
Merge pull request #34 from seanpedrick-case/dev
Browse files- README.md +2 -2
- pyproject.toml +1 -1
- tools/redaction_review.py +78 -138
README.md
CHANGED
|
@@ -10,7 +10,7 @@ license: agpl-3.0
|
|
| 10 |
---
|
| 11 |
# Document redaction
|
| 12 |
|
| 13 |
-
version: 0.6.
|
| 14 |
|
| 15 |
Redact personally identifiable information (PII) from documents (pdf, images), open text, or tabular data (xlsx/csv/parquet). Please see the [User Guide](#user-guide) for a walkthrough on how to use the app. Below is a very brief overview.
|
| 16 |
|
|
@@ -512,7 +512,7 @@ If you open up a 'review_file' csv output using a spreadsheet software program s
|
|
| 512 |
|
| 513 |
|
| 514 |
|
| 515 |
-
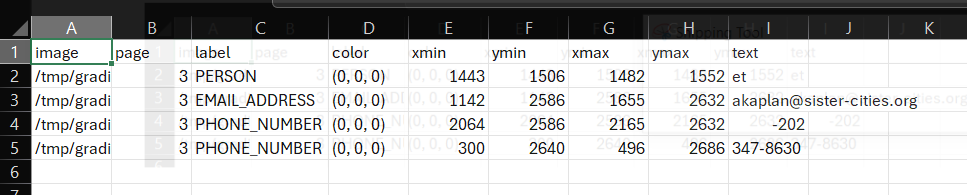
The first thing we can do is remove the first row - 'et' is suggested as a person, but is obviously not a genuine instance of personal information. Right click on the row number and select delete on this menu. Next, let's imagine that what the app identified as a 'phone number' was in fact another type of number and so we wanted to change the label. Simply click on the relevant label cells, let's change it to 'SECURITY_NUMBER'. You could also use '
|
| 516 |
|
| 517 |
How about we wanted to change the colour of the 'email address' entry on the redaction review tab of the redaction app? The colours in a review file are based on an RGB scale with three numbers ranging from 0-255. [You can find suitable colours here](https://rgbcolorpicker.com). Using this scale, if I wanted my review box to be pure blue, I can change the cell value to (0,0,255).
|
| 518 |
|
|
|
|
| 10 |
---
|
| 11 |
# Document redaction
|
| 12 |
|
| 13 |
+
version: 0.6.7
|
| 14 |
|
| 15 |
Redact personally identifiable information (PII) from documents (pdf, images), open text, or tabular data (xlsx/csv/parquet). Please see the [User Guide](#user-guide) for a walkthrough on how to use the app. Below is a very brief overview.
|
| 16 |
|
|
|
|
| 512 |
|
| 513 |

|
| 514 |
|
| 515 |
+
The first thing we can do is remove the first row - 'et' is suggested as a person, but is obviously not a genuine instance of personal information. Right click on the row number and select delete on this menu. Next, let's imagine that what the app identified as a 'phone number' was in fact another type of number and so we wanted to change the label. Simply click on the relevant label cells, let's change it to 'SECURITY_NUMBER'. You could also use 'Find & Select' -> 'Replace' from the top ribbon menu if you wanted to change a number of labels simultaneously.
|
| 516 |
|
| 517 |
How about we wanted to change the colour of the 'email address' entry on the redaction review tab of the redaction app? The colours in a review file are based on an RGB scale with three numbers ranging from 0-255. [You can find suitable colours here](https://rgbcolorpicker.com). Using this scale, if I wanted my review box to be pure blue, I can change the cell value to (0,0,255).
|
| 518 |
|
pyproject.toml
CHANGED
|
@@ -4,7 +4,7 @@ build-backend = "setuptools.build_meta"
|
|
| 4 |
|
| 5 |
[project]
|
| 6 |
name = "doc_redaction"
|
| 7 |
-
version = "0.6.
