Spaces:
Sleeping

Sleeping
Commit
·
c3d1c4c
1
Parent(s):
36574ae
Added source files for quarto documentation website
Browse files- _quarto.yml +28 -0
- src/app_settings.qmd +481 -0
- src/faq.qmd +222 -0
- src/installation_guide.qmd +233 -0
- src/management_guide.qmd +226 -0
- src/styles.css +1 -0
- src/user_guide.qmd +511 -0
- tld/.tld_set_snapshot +0 -0
_quarto.yml
ADDED
|
@@ -0,0 +1,28 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
project:
|
| 2 |
+
type: website
|
| 3 |
+
output-dir: docs # Common for GitHub Pages
|
| 4 |
+
render:
|
| 5 |
+
- "*.qmd"
|
| 6 |
+
|
| 7 |
+
website:
|
| 8 |
+
title: "Document Redaction App"
|
| 9 |
+
page-navigation: true # Often enabled for floating TOC to highlight current section
|
| 10 |
+
back-to-top-navigation: true
|
| 11 |
+
search: true
|
| 12 |
+
navbar:
|
| 13 |
+
left:
|
| 14 |
+
- href: index.qmd
|
| 15 |
+
text: Home
|
| 16 |
+
- href: src/user_guide.qmd
|
| 17 |
+
text: User guide
|
| 18 |
+
- href: src/faq.qmd
|
| 19 |
+
text: User FAQ
|
| 20 |
+
- href: src/installation_guide.qmd
|
| 21 |
+
text: App installation guide (with CDK)
|
| 22 |
+
- href: src/app_settings.qmd
|
| 23 |
+
text: App settings management guide
|
| 24 |
+
|
| 25 |
+
format:
|
| 26 |
+
html:
|
| 27 |
+
theme: cosmo
|
| 28 |
+
css: styles.css
|
src/app_settings.qmd
ADDED
|
@@ -0,0 +1,481 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: "App settings management guide"
|
| 3 |
+
format:
|
| 4 |
+
html:
|
| 5 |
+
toc: true # Enable the table of contents
|
| 6 |
+
toc-depth: 3 # Include headings up to level 2 (##)
|
| 7 |
+
toc-title: "On this page" # Optional: Title for your TOC
|
| 8 |
+
---
|
| 9 |
+
|
| 10 |
+
Settings for the redaction app can be set from outside by changing values in the `config.env` file stored in your local config folder, or in S3 if running on AWS. This guide provides an overview of how to configure the application using environment variables. The application loads configurations using `os.environ.get()`. It first attempts to load variables from the file specified by `APP_CONFIG_PATH` (which defaults to `config/app_config.env`). If `AWS_CONFIG_PATH` is also set (e.g., to `config/aws_config.env`), variables are loaded from that file as well. Environment variables set directly in the system will always take precedence over those defined in these `.env` files.
|
| 11 |
+
|
| 12 |
+
## App Configuration File (config.env)
|
| 13 |
+
|
| 14 |
+
This section details variables related to the main application configuration file.
|
| 15 |
+
|
| 16 |
+
* **`APP_CONFIG_PATH`**
|
| 17 |
+
* **Description:** Specifies the path to the application configuration `.env` file. This file contains various settings that control the application's behavior.
|
| 18 |
+
* **Default Value:** `config/app_config.env`
|
| 19 |
+
* **Configuration:** Set as an environment variable directly. This variable defines where to load other application configurations, so it cannot be set within `config/app_config.env` itself.
|
| 20 |
+
|
| 21 |
+
## AWS Options
|
| 22 |
+
|
| 23 |
+
This section covers configurations related to AWS services used by the application.
|
| 24 |
+
|
| 25 |
+
* **`AWS_CONFIG_PATH`**
|
| 26 |
+
* **Description:** Specifies the path to the AWS configuration `.env` file. This file is intended to store AWS credentials and specific settings.
|
| 27 |
+
* **Default Value:** `''` (empty string)
|
| 28 |
+
* **Configuration:** Set as an environment variable directly. This variable defines an additional source for AWS-specific configurations.
|
| 29 |
+
|
| 30 |
+
* **`RUN_AWS_FUNCTIONS`**
|
| 31 |
+
* **Description:** Enables or disables AWS-specific functionalities within the application. Set to `"1"` to enable and `"0"` to disable.
|
| 32 |
+
* **Default Value:** `"0"`
|
| 33 |
+
* **Configuration:** Set as an environment variable directly, or include in `config/app_config.env` (or `config/aws_config.env` if `AWS_CONFIG_PATH` is configured).
|
| 34 |
+
|
| 35 |
+
* **`AWS_REGION`**
|
| 36 |
+
* **Description:** Defines the AWS region where services like S3, Cognito, and Textract are located.
|
| 37 |
+
* **Default Value:** `''`
|
| 38 |
+
* **Configuration:** Set as an environment variable directly, or include in `config/aws_config.env` (if `AWS_CONFIG_PATH` is configured).
|
| 39 |
+
|
| 40 |
+
* **`AWS_CLIENT_ID`**
|
| 41 |
+
* **Description:** The client ID for AWS Cognito, used for user authentication.
|
| 42 |
+
* **Default Value:** `''`
|
| 43 |
+
* **Configuration:** Set as an environment variable directly, or include in `config/aws_config.env` (if `AWS_CONFIG_PATH` is configured).
|
| 44 |
+
|
| 45 |
+
* **`AWS_CLIENT_SECRET`**
|
| 46 |
+
* **Description:** The client secret for AWS Cognito, used in conjunction with the client ID for authentication.
|
| 47 |
+
* **Default Value:** `''`
|
| 48 |
+
* **Configuration:** Set as an environment variable directly, or include in `config/aws_config.env` (if `AWS_CONFIG_PATH` is configured).
|
| 49 |
+
|
| 50 |
+
* **`AWS_USER_POOL_ID`**
|
| 51 |
+
* **Description:** The user pool ID for AWS Cognito, identifying the user directory.
|
| 52 |
+
* **Default Value:** `''`
|
| 53 |
+
* **Configuration:** Set as an environment variable directly, or include in `config/aws_config.env` (if `AWS_CONFIG_PATH` is configured).
|
| 54 |
+
|
| 55 |
+
* **`AWS_ACCESS_KEY`**
|
| 56 |
+
* **Description:** The AWS access key ID for programmatic access to AWS services.
|
| 57 |
+
* **Default Value:** `''` (Note: Often found in the environment or AWS credentials file.)
|
| 58 |
+
* **Configuration:** Set as an environment variable directly, or include in `config/aws_config.env` (if `AWS_CONFIG_PATH` is configured). It's also commonly configured via shared AWS credentials files or IAM roles.
|
| 59 |
+
|
| 60 |
+
* **`AWS_SECRET_KEY`**
|
| 61 |
+
* **Description:** The AWS secret access key corresponding to the AWS access key ID.
|
| 62 |
+
* **Default Value:** `''` (Note: Often found in the environment or AWS credentials file.)
|
| 63 |
+
* **Configuration:** Set as an environment variable directly, or include in `config/aws_config.env` (if `AWS_CONFIG_PATH` is configured). It's also commonly configured via shared AWS credentials files or IAM roles.
|
| 64 |
+
|
| 65 |
+
* **`DOCUMENT_REDACTION_BUCKET`**
|
| 66 |
+
* **Description:** The name of the S3 bucket used for storing documents related to the redaction process.
|
| 67 |
+
* **Default Value:** `''`
|
| 68 |
+
* **Configuration:** Set as an environment variable directly, or include in `config/aws_config.env` (if `AWS_CONFIG_PATH` is configured).
|
| 69 |
+
|
| 70 |
+
* **`CUSTOM_HEADER`**
|
| 71 |
+
* **Description:** Specifies a custom header name to be included in requests, often used for services like AWS CloudFront.
|
| 72 |
+
* **Default Value:** `''`
|
| 73 |
+
* **Configuration:** Set as an environment variable directly, or include in `config/app_config.env` (or `config/aws_config.env` if `AWS_CONFIG_PATH` is configured).
|
| 74 |
+
|
| 75 |
+
* **`CUSTOM_HEADER_VALUE`**
|
| 76 |
+
* **Description:** The value for the custom header specified by `CUSTOM_HEADER`.
|
| 77 |
+
* **Default Value:** `''`
|
| 78 |
+
* **Configuration:** Set as an environment variable directly, or include in `config/app_config.env` (or `config/aws_config.env` if `AWS_CONFIG_PATH` is configured).
|
| 79 |
+
|
| 80 |
+
## Image Options
|
| 81 |
+
|
| 82 |
+
Settings related to image processing within the application.
|
| 83 |
+
|
| 84 |
+
* **`IMAGES_DPI`**
|
| 85 |
+
* **Description:** Dots Per Inch (DPI) setting for image processing, affecting the resolution and quality of processed images.
|
| 86 |
+
* **Default Value:** `'300.0'`
|
| 87 |
+
* **Configuration:** Set as an environment variable directly, or include in `config/app_config.env`.
|
| 88 |
+
|
| 89 |
+
* **`LOAD_TRUNCATED_IMAGES`**
|
| 90 |
+
* **Description:** Controls whether the application attempts to load truncated images. Set to `'True'` to enable.
|
| 91 |
+
* **Default Value:** `'True'`
|
| 92 |
+
* **Configuration:** Set as an environment variable directly, or include in `config/app_config.env`.
|
| 93 |
+
|
| 94 |
+
* **`MAX_IMAGE_PIXELS`**
|
| 95 |
+
* **Description:** Sets the maximum number of pixels for an image that the application will process. Leave blank for no limit. This can help prevent issues with very large images.
|
| 96 |
+
* **Default Value:** `''`
|
| 97 |
+
* **Configuration:** Set as an environment variable directly, or include in `config/app_config.env`.
|
| 98 |
+
|
| 99 |
+
## File I/O Options
|
| 100 |
+
|
| 101 |
+
Configuration for input and output file handling.
|
| 102 |
+
|
| 103 |
+
* **`SESSION_OUTPUT_FOLDER`**
|
| 104 |
+
* **Description:** If set to `'True'`, the application will save output and input files into session-specific subfolders, helping to organise files from different user sessions.
|
| 105 |
+
* **Default Value:** `'False'`
|
| 106 |
+
* **Configuration:** Set as an environment variable directly, or include in `config/app_config.env`.
|
| 107 |
+
|
| 108 |
+
* **`GRADIO_OUTPUT_FOLDER`** (aliased as `OUTPUT_FOLDER`)
|
| 109 |
+
* **Description:** Specifies the default output folder for files generated by Gradio components. Can be set to "TEMP" to use a temporary directory.
|
| 110 |
+
* **Default Value:** `'output/'`
|
| 111 |
+
* **Configuration:** Set as an environment variable directly, or include in `config/app_config.env`.
|
| 112 |
+
|
| 113 |
+
* **`GRADIO_INPUT_FOLDER`** (aliased as `INPUT_FOLDER`)
|
| 114 |
+
* **Description:** Specifies the default input folder for files used by Gradio components. Can be set to "TEMP" to use a temporary directory.
|
| 115 |
+
* **Default Value:** `'input/'`
|
| 116 |
+
* **Configuration:** Set as an environment variable directly, or include in `config/app_config.env`.
|
| 117 |
+
|
| 118 |
+
## Logging Options
|
| 119 |
+
|
| 120 |
+
Settings for configuring application logging, including log formats and storage locations.
|
| 121 |
+
|
| 122 |
+
* **`SAVE_LOGS_TO_CSV`**
|
| 123 |
+
* **Description:** Enables or disables saving logs to CSV files. Set to `'True'` to enable.
|
| 124 |
+
* **Default Value:** `'True'`
|
| 125 |
+
* **Configuration:** Set as an environment variable directly, or include in `config/app_config.env`.
|
| 126 |
+
|
| 127 |
+
* **`USE_LOG_SUBFOLDERS`**
|
| 128 |
+
* **Description:** If enabled (`'True'`), logs will be stored in subfolders based on date and hostname, aiding in log organisation.
|
| 129 |
+
* **Default Value:** `'True'`
|
| 130 |
+
* **Configuration:** Set as an environment variable directly, or include in `config/app_config.env`.
|
| 131 |
+
|
| 132 |
+
* **`FEEDBACK_LOGS_FOLDER`**
|
| 133 |
+
* **Description:** Specifies the base folder for storing feedback logs. If `USE_LOG_SUBFOLDERS` is true, date/hostname subfolders will be created within this folder.
|
| 134 |
+
* **Default Value:** `'feedback/'`
|
| 135 |
+
* **Configuration:** Set as an environment variable directly, or include in `config/app_config.env`.
|
| 136 |
+
|
| 137 |
+
* **`ACCESS_LOGS_FOLDER`**
|
| 138 |
+
* **Description:** Specifies the base folder for storing access logs. If `USE_LOG_SUBFOLDERS` is true, date/hostname subfolders will be created within this folder.
|
| 139 |
+
* **Default Value:** `'logs/'`
|
| 140 |
+
* **Configuration:** Set as an environment variable directly, or include in `config/app_config.env`.
|
| 141 |
+
|
| 142 |
+
* **`USAGE_LOGS_FOLDER`**
|
| 143 |
+
* **Description:** Specifies the base folder for storing usage logs. If `USE_LOG_SUBFOLDERS` is true, date/hostname subfolders will be created within this folder.
|
| 144 |
+
* **Default Value:** `'usage/'`
|
| 145 |
+
* **Configuration:** Set as an environment variable directly, or include in `config/app_config.env`.
|
| 146 |
+
|
| 147 |
+
* **`DISPLAY_FILE_NAMES_IN_LOGS`**
|
| 148 |
+
* **Description:** If set to `'True'`, file names will be included in the log entries.
|
| 149 |
+
* **Default Value:** `'False'`
|
| 150 |
+
* **Configuration:** Set as an environment variable directly, or include in `config/app_config.env`.
|
| 151 |
+
|
| 152 |
+
* **`CSV_ACCESS_LOG_HEADERS`**
|
| 153 |
+
* **Description:** Defines custom headers for CSV access logs. If left blank, component labels will be used as headers.
|
| 154 |
+
* **Default Value:** `''`
|
| 155 |
+
* **Configuration:** Set as an environment variable directly, or include in `config/app_config.env`.
|
| 156 |
+
|
| 157 |
+
* **`CSV_FEEDBACK_LOG_HEADERS`**
|
| 158 |
+
* **Description:** Defines custom headers for CSV feedback logs. If left blank, component labels will be used as headers.
|
| 159 |
+
* **Default Value:** `''`
|
| 160 |
+
* **Configuration:** Set as an environment variable directly, or include in `config/app_config.env`.
|
| 161 |
+
|
| 162 |
+
* **`CSV_USAGE_LOG_HEADERS`**
|
| 163 |
+
* **Description:** Defines custom headers for CSV usage logs.
|
| 164 |
+
* **Default Value:** A predefined list of header names. Refer to `tools/config.py` for the complete list.
|
| 165 |
+
* **Configuration:** Set as an environment variable directly, or include in `config/app_config.env`.
|
| 166 |
+
|
| 167 |
+
* **`SAVE_LOGS_TO_DYNAMODB`**
|
| 168 |
+
* **Description:** Enables or disables saving logs to AWS DynamoDB. Set to `'True'` to enable. Requires appropriate AWS setup.
|
| 169 |
+
* **Default Value:** `'False'`
|
| 170 |
+
* **Configuration:** Set as an environment variable directly, or include in `config/app_config.env` (or `config/aws_config.env` if `AWS_CONFIG_PATH` is configured).
|
| 171 |
+
|
| 172 |
+
* **`ACCESS_LOG_DYNAMODB_TABLE_NAME`**
|
| 173 |
+
* **Description:** The name of the DynamoDB table used for storing access logs.
|
| 174 |
+
* **Default Value:** `'redaction_access_log'`
|
| 175 |
+
* **Configuration:** Set as an environment variable directly, or include in `config/app_config.env` (or `config/aws_config.env` if `AWS_CONFIG_PATH` is configured).
|
| 176 |
+
|
| 177 |
+
* **`DYNAMODB_ACCESS_LOG_HEADERS`**
|
| 178 |
+
* **Description:** Specifies the headers (attributes) for the DynamoDB access log table.
|
| 179 |
+
* **Default Value:** `''`
|
| 180 |
+
* **Configuration:** Set as an environment variable directly, or include in `config/app_config.env` (or `config/aws_config.env` if `AWS_CONFIG_PATH` is configured).
|
| 181 |
+
|
| 182 |
+
* **`FEEDBACK_LOG_DYNAMODB_TABLE_NAME`**
|
| 183 |
+
* **Description:** The name of the DynamoDB table used for storing feedback logs.
|
| 184 |
+
* **Default Value:** `'redaction_feedback'`
|
| 185 |
+
* **Configuration:** Set as an environment variable directly, or include in `config/app_config.env` (or `config/aws_config.env` if `AWS_CONFIG_PATH` is configured).
|
| 186 |
+
|
| 187 |
+
* **`DYNAMODB_FEEDBACK_LOG_HEADERS`**
|
| 188 |
+
* **Description:** Specifies the headers (attributes) for the DynamoDB feedback log table.
|
| 189 |
+
* **Default Value:** `''`
|
| 190 |
+
* **Configuration:** Set as an environment variable directly, or include in `config/app_config.env` (or `config/aws_config.env` if `AWS_CONFIG_PATH` is configured).
|
| 191 |
+
|
| 192 |
+
* **`USAGE_LOG_DYNAMODB_TABLE_NAME`**
|
| 193 |
+
* **Description:** The name of the DynamoDB table used for storing usage logs.
|
| 194 |
+
* **Default Value:** `'redaction_usage'`
|
| 195 |
+
* **Configuration:** Set as an environment variable directly, or include in `config/app_config.env` (or `config/aws_config.env` if `AWS_CONFIG_PATH` is configured).
|
| 196 |
+
|
| 197 |
+
* **`DYNAMODB_USAGE_LOG_HEADERS`**
|
| 198 |
+
* **Description:** Specifies the headers (attributes) for the DynamoDB usage log table.
|
| 199 |
+
* **Default Value:** `''`
|
| 200 |
+
* **Configuration:** Set as an environment variable directly, or include in `config/app_config.env` (or `config/aws_config.env` if `AWS_CONFIG_PATH` is configured).
|
| 201 |
+
|
| 202 |
+
* **`LOGGING`**
|
| 203 |
+
* **Description:** Enables or disables general console logging. Set to `'True'` to enable.
|
| 204 |
+
* **Default Value:** `'False'`
|
| 205 |
+
* **Configuration:** Set as an environment variable directly, or include in `config/app_config.env`.
|
| 206 |
+
|
| 207 |
+
* **`LOG_FILE_NAME`**
|
| 208 |
+
* **Description:** Specifies the name for the CSV log file if `SAVE_LOGS_TO_CSV` is enabled.
|
| 209 |
+
* **Default Value:** `'log.csv'`
|
| 210 |
+
* **Configuration:** Set as an environment variable directly, or include in `config/app_config.env`.
|
| 211 |
+
|
| 212 |
+
## Redaction Options
|
| 213 |
+
|
| 214 |
+
Configurations related to the text redaction process, including PII detection models and external tool paths.
|
| 215 |
+
|
| 216 |
+
* **`TESSERACT_FOLDER`**
|
| 217 |
+
* **Description:** Path to the local Tesseract OCR installation folder. Only required if Tesseract is not in path, or you are running a version of the app as an .exe installed with Pyinstaller. Gives the path to the local Tesseract OCR model for text extraction.
|
| 218 |
+
* **Default Value:** `""` (empty string)
|
| 219 |
+
* **Configuration:** Set as an environment variable directly, or include in `config/app_config.env`.
|
| 220 |
+
|
| 221 |
+
* **`POPPLER_FOLDER`**
|
| 222 |
+
* **Description:** Path to the local Poppler installation's `bin` folder. Only required if Tesseract is not in path, or you are running a version of the app as an .exe installed with Pyinstaller. Poppler is used for PDF processing.
|
| 223 |
+
* **Default Value:** `""` (empty string)
|
| 224 |
+
* **Configuration:** Set as an environment variable directly, or include in `config/app_config.env`.
|
| 225 |
+
|
| 226 |
+
* **`SELECTABLE_TEXT_EXTRACT_OPTION`**
|
| 227 |
+
* **Description:** Display name in the UI for the text extraction method that processes selectable text directly from PDFs.
|
| 228 |
+
* **Default Value:** `"Local model - selectable text"`
|
| 229 |
+
* **Configuration:** Set as an environment variable directly, or include in `config/app_config.env`.
|
| 230 |
+
|
| 231 |
+
* **`TESSERACT_TEXT_EXTRACT_OPTION`**
|
| 232 |
+
* **Description:** Display name in the UI for the text extraction method using local Tesseract OCR (for PDFs without selectable text).
|
| 233 |
+
* **Default Value:** `"Local OCR model - PDFs without selectable text"`
|
| 234 |
+
* **Configuration:** Set as an environment variable directly, or include in `config/app_config.env`.
|
| 235 |
+
|
| 236 |
+
* **`TEXTRACT_TEXT_EXTRACT_OPTION`**
|
| 237 |
+
* **Description:** Display name in the UI for the text extraction method using AWS Textract service.
|
| 238 |
+
* **Default Value:** `"AWS Textract service - all PDF types"`
|
| 239 |
+
* **Configuration:** Set as an environment variable directly, or include in `config/app_config.env`.
|
| 240 |
+
|
| 241 |
+
* **`NO_REDACTION_PII_OPTION`**
|
| 242 |
+
* **Description:** Display name in the UI for the option to only extract text without performing any PII detection or redaction.
|
| 243 |
+
* **Default Value:** `"Only extract text (no redaction)"`
|
| 244 |
+
* **Configuration:** Set as an environment variable directly, or include in `config/app_config.env`.
|
| 245 |
+
|
| 246 |
+
* **`LOCAL_PII_OPTION`**
|
| 247 |
+
* **Description:** Display name in the UI for the PII detection method using a local model.
|
| 248 |
+
* **Default Value:** `"Local"`
|
| 249 |
+
* **Configuration:** Set as an environment variable directly, or include in `config/app_config.env`.
|
| 250 |
+
|
| 251 |
+
* **`AWS_PII_OPTION`**
|
| 252 |
+
* **Description:** Display name in the UI for the PII detection method using AWS Comprehend.
|
| 253 |
+
* **Default Value:** `"AWS Comprehend"`
|
| 254 |
+
* **Configuration:** Set as an environment variable directly, or include in `config/app_config.env`.
|
| 255 |
+
|
| 256 |
+
* **`SHOW_LOCAL_TEXT_EXTRACTION_OPTIONS`**
|
| 257 |
+
* **Description:** Controls whether local text extraction options (selectable text, Tesseract) are shown in the UI. Set to `'True'` to show.
|
| 258 |
+
* **Default Value:** `'True'`
|
| 259 |
+
* **Configuration:** Set as an environment variable directly, or include in `config/app_config.env`.
|
| 260 |
+
|
| 261 |
+
* **`SHOW_AWS_TEXT_EXTRACTION_OPTIONS`**
|
| 262 |
+
* **Description:** Controls whether AWS Textract text extraction option is shown in the UI. Set to `'True'` to show.
|
| 263 |
+
* **Default Value:** `'True'`
|
| 264 |
+
* **Configuration:** Set as an environment variable directly, or include in `config/app_config.env`.
|
| 265 |
+
|
| 266 |
+
* **`DEFAULT_TEXT_EXTRACTION_MODEL`**
|
| 267 |
+
* **Description:** Sets the default text extraction model selected in the UI. Defaults to `TEXTRACT_TEXT_EXTRACT_OPTION` if AWS options are shown; otherwise, defaults to `SELECTABLE_TEXT_EXTRACT_OPTION`.
|
| 268 |
+
* **Default Value:** Value of `TEXTRACT_TEXT_EXTRACT_OPTION` if `SHOW_AWS_TEXT_EXTRACTION_OPTIONS` is True, else value of `SELECTABLE_TEXT_EXTRACT_OPTION`.
|
| 269 |
+
* **Configuration:** Set as an environment variable directly, or include in `config/app_config.env`. Provide one of the text extraction option display names.
|
| 270 |
+
|
| 271 |
+
* **`SHOW_LOCAL_PII_DETECTION_OPTIONS`**
|
| 272 |
+
* **Description:** Controls whether the local PII detection option is shown in the UI. Set to `'True'` to show.
|
| 273 |
+
* **Default Value:** `'True'`
|
| 274 |
+
* **Configuration:** Set as an environment variable directly, or include in `config/app_config.env`.
|
| 275 |
+
|
| 276 |
+
* **`SHOW_AWS_PII_DETECTION_OPTIONS`**
|
| 277 |
+
* **Description:** Controls whether the AWS Comprehend PII detection option is shown in the UI. Set to `'True'` to show.
|
| 278 |
+
* **Default Value:** `'True'`
|
| 279 |
+
* **Configuration:** Set as an environment variable directly, or include in `config/app_config.env`.
|
| 280 |
+
|
| 281 |
+
* **`DEFAULT_PII_DETECTION_MODEL`**
|
| 282 |
+
* **Description:** Sets the default PII detection model selected in the UI. Defaults to `AWS_PII_OPTION` if AWS options are shown; otherwise, defaults to `LOCAL_PII_OPTION`.
|
| 283 |
+
* **Default Value:** Value of `AWS_PII_OPTION` if `SHOW_AWS_PII_DETECTION_OPTIONS` is True, else value of `LOCAL_PII_OPTION`.
|
| 284 |
+
* **Configuration:** Set as an environment variable directly, or include in `config/app_config.env`. Provide one of the PII detection option display names.
|
| 285 |
+
|
| 286 |
+
* **`CHOSEN_COMPREHEND_ENTITIES`**
|
| 287 |
+
* **Description:** A list of AWS Comprehend PII entity types to be redacted when using AWS Comprehend.
|
| 288 |
+
* **Default Value:** A predefined list of entity types. Refer to `tools/config.py` for the complete list.
|
| 289 |
+
* **Configuration:** Set as an environment variable directly, or include in `config/app_config.env`. This should be a string representation of a Python list.
|
| 290 |
+
|
| 291 |
+
* **`FULL_COMPREHEND_ENTITY_LIST`**
|
| 292 |
+
* **Description:** The complete list of PII entity types supported by AWS Comprehend that can be selected for redaction.
|
| 293 |
+
* **Default Value:** A predefined list of entity types. Refer to `tools/config.py` for the complete list.
|
| 294 |
+
* **Configuration:** This is typically an informational variable reflecting the capabilities of AWS Comprehend and is not meant to be changed by users directly affecting redaction behavior (use `CHOSEN_COMPREHEND_ENTITIES` for that). Set as an environment variable directly, or include in `config/app_config.env`.
|
| 295 |
+
|
| 296 |
+
* **`CHOSEN_REDACT_ENTITIES`**
|
| 297 |
+
* **Description:** A list of local PII entity types to be redacted when using the local PII detection model.
|
| 298 |
+
* **Default Value:** A predefined list of entity types. Refer to `tools/config.py` for the complete list.
|
| 299 |
+
* **Configuration:** Set as an environment variable directly, or include in `config/app_config.env`. This should be a string representation of a Python list.
|
| 300 |
+
|
| 301 |
+
* **`FULL_ENTITY_LIST`**
|
| 302 |
+
* **Description:** The complete list of PII entity types supported by the local PII detection model that can be selected for redaction.
|
| 303 |
+
* **Default Value:** A predefined list of entity types. Refer to `tools/config.py` for the complete list.
|
| 304 |
+
* **Configuration:** This is typically an informational variable reflecting the capabilities of the local model and is not meant to be changed by users directly affecting redaction behavior (use `CHOSEN_REDACT_ENTITIES` for that). Set as an environment variable directly, or include in `config/app_config.env`.
|
| 305 |
+
|
| 306 |
+
* **`PAGE_BREAK_VALUE`**
|
| 307 |
+
* **Description:** Defines a page count after which a function might restart. (Note: Currently not activated).
|
| 308 |
+
* **Default Value:** `'99999'`
|
| 309 |
+
* **Configuration:** Set as an environment variable directly, or include in `config/app_config.env`.
|
| 310 |
+
|
| 311 |
+
* **`MAX_TIME_VALUE`**
|
| 312 |
+
* **Description:** Specifies the maximum time (in arbitrary units, likely seconds or milliseconds depending on implementation) for a process before it might be timed out.
|
| 313 |
+
* **Default Value:** `'999999'`
|
| 314 |
+
* **Configuration:** Set as an environment variable directly, or include in `config/app_config.env`.
|
| 315 |
+
|
| 316 |
+
* **`CUSTOM_BOX_COLOUR`**
|
| 317 |
+
* **Description:** Allows specifying a custom color for the redaction boxes drawn on documents (e.g., "grey", "red", "#FF0000"). If empty, a default color is used.
|
| 318 |
+
* **Default Value:** `""` (empty string)
|
| 319 |
+
* **Configuration:** Set as an environment variable directly, or include in `config/app_config.env`.
|
| 320 |
+
|
| 321 |
+
* **`REDACTION_LANGUAGE`**
|
| 322 |
+
* **Description:** Specifies the language for redaction processing. Currently, only "en" (English) is supported.
|
| 323 |
+
* **Default Value:** `"en"`
|
| 324 |
+
* **Configuration:** Set as an environment variable directly, or include in `config/app_config.env`.
