
Commit
·
c543ba0
1
Parent(s):
febacad
Updated user guide and app settings. Updated some additional lambda_entrypoint arguments. Ensured that examples are correctly displayed on GUI.
Browse files- README.md +312 -55
- app.py +30 -41
- lambda_entrypoint.py +6 -4
- pyproject.toml +1 -1
- src/app_settings.qmd +534 -490
- src/user_guide.qmd +310 -53
- tools/config.py +48 -32
README.md
CHANGED
|
@@ -10,7 +10,7 @@ license: agpl-3.0
|
|
| 10 |
---
|
| 11 |
# Document redaction
|
| 12 |
|
| 13 |
-
version: 1.4.
|
| 14 |
|
| 15 |
Redact personally identifiable information (PII) from documents (pdf, png, jpg), Word files (docx), or tabular data (xlsx/csv/parquet). Please see the [User Guide](#user-guide) for a full walkthrough of all the features in the app.
|
| 16 |
|
|
@@ -204,11 +204,12 @@ These settings are only relevant if you intend to use AWS services like Textract
|
|
| 204 |
|
| 205 |
Now you have the app installed, what follows is a guide on how to use it for basic and advanced redaction.
|
| 206 |
|
| 207 |
-
# User
|
| 208 |
|
| 209 |
## Table of contents
|
| 210 |
|
| 211 |
-
|
|
|
|
| 212 |
- [Basic redaction](#basic-redaction)
|
| 213 |
- [Customising redaction options](#customising-redaction-options)
|
| 214 |
- [Custom allow, deny, and page redaction lists](#custom-allow-deny-and-page-redaction-lists)
|
|
@@ -220,21 +221,60 @@ Now you have the app installed, what follows is a guide on how to use it for bas
|
|
| 220 |
- [Handwriting and signature redaction](#handwriting-and-signature-redaction)
|
| 221 |
- [Reviewing and modifying suggested redactions](#reviewing-and-modifying-suggested-redactions)
|
| 222 |
- [Redacting Word, tabular data files (CSV/XLSX) or copy and pasted text](#redacting-word-tabular-data-files-xlsxcsv-or-copy-and-pasted-text)
|
| 223 |
-
|
| 224 |
-
See the [advanced user guide here](#advanced-user-guide):
|
| 225 |
-
- [Merging redaction review files](#merging-redaction-review-files)
|
| 226 |
- [Identifying and redacting duplicate pages](#identifying-and-redacting-duplicate-pages)
|
|
|
|
|
|
|
|
|
|
| 227 |
- [Fuzzy search and redaction](#fuzzy-search-and-redaction)
|
| 228 |
- [Export redactions to and import from Adobe Acrobat](#export-to-and-import-from-adobe)
|
|
|
|
| 229 |
- [Exporting to Adobe Acrobat](#exporting-to-adobe-acrobat)
|
| 230 |
- [Importing from Adobe Acrobat](#importing-from-adobe-acrobat)
|
| 231 |
- [Using the AWS Textract document API](#using-the-aws-textract-document-api)
|
| 232 |
- [Using AWS Textract and Comprehend when not running in an AWS environment](#using-aws-textract-and-comprehend-when-not-running-in-an-aws-environment)
|
| 233 |
- [Modifying existing redaction review files](#modifying-existing-redaction-review-files)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 234 |
|
| 235 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 236 |
|
| 237 |
-
Please try these example files to follow along with this guide:
|
| 238 |
- [Example of files sent to a professor before applying](https://github.com/seanpedrick-case/document_redaction_examples/blob/main/example_of_emails_sent_to_a_professor_before_applying.pdf)
|
| 239 |
- [Example complaint letter (jpg)](https://github.com/seanpedrick-case/document_redaction_examples/blob/main/example_complaint_letter.jpg)
|
| 240 |
- [Partnership Agreement Toolkit (for signatures and more advanced usage)](https://github.com/seanpedrick-case/document_redaction_examples/blob/main/Partnership-Agreement-Toolkit_0_0.pdf)
|
|
@@ -254,16 +294,20 @@ The 'Redact PDFs/images tab' currently accepts PDFs and image files (JPG, PNG) f
|
|
| 254 |
|
| 255 |
### Text extraction
|
| 256 |
|
| 257 |
-
|
|
|
|
|
|
|
| 258 |
- **'Local model - selectable text'** - This will read text directly from PDFs that have selectable text to redact (using PikePDF). This is fine for most PDFs, but will find nothing if the PDF does not have selectable text, and it is not good for handwriting or signatures. If it encounters an image file, it will send it onto the second option below.
|
| 259 |
- **'Local OCR model - PDFs without selectable text'** - This option will use a simple Optical Character Recognition (OCR) model (Tesseract) to pull out text from a PDF/image that it 'sees'. This can handle most typed text in PDFs/images without selectable text, but struggles with handwriting/signatures. If you are interested in the latter, then you should use the third option if available.
|
| 260 |
- **'AWS Textract service - all PDF types'** - Only available for instances of the app running on AWS. AWS Textract is a service that performs OCR on documents within their secure service. This is a more advanced version of OCR compared to the local option, and carries a (relatively small) cost. Textract excels in complex documents based on images, or documents that contain a lot of handwriting and signatures.
|
| 261 |
|
| 262 |
-
###
|
| 263 |
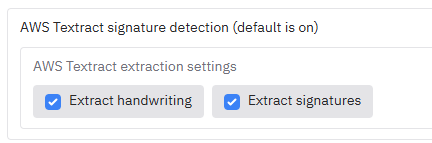
If you chose the AWS Textract service above, you can choose if you want handwriting and/or signatures redacted by default. Choosing signatures here will have a cost implication, as identifying signatures will cost ~£2.66 ($3.50) per 1,000 pages vs ~£1.14 ($1.50) per 1,000 pages without signature detection.
|
| 264 |
|
| 265 |
|
| 266 |
|
|
|
|
|
|
|
| 267 |
### PII redaction method
|
| 268 |
|
| 269 |
If you are running with the AWS service enabled, here you will also have a choice for PII redaction method:
|
|
@@ -297,6 +341,7 @@ Click 'Redact document'. After loading in the document, the app should be able t
|
|
| 297 |

|
| 298 |
|
| 299 |
- **'...redacted.pdf'** files contain the original pdf with suggested redacted text deleted and replaced by a black box on top of the document.
|
|
|
|
| 300 |
- **'...ocr_results.csv'** files contain the line-by-line text outputs from the entire document. This file can be useful for later searching through for any terms of interest in the document (e.g. using Excel or a similar program).
|
| 301 |
- **'...review_file.csv'** files are the review files that contain details and locations of all of the suggested redactions in the document. This file is key to the [review process](#reviewing-and-modifying-suggested-redactions), and should be downloaded to use later for this.
|
| 302 |
|
|
@@ -365,8 +410,6 @@ If the table is empty, you can add a new entry, you can add a new row by clickin
|
|
| 365 |
|
| 366 |

|
| 367 |
|
| 368 |
-
**Note:** As of version 0.7.0 you can now apply your whole page redaction list directly to the document file currently under review by clicking the 'Apply whole page redaction list to document currently under review' button that appears here.
|
| 369 |
-
|
| 370 |
### Redacting additional types of personal information
|
| 371 |
|
| 372 |
You may want to redact additional types of information beyond the defaults, or you may not be interested in default suggested entity types. There are dates in the example complaint letter. Say we wanted to redact those dates also?
|
|
@@ -381,7 +424,7 @@ If you want to redact different files, I suggest you refresh your browser page t
|
|
| 381 |
|
| 382 |
## Redacting only specific pages
|
| 383 |
|
| 384 |
-
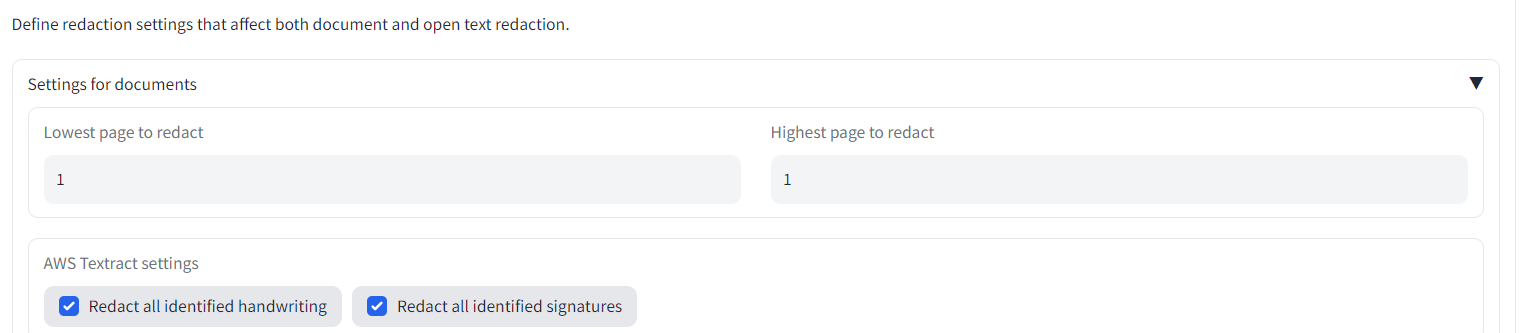
Say also we are only interested in redacting page 1 of the loaded documents. On the Redaction settings tab, select 'Lowest page to redact' as 1, and 'Highest page to redact' also as 1. When you next redact your documents, only the first page will be modified.
|
| 385 |
|
| 386 |
|
| 387 |
|
|
@@ -618,39 +661,16 @@ You can also write open text into an input box and redact that using the same me
|
|
| 618 |
### Redaction log outputs
|
| 619 |
A list of the suggested redaction outputs from the tabular data / open text data redaction is available on the Redaction settings page under 'Log file outputs'.
|
| 620 |
|
| 621 |
-
# ADVANCED USER GUIDE
|
| 622 |
-
|
| 623 |
-
This advanced user guide will go over some of the features recently added to the app, including: modifying and merging redaction review files, identifying and redacting duplicate pages across multiple PDFs, 'fuzzy' search and redact, and exporting redactions to Adobe Acrobat.
|
| 624 |
-
|
| 625 |
-
## Table of contents
|
| 626 |
-
|
| 627 |
-
- [Merging redaction review files](#merging-redaction-review-files)
|
| 628 |
-
- [Identifying and redacting duplicate pages](#identifying-and-redacting-duplicate-pages)
|
| 629 |
-
- [Fuzzy search and redaction](#fuzzy-search-and-redaction)
|
| 630 |
-
- [Export redactions to and import from Adobe Acrobat](#export-to-and-import-from-adobe)
|
| 631 |
-
- [Exporting to Adobe Acrobat](#exporting-to-adobe-acrobat)
|
| 632 |
-
- [Importing from Adobe Acrobat](#importing-from-adobe-acrobat)
|
| 633 |
-
- [Using the AWS Textract document API](#using-the-aws-textract-document-api)
|
| 634 |
-
- [Using AWS Textract and Comprehend when not running in an AWS environment](#using-aws-textract-and-comprehend-when-not-running-in-an-aws-environment)
|
| 635 |
-
- [Modifying existing redaction review files](#modifying-existing-redaction-review-files)
|
| 636 |
-
|
| 637 |
-
|
| 638 |
-
## Merging redaction review files
|
| 639 |
-
|
| 640 |
-
Say you have run multiple redaction tasks on the same document, and you want to merge all of these redactions together. You could do this in your spreadsheet editor, but this could be fiddly especially if dealing with multiple review files or large numbers of redactions. The app has a feature to combine multiple review files together to create a 'merged' review file.
|
| 641 |
-
|
| 642 |
-

|
| 643 |
-
|
| 644 |
-
You can find this option at the bottom of the 'Redaction Settings' tab. Upload multiple review files here to get a single output 'merged' review_file. In the examples file, merging the 'review_file_custom.csv' and 'review_file_local.csv' files give you an output containing redaction boxes from both. This combined review file can then be uploaded into the review tab following the usual procedure.
|
| 645 |
-
|
| 646 |
-
|
| 647 |
-
|
| 648 |
## Identifying and redacting duplicate pages
|
| 649 |
|
| 650 |
The files for this section are stored [here](https://github.com/seanpedrick-case/document_redaction_examples/blob/main/duplicate_page_find_in_app/).
|
| 651 |
|
| 652 |
Some redaction tasks involve removing duplicate pages of text that may exist across multiple documents. This feature helps you find and remove duplicate content that may exist in single or multiple documents. It can identify everything from single identical pages to multi-page sections (subdocuments). The process involves three main steps: configuring the analysis, reviewing the results in the interactive interface, and then using the generated files to perform the redactions.
|
| 653 |
|
|
|
|
|
|
|
|
|
|
|
|
|
| 654 |

|
| 655 |
|
| 656 |
**Step 1: Upload and Configure the Analysis**
|
|
@@ -695,11 +715,43 @@ The analysis also generates a set of downloadable files for your records and for
|
|
| 695 |
|
| 696 |
If you want to combine the results from this redaction process with previous redaction tasks for the same PDF, you could merge review file outputs following the steps described in [Merging existing redaction review files](#merging-existing-redaction-review-files) above.
|
| 697 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 698 |
## Fuzzy search and redaction
|
| 699 |
|
| 700 |
The files for this section are stored [here](https://github.com/seanpedrick-case/document_redaction_examples/blob/main/fuzzy_search/).
|
| 701 |
|
| 702 |
-
Sometimes you may be searching for
|
| 703 |
|
| 704 |
To do this, go to the Redaction Settings, and the 'Select entity types to redact' area. In the box below relevant to your chosen redaction method (local or AWS Comprehend), select 'CUSTOM_FUZZY' from the list. Next, we can select the maximum number of spelling mistakes allowed in the search (up to nine). Here, you can either type in a number or use the small arrows to the right of the box. Change this option to 3. This will allow for a maximum of three 'changes' in text needed to match to the desired search terms.
|
| 705 |
|
|
@@ -719,9 +771,20 @@ Using these deny list with spelling mistakes, the app fuzzy match these terms to
|
|
| 719 |
|
| 720 |
Files for this section are stored [here](https://github.com/seanpedrick-case/document_redaction_examples/blob/main/export_to_adobe/).
|
| 721 |
|
| 722 |
-
|
|
|
|
|
|
|
| 723 |
|
| 724 |
-
The
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 725 |
|
| 726 |
To convert suggested redactions to Adobe format, you need to have the original PDF and a review file csv in the input box at the top of the Review redactions page.
|
| 727 |
|
|
@@ -769,6 +832,46 @@ The '_textract.json' output can be used to speed up further redaction tasks as [
|
|
| 769 |
|
| 770 |
You can now easily get the '..._ocr_output.csv' redaction output based on this '_textract.json' (described in [Redaction outputs](#redaction-outputs)) by clicking on the button 'Convert Textract job outputs to OCR results'. You can now use this file e.g. for [identifying duplicate pages](#identifying-and-redacting-duplicate-pages), or for redaction review.
|
| 771 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
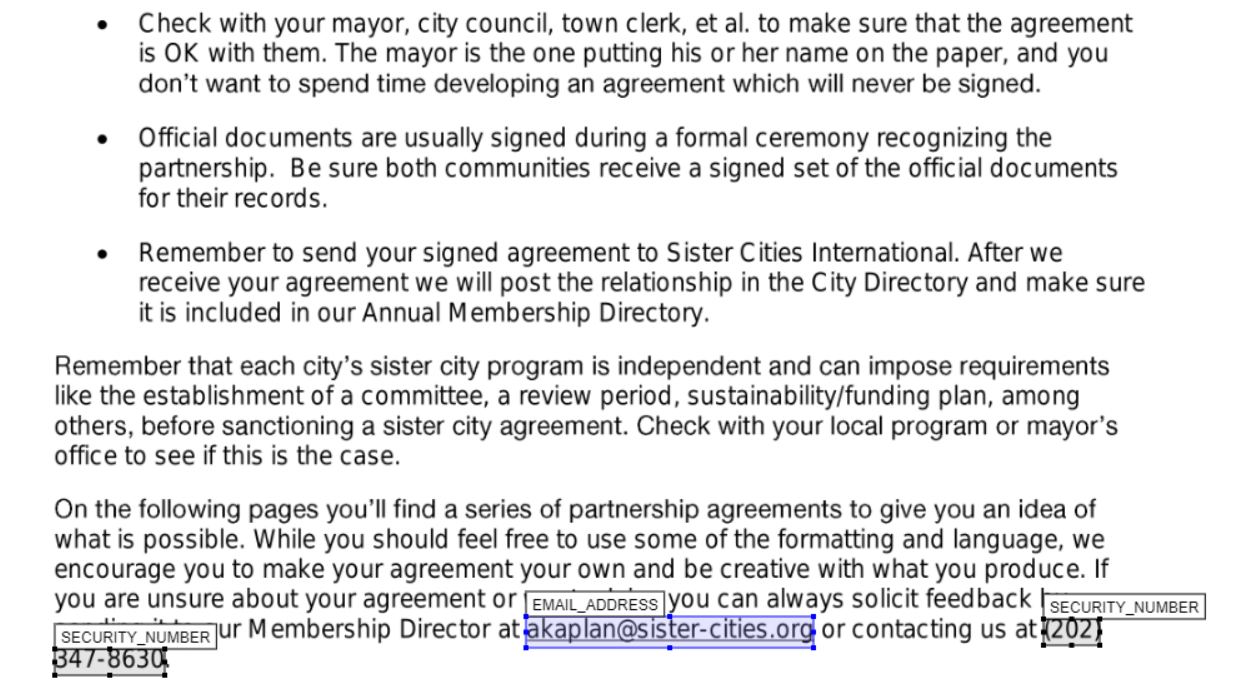
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 772 |
## Using AWS Textract and Comprehend when not running in an AWS environment
|
| 773 |
|
| 774 |
AWS Textract and Comprehend give much better results for text extraction and document redaction than the local model options in the app. The most secure way to access them in the Redaction app is to run the app in a secure AWS environment with relevant permissions. Alternatively, you could run the app on your own system while logged in to AWS SSO with relevant permissions.
|
|
@@ -790,26 +893,180 @@ The app should then pick up these keys when trying to access the AWS Textract an
|
|
| 790 |
|
| 791 |
Again, a lot can potentially go wrong with AWS solutions that are insecure, so before trying the above please consult with your AWS and data security teams.
|
| 792 |
|
| 793 |
-
##
|
| 794 |
|
| 795 |
-
|
| 796 |
|
| 797 |
-
|
| 798 |
|
| 799 |
-
|
|
|
|
|
|
|
| 800 |
|
| 801 |
-
|
| 802 |
|
| 803 |
-
|
| 804 |
|
| 805 |
-
|
|
|
|
|
|
|
| 806 |
|
| 807 |
-
|
|
|
|
|
|
|
|
|
|
| 808 |
|
| 809 |
-
|
| 810 |
|
| 811 |
-
|
| 812 |
|
| 813 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 814 |
|
| 815 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 10 |
---
|
| 11 |
# Document redaction
|
| 12 |
|
| 13 |
+
version: 1.4.1
|
| 14 |
|
| 15 |
Redact personally identifiable information (PII) from documents (pdf, png, jpg), Word files (docx), or tabular data (xlsx/csv/parquet). Please see the [User Guide](#user-guide) for a full walkthrough of all the features in the app.
|
| 16 |
|
|
|
|
| 204 |
|
| 205 |
Now you have the app installed, what follows is a guide on how to use it for basic and advanced redaction.
|
| 206 |
|
| 207 |
+
# User guide
|
| 208 |
|
| 209 |
## Table of contents
|
| 210 |
|
| 211 |
+
### Getting Started
|
| 212 |
+
- [Built-in example data](#built-in-example-data)
|
| 213 |
- [Basic redaction](#basic-redaction)
|
| 214 |
- [Customising redaction options](#customising-redaction-options)
|
| 215 |
- [Custom allow, deny, and page redaction lists](#custom-allow-deny-and-page-redaction-lists)
|
|
|
|
| 221 |
- [Handwriting and signature redaction](#handwriting-and-signature-redaction)
|
| 222 |
- [Reviewing and modifying suggested redactions](#reviewing-and-modifying-suggested-redactions)
|
| 223 |
- [Redacting Word, tabular data files (CSV/XLSX) or copy and pasted text](#redacting-word-tabular-data-files-xlsxcsv-or-copy-and-pasted-text)
|
|
|
|
|
|
|
|
|
|
| 224 |
- [Identifying and redacting duplicate pages](#identifying-and-redacting-duplicate-pages)
|
| 225 |
+
|
| 226 |
+
### Advanced user guide
|
| 227 |
+
- [Advanced user guide](#advanced-user-guide)
|
| 228 |
- [Fuzzy search and redaction](#fuzzy-search-and-redaction)
|
| 229 |
- [Export redactions to and import from Adobe Acrobat](#export-to-and-import-from-adobe)
|
| 230 |
+
- [Using _for_review.pdf files with Adobe Acrobat](#using-_for_reviewpdf-files-with-adobe-acrobat)
|
| 231 |
- [Exporting to Adobe Acrobat](#exporting-to-adobe-acrobat)
|
| 232 |
- [Importing from Adobe Acrobat](#importing-from-adobe-acrobat)
|
| 233 |
- [Using the AWS Textract document API](#using-the-aws-textract-document-api)
|
| 234 |
- [Using AWS Textract and Comprehend when not running in an AWS environment](#using-aws-textract-and-comprehend-when-not-running-in-an-aws-environment)
|
| 235 |
- [Modifying existing redaction review files](#modifying-existing-redaction-review-files)
|
| 236 |
+
- [Merging redaction review files](#merging-redaction-review-files)
|
| 237 |
+
|
| 238 |
+
### Features for expert users/system administrators
|
| 239 |
+
- [Features for expert users/system administrators](#features-for-expert-userssystem-administrators)
|
| 240 |
+
- [Advanced OCR options (Hybrid OCR)](#advanced-ocr-options-hybrid-ocr)
|
| 241 |
+
- [Command Line Interface (CLI)](#command-line-interface-cli)
|
| 242 |
+
|
| 243 |
+
## Built-in example data
|
| 244 |
+
|
| 245 |
+
The app now includes built-in example files that you can use to quickly test different features. These examples are automatically loaded and can be accessed directly from the interface without needing to download files separately.
|
| 246 |
+
|
| 247 |
+
### Using built-in examples
|
| 248 |
+
|
| 249 |
+
**For PDF/image redaction:** On the 'Redact PDFs/images' tab, you'll see a section titled "Try an example - Click on an example below and then the 'Extract text and redact document' button". Simply click on any of the available examples to load them with pre-configured settings:
|
| 250 |
+
|
| 251 |
+
- **PDF with selectable text redaction** - Uses local text extraction with standard PII detection
|
| 252 |
+
- **Image redaction with local OCR** - Processes an image file using OCR
|
| 253 |
+
- **PDF redaction with custom entities** - Demonstrates custom entity selection (Titles, Person, Dates)
|
| 254 |
+
- **PDF redaction with AWS services and signature detection** - Shows AWS Textract with signature extraction (if AWS is enabled)
|
| 255 |
+
- **PDF redaction with custom deny list and whole page redaction** - Demonstrates advanced redaction features
|
| 256 |
+
|
| 257 |
+
Once you have clicked on an example, you can click the 'Extract text and redact document' button to load the example into the app and redact it.
|
| 258 |
+
|
| 259 |
+
**For tabular data:** On the 'Word or Excel/csv files' tab, you'll find examples for both redaction and duplicate detection:
|
| 260 |
|
| 261 |
+
- **CSV file redaction** - Shows how to redact specific columns in tabular data
|
| 262 |
+
- **Word document redaction** - Demonstrates Word document processing
|
| 263 |
+
- **Excel file duplicate detection** - Shows how to find duplicate rows in spreadsheet data
|
| 264 |
+
|
| 265 |
+
Once you have clicked on an example, you can click the 'Redact text/data files' button to load the example into the app and redact it. For the duplicate detection example, you can click the 'Find duplicate cells/rows' button to load the example into the app and find duplicates.
|
| 266 |
+
|
| 267 |
+
**For duplicate page detection:** On the 'Identify duplicate pages' tab, you'll find examples for finding duplicate content in documents:
|
| 268 |
+
|
| 269 |
+
- **Find duplicate pages of text in document OCR outputs** - Uses page-level analysis with a similarity threshold of 0.95 and minimum word count of 10
|
| 270 |
+
- **Find duplicate text lines in document OCR outputs** - Uses line-level analysis with a similarity threshold of 0.95 and minimum word count of 3
|
| 271 |
+
|
| 272 |
+
Once you have clicked on an example, you can click the 'Identify duplicate pages/subdocuments' button to load the example into the app and find duplicate content.
|
| 273 |
+
|
| 274 |
+
### External example files (optional)
|
| 275 |
+
|
| 276 |
+
If you prefer to use your own example files or want to follow along with specific tutorials, you can still download these external example files:
|
| 277 |
|
|
|
|
| 278 |
- [Example of files sent to a professor before applying](https://github.com/seanpedrick-case/document_redaction_examples/blob/main/example_of_emails_sent_to_a_professor_before_applying.pdf)
|
| 279 |
- [Example complaint letter (jpg)](https://github.com/seanpedrick-case/document_redaction_examples/blob/main/example_complaint_letter.jpg)
|
| 280 |
- [Partnership Agreement Toolkit (for signatures and more advanced usage)](https://github.com/seanpedrick-case/document_redaction_examples/blob/main/Partnership-Agreement-Toolkit_0_0.pdf)
|
|
|
|
| 294 |
|
| 295 |
### Text extraction
|
| 296 |
|
| 297 |
+
You can modify default text extraction methods by clicking on the 'Change default text extraction method...' box'.
|
| 298 |
+
|
| 299 |
+
Here you can select one of the three text extraction options:
|
| 300 |
- **'Local model - selectable text'** - This will read text directly from PDFs that have selectable text to redact (using PikePDF). This is fine for most PDFs, but will find nothing if the PDF does not have selectable text, and it is not good for handwriting or signatures. If it encounters an image file, it will send it onto the second option below.
|
| 301 |
- **'Local OCR model - PDFs without selectable text'** - This option will use a simple Optical Character Recognition (OCR) model (Tesseract) to pull out text from a PDF/image that it 'sees'. This can handle most typed text in PDFs/images without selectable text, but struggles with handwriting/signatures. If you are interested in the latter, then you should use the third option if available.
|
| 302 |
- **'AWS Textract service - all PDF types'** - Only available for instances of the app running on AWS. AWS Textract is a service that performs OCR on documents within their secure service. This is a more advanced version of OCR compared to the local option, and carries a (relatively small) cost. Textract excels in complex documents based on images, or documents that contain a lot of handwriting and signatures.
|
| 303 |
|
| 304 |
+
### Enable AWS Textract signature extraction
|
| 305 |
If you chose the AWS Textract service above, you can choose if you want handwriting and/or signatures redacted by default. Choosing signatures here will have a cost implication, as identifying signatures will cost ~£2.66 ($3.50) per 1,000 pages vs ~£1.14 ($1.50) per 1,000 pages without signature detection.
|
| 306 |
|
| 307 |

