.Accordion("Anonymisation output format", open = False):
|
| 422 |
+
anon_strat = gr.Radio(choices=["replace with 'REDACTED'", "replace with <ENTITY_NAME>", "redact completely", "hash", "mask"], label="Select an anonymisation method.", value = "replace with 'REDACTED'") # , "encrypt", "fake_first_name" are also available, but are not currently included as not that useful in current form
|
| 423 |
|
| 424 |
tabular_data_redact_btn = gr.Button("Redact text/data files", variant="primary")
|
| 425 |
|
|
|
|
| 477 |
aws_access_key_textbox = gr.Textbox(value='', label="AWS access key for account with permissions for AWS Textract and Comprehend", visible=True, type="password")
|
| 478 |
aws_secret_key_textbox = gr.Textbox(value='', label="AWS secret key for account with permissions for AWS Textract and Comprehend", visible=True, type="password")
|
| 479 |
|
| 480 |
+
|
|
|
|
| 481 |
|
| 482 |
+
with gr.Accordion("Log file outputs", open = False):
|
| 483 |
+
log_files_output = gr.File(label="Log file output", interactive=False)
|
| 484 |
|
| 485 |
with gr.Accordion("Combine multiple review files", open = False):
|
| 486 |
multiple_review_files_in_out = gr.File(label="Combine multiple review_file.csv files together here.", file_count='multiple', file_types=['.csv'])
|
|
|
|
| 506 |
handwrite_signature_checkbox.change(calculate_aws_costs, inputs=[total_pdf_page_count, text_extract_method_radio, handwrite_signature_checkbox, pii_identification_method_drop, textract_output_found_checkbox, only_extract_text_radio], outputs=[estimated_aws_costs_number])
|
| 507 |
textract_output_found_checkbox.change(calculate_aws_costs, inputs=[total_pdf_page_count, text_extract_method_radio, handwrite_signature_checkbox, pii_identification_method_drop, textract_output_found_checkbox, only_extract_text_radio], outputs=[estimated_aws_costs_number])
|
| 508 |
only_extract_text_radio.change(calculate_aws_costs, inputs=[total_pdf_page_count, text_extract_method_radio, handwrite_signature_checkbox, pii_identification_method_drop, textract_output_found_checkbox, only_extract_text_radio], outputs=[estimated_aws_costs_number])
|
| 509 |
+
textract_output_found_checkbox.change(calculate_aws_costs, inputs=[total_pdf_page_count, text_extract_method_radio, handwrite_signature_checkbox, pii_identification_method_drop, textract_output_found_checkbox, only_extract_text_radio], outputs=[estimated_aws_costs_number])
|
| 510 |
|
| 511 |
# Calculate time taken
|
| 512 |
+
total_pdf_page_count.change(calculate_time_taken, inputs=[total_pdf_page_count, text_extract_method_radio, pii_identification_method_drop, textract_output_found_checkbox, only_extract_text_radio, local_ocr_output_found_checkbox], outputs=[estimated_time_taken_number])
|
| 513 |
+
text_extract_method_radio.change(calculate_time_taken, inputs=[total_pdf_page_count, text_extract_method_radio, pii_identification_method_drop, textract_output_found_checkbox, only_extract_text_radio, local_ocr_output_found_checkbox], outputs=[estimated_time_taken_number])
|
| 514 |
+
pii_identification_method_drop.change(calculate_time_taken, inputs=[total_pdf_page_count, text_extract_method_radio, pii_identification_method_drop, textract_output_found_checkbox, only_extract_text_radio, local_ocr_output_found_checkbox], outputs=[estimated_time_taken_number])
|
| 515 |
+
handwrite_signature_checkbox.change(calculate_time_taken, inputs=[total_pdf_page_count, text_extract_method_radio, pii_identification_method_drop, textract_output_found_checkbox, only_extract_text_radio, local_ocr_output_found_checkbox], outputs=[estimated_time_taken_number])
|
| 516 |
+
textract_output_found_checkbox.change(calculate_time_taken, inputs=[total_pdf_page_count, text_extract_method_radio, handwrite_signature_checkbox, pii_identification_method_drop, textract_output_found_checkbox, only_extract_text_radio, local_ocr_output_found_checkbox], outputs=[estimated_time_taken_number])
|
| 517 |
+
only_extract_text_radio.change(calculate_time_taken, inputs=[total_pdf_page_count, text_extract_method_radio, pii_identification_method_drop, textract_output_found_checkbox, only_extract_text_radio, local_ocr_output_found_checkbox], outputs=[estimated_time_taken_number])
|
| 518 |
+
textract_output_found_checkbox.change(calculate_time_taken, inputs=[total_pdf_page_count, text_extract_method_radio, pii_identification_method_drop, textract_output_found_checkbox, only_extract_text_radio, local_ocr_output_found_checkbox], outputs=[estimated_time_taken_number])
|
| 519 |
+
local_ocr_output_found_checkbox.change(calculate_time_taken, inputs=[total_pdf_page_count, text_extract_method_radio, pii_identification_method_drop, textract_output_found_checkbox, only_extract_text_radio, local_ocr_output_found_checkbox], outputs=[estimated_time_taken_number])
|
| 520 |
|
| 521 |
# Allow user to select items from cost code dataframe for cost code
|
| 522 |
if SHOW_COSTS=="True" and (GET_COST_CODES == "True" or ENFORCE_COST_CODES == "True"):
|
|
|
|
| 526 |
cost_code_choice_drop.select(update_cost_code_dataframe_from_dropdown_select, inputs=[cost_code_choice_drop, cost_code_dataframe_base], outputs=[cost_code_dataframe])
|
| 527 |
|
| 528 |
in_doc_files.upload(fn=get_input_file_names, inputs=[in_doc_files], outputs=[doc_file_name_no_extension_textbox, doc_file_name_with_extension_textbox, doc_full_file_name_textbox, doc_file_name_textbox_list, total_pdf_page_count]).\
|
| 529 |
+
success(fn = prepare_image_or_pdf, inputs=[in_doc_files, text_extract_method_radio, latest_file_completed_text, redaction_output_summary_textbox, first_loop_state, annotate_max_pages, all_image_annotations_state, prepare_for_review_bool_false, in_fully_redacted_list_state, output_folder_textbox, input_folder_textbox, prepare_images_bool_false], outputs=[redaction_output_summary_textbox, prepared_pdf_state, images_pdf_state, annotate_max_pages, annotate_max_pages_bottom, pdf_doc_state, all_image_annotations_state, review_file_state, document_cropboxes, page_sizes, textract_output_found_checkbox, all_img_details_state, all_line_level_ocr_results_df_base, local_ocr_output_found_checkbox]).\
|
| 530 |
+
success(fn=check_for_existing_textract_file, inputs=[doc_file_name_no_extension_textbox, output_folder_textbox], outputs=[textract_output_found_checkbox]).\
|
| 531 |
+
success(fn=check_for_existing_local_ocr_file, inputs=[doc_file_name_no_extension_textbox, output_folder_textbox], outputs=[local_ocr_output_found_checkbox])
|
| 532 |
|
| 533 |
# Run redaction function
|
| 534 |
document_redact_btn.click(fn = reset_state_vars, outputs=[all_image_annotations_state, all_line_level_ocr_results_df_base, all_decision_process_table_state, comprehend_query_number, textract_metadata_textbox, annotator, output_file_list_state, log_files_output_list_state, recogniser_entity_dataframe, recogniser_entity_dataframe_base, pdf_doc_state, duplication_file_path_outputs_list_state, redaction_output_summary_textbox, is_a_textract_api_call, textract_query_number]).\
|
| 535 |
success(fn= enforce_cost_codes, inputs=[enforce_cost_code_textbox, cost_code_choice_drop, cost_code_dataframe_base]).\
|
| 536 |
+
success(fn= choose_and_run_redactor, inputs=[in_doc_files, prepared_pdf_state, images_pdf_state, in_redact_language, in_redact_entities, in_redact_comprehend_entities, text_extract_method_radio, in_allow_list_state, in_deny_list_state, in_fully_redacted_list_state, latest_file_completed_text, redaction_output_summary_textbox, output_file_list_state, log_files_output_list_state, first_loop_state, page_min, page_max, actual_time_taken_number, handwrite_signature_checkbox, textract_metadata_textbox, all_image_annotations_state, all_line_level_ocr_results_df_base, all_decision_process_table_state, pdf_doc_state, current_loop_page_number, page_break_return, pii_identification_method_drop, comprehend_query_number, max_fuzzy_spelling_mistakes_num, match_fuzzy_whole_phrase_bool, aws_access_key_textbox, aws_secret_key_textbox, annotate_max_pages, review_file_state, output_folder_textbox, document_cropboxes, page_sizes, textract_output_found_checkbox, only_extract_text_radio, duplication_file_path_outputs_list_state, latest_review_file_path, input_folder_textbox, textract_query_number, latest_ocr_file_path, all_page_line_level_ocr_results, all_page_line_level_ocr_results_with_children],
|
| 537 |
+
outputs=[redaction_output_summary_textbox, output_file, output_file_list_state, latest_file_completed_text, log_files_output, log_files_output_list_state, actual_time_taken_number, textract_metadata_textbox, pdf_doc_state, all_image_annotations_state, current_loop_page_number, page_break_return, all_line_level_ocr_results_df_base, all_decision_process_table_state, comprehend_query_number, output_review_files, annotate_max_pages, annotate_max_pages_bottom, prepared_pdf_state, images_pdf_state, review_file_state, page_sizes, duplication_file_path_outputs_list_state, in_duplicate_pages, latest_review_file_path, textract_query_number, latest_ocr_file_path, all_page_line_level_ocr_results, all_page_line_level_ocr_results_with_children], api_name="redact_doc").\
|
| 538 |
success(fn=update_annotator_object_and_filter_df, inputs=[all_image_annotations_state, page_min, recogniser_entity_dropdown, page_entity_dropdown, text_entity_dropdown, recogniser_entity_dataframe_base, annotator_zoom_number, review_file_state, page_sizes, doc_full_file_name_textbox, input_folder_textbox], outputs=[annotator, annotate_current_page, annotate_current_page_bottom, annotate_previous_page, recogniser_entity_dropdown, recogniser_entity_dataframe, recogniser_entity_dataframe_base, text_entity_dropdown, page_entity_dropdown, page_sizes, all_image_annotations_state])
|
| 539 |
|
| 540 |
# If the app has completed a batch of pages, it will rerun the redaction process until the end of all pages in the document
|
| 541 |
+
current_loop_page_number.change(fn = choose_and_run_redactor, inputs=[in_doc_files, prepared_pdf_state, images_pdf_state, in_redact_language, in_redact_entities, in_redact_comprehend_entities, text_extract_method_radio, in_allow_list_state, in_deny_list_state, in_fully_redacted_list_state, latest_file_completed_text, redaction_output_summary_textbox, output_file_list_state, log_files_output_list_state, second_loop_state, page_min, page_max, actual_time_taken_number, handwrite_signature_checkbox, textract_metadata_textbox, all_image_annotations_state, all_line_level_ocr_results_df_base, all_decision_process_table_state, pdf_doc_state, current_loop_page_number, page_break_return, pii_identification_method_drop, comprehend_query_number, max_fuzzy_spelling_mistakes_num, match_fuzzy_whole_phrase_bool, aws_access_key_textbox, aws_secret_key_textbox, annotate_max_pages, review_file_state, output_folder_textbox, document_cropboxes, page_sizes, textract_output_found_checkbox, only_extract_text_radio, duplication_file_path_outputs_list_state, latest_review_file_path, input_folder_textbox, textract_query_number, latest_ocr_file_path, all_page_line_level_ocr_results, all_page_line_level_ocr_results_with_children],
|
| 542 |
+
outputs=[redaction_output_summary_textbox, output_file, output_file_list_state, latest_file_completed_text, log_files_output, log_files_output_list_state, actual_time_taken_number, textract_metadata_textbox, pdf_doc_state, all_image_annotations_state, current_loop_page_number, page_break_return, all_line_level_ocr_results_df_base, all_decision_process_table_state, comprehend_query_number, output_review_files, annotate_max_pages, annotate_max_pages_bottom, prepared_pdf_state, images_pdf_state, review_file_state, page_sizes, duplication_file_path_outputs_list_state, in_duplicate_pages, latest_review_file_path, textract_query_number, latest_ocr_file_path, all_page_line_level_ocr_results, all_page_line_level_ocr_results_with_children]).\
|
| 543 |
success(fn=update_annotator_object_and_filter_df, inputs=[all_image_annotations_state, page_min, recogniser_entity_dropdown, page_entity_dropdown, text_entity_dropdown, recogniser_entity_dataframe_base, annotator_zoom_number, review_file_state, page_sizes, doc_full_file_name_textbox, input_folder_textbox], outputs=[annotator, annotate_current_page, annotate_current_page_bottom, annotate_previous_page, recogniser_entity_dropdown, recogniser_entity_dataframe, recogniser_entity_dataframe_base, text_entity_dropdown, page_entity_dropdown, page_sizes, all_image_annotations_state])
|
| 544 |
|
| 545 |
# If a file has been completed, the function will continue onto the next document
|
| 546 |
+
latest_file_completed_text.change(fn = choose_and_run_redactor, inputs=[in_doc_files, prepared_pdf_state, images_pdf_state, in_redact_language, in_redact_entities, in_redact_comprehend_entities, text_extract_method_radio, in_allow_list_state, in_deny_list_state, in_fully_redacted_list_state, latest_file_completed_text, redaction_output_summary_textbox, output_file_list_state, log_files_output_list_state, second_loop_state, page_min, page_max, actual_time_taken_number, handwrite_signature_checkbox, textract_metadata_textbox, all_image_annotations_state, all_line_level_ocr_results_df_base, all_decision_process_table_state, pdf_doc_state, current_loop_page_number, page_break_return, pii_identification_method_drop, comprehend_query_number, max_fuzzy_spelling_mistakes_num, match_fuzzy_whole_phrase_bool, aws_access_key_textbox, aws_secret_key_textbox, annotate_max_pages, review_file_state, output_folder_textbox, document_cropboxes, page_sizes, textract_output_found_checkbox, only_extract_text_radio, duplication_file_path_outputs_list_state, latest_review_file_path, input_folder_textbox, textract_query_number, latest_ocr_file_path, all_page_line_level_ocr_results, all_page_line_level_ocr_results_with_children],
|
| 547 |
+
outputs=[redaction_output_summary_textbox, output_file, output_file_list_state, latest_file_completed_text, log_files_output, log_files_output_list_state, actual_time_taken_number, textract_metadata_textbox, pdf_doc_state, all_image_annotations_state, current_loop_page_number, page_break_return, all_line_level_ocr_results_df_base, all_decision_process_table_state, comprehend_query_number, output_review_files, annotate_max_pages, annotate_max_pages_bottom, prepared_pdf_state, images_pdf_state, review_file_state, page_sizes, duplication_file_path_outputs_list_state, in_duplicate_pages, latest_review_file_path, textract_query_number, latest_ocr_file_path, all_page_line_level_ocr_results, all_page_line_level_ocr_results_with_children]).\
|
| 548 |
success(fn=update_annotator_object_and_filter_df, inputs=[all_image_annotations_state, page_min, recogniser_entity_dropdown, page_entity_dropdown, text_entity_dropdown, recogniser_entity_dataframe_base, annotator_zoom_number, review_file_state, page_sizes, doc_full_file_name_textbox, input_folder_textbox], outputs=[annotator, annotate_current_page, annotate_current_page_bottom, annotate_previous_page, recogniser_entity_dropdown, recogniser_entity_dataframe, recogniser_entity_dataframe_base, text_entity_dropdown, page_entity_dropdown, page_sizes, all_image_annotations_state]).\
|
| 549 |
success(fn=check_for_existing_textract_file, inputs=[doc_file_name_no_extension_textbox, output_folder_textbox], outputs=[textract_output_found_checkbox]).\
|
| 550 |
+
success(fn=check_for_existing_local_ocr_file, inputs=[doc_file_name_no_extension_textbox, output_folder_textbox], outputs=[local_ocr_output_found_checkbox]).\
|
| 551 |
+
success(fn=reveal_feedback_buttons, outputs=[pdf_feedback_radio, pdf_further_details_text, pdf_submit_feedback_btn, pdf_feedback_title]).\
|
| 552 |
+
success(fn = reset_aws_call_vars, outputs=[comprehend_query_number, textract_query_number])
|
| 553 |
|
| 554 |
# If the line level ocr results are changed by load in by user or by a new redaction task, replace the ocr results displayed in the table
|
| 555 |
all_line_level_ocr_results_df_base.change(reset_ocr_base_dataframe, inputs=[all_line_level_ocr_results_df_base], outputs=[all_line_level_ocr_results_df])
|
|
|
|
| 567 |
convert_textract_outputs_to_ocr_results.click(fn=check_for_existing_textract_file, inputs=[doc_file_name_no_extension_textbox, output_folder_textbox], outputs=[textract_output_found_checkbox]).\
|
| 568 |
success(fn= check_textract_outputs_exist, inputs=[textract_output_found_checkbox]).\
|
| 569 |
success(fn = reset_state_vars, outputs=[all_image_annotations_state, all_line_level_ocr_results_df_base, all_decision_process_table_state, comprehend_query_number, textract_metadata_textbox, annotator, output_file_list_state, log_files_output_list_state, recogniser_entity_dataframe, recogniser_entity_dataframe_base, pdf_doc_state, duplication_file_path_outputs_list_state, redaction_output_summary_textbox, is_a_textract_api_call]).\
|
| 570 |
+
success(fn= choose_and_run_redactor, inputs=[in_doc_files, prepared_pdf_state, images_pdf_state, in_redact_language, in_redact_entities, in_redact_comprehend_entities, textract_only_method_drop, in_allow_list_state, in_deny_list_state, in_fully_redacted_list_state, latest_file_completed_text, redaction_output_summary_textbox, output_file_list_state, log_files_output_list_state, first_loop_state, page_min, page_max, actual_time_taken_number, handwrite_signature_checkbox, textract_metadata_textbox, all_image_annotations_state, all_line_level_ocr_results_df_base, all_decision_process_table_state, pdf_doc_state, current_loop_page_number, page_break_return, no_redaction_method_drop, comprehend_query_number, max_fuzzy_spelling_mistakes_num, match_fuzzy_whole_phrase_bool, aws_access_key_textbox, aws_secret_key_textbox, annotate_max_pages, review_file_state, output_folder_textbox, document_cropboxes, page_sizes, textract_output_found_checkbox, only_extract_text_radio, duplication_file_path_outputs_list_state, latest_review_file_path, input_folder_textbox, textract_query_number, latest_ocr_file_path, all_page_line_level_ocr_results, all_page_line_level_ocr_results_with_children],
|
| 571 |
+
outputs=[redaction_output_summary_textbox, output_file, output_file_list_state, latest_file_completed_text, log_files_output, log_files_output_list_state, actual_time_taken_number, textract_metadata_textbox, pdf_doc_state, all_image_annotations_state, current_loop_page_number, page_break_return, all_line_level_ocr_results_df_base, all_decision_process_table_state, comprehend_query_number, output_review_files, annotate_max_pages, annotate_max_pages_bottom, prepared_pdf_state, images_pdf_state, review_file_state, page_sizes, duplication_file_path_outputs_list_state, in_duplicate_pages, latest_review_file_path, textract_query_number, latest_ocr_file_path, all_page_line_level_ocr_results, all_page_line_level_ocr_results_with_children])
|
| 572 |
|
| 573 |
###
|
| 574 |
# REVIEW PDF REDACTIONS
|
|
|
|
| 577 |
# Upload previous files for modifying redactions
|
| 578 |
upload_previous_review_file_btn.click(fn=reset_review_vars, inputs=None, outputs=[recogniser_entity_dataframe, recogniser_entity_dataframe_base]).\
|
| 579 |
success(fn=get_input_file_names, inputs=[output_review_files], outputs=[doc_file_name_no_extension_textbox, doc_file_name_with_extension_textbox, doc_full_file_name_textbox, doc_file_name_textbox_list, total_pdf_page_count]).\
|
| 580 |
+