|
| 325 |
+
|
| 326 |
+
* **`RETURN_PDF_END_OF_REDACTION`**
|
| 327 |
+
* **Description:** If set to `'True'`, the application will return a PDF document at the end of the redaction task.
|
| 328 |
+
* **Default Value:** `"True"`
|
| 329 |
+
* **Configuration:** Set as an environment variable directly, or include in `config/app_config.env`.
|
| 330 |
+
|
| 331 |
+
* **`COMPRESS_REDACTED_PDF`**
|
| 332 |
+
* **Description:** If set to `'True'`, the redacted PDF output will be compressed. This can reduce file size but may cause issues on systems with low memory.
|
| 333 |
+
* **Default Value:** `"False"`
|
| 334 |
+
* **Configuration:** Set as an environment variable directly, or include in `config/app_config.env`.
|
| 335 |
+
|
| 336 |
+
## App Run Options
|
| 337 |
+
|
| 338 |
+
General runtime configurations for the application.
|
| 339 |
+
|
| 340 |
+
* **`TLDEXTRACT_CACHE`**
|
| 341 |
+
* **Description:** Path to the cache file used by the `tldextract` library, which helps in accurately extracting top-level domains (TLDs) from URLs.
|
| 342 |
+
* **Default Value:** `'tld/.tld_set_snapshot'`
|
| 343 |
+
* **Configuration:** Set as an environment variable directly, or include in `config/app_config.env`.
|
| 344 |
+
|
| 345 |
+
* **`COGNITO_AUTH`**
|
| 346 |
+
* **Description:** Enables or disables AWS Cognito authentication for the application. Set to `'1'` to enable.
|
| 347 |
+
* **Default Value:** `'0'`
|
| 348 |
+
* **Configuration:** Set as an environment variable directly, or include in `config/app_config.env` (or `config/aws_config.env` if `AWS_CONFIG_PATH` is configured).
|
| 349 |
+
|
| 350 |
+
* **`RUN_DIRECT_MODE`**
|
| 351 |
+
* **Description:** If set to `'1'`, runs the application in a "direct mode", which might alter certain behaviors (e.g., UI elements, processing flow).
|
| 352 |
+
* **Default Value:** `'0'`
|
| 353 |
+
* **Configuration:** Set as an environment variable directly, or include in `config/app_config.env`.
|
| 354 |
+
|
| 355 |
+
* **`MAX_QUEUE_SIZE`**
|
| 356 |
+
* **Description:** The maximum number of requests that can be queued in the Gradio interface.
|
| 357 |
+
* **Default Value:** `'5'` (integer)
|
| 358 |
+
* **Configuration:** Set as an environment variable directly, or include in `config/app_config.env`.
|
| 359 |
+
|
| 360 |
+
* **`MAX_FILE_SIZE`**
|
| 361 |
+
* **Description:** Maximum file size allowed for uploads (e.g., "250mb", "1gb").
|
| 362 |
+
* **Default Value:** `'250mb'`
|
| 363 |
+
* **Configuration:** Set as an environment variable directly, or include in `config/app_config.env`.
|
| 364 |
+
|
| 365 |
+
* **`GRADIO_SERVER_PORT`**
|
| 366 |
+
* **Description:** The network port on which the Gradio server will listen.
|
| 367 |
+
* **Default Value:** `'7860'` (integer)
|
| 368 |
+
* **Configuration:** Set as an environment variable directly, or include in `config/app_config.env`.
|
| 369 |
+
|
| 370 |
+
* **`ROOT_PATH`**
|
| 371 |
+
* **Description:** The root path for the application, useful if running behind a reverse proxy (e.g., `/app`).
|
| 372 |
+
* **Default Value:** `''` (empty string)
|
| 373 |
+
* **Configuration:** Set as an environment variable directly, or include in `config/app_config.env`.
|
| 374 |
+
|
| 375 |
+
* **`DEFAULT_CONCURRENCY_LIMIT`**
|
| 376 |
+
* **Description:** The default concurrency limit for Gradio event handlers, controlling how many requests can be processed simultaneously.
|
| 377 |
+
* **Default Value:** `'3'`
|
| 378 |
+
* **Configuration:** Set as an environment variable directly, or include in `config/app_config.env`.
|
| 379 |
+
|
| 380 |
+
* **`GET_DEFAULT_ALLOW_LIST`**
|
| 381 |
+
* **Description:** If set, enables the use of a default allow list for user access or specific functionalities. The exact behavior depends on application logic.
|
| 382 |
+
* **Default Value:** `''` (empty string)
|
| 383 |
+
* **Configuration:** Set as an environment variable directly, or include in `config/app_config.env`.
|
| 384 |
+
|
| 385 |
+
* **`ALLOW_LIST_PATH`**
|
| 386 |
+
* **Description:** Path to a local CSV file containing an allow list (e.g., `config/default_allow_list.csv`).
|
| 387 |
+
* **Default Value:** `''` (empty string)
|
| 388 |
+
* **Configuration:** Set as an environment variable directly, or include in `config/app_config.env`.
|
| 389 |
+
|
| 390 |
+
* **`S3_ALLOW_LIST_PATH`**
|
| 391 |
+
* **Description:** Path to an allow list CSV file stored in an S3 bucket (e.g., `default_allow_list.csv`). Requires `DOCUMENT_REDACTION_BUCKET` to be set.
|
| 392 |
+
* **Default Value:** `''` (empty string)
|
| 393 |
+
* **Configuration:** Set as an environment variable directly, or include in `config/app_config.env` (or `config/aws_config.env` if `AWS_CONFIG_PATH` is configured).
|
| 394 |
+
|
| 395 |
+
* **`FILE_INPUT_HEIGHT`**
|
| 396 |
+
* **Description:** Sets the height (in pixels or other CSS unit) of the file input component in the Gradio UI.
|
| 397 |
+
* **Default Value:** `'200'`
|
| 398 |
+
* **Configuration:** Set as an environment variable directly, or include in `config/app_config.env`.
|
| 399 |
+
|
| 400 |
+
## Cost Code Options
|
| 401 |
+
|
| 402 |
+
Settings related to tracking and applying cost codes for application usage.
|
| 403 |
+
|
| 404 |
+
* **`SHOW_COSTS`**
|
| 405 |
+
* **Description:** If set to `'True'`, cost-related information will be displayed in the UI.
|
| 406 |
+
* **Default Value:** `'False'`
|
| 407 |
+
* **Configuration:** Set as an environment variable directly, or include in `config/app_config.env`.
|
| 408 |
+
|
| 409 |
+
* **`GET_COST_CODES`**
|
| 410 |
+
* **Description:** Enables fetching and using cost codes within the application. Set to `'True'` to enable.
|
| 411 |
+
* **Default Value:** `'False'`
|
| 412 |
+
* **Configuration:** Set as an environment variable directly, or include in `config/app_config.env`.
|
| 413 |
+
|
| 414 |
+
* **`DEFAULT_COST_CODE`**
|
| 415 |
+
* **Description:** Specifies a default cost code to be used if cost codes are enabled but none is selected by the user.
|
| 416 |
+
* **Default Value:** `''` (empty string)
|
| 417 |
+
* **Configuration:** Set as an environment variable directly, or include in `config/app_config.env`.
|
| 418 |
+
|
| 419 |
+
* **`COST_CODES_PATH`**
|
| 420 |
+
* **Description:** Path to a local CSV file containing available cost codes (e.g., `config/COST_CENTRES.csv`).
|
| 421 |
+
* **Default Value:** `''` (empty string)
|
| 422 |
+
* **Configuration:** Set as an environment variable directly, or include in `config/app_config.env`.
|
| 423 |
+
|
| 424 |
+
* **`S3_COST_CODES_PATH`**
|
| 425 |
+
* **Description:** Path to a cost codes CSV file stored in an S3 bucket (e.g., `COST_CENTRES.csv`). Requires `DOCUMENT_REDACTION_BUCKET` to be set.
|
| 426 |
+
* **Default Value:** `''` (empty string)
|
| 427 |
+
* **Configuration:** Set as an environment variable directly, or include in `config/app_config.env` (or `config/aws_config.env` if `AWS_CONFIG_PATH` is configured).
|
| 428 |
+
|
| 429 |
+
* **`ENFORCE_COST_CODES`**
|
| 430 |
+
* **Description:** If set to `'True'` and `GET_COST_CODES` is also enabled, makes the selection of a cost code mandatory for users.
|
| 431 |
+
* **Default Value:** `'False'`
|
| 432 |
+
* **Configuration:** Set as an environment variable directly, or include in `config/app_config.env`.
|
| 433 |
+
|
| 434 |
+
## Whole Document API Options
|
| 435 |
+
|
| 436 |
+
Configurations for features related to processing whole documents via APIs, particularly AWS Textract for large documents.
|
| 437 |
+
|
| 438 |
+
* **`SHOW_WHOLE_DOCUMENT_TEXTRACT_CALL_OPTIONS`**
|
| 439 |
+
* **Description:** Controls whether UI options for whole document Textract calls are displayed. (Note: Mentioned as not currently implemented in the source).
|
| 440 |
+
* **Default Value:** `'False'`
|
| 441 |
+
* **Configuration:** Set as an environment variable directly, or include in `config/app_config.env`.
|
| 442 |
+
|
| 443 |
+
* **`TEXTRACT_WHOLE_DOCUMENT_ANALYSIS_BUCKET`**
|
| 444 |
+
* **Description:** The S3 bucket used for input and output of whole document analysis with AWS Textract.
|
| 445 |
+
* **Default Value:** `''` (empty string)
|
| 446 |
+
* **Configuration:** Set as an environment variable directly, or include in `config/app_config.env` (or `config/aws_config.env` if `AWS_CONFIG_PATH` is configured).
|
| 447 |
+
|
| 448 |
+
* **`TEXTRACT_WHOLE_DOCUMENT_ANALYSIS_INPUT_SUBFOLDER`**
|
| 449 |
+
* **Description:** The subfolder within `TEXTRACT_WHOLE_DOCUMENT_ANALYSIS_BUCKET` where input documents for Textract analysis are placed.
|
| 450 |
+
* **Default Value:** `'input'`
|
| 451 |
+
* **Configuration:** Set as an environment variable directly, or include in `config/app_config.env` (or `config/aws_config.env` if `AWS_CONFIG_PATH` is configured).
|
| 452 |
+
|
| 453 |
+
* **`TEXTRACT_WHOLE_DOCUMENT_ANALYSIS_OUTPUT_SUBFOLDER`**
|
| 454 |
+
* **Description:** The subfolder within `TEXTRACT_WHOLE_DOCUMENT_ANALYSIS_BUCKET` where output results from Textract analysis are stored.
|
| 455 |
+
* **Default Value:** `'output'`
|
| 456 |
+
* **Configuration:** Set as an environment variable directly, or include in `config/app_config.env` (or `config/aws_config.env` if `AWS_CONFIG_PATH` is configured).
|
| 457 |
+
|
| 458 |
+
* **`LOAD_PREVIOUS_TEXTRACT_JOBS_S3`**
|
| 459 |
+
* **Description:** If set to `'True'`, the application will attempt to load data from previous Textract jobs stored in S3.
|
| 460 |
+
* **Default Value:** `'False'`
|
| 461 |
+
* **Configuration:** Set as an environment variable directly, or include in `config/app_config.env` (or `config/aws_config.env` if `AWS_CONFIG_PATH` is configured).
|
| 462 |
+
|
| 463 |
+
* **`TEXTRACT_JOBS_S3_LOC`**
|
| 464 |
+
* **Description:** The S3 subfolder (within `TEXTRACT_WHOLE_DOCUMENT_ANALYSIS_BUCKET`) where Textract job data (output) is stored.
|
| 465 |
+
* **Default Value:** `'output'`
|
| 466 |
+
* **Configuration:** Set as an environment variable directly, or include in `config/app_config.env` (or `config/aws_config.env` if `AWS_CONFIG_PATH` is configured).
|
| 467 |
+
|
| 468 |
+
* **`TEXTRACT_JOBS_S3_INPUT_LOC`**
|
| 469 |
+
* **Description:** The S3 subfolder (within `TEXTRACT_WHOLE_DOCUMENT_ANALYSIS_BUCKET`) where Textract job input is stored.
|
| 470 |
+
* **Default Value:** `'input'`
|
| 471 |
+
* **Configuration:** Set as an environment variable directly, or include in `config/app_config.env` (or `config/aws_config.env` if `AWS_CONFIG_PATH` is configured).
|
| 472 |
+
|
| 473 |
+
* **`TEXTRACT_JOBS_LOCAL_LOC`**
|
| 474 |
+
* **Description:** The local subfolder where Textract job data is stored if not using S3 or as a cache.
|
| 475 |
+
* **Default Value:** `'output'`
|
| 476 |
+
* **Configuration:** Set as an environment variable directly, or include in `config/app_config.env`.
|
| 477 |
+
|
| 478 |
+
* **`DAYS_TO_DISPLAY_WHOLE_DOCUMENT_JOBS`**
|
| 479 |
+
* **Description:** Specifies the number of past days for which to display whole document Textract jobs in the UI.
|
| 480 |
+
* **Default Value:** `'7'`
|
| 481 |
+
* **Configuration:** Set as an environment variable directly, or include in `config/app_config.env`.
|
src/faq.qmd
ADDED
|
@@ -0,0 +1,222 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: "User FAQ"
|
| 3 |
+
format:
|
| 4 |
+
html:
|
| 5 |
+
toc: true # Enable the table of contents
|
| 6 |
+
toc-depth: 3 # Include headings up to level 2 (##)
|
| 7 |
+
toc-title: "On this page" # Optional: Title for your TOC
|
| 8 |
+
---
|
| 9 |
+
|
| 10 |
+
## General Advice:
|
| 11 |
+
* **Read the User Guide**: Many common questions are addressed in the detailed User Guide sections.
|
| 12 |
+
* **Start Simple**: If you're new, try redacting with default options first before customising extensively.
|
| 13 |
+
* **Human Review is Key**: Always manually review the `...redacted.pdf` or use the '**Review redactions**' tab. No automated system is perfect.
|
| 14 |
+
* **Save Incrementally**: When working on the '**Review redactions**' tab, use the '**Save changes on current page to file**' button periodically, especially for large documents.
|
| 15 |
+
|
| 16 |
+
## General questions
|
| 17 |
+
|
| 18 |
+
#### What is document redaction and what does this app do?
|
| 19 |
+
Document redaction is the process of removing sensitive or personally identifiable information (PII) from documents. This application is a tool that automates this process for various document types, including PDFs, images, open text, and tabular data (`XLSX`/`CSV`/`Parquet`). It identifies potential PII using different methods and allows users to review, modify, and export the suggested redactions.
|
| 20 |
+
|
| 21 |
+
#### What types of documents and data can be redacted?
|
| 22 |
+
The app can handle a variety of formats. For documents, it supports `PDF`s and images (`JPG`, `PNG`). For tabular data, it works with `XLSX`, `CSV`, and `Parquet` files. Additionally, it can redact open text that is copied and pasted directly into the application interface.
|
| 23 |
+
|
| 24 |
+
#### How does the app identify text and PII for redaction?
|
| 25 |
+
The app employs several methods for text extraction and PII identification. Text can be extracted directly from selectable `PDF` text, using a local Optical Character Recognition (OCR) model for image-based content, or through the **AWS Textract service** for more complex documents, handwriting, and signatures (if available). For PII identification, it can use a local model based on the `spacy` package or the **AWS Comprehend service** for more accurate results (if available).
|
| 26 |
+
|
| 27 |
+
#### Can I customise what information is redacted?
|
| 28 |
+
Yes, the app offers extensive customisation options. You can define terms that should never be redacted (an '**allow list**'), terms that should always be redacted (a '**deny list**'), and specify entire pages to be fully redacted using `CSV` files. You can also select specific types of entities to redact, such as dates, or remove default entity types that are not relevant to your needs.
|
| 29 |
+
|
| 30 |
+
#### How can I review and modify the suggested redactions?
|
| 31 |
+
The app provides a dedicated '**Review redactions**' tab with a visual interface. You can upload the original document and the generated review file (`CSV`) to see the suggested redactions overlaid on the document. Here, you can move, resize, delete, and add new redaction boxes. You can also filter suggested redactions based on criteria and exclude them individually or in groups.
|
| 32 |
+
|
| 33 |
+
#### Can I work with tabular data or copy and pasted text?
|
| 34 |
+
Yes, the app has a dedicated tab for redacting tabular data files (`XLSX`/`CSV`) and open text. For tabular data, you can upload your file and select which columns to redact. For open text, you can simply paste the text into a box. You can then choose the redaction method and the desired output format for the anonymised data.
|
| 35 |
+
|
| 36 |
+
#### What are the options for the anonymisation format of redacted text?
|
| 37 |
+
When redacting tabular data or open text, you have several options for how the redacted information is replaced. The default is to replace the text with '**REDACTED**'. Other options include replacing it with the entity type (e.g., 'PERSON'), redacting completely (removing the text), replacing it with a consistent hash value, or masking it with stars ('*').
|
| 38 |
+
|
| 39 |
+
#### Can I export or import redactions to/from other software like Adobe Acrobat?
|
| 40 |
+
Yes, the app supports exporting and importing redaction data using the **Adobe Acrobat** comment file format (`.xfdf`). You can export suggested redactions from the app to an `.xfdf` file that can be opened in **Adobe**. Conversely, you can import an `.xfdf` file created in **Adobe** into the app to generate a review file (`CSV`) for further work within the application.
|
| 41 |
+
|
| 42 |
+
## Troubleshooting
|
| 43 |
+
|
| 44 |
+
#### Q1: The app missed some personal information or redacted things it shouldn't have. Is it broken?
|
| 45 |
+
A: Not necessarily. The app is not 100% accurate and is designed as an aid. The `README` explicitly states: "**NOTE: The app is not 100% accurate, and it will miss some personal information. It is essential that all outputs are reviewed by a human before using the final outputs.**"
|
| 46 |
+
* **Solution**: Always use the '**Review redactions**' tab to manually inspect, add, remove, or modify redactions.
|
| 47 |
+
|
| 48 |
+
#### Q2: I uploaded a `PDF`, but no text was found, or redactions are very poor using the '**Local model - selectable text**' option.
|
| 49 |
+
A: This option only works if your `PDF` has actual selectable text. If your `PDF` is an image scan (even if it looks like text), this method won't work well.
|
| 50 |
+
* **Solution**:
|
| 51 |
+
* Try the '**Local OCR model - PDFs without selectable text**' option. This uses Tesseract OCR to "read" the text from images.
|
| 52 |
+
* For best results, especially with complex documents, handwriting, or signatures, use the '**AWS Textract service - all PDF types**' if available.
|
| 53 |
+
|
| 54 |
+
#### Q3: Handwriting or signatures are not being redacted properly.
|
| 55 |
+
A: The '**Local**' text/OCR methods (selectable text or Tesseract) struggle with handwriting and signatures.
|
| 56 |
+
* **Solution**:
|
| 57 |
+
* Use the '**AWS Textract service**' for text extraction.
|
| 58 |
+
* Ensure that on the main '**Redact PDFs/images**' tab, under "**Optional - select signature extraction**" (when **AWS Textract** is chosen), you have enabled handwriting and/or signature detection. Note that signature detection has higher cost implications.
|
| 59 |
+
|
| 60 |
+
#### Q4: The options for '**AWS Textract service**' or '**AWS Comprehend**' are missing or greyed out.
|
| 61 |
+
A: These services are typically only available when the app is running in an **AWS** environment or has been specifically configured by your system admin to access these services (e.g., via `API` keys).
|
| 62 |
+
* **Solution**:
|
| 63 |
+
* Check if your instance of the app is supposed to have **AWS** services enabled.
|
| 64 |
+
* If running outside **AWS**, see the "**Using AWS Textract and Comprehend when not running in an AWS environment**" section in the advanced guide. This involves configuring **AWS** access keys, which should be done with IT and data security approval.
|
| 65 |
+
|
| 66 |
+
#### Q5: I re-processed the same document, and it seems to be taking a long time and potentially costing more with **AWS** services. Can I avoid this?
|
| 67 |
+
A: Yes. If you have previously processed a document with **AWS Textract** or the **Local OCR** model, the app generates a `.json` output file (`..._textract.json` or `..._ocr_results_with_words.json`).
|
| 68 |
+
* **Solution**: When re-uploading your original document for redaction, also upload the corresponding `.json` file. The app should detect this (the "**Existing Textract output file found**" box may be checked), skipping the expensive text extraction step.
|
| 69 |
+
|
| 70 |
+
#### Q6: My app crashed, or I reloaded the page. Are my output files lost?
|
| 71 |
+
A: If you are logged in via **AWS Cognito** and the server hasn't been shut down, you might be able to recover them.
|
| 72 |
+
* **Solution**: Go to the '**Redaction settings**' tab, scroll to the bottom, and look for '**View all output files from this session**'.
|
| 73 |
+
|
| 74 |
+
#### Q7: My custom allow list (terms to never redact) or deny list (terms to always redact) isn't working.
|
| 75 |
+
A: There are a few common reasons:
|
| 76 |
+
* **File Format**: Ensure your list is a `.csv` file with terms in the first column only, with no column header.
|
| 77 |
+
* **Case Sensitivity**: Terms in the allow/deny list are case sensitive.
|
| 78 |
+
* **Deny List & 'CUSTOM' Entity**: For a deny list to work, you must select the '**CUSTOM**' entity type in '**Redaction settings**' under '**Entities to redact**'.
|
| 79 |
+
* **Manual Additions**: If you manually added terms in the app interface (under '**Manually modify custom allow...**'), ensure you pressed `Enter` after typing each term in its cell.
|
| 80 |
+
* **Fuzzy Search for Deny List**: If you intend to use fuzzy matching for your deny list, ensure '**CUSTOM_FUZZY**' is selected as an entity type, and you've configured the "**maximum number of spelling mistakes allowed.**"
|
| 81 |
+
|
| 82 |
+
#### Q8: I'm trying to review redactions, but the `PDF` in the viewer looks like it's already redacted with black boxes.
|
| 83 |
+
A: You likely uploaded the `...redacted.pdf` file instead of the original document.
|
| 84 |
+
* **Solution**: On the '**Review redactions**' tab, ensure you upload the original, unredacted `PDF` alongside the `..._review_file.csv`.
|
| 85 |
+
|
| 86 |
+
#### Q9: I can't move or pan the document in the '**Review redactions**' viewer when zoomed in.
|
| 87 |
+
A: You are likely in "**add redaction boxes**" mode.
|
| 88 |
+
* **Solution**: Scroll to the bottom of the document viewer pane and click the hand icon. This switches to "**modify mode**," allowing you to pan the document by clicking and dragging, and also to move/resize existing redaction boxes.
|
| 89 |
+
|
| 90 |
+
#### Q10: I accidentally clicked "**Exclude all items in table from redactions**" on the '**Review redactions**' tab without filtering, and now all my redactions are gone!
|
| 91 |
+
A: This can happen if you don't apply a filter first.
|
| 92 |
+
* **Solution**: Click the '**Undo last element removal**' button immediately. This should restore the redactions. Always ensure you have clicked the blue tick icon next to the search box to apply your filter before using "**Exclude all items...**".
|
| 93 |
+
|
| 94 |
+
#### Q11: Redaction of my `CSV` or `XLSX` file isn't working correctly.
|
| 95 |
+
A: The app expects a specific format for tabular data.
|
| 96 |
+
* **Solution**: Ensure your data file has a simple table format, with the table starting in the first cell (`A1`). There should be no other information or multiple tables within the sheet you intend to redact. For `XLSX` files, each sheet to be redacted must follow this format.
|
| 97 |
+
|
| 98 |
+
#### Q12: The "**Identify duplicate pages**" feature isn't finding duplicates I expect, or it's flagging too many pages.
|
| 99 |
+
A: This feature uses text similarity based on the `ocr_outputs.csv` files and has a default similarity threshold (e.g., 90%).
|
| 100 |
+
* **Solution**:
|
| 101 |
+
* Ensure you've uploaded the correct `ocr_outputs.csv` files for all documents you're comparing.
|
| 102 |
+
* Review the `page_similarity_results.csv` output to see the similarity scores. The 90% threshold might be too high or too low for your specific documents. The current version of the app described doesn't seem to allow changing this threshold in the `UI`, so you'd mainly use the output to inform your manual review.
|
| 103 |
+
|
| 104 |
+
#### Q13: I exported a review file to Adobe (`.xfdf`), but when I open it in Adobe Acrobat, it can't find the `PDF` or shows no redactions.
|
| 105 |
+
A: When **Adobe Acrobat** prompts you, it needs to be pointed to the exact original `PDF`.
|
| 106 |
+
* **Solution**: Ensure you select the original, unredacted `PDF` file that was used to generate the `..._review_file.csv` (and subsequently the `.xfdf` file) when **Adobe Acrobat** asks for the associated document.
|
| 107 |
+
|
| 108 |
+
#### Q14: My **AWS Textract API** job (submitted via "**Submit whole document to AWS Textract API...**") is taking a long time, or I don't know if it's finished.
|
| 109 |
+
A: Large documents can take time. The document estimates about five seconds per page as a rough guide.
|
| 110 |
+
* **Solution**:
|
| 111 |
+
* After submitting, a **Job ID** will appear.
|
| 112 |
+
* Periodically click the '**Check status of Textract job and download**' button. Processing continues in the background.
|
| 113 |
+
* Once ready, the `_textract.json` output will appear in the output area.
|
| 114 |
+
|
| 115 |
+
#### Q15: I'm trying to redact specific terms from my deny list, but they are not being picked up, even though the '**CUSTOM**' entity is selected.
|
| 116 |
+
A: The deny list matches whole words with exact spelling by default.
|
| 117 |
+
* **Solution**:
|
| 118 |
+
* Double-check the spelling and case in your deny list.
|
| 119 |
+
* If you expect misspellings to be caught, you need to use the '**CUSTOM_FUZZY**' entity type and configure the "**maximum number of spelling mistakes allowed**" under '**Redaction settings**'. Then, upload your deny list.
|
| 120 |
+
|
| 121 |
+
#### Q16: I set the "**Lowest page to redact**" and "**Highest page to redact**" in '**Redaction settings**', but the app still seems to process or show redactions outside this range.
|
| 122 |
+
A: The page range setting primarily controls which pages have redactions applied in the final `...redacted.pdf`. The underlying text extraction (especially with OCR/Textract) might still process the whole document to generate the `...ocr_results.csv` or `..._textract.json`. When reviewing, the `review_file.csv` might initially contain all potential redactions found across the document.
|
| 123 |
+
* **Solution**:
|
| 124 |
+
* Ensure the `...redacted.pdf` correctly reflects the page range.
|
| 125 |
+
* When reviewing, use the page navigation and filters on the '**Review redactions**' tab to focus on your desired page range. The final application of redactions from the review tab should also respect the range if it's still set, but primarily it works off the `review_file.csv`.
|
| 126 |
+
|
| 127 |
+
#### Q17: My "**Full page redaction list**" isn't working. I uploaded a `CSV` with page numbers, but those pages aren't blacked out.
|
| 128 |
+
A: Common issues include:
|
| 129 |
+