|
| 308 |
|
| 309 |
+
**NOTE:** it is also possible to enable form extraction, layout extraction, and table extraction with AWS Textract. This is not enabled by default, but it is possible for your system admin to enable this feature in the config file.
|
| 310 |
+
|
| 311 |
### PII redaction method
|
| 312 |
|
| 313 |
If you are running with the AWS service enabled, here you will also have a choice for PII redaction method:
|
|
|
|
| 341 |

|
| 342 |
|
| 343 |
- **'...redacted.pdf'** files contain the original pdf with suggested redacted text deleted and replaced by a black box on top of the document.
|
| 344 |
+
- **'...redactions_for_review.pdf'** files contain the original PDF with redaction boxes overlaid but the original text still visible underneath. This file is designed for use in Adobe Acrobat and other PDF viewers where you can see the suggested redactions without the text being permanently removed. This is particularly useful for reviewing redactions before finalising them.
|
| 345 |
- **'...ocr_results.csv'** files contain the line-by-line text outputs from the entire document. This file can be useful for later searching through for any terms of interest in the document (e.g. using Excel or a similar program).
|
| 346 |
- **'...review_file.csv'** files are the review files that contain details and locations of all of the suggested redactions in the document. This file is key to the [review process](#reviewing-and-modifying-suggested-redactions), and should be downloaded to use later for this.
|
| 347 |
|
|
|
|
| 410 |
|
| 411 |

|
| 412 |
|
|
|
|
|
|
|
| 413 |
### Redacting additional types of personal information
|
| 414 |
|
| 415 |
You may want to redact additional types of information beyond the defaults, or you may not be interested in default suggested entity types. There are dates in the example complaint letter. Say we wanted to redact those dates also?
|
|
|
|
| 424 |
|
| 425 |
## Redacting only specific pages
|
| 426 |
|
| 427 |
+
Say also we are only interested in redacting page 1 of the loaded documents. On the Redaction settings tab, select 'Lowest page to redact' as 1, and 'Highest page to redact' also as 1. When you next redact your documents, only the first page will be modified. The output files should now have a suffix similar to '..._1_1.pdf', indicating the lowest and highest page numbers that were redacted.
|
| 428 |
|
| 429 |

|
| 430 |
|
|
|
|
| 661 |
### Redaction log outputs
|
| 662 |
A list of the suggested redaction outputs from the tabular data / open text data redaction is available on the Redaction settings page under 'Log file outputs'.
|
| 663 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 664 |
## Identifying and redacting duplicate pages
|
| 665 |
|
| 666 |
The files for this section are stored [here](https://github.com/seanpedrick-case/document_redaction_examples/blob/main/duplicate_page_find_in_app/).
|
| 667 |
|
| 668 |
Some redaction tasks involve removing duplicate pages of text that may exist across multiple documents. This feature helps you find and remove duplicate content that may exist in single or multiple documents. It can identify everything from single identical pages to multi-page sections (subdocuments). The process involves three main steps: configuring the analysis, reviewing the results in the interactive interface, and then using the generated files to perform the redactions.
|
| 669 |
|
| 670 |
+
### Duplicate page detection in documents
|
| 671 |
+
|
| 672 |
+
This section covers finding duplicate pages across PDF documents using OCR output files.
|
| 673 |
+
|
| 674 |

|
| 675 |
|
| 676 |
**Step 1: Upload and Configure the Analysis**
|
|
|
|
| 715 |
|
| 716 |
If you want to combine the results from this redaction process with previous redaction tasks for the same PDF, you could merge review file outputs following the steps described in [Merging existing redaction review files](#merging-existing-redaction-review-files) above.
|
| 717 |
|
| 718 |
+
### Duplicate detection in tabular data
|
| 719 |
+
|
| 720 |
+
The app also includes functionality to find duplicate cells or rows in CSV, Excel, or Parquet files. This is particularly useful for cleaning datasets where you need to identify and remove duplicate entries.
|
| 721 |
+
|
| 722 |
+
**Step 1: Upload files and configure analysis**
|
| 723 |
+
|
| 724 |
+
Navigate to the 'Word or Excel/csv files' tab and scroll down to the "Find duplicate cells in tabular data" section. Upload your tabular files (CSV, Excel, or Parquet) and configure the analysis parameters:
|
| 725 |
+
|
| 726 |
+
- **Similarity threshold**: Score (0-1) to consider cells a match. 1 = perfect match
|
| 727 |
+
- **Minimum word count**: Cells with fewer words than this value are ignored
|
| 728 |
+
- **Do initial clean of text**: Remove URLs, HTML tags, and non-ASCII characters
|
| 729 |
+
- **Remove duplicate rows**: Automatically remove duplicate rows from deduplicated files
|
| 730 |
+
- **Select Excel sheet names**: Choose which sheets to analyze (for Excel files)
|
| 731 |
+
- **Select text columns**: Choose which columns contain text to analyze
|
| 732 |
+
|
| 733 |
+
**Step 2: Review results**
|
| 734 |
+
|
| 735 |
+
After clicking "Find duplicate cells/rows", the results will be displayed in a table showing:
|
| 736 |
+
- File1, Row1, File2, Row2
|
| 737 |
+
- Similarity_Score
|
| 738 |
+
- Text1, Text2 (the actual text content being compared)
|
| 739 |
+
|
| 740 |
+
Click on any row to see more details about the duplicate match in the preview boxes below.
|
| 741 |
+
|
| 742 |
+
**Step 3: Remove duplicates**
|
| 743 |
+
|
| 744 |
+
Select a file from the dropdown and click "Remove duplicate rows from selected file" to create a cleaned version with duplicates removed. The cleaned file will be available for download.
|
| 745 |
+
|
| 746 |
+
# Advanced user guide
|
| 747 |
+
|
| 748 |
+
This advanced user guide covers features that require system administration access or command-line usage. These features are typically used by system administrators or advanced users who need more control over the redaction process.
|
| 749 |
+
|
| 750 |
## Fuzzy search and redaction
|
| 751 |
|
| 752 |
The files for this section are stored [here](https://github.com/seanpedrick-case/document_redaction_examples/blob/main/fuzzy_search/).
|
| 753 |
|
| 754 |
+
Sometimes you may be searching for terms that are slightly mispelled throughout a document, for example names. The document redaction app gives the option for searching for long phrases that may contain spelling mistakes, a method called 'fuzzy matching'.
|
| 755 |
|
| 756 |
To do this, go to the Redaction Settings, and the 'Select entity types to redact' area. In the box below relevant to your chosen redaction method (local or AWS Comprehend), select 'CUSTOM_FUZZY' from the list. Next, we can select the maximum number of spelling mistakes allowed in the search (up to nine). Here, you can either type in a number or use the small arrows to the right of the box. Change this option to 3. This will allow for a maximum of three 'changes' in text needed to match to the desired search terms.
|
| 757 |
|
|
|
|
| 771 |
|
| 772 |
Files for this section are stored [here](https://github.com/seanpedrick-case/document_redaction_examples/blob/main/export_to_adobe/).
|
| 773 |
|
| 774 |
+
The Document Redaction app has enhanced features for working with Adobe Acrobat. You can now export suggested redactions to Adobe, import Adobe comment files into the app, and use the new `_for_review.pdf` files directly in Adobe Acrobat.
|
| 775 |
+
|
| 776 |
+
### Using _for_review.pdf files with Adobe Acrobat
|
| 777 |
|
| 778 |
+
The app now generates `...redactions_for_review.pdf` files that contain the original PDF with redaction boxes overlaid but the original text still visible underneath. These files are specifically designed for use in Adobe Acrobat and other PDF viewers where you can:
|
| 779 |
+
|
| 780 |
+
- See the suggested redactions without the text being permanently removed
|
| 781 |
+
- Review redactions before finalising them
|
| 782 |
+
- Use Adobe Acrobat's built-in redaction tools to modify or apply the redactions
|
| 783 |
+
- Export the final redacted version directly from Adobe
|
| 784 |
+
|
| 785 |
+
Simply open the `...redactions_for_review.pdf` file in Adobe Acrobat to begin reviewing and modifying the suggested redactions.
|
| 786 |
+
|
| 787 |
+
### Exporting to Adobe Acrobat
|
| 788 |
|
| 789 |
To convert suggested redactions to Adobe format, you need to have the original PDF and a review file csv in the input box at the top of the Review redactions page.
|
| 790 |
|
|
|
|
| 832 |
|
| 833 |
You can now easily get the '..._ocr_output.csv' redaction output based on this '_textract.json' (described in [Redaction outputs](#redaction-outputs)) by clicking on the button 'Convert Textract job outputs to OCR results'. You can now use this file e.g. for [identifying duplicate pages](#identifying-and-redacting-duplicate-pages), or for redaction review.
|
| 834 |
|
| 835 |
+
|
| 836 |
+
|
| 837 |
+
## Modifying existing redaction review files
|
| 838 |
+
You can find the folder containing the files discussed in this section [here](https://github.com/seanpedrick-case/document_redaction_examples/blob/main/merge_review_files/).
|
| 839 |
+
|
| 840 |
+
As well as serving as inputs to the document redaction app's review function, the 'review_file.csv' output can be modified insider or outside of the app. This gives you the flexibility to change redaction details outside of the app.
|
| 841 |
+
|
| 842 |
+
### Inside the app
|
| 843 |
+
You can now modify redaction review files directly in the app on the 'Review redactions' tab. Open the accordion 'View and edit review data' under the file input area. You can edit review file data cells here - press Enter to apply changes. You should see the effect on the current page if you click the 'Save changes on current page to file' button to the right.
|
| 844 |
+
|
| 845 |
+
### Outside the app
|
| 846 |
+
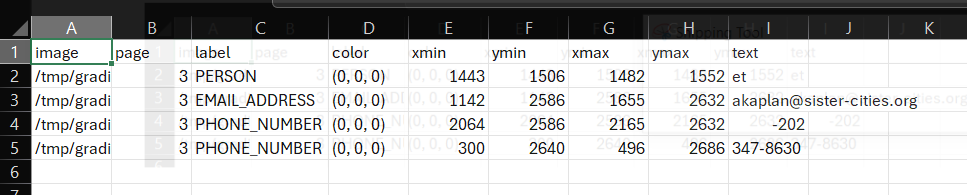
If you open up a 'review_file' csv output using a spreadsheet software program such as Microsoft Excel you can easily modify redaction properties. Open the file '[Partnership-Agreement-Toolkit_0_0_redacted.pdf_review_file_local.csv](https://github.com/seanpedrick-case/document_redaction_examples/blob/main/merge_review_files/Partnership-Agreement-Toolkit_0_0.pdf_review_file_local.csv)', and you should see a spreadshet with just four suggested redactions (see below). The following instructions are for using Excel.
|
| 847 |
+
|
| 848 |
+
|
| 849 |
+
|
| 850 |
+
The first thing we can do is remove the first row - 'et' is suggested as a person, but is obviously not a genuine instance of personal information. Right click on the row number and select delete on this menu. Next, let's imagine that what the app identified as a 'phone number' was in fact another type of number and so we wanted to change the label. Simply click on the relevant label cells, let's change it to 'SECURITY_NUMBER'. You could also use 'Find & Select' -> 'Replace' from the top ribbon menu if you wanted to change a number of labels simultaneously.
|
| 851 |
+
|
| 852 |
+
How about we wanted to change the colour of the 'email address' entry on the redaction review tab of the redaction app? The colours in a review file are based on an RGB scale with three numbers ranging from 0-255. [You can find suitable colours here](https://rgbcolorpicker.com). Using this scale, if I wanted my review box to be pure blue, I can change the cell value to (0,0,255).
|
| 853 |
+
|
| 854 |
+
Imagine that a redaction box was slightly too small, and I didn't want to use the in-app options to change the size. In the review file csv, we can modify e.g. the ymin and ymax values for any box to increase the extent of the redaction box. For the 'email address' entry, let's decrease ymin by 5, and increase ymax by 5.
|
| 855 |
+
|
| 856 |
+
I have saved an output file following the above steps as '[Partnership-Agreement-Toolkit_0_0_redacted.pdf_review_file_local_mod.csv](https://github.com/seanpedrick-case/document_redaction_examples/blob/main/merge_review_files/outputs/Partnership-Agreement-Toolkit_0_0.pdf_review_file_local_mod.csv)' in the same folder that the original was found. Let's upload this file to the app along with the original pdf to see how the redactions look now.
|
| 857 |
+
|
| 858 |
+
|
| 859 |
+
|
| 860 |
+
We can see from the above that we have successfully removed a redaction box, changed labels, colours, and redaction box sizes.
|
| 861 |
+
|
| 862 |
+
## Merging redaction review files
|
| 863 |
+
|
| 864 |
+
Say you have run multiple redaction tasks on the same document, and you want to merge all of these redactions together. You could do this in your spreadsheet editor, but this could be fiddly especially if dealing with multiple review files or large numbers of redactions. The app has a feature to combine multiple review files together to create a 'merged' review file.
|
| 865 |
+
|
| 866 |
+

|
| 867 |
+
|
| 868 |
+
You can find this option at the bottom of the 'Redaction Settings' tab. Upload multiple review files here to get a single output 'merged' review_file. In the examples file, merging the 'review_file_custom.csv' and 'review_file_local.csv' files give you an output containing redaction boxes from both. This combined review file can then be uploaded into the review tab following the usual procedure.
|
| 869 |
+
|
| 870 |
+