|
| 8 |
description = "Redact PDF/image-based documents, or CSV/XLSX files using a Gradio-based GUI interface"
|
| 9 |
readme = "README.md"
|
| 10 |
requires-python = ">=3.10"
|
|
|
|
| 4 |
|
| 5 |
[project]
|
| 6 |
name = "doc_redaction"
|
| 7 |
+
version = "0.6.7"
|
| 8 |
description = "Redact PDF/image-based documents, or CSV/XLSX files using a Gradio-based GUI interface"
|
| 9 |
readme = "README.md"
|
| 10 |
requires-python = ">=3.10"
|
tools/redaction_review.py
CHANGED
|
@@ -12,6 +12,7 @@ from gradio_image_annotation.image_annotator import AnnotatedImageData
|
|
| 12 |
from pymupdf import Document, Rect
|
| 13 |
import pymupdf
|
| 14 |
from PIL import ImageDraw, Image
|
|
|
|
| 15 |
|
| 16 |
from tools.config import OUTPUT_FOLDER, CUSTOM_BOX_COLOUR, MAX_IMAGE_PIXELS, INPUT_FOLDER, COMPRESS_REDACTED_PDF
|
| 17 |
from tools.file_conversion import is_pdf, convert_annotation_json_to_review_df, convert_review_df_to_annotation_json, process_single_page_for_image_conversion, multiply_coordinates_by_page_sizes, convert_annotation_data_to_dataframe, create_annotation_dicts_from_annotation_df, remove_duplicate_images_with_blank_boxes, fill_missing_ids, divide_coordinates_by_page_sizes, save_pdf_with_or_without_compression
|
|
@@ -1264,160 +1265,97 @@ def convert_pymupdf_coords_to_adobe(x1: float, y1: float, x2: float, y2: float,
|
|
| 1264 |
|
| 1265 |
return x1, adobe_y1, x2, adobe_y2
|
| 1266 |
|
| 1267 |
-
def create_xfdf(review_file_df:pd.DataFrame, pdf_path:str, pymupdf_doc:object, image_paths:List[str], document_cropboxes:List=[], page_sizes:List[dict]=[]):
|
| 1268 |
'''
|
| 1269 |
Create an xfdf file from a review csv file and a pdf
|
| 1270 |
'''
|
| 1271 |
-
|
|
|
|
| 1272 |
|
| 1273 |
-
|
| 1274 |
-
xfdf = Element('xfdf', xmlns="http://ns.adobe.com/xfdf/", xml_space="preserve")
|
| 1275 |
-
|
| 1276 |
-
# Add header
|
| 1277 |
-
header = SubElement(xfdf, 'header')
|
| 1278 |
-
header.set('pdf-filepath', pdf_path)
|
| 1279 |
-
|
| 1280 |
-
# Add annots
|
| 1281 |
-
annots = SubElement(xfdf, 'annots')
|
| 1282 |
-
|
| 1283 |
-
# Check if page size object exists, and if current coordinates are in relative format or image coordinates format.
|
| 1284 |
-
if page_sizes:
|
| 1285 |
-
|
| 1286 |
page_sizes_df = pd.DataFrame(page_sizes)
|
| 1287 |
-
|
| 1288 |
-
|
| 1289 |
-
|
| 1290 |
-
|
| 1291 |
-
|
| 1292 |
-
review_file_df = review_file_df
|
| 1293 |
-
|
| 1294 |
-
|
| 1295 |
-
|
| 1296 |
-
review_file_df["xmin"] = review_file_df["xmin"] * review_file_df["mediabox_width"]
|
| 1297 |
-
review_file_df["xmax"] = review_file_df["xmax"] * review_file_df["mediabox_width"]
|
| 1298 |
-
review_file_df["ymin"] = review_file_df["ymin"] * review_file_df["mediabox_height"]
|
| 1299 |
-
review_file_df["ymax"] = review_file_df["ymax"] * review_file_df["mediabox_height"]
|
| 1300 |
-
|
| 1301 |
-
# If all nulls, then can do image coordinate conversion
|
| 1302 |
-
if len(page_sizes_df.loc[page_sizes_df["mediabox_width"].isnull(),"mediabox_width"]) == len(page_sizes_df["mediabox_width"]):
|
| 1303 |
-
|
| 1304 |
-
pages_are_images = True
|
| 1305 |
-
|
| 1306 |
review_file_df = multiply_coordinates_by_page_sizes(review_file_df, page_sizes_df, xmin="xmin", xmax="xmax", ymin="ymin", ymax="ymax")
|
| 1307 |
|
| 1308 |
-
# if "image_width" not in review_file_df.columns:
|
| 1309 |
-
# review_file_df = review_file_df.merge(page_sizes_df, how="left", on = "page")
|
| 1310 |
-
|
| 1311 |
-
# # If all coordinates are less or equal to one, this is a relative page scaling - change back to image coordinates
|
| 1312 |
-
# if review_file_df["xmin"].max() <= 1 and review_file_df["xmax"].max() <= 1 and review_file_df["ymin"].max() <= 1 and review_file_df["ymax"].max() <= 1:
|
| 1313 |
-
# review_file_df["xmin"] = review_file_df["xmin"] * review_file_df["image_width"]
|
| 1314 |
-
# review_file_df["xmax"] = review_file_df["xmax"] * review_file_df["image_width"]
|
| 1315 |
-
# review_file_df["ymin"] = review_file_df["ymin"] * review_file_df["image_height"]
|
| 1316 |
-
# review_file_df["ymax"] = review_file_df["ymax"] * review_file_df["image_height"]
|
| 1317 |
-
|
| 1318 |
-
|
| 1319 |
-
|
| 1320 |
-
# Go through each row of the review_file_df, create an entry in the output Adobe xfdf file.
|
| 1321 |
for _, row in review_file_df.iterrows():
|
| 1322 |
-
page_num_reported = row["page"]
|
| 1323 |
-
page_python_format =
|
| 1324 |
-
|
| 1325 |
pymupdf_page = pymupdf_doc.load_page(page_python_format)
|
| 1326 |
|
| 1327 |
-
|
| 1328 |
-
if document_cropboxes:
|
| 1329 |
-
|
| 1330 |
-
# Extract numbers safely using regex
|
| 1331 |
match = re.findall(r"[-+]?\d*\.\d+|\d+", document_cropboxes[page_python_format])
|
| 1332 |
-
|
| 1333 |
if match and len(match) == 4:
|
| 1334 |
-
rect_values = list(map(float, match))
|
| 1335 |
pymupdf_page.set_cropbox(Rect(*rect_values))
|
| 1336 |
-
else:
|
| 1337 |
-
raise ValueError(f"Invalid cropbox format: {document_cropboxes[page_python_format]}")
|
| 1338 |
-
else:
|
| 1339 |
-
print("Document cropboxes not found.")
|
| 1340 |
-
|
| 1341 |
-
pdf_page_height = pymupdf_page.mediabox.height
|
| 1342 |
-
pdf_page_width = pymupdf_page.mediabox.width
|
| 1343 |
|
| 1344 |
-
|
| 1345 |
redact_annot = SubElement(annots, 'redact')
|
| 1346 |
-
|
| 1347 |
-
#
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1348 |
annot_id = str(uuid.uuid4())
|
| 1349 |
redact_annot.set('name', annot_id)
|
| 1350 |
-
|
| 1351 |
-
# Set page number (subtract 1 as PDF pages are 0-based)
|
| 1352 |
-
redact_annot.set('page', str(int(row['page']) - 1))
|
| 1353 |
-
|
| 1354 |
-
# # Convert coordinates
|
| 1355 |
-
# if pages_are_images == True:
|
| 1356 |
-
# x1, y1, x2, y2 = convert_image_coords_to_adobe(
|
| 1357 |
-
# pdf_page_width,
|
| 1358 |
-
# pdf_page_height,
|
| 1359 |
-
# image_page_width,
|
| 1360 |
-
# image_page_height,
|
| 1361 |
-
# row['xmin'],
|
| 1362 |
-
# row['ymin'],
|
| 1363 |
-
# row['xmax'],
|
| 1364 |
-
# row['ymax']
|
| 1365 |
-
# )
|
| 1366 |
-
# else:
|
| 1367 |
-
x1, y1, x2, y2 = convert_pymupdf_coords_to_adobe(row['xmin'],
|
| 1368 |
-
row['ymin'],
|
| 1369 |
-
row['xmax'],
|
| 1370 |
-
row['ymax'], pdf_page_height)
|
| 1371 |
-
|
| 1372 |
-
if CUSTOM_BOX_COLOUR == "grey":
|
| 1373 |
-
colour_str = "0.5,0.5,0.5"
|
| 1374 |
-
else:
|
| 1375 |
-
colour_str = row['color'].strip('()').replace(' ', '')
|
| 1376 |
-
|
| 1377 |
-
# Set coordinates
|
| 1378 |
-
redact_annot.set('rect', f"{x1:.2f},{y1:.2f},{x2:.2f},{y2:.2f}")
|
| 1379 |
-
|
| 1380 |
-
# Set redaction properties
|
| 1381 |
-
redact_annot.set('title', row['label']) # The type of redaction (e.g., "PERSON")
|
| 1382 |
-
redact_annot.set('contents', row['text']) # The redacted text
|
| 1383 |
-
redact_annot.set('subject', row['label']) # The redacted text
