---
title: "Hugging Face Accelerate: Making device-agnostic ML training and inference easy at scale"
format:
revealjs:
theme: moon
fig-format: png
auto-play-media: true
---
## Who am I?
- Zachary Mueller
- Technical Lead for the 🤗 Accelerate project
- Maintain the `transformers` Trainer
- API design geek
## What is 🤗 Accelerate?
* A training framework
* An inference framework
* A command-line interface
## A Training Framework
* Powered by PyTorch
* Change a few lines of code, gain device *and* hardware-agnostic capabilities
* Low-code, with minimal magic aimed at easy hackability and use without high-level abstractions
* We handle the intracies so you don't have to
## A Training Framework
::: {style="font-size: 70%;"}
* Support for any hardware-accelerator on the market:
* CPU, GPU, TPU, XPU, NPU, MLU
* Automatic mixed-precision training *safely* in whatever fashion you may choose:
* FP16, BF16, FP8 (through either `TransformerEngine` or `MS-AMP`)
* Automatic and efficient gradient accumulation
* Support for quantization through `bitsandbytes`
* Support your favorite experiment trackers (`aim`, `clearml`, `comet_ml`, `dvc-lite`, `ml-flow`, `tensorboard`, `wandb`)
* Easy to configure plugin or YAML-level API for setting up advanced frameworks like `FSDP`, `DeepSpeed`, and `Megatron-LM`
:::
## Low-Code
::: {style="font-size: 70%;"}
* Biggest friction with "wrapper" libraries is control of your code
* By being minimally intrusive, your code just "works" while still giving you complete control
:::
::: {style="font-size: 60%;padding-left:15%;padding-top:0%;padding-right:20%"}
```diff
import torch
import torch.nn.functional as F
from datasets import load_dataset
+ from accelerate import Accelerator
+ accelerator = Accelerator()
- device = 'cpu'
+ device = accelerator.device
model = torch.nn.Transformer().to(device)
optimizer = torch.optim.Adam(model.parameters())
dataset = load_dataset('my_dataset')
data = torch.utils.data.DataLoader(dataset, shuffle=True)
+ model, optimizer, dataloader = accelerator.prepare(model, optimizer, dataloader)
model.train()
for epoch in range(10):
for source, targets in dataloader:
source, targets = source.to(device), targets.to(device)
optimizer.zero_grad()
output = model(source)
loss = F.cross_entropy(output, targets)
- loss.backward()
+ accelerator.backward(loss)
optimizer.step()
```
:::
## Easy to integrate
::: {style="font-size: 70%;"}
* Due to the low-code nature, it's trivial to integrate into existing PyTorch frameworks:
1. Create an `Accelerator`
:::
::: {style="font-size: 60%;padding-left:15%;padding-top:0%;padding-right:20%"}
```diff
import torch
import torch.nn.functional as F
from datasets import load_dataset
+ from accelerate import Accelerator
+ accelerator = Accelerator()
device = 'cpu'
model = torch.nn.Transformer().to(device)
optimizer = torch.optim.Adam(model.parameters())
dataset = load_dataset('my_dataset')
data = torch.utils.data.DataLoader(dataset, shuffle=True)
model.train()
for epoch in range(10):
for source, targets in dataloader:
source, targets = source.to(device), targets.to(device)
optimizer.zero_grad()
output = model(source)
loss = F.cross_entropy(output, targets)
loss.backward()
optimizer.step()
```
:::
## Easy to integrate
::: {style="font-size: 70%;"}
* Due to the low-code nature, it's trivial to integrate into existing PyTorch frameworks:
2. Wrap your PyTorch objects with `accelerator.prepare` and remove device-placements
:::
::: {style="font-size: 60%;padding-left:15%;padding-top:0%;padding-right:20%"}
```diff
import torch
import torch.nn.functional as F
from datasets import load_dataset
from accelerate import Accelerator
accelerator = Accelerator()
- device = 'cpu'
model = torch.nn.Transformer().to(device)
optimizer = torch.optim.Adam(model.parameters())
dataset = load_dataset('my_dataset')
data = torch.utils.data.DataLoader(dataset, shuffle=True)