success(fn = prepare_image_or_pdf, inputs=[output_review_files, text_extract_method_radio, latest_file_completed_text, redaction_output_summary_textbox, second_loop_state, annotate_max_pages, all_image_annotations_state, prepare_for_review_bool, in_fully_redacted_list_state, output_folder_textbox, input_folder_textbox, prepare_images_bool_false], outputs=[redaction_output_summary_textbox, prepared_pdf_state, images_pdf_state, annotate_max_pages, annotate_max_pages_bottom, pdf_doc_state, all_image_annotations_state, review_file_state, document_cropboxes, page_sizes, textract_output_found_checkbox, all_img_details_state, all_line_level_ocr_results_df_base, local_ocr_output_found_checkbox], api_name="prepare_doc").\
|
| 581 |
success(update_annotator_object_and_filter_df, inputs=[all_image_annotations_state, annotate_current_page, recogniser_entity_dropdown, page_entity_dropdown, text_entity_dropdown, recogniser_entity_dataframe_base, annotator_zoom_number, review_file_state, page_sizes, doc_full_file_name_textbox, input_folder_textbox], outputs = [annotator, annotate_current_page, annotate_current_page_bottom, annotate_previous_page, recogniser_entity_dropdown, recogniser_entity_dataframe, recogniser_entity_dataframe_base, text_entity_dropdown, page_entity_dropdown, page_sizes, all_image_annotations_state])
|
| 582 |
|
| 583 |
# Page number controls
|
|
|
|
| 639 |
|
| 640 |
# Convert review file to xfdf Adobe format
|
| 641 |
convert_review_file_to_adobe_btn.click(fn=get_input_file_names, inputs=[output_review_files], outputs=[doc_file_name_no_extension_textbox, doc_file_name_with_extension_textbox, doc_full_file_name_textbox, doc_file_name_textbox_list, total_pdf_page_count]).\
|
| 642 |
+
success(fn = prepare_image_or_pdf, inputs=[output_review_files, text_extract_method_radio, latest_file_completed_text, redaction_output_summary_textbox, second_loop_state, annotate_max_pages, all_image_annotations_state, prepare_for_review_bool, in_fully_redacted_list_state, output_folder_textbox, input_folder_textbox, prepare_images_bool_false], outputs=[redaction_output_summary_textbox, prepared_pdf_state, images_pdf_state, annotate_max_pages, annotate_max_pages_bottom, pdf_doc_state, all_image_annotations_state, review_file_state, document_cropboxes, page_sizes, textract_output_found_checkbox, all_img_details_state, all_line_level_ocr_results_df_placeholder, local_ocr_output_found_checkbox]).\
|
| 643 |
success(convert_df_to_xfdf, inputs=[output_review_files, pdf_doc_state, images_pdf_state, output_folder_textbox, document_cropboxes, page_sizes], outputs=[adobe_review_files_out])
|
| 644 |
|
| 645 |
# Convert xfdf Adobe file back to review_file.csv
|
| 646 |
convert_adobe_to_review_file_btn.click(fn=get_input_file_names, inputs=[adobe_review_files_out], outputs=[doc_file_name_no_extension_textbox, doc_file_name_with_extension_textbox, doc_full_file_name_textbox, doc_file_name_textbox_list, total_pdf_page_count]).\
|
| 647 |
+
success(fn = prepare_image_or_pdf, inputs=[adobe_review_files_out, text_extract_method_radio, latest_file_completed_text, redaction_output_summary_textbox, second_loop_state, annotate_max_pages, all_image_annotations_state, prepare_for_review_bool, in_fully_redacted_list_state, output_folder_textbox, input_folder_textbox, prepare_images_bool_false], outputs=[redaction_output_summary_textbox, prepared_pdf_state, images_pdf_state, annotate_max_pages, annotate_max_pages_bottom, pdf_doc_state, all_image_annotations_state, review_file_state, document_cropboxes, page_sizes, textract_output_found_checkbox, all_img_details_state, all_line_level_ocr_results_df_placeholder, local_ocr_output_found_checkbox]).\
|
| 648 |
success(fn=convert_xfdf_to_dataframe, inputs=[adobe_review_files_out, pdf_doc_state, images_pdf_state, output_folder_textbox], outputs=[output_review_files], scroll_to_output=True)
|
| 649 |
|
| 650 |
###
|
|
|
|
| 653 |
in_data_files.upload(fn=put_columns_in_df, inputs=[in_data_files], outputs=[in_colnames, in_excel_sheets]).\
|
| 654 |
success(fn=get_input_file_names, inputs=[in_data_files], outputs=[data_file_name_no_extension_textbox, data_file_name_with_extension_textbox, data_full_file_name_textbox, data_file_name_textbox_list, total_pdf_page_count])
|
| 655 |
|
| 656 |
+
tabular_data_redact_btn.click(reset_data_vars, outputs=[actual_time_taken_number, log_files_output_list_state, comprehend_query_number]).\
|
| 657 |
+
success(fn=anonymise_data_files, inputs=[in_data_files, in_text, anon_strat, in_colnames, in_redact_language, in_redact_entities, in_allow_list_state, text_tabular_files_done, text_output_summary, text_output_file_list_state, log_files_output_list_state, in_excel_sheets, first_loop_state, output_folder_textbox, in_deny_list_state, max_fuzzy_spelling_mistakes_num, pii_identification_method_drop_tabular, in_redact_comprehend_entities, comprehend_query_number, aws_access_key_textbox, aws_secret_key_textbox, actual_time_taken_number], outputs=[text_output_summary, text_output_file, text_output_file_list_state, text_tabular_files_done, log_files_output, log_files_output_list_state, actual_time_taken_number], api_name="redact_data").\
|
| 658 |
+
success(fn = reveal_feedback_buttons, outputs=[data_feedback_radio, data_further_details_text, data_submit_feedback_btn, data_feedback_title])
|
| 659 |
|
| 660 |
+
# Currently only supports redacting one data file at a time
|
| 661 |
# If the output file count text box changes, keep going with redacting each data file until done
|
| 662 |
+
# text_tabular_files_done.change(fn=anonymise_data_files, inputs=[in_data_files, in_text, anon_strat, in_colnames, in_redact_language, in_redact_entities, in_allow_list_state, text_tabular_files_done, text_output_summary, text_output_file_list_state, log_files_output_list_state, in_excel_sheets, second_loop_state, output_folder_textbox, in_deny_list_state, max_fuzzy_spelling_mistakes_num, pii_identification_method_drop_tabular, in_redact_comprehend_entities, comprehend_query_number, aws_access_key_textbox, aws_secret_key_textbox, actual_time_taken_number], outputs=[text_output_summary, text_output_file, text_output_file_list_state, text_tabular_files_done, log_files_output, log_files_output_list_state, actual_time_taken_number]).\
|
| 663 |
+
# success(fn = reveal_feedback_buttons, outputs=[data_feedback_radio, data_further_details_text, data_submit_feedback_btn, data_feedback_title])
|
| 664 |
|
| 665 |
###
|
| 666 |
# IDENTIFY DUPLICATE PAGES
|
|
|
|
| 737 |
success(fn = upload_log_file_to_s3, inputs=[access_logs_state, access_s3_logs_loc_state], outputs=[s3_logs_output_textbox])
|
| 738 |
|
| 739 |
### FEEDBACK LOGS
|
| 740 |
+
if DISPLAY_FILE_NAMES_IN_LOGS == 'True':
|
| 741 |
+
# User submitted feedback for pdf redactions
|
| 742 |
+
pdf_callback = CSVLogger_custom(dataset_file_name=log_file_name)
|
| 743 |
+
pdf_callback.setup([pdf_feedback_radio, pdf_further_details_text, doc_file_name_no_extension_textbox], FEEDBACK_LOGS_FOLDER)
|
| 744 |
+
pdf_submit_feedback_btn.click(lambda *args: pdf_callback.flag(list(args), save_to_csv=SAVE_LOGS_TO_CSV, save_to_dynamodb=SAVE_LOGS_TO_DYNAMODB, dynamodb_table_name=FEEDBACK_LOG_DYNAMODB_TABLE_NAME, dynamodb_headers=DYNAMODB_FEEDBACK_LOG_HEADERS, replacement_headers=CSV_FEEDBACK_LOG_HEADERS), [pdf_feedback_radio, pdf_further_details_text, doc_file_name_no_extension_textbox], None, preprocess=False).\
|
| 745 |
+
success(fn = upload_log_file_to_s3, inputs=[feedback_logs_state, feedback_s3_logs_loc_state], outputs=[pdf_further_details_text])
|
| 746 |
+
|
| 747 |
+
# User submitted feedback for data redactions
|
| 748 |
+
data_callback = CSVLogger_custom(dataset_file_name=log_file_name)
|
| 749 |
+
data_callback.setup([data_feedback_radio, data_further_details_text, data_full_file_name_textbox], FEEDBACK_LOGS_FOLDER)
|
| 750 |
+
data_submit_feedback_btn.click(lambda *args: data_callback.flag(list(args), save_to_csv=SAVE_LOGS_TO_CSV, save_to_dynamodb=SAVE_LOGS_TO_DYNAMODB, dynamodb_table_name=FEEDBACK_LOG_DYNAMODB_TABLE_NAME, dynamodb_headers=DYNAMODB_FEEDBACK_LOG_HEADERS, replacement_headers=CSV_FEEDBACK_LOG_HEADERS), [data_feedback_radio, data_further_details_text, data_full_file_name_textbox], None, preprocess=False).\
|
| 751 |
+
success(fn = upload_log_file_to_s3, inputs=[feedback_logs_state, feedback_s3_logs_loc_state], outputs=[data_further_details_text])
|
| 752 |
+
else:
|
| 753 |
+
# User submitted feedback for pdf redactions
|
| 754 |
+
pdf_callback = CSVLogger_custom(dataset_file_name=log_file_name)
|
| 755 |
+
pdf_callback.setup([pdf_feedback_radio, pdf_further_details_text, doc_file_name_no_extension_textbox], FEEDBACK_LOGS_FOLDER)
|
| 756 |
+
pdf_submit_feedback_btn.click(lambda *args: pdf_callback.flag(list(args), save_to_csv=SAVE_LOGS_TO_CSV, save_to_dynamodb=SAVE_LOGS_TO_DYNAMODB, dynamodb_table_name=FEEDBACK_LOG_DYNAMODB_TABLE_NAME, dynamodb_headers=DYNAMODB_FEEDBACK_LOG_HEADERS, replacement_headers=CSV_FEEDBACK_LOG_HEADERS), [pdf_feedback_radio, pdf_further_details_text, placeholder_doc_file_name_no_extension_textbox_for_logs], None, preprocess=False).\
|
| 757 |
+
success(fn = upload_log_file_to_s3, inputs=[feedback_logs_state, feedback_s3_logs_loc_state], outputs=[pdf_further_details_text])
|
| 758 |
+
|
| 759 |
+
# User submitted feedback for data redactions
|
| 760 |
+
data_callback = CSVLogger_custom(dataset_file_name=log_file_name)
|
| 761 |
+
data_callback.setup([data_feedback_radio, data_further_details_text, data_full_file_name_textbox], FEEDBACK_LOGS_FOLDER)
|
| 762 |
+
data_submit_feedback_btn.click(lambda *args: data_callback.flag(list(args), save_to_csv=SAVE_LOGS_TO_CSV, save_to_dynamodb=SAVE_LOGS_TO_DYNAMODB, dynamodb_table_name=FEEDBACK_LOG_DYNAMODB_TABLE_NAME, dynamodb_headers=DYNAMODB_FEEDBACK_LOG_HEADERS, replacement_headers=CSV_FEEDBACK_LOG_HEADERS), [data_feedback_radio, data_further_details_text, placeholder_data_file_name_no_extension_textbox_for_logs], None, preprocess=False).\
|
| 763 |
+
success(fn = upload_log_file_to_s3, inputs=[feedback_logs_state, feedback_s3_logs_loc_state], outputs=[data_further_details_text])
|
| 764 |
|
| 765 |
### USAGE LOGS
|
| 766 |
# Log processing usage - time taken for redaction queries, and also logs for queries to Textract/Comprehend
|
|
|
|
| 773 |
latest_file_completed_text.change(lambda *args: usage_callback.flag(list(args), save_to_csv=SAVE_LOGS_TO_CSV, save_to_dynamodb=SAVE_LOGS_TO_DYNAMODB, dynamodb_table_name=USAGE_LOG_DYNAMODB_TABLE_NAME, dynamodb_headers=DYNAMODB_USAGE_LOG_HEADERS, replacement_headers=CSV_USAGE_LOG_HEADERS), [session_hash_textbox, doc_file_name_no_extension_textbox, data_full_file_name_textbox, total_pdf_page_count, actual_time_taken_number, textract_query_number, pii_identification_method_drop, comprehend_query_number, cost_code_choice_drop, handwrite_signature_checkbox, host_name_textbox, text_extract_method_radio, is_a_textract_api_call], None, preprocess=False).\
|
| 774 |
success(fn = upload_log_file_to_s3, inputs=[usage_logs_state, usage_s3_logs_loc_state], outputs=[s3_logs_output_textbox])
|
| 775 |
|
| 776 |
+
text_tabular_files_done.change(lambda *args: usage_callback.flag(list(args), save_to_csv=SAVE_LOGS_TO_CSV, save_to_dynamodb=SAVE_LOGS_TO_DYNAMODB, dynamodb_table_name=USAGE_LOG_DYNAMODB_TABLE_NAME, dynamodb_headers=DYNAMODB_USAGE_LOG_HEADERS, replacement_headers=CSV_USAGE_LOG_HEADERS), [session_hash_textbox, doc_file_name_no_extension_textbox, data_full_file_name_textbox, total_pdf_page_count, actual_time_taken_number, textract_query_number, pii_identification_method_drop_tabular, comprehend_query_number, cost_code_choice_drop, handwrite_signature_checkbox, host_name_textbox, text_extract_method_radio, is_a_textract_api_call], None, preprocess=False).\
|
| 777 |
+
success(fn = upload_log_file_to_s3, inputs=[usage_logs_state, usage_s3_logs_loc_state], outputs=[s3_logs_output_textbox])
|
| 778 |
+
|
| 779 |
successful_textract_api_call_number.change(lambda *args: usage_callback.flag(list(args), save_to_csv=SAVE_LOGS_TO_CSV, save_to_dynamodb=SAVE_LOGS_TO_DYNAMODB, dynamodb_table_name=USAGE_LOG_DYNAMODB_TABLE_NAME, dynamodb_headers=DYNAMODB_USAGE_LOG_HEADERS, replacement_headers=CSV_USAGE_LOG_HEADERS), [session_hash_textbox, doc_file_name_no_extension_textbox, data_full_file_name_textbox, total_pdf_page_count, actual_time_taken_number, textract_query_number, pii_identification_method_drop, comprehend_query_number, cost_code_choice_drop, handwrite_signature_checkbox, host_name_textbox, text_extract_method_radio, is_a_textract_api_call], None, preprocess=False).\
|
| 780 |
success(fn = upload_log_file_to_s3, inputs=[usage_logs_state, usage_s3_logs_loc_state], outputs=[s3_logs_output_textbox])
|
| 781 |
else:
|
| 782 |
+
usage_callback.setup([session_hash_textbox, blank_doc_file_name_no_extension_textbox_for_logs, blank_data_file_name_no_extension_textbox_for_logs, actual_time_taken_number, total_pdf_page_count, textract_query_number, pii_identification_method_drop, comprehend_query_number, cost_code_choice_drop, handwrite_signature_checkbox, host_name_textbox, text_extract_method_radio, is_a_textract_api_call], USAGE_LOGS_FOLDER)
|
| 783 |
+
|
| 784 |
+
latest_file_completed_text.change(lambda *args: usage_callback.flag(list(args), save_to_csv=SAVE_LOGS_TO_CSV, save_to_dynamodb=SAVE_LOGS_TO_DYNAMODB, dynamodb_table_name=USAGE_LOG_DYNAMODB_TABLE_NAME, dynamodb_headers=DYNAMODB_USAGE_LOG_HEADERS, replacement_headers=CSV_USAGE_LOG_HEADERS), [session_hash_textbox, placeholder_doc_file_name_no_extension_textbox_for_logs, blank_data_file_name_no_extension_textbox_for_logs, actual_time_taken_number, total_pdf_page_count, textract_query_number, pii_identification_method_drop, comprehend_query_number, cost_code_choice_drop, handwrite_signature_checkbox, host_name_textbox, text_extract_method_radio, is_a_textract_api_call], None, preprocess=False).\
|
| 785 |
+
success(fn = upload_log_file_to_s3, inputs=[usage_logs_state, usage_s3_logs_loc_state], outputs=[s3_logs_output_textbox])
|
| 786 |
|
| 787 |
+
text_tabular_files_done.change(lambda *args: usage_callback.flag(list(args), save_to_csv=SAVE_LOGS_TO_CSV, save_to_dynamodb=SAVE_LOGS_TO_DYNAMODB, dynamodb_table_name=USAGE_LOG_DYNAMODB_TABLE_NAME, dynamodb_headers=DYNAMODB_USAGE_LOG_HEADERS, replacement_headers=CSV_USAGE_LOG_HEADERS), [session_hash_textbox, blank_doc_file_name_no_extension_textbox_for_logs, placeholder_data_file_name_no_extension_textbox_for_logs, actual_time_taken_number, total_pdf_page_count, textract_query_number, pii_identification_method_drop_tabular, comprehend_query_number, cost_code_choice_drop, handwrite_signature_checkbox, host_name_textbox, text_extract_method_radio, is_a_textract_api_call], None, preprocess=False).\
|
| 788 |
success(fn = upload_log_file_to_s3, inputs=[usage_logs_state, usage_s3_logs_loc_state], outputs=[s3_logs_output_textbox])
|
| 789 |
|
| 790 |
+
successful_textract_api_call_number.change(lambda *args: usage_callback.flag(list(args), save_to_csv=SAVE_LOGS_TO_CSV, save_to_dynamodb=SAVE_LOGS_TO_DYNAMODB, dynamodb_table_name=USAGE_LOG_DYNAMODB_TABLE_NAME, dynamodb_headers=DYNAMODB_USAGE_LOG_HEADERS, replacement_headers=CSV_USAGE_LOG_HEADERS), [session_hash_textbox, placeholder_doc_file_name_no_extension_textbox_for_logs, blank_data_file_name_no_extension_textbox_for_logs, actual_time_taken_number, total_pdf_page_count, textract_query_number, pii_identification_method_drop, comprehend_query_number, cost_code_choice_drop, handwrite_signature_checkbox, host_name_textbox, text_extract_method_radio, is_a_textract_api_call], None, preprocess=False).\
|
| 791 |
success(fn = upload_log_file_to_s3, inputs=[usage_logs_state, usage_s3_logs_loc_state], outputs=[s3_logs_output_textbox])
|
| 792 |
|
| 793 |
if __name__ == "__main__":
|
tools/aws_textract.py
CHANGED
|
@@ -108,6 +108,174 @@ def convert_pike_pdf_page_to_bytes(pdf:object, page_num:int):
|
|
| 108 |
|
| 109 |
return pdf_bytes
|
| 110 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 111 |
def json_to_ocrresult(json_data:dict, page_width:float, page_height:float, page_no:int):
|
| 112 |
'''
|
| 113 |
Convert the json response from textract to the OCRResult format used elsewhere in the code. Looks for lines, words, and signatures. Handwriting and signatures are set aside especially for later in case the user wants to override the default behaviour and redact all handwriting/signatures.
|
|
@@ -118,7 +286,7 @@ def json_to_ocrresult(json_data:dict, page_width:float, page_height:float, page_
|
|
| 118 |
handwriting_recogniser_results = []
|
| 119 |
signatures = []
|
| 120 |
handwriting = []
|
| 121 |
-
|
| 122 |
text_block={}
|
| 123 |
|
| 124 |
i = 1
|
|
@@ -141,7 +309,7 @@ def json_to_ocrresult(json_data:dict, page_width:float, page_height:float, page_
|
|
| 141 |
is_signature = False
|
| 142 |
is_handwriting = False
|
| 143 |
|
| 144 |
-
for text_block in text_blocks:
|
| 145 |
|
| 146 |
if (text_block['BlockType'] == 'LINE') | (text_block['BlockType'] == 'SIGNATURE'): # (text_block['BlockType'] == 'WORD') |
|
| 147 |
|
|
@@ -244,36 +412,53 @@ def json_to_ocrresult(json_data:dict, page_width:float, page_height:float, page_
|
|
| 244 |
'text': line_text,
|
| 245 |
'bounding_box': (line_left, line_top, line_right, line_bottom)
|
| 246 |
}]
|
| 247 |
-
|
| 248 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 249 |
"line": i,
|
| 250 |
'text': line_text,
|
| 251 |
'bounding_box': (line_left, line_top, line_right, line_bottom),
|
| 252 |
-
'words': words
|
| 253 |
-
|
|
|
|
| 254 |
|
| 255 |
# Create OCRResult with absolute coordinates
|
| 256 |
ocr_result = OCRResult(line_text, line_left, line_top, width_abs, height_abs)
|
| 257 |
all_ocr_results.append(ocr_result)
|
| 258 |
|
| 259 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 260 |
|
| 261 |
-
|
| 262 |
-
|
| 263 |
-
|
| 264 |
-
signature_or_handwriting_recogniser_results.append(recogniser_result)
|
| 265 |
|
| 266 |
-
|
| 267 |
-
if recogniser_result not in signature_recogniser_results:
|
| 268 |
-
signature_recogniser_results.append(recogniser_result)
|
| 269 |
|
| 270 |
-
|
| 271 |
-
|
| 272 |
-
|
| 273 |
|
| 274 |
-
|
| 275 |
|
| 276 |
-
return all_ocr_results, signature_or_handwriting_recogniser_results, signature_recogniser_results, handwriting_recogniser_results, ocr_results_with_children
|
| 277 |
|
| 278 |
def load_and_convert_textract_json(textract_json_file_path:str, log_files_output_paths:str, page_sizes_df:pd.DataFrame):
|
| 279 |
"""
|
|
@@ -315,7 +500,7 @@ def load_and_convert_textract_json(textract_json_file_path:str, log_files_output
|
|
| 315 |
return {}, True, log_files_output_paths # Conversion failed
|
| 316 |
else:
|
| 317 |
print("Invalid Textract JSON format: 'Blocks' missing.")
|
| 318 |
-
print("textract data:", textract_data)
|
| 319 |
return {}, True, log_files_output_paths # Return empty data if JSON is not recognized
|
| 320 |
|
| 321 |
def restructure_textract_output(textract_output: dict, page_sizes_df:pd.DataFrame):
|
|
|
|
| 108 |
|
| 109 |
return pdf_bytes
|
| 110 |
|
| 111 |
+
# def json_to_ocrresult(json_data:dict, page_width:float, page_height:float, page_no:int):
|
| 112 |
+
# '''
|
| 113 |
+
# Convert the json response from textract to the OCRResult format used elsewhere in the code. Looks for lines, words, and signatures. Handwriting and signatures are set aside especially for later in case the user wants to override the default behaviour and redact all handwriting/signatures.