* **File Format**: Ensure your list is a `.csv` file with page numbers in the first column only, with no column header. Each page number should be on a new row.
|
| 130 |
+
* **Redaction Task**: Simply uploading the list doesn't automatically redact. You need to:
|
| 131 |
+
1. Upload the `PDF` you want to redact.
|
| 132 |
+
2. Upload the full page redaction `CSV` in '**Redaction settings**'.
|
| 133 |
+
3. It's often best to deselect all other entity types in '**Redaction settings**' if you only want to redact these full pages.
|
| 134 |
+
4. Run the '**Redact document**' process. The output `...redacted.pdf` should show the full pages redacted, and the `...review_file.csv` will list these pages.
|
| 135 |
+
|
| 136 |
+
#### Q18: I merged multiple `...review_file.csv` files, but the output seems to have duplicate redaction boxes or some are missing.
|
| 137 |
+
A: The merge feature simply combines all rows from the input review files.
|
| 138 |
+
* **Solution**:
|
| 139 |
+
* **Duplicates**: If the same redaction (same location, text, label) was present in multiple input files, it will appear multiple times in the merged file. You'll need to manually remove these duplicates on the '**Review redactions**' tab or by editing the merged `...review_file.csv` in a spreadsheet editor before review.
|
| 140 |
+
* **Missing**: Double-check that all intended `...review_file.csv` files were correctly uploaded for the merge. Ensure the files themselves contained the expected redactions.
|
| 141 |
+
|
| 142 |
+
#### Q19: I imported an `.xfdf` Adobe comment file, but the `review_file.csv` generated doesn't accurately reflect the highlights or comments I made in Adobe Acrobat.
|
| 143 |
+
A: The app converts Adobe's comment/highlight information into its review_file format. Discrepancies can occur if:
|
| 144 |
+
* **Comment Types**: The app primarily looks for highlight-style annotations that it can interpret as redaction areas. Other Adobe comment types (e.g., sticky notes without highlights, text strike-throughs not intended as redactions) might not translate.
|
| 145 |
+
* **Complexity**: Very complex or unusually shaped Adobe annotations might not convert perfectly.
|
| 146 |
+
* **PDF Version**: Ensure the `PDF` uploaded alongside the `.xfdf` is the exact same original, unredacted `PDF` that the comments were made on in Adobe.
|
| 147 |
+
* **Solution**: After import, always open the generated `review_file.csv` (with the original `PDF`) on the '**Review redactions**' tab to verify and adjust as needed.
|
| 148 |
+
|
| 149 |
+
#### Q20: The **Textract API** job status table (under "**Submit whole document to AWS Textract API...**") only shows recent jobs, or I can't find an older **Job ID** I submitted.
|
| 150 |
+
A: The table showing **Textract** job statuses might have a limit or only show jobs from the current session or within a certain timeframe (e.g., "up to seven days old" is mentioned).
|
| 151 |
+
* **Solution**:
|
| 152 |
+
* It's good practice to note down the **Job ID** immediately after submission if you plan to check it much later.
|
| 153 |
+
* If the `_textract.json` file was successfully created from a previous job, you can re-upload that `.json` file with your original `PDF` to bypass the `API` call and proceed directly to redaction or OCR conversion.
|
| 154 |
+
|
| 155 |
+
#### Q21: I edited a `...review_file.csv` in Excel (e.g., changed coordinates, labels, colors), but when I upload it to the '**Review redactions**' tab, the boxes are misplaced, the wrong color, or it causes errors.
|
| 156 |
+
A: The `review_file.csv` has specific columns and data formats (e.g., coordinates, `RGB` color tuples like `(0,0,255)`).
|
| 157 |
+
* **Solution**:
|
| 158 |
+
* **Coordinates (xmin, ymin, xmax, ymax)**: Ensure these are numeric and make sense for `PDF` coordinates. Drastic incorrect changes can misplace boxes.
|
| 159 |
+
* **Colors**: Ensure the color column uses the `(R,G,B)` format, e.g., `(0,0,255)` for blue, not hex codes or color names, unless the app specifically handles that (the guide mentions `RGB`).
|
| 160 |
+
* **CSV Integrity**: Ensure you save the file strictly as a `CSV`. Excel sometimes adds extra formatting or changes delimiters if not saved carefully.
|
| 161 |
+
* **Column Order**: Do not change the order of columns in the `review_file.csv`.
|
| 162 |
+
* **Test Small Changes**: Modify one or two rows/values first to see the effect before making bulk changes.
|
| 163 |
+
|
| 164 |
+
#### Q22: The cost and time estimation feature isn't showing up, or it's giving unexpected results.
|
| 165 |
+
A: This feature depends on admin configuration and certain conditions.
|
| 166 |
+
* **Solution**:
|
| 167 |
+
* **Admin Enabled**: Confirm with your system admin that the cost/time estimation feature is enabled in the app's configuration.
|
| 168 |
+
* **AWS Services**: Estimation is typically most relevant when using **AWS Textract** or **Comprehend**. If you're only using '**Local**' models, the estimation might be simpler or not show **AWS**-related costs.
|
| 169 |
+
* **Existing Output**: If "**Existing Textract output file found**" is checked (because you uploaded a pre-existing `_textract.json`), the estimated cost and time should be significantly lower for the **Textract** part of the process.
|
| 170 |
+
|
| 171 |
+
#### Q23: I'm prompted for a "**cost code**," but I don't know what to enter, or my search isn't finding it.
|
| 172 |
+
A: Cost code selection is an optional feature enabled by system admins for tracking **AWS** usage.
|
| 173 |
+
* **Solution**:
|
| 174 |
+
* **Contact Admin/Team**: If you're unsure which cost code to use, consult your team lead or the system administrator who manages the redaction app. They should provide the correct code or guidance.
|
| 175 |
+
* **Search Tips**: Try searching by project name, department, or any known identifiers for your cost center. The search might be case-sensitive or require exact phrasing.
|
| 176 |
+
|
| 177 |
+
#### Q24: I selected "**hash**" as the anonymisation output format for my tabular data, but the output still shows "**REDACTED**" or something else.
|
| 178 |
+
A: Ensure the selection was correctly registered before redacting.
|
| 179 |
+
* **Solution**:
|
| 180 |
+
* Double-check on the '**Open text or Excel/csv files**' tab, under '**Anonymisation output format**,' that "**hash**" (or your desired format) is indeed selected.
|
| 181 |
+
* Try re-selecting it and then click '**Redact text/data files**' again.
|
| 182 |
+
* If the issue persists, it might be a bug or a specific interaction with your data type that prevents hashing. Report this to your app administrator. "**Hash**" should replace PII with a consistent unique `ID` for each unique piece of PII.
|
| 183 |
+
|
| 184 |
+
#### Q25: I'm using '**CUSTOM_FUZZY**' for my deny list. I have "**Should fuzzy search match on entire phrases in deny list**" checked, but it's still matching individual words within my phrases or matching things I don't expect.
|
| 185 |
+
A: Fuzzy matching on entire phrases can be complex. The "**maximum number of spelling mistakes allowed**" applies to the entire phrase.
|
| 186 |
+
* **Solution**:
|
| 187 |
+
* **Mistake Count**: If your phrase is long and the allowed mistakes are few, it might not find matches if the errors are distributed. Conversely, too many allowed mistakes on a short phrase can lead to over-matching. Experiment with the mistake count.
|
| 188 |
+
* **Specificity**: If "**match on entire phrases**" is unchecked, it will fuzzy match each individual word (excluding stop words) in your deny list phrases. This can be very broad. Ensure this option is set according to your needs.
|
| 189 |
+
* **Test with Simple Phrases**: Try a very simple phrase with a known, small number of errors to see if the core fuzzy logic is working as you expect, then build up complexity.
|
| 190 |
+
|
| 191 |
+
#### Q26: I "**locked in**" a new redaction box format on the '**Review redactions**' tab (label, colour), but now I want to change it or go back to the pop-up for each new box.
|
| 192 |
+
A: When a format is locked, a new icon (described as looking like a "**gift tag**") appears at the bottom of the document viewer.
|
| 193 |
+
* **Solution**:
|
| 194 |
+
* Click the "**gift tag**" icon at the bottom of the document viewer pane.
|
| 195 |
+
* This will allow you to change the default locked format.
|
| 196 |
+
* To go back to the pop-up appearing for each new box, click the lock icon within that "**gift tag**" menu again to "**unlock**" it (it should turn from blue to its original state).
|
| 197 |
+
|
| 198 |
+
#### Q27: I clicked "**Redact document**," processing seemed to complete (e.g., progress bar finished, "complete" message shown), but no output files (`...redacted.pdf`, `...review_file.csv`) appeared in the output area.
|
| 199 |
+
A: This could be due to various reasons:
|
| 200 |
+
* **No PII Found**: If absolutely no PII was detected according to your settings (entities, allow/deny lists), the app might not generate a `...redacted.pdf` if there's nothing to redact, though a `review_file.csv` (potentially empty) and `ocr_results.csv` should still ideally appear.
|
| 201 |
+
* **Error During File Generation**: An unhandled error might have occurred silently during the final file creation step.
|
| 202 |
+
* **Browser/UI Issue**: The `UI` might not have refreshed to show the files.
|
| 203 |
+
* **Permissions**: In rare cases, if running locally, there might be file system permission issues preventing the app from writing outputs.
|
| 204 |
+
* **Solution**:
|
| 205 |
+
* Try refreshing the browser page (if feasible without losing input data, or after re-uploading).
|
| 206 |
+
* Check the '**Redaction settings**' tab for '**View all output files from this session**' (if logged in via Cognito) – they might be listed there.
|
| 207 |
+
* Try a very simple document with obvious PII and default settings to see if any output is generated.
|
| 208 |
+
* Check browser developer console (`F12`) for any error messages.
|
| 209 |
+
|
| 210 |
+
#### Q28: When reviewing, I click on a row in the '**Search suggested redactions**' table. The page changes, but the specific redaction box isn't highlighted, or the view doesn't scroll to it.
|
| 211 |
+
A: The highlighting feature ("should change the colour of redaction box to blue") is an aid.
|
| 212 |
+
* **Solution**:
|
| 213 |
+
* Ensure you are on the correct page. The table click should take you there.
|
| 214 |
+
* The highlighting might be subtle or conflict with other `UI` elements. Manually scan the page for the text/label mentioned in the table row.
|
| 215 |
+
* Scrolling to the exact box isn't explicitly guaranteed, especially on very dense pages. The main function is page navigation.
|
| 216 |
+
|
| 217 |
+
#### Q29: I rotated a page in the '**Review redactions**' document viewer, and now all subsequent pages are also rotated, or if I navigate away and back, the rotation is lost.
|
| 218 |
+
A: The `README` states: "**When you switch page, the viewer will stay in your selected orientation, so if it looks strange, just rotate the page again and hopefully it will look correct!**"
|
| 219 |
+
* **Solution**:
|
| 220 |
+
* The rotation is a viewing aid for the current page session in the viewer. It does not permanently alter the original `PDF`.
|
| 221 |
+
* If subsequent pages appear incorrectly rotated, use the rotation buttons again for that new page.
|
| 222 |
+
* The rotation state might reset if you reload files or perform certain actions. Simply re-apply rotation as needed for viewing.
|
src/installation_guide.qmd
ADDED
|
@@ -0,0 +1,233 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: "App installation guide (with CDK)"
|
| 3 |
+
format:
|
| 4 |
+
html:
|
| 5 |
+
toc: true # Enable the table of contents
|
| 6 |
+
toc-depth: 3 # Include headings up to level 2 (##)
|
| 7 |
+
toc-title: "On this page" # Optional: Title for your TOC
|
| 8 |
+
---
|
| 9 |
+
|
| 10 |
+
# Introduction
|
| 11 |
+
|
| 12 |
+
This guide gives an overview of how to install the app in an AWS environment using the code in the cdk/ folder of this Github repo. The most important thing you need is some familiarity with AWS and how to use it via console or command line, as well as administrator access to at least one region. Then follow the below steps.
|
| 13 |
+
|
| 14 |
+
## Prerequisites
|
| 15 |
+
|
| 16 |
+
* Install git on your computer from: [https://git-scm.com](https://git-scm.com)
|
| 17 |
+
* You will also need to install nodejs and npm: [https://docs.npmjs.com/downloading-and-installing-node-js-and-npm](https://docs.npmjs.com/downloading-and-installing-node-js-and-npm)
|
| 18 |
+
* You will need an AWS Administrator account in your desired region to install.
|
| 19 |
+
* You will need AWS CDK v2 installed: [https://docs.aws.amazon.com/cli/latest/userguide/getting-started-install.html](https://docs.aws.amazon.com/cli/latest/userguide/getting-started-install.html)
|
| 20 |
+
* You will need to bootstrap the environment with CDK in both your primary region, and `us-east-1` if installing CloudFront and associated WAF.
|
| 21 |
+
```bash
|
| 22 |
+
# Bootstrap your primary region
|
| 23 |
+
cdk bootstrap aws://<YOUR_AWS_ACCOUNT>/eu-west-1
|
| 24 |
+
|
| 25 |
+
# Bootstrap the us-east-1 region
|
| 26 |
+
cdk bootstrap aws://<YOUR_AWS_ACCOUNT>/us-east-1
|
| 27 |
+
```
|
| 28 |
+
* In command line, write:
|
| 29 |
+
```bash
|
| 30 |
+
git clone https://github.com/seanpedrick-case/doc_redaction.git
|
| 31 |
+
```
|
| 32 |
+
|
| 33 |
+
# VPC ACM Certificate
|
| 34 |
+
|
| 35 |
+
This CDK code is designed to work within an existing VPC. The code does not create a new VPC if it doesn't exist. So you will need to do that yourself.
|
| 36 |
+
|
| 37 |
+
Additionally, to get full HTTPS data transfer through the app, you will need an SSL certificate registered with AWS Certificate Manager.
|
| 38 |
+
|
| 39 |
+
You can either use the SSL certificate from a domain, or import an existing certificate into Certificate Manager. Ask your IT admin if you need help with this.
|
| 40 |
+
|
| 41 |
+
## If getting an SSL certificate for an existing domain
|
| 42 |
+
|
| 43 |
+
Make sure to point the certificate to `*.<domain-name>`.
|
| 44 |
+
|
| 45 |
+
Update your DNS records to include the CNAME record given by AWS. After your stack has been created, you will also need to create a CNAME DNS record for your domain pointing to your load balancer DNS with a subdomain, e.g., `redaction.<domain-name>`.
|
| 46 |
+
|
| 47 |
+
1. Create a python environment, load in packages from `requirements.txt`.
|
| 48 |
+
|
| 49 |
+
Need a `cdk.json` in the `cdk` folder. It should contain the following:
|
| 50 |
+
|
| 51 |
+
```json
|
| 52 |
+
{
|
| 53 |
+
"app": "<PATH TO PYTHON ENVIRONMENT FOLDER WHERE REQUIREMENTS HAVE BEEN LOADED>python.exe app.py",
|
| 54 |
+
"context": {
|
| 55 |
+
"@aws-cdk/aws-apigateway:usagePlanKeyOrderInsensitiveId": true,
|
| 56 |
+
"@aws-cdk/core:stackRelativeExports": true,
|
| 57 |
+
"@aws-cdk/aws-rds:lowercaseDbIdentifier": true,
|
| 58 |
+
"@aws-cdk/aws-lambda:recognizeVersionProps": true,
|
| 59 |
+
"@aws-cdk/aws-lambda:recognizeLayerVersion": true,
|
| 60 |
+
"@aws-cdk/aws-cloudfront:defaultSecurityPolicyTLSv1.2_2021": true,
|
| 61 |
+
"@aws-cdk/aws-ecs:arnFormatIncludesClusterName": true,
|
| 62 |
+
"@aws-cdk/core:newStyleStackSynthesis": true,
|
| 63 |
+
"aws-cdk:enableDiffNoFail": true,
|
| 64 |
+
"@aws-cdk/aws-ec2:restrictDefaultSecurityGroup": true,
|
| 65 |
+
"@aws-cdk/aws-apigateway:disableCloudWatchRole": true,
|
| 66 |
+
"@aws-cdk/core:target-partitions": [
|
| 67 |
+
"aws",
|
| 68 |
+
"aws-cn"
|
| 69 |
+
]
|
| 70 |
+
}
|
| 71 |
+
}
|
| 72 |
+
```
|
| 73 |
+
|
| 74 |
+
2. Create a `cdk_config.env` file in the `config` subfolder. Here as a minimum it would be useful to put the following details in the env file (below are example values, other possible variables to use here can be seen in the `cdk` folder/`cdk_config.py`).
|
| 75 |
+
|
| 76 |
+
```ini
|
| 77 |
+
CDK_PREFIX=example-prefix # Prefix to most created elements in your stack
|
| 78 |
+
VPC_NAME=example-vpc-name # Name of the VPC within which all the other elements will be created
|
| 79 |
+
AWS_REGION=us-west-1 # Region where elements will be created
|
| 80 |
+
AWS_ACCOUNT_ID=1234567890 # AWS account ID that has administrator access that you will use for deploying the stack
|
| 81 |
+
CDK_FOLDER=C:/path_to_cdk_folder/ # The place where the cdk folder code is located
|
| 82 |
+
CONTEXT_FILE=C:/path_to_cdk_folder/cdk.context.json
|
| 83 |
+
EXISTING_IGW_ID=igw-1234567890 # (optional) The ID for an existing internet gateway that you want to use instead of creating a new one
|
| 84 |
+
SINGLE_NAT_GATEWAY_ID=nat-123456789 # (optional) The ID for an existing NAT gateway that you want to use instead of creating a new one
|
| 85 |
+
COGNITO_USER_POOL_DOMAIN_PREFIX=lambeth-redaction-37924 # The prefix of the login / user sign up domain that you want to use with Cognito login. Should not contain the terms amazon, aws, or cognito.
|
| 86 |
+
RUN_USEAST_STACK=False # Set this to True only if you have permissions to create a Cloudfront distribution and web ACL on top of it in the us-east-1 region. If you don't, the section below shows how you can create the CloudFront resource manually and map it to your application load balancer (as you should have permissions for that if you are admin in your region).
|
| 87 |
+
```
|
| 88 |
+
|
| 89 |
+
**Note: If you are using an SSL certificate with Cognito login on the application load balancer, you can set COGNITO_AUTH to 0 above, as you don't need the second login step to get to the app**
|
| 90 |
+
|
| 91 |
+
# Subnets
|
| 92 |
+
|
| 93 |
+
### NOTE: I would generally advise creating new subnets as then you will be sure about connectivity between AWS resources that underpin your app.
|
| 94 |
+
|
| 95 |
+
* If you set no subnets, the app will try to use existing private and public subnets. This approach is risky as the app may overlap with IP addresses assigned to existing AWS resources. It is advised to at least specify existing subnets that you know are available, or create your own using one of the below methods.
|
| 96 |
+
|
| 97 |
+
* If you want to use existing subnets, you can list them in the following environment variables:
|
| 98 |
+
* `PUBLIC_SUBNETS_TO_USE=["PublicSubnet1", "PublicSubnet2", "PublicSubnet3"]`
|
| 99 |
+
* `PRIVATE_SUBNETS_TO_USE=["PrivateSubnet1", "PrivateSubnet2", "PrivateSubnet3"]`
|
| 100 |
+
|
| 101 |
+
* If you want to create new subnets, you need to also specify CIDR blocks and availability zones for the new subnets. The app will check with you upon deployment whether these CIDR blocks are available before trying to create.
|
| 102 |
+
* `PUBLIC_SUBNET_CIDR_BLOCKS=['10.222.333.0/28', '10.222.333.16/28', '10.222.333.32/28']`
|
| 103 |
+
* `PUBLIC_SUBNET_AVAILABILITY_ZONES=['eu-east-1a', 'eu-east-1b', 'eu-east-1c']`
|
| 104 |
+
* `PRIVATE_SUBNET_CIDR_BLOCKS=['10.222.333.48/28', '10.222.333.64/28', '10.222.333.80/28']`
|
| 105 |
+
* `PRIVATE_SUBNET_AVAILABILITY_ZONES=['eu-east-1a', 'eu-east-1b', 'eu-east-1c']`
|
| 106 |
+
|
| 107 |
+
If you try to create subnets in invalid CIDR blocks / availability zones, the console output will tell you and it will show you the currently occupied CIDR blocks to help find a space for new subnets you want to create.
|
| 108 |
+
|
| 109 |
+
3. In command line in console, go to your `cdk` folder in the redaction app folder. Run `cdk deploy --all`. This should try to deploy the first stack in the `app.py` file.
|
| 110 |
+
|
| 111 |
+
Hopefully everything will deploy successfully and you will be able to see your new stack in CloudFormation in the AWS console.
|
| 112 |
+
|
| 113 |
+
4. Tasks for after CDK deployment
|
| 114 |
+
|
| 115 |
+
# Tasks performed by `post_cdk_build_quickstart.py`
|
| 116 |
+
|
| 117 |
+
**Note:** The following tasks are done by the `post_cdk_build_quickstart.py` file that you can find in the `cdk` folder. You will need to run this when logged in with AWS SSO through command line. I will describe how to do this in AWS console just in case the `.py` file doesn't work for you.
|
| 118 |
+
|
| 119 |
+
## Codebuild
|
| 120 |
+
|
| 121 |
+
Need to build CodeBuild project after stack has finished building, as there will be no container in ECR.
|
| 122 |
+
|
| 123 |
+
Go to CodeBuild -> your project -> click Start build. Check the logs, the build should be progressing.
|
| 124 |
+
|
| 125 |
+
## Create a `config.env` file and upload to S3
|
| 126 |
+
|
| 127 |
+
The Fargate task definition references a `config.env` file.
|
| 128 |
+
|
| 129 |
+
Need to create a `config.env` file to upload to the S3 bucket that has the variables:
|
| 130 |
+
|
| 131 |
+
```ini
|
| 132 |
+
COGNITO_AUTH=1
|
| 133 |
+
RUN_AWS_FUNCTIONS=1
|
| 134 |
+
SESSION_OUTPUT_FOLDER=True # If this is False it currently seems to fail to allow for writable log directories
|
| 135 |
+
```
|
| 136 |
+
|
| 137 |
+
Go to S3 and choose the new `...-logs` bucket that you created. Upload the `config.env` file into this bucket.
|
| 138 |
+
|
| 139 |
+
## Update Elastic Container Service
|
| 140 |
+
|
| 141 |
+
Now that the app container is in Elastic Container Registry, you can proceed to run the app on a Fargate server.
|
| 142 |
+
|
| 143 |
+
Go to your new cluster, your new service, and select 'Update service'.
|
| 144 |
+
|
| 145 |
+
Select 'Force new deployment', and then set 'Desired number of tasks' to 1.
|
| 146 |
+
|
| 147 |
+
# Additional Manual Tasks
|
| 148 |
+
|
| 149 |
+
# Update DNS records for your domain (If using a domain for the SSL certificate)
|
| 150 |
+
|
| 151 |
+
To do this, you need to create a CNAME DNS record for your domain pointing to your load balancer DNS from a subdomain of your main domain registration, e.g., `redaction.<domain-name>`.
|
| 152 |
+
|
| 153 |
+
# Cognito
|
| 154 |
+
|
| 155 |
+
Go to Cognito and create a user with your own email address. Generate a password.
|
| 156 |
+
|
| 157 |
+
Go to Cognito -> App clients -> Login pages -> View login page.
|
| 158 |
+
|
| 159 |
+
Enter the email and temporary password details that come in the email (don't include the last full stop!).
|
| 160 |
+
|
| 161 |
+
Change your password.
|
| 162 |
+
|
| 163 |
+
## Set MFA (optional)
|
| 164 |
+
On the Cognito user pool page you can also enable MFA, if you are using an SSL certificate with Cognito login on the Application Load Balancer. Go to Cognito -> your user pool -> Sign in -> Multi-factor authentication
|
| 165 |
+
|
| 166 |
+
# Create CloudFront distribution
|
| 167 |
+
**Note: this is only relevant if you set `RUN_USEAST_STACK` to 'False' during CDK deployment**
|
| 168 |
+
|
| 169 |
+
If you were not able to create a CloudFront distribution via CDK, you should be able to do it through console. I would advise using CloudFront as the front end to the app.
|
| 170 |
+
|
| 171 |
+
Create a new CloudFront distribution.
|
| 172 |
+
|
| 173 |
+
* **If you have used an SSL certificate in your CDK code:**
|
| 174 |
+
* **For Origin:**
|
| 175 |
+
* Choose the domain name associated with the certificate as the origin.
|
| 176 |
+
* Choose HTTPS only as the protocol.
|
| 177 |
+
* Keep everything else default.
|
| 178 |
+
* **For Behavior (modify default behavior):**
|
| 179 |
+
* Under Viewer protocol policy choose 'Redirect HTTP to HTTPS'.
|
| 180 |
+
|
| 181 |
+
* **If you have not used an SSL certificate in your CDK code:**
|
| 182 |
+
* **For Origin:**
|
| 183 |
+
* Choose your elastic load balancer as the origin. This will fill in the elastic load balancer DNS.
|
| 184 |
+
* Choose HTTP only as the protocol.
|
| 185 |
+
* Keep everything else default.
|
| 186 |
+
* **For Behavior (modify default behavior):**
|
| 187 |
+
* Under Viewer protocol policy choose 'HTTP and HTTPS'.
|
| 188 |
+
|
| 189 |
+
## Security features
|
| 190 |
+
|
| 191 |
+
In your CloudFront distribution, under 'Security' -> Edit -> Enable security protections.
|
| 192 |
+
|
| 193 |
+
Choose rate limiting (default is fine).
|
| 194 |
+
|
| 195 |
+
Create.
|
| 196 |
+
|
| 197 |
+
In CloudFront geographic restrictions -> Countries -> choose an Allow list of countries.
|
| 198 |
+
|
| 199 |
+
Click again on Edit.
|
| 200 |
+
|
| 201 |
+
AWS WAF protection enabled you should see a link titled 'View details of your configuration'.
|
| 202 |
+
|
| 203 |
+
Go to Rules -> `AWS-AWSManagedRulesCommonRuleSet`, click Edit.
|
| 204 |
+
|
| 205 |
+
Under `SizeRestrictions_BODY` choose rule action override 'Override to Allow'. This is needed to allow for file upload to the app.
|
| 206 |
+
|
| 207 |
+
# Change Cognito redirection URL to your CloudFront distribution
|
| 208 |
+
|
| 209 |
+
Go to Cognito -> your user pool -> App Clients -> Login pages -> Managed login configuration.
|
| 210 |
+
|
| 211 |
+
Ensure that the callback URL is:
|
| 212 |
+
* If not using an SSL certificate and Cognito login - `https://<CloudFront domain name>`
|
| 213 |
+
* If using an SSL certificate, you should have three:
|
| 214 |
+
* `https://<CloudFront domain name>`
|
| 215 |
+
* `https://<CloudFront domain name>/oauth2/idpresponse`
|
| 216 |
+
* `https://<CloudFront domain name>/oauth/idpresponse`
|
| 217 |
+
|
| 218 |
+
# Force traffic to come from specific CloudFront distribution (optional)
|
| 219 |
+
|
| 220 |
+
Note that this only potentially helps with security if you are not using an SSL certificate with Cognito login on your application load balancer.
|
| 221 |
+
|
| 222 |
+
Go to EC2 - Load Balancers -> Your load balancer -> Listeners -> Your listener -> Add rule.
|
| 223 |
+
|
| 224 |
+
* Add Condition -> Host header.
|
| 225 |
+
* Change Host header value to your CloudFront distribution without the `https://` or `http://` at the front.
|
| 226 |
+
* Forward to redaction target group.
|
| 227 |
+
* Turn on group stickiness for 12 hours.
|
| 228 |
+
* Next.
|
| 229 |
+
* Choose priority 1.
|
