+
+  +
+ 
+
+
+
+
+
+
+ 
+
+
+
+
+  +
+
+ + Support This Project + + + +
+ + [](https://github.com/Gourieff/ComfyUI-ReActor/commits/main) +  + [](https://github.com/Gourieff/ComfyUI-ReActor/issues?cacheSeconds=0) + [](https://github.com/Gourieff/ComfyUI-ReActor/issues?q=is%3Aissue+state%3Aclosed) +  + + English | [Русский](/README_RU.md) + +# ReActor Nodes for ComfyUI
-=SFW-Friendly=- + +
+
+### The Fast and Simple Face Swap Extension Nodes for ComfyUI, based on [blocked ReActor](https://github.com/Gourieff/comfyui-reactor-node) - now it has a nudity detector to avoid using this software with 18+ content
+
+> By using this Node you accept and assume [responsibility](#disclaimer)
+
+
+ + + Support This Project + + + +
+ + [](https://github.com/Gourieff/ComfyUI-ReActor/commits/main) +  + [](https://github.com/Gourieff/ComfyUI-ReActor/issues?cacheSeconds=0) + [](https://github.com/Gourieff/ComfyUI-ReActor/issues?q=is%3Aissue+state%3Aclosed) +  + + English | [Русский](/README_RU.md) + +# ReActor Nodes for ComfyUI
-=SFW-Friendly=- + +
+
+---
+[**What's new**](#latestupdate) | [**Installation**](#installation) | [**Usage**](#usage) | [**Troubleshooting**](#troubleshooting) | [**Updating**](#updating) | [**Disclaimer**](#disclaimer) | [**Credits**](#credits) | [**Note!**](#note)
+
+---
+
+
+
+
+
+## What's new in the latest update
+
+### 0.6.0 ALPHA1
+
+- New Node `ReActorSetWeight` - you can now set the strength of face swap for `source_image` or `face_model` from 0% to 100% (in 12.5% step)
+
+ +
+ +
+ +
+
+
+ +
+ +
+
+
+You can download ReSwapper models here:
+https://huggingface.co/datasets/Gourieff/ReActor/tree/main/models
+Just put them into the "models/reswapper" directory.
+
+- NSFW-detector to not violate [GitHub rules](https://docs.github.com/en/site-policy/acceptable-use-policies/github-misinformation-and-disinformation#synthetic--manipulated-media-tools)
+- New node "Unload ReActor Models" - is useful for complex WFs when you need to free some VRAM utilized by ReActor
+
+ +
+- Support of ORT CoreML and ROCM EPs, just install onnxruntime version you need
+- Install script improvements to install latest versions of ORT-GPU
+
+
+
+- Support of ORT CoreML and ROCM EPs, just install onnxruntime version you need
+- Install script improvements to install latest versions of ORT-GPU
+
+
+ +
+
+
+- Fixes and improvements
+
+
+### 0.5.1
+
+- Support of GPEN 1024/2048 restoration models (available in the HF dataset https://huggingface.co/datasets/Gourieff/ReActor/tree/main/models/facerestore_models)
+- ReActorFaceBoost Node - an attempt to improve the quality of swapped faces. The idea is to restore and scale the swapped face (according to the `face_size` parameter of the restoration model) BEFORE pasting it to the target image (via inswapper algorithms), more information is [here (PR#321)](https://github.com/Gourieff/comfyui-reactor-node/pull/321)
+
+ +
+[Full size demo preview](https://github.com/Gourieff/Assets/blob/main/comfyui-reactor-node/0.5.1-whatsnew-02.png)
+
+- Sorting facemodels alphabetically
+- A lot of fixes and improvements
+
+### [0.5.0 BETA4](https://github.com/Gourieff/comfyui-reactor-node/releases/tag/v0.5.0)
+
+- Spandrel lib support for GFPGAN
+
+### 0.5.0 BETA3
+
+- Fixes: "RAM issue", "No detection" for MaskingHelper
+
+### 0.5.0 BETA2
+
+- You can now build a blended face model from a batch of face models you already have, just add the "Make Face Model Batch" node to your workflow and connect several models via "Load Face Model"
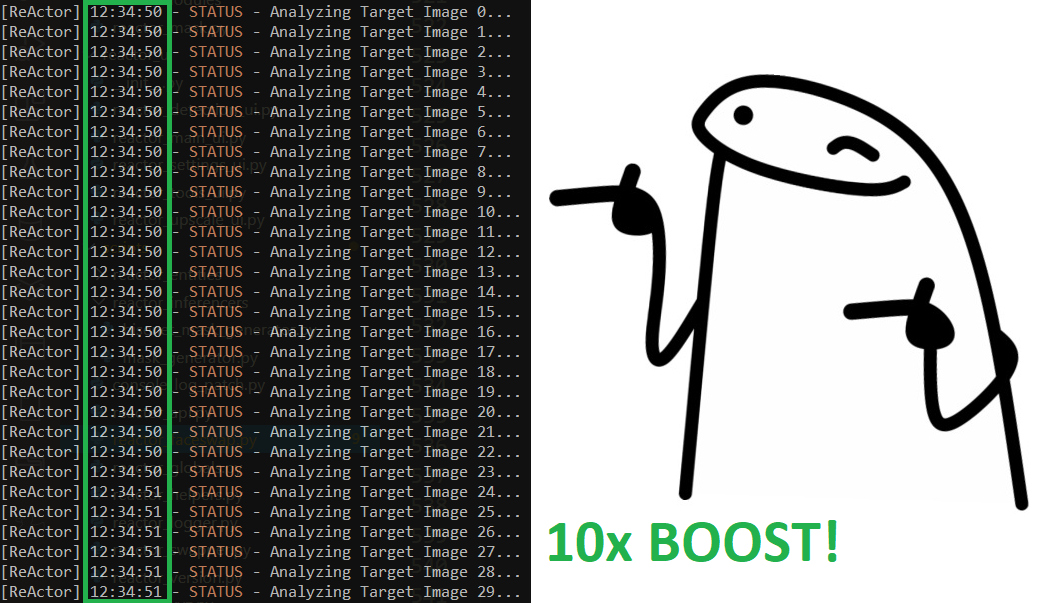
+- Huge performance boost of the image analyzer's module! 10x speed up! Working with videos is now a pleasure!
+
+
+
+[Full size demo preview](https://github.com/Gourieff/Assets/blob/main/comfyui-reactor-node/0.5.1-whatsnew-02.png)
+
+- Sorting facemodels alphabetically
+- A lot of fixes and improvements
+
+### [0.5.0 BETA4](https://github.com/Gourieff/comfyui-reactor-node/releases/tag/v0.5.0)
+
+- Spandrel lib support for GFPGAN
+
+### 0.5.0 BETA3
+
+- Fixes: "RAM issue", "No detection" for MaskingHelper
+
+### 0.5.0 BETA2
+
+- You can now build a blended face model from a batch of face models you already have, just add the "Make Face Model Batch" node to your workflow and connect several models via "Load Face Model"
+- Huge performance boost of the image analyzer's module! 10x speed up! Working with videos is now a pleasure!
+
+ +
+### 0.5.0 BETA1
+
+- SWAPPED_FACE output for the Masking Helper Node
+- FIX: Empty A-channel for Masking Helper IMAGE output (causing errors with some nodes) was removed
+
+### 0.5.0 ALPHA1
+
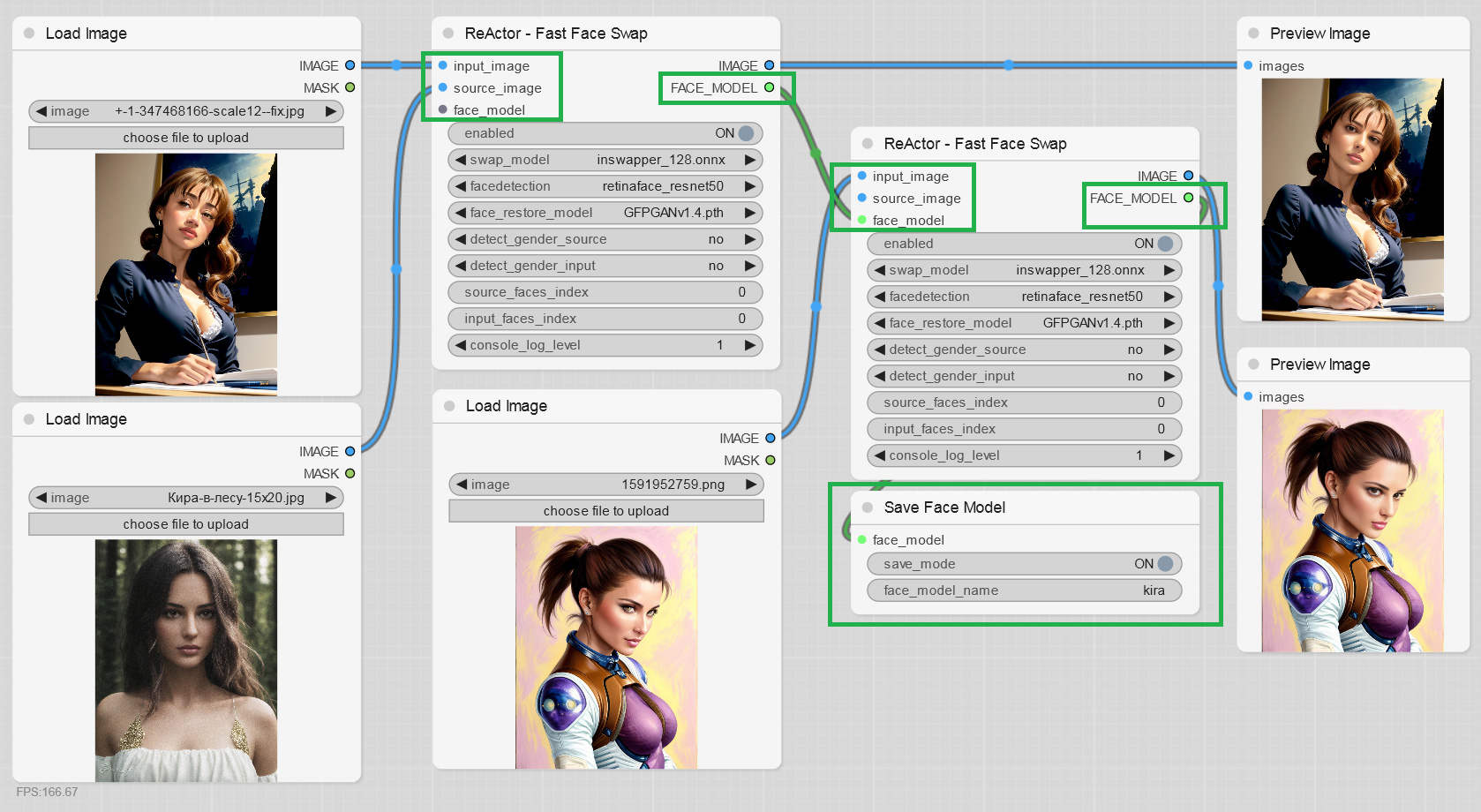
+- ReActorBuildFaceModel Node got "face_model" output to provide a blended face model directly to the main Node:
+
+Basic workflow [💾](https://github.com/Gourieff/Assets/blob/main/comfyui-reactor-node/workflows/ReActor--Build-Blended-Face-Model--v2.json)
+
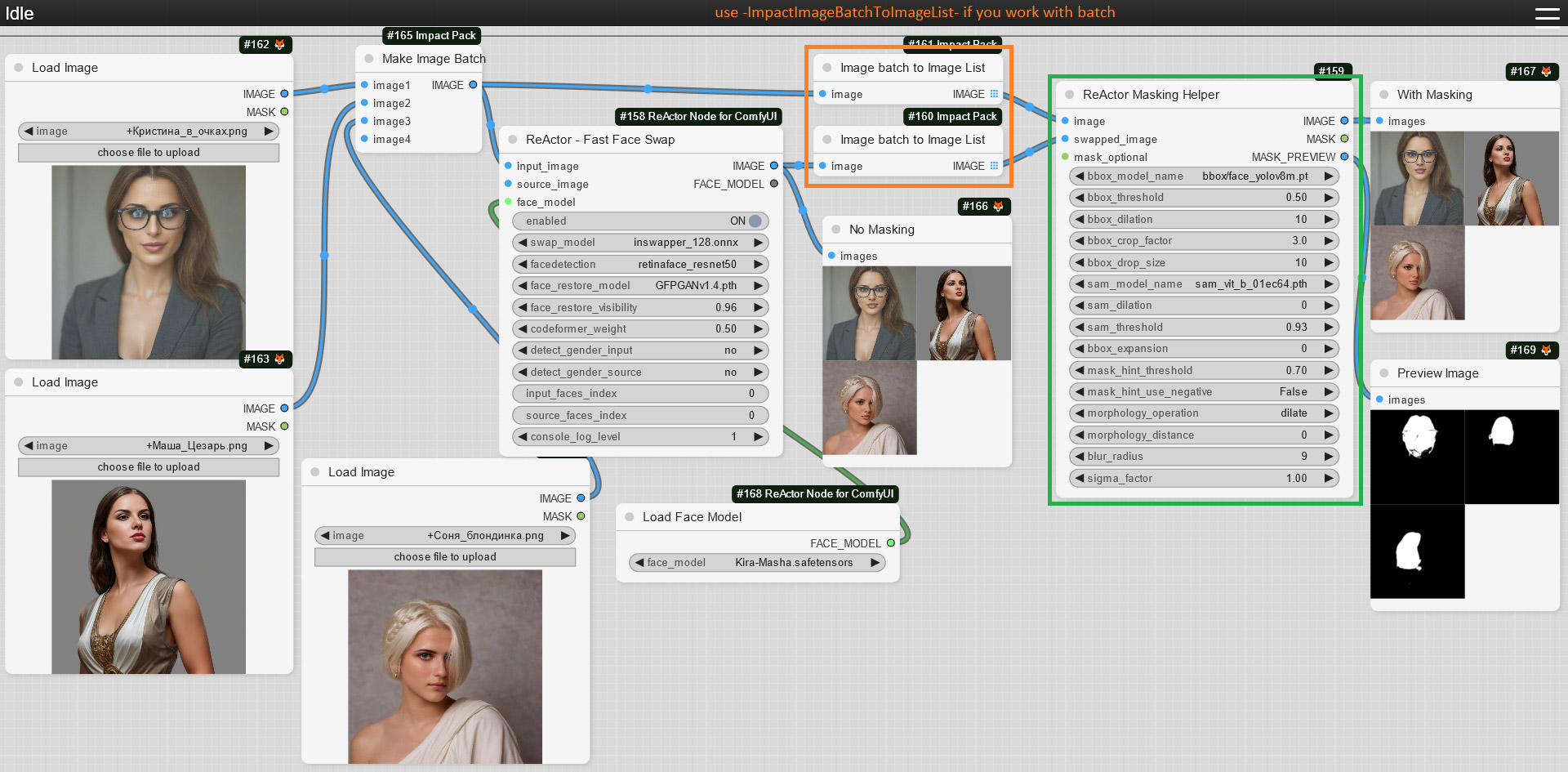
+- Face Masking feature is available now, just add the "ReActorMaskHelper" Node to the workflow and connect it as shown below:
+
+
+
+### 0.5.0 BETA1
+
+- SWAPPED_FACE output for the Masking Helper Node
+- FIX: Empty A-channel for Masking Helper IMAGE output (causing errors with some nodes) was removed
+
+### 0.5.0 ALPHA1
+
+- ReActorBuildFaceModel Node got "face_model" output to provide a blended face model directly to the main Node:
+
+Basic workflow [💾](https://github.com/Gourieff/Assets/blob/main/comfyui-reactor-node/workflows/ReActor--Build-Blended-Face-Model--v2.json)
+
+- Face Masking feature is available now, just add the "ReActorMaskHelper" Node to the workflow and connect it as shown below:
+
+ +
+If you don't have the "face_yolov8m.pt" Ultralytics model - you can download it from the [Assets](https://huggingface.co/datasets/Gourieff/ReActor/blob/main/models/detection/bbox/face_yolov8m.pt) and put it into the "ComfyUI\models\ultralytics\bbox" directory
+
+
+If you don't have the "face_yolov8m.pt" Ultralytics model - you can download it from the [Assets](https://huggingface.co/datasets/Gourieff/ReActor/blob/main/models/detection/bbox/face_yolov8m.pt) and put it into the "ComfyUI\models\ultralytics\bbox" directory
+
+As well as ["sam_vit_b_01ec64.pth"](https://huggingface.co/datasets/Gourieff/ReActor/blob/main/models/sams/sam_vit_b_01ec64.pth) model - download (if you don't have it) and put it into the "ComfyUI\models\sams" directory; + +Use this Node to gain the best results of the face swapping process: + + +
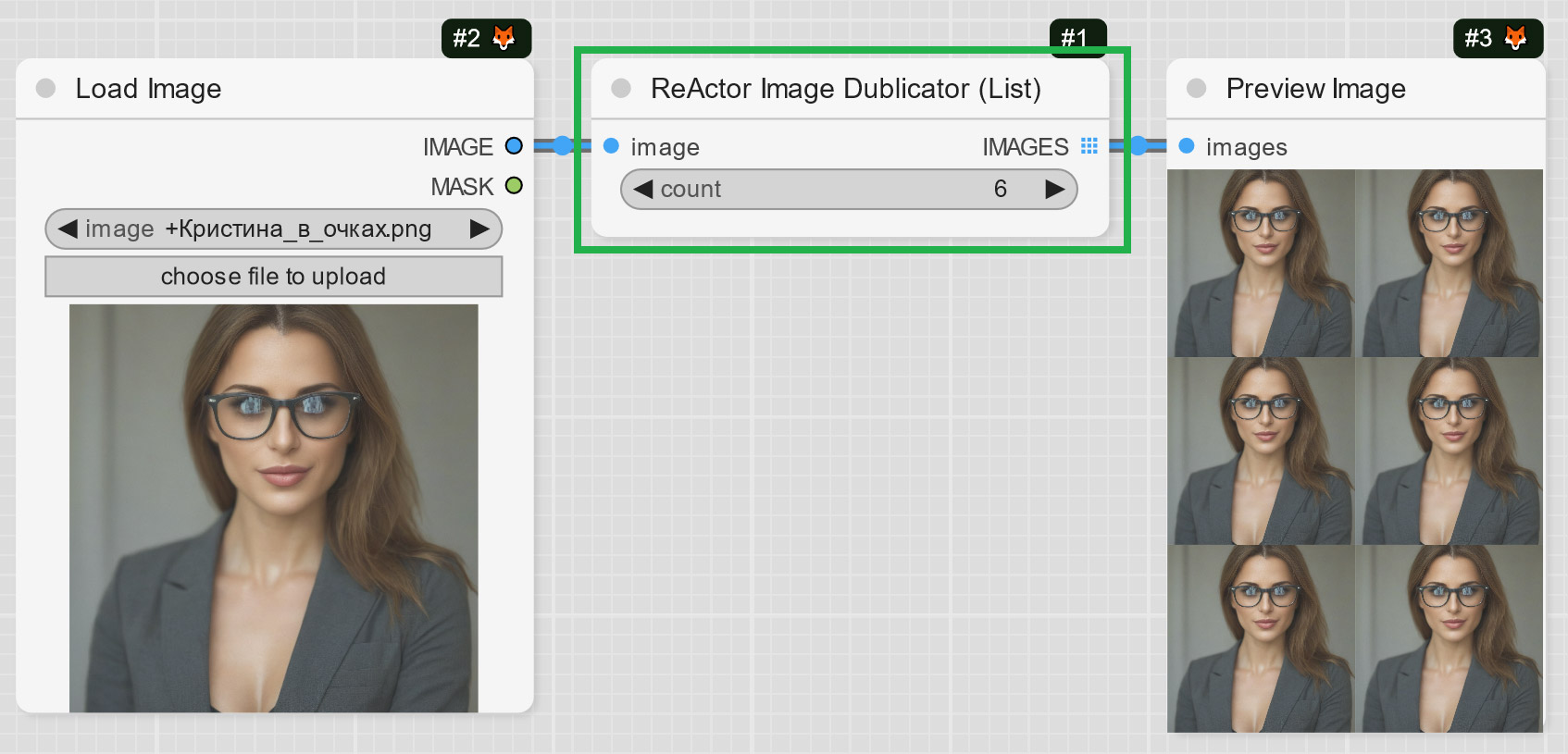
+- ReActorImageDublicator Node - rather useful for those who create videos, it helps to duplicate one image to several frames to use them with VAE Encoder (e.g. live avatars):
+
+
+
+- ReActorImageDublicator Node - rather useful for those who create videos, it helps to duplicate one image to several frames to use them with VAE Encoder (e.g. live avatars):
+
+ +
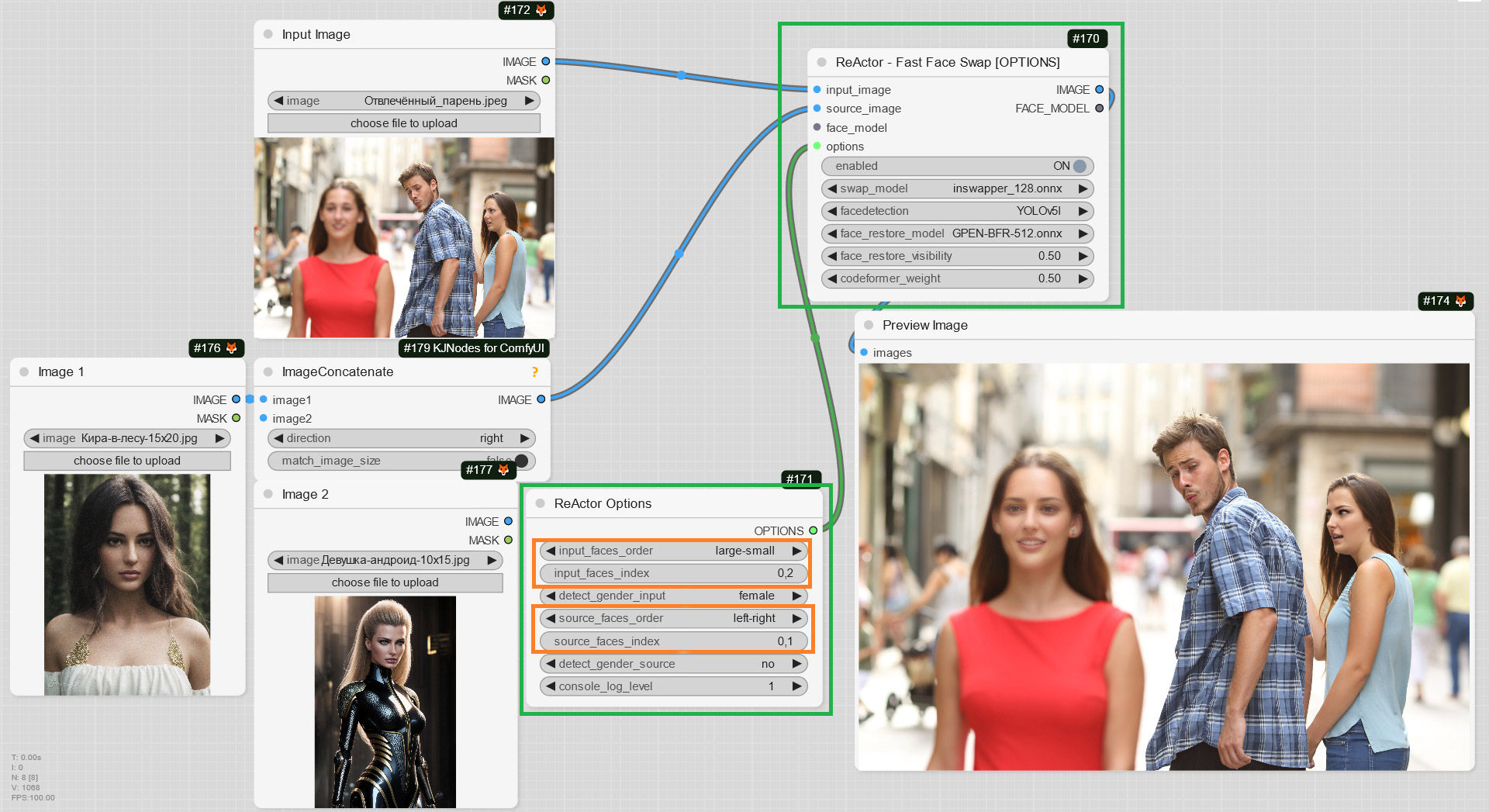
+- ReActorFaceSwapOpt (a simplified version of the Main Node) + ReActorOptions Nodes to set some additional options such as (new) "input/source faces separate order". Yes! You can now set the order of faces in the index in the way you want ("large to small" goes by default)!
+
+
+
+- ReActorFaceSwapOpt (a simplified version of the Main Node) + ReActorOptions Nodes to set some additional options such as (new) "input/source faces separate order". Yes! You can now set the order of faces in the index in the way you want ("large to small" goes by default)!
+
+ +
+- Little speed boost when analyzing target images (unfortunately it is still quite slow in compare to swapping and restoring...)
+
+### [0.4.2](https://github.com/Gourieff/comfyui-reactor-node/releases/tag/v0.4.2)
+
+- GPEN-BFR-512 and RestoreFormer_Plus_Plus face restoration models support
+
+You can download models here: https://huggingface.co/datasets/Gourieff/ReActor/tree/main/models/facerestore_models
+
+
+- Little speed boost when analyzing target images (unfortunately it is still quite slow in compare to swapping and restoring...)
+
+### [0.4.2](https://github.com/Gourieff/comfyui-reactor-node/releases/tag/v0.4.2)
+
+- GPEN-BFR-512 and RestoreFormer_Plus_Plus face restoration models support
+
+You can download models here: https://huggingface.co/datasets/Gourieff/ReActor/tree/main/models/facerestore_models
+
Put them into the `ComfyUI\models\facerestore_models` folder + +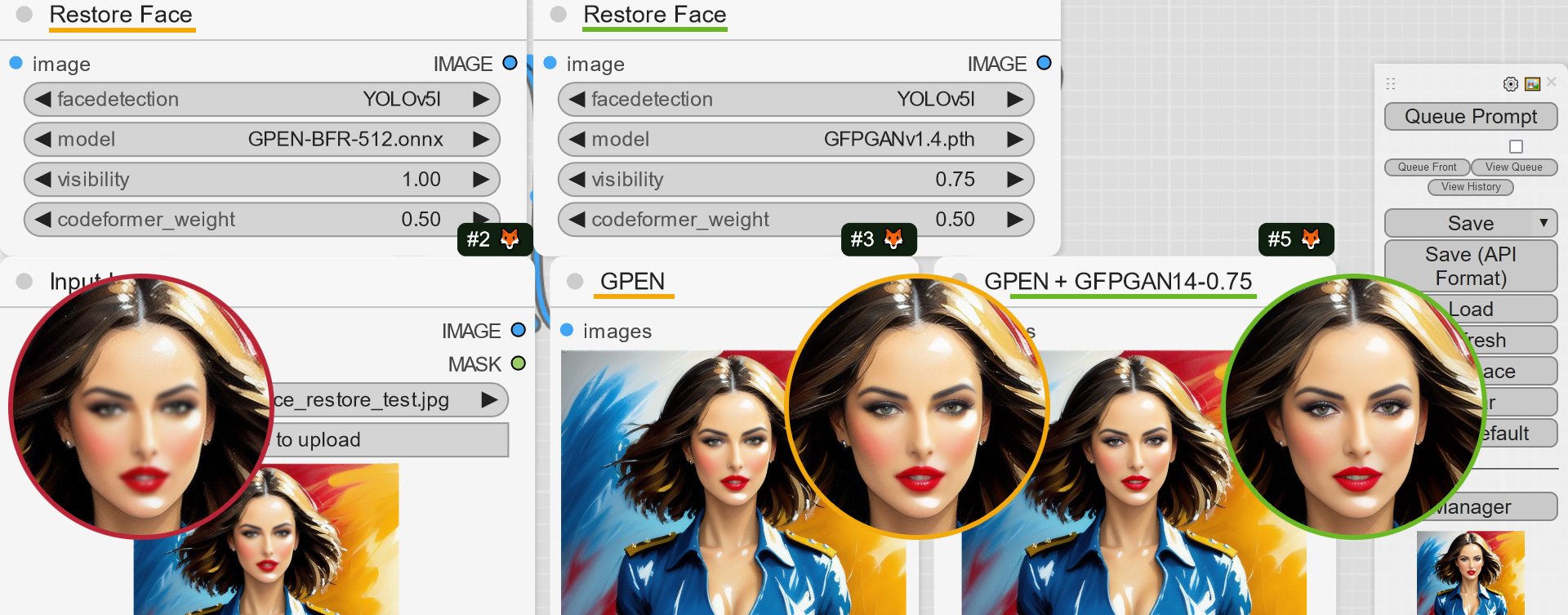 +
+- Due to popular demand - you can now blend several images with persons into one face model file and use it with "Load Face Model" Node or in SD WebUI as well;
+
+Experiment and create new faces or blend faces of one person to gain better accuracy and likeness!
+
+Just add the ImpactPack's "Make Image Batch" Node as the input to the ReActor's one and load images you want to blend into one model:
+
+
+
+- Due to popular demand - you can now blend several images with persons into one face model file and use it with "Load Face Model" Node or in SD WebUI as well;
+
+Experiment and create new faces or blend faces of one person to gain better accuracy and likeness!
+
+Just add the ImpactPack's "Make Image Batch" Node as the input to the ReActor's one and load images you want to blend into one model:
+
+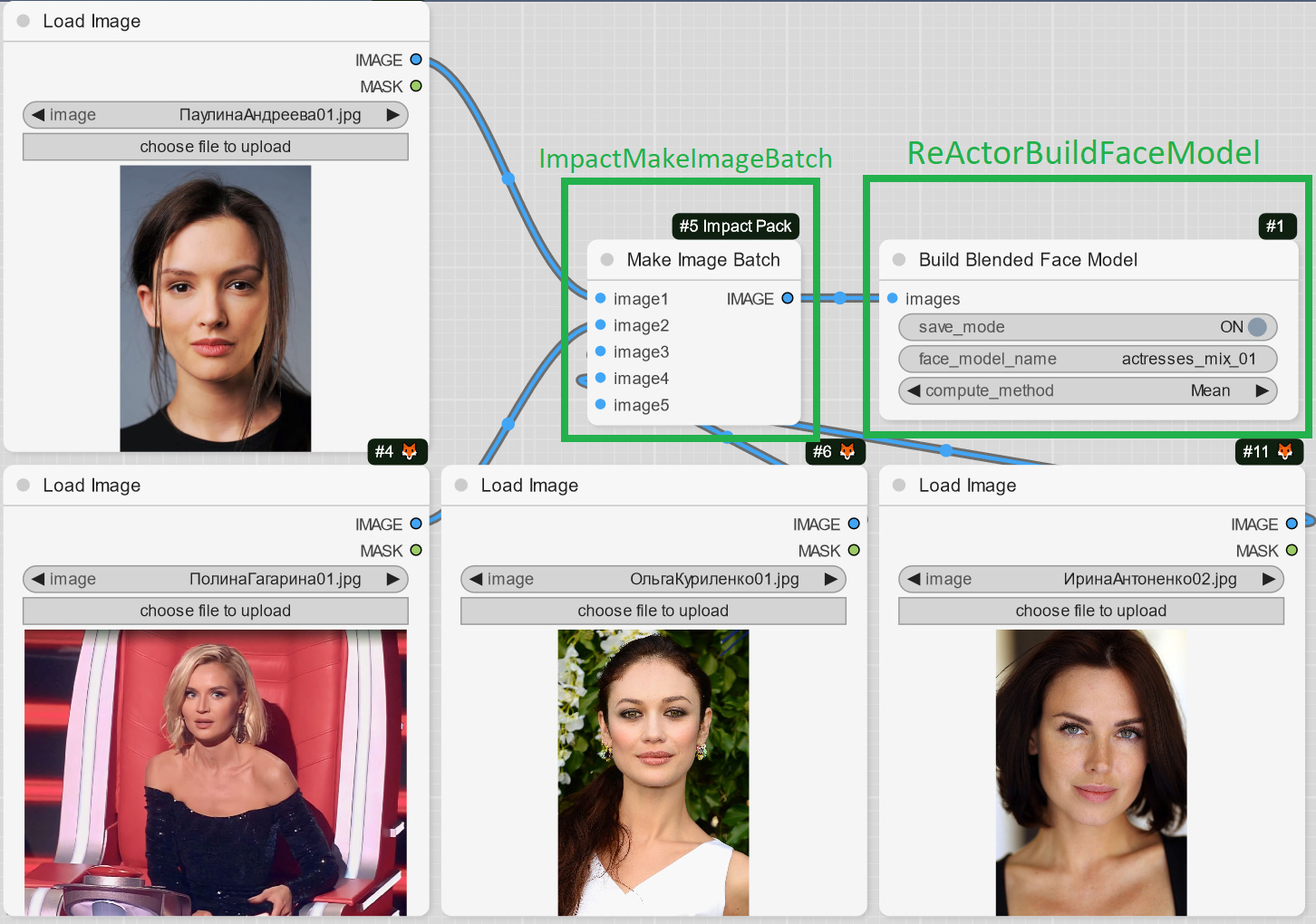 +
+Result example (the new face was created from 4 faces of different actresses):
+
+
+
+Result example (the new face was created from 4 faces of different actresses):
+
+ +
+Basic workflow [💾](https://github.com/Gourieff/Assets/blob/main/comfyui-reactor-node/workflows/ReActor--Build-Blended-Face-Model--v1.json)
+
+### [0.4.1](https://github.com/Gourieff/comfyui-reactor-node/releases/tag/v0.4.1)
+
+- CUDA 12 Support - don't forget to run (Windows) `install.bat` or (Linux/MacOS) `install.py` for ComfyUI's Python enclosure or try to install ORT-GPU for CU12 manually (https://onnxruntime.ai/docs/install/#install-onnx-runtime-gpu-cuda-12x)
+- Issue https://github.com/Gourieff/comfyui-reactor-node/issues/173 fix
+
+- Separate Node for the Face Restoration postprocessing (FR https://github.com/Gourieff/comfyui-reactor-node/issues/191), can be found inside ReActor's menu (RestoreFace Node)
+- (Windows) Installation can be done for Python from the System's PATH
+- Different fixes and improvements
+
+- Face Restore Visibility and CodeFormer Weight (Fidelity) options are now available! Don't forget to reload the Node in your existing workflow
+
+
+
+Basic workflow [💾](https://github.com/Gourieff/Assets/blob/main/comfyui-reactor-node/workflows/ReActor--Build-Blended-Face-Model--v1.json)
+
+### [0.4.1](https://github.com/Gourieff/comfyui-reactor-node/releases/tag/v0.4.1)
+
+- CUDA 12 Support - don't forget to run (Windows) `install.bat` or (Linux/MacOS) `install.py` for ComfyUI's Python enclosure or try to install ORT-GPU for CU12 manually (https://onnxruntime.ai/docs/install/#install-onnx-runtime-gpu-cuda-12x)
+- Issue https://github.com/Gourieff/comfyui-reactor-node/issues/173 fix
+
+- Separate Node for the Face Restoration postprocessing (FR https://github.com/Gourieff/comfyui-reactor-node/issues/191), can be found inside ReActor's menu (RestoreFace Node)
+- (Windows) Installation can be done for Python from the System's PATH
+- Different fixes and improvements
+
+- Face Restore Visibility and CodeFormer Weight (Fidelity) options are now available! Don't forget to reload the Node in your existing workflow
+
+ +
+### [0.4.0](https://github.com/Gourieff/comfyui-reactor-node/releases/tag/v0.4.0)
+
+- Input "input_image" goes first now, it gives a correct bypass and also it is right to have the main input first;
+- You can now save face models as "safetensors" files (`ComfyUI\models\reactor\faces`) and load them into ReActor implementing different scenarios and keeping super lightweight face models of the faces you use:
+
+
+
+### [0.4.0](https://github.com/Gourieff/comfyui-reactor-node/releases/tag/v0.4.0)
+
+- Input "input_image" goes first now, it gives a correct bypass and also it is right to have the main input first;
+- You can now save face models as "safetensors" files (`ComfyUI\models\reactor\faces`) and load them into ReActor implementing different scenarios and keeping super lightweight face models of the faces you use:
+
+ +
+ +
+- Ability to build and save face models directly from an image:
+
+
+
+- Ability to build and save face models directly from an image:
+
+ +
+- Both the inputs are optional, just connect one of them according to your workflow; if both is connected - `image` has a priority.
+- Different fixes making this extension better.
+
+Thanks to everyone who finds bugs, suggests new features and supports this project!
+
+
+
+- Both the inputs are optional, just connect one of them according to your workflow; if both is connected - `image` has a priority.
+- Different fixes making this extension better.
+
+Thanks to everyone who finds bugs, suggests new features and supports this project!
+
+
+
+## Installation
+
+Previous versions
+ +### 0.5.2 + +- ReSwapper models support. Although Inswapper still has the best similarity, but ReSwapper is evolving - thanks @somanchiu https://github.com/somanchiu/ReSwapper for the ReSwapper models and the ReSwapper project! This is a good step for the Community in the Inswapper's alternative creation! + +
+
+
+
+- Support of ORT CoreML and ROCM EPs, just install onnxruntime version you need
+- Install script improvements to install latest versions of ORT-GPU
+
+
+
+
+[Full size demo preview](https://github.com/Gourieff/Assets/blob/main/comfyui-reactor-node/0.5.1-whatsnew-02.png)
+
+- Sorting facemodels alphabetically
+- A lot of fixes and improvements
+
+### [0.5.0 BETA4](https://github.com/Gourieff/comfyui-reactor-node/releases/tag/v0.5.0)
+
+- Spandrel lib support for GFPGAN
+
+### 0.5.0 BETA3
+
+- Fixes: "RAM issue", "No detection" for MaskingHelper
+
+### 0.5.0 BETA2
+
+- You can now build a blended face model from a batch of face models you already have, just add the "Make Face Model Batch" node to your workflow and connect several models via "Load Face Model"
+- Huge performance boost of the image analyzer's module! 10x speed up! Working with videos is now a pleasure!
+
+
+
+### 0.5.0 BETA1
+
+- SWAPPED_FACE output for the Masking Helper Node
+- FIX: Empty A-channel for Masking Helper IMAGE output (causing errors with some nodes) was removed
+
+### 0.5.0 ALPHA1
+
+- ReActorBuildFaceModel Node got "face_model" output to provide a blended face model directly to the main Node:
+
+Basic workflow [💾](https://github.com/Gourieff/Assets/blob/main/comfyui-reactor-node/workflows/ReActor--Build-Blended-Face-Model--v2.json)
+
+- Face Masking feature is available now, just add the "ReActorMaskHelper" Node to the workflow and connect it as shown below:
+
+
+
+If you don't have the "face_yolov8m.pt" Ultralytics model - you can download it from the [Assets](https://huggingface.co/datasets/Gourieff/ReActor/blob/main/models/detection/bbox/face_yolov8m.pt) and put it into the "ComfyUI\models\ultralytics\bbox" directory
++As well as ["sam_vit_b_01ec64.pth"](https://huggingface.co/datasets/Gourieff/ReActor/blob/main/models/sams/sam_vit_b_01ec64.pth) model - download (if you don't have it) and put it into the "ComfyUI\models\sams" directory; + +Use this Node to gain the best results of the face swapping process: + +
+
+- ReActorImageDublicator Node - rather useful for those who create videos, it helps to duplicate one image to several frames to use them with VAE Encoder (e.g. live avatars):
+
+
+
+- ReActorFaceSwapOpt (a simplified version of the Main Node) + ReActorOptions Nodes to set some additional options such as (new) "input/source faces separate order". Yes! You can now set the order of faces in the index in the way you want ("large to small" goes by default)!
+
+
+
+- Little speed boost when analyzing target images (unfortunately it is still quite slow in compare to swapping and restoring...)
+
+### [0.4.2](https://github.com/Gourieff/comfyui-reactor-node/releases/tag/v0.4.2)
+
+- GPEN-BFR-512 and RestoreFormer_Plus_Plus face restoration models support
+
+You can download models here: https://huggingface.co/datasets/Gourieff/ReActor/tree/main/models/facerestore_models
+Put them into the `ComfyUI\models\facerestore_models` folder + +
+
+- Due to popular demand - you can now blend several images with persons into one face model file and use it with "Load Face Model" Node or in SD WebUI as well;
+
+Experiment and create new faces or blend faces of one person to gain better accuracy and likeness!
+
+Just add the ImpactPack's "Make Image Batch" Node as the input to the ReActor's one and load images you want to blend into one model:
+
+
+
+Result example (the new face was created from 4 faces of different actresses):
+
+
+
+Basic workflow [💾](https://github.com/Gourieff/Assets/blob/main/comfyui-reactor-node/workflows/ReActor--Build-Blended-Face-Model--v1.json)
+
+### [0.4.1](https://github.com/Gourieff/comfyui-reactor-node/releases/tag/v0.4.1)
+
+- CUDA 12 Support - don't forget to run (Windows) `install.bat` or (Linux/MacOS) `install.py` for ComfyUI's Python enclosure or try to install ORT-GPU for CU12 manually (https://onnxruntime.ai/docs/install/#install-onnx-runtime-gpu-cuda-12x)
+- Issue https://github.com/Gourieff/comfyui-reactor-node/issues/173 fix
+
+- Separate Node for the Face Restoration postprocessing (FR https://github.com/Gourieff/comfyui-reactor-node/issues/191), can be found inside ReActor's menu (RestoreFace Node)
+- (Windows) Installation can be done for Python from the System's PATH
+- Different fixes and improvements
+
+- Face Restore Visibility and CodeFormer Weight (Fidelity) options are now available! Don't forget to reload the Node in your existing workflow
+
+
+
+### [0.4.0](https://github.com/Gourieff/comfyui-reactor-node/releases/tag/v0.4.0)
+
+- Input "input_image" goes first now, it gives a correct bypass and also it is right to have the main input first;
+- You can now save face models as "safetensors" files (`ComfyUI\models\reactor\faces`) and load them into ReActor implementing different scenarios and keeping super lightweight face models of the faces you use:
+
+
+
+
+- Ability to build and save face models directly from an image:
+
+
+
+- Both the inputs are optional, just connect one of them according to your workflow; if both is connected - `image` has a priority.
+- Different fixes making this extension better.
+
+Thanks to everyone who finds bugs, suggests new features and supports this project!
+
+
+
+https://huggingface.co/datasets/Gourieff/ReActor/tree/main/models/facerestore_models +11. Run SD WebUI and check console for the message that ReActor Node is running: + +
+12. Go to the ComfyUI tab and find there ReActor Node inside the menu `ReActor` or by using a search:
+
+
+12. Go to the ComfyUI tab and find there ReActor Node inside the menu `ReActor` or by using a search:
+ +
+ +
+
+
+
+
+SD WebUI: AUTOMATIC1111 or SD.Next
+ +1. Close (stop) your SD-WebUI/Comfy Server if it's running +2. (For Windows Users): + - Install [Visual Studio 2022](https://visualstudio.microsoft.com/downloads/) (Community version - you need this step to build Insightface) + - OR only [VS C++ Build Tools](https://visualstudio.microsoft.com/visual-cpp-build-tools/) and select "Desktop Development with C++" under "Workloads -> Desktop & Mobile" + - OR if you don't want to install VS or VS C++ BT - follow [this steps (sec. I)](#insightfacebuild) +3. Go to the `extensions\sd-webui-comfyui\ComfyUI\custom_nodes` +4. Open Console or Terminal and run `git clone https://github.com/Gourieff/ComfyUI-ReActor` +5. Go to the SD WebUI root folder, open Console or Terminal and run (Windows users)`.\venv\Scripts\activate` or (Linux/MacOS)`venv/bin/activate` +6. `python -m pip install -U pip` +7. `cd extensions\sd-webui-comfyui\ComfyUI\custom_nodes\ComfyUI-ReActor` +8. `python install.py` +9. Please, wait until the installation process will be finished +10. (From the version 0.3.0) Download additional facerestorers models from the link below and put them into the `extensions\sd-webui-comfyui\ComfyUI\models\facerestore_models` directory:+https://huggingface.co/datasets/Gourieff/ReActor/tree/main/models/facerestore_models +11. Run SD WebUI and check console for the message that ReActor Node is running: +
+
+12. Go to the ComfyUI tab and find there ReActor Node inside the menu `ReActor` or by using a search:
+
+
+
+
+
As well as one or both of "Sams" models from [here](https://huggingface.co/datasets/Gourieff/ReActor/tree/main/models/sams) - download (if you don't have them) and put into the "ComfyUI\models\sams" directory +5. Run ComfyUI and find there ReActor Nodes inside the menu `ReActor` or by using a search + +
+
+## Usage
+
+You can find ReActor Nodes inside the menu `ReActor` or by using a search (just type "ReActor" in the search field)
+
+List of Nodes:
+- ••• Main Nodes •••
+ - ReActorFaceSwap (Main Node)
+ - ReActorFaceSwapOpt (Main Node with the additional Options input)
+ - ReActorOptions (Options for ReActorFaceSwapOpt)
+ - ReActorFaceBoost (Face Booster Node)
+ - ReActorMaskHelper (Masking Helper)
+- ••• Operations with Face Models •••
+ - ReActorSaveFaceModel (Save Face Model)
+ - ReActorLoadFaceModel (Load Face Model)
+ - ReActorBuildFaceModel (Build Blended Face Model)
+ - ReActorMakeFaceModelBatch (Make Face Model Batch)
+- ••• Additional Nodes •••
+ - ReActorRestoreFace (Face Restoration)
+ - ReActorImageDublicator (Dublicate one Image to Images List)
+ - ImageRGBA2RGB (Convert RGBA to RGB)
+
+Connect all required slots and run the query.
+
+### Main Node Inputs
+
+- `input_image` - is an image to be processed (target image, analog of "target image" in the SD WebUI extension);
+ - Supported Nodes: "Load Image", "Load Video" or any other nodes providing images as an output;
+- `source_image` - is an image with a face or faces to swap in the `input_image` (source image, analog of "source image" in the SD WebUI extension);
+ - Supported Nodes: "Load Image" or any other nodes providing images as an output;
+- `face_model` - is the input for the "Load Face Model" Node or another ReActor node to provide a face model file (face embedding) you created earlier via the "Save Face Model" Node;
+ - Supported Nodes: "Load Face Model", "Build Blended Face Model";
+
+### Main Node Outputs
+
+- `IMAGE` - is an output with the resulted image;
+ - Supported Nodes: any nodes which have images as an input;
+- `FACE_MODEL` - is an output providing a source face's model being built during the swapping process;
+ - Supported Nodes: "Save Face Model", "ReActor", "Make Face Model Batch";
+
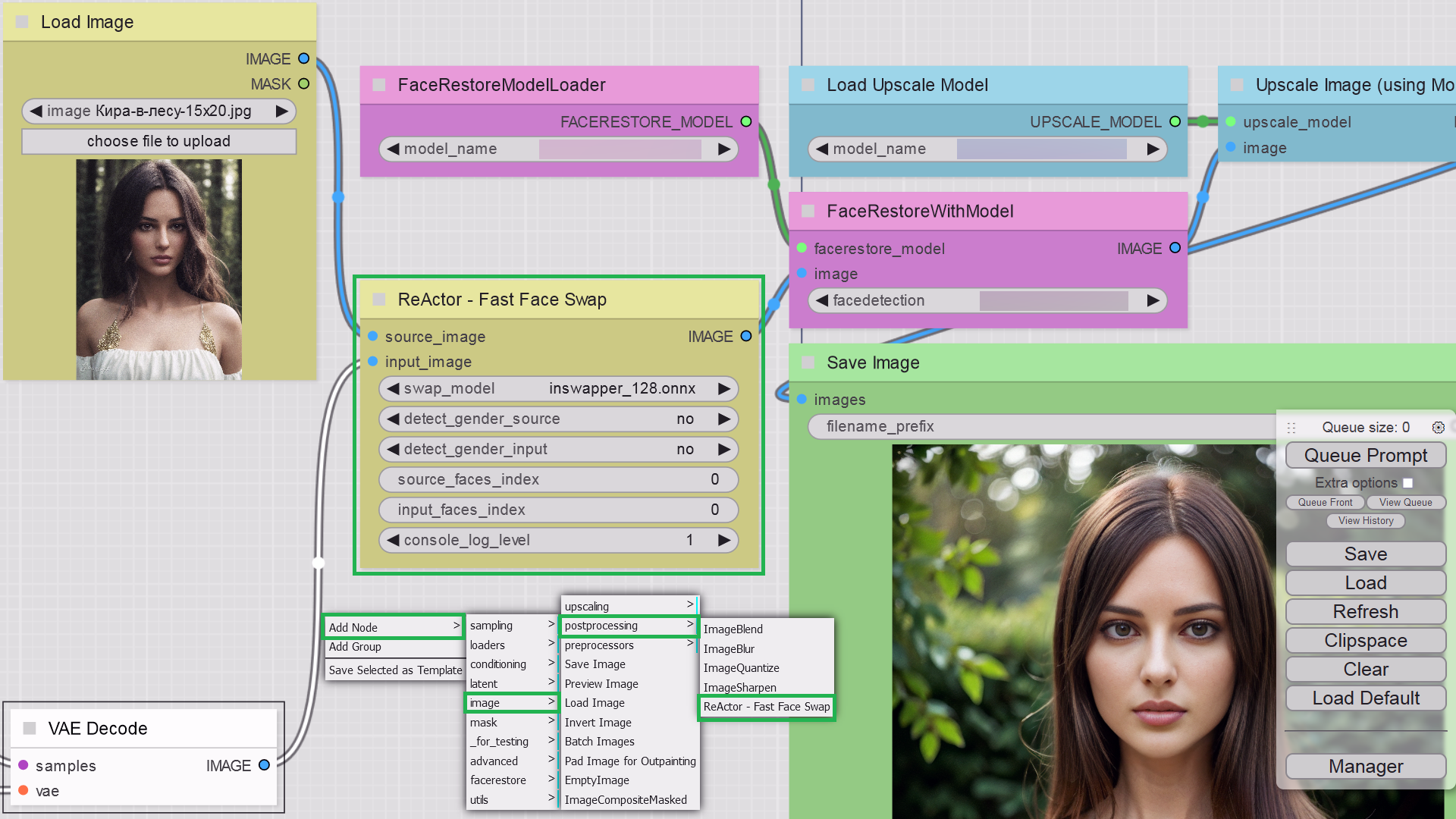
+### Face Restoration
+
+Since version 0.3.0 ReActor Node has a buil-in face restoration.Standalone (Portable) ComfyUI for Windows
+ +1. Do the following: + - Install [Visual Studio 2022](https://visualstudio.microsoft.com/downloads/) (Community version - you need this step to build Insightface) + - OR only [VS C++ Build Tools](https://visualstudio.microsoft.com/visual-cpp-build-tools/) and select "Desktop Development with C++" under "Workloads -> Desktop & Mobile" + - OR if you don't want to install VS or VS C++ BT - follow [this steps (sec. I)](#insightfacebuild) +2. Choose between two options: + - (ComfyUI Manager) Open ComfyUI Manager, click "Install Custom Nodes", type "ReActor" in the "Search" field and then click "Install". After ComfyUI will complete the process - please restart the Server. + - (Manually) Go to `ComfyUI\custom_nodes`, open Console and run `git clone https://github.com/Gourieff/ComfyUI-ReActor` +3. Go to `ComfyUI\custom_nodes\ComfyUI-ReActor` and run `install.bat` +4. If you don't have the "face_yolov8m.pt" Ultralytics model - you can download it from the [Assets](https://huggingface.co/datasets/Gourieff/ReActor/blob/main/models/detection/bbox/face_yolov8m.pt) and put it into the "ComfyUI\models\ultralytics\bbox" directoryAs well as one or both of "Sams" models from [here](https://huggingface.co/datasets/Gourieff/ReActor/tree/main/models/sams) - download (if you don't have them) and put into the "ComfyUI\models\sams" directory +5. Run ComfyUI and find there ReActor Nodes inside the menu `ReActor` or by using a search + +
Just download the models you want (see [Installation](#installation) instruction) and select one of them to restore the resulting face(s) during the faceswap. It will enhance face details and make your result more accurate. + +### Face Indexes + +By default ReActor detects faces in images from "large" to "small".
You can change this option by adding ReActorFaceSwapOpt node with ReActorOptions. + +And if you need to specify faces, you can set indexes for source and input images. + +Index of the first detected face is 0. + +You can set indexes in the order you need.
+E.g.: 0,1,2 (for Source); 1,0,2 (for Input).
This means: the second Input face (index = 1) will be swapped by the first Source face (index = 0) and so on. + +### Genders + +You can specify the gender to detect in images.
+ReActor will swap a face only if it meets the given condition. + +### Face Models + +Since version 0.4.0 you can save face models as "safetensors" files (stored in `ComfyUI\models\reactor\faces`) and load them into ReActor implementing different scenarios and keeping super lightweight face models of the faces you use. + +To make new models appear in the list of the "Load Face Model" Node - just refresh the page of your ComfyUI web application.
+(I recommend you to use ComfyUI Manager - otherwise you workflow can be lost after you refresh the page if you didn't save it before that). + +## Troubleshooting + + + +### **I. (For Windows users) If you still cannot build Insightface for some reasons or just don't want to install Visual Studio or VS C++ Build Tools - do the following:** + +1. (ComfyUI Portable) From the root folder check the version of Python:
run CMD and type `python_embeded\python.exe -V` +2. Download prebuilt Insightface package [for Python 3.10](https://github.com/Gourieff/Assets/raw/main/Insightface/insightface-0.7.3-cp310-cp310-win_amd64.whl) or [for Python 3.11](https://github.com/Gourieff/Assets/raw/main/Insightface/insightface-0.7.3-cp311-cp311-win_amd64.whl) (if in the previous step you see 3.11) or [for Python 3.12](https://github.com/Gourieff/Assets/raw/main/Insightface/insightface-0.7.3-cp312-cp312-win_amd64.whl) (if in the previous step you see 3.12) and put into the stable-diffusion-webui (A1111 or SD.Next) root folder (where you have "webui-user.bat" file) or into ComfyUI root folder if you use ComfyUI Portable +3. From the root folder run: + - (SD WebUI) CMD and `.\venv\Scripts\activate` + - (ComfyUI Portable) run CMD +4. Then update your PIP: + - (SD WebUI) `python -m pip install -U pip` + - (ComfyUI Portable) `python_embeded\python.exe -m pip install -U pip` +5. Then install Insightface: + - (SD WebUI) `pip install insightface-0.7.3-cp310-cp310-win_amd64.whl` (for 3.10) or `pip install insightface-0.7.3-cp311-cp311-win_amd64.whl` (for 3.11) or `pip install insightface-0.7.3-cp312-cp312-win_amd64.whl` (for 3.12) + - (ComfyUI Portable) `python_embeded\python.exe -m pip install insightface-0.7.3-cp310-cp310-win_amd64.whl` (for 3.10) or `python_embeded\python.exe -m pip install insightface-0.7.3-cp311-cp311-win_amd64.whl` (for 3.11) or `python_embeded\python.exe -m pip install insightface-0.7.3-cp312-cp312-win_amd64.whl` (for 3.12) +6. Enjoy! + +### **II. "AttributeError: 'NoneType' object has no attribute 'get'"** + +This error may occur if there's smth wrong with the model file `inswapper_128.onnx` + +Try to download it manually from [here](https://github.com/facefusion/facefusion-assets/releases/download/models/inswapper_128.onnx) +and put it to the `ComfyUI\models\insightface` replacing existing one + +### **III. "reactor.execute() got an unexpected keyword argument 'reference_image'"** + +This means that input points have been changed with the latest update
+Remove the current ReActor Node from your workflow and add it again + +### **IV. ControlNet Aux Node IMPORT failed error when using with ReActor Node** + +1. Close ComfyUI if it runs +2. Go to the ComfyUI root folder, open CMD there and run: + - `python_embeded\python.exe -m pip uninstall -y opencv-python opencv-contrib-python opencv-python-headless` + - `python_embeded\python.exe -m pip install opencv-python==4.7.0.72` +3. That's it! + +
 +
+### **V. "ModuleNotFoundError: No module named 'basicsr'" or "subprocess-exited-with-error" during future-0.18.3 installation**
+
+- Download https://github.com/Gourieff/Assets/raw/main/comfyui-reactor-node/future-0.18.3-py3-none-any.whl
+
+### **V. "ModuleNotFoundError: No module named 'basicsr'" or "subprocess-exited-with-error" during future-0.18.3 installation**
+
+- Download https://github.com/Gourieff/Assets/raw/main/comfyui-reactor-node/future-0.18.3-py3-none-any.whl+- Put it to ComfyUI root And run: + + python_embeded\python.exe -m pip install future-0.18.3-py3-none-any.whl + +- Then: + + python_embeded\python.exe -m pip install basicsr + +### **VI. "fatal: fetch-pack: invalid index-pack output" when you try to `git clone` the repository"** + +Try to clone with `--depth=1` (last commit only): + + git clone --depth=1 https://github.com/Gourieff/ComfyUI-ReActor + +Then retrieve the rest (if you need): + + git fetch --unshallow + +## Updating + +Just put .bat or .sh script from this [Repo](https://github.com/Gourieff/sd-webui-extensions-updater) to the `ComfyUI\custom_nodes` directory and run it when you need to check for updates + +### Disclaimer + +This software is meant to be a productive contribution to the rapidly growing AI-generated media industry. It will help artists with tasks such as animating a custom character or using the character as a model for clothing etc. + +The developers of this software are aware of its possible unethical applications and are committed to take preventative measures against them. We will continue to develop this project in the positive direction while adhering to law and ethics. + +Users of this software are expected to use this software responsibly while abiding the local law. If face of a real person is being used, users are suggested to get consent from the concerned person and clearly mention that it is a deepfake when posting content online. **Developers and Contributors of this software are not responsible for actions of end-users.** + +By using this extension you are agree not to create any content that: +- violates any laws; +- causes any harm to a person or persons; +- propagates (spreads) any information (both public or personal) or images (both public or personal) which could be meant for harm; +- spreads misinformation; +- targets vulnerable groups of people. + +This software utilizes the pre-trained models `buffalo_l` and `inswapper_128.onnx`, which are provided by [InsightFace](https://github.com/deepinsight/insightface/). These models are included under the following conditions: + +[From insighface license](https://github.com/deepinsight/insightface/tree/master/python-package): The InsightFace’s pre-trained models are available for non-commercial research purposes only. This includes both auto-downloading models and manually downloaded models. + +Users of this software must strictly adhere to these conditions of use. The developers and maintainers of this software are not responsible for any misuse of InsightFace’s pre-trained models. + +Please note that if you intend to use this software for any commercial purposes, you will need to train your own models or find models that can be used commercially. + +### Models Hashsum + +#### Safe-to-use models have the following hash: + +inswapper_128.onnx +``` +MD5:a3a155b90354160350efd66fed6b3d80 +SHA256:e4a3f08c753cb72d04e10aa0f7dbe3deebbf39567d4ead6dce08e98aa49e16af +``` + +1k3d68.onnx + +``` +MD5:6fb94fcdb0055e3638bf9158e6a108f4 +SHA256:df5c06b8a0c12e422b2ed8947b8869faa4105387f199c477af038aa01f9a45cc +``` + +2d106det.onnx + +``` +MD5:a3613ef9eb3662b4ef88eb90db1fcf26 +SHA256:f001b856447c413801ef5c42091ed0cd516fcd21f2d6b79635b1e733a7109dbf +``` + +det_10g.onnx + +``` +MD5:4c10eef5c9e168357a16fdd580fa8371 +SHA256:5838f7fe053675b1c7a08b633df49e7af5495cee0493c7dcf6697200b85b5b91 +``` + +genderage.onnx + +``` +MD5:81c77ba87ab38163b0dec6b26f8e2af2 +SHA256:4fde69b1c810857b88c64a335084f1c3fe8f01246c9a191b48c7bb756d6652fb +``` + +w600k_r50.onnx + +``` +MD5:80248d427976241cbd1343889ed132b3 +SHA256:4c06341c33c2ca1f86781dab0e829f88ad5b64be9fba56e56bc9ebdefc619e43 +``` + +**Please check hashsums if you download these models from unverified (or untrusted) sources** + + + +## Thanks and Credits + +
+
+ +|file|source|license| +|----|------|-------| +|[buffalo_l.zip](https://huggingface.co/datasets/Gourieff/ReActor/blob/main/models/buffalo_l.zip) | [DeepInsight](https://github.com/deepinsight/insightface) |  | +| [codeformer-v0.1.0.pth](https://huggingface.co/datasets/Gourieff/ReActor/blob/main/models/facerestore_models/codeformer-v0.1.0.pth) | [sczhou](https://github.com/sczhou/CodeFormer) |  | +| [GFPGANv1.3.pth](https://huggingface.co/datasets/Gourieff/ReActor/blob/main/models/facerestore_models/GFPGANv1.3.pth) | [TencentARC](https://github.com/TencentARC/GFPGAN) |  | +| [GFPGANv1.4.pth](https://huggingface.co/datasets/Gourieff/ReActor/blob/main/models/facerestore_models/GFPGANv1.4.pth) | [TencentARC](https://github.com/TencentARC/GFPGAN) |  | +| [inswapper_128.onnx](https://github.com/facefusion/facefusion-assets/releases/download/models/inswapper_128.onnx) | [DeepInsight](https://github.com/deepinsight/insightface) |  | +| [inswapper_128_fp16.onnx](https://github.com/facefusion/facefusion-assets/releases/download/models/inswapper_128_fp16.onnx) | [Hillobar](https://github.com/Hillobar/Rope) |  | + +[BasicSR](https://github.com/XPixelGroup/BasicSR) - [@XPixelGroup](https://github.com/XPixelGroup)
+[facexlib](https://github.com/xinntao/facexlib) - [@xinntao](https://github.com/xinntao)
+ +[@s0md3v](https://github.com/s0md3v), [@henryruhs](https://github.com/henryruhs) - the original Roop App
+[@ssitu](https://github.com/ssitu) - the first version of [ComfyUI_roop](https://github.com/ssitu/ComfyUI_roop) extension + +
+
+
+
+### Note!
+
+**If you encounter any errors when you use ReActor Node - don't rush to open an issue, first try to remove current ReActor node in your workflow and add it again**
+
+**ReActor Node gets updates from time to time, new functions appear and old node can work with errors or not work at all**
diff --git a/custom_nodes/ComfyUI-ReActor/README_RU.md b/custom_nodes/ComfyUI-ReActor/README_RU.md
new file mode 100644
index 0000000000000000000000000000000000000000..0f9962d14c3720197a0983383c79db9872d651c5
--- /dev/null
+++ b/custom_nodes/ComfyUI-ReActor/README_RU.md
@@ -0,0 +1,497 @@
+Click to expand
+ ++ +|file|source|license| +|----|------|-------| +|[buffalo_l.zip](https://huggingface.co/datasets/Gourieff/ReActor/blob/main/models/buffalo_l.zip) | [DeepInsight](https://github.com/deepinsight/insightface) |  | +| [codeformer-v0.1.0.pth](https://huggingface.co/datasets/Gourieff/ReActor/blob/main/models/facerestore_models/codeformer-v0.1.0.pth) | [sczhou](https://github.com/sczhou/CodeFormer) |  | +| [GFPGANv1.3.pth](https://huggingface.co/datasets/Gourieff/ReActor/blob/main/models/facerestore_models/GFPGANv1.3.pth) | [TencentARC](https://github.com/TencentARC/GFPGAN) |  | +| [GFPGANv1.4.pth](https://huggingface.co/datasets/Gourieff/ReActor/blob/main/models/facerestore_models/GFPGANv1.4.pth) | [TencentARC](https://github.com/TencentARC/GFPGAN) |  | +| [inswapper_128.onnx](https://github.com/facefusion/facefusion-assets/releases/download/models/inswapper_128.onnx) | [DeepInsight](https://github.com/deepinsight/insightface) |  | +| [inswapper_128_fp16.onnx](https://github.com/facefusion/facefusion-assets/releases/download/models/inswapper_128_fp16.onnx) | [Hillobar](https://github.com/Hillobar/Rope) |  | + +[BasicSR](https://github.com/XPixelGroup/BasicSR) - [@XPixelGroup](https://github.com/XPixelGroup)
+[facexlib](https://github.com/xinntao/facexlib) - [@xinntao](https://github.com/xinntao)
+ +[@s0md3v](https://github.com/s0md3v), [@henryruhs](https://github.com/henryruhs) - the original Roop App
+[@ssitu](https://github.com/ssitu) - the first version of [ComfyUI_roop](https://github.com/ssitu/ComfyUI_roop) extension + +
+
+  +
+ 
+
+
+
+
+
+
+
+ 
+
+
+
+
+
+
+ + Поддержать проект + + + +
+ + [](https://github.com/Gourieff/ComfyUI-ReActor/commits/main) +  + [](https://github.com/Gourieff/ComfyUI-ReActor/issues?cacheSeconds=0) + [](https://github.com/Gourieff/ComfyUI-ReActor/issues?q=is%3Aissue+state%3Aclosed) +  + + [English](/README.md) | Русский + +# ReActor Nodes для ComfyUI
-=Безопасно для работы | SFW-Friendly=- + +
+
+### Ноды (nodes) для быстрой и простой замены лиц на любых изображениях для работы с ComfyUI, основан на [ранее заблокированном РеАкторе](https://github.com/Gourieff/comfyui-reactor-node) - теперь имеется встроенный NSFW-детектор, исключающий замену лиц на изображениях с контентом 18+
+
+> Используя данное ПО, вы понимаете и принимаете [ответственность](#disclaimer)
+
+
+ + + Поддержать проект + + + +
+ + [](https://github.com/Gourieff/ComfyUI-ReActor/commits/main) +  + [](https://github.com/Gourieff/ComfyUI-ReActor/issues?cacheSeconds=0) + [](https://github.com/Gourieff/ComfyUI-ReActor/issues?q=is%3Aissue+state%3Aclosed) +  + + [English](/README.md) | Русский + +# ReActor Nodes для ComfyUI
-=Безопасно для работы | SFW-Friendly=- + +
+
+---
+[**Что нового**](#latestupdate) | [**Установка**](#installation) | [**Использование**](#usage) | [**Устранение проблем**](#troubleshooting) | [**Обновление**](#updating) | [**Ответственность**](#disclaimer) | [**Благодарности**](#credits) | [**Заметка**](#note)
+
+---
+
+
+
+
+
+## Что нового в последнем обновлении
+
+### 0.6.0 ALPHA1
+
+- Новый нод `ReActorSetWeight` - теперь можно установить силу замены лица для `source_image` или `face_model` от 0% до 100% (с шагом 12.5%)
+
+
+
+
+
+
+
+
+
+
+Скачать модели ReSwapper можно отсюда:
+https://huggingface.co/datasets/Gourieff/ReActor/tree/main/models
+Сохраните их в директорию "models/reswapper".
+
+- NSFW-детектор, чтобы не нарушать [правила GitHub](https://docs.github.com/en/site-policy/acceptable-use-policies/github-misinformation-and-disinformation#synthetic--manipulated-media-tools)
+- Новый нод "Unload ReActor Models" - полезен для сложных воркфлоу, когда вам нужно освободить ОЗУ, занятую РеАктором
+
+
+
+- Поддержка ORT CoreML and ROCM EPs, достаточно установить ту версию onnxruntime, которая соответствует вашему GPU
+- Некоторые улучшения скрипта установки для поддержки последней версии ORT-GPU
+
+
+
+
+
+- Исправления и улучшения
+
+### 0.5.1
+
+- Поддержка моделей восстановления лиц GPEN 1024/2048 (доступны в датасете на HF https://huggingface.co/datasets/Gourieff/ReActor/tree/main/models/facerestore_models)
+- Нод ReActorFaceBoost - попытка улучшить качество заменённых лиц. Идея состоит в том, чтобы восстановить и увеличить заменённое лицо (в соответствии с параметром `face_size` модели реставрации) ДО того, как лицо будет вставлено в целевое изображения (через алгоритмы инсваппера), больше информации [здесь (PR#321)](https://github.com/Gourieff/comfyui-reactor-node/pull/321)
+
+
+
+[Полноразмерное демо-превью](https://github.com/Gourieff/Assets/blob/main/comfyui-reactor-node/0.5.1-whatsnew-02.png)
+
+- Сортировка моделей лиц по алфавиту
+- Множество исправлений и улучшений
+
+### [0.5.0 BETA4](https://github.com/Gourieff/comfyui-reactor-node/releases/tag/v0.5.0)
+
+- Поддержка библиотеки Spandrel при работе с GFPGAN
+
+### 0.5.0 BETA3
+
+- Исправления: "RAM issue", "No detection" для MaskingHelper
+
+### 0.5.0 BETA2
+
+- Появилась возможность строить смешанные модели лиц из пачки уже имеющихся моделей - добавьте для этого нод "Make Face Model Batch" в свой воркфлоу и загрузите несколько моделей через ноды "Load Face Model"
+- Огромный буст производительности модуля анализа изображений! 10-кратный прирост скорости! Работа с видео теперь в удовольствие!
+
+
+
+### 0.5.0 BETA1
+
+- Добавлен выход SWAPPED_FACE для нода Masking Helper
+- FIX: Удалён пустой A-канал на выходе IMAGE нода Masking Helper (вызывавший ошибки с некоторым нодами)
+
+### 0.5.0 ALPHA1
+
+- Нод ReActorBuildFaceModel получил выход "face_model" для отправки совмещенной модели лиц непосредственно в основной Нод:
+
+Basic workflow [💾](https://github.com/Gourieff/Assets/blob/main/comfyui-reactor-node/workflows/ReActor--Build-Blended-Face-Model--v2.json)
+
+- Функции маски лица теперь доступна и в версии для Комфи, просто добавьте нод "ReActorMaskHelper" в воркфлоу и соедините узлы, как показано ниже:
+
+
+
+Если модель "face_yolov8m.pt" у вас отсутствует - можете скачать её [отсюда](https://huggingface.co/datasets/Gourieff/ReActor/blob/main/models/detection/bbox/face_yolov8m.pt) и положить в папку "ComfyUI\models\ultralytics\bbox"
+
+То же самое и с ["sam_vit_b_01ec64.pth"](https://huggingface.co/datasets/Gourieff/ReActor/blob/main/models/sams/sam_vit_b_01ec64.pth) - скачайте (если отсутствует) и положите в папку "ComfyUI\models\sams"; + +Данный нод поможет вам получить куда более аккуратный результат при замене лиц: + +
+
+- Нод ReActorImageDublicator - полезен тем, кто создает видео, помогает продублировать одиночное изображение в несколько копий, чтобы использовать их, к примеру, с VAE энкодером:
+
+
+
+- ReActorFaceSwapOpt (упрощенная версия основного нода) + нод ReActorOptions для установки дополнительных опций, как (новые) "отдельный порядок лиц для input/source". Да! Теперь можно установить любой порядок "чтения" индекса лиц на изображении, в т.ч. от большего к меньшему (по умолчанию)!
+
+
+
+- Небольшое улучшение скорости анализа целевых изображений (input)
+
+### [0.4.2](https://github.com/Gourieff/comfyui-reactor-node/releases/tag/v0.4.2)
+
+- Добавлена поддержка GPEN-BFR-512 и RestoreFormer_Plus_Plus моделей восстановления лиц
+
+Скачать можно здесь: https://huggingface.co/datasets/Gourieff/ReActor/tree/main/models/facerestore_models
+
Добавьте модели в папку `ComfyUI\models\facerestore_models` + +
+
+- По многочисленным просьбам появилась возможность строить смешанные модели лиц и в ComfyUI тоже и использовать их с нодом "Load Face Model" Node или в SD WebUI;
+
+Экспериментируйте и создавайте новые лица или совмещайте разные лица нужного вам персонажа, чтобы добиться лучшей точности и схожести с оригиналом!
+
+Достаточно добавить нод "Make Image Batch" (ImpactPack) на вход нового нода РеАктора и загрузить в пачку необходимые вам изображения для построения смешанной модели:
+
+
+
+Пример результата (на основе лиц 4-х актрис создано новое лицо):
+
+
+
+Базовый воркфлоу [💾](https://github.com/Gourieff/Assets/blob/main/comfyui-reactor-node/workflows/ReActor--Build-Blended-Face-Model--v1.json)
+
+### [0.4.1](https://github.com/Gourieff/comfyui-reactor-node/releases/tag/v0.4.1)
+
+- Поддержка CUDA 12 - не забудьте запустить (Windows) `install.bat` или (Linux/MacOS) `install.py` для используемого Python окружения или попробуйте установить ORT-GPU для CU12 вручную (https://onnxruntime.ai/docs/install/#install-onnx-runtime-gpu-cuda-12x)
+- Исправление Issue https://github.com/Gourieff/comfyui-reactor-node/issues/173
+
+- Отдельный Нод для восстаноления лиц (FR https://github.com/Gourieff/comfyui-reactor-node/issues/191), располагается внутри меню ReActor (нод RestoreFace)
+- (Windows) Установка зависимостей теперь может быть выполнена в Python из PATH ОС
+- Разные исправления и улучшения
+
+- Face Restore Visibility и CodeFormer Weight (Fidelity) теперь доступны; не забудьте заново добавить Нод в ваших существующих воркфлоу
+
+
+
+### [0.4.0](https://github.com/Gourieff/comfyui-reactor-node/releases/tag/v0.4.0)
+
+- Вход "input_image" теперь идёт первым, это даёт возможность корректного байпаса, а также это правильно с точки зрения расположения входов (главный вход - первый);
+- Теперь можно сохранять модели лиц в качестве файлов "safetensors" (`ComfyUI\models\reactor\faces`) и загружать их в ReActor, реализуя разные сценарии использования, а также храня супер легкие модели лиц, которые вы чаще всего используете:
+
+
+
+
+- Возможность сохранять модели лиц напрямую из изображения:
+
+
+
+- Оба входа опциональны, присоедините один из них в соответствии с вашим воркфлоу; если присоеденены оба - вход `image` имеет приоритет.
+- Различные исправления, делающие это расширение лучше.
+
+Спасибо всем, кто находит ошибки, предлагает новые функции и поддерживает данный проект!
+
+
+
+
+
+## Установка
+
+Предыдущие версии
+ +### 0.5.2 + +- Поддержка моделей ReSwapper. Несмотря на то, что Inswapper по-прежнему даёт лучшее сходство, но ReSwapper развивается - спасибо @somanchiu https://github.com/somanchiu/ReSwapper за эти модели и проект ReSwapper! Это хороший шаг для Сообщества в создании альтернативы Инсваппера! + +
+
+
+
+- Поддержка ORT CoreML and ROCM EPs, достаточно установить ту версию onnxruntime, которая соответствует вашему GPU
+- Некоторые улучшения скрипта установки для поддержки последней версии ORT-GPU
+
+
+
+
+[Полноразмерное демо-превью](https://github.com/Gourieff/Assets/blob/main/comfyui-reactor-node/0.5.1-whatsnew-02.png)
+
+- Сортировка моделей лиц по алфавиту
+- Множество исправлений и улучшений
+
+### [0.5.0 BETA4](https://github.com/Gourieff/comfyui-reactor-node/releases/tag/v0.5.0)
+
+- Поддержка библиотеки Spandrel при работе с GFPGAN
+
+### 0.5.0 BETA3
+
+- Исправления: "RAM issue", "No detection" для MaskingHelper
+
+### 0.5.0 BETA2
+
+- Появилась возможность строить смешанные модели лиц из пачки уже имеющихся моделей - добавьте для этого нод "Make Face Model Batch" в свой воркфлоу и загрузите несколько моделей через ноды "Load Face Model"
+- Огромный буст производительности модуля анализа изображений! 10-кратный прирост скорости! Работа с видео теперь в удовольствие!
+
+
+
+### 0.5.0 BETA1
+
+- Добавлен выход SWAPPED_FACE для нода Masking Helper
+- FIX: Удалён пустой A-канал на выходе IMAGE нода Masking Helper (вызывавший ошибки с некоторым нодами)
+
+### 0.5.0 ALPHA1
+
+- Нод ReActorBuildFaceModel получил выход "face_model" для отправки совмещенной модели лиц непосредственно в основной Нод:
+
+Basic workflow [💾](https://github.com/Gourieff/Assets/blob/main/comfyui-reactor-node/workflows/ReActor--Build-Blended-Face-Model--v2.json)
+
+- Функции маски лица теперь доступна и в версии для Комфи, просто добавьте нод "ReActorMaskHelper" в воркфлоу и соедините узлы, как показано ниже:
+
+
+
+Если модель "face_yolov8m.pt" у вас отсутствует - можете скачать её [отсюда](https://huggingface.co/datasets/Gourieff/ReActor/blob/main/models/detection/bbox/face_yolov8m.pt) и положить в папку "ComfyUI\models\ultralytics\bbox"
++То же самое и с ["sam_vit_b_01ec64.pth"](https://huggingface.co/datasets/Gourieff/ReActor/blob/main/models/sams/sam_vit_b_01ec64.pth) - скачайте (если отсутствует) и положите в папку "ComfyUI\models\sams"; + +Данный нод поможет вам получить куда более аккуратный результат при замене лиц: + +
+
+- Нод ReActorImageDublicator - полезен тем, кто создает видео, помогает продублировать одиночное изображение в несколько копий, чтобы использовать их, к примеру, с VAE энкодером:
+
+
+
+- ReActorFaceSwapOpt (упрощенная версия основного нода) + нод ReActorOptions для установки дополнительных опций, как (новые) "отдельный порядок лиц для input/source". Да! Теперь можно установить любой порядок "чтения" индекса лиц на изображении, в т.ч. от большего к меньшему (по умолчанию)!
+
+
+
+- Небольшое улучшение скорости анализа целевых изображений (input)
+
+### [0.4.2](https://github.com/Gourieff/comfyui-reactor-node/releases/tag/v0.4.2)
+
+- Добавлена поддержка GPEN-BFR-512 и RestoreFormer_Plus_Plus моделей восстановления лиц
+
+Скачать можно здесь: https://huggingface.co/datasets/Gourieff/ReActor/tree/main/models/facerestore_models
+Добавьте модели в папку `ComfyUI\models\facerestore_models` + +
+
+- По многочисленным просьбам появилась возможность строить смешанные модели лиц и в ComfyUI тоже и использовать их с нодом "Load Face Model" Node или в SD WebUI;
+
+Экспериментируйте и создавайте новые лица или совмещайте разные лица нужного вам персонажа, чтобы добиться лучшей точности и схожести с оригиналом!
+
+Достаточно добавить нод "Make Image Batch" (ImpactPack) на вход нового нода РеАктора и загрузить в пачку необходимые вам изображения для построения смешанной модели:
+
+
+
+Пример результата (на основе лиц 4-х актрис создано новое лицо):
+
+
+
+Базовый воркфлоу [💾](https://github.com/Gourieff/Assets/blob/main/comfyui-reactor-node/workflows/ReActor--Build-Blended-Face-Model--v1.json)
+
+### [0.4.1](https://github.com/Gourieff/comfyui-reactor-node/releases/tag/v0.4.1)
+
+- Поддержка CUDA 12 - не забудьте запустить (Windows) `install.bat` или (Linux/MacOS) `install.py` для используемого Python окружения или попробуйте установить ORT-GPU для CU12 вручную (https://onnxruntime.ai/docs/install/#install-onnx-runtime-gpu-cuda-12x)
+- Исправление Issue https://github.com/Gourieff/comfyui-reactor-node/issues/173
+
+- Отдельный Нод для восстаноления лиц (FR https://github.com/Gourieff/comfyui-reactor-node/issues/191), располагается внутри меню ReActor (нод RestoreFace)
+- (Windows) Установка зависимостей теперь может быть выполнена в Python из PATH ОС
+- Разные исправления и улучшения
+
+- Face Restore Visibility и CodeFormer Weight (Fidelity) теперь доступны; не забудьте заново добавить Нод в ваших существующих воркфлоу
+
+
+
+### [0.4.0](https://github.com/Gourieff/comfyui-reactor-node/releases/tag/v0.4.0)
+
+- Вход "input_image" теперь идёт первым, это даёт возможность корректного байпаса, а также это правильно с точки зрения расположения входов (главный вход - первый);
+- Теперь можно сохранять модели лиц в качестве файлов "safetensors" (`ComfyUI\models\reactor\faces`) и загружать их в ReActor, реализуя разные сценарии использования, а также храня супер легкие модели лиц, которые вы чаще всего используете:
+
+
+
+
+- Возможность сохранять модели лиц напрямую из изображения:
+
+
+
+- Оба входа опциональны, присоедините один из них в соответствии с вашим воркфлоу; если присоеденены оба - вход `image` имеет приоритет.
+- Различные исправления, делающие это расширение лучше.
+
+Спасибо всем, кто находит ошибки, предлагает новые функции и поддерживает данный проект!
+
+
+
+https://huggingface.co/datasets/Gourieff/ReActor/tree/main/models/facerestore_models +11. Запустите SD WebUI и проверьте консоль на сообщение, что ReActor Node работает: +
+
+12. Перейдите во вкладку ComfyUI и найдите там ReActor Node внутри меню `ReActor` или через поиск:
+
+
+
+
+
+SD WebUI: AUTOMATIC1111 или SD.Next
+ +1. Закройте (остановите) SD-WebUI Сервер, если запущен +2. (Для пользователей Windows): + - Установите [Visual Studio 2022](https://visualstudio.microsoft.com/downloads/) (Например, версию Community - этот шаг нужен для правильной компиляции библиотеки Insightface) + - ИЛИ только [VS C++ Build Tools](https://visualstudio.microsoft.com/visual-cpp-build-tools/), выберите "Desktop Development with C++" в разделе "Workloads -> Desktop & Mobile" + - ИЛИ если же вы не хотите устанавливать что-либо из вышеуказанного - выполните [данные шаги (раздел. I)](#insightfacebuild) +3. Перейдите в `extensions\sd-webui-comfyui\ComfyUI\custom_nodes` +4. Откройте Консоль или Терминал и выполните `git clone https://github.com/Gourieff/ComfyUI-ReActor` +5. Перейдите в корневую директорию SD WebUI, откройте Консоль или Терминал и выполните (для пользователей Windows)`.\venv\Scripts\activate` или (для пользователей Linux/MacOS)`venv/bin/activate` +6. `python -m pip install -U pip` +7. `cd extensions\sd-webui-comfyui\ComfyUI\custom_nodes\ComfyUI-ReActor` +8. `python install.py` +9. Пожалуйста, дождитесь полного завершения установки +10. (Начиная с версии 0.3.0) Скачайте дополнительные модели восстановления лиц (по ссылке ниже) и сохраните их в папку `extensions\sd-webui-comfyui\ComfyUI\models\facerestore_models`:+https://huggingface.co/datasets/Gourieff/ReActor/tree/main/models/facerestore_models +11. Запустите SD WebUI и проверьте консоль на сообщение, что ReActor Node работает: +
+
+12. Перейдите во вкладку ComfyUI и найдите там ReActor Node внутри меню `ReActor` или через поиск:
+
+
+
+
+
+То же самое и с "Sams" моделями, скачайте одну или обе [отсюда](https://huggingface.co/datasets/Gourieff/ReActor/tree/main/models/sams) - и положите в папку "ComfyUI\models\sams" +5. Запустите ComfyUI и найдите ReActor Node внутри меню `ReActor` или через поиск + +
+
+
+
+## Использование
+
+Вы можете найти ноды ReActor внутри меню `ReActor` или через поиск (достаточно ввести "ReActor" в поисковой строке)
+
+Список нодов:
+- ••• Main Nodes •••
+ - ReActorFaceSwap (Основной нод)
+ - ReActorFaceSwapOpt (Основной нод с доп. входом Options)
+ - ReActorOptions (Опции для ReActorFaceSwapOpt)
+ - ReActorFaceBoost (Нод Face Booster)
+ - ReActorMaskHelper (Masking Helper)
+- ••• Operations with Face Models •••
+ - ReActorSaveFaceModel (Save Face Model)
+ - ReActorLoadFaceModel (Load Face Model)
+ - ReActorBuildFaceModel (Build Blended Face Model)
+ - ReActorMakeFaceModelBatch (Make Face Model Batch)
+- ••• Additional Nodes •••
+ - ReActorRestoreFace (Face Restoration)
+ - ReActorImageDublicator (Dublicate one Image to Images List)
+ - ImageRGBA2RGB (Convert RGBA to RGB)
+
+Соедините все необходимые слоты (slots) и запустите очередь (query).
+
+### Входы основного Нода
+
+- `input_image` - это изображение, на котором надо поменять лицо или лица (целевое изображение, аналог "target image" в версии для SD WebUI);
+ - Поддерживаемые ноды: "Load Image", "Load Video" или любые другие ноды предоставляющие изображение в качестве выхода;
+- `source_image` - это изображение с лицом или лицами для замены (изображение-источник, аналог "source image" в версии для SD WebUI);
+ - Поддерживаемые ноды: "Load Image" или любые другие ноды с выходом Image(s);
+- `face_model` - это вход для выхода с нода "Load Face Model" или другого нода ReActor для загрузки модели лица (face model или face embedding), которое вы создали ранее через нод "Save Face Model";
+ - Поддерживаемые ноды: "Load Face Model", "Build Blended Face Model";
+
+### Выходы основного Нода
+
+- `IMAGE` - выход с готовым изображением (результатом);
+ - Поддерживаемые ноды: любые ноды с изображением на входе;
+- `FACE_MODEL` - выход, предоставляющий модель лица, построенную в ходе замены;
+ - Поддерживаемые ноды: "Save Face Model", "ReActor", "Make Face Model Batch";
+
+### Восстановление лиц
+
+Начиная с версии 0.3.0 ReActor Node имеет встроенное восстановление лиц.Портативная версия ComfyUI для Windows
+ +1. Сделайте следующее: + - Установите [Visual Studio 2022](https://visualstudio.microsoft.com/downloads/) (Например, версию Community - этот шаг нужен для правильной компиляции библиотеки Insightface) + - ИЛИ только [VS C++ Build Tools](https://visualstudio.microsoft.com/visual-cpp-build-tools/), выберите "Desktop Development with C++" в разделе "Workloads -> Desktop & Mobile" + - ИЛИ если же вы не хотите устанавливать что-либо из вышеуказанного - выполните [данные шаги (раздел. I)](#insightfacebuild) +2. Выберите из двух вариантов: + - (ComfyUI Manager) Откройте ComfyUI Manager, нажвите "Install Custom Nodes", введите "ReActor" в поле "Search" и далее нажмите "Install". После того, как ComfyUI завершит установку, перезагрузите сервер. + - (Вручную) Перейдите в `ComfyUI\custom_nodes`, откройте Консоль и выполните `git clone https://github.com/Gourieff/ComfyUI-ReActor` +3. Перейдите `ComfyUI\custom_nodes\ComfyUI-ReActor` и запустите `install.bat`, дождитесь окончания установки +4. Если модель "face_yolov8m.pt" у вас отсутствует - можете скачать её [отсюда](https://huggingface.co/datasets/Gourieff/ReActor/blob/main/models/detection/bbox/face_yolov8m.pt) и положить в папку "ComfyUI\models\ultralytics\bbox"+То же самое и с "Sams" моделями, скачайте одну или обе [отсюда](https://huggingface.co/datasets/Gourieff/ReActor/tree/main/models/sams) - и положите в папку "ComfyUI\models\sams" +5. Запустите ComfyUI и найдите ReActor Node внутри меню `ReActor` или через поиск + +
Скачайте нужные вам модели (см. инструкцию по [Установке](#installation)) и выберите одну из них, чтобы улучшить качество финального лица. + +### Индексы Лиц (Face Indexes) + +По умолчанию ReActor определяет лица на изображении в порядке от "большого" к "малому".
Вы можете поменять эту опцию, используя нод ReActorFaceSwapOpt вместе с ReActorOptions. + +Если вам нужно заменить определенное лицо, вы можете указать индекс для исходного (source, с лицом) и входного (input, где будет замена лица) изображений. + +Индекс первого обнаруженного лица - 0. + +Вы можете задать индексы в том порядке, который вам нужен.
+Например: 0,1,2 (для Source); 1,0,2 (для Input).
Это означает, что: второе лицо из Input (индекс = 1) будет заменено первым лицом из Source (индекс = 0) и так далее. + +### Определение Пола + +Вы можете обозначить, какой пол нужно определять на изображении.
+ReActor заменит только то лицо, которое удовлетворяет заданному условию. + +### Модели Лиц +Начиная с версии 0.4.0, вы можете сохранять модели лиц как файлы "safetensors" (хранятся в папке `ComfyUI\models\reactor\faces`) и загружать их в ReActor, реализуя разные сценарии использования, а также храня супер легкие модели лиц, которые вы чаще всего используете. + +Чтобы новые модели появились в списке моделей нода "Load Face Model" - обновите страницу of с ComfyUI.