|
| 114 |
+
# '''
|
| 115 |
+
# all_ocr_results = []
|
| 116 |
+
# signature_or_handwriting_recogniser_results = []
|
| 117 |
+
# signature_recogniser_results = []
|
| 118 |
+
# handwriting_recogniser_results = []
|
| 119 |
+
# signatures = []
|
| 120 |
+
# handwriting = []
|
| 121 |
+
# ocr_results_with_words = {}
|
| 122 |
+
# text_block={}
|
| 123 |
+
|
| 124 |
+
# i = 1
|
| 125 |
+
|
| 126 |
+
# # Assuming json_data is structured as a dictionary with a "pages" key
|
| 127 |
+
# #if "pages" in json_data:
|
| 128 |
+
# # Find the specific page data
|
| 129 |
+
# page_json_data = json_data #next((page for page in json_data["pages"] if page["page_no"] == page_no), None)
|
| 130 |
+
|
| 131 |
+
# #print("page_json_data:", page_json_data)
|
| 132 |
+
|
| 133 |
+
# if "Blocks" in page_json_data:
|
| 134 |
+
# # Access the data for the specific page
|
| 135 |
+
# text_blocks = page_json_data["Blocks"] # Access the Blocks within the page data
|
| 136 |
+
# # This is a new page
|
| 137 |
+
# elif "page_no" in page_json_data:
|
| 138 |
+
# text_blocks = page_json_data["data"]["Blocks"]
|
| 139 |
+
# else: text_blocks = []
|
| 140 |
+
|
| 141 |
+
# is_signature = False
|
| 142 |
+
# is_handwriting = False
|
| 143 |
+
|
| 144 |
+
# for text_block in text_blocks:
|
| 145 |
+
|
| 146 |
+
# if (text_block['BlockType'] == 'LINE') | (text_block['BlockType'] == 'SIGNATURE'): # (text_block['BlockType'] == 'WORD') |
|
| 147 |
+
|
| 148 |
+
# # Extract text and bounding box for the line
|
| 149 |
+
# line_bbox = text_block["Geometry"]["BoundingBox"]
|
| 150 |
+
# line_left = int(line_bbox["Left"] * page_width)
|
| 151 |
+
# line_top = int(line_bbox["Top"] * page_height)
|
| 152 |
+
# line_right = int((line_bbox["Left"] + line_bbox["Width"]) * page_width)
|
| 153 |
+
# line_bottom = int((line_bbox["Top"] + line_bbox["Height"]) * page_height)
|
| 154 |
+
|
| 155 |
+
# width_abs = int(line_bbox["Width"] * page_width)
|
| 156 |
+
# height_abs = int(line_bbox["Height"] * page_height)
|
| 157 |
+
|
| 158 |
+
# if text_block['BlockType'] == 'LINE':
|
| 159 |
+
|
| 160 |
+
# # Extract text and bounding box for the line
|
| 161 |
+
# line_text = text_block.get('Text', '')
|
| 162 |
+
# words = []
|
| 163 |
+
# current_line_handwriting_results = [] # Track handwriting results for this line
|
| 164 |
+
|
| 165 |
+
# if 'Relationships' in text_block:
|
| 166 |
+
# for relationship in text_block['Relationships']:
|
| 167 |
+
# if relationship['Type'] == 'CHILD':
|
| 168 |
+
# for child_id in relationship['Ids']:
|
| 169 |
+
# child_block = next((block for block in text_blocks if block['Id'] == child_id), None)
|
| 170 |
+
# if child_block and child_block['BlockType'] == 'WORD':
|
| 171 |
+
# word_text = child_block.get('Text', '')
|
| 172 |
+
# word_bbox = child_block["Geometry"]["BoundingBox"]
|
| 173 |
+
# confidence = child_block.get('Confidence','')
|
| 174 |
+
# word_left = int(word_bbox["Left"] * page_width)
|
| 175 |
+
# word_top = int(word_bbox["Top"] * page_height)
|
| 176 |
+
# word_right = int((word_bbox["Left"] + word_bbox["Width"]) * page_width)
|
| 177 |
+
# word_bottom = int((word_bbox["Top"] + word_bbox["Height"]) * page_height)
|
| 178 |
+
|
| 179 |
+
# # Extract BoundingBox details
|
| 180 |
+
# word_width = word_bbox["Width"]
|
| 181 |
+
# word_height = word_bbox["Height"]
|
| 182 |
+
|
| 183 |
+
# # Convert proportional coordinates to absolute coordinates
|
| 184 |
+
# word_width_abs = int(word_width * page_width)
|
| 185 |
+
# word_height_abs = int(word_height * page_height)
|
| 186 |
+
|
| 187 |
+
# words.append({
|
| 188 |
+
# 'text': word_text,
|
| 189 |
+
# 'bounding_box': (word_left, word_top, word_right, word_bottom)
|
| 190 |
+
# })
|
| 191 |
+
# # Check for handwriting
|
| 192 |
+
# text_type = child_block.get("TextType", '')
|
| 193 |
+
|
| 194 |
+
# if text_type == "HANDWRITING":
|
| 195 |
+
# is_handwriting = True
|
| 196 |
+
# entity_name = "HANDWRITING"
|
| 197 |
+
# word_end = len(word_text)
|
| 198 |
+
|
| 199 |
+
# recogniser_result = CustomImageRecognizerResult(
|
| 200 |
+
# entity_type=entity_name,
|
| 201 |
+
# text=word_text,
|
| 202 |
+
# score=confidence,
|
| 203 |
+
# start=0,
|
| 204 |
+
# end=word_end,
|
| 205 |
+
# left=word_left,
|
| 206 |
+
# top=word_top,
|
| 207 |
+
# width=word_width_abs,
|
| 208 |
+
# height=word_height_abs
|
| 209 |
+
# )
|
| 210 |
+
|
| 211 |
+
# # Add to handwriting collections immediately
|
| 212 |
+
# handwriting.append(recogniser_result)
|
| 213 |
+
# handwriting_recogniser_results.append(recogniser_result)
|
| 214 |
+
# signature_or_handwriting_recogniser_results.append(recogniser_result)
|
| 215 |
+
# current_line_handwriting_results.append(recogniser_result)
|
| 216 |
+
|
| 217 |
+
# # If handwriting or signature, add to bounding box
|
| 218 |
+
|
| 219 |
+
# elif (text_block['BlockType'] == 'SIGNATURE'):
|
| 220 |
+
# line_text = "SIGNATURE"
|
| 221 |
+
# is_signature = True
|
| 222 |
+
# entity_name = "SIGNATURE"
|
| 223 |
+
# confidence = text_block.get('Confidence', 0)
|
| 224 |
+
# word_end = len(line_text)
|
| 225 |
+
|
| 226 |
+
# recogniser_result = CustomImageRecognizerResult(
|
| 227 |
+
# entity_type=entity_name,
|
| 228 |
+
# text=line_text,
|
| 229 |
+
# score=confidence,
|
| 230 |
+
# start=0,
|
| 231 |
+
# end=word_end,
|
| 232 |
+
# left=line_left,
|
| 233 |
+
# top=line_top,
|
| 234 |
+
# width=width_abs,
|
| 235 |
+
# height=height_abs
|
| 236 |
+
# )
|
| 237 |
+
|
| 238 |
+
# # Add to signature collections immediately
|
| 239 |
+
# signatures.append(recogniser_result)
|
| 240 |
+
# signature_recogniser_results.append(recogniser_result)
|
| 241 |
+
# signature_or_handwriting_recogniser_results.append(recogniser_result)
|
| 242 |
+
|
| 243 |
+
# words = [{
|
| 244 |
+
# 'text': line_text,
|
| 245 |
+
# 'bounding_box': (line_left, line_top, line_right, line_bottom)
|
| 246 |
+
# }]
|
| 247 |
+
|
| 248 |
+
# ocr_results_with_words["text_line_" + str(i)] = {
|
| 249 |
+
# "line": i,
|
| 250 |
+
# 'text': line_text,
|
| 251 |
+
# 'bounding_box': (line_left, line_top, line_right, line_bottom),
|
| 252 |
+
# 'words': words
|
| 253 |
+
# }
|
| 254 |
+
|
| 255 |
+
# # Create OCRResult with absolute coordinates
|
| 256 |
+
# ocr_result = OCRResult(line_text, line_left, line_top, width_abs, height_abs)
|
| 257 |
+
# all_ocr_results.append(ocr_result)
|
| 258 |
+
|
| 259 |
+
# is_signature_or_handwriting = is_signature | is_handwriting
|
| 260 |
+
|
| 261 |
+
# # If it is signature or handwriting, will overwrite the default behaviour of the PII analyser
|
| 262 |
+
# if is_signature_or_handwriting:
|
| 263 |
+
# if recogniser_result not in signature_or_handwriting_recogniser_results:
|
| 264 |
+
# signature_or_handwriting_recogniser_results.append(recogniser_result)
|
| 265 |
+
|
| 266 |
+
# if is_signature:
|
| 267 |
+
# if recogniser_result not in signature_recogniser_results:
|
| 268 |
+
# signature_recogniser_results.append(recogniser_result)
|
| 269 |
+
|
| 270 |
+
# if is_handwriting:
|
| 271 |
+
# if recogniser_result not in handwriting_recogniser_results:
|
| 272 |
+
# handwriting_recogniser_results.append(recogniser_result)
|
| 273 |
+
|
| 274 |
+
# i += 1
|
| 275 |
+
|
| 276 |
+
# return all_ocr_results, signature_or_handwriting_recogniser_results, signature_recogniser_results, handwriting_recogniser_results, ocr_results_with_words
|
| 277 |
+
|
| 278 |
+
|
| 279 |
def json_to_ocrresult(json_data:dict, page_width:float, page_height:float, page_no:int):
|
| 280 |
'''
|
| 281 |
Convert the json response from textract to the OCRResult format used elsewhere in the code. Looks for lines, words, and signatures. Handwriting and signatures are set aside especially for later in case the user wants to override the default behaviour and redact all handwriting/signatures.
|
|
|
|
| 286 |
handwriting_recogniser_results = []
|
| 287 |
signatures = []
|
| 288 |
handwriting = []
|
| 289 |
+
ocr_results_with_words = {}
|
| 290 |
text_block={}
|
| 291 |
|
| 292 |
i = 1
|
|
|
|
| 309 |
is_signature = False
|
| 310 |
is_handwriting = False
|
| 311 |
|
| 312 |
+
for text_block in text_blocks:
|
| 313 |
|
| 314 |
if (text_block['BlockType'] == 'LINE') | (text_block['BlockType'] == 'SIGNATURE'): # (text_block['BlockType'] == 'WORD') |
|
| 315 |
|
|
|
|
| 412 |
'text': line_text,
|
| 413 |
'bounding_box': (line_left, line_top, line_right, line_bottom)
|
| 414 |
}]
|
| 415 |
+
else:
|
| 416 |
+
line_text = ""
|
| 417 |
+
words=[]
|
| 418 |
+
line_left = 0
|
| 419 |
+
line_top = 0
|
| 420 |
+
line_right = 0
|
| 421 |
+
line_bottom = 0
|
| 422 |
+
width_abs = 0
|
| 423 |
+
height_abs = 0
|
| 424 |
+
|
| 425 |
+
if line_text:
|
| 426 |
+
|
| 427 |
+
ocr_results_with_words["text_line_" + str(i)] = {
|
| 428 |
"line": i,
|
| 429 |
'text': line_text,
|
| 430 |
'bounding_box': (line_left, line_top, line_right, line_bottom),
|
| 431 |
+
'words': words,
|
| 432 |
+
'page': page_no
|
| 433 |
+
}
|
| 434 |
|
| 435 |
# Create OCRResult with absolute coordinates
|
| 436 |
ocr_result = OCRResult(line_text, line_left, line_top, width_abs, height_abs)
|
| 437 |
all_ocr_results.append(ocr_result)
|
| 438 |
|
| 439 |
+
is_signature_or_handwriting = is_signature | is_handwriting
|
| 440 |
+
|
| 441 |
+
# If it is signature or handwriting, will overwrite the default behaviour of the PII analyser
|
| 442 |
+
if is_signature_or_handwriting:
|
| 443 |
+
if recogniser_result not in signature_or_handwriting_recogniser_results:
|
| 444 |
+
signature_or_handwriting_recogniser_results.append(recogniser_result)
|
| 445 |
+
|
| 446 |
+
if is_signature:
|
| 447 |
+
if recogniser_result not in signature_recogniser_results:
|
| 448 |
+
signature_recogniser_results.append(recogniser_result)
|
| 449 |
|
| 450 |
+
if is_handwriting:
|
| 451 |
+
if recogniser_result not in handwriting_recogniser_results:
|
| 452 |
+
handwriting_recogniser_results.append(recogniser_result)
|
|
|
|
| 453 |
|
| 454 |
+
i += 1
|
|
|
|
|
|
|
| 455 |
|
| 456 |
+
# Add page key to the line level results
|
| 457 |
+
all_ocr_results_with_page = {"page": page_no, "results": all_ocr_results}
|
| 458 |
+
ocr_results_with_words_with_page = {"page": page_no, "results": ocr_results_with_words}
|
| 459 |
|
| 460 |
+
return all_ocr_results_with_page, signature_or_handwriting_recogniser_results, signature_recogniser_results, handwriting_recogniser_results, ocr_results_with_words_with_page
|
| 461 |
|
|
|
|
| 462 |
|
| 463 |
def load_and_convert_textract_json(textract_json_file_path:str, log_files_output_paths:str, page_sizes_df:pd.DataFrame):
|
| 464 |
"""
|
|
|
|
| 500 |
return {}, True, log_files_output_paths # Conversion failed
|
| 501 |
else:
|
| 502 |
print("Invalid Textract JSON format: 'Blocks' missing.")
|
| 503 |
+
#print("textract data:", textract_data)
|
| 504 |
return {}, True, log_files_output_paths # Return empty data if JSON is not recognized
|
| 505 |
|
| 506 |
def restructure_textract_output(textract_output: dict, page_sizes_df:pd.DataFrame):
|
tools/config.py
CHANGED
|
@@ -108,21 +108,7 @@ if AWS_SECRET_KEY: print(f'AWS_SECRET_KEY found in environment variables')
|
|
| 108 |
|
| 109 |
DOCUMENT_REDACTION_BUCKET = get_or_create_env_var('DOCUMENT_REDACTION_BUCKET', '')
|
| 110 |
|
| 111 |
-
### WHOLE DOCUMENT API OPTIONS
|
| 112 |
-
|
| 113 |
-
SHOW_WHOLE_DOCUMENT_TEXTRACT_CALL_OPTIONS = get_or_create_env_var('SHOW_WHOLE_DOCUMENT_TEXTRACT_CALL_OPTIONS', 'False') # This feature not currently implemented
|
| 114 |
-
|
| 115 |
-
TEXTRACT_WHOLE_DOCUMENT_ANALYSIS_BUCKET = get_or_create_env_var('TEXTRACT_WHOLE_DOCUMENT_ANALYSIS_BUCKET', '')
|
| 116 |
-
|
| 117 |
-
TEXTRACT_WHOLE_DOCUMENT_ANALYSIS_INPUT_SUBFOLDER = get_or_create_env_var('TEXTRACT_WHOLE_DOCUMENT_ANALYSIS_INPUT_SUBFOLDER', 'input')
|
| 118 |
|
| 119 |
-
TEXTRACT_WHOLE_DOCUMENT_ANALYSIS_OUTPUT_SUBFOLDER = get_or_create_env_var('TEXTRACT_WHOLE_DOCUMENT_ANALYSIS_OUTPUT_SUBFOLDER', 'output')
|
| 120 |
-
|
| 121 |
-
LOAD_PREVIOUS_TEXTRACT_JOBS_S3 = get_or_create_env_var('LOAD_PREVIOUS_TEXTRACT_JOBS_S3', 'False') # Whether or not to load previous Textract jobs from S3
|
| 122 |
-
|
| 123 |
-
TEXTRACT_JOBS_S3_LOC = get_or_create_env_var('TEXTRACT_JOBS_S3_LOC', 'output') # Subfolder in the DOCUMENT_REDACTION_BUCKET where the Textract jobs are stored
|
| 124 |
-
|
| 125 |
-
TEXTRACT_JOBS_LOCAL_LOC = get_or_create_env_var('TEXTRACT_JOBS_LOCAL_LOC', 'output') # Local subfolder where the Textract jobs are stored
|
| 126 |
|
| 127 |
# Custom headers e.g. if routing traffic through Cloudfront
|
| 128 |
# Retrieving or setting CUSTOM_HEADER
|
|
@@ -191,7 +177,6 @@ CSV_ACCESS_LOG_HEADERS = get_or_create_env_var('CSV_ACCESS_LOG_HEADERS', '') # I
|
|
| 191 |
CSV_FEEDBACK_LOG_HEADERS = get_or_create_env_var('CSV_FEEDBACK_LOG_HEADERS', '') # If blank, uses component labels
|
| 192 |
CSV_USAGE_LOG_HEADERS = get_or_create_env_var('CSV_USAGE_LOG_HEADERS', '["session_hash_textbox", "doc_full_file_name_textbox", "data_full_file_name_textbox", "actual_time_taken_number", "total_page_count", "textract_query_number", "pii_detection_method", "comprehend_query_number", "cost_code", "textract_handwriting_signature", "host_name_textbox", "text_extraction_method", "is_this_a_textract_api_call"]') # If blank, uses component labels
|
| 193 |
|
| 194 |
-
|
| 195 |
### DYNAMODB logs. Whether to save to DynamoDB, and the headers of the table
|
| 196 |
|
| 197 |
SAVE_LOGS_TO_DYNAMODB = get_or_create_env_var('SAVE_LOGS_TO_DYNAMODB', 'False')
|
|
@@ -260,6 +245,8 @@ S3_ALLOW_LIST_PATH = get_or_create_env_var('S3_ALLOW_LIST_PATH', '') # default_a
|
|
| 260 |
if ALLOW_LIST_PATH: OUTPUT_ALLOW_LIST_PATH = ALLOW_LIST_PATH
|
| 261 |
else: OUTPUT_ALLOW_LIST_PATH = 'config/default_allow_list.csv'
|
| 262 |
|
|
|
|
|
|
|
| 263 |
SHOW_COSTS = get_or_create_env_var('SHOW_COSTS', 'False')
|
| 264 |
|
| 265 |
GET_COST_CODES = get_or_create_env_var('GET_COST_CODES', 'True')
|
|
@@ -275,4 +262,20 @@ else: OUTPUT_COST_CODES_PATH = ''
|
|
| 275 |
|
| 276 |
ENFORCE_COST_CODES = get_or_create_env_var('ENFORCE_COST_CODES', 'False') # If you have cost codes listed, is it compulsory to choose one before redacting?
|
| 277 |
|
| 278 |
-
if ENFORCE_COST_CODES == 'True': GET_COST_CODES = 'True'
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 108 |
|
| 109 |
DOCUMENT_REDACTION_BUCKET = get_or_create_env_var('DOCUMENT_REDACTION_BUCKET', '')
|
| 110 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 111 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 112 |
|
| 113 |
# Custom headers e.g. if routing traffic through Cloudfront
|
| 114 |
# Retrieving or setting CUSTOM_HEADER
|
|
|
|
| 177 |
CSV_FEEDBACK_LOG_HEADERS = get_or_create_env_var('CSV_FEEDBACK_LOG_HEADERS', '') # If blank, uses component labels
|
| 178 |
CSV_USAGE_LOG_HEADERS = get_or_create_env_var('CSV_USAGE_LOG_HEADERS', '["session_hash_textbox", "doc_full_file_name_textbox", "data_full_file_name_textbox", "actual_time_taken_number", "total_page_count", "textract_query_number", "pii_detection_method", "comprehend_query_number", "cost_code", "textract_handwriting_signature", "host_name_textbox", "text_extraction_method", "is_this_a_textract_api_call"]') # If blank, uses component labels
|
| 179 |
|
|
|
|
| 180 |
### DYNAMODB logs. Whether to save to DynamoDB, and the headers of the table
|
| 181 |
|
| 182 |
SAVE_LOGS_TO_DYNAMODB = get_or_create_env_var('SAVE_LOGS_TO_DYNAMODB', 'False')
|
|
|
|
| 245 |
if ALLOW_LIST_PATH: OUTPUT_ALLOW_LIST_PATH = ALLOW_LIST_PATH
|
| 246 |
else: OUTPUT_ALLOW_LIST_PATH = 'config/default_allow_list.csv'
|
| 247 |
|
| 248 |
+
### COST CODE OPTIONS
|
| 249 |
+
|
| 250 |
SHOW_COSTS = get_or_create_env_var('SHOW_COSTS', 'False')
|
| 251 |
|
| 252 |
GET_COST_CODES = get_or_create_env_var('GET_COST_CODES', 'True')
|
|
|
|
| 262 |
|
| 263 |
ENFORCE_COST_CODES = get_or_create_env_var('ENFORCE_COST_CODES', 'False') # If you have cost codes listed, is it compulsory to choose one before redacting?