| 230 |
+
|
| 231 |
+
Then, change the default listener rule.
|
| 232 |
+
|
| 233 |
+
* Under Routing action change to 'Return fixed response'.
|
src/management_guide.qmd
ADDED
|
@@ -0,0 +1,226 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: "User and AWS instance management guide"
|
| 3 |
+
format:
|
| 4 |
+
html:
|
| 5 |
+
toc: true # Enable the table of contents
|
| 6 |
+
toc-depth: 3 # Include headings up to level 2 (##)
|
| 7 |
+
toc-title: "On this page" # Optional: Title for your TOC
|
| 8 |
+
---
|
| 9 |
+
|
| 10 |
+
This guide gives an overview of how to manage users of the redaction app, and how to start, stop, and manage instances of the app running on AWS Cloud.
|
| 11 |
+
|
| 12 |
+
# User management guide
|
| 13 |
+
|
| 14 |
+
This guide provides an overview for administrators to manage users within an AWS Cognito User Pool, specifically for an application utilising phone-app-based Two-Factor Authentication (2FA).
|
| 15 |
+
|
| 16 |
+
## Managing Users in AWS Cognito User Pools
|
| 17 |
+
|
| 18 |
+
AWS Cognito User Pools provide a secure and scalable user directory for your applications. This guide focuses on common administrative tasks within the AWS Management Console.
|
| 19 |
+
|
| 20 |
+
### Accessing Your User Pool
|
| 21 |
+
|
| 22 |
+
1. Log in to the AWS Management Console.
|
| 23 |
+
2. Navigate to **Cognito** (you can use the search bar).
|
| 24 |
+
3. In the left navigation pane, select **User Pools**.
|
| 25 |
+
4. Click on the name of the user pool associated with your redaction app.
|
| 26 |
+
|
| 27 |
+
### Creating Users
|
| 28 |
+
|
| 29 |
+
Creating a new user in Cognito involves setting their initial credentials and attributes.
|
| 30 |
+
|
| 31 |
+
1. From your User Pool's dashboard, click on the **Users** tab.
|
| 32 |
+
2. Click the **Create user** button.
|
| 33 |
+
3. **Username:** Enter a unique username for the user. This is what they will use to log in.
|
| 34 |
+
4. **Temporary password:**
|
| 35 |
+
* Select **Generate a password** to have Cognito create a strong, temporary password.
|
| 36 |
+
* Alternatively, you can choose **Set a password** and enter one manually. If you do this, ensure it meets the password policy configured for your user pool.
|
| 37 |
+
* **Important:** Cognito will typically require users to change this temporary password upon their first login.
|
| 38 |
+
5. **Email:** Enter the user's email address. This is crucial for communication and potentially for password recovery if configured.
|
| 39 |
+
6. **Phone number (optional):** The phone number is not needed for login or user management in this app, you can leave this blank.
|
| 40 |
+
7. **Mark email as verified/Mark phone number as verified:** For new users, you can choose to automatically verify their email and/or phone number. If unchecked, the user might need to verify these themselves during the signup process (depending on your User Pool's verification settings).
|
| 41 |
+
8. **Groups (optional):** If you have defined groups in your user pool, you can add the user to relevant groups here. Groups are useful for managing permissions and access control within your application.
|
| 42 |
+
9. Click **Create user**.
|
| 43 |
+
|
| 44 |
+
### Information to Give to Users to Sign Up
|
| 45 |
+
|
| 46 |
+
Once a user is created, they'll need specific information to access the application.
|
| 47 |
+
|
| 48 |
+
* **Application URL:** The web address of your redaction app's login page.
|
| 49 |
+
* **Username:** The username you created for them in Cognito.
|
| 50 |
+
* **Temporary Password:** The temporary password you generated or set.
|
| 51 |
+
* **Instructions for First Login:**
|
| 52 |
+
* "Upon your first login, you will be prompted to change your temporary password to a new, secure password."
|
| 53 |
+
* "You will also need to set up Two-Factor Authentication using a phone authenticator app (e.g., Google Authenticator, Authy)."
|
| 54 |
+
|
| 55 |
+
### Resetting User Access (Password Reset)
|
| 56 |
+
|
| 57 |
+
If a user forgets their password or needs their access reset, you can do this in the console.
|
| 58 |
+
|
| 59 |
+
1. From your User Pool's dashboard, click on the **Users** tab.
|
| 60 |
+
2. Locate the user you wish to reset. You can use the search bar.
|
| 61 |
+
3. Click on the user's username.
|
| 62 |
+
4. On the user details page, click the **Reset password** button.
|
| 63 |
+
5. Cognito will generate a new temporary password and mark the user to change it on next login.
|
| 64 |
+
6. **Important:** You will need to communicate this new temporary password to the user securely.
|
| 65 |
+
|
| 66 |
+
### Two-Factor Authentication (2FA) with Apps Only
|
| 67 |
+
|
| 68 |
+
Your application uses phone app-based 2FA. This section covers what administrators need to know.
|
| 69 |
+
|
| 70 |
+
#### How it Works for the User
|
| 71 |
+
|
| 72 |
+
When a user logs in for the first time or when 2FA is enabled for their account, they will be prompted to set up 2FA. This typically involves:
|
| 73 |
+
|
| 74 |
+
1. **Scanning a QR Code:** The application will display a QR code.
|
| 75 |
+
2. **Using an Authenticator App:** The user opens their authenticator app (e.g., Google Authenticator, Authy, Microsoft Authenticator) and scans the QR code.
|
| 76 |
+
3. **Entering a Code:** The authenticator app will generate a time-based one-time password (TOTP). The user enters this code into the application to verify the setup.
|
| 77 |
+
|
| 78 |
+
#### Administrator's Role in 2FA
|
| 79 |
+
|
| 80 |
+
As an administrator, you generally don't directly "set up" the user's 2FA device in the console. The user performs this self-enrollment process within the application. However, you can manage the 2FA status of a user:
|
| 81 |
+
|
| 82 |
+
1. **Enabling/Disabling 2FA for a User:**
|
| 83 |
+
* From your User Pool's dashboard, click on the **Users** tab.
|
| 84 |
+
* Click on the user's username.
|
| 85 |
+
* Under the "Multi-factor authentication (MFA)" section, you'll see the current MFA status.
|
| 86 |
+
* If 2FA is not enabled, you might have the option to "Enable MFA" for the user. If your user pool requires 2FA, it might be automatically enabled upon signup.
|
| 87 |
+
* You can also **Disable MFA** for a user if necessary. This will remove their registered 2FA device and they will no longer be prompted for a 2FA code during login until they re-enroll.
|
| 88 |
+
2. **Removing a User's 2FA Device:** If a user loses their phone or needs to re-configure 2FA, you can remove their existing MFA device.
|
| 89 |
+
* On the user's details page, under the "Multi-factor authentication (MFA)" section, you will see a list of registered MFA devices (if any).
|
| 90 |
+
* Select the device and click **Remove**.
|
| 91 |
+
* The next time the user logs in, they will be prompted to set up 2FA again.
|
| 92 |
+
|
| 93 |
+
### Other Useful Information for Administrators
|
| 94 |
+
|
| 95 |
+
* **User Status:** In the "Users" tab, you'll see the status of each user (e.g., `CONFIRMED`, `UNCONFIRMED`, `FORCE_CHANGE_PASSWORD`, `ARCHIVED`, `COMPROMISED`).
|
| 96 |
+
* `CONFIRMED`: User has confirmed their account and set their password.
|
| 97 |
+
* `UNCONFIRMED`: User has been created but hasn't confirmed their account (e.g., through email verification) or changed their temporary password.
|
| 98 |
+
* `FORCE_CHANGE_PASSWORD`: User must change their password on next login.
|
| 99 |
+
* **Searching and Filtering Users:** The "Users" tab provides search and filtering options to quickly find specific users or groups of users.
|
| 100 |
+
* **User Attributes:** You can view and sometimes edit user attributes (like email, phone number, custom attributes) on the user's detail page.
|
| 101 |
+
* **Groups:**
|
| 102 |
+
* You can create and manage groups under the **Groups** tab of your User Pool.
|
| 103 |
+
* Groups are useful for organising users and applying different permissions or configurations through AWS Identity and Access Management (IAM) roles.
|
| 104 |
+
* **User Pool Settings:**
|
| 105 |
+
* Explore the various settings under the **User Pool Properties** tab (e.g., Policies, MFA and verifications, Message customisations).
|
| 106 |
+
* **Policies:** Define password complexity requirements.
|
| 107 |
+
* **MFA and verifications:** Configure whether MFA is optional, required, or disabled, and the types of MFA allowed (SMS, TOTP). Ensure "Authenticator apps" is enabled for your setup.
|
| 108 |
+
* **Message customisations:** Customise the email and SMS messages sent by Cognito (e.g., for verification codes, password resets).
|
| 109 |
+
* **Monitoring and Logging:**
|
| 110 |
+
* Integrate your Cognito User Pool with AWS CloudWatch to monitor user activities and potential issues.
|
| 111 |
+
* Enable CloudTrail logging for Cognito to track API calls and administrative actions.
|
| 112 |
+
* **Security Best Practices:**
|
| 113 |
+
* Always use strong, unique passwords for your AWS console login.
|
| 114 |
+
* Enable MFA for your AWS console login.
|
| 115 |
+
* Regularly review user access and permissions.
|
| 116 |
+
* Educate users on strong password practices and the importance of 2FA.
|
| 117 |
+
|
| 118 |
+
By understanding these features and following best practices, administrators can effectively manage users within their AWS Cognito User Pool, ensuring secure and smooth operation of their redaction application.
|
| 119 |
+
|
| 120 |
+
# Guide to running app instances on AWS
|
| 121 |
+
|
| 122 |
+
This guide provides basic instructions for administrators to manage service tasks within AWS Elastic Container Service (ECS) using the AWS Management Console, focusing on scaling services on and off and forcing redeployments.
|
| 123 |
+
|
| 124 |
+
## Basic Service Task Management in AWS ECS Console
|
| 125 |
+
|
| 126 |
+
AWS Elastic Container Service (ECS) allows you to run, stop, and manage Docker containers on a cluster. This guide focuses on managing your ECS *services*, which maintain a desired number of tasks (container instances).
|
| 127 |
+
|
| 128 |
+
### Accessing Your ECS Cluster and Services
|
| 129 |
+
|
| 130 |
+
1. Log in to the AWS Management Console.
|
| 131 |
+
2. Navigate to **ECS (Elastic Container Service)** (you can use the search bar).
|
| 132 |
+
3. In the left navigation pane, select **Clusters**.
|
| 133 |
+
4. Click on the name of the ECS cluster where your redaction app's service is running.
|
| 134 |
+
|
| 135 |
+
### Understanding Services and Tasks
|
| 136 |
+
|
| 137 |
+
Before we dive into management, let's clarify key concepts:
|
| 138 |
+
|
| 139 |
+
* **Task Definition:** A blueprint for your application. It specifies the Docker image, CPU, memory, environment variables, port mappings, and other configurations for your containers.
|
| 140 |
+
* **Task:** An actual running instance of a task definition. It's an individual container or a set of tightly coupled containers running together.
|
| 141 |
+
* **Service:** A mechanism that allows you to run and maintain a specified number of identical tasks simultaneously in an ECS cluster. The service ensures that if a task fails or stops, it's replaced. It also handles load balancing and scaling.
|
| 142 |
+
|
| 143 |
+
### Setting the Number of Running Tasks to 0 (Turning Everything Off)
|
| 144 |
+
|
| 145 |
+
Setting the desired number of tasks to 0 for a service effectively "turns off" your application by stopping all its running containers.
|
| 146 |
+
|
| 147 |
+
1. From your Cluster's dashboard, click on the **Services** tab.
|
| 148 |
+
2. Locate the service associated with your redaction app (e.g., `redaction-app-service`).
|
| 149 |
+
3. Select the service by checking the box next to its name.
|
| 150 |
+
4. Click the **Update** button.
|
| 151 |
+
5. On the "Configure service" page, find the **Number of tasks** field.
|
| 152 |
+
6. Change the value in this field to `0`.
|
| 153 |
+
7. Scroll to the bottom and click **Update service**.
|
| 154 |
+
|
| 155 |
+
**What happens next:**
|
| 156 |
+
|
| 157 |
+
* ECS will begin terminating all running tasks associated with that service.
|
| 158 |
+
* The "Running tasks" count for your service will gradually decrease to 0.
|
| 159 |
+
* Your application will become inaccessible as its containers are stopped.
|
| 160 |
+
|
| 161 |
+
**Important Considerations:**
|
| 162 |
+
|
| 163 |
+
* **Cost Savings:** Setting tasks to 0 can save costs by stopping the consumption of compute resources (CPU, memory) for your containers.
|
| 164 |
+
* **Associated Resources:** This action *only* stops the ECS tasks. It does not stop underlying EC2 instances (if using EC2 launch type), associated databases, load balancers, or other AWS resources. You'll need to manage those separately if you want to completely shut down your environment.
|
| 165 |
+
* **Container Images:** Your Docker images will still reside in Amazon ECR (or wherever you store them).
|
| 166 |
+
* **Downtime:** This action will cause immediate downtime for your application.
|
| 167 |
+
|
| 168 |
+
### Turning the Desired Number of Tasks On
|
| 169 |
+
|
| 170 |
+
To bring your application back online, you'll set the desired number of tasks to your operational value (usually 1 or more).
|
| 171 |
+
|
| 172 |
+
1. From your Cluster's dashboard, click on the **Services** tab.
|
| 173 |
+
2. Locate the service associated with your redaction app.
|
| 174 |
+
3. Select the service by checking the box next to its name.
|
| 175 |
+
4. Click the **Update** button.
|
| 176 |
+
5. On the "Configure service" page, find the **Number of tasks** field.
|
| 177 |
+
6. Change the value in this field to your desired number of running tasks (e.g., `1`, `2`, etc.).
|
| 178 |
+
7. Scroll to the bottom and click **Update service**.
|
| 179 |
+
|
| 180 |
+
**What happens next:**
|
| 181 |
+
|
| 182 |
+
* ECS will begin launching new tasks based on your service's configuration and task definition.
|
| 183 |
+
* The "Running tasks" count will increase until it reaches your desired number.
|
| 184 |
+
* Once tasks are running and healthy (according to your health checks), your application should become accessible again.
|
| 185 |
+
|
| 186 |
+
**Important Considerations:**
|
| 187 |
+
|
| 188 |
+
* **Startup Time:** Allow some time for tasks to pull images, start containers, and pass health checks before your application is fully available.
|
| 189 |
+
* **Resource Availability:** Ensure your ECS cluster has sufficient available resources (EC2 instances or Fargate capacity) to launch the desired number of tasks.
|
| 190 |
+
|
| 191 |
+
### Forcing Redeployment
|
| 192 |
+
|
| 193 |
+
Forcing a redeployment is useful when you've updated your task definition (e.g., pushed a new Docker image, changed environment variables) but the service hasn't automatically picked up the new version. It's also useful for "restarting" a service.
|
| 194 |
+
|
| 195 |
+
1. From your Cluster's dashboard, click on the **Services** tab.
|
| 196 |
+
2. Locate the service you want to redeploy.
|
| 197 |
+
3. Select the service by checking the box next to its name.
|
| 198 |
+
4. Click the **Update** button.
|
| 199 |
+
5. On the "Configure service" page, scroll down to the **Deployment options** section.
|
| 200 |
+
6. Check the box next to **Force new deployment**.
|
| 201 |
+
7. Scroll to the bottom and click **Update service**.
|
| 202 |
+
|
| 203 |
+
**What happens next:**
|
| 204 |
+
|
| 205 |
+
* ECS will initiate a new deployment for your service.
|
| 206 |
+
* It will launch new tasks using the *latest active task definition revision* associated with your service.
|
| 207 |
+
* Existing tasks will be drained and terminated according to your service's deployment configuration (e.g., `minimum healthy percent`, `maximum percent`).
|
| 208 |
+
* This process effectively replaces all running tasks with fresh instances.
|
| 209 |
+
|
| 210 |
+
**Important Considerations:**
|
| 211 |
+
|
| 212 |
+
* **Latest Task Definition:** Ensure you have activated the correct and latest task definition revision before forcing a new deployment if your intention is to deploy new code. You can update the task definition used by a service via the "Update" service flow.
|
| 213 |
+
* **Downtime (minimal if configured correctly):** If your service has a properly configured load balancer and healthy deployment settings (e.g., blue/green or rolling updates), forced redeployments should result in minimal to no downtime. ECS will bring up new tasks before shutting down old ones.
|
| 214 |
+
* **Troubleshooting:** If a deployment gets stuck or tasks fail to start, check the "Events" tab of your service for error messages. Also, check the CloudWatch logs for your tasks.
|
| 215 |
+
|
| 216 |
+
### Other Useful Information for Administrators
|
| 217 |
+
|
| 218 |
+
* **Service Events:** On your service's detail page, click the **Events** tab. This provides a chronological log of actions taken by the ECS service, such as task launches, stops, and scaling events. This is invaluable for troubleshooting.
|
| 219 |
+
* **Tasks Tab:** On your service's detail page, click the **Tasks** tab to see a list of all individual tasks running (or recently stopped) for that service. You can click on individual tasks to view their details, including logs, network configuration, and CPU/memory utilisation.
|
| 220 |
+
* **Logs:** For each task, you can often find a link to its CloudWatch Logs under the "Logs" section of the task details. This is critical for debugging application errors.
|
| 221 |
+
* **Metrics:** The **Metrics** tab on your service provides graphs for CPU utilisation, memory utilisation, and the number of running tasks, helping you monitor your service's performance.
|
| 222 |
+
* **Deployment Configuration:** When updating a service, review the **Deployment options** section. This allows you to control how new deployments are rolled out (e.g., minimum healthy percent, maximum percent). Proper configuration here ensures minimal impact during updates.
|
| 223 |
+
* **Auto Scaling (beyond basic management):** For dynamic scaling based on demand, explore **Service Auto Scaling**. This allows ECS to automatically adjust the desired number of tasks up or down based on metrics like CPU utilisation or request count.
|
| 224 |
+
* **Task Definitions:** Before updating a service, you might need to create a new revision of your task definition if you're deploying new code or configuration changes to your containers. You can find Task Definitions in the left navigation pane under ECS.
|
| 225 |
+
|
| 226 |
+
By mastering these basic service management operations in the AWS Console, administrators can effectively control the lifecycle of their ECS-based applications.
|
src/styles.css
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
/* Custom styles can be added here later */
|
src/user_guide.qmd
ADDED
|
@@ -0,0 +1,511 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: "User guide"
|
| 3 |
+
format:
|
| 4 |
+
html:
|
| 5 |
+
toc: true # Enable the table of contents
|
| 6 |
+
toc-depth: 3 # Include headings up to level 2 (##)
|
| 7 |
+
toc-title: "On this page" # Optional: Title for your TOC
|
| 8 |
+
---
|
| 9 |
+
|
| 10 |
+
## Table of contents
|
| 11 |
+
|
| 12 |
+
- [Example data files](#example-data-files)
|
| 13 |
+
- [Basic redaction](#basic-redaction)
|
| 14 |
+
- [Customising redaction options](#customising-redaction-options)
|
| 15 |
+
- [Custom allow, deny, and page redaction lists](#custom-allow-deny-and-page-redaction-lists)
|
| 16 |
+
- [Allow list example](#allow-list-example)
|
| 17 |
+
- [Deny list example](#deny-list-example)
|
| 18 |
+
- [Full page redaction list example](#full-page-redaction-list-example)
|
| 19 |
+
- [Redacting additional types of personal information](#redacting-additional-types-of-personal-information)
|
| 20 |
+
- [Redacting only specific pages](#redacting-only-specific-pages)
|
| 21 |
+
- [Handwriting and signature redaction](#handwriting-and-signature-redaction)
|
| 22 |
+
- [Reviewing and modifying suggested redactions](#reviewing-and-modifying-suggested-redactions)
|
| 23 |
+
- [Redacting tabular data files (CSV/XLSX) or copy and pasted text](#redacting-tabular-data-files-xlsxcsv-or-copy-and-pasted-text)
|
| 24 |
+
|
| 25 |
+
See the [advanced user guide here](#advanced-user-guide):
|
| 26 |
+
- [Merging redaction review files](#merging-redaction-review-files)
|
| 27 |
+
- [Identifying and redacting duplicate pages](#identifying-and-redacting-duplicate-pages)
|
| 28 |
+
- [Fuzzy search and redaction](#fuzzy-search-and-redaction)
|
| 29 |
+
- [Export redactions to and import from Adobe Acrobat](#export-to-and-import-from-adobe)
|
| 30 |
+
- [Exporting to Adobe Acrobat](#exporting-to-adobe-acrobat)
|
| 31 |
+
- [Importing from Adobe Acrobat](#importing-from-adobe-acrobat)
|
| 32 |
+
- [Using the AWS Textract document API](#using-the-aws-textract-document-api)
|
| 33 |
+
- [Using AWS Textract and Comprehend when not running in an AWS environment](#using-aws-textract-and-comprehend-when-not-running-in-an-aws-environment)
|
| 34 |
+
- [Modifying existing redaction review files](#modifying-existing-redaction-review-files)
|
| 35 |
+
|
| 36 |
+
## Example data files
|
| 37 |
+
|
| 38 |
+
Please try these example files to follow along with this guide:
|
| 39 |
+
- [Example of files sent to a professor before applying](https://github.com/seanpedrick-case/document_redaction_examples/blob/main/example_of_emails_sent_to_a_professor_before_applying.pdf)
|
| 40 |
+
- [Example complaint letter (jpg)](https://github.com/seanpedrick-case/document_redaction_examples/blob/main/example_complaint_letter.jpg)
|
| 41 |
+
- [Partnership Agreement Toolkit (for signatures and more advanced usage)](https://github.com/seanpedrick-case/document_redaction_examples/blob/main/Partnership-Agreement-Toolkit_0_0.pdf)
|
| 42 |
+
- [Dummy case note data](https://github.com/seanpedrick-case/document_redaction_examples/blob/main/combined_case_notes.csv)
|
| 43 |
+
|
| 44 |
+
## Basic redaction
|
| 45 |
+
|
| 46 |
+
The document redaction app can detect personally-identifiable information (PII) in documents. Documents can be redacted directly, or suggested redactions can be reviewed and modified using a grapical user interface. Basic document redaction can be performed quickly using the default options.
|
| 47 |
+
|
| 48 |
+
Download the example PDFs above to your computer. Open up the redaction app with the link provided by email.
|
| 49 |
+
|
| 50 |
+
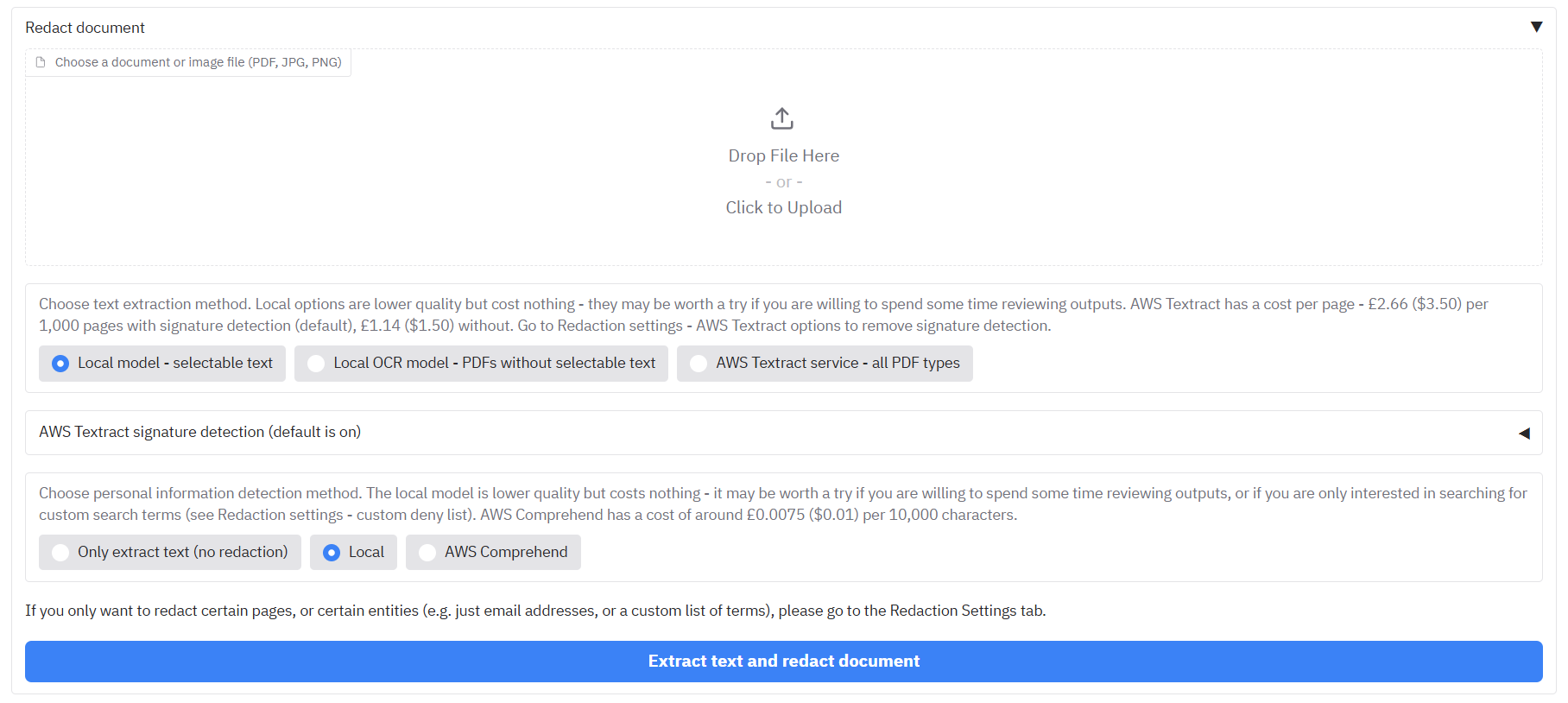
|
| 51 |
+
|
| 52 |
+
### Upload files to the app
|
| 53 |
+
|
| 54 |
+
The 'Redact PDFs/images tab' currently accepts PDFs and image files (JPG, PNG) for redaction. Click on the 'Drop files here or Click to Upload' area of the screen, and select one of the three different [example files](#example-data-files) (they should all be stored in the same folder if you want them to be redacted at the same time).
|
| 55 |
+
|
| 56 |
+
### Text extraction
|
| 57 |
+
|
| 58 |
+
First, select one of the three text extraction options:
|
| 59 |
+
- **'Local model - selectable text'** - This will read text directly from PDFs that have selectable text to redact (using PikePDF). This is fine for most PDFs, but will find nothing if the PDF does not have selectable text, and it is not good for handwriting or signatures. If it encounters an image file, it will send it onto the second option below.
|
| 60 |
+
- **'Local OCR model - PDFs without selectable text'** - This option will use a simple Optical Character Recognition (OCR) model (Tesseract) to pull out text from a PDF/image that it 'sees'. This can handle most typed text in PDFs/images without selectable text, but struggles with handwriting/signatures. If you are interested in the latter, then you should use the third option if available.
|
| 61 |
+
- **'AWS Textract service - all PDF types'** - Only available for instances of the app running on AWS. AWS Textract is a service that performs OCR on documents within their secure service. This is a more advanced version of OCR compared to the local option, and carries a (relatively small) cost. Textract excels in complex documents based on images, or documents that contain a lot of handwriting and signatures.
|
| 62 |
+
|
| 63 |
+
### Optional - select signature extraction
|
| 64 |
+
If you chose the AWS Textract service above, you can choose if you want handwriting and/or signatures redacted by default. Choosing signatures here will have a cost implication, as identifying signatures will cost ~£2.66 ($3.50) per 1,000 pages vs ~£1.14 ($1.50) per 1,000 pages without signature detection.
|
| 65 |
+
|
| 66 |
+
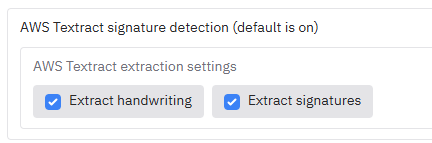
|
| 67 |
+
|
| 68 |
+
### PII redaction method
|
| 69 |
+
|
| 70 |
+
If you are running with the AWS service enabled, here you will also have a choice for PII redaction method:
|
| 71 |
+
- **'Only extract text - (no redaction)'** - If you are only interested in getting the text out of the document for further processing (e.g. to find duplicate pages, or to review text on the Review redactions page)
|
| 72 |
+
- **'Local'** - This uses the spacy package to rapidly detect PII in extracted text. This method is often sufficient if you are just interested in redacting specific terms defined in a custom list.
|
| 73 |
+
- **'AWS Comprehend'** - This method calls an AWS service to provide more accurate identification of PII in extracted text.
|
| 74 |
+
|
| 75 |
+
### Optional - costs and time estimation
|
| 76 |
+
If the option is enabled (by your system admin, in the config file), you will see a cost and time estimate for the redaction process. 'Existing Textract output file found' will be checked automatically if previous Textract text extraction files exist in the output folder, or have been [previously uploaded by the user](#aws-textract-outputs) (saving time and money for redaction).
|
| 77 |
+
|
| 78 |
+

