
Commit
·
f47b137
1
Parent(s):
ab04c92
Updated duplicate pages interface to include subdocuments and review. Updated relevant user guide. Minor package updates
Browse files- README.md +40 -8
- app.py +166 -107
- pyproject.toml +1 -1
- requirements.txt +1 -1
- src/user_guide.qmd +44 -12
- tools/file_conversion.py +17 -5
- tools/find_duplicate_pages.py +269 -139
- tools/helper_functions.py +8 -0
- tools/redaction_review.py +10 -2
README.md
CHANGED
|
@@ -14,7 +14,7 @@ version: 0.7.0
|
|
| 14 |
|
| 15 |
Redact personally identifiable information (PII) from documents (pdf, images), open text, or tabular data (xlsx/csv/parquet). Please see the [User Guide](#user-guide) for a walkthrough on how to use the app. Below is a very brief overview.
|
| 16 |
|
| 17 |
-
To identify text in documents, the 'local' text/OCR image analysis uses spacy/tesseract, and works
|
| 18 |
|
| 19 |
After redaction, review suggested redactions on the 'Review redactions' tab. The original pdf can be uploaded here alongside a '...redaction_file.csv' to continue a previous redaction/review task. See the 'Redaction settings' tab to choose which pages to redact, the type of information to redact (e.g. people, places), or custom terms to always include/ exclude from redaction.
|
| 20 |
|
|
@@ -181,6 +181,8 @@ If the table is empty, you can add a new entry, you can add a new row by clickin
|
|
| 181 |
|
| 182 |

|
| 183 |
|
|
|
|
|
|
|
| 184 |
### Redacting additional types of personal information
|
| 185 |
|
| 186 |
You may want to redact additional types of information beyond the defaults, or you may not be interested in default suggested entity types. There are dates in the example complaint letter. Say we wanted to redact those dates also?
|
|
@@ -390,21 +392,49 @@ You can find this option at the bottom of the 'Redaction Settings' tab. Upload m
|
|
| 390 |
|
| 391 |
The files for this section are stored [here](https://github.com/seanpedrick-case/document_redaction_examples/blob/main/duplicate_page_find_in_app/).
|
| 392 |
|
| 393 |
-
Some redaction tasks involve removing duplicate pages of text that may exist across multiple documents. This feature
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 394 |
|
| 395 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 396 |
|
| 397 |
-
|
| 398 |
|
| 399 |
-
|
|
|
|
| 400 |
|
| 401 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 402 |
|
| 403 |
|
| 404 |
|
| 405 |
-
|
| 406 |
|
| 407 |
-
 above.
|
| 410 |
|
|
@@ -505,6 +535,8 @@ Again, a lot can potentially go wrong with AWS solutions that are insecure, so b
|
|
| 505 |
|
| 506 |
## Modifying existing redaction review files
|
| 507 |
|
|
|
|
|
|
|
| 508 |
You can find the folder containing the files discussed in this section [here](https://github.com/seanpedrick-case/document_redaction_examples/blob/main/merge_review_files/).
|
| 509 |
|
| 510 |
As well as serving as inputs to the document redaction app's review function, the 'review_file.csv' output can be modified outside of the app, and also merged with others from multiple redaction attempts on the same file. This gives you the flexibility to change redaction details outside of the app.
|
|
|
|
| 14 |
|
| 15 |
Redact personally identifiable information (PII) from documents (pdf, images), open text, or tabular data (xlsx/csv/parquet). Please see the [User Guide](#user-guide) for a walkthrough on how to use the app. Below is a very brief overview.
|
| 16 |
|
| 17 |
+
To identify text in documents, the 'local' text/OCR image analysis uses spacy/tesseract, and works quite well for documents with typed text. If available, choose 'AWS Textract service' to redact more complex elements e.g. signatures or handwriting. Then, choose a method for PII identification. 'Local' is quick and gives good results if you are primarily looking for a custom list of terms to redact (see Redaction settings). If available, AWS Comprehend gives better results at a small cost.
|
| 18 |
|
| 19 |
After redaction, review suggested redactions on the 'Review redactions' tab. The original pdf can be uploaded here alongside a '...redaction_file.csv' to continue a previous redaction/review task. See the 'Redaction settings' tab to choose which pages to redact, the type of information to redact (e.g. people, places), or custom terms to always include/ exclude from redaction.
|
| 20 |
|
|
|
|
| 181 |
|
| 182 |

|
| 183 |
|
| 184 |
+
**Note:** As of version 0.7.0 you can now apply your whole page redaction list directly to the document file currently under review by clicking the 'Apply whole page redaction list to document currently under review' button that appears here.
|
| 185 |
+
|
| 186 |
### Redacting additional types of personal information
|
| 187 |
|
| 188 |
You may want to redact additional types of information beyond the defaults, or you may not be interested in default suggested entity types. There are dates in the example complaint letter. Say we wanted to redact those dates also?
|
|
|
|
| 392 |
|
| 393 |
The files for this section are stored [here](https://github.com/seanpedrick-case/document_redaction_examples/blob/main/duplicate_page_find_in_app/).
|
| 394 |
|
| 395 |
+
Some redaction tasks involve removing duplicate pages of text that may exist across multiple documents. This feature helps you find and remove duplicate content that may exist in single or multiple documents. It can identify everything from single identical pages to multi-page sections (subdocuments). The process involves three main steps: configuring the analysis, reviewing the results in the interactive interface, and then using the generated files to perform the redactions.
|
| 396 |
+
|
| 397 |
+

|
| 398 |
+
|
| 399 |
+
**Step 1: Upload and Configure the Analysis**
|
| 400 |
+
First, navigate to the "Identify duplicate pages" tab. Upload all the ocr_output.csv files you wish to compare into the file area. These files are generated every time you run a redaction task and contain the text for each page of a document.
|
| 401 |
+
|
| 402 |
+
For our example, you can upload the four 'ocr_output.csv' files provided in the example folder into the file area. Click 'Identify duplicate pages' and you will see a number of files returned. In case you want to see the original PDFs, they are available [here](https://github.com/seanpedrick-case/document_redaction_examples/blob/main/duplicate_page_find_in_app/input_pdfs/).
|
| 403 |
+
|
| 404 |
+
The default options will search for matching subdocuments of any length. Before running the analysis, you can configure these matching parameters to tell the tool what you're looking for:
|
| 405 |
+
|
| 406 |
+
|
| 407 |
|
| 408 |
+
*Matching Parameters*
|
| 409 |
+
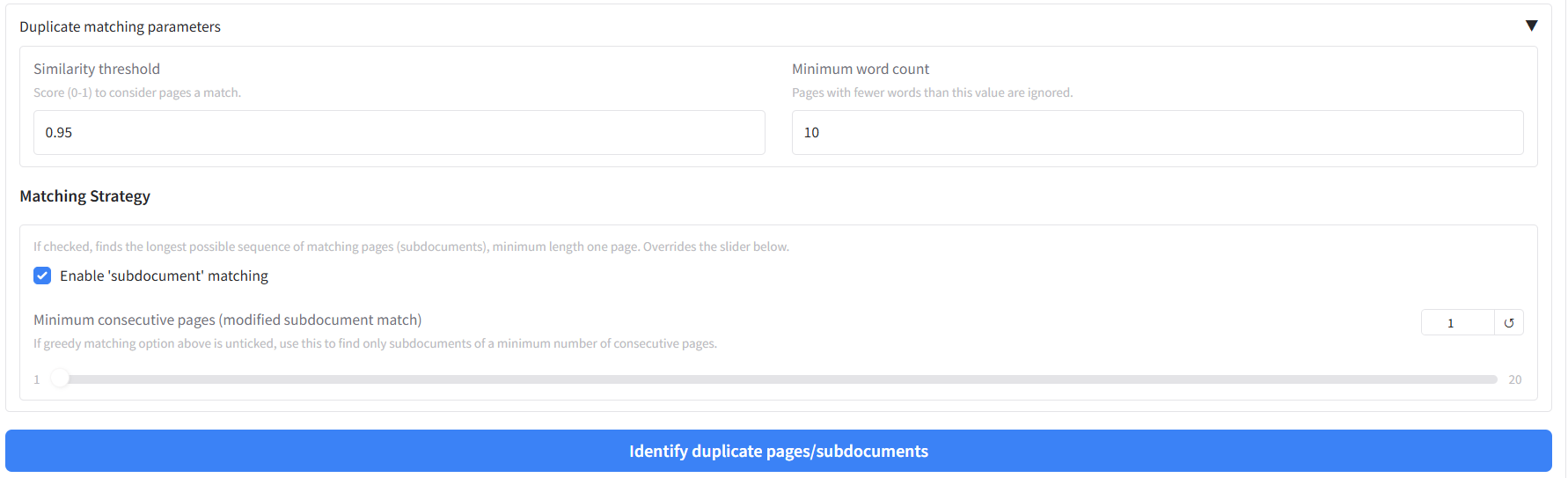
- **Similarity Threshold:** A score from 0 to 1. Pages or sequences of pages with a calculated text similarity above this value will be considered a match. The default of 0.9 (90%) is a good starting point for finding near-identical pages.
|
| 410 |
+
- **Min Word Count:** Pages with fewer words than this value will be completely ignored during the comparison. This is extremely useful for filtering out blank pages, title pages, or boilerplate pages that might otherwise create noise in the results. The default is 10.
|
| 411 |
+
- **Choosing a Matching Strategy:** You have three main options to find duplicate content.
|
| 412 |
+
- *'Subdocument' matching (default):* Use this to find the longest possible sequence of matching pages. The tool will find an initial match and then automatically expand it forward page-by-page until the consecutive match breaks. This is the best method for identifying complete copied chapters or sections of unknown length. This is enabled by default by ticking the "Enable 'subdocument' matching" box. This setting overrides the described below.
|
| 413 |
+
- *Minimum length subdocument matching:* Use this to find sequences of consecutively matching pages with a minimum page lenght. For example, setting the slider to 3 will only return sections that are at least 3 pages long. How to enable: Untick the "Enable 'subdocument' matching" box and set the "Minimum consecutive pages" slider to a value greater than 1.
|
| 414 |
+
- *Single Page Matching:* Use this to find all individual page pairs that are similar to each other. Leave the "Enable 'subdocument' matching" box unchecked and keep the "Minimum consecutive pages" slider at 1.
|
| 415 |
|
| 416 |
+
Once your parameters are set, click the "Identify duplicate pages/subdocuments" button.
|
| 417 |
|
| 418 |
+
**Step 2: Review Results in the Interface**
|
| 419 |
+
After the analysis is complete, the results will be displayed directly in the interface.
|
| 420 |
|
| 421 |
+
*Analysis Summary:* A table will appear showing a summary of all the matches found. The columns will change depending on the matching strategy you chose. For subdocument matches, it will show the start and end pages of the matched sequence.
|
| 422 |
+
|
| 423 |
+
*Interactive Preview:* This is the most important part of the review process. Click on any row in the summary table. The full text of the matching page(s) will appear side-by-side in the "Full Text Preview" section below, allowing you to instantly verify the accuracy of the match.
|
| 424 |
+
|
| 425 |
+

|
| 426 |
+
|
| 427 |
+
**Step 3: Download and Use the Output Files**
|
| 428 |
+
The analysis also generates a set of downloadable files for your records and for performing redactions.
|
| 429 |
+
|
| 430 |
+
|
| 431 |
+
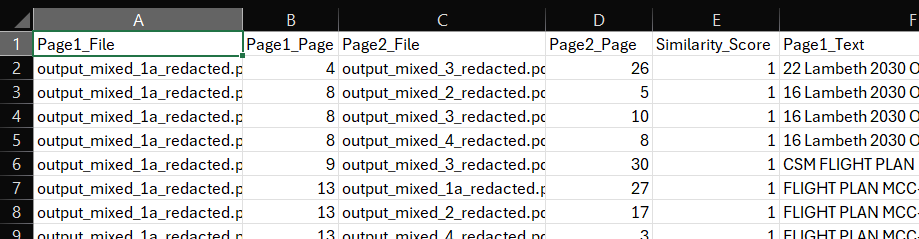
- page_similarity_results.csv: This is a detailed report of the analysis you just ran. It shows a breakdown of the pages from each file that are most similar to each other above the similarity threshold. You can compare the text in the two columns 'Page_1_Text' and 'Page_2_Text'. For single-page matches, it will list each pair of matching pages. For subdocument matches, it will list the start and end pages of each matched sequence, along with the total length of the match.
|
| 432 |
|
| 433 |

|
| 434 |
|
| 435 |
+
- [Original_Filename]_pages_to_redact.csv: For each input document that was found to contain duplicate content, a separate redaction list is created. This is a simple, one-column CSV file containing a list of all page numbers that should be removed. To use these files, you can either upload the original document (i.e. the PDF) on the 'Review redactions' tab, and then click on the 'Apply relevant duplicate page output to document currently under review' button. You should see the whole pages suggested for redaction on the 'Review redactions' tab. Alternatively, you can reupload the file into the whole page redaction section as described in the ['Full page redaction list example' section](#full-page-redaction-list-example).
|
| 436 |
|
| 437 |
+