|
| 1384 |
redact_annot.set('mimetype', "Form")
|
| 1385 |
-
|
| 1386 |
-
|
| 1387 |
-
|
| 1388 |
-
|
| 1389 |
-
|
| 1390 |
-
|
| 1391 |
-
|
| 1392 |
-
|
| 1393 |
-
|
| 1394 |
-
|
| 1395 |
-
|
| 1396 |
-
|
| 1397 |
-
|
| 1398 |
-
|
| 1399 |
-
|
| 1400 |
-
|
| 1401 |
-
|
| 1402 |
-
|
| 1403 |
-
|
| 1404 |
-
|
| 1405 |
-
|
| 1406 |
-
|
| 1407 |
-
|
| 1408 |
-
|
| 1409 |
-
|
| 1410 |
-
|
| 1411 |
-
|
| 1412 |
-
|
| 1413 |
-
|
| 1414 |
-
|
| 1415 |
-
|
| 1416 |
-
|
| 1417 |
-
|
| 1418 |
-
|
| 1419 |
-
|
| 1420 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1421 |
|
| 1422 |
def convert_df_to_xfdf(input_files:List[str], pdf_doc:Document, image_paths:List[str], output_folder:str = OUTPUT_FOLDER, document_cropboxes:List=[], page_sizes:List[dict]=[]):
|
| 1423 |
'''
|
|
@@ -1448,14 +1386,16 @@ def convert_df_to_xfdf(input_files:List[str], pdf_doc:Document, image_paths:List
|
|
| 1448 |
if file_path_end == "pdf":
|
| 1449 |
pdf_name = os.path.basename(file_path)
|
| 1450 |
|
| 1451 |
-
if file_path_end == "csv":
|
| 1452 |
# If no pdf name, just get the name of the file path
|
| 1453 |
if not pdf_name:
|
| 1454 |
pdf_name = file_path_name
|
| 1455 |
# Read CSV file
|
| 1456 |
review_file_df = pd.read_csv(file_path)
|
| 1457 |
|
| 1458 |
-
|
|
|
|
|
|
|
| 1459 |
|
| 1460 |
xfdf_content = create_xfdf(review_file_df, pdf_name, pdf_doc, image_paths, document_cropboxes, page_sizes)
|
| 1461 |
|
|
|
|
| 12 |
from pymupdf import Document, Rect
|
| 13 |
import pymupdf
|
| 14 |
from PIL import ImageDraw, Image
|
| 15 |
+
from datetime import datetime, timezone, timedelta
|
| 16 |
|
| 17 |
from tools.config import OUTPUT_FOLDER, CUSTOM_BOX_COLOUR, MAX_IMAGE_PIXELS, INPUT_FOLDER, COMPRESS_REDACTED_PDF
|
| 18 |
from tools.file_conversion import is_pdf, convert_annotation_json_to_review_df, convert_review_df_to_annotation_json, process_single_page_for_image_conversion, multiply_coordinates_by_page_sizes, convert_annotation_data_to_dataframe, create_annotation_dicts_from_annotation_df, remove_duplicate_images_with_blank_boxes, fill_missing_ids, divide_coordinates_by_page_sizes, save_pdf_with_or_without_compression
|
|
|
|
| 1265 |
|
| 1266 |
return x1, adobe_y1, x2, adobe_y2
|
| 1267 |
|
| 1268 |
+
def create_xfdf(review_file_df:pd.DataFrame, pdf_path:str, pymupdf_doc:object, image_paths:List[str]=[], document_cropboxes:List=[], page_sizes:List[dict]=[]):
|
| 1269 |
'''
|
| 1270 |
Create an xfdf file from a review csv file and a pdf
|
| 1271 |
'''
|
| 1272 |
+
xfdf_root = Element('xfdf', xmlns="http://ns.adobe.com/xfdf/", **{'xml:space':"preserve"})
|
| 1273 |
+
annots = SubElement(xfdf_root, 'annots')
|
| 1274 |
|
| 1275 |
+
if page_sizes:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1276 |
page_sizes_df = pd.DataFrame(page_sizes)
|
| 1277 |
+
if not page_sizes_df.empty and "mediabox_width" not in review_file_df.columns:
|
| 1278 |
+
review_file_df = review_file_df.merge(page_sizes_df, how="left", on="page")
|
| 1279 |
+
if "xmin" in review_file_df.columns and review_file_df["xmin"].max() <= 1:
|
| 1280 |
+
if "mediabox_width" in review_file_df.columns and "mediabox_height" in review_file_df.columns:
|
| 1281 |
+
review_file_df["xmin"] = review_file_df["xmin"] * review_file_df["mediabox_width"]
|
| 1282 |
+
review_file_df["xmax"] = review_file_df["xmax"] * review_file_df["mediabox_width"]
|
| 1283 |
+
review_file_df["ymin"] = review_file_df["ymin"] * review_file_df["mediabox_height"]
|
| 1284 |
+
review_file_df["ymax"] = review_file_df["ymax"] * review_file_df["mediabox_height"]
|
| 1285 |
+
elif "image_width" in review_file_df.columns and not page_sizes_df.empty :
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1286 |
review_file_df = multiply_coordinates_by_page_sizes(review_file_df, page_sizes_df, xmin="xmin", xmax="xmax", ymin="ymin", ymax="ymax")
|
| 1287 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1288 |
for _, row in review_file_df.iterrows():
|
| 1289 |
+
page_num_reported = int(row["page"])
|
| 1290 |
+
page_python_format = page_num_reported - 1
|
|
|
|
| 1291 |
pymupdf_page = pymupdf_doc.load_page(page_python_format)
|
| 1292 |
|
| 1293 |
+
if document_cropboxes and page_python_format < len(document_cropboxes):
|
|
|
|
|
|
|
|
|
|
| 1294 |
match = re.findall(r"[-+]?\d*\.\d+|\d+", document_cropboxes[page_python_format])
|
|
|
|
| 1295 |
if match and len(match) == 4:
|
| 1296 |
+
rect_values = list(map(float, match))
|
| 1297 |
pymupdf_page.set_cropbox(Rect(*rect_values))
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1298 |
|
| 1299 |
+
pdf_page_height = pymupdf_page.mediabox.height
|
| 1300 |
redact_annot = SubElement(annots, 'redact')
|
| 1301 |
+
redact_annot.set('opacity', "0.500000")
|
| 1302 |
+
redact_annot.set('interior-color', "#000000")
|
| 1303 |
+
|
| 1304 |
+
now = datetime.now(timezone(timedelta(hours=1))) # Consider making tz configurable or UTC
|
| 1305 |
+
date_str = now.strftime("D:%Y%m%d%H%M%S") + now.strftime("%z")[:3] + "'" + now.strftime("%z")[3:] + "'"
|
| 1306 |
+
redact_annot.set('date', date_str)
|
| 1307 |
+
|
| 1308 |
annot_id = str(uuid.uuid4())
|
| 1309 |
redact_annot.set('name', annot_id)
|
| 1310 |
+
redact_annot.set('page', str(page_python_format))
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1311 |
redact_annot.set('mimetype', "Form")
|
| 1312 |
+
|
| 1313 |
+
x1_pdf, y1_pdf, x2_pdf, y2_pdf = row['xmin'], row['ymin'], row['xmax'], row['ymax']
|
| 1314 |
+
adobe_x1, adobe_y1, adobe_x2, adobe_y2 = convert_pymupdf_coords_to_adobe(
|
| 1315 |
+
x1_pdf, y1_pdf, x2_pdf, y2_pdf, pdf_page_height
|
| 1316 |
+
)
|
| 1317 |
+
redact_annot.set('rect', f"{adobe_x1:.6f},{adobe_y1:.6f},{adobe_x2:.6f},{adobe_y2:.6f}")
|
| 1318 |
+
|
| 1319 |
+
redact_annot.set('subject', str(row['label'])) # Changed from row['text'] to row['label']
|
| 1320 |
+
redact_annot.set('title', str(row.get('label', 'Unknown'))) # Fallback for title
|
| 1321 |
+
|
| 1322 |
+
contents_richtext = SubElement(redact_annot, 'contents-richtext')
|
| 1323 |
+
body_attrs = {
|
| 1324 |
+
'xmlns': "http://www.w3.org/1999/xhtml",
|