|
| 79 |
+
|
| 80 |
+
### Optional - cost code selection
|
| 81 |
+
If the option is enabled (by your system admin, in the config file), you may be prompted to select a cost code before continuing with the redaction task.
|
| 82 |
+
|
| 83 |
+

|
| 84 |
+
|
| 85 |
+
The relevant cost code can be found either by: 1. Using the search bar above the data table to find relevant cost codes, then clicking on the relevant row, or 2. typing it directly into the dropdown to the right, where it should filter as you type.
|
| 86 |
+
|
| 87 |
+
### Optional - Submit whole documents to Textract API
|
| 88 |
+
If this option is enabled (by your system admin, in the config file), you will have the option to submit whole documents in quick succession to the AWS Textract service to get extracted text outputs quickly (faster than using the 'Redact document' process described here). This feature is described in more detail in the [advanced user guide](#using-the-aws-textract-document-api).
|
| 89 |
+
|
| 90 |
+
|
| 91 |
+
|
| 92 |
+
### Redact the document
|
| 93 |
+
|
| 94 |
+
Click 'Redact document'. After loading in the document, the app should be able to process about 30 pages per minute (depending on redaction methods chose above). When ready, you should see a message saying that processing is complete, with output files appearing in the bottom right.
|
| 95 |
+
|
| 96 |
+
### Redaction outputs
|
| 97 |
+
|
| 98 |
+