|
| 438 |
|
| 439 |
If you want to combine the results from this redaction process with previous redaction tasks for the same PDF, you could merge review file outputs following the steps described in [Merging existing redaction review files](#merging-existing-redaction-review-files) above.
|
| 440 |
|
|
|
|
| 535 |
|
| 536 |
## Modifying existing redaction review files
|
| 537 |
|
| 538 |
+
*Note:* As of version 0.7.0 you can now modify redaction review files directly in the app on the 'Review redactions' tab. Open the accordion 'View and edit review data' under the file input area. You can edit review file data cells here - press Enter to apply changes. You should see the effect on the current page if you click the 'Save changes on current page to file' button to the right.
|
| 539 |
+
|
| 540 |
You can find the folder containing the files discussed in this section [here](https://github.com/seanpedrick-case/document_redaction_examples/blob/main/merge_review_files/).
|
| 541 |
|
| 542 |
As well as serving as inputs to the document redaction app's review function, the 'review_file.csv' output can be modified outside of the app, and also merged with others from multiple redaction attempts on the same file. This gives you the flexibility to change redaction details outside of the app.
|
app.py
CHANGED
|
@@ -3,37 +3,39 @@ import pandas as pd
|
|
| 3 |
import gradio as gr
|
| 4 |
from gradio_image_annotation import image_annotator
|
| 5 |
from tools.config import OUTPUT_FOLDER, INPUT_FOLDER, RUN_DIRECT_MODE, MAX_QUEUE_SIZE, DEFAULT_CONCURRENCY_LIMIT, MAX_FILE_SIZE, GRADIO_SERVER_PORT, ROOT_PATH, GET_DEFAULT_ALLOW_LIST, ALLOW_LIST_PATH, S3_ALLOW_LIST_PATH, FEEDBACK_LOGS_FOLDER, ACCESS_LOGS_FOLDER, USAGE_LOGS_FOLDER, REDACTION_LANGUAGE, GET_COST_CODES, COST_CODES_PATH, S3_COST_CODES_PATH, ENFORCE_COST_CODES, DISPLAY_FILE_NAMES_IN_LOGS, SHOW_COSTS, RUN_AWS_FUNCTIONS, DOCUMENT_REDACTION_BUCKET, SHOW_WHOLE_DOCUMENT_TEXTRACT_CALL_OPTIONS, TEXTRACT_WHOLE_DOCUMENT_ANALYSIS_BUCKET, TEXTRACT_WHOLE_DOCUMENT_ANALYSIS_INPUT_SUBFOLDER, TEXTRACT_WHOLE_DOCUMENT_ANALYSIS_OUTPUT_SUBFOLDER, SESSION_OUTPUT_FOLDER, LOAD_PREVIOUS_TEXTRACT_JOBS_S3, TEXTRACT_JOBS_S3_LOC, TEXTRACT_JOBS_LOCAL_LOC, HOST_NAME, DEFAULT_COST_CODE, OUTPUT_COST_CODES_PATH, OUTPUT_ALLOW_LIST_PATH, COGNITO_AUTH, SAVE_LOGS_TO_CSV, SAVE_LOGS_TO_DYNAMODB, ACCESS_LOG_DYNAMODB_TABLE_NAME, DYNAMODB_ACCESS_LOG_HEADERS, CSV_ACCESS_LOG_HEADERS, FEEDBACK_LOG_DYNAMODB_TABLE_NAME, DYNAMODB_FEEDBACK_LOG_HEADERS, CSV_FEEDBACK_LOG_HEADERS, USAGE_LOG_DYNAMODB_TABLE_NAME, DYNAMODB_USAGE_LOG_HEADERS, CSV_USAGE_LOG_HEADERS, TEXTRACT_JOBS_S3_INPUT_LOC, TEXTRACT_TEXT_EXTRACT_OPTION, NO_REDACTION_PII_OPTION, TEXT_EXTRACTION_MODELS, PII_DETECTION_MODELS, DEFAULT_TEXT_EXTRACTION_MODEL, DEFAULT_PII_DETECTION_MODEL, LOG_FILE_NAME, CHOSEN_COMPREHEND_ENTITIES, FULL_COMPREHEND_ENTITY_LIST, CHOSEN_REDACT_ENTITIES, FULL_ENTITY_LIST, FILE_INPUT_HEIGHT, TABULAR_PII_DETECTION_MODELS
|
| 6 |
-
from tools.helper_functions import put_columns_in_df, get_connection_params, reveal_feedback_buttons, custom_regex_load, reset_state_vars, load_in_default_allow_list, reset_review_vars, merge_csv_files, load_all_output_files, update_dataframe, check_for_existing_textract_file, load_in_default_cost_codes, enforce_cost_codes, calculate_aws_costs, calculate_time_taken, reset_base_dataframe, reset_ocr_base_dataframe, update_cost_code_dataframe_from_dropdown_select, check_for_existing_local_ocr_file, reset_data_vars, reset_aws_call_vars
|
| 7 |
from tools.aws_functions import download_file_from_s3, upload_log_file_to_s3
|
| 8 |
from tools.file_redaction import choose_and_run_redactor
|
| 9 |
from tools.file_conversion import prepare_image_or_pdf, get_input_file_names
|
| 10 |
-
from tools.redaction_review import apply_redactions_to_review_df_and_files, update_all_page_annotation_object_based_on_previous_page, decrease_page, increase_page, update_annotator_object_and_filter_df, update_entities_df_recogniser_entities, update_entities_df_page, update_entities_df_text, df_select_callback_dataframe_row, convert_df_to_xfdf, convert_xfdf_to_dataframe, reset_dropdowns, exclude_selected_items_from_redaction, undo_last_removal, update_selected_review_df_row_colour, update_all_entity_df_dropdowns, df_select_callback_cost, update_other_annotator_number_from_current, update_annotator_page_from_review_df, df_select_callback_ocr, df_select_callback_textract_api, get_all_rows_with_same_text, increase_bottom_page_count_based_on_top
|
| 11 |
from tools.data_anonymise import anonymise_data_files
|
| 12 |
from tools.auth import authenticate_user
|
| 13 |
from tools.load_spacy_model_custom_recognisers import custom_entities
|
| 14 |
from tools.custom_csvlogger import CSVLogger_custom
|
| 15 |
-
from tools.find_duplicate_pages import
|
| 16 |
from tools.textract_batch_call import analyse_document_with_textract_api, poll_whole_document_textract_analysis_progress_and_download, load_in_textract_job_details, check_for_provided_job_id, check_textract_outputs_exist, replace_existing_pdf_input_for_whole_document_outputs
|
| 17 |
|
| 18 |
# Suppress downcasting warnings
|
| 19 |
pd.set_option('future.no_silent_downcasting', True)
|
| 20 |
|
| 21 |
# Convert string environment variables to string or list
|
| 22 |
-
SAVE_LOGS_TO_CSV =
|
| 23 |
-
|
|
|
|
|
|
|
| 24 |
|
| 25 |
-
if CSV_ACCESS_LOG_HEADERS: CSV_ACCESS_LOG_HEADERS =
|
| 26 |
-
if CSV_FEEDBACK_LOG_HEADERS: CSV_FEEDBACK_LOG_HEADERS =
|
| 27 |
-
if CSV_USAGE_LOG_HEADERS: CSV_USAGE_LOG_HEADERS =
|
| 28 |
|
| 29 |
-
if DYNAMODB_ACCESS_LOG_HEADERS: DYNAMODB_ACCESS_LOG_HEADERS =
|
| 30 |
-
if DYNAMODB_FEEDBACK_LOG_HEADERS: DYNAMODB_FEEDBACK_LOG_HEADERS =
|
| 31 |
-
if DYNAMODB_USAGE_LOG_HEADERS: DYNAMODB_USAGE_LOG_HEADERS =
|
| 32 |
|
| 33 |
-
if CHOSEN_COMPREHEND_ENTITIES: CHOSEN_COMPREHEND_ENTITIES =
|
| 34 |
-
if FULL_COMPREHEND_ENTITY_LIST: FULL_COMPREHEND_ENTITY_LIST =
|
| 35 |
-
if CHOSEN_REDACT_ENTITIES: CHOSEN_REDACT_ENTITIES =
|
| 36 |
-
if FULL_ENTITY_LIST: FULL_ENTITY_LIST =
|
| 37 |
|
| 38 |
# Add custom spacy recognisers to the Comprehend list, so that local Spacy model can be used to pick up e.g. titles, streetnames, UK postcodes that are sometimes missed by comprehend
|
| 39 |
CHOSEN_COMPREHEND_ENTITIES.extend(custom_entities)
|
|
@@ -42,7 +44,7 @@ FULL_COMPREHEND_ENTITY_LIST.extend(custom_entities)
|
|
| 42 |
FILE_INPUT_HEIGHT = int(FILE_INPUT_HEIGHT)
|
| 43 |
|
| 44 |
# Create the gradio interface
|
| 45 |
-
app = gr.Blocks(theme = gr.themes.
|
| 46 |
|
| 47 |
with app:
|
| 48 |
|
|
@@ -55,7 +57,7 @@ with app:
|
|
| 55 |
all_image_annotations_state = gr.State([])
|
| 56 |
|
| 57 |
all_decision_process_table_state = gr.Dataframe(value=pd.DataFrame(), headers=None, col_count=0, row_count = (0, "dynamic"), label="all_decision_process_table", visible=False, type="pandas", wrap=True)
|
| 58 |
-
|
| 59 |
|
| 60 |
all_page_line_level_ocr_results = gr.State([])
|
| 61 |
all_page_line_level_ocr_results_with_children = gr.State([])
|
|
@@ -186,7 +188,9 @@ with app:
|
|
| 186 |
# Duplicate page detection
|
| 187 |
in_duplicate_pages_text = gr.Textbox(label="in_duplicate_pages_text", visible=False)
|
| 188 |
duplicate_pages_df = gr.Dataframe(value=pd.DataFrame(), headers=None, col_count=0, row_count = (0, "dynamic"), label="duplicate_pages_df", visible=False, type="pandas", wrap=True)
|
| 189 |
-
|
|
|
|
|
|
|
| 190 |
|
| 191 |
# Tracking variables for current page (not visible)
|
| 192 |
current_loop_page_number = gr.Number(value=0,precision=0, interactive=False, label = "Last redacted page in document", visible=False)
|
|
@@ -231,7 +235,7 @@ with app:
|
|
| 231 |
|
| 232 |
Redact personally identifiable information (PII) from documents (PDF, images), open text, or tabular data (XLSX/CSV/Parquet). Please see the [User Guide](https://github.com/seanpedrick-case/doc_redaction/blob/main/README.md) for a walkthrough on how to use the app. Below is a very brief overview.
|
| 233 |
|
| 234 |
-
To identify text in documents, the 'Local' text/OCR image analysis uses
|
| 235 |
|
| 236 |
After redaction, review suggested redactions on the 'Review redactions' tab. The original pdf can be uploaded here alongside a '...review_file.csv' to continue a previous redaction/review task. See the 'Redaction settings' tab to choose which pages to redact, the type of information to redact (e.g. people, places), or custom terms to always include/ exclude from redaction.
|
| 237 |
|
|
@@ -260,9 +264,9 @@ with app:
|
|
| 260 |
local_ocr_output_found_checkbox = gr.Checkbox(value= False, label="Existing local OCR output file found", interactive=False, visible=True)
|
| 261 |
with gr.Column(scale=4):
|
| 262 |
with gr.Row(equal_height=True):
|
| 263 |
-
total_pdf_page_count = gr.Number(label = "Total page count", value=0, visible=True)
|
| 264 |
-
estimated_aws_costs_number = gr.Number(label = "Approximate AWS Textract and/or Comprehend cost (£)", value=0.00, precision=2, visible=True)
|
| 265 |
-
estimated_time_taken_number = gr.Number(label = "Approximate time taken to extract text/redact (minutes)", value=0, visible=True, precision=2)
|
| 266 |
|
| 267 |
if GET_COST_CODES == "True" or ENFORCE_COST_CODES == "True":
|
| 268 |
with gr.Accordion("Assign task to cost code", open = True, visible=True):
|
|
@@ -318,7 +322,10 @@ with app:
|
|
| 318 |
annotate_zoom_in = gr.Button("Zoom in", visible=False)
|
| 319 |
annotate_zoom_out = gr.Button("Zoom out", visible=False)
|
| 320 |
with gr.Row():
|
| 321 |
-
clear_all_redactions_on_page_btn = gr.Button("Clear all redactions on page", visible=False)
|
|
|
|
|
|
|
|
|
|
| 322 |
|
| 323 |
with gr.Row():
|
| 324 |
with gr.Column(scale=2):
|
|
@@ -389,47 +396,67 @@ with app:
|
|
| 389 |
# IDENTIFY DUPLICATE PAGES TAB
|
| 390 |
###
|
| 391 |
with gr.Tab(label="Identify duplicate pages"):
|
| 392 |
-
|
|
|
|
|
|
|
| 393 |
in_duplicate_pages = gr.File(
|
| 394 |
-
label="Upload multiple 'ocr_output.csv' files to
|
| 395 |
file_count="multiple", height=FILE_INPUT_HEIGHT, file_types=['.csv']
|
| 396 |
)
|
| 397 |
|
| 398 |
-
gr.
|
| 399 |
-
|
| 400 |
-
|
| 401 |
-
|
| 402 |
-
|
| 403 |
-
|
| 404 |
-
|
| 405 |
-
|
| 406 |
-
|
| 407 |
-
|
| 408 |
-
|
| 409 |
-
|
| 410 |
-
|
| 411 |
-
|
| 412 |
-
|
| 413 |
-
|
| 414 |
|
| 415 |
-
find_duplicate_pages_btn = gr.Button(value="Identify
|
| 416 |
|
| 417 |
-
with gr.Accordion("Step 2: Review
|
| 418 |
-
gr.Markdown("### Analysis
|
| 419 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 420 |
|
| 421 |
-
gr.Markdown("### Full Text Preview")
|
| 422 |
with gr.Row():
|
| 423 |
-
page1_text_preview = gr.
|
| 424 |
-
page2_text_preview = gr.
|
| 425 |
|
| 426 |
gr.Markdown("### Downloadable Files")
|
| 427 |
-
|
| 428 |
label="Download analysis summary and redaction lists (.csv)",
|
| 429 |
-
file_count="multiple",
|
|
|
|
| 430 |
)
|
| 431 |
|
| 432 |
-
|
|
|
|
|
|
|
|
|
|
| 433 |
|
| 434 |
###
|
| 435 |
# TEXT / TABULAR DATA TAB
|
|
@@ -484,6 +511,13 @@ with app:
|
|
| 484 |
in_allow_list_state = gr.Dataframe(value=pd.DataFrame(), headers=["allow_list"], col_count=(1, "fixed"), row_count = (0, "dynamic"), label="Allow list", visible=True, type="pandas", interactive=True, show_fullscreen_button=True, show_copy_button=True, wrap=True)
|
| 485 |
in_deny_list_state = gr.Dataframe(value=pd.DataFrame(), headers=["deny_list"], col_count=(1, "fixed"), row_count = (0, "dynamic"), label="Deny list", visible=True, type="pandas", interactive=True, show_fullscreen_button=True, show_copy_button=True, wrap=True)
|
| 486 |
in_fully_redacted_list_state = gr.Dataframe(value=pd.DataFrame(), headers=["fully_redacted_pages_list"], col_count=(1, "fixed"), row_count = (0, "dynamic"), label="Fully redacted pages", visible=True, type="pandas", interactive=True, show_fullscreen_button=True, show_copy_button=True, datatype='number', wrap=True)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 487 |
|
| 488 |
with gr.Accordion("Select entity types to redact", open = True):
|
| 489 |
in_redact_entities = gr.Dropdown(value=CHOSEN_REDACT_ENTITIES, choices=FULL_ENTITY_LIST, multiselect=True, label="Local PII identification model (click empty space in box for full list)")
|
|
@@ -553,24 +587,24 @@ with app:
|
|
| 553 |
cost_code_choice_drop.select(update_cost_code_dataframe_from_dropdown_select, inputs=[cost_code_choice_drop, cost_code_dataframe_base], outputs=[cost_code_dataframe])
|
| 554 |
|
| 555 |
in_doc_files.upload(fn=get_input_file_names, inputs=[in_doc_files], outputs=[doc_file_name_no_extension_textbox, doc_file_name_with_extension_textbox, doc_full_file_name_textbox, doc_file_name_textbox_list, total_pdf_page_count]).\
|
| 556 |
-
success(fn = prepare_image_or_pdf, inputs=[in_doc_files, text_extract_method_radio, latest_file_completed_text, redaction_output_summary_textbox, first_loop_state, annotate_max_pages, all_image_annotations_state, prepare_for_review_bool_false, in_fully_redacted_list_state, output_folder_textbox, input_folder_textbox, prepare_images_bool_false], outputs=[redaction_output_summary_textbox, prepared_pdf_state, images_pdf_state, annotate_max_pages, annotate_max_pages_bottom, pdf_doc_state, all_image_annotations_state,
|
| 557 |
success(fn=check_for_existing_textract_file, inputs=[doc_file_name_no_extension_textbox, output_folder_textbox], outputs=[textract_output_found_checkbox]).\
|
| 558 |
success(fn=check_for_existing_local_ocr_file, inputs=[doc_file_name_no_extension_textbox, output_folder_textbox], outputs=[local_ocr_output_found_checkbox])
|
| 559 |
|
| 560 |
# Run redaction function
|
| 561 |
document_redact_btn.click(fn = reset_state_vars, outputs=[all_image_annotations_state, all_line_level_ocr_results_df_base, all_decision_process_table_state, comprehend_query_number, textract_metadata_textbox, annotator, output_file_list_state, log_files_output_list_state, recogniser_entity_dataframe, recogniser_entity_dataframe_base, pdf_doc_state, duplication_file_path_outputs_list_state, redaction_output_summary_textbox, is_a_textract_api_call, textract_query_number]).\
|
| 562 |
success(fn= enforce_cost_codes, inputs=[enforce_cost_code_textbox, cost_code_choice_drop, cost_code_dataframe_base]).\
|
| 563 |
-
success(fn= choose_and_run_redactor, inputs=[in_doc_files, prepared_pdf_state, images_pdf_state, in_redact_language, in_redact_entities, in_redact_comprehend_entities, text_extract_method_radio, in_allow_list_state, in_deny_list_state, in_fully_redacted_list_state, latest_file_completed_text, redaction_output_summary_textbox, output_file_list_state, log_files_output_list_state, first_loop_state, page_min, page_max, actual_time_taken_number, handwrite_signature_checkbox, textract_metadata_textbox, all_image_annotations_state, all_line_level_ocr_results_df_base, all_decision_process_table_state, pdf_doc_state, current_loop_page_number, page_break_return, pii_identification_method_drop, comprehend_query_number, max_fuzzy_spelling_mistakes_num, match_fuzzy_whole_phrase_bool, aws_access_key_textbox, aws_secret_key_textbox, annotate_max_pages,
|
| 564 |
-
outputs=[redaction_output_summary_textbox, output_file, output_file_list_state, latest_file_completed_text, log_files_output, log_files_output_list_state, actual_time_taken_number, textract_metadata_textbox, pdf_doc_state, all_image_annotations_state, current_loop_page_number, page_break_return, all_line_level_ocr_results_df_base, all_decision_process_table_state, comprehend_query_number, output_review_files, annotate_max_pages, annotate_max_pages_bottom, prepared_pdf_state, images_pdf_state,
|
| 565 |
|
| 566 |
# If the app has completed a batch of pages, it will rerun the redaction process until the end of all pages in the document
|
| 567 |
-
current_loop_page_number.change(fn = choose_and_run_redactor, inputs=[in_doc_files, prepared_pdf_state, images_pdf_state, in_redact_language, in_redact_entities, in_redact_comprehend_entities, text_extract_method_radio, in_allow_list_state, in_deny_list_state, in_fully_redacted_list_state, latest_file_completed_text, redaction_output_summary_textbox, output_file_list_state, log_files_output_list_state, second_loop_state, page_min, page_max, actual_time_taken_number, handwrite_signature_checkbox, textract_metadata_textbox, all_image_annotations_state, all_line_level_ocr_results_df_base, all_decision_process_table_state, pdf_doc_state, current_loop_page_number, page_break_return, pii_identification_method_drop, comprehend_query_number, max_fuzzy_spelling_mistakes_num, match_fuzzy_whole_phrase_bool, aws_access_key_textbox, aws_secret_key_textbox, annotate_max_pages,
|
| 568 |
-
outputs=[redaction_output_summary_textbox, output_file, output_file_list_state, latest_file_completed_text, log_files_output, log_files_output_list_state, actual_time_taken_number, textract_metadata_textbox, pdf_doc_state, all_image_annotations_state, current_loop_page_number, page_break_return, all_line_level_ocr_results_df_base, all_decision_process_table_state, comprehend_query_number, output_review_files, annotate_max_pages, annotate_max_pages_bottom, prepared_pdf_state, images_pdf_state,
|
| 569 |
|
| 570 |
# If a file has been completed, the function will continue onto the next document
|
| 571 |
-
latest_file_completed_text.change(fn = choose_and_run_redactor, inputs=[in_doc_files, prepared_pdf_state, images_pdf_state, in_redact_language, in_redact_entities, in_redact_comprehend_entities, text_extract_method_radio, in_allow_list_state, in_deny_list_state, in_fully_redacted_list_state, latest_file_completed_text, redaction_output_summary_textbox, output_file_list_state, log_files_output_list_state, second_loop_state, page_min, page_max, actual_time_taken_number, handwrite_signature_checkbox, textract_metadata_textbox, all_image_annotations_state, all_line_level_ocr_results_df_base, all_decision_process_table_state, pdf_doc_state, current_loop_page_number, page_break_return, pii_identification_method_drop, comprehend_query_number, max_fuzzy_spelling_mistakes_num, match_fuzzy_whole_phrase_bool, aws_access_key_textbox, aws_secret_key_textbox, annotate_max_pages,
|
| 572 |
-
outputs=[redaction_output_summary_textbox, output_file, output_file_list_state, latest_file_completed_text, log_files_output, log_files_output_list_state, actual_time_taken_number, textract_metadata_textbox, pdf_doc_state, all_image_annotations_state, current_loop_page_number, page_break_return, all_line_level_ocr_results_df_base, all_decision_process_table_state, comprehend_query_number, output_review_files, annotate_max_pages, annotate_max_pages_bottom, prepared_pdf_state, images_pdf_state,
|
| 573 |
-
success(fn=update_annotator_object_and_filter_df, inputs=[all_image_annotations_state, page_min, recogniser_entity_dropdown, page_entity_dropdown, text_entity_dropdown, recogniser_entity_dataframe_base, annotator_zoom_number,
|
| 574 |
success(fn=check_for_existing_textract_file, inputs=[doc_file_name_no_extension_textbox, output_folder_textbox], outputs=[textract_output_found_checkbox]).\
|
| 575 |
success(fn=check_for_existing_local_ocr_file, inputs=[doc_file_name_no_extension_textbox, output_folder_textbox], outputs=[local_ocr_output_found_checkbox]).\
|
| 576 |
success(fn=reveal_feedback_buttons, outputs=[pdf_feedback_radio, pdf_further_details_text, pdf_submit_feedback_btn, pdf_feedback_title]).\
|
|
@@ -592,62 +626,67 @@ with app:
|
|
| 592 |
textract_job_detail_df.select(df_select_callback_textract_api, inputs=[textract_output_found_checkbox], outputs=[job_id_textbox, job_type_dropdown, selected_job_id_row])
|
| 593 |
|
| 594 |
convert_textract_outputs_to_ocr_results.click(replace_existing_pdf_input_for_whole_document_outputs, inputs = [s3_whole_document_textract_input_subfolder, doc_file_name_no_extension_textbox, output_folder_textbox, s3_whole_document_textract_default_bucket, in_doc_files, input_folder_textbox], outputs = [in_doc_files, doc_file_name_no_extension_textbox, doc_file_name_with_extension_textbox, doc_full_file_name_textbox, doc_file_name_textbox_list, total_pdf_page_count]).\
|
| 595 |
-
success(fn = prepare_image_or_pdf, inputs=[in_doc_files, text_extract_method_radio, latest_file_completed_text, redaction_output_summary_textbox, first_loop_state, annotate_max_pages, all_image_annotations_state, prepare_for_review_bool_false, in_fully_redacted_list_state, output_folder_textbox, input_folder_textbox, prepare_images_bool_false], outputs=[redaction_output_summary_textbox, prepared_pdf_state, images_pdf_state, annotate_max_pages, annotate_max_pages_bottom, pdf_doc_state, all_image_annotations_state,
|
| 596 |
success(fn=check_for_existing_textract_file, inputs=[doc_file_name_no_extension_textbox, output_folder_textbox], outputs=[textract_output_found_checkbox]).\
|
| 597 |
success(fn=check_for_existing_local_ocr_file, inputs=[doc_file_name_no_extension_textbox, output_folder_textbox], outputs=[local_ocr_output_found_checkbox]).\
|
| 598 |
success(fn= check_textract_outputs_exist, inputs=[textract_output_found_checkbox]).\
|
| 599 |
success(fn = reset_state_vars, outputs=[all_image_annotations_state, all_line_level_ocr_results_df_base, all_decision_process_table_state, comprehend_query_number, textract_metadata_textbox, annotator, output_file_list_state, log_files_output_list_state, recogniser_entity_dataframe, recogniser_entity_dataframe_base, pdf_doc_state, duplication_file_path_outputs_list_state, redaction_output_summary_textbox, is_a_textract_api_call, textract_query_number]).\
|
| 600 |
-
success(fn= choose_and_run_redactor, inputs=[in_doc_files, prepared_pdf_state, images_pdf_state, in_redact_language, in_redact_entities, in_redact_comprehend_entities, textract_only_method_drop, in_allow_list_state, in_deny_list_state, in_fully_redacted_list_state, latest_file_completed_text, redaction_output_summary_textbox, output_file_list_state, log_files_output_list_state, first_loop_state, page_min, page_max, actual_time_taken_number, handwrite_signature_checkbox, textract_metadata_textbox, all_image_annotations_state, all_line_level_ocr_results_df_base, all_decision_process_table_state, pdf_doc_state, current_loop_page_number, page_break_return, no_redaction_method_drop, comprehend_query_number, max_fuzzy_spelling_mistakes_num, match_fuzzy_whole_phrase_bool, aws_access_key_textbox, aws_secret_key_textbox, annotate_max_pages,
|
| 601 |
-
outputs=[redaction_output_summary_textbox, output_file, output_file_list_state, latest_file_completed_text, log_files_output, log_files_output_list_state, actual_time_taken_number, textract_metadata_textbox, pdf_doc_state, all_image_annotations_state, current_loop_page_number, page_break_return, all_line_level_ocr_results_df_base, all_decision_process_table_state, comprehend_query_number, output_review_files, annotate_max_pages, annotate_max_pages_bottom, prepared_pdf_state, images_pdf_state,
|
| 602 |
-
success(fn=update_annotator_object_and_filter_df, inputs=[all_image_annotations_state, page_min, recogniser_entity_dropdown, page_entity_dropdown, text_entity_dropdown, recogniser_entity_dataframe_base, annotator_zoom_number,
|
| 603 |
|
| 604 |
###
|
| 605 |
# REVIEW PDF REDACTIONS
|
| 606 |
###
|
|
|
|
| 607 |
|
| 608 |
# Upload previous files for modifying redactions
|
| 609 |
upload_previous_review_file_btn.click(fn=reset_review_vars, inputs=None, outputs=[recogniser_entity_dataframe, recogniser_entity_dataframe_base]).\
|
| 610 |
success(fn=get_input_file_names, inputs=[output_review_files], outputs=[doc_file_name_no_extension_textbox, doc_file_name_with_extension_textbox, doc_full_file_name_textbox, doc_file_name_textbox_list, total_pdf_page_count]).\
|
| 611 |
-
success(fn = prepare_image_or_pdf, inputs=[output_review_files, text_extract_method_radio, latest_file_completed_text, redaction_output_summary_textbox, second_loop_state, annotate_max_pages, all_image_annotations_state, prepare_for_review_bool, in_fully_redacted_list_state, output_folder_textbox, input_folder_textbox, prepare_images_bool_false], outputs=[redaction_output_summary_textbox, prepared_pdf_state, images_pdf_state, annotate_max_pages, annotate_max_pages_bottom, pdf_doc_state, all_image_annotations_state,
|
| 612 |
-
success(update_annotator_object_and_filter_df, inputs=[all_image_annotations_state, annotate_current_page, recogniser_entity_dropdown, page_entity_dropdown, text_entity_dropdown, recogniser_entity_dataframe_base, annotator_zoom_number,
|
|
|
|
|
|
|
|
|
|
|
|
|
| 613 |
|
| 614 |
# Page number controls
|
| 615 |
annotate_current_page.submit(update_all_page_annotation_object_based_on_previous_page, inputs = [annotator, annotate_current_page, annotate_previous_page, all_image_annotations_state, page_sizes], outputs = [all_image_annotations_state, annotate_previous_page, annotate_current_page_bottom]).\
|
| 616 |
-
success(update_annotator_object_and_filter_df, inputs=[all_image_annotations_state, annotate_current_page, recogniser_entity_dropdown, page_entity_dropdown, text_entity_dropdown, recogniser_entity_dataframe_base, annotator_zoom_number,
|
| 617 |
-
success(apply_redactions_to_review_df_and_files, inputs=[annotator, doc_full_file_name_textbox, pdf_doc_state, all_image_annotations_state, annotate_current_page,
|
| 618 |
|
| 619 |
annotation_last_page_button.click(fn=decrease_page, inputs=[annotate_current_page], outputs=[annotate_current_page, annotate_current_page_bottom]).\
|
| 620 |
success(update_all_page_annotation_object_based_on_previous_page, inputs = [annotator, annotate_current_page, annotate_previous_page, all_image_annotations_state, page_sizes], outputs = [all_image_annotations_state, annotate_previous_page, annotate_current_page_bottom]).\
|
| 621 |
-
success(update_annotator_object_and_filter_df, inputs=[all_image_annotations_state, annotate_current_page, recogniser_entity_dropdown, page_entity_dropdown, text_entity_dropdown, recogniser_entity_dataframe_base, annotator_zoom_number,
|
| 622 |
-
success(apply_redactions_to_review_df_and_files, inputs=[annotator, doc_full_file_name_textbox, pdf_doc_state, all_image_annotations_state, annotate_current_page,
|
| 623 |
|
| 624 |
annotation_next_page_button.click(fn=increase_page, inputs=[annotate_current_page, all_image_annotations_state], outputs=[annotate_current_page, annotate_current_page_bottom]).\
|
| 625 |
success(update_all_page_annotation_object_based_on_previous_page, inputs = [annotator, annotate_current_page, annotate_previous_page, all_image_annotations_state, page_sizes], outputs = [all_image_annotations_state, annotate_previous_page, annotate_current_page_bottom]).\
|
| 626 |
-
success(update_annotator_object_and_filter_df, inputs=[all_image_annotations_state, annotate_current_page, recogniser_entity_dropdown, page_entity_dropdown, text_entity_dropdown, recogniser_entity_dataframe_base, annotator_zoom_number,
|
| 627 |
-
success(apply_redactions_to_review_df_and_files, inputs=[annotator, doc_full_file_name_textbox, pdf_doc_state, all_image_annotations_state, annotate_current_page,
|
| 628 |
|
| 629 |
annotation_last_page_button_bottom.click(fn=decrease_page, inputs=[annotate_current_page], outputs=[annotate_current_page, annotate_current_page_bottom]).\
|
| 630 |
success(update_all_page_annotation_object_based_on_previous_page, inputs = [annotator, annotate_current_page, annotate_previous_page, all_image_annotations_state, page_sizes], outputs = [all_image_annotations_state, annotate_previous_page, annotate_current_page_bottom]).\
|
| 631 |
-
success(update_annotator_object_and_filter_df, inputs=[all_image_annotations_state, annotate_current_page, recogniser_entity_dropdown, page_entity_dropdown, text_entity_dropdown, recogniser_entity_dataframe_base, annotator_zoom_number,
|
| 632 |
-
success(apply_redactions_to_review_df_and_files, inputs=[annotator, doc_full_file_name_textbox, pdf_doc_state, all_image_annotations_state, annotate_current_page,
|
| 633 |
|
| 634 |
annotation_next_page_button_bottom.click(fn=increase_page, inputs=[annotate_current_page, all_image_annotations_state], outputs=[annotate_current_page, annotate_current_page_bottom]).\
|
| 635 |
success(update_all_page_annotation_object_based_on_previous_page, inputs = [annotator, annotate_current_page, annotate_previous_page, all_image_annotations_state, page_sizes], outputs = [all_image_annotations_state, annotate_previous_page, annotate_current_page_bottom]).\
|
| 636 |
-
success(update_annotator_object_and_filter_df, inputs=[all_image_annotations_state, annotate_current_page, recogniser_entity_dropdown, page_entity_dropdown, text_entity_dropdown, recogniser_entity_dataframe_base, annotator_zoom_number,
|
| 637 |
-
success(apply_redactions_to_review_df_and_files, inputs=[annotator, doc_full_file_name_textbox, pdf_doc_state, all_image_annotations_state, annotate_current_page,
|
| 638 |
|
| 639 |
annotate_current_page_bottom.submit(update_other_annotator_number_from_current, inputs=[annotate_current_page_bottom], outputs=[annotate_current_page]).\
|
| 640 |
success(update_all_page_annotation_object_based_on_previous_page, inputs = [annotator, annotate_current_page, annotate_previous_page, all_image_annotations_state, page_sizes], outputs = [all_image_annotations_state, annotate_previous_page, annotate_current_page_bottom]).\
|
| 641 |
-
success(update_annotator_object_and_filter_df, inputs=[all_image_annotations_state, annotate_current_page, recogniser_entity_dropdown, page_entity_dropdown, text_entity_dropdown, recogniser_entity_dataframe_base, annotator_zoom_number,
|
| 642 |
-
success(apply_redactions_to_review_df_and_files, inputs=[annotator, doc_full_file_name_textbox, pdf_doc_state, all_image_annotations_state, annotate_current_page,
|
| 643 |
|
| 644 |
# Apply page redactions
|
| 645 |
-
annotation_button_apply.click(apply_redactions_to_review_df_and_files, inputs=[annotator, doc_full_file_name_textbox, pdf_doc_state, all_image_annotations_state, annotate_current_page,
|
| 646 |
|
| 647 |
# Save current page redactions
|
| 648 |
update_current_page_redactions_btn.click(update_all_page_annotation_object_based_on_previous_page, inputs = [annotator, annotate_current_page, annotate_current_page, all_image_annotations_state, page_sizes], outputs = [all_image_annotations_state, annotate_previous_page, annotate_current_page_bottom]).\
|
| 649 |
-
success(update_annotator_object_and_filter_df, inputs=[all_image_annotations_state, annotate_current_page, recogniser_entity_dropdown, page_entity_dropdown, text_entity_dropdown, recogniser_entity_dataframe_base, annotator_zoom_number,
|
| 650 |
-
success(apply_redactions_to_review_df_and_files, inputs=[annotator, doc_full_file_name_textbox, pdf_doc_state, all_image_annotations_state, annotate_current_page,
|
| 651 |
|
| 652 |
# Review table controls
|
| 653 |
recogniser_entity_dropdown.select(update_entities_df_recogniser_entities, inputs=[recogniser_entity_dropdown, recogniser_entity_dataframe_base, page_entity_dropdown, text_entity_dropdown], outputs=[recogniser_entity_dataframe, text_entity_dropdown, page_entity_dropdown])
|
|
@@ -656,54 +695,52 @@ with app:
|
|
| 656 |
|
| 657 |
# Clicking on a cell in the recogniser entity dataframe will take you to that page, and also highlight the target redaction box in blue
|
| 658 |
recogniser_entity_dataframe.select(df_select_callback_dataframe_row, inputs=[recogniser_entity_dataframe], outputs=[selected_entity_dataframe_row, selected_entity_dataframe_row_text]).\
|
| 659 |
-
success(update_selected_review_df_row_colour, inputs=[selected_entity_dataframe_row,
|
| 660 |
-
success(update_annotator_page_from_review_df, inputs=[
|
| 661 |
success(increase_bottom_page_count_based_on_top, inputs=[annotate_current_page], outputs=[annotate_current_page_bottom])
|
| 662 |
|
| 663 |
reset_dropdowns_btn.click(reset_dropdowns, inputs=[recogniser_entity_dataframe_base], outputs=[recogniser_entity_dropdown, text_entity_dropdown, page_entity_dropdown]).\
|
| 664 |
-
success(update_annotator_object_and_filter_df, inputs=[all_image_annotations_state, annotate_current_page, recogniser_entity_dropdown, page_entity_dropdown, text_entity_dropdown, recogniser_entity_dataframe_base, annotator_zoom_number,
|
| 665 |
|
| 666 |
# Exclude current selection from annotator and outputs
|
| 667 |
# Exclude only selected row
|
| 668 |
-
exclude_selected_row_btn.click(exclude_selected_items_from_redaction, inputs=[
|
| 669 |
-
success(update_annotator_object_and_filter_df, inputs=[all_image_annotations_state, annotate_current_page, recogniser_entity_dropdown, page_entity_dropdown, text_entity_dropdown, recogniser_entity_dataframe_base, annotator_zoom_number,
|
| 670 |
-
success(apply_redactions_to_review_df_and_files, inputs=[annotator, doc_full_file_name_textbox, pdf_doc_state, all_image_annotations_state, annotate_current_page,
|
| 671 |
success(update_all_entity_df_dropdowns, inputs=[recogniser_entity_dataframe_base, recogniser_entity_dropdown, page_entity_dropdown, text_entity_dropdown], outputs=[recogniser_entity_dropdown, text_entity_dropdown, page_entity_dropdown])
|
| 672 |
|
| 673 |
# Exclude all items with same text as selected row
|
| 674 |
exclude_text_with_same_as_selected_row_btn.click(get_all_rows_with_same_text, inputs=[recogniser_entity_dataframe_base, selected_entity_dataframe_row_text], outputs=[recogniser_entity_dataframe_same_text]).\
|
| 675 |
-
success(exclude_selected_items_from_redaction, inputs=[
|
| 676 |
-
success(update_annotator_object_and_filter_df, inputs=[all_image_annotations_state, annotate_current_page, recogniser_entity_dropdown, page_entity_dropdown, text_entity_dropdown, recogniser_entity_dataframe_base, annotator_zoom_number,
|
| 677 |
-
success(apply_redactions_to_review_df_and_files, inputs=[annotator, doc_full_file_name_textbox, pdf_doc_state, all_image_annotations_state, annotate_current_page,
|
| 678 |
success(update_all_entity_df_dropdowns, inputs=[recogniser_entity_dataframe_base, recogniser_entity_dropdown, page_entity_dropdown, text_entity_dropdown], outputs=[recogniser_entity_dropdown, text_entity_dropdown, page_entity_dropdown])
|
| 679 |
|
| 680 |
# Exclude everything visible in table
|
| 681 |
-
exclude_selected_btn.click(exclude_selected_items_from_redaction, inputs=[
|
| 682 |
-
success(update_annotator_object_and_filter_df, inputs=[all_image_annotations_state, annotate_current_page, recogniser_entity_dropdown, page_entity_dropdown, text_entity_dropdown, recogniser_entity_dataframe_base, annotator_zoom_number,
|
| 683 |
-
success(apply_redactions_to_review_df_and_files, inputs=[annotator, doc_full_file_name_textbox, pdf_doc_state, all_image_annotations_state, annotate_current_page,
|
| 684 |
success(update_all_entity_df_dropdowns, inputs=[recogniser_entity_dataframe_base, recogniser_entity_dropdown, page_entity_dropdown, text_entity_dropdown], outputs=[recogniser_entity_dropdown, text_entity_dropdown, page_entity_dropdown])
|
| 685 |
|
| 686 |
-
|
| 687 |
-
|
| 688 |
-
|
| 689 |
-
success(update_annotator_object_and_filter_df, inputs=[all_image_annotations_state, annotate_current_page, recogniser_entity_dropdown, page_entity_dropdown, text_entity_dropdown, recogniser_entity_dataframe_base, annotator_zoom_number, review_file_state, page_sizes, doc_full_file_name_textbox, input_folder_textbox], outputs = [annotator, annotate_current_page, annotate_current_page_bottom, annotate_previous_page, recogniser_entity_dropdown, recogniser_entity_dataframe, recogniser_entity_dataframe_base, text_entity_dropdown, page_entity_dropdown, page_sizes, all_image_annotations_state]).\
|
| 690 |
-
success(apply_redactions_to_review_df_and_files, inputs=[annotator, doc_full_file_name_textbox, pdf_doc_state, all_image_annotations_state, annotate_current_page, review_file_state, output_folder_textbox, do_not_save_pdf_state, page_sizes], outputs=[pdf_doc_state, all_image_annotations_state, output_review_files, log_files_output, review_file_state])
|
| 691 |
|
| 692 |
# Review OCR text button
|
| 693 |
all_line_level_ocr_results_df.select(df_select_callback_ocr, inputs=[all_line_level_ocr_results_df], outputs=[annotate_current_page, selected_ocr_dataframe_row]).\
|
| 694 |
-
success(update_annotator_page_from_review_df, inputs=[
|
| 695 |
success(increase_bottom_page_count_based_on_top, inputs=[annotate_current_page], outputs=[annotate_current_page_bottom])
|
| 696 |
|
| 697 |
reset_all_ocr_results_btn.click(reset_ocr_base_dataframe, inputs=[all_line_level_ocr_results_df_base], outputs=[all_line_level_ocr_results_df])
|
| 698 |
|
| 699 |
# Convert review file to xfdf Adobe format
|
| 700 |
convert_review_file_to_adobe_btn.click(fn=get_input_file_names, inputs=[output_review_files], outputs=[doc_file_name_no_extension_textbox, doc_file_name_with_extension_textbox, doc_full_file_name_textbox, doc_file_name_textbox_list, total_pdf_page_count]).\
|
| 701 |
-
success(fn = prepare_image_or_pdf, inputs=[output_review_files, text_extract_method_radio, latest_file_completed_text, redaction_output_summary_textbox, second_loop_state, annotate_max_pages, all_image_annotations_state, prepare_for_review_bool, in_fully_redacted_list_state, output_folder_textbox, input_folder_textbox, prepare_images_bool_false], outputs=[redaction_output_summary_textbox, prepared_pdf_state, images_pdf_state, annotate_max_pages, annotate_max_pages_bottom, pdf_doc_state, all_image_annotations_state,
|
| 702 |
success(convert_df_to_xfdf, inputs=[output_review_files, pdf_doc_state, images_pdf_state, output_folder_textbox, document_cropboxes, page_sizes], outputs=[adobe_review_files_out])
|
| 703 |
|
| 704 |
# Convert xfdf Adobe file back to review_file.csv
|
| 705 |
convert_adobe_to_review_file_btn.click(fn=get_input_file_names, inputs=[adobe_review_files_out], outputs=[doc_file_name_no_extension_textbox, doc_file_name_with_extension_textbox, doc_full_file_name_textbox, doc_file_name_textbox_list, total_pdf_page_count]).\
|
| 706 |
-
success(fn = prepare_image_or_pdf, inputs=[adobe_review_files_out, text_extract_method_radio, latest_file_completed_text, redaction_output_summary_textbox, second_loop_state, annotate_max_pages, all_image_annotations_state, prepare_for_review_bool, in_fully_redacted_list_state, output_folder_textbox, input_folder_textbox, prepare_images_bool_false], outputs=[redaction_output_summary_textbox, prepared_pdf_state, images_pdf_state, annotate_max_pages, annotate_max_pages_bottom, pdf_doc_state, all_image_annotations_state,
|
| 707 |
success(fn=convert_xfdf_to_dataframe, inputs=[adobe_review_files_out, pdf_doc_state, images_pdf_state, output_folder_textbox], outputs=[output_review_files], scroll_to_output=True)
|
| 708 |
|
| 709 |
###
|
|
@@ -716,7 +753,7 @@ with app:
|
|
| 716 |
success(fn=anonymise_data_files, inputs=[in_data_files, in_text, anon_strat, in_colnames, in_redact_language, in_redact_entities, in_allow_list_state, text_tabular_files_done, text_output_summary, text_output_file_list_state, log_files_output_list_state, in_excel_sheets, first_loop_state, output_folder_textbox, in_deny_list_state, max_fuzzy_spelling_mistakes_num, pii_identification_method_drop_tabular, in_redact_comprehend_entities, comprehend_query_number, aws_access_key_textbox, aws_secret_key_textbox, actual_time_taken_number], outputs=[text_output_summary, text_output_file, text_output_file_list_state, text_tabular_files_done, log_files_output, log_files_output_list_state, actual_time_taken_number], api_name="redact_data").\
|
| 717 |
success(fn = reveal_feedback_buttons, outputs=[data_feedback_radio, data_further_details_text, data_submit_feedback_btn, data_feedback_title])
|
| 718 |
|
| 719 |
-
# Currently only supports redacting one data file at a time
|
| 720 |
# If the output file count text box changes, keep going with redacting each data file until done
|
| 721 |
# text_tabular_files_done.change(fn=anonymise_data_files, inputs=[in_data_files, in_text, anon_strat, in_colnames, in_redact_language, in_redact_entities, in_allow_list_state, text_tabular_files_done, text_output_summary, text_output_file_list_state, log_files_output_list_state, in_excel_sheets, second_loop_state, output_folder_textbox, in_deny_list_state, max_fuzzy_spelling_mistakes_num, pii_identification_method_drop_tabular, in_redact_comprehend_entities, comprehend_query_number, aws_access_key_textbox, aws_secret_key_textbox, actual_time_taken_number], outputs=[text_output_summary, text_output_file, text_output_file_list_state, text_tabular_files_done, log_files_output, log_files_output_list_state, actual_time_taken_number]).\
|
| 722 |
# success(fn = reveal_feedback_buttons, outputs=[data_feedback_radio, data_further_details_text, data_submit_feedback_btn, data_feedback_title])
|
|
@@ -725,7 +762,7 @@ with app:
|
|
| 725 |
# IDENTIFY DUPLICATE PAGES
|
| 726 |
###
|
| 727 |
find_duplicate_pages_btn.click(
|
| 728 |
-
fn=
|
| 729 |
inputs=[
|
| 730 |
in_duplicate_pages,
|
| 731 |
duplicate_threshold_input,
|
|
@@ -735,17 +772,32 @@ with app:
|
|
| 735 |
],
|
| 736 |
outputs=[
|
| 737 |
results_df_preview,
|
| 738 |
-
|
| 739 |
-
|
| 740 |
]
|
| 741 |
)
|
| 742 |
|
|
|
|
| 743 |
results_df_preview.select(
|
| 744 |
-
fn=
|
| 745 |
-
inputs=[
|
| 746 |
-
outputs=[page1_text_preview, page2_text_preview]
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 747 |
)
|
| 748 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 749 |
###
|
| 750 |
# SETTINGS PAGE INPUT / OUTPUT
|
| 751 |
###
|
|
@@ -759,6 +811,13 @@ with app:
|
|
| 759 |
in_deny_list_state.input(update_dataframe, inputs=[in_deny_list_state], outputs=[in_deny_list_state])
|
| 760 |
in_fully_redacted_list_state.input(update_dataframe, inputs=[in_fully_redacted_list_state], outputs=[in_fully_redacted_list_state])
|
| 761 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 762 |
# Merge multiple review csv files together
|
| 763 |
merge_multiple_review_files_btn.click(fn=merge_csv_files, inputs=multiple_review_files_in_out, outputs=multiple_review_files_in_out)
|
| 764 |
|
|
|
|
| 3 |
import gradio as gr
|
| 4 |
from gradio_image_annotation import image_annotator
|
| 5 |
from tools.config import OUTPUT_FOLDER, INPUT_FOLDER, RUN_DIRECT_MODE, MAX_QUEUE_SIZE, DEFAULT_CONCURRENCY_LIMIT, MAX_FILE_SIZE, GRADIO_SERVER_PORT, ROOT_PATH, GET_DEFAULT_ALLOW_LIST, ALLOW_LIST_PATH, S3_ALLOW_LIST_PATH, FEEDBACK_LOGS_FOLDER, ACCESS_LOGS_FOLDER, USAGE_LOGS_FOLDER, REDACTION_LANGUAGE, GET_COST_CODES, COST_CODES_PATH, S3_COST_CODES_PATH, ENFORCE_COST_CODES, DISPLAY_FILE_NAMES_IN_LOGS, SHOW_COSTS, RUN_AWS_FUNCTIONS, DOCUMENT_REDACTION_BUCKET, SHOW_WHOLE_DOCUMENT_TEXTRACT_CALL_OPTIONS, TEXTRACT_WHOLE_DOCUMENT_ANALYSIS_BUCKET, TEXTRACT_WHOLE_DOCUMENT_ANALYSIS_INPUT_SUBFOLDER, TEXTRACT_WHOLE_DOCUMENT_ANALYSIS_OUTPUT_SUBFOLDER, SESSION_OUTPUT_FOLDER, LOAD_PREVIOUS_TEXTRACT_JOBS_S3, TEXTRACT_JOBS_S3_LOC, TEXTRACT_JOBS_LOCAL_LOC, HOST_NAME, DEFAULT_COST_CODE, OUTPUT_COST_CODES_PATH, OUTPUT_ALLOW_LIST_PATH, COGNITO_AUTH, SAVE_LOGS_TO_CSV, SAVE_LOGS_TO_DYNAMODB, ACCESS_LOG_DYNAMODB_TABLE_NAME, DYNAMODB_ACCESS_LOG_HEADERS, CSV_ACCESS_LOG_HEADERS, FEEDBACK_LOG_DYNAMODB_TABLE_NAME, DYNAMODB_FEEDBACK_LOG_HEADERS, CSV_FEEDBACK_LOG_HEADERS, USAGE_LOG_DYNAMODB_TABLE_NAME, DYNAMODB_USAGE_LOG_HEADERS, CSV_USAGE_LOG_HEADERS, TEXTRACT_JOBS_S3_INPUT_LOC, TEXTRACT_TEXT_EXTRACT_OPTION, NO_REDACTION_PII_OPTION, TEXT_EXTRACTION_MODELS, PII_DETECTION_MODELS, DEFAULT_TEXT_EXTRACTION_MODEL, DEFAULT_PII_DETECTION_MODEL, LOG_FILE_NAME, CHOSEN_COMPREHEND_ENTITIES, FULL_COMPREHEND_ENTITY_LIST, CHOSEN_REDACT_ENTITIES, FULL_ENTITY_LIST, FILE_INPUT_HEIGHT, TABULAR_PII_DETECTION_MODELS
|
| 6 |
+
from tools.helper_functions import put_columns_in_df, get_connection_params, reveal_feedback_buttons, custom_regex_load, reset_state_vars, load_in_default_allow_list, reset_review_vars, merge_csv_files, load_all_output_files, update_dataframe, check_for_existing_textract_file, load_in_default_cost_codes, enforce_cost_codes, calculate_aws_costs, calculate_time_taken, reset_base_dataframe, reset_ocr_base_dataframe, update_cost_code_dataframe_from_dropdown_select, check_for_existing_local_ocr_file, reset_data_vars, reset_aws_call_vars, _get_env_list
|
| 7 |
from tools.aws_functions import download_file_from_s3, upload_log_file_to_s3
|
| 8 |
from tools.file_redaction import choose_and_run_redactor
|
| 9 |
from tools.file_conversion import prepare_image_or_pdf, get_input_file_names
|
| 10 |
+
from tools.redaction_review import apply_redactions_to_review_df_and_files, update_all_page_annotation_object_based_on_previous_page, decrease_page, increase_page, update_annotator_object_and_filter_df, update_entities_df_recogniser_entities, update_entities_df_page, update_entities_df_text, df_select_callback_dataframe_row, convert_df_to_xfdf, convert_xfdf_to_dataframe, reset_dropdowns, exclude_selected_items_from_redaction, undo_last_removal, update_selected_review_df_row_colour, update_all_entity_df_dropdowns, df_select_callback_cost, update_other_annotator_number_from_current, update_annotator_page_from_review_df, df_select_callback_ocr, df_select_callback_textract_api, get_all_rows_with_same_text, increase_bottom_page_count_based_on_top, store_duplicate_selection
|
| 11 |
from tools.data_anonymise import anonymise_data_files
|
| 12 |
from tools.auth import authenticate_user
|
| 13 |
from tools.load_spacy_model_custom_recognisers import custom_entities
|
| 14 |
from tools.custom_csvlogger import CSVLogger_custom
|
| 15 |
+
from tools.find_duplicate_pages import run_duplicate_analysis, exclude_match, handle_selection_and_preview, apply_whole_page_redactions_from_list
|
| 16 |
from tools.textract_batch_call import analyse_document_with_textract_api, poll_whole_document_textract_analysis_progress_and_download, load_in_textract_job_details, check_for_provided_job_id, check_textract_outputs_exist, replace_existing_pdf_input_for_whole_document_outputs
|
| 17 |
|
| 18 |
# Suppress downcasting warnings
|
| 19 |
pd.set_option('future.no_silent_downcasting', True)
|
| 20 |
|
| 21 |
# Convert string environment variables to string or list
|
| 22 |
+
if SAVE_LOGS_TO_CSV == "True": SAVE_LOGS_TO_CSV = True
|
| 23 |
+
else: SAVE_LOGS_TO_CSV = False
|
| 24 |
+
if SAVE_LOGS_TO_DYNAMODB == "True": SAVE_LOGS_TO_DYNAMODB = True
|
| 25 |
+
else: SAVE_LOGS_TO_DYNAMODB = False
|
| 26 |
|
| 27 |
+
if CSV_ACCESS_LOG_HEADERS: CSV_ACCESS_LOG_HEADERS = _get_env_list(CSV_ACCESS_LOG_HEADERS)
|
| 28 |
+
if CSV_FEEDBACK_LOG_HEADERS: CSV_FEEDBACK_LOG_HEADERS = _get_env_list(CSV_FEEDBACK_LOG_HEADERS)
|
| 29 |
+
if CSV_USAGE_LOG_HEADERS: CSV_USAGE_LOG_HEADERS = _get_env_list(CSV_USAGE_LOG_HEADERS)
|
| 30 |
|
| 31 |
+
if DYNAMODB_ACCESS_LOG_HEADERS: DYNAMODB_ACCESS_LOG_HEADERS = _get_env_list(DYNAMODB_ACCESS_LOG_HEADERS)
|
| 32 |
+
if DYNAMODB_FEEDBACK_LOG_HEADERS: DYNAMODB_FEEDBACK_LOG_HEADERS = _get_env_list(DYNAMODB_FEEDBACK_LOG_HEADERS)
|
| 33 |
+
if DYNAMODB_USAGE_LOG_HEADERS: DYNAMODB_USAGE_LOG_HEADERS = _get_env_list(DYNAMODB_USAGE_LOG_HEADERS)
|
| 34 |
|
| 35 |
+
if CHOSEN_COMPREHEND_ENTITIES: CHOSEN_COMPREHEND_ENTITIES = _get_env_list(CHOSEN_COMPREHEND_ENTITIES)
|
| 36 |
+
if FULL_COMPREHEND_ENTITY_LIST: FULL_COMPREHEND_ENTITY_LIST = _get_env_list(FULL_COMPREHEND_ENTITY_LIST)
|
| 37 |
+
if CHOSEN_REDACT_ENTITIES: CHOSEN_REDACT_ENTITIES = _get_env_list(CHOSEN_REDACT_ENTITIES)
|
| 38 |
+
if FULL_ENTITY_LIST: FULL_ENTITY_LIST = _get_env_list(FULL_ENTITY_LIST)
|
| 39 |
|
| 40 |
# Add custom spacy recognisers to the Comprehend list, so that local Spacy model can be used to pick up e.g. titles, streetnames, UK postcodes that are sometimes missed by comprehend
|
| 41 |
CHOSEN_COMPREHEND_ENTITIES.extend(custom_entities)
|
|
|
|
| 44 |
FILE_INPUT_HEIGHT = int(FILE_INPUT_HEIGHT)
|
| 45 |
|
| 46 |
# Create the gradio interface
|
| 47 |
+
app = gr.Blocks(theme = gr.themes.Default(primary_hue="blue"), fill_width=True) #gr.themes.Base()
|
| 48 |
|
| 49 |
with app:
|
| 50 |
|
|
|
|
| 57 |
all_image_annotations_state = gr.State([])
|
| 58 |
|
| 59 |
all_decision_process_table_state = gr.Dataframe(value=pd.DataFrame(), headers=None, col_count=0, row_count = (0, "dynamic"), label="all_decision_process_table", visible=False, type="pandas", wrap=True)
|
| 60 |
+
|
| 61 |
|
| 62 |
all_page_line_level_ocr_results = gr.State([])
|
| 63 |
all_page_line_level_ocr_results_with_children = gr.State([])
|
|
|
|
| 188 |
# Duplicate page detection
|
| 189 |
in_duplicate_pages_text = gr.Textbox(label="in_duplicate_pages_text", visible=False)
|
| 190 |
duplicate_pages_df = gr.Dataframe(value=pd.DataFrame(), headers=None, col_count=0, row_count = (0, "dynamic"), label="duplicate_pages_df", visible=False, type="pandas", wrap=True)
|
| 191 |
+
full_duplicated_data_df = gr.Dataframe(value=pd.DataFrame(), headers=None, col_count=0, row_count = (0, "dynamic"), label="full_duplicated_data_df", visible=False, type="pandas", wrap=True)
|
| 192 |
+
selected_duplicate_data_row_index = gr.Number(value=None, label="selected_duplicate_data_row_index", visible=False)
|
| 193 |
+
full_duplicate_data_by_file = gr.State() # A dictionary of the full duplicate data indexed by file
|
| 194 |
|
| 195 |
# Tracking variables for current page (not visible)
|
| 196 |
current_loop_page_number = gr.Number(value=0,precision=0, interactive=False, label = "Last redacted page in document", visible=False)
|
|
|
|
| 235 |
|
| 236 |
Redact personally identifiable information (PII) from documents (PDF, images), open text, or tabular data (XLSX/CSV/Parquet). Please see the [User Guide](https://github.com/seanpedrick-case/doc_redaction/blob/main/README.md) for a walkthrough on how to use the app. Below is a very brief overview.
|
| 237 |
|
| 238 |
+
To identify text in documents, the 'Local' text/OCR image analysis uses spaCy/Tesseract, and works well only for documents with typed text. If available, choose 'AWS Textract' to redact more complex elements e.g. signatures or handwriting. Then, choose a method for PII identification. 'Local' is quick and gives good results if you are primarily looking for a custom list of terms to redact (see Redaction settings). If available, AWS Comprehend gives better results at a small cost.
|
| 239 |
|
| 240 |
After redaction, review suggested redactions on the 'Review redactions' tab. The original pdf can be uploaded here alongside a '...review_file.csv' to continue a previous redaction/review task. See the 'Redaction settings' tab to choose which pages to redact, the type of information to redact (e.g. people, places), or custom terms to always include/ exclude from redaction.
|
| 241 |
|
|
|
|
| 264 |
local_ocr_output_found_checkbox = gr.Checkbox(value= False, label="Existing local OCR output file found", interactive=False, visible=True)
|
| 265 |
with gr.Column(scale=4):
|
| 266 |
with gr.Row(equal_height=True):
|
| 267 |
+
total_pdf_page_count = gr.Number(label = "Total page count", value=0, visible=True, interactive=False)
|
| 268 |
+
estimated_aws_costs_number = gr.Number(label = "Approximate AWS Textract and/or Comprehend cost (£)", value=0.00, precision=2, visible=True, interactive=False)
|
| 269 |
+
estimated_time_taken_number = gr.Number(label = "Approximate time taken to extract text/redact (minutes)", value=0, visible=True, precision=2, interactive=False)
|
| 270 |
|
| 271 |
if GET_COST_CODES == "True" or ENFORCE_COST_CODES == "True":
|
| 272 |
with gr.Accordion("Assign task to cost code", open = True, visible=True):
|
|
|
|
| 322 |
annotate_zoom_in = gr.Button("Zoom in", visible=False)
|
| 323 |
annotate_zoom_out = gr.Button("Zoom out", visible=False)
|
| 324 |
with gr.Row():
|
| 325 |
+
clear_all_redactions_on_page_btn = gr.Button("Clear all redactions on page", visible=False)
|
| 326 |
+
|
| 327 |
+
with gr.Accordion(label = "View and edit review file data", open=False):
|
| 328 |
+
review_file_df = gr.Dataframe(value=pd.DataFrame(), headers=['image', 'page', 'label', 'color', 'xmin', 'ymin', 'xmax', 'ymax', 'text', 'id'], row_count = (0, "dynamic"), label="Review file data", visible=True, type="pandas", wrap=True, show_search=True, show_fullscreen_button=True, show_copy_button=True)
|
| 329 |
|
| 330 |
with gr.Row():
|
| 331 |
with gr.Column(scale=2):
|
|
|
|
| 396 |
# IDENTIFY DUPLICATE PAGES TAB
|
| 397 |
###
|
| 398 |
with gr.Tab(label="Identify duplicate pages"):
|
| 399 |
+
gr.Markdown("Search for duplicate pages/subdocuments in your ocr_output files. By default, this function will search for duplicate text across multiple pages, and then join consecutive matching pages together into matched 'subdocuments'. The results can be reviewed below, false positives removed, and then the verified results applied to a document you have loaded in on the 'Review redactions' tab.")
|
| 400 |
+
|
| 401 |
+
with gr.Accordion("Step 1: Configure and run analysis", open = True):
|
| 402 |
in_duplicate_pages = gr.File(
|
| 403 |
+
label="Upload one or multiple 'ocr_output.csv' files to find duplicate pages and subdocuments",
