+ 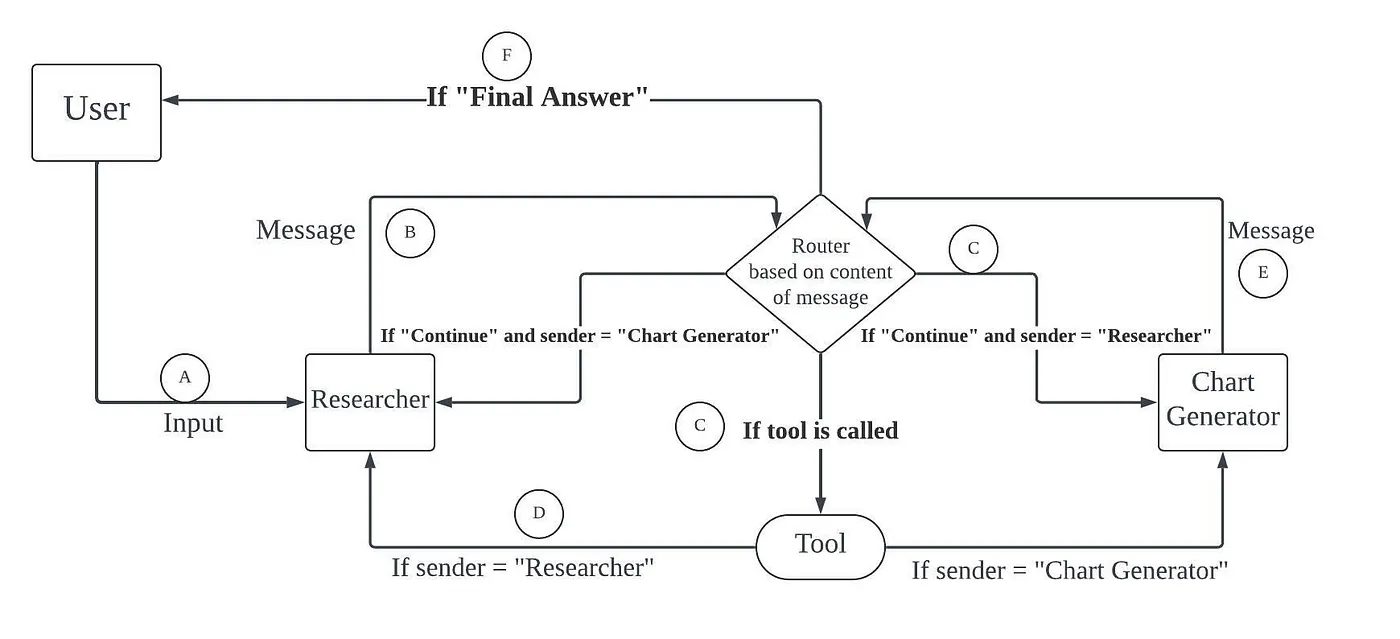 +
+
+
+````python
+import json
+from lagent.actions import IPythonInterpreter, WebBrowser, ActionExecutor
+from lagent.agents.stream import get_plugin_prompt
+from lagent.llms import GPTAPI
+from lagent.hooks import InternLMActionProcessor
+
+TOOL_TEMPLATE = (
+ "You are a helpful AI assistant, collaborating with other assistants. Use the provided tools to progress"
+ " towards answering the question. If you are unable to fully answer, that's OK, another assistant with"
+ " different tools will help where you left off. Execute what you can to make progress. If you or any of"
+ " the other assistants have the final answer or deliverable, prefix your response with {finish_pattern}"
+ " so the team knows to stop. You have access to the following tools:\n{tool_description}\nPlease provide"
+ " your thought process when you need to use a tool, followed by the call statement in this format:"
+ "\n{invocation_format}\\\\n**{system_prompt}**"
+)
+
+class DataVisualizer(Agent):
+ def __init__(self, model_path, research_prompt, chart_prompt, finish_pattern="Final Answer", max_turn=10):
+ super().__init__()
+ llm = GPTAPI(model_path, key='YOUR_OPENAI_API_KEY', retry=5, max_new_tokens=1024, stop_words=["```\n"])
+ interpreter, browser = IPythonInterpreter(), WebBrowser("BingSearch", api_key="YOUR_BING_API_KEY")
+ self.researcher = Agent(
+ llm,
+ TOOL_TEMPLATE.format(
+ finish_pattern=finish_pattern,
+ tool_description=get_plugin_prompt(browser),
+ invocation_format='```json\n{"name": {{tool name}}, "parameters": {{keyword arguments}}}\n```\n',
+ system_prompt=research_prompt,
+ ),
+ output_format=ToolParser(
+ "browser",
+ begin="```json\n",
+ end="\n```\n",
+ validate=lambda x: json.loads(x.rstrip('`')),
+ ),
+ aggregator=InternLMToolAggregator(),
+ name="researcher",
+ )
+ self.charter = Agent(
+ llm,
+ TOOL_TEMPLATE.format(
+ finish_pattern=finish_pattern,
+ tool_description=interpreter.name,
+ invocation_format='```python\n{{code}}\n```\n',
+ system_prompt=chart_prompt,
+ ),
+ output_format=ToolParser(
+ "interpreter",
+ begin="```python\n",
+ end="\n```\n",
+ validate=lambda x: x.rstrip('`'),
+ ),
+ aggregator=InternLMToolAggregator(),
+ name="charter",
+ )
+ self.executor = ActionExecutor([interpreter, browser], hooks=[InternLMActionProcessor()])
+ self.finish_pattern = finish_pattern
+ self.max_turn = max_turn
+
+ def forward(self, message, session_id=0):
+ for _ in range(self.max_turn):
+ message = self.researcher(message, session_id=session_id, stop_words=["```\n", "```python"]) # override llm stop words
+ while message.formatted["tool_type"]:
+ message = self.executor(message, session_id=session_id)
+ message = self.researcher(message, session_id=session_id, stop_words=["```\n", "```python"])
+ if self.finish_pattern in message.content:
+ return message
+ message = self.charter(message)
+ while message.formatted["tool_type"]:
+ message = self.executor(message, session_id=session_id)
+ message = self.charter(message, session_id=session_id)
+ if self.finish_pattern in message.content:
+ return message
+ return message
+
+visualizer = DataVisualizer(
+ "gpt-4o-2024-05-13",
+ research_prompt="You should provide accurate data for the chart generator to use.",
+ chart_prompt="Any charts you display will be visible by the user.",
+)
+user_msg = AgentMessage(
+ sender='user',
+ content="Fetch the China's GDP over the past 5 years, then draw a line graph of it. Once you code it up, finish.")
+bot_msg = visualizer(user_msg)
+print(bot_msg.content)
+json.dump(visualizer.state_dict(), open('visualizer.json', 'w'), ensure_ascii=False, indent=4)
+````
diff --git a/docs/en/index.rst b/docs/en/index.rst
new file mode 100644
index 0000000000000000000000000000000000000000..f51356c1d07724ba59c77574e960ecfbe9fdd72c
--- /dev/null
+++ b/docs/en/index.rst
@@ -0,0 +1,40 @@
+Welcome to Lagent's documentation!
+=======================================
+
+You can switch between English and Chinese in the lower-left corner of the layout.
+
+.. toctree::
+ :maxdepth: 2
+ :caption: Get Started
+
+ get_started/install.md
+ get_started/quickstart.md
+
+.. toctree::
+ :maxdepth: 2
+ :caption: Tutorials
+
+ tutorials/action.md
+
+.. toctree::
+ :caption: Switch Language
+
+ switch_language.md
+
+.. toctree::
+ :maxdepth: 1
+ :caption: API Reference
+
+ autoapi/lagent/actions/index
+ autoapi/lagent/agents/index
+ autoapi/lagent/llms/index
+ autoapi/lagent/utils/index
+ autoapi/lagent/schema/index
+ autoapi/lagent/version/index
+
+
+Indices and tables
+==================
+
+* :ref:`genindex`
+* :ref:`search`
diff --git a/docs/en/make.bat b/docs/en/make.bat
new file mode 100644
index 0000000000000000000000000000000000000000..8a3a0e25b49a52ade52c4f69ddeb0bc3d12527ff
--- /dev/null
+++ b/docs/en/make.bat
@@ -0,0 +1,36 @@
+@ECHO OFF
+
+pushd %~dp0
+
+REM Command file for Sphinx documentation
+
+if "%SPHINXBUILD%" == "" (
+ set SPHINXBUILD=sphinx-build
+)
+set SOURCEDIR=.
+set BUILDDIR=_build
+
+if "%1" == "" goto help
+
+%SPHINXBUILD% >NUL 2>NUL
+if errorlevel 9009 (
+ echo.
+ echo.The 'sphinx-build' command was not found. Make sure you have Sphinx
+ echo.installed, then set the SPHINXBUILD environment variable to point
+ echo.to the full path of the 'sphinx-build' executable. Alternatively you
+ echo.may add the Sphinx directory to PATH.
+ echo.
+ echo.If you don't have Sphinx installed, grab it from
+ echo.http://sphinx-doc.org/
+ exit /b 1
+)
+
+
+%SPHINXBUILD% -M %1 %SOURCEDIR% %BUILDDIR% %SPHINXOPTS% %O%
+goto end
+
+:help
+%SPHINXBUILD% -M help %SOURCEDIR% %BUILDDIR% %SPHINXOPTS% %O%
+
+:end
+popd
diff --git a/docs/en/requirements.txt b/docs/en/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..89fbf86c01cb29f10f7e99c910248c4d5229da58
--- /dev/null
+++ b/docs/en/requirements.txt
@@ -0,0 +1,4 @@
+recommonmark
+sphinx
+sphinx_markdown_tables
+sphinx_rtd_theme
diff --git a/docs/en/switch_language.md b/docs/en/switch_language.md
new file mode 100644
index 0000000000000000000000000000000000000000..950b4f0e74e09858eb3d627b8694e039eaa95603
--- /dev/null
+++ b/docs/en/switch_language.md
@@ -0,0 +1,3 @@
+## English
+
+## 简体中文
diff --git a/docs/en/tutorials/action.md b/docs/en/tutorials/action.md
new file mode 100644
index 0000000000000000000000000000000000000000..a2fa17284d22c3fa8fa262ab025b16a480abf134
--- /dev/null
+++ b/docs/en/tutorials/action.md
@@ -0,0 +1,400 @@
+# Action
+
+Actions, also called **tools**, provide a suite of functions LLM-driven agents can use to interact with the real world and perform complex tasks.
+
+## Basic Concepts
+
+### Tool & Toolkit
+
+There are two categories of tools:
+
+- tool: provide only one API to call.
+- toolkit: implement multiple APIs that undertake different sub-tasks.
+
+### Tool Description
+
+In Lagent, the tool description is a dictionary containing the action's core information of usage, observed by LLMs for decision-making.
+
+For simple tools, the description can be created as follows
+
+```python
+TOOL_DESCRIPTION = {
+ 'name': 'bold', # name of the tool
+ 'description': 'a function used to make text bold', # introduce the tool's function
+ 'parameters': [ # a list of parameters the tool take.
+ {
+ 'name': 'text', 'type': 'STRING', 'description': 'input content'
+ }
+ ],
+ 'required': ['text'], # specify names of parameters required
+}
+```
+
+In some situations there may be optional `return_data`, `parameter_description` keys describing the returns and argument passing format respectively.
+
+```{attention}
+`parameter_description` is usually inserted into the tool description automatically by the action's parser. It will be introduced in [Interface Design](#interface-design) .
+```
+
+For toolkits, the description is very similar but nest submethods
+
+```python
+TOOL_DESCRIPTION = {
+ 'name': 'PhraseEmphasis', # name of the toolkit
+ 'description': 'a toolkit which provides different styles of text emphasis', # introduce the tool's function
+ 'api_list': [
+ {
+ 'name': 'bold',
+ 'description': 'make text bold',
+ 'parameters': [
+ {
+ 'name': 'text', 'type': 'STRING', 'description': 'input content'
+ }
+ ],
+ 'required': ['text']
+ },
+ {
+ 'name': 'italic',
+ 'description': 'make text italic',
+ 'parameters': [
+ {
+ 'name': 'text', 'type': 'STRING', 'description': 'input content'
+ }
+ ],
+ 'required': ['text']
+ }
+ ]
+}
+```
+
+## Make Functions Tools
+
+It's not necessary to prepare an extra description for a defined function. In Lagent we provide a decorator `tool_api` which can conveniently turn a function into a tool by automatically parsing the function's typehints and dosctrings to generate the description dictionary and binding it to an attribute `api_description`.