+(Рекомендую использовать ComfyUI Manager - иначе ваше воркфлоу может быть потеряно после перезагрузки страницы, если вы не сохранили его). + + + +## Устранение проблем + + + +### **I. (Для пользователей Windows) Если вы до сих пор не можете установить пакет Insightface по каким-то причинам или же просто не желаете устанавливать Visual Studio или VS C++ Build Tools - сделайте следующее:** + +1. (ComfyUI Portable) Находясь в корневой директории, проверьте версию Python:
запустите CMD и выполните `python_embeded\python.exe -V`
Вы должны увидеть версию или 3.10, или 3.11, или 3.12 +2. Скачайте готовый пакет Insightface [для версии 3.10](https://github.com/Gourieff/sd-webui-reactor/raw/main/example/insightface-0.7.3-cp310-cp310-win_amd64.whl) или [для 3.11](https://github.com/Gourieff/Assets/raw/main/Insightface/insightface-0.7.3-cp311-cp311-win_amd64.whl) (если на предыдущем шаге вы увидели 3.11) или [для 3.12](https://github.com/Gourieff/Assets/raw/main/Insightface/insightface-0.7.3-cp312-cp312-win_amd64.whl) (если на предыдущем шаге вы увидели 3.12) и сохраните его в корневую директорию stable-diffusion-webui (A1111 или SD.Next) - туда, где лежит файл "webui-user.bat" -ИЛИ- в корневую директорию ComfyUI, если вы используете ComfyUI Portable +3. Из корневой директории запустите: + - (SD WebUI) CMD и `.\venv\Scripts\activate` + - (ComfyUI Portable) CMD +4. Обновите PIP: + - (SD WebUI) `python -m pip install -U pip` + - (ComfyUI Portable) `python_embeded\python.exe -m pip install -U pip` +5. Затем установите Insightface: + - (SD WebUI) `pip install insightface-0.7.3-cp310-cp310-win_amd64.whl` (для 3.10) или `pip install insightface-0.7.3-cp311-cp311-win_amd64.whl` (для 3.11) или `pip install insightface-0.7.3-cp312-cp312-win_amd64.whl` (for 3.12) + - (ComfyUI Portable) `python_embeded\python.exe -m pip install insightface-0.7.3-cp310-cp310-win_amd64.whl` (для 3.10) или `python_embeded\python.exe -m pip install insightface-0.7.3-cp311-cp311-win_amd64.whl` (для 3.11) или `python_embeded\python.exe -m pip install insightface-0.7.3-cp312-cp312-win_amd64.whl` (for 3.12) +6. Готово! + +### **II. "AttributeError: 'NoneType' object has no attribute 'get'"** + +Эта ошибка появляется, если что-то не так с файлом модели `inswapper_128.onnx` + +Скачайте вручную по ссылке [отсюда](https://github.com/facefusion/facefusion-assets/releases/download/models/inswapper_128.onnx) +и сохраните в директорию `ComfyUI\models\insightface`, заменив имеющийся файл + +### **III. "reactor.execute() got an unexpected keyword argument 'reference_image'"** + +Это означает, что поменялось обозначение входных точек (input points) всвязи с последним обновлением
+Удалите из вашего рабочего пространства имеющийся ReActor Node и добавьте его снова + +### **IV. ControlNet Aux Node IMPORT failed - при использовании совместно с нодом ReActor** + +1. Закройте или остановите ComfyUI сервер, если он запущен +2. Перейдите в корневую папку ComfyUI, откройте консоль CMD и выполните следующее: + - `python_embeded\python.exe -m pip uninstall -y opencv-python opencv-contrib-python opencv-python-headless` + - `python_embeded\python.exe -m pip install opencv-python==4.7.0.72` +3. Готово! + +
+
+### **V. "ModuleNotFoundError: No module named 'basicsr'" или "subprocess-exited-with-error" при установке пакета future-0.18.3**
+
+- Скачайте https://github.com/Gourieff/Assets/raw/main/comfyui-reactor-node/future-0.18.3-py3-none-any.whl+- Скопируйте файл в корневую папку ComfyUI и выполните в консоли: + + python_embeded\python.exe -m pip install future-0.18.3-py3-none-any.whl + +- Затем: + + python_embeded\python.exe -m pip install basicsr + +### **VI. "fatal: fetch-pack: invalid index-pack output" при исполнении команды `git clone`"** + +Попробуйте клонировать репозиторий с параметром `--depth=1` (только последний коммит): + + git clone --depth=1 https://github.com/Gourieff/ComfyUI-ReActor + +Затем вытяните оставшееся (если требуется): + + git fetch --unshallow + + + +## Обновление + +Положите .bat или .sh скрипт из [данного репозитория](https://github.com/Gourieff/sd-webui-extensions-updater) в папку `ComfyUI\custom_nodes` и запустите, когда желаете обновить ComfyUI и Ноды + + + +## Ответственность + +Это программное обеспечение призвано стать продуктивным вкладом в быстрорастущую медиаиндустрию на основе генеративных сетей и искусственного интеллекта. Данное ПО поможет художникам в решении таких задач, как анимация собственного персонажа или использование персонажа в качестве модели для одежды и т.д. + +Разработчики этого программного обеспечения осведомлены о возможных неэтичных применениях и обязуются принять против этого превентивные меры. Мы продолжим развивать этот проект в позитивном направлении, придерживаясь закона и этики. + +Подразумевается, что пользователи этого программного обеспечения будут использовать его ответственно, соблюдая локальное законодательство. Если используется лицо реального человека, пользователь обязан получить согласие заинтересованного лица и четко указать, что это дипфейк при размещении контента в Интернете. **Разработчики и Со-авторы данного программного обеспечения не несут ответственности за действия конечных пользователей.** + +Используя данное расширение, вы соглашаетесь не создавать материалы, которые: +- нарушают какие-либо действующие законы тех или иных государств или международных организаций; +- причиняют какой-либо вред человеку или лицам; +- пропагандируют любую информацию (как общедоступную, так и личную) или изображения (как общедоступные, так и личные), которые могут быть направлены на причинение вреда; +- используются для распространения дезинформации; +- нацелены на уязвимые группы людей. + +Данное программное обеспечение использует предварительно обученные модели `buffalo_l` и `inswapper_128.onnx`, представленные разработчиками [InsightFace](https://github.com/deepinsight/insightface/). Эти модели распространяются при следующих условиях: + +[Перевод из текста лицензии insighface](https://github.com/deepinsight/insightface/tree/master/python-package): Предварительно обученные модели InsightFace доступны только для некоммерческих исследовательских целей. Сюда входят как модели с автоматической загрузкой, так и модели, загруженные вручную. + +Пользователи данного программного обеспечения должны строго соблюдать данные условия использования. Разработчики и Со-авторы данного программного продукта не несут ответственности за неправильное использование предварительно обученных моделей InsightFace. + +Обратите внимание: если вы собираетесь использовать это программное обеспечение в каких-либо коммерческих целях, вам необходимо будет обучить свои собственные модели или найти модели, которые можно использовать в коммерческих целях. + +### Хэш файлов моделей + +#### Безопасные для использования модели имеют следующий хэш: + +inswapper_128.onnx +``` +MD5:a3a155b90354160350efd66fed6b3d80 +SHA256:e4a3f08c753cb72d04e10aa0f7dbe3deebbf39567d4ead6dce08e98aa49e16af +``` + +1k3d68.onnx + +``` +MD5:6fb94fcdb0055e3638bf9158e6a108f4 +SHA256:df5c06b8a0c12e422b2ed8947b8869faa4105387f199c477af038aa01f9a45cc +``` + +2d106det.onnx + +``` +MD5:a3613ef9eb3662b4ef88eb90db1fcf26 +SHA256:f001b856447c413801ef5c42091ed0cd516fcd21f2d6b79635b1e733a7109dbf +``` + +det_10g.onnx + +``` +MD5:4c10eef5c9e168357a16fdd580fa8371 +SHA256:5838f7fe053675b1c7a08b633df49e7af5495cee0493c7dcf6697200b85b5b91 +``` + +genderage.onnx + +``` +MD5:81c77ba87ab38163b0dec6b26f8e2af2 +SHA256:4fde69b1c810857b88c64a335084f1c3fe8f01246c9a191b48c7bb756d6652fb +``` + +w600k_r50.onnx + +``` +MD5:80248d427976241cbd1343889ed132b3 +SHA256:4c06341c33c2ca1f86781dab0e829f88ad5b64be9fba56e56bc9ebdefc619e43 +``` + +**Пожалуйста, сравните хэш, если вы скачиваете данные модели из непроверенных источников** + + + +## Благодарности и авторы компонентов + +
+
+ +|файл|источник|лицензия| +|----|--------|--------| +|[buffalo_l.zip](https://huggingface.co/datasets/Gourieff/ReActor/blob/main/models/buffalo_l.zip) | [DeepInsight](https://github.com/deepinsight/insightface) |  | +| [codeformer-v0.1.0.pth](https://huggingface.co/datasets/Gourieff/ReActor/blob/main/models/facerestore_models/codeformer-v0.1.0.pth) | [sczhou](https://github.com/sczhou/CodeFormer) |  | +| [GFPGANv1.3.pth](https://huggingface.co/datasets/Gourieff/ReActor/blob/main/models/facerestore_models/GFPGANv1.3.pth) | [TencentARC](https://github.com/TencentARC/GFPGAN) |  | +| [GFPGANv1.4.pth](https://huggingface.co/datasets/Gourieff/ReActor/blob/main/models/facerestore_models/GFPGANv1.4.pth) | [TencentARC](https://github.com/TencentARC/GFPGAN) |  | +| [inswapper_128.onnx](https://github.com/facefusion/facefusion-assets/releases/download/models/inswapper_128.onnx) | [DeepInsight](https://github.com/deepinsight/insightface) |  | +| [inswapper_128_fp16.onnx](https://github.com/facefusion/facefusion-assets/releases/download/models/inswapper_128_fp16.onnx) | [Hillobar](https://github.com/Hillobar/Rope) |  | + +[BasicSR](https://github.com/XPixelGroup/BasicSR) - [@XPixelGroup](https://github.com/XPixelGroup)
+[facexlib](https://github.com/xinntao/facexlib) - [@xinntao](https://github.com/xinntao)
+ +[@s0md3v](https://github.com/s0md3v), [@henryruhs](https://github.com/henryruhs) - оригинальное приложение Roop
+[@ssitu](https://github.com/ssitu) - первая версия расширения с поддержкой ComfyUI [ComfyUI_roop](https://github.com/ssitu/ComfyUI_roop) + +
+
+
+
+### Обратите внимание!
+
+**Если у вас возникли какие-либо ошибки при очередном использовании Нода ReActor - не торопитесь открывать Issue, для начала попробуйте удалить текущий Нод из вашего рабочего пространства и добавить его снова**
+
+**ReActor Node периодически получает обновления, появляются новые функции, из-за чего имеющийся Нод может работать с ошибками или не работать вовсе**
diff --git a/custom_nodes/ComfyUI-ReActor/__init__.py b/custom_nodes/ComfyUI-ReActor/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..eac9effa0d4d0b04f4a96f004cb295be55f99ba1
--- /dev/null
+++ b/custom_nodes/ComfyUI-ReActor/__init__.py
@@ -0,0 +1,39 @@
+import sys
+import os
+
+repo_dir = os.path.dirname(os.path.realpath(__file__))
+sys.path.insert(0, repo_dir)
+original_modules = sys.modules.copy()
+
+# Place aside existing modules if using a1111 web ui
+modules_used = [
+ "modules",
+ "modules.images",
+ "modules.processing",
+ "modules.scripts_postprocessing",
+ "modules.scripts",
+ "modules.shared",
+]
+original_webui_modules = {}
+for module in modules_used:
+ if module in sys.modules:
+ original_webui_modules[module] = sys.modules.pop(module)
+
+# Proceed with node setup
+from .nodes import NODE_CLASS_MAPPINGS, NODE_DISPLAY_NAME_MAPPINGS
+
+__all__ = ["NODE_CLASS_MAPPINGS", "NODE_DISPLAY_NAME_MAPPINGS"]
+
+# Clean up imports
+# Remove repo directory from path
+sys.path.remove(repo_dir)
+# Remove any new modules
+modules_to_remove = []
+for module in sys.modules:
+ if module not in original_modules and not module.startswith("google.protobuf") and not module.startswith("onnx") and not module.startswith("cv2"):
+ modules_to_remove.append(module)
+for module in modules_to_remove:
+ del sys.modules[module]
+
+# Restore original modules
+sys.modules.update(original_webui_modules)
diff --git a/custom_nodes/ComfyUI-ReActor/install.bat b/custom_nodes/ComfyUI-ReActor/install.bat
new file mode 100644
index 0000000000000000000000000000000000000000..290195e8e64f4bfd161828f5e8d224665296feea
--- /dev/null
+++ b/custom_nodes/ComfyUI-ReActor/install.bat
@@ -0,0 +1,37 @@
+@echo off
+setlocal enabledelayedexpansion
+
+:: Try to use embedded python first
+if exist ..\..\..\python_embeded\python.exe (
+ :: Use the embedded python
+ set PYTHON=..\..\..\python_embeded\python.exe
+) else (
+ :: Embedded python not found, check for python in the PATH
+ for /f "tokens=* USEBACKQ" %%F in (`python --version 2^>^&1`) do (
+ set PYTHON_VERSION=%%F
+ )
+ if errorlevel 1 (
+ echo I couldn't find an embedded version of Python, nor one in the Windows PATH. Please install manually.
+ pause
+ exit /b 1
+ ) else (
+ :: Use python from the PATH (if it's the right version and the user agrees)
+ echo I couldn't find an embedded version of Python, but I did find !PYTHON_VERSION! in your Windows PATH.
+ echo Would you like to proceed with the install using that version? (Y/N^)
+ set /p USE_PYTHON=
+ if /i "!USE_PYTHON!"=="Y" (
+ set PYTHON=python
+ ) else (
+ echo Okay. Please install manually.
+ pause
+ exit /b 1
+ )
+ )
+)
+
+:: Install the package
+echo Installing...
+%PYTHON% install.py
+echo Done^!
+
+@pause
\ No newline at end of file
diff --git a/custom_nodes/ComfyUI-ReActor/install.py b/custom_nodes/ComfyUI-ReActor/install.py
new file mode 100644
index 0000000000000000000000000000000000000000..14cd972f0e694a56dff3997fe142d4193d4433aa
--- /dev/null
+++ b/custom_nodes/ComfyUI-ReActor/install.py
@@ -0,0 +1,104 @@
+import warnings
+warnings.filterwarnings("ignore", category=DeprecationWarning)
+
+import subprocess
+import os, sys
+try:
+ from pkg_resources import get_distribution as distributions
+except:
+ from importlib_metadata import distributions
+from tqdm import tqdm
+import urllib.request
+from packaging import version as pv
+try:
+ from folder_paths import models_dir
+except:
+ from pathlib import Path
+ models_dir = os.path.join(Path(__file__).parents[2], "models")
+
+sys.path.append(os.path.dirname(os.path.realpath(__file__)))
+
+req_file = os.path.join(os.path.dirname(os.path.realpath(__file__)), "requirements.txt")
+
+model_url = "https://huggingface.co/datasets/Gourieff/ReActor/resolve/main/models/inswapper_128.onnx"
+model_name = os.path.basename(model_url)
+models_dir_path = os.path.join(models_dir, "insightface")
+model_path = os.path.join(models_dir_path, model_name)
+
+def run_pip(*args):
+ subprocess.run([sys.executable, "-m", "pip", "install", "--no-warn-script-location", *args])
+
+def is_installed (
+ package: str, version: str = None, strict: bool = True
+):
+ has_package = None
+ try:
+ has_package = distributions(package)
+ if has_package is not None:
+ if version is not None:
+ installed_version = has_package.version
+ if (installed_version != version and strict == True) or (pv.parse(installed_version) < pv.parse(version) and strict == False):
+ return False
+ else:
+ return True
+ else:
+ return True
+ else:
+ return False
+ except Exception as e:
+ print(f"Status: {e}")
+ return False
+
+def download(url, path, name):
+ request = urllib.request.urlopen(url)
+ total = int(request.headers.get('Content-Length', 0))
+ with tqdm(total=total, desc=f'[ReActor] Downloading {name} to {path}', unit='B', unit_scale=True, unit_divisor=1024) as progress:
+ urllib.request.urlretrieve(url, path, reporthook=lambda count, block_size, total_size: progress.update(block_size))
+
+if not os.path.exists(models_dir_path):
+ os.makedirs(models_dir_path)
+
+if not os.path.exists(model_path):
+ download(model_url, model_path, model_name)
+
+with open(req_file) as file:
+ try:
+ ort = "onnxruntime-gpu"
+ import torch
+ cuda_version = None
+ if torch.cuda.is_available():
+ cuda_version = torch.version.cuda
+ print(f"CUDA {cuda_version}")
+ elif torch.backends.mps.is_available() or hasattr(torch,'dml') or hasattr(torch,'privateuseone'):
+ ort = "onnxruntime"
+ if cuda_version is not None and float(cuda_version)>=12 and torch.torch_version.__version__ <= "2.2.0": # CU12.x and torch<=2.2.0
+ print(f"Torch: {torch.torch_version.__version__}")
+ if not is_installed(ort,"1.17.0",False):
+ run_pip(ort,"--extra-index-url", "https://aiinfra.pkgs.visualstudio.com/PublicPackages/_packaging/onnxruntime-cuda-12/pypi/simple/")
+ elif cuda_version is not None and float(cuda_version)>=12 and torch.torch_version.__version__ >= "2.4.0" : # CU12.x and latest torch
+ print(f"Torch: {torch.torch_version.__version__}")
+ if not is_installed(ort,"1.20.1",False): # latest ort-gpu
+ run_pip(ort,"-U")
+ elif not is_installed(ort,"1.16.1",False):
+ run_pip(ort, "-U")
+ except Exception as e:
+ print(e)
+ print(f"Warning: Failed to install {ort}, ReActor will not work.")
+ raise e
+ strict = True
+ for package in file:
+ package_version = None
+ try:
+ package = package.strip()
+ if "==" in package:
+ package_version = package.split('==')[1]
+ elif ">=" in package:
+ package_version = package.split('>=')[1]
+ strict = False
+ if not is_installed(package,package_version,strict):
+ run_pip(package)
+ except Exception as e:
+ print(e)
+ print(f"Warning: Failed to install {package}, ReActor will not work.")
+ raise e
+print("Ok")
diff --git a/custom_nodes/ComfyUI-ReActor/modules/__init__.py b/custom_nodes/ComfyUI-ReActor/modules/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/custom_nodes/ComfyUI-ReActor/modules/images.py b/custom_nodes/ComfyUI-ReActor/modules/images.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/custom_nodes/ComfyUI-ReActor/modules/processing.py b/custom_nodes/ComfyUI-ReActor/modules/processing.py
new file mode 100644
index 0000000000000000000000000000000000000000..d52541824a5d566516b8f8d1a24ad626a090f6cf
--- /dev/null
+++ b/custom_nodes/ComfyUI-ReActor/modules/processing.py
@@ -0,0 +1,13 @@
+class StableDiffusionProcessing:
+
+ def __init__(self, init_imgs):
+ self.init_images = init_imgs
+ self.width = init_imgs[0].width
+ self.height = init_imgs[0].height
+ self.extra_generation_params = {}
+
+
+class StableDiffusionProcessingImg2Img(StableDiffusionProcessing):
+
+ def __init__(self, init_img):
+ super().__init__(init_img)
diff --git a/custom_nodes/ComfyUI-ReActor/modules/scripts.py b/custom_nodes/ComfyUI-ReActor/modules/scripts.py
new file mode 100644
index 0000000000000000000000000000000000000000..5eae950c9db521fbdadf06ceeb7cd40de2bb18cc
--- /dev/null
+++ b/custom_nodes/ComfyUI-ReActor/modules/scripts.py
@@ -0,0 +1,13 @@
+import os
+
+
+class Script:
+ pass
+
+
+def basedir():
+ return os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
+
+
+class PostprocessImageArgs:
+ pass
diff --git a/custom_nodes/ComfyUI-ReActor/modules/scripts_postprocessing.py b/custom_nodes/ComfyUI-ReActor/modules/scripts_postprocessing.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/custom_nodes/ComfyUI-ReActor/modules/shared.py b/custom_nodes/ComfyUI-ReActor/modules/shared.py
new file mode 100644
index 0000000000000000000000000000000000000000..01263864aa9b0d94462b1466d44f61d295a9d9e4
--- /dev/null
+++ b/custom_nodes/ComfyUI-ReActor/modules/shared.py
@@ -0,0 +1,19 @@
+class Options:
+ img2img_background_color = "#ffffff" # Set to white for now
+
+
+class State:
+ interrupted = False
+
+ def begin(self):
+ pass
+
+ def end(self):
+ pass
+
+
+opts = Options()
+state = State()
+cmd_opts = None
+sd_upscalers = []
+face_restorers = []
diff --git a/custom_nodes/ComfyUI-ReActor/nodes.py b/custom_nodes/ComfyUI-ReActor/nodes.py
new file mode 100644
index 0000000000000000000000000000000000000000..a3b09eda0c6cf16c824c04ec8a4f6a3ddda55c36
--- /dev/null
+++ b/custom_nodes/ComfyUI-ReActor/nodes.py
@@ -0,0 +1,1364 @@
+import os, glob, sys
+import logging
+
+import torch
+import torch.nn.functional as torchfn
+from torchvision.transforms.functional import normalize
+from torchvision.ops import masks_to_boxes
+
+import numpy as np
+import cv2
+import math
+from typing import List
+from PIL import Image
+from scipy import stats
+from insightface.app.common import Face
+from segment_anything import sam_model_registry
+
+from modules.processing import StableDiffusionProcessingImg2Img
+from modules.shared import state
+# from comfy_extras.chainner_models import model_loading
+import comfy.model_management as model_management
+import comfy.utils
+import folder_paths
+
+import scripts.reactor_version
+from r_chainner import model_loading
+from scripts.reactor_faceswap import (
+ FaceSwapScript,
+ get_models,
+ get_current_faces_model,
+ analyze_faces,
+ half_det_size,
+ providers
+)
+from scripts.reactor_swapper import (
+ unload_all_models,
+)
+from scripts.reactor_logger import logger
+from reactor_utils import (
+ batch_tensor_to_pil,
+ batched_pil_to_tensor,
+ tensor_to_pil,
+ img2tensor,
+ tensor2img,
+ save_face_model,
+ load_face_model,
+ download,
+ set_ort_session,
+ prepare_cropped_face,
+ normalize_cropped_face,
+ add_folder_path_and_extensions,
+ rgba2rgb_tensor
+)
+from reactor_patcher import apply_patch
+from r_facelib.utils.face_restoration_helper import FaceRestoreHelper
+from r_basicsr.utils.registry import ARCH_REGISTRY
+import scripts.r_archs.codeformer_arch
+import scripts.r_masking.subcore as subcore
+import scripts.r_masking.core as core
+import scripts.r_masking.segs as masking_segs
+
+import scripts.reactor_sfw as sfw
+
+
+models_dir = folder_paths.models_dir
+REACTOR_MODELS_PATH = os.path.join(models_dir, "reactor")
+FACE_MODELS_PATH = os.path.join(REACTOR_MODELS_PATH, "faces")
+NSFWDET_MODEL_PATH = os.path.join(models_dir, "nsfw_detector","vit-base-nsfw-detector")
+
+if not os.path.exists(REACTOR_MODELS_PATH):
+ os.makedirs(REACTOR_MODELS_PATH)
+ if not os.path.exists(FACE_MODELS_PATH):
+ os.makedirs(FACE_MODELS_PATH)
+
+dir_facerestore_models = os.path.join(models_dir, "facerestore_models")
+os.makedirs(dir_facerestore_models, exist_ok=True)
+folder_paths.folder_names_and_paths["facerestore_models"] = ([dir_facerestore_models], folder_paths.supported_pt_extensions)
+
+BLENDED_FACE_MODEL = None
+FACE_SIZE: int = 512
+FACE_HELPER = None
+
+if "ultralytics" not in folder_paths.folder_names_and_paths:
+ add_folder_path_and_extensions("ultralytics_bbox", [os.path.join(models_dir, "ultralytics", "bbox")], folder_paths.supported_pt_extensions)
+ add_folder_path_and_extensions("ultralytics_segm", [os.path.join(models_dir, "ultralytics", "segm")], folder_paths.supported_pt_extensions)
+ add_folder_path_and_extensions("ultralytics", [os.path.join(models_dir, "ultralytics")], folder_paths.supported_pt_extensions)
+if "sams" not in folder_paths.folder_names_and_paths:
+ add_folder_path_and_extensions("sams", [os.path.join(models_dir, "sams")], folder_paths.supported_pt_extensions)
+
+def get_facemodels():
+ models_path = os.path.join(FACE_MODELS_PATH, "*")
+ models = glob.glob(models_path)
+ models = [x for x in models if x.endswith(".safetensors")]
+ return models
+
+def get_restorers():
+ models_path = os.path.join(models_dir, "facerestore_models/*")
+ models = glob.glob(models_path)
+ models = [x for x in models if (x.endswith(".pth") or x.endswith(".onnx"))]
+ if len(models) == 0:
+ fr_urls = [
+ "https://huggingface.co/datasets/Gourieff/ReActor/resolve/main/models/facerestore_models/GFPGANv1.3.pth",
+ "https://huggingface.co/datasets/Gourieff/ReActor/resolve/main/models/facerestore_models/GFPGANv1.4.pth",
+ "https://huggingface.co/datasets/Gourieff/ReActor/resolve/main/models/facerestore_models/codeformer-v0.1.0.pth",
+ "https://huggingface.co/datasets/Gourieff/ReActor/resolve/main/models/facerestore_models/GPEN-BFR-512.onnx",
+ ]
+ for model_url in fr_urls:
+ model_name = os.path.basename(model_url)
+ model_path = os.path.join(dir_facerestore_models, model_name)
+ download(model_url, model_path, model_name)
+ models = glob.glob(models_path)
+ models = [x for x in models if (x.endswith(".pth") or x.endswith(".onnx"))]
+ return models
+
+def get_model_names(get_models):
+ models = get_models()
+ names = []
+ for x in models:
+ names.append(os.path.basename(x))
+ names.sort(key=str.lower)
+ names.insert(0, "none")
+ return names
+
+def model_names():
+ models = get_models()
+ return {os.path.basename(x): x for x in models}
+
+
+class reactor:
+ @classmethod
+ def INPUT_TYPES(s):
+ return {
+ "required": {
+ "enabled": ("BOOLEAN", {"default": True, "label_off": "OFF", "label_on": "ON"}),
+ "input_image": ("IMAGE",),
+ "swap_model": (list(model_names().keys()),),
+ "facedetection": (["retinaface_resnet50", "retinaface_mobile0.25", "YOLOv5l", "YOLOv5n"],),
+ "face_restore_model": (get_model_names(get_restorers),),
+ "face_restore_visibility": ("FLOAT", {"default": 1, "min": 0.1, "max": 1, "step": 0.05}),
+ "codeformer_weight": ("FLOAT", {"default": 0.5, "min": 0.0, "max": 1, "step": 0.05}),
+ "detect_gender_input": (["no","female","male"], {"default": "no"}),
+ "detect_gender_source": (["no","female","male"], {"default": "no"}),
+ "input_faces_index": ("STRING", {"default": "0"}),
+ "source_faces_index": ("STRING", {"default": "0"}),
+ "console_log_level": ([0, 1, 2], {"default": 1}),
+ },
+ "optional": {
+ "source_image": ("IMAGE",),
+ "face_model": ("FACE_MODEL",),
+ "face_boost": ("FACE_BOOST",),
+ },
+ "hidden": {"faces_order": "FACES_ORDER"},
+ }
+
+ RETURN_TYPES = ("IMAGE","FACE_MODEL")
+ FUNCTION = "execute"
+ CATEGORY = "🌌 ReActor"
+
+ def __init__(self):
+ # self.face_helper = None
+ self.faces_order = ["large-small", "large-small"]
+ # self.face_size = FACE_SIZE
+ self.face_boost_enabled = False
+ self.restore = True
+ self.boost_model = None
+ self.interpolation = "Bicubic"
+ self.boost_model_visibility = 1
+ self.boost_cf_weight = 0.5
+
+ def restore_face(
+ self,
+ input_image,
+ face_restore_model,
+ face_restore_visibility,
+ codeformer_weight,
+ facedetection,
+ ):
+
+ result = input_image
+
+ if face_restore_model != "none" and not model_management.processing_interrupted():
+
+ global FACE_SIZE, FACE_HELPER
+
+ self.face_helper = FACE_HELPER
+
+ faceSize = 512
+ if "1024" in face_restore_model.lower():
+ faceSize = 1024
+ elif "2048" in face_restore_model.lower():
+ faceSize = 2048
+
+ logger.status(f"Restoring with {face_restore_model} | Face Size is set to {faceSize}")
+
+ model_path = folder_paths.get_full_path("facerestore_models", face_restore_model)
+
+ device = model_management.get_torch_device()
+
+ if "codeformer" in face_restore_model.lower():
+
+ codeformer_net = ARCH_REGISTRY.get("CodeFormer")(
+ dim_embd=512,
+ codebook_size=1024,
+ n_head=8,
+ n_layers=9,
+ connect_list=["32", "64", "128", "256"],
+ ).to(device)
+ checkpoint = torch.load(model_path)["params_ema"]
+ codeformer_net.load_state_dict(checkpoint)
+ facerestore_model = codeformer_net.eval()
+
+ elif ".onnx" in face_restore_model:
+
+ ort_session = set_ort_session(model_path, providers=providers)
+ ort_session_inputs = {}
+ facerestore_model = ort_session
+
+ else:
+
+ sd = comfy.utils.load_torch_file(model_path, safe_load=True)
+ facerestore_model = model_loading.load_state_dict(sd).eval()
+ facerestore_model.to(device)
+
+ if faceSize != FACE_SIZE or self.face_helper is None:
+ self.face_helper = FaceRestoreHelper(1, face_size=faceSize, crop_ratio=(1, 1), det_model=facedetection, save_ext='png', use_parse=True, device=device)
+ FACE_SIZE = faceSize
+ FACE_HELPER = self.face_helper
+
+ image_np = 255. * result.numpy()
+
+ total_images = image_np.shape[0]
+
+ out_images = []
+
+ for i in range(total_images):
+
+ if total_images > 1:
+ logger.status(f"Restoring {i+1}")
+
+ cur_image_np = image_np[i,:, :, ::-1]
+
+ original_resolution = cur_image_np.shape[0:2]
+
+ if facerestore_model is None or self.face_helper is None:
+ return result
+
+ self.face_helper.clean_all()
+ self.face_helper.read_image(cur_image_np)
+ self.face_helper.get_face_landmarks_5(only_center_face=False, resize=640, eye_dist_threshold=5)
+ self.face_helper.align_warp_face()
+
+ restored_face = None
+
+ for idx, cropped_face in enumerate(self.face_helper.cropped_faces):
+
+ # if ".pth" in face_restore_model:
+ cropped_face_t = img2tensor(cropped_face / 255., bgr2rgb=True, float32=True)
+ normalize(cropped_face_t, (0.5, 0.5, 0.5), (0.5, 0.5, 0.5), inplace=True)
+ cropped_face_t = cropped_face_t.unsqueeze(0).to(device)
+
+ try:
+
+ with torch.no_grad():
+
+ if ".onnx" in face_restore_model: # ONNX models
+
+ for ort_session_input in ort_session.get_inputs():
+ if ort_session_input.name == "input":
+ cropped_face_prep = prepare_cropped_face(cropped_face)
+ ort_session_inputs[ort_session_input.name] = cropped_face_prep
+ if ort_session_input.name == "weight":
+ weight = np.array([ 1 ], dtype = np.double)
+ ort_session_inputs[ort_session_input.name] = weight
+
+ output = ort_session.run(None, ort_session_inputs)[0][0]
+ restored_face = normalize_cropped_face(output)
+
+ else: # PTH models
+
+ output = facerestore_model(cropped_face_t, w=codeformer_weight)[0] if "codeformer" in face_restore_model.lower() else facerestore_model(cropped_face_t)[0]
+ restored_face = tensor2img(output, rgb2bgr=True, min_max=(-1, 1))
+
+ del output
+ torch.cuda.empty_cache()
+
+ except Exception as error:
+
+ print(f"\tFailed inference: {error}", file=sys.stderr)
+ restored_face = tensor2img(cropped_face_t, rgb2bgr=True, min_max=(-1, 1))
+
+ if face_restore_visibility < 1:
+ restored_face = cropped_face * (1 - face_restore_visibility) + restored_face * face_restore_visibility
+
+ restored_face = restored_face.astype("uint8")
+ self.face_helper.add_restored_face(restored_face)
+
+ self.face_helper.get_inverse_affine(None)
+
+ restored_img = self.face_helper.paste_faces_to_input_image()
+ restored_img = restored_img[:, :, ::-1]
+
+ if original_resolution != restored_img.shape[0:2]:
+ restored_img = cv2.resize(restored_img, (0, 0), fx=original_resolution[1]/restored_img.shape[1], fy=original_resolution[0]/restored_img.shape[0], interpolation=cv2.INTER_AREA)
+
+ self.face_helper.clean_all()
+
+ # out_images[i] = restored_img
+ out_images.append(restored_img)
+
+ if state.interrupted or model_management.processing_interrupted():
+ logger.status("Interrupted by User")
+ return input_image
+
+ restored_img_np = np.array(out_images).astype(np.float32) / 255.0
+ restored_img_tensor = torch.from_numpy(restored_img_np)
+
+ result = restored_img_tensor
+
+ return result
+
+ def execute(self, enabled, input_image, swap_model, detect_gender_source, detect_gender_input, source_faces_index, input_faces_index, console_log_level, face_restore_model,face_restore_visibility, codeformer_weight, facedetection, source_image=None, face_model=None, faces_order=None, face_boost=None):
+
+ if face_boost is not None:
+ self.face_boost_enabled = face_boost["enabled"]
+ self.boost_model = face_boost["boost_model"]
+ self.interpolation = face_boost["interpolation"]
+ self.boost_model_visibility = face_boost["visibility"]
+ self.boost_cf_weight = face_boost["codeformer_weight"]
+ self.restore = face_boost["restore_with_main_after"]
+ else:
+ self.face_boost_enabled = False
+
+ if faces_order is None:
+ faces_order = self.faces_order
+
+ apply_patch(console_log_level)
+
+ if not enabled:
+ return (input_image,face_model)
+ elif source_image is None and face_model is None:
+ logger.error("Please provide 'source_image' or `face_model`")
+ return (input_image,face_model)
+
+ if face_model == "none":
+ face_model = None
+
+ script = FaceSwapScript()
+ pil_images = batch_tensor_to_pil(input_image)
+
+ # NSFW checker
+ logger.status("Checking for any unsafe content")
+ pil_images_sfw = []
+ tmp_img = "reactor_tmp.png"
+ for img in pil_images:
+ if state.interrupted or model_management.processing_interrupted():
+ logger.status("Interrupted by User")
+ break
+ img.save(tmp_img)
+ if not sfw.nsfw_image(tmp_img, NSFWDET_MODEL_PATH):
+ pil_images_sfw.append(img)
+ if os.path.exists(tmp_img):
+ os.remove(tmp_img)
+ pil_images = pil_images_sfw
+ # # #
+
+ if len(pil_images) > 0:
+
+ if source_image is not None:
+ source = tensor_to_pil(source_image)
+ else:
+ source = None
+ p = StableDiffusionProcessingImg2Img(pil_images)
+ script.process(
+ p=p,
+ img=source,
+ enable=True,
+ source_faces_index=source_faces_index,
+ faces_index=input_faces_index,
+ model=swap_model,
+ swap_in_source=True,
+ swap_in_generated=True,
+ gender_source=detect_gender_source,
+ gender_target=detect_gender_input,
+ face_model=face_model,
+ faces_order=faces_order,
+ # face boost:
+ face_boost_enabled=self.face_boost_enabled,
+ face_restore_model=self.boost_model,
+ face_restore_visibility=self.boost_model_visibility,
+ codeformer_weight=self.boost_cf_weight,
+ interpolation=self.interpolation,
+ )
+ result = batched_pil_to_tensor(p.init_images)
+
+ if face_model is None:
+ current_face_model = get_current_faces_model()
+ face_model_to_provide = current_face_model[0] if (current_face_model is not None and len(current_face_model) > 0) else face_model
+ else:
+ face_model_to_provide = face_model
+
+ if self.restore or not self.face_boost_enabled:
+ result = reactor.restore_face(self,result,face_restore_model,face_restore_visibility,codeformer_weight,facedetection)
+
+ else:
+ image_black = Image.new("RGB", (512, 512))
+ result = batched_pil_to_tensor([image_black])
+ face_model_to_provide = None
+
+ return (result,face_model_to_provide)
+
+
+class ReActorPlusOpt:
+ @classmethod
+ def INPUT_TYPES(s):
+ return {
+ "required": {
+ "enabled": ("BOOLEAN", {"default": True, "label_off": "OFF", "label_on": "ON"}),
+ "input_image": ("IMAGE",),
+ "swap_model": (list(model_names().keys()),),
+ "facedetection": (["retinaface_resnet50", "retinaface_mobile0.25", "YOLOv5l", "YOLOv5n"],),
+ "face_restore_model": (get_model_names(get_restorers),),
+ "face_restore_visibility": ("FLOAT", {"default": 1, "min": 0.1, "max": 1, "step": 0.05}),
+ "codeformer_weight": ("FLOAT", {"default": 0.5, "min": 0.0, "max": 1, "step": 0.05}),
+ },
+ "optional": {
+ "source_image": ("IMAGE",),
+ "face_model": ("FACE_MODEL",),
+ "options": ("OPTIONS",),
+ "face_boost": ("FACE_BOOST",),
+ }
+ }
+
+ RETURN_TYPES = ("IMAGE","FACE_MODEL")
+ FUNCTION = "execute"
+ CATEGORY = "🌌 ReActor"
+
+ def __init__(self):
+ # self.face_helper = None
+ self.faces_order = ["large-small", "large-small"]
+ self.detect_gender_input = "no"
+ self.detect_gender_source = "no"
+ self.input_faces_index = "0"
+ self.source_faces_index = "0"
+ self.console_log_level = 1
+ # self.face_size = 512
+ self.face_boost_enabled = False
+ self.restore = True
+ self.boost_model = None
+ self.interpolation = "Bicubic"
+ self.boost_model_visibility = 1
+ self.boost_cf_weight = 0.5
+
+ def execute(self, enabled, input_image, swap_model, facedetection, face_restore_model, face_restore_visibility, codeformer_weight, source_image=None, face_model=None, options=None, face_boost=None):
+
+ if options is not None:
+ self.faces_order = [options["input_faces_order"], options["source_faces_order"]]
+ self.console_log_level = options["console_log_level"]
+ self.detect_gender_input = options["detect_gender_input"]
+ self.detect_gender_source = options["detect_gender_source"]
+ self.input_faces_index = options["input_faces_index"]
+ self.source_faces_index = options["source_faces_index"]
+
+ if face_boost is not None:
+ self.face_boost_enabled = face_boost["enabled"]
+ self.restore = face_boost["restore_with_main_after"]
+ else:
+ self.face_boost_enabled = False
+
+ result = reactor.execute(
+ self,enabled,input_image,swap_model,self.detect_gender_source,self.detect_gender_input,self.source_faces_index,self.input_faces_index,self.console_log_level,face_restore_model,face_restore_visibility,codeformer_weight,facedetection,source_image,face_model,self.faces_order, face_boost=face_boost
+ )
+
+ return result
+
+
+class LoadFaceModel:
+ @classmethod
+ def INPUT_TYPES(s):
+ return {
+ "required": {
+ "face_model": (get_model_names(get_facemodels),),
+ }
+ }
+
+ RETURN_TYPES = ("FACE_MODEL",)
+ FUNCTION = "load_model"
+ CATEGORY = "🌌 ReActor"
+
+ def load_model(self, face_model):
+ self.face_model = face_model
+ self.face_models_path = FACE_MODELS_PATH
+ if self.face_model != "none":
+ face_model_path = os.path.join(self.face_models_path, self.face_model)
+ out = load_face_model(face_model_path)
+ else:
+ out = None
+ return (out, )
+
+
+class ReActorWeight:
+ @classmethod
+ def INPUT_TYPES(s):
+ return {
+ "required": {
+ "input_image": ("IMAGE",),
+ "faceswap_weight": (["0%", "12.5%", "25%", "37.5%", "50%", "62.5%", "75%", "87.5%", "100%"], {"default": "50%"}),
+ },
+ "optional": {
+ "source_image": ("IMAGE",),
+ "face_model": ("FACE_MODEL",),
+ }
+ }
+
+ RETURN_TYPES = ("IMAGE","FACE_MODEL")
+ RETURN_NAMES = ("INPUT_IMAGE","FACE_MODEL")
+ FUNCTION = "set_weight"
+
+ OUTPUT_NODE = True
+
+ CATEGORY = "🌌 ReActor"
+
+ def set_weight(self, input_image, faceswap_weight, face_model=None, source_image=None):
+
+ if input_image is None:
+ logger.error("Please provide `input_image`")
+ return (input_image,None)
+
+ if source_image is None and face_model is None:
+ logger.error("Please provide `source_image` or `face_model`")
+ return (input_image,None)
+
+ weight = float(faceswap_weight.split("%")[0])
+
+ images = []
+ faces = [] if face_model is None else [face_model]
+ embeddings = [] if face_model is None else [face_model.embedding]
+
+ if weight == 0:
+ images = [input_image]
+ faces = []
+ embeddings = []
+ elif weight == 100:
+ if face_model is None:
+ images = [source_image]
+ else:
+ if weight > 50:
+ images = [input_image]
+ count = round(100/(100-weight))
+ else:
+ if face_model is None:
+ images = [source_image]
+ count = round(100/(weight))
+ for i in range(count-1):
+ if weight > 50:
+ if face_model is None:
+ images.append(source_image)
+ else:
+ faces.append(face_model)
+ embeddings.append(face_model.embedding)
+ else:
+ images.append(input_image)
+
+ images_list: List[Image.Image] = []
+
+ apply_patch(1)
+
+ if len(images) > 0:
+
+ for image in images:
+ img = tensor_to_pil(image)
+ images_list.append(img)
+
+ for image in images_list:
+ face = BuildFaceModel.build_face_model(self,image)
+ if isinstance(face, str):
+ continue
+ faces.append(face)
+ embeddings.append(face.embedding)
+
+ if len(faces) > 0:
+ blended_embedding = np.mean(embeddings, axis=0)
+ blended_face = Face(
+ bbox=faces[0].bbox,
+ kps=faces[0].kps,
+ det_score=faces[0].det_score,
+ landmark_3d_68=faces[0].landmark_3d_68,
+ pose=faces[0].pose,
+ landmark_2d_106=faces[0].landmark_2d_106,
+ embedding=blended_embedding,
+ gender=faces[0].gender,
+ age=faces[0].age
+ )
+ if blended_face is None:
+ no_face_msg = "Something went wrong, please try another set of images"
+ logger.error(no_face_msg)
+
+ return (input_image,blended_face)
+
+
+class BuildFaceModel:
+ def __init__(self):
+ self.output_dir = FACE_MODELS_PATH
+
+ @classmethod
+ def INPUT_TYPES(s):
+ return {
+ "required": {
+ "save_mode": ("BOOLEAN", {"default": True, "label_off": "OFF", "label_on": "ON"}),
+ "send_only": ("BOOLEAN", {"default": False, "label_off": "NO", "label_on": "YES"}),
+ "face_model_name": ("STRING", {"default": "default"}),
+ "compute_method": (["Mean", "Median", "Mode"], {"default": "Mean"}),
+ },
+ "optional": {
+ "images": ("IMAGE",),
+ "face_models": ("FACE_MODEL",),
+ }
+ }
+
+ RETURN_TYPES = ("FACE_MODEL",)
+ FUNCTION = "blend_faces"
+
+ OUTPUT_NODE = True
+
+ CATEGORY = "🌌 ReActor"
+
+ def build_face_model(self, image: Image.Image, det_size=(640, 640)):
+ logging.StreamHandler.terminator = "\n"
+ if image is None:
+ error_msg = "Please load an Image"
+ logger.error(error_msg)
+ return error_msg
+ image = cv2.cvtColor(np.array(image), cv2.COLOR_RGB2BGR)
+ face_model = analyze_faces(image, det_size)
+
+ if len(face_model) == 0:
+ print("")
+ det_size_half = half_det_size(det_size)
+ face_model = analyze_faces(image, det_size_half)
+ if face_model is not None and len(face_model) > 0:
+ print("...........................................................", end=" ")
+
+ if face_model is not None and len(face_model) > 0:
+ return face_model[0]
+ else:
+ no_face_msg = "No face found, please try another image"
+ # logger.error(no_face_msg)
+ return no_face_msg
+
+ def blend_faces(self, save_mode, send_only, face_model_name, compute_method, images=None, face_models=None):
+ global BLENDED_FACE_MODEL
+ blended_face: Face = BLENDED_FACE_MODEL
+
+ if send_only and blended_face is None:
+ send_only = False
+
+ if (images is not None or face_models is not None) and not send_only:
+
+ faces = []
+ embeddings = []
+
+ apply_patch(1)
+
+ if images is not None:
+ images_list: List[Image.Image] = batch_tensor_to_pil(images)
+
+ n = len(images_list)
+
+ for i,image in enumerate(images_list):
+ logging.StreamHandler.terminator = " "
+ logger.status(f"Building Face Model {i+1} of {n}...")
+ face = self.build_face_model(image)
+ if isinstance(face, str):
+ logger.error(f"No faces found in image {i+1}, skipping")
+ continue
+ else:
+ print(f"{int(((i+1)/n)*100)}%")
+ faces.append(face)
+ embeddings.append(face.embedding)
+
+ elif face_models is not None:
+
+ n = len(face_models)
+
+ for i,face_model in enumerate(face_models):
+ logging.StreamHandler.terminator = " "
+ logger.status(f"Extracting Face Model {i+1} of {n}...")
+ face = face_model
+ if isinstance(face, str):
+ logger.error(f"No faces found for face_model {i+1}, skipping")
+ continue
+ else:
+ print(f"{int(((i+1)/n)*100)}%")
+ faces.append(face)
+ embeddings.append(face.embedding)
+
+ logging.StreamHandler.terminator = "\n"
+ if len(faces) > 0:
+ # compute_method_name = "Mean" if compute_method == 0 else "Median" if compute_method == 1 else "Mode"
+ logger.status(f"Blending with Compute Method '{compute_method}'...")
+ blended_embedding = np.mean(embeddings, axis=0) if compute_method == "Mean" else np.median(embeddings, axis=0) if compute_method == "Median" else stats.mode(embeddings, axis=0)[0].astype(np.float32)
+ blended_face = Face(
+ bbox=faces[0].bbox,
+ kps=faces[0].kps,
+ det_score=faces[0].det_score,
+ landmark_3d_68=faces[0].landmark_3d_68,
+ pose=faces[0].pose,
+ landmark_2d_106=faces[0].landmark_2d_106,
+ embedding=blended_embedding,
+ gender=faces[0].gender,
+ age=faces[0].age
+ )
+ if blended_face is not None:
+ BLENDED_FACE_MODEL = blended_face
+ if save_mode:
+ face_model_path = os.path.join(FACE_MODELS_PATH, face_model_name + ".safetensors")
+ save_face_model(blended_face,face_model_path)
+ # done_msg = f"Face model has been saved to '{face_model_path}'"
+ # logger.status(done_msg)
+ logger.status("--Done!--")
+ # return (blended_face,)
+ else:
+ no_face_msg = "Something went wrong, please try another set of images"
+ logger.error(no_face_msg)
+ # return (blended_face,)
+ # logger.status("--Done!--")
+ if images is None and face_models is None:
+ logger.error("Please provide `images` or `face_models`")
+ return (blended_face,)
+
+
+class SaveFaceModel:
+ def __init__(self):
+ self.output_dir = FACE_MODELS_PATH
+
+ @classmethod
+ def INPUT_TYPES(s):
+ return {
+ "required": {
+ "save_mode": ("BOOLEAN", {"default": True, "label_off": "OFF", "label_on": "ON"}),
+ "face_model_name": ("STRING", {"default": "default"}),
+ "select_face_index": ("INT", {"default": 0, "min": 0}),
+ },
+ "optional": {
+ "image": ("IMAGE",),
+ "face_model": ("FACE_MODEL",),
+ }
+ }
+
+ RETURN_TYPES = ()
+ FUNCTION = "save_model"
+
+ OUTPUT_NODE = True
+
+ CATEGORY = "🌌 ReActor"
+
+ def save_model(self, save_mode, face_model_name, select_face_index, image=None, face_model=None, det_size=(640, 640)):
+ if save_mode and image is not None:
+ source = tensor_to_pil(image)
+ source = cv2.cvtColor(np.array(source), cv2.COLOR_RGB2BGR)
+ apply_patch(1)
+ logger.status("Building Face Model...")
+ face_model_raw = analyze_faces(source, det_size)
+ if len(face_model_raw) == 0:
+ det_size_half = half_det_size(det_size)
+ face_model_raw = analyze_faces(source, det_size_half)
+ try:
+ face_model = face_model_raw[select_face_index]
+ except:
+ logger.error("No face(s) found")
+ return face_model_name
+ logger.status("--Done!--")
+ if save_mode and (face_model != "none" or face_model is not None):
+ face_model_path = os.path.join(self.output_dir, face_model_name + ".safetensors")
+ save_face_model(face_model,face_model_path)
+ if image is None and face_model is None:
+ logger.error("Please provide `face_model` or `image`")
+ return face_model_name
+
+
+class RestoreFace:
+ @classmethod
+ def INPUT_TYPES(s):
+ return {
+ "required": {
+ "image": ("IMAGE",),
+ "facedetection": (["retinaface_resnet50", "retinaface_mobile0.25", "YOLOv5l", "YOLOv5n"],),
+ "model": (get_model_names(get_restorers),),
+ "visibility": ("FLOAT", {"default": 1, "min": 0.0, "max": 1, "step": 0.05}),
+ "codeformer_weight": ("FLOAT", {"default": 0.5, "min": 0.0, "max": 1, "step": 0.05}),
+ },
+ }
+
+ RETURN_TYPES = ("IMAGE",)
+ FUNCTION = "execute"
+ CATEGORY = "🌌 ReActor"
+
+ # def __init__(self):
+ # self.face_helper = None
+ # self.face_size = 512
+
+ def execute(self, image, model, visibility, codeformer_weight, facedetection):
+ result = reactor.restore_face(self,image,model,visibility,codeformer_weight,facedetection)
+ return (result,)
+
+
+class MaskHelper:
+ def __init__(self):
+ # self.threshold = 0.5
+ # self.dilation = 10
+ # self.crop_factor = 3.0
+ # self.drop_size = 1
+ self.labels = "all"
+ self.detailer_hook = None
+ self.device_mode = "AUTO"
+ self.detection_hint = "center-1"
+ # self.sam_dilation = 0
+ # self.sam_threshold = 0.93
+ # self.bbox_expansion = 0
+ # self.mask_hint_threshold = 0.7
+ # self.mask_hint_use_negative = "False"
+ # self.force_resize_width = 0
+ # self.force_resize_height = 0
+ # self.resize_behavior = "source_size"
+
+ @classmethod
+ def INPUT_TYPES(s):
+ bboxs = ["bbox/"+x for x in folder_paths.get_filename_list("ultralytics_bbox")]
+ segms = ["segm/"+x for x in folder_paths.get_filename_list("ultralytics_segm")]
+ sam_models = [x for x in folder_paths.get_filename_list("sams") if 'hq' not in x]
+ return {
+ "required": {
+ "image": ("IMAGE",),
+ "swapped_image": ("IMAGE",),
+ "bbox_model_name": (bboxs + segms, ),
+ "bbox_threshold": ("FLOAT", {"default": 0.5, "min": 0.0, "max": 1.0, "step": 0.01}),
+ "bbox_dilation": ("INT", {"default": 10, "min": -512, "max": 512, "step": 1}),
+ "bbox_crop_factor": ("FLOAT", {"default": 3.0, "min": 1.0, "max": 100, "step": 0.1}),
+ "bbox_drop_size": ("INT", {"min": 1, "max": 8192, "step": 1, "default": 10}),
+ "sam_model_name": (sam_models, ),
+ "sam_dilation": ("INT", {"default": 0, "min": -512, "max": 512, "step": 1}),
+ "sam_threshold": ("FLOAT", {"default": 0.93, "min": 0.0, "max": 1.0, "step": 0.01}),
+ "bbox_expansion": ("INT", {"default": 0, "min": 0, "max": 1000, "step": 1}),
+ "mask_hint_threshold": ("FLOAT", {"default": 0.7, "min": 0.0, "max": 1.0, "step": 0.01}),
+ "mask_hint_use_negative": (["False", "Small", "Outter"], ),
+ "morphology_operation": (["dilate", "erode", "open", "close"],),
+ "morphology_distance": ("INT", {"default": 0, "min": 0, "max": 128, "step": 1}),
+ "blur_radius": ("INT", {"default": 9, "min": 0, "max": 48, "step": 1}),
+ "sigma_factor": ("FLOAT", {"default": 1.0, "min": 0.01, "max": 3., "step": 0.01}),
+ },
+ "optional": {
+ "mask_optional": ("MASK",),
+ }
+ }
+
+ RETURN_TYPES = ("IMAGE","MASK","IMAGE","IMAGE")
+ RETURN_NAMES = ("IMAGE","MASK","MASK_PREVIEW","SWAPPED_FACE")
+ FUNCTION = "execute"
+ CATEGORY = "🌌 ReActor"
+
+ def execute(self, image, swapped_image, bbox_model_name, bbox_threshold, bbox_dilation, bbox_crop_factor, bbox_drop_size, sam_model_name, sam_dilation, sam_threshold, bbox_expansion, mask_hint_threshold, mask_hint_use_negative, morphology_operation, morphology_distance, blur_radius, sigma_factor, mask_optional=None):
+
+ # images = [image[i:i + 1, ...] for i in range(image.shape[0])]
+
+ images = image
+
+ if mask_optional is None:
+
+ bbox_model_path = folder_paths.get_full_path("ultralytics", bbox_model_name)
+ bbox_model = subcore.load_yolo(bbox_model_path)
+ bbox_detector = subcore.UltraBBoxDetector(bbox_model)
+
+ segs = bbox_detector.detect(images, bbox_threshold, bbox_dilation, bbox_crop_factor, bbox_drop_size, self.detailer_hook)
+
+ if isinstance(self.labels, list):
+ self.labels = str(self.labels[0])
+
+ if self.labels is not None and self.labels != '':
+ self.labels = self.labels.split(',')
+ if len(self.labels) > 0:
+ segs, _ = masking_segs.filter(segs, self.labels)
+ # segs, _ = masking_segs.filter(segs, "all")
+
+ sam_modelname = folder_paths.get_full_path("sams", sam_model_name)
+
+ if 'vit_h' in sam_model_name:
+ model_kind = 'vit_h'
+ elif 'vit_l' in sam_model_name:
+ model_kind = 'vit_l'
+ else:
+ model_kind = 'vit_b'
+
+ sam = sam_model_registry[model_kind](checkpoint=sam_modelname)
+ size = os.path.getsize(sam_modelname)
+ sam.safe_to = core.SafeToGPU(size)
+
+ device = model_management.get_torch_device()
+
+ sam.safe_to.to_device(sam, device)
+
+ sam.is_auto_mode = self.device_mode == "AUTO"
+
+ combined_mask, _ = core.make_sam_mask_segmented(sam, segs, images, self.detection_hint, sam_dilation, sam_threshold, bbox_expansion, mask_hint_threshold, mask_hint_use_negative)
+
+ else:
+ combined_mask = mask_optional
+
+ # *** MASK TO IMAGE ***:
+
+ mask_image = combined_mask.reshape((-1, 1, combined_mask.shape[-2], combined_mask.shape[-1])).movedim(1, -1).expand(-1, -1, -1, 3)
+
+ # *** MASK MORPH ***:
+
+ mask_image = core.tensor2mask(mask_image)
+
+ if morphology_operation == "dilate":
+ mask_image = self.dilate(mask_image, morphology_distance)
+ elif morphology_operation == "erode":
+ mask_image = self.erode(mask_image, morphology_distance)
+ elif morphology_operation == "open":
+ mask_image = self.erode(mask_image, morphology_distance)
+ mask_image = self.dilate(mask_image, morphology_distance)
+ elif morphology_operation == "close":
+ mask_image = self.dilate(mask_image, morphology_distance)
+ mask_image = self.erode(mask_image, morphology_distance)
+
+ # *** MASK BLUR ***:
+
+ if len(mask_image.size()) == 3:
+ mask_image = mask_image.unsqueeze(3)
+
+ mask_image = mask_image.permute(0, 3, 1, 2)
+ kernel_size = blur_radius * 2 + 1
+ sigma = sigma_factor * (0.6 * blur_radius - 0.3)
+ mask_image_final = self.gaussian_blur(mask_image, kernel_size, sigma).permute(0, 2, 3, 1)
+ if mask_image_final.size()[3] == 1:
+ mask_image_final = mask_image_final[:, :, :, 0]
+
+ # *** CUT BY MASK ***:
+
+ if len(swapped_image.shape) < 4:
+ C = 1
+ else:
+ C = swapped_image.shape[3]
+
+ # We operate on RGBA to keep the code clean and then convert back after
+ swapped_image = core.tensor2rgba(swapped_image)
+ mask = core.tensor2mask(mask_image_final)
+
+ # Scale the mask to be a matching size if it isn't
+ B, H, W, _ = swapped_image.shape
+ mask = torch.nn.functional.interpolate(mask.unsqueeze(1), size=(H, W), mode='nearest')[:,0,:,:]
+ MB, _, _ = mask.shape
+
+ if MB < B:
+ assert(B % MB == 0)
+ mask = mask.repeat(B // MB, 1, 1)
+
+ # masks_to_boxes errors if the tensor is all zeros, so we'll add a single pixel and zero it out at the end
+ is_empty = ~torch.gt(torch.max(torch.reshape(mask,[MB, H * W]), dim=1).values, 0.)
+ mask[is_empty,0,0] = 1.
+ boxes = masks_to_boxes(mask)
+ mask[is_empty,0,0] = 0.
+
+ min_x = boxes[:,0]
+ min_y = boxes[:,1]
+ max_x = boxes[:,2]
+ max_y = boxes[:,3]
+
+ width = max_x - min_x + 1
+ height = max_y - min_y + 1
+
+ use_width = int(torch.max(width).item())
+ use_height = int(torch.max(height).item())
+
+ # if self.force_resize_width > 0:
+ # use_width = self.force_resize_width
+
+ # if self.force_resize_height > 0:
+ # use_height = self.force_resize_height
+
+ alpha_mask = torch.ones((B, H, W, 4))
+ alpha_mask[:,:,:,3] = mask
+
+ swapped_image = swapped_image * alpha_mask
+
+ cutted_image = torch.zeros((B, use_height, use_width, 4))
+ for i in range(0, B):
+ if not is_empty[i]:
+ ymin = int(min_y[i].item())
+ ymax = int(max_y[i].item())
+ xmin = int(min_x[i].item())
+ xmax = int(max_x[i].item())
+ single = (swapped_image[i, ymin:ymax+1, xmin:xmax+1,:]).unsqueeze(0)
+ resized = torch.nn.functional.interpolate(single.permute(0, 3, 1, 2), size=(use_height, use_width), mode='bicubic').permute(0, 2, 3, 1)
+ cutted_image[i] = resized[0]
+
+ # Preserve our type unless we were previously RGB and added non-opaque alpha due to the mask size
+ if C == 1:
+ cutted_image = core.tensor2mask(cutted_image)
+ elif C == 3 and torch.min(cutted_image[:,:,:,3]) == 1:
+ cutted_image = core.tensor2rgb(cutted_image)
+
+ # *** PASTE BY MASK ***:
+
+ image_base = core.tensor2rgba(images)
+ image_to_paste = core.tensor2rgba(cutted_image)
+ mask = core.tensor2mask(mask_image_final)
+
+ # Scale the mask to be a matching size if it isn't
+ B, H, W, C = image_base.shape
+ MB = mask.shape[0]
+ PB = image_to_paste.shape[0]
+
+ if B < PB:
+ assert(PB % B == 0)
+ image_base = image_base.repeat(PB // B, 1, 1, 1)
+ B, H, W, C = image_base.shape
+ if MB < B:
+ assert(B % MB == 0)
+ mask = mask.repeat(B // MB, 1, 1)
+ elif B < MB:
+ assert(MB % B == 0)
+ image_base = image_base.repeat(MB // B, 1, 1, 1)
+ if PB < B:
+ assert(B % PB == 0)
+ image_to_paste = image_to_paste.repeat(B // PB, 1, 1, 1)
+
+ mask = torch.nn.functional.interpolate(mask.unsqueeze(1), size=(H, W), mode='nearest')[:,0,:,:]
+ MB, MH, MW = mask.shape
+
+ # masks_to_boxes errors if the tensor is all zeros, so we'll add a single pixel and zero it out at the end
+ is_empty = ~torch.gt(torch.max(torch.reshape(mask,[MB, MH * MW]), dim=1).values, 0.)
+ mask[is_empty,0,0] = 1.
+ boxes = masks_to_boxes(mask)
+ mask[is_empty,0,0] = 0.
+
+ min_x = boxes[:,0]
+ min_y = boxes[:,1]
+ max_x = boxes[:,2]
+ max_y = boxes[:,3]
+ mid_x = (min_x + max_x) / 2
+ mid_y = (min_y + max_y) / 2
+
+ target_width = max_x - min_x + 1
+ target_height = max_y - min_y + 1
+
+ result = image_base.detach().clone()
+ face_segment = mask_image_final
+
+ for i in range(0, MB):
+ if is_empty[i]:
+ continue
+ else:
+ image_index = i
+ source_size = image_to_paste.size()
+ SB, SH, SW, _ = image_to_paste.shape
+
+ # Figure out the desired size
+ width = int(target_width[i].item())
+ height = int(target_height[i].item())
+ # if self.resize_behavior == "keep_ratio_fill":
+ # target_ratio = width / height
+ # actual_ratio = SW / SH
+ # if actual_ratio > target_ratio:
+ # width = int(height * actual_ratio)
+ # elif actual_ratio < target_ratio:
+ # height = int(width / actual_ratio)
+ # elif self.resize_behavior == "keep_ratio_fit":
+ # target_ratio = width / height
+ # actual_ratio = SW / SH
+ # if actual_ratio > target_ratio:
+ # height = int(width / actual_ratio)
+ # elif actual_ratio < target_ratio:
+ # width = int(height * actual_ratio)
+ # elif self.resize_behavior == "source_size" or self.resize_behavior == "source_size_unmasked":
+
+ width = SW
+ height = SH
+
+ # Resize the image we're pasting if needed
+ resized_image = image_to_paste[i].unsqueeze(0)
+ # if SH != height or SW != width:
+ # resized_image = torch.nn.functional.interpolate(resized_image.permute(0, 3, 1, 2), size=(height,width), mode='bicubic').permute(0, 2, 3, 1)
+
+ pasting = torch.ones([H, W, C])
+ ymid = float(mid_y[i].item())
+ ymin = int(math.floor(ymid - height / 2)) + 1
+ ymax = int(math.floor(ymid + height / 2)) + 1
+ xmid = float(mid_x[i].item())
+ xmin = int(math.floor(xmid - width / 2)) + 1
+ xmax = int(math.floor(xmid + width / 2)) + 1
+
+ _, source_ymax, source_xmax, _ = resized_image.shape
+ source_ymin, source_xmin = 0, 0
+
+ if xmin < 0:
+ source_xmin = abs(xmin)
+ xmin = 0
+ if ymin < 0:
+ source_ymin = abs(ymin)
+ ymin = 0
+ if xmax > W:
+ source_xmax -= (xmax - W)
+ xmax = W
+ if ymax > H:
+ source_ymax -= (ymax - H)
+ ymax = H
+
+ pasting[ymin:ymax, xmin:xmax, :] = resized_image[0, source_ymin:source_ymax, source_xmin:source_xmax, :]
+ pasting[:, :, 3] = 1.
+
+ pasting_alpha = torch.zeros([H, W])
+ pasting_alpha[ymin:ymax, xmin:xmax] = resized_image[0, source_ymin:source_ymax, source_xmin:source_xmax, 3]
+
+ # if self.resize_behavior == "keep_ratio_fill" or self.resize_behavior == "source_size_unmasked":
+ # # If we explicitly want to fill the area, we are ok with extending outside
+ # paste_mask = pasting_alpha.unsqueeze(2).repeat(1, 1, 4)
+ # else:
+ # paste_mask = torch.min(pasting_alpha, mask[i]).unsqueeze(2).repeat(1, 1, 4)
+ paste_mask = torch.min(pasting_alpha, mask[i]).unsqueeze(2).repeat(1, 1, 4)
+ result[image_index] = pasting * paste_mask + result[image_index] * (1. - paste_mask)
+
+ face_segment = result
+
+ face_segment[...,3] = mask[i]
+
+ result = rgba2rgb_tensor(result)
+
+ return (result,combined_mask,mask_image_final,face_segment,)
+
+ def gaussian_blur(self, image, kernel_size, sigma):
+ kernel = torch.Tensor(kernel_size, kernel_size).to(device=image.device)
+ center = kernel_size // 2
+ variance = sigma**2
+ for i in range(kernel_size):
+ for j in range(kernel_size):
+ x = i - center
+ y = j - center
+ kernel[i, j] = math.exp(-(x**2 + y**2)/(2*variance))
+ kernel /= kernel.sum()
+
+ # Pad the input tensor
+ padding = (kernel_size - 1) // 2
+ input_pad = torch.nn.functional.pad(image, (padding, padding, padding, padding), mode='reflect')
+
+ # Reshape the padded input tensor for batched convolution
+ batch_size, num_channels, height, width = image.shape
+ input_reshaped = input_pad.reshape(batch_size*num_channels, 1, height+padding*2, width+padding*2)
+
+ # Perform batched convolution with the Gaussian kernel
+ output_reshaped = torch.nn.functional.conv2d(input_reshaped, kernel.unsqueeze(0).unsqueeze(0))
+
+ # Reshape the output tensor to its original shape
+ output_tensor = output_reshaped.reshape(batch_size, num_channels, height, width)
+
+ return output_tensor
+
+ def erode(self, image, distance):
+ return 1. - self.dilate(1. - image, distance)
+
+ def dilate(self, image, distance):
+ kernel_size = 1 + distance * 2
+ # Add the channels dimension
+ image = image.unsqueeze(1)
+ out = torchfn.max_pool2d(image, kernel_size=kernel_size, stride=1, padding=kernel_size // 2).squeeze(1)
+ return out
+
+
+class ImageDublicator:
+ @classmethod
+ def INPUT_TYPES(s):
+ return {
+ "required": {
+ "image": ("IMAGE",),
+ "count": ("INT", {"default": 1, "min": 0}),
+ },
+ }
+
+ RETURN_TYPES = ("IMAGE",)
+ RETURN_NAMES = ("IMAGES",)
+ OUTPUT_IS_LIST = (True,)
+ FUNCTION = "execute"
+ CATEGORY = "🌌 ReActor"
+
+ def execute(self, image, count):
+ images = [image for i in range(count)]
+ return (images,)
+
+
+class ImageRGBA2RGB:
+ @classmethod
+ def INPUT_TYPES(s):
+ return {
+ "required": {
+ "image": ("IMAGE",),
+ },
+ }
+
+ RETURN_TYPES = ("IMAGE",)
+ FUNCTION = "execute"
+ CATEGORY = "🌌 ReActor"
+
+ def execute(self, image):
+ out = rgba2rgb_tensor(image)
+ return (out,)
+
+
+class MakeFaceModelBatch:
+ @classmethod
+ def INPUT_TYPES(s):
+ return {
+ "required": {
+ "face_model1": ("FACE_MODEL",),
+ },
+ "optional": {
+ "face_model2": ("FACE_MODEL",),
+ "face_model3": ("FACE_MODEL",),
+ "face_model4": ("FACE_MODEL",),
+ "face_model5": ("FACE_MODEL",),
+ "face_model6": ("FACE_MODEL",),
+ "face_model7": ("FACE_MODEL",),
+ "face_model8": ("FACE_MODEL",),
+ "face_model9": ("FACE_MODEL",),
+ "face_model10": ("FACE_MODEL",),
+ },
+ }
+
+ RETURN_TYPES = ("FACE_MODEL",)
+ RETURN_NAMES = ("FACE_MODELS",)
+ FUNCTION = "execute"
+
+ CATEGORY = "🌌 ReActor"
+
+ def execute(self, **kwargs):
+ if len(kwargs) > 0:
+ face_models = [value for value in kwargs.values()]
+ return (face_models,)
+ else:
+ logger.error("Please provide at least 1 `face_model`")
+ return (None,)
+
+
+class ReActorOptions:
+ @classmethod
+ def INPUT_TYPES(s):
+ return {
+ "required": {
+ "input_faces_order": (
+ ["left-right","right-left","top-bottom","bottom-top","small-large","large-small"], {"default": "large-small"}
+ ),
+ "input_faces_index": ("STRING", {"default": "0"}),
+ "detect_gender_input": (["no","female","male"], {"default": "no"}),
+ "source_faces_order": (
+ ["left-right","right-left","top-bottom","bottom-top","small-large","large-small"], {"default": "large-small"}
+ ),
+ "source_faces_index": ("STRING", {"default": "0"}),
+ "detect_gender_source": (["no","female","male"], {"default": "no"}),
+ "console_log_level": ([0, 1, 2], {"default": 1}),
+ }
+ }
+
+ RETURN_TYPES = ("OPTIONS",)
+ FUNCTION = "execute"
+ CATEGORY = "🌌 ReActor"
+
+ def execute(self,input_faces_order, input_faces_index, detect_gender_input, source_faces_order, source_faces_index, detect_gender_source, console_log_level):
+ options: dict = {
+ "input_faces_order": input_faces_order,
+ "input_faces_index": input_faces_index,
+ "detect_gender_input": detect_gender_input,
+ "source_faces_order": source_faces_order,
+ "source_faces_index": source_faces_index,
+ "detect_gender_source": detect_gender_source,
+ "console_log_level": console_log_level,
+ }
+ return (options, )
+
+
+class ReActorFaceBoost:
+ @classmethod
+ def INPUT_TYPES(s):
+ return {
+ "required": {
+ "enabled": ("BOOLEAN", {"default": True, "label_off": "OFF", "label_on": "ON"}),
+ "boost_model": (get_model_names(get_restorers),),
+ "interpolation": (["Nearest","Bilinear","Bicubic","Lanczos"], {"default": "Bicubic"}),
+ "visibility": ("FLOAT", {"default": 1, "min": 0.1, "max": 1, "step": 0.05}),
+ "codeformer_weight": ("FLOAT", {"default": 0.5, "min": 0.0, "max": 1, "step": 0.05}),
+ "restore_with_main_after": ("BOOLEAN", {"default": False}),
+ }
+ }
+
+ RETURN_TYPES = ("FACE_BOOST",)
+ FUNCTION = "execute"
+ CATEGORY = "🌌 ReActor"
+
+ def execute(self,enabled,boost_model,interpolation,visibility,codeformer_weight,restore_with_main_after):
+ face_boost: dict = {
+ "enabled": enabled,
+ "boost_model": boost_model,
+ "interpolation": interpolation,
+ "visibility": visibility,
+ "codeformer_weight": codeformer_weight,
+ "restore_with_main_after": restore_with_main_after,
+ }
+ return (face_boost, )
+
+class ReActorUnload:
+ @classmethod
+ def INPUT_TYPES(s):
+ return {
+ "required": {
+ "trigger": ("IMAGE", ),
+ },
+ }
+
+ RETURN_TYPES = ("IMAGE",)
+ FUNCTION = "execute"
+ CATEGORY = "🌌 ReActor"
+
+ def execute(self, trigger):
+ unload_all_models()
+ return (trigger,)
+
+
+NODE_CLASS_MAPPINGS = {
+ # --- MAIN NODES ---
+ "ReActorFaceSwap": reactor,
+ "ReActorFaceSwapOpt": ReActorPlusOpt,
+ "ReActorOptions": ReActorOptions,
+ "ReActorFaceBoost": ReActorFaceBoost,
+ "ReActorMaskHelper": MaskHelper,
+ "ReActorSetWeight": ReActorWeight,
+ # --- Operations with Face Models ---
+ "ReActorSaveFaceModel": SaveFaceModel,
+ "ReActorLoadFaceModel": LoadFaceModel,
+ "ReActorBuildFaceModel": BuildFaceModel,
+ "ReActorMakeFaceModelBatch": MakeFaceModelBatch,
+ # --- Additional Nodes ---
+ "ReActorRestoreFace": RestoreFace,
+ "ReActorImageDublicator": ImageDublicator,
+ "ImageRGBA2RGB": ImageRGBA2RGB,
+ "ReActorUnload": ReActorUnload,
+}
+
+NODE_DISPLAY_NAME_MAPPINGS = {
+ # --- MAIN NODES ---
+ "ReActorFaceSwap": "ReActor 🌌 Fast Face Swap",
+ "ReActorFaceSwapOpt": "ReActor 🌌 Fast Face Swap [OPTIONS]",
+ "ReActorOptions": "ReActor 🌌 Options",
+ "ReActorFaceBoost": "ReActor 🌌 Face Booster",
+ "ReActorMaskHelper": "ReActor 🌌 Masking Helper",
+ "ReActorSetWeight": "ReActor 🌌 Set Face Swap Weight",
+ # --- Operations with Face Models ---
+ "ReActorSaveFaceModel": "Save Face Model 🌌 ReActor",
+ "ReActorLoadFaceModel": "Load Face Model 🌌 ReActor",
+ "ReActorBuildFaceModel": "Build Blended Face Model 🌌 ReActor",
+ "ReActorMakeFaceModelBatch": "Make Face Model Batch 🌌 ReActor",
+ # --- Additional Nodes ---
+ "ReActorRestoreFace": "Restore Face 🌌 ReActor",
+ "ReActorImageDublicator": "Image Dublicator (List) 🌌 ReActor",
+ "ImageRGBA2RGB": "Convert RGBA to RGB 🌌 ReActor",
+ "ReActorUnload": "Unload ReActor Models 🌌 ReActor",
+}
diff --git a/custom_nodes/ComfyUI-ReActor/pyproject.toml b/custom_nodes/ComfyUI-ReActor/pyproject.toml
new file mode 100644
index 0000000000000000000000000000000000000000..384d9327048a1d8a9cfc0f46aa8702cb8b3ba4e3
--- /dev/null
+++ b/custom_nodes/ComfyUI-ReActor/pyproject.toml
@@ -0,0 +1,15 @@
+[project]
+name = "comfyui-reactor"
+description = "(SFW-Friendly) The Fast and Simple Face Swap Extension Node for ComfyUI, based on ReActor SD-WebUI Face Swap Extension"
+version = "0.6.0-a1"
+license = { file = "LICENSE" }
+dependencies = ["insightface==0.7.3", "onnx>=1.14.0", "opencv-python>=4.7.0.72", "numpy==1.26.3", "segment_anything", "albumentations>=1.4.16", "ultralytics"]
+
+[project.urls]
+Repository = "https://github.com/Gourieff/ComfyUI-ReActor"
+# Used by Comfy Registry https://comfyregistry.org
+
+[tool.comfy]
+PublisherId = "gourieff"
+DisplayName = "ComfyUI-ReActor"
+Icon = ""
diff --git a/custom_nodes/ComfyUI-ReActor/r_basicsr/__init__.py b/custom_nodes/ComfyUI-ReActor/r_basicsr/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..871b6366a986e7a816a5a0dd0ca900b3ca4450c1
--- /dev/null
+++ b/custom_nodes/ComfyUI-ReActor/r_basicsr/__init__.py
@@ -0,0 +1,12 @@
+# https://github.com/xinntao/BasicSR
+# flake8: noqa
+from .archs import *
+from .data import *
+from .losses import *
+from .metrics import *
+from .models import *
+from .ops import *
+from .test import *
+from .train import *
+from .utils import *
+from .version import __gitsha__, __version__
diff --git a/custom_nodes/ComfyUI-ReActor/r_basicsr/archs/__init__.py b/custom_nodes/ComfyUI-ReActor/r_basicsr/archs/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..94c531f5bfb143b4ca735a60ad3f3307a6d14978
--- /dev/null
+++ b/custom_nodes/ComfyUI-ReActor/r_basicsr/archs/__init__.py
@@ -0,0 +1,25 @@
+import importlib
+from copy import deepcopy
+from os import path as osp
+
+from r_basicsr.utils import get_root_logger, scandir
+from r_basicsr.utils.registry import ARCH_REGISTRY
+
+__all__ = ['build_network']
+
+# automatically scan and import arch modules for registry
+# scan all the files under the 'archs' folder and collect files ending with
+# '_arch.py'
+arch_folder = osp.dirname(osp.abspath(__file__))
+arch_filenames = [osp.splitext(osp.basename(v))[0] for v in scandir(arch_folder) if v.endswith('_arch.py')]
+# import all the arch modules
+_arch_modules = [importlib.import_module(f'r_basicsr.archs.{file_name}') for file_name in arch_filenames]
+
+
+def build_network(opt):
+ opt = deepcopy(opt)
+ network_type = opt.pop('type')
+ net = ARCH_REGISTRY.get(network_type)(**opt)
+ logger = get_root_logger()
+ logger.info(f'Network [{net.__class__.__name__}] is created.')
+ return net
diff --git a/custom_nodes/ComfyUI-ReActor/r_basicsr/archs/arch_util.py b/custom_nodes/ComfyUI-ReActor/r_basicsr/archs/arch_util.py
new file mode 100644
index 0000000000000000000000000000000000000000..fc628abb70d95bfc1c64906006307f1258417ffd
--- /dev/null
+++ b/custom_nodes/ComfyUI-ReActor/r_basicsr/archs/arch_util.py
@@ -0,0 +1,322 @@
+import collections.abc
+import math
+import torch
+import torchvision
+import warnings
+try:
+ from distutils.version import LooseVersion
+except:
+ from packaging.version import Version
+ LooseVersion = Version
+from itertools import repeat
+from torch import nn as nn
+from torch.nn import functional as F
+from torch.nn import init as init
+from torch.nn.modules.batchnorm import _BatchNorm
+
+from r_basicsr.ops.dcn import ModulatedDeformConvPack, modulated_deform_conv
+from r_basicsr.utils import get_root_logger
+
+
+@torch.no_grad()
+def default_init_weights(module_list, scale=1, bias_fill=0, **kwargs):
+ """Initialize network weights.
+
+ Args:
+ module_list (list[nn.Module] | nn.Module): Modules to be initialized.
+ scale (float): Scale initialized weights, especially for residual
+ blocks. Default: 1.
+ bias_fill (float): The value to fill bias. Default: 0
+ kwargs (dict): Other arguments for initialization function.
+ """
+ if not isinstance(module_list, list):
+ module_list = [module_list]
+ for module in module_list:
+ for m in module.modules():
+ if isinstance(m, nn.Conv2d):
+ init.kaiming_normal_(m.weight, **kwargs)
+ m.weight.data *= scale
+ if m.bias is not None:
+ m.bias.data.fill_(bias_fill)
+ elif isinstance(m, nn.Linear):
+ init.kaiming_normal_(m.weight, **kwargs)
+ m.weight.data *= scale
+ if m.bias is not None:
+ m.bias.data.fill_(bias_fill)
+ elif isinstance(m, _BatchNorm):
+ init.constant_(m.weight, 1)
+ if m.bias is not None:
+ m.bias.data.fill_(bias_fill)
+
+
+def make_layer(basic_block, num_basic_block, **kwarg):
+ """Make layers by stacking the same blocks.
+
+ Args:
+ basic_block (nn.module): nn.module class for basic block.
+ num_basic_block (int): number of blocks.
+
+ Returns:
+ nn.Sequential: Stacked blocks in nn.Sequential.
+ """
+ layers = []
+ for _ in range(num_basic_block):
+ layers.append(basic_block(**kwarg))
+ return nn.Sequential(*layers)
+
+
+class ResidualBlockNoBN(nn.Module):
+ """Residual block without BN.
+
+ It has a style of:
+ ---Conv-ReLU-Conv-+-
+ |________________|
+
+ Args:
+ num_feat (int): Channel number of intermediate features.
+ Default: 64.
+ res_scale (float): Residual scale. Default: 1.
+ pytorch_init (bool): If set to True, use pytorch default init,
+ otherwise, use default_init_weights. Default: False.
+ """
+
+ def __init__(self, num_feat=64, res_scale=1, pytorch_init=False):
+ super(ResidualBlockNoBN, self).__init__()
+ self.res_scale = res_scale
+ self.conv1 = nn.Conv2d(num_feat, num_feat, 3, 1, 1, bias=True)
+ self.conv2 = nn.Conv2d(num_feat, num_feat, 3, 1, 1, bias=True)
+ self.relu = nn.ReLU(inplace=True)
+
+ if not pytorch_init:
+ default_init_weights([self.conv1, self.conv2], 0.1)
+
+ def forward(self, x):
+ identity = x
+ out = self.conv2(self.relu(self.conv1(x)))
+ return identity + out * self.res_scale
+
+
+class Upsample(nn.Sequential):
+ """Upsample module.
+
+ Args:
+ scale (int): Scale factor. Supported scales: 2^n and 3.
+ num_feat (int): Channel number of intermediate features.
+ """
+
+ def __init__(self, scale, num_feat):
+ m = []
+ if (scale & (scale - 1)) == 0: # scale = 2^n
+ for _ in range(int(math.log(scale, 2))):
+ m.append(nn.Conv2d(num_feat, 4 * num_feat, 3, 1, 1))
+ m.append(nn.PixelShuffle(2))
+ elif scale == 3:
+ m.append(nn.Conv2d(num_feat, 9 * num_feat, 3, 1, 1))
+ m.append(nn.PixelShuffle(3))
+ else:
+ raise ValueError(f'scale {scale} is not supported. Supported scales: 2^n and 3.')
+ super(Upsample, self).__init__(*m)
+
+
+def flow_warp(x, flow, interp_mode='bilinear', padding_mode='zeros', align_corners=True):
+ """Warp an image or feature map with optical flow.
+
+ Args:
+ x (Tensor): Tensor with size (n, c, h, w).
+ flow (Tensor): Tensor with size (n, h, w, 2), normal value.
+ interp_mode (str): 'nearest' or 'bilinear'. Default: 'bilinear'.
+ padding_mode (str): 'zeros' or 'border' or 'reflection'.
+ Default: 'zeros'.
+ align_corners (bool): Before pytorch 1.3, the default value is
+ align_corners=True. After pytorch 1.3, the default value is
+ align_corners=False. Here, we use the True as default.
+
+ Returns:
+ Tensor: Warped image or feature map.
+ """
+ assert x.size()[-2:] == flow.size()[1:3]
+ _, _, h, w = x.size()
+ # create mesh grid
+ grid_y, grid_x = torch.meshgrid(torch.arange(0, h).type_as(x), torch.arange(0, w).type_as(x))
+ grid = torch.stack((grid_x, grid_y), 2).float() # W(x), H(y), 2
+ grid.requires_grad = False
+
+ vgrid = grid + flow
+ # scale grid to [-1,1]
+ vgrid_x = 2.0 * vgrid[:, :, :, 0] / max(w - 1, 1) - 1.0
+ vgrid_y = 2.0 * vgrid[:, :, :, 1] / max(h - 1, 1) - 1.0
+ vgrid_scaled = torch.stack((vgrid_x, vgrid_y), dim=3)
+ output = F.grid_sample(x, vgrid_scaled, mode=interp_mode, padding_mode=padding_mode, align_corners=align_corners)
+
+ # TODO, what if align_corners=False
+ return output
+
+
+def resize_flow(flow, size_type, sizes, interp_mode='bilinear', align_corners=False):
+ """Resize a flow according to ratio or shape.
+
+ Args:
+ flow (Tensor): Precomputed flow. shape [N, 2, H, W].
+ size_type (str): 'ratio' or 'shape'.
+ sizes (list[int | float]): the ratio for resizing or the final output
+ shape.
+ 1) The order of ratio should be [ratio_h, ratio_w]. For
+ downsampling, the ratio should be smaller than 1.0 (i.e., ratio
+ < 1.0). For upsampling, the ratio should be larger than 1.0 (i.e.,
+ ratio > 1.0).
+ 2) The order of output_size should be [out_h, out_w].
+ interp_mode (str): The mode of interpolation for resizing.
+ Default: 'bilinear'.
+ align_corners (bool): Whether align corners. Default: False.
+
+ Returns:
+ Tensor: Resized flow.
+ """
+ _, _, flow_h, flow_w = flow.size()
+ if size_type == 'ratio':
+ output_h, output_w = int(flow_h * sizes[0]), int(flow_w * sizes[1])
+ elif size_type == 'shape':
+ output_h, output_w = sizes[0], sizes[1]
+ else:
+ raise ValueError(f'Size type should be ratio or shape, but got type {size_type}.')
+
+ input_flow = flow.clone()
+ ratio_h = output_h / flow_h
+ ratio_w = output_w / flow_w
+ input_flow[:, 0, :, :] *= ratio_w
+ input_flow[:, 1, :, :] *= ratio_h
+ resized_flow = F.interpolate(
+ input=input_flow, size=(output_h, output_w), mode=interp_mode, align_corners=align_corners)
+ return resized_flow
+
+
+# TODO: may write a cpp file
+def pixel_unshuffle(x, scale):
+ """ Pixel unshuffle.
+
+ Args:
+ x (Tensor): Input feature with shape (b, c, hh, hw).
+ scale (int): Downsample ratio.
+
+ Returns:
+ Tensor: the pixel unshuffled feature.
+ """
+ b, c, hh, hw = x.size()
+ out_channel = c * (scale**2)
+ assert hh % scale == 0 and hw % scale == 0
+ h = hh // scale
+ w = hw // scale
+ x_view = x.view(b, c, h, scale, w, scale)
+ return x_view.permute(0, 1, 3, 5, 2, 4).reshape(b, out_channel, h, w)
+
+
+class DCNv2Pack(ModulatedDeformConvPack):
+ """Modulated deformable conv for deformable alignment.
+
+ Different from the official DCNv2Pack, which generates offsets and masks
+ from the preceding features, this DCNv2Pack takes another different
+ features to generate offsets and masks.
+
+ Ref:
+ Delving Deep into Deformable Alignment in Video Super-Resolution.
+ """
+
+ def forward(self, x, feat):
+ out = self.conv_offset(feat)
+ o1, o2, mask = torch.chunk(out, 3, dim=1)
+ offset = torch.cat((o1, o2), dim=1)
+ mask = torch.sigmoid(mask)
+
+ offset_absmean = torch.mean(torch.abs(offset))
+ if offset_absmean > 50:
+ logger = get_root_logger()
+ logger.warning(f'Offset abs mean is {offset_absmean}, larger than 50.')
+
+ if LooseVersion(torchvision.__version__) >= LooseVersion('0.9.0'):
+ return torchvision.ops.deform_conv2d(x, offset, self.weight, self.bias, self.stride, self.padding,
+ self.dilation, mask)
+ else:
+ return modulated_deform_conv(x, offset, mask, self.weight, self.bias, self.stride, self.padding,
+ self.dilation, self.groups, self.deformable_groups)
+
+
+def _no_grad_trunc_normal_(tensor, mean, std, a, b):
+ # From: https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/layers/weight_init.py
+ # Cut & paste from PyTorch official master until it's in a few official releases - RW
+ # Method based on https://people.sc.fsu.edu/~jburkardt/presentations/truncated_normal.pdf
+ def norm_cdf(x):
+ # Computes standard normal cumulative distribution function
+ return (1. + math.erf(x / math.sqrt(2.))) / 2.
+
+ if (mean < a - 2 * std) or (mean > b + 2 * std):
+ warnings.warn(
+ 'mean is more than 2 std from [a, b] in nn.init.trunc_normal_. '
+ 'The distribution of values may be incorrect.',
+ stacklevel=2)
+
+ with torch.no_grad():
+ # Values are generated by using a truncated uniform distribution and
+ # then using the inverse CDF for the normal distribution.
+ # Get upper and lower cdf values
+ low = norm_cdf((a - mean) / std)
+ up = norm_cdf((b - mean) / std)
+
+ # Uniformly fill tensor with values from [low, up], then translate to
+ # [2l-1, 2u-1].
+ tensor.uniform_(2 * low - 1, 2 * up - 1)
+
+ # Use inverse cdf transform for normal distribution to get truncated
+ # standard normal
+ tensor.erfinv_()
+
+ # Transform to proper mean, std
+ tensor.mul_(std * math.sqrt(2.))
+ tensor.add_(mean)
+
+ # Clamp to ensure it's in the proper range
+ tensor.clamp_(min=a, max=b)
+ return tensor
+
+
+def trunc_normal_(tensor, mean=0., std=1., a=-2., b=2.):
+ r"""Fills the input Tensor with values drawn from a truncated
+ normal distribution.
+
+ From: https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/layers/weight_init.py
+
+ The values are effectively drawn from the
+ normal distribution :math:`\mathcal{N}(\text{mean}, \text{std}^2)`
+ with values outside :math:`[a, b]` redrawn until they are within
+ the bounds. The method used for generating the random values works
+ best when :math:`a \leq \text{mean} \leq b`.
+
+ Args:
+ tensor: an n-dimensional `torch.Tensor`
+ mean: the mean of the normal distribution
+ std: the standard deviation of the normal distribution
+ a: the minimum cutoff value
+ b: the maximum cutoff value
+
+ Examples:
+ >>> w = torch.empty(3, 5)
+ >>> nn.init.trunc_normal_(w)
+ """
+ return _no_grad_trunc_normal_(tensor, mean, std, a, b)
+
+
+# From PyTorch
+def _ntuple(n):
+
+ def parse(x):
+ if isinstance(x, collections.abc.Iterable):
+ return x
+ return tuple(repeat(x, n))
+
+ return parse
+
+
+to_1tuple = _ntuple(1)
+to_2tuple = _ntuple(2)
+to_3tuple = _ntuple(3)
+to_4tuple = _ntuple(4)
+to_ntuple = _ntuple
diff --git a/custom_nodes/ComfyUI-ReActor/r_basicsr/archs/basicvsr_arch.py b/custom_nodes/ComfyUI-ReActor/r_basicsr/archs/basicvsr_arch.py
new file mode 100644
index 0000000000000000000000000000000000000000..c438d3513807e4b164ffaa9c843bfa0e6733ba44
--- /dev/null
+++ b/custom_nodes/ComfyUI-ReActor/r_basicsr/archs/basicvsr_arch.py
@@ -0,0 +1,336 @@
+import torch
+from torch import nn as nn
+from torch.nn import functional as F
+
+from r_basicsr.utils.registry import ARCH_REGISTRY
+from .arch_util import ResidualBlockNoBN, flow_warp, make_layer
+from .edvr_arch import PCDAlignment, TSAFusion
+from .spynet_arch import SpyNet
+
+
+@ARCH_REGISTRY.register()
+class BasicVSR(nn.Module):
+ """A recurrent network for video SR. Now only x4 is supported.
+
+ Args:
+ num_feat (int): Number of channels. Default: 64.
+ num_block (int): Number of residual blocks for each branch. Default: 15
+ spynet_path (str): Path to the pretrained weights of SPyNet. Default: None.
+ """
+
+ def __init__(self, num_feat=64, num_block=15, spynet_path=None):
+ super().__init__()
+ self.num_feat = num_feat
+
+ # alignment
+ self.spynet = SpyNet(spynet_path)
+
+ # propagation
+ self.backward_trunk = ConvResidualBlocks(num_feat + 3, num_feat, num_block)
+ self.forward_trunk = ConvResidualBlocks(num_feat + 3, num_feat, num_block)
+
+ # reconstruction
+ self.fusion = nn.Conv2d(num_feat * 2, num_feat, 1, 1, 0, bias=True)
+ self.upconv1 = nn.Conv2d(num_feat, num_feat * 4, 3, 1, 1, bias=True)
+ self.upconv2 = nn.Conv2d(num_feat, 64 * 4, 3, 1, 1, bias=True)
+ self.conv_hr = nn.Conv2d(64, 64, 3, 1, 1)
+ self.conv_last = nn.Conv2d(64, 3, 3, 1, 1)
+
+ self.pixel_shuffle = nn.PixelShuffle(2)
+
+ # activation functions
+ self.lrelu = nn.LeakyReLU(negative_slope=0.1, inplace=True)
+
+ def get_flow(self, x):
+ b, n, c, h, w = x.size()
+
+ x_1 = x[:, :-1, :, :, :].reshape(-1, c, h, w)
+ x_2 = x[:, 1:, :, :, :].reshape(-1, c, h, w)
+
+ flows_backward = self.spynet(x_1, x_2).view(b, n - 1, 2, h, w)
+ flows_forward = self.spynet(x_2, x_1).view(b, n - 1, 2, h, w)
+
+ return flows_forward, flows_backward
+
+ def forward(self, x):
+ """Forward function of BasicVSR.
+
+ Args:
+ x: Input frames with shape (b, n, c, h, w). n is the temporal dimension / number of frames.
+ """
+ flows_forward, flows_backward = self.get_flow(x)
+ b, n, _, h, w = x.size()
+
+ # backward branch
+ out_l = []
+ feat_prop = x.new_zeros(b, self.num_feat, h, w)
+ for i in range(n - 1, -1, -1):
+ x_i = x[:, i, :, :, :]
+ if i < n - 1:
+ flow = flows_backward[:, i, :, :, :]
+ feat_prop = flow_warp(feat_prop, flow.permute(0, 2, 3, 1))
+ feat_prop = torch.cat([x_i, feat_prop], dim=1)
+ feat_prop = self.backward_trunk(feat_prop)
+ out_l.insert(0, feat_prop)
+
+ # forward branch
+ feat_prop = torch.zeros_like(feat_prop)
+ for i in range(0, n):
+ x_i = x[:, i, :, :, :]
+ if i > 0:
+ flow = flows_forward[:, i - 1, :, :, :]
+ feat_prop = flow_warp(feat_prop, flow.permute(0, 2, 3, 1))
+
+ feat_prop = torch.cat([x_i, feat_prop], dim=1)
+ feat_prop = self.forward_trunk(feat_prop)
+
+ # upsample
+ out = torch.cat([out_l[i], feat_prop], dim=1)
+ out = self.lrelu(self.fusion(out))
+ out = self.lrelu(self.pixel_shuffle(self.upconv1(out)))
+ out = self.lrelu(self.pixel_shuffle(self.upconv2(out)))
+ out = self.lrelu(self.conv_hr(out))
+ out = self.conv_last(out)
+ base = F.interpolate(x_i, scale_factor=4, mode='bilinear', align_corners=False)
+ out += base
+ out_l[i] = out
+
+ return torch.stack(out_l, dim=1)
+
+
+class ConvResidualBlocks(nn.Module):
+ """Conv and residual block used in BasicVSR.
+
+ Args:
+ num_in_ch (int): Number of input channels. Default: 3.
+ num_out_ch (int): Number of output channels. Default: 64.
+ num_block (int): Number of residual blocks. Default: 15.
+ """
+
+ def __init__(self, num_in_ch=3, num_out_ch=64, num_block=15):
+ super().__init__()
+ self.main = nn.Sequential(
+ nn.Conv2d(num_in_ch, num_out_ch, 3, 1, 1, bias=True), nn.LeakyReLU(negative_slope=0.1, inplace=True),
+ make_layer(ResidualBlockNoBN, num_block, num_feat=num_out_ch))
+
+ def forward(self, fea):
+ return self.main(fea)
+
+
+@ARCH_REGISTRY.register()
+class IconVSR(nn.Module):
+ """IconVSR, proposed also in the BasicVSR paper.
+
+ Args:
+ num_feat (int): Number of channels. Default: 64.
+ num_block (int): Number of residual blocks for each branch. Default: 15.
+ keyframe_stride (int): Keyframe stride. Default: 5.
+ temporal_padding (int): Temporal padding. Default: 2.
+ spynet_path (str): Path to the pretrained weights of SPyNet. Default: None.
+ edvr_path (str): Path to the pretrained EDVR model. Default: None.