|
| 404 |
file_count="multiple", height=FILE_INPUT_HEIGHT, file_types=['.csv']
|
| 405 |
)
|
| 406 |
|
| 407 |
+
with gr.Accordion("Duplicate matching parameters", open = False):
|
| 408 |
+
with gr.Row():
|
| 409 |
+
duplicate_threshold_input = gr.Number(value=0.95, label="Similarity threshold", info="Score (0-1) to consider pages a match.")
|
| 410 |
+
min_word_count_input = gr.Number(value=10, label="Minimum word count", info="Pages with fewer words than this value are ignored.")
|
| 411 |
+
|
| 412 |
+
gr.Markdown("#### Matching Strategy")
|
| 413 |
+
greedy_match_input = gr.Checkbox(
|
| 414 |
+
label="Enable 'subdocument' matching",
|
| 415 |
+
value=True,
|
| 416 |
+
info="If checked, finds the longest possible sequence of matching pages (subdocuments), minimum length one page. Overrides the slider below."
|
| 417 |
+
)
|
| 418 |
+
min_consecutive_pages_input = gr.Slider(
|
| 419 |
+
minimum=1, maximum=20, value=1, step=1,
|
| 420 |
+
label="Minimum consecutive pages (modified subdocument match)",
|
| 421 |
+
info="If greedy matching option above is unticked, use this to find only subdocuments of a minimum number of consecutive pages."
|
| 422 |
+
)
|
| 423 |
|
| 424 |
+
find_duplicate_pages_btn = gr.Button(value="Identify duplicate pages/subdocuments", variant="primary")
|
| 425 |
|
| 426 |
+
with gr.Accordion("Step 2: Review and refine results", open=True):
|
| 427 |
+
gr.Markdown("### Analysis summary\nClick on a row to select it for preview or exclusion.")
|
| 428 |
+
|
| 429 |
+
with gr.Row():
|
| 430 |
+
results_df_preview = gr.Dataframe(
|
| 431 |
+
label="Similarity Results",
|
| 432 |
+
wrap=True,
|
| 433 |
+
show_fullscreen_button=True,
|
| 434 |
+
show_search=True,
|
| 435 |
+
show_copy_button=True
|
| 436 |
+
)
|
| 437 |
+
with gr.Row():
|
| 438 |
+
exclude_match_btn = gr.Button(
|
| 439 |
+
value="❌ Exclude Selected Match",
|
| 440 |
+
variant="stop"
|
| 441 |
+
)
|
| 442 |
+
gr.Markdown("Click a row in the table, then click this button to remove it from the results and update the downloadable files.")
|
| 443 |
|
| 444 |
+
gr.Markdown("### Full Text Preview of Selected Match")
|
| 445 |
with gr.Row():
|
| 446 |
+
page1_text_preview = gr.Dataframe(label="Match Source (Document 1)", wrap=True, headers=["page", "text"], show_fullscreen_button=True, show_search=True, show_copy_button=True)
|
| 447 |
+
page2_text_preview = gr.Dataframe(label="Match Duplicate (Document 2)", wrap=True, headers=["page", "text"], show_fullscreen_button=True, show_search=True, show_copy_button=True)
|
| 448 |
|
| 449 |
gr.Markdown("### Downloadable Files")
|
| 450 |
+
duplicate_files_out = gr.File(
|
| 451 |
label="Download analysis summary and redaction lists (.csv)",
|
| 452 |
+
file_count="multiple",
|
| 453 |
+
height=FILE_INPUT_HEIGHT
|
| 454 |
)
|
| 455 |
|
| 456 |
+
with gr.Row():
|
| 457 |
+
apply_match_btn = gr.Button(
|
| 458 |
+
value="Apply relevant duplicate page output to document currently under review",
|
| 459 |
+
variant="secondary")
|
| 460 |
|
| 461 |
###
|
| 462 |
# TEXT / TABULAR DATA TAB
|
|
|
|
| 511 |
in_allow_list_state = gr.Dataframe(value=pd.DataFrame(), headers=["allow_list"], col_count=(1, "fixed"), row_count = (0, "dynamic"), label="Allow list", visible=True, type="pandas", interactive=True, show_fullscreen_button=True, show_copy_button=True, wrap=True)
|
| 512 |
in_deny_list_state = gr.Dataframe(value=pd.DataFrame(), headers=["deny_list"], col_count=(1, "fixed"), row_count = (0, "dynamic"), label="Deny list", visible=True, type="pandas", interactive=True, show_fullscreen_button=True, show_copy_button=True, wrap=True)
|
| 513 |
in_fully_redacted_list_state = gr.Dataframe(value=pd.DataFrame(), headers=["fully_redacted_pages_list"], col_count=(1, "fixed"), row_count = (0, "dynamic"), label="Fully redacted pages", visible=True, type="pandas", interactive=True, show_fullscreen_button=True, show_copy_button=True, datatype='number', wrap=True)
|
| 514 |
+
with gr.Row():
|
| 515 |
+
with gr.Column(scale=2):
|
| 516 |
+
markdown_placeholder = gr.Markdown("")
|
| 517 |
+
with gr.Column(scale=1):
|
| 518 |
+
apply_fully_redacted_list_btn = gr.Button(
|
| 519 |
+
value="Apply whole page redaction list to document currently under review",
|
| 520 |
+
variant="secondary")
|
| 521 |
|
| 522 |
with gr.Accordion("Select entity types to redact", open = True):
|
| 523 |
in_redact_entities = gr.Dropdown(value=CHOSEN_REDACT_ENTITIES, choices=FULL_ENTITY_LIST, multiselect=True, label="Local PII identification model (click empty space in box for full list)")
|
|
|
|
| 587 |
cost_code_choice_drop.select(update_cost_code_dataframe_from_dropdown_select, inputs=[cost_code_choice_drop, cost_code_dataframe_base], outputs=[cost_code_dataframe])
|
| 588 |
|
| 589 |
in_doc_files.upload(fn=get_input_file_names, inputs=[in_doc_files], outputs=[doc_file_name_no_extension_textbox, doc_file_name_with_extension_textbox, doc_full_file_name_textbox, doc_file_name_textbox_list, total_pdf_page_count]).\
|
| 590 |
+
success(fn = prepare_image_or_pdf, inputs=[in_doc_files, text_extract_method_radio, latest_file_completed_text, redaction_output_summary_textbox, first_loop_state, annotate_max_pages, all_image_annotations_state, prepare_for_review_bool_false, in_fully_redacted_list_state, output_folder_textbox, input_folder_textbox, prepare_images_bool_false], outputs=[redaction_output_summary_textbox, prepared_pdf_state, images_pdf_state, annotate_max_pages, annotate_max_pages_bottom, pdf_doc_state, all_image_annotations_state, review_file_df, document_cropboxes, page_sizes, textract_output_found_checkbox, all_img_details_state, all_line_level_ocr_results_df_base, local_ocr_output_found_checkbox]).\
|
| 591 |
success(fn=check_for_existing_textract_file, inputs=[doc_file_name_no_extension_textbox, output_folder_textbox], outputs=[textract_output_found_checkbox]).\
|
| 592 |
success(fn=check_for_existing_local_ocr_file, inputs=[doc_file_name_no_extension_textbox, output_folder_textbox], outputs=[local_ocr_output_found_checkbox])
|
| 593 |
|
| 594 |
# Run redaction function
|
| 595 |
document_redact_btn.click(fn = reset_state_vars, outputs=[all_image_annotations_state, all_line_level_ocr_results_df_base, all_decision_process_table_state, comprehend_query_number, textract_metadata_textbox, annotator, output_file_list_state, log_files_output_list_state, recogniser_entity_dataframe, recogniser_entity_dataframe_base, pdf_doc_state, duplication_file_path_outputs_list_state, redaction_output_summary_textbox, is_a_textract_api_call, textract_query_number]).\
|
| 596 |
success(fn= enforce_cost_codes, inputs=[enforce_cost_code_textbox, cost_code_choice_drop, cost_code_dataframe_base]).\
|
| 597 |
+
success(fn= choose_and_run_redactor, inputs=[in_doc_files, prepared_pdf_state, images_pdf_state, in_redact_language, in_redact_entities, in_redact_comprehend_entities, text_extract_method_radio, in_allow_list_state, in_deny_list_state, in_fully_redacted_list_state, latest_file_completed_text, redaction_output_summary_textbox, output_file_list_state, log_files_output_list_state, first_loop_state, page_min, page_max, actual_time_taken_number, handwrite_signature_checkbox, textract_metadata_textbox, all_image_annotations_state, all_line_level_ocr_results_df_base, all_decision_process_table_state, pdf_doc_state, current_loop_page_number, page_break_return, pii_identification_method_drop, comprehend_query_number, max_fuzzy_spelling_mistakes_num, match_fuzzy_whole_phrase_bool, aws_access_key_textbox, aws_secret_key_textbox, annotate_max_pages, review_file_df, output_folder_textbox, document_cropboxes, page_sizes, textract_output_found_checkbox, only_extract_text_radio, duplication_file_path_outputs_list_state, latest_review_file_path, input_folder_textbox, textract_query_number, latest_ocr_file_path, all_page_line_level_ocr_results, all_page_line_level_ocr_results_with_children],
|
| 598 |
+
outputs=[redaction_output_summary_textbox, output_file, output_file_list_state, latest_file_completed_text, log_files_output, log_files_output_list_state, actual_time_taken_number, textract_metadata_textbox, pdf_doc_state, all_image_annotations_state, current_loop_page_number, page_break_return, all_line_level_ocr_results_df_base, all_decision_process_table_state, comprehend_query_number, output_review_files, annotate_max_pages, annotate_max_pages_bottom, prepared_pdf_state, images_pdf_state, review_file_df, page_sizes, duplication_file_path_outputs_list_state, in_duplicate_pages, latest_review_file_path, textract_query_number, latest_ocr_file_path, all_page_line_level_ocr_results, all_page_line_level_ocr_results_with_children], api_name="redact_doc")
|
| 599 |
|
| 600 |
# If the app has completed a batch of pages, it will rerun the redaction process until the end of all pages in the document
|
| 601 |
+
current_loop_page_number.change(fn = choose_and_run_redactor, inputs=[in_doc_files, prepared_pdf_state, images_pdf_state, in_redact_language, in_redact_entities, in_redact_comprehend_entities, text_extract_method_radio, in_allow_list_state, in_deny_list_state, in_fully_redacted_list_state, latest_file_completed_text, redaction_output_summary_textbox, output_file_list_state, log_files_output_list_state, second_loop_state, page_min, page_max, actual_time_taken_number, handwrite_signature_checkbox, textract_metadata_textbox, all_image_annotations_state, all_line_level_ocr_results_df_base, all_decision_process_table_state, pdf_doc_state, current_loop_page_number, page_break_return, pii_identification_method_drop, comprehend_query_number, max_fuzzy_spelling_mistakes_num, match_fuzzy_whole_phrase_bool, aws_access_key_textbox, aws_secret_key_textbox, annotate_max_pages, review_file_df, output_folder_textbox, document_cropboxes, page_sizes, textract_output_found_checkbox, only_extract_text_radio, duplication_file_path_outputs_list_state, latest_review_file_path, input_folder_textbox, textract_query_number, latest_ocr_file_path, all_page_line_level_ocr_results, all_page_line_level_ocr_results_with_children],
|
| 602 |
+
outputs=[redaction_output_summary_textbox, output_file, output_file_list_state, latest_file_completed_text, log_files_output, log_files_output_list_state, actual_time_taken_number, textract_metadata_textbox, pdf_doc_state, all_image_annotations_state, current_loop_page_number, page_break_return, all_line_level_ocr_results_df_base, all_decision_process_table_state, comprehend_query_number, output_review_files, annotate_max_pages, annotate_max_pages_bottom, prepared_pdf_state, images_pdf_state, review_file_df, page_sizes, duplication_file_path_outputs_list_state, in_duplicate_pages, latest_review_file_path, textract_query_number, latest_ocr_file_path, all_page_line_level_ocr_results, all_page_line_level_ocr_results_with_children])
|
| 603 |
|
| 604 |
# If a file has been completed, the function will continue onto the next document
|
| 605 |
+
latest_file_completed_text.change(fn = choose_and_run_redactor, inputs=[in_doc_files, prepared_pdf_state, images_pdf_state, in_redact_language, in_redact_entities, in_redact_comprehend_entities, text_extract_method_radio, in_allow_list_state, in_deny_list_state, in_fully_redacted_list_state, latest_file_completed_text, redaction_output_summary_textbox, output_file_list_state, log_files_output_list_state, second_loop_state, page_min, page_max, actual_time_taken_number, handwrite_signature_checkbox, textract_metadata_textbox, all_image_annotations_state, all_line_level_ocr_results_df_base, all_decision_process_table_state, pdf_doc_state, current_loop_page_number, page_break_return, pii_identification_method_drop, comprehend_query_number, max_fuzzy_spelling_mistakes_num, match_fuzzy_whole_phrase_bool, aws_access_key_textbox, aws_secret_key_textbox, annotate_max_pages, review_file_df, output_folder_textbox, document_cropboxes, page_sizes, textract_output_found_checkbox, only_extract_text_radio, duplication_file_path_outputs_list_state, latest_review_file_path, input_folder_textbox, textract_query_number, latest_ocr_file_path, all_page_line_level_ocr_results, all_page_line_level_ocr_results_with_children],
|
| 606 |
+
outputs=[redaction_output_summary_textbox, output_file, output_file_list_state, latest_file_completed_text, log_files_output, log_files_output_list_state, actual_time_taken_number, textract_metadata_textbox, pdf_doc_state, all_image_annotations_state, current_loop_page_number, page_break_return, all_line_level_ocr_results_df_base, all_decision_process_table_state, comprehend_query_number, output_review_files, annotate_max_pages, annotate_max_pages_bottom, prepared_pdf_state, images_pdf_state, review_file_df, page_sizes, duplication_file_path_outputs_list_state, in_duplicate_pages, latest_review_file_path, textract_query_number, latest_ocr_file_path, all_page_line_level_ocr_results, all_page_line_level_ocr_results_with_children]).\
|
| 607 |
+
success(fn=update_annotator_object_and_filter_df, inputs=[all_image_annotations_state, page_min, recogniser_entity_dropdown, page_entity_dropdown, text_entity_dropdown, recogniser_entity_dataframe_base, annotator_zoom_number, review_file_df, page_sizes, doc_full_file_name_textbox, input_folder_textbox], outputs=[annotator, annotate_current_page, annotate_current_page_bottom, annotate_previous_page, recogniser_entity_dropdown, recogniser_entity_dataframe, recogniser_entity_dataframe_base, text_entity_dropdown, page_entity_dropdown, page_sizes, all_image_annotations_state]).\
|
| 608 |
success(fn=check_for_existing_textract_file, inputs=[doc_file_name_no_extension_textbox, output_folder_textbox], outputs=[textract_output_found_checkbox]).\
|
| 609 |
success(fn=check_for_existing_local_ocr_file, inputs=[doc_file_name_no_extension_textbox, output_folder_textbox], outputs=[local_ocr_output_found_checkbox]).\
|
| 610 |
success(fn=reveal_feedback_buttons, outputs=[pdf_feedback_radio, pdf_further_details_text, pdf_submit_feedback_btn, pdf_feedback_title]).\
|
|
|
|
| 626 |
textract_job_detail_df.select(df_select_callback_textract_api, inputs=[textract_output_found_checkbox], outputs=[job_id_textbox, job_type_dropdown, selected_job_id_row])
|
| 627 |
|
| 628 |
convert_textract_outputs_to_ocr_results.click(replace_existing_pdf_input_for_whole_document_outputs, inputs = [s3_whole_document_textract_input_subfolder, doc_file_name_no_extension_textbox, output_folder_textbox, s3_whole_document_textract_default_bucket, in_doc_files, input_folder_textbox], outputs = [in_doc_files, doc_file_name_no_extension_textbox, doc_file_name_with_extension_textbox, doc_full_file_name_textbox, doc_file_name_textbox_list, total_pdf_page_count]).\
|
| 629 |
+
success(fn = prepare_image_or_pdf, inputs=[in_doc_files, text_extract_method_radio, latest_file_completed_text, redaction_output_summary_textbox, first_loop_state, annotate_max_pages, all_image_annotations_state, prepare_for_review_bool_false, in_fully_redacted_list_state, output_folder_textbox, input_folder_textbox, prepare_images_bool_false], outputs=[redaction_output_summary_textbox, prepared_pdf_state, images_pdf_state, annotate_max_pages, annotate_max_pages_bottom, pdf_doc_state, all_image_annotations_state, review_file_df, document_cropboxes, page_sizes, textract_output_found_checkbox, all_img_details_state, all_line_level_ocr_results_df_base, local_ocr_output_found_checkbox]).\
|
| 630 |
success(fn=check_for_existing_textract_file, inputs=[doc_file_name_no_extension_textbox, output_folder_textbox], outputs=[textract_output_found_checkbox]).\
|
| 631 |
success(fn=check_for_existing_local_ocr_file, inputs=[doc_file_name_no_extension_textbox, output_folder_textbox], outputs=[local_ocr_output_found_checkbox]).\
|
| 632 |
success(fn= check_textract_outputs_exist, inputs=[textract_output_found_checkbox]).\
|
| 633 |
success(fn = reset_state_vars, outputs=[all_image_annotations_state, all_line_level_ocr_results_df_base, all_decision_process_table_state, comprehend_query_number, textract_metadata_textbox, annotator, output_file_list_state, log_files_output_list_state, recogniser_entity_dataframe, recogniser_entity_dataframe_base, pdf_doc_state, duplication_file_path_outputs_list_state, redaction_output_summary_textbox, is_a_textract_api_call, textract_query_number]).\
|
| 634 |
+
success(fn= choose_and_run_redactor, inputs=[in_doc_files, prepared_pdf_state, images_pdf_state, in_redact_language, in_redact_entities, in_redact_comprehend_entities, textract_only_method_drop, in_allow_list_state, in_deny_list_state, in_fully_redacted_list_state, latest_file_completed_text, redaction_output_summary_textbox, output_file_list_state, log_files_output_list_state, first_loop_state, page_min, page_max, actual_time_taken_number, handwrite_signature_checkbox, textract_metadata_textbox, all_image_annotations_state, all_line_level_ocr_results_df_base, all_decision_process_table_state, pdf_doc_state, current_loop_page_number, page_break_return, no_redaction_method_drop, comprehend_query_number, max_fuzzy_spelling_mistakes_num, match_fuzzy_whole_phrase_bool, aws_access_key_textbox, aws_secret_key_textbox, annotate_max_pages, review_file_df, output_folder_textbox, document_cropboxes, page_sizes, textract_output_found_checkbox, only_extract_text_radio, duplication_file_path_outputs_list_state, latest_review_file_path, input_folder_textbox, textract_query_number, latest_ocr_file_path, all_page_line_level_ocr_results, all_page_line_level_ocr_results_with_children],
|
| 635 |
+
outputs=[redaction_output_summary_textbox, output_file, output_file_list_state, latest_file_completed_text, log_files_output, log_files_output_list_state, actual_time_taken_number, textract_metadata_textbox, pdf_doc_state, all_image_annotations_state, current_loop_page_number, page_break_return, all_line_level_ocr_results_df_base, all_decision_process_table_state, comprehend_query_number, output_review_files, annotate_max_pages, annotate_max_pages_bottom, prepared_pdf_state, images_pdf_state, review_file_df, page_sizes, duplication_file_path_outputs_list_state, in_duplicate_pages, latest_review_file_path, textract_query_number, latest_ocr_file_path, all_page_line_level_ocr_results, all_page_line_level_ocr_results_with_children]).\
|
| 636 |
+
success(fn=update_annotator_object_and_filter_df, inputs=[all_image_annotations_state, page_min, recogniser_entity_dropdown, page_entity_dropdown, text_entity_dropdown, recogniser_entity_dataframe_base, annotator_zoom_number, review_file_df, page_sizes, doc_full_file_name_textbox, input_folder_textbox], outputs=[annotator, annotate_current_page, annotate_current_page_bottom, annotate_previous_page, recogniser_entity_dropdown, recogniser_entity_dataframe, recogniser_entity_dataframe_base, text_entity_dropdown, page_entity_dropdown, page_sizes, all_image_annotations_state])
|
| 637 |
|
| 638 |
###
|
| 639 |
# REVIEW PDF REDACTIONS
|
| 640 |
###
|
| 641 |
+
|
| 642 |
|
| 643 |
# Upload previous files for modifying redactions
|
| 644 |
upload_previous_review_file_btn.click(fn=reset_review_vars, inputs=None, outputs=[recogniser_entity_dataframe, recogniser_entity_dataframe_base]).\
|
| 645 |
success(fn=get_input_file_names, inputs=[output_review_files], outputs=[doc_file_name_no_extension_textbox, doc_file_name_with_extension_textbox, doc_full_file_name_textbox, doc_file_name_textbox_list, total_pdf_page_count]).\
|
| 646 |
+
success(fn = prepare_image_or_pdf, inputs=[output_review_files, text_extract_method_radio, latest_file_completed_text, redaction_output_summary_textbox, second_loop_state, annotate_max_pages, all_image_annotations_state, prepare_for_review_bool, in_fully_redacted_list_state, output_folder_textbox, input_folder_textbox, prepare_images_bool_false], outputs=[redaction_output_summary_textbox, prepared_pdf_state, images_pdf_state, annotate_max_pages, annotate_max_pages_bottom, pdf_doc_state, all_image_annotations_state, review_file_df, document_cropboxes, page_sizes, textract_output_found_checkbox, all_img_details_state, all_line_level_ocr_results_df_base, local_ocr_output_found_checkbox], api_name="prepare_doc").\
|
| 647 |
+
success(update_annotator_object_and_filter_df, inputs=[all_image_annotations_state, annotate_current_page, recogniser_entity_dropdown, page_entity_dropdown, text_entity_dropdown, recogniser_entity_dataframe_base, annotator_zoom_number, review_file_df, page_sizes, doc_full_file_name_textbox, input_folder_textbox], outputs = [annotator, annotate_current_page, annotate_current_page_bottom, annotate_previous_page, recogniser_entity_dropdown, recogniser_entity_dataframe, recogniser_entity_dataframe_base, text_entity_dropdown, page_entity_dropdown, page_sizes, all_image_annotations_state])
|
| 648 |
+
|
| 649 |
+
# Manual updates to review di
|
| 650 |
+
review_file_df.input(update_annotator_page_from_review_df, inputs=[review_file_df, images_pdf_state, page_sizes, all_image_annotations_state, annotator, selected_entity_dataframe_row, input_folder_textbox, doc_full_file_name_textbox], outputs=[annotator, all_image_annotations_state, annotate_current_page, page_sizes, review_file_df, annotate_previous_page]).\
|
| 651 |
+
success(update_annotator_object_and_filter_df, inputs=[all_image_annotations_state, annotate_current_page, recogniser_entity_dropdown, page_entity_dropdown, text_entity_dropdown, recogniser_entity_dataframe_base, annotator_zoom_number, review_file_df, page_sizes, doc_full_file_name_textbox, input_folder_textbox], outputs = [annotator, annotate_current_page, annotate_current_page_bottom, annotate_previous_page, recogniser_entity_dropdown, recogniser_entity_dataframe, recogniser_entity_dataframe_base, text_entity_dropdown, page_entity_dropdown, page_sizes, all_image_annotations_state])
|
| 652 |
|
| 653 |
# Page number controls
|
| 654 |
annotate_current_page.submit(update_all_page_annotation_object_based_on_previous_page, inputs = [annotator, annotate_current_page, annotate_previous_page, all_image_annotations_state, page_sizes], outputs = [all_image_annotations_state, annotate_previous_page, annotate_current_page_bottom]).\
|
| 655 |
+
success(update_annotator_object_and_filter_df, inputs=[all_image_annotations_state, annotate_current_page, recogniser_entity_dropdown, page_entity_dropdown, text_entity_dropdown, recogniser_entity_dataframe_base, annotator_zoom_number, review_file_df, page_sizes, doc_full_file_name_textbox, input_folder_textbox], outputs = [annotator, annotate_current_page, annotate_current_page_bottom, annotate_previous_page, recogniser_entity_dropdown, recogniser_entity_dataframe, recogniser_entity_dataframe_base, text_entity_dropdown, page_entity_dropdown, page_sizes, all_image_annotations_state]).\
|
| 656 |
+
success(apply_redactions_to_review_df_and_files, inputs=[annotator, doc_full_file_name_textbox, pdf_doc_state, all_image_annotations_state, annotate_current_page, review_file_df, output_folder_textbox, do_not_save_pdf_state, page_sizes], outputs=[pdf_doc_state, all_image_annotations_state, output_review_files, log_files_output, review_file_df])
|
| 657 |
|
| 658 |
annotation_last_page_button.click(fn=decrease_page, inputs=[annotate_current_page], outputs=[annotate_current_page, annotate_current_page_bottom]).\
|
| 659 |
success(update_all_page_annotation_object_based_on_previous_page, inputs = [annotator, annotate_current_page, annotate_previous_page, all_image_annotations_state, page_sizes], outputs = [all_image_annotations_state, annotate_previous_page, annotate_current_page_bottom]).\
|
| 660 |
+
success(update_annotator_object_and_filter_df, inputs=[all_image_annotations_state, annotate_current_page, recogniser_entity_dropdown, page_entity_dropdown, text_entity_dropdown, recogniser_entity_dataframe_base, annotator_zoom_number, review_file_df, page_sizes, doc_full_file_name_textbox, input_folder_textbox], outputs = [annotator, annotate_current_page, annotate_current_page_bottom, annotate_previous_page, recogniser_entity_dropdown, recogniser_entity_dataframe, recogniser_entity_dataframe_base, text_entity_dropdown, page_entity_dropdown, page_sizes, all_image_annotations_state]).\
|
| 661 |
+
success(apply_redactions_to_review_df_and_files, inputs=[annotator, doc_full_file_name_textbox, pdf_doc_state, all_image_annotations_state, annotate_current_page, review_file_df, output_folder_textbox, do_not_save_pdf_state, page_sizes], outputs=[pdf_doc_state, all_image_annotations_state, output_review_files, log_files_output, review_file_df])
|
| 662 |
|
| 663 |
annotation_next_page_button.click(fn=increase_page, inputs=[annotate_current_page, all_image_annotations_state], outputs=[annotate_current_page, annotate_current_page_bottom]).\
|
| 664 |
success(update_all_page_annotation_object_based_on_previous_page, inputs = [annotator, annotate_current_page, annotate_previous_page, all_image_annotations_state, page_sizes], outputs = [all_image_annotations_state, annotate_previous_page, annotate_current_page_bottom]).\
|
| 665 |
+
success(update_annotator_object_and_filter_df, inputs=[all_image_annotations_state, annotate_current_page, recogniser_entity_dropdown, page_entity_dropdown, text_entity_dropdown, recogniser_entity_dataframe_base, annotator_zoom_number, review_file_df, page_sizes, doc_full_file_name_textbox, input_folder_textbox], outputs = [annotator, annotate_current_page, annotate_current_page_bottom, annotate_previous_page, recogniser_entity_dropdown, recogniser_entity_dataframe, recogniser_entity_dataframe_base, text_entity_dropdown, page_entity_dropdown, page_sizes, all_image_annotations_state]).\
|
| 666 |
+
success(apply_redactions_to_review_df_and_files, inputs=[annotator, doc_full_file_name_textbox, pdf_doc_state, all_image_annotations_state, annotate_current_page, review_file_df, output_folder_textbox, do_not_save_pdf_state, page_sizes], outputs=[pdf_doc_state, all_image_annotations_state, output_review_files, log_files_output, review_file_df])
|
| 667 |
|
| 668 |
annotation_last_page_button_bottom.click(fn=decrease_page, inputs=[annotate_current_page], outputs=[annotate_current_page, annotate_current_page_bottom]).\
|
| 669 |
success(update_all_page_annotation_object_based_on_previous_page, inputs = [annotator, annotate_current_page, annotate_previous_page, all_image_annotations_state, page_sizes], outputs = [all_image_annotations_state, annotate_previous_page, annotate_current_page_bottom]).\
|
| 670 |
+
success(update_annotator_object_and_filter_df, inputs=[all_image_annotations_state, annotate_current_page, recogniser_entity_dropdown, page_entity_dropdown, text_entity_dropdown, recogniser_entity_dataframe_base, annotator_zoom_number, review_file_df, page_sizes, doc_full_file_name_textbox, input_folder_textbox], outputs = [annotator, annotate_current_page, annotate_current_page_bottom, annotate_previous_page, recogniser_entity_dropdown, recogniser_entity_dataframe, recogniser_entity_dataframe_base, text_entity_dropdown, page_entity_dropdown, page_sizes, all_image_annotations_state]).\
|
| 671 |
+
success(apply_redactions_to_review_df_and_files, inputs=[annotator, doc_full_file_name_textbox, pdf_doc_state, all_image_annotations_state, annotate_current_page, review_file_df, output_folder_textbox, do_not_save_pdf_state, page_sizes], outputs=[pdf_doc_state, all_image_annotations_state, output_review_files, log_files_output, review_file_df])
|
| 672 |
|
| 673 |
annotation_next_page_button_bottom.click(fn=increase_page, inputs=[annotate_current_page, all_image_annotations_state], outputs=[annotate_current_page, annotate_current_page_bottom]).\
|
| 674 |
success(update_all_page_annotation_object_based_on_previous_page, inputs = [annotator, annotate_current_page, annotate_previous_page, all_image_annotations_state, page_sizes], outputs = [all_image_annotations_state, annotate_previous_page, annotate_current_page_bottom]).\
|
| 675 |
+
success(update_annotator_object_and_filter_df, inputs=[all_image_annotations_state, annotate_current_page, recogniser_entity_dropdown, page_entity_dropdown, text_entity_dropdown, recogniser_entity_dataframe_base, annotator_zoom_number, review_file_df, page_sizes, doc_full_file_name_textbox, input_folder_textbox], outputs = [annotator, annotate_current_page, annotate_current_page_bottom, annotate_previous_page, recogniser_entity_dropdown, recogniser_entity_dataframe, recogniser_entity_dataframe_base, text_entity_dropdown, page_entity_dropdown, page_sizes, all_image_annotations_state]).\
|
| 676 |
+
success(apply_redactions_to_review_df_and_files, inputs=[annotator, doc_full_file_name_textbox, pdf_doc_state, all_image_annotations_state, annotate_current_page, review_file_df, output_folder_textbox, do_not_save_pdf_state, page_sizes], outputs=[pdf_doc_state, all_image_annotations_state, output_review_files, log_files_output, review_file_df])
|
| 677 |
|
| 678 |
annotate_current_page_bottom.submit(update_other_annotator_number_from_current, inputs=[annotate_current_page_bottom], outputs=[annotate_current_page]).\
|
| 679 |
success(update_all_page_annotation_object_based_on_previous_page, inputs = [annotator, annotate_current_page, annotate_previous_page, all_image_annotations_state, page_sizes], outputs = [all_image_annotations_state, annotate_previous_page, annotate_current_page_bottom]).\
|
| 680 |
+
success(update_annotator_object_and_filter_df, inputs=[all_image_annotations_state, annotate_current_page, recogniser_entity_dropdown, page_entity_dropdown, text_entity_dropdown, recogniser_entity_dataframe_base, annotator_zoom_number, review_file_df, page_sizes, doc_full_file_name_textbox, input_folder_textbox], outputs = [annotator, annotate_current_page, annotate_current_page_bottom, annotate_previous_page, recogniser_entity_dropdown, recogniser_entity_dataframe, recogniser_entity_dataframe_base, text_entity_dropdown, page_entity_dropdown, page_sizes, all_image_annotations_state]).\
|
| 681 |
+
success(apply_redactions_to_review_df_and_files, inputs=[annotator, doc_full_file_name_textbox, pdf_doc_state, all_image_annotations_state, annotate_current_page, review_file_df, output_folder_textbox, do_not_save_pdf_state, page_sizes], outputs=[pdf_doc_state, all_image_annotations_state, output_review_files, log_files_output, review_file_df])
|
| 682 |
|
| 683 |
# Apply page redactions
|
| 684 |
+
annotation_button_apply.click(apply_redactions_to_review_df_and_files, inputs=[annotator, doc_full_file_name_textbox, pdf_doc_state, all_image_annotations_state, annotate_current_page, review_file_df, output_folder_textbox, save_pdf_state, page_sizes], outputs=[pdf_doc_state, all_image_annotations_state, output_review_files, log_files_output, review_file_df], scroll_to_output=True)
|
| 685 |
|
| 686 |
# Save current page redactions
|
| 687 |
update_current_page_redactions_btn.click(update_all_page_annotation_object_based_on_previous_page, inputs = [annotator, annotate_current_page, annotate_current_page, all_image_annotations_state, page_sizes], outputs = [all_image_annotations_state, annotate_previous_page, annotate_current_page_bottom]).\
|
| 688 |
+
success(update_annotator_object_and_filter_df, inputs=[all_image_annotations_state, annotate_current_page, recogniser_entity_dropdown, page_entity_dropdown, text_entity_dropdown, recogniser_entity_dataframe_base, annotator_zoom_number, review_file_df, page_sizes, doc_full_file_name_textbox, input_folder_textbox], outputs = [annotator, annotate_current_page, annotate_current_page_bottom, annotate_previous_page, recogniser_entity_dropdown, recogniser_entity_dataframe, recogniser_entity_dataframe_base, text_entity_dropdown, page_entity_dropdown, page_sizes, all_image_annotations_state]).\
|
| 689 |
+
success(apply_redactions_to_review_df_and_files, inputs=[annotator, doc_full_file_name_textbox, pdf_doc_state, all_image_annotations_state, annotate_current_page, review_file_df, output_folder_textbox, do_not_save_pdf_state, page_sizes], outputs=[pdf_doc_state, all_image_annotations_state, output_review_files, log_files_output, review_file_df])
|
| 690 |
|
| 691 |
# Review table controls
|
| 692 |
recogniser_entity_dropdown.select(update_entities_df_recogniser_entities, inputs=[recogniser_entity_dropdown, recogniser_entity_dataframe_base, page_entity_dropdown, text_entity_dropdown], outputs=[recogniser_entity_dataframe, text_entity_dropdown, page_entity_dropdown])
|
|
|
|
| 695 |
|
| 696 |
# Clicking on a cell in the recogniser entity dataframe will take you to that page, and also highlight the target redaction box in blue
|
| 697 |
recogniser_entity_dataframe.select(df_select_callback_dataframe_row, inputs=[recogniser_entity_dataframe], outputs=[selected_entity_dataframe_row, selected_entity_dataframe_row_text]).\
|
| 698 |
+
success(update_selected_review_df_row_colour, inputs=[selected_entity_dataframe_row, review_file_df, selected_entity_id, selected_entity_colour], outputs=[review_file_df, selected_entity_id, selected_entity_colour]).\
|
| 699 |
+
success(update_annotator_page_from_review_df, inputs=[review_file_df, images_pdf_state, page_sizes, all_image_annotations_state, annotator, selected_entity_dataframe_row, input_folder_textbox, doc_full_file_name_textbox], outputs=[annotator, all_image_annotations_state, annotate_current_page, page_sizes, review_file_df, annotate_previous_page]).\
|
| 700 |
success(increase_bottom_page_count_based_on_top, inputs=[annotate_current_page], outputs=[annotate_current_page_bottom])
|
| 701 |
|
| 702 |
reset_dropdowns_btn.click(reset_dropdowns, inputs=[recogniser_entity_dataframe_base], outputs=[recogniser_entity_dropdown, text_entity_dropdown, page_entity_dropdown]).\
|
| 703 |
+
success(update_annotator_object_and_filter_df, inputs=[all_image_annotations_state, annotate_current_page, recogniser_entity_dropdown, page_entity_dropdown, text_entity_dropdown, recogniser_entity_dataframe_base, annotator_zoom_number, review_file_df, page_sizes, doc_full_file_name_textbox, input_folder_textbox], outputs = [annotator, annotate_current_page, annotate_current_page_bottom, annotate_previous_page, recogniser_entity_dropdown, recogniser_entity_dataframe, recogniser_entity_dataframe_base, text_entity_dropdown, page_entity_dropdown, page_sizes, all_image_annotations_state])
|
| 704 |
|
| 705 |
# Exclude current selection from annotator and outputs
|
| 706 |
# Exclude only selected row
|
| 707 |
+
exclude_selected_row_btn.click(exclude_selected_items_from_redaction, inputs=[review_file_df, selected_entity_dataframe_row, images_pdf_state, page_sizes, all_image_annotations_state, recogniser_entity_dataframe_base], outputs=[review_file_df, all_image_annotations_state, recogniser_entity_dataframe_base, backup_review_state, backup_image_annotations_state, backup_recogniser_entity_dataframe_base]).\
|
| 708 |
+
success(update_annotator_object_and_filter_df, inputs=[all_image_annotations_state, annotate_current_page, recogniser_entity_dropdown, page_entity_dropdown, text_entity_dropdown, recogniser_entity_dataframe_base, annotator_zoom_number, review_file_df, page_sizes, doc_full_file_name_textbox, input_folder_textbox], outputs = [annotator, annotate_current_page, annotate_current_page_bottom, annotate_previous_page, recogniser_entity_dropdown, recogniser_entity_dataframe, recogniser_entity_dataframe_base, text_entity_dropdown, page_entity_dropdown, page_sizes, all_image_annotations_state]).\
|
| 709 |
+
success(apply_redactions_to_review_df_and_files, inputs=[annotator, doc_full_file_name_textbox, pdf_doc_state, all_image_annotations_state, annotate_current_page, review_file_df, output_folder_textbox, do_not_save_pdf_state, page_sizes], outputs=[pdf_doc_state, all_image_annotations_state, output_review_files, log_files_output, review_file_df]).\
|
| 710 |
success(update_all_entity_df_dropdowns, inputs=[recogniser_entity_dataframe_base, recogniser_entity_dropdown, page_entity_dropdown, text_entity_dropdown], outputs=[recogniser_entity_dropdown, text_entity_dropdown, page_entity_dropdown])
|
| 711 |
|
| 712 |
# Exclude all items with same text as selected row
|
| 713 |
exclude_text_with_same_as_selected_row_btn.click(get_all_rows_with_same_text, inputs=[recogniser_entity_dataframe_base, selected_entity_dataframe_row_text], outputs=[recogniser_entity_dataframe_same_text]).\
|
| 714 |
+
success(exclude_selected_items_from_redaction, inputs=[review_file_df, recogniser_entity_dataframe_same_text, images_pdf_state, page_sizes, all_image_annotations_state, recogniser_entity_dataframe_base], outputs=[review_file_df, all_image_annotations_state, recogniser_entity_dataframe_base, backup_review_state, backup_image_annotations_state, backup_recogniser_entity_dataframe_base]).\
|
| 715 |
+
success(update_annotator_object_and_filter_df, inputs=[all_image_annotations_state, annotate_current_page, recogniser_entity_dropdown, page_entity_dropdown, text_entity_dropdown, recogniser_entity_dataframe_base, annotator_zoom_number, review_file_df, page_sizes, doc_full_file_name_textbox, input_folder_textbox], outputs = [annotator, annotate_current_page, annotate_current_page_bottom, annotate_previous_page, recogniser_entity_dropdown, recogniser_entity_dataframe, recogniser_entity_dataframe_base, text_entity_dropdown, page_entity_dropdown, page_sizes, all_image_annotations_state]).\
|
| 716 |
+
success(apply_redactions_to_review_df_and_files, inputs=[annotator, doc_full_file_name_textbox, pdf_doc_state, all_image_annotations_state, annotate_current_page, review_file_df, output_folder_textbox, do_not_save_pdf_state, page_sizes], outputs=[pdf_doc_state, all_image_annotations_state, output_review_files, log_files_output, review_file_df]).\
|
| 717 |
success(update_all_entity_df_dropdowns, inputs=[recogniser_entity_dataframe_base, recogniser_entity_dropdown, page_entity_dropdown, text_entity_dropdown], outputs=[recogniser_entity_dropdown, text_entity_dropdown, page_entity_dropdown])
|
| 718 |
|
| 719 |
# Exclude everything visible in table
|
| 720 |
+
exclude_selected_btn.click(exclude_selected_items_from_redaction, inputs=[review_file_df, recogniser_entity_dataframe, images_pdf_state, page_sizes, all_image_annotations_state, recogniser_entity_dataframe_base], outputs=[review_file_df, all_image_annotations_state, recogniser_entity_dataframe_base, backup_review_state, backup_image_annotations_state, backup_recogniser_entity_dataframe_base]).\
|
| 721 |
+
success(update_annotator_object_and_filter_df, inputs=[all_image_annotations_state, annotate_current_page, recogniser_entity_dropdown, page_entity_dropdown, text_entity_dropdown, recogniser_entity_dataframe_base, annotator_zoom_number, review_file_df, page_sizes, doc_full_file_name_textbox, input_folder_textbox], outputs = [annotator, annotate_current_page, annotate_current_page_bottom, annotate_previous_page, recogniser_entity_dropdown, recogniser_entity_dataframe, recogniser_entity_dataframe_base, text_entity_dropdown, page_entity_dropdown, page_sizes, all_image_annotations_state]).\
|
| 722 |
+
success(apply_redactions_to_review_df_and_files, inputs=[annotator, doc_full_file_name_textbox, pdf_doc_state, all_image_annotations_state, annotate_current_page, review_file_df, output_folder_textbox, do_not_save_pdf_state, page_sizes], outputs=[pdf_doc_state, all_image_annotations_state, output_review_files, log_files_output, review_file_df]).\
|
| 723 |
success(update_all_entity_df_dropdowns, inputs=[recogniser_entity_dataframe_base, recogniser_entity_dropdown, page_entity_dropdown, text_entity_dropdown], outputs=[recogniser_entity_dropdown, text_entity_dropdown, page_entity_dropdown])
|
| 724 |
|
| 725 |
+
undo_last_removal_btn.click(undo_last_removal, inputs=[backup_review_state, backup_image_annotations_state, backup_recogniser_entity_dataframe_base], outputs=[review_file_df, all_image_annotations_state, recogniser_entity_dataframe_base]).\
|
| 726 |
+
success(update_annotator_object_and_filter_df, inputs=[all_image_annotations_state, annotate_current_page, recogniser_entity_dropdown, page_entity_dropdown, text_entity_dropdown, recogniser_entity_dataframe_base, annotator_zoom_number, review_file_df, page_sizes, doc_full_file_name_textbox, input_folder_textbox], outputs = [annotator, annotate_current_page, annotate_current_page_bottom, annotate_previous_page, recogniser_entity_dropdown, recogniser_entity_dataframe, recogniser_entity_dataframe_base, text_entity_dropdown, page_entity_dropdown, page_sizes, all_image_annotations_state]).\
|
| 727 |
+
success(apply_redactions_to_review_df_and_files, inputs=[annotator, doc_full_file_name_textbox, pdf_doc_state, all_image_annotations_state, annotate_current_page, review_file_df, output_folder_textbox, do_not_save_pdf_state, page_sizes], outputs=[pdf_doc_state, all_image_annotations_state, output_review_files, log_files_output, review_file_df])
|
|
|
|
|
|
|
| 728 |
|
| 729 |
# Review OCR text button
|
| 730 |
all_line_level_ocr_results_df.select(df_select_callback_ocr, inputs=[all_line_level_ocr_results_df], outputs=[annotate_current_page, selected_ocr_dataframe_row]).\
|
| 731 |
+
success(update_annotator_page_from_review_df, inputs=[review_file_df, images_pdf_state, page_sizes, all_image_annotations_state, annotator, selected_ocr_dataframe_row, input_folder_textbox, doc_full_file_name_textbox], outputs=[annotator, all_image_annotations_state, annotate_current_page, page_sizes, review_file_df, annotate_previous_page]).\
|
| 732 |
success(increase_bottom_page_count_based_on_top, inputs=[annotate_current_page], outputs=[annotate_current_page_bottom])
|
| 733 |
|
| 734 |
reset_all_ocr_results_btn.click(reset_ocr_base_dataframe, inputs=[all_line_level_ocr_results_df_base], outputs=[all_line_level_ocr_results_df])
|
| 735 |
|
| 736 |
# Convert review file to xfdf Adobe format
|
| 737 |
convert_review_file_to_adobe_btn.click(fn=get_input_file_names, inputs=[output_review_files], outputs=[doc_file_name_no_extension_textbox, doc_file_name_with_extension_textbox, doc_full_file_name_textbox, doc_file_name_textbox_list, total_pdf_page_count]).\
|
| 738 |
+
success(fn = prepare_image_or_pdf, inputs=[output_review_files, text_extract_method_radio, latest_file_completed_text, redaction_output_summary_textbox, second_loop_state, annotate_max_pages, all_image_annotations_state, prepare_for_review_bool, in_fully_redacted_list_state, output_folder_textbox, input_folder_textbox, prepare_images_bool_false], outputs=[redaction_output_summary_textbox, prepared_pdf_state, images_pdf_state, annotate_max_pages, annotate_max_pages_bottom, pdf_doc_state, all_image_annotations_state, review_file_df, document_cropboxes, page_sizes, textract_output_found_checkbox, all_img_details_state, all_line_level_ocr_results_df_placeholder, local_ocr_output_found_checkbox]).\
|
| 739 |
success(convert_df_to_xfdf, inputs=[output_review_files, pdf_doc_state, images_pdf_state, output_folder_textbox, document_cropboxes, page_sizes], outputs=[adobe_review_files_out])
|
| 740 |
|
| 741 |
# Convert xfdf Adobe file back to review_file.csv
|
| 742 |
convert_adobe_to_review_file_btn.click(fn=get_input_file_names, inputs=[adobe_review_files_out], outputs=[doc_file_name_no_extension_textbox, doc_file_name_with_extension_textbox, doc_full_file_name_textbox, doc_file_name_textbox_list, total_pdf_page_count]).\
|
| 743 |
+
success(fn = prepare_image_or_pdf, inputs=[adobe_review_files_out, text_extract_method_radio, latest_file_completed_text, redaction_output_summary_textbox, second_loop_state, annotate_max_pages, all_image_annotations_state, prepare_for_review_bool, in_fully_redacted_list_state, output_folder_textbox, input_folder_textbox, prepare_images_bool_false], outputs=[redaction_output_summary_textbox, prepared_pdf_state, images_pdf_state, annotate_max_pages, annotate_max_pages_bottom, pdf_doc_state, all_image_annotations_state, review_file_df, document_cropboxes, page_sizes, textract_output_found_checkbox, all_img_details_state, all_line_level_ocr_results_df_placeholder, local_ocr_output_found_checkbox]).\
|
| 744 |
success(fn=convert_xfdf_to_dataframe, inputs=[adobe_review_files_out, pdf_doc_state, images_pdf_state, output_folder_textbox], outputs=[output_review_files], scroll_to_output=True)
|
| 745 |
|
| 746 |
###
|
|
|
|
| 753 |
success(fn=anonymise_data_files, inputs=[in_data_files, in_text, anon_strat, in_colnames, in_redact_language, in_redact_entities, in_allow_list_state, text_tabular_files_done, text_output_summary, text_output_file_list_state, log_files_output_list_state, in_excel_sheets, first_loop_state, output_folder_textbox, in_deny_list_state, max_fuzzy_spelling_mistakes_num, pii_identification_method_drop_tabular, in_redact_comprehend_entities, comprehend_query_number, aws_access_key_textbox, aws_secret_key_textbox, actual_time_taken_number], outputs=[text_output_summary, text_output_file, text_output_file_list_state, text_tabular_files_done, log_files_output, log_files_output_list_state, actual_time_taken_number], api_name="redact_data").\
|
| 754 |
success(fn = reveal_feedback_buttons, outputs=[data_feedback_radio, data_further_details_text, data_submit_feedback_btn, data_feedback_title])
|
| 755 |
|
| 756 |
+
# Currently only supports redacting one data file at a time, following code block not used
|
| 757 |
# If the output file count text box changes, keep going with redacting each data file until done
|
| 758 |
# text_tabular_files_done.change(fn=anonymise_data_files, inputs=[in_data_files, in_text, anon_strat, in_colnames, in_redact_language, in_redact_entities, in_allow_list_state, text_tabular_files_done, text_output_summary, text_output_file_list_state, log_files_output_list_state, in_excel_sheets, second_loop_state, output_folder_textbox, in_deny_list_state, max_fuzzy_spelling_mistakes_num, pii_identification_method_drop_tabular, in_redact_comprehend_entities, comprehend_query_number, aws_access_key_textbox, aws_secret_key_textbox, actual_time_taken_number], outputs=[text_output_summary, text_output_file, text_output_file_list_state, text_tabular_files_done, log_files_output, log_files_output_list_state, actual_time_taken_number]).\
|
| 759 |
# success(fn = reveal_feedback_buttons, outputs=[data_feedback_radio, data_further_details_text, data_submit_feedback_btn, data_feedback_title])
|
|
|
|
| 762 |
# IDENTIFY DUPLICATE PAGES
|
| 763 |
###
|
| 764 |
find_duplicate_pages_btn.click(
|
| 765 |
+
fn=run_duplicate_analysis,
|
| 766 |
inputs=[
|
| 767 |
in_duplicate_pages,
|
| 768 |
duplicate_threshold_input,
|
|
|
|
| 772 |
],
|
| 773 |
outputs=[
|
| 774 |
results_df_preview,
|
| 775 |
+
duplicate_files_out,
|
| 776 |
+
full_duplicate_data_by_file
|
| 777 |
]
|
| 778 |
)
|
| 779 |
|
| 780 |
+
# full_duplicated_data_df,
|
| 781 |
results_df_preview.select(
|
| 782 |
+
fn=handle_selection_and_preview,
|
| 783 |
+
inputs=[results_df_preview, full_duplicate_data_by_file],
|
| 784 |
+
outputs=[selected_duplicate_data_row_index, page1_text_preview, page2_text_preview]
|
| 785 |
+
)
|
| 786 |
+
|
| 787 |
+
# When the user clicks the "Exclude" button
|
| 788 |
+
exclude_match_btn.click(
|
| 789 |
+
fn=exclude_match,
|
| 790 |
+
inputs=[results_df_preview, selected_duplicate_data_row_index],
|
| 791 |
+
outputs=[results_df_preview, duplicate_files_out, page1_text_preview, page2_text_preview]
|
| 792 |
)
|
| 793 |
|
| 794 |
+
apply_match_btn.click(
|
| 795 |
+
fn=apply_whole_page_redactions_from_list,
|
| 796 |
+
inputs=[in_fully_redacted_list_state, doc_file_name_with_extension_textbox, review_file_df, duplicate_files_out, pdf_doc_state, page_sizes, all_image_annotations_state],
|
| 797 |
+
outputs=[review_file_df, all_image_annotations_state]).\
|
| 798 |
+
success(update_annotator_page_from_review_df, inputs=[review_file_df, images_pdf_state, page_sizes, all_image_annotations_state, annotator, selected_entity_dataframe_row, input_folder_textbox, doc_full_file_name_textbox], outputs=[annotator, all_image_annotations_state, annotate_current_page, page_sizes, review_file_df, annotate_previous_page]).\
|
| 799 |
+
success(update_annotator_object_and_filter_df, inputs=[all_image_annotations_state, annotate_current_page, recogniser_entity_dropdown, page_entity_dropdown, text_entity_dropdown, recogniser_entity_dataframe_base, annotator_zoom_number, review_file_df, page_sizes, doc_full_file_name_textbox, input_folder_textbox], outputs = [annotator, annotate_current_page, annotate_current_page_bottom, annotate_previous_page, recogniser_entity_dropdown, recogniser_entity_dataframe, recogniser_entity_dataframe_base, text_entity_dropdown, page_entity_dropdown, page_sizes, all_image_annotations_state])
|
| 800 |
+
|
| 801 |
###
|
| 802 |
# SETTINGS PAGE INPUT / OUTPUT
|
| 803 |
###
|
|
|
|
| 811 |
in_deny_list_state.input(update_dataframe, inputs=[in_deny_list_state], outputs=[in_deny_list_state])
|
| 812 |
in_fully_redacted_list_state.input(update_dataframe, inputs=[in_fully_redacted_list_state], outputs=[in_fully_redacted_list_state])
|
| 813 |
|
| 814 |
+
apply_fully_redacted_list_btn.click(
|
| 815 |
+
fn=apply_whole_page_redactions_from_list,
|
| 816 |
+
inputs=[in_fully_redacted_list_state, doc_file_name_with_extension_textbox, review_file_df, duplicate_files_out, pdf_doc_state, page_sizes, all_image_annotations_state],
|
| 817 |
+
outputs=[review_file_df, all_image_annotations_state]).\
|
| 818 |
+
success(update_annotator_page_from_review_df, inputs=[review_file_df, images_pdf_state, page_sizes, all_image_annotations_state, annotator, selected_entity_dataframe_row, input_folder_textbox, doc_full_file_name_textbox], outputs=[annotator, all_image_annotations_state, annotate_current_page, page_sizes, review_file_df, annotate_previous_page]).\
|
| 819 |
+
success(update_annotator_object_and_filter_df, inputs=[all_image_annotations_state, annotate_current_page, recogniser_entity_dropdown, page_entity_dropdown, text_entity_dropdown, recogniser_entity_dataframe_base, annotator_zoom_number, review_file_df, page_sizes, doc_full_file_name_textbox, input_folder_textbox], outputs = [annotator, annotate_current_page, annotate_current_page_bottom, annotate_previous_page, recogniser_entity_dropdown, recogniser_entity_dataframe, recogniser_entity_dataframe_base, text_entity_dropdown, page_entity_dropdown, page_sizes, all_image_annotations_state])
|
| 820 |
+
|
| 821 |
# Merge multiple review csv files together
|
| 822 |
merge_multiple_review_files_btn.click(fn=merge_csv_files, inputs=multiple_review_files_in_out, outputs=multiple_review_files_in_out)
|
| 823 |
|
pyproject.toml
CHANGED
|
@@ -23,7 +23,7 @@ dependencies = [
|
|
| 23 |
"spacy==3.8.4",
|
| 24 |
# Direct URL dependency for spacy model
|
| 25 |
"en_core_web_lg @ https://github.com/explosion/spacy-models/releases/download/en_core_web_lg-3.8.0/en_core_web_lg-3.8.0.tar.gz",
|
| 26 |
-
"gradio==5.
|
| 27 |
"boto3==1.38.35",
|
| 28 |
"pyarrow==19.0.1",
|
| 29 |
"openpyxl==3.1.5",
|
|
|
|
| 23 |
"spacy==3.8.4",
|
| 24 |
# Direct URL dependency for spacy model
|
| 25 |
"en_core_web_lg @ https://github.com/explosion/spacy-models/releases/download/en_core_web_lg-3.8.0/en_core_web_lg-3.8.0.tar.gz",
|
| 26 |
+
"gradio==5.34.0",
|
| 27 |
"boto3==1.38.35",
|
| 28 |
"pyarrow==19.0.1",
|
| 29 |
"openpyxl==3.1.5",
|
requirements.txt
CHANGED
|
@@ -10,7 +10,7 @@ pandas==2.2.3
|
|
| 10 |
scikit-learn==1.6.1
|
| 11 |
spacy==3.8.4
|
| 12 |
en_core_web_lg @ https://github.com/explosion/spacy-models/releases/download/en_core_web_lg-3.8.0/en_core_web_lg-3.8.0.tar.gz
|
| 13 |
-
gradio==5.
|
| 14 |
boto3==1.38.35
|
| 15 |
pyarrow==19.0.1
|
| 16 |
openpyxl==3.1.5
|
|
|
|
| 10 |
scikit-learn==1.6.1
|
| 11 |
spacy==3.8.4
|
| 12 |
en_core_web_lg @ https://github.com/explosion/spacy-models/releases/download/en_core_web_lg-3.8.0/en_core_web_lg-3.8.0.tar.gz
|
| 13 |
+
gradio==5.34.0
|
| 14 |
boto3==1.38.35
|
| 15 |
pyarrow==19.0.1
|
| 16 |
openpyxl==3.1.5
|
src/user_guide.qmd
CHANGED
|
@@ -3,7 +3,7 @@ title: "User guide"
|
|
| 3 |
format:
|
| 4 |
html:
|
| 5 |
toc: true # Enable the table of contents
|
| 6 |
-
toc-depth: 3 # Include headings up to level
|
| 7 |
toc-title: "On this page" # Optional: Title for your TOC
|
| 8 |
---
|
| 9 |
|
|
@@ -73,7 +73,7 @@ If you are running with the AWS service enabled, here you will also have a choic
|
|
| 73 |
- **'AWS Comprehend'** - This method calls an AWS service to provide more accurate identification of PII in extracted text.
|
| 74 |
|
| 75 |
### Optional - costs and time estimation
|
| 76 |
-
If the option is enabled (by your system admin, in the config file), you will see a cost and time estimate for the redaction process. 'Existing Textract output file found' will be checked automatically if previous Textract text extraction files exist in the output folder, or have been [previously uploaded by the user](#aws-textract-outputs) (saving time and money for redaction).
|
| 77 |
|
| 78 |

