Spaces:
Runtime error


Runtime error
File size: 5,459 Bytes
263af70 d18dc3b 263af70 d18dc3b 263af70 9575e16 263af70 9575e16 263af70 9575e16 263af70 e67306e 263af70 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 |
In this guide, we explain how to get your agent evaluated by the [Open RL Leaderboard](https://huggingface.co/spaces/open-rl-leaderboard/leaderboard). For the sake of demonstration, we'll train a simple agent, but if you already have a trained agent, you can of course skip this step.
If your agent is already on the 🤗 Hub (trained with Stable-Baselines3, CleanRL, ...), we provide [scripts](https://github.com/qgallouedec/open-rl-leaderboard-utils) to automate conversion.
## 🛠️ Prerequisites
Ensure you have the necessary packages installed:
```bash
pip install torch huggingface-hub
```
## 🏋️♂️ Training the agent (optional, just for demonstration)
Here is a simple example of training a reinforcement learning agent using the `CartPole-v1` environment from Gymnasium. You can skip this step if you already have a trained model. For this example, you'll also need the `gymnasium` package:
```bash
pip install gymnasium
```
Now, let's train the agent with a simple policy gradient algorithm:
```python
import gymnasium as gym
import torch
from torch import nn, optim
from torch.distributions import Categorical
# Environment setup
env_id = "CartPole-v1"
env = gym.make(env_id, render_mode="human")
env = gym.wrappers.RecordEpisodeStatistics(env)
# Agent setup
policy = nn.Sequential(
nn.Linear(4, 128),
nn.Dropout(p=0.6),
nn.ReLU(),
nn.Linear(128, 2),
nn.Softmax(-1),
)
optimizer = optim.Adam(policy.parameters(), lr=1e-2)
# Training loop
global_step = 0
for episode_idx in range(10):
log_probs = torch.zeros((env.spec.max_episode_steps + 1))
returns = torch.zeros((env.spec.max_episode_steps + 1))
observation, info = env.reset()
terminated = truncated = False
step = 0
while not terminated and not truncated:
probs = policy(torch.tensor(observation))
distribution = Categorical(probs) # Create distribution
action = distribution.sample() # Sample action
log_probs[step] = distribution.log_prob(action) # Store log probability
action = action.cpu().numpy() # Convert to numpy array
observation, reward, terminated, truncated, info = env.step(action)
step += 1
global_step += 1
returns[:step] += 0.99 ** torch.flip(torch.arange(step), (0,)) * reward # return = sum(gamma^i * reward_i)
episodic_return = info["episode"]["r"][0]
print(f"Episode: {episode_idx} Global step: {global_step} Episodic return: {episodic_return:.2f}")
batch_returns = returns[:step]
batch_log_probs = log_probs[:step]
batch_returns = (batch_returns - batch_returns.mean()) / (batch_returns.std() + 10**-5)
policy_loss = torch.sum(-batch_log_probs * batch_returns)
optimizer.zero_grad()
policy_loss.backward()
optimizer.step()
```
That's it! You've trained a simple policy gradient agent. Now let's see how to upload the agent to the 🤗 Hub so that the [Open RL Leaderboard](https://huggingface.co/spaces/open-rl-leaderboard/leaderboard) can evaluate it.
## 🤖 From policy to agent
To make the agent compatible with the Open RL Leaderboard, you need your model to take a batch of observations as input and return a batch of actions. Here's how you can wrap your policy model into an agent class:
```python
class Agent(nn.Module):
def __init__(self, policy):
super().__init__()
self.policy = policy
def forward(self, observations):
probs = self.policy(observations)
distribution = Categorical(probs)
return distribution.sample()
agent = Agent(policy) # instantiate the agent
# A few tests to check if the agent is working
observations = torch.randn(env.observation_space.shape).unsqueeze(0) # dummy batch of observations
actions = agent(observations)
actions = actions.numpy()[0]
assert env.action_space.contains(actions)
```
## 💾 Saving the agent
For the Open RL Leaderboard to evaluate your agent, you need to save it as a [TorchScript module](https://pytorch.org/docs/stable/jit.html#) under the name `agent.pt`.
It must be loadable using `torch.jit.load`. Then you can push it to the 🤗 Hub.
```python
from huggingface_hub import metadata_save, HfApi
# Save model along with its card
metadata_save("model_card.md", {"tags": ["reinforcement-learning", env_id]})
dummy_input = torch.randn(env.observation_space.shape).unsqueeze(0) # dummy batch of observations
agent = torch.jit.trace(agent.eval(), dummy_input)
agent = torch.jit.freeze(agent) # required for the model not to depend on the training library
torch.jit.save(agent, "agent.pt")
# Upload model and card to the 🤗 Hub
api = HfApi()
repo_id = "username/REINFORCE-CartPole-v1" # can be any name
model_path = api.create_repo(repo_id, repo_type="model")
api.upload_file(path_or_fileobj="agent.pt", path_in_repo="agent.pt", repo_id=repo_id)
api.upload_file(path_or_fileobj="model_card.md", path_in_repo="README.md", repo_id=repo_id)
```
Now, you can find your agent on the 🤗 Hub at `https://huggingface.co/username/REINFORCE-CartPole-v1`.