+
+```python
+from lagent import tool_api
+
+@tool_api
+def bold(text: str) -> str:
+ """make text bold
+
+ Args:
+ text (str): input text
+
+ Returns:
+ str: bold text
+ """
+ return '**' + text + '**'
+
+
+bold.api_description
+```
+
+```python
+{'name': 'bold',
+ 'description': 'make text bold',
+ 'parameters': [{'name': 'text',
+ 'type': 'STRING',
+ 'description': 'input text'}],
+ 'required': ['text']}
+```
+
+Once `returns_named_value` is enabled you should declare the name of the return data, which will be processed to form a new field `return_data`:
+
+```python
+@tool_api(returns_named_value=True)
+def bold(text: str) -> str:
+ """make text bold
+
+ Args:
+ text (str): input text
+
+ Returns:
+ bold_text (str): bold text
+ """
+ return '**' + text + '**'
+
+bold.api_description
+```
+
+```python
+{'name': 'bold',
+ 'description': 'make text bold',
+ 'parameters': [{'name': 'text',
+ 'type': 'STRING',
+ 'description': 'input text'}],
+ 'required': ['text'],
+ 'return_data': [{'name': 'bold_text',
+ 'description': 'bold text',
+ 'type': 'STRING'}]}
+```
+
+Sometimes the tool may return a `dict` or `tuple`, and you want to elaborate each member in `return_data` rather than take them as a whole. Set `explode_return=True` and list them in the return part of docstrings.
+
+```python
+@tool_api(explode_return=True)
+def list_args(a: str, b: int, c: float = 0.0) -> dict:
+ """Return arguments in dict format
+
+ Args:
+ a (str): a
+ b (int): b
+ c (float): c
+
+ Returns:
+ dict: input arguments
+ - a (str): a
+ - b (int): b
+ - c: c
+ """
+ return {'a': a, 'b': b, 'c': c}
+```
+
+```python
+{'name': 'list_args',
+ 'description': 'Return arguments in dict format',
+ 'parameters': [{'name': 'a', 'type': 'STRING', 'description': 'a'},
+ {'name': 'b', 'type': 'NUMBER', 'description': 'b'},
+ {'name': 'c', 'type': 'FLOAT', 'description': 'c'}],
+ 'required': ['a', 'b'],
+ 'return_data': [{'name': 'a', 'description': 'a', 'type': 'STRING'},
+ {'name': 'b', 'description': 'b', 'type': 'NUMBER'},
+ {'name': 'c', 'description': 'c'}]}
+```
+
+```{warning}
+Only Google style Python docstrings is currently supported.
+```
+
+## Interface Design
+
+`BaseAction(description=None, parser=JsonParser, enable=True)` is the base class all actions should inherit from. It takes three initialization arguments
+
+- **description**: a tool description dictionary, used set instance attribute `description`. Mostly you don't need explicitly pass this argument since the meta class of `BaseAction` will search methods decorated by `tool_api` and assemble their `api_description` as a class attribute `__tool_description__`, and if the initial `description` is left null, then `__tool_description__` will be copied as `description`.
+
+- **parser**: `BaseParser` class. It will instantialize a parser used to validate the arguments of APIs in `description`.
+
+ For example, `JsonParser` requires arguments passed in the format of JSON or `dict`. To make LLMs aware of this, It inserts a field `parameter_description` into the `description`.
+
+ ```python
+ from lagent import BaseAction
+
+ action = BaseAction(
+ {
+ 'name': 'bold',
+ 'description': 'a function used to make text bold',
+ 'parameters': [
+ {
+ 'name': 'text', 'type': 'STRING', 'description': 'input content'
+ }
+ ],
+ 'required': ['text']
+ }
+ )
+ action.description
+ ```
+
+ ```python
+ {'name': 'bold',
+ 'description': 'a function used to make text bold',
+ 'parameters': [{'name': 'text',
+ 'type': 'STRING',
+ 'description': 'input content'}],
+ 'required': ['text'],
+ 'parameter_description': '如果调用该工具,你必须使用Json格式 {key: value} 传参,其中key为参数名称'}
+ ```
+
+- **enable**: specify whether the tool is available.
+
+### Custom Action
+
+A simple tool must have its `run` method implemented, while APIs of toolkits should avoid naming conflicts with this reserved word.
+
+```{tip}
+`run` is allowed not to be decorated by `tool_api` for simple tools unless you want to hint the return data.
+```
+
+```python
+class Bold(BaseAction):
+
+ def run(self, text: str):
+ """make text bold
+
+ Args:
+ text (str): input text
+
+ Returns:
+ str: bold text
+ """
+ return '**' + text + '**'
+
+class PhraseEmphasis(BaseAction):
+ """a toolkit which provides different styles of text emphasis"""
+
+ @tool_api
+ def bold(self, text):
+ """make text bold
+
+ Args:
+ text (str): input text
+
+ Returns:
+ str: bold text
+ """
+ return '**' + text + '**'
+
+ @tool_api
+ def italic(self, text):
+ """make text italic
+
+ Args:
+ text (str): input text
+
+ Returns:
+ str: italic text
+ """
+ return '*' + text + '*'
+
+# Inspect the default description
+# Bold.__tool_description__, PhraseEmphasis.__tool_description__
+```
+
+### Auto-registration
+
+Any subclass of `BaseAction` will be registered automatically. You can use `list_tools()` and `get_tool()` to view all tools and initialize by name.
+
+```python
+from lagent import list_tools, get_tool
+
+list_tools()
+```
+
+```python
+['BaseAction',
+ 'InvalidAction',
+ 'NoAction',
+ 'FinishAction',
+ 'ArxivSearch',
+ 'BINGMap',
+ 'GoogleScholar',
+ 'GoogleSearch',
+ 'IPythonInterpreter',
+ 'PPT',
+ 'PythonInterpreter',
+ 'Bold',
+ 'PhraseEmphasis']
+```
+
+Create a `PhraseEmphasis` object
+
+```python
+action = get_tool('PhraseEmphasis')
+action.description
+```
+
+```python
+{'name': 'PhraseEmphasis',
+ 'description': 'a toolkit which provides different styles of text emphasis',
+ 'api_list': [{'name': 'bold',
+ 'description': 'make text bold',
+ 'parameters': [{'name': 'text',
+ 'type': 'STRING',
+ 'description': 'input text'}],
+ 'required': ['text'],
+ 'parameter_description': '如果调用该工具,你必须使用Json格式 {key: value} 传参,其中key为参数名称'},
+ {'name': 'italic',
+ 'description': 'make text italic',
+ 'parameters': [{'name': 'text',
+ 'type': 'STRING',
+ 'description': 'input text'}],
+ 'required': ['text'],
+ 'parameter_description': '如果调用该工具,你必须使用Json格式 {key: value} 传参,其中key为参数名称'}]}
+```
+
+## Tool Calling
+
+### Run a Tool
+
+`__call__` method of `Action` takes two arguments
+
+- `inputs`: It depends on the action's parser. Often a string in specific formats generated by LLMs.
+ - `JsonParser`: Allow passing arguments in the format of JSON string or Python `dict`.
+ - `TupleParser`: Allow passing arguments in the format of tuple string format or Python `tuple`.
+- `name`: Which API to call. Default is `run`.
+
+It returns an `ActionReturn` object which encapsulates calling details
+
+- `args`: Dictionary of action inputs.
+- `type`: Action name.
+- `result`: List of dicts. Each contains two keys: 'type' and 'content'. when errors occur, it is `None`.
+- `errmsg`: Error message. Default is `None`.
+
+Below is an example
+
+```python
+from lagent import IPythonInterpreter, TupleParser
+
+action1 = IPythonInterpreter()
+ret = action1('{"command": "import math;math.sqrt(100)"}')
+print(ret.result)
+ret = action1({'command': 'import math;math.sqrt(100)'})
+print(ret.result)
+
+action2 = IPythonInterpreter(parser=TupleParser)
+ret = action2('("import math;math.sqrt(100)", )')
+print(ret.result)
+ret = action2(('import math;math.sqrt(100)',))
+print(ret.result)
+```
+
+```python
+[{'type': 'text', 'content': '10.0'}]
+[{'type': 'text', 'content': '10.0'}]
+[{'type': 'text', 'content': '10.0'}]
+[{'type': 'text', 'content': '10.0'}]
+```
+
+### Dynamic Invocation
+
+Lagent provides an `ActionExecutor` to manage multiple tools. It will flatten `api_list` of toolkits and rename each `{tool_name}.{api_name}`.
+
+```python
+from lagent import ActionExecutor, ArxivSearch, IPythonInterpreter
+
+executor = ActionExecutor(actions=[ArxivSearch(), IPythonInterpreter()])
+executor.get_actions_info() # This information is fed to LLMs as the tool meta prompt
+```
+
+```python
+[{'name': 'ArxivSearch.get_arxiv_article_information',
+ 'description': 'Run Arxiv search and get the article meta information.',
+ 'parameters': [{'name': 'query',
+ 'type': 'STRING',
+ 'description': 'the content of search query'}],
+ 'required': ['query'],
+ 'return_data': [{'name': 'content',
+ 'description': 'a list of 3 arxiv search papers',
+ 'type': 'STRING'}],
+ 'parameter_description': '如果调用该工具,你必须使用Json格式 {key: value} 传参,其中key为参数名称'},
+ {'name': 'IPythonInterpreter',
+ 'description': "When you send a message containing Python code to python, it will be executed in a stateful Jupyter notebook environment. python will respond with the output of the execution or time out after 60.0 seconds. The drive at '/mnt/data' can be used to save and persist user files. Internet access for this session is disabled. Do not make external web requests or API calls as they will fail.",
+ 'parameters': [{'name': 'command',
+ 'type': 'STRING',
+ 'description': 'Python code'},
+ {'name': 'timeout',
+ 'type': 'NUMBER',
+ 'description': 'Upper bound of waiting time for Python script execution.'}],
+ 'required': ['command'],
+ 'parameter_description': '如果调用该工具,你必须使用Json格式 {key: value} 传参,其中key为参数名称'}]
+```
+
+Trigger an action through the executor
+
+```python
+ret = executor('IPythonInterpreter', '{"command": "import math;math.sqrt(100)"}')
+ret.result
+```
+
+```python
+[{'type': 'text', 'content': '10.0'}]
+```
diff --git a/docs/imgs/lagent_icon.png b/docs/imgs/lagent_icon.png
new file mode 100644
index 0000000000000000000000000000000000000000..635b2f7851faf43641d18b6d27b6e6791a13073d
Binary files /dev/null and b/docs/imgs/lagent_icon.png differ
diff --git a/docs/imgs/lagent_logo.png b/docs/imgs/lagent_logo.png
new file mode 100644
index 0000000000000000000000000000000000000000..f3125fc801708231c8ea5a830f538aff82795a4b
Binary files /dev/null and b/docs/imgs/lagent_logo.png differ
diff --git a/docs/zh_cn/.readthedocs.yaml b/docs/zh_cn/.readthedocs.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..aa8bd3053446533683e1df21c398465210c7852f
--- /dev/null
+++ b/docs/zh_cn/.readthedocs.yaml
@@ -0,0 +1,15 @@
+version: 2
+
+formats: all
+
+build:
+ os: ubuntu-22.04
+ tools:
+ python: "3.10"
+
+python:
+ install:
+ - requirements: requirements/docs.txt
+
+sphinx:
+ configuration: docs/zh_cn/conf.py
diff --git a/docs/zh_cn/Makefile b/docs/zh_cn/Makefile
new file mode 100644
index 0000000000000000000000000000000000000000..d4bb2cbb9eddb1bb1b4f366623044af8e4830919
--- /dev/null
+++ b/docs/zh_cn/Makefile
@@ -0,0 +1,20 @@
+# Minimal makefile for Sphinx documentation
+#
+
+# You can set these variables from the command line, and also
+# from the environment for the first two.
+SPHINXOPTS ?=
+SPHINXBUILD ?= sphinx-build
+SOURCEDIR = .
+BUILDDIR = _build
+
+# Put it first so that "make" without argument is like "make help".
+help:
+ @$(SPHINXBUILD) -M help "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
+
+.PHONY: help Makefile
+
+# Catch-all target: route all unknown targets to Sphinx using the new
+# "make mode" option. $(O) is meant as a shortcut for $(SPHINXOPTS).
+%: Makefile
+ @$(SPHINXBUILD) -M $@ "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
diff --git a/docs/zh_cn/_static/css/readthedocs.css b/docs/zh_cn/_static/css/readthedocs.css
new file mode 100644
index 0000000000000000000000000000000000000000..5f3c55de0804e7f29b800d98c05f98ee5178be76
--- /dev/null
+++ b/docs/zh_cn/_static/css/readthedocs.css
@@ -0,0 +1,6 @@
+.header-logo {
+ background-image: url("../images/lagent_icon.png");
+ background-size: 40px 40px;
+ height: 40px;
+ width: 40px;
+}
diff --git a/docs/zh_cn/_static/images/lagent_icon.png b/docs/zh_cn/_static/images/lagent_icon.png
new file mode 100644
index 0000000000000000000000000000000000000000..635b2f7851faf43641d18b6d27b6e6791a13073d
Binary files /dev/null and b/docs/zh_cn/_static/images/lagent_icon.png differ
diff --git a/docs/zh_cn/_static/images/robot.png b/docs/zh_cn/_static/images/robot.png
new file mode 100644
index 0000000000000000000000000000000000000000..4979d4f2ee4743b21b64ff1bbdd978554a176b7e
Binary files /dev/null and b/docs/zh_cn/_static/images/robot.png differ
diff --git a/docs/zh_cn/_static/js/collapsed.js b/docs/zh_cn/_static/js/collapsed.js
new file mode 100644
index 0000000000000000000000000000000000000000..36179c7b4e0de6fc7eaa6aa4c1aba5790b8b5c4d
--- /dev/null
+++ b/docs/zh_cn/_static/js/collapsed.js
@@ -0,0 +1 @@
+var collapsedSections = ['API 文档']
diff --git a/docs/zh_cn/_static/js/table.js b/docs/zh_cn/_static/js/table.js
new file mode 100644
index 0000000000000000000000000000000000000000..8dacf477f33e81bba3a0c0edc11b135f648b1f0a
--- /dev/null
+++ b/docs/zh_cn/_static/js/table.js
@@ -0,0 +1,31 @@
+$(document).ready(function () {
+ table = $('.model-summary').DataTable({
+ "stateSave": false,
+ "lengthChange": false,
+ "pageLength": 10,
+ "order": [],
+ "scrollX": true,
+ "columnDefs": [
+ { "type": "summary", targets: '_all' },
+ ]
+ });
+ // Override the default sorting for the summary columns, which
+ // never takes the "-" character into account.