|
| 871 |
+
|
| 872 |
+
# Features for expert users/system administrators
|
| 873 |
+
This advanced user guide covers features that require system administration access or command-line usage. These options are not enabled by default but can be configured by your system administrator, and are not available to users who are just using the graphical user interface. These features are typically used by system administrators or advanced users who need more control over the redaction process.
|
| 874 |
+
|
| 875 |
## Using AWS Textract and Comprehend when not running in an AWS environment
|
| 876 |
|
| 877 |
AWS Textract and Comprehend give much better results for text extraction and document redaction than the local model options in the app. The most secure way to access them in the Redaction app is to run the app in a secure AWS environment with relevant permissions. Alternatively, you could run the app on your own system while logged in to AWS SSO with relevant permissions.
|
|
|
|
| 893 |
|
| 894 |
Again, a lot can potentially go wrong with AWS solutions that are insecure, so before trying the above please consult with your AWS and data security teams.
|
| 895 |
|
| 896 |
+
## Advanced OCR options (Hybrid OCR)
|
| 897 |
|
| 898 |
+
The app supports advanced OCR options that combine multiple OCR engines for improved accuracy. These options are not enabled by default but can be configured by your system administrator.
|
| 899 |
|
| 900 |
+
### Available OCR models
|
| 901 |
|
| 902 |
+
- **Tesseract** (default): The standard OCR engine that works well for most documents
|
| 903 |
+
- **PaddleOCR**: More accurate for whole line text extraction, but word-level bounding boxes may be less precise
|
| 904 |
+
- **Hybrid**: Combines Tesseract and PaddleOCR - uses Tesseract for initial extraction, then PaddleOCR for re-extraction of low-confidence text
|
| 905 |
|
| 906 |
+
### Enabling advanced OCR options
|
| 907 |
|
| 908 |
+
To enable these options, your system administrator needs to modify the configuration file (`config.py`) and set:
|
| 909 |
|
| 910 |
+
```
|
| 911 |
+
SHOW_LOCAL_OCR_MODEL_OPTIONS = "True"
|
| 912 |
+
```
|
| 913 |
|
| 914 |
+
Once enabled, users will see a "Change default local OCR model" section in the redaction settings where they can choose between:
|
| 915 |
+
- tesseract
|
| 916 |
+
- hybrid
|
| 917 |
+
- paddle
|
| 918 |
|
| 919 |
+
### Hybrid OCR configuration
|
| 920 |
|
| 921 |
+
The hybrid OCR mode uses several configurable parameters:
|
| 922 |
|
| 923 |
+
- **HYBRID_OCR_CONFIDENCE_THRESHOLD** (default: 65): Tesseract confidence score below which PaddleOCR will be used for re-extraction
|
| 924 |
+
- **HYBRID_OCR_PADDING** (default: 1): Padding added to word bounding boxes before re-extraction
|
| 925 |
+
- **SAVE_EXAMPLE_TESSERACT_VS_PADDLE_IMAGES** (default: False): Save comparison images when using hybrid mode
|
| 926 |
+
- **SAVE_PADDLE_VISUALISATIONS** (default: False): Save images with PaddleOCR bounding boxes overlaid
|
| 927 |
+
|
| 928 |
+
### When to use different OCR models
|
| 929 |
+
|
| 930 |
+
- **Tesseract**: Best for general use, good balance of speed and accuracy
|
| 931 |
+
- **PaddleOCR**: Best for documents with clear, well-formatted text where line-level accuracy is more important than word-level precision
|
| 932 |
+
- **Hybrid**: Best for challenging documents where some text has low confidence scores, providing the benefits of both engines
|
| 933 |
|
| 934 |
+
|
| 935 |
+
|
| 936 |
+
|
| 937 |
+
|
| 938 |
+
## Command Line Interface (CLI)
|
| 939 |
+
|
| 940 |
+
The app includes a comprehensive command-line interface (`cli_redact.py`) that allows you to perform redaction, deduplication, and AWS Textract operations directly from the terminal. This is particularly useful for batch processing, automation, and integration with other systems.
|
| 941 |
+
|
| 942 |
+
### Getting started with the CLI
|
| 943 |
+
|
| 944 |
+
To use the CLI, you need to:
|
| 945 |
+
|
| 946 |
+
1. Open a terminal window
|
| 947 |
+
2. Navigate to the app folder containing `cli_redact.py`
|
| 948 |
+
3. Activate your virtual environment (conda or venv)
|
| 949 |
+
4. Run commands using `python cli_redact.py` followed by your options
|
| 950 |
+
|
| 951 |
+
### Basic CLI syntax
|
| 952 |
+
|
| 953 |
+
```bash
|
| 954 |
+
python cli_redact.py --task [redact|deduplicate|textract] --input_file [file_path] [additional_options]
|
| 955 |
+
```
|
| 956 |
+
|
| 957 |
+
### Redaction examples
|
| 958 |
+
|
| 959 |
+
**Basic PDF redaction with default settings:**
|
| 960 |
+
```bash
|
| 961 |
+
python cli_redact.py --input_file example_data/example_of_emails_sent_to_a_professor_before_applying.pdf
|
| 962 |
+
```
|
| 963 |
+
|
| 964 |
+
**Extract text only (no redaction) with whole page redaction:**
|
| 965 |
+
```bash
|
| 966 |
+
python cli_redact.py --input_file example_data/Partnership-Agreement-Toolkit_0_0.pdf --redact_whole_page_file example_data/partnership_toolkit_redact_some_pages.csv --pii_detector None
|
| 967 |
+
```
|
| 968 |
+
|
| 969 |
+
**Redact with custom entities and allow list:**
|
| 970 |
+
```bash
|
| 971 |
+
python cli_redact.py --input_file example_data/graduate-job-example-cover-letter.pdf --allow_list_file example_data/test_allow_list_graduate.csv --local_redact_entities TITLES PERSON DATE_TIME
|
| 972 |
+
```
|
| 973 |
+
|
| 974 |
+
**Redact with fuzzy matching and custom deny list:**
|
| 975 |
+
```bash
|
| 976 |
+
python cli_redact.py --input_file example_data/Partnership-Agreement-Toolkit_0_0.pdf --deny_list_file example_data/Partnership-Agreement-Toolkit_test_deny_list_para_single_spell.csv --local_redact_entities CUSTOM_FUZZY --page_min 1 --page_max 3 --fuzzy_mistakes 3
|
| 977 |
+
```
|
| 978 |
+
|
| 979 |
+
**Redact with AWS services:**
|
| 980 |
+
```bash
|
| 981 |
+
python cli_redact.py --input_file example_data/example_of_emails_sent_to_a_professor_before_applying.pdf --ocr_method "AWS Textract" --pii_detector "AWS Comprehend"
|
| 982 |
+
```
|
| 983 |
+
|
| 984 |
+
**Redact specific pages with signature extraction:**
|
| 985 |
+
```bash
|
| 986 |
+
python cli_redact.py --input_file example_data/Partnership-Agreement-Toolkit_0_0.pdf --page_min 6 --page_max 7 --ocr_method "AWS Textract" --handwrite_signature_extraction "Extract handwriting" "Extract signatures"
|
| 987 |
+
```
|
| 988 |
+
|
| 989 |
+
### Tabular data redaction
|
| 990 |
+
|
| 991 |
+
**Anonymize CSV file with specific columns:**
|
| 992 |
+
```bash
|
| 993 |
+
python cli_redact.py --input_file example_data/combined_case_notes.csv --text_columns "Case Note" "Client" --anon_strategy replace_redacted
|
| 994 |
+
```
|
| 995 |
+
|
| 996 |
+
**Anonymize Excel file:**
|
| 997 |
+
```bash
|
| 998 |
+
python cli_redact.py --input_file example_data/combined_case_notes.xlsx --text_columns "Case Note" "Client" --excel_sheets combined_case_notes --anon_strategy redact
|
| 999 |
+
```
|
| 1000 |
+
|
| 1001 |
+
**Anonymize Word document:**
|
| 1002 |
+
```bash
|
| 1003 |
+
python cli_redact.py --input_file "example_data/Bold minimalist professional cover letter.docx" --anon_strategy replace_redacted
|
| 1004 |
+
```
|
| 1005 |
+
|
| 1006 |
+
### Duplicate detection
|
| 1007 |
+
|
| 1008 |
+
**Find duplicate pages in OCR files:**
|
| 1009 |
+
```bash
|
| 1010 |
+
python cli_redact.py --task deduplicate --input_file example_data/example_outputs/doubled_output_joined.pdf_ocr_output.csv --duplicate_type pages --similarity_threshold 0.95
|
| 1011 |
+
```
|
| 1012 |
+
|
| 1013 |
+
**Find duplicates at line level:**
|
| 1014 |
+
```bash
|
| 1015 |
+
python cli_redact.py --task deduplicate --input_file example_data/example_outputs/doubled_output_joined.pdf_ocr_output.csv --duplicate_type pages --similarity_threshold 0.95 --combine_pages False --min_word_count 3
|
| 1016 |
+
```
|
| 1017 |
+
|
| 1018 |
+
**Find duplicate rows in tabular data:**
|
| 1019 |
+
```bash
|
| 1020 |
+
python cli_redact.py --task deduplicate --input_file example_data/Lambeth_2030-Our_Future_Our_Lambeth.pdf.csv --duplicate_type tabular --text_columns "text" --similarity_threshold 0.95
|
| 1021 |
+
```
|
| 1022 |
+
|
| 1023 |
+
### AWS Textract operations
|
| 1024 |
+
|
| 1025 |
+
**Submit document for analysis:**
|
| 1026 |
+
```bash
|
| 1027 |
+
python cli_redact.py --task textract --textract_action submit --input_file example_data/example_of_emails_sent_to_a_professor_before_applying.pdf
|
| 1028 |
+
```
|
| 1029 |
+
|
| 1030 |
+
**Submit with signature extraction:**
|
| 1031 |
+
```bash
|
| 1032 |
+
python cli_redact.py --task textract --textract_action submit --input_file example_data/Partnership-Agreement-Toolkit_0_0.pdf --extract_signatures
|
| 1033 |
+
```
|
| 1034 |
+
|
| 1035 |
+
**Retrieve results by job ID:**
|
| 1036 |
+
```bash
|
| 1037 |
+
python cli_redact.py --task textract --textract_action retrieve --job_id 12345678-1234-1234-1234-123456789012
|
| 1038 |
+
```
|
| 1039 |
+
|
| 1040 |
+
**List recent jobs:**
|
| 1041 |
+
```bash
|
| 1042 |
+
python cli_redact.py --task textract --textract_action list
|
| 1043 |
+
```
|
| 1044 |
+
|
| 1045 |
+
### Common CLI options
|
| 1046 |
+
|
| 1047 |
+
- `--task`: Choose between "redact", "deduplicate", or "textract"
|
| 1048 |
+
- `--input_file`: Path to input file(s)
|
| 1049 |
+
- `--output_dir`: Directory for output files (default: output/)
|
| 1050 |
+
- `--page_min` / `--page_max`: Process only specific page range
|
| 1051 |
+
- `--ocr_method`: Choose text extraction method
|
| 1052 |
+
- `--pii_detector`: Choose PII detection method
|
| 1053 |
+
- `--local_redact_entities`: Specify local entities to redact
|
| 1054 |
+
- `--allow_list_file` / `--deny_list_file`: Custom lists
|
| 1055 |
+
- `--redact_whole_page_file`: List of pages to redact completely
|
| 1056 |
+
- `--fuzzy_mistakes`: Number of spelling mistakes allowed in fuzzy matching
|
| 1057 |
+
- `--similarity_threshold`: Threshold for duplicate detection
|
| 1058 |
+
- `--anon_strategy`: Anonymization strategy for tabular data
|
| 1059 |
+
|
| 1060 |
+
### Output files
|
| 1061 |
+
|
| 1062 |
+
The CLI generates the same output files as the GUI:
|
| 1063 |
+
- `...redacted.pdf`: Final redacted document
|
| 1064 |
+
- `...redactions_for_review.pdf`: Document with redaction boxes for review
|
| 1065 |
+
- `...review_file.csv`: Detailed redaction information
|
| 1066 |
+
- `...ocr_results.csv`: Extracted text results
|
| 1067 |
+
- `..._textract.json`: AWS Textract results (if applicable)
|
| 1068 |
+
|
| 1069 |
+
For more advanced options and configuration, refer to the help text by running:
|
| 1070 |
+
```bash
|
| 1071 |
+
python cli_redact.py --help
|
| 1072 |
+
```
|
app.py
CHANGED
|
@@ -22,14 +22,12 @@ from tools.config import (
|
|
| 22 |
CHOSEN_LOCAL_OCR_MODEL,
|
| 23 |
CHOSEN_REDACT_ENTITIES,
|
| 24 |
COGNITO_AUTH,
|
| 25 |
-
COMPRESS_REDACTED_PDF,
|
| 26 |
CONFIG_FOLDER,
|
| 27 |
COST_CODES_PATH,
|
| 28 |
CSV_ACCESS_LOG_HEADERS,
|
| 29 |
CSV_FEEDBACK_LOG_HEADERS,
|
| 30 |
CSV_USAGE_LOG_HEADERS,
|
| 31 |
CUSTOM_BOX_COLOUR,
|
| 32 |
-
DEFAULT_COMBINE_PAGES,
|
| 33 |
DEFAULT_CONCURRENCY_LIMIT,
|
| 34 |
DEFAULT_COST_CODE,
|
| 35 |
DEFAULT_DUPLICATE_DETECTION_THRESHOLD,
|
|
@@ -48,11 +46,37 @@ from tools.config import (
|
|
| 48 |
DEFAULT_TEXT_COLUMNS,
|
| 49 |
DEFAULT_TEXT_EXTRACTION_MODEL,
|
| 50 |
DENY_LIST_PATH,
|
|
|
|
|
|
|
|
|
|
|
|
|
| 51 |
DIRECT_MODE_DEFAULT_USER,
|
| 52 |
DIRECT_MODE_DUPLICATE_TYPE,
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 53 |
DIRECT_MODE_INPUT_FILE,
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 54 |
DIRECT_MODE_OUTPUT_DIR,
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 55 |
DIRECT_MODE_TASK,
|
|
|
|
| 56 |
DISPLAY_FILE_NAMES_IN_LOGS,
|
| 57 |
DO_INITIAL_TABULAR_DATA_CLEAN,
|
| 58 |
DOCUMENT_REDACTION_BUCKET,
|
|
@@ -76,11 +100,9 @@ from tools.config import (
|
|
| 76 |
GRADIO_TEMP_DIR,
|
| 77 |
HANDWRITE_SIGNATURE_TEXTBOX_FULL_OPTIONS,
|
| 78 |
HOST_NAME,
|
| 79 |
-
IMAGES_DPI,
|
| 80 |
INPUT_FOLDER,
|
| 81 |
LOAD_PREVIOUS_TEXTRACT_JOBS_S3,
|
| 82 |
LOCAL_OCR_MODEL_OPTIONS,
|
| 83 |
-
LOCAL_PII_OPTION,
|
| 84 |
LOG_FILE_NAME,
|
| 85 |
MAX_FILE_SIZE,
|
| 86 |
MAX_OPEN_TEXT_CHARACTERS,
|
|
@@ -91,38 +113,10 @@ from tools.config import (
|
|
| 91 |
OUTPUT_FOLDER,
|
| 92 |
PADDLE_MODEL_PATH,
|
| 93 |
PII_DETECTION_MODELS,
|
| 94 |
-
PREPROCESS_LOCAL_OCR_IMAGES,
|
| 95 |
REMOVE_DUPLICATE_ROWS,
|
| 96 |
-
RETURN_REDACTED_PDF,
|
| 97 |
ROOT_PATH,
|
| 98 |
RUN_AWS_FUNCTIONS,
|
| 99 |
RUN_DIRECT_MODE,
|
| 100 |
-
# Additional direct mode configuration options
|
| 101 |
-
DIRECT_MODE_LANGUAGE,
|
| 102 |
-
DIRECT_MODE_PII_DETECTOR,
|
| 103 |
-
DIRECT_MODE_OCR_METHOD,
|
| 104 |
-
DIRECT_MODE_PAGE_MIN,
|
| 105 |
-
DIRECT_MODE_PAGE_MAX,
|
| 106 |
-
DIRECT_MODE_IMAGES_DPI,
|
| 107 |
-
DIRECT_MODE_CHOSEN_LOCAL_OCR_MODEL,
|
| 108 |
-
DIRECT_MODE_PREPROCESS_LOCAL_OCR_IMAGES,
|
| 109 |
-
DIRECT_MODE_COMPRESS_REDACTED_PDF,
|
| 110 |
-
DIRECT_MODE_RETURN_PDF_END_OF_REDACTION,
|
| 111 |
-
DIRECT_MODE_EXTRACT_FORMS,
|
| 112 |
-
DIRECT_MODE_EXTRACT_TABLES,
|
| 113 |
-
DIRECT_MODE_EXTRACT_LAYOUT,
|
| 114 |
-
DIRECT_MODE_EXTRACT_SIGNATURES,
|
| 115 |
-
DIRECT_MODE_MATCH_FUZZY_WHOLE_PHRASE_BOOL,
|
| 116 |
-
DIRECT_MODE_ANON_STRATEGY,
|
| 117 |
-
DIRECT_MODE_FUZZY_MISTAKES,
|
| 118 |
-
DIRECT_MODE_SIMILARITY_THRESHOLD,
|
| 119 |
-
DIRECT_MODE_MIN_WORD_COUNT,
|
| 120 |
-
DIRECT_MODE_MIN_CONSECUTIVE_PAGES,
|
| 121 |
-
DIRECT_MODE_GREEDY_MATCH,
|
| 122 |
-
DIRECT_MODE_COMBINE_PAGES,
|
| 123 |
-
DIRECT_MODE_REMOVE_DUPLICATE_ROWS,
|
| 124 |
-
DIRECT_MODE_TEXTRACT_ACTION,
|
| 125 |
-
DIRECT_MODE_JOB_ID,
|
| 126 |
RUN_FASTAPI,
|
| 127 |
S3_ACCESS_LOGS_FOLDER,
|
| 128 |
S3_ALLOW_LIST_PATH,
|
|
@@ -141,7 +135,6 @@ from tools.config import (
|
|
| 141 |
SHOW_WHOLE_DOCUMENT_TEXTRACT_CALL_OPTIONS,
|
| 142 |
SPACY_MODEL_PATH,
|
| 143 |
TABULAR_PII_DETECTION_MODELS,
|
| 144 |
-
TESSERACT_TEXT_EXTRACT_OPTION,
|
| 145 |
TEXT_EXTRACTION_MODELS,
|
| 146 |
TEXTRACT_JOBS_LOCAL_LOC,
|
| 147 |
TEXTRACT_JOBS_S3_INPUT_LOC,
|
|
@@ -1045,7 +1038,7 @@ with blocks:
|
|
| 1045 |
with gr.Tab("Redact PDFs/images"):
|
| 1046 |
|
| 1047 |
# Examples for PDF/image redaction
|
| 1048 |
-
if SHOW_EXAMPLES
|
| 1049 |
gr.Markdown(
|
| 1050 |
"### Try an example - Click on an example below and then the 'Extract text and redact document' button:"
|
| 1051 |
)
|
|
@@ -1834,7 +1827,7 @@ with blocks:
|
|
| 1834 |
)
|
| 1835 |
|
| 1836 |
# Examples for duplicate page detection
|
| 1837 |
-
if SHOW_EXAMPLES
|
| 1838 |
gr.Markdown(
|
| 1839 |
"### Try an example - Click on an example below and then the 'Identify duplicate pages/subdocuments' button:"
|
| 1840 |
)
|
|
@@ -1989,7 +1982,7 @@ with blocks:
|
|
| 1989 |
)
|
| 1990 |
|
| 1991 |
# Examples for Word/Excel/csv redaction and tabular duplicate detection
|
| 1992 |
-
if SHOW_EXAMPLES
|
| 1993 |
gr.Markdown(
|
| 1994 |
"### Try an example - Click on an example below and then the 'Redact text/data files' button for redaction, or the 'Find duplicate cells/rows' button for duplicate detection:"
|
| 1995 |
)
|
|
@@ -6578,14 +6571,11 @@ with blocks:
|
|
| 6578 |
"extract_layout": DIRECT_MODE_EXTRACT_LAYOUT,
|
| 6579 |
"extract_signatures": DIRECT_MODE_EXTRACT_SIGNATURES,
|
| 6580 |
"match_fuzzy_whole_phrase_bool": DIRECT_MODE_MATCH_FUZZY_WHOLE_PHRASE_BOOL,
|
| 6581 |
-
|
| 6582 |
# Word/Tabular Anonymisation Arguments
|
| 6583 |
-
|
| 6584 |
"anon_strategy": DIRECT_MODE_ANON_STRATEGY,
|
| 6585 |
"text_columns": DEFAULT_TEXT_COLUMNS,
|
| 6586 |
"excel_sheets": DEFAULT_EXCEL_SHEETS,
|
| 6587 |
"fuzzy_mistakes": DIRECT_MODE_FUZZY_MISTAKES,
|
| 6588 |
-
|
| 6589 |
# Duplicate Detection Arguments
|
| 6590 |
"duplicate_type": DIRECT_MODE_DUPLICATE_TYPE,
|
| 6591 |
"similarity_threshold": DIRECT_MODE_SIMILARITY_THRESHOLD,
|
|
@@ -6594,10 +6584,9 @@ with blocks:
|
|
| 6594 |
"greedy_match": DIRECT_MODE_GREEDY_MATCH,
|
| 6595 |
"combine_pages": DIRECT_MODE_COMBINE_PAGES,
|
| 6596 |
"remove_duplicate_rows": DIRECT_MODE_REMOVE_DUPLICATE_ROWS,
|
| 6597 |
-
|
| 6598 |
# Textract Batch Operations Arguments
|
| 6599 |
"textract_action": DIRECT_MODE_TEXTRACT_ACTION,
|
| 6600 |
-
"job_id": DIRECT_MODE_JOB_ID,
|
| 6601 |
"textract_bucket": TEXTRACT_WHOLE_DOCUMENT_ANALYSIS_BUCKET,
|
| 6602 |
"textract_input_prefix": TEXTRACT_WHOLE_DOCUMENT_ANALYSIS_INPUT_SUBFOLDER,
|
| 6603 |
"textract_output_prefix": TEXTRACT_WHOLE_DOCUMENT_ANALYSIS_OUTPUT_SUBFOLDER,
|
|
|
|
| 22 |
CHOSEN_LOCAL_OCR_MODEL,
|
| 23 |
CHOSEN_REDACT_ENTITIES,
|
| 24 |
COGNITO_AUTH,
|
|
|
|
| 25 |
CONFIG_FOLDER,
|
| 26 |
COST_CODES_PATH,
|
| 27 |
CSV_ACCESS_LOG_HEADERS,
|
| 28 |
CSV_FEEDBACK_LOG_HEADERS,
|
| 29 |
CSV_USAGE_LOG_HEADERS,
|
| 30 |
CUSTOM_BOX_COLOUR,
|
|
|
|
| 31 |
DEFAULT_CONCURRENCY_LIMIT,
|
| 32 |
DEFAULT_COST_CODE,
|
| 33 |
DEFAULT_DUPLICATE_DETECTION_THRESHOLD,
|
|
|
|
| 46 |
DEFAULT_TEXT_COLUMNS,
|
| 47 |
DEFAULT_TEXT_EXTRACTION_MODEL,
|
| 48 |
DENY_LIST_PATH,
|
| 49 |
+
DIRECT_MODE_ANON_STRATEGY,
|
| 50 |
+
DIRECT_MODE_CHOSEN_LOCAL_OCR_MODEL,
|
| 51 |
+
DIRECT_MODE_COMBINE_PAGES,
|
| 52 |
+
DIRECT_MODE_COMPRESS_REDACTED_PDF,
|
| 53 |
DIRECT_MODE_DEFAULT_USER,
|
| 54 |
DIRECT_MODE_DUPLICATE_TYPE,
|
| 55 |
+
DIRECT_MODE_EXTRACT_FORMS,
|
| 56 |
+
DIRECT_MODE_EXTRACT_LAYOUT,
|
| 57 |
+
DIRECT_MODE_EXTRACT_SIGNATURES,
|
| 58 |
+
DIRECT_MODE_EXTRACT_TABLES,
|
| 59 |
+
DIRECT_MODE_FUZZY_MISTAKES,
|
| 60 |
+
DIRECT_MODE_GREEDY_MATCH,
|
| 61 |
+
DIRECT_MODE_IMAGES_DPI,
|
| 62 |
DIRECT_MODE_INPUT_FILE,
|
| 63 |
+
DIRECT_MODE_JOB_ID,
|
| 64 |
+
# Additional direct mode configuration options
|
| 65 |
+
DIRECT_MODE_LANGUAGE,
|
| 66 |
+
DIRECT_MODE_MATCH_FUZZY_WHOLE_PHRASE_BOOL,
|
| 67 |
+
DIRECT_MODE_MIN_CONSECUTIVE_PAGES,
|
| 68 |
+
DIRECT_MODE_MIN_WORD_COUNT,
|
| 69 |
+
DIRECT_MODE_OCR_METHOD,
|
| 70 |
DIRECT_MODE_OUTPUT_DIR,
|
| 71 |
+
DIRECT_MODE_PAGE_MAX,
|
| 72 |
+
DIRECT_MODE_PAGE_MIN,
|
| 73 |
+
DIRECT_MODE_PII_DETECTOR,
|
| 74 |
+
DIRECT_MODE_PREPROCESS_LOCAL_OCR_IMAGES,
|
| 75 |
+
DIRECT_MODE_REMOVE_DUPLICATE_ROWS,
|
| 76 |
+
DIRECT_MODE_RETURN_PDF_END_OF_REDACTION,
|
| 77 |
+
DIRECT_MODE_SIMILARITY_THRESHOLD,
|
| 78 |
DIRECT_MODE_TASK,
|
| 79 |
+
DIRECT_MODE_TEXTRACT_ACTION,
|
| 80 |
DISPLAY_FILE_NAMES_IN_LOGS,
|
| 81 |
DO_INITIAL_TABULAR_DATA_CLEAN,
|
| 82 |
DOCUMENT_REDACTION_BUCKET,
|
|
|
|
| 100 |
GRADIO_TEMP_DIR,
|
| 101 |
HANDWRITE_SIGNATURE_TEXTBOX_FULL_OPTIONS,
|
| 102 |
HOST_NAME,
|
|
|
|
| 103 |
INPUT_FOLDER,
|
| 104 |
LOAD_PREVIOUS_TEXTRACT_JOBS_S3,
|
| 105 |
LOCAL_OCR_MODEL_OPTIONS,
|
|
|
|
| 106 |
LOG_FILE_NAME,
|
| 107 |
MAX_FILE_SIZE,
|
| 108 |
MAX_OPEN_TEXT_CHARACTERS,
|
|
|
|
| 113 |
OUTPUT_FOLDER,
|
| 114 |
PADDLE_MODEL_PATH,
|
| 115 |
PII_DETECTION_MODELS,
|
|
|
|
| 116 |
REMOVE_DUPLICATE_ROWS,
|
|
|
|
| 117 |
ROOT_PATH,
|
| 118 |
RUN_AWS_FUNCTIONS,
|
| 119 |
RUN_DIRECT_MODE,
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 120 |
RUN_FASTAPI,
|
| 121 |
S3_ACCESS_LOGS_FOLDER,
|
| 122 |
S3_ALLOW_LIST_PATH,
|
|
|
|
| 135 |
SHOW_WHOLE_DOCUMENT_TEXTRACT_CALL_OPTIONS,
|
| 136 |
SPACY_MODEL_PATH,
|
| 137 |
TABULAR_PII_DETECTION_MODELS,
|
|
|
|
| 138 |
TEXT_EXTRACTION_MODELS,
|
| 139 |
TEXTRACT_JOBS_LOCAL_LOC,
|
| 140 |
TEXTRACT_JOBS_S3_INPUT_LOC,
|
|
|
|
| 1038 |
with gr.Tab("Redact PDFs/images"):
|
| 1039 |
|
| 1040 |
# Examples for PDF/image redaction
|
| 1041 |
+
if SHOW_EXAMPLES:
|
| 1042 |
gr.Markdown(
|
| 1043 |
"### Try an example - Click on an example below and then the 'Extract text and redact document' button:"
|
| 1044 |
)
|
|
|
|
| 1827 |
)
|
| 1828 |
|
| 1829 |
# Examples for duplicate page detection
|
| 1830 |
+
if SHOW_EXAMPLES:
|
| 1831 |
gr.Markdown(
|
| 1832 |
"### Try an example - Click on an example below and then the 'Identify duplicate pages/subdocuments' button:"
|
| 1833 |
)
|
|
|
|
| 1982 |
)
|
| 1983 |
|
| 1984 |
# Examples for Word/Excel/csv redaction and tabular duplicate detection
|
| 1985 |
+
if SHOW_EXAMPLES:
|
| 1986 |
gr.Markdown(
|
| 1987 |
"### Try an example - Click on an example below and then the 'Redact text/data files' button for redaction, or the 'Find duplicate cells/rows' button for duplicate detection:"
|
| 1988 |
)
|
|
|
|
| 6571 |
"extract_layout": DIRECT_MODE_EXTRACT_LAYOUT,
|
| 6572 |
"extract_signatures": DIRECT_MODE_EXTRACT_SIGNATURES,
|
| 6573 |
"match_fuzzy_whole_phrase_bool": DIRECT_MODE_MATCH_FUZZY_WHOLE_PHRASE_BOOL,
|
|
|
|
| 6574 |
# Word/Tabular Anonymisation Arguments
|
|
|
|
| 6575 |
"anon_strategy": DIRECT_MODE_ANON_STRATEGY,
|
| 6576 |
"text_columns": DEFAULT_TEXT_COLUMNS,
|
| 6577 |
"excel_sheets": DEFAULT_EXCEL_SHEETS,
|
| 6578 |
"fuzzy_mistakes": DIRECT_MODE_FUZZY_MISTAKES,
|
|
|
|
| 6579 |
# Duplicate Detection Arguments
|
| 6580 |
"duplicate_type": DIRECT_MODE_DUPLICATE_TYPE,
|
| 6581 |
"similarity_threshold": DIRECT_MODE_SIMILARITY_THRESHOLD,
|
|
|
|
| 6584 |
"greedy_match": DIRECT_MODE_GREEDY_MATCH,
|
| 6585 |
"combine_pages": DIRECT_MODE_COMBINE_PAGES,
|
| 6586 |
"remove_duplicate_rows": DIRECT_MODE_REMOVE_DUPLICATE_ROWS,
|
|
|
|
| 6587 |
# Textract Batch Operations Arguments
|
| 6588 |
"textract_action": DIRECT_MODE_TEXTRACT_ACTION,
|
| 6589 |
+
"job_id": DIRECT_MODE_JOB_ID,
|
| 6590 |
"textract_bucket": TEXTRACT_WHOLE_DOCUMENT_ANALYSIS_BUCKET,
|
| 6591 |
"textract_input_prefix": TEXTRACT_WHOLE_DOCUMENT_ANALYSIS_INPUT_SUBFOLDER,
|
| 6592 |
"textract_output_prefix": TEXTRACT_WHOLE_DOCUMENT_ANALYSIS_OUTPUT_SUBFOLDER,
|
lambda_entrypoint.py
CHANGED
|
@@ -15,11 +15,11 @@ from tools.config import (
|
|
| 15 |
DEFAULT_PAGE_MAX,
|
| 16 |
DEFAULT_PAGE_MIN,
|
| 17 |
IMAGES_DPI,
|
| 18 |
-
|
|
|
|
| 19 |
LAMBDA_MAX_POLL_ATTEMPTS,
|
|
|
|
| 20 |
LAMBDA_PREPARE_IMAGES,
|
| 21 |
-
LAMBDA_EXTRACT_SIGNATURES,
|
| 22 |
-
LAMBDA_DEFAULT_USERNAME,
|
| 23 |
)
|
| 24 |
|
| 25 |
|
|
@@ -532,7 +532,9 @@ def lambda_handler(event, context):
|
|
| 532 |
os.getenv("TEXTRACT_JOBS_LOCAL_LOC", ""),
|
| 533 |
),
|
| 534 |
"poll_interval": int(arguments.get("poll_interval", LAMBDA_POLL_INTERVAL)),
|
| 535 |
-
"max_poll_attempts": int(
|
|
|
|
|
|
|
| 536 |
# Additional arguments that were missing
|
| 537 |
"search_query": arguments.get(
|
| 538 |
"search_query", os.getenv("DEFAULT_SEARCH_QUERY", "")
|
|
|
|
| 15 |
DEFAULT_PAGE_MAX,
|
| 16 |
DEFAULT_PAGE_MIN,
|
| 17 |
IMAGES_DPI,
|
| 18 |
+
LAMBDA_DEFAULT_USERNAME,
|
| 19 |
+
LAMBDA_EXTRACT_SIGNATURES,
|
| 20 |
LAMBDA_MAX_POLL_ATTEMPTS,
|
| 21 |
+
LAMBDA_POLL_INTERVAL,
|
| 22 |
LAMBDA_PREPARE_IMAGES,
|
|
|
|
|
|
|
| 23 |
)
|
| 24 |
|
| 25 |
|
|
|
|
| 532 |
os.getenv("TEXTRACT_JOBS_LOCAL_LOC", ""),
|
| 533 |
),
|
| 534 |
"poll_interval": int(arguments.get("poll_interval", LAMBDA_POLL_INTERVAL)),
|
| 535 |
+
"max_poll_attempts": int(
|
| 536 |
+
arguments.get("max_poll_attempts", LAMBDA_MAX_POLL_ATTEMPTS)
|
| 537 |
+
),
|
| 538 |
# Additional arguments that were missing
|
| 539 |
"search_query": arguments.get(
|
| 540 |
"search_query", os.getenv("DEFAULT_SEARCH_QUERY", "")
|
pyproject.toml
CHANGED
|
@@ -4,7 +4,7 @@ build-backend = "setuptools.build_meta"
|
|
| 4 |
|
| 5 |
[project]
|
| 6 |
name = "doc_redaction"
|
| 7 |
-
version = "1.4.
|
| 8 |
description = "Redact PDF/image-based documents, Word, or CSV/XLSX files using a Gradio-based GUI interface"