| 1325 |
+
'{http://www.xfa.org/schema/xfa-data/1.0/}APIVersion': "Acrobat:25.1.0",
|
| 1326 |
+
'{http://www.xfa.org/schema/xfa-data/1.0/}spec': "2.0.2"
|
| 1327 |
+
}
|
| 1328 |
+
body = SubElement(contents_richtext, 'body', attrib=body_attrs)
|
| 1329 |
+
p_element = SubElement(body, 'p', dir="ltr")
|
| 1330 |
+
span_attrs = {
|
| 1331 |
+
'dir': "ltr",
|
| 1332 |
+
'style': "font-size:10.0pt;text-align:left;color:#000000;font-weight:normal;font-style:normal"
|
| 1333 |
+
}
|
| 1334 |
+
span_element = SubElement(p_element, 'span', attrib=span_attrs)
|
| 1335 |
+
span_element.text = str(row['text']).strip() # Added .strip()
|
| 1336 |
+
|
| 1337 |
+
pdf_ops_for_black_fill_and_outline = [
|
| 1338 |
+
"1 w", # 1. Set line width to 1 point for the stroke
|
| 1339 |
+
"0 g", # 2. Set NON-STROKING (fill) color to black
|
| 1340 |
+
"0 G", # 3. Set STROKING (outline) color to black
|
| 1341 |
+
"1 0 0 1 0 0 cm", # 4. CTM (using absolute page coordinates)
|
| 1342 |
+
f"{adobe_x1:.2f} {adobe_y1:.2f} m", # 5. Path definition: move to start
|
| 1343 |
+
f"{adobe_x2:.2f} {adobe_y1:.2f} l", # line
|
| 1344 |
+
f"{adobe_x2:.2f} {adobe_y2:.2f} l", # line
|
| 1345 |
+
f"{adobe_x1:.2f} {adobe_y2:.2f} l", # line
|
| 1346 |
+
"h", # 6. Close the path (creates the last line back to start)
|
| 1347 |
+
"B" # 7. Fill AND Stroke the path using non-zero winding rule
|
| 1348 |
+
]
|
| 1349 |
+
data_content_string = "\n".join(pdf_ops_for_black_fill_and_outline) + "\n"
|
| 1350 |
+
data_element = SubElement(redact_annot, 'data')
|
| 1351 |
+
data_element.set('MODE', "filtered")
|
| 1352 |
+
data_element.set('encoding', "ascii")
|
| 1353 |
+
data_element.set('length', str(len(data_content_string.encode('ascii'))))
|
| 1354 |
+
data_element.text = data_content_string
|
| 1355 |
+
|
| 1356 |
+
rough_string = tostring(xfdf_root, encoding='unicode', method='xml')
|
| 1357 |
+
reparsed = minidom.parseString(rough_string)
|
| 1358 |
+
return reparsed.toxml() #.toprettyxml(indent=" ")
|
| 1359 |
|
| 1360 |
def convert_df_to_xfdf(input_files:List[str], pdf_doc:Document, image_paths:List[str], output_folder:str = OUTPUT_FOLDER, document_cropboxes:List=[], page_sizes:List[dict]=[]):
|
| 1361 |
'''
|
|
|
|
| 1386 |
if file_path_end == "pdf":
|
| 1387 |
pdf_name = os.path.basename(file_path)
|
| 1388 |
|
| 1389 |
+
if file_path_end == "csv" and "review_file" in file_path_name:
|
| 1390 |
# If no pdf name, just get the name of the file path
|
| 1391 |
if not pdf_name:
|
| 1392 |
pdf_name = file_path_name
|
| 1393 |
# Read CSV file
|
| 1394 |
review_file_df = pd.read_csv(file_path)
|
| 1395 |
|
| 1396 |
+
# Replace NaN in review file with an empty string
|
| 1397 |
+
if 'text' in review_file_df.columns: review_file_df['text'] = review_file_df['text'].fillna('')
|
| 1398 |
+
if 'label' in review_file_df.columns: review_file_df['label'] = review_file_df['label'].fillna('')
|
| 1399 |
|
| 1400 |
xfdf_content = create_xfdf(review_file_df, pdf_name, pdf_doc, image_paths, document_cropboxes, page_sizes)
|
| 1401 |
|