+ """
+
+ def __init__(self,
+ num_feat=64,
+ num_block=15,
+ keyframe_stride=5,
+ temporal_padding=2,
+ spynet_path=None,
+ edvr_path=None):
+ super().__init__()
+
+ self.num_feat = num_feat
+ self.temporal_padding = temporal_padding
+ self.keyframe_stride = keyframe_stride
+
+ # keyframe_branch
+ self.edvr = EDVRFeatureExtractor(temporal_padding * 2 + 1, num_feat, edvr_path)
+ # alignment
+ self.spynet = SpyNet(spynet_path)
+
+ # propagation
+ self.backward_fusion = nn.Conv2d(2 * num_feat, num_feat, 3, 1, 1, bias=True)
+ self.backward_trunk = ConvResidualBlocks(num_feat + 3, num_feat, num_block)
+
+ self.forward_fusion = nn.Conv2d(2 * num_feat, num_feat, 3, 1, 1, bias=True)
+ self.forward_trunk = ConvResidualBlocks(2 * num_feat + 3, num_feat, num_block)
+
+ # reconstruction
+ self.upconv1 = nn.Conv2d(num_feat, num_feat * 4, 3, 1, 1, bias=True)
+ self.upconv2 = nn.Conv2d(num_feat, 64 * 4, 3, 1, 1, bias=True)
+ self.conv_hr = nn.Conv2d(64, 64, 3, 1, 1)
+ self.conv_last = nn.Conv2d(64, 3, 3, 1, 1)
+
+ self.pixel_shuffle = nn.PixelShuffle(2)
+
+ # activation functions
+ self.lrelu = nn.LeakyReLU(negative_slope=0.1, inplace=True)
+
+ def pad_spatial(self, x):
+ """Apply padding spatially.
+
+ Since the PCD module in EDVR requires that the resolution is a multiple
+ of 4, we apply padding to the input LR images if their resolution is
+ not divisible by 4.
+
+ Args:
+ x (Tensor): Input LR sequence with shape (n, t, c, h, w).
+ Returns:
+ Tensor: Padded LR sequence with shape (n, t, c, h_pad, w_pad).
+ """
+ n, t, c, h, w = x.size()
+
+ pad_h = (4 - h % 4) % 4
+ pad_w = (4 - w % 4) % 4
+
+ # padding
+ x = x.view(-1, c, h, w)
+ x = F.pad(x, [0, pad_w, 0, pad_h], mode='reflect')
+
+ return x.view(n, t, c, h + pad_h, w + pad_w)
+
+ def get_flow(self, x):
+ b, n, c, h, w = x.size()
+
+ x_1 = x[:, :-1, :, :, :].reshape(-1, c, h, w)
+ x_2 = x[:, 1:, :, :, :].reshape(-1, c, h, w)
+
+ flows_backward = self.spynet(x_1, x_2).view(b, n - 1, 2, h, w)
+ flows_forward = self.spynet(x_2, x_1).view(b, n - 1, 2, h, w)
+
+ return flows_forward, flows_backward
+
+ def get_keyframe_feature(self, x, keyframe_idx):
+ if self.temporal_padding == 2:
+ x = [x[:, [4, 3]], x, x[:, [-4, -5]]]
+ elif self.temporal_padding == 3:
+ x = [x[:, [6, 5, 4]], x, x[:, [-5, -6, -7]]]
+ x = torch.cat(x, dim=1)
+
+ num_frames = 2 * self.temporal_padding + 1
+ feats_keyframe = {}
+ for i in keyframe_idx:
+ feats_keyframe[i] = self.edvr(x[:, i:i + num_frames].contiguous())
+ return feats_keyframe
+
+ def forward(self, x):
+ b, n, _, h_input, w_input = x.size()
+
+ x = self.pad_spatial(x)
+ h, w = x.shape[3:]
+
+ keyframe_idx = list(range(0, n, self.keyframe_stride))
+ if keyframe_idx[-1] != n - 1:
+ keyframe_idx.append(n - 1) # last frame is a keyframe
+
+ # compute flow and keyframe features
+ flows_forward, flows_backward = self.get_flow(x)
+ feats_keyframe = self.get_keyframe_feature(x, keyframe_idx)
+
+ # backward branch
+ out_l = []
+ feat_prop = x.new_zeros(b, self.num_feat, h, w)
+ for i in range(n - 1, -1, -1):
+ x_i = x[:, i, :, :, :]
+ if i < n - 1:
+ flow = flows_backward[:, i, :, :, :]
+ feat_prop = flow_warp(feat_prop, flow.permute(0, 2, 3, 1))
+ if i in keyframe_idx:
+ feat_prop = torch.cat([feat_prop, feats_keyframe[i]], dim=1)
+ feat_prop = self.backward_fusion(feat_prop)
+ feat_prop = torch.cat([x_i, feat_prop], dim=1)
+ feat_prop = self.backward_trunk(feat_prop)
+ out_l.insert(0, feat_prop)
+
+ # forward branch
+ feat_prop = torch.zeros_like(feat_prop)
+ for i in range(0, n):
+ x_i = x[:, i, :, :, :]
+ if i > 0:
+ flow = flows_forward[:, i - 1, :, :, :]
+ feat_prop = flow_warp(feat_prop, flow.permute(0, 2, 3, 1))
+ if i in keyframe_idx:
+ feat_prop = torch.cat([feat_prop, feats_keyframe[i]], dim=1)
+ feat_prop = self.forward_fusion(feat_prop)
+
+ feat_prop = torch.cat([x_i, out_l[i], feat_prop], dim=1)
+ feat_prop = self.forward_trunk(feat_prop)
+
+ # upsample
+ out = self.lrelu(self.pixel_shuffle(self.upconv1(feat_prop)))
+ out = self.lrelu(self.pixel_shuffle(self.upconv2(out)))
+ out = self.lrelu(self.conv_hr(out))
+ out = self.conv_last(out)
+ base = F.interpolate(x_i, scale_factor=4, mode='bilinear', align_corners=False)
+ out += base
+ out_l[i] = out
+
+ return torch.stack(out_l, dim=1)[..., :4 * h_input, :4 * w_input]
+
+
+class EDVRFeatureExtractor(nn.Module):
+ """EDVR feature extractor used in IconVSR.
+
+ Args:
+ num_input_frame (int): Number of input frames.
+ num_feat (int): Number of feature channels
+ load_path (str): Path to the pretrained weights of EDVR. Default: None.
+ """
+
+ def __init__(self, num_input_frame, num_feat, load_path):
+
+ super(EDVRFeatureExtractor, self).__init__()
+
+ self.center_frame_idx = num_input_frame // 2
+
+ # extract pyramid features
+ self.conv_first = nn.Conv2d(3, num_feat, 3, 1, 1)
+ self.feature_extraction = make_layer(ResidualBlockNoBN, 5, num_feat=num_feat)
+ self.conv_l2_1 = nn.Conv2d(num_feat, num_feat, 3, 2, 1)
+ self.conv_l2_2 = nn.Conv2d(num_feat, num_feat, 3, 1, 1)
+ self.conv_l3_1 = nn.Conv2d(num_feat, num_feat, 3, 2, 1)
+ self.conv_l3_2 = nn.Conv2d(num_feat, num_feat, 3, 1, 1)
+
+ # pcd and tsa module
+ self.pcd_align = PCDAlignment(num_feat=num_feat, deformable_groups=8)
+ self.fusion = TSAFusion(num_feat=num_feat, num_frame=num_input_frame, center_frame_idx=self.center_frame_idx)
+
+ # activation function
+ self.lrelu = nn.LeakyReLU(negative_slope=0.1, inplace=True)
+
+ if load_path:
+ self.load_state_dict(torch.load(load_path, map_location=lambda storage, loc: storage)['params'])
+
+ def forward(self, x):
+ b, n, c, h, w = x.size()
+
+ # extract features for each frame
+ # L1
+ feat_l1 = self.lrelu(self.conv_first(x.view(-1, c, h, w)))
+ feat_l1 = self.feature_extraction(feat_l1)
+ # L2
+ feat_l2 = self.lrelu(self.conv_l2_1(feat_l1))
+ feat_l2 = self.lrelu(self.conv_l2_2(feat_l2))
+ # L3
+ feat_l3 = self.lrelu(self.conv_l3_1(feat_l2))
+ feat_l3 = self.lrelu(self.conv_l3_2(feat_l3))
+
+ feat_l1 = feat_l1.view(b, n, -1, h, w)
+ feat_l2 = feat_l2.view(b, n, -1, h // 2, w // 2)
+ feat_l3 = feat_l3.view(b, n, -1, h // 4, w // 4)
+
+ # PCD alignment
+ ref_feat_l = [ # reference feature list
+ feat_l1[:, self.center_frame_idx, :, :, :].clone(), feat_l2[:, self.center_frame_idx, :, :, :].clone(),
+ feat_l3[:, self.center_frame_idx, :, :, :].clone()
+ ]
+ aligned_feat = []
+ for i in range(n):
+ nbr_feat_l = [ # neighboring feature list
+ feat_l1[:, i, :, :, :].clone(), feat_l2[:, i, :, :, :].clone(), feat_l3[:, i, :, :, :].clone()
+ ]
+ aligned_feat.append(self.pcd_align(nbr_feat_l, ref_feat_l))
+ aligned_feat = torch.stack(aligned_feat, dim=1) # (b, t, c, h, w)
+
+ # TSA fusion
+ return self.fusion(aligned_feat)
diff --git a/custom_nodes/ComfyUI-ReActor/r_basicsr/archs/basicvsrpp_arch.py b/custom_nodes/ComfyUI-ReActor/r_basicsr/archs/basicvsrpp_arch.py
new file mode 100644
index 0000000000000000000000000000000000000000..fd9d396dddac81fc4d03a6d97dc46faab83a4bab
--- /dev/null
+++ b/custom_nodes/ComfyUI-ReActor/r_basicsr/archs/basicvsrpp_arch.py
@@ -0,0 +1,407 @@
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+import torchvision
+import warnings
+
+from r_basicsr.archs.arch_util import flow_warp
+from r_basicsr.archs.basicvsr_arch import ConvResidualBlocks
+from r_basicsr.archs.spynet_arch import SpyNet
+from r_basicsr.ops.dcn import ModulatedDeformConvPack
+from r_basicsr.utils.registry import ARCH_REGISTRY
+
+
+@ARCH_REGISTRY.register()
+class BasicVSRPlusPlus(nn.Module):
+ """BasicVSR++ network structure.
+ Support either x4 upsampling or same size output. Since DCN is used in this
+ model, it can only be used with CUDA enabled. If CUDA is not enabled,
+ feature alignment will be skipped. Besides, we adopt the official DCN
+ implementation and the version of torch need to be higher than 1.9.
+ Paper:
+ BasicVSR++: Improving Video Super-Resolution with Enhanced Propagation
+ and Alignment
+ Args:
+ mid_channels (int, optional): Channel number of the intermediate
+ features. Default: 64.
+ num_blocks (int, optional): The number of residual blocks in each
+ propagation branch. Default: 7.
+ max_residue_magnitude (int): The maximum magnitude of the offset
+ residue (Eq. 6 in paper). Default: 10.
+ is_low_res_input (bool, optional): Whether the input is low-resolution
+ or not. If False, the output resolution is equal to the input
+ resolution. Default: True.
+ spynet_path (str): Path to the pretrained weights of SPyNet. Default: None.
+ cpu_cache_length (int, optional): When the length of sequence is larger
+ than this value, the intermediate features are sent to CPU. This
+ saves GPU memory, but slows down the inference speed. You can
+ increase this number if you have a GPU with large memory.
+ Default: 100.
+ """
+
+ def __init__(self,
+ mid_channels=64,
+ num_blocks=7,
+ max_residue_magnitude=10,
+ is_low_res_input=True,
+ spynet_path=None,
+ cpu_cache_length=100):
+
+ super().__init__()
+ self.mid_channels = mid_channels
+ self.is_low_res_input = is_low_res_input
+ self.cpu_cache_length = cpu_cache_length
+
+ # optical flow
+ self.spynet = SpyNet(spynet_path)
+
+ # feature extraction module
+ if is_low_res_input:
+ self.feat_extract = ConvResidualBlocks(3, mid_channels, 5)
+ else:
+ self.feat_extract = nn.Sequential(
+ nn.Conv2d(3, mid_channels, 3, 2, 1), nn.LeakyReLU(negative_slope=0.1, inplace=True),
+ nn.Conv2d(mid_channels, mid_channels, 3, 2, 1), nn.LeakyReLU(negative_slope=0.1, inplace=True),
+ ConvResidualBlocks(mid_channels, mid_channels, 5))
+
+ # propagation branches
+ self.deform_align = nn.ModuleDict()
+ self.backbone = nn.ModuleDict()
+ modules = ['backward_1', 'forward_1', 'backward_2', 'forward_2']
+ for i, module in enumerate(modules):
+ if torch.cuda.is_available():
+ self.deform_align[module] = SecondOrderDeformableAlignment(
+ 2 * mid_channels,
+ mid_channels,
+ 3,
+ padding=1,
+ deformable_groups=16,
+ max_residue_magnitude=max_residue_magnitude)
+ self.backbone[module] = ConvResidualBlocks((2 + i) * mid_channels, mid_channels, num_blocks)
+
+ # upsampling module
+ self.reconstruction = ConvResidualBlocks(5 * mid_channels, mid_channels, 5)
+
+ self.upconv1 = nn.Conv2d(mid_channels, mid_channels * 4, 3, 1, 1, bias=True)
+ self.upconv2 = nn.Conv2d(mid_channels, 64 * 4, 3, 1, 1, bias=True)
+
+ self.pixel_shuffle = nn.PixelShuffle(2)
+
+ self.conv_hr = nn.Conv2d(64, 64, 3, 1, 1)
+ self.conv_last = nn.Conv2d(64, 3, 3, 1, 1)
+ self.img_upsample = nn.Upsample(scale_factor=4, mode='bilinear', align_corners=False)
+
+ # activation function
+ self.lrelu = nn.LeakyReLU(negative_slope=0.1, inplace=True)
+
+ # check if the sequence is augmented by flipping
+ self.is_mirror_extended = False
+
+ if len(self.deform_align) > 0:
+ self.is_with_alignment = True
+ else:
+ self.is_with_alignment = False
+ warnings.warn('Deformable alignment module is not added. '
+ 'Probably your CUDA is not configured correctly. DCN can only '
+ 'be used with CUDA enabled. Alignment is skipped now.')
+
+ def check_if_mirror_extended(self, lqs):
+ """Check whether the input is a mirror-extended sequence.
+ If mirror-extended, the i-th (i=0, ..., t-1) frame is equal to the
+ (t-1-i)-th frame.
+ Args:
+ lqs (tensor): Input low quality (LQ) sequence with
+ shape (n, t, c, h, w).
+ """
+
+ if lqs.size(1) % 2 == 0:
+ lqs_1, lqs_2 = torch.chunk(lqs, 2, dim=1)
+ if torch.norm(lqs_1 - lqs_2.flip(1)) == 0:
+ self.is_mirror_extended = True
+
+ def compute_flow(self, lqs):
+ """Compute optical flow using SPyNet for feature alignment.
+ Note that if the input is an mirror-extended sequence, 'flows_forward'
+ is not needed, since it is equal to 'flows_backward.flip(1)'.
+ Args:
+ lqs (tensor): Input low quality (LQ) sequence with
+ shape (n, t, c, h, w).
+ Return:
+ tuple(Tensor): Optical flow. 'flows_forward' corresponds to the
+ flows used for forward-time propagation (current to previous).
+ 'flows_backward' corresponds to the flows used for
+ backward-time propagation (current to next).
+ """
+
+ n, t, c, h, w = lqs.size()
+ lqs_1 = lqs[:, :-1, :, :, :].reshape(-1, c, h, w)
+ lqs_2 = lqs[:, 1:, :, :, :].reshape(-1, c, h, w)
+
+ flows_backward = self.spynet(lqs_1, lqs_2).view(n, t - 1, 2, h, w)
+
+ if self.is_mirror_extended: # flows_forward = flows_backward.flip(1)
+ flows_forward = flows_backward.flip(1)
+ else:
+ flows_forward = self.spynet(lqs_2, lqs_1).view(n, t - 1, 2, h, w)
+
+ if self.cpu_cache:
+ flows_backward = flows_backward.cpu()
+ flows_forward = flows_forward.cpu()
+
+ return flows_forward, flows_backward
+
+ def propagate(self, feats, flows, module_name):
+ """Propagate the latent features throughout the sequence.
+ Args:
+ feats dict(list[tensor]): Features from previous branches. Each
+ component is a list of tensors with shape (n, c, h, w).
+ flows (tensor): Optical flows with shape (n, t - 1, 2, h, w).
+ module_name (str): The name of the propgation branches. Can either
+ be 'backward_1', 'forward_1', 'backward_2', 'forward_2'.
+ Return:
+ dict(list[tensor]): A dictionary containing all the propagated
+ features. Each key in the dictionary corresponds to a
+ propagation branch, which is represented by a list of tensors.
+ """
+
+ n, t, _, h, w = flows.size()
+
+ frame_idx = range(0, t + 1)
+ flow_idx = range(-1, t)
+ mapping_idx = list(range(0, len(feats['spatial'])))
+ mapping_idx += mapping_idx[::-1]
+
+ if 'backward' in module_name:
+ frame_idx = frame_idx[::-1]
+ flow_idx = frame_idx
+
+ feat_prop = flows.new_zeros(n, self.mid_channels, h, w)
+ for i, idx in enumerate(frame_idx):
+ feat_current = feats['spatial'][mapping_idx[idx]]
+ if self.cpu_cache:
+ feat_current = feat_current.cuda()
+ feat_prop = feat_prop.cuda()
+ # second-order deformable alignment
+ if i > 0 and self.is_with_alignment:
+ flow_n1 = flows[:, flow_idx[i], :, :, :]
+ if self.cpu_cache:
+ flow_n1 = flow_n1.cuda()
+
+ cond_n1 = flow_warp(feat_prop, flow_n1.permute(0, 2, 3, 1))
+
+ # initialize second-order features
+ feat_n2 = torch.zeros_like(feat_prop)
+ flow_n2 = torch.zeros_like(flow_n1)
+ cond_n2 = torch.zeros_like(cond_n1)
+
+ if i > 1: # second-order features
+ feat_n2 = feats[module_name][-2]
+ if self.cpu_cache:
+ feat_n2 = feat_n2.cuda()
+
+ flow_n2 = flows[:, flow_idx[i - 1], :, :, :]
+ if self.cpu_cache:
+ flow_n2 = flow_n2.cuda()
+
+ flow_n2 = flow_n1 + flow_warp(flow_n2, flow_n1.permute(0, 2, 3, 1))
+ cond_n2 = flow_warp(feat_n2, flow_n2.permute(0, 2, 3, 1))
+
+ # flow-guided deformable convolution
+ cond = torch.cat([cond_n1, feat_current, cond_n2], dim=1)
+ feat_prop = torch.cat([feat_prop, feat_n2], dim=1)
+ feat_prop = self.deform_align[module_name](feat_prop, cond, flow_n1, flow_n2)
+
+ # concatenate and residual blocks
+ feat = [feat_current] + [feats[k][idx] for k in feats if k not in ['spatial', module_name]] + [feat_prop]
+ if self.cpu_cache:
+ feat = [f.cuda() for f in feat]
+
+ feat = torch.cat(feat, dim=1)
+ feat_prop = feat_prop + self.backbone[module_name](feat)
+ feats[module_name].append(feat_prop)
+
+ if self.cpu_cache:
+ feats[module_name][-1] = feats[module_name][-1].cpu()
+ torch.cuda.empty_cache()
+
+ if 'backward' in module_name:
+ feats[module_name] = feats[module_name][::-1]
+
+ return feats
+
+ def upsample(self, lqs, feats):
+ """Compute the output image given the features.
+ Args:
+ lqs (tensor): Input low quality (LQ) sequence with
+ shape (n, t, c, h, w).
+ feats (dict): The features from the propgation branches.
+ Returns:
+ Tensor: Output HR sequence with shape (n, t, c, 4h, 4w).
+ """
+
+ outputs = []
+ num_outputs = len(feats['spatial'])
+
+ mapping_idx = list(range(0, num_outputs))
+ mapping_idx += mapping_idx[::-1]
+
+ for i in range(0, lqs.size(1)):
+ hr = [feats[k].pop(0) for k in feats if k != 'spatial']
+ hr.insert(0, feats['spatial'][mapping_idx[i]])
+ hr = torch.cat(hr, dim=1)
+ if self.cpu_cache:
+ hr = hr.cuda()
+
+ hr = self.reconstruction(hr)
+ hr = self.lrelu(self.pixel_shuffle(self.upconv1(hr)))
+ hr = self.lrelu(self.pixel_shuffle(self.upconv2(hr)))
+ hr = self.lrelu(self.conv_hr(hr))
+ hr = self.conv_last(hr)
+ if self.is_low_res_input:
+ hr += self.img_upsample(lqs[:, i, :, :, :])
+ else:
+ hr += lqs[:, i, :, :, :]
+
+ if self.cpu_cache:
+ hr = hr.cpu()
+ torch.cuda.empty_cache()
+
+ outputs.append(hr)
+
+ return torch.stack(outputs, dim=1)
+
+ def forward(self, lqs):
+ """Forward function for BasicVSR++.
+ Args:
+ lqs (tensor): Input low quality (LQ) sequence with
+ shape (n, t, c, h, w).
+ Returns:
+ Tensor: Output HR sequence with shape (n, t, c, 4h, 4w).
+ """
+
+ n, t, c, h, w = lqs.size()
+
+ # whether to cache the features in CPU
+ self.cpu_cache = True if t > self.cpu_cache_length else False
+
+ if self.is_low_res_input:
+ lqs_downsample = lqs.clone()
+ else:
+ lqs_downsample = F.interpolate(
+ lqs.view(-1, c, h, w), scale_factor=0.25, mode='bicubic').view(n, t, c, h // 4, w // 4)
+
+ # check whether the input is an extended sequence
+ self.check_if_mirror_extended(lqs)
+
+ feats = {}
+ # compute spatial features
+ if self.cpu_cache:
+ feats['spatial'] = []
+ for i in range(0, t):
+ feat = self.feat_extract(lqs[:, i, :, :, :]).cpu()
+ feats['spatial'].append(feat)
+ torch.cuda.empty_cache()
+ else:
+ feats_ = self.feat_extract(lqs.view(-1, c, h, w))
+ h, w = feats_.shape[2:]
+ feats_ = feats_.view(n, t, -1, h, w)
+ feats['spatial'] = [feats_[:, i, :, :, :] for i in range(0, t)]
+
+ # compute optical flow using the low-res inputs
+ assert lqs_downsample.size(3) >= 64 and lqs_downsample.size(4) >= 64, (
+ 'The height and width of low-res inputs must be at least 64, '
+ f'but got {h} and {w}.')
+ flows_forward, flows_backward = self.compute_flow(lqs_downsample)
+
+ # feature propgation
+ for iter_ in [1, 2]:
+ for direction in ['backward', 'forward']:
+ module = f'{direction}_{iter_}'
+
+ feats[module] = []
+
+ if direction == 'backward':
+ flows = flows_backward
+ elif flows_forward is not None:
+ flows = flows_forward
+ else:
+ flows = flows_backward.flip(1)
+
+ feats = self.propagate(feats, flows, module)
+ if self.cpu_cache:
+ del flows
+ torch.cuda.empty_cache()
+
+ return self.upsample(lqs, feats)
+
+
+class SecondOrderDeformableAlignment(ModulatedDeformConvPack):
+ """Second-order deformable alignment module.
+ Args:
+ in_channels (int): Same as nn.Conv2d.
+ out_channels (int): Same as nn.Conv2d.
+ kernel_size (int or tuple[int]): Same as nn.Conv2d.
+ stride (int or tuple[int]): Same as nn.Conv2d.
+ padding (int or tuple[int]): Same as nn.Conv2d.
+ dilation (int or tuple[int]): Same as nn.Conv2d.
+ groups (int): Same as nn.Conv2d.
+ bias (bool or str): If specified as `auto`, it will be decided by the
+ norm_cfg. Bias will be set as True if norm_cfg is None, otherwise
+ False.
+ max_residue_magnitude (int): The maximum magnitude of the offset
+ residue (Eq. 6 in paper). Default: 10.
+ """
+
+ def __init__(self, *args, **kwargs):
+ self.max_residue_magnitude = kwargs.pop('max_residue_magnitude', 10)
+
+ super(SecondOrderDeformableAlignment, self).__init__(*args, **kwargs)
+
+ self.conv_offset = nn.Sequential(
+ nn.Conv2d(3 * self.out_channels + 4, self.out_channels, 3, 1, 1),
+ nn.LeakyReLU(negative_slope=0.1, inplace=True),
+ nn.Conv2d(self.out_channels, self.out_channels, 3, 1, 1),
+ nn.LeakyReLU(negative_slope=0.1, inplace=True),
+ nn.Conv2d(self.out_channels, self.out_channels, 3, 1, 1),
+ nn.LeakyReLU(negative_slope=0.1, inplace=True),
+ nn.Conv2d(self.out_channels, 27 * self.deformable_groups, 3, 1, 1),
+ )
+
+ self.init_offset()
+
+ def init_offset(self):
+
+ def _constant_init(module, val, bias=0):
+ if hasattr(module, 'weight') and module.weight is not None:
+ nn.init.constant_(module.weight, val)
+ if hasattr(module, 'bias') and module.bias is not None:
+ nn.init.constant_(module.bias, bias)
+
+ _constant_init(self.conv_offset[-1], val=0, bias=0)
+
+ def forward(self, x, extra_feat, flow_1, flow_2):
+ extra_feat = torch.cat([extra_feat, flow_1, flow_2], dim=1)
+ out = self.conv_offset(extra_feat)
+ o1, o2, mask = torch.chunk(out, 3, dim=1)
+
+ # offset
+ offset = self.max_residue_magnitude * torch.tanh(torch.cat((o1, o2), dim=1))
+ offset_1, offset_2 = torch.chunk(offset, 2, dim=1)
+ offset_1 = offset_1 + flow_1.flip(1).repeat(1, offset_1.size(1) // 2, 1, 1)
+ offset_2 = offset_2 + flow_2.flip(1).repeat(1, offset_2.size(1) // 2, 1, 1)
+ offset = torch.cat([offset_1, offset_2], dim=1)
+
+ # mask
+ mask = torch.sigmoid(mask)
+
+ return torchvision.ops.deform_conv2d(x, offset, self.weight, self.bias, self.stride, self.padding,
+ self.dilation, mask)
+
+
+# if __name__ == '__main__':
+# spynet_path = 'experiments/pretrained_models/flownet/spynet_sintel_final-3d2a1287.pth'
+# model = BasicVSRPlusPlus(spynet_path=spynet_path).cuda()
+# input = torch.rand(1, 2, 3, 64, 64).cuda()
+# output = model(input)
+# print('===================')
+# print(output.shape)
diff --git a/custom_nodes/ComfyUI-ReActor/r_basicsr/archs/dfdnet_arch.py b/custom_nodes/ComfyUI-ReActor/r_basicsr/archs/dfdnet_arch.py
new file mode 100644
index 0000000000000000000000000000000000000000..646da689c5e8f88ce879ce5f735e6273d6724319
--- /dev/null
+++ b/custom_nodes/ComfyUI-ReActor/r_basicsr/archs/dfdnet_arch.py
@@ -0,0 +1,169 @@
+import numpy as np
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from torch.nn.utils.spectral_norm import spectral_norm
+
+from r_basicsr.utils.registry import ARCH_REGISTRY
+from .dfdnet_util import AttentionBlock, Blur, MSDilationBlock, UpResBlock, adaptive_instance_normalization
+from .vgg_arch import VGGFeatureExtractor
+
+
+class SFTUpBlock(nn.Module):
+ """Spatial feature transform (SFT) with upsampling block.
+
+ Args:
+ in_channel (int): Number of input channels.
+ out_channel (int): Number of output channels.
+ kernel_size (int): Kernel size in convolutions. Default: 3.
+ padding (int): Padding in convolutions. Default: 1.
+ """
+
+ def __init__(self, in_channel, out_channel, kernel_size=3, padding=1):
+ super(SFTUpBlock, self).__init__()
+ self.conv1 = nn.Sequential(
+ Blur(in_channel),
+ spectral_norm(nn.Conv2d(in_channel, out_channel, kernel_size, padding=padding)),
+ nn.LeakyReLU(0.04, True),
+ # The official codes use two LeakyReLU here, so 0.04 for equivalent
+ )
+ self.convup = nn.Sequential(
+ nn.Upsample(scale_factor=2, mode='bilinear', align_corners=False),
+ spectral_norm(nn.Conv2d(out_channel, out_channel, kernel_size, padding=padding)),
+ nn.LeakyReLU(0.2, True),
+ )
+
+ # for SFT scale and shift
+ self.scale_block = nn.Sequential(
+ spectral_norm(nn.Conv2d(in_channel, out_channel, 3, 1, 1)), nn.LeakyReLU(0.2, True),
+ spectral_norm(nn.Conv2d(out_channel, out_channel, 3, 1, 1)))
+ self.shift_block = nn.Sequential(
+ spectral_norm(nn.Conv2d(in_channel, out_channel, 3, 1, 1)), nn.LeakyReLU(0.2, True),
+ spectral_norm(nn.Conv2d(out_channel, out_channel, 3, 1, 1)), nn.Sigmoid())
+ # The official codes use sigmoid for shift block, do not know why
+
+ def forward(self, x, updated_feat):
+ out = self.conv1(x)
+ # SFT
+ scale = self.scale_block(updated_feat)
+ shift = self.shift_block(updated_feat)
+ out = out * scale + shift
+ # upsample
+ out = self.convup(out)
+ return out
+
+
+@ARCH_REGISTRY.register()
+class DFDNet(nn.Module):
+ """DFDNet: Deep Face Dictionary Network.
+
+ It only processes faces with 512x512 size.
+
+ Args:
+ num_feat (int): Number of feature channels.
+ dict_path (str): Path to the facial component dictionary.
+ """
+
+ def __init__(self, num_feat, dict_path):
+ super().__init__()
+ self.parts = ['left_eye', 'right_eye', 'nose', 'mouth']
+ # part_sizes: [80, 80, 50, 110]
+ channel_sizes = [128, 256, 512, 512]
+ self.feature_sizes = np.array([256, 128, 64, 32])
+ self.vgg_layers = ['relu2_2', 'relu3_4', 'relu4_4', 'conv5_4']
+ self.flag_dict_device = False
+
+ # dict
+ self.dict = torch.load(dict_path)
+
+ # vgg face extractor
+ self.vgg_extractor = VGGFeatureExtractor(
+ layer_name_list=self.vgg_layers,
+ vgg_type='vgg19',
+ use_input_norm=True,
+ range_norm=True,
+ requires_grad=False)
+
+ # attention block for fusing dictionary features and input features
+ self.attn_blocks = nn.ModuleDict()
+ for idx, feat_size in enumerate(self.feature_sizes):
+ for name in self.parts:
+ self.attn_blocks[f'{name}_{feat_size}'] = AttentionBlock(channel_sizes[idx])
+
+ # multi scale dilation block
+ self.multi_scale_dilation = MSDilationBlock(num_feat * 8, dilation=[4, 3, 2, 1])
+
+ # upsampling and reconstruction
+ self.upsample0 = SFTUpBlock(num_feat * 8, num_feat * 8)
+ self.upsample1 = SFTUpBlock(num_feat * 8, num_feat * 4)
+ self.upsample2 = SFTUpBlock(num_feat * 4, num_feat * 2)
+ self.upsample3 = SFTUpBlock(num_feat * 2, num_feat)
+ self.upsample4 = nn.Sequential(
+ spectral_norm(nn.Conv2d(num_feat, num_feat, 3, 1, 1)), nn.LeakyReLU(0.2, True), UpResBlock(num_feat),
+ UpResBlock(num_feat), nn.Conv2d(num_feat, 3, kernel_size=3, stride=1, padding=1), nn.Tanh())
+
+ def swap_feat(self, vgg_feat, updated_feat, dict_feat, location, part_name, f_size):
+ """swap the features from the dictionary."""
+ # get the original vgg features
+ part_feat = vgg_feat[:, :, location[1]:location[3], location[0]:location[2]].clone()
+ # resize original vgg features
+ part_resize_feat = F.interpolate(part_feat, dict_feat.size()[2:4], mode='bilinear', align_corners=False)
+ # use adaptive instance normalization to adjust color and illuminations
+ dict_feat = adaptive_instance_normalization(dict_feat, part_resize_feat)
+ # get similarity scores
+ similarity_score = F.conv2d(part_resize_feat, dict_feat)
+ similarity_score = F.softmax(similarity_score.view(-1), dim=0)
+ # select the most similar features in the dict (after norm)
+ select_idx = torch.argmax(similarity_score)
+ swap_feat = F.interpolate(dict_feat[select_idx:select_idx + 1], part_feat.size()[2:4])
+ # attention
+ attn = self.attn_blocks[f'{part_name}_' + str(f_size)](swap_feat - part_feat)
+ attn_feat = attn * swap_feat
+ # update features
+ updated_feat[:, :, location[1]:location[3], location[0]:location[2]] = attn_feat + part_feat
+ return updated_feat
+
+ def put_dict_to_device(self, x):
+ if self.flag_dict_device is False:
+ for k, v in self.dict.items():
+ for kk, vv in v.items():
+ self.dict[k][kk] = vv.to(x)
+ self.flag_dict_device = True
+
+ def forward(self, x, part_locations):
+ """
+ Now only support testing with batch size = 0.
+
+ Args:
+ x (Tensor): Input faces with shape (b, c, 512, 512).
+ part_locations (list[Tensor]): Part locations.
+ """
+ self.put_dict_to_device(x)
+ # extract vggface features
+ vgg_features = self.vgg_extractor(x)
+ # update vggface features using the dictionary for each part
+ updated_vgg_features = []
+ batch = 0 # only supports testing with batch size = 0
+ for vgg_layer, f_size in zip(self.vgg_layers, self.feature_sizes):
+ dict_features = self.dict[f'{f_size}']
+ vgg_feat = vgg_features[vgg_layer]
+ updated_feat = vgg_feat.clone()
+
+ # swap features from dictionary
+ for part_idx, part_name in enumerate(self.parts):
+ location = (part_locations[part_idx][batch] // (512 / f_size)).int()
+ updated_feat = self.swap_feat(vgg_feat, updated_feat, dict_features[part_name], location, part_name,
+ f_size)
+
+ updated_vgg_features.append(updated_feat)
+
+ vgg_feat_dilation = self.multi_scale_dilation(vgg_features['conv5_4'])
+ # use updated vgg features to modulate the upsampled features with
+ # SFT (Spatial Feature Transform) scaling and shifting manner.
+ upsampled_feat = self.upsample0(vgg_feat_dilation, updated_vgg_features[3])
+ upsampled_feat = self.upsample1(upsampled_feat, updated_vgg_features[2])
+ upsampled_feat = self.upsample2(upsampled_feat, updated_vgg_features[1])
+ upsampled_feat = self.upsample3(upsampled_feat, updated_vgg_features[0])
+ out = self.upsample4(upsampled_feat)
+
+ return out
diff --git a/custom_nodes/ComfyUI-ReActor/r_basicsr/archs/dfdnet_util.py b/custom_nodes/ComfyUI-ReActor/r_basicsr/archs/dfdnet_util.py
new file mode 100644
index 0000000000000000000000000000000000000000..b4dc0ff738c76852e830b32fffbe65bffb5ddf50
--- /dev/null
+++ b/custom_nodes/ComfyUI-ReActor/r_basicsr/archs/dfdnet_util.py
@@ -0,0 +1,162 @@
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from torch.autograd import Function
+from torch.nn.utils.spectral_norm import spectral_norm
+
+
+class BlurFunctionBackward(Function):
+
+ @staticmethod
+ def forward(ctx, grad_output, kernel, kernel_flip):
+ ctx.save_for_backward(kernel, kernel_flip)
+ grad_input = F.conv2d(grad_output, kernel_flip, padding=1, groups=grad_output.shape[1])
+ return grad_input
+
+ @staticmethod
+ def backward(ctx, gradgrad_output):
+ kernel, _ = ctx.saved_tensors
+ grad_input = F.conv2d(gradgrad_output, kernel, padding=1, groups=gradgrad_output.shape[1])
+ return grad_input, None, None
+
+
+class BlurFunction(Function):
+
+ @staticmethod
+ def forward(ctx, x, kernel, kernel_flip):
+ ctx.save_for_backward(kernel, kernel_flip)
+ output = F.conv2d(x, kernel, padding=1, groups=x.shape[1])
+ return output
+
+ @staticmethod
+ def backward(ctx, grad_output):
+ kernel, kernel_flip = ctx.saved_tensors
+ grad_input = BlurFunctionBackward.apply(grad_output, kernel, kernel_flip)
+ return grad_input, None, None
+
+
+blur = BlurFunction.apply
+
+
+class Blur(nn.Module):
+
+ def __init__(self, channel):
+ super().__init__()
+ kernel = torch.tensor([[1, 2, 1], [2, 4, 2], [1, 2, 1]], dtype=torch.float32)
+ kernel = kernel.view(1, 1, 3, 3)
+ kernel = kernel / kernel.sum()
+ kernel_flip = torch.flip(kernel, [2, 3])
+
+ self.kernel = kernel.repeat(channel, 1, 1, 1)
+ self.kernel_flip = kernel_flip.repeat(channel, 1, 1, 1)
+
+ def forward(self, x):
+ return blur(x, self.kernel.type_as(x), self.kernel_flip.type_as(x))
+
+
+def calc_mean_std(feat, eps=1e-5):
+ """Calculate mean and std for adaptive_instance_normalization.
+
+ Args:
+ feat (Tensor): 4D tensor.
+ eps (float): A small value added to the variance to avoid
+ divide-by-zero. Default: 1e-5.
+ """
+ size = feat.size()
+ assert len(size) == 4, 'The input feature should be 4D tensor.'
+ n, c = size[:2]
+ feat_var = feat.view(n, c, -1).var(dim=2) + eps
+ feat_std = feat_var.sqrt().view(n, c, 1, 1)
+ feat_mean = feat.view(n, c, -1).mean(dim=2).view(n, c, 1, 1)
+ return feat_mean, feat_std
+
+
+def adaptive_instance_normalization(content_feat, style_feat):
+ """Adaptive instance normalization.
+
+ Adjust the reference features to have the similar color and illuminations
+ as those in the degradate features.
+
+ Args:
+ content_feat (Tensor): The reference feature.
+ style_feat (Tensor): The degradate features.
+ """
+ size = content_feat.size()
+ style_mean, style_std = calc_mean_std(style_feat)
+ content_mean, content_std = calc_mean_std(content_feat)
+ normalized_feat = (content_feat - content_mean.expand(size)) / content_std.expand(size)
+ return normalized_feat * style_std.expand(size) + style_mean.expand(size)
+
+
+def AttentionBlock(in_channel):
+ return nn.Sequential(
+ spectral_norm(nn.Conv2d(in_channel, in_channel, 3, 1, 1)), nn.LeakyReLU(0.2, True),
+ spectral_norm(nn.Conv2d(in_channel, in_channel, 3, 1, 1)))
+
+
+def conv_block(in_channels, out_channels, kernel_size=3, stride=1, dilation=1, bias=True):
+ """Conv block used in MSDilationBlock."""
+
+ return nn.Sequential(
+ spectral_norm(
+ nn.Conv2d(
+ in_channels,
+ out_channels,
+ kernel_size=kernel_size,
+ stride=stride,
+ dilation=dilation,
+ padding=((kernel_size - 1) // 2) * dilation,
+ bias=bias)),
+ nn.LeakyReLU(0.2),
+ spectral_norm(
+ nn.Conv2d(
+ out_channels,
+ out_channels,
+ kernel_size=kernel_size,
+ stride=stride,
+ dilation=dilation,
+ padding=((kernel_size - 1) // 2) * dilation,
+ bias=bias)),
+ )
+
+
+class MSDilationBlock(nn.Module):
+ """Multi-scale dilation block."""
+
+ def __init__(self, in_channels, kernel_size=3, dilation=(1, 1, 1, 1), bias=True):
+ super(MSDilationBlock, self).__init__()
+
+ self.conv_blocks = nn.ModuleList()
+ for i in range(4):
+ self.conv_blocks.append(conv_block(in_channels, in_channels, kernel_size, dilation=dilation[i], bias=bias))
+ self.conv_fusion = spectral_norm(
+ nn.Conv2d(
+ in_channels * 4,
+ in_channels,
+ kernel_size=kernel_size,
+ stride=1,
+ padding=(kernel_size - 1) // 2,
+ bias=bias))
+
+ def forward(self, x):
+ out = []
+ for i in range(4):
+ out.append(self.conv_blocks[i](x))
+ out = torch.cat(out, 1)
+ out = self.conv_fusion(out) + x
+ return out
+
+
+class UpResBlock(nn.Module):
+
+ def __init__(self, in_channel):
+ super(UpResBlock, self).__init__()
+ self.body = nn.Sequential(
+ nn.Conv2d(in_channel, in_channel, 3, 1, 1),
+ nn.LeakyReLU(0.2, True),
+ nn.Conv2d(in_channel, in_channel, 3, 1, 1),
+ )
+
+ def forward(self, x):
+ out = x + self.body(x)
+ return out
diff --git a/custom_nodes/ComfyUI-ReActor/r_basicsr/archs/discriminator_arch.py b/custom_nodes/ComfyUI-ReActor/r_basicsr/archs/discriminator_arch.py
new file mode 100644
index 0000000000000000000000000000000000000000..9c5ae93aaffc749bc00f27947a6b67d2ae327109
--- /dev/null
+++ b/custom_nodes/ComfyUI-ReActor/r_basicsr/archs/discriminator_arch.py
@@ -0,0 +1,150 @@
+from torch import nn as nn
+from torch.nn import functional as F
+from torch.nn.utils import spectral_norm
+
+from r_basicsr.utils.registry import ARCH_REGISTRY
+
+
+@ARCH_REGISTRY.register()
+class VGGStyleDiscriminator(nn.Module):
+ """VGG style discriminator with input size 128 x 128 or 256 x 256.
+
+ It is used to train SRGAN, ESRGAN, and VideoGAN.
+
+ Args:
+ num_in_ch (int): Channel number of inputs. Default: 3.
+ num_feat (int): Channel number of base intermediate features.Default: 64.
+ """
+
+ def __init__(self, num_in_ch, num_feat, input_size=128):
+ super(VGGStyleDiscriminator, self).__init__()
+ self.input_size = input_size
+ assert self.input_size == 128 or self.input_size == 256, (
+ f'input size must be 128 or 256, but received {input_size}')
+
+ self.conv0_0 = nn.Conv2d(num_in_ch, num_feat, 3, 1, 1, bias=True)
+ self.conv0_1 = nn.Conv2d(num_feat, num_feat, 4, 2, 1, bias=False)
+ self.bn0_1 = nn.BatchNorm2d(num_feat, affine=True)
+
+ self.conv1_0 = nn.Conv2d(num_feat, num_feat * 2, 3, 1, 1, bias=False)
+ self.bn1_0 = nn.BatchNorm2d(num_feat * 2, affine=True)
+ self.conv1_1 = nn.Conv2d(num_feat * 2, num_feat * 2, 4, 2, 1, bias=False)
+ self.bn1_1 = nn.BatchNorm2d(num_feat * 2, affine=True)
+
+ self.conv2_0 = nn.Conv2d(num_feat * 2, num_feat * 4, 3, 1, 1, bias=False)
+ self.bn2_0 = nn.BatchNorm2d(num_feat * 4, affine=True)
+ self.conv2_1 = nn.Conv2d(num_feat * 4, num_feat * 4, 4, 2, 1, bias=False)
+ self.bn2_1 = nn.BatchNorm2d(num_feat * 4, affine=True)
+
+ self.conv3_0 = nn.Conv2d(num_feat * 4, num_feat * 8, 3, 1, 1, bias=False)
+ self.bn3_0 = nn.BatchNorm2d(num_feat * 8, affine=True)
+ self.conv3_1 = nn.Conv2d(num_feat * 8, num_feat * 8, 4, 2, 1, bias=False)
+ self.bn3_1 = nn.BatchNorm2d(num_feat * 8, affine=True)
+
+ self.conv4_0 = nn.Conv2d(num_feat * 8, num_feat * 8, 3, 1, 1, bias=False)
+ self.bn4_0 = nn.BatchNorm2d(num_feat * 8, affine=True)
+ self.conv4_1 = nn.Conv2d(num_feat * 8, num_feat * 8, 4, 2, 1, bias=False)
+ self.bn4_1 = nn.BatchNorm2d(num_feat * 8, affine=True)
+
+ if self.input_size == 256:
+ self.conv5_0 = nn.Conv2d(num_feat * 8, num_feat * 8, 3, 1, 1, bias=False)
+ self.bn5_0 = nn.BatchNorm2d(num_feat * 8, affine=True)
+ self.conv5_1 = nn.Conv2d(num_feat * 8, num_feat * 8, 4, 2, 1, bias=False)
+ self.bn5_1 = nn.BatchNorm2d(num_feat * 8, affine=True)
+
+ self.linear1 = nn.Linear(num_feat * 8 * 4 * 4, 100)
+ self.linear2 = nn.Linear(100, 1)
+
+ # activation function
+ self.lrelu = nn.LeakyReLU(negative_slope=0.2, inplace=True)
+
+ def forward(self, x):
+ assert x.size(2) == self.input_size, (f'Input size must be identical to input_size, but received {x.size()}.')
+
+ feat = self.lrelu(self.conv0_0(x))
+ feat = self.lrelu(self.bn0_1(self.conv0_1(feat))) # output spatial size: /2
+
+ feat = self.lrelu(self.bn1_0(self.conv1_0(feat)))
+ feat = self.lrelu(self.bn1_1(self.conv1_1(feat))) # output spatial size: /4
+
+ feat = self.lrelu(self.bn2_0(self.conv2_0(feat)))
+ feat = self.lrelu(self.bn2_1(self.conv2_1(feat))) # output spatial size: /8
+
+ feat = self.lrelu(self.bn3_0(self.conv3_0(feat)))
+ feat = self.lrelu(self.bn3_1(self.conv3_1(feat))) # output spatial size: /16
+
+ feat = self.lrelu(self.bn4_0(self.conv4_0(feat)))
+ feat = self.lrelu(self.bn4_1(self.conv4_1(feat))) # output spatial size: /32
+
+ if self.input_size == 256:
+ feat = self.lrelu(self.bn5_0(self.conv5_0(feat)))
+ feat = self.lrelu(self.bn5_1(self.conv5_1(feat))) # output spatial size: / 64
+
+ # spatial size: (4, 4)
+ feat = feat.view(feat.size(0), -1)
+ feat = self.lrelu(self.linear1(feat))
+ out = self.linear2(feat)
+ return out
+
+
+@ARCH_REGISTRY.register(suffix='basicsr')
+class UNetDiscriminatorSN(nn.Module):
+ """Defines a U-Net discriminator with spectral normalization (SN)
+
+ It is used in Real-ESRGAN: Training Real-World Blind Super-Resolution with Pure Synthetic Data.
+
+ Arg:
+ num_in_ch (int): Channel number of inputs. Default: 3.
+ num_feat (int): Channel number of base intermediate features. Default: 64.
+ skip_connection (bool): Whether to use skip connections between U-Net. Default: True.
+ """
+
+ def __init__(self, num_in_ch, num_feat=64, skip_connection=True):
+ super(UNetDiscriminatorSN, self).__init__()
+ self.skip_connection = skip_connection
+ norm = spectral_norm
+ # the first convolution
+ self.conv0 = nn.Conv2d(num_in_ch, num_feat, kernel_size=3, stride=1, padding=1)
+ # downsample
+ self.conv1 = norm(nn.Conv2d(num_feat, num_feat * 2, 4, 2, 1, bias=False))
+ self.conv2 = norm(nn.Conv2d(num_feat * 2, num_feat * 4, 4, 2, 1, bias=False))
+ self.conv3 = norm(nn.Conv2d(num_feat * 4, num_feat * 8, 4, 2, 1, bias=False))
+ # upsample
+ self.conv4 = norm(nn.Conv2d(num_feat * 8, num_feat * 4, 3, 1, 1, bias=False))
+ self.conv5 = norm(nn.Conv2d(num_feat * 4, num_feat * 2, 3, 1, 1, bias=False))
+ self.conv6 = norm(nn.Conv2d(num_feat * 2, num_feat, 3, 1, 1, bias=False))
+ # extra convolutions
+ self.conv7 = norm(nn.Conv2d(num_feat, num_feat, 3, 1, 1, bias=False))
+ self.conv8 = norm(nn.Conv2d(num_feat, num_feat, 3, 1, 1, bias=False))
+ self.conv9 = nn.Conv2d(num_feat, 1, 3, 1, 1)
+
+ def forward(self, x):
+ # downsample
+ x0 = F.leaky_relu(self.conv0(x), negative_slope=0.2, inplace=True)
+ x1 = F.leaky_relu(self.conv1(x0), negative_slope=0.2, inplace=True)
+ x2 = F.leaky_relu(self.conv2(x1), negative_slope=0.2, inplace=True)
+ x3 = F.leaky_relu(self.conv3(x2), negative_slope=0.2, inplace=True)
+
+ # upsample
+ x3 = F.interpolate(x3, scale_factor=2, mode='bilinear', align_corners=False)
+ x4 = F.leaky_relu(self.conv4(x3), negative_slope=0.2, inplace=True)
+
+ if self.skip_connection:
+ x4 = x4 + x2
+ x4 = F.interpolate(x4, scale_factor=2, mode='bilinear', align_corners=False)
+ x5 = F.leaky_relu(self.conv5(x4), negative_slope=0.2, inplace=True)
+
+ if self.skip_connection:
+ x5 = x5 + x1
+ x5 = F.interpolate(x5, scale_factor=2, mode='bilinear', align_corners=False)
+ x6 = F.leaky_relu(self.conv6(x5), negative_slope=0.2, inplace=True)
+
+ if self.skip_connection:
+ x6 = x6 + x0
+
+ # extra convolutions
+ out = F.leaky_relu(self.conv7(x6), negative_slope=0.2, inplace=True)
+ out = F.leaky_relu(self.conv8(out), negative_slope=0.2, inplace=True)
+ out = self.conv9(out)
+
+ return out
diff --git a/custom_nodes/ComfyUI-ReActor/r_basicsr/archs/duf_arch.py b/custom_nodes/ComfyUI-ReActor/r_basicsr/archs/duf_arch.py
new file mode 100644
index 0000000000000000000000000000000000000000..1c9dec88bf4f183e807c22a4e103845defc7228c
--- /dev/null
+++ b/custom_nodes/ComfyUI-ReActor/r_basicsr/archs/duf_arch.py
@@ -0,0 +1,277 @@
+import numpy as np
+import torch
+from torch import nn as nn
+from torch.nn import functional as F
+
+from r_basicsr.utils.registry import ARCH_REGISTRY
+
+
+class DenseBlocksTemporalReduce(nn.Module):
+ """A concatenation of 3 dense blocks with reduction in temporal dimension.
+
+ Note that the output temporal dimension is 6 fewer the input temporal dimension, since there are 3 blocks.
+
+ Args:
+ num_feat (int): Number of channels in the blocks. Default: 64.
+ num_grow_ch (int): Growing factor of the dense blocks. Default: 32
+ adapt_official_weights (bool): Whether to adapt the weights translated from the official implementation.
+ Set to false if you want to train from scratch. Default: False.
+ """
+
+ def __init__(self, num_feat=64, num_grow_ch=32, adapt_official_weights=False):
+ super(DenseBlocksTemporalReduce, self).__init__()
+ if adapt_official_weights:
+ eps = 1e-3
+ momentum = 1e-3
+ else: # pytorch default values
+ eps = 1e-05
+ momentum = 0.1
+
+ self.temporal_reduce1 = nn.Sequential(
+ nn.BatchNorm3d(num_feat, eps=eps, momentum=momentum), nn.ReLU(inplace=True),
+ nn.Conv3d(num_feat, num_feat, (1, 1, 1), stride=(1, 1, 1), padding=(0, 0, 0), bias=True),
+ nn.BatchNorm3d(num_feat, eps=eps, momentum=momentum), nn.ReLU(inplace=True),
+ nn.Conv3d(num_feat, num_grow_ch, (3, 3, 3), stride=(1, 1, 1), padding=(0, 1, 1), bias=True))
+
+ self.temporal_reduce2 = nn.Sequential(
+ nn.BatchNorm3d(num_feat + num_grow_ch, eps=eps, momentum=momentum), nn.ReLU(inplace=True),
+ nn.Conv3d(
+ num_feat + num_grow_ch,
+ num_feat + num_grow_ch, (1, 1, 1),
+ stride=(1, 1, 1),
+ padding=(0, 0, 0),
+ bias=True), nn.BatchNorm3d(num_feat + num_grow_ch, eps=eps, momentum=momentum), nn.ReLU(inplace=True),
+ nn.Conv3d(num_feat + num_grow_ch, num_grow_ch, (3, 3, 3), stride=(1, 1, 1), padding=(0, 1, 1), bias=True))
+
+ self.temporal_reduce3 = nn.Sequential(
+ nn.BatchNorm3d(num_feat + 2 * num_grow_ch, eps=eps, momentum=momentum), nn.ReLU(inplace=True),
+ nn.Conv3d(
+ num_feat + 2 * num_grow_ch,
+ num_feat + 2 * num_grow_ch, (1, 1, 1),
+ stride=(1, 1, 1),
+ padding=(0, 0, 0),
+ bias=True), nn.BatchNorm3d(num_feat + 2 * num_grow_ch, eps=eps, momentum=momentum),
+ nn.ReLU(inplace=True),
+ nn.Conv3d(
+ num_feat + 2 * num_grow_ch, num_grow_ch, (3, 3, 3), stride=(1, 1, 1), padding=(0, 1, 1), bias=True))
+
+ def forward(self, x):
+ """
+ Args:
+ x (Tensor): Input tensor with shape (b, num_feat, t, h, w).
+
+ Returns:
+ Tensor: Output with shape (b, num_feat + num_grow_ch * 3, 1, h, w).
+ """
+ x1 = self.temporal_reduce1(x)
+ x1 = torch.cat((x[:, :, 1:-1, :, :], x1), 1)
+
+ x2 = self.temporal_reduce2(x1)
+ x2 = torch.cat((x1[:, :, 1:-1, :, :], x2), 1)
+
+ x3 = self.temporal_reduce3(x2)
+ x3 = torch.cat((x2[:, :, 1:-1, :, :], x3), 1)
+
+ return x3
+
+
+class DenseBlocks(nn.Module):
+ """ A concatenation of N dense blocks.
+
+ Args:
+ num_feat (int): Number of channels in the blocks. Default: 64.
+ num_grow_ch (int): Growing factor of the dense blocks. Default: 32.
+ num_block (int): Number of dense blocks. The values are:
+ DUF-S (16 layers): 3
+ DUF-M (18 layers): 9
+ DUF-L (52 layers): 21
+ adapt_official_weights (bool): Whether to adapt the weights translated from the official implementation.
+ Set to false if you want to train from scratch. Default: False.
+ """
+
+ def __init__(self, num_block, num_feat=64, num_grow_ch=16, adapt_official_weights=False):
+ super(DenseBlocks, self).__init__()
+ if adapt_official_weights:
+ eps = 1e-3
+ momentum = 1e-3
+ else: # pytorch default values
+ eps = 1e-05
+ momentum = 0.1
+
+ self.dense_blocks = nn.ModuleList()
+ for i in range(0, num_block):
+ self.dense_blocks.append(
+ nn.Sequential(
+ nn.BatchNorm3d(num_feat + i * num_grow_ch, eps=eps, momentum=momentum), nn.ReLU(inplace=True),
+ nn.Conv3d(
+ num_feat + i * num_grow_ch,
+ num_feat + i * num_grow_ch, (1, 1, 1),
+ stride=(1, 1, 1),
+ padding=(0, 0, 0),
+ bias=True), nn.BatchNorm3d(num_feat + i * num_grow_ch, eps=eps, momentum=momentum),
+ nn.ReLU(inplace=True),
+ nn.Conv3d(
+ num_feat + i * num_grow_ch,
+ num_grow_ch, (3, 3, 3),
+ stride=(1, 1, 1),
+ padding=(1, 1, 1),
+ bias=True)))
+
+ def forward(self, x):
+ """
+ Args:
+ x (Tensor): Input tensor with shape (b, num_feat, t, h, w).
+
+ Returns:
+ Tensor: Output with shape (b, num_feat + num_block * num_grow_ch, t, h, w).
+ """
+ for i in range(0, len(self.dense_blocks)):
+ y = self.dense_blocks[i](x)
+ x = torch.cat((x, y), 1)
+ return x
+
+
+class DynamicUpsamplingFilter(nn.Module):
+ """Dynamic upsampling filter used in DUF.
+
+ Ref: https://github.com/yhjo09/VSR-DUF.
+ It only supports input with 3 channels. And it applies the same filters to 3 channels.
+
+ Args:
+ filter_size (tuple): Filter size of generated filters. The shape is (kh, kw). Default: (5, 5).
+ """
+
+ def __init__(self, filter_size=(5, 5)):
+ super(DynamicUpsamplingFilter, self).__init__()
+ if not isinstance(filter_size, tuple):
+ raise TypeError(f'The type of filter_size must be tuple, but got type{filter_size}')
+ if len(filter_size) != 2:
+ raise ValueError(f'The length of filter size must be 2, but got {len(filter_size)}.')
+ # generate a local expansion filter, similar to im2col
+ self.filter_size = filter_size
+ filter_prod = np.prod(filter_size)
+ expansion_filter = torch.eye(int(filter_prod)).view(filter_prod, 1, *filter_size) # (kh*kw, 1, kh, kw)
+ self.expansion_filter = expansion_filter.repeat(3, 1, 1, 1) # repeat for all the 3 channels
+
+ def forward(self, x, filters):
+ """Forward function for DynamicUpsamplingFilter.
+
+ Args:
+ x (Tensor): Input image with 3 channels. The shape is (n, 3, h, w).
+ filters (Tensor): Generated dynamic filters.
+ The shape is (n, filter_prod, upsampling_square, h, w).
+ filter_prod: prod of filter kernel size, e.g., 1*5*5=25.
+ upsampling_square: similar to pixel shuffle,
+ upsampling_square = upsampling * upsampling
+ e.g., for x 4 upsampling, upsampling_square= 4*4 = 16
+
+ Returns:
+ Tensor: Filtered image with shape (n, 3*upsampling_square, h, w)
+ """
+ n, filter_prod, upsampling_square, h, w = filters.size()
+ kh, kw = self.filter_size
+ expanded_input = F.conv2d(
+ x, self.expansion_filter.to(x), padding=(kh // 2, kw // 2), groups=3) # (n, 3*filter_prod, h, w)
+ expanded_input = expanded_input.view(n, 3, filter_prod, h, w).permute(0, 3, 4, 1,
+ 2) # (n, h, w, 3, filter_prod)
+ filters = filters.permute(0, 3, 4, 1, 2) # (n, h, w, filter_prod, upsampling_square]
+ out = torch.matmul(expanded_input, filters) # (n, h, w, 3, upsampling_square)
+ return out.permute(0, 3, 4, 1, 2).view(n, 3 * upsampling_square, h, w)
+
+
+@ARCH_REGISTRY.register()
+class DUF(nn.Module):
+ """Network architecture for DUF
+
+ Paper: Jo et.al. Deep Video Super-Resolution Network Using Dynamic
+ Upsampling Filters Without Explicit Motion Compensation, CVPR, 2018
+ Code reference:
+ https://github.com/yhjo09/VSR-DUF
+ For all the models below, 'adapt_official_weights' is only necessary when
+ loading the weights converted from the official TensorFlow weights.
+ Please set it to False if you are training the model from scratch.
+
+ There are three models with different model size: DUF16Layers, DUF28Layers,
+ and DUF52Layers. This class is the base class for these models.
+
+ Args:
+ scale (int): The upsampling factor. Default: 4.
+ num_layer (int): The number of layers. Default: 52.
+ adapt_official_weights_weights (bool): Whether to adapt the weights
+ translated from the official implementation. Set to false if you
+ want to train from scratch. Default: False.
+ """
+
+ def __init__(self, scale=4, num_layer=52, adapt_official_weights=False):
+ super(DUF, self).__init__()
+ self.scale = scale
+ if adapt_official_weights:
+ eps = 1e-3
+ momentum = 1e-3
+ else: # pytorch default values
+ eps = 1e-05
+ momentum = 0.1
+
+ self.conv3d1 = nn.Conv3d(3, 64, (1, 3, 3), stride=(1, 1, 1), padding=(0, 1, 1), bias=True)
+ self.dynamic_filter = DynamicUpsamplingFilter((5, 5))
+
+ if num_layer == 16:
+ num_block = 3
+ num_grow_ch = 32
+ elif num_layer == 28:
+ num_block = 9
+ num_grow_ch = 16
+ elif num_layer == 52:
+ num_block = 21
+ num_grow_ch = 16
+ else:
+ raise ValueError(f'Only supported (16, 28, 52) layers, but got {num_layer}.')
+
+ self.dense_block1 = DenseBlocks(
+ num_block=num_block, num_feat=64, num_grow_ch=num_grow_ch,
+ adapt_official_weights=adapt_official_weights) # T = 7
+ self.dense_block2 = DenseBlocksTemporalReduce(
+ 64 + num_grow_ch * num_block, num_grow_ch, adapt_official_weights=adapt_official_weights) # T = 1
+ channels = 64 + num_grow_ch * num_block + num_grow_ch * 3
+ self.bn3d2 = nn.BatchNorm3d(channels, eps=eps, momentum=momentum)
+ self.conv3d2 = nn.Conv3d(channels, 256, (1, 3, 3), stride=(1, 1, 1), padding=(0, 1, 1), bias=True)
+
+ self.conv3d_r1 = nn.Conv3d(256, 256, (1, 1, 1), stride=(1, 1, 1), padding=(0, 0, 0), bias=True)
+ self.conv3d_r2 = nn.Conv3d(256, 3 * (scale**2), (1, 1, 1), stride=(1, 1, 1), padding=(0, 0, 0), bias=True)
+
+ self.conv3d_f1 = nn.Conv3d(256, 512, (1, 1, 1), stride=(1, 1, 1), padding=(0, 0, 0), bias=True)
+ self.conv3d_f2 = nn.Conv3d(
+ 512, 1 * 5 * 5 * (scale**2), (1, 1, 1), stride=(1, 1, 1), padding=(0, 0, 0), bias=True)
+
+ def forward(self, x):
+ """
+ Args:
+ x (Tensor): Input with shape (b, 7, c, h, w)
+
+ Returns:
+ Tensor: Output with shape (b, c, h * scale, w * scale)
+ """
+ num_batches, num_imgs, _, h, w = x.size()
+
+ x = x.permute(0, 2, 1, 3, 4) # (b, c, 7, h, w) for Conv3D
+ x_center = x[:, :, num_imgs // 2, :, :]
+
+ x = self.conv3d1(x)
+ x = self.dense_block1(x)
+ x = self.dense_block2(x)
+ x = F.relu(self.bn3d2(x), inplace=True)
+ x = F.relu(self.conv3d2(x), inplace=True)
+
+ # residual image
+ res = self.conv3d_r2(F.relu(self.conv3d_r1(x), inplace=True))
+
+ # filter
+ filter_ = self.conv3d_f2(F.relu(self.conv3d_f1(x), inplace=True))
+ filter_ = F.softmax(filter_.view(num_batches, 25, self.scale**2, h, w), dim=1)
+
+ # dynamic filter
+ out = self.dynamic_filter(x_center, filter_)
+ out += res.squeeze_(2)
+ out = F.pixel_shuffle(out, self.scale)
+
+ return out
diff --git a/custom_nodes/ComfyUI-ReActor/r_basicsr/archs/ecbsr_arch.py b/custom_nodes/ComfyUI-ReActor/r_basicsr/archs/ecbsr_arch.py
new file mode 100644
index 0000000000000000000000000000000000000000..199d786fddfdd160ef524fb161bcbcb4668a38e6
--- /dev/null
+++ b/custom_nodes/ComfyUI-ReActor/r_basicsr/archs/ecbsr_arch.py
@@ -0,0 +1,274 @@
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+
+from r_basicsr.utils.registry import ARCH_REGISTRY
+
+
+class SeqConv3x3(nn.Module):
+ """The re-parameterizable block used in the ECBSR architecture.
+
+ Paper: Edge-oriented Convolution Block for Real-time Super Resolution on Mobile Devices
+ Ref git repo: https://github.com/xindongzhang/ECBSR
+
+ Args:
+ seq_type (str): Sequence type, option: conv1x1-conv3x3 | conv1x1-sobelx | conv1x1-sobely | conv1x1-laplacian.
+ in_channels (int): Channel number of input.
+ out_channels (int): Channel number of output.
+ depth_multiplier (int): Width multiplier in the expand-and-squeeze conv. Default: 1.
+ """
+
+ def __init__(self, seq_type, in_channels, out_channels, depth_multiplier=1):
+ super(SeqConv3x3, self).__init__()
+ self.seq_type = seq_type
+ self.in_channels = in_channels
+ self.out_channels = out_channels
+
+ if self.seq_type == 'conv1x1-conv3x3':
+ self.mid_planes = int(out_channels * depth_multiplier)
+ conv0 = torch.nn.Conv2d(self.in_channels, self.mid_planes, kernel_size=1, padding=0)
+ self.k0 = conv0.weight
+ self.b0 = conv0.bias
+
+ conv1 = torch.nn.Conv2d(self.mid_planes, self.out_channels, kernel_size=3)
+ self.k1 = conv1.weight
+ self.b1 = conv1.bias
+
+ elif self.seq_type == 'conv1x1-sobelx':
+ conv0 = torch.nn.Conv2d(self.in_channels, self.out_channels, kernel_size=1, padding=0)
+ self.k0 = conv0.weight
+ self.b0 = conv0.bias
+
+ # init scale and bias
+ scale = torch.randn(size=(self.out_channels, 1, 1, 1)) * 1e-3
+ self.scale = nn.Parameter(scale)
+ bias = torch.randn(self.out_channels) * 1e-3
+ bias = torch.reshape(bias, (self.out_channels, ))
+ self.bias = nn.Parameter(bias)
+ # init mask
+ self.mask = torch.zeros((self.out_channels, 1, 3, 3), dtype=torch.float32)
+ for i in range(self.out_channels):
+ self.mask[i, 0, 0, 0] = 1.0
+ self.mask[i, 0, 1, 0] = 2.0
+ self.mask[i, 0, 2, 0] = 1.0
+ self.mask[i, 0, 0, 2] = -1.0
+ self.mask[i, 0, 1, 2] = -2.0
+ self.mask[i, 0, 2, 2] = -1.0
+ self.mask = nn.Parameter(data=self.mask, requires_grad=False)
+
+ elif self.seq_type == 'conv1x1-sobely':
+ conv0 = torch.nn.Conv2d(self.in_channels, self.out_channels, kernel_size=1, padding=0)
+ self.k0 = conv0.weight
+ self.b0 = conv0.bias
+
+ # init scale and bias
+ scale = torch.randn(size=(self.out_channels, 1, 1, 1)) * 1e-3
+ self.scale = nn.Parameter(torch.FloatTensor(scale))
+ bias = torch.randn(self.out_channels) * 1e-3
+ bias = torch.reshape(bias, (self.out_channels, ))
+ self.bias = nn.Parameter(torch.FloatTensor(bias))
+ # init mask
+ self.mask = torch.zeros((self.out_channels, 1, 3, 3), dtype=torch.float32)
+ for i in range(self.out_channels):
+ self.mask[i, 0, 0, 0] = 1.0
+ self.mask[i, 0, 0, 1] = 2.0
+ self.mask[i, 0, 0, 2] = 1.0
+ self.mask[i, 0, 2, 0] = -1.0
+ self.mask[i, 0, 2, 1] = -2.0
+ self.mask[i, 0, 2, 2] = -1.0
+ self.mask = nn.Parameter(data=self.mask, requires_grad=False)
+
+ elif self.seq_type == 'conv1x1-laplacian':
+ conv0 = torch.nn.Conv2d(self.in_channels, self.out_channels, kernel_size=1, padding=0)
+ self.k0 = conv0.weight
+ self.b0 = conv0.bias
+
+ # init scale and bias
+ scale = torch.randn(size=(self.out_channels, 1, 1, 1)) * 1e-3
+ self.scale = nn.Parameter(torch.FloatTensor(scale))
+ bias = torch.randn(self.out_channels) * 1e-3
+ bias = torch.reshape(bias, (self.out_channels, ))
+ self.bias = nn.Parameter(torch.FloatTensor(bias))
+ # init mask
+ self.mask = torch.zeros((self.out_channels, 1, 3, 3), dtype=torch.float32)
+ for i in range(self.out_channels):
+ self.mask[i, 0, 0, 1] = 1.0
+ self.mask[i, 0, 1, 0] = 1.0
+ self.mask[i, 0, 1, 2] = 1.0
+ self.mask[i, 0, 2, 1] = 1.0
+ self.mask[i, 0, 1, 1] = -4.0
+ self.mask = nn.Parameter(data=self.mask, requires_grad=False)
+ else:
+ raise ValueError('The type of seqconv is not supported!')
+
+ def forward(self, x):
+ if self.seq_type == 'conv1x1-conv3x3':
+ # conv-1x1
+ y0 = F.conv2d(input=x, weight=self.k0, bias=self.b0, stride=1)
+ # explicitly padding with bias
+ y0 = F.pad(y0, (1, 1, 1, 1), 'constant', 0)
+ b0_pad = self.b0.view(1, -1, 1, 1)
+ y0[:, :, 0:1, :] = b0_pad
+ y0[:, :, -1:, :] = b0_pad
+ y0[:, :, :, 0:1] = b0_pad
+ y0[:, :, :, -1:] = b0_pad
+ # conv-3x3
+ y1 = F.conv2d(input=y0, weight=self.k1, bias=self.b1, stride=1)
+ else:
+ y0 = F.conv2d(input=x, weight=self.k0, bias=self.b0, stride=1)
+ # explicitly padding with bias
+ y0 = F.pad(y0, (1, 1, 1, 1), 'constant', 0)
+ b0_pad = self.b0.view(1, -1, 1, 1)
+ y0[:, :, 0:1, :] = b0_pad
+ y0[:, :, -1:, :] = b0_pad
+ y0[:, :, :, 0:1] = b0_pad
+ y0[:, :, :, -1:] = b0_pad
+ # conv-3x3
+ y1 = F.conv2d(input=y0, weight=self.scale * self.mask, bias=self.bias, stride=1, groups=self.out_channels)
+ return y1
+
+ def rep_params(self):
+ device = self.k0.get_device()
+ if device < 0:
+ device = None
+
+ if self.seq_type == 'conv1x1-conv3x3':
+ # re-param conv kernel
+ rep_weight = F.conv2d(input=self.k1, weight=self.k0.permute(1, 0, 2, 3))
+ # re-param conv bias
+ rep_bias = torch.ones(1, self.mid_planes, 3, 3, device=device) * self.b0.view(1, -1, 1, 1)
+ rep_bias = F.conv2d(input=rep_bias, weight=self.k1).view(-1, ) + self.b1
+ else:
+ tmp = self.scale * self.mask
+ k1 = torch.zeros((self.out_channels, self.out_channels, 3, 3), device=device)
+ for i in range(self.out_channels):
+ k1[i, i, :, :] = tmp[i, 0, :, :]
+ b1 = self.bias
+ # re-param conv kernel
+ rep_weight = F.conv2d(input=k1, weight=self.k0.permute(1, 0, 2, 3))
+ # re-param conv bias
+ rep_bias = torch.ones(1, self.out_channels, 3, 3, device=device) * self.b0.view(1, -1, 1, 1)
+ rep_bias = F.conv2d(input=rep_bias, weight=k1).view(-1, ) + b1
+ return rep_weight, rep_bias
+
+
+class ECB(nn.Module):
+ """The ECB block used in the ECBSR architecture.
+
+ Paper: Edge-oriented Convolution Block for Real-time Super Resolution on Mobile Devices
+ Ref git repo: https://github.com/xindongzhang/ECBSR
+
+ Args:
+ in_channels (int): Channel number of input.
+ out_channels (int): Channel number of output.
+ depth_multiplier (int): Width multiplier in the expand-and-squeeze conv. Default: 1.
+ act_type (str): Activation type. Option: prelu | relu | rrelu | softplus | linear. Default: prelu.
+ with_idt (bool): Whether to use identity connection. Default: False.
+ """
+
+ def __init__(self, in_channels, out_channels, depth_multiplier, act_type='prelu', with_idt=False):
+ super(ECB, self).__init__()
+
+ self.depth_multiplier = depth_multiplier
+ self.in_channels = in_channels
+ self.out_channels = out_channels
+ self.act_type = act_type
+
+ if with_idt and (self.in_channels == self.out_channels):
+ self.with_idt = True
+ else:
+ self.with_idt = False
+
+ self.conv3x3 = torch.nn.Conv2d(self.in_channels, self.out_channels, kernel_size=3, padding=1)
+ self.conv1x1_3x3 = SeqConv3x3('conv1x1-conv3x3', self.in_channels, self.out_channels, self.depth_multiplier)
+ self.conv1x1_sbx = SeqConv3x3('conv1x1-sobelx', self.in_channels, self.out_channels)
+ self.conv1x1_sby = SeqConv3x3('conv1x1-sobely', self.in_channels, self.out_channels)
+ self.conv1x1_lpl = SeqConv3x3('conv1x1-laplacian', self.in_channels, self.out_channels)
+
+ if self.act_type == 'prelu':
+ self.act = nn.PReLU(num_parameters=self.out_channels)
+ elif self.act_type == 'relu':
+ self.act = nn.ReLU(inplace=True)
+ elif self.act_type == 'rrelu':
+ self.act = nn.RReLU(lower=-0.05, upper=0.05)
+ elif self.act_type == 'softplus':
+ self.act = nn.Softplus()
+ elif self.act_type == 'linear':
+ pass
+ else:
+ raise ValueError('The type of activation if not support!')
+
+ def forward(self, x):
+ if self.training:
+ y = self.conv3x3(x) + self.conv1x1_3x3(x) + self.conv1x1_sbx(x) + self.conv1x1_sby(x) + self.conv1x1_lpl(x)
+ if self.with_idt:
+ y += x
+ else:
+ rep_weight, rep_bias = self.rep_params()
+ y = F.conv2d(input=x, weight=rep_weight, bias=rep_bias, stride=1, padding=1)
+ if self.act_type != 'linear':
+ y = self.act(y)
+ return y
+
+ def rep_params(self):
+ weight0, bias0 = self.conv3x3.weight, self.conv3x3.bias
+ weight1, bias1 = self.conv1x1_3x3.rep_params()
+ weight2, bias2 = self.conv1x1_sbx.rep_params()
+ weight3, bias3 = self.conv1x1_sby.rep_params()
+ weight4, bias4 = self.conv1x1_lpl.rep_params()
+ rep_weight, rep_bias = (weight0 + weight1 + weight2 + weight3 + weight4), (
+ bias0 + bias1 + bias2 + bias3 + bias4)
+
+ if self.with_idt:
+ device = rep_weight.get_device()
+ if device < 0:
+ device = None
+ weight_idt = torch.zeros(self.out_channels, self.out_channels, 3, 3, device=device)
+ for i in range(self.out_channels):
+ weight_idt[i, i, 1, 1] = 1.0
+ bias_idt = 0.0
+ rep_weight, rep_bias = rep_weight + weight_idt, rep_bias + bias_idt
+ return rep_weight, rep_bias
+
+
+@ARCH_REGISTRY.register()
+class ECBSR(nn.Module):
+ """ECBSR architecture.
+
+ Paper: Edge-oriented Convolution Block for Real-time Super Resolution on Mobile Devices
+ Ref git repo: https://github.com/xindongzhang/ECBSR
+
+ Args:
+ num_in_ch (int): Channel number of inputs.
+ num_out_ch (int): Channel number of outputs.
+ num_block (int): Block number in the trunk network.
+ num_channel (int): Channel number.
+ with_idt (bool): Whether use identity in convolution layers.
+ act_type (str): Activation type.
+ scale (int): Upsampling factor.
+ """
+
+ def __init__(self, num_in_ch, num_out_ch, num_block, num_channel, with_idt, act_type, scale):
+ super(ECBSR, self).__init__()
+ self.num_in_ch = num_in_ch
+ self.scale = scale
+
+ backbone = []
+ backbone += [ECB(num_in_ch, num_channel, depth_multiplier=2.0, act_type=act_type, with_idt=with_idt)]
+ for _ in range(num_block):
+ backbone += [ECB(num_channel, num_channel, depth_multiplier=2.0, act_type=act_type, with_idt=with_idt)]
+ backbone += [
+ ECB(num_channel, num_out_ch * scale * scale, depth_multiplier=2.0, act_type='linear', with_idt=with_idt)
+ ]
+
+ self.backbone = nn.Sequential(*backbone)
+ self.upsampler = nn.PixelShuffle(scale)
+
+ def forward(self, x):
+ if self.num_in_ch > 1:
+ shortcut = torch.repeat_interleave(x, self.scale * self.scale, dim=1)
+ else:
+ shortcut = x # will repeat the input in the channel dimension (repeat scale * scale times)
+ y = self.backbone(x) + shortcut
+ y = self.upsampler(y)
+ return y
diff --git a/custom_nodes/ComfyUI-ReActor/r_basicsr/archs/edsr_arch.py b/custom_nodes/ComfyUI-ReActor/r_basicsr/archs/edsr_arch.py
new file mode 100644
index 0000000000000000000000000000000000000000..78ef9c4eb7b0d1c78ac6f56403b57f3862a32902
--- /dev/null
+++ b/custom_nodes/ComfyUI-ReActor/r_basicsr/archs/edsr_arch.py
@@ -0,0 +1,61 @@
+import torch
+from torch import nn as nn
+
+from r_basicsr.archs.arch_util import ResidualBlockNoBN, Upsample, make_layer
+from r_basicsr.utils.registry import ARCH_REGISTRY
+
+
+@ARCH_REGISTRY.register()
+class EDSR(nn.Module):
+ """EDSR network structure.
+
+ Paper: Enhanced Deep Residual Networks for Single Image Super-Resolution.
+ Ref git repo: https://github.com/thstkdgus35/EDSR-PyTorch
+
+ Args:
+ num_in_ch (int): Channel number of inputs.
+ num_out_ch (int): Channel number of outputs.
+ num_feat (int): Channel number of intermediate features.
+ Default: 64.
+ num_block (int): Block number in the trunk network. Default: 16.
+ upscale (int): Upsampling factor. Support 2^n and 3.
+ Default: 4.
+ res_scale (float): Used to scale the residual in residual block.
+ Default: 1.
+ img_range (float): Image range. Default: 255.
+ rgb_mean (tuple[float]): Image mean in RGB orders.
+ Default: (0.4488, 0.4371, 0.4040), calculated from DIV2K dataset.
+ """
+
+ def __init__(self,
+ num_in_ch,
+ num_out_ch,
+ num_feat=64,
+ num_block=16,
+ upscale=4,
+ res_scale=1,
+ img_range=255.,
+ rgb_mean=(0.4488, 0.4371, 0.4040)):
+ super(EDSR, self).__init__()
+
+ self.img_range = img_range
+ self.mean = torch.Tensor(rgb_mean).view(1, 3, 1, 1)
+
+ self.conv_first = nn.Conv2d(num_in_ch, num_feat, 3, 1, 1)
+ self.body = make_layer(ResidualBlockNoBN, num_block, num_feat=num_feat, res_scale=res_scale, pytorch_init=True)
+ self.conv_after_body = nn.Conv2d(num_feat, num_feat, 3, 1, 1)
+ self.upsample = Upsample(upscale, num_feat)
+ self.conv_last = nn.Conv2d(num_feat, num_out_ch, 3, 1, 1)
+
+ def forward(self, x):
+ self.mean = self.mean.type_as(x)
+
+ x = (x - self.mean) * self.img_range
+ x = self.conv_first(x)
+ res = self.conv_after_body(self.body(x))
+ res += x
+
+ x = self.conv_last(self.upsample(res))
+ x = x / self.img_range + self.mean
+
+ return x
diff --git a/custom_nodes/ComfyUI-ReActor/r_basicsr/archs/edvr_arch.py b/custom_nodes/ComfyUI-ReActor/r_basicsr/archs/edvr_arch.py
new file mode 100644
index 0000000000000000000000000000000000000000..fe5e0388d01f1552592d0dc50854d38f5aad55ad
--- /dev/null
+++ b/custom_nodes/ComfyUI-ReActor/r_basicsr/archs/edvr_arch.py
@@ -0,0 +1,383 @@
+import torch
+from torch import nn as nn
+from torch.nn import functional as F
+
+from r_basicsr.utils.registry import ARCH_REGISTRY
+from .arch_util import DCNv2Pack, ResidualBlockNoBN, make_layer
+
+
+class PCDAlignment(nn.Module):
+ """Alignment module using Pyramid, Cascading and Deformable convolution
+ (PCD). It is used in EDVR.
+
+ Ref:
+ EDVR: Video Restoration with Enhanced Deformable Convolutional Networks
+
+ Args:
+ num_feat (int): Channel number of middle features. Default: 64.
+ deformable_groups (int): Deformable groups. Defaults: 8.
+ """
+
+ def __init__(self, num_feat=64, deformable_groups=8):
+ super(PCDAlignment, self).__init__()
+
+ # Pyramid has three levels:
+ # L3: level 3, 1/4 spatial size
+ # L2: level 2, 1/2 spatial size
+ # L1: level 1, original spatial size
+ self.offset_conv1 = nn.ModuleDict()
+ self.offset_conv2 = nn.ModuleDict()
+ self.offset_conv3 = nn.ModuleDict()
+ self.dcn_pack = nn.ModuleDict()
+ self.feat_conv = nn.ModuleDict()
+
+ # Pyramids
+ for i in range(3, 0, -1):
+ level = f'l{i}'
+ self.offset_conv1[level] = nn.Conv2d(num_feat * 2, num_feat, 3, 1, 1)
+ if i == 3:
+ self.offset_conv2[level] = nn.Conv2d(num_feat, num_feat, 3, 1, 1)
+ else:
+ self.offset_conv2[level] = nn.Conv2d(num_feat * 2, num_feat, 3, 1, 1)
+ self.offset_conv3[level] = nn.Conv2d(num_feat, num_feat, 3, 1, 1)
+ self.dcn_pack[level] = DCNv2Pack(num_feat, num_feat, 3, padding=1, deformable_groups=deformable_groups)
+
+ if i < 3:
+ self.feat_conv[level] = nn.Conv2d(num_feat * 2, num_feat, 3, 1, 1)
+
+ # Cascading dcn
+ self.cas_offset_conv1 = nn.Conv2d(num_feat * 2, num_feat, 3, 1, 1)
+ self.cas_offset_conv2 = nn.Conv2d(num_feat, num_feat, 3, 1, 1)
+ self.cas_dcnpack = DCNv2Pack(num_feat, num_feat, 3, padding=1, deformable_groups=deformable_groups)
+
+ self.upsample = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=False)
+ self.lrelu = nn.LeakyReLU(negative_slope=0.1, inplace=True)
+
+ def forward(self, nbr_feat_l, ref_feat_l):
+ """Align neighboring frame features to the reference frame features.
+
+ Args:
+ nbr_feat_l (list[Tensor]): Neighboring feature list. It
+ contains three pyramid levels (L1, L2, L3),
+ each with shape (b, c, h, w).
+ ref_feat_l (list[Tensor]): Reference feature list. It
+ contains three pyramid levels (L1, L2, L3),
+ each with shape (b, c, h, w).
+
+ Returns:
+ Tensor: Aligned features.
+ """
+ # Pyramids
+ upsampled_offset, upsampled_feat = None, None
+ for i in range(3, 0, -1):
+ level = f'l{i}'
+ offset = torch.cat([nbr_feat_l[i - 1], ref_feat_l[i - 1]], dim=1)
+ offset = self.lrelu(self.offset_conv1[level](offset))
+ if i == 3:
+ offset = self.lrelu(self.offset_conv2[level](offset))
+ else:
+ offset = self.lrelu(self.offset_conv2[level](torch.cat([offset, upsampled_offset], dim=1)))
+ offset = self.lrelu(self.offset_conv3[level](offset))
+
+ feat = self.dcn_pack[level](nbr_feat_l[i - 1], offset)
+ if i < 3:
+ feat = self.feat_conv[level](torch.cat([feat, upsampled_feat], dim=1))
+ if i > 1:
+ feat = self.lrelu(feat)
+
+ if i > 1: # upsample offset and features
+ # x2: when we upsample the offset, we should also enlarge
+ # the magnitude.
+ upsampled_offset = self.upsample(offset) * 2
+ upsampled_feat = self.upsample(feat)
+
+ # Cascading
+ offset = torch.cat([feat, ref_feat_l[0]], dim=1)
+ offset = self.lrelu(self.cas_offset_conv2(self.lrelu(self.cas_offset_conv1(offset))))
+ feat = self.lrelu(self.cas_dcnpack(feat, offset))
+ return feat
+
+
+class TSAFusion(nn.Module):
+ """Temporal Spatial Attention (TSA) fusion module.
+
+ Temporal: Calculate the correlation between center frame and
+ neighboring frames;
+ Spatial: It has 3 pyramid levels, the attention is similar to SFT.
+ (SFT: Recovering realistic texture in image super-resolution by deep
+ spatial feature transform.)
+
+ Args:
+ num_feat (int): Channel number of middle features. Default: 64.
+ num_frame (int): Number of frames. Default: 5.
+ center_frame_idx (int): The index of center frame. Default: 2.
+ """
+
+ def __init__(self, num_feat=64, num_frame=5, center_frame_idx=2):
+ super(TSAFusion, self).__init__()
+ self.center_frame_idx = center_frame_idx
+ # temporal attention (before fusion conv)
+ self.temporal_attn1 = nn.Conv2d(num_feat, num_feat, 3, 1, 1)
+ self.temporal_attn2 = nn.Conv2d(num_feat, num_feat, 3, 1, 1)
+ self.feat_fusion = nn.Conv2d(num_frame * num_feat, num_feat, 1, 1)
+
+ # spatial attention (after fusion conv)
+ self.max_pool = nn.MaxPool2d(3, stride=2, padding=1)
+ self.avg_pool = nn.AvgPool2d(3, stride=2, padding=1)
+ self.spatial_attn1 = nn.Conv2d(num_frame * num_feat, num_feat, 1)
+ self.spatial_attn2 = nn.Conv2d(num_feat * 2, num_feat, 1)
+ self.spatial_attn3 = nn.Conv2d(num_feat, num_feat, 3, 1, 1)
+ self.spatial_attn4 = nn.Conv2d(num_feat, num_feat, 1)
+ self.spatial_attn5 = nn.Conv2d(num_feat, num_feat, 3, 1, 1)
+ self.spatial_attn_l1 = nn.Conv2d(num_feat, num_feat, 1)
+ self.spatial_attn_l2 = nn.Conv2d(num_feat * 2, num_feat, 3, 1, 1)
+ self.spatial_attn_l3 = nn.Conv2d(num_feat, num_feat, 3, 1, 1)
+ self.spatial_attn_add1 = nn.Conv2d(num_feat, num_feat, 1)
+ self.spatial_attn_add2 = nn.Conv2d(num_feat, num_feat, 1)
+
+ self.lrelu = nn.LeakyReLU(negative_slope=0.1, inplace=True)
+ self.upsample = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=False)
+
+ def forward(self, aligned_feat):
+ """
+ Args:
+ aligned_feat (Tensor): Aligned features with shape (b, t, c, h, w).
+
+ Returns:
+ Tensor: Features after TSA with the shape (b, c, h, w).
+ """
+ b, t, c, h, w = aligned_feat.size()
+ # temporal attention
+ embedding_ref = self.temporal_attn1(aligned_feat[:, self.center_frame_idx, :, :, :].clone())
+ embedding = self.temporal_attn2(aligned_feat.view(-1, c, h, w))
+ embedding = embedding.view(b, t, -1, h, w) # (b, t, c, h, w)
+
+ corr_l = [] # correlation list
+ for i in range(t):
+ emb_neighbor = embedding[:, i, :, :, :]
+ corr = torch.sum(emb_neighbor * embedding_ref, 1) # (b, h, w)
+ corr_l.append(corr.unsqueeze(1)) # (b, 1, h, w)
+ corr_prob = torch.sigmoid(torch.cat(corr_l, dim=1)) # (b, t, h, w)
+ corr_prob = corr_prob.unsqueeze(2).expand(b, t, c, h, w)
+ corr_prob = corr_prob.contiguous().view(b, -1, h, w) # (b, t*c, h, w)
+ aligned_feat = aligned_feat.view(b, -1, h, w) * corr_prob
+
+ # fusion
+ feat = self.lrelu(self.feat_fusion(aligned_feat))
+
+ # spatial attention
+ attn = self.lrelu(self.spatial_attn1(aligned_feat))
+ attn_max = self.max_pool(attn)
+ attn_avg = self.avg_pool(attn)
+ attn = self.lrelu(self.spatial_attn2(torch.cat([attn_max, attn_avg], dim=1)))
+ # pyramid levels
+ attn_level = self.lrelu(self.spatial_attn_l1(attn))
+ attn_max = self.max_pool(attn_level)
+ attn_avg = self.avg_pool(attn_level)
+ attn_level = self.lrelu(self.spatial_attn_l2(torch.cat([attn_max, attn_avg], dim=1)))
+ attn_level = self.lrelu(self.spatial_attn_l3(attn_level))
+ attn_level = self.upsample(attn_level)
+
+ attn = self.lrelu(self.spatial_attn3(attn)) + attn_level
+ attn = self.lrelu(self.spatial_attn4(attn))
+ attn = self.upsample(attn)
+ attn = self.spatial_attn5(attn)
+ attn_add = self.spatial_attn_add2(self.lrelu(self.spatial_attn_add1(attn)))
+ attn = torch.sigmoid(attn)
+
+ # after initialization, * 2 makes (attn * 2) to be close to 1.
+ feat = feat * attn * 2 + attn_add
+ return feat
+
+
+class PredeblurModule(nn.Module):
+ """Pre-dublur module.
+
+ Args:
+ num_in_ch (int): Channel number of input image. Default: 3.
+ num_feat (int): Channel number of intermediate features. Default: 64.
+ hr_in (bool): Whether the input has high resolution. Default: False.
+ """
+
+ def __init__(self, num_in_ch=3, num_feat=64, hr_in=False):
+ super(PredeblurModule, self).__init__()
+ self.hr_in = hr_in
+
+ self.conv_first = nn.Conv2d(num_in_ch, num_feat, 3, 1, 1)
+ if self.hr_in:
+ # downsample x4 by stride conv
+ self.stride_conv_hr1 = nn.Conv2d(num_feat, num_feat, 3, 2, 1)
+ self.stride_conv_hr2 = nn.Conv2d(num_feat, num_feat, 3, 2, 1)
+
+ # generate feature pyramid
+ self.stride_conv_l2 = nn.Conv2d(num_feat, num_feat, 3, 2, 1)
+ self.stride_conv_l3 = nn.Conv2d(num_feat, num_feat, 3, 2, 1)
+
+ self.resblock_l3 = ResidualBlockNoBN(num_feat=num_feat)
+ self.resblock_l2_1 = ResidualBlockNoBN(num_feat=num_feat)
+ self.resblock_l2_2 = ResidualBlockNoBN(num_feat=num_feat)
+ self.resblock_l1 = nn.ModuleList([ResidualBlockNoBN(num_feat=num_feat) for i in range(5)])
+
+ self.upsample = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=False)
+ self.lrelu = nn.LeakyReLU(negative_slope=0.1, inplace=True)
+
+ def forward(self, x):
+ feat_l1 = self.lrelu(self.conv_first(x))
+ if self.hr_in:
+ feat_l1 = self.lrelu(self.stride_conv_hr1(feat_l1))
+ feat_l1 = self.lrelu(self.stride_conv_hr2(feat_l1))
+
+ # generate feature pyramid
+ feat_l2 = self.lrelu(self.stride_conv_l2(feat_l1))
+ feat_l3 = self.lrelu(self.stride_conv_l3(feat_l2))
+
+ feat_l3 = self.upsample(self.resblock_l3(feat_l3))
+ feat_l2 = self.resblock_l2_1(feat_l2) + feat_l3
+ feat_l2 = self.upsample(self.resblock_l2_2(feat_l2))
+
+ for i in range(2):
+ feat_l1 = self.resblock_l1[i](feat_l1)
+ feat_l1 = feat_l1 + feat_l2
+ for i in range(2, 5):
+ feat_l1 = self.resblock_l1[i](feat_l1)
+ return feat_l1
+
+
+@ARCH_REGISTRY.register()
+class EDVR(nn.Module):
+ """EDVR network structure for video super-resolution.
+
+ Now only support X4 upsampling factor.
+ Paper:
+ EDVR: Video Restoration with Enhanced Deformable Convolutional Networks
+
+ Args:
+ num_in_ch (int): Channel number of input image. Default: 3.
+ num_out_ch (int): Channel number of output image. Default: 3.
+ num_feat (int): Channel number of intermediate features. Default: 64.
+ num_frame (int): Number of input frames. Default: 5.
+ deformable_groups (int): Deformable groups. Defaults: 8.
+ num_extract_block (int): Number of blocks for feature extraction.
+ Default: 5.
+ num_reconstruct_block (int): Number of blocks for reconstruction.