|
| 264 |
|
| 265 |
+
if ENFORCE_COST_CODES == 'True': GET_COST_CODES = 'True'
|
| 266 |
+
|
| 267 |
+
### WHOLE DOCUMENT API OPTIONS
|
| 268 |
+
|
| 269 |
+
SHOW_WHOLE_DOCUMENT_TEXTRACT_CALL_OPTIONS = get_or_create_env_var('SHOW_WHOLE_DOCUMENT_TEXTRACT_CALL_OPTIONS', 'False') # This feature not currently implemented
|
| 270 |
+
|
| 271 |
+
TEXTRACT_WHOLE_DOCUMENT_ANALYSIS_BUCKET = get_or_create_env_var('TEXTRACT_WHOLE_DOCUMENT_ANALYSIS_BUCKET', '')
|
| 272 |
+
|
| 273 |
+
TEXTRACT_WHOLE_DOCUMENT_ANALYSIS_INPUT_SUBFOLDER = get_or_create_env_var('TEXTRACT_WHOLE_DOCUMENT_ANALYSIS_INPUT_SUBFOLDER', 'input')
|
| 274 |
+
|
| 275 |
+
TEXTRACT_WHOLE_DOCUMENT_ANALYSIS_OUTPUT_SUBFOLDER = get_or_create_env_var('TEXTRACT_WHOLE_DOCUMENT_ANALYSIS_OUTPUT_SUBFOLDER', 'output')
|
| 276 |
+
|
| 277 |
+
LOAD_PREVIOUS_TEXTRACT_JOBS_S3 = get_or_create_env_var('LOAD_PREVIOUS_TEXTRACT_JOBS_S3', 'False') # Whether or not to load previous Textract jobs from S3
|
| 278 |
+
|
| 279 |
+
TEXTRACT_JOBS_S3_LOC = get_or_create_env_var('TEXTRACT_JOBS_S3_LOC', 'output') # Subfolder in the DOCUMENT_REDACTION_BUCKET where the Textract jobs are stored
|
| 280 |
+
|
| 281 |
+
TEXTRACT_JOBS_LOCAL_LOC = get_or_create_env_var('TEXTRACT_JOBS_LOCAL_LOC', 'output') # Local subfolder where the Textract jobs are stored
|
tools/custom_csvlogger.py
CHANGED
|
@@ -15,6 +15,9 @@ from typing import TYPE_CHECKING, Any
|
|
| 15 |
from gradio_client import utils as client_utils
|
| 16 |
import gradio as gr
|
| 17 |
from gradio import utils, wasm_utils
|
|
|
|
|
|
|
|
|
|
| 18 |
|
| 19 |
if TYPE_CHECKING:
|
| 20 |
from gradio.components import Component
|
|
@@ -202,12 +205,30 @@ class CSVLogger_custom(FlaggingCallback):
|
|
| 202 |
line_count = len(list(csv.reader(csvfile))) - 1
|
| 203 |
|
| 204 |
if save_to_dynamodb == True:
|
| 205 |
-
if dynamodb_table_name is None:
|
| 206 |
-
raise ValueError("You must provide a dynamodb_table_name if save_to_dynamodb is True")
|
| 207 |
-
|
| 208 |
-
dynamodb = boto3.resource('dynamodb')
|
| 209 |
-
client = boto3.client('dynamodb')
|
| 210 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 211 |
|
| 212 |
if dynamodb_headers:
|
| 213 |
dynamodb_headers = dynamodb_headers
|
|
|
|
| 15 |
from gradio_client import utils as client_utils
|
| 16 |
import gradio as gr
|
| 17 |
from gradio import utils, wasm_utils
|
| 18 |
+
from tools.config import AWS_REGION, AWS_ACCESS_KEY, AWS_SECRET_KEY, RUN_AWS_FUNCTIONS
|
| 19 |
+
from botocore.exceptions import NoCredentialsError, TokenRetrievalError
|
| 20 |
+
|
| 21 |
|
| 22 |
if TYPE_CHECKING:
|
| 23 |
from gradio.components import Component
|
|
|
|
| 205 |
line_count = len(list(csv.reader(csvfile))) - 1
|
| 206 |
|
| 207 |
if save_to_dynamodb == True:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 208 |
|
| 209 |
+
if RUN_AWS_FUNCTIONS == "1":
|
| 210 |
+
try:
|
| 211 |
+
print("Connecting to DynamoDB via existing SSO connection")
|
| 212 |
+
dynamodb = boto3.resource('dynamodb', region_name=AWS_REGION)
|
| 213 |
+
#client = boto3.client('dynamodb')
|
| 214 |
+
|
| 215 |
+
test_connection = dynamodb.meta.client.list_tables()
|
| 216 |
+
|
| 217 |
+
except Exception as e:
|
| 218 |
+
print("No SSO credentials found:", e)
|
| 219 |
+
if AWS_ACCESS_KEY and AWS_SECRET_KEY:
|
| 220 |
+
print("Trying DynamoDB credentials from environment variables")
|
| 221 |
+
dynamodb = boto3.resource('dynamodb',aws_access_key_id=AWS_ACCESS_KEY,
|
| 222 |
+
aws_secret_access_key=AWS_SECRET_KEY, region_name=AWS_REGION)
|
| 223 |
+
# client = boto3.client('dynamodb',aws_access_key_id=AWS_ACCESS_KEY,
|
| 224 |
+
# aws_secret_access_key=AWS_SECRET_KEY, region_name=AWS_REGION)
|
| 225 |
+
else:
|
| 226 |
+
raise Exception("AWS credentials for DynamoDB logging not found")
|
| 227 |
+
else:
|
| 228 |
+
raise Exception("AWS credentials for DynamoDB logging not found")
|
| 229 |
+
|
| 230 |
+
if dynamodb_table_name is None:
|
| 231 |
+
raise ValueError("You must provide a dynamodb_table_name if save_to_dynamodb is True")
|
| 232 |
|
| 233 |
if dynamodb_headers:
|
| 234 |
dynamodb_headers = dynamodb_headers
|
tools/custom_image_analyser_engine.py
CHANGED
|
@@ -775,9 +775,52 @@ def merge_text_bounding_boxes(analyser_results:dict, characters: List[LTChar], c
|
|
| 775 |
|
| 776 |
return analysed_bounding_boxes
|
| 777 |
|
| 778 |
-
|
| 779 |
-
|
| 780 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 781 |
lines = []
|
| 782 |
current_line = []
|
| 783 |
for result in sorted(ocr_results, key=lambda x: x.top):
|
|
@@ -796,26 +839,11 @@ def combine_ocr_results(ocr_results:dict, x_threshold:float=50.0, y_threshold:fl
|
|
| 796 |
# Flatten the sorted lines back into a single list
|
| 797 |
sorted_results = [result for line in lines for result in line]
|
| 798 |
|
| 799 |
-
|
| 800 |
-
|
| 801 |
current_line = []
|
| 802 |
current_bbox = None
|
| 803 |
-
line_counter = 1
|
| 804 |
-
|
| 805 |
-
def create_ocr_result_with_children(combined_results, i, current_bbox, current_line):
|
| 806 |
-
combined_results["text_line_" + str(i)] = {
|
| 807 |
-
"line": i,
|
| 808 |
-
'text': current_bbox.text,
|
| 809 |
-
'bounding_box': (current_bbox.left, current_bbox.top,
|
| 810 |
-
current_bbox.left + current_bbox.width,
|
| 811 |
-
current_bbox.top + current_bbox.height),
|
| 812 |
-
'words': [{'text': word.text,
|
| 813 |
-
'bounding_box': (word.left, word.top,
|
| 814 |
-
word.left + word.width,
|
| 815 |
-
word.top + word.height)}
|
| 816 |
-
for word in current_line]
|
| 817 |
-
}
|
| 818 |
-
return combined_results["text_line_" + str(i)]
|
| 819 |
|
| 820 |
for result in sorted_results:
|
| 821 |
if not current_line:
|
|
@@ -841,22 +869,98 @@ def combine_ocr_results(ocr_results:dict, x_threshold:float=50.0, y_threshold:fl
|
|
| 841 |
else:
|
| 842 |
|
| 843 |
# Commit the current line and start a new one
|
| 844 |
-
|
| 845 |
|
| 846 |
-
|
|
|
|
| 847 |
|
| 848 |
line_counter += 1
|
| 849 |
current_line = [result]
|
| 850 |
current_bbox = result
|
| 851 |
-
|
| 852 |
# Append the last line
|
| 853 |
if current_bbox:
|
| 854 |
-
|
|
|
|
|
|
|
|
|
|
| 855 |
|
| 856 |
-
|
|
|
|
|
|
|
| 857 |
|
|
|
|
| 858 |
|
| 859 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 860 |
|
| 861 |
class CustomImageAnalyzerEngine:
|
| 862 |
def __init__(
|
|
@@ -910,7 +1014,7 @@ class CustomImageAnalyzerEngine:
|
|
| 910 |
def analyze_text(
|
| 911 |
self,
|
| 912 |
line_level_ocr_results: List[OCRResult],
|
| 913 |
-
|
| 914 |
chosen_redact_comprehend_entities: List[str],
|
| 915 |
pii_identification_method: str = "Local",
|
| 916 |
comprehend_client = "",
|
|
@@ -1035,9 +1139,9 @@ class CustomImageAnalyzerEngine:
|
|
| 1035 |
combined_results = []
|
| 1036 |
for i, text_line in enumerate(line_level_ocr_results):
|
| 1037 |
line_results = next((results for idx, results in all_text_line_results if idx == i), [])
|
| 1038 |
-
if line_results and i < len(
|
| 1039 |
-
child_level_key = list(
|
| 1040 |
-
|
| 1041 |
|
| 1042 |
for result in line_results:
|
| 1043 |
bbox_results = self.map_analyzer_results_to_bounding_boxes(
|
|
@@ -1051,7 +1155,7 @@ class CustomImageAnalyzerEngine:
|
|
| 1051 |
)],
|
| 1052 |
text_line.text,
|
| 1053 |
text_analyzer_kwargs.get('allow_list', []),
|
| 1054 |
-
|
| 1055 |
)
|
| 1056 |
combined_results.extend(bbox_results)
|
| 1057 |
|
|
@@ -1063,14 +1167,14 @@ class CustomImageAnalyzerEngine:
|
|
| 1063 |
redaction_relevant_ocr_results: List[OCRResult],
|
| 1064 |
full_text: str,
|
| 1065 |
allow_list: List[str],
|
| 1066 |
-
|
| 1067 |
) -> List[CustomImageRecognizerResult]:
|
| 1068 |
redaction_bboxes = []
|
| 1069 |
|
| 1070 |
for redaction_relevant_ocr_result in redaction_relevant_ocr_results:
|
| 1071 |
-
#print("
|
| 1072 |
|
| 1073 |
-
line_text =
|
| 1074 |
line_length = len(line_text)
|
| 1075 |
redaction_text = redaction_relevant_ocr_result.text
|
| 1076 |
|
|
@@ -1096,7 +1200,7 @@ class CustomImageAnalyzerEngine:
|
|
| 1096 |
|
| 1097 |
# print(f"Found match: '{matched_text}' in line")
|
| 1098 |
|
| 1099 |
-
# for word_info in
|
| 1100 |
# # Check if this word is part of our match
|
| 1101 |
# if any(word.lower() in word_info['text'].lower() for word in matched_words):
|
| 1102 |
# matching_word_boxes.append(word_info['bounding_box'])
|
|
@@ -1105,11 +1209,11 @@ class CustomImageAnalyzerEngine:
|
|
| 1105 |
# Find the corresponding words in the OCR results
|
| 1106 |
matching_word_boxes = []
|
| 1107 |
|
| 1108 |
-
#print("
|
| 1109 |
|
| 1110 |
current_position = 0
|
| 1111 |
|
| 1112 |
-
for word_info in
|
| 1113 |
word_text = word_info['text']
|
| 1114 |
word_length = len(word_text)
|
| 1115 |
|
|
|
|
| 775 |
|
| 776 |
return analysed_bounding_boxes
|
| 777 |
|
| 778 |
+
def recreate_page_line_level_ocr_results_with_page(page_line_level_ocr_results_with_words: dict):
|
| 779 |
+
reconstructed_results = []
|
| 780 |
+
|
| 781 |
+
# Assume all lines belong to the same page, so we can just read it from one item
|
| 782 |
+
#page = next(iter(page_line_level_ocr_results_with_words.values()))["page"]
|
| 783 |
+
|
| 784 |
+
page = page_line_level_ocr_results_with_words["page"]
|
| 785 |
+
|
| 786 |
+
for line_data in page_line_level_ocr_results_with_words["results"].values():
|
| 787 |
+
bbox = line_data["bounding_box"]
|
| 788 |
+
text = line_data["text"]
|
| 789 |
+
|
| 790 |
+
# Recreate the OCRResult (you'll need the OCRResult class imported)
|
| 791 |
+
line_result = OCRResult(
|
| 792 |
+
text=text,
|
| 793 |
+
left=bbox[0],
|
| 794 |
+
top=bbox[1],
|
| 795 |
+
width=bbox[2] - bbox[0],
|
| 796 |
+
height=bbox[3] - bbox[1],
|
| 797 |
+
)
|
| 798 |
+
reconstructed_results.append(line_result)
|
| 799 |
+
|
| 800 |
+
page_line_level_ocr_results_with_page = {"page": page, "results": reconstructed_results}
|
| 801 |
+
|
| 802 |
+
return page_line_level_ocr_results_with_page
|
| 803 |
+
|
| 804 |
+
def create_ocr_result_with_children(combined_results:dict, i:int, current_bbox:dict, current_line:list):
|
| 805 |
+
combined_results["text_line_" + str(i)] = {
|
| 806 |
+
"line": i,
|
| 807 |
+
'text': current_bbox.text,
|
| 808 |
+
'bounding_box': (current_bbox.left, current_bbox.top,
|
| 809 |
+
current_bbox.left + current_bbox.width,
|
| 810 |
+
current_bbox.top + current_bbox.height),
|
| 811 |
+
'words': [{'text': word.text,
|
| 812 |
+
'bounding_box': (word.left, word.top,
|
| 813 |
+
word.left + word.width,
|
| 814 |
+
word.top + word.height)}
|
| 815 |
+
for word in current_line]
|
| 816 |
+
}
|
| 817 |
+
return combined_results["text_line_" + str(i)]
|
| 818 |
+
|
| 819 |
+
def combine_ocr_results(ocr_results: dict, x_threshold: float = 50.0, y_threshold: float = 12.0, page: int = 1):
|
| 820 |
+
'''
|
| 821 |
+
Group OCR results into lines based on y_threshold. Create line level ocr results, and word level OCR results
|
| 822 |
+
'''
|
| 823 |
+
|
| 824 |
lines = []
|
| 825 |
current_line = []
|
| 826 |
for result in sorted(ocr_results, key=lambda x: x.top):
|
|
|
|
| 839 |
# Flatten the sorted lines back into a single list
|
| 840 |
sorted_results = [result for line in lines for result in line]
|
| 841 |
|
| 842 |
+
page_line_level_ocr_results = []
|
| 843 |
+
page_line_level_ocr_results_with_words = {}
|
| 844 |
current_line = []
|
| 845 |
current_bbox = None
|
| 846 |
+
line_counter = 1
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 847 |
|
| 848 |
for result in sorted_results:
|
| 849 |
if not current_line:
|
|
|
|
| 869 |
else:
|
| 870 |
|
| 871 |
# Commit the current line and start a new one
|
| 872 |
+
page_line_level_ocr_results.append(current_bbox)
|
| 873 |
|
| 874 |
+
page_line_level_ocr_results_with_words["text_line_" + str(line_counter)] = create_ocr_result_with_children(page_line_level_ocr_results_with_words, line_counter, current_bbox, current_line)
|
| 875 |
+
#page_line_level_ocr_results_with_words["text_line_" + str(line_counter)]["page"] = page
|
| 876 |
|
| 877 |
line_counter += 1
|
| 878 |
current_line = [result]
|
| 879 |
current_bbox = result
|
|
|
|
| 880 |
# Append the last line
|
| 881 |
if current_bbox:
|
| 882 |
+
page_line_level_ocr_results.append(current_bbox)
|
| 883 |
+
|
| 884 |
+
page_line_level_ocr_results_with_words["text_line_" + str(line_counter)] = create_ocr_result_with_children(page_line_level_ocr_results_with_words, line_counter, current_bbox, current_line)
|
| 885 |
+
#page_line_level_ocr_results_with_words["text_line_" + str(line_counter)]["page"] = page
|
| 886 |
|
| 887 |
+
# Add page key to the line level results
|
| 888 |
+
page_line_level_ocr_results_with_page = {"page": page, "results": page_line_level_ocr_results}
|
| 889 |
+
page_line_level_ocr_results_with_words = {"page": page, "results": page_line_level_ocr_results_with_words}
|
| 890 |
|
| 891 |
+
return page_line_level_ocr_results_with_page, page_line_level_ocr_results_with_words
|
| 892 |
|
| 893 |
+
|
| 894 |
+
# Function to combine OCR results into line-level results
|
| 895 |
+
# def combine_ocr_results(ocr_results:dict, x_threshold:float=50.0, y_threshold:float=12.0):
|
| 896 |
+
# '''
|
| 897 |
+
# Group OCR results into lines based on y_threshold. Create line level ocr results, and word level OCR results
|
| 898 |
+
# '''
|
| 899 |
+
|
| 900 |
+
# lines = []
|
| 901 |
+
# current_line = []
|
| 902 |
+
# for result in sorted(ocr_results, key=lambda x: x.top):
|
| 903 |
+
# if not current_line or abs(result.top - current_line[0].top) <= y_threshold:
|
| 904 |
+
# current_line.append(result)
|
| 905 |
+
# else:
|
| 906 |
+
# lines.append(current_line)
|
| 907 |
+
# current_line = [result]
|
| 908 |
+
# if current_line:
|
| 909 |
+
# lines.append(current_line)
|
| 910 |
+
|
| 911 |
+
# # Sort each line by left position
|
| 912 |
+
# for line in lines:
|
| 913 |
+
# line.sort(key=lambda x: x.left)
|
| 914 |
+
|
| 915 |
+
# # Flatten the sorted lines back into a single list
|
| 916 |
+
# sorted_results = [result for line in lines for result in line]
|
| 917 |
+
|
| 918 |
+
# page_line_level_ocr_results = []
|
| 919 |
+
# page_line_level_ocr_results_with_words = {}
|
| 920 |
+
# current_line = []
|
| 921 |
+
# current_bbox = None
|
| 922 |
+
# line_counter = 1
|
| 923 |
+
|
| 924 |
+
# for result in sorted_results:
|
| 925 |
+
# if not current_line:
|
| 926 |
+
# # Start a new line
|
| 927 |
+
# current_line.append(result)
|
| 928 |
+
# current_bbox = result
|
| 929 |
+
# else:
|
| 930 |
+
# # Check if the result is on the same line (y-axis) and close horizontally (x-axis)
|
| 931 |
+
# last_result = current_line[-1]
|
| 932 |
+
|
| 933 |
+
# if abs(result.top - last_result.top) <= y_threshold and \
|
| 934 |
+
# (result.left - (last_result.left + last_result.width)) <= x_threshold:
|
| 935 |
+
# # Update the bounding box to include the new word
|
| 936 |
+
# new_right = max(current_bbox.left + current_bbox.width, result.left + result.width)
|
| 937 |
+
# current_bbox = OCRResult(
|
| 938 |
+
# text=f"{current_bbox.text} {result.text}",
|
| 939 |
+
# left=current_bbox.left,
|
| 940 |
+
# top=current_bbox.top,
|
| 941 |
+
# width=new_right - current_bbox.left,
|
| 942 |
+
# height=max(current_bbox.height, result.height)
|
| 943 |
+
# )
|
| 944 |
+
# current_line.append(result)
|
| 945 |
+
# else:
|
| 946 |
+
|
| 947 |
+
# # Commit the current line and start a new one
|
| 948 |
+
# page_line_level_ocr_results.append(current_bbox)
|
| 949 |
+
|
| 950 |
+
# page_line_level_ocr_results_with_words["text_line_" + str(line_counter)] = create_ocr_result_with_children(page_line_level_ocr_results_with_words, line_counter, current_bbox, current_line)
|
| 951 |
+
|
| 952 |
+
# line_counter += 1
|
| 953 |
+
# current_line = [result]
|
| 954 |
+
# current_bbox = result
|
| 955 |
+
|
| 956 |
+
# # Append the last line
|
| 957 |
+
# if current_bbox:
|
| 958 |
+
# page_line_level_ocr_results.append(current_bbox)
|
| 959 |
+
|
| 960 |
+
# page_line_level_ocr_results_with_words["text_line_" + str(line_counter)] = create_ocr_result_with_children(page_line_level_ocr_results_with_words, line_counter, current_bbox, current_line)
|
| 961 |
+
|
| 962 |
+
|
| 963 |
+
# return page_line_level_ocr_results, page_line_level_ocr_results_with_words
|
| 964 |
|
| 965 |
class CustomImageAnalyzerEngine:
|
| 966 |
def __init__(
|
|
|
|
| 1014 |
def analyze_text(
|
| 1015 |
self,
|
| 1016 |
line_level_ocr_results: List[OCRResult],
|
| 1017 |
+
ocr_results_with_words: Dict[str, Dict],
|
| 1018 |
chosen_redact_comprehend_entities: List[str],
|
| 1019 |
pii_identification_method: str = "Local",
|
| 1020 |
comprehend_client = "",
|
|
|
|
| 1139 |
combined_results = []
|
| 1140 |
for i, text_line in enumerate(line_level_ocr_results):
|
| 1141 |
line_results = next((results for idx, results in all_text_line_results if idx == i), [])
|
| 1142 |
+
if line_results and i < len(ocr_results_with_words):
|
| 1143 |
+
child_level_key = list(ocr_results_with_words.keys())[i]
|
| 1144 |
+
ocr_results_with_words_line_level = ocr_results_with_words[child_level_key]
|
| 1145 |
|
| 1146 |
for result in line_results:
|
| 1147 |
bbox_results = self.map_analyzer_results_to_bounding_boxes(
|
|
|
|
| 1155 |
)],
|
| 1156 |
text_line.text,
|
| 1157 |
text_analyzer_kwargs.get('allow_list', []),
|
| 1158 |
+
ocr_results_with_words_line_level
|
| 1159 |
)
|
| 1160 |
combined_results.extend(bbox_results)
|
| 1161 |
|
|
|
|
| 1167 |
redaction_relevant_ocr_results: List[OCRResult],
|
| 1168 |
full_text: str,
|
| 1169 |
allow_list: List[str],
|
| 1170 |
+
ocr_results_with_words_child_info: Dict[str, Dict]
|
| 1171 |
) -> List[CustomImageRecognizerResult]:
|
| 1172 |
redaction_bboxes = []
|
| 1173 |
|
| 1174 |
for redaction_relevant_ocr_result in redaction_relevant_ocr_results:
|
| 1175 |
+
#print("ocr_results_with_words_child_info:", ocr_results_with_words_child_info)
|
| 1176 |
|
| 1177 |
+
line_text = ocr_results_with_words_child_info['text']
|
| 1178 |
line_length = len(line_text)
|
| 1179 |
redaction_text = redaction_relevant_ocr_result.text
|
| 1180 |
|
|
|
|
| 1200 |
|
| 1201 |
# print(f"Found match: '{matched_text}' in line")
|
| 1202 |
|
| 1203 |
+
# for word_info in ocr_results_with_words_child_info.get('words', []):
|
| 1204 |
# # Check if this word is part of our match
|
| 1205 |
# if any(word.lower() in word_info['text'].lower() for word in matched_words):
|
| 1206 |
# matching_word_boxes.append(word_info['bounding_box'])
|
|
|
|
| 1209 |
# Find the corresponding words in the OCR results
|
| 1210 |
matching_word_boxes = []
|
| 1211 |
|
| 1212 |
+
#print("ocr_results_with_words_child_info:", ocr_results_with_words_child_info)
|
| 1213 |
|
| 1214 |
current_position = 0
|
| 1215 |
|
| 1216 |
+
for word_info in ocr_results_with_words_child_info.get('words', []):
|
| 1217 |
word_text = word_info['text']
|
| 1218 |
word_length = len(word_text)
|
| 1219 |
|
tools/data_anonymise.py
CHANGED
|
@@ -1,10 +1,12 @@
|
|
| 1 |
import re
|
|
|
|
| 2 |
import secrets
|
| 3 |
import base64
|
| 4 |
import time
|
| 5 |
import boto3
|
| 6 |
import botocore
|
| 7 |
import pandas as pd
|
|
|
|
| 8 |
|
| 9 |
from faker import Faker
|
| 10 |
from gradio import Progress
|
|
@@ -226,6 +228,7 @@ def anonymise_data_files(file_paths: List[str],
|
|
| 226 |
comprehend_query_number:int=0,
|
| 227 |
aws_access_key_textbox:str='',
|
| 228 |
aws_secret_key_textbox:str='',
|
|
|
|
| 229 |
progress: Progress = Progress(track_tqdm=True)):
|
| 230 |
"""
|
| 231 |
This function anonymises data files based on the provided parameters.
|
|
@@ -252,6 +255,7 @@ def anonymise_data_files(file_paths: List[str],
|
|
| 252 |
- comprehend_query_number (int, optional): A counter tracking the number of queries to AWS Comprehend.