|
| 99 |
+
|
| 100 |
+
- **'...redacted.pdf'** files contain the original pdf with suggested redacted text deleted and replaced by a black box on top of the document.
|
| 101 |
+
- **'...ocr_results.csv'** files contain the line-by-line text outputs from the entire document. This file can be useful for later searching through for any terms of interest in the document (e.g. using Excel or a similar program).
|
| 102 |
+
- **'...review_file.csv'** files are the review files that contain details and locations of all of the suggested redactions in the document. This file is key to the [review process](#reviewing-and-modifying-suggested-redactions), and should be downloaded to use later for this.
|
| 103 |
+
|
| 104 |
+
### Additional AWS Textract / local OCR outputs {#aws-textract-outputs}
|
| 105 |
+
|
| 106 |
+
If you have used the AWS Textract option for extracting text, you may also see a '..._textract.json' file. This file contains all the relevant extracted text information that comes from the AWS Textract service. You can keep this file and upload it at a later date alongside your input document, which will enable you to skip calling AWS Textract every single time you want to do a redaction task, as follows:
|
| 107 |
+
|
| 108 |
+

|
| 109 |
+
|
| 110 |
+
Similarly, if you have used the 'Local OCR method' to extract text, you may see a '..._ocr_results_with_words.json' file. This file works in the same way as the AWS Textract .json results described above, and can be uploaded alongside an input document to save time on text extraction in future in the same way.
|
| 111 |
+
|
| 112 |
+
### Downloading output files from previous redaction tasks
|
| 113 |
+
|
| 114 |
+
If you are logged in via AWS Cognito and you lose your app page for some reason (e.g. from a crash, reloading), it is possible recover your previous output files, provided the server has not been shut down since you redacted the document. Go to 'Redaction settings', then scroll to the bottom to see 'View all output files from this session'.
|
| 115 |
+
|
| 116 |
+

|
| 117 |
+
|
| 118 |
+
### Basic redaction summary
|
| 119 |
+
|
| 120 |
+
We have covered redacting documents with the default redaction options. The '...redacted.pdf' file output may be enough for your purposes. But it is very likely that you will need to customise your redaction options, which we will cover below.
|
| 121 |
+
|
| 122 |
+
## Customising redaction options
|
| 123 |
+
|
| 124 |
+
On the 'Redaction settings' page, there are a number of options that you can tweak to better match your use case and needs.
|
| 125 |
+
|
| 126 |
+
### Custom allow, deny, and page redaction lists
|
| 127 |
+
|
| 128 |
+
The app allows you to specify terms that should never be redacted (an allow list), terms that should always be redacted (a deny list), and also to provide a list of page numbers for pages that should be fully redacted.
|
| 129 |
+
|
| 130 |
+
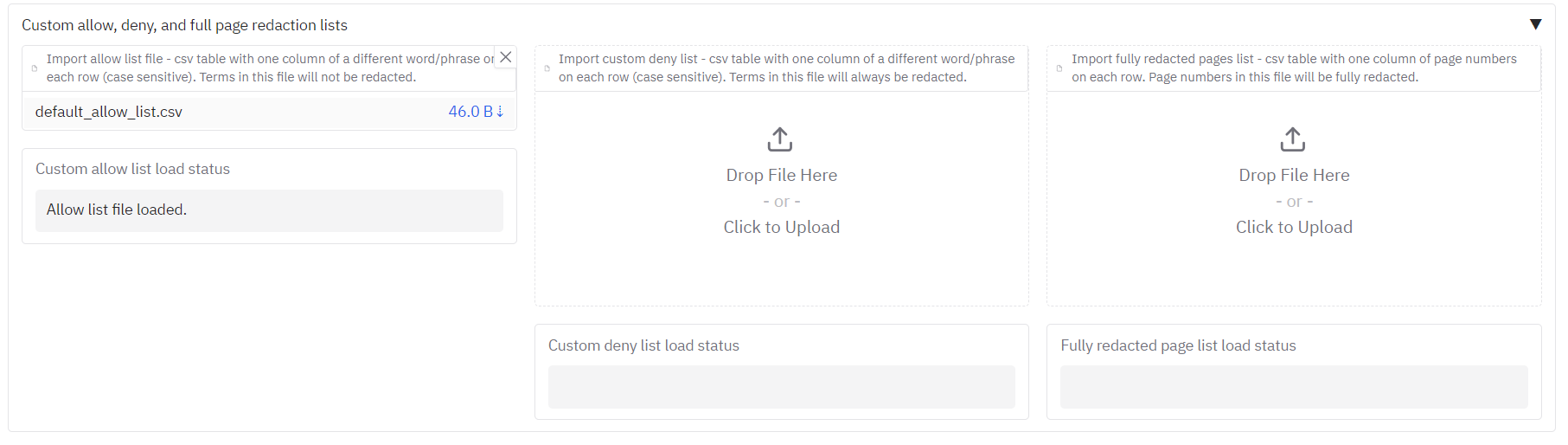
|
| 131 |
+
|
| 132 |
+
#### Allow list example
|
| 133 |
+
|
| 134 |
+
It may be the case that specific terms that are frequently redacted are not interesting to
|
| 135 |
+
|
| 136 |
+
In the redacted outputs of the 'Example of files sent to a professor before applying' PDF, you can see that it is frequently redacting references to Dr Hyde's lab in the main body of the text. Let's say that references to Dr Hyde were not considered personal information in this context. You can exclude this term from redaction (and others) by providing an 'allow list' file. This is simply a csv that contains the case sensitive terms to exclude in the first column, in our example, 'Hyde' and 'Muller glia'. The example file is provided [here](https://github.com/seanpedrick-case/document_redaction_examples/blob/main/allow_list/allow_list.csv).
|
| 137 |
+
|
| 138 |
+
To import this to use with your redaction tasks, go to the 'Redaction settings' tab, click on the 'Import allow list file' button halfway down, and select the csv file you have created. It should be loaded for next time you hit the redact button. Go back to the first tab and do this.
|
| 139 |
+
|
| 140 |
+
#### Deny list example
|
| 141 |
+
|
| 142 |
+
Say you wanted to remove specific terms from a document. In this app you can do this by providing a custom deny list as a csv. Like for the allow list described above, this should be a one-column csv without a column header. The app will suggest each individual term in the list with exact spelling as whole words. So it won't select text from within words. To enable this feature, the 'CUSTOM' tag needs to be chosen as a redaction entity [(the process for adding/removing entity types to redact is described below)](#redacting-additional-types-of-personal-information).
|
| 143 |
+
|
| 144 |
+
Here is an example using the [Partnership Agreement Toolkit file](https://github.com/seanpedrick-case/document_redaction_examples/blob/main/Partnership-Agreement-Toolkit_0_0.pdf). This is an [example of a custom deny list file](https://github.com/seanpedrick-case/document_redaction_examples/blob/main/allow_list/partnership_toolkit_redact_custom_deny_list.csv). 'Sister', 'Sister City'
|
| 145 |
+
'Sister Cities', 'Friendship City' have been listed as specific terms to redact. You can see the outputs of this redaction process on the review page:
|
| 146 |
+
|
| 147 |
+
.
|
| 148 |
+
|
| 149 |
+
You can see that the app has highlighted all instances of these terms on the page shown. You can then consider each of these terms for modification or removal on the review page [explained here](#reviewing-and-modifying-suggested-redactions).
|
| 150 |
+
|
| 151 |
+
#### Full page redaction list example
|
| 152 |
+
|
| 153 |
+
There may be full pages in a document that you want to redact. The app also provides the capability of redacting pages completely based on a list of input page numbers in a csv. The format of the input file is the same as that for the allow and deny lists described above - a one-column csv without a column header. An [example of this is here](https://github.com/seanpedrick-case/document_redaction_examples/blob/main/allow_list/partnership_toolkit_redact_some_pages.csv). You can see an example of the redacted page on the review page:
|
| 154 |
+
|
| 155 |
+
.
|
| 156 |
+
|
| 157 |
+
Using the above approaches to allow, deny, and full page redaction lists will give you an output [like this](https://github.com/seanpedrick-case/document_redaction_examples/blob/main/allow_list/Partnership-Agreement-Toolkit_0_0_redacted.pdf).
|
| 158 |
+
|
| 159 |
+
#### Adding to the loaded allow, deny, and whole page lists in-app
|
| 160 |
+
|
| 161 |
+
If you open the accordion below the allow list options called 'Manually modify custom allow...', you should be able to see a few tables with options to add new rows:
|
| 162 |
+
|
| 163 |
+

|
| 164 |
+
|
| 165 |
+
If the table is empty, you can add a new entry, you can add a new row by clicking on the '+' item below each table header. If there is existing data, you may need to click on the three dots to the right and select 'Add row below'. Type the item you wish to keep/remove in the cell, and then (important) press enter to add this new item to the allow/deny/whole page list. Your output tables should look something like below.
|
| 166 |
+
|
| 167 |
+

|
| 168 |
+
|
| 169 |
+
### Redacting additional types of personal information
|
| 170 |
+
|
| 171 |
+
You may want to redact additional types of information beyond the defaults, or you may not be interested in default suggested entity types. There are dates in the example complaint letter. Say we wanted to redact those dates also?
|
| 172 |
+
|
| 173 |
+
Under the 'Redaction settings' tab, go to 'Entities to redact (click close to down arrow for full list)'. Different dropdowns are provided according to whether you are using the Local service to redact PII, or the AWS Comprehend service. Click within the empty box close to the dropdown arrow and you should see a list of possible 'entities' to redact. Select 'DATE_TIME' and it should appear in the main list. To remove items, click on the 'x' next to their name.
|
| 174 |
+
|
| 175 |
+
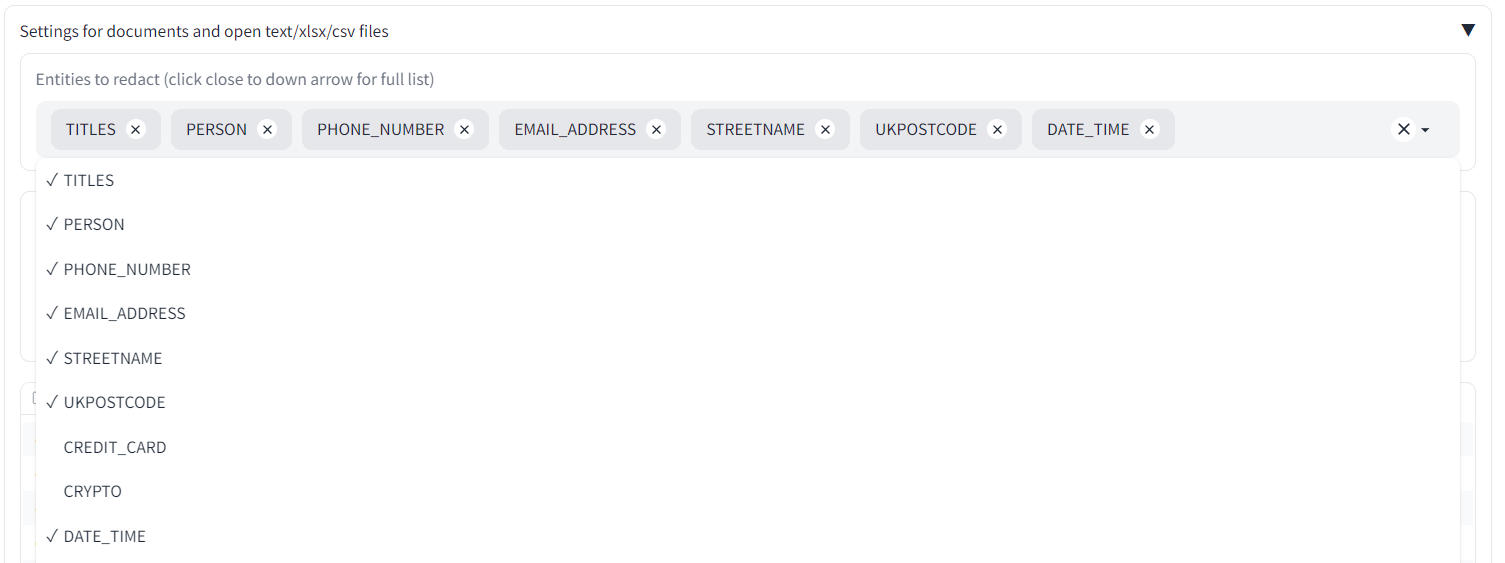
|
| 176 |
+
|
| 177 |
+
Now, go back to the main screen and click 'Redact Document' again. You should now get a redacted version of 'Example complaint letter' that has the dates and times removed.
|
| 178 |
+
|
| 179 |
+
If you want to redact different files, I suggest you refresh your browser page to start a new session and unload all previous data.
|
| 180 |
+
|
| 181 |
+
## Redacting only specific pages
|
| 182 |
+
|
| 183 |
+
Say also we are only interested in redacting page 1 of the loaded documents. On the Redaction settings tab, select 'Lowest page to redact' as 1, and 'Highest page to redact' also as 1. When you next redact your documents, only the first page will be modified.
|
| 184 |
+
|
| 185 |
+
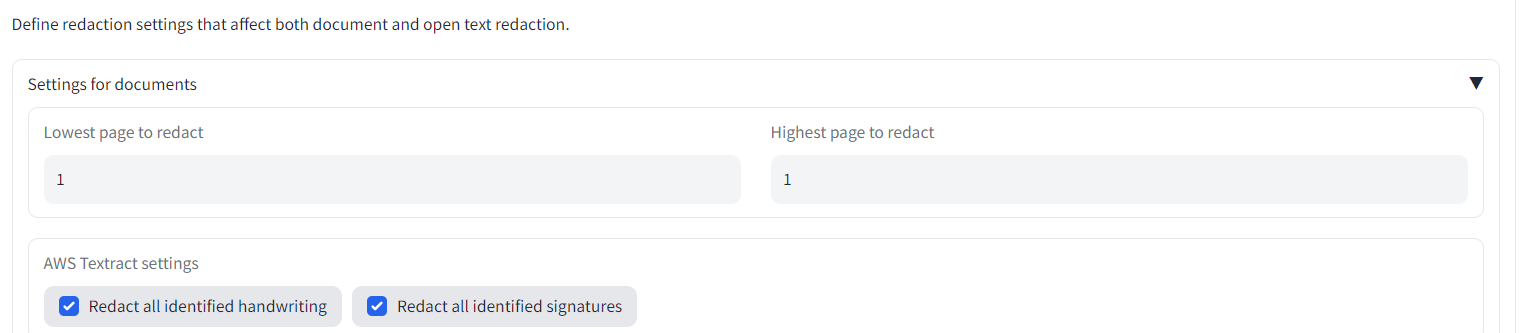
|
| 186 |
+
|
| 187 |
+
## Handwriting and signature redaction
|
| 188 |
+
|
| 189 |
+
The file [Partnership Agreement Toolkit (for signatures and more advanced usage)](https://github.com/seanpedrick-case/document_redaction_examples/blob/main/Partnership-Agreement-Toolkit_0_0.pdf) is provided as an example document to test AWS Textract + redaction with a document that has signatures in. If you have access to AWS Textract in the app, try removing all entity types from redaction on the Redaction settings and clicking the big X to the right of 'Entities to redact'.
|
| 190 |
+
|
| 191 |
+
To ensure that handwriting and signatures are enabled (enabled by default), on the front screen go the 'AWS Textract signature detection' to enable/disable the following options :
|
| 192 |
+
|
| 193 |
+
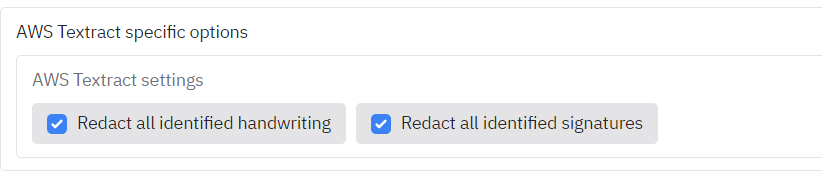
|
| 194 |
+
|
| 195 |
+
The outputs should show handwriting/signatures redacted (see pages 5 - 7), which you can inspect and modify on the 'Review redactions' tab.
|
| 196 |
+
|
| 197 |
+

|
| 198 |
+
|
| 199 |
+
## Reviewing and modifying suggested redactions
|
| 200 |
+
|
| 201 |
+
Sometimes the app will suggest redactions that are incorrect, or will miss personal information entirely. The app allows you to review and modify suggested redactions to compensate for this. You can do this on the 'Review redactions' tab.
|
| 202 |
+
|
| 203 |
+
We will go through ways to review suggested redactions with an example.On the first tab 'PDFs/images' upload the ['Example of files sent to a professor before applying.pdf'](https://github.com/seanpedrick-case/document_redaction_examples/blob/main/example_of_emails_sent_to_a_professor_before_applying.pdf) file. Let's stick with the 'Local model - selectable text' option, and click 'Redact document'. Once the outputs are created, go to the 'Review redactions' tab.
|
| 204 |
+
|
| 205 |
+
On the 'Review redactions' tab you have a visual interface that allows you to inspect and modify redactions suggested by the app. There are quite a few options to look at, so we'll go from top to bottom.
|
| 206 |
+
|
| 207 |
+
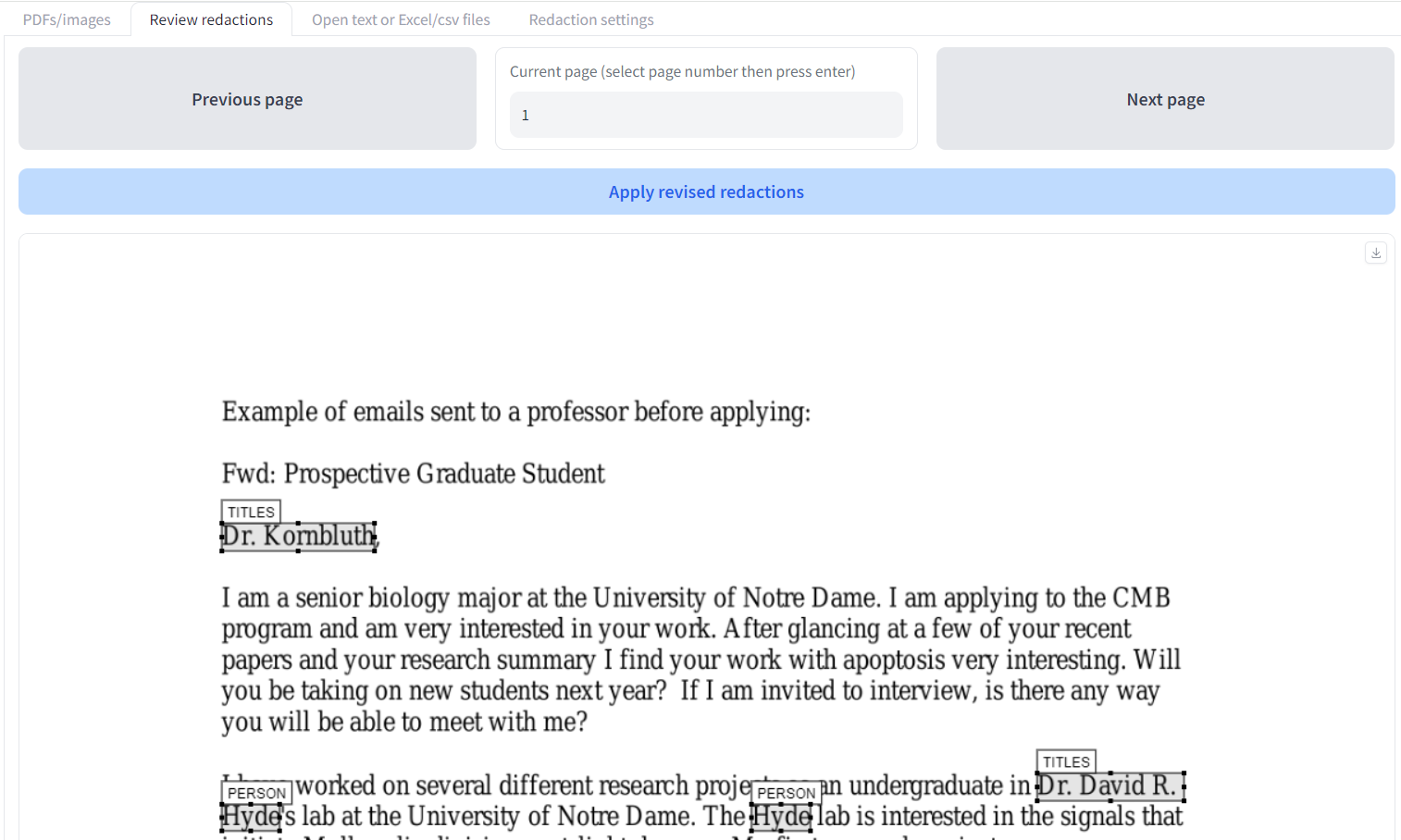
|
| 208 |
+
|
| 209 |
+
### Uploading documents for review
|
| 210 |
+
|
| 211 |
+
The top area has a file upload area where you can upload original, unredacted PDFs, alongside the '..._review_file.csv' that is produced by the redaction process. Once you have uploaded these two files, click the '**Review redactions based on original PDF...**' button to load in the files for review. This will allow you to visualise and modify the suggested redactions using the interface below.
|
| 212 |
+
|
| 213 |
+
Optionally, you can also upload one of the '..._ocr_output.csv' files here that comes out of a redaction task, so that you can navigate the extracted text from the document.
|
| 214 |
+
|
| 215 |
+

|
| 216 |
+
|
| 217 |
+
You can upload the three review files in the box (unredacted document, '..._review_file.csv' and '..._ocr_output.csv' file) before clicking '**Review redactions based on original PDF...**', as in the image below:
|
| 218 |
+
|
| 219 |
+