|
| 9 |
readme = "README.md"
|
| 10 |
requires-python = ">=3.10"
|
|
|
|
| 4 |
|
| 5 |
[project]
|
| 6 |
name = "doc_redaction"
|
| 7 |
+
version = "1.4.1"
|
| 8 |
description = "Redact PDF/image-based documents, Word, or CSV/XLSX files using a Gradio-based GUI interface"
|
| 9 |
readme = "README.md"
|
| 10 |
requires-python = ">=3.10"
|
src/app_settings.qmd
CHANGED
|
@@ -2,529 +2,573 @@
|
|
| 2 |
title: "App settings management guide"
|
| 3 |
format:
|
| 4 |
html:
|
| 5 |
-
toc: true
|
| 6 |
-
toc-depth: 3
|
| 7 |
-
toc-title: "On this page"
|
| 8 |
---
|
| 9 |
|
| 10 |
-
Settings for the redaction app can be set from outside by changing values in the
|
| 11 |
|
| 12 |
-
## App Configuration File (config.env)
|
| 13 |
|
| 14 |
This section details variables related to the main application configuration file.
|
| 15 |
|
| 16 |
-
*
|
| 17 |
-
*
|
| 18 |
-
*
|
| 19 |
-
|
|
|
|
|
|
|
|
|
|
| 20 |
|
| 21 |
## AWS Options
|
| 22 |
|
| 23 |
This section covers configurations related to AWS services used by the application.
|
| 24 |
|
| 25 |
-
*
|
| 26 |
-
*
|
| 27 |
-
*
|
| 28 |
-
|
| 29 |
-
|
| 30 |
-
*
|
| 31 |
-
*
|
| 32 |
-
|
| 33 |
-
|
| 34 |
-
|
| 35 |
-
*
|
| 36 |
-
|
| 37 |
-
|
| 38 |
-
*
|
| 39 |
-
|
| 40 |
-
|
| 41 |
-
|
| 42 |
-
*
|
| 43 |
-
*
|
| 44 |
-
|
| 45 |
-
*
|
| 46 |
-
*
|
| 47 |
-
*
|
| 48 |
-
|
| 49 |
-
|
| 50 |
-
*
|
| 51 |
-
*
|
| 52 |
-
|
| 53 |
-
|
| 54 |
-
|
| 55 |
-
*
|
| 56 |
-
|
| 57 |
-
|
| 58 |
-
*
|
| 59 |
-
|
| 60 |
-
|
| 61 |
-
|
| 62 |
-
*
|
| 63 |
-
*
|
| 64 |
-
|
| 65 |
-
*
|
| 66 |
-
*
|
| 67 |
-
*
|
| 68 |
-
|
| 69 |
-
|
| 70 |
-
*
|
| 71 |
-
*
|
| 72 |
-
* **Default Value:** `''`
|
| 73 |
-
* **Configuration:** Set as an environment variable directly, or include in `config/app_config.env` (or `config/aws_config.env` if `AWS_CONFIG_PATH` is configured).
|
| 74 |
-
|
| 75 |
-
* **`CUSTOM_HEADER_VALUE`**
|
| 76 |
-
* **Description:** The value for the custom header specified by `CUSTOM_HEADER`.
|
| 77 |
-
* **Default Value:** `''`
|
| 78 |
-
* **Configuration:** Set as an environment variable directly, or include in `config/app_config.env` (or `config/aws_config.env` if `AWS_CONFIG_PATH` is configured).
|
| 79 |
|
| 80 |
## Image Options
|
| 81 |
|
| 82 |
Settings related to image processing within the application.
|
| 83 |
|
| 84 |
-
*
|
| 85 |
-
*
|
| 86 |
-
*
|
| 87 |
-
* **Configuration:** Set as an environment variable directly, or include in `config/app_config.env`.
|
| 88 |
|
| 89 |
-
*
|
| 90 |
-
*
|
| 91 |
-
*
|
| 92 |
-
* **Configuration:** Set as an environment variable directly, or include in `config/app_config.env`.
|
| 93 |
|
| 94 |
-
*
|
| 95 |
-
*
|
| 96 |
-
*
|
| 97 |
-
* **Configuration:** Set as an environment variable directly, or include in `config/app_config.env`.
|
| 98 |
|
| 99 |
## File I/O Options
|
| 100 |
|
| 101 |
Configuration for input and output file handling.
|
| 102 |
|
| 103 |
-
*
|
| 104 |
-
*
|
| 105 |
-
*
|
| 106 |
-
* **Configuration:** Set as an environment variable directly, or include in `config/app_config.env`.
|
| 107 |
|
| 108 |
-
*
|
| 109 |
-
*
|
| 110 |
-
*
|
| 111 |
-
* **Configuration:** Set as an environment variable directly, or include in `config/app_config.env`.
|
| 112 |
|
| 113 |
-
*
|
| 114 |
-
*
|
| 115 |
-
*
|
| 116 |
-
* **Configuration:** Set as an environment variable directly, or include in `config/app_config.env`.
|
| 117 |
|
| 118 |
-
*
|
| 119 |
-
*
|
| 120 |
-
*
|
| 121 |
-
* **Configuration:** Set as an environment variable directly, or include in `config/app_config.env`.
|
| 122 |
|
| 123 |
-
*
|
| 124 |
-
*
|
| 125 |
-
*
|
| 126 |
-
* **Configuration:** Set as an environment variable directly, or include in `config/app_config.env`.
|
| 127 |
|
| 128 |
## Logging Options
|
| 129 |
|
| 130 |
-
Settings for configuring application logging
|
| 131 |
-
|
| 132 |
-
*
|
| 133 |
-
*
|
| 134 |
-
*
|
| 135 |
-
|
| 136 |
-
|
| 137 |
-
*
|
| 138 |
-
*
|
| 139 |
-
|
| 140 |
-
|
| 141 |
-
|
| 142 |
-
*
|
| 143 |
-
|
| 144 |
-
|
| 145 |
-
*
|
| 146 |
-
|
| 147 |
-
|
| 148 |
-
|
| 149 |
-
*
|
| 150 |
-
*
|
| 151 |
-
|
| 152 |
-
*
|
| 153 |
-
*
|
| 154 |
-
*
|
| 155 |
-
|
| 156 |
-
|
| 157 |
-
*
|
| 158 |
-
*
|
| 159 |
-
|
| 160 |
-
|
| 161 |
-
|
| 162 |
-
*
|
| 163 |
-
|
| 164 |
-
|
| 165 |
-
*
|
| 166 |
-
|
| 167 |
-
|
| 168 |
-
|
| 169 |
-
*
|
| 170 |
-
*
|
| 171 |
-
|
| 172 |
-
*
|
| 173 |
-
*
|
| 174 |
-
*
|
| 175 |
-
|
| 176 |
-
|
| 177 |
-
|
| 178 |
-
|
| 179 |
-
|
| 180 |
-
|
| 181 |
-
|
| 182 |
-
*
|
| 183 |
-
|
| 184 |
-
|
| 185 |
-
*
|
| 186 |
-
|
| 187 |
-
|
| 188 |
-
|
| 189 |
-
*
|
| 190 |
-
*
|
| 191 |
-
|
| 192 |
-
*
|
| 193 |
-
*
|
| 194 |
-
*
|
| 195 |
-
|
| 196 |
-
|
| 197 |
-
*
|
| 198 |
-
*
|
| 199 |
-
|
| 200 |
-
|
| 201 |
-
|
| 202 |
-
*
|
| 203 |
-
|
| 204 |
-
|
| 205 |
-
*
|
| 206 |
-
|
| 207 |
-
|
| 208 |
-
|
| 209 |
-
*
|
| 210 |
-
*
|
| 211 |
-
|
| 212 |
-
*
|
| 213 |
-
*
|
| 214 |
-
*
|
| 215 |
-
|
| 216 |
-
|
| 217 |
-
*
|
| 218 |
-
*
|
| 219 |
-
|
| 220 |
-
|
| 221 |
-
|
| 222 |
-
|
| 223 |
-
|
| 224 |
-
|
| 225 |
-
|
| 226 |
-
*
|
| 227 |
-
|
| 228 |
-
|
| 229 |
-
*
|
| 230 |
-
|
| 231 |
-
|
| 232 |
-
|
| 233 |
-
*
|
| 234 |
-
*
|
| 235 |
-
|
| 236 |
-
*
|
| 237 |
-
*
|
| 238 |
-
*
|
| 239 |
-
|
| 240 |
-
|
| 241 |
-
*
|
| 242 |
-
*
|
| 243 |
-
|
| 244 |
-
|
| 245 |
-
|
| 246 |
-
*
|
| 247 |
-
|
| 248 |
-
|
| 249 |
-
*
|
| 250 |
-
|
| 251 |
-
|
| 252 |
-
|
| 253 |
-
*
|
| 254 |
-
*
|
| 255 |
-
|
| 256 |
-
*
|
| 257 |
-
*
|
| 258 |
-
*
|
| 259 |
-
|
| 260 |
-
|
| 261 |
-
*
|
| 262 |
-
*
|
| 263 |
-
|
| 264 |
-
|
| 265 |
-
|
| 266 |
-
|
| 267 |
-
|
| 268 |
-
|
| 269 |
-
|
| 270 |
-
|
| 271 |
-
*
|
| 272 |
-
*
|
| 273 |
-
|
| 274 |
-
|
| 275 |
-
|
| 276 |
-
*
|
| 277 |
-
|
| 278 |
-
|
| 279 |
-
*
|
| 280 |
-
|
| 281 |
-
|
| 282 |
-
|
| 283 |
-
*
|
| 284 |
-
*
|
| 285 |
-
|
| 286 |
-
*
|
| 287 |
-
*
|
| 288 |
-
*
|
| 289 |
-
|
| 290 |
-
|
| 291 |
-
*
|
| 292 |
-
*
|
| 293 |
-
|
| 294 |
-
|
| 295 |
-
|
| 296 |
-
*
|
| 297 |
-
*
|
| 298 |
-
*
|
| 299 |
-
|
| 300 |
-
|
| 301 |
-
*
|
| 302 |
-
*
|
| 303 |
-
|
| 304 |
-
|
| 305 |
-
|
| 306 |
-
*
|
| 307 |
-
|
| 308 |
-
|
| 309 |
-
*
|
| 310 |
-
|
| 311 |
-
|
| 312 |
-
|
| 313 |
-
|
| 314 |
-
|
| 315 |
-
|
| 316 |
-
*
|
| 317 |
-
|
| 318 |
-
|
| 319 |
-
*
|
| 320 |
-
|
| 321 |
-
|
| 322 |
-
|
| 323 |
-
*
|
| 324 |
-
*
|
| 325 |
-
|
| 326 |
-
*
|
| 327 |
-
*
|
| 328 |
-
*
|
| 329 |
-
|
| 330 |
-
|
| 331 |
-
*
|
| 332 |
-
*
|
| 333 |
-
|
| 334 |
-
|
| 335 |
-
|
| 336 |
-
*
|
| 337 |
-
|
| 338 |
-
|
| 339 |
-
*
|
| 340 |
-
|
| 341 |
-
|
| 342 |
-
|
| 343 |
-
*
|
| 344 |
-
*
|
| 345 |
-
|
| 346 |
-
*
|
| 347 |
-
*
|
| 348 |
-
*
|
| 349 |
-
|
| 350 |
-
|
| 351 |
-
|
| 352 |
-
|
| 353 |
-
*
|
| 354 |
-
*
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 355 |
|
| 356 |
## Language Options
|
| 357 |
|
| 358 |
-
Settings for multi-language support
|
| 359 |
-
|
| 360 |
-
*
|
| 361 |
-
*
|
| 362 |
-
*
|
| 363 |
-
|
| 364 |
-
|
| 365 |
-
*
|
| 366 |
-
*
|
| 367 |
-
|
| 368 |
-
|
| 369 |
-
|
| 370 |
-
*
|
| 371 |
-
|
| 372 |
-
|
| 373 |
-
*
|
| 374 |
-
|
| 375 |
-
|
| 376 |
-
|
| 377 |
-
|
| 378 |
-
|
| 379 |
-
|
| 380 |
-
*
|
| 381 |
-
|
| 382 |
-
|
| 383 |
-
*
|
| 384 |
-
|
| 385 |
-
|
| 386 |
-
|
| 387 |
-
|
| 388 |
-
|
| 389 |
-
|
| 390 |
-
|
| 391 |
-
*
|
| 392 |
-
*
|
| 393 |
-
|
| 394 |
-
*
|
| 395 |
-
*
|
| 396 |
-
*
|
| 397 |
-
|
| 398 |
-
|
| 399 |
-
*
|
| 400 |
-
*
|
| 401 |
-
|
| 402 |
-
|
| 403 |
-
|
| 404 |
-
*
|
| 405 |
-
*
|
| 406 |
-
*
|
| 407 |
-
|
| 408 |
-
|
| 409 |
-
*
|
| 410 |
-
*
|
| 411 |
-
|
| 412 |
-
|
| 413 |
-
|
| 414 |
-
*
|
| 415 |
-
|
| 416 |
-
|
| 417 |
-
*
|
| 418 |
-
|
| 419 |
-
|
| 420 |
-
|
| 421 |
-
*
|
| 422 |
-
*
|
| 423 |
-
|
| 424 |
-
*
|
| 425 |
-
*
|
| 426 |
-
*
|
| 427 |
-
|
| 428 |
-
|
| 429 |
-
|
| 430 |
-
|
| 431 |
-
|
| 432 |
-
|
| 433 |
-
|
| 434 |
-
*
|
| 435 |
-
*
|
| 436 |
-
*
|
| 437 |
-
|
| 438 |
-
|
| 439 |
-
*
|
| 440 |
-
*
|
| 441 |
-
|
| 442 |
-
|
| 443 |
-
|
| 444 |
-
*
|
| 445 |
-
|
| 446 |
-
|
| 447 |
-
*
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 448 |
|
| 449 |
## Cost Code Options
|
| 450 |
|
| 451 |
-
|
| 452 |
-
|
| 453 |
-
*
|
| 454 |
-
|
| 455 |
-
|
| 456 |
-
*
|
| 457 |
-
|
| 458 |
-
|
| 459 |
-
|
| 460 |
-
*
|
| 461 |
-
*
|
| 462 |
-
|
| 463 |
-
*
|
| 464 |
-
*
|
| 465 |
-
*
|
| 466 |
-
|
| 467 |
-
|
| 468 |
-
*
|
| 469 |
-
*
|
| 470 |
-
|
| 471 |
-
|
| 472 |
-
|
| 473 |
-
*
|
| 474 |
-
*
|
| 475 |
-
*
|
| 476 |
-
|
| 477 |
-
|
| 478 |
-
*
|
| 479 |
-
*
|
| 480 |
-
|
| 481 |
-
|
| 482 |
-
|
| 483 |
-
|
| 484 |
-
|
| 485 |
-
|
| 486 |
-
|
| 487 |
-
*
|
| 488 |
-
|
| 489 |
-
|
| 490 |
-
*
|
| 491 |
-
|
| 492 |
-
|
| 493 |
-
|
| 494 |
-
*
|
| 495 |
-
*
|
| 496 |
-
|
| 497 |
-
*
|
| 498 |
-
*
|
| 499 |
-
*
|
| 500 |
-
* **Configuration:** Set as an environment variable directly, or include in `config/app_config.env` (or `config/aws_config.env` if `AWS_CONFIG_PATH` is configured).
|
| 501 |
-
|
| 502 |
-
* **`TEXTRACT_WHOLE_DOCUMENT_ANALYSIS_OUTPUT_SUBFOLDER`**
|
| 503 |
-
* **Description:** The subfolder within `TEXTRACT_WHOLE_DOCUMENT_ANALYSIS_BUCKET` where output results from Textract analysis are stored.
|
| 504 |
-
* **Default Value:** `'output'`
|
| 505 |
-
* **Configuration:** Set as an environment variable directly, or include in `config/app_config.env` (or `config/aws_config.env` if `AWS_CONFIG_PATH` is configured).
|
| 506 |
-
|
| 507 |
-
* **`LOAD_PREVIOUS_TEXTRACT_JOBS_S3`**
|
| 508 |
-
* **Description:** If set to `'True'`, the application will attempt to load data from previous Textract jobs stored in S3.
|
| 509 |
-
* **Default Value:** `'False'`
|
| 510 |
-
* **Configuration:** Set as an environment variable directly, or include in `config/app_config.env` (or `config/aws_config.env` if `AWS_CONFIG_PATH` is configured).
|
| 511 |
-
|
| 512 |
-
* **`TEXTRACT_JOBS_S3_LOC`**
|
| 513 |
-
* **Description:** The S3 subfolder (within the main redaction bucket) where Textract job data (output) is stored.
|
| 514 |
-
* **Default Value:** `'output'`
|
| 515 |
-
* **Configuration:** Set as an environment variable directly, or include in `config/app_config.env` (or `config/aws_config.env` if `AWS_CONFIG_PATH` is configured).
|
| 516 |
-
|
| 517 |
-
* **`TEXTRACT_JOBS_S3_INPUT_LOC`**
|
| 518 |
-
* **Description:** The S3 subfolder (within the main redaction bucket) where Textract job input is stored.
|
| 519 |
-
* **Default Value:** `'input'`
|
| 520 |
-
* **Configuration:** Set as an environment variable directly, or include in `config/app_config.env` (or `config/aws_config.env` if `AWS_CONFIG_PATH` is configured).
|
| 521 |
-
|
| 522 |
-
* **`TEXTRACT_JOBS_LOCAL_LOC`**
|
| 523 |
-
* **Description:** The local subfolder where Textract job data is stored if not using S3 or as a cache.
|
| 524 |
-
* **Default Value:** `'output'`
|
| 525 |
-
* **Configuration:** Set as an environment variable directly, or include in `config/app_config.env`.
|
| 526 |
-
|
| 527 |
-
* **`DAYS_TO_DISPLAY_WHOLE_DOCUMENT_JOBS`**
|
| 528 |
-
* **Description:** Specifies the number of past days for which to display whole document Textract jobs in the UI.
|
| 529 |
-
* **Default Value:** `'7'`
|
| 530 |
-
* **Configuration:** Set as an environment variable directly, or include in `config/app_config.env`.
|
|
|
|
| 2 |
title: "App settings management guide"
|
| 3 |
format:
|
| 4 |
html:
|
| 5 |
+
toc: true
|
| 6 |
+
toc-depth: 3
|
| 7 |
+
toc-title: "On this page"
|
| 8 |
---
|
| 9 |
|
| 10 |
+
Settings for the redaction app can be set from outside by changing values in the `.env` file stored in your local config folder, or in S3 if running on AWS. This guide provides an overview of how to configure the application using environment variables. The application loads configurations using `os.environ.get()`. It first attempts to load variables from the file specified by `APP_CONFIG_PATH` (which defaults to `config/app_config.env`). If `AWS_CONFIG_PATH` is also set (e.g., to `config/aws_config.env`), variables are loaded from that file as well. Environment variables set directly in the system will always take precedence over those defined in these `.env` files.
|
| 11 |
|
| 12 |
+
## App Configuration File (`config.env`)
|
| 13 |
|
| 14 |
This section details variables related to the main application configuration file.
|
| 15 |
|
| 16 |
+
* **`CONFIG_FOLDER`**
|
| 17 |
+
* **Description:** The folder where configuration files are stored.
|
| 18 |
+
* **Default Value:** `config/`
|
| 19 |
+
|
| 20 |
+
* **`APP_CONFIG_PATH`**
|
| 21 |
+
* **Description:** Specifies the path to the application configuration `.env` file. This file contains various settings that control the application's behavior.
|
| 22 |
+
* **Default Value:** `config/app_config.env`
|
| 23 |
|
| 24 |
## AWS Options
|
| 25 |
|
| 26 |
This section covers configurations related to AWS services used by the application.
|
| 27 |
|
| 28 |
+
* **`AWS_CONFIG_PATH`**
|
| 29 |
+
* **Description:** Specifies the path to the AWS configuration `.env` file. This file is intended to store AWS credentials and specific settings.
|
| 30 |
+
* **Default Value:** `''` (empty string)
|
| 31 |
+
|
| 32 |
+
* **`RUN_AWS_FUNCTIONS`**
|
| 33 |
+
* **Description:** Enables or disables AWS-specific functionalities within the application. Set to `"True"` to enable.
|
| 34 |
+
* **Default Value:** `"False"`
|
| 35 |
+
|
| 36 |
+
* **`AWS_REGION`**
|
| 37 |
+
* **Description:** Defines the AWS region where services like S3, Cognito, and Textract are located.
|
| 38 |
+
* **Default Value:** `''`
|
| 39 |
+
|
| 40 |
+
* **`AWS_CLIENT_ID`**
|
| 41 |
+
* **Description:** The client ID for AWS Cognito, used for user authentication.
|
| 42 |
+
* **Default Value:** `''`
|
| 43 |
+
|
| 44 |
+
* **`AWS_CLIENT_SECRET`**
|
| 45 |
+
* **Description:** The client secret for AWS Cognito, used in conjunction with the client ID for authentication.
|
| 46 |
+
* **Default Value:** `''`
|
| 47 |
+
|
| 48 |
+
* **`AWS_USER_POOL_ID`**
|
| 49 |
+
* **Description:** The user pool ID for AWS Cognito, identifying the user directory.
|
| 50 |
+
* **Default Value:** `''`
|
| 51 |
+
|
| 52 |
+
* **`AWS_ACCESS_KEY`**
|
| 53 |
+
* **Description:** The AWS access key ID for programmatic access to AWS services.
|
| 54 |
+
* **Default Value:** `''`
|
| 55 |
+
|
| 56 |
+
* **`AWS_SECRET_KEY`**
|
| 57 |
+
* **Description:** The AWS secret access key corresponding to the AWS access key ID.
|
| 58 |
+
* **Default Value:** `''`
|
| 59 |
+
|
| 60 |
+
* **`DOCUMENT_REDACTION_BUCKET`**
|
| 61 |
+
* **Description:** The name of the S3 bucket used for storing documents related to the redaction process.
|
| 62 |
+
* **Default Value:** `''`
|
| 63 |
+
|
| 64 |
+
* **`PRIORITISE_SSO_OVER_AWS_ENV_ACCESS_KEYS`**
|
| 65 |
+
* **Description:** If set to `"True"`, the app will prioritize using AWS SSO credentials over access keys stored in environment variables.
|
| 66 |
+
* **Default Value:** `"True"`
|
| 67 |
+
|
| 68 |
+
* **`CUSTOM_HEADER`**
|
| 69 |
+
* **Description:** Specifies a custom header name to be included in requests, often used for services like AWS CloudFront.
|
| 70 |
+
* **Default Value:** `''`
|
| 71 |
+
|
| 72 |
+
* **`CUSTOM_HEADER_VALUE`**
|
| 73 |
+
* **Description:** The value for the custom header specified by `CUSTOM_HEADER`.
|
| 74 |
+
* **Default Value:** `''`
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 75 |
|
| 76 |
## Image Options
|
| 77 |
|
| 78 |
Settings related to image processing within the application.
|
| 79 |
|
| 80 |
+
* **`IMAGES_DPI`**
|
| 81 |
+
* **Description:** Dots Per Inch (DPI) setting for image processing, affecting the resolution and quality of processed images.
|
| 82 |
+
* **Default Value:** `'300.0'`
|
|
|
|
| 83 |
|
| 84 |
+
* **`LOAD_TRUNCATED_IMAGES`**
|
| 85 |
+
* **Description:** Controls whether the application attempts to load truncated images. Set to `'True'` to enable.
|
| 86 |
+
* **Default Value:** `'True'`
|
|
|
|
| 87 |
|
| 88 |
+
* **`MAX_IMAGE_PIXELS`**
|
| 89 |
+
* **Description:** Sets the maximum number of pixels for an image that the application will process. Leave blank for no limit. This can help prevent issues with very large images.
|
| 90 |
+
* **Default Value:** `''`
|
|
|
|
| 91 |
|
| 92 |
## File I/O Options
|
| 93 |
|
| 94 |
Configuration for input and output file handling.
|
| 95 |
|
| 96 |
+
* **`SESSION_OUTPUT_FOLDER`**
|
| 97 |
+
* **Description:** If set to `'True'`, the application will save output and input files into session-specific subfolders.
|
| 98 |
+
* **Default Value:** `'False'`
|
|
|
|
| 99 |
|
| 100 |
+
* **`OUTPUT_FOLDER`**
|
| 101 |
+
* **Description:** Specifies the default output folder for generated files. Can be set to `"TEMP"` to use a temporary directory.
|
| 102 |
+
* **Default Value:** `'output/'`
|
|
|
|
| 103 |
|
| 104 |
+
* **`INPUT_FOLDER`**
|
| 105 |
+
* **Description:** Specifies the default input folder for files. Can be set to `"TEMP"` to use a temporary directory.
|
| 106 |
+
* **Default Value:** `'input/'`
|
|
|
|
| 107 |
|
| 108 |
+
* **`GRADIO_TEMP_DIR`**
|
| 109 |
+
* **Description:** Defines the path for Gradio's temporary file storage.
|
| 110 |
+
* **Default Value:** `''`
|
|
|
|
| 111 |
|
| 112 |
+
* **`MPLCONFIGDIR`**
|
| 113 |
+
* **Description:** Specifies the cache directory for the Matplotlib library.
|
| 114 |
+
* **Default Value:** `''`
|
|
|
|
| 115 |
|
| 116 |
## Logging Options
|
| 117 |
|
| 118 |
+
Settings for configuring application logging.
|
| 119 |
+
|
| 120 |
+
* **`SAVE_LOGS_TO_CSV`**
|
| 121 |
+
* **Description:** Enables or disables saving logs to CSV files. Set to `'True'` to enable.
|
| 122 |
+
* **Default Value:** `'True'`
|
| 123 |
+
|
| 124 |
+
* **`USE_LOG_SUBFOLDERS`**
|
| 125 |
+
* **Description:** If enabled (`'True'`), logs will be stored in subfolders based on date and hostname.
|
| 126 |
+
* **Default Value:** `'True'`
|
| 127 |
+
|
| 128 |
+
* **`FEEDBACK_LOGS_FOLDER`**, **`ACCESS_LOGS_FOLDER`**, **`USAGE_LOGS_FOLDER`**
|
| 129 |
+
* **Description:** Base folders for feedback, access, and usage logs respectively.
|
| 130 |
+
* **Default Values:** `'feedback/'`, `'logs/'`, `'usage/'`
|
| 131 |
+
|
| 132 |
+
* **`S3_FEEDBACK_LOGS_FOLDER`**, **`S3_ACCESS_LOGS_FOLDER`**, **`S3_USAGE_LOGS_FOLDER`**
|
| 133 |
+
* **Description:** S3 paths where feedback, access, and usage logs will be stored if `RUN_AWS_FUNCTIONS` is enabled.
|
| 134 |
+
* **Default Values:** Dynamically generated based on date and hostname, e.g., `'feedback/YYYYMMDD/hostname/'`.
|
| 135 |
+
|
| 136 |
+
* **`LOG_FILE_NAME`**, **`USAGE_LOG_FILE_NAME`**, **`FEEDBACK_LOG_FILE_NAME`**
|
| 137 |
+
* **Description:** Specifies the name for log files. `USAGE_LOG_FILE_NAME` and `FEEDBACK_LOG_FILE_NAME` default to the value of `LOG_FILE_NAME`.
|
| 138 |
+
* **Default Value:** `'log.csv'`
|
| 139 |
+
|
| 140 |
+
* **`DISPLAY_FILE_NAMES_IN_LOGS`**
|
| 141 |
+
* **Description:** If set to `'True'`, file names will be included in log entries.
|
| 142 |
+
* **Default Value:** `'False'`
|
| 143 |
+
|
| 144 |
+
* **`CSV_ACCESS_LOG_HEADERS`**, **`CSV_FEEDBACK_LOG_HEADERS`**, **`CSV_USAGE_LOG_HEADERS`**
|
| 145 |
+
* **Description:** Defines custom headers for the respective CSV logs as a string representation of a list. If blank, component labels are used.
|
| 146 |
+
* **Default Value:** Varies; see script for `CSV_USAGE_LOG_HEADERS` default.
|
| 147 |
+
|
| 148 |
+
* **`SAVE_LOGS_TO_DYNAMODB`**
|
| 149 |
+
* **Description:** Enables or disables saving logs to AWS DynamoDB. Set to `'True'` to enable.
|
| 150 |
+
* **Default Value:** `'False'`
|
| 151 |
+
|
| 152 |
+
* **`ACCESS_LOG_DYNAMODB_TABLE_NAME`**, **`FEEDBACK_LOG_DYNAMODB_TABLE_NAME`**, **`USAGE_LOG_DYNAMODB_TABLE_NAME`**
|
| 153 |
+
* **Description:** Names of the DynamoDB tables for storing access, feedback, and usage logs.
|
| 154 |
+
* **Default Values:** `'redaction_access_log'`, `'redaction_feedback'`, `'redaction_usage'`
|
| 155 |
+
|
| 156 |
+
* **`DYNAMODB_ACCESS_LOG_HEADERS`**, **`DYNAMODB_FEEDBACK_LOG_HEADERS`**, **`DYNAMODB_USAGE_LOG_HEADERS`**
|
| 157 |
+
* **Description:** Specifies the headers (attributes) for the respective DynamoDB log tables.
|
| 158 |
+
* **Default Value:** `''`
|
| 159 |
+
|
| 160 |
+
* **`LOGGING`**
|
| 161 |
+
* **Description:** Enables or disables general console logging. Set to `'True'` to enable.
|
| 162 |
+
* **Default Value:** `'False'`
|
| 163 |
+
|
| 164 |
+
## Gradio & General App Options
|
| 165 |
+
|
| 166 |
+
Configurations for the Gradio UI, server behavior, and application limits.
|
| 167 |
+
|
| 168 |
+
* **`FAVICON_PATH`**
|
| 169 |
+
* **Description:** Path to the favicon icon file for the web interface.
|
| 170 |
+
* **Default Value:** `"favicon.png"`
|
| 171 |
+
|
| 172 |
+
* **`RUN_FASTAPI`**
|
| 173 |
+
* **Description:** If set to `"True"`, the application will be served via FastAPI, allowing for API endpoint integration.
|
| 174 |
+
* **Default Value:** `"False"`
|
| 175 |
+
|
| 176 |
+
* **`GRADIO_SERVER_NAME`**
|
| 177 |
+
* **Description:** The IP address the Gradio server will bind to. Use `"0.0.0.0"` to allow external access.
|
| 178 |
+
* **Default Value:** `"0.0.0.0"`
|
| 179 |
+
|
| 180 |
+
* **`GRADIO_SERVER_PORT`**
|
| 181 |
+
* **Description:** The network port on which the Gradio server will listen.
|
| 182 |
+
* **Default Value:** `7860`
|
| 183 |
+
|
| 184 |
+
* **`ALLOWED_ORIGINS`**
|
| 185 |
+
* **Description:** A comma-separated list of allowed origins for Cross-Origin Resource Sharing (CORS).
|
| 186 |
+
* **Default Value:** `''`
|
| 187 |
+
|
| 188 |
+
* **`ALLOWED_HOSTS`**
|
| 189 |
+
* **Description:** A comma-separated list of allowed hostnames.
|
| 190 |
+
* **Default Value:** `''`
|
| 191 |
+
|
| 192 |
+
* **`ROOT_PATH`**
|
| 193 |
+
* **Description:** The root path for the application, useful if running behind a reverse proxy (e.g., `/app`).
|
| 194 |
+
* **Default Value:** `''`
|
| 195 |
+
|
| 196 |
+
* **`FASTAPI_ROOT_PATH`**
|
| 197 |
+
* **Description:** The root path for the FastAPI application, used when `RUN_FASTAPI` is true.
|
| 198 |
+
* **Default Value:** `"/"`
|
| 199 |
+
|
| 200 |
+
* **`MAX_QUEUE_SIZE`**
|
| 201 |
+
* **Description:** The maximum number of requests that can be queued in the Gradio interface.
|
| 202 |
+
* **Default Value:** `5`
|
| 203 |
+
|
| 204 |
+
* **`MAX_FILE_SIZE`**
|
| 205 |
+
* **Description:** Maximum file size allowed for uploads (e.g., "250mb", "1gb").
|
| 206 |
+
* **Default Value:** `'250mb'`
|
| 207 |
+
|
| 208 |
+
* **`DEFAULT_CONCURRENCY_LIMIT`**
|
| 209 |
+
* **Description:** The default concurrency limit for Gradio event handlers, controlling how many requests can be processed simultaneously.
|
| 210 |
+
* **Default Value:** `3`
|
| 211 |
+
|
| 212 |
+
* **`MAX_SIMULTANEOUS_FILES`**
|
| 213 |
+
* **Description:** The maximum number of files that can be processed at once.
|
| 214 |
+
* **Default Value:** `10`
|
| 215 |
+
|
| 216 |
+
* **`MAX_DOC_PAGES`**
|
| 217 |
+
* **Description:** The maximum number of pages a document can have.
|
| 218 |
+
* **Default Value:** `3000`