|
| 253 |
- aws_access_key_textbox (str, optional): AWS access key for account with Textract and Comprehend permissions.
|
| 254 |
- aws_secret_key_textbox (str, optional): AWS secret key for account with Textract and Comprehend permissions.
|
|
|
|
| 255 |
- progress (Progress, optional): A Progress object to track progress. Defaults to a Progress object with track_tqdm=True.
|
| 256 |
"""
|
| 257 |
|
|
@@ -277,9 +281,16 @@ def anonymise_data_files(file_paths: List[str],
|
|
| 277 |
if not out_file_paths:
|
| 278 |
out_file_paths = []
|
| 279 |
|
| 280 |
-
|
| 281 |
-
|
| 282 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 283 |
else:
|
| 284 |
in_allow_list_flat = []
|
| 285 |
|
|
@@ -306,7 +317,7 @@ def anonymise_data_files(file_paths: List[str],
|
|
| 306 |
else:
|
| 307 |
comprehend_client = ""
|
| 308 |
out_message = "Cannot connect to AWS Comprehend service. Please provide access keys under Textract settings on the Redaction settings tab, or choose another PII identification method."
|
| 309 |
-
|
| 310 |
|
| 311 |
# Check if files and text exist
|
| 312 |
if not file_paths:
|
|
@@ -314,7 +325,7 @@ def anonymise_data_files(file_paths: List[str],
|
|
| 314 |
file_paths=['open_text']
|
| 315 |
else:
|
| 316 |
out_message = "Please enter text or a file to redact."
|
| 317 |
-
|
| 318 |
|
| 319 |
# If we have already redacted the last file, return the input out_message and file list to the relevant components
|
| 320 |
if latest_file_completed >= len(file_paths):
|
|
@@ -322,18 +333,18 @@ def anonymise_data_files(file_paths: List[str],
|
|
| 322 |
# Set to a very high number so as not to mess with subsequent file processing by the user
|
| 323 |
latest_file_completed = 99
|
| 324 |
final_out_message = '\n'.join(out_message)
|
| 325 |
-
return final_out_message, out_file_paths, out_file_paths, latest_file_completed, log_files_output_paths, log_files_output_paths
|
| 326 |
|
| 327 |
file_path_loop = [file_paths[int(latest_file_completed)]]
|
| 328 |
|
| 329 |
-
for anon_file in progress.tqdm(file_path_loop, desc="Anonymising files", unit = "
|
| 330 |
|
| 331 |
if anon_file=='open_text':
|
| 332 |
anon_df = pd.DataFrame(data={'text':[in_text]})
|
| 333 |
chosen_cols=['text']
|
|
|
|
| 334 |
sheet_name = ""
|
| 335 |
file_type = ""
|
| 336 |
-
out_file_part = anon_file
|
| 337 |
|
| 338 |
out_file_paths, out_message, key_string, log_files_output_paths = anon_wrapper_func(anon_file, anon_df, chosen_cols, out_file_paths, out_file_part, out_message, sheet_name, anon_strat, language, chosen_redact_entities, in_allow_list, file_type, "", log_files_output_paths, in_deny_list, max_fuzzy_spelling_mistakes_num, pii_identification_method, chosen_redact_comprehend_entities, comprehend_query_number, comprehend_client, output_folder=OUTPUT_FOLDER)
|
| 339 |
else:
|
|
@@ -350,26 +361,22 @@ def anonymise_data_files(file_paths: List[str],
|
|
| 350 |
out_message.append("No Excel sheets selected. Please select at least one to anonymise.")
|
| 351 |
continue
|
| 352 |
|
| 353 |
-
anon_xlsx = pd.ExcelFile(anon_file)
|
| 354 |
-
|
| 355 |
# Create xlsx file:
|
| 356 |
-
|
| 357 |
-
|
| 358 |
-
from openpyxl import Workbook
|
| 359 |
|
| 360 |
-
|
| 361 |
-
wb.save(anon_xlsx_export_file_name)
|
| 362 |
|
| 363 |
# Iterate through the sheet names
|
| 364 |
-
for sheet_name in in_excel_sheets:
|
| 365 |
# Read each sheet into a DataFrame
|
| 366 |
if sheet_name not in anon_xlsx.sheet_names:
|
| 367 |
continue
|
| 368 |
|
| 369 |
anon_df = pd.read_excel(anon_file, sheet_name=sheet_name)
|
| 370 |
|
| 371 |
-
out_file_paths, out_message, key_string, log_files_output_paths = anon_wrapper_func(anon_file, anon_df, chosen_cols, out_file_paths, out_file_part, out_message, sheet_name, anon_strat, language, chosen_redact_entities, in_allow_list, file_type,
|
| 372 |
-
|
| 373 |
else:
|
| 374 |
sheet_name = ""
|
| 375 |
anon_df = read_file(anon_file)
|
|
@@ -380,23 +387,28 @@ def anonymise_data_files(file_paths: List[str],
|
|
| 380 |
# Increase latest file completed count unless we are at the last file
|
| 381 |
if latest_file_completed != len(file_paths):
|
| 382 |
print("Completed file number:", str(latest_file_completed))
|
| 383 |
-
latest_file_completed += 1
|
| 384 |
|
| 385 |
toc = time.perf_counter()
|
| 386 |
-
|
| 387 |
-
|
| 388 |
-
|
| 389 |
-
|
| 390 |
-
|
| 391 |
|
| 392 |
out_message.append("Anonymisation of file '" + out_file_part + "' successfully completed in")
|
| 393 |
|
| 394 |
out_message_out = '\n'.join(out_message)
|
| 395 |
out_message_out = out_message_out + " " + out_time
|
| 396 |
|
|
|
|
|
|
|
|
|
|
| 397 |
out_message_out = out_message_out + "\n\nGo to to the Redaction settings tab to see redaction logs. Please give feedback on the results below to help improve this app."
|
|
|
|
|
|
|
| 398 |
|
| 399 |
-
return out_message_out, out_file_paths, out_file_paths, latest_file_completed, log_files_output_paths, log_files_output_paths
|
| 400 |
|
| 401 |
def anon_wrapper_func(
|
| 402 |
anon_file: str,
|
|
@@ -495,7 +507,6 @@ def anon_wrapper_func(
|
|
| 495 |
anon_df_out = anon_df_out[all_cols_original_order]
|
| 496 |
|
| 497 |
# Export file
|
| 498 |
-
|
| 499 |
# Rename anonymisation strategy for file path naming
|
| 500 |
if anon_strat == "replace with 'REDACTED'": anon_strat_txt = "redact_replace"
|
| 501 |
elif anon_strat == "replace with <ENTITY_NAME>": anon_strat_txt = "redact_entity_type"
|
|
@@ -507,8 +518,14 @@ def anon_wrapper_func(
|
|
| 507 |
|
| 508 |
anon_export_file_name = anon_xlsx_export_file_name
|
| 509 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 510 |
# Create a Pandas Excel writer using XlsxWriter as the engine.
|
| 511 |
-
with pd.ExcelWriter(anon_xlsx_export_file_name, engine='openpyxl', mode='a') as writer:
|
| 512 |
# Write each DataFrame to a different worksheet.
|
| 513 |
anon_df_out.to_excel(writer, sheet_name=excel_sheet_name, index=None)
|
| 514 |
|
|
@@ -532,7 +549,7 @@ def anon_wrapper_func(
|
|
| 532 |
|
| 533 |
# Print result text to output text box if just anonymising open text
|
| 534 |
if anon_file=='open_text':
|
| 535 |
-
out_message = [anon_df_out['text'][0]]
|
| 536 |
|
| 537 |
return out_file_paths, out_message, key_string, log_files_output_paths
|
| 538 |
|
|
@@ -551,8 +568,16 @@ def anonymise_script(df:pd.DataFrame, anon_strat:str, language:str, chosen_redac
|
|
| 551 |
# DataFrame to dict
|
| 552 |
df_dict = df.to_dict(orient="list")
|
| 553 |
|
| 554 |
-
if in_allow_list:
|
| 555 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 556 |
else:
|
| 557 |
in_allow_list_flat = []
|
| 558 |
|
|
@@ -577,11 +602,8 @@ def anonymise_script(df:pd.DataFrame, anon_strat:str, language:str, chosen_redac
|
|
| 577 |
|
| 578 |
#analyzer = nlp_analyser #AnalyzerEngine()
|
| 579 |
batch_analyzer = BatchAnalyzerEngine(analyzer_engine=nlp_analyser)
|
| 580 |
-
|
| 581 |
anonymizer = AnonymizerEngine()#conflict_resolution=ConflictResolutionStrategy.MERGE_SIMILAR_OR_CONTAINED)
|
| 582 |
-
|
| 583 |
-
batch_anonymizer = BatchAnonymizerEngine(anonymizer_engine = anonymizer)
|
| 584 |
-
|
| 585 |
analyzer_results = []
|
| 586 |
|
| 587 |
if pii_identification_method == "Local":
|
|
@@ -692,12 +714,6 @@ def anonymise_script(df:pd.DataFrame, anon_strat:str, language:str, chosen_redac
|
|
| 692 |
analyse_time_out = f"Analysing the text took {analyse_toc - analyse_tic:0.1f} seconds."
|
| 693 |
print(analyse_time_out)
|
| 694 |
|
| 695 |
-
# Create faker function (note that it has to receive a value)
|
| 696 |
-
#fake = Faker("en_UK")
|
| 697 |
-
|
| 698 |
-
#def fake_first_name(x):
|
| 699 |
-
# return fake.first_name()
|
| 700 |
-
|
| 701 |
# Set up the anonymization configuration WITHOUT DATE_TIME
|
| 702 |
simple_replace_config = eval('{"DEFAULT": OperatorConfig("replace", {"new_value": "REDACTED"})}')
|
| 703 |
replace_config = eval('{"DEFAULT": OperatorConfig("replace")}')
|
|
@@ -714,9 +730,13 @@ def anonymise_script(df:pd.DataFrame, anon_strat:str, language:str, chosen_redac
|
|
| 714 |
if anon_strat == "mask": chosen_mask_config = mask_config
|
| 715 |
if anon_strat == "encrypt":
|
| 716 |
chosen_mask_config = people_encrypt_config
|
| 717 |
-
|
| 718 |
-
key = secrets.token_bytes(16) # 128 bits = 16 bytes
|
| 719 |
key_string = base64.b64encode(key).decode('utf-8')
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 720 |
elif anon_strat == "fake_first_name": chosen_mask_config = fake_first_name_config
|
| 721 |
|
| 722 |
# I think in general people will want to keep date / times - removed Mar 2025 as I don't want to assume for people.
|
|
|
|
| 1 |
import re
|
| 2 |
+
import os
|
| 3 |
import secrets
|
| 4 |
import base64
|
| 5 |
import time
|
| 6 |
import boto3
|
| 7 |
import botocore
|
| 8 |
import pandas as pd
|
| 9 |
+
from openpyxl import Workbook, load_workbook
|
| 10 |
|
| 11 |
from faker import Faker
|
| 12 |
from gradio import Progress
|
|
|
|
| 228 |
comprehend_query_number:int=0,
|
| 229 |
aws_access_key_textbox:str='',
|
| 230 |
aws_secret_key_textbox:str='',
|
| 231 |
+
actual_time_taken_number:float=0,
|
| 232 |
progress: Progress = Progress(track_tqdm=True)):
|
| 233 |
"""
|
| 234 |
This function anonymises data files based on the provided parameters.
|
|
|
|
| 255 |
- comprehend_query_number (int, optional): A counter tracking the number of queries to AWS Comprehend.
|
| 256 |
- aws_access_key_textbox (str, optional): AWS access key for account with Textract and Comprehend permissions.
|
| 257 |
- aws_secret_key_textbox (str, optional): AWS secret key for account with Textract and Comprehend permissions.
|
| 258 |
+
- actual_time_taken_number (float, optional): Time taken to do the redaction.
|
| 259 |
- progress (Progress, optional): A Progress object to track progress. Defaults to a Progress object with track_tqdm=True.
|
| 260 |
"""
|
| 261 |
|
|
|
|
| 281 |
if not out_file_paths:
|
| 282 |
out_file_paths = []
|
| 283 |
|
| 284 |
+
if isinstance(in_allow_list, list):
|
| 285 |
+
if in_allow_list:
|
| 286 |
+
in_allow_list_flat = in_allow_list
|
| 287 |
+
else:
|
| 288 |
+
in_allow_list_flat = []
|
| 289 |
+
elif isinstance(in_allow_list, pd.DataFrame):
|
| 290 |
+
if not in_allow_list.empty:
|
| 291 |
+
in_allow_list_flat = list(in_allow_list.iloc[:, 0].unique())
|
| 292 |
+
else:
|
| 293 |
+
in_allow_list_flat = []
|
| 294 |
else:
|
| 295 |
in_allow_list_flat = []
|
| 296 |
|
|
|
|
| 317 |
else:
|
| 318 |
comprehend_client = ""
|
| 319 |
out_message = "Cannot connect to AWS Comprehend service. Please provide access keys under Textract settings on the Redaction settings tab, or choose another PII identification method."
|
| 320 |
+
raise(out_message)
|
| 321 |
|
| 322 |
# Check if files and text exist
|
| 323 |
if not file_paths:
|
|
|
|
| 325 |
file_paths=['open_text']
|
| 326 |
else:
|
| 327 |
out_message = "Please enter text or a file to redact."
|
| 328 |
+
raise Exception(out_message)
|
| 329 |
|
| 330 |
# If we have already redacted the last file, return the input out_message and file list to the relevant components
|
| 331 |
if latest_file_completed >= len(file_paths):
|
|
|
|
| 333 |
# Set to a very high number so as not to mess with subsequent file processing by the user
|
| 334 |
latest_file_completed = 99
|
| 335 |
final_out_message = '\n'.join(out_message)
|
| 336 |
+
return final_out_message, out_file_paths, out_file_paths, latest_file_completed, log_files_output_paths, log_files_output_paths, actual_time_taken_number
|
| 337 |
|
| 338 |
file_path_loop = [file_paths[int(latest_file_completed)]]
|
| 339 |
|
| 340 |
+
for anon_file in progress.tqdm(file_path_loop, desc="Anonymising files", unit = "files"):
|
| 341 |
|
| 342 |
if anon_file=='open_text':
|
| 343 |
anon_df = pd.DataFrame(data={'text':[in_text]})
|
| 344 |
chosen_cols=['text']
|
| 345 |
+
out_file_part = anon_file
|
| 346 |
sheet_name = ""
|
| 347 |
file_type = ""
|
|
|
|
| 348 |
|
| 349 |
out_file_paths, out_message, key_string, log_files_output_paths = anon_wrapper_func(anon_file, anon_df, chosen_cols, out_file_paths, out_file_part, out_message, sheet_name, anon_strat, language, chosen_redact_entities, in_allow_list, file_type, "", log_files_output_paths, in_deny_list, max_fuzzy_spelling_mistakes_num, pii_identification_method, chosen_redact_comprehend_entities, comprehend_query_number, comprehend_client, output_folder=OUTPUT_FOLDER)
|
| 350 |
else:
|
|
|
|
| 361 |
out_message.append("No Excel sheets selected. Please select at least one to anonymise.")
|
| 362 |
continue
|
| 363 |
|
|
|
|
|
|
|
| 364 |
# Create xlsx file:
|
| 365 |
+
anon_xlsx = pd.ExcelFile(anon_file)
|
| 366 |
+
anon_xlsx_export_file_name = output_folder + out_file_part + "_redacted.xlsx"
|
|
|
|
| 367 |
|
| 368 |
+
|
|
|
|
| 369 |
|
| 370 |
# Iterate through the sheet names
|
| 371 |
+
for sheet_name in progress.tqdm(in_excel_sheets, desc="Anonymising sheets", unit = "sheets"):
|
| 372 |
# Read each sheet into a DataFrame
|
| 373 |
if sheet_name not in anon_xlsx.sheet_names:
|
| 374 |
continue
|
| 375 |
|
| 376 |
anon_df = pd.read_excel(anon_file, sheet_name=sheet_name)
|
| 377 |
|
| 378 |
+
out_file_paths, out_message, key_string, log_files_output_paths = anon_wrapper_func(anon_file, anon_df, chosen_cols, out_file_paths, out_file_part, out_message, sheet_name, anon_strat, language, chosen_redact_entities, in_allow_list, file_type, anon_xlsx_export_file_name, log_files_output_paths, in_deny_list, max_fuzzy_spelling_mistakes_num, pii_identification_method, chosen_redact_comprehend_entities, comprehend_query_number, comprehend_client, output_folder=output_folder)
|
| 379 |
+
|
| 380 |
else:
|
| 381 |
sheet_name = ""
|
| 382 |
anon_df = read_file(anon_file)
|
|
|
|
| 387 |
# Increase latest file completed count unless we are at the last file
|
| 388 |
if latest_file_completed != len(file_paths):
|
| 389 |
print("Completed file number:", str(latest_file_completed))
|
| 390 |
+
latest_file_completed += 1
|
| 391 |
|
| 392 |
toc = time.perf_counter()
|
| 393 |
+
out_time_float = toc - tic
|
| 394 |
+
out_time = f"in {out_time_float:0.1f} seconds."
|
| 395 |
+
print(out_time)
|
| 396 |
+
|
| 397 |
+
actual_time_taken_number += out_time_float
|
| 398 |
|
| 399 |
out_message.append("Anonymisation of file '" + out_file_part + "' successfully completed in")
|
| 400 |
|
| 401 |
out_message_out = '\n'.join(out_message)
|
| 402 |
out_message_out = out_message_out + " " + out_time
|
| 403 |
|
| 404 |
+
if anon_strat == "encrypt":
|
| 405 |
+
out_message_out.append(". Your decryption key is " + key_string)
|
| 406 |
+
|
| 407 |
out_message_out = out_message_out + "\n\nGo to to the Redaction settings tab to see redaction logs. Please give feedback on the results below to help improve this app."
|
| 408 |
+
|
| 409 |
+
out_message_out = re.sub(r'^\n+|^\. ', '', out_message_out).strip()
|
| 410 |
|
| 411 |
+
return out_message_out, out_file_paths, out_file_paths, latest_file_completed, log_files_output_paths, log_files_output_paths, actual_time_taken_number
|
| 412 |
|
| 413 |
def anon_wrapper_func(
|
| 414 |
anon_file: str,
|
|
|
|
| 507 |
anon_df_out = anon_df_out[all_cols_original_order]
|
| 508 |
|
| 509 |
# Export file
|
|
|
|
| 510 |
# Rename anonymisation strategy for file path naming
|
| 511 |
if anon_strat == "replace with 'REDACTED'": anon_strat_txt = "redact_replace"
|
| 512 |
elif anon_strat == "replace with <ENTITY_NAME>": anon_strat_txt = "redact_entity_type"
|
|
|
|
| 518 |
|
| 519 |
anon_export_file_name = anon_xlsx_export_file_name
|
| 520 |
|
| 521 |
+
if not os.path.exists(anon_xlsx_export_file_name):
|
| 522 |
+
wb = Workbook()
|
| 523 |
+
ws = wb.active # Get the default active sheet
|
| 524 |
+
ws.title = excel_sheet_name
|
| 525 |
+
wb.save(anon_xlsx_export_file_name)
|
| 526 |
+
|
| 527 |
# Create a Pandas Excel writer using XlsxWriter as the engine.
|
| 528 |
+
with pd.ExcelWriter(anon_xlsx_export_file_name, engine='openpyxl', mode='a', if_sheet_exists='replace') as writer:
|
| 529 |
# Write each DataFrame to a different worksheet.
|
| 530 |
anon_df_out.to_excel(writer, sheet_name=excel_sheet_name, index=None)
|
| 531 |
|
|
|
|
| 549 |
|
| 550 |
# Print result text to output text box if just anonymising open text
|
| 551 |
if anon_file=='open_text':
|
| 552 |
+
out_message = ["'" + anon_df_out['text'][0] + "'"]
|
| 553 |
|
| 554 |
return out_file_paths, out_message, key_string, log_files_output_paths
|
| 555 |
|
|
|
|
| 568 |
# DataFrame to dict
|
| 569 |
df_dict = df.to_dict(orient="list")
|
| 570 |
|
| 571 |
+
if isinstance(in_allow_list, list):
|
| 572 |
+
if in_allow_list:
|
| 573 |
+
in_allow_list_flat = in_allow_list
|
| 574 |
+
else:
|
| 575 |
+
in_allow_list_flat = []
|
| 576 |
+
elif isinstance(in_allow_list, pd.DataFrame):
|
| 577 |
+
if not in_allow_list.empty:
|
| 578 |
+
in_allow_list_flat = list(in_allow_list.iloc[:, 0].unique())
|
| 579 |
+
else:
|
| 580 |
+
in_allow_list_flat = []
|
| 581 |
else:
|
| 582 |
in_allow_list_flat = []
|
| 583 |
|
|
|
|
| 602 |
|
| 603 |
#analyzer = nlp_analyser #AnalyzerEngine()
|
| 604 |
batch_analyzer = BatchAnalyzerEngine(analyzer_engine=nlp_analyser)
|
|
|
|
| 605 |
anonymizer = AnonymizerEngine()#conflict_resolution=ConflictResolutionStrategy.MERGE_SIMILAR_OR_CONTAINED)
|
| 606 |
+
batch_anonymizer = BatchAnonymizerEngine(anonymizer_engine = anonymizer)
|
|
|
|
|
|
|
| 607 |
analyzer_results = []
|
| 608 |
|
| 609 |
if pii_identification_method == "Local":
|
|
|
|
| 714 |
analyse_time_out = f"Analysing the text took {analyse_toc - analyse_tic:0.1f} seconds."