+ Default: 10.
+ center_frame_idx (int): The index of center frame. Frame counting from
+ 0. Default: Middle of input frames.
+ hr_in (bool): Whether the input has high resolution. Default: False.
+ with_predeblur (bool): Whether has predeblur module.
+ Default: False.
+ with_tsa (bool): Whether has TSA module. Default: True.
+ """
+
+ def __init__(self,
+ num_in_ch=3,
+ num_out_ch=3,
+ num_feat=64,
+ num_frame=5,
+ deformable_groups=8,
+ num_extract_block=5,
+ num_reconstruct_block=10,
+ center_frame_idx=None,
+ hr_in=False,
+ with_predeblur=False,
+ with_tsa=True):
+ super(EDVR, self).__init__()
+ if center_frame_idx is None:
+ self.center_frame_idx = num_frame // 2
+ else:
+ self.center_frame_idx = center_frame_idx
+ self.hr_in = hr_in
+ self.with_predeblur = with_predeblur
+ self.with_tsa = with_tsa
+
+ # extract features for each frame
+ if self.with_predeblur:
+ self.predeblur = PredeblurModule(num_feat=num_feat, hr_in=self.hr_in)
+ self.conv_1x1 = nn.Conv2d(num_feat, num_feat, 1, 1)
+ else:
+ self.conv_first = nn.Conv2d(num_in_ch, num_feat, 3, 1, 1)
+
+ # extract pyramid features
+ self.feature_extraction = make_layer(ResidualBlockNoBN, num_extract_block, num_feat=num_feat)
+ self.conv_l2_1 = nn.Conv2d(num_feat, num_feat, 3, 2, 1)
+ self.conv_l2_2 = nn.Conv2d(num_feat, num_feat, 3, 1, 1)
+ self.conv_l3_1 = nn.Conv2d(num_feat, num_feat, 3, 2, 1)
+ self.conv_l3_2 = nn.Conv2d(num_feat, num_feat, 3, 1, 1)
+
+ # pcd and tsa module
+ self.pcd_align = PCDAlignment(num_feat=num_feat, deformable_groups=deformable_groups)
+ if self.with_tsa:
+ self.fusion = TSAFusion(num_feat=num_feat, num_frame=num_frame, center_frame_idx=self.center_frame_idx)
+ else:
+ self.fusion = nn.Conv2d(num_frame * num_feat, num_feat, 1, 1)
+
+ # reconstruction
+ self.reconstruction = make_layer(ResidualBlockNoBN, num_reconstruct_block, num_feat=num_feat)
+ # upsample
+ self.upconv1 = nn.Conv2d(num_feat, num_feat * 4, 3, 1, 1)
+ self.upconv2 = nn.Conv2d(num_feat, 64 * 4, 3, 1, 1)
+ self.pixel_shuffle = nn.PixelShuffle(2)
+ self.conv_hr = nn.Conv2d(64, 64, 3, 1, 1)
+ self.conv_last = nn.Conv2d(64, 3, 3, 1, 1)
+
+ # activation function
+ self.lrelu = nn.LeakyReLU(negative_slope=0.1, inplace=True)
+
+ def forward(self, x):
+ b, t, c, h, w = x.size()
+ if self.hr_in:
+ assert h % 16 == 0 and w % 16 == 0, ('The height and width must be multiple of 16.')
+ else:
+ assert h % 4 == 0 and w % 4 == 0, ('The height and width must be multiple of 4.')
+
+ x_center = x[:, self.center_frame_idx, :, :, :].contiguous()
+
+ # extract features for each frame
+ # L1
+ if self.with_predeblur:
+ feat_l1 = self.conv_1x1(self.predeblur(x.view(-1, c, h, w)))
+ if self.hr_in:
+ h, w = h // 4, w // 4
+ else:
+ feat_l1 = self.lrelu(self.conv_first(x.view(-1, c, h, w)))
+
+ feat_l1 = self.feature_extraction(feat_l1)
+ # L2
+ feat_l2 = self.lrelu(self.conv_l2_1(feat_l1))
+ feat_l2 = self.lrelu(self.conv_l2_2(feat_l2))
+ # L3
+ feat_l3 = self.lrelu(self.conv_l3_1(feat_l2))
+ feat_l3 = self.lrelu(self.conv_l3_2(feat_l3))
+
+ feat_l1 = feat_l1.view(b, t, -1, h, w)
+ feat_l2 = feat_l2.view(b, t, -1, h // 2, w // 2)
+ feat_l3 = feat_l3.view(b, t, -1, h // 4, w // 4)
+
+ # PCD alignment
+ ref_feat_l = [ # reference feature list
+ feat_l1[:, self.center_frame_idx, :, :, :].clone(), feat_l2[:, self.center_frame_idx, :, :, :].clone(),
+ feat_l3[:, self.center_frame_idx, :, :, :].clone()
+ ]
+ aligned_feat = []
+ for i in range(t):
+ nbr_feat_l = [ # neighboring feature list
+ feat_l1[:, i, :, :, :].clone(), feat_l2[:, i, :, :, :].clone(), feat_l3[:, i, :, :, :].clone()
+ ]
+ aligned_feat.append(self.pcd_align(nbr_feat_l, ref_feat_l))
+ aligned_feat = torch.stack(aligned_feat, dim=1) # (b, t, c, h, w)
+
+ if not self.with_tsa:
+ aligned_feat = aligned_feat.view(b, -1, h, w)
+ feat = self.fusion(aligned_feat)
+
+ out = self.reconstruction(feat)
+ out = self.lrelu(self.pixel_shuffle(self.upconv1(out)))
+ out = self.lrelu(self.pixel_shuffle(self.upconv2(out)))
+ out = self.lrelu(self.conv_hr(out))
+ out = self.conv_last(out)
+ if self.hr_in:
+ base = x_center
+ else:
+ base = F.interpolate(x_center, scale_factor=4, mode='bilinear', align_corners=False)
+ out += base
+ return out
diff --git a/custom_nodes/ComfyUI-ReActor/r_basicsr/archs/hifacegan_arch.py b/custom_nodes/ComfyUI-ReActor/r_basicsr/archs/hifacegan_arch.py
new file mode 100644
index 0000000000000000000000000000000000000000..507ed3c999e4c4954079f1eae7d402587827f621
--- /dev/null
+++ b/custom_nodes/ComfyUI-ReActor/r_basicsr/archs/hifacegan_arch.py
@@ -0,0 +1,259 @@
+import numpy as np
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+
+from r_basicsr.utils.registry import ARCH_REGISTRY
+from .hifacegan_util import BaseNetwork, LIPEncoder, SPADEResnetBlock, get_nonspade_norm_layer
+
+
+class SPADEGenerator(BaseNetwork):
+ """Generator with SPADEResBlock"""
+
+ def __init__(self,
+ num_in_ch=3,
+ num_feat=64,
+ use_vae=False,
+ z_dim=256,
+ crop_size=512,
+ norm_g='spectralspadesyncbatch3x3',
+ is_train=True,
+ init_train_phase=3): # progressive training disabled
+ super().__init__()
+ self.nf = num_feat
+ self.input_nc = num_in_ch
+ self.is_train = is_train
+ self.train_phase = init_train_phase
+
+ self.scale_ratio = 5 # hardcoded now
+ self.sw = crop_size // (2**self.scale_ratio)
+ self.sh = self.sw # 20210519: By default use square image, aspect_ratio = 1.0
+
+ if use_vae:
+ # In case of VAE, we will sample from random z vector
+ self.fc = nn.Linear(z_dim, 16 * self.nf * self.sw * self.sh)
+ else:
+ # Otherwise, we make the network deterministic by starting with
+ # downsampled segmentation map instead of random z
+ self.fc = nn.Conv2d(num_in_ch, 16 * self.nf, 3, padding=1)
+
+ self.head_0 = SPADEResnetBlock(16 * self.nf, 16 * self.nf, norm_g)
+
+ self.g_middle_0 = SPADEResnetBlock(16 * self.nf, 16 * self.nf, norm_g)
+ self.g_middle_1 = SPADEResnetBlock(16 * self.nf, 16 * self.nf, norm_g)
+
+ self.ups = nn.ModuleList([
+ SPADEResnetBlock(16 * self.nf, 8 * self.nf, norm_g),
+ SPADEResnetBlock(8 * self.nf, 4 * self.nf, norm_g),
+ SPADEResnetBlock(4 * self.nf, 2 * self.nf, norm_g),
+ SPADEResnetBlock(2 * self.nf, 1 * self.nf, norm_g)
+ ])
+
+ self.to_rgbs = nn.ModuleList([
+ nn.Conv2d(8 * self.nf, 3, 3, padding=1),
+ nn.Conv2d(4 * self.nf, 3, 3, padding=1),
+ nn.Conv2d(2 * self.nf, 3, 3, padding=1),
+ nn.Conv2d(1 * self.nf, 3, 3, padding=1)
+ ])
+
+ self.up = nn.Upsample(scale_factor=2)
+
+ def encode(self, input_tensor):
+ """
+ Encode input_tensor into feature maps, can be overridden in derived classes
+ Default: nearest downsampling of 2**5 = 32 times
+ """
+ h, w = input_tensor.size()[-2:]
+ sh, sw = h // 2**self.scale_ratio, w // 2**self.scale_ratio
+ x = F.interpolate(input_tensor, size=(sh, sw))
+ return self.fc(x)
+
+ def forward(self, x):
+ # In oroginal SPADE, seg means a segmentation map, but here we use x instead.
+ seg = x
+
+ x = self.encode(x)
+ x = self.head_0(x, seg)
+
+ x = self.up(x)
+ x = self.g_middle_0(x, seg)
+ x = self.g_middle_1(x, seg)
+
+ if self.is_train:
+ phase = self.train_phase + 1
+ else:
+ phase = len(self.to_rgbs)
+
+ for i in range(phase):
+ x = self.up(x)
+ x = self.ups[i](x, seg)
+
+ x = self.to_rgbs[phase - 1](F.leaky_relu(x, 2e-1))
+ x = torch.tanh(x)
+
+ return x
+
+ def mixed_guidance_forward(self, input_x, seg=None, n=0, mode='progressive'):
+ """
+ A helper class for subspace visualization. Input and seg are different images.
+ For the first n levels (including encoder) we use input, for the rest we use seg.
+
+ If mode = 'progressive', the output's like: AAABBB
+ If mode = 'one_plug', the output's like: AAABAA
+ If mode = 'one_ablate', the output's like: BBBABB
+ """
+
+ if seg is None:
+ return self.forward(input_x)
+
+ if self.is_train:
+ phase = self.train_phase + 1
+ else:
+ phase = len(self.to_rgbs)
+
+ if mode == 'progressive':
+ n = max(min(n, 4 + phase), 0)
+ guide_list = [input_x] * n + [seg] * (4 + phase - n)
+ elif mode == 'one_plug':
+ n = max(min(n, 4 + phase - 1), 0)
+ guide_list = [seg] * (4 + phase)
+ guide_list[n] = input_x
+ elif mode == 'one_ablate':
+ if n > 3 + phase:
+ return self.forward(input_x)
+ guide_list = [input_x] * (4 + phase)
+ guide_list[n] = seg
+
+ x = self.encode(guide_list[0])
+ x = self.head_0(x, guide_list[1])
+
+ x = self.up(x)
+ x = self.g_middle_0(x, guide_list[2])
+ x = self.g_middle_1(x, guide_list[3])
+
+ for i in range(phase):
+ x = self.up(x)
+ x = self.ups[i](x, guide_list[4 + i])
+
+ x = self.to_rgbs[phase - 1](F.leaky_relu(x, 2e-1))
+ x = torch.tanh(x)
+
+ return x
+
+
+@ARCH_REGISTRY.register()
+class HiFaceGAN(SPADEGenerator):
+ """
+ HiFaceGAN: SPADEGenerator with a learnable feature encoder
+ Current encoder design: LIPEncoder
+ """
+
+ def __init__(self,
+ num_in_ch=3,
+ num_feat=64,
+ use_vae=False,
+ z_dim=256,
+ crop_size=512,
+ norm_g='spectralspadesyncbatch3x3',
+ is_train=True,
+ init_train_phase=3):
+ super().__init__(num_in_ch, num_feat, use_vae, z_dim, crop_size, norm_g, is_train, init_train_phase)
+ self.lip_encoder = LIPEncoder(num_in_ch, num_feat, self.sw, self.sh, self.scale_ratio)
+
+ def encode(self, input_tensor):
+ return self.lip_encoder(input_tensor)
+
+
+@ARCH_REGISTRY.register()
+class HiFaceGANDiscriminator(BaseNetwork):
+ """
+ Inspired by pix2pixHD multiscale discriminator.
+ Args:
+ num_in_ch (int): Channel number of inputs. Default: 3.
+ num_out_ch (int): Channel number of outputs. Default: 3.
+ conditional_d (bool): Whether use conditional discriminator.
+ Default: True.
+ num_d (int): Number of Multiscale discriminators. Default: 3.
+ n_layers_d (int): Number of downsample layers in each D. Default: 4.
+ num_feat (int): Channel number of base intermediate features.
+ Default: 64.
+ norm_d (str): String to determine normalization layers in D.
+ Choices: [spectral][instance/batch/syncbatch]
+ Default: 'spectralinstance'.
+ keep_features (bool): Keep intermediate features for matching loss, etc.
+ Default: True.
+ """
+
+ def __init__(self,
+ num_in_ch=3,
+ num_out_ch=3,
+ conditional_d=True,
+ num_d=2,
+ n_layers_d=4,
+ num_feat=64,
+ norm_d='spectralinstance',
+ keep_features=True):
+ super().__init__()
+ self.num_d = num_d
+
+ input_nc = num_in_ch
+ if conditional_d:
+ input_nc += num_out_ch
+
+ for i in range(num_d):
+ subnet_d = NLayerDiscriminator(input_nc, n_layers_d, num_feat, norm_d, keep_features)
+ self.add_module(f'discriminator_{i}', subnet_d)
+
+ def downsample(self, x):
+ return F.avg_pool2d(x, kernel_size=3, stride=2, padding=[1, 1], count_include_pad=False)
+
+ # Returns list of lists of discriminator outputs.
+ # The final result is of size opt.num_d x opt.n_layers_D
+ def forward(self, x):
+ result = []
+ for _, _net_d in self.named_children():
+ out = _net_d(x)
+ result.append(out)
+ x = self.downsample(x)
+
+ return result
+
+
+class NLayerDiscriminator(BaseNetwork):
+ """Defines the PatchGAN discriminator with the specified arguments."""
+
+ def __init__(self, input_nc, n_layers_d, num_feat, norm_d, keep_features):
+ super().__init__()
+ kw = 4
+ padw = int(np.ceil((kw - 1.0) / 2))
+ nf = num_feat
+ self.keep_features = keep_features
+
+ norm_layer = get_nonspade_norm_layer(norm_d)
+ sequence = [[nn.Conv2d(input_nc, nf, kernel_size=kw, stride=2, padding=padw), nn.LeakyReLU(0.2, False)]]
+
+ for n in range(1, n_layers_d):
+ nf_prev = nf
+ nf = min(nf * 2, 512)
+ stride = 1 if n == n_layers_d - 1 else 2
+ sequence += [[
+ norm_layer(nn.Conv2d(nf_prev, nf, kernel_size=kw, stride=stride, padding=padw)),
+ nn.LeakyReLU(0.2, False)
+ ]]
+
+ sequence += [[nn.Conv2d(nf, 1, kernel_size=kw, stride=1, padding=padw)]]
+
+ # We divide the layers into groups to extract intermediate layer outputs
+ for n in range(len(sequence)):
+ self.add_module('model' + str(n), nn.Sequential(*sequence[n]))
+
+ def forward(self, x):
+ results = [x]
+ for submodel in self.children():
+ intermediate_output = submodel(results[-1])
+ results.append(intermediate_output)
+
+ if self.keep_features:
+ return results[1:]
+ else:
+ return results[-1]
diff --git a/custom_nodes/ComfyUI-ReActor/r_basicsr/archs/hifacegan_util.py b/custom_nodes/ComfyUI-ReActor/r_basicsr/archs/hifacegan_util.py
new file mode 100644
index 0000000000000000000000000000000000000000..35cbef3f532fcc6aab0fa57ab316a546d3a17bd5
--- /dev/null
+++ b/custom_nodes/ComfyUI-ReActor/r_basicsr/archs/hifacegan_util.py
@@ -0,0 +1,255 @@
+import re
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from torch.nn import init
+# Warning: spectral norm could be buggy
+# under eval mode and multi-GPU inference
+# A workaround is sticking to single-GPU inference and train mode
+from torch.nn.utils import spectral_norm
+
+
+class SPADE(nn.Module):
+
+ def __init__(self, config_text, norm_nc, label_nc):
+ super().__init__()
+
+ assert config_text.startswith('spade')
+ parsed = re.search('spade(\\D+)(\\d)x\\d', config_text)
+ param_free_norm_type = str(parsed.group(1))
+ ks = int(parsed.group(2))
+
+ if param_free_norm_type == 'instance':
+ self.param_free_norm = nn.InstanceNorm2d(norm_nc)
+ elif param_free_norm_type == 'syncbatch':
+ print('SyncBatchNorm is currently not supported under single-GPU mode, switch to "instance" instead')
+ self.param_free_norm = nn.InstanceNorm2d(norm_nc)
+ elif param_free_norm_type == 'batch':
+ self.param_free_norm = nn.BatchNorm2d(norm_nc, affine=False)
+ else:
+ raise ValueError(f'{param_free_norm_type} is not a recognized param-free norm type in SPADE')
+
+ # The dimension of the intermediate embedding space. Yes, hardcoded.
+ nhidden = 128 if norm_nc > 128 else norm_nc
+
+ pw = ks // 2
+ self.mlp_shared = nn.Sequential(nn.Conv2d(label_nc, nhidden, kernel_size=ks, padding=pw), nn.ReLU())
+ self.mlp_gamma = nn.Conv2d(nhidden, norm_nc, kernel_size=ks, padding=pw, bias=False)
+ self.mlp_beta = nn.Conv2d(nhidden, norm_nc, kernel_size=ks, padding=pw, bias=False)
+
+ def forward(self, x, segmap):
+
+ # Part 1. generate parameter-free normalized activations
+ normalized = self.param_free_norm(x)
+
+ # Part 2. produce scaling and bias conditioned on semantic map
+ segmap = F.interpolate(segmap, size=x.size()[2:], mode='nearest')
+ actv = self.mlp_shared(segmap)
+ gamma = self.mlp_gamma(actv)
+ beta = self.mlp_beta(actv)
+
+ # apply scale and bias
+ out = normalized * gamma + beta
+
+ return out
+
+
+class SPADEResnetBlock(nn.Module):
+ """
+ ResNet block that uses SPADE. It differs from the ResNet block of pix2pixHD in that
+ it takes in the segmentation map as input, learns the skip connection if necessary,
+ and applies normalization first and then convolution.
+ This architecture seemed like a standard architecture for unconditional or
+ class-conditional GAN architecture using residual block.
+ The code was inspired from https://github.com/LMescheder/GAN_stability.
+ """
+
+ def __init__(self, fin, fout, norm_g='spectralspadesyncbatch3x3', semantic_nc=3):
+ super().__init__()
+ # Attributes
+ self.learned_shortcut = (fin != fout)
+ fmiddle = min(fin, fout)
+
+ # create conv layers
+ self.conv_0 = nn.Conv2d(fin, fmiddle, kernel_size=3, padding=1)
+ self.conv_1 = nn.Conv2d(fmiddle, fout, kernel_size=3, padding=1)
+ if self.learned_shortcut:
+ self.conv_s = nn.Conv2d(fin, fout, kernel_size=1, bias=False)
+
+ # apply spectral norm if specified
+ if 'spectral' in norm_g:
+ self.conv_0 = spectral_norm(self.conv_0)
+ self.conv_1 = spectral_norm(self.conv_1)
+ if self.learned_shortcut:
+ self.conv_s = spectral_norm(self.conv_s)
+
+ # define normalization layers
+ spade_config_str = norm_g.replace('spectral', '')
+ self.norm_0 = SPADE(spade_config_str, fin, semantic_nc)
+ self.norm_1 = SPADE(spade_config_str, fmiddle, semantic_nc)
+ if self.learned_shortcut:
+ self.norm_s = SPADE(spade_config_str, fin, semantic_nc)
+
+ # note the resnet block with SPADE also takes in |seg|,
+ # the semantic segmentation map as input
+ def forward(self, x, seg):
+ x_s = self.shortcut(x, seg)
+ dx = self.conv_0(self.act(self.norm_0(x, seg)))
+ dx = self.conv_1(self.act(self.norm_1(dx, seg)))
+ out = x_s + dx
+ return out
+
+ def shortcut(self, x, seg):
+ if self.learned_shortcut:
+ x_s = self.conv_s(self.norm_s(x, seg))
+ else:
+ x_s = x
+ return x_s
+
+ def act(self, x):
+ return F.leaky_relu(x, 2e-1)
+
+
+class BaseNetwork(nn.Module):
+ """ A basis for hifacegan archs with custom initialization """
+
+ def init_weights(self, init_type='normal', gain=0.02):
+
+ def init_func(m):
+ classname = m.__class__.__name__
+ if classname.find('BatchNorm2d') != -1:
+ if hasattr(m, 'weight') and m.weight is not None:
+ init.normal_(m.weight.data, 1.0, gain)
+ if hasattr(m, 'bias') and m.bias is not None:
+ init.constant_(m.bias.data, 0.0)
+ elif hasattr(m, 'weight') and (classname.find('Conv') != -1 or classname.find('Linear') != -1):
+ if init_type == 'normal':
+ init.normal_(m.weight.data, 0.0, gain)
+ elif init_type == 'xavier':
+ init.xavier_normal_(m.weight.data, gain=gain)
+ elif init_type == 'xavier_uniform':
+ init.xavier_uniform_(m.weight.data, gain=1.0)
+ elif init_type == 'kaiming':
+ init.kaiming_normal_(m.weight.data, a=0, mode='fan_in')
+ elif init_type == 'orthogonal':
+ init.orthogonal_(m.weight.data, gain=gain)
+ elif init_type == 'none': # uses pytorch's default init method
+ m.reset_parameters()
+ else:
+ raise NotImplementedError(f'initialization method [{init_type}] is not implemented')
+ if hasattr(m, 'bias') and m.bias is not None:
+ init.constant_(m.bias.data, 0.0)
+
+ self.apply(init_func)
+
+ # propagate to children
+ for m in self.children():
+ if hasattr(m, 'init_weights'):
+ m.init_weights(init_type, gain)
+
+ def forward(self, x):
+ pass
+
+
+def lip2d(x, logit, kernel=3, stride=2, padding=1):
+ weight = logit.exp()
+ return F.avg_pool2d(x * weight, kernel, stride, padding) / F.avg_pool2d(weight, kernel, stride, padding)
+
+
+class SoftGate(nn.Module):
+ COEFF = 12.0
+
+ def forward(self, x):
+ return torch.sigmoid(x).mul(self.COEFF)
+
+
+class SimplifiedLIP(nn.Module):
+
+ def __init__(self, channels):
+ super(SimplifiedLIP, self).__init__()
+ self.logit = nn.Sequential(
+ nn.Conv2d(channels, channels, 3, padding=1, bias=False), nn.InstanceNorm2d(channels, affine=True),
+ SoftGate())
+
+ def init_layer(self):
+ self.logit[0].weight.data.fill_(0.0)
+
+ def forward(self, x):
+ frac = lip2d(x, self.logit(x))
+ return frac
+
+
+class LIPEncoder(BaseNetwork):
+ """Local Importance-based Pooling (Ziteng Gao et.al.,ICCV 2019)"""
+
+ def __init__(self, input_nc, ngf, sw, sh, n_2xdown, norm_layer=nn.InstanceNorm2d):
+ super().__init__()
+ self.sw = sw
+ self.sh = sh
+ self.max_ratio = 16
+ # 20200310: Several Convolution (stride 1) + LIP blocks, 4 fold
+ kw = 3
+ pw = (kw - 1) // 2
+
+ model = [
+ nn.Conv2d(input_nc, ngf, kw, stride=1, padding=pw, bias=False),
+ norm_layer(ngf),
+ nn.ReLU(),
+ ]
+ cur_ratio = 1
+ for i in range(n_2xdown):
+ next_ratio = min(cur_ratio * 2, self.max_ratio)
+ model += [
+ SimplifiedLIP(ngf * cur_ratio),
+ nn.Conv2d(ngf * cur_ratio, ngf * next_ratio, kw, stride=1, padding=pw),
+ norm_layer(ngf * next_ratio),
+ ]
+ cur_ratio = next_ratio
+ if i < n_2xdown - 1:
+ model += [nn.ReLU(inplace=True)]
+
+ self.model = nn.Sequential(*model)
+
+ def forward(self, x):
+ return self.model(x)
+
+
+def get_nonspade_norm_layer(norm_type='instance'):
+ # helper function to get # output channels of the previous layer
+ def get_out_channel(layer):
+ if hasattr(layer, 'out_channels'):
+ return getattr(layer, 'out_channels')
+ return layer.weight.size(0)
+
+ # this function will be returned
+ def add_norm_layer(layer):
+ nonlocal norm_type
+ if norm_type.startswith('spectral'):
+ layer = spectral_norm(layer)
+ subnorm_type = norm_type[len('spectral'):]
+
+ if subnorm_type == 'none' or len(subnorm_type) == 0:
+ return layer
+
+ # remove bias in the previous layer, which is meaningless
+ # since it has no effect after normalization
+ if getattr(layer, 'bias', None) is not None:
+ delattr(layer, 'bias')
+ layer.register_parameter('bias', None)
+
+ if subnorm_type == 'batch':
+ norm_layer = nn.BatchNorm2d(get_out_channel(layer), affine=True)
+ elif subnorm_type == 'sync_batch':
+ print('SyncBatchNorm is currently not supported under single-GPU mode, switch to "instance" instead')
+ # norm_layer = SynchronizedBatchNorm2d(
+ # get_out_channel(layer), affine=True)
+ norm_layer = nn.InstanceNorm2d(get_out_channel(layer), affine=False)
+ elif subnorm_type == 'instance':
+ norm_layer = nn.InstanceNorm2d(get_out_channel(layer), affine=False)
+ else:
+ raise ValueError(f'normalization layer {subnorm_type} is not recognized')
+
+ return nn.Sequential(layer, norm_layer)
+
+ print('This is a legacy from nvlabs/SPADE, and will be removed in future versions.')
+ return add_norm_layer
diff --git a/custom_nodes/ComfyUI-ReActor/r_basicsr/archs/inception.py b/custom_nodes/ComfyUI-ReActor/r_basicsr/archs/inception.py
new file mode 100644
index 0000000000000000000000000000000000000000..de1abef67270dc1aba770943b53577029141f527
--- /dev/null
+++ b/custom_nodes/ComfyUI-ReActor/r_basicsr/archs/inception.py
@@ -0,0 +1,307 @@
+# Modified from https://github.com/mseitzer/pytorch-fid/blob/master/pytorch_fid/inception.py # noqa: E501
+# For FID metric
+
+import os
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from torch.utils.model_zoo import load_url
+from torchvision import models
+
+# Inception weights ported to Pytorch from
+# http://download.tensorflow.org/models/image/imagenet/inception-2015-12-05.tgz
+FID_WEIGHTS_URL = 'https://github.com/mseitzer/pytorch-fid/releases/download/fid_weights/pt_inception-2015-12-05-6726825d.pth' # noqa: E501
+LOCAL_FID_WEIGHTS = 'experiments/pretrained_models/pt_inception-2015-12-05-6726825d.pth' # noqa: E501
+
+
+class InceptionV3(nn.Module):
+ """Pretrained InceptionV3 network returning feature maps"""
+
+ # Index of default block of inception to return,
+ # corresponds to output of final average pooling
+ DEFAULT_BLOCK_INDEX = 3
+
+ # Maps feature dimensionality to their output blocks indices
+ BLOCK_INDEX_BY_DIM = {
+ 64: 0, # First max pooling features
+ 192: 1, # Second max pooling features
+ 768: 2, # Pre-aux classifier features
+ 2048: 3 # Final average pooling features
+ }
+
+ def __init__(self,
+ output_blocks=(DEFAULT_BLOCK_INDEX),
+ resize_input=True,
+ normalize_input=True,
+ requires_grad=False,
+ use_fid_inception=True):
+ """Build pretrained InceptionV3.
+
+ Args:
+ output_blocks (list[int]): Indices of blocks to return features of.
+ Possible values are:
+ - 0: corresponds to output of first max pooling
+ - 1: corresponds to output of second max pooling
+ - 2: corresponds to output which is fed to aux classifier
+ - 3: corresponds to output of final average pooling
+ resize_input (bool): If true, bilinearly resizes input to width and
+ height 299 before feeding input to model. As the network
+ without fully connected layers is fully convolutional, it
+ should be able to handle inputs of arbitrary size, so resizing
+ might not be strictly needed. Default: True.
+ normalize_input (bool): If true, scales the input from range (0, 1)
+ to the range the pretrained Inception network expects,
+ namely (-1, 1). Default: True.
+ requires_grad (bool): If true, parameters of the model require
+ gradients. Possibly useful for finetuning the network.
+ Default: False.
+ use_fid_inception (bool): If true, uses the pretrained Inception
+ model used in Tensorflow's FID implementation.
+ If false, uses the pretrained Inception model available in
+ torchvision. The FID Inception model has different weights
+ and a slightly different structure from torchvision's
+ Inception model. If you want to compute FID scores, you are
+ strongly advised to set this parameter to true to get
+ comparable results. Default: True.
+ """
+ super(InceptionV3, self).__init__()
+
+ self.resize_input = resize_input
+ self.normalize_input = normalize_input
+ self.output_blocks = sorted(output_blocks)
+ self.last_needed_block = max(output_blocks)
+
+ assert self.last_needed_block <= 3, ('Last possible output block index is 3')
+
+ self.blocks = nn.ModuleList()
+
+ if use_fid_inception:
+ inception = fid_inception_v3()
+ else:
+ try:
+ inception = models.inception_v3(pretrained=True, init_weights=False)
+ except TypeError:
+ # pytorch < 1.5 does not have init_weights for inception_v3
+ inception = models.inception_v3(pretrained=True)
+
+ # Block 0: input to maxpool1
+ block0 = [
+ inception.Conv2d_1a_3x3, inception.Conv2d_2a_3x3, inception.Conv2d_2b_3x3,
+ nn.MaxPool2d(kernel_size=3, stride=2)
+ ]
+ self.blocks.append(nn.Sequential(*block0))
+
+ # Block 1: maxpool1 to maxpool2
+ if self.last_needed_block >= 1:
+ block1 = [inception.Conv2d_3b_1x1, inception.Conv2d_4a_3x3, nn.MaxPool2d(kernel_size=3, stride=2)]
+ self.blocks.append(nn.Sequential(*block1))
+
+ # Block 2: maxpool2 to aux classifier
+ if self.last_needed_block >= 2:
+ block2 = [
+ inception.Mixed_5b,
+ inception.Mixed_5c,
+ inception.Mixed_5d,
+ inception.Mixed_6a,
+ inception.Mixed_6b,
+ inception.Mixed_6c,
+ inception.Mixed_6d,
+ inception.Mixed_6e,
+ ]
+ self.blocks.append(nn.Sequential(*block2))
+
+ # Block 3: aux classifier to final avgpool
+ if self.last_needed_block >= 3:
+ block3 = [
+ inception.Mixed_7a, inception.Mixed_7b, inception.Mixed_7c,
+ nn.AdaptiveAvgPool2d(output_size=(1, 1))
+ ]
+ self.blocks.append(nn.Sequential(*block3))
+
+ for param in self.parameters():
+ param.requires_grad = requires_grad
+
+ def forward(self, x):
+ """Get Inception feature maps.
+
+ Args:
+ x (Tensor): Input tensor of shape (b, 3, h, w).
+ Values are expected to be in range (-1, 1). You can also input
+ (0, 1) with setting normalize_input = True.
+
+ Returns:
+ list[Tensor]: Corresponding to the selected output block, sorted
+ ascending by index.
+ """
+ output = []
+
+ if self.resize_input:
+ x = F.interpolate(x, size=(299, 299), mode='bilinear', align_corners=False)
+
+ if self.normalize_input:
+ x = 2 * x - 1 # Scale from range (0, 1) to range (-1, 1)
+
+ for idx, block in enumerate(self.blocks):
+ x = block(x)
+ if idx in self.output_blocks:
+ output.append(x)
+
+ if idx == self.last_needed_block:
+ break
+
+ return output
+
+
+def fid_inception_v3():
+ """Build pretrained Inception model for FID computation.
+
+ The Inception model for FID computation uses a different set of weights
+ and has a slightly different structure than torchvision's Inception.
+
+ This method first constructs torchvision's Inception and then patches the
+ necessary parts that are different in the FID Inception model.
+ """
+ try:
+ inception = models.inception_v3(num_classes=1008, aux_logits=False, pretrained=False, init_weights=False)
+ except TypeError:
+ # pytorch < 1.5 does not have init_weights for inception_v3
+ inception = models.inception_v3(num_classes=1008, aux_logits=False, pretrained=False)
+
+ inception.Mixed_5b = FIDInceptionA(192, pool_features=32)
+ inception.Mixed_5c = FIDInceptionA(256, pool_features=64)
+ inception.Mixed_5d = FIDInceptionA(288, pool_features=64)
+ inception.Mixed_6b = FIDInceptionC(768, channels_7x7=128)
+ inception.Mixed_6c = FIDInceptionC(768, channels_7x7=160)
+ inception.Mixed_6d = FIDInceptionC(768, channels_7x7=160)
+ inception.Mixed_6e = FIDInceptionC(768, channels_7x7=192)
+ inception.Mixed_7b = FIDInceptionE_1(1280)
+ inception.Mixed_7c = FIDInceptionE_2(2048)
+
+ if os.path.exists(LOCAL_FID_WEIGHTS):
+ state_dict = torch.load(LOCAL_FID_WEIGHTS, map_location=lambda storage, loc: storage)
+ else:
+ state_dict = load_url(FID_WEIGHTS_URL, progress=True)
+
+ inception.load_state_dict(state_dict)
+ return inception
+
+
+class FIDInceptionA(models.inception.InceptionA):
+ """InceptionA block patched for FID computation"""
+
+ def __init__(self, in_channels, pool_features):
+ super(FIDInceptionA, self).__init__(in_channels, pool_features)
+
+ def forward(self, x):
+ branch1x1 = self.branch1x1(x)
+
+ branch5x5 = self.branch5x5_1(x)
+ branch5x5 = self.branch5x5_2(branch5x5)
+
+ branch3x3dbl = self.branch3x3dbl_1(x)
+ branch3x3dbl = self.branch3x3dbl_2(branch3x3dbl)
+ branch3x3dbl = self.branch3x3dbl_3(branch3x3dbl)
+
+ # Patch: Tensorflow's average pool does not use the padded zero's in
+ # its average calculation
+ branch_pool = F.avg_pool2d(x, kernel_size=3, stride=1, padding=1, count_include_pad=False)
+ branch_pool = self.branch_pool(branch_pool)
+
+ outputs = [branch1x1, branch5x5, branch3x3dbl, branch_pool]
+ return torch.cat(outputs, 1)
+
+
+class FIDInceptionC(models.inception.InceptionC):
+ """InceptionC block patched for FID computation"""
+
+ def __init__(self, in_channels, channels_7x7):
+ super(FIDInceptionC, self).__init__(in_channels, channels_7x7)
+
+ def forward(self, x):
+ branch1x1 = self.branch1x1(x)
+
+ branch7x7 = self.branch7x7_1(x)
+ branch7x7 = self.branch7x7_2(branch7x7)
+ branch7x7 = self.branch7x7_3(branch7x7)
+
+ branch7x7dbl = self.branch7x7dbl_1(x)
+ branch7x7dbl = self.branch7x7dbl_2(branch7x7dbl)
+ branch7x7dbl = self.branch7x7dbl_3(branch7x7dbl)
+ branch7x7dbl = self.branch7x7dbl_4(branch7x7dbl)
+ branch7x7dbl = self.branch7x7dbl_5(branch7x7dbl)
+
+ # Patch: Tensorflow's average pool does not use the padded zero's in
+ # its average calculation
+ branch_pool = F.avg_pool2d(x, kernel_size=3, stride=1, padding=1, count_include_pad=False)
+ branch_pool = self.branch_pool(branch_pool)
+
+ outputs = [branch1x1, branch7x7, branch7x7dbl, branch_pool]
+ return torch.cat(outputs, 1)
+
+
+class FIDInceptionE_1(models.inception.InceptionE):
+ """First InceptionE block patched for FID computation"""
+
+ def __init__(self, in_channels):
+ super(FIDInceptionE_1, self).__init__(in_channels)
+
+ def forward(self, x):
+ branch1x1 = self.branch1x1(x)
+
+ branch3x3 = self.branch3x3_1(x)
+ branch3x3 = [
+ self.branch3x3_2a(branch3x3),
+ self.branch3x3_2b(branch3x3),
+ ]
+ branch3x3 = torch.cat(branch3x3, 1)
+
+ branch3x3dbl = self.branch3x3dbl_1(x)
+ branch3x3dbl = self.branch3x3dbl_2(branch3x3dbl)
+ branch3x3dbl = [
+ self.branch3x3dbl_3a(branch3x3dbl),
+ self.branch3x3dbl_3b(branch3x3dbl),
+ ]
+ branch3x3dbl = torch.cat(branch3x3dbl, 1)
+
+ # Patch: Tensorflow's average pool does not use the padded zero's in
+ # its average calculation
+ branch_pool = F.avg_pool2d(x, kernel_size=3, stride=1, padding=1, count_include_pad=False)
+ branch_pool = self.branch_pool(branch_pool)
+
+ outputs = [branch1x1, branch3x3, branch3x3dbl, branch_pool]
+ return torch.cat(outputs, 1)
+
+
+class FIDInceptionE_2(models.inception.InceptionE):
+ """Second InceptionE block patched for FID computation"""
+
+ def __init__(self, in_channels):
+ super(FIDInceptionE_2, self).__init__(in_channels)
+
+ def forward(self, x):
+ branch1x1 = self.branch1x1(x)
+
+ branch3x3 = self.branch3x3_1(x)
+ branch3x3 = [
+ self.branch3x3_2a(branch3x3),
+ self.branch3x3_2b(branch3x3),
+ ]
+ branch3x3 = torch.cat(branch3x3, 1)
+
+ branch3x3dbl = self.branch3x3dbl_1(x)
+ branch3x3dbl = self.branch3x3dbl_2(branch3x3dbl)
+ branch3x3dbl = [
+ self.branch3x3dbl_3a(branch3x3dbl),
+ self.branch3x3dbl_3b(branch3x3dbl),
+ ]
+ branch3x3dbl = torch.cat(branch3x3dbl, 1)
+
+ # Patch: The FID Inception model uses max pooling instead of average
+ # pooling. This is likely an error in this specific Inception
+ # implementation, as other Inception models use average pooling here
+ # (which matches the description in the paper).
+ branch_pool = F.max_pool2d(x, kernel_size=3, stride=1, padding=1)
+ branch_pool = self.branch_pool(branch_pool)
+
+ outputs = [branch1x1, branch3x3, branch3x3dbl, branch_pool]
+ return torch.cat(outputs, 1)
diff --git a/custom_nodes/ComfyUI-ReActor/r_basicsr/archs/rcan_arch.py b/custom_nodes/ComfyUI-ReActor/r_basicsr/archs/rcan_arch.py
new file mode 100644
index 0000000000000000000000000000000000000000..1714361b083777156cefe188a047ef6819a3b940
--- /dev/null
+++ b/custom_nodes/ComfyUI-ReActor/r_basicsr/archs/rcan_arch.py
@@ -0,0 +1,135 @@
+import torch
+from torch import nn as nn
+
+from r_basicsr.utils.registry import ARCH_REGISTRY
+from .arch_util import Upsample, make_layer
+
+
+class ChannelAttention(nn.Module):
+ """Channel attention used in RCAN.
+
+ Args:
+ num_feat (int): Channel number of intermediate features.
+ squeeze_factor (int): Channel squeeze factor. Default: 16.
+ """
+
+ def __init__(self, num_feat, squeeze_factor=16):
+ super(ChannelAttention, self).__init__()
+ self.attention = nn.Sequential(
+ nn.AdaptiveAvgPool2d(1), nn.Conv2d(num_feat, num_feat // squeeze_factor, 1, padding=0),
+ nn.ReLU(inplace=True), nn.Conv2d(num_feat // squeeze_factor, num_feat, 1, padding=0), nn.Sigmoid())
+
+ def forward(self, x):
+ y = self.attention(x)
+ return x * y
+
+
+class RCAB(nn.Module):
+ """Residual Channel Attention Block (RCAB) used in RCAN.
+
+ Args:
+ num_feat (int): Channel number of intermediate features.
+ squeeze_factor (int): Channel squeeze factor. Default: 16.
+ res_scale (float): Scale the residual. Default: 1.
+ """
+
+ def __init__(self, num_feat, squeeze_factor=16, res_scale=1):
+ super(RCAB, self).__init__()
+ self.res_scale = res_scale
+
+ self.rcab = nn.Sequential(
+ nn.Conv2d(num_feat, num_feat, 3, 1, 1), nn.ReLU(True), nn.Conv2d(num_feat, num_feat, 3, 1, 1),
+ ChannelAttention(num_feat, squeeze_factor))
+
+ def forward(self, x):
+ res = self.rcab(x) * self.res_scale
+ return res + x
+
+
+class ResidualGroup(nn.Module):
+ """Residual Group of RCAB.
+
+ Args:
+ num_feat (int): Channel number of intermediate features.
+ num_block (int): Block number in the body network.
+ squeeze_factor (int): Channel squeeze factor. Default: 16.
+ res_scale (float): Scale the residual. Default: 1.
+ """
+
+ def __init__(self, num_feat, num_block, squeeze_factor=16, res_scale=1):
+ super(ResidualGroup, self).__init__()
+
+ self.residual_group = make_layer(
+ RCAB, num_block, num_feat=num_feat, squeeze_factor=squeeze_factor, res_scale=res_scale)
+ self.conv = nn.Conv2d(num_feat, num_feat, 3, 1, 1)
+
+ def forward(self, x):
+ res = self.conv(self.residual_group(x))
+ return res + x
+
+
+@ARCH_REGISTRY.register()
+class RCAN(nn.Module):
+ """Residual Channel Attention Networks.
+
+ Paper: Image Super-Resolution Using Very Deep Residual Channel Attention
+ Networks
+ Ref git repo: https://github.com/yulunzhang/RCAN.
+
+ Args:
+ num_in_ch (int): Channel number of inputs.
+ num_out_ch (int): Channel number of outputs.
+ num_feat (int): Channel number of intermediate features.
+ Default: 64.
+ num_group (int): Number of ResidualGroup. Default: 10.
+ num_block (int): Number of RCAB in ResidualGroup. Default: 16.
+ squeeze_factor (int): Channel squeeze factor. Default: 16.
+ upscale (int): Upsampling factor. Support 2^n and 3.
+ Default: 4.
+ res_scale (float): Used to scale the residual in residual block.
+ Default: 1.
+ img_range (float): Image range. Default: 255.
+ rgb_mean (tuple[float]): Image mean in RGB orders.
+ Default: (0.4488, 0.4371, 0.4040), calculated from DIV2K dataset.
+ """
+
+ def __init__(self,
+ num_in_ch,
+ num_out_ch,
+ num_feat=64,
+ num_group=10,
+ num_block=16,
+ squeeze_factor=16,
+ upscale=4,
+ res_scale=1,
+ img_range=255.,
+ rgb_mean=(0.4488, 0.4371, 0.4040)):
+ super(RCAN, self).__init__()
+
+ self.img_range = img_range
+ self.mean = torch.Tensor(rgb_mean).view(1, 3, 1, 1)
+
+ self.conv_first = nn.Conv2d(num_in_ch, num_feat, 3, 1, 1)
+ self.body = make_layer(
+ ResidualGroup,
+ num_group,
+ num_feat=num_feat,
+ num_block=num_block,
+ squeeze_factor=squeeze_factor,
+ res_scale=res_scale)
+ self.conv_after_body = nn.Conv2d(num_feat, num_feat, 3, 1, 1)
+ self.upsample = Upsample(upscale, num_feat)
+ self.conv_last = nn.Conv2d(num_feat, num_out_ch, 3, 1, 1)
+
+ def forward(self, x):
+ self.mean = self.mean.type_as(x)
+
+ x = (x - self.mean) * self.img_range
+ x = self.conv_first(x)
+ res = self.conv_after_body(self.body(x))
+ res += x
+
+ x = self.conv_last(self.upsample(res))
+ x = x / self.img_range + self.mean
+
+ return x
diff --git a/custom_nodes/ComfyUI-ReActor/r_basicsr/archs/ridnet_arch.py b/custom_nodes/ComfyUI-ReActor/r_basicsr/archs/ridnet_arch.py
new file mode 100644
index 0000000000000000000000000000000000000000..22a0ae25ed8f9b818f570c802a99b18ca9e96118
--- /dev/null
+++ b/custom_nodes/ComfyUI-ReActor/r_basicsr/archs/ridnet_arch.py
@@ -0,0 +1,184 @@
+import torch
+import torch.nn as nn
+
+from r_basicsr.utils.registry import ARCH_REGISTRY
+from .arch_util import ResidualBlockNoBN, make_layer
+
+
+class MeanShift(nn.Conv2d):
+ """ Data normalization with mean and std.
+
+ Args:
+ rgb_range (int): Maximum value of RGB.
+ rgb_mean (list[float]): Mean for RGB channels.
+ rgb_std (list[float]): Std for RGB channels.
+ sign (int): For subtraction, sign is -1, for addition, sign is 1.
+ Default: -1.
+ requires_grad (bool): Whether to update the self.weight and self.bias.
+ Default: True.
+ """
+
+ def __init__(self, rgb_range, rgb_mean, rgb_std, sign=-1, requires_grad=True):
+ super(MeanShift, self).__init__(3, 3, kernel_size=1)
+ std = torch.Tensor(rgb_std)
+ self.weight.data = torch.eye(3).view(3, 3, 1, 1)
+ self.weight.data.div_(std.view(3, 1, 1, 1))
+ self.bias.data = sign * rgb_range * torch.Tensor(rgb_mean)
+ self.bias.data.div_(std)
+ self.requires_grad = requires_grad
+
+
+class EResidualBlockNoBN(nn.Module):
+ """Enhanced Residual block without BN.
+
+ There are three convolution layers in residual branch.
+
+ It has a style of:
+ ---Conv-ReLU-Conv-ReLU-Conv-+-ReLU-
+ |__________________________|
+ """
+
+ def __init__(self, in_channels, out_channels):
+ super(EResidualBlockNoBN, self).__init__()
+
+ self.body = nn.Sequential(
+ nn.Conv2d(in_channels, out_channels, 3, 1, 1),
+ nn.ReLU(inplace=True),
+ nn.Conv2d(out_channels, out_channels, 3, 1, 1),
+ nn.ReLU(inplace=True),
+ nn.Conv2d(out_channels, out_channels, 1, 1, 0),
+ )
+ self.relu = nn.ReLU(inplace=True)
+
+ def forward(self, x):
+ out = self.body(x)
+ out = self.relu(out + x)
+ return out
+
+
+class MergeRun(nn.Module):
+ """ Merge-and-run unit.
+
+ This unit contains two branches with different dilated convolutions,
+ followed by a convolution to process the concatenated features.
+
+ Paper: Real Image Denoising with Feature Attention
+ Ref git repo: https://github.com/saeed-anwar/RIDNet
+ """
+
+ def __init__(self, in_channels, out_channels, kernel_size=3, stride=1, padding=1):
+ super(MergeRun, self).__init__()
+
+ self.dilation1 = nn.Sequential(
+ nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding), nn.ReLU(inplace=True),
+ nn.Conv2d(out_channels, out_channels, kernel_size, stride, 2, 2), nn.ReLU(inplace=True))
+ self.dilation2 = nn.Sequential(
+ nn.Conv2d(in_channels, out_channels, kernel_size, stride, 3, 3), nn.ReLU(inplace=True),
+ nn.Conv2d(out_channels, out_channels, kernel_size, stride, 4, 4), nn.ReLU(inplace=True))
+
+ self.aggregation = nn.Sequential(
+ nn.Conv2d(out_channels * 2, out_channels, kernel_size, stride, padding), nn.ReLU(inplace=True))
+
+ def forward(self, x):
+ dilation1 = self.dilation1(x)
+ dilation2 = self.dilation2(x)
+ out = torch.cat([dilation1, dilation2], dim=1)
+ out = self.aggregation(out)
+ out = out + x
+ return out
+
+
+class ChannelAttention(nn.Module):
+ """Channel attention.
+
+ Args:
+ num_feat (int): Channel number of intermediate features.
+ squeeze_factor (int): Channel squeeze factor. Default:
+ """
+
+ def __init__(self, mid_channels, squeeze_factor=16):
+ super(ChannelAttention, self).__init__()
+ self.attention = nn.Sequential(
+ nn.AdaptiveAvgPool2d(1), nn.Conv2d(mid_channels, mid_channels // squeeze_factor, 1, padding=0),
+ nn.ReLU(inplace=True), nn.Conv2d(mid_channels // squeeze_factor, mid_channels, 1, padding=0), nn.Sigmoid())
+
+ def forward(self, x):
+ y = self.attention(x)
+ return x * y
+
+
+class EAM(nn.Module):
+ """Enhancement attention modules (EAM) in RIDNet.
+
+ This module contains a merge-and-run unit, a residual block,
+ an enhanced residual block and a feature attention unit.
+
+ Attributes:
+ merge: The merge-and-run unit.
+ block1: The residual block.
+ block2: The enhanced residual block.
+ ca: The feature/channel attention unit.
+ """
+
+ def __init__(self, in_channels, mid_channels, out_channels):
+ super(EAM, self).__init__()
+
+ self.merge = MergeRun(in_channels, mid_channels)
+ self.block1 = ResidualBlockNoBN(mid_channels)
+ self.block2 = EResidualBlockNoBN(mid_channels, out_channels)
+ self.ca = ChannelAttention(out_channels)
+ # The residual block in the paper contains a relu after addition.
+ self.relu = nn.ReLU(inplace=True)
+
+ def forward(self, x):
+ out = self.merge(x)
+ out = self.relu(self.block1(out))
+ out = self.block2(out)
+ out = self.ca(out)
+ return out
+
+
+@ARCH_REGISTRY.register()
+class RIDNet(nn.Module):
+ """RIDNet: Real Image Denoising with Feature Attention.
+
+ Ref git repo: https://github.com/saeed-anwar/RIDNet
+
+ Args:
+ in_channels (int): Channel number of inputs.
+ mid_channels (int): Channel number of EAM modules.
+ Default: 64.
+ out_channels (int): Channel number of outputs.
+ num_block (int): Number of EAM. Default: 4.
+ img_range (float): Image range. Default: 255.
+ rgb_mean (tuple[float]): Image mean in RGB orders.
+ Default: (0.4488, 0.4371, 0.4040), calculated from DIV2K dataset.
+ """
+
+ def __init__(self,
+ in_channels,
+ mid_channels,
+ out_channels,
+ num_block=4,
+ img_range=255.,
+ rgb_mean=(0.4488, 0.4371, 0.4040),
+ rgb_std=(1.0, 1.0, 1.0)):
+ super(RIDNet, self).__init__()
+
+ self.sub_mean = MeanShift(img_range, rgb_mean, rgb_std)
+ self.add_mean = MeanShift(img_range, rgb_mean, rgb_std, 1)
+
+ self.head = nn.Conv2d(in_channels, mid_channels, 3, 1, 1)
+ self.body = make_layer(
+ EAM, num_block, in_channels=mid_channels, mid_channels=mid_channels, out_channels=mid_channels)
+ self.tail = nn.Conv2d(mid_channels, out_channels, 3, 1, 1)
+
+ self.relu = nn.ReLU(inplace=True)
+
+ def forward(self, x):
+ res = self.sub_mean(x)
+ res = self.tail(self.body(self.relu(self.head(res))))
+ res = self.add_mean(res)
+
+ out = x + res
+ return out
diff --git a/custom_nodes/ComfyUI-ReActor/r_basicsr/archs/rrdbnet_arch.py b/custom_nodes/ComfyUI-ReActor/r_basicsr/archs/rrdbnet_arch.py
new file mode 100644
index 0000000000000000000000000000000000000000..a8c4c4de08c25e87f4ab6ba0bf0eac5b6f003d35
--- /dev/null
+++ b/custom_nodes/ComfyUI-ReActor/r_basicsr/archs/rrdbnet_arch.py
@@ -0,0 +1,119 @@
+import torch
+from torch import nn as nn
+from torch.nn import functional as F
+
+from r_basicsr.utils.registry import ARCH_REGISTRY
+from .arch_util import default_init_weights, make_layer, pixel_unshuffle
+
+
+class ResidualDenseBlock(nn.Module):
+ """Residual Dense Block.
+
+ Used in RRDB block in ESRGAN.
+
+ Args:
+ num_feat (int): Channel number of intermediate features.
+ num_grow_ch (int): Channels for each growth.
+ """
+
+ def __init__(self, num_feat=64, num_grow_ch=32):
+ super(ResidualDenseBlock, self).__init__()
+ self.conv1 = nn.Conv2d(num_feat, num_grow_ch, 3, 1, 1)
+ self.conv2 = nn.Conv2d(num_feat + num_grow_ch, num_grow_ch, 3, 1, 1)
+ self.conv3 = nn.Conv2d(num_feat + 2 * num_grow_ch, num_grow_ch, 3, 1, 1)
+ self.conv4 = nn.Conv2d(num_feat + 3 * num_grow_ch, num_grow_ch, 3, 1, 1)
+ self.conv5 = nn.Conv2d(num_feat + 4 * num_grow_ch, num_feat, 3, 1, 1)
+
+ self.lrelu = nn.LeakyReLU(negative_slope=0.2, inplace=True)
+
+ # initialization
+ default_init_weights([self.conv1, self.conv2, self.conv3, self.conv4, self.conv5], 0.1)
+
+ def forward(self, x):
+ x1 = self.lrelu(self.conv1(x))
+ x2 = self.lrelu(self.conv2(torch.cat((x, x1), 1)))
+ x3 = self.lrelu(self.conv3(torch.cat((x, x1, x2), 1)))
+ x4 = self.lrelu(self.conv4(torch.cat((x, x1, x2, x3), 1)))
+ x5 = self.conv5(torch.cat((x, x1, x2, x3, x4), 1))
+ # Empirically, we use 0.2 to scale the residual for better performance
+ return x5 * 0.2 + x
+
+
+class RRDB(nn.Module):
+ """Residual in Residual Dense Block.
+
+ Used in RRDB-Net in ESRGAN.
+
+ Args:
+ num_feat (int): Channel number of intermediate features.
+ num_grow_ch (int): Channels for each growth.
+ """
+
+ def __init__(self, num_feat, num_grow_ch=32):
+ super(RRDB, self).__init__()
+ self.rdb1 = ResidualDenseBlock(num_feat, num_grow_ch)
+ self.rdb2 = ResidualDenseBlock(num_feat, num_grow_ch)
+ self.rdb3 = ResidualDenseBlock(num_feat, num_grow_ch)
+
+ def forward(self, x):
+ out = self.rdb1(x)
+ out = self.rdb2(out)
+ out = self.rdb3(out)
+ # Empirically, we use 0.2 to scale the residual for better performance
+ return out * 0.2 + x
+
+
+@ARCH_REGISTRY.register()
+class RRDBNet(nn.Module):
+ """Networks consisting of Residual in Residual Dense Block, which is used
+ in ESRGAN.
+
+ ESRGAN: Enhanced Super-Resolution Generative Adversarial Networks.
+
+ We extend ESRGAN for scale x2 and scale x1.
+ Note: This is one option for scale 1, scale 2 in RRDBNet.
+ We first employ the pixel-unshuffle (an inverse operation of pixelshuffle to reduce the spatial size
+ and enlarge the channel size before feeding inputs into the main ESRGAN architecture.
+
+ Args:
+ num_in_ch (int): Channel number of inputs.
+ num_out_ch (int): Channel number of outputs.
+ num_feat (int): Channel number of intermediate features.
+ Default: 64
+ num_block (int): Block number in the trunk network. Defaults: 23
+ num_grow_ch (int): Channels for each growth. Default: 32.
+ """
+
+ def __init__(self, num_in_ch, num_out_ch, scale=4, num_feat=64, num_block=23, num_grow_ch=32):
+ super(RRDBNet, self).__init__()
+ self.scale = scale
+ if scale == 2:
+ num_in_ch = num_in_ch * 4
+ elif scale == 1:
+ num_in_ch = num_in_ch * 16
+ self.conv_first = nn.Conv2d(num_in_ch, num_feat, 3, 1, 1)
+ self.body = make_layer(RRDB, num_block, num_feat=num_feat, num_grow_ch=num_grow_ch)
+ self.conv_body = nn.Conv2d(num_feat, num_feat, 3, 1, 1)
+ # upsample
+ self.conv_up1 = nn.Conv2d(num_feat, num_feat, 3, 1, 1)
+ self.conv_up2 = nn.Conv2d(num_feat, num_feat, 3, 1, 1)
+ self.conv_hr = nn.Conv2d(num_feat, num_feat, 3, 1, 1)
+ self.conv_last = nn.Conv2d(num_feat, num_out_ch, 3, 1, 1)
+
+ self.lrelu = nn.LeakyReLU(negative_slope=0.2, inplace=True)
+
+ def forward(self, x):
+ if self.scale == 2:
+ feat = pixel_unshuffle(x, scale=2)
+ elif self.scale == 1:
+ feat = pixel_unshuffle(x, scale=4)
+ else:
+ feat = x
+ feat = self.conv_first(feat)
+ body_feat = self.conv_body(self.body(feat))
+ feat = feat + body_feat
+ # upsample
+ feat = self.lrelu(self.conv_up1(F.interpolate(feat, scale_factor=2, mode='nearest')))
+ feat = self.lrelu(self.conv_up2(F.interpolate(feat, scale_factor=2, mode='nearest')))
+ out = self.conv_last(self.lrelu(self.conv_hr(feat)))
+ return out
diff --git a/custom_nodes/ComfyUI-ReActor/r_basicsr/archs/spynet_arch.py b/custom_nodes/ComfyUI-ReActor/r_basicsr/archs/spynet_arch.py
new file mode 100644
index 0000000000000000000000000000000000000000..1c0756acf982292f077a20cf499ed19936919c1c
--- /dev/null
+++ b/custom_nodes/ComfyUI-ReActor/r_basicsr/archs/spynet_arch.py
@@ -0,0 +1,96 @@
+import math
+import torch
+from torch import nn as nn
+from torch.nn import functional as F
+
+from r_basicsr.utils.registry import ARCH_REGISTRY
+from .arch_util import flow_warp
+
+
+class BasicModule(nn.Module):
+ """Basic Module for SpyNet.
+ """
+
+ def __init__(self):
+ super(BasicModule, self).__init__()
+
+ self.basic_module = nn.Sequential(
+ nn.Conv2d(in_channels=8, out_channels=32, kernel_size=7, stride=1, padding=3), nn.ReLU(inplace=False),
+ nn.Conv2d(in_channels=32, out_channels=64, kernel_size=7, stride=1, padding=3), nn.ReLU(inplace=False),
+ nn.Conv2d(in_channels=64, out_channels=32, kernel_size=7, stride=1, padding=3), nn.ReLU(inplace=False),
+ nn.Conv2d(in_channels=32, out_channels=16, kernel_size=7, stride=1, padding=3), nn.ReLU(inplace=False),
+ nn.Conv2d(in_channels=16, out_channels=2, kernel_size=7, stride=1, padding=3))
+
+ def forward(self, tensor_input):
+ return self.basic_module(tensor_input)
+
+
+@ARCH_REGISTRY.register()
+class SpyNet(nn.Module):
+ """SpyNet architecture.
+
+ Args:
+ load_path (str): path for pretrained SpyNet. Default: None.
+ """
+
+ def __init__(self, load_path=None):
+ super(SpyNet, self).__init__()
+ self.basic_module = nn.ModuleList([BasicModule() for _ in range(6)])
+ if load_path:
+ self.load_state_dict(torch.load(load_path, map_location=lambda storage, loc: storage)['params'])
+
+ self.register_buffer('mean', torch.Tensor([0.485, 0.456, 0.406]).view(1, 3, 1, 1))
+ self.register_buffer('std', torch.Tensor([0.229, 0.224, 0.225]).view(1, 3, 1, 1))
+
+ def preprocess(self, tensor_input):
+ tensor_output = (tensor_input - self.mean) / self.std
+ return tensor_output
+
+ def process(self, ref, supp):
+ flow = []
+
+ ref = [self.preprocess(ref)]
+ supp = [self.preprocess(supp)]
+
+ for level in range(5):
+ ref.insert(0, F.avg_pool2d(input=ref[0], kernel_size=2, stride=2, count_include_pad=False))
+ supp.insert(0, F.avg_pool2d(input=supp[0], kernel_size=2, stride=2, count_include_pad=False))
+
+ flow = ref[0].new_zeros(
+ [ref[0].size(0), 2,
+ int(math.floor(ref[0].size(2) / 2.0)),
+ int(math.floor(ref[0].size(3) / 2.0))])
+
+ for level in range(len(ref)):
+ upsampled_flow = F.interpolate(input=flow, scale_factor=2, mode='bilinear', align_corners=True) * 2.0
+
+ if upsampled_flow.size(2) != ref[level].size(2):
+ upsampled_flow = F.pad(input=upsampled_flow, pad=[0, 0, 0, 1], mode='replicate')
+ if upsampled_flow.size(3) != ref[level].size(3):
+ upsampled_flow = F.pad(input=upsampled_flow, pad=[0, 1, 0, 0], mode='replicate')
+
+ flow = self.basic_module[level](torch.cat([
+ ref[level],
+ flow_warp(
+ supp[level], upsampled_flow.permute(0, 2, 3, 1), interp_mode='bilinear', padding_mode='border'),
+ upsampled_flow
+ ], 1)) + upsampled_flow
+
+ return flow
+
+ def forward(self, ref, supp):
+ assert ref.size() == supp.size()
+
+ h, w = ref.size(2), ref.size(3)
+ w_floor = math.floor(math.ceil(w / 32.0) * 32.0)
+ h_floor = math.floor(math.ceil(h / 32.0) * 32.0)
+
+ ref = F.interpolate(input=ref, size=(h_floor, w_floor), mode='bilinear', align_corners=False)
+ supp = F.interpolate(input=supp, size=(h_floor, w_floor), mode='bilinear', align_corners=False)
+
+ flow = F.interpolate(input=self.process(ref, supp), size=(h, w), mode='bilinear', align_corners=False)
+
+ flow[:, 0, :, :] *= float(w) / float(w_floor)
+ flow[:, 1, :, :] *= float(h) / float(h_floor)
+
+ return flow
diff --git a/custom_nodes/ComfyUI-ReActor/r_basicsr/archs/srresnet_arch.py b/custom_nodes/ComfyUI-ReActor/r_basicsr/archs/srresnet_arch.py
new file mode 100644
index 0000000000000000000000000000000000000000..f922ecc1a82428d0770d8f566e6c501b332be3e7
--- /dev/null
+++ b/custom_nodes/ComfyUI-ReActor/r_basicsr/archs/srresnet_arch.py
@@ -0,0 +1,65 @@
+from torch import nn as nn
+from torch.nn import functional as F
+
+from r_basicsr.utils.registry import ARCH_REGISTRY
+from .arch_util import ResidualBlockNoBN, default_init_weights, make_layer
+
+
+@ARCH_REGISTRY.register()
+class MSRResNet(nn.Module):
+ """Modified SRResNet.
+
+ A compacted version modified from SRResNet in
+ "Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network"
+ It uses residual blocks without BN, similar to EDSR.
+ Currently, it supports x2, x3 and x4 upsampling scale factor.
+
+ Args:
+ num_in_ch (int): Channel number of inputs. Default: 3.
+ num_out_ch (int): Channel number of outputs. Default: 3.
+ num_feat (int): Channel number of intermediate features. Default: 64.
+ num_block (int): Block number in the body network. Default: 16.
+ upscale (int): Upsampling factor. Support x2, x3 and x4. Default: 4.
+ """
+
+ def __init__(self, num_in_ch=3, num_out_ch=3, num_feat=64, num_block=16, upscale=4):
+ super(MSRResNet, self).__init__()
+ self.upscale = upscale
+
+ self.conv_first = nn.Conv2d(num_in_ch, num_feat, 3, 1, 1)
+ self.body = make_layer(ResidualBlockNoBN, num_block, num_feat=num_feat)
+
+ # upsampling
+ if self.upscale in [2, 3]:
+ self.upconv1 = nn.Conv2d(num_feat, num_feat * self.upscale * self.upscale, 3, 1, 1)
+ self.pixel_shuffle = nn.PixelShuffle(self.upscale)
+ elif self.upscale == 4:
+ self.upconv1 = nn.Conv2d(num_feat, num_feat * 4, 3, 1, 1)
+ self.upconv2 = nn.Conv2d(num_feat, num_feat * 4, 3, 1, 1)
+ self.pixel_shuffle = nn.PixelShuffle(2)
+
+ self.conv_hr = nn.Conv2d(num_feat, num_feat, 3, 1, 1)
+ self.conv_last = nn.Conv2d(num_feat, num_out_ch, 3, 1, 1)
+
+ # activation function
+ self.lrelu = nn.LeakyReLU(negative_slope=0.1, inplace=True)
+
+ # initialization
+ default_init_weights([self.conv_first, self.upconv1, self.conv_hr, self.conv_last], 0.1)
+ if self.upscale == 4:
+ default_init_weights(self.upconv2, 0.1)
+
+ def forward(self, x):
+ feat = self.lrelu(self.conv_first(x))
+ out = self.body(feat)
+
+ if self.upscale == 4:
+ out = self.lrelu(self.pixel_shuffle(self.upconv1(out)))
+ out = self.lrelu(self.pixel_shuffle(self.upconv2(out)))
+ elif self.upscale in [2, 3]:
+ out = self.lrelu(self.pixel_shuffle(self.upconv1(out)))
+
+ out = self.conv_last(self.lrelu(self.conv_hr(out)))
+ base = F.interpolate(x, scale_factor=self.upscale, mode='bilinear', align_corners=False)
+ out += base
+ return out
diff --git a/custom_nodes/ComfyUI-ReActor/r_basicsr/archs/srvgg_arch.py b/custom_nodes/ComfyUI-ReActor/r_basicsr/archs/srvgg_arch.py
new file mode 100644
index 0000000000000000000000000000000000000000..02267d80c6d4fbdcc2ed8ac96ef0e51ab21ac727
--- /dev/null
+++ b/custom_nodes/ComfyUI-ReActor/r_basicsr/archs/srvgg_arch.py
@@ -0,0 +1,70 @@
+from torch import nn as nn
+from torch.nn import functional as F
+
+from r_basicsr.utils.registry import ARCH_REGISTRY
+
+
+@ARCH_REGISTRY.register(suffix='basicsr')
+class SRVGGNetCompact(nn.Module):
+ """A compact VGG-style network structure for super-resolution.
+
+ It is a compact network structure, which performs upsampling in the last layer and no convolution is
+ conducted on the HR feature space.
+
+ Args:
+ num_in_ch (int): Channel number of inputs. Default: 3.
+ num_out_ch (int): Channel number of outputs. Default: 3.
+ num_feat (int): Channel number of intermediate features. Default: 64.
+ num_conv (int): Number of convolution layers in the body network. Default: 16.
+ upscale (int): Upsampling factor. Default: 4.
+ act_type (str): Activation type, options: 'relu', 'prelu', 'leakyrelu'. Default: prelu.
+ """
+
+ def __init__(self, num_in_ch=3, num_out_ch=3, num_feat=64, num_conv=16, upscale=4, act_type='prelu'):
+ super(SRVGGNetCompact, self).__init__()
+ self.num_in_ch = num_in_ch
+ self.num_out_ch = num_out_ch
+ self.num_feat = num_feat
+ self.num_conv = num_conv
+ self.upscale = upscale
+ self.act_type = act_type
+
+ self.body = nn.ModuleList()
+ # the first conv
+ self.body.append(nn.Conv2d(num_in_ch, num_feat, 3, 1, 1))
+ # the first activation
+ if act_type == 'relu':
+ activation = nn.ReLU(inplace=True)
+ elif act_type == 'prelu':
+ activation = nn.PReLU(num_parameters=num_feat)
+ elif act_type == 'leakyrelu':
+ activation = nn.LeakyReLU(negative_slope=0.1, inplace=True)
+ self.body.append(activation)
+
+ # the body structure
+ for _ in range(num_conv):
+ self.body.append(nn.Conv2d(num_feat, num_feat, 3, 1, 1))
+ # activation
+ if act_type == 'relu':
+ activation = nn.ReLU(inplace=True)
+ elif act_type == 'prelu':
+ activation = nn.PReLU(num_parameters=num_feat)
+ elif act_type == 'leakyrelu':
+ activation = nn.LeakyReLU(negative_slope=0.1, inplace=True)
+ self.body.append(activation)
+
+ # the last conv
+ self.body.append(nn.Conv2d(num_feat, num_out_ch * upscale * upscale, 3, 1, 1))
+ # upsample
+ self.upsampler = nn.PixelShuffle(upscale)
+
+ def forward(self, x):
+ out = x
+ for i in range(0, len(self.body)):
+ out = self.body[i](out)
+
+ out = self.upsampler(out)
+ # add the nearest upsampled image, so that the network learns the residual
+ base = F.interpolate(x, scale_factor=self.upscale, mode='nearest')
+ out += base
+ return out
diff --git a/custom_nodes/ComfyUI-ReActor/r_basicsr/archs/stylegan2_arch.py b/custom_nodes/ComfyUI-ReActor/r_basicsr/archs/stylegan2_arch.py
new file mode 100644
index 0000000000000000000000000000000000000000..b9bbf4de7a74a1631bcefe6c721d14e37d15de11
--- /dev/null
+++ b/custom_nodes/ComfyUI-ReActor/r_basicsr/archs/stylegan2_arch.py
@@ -0,0 +1,799 @@
+import math
+import random
+import torch
+from torch import nn
+from torch.nn import functional as F
+
+from r_basicsr.ops.fused_act import FusedLeakyReLU, fused_leaky_relu
+from r_basicsr.ops.upfirdn2d import upfirdn2d
+from r_basicsr.utils.registry import ARCH_REGISTRY
+
+
+class NormStyleCode(nn.Module):
+
+ def forward(self, x):
+ """Normalize the style codes.
+
+ Args:
+ x (Tensor): Style codes with shape (b, c).
+
+ Returns:
+ Tensor: Normalized tensor.
+ """
+ return x * torch.rsqrt(torch.mean(x**2, dim=1, keepdim=True) + 1e-8)
+
+
+def make_resample_kernel(k):
+ """Make resampling kernel for UpFirDn.
+
+ Args:
+ k (list[int]): A list indicating the 1D resample kernel magnitude.
+
+ Returns:
+ Tensor: 2D resampled kernel.
+ """
+ k = torch.tensor(k, dtype=torch.float32)
+ if k.ndim == 1:
+ k = k[None, :] * k[:, None] # to 2D kernel, outer product
+ # normalize
+ k /= k.sum()
+ return k
+
+
+class UpFirDnUpsample(nn.Module):
+ """Upsample, FIR filter, and downsample (upsampole version).
+
+ References:
+ 1. https://docs.scipy.org/doc/scipy/reference/generated/scipy.signal.upfirdn.html # noqa: E501
+ 2. http://www.ece.northwestern.edu/local-apps/matlabhelp/toolbox/signal/upfirdn.html # noqa: E501
+
+ Args:
+ resample_kernel (list[int]): A list indicating the 1D resample kernel
+ magnitude.
+ factor (int): Upsampling scale factor. Default: 2.
+ """
+
+ def __init__(self, resample_kernel, factor=2):
+ super(UpFirDnUpsample, self).__init__()
+ self.kernel = make_resample_kernel(resample_kernel) * (factor**2)
+ self.factor = factor
+
+ pad = self.kernel.shape[0] - factor
+ self.pad = ((pad + 1) // 2 + factor - 1, pad // 2)
+
+ def forward(self, x):
+ out = upfirdn2d(x, self.kernel.type_as(x), up=self.factor, down=1, pad=self.pad)
+ return out
+
+ def __repr__(self):
+ return (f'{self.__class__.__name__}(factor={self.factor})')
+
+
+class UpFirDnDownsample(nn.Module):
+ """Upsample, FIR filter, and downsample (downsampole version).
+
+ Args:
+ resample_kernel (list[int]): A list indicating the 1D resample kernel
+ magnitude.
+ factor (int): Downsampling scale factor. Default: 2.
+ """
+
+ def __init__(self, resample_kernel, factor=2):
+ super(UpFirDnDownsample, self).__init__()
+ self.kernel = make_resample_kernel(resample_kernel)
+ self.factor = factor
+
+ pad = self.kernel.shape[0] - factor
+ self.pad = ((pad + 1) // 2, pad // 2)
+
+ def forward(self, x):
+ out = upfirdn2d(x, self.kernel.type_as(x), up=1, down=self.factor, pad=self.pad)
+ return out
+
+ def __repr__(self):
+ return (f'{self.__class__.__name__}(factor={self.factor})')
+
+
+class UpFirDnSmooth(nn.Module):
+ """Upsample, FIR filter, and downsample (smooth version).
+
+ Args:
+ resample_kernel (list[int]): A list indicating the 1D resample kernel
+ magnitude.
+ upsample_factor (int): Upsampling scale factor. Default: 1.
+ downsample_factor (int): Downsampling scale factor. Default: 1.
+ kernel_size (int): Kernel size: Default: 1.
+ """
+
+ def __init__(self, resample_kernel, upsample_factor=1, downsample_factor=1, kernel_size=1):
+ super(UpFirDnSmooth, self).__init__()
+ self.upsample_factor = upsample_factor
+ self.downsample_factor = downsample_factor
+ self.kernel = make_resample_kernel(resample_kernel)
+ if upsample_factor > 1:
+ self.kernel = self.kernel * (upsample_factor**2)
+
+ if upsample_factor > 1:
+ pad = (self.kernel.shape[0] - upsample_factor) - (kernel_size - 1)
+ self.pad = ((pad + 1) // 2 + upsample_factor - 1, pad // 2 + 1)
+ elif downsample_factor > 1:
+ pad = (self.kernel.shape[0] - downsample_factor) + (kernel_size - 1)
+ self.pad = ((pad + 1) // 2, pad // 2)
+ else:
+ raise NotImplementedError
+
+ def forward(self, x):
+ out = upfirdn2d(x, self.kernel.type_as(x), up=1, down=1, pad=self.pad)
+ return out
+
+ def __repr__(self):
+ return (f'{self.__class__.__name__}(upsample_factor={self.upsample_factor}'
+ f', downsample_factor={self.downsample_factor})')
+
+
+class EqualLinear(nn.Module):
+ """Equalized Linear as StyleGAN2.
+
+ Args:
+ in_channels (int): Size of each sample.
+ out_channels (int): Size of each output sample.
+ bias (bool): If set to ``False``, the layer will not learn an additive
+ bias. Default: ``True``.
+ bias_init_val (float): Bias initialized value. Default: 0.
+ lr_mul (float): Learning rate multiplier. Default: 1.
+ activation (None | str): The activation after ``linear`` operation.
+ Supported: 'fused_lrelu', None. Default: None.
+ """
+
+ def __init__(self, in_channels, out_channels, bias=True, bias_init_val=0, lr_mul=1, activation=None):
+ super(EqualLinear, self).__init__()
+ self.in_channels = in_channels
+ self.out_channels = out_channels
+ self.lr_mul = lr_mul
+ self.activation = activation
+ if self.activation not in ['fused_lrelu', None]:
+ raise ValueError(f'Wrong activation value in EqualLinear: {activation}'
+ "Supported ones are: ['fused_lrelu', None].")
+ self.scale = (1 / math.sqrt(in_channels)) * lr_mul
+
+ self.weight = nn.Parameter(torch.randn(out_channels, in_channels).div_(lr_mul))
+ if bias:
+ self.bias = nn.Parameter(torch.zeros(out_channels).fill_(bias_init_val))
+ else:
+ self.register_parameter('bias', None)
+
+ def forward(self, x):
+ if self.bias is None:
+ bias = None
+ else:
+ bias = self.bias * self.lr_mul
+ if self.activation == 'fused_lrelu':
+ out = F.linear(x, self.weight * self.scale)
+ out = fused_leaky_relu(out, bias)
+ else:
+ out = F.linear(x, self.weight * self.scale, bias=bias)
+ return out
+
+ def __repr__(self):
+ return (f'{self.__class__.__name__}(in_channels={self.in_channels}, '
+ f'out_channels={self.out_channels}, bias={self.bias is not None})')
+
+
+class ModulatedConv2d(nn.Module):
+ """Modulated Conv2d used in StyleGAN2.
+
+ There is no bias in ModulatedConv2d.
+
+ Args:
+ in_channels (int): Channel number of the input.
+ out_channels (int): Channel number of the output.
+ kernel_size (int): Size of the convolving kernel.
+ num_style_feat (int): Channel number of style features.
+ demodulate (bool): Whether to demodulate in the conv layer.
+ Default: True.
+ sample_mode (str | None): Indicating 'upsample', 'downsample' or None.
+ Default: None.
+ resample_kernel (list[int]): A list indicating the 1D resample kernel
+ magnitude. Default: (1, 3, 3, 1).
+ eps (float): A value added to the denominator for numerical stability.
+ Default: 1e-8.
+ """
+
+ def __init__(self,
+ in_channels,
+ out_channels,
+ kernel_size,
+ num_style_feat,
+ demodulate=True,
+ sample_mode=None,
+ resample_kernel=(1, 3, 3, 1),
+ eps=1e-8):
+ super(ModulatedConv2d, self).__init__()
+ self.in_channels = in_channels
+ self.out_channels = out_channels
+ self.kernel_size = kernel_size
+ self.demodulate = demodulate
+ self.sample_mode = sample_mode
+ self.eps = eps
+
+ if self.sample_mode == 'upsample':
+ self.smooth = UpFirDnSmooth(
+ resample_kernel, upsample_factor=2, downsample_factor=1, kernel_size=kernel_size)
+ elif self.sample_mode == 'downsample':
+ self.smooth = UpFirDnSmooth(
+ resample_kernel, upsample_factor=1, downsample_factor=2, kernel_size=kernel_size)
+ elif self.sample_mode is None:
+ pass
+ else:
+ raise ValueError(f'Wrong sample mode {self.sample_mode}, '
+ "supported ones are ['upsample', 'downsample', None].")
+
+ self.scale = 1 / math.sqrt(in_channels * kernel_size**2)
+ # modulation inside each modulated conv
+ self.modulation = EqualLinear(
+ num_style_feat, in_channels, bias=True, bias_init_val=1, lr_mul=1, activation=None)
+
+ self.weight = nn.Parameter(torch.randn(1, out_channels, in_channels, kernel_size, kernel_size))
+ self.padding = kernel_size // 2
+
+ def forward(self, x, style):
+ """Forward function.
+
+ Args:
+ x (Tensor): Tensor with shape (b, c, h, w).
+ style (Tensor): Tensor with shape (b, num_style_feat).
+
+ Returns:
+ Tensor: Modulated tensor after convolution.
+ """
+ b, c, h, w = x.shape # c = c_in
+ # weight modulation
+ style = self.modulation(style).view(b, 1, c, 1, 1)
+ # self.weight: (1, c_out, c_in, k, k); style: (b, 1, c, 1, 1)
+ weight = self.scale * self.weight * style # (b, c_out, c_in, k, k)
+
+ if self.demodulate:
+ demod = torch.rsqrt(weight.pow(2).sum([2, 3, 4]) + self.eps)
+ weight = weight * demod.view(b, self.out_channels, 1, 1, 1)
+
+ weight = weight.view(b * self.out_channels, c, self.kernel_size, self.kernel_size)
+
+ if self.sample_mode == 'upsample':
+ x = x.view(1, b * c, h, w)
+ weight = weight.view(b, self.out_channels, c, self.kernel_size, self.kernel_size)
+ weight = weight.transpose(1, 2).reshape(b * c, self.out_channels, self.kernel_size, self.kernel_size)
+ out = F.conv_transpose2d(x, weight, padding=0, stride=2, groups=b)
+ out = out.view(b, self.out_channels, *out.shape[2:4])
+ out = self.smooth(out)
+ elif self.sample_mode == 'downsample':
+ x = self.smooth(x)
+ x = x.view(1, b * c, *x.shape[2:4])
+ out = F.conv2d(x, weight, padding=0, stride=2, groups=b)
+ out = out.view(b, self.out_channels, *out.shape[2:4])
+ else:
+ x = x.view(1, b * c, h, w)
+ # weight: (b*c_out, c_in, k, k), groups=b
+ out = F.conv2d(x, weight, padding=self.padding, groups=b)
+ out = out.view(b, self.out_channels, *out.shape[2:4])
+
+ return out
+
+ def __repr__(self):
+ return (f'{self.__class__.__name__}(in_channels={self.in_channels}, '
+ f'out_channels={self.out_channels}, '
+ f'kernel_size={self.kernel_size}, '
+ f'demodulate={self.demodulate}, sample_mode={self.sample_mode})')
+
+
+class StyleConv(nn.Module):
+ """Style conv.
+
+ Args:
+ in_channels (int): Channel number of the input.
+ out_channels (int): Channel number of the output.
+ kernel_size (int): Size of the convolving kernel.
+ num_style_feat (int): Channel number of style features.
+ demodulate (bool): Whether demodulate in the conv layer. Default: True.
+ sample_mode (str | None): Indicating 'upsample', 'downsample' or None.
+ Default: None.
+ resample_kernel (list[int]): A list indicating the 1D resample kernel
+ magnitude. Default: (1, 3, 3, 1).
+ """
+
+ def __init__(self,
+ in_channels,
+ out_channels,
+ kernel_size,
+ num_style_feat,
+ demodulate=True,
+ sample_mode=None,
+ resample_kernel=(1, 3, 3, 1)):
+ super(StyleConv, self).__init__()
+ self.modulated_conv = ModulatedConv2d(
+ in_channels,
+ out_channels,
+ kernel_size,
+ num_style_feat,
+ demodulate=demodulate,
+ sample_mode=sample_mode,
+ resample_kernel=resample_kernel)
+ self.weight = nn.Parameter(torch.zeros(1)) # for noise injection
+ self.activate = FusedLeakyReLU(out_channels)
+
+ def forward(self, x, style, noise=None):
+ # modulate
+ out = self.modulated_conv(x, style)
+ # noise injection
+ if noise is None:
+ b, _, h, w = out.shape
+ noise = out.new_empty(b, 1, h, w).normal_()
+ out = out + self.weight * noise
+ # activation (with bias)
+ out = self.activate(out)
+ return out
+
+
+class ToRGB(nn.Module):
+ """To RGB from features.
+
+ Args:
+ in_channels (int): Channel number of input.
+ num_style_feat (int): Channel number of style features.
+ upsample (bool): Whether to upsample. Default: True.
+ resample_kernel (list[int]): A list indicating the 1D resample kernel
+ magnitude. Default: (1, 3, 3, 1).
+ """
+
+ def __init__(self, in_channels, num_style_feat, upsample=True, resample_kernel=(1, 3, 3, 1)):
+ super(ToRGB, self).__init__()
+ if upsample:
+ self.upsample = UpFirDnUpsample(resample_kernel, factor=2)
+ else:
+ self.upsample = None
+ self.modulated_conv = ModulatedConv2d(
+ in_channels, 3, kernel_size=1, num_style_feat=num_style_feat, demodulate=False, sample_mode=None)
+ self.bias = nn.Parameter(torch.zeros(1, 3, 1, 1))
+
+ def forward(self, x, style, skip=None):
+ """Forward function.
+
+ Args:
+ x (Tensor): Feature tensor with shape (b, c, h, w).
+ style (Tensor): Tensor with shape (b, num_style_feat).
+ skip (Tensor): Base/skip tensor. Default: None.
+
+ Returns:
+ Tensor: RGB images.
+ """
+ out = self.modulated_conv(x, style)
+ out = out + self.bias
+ if skip is not None:
+ if self.upsample:
+ skip = self.upsample(skip)
+ out = out + skip
+ return out
+
+
+class ConstantInput(nn.Module):
+ """Constant input.
+
+ Args:
+ num_channel (int): Channel number of constant input.
+ size (int): Spatial size of constant input.
+ """
+
+ def __init__(self, num_channel, size):
+ super(ConstantInput, self).__init__()
+ self.weight = nn.Parameter(torch.randn(1, num_channel, size, size))
+
+ def forward(self, batch):
+ out = self.weight.repeat(batch, 1, 1, 1)
+ return out
+
+
+@ARCH_REGISTRY.register()
+class StyleGAN2Generator(nn.Module):
+ """StyleGAN2 Generator.
+
+ Args:
+ out_size (int): The spatial size of outputs.
+ num_style_feat (int): Channel number of style features. Default: 512.
+ num_mlp (int): Layer number of MLP style layers. Default: 8.
+ channel_multiplier (int): Channel multiplier for large networks of
+ StyleGAN2. Default: 2.
+ resample_kernel (list[int]): A list indicating the 1D resample kernel
+ magnitude. A cross production will be applied to extent 1D resample
+ kernel to 2D resample kernel. Default: (1, 3, 3, 1).
+ lr_mlp (float): Learning rate multiplier for mlp layers. Default: 0.01.
+ narrow (float): Narrow ratio for channels. Default: 1.0.
+ """
+
+ def __init__(self,
+ out_size,
+ num_style_feat=512,
+ num_mlp=8,
+ channel_multiplier=2,
+ resample_kernel=(1, 3, 3, 1),
+ lr_mlp=0.01,
+ narrow=1):
+ super(StyleGAN2Generator, self).__init__()
+ # Style MLP layers
+ self.num_style_feat = num_style_feat
+ style_mlp_layers = [NormStyleCode()]
+ for i in range(num_mlp):
+ style_mlp_layers.append(
+ EqualLinear(
+ num_style_feat, num_style_feat, bias=True, bias_init_val=0, lr_mul=lr_mlp,
+ activation='fused_lrelu'))
+ self.style_mlp = nn.Sequential(*style_mlp_layers)
+
+ channels = {
+ '4': int(512 * narrow),
+ '8': int(512 * narrow),
+ '16': int(512 * narrow),
+ '32': int(512 * narrow),
+ '64': int(256 * channel_multiplier * narrow),
+ '128': int(128 * channel_multiplier * narrow),
+ '256': int(64 * channel_multiplier * narrow),
+ '512': int(32 * channel_multiplier * narrow),
+ '1024': int(16 * channel_multiplier * narrow)
+ }
+ self.channels = channels
+
+ self.constant_input = ConstantInput(channels['4'], size=4)
+ self.style_conv1 = StyleConv(
+ channels['4'],
+ channels['4'],
+ kernel_size=3,
+ num_style_feat=num_style_feat,
+ demodulate=True,
+ sample_mode=None,
+ resample_kernel=resample_kernel)
+ self.to_rgb1 = ToRGB(channels['4'], num_style_feat, upsample=False, resample_kernel=resample_kernel)
+
+ self.log_size = int(math.log(out_size, 2))
+ self.num_layers = (self.log_size - 2) * 2 + 1
+ self.num_latent = self.log_size * 2 - 2
+
+ self.style_convs = nn.ModuleList()
+ self.to_rgbs = nn.ModuleList()
+ self.noises = nn.Module()
+
+ in_channels = channels['4']
+ # noise
+ for layer_idx in range(self.num_layers):
+ resolution = 2**((layer_idx + 5) // 2)
+ shape = [1, 1, resolution, resolution]
+ self.noises.register_buffer(f'noise{layer_idx}', torch.randn(*shape))
+ # style convs and to_rgbs
+ for i in range(3, self.log_size + 1):
+ out_channels = channels[f'{2**i}']
+ self.style_convs.append(
+ StyleConv(
+ in_channels,
+ out_channels,
+ kernel_size=3,
+ num_style_feat=num_style_feat,
+ demodulate=True,
+ sample_mode='upsample',
+ resample_kernel=resample_kernel,
+ ))
+ self.style_convs.append(
+ StyleConv(
+ out_channels,
+ out_channels,
+ kernel_size=3,
+ num_style_feat=num_style_feat,
+ demodulate=True,
+ sample_mode=None,
+ resample_kernel=resample_kernel))
+ self.to_rgbs.append(ToRGB(out_channels, num_style_feat, upsample=True, resample_kernel=resample_kernel))
+ in_channels = out_channels
+
+ def make_noise(self):
+ """Make noise for noise injection."""
+ device = self.constant_input.weight.device
+ noises = [torch.randn(1, 1, 4, 4, device=device)]
+
+ for i in range(3, self.log_size + 1):
+ for _ in range(2):
+ noises.append(torch.randn(1, 1, 2**i, 2**i, device=device))
+
+ return noises
+
+ def get_latent(self, x):
+ return self.style_mlp(x)
+
+ def mean_latent(self, num_latent):
+ latent_in = torch.randn(num_latent, self.num_style_feat, device=self.constant_input.weight.device)
+ latent = self.style_mlp(latent_in).mean(0, keepdim=True)
+ return latent
+
+ def forward(self,
+ styles,
+ input_is_latent=False,
+ noise=None,
+ randomize_noise=True,
+ truncation=1,
+ truncation_latent=None,
+ inject_index=None,
+ return_latents=False):
+ """Forward function for StyleGAN2Generator.
+
+ Args:
+ styles (list[Tensor]): Sample codes of styles.
+ input_is_latent (bool): Whether input is latent style.
+ Default: False.
+ noise (Tensor | None): Input noise or None. Default: None.
+ randomize_noise (bool): Randomize noise, used when 'noise' is
+ False. Default: True.
+ truncation (float): TODO. Default: 1.
+ truncation_latent (Tensor | None): TODO. Default: None.
+ inject_index (int | None): The injection index for mixing noise.
+ Default: None.
+ return_latents (bool): Whether to return style latents.
+ Default: False.
+ """
+ # style codes -> latents with Style MLP layer
+ if not input_is_latent:
+ styles = [self.style_mlp(s) for s in styles]
+ # noises
+ if noise is None:
+ if randomize_noise:
+ noise = [None] * self.num_layers # for each style conv layer
+ else: # use the stored noise
+ noise = [getattr(self.noises, f'noise{i}') for i in range(self.num_layers)]
+ # style truncation
+ if truncation < 1:
+ style_truncation = []
+ for style in styles:
+ style_truncation.append(truncation_latent + truncation * (style - truncation_latent))
+ styles = style_truncation
+ # get style latent with injection
+ if len(styles) == 1:
+ inject_index = self.num_latent
+
+ if styles[0].ndim < 3:
+ # repeat latent code for all the layers
+ latent = styles[0].unsqueeze(1).repeat(1, inject_index, 1)
+ else: # used for encoder with different latent code for each layer
+ latent = styles[0]
+ elif len(styles) == 2: # mixing noises
+ if inject_index is None:
+ inject_index = random.randint(1, self.num_latent - 1)
+ latent1 = styles[0].unsqueeze(1).repeat(1, inject_index, 1)
+ latent2 = styles[1].unsqueeze(1).repeat(1, self.num_latent - inject_index, 1)
+ latent = torch.cat([latent1, latent2], 1)
+
+ # main generation
+ out = self.constant_input(latent.shape[0])
+ out = self.style_conv1(out, latent[:, 0], noise=noise[0])
+ skip = self.to_rgb1(out, latent[:, 1])
+
+ i = 1
+ for conv1, conv2, noise1, noise2, to_rgb in zip(self.style_convs[::2], self.style_convs[1::2], noise[1::2],
+ noise[2::2], self.to_rgbs):
+ out = conv1(out, latent[:, i], noise=noise1)
+ out = conv2(out, latent[:, i + 1], noise=noise2)
+ skip = to_rgb(out, latent[:, i + 2], skip)
+ i += 2
+
+ image = skip
+
+ if return_latents:
+ return image, latent
+ else:
+ return image, None
+
+
+class ScaledLeakyReLU(nn.Module):
+ """Scaled LeakyReLU.
+
+ Args:
+ negative_slope (float): Negative slope. Default: 0.2.
+ """
+
+ def __init__(self, negative_slope=0.2):
+ super(ScaledLeakyReLU, self).__init__()
+ self.negative_slope = negative_slope
+
+ def forward(self, x):
+ out = F.leaky_relu(x, negative_slope=self.negative_slope)
+ return out * math.sqrt(2)
+
+
+class EqualConv2d(nn.Module):
+ """Equalized Linear as StyleGAN2.
+
+ Args:
+ in_channels (int): Channel number of the input.
+ out_channels (int): Channel number of the output.
+ kernel_size (int): Size of the convolving kernel.