|
| 79 |
|
|
@@ -101,7 +101,7 @@ Click 'Redact document'. After loading in the document, the app should be able t
|
|
| 101 |
- **'...ocr_results.csv'** files contain the line-by-line text outputs from the entire document. This file can be useful for later searching through for any terms of interest in the document (e.g. using Excel or a similar program).
|
| 102 |
- **'...review_file.csv'** files are the review files that contain details and locations of all of the suggested redactions in the document. This file is key to the [review process](#reviewing-and-modifying-suggested-redactions), and should be downloaded to use later for this.
|
| 103 |
|
| 104 |
-
### Additional AWS Textract / local OCR outputs
|
| 105 |
|
| 106 |
If you have used the AWS Textract option for extracting text, you may also see a '..._textract.json' file. This file contains all the relevant extracted text information that comes from the AWS Textract service. You can keep this file and upload it at a later date alongside your input document, which will enable you to skip calling AWS Textract every single time you want to do a redaction task, as follows:
|
| 107 |
|
|
@@ -166,6 +166,8 @@ If the table is empty, you can add a new entry, you can add a new row by clickin
|
|
| 166 |
|
| 167 |

|
| 168 |
|
|
|
|
|
|
|
| 169 |
### Redacting additional types of personal information
|
| 170 |
|
| 171 |
You may want to redact additional types of information beyond the defaults, or you may not be interested in default suggested entity types. There are dates in the example complaint letter. Say we wanted to redact those dates also?
|
|
@@ -344,7 +346,7 @@ You can also write open text into an input box and redact that using the same me
|
|
| 344 |
### Redaction log outputs
|
| 345 |
A list of the suggested redaction outputs from the tabular data / open text data redaction is available on the Redaction settings page under 'Log file outputs'.
|
| 346 |
|
| 347 |
-
#
|
| 348 |
|
| 349 |
This advanced user guide will go over some of the features recently added to the app, including: modifying and merging redaction review files, identifying and redacting duplicate pages across multiple PDFs, 'fuzzy' search and redact, and exporting redactions to Adobe Acrobat.
|
| 350 |
|
|
@@ -375,21 +377,49 @@ You can find this option at the bottom of the 'Redaction Settings' tab. Upload m
|
|
| 375 |
|
| 376 |
The files for this section are stored [here](https://github.com/seanpedrick-case/document_redaction_examples/blob/main/duplicate_page_find_in_app/).
|
| 377 |
|
| 378 |
-
Some redaction tasks involve removing duplicate pages of text that may exist across multiple documents. This feature
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 379 |
|
| 380 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 381 |
|
| 382 |
-
|
| 383 |
|
| 384 |
-
|
|
|
|
| 385 |
|
| 386 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 387 |
|
| 388 |