|
| 220 |
+
|
| 221 |
+
**NOTE:** ensure you upload the ***unredacted*** document here and not the redacted version, otherwise you will be checking over a document that already has redaction boxes applied!
|
| 222 |
+
|
| 223 |
+
### Page navigation
|
| 224 |
+
|
| 225 |
+
You can change the page viewed either by clicking 'Previous page' or 'Next page', or by typing a specific page number in the 'Current page' box and pressing Enter on your keyboard. Each time you switch page, it will save redactions you have made on the page you are moving from, so you will not lose changes you have made.
|
| 226 |
+
|
| 227 |
+
You can also navigate to different pages by clicking on rows in the tables under 'Search suggested redactions' to the right, or 'search all extracted text' (if enabled) beneath that.
|
| 228 |
+
|
| 229 |
+
### The document viewer pane
|
| 230 |
+
|
| 231 |
+
On the selected page, each redaction is highlighted with a box next to its suggested redaction label (e.g. person, email).
|
| 232 |
+
|
| 233 |
+
|
| 234 |
+
|
| 235 |
+
There are a number of different options to add and modify redaction boxes and page on the document viewer pane. To zoom in and out of the page, use your mouse wheel. To move around the page while zoomed, you need to be in modify mode. Scroll to the bottom of the document viewer to see the relevant controls. You should see a box icon, a hand icon, and two arrows pointing counter-clockwise and clockwise.
|
| 236 |
+
|
| 237 |
+
|
| 238 |
+
|
| 239 |
+
Click on the hand icon to go into modify mode. When you click and hold on the document viewer, This will allow you to move around the page when zoomed in. To rotate the page, you can click on either of the round arrow buttons to turn in that direction.
|
| 240 |
+
|
| 241 |
+
**NOTE:** When you switch page, the viewer will stay in your selected orientation, so if it looks strange, just rotate the page again and hopefully it will look correct!
|
| 242 |
+
|
| 243 |
+
#### Modify existing redactions (hand icon)
|
| 244 |
+
|
| 245 |
+
After clicking on the hand icon, the interface allows you to modify existing redaction boxes. When in this mode, you can click and hold on an existing box to move it.
|
| 246 |
+
|
| 247 |
+

|
| 248 |
+
|
| 249 |
+
Click on one of the small boxes at the edges to change the size of the box. To delete a box, click on it to highlight it, then press delete on your keyboard. Alternatively, double click on a box and click 'Remove' on the box that appears.
|
| 250 |
+
|
| 251 |
+
|
| 252 |
+
|
| 253 |
+
#### Add new redaction boxes (box icon)
|
| 254 |
+
|
| 255 |
+
To change to 'add redaction boxes' mode, scroll to the bottom of the page. Click on the box icon, and your cursor will change into a crosshair. Now you can add new redaction boxes where you wish. A popup will appear when you create a new box so you can select a label and colour for the new box.
|
| 256 |
+
|
| 257 |
+
#### 'Locking in' new redaction box format
|
| 258 |
+
|
| 259 |
+
It is possible to lock in a chosen format for new redaction boxes so that you don't have the popup appearing each time. When you make a new box, select the options for your 'locked' format, and then click on the lock icon on the left side of the popup, which should turn blue.
|
| 260 |
+
|
| 261 |
+

|
| 262 |
+
|
| 263 |
+
You can now add new redaction boxes without a popup appearing. If you want to change or 'unlock' the your chosen box format, you can click on the new icon that has appeared at the bottom of the document viewer pane that looks a little like a gift tag. You can then change the defaults, or click on the lock icon again to 'unlock' the new box format - then popups will appear again each time you create a new box.
|
| 264 |
+
|
| 265 |
+
|
| 266 |
+
|
| 267 |
+
### Apply redactions to PDF and Save changes on current page
|
| 268 |
+
|
| 269 |
+
Once you have reviewed all the redactions in your document and you are happy with the outputs, you can click 'Apply revised redactions to PDF' to create a new '_redacted.pdf' output alongside a new '_review_file.csv' output.
|
| 270 |
+
|
| 271 |
+
If you are working on a page and haven't saved for a while, you can click 'Save changes on current page to file' to ensure that they are saved to an updated 'review_file.csv' output.
|
| 272 |
+
|
| 273 |
+

|
| 274 |
+
|
| 275 |
+
### Selecting and removing redaction boxes using the 'Search suggested redactions' table
|
| 276 |
+
|
| 277 |
+
The table shows a list of all the suggested redactions in the document alongside the page, label, and text (if available).
|
| 278 |
+
|
| 279 |
+
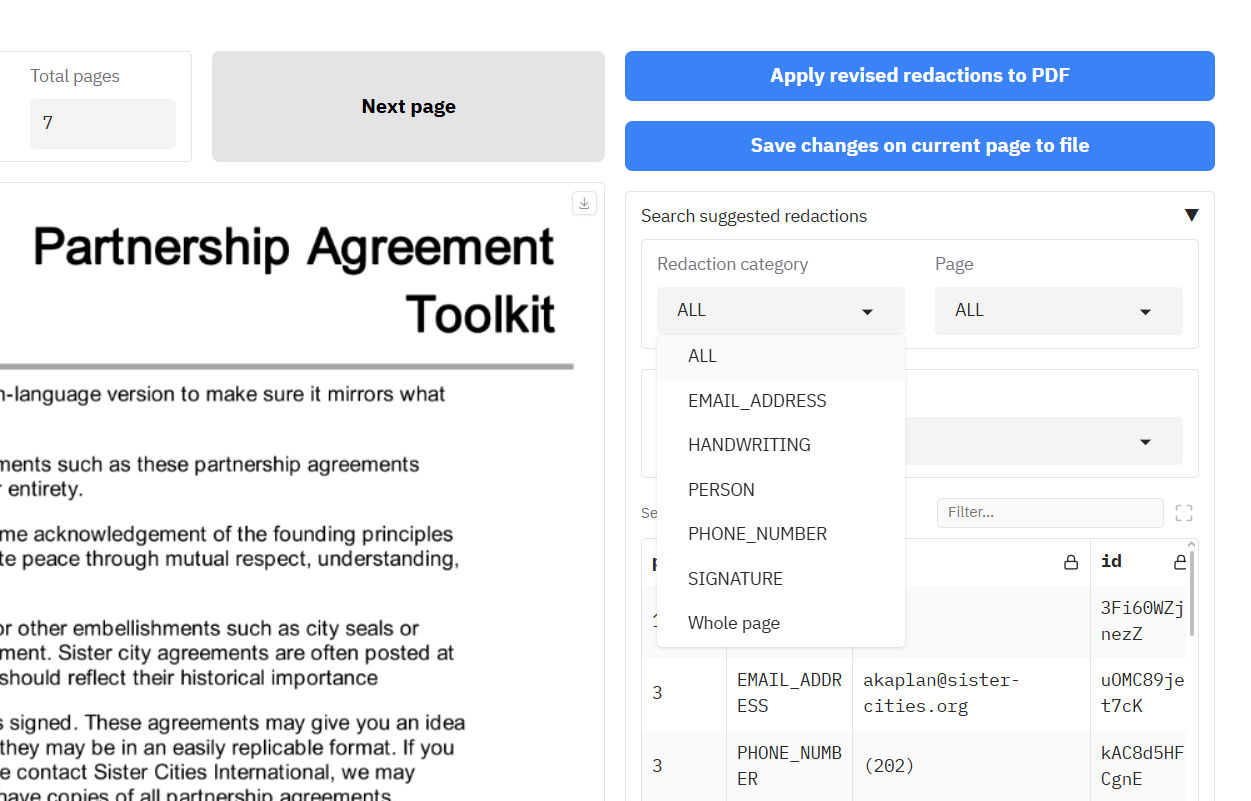
|
| 280 |
+
|
| 281 |
+
If you click on one of the rows in this table, you will be taken to the page of the redaction. Clicking on a redaction row on the same page will change the colour of redaction box to blue to help you locate it in the document viewer (just when using the app, not in redacted output PDFs).
|
| 282 |
+
|
| 283 |
+

|
| 284 |
+
|
| 285 |
+
You can choose a specific entity type to see which pages the entity is present on. If you want to go to the page specified in the table, you can click on a cell in the table and the review page will be changed to that page.
|
| 286 |
+
|
| 287 |
+
To filter the 'Search suggested redactions' table you can:
|
| 288 |
+
1. Click on one of the dropdowns (Redaction category, Page, Text), and select an option, or
|
| 289 |
+
2. Write text in the 'Filter' box just above the table. Click the blue box to apply the filter to the table.
|
| 290 |
+
|
| 291 |
+
Once you have filtered the table, or selected a row from the table, you have a few options underneath on what you can do with the filtered rows:
|
| 292 |
+
|
| 293 |
+
- Click the **Exclude all redactions in table** button to remove all redactions visible in the table from the document. **Important:** ensure that you have clicked the blue tick icon next to the search box before doing this, or you will remove all redactions from the document. If you do end up doing this, click the 'Undo last element removal' button below to restore the redactions.
|
| 294 |
+
- Click the **Exclude specific redaction row** button to remove only the redaction from the last row you clicked on from the document. The currently selected row is visible below.
|
| 295 |
+
- Click the **Exclude all redactions with the same text as selected row** button to remove all redactions from the document that are exactly the same as the selected row text.
|
| 296 |
+
|
| 297 |
+
**NOTE**: After excluding redactions using any of the above options, click the 'Reset filters' button below to ensure that the dropdowns and table return to seeing all remaining redactions in the document.
|
| 298 |
+
|
| 299 |
+
If you made a mistake, click the 'Undo last element removal' button to restore the Search suggested redactions table to its previous state (can only undo the last action).
|
| 300 |
+
|
| 301 |
+
### Navigating through the document using the 'Search all extracted text'
|
| 302 |
+
|
| 303 |
+
The 'search all extracted text' table will contain text if you have just redacted a document, or if you have uploaded a '..._ocr_output.csv' file alongside a document file and review file on the Review redactions tab as [described above](#uploading-documents-for-review).
|
| 304 |
+
|
| 305 |
+
You can navigate through the document using this table. When you click on a row, the Document viewer pane to the left will change to the selected page.
|
| 306 |
+
|
| 307 |
+
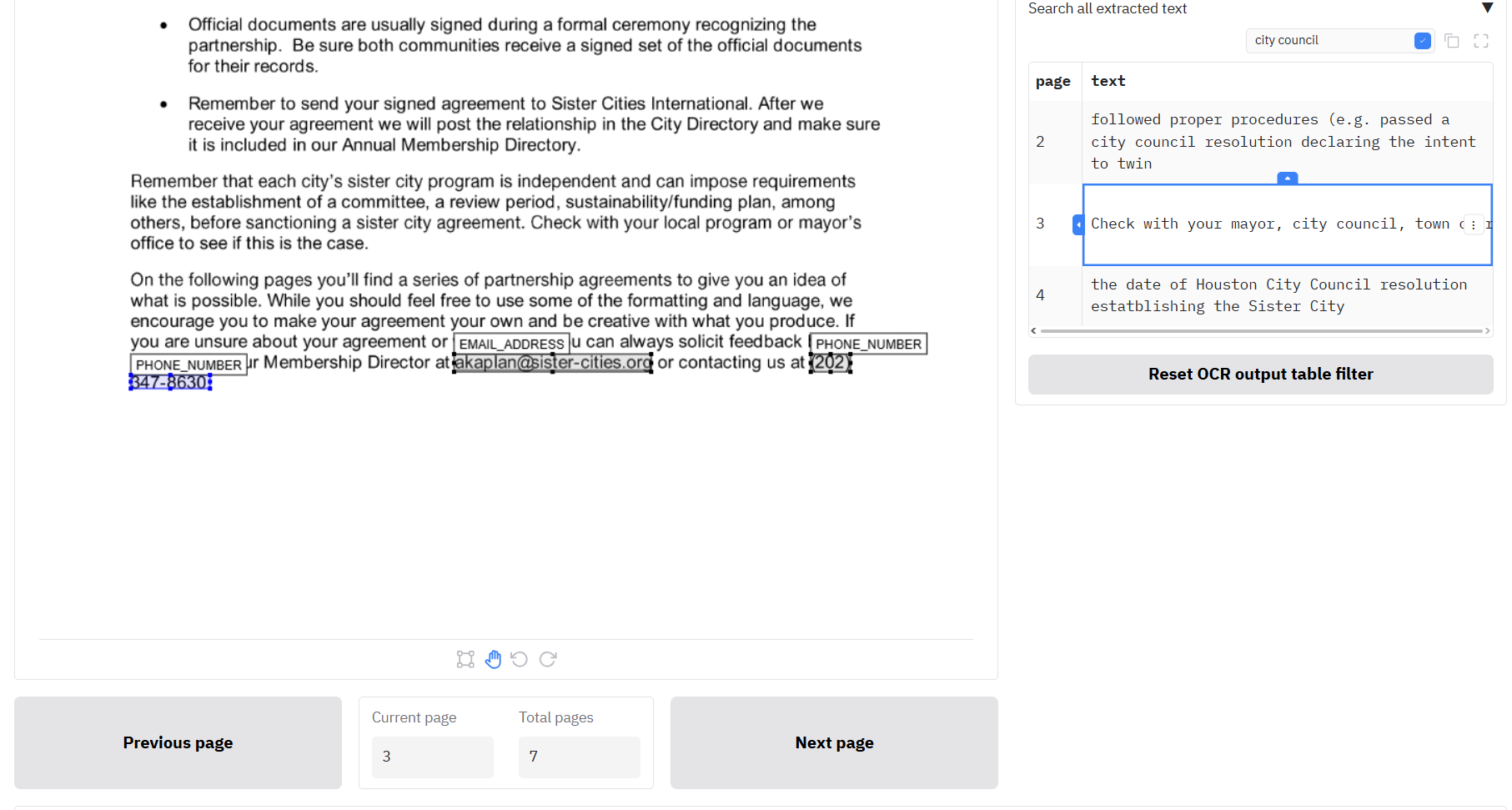
|
| 308 |
+
|
| 309 |
+
You can search through the extracted text by using the search bar just above the table, which should filter as you type. To apply the filter and 'cut' the table, click on the blue tick inside the box next to your search term. To return the table to its original content, click the button below the table 'Reset OCR output table filter'.
|
| 310 |
+
|
| 311 |
+

|
| 312 |
+
|
| 313 |
+
## Redacting tabular data files (XLSX/CSV) or copy and pasted text
|
| 314 |
+
|
| 315 |
+
### Tabular data files (XLSX/CSV)
|
| 316 |
+
|
| 317 |
+
The app can be used to redact tabular data files such as xlsx or csv files. For this to work properly, your data file needs to be in a simple table format, with a single table starting from the first cell (A1), and no other information in the sheet. Similarly for .xlsx files, each sheet in the file that you want to redact should be in this simple format.
|
| 318 |
+
|
| 319 |
+
To demonstrate this, we can use [the example csv file 'combined_case_notes.csv'](https://github.com/seanpedrick-case/document_redaction_examples/blob/main/combined_case_notes.csv), which is a small dataset of dummy social care case notes. Go to the 'Open text or Excel/csv files' tab. Drop the file into the upload area. After the file is loaded, you should see the suggested columns for redaction in the box underneath. You can select and deselect columns to redact as you wish from this list.
|
| 320 |
+
|
| 321 |
+
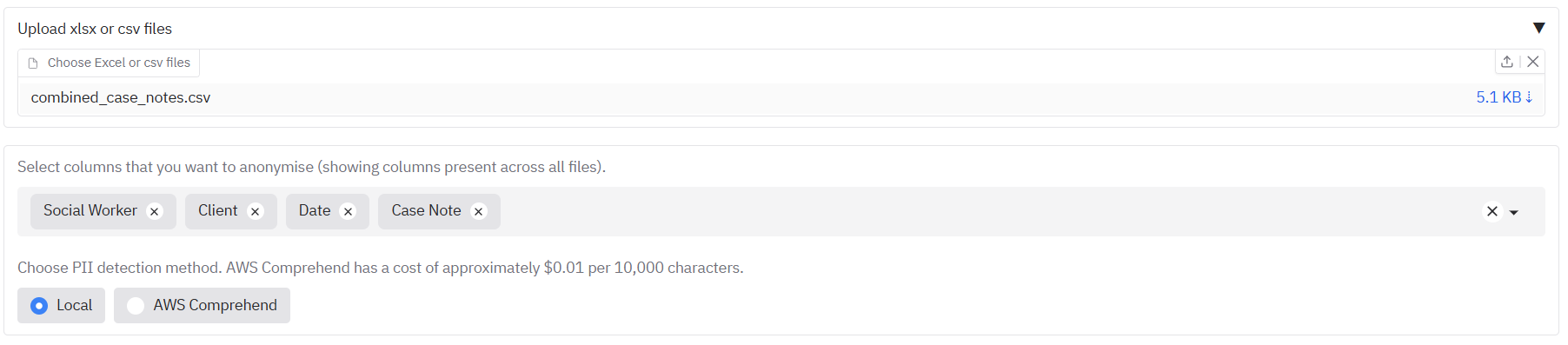
|
| 322 |
+
|
| 323 |
+
If you were instead to upload an xlsx file, you would see also a list of all the sheets in the xlsx file that can be redacted. The 'Select columns' area underneath will suggest a list of all columns in the file across all sheets.
|
| 324 |
+
|
| 325 |
+
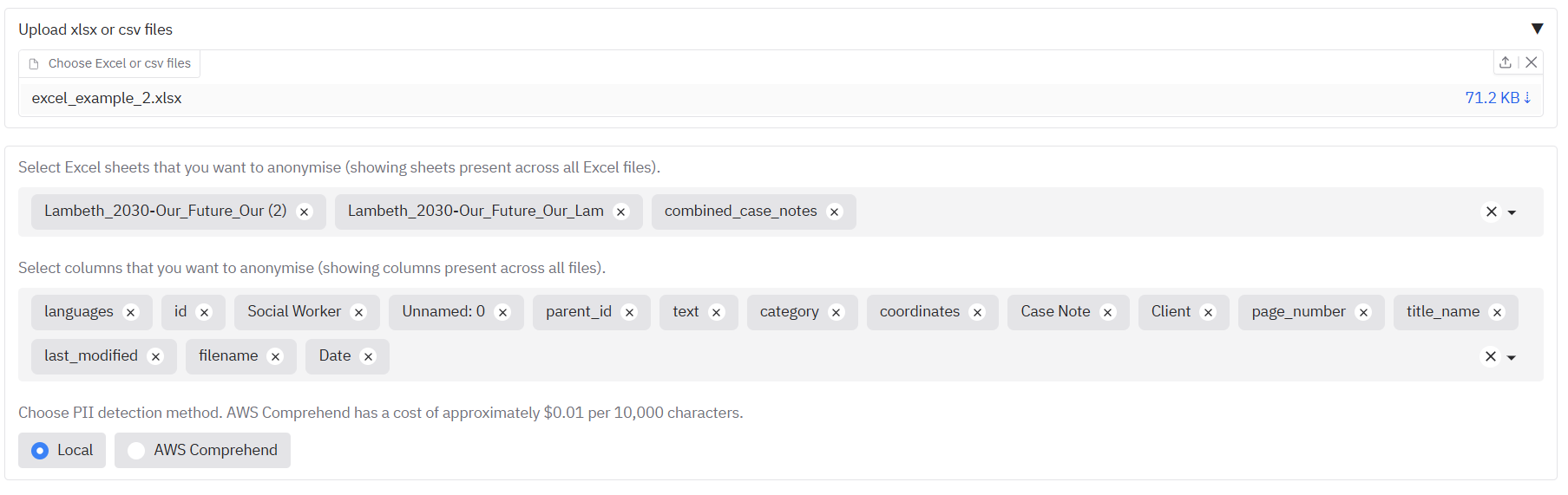
|
| 326 |
+
|
| 327 |
+
Once you have chosen your input file and sheets/columns to redact, you can choose the redaction method. 'Local' will use the same local model as used for documents on the first tab. 'AWS Comprehend' will give better results, at a slight cost.
|
| 328 |
+
|
| 329 |
+
When you click Redact text/data files, you will see the progress of the redaction task by file and sheet, and you will receive a csv output with the redacted data.
|
| 330 |
+
|
| 331 |
+
### Choosing output anonymisation format
|
| 332 |
+
You can also choose the anonymisation format of your output results. Open the tab 'Anonymisation output format' to see the options. By default, any detected PII will be replaced with the word 'REDACTED' in the cell. You can choose one of the following options as the form of replacement for the redacted text:
|
| 333 |
+
- replace with 'REDACTED': Replaced by the word 'REDACTED' (default)
|
| 334 |
+
- replace with <ENTITY_NAME>: Replaced by e.g. 'PERSON' for people, 'EMAIL_ADDRESS' for emails etc.
|
| 335 |
+
- redact completely: Text is removed completely and replaced by nothing.
|
| 336 |
+
- hash: Replaced by a unique long ID code that is consistent with entity text. I.e. a particular name will always have the same ID code.
|
| 337 |
+
- mask: Replace with stars '*'.
|
| 338 |
+
|
| 339 |
+
### Redacting copy and pasted text
|
| 340 |
+
You can also write open text into an input box and redact that using the same methods as described above. To do this, write or paste text into the 'Enter open text' box that appears when you open the 'Redact open text' tab. Then select a redaction method, and an anonymisation output format as described above. The redacted text will be printed in the output textbox, and will also be saved to a simple csv file in the output file box.
|
| 341 |
+
|
| 342 |
+
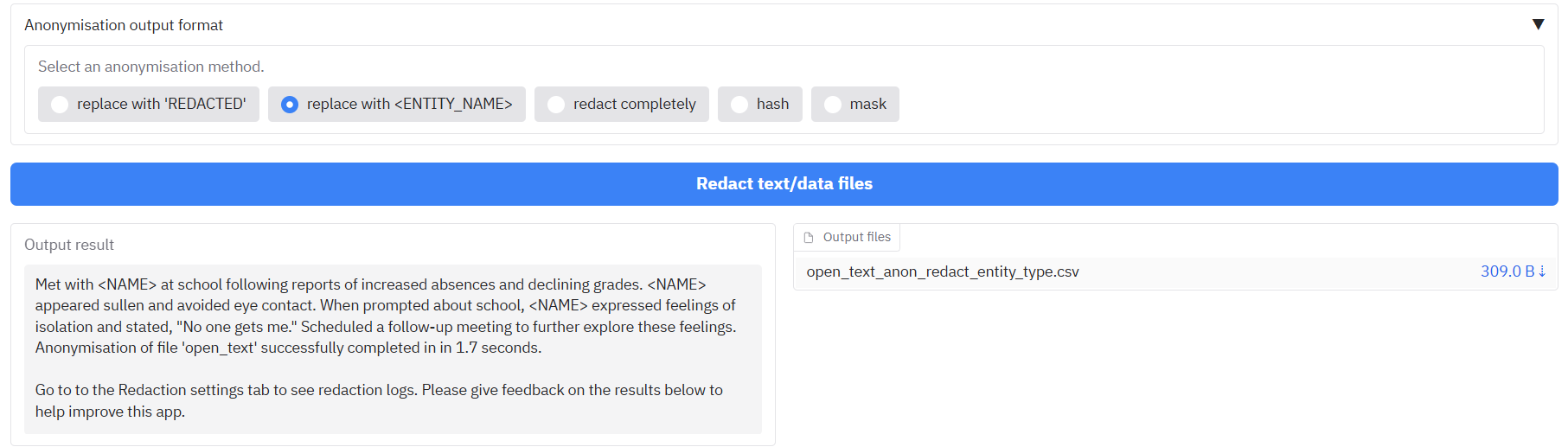
|
| 343 |
+
|
| 344 |
+
### Redaction log outputs
|
| 345 |
+
A list of the suggested redaction outputs from the tabular data / open text data redaction is available on the Redaction settings page under 'Log file outputs'.
|
| 346 |
+
|
| 347 |
+
# Advanced user guide
|
| 348 |
+
|
| 349 |
+
This advanced user guide will go over some of the features recently added to the app, including: modifying and merging redaction review files, identifying and redacting duplicate pages across multiple PDFs, 'fuzzy' search and redact, and exporting redactions to Adobe Acrobat.
|
| 350 |
+
|
| 351 |
+
## Table of contents
|
| 352 |
+
|
| 353 |
+
- [Merging redaction review files](#merging-redaction-review-files)
|
| 354 |
+
- [Identifying and redacting duplicate pages](#identifying-and-redacting-duplicate-pages)
|
| 355 |
+
- [Fuzzy search and redaction](#fuzzy-search-and-redaction)
|
| 356 |
+
- [Export redactions to and import from Adobe Acrobat](#export-to-and-import-from-adobe)
|
| 357 |
+
- [Exporting to Adobe Acrobat](#exporting-to-adobe-acrobat)
|
| 358 |
+
- [Importing from Adobe Acrobat](#importing-from-adobe-acrobat)
|
| 359 |
+
- [Using the AWS Textract document API](#using-the-aws-textract-document-api)
|
| 360 |
+
- [Using AWS Textract and Comprehend when not running in an AWS environment](#using-aws-textract-and-comprehend-when-not-running-in-an-aws-environment)
|
| 361 |
+
- [Modifying existing redaction review files](#modifying-existing-redaction-review-files)
|
| 362 |
+
|
| 363 |
+
|
| 364 |
+
## Merging redaction review files
|
| 365 |
+
|
| 366 |
+
Say you have run multiple redaction tasks on the same document, and you want to merge all of these redactions together. You could do this in your spreadsheet editor, but this could be fiddly especially if dealing with multiple review files or large numbers of redactions. The app has a feature to combine multiple review files together to create a 'merged' review file.
|
| 367 |
+
|
| 368 |
+