+ jQuery.extend(jQuery.fn.dataTableExt.oSort, {
+ "summary-asc": function (str1, str2) {
+ if (str1 == "
+-
") + return 1; + if (str2 == "-
") + return -1; + return ((str1 < str2) ? -1 : ((str1 > str2) ? 1 : 0)); + }, + + "summary-desc": function (str1, str2) { + if (str1 == "-
") + return 1; + if (str2 == "-
") + return -1; + return ((str1 < str2) ? 1 : ((str1 > str2) ? -1 : 0)); + } + }); +}) diff --git a/docs/zh_cn/_templates/autoapi/index.rst b/docs/zh_cn/_templates/autoapi/index.rst new file mode 100644 index 0000000000000000000000000000000000000000..b2ba92c0fdead48ec6602736fe18163f32f7bdf2 --- /dev/null +++ b/docs/zh_cn/_templates/autoapi/index.rst @@ -0,0 +1,14 @@ +API Reference +============= + +This page contains auto-generated API reference documentation. + +.. toctree:: + :titlesonly: + :maxdepth: 3 + + {% for page in pages %} + {% if page.top_level_object and page.display %} + {{ page.include_path }} + {% endif %} + {% endfor %} diff --git a/docs/zh_cn/_templates/autoapi/python/module.rst b/docs/zh_cn/_templates/autoapi/python/module.rst new file mode 100644 index 0000000000000000000000000000000000000000..7cb039f1b8b6712cb431be0d3b3d9c8615e36a12 --- /dev/null +++ b/docs/zh_cn/_templates/autoapi/python/module.rst @@ -0,0 +1,112 @@ +{% if not obj.display %} +:orphan: + +{% endif %} +:py:mod:`{{ obj.name if obj.name.count(".") <= 1 else obj.short_name }}` +=========={{ "=" * (obj.name|length if obj.name.count(".") <= 1 else obj.short_name|length) }} + +.. py:module:: {{ obj.name }} + +{% if obj.docstring %} +.. autoapi-nested-parse:: + + {{ obj.docstring|indent(3) }} + +{% endif %} + +{% block subpackages %} +{% set visible_subpackages = obj.subpackages|selectattr("display")|list %} +{% if visible_subpackages %} +Subpackages +----------- +.. toctree:: + :titlesonly: + :maxdepth: 3 + +{% for subpackage in visible_subpackages %} + {{ subpackage.short_name }}/index.rst +{% endfor %} + + +{% endif %} +{% endblock %} +{% block submodules %} +{% set visible_submodules = obj.submodules|selectattr("display")|list %} +{% if visible_submodules %} +Submodules +---------- +.. toctree:: + :titlesonly: + :maxdepth: 1 + +{% for submodule in visible_submodules %} + {{ submodule.short_name }}/index.rst +{% endfor %} + + +{% endif %} +{% endblock %} +{% block content %} +{% if obj.type is equalto("package") %} +{% set visible_children = obj.children|selectattr("display")|list %} +{% else %} +{% set visible_children = obj.children|selectattr("display")|rejectattr("imported")|list %} +{% endif %} +{% if visible_children %} +{{ obj.type|title }} Contents +{{ "-" * obj.type|length }}--------- + +{% set visible_classes = visible_children|selectattr("type", "equalto", "class")|list %} +{% set visible_functions = visible_children|selectattr("type", "equalto", "function")|list %} +{% set visible_attributes = visible_children|selectattr("type", "equalto", "data")|list %} +{% if "show-module-summary" in autoapi_options and (visible_classes or visible_functions) %} +{% block classes scoped %} +{% if visible_classes %} +Classes +~~~~~~~ + +.. autoapisummary:: + +{% for klass in visible_classes %} + {{ klass.id }} +{% endfor %} + + +{% endif %} +{% endblock %} + +{% block functions scoped %} +{% if visible_functions %} +Functions +~~~~~~~~~ + +.. autoapisummary:: + +{% for function in visible_functions %} + {{ function.id }} +{% endfor %} + + +{% endif %} +{% endblock %} + +{% block attributes scoped %} +{% if visible_attributes %} +Attributes +~~~~~~~~~~ + +.. autoapisummary:: + +{% for attribute in visible_attributes %} + {{ attribute.id }} +{% endfor %} + + +{% endif %} +{% endblock %} +{% endif %} +{% for obj_item in visible_children %} +{{ obj_item.render()|indent(0) }} +{% endfor %} +{% endif %} +{% endblock %} diff --git a/docs/zh_cn/_templates/classtemplate.rst b/docs/zh_cn/_templates/classtemplate.rst new file mode 100644 index 0000000000000000000000000000000000000000..4f74842394ec9807fb1ae2d8f05a8a57e9a2e24c --- /dev/null +++ b/docs/zh_cn/_templates/classtemplate.rst @@ -0,0 +1,14 @@ +.. role:: hidden + :class: hidden-section +.. currentmodule:: {{ module }} + + +{{ name | underline}} + +.. autoclass:: {{ name }} + :members: + + +.. + autogenerated from source/_templates/classtemplate.rst + note it does not have :inherited-members: diff --git a/docs/zh_cn/conf.py b/docs/zh_cn/conf.py new file mode 100644 index 0000000000000000000000000000000000000000..b670f1249ac6c7fa3e78b1702b202fe2f79aecc5 --- /dev/null +++ b/docs/zh_cn/conf.py @@ -0,0 +1,108 @@ +# Configuration file for the Sphinx documentation builder. +# +# This file only contains a selection of the most common options. For a full +# list see the documentation: +# https://www.sphinx-doc.org/en/master/usage/configuration.html + +# -- Path setup -------------------------------------------------------------- + +# If extensions (or modules to document with autodoc) are in another directory, +# add these directories to sys.path here. If the directory is relative to the +# documentation root, use os.path.abspath to make it absolute, like shown here. + +import os +import re +import sys + +sys.path.insert(0, os.path.abspath('../..')) + +# -- Project information ----------------------------------------------------- +project = 'Lagent' +copyright = '2020-2030, InternLM' +author = 'InternLM' +language = 'zh_CN' + +# The full version, including alpha/beta/rc tags +version_file = '../../lagent/version.py' +with open(version_file) as f: + exec(compile(f.read(), version_file, 'exec')) +__version__ = locals()['__version__'] +release = __version__ + +# -- General configuration --------------------------------------------------- + +# Add any Sphinx extension module names here, as strings. They can be +# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom +# ones. +extensions = [ + 'sphinx_rtd_theme', + 'myst_nb', + 'autoapi.extension', + 'sphinx_markdown_tables', + 'sphinx.ext.autodoc', + 'sphinx.ext.napoleon', + 'sphinx.ext.viewcode', +] + +nb_output_stderr = 'remove-warn' +autodoc_typehints = 'description' + +# sphinx-autoapi configuration +autoapi_dirs = ['../../lagent'] +autoapi_options = [ + 'members', + 'undoc-members', + 'show-inheritance', + 'show-module-summary', +] +autoapi_ignore = ['*migrations*', '*command.py', '*cli.py'] +autoapi_template_dir = '_templates/autoapi' +autoapi_add_toctree_entry = False + +# Add any paths that contain templates here, relative to this directory. +templates_path = ['_templates'] + +# List of patterns, relative to source directory, that match files and +# directories to ignore when looking for source files. +# This pattern also affects html_static_path and html_extra_path. +exclude_patterns = [] + +# -- Options for HTML output ------------------------------------------------- + +# The theme to use for HTML and HTML Help pages. See the documentation for +# a list of builtin themes. +# +html_theme = 'sphinx_rtd_theme' +html_theme_options = { + 'navigation_depth': 3, + 'titles_only': False, + 'style_nav_header_background': '#4fabab', +} +html_context = { + 'display_github': True, + 'github_host': 'github.com', + 'github_user': 'InternLM', + 'github_repo': 'lagent', + 'github_version': 'main', + 'conf_py_path': '/docs/zh_cn/', +} +html_title = 'Lagent' +html_logo = '../imgs/lagent_logo.png' +html_favicon = '../imgs/lagent_icon.png' + +master_doc = 'index' + +# Add any paths that contain custom static files (such as style sheets) here, +# relative to this directory. They are copied after the builtin static files, +# so a file named 'default.css' will overwrite the builtin 'default.css'. +html_static_path = ['_static'] + + +def custom_skip(app, what, name, obj, skip, options): + if what in ['data', 'function', 'class'] and re.search('logger', name): + skip = True + return skip + + +def setup(sphinx): + sphinx.connect('autoapi-skip-member', custom_skip) diff --git a/docs/zh_cn/cp_origin_docs.sh b/docs/zh_cn/cp_origin_docs.sh new file mode 100755 index 0000000000000000000000000000000000000000..1e728323684a0aad1571eb392871d6c5de6644fc --- /dev/null +++ b/docs/zh_cn/cp_origin_docs.sh @@ -0,0 +1,9 @@ +#!/usr/bin/env bash + +# Copy *.md files from docs/ if it doesn't have a Chinese translation + +for filename in $(find ../en/ -name '*.md' -printf "%P\n"); +do + mkdir -p $(dirname $filename) + cp -n ../en/$filename ./$filename +done diff --git a/docs/zh_cn/docutils.conf b/docs/zh_cn/docutils.conf new file mode 100644 index 0000000000000000000000000000000000000000..0c00c84688701117f231fd0c8ec295fb747b7d8f --- /dev/null +++ b/docs/zh_cn/docutils.conf @@ -0,0 +1,2 @@ +[html writers] +table_style: colwidths-auto diff --git a/docs/zh_cn/get_started/install.md b/docs/zh_cn/get_started/install.md new file mode 100644 index 0000000000000000000000000000000000000000..2e844f907a1330391cb0464bbe0b84339cca6556 --- /dev/null +++ b/docs/zh_cn/get_started/install.md @@ -0,0 +1,19 @@ +# 安装方式 + +## pip安装 + +推荐使用 pip 安装 + +```bash +pip install lagent +``` + +## 源码安装 + +如需修改部分功能,可以从源码构建 Lagent + +```bash +git clone https://github.com/InternLM/lagent.git +cd lagent +pip install -e . +``` diff --git a/docs/zh_cn/index.rst b/docs/zh_cn/index.rst new file mode 100644 index 0000000000000000000000000000000000000000..c62bff684d8397e83946b731fb83457ee72c7dd9 --- /dev/null +++ b/docs/zh_cn/index.rst @@ -0,0 +1,39 @@ +欢迎来到 Lagent 的中文文档! +======================================= + +您可以在页面左下角切换中英文文档。 + +.. toctree:: + :maxdepth: 2 + :caption: 新手入门 + + get_started/install.md + +.. toctree:: + :maxdepth: 2 + :caption: 教程 + + tutorials/action.md + +.. toctree:: + :caption: 切换语言 + + switch_language.md + +.. toctree:: + :maxdepth: 1 + :caption: API 参考 + + autoapi/lagent/actions/index + autoapi/lagent/agents/index + autoapi/lagent/llms/index + autoapi/lagent/utils/index + autoapi/lagent/schema/index + autoapi/lagent/version/index + + +导引 +================== + +* :ref:`genindex` +* :ref:`search` diff --git a/docs/zh_cn/make.bat b/docs/zh_cn/make.bat new file mode 100644 index 0000000000000000000000000000000000000000..8a3a0e25b49a52ade52c4f69ddeb0bc3d12527ff --- /dev/null +++ b/docs/zh_cn/make.bat @@ -0,0 +1,36 @@ +@ECHO OFF + +pushd %~dp0 + +REM Command file for Sphinx documentation + +if "%SPHINXBUILD%" == "" ( + set SPHINXBUILD=sphinx-build +) +set SOURCEDIR=. +set BUILDDIR=_build + +if "%1" == "" goto help + +%SPHINXBUILD% >NUL 2>NUL +if errorlevel 9009 ( + echo. + echo.The 'sphinx-build' command was not found. Make sure you have Sphinx + echo.installed, then set the SPHINXBUILD environment variable to point + echo.to the full path of the 'sphinx-build' executable. Alternatively you + echo.may add the Sphinx directory to PATH. + echo. + echo.If you don't have Sphinx installed, grab it from + echo.http://sphinx-doc.org/ + exit /b 1 +) + + +%SPHINXBUILD% -M %1 %SOURCEDIR% %BUILDDIR% %SPHINXOPTS% %O% +goto end + +:help +%SPHINXBUILD% -M help %SOURCEDIR% %BUILDDIR% %SPHINXOPTS% %O% + +:end +popd diff --git a/docs/zh_cn/switch_language.md b/docs/zh_cn/switch_language.md new file mode 100644 index 0000000000000000000000000000000000000000..950b4f0e74e09858eb3d627b8694e039eaa95603 --- /dev/null +++ b/docs/zh_cn/switch_language.md @@ -0,0 +1,3 @@ +## English + +## 简体中文 diff --git a/docs/zh_cn/tutorials/action.md b/docs/zh_cn/tutorials/action.md new file mode 100644 index 0000000000000000000000000000000000000000..a686aeb82af7839472aad73cbdfa6a3d78a5ef54 --- /dev/null +++ b/docs/zh_cn/tutorials/action.md @@ -0,0 +1,398 @@ +# 动作 + +动作,也被称为工具,提供了一套LLM驱动的智能体用来与真实世界交互并执行复杂任务的函数。 + +## 基本概念 + +### 工具 & 工具包 + +有两种类型的工具: + +- 简单工具: 只提供一个API接口供调用。 +- 工具包: 实现多个API接口,承担不同的子任务。 + +### 工具描述 + +在Lagent中,工具描述是一个刻画工具调用方式的字典,能够被LLM观察并用于决策。 + +对于简单工具,描述可按如下格式声明: + +```python +TOOL_DESCRIPTION = { + 'name': 'bold', # 工具名称 + 'description': 'a function used to make text bold', # 介绍工具的功能 + 'parameters': [ # 这个工具所需要的参数列表 + { + 'name': 'text', 'type': 'STRING', 'description': 'input content' + } + ], + 'required': ['text'], # 指定必需的参数名 +} +``` + +在某些情况下,可能还包含 `return_data`,`parameter_description` 字段,分别描述返回内容及参数传递格式。 + +```{attention} +`parameter_description` 通常被动作的解析器自动插入到工具描述中,这部分将在[接口设计](#id6)中进行介绍。 +``` + +对于工具包,描述非常相似,但嵌套了子方法 + +```python +TOOL_DESCRIPTION = { + 'name': 'PhraseEmphasis', # 工具包的名字 + 'description': 'a toolkit which provides different styles of text emphasis', # 介绍工具包的功能 + 'api_list': [ + { + 'name': 'bold', + 'description': 'make text bold', + 'parameters': [ + { + 'name': 'text', 'type': 'STRING', 'description': 'input content' + } + ], + 'required': ['text'] + }, + { + 'name': 'italic', + 'description': 'make text italic', + 'parameters': [ + { + 'name': 'text', 'type': 'STRING', 'description': 'input content' + } + ], + 'required': ['text'] + } + ] +} +``` + +## 将函数转换为工具 + +对于已定义好的函数,无需人工添加额外的描述。在 Lagent 中,我们提供了一个修饰器 `tool_api`,它可以通过自动解析函数的类型提示和文档字符串来生成描述字典,并将其绑定到属性 `api_description`。 + +```python +from lagent import tool_api + +@tool_api +def bold(text: str) -> str: + """make text bold + + Args: + text (str): input text + + Returns: + str: bold text + """ + return '**' + text + '**' + + +bold.api_description +``` + +```python +{'name': 'bold', + 'description': 'make text bold', + 'parameters': [{'name': 'text', + 'type': 'STRING', + 'description': 'input text'}], + 'required': ['text']} +``` + +一旦启用 `returns_named_value`,您应当声明返回值的名称,这将被处理成一个新的字段 `return_data`: + +```python +@tool_api(returns_named_value=True) +def bold(text: str) -> str: + """make text bold + + Args: + text (str): input text + + Returns: + bold_text (str): bold text + """ + return '**' + text + '**' + +bold.api_description +``` + +```python +{'name': 'bold', + 'description': 'make text bold', + 'parameters': [{'name': 'text', + 'type': 'STRING', + 'description': 'input text'}], + 'required': ['text'], + 'return_data': [{'name': 'bold_text', + 'description': 'bold text', + 'type': 'STRING'}]} +``` + +有时工具可能返回一个 `dict` 或 `tuple`,如果你想在 `return_data` 中详细说明每个成员的含义而不是把它们当作一个整体,设置 `explode_return=True` 并在文档字符串的 Returns 部分中罗列它们。 + +```python +@tool_api(explode_return=True) +def list_args(a: str, b: int, c: float = 0.0) -> dict: + """Return arguments in dict format + + Args: + a (str): a + b (int): b + c (float): c + + Returns: + dict: input arguments + - a (str): a + - b (int): b + - c: c + """ + return {'a': a, 'b': b, 'c': c} +``` + +```python +{'name': 'list_args', + 'description': 'Return arguments in dict format', + 'parameters': [{'name': 'a', 'type': 'STRING', 'description': 'a'}, + {'name': 'b', 'type': 'NUMBER', 'description': 'b'}, + {'name': 'c', 'type': 'FLOAT', 'description': 'c'}], + 'required': ['a', 'b'], + 'return_data': [{'name': 'a', 'description': 'a', 'type': 'STRING'}, + {'name': 'b', 'description': 'b', 'type': 'NUMBER'}, + {'name': 'c', 'description': 'c'}]} +``` + +```{warning} +目前仅支持 Google 格式的 Python 文档字符串。 +``` + +## 接口设计 + +`BaseAction(description=None, parser=JsonParser, enable=True)` 是所有动作应该继承的基类,它接收三个初始化参数: + +- **description**:一个工具描述的字典,用于设置实例属性 `description`。通常不需要显式地传递这个参数,因为 `BaseAction` 的元类将查找被 `tool_api` 装饰的方法,并组装它们的 `api_description` 构造一个类属性 `__tool_description__`,如果实例化时 `description` 为空,那么该实例属性将置为 `__tool_description__`。 + +- **parser**:`BaseParser` 类,用于实例化一个动作解析器校验 `description` 所描述的工具的参数。例如,`JsonParser` 会要求模型在调用工具时传入一个 JSON 格式字符串或者 Python 字典,为了让 LLM 感知到该指令,它会在 `description` 中插入一个 `parameter_description` 字段。 + + ```python + from lagent import BaseAction + + action = BaseAction( + { + 'name': 'bold', + 'description': 'a function used to make text bold', + 'parameters': [ + { + 'name': 'text', 'type': 'STRING', 'description': 'input content' + } + ], + 'required': ['text'] + } + ) + action.description + ``` + + ```python + {'name': 'bold', + 'description': 'a function used to make text bold', + 'parameters': [{'name': 'text', + 'type': 'STRING', + 'description': 'input content'}], + 'required': ['text'], + 'parameter_description': '如果调用该工具,你必须使用Json格式 {key: value} 传参,其中key为参数名称'} + ``` + +- **enable**: 指明该动作是否生效。 + +### 自定义动作 + +一个简单工具必须实现 `run` 方法,而工具包则应当避免将各子API名称定义为该保留字段。 + +```{tip} +对于非工具包的 Action,`run` 允许不被 `tool_api` 装饰,除非你想提示返回信息。 +``` + +```python +class Bold(BaseAction): + + def run(self, text: str): + """make text bold + + Args: + text (str): input text + + Returns: + str: bold text + """ + return '**' + text + '**' + +class PhraseEmphasis(BaseAction): + """a toolkit which provides different styles of text emphasis""" + + @tool_api + def bold(self, text): + """make text bold + + Args: + text (str): input text + + Returns: + str: bold text + """ + return '**' + text + '**' + + @tool_api + def italic(self, text): + """make text italic + + Args: + text (str): input text + + Returns: + str: italic text + """ + return '*' + text + '*' + +# 查看默认工具描述 +# Bold.__tool_description__, PhraseEmphasis.__tool_description__ +``` + +### 自动注册 + +任何 `BaseAction` 的子类都会自动被注册。你可以使用 `list_tools()` 和 `get_tool()` 来查看所有工具类并通过工具名进行初始化。 + +```python +from lagent import list_tools, get_tool + +list_tools() +``` + +```python +['BaseAction', + 'InvalidAction', + 'NoAction', + 'FinishAction', + 'ArxivSearch', + 'BINGMap', + 'GoogleScholar', + 'GoogleSearch', + 'IPythonInterpreter', + 'PPT', + 'PythonInterpreter', + 'Bold', + 'PhraseEmphasis'] +``` + +创建一个 `PhraseEmphasis` 对象。 + +```python +action = get_tool('PhraseEmphasis') +action.description +``` + +```python +{'name': 'PhraseEmphasis', + 'description': 'a toolkit which provides different styles of text emphasis', + 'api_list': [{'name': 'bold', + 'description': 'make text bold', + 'parameters': [{'name': 'text', + 'type': 'STRING', + 'description': 'input text'}], + 'required': ['text'], + 'parameter_description': '如果调用该工具,你必须使用Json格式 {key: value} 传参,其中key为参数名称'}, + {'name': 'italic', + 'description': 'make text italic', + 'parameters': [{'name': 'text', + 'type': 'STRING', + 'description': 'input text'}], + 'required': ['text'], + 'parameter_description': '如果调用该工具,你必须使用Json格式 {key: value} 传参,其中key为参数名称'}]} +``` + +## 工具调用 + +### 执行工具 + +`Action` 的 `__call__` 方法需要传入两个参数 + +- `inputs`: 其类型与动作绑定的 `BaseParser` 相关,通常是由大语言模型生成的字符串。 + - `JsonParser`: 允许传入 JSON 格式字符串或 Python 字典。 + - `TupleParser`: 允许传入字面量为元组的字符串或 Python 元组。 +- `name`: 调用哪个 API,默认为 `run`。 + +工具会返回一个封装了调用细节的 `ActionReturn` 对象。 + +- `args`: 一个字典,表示该动作的入参。 +- `type`: 动作名称。 +- `result`: 以字典为成员的列表,每个字典包含两个键——'type' 和 'content',发生异常时该字段为 `None`。 +- `errmsg`: 错误信息,默认为 `None`。 + +以下是一个例子: + +```python +from lagent import IPythonInterpreter, TupleParser + +action1 = IPythonInterpreter() +ret = action1('{"command": "import math;math.sqrt(100)"}') +print(ret.result) +ret = action1({'command': 'import math;math.sqrt(100)'}) +print(ret.result) + +action2 = IPythonInterpreter(parser=TupleParser) +ret = action2('("import math;math.sqrt(100)", )') +print(ret.result) +ret = action2(('import math;math.sqrt(100)',)) +print(ret.result) +``` + +```python +[{'type': 'text', 'content': '10.0'}] +[{'type': 'text', 'content': '10.0'}] +[{'type': 'text', 'content': '10.0'}] +[{'type': 'text', 'content': '10.0'}] +``` + +### 动态触发 + +Lagent 提供 `ActionExecutor` 接口管理多个工具,它会将工具包的 `api_list` 平展并将各 API 更名为 `{tool_name}.{api_name}`。 + +```python +from lagent import ActionExecutor, ArxivSearch, IPythonInterpreter + +executor = ActionExecutor(actions=[ArxivSearch(), IPythonInterpreter()]) +executor.get_actions_info() # 该结果会作为LLM系统提示词的一部分 +``` + +```python +[{'name': 'ArxivSearch.get_arxiv_article_information', + 'description': 'Run Arxiv search and get the article meta information.', + 'parameters': [{'name': 'query', + 'type': 'STRING', + 'description': 'the content of search query'}], + 'required': ['query'], + 'return_data': [{'name': 'content', + 'description': 'a list of 3 arxiv search papers', + 'type': 'STRING'}], + 'parameter_description': '如果调用该工具,你必须使用Json格式 {key: value} 传参,其中key为参数名称'}, + {'name': 'IPythonInterpreter', + 'description': "When you send a message containing Python code to python, it will be executed in a stateful Jupyter notebook environment. python will respond with the output of the execution or time out after 60.0 seconds. The drive at '/mnt/data' can be used to save and persist user files. Internet access for this session is disabled. Do not make external web requests or API calls as they will fail.", + 'parameters': [{'name': 'command', + 'type': 'STRING', + 'description': 'Python code'}, + {'name': 'timeout', + 'type': 'NUMBER', + 'description': 'Upper bound of waiting time for Python script execution.'}], + 'required': ['command'], + 'parameter_description': '如果调用该工具,你必须使用Json格式 {key: value} 传参,其中key为参数名称'}] +``` + +通过动作执行器来触发一个工具 + +```python +ret = executor('IPythonInterpreter', '{"command": "import math;math.sqrt(100)"}') +ret.result +``` + +```python +[{'type': 'text', 'content': '10.0'}] +``` diff --git a/examples/agent_api_web_demo.py b/examples/agent_api_web_demo.py new file mode 100644 index 0000000000000000000000000000000000000000..9c53b075210acd7287e6a7a3f11d5f9d88f2df33 --- /dev/null +++ b/examples/agent_api_web_demo.py @@ -0,0 +1,186 @@ +import copy +import os +from typing import List +import streamlit as st +from lagent.actions import ArxivSearch, WeatherQuery +from lagent.prompts.parsers import PluginParser +from lagent.agents.stream import INTERPRETER_CN, META_CN, PLUGIN_CN, AgentForInternLM, get_plugin_prompt +from lagent.llms import GPTAPI + +class SessionState: + """管理会话状态的类。""" + + def init_state(self): + """初始化会话状态变量。""" + st.session_state['assistant'] = [] # 助手消息历史 + st.session_state['user'] = [] # 用户消息历史 + # 初始化插件列表 + action_list = [ + ArxivSearch(), + WeatherQuery(), + ] + st.session_state['plugin_map'] = {action.name: action for action in action_list} + st.session_state['model_map'] = {} # 存储模型实例 + st.session_state['model_selected'] = None # 当前选定模型 + st.session_state['plugin_actions'] = set() # 当前激活插件 + st.session_state['history'] = [] # 聊天历史 + st.session_state['api_base'] = None # 初始化API base地址 + + def clear_state(self): + """清除当前会话状态。""" + st.session_state['assistant'] = [] + st.session_state['user'] = [] + st.session_state['model_selected'] = None + + +class StreamlitUI: + """管理 Streamlit 界面的类。""" + + def __init__(self, session_state: SessionState): + self.session_state = session_state + self.plugin_action = [] # 当前选定的插件 + # 初始化提示词 + self.meta_prompt = META_CN + self.plugin_prompt = PLUGIN_CN + self.init_streamlit() + + def init_streamlit(self): + """初始化 Streamlit 的 UI 设置。""" + st.header(':robot_face: :blue[Lagent] Web Demo ', divider='rainbow') + + def setup_sidebar(self): + """设置侧边栏,选择模型和插件。""" + # 模型名称和 API Base 输入框 + model_name = st.sidebar.text_input('模型名称:', value='internlm2.5-latest') + + # ================================== 硅基流动的API ================================== + # 注意,如果采用硅基流动API,模型名称需要更改为:internlm/internlm2_5-7b-chat 或者 internlm/internlm2_5-20b-chat + # api_base = st.sidebar.text_input( + # 