|
| 389 |
|
| 390 |
-
|
| 391 |
|
| 392 |
-
 above.
|
| 395 |
|
|
@@ -490,6 +520,8 @@ Again, a lot can potentially go wrong with AWS solutions that are insecure, so b
|
|
| 490 |
|
| 491 |
## Modifying existing redaction review files
|
| 492 |
|
|
|
|
|
|
|
| 493 |
You can find the folder containing the files discussed in this section [here](https://github.com/seanpedrick-case/document_redaction_examples/blob/main/merge_review_files/).
|
| 494 |
|
| 495 |
As well as serving as inputs to the document redaction app's review function, the 'review_file.csv' output can be modified outside of the app, and also merged with others from multiple redaction attempts on the same file. This gives you the flexibility to change redaction details outside of the app.
|
|
@@ -508,4 +540,4 @@ I have saved an output file following the above steps as '[Partnership-Agreement
|
|
| 508 |
|
| 509 |
|
| 510 |
|
| 511 |
-
We can see from the above that we have successfully removed a redaction box, changed labels, colours, and redaction box sizes.
|
|
|
|
| 3 |
format:
|
| 4 |
html:
|
| 5 |
toc: true # Enable the table of contents
|
| 6 |
+
toc-depth: 3 # Include headings up to level 3 (##)
|
| 7 |
toc-title: "On this page" # Optional: Title for your TOC
|
| 8 |
---
|
| 9 |
|
|
|
|
| 73 |
- **'AWS Comprehend'** - This method calls an AWS service to provide more accurate identification of PII in extracted text.
|
| 74 |
|
| 75 |
### Optional - costs and time estimation
|
| 76 |
+
If the option is enabled (by your system admin, in the config file), you will see a cost and time estimate for the redaction process. 'Existing Textract output file found' will be checked automatically if previous Textract text extraction files exist in the output folder, or have been [previously uploaded by the user](#aws-textract-outputs) (saving time and money for redaction).
|
| 77 |
|
| 78 |