|
| 369 |
+
|
| 370 |
+
You can find this option at the bottom of the 'Redaction Settings' tab. Upload multiple review files here to get a single output 'merged' review_file. In the examples file, merging the 'review_file_custom.csv' and 'review_file_local.csv' files give you an output containing redaction boxes from both. This combined review file can then be uploaded into the review tab following the usual procedure.
|
| 371 |
+
|
| 372 |
+
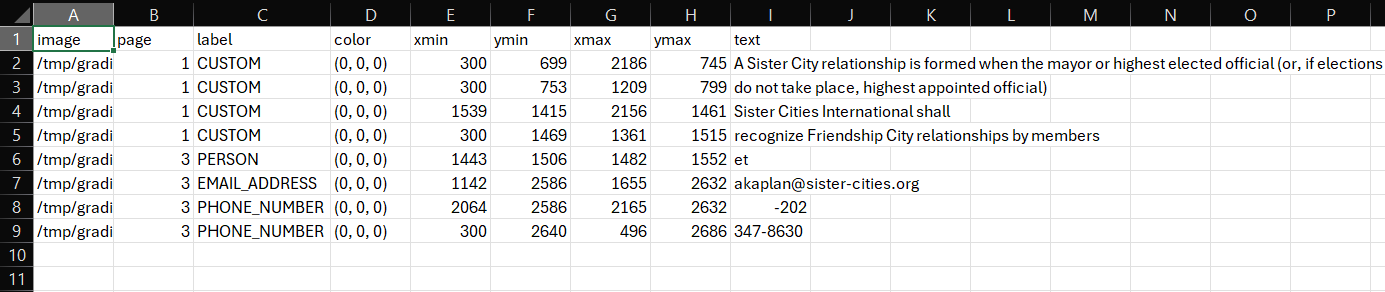
|
| 373 |
+
|
| 374 |
+
## Identifying and redacting duplicate pages
|
| 375 |
+
|
| 376 |
+
The files for this section are stored [here](https://github.com/seanpedrick-case/document_redaction_examples/blob/main/duplicate_page_find_in_app/).
|
| 377 |
+
|
| 378 |
+
Some redaction tasks involve removing duplicate pages of text that may exist across multiple documents. This feature calculates the similarity of text in all pages of input PDFs, calculates a similarity score, and then flags pages above a certain similarity score (90%) for removal by creating a 'whole page' redaction list file for each input PDF.
|
| 379 |
+
|
| 380 |
+

|
| 381 |
+
|
| 382 |
+
The similarity calculation is based on using the 'ocr_outputs.csv' file that is output every time that you perform a redaction task. From the file folder, upload the four 'ocr_output.csv' files provided in the example folder into the file area. Click 'Identify duplicate pages' and you will see a number of files returned. In case you want to see the original PDFs, they are available [here](https://github.com/seanpedrick-case/document_redaction_examples/blob/main/duplicate_page_find_in_app/input_pdfs/).
|
| 383 |
+
|
| 384 |
+

|
| 385 |
+
|
| 386 |
+
First, there is a 'combined_ocr_result...' file that just merges together all the text from the input files. 'page_similarity_results.csv' shows a breakdown of the pages from each file that are most similar to each other above the threshold (90% similarity). You can compare the text in the two columns 'Page_1_Text' and 'Page_2_Text'.
|
| 387 |
+
|
| 388 |
+
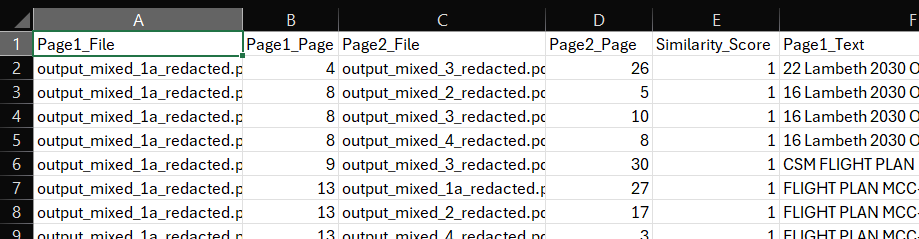
|
| 389 |
+
|
| 390 |
+
The remaining output files are suffixed with '_whole_page.csv'. These are the same files that can be used to redact whole pages as described in the ['Full page redaction list example' section](#full-page-redaction-list-example). For each PDF involved in the duplicate detection process, you can upload the relevant '_whole_page.csv' file into the relevant area, then do a new redaction task for the PDF file without any entity types selected. This way, only the suggested whole pages will be suggested for redaction and nothing else.
|
| 391 |
+
|
| 392 |
+

|
| 393 |
+
|
| 394 |
+
If you want to combine the results from this redaction process with previous redaction tasks for the same PDF, you could merge review file outputs following the steps described in [Merging existing redaction review files](#merging-existing-redaction-review-files) above.
|
| 395 |
+
|
| 396 |
+
## Fuzzy search and redaction
|
| 397 |
+
|
| 398 |
+
The files for this section are stored [here](https://github.com/seanpedrick-case/document_redaction_examples/blob/main/fuzzy_search/).
|
| 399 |
+
|
| 400 |
+
Sometimes you may be searching for terns that are slightly mispelled throughout a document, for example names. The document redaction app gives the option for searching for long phrases that may contain spelling mistakes, a method called 'fuzzy matching'.
|
| 401 |
+
|
| 402 |
+
To do this, go to the Redaction Settings, and the 'Select entity types to redact' area. In the box below relevant to your chosen redaction method (local or AWS Comprehend), select 'CUSTOM_FUZZY' from the list. Next, we can select the maximum number of spelling mistakes allowed in the search (up to nine). Here, you can either type in a number or use the small arrows to the right of the box. Change this option to 3. This will allow for a maximum of three 'changes' in text needed to match to the desired search terms.
|
| 403 |
+
|
| 404 |
+
The other option we can leave as is (should fuzzy search match on entire phrases in deny list) - this option would allow you to fuzzy search on each individual word in the search phrase (apart from stop words).
|
| 405 |
+
|
| 406 |
+
Next, we can upload a deny list on the same page to do the fuzzy search. A relevant deny list file can be found [here](https://github.com/seanpedrick-case/document_redaction_examples/blob/main/fuzzy_search/Partnership-Agreement-Toolkit_test_deny_list_para_single_spell.csv) - you can upload it following [these steps](#deny-list-example). You will notice that the suggested deny list has spelling mistakes compared to phrases found in the example document.
|
| 407 |
+
|
| 408 |
+

|
| 409 |
+
|
| 410 |
+
Upload the [Partnership-Agreement-Toolkit file](https://github.com/seanpedrick-case/document_redaction_examples/blob/main/Partnership-Agreement-Toolkit_0_0.pdf) into the 'Redact document' area on the first tab. Now, press the 'Redact document' button.
|
| 411 |
+
|
| 412 |
+
Using these deny list with spelling mistakes, the app fuzzy match these terms to the correct text in the document. After redaction is complete, go to the Review Redactions tab to check the first tabs. You should see that the phrases in the deny list have been successfully matched.
|
| 413 |
+
|
| 414 |
+

|
| 415 |
+
|
| 416 |
+
## Export to and import from Adobe
|
| 417 |
+
|
| 418 |
+
Files for this section are stored [here](https://github.com/seanpedrick-case/document_redaction_examples/blob/main/export_to_adobe/).
|
| 419 |
+
|
| 420 |
+
### Exporting to Adobe Acrobat
|
| 421 |
+
|
| 422 |
+
The Document Redaction app has a feature to export suggested redactions to Adobe, and likewise to import Adobe comment files into the app. The file format used is the .xfdf Adobe comment file format - [you can find more information about how to use these files here](https://helpx.adobe.com/uk/acrobat/using/importing-exporting-comments.html).
|
| 423 |
+
|
| 424 |
+
To convert suggested redactions to Adobe format, you need to have the original PDF and a review file csv in the input box at the top of the Review redactions page.
|
| 425 |
+
|
| 426 |
+

|
| 427 |
+
|
| 428 |
+
Then, you can find the export to Adobe option at the bottom of the Review redactions tab. Adobe comment files will be output here.
|
| 429 |
+
|
| 430 |
+

|
| 431 |
+
|
| 432 |
+
Once the input files are ready, you can click on the 'Convert review file to Adobe comment format'. You should see a file appear in the output box with a '.xfdf' file type. To use this in Adobe, after download to your computer, you should be able to double click on it, and a pop-up box will appear asking you to find the PDF file associated with it. Find the original PDF file used for your redaction task. The file should be opened up in Adobe Acrobat with the suggested redactions.
|
| 433 |
+
|
| 434 |
+
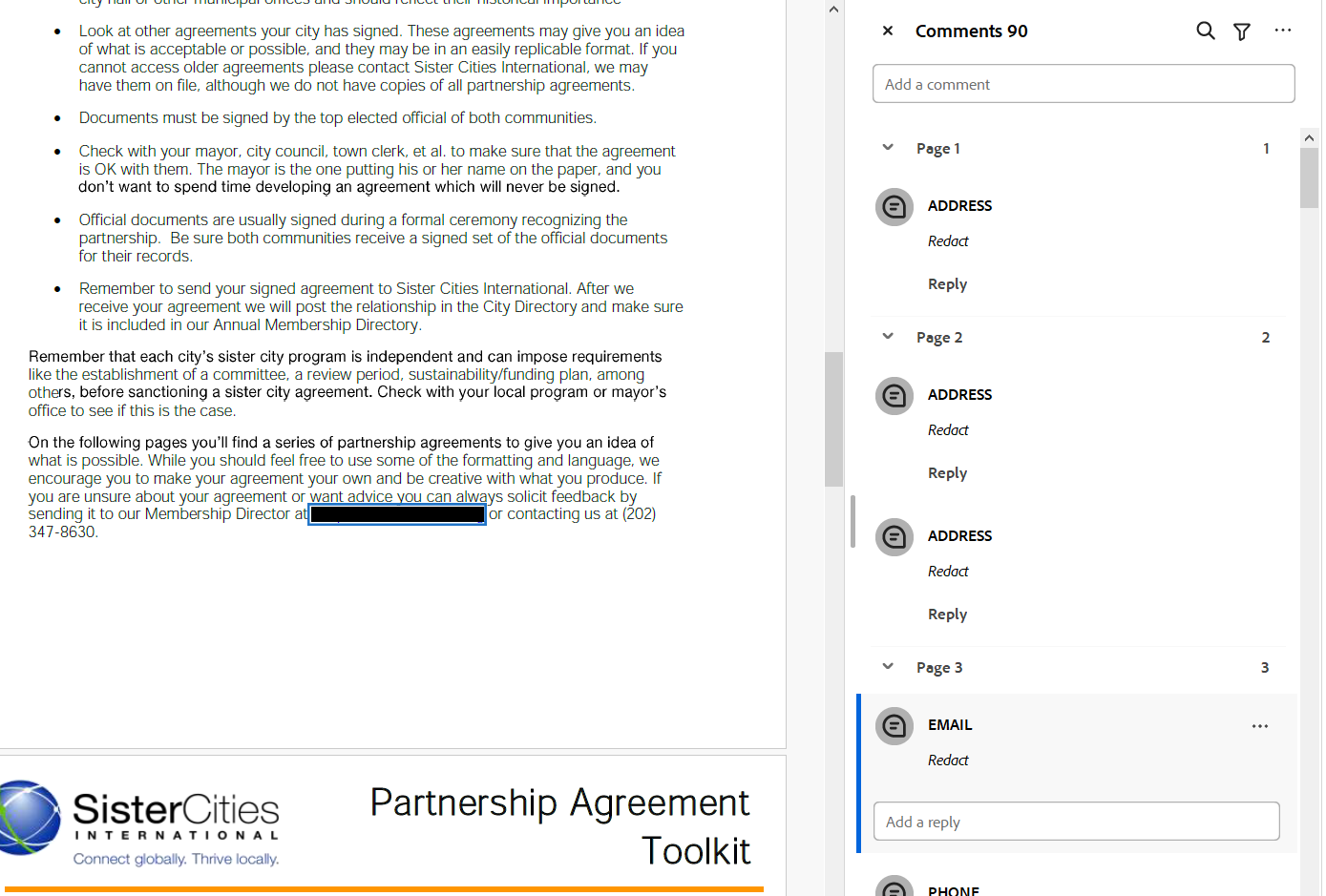
|
| 435 |
+
|
| 436 |
+
### Importing from Adobe Acrobat
|
| 437 |
+
|
| 438 |
+
The app also allows you to import .xfdf files from Adobe Acrobat. To do this, go to the same Adobe import/export area as described above at the bottom of the Review Redactions tab. In this box, you need to upload a .xfdf Adobe comment file, along with the relevant original PDF for redaction.
|
| 439 |
+
|
| 440 |
+

|
| 441 |
+
|
| 442 |
+
When you click the 'convert .xfdf comment file to review_file.csv' button, the app should take you up to the top of the screen where the new review file has been created and can be downloaded.
|
| 443 |
+
|
| 444 |
+

|
| 445 |
+
|
| 446 |
+
## Using the AWS Textract document API
|
| 447 |
+
|
| 448 |
+
This option can be enabled by your system admin, in the config file ('SHOW_WHOLE_DOCUMENT_TEXTRACT_CALL_OPTIONS' environment variable, and subsequent variables). Using this, you will have the option to submit whole documents in quick succession to the AWS Textract service to get extracted text outputs quickly (faster than using the 'Redact document' process described here).
|
| 449 |
+
|
| 450 |
+
### Starting a new Textract API job
|
| 451 |
+
|
| 452 |
+
To use this feature, first upload a document file in the file input box [in the usual way](#upload-files-to-the-app) on the first tab of the app. Under AWS Textract signature detection you can select whether or not you would like to analyse signatures or not (with a [cost implication](#optional---select-signature-extraction)).
|
| 453 |
+
|
| 454 |
+
Then, open the section under the heading 'Submit whole document to AWS Textract API...'.
|
| 455 |
+
|
| 456 |
+

|
| 457 |
+
|
| 458 |
+
Click 'Analyse document with AWS Textract API call'. After a few seconds, the job should be submitted to the AWS Textract service. The box 'Job ID to check status' should now have an ID filled in. If it is not already filled with previous jobs (up to seven days old), the table should have a row added with details of the new API job.
|
| 459 |
+
|
| 460 |
+
Click the button underneath, 'Check status of Textract job and download', to see progress on the job. Processing will continue in the background until the job is ready, so it is worth periodically clicking this button to see if the outputs are ready. In testing, and as a rough estimate, it seems like this process takes about five seconds per page. However, this has not been tested with very large documents. Once ready, the '_textract.json' output should appear below.
|
| 461 |
+
|
| 462 |
+
### Textract API job outputs
|
| 463 |
+
|
| 464 |
+
The '_textract.json' output can be used to speed up further redaction tasks as [described previously](#optional---costs-and-time-estimation), the 'Existing Textract output file found' flag should now be ticked.
|
| 465 |
+
|
| 466 |
+

|
| 467 |
+
|
| 468 |
+
You can now easily get the '..._ocr_output.csv' redaction output based on this '_textract.json' (described in [Redaction outputs](#redaction-outputs)) by clicking on the button 'Convert Textract job outputs to OCR results'. You can now use this file e.g. for [identifying duplicate pages](#identifying-and-redacting-duplicate-pages), or for redaction review.
|
| 469 |
+
|
| 470 |
+
## Using AWS Textract and Comprehend when not running in an AWS environment
|
| 471 |
+
|
| 472 |
+
AWS Textract and Comprehend give much better results for text extraction and document redaction than the local model options in the app. The most secure way to access them in the Redaction app is to run the app in a secure AWS environment with relevant permissions. Alternatively, you could run the app on your own system while logged in to AWS SSO with relevant permissions.
|
| 473 |
+
|
| 474 |
+
However, it is possible to access these services directly via API from outside an AWS environment by creating IAM users and access keys with relevant permissions to access AWS Textract and Comprehend services. Please check with your IT and data security teams that this approach is acceptable for your data before trying the following approaches.
|
| 475 |
+
|
| 476 |
+
To do the following, in your AWS environment you will need to create a new user with permissions for "textract:AnalyzeDocument", "textract:DetectDocumentText", and "comprehend:DetectPiiEntities". Under security credentials, create new access keys - note down the access key and secret key.
|
| 477 |
+
|
| 478 |
+
### Direct access by passing AWS access keys through app
|
| 479 |
+
The Redaction Settings tab now has boxes for entering the AWS access key and secret key. If you paste the relevant keys into these boxes before performing redaction, you should be able to use these services in the app.
|
| 480 |
+
|
| 481 |
+
### Picking up AWS access keys through an .env file
|
| 482 |
+
The app also has the capability of picking up AWS access key details through a .env file located in a '/config/aws_config.env' file (default), or alternative .env file location specified by the environment variable AWS_CONFIG_PATH. The env file should look like the following with just two lines:
|
| 483 |
+
|
| 484 |
+
AWS_ACCESS_KEY= your-access-key
|
| 485 |
+
AWS_SECRET_KEY= your-secret-key
|
| 486 |
+
|
| 487 |
+
The app should then pick up these keys when trying to access the AWS Textract and Comprehend services during redaction.
|
| 488 |
+
|
| 489 |
+
Again, a lot can potentially go wrong with AWS solutions that are insecure, so before trying the above please consult with your AWS and data security teams.
|
| 490 |
+
|
| 491 |
+
## Modifying existing redaction review files
|
| 492 |
+
|
| 493 |
+
You can find the folder containing the files discussed in this section [here](https://github.com/seanpedrick-case/document_redaction_examples/blob/main/merge_review_files/).
|
| 494 |
+
|
| 495 |
+
As well as serving as inputs to the document redaction app's review function, the 'review_file.csv' output can be modified outside of the app, and also merged with others from multiple redaction attempts on the same file. This gives you the flexibility to change redaction details outside of the app.
|
| 496 |
+
|
| 497 |
+
If you open up a 'review_file' csv output using a spreadsheet software program such as Microsoft Excel you can easily modify redaction properties. Open the file '[Partnership-Agreement-Toolkit_0_0_redacted.pdf_review_file_local.csv](https://github.com/seanpedrick-case/document_redaction_examples/blob/main/merge_review_files/Partnership-Agreement-Toolkit_0_0.pdf_review_file_local.csv)', and you should see a spreadshet with just four suggested redactions (see below). The following instructions are for using Excel.
|
| 498 |
+
|
| 499 |
+
|
| 500 |
+
|
| 501 |
+
The first thing we can do is remove the first row - 'et' is suggested as a person, but is obviously not a genuine instance of personal information. Right click on the row number and select delete on this menu. Next, let's imagine that what the app identified as a 'phone number' was in fact another type of number and so we wanted to change the label. Simply click on the relevant label cells, let's change it to 'SECURITY_NUMBER'. You could also use 'Find & Select' -> 'Replace' from the top ribbon menu if you wanted to change a number of labels simultaneously.
|
| 502 |
+
|
| 503 |
+
How about we wanted to change the colour of the 'email address' entry on the redaction review tab of the redaction app? The colours in a review file are based on an RGB scale with three numbers ranging from 0-255. [You can find suitable colours here](https://rgbcolorpicker.com). Using this scale, if I wanted my review box to be pure blue, I can change the cell value to (0,0,255).
|
| 504 |
+
|
| 505 |
+
Imagine that a redaction box was slightly too small, and I didn't want to use the in-app options to change the size. In the review file csv, we can modify e.g. the ymin and ymax values for any box to increase the extent of the redaction box. For the 'email address' entry, let's decrease ymin by 5, and increase ymax by 5.
|
| 506 |
+
|
| 507 |
+
I have saved an output file following the above steps as '[Partnership-Agreement-Toolkit_0_0_redacted.pdf_review_file_local_mod.csv](https://github.com/seanpedrick-case/document_redaction_examples/blob/main/merge_review_files/outputs/Partnership-Agreement-Toolkit_0_0.pdf_review_file_local_mod.csv)' in the same folder that the original was found. Let's upload this file to the app along with the original pdf to see how the redactions look now.
|
| 508 |
+
|
| 509 |
+
|
| 510 |
+
|
| 511 |
+
We can see from the above that we have successfully removed a redaction box, changed labels, colours, and redaction box sizes.
|
tld/.tld_set_snapshot
DELETED
|
The diff for this file is too large to render.
See raw diff
|
|
|