'API Base 地址:', value='https://api.siliconflow.cn/v1/chat/completions' + # ) + # ================================== 浦语官方的API ================================== + api_base = st.sidebar.text_input( + 'API Base 地址:', value='https://internlm-chat.intern-ai.org.cn/puyu/api/v1/chat/completions' + ) + # ================================================================================== + # 插件选择 + plugin_name = st.sidebar.multiselect( + '插件选择', + options=list(st.session_state['plugin_map'].keys()), + default=[], + ) + + # 根据选择的插件生成插件操作列表 + self.plugin_action = [st.session_state['plugin_map'][name] for name in plugin_name] + + # 动态生成插件提示 + if self.plugin_action: + self.plugin_prompt = get_plugin_prompt(self.plugin_action) + + # 清空对话按钮 + if st.sidebar.button('清空对话', key='clear'): + self.session_state.clear_state() + + return model_name, api_base, self.plugin_action + + def initialize_chatbot(self, model_name, api_base, plugin_action): + """初始化 GPTAPI 实例作为 chatbot。""" + token = os.getenv("token") + if not token: + st.error("未检测到环境变量 `token`,请设置环境变量,例如 `export token='your_token_here'` 后重新运行 X﹏X") + st.stop() # 停止运行应用 + + # 创建完整的 meta_prompt,保留原始结构并动态插入侧边栏配置 + meta_prompt = [ + {"role": "system", "content": self.meta_prompt, "api_role": "system"}, + {"role": "user", "content": "", "api_role": "user"}, + {"role": "assistant", "content": self.plugin_prompt, "api_role": "assistant"}, + {"role": "environment", "content": "", "api_role": "environment"} + ] + + api_model = GPTAPI( + model_type=model_name, + api_base=api_base, + key=token, # 从环境变量中获取授权令牌 + meta_template=meta_prompt, + max_new_tokens=512, + temperature=0.8, + top_p=0.9 + ) + return api_model + + def render_user(self, prompt: str): + """渲染用户输入内容。""" + with st.chat_message('user'): + st.markdown(prompt) + + def render_assistant(self, agent_return): + """渲染助手响应内容。""" + with st.chat_message('assistant'): + content = getattr(agent_return, "content", str(agent_return)) + st.markdown(content if isinstance(content, str) else str(content)) + + +def main(): + """主函数,运行 Streamlit 应用。""" + if 'ui' not in st.session_state: + session_state = SessionState() + session_state.init_state() + st.session_state['ui'] = StreamlitUI(session_state) + else: + st.header(':robot_face: :blue[Lagent] Web Demo ', divider='rainbow') + + # 设置侧边栏并获取模型和插件信息 + model_name, api_base, plugin_action = st.session_state['ui'].setup_sidebar() + plugins = [dict(type=f"lagent.actions.{plugin.__class__.__name__}") for plugin in plugin_action] + + if ( + 'chatbot' not in st.session_state or + model_name != st.session_state['chatbot'].model_type or + 'last_plugin_action' not in st.session_state or + plugin_action != st.session_state['last_plugin_action'] or + api_base != st.session_state['api_base'] + ): + # 更新 Chatbot + st.session_state['chatbot'] = st.session_state['ui'].initialize_chatbot(model_name, api_base, plugin_action) + st.session_state['last_plugin_action'] = plugin_action # 更新插件状态 + st.session_state['api_base'] = api_base # 更新 API Base 地址 + + # 初始化 AgentForInternLM + st.session_state['agent'] = AgentForInternLM( + llm=st.session_state['chatbot'], + plugins=plugins, + output_format=dict( + type=PluginParser, + template=PLUGIN_CN, + prompt=get_plugin_prompt(plugin_action) + ) + ) + # 清空对话历史 + st.session_state['session_history'] = [] + + if 'agent' not in st.session_state: + st.session_state['agent'] = None + + agent = st.session_state['agent'] + for prompt, agent_return in zip(st.session_state['user'], st.session_state['assistant']): + st.session_state['ui'].render_user(prompt) + st.session_state['ui'].render_assistant(agent_return) + + # 处理用户输入 + if user_input := st.chat_input(''): + st.session_state['ui'].render_user(user_input) + + # 调用模型时确保侧边栏的系统提示词和插件提示词生效 + res = agent(user_input, session_id=0) + st.session_state['ui'].render_assistant(res) + + # 更新会话状态 + st.session_state['user'].append(user_input) + st.session_state['assistant'].append(copy.deepcopy(res)) + + st.session_state['last_status'] = None + + +if __name__ == '__main__': + main() diff --git a/examples/model_cli_demo.py b/examples/model_cli_demo.py new file mode 100644 index 0000000000000000000000000000000000000000..0cdd60fe6f8304ba85641140998cc7b09022817b --- /dev/null +++ b/examples/model_cli_demo.py @@ -0,0 +1,63 @@ +from argparse import ArgumentParser + +from lagent.llms import HFTransformer +from lagent.llms.meta_template import INTERNLM2_META as META + + +def parse_args(): + parser = ArgumentParser(description='chatbot') + parser.add_argument( + '--path', + type=str, + default='internlm/internlm2-chat-20b', + help='The path to the model') + parser.add_argument( + '--mode', + type=str, + default='chat', + help='Completion through chat or generate') + args = parser.parse_args() + return args + + +def main(): + args = parse_args() + # Initialize the HFTransformer-based Language Model (llm) + model = HFTransformer( + path=args.path, + meta_template=META, + max_new_tokens=1024, + top_p=0.8, + top_k=None, + temperature=0.1, + repetition_penalty=1.0, + stop_words=['<|im_end|>']) + + def input_prompt(): + print('\ndouble enter to end input >>> ', end='', flush=True) + sentinel = '' # ends when this string is seen + return '\n'.join(iter(input, sentinel)) + + history = [] + while True: + try: + prompt = input_prompt() + except UnicodeDecodeError: + print('UnicodeDecodeError') + continue + if prompt == 'exit': + exit(0) + history.append(dict(role='user', content=prompt)) + if args.mode == 'generate': + history = [dict(role='user', content=prompt)] + print('\nInternLm2:', end='') + current_length = 0 + for status, response, _ in model.stream_chat(history): + print(response[current_length:], end='', flush=True) + current_length = len(response) + history.append(dict(role='assistant', content=response)) + print('') + + +if __name__ == '__main__': + main() diff --git a/examples/multi_agents_api_web_demo.py b/examples/multi_agents_api_web_demo.py new file mode 100644 index 0000000000000000000000000000000000000000..4b6873f418b2643f0b0507a25e0bcb68adf86752 --- /dev/null +++ b/examples/multi_agents_api_web_demo.py @@ -0,0 +1,197 @@ +import os +import asyncio +import json +import re +import requests +import streamlit as st + +from lagent.agents import Agent +from lagent.prompts.parsers import PluginParser +from lagent.agents.stream import PLUGIN_CN, get_plugin_prompt +from lagent.schema import AgentMessage +from lagent.actions import ArxivSearch +from lagent.hooks import Hook +from lagent.llms import GPTAPI + +YOUR_TOKEN_HERE = os.getenv("token") +if not YOUR_TOKEN_HERE: + raise EnvironmentError("未找到环境变量 'token',请设置后再运行程序。") + +# Hook类,用于对消息添加前缀 +class PrefixedMessageHook(Hook): + def __init__(self, prefix, senders=None): + """ + 初始化Hook + :param prefix: 消息前缀 + :param senders: 指定发送者列表 + """ + self.prefix = prefix + self.senders = senders or [] + + def before_agent(self, agent, messages, session_id): + """ + 在代理处理消息前修改消息内容 + :param agent: 当前代理 + :param messages: 消息列表 + :param session_id: 会话ID + """ + for message in messages: + if message.sender in self.senders: + message.content = self.prefix + message.content + +class AsyncBlogger: + """博客生成类,整合写作者和批评者。""" + + def __init__(self, model_type, api_base, writer_prompt, critic_prompt, critic_prefix='', max_turn=2): + """ + 初始化博客生成器 + :param model_type: 模型类型 + :param api_base: API 基地址 + :param writer_prompt: 写作者提示词 + :param critic_prompt: 批评者提示词 + :param critic_prefix: 批评消息前缀 + :param max_turn: 最大轮次 + """ + self.model_type = model_type + self.api_base = api_base + self.llm = GPTAPI( + model_type=model_type, + api_base=api_base, + key=YOUR_TOKEN_HERE, + max_new_tokens=4096, + ) + self.plugins = [dict(type='lagent.actions.ArxivSearch')] + self.writer = Agent( + self.llm, + writer_prompt, + name='写作者', + output_format=dict( + type=PluginParser, + template=PLUGIN_CN, + prompt=get_plugin_prompt(self.plugins) + ) + ) + self.critic = Agent( + self.llm, + critic_prompt, + name='批评者', + hooks=[PrefixedMessageHook(critic_prefix, ['写作者'])] + ) + self.max_turn = max_turn + + async def forward(self, message: AgentMessage, update_placeholder): + """ + 执行多阶段博客生成流程 + :param message: 初始消息 + :param update_placeholder: Streamlit占位符 + :return: 最终优化的博客内容 + """ + step1_placeholder = update_placeholder.container() + step2_placeholder = update_placeholder.container() + step3_placeholder = update_placeholder.container() + + # 第一步:生成初始内容 + step1_placeholder.markdown("**Step 1: 生成初始内容...**") + message = self.writer(message) + if message.content: + step1_placeholder.markdown(f"**生成的初始内容**:\n\n{message.content}") + else: + step1_placeholder.markdown("**生成的初始内容为空,请检查生成逻辑。**") + + # 第二步:批评者提供反馈 + step2_placeholder.markdown("**Step 2: 批评者正在提供反馈和文献推荐...**") + message = self.critic(message) + if message.content: + # 解析批评者反馈 + suggestions = re.search(r"1\. 批评建议:\n(.*?)2\. 推荐的关键词:", message.content, re.S) + keywords = re.search(r"2\. 推荐的关键词:\n- (.*)", message.content) + feedback = suggestions.group(1).strip() if suggestions else "未提供批评建议" + keywords = keywords.group(1).strip() if keywords else "未提供关键词" + + # Arxiv 文献查询 + arxiv_search = ArxivSearch() + arxiv_results = arxiv_search.get_arxiv_article_information(keywords) + + # 显示批评内容和文献推荐 + message.content = f"**批评建议**:\n{feedback}\n\n**推荐的文献**:\n{arxiv_results}" + step2_placeholder.markdown(f"**批评和文献推荐**:\n\n{message.content}") + else: + step2_placeholder.markdown("**批评内容为空,请检查批评逻辑。**") + + # 第三步:写作者根据反馈优化内容 + step3_placeholder.markdown("**Step 3: 根据反馈改进内容...**") + improvement_prompt = AgentMessage( + sender="critic", + content=( + f"根据以下批评建议和推荐文献对内容进行改进:\n\n" + f"批评建议:\n{feedback}\n\n" + f"推荐文献:\n{arxiv_results}\n\n" + f"请优化初始内容,使其更加清晰、丰富,并符合专业水准。" + ), + ) + message = self.writer(improvement_prompt) + if message.content: + step3_placeholder.markdown(f"**最终优化的博客内容**:\n\n{message.content}") + else: + step3_placeholder.markdown("**最终优化的博客内容为空,请检查生成逻辑。**") + + return message + +def setup_sidebar(): + """设置侧边栏,选择模型。""" + model_name = st.sidebar.text_input('模型名称:', value='internlm2.5-latest') + api_base = st.sidebar.text_input( + 'API Base 地址:', value='https://internlm-chat.intern-ai.org.cn/puyu/api/v1/chat/completions' + ) + + return model_name, api_base + +def main(): + """ + 主函数:构建Streamlit界面并处理用户交互 + """ + st.title("多代理博客优化助手") + + model_type, api_base = setup_sidebar() + topic = st.text_input('输入一个话题:', 'Self-Supervised Learning') + generate_button = st.button('生成博客内容') + + if ( + 'blogger' not in st.session_state or + st.session_state['model_type'] != model_type or + st.session_state['api_base'] != api_base + ): + st.session_state['blogger'] = AsyncBlogger( + model_type=model_type, + api_base=api_base, + writer_prompt="你是一位优秀的AI内容写作者,请撰写一篇有吸引力且信息丰富的博客内容。", + critic_prompt=""" + 作为一位严谨的批评者,请给出建设性的批评和改进建议,并基于相关主题使用已有的工具推荐一些参考文献,推荐的关键词应该是英语形式,简洁且切题。 + 请按照以下格式提供反馈: + 1. 批评建议: + - (具体建议) + 2. 