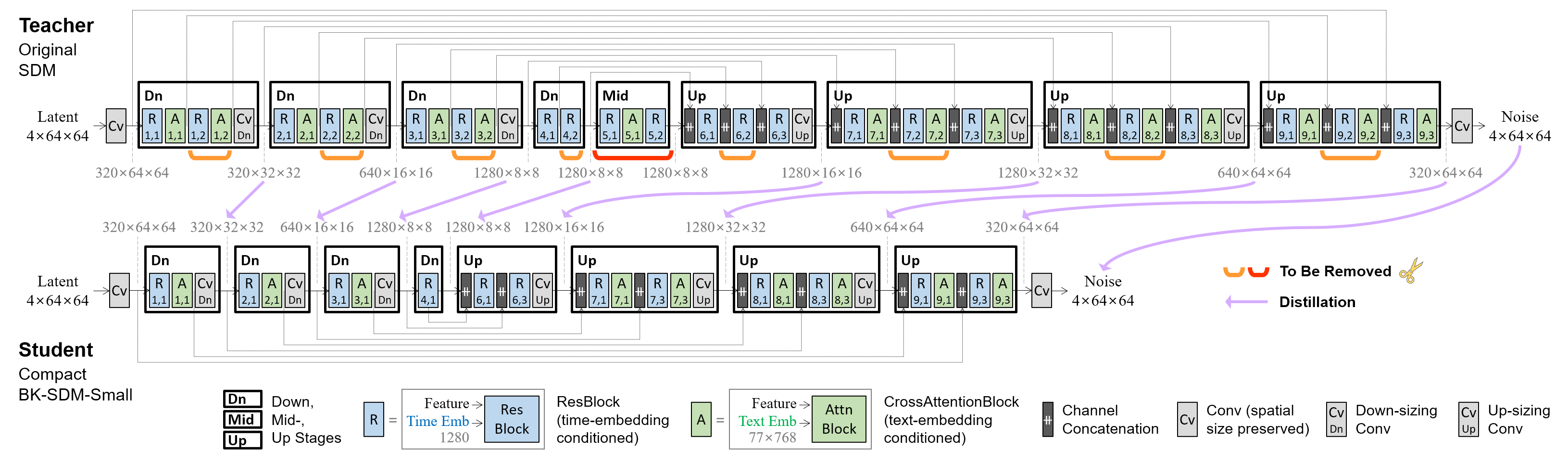
This demo showcases a lightweight Stable Diffusion model (SDM) for general-purpose text-to-image synthesis. Our model **BK-SDM-Small** achieves **36% reduced** parameters and latency. This model is bulit with (i) removing several residual and attention blocks from the U-Net of SDM-v1.4 and (ii) distillation pretraining on only 0.22M LAION pairs (fewer than 0.1% of the full training set). Despite very limited training resources, our model can imitate the original SDM by benefiting from transferred knowledge.
Our compressed model accelerates inference speed while preserving visually compelling results.
### Notice
- This research was accepted to
- [**ICML 2023 Workshop on Efficient Systems for Foundation Models** (ES-FoMo)](https://es-fomo.com/)
- [**ICCV 2023 Demo Track**](https://iccv2023.thecvf.com/)
- Please be aware that your prompts are logged (_without_ any personally identifiable information).
- For different images with the same prompt, please change _Random Seed_ in Advanced Settings (because of using the firstly sampled latent code per seed).
- Some demo codes were borrowed from the repo of Stability AI ([stabilityai/stable-diffusion](https://huggingface.co/spaces/stabilityai/stable-diffusion)) and AK ([akhaliq/small-stable-diffusion-v0](https://huggingface.co/spaces/akhaliq/small-stable-diffusion-v0)). Thanks!
### Compute environment for the demo
- [June/30/2023] **Free CPU-basic** (2 vCPU · 16 GB RAM) — quite slow inference.
- [May/31/2023] **T4-small** (4 vCPU · 15 GB RAM · 16GB VRAM) — 5~10 sec for the original model to generate a 512×512 image with 25 denoising steps.