+ model, optimizer, dataloader = accelerator.prepare(model, optimizer, dataloader)
model.train()
for epoch in range(10):
for source, targets in dataloader:
source, targets = source.to(device), targets.to(device)
optimizer.zero_grad()
output = model(source)
loss = F.cross_entropy(output, targets)
loss.backward()
optimizer.step()
```
:::
## Easy to integrate
::: {style="font-size: 70%;"}
* Due to the low-code nature, it's trivial to integrate into existing PyTorch frameworks:
3. Use `accelerator.backward` for the backward pass
:::
::: {style="font-size: 60%;padding-left:15%;padding-top:0%;padding-right:20%"}
```diff
import torch
import torch.nn.functional as F
from datasets import load_dataset
from accelerate import Accelerator
accelerator = Accelerator()
model = torch.nn.Transformer().to(device)
optimizer = torch.optim.Adam(model.parameters())
dataset = load_dataset('my_dataset')
data = torch.utils.data.DataLoader(dataset, shuffle=True)
model, optimizer, dataloader = accelerator.prepare(model, optimizer, dataloader)
model.train()
for epoch in range(10):
for source, targets in dataloader:
source, targets = source.to(device), targets.to(device)
optimizer.zero_grad()
output = model(source)
loss = F.cross_entropy(output, targets)
- loss.backward()
+ accelerator.backward(loss)
optimizer.step()
```
:::
## But what about inference?
* 🤗 Accelerate is not just for training, and has helped make the GPU-Poor take control of the narrative
* Using tools like Big Model Inference, users with *tiny* compute can run large models locally
* Started with the boom of stable diffusion, and now has scaled to having the ability to run huge LLMs locally with a single graphics card
## How does it work?
* PyTorch introduced `device="meta"`
* 🤗 Accelerate introduced `device_map="auto"`
::: {style="padding-left:15%;padding-right:20%"}
{{< video big_model_visualization.mp4 width="800" height="400" >}}
:::
## A CLI Interface
* `accelerate config`
* Configure the environment
* `accelerate launch`
* How to run your script
## Launching distributed training is hard
::: {style="padding-top:0%;padding-left:10%;padding-right:15%;padding-bottom:0%"}
```bash
python script.py
```
:::
::: {style="padding-left:50%;padding-bottom:0%;padding-top:0%;"}
vs.
:::
::: {style="padding-top:0%;padding-left:10%;padding-right:15%;padding-bottom:0%"}
```bash
torchrun --nnodes=1 --nproc_per_node=2 script.py
```
:::
::: {style="padding-left:50%;padding-bottom:0%;padding-top:0%;"}
vs.
:::
::: {style="padding-top:0%;padding-left:10%;padding-right:15%;padding-bottom:0%"}
```bash
deepspeed --num_gpus=2 script.py
```
:::
How can we make this better?
## `accelerate launch`
::: {style="padding-top:0%;padding-left:5%;padding-right:10%;padding-bottom:0%"}
```bash
accelerate launch script.py
```
```bash
accelerate launch --multi_gpu --num_processes 2 script.py
```
```bash
accelerate launch \
--multi_gpu \
--use_deepspeed \
--num_processes 2 \
script.py
```
:::
## `accelerate config`
* Rely on `config.yaml` files
* Choose to either running `accelerate config` or write your own:
:::: {.columns style="font-size: 60%;padding-left:5%;padding-right:5%"}
::: {.column width="40%"}
```{.yaml filename=ddp_config.yaml}
compute_environment: LOCAL_MACHINE
distributed_type: MULTI_GPU
main_training_function: main
mixed_precision: bf16
num_machines: 1
num_processes: 8
```
:::
::: {.column width="40%"}
```{.yaml filename=fsdp_config.yaml}
compute_environment: LOCAL_MACHINE
distributed_type: FSDP
fsdp_config:
fsdp_auto_wrap_policy: TRANSFORMER_BASED_WRAP
fsdp_backward_prefetch: BACKWARD_PRE
fsdp_cpu_ram_efficient_loading: true
fsdp_forward_prefetch: false
fsdp_offload_params: false
fsdp_sharding_strategy: FULL_SHARD
fsdp_state_dict_type: SHARDED_STATE_DICT
fsdp_sync_module_states: true
fsdp_use_orig_params: false
main_training_function: main
mixed_precision: bf16
num_machines: 1
num_processes: 8
```
:::
::::