|
| 79 |
|
|
|
|
| 101 |
- **'...ocr_results.csv'** files contain the line-by-line text outputs from the entire document. This file can be useful for later searching through for any terms of interest in the document (e.g. using Excel or a similar program).
|
| 102 |
- **'...review_file.csv'** files are the review files that contain details and locations of all of the suggested redactions in the document. This file is key to the [review process](#reviewing-and-modifying-suggested-redactions), and should be downloaded to use later for this.
|
| 103 |
|
| 104 |
+
### Additional AWS Textract / local OCR outputs
|
| 105 |
|
| 106 |
If you have used the AWS Textract option for extracting text, you may also see a '..._textract.json' file. This file contains all the relevant extracted text information that comes from the AWS Textract service. You can keep this file and upload it at a later date alongside your input document, which will enable you to skip calling AWS Textract every single time you want to do a redaction task, as follows:
|
| 107 |
|
|
|
|
| 166 |
|
| 167 |

|
| 168 |
|
| 169 |
+
**Note:** As of version 0.7.0 you can now apply your whole page redaction list directly to the document file currently under review by clicking the 'Apply whole page redaction list to document currently under review' button that appears here.
|
| 170 |
+
|
| 171 |
### Redacting additional types of personal information
|
| 172 |
|
| 173 |
You may want to redact additional types of information beyond the defaults, or you may not be interested in default suggested entity types. There are dates in the example complaint letter. Say we wanted to redact those dates also?
|
|
|
|
| 346 |
### Redaction log outputs
|
| 347 |
A list of the suggested redaction outputs from the tabular data / open text data redaction is available on the Redaction settings page under 'Log file outputs'.
|
| 348 |
|
| 349 |
+
# ADVANCED USER GUIDE
|
| 350 |
|
| 351 |
This advanced user guide will go over some of the features recently added to the app, including: modifying and merging redaction review files, identifying and redacting duplicate pages across multiple PDFs, 'fuzzy' search and redact, and exporting redactions to Adobe Acrobat.
|
| 352 |
|
|
|
|
| 377 |
|
| 378 |
The files for this section are stored [here](https://github.com/seanpedrick-case/document_redaction_examples/blob/main/duplicate_page_find_in_app/).
|
| 379 |
|
| 380 |
+
Some redaction tasks involve removing duplicate pages of text that may exist across multiple documents. This feature helps you find and remove duplicate content that may exist in single or multiple documents. It can identify everything from single identical pages to multi-page sections (subdocuments). The process involves three main steps: configuring the analysis, reviewing the results in the interactive interface, and then using the generated files to perform the redactions.
|
| 381 |
+
|
| 382 |
+

|
| 383 |
+
|
| 384 |
+
**Step 1: Upload and Configure the Analysis**
|
| 385 |
+
First, navigate to the "Identify duplicate pages" tab. Upload all the ocr_output.csv files you wish to compare into the file area. These files are generated every time you run a redaction task and contain the text for each page of a document.
|
| 386 |
+
|
| 387 |
+
For our example, you can upload the four 'ocr_output.csv' files provided in the example folder into the file area. Click 'Identify duplicate pages' and you will see a number of files returned. In case you want to see the original PDFs, they are available [here](https://github.com/seanpedrick-case/document_redaction_examples/blob/main/duplicate_page_find_in_app/input_pdfs/).
|
| 388 |
+
|
| 389 |
+
The default options will search for matching subdocuments of any length. Before running the analysis, you can configure these matching parameters to tell the tool what you're looking for:
|
| 390 |
+
|
| 391 |
+

|
| 392 |
|
| 393 |
+
*Matching Parameters*
|
| 394 |
+
- **Similarity Threshold:** A score from 0 to 1. Pages or sequences of pages with a calculated text similarity above this value will be considered a match. The default of 0.9 (90%) is a good starting point for finding near-identical pages.
|
| 395 |
+
- **Min Word Count:** Pages with fewer words than this value will be completely ignored during the comparison. This is extremely useful for filtering out blank pages, title pages, or boilerplate pages that might otherwise create noise in the results. The default is 10.
|
| 396 |
+
- **Choosing a Matching Strategy:** You have three main options to find duplicate content.
|
| 397 |
+
- *'Subdocument' matching (default):* Use this to find the longest possible sequence of matching pages. The tool will find an initial match and then automatically expand it forward page-by-page until the consecutive match breaks. This is the best method for identifying complete copied chapters or sections of unknown length. This is enabled by default by ticking the "Enable 'subdocument' matching" box. This setting overrides the described below.
|
| 398 |
+
- *Minimum length subdocument matching:* Use this to find sequences of consecutively matching pages with a minimum page lenght. For example, setting the slider to 3 will only return sections that are at least 3 pages long. How to enable: Untick the "Enable 'subdocument' matching" box and set the "Minimum consecutive pages" slider to a value greater than 1.
|
| 399 |
+
- *Single Page Matching:* Use this to find all individual page pairs that are similar to each other. Leave the "Enable 'subdocument' matching" box unchecked and keep the "Minimum consecutive pages" slider at 1.
|
| 400 |
|
| 401 |
+
Once your parameters are set, click the "Identify duplicate pages/subdocuments" button.
|
| 402 |
|
| 403 |
+
**Step 2: Review Results in the Interface**
|
| 404 |
+
After the analysis is complete, the results will be displayed directly in the interface.
|
| 405 |
|
| 406 |
+
*Analysis Summary:* A table will appear showing a summary of all the matches found. The columns will change depending on the matching strategy you chose. For subdocument matches, it will show the start and end pages of the matched sequence.
|
| 407 |
+
|
| 408 |
+
*Interactive Preview:* This is the most important part of the review process. Click on any row in the summary table. The full text of the matching page(s) will appear side-by-side in the "Full Text Preview" section below, allowing you to instantly verify the accuracy of the match.
|
| 409 |
+
|
| 410 |
+