|
| 219 |
+
|
| 220 |
+
* **`MAX_TABLE_ROWS`** / **`MAX_TABLE_COLUMNS`**
|
| 221 |
+
* **Description:** Maximum number of rows and columns for tabular data processing.
|
| 222 |
+
* **Default Values:** `250000` / `100`
|
| 223 |
+
|
| 224 |
+
* **`MAX_OPEN_TEXT_CHARACTERS`**
|
| 225 |
+
* **Description:** Maximum number of characters for open text input.
|
| 226 |
+
* **Default Value:** `50000`
|
| 227 |
+
|
| 228 |
+
* **`TLDEXTRACT_CACHE`**
|
| 229 |
+
* **Description:** Path to the cache directory used by the `tldextract` library.
|
| 230 |
+
* **Default Value:** `'tmp/tld/'`
|
| 231 |
+
|
| 232 |
+
* **`COGNITO_AUTH`**
|
| 233 |
+
* **Description:** Enables or disables AWS Cognito authentication. Set to `'True'` to enable.
|
| 234 |
+
* **Default Value:** `'False'`
|
| 235 |
+
|
| 236 |
+
* **`USER_GUIDE_URL`**
|
| 237 |
+
* **Description:** A safe URL pointing to the user guide. The URL is validated against a list of allowed domains.
|
| 238 |
+
* **Default Value:** `"https://seanpedrick-case.github.io/doc_redaction"`
|
| 239 |
+
|
| 240 |
+
* **`SHOW_EXAMPLES`**
|
| 241 |
+
* **Description:** If set to `"True"`, displays example files in the Gradio interface.
|
| 242 |
+
* **Default Value:** `"True"`
|
| 243 |
+
|
| 244 |
+
* **`SHOW_AWS_EXAMPLES`**
|
| 245 |
+
* **Description:** If set to `"True"`, includes AWS-specific examples.
|
| 246 |
+
* **Default Value:** `"False"`
|
| 247 |
+
|
| 248 |
+
* **`FILE_INPUT_HEIGHT`**
|
| 249 |
+
* **Description:** Sets the height (in pixels) of the file input component in the Gradio UI.
|
| 250 |
+
* **Default Value:** `200`
|
| 251 |
+
|
| 252 |
+
## Redaction & PII Options
|
| 253 |
+
|
| 254 |
+
Configurations related to text extraction, PII detection, and the redaction process.
|
| 255 |
+
|
| 256 |
+
### UI and Model Selection
|
| 257 |
+
|
| 258 |
+
* **`EXTRACTION_AND_PII_OPTIONS_OPEN_BY_DEFAULT`**
|
| 259 |
+
* **Description:** If set to `"True"`, the "Extraction and PII Options" accordion in the UI will be open by default.
|
| 260 |
+
* **Default Value:** `"True"`
|
| 261 |
+
|
| 262 |
+
* **`SHOW_LOCAL_TEXT_EXTRACTION_OPTIONS`** / **`SHOW_AWS_TEXT_EXTRACTION_OPTIONS`**
|
| 263 |
+
* **Description:** Controls whether local (Tesseract) or AWS (Textract) text extraction options are shown in the UI.
|
| 264 |
+
* **Default Value:** `"True"` for both.
|
| 265 |
+
|
| 266 |
+
* **`SHOW_LOCAL_PII_DETECTION_OPTIONS`** / **`SHOW_AWS_PII_DETECTION_OPTIONS`**
|
| 267 |
+
* **Description:** Controls whether local or AWS (Comprehend) PII detection options are shown in the UI.
|
| 268 |
+
* **Default Value:** `"True"` for both.
|
| 269 |
+
|
| 270 |
+
* **`DEFAULT_TEXT_EXTRACTION_MODEL`**
|
| 271 |
+
* **Description:** Sets the default text extraction model selected in the UI.
|
| 272 |
+
* **Default Value:** Defaults to AWS Textract if available, otherwise local selectable text.
|
| 273 |
+
|
| 274 |
+
* **`DEFAULT_PII_DETECTION_MODEL`**
|
| 275 |
+
* **Description:** Sets the default PII detection model selected in the UI.
|
| 276 |
+
* **Default Value:** Defaults to AWS Comprehend if available, otherwise the local model.
|
| 277 |
+
|
| 278 |
+
* **`LOAD_REDACTION_ANNOTATIONS_FROM_PDF`**
|
| 279 |
+
* **Description:** If set to `"True"`, the application will load existing redaction annotations from PDFs during the review step.
|
| 280 |
+
* **Default Value:** `"True"`
|
| 281 |
+
|
| 282 |
+
### External Tool Paths
|
| 283 |
+
|
| 284 |
+
* **`TESSERACT_FOLDER`**
|
| 285 |
+
* **Description:** Path to the local Tesseract OCR installation folder.
|
| 286 |
+
* **Default Value:** `''`
|
| 287 |
+
|
| 288 |
+
* **`TESSERACT_DATA_FOLDER`**
|
| 289 |
+
* **Description:** Path to the Tesseract trained data files (`tessdata`).
|
| 290 |
+
* **Default Value:** `"/usr/share/tessdata"`
|
| 291 |
+
|
| 292 |
+
* **`POPPLER_FOLDER`**
|
| 293 |
+
* **Description:** Path to the local Poppler installation's `bin` folder.
|
| 294 |
+
* **Default Value:** `''`
|
| 295 |
+
|
| 296 |
+
* **`PADDLE_MODEL_PATH`** / **`SPACY_MODEL_PATH`**
|
| 297 |
+
* **Description:** Custom directory for PaddleOCR and spaCy model storage, useful for environments like AWS Lambda.
|
| 298 |
+
* **Default Value:** `''` (uses default location).
|
| 299 |
+
|
| 300 |
+
### Local OCR (Tesseract & PaddleOCR)
|
| 301 |
+
|
| 302 |
+
* **`CHOSEN_LOCAL_OCR_MODEL`**
|
| 303 |
+
* **Description:** Choose the engine for local OCR: `"tesseract"`, `"paddle"`, or `"hybrid"`.
|
| 304 |
+
* **Default Value:** `"tesseract"`
|
| 305 |
+
|
| 306 |
+
* **`SHOW_LOCAL_OCR_MODEL_OPTIONS`**
|
| 307 |
+
* **Description:** If set to `"True"`, allows the user to select the local OCR model from the UI.
|
| 308 |
+
* **Default Value:** `"False"`
|
| 309 |
+
|
| 310 |
+
* **`HYBRID_OCR_CONFIDENCE_THRESHOLD`**
|
| 311 |
+
* **Description:** In "hybrid" mode, this is the Tesseract confidence score below which PaddleOCR will be used for re-extraction.
|
| 312 |
+
* **Default Value:** `65`
|
| 313 |
+
|
| 314 |
+
* **`HYBRID_OCR_PADDING`**
|
| 315 |
+
* **Description:** In "hybrid" mode, padding added to the word's bounding box before re-extraction.
|
| 316 |
+
* **Default Value:** `1`
|
| 317 |
+
|
| 318 |
+
* **`PADDLE_USE_TEXTLINE_ORIENTATION`**
|
| 319 |
+
* **Description:** Toggles textline orientation detection for PaddleOCR.
|
| 320 |
+
* **Default Value:** `"False"`
|
| 321 |
+
|
| 322 |
+
* **`PADDLE_DET_DB_UNCLIP_RATIO`**
|
| 323 |
+
* **Description:** Controls the expansion ratio of the detected text region in PaddleOCR.
|
| 324 |
+
* **Default Value:** `1.2`
|
| 325 |
+
|
| 326 |
+
* **`SAVE_EXAMPLE_TESSERACT_VS_PADDLE_IMAGES`**
|
| 327 |
+
* **Description:** Saves comparison images when using "hybrid" OCR mode.
|
| 328 |
+
* **Default Value:** `"False"`
|
| 329 |
+
|
| 330 |
+
* **`SAVE_PADDLE_VISUALISATIONS`**
|
| 331 |
+
* **Description:** Saves images with PaddleOCR's detected bounding boxes overlaid.
|
| 332 |
+
* **Default Value:** `"False"`
|
| 333 |
+
|
| 334 |
+
* **`PREPROCESS_LOCAL_OCR_IMAGES`**
|
| 335 |
+
* **Description:** If set to `"True"`, images will be preprocessed before local OCR. Can slow down processing.
|
| 336 |
+
* **Default Value:** `"False"`
|
| 337 |
+
|
| 338 |
+
### Entity and Search Options
|
| 339 |
+
|
| 340 |
+
* **`CHOSEN_COMPREHEND_ENTITIES`** / **`FULL_COMPREHEND_ENTITY_LIST`**
|
| 341 |
+
* **Description:** The selected and available PII entity types for AWS Comprehend.
|
| 342 |
+
* **Default Value:** Predefined lists of entities (see script).
|
| 343 |
+
|
| 344 |
+
* **`CHOSEN_REDACT_ENTITIES`** / **`FULL_ENTITY_LIST`**
|
| 345 |
+
* **Description:** The selected and available PII entity types for the local model.
|
| 346 |
+
* **Default Value:** Predefined lists of entities (see script).
|
| 347 |
+
|
| 348 |
+
* **`CUSTOM_ENTITIES`**
|
| 349 |
+
* **Description:** A list of entities that are considered "custom" and may have special handling.
|
| 350 |
+
* **Default Value:** `['TITLES', 'UKPOSTCODE', 'STREETNAME', 'CUSTOM']`
|
| 351 |
+
|
| 352 |
+
* **`DEFAULT_SEARCH_QUERY`**
|
| 353 |
+
* **Description:** The default text for the custom search/redact input box.
|
| 354 |
+
* **Default Value:** `''`
|
| 355 |
+
|
| 356 |
+
* **`DEFAULT_FUZZY_SPELLING_MISTAKES_NUM`**
|
| 357 |
+
* **Description:** Default number of allowed spelling mistakes for fuzzy searches.
|
| 358 |
+
* **Default Value:** `1`
|
| 359 |
+
|
| 360 |
+
* **`DEFAULT_PAGE_MIN`** / **`DEFAULT_PAGE_MAX`**
|
| 361 |
+
* **Description:** Default start and end pages for processing. `0` for max means process all pages.
|
| 362 |
+
* **Default Value:** `0` for both.
|
| 363 |
+
|
| 364 |
+
### Textract Feature Selection
|
| 365 |
+
|
| 366 |
+
* **`DEFAULT_HANDWRITE_SIGNATURE_CHECKBOX`**
|
| 367 |
+
* **Description:** The default options selected for Textract's handwriting and signature detection.
|
| 368 |
+
* **Default Value:** `['Extract handwriting']`
|
| 369 |
+
|
| 370 |
+
* **`INCLUDE_FORM_EXTRACTION_TEXTRACT_OPTION`**
|
| 371 |
+
* **`INCLUDE_LAYOUT_EXTRACTION_TEXTRACT_OPTION`**
|
| 372 |
+
* **`INCLUDE_TABLE_EXTRACTION_TEXTRACT_OPTION`**
|
| 373 |
+
* **Description:** Booleans (`"True"`/`"False"`) to include Forms, Layout, and Tables as selectable options for Textract analysis.
|
| 374 |
+
* **Default Value:** `"False"` for all.
|
| 375 |
+
|
| 376 |
+
### Tabular Data Options
|
| 377 |
+
|
| 378 |
+
* **`DO_INITIAL_TABULAR_DATA_CLEAN`**
|
| 379 |
+
* **Description:** If `"True"`, performs an initial cleaning step on tabular data.
|
| 380 |
+
* **Default Value:** `"True"`
|
| 381 |
+
|
| 382 |
+
* **`DEFAULT_TEXT_COLUMNS`** / **`DEFAULT_EXCEL_SHEETS`**
|
| 383 |
+
* **Description:** Default values for specifying which columns or sheets to process in tabular files.
|
| 384 |
+
* **Default Value:** `[]` (empty list)
|
| 385 |
+
|
| 386 |
+
* **`DEFAULT_TABULAR_ANONYMISATION_STRATEGY`**
|
| 387 |
+
* **Description:** The default method for anonymizing tabular data (e.g., "redact completely").
|
| 388 |
+
* **Default Value:** `"redact completely"`
|
| 389 |
|
| 390 |
## Language Options
|
| 391 |
|
| 392 |
+
Settings for multi-language support.
|
| 393 |
+
|
| 394 |
+
* **`SHOW_LANGUAGE_SELECTION`**
|
| 395 |
+
* **Description:** If set to `"True"`, a language selection dropdown will be visible in the UI.
|
| 396 |
+
* **Default Value:** `"False"`
|
| 397 |
+
|
| 398 |
+
* **`DEFAULT_LANGUAGE_FULL_NAME`** / **`DEFAULT_LANGUAGE`**
|
| 399 |
+
* **Description:** The default language's full name (e.g., "english") and its short code (e.g., "en").
|
| 400 |
+
* **Default Values:** `"english"`, `"en"`
|
| 401 |
+
|
| 402 |
+
* **`textract_language_choices`** / **`aws_comprehend_language_choices`**
|
| 403 |
+
* **Description:** Lists of supported language codes for Textract and Comprehend.
|
| 404 |
+
* **Default Value:** `['en', 'es', 'fr', 'de', 'it', 'pt']` and `['en', 'es']`
|
| 405 |
+
|
| 406 |
+
* **`MAPPED_LANGUAGE_CHOICES`** / **`LANGUAGE_CHOICES`**
|
| 407 |
+
* **Description:** Paired lists of full language names and their corresponding short codes for the UI dropdown.
|
| 408 |
+
* **Default Value:** Predefined lists (see script).
|
| 409 |
+
|
| 410 |
+
## Duplicate Detection Settings
|
| 411 |
+
|
| 412 |
+
* **`DEFAULT_DUPLICATE_DETECTION_THRESHOLD`**
|
| 413 |
+
* **Description:** The similarity score (0.0 to 1.0) above which documents/pages are considered duplicates.
|
| 414 |
+
* **Default Value:** `0.95`
|
| 415 |
+
|
| 416 |
+
* **`DEFAULT_MIN_CONSECUTIVE_PAGES`**
|
| 417 |
+
* **Description:** Minimum number of consecutive pages that must be duplicates to be flagged.
|
| 418 |
+
* **Default Value:** `1`
|
| 419 |
+
|
| 420 |
+
* **`USE_GREEDY_DUPLICATE_DETECTION`**
|
| 421 |
+
* **Description:** If `"True"`, uses a greedy algorithm that may find more duplicates but can be less precise.
|
| 422 |
+
* **Default Value:** `"True"`
|
| 423 |
+
|
| 424 |
+
* **`DEFAULT_COMBINE_PAGES`**
|
| 425 |
+
* **Description:** If `"True"`, text from the same page number across different files is combined before checking for duplicates.
|
| 426 |
+
* **Default Value:** `"True"`
|
| 427 |
+
|
| 428 |
+
* **`DEFAULT_MIN_WORD_COUNT`**
|
| 429 |
+
* **Description:** Pages with fewer words than this value will be ignored by the duplicate detector.
|
| 430 |
+
* **Default Value:** `10`
|
| 431 |
+
|
| 432 |
+
* **`REMOVE_DUPLICATE_ROWS`**
|
| 433 |
+
* **Description:** If `"True"`, enables duplicate row detection in tabular data.
|
| 434 |
+
* **Default Value:** `"False"`
|
| 435 |
+
|
| 436 |
+
## File Output Options
|
| 437 |
+
|
| 438 |
+
* **`USE_GUI_BOX_COLOURS_FOR_OUTPUTS`**
|
| 439 |
+
* **Description:** If `"True"`, the final redacted PDF will use the same redaction box colors as shown in the review UI.
|
| 440 |
+
* **Default Value:** `"False"`
|
| 441 |
+
|
| 442 |
+
* **`CUSTOM_BOX_COLOUR`**
|
| 443 |
+
* **Description:** Specifies the color for redaction boxes as an RGB tuple string, e.g., `"(0, 0, 0)"` for black.
|
| 444 |
+
* **Default Value:** `"(0, 0, 0)"`
|
| 445 |
+
|
| 446 |
+
* **`APPLY_REDACTIONS_IMAGES`**, **`APPLY_REDACTIONS_GRAPHICS`**, **`APPLY_REDACTIONS_TEXT`**
|
| 447 |
+
* **Description:** Advanced control over how redactions are applied to underlying images, vector graphics, and text in the PDF, based on PyMuPDF options. `0` is the default for a standard redaction workflow.
|
| 448 |
+
* **Default Value:** `0` for all.
|
| 449 |
+
|
| 450 |
+
* **`RETURN_PDF_FOR_REVIEW`**
|
| 451 |
+
* **Description:** If set to `"True"`, a PDF with redaction boxes drawn on it (but text not removed) is generated for the "Review" tab.
|
| 452 |
+
* **Default Value:** `"True"`
|
| 453 |
+
|
| 454 |
+
* **`RETURN_REDACTED_PDF`**
|
| 455 |
+
* **Description:** If set to `'True'`, the application will return a fully redacted PDF at the end of the main task.
|
| 456 |
+
* **Default Value:** `"True"`
|
| 457 |
+
|
| 458 |
+
* **`COMPRESS_REDACTED_PDF`**
|
| 459 |
+
* **Description:** If set to `'True'`, the redacted PDF output will be compressed.
|
| 460 |
+
* **Default Value:** `"False"`
|
| 461 |
+
|
| 462 |
+
## Direct Mode & Lambda Configuration
|
| 463 |
+
|
| 464 |
+
Settings for running the application from the command line (Direct Mode) or as an AWS Lambda function.
|
| 465 |
+
|
| 466 |
+
### Direct Mode
|
| 467 |
+
|
| 468 |
+
* **`RUN_DIRECT_MODE`**
|
| 469 |
+
* **Description:** Set to `'True'` to enable direct command-line mode.
|
| 470 |
+
* **Default Value:** `'False'`
|
| 471 |
+
|
| 472 |
+
* **`DIRECT_MODE_DEFAULT_USER`**
|
| 473 |
+
* **Description:** Default username for CLI requests.
|
| 474 |
+
* **Default Value:** `''`
|
| 475 |
+
|
| 476 |
+
* **`DIRECT_MODE_TASK`**
|
| 477 |
+
* **Description:** The task to perform: `'redact'` or `'deduplicate'`.
|
| 478 |
+
* **Default Value:** `'redact'`
|
| 479 |
+
|
| 480 |
+
* **`DIRECT_MODE_INPUT_FILE`** / **`DIRECT_MODE_OUTPUT_DIR`**
|
| 481 |
+
* **Description:** Path to the input file and output directory for the task.
|
| 482 |
+
* **Default Values:** `''`, `output/`
|
| 483 |
+
|
| 484 |
+
* **Other `DIRECT_MODE_*` variables:**
|
| 485 |
+
* **Description:** These variables allow for setting nearly all application options (e.g., `DIRECT_MODE_PII_DETECTOR`, `DIRECT_MODE_SIMILARITY_THRESHOLD`) directly for a single CLI run, overriding other configurations.
|
| 486 |
+
* **Default Value:** Defaults are inherited from the main application settings (e.g., `LOCAL_PII_OPTION`, `DEFAULT_DUPLICATE_DETECTION_THRESHOLD`).
|
| 487 |
+
|
| 488 |
+
### Lambda Configuration
|
| 489 |
+
|
| 490 |
+
* **`LAMBDA_POLL_INTERVAL`**
|
| 491 |
+
* **Description:** Polling interval in seconds for checking Textract job status.
|
| 492 |
+
* **Default Value:** `30`
|
| 493 |
+
|
| 494 |
+
* **`LAMBDA_MAX_POLL_ATTEMPTS`**
|
| 495 |
+
* **Description:** Maximum number of polling attempts before timeout.
|
| 496 |
+
* **Default Value:** `120`
|
| 497 |
+
|
| 498 |
+
* **`LAMBDA_PREPARE_IMAGES`**
|
| 499 |
+
* **Description:** If `"True"`, prepares images for OCR processing within the Lambda environment.
|
| 500 |
+
* **Default Value:** `"True"`
|
| 501 |
+
|
| 502 |
+
* **`LAMBDA_EXTRACT_SIGNATURES`**
|
| 503 |
+
* **Description:** Enables signature extraction during Textract analysis in Lambda.
|
| 504 |
+
* **Default Value:** `"False"`
|
| 505 |
+
|
| 506 |
+
* **`LAMBDA_DEFAULT_USERNAME`**
|
| 507 |
+
* **Description:** Default username for operations initiated by Lambda.
|
| 508 |
+
* **Default Value:** `"lambda_user"`
|
| 509 |
+
|
| 510 |
+
## Allow, Deny, & Whole Page Redaction Lists
|
| 511 |
+
|
| 512 |
+
* **`GET_DEFAULT_ALLOW_LIST`**, **`GET_DEFAULT_DENY_LIST`**, **`GET_DEFAULT_WHOLE_PAGE_REDACTION_LIST`**
|
| 513 |
+
* **Description:** Booleans (`"True"`/`"False"`) to enable the use of allow, deny, or whole-page redaction lists.
|
| 514 |
+
* **Default Value:** `"False"`
|
| 515 |
+
|
| 516 |
+
* **`ALLOW_LIST_PATH`**, **`DENY_LIST_PATH`**, **`WHOLE_PAGE_REDACTION_LIST_PATH`**
|
| 517 |
+
* **Description:** Local paths to the respective CSV list files.
|
| 518 |
+
* **Default Value:** `''`
|
| 519 |
+
|
| 520 |
+
* **`S3_ALLOW_LIST_PATH`**, **`S3_DENY_LIST_PATH`**, **`S3_WHOLE_PAGE_REDACTION_LIST_PATH`**
|
| 521 |
+
* **Description:** Paths to the respective list files within the `DOCUMENT_REDACTION_BUCKET`.
|
| 522 |
+
* **Default Value:** `''`
|
| 523 |
|
| 524 |
## Cost Code Options
|
| 525 |
|
| 526 |
+
* **`SHOW_COSTS`**
|
| 527 |
+
* **Description:** If set to `'True'`, cost-related information will be displayed in the UI.
|
| 528 |
+
* **Default Value:** `'False'`
|
| 529 |
+
|
| 530 |
+
* **`GET_COST_CODES`**
|
| 531 |
+
* **Description:** Enables fetching and using cost codes. Set to `'True'` to enable.
|
| 532 |
+
* **Default Value:** `'False'`
|
| 533 |
+
|
| 534 |
+
* **`DEFAULT_COST_CODE`**
|
| 535 |
+
* **Description:** Specifies a default cost code.
|
| 536 |
+
* **Default Value:** `''`
|
| 537 |
+
|
| 538 |
+
* **`COST_CODES_PATH`** / **`S3_COST_CODES_PATH`**
|
| 539 |
+
* **Description:** Local or S3 path to a CSV file containing available cost codes.
|
| 540 |
+
* **Default Value:** `''`
|
| 541 |
+
|
| 542 |
+
* **`ENFORCE_COST_CODES`**
|
| 543 |
+
* **Description:** If set to `'True'`, makes the selection of a cost code mandatory.
|
| 544 |
+
* **Default Value:** `'False'`
|
| 545 |
+
|
| 546 |
+
## Whole Document API Options (Textract Async)
|
| 547 |
+
|
| 548 |
+
* **`SHOW_WHOLE_DOCUMENT_TEXTRACT_CALL_OPTIONS`**
|
| 549 |
+
* **Description:** Controls whether UI options for asynchronous whole document Textract calls are displayed.
|
| 550 |
+
* **Default Value:** `'False'`
|
| 551 |
+
|
| 552 |
+
* **`TEXTRACT_WHOLE_DOCUMENT_ANALYSIS_BUCKET`**
|
| 553 |
+
* **Description:** The S3 bucket used for asynchronous Textract analysis.
|
| 554 |
+
* **Default Value:** `''`
|
| 555 |
+
|
| 556 |
+
* **`TEXTRACT_WHOLE_DOCUMENT_ANALYSIS_INPUT_SUBFOLDER`** / **`..._OUTPUT_SUBFOLDER`**
|
| 557 |
+
* **Description:** Input and output subfolders within the analysis bucket.
|
| 558 |
+
* **Default Values:** `'input'`, `'output'`
|
| 559 |
+
|
| 560 |
+
* **`LOAD_PREVIOUS_TEXTRACT_JOBS_S3`**
|
| 561 |
+
* **Description:** If set to `'True'`, the application will load data from previous Textract jobs stored in S3.
|
| 562 |
+
* **Default Value:** `'False'`
|
| 563 |
+
|
| 564 |
+
* **`TEXTRACT_JOBS_S3_LOC`** / **`TEXTRACT_JOBS_S3_INPUT_LOC`**
|
| 565 |
+
* **Description:** S3 subfolders where Textract job output and input are stored.
|
| 566 |
+
* **Default Value:** `'output'`, `'input'`
|
| 567 |
+
|
| 568 |
+
* **`TEXTRACT_JOBS_LOCAL_LOC`**
|
| 569 |
+
* **Description:** The local subfolder for storing Textract job data.
|
| 570 |
+
* **Default Value:** `'output'`
|
| 571 |
+
|
| 572 |
+
* **`DAYS_TO_DISPLAY_WHOLE_DOCUMENT_JOBS`**
|
| 573 |
+
* **Description:** Specifies the number of past days for which to display whole document Textract jobs.
|
| 574 |
+
* **Default Value:** `7`
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
src/user_guide.qmd
CHANGED
|
@@ -9,7 +9,8 @@ format:
|
|
| 9 |
|
| 10 |
## Table of contents
|
| 11 |
|
| 12 |
-
|
|
|
|
| 13 |
- [Basic redaction](#basic-redaction)
|
| 14 |
- [Customising redaction options](#customising-redaction-options)
|
| 15 |
- [Custom allow, deny, and page redaction lists](#custom-allow-deny-and-page-redaction-lists)
|
|
@@ -21,21 +22,60 @@ format:
|
|
| 21 |
- [Handwriting and signature redaction](#handwriting-and-signature-redaction)
|
| 22 |
- [Reviewing and modifying suggested redactions](#reviewing-and-modifying-suggested-redactions)
|
| 23 |
- [Redacting Word, tabular data files (CSV/XLSX) or copy and pasted text](#redacting-word-tabular-data-files-xlsxcsv-or-copy-and-pasted-text)
|
| 24 |
-
|
| 25 |
-
See the [advanced user guide here](#advanced-user-guide):
|
| 26 |
-
- [Merging redaction review files](#merging-redaction-review-files)
|
| 27 |
- [Identifying and redacting duplicate pages](#identifying-and-redacting-duplicate-pages)
|
|
|
|
|
|
|
|
|
|
| 28 |
- [Fuzzy search and redaction](#fuzzy-search-and-redaction)
|
| 29 |
- [Export redactions to and import from Adobe Acrobat](#export-to-and-import-from-adobe)
|
|
|
|
| 30 |
- [Exporting to Adobe Acrobat](#exporting-to-adobe-acrobat)
|
| 31 |
- [Importing from Adobe Acrobat](#importing-from-adobe-acrobat)
|
| 32 |
- [Using the AWS Textract document API](#using-the-aws-textract-document-api)
|
| 33 |
- [Using AWS Textract and Comprehend when not running in an AWS environment](#using-aws-textract-and-comprehend-when-not-running-in-an-aws-environment)
|
| 34 |
- [Modifying existing redaction review files](#modifying-existing-redaction-review-files)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 35 |
|
| 36 |
-
|
| 37 |
|
| 38 |
-
Please try these example files to follow along with this guide:
|
| 39 |
- [Example of files sent to a professor before applying](https://github.com/seanpedrick-case/document_redaction_examples/blob/main/example_of_emails_sent_to_a_professor_before_applying.pdf)
|
| 40 |
- [Example complaint letter (jpg)](https://github.com/seanpedrick-case/document_redaction_examples/blob/main/example_complaint_letter.jpg)
|
| 41 |
- [Partnership Agreement Toolkit (for signatures and more advanced usage)](https://github.com/seanpedrick-case/document_redaction_examples/blob/main/Partnership-Agreement-Toolkit_0_0.pdf)
|
|
@@ -55,16 +95,20 @@ The 'Redact PDFs/images tab' currently accepts PDFs and image files (JPG, PNG) f
|
|
| 55 |
|
| 56 |
### Text extraction
|
| 57 |
|
| 58 |
-
|
|
|
|
|
|
|
| 59 |
- **'Local model - selectable text'** - This will read text directly from PDFs that have selectable text to redact (using PikePDF). This is fine for most PDFs, but will find nothing if the PDF does not have selectable text, and it is not good for handwriting or signatures. If it encounters an image file, it will send it onto the second option below.
|
| 60 |
- **'Local OCR model - PDFs without selectable text'** - This option will use a simple Optical Character Recognition (OCR) model (Tesseract) to pull out text from a PDF/image that it 'sees'. This can handle most typed text in PDFs/images without selectable text, but struggles with handwriting/signatures. If you are interested in the latter, then you should use the third option if available.
|
| 61 |
- **'AWS Textract service - all PDF types'** - Only available for instances of the app running on AWS. AWS Textract is a service that performs OCR on documents within their secure service. This is a more advanced version of OCR compared to the local option, and carries a (relatively small) cost. Textract excels in complex documents based on images, or documents that contain a lot of handwriting and signatures.
|
| 62 |
|
| 63 |
-
###
|
| 64 |
If you chose the AWS Textract service above, you can choose if you want handwriting and/or signatures redacted by default. Choosing signatures here will have a cost implication, as identifying signatures will cost ~£2.66 ($3.50) per 1,000 pages vs ~£1.14 ($1.50) per 1,000 pages without signature detection.
|
| 65 |
|
| 66 |