|
| 715 |
print(analyse_time_out)
|
| 716 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 717 |
# Set up the anonymization configuration WITHOUT DATE_TIME
|
| 718 |
simple_replace_config = eval('{"DEFAULT": OperatorConfig("replace", {"new_value": "REDACTED"})}')
|
| 719 |
replace_config = eval('{"DEFAULT": OperatorConfig("replace")}')
|
|
|
|
| 730 |
if anon_strat == "mask": chosen_mask_config = mask_config
|
| 731 |
if anon_strat == "encrypt":
|
| 732 |
chosen_mask_config = people_encrypt_config
|
| 733 |
+
key = secrets.token_bytes(16) # 128 bits = 16 bytes
|
|
|
|
| 734 |
key_string = base64.b64encode(key).decode('utf-8')
|
| 735 |
+
|
| 736 |
+
# Now inject the key into the operator config
|
| 737 |
+
for entity, operator in chosen_mask_config.items():
|
| 738 |
+
if operator.operator_name == "encrypt":
|
| 739 |
+
operator.params = {"key": key_string}
|
| 740 |
elif anon_strat == "fake_first_name": chosen_mask_config = fake_first_name_config
|
| 741 |
|
| 742 |
# I think in general people will want to keep date / times - removed Mar 2025 as I don't want to assume for people.
|
tools/file_conversion.py
CHANGED
|
@@ -462,7 +462,8 @@ def prepare_image_or_pdf(
|
|
| 462 |
input_folder:str=INPUT_FOLDER,
|
| 463 |
prepare_images:bool=True,
|
| 464 |
page_sizes:list[dict]=[],
|
| 465 |
-
textract_output_found:bool = False,
|
|
|
|
| 466 |
progress: Progress = Progress(track_tqdm=True)
|
| 467 |
) -> tuple[List[str], List[str]]:
|
| 468 |
"""
|
|
@@ -484,7 +485,8 @@ def prepare_image_or_pdf(
|
|
| 484 |
output_folder (optional, str): The output folder for file save
|
| 485 |
prepare_images (optional, bool): A boolean indicating whether to create images for each PDF page. Defaults to True.
|
| 486 |
page_sizes(optional, List[dict]): A list of dicts containing information about page sizes in various formats.
|
| 487 |
-
textract_output_found (optional, bool): A boolean indicating whether
|
|
|
|
| 488 |
progress (optional, Progress): Progress tracker for the operation
|
| 489 |
|
| 490 |
|
|
@@ -536,7 +538,7 @@ def prepare_image_or_pdf(
|
|
| 536 |
final_out_message = '\n'.join(out_message)
|
| 537 |
else:
|
| 538 |
final_out_message = out_message
|
| 539 |
-
return final_out_message, converted_file_paths, image_file_paths, number_of_pages, number_of_pages, pymupdf_doc, all_annotations_object, review_file_csv, original_cropboxes, page_sizes, textract_output_found, all_img_details, all_line_level_ocr_results_df
|
| 540 |
|
| 541 |
progress(0.1, desc='Preparing file')
|
| 542 |
|
|
@@ -639,8 +641,8 @@ def prepare_image_or_pdf(
|
|
| 639 |
# Assuming file_path is a NamedString or similar
|
| 640 |
all_annotations_object = json.loads(file_path) # Use loads for string content
|
| 641 |
|
| 642 |
-
#
|
| 643 |
-
elif (file_extension in ['.json']) and (prepare_for_review != True):
|
| 644 |
print("Saving Textract output")
|
| 645 |
# Copy it to the output folder so it can be used later.
|
| 646 |
output_textract_json_file_name = file_path_without_ext
|
|
@@ -654,6 +656,20 @@ def prepare_image_or_pdf(
|
|
| 654 |
textract_output_found = True
|
| 655 |
continue
|
| 656 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 657 |
# NEW IF STATEMENT
|
| 658 |
# If you have an annotations object from the above code
|
| 659 |
if all_annotations_object:
|
|
@@ -773,7 +789,40 @@ def prepare_image_or_pdf(
|
|
| 773 |
|
| 774 |
number_of_pages = len(page_sizes)#len(image_file_paths)
|
| 775 |
|
| 776 |
-
return combined_out_message, converted_file_paths, image_file_paths, number_of_pages, number_of_pages, pymupdf_doc, all_annotations_object, review_file_csv, original_cropboxes, page_sizes, textract_output_found, all_img_details, all_line_level_ocr_results_df
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 777 |
|
| 778 |
def convert_text_pdf_to_img_pdf(in_file_path:str, out_text_file_path:List[str], image_dpi:float=image_dpi, output_folder:str=OUTPUT_FOLDER, input_folder:str=INPUT_FOLDER):
|
| 779 |
file_path_without_ext = get_file_name_without_type(in_file_path)
|
|
@@ -1280,6 +1329,8 @@ def convert_annotation_data_to_dataframe(all_annotations: List[Dict[str, Any]]):
|
|
| 1280 |
# but it's good practice if columns could be missing for other reasons.
|
| 1281 |
final_df = final_df.reindex(columns=final_col_order, fill_value=pd.NA)
|
| 1282 |
|
|
|
|
|
|
|
| 1283 |
return final_df
|
| 1284 |
|
| 1285 |
def create_annotation_dicts_from_annotation_df(
|
|
@@ -1558,6 +1609,9 @@ def convert_annotation_json_to_review_df(
|
|
| 1558 |
except TypeError as e:
|
| 1559 |
print(f"Warning: Could not sort DataFrame due to type error in sort columns: {e}")
|
| 1560 |
# Proceed without sorting
|
|
|
|
|
|
|
|
|
|
| 1561 |
return review_file_df
|
| 1562 |
|
| 1563 |
def fill_missing_box_ids(data_input: dict) -> dict:
|
|
@@ -1787,6 +1841,8 @@ def convert_review_df_to_annotation_json(
|
|
| 1787 |
Returns:
|
| 1788 |
List of dictionaries suitable for Gradio Annotation output, one dict per image/page.
|
| 1789 |
"""
|
|
|
|
|
|
|
| 1790 |
if not page_sizes:
|
| 1791 |
raise ValueError("page_sizes argument is required and cannot be empty.")
|
| 1792 |
|
|
|
|
| 462 |
input_folder:str=INPUT_FOLDER,
|
| 463 |
prepare_images:bool=True,
|
| 464 |
page_sizes:list[dict]=[],
|
| 465 |
+
textract_output_found:bool = False,
|
| 466 |
+
local_ocr_output_found:bool = False,
|
| 467 |
progress: Progress = Progress(track_tqdm=True)
|
| 468 |
) -> tuple[List[str], List[str]]:
|
| 469 |
"""
|
|
|
|
| 485 |
output_folder (optional, str): The output folder for file save
|
| 486 |
prepare_images (optional, bool): A boolean indicating whether to create images for each PDF page. Defaults to True.
|
| 487 |
page_sizes(optional, List[dict]): A list of dicts containing information about page sizes in various formats.
|
| 488 |
+
textract_output_found (optional, bool): A boolean indicating whether Textract analysis output has already been found. Defaults to False.
|
| 489 |
+
local_ocr_output_found (optional, bool): A boolean indicating whether local OCR analysis output has already been found. Defaults to False.
|
| 490 |
progress (optional, Progress): Progress tracker for the operation
|
| 491 |
|
| 492 |
|
|
|
|
| 538 |
final_out_message = '\n'.join(out_message)
|
| 539 |
else:
|
| 540 |
final_out_message = out_message
|
| 541 |
+
return final_out_message, converted_file_paths, image_file_paths, number_of_pages, number_of_pages, pymupdf_doc, all_annotations_object, review_file_csv, original_cropboxes, page_sizes, textract_output_found, all_img_details, all_line_level_ocr_results_df, local_ocr_output_found
|
| 542 |
|
| 543 |
progress(0.1, desc='Preparing file')
|
| 544 |
|
|
|
|
| 641 |
# Assuming file_path is a NamedString or similar
|
| 642 |
all_annotations_object = json.loads(file_path) # Use loads for string content
|
| 643 |
|
| 644 |
+
# Save Textract file to folder
|
| 645 |
+
elif (file_extension in ['.json']) and '_textract' in file_path_without_ext: #(prepare_for_review != True):
|
| 646 |
print("Saving Textract output")
|
| 647 |
# Copy it to the output folder so it can be used later.
|
| 648 |
output_textract_json_file_name = file_path_without_ext
|
|
|
|
| 656 |
textract_output_found = True
|
| 657 |
continue
|
| 658 |
|
| 659 |
+
elif (file_extension in ['.json']) and '_ocr_results_with_words' in file_path_without_ext: #(prepare_for_review != True):
|
| 660 |
+
print("Saving local OCR output")
|
| 661 |
+
# Copy it to the output folder so it can be used later.
|
| 662 |
+
output_ocr_results_with_words_json_file_name = file_path_without_ext
|
| 663 |
+
if not file_path.endswith("_ocr_results_with_words.json"): output_ocr_results_with_words_json_file_name = file_path_without_ext + "_ocr_results_with_words.json"
|
| 664 |
+
else: output_ocr_results_with_words_json_file_name = file_path_without_ext + ".json"
|
| 665 |
+
|
| 666 |
+
out_ocr_results_with_words_path = os.path.join(output_folder, output_ocr_results_with_words_json_file_name)
|
| 667 |
+
|
| 668 |
+
# Use shutil to copy the file directly
|
| 669 |
+
shutil.copy2(file_path, out_ocr_results_with_words_path) # Preserves metadata
|
| 670 |
+
local_ocr_output_found = True
|
| 671 |
+
continue
|
| 672 |
+
|
| 673 |
# NEW IF STATEMENT
|
| 674 |
# If you have an annotations object from the above code
|
| 675 |
if all_annotations_object:
|
|
|
|
| 789 |
|
| 790 |
number_of_pages = len(page_sizes)#len(image_file_paths)
|
| 791 |
|
| 792 |
+
return combined_out_message, converted_file_paths, image_file_paths, number_of_pages, number_of_pages, pymupdf_doc, all_annotations_object, review_file_csv, original_cropboxes, page_sizes, textract_output_found, all_img_details, all_line_level_ocr_results_df, local_ocr_output_found
|
| 793 |
+
|
| 794 |
+
def load_and_convert_ocr_results_with_words_json(ocr_results_with_words_json_file_path:str, log_files_output_paths:str, page_sizes_df:pd.DataFrame):
|
| 795 |
+
"""
|
| 796 |
+
Loads Textract JSON from a file, detects if conversion is needed, and converts if necessary.
|
| 797 |
+
"""
|
| 798 |
+
|
| 799 |
+
if not os.path.exists(ocr_results_with_words_json_file_path):
|
| 800 |
+
print("No existing OCR results file found.")
|
| 801 |
+
return [], True, log_files_output_paths # Return empty dict and flag indicating missing file
|
| 802 |
+
|
| 803 |
+
no_ocr_results_with_words_file = False
|
| 804 |
+
print("Found existing OCR results json results file.")
|
| 805 |
+
|
| 806 |
+
# Track log files
|
| 807 |
+
if ocr_results_with_words_json_file_path not in log_files_output_paths:
|
| 808 |
+
log_files_output_paths.append(ocr_results_with_words_json_file_path)
|
| 809 |
+
|
| 810 |
+
try:
|
| 811 |
+
with open(ocr_results_with_words_json_file_path, 'r', encoding='utf-8') as json_file:
|
| 812 |
+
ocr_results_with_words_data = json.load(json_file)
|
| 813 |
+
except json.JSONDecodeError:
|
| 814 |
+
print("Error: Failed to parse OCR results JSON file. Returning empty data.")
|
| 815 |
+
return [], True, log_files_output_paths # Indicate failure
|
| 816 |
+
|
| 817 |
+
# Check if conversion is needed
|
| 818 |
+
if "page" and "results" in ocr_results_with_words_data[0]:
|
| 819 |
+
print("JSON already in the correct format for app. No changes needed.")
|
| 820 |
+
return ocr_results_with_words_data, False, log_files_output_paths # No conversion required
|
| 821 |
+
|
| 822 |
+
else:
|
| 823 |
+
print("Invalid OCR result JSON format: 'page' or 'results' key missing.")
|
| 824 |
+
#print("OCR results with words data:", ocr_results_with_words_data)
|
| 825 |
+
return [], True, log_files_output_paths # Return empty data if JSON is not recognized
|
| 826 |
|
| 827 |
def convert_text_pdf_to_img_pdf(in_file_path:str, out_text_file_path:List[str], image_dpi:float=image_dpi, output_folder:str=OUTPUT_FOLDER, input_folder:str=INPUT_FOLDER):
|
| 828 |
file_path_without_ext = get_file_name_without_type(in_file_path)
|
|
|
|
| 1329 |
# but it's good practice if columns could be missing for other reasons.
|
| 1330 |
final_df = final_df.reindex(columns=final_col_order, fill_value=pd.NA)
|
| 1331 |
|
| 1332 |
+
final_df = final_df.dropna(subset=["xmin", "xmax", "ymin", "ymax", "text", "id", "label"])
|
| 1333 |
+
|
| 1334 |
return final_df
|
| 1335 |
|
| 1336 |
def create_annotation_dicts_from_annotation_df(
|
|
|
|
| 1609 |
except TypeError as e:
|
| 1610 |
print(f"Warning: Could not sort DataFrame due to type error in sort columns: {e}")
|
| 1611 |
# Proceed without sorting
|
| 1612 |
+
|
| 1613 |
+
review_file_df = review_file_df.dropna(subset=["xmin", "xmax", "ymin", "ymax", "text", "id", "label"])
|
| 1614 |
+
|
| 1615 |
return review_file_df
|
| 1616 |
|
| 1617 |
def fill_missing_box_ids(data_input: dict) -> dict:
|
|
|
|
| 1841 |
Returns:
|
| 1842 |
List of dictionaries suitable for Gradio Annotation output, one dict per image/page.
|
| 1843 |
"""
|
| 1844 |
+
review_file_df = review_file_df.dropna(subset=["xmin", "xmax", "ymin", "ymax", "text", "id", "label"])
|
| 1845 |
+
|
| 1846 |
if not page_sizes:
|
| 1847 |
raise ValueError("page_sizes argument is required and cannot be empty.")
|
| 1848 |
|
tools/file_redaction.py
CHANGED
|
@@ -20,8 +20,8 @@ from gradio import Progress
|
|
| 20 |
from collections import defaultdict # For efficient grouping
|
| 21 |
|
| 22 |
from tools.config import OUTPUT_FOLDER, IMAGES_DPI, MAX_IMAGE_PIXELS, RUN_AWS_FUNCTIONS, AWS_ACCESS_KEY, AWS_SECRET_KEY, AWS_REGION, PAGE_BREAK_VALUE, MAX_TIME_VALUE, LOAD_TRUNCATED_IMAGES, INPUT_FOLDER
|
| 23 |
-
from tools.custom_image_analyser_engine import CustomImageAnalyzerEngine, OCRResult, combine_ocr_results, CustomImageRecognizerResult, run_page_text_redaction, merge_text_bounding_boxes
|
| 24 |
-
from tools.file_conversion import convert_annotation_json_to_review_df, redact_whole_pymupdf_page, redact_single_box, convert_pymupdf_to_image_coords, is_pdf, is_pdf_or_image, prepare_image_or_pdf, divide_coordinates_by_page_sizes, multiply_coordinates_by_page_sizes, convert_annotation_data_to_dataframe, divide_coordinates_by_page_sizes, create_annotation_dicts_from_annotation_df, remove_duplicate_images_with_blank_boxes, fill_missing_ids, fill_missing_box_ids
|
| 25 |
from tools.load_spacy_model_custom_recognisers import nlp_analyser, score_threshold, custom_entities, custom_recogniser, custom_word_list_recogniser, CustomWordFuzzyRecognizer
|
| 26 |
from tools.helper_functions import get_file_name_without_type, clean_unicode_text, tesseract_ocr_option, text_ocr_option, textract_option, local_pii_detector, aws_pii_detector, no_redaction_option
|
| 27 |
from tools.aws_textract import analyse_page_with_textract, json_to_ocrresult, load_and_convert_textract_json
|
|
@@ -101,6 +101,8 @@ def choose_and_run_redactor(file_paths:List[str],
|
|
| 101 |
input_folder:str=INPUT_FOLDER,
|
| 102 |
total_textract_query_number:int=0,
|
| 103 |
ocr_file_path:str="",
|
|
|
|
|
|
|
| 104 |
prepare_images:bool=True,
|
| 105 |
progress=gr.Progress(track_tqdm=True)):
|
| 106 |
'''
|
|
@@ -149,7 +151,9 @@ def choose_and_run_redactor(file_paths:List[str],
|
|
| 149 |
- review_file_path (str, optional): The latest review file path created by the app
|
| 150 |
- input_folder (str, optional): The custom input path, if provided
|
| 151 |
- total_textract_query_number (int, optional): The number of textract queries up until this point.
|
| 152 |
-
- ocr_file_path (str, optional): The latest ocr file path created by the app
|
|
|
|
|
|
|
| 153 |
- prepare_images (bool, optional): Boolean to determine whether to load images for the PDF.
|
| 154 |
- progress (gr.Progress, optional): A progress tracker for the redaction process. Defaults to a Progress object with track_tqdm set to True.
|
| 155 |
|
|
@@ -179,9 +183,16 @@ def choose_and_run_redactor(file_paths:List[str],
|
|
| 179 |
out_file_paths = []
|
| 180 |
estimate_total_processing_time = 0
|
| 181 |
estimated_time_taken_state = 0
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 182 |
# If not the first time around, and the current page loop has been set to a huge number (been through all pages), reset current page to 0
|
| 183 |
elif (first_loop_state == False) & (current_loop_page == 999):
|
| 184 |
current_loop_page = 0
|
|
|
|
|
|
|
| 185 |
|
| 186 |
# Choose the correct file to prepare
|
| 187 |
if isinstance(file_paths, str): file_paths_list = [os.path.abspath(file_paths)]
|
|
@@ -219,6 +230,8 @@ def choose_and_run_redactor(file_paths:List[str],
|
|
| 219 |
elif out_message:
|
| 220 |
combined_out_message = combined_out_message + '\n' + out_message
|
| 221 |
|
|
|
|
|
|
|
| 222 |
# Only send across review file if redaction has been done
|
| 223 |
if pii_identification_method != no_redaction_option:
|
| 224 |
|
|
@@ -226,10 +239,15 @@ def choose_and_run_redactor(file_paths:List[str],
|
|
| 226 |
#review_file_path = [x for x in out_file_paths if "review_file" in x]
|
| 227 |
if review_file_path: review_out_file_paths.append(review_file_path)
|
| 228 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 229 |
estimate_total_processing_time = sum_numbers_before_seconds(combined_out_message)
|
| 230 |
print("Estimated total processing time:", str(estimate_total_processing_time))
|
| 231 |
|
| 232 |
-
return combined_out_message, out_file_paths, out_file_paths, gr.Number(value=latest_file_completed, label="Number of documents redacted", interactive=False, visible=False), log_files_output_paths, log_files_output_paths, estimated_time_taken_state, all_request_metadata_str, pymupdf_doc, annotations_all_pages, gr.Number(value=current_loop_page,precision=0, interactive=False, label = "Last redacted page in document", visible=False), gr.Checkbox(value = True, label="Page break reached", visible=False), all_line_level_ocr_results_df, all_pages_decision_process_table, comprehend_query_number, review_out_file_paths, annotate_max_pages, annotate_max_pages, prepared_pdf_file_paths, pdf_image_file_paths, review_file_state, page_sizes, duplication_file_path_outputs, duplication_file_path_outputs, review_file_path, total_textract_query_number, ocr_file_path
|
| 233 |
|
| 234 |
#if first_loop_state == False:
|
| 235 |
# Prepare documents and images as required if they don't already exist
|
|
@@ -259,7 +277,7 @@ def choose_and_run_redactor(file_paths:List[str],
|
|
| 259 |
|
| 260 |
# Call prepare_image_or_pdf only if needed
|
| 261 |
if prepare_images_flag is not None:
|
| 262 |
-
out_message, prepared_pdf_file_paths, pdf_image_file_paths, annotate_max_pages, annotate_max_pages_bottom, pymupdf_doc, annotations_all_pages, review_file_state, document_cropboxes, page_sizes, textract_output_found, all_img_details_state, placeholder_ocr_results_df = prepare_image_or_pdf(
|
| 263 |
file_paths_loop, text_extraction_method, 0, out_message, True,
|
| 264 |
annotate_max_pages, annotations_all_pages, document_cropboxes, redact_whole_page_list,
|
| 265 |
output_folder, prepare_images=prepare_images_flag, page_sizes=page_sizes, input_folder=input_folder
|
|
@@ -274,11 +292,15 @@ def choose_and_run_redactor(file_paths:List[str],
|
|
| 274 |
page_sizes = page_sizes_df.to_dict(orient="records")
|
| 275 |
|
| 276 |
number_of_pages = pymupdf_doc.page_count
|
|
|
|
| 277 |
|
| 278 |
# If we have reached the last page, return message and outputs
|
| 279 |
if current_loop_page >= number_of_pages:
|
| 280 |
print("Reached last page of document:", current_loop_page)
|
| 281 |
|
|
|
|
|
|
|
|
|
|
| 282 |
# Set to a very high number so as not to mix up with subsequent file processing by the user
|
| 283 |
current_loop_page = 999
|
| 284 |
if out_message:
|
|
@@ -291,7 +313,7 @@ def choose_and_run_redactor(file_paths:List[str],
|
|
| 291 |
#review_file_path = [x for x in out_file_paths if "review_file" in x]
|
| 292 |
if review_file_path: review_out_file_paths.append(review_file_path)
|
| 293 |
|
| 294 |
-
return combined_out_message, out_file_paths, out_file_paths, gr.Number(value=latest_file_completed, label="Number of documents redacted", interactive=False, visible=False), log_files_output_paths, log_files_output_paths, estimated_time_taken_state, all_request_metadata_str, pymupdf_doc, annotations_all_pages, gr.Number(value=current_loop_page,precision=0, interactive=False, label = "Last redacted page in document", visible=False), gr.Checkbox(value = False, label="Page break reached", visible=False), all_line_level_ocr_results_df, all_pages_decision_process_table, comprehend_query_number, review_out_file_paths, annotate_max_pages, annotate_max_pages, prepared_pdf_file_paths, pdf_image_file_paths, review_file_state, page_sizes, duplication_file_path_outputs, duplication_file_path_outputs, review_file_path, total_textract_query_number, ocr_file_path
|
| 295 |
|
| 296 |
# Load/create allow list
|
| 297 |
# If string, assume file path
|
|
@@ -421,7 +443,7 @@ def choose_and_run_redactor(file_paths:List[str],
|
|
| 421 |
|
| 422 |
print("Redacting file " + pdf_file_name_with_ext + " as an image-based file")
|
| 423 |
|
| 424 |
-
pymupdf_doc, all_pages_decision_process_table, out_file_paths, new_textract_request_metadata, annotations_all_pages, current_loop_page, page_break_return, all_line_level_ocr_results_df, comprehend_query_number = redact_image_pdf(file_path,
|
| 425 |
pdf_image_file_paths,
|
| 426 |
language,
|
| 427 |
chosen_redact_entities,
|
|
@@ -447,7 +469,9 @@ def choose_and_run_redactor(file_paths:List[str],
|
|
| 447 |
max_fuzzy_spelling_mistakes_num,
|
| 448 |
match_fuzzy_whole_phrase_bool,
|
| 449 |
page_sizes_df,
|
| 450 |
-
text_extraction_only,
|
|
|
|
|
|
|
| 451 |
log_files_output_paths=log_files_output_paths,
|
| 452 |
output_folder=output_folder)
|
| 453 |
|
|
@@ -598,7 +622,10 @@ def choose_and_run_redactor(file_paths:List[str],
|
|
| 598 |
if not review_file_path: review_out_file_paths = [prepared_pdf_file_paths[-1]]
|
| 599 |
else: review_out_file_paths = [prepared_pdf_file_paths[-1], review_file_path]
|
| 600 |
|
| 601 |
-
|
|
|
|
|
|
|
|
|
|
| 602 |
|
| 603 |
def convert_pikepdf_coords_to_pymupdf(pymupdf_page:Page, pikepdf_bbox, type="pikepdf_annot"):
|
| 604 |
'''
|
|
@@ -1163,7 +1190,9 @@ def redact_image_pdf(file_path:str,
|
|
| 1163 |
max_fuzzy_spelling_mistakes_num:int=1,
|
| 1164 |
match_fuzzy_whole_phrase_bool:bool=True,
|
| 1165 |
page_sizes_df:pd.DataFrame=pd.DataFrame(),
|
| 1166 |
-
text_extraction_only:bool=False,
|
|
|
|
|
|
|
| 1167 |
page_break_val:int=int(PAGE_BREAK_VALUE),
|
| 1168 |
log_files_output_paths:List=[],
|
| 1169 |
max_time:int=int(MAX_TIME_VALUE),
|
|
@@ -1235,7 +1264,6 @@ def redact_image_pdf(file_path:str,
|
|
| 1235 |
print(out_message_warning)
|
| 1236 |
#raise Exception(out_message)
|
| 1237 |
|
| 1238 |
-
|
| 1239 |
number_of_pages = pymupdf_doc.page_count
|
| 1240 |
print("Number of pages:", str(number_of_pages))
|
| 1241 |
|
|
@@ -1253,14 +1281,24 @@ def redact_image_pdf(file_path:str,
|
|
| 1253 |
textract_data, is_missing, log_files_output_paths = load_and_convert_textract_json(textract_json_file_path, log_files_output_paths, page_sizes_df)
|
| 1254 |
original_textract_data = textract_data.copy()
|
| 1255 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1256 |
###
|
| 1257 |
if current_loop_page == 0: page_loop_start = 0
|
| 1258 |
else: page_loop_start = current_loop_page
|
| 1259 |
|
| 1260 |
progress_bar = tqdm(range(page_loop_start, number_of_pages), unit="pages remaining", desc="Redacting pages")
|
| 1261 |
|
| 1262 |
-
all_pages_decision_process_table_list = [all_pages_decision_process_table]
|
| 1263 |
all_line_level_ocr_results_df_list = [all_line_level_ocr_results_df]
|
|
|
|
| 1264 |
|
| 1265 |
# Go through each page
|
| 1266 |
for page_no in progress_bar:
|
|
@@ -1268,6 +1306,7 @@ def redact_image_pdf(file_path:str,
|
|
| 1268 |
handwriting_or_signature_boxes = []
|
| 1269 |
page_signature_recogniser_results = []
|
| 1270 |
page_handwriting_recogniser_results = []
|
|
|
|
| 1271 |
page_break_return = False
|
| 1272 |
reported_page_number = str(page_no + 1)
|
| 1273 |
|
|
@@ -1317,8 +1356,44 @@ def redact_image_pdf(file_path:str,
|
|
| 1317 |
#print("print(type(image_path)):", print(type(image_path)))
|
| 1318 |
#if not isinstance(image_path, image_path.image_path) or not isinstance(image_path, str): raise Exception("image_path object for page", reported_page_number, "not found, cannot perform local OCR analysis.")