|
| 411 |
+
|
| 412 |
+
**Step 3: Download and Use the Output Files**
|
| 413 |
+
The analysis also generates a set of downloadable files for your records and for performing redactions.
|
| 414 |
+
|
| 415 |
+
|
| 416 |
+
- page_similarity_results.csv: This is a detailed report of the analysis you just ran. It shows a breakdown of the pages from each file that are most similar to each other above the similarity threshold. You can compare the text in the two columns 'Page_1_Text' and 'Page_2_Text'. For single-page matches, it will list each pair of matching pages. For subdocument matches, it will list the start and end pages of each matched sequence, along with the total length of the match.
|
| 417 |
|
| 418 |

|
| 419 |
|
| 420 |
+
- [Original_Filename]_pages_to_redact.csv: For each input document that was found to contain duplicate content, a separate redaction list is created. This is a simple, one-column CSV file containing a list of all page numbers that should be removed. To use these files, you can either upload the original document (i.e. the PDF) on the 'Review redactions' tab, and then click on the 'Apply relevant duplicate page output to document currently under review' button. You should see the whole pages suggested for redaction on the 'Review redactions' tab. Alternatively, you can reupload the file into the whole page redaction section as described in the ['Full page redaction list example' section](#full-page-redaction-list-example).
|
| 421 |
|
| 422 |
+

|
| 423 |
|
| 424 |
If you want to combine the results from this redaction process with previous redaction tasks for the same PDF, you could merge review file outputs following the steps described in [Merging existing redaction review files](#merging-existing-redaction-review-files) above.
|
| 425 |
|
|
|
|
| 520 |
|
| 521 |
## Modifying existing redaction review files
|
| 522 |
|
| 523 |
+
*Note:* As of version 0.7.0 you can now modify redaction review files directly in the app on the 'Review redactions' tab. Open the accordion 'View and edit review data' under the file input area. You can edit review file data cells here - press Enter to apply changes. You should see the effect on the current page if you click the 'Save changes on current page to file' button to the right.
|
| 524 |
+
|
| 525 |
You can find the folder containing the files discussed in this section [here](https://github.com/seanpedrick-case/document_redaction_examples/blob/main/merge_review_files/).
|
| 526 |
|
| 527 |
As well as serving as inputs to the document redaction app's review function, the 'review_file.csv' output can be modified outside of the app, and also merged with others from multiple redaction attempts on the same file. This gives you the flexibility to change redaction details outside of the app.
|
|
|
|
| 540 |
|
| 541 |