# Now that you're up to speed, what's new?
# We've had a busy last year, and so has the ML Community!
## New training techniques
- Quantization has taken the field by storm
- New ideas such as FSDP + QLoRA to train huge models on tiny compute!
- New precision backends as we train natively on smaller precision
- Optimizing futher how much we can push on a single machine through efficient RAM and timing techniques
## Larger compute landscape
- As we search for alternatives to NVIDIA, new compilers rise:
- XPU (Intel)
- NPU (Intel)
- MLU (Cambricon)
All of which are supported by 🤗 Accelerate
## Lower abstractions
* While the `Accelerator` was great, needed better abstractions focused on controlling behaviors
* Introduced the `PartialState`
::: {style="padding-left:10%;padding-top:0%;padding-right:15%"}
```python
from accelerate import PartialState
if PartialState().is_main_process:
# Run on only 1 device
with PartialState().main_process_first:
# Useful for dataset processing
# Device-agnostic without the bulk of the `Accelerator`
device = PartialState().device
```
:::
## Faster and better inference alternatives
::: {style="font-size:70%"}
- `PiPPy` gives us efficient pipeline-parallelism in distributed environments to increase throughput while keeping a simple torch-bound API
- Rather than having to wait for each GPU, every GPU can be busy in parallel
- Will be critical as larger LLMs take hold and more than one computer is needed
:::
::: {style="font-size:60%;padding-left:19%;padding-top:0%;padding-right:24%;"}
```python
import torch
from transformers import AutoModelForSequenceClassification
from accelerate import PartialState, prepare_pippy
model = AutoModelForSequenceClassification.from_pretrained("gpt2")
model.eval()
input = torch.randint(
low=0,
high=model.config.vocab_size,
size=(2, 1024), # bs x seq_len
device="cpu",
)
model = prepare_pippy(model, split_points="auto", example_args=(input,))
with torch.no_grad():
output = model(input)
```
:::
# Adoption: Accelerate in the ecosystem
## Accelerate in the Ecosystem
* Many of the frameworks you use daily already rely on 🤗 Accelerate!