+ stride (int): Stride of the convolution. Default: 1
+ padding (int): Zero-padding added to both sides of the input.
+ Default: 0.
+ bias (bool): If ``True``, adds a learnable bias to the output.
+ Default: ``True``.
+ bias_init_val (float): Bias initialized value. Default: 0.
+ """
+
+ def __init__(self, in_channels, out_channels, kernel_size, stride=1, padding=0, bias=True, bias_init_val=0):
+ super(EqualConv2d, self).__init__()
+ self.in_channels = in_channels
+ self.out_channels = out_channels
+ self.kernel_size = kernel_size
+ self.stride = stride
+ self.padding = padding
+ self.scale = 1 / math.sqrt(in_channels * kernel_size**2)
+
+ self.weight = nn.Parameter(torch.randn(out_channels, in_channels, kernel_size, kernel_size))
+ if bias:
+ self.bias = nn.Parameter(torch.zeros(out_channels).fill_(bias_init_val))
+ else:
+ self.register_parameter('bias', None)
+
+ def forward(self, x):
+ out = F.conv2d(
+ x,
+ self.weight * self.scale,
+ bias=self.bias,
+ stride=self.stride,
+ padding=self.padding,
+ )
+
+ return out
+
+ def __repr__(self):
+ return (f'{self.__class__.__name__}(in_channels={self.in_channels}, '
+ f'out_channels={self.out_channels}, '
+ f'kernel_size={self.kernel_size},'
+ f' stride={self.stride}, padding={self.padding}, '
+ f'bias={self.bias is not None})')
+
+
+class ConvLayer(nn.Sequential):
+ """Conv Layer used in StyleGAN2 Discriminator.
+
+ Args:
+ in_channels (int): Channel number of the input.
+ out_channels (int): Channel number of the output.
+ kernel_size (int): Kernel size.
+ downsample (bool): Whether downsample by a factor of 2.
+ Default: False.
+ resample_kernel (list[int]): A list indicating the 1D resample
+ kernel magnitude. A cross production will be applied to
+ extent 1D resample kernel to 2D resample kernel.
+ Default: (1, 3, 3, 1).
+ bias (bool): Whether with bias. Default: True.
+ activate (bool): Whether use activateion. Default: True.
+ """
+
+ def __init__(self,
+ in_channels,
+ out_channels,
+ kernel_size,
+ downsample=False,
+ resample_kernel=(1, 3, 3, 1),
+ bias=True,
+ activate=True):
+ layers = []
+ # downsample
+ if downsample:
+ layers.append(
+ UpFirDnSmooth(resample_kernel, upsample_factor=1, downsample_factor=2, kernel_size=kernel_size))
+ stride = 2
+ self.padding = 0
+ else:
+ stride = 1
+ self.padding = kernel_size // 2
+ # conv
+ layers.append(
+ EqualConv2d(
+ in_channels, out_channels, kernel_size, stride=stride, padding=self.padding, bias=bias
+ and not activate))
+ # activation
+ if activate:
+ if bias:
+ layers.append(FusedLeakyReLU(out_channels))
+ else:
+ layers.append(ScaledLeakyReLU(0.2))
+
+ super(ConvLayer, self).__init__(*layers)
+
+
+class ResBlock(nn.Module):
+ """Residual block used in StyleGAN2 Discriminator.
+
+ Args:
+ in_channels (int): Channel number of the input.
+ out_channels (int): Channel number of the output.
+ resample_kernel (list[int]): A list indicating the 1D resample
+ kernel magnitude. A cross production will be applied to
+ extent 1D resample kernel to 2D resample kernel.
+ Default: (1, 3, 3, 1).
+ """
+
+ def __init__(self, in_channels, out_channels, resample_kernel=(1, 3, 3, 1)):
+ super(ResBlock, self).__init__()
+
+ self.conv1 = ConvLayer(in_channels, in_channels, 3, bias=True, activate=True)
+ self.conv2 = ConvLayer(
+ in_channels, out_channels, 3, downsample=True, resample_kernel=resample_kernel, bias=True, activate=True)
+ self.skip = ConvLayer(
+ in_channels, out_channels, 1, downsample=True, resample_kernel=resample_kernel, bias=False, activate=False)
+
+ def forward(self, x):
+ out = self.conv1(x)
+ out = self.conv2(out)
+ skip = self.skip(x)
+ out = (out + skip) / math.sqrt(2)
+ return out
+
+
+@ARCH_REGISTRY.register()
+class StyleGAN2Discriminator(nn.Module):
+ """StyleGAN2 Discriminator.
+
+ Args:
+ out_size (int): The spatial size of outputs.
+ channel_multiplier (int): Channel multiplier for large networks of
+ StyleGAN2. Default: 2.
+ resample_kernel (list[int]): A list indicating the 1D resample kernel
+ magnitude. A cross production will be applied to extent 1D resample
+ kernel to 2D resample kernel. Default: (1, 3, 3, 1).
+ stddev_group (int): For group stddev statistics. Default: 4.
+ narrow (float): Narrow ratio for channels. Default: 1.0.
+ """
+
+ def __init__(self, out_size, channel_multiplier=2, resample_kernel=(1, 3, 3, 1), stddev_group=4, narrow=1):
+ super(StyleGAN2Discriminator, self).__init__()
+
+ channels = {
+ '4': int(512 * narrow),
+ '8': int(512 * narrow),
+ '16': int(512 * narrow),
+ '32': int(512 * narrow),
+ '64': int(256 * channel_multiplier * narrow),
+ '128': int(128 * channel_multiplier * narrow),
+ '256': int(64 * channel_multiplier * narrow),
+ '512': int(32 * channel_multiplier * narrow),
+ '1024': int(16 * channel_multiplier * narrow)
+ }
+
+ log_size = int(math.log(out_size, 2))
+
+ conv_body = [ConvLayer(3, channels[f'{out_size}'], 1, bias=True, activate=True)]
+
+ in_channels = channels[f'{out_size}']
+ for i in range(log_size, 2, -1):
+ out_channels = channels[f'{2**(i - 1)}']
+ conv_body.append(ResBlock(in_channels, out_channels, resample_kernel))
+ in_channels = out_channels
+ self.conv_body = nn.Sequential(*conv_body)
+
+ self.final_conv = ConvLayer(in_channels + 1, channels['4'], 3, bias=True, activate=True)
+ self.final_linear = nn.Sequential(
+ EqualLinear(
+ channels['4'] * 4 * 4, channels['4'], bias=True, bias_init_val=0, lr_mul=1, activation='fused_lrelu'),
+ EqualLinear(channels['4'], 1, bias=True, bias_init_val=0, lr_mul=1, activation=None),
+ )
+ self.stddev_group = stddev_group
+ self.stddev_feat = 1
+
+ def forward(self, x):
+ out = self.conv_body(x)
+
+ b, c, h, w = out.shape
+ # concatenate a group stddev statistics to out
+ group = min(b, self.stddev_group) # Minibatch must be divisible by (or smaller than) group_size
+ stddev = out.view(group, -1, self.stddev_feat, c // self.stddev_feat, h, w)
+ stddev = torch.sqrt(stddev.var(0, unbiased=False) + 1e-8)
+ stddev = stddev.mean([2, 3, 4], keepdims=True).squeeze(2)
+ stddev = stddev.repeat(group, 1, h, w)
+ out = torch.cat([out, stddev], 1)
+
+ out = self.final_conv(out)
+ out = out.view(b, -1)
+ out = self.final_linear(out)
+
+ return out
diff --git a/custom_nodes/ComfyUI-ReActor/r_basicsr/archs/swinir_arch.py b/custom_nodes/ComfyUI-ReActor/r_basicsr/archs/swinir_arch.py
new file mode 100644
index 0000000000000000000000000000000000000000..a8468cf6252138fefdfcc3089c2a277f9162ab45
--- /dev/null
+++ b/custom_nodes/ComfyUI-ReActor/r_basicsr/archs/swinir_arch.py
@@ -0,0 +1,956 @@
+# Modified from https://github.com/JingyunLiang/SwinIR
+# SwinIR: Image Restoration Using Swin Transformer, https://arxiv.org/abs/2108.10257
+# Originally Written by Ze Liu, Modified by Jingyun Liang.
+
+import math
+import torch
+import torch.nn as nn
+import torch.utils.checkpoint as checkpoint
+
+from r_basicsr.utils.registry import ARCH_REGISTRY
+from .arch_util import to_2tuple, trunc_normal_
+
+
+def drop_path(x, drop_prob: float = 0., training: bool = False):
+ """Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
+
+ From: https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/layers/drop.py
+ """
+ if drop_prob == 0. or not training:
+ return x
+ keep_prob = 1 - drop_prob
+ shape = (x.shape[0], ) + (1, ) * (x.ndim - 1) # work with diff dim tensors, not just 2D ConvNets
+ random_tensor = keep_prob + torch.rand(shape, dtype=x.dtype, device=x.device)
+ random_tensor.floor_() # binarize
+ output = x.div(keep_prob) * random_tensor
+ return output
+
+
+class DropPath(nn.Module):
+ """Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
+
+ From: https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/layers/drop.py
+ """
+
+ def __init__(self, drop_prob=None):
+ super(DropPath, self).__init__()
+ self.drop_prob = drop_prob
+
+ def forward(self, x):
+ return drop_path(x, self.drop_prob, self.training)
+
+
+class Mlp(nn.Module):
+
+ def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
+ super().__init__()
+ out_features = out_features or in_features
+ hidden_features = hidden_features or in_features
+ self.fc1 = nn.Linear(in_features, hidden_features)
+ self.act = act_layer()
+ self.fc2 = nn.Linear(hidden_features, out_features)
+ self.drop = nn.Dropout(drop)
+
+ def forward(self, x):
+ x = self.fc1(x)
+ x = self.act(x)
+ x = self.drop(x)
+ x = self.fc2(x)
+ x = self.drop(x)
+ return x
+
+
+def window_partition(x, window_size):
+ """
+ Args:
+ x: (b, h, w, c)
+ window_size (int): window size
+
+ Returns:
+ windows: (num_windows*b, window_size, window_size, c)
+ """
+ b, h, w, c = x.shape
+ x = x.view(b, h // window_size, window_size, w // window_size, window_size, c)
+ windows = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, window_size, window_size, c)
+ return windows
+
+
+def window_reverse(windows, window_size, h, w):
+ """
+ Args:
+ windows: (num_windows*b, window_size, window_size, c)
+ window_size (int): Window size
+ h (int): Height of image
+ w (int): Width of image
+
+ Returns:
+ x: (b, h, w, c)
+ """
+ b = int(windows.shape[0] / (h * w / window_size / window_size))
+ x = windows.view(b, h // window_size, w // window_size, window_size, window_size, -1)
+ x = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(b, h, w, -1)
+ return x
+
+
+class WindowAttention(nn.Module):
+ r""" Window based multi-head self attention (W-MSA) module with relative position bias.
+ It supports both of shifted and non-shifted window.
+
+ Args:
+ dim (int): Number of input channels.
+ window_size (tuple[int]): The height and width of the window.
+ num_heads (int): Number of attention heads.
+ qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
+ qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set
+ attn_drop (float, optional): Dropout ratio of attention weight. Default: 0.0
+ proj_drop (float, optional): Dropout ratio of output. Default: 0.0
+ """
+
+ def __init__(self, dim, window_size, num_heads, qkv_bias=True, qk_scale=None, attn_drop=0., proj_drop=0.):
+
+ super().__init__()
+ self.dim = dim
+ self.window_size = window_size # Wh, Ww
+ self.num_heads = num_heads
+ head_dim = dim // num_heads
+ self.scale = qk_scale or head_dim**-0.5
+
+ # define a parameter table of relative position bias
+ self.relative_position_bias_table = nn.Parameter(
+ torch.zeros((2 * window_size[0] - 1) * (2 * window_size[1] - 1), num_heads)) # 2*Wh-1 * 2*Ww-1, nH
+
+ # get pair-wise relative position index for each token inside the window
+ coords_h = torch.arange(self.window_size[0])
+ coords_w = torch.arange(self.window_size[1])
+ coords = torch.stack(torch.meshgrid([coords_h, coords_w])) # 2, Wh, Ww
+ coords_flatten = torch.flatten(coords, 1) # 2, Wh*Ww
+ relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 2, Wh*Ww, Wh*Ww
+ relative_coords = relative_coords.permute(1, 2, 0).contiguous() # Wh*Ww, Wh*Ww, 2
+ relative_coords[:, :, 0] += self.window_size[0] - 1 # shift to start from 0
+ relative_coords[:, :, 1] += self.window_size[1] - 1
+ relative_coords[:, :, 0] *= 2 * self.window_size[1] - 1
+ relative_position_index = relative_coords.sum(-1) # Wh*Ww, Wh*Ww
+ self.register_buffer('relative_position_index', relative_position_index)
+
+ self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
+ self.attn_drop = nn.Dropout(attn_drop)
+ self.proj = nn.Linear(dim, dim)
+
+ self.proj_drop = nn.Dropout(proj_drop)
+
+ trunc_normal_(self.relative_position_bias_table, std=.02)
+ self.softmax = nn.Softmax(dim=-1)
+
+ def forward(self, x, mask=None):
+ """
+ Args:
+ x: input features with shape of (num_windows*b, n, c)
+ mask: (0/-inf) mask with shape of (num_windows, Wh*Ww, Wh*Ww) or None
+ """
+ b_, n, c = x.shape
+ qkv = self.qkv(x).reshape(b_, n, 3, self.num_heads, c // self.num_heads).permute(2, 0, 3, 1, 4)
+ q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)
+
+ q = q * self.scale
+ attn = (q @ k.transpose(-2, -1))
+
+ relative_position_bias = self.relative_position_bias_table[self.relative_position_index.view(-1)].view(
+ self.window_size[0] * self.window_size[1], self.window_size[0] * self.window_size[1], -1) # Wh*Ww,Wh*Ww,nH
+ relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Ww
+ attn = attn + relative_position_bias.unsqueeze(0)
+
+ if mask is not None:
+ nw = mask.shape[0]
+ attn = attn.view(b_ // nw, nw, self.num_heads, n, n) + mask.unsqueeze(1).unsqueeze(0)
+ attn = attn.view(-1, self.num_heads, n, n)
+ attn = self.softmax(attn)
+ else:
+ attn = self.softmax(attn)
+
+ attn = self.attn_drop(attn)
+
+ x = (attn @ v).transpose(1, 2).reshape(b_, n, c)
+ x = self.proj(x)
+ x = self.proj_drop(x)
+ return x
+
+ def extra_repr(self) -> str:
+ return f'dim={self.dim}, window_size={self.window_size}, num_heads={self.num_heads}'
+
+ def flops(self, n):
+ # calculate flops for 1 window with token length of n
+ flops = 0
+ # qkv = self.qkv(x)
+ flops += n * self.dim * 3 * self.dim
+ # attn = (q @ k.transpose(-2, -1))
+ flops += self.num_heads * n * (self.dim // self.num_heads) * n
+ # x = (attn @ v)
+ flops += self.num_heads * n * n * (self.dim // self.num_heads)
+ # x = self.proj(x)
+ flops += n * self.dim * self.dim
+ return flops
+
+
+class SwinTransformerBlock(nn.Module):
+ r""" Swin Transformer Block.
+
+ Args:
+ dim (int): Number of input channels.
+ input_resolution (tuple[int]): Input resolution.
+ num_heads (int): Number of attention heads.
+ window_size (int): Window size.
+ shift_size (int): Shift size for SW-MSA.
+ mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
+ qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
+ qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set.
+ drop (float, optional): Dropout rate. Default: 0.0
+ attn_drop (float, optional): Attention dropout rate. Default: 0.0
+ drop_path (float, optional): Stochastic depth rate. Default: 0.0
+ act_layer (nn.Module, optional): Activation layer. Default: nn.GELU
+ norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
+ """
+
+ def __init__(self,
+ dim,
+ input_resolution,
+ num_heads,
+ window_size=7,
+ shift_size=0,
+ mlp_ratio=4.,
+ qkv_bias=True,
+ qk_scale=None,
+ drop=0.,
+ attn_drop=0.,
+ drop_path=0.,
+ act_layer=nn.GELU,
+ norm_layer=nn.LayerNorm):
+ super().__init__()
+ self.dim = dim
+ self.input_resolution = input_resolution
+ self.num_heads = num_heads
+ self.window_size = window_size
+ self.shift_size = shift_size
+ self.mlp_ratio = mlp_ratio
+ if min(self.input_resolution) <= self.window_size:
+ # if window size is larger than input resolution, we don't partition windows
+ self.shift_size = 0
+ self.window_size = min(self.input_resolution)
+ assert 0 <= self.shift_size < self.window_size, 'shift_size must in 0-window_size'
+
+ self.norm1 = norm_layer(dim)
+ self.attn = WindowAttention(
+ dim,
+ window_size=to_2tuple(self.window_size),
+ num_heads=num_heads,
+ qkv_bias=qkv_bias,
+ qk_scale=qk_scale,
+ attn_drop=attn_drop,
+ proj_drop=drop)
+
+ self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
+ self.norm2 = norm_layer(dim)
+ mlp_hidden_dim = int(dim * mlp_ratio)
+ self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
+
+ if self.shift_size > 0:
+ attn_mask = self.calculate_mask(self.input_resolution)
+ else:
+ attn_mask = None
+
+ self.register_buffer('attn_mask', attn_mask)
+
+ def calculate_mask(self, x_size):
+ # calculate attention mask for SW-MSA
+ h, w = x_size
+ img_mask = torch.zeros((1, h, w, 1)) # 1 h w 1
+ h_slices = (slice(0, -self.window_size), slice(-self.window_size,
+ -self.shift_size), slice(-self.shift_size, None))
+ w_slices = (slice(0, -self.window_size), slice(-self.window_size,
+ -self.shift_size), slice(-self.shift_size, None))
+ cnt = 0
+ for h in h_slices:
+ for w in w_slices:
+ img_mask[:, h, w, :] = cnt
+ cnt += 1
+
+ mask_windows = window_partition(img_mask, self.window_size) # nw, window_size, window_size, 1
+ mask_windows = mask_windows.view(-1, self.window_size * self.window_size)
+ attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2)
+ attn_mask = attn_mask.masked_fill(attn_mask != 0, float(-100.0)).masked_fill(attn_mask == 0, float(0.0))
+
+ return attn_mask
+
+ def forward(self, x, x_size):
+ h, w = x_size
+ b, _, c = x.shape
+ # assert seq_len == h * w, "input feature has wrong size"
+
+ shortcut = x
+ x = self.norm1(x)
+ x = x.view(b, h, w, c)
+
+ # cyclic shift
+ if self.shift_size > 0:
+ shifted_x = torch.roll(x, shifts=(-self.shift_size, -self.shift_size), dims=(1, 2))
+ else:
+ shifted_x = x
+
+ # partition windows
+ x_windows = window_partition(shifted_x, self.window_size) # nw*b, window_size, window_size, c
+ x_windows = x_windows.view(-1, self.window_size * self.window_size, c) # nw*b, window_size*window_size, c
+
+ # W-MSA/SW-MSA (to be compatible for testing on images whose shapes are the multiple of window size
+ if self.input_resolution == x_size:
+ attn_windows = self.attn(x_windows, mask=self.attn_mask) # nw*b, window_size*window_size, c
+ else:
+ attn_windows = self.attn(x_windows, mask=self.calculate_mask(x_size).to(x.device))
+
+ # merge windows
+ attn_windows = attn_windows.view(-1, self.window_size, self.window_size, c)
+ shifted_x = window_reverse(attn_windows, self.window_size, h, w) # b h' w' c
+
+ # reverse cyclic shift
+ if self.shift_size > 0:
+ x = torch.roll(shifted_x, shifts=(self.shift_size, self.shift_size), dims=(1, 2))
+ else:
+ x = shifted_x
+ x = x.view(b, h * w, c)
+
+ # FFN
+ x = shortcut + self.drop_path(x)
+ x = x + self.drop_path(self.mlp(self.norm2(x)))
+
+ return x
+
+ def extra_repr(self) -> str:
+ return (f'dim={self.dim}, input_resolution={self.input_resolution}, num_heads={self.num_heads}, '
+ f'window_size={self.window_size}, shift_size={self.shift_size}, mlp_ratio={self.mlp_ratio}')
+
+ def flops(self):
+ flops = 0
+ h, w = self.input_resolution
+ # norm1
+ flops += self.dim * h * w
+ # W-MSA/SW-MSA
+ nw = h * w / self.window_size / self.window_size
+ flops += nw * self.attn.flops(self.window_size * self.window_size)
+ # mlp
+ flops += 2 * h * w * self.dim * self.dim * self.mlp_ratio
+ # norm2
+ flops += self.dim * h * w
+ return flops
+
+
+class PatchMerging(nn.Module):
+ r""" Patch Merging Layer.
+
+ Args:
+ input_resolution (tuple[int]): Resolution of input feature.
+ dim (int): Number of input channels.
+ norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
+ """
+
+ def __init__(self, input_resolution, dim, norm_layer=nn.LayerNorm):
+ super().__init__()
+ self.input_resolution = input_resolution
+ self.dim = dim
+ self.reduction = nn.Linear(4 * dim, 2 * dim, bias=False)
+ self.norm = norm_layer(4 * dim)
+
+ def forward(self, x):
+ """
+ x: b, h*w, c
+ """
+ h, w = self.input_resolution
+ b, seq_len, c = x.shape
+ assert seq_len == h * w, 'input feature has wrong size'
+ assert h % 2 == 0 and w % 2 == 0, f'x size ({h}*{w}) are not even.'
+
+ x = x.view(b, h, w, c)
+
+ x0 = x[:, 0::2, 0::2, :] # b h/2 w/2 c
+ x1 = x[:, 1::2, 0::2, :] # b h/2 w/2 c
+ x2 = x[:, 0::2, 1::2, :] # b h/2 w/2 c
+ x3 = x[:, 1::2, 1::2, :] # b h/2 w/2 c
+ x = torch.cat([x0, x1, x2, x3], -1) # b h/2 w/2 4*c
+ x = x.view(b, -1, 4 * c) # b h/2*w/2 4*c
+
+ x = self.norm(x)
+ x = self.reduction(x)
+
+ return x
+
+ def extra_repr(self) -> str:
+ return f'input_resolution={self.input_resolution}, dim={self.dim}'
+
+ def flops(self):
+ h, w = self.input_resolution
+ flops = h * w * self.dim
+ flops += (h // 2) * (w // 2) * 4 * self.dim * 2 * self.dim
+ return flops
+
+
+class BasicLayer(nn.Module):
+ """ A basic Swin Transformer layer for one stage.
+
+ Args:
+ dim (int): Number of input channels.
+ input_resolution (tuple[int]): Input resolution.
+ depth (int): Number of blocks.
+ num_heads (int): Number of attention heads.
+ window_size (int): Local window size.
+ mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
+ qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
+ qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set.
+ drop (float, optional): Dropout rate. Default: 0.0
+ attn_drop (float, optional): Attention dropout rate. Default: 0.0
+ drop_path (float | tuple[float], optional): Stochastic depth rate. Default: 0.0
+ norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
+ downsample (nn.Module | None, optional): Downsample layer at the end of the layer. Default: None
+ use_checkpoint (bool): Whether to use checkpointing to save memory. Default: False.
+ """
+
+ def __init__(self,
+ dim,
+ input_resolution,
+ depth,
+ num_heads,
+ window_size,
+ mlp_ratio=4.,
+ qkv_bias=True,
+ qk_scale=None,
+ drop=0.,
+ attn_drop=0.,
+ drop_path=0.,
+ norm_layer=nn.LayerNorm,
+ downsample=None,
+ use_checkpoint=False):
+
+ super().__init__()
+ self.dim = dim
+ self.input_resolution = input_resolution
+ self.depth = depth
+ self.use_checkpoint = use_checkpoint
+
+ # build blocks
+ self.blocks = nn.ModuleList([
+ SwinTransformerBlock(
+ dim=dim,
+ input_resolution=input_resolution,
+ num_heads=num_heads,
+ window_size=window_size,
+ shift_size=0 if (i % 2 == 0) else window_size // 2,
+ mlp_ratio=mlp_ratio,
+ qkv_bias=qkv_bias,
+ qk_scale=qk_scale,
+ drop=drop,
+ attn_drop=attn_drop,
+ drop_path=drop_path[i] if isinstance(drop_path, list) else drop_path,
+ norm_layer=norm_layer) for i in range(depth)
+ ])
+
+ # patch merging layer
+ if downsample is not None:
+ self.downsample = downsample(input_resolution, dim=dim, norm_layer=norm_layer)
+ else:
+ self.downsample = None
+
+ def forward(self, x, x_size):
+ for blk in self.blocks:
+ if self.use_checkpoint:
+ x = checkpoint.checkpoint(blk, x)
+ else:
+ x = blk(x, x_size)
+ if self.downsample is not None:
+ x = self.downsample(x)
+ return x
+
+ def extra_repr(self) -> str:
+ return f'dim={self.dim}, input_resolution={self.input_resolution}, depth={self.depth}'
+
+ def flops(self):
+ flops = 0
+ for blk in self.blocks:
+ flops += blk.flops()
+ if self.downsample is not None:
+ flops += self.downsample.flops()
+ return flops
+
+
+class RSTB(nn.Module):
+ """Residual Swin Transformer Block (RSTB).
+
+ Args:
+ dim (int): Number of input channels.
+ input_resolution (tuple[int]): Input resolution.
+ depth (int): Number of blocks.
+ num_heads (int): Number of attention heads.
+ window_size (int): Local window size.
+ mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
+ qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
+ qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set.
+ drop (float, optional): Dropout rate. Default: 0.0
+ attn_drop (float, optional): Attention dropout rate. Default: 0.0
+ drop_path (float | tuple[float], optional): Stochastic depth rate. Default: 0.0
+ norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
+ downsample (nn.Module | None, optional): Downsample layer at the end of the layer. Default: None
+ use_checkpoint (bool): Whether to use checkpointing to save memory. Default: False.
+ img_size: Input image size.
+ patch_size: Patch size.
+ resi_connection: The convolutional block before residual connection.
+ """
+
+ def __init__(self,
+ dim,
+ input_resolution,
+ depth,
+ num_heads,
+ window_size,
+ mlp_ratio=4.,
+ qkv_bias=True,
+ qk_scale=None,
+ drop=0.,
+ attn_drop=0.,
+ drop_path=0.,
+ norm_layer=nn.LayerNorm,
+ downsample=None,
+ use_checkpoint=False,
+ img_size=224,
+ patch_size=4,
+ resi_connection='1conv'):
+ super(RSTB, self).__init__()
+
+ self.dim = dim
+ self.input_resolution = input_resolution
+
+ self.residual_group = BasicLayer(
+ dim=dim,
+ input_resolution=input_resolution,
+ depth=depth,
+ num_heads=num_heads,
+ window_size=window_size,
+ mlp_ratio=mlp_ratio,
+ qkv_bias=qkv_bias,
+ qk_scale=qk_scale,
+ drop=drop,
+ attn_drop=attn_drop,
+ drop_path=drop_path,
+ norm_layer=norm_layer,
+ downsample=downsample,
+ use_checkpoint=use_checkpoint)
+
+ if resi_connection == '1conv':
+ self.conv = nn.Conv2d(dim, dim, 3, 1, 1)
+ elif resi_connection == '3conv':
+ # to save parameters and memory
+ self.conv = nn.Sequential(
+ nn.Conv2d(dim, dim // 4, 3, 1, 1), nn.LeakyReLU(negative_slope=0.2, inplace=True),
+ nn.Conv2d(dim // 4, dim // 4, 1, 1, 0), nn.LeakyReLU(negative_slope=0.2, inplace=True),
+ nn.Conv2d(dim // 4, dim, 3, 1, 1))
+
+ self.patch_embed = PatchEmbed(
+ img_size=img_size, patch_size=patch_size, in_chans=0, embed_dim=dim, norm_layer=None)
+
+ self.patch_unembed = PatchUnEmbed(
+ img_size=img_size, patch_size=patch_size, in_chans=0, embed_dim=dim, norm_layer=None)
+
+ def forward(self, x, x_size):
+ return self.patch_embed(self.conv(self.patch_unembed(self.residual_group(x, x_size), x_size))) + x
+
+ def flops(self):
+ flops = 0
+ flops += self.residual_group.flops()
+ h, w = self.input_resolution
+ flops += h * w * self.dim * self.dim * 9
+ flops += self.patch_embed.flops()
+ flops += self.patch_unembed.flops()
+
+ return flops
+
+
+class PatchEmbed(nn.Module):
+ r""" Image to Patch Embedding
+
+ Args:
+ img_size (int): Image size. Default: 224.
+ patch_size (int): Patch token size. Default: 4.
+ in_chans (int): Number of input image channels. Default: 3.
+ embed_dim (int): Number of linear projection output channels. Default: 96.
+ norm_layer (nn.Module, optional): Normalization layer. Default: None
+ """
+
+ def __init__(self, img_size=224, patch_size=4, in_chans=3, embed_dim=96, norm_layer=None):
+ super().__init__()
+ img_size = to_2tuple(img_size)
+ patch_size = to_2tuple(patch_size)
+ patches_resolution = [img_size[0] // patch_size[0], img_size[1] // patch_size[1]]
+ self.img_size = img_size
+ self.patch_size = patch_size
+ self.patches_resolution = patches_resolution
+ self.num_patches = patches_resolution[0] * patches_resolution[1]
+
+ self.in_chans = in_chans
+ self.embed_dim = embed_dim
+
+ if norm_layer is not None:
+ self.norm = norm_layer(embed_dim)
+ else:
+ self.norm = None
+
+ def forward(self, x):
+ x = x.flatten(2).transpose(1, 2) # b Ph*Pw c
+ if self.norm is not None:
+ x = self.norm(x)
+ return x
+
+ def flops(self):
+ flops = 0
+ h, w = self.img_size
+ if self.norm is not None:
+ flops += h * w * self.embed_dim
+ return flops
+
+
+class PatchUnEmbed(nn.Module):
+ r""" Image to Patch Unembedding
+
+ Args:
+ img_size (int): Image size. Default: 224.
+ patch_size (int): Patch token size. Default: 4.
+ in_chans (int): Number of input image channels. Default: 3.
+ embed_dim (int): Number of linear projection output channels. Default: 96.
+ norm_layer (nn.Module, optional): Normalization layer. Default: None
+ """
+
+ def __init__(self, img_size=224, patch_size=4, in_chans=3, embed_dim=96, norm_layer=None):
+ super().__init__()
+ img_size = to_2tuple(img_size)
+ patch_size = to_2tuple(patch_size)
+ patches_resolution = [img_size[0] // patch_size[0], img_size[1] // patch_size[1]]
+ self.img_size = img_size
+ self.patch_size = patch_size
+ self.patches_resolution = patches_resolution
+ self.num_patches = patches_resolution[0] * patches_resolution[1]
+
+ self.in_chans = in_chans
+ self.embed_dim = embed_dim
+
+ def forward(self, x, x_size):
+ x = x.transpose(1, 2).view(x.shape[0], self.embed_dim, x_size[0], x_size[1]) # b Ph*Pw c
+ return x
+
+ def flops(self):
+ flops = 0
+ return flops
+
+
+class Upsample(nn.Sequential):
+ """Upsample module.
+
+ Args:
+ scale (int): Scale factor. Supported scales: 2^n and 3.
+ num_feat (int): Channel number of intermediate features.
+ """
+
+ def __init__(self, scale, num_feat):
+ m = []
+ if (scale & (scale - 1)) == 0: # scale = 2^n
+ for _ in range(int(math.log(scale, 2))):
+ m.append(nn.Conv2d(num_feat, 4 * num_feat, 3, 1, 1))
+ m.append(nn.PixelShuffle(2))
+ elif scale == 3:
+ m.append(nn.Conv2d(num_feat, 9 * num_feat, 3, 1, 1))
+ m.append(nn.PixelShuffle(3))
+ else:
+ raise ValueError(f'scale {scale} is not supported. Supported scales: 2^n and 3.')
+ super(Upsample, self).__init__(*m)
+
+
+class UpsampleOneStep(nn.Sequential):
+ """UpsampleOneStep module (the difference with Upsample is that it always only has 1conv + 1pixelshuffle)
+ Used in lightweight SR to save parameters.
+
+ Args:
+ scale (int): Scale factor. Supported scales: 2^n and 3.
+ num_feat (int): Channel number of intermediate features.
+
+ """
+
+ def __init__(self, scale, num_feat, num_out_ch, input_resolution=None):
+ self.num_feat = num_feat
+ self.input_resolution = input_resolution
+ m = []
+ m.append(nn.Conv2d(num_feat, (scale**2) * num_out_ch, 3, 1, 1))
+ m.append(nn.PixelShuffle(scale))
+ super(UpsampleOneStep, self).__init__(*m)
+
+ def flops(self):
+ h, w = self.input_resolution
+ flops = h * w * self.num_feat * 3 * 9
+ return flops
+
+
+@ARCH_REGISTRY.register()
+class SwinIR(nn.Module):
+ r""" SwinIR
+ A PyTorch impl of : `SwinIR: Image Restoration Using Swin Transformer`, based on Swin Transformer.
+
+ Args:
+ img_size (int | tuple(int)): Input image size. Default 64
+ patch_size (int | tuple(int)): Patch size. Default: 1
+ in_chans (int): Number of input image channels. Default: 3
+ embed_dim (int): Patch embedding dimension. Default: 96
+ depths (tuple(int)): Depth of each Swin Transformer layer.
+ num_heads (tuple(int)): Number of attention heads in different layers.
+ window_size (int): Window size. Default: 7
+ mlp_ratio (float): Ratio of mlp hidden dim to embedding dim. Default: 4
+ qkv_bias (bool): If True, add a learnable bias to query, key, value. Default: True
+ qk_scale (float): Override default qk scale of head_dim ** -0.5 if set. Default: None
+ drop_rate (float): Dropout rate. Default: 0
+ attn_drop_rate (float): Attention dropout rate. Default: 0
+ drop_path_rate (float): Stochastic depth rate. Default: 0.1
+ norm_layer (nn.Module): Normalization layer. Default: nn.LayerNorm.
+ ape (bool): If True, add absolute position embedding to the patch embedding. Default: False
+ patch_norm (bool): If True, add normalization after patch embedding. Default: True
+ use_checkpoint (bool): Whether to use checkpointing to save memory. Default: False
+ upscale: Upscale factor. 2/3/4/8 for image SR, 1 for denoising and compress artifact reduction
+ img_range: Image range. 1. or 255.
+ upsampler: The reconstruction reconstruction module. 'pixelshuffle'/'pixelshuffledirect'/'nearest+conv'/None
+ resi_connection: The convolutional block before residual connection. '1conv'/'3conv'
+ """
+
+ def __init__(self,
+ img_size=64,
+ patch_size=1,
+ in_chans=3,
+ embed_dim=96,
+ depths=(6, 6, 6, 6),
+ num_heads=(6, 6, 6, 6),
+ window_size=7,
+ mlp_ratio=4.,
+ qkv_bias=True,
+ qk_scale=None,
+ drop_rate=0.,
+ attn_drop_rate=0.,
+ drop_path_rate=0.1,
+ norm_layer=nn.LayerNorm,
+ ape=False,
+ patch_norm=True,
+ use_checkpoint=False,
+ upscale=2,
+ img_range=1.,
+ upsampler='',
+ resi_connection='1conv',
+ **kwargs):
+ super(SwinIR, self).__init__()
+ num_in_ch = in_chans
+ num_out_ch = in_chans
+ num_feat = 64
+ self.img_range = img_range
+ if in_chans == 3:
+ rgb_mean = (0.4488, 0.4371, 0.4040)
+ self.mean = torch.Tensor(rgb_mean).view(1, 3, 1, 1)
+ else:
+ self.mean = torch.zeros(1, 1, 1, 1)
+ self.upscale = upscale
+ self.upsampler = upsampler
+
+ # ------------------------- 1, shallow feature extraction ------------------------- #
+ self.conv_first = nn.Conv2d(num_in_ch, embed_dim, 3, 1, 1)
+
+ # ------------------------- 2, deep feature extraction ------------------------- #
+ self.num_layers = len(depths)
+ self.embed_dim = embed_dim
+ self.ape = ape
+ self.patch_norm = patch_norm
+ self.num_features = embed_dim
+ self.mlp_ratio = mlp_ratio
+
+ # split image into non-overlapping patches
+ self.patch_embed = PatchEmbed(
+ img_size=img_size,
+ patch_size=patch_size,
+ in_chans=embed_dim,
+ embed_dim=embed_dim,
+ norm_layer=norm_layer if self.patch_norm else None)
+ num_patches = self.patch_embed.num_patches
+ patches_resolution = self.patch_embed.patches_resolution
+ self.patches_resolution = patches_resolution
+
+ # merge non-overlapping patches into image
+ self.patch_unembed = PatchUnEmbed(
+ img_size=img_size,
+ patch_size=patch_size,
+ in_chans=embed_dim,
+ embed_dim=embed_dim,
+ norm_layer=norm_layer if self.patch_norm else None)
+
+ # absolute position embedding
+ if self.ape:
+ self.absolute_pos_embed = nn.Parameter(torch.zeros(1, num_patches, embed_dim))
+ trunc_normal_(self.absolute_pos_embed, std=.02)
+
+ self.pos_drop = nn.Dropout(p=drop_rate)
+
+ # stochastic depth
+ dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))] # stochastic depth decay rule
+
+ # build Residual Swin Transformer blocks (RSTB)
+ self.layers = nn.ModuleList()
+ for i_layer in range(self.num_layers):
+ layer = RSTB(
+ dim=embed_dim,
+ input_resolution=(patches_resolution[0], patches_resolution[1]),
+ depth=depths[i_layer],
+ num_heads=num_heads[i_layer],
+ window_size=window_size,
+ mlp_ratio=self.mlp_ratio,
+ qkv_bias=qkv_bias,
+ qk_scale=qk_scale,
+ drop=drop_rate,
+ attn_drop=attn_drop_rate,
+ drop_path=dpr[sum(depths[:i_layer]):sum(depths[:i_layer + 1])], # no impact on SR results
+ norm_layer=norm_layer,
+ downsample=None,
+ use_checkpoint=use_checkpoint,
+ img_size=img_size,
+ patch_size=patch_size,
+ resi_connection=resi_connection)
+ self.layers.append(layer)
+ self.norm = norm_layer(self.num_features)
+
+ # build the last conv layer in deep feature extraction
+ if resi_connection == '1conv':
+ self.conv_after_body = nn.Conv2d(embed_dim, embed_dim, 3, 1, 1)
+ elif resi_connection == '3conv':
+ # to save parameters and memory
+ self.conv_after_body = nn.Sequential(
+ nn.Conv2d(embed_dim, embed_dim // 4, 3, 1, 1), nn.LeakyReLU(negative_slope=0.2, inplace=True),
+ nn.Conv2d(embed_dim // 4, embed_dim // 4, 1, 1, 0), nn.LeakyReLU(negative_slope=0.2, inplace=True),
+ nn.Conv2d(embed_dim // 4, embed_dim, 3, 1, 1))
+
+ # ------------------------- 3, high quality image reconstruction ------------------------- #
+ if self.upsampler == 'pixelshuffle':
+ # for classical SR
+ self.conv_before_upsample = nn.Sequential(
+ nn.Conv2d(embed_dim, num_feat, 3, 1, 1), nn.LeakyReLU(inplace=True))
+ self.upsample = Upsample(upscale, num_feat)
+ self.conv_last = nn.Conv2d(num_feat, num_out_ch, 3, 1, 1)
+ elif self.upsampler == 'pixelshuffledirect':
+ # for lightweight SR (to save parameters)
+ self.upsample = UpsampleOneStep(upscale, embed_dim, num_out_ch,
+ (patches_resolution[0], patches_resolution[1]))
+ elif self.upsampler == 'nearest+conv':
+ # for real-world SR (less artifacts)
+ assert self.upscale == 4, 'only support x4 now.'
+ self.conv_before_upsample = nn.Sequential(
+ nn.Conv2d(embed_dim, num_feat, 3, 1, 1), nn.LeakyReLU(inplace=True))
+ self.conv_up1 = nn.Conv2d(num_feat, num_feat, 3, 1, 1)
+ self.conv_up2 = nn.Conv2d(num_feat, num_feat, 3, 1, 1)
+ self.conv_hr = nn.Conv2d(num_feat, num_feat, 3, 1, 1)
+ self.conv_last = nn.Conv2d(num_feat, num_out_ch, 3, 1, 1)
+ self.lrelu = nn.LeakyReLU(negative_slope=0.2, inplace=True)
+ else:
+ # for image denoising and JPEG compression artifact reduction
+ self.conv_last = nn.Conv2d(embed_dim, num_out_ch, 3, 1, 1)
+
+ self.apply(self._init_weights)
+
+ def _init_weights(self, m):
+ if isinstance(m, nn.Linear):
+ trunc_normal_(m.weight, std=.02)
+ if isinstance(m, nn.Linear) and m.bias is not None:
+ nn.init.constant_(m.bias, 0)
+ elif isinstance(m, nn.LayerNorm):
+ nn.init.constant_(m.bias, 0)
+ nn.init.constant_(m.weight, 1.0)
+
+ @torch.jit.ignore
+ def no_weight_decay(self):
+ return {'absolute_pos_embed'}
+
+ @torch.jit.ignore
+ def no_weight_decay_keywords(self):
+ return {'relative_position_bias_table'}
+
+ def forward_features(self, x):
+ x_size = (x.shape[2], x.shape[3])
+ x = self.patch_embed(x)
+ if self.ape:
+ x = x + self.absolute_pos_embed
+ x = self.pos_drop(x)
+
+ for layer in self.layers:
+ x = layer(x, x_size)
+
+ x = self.norm(x) # b seq_len c
+ x = self.patch_unembed(x, x_size)
+
+ return x
+
+ def forward(self, x):
+ self.mean = self.mean.type_as(x)
+ x = (x - self.mean) * self.img_range
+
+ if self.upsampler == 'pixelshuffle':
+ # for classical SR
+ x = self.conv_first(x)
+ x = self.conv_after_body(self.forward_features(x)) + x
+ x = self.conv_before_upsample(x)
+ x = self.conv_last(self.upsample(x))
+ elif self.upsampler == 'pixelshuffledirect':
+ # for lightweight SR
+ x = self.conv_first(x)
+ x = self.conv_after_body(self.forward_features(x)) + x
+ x = self.upsample(x)
+ elif self.upsampler == 'nearest+conv':
+ # for real-world SR
+ x = self.conv_first(x)
+ x = self.conv_after_body(self.forward_features(x)) + x
+ x = self.conv_before_upsample(x)
+ x = self.lrelu(self.conv_up1(torch.nn.functional.interpolate(x, scale_factor=2, mode='nearest')))
+ x = self.lrelu(self.conv_up2(torch.nn.functional.interpolate(x, scale_factor=2, mode='nearest')))
+ x = self.conv_last(self.lrelu(self.conv_hr(x)))
+ else:
+ # for image denoising and JPEG compression artifact reduction
+ x_first = self.conv_first(x)
+ res = self.conv_after_body(self.forward_features(x_first)) + x_first
+ x = x + self.conv_last(res)
+
+ x = x / self.img_range + self.mean
+
+ return x
+
+ def flops(self):
+ flops = 0
+ h, w = self.patches_resolution
+ flops += h * w * 3 * self.embed_dim * 9
+ flops += self.patch_embed.flops()
+ for layer in self.layers:
+ flops += layer.flops()
+ flops += h * w * 3 * self.embed_dim * self.embed_dim
+ flops += self.upsample.flops()
+ return flops
+
+
+if __name__ == '__main__':
+ upscale = 4
+ window_size = 8
+ height = (1024 // upscale // window_size + 1) * window_size
+ width = (720 // upscale // window_size + 1) * window_size
+ model = SwinIR(
+ upscale=2,
+ img_size=(height, width),
+ window_size=window_size,
+ img_range=1.,
+ depths=[6, 6, 6, 6],
+ embed_dim=60,
+ num_heads=[6, 6, 6, 6],
+ mlp_ratio=2,
+ upsampler='pixelshuffledirect')
+ print(model)
+ print(height, width, model.flops() / 1e9)
+
+ x = torch.randn((1, 3, height, width))
+ x = model(x)
+ print(x.shape)
diff --git a/custom_nodes/ComfyUI-ReActor/r_basicsr/archs/tof_arch.py b/custom_nodes/ComfyUI-ReActor/r_basicsr/archs/tof_arch.py
new file mode 100644
index 0000000000000000000000000000000000000000..81ce55a41a3069db234177f48711fead76b9fe09
--- /dev/null
+++ b/custom_nodes/ComfyUI-ReActor/r_basicsr/archs/tof_arch.py
@@ -0,0 +1,172 @@
+import torch
+from torch import nn as nn
+from torch.nn import functional as F
+
+from r_basicsr.utils.registry import ARCH_REGISTRY
+from .arch_util import flow_warp
+
+
+class BasicModule(nn.Module):
+ """Basic module of SPyNet.
+
+ Note that unlike the architecture in spynet_arch.py, the basic module
+ here contains batch normalization.
+ """
+
+ def __init__(self):
+ super(BasicModule, self).__init__()
+ self.basic_module = nn.Sequential(
+ nn.Conv2d(in_channels=8, out_channels=32, kernel_size=7, stride=1, padding=3, bias=False),
+ nn.BatchNorm2d(32), nn.ReLU(inplace=True),
+ nn.Conv2d(in_channels=32, out_channels=64, kernel_size=7, stride=1, padding=3, bias=False),
+ nn.BatchNorm2d(64), nn.ReLU(inplace=True),
+ nn.Conv2d(in_channels=64, out_channels=32, kernel_size=7, stride=1, padding=3, bias=False),
+ nn.BatchNorm2d(32), nn.ReLU(inplace=True),
+ nn.Conv2d(in_channels=32, out_channels=16, kernel_size=7, stride=1, padding=3, bias=False),
+ nn.BatchNorm2d(16), nn.ReLU(inplace=True),
+ nn.Conv2d(in_channels=16, out_channels=2, kernel_size=7, stride=1, padding=3))
+
+ def forward(self, tensor_input):
+ """
+ Args:
+ tensor_input (Tensor): Input tensor with shape (b, 8, h, w).
+ 8 channels contain:
+ [reference image (3), neighbor image (3), initial flow (2)].
+
+ Returns:
+ Tensor: Estimated flow with shape (b, 2, h, w)
+ """
+ return self.basic_module(tensor_input)
+
+
+class SPyNetTOF(nn.Module):
+ """SPyNet architecture for TOF.
+
+ Note that this implementation is specifically for TOFlow. Please use
+ spynet_arch.py for general use. They differ in the following aspects:
+ 1. The basic modules here contain BatchNorm.
+ 2. Normalization and denormalization are not done here, as
+ they are done in TOFlow.
+ Paper:
+ Optical Flow Estimation using a Spatial Pyramid Network
+ Code reference:
+ https://github.com/Coldog2333/pytoflow
+
+ Args:
+ load_path (str): Path for pretrained SPyNet. Default: None.
+ """
+
+ def __init__(self, load_path=None):
+ super(SPyNetTOF, self).__init__()
+
+ self.basic_module = nn.ModuleList([BasicModule() for _ in range(4)])
+ if load_path:
+ self.load_state_dict(torch.load(load_path, map_location=lambda storage, loc: storage)['params'])
+
+ def forward(self, ref, supp):
+ """
+ Args:
+ ref (Tensor): Reference image with shape of (b, 3, h, w).
+ supp: The supporting image to be warped: (b, 3, h, w).
+
+ Returns:
+ Tensor: Estimated optical flow: (b, 2, h, w).
+ """
+ num_batches, _, h, w = ref.size()
+ ref = [ref]
+ supp = [supp]
+
+ # generate downsampled frames
+ for _ in range(3):
+ ref.insert(0, F.avg_pool2d(input=ref[0], kernel_size=2, stride=2, count_include_pad=False))
+ supp.insert(0, F.avg_pool2d(input=supp[0], kernel_size=2, stride=2, count_include_pad=False))
+
+ # flow computation
+ flow = ref[0].new_zeros(num_batches, 2, h // 16, w // 16)
+ for i in range(4):
+ flow_up = F.interpolate(input=flow, scale_factor=2, mode='bilinear', align_corners=True) * 2.0
+ flow = flow_up + self.basic_module[i](
+ torch.cat([ref[i], flow_warp(supp[i], flow_up.permute(0, 2, 3, 1)), flow_up], 1))
+ return flow
+
+
+@ARCH_REGISTRY.register()
+class TOFlow(nn.Module):
+ """PyTorch implementation of TOFlow.
+
+ In TOFlow, the LR frames are pre-upsampled and have the same size with
+ the GT frames.
+ Paper:
+ Xue et al., Video Enhancement with Task-Oriented Flow, IJCV 2018
+ Code reference:
+ 1. https://github.com/anchen1011/toflow
+ 2. https://github.com/Coldog2333/pytoflow
+
+ Args:
+ adapt_official_weights (bool): Whether to adapt the weights translated
+ from the official implementation. Set to false if you want to
+ train from scratch. Default: False
+ """
+
+ def __init__(self, adapt_official_weights=False):
+ super(TOFlow, self).__init__()
+ self.adapt_official_weights = adapt_official_weights
+ self.ref_idx = 0 if adapt_official_weights else 3
+
+ self.register_buffer('mean', torch.Tensor([0.485, 0.456, 0.406]).view(1, 3, 1, 1))
+ self.register_buffer('std', torch.Tensor([0.229, 0.224, 0.225]).view(1, 3, 1, 1))
+
+ # flow estimation module
+ self.spynet = SPyNetTOF()
+
+ # reconstruction module
+ self.conv_1 = nn.Conv2d(3 * 7, 64, 9, 1, 4)
+ self.conv_2 = nn.Conv2d(64, 64, 9, 1, 4)
+ self.conv_3 = nn.Conv2d(64, 64, 1)
+ self.conv_4 = nn.Conv2d(64, 3, 1)
+
+ # activation function
+ self.relu = nn.ReLU(inplace=True)
+
+ def normalize(self, img):
+ return (img - self.mean) / self.std
+
+ def denormalize(self, img):
+ return img * self.std + self.mean
+
+ def forward(self, lrs):
+ """
+ Args:
+ lrs: Input lr frames: (b, 7, 3, h, w).
+
+ Returns:
+ Tensor: SR frame: (b, 3, h, w).
+ """
+ # In the official implementation, the 0-th frame is the reference frame
+ if self.adapt_official_weights:
+ lrs = lrs[:, [3, 0, 1, 2, 4, 5, 6], :, :, :]
+
+ num_batches, num_lrs, _, h, w = lrs.size()
+
+ lrs = self.normalize(lrs.view(-1, 3, h, w))
+ lrs = lrs.view(num_batches, num_lrs, 3, h, w)
+
+ lr_ref = lrs[:, self.ref_idx, :, :, :]
+ lr_aligned = []
+ for i in range(7): # 7 frames
+ if i == self.ref_idx:
+ lr_aligned.append(lr_ref)
+ else:
+ lr_supp = lrs[:, i, :, :, :]
+ flow = self.spynet(lr_ref, lr_supp)
+ lr_aligned.append(flow_warp(lr_supp, flow.permute(0, 2, 3, 1)))
+
+ # reconstruction
+ hr = torch.stack(lr_aligned, dim=1)
+ hr = hr.view(num_batches, -1, h, w)
+ hr = self.relu(self.conv_1(hr))
+ hr = self.relu(self.conv_2(hr))
+ hr = self.relu(self.conv_3(hr))
+ hr = self.conv_4(hr) + lr_ref
+
+ return self.denormalize(hr)
diff --git a/custom_nodes/ComfyUI-ReActor/r_basicsr/archs/vgg_arch.py b/custom_nodes/ComfyUI-ReActor/r_basicsr/archs/vgg_arch.py
new file mode 100644
index 0000000000000000000000000000000000000000..517b79ae094d63648707c9700d5cbfb6c520b6fb
--- /dev/null
+++ b/custom_nodes/ComfyUI-ReActor/r_basicsr/archs/vgg_arch.py
@@ -0,0 +1,161 @@
+import os
+import torch
+from collections import OrderedDict
+from torch import nn as nn
+from torchvision.models import vgg as vgg
+
+from r_basicsr.utils.registry import ARCH_REGISTRY
+
+VGG_PRETRAIN_PATH = 'experiments/pretrained_models/vgg19-dcbb9e9d.pth'
+NAMES = {
+ 'vgg11': [
+ 'conv1_1', 'relu1_1', 'pool1', 'conv2_1', 'relu2_1', 'pool2', 'conv3_1', 'relu3_1', 'conv3_2', 'relu3_2',
+ 'pool3', 'conv4_1', 'relu4_1', 'conv4_2', 'relu4_2', 'pool4', 'conv5_1', 'relu5_1', 'conv5_2', 'relu5_2',
+ 'pool5'
+ ],
+ 'vgg13': [
+ 'conv1_1', 'relu1_1', 'conv1_2', 'relu1_2', 'pool1', 'conv2_1', 'relu2_1', 'conv2_2', 'relu2_2', 'pool2',
+ 'conv3_1', 'relu3_1', 'conv3_2', 'relu3_2', 'pool3', 'conv4_1', 'relu4_1', 'conv4_2', 'relu4_2', 'pool4',
+ 'conv5_1', 'relu5_1', 'conv5_2', 'relu5_2', 'pool5'
+ ],
+ 'vgg16': [
+ 'conv1_1', 'relu1_1', 'conv1_2', 'relu1_2', 'pool1', 'conv2_1', 'relu2_1', 'conv2_2', 'relu2_2', 'pool2',
+ 'conv3_1', 'relu3_1', 'conv3_2', 'relu3_2', 'conv3_3', 'relu3_3', 'pool3', 'conv4_1', 'relu4_1', 'conv4_2',
+ 'relu4_2', 'conv4_3', 'relu4_3', 'pool4', 'conv5_1', 'relu5_1', 'conv5_2', 'relu5_2', 'conv5_3', 'relu5_3',
+ 'pool5'
+ ],
+ 'vgg19': [
+ 'conv1_1', 'relu1_1', 'conv1_2', 'relu1_2', 'pool1', 'conv2_1', 'relu2_1', 'conv2_2', 'relu2_2', 'pool2',
+ 'conv3_1', 'relu3_1', 'conv3_2', 'relu3_2', 'conv3_3', 'relu3_3', 'conv3_4', 'relu3_4', 'pool3', 'conv4_1',
+ 'relu4_1', 'conv4_2', 'relu4_2', 'conv4_3', 'relu4_3', 'conv4_4', 'relu4_4', 'pool4', 'conv5_1', 'relu5_1',
+ 'conv5_2', 'relu5_2', 'conv5_3', 'relu5_3', 'conv5_4', 'relu5_4', 'pool5'
+ ]
+}
+
+
+def insert_bn(names):
+ """Insert bn layer after each conv.
+
+ Args:
+ names (list): The list of layer names.
+
+ Returns:
+ list: The list of layer names with bn layers.
+ """
+ names_bn = []
+ for name in names:
+ names_bn.append(name)
+ if 'conv' in name:
+ position = name.replace('conv', '')
+ names_bn.append('bn' + position)
+ return names_bn
+
+
+@ARCH_REGISTRY.register()
+class VGGFeatureExtractor(nn.Module):
+ """VGG network for feature extraction.
+
+ In this implementation, we allow users to choose whether use normalization
+ in the input feature and the type of vgg network. Note that the pretrained
+ path must fit the vgg type.
+
+ Args:
+ layer_name_list (list[str]): Forward function returns the corresponding
+ features according to the layer_name_list.
+ Example: {'relu1_1', 'relu2_1', 'relu3_1'}.
+ vgg_type (str): Set the type of vgg network. Default: 'vgg19'.
+ use_input_norm (bool): If True, normalize the input image. Importantly,
+ the input feature must in the range [0, 1]. Default: True.
+ range_norm (bool): If True, norm images with range [-1, 1] to [0, 1].
+ Default: False.
+ requires_grad (bool): If true, the parameters of VGG network will be
+ optimized. Default: False.
+ remove_pooling (bool): If true, the max pooling operations in VGG net
+ will be removed. Default: False.
+ pooling_stride (int): The stride of max pooling operation. Default: 2.
+ """
+
+ def __init__(self,
+ layer_name_list,
+ vgg_type='vgg19',
+ use_input_norm=True,
+ range_norm=False,
+ requires_grad=False,
+ remove_pooling=False,
+ pooling_stride=2):
+ super(VGGFeatureExtractor, self).__init__()
+
+ self.layer_name_list = layer_name_list
+ self.use_input_norm = use_input_norm
+ self.range_norm = range_norm
+
+ self.names = NAMES[vgg_type.replace('_bn', '')]
+ if 'bn' in vgg_type:
+ self.names = insert_bn(self.names)
+
+ # only borrow layers that will be used to avoid unused params
+ max_idx = 0
+ for v in layer_name_list:
+ idx = self.names.index(v)
+ if idx > max_idx:
+ max_idx = idx
+
+ if os.path.exists(VGG_PRETRAIN_PATH):
+ vgg_net = getattr(vgg, vgg_type)(pretrained=False)
+ state_dict = torch.load(VGG_PRETRAIN_PATH, map_location=lambda storage, loc: storage)
+ vgg_net.load_state_dict(state_dict)
+ else:
+ vgg_net = getattr(vgg, vgg_type)(pretrained=True)
+
+ features = vgg_net.features[:max_idx + 1]
+
+ modified_net = OrderedDict()
+ for k, v in zip(self.names, features):
+ if 'pool' in k:
+ # if remove_pooling is true, pooling operation will be removed
+ if remove_pooling:
+ continue
+ else:
+ # in some cases, we may want to change the default stride
+ modified_net[k] = nn.MaxPool2d(kernel_size=2, stride=pooling_stride)
+ else:
+ modified_net[k] = v
+
+ self.vgg_net = nn.Sequential(modified_net)
+
+ if not requires_grad:
+ self.vgg_net.eval()
+ for param in self.parameters():
+ param.requires_grad = False
+ else:
+ self.vgg_net.train()
+ for param in self.parameters():
+ param.requires_grad = True
+
+ if self.use_input_norm:
+ # the mean is for image with range [0, 1]
+ self.register_buffer('mean', torch.Tensor([0.485, 0.456, 0.406]).view(1, 3, 1, 1))
+ # the std is for image with range [0, 1]
+ self.register_buffer('std', torch.Tensor([0.229, 0.224, 0.225]).view(1, 3, 1, 1))
+
+ def forward(self, x):
+ """Forward function.
+
+ Args:
+ x (Tensor): Input tensor with shape (n, c, h, w).
+
+ Returns:
+ Tensor: Forward results.
+ """
+ if self.range_norm:
+ x = (x + 1) / 2
+ if self.use_input_norm:
+ x = (x - self.mean) / self.std
+
+ output = {}
+ for key, layer in self.vgg_net._modules.items():
+ x = layer(x)
+ if key in self.layer_name_list:
+ output[key] = x.clone()
+
+ return output
diff --git a/custom_nodes/ComfyUI-ReActor/r_basicsr/data/__init__.py b/custom_nodes/ComfyUI-ReActor/r_basicsr/data/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..b53e5eedf2b839738944166d88f9f8a95177bf2e
--- /dev/null
+++ b/custom_nodes/ComfyUI-ReActor/r_basicsr/data/__init__.py
@@ -0,0 +1,101 @@
+import importlib
+import numpy as np
+import random
+import torch
+import torch.utils.data
+from copy import deepcopy
+from functools import partial
+from os import path as osp
+
+from r_basicsr.data.prefetch_dataloader import PrefetchDataLoader
+from r_basicsr.utils import get_root_logger, scandir
+from r_basicsr.utils.dist_util import get_dist_info
+from r_basicsr.utils.registry import DATASET_REGISTRY
+
+__all__ = ['build_dataset', 'build_dataloader']
+
+# automatically scan and import dataset modules for registry
+# scan all the files under the data folder with '_dataset' in file names
+data_folder = osp.dirname(osp.abspath(__file__))
+dataset_filenames = [osp.splitext(osp.basename(v))[0] for v in scandir(data_folder) if v.endswith('_dataset.py')]
+# import all the dataset modules
+_dataset_modules = [importlib.import_module(f'r_basicsr.data.{file_name}') for file_name in dataset_filenames]
+
+
+def build_dataset(dataset_opt):
+ """Build dataset from options.
+
+ Args:
+ dataset_opt (dict): Configuration for dataset. It must contain:
+ name (str): Dataset name.
+ type (str): Dataset type.
+ """
+ dataset_opt = deepcopy(dataset_opt)
+ dataset = DATASET_REGISTRY.get(dataset_opt['type'])(dataset_opt)
+ logger = get_root_logger()
+ logger.info(f'Dataset [{dataset.__class__.__name__}] - {dataset_opt["name"]} is built.')
+ return dataset
+
+
+def build_dataloader(dataset, dataset_opt, num_gpu=1, dist=False, sampler=None, seed=None):
+ """Build dataloader.
+
+ Args:
+ dataset (torch.utils.data.Dataset): Dataset.
+ dataset_opt (dict): Dataset options. It contains the following keys:
+ phase (str): 'train' or 'val'.
+ num_worker_per_gpu (int): Number of workers for each GPU.
+ batch_size_per_gpu (int): Training batch size for each GPU.
+ num_gpu (int): Number of GPUs. Used only in the train phase.
+ Default: 1.
+ dist (bool): Whether in distributed training. Used only in the train
+ phase. Default: False.
+ sampler (torch.utils.data.sampler): Data sampler. Default: None.
+ seed (int | None): Seed. Default: None
+ """
+ phase = dataset_opt['phase']
+ rank, _ = get_dist_info()
+ if phase == 'train':
+ if dist: # distributed training
+ batch_size = dataset_opt['batch_size_per_gpu']
+ num_workers = dataset_opt['num_worker_per_gpu']
+ else: # non-distributed training
+ multiplier = 1 if num_gpu == 0 else num_gpu
+ batch_size = dataset_opt['batch_size_per_gpu'] * multiplier
+ num_workers = dataset_opt['num_worker_per_gpu'] * multiplier
+ dataloader_args = dict(
+ dataset=dataset,
+ batch_size=batch_size,
+ shuffle=False,
+ num_workers=num_workers,
+ sampler=sampler,
+ drop_last=True)
+ if sampler is None:
+ dataloader_args['shuffle'] = True
+ dataloader_args['worker_init_fn'] = partial(
+ worker_init_fn, num_workers=num_workers, rank=rank, seed=seed) if seed is not None else None
+ elif phase in ['val', 'test']: # validation
+ dataloader_args = dict(dataset=dataset, batch_size=1, shuffle=False, num_workers=0)
+ else:
+ raise ValueError(f"Wrong dataset phase: {phase}. Supported ones are 'train', 'val' and 'test'.")
+
+ dataloader_args['pin_memory'] = dataset_opt.get('pin_memory', False)
+ dataloader_args['persistent_workers'] = dataset_opt.get('persistent_workers', False)
+
+ prefetch_mode = dataset_opt.get('prefetch_mode')
+ if prefetch_mode == 'cpu': # CPUPrefetcher
+ num_prefetch_queue = dataset_opt.get('num_prefetch_queue', 1)
+ logger = get_root_logger()
+ logger.info(f'Use {prefetch_mode} prefetch dataloader: num_prefetch_queue = {num_prefetch_queue}')
+ return PrefetchDataLoader(num_prefetch_queue=num_prefetch_queue, **dataloader_args)
+ else:
+ # prefetch_mode=None: Normal dataloader
+ # prefetch_mode='cuda': dataloader for CUDAPrefetcher
+ return torch.utils.data.DataLoader(**dataloader_args)
+
+
+def worker_init_fn(worker_id, num_workers, rank, seed):
+ # Set the worker seed to num_workers * rank + worker_id + seed
+ worker_seed = num_workers * rank + worker_id + seed
+ np.random.seed(worker_seed)
+ random.seed(worker_seed)
diff --git a/custom_nodes/ComfyUI-ReActor/r_basicsr/data/data_sampler.py b/custom_nodes/ComfyUI-ReActor/r_basicsr/data/data_sampler.py
new file mode 100644
index 0000000000000000000000000000000000000000..575452d9f844a928f7f42296c81635cfbadec7c2
--- /dev/null
+++ b/custom_nodes/ComfyUI-ReActor/r_basicsr/data/data_sampler.py
@@ -0,0 +1,48 @@
+import math
+import torch
+from torch.utils.data.sampler import Sampler
+
+
+class EnlargedSampler(Sampler):
+ """Sampler that restricts data loading to a subset of the dataset.
+
+ Modified from torch.utils.data.distributed.DistributedSampler
+ Support enlarging the dataset for iteration-based training, for saving
+ time when restart the dataloader after each epoch
+
+ Args:
+ dataset (torch.utils.data.Dataset): Dataset used for sampling.
+ num_replicas (int | None): Number of processes participating in
+ the training. It is usually the world_size.
+ rank (int | None): Rank of the current process within num_replicas.
+ ratio (int): Enlarging ratio. Default: 1.
+ """
+
+ def __init__(self, dataset, num_replicas, rank, ratio=1):
+ self.dataset = dataset
+ self.num_replicas = num_replicas
+ self.rank = rank
+ self.epoch = 0
+ self.num_samples = math.ceil(len(self.dataset) * ratio / self.num_replicas)
+ self.total_size = self.num_samples * self.num_replicas
+
+ def __iter__(self):
+ # deterministically shuffle based on epoch
+ g = torch.Generator()
+ g.manual_seed(self.epoch)
+ indices = torch.randperm(self.total_size, generator=g).tolist()
+
+ dataset_size = len(self.dataset)
+ indices = [v % dataset_size for v in indices]
+
+ # subsample
+ indices = indices[self.rank:self.total_size:self.num_replicas]
+ assert len(indices) == self.num_samples
+
+ return iter(indices)
+
+ def __len__(self):
+ return self.num_samples
+
+ def set_epoch(self, epoch):
+ self.epoch = epoch
diff --git a/custom_nodes/ComfyUI-ReActor/r_basicsr/data/data_util.py b/custom_nodes/ComfyUI-ReActor/r_basicsr/data/data_util.py
new file mode 100644
index 0000000000000000000000000000000000000000..501f14c8cc8a47e768b4531e44e5d3e39d271e0d
--- /dev/null
+++ b/custom_nodes/ComfyUI-ReActor/r_basicsr/data/data_util.py
@@ -0,0 +1,313 @@
+import cv2
+import numpy as np
+import torch
+from os import path as osp
+from torch.nn import functional as F
+
+from r_basicsr.data.transforms import mod_crop
+from r_basicsr.utils import img2tensor, scandir
+
+
+def read_img_seq(path, require_mod_crop=False, scale=1, return_imgname=False):
+ """Read a sequence of images from a given folder path.
+
+ Args:
+ path (list[str] | str): List of image paths or image folder path.
+ require_mod_crop (bool): Require mod crop for each image.
+ Default: False.
+ scale (int): Scale factor for mod_crop. Default: 1.
+ return_imgname(bool): Whether return image names. Default False.
+
+ Returns:
+ Tensor: size (t, c, h, w), RGB, [0, 1].
+ list[str]: Returned image name list.
+ """
+ if isinstance(path, list):
+ img_paths = path
+ else:
+ img_paths = sorted(list(scandir(path, full_path=True)))
+ imgs = [cv2.imread(v).astype(np.float32) / 255. for v in img_paths]
+
+ if require_mod_crop:
+ imgs = [mod_crop(img, scale) for img in imgs]
+ imgs = img2tensor(imgs, bgr2rgb=True, float32=True)
+ imgs = torch.stack(imgs, dim=0)
+
+ if return_imgname:
+ imgnames = [osp.splitext(osp.basename(path))[0] for path in img_paths]
+ return imgs, imgnames
+ else:
+ return imgs
+
+
+def generate_frame_indices(crt_idx, max_frame_num, num_frames, padding='reflection'):
+ """Generate an index list for reading `num_frames` frames from a sequence
+ of images.
+
+ Args:
+ crt_idx (int): Current center index.
+ max_frame_num (int): Max number of the sequence of images (from 1).
+ num_frames (int): Reading num_frames frames.
+ padding (str): Padding mode, one of
+ 'replicate' | 'reflection' | 'reflection_circle' | 'circle'
+ Examples: current_idx = 0, num_frames = 5
+ The generated frame indices under different padding mode:
+ replicate: [0, 0, 0, 1, 2]
+ reflection: [2, 1, 0, 1, 2]
+ reflection_circle: [4, 3, 0, 1, 2]
+ circle: [3, 4, 0, 1, 2]
+
+ Returns:
+ list[int]: A list of indices.
+ """
+ assert num_frames % 2 == 1, 'num_frames should be an odd number.'
+ assert padding in ('replicate', 'reflection', 'reflection_circle', 'circle'), f'Wrong padding mode: {padding}.'
+
+ max_frame_num = max_frame_num - 1 # start from 0
+ num_pad = num_frames // 2
+
+ indices = []
+ for i in range(crt_idx - num_pad, crt_idx + num_pad + 1):
+ if i < 0:
+ if padding == 'replicate':
+ pad_idx = 0
+ elif padding == 'reflection':
+ pad_idx = -i
+ elif padding == 'reflection_circle':
+ pad_idx = crt_idx + num_pad - i
+ else:
+ pad_idx = num_frames + i
+ elif i > max_frame_num:
+ if padding == 'replicate':
+ pad_idx = max_frame_num
+ elif padding == 'reflection':
+ pad_idx = max_frame_num * 2 - i
+ elif padding == 'reflection_circle':
+ pad_idx = (crt_idx - num_pad) - (i - max_frame_num)
+ else:
+ pad_idx = i - num_frames
+ else:
+ pad_idx = i
+ indices.append(pad_idx)
+ return indices
+
+
+def paired_paths_from_lmdb(folders, keys):
+ """Generate paired paths from lmdb files.
+
+ Contents of lmdb. Taking the `lq.lmdb` for example, the file structure is:
+
+ lq.lmdb
+ ├── data.mdb
+ ├── lock.mdb
+ ├── meta_info.txt
+
+ The data.mdb and lock.mdb are standard lmdb files and you can refer to
+ https://lmdb.readthedocs.io/en/release/ for more details.
+
+ The meta_info.txt is a specified txt file to record the meta information
+ of our datasets. It will be automatically created when preparing
+ datasets by our provided dataset tools.
+ Each line in the txt file records
+ 1)image name (with extension),
+ 2)image shape,
+ 3)compression level, separated by a white space.
+ Example: `baboon.png (120,125,3) 1`
+
+ We use the image name without extension as the lmdb key.
+ Note that we use the same key for the corresponding lq and gt images.
+
+ Args:
+ folders (list[str]): A list of folder path. The order of list should
+ be [input_folder, gt_folder].
+ keys (list[str]): A list of keys identifying folders. The order should
+ be in consistent with folders, e.g., ['lq', 'gt'].
+ Note that this key is different from lmdb keys.
+
+ Returns:
+ list[str]: Returned path list.
+ """
+ assert len(folders) == 2, ('The len of folders should be 2 with [input_folder, gt_folder]. '
+ f'But got {len(folders)}')
+ assert len(keys) == 2, f'The len of keys should be 2 with [input_key, gt_key]. But got {len(keys)}'
+ input_folder, gt_folder = folders
+ input_key, gt_key = keys
+
+ if not (input_folder.endswith('.lmdb') and gt_folder.endswith('.lmdb')):
+ raise ValueError(f'{input_key} folder and {gt_key} folder should both in lmdb '
+ f'formats. But received {input_key}: {input_folder}; '
+ f'{gt_key}: {gt_folder}')
+ # ensure that the two meta_info files are the same
+ with open(osp.join(input_folder, 'meta_info.txt')) as fin:
+ input_lmdb_keys = [line.split('.')[0] for line in fin]
+ with open(osp.join(gt_folder, 'meta_info.txt')) as fin:
+ gt_lmdb_keys = [line.split('.')[0] for line in fin]
+ if set(input_lmdb_keys) != set(gt_lmdb_keys):
+ raise ValueError(f'Keys in {input_key}_folder and {gt_key}_folder are different.')
+ else:
+ paths = []
+ for lmdb_key in sorted(input_lmdb_keys):
+ paths.append(dict([(f'{input_key}_path', lmdb_key), (f'{gt_key}_path', lmdb_key)]))
+ return paths
+
+
+def paired_paths_from_meta_info_file(folders, keys, meta_info_file, filename_tmpl):
+ """Generate paired paths from an meta information file.
+
+ Each line in the meta information file contains the image names and
+ image shape (usually for gt), separated by a white space.
+
+ Example of an meta information file:
+ ```
+ 0001_s001.png (480,480,3)
+ 0001_s002.png (480,480,3)
+ ```
+
+ Args:
+ folders (list[str]): A list of folder path. The order of list should
+ be [input_folder, gt_folder].
+ keys (list[str]): A list of keys identifying folders. The order should
+ be in consistent with folders, e.g., ['lq', 'gt'].
+ meta_info_file (str): Path to the meta information file.
+ filename_tmpl (str): Template for each filename. Note that the
+ template excludes the file extension. Usually the filename_tmpl is
+ for files in the input folder.
+
+ Returns:
+ list[str]: Returned path list.
+ """
+ assert len(folders) == 2, ('The len of folders should be 2 with [input_folder, gt_folder]. '
+ f'But got {len(folders)}')
+ assert len(keys) == 2, f'The len of keys should be 2 with [input_key, gt_key]. But got {len(keys)}'
+ input_folder, gt_folder = folders
+ input_key, gt_key = keys
+
+ with open(meta_info_file, 'r') as fin:
+ gt_names = [line.strip().split(' ')[0] for line in fin]
+
+ paths = []
+ for gt_name in gt_names:
+ basename, ext = osp.splitext(osp.basename(gt_name))
+ input_name = f'{filename_tmpl.format(basename)}{ext}'
+ input_path = osp.join(input_folder, input_name)
+ gt_path = osp.join(gt_folder, gt_name)
+ paths.append(dict([(f'{input_key}_path', input_path), (f'{gt_key}_path', gt_path)]))
+ return paths
+
+
+def paired_paths_from_folder(folders, keys, filename_tmpl):
+ """Generate paired paths from folders.
+
+ Args:
+ folders (list[str]): A list of folder path. The order of list should
+ be [input_folder, gt_folder].
+ keys (list[str]): A list of keys identifying folders. The order should
+ be in consistent with folders, e.g., ['lq', 'gt'].
+ filename_tmpl (str): Template for each filename. Note that the
+ template excludes the file extension. Usually the filename_tmpl is
+ for files in the input folder.
+
+ Returns:
+ list[str]: Returned path list.
+ """
+ assert len(folders) == 2, ('The len of folders should be 2 with [input_folder, gt_folder]. '
+ f'But got {len(folders)}')
+ assert len(keys) == 2, f'The len of keys should be 2 with [input_key, gt_key]. But got {len(keys)}'
+ input_folder, gt_folder = folders
+ input_key, gt_key = keys
+
+ input_paths = list(scandir(input_folder))
+ gt_paths = list(scandir(gt_folder))
+ assert len(input_paths) == len(gt_paths), (f'{input_key} and {gt_key} datasets have different number of images: '
+ f'{len(input_paths)}, {len(gt_paths)}.')
+ paths = []
+ for gt_path in gt_paths:
+ basename, ext = osp.splitext(osp.basename(gt_path))
+ input_name = f'{filename_tmpl.format(basename)}{ext}'
+ input_path = osp.join(input_folder, input_name)
+ assert input_name in input_paths, f'{input_name} is not in {input_key}_paths.'
+ gt_path = osp.join(gt_folder, gt_path)
+ paths.append(dict([(f'{input_key}_path', input_path), (f'{gt_key}_path', gt_path)]))
+ return paths
+
+
+def paths_from_folder(folder):
+ """Generate paths from folder.
+
+ Args:
+ folder (str): Folder path.
+
+ Returns:
+ list[str]: Returned path list.
+ """
+
+ paths = list(scandir(folder))
+ paths = [osp.join(folder, path) for path in paths]
+ return paths
+
+
+def paths_from_lmdb(folder):
+ """Generate paths from lmdb.
+
+ Args:
+ folder (str): Folder path.
+
+ Returns:
+ list[str]: Returned path list.
+ """
+ if not folder.endswith('.lmdb'):
+ raise ValueError(f'Folder {folder}folder should in lmdb format.')
+ with open(osp.join(folder, 'meta_info.txt')) as fin:
+ paths = [line.split('.')[0] for line in fin]
+ return paths
+
+
+def generate_gaussian_kernel(kernel_size=13, sigma=1.6):
+ """Generate Gaussian kernel used in `duf_downsample`.
+
+ Args:
+ kernel_size (int): Kernel size. Default: 13.
+ sigma (float): Sigma of the Gaussian kernel. Default: 1.6.
+
+ Returns:
+ np.array: The Gaussian kernel.
+ """
+ from scipy.ndimage import filters as filters
+ kernel = np.zeros((kernel_size, kernel_size))
+ # set element at the middle to one, a dirac delta
+ kernel[kernel_size // 2, kernel_size // 2] = 1
+ # gaussian-smooth the dirac, resulting in a gaussian filter
+ return filters.gaussian_filter(kernel, sigma)
+
+
+def duf_downsample(x, kernel_size=13, scale=4):
+ """Downsamping with Gaussian kernel used in the DUF official code.
+
+ Args:
+ x (Tensor): Frames to be downsampled, with shape (b, t, c, h, w).
+ kernel_size (int): Kernel size. Default: 13.
+ scale (int): Downsampling factor. Supported scale: (2, 3, 4).
+ Default: 4.
+
+ Returns:
+ Tensor: DUF downsampled frames.
+ """
+ assert scale in (2, 3, 4), f'Only support scale (2, 3, 4), but got {scale}.'
+
+ squeeze_flag = False
+ if x.ndim == 4:
+ squeeze_flag = True
+ x = x.unsqueeze(0)
+ b, t, c, h, w = x.size()
+ x = x.view(-1, 1, h, w)
+ pad_w, pad_h = kernel_size // 2 + scale * 2, kernel_size // 2 + scale * 2
+ x = F.pad(x, (pad_w, pad_w, pad_h, pad_h), 'reflect')
+
+ gaussian_filter = generate_gaussian_kernel(kernel_size, 0.4 * scale)
+ gaussian_filter = torch.from_numpy(gaussian_filter).type_as(x).unsqueeze(0).unsqueeze(0)
+ x = F.conv2d(x, gaussian_filter, stride=scale)
+ x = x[:, :, 2:-2, 2:-2]
+ x = x.view(b, t, c, x.size(2), x.size(3))
+ if squeeze_flag:
+ x = x.squeeze(0)
+ return x
diff --git a/custom_nodes/ComfyUI-ReActor/r_basicsr/data/degradations.py b/custom_nodes/ComfyUI-ReActor/r_basicsr/data/degradations.py
new file mode 100644
index 0000000000000000000000000000000000000000..697d35ccb560e902eee975c12ec728bea3b8b3c6
--- /dev/null
+++ b/custom_nodes/ComfyUI-ReActor/r_basicsr/data/degradations.py
@@ -0,0 +1,768 @@
+import cv2
+import math
+import numpy as np
+import random
+import torch
+from scipy import special
+from scipy.stats import multivariate_normal
+try:
+ from torchvision.transforms.functional_tensor import rgb_to_grayscale
+except:
+ from torchvision.transforms.functional import rgb_to_grayscale
+
+# -------------------------------------------------------------------- #
+# --------------------------- blur kernels --------------------------- #
+# -------------------------------------------------------------------- #
+
+
+# --------------------------- util functions --------------------------- #
+def sigma_matrix2(sig_x, sig_y, theta):
+ """Calculate the rotated sigma matrix (two dimensional matrix).
+
+ Args:
+ sig_x (float):
+ sig_y (float):
+ theta (float): Radian measurement.
+
+ Returns:
+ ndarray: Rotated sigma matrix.
+ """
+ d_matrix = np.array([[sig_x**2, 0], [0, sig_y**2]])
+ u_matrix = np.array([[np.cos(theta), -np.sin(theta)], [np.sin(theta), np.cos(theta)]])
+ return np.dot(u_matrix, np.dot(d_matrix, u_matrix.T))
+
+
+def mesh_grid(kernel_size):
+ """Generate the mesh grid, centering at zero.
+
+ Args:
+ kernel_size (int):
+
+ Returns:
+ xy (ndarray): with the shape (kernel_size, kernel_size, 2)
+ xx (ndarray): with the shape (kernel_size, kernel_size)
+ yy (ndarray): with the shape (kernel_size, kernel_size)
+ """
+ ax = np.arange(-kernel_size // 2 + 1., kernel_size // 2 + 1.)
+ xx, yy = np.meshgrid(ax, ax)
+ xy = np.hstack((xx.reshape((kernel_size * kernel_size, 1)), yy.reshape(kernel_size * kernel_size,
+ 1))).reshape(kernel_size, kernel_size, 2)
+ return xy, xx, yy
+
+
+def pdf2(sigma_matrix, grid):
+ """Calculate PDF of the bivariate Gaussian distribution.
+
+ Args:
+ sigma_matrix (ndarray): with the shape (2, 2)
+ grid (ndarray): generated by :func:`mesh_grid`,
+ with the shape (K, K, 2), K is the kernel size.
+
+ Returns:
+ kernel (ndarrray): un-normalized kernel.
+ """
+ inverse_sigma = np.linalg.inv(sigma_matrix)
+ kernel = np.exp(-0.5 * np.sum(np.dot(grid, inverse_sigma) * grid, 2))
+ return kernel
+
+
+def cdf2(d_matrix, grid):
+ """Calculate the CDF of the standard bivariate Gaussian distribution.
+ Used in skewed Gaussian distribution.
+
+ Args:
+ d_matrix (ndarrasy): skew matrix.
+ grid (ndarray): generated by :func:`mesh_grid`,
+ with the shape (K, K, 2), K is the kernel size.
+
+ Returns:
+ cdf (ndarray): skewed cdf.
+ """
+ rv = multivariate_normal([0, 0], [[1, 0], [0, 1]])
+ grid = np.dot(grid, d_matrix)
+ cdf = rv.cdf(grid)
+ return cdf
+
+
+def bivariate_Gaussian(kernel_size, sig_x, sig_y, theta, grid=None, isotropic=True):
+ """Generate a bivariate isotropic or anisotropic Gaussian kernel.
+
+ In the isotropic mode, only `sig_x` is used. `sig_y` and `theta` is ignored.
+
+ Args:
+ kernel_size (int):
+ sig_x (float):
+ sig_y (float):
+ theta (float): Radian measurement.
+ grid (ndarray, optional): generated by :func:`mesh_grid`,
+ with the shape (K, K, 2), K is the kernel size. Default: None
+ isotropic (bool):
+
+ Returns:
+ kernel (ndarray): normalized kernel.
+ """
+ if grid is None:
+ grid, _, _ = mesh_grid(kernel_size)
+ if isotropic:
+ sigma_matrix = np.array([[sig_x**2, 0], [0, sig_x**2]])
+ else:
+ sigma_matrix = sigma_matrix2(sig_x, sig_y, theta)
+ kernel = pdf2(sigma_matrix, grid)
+ kernel = kernel / np.sum(kernel)
+ return kernel
+
+
+def bivariate_generalized_Gaussian(kernel_size, sig_x, sig_y, theta, beta, grid=None, isotropic=True):
+ """Generate a bivariate generalized Gaussian kernel.
+ Described in `Parameter Estimation For Multivariate Generalized
+ Gaussian Distributions`_
+ by Pascal et. al (2013).
+
+ In the isotropic mode, only `sig_x` is used. `sig_y` and `theta` is ignored.
+
+ Args:
+ kernel_size (int):
+ sig_x (float):
+ sig_y (float):
+ theta (float): Radian measurement.
+ beta (float): shape parameter, beta = 1 is the normal distribution.
+ grid (ndarray, optional): generated by :func:`mesh_grid`,
+ with the shape (K, K, 2), K is the kernel size. Default: None
+
+ Returns:
+ kernel (ndarray): normalized kernel.
+
+ .. _Parameter Estimation For Multivariate Generalized Gaussian
+ Distributions: https://arxiv.org/abs/1302.6498
+ """
+ if grid is None:
+ grid, _, _ = mesh_grid(kernel_size)
+ if isotropic:
+ sigma_matrix = np.array([[sig_x**2, 0], [0, sig_x**2]])
+ else:
+ sigma_matrix = sigma_matrix2(sig_x, sig_y, theta)
+ inverse_sigma = np.linalg.inv(sigma_matrix)
+ kernel = np.exp(-0.5 * np.power(np.sum(np.dot(grid, inverse_sigma) * grid, 2), beta))
+ kernel = kernel / np.sum(kernel)
+ return kernel
+
+
+def bivariate_plateau(kernel_size, sig_x, sig_y, theta, beta, grid=None, isotropic=True):
+ """Generate a plateau-like anisotropic kernel.
+ 1 / (1+x^(beta))
+
+ Ref: https://stats.stackexchange.com/questions/203629/is-there-a-plateau-shaped-distribution
+
+ In the isotropic mode, only `sig_x` is used. `sig_y` and `theta` is ignored.
+
+ Args:
+ kernel_size (int):
+ sig_x (float):
+ sig_y (float):
+ theta (float): Radian measurement.
+ beta (float): shape parameter, beta = 1 is the normal distribution.
+ grid (ndarray, optional): generated by :func:`mesh_grid`,
+ with the shape (K, K, 2), K is the kernel size. Default: None
+
+ Returns:
+ kernel (ndarray): normalized kernel.
+ """
+ if grid is None:
+ grid, _, _ = mesh_grid(kernel_size)
+ if isotropic:
+ sigma_matrix = np.array([[sig_x**2, 0], [0, sig_x**2]])
+ else:
+ sigma_matrix = sigma_matrix2(sig_x, sig_y, theta)
+ inverse_sigma = np.linalg.inv(sigma_matrix)
+ kernel = np.reciprocal(np.power(np.sum(np.dot(grid, inverse_sigma) * grid, 2), beta) + 1)
+ kernel = kernel / np.sum(kernel)
+ return kernel
+
+
+def random_bivariate_Gaussian(kernel_size,
+ sigma_x_range,
+ sigma_y_range,
+ rotation_range,
+ noise_range=None,
+ isotropic=True):
+ """Randomly generate bivariate isotropic or anisotropic Gaussian kernels.
+
+ In the isotropic mode, only `sigma_x_range` is used. `sigma_y_range` and `rotation_range` is ignored.
+
+ Args:
+ kernel_size (int):
+ sigma_x_range (tuple): [0.6, 5]
+ sigma_y_range (tuple): [0.6, 5]
+ rotation range (tuple): [-math.pi, math.pi]
+ noise_range(tuple, optional): multiplicative kernel noise,
+ [0.75, 1.25]. Default: None
+
+ Returns:
+ kernel (ndarray):
+ """
+ assert kernel_size % 2 == 1, 'Kernel size must be an odd number.'
+ assert sigma_x_range[0] < sigma_x_range[1], 'Wrong sigma_x_range.'
+ sigma_x = np.random.uniform(sigma_x_range[0], sigma_x_range[1])
+ if isotropic is False:
+ assert sigma_y_range[0] < sigma_y_range[1], 'Wrong sigma_y_range.'
+ assert rotation_range[0] < rotation_range[1], 'Wrong rotation_range.'
+ sigma_y = np.random.uniform(sigma_y_range[0], sigma_y_range[1])
+ rotation = np.random.uniform(rotation_range[0], rotation_range[1])
+ else:
+ sigma_y = sigma_x
+ rotation = 0
+
+ kernel = bivariate_Gaussian(kernel_size, sigma_x, sigma_y, rotation, isotropic=isotropic)
+
+ # add multiplicative noise
+ if noise_range is not None:
+ assert noise_range[0] < noise_range[1], 'Wrong noise range.'
+ noise = np.random.uniform(noise_range[0], noise_range[1], size=kernel.shape)
+ kernel = kernel * noise
+ kernel = kernel / np.sum(kernel)
+ return kernel
+
+
+def random_bivariate_generalized_Gaussian(kernel_size,
+ sigma_x_range,
+ sigma_y_range,
+ rotation_range,
+ beta_range,
+ noise_range=None,
+ isotropic=True):
+ """Randomly generate bivariate generalized Gaussian kernels.
+
+ In the isotropic mode, only `sigma_x_range` is used. `sigma_y_range` and `rotation_range` is ignored.
+
+ Args:
+ kernel_size (int):
+ sigma_x_range (tuple): [0.6, 5]
+ sigma_y_range (tuple): [0.6, 5]
+ rotation range (tuple): [-math.pi, math.pi]
+ beta_range (tuple): [0.5, 8]
+ noise_range(tuple, optional): multiplicative kernel noise,
+ [0.75, 1.25]. Default: None
+
+ Returns:
+ kernel (ndarray):
+ """
+ assert kernel_size % 2 == 1, 'Kernel size must be an odd number.'
+ assert sigma_x_range[0] < sigma_x_range[1], 'Wrong sigma_x_range.'
+ sigma_x = np.random.uniform(sigma_x_range[0], sigma_x_range[1])
+ if isotropic is False:
+ assert sigma_y_range[0] < sigma_y_range[1], 'Wrong sigma_y_range.'
+ assert rotation_range[0] < rotation_range[1], 'Wrong rotation_range.'
+ sigma_y = np.random.uniform(sigma_y_range[0], sigma_y_range[1])
+ rotation = np.random.uniform(rotation_range[0], rotation_range[1])
+ else:
+ sigma_y = sigma_x
+ rotation = 0
+
+ # assume beta_range[0] < 1 < beta_range[1]
+ if np.random.uniform() < 0.5:
+ beta = np.random.uniform(beta_range[0], 1)
+ else:
+ beta = np.random.uniform(1, beta_range[1])
+
+ kernel = bivariate_generalized_Gaussian(kernel_size, sigma_x, sigma_y, rotation, beta, isotropic=isotropic)
+
+ # add multiplicative noise
+ if noise_range is not None:
+ assert noise_range[0] < noise_range[1], 'Wrong noise range.'
+ noise = np.random.uniform(noise_range[0], noise_range[1], size=kernel.shape)
+ kernel = kernel * noise
+ kernel = kernel / np.sum(kernel)
+ return kernel
+
+
+def random_bivariate_plateau(kernel_size,
+ sigma_x_range,
+ sigma_y_range,
+ rotation_range,
+ beta_range,
+ noise_range=None,
+ isotropic=True):
+ """Randomly generate bivariate plateau kernels.
+
+ In the isotropic mode, only `sigma_x_range` is used. `sigma_y_range` and `rotation_range` is ignored.
+
+ Args:
+ kernel_size (int):
+ sigma_x_range (tuple): [0.6, 5]
+ sigma_y_range (tuple): [0.6, 5]
+ rotation range (tuple): [-math.pi/2, math.pi/2]
+ beta_range (tuple): [1, 4]
+ noise_range(tuple, optional): multiplicative kernel noise,
+ [0.75, 1.25]. Default: None
+
+ Returns:
+ kernel (ndarray):
+ """
+ assert kernel_size % 2 == 1, 'Kernel size must be an odd number.'
+ assert sigma_x_range[0] < sigma_x_range[1], 'Wrong sigma_x_range.'
+ sigma_x = np.random.uniform(sigma_x_range[0], sigma_x_range[1])
+ if isotropic is False:
+ assert sigma_y_range[0] < sigma_y_range[1], 'Wrong sigma_y_range.'
+ assert rotation_range[0] < rotation_range[1], 'Wrong rotation_range.'
+ sigma_y = np.random.uniform(sigma_y_range[0], sigma_y_range[1])
+ rotation = np.random.uniform(rotation_range[0], rotation_range[1])
+ else:
+ sigma_y = sigma_x
+ rotation = 0
+
+ # TODO: this may be not proper
+ if np.random.uniform() < 0.5:
+ beta = np.random.uniform(beta_range[0], 1)
+ else:
+ beta = np.random.uniform(1, beta_range[1])
+
+ kernel = bivariate_plateau(kernel_size, sigma_x, sigma_y, rotation, beta, isotropic=isotropic)
+ # add multiplicative noise
+ if noise_range is not None:
+ assert noise_range[0] < noise_range[1], 'Wrong noise range.'
+ noise = np.random.uniform(noise_range[0], noise_range[1], size=kernel.shape)
+ kernel = kernel * noise
+ kernel = kernel / np.sum(kernel)
+
+ return kernel
+
+
+def random_mixed_kernels(kernel_list,
+ kernel_prob,
+ kernel_size=21,
+ sigma_x_range=(0.6, 5),
+ sigma_y_range=(0.6, 5),
+ rotation_range=(-math.pi, math.pi),
+ betag_range=(0.5, 8),
+ betap_range=(0.5, 8),
+ noise_range=None):
+ """Randomly generate mixed kernels.