|
| 67 |
|
|
|
|
|
|
|
| 68 |
### PII redaction method
|
| 69 |
|
| 70 |
If you are running with the AWS service enabled, here you will also have a choice for PII redaction method:
|
|
@@ -98,6 +142,7 @@ Click 'Redact document'. After loading in the document, the app should be able t
|
|
| 98 |

|
| 99 |
|
| 100 |
- **'...redacted.pdf'** files contain the original pdf with suggested redacted text deleted and replaced by a black box on top of the document.
|
|
|
|
| 101 |
- **'...ocr_results.csv'** files contain the line-by-line text outputs from the entire document. This file can be useful for later searching through for any terms of interest in the document (e.g. using Excel or a similar program).
|
| 102 |
- **'...review_file.csv'** files are the review files that contain details and locations of all of the suggested redactions in the document. This file is key to the [review process](#reviewing-and-modifying-suggested-redactions), and should be downloaded to use later for this.
|
| 103 |
|
|
@@ -166,8 +211,6 @@ If the table is empty, you can add a new entry, you can add a new row by clickin
|
|
| 166 |
|
| 167 |

|
| 168 |
|
| 169 |
-
**Note:** As of version 0.7.0 you can now apply your whole page redaction list directly to the document file currently under review by clicking the 'Apply whole page redaction list to document currently under review' button that appears here.
|
| 170 |
-
|
| 171 |
### Redacting additional types of personal information
|
| 172 |
|
| 173 |
You may want to redact additional types of information beyond the defaults, or you may not be interested in default suggested entity types. There are dates in the example complaint letter. Say we wanted to redact those dates also?
|
|
@@ -182,7 +225,7 @@ If you want to redact different files, I suggest you refresh your browser page t
|
|
| 182 |
|
| 183 |
## Redacting only specific pages
|
| 184 |
|
| 185 |
-
Say also we are only interested in redacting page 1 of the loaded documents. On the Redaction settings tab, select 'Lowest page to redact' as 1, and 'Highest page to redact' also as 1. When you next redact your documents, only the first page will be modified.
|
| 186 |
|
| 187 |

|
| 188 |
|
|
@@ -419,39 +462,16 @@ You can also write open text into an input box and redact that using the same me
|
|
| 419 |
### Redaction log outputs
|
| 420 |
A list of the suggested redaction outputs from the tabular data / open text data redaction is available on the Redaction settings page under 'Log file outputs'.
|
| 421 |
|
| 422 |
-
# ADVANCED USER GUIDE
|
| 423 |
-
|
| 424 |
-
This advanced user guide will go over some of the features recently added to the app, including: modifying and merging redaction review files, identifying and redacting duplicate pages across multiple PDFs, 'fuzzy' search and redact, and exporting redactions to Adobe Acrobat.
|
| 425 |
-
|
| 426 |
-
## Table of contents
|
| 427 |
-
|
| 428 |
-
- [Merging redaction review files](#merging-redaction-review-files)
|
| 429 |
-
- [Identifying and redacting duplicate pages](#identifying-and-redacting-duplicate-pages)
|
| 430 |
-
- [Fuzzy search and redaction](#fuzzy-search-and-redaction)
|
| 431 |
-
- [Export redactions to and import from Adobe Acrobat](#export-to-and-import-from-adobe)
|
| 432 |
-
- [Exporting to Adobe Acrobat](#exporting-to-adobe-acrobat)
|
| 433 |
-
- [Importing from Adobe Acrobat](#importing-from-adobe-acrobat)
|
| 434 |
-
- [Using the AWS Textract document API](#using-the-aws-textract-document-api)
|
| 435 |
-
- [Using AWS Textract and Comprehend when not running in an AWS environment](#using-aws-textract-and-comprehend-when-not-running-in-an-aws-environment)
|
| 436 |
-
- [Modifying existing redaction review files](#modifying-existing-redaction-review-files)
|
| 437 |
-
|
| 438 |
-
|
| 439 |
-
## Merging redaction review files
|
| 440 |
-
|
| 441 |
-
Say you have run multiple redaction tasks on the same document, and you want to merge all of these redactions together. You could do this in your spreadsheet editor, but this could be fiddly especially if dealing with multiple review files or large numbers of redactions. The app has a feature to combine multiple review files together to create a 'merged' review file.
|
| 442 |
-
|
| 443 |
-

|
| 444 |
-
|
| 445 |
-
You can find this option at the bottom of the 'Redaction Settings' tab. Upload multiple review files here to get a single output 'merged' review_file. In the examples file, merging the 'review_file_custom.csv' and 'review_file_local.csv' files give you an output containing redaction boxes from both. This combined review file can then be uploaded into the review tab following the usual procedure.
|
| 446 |
-
|
| 447 |
-

|
| 448 |
-
|
| 449 |
## Identifying and redacting duplicate pages
|
| 450 |
|
| 451 |
The files for this section are stored [here](https://github.com/seanpedrick-case/document_redaction_examples/blob/main/duplicate_page_find_in_app/).
|
| 452 |
|
| 453 |
Some redaction tasks involve removing duplicate pages of text that may exist across multiple documents. This feature helps you find and remove duplicate content that may exist in single or multiple documents. It can identify everything from single identical pages to multi-page sections (subdocuments). The process involves three main steps: configuring the analysis, reviewing the results in the interactive interface, and then using the generated files to perform the redactions.
|
| 454 |
|
|
|
|
|
|
|
|
|
|
|
|
|
| 455 |