推荐的关键词: + - (关键词1, 关键词2, ...) + """, + critic_prefix="请批评以下内容,并提供改进建议:\n\n" + ) + st.session_state['model_type'] = model_type + st.session_state['api_base'] = api_base + + if generate_button: + update_placeholder = st.empty() + + async def run_async_blogger(): + message = AgentMessage( + sender='user', + content=f"请撰写一篇关于{topic}的博客文章,要求表达专业,生动有趣,并且易于理解。" + ) + result = await st.session_state['blogger'].forward(message, update_placeholder) + return result + + loop = asyncio.new_event_loop() + asyncio.set_event_loop(loop) + loop.run_until_complete(run_async_blogger()) + +if __name__ == '__main__': + main() \ No newline at end of file diff --git a/examples/run_agent_lmdeploy.py b/examples/run_agent_lmdeploy.py new file mode 100644 index 0000000000000000000000000000000000000000..21b80592a16cee4e6c572d47caca574c0778df27 --- /dev/null +++ b/examples/run_agent_lmdeploy.py @@ -0,0 +1,177 @@ +import json +import time + +from lagent.agents.aggregator import InternLMToolAggregator +from lagent.agents.stream import PLUGIN_CN, AgentForInternLM, MathCoder, get_plugin_prompt +from lagent.llms import INTERNLM2_META, LMDeployPipeline +from lagent.prompts.parsers import PluginParser + +model = LMDeployPipeline( + path='internlm/internlm2_5-7b-chat', + meta_template=INTERNLM2_META, + tp=1, + top_k=1, + temperature=1.0, + stop_words=['<|im_end|>', '<|action_end|>'], + max_new_tokens=1024, +) + +# ----------------------- interpreter ----------------------- +print('-' * 80, 'interpreter', '-' * 80) +coder = MathCoder( + llm=model, + aggregator=InternLMToolAggregator(few_shot=[[ + { + 'role': + 'user', + 'content': + "Mike paid $\\$1.25$ for a stamp three years ago. He was just offered double that amount for the stamp. Assuming the stamp's offer price doubles every three years, how many dollars will he be offered in 12 more years?" + }, + { + 'role': + 'language', + 'content': + "Let's break down the problem into smaller steps to understand how to approach it.\n\n**Step 1:** Determine the initial amount paid for the stamp, which is $1.25.\n\n**Step 2:** Understand the pattern of the offer price increase. The offer price doubles every three years.\n\n**Step 3:** Calculate the offer price in 12 more years.\n\nSince the offer price doubles every three years, in 12 years, the price will double 12 / 3 = 4 times.\n\nWe can represent the offer price after 12 more years as:\n\\[ \\text{Offer Price} = \\text{Initial Price} \\times 2^{(\\text{Number of Doublings})} \\]\n\nLet's calculate this using Python to get the exact figure.\n\n" + }, + { + 'role': 'tool', + 'content': + '```python\nfrom sympy import symbols, Eq, solve\n\n# Define the variables\ninitial_price = 1.25\ndoublings_in_12_years = 12 / 3\n\n# Calculate the offer price after 12 years\noffer_price_12_years = initial_price * 2**doublings_in_12_years\n\noffer_price_12_years\n```', + 'name': 'interpreter', + }, + { + 'role': 'environment', + 'content': '20.0', + 'name': 'interpreter' + }, + { + 'role': + 'language', + 'content': + 'After calculating the given formula, the offer price for the stamp in 12 more years is found to be $\\boxed{20.0}$ dollars.' + }, + ]])) +query = ( + 'Marie is thinking of a multiple of 63, while Jay is thinking of a factor ' + 'of 63. They happen to be thinking of the same number. There are two ' + 'possibilities for the number that each of them is thinking of, one ' + 'positive and one negative. Find the product of these two numbers.') +res = coder(query, session_id=0) +# print(res.model_dump_json()) +# print('-' * 120) +print(coder.get_steps(0)) +import json + +print( + json.dumps( + coder.agent.aggregator.aggregate(coder.agent.memory, coder.agent.name, + coder.agent.output_format), + ensure_ascii=False, + indent=4)) + +state_dict = { + 'memory': [{ + 'sender': 'user', + 'content': + 'Marie is thinking of a multiple of 63, while Jay is thinking of a factor of 63. They happen to be thinking of the same number. There are two possibilities for the number that each of them is thinking of, one positive and one negative. Find the product of these two numbers.', + 'formatted': None, + 'type': None, + 'receiver': None + }, { + 'sender': 'Agent', + 'content': + 'The product of the two numbers, \\(63\\) and \\(-63\\), is \\(-3969\\). Therefore, the product of the two numbers that Marie and Jay are thinking of is \\(\\boxed{-3969}\\).', + 'formatted': { + 'tool_type': None, + 'thought': + 'The product of the two numbers, \\(63\\) and \\(-63\\), is \\(-3969\\). Therefore, the product of the two numbers that Marie and Jay are thinking of is \\(\\boxed{-3969}\\).', + 'action': None, + 'status': 0 + }, + 'type': None, + 'receiver': None + }], + 'agent.memory': [{ + 'sender': 'user', + 'content': + 'Marie is thinking of a multiple of 63, while Jay is thinking of a factor of 63. They happen to be thinking of the same number. There are two possibilities for the number that each of them is thinking of, one positive and one negative. Find the product of these two numbers.', + 'formatted': None, + 'type': None, + 'receiver': None + }, { + 'sender': 'Agent', + 'content': + "To solve this problem, we first need to identify the factors of 63. Since Marie is thinking of a multiple of 63 and Jay is thinking of a factor of 63, and they are thinking of the same number, we need to find the factors of 63 and then determine the multiples of 63 that match these factors.\n\nLet's start by finding the factors of 63 using Python.<|action_start|><|interpreter|>\n```python\nfrom sympy import divisors\n\n# Find the factors of 63\nfactors_of_63 = divisors(63)\nfactors_of_63\n```", + 'formatted': { + 'tool_type': 'interpreter', + 'thought': + "To solve this problem, we first need to identify the factors of 63. Since Marie is thinking of a multiple of 63 and Jay is thinking of a factor of 63, and they are thinking of the same number, we need to find the factors of 63 and then determine the multiples of 63 that match these factors.\n\nLet's start by finding the factors of 63 using Python.", + 'action': + '```python\nfrom sympy import divisors\n\n# Find the factors of 63\nfactors_of_63 = divisors(63)\nfactors_of_63\n```', + 'status': 1 + }, + 'type': None, + 'receiver': None + }, { + 'sender': 'ActionExecutor', + 'content': '[1, 3, 7, 9, 21, 63]', + 'formatted': None, + 'type': None, + 'receiver': None + }, { + 'sender': 'Agent', + 'content': + "The factors of 63 are \\(1, 3, 7, 9, 21,\\) and \\(63\\). Since Marie is thinking of a multiple of 63 and Jay is thinking of a factor of 63, and they are thinking of the same number, the number they are thinking of must be one of the factors of 63.\n\nGiven that there are two possibilities for the number they are thinking of, one positive and one negative, we need to consider both \\(63\\) and \\(-63\\) as the number they might be thinking of.\n\nNow, let's calculate the product of these two numbers, \\(63\\) and \\(-63\\).<|action_start|><|interpreter|>\n```python\n# Calculate the product of 63 and -63\nproduct = 63 * (-63)\nproduct\n```", + 'formatted': { + 'tool_type': 'interpreter', + 'thought': + "The factors of 63 are \\(1, 3, 7, 9, 21,\\) and \\(63\\). Since Marie is thinking of a multiple of 63 and Jay is thinking of a factor of 63, and they are thinking of the same number, the number they are thinking of must be one of the factors of 63.\n\nGiven that there are two possibilities for the number they are thinking of, one positive and one negative, we need to consider both \\(63\\) and \\(-63\\) as the number they might be thinking of.\n\nNow, let's calculate the product of these two numbers, \\(63\\) and \\(-63\\).", + 'action': + '```python\n# Calculate the product of 63 and -63\nproduct = 63 * (-63)\nproduct\n```', + 'status': 1 + }, + 'type': None, + 'receiver': None + }, { + 'sender': 'ActionExecutor', + 'content': '-3969', + 'formatted': None, + 'type': None, + 'receiver': None + }, { + 'sender': 'Agent', + 'content': + 'The product of the two numbers, \\(63\\) and \\(-63\\), is \\(-3969\\). Therefore, the product of the two numbers that Marie and Jay are thinking of is \\(\\boxed{-3969}\\).', + 'formatted': { + 'tool_type': None, + 'thought': + 'The product of the two numbers, \\(63\\) and \\(-63\\), is \\(-3969\\). Therefore, the product of the two numbers that Marie and Jay are thinking of is \\(\\boxed{-3969}\\).', + 'action': None, + 'status': 0 + }, + 'type': None, + 'receiver': None + }] +} +coder.load_state_dict(state_dict) +print(coder.state_dict() == state_dict) +print(coder.state_dict()) + +# ----------------------- plugin ----------------------- +print('-' * 80, 'plugin', '-' * 80) +plugins = [dict(type='lagent.actions.ArxivSearch')] +agent = AgentForInternLM( + llm=model, + plugins=plugins, + output_format=dict( + type=PluginParser, + template=PLUGIN_CN, + prompt=get_plugin_prompt(plugins))) + +tic = time.time() +query = 'LLM智能体方向的最新论文有哪些?' +res = agent(query, session_id=0) +print(res.model_dump_json()) +print('-' * 120) +print(agent.get_steps(0)) +print(f'time elapsed: {time.time() - tic}') diff --git a/examples/run_agent_services.py b/examples/run_agent_services.py new file mode 100644 index 0000000000000000000000000000000000000000..65fd8e9fab4f06414ed1a2c452eb39fd38028dca --- /dev/null +++ b/examples/run_agent_services.py @@ -0,0 +1,110 @@ +import asyncio +import time + +from lagent.agents.stream import PLUGIN_CN, get_plugin_prompt +from lagent.distributed import AsyncHTTPAgentClient, AsyncHTTPAgentServer, HTTPAgentClient, HTTPAgentServer +from lagent.llms import INTERNLM2_META +from lagent.schema import AgentMessage +from lagent.utils import create_object + +loop = asyncio.new_event_loop() +asyncio.set_event_loop(loop) + +server = HTTPAgentServer( + '1', + { + 'type': 'lagent.agents.AsyncAgent', + 'llm': { + 'type': 'lagent.llms.AsyncLMDeployPipeline', + 'path': 'internlm/internlm2_5-7b-chat', + 'meta_template': INTERNLM2_META, + } + }, + port=8090, +) +print(server.is_alive) +message = AgentMessage(sender='user', content='hello') +result = server(message) +print(result) +server.shutdown() + +# math coder +server = AsyncHTTPAgentServer( + '1', + { + 'type': 'lagent.agents.AsyncMathCoder', + 'llm': { + 'type': 'lagent.llms.AsyncLMDeployPipeline', + 'path': 'internlm/internlm2_5-7b-chat', + 'meta_template': INTERNLM2_META, + 'tp': 1, + 'top_k': 1, + 'temperature': 1.0, + 'stop_words': ['<|im_end|>', '<|action_end|>'], + 'max_new_tokens': 1024, + }, + 'interpreter': { + 'type': 'lagent.actions.AsyncIPythonInterpreter', + 'max_kernels': 100 + }, + }, + port=8091, +) +message = AgentMessage( + sender='user', + content= + ('Marie is thinking of a multiple of 63, while Jay is thinking of a factor ' + 'of 63. They happen to be thinking of the same number. There are two ' + 'possibilities for the number that each of them is thinking of, one ' + 'positive and one negative. Find the product of these two numbers.')) +result = server(message) +print(loop.run_until_complete(result)) +print(server.state_dict()) + +client = AsyncHTTPAgentClient(port=8091) +result = client('hello', session_id=1) +print(loop.run_until_complete(result)) +print(client.state_dict(1)) + +client = HTTPAgentClient(port=8091) +print(client.state_dict(1)) +print(client('introduce yourself', session_id=1)) +print(client.state_dict(1)) +server.shutdown() + +# plugins +plugins = [dict(type='lagent.actions.AsyncArxivSearch')] +server_cfg = dict( + type='lagent.distributed.AsyncHTTPAgentServer', + gpu_id='1', + config={ + 'type': 'lagent.agents.AsyncAgentForInternLM', + 'llm': { + 'type': 'lagent.llms.AsyncLMDeployPipeline', + 'path': 'internlm/internlm2_5-7b-chat', + 'meta_template': INTERNLM2_META, + 'tp': 1, + 'top_k': 1, + 'temperature': 1.0, + 'stop_words': ['<|im_end|>', '<|action_end|>'], + 'max_new_tokens': 1024, + }, + 'plugins': plugins, + 'output_format': { + 'type': 'lagent.prompts.parsers.PluginParser', + 'template': PLUGIN_CN, + 