|
| 1319 |
|
| 1320 |
-
|
| 1321 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1322 |
|
| 1323 |
# Check if page exists in existing textract data. If not, send to service to analyse
|
| 1324 |
if text_extraction_method == textract_option:
|
|
@@ -1382,16 +1457,28 @@ def redact_image_pdf(file_path:str,
|
|
| 1382 |
# If the page exists, retrieve the data
|
| 1383 |
text_blocks = next(page['data'] for page in textract_data["pages"] if page['page_no'] == reported_page_number)
|
| 1384 |
|
| 1385 |
-
|
| 1386 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1387 |
|
| 1388 |
if pii_identification_method != no_redaction_option:
|
| 1389 |
# Step 2: Analyse text and identify PII
|
| 1390 |
if chosen_redact_entities or chosen_redact_comprehend_entities:
|
| 1391 |
|
| 1392 |
page_redaction_bounding_boxes, comprehend_query_number_new = image_analyser.analyze_text(
|
| 1393 |
-
page_line_level_ocr_results,
|
| 1394 |
-
|
| 1395 |
chosen_redact_comprehend_entities = chosen_redact_comprehend_entities,
|
| 1396 |
pii_identification_method = pii_identification_method,
|
| 1397 |
comprehend_client=comprehend_client,
|
|
@@ -1406,7 +1493,7 @@ def redact_image_pdf(file_path:str,
|
|
| 1406 |
else: page_redaction_bounding_boxes = []
|
| 1407 |
|
| 1408 |
# Merge redaction bounding boxes that are close together
|
| 1409 |
-
page_merged_redaction_bboxes = merge_img_bboxes(page_redaction_bounding_boxes,
|
| 1410 |
|
| 1411 |
else: page_merged_redaction_bboxes = []
|
| 1412 |
|
|
@@ -1492,19 +1579,6 @@ def redact_image_pdf(file_path:str,
|
|
| 1492 |
decision_process_table = fill_missing_ids(decision_process_table)
|
| 1493 |
#decision_process_table.to_csv("output/decision_process_table_with_ids.csv")
|
| 1494 |
|
| 1495 |
-
|
| 1496 |
-
# Convert to DataFrame and add to ongoing logging table
|
| 1497 |
-
line_level_ocr_results_df = pd.DataFrame([{
|
| 1498 |
-
'page': reported_page_number,
|
| 1499 |
-
'text': result.text,
|
| 1500 |
-
'left': result.left,
|
| 1501 |
-
'top': result.top,
|
| 1502 |
-
'width': result.width,
|
| 1503 |
-
'height': result.height
|
| 1504 |
-
} for result in page_line_level_ocr_results])
|
| 1505 |
-
|
| 1506 |
-
all_line_level_ocr_results_df_list.append(line_level_ocr_results_df)
|
| 1507 |
-
|
| 1508 |
toc = time.perf_counter()
|
| 1509 |
|
| 1510 |
time_taken = toc - tic
|
|
@@ -1529,6 +1603,8 @@ def redact_image_pdf(file_path:str,
|
|
| 1529 |
# Append new annotation if it doesn't exist
|
| 1530 |
annotations_all_pages.append(page_image_annotations)
|
| 1531 |
|
|
|
|
|
|
|
| 1532 |
if text_extraction_method == textract_option:
|
| 1533 |
if original_textract_data != textract_data:
|
| 1534 |
# Write the updated existing textract data back to the JSON file
|
|
@@ -1538,12 +1614,21 @@ def redact_image_pdf(file_path:str,
|
|
| 1538 |
if textract_json_file_path not in log_files_output_paths:
|
| 1539 |
log_files_output_paths.append(textract_json_file_path)
|
| 1540 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1541 |
all_pages_decision_process_table = pd.concat(all_pages_decision_process_table_list)
|
| 1542 |
all_line_level_ocr_results_df = pd.concat(all_line_level_ocr_results_df_list)
|
| 1543 |
|
| 1544 |
current_loop_page += 1
|
| 1545 |
|
| 1546 |
-
return pymupdf_doc, all_pages_decision_process_table, log_files_output_paths, textract_request_metadata, annotations_all_pages, current_loop_page, page_break_return, all_line_level_ocr_results_df, comprehend_query_number
|
| 1547 |
|
| 1548 |
# If it's an image file
|
| 1549 |
if is_pdf(file_path) == False:
|
|
@@ -1576,10 +1661,20 @@ def redact_image_pdf(file_path:str,
|
|
| 1576 |
if textract_json_file_path not in log_files_output_paths:
|
| 1577 |
log_files_output_paths.append(textract_json_file_path)
|
| 1578 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1579 |
all_pages_decision_process_table = pd.concat(all_pages_decision_process_table_list)
|
| 1580 |
all_line_level_ocr_results_df = pd.concat(all_line_level_ocr_results_df_list)
|
| 1581 |
|
| 1582 |
-
return pymupdf_doc, all_pages_decision_process_table, log_files_output_paths, textract_request_metadata, annotations_all_pages, current_loop_page, page_break_return, all_line_level_ocr_results_df, comprehend_query_number
|
| 1583 |
|
| 1584 |
if text_extraction_method == textract_option:
|
| 1585 |
# Write the updated existing textract data back to the JSON file
|
|
@@ -1591,15 +1686,24 @@ def redact_image_pdf(file_path:str,
|
|
| 1591 |
if textract_json_file_path not in log_files_output_paths:
|
| 1592 |
log_files_output_paths.append(textract_json_file_path)
|
| 1593 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1594 |
all_pages_decision_process_table = pd.concat(all_pages_decision_process_table_list)
|
| 1595 |
all_line_level_ocr_results_df = pd.concat(all_line_level_ocr_results_df_list)
|
| 1596 |
|
| 1597 |
-
# Convert decision table to relative coordinates
|
| 1598 |
all_pages_decision_process_table = divide_coordinates_by_page_sizes(all_pages_decision_process_table, page_sizes_df, xmin="xmin", xmax="xmax", ymin="ymin", ymax="ymax")
|
| 1599 |
|
| 1600 |
all_line_level_ocr_results_df = divide_coordinates_by_page_sizes(all_line_level_ocr_results_df, page_sizes_df, xmin="left", xmax="width", ymin="top", ymax="height")
|
| 1601 |
|
| 1602 |
-
return pymupdf_doc, all_pages_decision_process_table, log_files_output_paths, textract_request_metadata, annotations_all_pages, current_loop_page, page_break_return, all_line_level_ocr_results_df, comprehend_query_number
|
| 1603 |
|
| 1604 |
|
| 1605 |
###
|
|
|
|
| 20 |
from collections import defaultdict # For efficient grouping
|
| 21 |
|
| 22 |
from tools.config import OUTPUT_FOLDER, IMAGES_DPI, MAX_IMAGE_PIXELS, RUN_AWS_FUNCTIONS, AWS_ACCESS_KEY, AWS_SECRET_KEY, AWS_REGION, PAGE_BREAK_VALUE, MAX_TIME_VALUE, LOAD_TRUNCATED_IMAGES, INPUT_FOLDER
|
| 23 |
+
from tools.custom_image_analyser_engine import CustomImageAnalyzerEngine, OCRResult, combine_ocr_results, CustomImageRecognizerResult, run_page_text_redaction, merge_text_bounding_boxes, recreate_page_line_level_ocr_results_with_page
|
| 24 |
+
from tools.file_conversion import convert_annotation_json_to_review_df, redact_whole_pymupdf_page, redact_single_box, convert_pymupdf_to_image_coords, is_pdf, is_pdf_or_image, prepare_image_or_pdf, divide_coordinates_by_page_sizes, multiply_coordinates_by_page_sizes, convert_annotation_data_to_dataframe, divide_coordinates_by_page_sizes, create_annotation_dicts_from_annotation_df, remove_duplicate_images_with_blank_boxes, fill_missing_ids, fill_missing_box_ids, load_and_convert_ocr_results_with_words_json
|
| 25 |
from tools.load_spacy_model_custom_recognisers import nlp_analyser, score_threshold, custom_entities, custom_recogniser, custom_word_list_recogniser, CustomWordFuzzyRecognizer
|
| 26 |
from tools.helper_functions import get_file_name_without_type, clean_unicode_text, tesseract_ocr_option, text_ocr_option, textract_option, local_pii_detector, aws_pii_detector, no_redaction_option
|
| 27 |
from tools.aws_textract import analyse_page_with_textract, json_to_ocrresult, load_and_convert_textract_json
|
|
|
|
| 101 |
input_folder:str=INPUT_FOLDER,
|
| 102 |
total_textract_query_number:int=0,
|
| 103 |
ocr_file_path:str="",
|
| 104 |
+
all_page_line_level_ocr_results = [],
|
| 105 |
+
all_page_line_level_ocr_results_with_words = [],
|
| 106 |
prepare_images:bool=True,
|
| 107 |
progress=gr.Progress(track_tqdm=True)):
|
| 108 |
'''
|
|
|
|
| 151 |
- review_file_path (str, optional): The latest review file path created by the app
|
| 152 |
- input_folder (str, optional): The custom input path, if provided
|
| 153 |
- total_textract_query_number (int, optional): The number of textract queries up until this point.
|
| 154 |
+
- ocr_file_path (str, optional): The latest ocr file path created by the app.
|
| 155 |
+
- all_page_line_level_ocr_results (list, optional): All line level text on the page with bounding boxes.
|
| 156 |
+
- all_page_line_level_ocr_results_with_words (list, optional): All word level text on the page with bounding boxes.
|
| 157 |
- prepare_images (bool, optional): Boolean to determine whether to load images for the PDF.
|
| 158 |
- progress (gr.Progress, optional): A progress tracker for the redaction process. Defaults to a Progress object with track_tqdm set to True.
|
| 159 |
|
|
|
|
| 183 |
out_file_paths = []
|
| 184 |
estimate_total_processing_time = 0
|
| 185 |
estimated_time_taken_state = 0
|
| 186 |
+
comprehend_query_number = 0
|
| 187 |
+
total_textract_query_number = 0
|
| 188 |
+
elif current_loop_page == 0:
|
| 189 |
+
comprehend_query_number = 0
|
| 190 |
+
total_textract_query_number = 0
|
| 191 |
# If not the first time around, and the current page loop has been set to a huge number (been through all pages), reset current page to 0
|
| 192 |
elif (first_loop_state == False) & (current_loop_page == 999):
|
| 193 |
current_loop_page = 0
|
| 194 |
+
total_textract_query_number = 0
|
| 195 |
+
comprehend_query_number = 0
|
| 196 |
|
| 197 |
# Choose the correct file to prepare
|
| 198 |
if isinstance(file_paths, str): file_paths_list = [os.path.abspath(file_paths)]
|
|
|
|
| 230 |
elif out_message:
|
| 231 |
combined_out_message = combined_out_message + '\n' + out_message
|
| 232 |
|
| 233 |
+
combined_out_message = re.sub(r'^\n+', '', combined_out_message).strip()
|
| 234 |
+
|
| 235 |
# Only send across review file if redaction has been done
|
| 236 |
if pii_identification_method != no_redaction_option:
|
| 237 |
|
|
|
|
| 239 |
#review_file_path = [x for x in out_file_paths if "review_file" in x]
|
| 240 |
if review_file_path: review_out_file_paths.append(review_file_path)
|
| 241 |
|
| 242 |
+
if not isinstance(pymupdf_doc, list):
|
| 243 |
+
number_of_pages = pymupdf_doc.page_count
|
| 244 |
+
if total_textract_query_number > number_of_pages:
|
| 245 |
+
total_textract_query_number = number_of_pages
|
| 246 |
+
|
| 247 |
estimate_total_processing_time = sum_numbers_before_seconds(combined_out_message)
|
| 248 |
print("Estimated total processing time:", str(estimate_total_processing_time))
|
| 249 |
|
| 250 |
+
return combined_out_message, out_file_paths, out_file_paths, gr.Number(value=latest_file_completed, label="Number of documents redacted", interactive=False, visible=False), log_files_output_paths, log_files_output_paths, estimated_time_taken_state, all_request_metadata_str, pymupdf_doc, annotations_all_pages, gr.Number(value=current_loop_page,precision=0, interactive=False, label = "Last redacted page in document", visible=False), gr.Checkbox(value = True, label="Page break reached", visible=False), all_line_level_ocr_results_df, all_pages_decision_process_table, comprehend_query_number, review_out_file_paths, annotate_max_pages, annotate_max_pages, prepared_pdf_file_paths, pdf_image_file_paths, review_file_state, page_sizes, duplication_file_path_outputs, duplication_file_path_outputs, review_file_path, total_textract_query_number, ocr_file_path, all_page_line_level_ocr_results, all_page_line_level_ocr_results_with_words
|
| 251 |
|
| 252 |
#if first_loop_state == False:
|
| 253 |
# Prepare documents and images as required if they don't already exist
|
|
|
|
| 277 |
|
| 278 |
# Call prepare_image_or_pdf only if needed
|
| 279 |
if prepare_images_flag is not None:
|
| 280 |
+
out_message, prepared_pdf_file_paths, pdf_image_file_paths, annotate_max_pages, annotate_max_pages_bottom, pymupdf_doc, annotations_all_pages, review_file_state, document_cropboxes, page_sizes, textract_output_found, all_img_details_state, placeholder_ocr_results_df, local_ocr_output_found_checkbox = prepare_image_or_pdf(
|
| 281 |
file_paths_loop, text_extraction_method, 0, out_message, True,
|
| 282 |
annotate_max_pages, annotations_all_pages, document_cropboxes, redact_whole_page_list,
|
| 283 |
output_folder, prepare_images=prepare_images_flag, page_sizes=page_sizes, input_folder=input_folder
|
|
|
|
| 292 |
page_sizes = page_sizes_df.to_dict(orient="records")
|
| 293 |
|
| 294 |
number_of_pages = pymupdf_doc.page_count
|
| 295 |
+
|
| 296 |
|
| 297 |
# If we have reached the last page, return message and outputs
|
| 298 |
if current_loop_page >= number_of_pages:
|
| 299 |
print("Reached last page of document:", current_loop_page)
|
| 300 |
|
| 301 |
+
if total_textract_query_number > number_of_pages:
|
| 302 |
+
total_textract_query_number = number_of_pages
|
| 303 |
+
|
| 304 |
# Set to a very high number so as not to mix up with subsequent file processing by the user
|
| 305 |
current_loop_page = 999
|
| 306 |
if out_message:
|
|
|
|
| 313 |
#review_file_path = [x for x in out_file_paths if "review_file" in x]
|
| 314 |
if review_file_path: review_out_file_paths.append(review_file_path)
|
| 315 |
|
| 316 |
+
return combined_out_message, out_file_paths, out_file_paths, gr.Number(value=latest_file_completed, label="Number of documents redacted", interactive=False, visible=False), log_files_output_paths, log_files_output_paths, estimated_time_taken_state, all_request_metadata_str, pymupdf_doc, annotations_all_pages, gr.Number(value=current_loop_page,precision=0, interactive=False, label = "Last redacted page in document", visible=False), gr.Checkbox(value = False, label="Page break reached", visible=False), all_line_level_ocr_results_df, all_pages_decision_process_table, comprehend_query_number, review_out_file_paths, annotate_max_pages, annotate_max_pages, prepared_pdf_file_paths, pdf_image_file_paths, review_file_state, page_sizes, duplication_file_path_outputs, duplication_file_path_outputs, review_file_path, total_textract_query_number, ocr_file_path, all_page_line_level_ocr_results, all_page_line_level_ocr_results_with_words
|
| 317 |
|
| 318 |
# Load/create allow list
|
| 319 |
# If string, assume file path
|
|
|
|
| 443 |
|
| 444 |
print("Redacting file " + pdf_file_name_with_ext + " as an image-based file")
|
| 445 |
|
| 446 |
+
pymupdf_doc, all_pages_decision_process_table, out_file_paths, new_textract_request_metadata, annotations_all_pages, current_loop_page, page_break_return, all_line_level_ocr_results_df, comprehend_query_number, all_page_line_level_ocr_results, all_page_line_level_ocr_results_with_words = redact_image_pdf(file_path,
|
| 447 |
pdf_image_file_paths,
|
| 448 |
language,
|
| 449 |
chosen_redact_entities,
|
|
|
|
| 469 |
max_fuzzy_spelling_mistakes_num,
|
| 470 |
match_fuzzy_whole_phrase_bool,
|
| 471 |
page_sizes_df,
|
| 472 |
+
text_extraction_only,
|
| 473 |
+
all_page_line_level_ocr_results,
|
| 474 |
+
all_page_line_level_ocr_results_with_words,
|
| 475 |
log_files_output_paths=log_files_output_paths,
|
| 476 |
output_folder=output_folder)
|
| 477 |
|
|
|
|
| 622 |
if not review_file_path: review_out_file_paths = [prepared_pdf_file_paths[-1]]
|
| 623 |
else: review_out_file_paths = [prepared_pdf_file_paths[-1], review_file_path]
|
| 624 |
|
| 625 |
+
if total_textract_query_number > number_of_pages:
|
| 626 |
+
total_textract_query_number = number_of_pages
|
| 627 |
+
|
| 628 |
+
return combined_out_message, out_file_paths, out_file_paths, gr.Number(value=latest_file_completed, label="Number of documents redacted", interactive=False, visible=False), log_files_output_paths, log_files_output_paths, estimated_time_taken_state, all_request_metadata_str, pymupdf_doc, annotations_all_pages, gr.Number(value=current_loop_page, precision=0, interactive=False, label = "Last redacted page in document", visible=False), gr.Checkbox(value = True, label="Page break reached", visible=False), all_line_level_ocr_results_df, all_pages_decision_process_table, comprehend_query_number, review_out_file_paths, annotate_max_pages, annotate_max_pages, prepared_pdf_file_paths, pdf_image_file_paths, review_file_state, page_sizes, duplication_file_path_outputs, duplication_file_path_outputs, review_file_path, total_textract_query_number, ocr_file_path, all_page_line_level_ocr_results, all_page_line_level_ocr_results_with_words
|
| 629 |
|
| 630 |
def convert_pikepdf_coords_to_pymupdf(pymupdf_page:Page, pikepdf_bbox, type="pikepdf_annot"):
|
| 631 |
'''
|
|
|
|
| 1190 |
max_fuzzy_spelling_mistakes_num:int=1,
|
| 1191 |
match_fuzzy_whole_phrase_bool:bool=True,
|
| 1192 |
page_sizes_df:pd.DataFrame=pd.DataFrame(),
|
| 1193 |
+
text_extraction_only:bool=False,
|
| 1194 |
+
all_page_line_level_ocr_results = [],
|
| 1195 |
+
all_page_line_level_ocr_results_with_words = [],
|
| 1196 |
page_break_val:int=int(PAGE_BREAK_VALUE),
|
| 1197 |
log_files_output_paths:List=[],
|
| 1198 |
max_time:int=int(MAX_TIME_VALUE),
|
|
|
|
| 1264 |
print(out_message_warning)
|
| 1265 |
#raise Exception(out_message)
|
| 1266 |
|
|
|
|
| 1267 |
number_of_pages = pymupdf_doc.page_count
|
| 1268 |
print("Number of pages:", str(number_of_pages))
|
| 1269 |
|
|
|
|
| 1281 |
textract_data, is_missing, log_files_output_paths = load_and_convert_textract_json(textract_json_file_path, log_files_output_paths, page_sizes_df)
|
| 1282 |
original_textract_data = textract_data.copy()
|
| 1283 |
|
| 1284 |
+
print("Successfully loaded in Textract analysis results from file")
|
| 1285 |
+
|
| 1286 |
+
# If running local OCR option, check if file already exists. If it does, load in existing data
|
| 1287 |
+
if text_extraction_method == tesseract_ocr_option:
|
| 1288 |
+
all_page_line_level_ocr_results_with_words_json_file_path = output_folder + file_name + "_ocr_results_with_words.json"
|
| 1289 |
+
all_page_line_level_ocr_results_with_words, is_missing, log_files_output_paths = load_and_convert_ocr_results_with_words_json(all_page_line_level_ocr_results_with_words_json_file_path, log_files_output_paths, page_sizes_df)
|
| 1290 |
+
original_all_page_line_level_ocr_results_with_words = all_page_line_level_ocr_results_with_words.copy()
|
| 1291 |
+
|
| 1292 |
+
print("Loaded in local OCR analysis results from file")
|
| 1293 |
+
|
| 1294 |
###
|
| 1295 |
if current_loop_page == 0: page_loop_start = 0
|
| 1296 |
else: page_loop_start = current_loop_page
|
| 1297 |
|
| 1298 |
progress_bar = tqdm(range(page_loop_start, number_of_pages), unit="pages remaining", desc="Redacting pages")
|
| 1299 |
|
|
|
|
| 1300 |
all_line_level_ocr_results_df_list = [all_line_level_ocr_results_df]
|
| 1301 |
+
all_pages_decision_process_table_list = [all_pages_decision_process_table]
|
| 1302 |
|
| 1303 |
# Go through each page
|
| 1304 |
for page_no in progress_bar:
|
|
|
|
| 1306 |
handwriting_or_signature_boxes = []
|
| 1307 |
page_signature_recogniser_results = []
|
| 1308 |
page_handwriting_recogniser_results = []
|
| 1309 |
+
page_line_level_ocr_results_with_words = []
|
| 1310 |
page_break_return = False
|
| 1311 |
reported_page_number = str(page_no + 1)
|
| 1312 |
|
|
|
|
| 1356 |
#print("print(type(image_path)):", print(type(image_path)))
|
| 1357 |
#if not isinstance(image_path, image_path.image_path) or not isinstance(image_path, str): raise Exception("image_path object for page", reported_page_number, "not found, cannot perform local OCR analysis.")