|
| 456 |
|
| 457 |
**Step 1: Upload and Configure the Analysis**
|
|
@@ -496,11 +516,43 @@ The analysis also generates a set of downloadable files for your records and for
|
|
| 496 |
|
| 497 |
If you want to combine the results from this redaction process with previous redaction tasks for the same PDF, you could merge review file outputs following the steps described in [Merging existing redaction review files](#merging-existing-redaction-review-files) above.
|
| 498 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 499 |
## Fuzzy search and redaction
|
| 500 |
|
| 501 |
The files for this section are stored [here](https://github.com/seanpedrick-case/document_redaction_examples/blob/main/fuzzy_search/).
|
| 502 |
|
| 503 |
-
Sometimes you may be searching for
|
| 504 |
|
| 505 |
To do this, go to the Redaction Settings, and the 'Select entity types to redact' area. In the box below relevant to your chosen redaction method (local or AWS Comprehend), select 'CUSTOM_FUZZY' from the list. Next, we can select the maximum number of spelling mistakes allowed in the search (up to nine). Here, you can either type in a number or use the small arrows to the right of the box. Change this option to 3. This will allow for a maximum of three 'changes' in text needed to match to the desired search terms.
|
| 506 |
|
|
@@ -520,9 +572,20 @@ Using these deny list with spelling mistakes, the app fuzzy match these terms to
|
|
| 520 |
|
| 521 |
Files for this section are stored [here](https://github.com/seanpedrick-case/document_redaction_examples/blob/main/export_to_adobe/).
|
| 522 |
|
| 523 |
-
|
|
|
|
|
|
|
| 524 |
|
| 525 |
-
The
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 526 |
|
| 527 |
To convert suggested redactions to Adobe format, you need to have the original PDF and a review file csv in the input box at the top of the Review redactions page.
|
| 528 |
|
|
@@ -570,6 +633,46 @@ The '_textract.json' output can be used to speed up further redaction tasks as [
|
|
| 570 |
|
| 571 |
You can now easily get the '..._ocr_output.csv' redaction output based on this '_textract.json' (described in [Redaction outputs](#redaction-outputs)) by clicking on the button 'Convert Textract job outputs to OCR results'. You can now use this file e.g. for [identifying duplicate pages](#identifying-and-redacting-duplicate-pages), or for redaction review.
|
| 572 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 573 |
## Using AWS Textract and Comprehend when not running in an AWS environment
|
| 574 |
|
| 575 |
AWS Textract and Comprehend give much better results for text extraction and document redaction than the local model options in the app. The most secure way to access them in the Redaction app is to run the app in a secure AWS environment with relevant permissions. Alternatively, you could run the app on your own system while logged in to AWS SSO with relevant permissions.
|
|
@@ -591,26 +694,180 @@ The app should then pick up these keys when trying to access the AWS Textract an
|
|
| 591 |
|
| 592 |
Again, a lot can potentially go wrong with AWS solutions that are insecure, so before trying the above please consult with your AWS and data security teams.
|
| 593 |
|
| 594 |
-
##
|
| 595 |
|
| 596 |
-
|
| 597 |
|
| 598 |
-
|
| 599 |
|
| 600 |
-
|
|
|
|
|
|
|
| 601 |
|
| 602 |
-
|
| 603 |
|
| 604 |
-
|
| 605 |
|
| 606 |
-
|
|
|
|
|
|
|
| 607 |
|
| 608 |
-
|
|
|
|
|
|
|
|
|
|
| 609 |
|
| 610 |
-
|
| 611 |
|
| 612 |
-
|
| 613 |
|
| 614 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 615 |
|
| 616 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 9 |
|
| 10 |
## Table of contents
|
| 11 |
|
| 12 |
+
### Getting Started
|
| 13 |
+
- [Built-in example data](#built-in-example-data)
|
| 14 |
- [Basic redaction](#basic-redaction)
|
| 15 |
- [Customising redaction options](#customising-redaction-options)
|
| 16 |
- [Custom allow, deny, and page redaction lists](#custom-allow-deny-and-page-redaction-lists)
|
|
|
|
| 22 |
- [Handwriting and signature redaction](#handwriting-and-signature-redaction)
|
| 23 |
- [Reviewing and modifying suggested redactions](#reviewing-and-modifying-suggested-redactions)
|
| 24 |
- [Redacting Word, tabular data files (CSV/XLSX) or copy and pasted text](#redacting-word-tabular-data-files-xlsxcsv-or-copy-and-pasted-text)
|
|
|
|
|
|
|
|
|
|
| 25 |
- [Identifying and redacting duplicate pages](#identifying-and-redacting-duplicate-pages)
|
| 26 |
+
|
| 27 |
+
### Advanced user guide
|
| 28 |
+
- [Advanced user guide](#advanced-user-guide)
|
| 29 |
- [Fuzzy search and redaction](#fuzzy-search-and-redaction)
|
| 30 |
- [Export redactions to and import from Adobe Acrobat](#export-to-and-import-from-adobe)
|
| 31 |
+
- [Using _for_review.pdf files with Adobe Acrobat](#using-_for_reviewpdf-files-with-adobe-acrobat)
|
| 32 |
- [Exporting to Adobe Acrobat](#exporting-to-adobe-acrobat)
|
| 33 |
- [Importing from Adobe Acrobat](#importing-from-adobe-acrobat)
|
| 34 |
- [Using the AWS Textract document API](#using-the-aws-textract-document-api)
|
| 35 |
- [Using AWS Textract and Comprehend when not running in an AWS environment](#using-aws-textract-and-comprehend-when-not-running-in-an-aws-environment)
|
| 36 |
- [Modifying existing redaction review files](#modifying-existing-redaction-review-files)
|
| 37 |
+
- [Merging redaction review files](#merging-redaction-review-files)
|
| 38 |
+
|
| 39 |
+
### Features for expert users/system administrators
|
| 40 |
+
- [Features for expert users/system administrators](#features-for-expert-userssystem-administrators)
|
| 41 |
+
- [Advanced OCR options (Hybrid OCR)](#advanced-ocr-options-hybrid-ocr)
|
| 42 |
+
- [Command Line Interface (CLI)](#command-line-interface-cli)
|
| 43 |
+
|
| 44 |
+
## Built-in example data
|
| 45 |
+
|
| 46 |
+
The app now includes built-in example files that you can use to quickly test different features. These examples are automatically loaded and can be accessed directly from the interface without needing to download files separately.
|
| 47 |
+
|
| 48 |
+
### Using built-in examples
|
| 49 |
+
|
| 50 |
+
**For PDF/image redaction:** On the 'Redact PDFs/images' tab, you'll see a section titled "Try an example - Click on an example below and then the 'Extract text and redact document' button". Simply click on any of the available examples to load them with pre-configured settings:
|
| 51 |
+
|
| 52 |
+
- **PDF with selectable text redaction** - Uses local text extraction with standard PII detection
|
| 53 |
+
- **Image redaction with local OCR** - Processes an image file using OCR
|
| 54 |
+
- **PDF redaction with custom entities** - Demonstrates custom entity selection (Titles, Person, Dates)
|
| 55 |
+
- **PDF redaction with AWS services and signature detection** - Shows AWS Textract with signature extraction (if AWS is enabled)
|
| 56 |
+
- **PDF redaction with custom deny list and whole page redaction** - Demonstrates advanced redaction features
|
| 57 |
+
|
| 58 |
+
Once you have clicked on an example, you can click the 'Extract text and redact document' button to load the example into the app and redact it.
|
| 59 |
+
|
| 60 |
+
**For tabular data:** On the 'Word or Excel/csv files' tab, you'll find examples for both redaction and duplicate detection:
|
| 61 |
+
|
| 62 |
+
- **CSV file redaction** - Shows how to redact specific columns in tabular data
|
| 63 |
+
- **Word document redaction** - Demonstrates Word document processing
|
| 64 |
+
- **Excel file duplicate detection** - Shows how to find duplicate rows in spreadsheet data
|
| 65 |
+
|
| 66 |
+
Once you have clicked on an example, you can click the 'Redact text/data files' button to load the example into the app and redact it. For the duplicate detection example, you can click the 'Find duplicate cells/rows' button to load the example into the app and find duplicates.
|
| 67 |
+
|
| 68 |
+
**For duplicate page detection:** On the 'Identify duplicate pages' tab, you'll find examples for finding duplicate content in documents:
|
| 69 |
+
|
| 70 |
+
- **Find duplicate pages of text in document OCR outputs** - Uses page-level analysis with a similarity threshold of 0.95 and minimum word count of 10
|
| 71 |
+
- **Find duplicate text lines in document OCR outputs** - Uses line-level analysis with a similarity threshold of 0.95 and minimum word count of 3
|
| 72 |
+
|
| 73 |
+
Once you have clicked on an example, you can click the 'Identify duplicate pages/subdocuments' button to load the example into the app and find duplicate content.
|
| 74 |
+
|
| 75 |
+
### External example files (optional)
|
| 76 |
|
| 77 |
+
If you prefer to use your own example files or want to follow along with specific tutorials, you can still download these external example files:
|
| 78 |
|
|
|
|
| 79 |
- [Example of files sent to a professor before applying](https://github.com/seanpedrick-case/document_redaction_examples/blob/main/example_of_emails_sent_to_a_professor_before_applying.pdf)
|
| 80 |
- [Example complaint letter (jpg)](https://github.com/seanpedrick-case/document_redaction_examples/blob/main/example_complaint_letter.jpg)
|
| 81 |
- [Partnership Agreement Toolkit (for signatures and more advanced usage)](https://github.com/seanpedrick-case/document_redaction_examples/blob/main/Partnership-Agreement-Toolkit_0_0.pdf)
|
|
|
|
| 95 |
|
| 96 |
### Text extraction
|
| 97 |
|
| 98 |
+
You can modify default text extraction methods by clicking on the 'Change default text extraction method...' box'.
|
| 99 |
+
|
| 100 |
+
Here you can select one of the three text extraction options:
|
| 101 |
- **'Local model - selectable text'** - This will read text directly from PDFs that have selectable text to redact (using PikePDF). This is fine for most PDFs, but will find nothing if the PDF does not have selectable text, and it is not good for handwriting or signatures. If it encounters an image file, it will send it onto the second option below.
|
| 102 |
- **'Local OCR model - PDFs without selectable text'** - This option will use a simple Optical Character Recognition (OCR) model (Tesseract) to pull out text from a PDF/image that it 'sees'. This can handle most typed text in PDFs/images without selectable text, but struggles with handwriting/signatures. If you are interested in the latter, then you should use the third option if available.
|
| 103 |
- **'AWS Textract service - all PDF types'** - Only available for instances of the app running on AWS. AWS Textract is a service that performs OCR on documents within their secure service. This is a more advanced version of OCR compared to the local option, and carries a (relatively small) cost. Textract excels in complex documents based on images, or documents that contain a lot of handwriting and signatures.
|
| 104 |
|
| 105 |
+
### Enable AWS Textract signature extraction
|
| 106 |
If you chose the AWS Textract service above, you can choose if you want handwriting and/or signatures redacted by default. Choosing signatures here will have a cost implication, as identifying signatures will cost ~£2.66 ($3.50) per 1,000 pages vs ~£1.14 ($1.50) per 1,000 pages without signature detection.
|
| 107 |
|
| 108 |

|
| 109 |
|
| 110 |
+
**NOTE:** it is also possible to enable form extraction, layout extraction, and table extraction with AWS Textract. This is not enabled by default, but it is possible for your system admin to enable this feature in the config file.
|
| 111 |
+
|
| 112 |
### PII redaction method
|
| 113 |
|
| 114 |
If you are running with the AWS service enabled, here you will also have a choice for PII redaction method:
|
|
|
|
| 142 |

|
| 143 |
|
| 144 |
- **'...redacted.pdf'** files contain the original pdf with suggested redacted text deleted and replaced by a black box on top of the document.
|
| 145 |
+
- **'...redactions_for_review.pdf'** files contain the original PDF with redaction boxes overlaid but the original text still visible underneath. This file is designed for use in Adobe Acrobat and other PDF viewers where you can see the suggested redactions without the text being permanently removed. This is particularly useful for reviewing redactions before finalising them.
|
| 146 |
- **'...ocr_results.csv'** files contain the line-by-line text outputs from the entire document. This file can be useful for later searching through for any terms of interest in the document (e.g. using Excel or a similar program).
|
| 147 |
- **'...review_file.csv'** files are the review files that contain details and locations of all of the suggested redactions in the document. This file is key to the [review process](#reviewing-and-modifying-suggested-redactions), and should be downloaded to use later for this.
|
| 148 |
|
|
|
|
| 211 |
|
| 212 |

|
| 213 |
|
|
|
|
|
|
|
| 214 |
### Redacting additional types of personal information
|
| 215 |
|
| 216 |
You may want to redact additional types of information beyond the defaults, or you may not be interested in default suggested entity types. There are dates in the example complaint letter. Say we wanted to redact those dates also?
|
|
|
|
| 225 |
|
| 226 |
## Redacting only specific pages
|
| 227 |
|
| 228 |
+
Say also we are only interested in redacting page 1 of the loaded documents. On the Redaction settings tab, select 'Lowest page to redact' as 1, and 'Highest page to redact' also as 1. When you next redact your documents, only the first page will be modified. The output files should now have a suffix similar to '..._1_1.pdf', indicating the lowest and highest page numbers that were redacted.
|
| 229 |
|
| 230 |

|
| 231 |
|
|
|
|
| 462 |
### Redaction log outputs
|
| 463 |
A list of the suggested redaction outputs from the tabular data / open text data redaction is available on the Redaction settings page under 'Log file outputs'.
|
| 464 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 465 |
## Identifying and redacting duplicate pages
|
| 466 |
|
| 467 |
The files for this section are stored [here](https://github.com/seanpedrick-case/document_redaction_examples/blob/main/duplicate_page_find_in_app/).
|
| 468 |
|
| 469 |
Some redaction tasks involve removing duplicate pages of text that may exist across multiple documents. This feature helps you find and remove duplicate content that may exist in single or multiple documents. It can identify everything from single identical pages to multi-page sections (subdocuments). The process involves three main steps: configuring the analysis, reviewing the results in the interactive interface, and then using the generated files to perform the redactions.
|
| 470 |
|
| 471 |
+
### Duplicate page detection in documents
|
| 472 |
+
|
| 473 |
+
This section covers finding duplicate pages across PDF documents using OCR output files.
|
| 474 |
+
|
| 475 |

|
| 476 |
|
| 477 |
**Step 1: Upload and Configure the Analysis**
|
|
|
|
| 516 |
|
| 517 |
If you want to combine the results from this redaction process with previous redaction tasks for the same PDF, you could merge review file outputs following the steps described in [Merging existing redaction review files](#merging-existing-redaction-review-files) above.
|
| 518 |
|
| 519 |
+
### Duplicate detection in tabular data
|
| 520 |
+
|
| 521 |
+
The app also includes functionality to find duplicate cells or rows in CSV, Excel, or Parquet files. This is particularly useful for cleaning datasets where you need to identify and remove duplicate entries.
|
| 522 |
+
|
| 523 |
+
**Step 1: Upload files and configure analysis**
|
| 524 |
+
|
| 525 |
+
Navigate to the 'Word or Excel/csv files' tab and scroll down to the "Find duplicate cells in tabular data" section. Upload your tabular files (CSV, Excel, or Parquet) and configure the analysis parameters:
|
| 526 |
+
|
| 527 |
+
- **Similarity threshold**: Score (0-1) to consider cells a match. 1 = perfect match
|
| 528 |
+
- **Minimum word count**: Cells with fewer words than this value are ignored
|
| 529 |
+
- **Do initial clean of text**: Remove URLs, HTML tags, and non-ASCII characters
|
| 530 |
+
- **Remove duplicate rows**: Automatically remove duplicate rows from deduplicated files
|
| 531 |
+
- **Select Excel sheet names**: Choose which sheets to analyze (for Excel files)
|
| 532 |
+
- **Select text columns**: Choose which columns contain text to analyze
|
| 533 |
+
|
| 534 |
+
**Step 2: Review results**
|
| 535 |
+
|
| 536 |
+
After clicking "Find duplicate cells/rows", the results will be displayed in a table showing:
|
| 537 |
+
- File1, Row1, File2, Row2
|
| 538 |
+
- Similarity_Score
|
| 539 |
+
- Text1, Text2 (the actual text content being compared)
|
| 540 |
+
|
| 541 |
+
Click on any row to see more details about the duplicate match in the preview boxes below.
|
| 542 |
+
|
| 543 |
+
**Step 3: Remove duplicates**
|
| 544 |
+
|
| 545 |
+
Select a file from the dropdown and click "Remove duplicate rows from selected file" to create a cleaned version with duplicates removed. The cleaned file will be available for download.
|
| 546 |
+
|
| 547 |
+
# Advanced user guide
|
| 548 |
+
|
| 549 |
+
This advanced user guide covers features that require system administration access or command-line usage. These features are typically used by system administrators or advanced users who need more control over the redaction process.
|
| 550 |
+
|
| 551 |
## Fuzzy search and redaction
|
| 552 |
|
| 553 |
The files for this section are stored [here](https://github.com/seanpedrick-case/document_redaction_examples/blob/main/fuzzy_search/).
|
| 554 |
|
| 555 |
+
Sometimes you may be searching for terms that are slightly mispelled throughout a document, for example names. The document redaction app gives the option for searching for long phrases that may contain spelling mistakes, a method called 'fuzzy matching'.
|
| 556 |
|
| 557 |
To do this, go to the Redaction Settings, and the 'Select entity types to redact' area. In the box below relevant to your chosen redaction method (local or AWS Comprehend), select 'CUSTOM_FUZZY' from the list. Next, we can select the maximum number of spelling mistakes allowed in the search (up to nine). Here, you can either type in a number or use the small arrows to the right of the box. Change this option to 3. This will allow for a maximum of three 'changes' in text needed to match to the desired search terms.
|
| 558 |
|
|
|
|
| 572 |
|
| 573 |
Files for this section are stored [here](https://github.com/seanpedrick-case/document_redaction_examples/blob/main/export_to_adobe/).
|
| 574 |
|
| 575 |
+
The Document Redaction app has enhanced features for working with Adobe Acrobat. You can now export suggested redactions to Adobe, import Adobe comment files into the app, and use the new `_for_review.pdf` files directly in Adobe Acrobat.
|
| 576 |
+
|
| 577 |
+
### Using _for_review.pdf files with Adobe Acrobat
|
| 578 |
|
| 579 |
+
The app now generates `...redactions_for_review.pdf` files that contain the original PDF with redaction boxes overlaid but the original text still visible underneath. These files are specifically designed for use in Adobe Acrobat and other PDF viewers where you can:
|
| 580 |
+
|
| 581 |
+
- See the suggested redactions without the text being permanently removed
|
| 582 |
+
- Review redactions before finalising them
|
| 583 |
+
- Use Adobe Acrobat's built-in redaction tools to modify or apply the redactions
|
| 584 |
+
- Export the final redacted version directly from Adobe
|
| 585 |
+
|
| 586 |
+
Simply open the `...redactions_for_review.pdf` file in Adobe Acrobat to begin reviewing and modifying the suggested redactions.
|
| 587 |
+
|
| 588 |
+
### Exporting to Adobe Acrobat
|
| 589 |
|
| 590 |
To convert suggested redactions to Adobe format, you need to have the original PDF and a review file csv in the input box at the top of the Review redactions page.
|
| 591 |
|
|
|
|
| 633 |
|
| 634 |
You can now easily get the '..._ocr_output.csv' redaction output based on this '_textract.json' (described in [Redaction outputs](#redaction-outputs)) by clicking on the button 'Convert Textract job outputs to OCR results'. You can now use this file e.g. for [identifying duplicate pages](#identifying-and-redacting-duplicate-pages), or for redaction review.
|
| 635 |
|
| 636 |
+
|
| 637 |
+
|
| 638 |
+
## Modifying existing redaction review files
|
| 639 |
+
You can find the folder containing the files discussed in this section [here](https://github.com/seanpedrick-case/document_redaction_examples/blob/main/merge_review_files/).
|
| 640 |
+
|
| 641 |
+
As well as serving as inputs to the document redaction app's review function, the 'review_file.csv' output can be modified insider or outside of the app. This gives you the flexibility to change redaction details outside of the app.
|
| 642 |
+
|
| 643 |
+
### Inside the app
|
| 644 |
+
You can now modify redaction review files directly in the app on the 'Review redactions' tab. Open the accordion 'View and edit review data' under the file input area. You can edit review file data cells here - press Enter to apply changes. You should see the effect on the current page if you click the 'Save changes on current page to file' button to the right.
|
| 645 |
+
|
| 646 |
+
### Outside the app
|
| 647 |
+
If you open up a 'review_file' csv output using a spreadsheet software program such as Microsoft Excel you can easily modify redaction properties. Open the file '[Partnership-Agreement-Toolkit_0_0_redacted.pdf_review_file_local.csv](https://github.com/seanpedrick-case/document_redaction_examples/blob/main/merge_review_files/Partnership-Agreement-Toolkit_0_0.pdf_review_file_local.csv)', and you should see a spreadshet with just four suggested redactions (see below). The following instructions are for using Excel.
|
| 648 |
+
|
| 649 |
+

|
| 650 |
+
|
| 651 |
+
The first thing we can do is remove the first row - 'et' is suggested as a person, but is obviously not a genuine instance of personal information. Right click on the row number and select delete on this menu. Next, let's imagine that what the app identified as a 'phone number' was in fact another type of number and so we wanted to change the label. Simply click on the relevant label cells, let's change it to 'SECURITY_NUMBER'. You could also use 'Find & Select' -> 'Replace' from the top ribbon menu if you wanted to change a number of labels simultaneously.
|
| 652 |
+
|
| 653 |
+
How about we wanted to change the colour of the 'email address' entry on the redaction review tab of the redaction app? The colours in a review file are based on an RGB scale with three numbers ranging from 0-255. [You can find suitable colours here](https://rgbcolorpicker.com). Using this scale, if I wanted my review box to be pure blue, I can change the cell value to (0,0,255).
|
| 654 |
+
|
| 655 |
+
Imagine that a redaction box was slightly too small, and I didn't want to use the in-app options to change the size. In the review file csv, we can modify e.g. the ymin and ymax values for any box to increase the extent of the redaction box. For the 'email address' entry, let's decrease ymin by 5, and increase ymax by 5.
|
| 656 |
+
|
| 657 |
+
I have saved an output file following the above steps as '[Partnership-Agreement-Toolkit_0_0_redacted.pdf_review_file_local_mod.csv](https://github.com/seanpedrick-case/document_redaction_examples/blob/main/merge_review_files/outputs/Partnership-Agreement-Toolkit_0_0.pdf_review_file_local_mod.csv)' in the same folder that the original was found. Let's upload this file to the app along with the original pdf to see how the redactions look now.
|
| 658 |
+
|
| 659 |
+

|
| 660 |
+
|
| 661 |
+
We can see from the above that we have successfully removed a redaction box, changed labels, colours, and redaction box sizes.
|
| 662 |
+
|
| 663 |
+
## Merging redaction review files
|
| 664 |
+
|
| 665 |
+
Say you have run multiple redaction tasks on the same document, and you want to merge all of these redactions together. You could do this in your spreadsheet editor, but this could be fiddly especially if dealing with multiple review files or large numbers of redactions. The app has a feature to combine multiple review files together to create a 'merged' review file.
|
| 666 |
+
|
| 667 |
+

|
| 668 |
+
|
| 669 |
+
You can find this option at the bottom of the 'Redaction Settings' tab. Upload multiple review files here to get a single output 'merged' review_file. In the examples file, merging the 'review_file_custom.csv' and 'review_file_local.csv' files give you an output containing redaction boxes from both. This combined review file can then be uploaded into the review tab following the usual procedure.
|
| 670 |
+
|
| 671 |
+