+
+ Args:
+ kernel_list (tuple): a list name of kernel types,
+ support ['iso', 'aniso', 'skew', 'generalized', 'plateau_iso',
+ 'plateau_aniso']
+ kernel_prob (tuple): corresponding kernel probability for each
+ kernel type
+ kernel_size (int):
+ sigma_x_range (tuple): [0.6, 5]
+ sigma_y_range (tuple): [0.6, 5]
+ rotation range (tuple): [-math.pi, math.pi]
+ beta_range (tuple): [0.5, 8]
+ noise_range(tuple, optional): multiplicative kernel noise,
+ [0.75, 1.25]. Default: None
+
+ Returns:
+ kernel (ndarray):
+ """
+ kernel_type = random.choices(kernel_list, kernel_prob)[0]
+ if kernel_type == 'iso':
+ kernel = random_bivariate_Gaussian(
+ kernel_size, sigma_x_range, sigma_y_range, rotation_range, noise_range=noise_range, isotropic=True)
+ elif kernel_type == 'aniso':
+ kernel = random_bivariate_Gaussian(
+ kernel_size, sigma_x_range, sigma_y_range, rotation_range, noise_range=noise_range, isotropic=False)
+ elif kernel_type == 'generalized_iso':
+ kernel = random_bivariate_generalized_Gaussian(
+ kernel_size,
+ sigma_x_range,
+ sigma_y_range,
+ rotation_range,
+ betag_range,
+ noise_range=noise_range,
+ isotropic=True)
+ elif kernel_type == 'generalized_aniso':
+ kernel = random_bivariate_generalized_Gaussian(
+ kernel_size,
+ sigma_x_range,
+ sigma_y_range,
+ rotation_range,
+ betag_range,
+ noise_range=noise_range,
+ isotropic=False)
+ elif kernel_type == 'plateau_iso':
+ kernel = random_bivariate_plateau(
+ kernel_size, sigma_x_range, sigma_y_range, rotation_range, betap_range, noise_range=None, isotropic=True)
+ elif kernel_type == 'plateau_aniso':
+ kernel = random_bivariate_plateau(
+ kernel_size, sigma_x_range, sigma_y_range, rotation_range, betap_range, noise_range=None, isotropic=False)
+ return kernel
+
+
+np.seterr(divide='ignore', invalid='ignore')
+
+
+def circular_lowpass_kernel(cutoff, kernel_size, pad_to=0):
+ """2D sinc filter, ref: https://dsp.stackexchange.com/questions/58301/2-d-circularly-symmetric-low-pass-filter
+
+ Args:
+ cutoff (float): cutoff frequency in radians (pi is max)
+ kernel_size (int): horizontal and vertical size, must be odd.
+ pad_to (int): pad kernel size to desired size, must be odd or zero.
+ """
+ assert kernel_size % 2 == 1, 'Kernel size must be an odd number.'
+ kernel = np.fromfunction(
+ lambda x, y: cutoff * special.j1(cutoff * np.sqrt(
+ (x - (kernel_size - 1) / 2)**2 + (y - (kernel_size - 1) / 2)**2)) / (2 * np.pi * np.sqrt(
+ (x - (kernel_size - 1) / 2)**2 + (y - (kernel_size - 1) / 2)**2)), [kernel_size, kernel_size])
+ kernel[(kernel_size - 1) // 2, (kernel_size - 1) // 2] = cutoff**2 / (4 * np.pi)
+ kernel = kernel / np.sum(kernel)
+ if pad_to > kernel_size:
+ pad_size = (pad_to - kernel_size) // 2
+ kernel = np.pad(kernel, ((pad_size, pad_size), (pad_size, pad_size)))
+ return kernel
+
+
+# ------------------------------------------------------------- #
+# --------------------------- noise --------------------------- #
+# ------------------------------------------------------------- #
+
+# ----------------------- Gaussian Noise ----------------------- #
+
+
+def generate_gaussian_noise(img, sigma=10, gray_noise=False):
+ """Generate Gaussian noise.
+
+ Args:
+ img (Numpy array): Input image, shape (h, w, c), range [0, 1], float32.
+ sigma (float): Noise scale (measured in range 255). Default: 10.
+
+ Returns:
+ (Numpy array): Returned noisy image, shape (h, w, c), range[0, 1],
+ float32.
+ """
+ if gray_noise:
+ noise = np.float32(np.random.randn(*(img.shape[0:2]))) * sigma / 255.
+ noise = np.expand_dims(noise, axis=2).repeat(3, axis=2)
+ else:
+ noise = np.float32(np.random.randn(*(img.shape))) * sigma / 255.
+ return noise
+
+
+def add_gaussian_noise(img, sigma=10, clip=True, rounds=False, gray_noise=False):
+ """Add Gaussian noise.
+
+ Args:
+ img (Numpy array): Input image, shape (h, w, c), range [0, 1], float32.
+ sigma (float): Noise scale (measured in range 255). Default: 10.
+
+ Returns:
+ (Numpy array): Returned noisy image, shape (h, w, c), range[0, 1],
+ float32.
+ """
+ noise = generate_gaussian_noise(img, sigma, gray_noise)
+ out = img + noise
+ if clip and rounds:
+ out = np.clip((out * 255.0).round(), 0, 255) / 255.
+ elif clip:
+ out = np.clip(out, 0, 1)
+ elif rounds:
+ out = (out * 255.0).round() / 255.
+ return out
+
+
+def generate_gaussian_noise_pt(img, sigma=10, gray_noise=0):
+ """Add Gaussian noise (PyTorch version).
+
+ Args:
+ img (Tensor): Shape (b, c, h, w), range[0, 1], float32.
+ scale (float | Tensor): Noise scale. Default: 1.0.
+
+ Returns:
+ (Tensor): Returned noisy image, shape (b, c, h, w), range[0, 1],
+ float32.
+ """
+ b, _, h, w = img.size()
+ if not isinstance(sigma, (float, int)):
+ sigma = sigma.view(img.size(0), 1, 1, 1)
+ if isinstance(gray_noise, (float, int)):
+ cal_gray_noise = gray_noise > 0
+ else:
+ gray_noise = gray_noise.view(b, 1, 1, 1)
+ cal_gray_noise = torch.sum(gray_noise) > 0
+
+ if cal_gray_noise:
+ noise_gray = torch.randn(*img.size()[2:4], dtype=img.dtype, device=img.device) * sigma / 255.
+ noise_gray = noise_gray.view(b, 1, h, w)
+
+ # always calculate color noise
+ noise = torch.randn(*img.size(), dtype=img.dtype, device=img.device) * sigma / 255.
+
+ if cal_gray_noise:
+ noise = noise * (1 - gray_noise) + noise_gray * gray_noise
+ return noise
+
+
+def add_gaussian_noise_pt(img, sigma=10, gray_noise=0, clip=True, rounds=False):
+ """Add Gaussian noise (PyTorch version).
+
+ Args:
+ img (Tensor): Shape (b, c, h, w), range[0, 1], float32.
+ scale (float | Tensor): Noise scale. Default: 1.0.
+
+ Returns:
+ (Tensor): Returned noisy image, shape (b, c, h, w), range[0, 1],
+ float32.
+ """
+ noise = generate_gaussian_noise_pt(img, sigma, gray_noise)
+ out = img + noise
+ if clip and rounds:
+ out = torch.clamp((out * 255.0).round(), 0, 255) / 255.
+ elif clip:
+ out = torch.clamp(out, 0, 1)
+ elif rounds:
+ out = (out * 255.0).round() / 255.
+ return out
+
+
+# ----------------------- Random Gaussian Noise ----------------------- #
+def random_generate_gaussian_noise(img, sigma_range=(0, 10), gray_prob=0):
+ sigma = np.random.uniform(sigma_range[0], sigma_range[1])
+ if np.random.uniform() < gray_prob:
+ gray_noise = True
+ else:
+ gray_noise = False
+ return generate_gaussian_noise(img, sigma, gray_noise)
+
+
+def random_add_gaussian_noise(img, sigma_range=(0, 1.0), gray_prob=0, clip=True, rounds=False):
+ noise = random_generate_gaussian_noise(img, sigma_range, gray_prob)
+ out = img + noise
+ if clip and rounds:
+ out = np.clip((out * 255.0).round(), 0, 255) / 255.
+ elif clip:
+ out = np.clip(out, 0, 1)
+ elif rounds:
+ out = (out * 255.0).round() / 255.
+ return out
+
+
+def random_generate_gaussian_noise_pt(img, sigma_range=(0, 10), gray_prob=0):
+ sigma = torch.rand(
+ img.size(0), dtype=img.dtype, device=img.device) * (sigma_range[1] - sigma_range[0]) + sigma_range[0]
+ gray_noise = torch.rand(img.size(0), dtype=img.dtype, device=img.device)
+ gray_noise = (gray_noise < gray_prob).float()
+ return generate_gaussian_noise_pt(img, sigma, gray_noise)
+
+
+def random_add_gaussian_noise_pt(img, sigma_range=(0, 1.0), gray_prob=0, clip=True, rounds=False):
+ noise = random_generate_gaussian_noise_pt(img, sigma_range, gray_prob)
+ out = img + noise
+ if clip and rounds:
+ out = torch.clamp((out * 255.0).round(), 0, 255) / 255.
+ elif clip:
+ out = torch.clamp(out, 0, 1)
+ elif rounds:
+ out = (out * 255.0).round() / 255.
+ return out
+
+
+# ----------------------- Poisson (Shot) Noise ----------------------- #
+
+
+def generate_poisson_noise(img, scale=1.0, gray_noise=False):
+ """Generate poisson noise.
+
+ Ref: https://github.com/scikit-image/scikit-image/blob/main/skimage/util/noise.py#L37-L219
+
+ Args:
+ img (Numpy array): Input image, shape (h, w, c), range [0, 1], float32.
+ scale (float): Noise scale. Default: 1.0.
+ gray_noise (bool): Whether generate gray noise. Default: False.
+
+ Returns:
+ (Numpy array): Returned noisy image, shape (h, w, c), range[0, 1],
+ float32.
+ """
+ if gray_noise:
+ img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
+ # round and clip image for counting vals correctly
+ img = np.clip((img * 255.0).round(), 0, 255) / 255.
+ vals = len(np.unique(img))
+ vals = 2**np.ceil(np.log2(vals))
+ out = np.float32(np.random.poisson(img * vals) / float(vals))
+ noise = out - img
+ if gray_noise:
+ noise = np.repeat(noise[:, :, np.newaxis], 3, axis=2)
+ return noise * scale
+
+
+def add_poisson_noise(img, scale=1.0, clip=True, rounds=False, gray_noise=False):
+ """Add poisson noise.
+
+ Args:
+ img (Numpy array): Input image, shape (h, w, c), range [0, 1], float32.
+ scale (float): Noise scale. Default: 1.0.
+ gray_noise (bool): Whether generate gray noise. Default: False.
+
+ Returns:
+ (Numpy array): Returned noisy image, shape (h, w, c), range[0, 1],
+ float32.
+ """
+ noise = generate_poisson_noise(img, scale, gray_noise)
+ out = img + noise
+ if clip and rounds:
+ out = np.clip((out * 255.0).round(), 0, 255) / 255.
+ elif clip:
+ out = np.clip(out, 0, 1)
+ elif rounds:
+ out = (out * 255.0).round() / 255.
+ return out
+
+
+def generate_poisson_noise_pt(img, scale=1.0, gray_noise=0):
+ """Generate a batch of poisson noise (PyTorch version)
+
+ Args:
+ img (Tensor): Input image, shape (b, c, h, w), range [0, 1], float32.
+ scale (float | Tensor): Noise scale. Number or Tensor with shape (b).
+ Default: 1.0.
+ gray_noise (float | Tensor): 0-1 number or Tensor with shape (b).
+ 0 for False, 1 for True. Default: 0.
+
+ Returns:
+ (Tensor): Returned noisy image, shape (b, c, h, w), range[0, 1],
+ float32.
+ """
+ b, _, h, w = img.size()
+ if isinstance(gray_noise, (float, int)):
+ cal_gray_noise = gray_noise > 0
+ else:
+ gray_noise = gray_noise.view(b, 1, 1, 1)
+ cal_gray_noise = torch.sum(gray_noise) > 0
+ if cal_gray_noise:
+ img_gray = rgb_to_grayscale(img, num_output_channels=1)
+ # round and clip image for counting vals correctly
+ img_gray = torch.clamp((img_gray * 255.0).round(), 0, 255) / 255.
+ # use for-loop to get the unique values for each sample
+ vals_list = [len(torch.unique(img_gray[i, :, :, :])) for i in range(b)]
+ vals_list = [2**np.ceil(np.log2(vals)) for vals in vals_list]
+ vals = img_gray.new_tensor(vals_list).view(b, 1, 1, 1)
+ out = torch.poisson(img_gray * vals) / vals
+ noise_gray = out - img_gray
+ noise_gray = noise_gray.expand(b, 3, h, w)
+
+ # always calculate color noise
+ # round and clip image for counting vals correctly
+ img = torch.clamp((img * 255.0).round(), 0, 255) / 255.
+ # use for-loop to get the unique values for each sample
+ vals_list = [len(torch.unique(img[i, :, :, :])) for i in range(b)]
+ vals_list = [2**np.ceil(np.log2(vals)) for vals in vals_list]
+ vals = img.new_tensor(vals_list).view(b, 1, 1, 1)
+ out = torch.poisson(img * vals) / vals
+ noise = out - img
+ if cal_gray_noise:
+ noise = noise * (1 - gray_noise) + noise_gray * gray_noise
+ if not isinstance(scale, (float, int)):
+ scale = scale.view(b, 1, 1, 1)
+ return noise * scale
+
+
+def add_poisson_noise_pt(img, scale=1.0, clip=True, rounds=False, gray_noise=0):
+ """Add poisson noise to a batch of images (PyTorch version).
+
+ Args:
+ img (Tensor): Input image, shape (b, c, h, w), range [0, 1], float32.
+ scale (float | Tensor): Noise scale. Number or Tensor with shape (b).
+ Default: 1.0.
+ gray_noise (float | Tensor): 0-1 number or Tensor with shape (b).
+ 0 for False, 1 for True. Default: 0.
+
+ Returns:
+ (Tensor): Returned noisy image, shape (b, c, h, w), range[0, 1],
+ float32.
+ """
+ noise = generate_poisson_noise_pt(img, scale, gray_noise)
+ out = img + noise
+ if clip and rounds:
+ out = torch.clamp((out * 255.0).round(), 0, 255) / 255.
+ elif clip:
+ out = torch.clamp(out, 0, 1)
+ elif rounds:
+ out = (out * 255.0).round() / 255.
+ return out
+
+
+# ----------------------- Random Poisson (Shot) Noise ----------------------- #
+
+
+def random_generate_poisson_noise(img, scale_range=(0, 1.0), gray_prob=0):
+ scale = np.random.uniform(scale_range[0], scale_range[1])
+ if np.random.uniform() < gray_prob:
+ gray_noise = True
+ else:
+ gray_noise = False
+ return generate_poisson_noise(img, scale, gray_noise)
+
+
+def random_add_poisson_noise(img, scale_range=(0, 1.0), gray_prob=0, clip=True, rounds=False):
+ noise = random_generate_poisson_noise(img, scale_range, gray_prob)
+ out = img + noise
+ if clip and rounds:
+ out = np.clip((out * 255.0).round(), 0, 255) / 255.
+ elif clip:
+ out = np.clip(out, 0, 1)
+ elif rounds:
+ out = (out * 255.0).round() / 255.
+ return out
+
+
+def random_generate_poisson_noise_pt(img, scale_range=(0, 1.0), gray_prob=0):
+ scale = torch.rand(
+ img.size(0), dtype=img.dtype, device=img.device) * (scale_range[1] - scale_range[0]) + scale_range[0]
+ gray_noise = torch.rand(img.size(0), dtype=img.dtype, device=img.device)
+ gray_noise = (gray_noise < gray_prob).float()
+ return generate_poisson_noise_pt(img, scale, gray_noise)
+
+
+def random_add_poisson_noise_pt(img, scale_range=(0, 1.0), gray_prob=0, clip=True, rounds=False):
+ noise = random_generate_poisson_noise_pt(img, scale_range, gray_prob)
+ out = img + noise
+ if clip and rounds:
+ out = torch.clamp((out * 255.0).round(), 0, 255) / 255.
+ elif clip:
+ out = torch.clamp(out, 0, 1)
+ elif rounds:
+ out = (out * 255.0).round() / 255.
+ return out
+
+
+# ------------------------------------------------------------------------ #
+# --------------------------- JPEG compression --------------------------- #
+# ------------------------------------------------------------------------ #
+
+
+def add_jpg_compression(img, quality=90):
+ """Add JPG compression artifacts.
+
+ Args:
+ img (Numpy array): Input image, shape (h, w, c), range [0, 1], float32.
+ quality (float): JPG compression quality. 0 for lowest quality, 100 for
+ best quality. Default: 90.
+
+ Returns:
+ (Numpy array): Returned image after JPG, shape (h, w, c), range[0, 1],
+ float32.
+ """
+ img = np.clip(img, 0, 1)
+ encode_param = [int(cv2.IMWRITE_JPEG_QUALITY), quality]
+ _, encimg = cv2.imencode('.jpg', img * 255., encode_param)
+ img = np.float32(cv2.imdecode(encimg, 1)) / 255.
+ return img
+
+
+def random_add_jpg_compression(img, quality_range=(90, 100)):
+ """Randomly add JPG compression artifacts.
+
+ Args:
+ img (Numpy array): Input image, shape (h, w, c), range [0, 1], float32.
+ quality_range (tuple[float] | list[float]): JPG compression quality
+ range. 0 for lowest quality, 100 for best quality.
+ Default: (90, 100).
+
+ Returns:
+ (Numpy array): Returned image after JPG, shape (h, w, c), range[0, 1],
+ float32.
+ """
+ quality = np.random.uniform(quality_range[0], quality_range[1])
+ return add_jpg_compression(img, quality)
diff --git a/custom_nodes/ComfyUI-ReActor/r_basicsr/data/ffhq_dataset.py b/custom_nodes/ComfyUI-ReActor/r_basicsr/data/ffhq_dataset.py
new file mode 100644
index 0000000000000000000000000000000000000000..48e2c3a0ce93dd8f8e2660422462b17b2fbd340c
--- /dev/null
+++ b/custom_nodes/ComfyUI-ReActor/r_basicsr/data/ffhq_dataset.py
@@ -0,0 +1,80 @@
+import random
+import time
+from os import path as osp
+from torch.utils import data as data
+from torchvision.transforms.functional import normalize
+
+from r_basicsr.data.transforms import augment
+from r_basicsr.utils import FileClient, get_root_logger, imfrombytes, img2tensor
+from r_basicsr.utils.registry import DATASET_REGISTRY
+
+
+@DATASET_REGISTRY.register()
+class FFHQDataset(data.Dataset):
+ """FFHQ dataset for StyleGAN.
+
+ Args:
+ opt (dict): Config for train datasets. It contains the following keys:
+ dataroot_gt (str): Data root path for gt.
+ io_backend (dict): IO backend type and other kwarg.
+ mean (list | tuple): Image mean.
+ std (list | tuple): Image std.
+ use_hflip (bool): Whether to horizontally flip.
+
+ """
+
+ def __init__(self, opt):
+ super(FFHQDataset, self).__init__()
+ self.opt = opt
+ # file client (io backend)
+ self.file_client = None
+ self.io_backend_opt = opt['io_backend']
+
+ self.gt_folder = opt['dataroot_gt']
+ self.mean = opt['mean']
+ self.std = opt['std']
+
+ if self.io_backend_opt['type'] == 'lmdb':
+ self.io_backend_opt['db_paths'] = self.gt_folder
+ if not self.gt_folder.endswith('.lmdb'):
+ raise ValueError("'dataroot_gt' should end with '.lmdb', but received {self.gt_folder}")
+ with open(osp.join(self.gt_folder, 'meta_info.txt')) as fin:
+ self.paths = [line.split('.')[0] for line in fin]
+ else:
+ # FFHQ has 70000 images in total
+ self.paths = [osp.join(self.gt_folder, f'{v:08d}.png') for v in range(70000)]
+
+ def __getitem__(self, index):
+ if self.file_client is None:
+ self.file_client = FileClient(self.io_backend_opt.pop('type'), **self.io_backend_opt)
+
+ # load gt image
+ gt_path = self.paths[index]
+ # avoid errors caused by high latency in reading files
+ retry = 3
+ while retry > 0:
+ try:
+ img_bytes = self.file_client.get(gt_path)
+ except Exception as e:
+ logger = get_root_logger()
+ logger.warning(f'File client error: {e}, remaining retry times: {retry - 1}')
+ # change another file to read
+ index = random.randint(0, self.__len__())
+ gt_path = self.paths[index]
+ time.sleep(1) # sleep 1s for occasional server congestion
+ else:
+ break
+ finally:
+ retry -= 1
+ img_gt = imfrombytes(img_bytes, float32=True)
+
+ # random horizontal flip
+ img_gt = augment(img_gt, hflip=self.opt['use_hflip'], rotation=False)
+ # BGR to RGB, HWC to CHW, numpy to tensor
+ img_gt = img2tensor(img_gt, bgr2rgb=True, float32=True)
+ # normalize
+ normalize(img_gt, self.mean, self.std, inplace=True)
+ return {'gt': img_gt, 'gt_path': gt_path}
+
+ def __len__(self):
+ return len(self.paths)
diff --git a/custom_nodes/ComfyUI-ReActor/r_basicsr/data/paired_image_dataset.py b/custom_nodes/ComfyUI-ReActor/r_basicsr/data/paired_image_dataset.py
new file mode 100644
index 0000000000000000000000000000000000000000..480c7d2b2a41c728a40507ea88b14cf83dac6e75
--- /dev/null
+++ b/custom_nodes/ComfyUI-ReActor/r_basicsr/data/paired_image_dataset.py
@@ -0,0 +1,108 @@
+from torch.utils import data as data
+from torchvision.transforms.functional import normalize
+
+from r_basicsr.data.data_util import paired_paths_from_folder, paired_paths_from_lmdb, paired_paths_from_meta_info_file
+from r_basicsr.data.transforms import augment, paired_random_crop
+from r_basicsr.utils import FileClient, bgr2ycbcr, imfrombytes, img2tensor
+from r_basicsr.utils.registry import DATASET_REGISTRY
+
+
+@DATASET_REGISTRY.register()
+class PairedImageDataset(data.Dataset):
+ """Paired image dataset for image restoration.
+
+ Read LQ (Low Quality, e.g. LR (Low Resolution), blurry, noisy, etc) and GT image pairs.
+
+ There are three modes:
+ 1. 'lmdb': Use lmdb files.
+ If opt['io_backend'] == lmdb.
+ 2. 'meta_info_file': Use meta information file to generate paths.
+ If opt['io_backend'] != lmdb and opt['meta_info_file'] is not None.
+ 3. 'folder': Scan folders to generate paths.
+ The rest.
+
+ Args:
+ opt (dict): Config for train datasets. It contains the following keys:
+ dataroot_gt (str): Data root path for gt.
+ dataroot_lq (str): Data root path for lq.
+ meta_info_file (str): Path for meta information file.
+ io_backend (dict): IO backend type and other kwarg.
+ filename_tmpl (str): Template for each filename. Note that the template excludes the file extension.
+ Default: '{}'.
+ gt_size (int): Cropped patched size for gt patches.
+ use_hflip (bool): Use horizontal flips.
+ use_rot (bool): Use rotation (use vertical flip and transposing h and w for implementation).
+
+ scale (bool): Scale, which will be added automatically.
+ phase (str): 'train' or 'val'.
+ """
+
+ def __init__(self, opt):
+ super(PairedImageDataset, self).__init__()
+ self.opt = opt
+ # file client (io backend)
+ self.file_client = None
+ self.io_backend_opt = opt['io_backend']
+ self.mean = opt['mean'] if 'mean' in opt else None
+ self.std = opt['std'] if 'std' in opt else None
+
+ self.gt_folder, self.lq_folder = opt['dataroot_gt'], opt['dataroot_lq']
+ if 'filename_tmpl' in opt:
+ self.filename_tmpl = opt['filename_tmpl']
+ else:
+ self.filename_tmpl = '{}'
+
+ if self.io_backend_opt['type'] == 'lmdb':
+ self.io_backend_opt['db_paths'] = [self.lq_folder, self.gt_folder]
+ self.io_backend_opt['client_keys'] = ['lq', 'gt']
+ self.paths = paired_paths_from_lmdb([self.lq_folder, self.gt_folder], ['lq', 'gt'])
+ elif 'meta_info_file' in self.opt and self.opt['meta_info_file'] is not None:
+ self.paths = paired_paths_from_meta_info_file([self.lq_folder, self.gt_folder], ['lq', 'gt'],
+ self.opt['meta_info_file'], self.filename_tmpl)
+ else:
+ self.paths = paired_paths_from_folder([self.lq_folder, self.gt_folder], ['lq', 'gt'], self.filename_tmpl)
+
+ def __getitem__(self, index):
+ if self.file_client is None:
+ self.file_client = FileClient(self.io_backend_opt.pop('type'), **self.io_backend_opt)
+
+ scale = self.opt['scale']
+
+ # Load gt and lq images. Dimension order: HWC; channel order: BGR;
+ # image range: [0, 1], float32.
+ gt_path = self.paths[index]['gt_path']
+ img_bytes = self.file_client.get(gt_path, 'gt')
+ img_gt = imfrombytes(img_bytes, float32=True)
+ lq_path = self.paths[index]['lq_path']
+ img_bytes = self.file_client.get(lq_path, 'lq')
+ img_lq = imfrombytes(img_bytes, float32=True)
+
+ # augmentation for training
+ if self.opt['phase'] == 'train':
+ gt_size = self.opt['gt_size']
+ # random crop
+ img_gt, img_lq = paired_random_crop(img_gt, img_lq, gt_size, scale, gt_path)
+ # flip, rotation
+ img_gt, img_lq = augment([img_gt, img_lq], self.opt['use_hflip'], self.opt['use_rot'])
+
+ # color space transform
+ if 'color' in self.opt and self.opt['color'] == 'y':
+ img_gt = bgr2ycbcr(img_gt, y_only=True)[..., None]
+ img_lq = bgr2ycbcr(img_lq, y_only=True)[..., None]
+
+ # crop the unmatched GT images during validation or testing, especially for SR benchmark datasets
+ # TODO: It is better to update the datasets, rather than force to crop
+ if self.opt['phase'] != 'train':
+ img_gt = img_gt[0:img_lq.shape[0] * scale, 0:img_lq.shape[1] * scale, :]
+
+ # BGR to RGB, HWC to CHW, numpy to tensor
+ img_gt, img_lq = img2tensor([img_gt, img_lq], bgr2rgb=True, float32=True)
+ # normalize
+ if self.mean is not None or self.std is not None:
+ normalize(img_lq, self.mean, self.std, inplace=True)
+ normalize(img_gt, self.mean, self.std, inplace=True)
+
+ return {'lq': img_lq, 'gt': img_gt, 'lq_path': lq_path, 'gt_path': gt_path}
+
+ def __len__(self):
+ return len(self.paths)
diff --git a/custom_nodes/ComfyUI-ReActor/r_basicsr/data/prefetch_dataloader.py b/custom_nodes/ComfyUI-ReActor/r_basicsr/data/prefetch_dataloader.py
new file mode 100644
index 0000000000000000000000000000000000000000..5088425050d4cc98114a9b93eb50ea60273f35a0
--- /dev/null
+++ b/custom_nodes/ComfyUI-ReActor/r_basicsr/data/prefetch_dataloader.py
@@ -0,0 +1,125 @@
+import queue as Queue
+import threading
+import torch
+from torch.utils.data import DataLoader
+
+
+class PrefetchGenerator(threading.Thread):
+ """A general prefetch generator.
+
+ Ref:
+ https://stackoverflow.com/questions/7323664/python-generator-pre-fetch
+
+ Args:
+ generator: Python generator.
+ num_prefetch_queue (int): Number of prefetch queue.
+ """
+
+ def __init__(self, generator, num_prefetch_queue):
+ threading.Thread.__init__(self)
+ self.queue = Queue.Queue(num_prefetch_queue)
+ self.generator = generator
+ self.daemon = True
+ self.start()
+
+ def run(self):
+ for item in self.generator:
+ self.queue.put(item)
+ self.queue.put(None)
+
+ def __next__(self):
+ next_item = self.queue.get()
+ if next_item is None:
+ raise StopIteration
+ return next_item
+
+ def __iter__(self):
+ return self
+
+
+class PrefetchDataLoader(DataLoader):
+ """Prefetch version of dataloader.
+
+ Ref:
+ https://github.com/IgorSusmelj/pytorch-styleguide/issues/5#
+
+ TODO:
+ Need to test on single gpu and ddp (multi-gpu). There is a known issue in
+ ddp.
+
+ Args:
+ num_prefetch_queue (int): Number of prefetch queue.
+ kwargs (dict): Other arguments for dataloader.
+ """
+
+ def __init__(self, num_prefetch_queue, **kwargs):
+ self.num_prefetch_queue = num_prefetch_queue
+ super(PrefetchDataLoader, self).__init__(**kwargs)
+
+ def __iter__(self):
+ return PrefetchGenerator(super().__iter__(), self.num_prefetch_queue)
+
+
+class CPUPrefetcher():
+ """CPU prefetcher.
+
+ Args:
+ loader: Dataloader.
+ """
+
+ def __init__(self, loader):
+ self.ori_loader = loader
+ self.loader = iter(loader)
+
+ def next(self):
+ try:
+ return next(self.loader)
+ except StopIteration:
+ return None
+
+ def reset(self):
+ self.loader = iter(self.ori_loader)
+
+
+class CUDAPrefetcher():
+ """CUDA prefetcher.
+
+ Ref:
+ https://github.com/NVIDIA/apex/issues/304#
+
+ It may consums more GPU memory.
+
+ Args:
+ loader: Dataloader.
+ opt (dict): Options.
+ """
+
+ def __init__(self, loader, opt):
+ self.ori_loader = loader
+ self.loader = iter(loader)
+ self.opt = opt
+ self.stream = torch.cuda.Stream()
+ self.device = torch.device('cuda' if opt['num_gpu'] != 0 else 'cpu')
+ self.preload()
+
+ def preload(self):
+ try:
+ self.batch = next(self.loader) # self.batch is a dict
+ except StopIteration:
+ self.batch = None
+ return None
+ # put tensors to gpu
+ with torch.cuda.stream(self.stream):
+ for k, v in self.batch.items():
+ if torch.is_tensor(v):
+ self.batch[k] = self.batch[k].to(device=self.device, non_blocking=True)
+
+ def next(self):
+ torch.cuda.current_stream().wait_stream(self.stream)
+ batch = self.batch
+ self.preload()
+ return batch
+
+ def reset(self):
+ self.loader = iter(self.ori_loader)
+ self.preload()
diff --git a/custom_nodes/ComfyUI-ReActor/r_basicsr/data/realesrgan_dataset.py b/custom_nodes/ComfyUI-ReActor/r_basicsr/data/realesrgan_dataset.py
new file mode 100644
index 0000000000000000000000000000000000000000..d8ab7ba84b08f624cfc0e294c55066d70283f169
--- /dev/null
+++ b/custom_nodes/ComfyUI-ReActor/r_basicsr/data/realesrgan_dataset.py
@@ -0,0 +1,193 @@
+import cv2
+import math
+import numpy as np
+import os
+import os.path as osp
+import random
+import time
+import torch
+from torch.utils import data as data
+
+from r_basicsr.data.degradations import circular_lowpass_kernel, random_mixed_kernels
+from r_basicsr.data.transforms import augment
+from r_basicsr.utils import FileClient, get_root_logger, imfrombytes, img2tensor
+from r_basicsr.utils.registry import DATASET_REGISTRY
+
+
+@DATASET_REGISTRY.register(suffix='basicsr')
+class RealESRGANDataset(data.Dataset):
+ """Dataset used for Real-ESRGAN model:
+ Real-ESRGAN: Training Real-World Blind Super-Resolution with Pure Synthetic Data.
+
+ It loads gt (Ground-Truth) images, and augments them.
+ It also generates blur kernels and sinc kernels for generating low-quality images.
+ Note that the low-quality images are processed in tensors on GPUS for faster processing.
+
+ Args:
+ opt (dict): Config for train datasets. It contains the following keys:
+ dataroot_gt (str): Data root path for gt.
+ meta_info (str): Path for meta information file.
+ io_backend (dict): IO backend type and other kwarg.
+ use_hflip (bool): Use horizontal flips.
+ use_rot (bool): Use rotation (use vertical flip and transposing h and w for implementation).
+ Please see more options in the codes.
+ """
+
+ def __init__(self, opt):
+ super(RealESRGANDataset, self).__init__()
+ self.opt = opt
+ self.file_client = None
+ self.io_backend_opt = opt['io_backend']
+ self.gt_folder = opt['dataroot_gt']
+
+ # file client (lmdb io backend)
+ if self.io_backend_opt['type'] == 'lmdb':
+ self.io_backend_opt['db_paths'] = [self.gt_folder]
+ self.io_backend_opt['client_keys'] = ['gt']
+ if not self.gt_folder.endswith('.lmdb'):
+ raise ValueError(f"'dataroot_gt' should end with '.lmdb', but received {self.gt_folder}")
+ with open(osp.join(self.gt_folder, 'meta_info.txt')) as fin:
+ self.paths = [line.split('.')[0] for line in fin]
+ else:
+ # disk backend with meta_info
+ # Each line in the meta_info describes the relative path to an image
+ with open(self.opt['meta_info']) as fin:
+ paths = [line.strip().split(' ')[0] for line in fin]
+ self.paths = [os.path.join(self.gt_folder, v) for v in paths]
+
+ # blur settings for the first degradation
+ self.blur_kernel_size = opt['blur_kernel_size']
+ self.kernel_list = opt['kernel_list']
+ self.kernel_prob = opt['kernel_prob'] # a list for each kernel probability
+ self.blur_sigma = opt['blur_sigma']
+ self.betag_range = opt['betag_range'] # betag used in generalized Gaussian blur kernels
+ self.betap_range = opt['betap_range'] # betap used in plateau blur kernels
+ self.sinc_prob = opt['sinc_prob'] # the probability for sinc filters
+
+ # blur settings for the second degradation
+ self.blur_kernel_size2 = opt['blur_kernel_size2']
+ self.kernel_list2 = opt['kernel_list2']
+ self.kernel_prob2 = opt['kernel_prob2']
+ self.blur_sigma2 = opt['blur_sigma2']
+ self.betag_range2 = opt['betag_range2']
+ self.betap_range2 = opt['betap_range2']
+ self.sinc_prob2 = opt['sinc_prob2']
+
+ # a final sinc filter
+ self.final_sinc_prob = opt['final_sinc_prob']
+
+ self.kernel_range = [2 * v + 1 for v in range(3, 11)] # kernel size ranges from 7 to 21
+ # TODO: kernel range is now hard-coded, should be in the configure file
+ self.pulse_tensor = torch.zeros(21, 21).float() # convolving with pulse tensor brings no blurry effect
+ self.pulse_tensor[10, 10] = 1
+
+ def __getitem__(self, index):
+ if self.file_client is None:
+ self.file_client = FileClient(self.io_backend_opt.pop('type'), **self.io_backend_opt)
+
+ # -------------------------------- Load gt images -------------------------------- #
+ # Shape: (h, w, c); channel order: BGR; image range: [0, 1], float32.
+ gt_path = self.paths[index]
+ # avoid errors caused by high latency in reading files
+ retry = 3
+ while retry > 0:
+ try:
+ img_bytes = self.file_client.get(gt_path, 'gt')
+ except (IOError, OSError) as e:
+ logger = get_root_logger()
+ logger.warn(f'File client error: {e}, remaining retry times: {retry - 1}')
+ # change another file to read
+ index = random.randint(0, self.__len__())
+ gt_path = self.paths[index]
+ time.sleep(1) # sleep 1s for occasional server congestion
+ else:
+ break
+ finally:
+ retry -= 1
+ img_gt = imfrombytes(img_bytes, float32=True)
+
+ # -------------------- Do augmentation for training: flip, rotation -------------------- #
+ img_gt = augment(img_gt, self.opt['use_hflip'], self.opt['use_rot'])
+
+ # crop or pad to 400
+ # TODO: 400 is hard-coded. You may change it accordingly
+ h, w = img_gt.shape[0:2]
+ crop_pad_size = 400
+ # pad
+ if h < crop_pad_size or w < crop_pad_size:
+ pad_h = max(0, crop_pad_size - h)
+ pad_w = max(0, crop_pad_size - w)
+ img_gt = cv2.copyMakeBorder(img_gt, 0, pad_h, 0, pad_w, cv2.BORDER_REFLECT_101)
+ # crop
+ if img_gt.shape[0] > crop_pad_size or img_gt.shape[1] > crop_pad_size:
+ h, w = img_gt.shape[0:2]
+ # randomly choose top and left coordinates
+ top = random.randint(0, h - crop_pad_size)
+ left = random.randint(0, w - crop_pad_size)
+ img_gt = img_gt[top:top + crop_pad_size, left:left + crop_pad_size, ...]
+
+ # ------------------------ Generate kernels (used in the first degradation) ------------------------ #
+ kernel_size = random.choice(self.kernel_range)
+ if np.random.uniform() < self.opt['sinc_prob']:
+ # this sinc filter setting is for kernels ranging from [7, 21]
+ if kernel_size < 13:
+ omega_c = np.random.uniform(np.pi / 3, np.pi)
+ else:
+ omega_c = np.random.uniform(np.pi / 5, np.pi)
+ kernel = circular_lowpass_kernel(omega_c, kernel_size, pad_to=False)
+ else:
+ kernel = random_mixed_kernels(
+ self.kernel_list,
+ self.kernel_prob,
+ kernel_size,
+ self.blur_sigma,
+ self.blur_sigma, [-math.pi, math.pi],
+ self.betag_range,
+ self.betap_range,
+ noise_range=None)
+ # pad kernel
+ pad_size = (21 - kernel_size) // 2
+ kernel = np.pad(kernel, ((pad_size, pad_size), (pad_size, pad_size)))
+
+ # ------------------------ Generate kernels (used in the second degradation) ------------------------ #
+ kernel_size = random.choice(self.kernel_range)
+ if np.random.uniform() < self.opt['sinc_prob2']:
+ if kernel_size < 13:
+ omega_c = np.random.uniform(np.pi / 3, np.pi)
+ else:
+ omega_c = np.random.uniform(np.pi / 5, np.pi)
+ kernel2 = circular_lowpass_kernel(omega_c, kernel_size, pad_to=False)
+ else:
+ kernel2 = random_mixed_kernels(
+ self.kernel_list2,
+ self.kernel_prob2,
+ kernel_size,
+ self.blur_sigma2,
+ self.blur_sigma2, [-math.pi, math.pi],
+ self.betag_range2,
+ self.betap_range2,
+ noise_range=None)
+
+ # pad kernel
+ pad_size = (21 - kernel_size) // 2
+ kernel2 = np.pad(kernel2, ((pad_size, pad_size), (pad_size, pad_size)))
+
+ # ------------------------------------- the final sinc kernel ------------------------------------- #
+ if np.random.uniform() < self.opt['final_sinc_prob']:
+ kernel_size = random.choice(self.kernel_range)
+ omega_c = np.random.uniform(np.pi / 3, np.pi)
+ sinc_kernel = circular_lowpass_kernel(omega_c, kernel_size, pad_to=21)
+ sinc_kernel = torch.FloatTensor(sinc_kernel)
+ else:
+ sinc_kernel = self.pulse_tensor
+
+ # BGR to RGB, HWC to CHW, numpy to tensor
+ img_gt = img2tensor([img_gt], bgr2rgb=True, float32=True)[0]
+ kernel = torch.FloatTensor(kernel)
+ kernel2 = torch.FloatTensor(kernel2)
+
+ return_d = {'gt': img_gt, 'kernel1': kernel, 'kernel2': kernel2, 'sinc_kernel': sinc_kernel, 'gt_path': gt_path}
+ return return_d
+
+ def __len__(self):
+ return len(self.paths)
diff --git a/custom_nodes/ComfyUI-ReActor/r_basicsr/data/realesrgan_paired_dataset.py b/custom_nodes/ComfyUI-ReActor/r_basicsr/data/realesrgan_paired_dataset.py
new file mode 100644
index 0000000000000000000000000000000000000000..29bc126fc892310d8c3c13d38a077885189a54f9
--- /dev/null
+++ b/custom_nodes/ComfyUI-ReActor/r_basicsr/data/realesrgan_paired_dataset.py
@@ -0,0 +1,109 @@
+import os
+from torch.utils import data as data
+from torchvision.transforms.functional import normalize
+
+from r_basicsr.data.data_util import paired_paths_from_folder, paired_paths_from_lmdb
+from r_basicsr.data.transforms import augment, paired_random_crop
+from r_basicsr.utils import FileClient, imfrombytes, img2tensor
+from r_basicsr.utils.registry import DATASET_REGISTRY
+
+
+@DATASET_REGISTRY.register(suffix='basicsr')
+class RealESRGANPairedDataset(data.Dataset):
+ """Paired image dataset for image restoration.
+
+ Read LQ (Low Quality, e.g. LR (Low Resolution), blurry, noisy, etc) and GT image pairs.
+
+ There are three modes:
+ 1. 'lmdb': Use lmdb files.
+ If opt['io_backend'] == lmdb.
+ 2. 'meta_info': Use meta information file to generate paths.
+ If opt['io_backend'] != lmdb and opt['meta_info'] is not None.
+ 3. 'folder': Scan folders to generate paths.
+ The rest.
+
+ Args:
+ opt (dict): Config for train datasets. It contains the following keys:
+ dataroot_gt (str): Data root path for gt.
+ dataroot_lq (str): Data root path for lq.
+ meta_info (str): Path for meta information file.
+ io_backend (dict): IO backend type and other kwarg.
+ filename_tmpl (str): Template for each filename. Note that the template excludes the file extension.
+ Default: '{}'.
+ gt_size (int): Cropped patched size for gt patches.
+ use_hflip (bool): Use horizontal flips.
+ use_rot (bool): Use rotation (use vertical flip and transposing h
+ and w for implementation).
+
+ scale (bool): Scale, which will be added automatically.
+ phase (str): 'train' or 'val'.
+ """
+
+ def __init__(self, opt):
+ super(RealESRGANPairedDataset, self).__init__()
+ self.opt = opt
+ self.file_client = None
+ self.io_backend_opt = opt['io_backend']
+ # mean and std for normalizing the input images
+ self.mean = opt['mean'] if 'mean' in opt else None
+ self.std = opt['std'] if 'std' in opt else None
+
+ self.gt_folder, self.lq_folder = opt['dataroot_gt'], opt['dataroot_lq']
+ self.filename_tmpl = opt['filename_tmpl'] if 'filename_tmpl' in opt else '{}'
+
+ # file client (lmdb io backend)
+ if self.io_backend_opt['type'] == 'lmdb':
+ self.io_backend_opt['db_paths'] = [self.lq_folder, self.gt_folder]
+ self.io_backend_opt['client_keys'] = ['lq', 'gt']
+ self.paths = paired_paths_from_lmdb([self.lq_folder, self.gt_folder], ['lq', 'gt'])
+ elif 'meta_info' in self.opt and self.opt['meta_info'] is not None:
+ # disk backend with meta_info
+ # Each line in the meta_info describes the relative path to an image
+ with open(self.opt['meta_info']) as fin:
+ paths = [line.strip() for line in fin]
+ self.paths = []
+ for path in paths:
+ gt_path, lq_path = path.split(', ')
+ gt_path = os.path.join(self.gt_folder, gt_path)
+ lq_path = os.path.join(self.lq_folder, lq_path)
+ self.paths.append(dict([('gt_path', gt_path), ('lq_path', lq_path)]))
+ else:
+ # disk backend
+ # it will scan the whole folder to get meta info
+ # it will be time-consuming for folders with too many files. It is recommended using an extra meta txt file
+ self.paths = paired_paths_from_folder([self.lq_folder, self.gt_folder], ['lq', 'gt'], self.filename_tmpl)
+
+ def __getitem__(self, index):
+ if self.file_client is None:
+ self.file_client = FileClient(self.io_backend_opt.pop('type'), **self.io_backend_opt)
+
+ scale = self.opt['scale']
+
+ # Load gt and lq images. Dimension order: HWC; channel order: BGR;
+ # image range: [0, 1], float32.
+ gt_path = self.paths[index]['gt_path']
+ img_bytes = self.file_client.get(gt_path, 'gt')
+ img_gt = imfrombytes(img_bytes, float32=True)
+ lq_path = self.paths[index]['lq_path']
+ img_bytes = self.file_client.get(lq_path, 'lq')
+ img_lq = imfrombytes(img_bytes, float32=True)
+
+ # augmentation for training
+ if self.opt['phase'] == 'train':
+ gt_size = self.opt['gt_size']
+ # random crop
+ img_gt, img_lq = paired_random_crop(img_gt, img_lq, gt_size, scale, gt_path)
+ # flip, rotation
+ img_gt, img_lq = augment([img_gt, img_lq], self.opt['use_hflip'], self.opt['use_rot'])
+
+ # BGR to RGB, HWC to CHW, numpy to tensor
+ img_gt, img_lq = img2tensor([img_gt, img_lq], bgr2rgb=True, float32=True)
+ # normalize
+ if self.mean is not None or self.std is not None:
+ normalize(img_lq, self.mean, self.std, inplace=True)
+ normalize(img_gt, self.mean, self.std, inplace=True)
+
+ return {'lq': img_lq, 'gt': img_gt, 'lq_path': lq_path, 'gt_path': gt_path}
+
+ def __len__(self):
+ return len(self.paths)
diff --git a/custom_nodes/ComfyUI-ReActor/r_basicsr/data/reds_dataset.py b/custom_nodes/ComfyUI-ReActor/r_basicsr/data/reds_dataset.py
new file mode 100644
index 0000000000000000000000000000000000000000..7be362e00b83d60350a4c98a2d56a14aedf24ac5
--- /dev/null
+++ b/custom_nodes/ComfyUI-ReActor/r_basicsr/data/reds_dataset.py
@@ -0,0 +1,360 @@
+import numpy as np
+import random
+import torch
+from pathlib import Path
+from torch.utils import data as data
+
+from r_basicsr.data.transforms import augment, paired_random_crop
+from r_basicsr.utils import FileClient, get_root_logger, imfrombytes, img2tensor
+from r_basicsr.utils.flow_util import dequantize_flow
+from r_basicsr.utils.registry import DATASET_REGISTRY
+
+
+@DATASET_REGISTRY.register()
+class REDSDataset(data.Dataset):
+ """REDS dataset for training.
+
+ The keys are generated from a meta info txt file.
+ basicsr/data/meta_info/meta_info_REDS_GT.txt
+
+ Each line contains:
+ 1. subfolder (clip) name; 2. frame number; 3. image shape, separated by
+ a white space.
+ Examples:
+ 000 100 (720,1280,3)
+ 001 100 (720,1280,3)
+ ...
+
+ Key examples: "000/00000000"
+ GT (gt): Ground-Truth;
+ LQ (lq): Low-Quality, e.g., low-resolution/blurry/noisy/compressed frames.
+
+ Args:
+ opt (dict): Config for train dataset. It contains the following keys:
+ dataroot_gt (str): Data root path for gt.
+ dataroot_lq (str): Data root path for lq.
+ dataroot_flow (str, optional): Data root path for flow.
+ meta_info_file (str): Path for meta information file.
+ val_partition (str): Validation partition types. 'REDS4' or
+ 'official'.
+ io_backend (dict): IO backend type and other kwarg.
+
+ num_frame (int): Window size for input frames.
+ gt_size (int): Cropped patched size for gt patches.
+ interval_list (list): Interval list for temporal augmentation.
+ random_reverse (bool): Random reverse input frames.
+ use_hflip (bool): Use horizontal flips.
+ use_rot (bool): Use rotation (use vertical flip and transposing h
+ and w for implementation).
+
+ scale (bool): Scale, which will be added automatically.
+ """
+
+ def __init__(self, opt):
+ super(REDSDataset, self).__init__()
+ self.opt = opt
+ self.gt_root, self.lq_root = Path(opt['dataroot_gt']), Path(opt['dataroot_lq'])
+ self.flow_root = Path(opt['dataroot_flow']) if opt['dataroot_flow'] is not None else None
+ assert opt['num_frame'] % 2 == 1, (f'num_frame should be odd number, but got {opt["num_frame"]}')
+ self.num_frame = opt['num_frame']
+ self.num_half_frames = opt['num_frame'] // 2
+
+ self.keys = []
+ with open(opt['meta_info_file'], 'r') as fin:
+ for line in fin:
+ folder, frame_num, _ = line.split(' ')
+ self.keys.extend([f'{folder}/{i:08d}' for i in range(int(frame_num))])
+
+ # remove the video clips used in validation
+ if opt['val_partition'] == 'REDS4':
+ val_partition = ['000', '011', '015', '020']
+ elif opt['val_partition'] == 'official':
+ val_partition = [f'{v:03d}' for v in range(240, 270)]
+ else:
+ raise ValueError(f'Wrong validation partition {opt["val_partition"]}.'
+ f"Supported ones are ['official', 'REDS4'].")
+ self.keys = [v for v in self.keys if v.split('/')[0] not in val_partition]
+
+ # file client (io backend)
+ self.file_client = None
+ self.io_backend_opt = opt['io_backend']
+ self.is_lmdb = False
+ if self.io_backend_opt['type'] == 'lmdb':
+ self.is_lmdb = True
+ if self.flow_root is not None:
+ self.io_backend_opt['db_paths'] = [self.lq_root, self.gt_root, self.flow_root]
+ self.io_backend_opt['client_keys'] = ['lq', 'gt', 'flow']
+ else:
+ self.io_backend_opt['db_paths'] = [self.lq_root, self.gt_root]
+ self.io_backend_opt['client_keys'] = ['lq', 'gt']
+
+ # temporal augmentation configs
+ self.interval_list = opt['interval_list']
+ self.random_reverse = opt['random_reverse']
+ interval_str = ','.join(str(x) for x in opt['interval_list'])
+ logger = get_root_logger()
+ logger.info(f'Temporal augmentation interval list: [{interval_str}]; '
+ f'random reverse is {self.random_reverse}.')
+
+ def __getitem__(self, index):
+ if self.file_client is None:
+ self.file_client = FileClient(self.io_backend_opt.pop('type'), **self.io_backend_opt)
+
+ scale = self.opt['scale']
+ gt_size = self.opt['gt_size']
+ key = self.keys[index]
+ clip_name, frame_name = key.split('/') # key example: 000/00000000
+ center_frame_idx = int(frame_name)
+
+ # determine the neighboring frames
+ interval = random.choice(self.interval_list)
+
+ # ensure not exceeding the borders
+ start_frame_idx = center_frame_idx - self.num_half_frames * interval
+ end_frame_idx = center_frame_idx + self.num_half_frames * interval
+ # each clip has 100 frames starting from 0 to 99
+ while (start_frame_idx < 0) or (end_frame_idx > 99):
+ center_frame_idx = random.randint(0, 99)
+ start_frame_idx = (center_frame_idx - self.num_half_frames * interval)
+ end_frame_idx = center_frame_idx + self.num_half_frames * interval
+ frame_name = f'{center_frame_idx:08d}'
+ neighbor_list = list(range(start_frame_idx, end_frame_idx + 1, interval))
+ # random reverse
+ if self.random_reverse and random.random() < 0.5:
+ neighbor_list.reverse()
+
+ assert len(neighbor_list) == self.num_frame, (f'Wrong length of neighbor list: {len(neighbor_list)}')
+
+ # get the GT frame (as the center frame)
+ if self.is_lmdb:
+ img_gt_path = f'{clip_name}/{frame_name}'
+ else:
+ img_gt_path = self.gt_root / clip_name / f'{frame_name}.png'
+ img_bytes = self.file_client.get(img_gt_path, 'gt')
+ img_gt = imfrombytes(img_bytes, float32=True)
+
+ # get the neighboring LQ frames
+ img_lqs = []
+ for neighbor in neighbor_list:
+ if self.is_lmdb:
+ img_lq_path = f'{clip_name}/{neighbor:08d}'
+ else:
+ img_lq_path = self.lq_root / clip_name / f'{neighbor:08d}.png'
+ img_bytes = self.file_client.get(img_lq_path, 'lq')
+ img_lq = imfrombytes(img_bytes, float32=True)
+ img_lqs.append(img_lq)
+
+ # get flows
+ if self.flow_root is not None:
+ img_flows = []
+ # read previous flows
+ for i in range(self.num_half_frames, 0, -1):
+ if self.is_lmdb:
+ flow_path = f'{clip_name}/{frame_name}_p{i}'
+ else:
+ flow_path = (self.flow_root / clip_name / f'{frame_name}_p{i}.png')
+ img_bytes = self.file_client.get(flow_path, 'flow')
+ cat_flow = imfrombytes(img_bytes, flag='grayscale', float32=False) # uint8, [0, 255]
+ dx, dy = np.split(cat_flow, 2, axis=0)
+ flow = dequantize_flow(dx, dy, max_val=20, denorm=False) # we use max_val 20 here.
+ img_flows.append(flow)
+ # read next flows
+ for i in range(1, self.num_half_frames + 1):
+ if self.is_lmdb:
+ flow_path = f'{clip_name}/{frame_name}_n{i}'
+ else:
+ flow_path = (self.flow_root / clip_name / f'{frame_name}_n{i}.png')
+ img_bytes = self.file_client.get(flow_path, 'flow')
+ cat_flow = imfrombytes(img_bytes, flag='grayscale', float32=False) # uint8, [0, 255]
+ dx, dy = np.split(cat_flow, 2, axis=0)
+ flow = dequantize_flow(dx, dy, max_val=20, denorm=False) # we use max_val 20 here.
+ img_flows.append(flow)
+
+ # for random crop, here, img_flows and img_lqs have the same
+ # spatial size
+ img_lqs.extend(img_flows)
+
+ # randomly crop
+ img_gt, img_lqs = paired_random_crop(img_gt, img_lqs, gt_size, scale, img_gt_path)
+ if self.flow_root is not None:
+ img_lqs, img_flows = img_lqs[:self.num_frame], img_lqs[self.num_frame:]
+
+ # augmentation - flip, rotate
+ img_lqs.append(img_gt)
+ if self.flow_root is not None:
+ img_results, img_flows = augment(img_lqs, self.opt['use_hflip'], self.opt['use_rot'], img_flows)
+ else:
+ img_results = augment(img_lqs, self.opt['use_hflip'], self.opt['use_rot'])
+
+ img_results = img2tensor(img_results)
+ img_lqs = torch.stack(img_results[0:-1], dim=0)
+ img_gt = img_results[-1]
+
+ if self.flow_root is not None:
+ img_flows = img2tensor(img_flows)
+ # add the zero center flow
+ img_flows.insert(self.num_half_frames, torch.zeros_like(img_flows[0]))
+ img_flows = torch.stack(img_flows, dim=0)
+
+ # img_lqs: (t, c, h, w)
+ # img_flows: (t, 2, h, w)
+ # img_gt: (c, h, w)
+ # key: str
+ if self.flow_root is not None:
+ return {'lq': img_lqs, 'flow': img_flows, 'gt': img_gt, 'key': key}
+ else:
+ return {'lq': img_lqs, 'gt': img_gt, 'key': key}
+
+ def __len__(self):
+ return len(self.keys)
+
+
+@DATASET_REGISTRY.register()
+class REDSRecurrentDataset(data.Dataset):
+ """REDS dataset for training recurrent networks.
+
+ The keys are generated from a meta info txt file.
+ basicsr/data/meta_info/meta_info_REDS_GT.txt
+
+ Each line contains:
+ 1. subfolder (clip) name; 2. frame number; 3. image shape, separated by
+ a white space.
+ Examples:
+ 000 100 (720,1280,3)
+ 001 100 (720,1280,3)
+ ...
+
+ Key examples: "000/00000000"
+ GT (gt): Ground-Truth;
+ LQ (lq): Low-Quality, e.g., low-resolution/blurry/noisy/compressed frames.
+
+ Args:
+ opt (dict): Config for train dataset. It contains the following keys:
+ dataroot_gt (str): Data root path for gt.
+ dataroot_lq (str): Data root path for lq.
+ dataroot_flow (str, optional): Data root path for flow.
+ meta_info_file (str): Path for meta information file.
+ val_partition (str): Validation partition types. 'REDS4' or
+ 'official'.
+ io_backend (dict): IO backend type and other kwarg.
+
+ num_frame (int): Window size for input frames.
+ gt_size (int): Cropped patched size for gt patches.
+ interval_list (list): Interval list for temporal augmentation.
+ random_reverse (bool): Random reverse input frames.
+ use_hflip (bool): Use horizontal flips.
+ use_rot (bool): Use rotation (use vertical flip and transposing h
+ and w for implementation).
+
+ scale (bool): Scale, which will be added automatically.
+ """
+
+ def __init__(self, opt):
+ super(REDSRecurrentDataset, self).__init__()
+ self.opt = opt
+ self.gt_root, self.lq_root = Path(opt['dataroot_gt']), Path(opt['dataroot_lq'])
+ self.num_frame = opt['num_frame']
+
+ self.keys = []
+ with open(opt['meta_info_file'], 'r') as fin:
+ for line in fin:
+ folder, frame_num, _ = line.split(' ')
+ self.keys.extend([f'{folder}/{i:08d}' for i in range(int(frame_num))])
+
+ # remove the video clips used in validation
+ if opt['val_partition'] == 'REDS4':
+ val_partition = ['000', '011', '015', '020']
+ elif opt['val_partition'] == 'official':
+ val_partition = [f'{v:03d}' for v in range(240, 270)]
+ else:
+ raise ValueError(f'Wrong validation partition {opt["val_partition"]}.'
+ f"Supported ones are ['official', 'REDS4'].")
+ if opt['test_mode']:
+ self.keys = [v for v in self.keys if v.split('/')[0] in val_partition]
+ else:
+ self.keys = [v for v in self.keys if v.split('/')[0] not in val_partition]
+
+ # file client (io backend)
+ self.file_client = None
+ self.io_backend_opt = opt['io_backend']
+ self.is_lmdb = False
+ if self.io_backend_opt['type'] == 'lmdb':
+ self.is_lmdb = True
+ if hasattr(self, 'flow_root') and self.flow_root is not None:
+ self.io_backend_opt['db_paths'] = [self.lq_root, self.gt_root, self.flow_root]
+ self.io_backend_opt['client_keys'] = ['lq', 'gt', 'flow']
+ else:
+ self.io_backend_opt['db_paths'] = [self.lq_root, self.gt_root]
+ self.io_backend_opt['client_keys'] = ['lq', 'gt']
+
+ # temporal augmentation configs
+ self.interval_list = opt.get('interval_list', [1])
+ self.random_reverse = opt.get('random_reverse', False)
+ interval_str = ','.join(str(x) for x in self.interval_list)
+ logger = get_root_logger()
+ logger.info(f'Temporal augmentation interval list: [{interval_str}]; '
+ f'random reverse is {self.random_reverse}.')
+
+ def __getitem__(self, index):
+ if self.file_client is None:
+ self.file_client = FileClient(self.io_backend_opt.pop('type'), **self.io_backend_opt)
+
+ scale = self.opt['scale']
+ gt_size = self.opt['gt_size']
+ key = self.keys[index]
+ clip_name, frame_name = key.split('/') # key example: 000/00000000
+
+ # determine the neighboring frames
+ interval = random.choice(self.interval_list)
+
+ # ensure not exceeding the borders
+ start_frame_idx = int(frame_name)
+ if start_frame_idx > 100 - self.num_frame * interval:
+ start_frame_idx = random.randint(0, 100 - self.num_frame * interval)
+ end_frame_idx = start_frame_idx + self.num_frame * interval
+
+ neighbor_list = list(range(start_frame_idx, end_frame_idx, interval))
+
+ # random reverse
+ if self.random_reverse and random.random() < 0.5:
+ neighbor_list.reverse()
+
+ # get the neighboring LQ and GT frames
+ img_lqs = []
+ img_gts = []
+ for neighbor in neighbor_list:
+ if self.is_lmdb:
+ img_lq_path = f'{clip_name}/{neighbor:08d}'
+ img_gt_path = f'{clip_name}/{neighbor:08d}'
+ else:
+ img_lq_path = self.lq_root / clip_name / f'{neighbor:08d}.png'
+ img_gt_path = self.gt_root / clip_name / f'{neighbor:08d}.png'
+
+ # get LQ
+ img_bytes = self.file_client.get(img_lq_path, 'lq')
+ img_lq = imfrombytes(img_bytes, float32=True)
+ img_lqs.append(img_lq)
+
+ # get GT
+ img_bytes = self.file_client.get(img_gt_path, 'gt')
+ img_gt = imfrombytes(img_bytes, float32=True)
+ img_gts.append(img_gt)
+
+ # randomly crop
+ img_gts, img_lqs = paired_random_crop(img_gts, img_lqs, gt_size, scale, img_gt_path)
+
+ # augmentation - flip, rotate
+ img_lqs.extend(img_gts)
+ img_results = augment(img_lqs, self.opt['use_hflip'], self.opt['use_rot'])
+
+ img_results = img2tensor(img_results)
+ img_gts = torch.stack(img_results[len(img_lqs) // 2:], dim=0)
+ img_lqs = torch.stack(img_results[:len(img_lqs) // 2], dim=0)
+
+ # img_lqs: (t, c, h, w)
+ # img_gts: (t, c, h, w)
+ # key: str
+ return {'lq': img_lqs, 'gt': img_gts, 'key': key}
+
+ def __len__(self):
+ return len(self.keys)
diff --git a/custom_nodes/ComfyUI-ReActor/r_basicsr/data/single_image_dataset.py b/custom_nodes/ComfyUI-ReActor/r_basicsr/data/single_image_dataset.py
new file mode 100644
index 0000000000000000000000000000000000000000..02c501a85f04a43372b0e16f5d7fef52fd63427d
--- /dev/null
+++ b/custom_nodes/ComfyUI-ReActor/r_basicsr/data/single_image_dataset.py
@@ -0,0 +1,68 @@
+from os import path as osp
+from torch.utils import data as data
+from torchvision.transforms.functional import normalize
+
+from r_basicsr.data.data_util import paths_from_lmdb
+from r_basicsr.utils import FileClient, imfrombytes, img2tensor, rgb2ycbcr, scandir
+from r_basicsr.utils.registry import DATASET_REGISTRY
+
+
+@DATASET_REGISTRY.register()
+class SingleImageDataset(data.Dataset):
+ """Read only lq images in the test phase.
+
+ Read LQ (Low Quality, e.g. LR (Low Resolution), blurry, noisy, etc).
+
+ There are two modes:
+ 1. 'meta_info_file': Use meta information file to generate paths.
+ 2. 'folder': Scan folders to generate paths.
+
+ Args:
+ opt (dict): Config for train datasets. It contains the following keys:
+ dataroot_lq (str): Data root path for lq.
+ meta_info_file (str): Path for meta information file.
+ io_backend (dict): IO backend type and other kwarg.
+ """
+
+ def __init__(self, opt):
+ super(SingleImageDataset, self).__init__()
+ self.opt = opt
+ # file client (io backend)
+ self.file_client = None
+ self.io_backend_opt = opt['io_backend']
+ self.mean = opt['mean'] if 'mean' in opt else None
+ self.std = opt['std'] if 'std' in opt else None
+ self.lq_folder = opt['dataroot_lq']
+
+ if self.io_backend_opt['type'] == 'lmdb':
+ self.io_backend_opt['db_paths'] = [self.lq_folder]
+ self.io_backend_opt['client_keys'] = ['lq']
+ self.paths = paths_from_lmdb(self.lq_folder)
+ elif 'meta_info_file' in self.opt:
+ with open(self.opt['meta_info_file'], 'r') as fin:
+ self.paths = [osp.join(self.lq_folder, line.rstrip().split(' ')[0]) for line in fin]
+ else:
+ self.paths = sorted(list(scandir(self.lq_folder, full_path=True)))
+
+ def __getitem__(self, index):
+ if self.file_client is None:
+ self.file_client = FileClient(self.io_backend_opt.pop('type'), **self.io_backend_opt)
+
+ # load lq image
+ lq_path = self.paths[index]
+ img_bytes = self.file_client.get(lq_path, 'lq')
+ img_lq = imfrombytes(img_bytes, float32=True)
+
+ # color space transform
+ if 'color' in self.opt and self.opt['color'] == 'y':
+ img_lq = rgb2ycbcr(img_lq, y_only=True)[..., None]
+
+ # BGR to RGB, HWC to CHW, numpy to tensor
+ img_lq = img2tensor(img_lq, bgr2rgb=True, float32=True)
+ # normalize
+ if self.mean is not None or self.std is not None:
+ normalize(img_lq, self.mean, self.std, inplace=True)
+ return {'lq': img_lq, 'lq_path': lq_path}
+
+ def __len__(self):
+ return len(self.paths)
diff --git a/custom_nodes/ComfyUI-ReActor/r_basicsr/data/transforms.py b/custom_nodes/ComfyUI-ReActor/r_basicsr/data/transforms.py
new file mode 100644
index 0000000000000000000000000000000000000000..d9bbb5fb7daef5edfb425fafb4d67d471b3001e6
--- /dev/null
+++ b/custom_nodes/ComfyUI-ReActor/r_basicsr/data/transforms.py
@@ -0,0 +1,179 @@
+import cv2
+import random
+import torch
+
+
+def mod_crop(img, scale):
+ """Mod crop images, used during testing.
+
+ Args:
+ img (ndarray): Input image.
+ scale (int): Scale factor.
+
+ Returns:
+ ndarray: Result image.
+ """
+ img = img.copy()
+ if img.ndim in (2, 3):
+ h, w = img.shape[0], img.shape[1]
+ h_remainder, w_remainder = h % scale, w % scale
+ img = img[:h - h_remainder, :w - w_remainder, ...]
+ else:
+ raise ValueError(f'Wrong img ndim: {img.ndim}.')
+ return img
+
+
+def paired_random_crop(img_gts, img_lqs, gt_patch_size, scale, gt_path=None):
+ """Paired random crop. Support Numpy array and Tensor inputs.
+
+ It crops lists of lq and gt images with corresponding locations.
+
+ Args:
+ img_gts (list[ndarray] | ndarray | list[Tensor] | Tensor): GT images. Note that all images
+ should have the same shape. If the input is an ndarray, it will
+ be transformed to a list containing itself.
+ img_lqs (list[ndarray] | ndarray): LQ images. Note that all images
+ should have the same shape. If the input is an ndarray, it will
+ be transformed to a list containing itself.
+ gt_patch_size (int): GT patch size.
+ scale (int): Scale factor.
+ gt_path (str): Path to ground-truth. Default: None.
+
+ Returns:
+ list[ndarray] | ndarray: GT images and LQ images. If returned results
+ only have one element, just return ndarray.
+ """
+
+ if not isinstance(img_gts, list):
+ img_gts = [img_gts]
+ if not isinstance(img_lqs, list):
+ img_lqs = [img_lqs]
+
+ # determine input type: Numpy array or Tensor
+ input_type = 'Tensor' if torch.is_tensor(img_gts[0]) else 'Numpy'
+
+ if input_type == 'Tensor':
+ h_lq, w_lq = img_lqs[0].size()[-2:]
+ h_gt, w_gt = img_gts[0].size()[-2:]
+ else:
+ h_lq, w_lq = img_lqs[0].shape[0:2]
+ h_gt, w_gt = img_gts[0].shape[0:2]
+ lq_patch_size = gt_patch_size // scale
+
+ if h_gt != h_lq * scale or w_gt != w_lq * scale:
+ raise ValueError(f'Scale mismatches. GT ({h_gt}, {w_gt}) is not {scale}x ',
+ f'multiplication of LQ ({h_lq}, {w_lq}).')
+ if h_lq < lq_patch_size or w_lq < lq_patch_size:
+ raise ValueError(f'LQ ({h_lq}, {w_lq}) is smaller than patch size '
+ f'({lq_patch_size}, {lq_patch_size}). '
+ f'Please remove {gt_path}.')
+
+ # randomly choose top and left coordinates for lq patch
+ top = random.randint(0, h_lq - lq_patch_size)
+ left = random.randint(0, w_lq - lq_patch_size)
+
+ # crop lq patch
+ if input_type == 'Tensor':
+ img_lqs = [v[:, :, top:top + lq_patch_size, left:left + lq_patch_size] for v in img_lqs]
+ else:
+ img_lqs = [v[top:top + lq_patch_size, left:left + lq_patch_size, ...] for v in img_lqs]
+
+ # crop corresponding gt patch
+ top_gt, left_gt = int(top * scale), int(left * scale)
+ if input_type == 'Tensor':
+ img_gts = [v[:, :, top_gt:top_gt + gt_patch_size, left_gt:left_gt + gt_patch_size] for v in img_gts]
+ else:
+ img_gts = [v[top_gt:top_gt + gt_patch_size, left_gt:left_gt + gt_patch_size, ...] for v in img_gts]
+ if len(img_gts) == 1:
+ img_gts = img_gts[0]
+ if len(img_lqs) == 1:
+ img_lqs = img_lqs[0]
+ return img_gts, img_lqs
+
+
+def augment(imgs, hflip=True, rotation=True, flows=None, return_status=False):
+ """Augment: horizontal flips OR rotate (0, 90, 180, 270 degrees).
+
+ We use vertical flip and transpose for rotation implementation.
+ All the images in the list use the same augmentation.
+
+ Args:
+ imgs (list[ndarray] | ndarray): Images to be augmented. If the input
+ is an ndarray, it will be transformed to a list.
+ hflip (bool): Horizontal flip. Default: True.
+ rotation (bool): Ratotation. Default: True.
+ flows (list[ndarray]: Flows to be augmented. If the input is an
+ ndarray, it will be transformed to a list.
+ Dimension is (h, w, 2). Default: None.
+ return_status (bool): Return the status of flip and rotation.
+ Default: False.
+
+ Returns:
+ list[ndarray] | ndarray: Augmented images and flows. If returned
+ results only have one element, just return ndarray.
+
+ """
+ hflip = hflip and random.random() < 0.5
+ vflip = rotation and random.random() < 0.5
+ rot90 = rotation and random.random() < 0.5
+
+ def _augment(img):
+ if hflip: # horizontal
+ cv2.flip(img, 1, img)
+ if vflip: # vertical
+ cv2.flip(img, 0, img)
+ if rot90:
+ img = img.transpose(1, 0, 2)
+ return img
+
+ def _augment_flow(flow):
+ if hflip: # horizontal
+ cv2.flip(flow, 1, flow)
+ flow[:, :, 0] *= -1
+ if vflip: # vertical
+ cv2.flip(flow, 0, flow)
+ flow[:, :, 1] *= -1
+ if rot90:
+ flow = flow.transpose(1, 0, 2)
+ flow = flow[:, :, [1, 0]]
+ return flow
+
+ if not isinstance(imgs, list):
+ imgs = [imgs]
+ imgs = [_augment(img) for img in imgs]
+ if len(imgs) == 1:
+ imgs = imgs[0]
+
+ if flows is not None:
+ if not isinstance(flows, list):
+ flows = [flows]
+ flows = [_augment_flow(flow) for flow in flows]
+ if len(flows) == 1:
+ flows = flows[0]
+ return imgs, flows
+ else:
+ if return_status:
+ return imgs, (hflip, vflip, rot90)
+ else:
+ return imgs
+
+
+def img_rotate(img, angle, center=None, scale=1.0):
+ """Rotate image.
+
+ Args:
+ img (ndarray): Image to be rotated.
+ angle (float): Rotation angle in degrees. Positive values mean
+ counter-clockwise rotation.
+ center (tuple[int]): Rotation center. If the center is None,
+ initialize it as the center of the image. Default: None.
+ scale (float): Isotropic scale factor. Default: 1.0.
+ """
+ (h, w) = img.shape[:2]
+
+ if center is None:
+ center = (w // 2, h // 2)
+
+ matrix = cv2.getRotationMatrix2D(center, angle, scale)
+ rotated_img = cv2.warpAffine(img, matrix, (w, h))
+ return rotated_img
diff --git a/custom_nodes/ComfyUI-ReActor/r_basicsr/data/video_test_dataset.py b/custom_nodes/ComfyUI-ReActor/r_basicsr/data/video_test_dataset.py
new file mode 100644
index 0000000000000000000000000000000000000000..b730a677ca540fa429f7ea9c99c6113a384655d2
--- /dev/null
+++ b/custom_nodes/ComfyUI-ReActor/r_basicsr/data/video_test_dataset.py
@@ -0,0 +1,287 @@
+import glob
+import torch
+from os import path as osp
+from torch.utils import data as data
+
+from r_basicsr.data.data_util import duf_downsample, generate_frame_indices, read_img_seq
+from r_basicsr.utils import get_root_logger, scandir
+from r_basicsr.utils.registry import DATASET_REGISTRY
+
+
+@DATASET_REGISTRY.register()
+class VideoTestDataset(data.Dataset):
+ """Video test dataset.
+
+ Supported datasets: Vid4, REDS4, REDSofficial.
+ More generally, it supports testing dataset with following structures:
+
+ dataroot
+ ├── subfolder1
+ ├── frame000
+ ├── frame001
+ ├── ...
+ ├── subfolder1
+ ├── frame000
+ ├── frame001
+ ├── ...
+ ├── ...
+
+ For testing datasets, there is no need to prepare LMDB files.
+
+ Args:
+ opt (dict): Config for train dataset. It contains the following keys:
+ dataroot_gt (str): Data root path for gt.
+ dataroot_lq (str): Data root path for lq.
+ io_backend (dict): IO backend type and other kwarg.
+ cache_data (bool): Whether to cache testing datasets.
+ name (str): Dataset name.
+ meta_info_file (str): The path to the file storing the list of test
+ folders. If not provided, all the folders in the dataroot will
+ be used.
+ num_frame (int): Window size for input frames.
+ padding (str): Padding mode.
+ """
+
+ def __init__(self, opt):
+ super(VideoTestDataset, self).__init__()
+ self.opt = opt
+ self.cache_data = opt['cache_data']
+ self.gt_root, self.lq_root = opt['dataroot_gt'], opt['dataroot_lq']
+ self.data_info = {'lq_path': [], 'gt_path': [], 'folder': [], 'idx': [], 'border': []}
+ # file client (io backend)
+ self.file_client = None
+ self.io_backend_opt = opt['io_backend']
+ assert self.io_backend_opt['type'] != 'lmdb', 'No need to use lmdb during validation/test.'
+
+ logger = get_root_logger()
+ logger.info(f'Generate data info for VideoTestDataset - {opt["name"]}')
+ self.imgs_lq, self.imgs_gt = {}, {}
+ if 'meta_info_file' in opt:
+ with open(opt['meta_info_file'], 'r') as fin:
+ subfolders = [line.split(' ')[0] for line in fin]
+ subfolders_lq = [osp.join(self.lq_root, key) for key in subfolders]
+ subfolders_gt = [osp.join(self.gt_root, key) for key in subfolders]
+ else:
+ subfolders_lq = sorted(glob.glob(osp.join(self.lq_root, '*')))
+ subfolders_gt = sorted(glob.glob(osp.join(self.gt_root, '*')))
+
+ if opt['name'].lower() in ['vid4', 'reds4', 'redsofficial']:
+ for subfolder_lq, subfolder_gt in zip(subfolders_lq, subfolders_gt):
+ # get frame list for lq and gt
+ subfolder_name = osp.basename(subfolder_lq)
+ img_paths_lq = sorted(list(scandir(subfolder_lq, full_path=True)))
+ img_paths_gt = sorted(list(scandir(subfolder_gt, full_path=True)))
+
+ max_idx = len(img_paths_lq)
+ assert max_idx == len(img_paths_gt), (f'Different number of images in lq ({max_idx})'
+ f' and gt folders ({len(img_paths_gt)})')
+
+ self.data_info['lq_path'].extend(img_paths_lq)
+ self.data_info['gt_path'].extend(img_paths_gt)
+ self.data_info['folder'].extend([subfolder_name] * max_idx)
+ for i in range(max_idx):
+ self.data_info['idx'].append(f'{i}/{max_idx}')
+ border_l = [0] * max_idx
+ for i in range(self.opt['num_frame'] // 2):
+ border_l[i] = 1
+ border_l[max_idx - i - 1] = 1
+ self.data_info['border'].extend(border_l)
+
+ # cache data or save the frame list
+ if self.cache_data:
+ logger.info(f'Cache {subfolder_name} for VideoTestDataset...')
+ self.imgs_lq[subfolder_name] = read_img_seq(img_paths_lq)
+ self.imgs_gt[subfolder_name] = read_img_seq(img_paths_gt)
+ else:
+ self.imgs_lq[subfolder_name] = img_paths_lq
+ self.imgs_gt[subfolder_name] = img_paths_gt
+ else:
+ raise ValueError(f'Non-supported video test dataset: {type(opt["name"])}')
+
+ def __getitem__(self, index):
+ folder = self.data_info['folder'][index]
+ idx, max_idx = self.data_info['idx'][index].split('/')
+ idx, max_idx = int(idx), int(max_idx)
+ border = self.data_info['border'][index]
+ lq_path = self.data_info['lq_path'][index]
+
+ select_idx = generate_frame_indices(idx, max_idx, self.opt['num_frame'], padding=self.opt['padding'])
+
+ if self.cache_data:
+ imgs_lq = self.imgs_lq[folder].index_select(0, torch.LongTensor(select_idx))
+ img_gt = self.imgs_gt[folder][idx]
+ else:
+ img_paths_lq = [self.imgs_lq[folder][i] for i in select_idx]
+ imgs_lq = read_img_seq(img_paths_lq)
+ img_gt = read_img_seq([self.imgs_gt[folder][idx]])
+ img_gt.squeeze_(0)
+
+ return {
+ 'lq': imgs_lq, # (t, c, h, w)
+ 'gt': img_gt, # (c, h, w)
+ 'folder': folder, # folder name
+ 'idx': self.data_info['idx'][index], # e.g., 0/99
+ 'border': border, # 1 for border, 0 for non-border
+ 'lq_path': lq_path # center frame
+ }
+
+ def __len__(self):
+ return len(self.data_info['gt_path'])
+
+
+@DATASET_REGISTRY.register()
+class VideoTestVimeo90KDataset(data.Dataset):
+ """Video test dataset for Vimeo90k-Test dataset.
+
+ It only keeps the center frame for testing.
+ For testing datasets, there is no need to prepare LMDB files.
+
+ Args:
+ opt (dict): Config for train dataset. It contains the following keys:
+ dataroot_gt (str): Data root path for gt.
+ dataroot_lq (str): Data root path for lq.
+ io_backend (dict): IO backend type and other kwarg.
+ cache_data (bool): Whether to cache testing datasets.
+ name (str): Dataset name.
+ meta_info_file (str): The path to the file storing the list of test
+ folders. If not provided, all the folders in the dataroot will
+ be used.
+ num_frame (int): Window size for input frames.
+ padding (str): Padding mode.
+ """
+
+ def __init__(self, opt):
+ super(VideoTestVimeo90KDataset, self).__init__()
+ self.opt = opt
+ self.cache_data = opt['cache_data']
+ if self.cache_data:
+ raise NotImplementedError('cache_data in Vimeo90K-Test dataset is not implemented.')
+ self.gt_root, self.lq_root = opt['dataroot_gt'], opt['dataroot_lq']
+ self.data_info = {'lq_path': [], 'gt_path': [], 'folder': [], 'idx': [], 'border': []}
+ neighbor_list = [i + (9 - opt['num_frame']) // 2 for i in range(opt['num_frame'])]
+
+ # file client (io backend)
+ self.file_client = None
+ self.io_backend_opt = opt['io_backend']
+ assert self.io_backend_opt['type'] != 'lmdb', 'No need to use lmdb during validation/test.'
+
+ logger = get_root_logger()
+ logger.info(f'Generate data info for VideoTestDataset - {opt["name"]}')
+ with open(opt['meta_info_file'], 'r') as fin:
+ subfolders = [line.split(' ')[0] for line in fin]
+ for idx, subfolder in enumerate(subfolders):
+ gt_path = osp.join(self.gt_root, subfolder, 'im4.png')
+ self.data_info['gt_path'].append(gt_path)
+ lq_paths = [osp.join(self.lq_root, subfolder, f'im{i}.png') for i in neighbor_list]
+ self.data_info['lq_path'].append(lq_paths)
+ self.data_info['folder'].append('vimeo90k')
+ self.data_info['idx'].append(f'{idx}/{len(subfolders)}')
+ self.data_info['border'].append(0)
+
+ def __getitem__(self, index):
+ lq_path = self.data_info['lq_path'][index]
+ gt_path = self.data_info['gt_path'][index]
+ imgs_lq = read_img_seq(lq_path)
+ img_gt = read_img_seq([gt_path])
+ img_gt.squeeze_(0)
+
+ return {
+ 'lq': imgs_lq, # (t, c, h, w)
+ 'gt': img_gt, # (c, h, w)
+ 'folder': self.data_info['folder'][index], # folder name
+ 'idx': self.data_info['idx'][index], # e.g., 0/843
+ 'border': self.data_info['border'][index], # 0 for non-border
+ 'lq_path': lq_path[self.opt['num_frame'] // 2] # center frame
+ }
+
+ def __len__(self):
+ return len(self.data_info['gt_path'])
+
+
+@DATASET_REGISTRY.register()
+class VideoTestDUFDataset(VideoTestDataset):
+ """ Video test dataset for DUF dataset.
+
+ Args:
+ opt (dict): Config for train dataset.
+ Most of keys are the same as VideoTestDataset.
+ It has the following extra keys:
+
+ use_duf_downsampling (bool): Whether to use duf downsampling to
+ generate low-resolution frames.
+ scale (bool): Scale, which will be added automatically.
+ """
+
+ def __getitem__(self, index):
+ folder = self.data_info['folder'][index]
+ idx, max_idx = self.data_info['idx'][index].split('/')
+ idx, max_idx = int(idx), int(max_idx)
+ border = self.data_info['border'][index]
+ lq_path = self.data_info['lq_path'][index]
+
+ select_idx = generate_frame_indices(idx, max_idx, self.opt['num_frame'], padding=self.opt['padding'])
+
+ if self.cache_data:
+ if self.opt['use_duf_downsampling']:
+ # read imgs_gt to generate low-resolution frames
+ imgs_lq = self.imgs_gt[folder].index_select(0, torch.LongTensor(select_idx))
+ imgs_lq = duf_downsample(imgs_lq, kernel_size=13, scale=self.opt['scale'])
+ else:
+ imgs_lq = self.imgs_lq[folder].index_select(0, torch.LongTensor(select_idx))
+ img_gt = self.imgs_gt[folder][idx]
+ else:
+ if self.opt['use_duf_downsampling']:
+ img_paths_lq = [self.imgs_gt[folder][i] for i in select_idx]
+ # read imgs_gt to generate low-resolution frames
+ imgs_lq = read_img_seq(img_paths_lq, require_mod_crop=True, scale=self.opt['scale'])
+ imgs_lq = duf_downsample(imgs_lq, kernel_size=13, scale=self.opt['scale'])
+ else:
+ img_paths_lq = [self.imgs_lq[folder][i] for i in select_idx]
+ imgs_lq = read_img_seq(img_paths_lq)
+ img_gt = read_img_seq([self.imgs_gt[folder][idx]], require_mod_crop=True, scale=self.opt['scale'])
+ img_gt.squeeze_(0)
+
+ return {
+ 'lq': imgs_lq, # (t, c, h, w)
+ 'gt': img_gt, # (c, h, w)
+ 'folder': folder, # folder name
+ 'idx': self.data_info['idx'][index], # e.g., 0/99
+ 'border': border, # 1 for border, 0 for non-border
+ 'lq_path': lq_path # center frame
+ }
+
+
+@DATASET_REGISTRY.register()
+class VideoRecurrentTestDataset(VideoTestDataset):
+ """Video test dataset for recurrent architectures, which takes LR video
+ frames as input and output corresponding HR video frames.
+
+ Args:
+ Same as VideoTestDataset.
+ Unused opt:
+ padding (str): Padding mode.
+
+ """
+
+ def __init__(self, opt):
+ super(VideoRecurrentTestDataset, self).__init__(opt)
+ # Find unique folder strings
+ self.folders = sorted(list(set(self.data_info['folder'])))
+
+ def __getitem__(self, index):
+ folder = self.folders[index]
+
+ if self.cache_data:
+ imgs_lq = self.imgs_lq[folder]
+ imgs_gt = self.imgs_gt[folder]
+ else:
+ raise NotImplementedError('Without cache_data is not implemented.')
+
+ return {
+ 'lq': imgs_lq,
+ 'gt': imgs_gt,
+ 'folder': folder,
+ }
+
+ def __len__(self):
+ return len(self.folders)
diff --git a/custom_nodes/ComfyUI-ReActor/r_basicsr/data/vimeo90k_dataset.py b/custom_nodes/ComfyUI-ReActor/r_basicsr/data/vimeo90k_dataset.py
new file mode 100644
index 0000000000000000000000000000000000000000..de816999728d193b5b8c9a8d7fc02a8f77967a78
--- /dev/null
+++ b/custom_nodes/ComfyUI-ReActor/r_basicsr/data/vimeo90k_dataset.py
@@ -0,0 +1,192 @@
+import random
+import torch
+from pathlib import Path
+from torch.utils import data as data
+
+from r_basicsr.data.transforms import augment, paired_random_crop
+from r_basicsr.utils import FileClient, get_root_logger, imfrombytes, img2tensor
+from r_basicsr.utils.registry import DATASET_REGISTRY
+
+
+@DATASET_REGISTRY.register()
+class Vimeo90KDataset(data.Dataset):
+ """Vimeo90K dataset for training.
+
+ The keys are generated from a meta info txt file.
+ basicsr/data/meta_info/meta_info_Vimeo90K_train_GT.txt
+
+ Each line contains:
+ 1. clip name; 2. frame number; 3. image shape, separated by a white space.
+ Examples:
+ 00001/0001 7 (256,448,3)
+ 00001/0002 7 (256,448,3)
+
+ Key examples: "00001/0001"
+ GT (gt): Ground-Truth;
+ LQ (lq): Low-Quality, e.g., low-resolution/blurry/noisy/compressed frames.
+
+ The neighboring frame list for different num_frame:
+ num_frame | frame list
+ 1 | 4
+ 3 | 3,4,5
+ 5 | 2,3,4,5,6
+ 7 | 1,2,3,4,5,6,7
+
+ Args:
+ opt (dict): Config for train dataset. It contains the following keys:
+ dataroot_gt (str): Data root path for gt.
+ dataroot_lq (str): Data root path for lq.
+ meta_info_file (str): Path for meta information file.
+ io_backend (dict): IO backend type and other kwarg.
+
+ num_frame (int): Window size for input frames.
+ gt_size (int): Cropped patched size for gt patches.
+ random_reverse (bool): Random reverse input frames.
+ use_hflip (bool): Use horizontal flips.
+ use_rot (bool): Use rotation (use vertical flip and transposing h
+ and w for implementation).
+
+ scale (bool): Scale, which will be added automatically.
+ """
+
+ def __init__(self, opt):
+ super(Vimeo90KDataset, self).__init__()
+ self.opt = opt
+ self.gt_root, self.lq_root = Path(opt['dataroot_gt']), Path(opt['dataroot_lq'])
+
+ with open(opt['meta_info_file'], 'r') as fin:
+ self.keys = [line.split(' ')[0] for line in fin]
+
+ # file client (io backend)
+ self.file_client = None
+ self.io_backend_opt = opt['io_backend']
+ self.is_lmdb = False
+ if self.io_backend_opt['type'] == 'lmdb':
+ self.is_lmdb = True
+ self.io_backend_opt['db_paths'] = [self.lq_root, self.gt_root]
+ self.io_backend_opt['client_keys'] = ['lq', 'gt']
+
+ # indices of input images
+ self.neighbor_list = [i + (9 - opt['num_frame']) // 2 for i in range(opt['num_frame'])]
+
+ # temporal augmentation configs
+ self.random_reverse = opt['random_reverse']
+ logger = get_root_logger()
+ logger.info(f'Random reverse is {self.random_reverse}.')
+
+ def __getitem__(self, index):
+ if self.file_client is None:
+ self.file_client = FileClient(self.io_backend_opt.pop('type'), **self.io_backend_opt)
+
+ # random reverse
+ if self.random_reverse and random.random() < 0.5:
+ self.neighbor_list.reverse()
+
+ scale = self.opt['scale']
+ gt_size = self.opt['gt_size']
+ key = self.keys[index]
+ clip, seq = key.split('/') # key example: 00001/0001
+
+ # get the GT frame (im4.png)
+ if self.is_lmdb:
+ img_gt_path = f'{key}/im4'
+ else:
+ img_gt_path = self.gt_root / clip / seq / 'im4.png'
+ img_bytes = self.file_client.get(img_gt_path, 'gt')
+ img_gt = imfrombytes(img_bytes, float32=True)
+
+ # get the neighboring LQ frames
+ img_lqs = []
+ for neighbor in self.neighbor_list:
+ if self.is_lmdb:
+ img_lq_path = f'{clip}/{seq}/im{neighbor}'
+ else:
+ img_lq_path = self.lq_root / clip / seq / f'im{neighbor}.png'
+ img_bytes = self.file_client.get(img_lq_path, 'lq')
+ img_lq = imfrombytes(img_bytes, float32=True)
+ img_lqs.append(img_lq)
+
+ # randomly crop
+ img_gt, img_lqs = paired_random_crop(img_gt, img_lqs, gt_size, scale, img_gt_path)
+
+ # augmentation - flip, rotate
+ img_lqs.append(img_gt)
+ img_results = augment(img_lqs, self.opt['use_hflip'], self.opt['use_rot'])
+
+ img_results = img2tensor(img_results)
+ img_lqs = torch.stack(img_results[0:-1], dim=0)
+ img_gt = img_results[-1]
+
+ # img_lqs: (t, c, h, w)
+ # img_gt: (c, h, w)
+ # key: str
+ return {'lq': img_lqs, 'gt': img_gt, 'key': key}
+
+ def __len__(self):
+ return len(self.keys)
+
+
+@DATASET_REGISTRY.register()
+class Vimeo90KRecurrentDataset(Vimeo90KDataset):
+
+ def __init__(self, opt):
+ super(Vimeo90KRecurrentDataset, self).__init__(opt)
+
+ self.flip_sequence = opt['flip_sequence']
+ self.neighbor_list = [1, 2, 3, 4, 5, 6, 7]
+
+ def __getitem__(self, index):
+ if self.file_client is None:
+ self.file_client = FileClient(self.io_backend_opt.pop('type'), **self.io_backend_opt)
+
+ # random reverse
+ if self.random_reverse and random.random() < 0.5:
+ self.neighbor_list.reverse()
+
+ scale = self.opt['scale']
+ gt_size = self.opt['gt_size']
+ key = self.keys[index]
+ clip, seq = key.split('/') # key example: 00001/0001
+
+ # get the neighboring LQ and GT frames
+ img_lqs = []
+ img_gts = []
+ for neighbor in self.neighbor_list:
+ if self.is_lmdb:
+ img_lq_path = f'{clip}/{seq}/im{neighbor}'
+ img_gt_path = f'{clip}/{seq}/im{neighbor}'
+ else:
+ img_lq_path = self.lq_root / clip / seq / f'im{neighbor}.png'
+ img_gt_path = self.gt_root / clip / seq / f'im{neighbor}.png'
+ # LQ
+ img_bytes = self.file_client.get(img_lq_path, 'lq')
+ img_lq = imfrombytes(img_bytes, float32=True)
+ # GT
+ img_bytes = self.file_client.get(img_gt_path, 'gt')
+ img_gt = imfrombytes(img_bytes, float32=True)
+
+ img_lqs.append(img_lq)
+ img_gts.append(img_gt)
+
+ # randomly crop
+ img_gts, img_lqs = paired_random_crop(img_gts, img_lqs, gt_size, scale, img_gt_path)
+
+ # augmentation - flip, rotate
+ img_lqs.extend(img_gts)
+ img_results = augment(img_lqs, self.opt['use_hflip'], self.opt['use_rot'])
+
+ img_results = img2tensor(img_results)
+ img_lqs = torch.stack(img_results[:7], dim=0)
+ img_gts = torch.stack(img_results[7:], dim=0)
+
+ if self.flip_sequence: # flip the sequence: 7 frames to 14 frames
+ img_lqs = torch.cat([img_lqs, img_lqs.flip(0)], dim=0)
+ img_gts = torch.cat([img_gts, img_gts.flip(0)], dim=0)
+
+ # img_lqs: (t, c, h, w)
+ # img_gt: (c, h, w)
+ # key: str
+ return {'lq': img_lqs, 'gt': img_gts, 'key': key}
+
+ def __len__(self):
+ return len(self.keys)
diff --git a/custom_nodes/ComfyUI-ReActor/r_basicsr/losses/__init__.py b/custom_nodes/ComfyUI-ReActor/r_basicsr/losses/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..0350223ae30c092262bde2ed4ed817aeed04ed30
--- /dev/null
+++ b/custom_nodes/ComfyUI-ReActor/r_basicsr/losses/__init__.py
@@ -0,0 +1,31 @@
+import importlib
+from copy import deepcopy
+from os import path as osp
+
+from r_basicsr.utils import get_root_logger, scandir
+from r_basicsr.utils.registry import LOSS_REGISTRY
+from .gan_loss import g_path_regularize, gradient_penalty_loss, r1_penalty
+
+__all__ = ['build_loss', 'gradient_penalty_loss', 'r1_penalty', 'g_path_regularize']
+
+# automatically scan and import loss modules for registry
+# scan all the files under the 'losses' folder and collect files ending with '_loss.py'
+loss_folder = osp.dirname(osp.abspath(__file__))
+loss_filenames = [osp.splitext(osp.basename(v))[0] for v in scandir(loss_folder) if v.endswith('_loss.py')]
+# import all the loss modules
+_model_modules = [importlib.import_module(f'r_basicsr.losses.{file_name}') for file_name in loss_filenames]
+
+
+def build_loss(opt):
+ """Build loss from options.