* Nearly all of 🤗
* `axolotl`
* `fastai`
* `FastChat`
* `lucidrains`
* `kornia`
## Accelerate in the Ecosystem
::: {style="font-size: 70%;"}
- Started as a way to isolate out distributed code on TPU and `DistributedDataParallelism`
:::
::: {style="padding-left: 30%"}
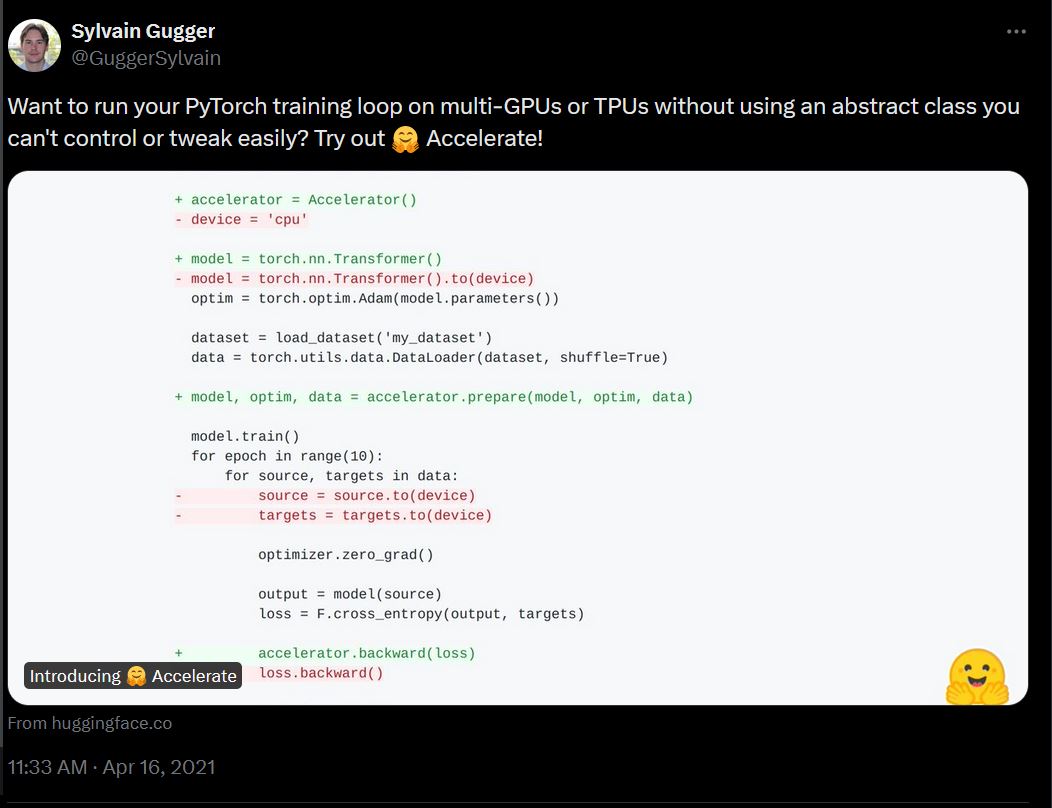{width="70%"}
:::
## Accelerate in the Ecosystem
::: {style="font-size: 70%;"}
- Now is the backbone of some of the largest PyTorch training frameworks in the ecosystem
:::
::: {style="padding-left: 30%;"}
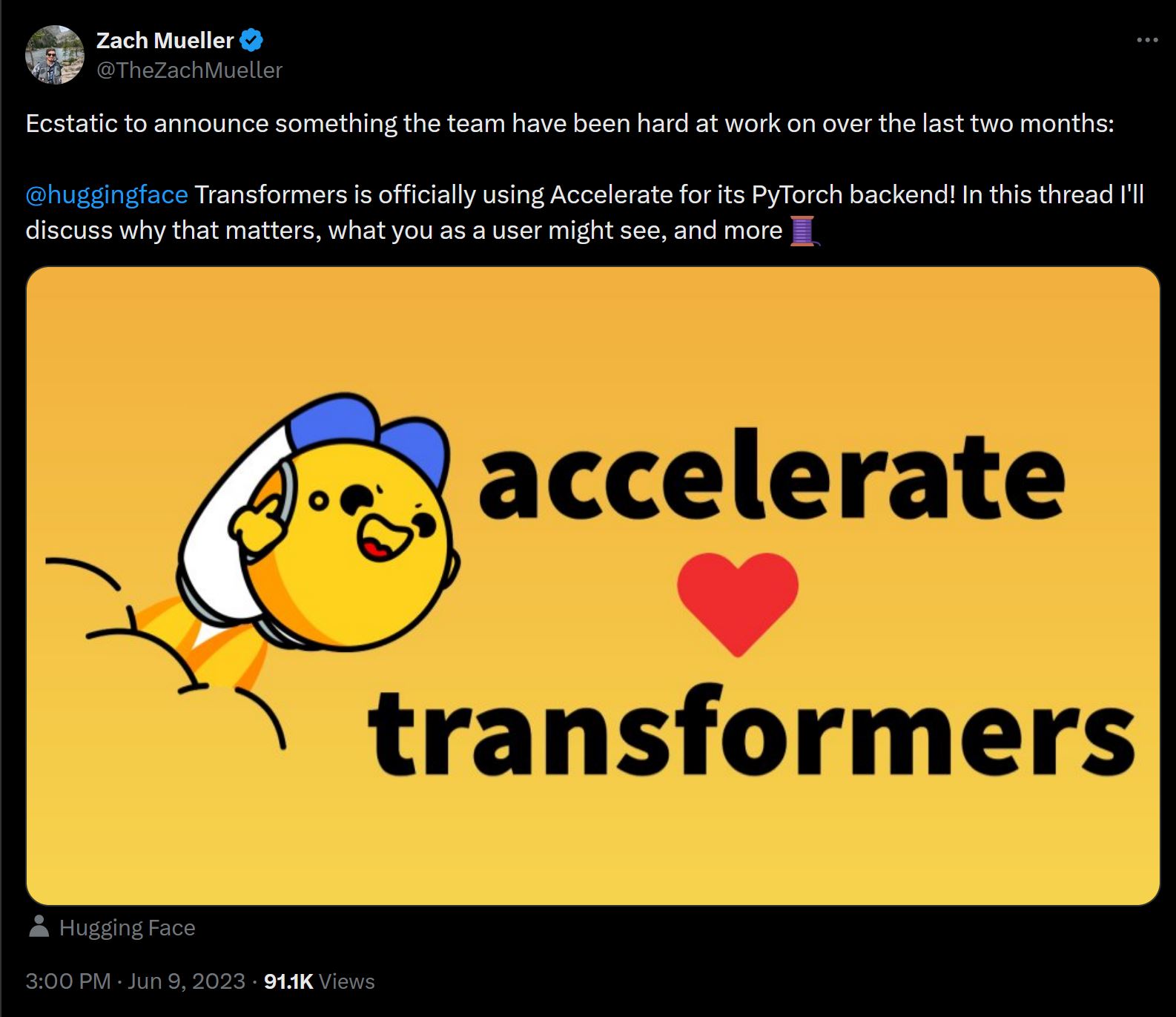{width="70%"}
:::
# What's next?
# Elevating the community
* Now that more advanced training techniques are reachable (FSDP, DeepSpeed, etc), we need to focus on educating the community on how to use it best
* Goes beyond how to use the `Trainer` or `Accelerator`, but how to use *what* where
* Keep Accelerate as a tool for the community to utilize when new techniques come out and play with, to push new ideas to scale quickly
# 1.0.0: Soon!
* Tried and battle-tested by over 7M users/month | 110M+ total downloads
* As we've been stable for over a year now, we're near ready to release 1.0.0
# Thanks for joining!
::: {style="font-size: 70%;"}
- [🤗 Accelerate documentation](https://hf.co/docs/accelerate)
- [Launching distributed code](https://huggingface.co/docs/accelerate/basic_tutorials/launch)
- [Distributed code and Jupyter Notebooks](https://huggingface.co/docs/accelerate/basic_tutorials/notebook)
- [Migrating to 🤗 Accelerate easily](https://huggingface.co/docs/accelerate/basic_tutorials/migration)
- [Big Model Inference tutorial](https://huggingface.co/docs/accelerate/usage_guides/big_modeling)
- [DeepSpeed and 🤗 Accelerate](https://huggingface.co/docs/accelerate/usage_guides/deepspeed)
- [Fully Sharded Data Parallelism and 🤗 Accelerate](https://huggingface.co/docs/accelerate/usage_guides/fsdp)
- [FSDP vs DeepSpeed In-Depth](https://huggingface.co/docs/accelerate/concept_guides/fsdp_and_deepspeed)
:::