|
| 672 |
+
|
| 673 |
+
# Features for expert users/system administrators
|
| 674 |
+
This advanced user guide covers features that require system administration access or command-line usage. These options are not enabled by default but can be configured by your system administrator, and are not available to users who are just using the graphical user interface. These features are typically used by system administrators or advanced users who need more control over the redaction process.
|
| 675 |
+
|
| 676 |
## Using AWS Textract and Comprehend when not running in an AWS environment
|
| 677 |
|
| 678 |
AWS Textract and Comprehend give much better results for text extraction and document redaction than the local model options in the app. The most secure way to access them in the Redaction app is to run the app in a secure AWS environment with relevant permissions. Alternatively, you could run the app on your own system while logged in to AWS SSO with relevant permissions.
|
|
|
|
| 694 |
|
| 695 |
Again, a lot can potentially go wrong with AWS solutions that are insecure, so before trying the above please consult with your AWS and data security teams.
|
| 696 |
|
| 697 |
+
## Advanced OCR options (Hybrid OCR)
|
| 698 |
|
| 699 |
+
The app supports advanced OCR options that combine multiple OCR engines for improved accuracy. These options are not enabled by default but can be configured by your system administrator.
|
| 700 |
|
| 701 |
+
### Available OCR models
|
| 702 |
|
| 703 |
+
- **Tesseract** (default): The standard OCR engine that works well for most documents
|
| 704 |
+
- **PaddleOCR**: More accurate for whole line text extraction, but word-level bounding boxes may be less precise
|
| 705 |
+
- **Hybrid**: Combines Tesseract and PaddleOCR - uses Tesseract for initial extraction, then PaddleOCR for re-extraction of low-confidence text
|
| 706 |
|
| 707 |
+
### Enabling advanced OCR options
|
| 708 |
|
| 709 |
+
To enable these options, your system administrator needs to modify the configuration file (`config.py`) and set:
|
| 710 |
|
| 711 |
+
```
|
| 712 |
+
SHOW_LOCAL_OCR_MODEL_OPTIONS = "True"
|
| 713 |
+
```
|
| 714 |
|
| 715 |
+
Once enabled, users will see a "Change default local OCR model" section in the redaction settings where they can choose between:
|
| 716 |
+
- tesseract
|
| 717 |
+
- hybrid
|
| 718 |
+
- paddle
|
| 719 |
|
| 720 |
+
### Hybrid OCR configuration
|
| 721 |
|
| 722 |
+
The hybrid OCR mode uses several configurable parameters:
|
| 723 |
|
| 724 |
+
- **HYBRID_OCR_CONFIDENCE_THRESHOLD** (default: 65): Tesseract confidence score below which PaddleOCR will be used for re-extraction
|
| 725 |
+
- **HYBRID_OCR_PADDING** (default: 1): Padding added to word bounding boxes before re-extraction
|
| 726 |
+
- **SAVE_EXAMPLE_TESSERACT_VS_PADDLE_IMAGES** (default: False): Save comparison images when using hybrid mode
|
| 727 |
+
- **SAVE_PADDLE_VISUALISATIONS** (default: False): Save images with PaddleOCR bounding boxes overlaid
|
| 728 |
+
|
| 729 |
+
### When to use different OCR models
|
| 730 |
+
|
| 731 |
+
- **Tesseract**: Best for general use, good balance of speed and accuracy
|
| 732 |
+
- **PaddleOCR**: Best for documents with clear, well-formatted text where line-level accuracy is more important than word-level precision
|
| 733 |
+
- **Hybrid**: Best for challenging documents where some text has low confidence scores, providing the benefits of both engines
|
| 734 |
+
|
| 735 |
+
|
| 736 |
+
|
| 737 |
+
|
| 738 |
+
|
| 739 |
+
## Command Line Interface (CLI)
|
| 740 |
+
|
| 741 |
+
The app includes a comprehensive command-line interface (`cli_redact.py`) that allows you to perform redaction, deduplication, and AWS Textract operations directly from the terminal. This is particularly useful for batch processing, automation, and integration with other systems.
|
| 742 |
+
|
| 743 |
+
### Getting started with the CLI
|
| 744 |
+
|
| 745 |
+
To use the CLI, you need to:
|
| 746 |
+
|
| 747 |
+
1. Open a terminal window
|
| 748 |
+
2. Navigate to the app folder containing `cli_redact.py`
|
| 749 |
+
3. Activate your virtual environment (conda or venv)
|
| 750 |
+
4. Run commands using `python cli_redact.py` followed by your options
|
| 751 |
+
|
| 752 |
+
### Basic CLI syntax
|
| 753 |
+
|
| 754 |
+
```bash
|
| 755 |
+
python cli_redact.py --task [redact|deduplicate|textract] --input_file [file_path] [additional_options]
|
| 756 |
+
```
|
| 757 |
+
|
| 758 |
+
### Redaction examples
|
| 759 |
+
|
| 760 |
+
**Basic PDF redaction with default settings:**
|
| 761 |
+
```bash
|
| 762 |
+
python cli_redact.py --input_file example_data/example_of_emails_sent_to_a_professor_before_applying.pdf
|
| 763 |
+
```
|
| 764 |
+
|
| 765 |
+
**Extract text only (no redaction) with whole page redaction:**
|
| 766 |
+
```bash
|
| 767 |
+
python cli_redact.py --input_file example_data/Partnership-Agreement-Toolkit_0_0.pdf --redact_whole_page_file example_data/partnership_toolkit_redact_some_pages.csv --pii_detector None
|
| 768 |
+
```
|
| 769 |
+
|
| 770 |
+
**Redact with custom entities and allow list:**
|
| 771 |
+
```bash
|
| 772 |
+
python cli_redact.py --input_file example_data/graduate-job-example-cover-letter.pdf --allow_list_file example_data/test_allow_list_graduate.csv --local_redact_entities TITLES PERSON DATE_TIME
|
| 773 |
+
```
|
| 774 |
+
|
| 775 |
+
**Redact with fuzzy matching and custom deny list:**
|
| 776 |
+
```bash
|
| 777 |
+
python cli_redact.py --input_file example_data/Partnership-Agreement-Toolkit_0_0.pdf --deny_list_file example_data/Partnership-Agreement-Toolkit_test_deny_list_para_single_spell.csv --local_redact_entities CUSTOM_FUZZY --page_min 1 --page_max 3 --fuzzy_mistakes 3
|
| 778 |
+
```
|
| 779 |
+
|
| 780 |
+
**Redact with AWS services:**
|
| 781 |
+
```bash
|
| 782 |
+
python cli_redact.py --input_file example_data/example_of_emails_sent_to_a_professor_before_applying.pdf --ocr_method "AWS Textract" --pii_detector "AWS Comprehend"
|
| 783 |
+
```
|
| 784 |
+
|
| 785 |
+
**Redact specific pages with signature extraction:**
|
| 786 |
+
```bash
|
| 787 |
+
python cli_redact.py --input_file example_data/Partnership-Agreement-Toolkit_0_0.pdf --page_min 6 --page_max 7 --ocr_method "AWS Textract" --handwrite_signature_extraction "Extract handwriting" "Extract signatures"
|
| 788 |
+
```
|
| 789 |
+
|
| 790 |
+
### Tabular data redaction
|
| 791 |
+
|
| 792 |
+
**Anonymize CSV file with specific columns:**
|
| 793 |
+
```bash
|
| 794 |
+
python cli_redact.py --input_file example_data/combined_case_notes.csv --text_columns "Case Note" "Client" --anon_strategy replace_redacted
|
| 795 |
+
```
|
| 796 |
+
|
| 797 |
+
**Anonymize Excel file:**
|
| 798 |
+
```bash
|
| 799 |
+
python cli_redact.py --input_file example_data/combined_case_notes.xlsx --text_columns "Case Note" "Client" --excel_sheets combined_case_notes --anon_strategy redact
|
| 800 |
+
```
|
| 801 |
+
|
| 802 |
+
**Anonymize Word document:**
|
| 803 |
+
```bash
|
| 804 |
+
python cli_redact.py --input_file "example_data/Bold minimalist professional cover letter.docx" --anon_strategy replace_redacted
|
| 805 |
+
```
|
| 806 |
+
|
| 807 |
+
### Duplicate detection
|
| 808 |
+
|
| 809 |
+
**Find duplicate pages in OCR files:**
|
| 810 |
+
```bash
|
| 811 |
+
python cli_redact.py --task deduplicate --input_file example_data/example_outputs/doubled_output_joined.pdf_ocr_output.csv --duplicate_type pages --similarity_threshold 0.95
|
| 812 |
+
```
|
| 813 |
+
|
| 814 |
+
**Find duplicates at line level:**
|
| 815 |
+
```bash
|
| 816 |
+
python cli_redact.py --task deduplicate --input_file example_data/example_outputs/doubled_output_joined.pdf_ocr_output.csv --duplicate_type pages --similarity_threshold 0.95 --combine_pages False --min_word_count 3
|
| 817 |
+
```
|
| 818 |
+
|
| 819 |
+
**Find duplicate rows in tabular data:**
|
| 820 |
+
```bash
|
| 821 |
+
python cli_redact.py --task deduplicate --input_file example_data/Lambeth_2030-Our_Future_Our_Lambeth.pdf.csv --duplicate_type tabular --text_columns "text" --similarity_threshold 0.95
|
| 822 |
+
```
|
| 823 |
+
|
| 824 |
+
### AWS Textract operations
|
| 825 |
+
|
| 826 |
+
**Submit document for analysis:**
|
| 827 |
+
```bash
|
| 828 |
+
python cli_redact.py --task textract --textract_action submit --input_file example_data/example_of_emails_sent_to_a_professor_before_applying.pdf
|
| 829 |
+
```
|
| 830 |
+
|
| 831 |
+
**Submit with signature extraction:**
|
| 832 |
+
```bash
|
| 833 |
+
python cli_redact.py --task textract --textract_action submit --input_file example_data/Partnership-Agreement-Toolkit_0_0.pdf --extract_signatures
|
| 834 |
+
```
|
| 835 |
|
| 836 |
+
**Retrieve results by job ID:**
|
| 837 |
+
```bash
|
| 838 |
+
python cli_redact.py --task textract --textract_action retrieve --job_id 12345678-1234-1234-1234-123456789012
|
| 839 |
+
```
|
| 840 |
+
|
| 841 |
+
**List recent jobs:**
|
| 842 |
+
```bash
|
| 843 |
+
python cli_redact.py --task textract --textract_action list
|
| 844 |
+
```
|
| 845 |
+
|
| 846 |
+
### Common CLI options
|
| 847 |
+
|
| 848 |
+
- `--task`: Choose between "redact", "deduplicate", or "textract"
|
| 849 |
+
- `--input_file`: Path to input file(s)
|
| 850 |
+
- `--output_dir`: Directory for output files (default: output/)
|
| 851 |
+
- `--page_min` / `--page_max`: Process only specific page range
|
| 852 |
+
- `--ocr_method`: Choose text extraction method
|
| 853 |
+
- `--pii_detector`: Choose PII detection method
|
| 854 |
+
- `--local_redact_entities`: Specify local entities to redact
|
| 855 |
+
- `--allow_list_file` / `--deny_list_file`: Custom lists
|
| 856 |
+
- `--redact_whole_page_file`: List of pages to redact completely
|
| 857 |
+
- `--fuzzy_mistakes`: Number of spelling mistakes allowed in fuzzy matching
|
| 858 |
+
- `--similarity_threshold`: Threshold for duplicate detection
|
| 859 |
+
- `--anon_strategy`: Anonymization strategy for tabular data
|
| 860 |
+
|
| 861 |
+
### Output files
|
| 862 |
+
|
| 863 |
+
The CLI generates the same output files as the GUI:
|
| 864 |
+
- `...redacted.pdf`: Final redacted document
|
| 865 |
+
- `...redactions_for_review.pdf`: Document with redaction boxes for review
|
| 866 |
+
- `...review_file.csv`: Detailed redaction information
|
| 867 |
+
- `...ocr_results.csv`: Extracted text results
|
| 868 |
+
- `..._textract.json`: AWS Textract results (if applicable)
|
| 869 |
+
|
| 870 |
+
For more advanced options and configuration, refer to the help text by running:
|
| 871 |
+
```bash
|
| 872 |
+
python cli_redact.py --help
|
| 873 |
+
```
|
tools/config.py
CHANGED
|
@@ -773,26 +773,32 @@ DIRECT_MODE_PII_DETECTOR = get_or_create_env_var(
|
|
| 773 |
DIRECT_MODE_OCR_METHOD = get_or_create_env_var(
|
| 774 |
"DIRECT_MODE_OCR_METHOD", "Local OCR"
|
| 775 |
) # OCR method for PDF/image processing
|
| 776 |
-
DIRECT_MODE_PAGE_MIN = int(
|
| 777 |
-
"DIRECT_MODE_PAGE_MIN", str(DEFAULT_PAGE_MIN)
|
| 778 |
-
)
|
| 779 |
-
DIRECT_MODE_PAGE_MAX = int(
|
| 780 |
-
"DIRECT_MODE_PAGE_MAX", str(DEFAULT_PAGE_MAX)
|
| 781 |
-
)
|
| 782 |
-
DIRECT_MODE_IMAGES_DPI = float(
|
| 783 |
-
"DIRECT_MODE_IMAGES_DPI", str(IMAGES_DPI)
|
| 784 |
-
)
|
| 785 |
DIRECT_MODE_CHOSEN_LOCAL_OCR_MODEL = get_or_create_env_var(
|
| 786 |
"DIRECT_MODE_CHOSEN_LOCAL_OCR_MODEL", CHOSEN_LOCAL_OCR_MODEL
|
| 787 |
) # Local OCR model choice
|
| 788 |
DIRECT_MODE_PREPROCESS_LOCAL_OCR_IMAGES = convert_string_to_boolean(
|
| 789 |
-
get_or_create_env_var(
|
|
|
|
|
|
|
| 790 |
) # Preprocess images before OCR
|
| 791 |
DIRECT_MODE_COMPRESS_REDACTED_PDF = convert_string_to_boolean(
|
| 792 |
-
get_or_create_env_var(
|
|
|
|
|
|
|
| 793 |
) # Compress redacted PDF
|
| 794 |
DIRECT_MODE_RETURN_PDF_END_OF_REDACTION = convert_string_to_boolean(
|
| 795 |
-
get_or_create_env_var(
|
|
|
|
|
|
|
| 796 |
) # Return PDF at end of redaction
|
| 797 |
DIRECT_MODE_EXTRACT_FORMS = convert_string_to_boolean(
|
| 798 |
get_or_create_env_var("DIRECT_MODE_EXTRACT_FORMS", "False")
|
|
@@ -812,26 +818,36 @@ DIRECT_MODE_MATCH_FUZZY_WHOLE_PHRASE_BOOL = convert_string_to_boolean(
|
|
| 812 |
DIRECT_MODE_ANON_STRATEGY = get_or_create_env_var(
|
| 813 |
"DIRECT_MODE_ANON_STRATEGY", DEFAULT_TABULAR_ANONYMISATION_STRATEGY
|
| 814 |
) # Anonymisation strategy for tabular data
|
| 815 |
-
DIRECT_MODE_FUZZY_MISTAKES = int(
|
| 816 |
-
|
| 817 |
-
)
|
| 818 |
-
|
| 819 |
-
|
| 820 |
-
|
| 821 |
-
|
| 822 |
-
|
| 823 |
-
)
|
| 824 |
-
|
| 825 |
-
|
| 826 |
-
))
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 827 |
DIRECT_MODE_GREEDY_MATCH = convert_string_to_boolean(
|
| 828 |
-
get_or_create_env_var(
|
|
|
|
|
|
|
| 829 |
) # Use greedy matching for duplicate detection
|
| 830 |
DIRECT_MODE_COMBINE_PAGES = convert_string_to_boolean(
|
| 831 |
get_or_create_env_var("DIRECT_MODE_COMBINE_PAGES", str(DEFAULT_COMBINE_PAGES))
|
| 832 |
) # Combine pages for duplicate detection
|
| 833 |
DIRECT_MODE_REMOVE_DUPLICATE_ROWS = convert_string_to_boolean(
|
| 834 |
-
get_or_create_env_var(
|
|
|
|
|
|
|
| 835 |
) # Remove duplicate rows in tabular data
|
| 836 |
|
| 837 |
# Textract Batch Operations Options
|
|
@@ -843,12 +859,12 @@ DIRECT_MODE_JOB_ID = get_or_create_env_var(
|
|
| 843 |
) # Job ID for Textract operations
|
| 844 |
|
| 845 |
# Lambda-specific configuration options
|
| 846 |
-
LAMBDA_POLL_INTERVAL = int(
|
| 847 |
-
"LAMBDA_POLL_INTERVAL", "30"
|
| 848 |
-
)
|
| 849 |
-
LAMBDA_MAX_POLL_ATTEMPTS = int(
|
| 850 |
-
"LAMBDA_MAX_POLL_ATTEMPTS", "120"
|
| 851 |
-
)
|
| 852 |
LAMBDA_PREPARE_IMAGES = convert_string_to_boolean(
|
| 853 |
get_or_create_env_var("LAMBDA_PREPARE_IMAGES", "True")
|
| 854 |
) # Prepare images for OCR processing
|
|
|
|
| 773 |
DIRECT_MODE_OCR_METHOD = get_or_create_env_var(
|
| 774 |
"DIRECT_MODE_OCR_METHOD", "Local OCR"
|
| 775 |
) # OCR method for PDF/image processing
|
| 776 |
+
DIRECT_MODE_PAGE_MIN = int(
|
| 777 |
+
get_or_create_env_var("DIRECT_MODE_PAGE_MIN", str(DEFAULT_PAGE_MIN))
|
| 778 |
+
) # First page to process
|
| 779 |
+
DIRECT_MODE_PAGE_MAX = int(
|
| 780 |
+
get_or_create_env_var("DIRECT_MODE_PAGE_MAX", str(DEFAULT_PAGE_MAX))
|
| 781 |
+
) # Last page to process
|
| 782 |
+
DIRECT_MODE_IMAGES_DPI = float(
|
| 783 |
+
get_or_create_env_var("DIRECT_MODE_IMAGES_DPI", str(IMAGES_DPI))
|
| 784 |
+
) # DPI for image processing
|
| 785 |
DIRECT_MODE_CHOSEN_LOCAL_OCR_MODEL = get_or_create_env_var(
|
| 786 |
"DIRECT_MODE_CHOSEN_LOCAL_OCR_MODEL", CHOSEN_LOCAL_OCR_MODEL
|
| 787 |
) # Local OCR model choice
|
| 788 |
DIRECT_MODE_PREPROCESS_LOCAL_OCR_IMAGES = convert_string_to_boolean(
|
| 789 |
+
get_or_create_env_var(
|
| 790 |
+
"DIRECT_MODE_PREPROCESS_LOCAL_OCR_IMAGES", str(PREPROCESS_LOCAL_OCR_IMAGES)
|
| 791 |
+
)
|
| 792 |
) # Preprocess images before OCR
|
| 793 |
DIRECT_MODE_COMPRESS_REDACTED_PDF = convert_string_to_boolean(
|
| 794 |
+
get_or_create_env_var(
|
| 795 |
+
"DIRECT_MODE_COMPRESS_REDACTED_PDF", str(COMPRESS_REDACTED_PDF)
|
| 796 |
+
)
|
| 797 |
) # Compress redacted PDF
|
| 798 |
DIRECT_MODE_RETURN_PDF_END_OF_REDACTION = convert_string_to_boolean(
|
| 799 |
+
get_or_create_env_var(
|
| 800 |
+
"DIRECT_MODE_RETURN_PDF_END_OF_REDACTION", str(RETURN_REDACTED_PDF)
|
| 801 |
+
)
|
| 802 |
) # Return PDF at end of redaction
|
| 803 |
DIRECT_MODE_EXTRACT_FORMS = convert_string_to_boolean(
|
| 804 |
get_or_create_env_var("DIRECT_MODE_EXTRACT_FORMS", "False")
|
|
|
|
| 818 |
DIRECT_MODE_ANON_STRATEGY = get_or_create_env_var(
|
| 819 |
"DIRECT_MODE_ANON_STRATEGY", DEFAULT_TABULAR_ANONYMISATION_STRATEGY
|
| 820 |
) # Anonymisation strategy for tabular data
|
| 821 |
+
DIRECT_MODE_FUZZY_MISTAKES = int(
|
| 822 |
+
get_or_create_env_var(
|
| 823 |
+
"DIRECT_MODE_FUZZY_MISTAKES", str(DEFAULT_FUZZY_SPELLING_MISTAKES_NUM)
|
| 824 |
+
)
|
| 825 |
+
) # Number of fuzzy spelling mistakes allowed
|
| 826 |
+
DIRECT_MODE_SIMILARITY_THRESHOLD = float(
|
| 827 |
+
get_or_create_env_var(
|
| 828 |
+
"DIRECT_MODE_SIMILARITY_THRESHOLD", str(DEFAULT_DUPLICATE_DETECTION_THRESHOLD)
|
| 829 |
+
)
|
| 830 |
+
) # Similarity threshold for duplicate detection
|
| 831 |
+
DIRECT_MODE_MIN_WORD_COUNT = int(
|
| 832 |
+
get_or_create_env_var("DIRECT_MODE_MIN_WORD_COUNT", str(DEFAULT_MIN_WORD_COUNT))
|
| 833 |
+
) # Minimum word count for duplicate detection
|
| 834 |
+
DIRECT_MODE_MIN_CONSECUTIVE_PAGES = int(
|
| 835 |
+
get_or_create_env_var(
|
| 836 |
+
"DIRECT_MODE_MIN_CONSECUTIVE_PAGES", str(DEFAULT_MIN_CONSECUTIVE_PAGES)
|
| 837 |
+
)
|
| 838 |
+
) # Minimum consecutive pages for duplicate detection
|
| 839 |
DIRECT_MODE_GREEDY_MATCH = convert_string_to_boolean(
|
| 840 |
+
get_or_create_env_var(
|
| 841 |
+
"DIRECT_MODE_GREEDY_MATCH", str(USE_GREEDY_DUPLICATE_DETECTION)
|
| 842 |
+
)
|
| 843 |
) # Use greedy matching for duplicate detection
|
| 844 |
DIRECT_MODE_COMBINE_PAGES = convert_string_to_boolean(
|
| 845 |
get_or_create_env_var("DIRECT_MODE_COMBINE_PAGES", str(DEFAULT_COMBINE_PAGES))
|
| 846 |
) # Combine pages for duplicate detection
|
| 847 |
DIRECT_MODE_REMOVE_DUPLICATE_ROWS = convert_string_to_boolean(
|
| 848 |
+
get_or_create_env_var(
|
| 849 |
+
"DIRECT_MODE_REMOVE_DUPLICATE_ROWS", str(REMOVE_DUPLICATE_ROWS)
|
| 850 |
+
)
|
| 851 |
) # Remove duplicate rows in tabular data
|
| 852 |
|
| 853 |
# Textract Batch Operations Options
|
|
|
|
| 859 |
) # Job ID for Textract operations
|
| 860 |
|
| 861 |
# Lambda-specific configuration options
|
| 862 |
+
LAMBDA_POLL_INTERVAL = int(
|
| 863 |
+
get_or_create_env_var("LAMBDA_POLL_INTERVAL", "30")
|
| 864 |
+
) # Polling interval in seconds for Textract job status
|
| 865 |
+
LAMBDA_MAX_POLL_ATTEMPTS = int(
|
| 866 |
+
get_or_create_env_var("LAMBDA_MAX_POLL_ATTEMPTS", "120")
|
| 867 |
+
) # Maximum number of polling attempts for Textract job completion
|
| 868 |
LAMBDA_PREPARE_IMAGES = convert_string_to_boolean(
|
| 869 |
get_or_create_env_var("LAMBDA_PREPARE_IMAGES", "True")
|
| 870 |
) # Prepare images for OCR processing
|