+
+ Args:
+ opt (dict): Configuration. It must contain:
+ type (str): Model type.
+ """
+ opt = deepcopy(opt)
+ loss_type = opt.pop('type')
+ loss = LOSS_REGISTRY.get(loss_type)(**opt)
+ logger = get_root_logger()
+ logger.info(f'Loss [{loss.__class__.__name__}] is created.')
+ return loss
diff --git a/custom_nodes/ComfyUI-ReActor/r_basicsr/losses/basic_loss.py b/custom_nodes/ComfyUI-ReActor/r_basicsr/losses/basic_loss.py
new file mode 100644
index 0000000000000000000000000000000000000000..0156fb7afd6f2ddeb2d3dea6c96eef04183da8ea
--- /dev/null
+++ b/custom_nodes/ComfyUI-ReActor/r_basicsr/losses/basic_loss.py
@@ -0,0 +1,253 @@
+import torch
+from torch import nn as nn
+from torch.nn import functional as F
+
+from r_basicsr.archs.vgg_arch import VGGFeatureExtractor
+from r_basicsr.utils.registry import LOSS_REGISTRY
+from .loss_util import weighted_loss
+
+_reduction_modes = ['none', 'mean', 'sum']
+
+
+@weighted_loss
+def l1_loss(pred, target):
+ return F.l1_loss(pred, target, reduction='none')
+
+
+@weighted_loss
+def mse_loss(pred, target):
+ return F.mse_loss(pred, target, reduction='none')
+
+
+@weighted_loss
+def charbonnier_loss(pred, target, eps=1e-12):
+ return torch.sqrt((pred - target)**2 + eps)
+
+
+@LOSS_REGISTRY.register()
+class L1Loss(nn.Module):
+ """L1 (mean absolute error, MAE) loss.
+
+ Args:
+ loss_weight (float): Loss weight for L1 loss. Default: 1.0.
+ reduction (str): Specifies the reduction to apply to the output.
+ Supported choices are 'none' | 'mean' | 'sum'. Default: 'mean'.
+ """
+
+ def __init__(self, loss_weight=1.0, reduction='mean'):
+ super(L1Loss, self).__init__()
+ if reduction not in ['none', 'mean', 'sum']:
+ raise ValueError(f'Unsupported reduction mode: {reduction}. Supported ones are: {_reduction_modes}')
+
+ self.loss_weight = loss_weight
+ self.reduction = reduction
+
+ def forward(self, pred, target, weight=None, **kwargs):
+ """
+ Args:
+ pred (Tensor): of shape (N, C, H, W). Predicted tensor.
+ target (Tensor): of shape (N, C, H, W). Ground truth tensor.
+ weight (Tensor, optional): of shape (N, C, H, W). Element-wise weights. Default: None.
+ """
+ return self.loss_weight * l1_loss(pred, target, weight, reduction=self.reduction)
+
+
+@LOSS_REGISTRY.register()
+class MSELoss(nn.Module):
+ """MSE (L2) loss.
+
+ Args:
+ loss_weight (float): Loss weight for MSE loss. Default: 1.0.
+ reduction (str): Specifies the reduction to apply to the output.
+ Supported choices are 'none' | 'mean' | 'sum'. Default: 'mean'.
+ """
+
+ def __init__(self, loss_weight=1.0, reduction='mean'):
+ super(MSELoss, self).__init__()
+ if reduction not in ['none', 'mean', 'sum']:
+ raise ValueError(f'Unsupported reduction mode: {reduction}. Supported ones are: {_reduction_modes}')
+
+ self.loss_weight = loss_weight
+ self.reduction = reduction
+
+ def forward(self, pred, target, weight=None, **kwargs):
+ """
+ Args:
+ pred (Tensor): of shape (N, C, H, W). Predicted tensor.
+ target (Tensor): of shape (N, C, H, W). Ground truth tensor.
+ weight (Tensor, optional): of shape (N, C, H, W). Element-wise weights. Default: None.
+ """
+ return self.loss_weight * mse_loss(pred, target, weight, reduction=self.reduction)
+
+
+@LOSS_REGISTRY.register()
+class CharbonnierLoss(nn.Module):
+ """Charbonnier loss (one variant of Robust L1Loss, a differentiable
+ variant of L1Loss).
+
+ Described in "Deep Laplacian Pyramid Networks for Fast and Accurate
+ Super-Resolution".
+
+ Args:
+ loss_weight (float): Loss weight for L1 loss. Default: 1.0.
+ reduction (str): Specifies the reduction to apply to the output.
+ Supported choices are 'none' | 'mean' | 'sum'. Default: 'mean'.
+ eps (float): A value used to control the curvature near zero. Default: 1e-12.
+ """
+
+ def __init__(self, loss_weight=1.0, reduction='mean', eps=1e-12):
+ super(CharbonnierLoss, self).__init__()
+ if reduction not in ['none', 'mean', 'sum']:
+ raise ValueError(f'Unsupported reduction mode: {reduction}. Supported ones are: {_reduction_modes}')
+
+ self.loss_weight = loss_weight
+ self.reduction = reduction
+ self.eps = eps
+
+ def forward(self, pred, target, weight=None, **kwargs):
+ """
+ Args:
+ pred (Tensor): of shape (N, C, H, W). Predicted tensor.
+ target (Tensor): of shape (N, C, H, W). Ground truth tensor.
+ weight (Tensor, optional): of shape (N, C, H, W). Element-wise weights. Default: None.
+ """
+ return self.loss_weight * charbonnier_loss(pred, target, weight, eps=self.eps, reduction=self.reduction)
+
+
+@LOSS_REGISTRY.register()
+class WeightedTVLoss(L1Loss):
+ """Weighted TV loss.
+
+ Args:
+ loss_weight (float): Loss weight. Default: 1.0.
+ """
+
+ def __init__(self, loss_weight=1.0, reduction='mean'):
+ if reduction not in ['mean', 'sum']:
+ raise ValueError(f'Unsupported reduction mode: {reduction}. Supported ones are: mean | sum')
+ super(WeightedTVLoss, self).__init__(loss_weight=loss_weight, reduction=reduction)
+
+ def forward(self, pred, weight=None):
+ if weight is None:
+ y_weight = None
+ x_weight = None
+ else:
+ y_weight = weight[:, :, :-1, :]
+ x_weight = weight[:, :, :, :-1]
+
+ y_diff = super().forward(pred[:, :, :-1, :], pred[:, :, 1:, :], weight=y_weight)
+ x_diff = super().forward(pred[:, :, :, :-1], pred[:, :, :, 1:], weight=x_weight)
+
+ loss = x_diff + y_diff
+
+ return loss
+
+
+@LOSS_REGISTRY.register()
+class PerceptualLoss(nn.Module):
+ """Perceptual loss with commonly used style loss.
+
+ Args:
+ layer_weights (dict): The weight for each layer of vgg feature.
+ Here is an example: {'conv5_4': 1.}, which means the conv5_4
+ feature layer (before relu5_4) will be extracted with weight
+ 1.0 in calculating losses.
+ vgg_type (str): The type of vgg network used as feature extractor.
+ Default: 'vgg19'.
+ use_input_norm (bool): If True, normalize the input image in vgg.
+ Default: True.
+ range_norm (bool): If True, norm images with range [-1, 1] to [0, 1].
+ Default: False.
+ perceptual_weight (float): If `perceptual_weight > 0`, the perceptual
+ loss will be calculated and the loss will multiplied by the
+ weight. Default: 1.0.
+ style_weight (float): If `style_weight > 0`, the style loss will be
+ calculated and the loss will multiplied by the weight.
+ Default: 0.
+ criterion (str): Criterion used for perceptual loss. Default: 'l1'.
+ """
+
+ def __init__(self,
+ layer_weights,
+ vgg_type='vgg19',
+ use_input_norm=True,
+ range_norm=False,
+ perceptual_weight=1.0,
+ style_weight=0.,
+ criterion='l1'):
+ super(PerceptualLoss, self).__init__()
+ self.perceptual_weight = perceptual_weight
+ self.style_weight = style_weight
+ self.layer_weights = layer_weights
+ self.vgg = VGGFeatureExtractor(
+ layer_name_list=list(layer_weights.keys()),
+ vgg_type=vgg_type,
+ use_input_norm=use_input_norm,
+ range_norm=range_norm)
+
+ self.criterion_type = criterion
+ if self.criterion_type == 'l1':
+ self.criterion = torch.nn.L1Loss()
+ elif self.criterion_type == 'l2':
+ self.criterion = torch.nn.L2loss()
+ elif self.criterion_type == 'fro':
+ self.criterion = None
+ else:
+ raise NotImplementedError(f'{criterion} criterion has not been supported.')
+
+ def forward(self, x, gt):
+ """Forward function.
+
+ Args:
+ x (Tensor): Input tensor with shape (n, c, h, w).
+ gt (Tensor): Ground-truth tensor with shape (n, c, h, w).
+
+ Returns:
+ Tensor: Forward results.
+ """
+ # extract vgg features
+ x_features = self.vgg(x)
+ gt_features = self.vgg(gt.detach())
+
+ # calculate perceptual loss
+ if self.perceptual_weight > 0:
+ percep_loss = 0
+ for k in x_features.keys():
+ if self.criterion_type == 'fro':
+ percep_loss += torch.norm(x_features[k] - gt_features[k], p='fro') * self.layer_weights[k]
+ else:
+ percep_loss += self.criterion(x_features[k], gt_features[k]) * self.layer_weights[k]
+ percep_loss *= self.perceptual_weight
+ else:
+ percep_loss = None
+
+ # calculate style loss
+ if self.style_weight > 0:
+ style_loss = 0
+ for k in x_features.keys():
+ if self.criterion_type == 'fro':
+ style_loss += torch.norm(
+ self._gram_mat(x_features[k]) - self._gram_mat(gt_features[k]), p='fro') * self.layer_weights[k]
+ else:
+ style_loss += self.criterion(self._gram_mat(x_features[k]), self._gram_mat(
+ gt_features[k])) * self.layer_weights[k]
+ style_loss *= self.style_weight
+ else:
+ style_loss = None
+
+ return percep_loss, style_loss
+
+ def _gram_mat(self, x):
+ """Calculate Gram matrix.
+
+ Args:
+ x (torch.Tensor): Tensor with shape of (n, c, h, w).
+
+ Returns:
+ torch.Tensor: Gram matrix.
+ """
+ n, c, h, w = x.size()
+ features = x.view(n, c, w * h)
+ features_t = features.transpose(1, 2)
+ gram = features.bmm(features_t) / (c * h * w)
+ return gram
diff --git a/custom_nodes/ComfyUI-ReActor/r_basicsr/losses/gan_loss.py b/custom_nodes/ComfyUI-ReActor/r_basicsr/losses/gan_loss.py
new file mode 100644
index 0000000000000000000000000000000000000000..88b4c196f0bc44cb3fb4822256fdf320a8f85203
--- /dev/null
+++ b/custom_nodes/ComfyUI-ReActor/r_basicsr/losses/gan_loss.py
@@ -0,0 +1,208 @@
+import math
+import torch
+from torch import autograd as autograd
+from torch import nn as nn
+from torch.nn import functional as F
+
+from r_basicsr.utils.registry import LOSS_REGISTRY
+
+
+@LOSS_REGISTRY.register()
+class GANLoss(nn.Module):
+ """Define GAN loss.
+
+ Args:
+ gan_type (str): Support 'vanilla', 'lsgan', 'wgan', 'hinge'.
+ real_label_val (float): The value for real label. Default: 1.0.
+ fake_label_val (float): The value for fake label. Default: 0.0.
+ loss_weight (float): Loss weight. Default: 1.0.
+ Note that loss_weight is only for generators; and it is always 1.0
+ for discriminators.
+ """
+
+ def __init__(self, gan_type, real_label_val=1.0, fake_label_val=0.0, loss_weight=1.0):
+ super(GANLoss, self).__init__()
+ self.gan_type = gan_type
+ self.loss_weight = loss_weight
+ self.real_label_val = real_label_val
+ self.fake_label_val = fake_label_val
+
+ if self.gan_type == 'vanilla':
+ self.loss = nn.BCEWithLogitsLoss()
+ elif self.gan_type == 'lsgan':
+ self.loss = nn.MSELoss()
+ elif self.gan_type == 'wgan':
+ self.loss = self._wgan_loss
+ elif self.gan_type == 'wgan_softplus':
+ self.loss = self._wgan_softplus_loss
+ elif self.gan_type == 'hinge':
+ self.loss = nn.ReLU()
+ else:
+ raise NotImplementedError(f'GAN type {self.gan_type} is not implemented.')
+
+ def _wgan_loss(self, input, target):
+ """wgan loss.
+
+ Args:
+ input (Tensor): Input tensor.
+ target (bool): Target label.
+
+ Returns:
+ Tensor: wgan loss.
+ """
+ return -input.mean() if target else input.mean()
+
+ def _wgan_softplus_loss(self, input, target):
+ """wgan loss with soft plus. softplus is a smooth approximation to the
+ ReLU function.
+
+ In StyleGAN2, it is called:
+ Logistic loss for discriminator;
+ Non-saturating loss for generator.
+
+ Args:
+ input (Tensor): Input tensor.
+ target (bool): Target label.
+
+ Returns:
+ Tensor: wgan loss.
+ """
+ return F.softplus(-input).mean() if target else F.softplus(input).mean()
+
+ def get_target_label(self, input, target_is_real):
+ """Get target label.
+
+ Args:
+ input (Tensor): Input tensor.
+ target_is_real (bool): Whether the target is real or fake.
+
+ Returns:
+ (bool | Tensor): Target tensor. Return bool for wgan, otherwise,
+ return Tensor.
+ """
+
+ if self.gan_type in ['wgan', 'wgan_softplus']:
+ return target_is_real
+ target_val = (self.real_label_val if target_is_real else self.fake_label_val)
+ return input.new_ones(input.size()) * target_val
+
+ def forward(self, input, target_is_real, is_disc=False):
+ """
+ Args:
+ input (Tensor): The input for the loss module, i.e., the network
+ prediction.
+ target_is_real (bool): Whether the targe is real or fake.
+ is_disc (bool): Whether the loss for discriminators or not.
+ Default: False.
+
+ Returns:
+ Tensor: GAN loss value.
+ """
+ target_label = self.get_target_label(input, target_is_real)
+ if self.gan_type == 'hinge':
+ if is_disc: # for discriminators in hinge-gan
+ input = -input if target_is_real else input
+ loss = self.loss(1 + input).mean()
+ else: # for generators in hinge-gan
+ loss = -input.mean()
+ else: # other gan types
+ loss = self.loss(input, target_label)
+
+ # loss_weight is always 1.0 for discriminators
+ return loss if is_disc else loss * self.loss_weight
+
+
+@LOSS_REGISTRY.register()
+class MultiScaleGANLoss(GANLoss):
+ """
+ MultiScaleGANLoss accepts a list of predictions
+ """
+
+ def __init__(self, gan_type, real_label_val=1.0, fake_label_val=0.0, loss_weight=1.0):
+ super(MultiScaleGANLoss, self).__init__(gan_type, real_label_val, fake_label_val, loss_weight)
+
+ def forward(self, input, target_is_real, is_disc=False):
+ """
+ The input is a list of tensors, or a list of (a list of tensors)
+ """
+ if isinstance(input, list):
+ loss = 0
+ for pred_i in input:
+ if isinstance(pred_i, list):
+ # Only compute GAN loss for the last layer
+ # in case of multiscale feature matching
+ pred_i = pred_i[-1]
+ # Safe operation: 0-dim tensor calling self.mean() does nothing
+ loss_tensor = super().forward(pred_i, target_is_real, is_disc).mean()
+ loss += loss_tensor
+ return loss / len(input)
+ else:
+ return super().forward(input, target_is_real, is_disc)
+
+
+def r1_penalty(real_pred, real_img):
+ """R1 regularization for discriminator. The core idea is to
+ penalize the gradient on real data alone: when the
+ generator distribution produces the true data distribution
+ and the discriminator is equal to 0 on the data manifold, the
+ gradient penalty ensures that the discriminator cannot create
+ a non-zero gradient orthogonal to the data manifold without
+ suffering a loss in the GAN game.
+
+ Ref:
+ Eq. 9 in Which training methods for GANs do actually converge.
+ """
+ grad_real = autograd.grad(outputs=real_pred.sum(), inputs=real_img, create_graph=True)[0]
+ grad_penalty = grad_real.pow(2).view(grad_real.shape[0], -1).sum(1).mean()
+ return grad_penalty
+
+
+def g_path_regularize(fake_img, latents, mean_path_length, decay=0.01):
+ noise = torch.randn_like(fake_img) / math.sqrt(fake_img.shape[2] * fake_img.shape[3])
+ grad = autograd.grad(outputs=(fake_img * noise).sum(), inputs=latents, create_graph=True)[0]
+ path_lengths = torch.sqrt(grad.pow(2).sum(2).mean(1))
+
+ path_mean = mean_path_length + decay * (path_lengths.mean() - mean_path_length)
+
+ path_penalty = (path_lengths - path_mean).pow(2).mean()
+
+ return path_penalty, path_lengths.detach().mean(), path_mean.detach()
+
+
+def gradient_penalty_loss(discriminator, real_data, fake_data, weight=None):
+ """Calculate gradient penalty for wgan-gp.
+
+ Args:
+ discriminator (nn.Module): Network for the discriminator.
+ real_data (Tensor): Real input data.
+ fake_data (Tensor): Fake input data.
+ weight (Tensor): Weight tensor. Default: None.
+
+ Returns:
+ Tensor: A tensor for gradient penalty.
+ """
+
+ batch_size = real_data.size(0)
+ alpha = real_data.new_tensor(torch.rand(batch_size, 1, 1, 1))
+
+ # interpolate between real_data and fake_data
+ interpolates = alpha * real_data + (1. - alpha) * fake_data
+ interpolates = autograd.Variable(interpolates, requires_grad=True)
+
+ disc_interpolates = discriminator(interpolates)
+ gradients = autograd.grad(
+ outputs=disc_interpolates,
+ inputs=interpolates,
+ grad_outputs=torch.ones_like(disc_interpolates),
+ create_graph=True,
+ retain_graph=True,
+ only_inputs=True)[0]
+
+ if weight is not None:
+ gradients = gradients * weight
+
+ gradients_penalty = ((gradients.norm(2, dim=1) - 1)**2).mean()
+ if weight is not None:
+ gradients_penalty /= torch.mean(weight)
+
+ return gradients_penalty
diff --git a/custom_nodes/ComfyUI-ReActor/r_basicsr/losses/loss_util.py b/custom_nodes/ComfyUI-ReActor/r_basicsr/losses/loss_util.py
new file mode 100644
index 0000000000000000000000000000000000000000..fd293ff9e6a22814e5aeff6ae11fb54d2e4bafff
--- /dev/null
+++ b/custom_nodes/ComfyUI-ReActor/r_basicsr/losses/loss_util.py
@@ -0,0 +1,145 @@
+import functools
+import torch
+from torch.nn import functional as F
+
+
+def reduce_loss(loss, reduction):
+ """Reduce loss as specified.
+
+ Args:
+ loss (Tensor): Elementwise loss tensor.
+ reduction (str): Options are 'none', 'mean' and 'sum'.
+
+ Returns:
+ Tensor: Reduced loss tensor.
+ """
+ reduction_enum = F._Reduction.get_enum(reduction)
+ # none: 0, elementwise_mean:1, sum: 2
+ if reduction_enum == 0:
+ return loss
+ elif reduction_enum == 1:
+ return loss.mean()
+ else:
+ return loss.sum()
+
+
+def weight_reduce_loss(loss, weight=None, reduction='mean'):
+ """Apply element-wise weight and reduce loss.
+
+ Args:
+ loss (Tensor): Element-wise loss.
+ weight (Tensor): Element-wise weights. Default: None.
+ reduction (str): Same as built-in losses of PyTorch. Options are
+ 'none', 'mean' and 'sum'. Default: 'mean'.
+
+ Returns:
+ Tensor: Loss values.
+ """
+ # if weight is specified, apply element-wise weight
+ if weight is not None:
+ assert weight.dim() == loss.dim()
+ assert weight.size(1) == 1 or weight.size(1) == loss.size(1)
+ loss = loss * weight
+
+ # if weight is not specified or reduction is sum, just reduce the loss
+ if weight is None or reduction == 'sum':
+ loss = reduce_loss(loss, reduction)
+ # if reduction is mean, then compute mean over weight region
+ elif reduction == 'mean':
+ if weight.size(1) > 1:
+ weight = weight.sum()
+ else:
+ weight = weight.sum() * loss.size(1)
+ loss = loss.sum() / weight
+
+ return loss
+
+
+def weighted_loss(loss_func):
+ """Create a weighted version of a given loss function.
+
+ To use this decorator, the loss function must have the signature like
+ `loss_func(pred, target, **kwargs)`. The function only needs to compute
+ element-wise loss without any reduction. This decorator will add weight
+ and reduction arguments to the function. The decorated function will have
+ the signature like `loss_func(pred, target, weight=None, reduction='mean',
+ **kwargs)`.
+
+ :Example:
+
+ >>> import torch
+ >>> @weighted_loss
+ >>> def l1_loss(pred, target):
+ >>> return (pred - target).abs()
+
+ >>> pred = torch.Tensor([0, 2, 3])
+ >>> target = torch.Tensor([1, 1, 1])
+ >>> weight = torch.Tensor([1, 0, 1])
+
+ >>> l1_loss(pred, target)
+ tensor(1.3333)
+ >>> l1_loss(pred, target, weight)
+ tensor(1.5000)
+ >>> l1_loss(pred, target, reduction='none')
+ tensor([1., 1., 2.])
+ >>> l1_loss(pred, target, weight, reduction='sum')
+ tensor(3.)
+ """
+
+ @functools.wraps(loss_func)
+ def wrapper(pred, target, weight=None, reduction='mean', **kwargs):
+ # get element-wise loss
+ loss = loss_func(pred, target, **kwargs)
+ loss = weight_reduce_loss(loss, weight, reduction)
+ return loss
+
+ return wrapper
+
+
+def get_local_weights(residual, ksize):
+ """Get local weights for generating the artifact map of LDL.
+
+ It is only called by the `get_refined_artifact_map` function.
+
+ Args:
+ residual (Tensor): Residual between predicted and ground truth images.
+ ksize (Int): size of the local window.
+
+ Returns:
+ Tensor: weight for each pixel to be discriminated as an artifact pixel
+ """
+
+ pad = (ksize - 1) // 2
+ residual_pad = F.pad(residual, pad=[pad, pad, pad, pad], mode='reflect')
+
+ unfolded_residual = residual_pad.unfold(2, ksize, 1).unfold(3, ksize, 1)
+ pixel_level_weight = torch.var(unfolded_residual, dim=(-1, -2), unbiased=True, keepdim=True).squeeze(-1).squeeze(-1)
+
+ return pixel_level_weight
+
+
+def get_refined_artifact_map(img_gt, img_output, img_ema, ksize):
+ """Calculate the artifact map of LDL
+ (Details or Artifacts: A Locally Discriminative Learning Approach to Realistic Image Super-Resolution. In CVPR 2022)
+
+ Args:
+ img_gt (Tensor): ground truth images.
+ img_output (Tensor): output images given by the optimizing model.
+ img_ema (Tensor): output images given by the ema model.
+ ksize (Int): size of the local window.
+
+ Returns:
+ overall_weight: weight for each pixel to be discriminated as an artifact pixel
+ (calculated based on both local and global observations).
+ """
+
+ residual_ema = torch.sum(torch.abs(img_gt - img_ema), 1, keepdim=True)
+ residual_sr = torch.sum(torch.abs(img_gt - img_output), 1, keepdim=True)
+
+ patch_level_weight = torch.var(residual_sr.clone(), dim=(-1, -2, -3), keepdim=True)**(1 / 5)
+ pixel_level_weight = get_local_weights(residual_sr.clone(), ksize)
+ overall_weight = patch_level_weight * pixel_level_weight
+
+ overall_weight[residual_sr < residual_ema] = 0
+
+ return overall_weight
diff --git a/custom_nodes/ComfyUI-ReActor/r_basicsr/metrics/__init__.py b/custom_nodes/ComfyUI-ReActor/r_basicsr/metrics/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..f397f9de59d2ddc56d431e5a8f60dc16389d9105
--- /dev/null
+++ b/custom_nodes/ComfyUI-ReActor/r_basicsr/metrics/__init__.py
@@ -0,0 +1,20 @@
+from copy import deepcopy
+
+from r_basicsr.utils.registry import METRIC_REGISTRY
+from .niqe import calculate_niqe
+from .psnr_ssim import calculate_psnr, calculate_ssim
+
+__all__ = ['calculate_psnr', 'calculate_ssim', 'calculate_niqe']
+
+
+def calculate_metric(data, opt):
+ """Calculate metric from data and options.
+
+ Args:
+ opt (dict): Configuration. It must contain:
+ type (str): Model type.
+ """
+ opt = deepcopy(opt)
+ metric_type = opt.pop('type')
+ metric = METRIC_REGISTRY.get(metric_type)(**data, **opt)
+ return metric
diff --git a/custom_nodes/ComfyUI-ReActor/r_basicsr/metrics/fid.py b/custom_nodes/ComfyUI-ReActor/r_basicsr/metrics/fid.py
new file mode 100644
index 0000000000000000000000000000000000000000..903ddf5810fe7dfa9959763ccfdaf1d01f12c6da
--- /dev/null
+++ b/custom_nodes/ComfyUI-ReActor/r_basicsr/metrics/fid.py
@@ -0,0 +1,93 @@
+import numpy as np
+import torch
+import torch.nn as nn
+from scipy import linalg
+from tqdm import tqdm
+
+from r_basicsr.archs.inception import InceptionV3
+
+
+def load_patched_inception_v3(device='cuda', resize_input=True, normalize_input=False):
+ # we may not resize the input, but in [rosinality/stylegan2-pytorch] it
+ # does resize the input.
+ inception = InceptionV3([3], resize_input=resize_input, normalize_input=normalize_input)
+ inception = nn.DataParallel(inception).eval().to(device)
+ return inception
+
+
+@torch.no_grad()
+def extract_inception_features(data_generator, inception, len_generator=None, device='cuda'):
+ """Extract inception features.
+
+ Args:
+ data_generator (generator): A data generator.
+ inception (nn.Module): Inception model.
+ len_generator (int): Length of the data_generator to show the
+ progressbar. Default: None.
+ device (str): Device. Default: cuda.
+
+ Returns:
+ Tensor: Extracted features.
+ """
+ if len_generator is not None:
+ pbar = tqdm(total=len_generator, unit='batch', desc='Extract')
+ else:
+ pbar = None
+ features = []
+
+ for data in data_generator:
+ if pbar:
+ pbar.update(1)
+ data = data.to(device)
+ feature = inception(data)[0].view(data.shape[0], -1)
+ features.append(feature.to('cpu'))
+ if pbar:
+ pbar.close()
+ features = torch.cat(features, 0)
+ return features
+
+
+def calculate_fid(mu1, sigma1, mu2, sigma2, eps=1e-6):
+ """Numpy implementation of the Frechet Distance.
+
+ The Frechet distance between two multivariate Gaussians X_1 ~ N(mu_1, C_1)
+ and X_2 ~ N(mu_2, C_2) is
+ d^2 = ||mu_1 - mu_2||^2 + Tr(C_1 + C_2 - 2*sqrt(C_1*C_2)).
+ Stable version by Dougal J. Sutherland.
+
+ Args:
+ mu1 (np.array): The sample mean over activations.
+ sigma1 (np.array): The covariance matrix over activations for
+ generated samples.
+ mu2 (np.array): The sample mean over activations, precalculated on an
+ representative data set.
+ sigma2 (np.array): The covariance matrix over activations,
+ precalculated on an representative data set.
+
+ Returns:
+ float: The Frechet Distance.
+ """
+ assert mu1.shape == mu2.shape, 'Two mean vectors have different lengths'
+ assert sigma1.shape == sigma2.shape, ('Two covariances have different dimensions')
+
+ cov_sqrt, _ = linalg.sqrtm(sigma1 @ sigma2, disp=False)
+
+ # Product might be almost singular
+ if not np.isfinite(cov_sqrt).all():
+ print('Product of cov matrices is singular. Adding {eps} to diagonal of cov estimates')
+ offset = np.eye(sigma1.shape[0]) * eps
+ cov_sqrt = linalg.sqrtm((sigma1 + offset) @ (sigma2 + offset))
+
+ # Numerical error might give slight imaginary component
+ if np.iscomplexobj(cov_sqrt):
+ if not np.allclose(np.diagonal(cov_sqrt).imag, 0, atol=1e-3):
+ m = np.max(np.abs(cov_sqrt.imag))
+ raise ValueError(f'Imaginary component {m}')
+ cov_sqrt = cov_sqrt.real
+
+ mean_diff = mu1 - mu2
+ mean_norm = mean_diff @ mean_diff
+ trace = np.trace(sigma1) + np.trace(sigma2) - 2 * np.trace(cov_sqrt)
+ fid = mean_norm + trace
+
+ return fid
diff --git a/custom_nodes/ComfyUI-ReActor/r_basicsr/metrics/metric_util.py b/custom_nodes/ComfyUI-ReActor/r_basicsr/metrics/metric_util.py
new file mode 100644
index 0000000000000000000000000000000000000000..b0f39fee4701a6eedc615cc450ac93fd7c57157e
--- /dev/null
+++ b/custom_nodes/ComfyUI-ReActor/r_basicsr/metrics/metric_util.py
@@ -0,0 +1,45 @@
+import numpy as np
+
+from r_basicsr.utils import bgr2ycbcr
+
+
+def reorder_image(img, input_order='HWC'):
+ """Reorder images to 'HWC' order.
+
+ If the input_order is (h, w), return (h, w, 1);
+ If the input_order is (c, h, w), return (h, w, c);
+ If the input_order is (h, w, c), return as it is.
+
+ Args:
+ img (ndarray): Input image.
+ input_order (str): Whether the input order is 'HWC' or 'CHW'.
+ If the input image shape is (h, w), input_order will not have
+ effects. Default: 'HWC'.
+
+ Returns:
+ ndarray: reordered image.
+ """
+
+ if input_order not in ['HWC', 'CHW']:
+ raise ValueError(f"Wrong input_order {input_order}. Supported input_orders are 'HWC' and 'CHW'")
+ if len(img.shape) == 2:
+ img = img[..., None]
+ if input_order == 'CHW':
+ img = img.transpose(1, 2, 0)
+ return img
+
+
+def to_y_channel(img):
+ """Change to Y channel of YCbCr.
+
+ Args:
+ img (ndarray): Images with range [0, 255].
+
+ Returns:
+ (ndarray): Images with range [0, 255] (float type) without round.
+ """
+ img = img.astype(np.float32) / 255.
+ if img.ndim == 3 and img.shape[2] == 3:
+ img = bgr2ycbcr(img, y_only=True)
+ img = img[..., None]
+ return img * 255.
diff --git a/custom_nodes/ComfyUI-ReActor/r_basicsr/metrics/niqe.py b/custom_nodes/ComfyUI-ReActor/r_basicsr/metrics/niqe.py
new file mode 100644
index 0000000000000000000000000000000000000000..c3a004f85b6a8028c3c5504a62b1651664029c1b
--- /dev/null
+++ b/custom_nodes/ComfyUI-ReActor/r_basicsr/metrics/niqe.py
@@ -0,0 +1,197 @@
+import cv2
+import math
+import numpy as np
+import os
+from scipy.ndimage.filters import convolve
+from scipy.special import gamma
+
+from r_basicsr.metrics.metric_util import reorder_image, to_y_channel
+from r_basicsr.utils.matlab_functions import imresize
+from r_basicsr.utils.registry import METRIC_REGISTRY
+
+
+def estimate_aggd_param(block):
+ """Estimate AGGD (Asymmetric Generalized Gaussian Distribution) parameters.
+
+ Args:
+ block (ndarray): 2D Image block.
+
+ Returns:
+ tuple: alpha (float), beta_l (float) and beta_r (float) for the AGGD
+ distribution (Estimating the parames in Equation 7 in the paper).
+ """
+ block = block.flatten()
+ gam = np.arange(0.2, 10.001, 0.001) # len = 9801
+ gam_reciprocal = np.reciprocal(gam)
+ r_gam = np.square(gamma(gam_reciprocal * 2)) / (gamma(gam_reciprocal) * gamma(gam_reciprocal * 3))
+
+ left_std = np.sqrt(np.mean(block[block < 0]**2))
+ right_std = np.sqrt(np.mean(block[block > 0]**2))
+ gammahat = left_std / right_std
+ rhat = (np.mean(np.abs(block)))**2 / np.mean(block**2)
+ rhatnorm = (rhat * (gammahat**3 + 1) * (gammahat + 1)) / ((gammahat**2 + 1)**2)
+ array_position = np.argmin((r_gam - rhatnorm)**2)
+
+ alpha = gam[array_position]
+ beta_l = left_std * np.sqrt(gamma(1 / alpha) / gamma(3 / alpha))
+ beta_r = right_std * np.sqrt(gamma(1 / alpha) / gamma(3 / alpha))
+ return (alpha, beta_l, beta_r)
+
+
+def compute_feature(block):
+ """Compute features.
+
+ Args:
+ block (ndarray): 2D Image block.
+
+ Returns:
+ list: Features with length of 18.
+ """
+ feat = []
+ alpha, beta_l, beta_r = estimate_aggd_param(block)
+ feat.extend([alpha, (beta_l + beta_r) / 2])
+
+ # distortions disturb the fairly regular structure of natural images.
+ # This deviation can be captured by analyzing the sample distribution of
+ # the products of pairs of adjacent coefficients computed along
+ # horizontal, vertical and diagonal orientations.
+ shifts = [[0, 1], [1, 0], [1, 1], [1, -1]]
+ for i in range(len(shifts)):
+ shifted_block = np.roll(block, shifts[i], axis=(0, 1))
+ alpha, beta_l, beta_r = estimate_aggd_param(block * shifted_block)
+ # Eq. 8
+ mean = (beta_r - beta_l) * (gamma(2 / alpha) / gamma(1 / alpha))
+ feat.extend([alpha, mean, beta_l, beta_r])
+ return feat
+
+
+def niqe(img, mu_pris_param, cov_pris_param, gaussian_window, block_size_h=96, block_size_w=96):
+ """Calculate NIQE (Natural Image Quality Evaluator) metric.
+
+ Ref: Making a "Completely Blind" Image Quality Analyzer.
+ This implementation could produce almost the same results as the official
+ MATLAB codes: http://live.ece.utexas.edu/research/quality/niqe_release.zip
+
+ Note that we do not include block overlap height and width, since they are
+ always 0 in the official implementation.
+
+ For good performance, it is advisable by the official implementation to
+ divide the distorted image in to the same size patched as used for the
+ construction of multivariate Gaussian model.
+
+ Args:
+ img (ndarray): Input image whose quality needs to be computed. The
+ image must be a gray or Y (of YCbCr) image with shape (h, w).
+ Range [0, 255] with float type.
+ mu_pris_param (ndarray): Mean of a pre-defined multivariate Gaussian
+ model calculated on the pristine dataset.
+ cov_pris_param (ndarray): Covariance of a pre-defined multivariate
+ Gaussian model calculated on the pristine dataset.
+ gaussian_window (ndarray): A 7x7 Gaussian window used for smoothing the
+ image.
+ block_size_h (int): Height of the blocks in to which image is divided.
+ Default: 96 (the official recommended value).
+ block_size_w (int): Width of the blocks in to which image is divided.
+ Default: 96 (the official recommended value).
+ """
+ assert img.ndim == 2, ('Input image must be a gray or Y (of YCbCr) image with shape (h, w).')
+ # crop image
+ h, w = img.shape
+ num_block_h = math.floor(h / block_size_h)
+ num_block_w = math.floor(w / block_size_w)
+ img = img[0:num_block_h * block_size_h, 0:num_block_w * block_size_w]
+
+ distparam = [] # dist param is actually the multiscale features
+ for scale in (1, 2): # perform on two scales (1, 2)
+ mu = convolve(img, gaussian_window, mode='nearest')
+ sigma = np.sqrt(np.abs(convolve(np.square(img), gaussian_window, mode='nearest') - np.square(mu)))
+ # normalize, as in Eq. 1 in the paper
+ img_nomalized = (img - mu) / (sigma + 1)
+
+ feat = []
+ for idx_w in range(num_block_w):
+ for idx_h in range(num_block_h):
+ # process ecah block
+ block = img_nomalized[idx_h * block_size_h // scale:(idx_h + 1) * block_size_h // scale,
+ idx_w * block_size_w // scale:(idx_w + 1) * block_size_w // scale]
+ feat.append(compute_feature(block))
+
+ distparam.append(np.array(feat))
+
+ if scale == 1:
+ img = imresize(img / 255., scale=0.5, antialiasing=True)
+ img = img * 255.
+
+ distparam = np.concatenate(distparam, axis=1)
+
+ # fit a MVG (multivariate Gaussian) model to distorted patch features
+ mu_distparam = np.nanmean(distparam, axis=0)
+ # use nancov. ref: https://ww2.mathworks.cn/help/stats/nancov.html
+ distparam_no_nan = distparam[~np.isnan(distparam).any(axis=1)]
+ cov_distparam = np.cov(distparam_no_nan, rowvar=False)
+
+ # compute niqe quality, Eq. 10 in the paper
+ invcov_param = np.linalg.pinv((cov_pris_param + cov_distparam) / 2)
+ quality = np.matmul(
+ np.matmul((mu_pris_param - mu_distparam), invcov_param), np.transpose((mu_pris_param - mu_distparam)))
+
+ quality = np.sqrt(quality)
+ quality = float(np.squeeze(quality))
+ return quality
+
+
+@METRIC_REGISTRY.register()
+def calculate_niqe(img, crop_border, input_order='HWC', convert_to='y', **kwargs):
+ """Calculate NIQE (Natural Image Quality Evaluator) metric.
+
+ Ref: Making a "Completely Blind" Image Quality Analyzer.
+ This implementation could produce almost the same results as the official
+ MATLAB codes: http://live.ece.utexas.edu/research/quality/niqe_release.zip
+
+ > MATLAB R2021a result for tests/data/baboon.png: 5.72957338 (5.7296)
+ > Our re-implementation result for tests/data/baboon.png: 5.7295763 (5.7296)
+
+ We use the official params estimated from the pristine dataset.
+ We use the recommended block size (96, 96) without overlaps.
+
+ Args:
+ img (ndarray): Input image whose quality needs to be computed.
+ The input image must be in range [0, 255] with float/int type.
+ The input_order of image can be 'HW' or 'HWC' or 'CHW'. (BGR order)
+ If the input order is 'HWC' or 'CHW', it will be converted to gray
+ or Y (of YCbCr) image according to the ``convert_to`` argument.
+ crop_border (int): Cropped pixels in each edge of an image. These
+ pixels are not involved in the metric calculation.
+ input_order (str): Whether the input order is 'HW', 'HWC' or 'CHW'.
+ Default: 'HWC'.
+ convert_to (str): Whether converted to 'y' (of MATLAB YCbCr) or 'gray'.
+ Default: 'y'.
+
+ Returns:
+ float: NIQE result.
+ """
+ ROOT_DIR = os.path.dirname(os.path.abspath(__file__))
+ # we use the official params estimated from the pristine dataset.
+ niqe_pris_params = np.load(os.path.join(ROOT_DIR, 'niqe_pris_params.npz'))
+ mu_pris_param = niqe_pris_params['mu_pris_param']
+ cov_pris_param = niqe_pris_params['cov_pris_param']
+ gaussian_window = niqe_pris_params['gaussian_window']
+
+ img = img.astype(np.float32)
+ if input_order != 'HW':
+ img = reorder_image(img, input_order=input_order)
+ if convert_to == 'y':
+ img = to_y_channel(img)
+ elif convert_to == 'gray':
+ img = cv2.cvtColor(img / 255., cv2.COLOR_BGR2GRAY) * 255.
+ img = np.squeeze(img)
+
+ if crop_border != 0:
+ img = img[crop_border:-crop_border, crop_border:-crop_border]
+
+ # round is necessary for being consistent with MATLAB's result
+ img = img.round()
+
+ niqe_result = niqe(img, mu_pris_param, cov_pris_param, gaussian_window)
+
+ return niqe_result
diff --git a/custom_nodes/ComfyUI-ReActor/r_basicsr/metrics/niqe_pris_params.npz b/custom_nodes/ComfyUI-ReActor/r_basicsr/metrics/niqe_pris_params.npz
new file mode 100644
index 0000000000000000000000000000000000000000..204ddcee87c4cd39aca04a42b539f0a5bfccecc3
Binary files /dev/null and b/custom_nodes/ComfyUI-ReActor/r_basicsr/metrics/niqe_pris_params.npz differ
diff --git a/custom_nodes/ComfyUI-ReActor/r_basicsr/metrics/psnr_ssim.py b/custom_nodes/ComfyUI-ReActor/r_basicsr/metrics/psnr_ssim.py
new file mode 100644
index 0000000000000000000000000000000000000000..79636d7fc983262b23e91c4cd65230c39dcbb5a7
--- /dev/null
+++ b/custom_nodes/ComfyUI-ReActor/r_basicsr/metrics/psnr_ssim.py
@@ -0,0 +1,233 @@
+import cv2
+import numpy as np
+import torch
+import torch.nn.functional as F
+
+from r_basicsr.metrics.metric_util import reorder_image, to_y_channel
+from r_basicsr.utils.color_util import rgb2ycbcr_pt
+from r_basicsr.utils.registry import METRIC_REGISTRY
+
+
+@METRIC_REGISTRY.register()
+def calculate_psnr(img, img2, crop_border, input_order='HWC', test_y_channel=False, **kwargs):
+ """Calculate PSNR (Peak Signal-to-Noise Ratio).
+
+ Ref: https://en.wikipedia.org/wiki/Peak_signal-to-noise_ratio
+
+ Args:
+ img (ndarray): Images with range [0, 255].
+ img2 (ndarray): Images with range [0, 255].
+ crop_border (int): Cropped pixels in each edge of an image. These pixels are not involved in the calculation.
+ input_order (str): Whether the input order is 'HWC' or 'CHW'. Default: 'HWC'.
+ test_y_channel (bool): Test on Y channel of YCbCr. Default: False.
+
+ Returns:
+ float: PSNR result.
+ """
+
+ assert img.shape == img2.shape, (f'Image shapes are different: {img.shape}, {img2.shape}.')
+ if input_order not in ['HWC', 'CHW']:
+ raise ValueError(f'Wrong input_order {input_order}. Supported input_orders are "HWC" and "CHW"')
+ img = reorder_image(img, input_order=input_order)
+ img2 = reorder_image(img2, input_order=input_order)
+
+ if crop_border != 0:
+ img = img[crop_border:-crop_border, crop_border:-crop_border, ...]
+ img2 = img2[crop_border:-crop_border, crop_border:-crop_border, ...]
+
+ if test_y_channel:
+ img = to_y_channel(img)
+ img2 = to_y_channel(img2)
+
+ img = img.astype(np.float64)
+ img2 = img2.astype(np.float64)
+
+ mse = np.mean((img - img2)**2)
+ if mse == 0:
+ return float('inf')
+ return 10. * np.log10(255. * 255. / mse)
+
+
+@METRIC_REGISTRY.register()
+def calculate_psnr_pt(img, img2, crop_border, test_y_channel=False, **kwargs):
+ """Calculate PSNR (Peak Signal-to-Noise Ratio) (PyTorch version).
+
+ Ref: https://en.wikipedia.org/wiki/Peak_signal-to-noise_ratio
+
+ Args:
+ img (Tensor): Images with range [0, 1], shape (n, 3/1, h, w).
+ img2 (Tensor): Images with range [0, 1], shape (n, 3/1, h, w).
+ crop_border (int): Cropped pixels in each edge of an image. These pixels are not involved in the calculation.
+ test_y_channel (bool): Test on Y channel of YCbCr. Default: False.
+
+ Returns:
+ float: PSNR result.
+ """
+
+ assert img.shape == img2.shape, (f'Image shapes are different: {img.shape}, {img2.shape}.')
+
+ if crop_border != 0:
+ img = img[:, :, crop_border:-crop_border, crop_border:-crop_border]
+ img2 = img2[:, :, crop_border:-crop_border, crop_border:-crop_border]
+
+ if test_y_channel:
+ img = rgb2ycbcr_pt(img, y_only=True)
+ img2 = rgb2ycbcr_pt(img2, y_only=True)
+
+ img = img.to(torch.float64)
+ img2 = img2.to(torch.float64)
+
+ mse = torch.mean((img - img2)**2, dim=[1, 2, 3])
+ return 10. * torch.log10(1. / (mse + 1e-8))
+
+
+@METRIC_REGISTRY.register()
+def calculate_ssim(img, img2, crop_border, input_order='HWC', test_y_channel=False, **kwargs):
+ """Calculate SSIM (structural similarity).
+
+ Ref:
+ Image quality assessment: From error visibility to structural similarity
+
+ The results are the same as that of the official released MATLAB code in
+ https://ece.uwaterloo.ca/~z70wang/research/ssim/.
+
+ For three-channel images, SSIM is calculated for each channel and then
+ averaged.
+
+ Args:
+ img (ndarray): Images with range [0, 255].
+ img2 (ndarray): Images with range [0, 255].
+ crop_border (int): Cropped pixels in each edge of an image. These pixels are not involved in the calculation.
+ input_order (str): Whether the input order is 'HWC' or 'CHW'.
+ Default: 'HWC'.
+ test_y_channel (bool): Test on Y channel of YCbCr. Default: False.
+
+ Returns:
+ float: SSIM result.
+ """
+
+ assert img.shape == img2.shape, (f'Image shapes are different: {img.shape}, {img2.shape}.')
+ if input_order not in ['HWC', 'CHW']:
+ raise ValueError(f'Wrong input_order {input_order}. Supported input_orders are "HWC" and "CHW"')
+ img = reorder_image(img, input_order=input_order)
+ img2 = reorder_image(img2, input_order=input_order)
+
+ if crop_border != 0:
+ img = img[crop_border:-crop_border, crop_border:-crop_border, ...]
+ img2 = img2[crop_border:-crop_border, crop_border:-crop_border, ...]
+
+ if test_y_channel:
+ img = to_y_channel(img)
+ img2 = to_y_channel(img2)
+
+ img = img.astype(np.float64)
+ img2 = img2.astype(np.float64)
+
+ ssims = []
+ for i in range(img.shape[2]):
+ ssims.append(_ssim(img[..., i], img2[..., i]))
+ return np.array(ssims).mean()
+
+
+@METRIC_REGISTRY.register()
+def calculate_ssim_pt(img, img2, crop_border, test_y_channel=False, **kwargs):
+ """Calculate SSIM (structural similarity) (PyTorch version).
+
+ Ref:
+ Image quality assessment: From error visibility to structural similarity
+
+ The results are the same as that of the official released MATLAB code in
+ https://ece.uwaterloo.ca/~z70wang/research/ssim/.
+
+ For three-channel images, SSIM is calculated for each channel and then
+ averaged.
+
+ Args:
+ img (Tensor): Images with range [0, 1], shape (n, 3/1, h, w).
+ img2 (Tensor): Images with range [0, 1], shape (n, 3/1, h, w).
+ crop_border (int): Cropped pixels in each edge of an image. These pixels are not involved in the calculation.
+ test_y_channel (bool): Test on Y channel of YCbCr. Default: False.
+
+ Returns:
+ float: SSIM result.
+ """
+
+ assert img.shape == img2.shape, (f'Image shapes are different: {img.shape}, {img2.shape}.')
+
+ if crop_border != 0:
+ img = img[:, :, crop_border:-crop_border, crop_border:-crop_border]
+ img2 = img2[:, :, crop_border:-crop_border, crop_border:-crop_border]
+
+ if test_y_channel:
+ img = rgb2ycbcr_pt(img, y_only=True)
+ img2 = rgb2ycbcr_pt(img2, y_only=True)
+
+ img = img.to(torch.float64)
+ img2 = img2.to(torch.float64)
+
+ ssim = _ssim_pth(img * 255., img2 * 255.)
+ return ssim
+
+
+def _ssim(img, img2):
+ """Calculate SSIM (structural similarity) for one channel images.
+
+ It is called by func:`calculate_ssim`.
+
+ Args:
+ img (ndarray): Images with range [0, 255] with order 'HWC'.
+ img2 (ndarray): Images with range [0, 255] with order 'HWC'.
+
+ Returns:
+ float: SSIM result.
+ """
+
+ c1 = (0.01 * 255)**2
+ c2 = (0.03 * 255)**2
+ kernel = cv2.getGaussianKernel(11, 1.5)
+ window = np.outer(kernel, kernel.transpose())
+
+ mu1 = cv2.filter2D(img, -1, window)[5:-5, 5:-5] # valid mode for window size 11
+ mu2 = cv2.filter2D(img2, -1, window)[5:-5, 5:-5]
+ mu1_sq = mu1**2
+ mu2_sq = mu2**2
+ mu1_mu2 = mu1 * mu2
+ sigma1_sq = cv2.filter2D(img**2, -1, window)[5:-5, 5:-5] - mu1_sq
+ sigma2_sq = cv2.filter2D(img2**2, -1, window)[5:-5, 5:-5] - mu2_sq
+ sigma12 = cv2.filter2D(img * img2, -1, window)[5:-5, 5:-5] - mu1_mu2
+
+ ssim_map = ((2 * mu1_mu2 + c1) * (2 * sigma12 + c2)) / ((mu1_sq + mu2_sq + c1) * (sigma1_sq + sigma2_sq + c2))
+ return ssim_map.mean()
+
+
+def _ssim_pth(img, img2):
+ """Calculate SSIM (structural similarity) (PyTorch version).
+
+ It is called by func:`calculate_ssim_pt`.
+
+ Args:
+ img (Tensor): Images with range [0, 1], shape (n, 3/1, h, w).
+ img2 (Tensor): Images with range [0, 1], shape (n, 3/1, h, w).
+
+ Returns:
+ float: SSIM result.
+ """
+ c1 = (0.01 * 255)**2
+ c2 = (0.03 * 255)**2
+
+ kernel = cv2.getGaussianKernel(11, 1.5)
+ window = np.outer(kernel, kernel.transpose())
+ window = torch.from_numpy(window).view(1, 1, 11, 11).expand(img.size(1), 1, 11, 11).to(img.dtype).to(img.device)
+
+ mu1 = F.conv2d(img, window, stride=1, padding=0, groups=img.shape[1]) # valid mode
+ mu2 = F.conv2d(img2, window, stride=1, padding=0, groups=img2.shape[1]) # valid mode
+ mu1_sq = mu1.pow(2)
+ mu2_sq = mu2.pow(2)
+ mu1_mu2 = mu1 * mu2
+ sigma1_sq = F.conv2d(img * img, window, stride=1, padding=0, groups=img.shape[1]) - mu1_sq
+ sigma2_sq = F.conv2d(img2 * img2, window, stride=1, padding=0, groups=img.shape[1]) - mu2_sq
+ sigma12 = F.conv2d(img * img2, window, stride=1, padding=0, groups=img.shape[1]) - mu1_mu2
+
+ cs_map = (2 * sigma12 + c2) / (sigma1_sq + sigma2_sq + c2)
+ ssim_map = ((2 * mu1_mu2 + c1) / (mu1_sq + mu2_sq + c1)) * cs_map
+ return ssim_map.mean([1, 2, 3])
diff --git a/custom_nodes/ComfyUI-ReActor/r_basicsr/models/__init__.py b/custom_nodes/ComfyUI-ReActor/r_basicsr/models/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..f3096755c58766883a42406a1186e9c16f7de712
--- /dev/null
+++ b/custom_nodes/ComfyUI-ReActor/r_basicsr/models/__init__.py
@@ -0,0 +1,29 @@
+import importlib
+from copy import deepcopy
+from os import path as osp
+
+from r_basicsr.utils import get_root_logger, scandir
+from r_basicsr.utils.registry import MODEL_REGISTRY
+
+__all__ = ['build_model']
+
+# automatically scan and import model modules for registry
+# scan all the files under the 'models' folder and collect files ending with '_model.py'
+model_folder = osp.dirname(osp.abspath(__file__))
+model_filenames = [osp.splitext(osp.basename(v))[0] for v in scandir(model_folder) if v.endswith('_model.py')]
+# import all the model modules
+_model_modules = [importlib.import_module(f'r_basicsr.models.{file_name}') for file_name in model_filenames]
+
+
+def build_model(opt):
+ """Build model from options.
+
+ Args:
+ opt (dict): Configuration. It must contain:
+ model_type (str): Model type.
+ """
+ opt = deepcopy(opt)
+ model = MODEL_REGISTRY.get(opt['model_type'])(opt)
+ logger = get_root_logger()
+ logger.info(f'Model [{model.__class__.__name__}] is created.')
+ return model
diff --git a/custom_nodes/ComfyUI-ReActor/r_basicsr/models/base_model.py b/custom_nodes/ComfyUI-ReActor/r_basicsr/models/base_model.py
new file mode 100644
index 0000000000000000000000000000000000000000..8c79c820dee5636dc4336dead2d9936aa698d881
--- /dev/null
+++ b/custom_nodes/ComfyUI-ReActor/r_basicsr/models/base_model.py
@@ -0,0 +1,380 @@
+import os
+import time
+import torch
+from collections import OrderedDict
+from copy import deepcopy
+from torch.nn.parallel import DataParallel, DistributedDataParallel
+
+from r_basicsr.models import lr_scheduler as lr_scheduler
+from r_basicsr.utils import get_root_logger
+from r_basicsr.utils.dist_util import master_only
+
+
+class BaseModel():
+ """Base model."""
+
+ def __init__(self, opt):
+ self.opt = opt
+ self.device = torch.device('cuda' if opt['num_gpu'] != 0 else 'cpu')
+ self.is_train = opt['is_train']
+ self.schedulers = []
+ self.optimizers = []
+
+ def feed_data(self, data):
+ pass
+
+ def optimize_parameters(self):
+ pass
+
+ def get_current_visuals(self):
+ pass
+
+ def save(self, epoch, current_iter):
+ """Save networks and training state."""
+ pass
+
+ def validation(self, dataloader, current_iter, tb_logger, save_img=False):
+ """Validation function.
+
+ Args:
+ dataloader (torch.utils.data.DataLoader): Validation dataloader.
+ current_iter (int): Current iteration.
+ tb_logger (tensorboard logger): Tensorboard logger.
+ save_img (bool): Whether to save images. Default: False.
+ """
+ if self.opt['dist']:
+ self.dist_validation(dataloader, current_iter, tb_logger, save_img)
+ else:
+ self.nondist_validation(dataloader, current_iter, tb_logger, save_img)
+
+ def _initialize_best_metric_results(self, dataset_name):
+ """Initialize the best metric results dict for recording the best metric value and iteration."""
+ if hasattr(self, 'best_metric_results') and dataset_name in self.best_metric_results:
+ return
+ elif not hasattr(self, 'best_metric_results'):
+ self.best_metric_results = dict()
+
+ # add a dataset record
+ record = dict()
+ for metric, content in self.opt['val']['metrics'].items():
+ better = content.get('better', 'higher')
+ init_val = float('-inf') if better == 'higher' else float('inf')
+ record[metric] = dict(better=better, val=init_val, iter=-1)
+ self.best_metric_results[dataset_name] = record
+
+ def _update_best_metric_result(self, dataset_name, metric, val, current_iter):
+ if self.best_metric_results[dataset_name][metric]['better'] == 'higher':
+ if val >= self.best_metric_results[dataset_name][metric]['val']:
+ self.best_metric_results[dataset_name][metric]['val'] = val
+ self.best_metric_results[dataset_name][metric]['iter'] = current_iter
+ else:
+ if val <= self.best_metric_results[dataset_name][metric]['val']:
+ self.best_metric_results[dataset_name][metric]['val'] = val
+ self.best_metric_results[dataset_name][metric]['iter'] = current_iter
+
+ def model_ema(self, decay=0.999):
+ net_g = self.get_bare_model(self.net_g)
+
+ net_g_params = dict(net_g.named_parameters())
+ net_g_ema_params = dict(self.net_g_ema.named_parameters())
+
+ for k in net_g_ema_params.keys():
+ net_g_ema_params[k].data.mul_(decay).add_(net_g_params[k].data, alpha=1 - decay)
+
+ def get_current_log(self):
+ return self.log_dict
+
+ def model_to_device(self, net):
+ """Model to device. It also warps models with DistributedDataParallel
+ or DataParallel.
+
+ Args:
+ net (nn.Module)
+ """
+ net = net.to(self.device)
+ if self.opt['dist']:
+ find_unused_parameters = self.opt.get('find_unused_parameters', False)
+ net = DistributedDataParallel(
+ net, device_ids=[torch.cuda.current_device()], find_unused_parameters=find_unused_parameters)
+ elif self.opt['num_gpu'] > 1:
+ net = DataParallel(net)
+ return net
+
+ def get_optimizer(self, optim_type, params, lr, **kwargs):
+ if optim_type == 'Adam':
+ optimizer = torch.optim.Adam(params, lr, **kwargs)
+ else:
+ raise NotImplementedError(f'optimizer {optim_type} is not supperted yet.')
+ return optimizer
+
+ def setup_schedulers(self):
+ """Set up schedulers."""
+ train_opt = self.opt['train']
+ scheduler_type = train_opt['scheduler'].pop('type')
+ if scheduler_type in ['MultiStepLR', 'MultiStepRestartLR']:
+ for optimizer in self.optimizers:
+ self.schedulers.append(lr_scheduler.MultiStepRestartLR(optimizer, **train_opt['scheduler']))
+ elif scheduler_type == 'CosineAnnealingRestartLR':
+ for optimizer in self.optimizers:
+ self.schedulers.append(lr_scheduler.CosineAnnealingRestartLR(optimizer, **train_opt['scheduler']))
+ else:
+ raise NotImplementedError(f'Scheduler {scheduler_type} is not implemented yet.')
+
+ def get_bare_model(self, net):
+ """Get bare model, especially under wrapping with
+ DistributedDataParallel or DataParallel.
+ """
+ if isinstance(net, (DataParallel, DistributedDataParallel)):
+ net = net.module
+ return net
+
+ @master_only
+ def print_network(self, net):
+ """Print the str and parameter number of a network.
+
+ Args:
+ net (nn.Module)
+ """
+ if isinstance(net, (DataParallel, DistributedDataParallel)):
+ net_cls_str = f'{net.__class__.__name__} - {net.module.__class__.__name__}'
+ else:
+ net_cls_str = f'{net.__class__.__name__}'
+
+ net = self.get_bare_model(net)
+ net_str = str(net)
+ net_params = sum(map(lambda x: x.numel(), net.parameters()))
+
+ logger = get_root_logger()
+ logger.info(f'Network: {net_cls_str}, with parameters: {net_params:,d}')
+ logger.info(net_str)
+
+ def _set_lr(self, lr_groups_l):
+ """Set learning rate for warm-up.
+
+ Args:
+ lr_groups_l (list): List for lr_groups, each for an optimizer.
+ """
+ for optimizer, lr_groups in zip(self.optimizers, lr_groups_l):
+ for param_group, lr in zip(optimizer.param_groups, lr_groups):
+ param_group['lr'] = lr
+
+ def _get_init_lr(self):
+ """Get the initial lr, which is set by the scheduler.
+ """
+ init_lr_groups_l = []
+ for optimizer in self.optimizers:
+ init_lr_groups_l.append([v['initial_lr'] for v in optimizer.param_groups])
+ return init_lr_groups_l
+
+ def update_learning_rate(self, current_iter, warmup_iter=-1):
+ """Update learning rate.
+
+ Args:
+ current_iter (int): Current iteration.
+ warmup_iter (int): Warm-up iter numbers. -1 for no warm-up.
+ Default: -1.
+ """
+ if current_iter > 1:
+ for scheduler in self.schedulers:
+ scheduler.step()
+ # set up warm-up learning rate
+ if current_iter < warmup_iter:
+ # get initial lr for each group
+ init_lr_g_l = self._get_init_lr()
+ # modify warming-up learning rates
+ # currently only support linearly warm up
+ warm_up_lr_l = []
+ for init_lr_g in init_lr_g_l:
+ warm_up_lr_l.append([v / warmup_iter * current_iter for v in init_lr_g])
+ # set learning rate
+ self._set_lr(warm_up_lr_l)
+
+ def get_current_learning_rate(self):
+ return [param_group['lr'] for param_group in self.optimizers[0].param_groups]
+
+ @master_only
+ def save_network(self, net, net_label, current_iter, param_key='params'):
+ """Save networks.
+
+ Args:
+ net (nn.Module | list[nn.Module]): Network(s) to be saved.
+ net_label (str): Network label.
+ current_iter (int): Current iter number.
+ param_key (str | list[str]): The parameter key(s) to save network.
+ Default: 'params'.
+ """
+ if current_iter == -1:
+ current_iter = 'latest'
+ save_filename = f'{net_label}_{current_iter}.pth'
+ save_path = os.path.join(self.opt['path']['models'], save_filename)
+
+ net = net if isinstance(net, list) else [net]
+ param_key = param_key if isinstance(param_key, list) else [param_key]
+ assert len(net) == len(param_key), 'The lengths of net and param_key should be the same.'
+
+ save_dict = {}
+ for net_, param_key_ in zip(net, param_key):
+ net_ = self.get_bare_model(net_)
+ state_dict = net_.state_dict()
+ for key, param in state_dict.items():
+ if key.startswith('module.'): # remove unnecessary 'module.'
+ key = key[7:]
+ state_dict[key] = param.cpu()
+ save_dict[param_key_] = state_dict
+
+ # avoid occasional writing errors
+ retry = 3
+ while retry > 0:
+ try:
+ torch.save(save_dict, save_path)
+ except Exception as e:
+ logger = get_root_logger()
+ logger.warning(f'Save model error: {e}, remaining retry times: {retry - 1}')
+ time.sleep(1)
+ else:
+ break
+ finally:
+ retry -= 1
+ if retry == 0:
+ logger.warning(f'Still cannot save {save_path}. Just ignore it.')
+ # raise IOError(f'Cannot save {save_path}.')
+
+ def _print_different_keys_loading(self, crt_net, load_net, strict=True):
+ """Print keys with different name or different size when loading models.
+
+ 1. Print keys with different names.
+ 2. If strict=False, print the same key but with different tensor size.
+ It also ignore these keys with different sizes (not load).
+
+ Args:
+ crt_net (torch model): Current network.
+ load_net (dict): Loaded network.
+ strict (bool): Whether strictly loaded. Default: True.
+ """
+ crt_net = self.get_bare_model(crt_net)
+ crt_net = crt_net.state_dict()
+ crt_net_keys = set(crt_net.keys())
+ load_net_keys = set(load_net.keys())
+
+ logger = get_root_logger()
+ if crt_net_keys != load_net_keys:
+ logger.warning('Current net - loaded net:')
+ for v in sorted(list(crt_net_keys - load_net_keys)):
+ logger.warning(f' {v}')
+ logger.warning('Loaded net - current net:')
+ for v in sorted(list(load_net_keys - crt_net_keys)):
+ logger.warning(f' {v}')
+
+ # check the size for the same keys
+ if not strict:
+ common_keys = crt_net_keys & load_net_keys
+ for k in common_keys:
+ if crt_net[k].size() != load_net[k].size():
+ logger.warning(f'Size different, ignore [{k}]: crt_net: '
+ f'{crt_net[k].shape}; load_net: {load_net[k].shape}')
+ load_net[k + '.ignore'] = load_net.pop(k)
+
+ def load_network(self, net, load_path, strict=True, param_key='params'):
+ """Load network.
+
+ Args:
+ load_path (str): The path of networks to be loaded.
+ net (nn.Module): Network.
+ strict (bool): Whether strictly loaded.
+ param_key (str): The parameter key of loaded network. If set to
+ None, use the root 'path'.
+ Default: 'params'.
+ """
+ logger = get_root_logger()
+ net = self.get_bare_model(net)
+ load_net = torch.load(load_path, map_location=lambda storage, loc: storage)
+ if param_key is not None:
+ if param_key not in load_net and 'params' in load_net:
+ param_key = 'params'
+ logger.info('Loading: params_ema does not exist, use params.')
+ load_net = load_net[param_key]
+ logger.info(f'Loading {net.__class__.__name__} model from {load_path}, with param key: [{param_key}].')
+ # remove unnecessary 'module.'
+ for k, v in deepcopy(load_net).items():
+ if k.startswith('module.'):
+ load_net[k[7:]] = v
+ load_net.pop(k)
+ self._print_different_keys_loading(net, load_net, strict)
+ net.load_state_dict(load_net, strict=strict)
+
+ @master_only
+ def save_training_state(self, epoch, current_iter):
+ """Save training states during training, which will be used for
+ resuming.
+
+ Args:
+ epoch (int): Current epoch.
+ current_iter (int): Current iteration.
+ """
+ if current_iter != -1:
+ state = {'epoch': epoch, 'iter': current_iter, 'optimizers': [], 'schedulers': []}
+ for o in self.optimizers:
+ state['optimizers'].append(o.state_dict())
+ for s in self.schedulers:
+ state['schedulers'].append(s.state_dict())
+ save_filename = f'{current_iter}.state'
+ save_path = os.path.join(self.opt['path']['training_states'], save_filename)
+
+ # avoid occasional writing errors
+ retry = 3
+ while retry > 0:
+ try:
+ torch.save(state, save_path)
+ except Exception as e:
+ logger = get_root_logger()
+ logger.warning(f'Save training state error: {e}, remaining retry times: {retry - 1}')
+ time.sleep(1)
+ else:
+ break
+ finally:
+ retry -= 1
+ if retry == 0:
+ logger.warning(f'Still cannot save {save_path}. Just ignore it.')
+ # raise IOError(f'Cannot save {save_path}.')
+
+ def resume_training(self, resume_state):
+ """Reload the optimizers and schedulers for resumed training.
+
+ Args:
+ resume_state (dict): Resume state.
+ """
+ resume_optimizers = resume_state['optimizers']
+ resume_schedulers = resume_state['schedulers']
+ assert len(resume_optimizers) == len(self.optimizers), 'Wrong lengths of optimizers'
+ assert len(resume_schedulers) == len(self.schedulers), 'Wrong lengths of schedulers'
+ for i, o in enumerate(resume_optimizers):
+ self.optimizers[i].load_state_dict(o)
+ for i, s in enumerate(resume_schedulers):
+ self.schedulers[i].load_state_dict(s)
+
+ def reduce_loss_dict(self, loss_dict):
+ """reduce loss dict.
+
+ In distributed training, it averages the losses among different GPUs .
+
+ Args:
+ loss_dict (OrderedDict): Loss dict.
+ """
+ with torch.no_grad():
+ if self.opt['dist']:
+ keys = []
+ losses = []
+ for name, value in loss_dict.items():
+ keys.append(name)
+ losses.append(value)
+ losses = torch.stack(losses, 0)
+ torch.distributed.reduce(losses, dst=0)
+ if self.opt['rank'] == 0:
+ losses /= self.opt['world_size']
+ loss_dict = {key: loss for key, loss in zip(keys, losses)}
+
+ log_dict = OrderedDict()
+ for name, value in loss_dict.items():
+ log_dict[name] = value.mean().item()
+
+ return log_dict
diff --git a/custom_nodes/ComfyUI-ReActor/r_basicsr/models/edvr_model.py b/custom_nodes/ComfyUI-ReActor/r_basicsr/models/edvr_model.py
new file mode 100644
index 0000000000000000000000000000000000000000..af2e302947083871922c145fe38b46580673c318
--- /dev/null
+++ b/custom_nodes/ComfyUI-ReActor/r_basicsr/models/edvr_model.py
@@ -0,0 +1,62 @@
+from r_basicsr.utils import get_root_logger
+from r_basicsr.utils.registry import MODEL_REGISTRY
+from .video_base_model import VideoBaseModel
+
+
+@MODEL_REGISTRY.register()
+class EDVRModel(VideoBaseModel):
+ """EDVR Model.
+
+ Paper: EDVR: Video Restoration with Enhanced Deformable Convolutional Networks. # noqa: E501
+ """
+
+ def __init__(self, opt):
+ super(EDVRModel, self).__init__(opt)
+ if self.is_train:
+ self.train_tsa_iter = opt['train'].get('tsa_iter')
+
+ def setup_optimizers(self):
+ train_opt = self.opt['train']
+ dcn_lr_mul = train_opt.get('dcn_lr_mul', 1)
+ logger = get_root_logger()
+ logger.info(f'Multiple the learning rate for dcn with {dcn_lr_mul}.')
+ if dcn_lr_mul == 1:
+ optim_params = self.net_g.parameters()
+ else: # separate dcn params and normal params for different lr
+ normal_params = []
+ dcn_params = []
+ for name, param in self.net_g.named_parameters():
+ if 'dcn' in name:
+ dcn_params.append(param)
+ else:
+ normal_params.append(param)
+ optim_params = [
+ { # add normal params first
+ 'params': normal_params,
+ 'lr': train_opt['optim_g']['lr']
+ },
+ {
+ 'params': dcn_params,
+ 'lr': train_opt['optim_g']['lr'] * dcn_lr_mul
+ },
+ ]
+
+ optim_type = train_opt['optim_g'].pop('type')
+ self.optimizer_g = self.get_optimizer(optim_type, optim_params, **train_opt['optim_g'])
+ self.optimizers.append(self.optimizer_g)
+
+ def optimize_parameters(self, current_iter):
+ if self.train_tsa_iter:
+ if current_iter == 1:
+ logger = get_root_logger()
+ logger.info(f'Only train TSA module for {self.train_tsa_iter} iters.')
+ for name, param in self.net_g.named_parameters():
+ if 'fusion' not in name:
+ param.requires_grad = False
+ elif current_iter == self.train_tsa_iter:
+ logger = get_root_logger()
+ logger.warning('Train all the parameters.')
+ for param in self.net_g.parameters():
+ param.requires_grad = True
+
+ super(EDVRModel, self).optimize_parameters(current_iter)
diff --git a/custom_nodes/ComfyUI-ReActor/r_basicsr/models/esrgan_model.py b/custom_nodes/ComfyUI-ReActor/r_basicsr/models/esrgan_model.py
new file mode 100644
index 0000000000000000000000000000000000000000..ae51e979e4588f245f241a233060ac9a2a9731b0
--- /dev/null
+++ b/custom_nodes/ComfyUI-ReActor/r_basicsr/models/esrgan_model.py
@@ -0,0 +1,83 @@
+import torch
+from collections import OrderedDict
+
+from r_basicsr.utils.registry import MODEL_REGISTRY
+from .srgan_model import SRGANModel
+
+
+@MODEL_REGISTRY.register()
+class ESRGANModel(SRGANModel):
+ """ESRGAN model for single image super-resolution."""
+
+ def optimize_parameters(self, current_iter):
+ # optimize net_g
+ for p in self.net_d.parameters():
+ p.requires_grad = False
+
+ self.optimizer_g.zero_grad()
+ self.output = self.net_g(self.lq)
+
+ l_g_total = 0
+ loss_dict = OrderedDict()
+ if (current_iter % self.net_d_iters == 0 and current_iter > self.net_d_init_iters):
+ # pixel loss
+ if self.cri_pix:
+ l_g_pix = self.cri_pix(self.output, self.gt)
+ l_g_total += l_g_pix
+ loss_dict['l_g_pix'] = l_g_pix
+ # perceptual loss
+ if self.cri_perceptual:
+ l_g_percep, l_g_style = self.cri_perceptual(self.output, self.gt)
+ if l_g_percep is not None:
+ l_g_total += l_g_percep
+ loss_dict['l_g_percep'] = l_g_percep
+ if l_g_style is not None:
+ l_g_total += l_g_style
+ loss_dict['l_g_style'] = l_g_style
+ # gan loss (relativistic gan)
+ real_d_pred = self.net_d(self.gt).detach()
+ fake_g_pred = self.net_d(self.output)
+ l_g_real = self.cri_gan(real_d_pred - torch.mean(fake_g_pred), False, is_disc=False)
+ l_g_fake = self.cri_gan(fake_g_pred - torch.mean(real_d_pred), True, is_disc=False)
+ l_g_gan = (l_g_real + l_g_fake) / 2
+
+ l_g_total += l_g_gan
+ loss_dict['l_g_gan'] = l_g_gan
+
+ l_g_total.backward()
+ self.optimizer_g.step()
+
+ # optimize net_d
+ for p in self.net_d.parameters():
+ p.requires_grad = True
+
+ self.optimizer_d.zero_grad()
+ # gan loss (relativistic gan)
+
+ # In order to avoid the error in distributed training:
+ # "Error detected in CudnnBatchNormBackward: RuntimeError: one of
+ # the variables needed for gradient computation has been modified by
+ # an inplace operation",
+ # we separate the backwards for real and fake, and also detach the
+ # tensor for calculating mean.
+
+ # real
+ fake_d_pred = self.net_d(self.output).detach()
+ real_d_pred = self.net_d(self.gt)
+ l_d_real = self.cri_gan(real_d_pred - torch.mean(fake_d_pred), True, is_disc=True) * 0.5
+ l_d_real.backward()
+ # fake
+ fake_d_pred = self.net_d(self.output.detach())
+ l_d_fake = self.cri_gan(fake_d_pred - torch.mean(real_d_pred.detach()), False, is_disc=True) * 0.5
+ l_d_fake.backward()
+ self.optimizer_d.step()
+
+ loss_dict['l_d_real'] = l_d_real
+ loss_dict['l_d_fake'] = l_d_fake
+ loss_dict['out_d_real'] = torch.mean(real_d_pred.detach())
+ loss_dict['out_d_fake'] = torch.mean(fake_d_pred.detach())
+
+ self.log_dict = self.reduce_loss_dict(loss_dict)
+
+ if self.ema_decay > 0:
+ self.model_ema(decay=self.ema_decay)
diff --git a/custom_nodes/ComfyUI-ReActor/r_basicsr/models/hifacegan_model.py b/custom_nodes/ComfyUI-ReActor/r_basicsr/models/hifacegan_model.py
new file mode 100644
index 0000000000000000000000000000000000000000..f22a13886db2bf53fc62380d63c4fd05ac4fb246
--- /dev/null
+++ b/custom_nodes/ComfyUI-ReActor/r_basicsr/models/hifacegan_model.py
@@ -0,0 +1,288 @@
+import torch
+from collections import OrderedDict
+from os import path as osp
+from tqdm import tqdm
+
+from r_basicsr.archs import build_network
+from r_basicsr.losses import build_loss
+from r_basicsr.metrics import calculate_metric
+from r_basicsr.utils import imwrite, tensor2img
+from r_basicsr.utils.registry import MODEL_REGISTRY
+from .sr_model import SRModel
+
+
+@MODEL_REGISTRY.register()
+class HiFaceGANModel(SRModel):
+ """HiFaceGAN model for generic-purpose face restoration.
+ No prior modeling required, works for any degradations.
+ Currently doesn't support EMA for inference.
+ """
+
+ def init_training_settings(self):
+
+ train_opt = self.opt['train']
+ self.ema_decay = train_opt.get('ema_decay', 0)
+ if self.ema_decay > 0:
+ raise (NotImplementedError('HiFaceGAN does not support EMA now. Pass'))
+
+ self.net_g.train()
+
+ self.net_d = build_network(self.opt['network_d'])
+ self.net_d = self.model_to_device(self.net_d)
+ self.print_network(self.net_d)
+
+ # define losses
+ # HiFaceGAN does not use pixel loss by default
+ if train_opt.get('pixel_opt'):
+ self.cri_pix = build_loss(train_opt['pixel_opt']).to(self.device)
+ else:
+ self.cri_pix = None
+
+ if train_opt.get('perceptual_opt'):
+ self.cri_perceptual = build_loss(train_opt['perceptual_opt']).to(self.device)
+ else:
+ self.cri_perceptual = None
+
+ if train_opt.get('feature_matching_opt'):
+ self.cri_feat = build_loss(train_opt['feature_matching_opt']).to(self.device)
+ else:
+ self.cri_feat = None
+
+ if self.cri_pix is None and self.cri_perceptual is None:
+ raise ValueError('Both pixel and perceptual losses are None.')
+
+ if train_opt.get('gan_opt'):
+ self.cri_gan = build_loss(train_opt['gan_opt']).to(self.device)
+
+ self.net_d_iters = train_opt.get('net_d_iters', 1)
+ self.net_d_init_iters = train_opt.get('net_d_init_iters', 0)
+ # set up optimizers and schedulers
+ self.setup_optimizers()
+ self.setup_schedulers()
+
+ def setup_optimizers(self):
+ train_opt = self.opt['train']
+ # optimizer g
+ optim_type = train_opt['optim_g'].pop('type')
+ self.optimizer_g = self.get_optimizer(optim_type, self.net_g.parameters(), **train_opt['optim_g'])
+ self.optimizers.append(self.optimizer_g)
+ # optimizer d
+ optim_type = train_opt['optim_d'].pop('type')
+ self.optimizer_d = self.get_optimizer(optim_type, self.net_d.parameters(), **train_opt['optim_d'])
+ self.optimizers.append(self.optimizer_d)
+
+ def discriminate(self, input_lq, output, ground_truth):
+ """
+ This is a conditional (on the input) discriminator
+ In Batch Normalization, the fake and real images are
+ recommended to be in the same batch to avoid disparate
+ statistics in fake and real images.
+ So both fake and real images are fed to D all at once.
+ """
+ h, w = output.shape[-2:]
+ if output.shape[-2:] != input_lq.shape[-2:]:
+ lq = torch.nn.functional.interpolate(input_lq, (h, w))
+ real = torch.nn.functional.interpolate(ground_truth, (h, w))
+ fake_concat = torch.cat([lq, output], dim=1)
+ real_concat = torch.cat([lq, real], dim=1)
+ else:
+ fake_concat = torch.cat([input_lq, output], dim=1)
+ real_concat = torch.cat([input_lq, ground_truth], dim=1)
+
+ fake_and_real = torch.cat([fake_concat, real_concat], dim=0)
+ discriminator_out = self.net_d(fake_and_real)
+ pred_fake, pred_real = self._divide_pred(discriminator_out)
+ return pred_fake, pred_real
+
+ @staticmethod
+ def _divide_pred(pred):
+ """
+ Take the prediction of fake and real images from the combined batch.
+ The prediction contains the intermediate outputs of multiscale GAN,
+ so it's usually a list
+ """
+ if type(pred) == list:
+ fake = []
+ real = []
+ for p in pred:
+ fake.append([tensor[:tensor.size(0) // 2] for tensor in p])
+ real.append([tensor[tensor.size(0) // 2:] for tensor in p])
+ else:
+ fake = pred[:pred.size(0) // 2]
+ real = pred[pred.size(0) // 2:]
+
+ return fake, real
+
+ def optimize_parameters(self, current_iter):
+ # optimize net_g
+ for p in self.net_d.parameters():
+ p.requires_grad = False
+
+ self.optimizer_g.zero_grad()
+ self.output = self.net_g(self.lq)
+
+ l_g_total = 0
+ loss_dict = OrderedDict()
+
+ if (current_iter % self.net_d_iters == 0 and current_iter > self.net_d_init_iters):
+ # pixel loss
+ if self.cri_pix:
+ l_g_pix = self.cri_pix(self.output, self.gt)
+ l_g_total += l_g_pix
+ loss_dict['l_g_pix'] = l_g_pix
+
+ # perceptual loss
+ if self.cri_perceptual:
+ l_g_percep, l_g_style = self.cri_perceptual(self.output, self.gt)
+ if l_g_percep is not None:
+ l_g_total += l_g_percep
+ loss_dict['l_g_percep'] = l_g_percep
+ if l_g_style is not None:
+ l_g_total += l_g_style
+ loss_dict['l_g_style'] = l_g_style
+
+ # Requires real prediction for feature matching loss
+ pred_fake, pred_real = self.discriminate(self.lq, self.output, self.gt)
+ l_g_gan = self.cri_gan(pred_fake, True, is_disc=False)
+ l_g_total += l_g_gan
+ loss_dict['l_g_gan'] = l_g_gan
+
+ # feature matching loss
+ if self.cri_feat:
+ l_g_feat = self.cri_feat(pred_fake, pred_real)
+ l_g_total += l_g_feat
+ loss_dict['l_g_feat'] = l_g_feat
+
+ l_g_total.backward()
+ self.optimizer_g.step()
+
+ # optimize net_d
+ for p in self.net_d.parameters():
+ p.requires_grad = True
+
+ self.optimizer_d.zero_grad()
+ # TODO: Benchmark test between HiFaceGAN and SRGAN implementation:
+ # SRGAN use the same fake output for discriminator update
+ # while HiFaceGAN regenerate a new output using updated net_g
+ # This should not make too much difference though. Stick to SRGAN now.
+ # -------------------------------------------------------------------
+ # ---------- Below are original HiFaceGAN code snippet --------------
+ # -------------------------------------------------------------------
+ # with torch.no_grad():
+ # fake_image = self.net_g(self.lq)
+ # fake_image = fake_image.detach()
+ # fake_image.requires_grad_()
+ # pred_fake, pred_real = self.discriminate(self.lq, fake_image, self.gt)
+
+ # real
+ pred_fake, pred_real = self.discriminate(self.lq, self.output.detach(), self.gt)
+ l_d_real = self.cri_gan(pred_real, True, is_disc=True)
+ loss_dict['l_d_real'] = l_d_real
+ # fake
+ l_d_fake = self.cri_gan(pred_fake, False, is_disc=True)
+ loss_dict['l_d_fake'] = l_d_fake
+
+ l_d_total = (l_d_real + l_d_fake) / 2
+ l_d_total.backward()
+ self.optimizer_d.step()
+
+ self.log_dict = self.reduce_loss_dict(loss_dict)
+
+ if self.ema_decay > 0:
+ print('HiFaceGAN does not support EMA now. pass')
+
+ def validation(self, dataloader, current_iter, tb_logger, save_img=False):
+ """
+ Warning: HiFaceGAN requires train() mode even for validation
+ For more info, see https://github.com/Lotayou/Face-Renovation/issues/31
+
+ Args:
+ dataloader (torch.utils.data.DataLoader): Validation dataloader.
+ current_iter (int): Current iteration.
+ tb_logger (tensorboard logger): Tensorboard logger.
+ save_img (bool): Whether to save images. Default: False.
+ """
+
+ if self.opt['network_g']['type'] in ('HiFaceGAN', 'SPADEGenerator'):
+ self.net_g.train()
+
+ if self.opt['dist']:
+ self.dist_validation(dataloader, current_iter, tb_logger, save_img)
+ else:
+ print('In HiFaceGANModel: The new metrics package is under development.' +
+ 'Using super method now (Only PSNR & SSIM are supported)')
+ super().nondist_validation(dataloader, current_iter, tb_logger, save_img)
+
+ def nondist_validation(self, dataloader, current_iter, tb_logger, save_img):
+ """
+ TODO: Validation using updated metric system
+ The metrics are now evaluated after all images have been tested
+ This allows batch processing, and also allows evaluation of
+ distributional metrics, such as:
+
+ @ Frechet Inception Distance: FID
+ @ Maximum Mean Discrepancy: MMD
+
+ Warning:
+ Need careful batch management for different inference settings.
+
+ """
+ dataset_name = dataloader.dataset.opt['name']
+ with_metrics = self.opt['val'].get('metrics') is not None
+ if with_metrics:
+ self.metric_results = dict() # {metric: 0 for metric in self.opt['val']['metrics'].keys()}
+ sr_tensors = []
+ gt_tensors = []
+
+ pbar = tqdm(total=len(dataloader), unit='image')
+ for val_data in dataloader:
+ img_name = osp.splitext(osp.basename(val_data['lq_path'][0]))[0]
+ self.feed_data(val_data)
+ self.test()
+
+ visuals = self.get_current_visuals() # detached cpu tensor, non-squeeze
+ sr_tensors.append(visuals['result'])
+ if 'gt' in visuals:
+ gt_tensors.append(visuals['gt'])
+ del self.gt
+
+ # tentative for out of GPU memory
+ del self.lq
+ del self.output
+ torch.cuda.empty_cache()
+
+ if save_img:
+ if self.opt['is_train']:
+ save_img_path = osp.join(self.opt['path']['visualization'], img_name,
+ f'{img_name}_{current_iter}.png')
+ else:
+ if self.opt['val']['suffix']:
+ save_img_path = osp.join(self.opt['path']['visualization'], dataset_name,
+ f'{img_name}_{self.opt["val"]["suffix"]}.png')
+ else:
+ save_img_path = osp.join(self.opt['path']['visualization'], dataset_name,
+ f'{img_name}_{self.opt["name"]}.png')
+
+ imwrite(tensor2img(visuals['result']), save_img_path)
+
+ pbar.update(1)
+ pbar.set_description(f'Test {img_name}')
+ pbar.close()
+
+ if with_metrics:
+ sr_pack = torch.cat(sr_tensors, dim=0)
+ gt_pack = torch.cat(gt_tensors, dim=0)
+ # calculate metrics
+ for name, opt_ in self.opt['val']['metrics'].items():
+ # The new metric caller automatically returns mean value
+ # FIXME: ERROR: calculate_metric only supports two arguments. Now the codes cannot be successfully run
+ self.metric_results[name] = calculate_metric(dict(sr_pack=sr_pack, gt_pack=gt_pack), opt_)
+ self._log_validation_metric_values(current_iter, dataset_name, tb_logger)
+
+ def save(self, epoch, current_iter):
+ if hasattr(self, 'net_g_ema'):
+ print('HiFaceGAN does not support EMA now. Fallback to normal mode.')
+
+ self.save_network(self.net_g, 'net_g', current_iter)
+ self.save_network(self.net_d, 'net_d', current_iter)
+ self.save_training_state(epoch, current_iter)
diff --git a/custom_nodes/ComfyUI-ReActor/r_basicsr/models/lr_scheduler.py b/custom_nodes/ComfyUI-ReActor/r_basicsr/models/lr_scheduler.py
new file mode 100644
index 0000000000000000000000000000000000000000..11e1c6c7a74f5233accda52370f92681d3d3cecf
--- /dev/null
+++ b/custom_nodes/ComfyUI-ReActor/r_basicsr/models/lr_scheduler.py
@@ -0,0 +1,96 @@
+import math
+from collections import Counter
+from torch.optim.lr_scheduler import _LRScheduler
+
+
+class MultiStepRestartLR(_LRScheduler):
+ """ MultiStep with restarts learning rate scheme.
+
+ Args:
+ optimizer (torch.nn.optimizer): Torch optimizer.
+ milestones (list): Iterations that will decrease learning rate.
+ gamma (float): Decrease ratio. Default: 0.1.
+ restarts (list): Restart iterations. Default: [0].
+ restart_weights (list): Restart weights at each restart iteration.
+ Default: [1].
+ last_epoch (int): Used in _LRScheduler. Default: -1.
+ """
+
+ def __init__(self, optimizer, milestones, gamma=0.1, restarts=(0, ), restart_weights=(1, ), last_epoch=-1):
+ self.milestones = Counter(milestones)
+ self.gamma = gamma
+ self.restarts = restarts
+ self.restart_weights = restart_weights
+ assert len(self.restarts) == len(self.restart_weights), 'restarts and their weights do not match.'
+ super(MultiStepRestartLR, self).__init__(optimizer, last_epoch)
+
+ def get_lr(self):
+ if self.last_epoch in self.restarts:
+ weight = self.restart_weights[self.restarts.index(self.last_epoch)]
+ return [group['initial_lr'] * weight for group in self.optimizer.param_groups]
+ if self.last_epoch not in self.milestones:
+ return [group['lr'] for group in self.optimizer.param_groups]
+ return [group['lr'] * self.gamma**self.milestones[self.last_epoch] for group in self.optimizer.param_groups]
+
+
+def get_position_from_periods(iteration, cumulative_period):
+ """Get the position from a period list.
+
+ It will return the index of the right-closest number in the period list.
+ For example, the cumulative_period = [100, 200, 300, 400],
+ if iteration == 50, return 0;
+ if iteration == 210, return 2;
+ if iteration == 300, return 2.
+
+ Args:
+ iteration (int): Current iteration.
+ cumulative_period (list[int]): Cumulative period list.
+
+ Returns:
+ int: The position of the right-closest number in the period list.
+ """
+ for i, period in enumerate(cumulative_period):
+ if iteration <= period:
+ return i
+
+
+class CosineAnnealingRestartLR(_LRScheduler):
+ """ Cosine annealing with restarts learning rate scheme.
+
+ An example of config:
+ periods = [10, 10, 10, 10]
+ restart_weights = [1, 0.5, 0.5, 0.5]
+ eta_min=1e-7
+
+ It has four cycles, each has 10 iterations. At 10th, 20th, 30th, the
+ scheduler will restart with the weights in restart_weights.
+
+ Args:
+ optimizer (torch.nn.optimizer): Torch optimizer.
+ periods (list): Period for each cosine anneling cycle.
+ restart_weights (list): Restart weights at each restart iteration.
+ Default: [1].
+ eta_min (float): The minimum lr. Default: 0.
+ last_epoch (int): Used in _LRScheduler. Default: -1.
+ """
+
+ def __init__(self, optimizer, periods, restart_weights=(1, ), eta_min=0, last_epoch=-1):
+ self.periods = periods
+ self.restart_weights = restart_weights
+ self.eta_min = eta_min
+ assert (len(self.periods) == len(
+ self.restart_weights)), 'periods and restart_weights should have the same length.'
+ self.cumulative_period = [sum(self.periods[0:i + 1]) for i in range(0, len(self.periods))]
+ super(CosineAnnealingRestartLR, self).__init__(optimizer, last_epoch)
+
+ def get_lr(self):
+ idx = get_position_from_periods(self.last_epoch, self.cumulative_period)
+ current_weight = self.restart_weights[idx]
+ nearest_restart = 0 if idx == 0 else self.cumulative_period[idx - 1]
+ current_period = self.periods[idx]
+
+ return [
+ self.eta_min + current_weight * 0.5 * (base_lr - self.eta_min) *
+ (1 + math.cos(math.pi * ((self.last_epoch - nearest_restart) / current_period)))
+ for base_lr in self.base_lrs
+ ]
diff --git a/custom_nodes/ComfyUI-ReActor/r_basicsr/models/realesrgan_model.py b/custom_nodes/ComfyUI-ReActor/r_basicsr/models/realesrgan_model.py
new file mode 100644
index 0000000000000000000000000000000000000000..54cde8f11bc489788d61acd61c5aaf71c51088e3
--- /dev/null
+++ b/custom_nodes/ComfyUI-ReActor/r_basicsr/models/realesrgan_model.py
@@ -0,0 +1,267 @@
+import numpy as np
+import random
+import torch
+from collections import OrderedDict
+from torch.nn import functional as F
+
+from r_basicsr.data.degradations import random_add_gaussian_noise_pt, random_add_poisson_noise_pt
+from r_basicsr.data.transforms import paired_random_crop
+from r_basicsr.losses.loss_util import get_refined_artifact_map
+from r_basicsr.models.srgan_model import SRGANModel
+from r_basicsr.utils import DiffJPEG, USMSharp
+from r_basicsr.utils.img_process_util import filter2D
+from r_basicsr.utils.registry import MODEL_REGISTRY
+
+
+@MODEL_REGISTRY.register(suffix='basicsr')
+class RealESRGANModel(SRGANModel):
+ """RealESRGAN Model for Real-ESRGAN: Training Real-World Blind Super-Resolution with Pure Synthetic Data.
+
+ It mainly performs:
+ 1. randomly synthesize LQ images in GPU tensors
+ 2. optimize the networks with GAN training.
+ """
+
+ def __init__(self, opt):
+ super(RealESRGANModel, self).__init__(opt)
+ self.jpeger = DiffJPEG(differentiable=False).cuda() # simulate JPEG compression artifacts
+ self.usm_sharpener = USMSharp().cuda() # do usm sharpening
+ self.queue_size = opt.get('queue_size', 180)
+
+ @torch.no_grad()
+ def _dequeue_and_enqueue(self):
+ """It is the training pair pool for increasing the diversity in a batch.