|
| 1358 |
|
| 1359 |
+
# Check for existing page_line_level_ocr_results_with_words object:
|
| 1360 |
+
|
| 1361 |
+
# page_line_level_ocr_results = (
|
| 1362 |
+
# all_page_line_level_ocr_results.get('results', [])
|
| 1363 |
+
# if all_page_line_level_ocr_results.get('page') == reported_page_number
|
| 1364 |
+
# else []
|
| 1365 |
+
# )
|
| 1366 |
+
|
| 1367 |
+
if all_page_line_level_ocr_results_with_words:
|
| 1368 |
+
# Find the first dict where 'page' matches
|
| 1369 |
+
|
| 1370 |
+
#print("all_page_line_level_ocr_results_with_words:", all_page_line_level_ocr_results_with_words)
|
| 1371 |
+
|
| 1372 |
+
print("All pages available:", [item.get('page') for item in all_page_line_level_ocr_results_with_words])
|
| 1373 |
+
#print("Looking for page:", reported_page_number)
|
| 1374 |
+
|
| 1375 |
+
matching_page = next(
|
| 1376 |
+
(item for item in all_page_line_level_ocr_results_with_words if int(item.get('page', -1)) == int(reported_page_number)),
|
| 1377 |
+
None
|
| 1378 |
+
)
|
| 1379 |
+
|
| 1380 |
+
#print("matching_page:", matching_page)
|
| 1381 |
+
|
| 1382 |
+
page_line_level_ocr_results_with_words = matching_page if matching_page else []
|
| 1383 |
+
else: page_line_level_ocr_results_with_words = []
|
| 1384 |
+
|
| 1385 |
+
if page_line_level_ocr_results_with_words:
|
| 1386 |
+
print("Found OCR results for page in existing OCR with words object")
|
| 1387 |
+
page_line_level_ocr_results = recreate_page_line_level_ocr_results_with_page(page_line_level_ocr_results_with_words)
|
| 1388 |
+
else:
|
| 1389 |
+
page_word_level_ocr_results = image_analyser.perform_ocr(image_path)
|
| 1390 |
+
|
| 1391 |
+
print("page_word_level_ocr_results:", page_word_level_ocr_results)
|
| 1392 |
+
page_line_level_ocr_results, page_line_level_ocr_results_with_words = combine_ocr_results(page_word_level_ocr_results, page=reported_page_number)
|
| 1393 |
+
|
| 1394 |
+
all_page_line_level_ocr_results_with_words.append(page_line_level_ocr_results_with_words)
|
| 1395 |
+
|
| 1396 |
+
print("All pages available:", [item.get('page') for item in all_page_line_level_ocr_results_with_words])
|
| 1397 |
|
| 1398 |
# Check if page exists in existing textract data. If not, send to service to analyse
|
| 1399 |
if text_extraction_method == textract_option:
|
|
|
|
| 1457 |
# If the page exists, retrieve the data
|
| 1458 |
text_blocks = next(page['data'] for page in textract_data["pages"] if page['page_no'] == reported_page_number)
|
| 1459 |
|
| 1460 |
+
page_line_level_ocr_results, handwriting_or_signature_boxes, page_signature_recogniser_results, page_handwriting_recogniser_results, page_line_level_ocr_results_with_words = json_to_ocrresult(text_blocks, page_width, page_height, reported_page_number)
|
| 1461 |
+
|
| 1462 |
+
# Convert to DataFrame and add to ongoing logging table
|
| 1463 |
+
line_level_ocr_results_df = pd.DataFrame([{
|
| 1464 |
+
'page': page_line_level_ocr_results['page'],
|
| 1465 |
+
'text': result.text,
|
| 1466 |
+
'left': result.left,
|
| 1467 |
+
'top': result.top,
|
| 1468 |
+
'width': result.width,
|
| 1469 |
+
'height': result.height
|
| 1470 |
+
} for result in page_line_level_ocr_results['results']])
|
| 1471 |
+
|
| 1472 |
+
all_line_level_ocr_results_df_list.append(line_level_ocr_results_df)
|
| 1473 |
+
|
| 1474 |
|
| 1475 |
if pii_identification_method != no_redaction_option:
|
| 1476 |
# Step 2: Analyse text and identify PII
|
| 1477 |
if chosen_redact_entities or chosen_redact_comprehend_entities:
|
| 1478 |
|
| 1479 |
page_redaction_bounding_boxes, comprehend_query_number_new = image_analyser.analyze_text(
|
| 1480 |
+
page_line_level_ocr_results['results'],
|
| 1481 |
+
page_line_level_ocr_results_with_words['results'],
|
| 1482 |
chosen_redact_comprehend_entities = chosen_redact_comprehend_entities,
|
| 1483 |
pii_identification_method = pii_identification_method,
|
| 1484 |
comprehend_client=comprehend_client,
|
|
|
|
| 1493 |
else: page_redaction_bounding_boxes = []
|
| 1494 |
|
| 1495 |
# Merge redaction bounding boxes that are close together
|
| 1496 |
+
page_merged_redaction_bboxes = merge_img_bboxes(page_redaction_bounding_boxes, page_line_level_ocr_results_with_words['results'], page_signature_recogniser_results, page_handwriting_recogniser_results, handwrite_signature_checkbox)
|
| 1497 |
|
| 1498 |
else: page_merged_redaction_bboxes = []
|
| 1499 |
|
|
|
|
| 1579 |
decision_process_table = fill_missing_ids(decision_process_table)
|
| 1580 |
#decision_process_table.to_csv("output/decision_process_table_with_ids.csv")
|
| 1581 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1582 |
toc = time.perf_counter()
|
| 1583 |
|
| 1584 |
time_taken = toc - tic
|
|
|
|
| 1603 |
# Append new annotation if it doesn't exist
|
| 1604 |
annotations_all_pages.append(page_image_annotations)
|
| 1605 |
|
| 1606 |
+
|
| 1607 |
+
|
| 1608 |
if text_extraction_method == textract_option:
|
| 1609 |
if original_textract_data != textract_data:
|
| 1610 |
# Write the updated existing textract data back to the JSON file
|
|
|
|
| 1614 |
if textract_json_file_path not in log_files_output_paths:
|
| 1615 |
log_files_output_paths.append(textract_json_file_path)
|
| 1616 |
|
| 1617 |
+
if text_extraction_method == tesseract_ocr_option:
|
| 1618 |
+
if original_all_page_line_level_ocr_results_with_words != all_page_line_level_ocr_results_with_words:
|
| 1619 |
+
# Write the updated existing textract data back to the JSON file
|
| 1620 |
+
with open(all_page_line_level_ocr_results_with_words_json_file_path, 'w') as json_file:
|
| 1621 |
+
json.dump(all_page_line_level_ocr_results_with_words, json_file, separators=(",", ":")) # indent=4 makes the JSON file pretty-printed
|
| 1622 |
+
|
| 1623 |
+
if all_page_line_level_ocr_results_with_words_json_file_path not in log_files_output_paths:
|
| 1624 |
+
log_files_output_paths.append(all_page_line_level_ocr_results_with_words_json_file_path)
|
| 1625 |
+
|
| 1626 |
all_pages_decision_process_table = pd.concat(all_pages_decision_process_table_list)
|
| 1627 |
all_line_level_ocr_results_df = pd.concat(all_line_level_ocr_results_df_list)
|
| 1628 |
|
| 1629 |
current_loop_page += 1
|
| 1630 |
|
| 1631 |
+
return pymupdf_doc, all_pages_decision_process_table, log_files_output_paths, textract_request_metadata, annotations_all_pages, current_loop_page, page_break_return, all_line_level_ocr_results_df, comprehend_query_number, all_page_line_level_ocr_results, all_page_line_level_ocr_results_with_words
|
| 1632 |
|
| 1633 |
# If it's an image file
|
| 1634 |
if is_pdf(file_path) == False:
|
|
|
|
| 1661 |
if textract_json_file_path not in log_files_output_paths:
|
| 1662 |
log_files_output_paths.append(textract_json_file_path)
|
| 1663 |
|
| 1664 |
+
if text_extraction_method == tesseract_ocr_option:
|
| 1665 |
+
if original_all_page_line_level_ocr_results_with_words != all_page_line_level_ocr_results_with_words:
|
| 1666 |
+
# Write the updated existing textract data back to the JSON file
|
| 1667 |
+
with open(all_page_line_level_ocr_results_with_words_json_file_path, 'w') as json_file:
|
| 1668 |
+
json.dump(all_page_line_level_ocr_results_with_words, json_file, separators=(",", ":")) # indent=4 makes the JSON file pretty-printed
|
| 1669 |
+
|
| 1670 |
+
if all_page_line_level_ocr_results_with_words_json_file_path not in log_files_output_paths:
|
| 1671 |
+
log_files_output_paths.append(all_page_line_level_ocr_results_with_words_json_file_path)
|
| 1672 |
+
|
| 1673 |
+
|
| 1674 |
all_pages_decision_process_table = pd.concat(all_pages_decision_process_table_list)
|
| 1675 |
all_line_level_ocr_results_df = pd.concat(all_line_level_ocr_results_df_list)
|
| 1676 |
|
| 1677 |
+
return pymupdf_doc, all_pages_decision_process_table, log_files_output_paths, textract_request_metadata, annotations_all_pages, current_loop_page, page_break_return, all_line_level_ocr_results_df, comprehend_query_number, all_page_line_level_ocr_results, all_page_line_level_ocr_results_with_words
|
| 1678 |
|
| 1679 |
if text_extraction_method == textract_option:
|
| 1680 |
# Write the updated existing textract data back to the JSON file
|
|
|
|
| 1686 |
if textract_json_file_path not in log_files_output_paths:
|
| 1687 |
log_files_output_paths.append(textract_json_file_path)
|
| 1688 |
|
| 1689 |
+
if text_extraction_method == tesseract_ocr_option:
|
| 1690 |
+
if original_all_page_line_level_ocr_results_with_words != all_page_line_level_ocr_results_with_words:
|
| 1691 |
+
# Write the updated existing textract data back to the JSON file
|
| 1692 |
+
with open(all_page_line_level_ocr_results_with_words_json_file_path, 'w') as json_file:
|
| 1693 |
+
json.dump(all_page_line_level_ocr_results_with_words, json_file, separators=(",", ":")) # indent=4 makes the JSON file pretty-printed
|
| 1694 |
+
|
| 1695 |
+
if all_page_line_level_ocr_results_with_words_json_file_path not in log_files_output_paths:
|
| 1696 |
+
log_files_output_paths.append(all_page_line_level_ocr_results_with_words_json_file_path)
|
| 1697 |
+
|
| 1698 |
all_pages_decision_process_table = pd.concat(all_pages_decision_process_table_list)
|
| 1699 |
all_line_level_ocr_results_df = pd.concat(all_line_level_ocr_results_df_list)
|
| 1700 |
|
| 1701 |
+
# Convert decision table and ocr results to relative coordinates
|
| 1702 |
all_pages_decision_process_table = divide_coordinates_by_page_sizes(all_pages_decision_process_table, page_sizes_df, xmin="xmin", xmax="xmax", ymin="ymin", ymax="ymax")
|
| 1703 |
|
| 1704 |
all_line_level_ocr_results_df = divide_coordinates_by_page_sizes(all_line_level_ocr_results_df, page_sizes_df, xmin="left", xmax="width", ymin="top", ymax="height")
|
| 1705 |
|
| 1706 |
+
return pymupdf_doc, all_pages_decision_process_table, log_files_output_paths, textract_request_metadata, annotations_all_pages, current_loop_page, page_break_return, all_line_level_ocr_results_df, comprehend_query_number, all_page_line_level_ocr_results, all_page_line_level_ocr_results_with_words
|
| 1707 |
|
| 1708 |
|
| 1709 |
###
|
tools/helper_functions.py
CHANGED
|
@@ -39,6 +39,12 @@ def reset_ocr_results_state():
|
|
| 39 |
def reset_review_vars():
|
| 40 |
return pd.DataFrame(), pd.DataFrame()
|
| 41 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 42 |
def load_in_default_allow_list(allow_list_file_path):
|
| 43 |
if isinstance(allow_list_file_path, str):
|
| 44 |
allow_list_file_path = [allow_list_file_path]
|
|
@@ -201,9 +207,6 @@ def put_columns_in_df(in_file:List[str]):
|
|
| 201 |
df = pd.read_excel(file_name, sheet_name=sheet_name)
|
| 202 |
|
| 203 |
# Process the DataFrame (e.g., print its contents)
|
| 204 |
-
print(f"Sheet Name: {sheet_name}")
|
| 205 |
-
print(df.head()) # Print the first few rows
|
| 206 |
-
|
| 207 |
new_choices.extend(list(df.columns))
|
| 208 |
|
| 209 |
all_sheet_names.extend(new_sheet_names)
|
|
@@ -226,7 +229,17 @@ def check_for_existing_textract_file(doc_file_name_no_extension_textbox:str, out
|
|
| 226 |
textract_output_path = os.path.join(output_folder, doc_file_name_no_extension_textbox + "_textract.json")
|
| 227 |
|
| 228 |
if os.path.exists(textract_output_path):
|
| 229 |
-
print("Existing Textract file found.")
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 230 |
return True
|
| 231 |
|
| 232 |
else:
|
|
@@ -477,9 +490,10 @@ def calculate_time_taken(number_of_pages:str,
|
|
| 477 |
pii_identification_method:str,
|
| 478 |
textract_output_found_checkbox:bool,
|
| 479 |
only_extract_text_radio:bool,
|
|
|
|
| 480 |
convert_page_time:float=0.5,
|
| 481 |
-
textract_page_time:float=1,
|
| 482 |
-
comprehend_page_time:float=1,
|
| 483 |
local_text_extraction_page_time:float=0.3,
|
| 484 |
local_pii_redaction_page_time:float=0.5,
|
| 485 |
local_ocr_extraction_page_time:float=1.5,
|
|
@@ -494,7 +508,9 @@ def calculate_time_taken(number_of_pages:str,
|
|
| 494 |
- number_of_pages: The number of pages in the uploaded document(s).
|
| 495 |
- text_extract_method_radio: The method of text extraction.
|
| 496 |
- pii_identification_method_drop: The method of personally-identifiable information removal.
|
|
|
|
| 497 |
- only_extract_text_radio (bool, optional): Option to only extract text from the document rather than redact.
|
|
|
|
| 498 |
- textract_page_time (float, optional): Approximate time to query AWS Textract.
|
| 499 |
- comprehend_page_time (float, optional): Approximate time to query text on a page with AWS Comprehend.
|
| 500 |
- local_text_redaction_page_time (float, optional): Approximate time to extract text on a page with the local text redaction option.
|
|
@@ -522,7 +538,8 @@ def calculate_time_taken(number_of_pages:str,
|
|
| 522 |
if textract_output_found_checkbox != True:
|
| 523 |
page_extraction_time_taken = number_of_pages * textract_page_time
|
| 524 |
elif text_extract_method_radio == local_ocr_option:
|
| 525 |
-
|
|
|
|
| 526 |
elif text_extract_method_radio == text_ocr_option:
|
| 527 |
page_conversion_time_taken = number_of_pages * local_text_extraction_page_time
|
| 528 |
|
|
|
|
| 39 |
def reset_review_vars():
|
| 40 |
return pd.DataFrame(), pd.DataFrame()
|
| 41 |
|
| 42 |
+
def reset_data_vars():
|
| 43 |
+
return 0, [], 0
|
| 44 |
+
|
| 45 |
+
def reset_aws_call_vars():
|
| 46 |
+
return 0, 0
|
| 47 |
+
|
| 48 |
def load_in_default_allow_list(allow_list_file_path):
|
| 49 |
if isinstance(allow_list_file_path, str):
|
| 50 |
allow_list_file_path = [allow_list_file_path]
|
|
|
|
| 207 |
df = pd.read_excel(file_name, sheet_name=sheet_name)
|
| 208 |
|
| 209 |
# Process the DataFrame (e.g., print its contents)
|
|
|
|
|
|
|
|
|
|
| 210 |
new_choices.extend(list(df.columns))
|
| 211 |
|
| 212 |
all_sheet_names.extend(new_sheet_names)
|
|
|
|
| 229 |
textract_output_path = os.path.join(output_folder, doc_file_name_no_extension_textbox + "_textract.json")
|
| 230 |
|
| 231 |
if os.path.exists(textract_output_path):
|
| 232 |
+
print("Existing Textract analysis output file found.")
|
| 233 |
+
return True
|
| 234 |
+
|
| 235 |
+
else:
|
| 236 |
+
return False
|
| 237 |
+
|
| 238 |
+
def check_for_existing_local_ocr_file(doc_file_name_no_extension_textbox:str, output_folder:str=OUTPUT_FOLDER):
|
| 239 |
+
local_ocr_output_path = os.path.join(output_folder, doc_file_name_no_extension_textbox + "_ocr_results_with_words.json")
|
| 240 |
+
|
| 241 |
+
if os.path.exists(local_ocr_output_path):
|
| 242 |
+
print("Existing local OCR analysis output file found.")
|
| 243 |
return True
|
| 244 |
|
| 245 |
else:
|
|
|
|
| 490 |
pii_identification_method:str,
|
| 491 |
textract_output_found_checkbox:bool,
|
| 492 |
only_extract_text_radio:bool,
|
| 493 |
+
local_ocr_output_found_checkbox:bool,
|
| 494 |
convert_page_time:float=0.5,
|
| 495 |
+
textract_page_time:float=1.2,
|
| 496 |
+
comprehend_page_time:float=1.2,
|
| 497 |
local_text_extraction_page_time:float=0.3,
|
| 498 |
local_pii_redaction_page_time:float=0.5,
|
| 499 |
local_ocr_extraction_page_time:float=1.5,
|
|
|
|
| 508 |
- number_of_pages: The number of pages in the uploaded document(s).
|
| 509 |
- text_extract_method_radio: The method of text extraction.
|
| 510 |
- pii_identification_method_drop: The method of personally-identifiable information removal.
|
| 511 |
+
- textract_output_found_checkbox (bool, optional): Boolean indicating if AWS Textract text extraction outputs have been found.
|
| 512 |
- only_extract_text_radio (bool, optional): Option to only extract text from the document rather than redact.
|
| 513 |
+
- local_ocr_output_found_checkbox (bool, optional): Boolean indicating if local OCR text extraction outputs have been found.
|
| 514 |
- textract_page_time (float, optional): Approximate time to query AWS Textract.
|
| 515 |
- comprehend_page_time (float, optional): Approximate time to query text on a page with AWS Comprehend.
|
| 516 |
- local_text_redaction_page_time (float, optional): Approximate time to extract text on a page with the local text redaction option.
|
|
|
|
| 538 |
if textract_output_found_checkbox != True:
|
| 539 |
page_extraction_time_taken = number_of_pages * textract_page_time
|
| 540 |
elif text_extract_method_radio == local_ocr_option:
|
| 541 |
+
if local_ocr_output_found_checkbox != True:
|
| 542 |
+
page_extraction_time_taken = number_of_pages * local_ocr_extraction_page_time
|
| 543 |
elif text_extract_method_radio == text_ocr_option:
|
| 544 |
page_conversion_time_taken = number_of_pages * local_text_extraction_page_time
|
| 545 |
|