|
| 542 |
|
| 543 |
+
We can see from the above that we have successfully removed a redaction box, changed labels, colours, and redaction box sizes.
|
tools/file_conversion.py
CHANGED
|
@@ -385,12 +385,17 @@ def convert_pymupdf_to_image_coords(pymupdf_page:Page, x1:float, y1:float, x2:fl
|
|
| 385 |
|
| 386 |
return x1_image, y1_image, x2_image, y2_image
|
| 387 |
|
| 388 |
-
def redact_whole_pymupdf_page(rect_height:float, rect_width:float, page:Page, custom_colours:bool, border:float = 5):
|
| 389 |
# Small border to page that remains white
|
| 390 |
-
|
| 391 |
# Define the coordinates for the Rect
|
| 392 |
whole_page_x1, whole_page_y1 = 0 + border, 0 + border # Bottom-left corner
|
| 393 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 394 |
|
| 395 |
# Create new image annotation element based on whole page coordinates
|
| 396 |
whole_page_rect = Rect(whole_page_x1, whole_page_y1, whole_page_x2, whole_page_y2)
|
|
@@ -404,7 +409,8 @@ def redact_whole_pymupdf_page(rect_height:float, rect_width:float, page:Page, cu
|
|
| 404 |
whole_page_img_annotation_box["color"] = (0,0,0)
|
| 405 |
whole_page_img_annotation_box["label"] = "Whole page"
|
| 406 |
|
| 407 |
-
|
|
|
|
| 408 |
|
| 409 |
return whole_page_img_annotation_box
|
| 410 |
|
|
@@ -1290,7 +1296,13 @@ def convert_annotation_data_to_dataframe(all_annotations: List[Dict[str, Any]]):
|
|
| 1290 |
df = pd.DataFrame({
|
| 1291 |
"image": [anno.get("image") for anno in all_annotations],
|
| 1292 |
# Ensure 'boxes' defaults to an empty list if missing or None
|
| 1293 |
-
"boxes": [
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1294 |
})
|
| 1295 |
|
| 1296 |
# 2. Calculate the page number using the helper function
|
|
|
|
| 385 |
|
| 386 |
return x1_image, y1_image, x2_image, y2_image
|
| 387 |
|
| 388 |
+
def redact_whole_pymupdf_page(rect_height:float, rect_width:float, page:Page, custom_colours:bool=False, border:float = 5, redact_pdf:bool=True):
|
| 389 |
# Small border to page that remains white
|
| 390 |
+
|
| 391 |
# Define the coordinates for the Rect
|
| 392 |
whole_page_x1, whole_page_y1 = 0 + border, 0 + border # Bottom-left corner
|
| 393 |
+
|
| 394 |
+
# If border is a tiny value, assume that we want relative values
|
| 395 |
+
if border < 0.1:
|
| 396 |
+
whole_page_x2, whole_page_y2 = 1 - border, 1 - border # Top-right corner
|
| 397 |
+
else:
|
| 398 |
+
whole_page_x2, whole_page_y2 = rect_width - border, rect_height - border # Top-right corner
|
| 399 |
|
| 400 |
# Create new image annotation element based on whole page coordinates
|
| 401 |
whole_page_rect = Rect(whole_page_x1, whole_page_y1, whole_page_x2, whole_page_y2)
|
|
|
|
| 409 |
whole_page_img_annotation_box["color"] = (0,0,0)
|
| 410 |
whole_page_img_annotation_box["label"] = "Whole page"
|
| 411 |
|
| 412 |
+
if redact_pdf == True:
|
| 413 |
+
redact_single_box(page, whole_page_rect, whole_page_img_annotation_box, custom_colours)
|
| 414 |
|
| 415 |
return whole_page_img_annotation_box
|
| 416 |
|
|
|
|
| 1296 |
df = pd.DataFrame({
|
| 1297 |
"image": [anno.get("image") for anno in all_annotations],
|
| 1298 |
# Ensure 'boxes' defaults to an empty list if missing or None
|
| 1299 |
+
"boxes": [
|
| 1300 |
+
anno.get("boxes") if isinstance(anno.get("boxes"), list)
|
| 1301 |
+
else [anno.get("boxes")] if isinstance(anno.get("boxes"), dict)
|
| 1302 |
+
else []
|
| 1303 |
+
for anno in all_annotations
|
| 1304 |
+
]
|
| 1305 |
+
|
| 1306 |
})
|
| 1307 |
|
| 1308 |
# 2. Calculate the page number using the helper function
|
tools/find_duplicate_pages.py
CHANGED
|
@@ -4,13 +4,12 @@ import re
|
|
| 4 |
from tools.helper_functions import OUTPUT_FOLDER
|
| 5 |
from sklearn.feature_extraction.text import TfidfVectorizer
|
| 6 |
from sklearn.metrics.pairwise import cosine_similarity
|
| 7 |
-
import random
|
| 8 |
-
import string
|
| 9 |
from typing import List, Tuple
|
| 10 |
import gradio as gr
|
| 11 |
from gradio import Progress
|
| 12 |
from pathlib import Path
|
| 13 |
-
|
|
|
|
| 14 |
import en_core_web_lg
|
| 15 |
nlp = en_core_web_lg.load()
|
| 16 |
|
|
@@ -84,31 +83,11 @@ def process_data(df:pd.DataFrame, column:str):
|
|
| 84 |
def _clean_text(raw_text):
|
| 85 |
# Remove HTML tags
|
| 86 |
clean = re.sub(r'<.*?>', '', raw_text)
|
| 87 |
-
# clean = re.sub(r' ', ' ', clean)
|
| 88 |
-
# clean = re.sub(r'\r\n', ' ', clean)
|
| 89 |
-
# clean = re.sub(r'<', ' ', clean)
|
| 90 |
-
# clean = re.sub(r'>', ' ', clean)
|
| 91 |
-
# clean = re.sub(r'<strong>', ' ', clean)
|
| 92 |
-
# clean = re.sub(r'</strong>', ' ', clean)
|
| 93 |
-
|
| 94 |
-
# Replace non-breaking space \xa0 with a space
|
| 95 |
-
# clean = clean.replace(u'\xa0', u' ')
|
| 96 |
-
# Remove extra whitespace
|
| 97 |
clean = ' '.join(clean.split())
|
| 98 |
-
|
| 99 |
-
# # Tokenize the text
|
| 100 |
-
# words = word_tokenize(clean.lower())
|
| 101 |
-
|
| 102 |
-
# # Remove punctuation and numbers
|
| 103 |
-
# words = [word for word in words if word.isalpha()]
|
| 104 |
-
|
| 105 |
-
# # Remove stopwords
|
| 106 |
-
# words = [word for word in words if word not in stop_words]
|
| 107 |
-
|
| 108 |
# Join the cleaned words back into a string
|
| 109 |
return clean
|
| 110 |
|
| 111 |
-
# Function to apply
|
| 112 |
def _apply_lemmatization(text):
|
| 113 |
doc = nlp(text)
|
| 114 |
# Keep only alphabetic tokens and remove stopwords
|
|
@@ -121,7 +100,7 @@ def process_data(df:pd.DataFrame, column:str):
|
|
| 121 |
|
| 122 |
return df
|
| 123 |
|
| 124 |
-
def map_metadata_single_page(similarity_df, metadata_source_df):
|
| 125 |
"""Helper to map metadata for single page results."""
|
| 126 |
metadata_df = metadata_source_df[['file', 'page', 'text']]
|
| 127 |
results_df = similarity_df.merge(metadata_df, left_on='Page1_Index', right_index=True)\
|
|
@@ -131,12 +110,11 @@ def map_metadata_single_page(similarity_df, metadata_source_df):
|
|
| 131 |
results_df["Similarity_Score"] = results_df["Similarity_Score"].round(3)
|
| 132 |
final_df = results_df[['Page1_File', 'Page1_Page', 'Page2_File', 'Page2_Page', 'Similarity_Score', 'Page1_Text', 'Page2_Text']]
|
| 133 |
final_df = final_df.sort_values(["Page1_File", "Page1_Page", "Page2_File", "Page2_Page"])
|
| 134 |
-
final_df['Page1_Text'] = final_df['Page1_Text'].str[:
|
| 135 |
-
final_df['Page2_Text'] = final_df['Page2_Text'].str[:
|
| 136 |
return final_df
|
| 137 |
|
| 138 |
-
|
| 139 |
-
def map_metadata_subdocument(subdocument_df, metadata_source_df):
|
| 140 |
"""Helper to map metadata for subdocument results."""
|
| 141 |
metadata_df = metadata_source_df[['file', 'page', 'text']]
|
| 142 |
|
|
@@ -160,10 +138,69 @@ def map_metadata_subdocument(subdocument_df, metadata_source_df):
|
|
| 160 |
|
| 161 |
final_df = subdocument_df[cols]
|
| 162 |
final_df = final_df.sort_values(['Page1_File', 'Page1_Start_Page', 'Page2_File', 'Page2_Start_Page'])
|
| 163 |
-
final_df['Page1_Text'] = final_df['Page1_Text'].str[:
|
| 164 |
-
final_df['Page2_Text'] = final_df['Page2_Text'].str[:
|
|
|
|
| 165 |
return final_df
|
| 166 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 167 |
def identify_similar_pages(
|
| 168 |
df_combined: pd.DataFrame,
|
| 169 |
similarity_threshold: float = 0.9,
|
|
@@ -179,8 +216,7 @@ def identify_similar_pages(
|
|
| 179 |
2. Fixed-Length Subdocument: If greedy_match=False and min_consecutive_pages > 1.
|
| 180 |
3. Greedy Consecutive Match: If greedy_match=True.
|
| 181 |
"""
|
| 182 |
-
|
| 183 |
-
# This part remains the same as before.
|
| 184 |
output_paths = []
|
| 185 |
progress(0.1, desc="Processing and filtering text")
|
| 186 |
df = process_data(df_combined, 'text')
|
|
@@ -215,11 +251,8 @@ def identify_similar_pages(
|
|
| 215 |
|
| 216 |
progress(0.6, desc="Aggregating results based on matching strategy")
|
| 217 |
|
| 218 |
-
# --- NEW: Logic to select matching strategy ---
|
| 219 |
-
|
| 220 |
if greedy_match:
|
| 221 |
-
|
| 222 |
-
print("Finding matches using GREEDY consecutive strategy.")
|
| 223 |
|
| 224 |
# A set of pairs for fast lookups of (page1_idx, page2_idx)
|
| 225 |
valid_pairs_set = set(zip(base_similarity_df['Page1_Index'], base_similarity_df['Page2_Index']))
|
|
@@ -308,53 +341,7 @@ def identify_similar_pages(
|
|
| 308 |
|
| 309 |
progress(0.8, desc="Saving output files")
|
| 310 |
|
| 311 |
-
|
| 312 |
-
if final_df.empty:
|
| 313 |
-
print("No matches found, no output files to save.")
|
| 314 |
-
return final_df, [], df_combined
|
| 315 |
-
|
| 316 |
-
# --- 1. Save the main results DataFrame ---
|
| 317 |
-
# This file contains the detailed summary of all matches found.
|
| 318 |
-
similarity_file_output_path = Path(output_folder) / 'page_similarity_results.csv'
|
| 319 |
-
final_df.to_csv(similarity_file_output_path, index=False)
|
| 320 |
-
output_paths.append(str(similarity_file_output_path))
|
| 321 |
-
print(f"Main results saved to {similarity_file_output_path}")
|
| 322 |
-
|
| 323 |
-
# --- 2. Save per-file redaction lists ---
|
| 324 |
-
# These files contain a simple list of page numbers to redact for each document
|
| 325 |
-
# that contains duplicate content.
|
| 326 |
-
|
| 327 |
-
# We group by the file containing the duplicates ('Page2_File')
|
| 328 |
-
for redact_file, group in final_df.groupby('Page2_File'):
|
| 329 |
-
output_file_name_stem = Path(redact_file).stem
|
| 330 |
-
output_file_path = Path(output_folder) / f"{output_file_name_stem}_pages_to_redact.csv"
|
| 331 |
-
|
| 332 |
-
all_pages_to_redact = set()
|
| 333 |
-
|
| 334 |
-
# Check if the results are for single pages or subdocuments
|
| 335 |
-
is_subdocument_match = 'Page2_Start_Page' in group.columns
|
| 336 |
-
|
| 337 |
-
if is_subdocument_match:
|
| 338 |
-
# For subdocument matches, create a range of pages for each match
|
| 339 |
-
for _, row in group.iterrows():
|
| 340 |
-
# Generate all page numbers from the start to the end of the match
|
| 341 |
-
pages_in_range = range(int(row['Page2_Start_Page']), int(row['Page2_End_Page']) + 1)
|
| 342 |
-
all_pages_to_redact.update(pages_in_range)
|
| 343 |
-
else:
|
| 344 |
-
# For single-page matches, just add the page number
|
| 345 |
-
pages = group['Page2_Page'].unique()
|
| 346 |
-
all_pages_to_redact.update(pages)
|
| 347 |
-
|
| 348 |
-
if all_pages_to_redact:
|
| 349 |
-
# Create a DataFrame from the sorted list of pages to redact
|
| 350 |
-
redaction_df = pd.DataFrame(sorted(list(all_pages_to_redact)), columns=['Page_to_Redact'])
|
| 351 |
-
redaction_df.to_csv(output_file_path, header=False, index=False)
|
| 352 |
-
output_paths.append(str(output_file_path))
|
| 353 |
-
print(f"Redaction list for {redact_file} saved to {output_file_path}")
|
| 354 |
-
|
| 355 |
-
# Note: The 'combined ocr output' csv was part of the original data loading function,
|
| 356 |
-
# not the analysis function itself. If you need that, it should be saved within
|
| 357 |
-
# your `combine_ocr_output_text` function.
|
| 358 |
|
| 359 |
return final_df, output_paths, df_combined
|
| 360 |
|
|
@@ -362,7 +349,53 @@ def identify_similar_pages(
|
|
| 362 |
# GRADIO HELPER FUNCTIONS
|
| 363 |
# ==============================================================================
|
| 364 |
|
| 365 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 366 |
"""
|
| 367 |
Wrapper function updated to include the 'greedy_match' boolean.
|
| 368 |
"""
|
|
@@ -383,85 +416,182 @@ def run_analysis(files, threshold, min_words, min_consecutive, greedy_match, pro
|
|
| 383 |
similarity_threshold=threshold,
|
| 384 |
min_word_count=min_words,
|
| 385 |
min_consecutive_pages=int(min_consecutive),
|
| 386 |
-
greedy_match=greedy_match,
|
| 387 |
progress=progress
|
| 388 |
)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 389 |
|
| 390 |
-
return results_df, output_paths, full_df
|
| 391 |
|
| 392 |
-
def show_page_previews(
|
| 393 |
"""
|
|
|
|
| 394 |
Triggered when a user selects a row in the results DataFrame.
|
| 395 |
-
It uses the stored 'full_data' to find and display the complete text.
|
| 396 |
"""
|
| 397 |
-
if
|
| 398 |
-
return None, None
|
|
|
|
|
|
|
| 399 |
|
| 400 |
-
selected_row = results_df.iloc[evt.index[0]]
|
| 401 |
-
|
| 402 |
-
# Determine if it's a single page or a multi-page (subdocument) match
|
| 403 |
is_subdocument_match = 'Page1_Start_Page' in selected_row
|
| 404 |
|
| 405 |
if is_subdocument_match:
|
| 406 |
-
# --- Handle Subdocument Match ---
|
| 407 |
file1, start1, end1 = selected_row['Page1_File'], selected_row['Page1_Start_Page'], selected_row['Page1_End_Page']
|
| 408 |
file2, start2, end2 = selected_row['Page2_File'], selected_row['Page2_Start_Page'], selected_row['Page2_End_Page']
|
| 409 |
|
| 410 |
-
page1_data =
|
| 411 |
-
|
| 412 |
-
|
| 413 |
-
].sort_values('page')[['page', 'text']]
|
| 414 |
-
|
| 415 |
-
page2_data = full_data[
|
| 416 |
-
(full_data['file'] == file2) &
|
| 417 |
-
(full_data['page'].between(start2, end2))
|
| 418 |
-
].sort_values('page')[['page', 'text']]
|
| 419 |
-
|
| 420 |
else:
|
| 421 |
-
# --- Handle Single Page Match ---
|
| 422 |
file1, page1 = selected_row['Page1_File'], selected_row['Page1_Page']
|
| 423 |
file2, page2 = selected_row['Page2_File'], selected_row['Page2_Page']
|
| 424 |
|
| 425 |
-
page1_data =
|
| 426 |
-
|
| 427 |
-
][['page', 'text']]
|
| 428 |
|
| 429 |
-
|
| 430 |
-
|
| 431 |
-
][['page', 'text']]
|
| 432 |
|
| 433 |
-
return page1_data, page2_data
|
| 434 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 435 |
|
| 436 |
-
|
| 437 |
-
|
| 438 |
-
|
|
|
|
| 439 |
|
| 440 |
-
|
| 441 |
-
|
| 442 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 443 |
|
| 444 |
-
for
|
| 445 |
-
|
| 446 |
-
|
| 447 |
-
|
| 448 |
-
|
| 449 |
-
|
| 450 |
-
|
| 451 |
-
|
| 452 |
-
|
| 453 |
-
|
| 454 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 455 |
|
| 456 |
-
|
| 457 |
-
|
| 458 |
-
|
| 459 |
-
|
| 460 |
|
| 461 |
-
|
| 462 |
-
|
| 463 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 464 |
|
| 465 |
-
|
| 466 |
|
| 467 |
-
return
|
|
|
|
| 4 |
from tools.helper_functions import OUTPUT_FOLDER
|
| 5 |
from sklearn.feature_extraction.text import TfidfVectorizer
|
| 6 |
from sklearn.metrics.pairwise import cosine_similarity
|
|
|
|
|
|
|
| 7 |
from typing import List, Tuple
|
| 8 |
import gradio as gr
|
| 9 |
from gradio import Progress
|
| 10 |
from pathlib import Path
|
| 11 |
+
from pymupdf import Document
|
| 12 |
+
from tools.file_conversion import redact_whole_pymupdf_page, convert_annotation_data_to_dataframe
|
| 13 |
import en_core_web_lg
|
| 14 |
nlp = en_core_web_lg.load()
|
| 15 |
|
|
|
|
| 83 |
def _clean_text(raw_text):
|
| 84 |
# Remove HTML tags
|
| 85 |
clean = re.sub(r'<.*?>', '', raw_text)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 86 |
clean = ' '.join(clean.split())
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 87 |
# Join the cleaned words back into a string
|
| 88 |
return clean
|
| 89 |
|
| 90 |
+
# Function to apply lemmatisation and remove stopwords
|
| 91 |
def _apply_lemmatization(text):
|
| 92 |
doc = nlp(text)
|
| 93 |
# Keep only alphabetic tokens and remove stopwords
|
|
|
|
| 100 |
|
| 101 |
return df
|
| 102 |
|
| 103 |
+
def map_metadata_single_page(similarity_df:pd.DataFrame, metadata_source_df:pd.DataFrame, preview_length:int=200):
|
| 104 |
"""Helper to map metadata for single page results."""
|
| 105 |
metadata_df = metadata_source_df[['file', 'page', 'text']]
|
| 106 |
results_df = similarity_df.merge(metadata_df, left_on='Page1_Index', right_index=True)\
|
|
|
|
| 110 |
results_df["Similarity_Score"] = results_df["Similarity_Score"].round(3)
|
| 111 |
final_df = results_df[['Page1_File', 'Page1_Page', 'Page2_File', 'Page2_Page', 'Similarity_Score', 'Page1_Text', 'Page2_Text']]
|
| 112 |
final_df = final_df.sort_values(["Page1_File", "Page1_Page", "Page2_File", "Page2_Page"])
|
| 113 |
+
final_df['Page1_Text'] = final_df['Page1_Text'].str[:preview_length]
|
| 114 |
+
final_df['Page2_Text'] = final_df['Page2_Text'].str[:preview_length]
|
| 115 |
return final_df
|
| 116 |
|
| 117 |
+
def map_metadata_subdocument(subdocument_df:pd.DataFrame, metadata_source_df:pd.DataFrame, preview_length:int=200):
|
|
|
|
| 118 |
"""Helper to map metadata for subdocument results."""
|
| 119 |
metadata_df = metadata_source_df[['file', 'page', 'text']]
|
| 120 |
|
|
|
|
| 138 |
|
| 139 |
final_df = subdocument_df[cols]
|
| 140 |
final_df = final_df.sort_values(['Page1_File', 'Page1_Start_Page', 'Page2_File', 'Page2_Start_Page'])
|
| 141 |
+
final_df['Page1_Text'] = final_df['Page1_Text'].str[:preview_length]
|
| 142 |
+
final_df['Page2_Text'] = final_df['Page2_Text'].str[:preview_length]
|
| 143 |
+
|
| 144 |
return final_df
|
| 145 |
|
| 146 |
+
def save_results_and_redaction_lists(final_df: pd.DataFrame, output_folder: str) -> list:
|
| 147 |
+
"""
|
| 148 |
+
Saves the main results DataFrame and generates per-file redaction lists.
|
| 149 |
+
This function is extracted to be reusable.
|
| 150 |
+
|
| 151 |
+
Args:
|
| 152 |
+
final_df (pd.DataFrame): The DataFrame containing the final match results.
|
| 153 |
+
output_folder (str): The folder to save the output files.
|
| 154 |
+
|
| 155 |
+
Returns:
|
| 156 |
+
list: A list of paths to all generated files.
|
| 157 |
+
"""
|
| 158 |
+
output_paths = []
|
| 159 |
+
output_folder_path = Path(output_folder)
|
| 160 |
+
output_folder_path.mkdir(exist_ok=True)
|
| 161 |
+
|
| 162 |
+
if final_df.empty:
|
| 163 |
+
print("No matches to save.")
|
| 164 |
+
return []
|
| 165 |
+
|
| 166 |
+
# 1. Save the main results DataFrame
|
| 167 |
+
similarity_file_output_path = output_folder_path / 'page_similarity_results.csv'
|
| 168 |
+
final_df.to_csv(similarity_file_output_path, index=False)
|
| 169 |
+
|
| 170 |
+
output_paths.append(str(similarity_file_output_path))
|
| 171 |
+
print(f"Main results saved to {similarity_file_output_path}")
|
| 172 |
+
|
| 173 |
+
# 2. Save per-file redaction lists
|
| 174 |
+
# Use 'Page2_File' as the source of duplicate content
|
| 175 |
+
grouping_col = 'Page2_File'
|
| 176 |
+
if grouping_col not in final_df.columns:
|
| 177 |
+
print("Warning: 'Page2_File' column not found. Cannot generate redaction lists.")
|
| 178 |
+
return output_paths
|
| 179 |
+
|
| 180 |
+
for redact_file, group in final_df.groupby(grouping_col):
|
| 181 |
+
output_file_name_stem = Path(redact_file).stem
|
| 182 |
+
output_file_path = output_folder_path / f"{output_file_name_stem}_pages_to_redact.csv"
|
| 183 |
+
|
| 184 |
+
all_pages_to_redact = set()
|
| 185 |
+
is_subdocument_match = 'Page2_Start_Page' in group.columns
|
| 186 |
+
|
| 187 |
+
if is_subdocument_match:
|
| 188 |
+
for _, row in group.iterrows():
|
| 189 |
+
pages_in_range = range(int(row['Page2_Start_Page']), int(row['Page2_End_Page']) + 1)
|
| 190 |
+
all_pages_to_redact.update(pages_in_range)
|
| 191 |
+
else:
|
| 192 |
+
pages = group['Page2_Page'].unique()
|
| 193 |
+
all_pages_to_redact.update(pages)
|
| 194 |
+
|
| 195 |
+
if all_pages_to_redact:
|
| 196 |
+
redaction_df = pd.DataFrame(sorted(list(all_pages_to_redact)), columns=['Page_to_Redact'])
|
| 197 |
+
redaction_df.to_csv(output_file_path, header=False, index=False)
|
| 198 |
+
|
| 199 |
+
output_paths.append(str(output_file_path))
|
| 200 |
+
print(f"Redaction list for {redact_file} saved to {output_file_path}")
|
| 201 |
+
|
| 202 |
+
return output_paths
|
| 203 |
+
|
| 204 |
def identify_similar_pages(
|
| 205 |
df_combined: pd.DataFrame,
|
| 206 |
similarity_threshold: float = 0.9,
|
|
|
|
| 216 |
2. Fixed-Length Subdocument: If greedy_match=False and min_consecutive_pages > 1.
|
| 217 |
3. Greedy Consecutive Match: If greedy_match=True.
|
| 218 |
"""
|
| 219 |
+
|
|
|
|
| 220 |
output_paths = []
|
| 221 |
progress(0.1, desc="Processing and filtering text")
|
| 222 |
df = process_data(df_combined, 'text')
|
|
|
|
| 251 |
|
| 252 |
progress(0.6, desc="Aggregating results based on matching strategy")
|
| 253 |
|
|
|
|
|
|
|
| 254 |
if greedy_match:
|
| 255 |
+
print("Finding matches using greedy consecutive strategy.")
|
|
|
|
| 256 |
|
| 257 |
# A set of pairs for fast lookups of (page1_idx, page2_idx)
|
| 258 |
valid_pairs_set = set(zip(base_similarity_df['Page1_Index'], base_similarity_df['Page2_Index']))
|
|
|
|
| 341 |
|
| 342 |
progress(0.8, desc="Saving output files")
|
| 343 |
|
| 344 |
+
output_paths = save_results_and_redaction_lists(final_df, output_folder)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 345 |
|
| 346 |
return final_df, output_paths, df_combined
|
| 347 |
|
|
|
|
| 349 |
# GRADIO HELPER FUNCTIONS
|
| 350 |
# ==============================================================================
|
| 351 |
|
| 352 |
+
# full_data:pd.DataFrame,
|
| 353 |
+
def handle_selection_and_preview(evt: gr.SelectData, results_df:pd.DataFrame, full_duplicate_data_by_file: dict):
|
| 354 |
+
"""
|
| 355 |
+
This single function handles a user selecting a row. It:
|
| 356 |
+
1. Determines the selected row index.
|
| 357 |
+
2. Calls the show_page_previews function to get the text data.
|
| 358 |
+
3. Returns all the necessary outputs for the UI.
|
| 359 |
+
"""
|
| 360 |
+
# If the user deselects, the event might be None.
|
| 361 |
+
if not evt:
|
| 362 |
+
return None, None, None # Clear state and both preview panes
|
| 363 |
+
|
| 364 |
+
# 1. Get the selected index
|
| 365 |
+
selected_index = evt.index[0]
|
| 366 |
+
|
| 367 |
+
# 2. Get the preview data
|
| 368 |
+
page1_data, page2_data = show_page_previews(full_duplicate_data_by_file, results_df, evt)
|
| 369 |
+
|
| 370 |
+
# 3. Return all three outputs in the correct order
|
| 371 |
+
return selected_index, page1_data, page2_data
|
| 372 |
+
|
| 373 |
+
def exclude_match(results_df:pd.DataFrame, selected_index:int, output_folder="./output/"):
|
| 374 |
+
"""
|
| 375 |
+
Removes a selected row from the results DataFrame, regenerates output files,
|
| 376 |
+
and clears the text preview panes.
|
| 377 |
+
"""
|
| 378 |
+
if selected_index is None:
|
| 379 |
+
gr.Warning("No match selected. Please click on a row in the table first.")
|
| 380 |
+
# Return the original dataframe and update=False for the files
|
| 381 |
+
return results_df, gr.update(), None, None
|
| 382 |
+
|
| 383 |
+
if results_df.empty:
|
| 384 |
+
gr.Warning("No duplicate page results found, nothing to exclude.")
|
| 385 |
+
return results_df, gr.update(), None, None
|
| 386 |
+
|
| 387 |
+
# Drop the selected row
|
| 388 |
+
updated_df = results_df.drop(selected_index).reset_index(drop=True)
|
| 389 |
+
|
| 390 |
+
# Recalculate all output files using the helper function
|
| 391 |
+
new_output_paths = save_results_and_redaction_lists(updated_df, output_folder)
|
| 392 |
+
|
| 393 |
+
gr.Info(f"Match at row {selected_index} excluded. Output files have been updated.")
|
| 394 |
+
|
| 395 |
+
# Return the updated dataframe, the new file list, and clear the preview panes
|
| 396 |
+
return updated_df, new_output_paths, None, None
|
| 397 |
+
|
| 398 |
+
def run_duplicate_analysis(files:list[pd.DataFrame], threshold:float, min_words:int, min_consecutive:int, greedy_match:bool, preview_length:int=500, progress=gr.Progress(track_tqdm=True)):
|
| 399 |
"""
|
| 400 |
Wrapper function updated to include the 'greedy_match' boolean.
|
| 401 |
"""
|
|
|
|
| 416 |
similarity_threshold=threshold,
|
| 417 |
min_word_count=min_words,
|
| 418 |
min_consecutive_pages=int(min_consecutive),
|
| 419 |
+
greedy_match=greedy_match,
|
| 420 |
progress=progress
|
| 421 |
)
|
| 422 |
+
|
| 423 |
+
# Clip text to first 200 characters
|
| 424 |
+
full_df['text'] = full_df['text'].str[:preview_length]
|
| 425 |
+
|
| 426 |
+
# Preprocess full_data (without preview text) for fast access (run once)
|
| 427 |
+
full_data_by_file = {
|
| 428 |
+
file: df.sort_values('page').set_index('page')
|
| 429 |
+
for file, df in full_df.drop(["text_clean"],axis=1).groupby('file')
|
| 430 |
+
}
|
| 431 |
+
|
| 432 |
+
if results_df.empty:
|
| 433 |
+
gr.Info(f"No duplicate pages found, no results returned.")
|
| 434 |
|
| 435 |
+
return results_df, output_paths, full_data_by_file # full_df,
|
| 436 |
|
| 437 |
+
def show_page_previews(full_data_by_file: dict, results_df: pd.DataFrame, evt: gr.SelectData, preview_length:int=500):
|
| 438 |
"""
|
| 439 |
+
Optimized version using pre-partitioned and indexed full_data.
|
| 440 |
Triggered when a user selects a row in the results DataFrame.
|
|
|
|
| 441 |
"""
|
| 442 |
+
if not full_data_by_file or results_df is None or not evt:
|
| 443 |
+
return None, None
|
| 444 |
+
|
| 445 |
+
selected_row = results_df.iloc[evt.index[0], :]
|
| 446 |
|
|
|
|
|
|
|
|
|
|
| 447 |
is_subdocument_match = 'Page1_Start_Page' in selected_row
|
| 448 |
|
| 449 |
if is_subdocument_match:
|
|
|
|
| 450 |
file1, start1, end1 = selected_row['Page1_File'], selected_row['Page1_Start_Page'], selected_row['Page1_End_Page']
|
| 451 |
file2, start2, end2 = selected_row['Page2_File'], selected_row['Page2_Start_Page'], selected_row['Page2_End_Page']
|
| 452 |
|
| 453 |
+
page1_data = full_data_by_file[file1].loc[start1:end1, ['text']].reset_index()
|
| 454 |
+
page2_data = full_data_by_file[file2].loc[start2:end2, ['text']].reset_index()
|
| 455 |
+
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 456 |
else:
|
|
|
|
| 457 |
file1, page1 = selected_row['Page1_File'], selected_row['Page1_Page']
|
| 458 |
file2, page2 = selected_row['Page2_File'], selected_row['Page2_Page']
|
| 459 |
|
| 460 |
+
page1_data = full_data_by_file[file1].loc[[page1], ['text']].reset_index()
|
| 461 |
+
page2_data = full_data_by_file[file2].loc[[page2], ['text']].reset_index()
|
|
|
|
| 462 |
|
| 463 |
+
page1_data['text'] = page1_data['text'].str[:preview_length]
|
| 464 |
+
page2_data['text'] = page2_data['text'].str[:preview_length]
|
|
|
|
| 465 |
|
| 466 |
+
return page1_data[['page', 'text']], page2_data[['page', 'text']]
|
| 467 |
|
| 468 |
+
def apply_whole_page_redactions_from_list(duplicate_page_numbers_df:pd.DataFrame, doc_file_name_with_extension_textbox:str, review_file_state:pd.DataFrame, duplicate_output_paths:list[str], pymupdf_doc:object, page_sizes:list[dict], all_existing_annotations:list[dict]):
|
| 469 |
+
'''
|
| 470 |
+
Take a list of suggested whole pages to redact and apply it to review file data currently available from an existing PDF under review
|
| 471 |
+
'''
|
| 472 |
+
# Create a copy of annotations to avoid modifying the original
|
| 473 |
+
all_annotations = all_existing_annotations.copy()
|
| 474 |
|
| 475 |
+
if not pymupdf_doc:
|
| 476 |
+
print("Warning: No document file currently under review. Please upload a document on the 'Review redactions' tab to apply whole page redactions.")
|
| 477 |
+
raise Warning("No document file currently under review. Please upload a document on the 'Review redactions' tab to apply whole page redactions.")
|
| 478 |
+
return review_file_state, all_annotations
|
| 479 |
|
| 480 |
+
# Initialize list of pages to redact
|
| 481 |
+
list_whole_pages_to_redact = []
|
| 482 |
+
|
| 483 |
+
# Get list of pages to redact from either dataframe or file
|
| 484 |
+
if not duplicate_page_numbers_df.empty:
|
| 485 |
+
list_whole_pages_to_redact = duplicate_page_numbers_df.iloc[:, 0].tolist()
|
| 486 |
+
elif duplicate_output_paths:
|
| 487 |
+
expected_duplicate_pages_to_redact_name = f"{doc_file_name_with_extension_textbox}"
|
| 488 |
+
whole_pages_list = pd.DataFrame() # Initialize empty DataFrame
|
| 489 |
|
| 490 |
+
for output_file in duplicate_output_paths:
|
| 491 |
+
# Note: output_file.name might not be available if output_file is just a string path
|
| 492 |
+
# If it's a Path object or similar, .name is fine. Otherwise, parse from string.
|
| 493 |
+
file_name_from_path = output_file.split('/')[-1] if isinstance(output_file, str) else output_file.name
|
| 494 |
+
if expected_duplicate_pages_to_redact_name in file_name_from_path:
|
| 495 |
+
whole_pages_list = pd.read_csv(output_file, header=None) # Use output_file directly if it's a path
|
| 496 |
+
break
|
| 497 |
+
|
| 498 |
+
if not whole_pages_list.empty:
|
| 499 |
+
list_whole_pages_to_redact = whole_pages_list.iloc[:, 0].tolist()
|
| 500 |
+
|
| 501 |
+
# Convert to set to remove duplicates, then back to list
|
| 502 |
+
list_whole_pages_to_redact = list(set(list_whole_pages_to_redact))
|
| 503 |
+
|
| 504 |
+
if not list_whole_pages_to_redact:
|
| 505 |
+
# Assuming gr is defined (e.g., gradio)
|
| 506 |
+
print("No relevant list of whole pages to redact found, returning inputs.")
|
| 507 |
+
raise Warning("Warning: No relevant list of whole pages to redact found, returning inputs.")
|
| 508 |
+
return review_file_state, all_existing_annotations
|
| 509 |
+
|
| 510 |
+
new_annotations = []
|
| 511 |
+
|
| 512 |
+
# Process each page for redaction
|
| 513 |
+
for page in list_whole_pages_to_redact:
|
| 514 |
+
try:
|
| 515 |
+
page_index = int(page) - 1
|
| 516 |
+
if page_index < 0 or page_index >= len(pymupdf_doc):
|
| 517 |
+
print(f"Page {page} is out of bounds for a document with {len(pymupdf_doc)} pages, skipping.")
|
| 518 |
+
continue
|
| 519 |
|
| 520 |
+
pymupdf_page = pymupdf_doc[page_index]
|
| 521 |
+
|
| 522 |
+
# Find the matching page size dictionary
|
| 523 |
+
page_size = next((size for size in page_sizes if size["page"] == int(page)), None)
|
| 524 |
|
| 525 |
+
if not page_size:
|
| 526 |
+
print(f"Page {page} not found in page_sizes object, skipping.")
|
| 527 |
+
continue
|
| 528 |
+
|
| 529 |
+
rect_height = page_size["cropbox_height"]
|
| 530 |
+
rect_width = page_size["cropbox_width"]
|
| 531 |
+
image = page_size["image_path"] # This `image` likely represents the page identifier
|
| 532 |
+
|
| 533 |
+
# Create the whole page redaction box
|
| 534 |
+
annotation_box = redact_whole_pymupdf_page(rect_height, rect_width, pymupdf_page, border=0.005, redact_pdf=False)
|
| 535 |
+
|
| 536 |
+
# Find existing annotation for this image/page
|
| 537 |
+
current_page_existing_boxes_group = next((annot_group for annot_group in all_annotations if annot_group["image"] == image), None)
|
| 538 |
+
|
| 539 |
+
new_annotation_group = {
|
| 540 |
+
"image": image,
|
| 541 |
+
"boxes": [annotation_box]
|
| 542 |
+
}
|
| 543 |
+
|
| 544 |
+
if current_page_existing_boxes_group:
|
| 545 |
+
# Check if we already have a whole page redaction for this page
|
| 546 |
+
if not any(box.get("label", "Whole page") for box in current_page_existing_boxes_group["boxes"]):
|
| 547 |
+
current_page_existing_boxes_group["boxes"].append(annotation_box)
|
| 548 |
+
|
| 549 |
+
else:
|
| 550 |
+
# Optional: Print a message if a whole-page redaction already exists for this page
|
| 551 |
+
print(f"Whole page redaction for page {page} already exists in annotations, skipping addition.")
|
| 552 |
+
pass
|
| 553 |
+
else:
|
| 554 |
+
# Create new annotation entry
|
| 555 |
+
|
| 556 |
+
all_annotations.append(new_annotation_group)
|
| 557 |
+
|
| 558 |
+
new_annotations.append(new_annotation_group)
|
| 559 |
+
|
| 560 |
+
except Exception as e:
|
| 561 |
+
print(f"Error processing page {page}: {str(e)}")
|
| 562 |
+
continue
|
| 563 |
+
|
| 564 |
+
# Convert annotations to dataframe and combine with existing review file
|
| 565 |
+
whole_page_review_file = convert_annotation_data_to_dataframe(new_annotations)
|
| 566 |
+
|
| 567 |
+
# Ensure all required columns are present in both DataFrames before concat
|
| 568 |
+
# This is a common point of error if DFs have different schemas
|
| 569 |
+
expected_cols = ['image', 'page', 'label', 'color', 'xmin', 'ymin', 'xmax', 'ymax', 'text', 'id']
|
| 570 |
+
|
| 571 |
+
for col in expected_cols:
|
| 572 |
+
if col not in review_file_state.columns:
|
| 573 |
+
review_file_state[col] = None # Or an appropriate default value
|
| 574 |
+
if col not in whole_page_review_file.columns:
|
| 575 |
+
whole_page_review_file[col] = None
|
| 576 |
+
|
| 577 |
+
review_file_out = pd.concat([review_file_state, whole_page_review_file], ignore_index=True)
|
| 578 |
+
review_file_out = review_file_out.sort_values(by=["page", "ymin", "xmin"])
|
| 579 |
+
|
| 580 |
+
# --- Remove duplicate entries from the final DataFrame ---
|
| 581 |
+
dedup_subset_cols = ['page', 'label', 'text', 'id']
|
| 582 |
+
|
| 583 |
+
# Ensure these columns exist before trying to use them as subset for drop_duplicates
|
| 584 |
+
if all(col in review_file_out.columns for col in dedup_subset_cols):
|
| 585 |
+
review_file_out = review_file_out.drop_duplicates(
|
| 586 |
+
subset=dedup_subset_cols,
|
| 587 |
+
keep='first' # Keep the first occurrence of a duplicate redaction
|
| 588 |
+
)
|
| 589 |
+
else:
|
| 590 |
+
print(f"Warning: Not all columns required for de-duplication ({dedup_subset_cols}) are present in review_file_out. Skipping specific de-duplication.")
|
| 591 |
+
# You might want a fallback or to inspect what's missing
|
| 592 |
+
|
| 593 |
+
review_file_out.to_csv(OUTPUT_FOLDER + "review_file_out_after_whole_page.csv")
|
| 594 |
|
| 595 |
+
gr.Info("Successfully created whole page redactions. Go to the 'Review redactions' tab to see them.")
|
| 596 |
|
| 597 |
+
return review_file_out, all_annotations
|
tools/helper_functions.py
CHANGED
|
@@ -146,6 +146,14 @@ def ensure_output_folder_exists(output_folder:str):
|
|
| 146 |
else:
|
| 147 |
print(f"The {output_folder} folder already exists.")
|
| 148 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 149 |
def custom_regex_load(in_file:List[str], file_type:str = "allow_list"):
|
| 150 |
'''
|
| 151 |
When file is loaded, update the column dropdown choices and write to relevant data states.
|
|
|
|
| 146 |
else:
|
| 147 |
print(f"The {output_folder} folder already exists.")
|
| 148 |
|
| 149 |
+
def _get_env_list(env_var_name: str) -> List[str]:
|
| 150 |
+
"""Parses a comma-separated environment variable into a list of strings."""
|
| 151 |
+
value = env_var_name[1:-1].strip().replace('\"', '').replace("\'","")
|
| 152 |
+
if not value:
|
| 153 |
+
return []
|
| 154 |
+
# Split by comma and filter out any empty strings that might result from extra commas
|
| 155 |
+
return [s.strip() for s in value.split(',') if s.strip()]
|
| 156 |
+
|
| 157 |
def custom_regex_load(in_file:List[str], file_type:str = "allow_list"):
|
| 158 |
'''
|
| 159 |
When file is loaded, update the column dropdown choices and write to relevant data states.
|
tools/redaction_review.py
CHANGED
|
@@ -180,7 +180,7 @@ def update_annotator_page_from_review_df(
|
|
| 180 |
) -> Tuple[object, List[dict], int, List[dict], pd.DataFrame, int]: # Correcting return types based on usage
|
| 181 |
'''
|
| 182 |
Update the visible annotation object and related objects with the latest review file information,
|
| 183 |
-
|
| 184 |
'''
|
| 185 |
# Assume current_image_annotations_state is List[dict] and current_page_annotator is dict
|
| 186 |
out_image_annotations_state: List[dict] = list(current_image_annotations_state) # Make a copy to avoid modifying input in place
|
|
@@ -220,7 +220,6 @@ def update_annotator_page_from_review_df(
|
|
| 220 |
else:
|
| 221 |
print("Warning: Page sizes DataFrame became empty after processing.")
|
| 222 |
|
| 223 |
-
# --- OPTIMIZATION: Process only the current page's data from review_df ---
|
| 224 |
if not review_df.empty:
|
| 225 |
# Filter review_df for the current page
|
| 226 |
# Ensure 'page' column in review_df is comparable to page_num_reported
|
|
@@ -1082,6 +1081,15 @@ def df_select_callback_ocr(df: pd.DataFrame, evt: gr.SelectData):
|
|
| 1082 |
|
| 1083 |
return row_value_page, row_value_df
|
| 1084 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1085 |
def get_all_rows_with_same_text(df: pd.DataFrame, text: str):
|
| 1086 |
'''
|
| 1087 |
Get all rows with the same text as the selected row
|
|
|
|
| 180 |
) -> Tuple[object, List[dict], int, List[dict], pd.DataFrame, int]: # Correcting return types based on usage
|
| 181 |
'''
|
| 182 |
Update the visible annotation object and related objects with the latest review file information,
|
| 183 |
+
optimising by processing only the current page's data.
|
| 184 |
'''
|
| 185 |
# Assume current_image_annotations_state is List[dict] and current_page_annotator is dict
|
| 186 |
out_image_annotations_state: List[dict] = list(current_image_annotations_state) # Make a copy to avoid modifying input in place
|
|
|
|
| 220 |
else:
|
| 221 |
print("Warning: Page sizes DataFrame became empty after processing.")
|
| 222 |
|
|
|
|
| 223 |
if not review_df.empty:
|
| 224 |
# Filter review_df for the current page
|
| 225 |
# Ensure 'page' column in review_df is comparable to page_num_reported
|
|
|
|
| 1081 |
|
| 1082 |
return row_value_page, row_value_df
|
| 1083 |
|
| 1084 |
+
# When a user selects a row in the duplicate results table
|
| 1085 |
+
def store_duplicate_selection(evt: gr.SelectData):
|
| 1086 |
+
if not evt.empty:
|
| 1087 |
+
selected_index = evt.index[0]
|
| 1088 |
+
else:
|
| 1089 |
+
selected_index = None
|
| 1090 |
+
|
| 1091 |
+
return selected_index
|
| 1092 |
+
|
| 1093 |
def get_all_rows_with_same_text(df: pd.DataFrame, text: str):
|
| 1094 |
'''
|
| 1095 |
Get all rows with the same text as the selected row
|