+
+ Batch processing limits the diversity of synthetic degradations in a batch. For example, samples in a
+ batch could not have different resize scaling factors. Therefore, we employ this training pair pool
+ to increase the degradation diversity in a batch.
+ """
+ # initialize
+ b, c, h, w = self.lq.size()
+ if not hasattr(self, 'queue_lr'):
+ assert self.queue_size % b == 0, f'queue size {self.queue_size} should be divisible by batch size {b}'
+ self.queue_lr = torch.zeros(self.queue_size, c, h, w).cuda()
+ _, c, h, w = self.gt.size()
+ self.queue_gt = torch.zeros(self.queue_size, c, h, w).cuda()
+ self.queue_ptr = 0
+ if self.queue_ptr == self.queue_size: # the pool is full
+ # do dequeue and enqueue
+ # shuffle
+ idx = torch.randperm(self.queue_size)
+ self.queue_lr = self.queue_lr[idx]
+ self.queue_gt = self.queue_gt[idx]
+ # get first b samples
+ lq_dequeue = self.queue_lr[0:b, :, :, :].clone()
+ gt_dequeue = self.queue_gt[0:b, :, :, :].clone()
+ # update the queue
+ self.queue_lr[0:b, :, :, :] = self.lq.clone()
+ self.queue_gt[0:b, :, :, :] = self.gt.clone()
+
+ self.lq = lq_dequeue
+ self.gt = gt_dequeue
+ else:
+ # only do enqueue
+ self.queue_lr[self.queue_ptr:self.queue_ptr + b, :, :, :] = self.lq.clone()
+ self.queue_gt[self.queue_ptr:self.queue_ptr + b, :, :, :] = self.gt.clone()
+ self.queue_ptr = self.queue_ptr + b
+
+ @torch.no_grad()
+ def feed_data(self, data):
+ """Accept data from dataloader, and then add two-order degradations to obtain LQ images.
+ """
+ if self.is_train and self.opt.get('high_order_degradation', True):
+ # training data synthesis
+ self.gt = data['gt'].to(self.device)
+ self.gt_usm = self.usm_sharpener(self.gt)
+
+ self.kernel1 = data['kernel1'].to(self.device)
+ self.kernel2 = data['kernel2'].to(self.device)
+ self.sinc_kernel = data['sinc_kernel'].to(self.device)
+
+ ori_h, ori_w = self.gt.size()[2:4]
+
+ # ----------------------- The first degradation process ----------------------- #
+ # blur
+ out = filter2D(self.gt_usm, self.kernel1)
+ # random resize
+ updown_type = random.choices(['up', 'down', 'keep'], self.opt['resize_prob'])[0]
+ if updown_type == 'up':
+ scale = np.random.uniform(1, self.opt['resize_range'][1])
+ elif updown_type == 'down':
+ scale = np.random.uniform(self.opt['resize_range'][0], 1)
+ else:
+ scale = 1
+ mode = random.choice(['area', 'bilinear', 'bicubic'])
+ out = F.interpolate(out, scale_factor=scale, mode=mode)
+ # add noise
+ gray_noise_prob = self.opt['gray_noise_prob']
+ if np.random.uniform() < self.opt['gaussian_noise_prob']:
+ out = random_add_gaussian_noise_pt(
+ out, sigma_range=self.opt['noise_range'], clip=True, rounds=False, gray_prob=gray_noise_prob)
+ else:
+ out = random_add_poisson_noise_pt(
+ out,
+ scale_range=self.opt['poisson_scale_range'],
+ gray_prob=gray_noise_prob,
+ clip=True,
+ rounds=False)
+ # JPEG compression
+ jpeg_p = out.new_zeros(out.size(0)).uniform_(*self.opt['jpeg_range'])
+ out = torch.clamp(out, 0, 1) # clamp to [0, 1], otherwise JPEGer will result in unpleasant artifacts
+ out = self.jpeger(out, quality=jpeg_p)
+
+ # ----------------------- The second degradation process ----------------------- #
+ # blur
+ if np.random.uniform() < self.opt['second_blur_prob']:
+ out = filter2D(out, self.kernel2)
+ # random resize
+ updown_type = random.choices(['up', 'down', 'keep'], self.opt['resize_prob2'])[0]
+ if updown_type == 'up':
+ scale = np.random.uniform(1, self.opt['resize_range2'][1])
+ elif updown_type == 'down':
+ scale = np.random.uniform(self.opt['resize_range2'][0], 1)
+ else:
+ scale = 1
+ mode = random.choice(['area', 'bilinear', 'bicubic'])
+ out = F.interpolate(
+ out, size=(int(ori_h / self.opt['scale'] * scale), int(ori_w / self.opt['scale'] * scale)), mode=mode)
+ # add noise
+ gray_noise_prob = self.opt['gray_noise_prob2']
+ if np.random.uniform() < self.opt['gaussian_noise_prob2']:
+ out = random_add_gaussian_noise_pt(
+ out, sigma_range=self.opt['noise_range2'], clip=True, rounds=False, gray_prob=gray_noise_prob)
+ else:
+ out = random_add_poisson_noise_pt(
+ out,
+ scale_range=self.opt['poisson_scale_range2'],
+ gray_prob=gray_noise_prob,
+ clip=True,
+ rounds=False)
+
+ # JPEG compression + the final sinc filter
+ # We also need to resize images to desired sizes. We group [resize back + sinc filter] together
+ # as one operation.
+ # We consider two orders:
+ # 1. [resize back + sinc filter] + JPEG compression
+ # 2. JPEG compression + [resize back + sinc filter]
+ # Empirically, we find other combinations (sinc + JPEG + Resize) will introduce twisted lines.
+ if np.random.uniform() < 0.5:
+ # resize back + the final sinc filter
+ mode = random.choice(['area', 'bilinear', 'bicubic'])
+ out = F.interpolate(out, size=(ori_h // self.opt['scale'], ori_w // self.opt['scale']), mode=mode)
+ out = filter2D(out, self.sinc_kernel)
+ # JPEG compression
+ jpeg_p = out.new_zeros(out.size(0)).uniform_(*self.opt['jpeg_range2'])
+ out = torch.clamp(out, 0, 1)
+ out = self.jpeger(out, quality=jpeg_p)
+ else:
+ # JPEG compression
+ jpeg_p = out.new_zeros(out.size(0)).uniform_(*self.opt['jpeg_range2'])
+ out = torch.clamp(out, 0, 1)
+ out = self.jpeger(out, quality=jpeg_p)
+ # resize back + the final sinc filter
+ mode = random.choice(['area', 'bilinear', 'bicubic'])
+ out = F.interpolate(out, size=(ori_h // self.opt['scale'], ori_w // self.opt['scale']), mode=mode)
+ out = filter2D(out, self.sinc_kernel)
+
+ # clamp and round
+ self.lq = torch.clamp((out * 255.0).round(), 0, 255) / 255.
+
+ # random crop
+ gt_size = self.opt['gt_size']
+ (self.gt, self.gt_usm), self.lq = paired_random_crop([self.gt, self.gt_usm], self.lq, gt_size,
+ self.opt['scale'])
+
+ # training pair pool
+ self._dequeue_and_enqueue()
+ # sharpen self.gt again, as we have changed the self.gt with self._dequeue_and_enqueue
+ self.gt_usm = self.usm_sharpener(self.gt)
+ self.lq = self.lq.contiguous() # for the warning: grad and param do not obey the gradient layout contract
+ else:
+ # for paired training or validation
+ self.lq = data['lq'].to(self.device)
+ if 'gt' in data:
+ self.gt = data['gt'].to(self.device)
+ self.gt_usm = self.usm_sharpener(self.gt)
+
+ def nondist_validation(self, dataloader, current_iter, tb_logger, save_img):
+ # do not use the synthetic process during validation
+ self.is_train = False
+ super(RealESRGANModel, self).nondist_validation(dataloader, current_iter, tb_logger, save_img)
+ self.is_train = True
+
+ def optimize_parameters(self, current_iter):
+ # usm sharpening
+ l1_gt = self.gt_usm
+ percep_gt = self.gt_usm
+ gan_gt = self.gt_usm
+ if self.opt['l1_gt_usm'] is False:
+ l1_gt = self.gt
+ if self.opt['percep_gt_usm'] is False:
+ percep_gt = self.gt
+ if self.opt['gan_gt_usm'] is False:
+ gan_gt = self.gt
+
+ # optimize net_g
+ for p in self.net_d.parameters():
+ p.requires_grad = False
+
+ self.optimizer_g.zero_grad()
+ self.output = self.net_g(self.lq)
+ if self.cri_ldl:
+ self.output_ema = self.net_g_ema(self.lq)
+
+ l_g_total = 0
+ loss_dict = OrderedDict()
+ if (current_iter % self.net_d_iters == 0 and current_iter > self.net_d_init_iters):
+ # pixel loss
+ if self.cri_pix:
+ l_g_pix = self.cri_pix(self.output, l1_gt)
+ l_g_total += l_g_pix
+ loss_dict['l_g_pix'] = l_g_pix
+ if self.cri_ldl:
+ pixel_weight = get_refined_artifact_map(self.gt, self.output, self.output_ema, 7)
+ l_g_ldl = self.cri_ldl(torch.mul(pixel_weight, self.output), torch.mul(pixel_weight, self.gt))
+ l_g_total += l_g_ldl
+ loss_dict['l_g_ldl'] = l_g_ldl
+ # perceptual loss
+ if self.cri_perceptual:
+ l_g_percep, l_g_style = self.cri_perceptual(self.output, percep_gt)
+ if l_g_percep is not None:
+ l_g_total += l_g_percep
+ loss_dict['l_g_percep'] = l_g_percep
+ if l_g_style is not None:
+ l_g_total += l_g_style
+ loss_dict['l_g_style'] = l_g_style
+ # gan loss
+ fake_g_pred = self.net_d(self.output)
+ l_g_gan = self.cri_gan(fake_g_pred, True, is_disc=False)
+ l_g_total += l_g_gan
+ loss_dict['l_g_gan'] = l_g_gan
+
+ l_g_total.backward()
+ self.optimizer_g.step()
+
+ # optimize net_d
+ for p in self.net_d.parameters():
+ p.requires_grad = True
+
+ self.optimizer_d.zero_grad()
+ # real
+ real_d_pred = self.net_d(gan_gt)
+ l_d_real = self.cri_gan(real_d_pred, True, is_disc=True)
+ loss_dict['l_d_real'] = l_d_real
+ loss_dict['out_d_real'] = torch.mean(real_d_pred.detach())
+ l_d_real.backward()
+ # fake
+ fake_d_pred = self.net_d(self.output.detach().clone()) # clone for pt1.9
+ l_d_fake = self.cri_gan(fake_d_pred, False, is_disc=True)
+ loss_dict['l_d_fake'] = l_d_fake
+ loss_dict['out_d_fake'] = torch.mean(fake_d_pred.detach())
+ l_d_fake.backward()
+ self.optimizer_d.step()
+
+ if self.ema_decay > 0:
+ self.model_ema(decay=self.ema_decay)
+
+ self.log_dict = self.reduce_loss_dict(loss_dict)
diff --git a/custom_nodes/ComfyUI-ReActor/r_basicsr/models/realesrnet_model.py b/custom_nodes/ComfyUI-ReActor/r_basicsr/models/realesrnet_model.py
new file mode 100644
index 0000000000000000000000000000000000000000..4108dd480588d7006e8e5400b58dccb6d22e632b
--- /dev/null
+++ b/custom_nodes/ComfyUI-ReActor/r_basicsr/models/realesrnet_model.py
@@ -0,0 +1,189 @@
+import numpy as np
+import random
+import torch
+from torch.nn import functional as F
+
+from r_basicsr.data.degradations import random_add_gaussian_noise_pt, random_add_poisson_noise_pt
+from r_basicsr.data.transforms import paired_random_crop
+from r_basicsr.models.sr_model import SRModel
+from r_basicsr.utils import DiffJPEG, USMSharp
+from r_basicsr.utils.img_process_util import filter2D
+from r_basicsr.utils.registry import MODEL_REGISTRY
+
+
+@MODEL_REGISTRY.register(suffix='basicsr')
+class RealESRNetModel(SRModel):
+ """RealESRNet Model for Real-ESRGAN: Training Real-World Blind Super-Resolution with Pure Synthetic Data.
+
+ It is trained without GAN losses.
+ It mainly performs:
+ 1. randomly synthesize LQ images in GPU tensors
+ 2. optimize the networks with GAN training.
+ """
+
+ def __init__(self, opt):
+ super(RealESRNetModel, self).__init__(opt)
+ self.jpeger = DiffJPEG(differentiable=False).cuda() # simulate JPEG compression artifacts
+ self.usm_sharpener = USMSharp().cuda() # do usm sharpening
+ self.queue_size = opt.get('queue_size', 180)
+
+ @torch.no_grad()
+ def _dequeue_and_enqueue(self):
+ """It is the training pair pool for increasing the diversity in a batch.
+
+ Batch processing limits the diversity of synthetic degradations in a batch. For example, samples in a
+ batch could not have different resize scaling factors. Therefore, we employ this training pair pool
+ to increase the degradation diversity in a batch.
+ """
+ # initialize
+ b, c, h, w = self.lq.size()
+ if not hasattr(self, 'queue_lr'):
+ assert self.queue_size % b == 0, f'queue size {self.queue_size} should be divisible by batch size {b}'
+ self.queue_lr = torch.zeros(self.queue_size, c, h, w).cuda()
+ _, c, h, w = self.gt.size()
+ self.queue_gt = torch.zeros(self.queue_size, c, h, w).cuda()
+ self.queue_ptr = 0
+ if self.queue_ptr == self.queue_size: # the pool is full
+ # do dequeue and enqueue
+ # shuffle
+ idx = torch.randperm(self.queue_size)
+ self.queue_lr = self.queue_lr[idx]
+ self.queue_gt = self.queue_gt[idx]
+ # get first b samples
+ lq_dequeue = self.queue_lr[0:b, :, :, :].clone()
+ gt_dequeue = self.queue_gt[0:b, :, :, :].clone()
+ # update the queue
+ self.queue_lr[0:b, :, :, :] = self.lq.clone()
+ self.queue_gt[0:b, :, :, :] = self.gt.clone()
+
+ self.lq = lq_dequeue
+ self.gt = gt_dequeue
+ else:
+ # only do enqueue
+ self.queue_lr[self.queue_ptr:self.queue_ptr + b, :, :, :] = self.lq.clone()
+ self.queue_gt[self.queue_ptr:self.queue_ptr + b, :, :, :] = self.gt.clone()
+ self.queue_ptr = self.queue_ptr + b
+
+ @torch.no_grad()
+ def feed_data(self, data):
+ """Accept data from dataloader, and then add two-order degradations to obtain LQ images.
+ """
+ if self.is_train and self.opt.get('high_order_degradation', True):
+ # training data synthesis
+ self.gt = data['gt'].to(self.device)
+ # USM sharpen the GT images
+ if self.opt['gt_usm'] is True:
+ self.gt = self.usm_sharpener(self.gt)
+
+ self.kernel1 = data['kernel1'].to(self.device)
+ self.kernel2 = data['kernel2'].to(self.device)
+ self.sinc_kernel = data['sinc_kernel'].to(self.device)
+
+ ori_h, ori_w = self.gt.size()[2:4]
+
+ # ----------------------- The first degradation process ----------------------- #
+ # blur
+ out = filter2D(self.gt, self.kernel1)
+ # random resize
+ updown_type = random.choices(['up', 'down', 'keep'], self.opt['resize_prob'])[0]
+ if updown_type == 'up':
+ scale = np.random.uniform(1, self.opt['resize_range'][1])
+ elif updown_type == 'down':
+ scale = np.random.uniform(self.opt['resize_range'][0], 1)
+ else:
+ scale = 1
+ mode = random.choice(['area', 'bilinear', 'bicubic'])
+ out = F.interpolate(out, scale_factor=scale, mode=mode)
+ # add noise
+ gray_noise_prob = self.opt['gray_noise_prob']
+ if np.random.uniform() < self.opt['gaussian_noise_prob']:
+ out = random_add_gaussian_noise_pt(
+ out, sigma_range=self.opt['noise_range'], clip=True, rounds=False, gray_prob=gray_noise_prob)
+ else:
+ out = random_add_poisson_noise_pt(
+ out,
+ scale_range=self.opt['poisson_scale_range'],
+ gray_prob=gray_noise_prob,
+ clip=True,
+ rounds=False)
+ # JPEG compression
+ jpeg_p = out.new_zeros(out.size(0)).uniform_(*self.opt['jpeg_range'])
+ out = torch.clamp(out, 0, 1) # clamp to [0, 1], otherwise JPEGer will result in unpleasant artifacts
+ out = self.jpeger(out, quality=jpeg_p)
+
+ # ----------------------- The second degradation process ----------------------- #
+ # blur
+ if np.random.uniform() < self.opt['second_blur_prob']:
+ out = filter2D(out, self.kernel2)
+ # random resize
+ updown_type = random.choices(['up', 'down', 'keep'], self.opt['resize_prob2'])[0]
+ if updown_type == 'up':
+ scale = np.random.uniform(1, self.opt['resize_range2'][1])
+ elif updown_type == 'down':
+ scale = np.random.uniform(self.opt['resize_range2'][0], 1)
+ else:
+ scale = 1
+ mode = random.choice(['area', 'bilinear', 'bicubic'])
+ out = F.interpolate(
+ out, size=(int(ori_h / self.opt['scale'] * scale), int(ori_w / self.opt['scale'] * scale)), mode=mode)
+ # add noise
+ gray_noise_prob = self.opt['gray_noise_prob2']
+ if np.random.uniform() < self.opt['gaussian_noise_prob2']:
+ out = random_add_gaussian_noise_pt(
+ out, sigma_range=self.opt['noise_range2'], clip=True, rounds=False, gray_prob=gray_noise_prob)
+ else:
+ out = random_add_poisson_noise_pt(
+ out,
+ scale_range=self.opt['poisson_scale_range2'],
+ gray_prob=gray_noise_prob,
+ clip=True,
+ rounds=False)
+
+ # JPEG compression + the final sinc filter
+ # We also need to resize images to desired sizes. We group [resize back + sinc filter] together
+ # as one operation.
+ # We consider two orders:
+ # 1. [resize back + sinc filter] + JPEG compression
+ # 2. JPEG compression + [resize back + sinc filter]
+ # Empirically, we find other combinations (sinc + JPEG + Resize) will introduce twisted lines.
+ if np.random.uniform() < 0.5:
+ # resize back + the final sinc filter
+ mode = random.choice(['area', 'bilinear', 'bicubic'])
+ out = F.interpolate(out, size=(ori_h // self.opt['scale'], ori_w // self.opt['scale']), mode=mode)
+ out = filter2D(out, self.sinc_kernel)
+ # JPEG compression
+ jpeg_p = out.new_zeros(out.size(0)).uniform_(*self.opt['jpeg_range2'])
+ out = torch.clamp(out, 0, 1)
+ out = self.jpeger(out, quality=jpeg_p)
+ else:
+ # JPEG compression
+ jpeg_p = out.new_zeros(out.size(0)).uniform_(*self.opt['jpeg_range2'])
+ out = torch.clamp(out, 0, 1)
+ out = self.jpeger(out, quality=jpeg_p)
+ # resize back + the final sinc filter
+ mode = random.choice(['area', 'bilinear', 'bicubic'])
+ out = F.interpolate(out, size=(ori_h // self.opt['scale'], ori_w // self.opt['scale']), mode=mode)
+ out = filter2D(out, self.sinc_kernel)
+
+ # clamp and round
+ self.lq = torch.clamp((out * 255.0).round(), 0, 255) / 255.
+
+ # random crop
+ gt_size = self.opt['gt_size']
+ self.gt, self.lq = paired_random_crop(self.gt, self.lq, gt_size, self.opt['scale'])
+
+ # training pair pool
+ self._dequeue_and_enqueue()
+ self.lq = self.lq.contiguous() # for the warning: grad and param do not obey the gradient layout contract
+ else:
+ # for paired training or validation
+ self.lq = data['lq'].to(self.device)
+ if 'gt' in data:
+ self.gt = data['gt'].to(self.device)
+ self.gt_usm = self.usm_sharpener(self.gt)
+
+ def nondist_validation(self, dataloader, current_iter, tb_logger, save_img):
+ # do not use the synthetic process during validation
+ self.is_train = False
+ super(RealESRNetModel, self).nondist_validation(dataloader, current_iter, tb_logger, save_img)
+ self.is_train = True
diff --git a/custom_nodes/ComfyUI-ReActor/r_basicsr/models/sr_model.py b/custom_nodes/ComfyUI-ReActor/r_basicsr/models/sr_model.py
new file mode 100644
index 0000000000000000000000000000000000000000..56322850990e7e2893a40b4e70e2ee6554ca9db3
--- /dev/null
+++ b/custom_nodes/ComfyUI-ReActor/r_basicsr/models/sr_model.py
@@ -0,0 +1,231 @@
+import torch
+from collections import OrderedDict
+from os import path as osp
+from tqdm import tqdm
+
+from r_basicsr.archs import build_network
+from r_basicsr.losses import build_loss
+from r_basicsr.metrics import calculate_metric
+from r_basicsr.utils import get_root_logger, imwrite, tensor2img
+from r_basicsr.utils.registry import MODEL_REGISTRY
+from .base_model import BaseModel
+
+
+@MODEL_REGISTRY.register()
+class SRModel(BaseModel):
+ """Base SR model for single image super-resolution."""
+
+ def __init__(self, opt):
+ super(SRModel, self).__init__(opt)
+
+ # define network
+ self.net_g = build_network(opt['network_g'])
+ self.net_g = self.model_to_device(self.net_g)
+ self.print_network(self.net_g)
+
+ # load pretrained models
+ load_path = self.opt['path'].get('pretrain_network_g', None)
+ if load_path is not None:
+ param_key = self.opt['path'].get('param_key_g', 'params')
+ self.load_network(self.net_g, load_path, self.opt['path'].get('strict_load_g', True), param_key)
+
+ if self.is_train:
+ self.init_training_settings()
+
+ def init_training_settings(self):
+ self.net_g.train()
+ train_opt = self.opt['train']
+
+ self.ema_decay = train_opt.get('ema_decay', 0)
+ if self.ema_decay > 0:
+ logger = get_root_logger()
+ logger.info(f'Use Exponential Moving Average with decay: {self.ema_decay}')
+ # define network net_g with Exponential Moving Average (EMA)
+ # net_g_ema is used only for testing on one GPU and saving
+ # There is no need to wrap with DistributedDataParallel
+ self.net_g_ema = build_network(self.opt['network_g']).to(self.device)
+ # load pretrained model
+ load_path = self.opt['path'].get('pretrain_network_g', None)
+ if load_path is not None:
+ self.load_network(self.net_g_ema, load_path, self.opt['path'].get('strict_load_g', True), 'params_ema')
+ else:
+ self.model_ema(0) # copy net_g weight
+ self.net_g_ema.eval()
+
+ # define losses
+ if train_opt.get('pixel_opt'):
+ self.cri_pix = build_loss(train_opt['pixel_opt']).to(self.device)
+ else:
+ self.cri_pix = None
+
+ if train_opt.get('perceptual_opt'):
+ self.cri_perceptual = build_loss(train_opt['perceptual_opt']).to(self.device)
+ else:
+ self.cri_perceptual = None
+
+ if self.cri_pix is None and self.cri_perceptual is None:
+ raise ValueError('Both pixel and perceptual losses are None.')
+
+ # set up optimizers and schedulers
+ self.setup_optimizers()
+ self.setup_schedulers()
+
+ def setup_optimizers(self):
+ train_opt = self.opt['train']
+ optim_params = []
+ for k, v in self.net_g.named_parameters():
+ if v.requires_grad:
+ optim_params.append(v)
+ else:
+ logger = get_root_logger()
+ logger.warning(f'Params {k} will not be optimized.')
+
+ optim_type = train_opt['optim_g'].pop('type')
+ self.optimizer_g = self.get_optimizer(optim_type, optim_params, **train_opt['optim_g'])
+ self.optimizers.append(self.optimizer_g)
+
+ def feed_data(self, data):
+ self.lq = data['lq'].to(self.device)
+ if 'gt' in data:
+ self.gt = data['gt'].to(self.device)
+
+ def optimize_parameters(self, current_iter):
+ self.optimizer_g.zero_grad()
+ self.output = self.net_g(self.lq)
+
+ l_total = 0
+ loss_dict = OrderedDict()
+ # pixel loss
+ if self.cri_pix:
+ l_pix = self.cri_pix(self.output, self.gt)
+ l_total += l_pix
+ loss_dict['l_pix'] = l_pix
+ # perceptual loss
+ if self.cri_perceptual:
+ l_percep, l_style = self.cri_perceptual(self.output, self.gt)
+ if l_percep is not None:
+ l_total += l_percep
+ loss_dict['l_percep'] = l_percep
+ if l_style is not None:
+ l_total += l_style
+ loss_dict['l_style'] = l_style
+
+ l_total.backward()
+ self.optimizer_g.step()
+
+ self.log_dict = self.reduce_loss_dict(loss_dict)
+
+ if self.ema_decay > 0:
+ self.model_ema(decay=self.ema_decay)
+
+ def test(self):
+ if hasattr(self, 'net_g_ema'):
+ self.net_g_ema.eval()
+ with torch.no_grad():
+ self.output = self.net_g_ema(self.lq)
+ else:
+ self.net_g.eval()
+ with torch.no_grad():
+ self.output = self.net_g(self.lq)
+ self.net_g.train()
+
+ def dist_validation(self, dataloader, current_iter, tb_logger, save_img):
+ if self.opt['rank'] == 0:
+ self.nondist_validation(dataloader, current_iter, tb_logger, save_img)
+
+ def nondist_validation(self, dataloader, current_iter, tb_logger, save_img):
+ dataset_name = dataloader.dataset.opt['name']
+ with_metrics = self.opt['val'].get('metrics') is not None
+ use_pbar = self.opt['val'].get('pbar', False)
+
+ if with_metrics:
+ if not hasattr(self, 'metric_results'): # only execute in the first run
+ self.metric_results = {metric: 0 for metric in self.opt['val']['metrics'].keys()}
+ # initialize the best metric results for each dataset_name (supporting multiple validation datasets)
+ self._initialize_best_metric_results(dataset_name)
+ # zero self.metric_results
+ if with_metrics:
+ self.metric_results = {metric: 0 for metric in self.metric_results}
+
+ metric_data = dict()
+ if use_pbar:
+ pbar = tqdm(total=len(dataloader), unit='image')
+
+ for idx, val_data in enumerate(dataloader):
+ img_name = osp.splitext(osp.basename(val_data['lq_path'][0]))[0]
+ self.feed_data(val_data)
+ self.test()
+
+ visuals = self.get_current_visuals()
+ sr_img = tensor2img([visuals['result']])
+ metric_data['img'] = sr_img
+ if 'gt' in visuals:
+ gt_img = tensor2img([visuals['gt']])
+ metric_data['img2'] = gt_img
+ del self.gt
+
+ # tentative for out of GPU memory
+ del self.lq
+ del self.output
+ torch.cuda.empty_cache()
+
+ if save_img:
+ if self.opt['is_train']:
+ save_img_path = osp.join(self.opt['path']['visualization'], img_name,
+ f'{img_name}_{current_iter}.png')
+ else:
+ if self.opt['val']['suffix']:
+ save_img_path = osp.join(self.opt['path']['visualization'], dataset_name,
+ f'{img_name}_{self.opt["val"]["suffix"]}.png')
+ else:
+ save_img_path = osp.join(self.opt['path']['visualization'], dataset_name,
+ f'{img_name}_{self.opt["name"]}.png')
+ imwrite(sr_img, save_img_path)
+
+ if with_metrics:
+ # calculate metrics
+ for name, opt_ in self.opt['val']['metrics'].items():
+ self.metric_results[name] += calculate_metric(metric_data, opt_)
+ if use_pbar:
+ pbar.update(1)
+ pbar.set_description(f'Test {img_name}')
+ if use_pbar:
+ pbar.close()
+
+ if with_metrics:
+ for metric in self.metric_results.keys():
+ self.metric_results[metric] /= (idx + 1)
+ # update the best metric result
+ self._update_best_metric_result(dataset_name, metric, self.metric_results[metric], current_iter)
+
+ self._log_validation_metric_values(current_iter, dataset_name, tb_logger)
+
+ def _log_validation_metric_values(self, current_iter, dataset_name, tb_logger):
+ log_str = f'Validation {dataset_name}\n'
+ for metric, value in self.metric_results.items():
+ log_str += f'\t # {metric}: {value:.4f}'
+ if hasattr(self, 'best_metric_results'):
+ log_str += (f'\tBest: {self.best_metric_results[dataset_name][metric]["val"]:.4f} @ '
+ f'{self.best_metric_results[dataset_name][metric]["iter"]} iter')
+ log_str += '\n'
+
+ logger = get_root_logger()
+ logger.info(log_str)
+ if tb_logger:
+ for metric, value in self.metric_results.items():
+ tb_logger.add_scalar(f'metrics/{dataset_name}/{metric}', value, current_iter)
+
+ def get_current_visuals(self):
+ out_dict = OrderedDict()
+ out_dict['lq'] = self.lq.detach().cpu()
+ out_dict['result'] = self.output.detach().cpu()
+ if hasattr(self, 'gt'):
+ out_dict['gt'] = self.gt.detach().cpu()
+ return out_dict
+
+ def save(self, epoch, current_iter):
+ if hasattr(self, 'net_g_ema'):
+ self.save_network([self.net_g, self.net_g_ema], 'net_g', current_iter, param_key=['params', 'params_ema'])
+ else:
+ self.save_network(self.net_g, 'net_g', current_iter)
+ self.save_training_state(epoch, current_iter)
diff --git a/custom_nodes/ComfyUI-ReActor/r_basicsr/models/srgan_model.py b/custom_nodes/ComfyUI-ReActor/r_basicsr/models/srgan_model.py
new file mode 100644
index 0000000000000000000000000000000000000000..593bbb5f912989ad6d934a0d9b6ac4550b6b4c58
--- /dev/null
+++ b/custom_nodes/ComfyUI-ReActor/r_basicsr/models/srgan_model.py
@@ -0,0 +1,149 @@
+import torch
+from collections import OrderedDict
+
+from r_basicsr.archs import build_network
+from r_basicsr.losses import build_loss
+from r_basicsr.utils import get_root_logger
+from r_basicsr.utils.registry import MODEL_REGISTRY
+from .sr_model import SRModel
+
+
+@MODEL_REGISTRY.register()
+class SRGANModel(SRModel):
+ """SRGAN model for single image super-resolution."""
+
+ def init_training_settings(self):
+ train_opt = self.opt['train']
+
+ self.ema_decay = train_opt.get('ema_decay', 0)
+ if self.ema_decay > 0:
+ logger = get_root_logger()
+ logger.info(f'Use Exponential Moving Average with decay: {self.ema_decay}')
+ # define network net_g with Exponential Moving Average (EMA)
+ # net_g_ema is used only for testing on one GPU and saving
+ # There is no need to wrap with DistributedDataParallel
+ self.net_g_ema = build_network(self.opt['network_g']).to(self.device)
+ # load pretrained model
+ load_path = self.opt['path'].get('pretrain_network_g', None)
+ if load_path is not None:
+ self.load_network(self.net_g_ema, load_path, self.opt['path'].get('strict_load_g', True), 'params_ema')
+ else:
+ self.model_ema(0) # copy net_g weight
+ self.net_g_ema.eval()
+
+ # define network net_d
+ self.net_d = build_network(self.opt['network_d'])
+ self.net_d = self.model_to_device(self.net_d)
+ self.print_network(self.net_d)
+
+ # load pretrained models
+ load_path = self.opt['path'].get('pretrain_network_d', None)
+ if load_path is not None:
+ param_key = self.opt['path'].get('param_key_d', 'params')
+ self.load_network(self.net_d, load_path, self.opt['path'].get('strict_load_d', True), param_key)
+
+ self.net_g.train()
+ self.net_d.train()
+
+ # define losses
+ if train_opt.get('pixel_opt'):
+ self.cri_pix = build_loss(train_opt['pixel_opt']).to(self.device)
+ else:
+ self.cri_pix = None
+
+ if train_opt.get('ldl_opt'):
+ self.cri_ldl = build_loss(train_opt['ldl_opt']).to(self.device)
+ else:
+ self.cri_ldl = None
+
+ if train_opt.get('perceptual_opt'):
+ self.cri_perceptual = build_loss(train_opt['perceptual_opt']).to(self.device)
+ else:
+ self.cri_perceptual = None
+
+ if train_opt.get('gan_opt'):
+ self.cri_gan = build_loss(train_opt['gan_opt']).to(self.device)
+
+ self.net_d_iters = train_opt.get('net_d_iters', 1)
+ self.net_d_init_iters = train_opt.get('net_d_init_iters', 0)
+
+ # set up optimizers and schedulers
+ self.setup_optimizers()
+ self.setup_schedulers()
+
+ def setup_optimizers(self):
+ train_opt = self.opt['train']
+ # optimizer g
+ optim_type = train_opt['optim_g'].pop('type')
+ self.optimizer_g = self.get_optimizer(optim_type, self.net_g.parameters(), **train_opt['optim_g'])
+ self.optimizers.append(self.optimizer_g)
+ # optimizer d
+ optim_type = train_opt['optim_d'].pop('type')
+ self.optimizer_d = self.get_optimizer(optim_type, self.net_d.parameters(), **train_opt['optim_d'])
+ self.optimizers.append(self.optimizer_d)
+
+ def optimize_parameters(self, current_iter):
+ # optimize net_g
+ for p in self.net_d.parameters():
+ p.requires_grad = False
+
+ self.optimizer_g.zero_grad()
+ self.output = self.net_g(self.lq)
+
+ l_g_total = 0
+ loss_dict = OrderedDict()
+ if (current_iter % self.net_d_iters == 0 and current_iter > self.net_d_init_iters):
+ # pixel loss
+ if self.cri_pix:
+ l_g_pix = self.cri_pix(self.output, self.gt)
+ l_g_total += l_g_pix
+ loss_dict['l_g_pix'] = l_g_pix
+ # perceptual loss
+ if self.cri_perceptual:
+ l_g_percep, l_g_style = self.cri_perceptual(self.output, self.gt)
+ if l_g_percep is not None:
+ l_g_total += l_g_percep
+ loss_dict['l_g_percep'] = l_g_percep
+ if l_g_style is not None:
+ l_g_total += l_g_style
+ loss_dict['l_g_style'] = l_g_style
+ # gan loss
+ fake_g_pred = self.net_d(self.output)
+ l_g_gan = self.cri_gan(fake_g_pred, True, is_disc=False)
+ l_g_total += l_g_gan
+ loss_dict['l_g_gan'] = l_g_gan
+
+ l_g_total.backward()
+ self.optimizer_g.step()
+
+ # optimize net_d
+ for p in self.net_d.parameters():
+ p.requires_grad = True
+
+ self.optimizer_d.zero_grad()
+ # real
+ real_d_pred = self.net_d(self.gt)
+ l_d_real = self.cri_gan(real_d_pred, True, is_disc=True)
+ loss_dict['l_d_real'] = l_d_real
+ loss_dict['out_d_real'] = torch.mean(real_d_pred.detach())
+ l_d_real.backward()
+ # fake
+ fake_d_pred = self.net_d(self.output.detach())
+ l_d_fake = self.cri_gan(fake_d_pred, False, is_disc=True)
+ loss_dict['l_d_fake'] = l_d_fake
+ loss_dict['out_d_fake'] = torch.mean(fake_d_pred.detach())
+ l_d_fake.backward()
+ self.optimizer_d.step()
+
+ self.log_dict = self.reduce_loss_dict(loss_dict)
+
+ if self.ema_decay > 0:
+ self.model_ema(decay=self.ema_decay)
+
+ def save(self, epoch, current_iter):
+ if hasattr(self, 'net_g_ema'):
+ self.save_network([self.net_g, self.net_g_ema], 'net_g', current_iter, param_key=['params', 'params_ema'])
+ else:
+ self.save_network(self.net_g, 'net_g', current_iter)
+ self.save_network(self.net_d, 'net_d', current_iter)
+ self.save_training_state(epoch, current_iter)
diff --git a/custom_nodes/ComfyUI-ReActor/r_basicsr/models/stylegan2_model.py b/custom_nodes/ComfyUI-ReActor/r_basicsr/models/stylegan2_model.py
new file mode 100644
index 0000000000000000000000000000000000000000..24037cd0ff8708b1792662ede24af65fba5119db
--- /dev/null
+++ b/custom_nodes/ComfyUI-ReActor/r_basicsr/models/stylegan2_model.py
@@ -0,0 +1,283 @@
+import cv2
+import math
+import numpy as np
+import random
+import torch
+from collections import OrderedDict
+from os import path as osp
+
+from r_basicsr.archs import build_network
+from r_basicsr.losses import build_loss
+from r_basicsr.losses.gan_loss import g_path_regularize, r1_penalty
+from r_basicsr.utils import imwrite, tensor2img
+from r_basicsr.utils.registry import MODEL_REGISTRY
+from .base_model import BaseModel
+
+
+@MODEL_REGISTRY.register()
+class StyleGAN2Model(BaseModel):
+ """StyleGAN2 model."""
+
+ def __init__(self, opt):
+ super(StyleGAN2Model, self).__init__(opt)
+
+ # define network net_g
+ self.net_g = build_network(opt['network_g'])
+ self.net_g = self.model_to_device(self.net_g)
+ self.print_network(self.net_g)
+ # load pretrained model
+ load_path = self.opt['path'].get('pretrain_network_g', None)
+ if load_path is not None:
+ param_key = self.opt['path'].get('param_key_g', 'params')
+ self.load_network(self.net_g, load_path, self.opt['path'].get('strict_load_g', True), param_key)
+
+ # latent dimension: self.num_style_feat
+ self.num_style_feat = opt['network_g']['num_style_feat']
+ num_val_samples = self.opt['val'].get('num_val_samples', 16)
+ self.fixed_sample = torch.randn(num_val_samples, self.num_style_feat, device=self.device)
+
+ if self.is_train:
+ self.init_training_settings()
+
+ def init_training_settings(self):
+ train_opt = self.opt['train']
+
+ # define network net_d
+ self.net_d = build_network(self.opt['network_d'])
+ self.net_d = self.model_to_device(self.net_d)
+ self.print_network(self.net_d)
+
+ # load pretrained model
+ load_path = self.opt['path'].get('pretrain_network_d', None)
+ if load_path is not None:
+ param_key = self.opt['path'].get('param_key_d', 'params')
+ self.load_network(self.net_d, load_path, self.opt['path'].get('strict_load_d', True), param_key)
+
+ # define network net_g with Exponential Moving Average (EMA)
+ # net_g_ema only used for testing on one GPU and saving, do not need to
+ # wrap with DistributedDataParallel
+ self.net_g_ema = build_network(self.opt['network_g']).to(self.device)
+ # load pretrained model
+ load_path = self.opt['path'].get('pretrain_network_g', None)
+ if load_path is not None:
+ self.load_network(self.net_g_ema, load_path, self.opt['path'].get('strict_load_g', True), 'params_ema')
+ else:
+ self.model_ema(0) # copy net_g weight
+
+ self.net_g.train()
+ self.net_d.train()
+ self.net_g_ema.eval()
+
+ # define losses
+ # gan loss (wgan)
+ self.cri_gan = build_loss(train_opt['gan_opt']).to(self.device)
+ # regularization weights
+ self.r1_reg_weight = train_opt['r1_reg_weight'] # for discriminator
+ self.path_reg_weight = train_opt['path_reg_weight'] # for generator
+
+ self.net_g_reg_every = train_opt['net_g_reg_every']
+ self.net_d_reg_every = train_opt['net_d_reg_every']
+ self.mixing_prob = train_opt['mixing_prob']
+
+ self.mean_path_length = 0
+
+ # set up optimizers and schedulers
+ self.setup_optimizers()
+ self.setup_schedulers()
+
+ def setup_optimizers(self):
+ train_opt = self.opt['train']
+ # optimizer g
+ net_g_reg_ratio = self.net_g_reg_every / (self.net_g_reg_every + 1)
+ if self.opt['network_g']['type'] == 'StyleGAN2GeneratorC':
+ normal_params = []
+ style_mlp_params = []
+ modulation_conv_params = []
+ for name, param in self.net_g.named_parameters():
+ if 'modulation' in name:
+ normal_params.append(param)
+ elif 'style_mlp' in name:
+ style_mlp_params.append(param)
+ elif 'modulated_conv' in name:
+ modulation_conv_params.append(param)
+ else:
+ normal_params.append(param)
+ optim_params_g = [
+ { # add normal params first
+ 'params': normal_params,
+ 'lr': train_opt['optim_g']['lr']
+ },
+ {
+ 'params': style_mlp_params,
+ 'lr': train_opt['optim_g']['lr'] * 0.01
+ },
+ {
+ 'params': modulation_conv_params,
+ 'lr': train_opt['optim_g']['lr'] / 3
+ }
+ ]
+ else:
+ normal_params = []
+ for name, param in self.net_g.named_parameters():
+ normal_params.append(param)
+ optim_params_g = [{ # add normal params first
+ 'params': normal_params,
+ 'lr': train_opt['optim_g']['lr']
+ }]
+
+ optim_type = train_opt['optim_g'].pop('type')
+ lr = train_opt['optim_g']['lr'] * net_g_reg_ratio
+ betas = (0**net_g_reg_ratio, 0.99**net_g_reg_ratio)
+ self.optimizer_g = self.get_optimizer(optim_type, optim_params_g, lr, betas=betas)
+ self.optimizers.append(self.optimizer_g)
+
+ # optimizer d
+ net_d_reg_ratio = self.net_d_reg_every / (self.net_d_reg_every + 1)
+ if self.opt['network_d']['type'] == 'StyleGAN2DiscriminatorC':
+ normal_params = []
+ linear_params = []
+ for name, param in self.net_d.named_parameters():
+ if 'final_linear' in name:
+ linear_params.append(param)
+ else:
+ normal_params.append(param)
+ optim_params_d = [
+ { # add normal params first
+ 'params': normal_params,
+ 'lr': train_opt['optim_d']['lr']
+ },
+ {
+ 'params': linear_params,
+ 'lr': train_opt['optim_d']['lr'] * (1 / math.sqrt(512))
+ }
+ ]
+ else:
+ normal_params = []
+ for name, param in self.net_d.named_parameters():
+ normal_params.append(param)
+ optim_params_d = [{ # add normal params first
+ 'params': normal_params,
+ 'lr': train_opt['optim_d']['lr']
+ }]
+
+ optim_type = train_opt['optim_d'].pop('type')
+ lr = train_opt['optim_d']['lr'] * net_d_reg_ratio
+ betas = (0**net_d_reg_ratio, 0.99**net_d_reg_ratio)
+ self.optimizer_d = self.get_optimizer(optim_type, optim_params_d, lr, betas=betas)
+ self.optimizers.append(self.optimizer_d)
+
+ def feed_data(self, data):
+ self.real_img = data['gt'].to(self.device)
+
+ def make_noise(self, batch, num_noise):
+ if num_noise == 1:
+ noises = torch.randn(batch, self.num_style_feat, device=self.device)
+ else:
+ noises = torch.randn(num_noise, batch, self.num_style_feat, device=self.device).unbind(0)
+ return noises
+
+ def mixing_noise(self, batch, prob):
+ if random.random() < prob:
+ return self.make_noise(batch, 2)
+ else:
+ return [self.make_noise(batch, 1)]
+
+ def optimize_parameters(self, current_iter):
+ loss_dict = OrderedDict()
+
+ # optimize net_d
+ for p in self.net_d.parameters():
+ p.requires_grad = True
+ self.optimizer_d.zero_grad()
+
+ batch = self.real_img.size(0)
+ noise = self.mixing_noise(batch, self.mixing_prob)
+ fake_img, _ = self.net_g(noise)
+ fake_pred = self.net_d(fake_img.detach())
+
+ real_pred = self.net_d(self.real_img)
+ # wgan loss with softplus (logistic loss) for discriminator
+ l_d = self.cri_gan(real_pred, True, is_disc=True) + self.cri_gan(fake_pred, False, is_disc=True)
+ loss_dict['l_d'] = l_d
+ # In wgan, real_score should be positive and fake_score should be
+ # negative
+ loss_dict['real_score'] = real_pred.detach().mean()
+ loss_dict['fake_score'] = fake_pred.detach().mean()
+ l_d.backward()
+
+ if current_iter % self.net_d_reg_every == 0:
+ self.real_img.requires_grad = True
+ real_pred = self.net_d(self.real_img)
+ l_d_r1 = r1_penalty(real_pred, self.real_img)
+ l_d_r1 = (self.r1_reg_weight / 2 * l_d_r1 * self.net_d_reg_every + 0 * real_pred[0])
+ # TODO: why do we need to add 0 * real_pred, otherwise, a runtime
+ # error will arise: RuntimeError: Expected to have finished
+ # reduction in the prior iteration before starting a new one.
+ # This error indicates that your module has parameters that were
+ # not used in producing loss.
+ loss_dict['l_d_r1'] = l_d_r1.detach().mean()
+ l_d_r1.backward()
+
+ self.optimizer_d.step()
+
+ # optimize net_g
+ for p in self.net_d.parameters():
+ p.requires_grad = False
+ self.optimizer_g.zero_grad()
+
+ noise = self.mixing_noise(batch, self.mixing_prob)
+ fake_img, _ = self.net_g(noise)
+ fake_pred = self.net_d(fake_img)
+
+ # wgan loss with softplus (non-saturating loss) for generator
+ l_g = self.cri_gan(fake_pred, True, is_disc=False)
+ loss_dict['l_g'] = l_g
+ l_g.backward()
+
+ if current_iter % self.net_g_reg_every == 0:
+ path_batch_size = max(1, batch // self.opt['train']['path_batch_shrink'])
+ noise = self.mixing_noise(path_batch_size, self.mixing_prob)
+ fake_img, latents = self.net_g(noise, return_latents=True)
+ l_g_path, path_lengths, self.mean_path_length = g_path_regularize(fake_img, latents, self.mean_path_length)
+
+ l_g_path = (self.path_reg_weight * self.net_g_reg_every * l_g_path + 0 * fake_img[0, 0, 0, 0])
+ # TODO: why do we need to add 0 * fake_img[0, 0, 0, 0]
+ l_g_path.backward()
+ loss_dict['l_g_path'] = l_g_path.detach().mean()
+ loss_dict['path_length'] = path_lengths
+
+ self.optimizer_g.step()
+
+ self.log_dict = self.reduce_loss_dict(loss_dict)
+
+ # EMA
+ self.model_ema(decay=0.5**(32 / (10 * 1000)))
+
+ def test(self):
+ with torch.no_grad():
+ self.net_g_ema.eval()
+ self.output, _ = self.net_g_ema([self.fixed_sample])
+
+ def dist_validation(self, dataloader, current_iter, tb_logger, save_img):
+ if self.opt['rank'] == 0:
+ self.nondist_validation(dataloader, current_iter, tb_logger, save_img)
+
+ def nondist_validation(self, dataloader, current_iter, tb_logger, save_img):
+ assert dataloader is None, 'Validation dataloader should be None.'
+ self.test()
+ result = tensor2img(self.output, min_max=(-1, 1))
+ if self.opt['is_train']:
+ save_img_path = osp.join(self.opt['path']['visualization'], 'train', f'train_{current_iter}.png')
+ else:
+ save_img_path = osp.join(self.opt['path']['visualization'], 'test', f'test_{self.opt["name"]}.png')
+ imwrite(result, save_img_path)
+ # add sample images to tb_logger
+ result = (result / 255.).astype(np.float32)
+ result = cv2.cvtColor(result, cv2.COLOR_BGR2RGB)
+ if tb_logger is not None:
+ tb_logger.add_image('samples', result, global_step=current_iter, dataformats='HWC')
+
+ def save(self, epoch, current_iter):
+ self.save_network([self.net_g, self.net_g_ema], 'net_g', current_iter, param_key=['params', 'params_ema'])
+ self.save_network(self.net_d, 'net_d', current_iter)
+ self.save_training_state(epoch, current_iter)
diff --git a/custom_nodes/ComfyUI-ReActor/r_basicsr/models/swinir_model.py b/custom_nodes/ComfyUI-ReActor/r_basicsr/models/swinir_model.py
new file mode 100644
index 0000000000000000000000000000000000000000..7241324dc742379a0c246eec455d7a165bd8313d
--- /dev/null
+++ b/custom_nodes/ComfyUI-ReActor/r_basicsr/models/swinir_model.py
@@ -0,0 +1,33 @@
+import torch
+from torch.nn import functional as F
+
+from r_basicsr.utils.registry import MODEL_REGISTRY
+from .sr_model import SRModel
+
+
+@MODEL_REGISTRY.register()
+class SwinIRModel(SRModel):
+
+ def test(self):
+ # pad to multiplication of window_size
+ window_size = self.opt['network_g']['window_size']
+ scale = self.opt.get('scale', 1)
+ mod_pad_h, mod_pad_w = 0, 0
+ _, _, h, w = self.lq.size()
+ if h % window_size != 0:
+ mod_pad_h = window_size - h % window_size
+ if w % window_size != 0:
+ mod_pad_w = window_size - w % window_size
+ img = F.pad(self.lq, (0, mod_pad_w, 0, mod_pad_h), 'reflect')
+ if hasattr(self, 'net_g_ema'):
+ self.net_g_ema.eval()
+ with torch.no_grad():
+ self.output = self.net_g_ema(img)
+ else:
+ self.net_g.eval()
+ with torch.no_grad():
+ self.output = self.net_g(img)
+ self.net_g.train()
+
+ _, _, h, w = self.output.size()
+ self.output = self.output[:, :, 0:h - mod_pad_h * scale, 0:w - mod_pad_w * scale]
diff --git a/custom_nodes/ComfyUI-ReActor/r_basicsr/models/video_base_model.py b/custom_nodes/ComfyUI-ReActor/r_basicsr/models/video_base_model.py
new file mode 100644
index 0000000000000000000000000000000000000000..51a2eb89e1caabc4e007914414abb141852dd482
--- /dev/null
+++ b/custom_nodes/ComfyUI-ReActor/r_basicsr/models/video_base_model.py
@@ -0,0 +1,160 @@
+import torch
+from collections import Counter
+from os import path as osp
+from torch import distributed as dist
+from tqdm import tqdm
+
+from r_basicsr.metrics import calculate_metric
+from r_basicsr.utils import get_root_logger, imwrite, tensor2img
+from r_basicsr.utils.dist_util import get_dist_info
+from r_basicsr.utils.registry import MODEL_REGISTRY
+from .sr_model import SRModel
+
+
+@MODEL_REGISTRY.register()
+class VideoBaseModel(SRModel):
+ """Base video SR model."""
+
+ def dist_validation(self, dataloader, current_iter, tb_logger, save_img):
+ dataset = dataloader.dataset
+ dataset_name = dataset.opt['name']
+ with_metrics = self.opt['val']['metrics'] is not None
+ # initialize self.metric_results
+ # It is a dict: {
+ # 'folder1': tensor (num_frame x len(metrics)),
+ # 'folder2': tensor (num_frame x len(metrics))
+ # }
+ if with_metrics:
+ if not hasattr(self, 'metric_results'): # only execute in the first run
+ self.metric_results = {}
+ num_frame_each_folder = Counter(dataset.data_info['folder'])
+ for folder, num_frame in num_frame_each_folder.items():
+ self.metric_results[folder] = torch.zeros(
+ num_frame, len(self.opt['val']['metrics']), dtype=torch.float32, device='cuda')
+ # initialize the best metric results
+ self._initialize_best_metric_results(dataset_name)
+ # zero self.metric_results
+ rank, world_size = get_dist_info()
+ if with_metrics:
+ for _, tensor in self.metric_results.items():
+ tensor.zero_()
+
+ metric_data = dict()
+ # record all frames (border and center frames)
+ if rank == 0:
+ pbar = tqdm(total=len(dataset), unit='frame')
+ for idx in range(rank, len(dataset), world_size):
+ val_data = dataset[idx]
+ val_data['lq'].unsqueeze_(0)
+ val_data['gt'].unsqueeze_(0)
+ folder = val_data['folder']
+ frame_idx, max_idx = val_data['idx'].split('/')
+ lq_path = val_data['lq_path']
+
+ self.feed_data(val_data)
+ self.test()
+ visuals = self.get_current_visuals()
+ result_img = tensor2img([visuals['result']])
+ metric_data['img'] = result_img
+ if 'gt' in visuals:
+ gt_img = tensor2img([visuals['gt']])
+ metric_data['img2'] = gt_img
+ del self.gt
+
+ # tentative for out of GPU memory
+ del self.lq
+ del self.output
+ torch.cuda.empty_cache()
+
+ if save_img:
+ if self.opt['is_train']:
+ raise NotImplementedError('saving image is not supported during training.')
+ else:
+ if 'vimeo' in dataset_name.lower(): # vimeo90k dataset
+ split_result = lq_path.split('/')
+ img_name = f'{split_result[-3]}_{split_result[-2]}_{split_result[-1].split(".")[0]}'
+ else: # other datasets, e.g., REDS, Vid4
+ img_name = osp.splitext(osp.basename(lq_path))[0]
+
+ if self.opt['val']['suffix']:
+ save_img_path = osp.join(self.opt['path']['visualization'], dataset_name, folder,
+ f'{img_name}_{self.opt["val"]["suffix"]}.png')
+ else:
+ save_img_path = osp.join(self.opt['path']['visualization'], dataset_name, folder,
+ f'{img_name}_{self.opt["name"]}.png')
+ imwrite(result_img, save_img_path)
+
+ if with_metrics:
+ # calculate metrics
+ for metric_idx, opt_ in enumerate(self.opt['val']['metrics'].values()):
+ result = calculate_metric(metric_data, opt_)
+ self.metric_results[folder][int(frame_idx), metric_idx] += result
+
+ # progress bar
+ if rank == 0:
+ for _ in range(world_size):
+ pbar.update(1)
+ pbar.set_description(f'Test {folder}: {int(frame_idx) + world_size}/{max_idx}')
+ if rank == 0:
+ pbar.close()
+
+ if with_metrics:
+ if self.opt['dist']:
+ # collect data among GPUs
+ for _, tensor in self.metric_results.items():
+ dist.reduce(tensor, 0)
+ dist.barrier()
+ else:
+ pass # assume use one gpu in non-dist testing
+
+ if rank == 0:
+ self._log_validation_metric_values(current_iter, dataset_name, tb_logger)
+
+ def nondist_validation(self, dataloader, current_iter, tb_logger, save_img):
+ logger = get_root_logger()
+ logger.warning('nondist_validation is not implemented. Run dist_validation.')
+ self.dist_validation(dataloader, current_iter, tb_logger, save_img)
+
+ def _log_validation_metric_values(self, current_iter, dataset_name, tb_logger):
+ # ----------------- calculate the average values for each folder, and for each metric ----------------- #
+ # average all frames for each sub-folder
+ # metric_results_avg is a dict:{
+ # 'folder1': tensor (len(metrics)),
+ # 'folder2': tensor (len(metrics))
+ # }
+ metric_results_avg = {
+ folder: torch.mean(tensor, dim=0).cpu()
+ for (folder, tensor) in self.metric_results.items()
+ }
+ # total_avg_results is a dict: {
+ # 'metric1': float,
+ # 'metric2': float
+ # }
+ total_avg_results = {metric: 0 for metric in self.opt['val']['metrics'].keys()}
+ for folder, tensor in metric_results_avg.items():
+ for idx, metric in enumerate(total_avg_results.keys()):
+ total_avg_results[metric] += metric_results_avg[folder][idx].item()
+ # average among folders
+ for metric in total_avg_results.keys():
+ total_avg_results[metric] /= len(metric_results_avg)
+ # update the best metric result
+ self._update_best_metric_result(dataset_name, metric, total_avg_results[metric], current_iter)
+
+ # ------------------------------------------ log the metric ------------------------------------------ #
+ log_str = f'Validation {dataset_name}\n'
+ for metric_idx, (metric, value) in enumerate(total_avg_results.items()):
+ log_str += f'\t # {metric}: {value:.4f}'
+ for folder, tensor in metric_results_avg.items():
+ log_str += f'\t # {folder}: {tensor[metric_idx].item():.4f}'
+ if hasattr(self, 'best_metric_results'):
+ log_str += (f'\n\t Best: {self.best_metric_results[dataset_name][metric]["val"]:.4f} @ '
+ f'{self.best_metric_results[dataset_name][metric]["iter"]} iter')
+ log_str += '\n'
+
+ logger = get_root_logger()
+ logger.info(log_str)
+ if tb_logger:
+ for metric_idx, (metric, value) in enumerate(total_avg_results.items()):
+ tb_logger.add_scalar(f'metrics/{metric}', value, current_iter)
+ for folder, tensor in metric_results_avg.items():
+ tb_logger.add_scalar(f'metrics/{metric}/{folder}', tensor[metric_idx].item(), current_iter)
diff --git a/custom_nodes/ComfyUI-ReActor/r_basicsr/models/video_gan_model.py b/custom_nodes/ComfyUI-ReActor/r_basicsr/models/video_gan_model.py
new file mode 100644
index 0000000000000000000000000000000000000000..c98b11de249b4e62d1a177c9efcf4d420a94fa2e
--- /dev/null
+++ b/custom_nodes/ComfyUI-ReActor/r_basicsr/models/video_gan_model.py
@@ -0,0 +1,17 @@
+from r_basicsr.utils.registry import MODEL_REGISTRY
+from .srgan_model import SRGANModel
+from .video_base_model import VideoBaseModel
+
+
+@MODEL_REGISTRY.register()
+class VideoGANModel(SRGANModel, VideoBaseModel):
+ """Video GAN model.
+
+ Use multiple inheritance.
+ It will first use the functions of SRGANModel:
+ init_training_settings
+ setup_optimizers
+ optimize_parameters
+ save
+ Then find functions in VideoBaseModel.
+ """
diff --git a/custom_nodes/ComfyUI-ReActor/r_basicsr/models/video_recurrent_gan_model.py b/custom_nodes/ComfyUI-ReActor/r_basicsr/models/video_recurrent_gan_model.py
new file mode 100644
index 0000000000000000000000000000000000000000..0c737baf75e4da84f0cda070bc8b1e03a88de76e
--- /dev/null
+++ b/custom_nodes/ComfyUI-ReActor/r_basicsr/models/video_recurrent_gan_model.py
@@ -0,0 +1,180 @@
+import torch
+from collections import OrderedDict
+
+from r_basicsr.archs import build_network
+from r_basicsr.losses import build_loss
+from r_basicsr.utils import get_root_logger
+from r_basicsr.utils.registry import MODEL_REGISTRY
+from .video_recurrent_model import VideoRecurrentModel
+
+
+@MODEL_REGISTRY.register()
+class VideoRecurrentGANModel(VideoRecurrentModel):
+
+ def init_training_settings(self):
+ train_opt = self.opt['train']
+
+ self.ema_decay = train_opt.get('ema_decay', 0)
+ if self.ema_decay > 0:
+ logger = get_root_logger()
+ logger.info(f'Use Exponential Moving Average with decay: {self.ema_decay}')
+ # build network net_g with Exponential Moving Average (EMA)
+ # net_g_ema only used for testing on one GPU and saving.
+ # There is no need to wrap with DistributedDataParallel
+ self.net_g_ema = build_network(self.opt['network_g']).to(self.device)
+ # load pretrained model
+ load_path = self.opt['path'].get('pretrain_network_g', None)
+ if load_path is not None:
+ self.load_network(self.net_g_ema, load_path, self.opt['path'].get('strict_load_g', True), 'params_ema')
+ else:
+ self.model_ema(0) # copy net_g weight
+ self.net_g_ema.eval()
+
+ # define network net_d
+ self.net_d = build_network(self.opt['network_d'])
+ self.net_d = self.model_to_device(self.net_d)
+ self.print_network(self.net_d)
+
+ # load pretrained models
+ load_path = self.opt['path'].get('pretrain_network_d', None)
+ if load_path is not None:
+ param_key = self.opt['path'].get('param_key_d', 'params')
+ self.load_network(self.net_d, load_path, self.opt['path'].get('strict_load_d', True), param_key)
+
+ self.net_g.train()
+ self.net_d.train()
+
+ # define losses
+ if train_opt.get('pixel_opt'):
+ self.cri_pix = build_loss(train_opt['pixel_opt']).to(self.device)
+ else:
+ self.cri_pix = None
+
+ if train_opt.get('perceptual_opt'):
+ self.cri_perceptual = build_loss(train_opt['perceptual_opt']).to(self.device)
+ else:
+ self.cri_perceptual = None
+
+ if train_opt.get('gan_opt'):
+ self.cri_gan = build_loss(train_opt['gan_opt']).to(self.device)
+
+ self.net_d_iters = train_opt.get('net_d_iters', 1)
+ self.net_d_init_iters = train_opt.get('net_d_init_iters', 0)
+
+ # set up optimizers and schedulers
+ self.setup_optimizers()
+ self.setup_schedulers()
+
+ def setup_optimizers(self):
+ train_opt = self.opt['train']
+ if train_opt['fix_flow']:
+ normal_params = []
+ flow_params = []
+ for name, param in self.net_g.named_parameters():
+ if 'spynet' in name: # The fix_flow now only works for spynet.
+ flow_params.append(param)
+ else:
+ normal_params.append(param)
+
+ optim_params = [
+ { # add flow params first
+ 'params': flow_params,
+ 'lr': train_opt['lr_flow']
+ },
+ {
+ 'params': normal_params,
+ 'lr': train_opt['optim_g']['lr']
+ },
+ ]
+ else:
+ optim_params = self.net_g.parameters()
+
+ # optimizer g
+ optim_type = train_opt['optim_g'].pop('type')
+ self.optimizer_g = self.get_optimizer(optim_type, optim_params, **train_opt['optim_g'])
+ self.optimizers.append(self.optimizer_g)
+ # optimizer d
+ optim_type = train_opt['optim_d'].pop('type')
+ self.optimizer_d = self.get_optimizer(optim_type, self.net_d.parameters(), **train_opt['optim_d'])
+ self.optimizers.append(self.optimizer_d)
+
+ def optimize_parameters(self, current_iter):
+ logger = get_root_logger()
+ # optimize net_g
+ for p in self.net_d.parameters():
+ p.requires_grad = False
+
+ if self.fix_flow_iter:
+ if current_iter == 1:
+ logger.info(f'Fix flow network and feature extractor for {self.fix_flow_iter} iters.')
+ for name, param in self.net_g.named_parameters():
+ if 'spynet' in name or 'edvr' in name:
+ param.requires_grad_(False)
+ elif current_iter == self.fix_flow_iter:
+ logger.warning('Train all the parameters.')
+ self.net_g.requires_grad_(True)
+
+ self.optimizer_g.zero_grad()
+ self.output = self.net_g(self.lq)
+
+ _, _, c, h, w = self.output.size()
+
+ l_g_total = 0
+ loss_dict = OrderedDict()
+ if (current_iter % self.net_d_iters == 0 and current_iter > self.net_d_init_iters):
+ # pixel loss
+ if self.cri_pix:
+ l_g_pix = self.cri_pix(self.output, self.gt)
+ l_g_total += l_g_pix
+ loss_dict['l_g_pix'] = l_g_pix
+ # perceptual loss
+ if self.cri_perceptual:
+ l_g_percep, l_g_style = self.cri_perceptual(self.output.view(-1, c, h, w), self.gt.view(-1, c, h, w))
+ if l_g_percep is not None:
+ l_g_total += l_g_percep
+ loss_dict['l_g_percep'] = l_g_percep
+ if l_g_style is not None:
+ l_g_total += l_g_style
+ loss_dict['l_g_style'] = l_g_style
+ # gan loss
+ fake_g_pred = self.net_d(self.output.view(-1, c, h, w))
+ l_g_gan = self.cri_gan(fake_g_pred, True, is_disc=False)
+ l_g_total += l_g_gan
+ loss_dict['l_g_gan'] = l_g_gan
+
+ l_g_total.backward()
+ self.optimizer_g.step()
+
+ # optimize net_d
+ for p in self.net_d.parameters():
+ p.requires_grad = True
+
+ self.optimizer_d.zero_grad()
+ # real
+ # reshape to (b*n, c, h, w)
+ real_d_pred = self.net_d(self.gt.view(-1, c, h, w))
+ l_d_real = self.cri_gan(real_d_pred, True, is_disc=True)
+ loss_dict['l_d_real'] = l_d_real
+ loss_dict['out_d_real'] = torch.mean(real_d_pred.detach())
+ l_d_real.backward()
+ # fake
+ # reshape to (b*n, c, h, w)
+ fake_d_pred = self.net_d(self.output.view(-1, c, h, w).detach())
+ l_d_fake = self.cri_gan(fake_d_pred, False, is_disc=True)
+ loss_dict['l_d_fake'] = l_d_fake
+ loss_dict['out_d_fake'] = torch.mean(fake_d_pred.detach())
+ l_d_fake.backward()
+ self.optimizer_d.step()
+
+ self.log_dict = self.reduce_loss_dict(loss_dict)
+
+ if self.ema_decay > 0:
+ self.model_ema(decay=self.ema_decay)
+
+ def save(self, epoch, current_iter):
+ if self.ema_decay > 0:
+ self.save_network([self.net_g, self.net_g_ema], 'net_g', current_iter, param_key=['params', 'params_ema'])
+ else:
+ self.save_network(self.net_g, 'net_g', current_iter)
+ self.save_network(self.net_d, 'net_d', current_iter)
+ self.save_training_state(epoch, current_iter)
diff --git a/custom_nodes/ComfyUI-ReActor/r_basicsr/models/video_recurrent_model.py b/custom_nodes/ComfyUI-ReActor/r_basicsr/models/video_recurrent_model.py
new file mode 100644
index 0000000000000000000000000000000000000000..10bc98defe3e39c4f9f0725616cf208f01ab597a
--- /dev/null
+++ b/custom_nodes/ComfyUI-ReActor/r_basicsr/models/video_recurrent_model.py
@@ -0,0 +1,197 @@
+import torch
+from collections import Counter
+from os import path as osp
+from torch import distributed as dist
+from tqdm import tqdm
+
+from r_basicsr.metrics import calculate_metric
+from r_basicsr.utils import get_root_logger, imwrite, tensor2img
+from r_basicsr.utils.dist_util import get_dist_info
+from r_basicsr.utils.registry import MODEL_REGISTRY
+from .video_base_model import VideoBaseModel
+
+
+@MODEL_REGISTRY.register()
+class VideoRecurrentModel(VideoBaseModel):
+
+ def __init__(self, opt):
+ super(VideoRecurrentModel, self).__init__(opt)
+ if self.is_train:
+ self.fix_flow_iter = opt['train'].get('fix_flow')
+
+ def setup_optimizers(self):
+ train_opt = self.opt['train']
+ flow_lr_mul = train_opt.get('flow_lr_mul', 1)
+ logger = get_root_logger()
+ logger.info(f'Multiple the learning rate for flow network with {flow_lr_mul}.')
+ if flow_lr_mul == 1:
+ optim_params = self.net_g.parameters()
+ else: # separate flow params and normal params for different lr
+ normal_params = []
+ flow_params = []
+ for name, param in self.net_g.named_parameters():
+ if 'spynet' in name:
+ flow_params.append(param)
+ else:
+ normal_params.append(param)
+ optim_params = [
+ { # add normal params first
+ 'params': normal_params,
+ 'lr': train_opt['optim_g']['lr']
+ },
+ {
+ 'params': flow_params,
+ 'lr': train_opt['optim_g']['lr'] * flow_lr_mul
+ },
+ ]
+
+ optim_type = train_opt['optim_g'].pop('type')
+ self.optimizer_g = self.get_optimizer(optim_type, optim_params, **train_opt['optim_g'])
+ self.optimizers.append(self.optimizer_g)
+
+ def optimize_parameters(self, current_iter):
+ if self.fix_flow_iter:
+ logger = get_root_logger()
+ if current_iter == 1:
+ logger.info(f'Fix flow network and feature extractor for {self.fix_flow_iter} iters.')
+ for name, param in self.net_g.named_parameters():
+ if 'spynet' in name or 'edvr' in name:
+ param.requires_grad_(False)
+ elif current_iter == self.fix_flow_iter:
+ logger.warning('Train all the parameters.')
+ self.net_g.requires_grad_(True)
+
+ super(VideoRecurrentModel, self).optimize_parameters(current_iter)
+
+ def dist_validation(self, dataloader, current_iter, tb_logger, save_img):
+ dataset = dataloader.dataset
+ dataset_name = dataset.opt['name']
+ with_metrics = self.opt['val']['metrics'] is not None
+ # initialize self.metric_results
+ # It is a dict: {
+ # 'folder1': tensor (num_frame x len(metrics)),
+ # 'folder2': tensor (num_frame x len(metrics))
+ # }
+ if with_metrics:
+ if not hasattr(self, 'metric_results'): # only execute in the first run
+ self.metric_results = {}
+ num_frame_each_folder = Counter(dataset.data_info['folder'])
+ for folder, num_frame in num_frame_each_folder.items():
+ self.metric_results[folder] = torch.zeros(
+ num_frame, len(self.opt['val']['metrics']), dtype=torch.float32, device='cuda')
+ # initialize the best metric results
+ self._initialize_best_metric_results(dataset_name)
+ # zero self.metric_results
+ rank, world_size = get_dist_info()
+ if with_metrics:
+ for _, tensor in self.metric_results.items():
+ tensor.zero_()
+
+ metric_data = dict()
+ num_folders = len(dataset)
+ num_pad = (world_size - (num_folders % world_size)) % world_size
+ if rank == 0:
+ pbar = tqdm(total=len(dataset), unit='folder')
+ # Will evaluate (num_folders + num_pad) times, but only the first num_folders results will be recorded.
+ # (To avoid wait-dead)
+ for i in range(rank, num_folders + num_pad, world_size):
+ idx = min(i, num_folders - 1)
+ val_data = dataset[idx]
+ folder = val_data['folder']
+
+ # compute outputs
+ val_data['lq'].unsqueeze_(0)
+ val_data['gt'].unsqueeze_(0)
+ self.feed_data(val_data)
+ val_data['lq'].squeeze_(0)
+ val_data['gt'].squeeze_(0)
+
+ self.test()
+ visuals = self.get_current_visuals()
+
+ # tentative for out of GPU memory
+ del self.lq
+ del self.output
+ if 'gt' in visuals:
+ del self.gt
+ torch.cuda.empty_cache()
+
+ if self.center_frame_only:
+ visuals['result'] = visuals['result'].unsqueeze(1)
+ if 'gt' in visuals:
+ visuals['gt'] = visuals['gt'].unsqueeze(1)
+
+ # evaluate
+ if i < num_folders:
+ for idx in range(visuals['result'].size(1)):
+ result = visuals['result'][0, idx, :, :, :]
+ result_img = tensor2img([result]) # uint8, bgr
+ metric_data['img'] = result_img
+ if 'gt' in visuals:
+ gt = visuals['gt'][0, idx, :, :, :]
+ gt_img = tensor2img([gt]) # uint8, bgr
+ metric_data['img2'] = gt_img
+
+ if save_img:
+ if self.opt['is_train']:
+ raise NotImplementedError('saving image is not supported during training.')
+ else:
+ if self.center_frame_only: # vimeo-90k
+ clip_ = val_data['lq_path'].split('/')[-3]
+ seq_ = val_data['lq_path'].split('/')[-2]
+ name_ = f'{clip_}_{seq_}'
+ img_path = osp.join(self.opt['path']['visualization'], dataset_name, folder,
+ f"{name_}_{self.opt['name']}.png")
+ else: # others
+ img_path = osp.join(self.opt['path']['visualization'], dataset_name, folder,
+ f"{idx:08d}_{self.opt['name']}.png")
+ # image name only for REDS dataset
+ imwrite(result_img, img_path)
+
+ # calculate metrics
+ if with_metrics:
+ for metric_idx, opt_ in enumerate(self.opt['val']['metrics'].values()):
+ result = calculate_metric(metric_data, opt_)
+ self.metric_results[folder][idx, metric_idx] += result
+
+ # progress bar
+ if rank == 0:
+ for _ in range(world_size):
+ pbar.update(1)
+ pbar.set_description(f'Folder: {folder}')
+
+ if rank == 0:
+ pbar.close()
+
+ if with_metrics:
+ if self.opt['dist']:
+ # collect data among GPUs
+ for _, tensor in self.metric_results.items():
+ dist.reduce(tensor, 0)
+ dist.barrier()
+
+ if rank == 0:
+ self._log_validation_metric_values(current_iter, dataset_name, tb_logger)
+
+ def test(self):
+ n = self.lq.size(1)
+ self.net_g.eval()
+
+ flip_seq = self.opt['val'].get('flip_seq', False)
+ self.center_frame_only = self.opt['val'].get('center_frame_only', False)
+
+ if flip_seq:
+ self.lq = torch.cat([self.lq, self.lq.flip(1)], dim=1)
+
+ with torch.no_grad():
+ self.output = self.net_g(self.lq)
+
+ if flip_seq:
+ output_1 = self.output[:, :n, :, :, :]
+ output_2 = self.output[:, n:, :, :, :].flip(1)
+ self.output = 0.5 * (output_1 + output_2)
+
+ if self.center_frame_only:
+ self.output = self.output[:, n // 2, :, :, :]
+
+ self.net_g.train()
diff --git a/custom_nodes/ComfyUI-ReActor/r_basicsr/ops/__init__.py b/custom_nodes/ComfyUI-ReActor/r_basicsr/ops/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/custom_nodes/ComfyUI-ReActor/r_basicsr/ops/dcn/__init__.py b/custom_nodes/ComfyUI-ReActor/r_basicsr/ops/dcn/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..32e3592f896d61b4127e09d0476381b9d55e32ff
--- /dev/null
+++ b/custom_nodes/ComfyUI-ReActor/r_basicsr/ops/dcn/__init__.py
@@ -0,0 +1,7 @@
+from .deform_conv import (DeformConv, DeformConvPack, ModulatedDeformConv, ModulatedDeformConvPack, deform_conv,
+ modulated_deform_conv)
+
+__all__ = [
+ 'DeformConv', 'DeformConvPack', 'ModulatedDeformConv', 'ModulatedDeformConvPack', 'deform_conv',
+ 'modulated_deform_conv'
+]
diff --git a/custom_nodes/ComfyUI-ReActor/r_basicsr/ops/dcn/deform_conv.py b/custom_nodes/ComfyUI-ReActor/r_basicsr/ops/dcn/deform_conv.py
new file mode 100644
index 0000000000000000000000000000000000000000..6268ca825d59ef4a30d4d2156c4438cbbe9b3c1e
--- /dev/null
+++ b/custom_nodes/ComfyUI-ReActor/r_basicsr/ops/dcn/deform_conv.py
@@ -0,0 +1,379 @@
+import math
+import os
+import torch
+from torch import nn as nn
+from torch.autograd import Function
+from torch.autograd.function import once_differentiable
+from torch.nn import functional as F
+from torch.nn.modules.utils import _pair, _single
+
+BASICSR_JIT = os.getenv('BASICSR_JIT')
+if BASICSR_JIT == 'True':
+ from torch.utils.cpp_extension import load
+ module_path = os.path.dirname(__file__)
+ deform_conv_ext = load(
+ 'deform_conv',
+ sources=[
+ os.path.join(module_path, 'src', 'deform_conv_ext.cpp'),
+ os.path.join(module_path, 'src', 'deform_conv_cuda.cpp'),
+ os.path.join(module_path, 'src', 'deform_conv_cuda_kernel.cu'),
+ ],
+ )
+else:
+ try:
+ from . import deform_conv_ext
+ except ImportError:
+ pass
+ # avoid annoying print output
+ # print(f'Cannot import deform_conv_ext. Error: {error}. You may need to: \n '
+ # '1. compile with BASICSR_EXT=True. or\n '
+ # '2. set BASICSR_JIT=True during running')
+
+
+class DeformConvFunction(Function):
+
+ @staticmethod
+ def forward(ctx,
+ input,
+ offset,
+ weight,
+ stride=1,
+ padding=0,
+ dilation=1,
+ groups=1,
+ deformable_groups=1,
+ im2col_step=64):
+ if input is not None and input.dim() != 4:
+ raise ValueError(f'Expected 4D tensor as input, got {input.dim()}D tensor instead.')
+ ctx.stride = _pair(stride)
+ ctx.padding = _pair(padding)
+ ctx.dilation = _pair(dilation)
+ ctx.groups = groups
+ ctx.deformable_groups = deformable_groups
+ ctx.im2col_step = im2col_step
+
+ ctx.save_for_backward(input, offset, weight)
+
+ output = input.new_empty(DeformConvFunction._output_size(input, weight, ctx.padding, ctx.dilation, ctx.stride))
+
+ ctx.bufs_ = [input.new_empty(0), input.new_empty(0)] # columns, ones
+
+ if not input.is_cuda:
+ raise NotImplementedError
+ else:
+ cur_im2col_step = min(ctx.im2col_step, input.shape[0])
+ assert (input.shape[0] % cur_im2col_step) == 0, 'im2col step must divide batchsize'
+ deform_conv_ext.deform_conv_forward(input, weight,
+ offset, output, ctx.bufs_[0], ctx.bufs_[1], weight.size(3),
+ weight.size(2), ctx.stride[1], ctx.stride[0], ctx.padding[1],
+ ctx.padding[0], ctx.dilation[1], ctx.dilation[0], ctx.groups,
+ ctx.deformable_groups, cur_im2col_step)
+ return output
+
+ @staticmethod
+ @once_differentiable
+ def backward(ctx, grad_output):
+ input, offset, weight = ctx.saved_tensors
+
+ grad_input = grad_offset = grad_weight = None
+
+ if not grad_output.is_cuda:
+ raise NotImplementedError
+ else:
+ cur_im2col_step = min(ctx.im2col_step, input.shape[0])
+ assert (input.shape[0] % cur_im2col_step) == 0, 'im2col step must divide batchsize'
+
+ if ctx.needs_input_grad[0] or ctx.needs_input_grad[1]:
+ grad_input = torch.zeros_like(input)
+ grad_offset = torch.zeros_like(offset)
+ deform_conv_ext.deform_conv_backward_input(input, offset, grad_output, grad_input,
+ grad_offset, weight, ctx.bufs_[0], weight.size(3),
+ weight.size(2), ctx.stride[1], ctx.stride[0], ctx.padding[1],
+ ctx.padding[0], ctx.dilation[1], ctx.dilation[0], ctx.groups,
+ ctx.deformable_groups, cur_im2col_step)
+
+ if ctx.needs_input_grad[2]:
+ grad_weight = torch.zeros_like(weight)
+ deform_conv_ext.deform_conv_backward_parameters(input, offset, grad_output, grad_weight,
+ ctx.bufs_[0], ctx.bufs_[1], weight.size(3),
+ weight.size(2), ctx.stride[1], ctx.stride[0],
+ ctx.padding[1], ctx.padding[0], ctx.dilation[1],
+ ctx.dilation[0], ctx.groups, ctx.deformable_groups, 1,
+ cur_im2col_step)
+
+ return (grad_input, grad_offset, grad_weight, None, None, None, None, None)
+
+ @staticmethod
+ def _output_size(input, weight, padding, dilation, stride):
+ channels = weight.size(0)
+ output_size = (input.size(0), channels)
+ for d in range(input.dim() - 2):
+ in_size = input.size(d + 2)
+ pad = padding[d]
+ kernel = dilation[d] * (weight.size(d + 2) - 1) + 1
+ stride_ = stride[d]
+ output_size += ((in_size + (2 * pad) - kernel) // stride_ + 1, )
+ if not all(map(lambda s: s > 0, output_size)):
+ raise ValueError(f'convolution input is too small (output would be {"x".join(map(str, output_size))})')
+ return output_size
+
+
+class ModulatedDeformConvFunction(Function):
+
+ @staticmethod
+ def forward(ctx,
+ input,
+ offset,
+ mask,
+ weight,
+ bias=None,
+ stride=1,
+ padding=0,
+ dilation=1,
+ groups=1,
+ deformable_groups=1):
+ ctx.stride = stride
+ ctx.padding = padding
+ ctx.dilation = dilation
+ ctx.groups = groups
+ ctx.deformable_groups = deformable_groups
+ ctx.with_bias = bias is not None
+ if not ctx.with_bias:
+ bias = input.new_empty(1) # fake tensor
+ if not input.is_cuda:
+ raise NotImplementedError
+ if weight.requires_grad or mask.requires_grad or offset.requires_grad or input.requires_grad:
+ ctx.save_for_backward(input, offset, mask, weight, bias)
+ output = input.new_empty(ModulatedDeformConvFunction._infer_shape(ctx, input, weight))
+ ctx._bufs = [input.new_empty(0), input.new_empty(0)]
+ deform_conv_ext.modulated_deform_conv_forward(input, weight, bias, ctx._bufs[0], offset, mask, output,
+ ctx._bufs[1], weight.shape[2], weight.shape[3], ctx.stride,
+ ctx.stride, ctx.padding, ctx.padding, ctx.dilation, ctx.dilation,
+ ctx.groups, ctx.deformable_groups, ctx.with_bias)
+ return output
+
+ @staticmethod
+ @once_differentiable
+ def backward(ctx, grad_output):
+ if not grad_output.is_cuda:
+ raise NotImplementedError
+ input, offset, mask, weight, bias = ctx.saved_tensors
+ grad_input = torch.zeros_like(input)
+ grad_offset = torch.zeros_like(offset)
+ grad_mask = torch.zeros_like(mask)
+ grad_weight = torch.zeros_like(weight)
+ grad_bias = torch.zeros_like(bias)
+ deform_conv_ext.modulated_deform_conv_backward(input, weight, bias, ctx._bufs[0], offset, mask, ctx._bufs[1],
+ grad_input, grad_weight, grad_bias, grad_offset, grad_mask,
+ grad_output, weight.shape[2], weight.shape[3], ctx.stride,
+ ctx.stride, ctx.padding, ctx.padding, ctx.dilation, ctx.dilation,
+ ctx.groups, ctx.deformable_groups, ctx.with_bias)
+ if not ctx.with_bias:
+ grad_bias = None
+
+ return (grad_input, grad_offset, grad_mask, grad_weight, grad_bias, None, None, None, None, None)
+
+ @staticmethod
+ def _infer_shape(ctx, input, weight):
+ n = input.size(0)
+ channels_out = weight.size(0)
+ height, width = input.shape[2:4]
+ kernel_h, kernel_w = weight.shape[2:4]
+ height_out = (height + 2 * ctx.padding - (ctx.dilation * (kernel_h - 1) + 1)) // ctx.stride + 1
+ width_out = (width + 2 * ctx.padding - (ctx.dilation * (kernel_w - 1) + 1)) // ctx.stride + 1
+ return n, channels_out, height_out, width_out
+
+
+deform_conv = DeformConvFunction.apply
+modulated_deform_conv = ModulatedDeformConvFunction.apply
+
+
+class DeformConv(nn.Module):
+
+ def __init__(self,
+ in_channels,
+ out_channels,
+ kernel_size,
+ stride=1,
+ padding=0,
+ dilation=1,
+ groups=1,
+ deformable_groups=1,
+ bias=False):
+ super(DeformConv, self).__init__()
+
+ assert not bias
+ assert in_channels % groups == 0, f'in_channels {in_channels} is not divisible by groups {groups}'
+ assert out_channels % groups == 0, f'out_channels {out_channels} is not divisible by groups {groups}'
+
+ self.in_channels = in_channels
+ self.out_channels = out_channels
+ self.kernel_size = _pair(kernel_size)
+ self.stride = _pair(stride)
+ self.padding = _pair(padding)
+ self.dilation = _pair(dilation)
+ self.groups = groups
+ self.deformable_groups = deformable_groups
+ # enable compatibility with nn.Conv2d
+ self.transposed = False
+ self.output_padding = _single(0)
+
+ self.weight = nn.Parameter(torch.Tensor(out_channels, in_channels // self.groups, *self.kernel_size))
+
+ self.reset_parameters()
+
+ def reset_parameters(self):
+ n = self.in_channels
+ for k in self.kernel_size:
+ n *= k
+ stdv = 1. / math.sqrt(n)
+ self.weight.data.uniform_(-stdv, stdv)
+
+ def forward(self, x, offset):
+ # To fix an assert error in deform_conv_cuda.cpp:128
+ # input image is smaller than kernel
+ input_pad = (x.size(2) < self.kernel_size[0] or x.size(3) < self.kernel_size[1])
+ if input_pad:
+ pad_h = max(self.kernel_size[0] - x.size(2), 0)
+ pad_w = max(self.kernel_size[1] - x.size(3), 0)
+ x = F.pad(x, (0, pad_w, 0, pad_h), 'constant', 0).contiguous()
+ offset = F.pad(offset, (0, pad_w, 0, pad_h), 'constant', 0).contiguous()
+ out = deform_conv(x, offset, self.weight, self.stride, self.padding, self.dilation, self.groups,
+ self.deformable_groups)
+ if input_pad:
+ out = out[:, :, :out.size(2) - pad_h, :out.size(3) - pad_w].contiguous()
+ return out
+
+
+class DeformConvPack(DeformConv):
+ """A Deformable Conv Encapsulation that acts as normal Conv layers.
+
+ Args:
+ in_channels (int): Same as nn.Conv2d.
+ out_channels (int): Same as nn.Conv2d.
+ kernel_size (int or tuple[int]): Same as nn.Conv2d.
+ stride (int or tuple[int]): Same as nn.Conv2d.
+ padding (int or tuple[int]): Same as nn.Conv2d.
+ dilation (int or tuple[int]): Same as nn.Conv2d.
+ groups (int): Same as nn.Conv2d.
+ bias (bool or str): If specified as `auto`, it will be decided by the
+ norm_cfg. Bias will be set as True if norm_cfg is None, otherwise
+ False.
+ """
+
+ _version = 2
+
+ def __init__(self, *args, **kwargs):
+ super(DeformConvPack, self).__init__(*args, **kwargs)
+
+ self.conv_offset = nn.Conv2d(
+ self.in_channels,
+ self.deformable_groups * 2 * self.kernel_size[0] * self.kernel_size[1],
+ kernel_size=self.kernel_size,
+ stride=_pair(self.stride),
+ padding=_pair(self.padding),
+ dilation=_pair(self.dilation),
+ bias=True)
+ self.init_offset()
+
+ def init_offset(self):
+ self.conv_offset.weight.data.zero_()
+ self.conv_offset.bias.data.zero_()
+
+ def forward(self, x):
+ offset = self.conv_offset(x)
+ return deform_conv(x, offset, self.weight, self.stride, self.padding, self.dilation, self.groups,
+ self.deformable_groups)
+
+
+class ModulatedDeformConv(nn.Module):
+
+ def __init__(self,
+ in_channels,
+ out_channels,
+ kernel_size,
+ stride=1,
+ padding=0,
+ dilation=1,
+ groups=1,
+ deformable_groups=1,
+ bias=True):
+ super(ModulatedDeformConv, self).__init__()
+ self.in_channels = in_channels
+ self.out_channels = out_channels
+ self.kernel_size = _pair(kernel_size)
+ self.stride = stride
+ self.padding = padding
+ self.dilation = dilation
+ self.groups = groups
+ self.deformable_groups = deformable_groups
+ self.with_bias = bias
+ # enable compatibility with nn.Conv2d
+ self.transposed = False
+ self.output_padding = _single(0)
+
+ self.weight = nn.Parameter(torch.Tensor(out_channels, in_channels // groups, *self.kernel_size))
+ if bias:
+ self.bias = nn.Parameter(torch.Tensor(out_channels))
+ else:
+ self.register_parameter('bias', None)
+ self.init_weights()
+
+ def init_weights(self):
+ n = self.in_channels
+ for k in self.kernel_size:
+ n *= k
+ stdv = 1. / math.sqrt(n)
+ self.weight.data.uniform_(-stdv, stdv)
+ if self.bias is not None:
+ self.bias.data.zero_()
+
+ def forward(self, x, offset, mask):
+ return modulated_deform_conv(x, offset, mask, self.weight, self.bias, self.stride, self.padding, self.dilation,
+ self.groups, self.deformable_groups)
+
+
+class ModulatedDeformConvPack(ModulatedDeformConv):
+ """A ModulatedDeformable Conv Encapsulation that acts as normal Conv layers.
+
+ Args:
+ in_channels (int): Same as nn.Conv2d.
+ out_channels (int): Same as nn.Conv2d.
+ kernel_size (int or tuple[int]): Same as nn.Conv2d.
+ stride (int or tuple[int]): Same as nn.Conv2d.
+ padding (int or tuple[int]): Same as nn.Conv2d.
+ dilation (int or tuple[int]): Same as nn.Conv2d.
+ groups (int): Same as nn.Conv2d.
+ bias (bool or str): If specified as `auto`, it will be decided by the
+ norm_cfg. Bias will be set as True if norm_cfg is None, otherwise
+ False.
+ """
+
+ _version = 2
+
+ def __init__(self, *args, **kwargs):
+ super(ModulatedDeformConvPack, self).__init__(*args, **kwargs)
+
+ self.conv_offset = nn.Conv2d(
+ self.in_channels,
+ self.deformable_groups * 3 * self.kernel_size[0] * self.kernel_size[1],
+ kernel_size=self.kernel_size,
+ stride=_pair(self.stride),
+ padding=_pair(self.padding),
+ dilation=_pair(self.dilation),
+ bias=True)
+ self.init_weights()
+
+ def init_weights(self):
+ super(ModulatedDeformConvPack, self).init_weights()
+ if hasattr(self, 'conv_offset'):
+ self.conv_offset.weight.data.zero_()
+ self.conv_offset.bias.data.zero_()
+
+ def forward(self, x):
+ out = self.conv_offset(x)
+ o1, o2, mask = torch.chunk(out, 3, dim=1)
+ offset = torch.cat((o1, o2), dim=1)
+ mask = torch.sigmoid(mask)
+ return modulated_deform_conv(x, offset, mask, self.weight, self.bias, self.stride, self.padding, self.dilation,
+ self.groups, self.deformable_groups)
diff --git a/custom_nodes/ComfyUI-ReActor/r_basicsr/ops/dcn/src/deform_conv_cuda.cpp b/custom_nodes/ComfyUI-ReActor/r_basicsr/ops/dcn/src/deform_conv_cuda.cpp
new file mode 100644
index 0000000000000000000000000000000000000000..b465c493a3dd67d320b7a8997fbd501d2f89c807
--- /dev/null
+++ b/custom_nodes/ComfyUI-ReActor/r_basicsr/ops/dcn/src/deform_conv_cuda.cpp
@@ -0,0 +1,685 @@
+// modify from
+// https://github.com/chengdazhi/Deformable-Convolution-V2-PyTorch/blob/mmdetection/mmdet/ops/dcn/src/deform_conv_cuda.c
+
+#include Нажмите, чтобы посмотреть
+ ++ +|файл|источник|лицензия| +|----|--------|--------| +|[buffalo_l.zip](https://huggingface.co/datasets/Gourieff/ReActor/blob/main/models/buffalo_l.zip) | [DeepInsight](https://github.com/deepinsight/insightface) |  | +| [codeformer-v0.1.0.pth](https://huggingface.co/datasets/Gourieff/ReActor/blob/main/models/facerestore_models/codeformer-v0.1.0.pth) | [sczhou](https://github.com/sczhou/CodeFormer) |  | +| [GFPGANv1.3.pth](https://huggingface.co/datasets/Gourieff/ReActor/blob/main/models/facerestore_models/GFPGANv1.3.pth) | [TencentARC](https://github.com/TencentARC/GFPGAN) |  | +| [GFPGANv1.4.pth](https://huggingface.co/datasets/Gourieff/ReActor/blob/main/models/facerestore_models/GFPGANv1.4.pth) | [TencentARC](https://github.com/TencentARC/GFPGAN) |  | +| [inswapper_128.onnx](https://github.com/facefusion/facefusion-assets/releases/download/models/inswapper_128.onnx) | [DeepInsight](https://github.com/deepinsight/insightface) |  | +| [inswapper_128_fp16.onnx](https://github.com/facefusion/facefusion-assets/releases/download/models/inswapper_128_fp16.onnx) | [Hillobar](https://github.com/Hillobar/Rope) |  | + +[BasicSR](https://github.com/XPixelGroup/BasicSR) - [@XPixelGroup](https://github.com/XPixelGroup)
+[facexlib](https://github.com/xinntao/facexlib) - [@xinntao](https://github.com/xinntao)
+ +[@s0md3v](https://github.com/s0md3v), [@henryruhs](https://github.com/henryruhs) - оригинальное приложение Roop
+[@ssitu](https://github.com/ssitu) - первая версия расширения с поддержкой ComfyUI [ComfyUI_roop](https://github.com/ssitu/ComfyUI_roop) + +