## 📊 Open RL Leaderboard evaluation
At this point, all you have to do is to wait for the Open RL Leaderboard to evaluate your agent. It usually takes less than 10 minutes.
Speaking of which, my agent has just appeared on the leaderboard:
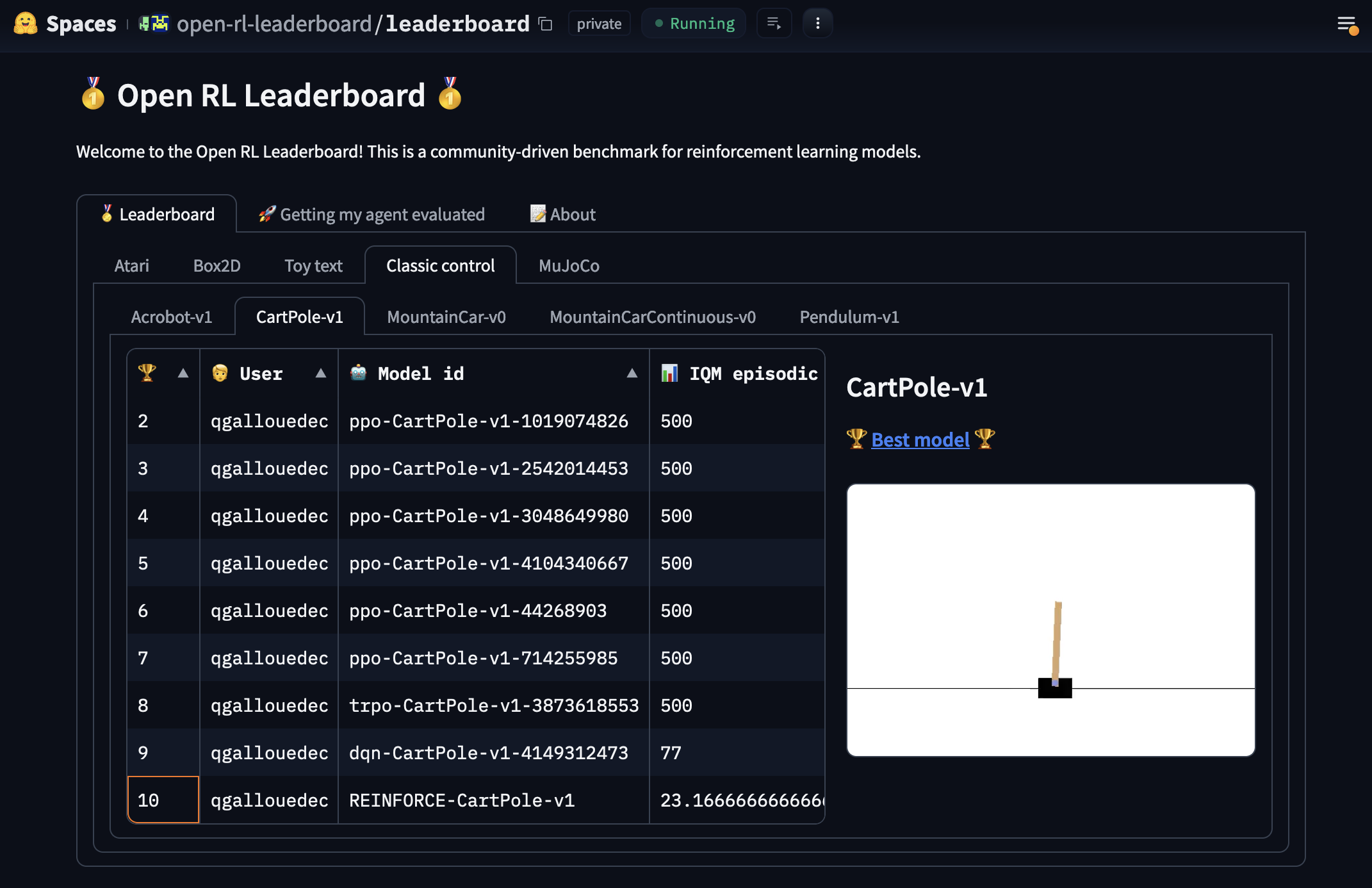
Last place 😢. Next time, our agent will do better 💪!
|