'prompt': get_plugin_prompt(plugins), + } + }, + port=8091, +) +server = create_object(server_cfg) +tic = time.time() +coros = [ + server(query, session_id=i) + for i, query in enumerate(['LLM智能体方向的最新论文有哪些?'] * 50) +] +res = loop.run_until_complete(asyncio.gather(*coros)) +print('-' * 120) +print(f'time elapsed: {time.time() - tic}') +server.shutdown() diff --git a/examples/run_async_agent_lmdeploy.py b/examples/run_async_agent_lmdeploy.py new file mode 100644 index 0000000000000000000000000000000000000000..dbd2b15f3db01f36c2bf7833ada31930dc28b192 --- /dev/null +++ b/examples/run_async_agent_lmdeploy.py @@ -0,0 +1,70 @@ +import asyncio +import json +import time + +from datasets import load_dataset + +from lagent.agents.stream import PLUGIN_CN, AsyncAgentForInternLM, AsyncMathCoder, get_plugin_prompt +from lagent.llms import INTERNLM2_META +from lagent.llms.lmdeploy_wrapper import AsyncLMDeployPipeline +from lagent.prompts.parsers import PluginParser + +# set up the loop +loop = asyncio.new_event_loop() +asyncio.set_event_loop(loop) +# initialize the model +model = AsyncLMDeployPipeline( + path='internlm/internlm2_5-7b-chat', + meta_template=INTERNLM2_META, + model_name='internlm-chat', + tp=1, + top_k=1, + temperature=1.0, + stop_words=['<|im_end|>', '<|action_end|>'], + max_new_tokens=1024, +) + +# ----------------------- interpreter ----------------------- +print('-' * 80, 'interpreter', '-' * 80) + +ds = load_dataset('lighteval/MATH', split='test') +problems = [item['problem'] for item in ds.select(range(0, 5000, 2))] + +coder = AsyncMathCoder( + llm=model, + interpreter=dict( + type='lagent.actions.AsyncIPythonInterpreter', max_kernels=300), + max_turn=11) +tic = time.time() +coros = [coder(query, session_id=i) for i, query in enumerate(problems)] +res = loop.run_until_complete(asyncio.gather(*coros)) +# print([r.model_dump_json() for r in res]) +print('-' * 120) +print(f'time elapsed: {time.time() - tic}') + +with open('./tmp_1.json', 'w') as f: + json.dump([coder.get_steps(i) for i in range(len(res))], + f, + ensure_ascii=False, + indent=4) + +# ----------------------- plugin ----------------------- +print('-' * 80, 'plugin', '-' * 80) +plugins = [dict(type='lagent.actions.AsyncArxivSearch')] +agent = AsyncAgentForInternLM( + llm=model, + plugins=plugins, + output_format=dict( + type=PluginParser, + template=PLUGIN_CN, + prompt=get_plugin_prompt(plugins))) + +tic = time.time() +coros = [ + agent(query, session_id=i) + for i, query in enumerate(['LLM智能体方向的最新论文有哪些?'] * 50) +] +res = loop.run_until_complete(asyncio.gather(*coros)) +# print([r.model_dump_json() for r in res]) +print('-' * 120) +print(f'time elapsed: {time.time() - tic}') diff --git a/examples/run_async_agent_lmdeploy_server.py b/examples/run_async_agent_lmdeploy_server.py new file mode 100644 index 0000000000000000000000000000000000000000..a3f78dea1bcc11101c5b71670d63c97707a9d3fa --- /dev/null +++ b/examples/run_async_agent_lmdeploy_server.py @@ -0,0 +1,86 @@ +import asyncio +import json +import time + +from datasets import load_dataset + +from lagent.agents.stream import AsyncAgentForInternLM, AsyncMathCoder, get_plugin_prompt +from lagent.llms import INTERNLM2_META +from lagent.llms.lmdeploy_wrapper import AsyncLMDeployClient, AsyncLMDeployServer + +# set up the loop +loop = asyncio.new_event_loop() +asyncio.set_event_loop(loop) +# initialize the model +model = AsyncLMDeployServer( + path='internlm/internlm2_5-7b-chat', + meta_template=INTERNLM2_META, + model_name='internlm-chat', + tp=1, + top_k=1, + temperature=1.0, + stop_words=['<|im_end|>', '<|action_end|>'], + max_new_tokens=1024, +) + +# ----------------------- interpreter ----------------------- +print('-' * 80, 'interpreter', '-' * 80) + +ds = load_dataset('lighteval/MATH', split='test') +problems = [item['problem'] for item in ds.select(range(50))] + + +# coder = AsyncMathCoder( +# llm=model, +# interpreter=dict(type='AsyncIPythonInterpreter', max_kernels=250)) +# tic = time.time() +# coros = [coder(query, session_id=i) for i, query in enumerate(problems)] +# res = loop.run_until_complete(asyncio.gather(*coros)) +# # print([r.model_dump_json() for r in res]) +# print('-' * 120) +# print(f'time elapsed: {time.time() - tic}') +# with open('./tmp_4.json', 'w') as f: +# json.dump([coder.get_steps(i) for i in range(len(res))], +# f, +# ensure_ascii=False, +# indent=4) + +# ----------------------- streaming chat ----------------------- +async def streaming(llm, problem): + async for out in llm.stream_chat([{'role': 'user', 'content': problem}]): + print(out) + + +tic = time.time() +client = AsyncLMDeployClient( + url='http://127.0.0.1:23333', + meta_template=INTERNLM2_META, + model_name='internlm2_5-7b-chat', + top_k=1, + temperature=1.0, + stop_words=['<|im_end|>', '<|action_end|>'], + max_new_tokens=1024, +) +# loop.run_until_complete(streaming(model, problems[0])) +loop.run_until_complete(streaming(client, problems[0])) +print(time.time() - tic) + +# ----------------------- plugin ----------------------- +# print('-' * 80, 'plugin', '-' * 80) +# plugins = [dict(type='AsyncArxivSearch')] +# agent = AsyncAgentForInternLM( +# llm=model, +# plugins=plugins, +# aggregator=dict( +# type='InternLMToolAggregator', +# plugin_prompt=get_plugin_prompt(plugins))) + +# tic = time.time() +# coros = [ +# agent(query, session_id=i) +# for i, query in enumerate(['LLM智能体方向的最新论文有哪些?'] * 50) +# ] +# res = loop.run_until_complete(asyncio.gather(*coros)) +# # print([r.model_dump_json() for r in res]) +# print('-' * 120) +# print(f'time elapsed: {time.time() - tic}') diff --git a/examples/run_async_agent_openai.py b/examples/run_async_agent_openai.py new file mode 100644 index 0000000000000000000000000000000000000000..a9952f276182b32f81880986b344dfed8b19c2d7 --- /dev/null +++ b/examples/run_async_agent_openai.py @@ -0,0 +1,61 @@ +import asyncio +import json +import time + +from datasets import load_dataset + +from lagent.agents import AsyncMathCoder +from lagent.agents.aggregator import InternLMToolAggregator +from lagent.llms import AsyncGPTAPI +from lagent.prompts.parsers import ToolParser + +loop = asyncio.new_event_loop() +asyncio.set_event_loop(loop) + +interpreter_prompt = ( + 'Below is a math problem. Please solve it step by step with the assistance of Python programming. Consider using Sympy or Numpy library ' + 'to facilitate your derivation, calculation and equation solving. Utilize the "pi" symbol and "Rational" from Sympy ' + 'for $$\pi$$ and fractions, and simplify all fractions and square roots without converting them to decimal values. ' + 'Please encapsulate each generated Jupyter Python code block with tags "{begin}" and "{end}". Conclude the ' + r'final answer when observations are sufficient and encapsulate the numerical result with LaTeX syntax "\boxed{{}}" ' + 'without any unit, and end your conclusion with the special token "[END]" to denote the completion of your response. ' + 'Keep the following points in mind:\n' + '- You must alternately use human and programming languages in the chain of thought;\n' + '- The number of your reasoning steps should not exceed **three**, which means you may merge some intermediate steps when the original answer is tedious.' +) + +async_llm = dict( + type=AsyncGPTAPI, + model='gpt-4o-2024-05-13', + retry=50, + key='', + max_new_tokens=2048, + stop_words=['', '\n```\n'], + max_new_tokens=1024, +) + +# ----------------------- interpreter ----------------------- +print('-' * 80, 'interpreter', '-' * 80) + +ds = load_dataset('lighteval/MATH', split='test') +problems = [item['problem'] for item in ds.select(range(50))] + +coder = AsyncMathCoder( + llm=model, + interpreter=dict( + type='lagent.actions.AsyncIPythonInterpreter', max_kernels=200), + output_format=ToolParser( + 'interpreter', + template= + ('Integrate step-by-step reasoning and Python code to solve math problems ' + 'using the following guidelines:\n' + '- Analyze the question and write jupyter code to solve the problem;\n' + r"- Present the final result in LaTeX using a '\boxed{{}}' without any " + 'units. \n'), + begin='\n```python\n', + end='\n```\n')) + +tic = time.time() +coros = [coder(query, session_id=i) for i, query in enumerate(problems)] +res = loop.run_until_complete(asyncio.gather(*coros)) +# print([r.model_dump_json() for r in res]) +print('-' * 120) +print(f'time elapsed: {time.time() - tic}') + +with open('./tmp_3.json', 'w') as f: + json.dump([coder.get_steps(i) for i in range(len(res))], + f, + ensure_ascii=False, + indent=4) diff --git a/examples/run_ray_async_agent_lmdeploy.py b/examples/run_ray_async_agent_lmdeploy.py new file mode 100644 index 0000000000000000000000000000000000000000..530ca1b2a472f847bff5a32990b3e896c3354b8c --- /dev/null +++ b/examples/run_ray_async_agent_lmdeploy.py @@ -0,0 +1,65 @@ +import asyncio +import json +import time + +import ray +from datasets import load_dataset + +from lagent.distributed.ray_serve import AsyncAgentRayActor +from lagent.llms import INTERNLM2_META +from lagent.llms.lmdeploy_wrapper import AsyncLMDeployPipeline + +ray.init() + +# set up the loop + +# initialize the model +loop = asyncio.new_event_loop() +asyncio.set_event_loop(loop) +model = dict( + type=AsyncLMDeployPipeline, + path='internlm/internlm2_5-7b-chat', + meta_template=INTERNLM2_META, + tp=1, + top_k=1, + temperature=1.0, + stop_words=['<|im_end|>', '<|action_end|>'], + max_new_tokens=1024, +) + +# ----------------------- interpreter ----------------------- +print('-' * 80, 'interpreter', '-' * 80) +ds = load_dataset('lighteval/MATH', split='test') +problems = [item['problem'] for item in ds.select(range(5000))] + +coder = dict( + type='lagent.agents.stream.AsyncMathCoder', + llm=model, + interpreter=dict(type='AsyncIPythonInterpreter', max_kernels=300), +) +tic = time.time() + +actor1 = AsyncAgentRayActor(coder.copy(), num_gpus=1) +actor2 = AsyncAgentRayActor(coder.copy(), num_gpus=1) +corots = [ + actor1(query, session_id=i) + for i, query in enumerate(problems[:len(problems) // 2]) +] +corots += [ + actor2(query, session_id=i) + for i, query in enumerate(problems[len(problems) // 2:]) +] +results = loop.run_until_complete(asyncio.gather(*corots)) + +print('-' * 120) +print(f'time elapsed: {time.time() - tic}') +all_step = ray.get([ + actor1.agent_actor.get_steps.remote(i) for i in range(len(problems) // 2) +]) +all_step += ray.get([ + actor2.agent_actor.get_steps.remote(i) + for i in range(len(problems[len(problems) // 2:])) +]) + +with open('./tmp_1.json', 'w') as f: + json.dump(all_step, f, ensure_ascii=False, indent=4) diff --git a/requirements/docs.txt b/requirements/docs.txt new file mode 100644 index 0000000000000000000000000000000000000000..0df2bf7f384b8f5286c480dadbc25bc78debdeca --- /dev/null +++ b/requirements/docs.txt @@ -0,0 +1,13 @@ +astroid<3.0.0 +docutils==0.18.1 +markdown>=3.4.0 +myst-nb +# -e git+https://github.com/open-mmlab/pytorch_sphinx_theme.git#egg=pytorch_sphinx_theme +# sphinx==4.0.2 +sphinx==6.1.0 +sphinx-autoapi +sphinx-rtd-theme==1.3.0 +sphinx-tabs +sphinx_copybutton +sphinx_markdown_tables>=0.0.16 +tabulate diff --git a/requirements/optional.txt b/requirements/optional.txt new file mode 100644 index 0000000000000000000000000000000000000000..75645dbe7bcd072298adc6660b7a139857171045 --- /dev/null +++ b/requirements/optional.txt @@ -0,0 +1,8 @@ +google-search-results +lmdeploy>=0.2.5 +pillow +python-pptx +timeout_decorator +torch +transformers>=4.34,<=4.40 +vllm>=0.3.3 diff --git a/requirements/runtime.txt b/requirements/runtime.txt new file mode 100644 index 0000000000000000000000000000000000000000..6fcd4ea1c8a27b67417be5c9bf4079340341c437 --- /dev/null +++ b/requirements/runtime.txt @@ -0,0 +1,20 @@ +aiohttp +arxiv +asyncache +asyncer +distro +duckduckgo_search==5.3.1b1 +filelock +func_timeout +griffe<1.0 +json5 +jsonschema +jupyter==1.0.0 +jupyter_client==8.6.2 +jupyter_core==5.7.2 +pydantic==2.6.4 +requests +termcolor +tiktoken +timeout-decorator +typing-extensions diff --git a/setup.cfg b/setup.cfg new file mode 100644 index 0000000000000000000000000000000000000000..ec9ff67985b153d031817c30ad378e92e9901431 --- /dev/null +++ b/setup.cfg @@ -0,0 +1,24 @@ +[isort] +line_length = 119 +multi_line_output = 0 +extra_standard_library = setuptools +known_first_party = mmdet +known_third_party = PIL,asynctest,cityscapesscripts,cv2,gather_models,matplotlib,mmcv,mmengine,numpy,onnx,onnxruntime,pycocotools,parameterized,pytest,pytorch_sphinx_theme,requests,scipy,seaborn,six,terminaltables,torch,ts,yaml +no_lines_before = STDLIB,LOCALFOLDER +default_section = THIRDPARTY + +[yapf] +BASED_ON_STYLE = pep8 +BLANK_LINE_BEFORE_NESTED_CLASS_OR_DEF = true +SPLIT_BEFORE_EXPRESSION_AFTER_OPENING_PAREN = true + +# ignore-words-list needs to be lowercase format. For example, if we want to +# ignore word "BA", then we need to append "ba" to ignore-words-list rather +# than "BA" +[codespell] +skip = *.ipynb +quiet-level = 3 +ignore-words-list = patten,nd,ty,mot,hist,formating,winn,gool,datas,wan,confids,TOOD,tood,ba,warmup,nam,DOTA,dota,conveyer,astroid + +[flake8] +max-line-length = 119 diff --git a/setup.py b/setup.py new file mode 100644 index 0000000000000000000000000000000000000000..699165da81c3f689d4364335fb39f0d88168411c --- /dev/null +++ b/setup.py @@ -0,0 +1,108 @@ +from pathlib import Path +from setuptools import find_packages, setup + + +def get_version(): + version_file = 'lagent/version.py' + with open(version_file, encoding='utf-8') as f: + exec(compile(f.read(), version_file, 'exec')) + return locals()['__version__'] + + +def parse_requirements(fname='requirements.txt', with_version=True): + """Parse the package dependencies listed in a requirements file but strip + specific version information. + + Args: + fname (str): Path to requirements file. + with_version (bool, default=False): If True, include version specs. + Returns: + info (list[str]): List of requirements items. + CommandLine: + python -c "import setup; print(setup.parse_requirements())" + """ + import re + import sys + from os.path import exists + + require_fpath = fname + + def parse_line(line): + """Parse information from a line in a requirements text file.""" + if line.startswith('-r '): + # Allow specifying requirements in other files + target = line.split(' ')[1] + for info in parse_require_file(target): + yield info + else: + info = {'line': line} + if line.startswith('-e '): + info['package'] = line.split('#egg=')[1] + else: + # Remove versioning from the package + pat = '(' + '|'.join(['>=', '==', '>']) + ')' + parts = re.split(pat, line, maxsplit=1) + parts = [p.strip() for p in parts] + + info['package'] = parts[0] + if len(parts) > 1: + op, rest = parts[1:] + if ';' in rest: + # Handle platform specific dependencies + # http://setuptools.readthedocs.io/en/latest/setuptools.html#declaring-platform-specific-dependencies + version, platform_deps = map(str.strip, + rest.split(';')) + info['platform_deps'] = platform_deps + else: + version = rest # NOQA + info['version'] = (op, version) + yield info + + def parse_require_file(fpath): + with open(fpath) as f: + for line in f.readlines(): + line = line.strip() + if line and not line.startswith('#'): + yield from parse_line(line) + + def gen_packages_items(): + if exists(require_fpath): + for info in parse_require_file(require_fpath): + parts = [info['package']] + if with_version and 'version' in info: + parts.extend(info['version']) + if not sys.version.startswith('3.4'): + # apparently package_deps are broken in 3.4 + platform_deps = info.get('platform_deps') + if platform_deps is not None: + parts.append(';' + platform_deps) + item = ''.join(parts) + yield item + + packages = list(gen_packages_items()) + return packages + + +if __name__ == '__main__': + with Path(Path(__file__).parent, + 'README.md').open(encoding='utf-8') as file: + long_description = file.read() + + setup( + name='lagent', + packages=find_packages(), + include_package_data=True, + version=get_version(), + license='Apache 2.0', + description='A lightweight framework for building LLM-based agents', + long_description=long_description, + long_description_content_type='text/markdown', + data_files=[('.', ['README.md'])], + keywords=['artificial general intelligence', 'agent', 'agi', 'llm'], + url='https://github.com/InternLM/lagent', + install_requires=parse_requirements('requirements/runtime.txt'), + extras_require={ + 'all': parse_requirements('requirements.txt'), + 'optional': parse_requirements('requirements/optional.txt'), + }, + ) diff --git a/tests/data/search.json b/tests/data/search.json new file mode 100644 index 0000000000000000000000000000000000000000..0aaa790f305b32c291183c82edea2632571ed438 --- /dev/null +++ b/tests/data/search.json @@ -0,0 +1,144 @@ +{ + "searchParameters": { + "q": "What is the capital of China?", + "gl": "us", + "hl": "en", + "num": 10, + "type": "search" + }, + "answerBox": { + "title": "China / Capital", + "answer": "Beijing" + }, + "organic": [ + { + "title": "Beijing - Wikipedia", + "link": "https://en.wikipedia.org/wiki/Beijing", + "snippet": "With over 21 million residents, Beijing is the world's most populous national capital city as well as China's second largest city after Shanghai.", + "sitelinks": [ + { + "title": "Etymology", + "link": "https://en.wikipedia.org/wiki/Beijing#Etymology" + }, + { + "title": "History", + "link": "https://en.wikipedia.org/wiki/Beijing#History" + }, + { + "title": "Geography", + "link": "https://en.wikipedia.org/wiki/Beijing#Geography" + } + ], + "position": 1 + }, + { + "title": "What is the Capital of China? - Mappr", + "link": "https://www.mappr.co/capital-cities/china/", + "snippet": "Beijing, also known as Peking, is the capital of China and one of the most populous cities in the world. It is the country's political, educational, ...", + "position": 2 + }, + { + "title": "Google Map of the City of Beijing, capital of P.R. China - Nations Online Project", + "link": "https://www.nationsonline.org/oneworld/map/google_map_Beijing.htm", + "snippet": "Google Earth: Searchable map/satellite view of Beijing, capital city of P.R. China. City Coordinates: 39°54′50″N 116°23′30″E, Bookmark/share this page ...", + "position": 3 + }, + { + "title": "Capital City of China - CountryReports.org", + "link": "https://www.countryreports.org/country/china/capital-city.htm", + "snippet": "Capital City, Beijing ; Capital location, 39 55 N, 116 23 E ; Capital - history, (Peking) Founded about 3,000 years ago on the site of a former Chinese capital, ...", + "position": 4 + }, + { + "title": "Capital of China - Beijing", + "link": "https://www.chinahighlights.com/beijing/capital-of-china.htm", + "snippet": "In Chinese, Beijing means 'Northern Capital'. Bei means 'north' and jing means 'capital'. In the history of China, Beijing's name has changed ...", + "date": "Dec 15, 2022", + "position": 5 + }, + { + "title": "Beijing is the capital of the People's Republic of China. It is the world's most populous capital city, with over 21 million residents within an... | By DL&D Consult | Facebook", + "link": "https://facebook.com/dldconsult/videos/beijing-capital-city-of-china/373001500555301/", + "snippet": "Beijing is an important world capital and global power ...", + "date": "Oct 19, 2020", + "attributes": { + "Duration": "2:58", + "Posted": "Oct 19, 2020" + }, + "imageUrl": "https://encrypted-tbn1.gstatic.com/images?q=tbn:ANd9GcQExx68yUr7xP_1wcRapEKlT5bxe4ptMa6WaLnwXdVAtAdloa7WeTIvCoJp", + "position": 6 + }, + { + "title": "What is the Capital of China? - WorldAtlas", + "link": "https://www.worldatlas.com/articles/what-is-the-capital-of-china.html", + "snippet": "The capital of China is Beijing.", + "date": "Jul 3, 2018", + "position": 7 + }, + { + "title": "A Chinese capital that's not Beijing - BBC Travel", + "link": "https://www.bbc.com/travel/article/20151008-a-chinese-capital-thats-not-beijing", + "snippet": "Beijing may be the capital of China today, but for many centuries the country was ruled from Nanjing, a historic city located on the shores ...", + "date": "Oct 13, 2015", + "position": 8 + }, + { + "title": "Beijing | Province, City, History, Map, & Facts - Britannica", + "link": "https://www.britannica.com/place/Beijing", + "snippet": "Beijing, city, province-level shi (municipality), and capital of the People's Republic of China. The city has been an integral part of China's history over ...", + "position": 9 + } + ], + "peopleAlsoAsk": [ + { + "question": "Does China have 2 capitals?", + "snippet": "There are traditionally four major historical capitals of China referred to as\nthe 'Four Great Ancient Capitals of China' (simplified Chinese: 中国四大古都;\ntraditional Chinese: 中國四大古都; pinyin: Zhōngguó Sì Dà Gǔ Dū). The four are\nBeijing, Nanjing, Luoyang and Xi\"an (Chang\"an).", + "title": "Historical capitals of China - Wikipedia", + "link": "https://en.wikipedia.org/wiki/Historical_capitals_of_China" + }, + { + "question": "What is the capital city of China USA?", + "snippet": "Capital City\nBeijing\nCapital - time difference\nUTC+8 (13 hours ahead of Washington, DC, during Standard Time) note; despite its\nsize, all of China falls within one time zone", + "title": "Capital City of China - CountryReports.org", + "link": "https://www.countryreports.org/country/china/capital-city.htm" + }, + { + "question": "Is Hong Kong is a part of China?", + "snippet": "Hong Kong (US: /ˈhɒŋkɒŋ/ or UK: /hɒŋˈkɒŋ/; Chinese: 香港, Cantonese: [hœ́ːŋ.kɔ̌ːŋ]\n( listen)), officially the Hong Kong Special Administrative Region of the\nPeople's Republic of China (abbr. Hong Kong SAR or HKSAR), is a city and a\nspecial administrative region in China.", + "title": "Hong Kong - Wikipedia", + "link": "https://en.wikipedia.org/wiki/Hong_Kong" + }, + { + "question": "Why China changed its capital?", + "snippet": "Once in charge, it wasn't uncommon for a new emperor to shift the imperial\ncapital in order to: Rebuild after a great loss, as in the Han era when Liu Bang\nmoved the capital from Xianyang to nearby Chang'an (now Xi'an), after the former\nwas destroyed during a rebellion.", + "title": "Why do they keep moving the Capital? - China Simplified", + "link": "https://www.chinasimplified.com/2014/09/29/why-do-they-keep-moving-the-capital/" + } + ], + "relatedSearches": [ + { + "query": "China map" + }, + { + "query": "Where is the capital of china on a map" + }, + { + "query": "Beijing population" + }, + { + "query": "Capital of Korea" + }, + { + "query": "Beijing pronunciation" + }, + { + "query": "What is the capital of India" + }, + { + "query": "What is the capital of Japan" + }, + { + "query": "What is the capital of Pakistan" + } + ] +} \ No newline at end of file diff --git a/tests/test_actions/test_builtin_actions.py b/tests/test_actions/test_builtin_actions.py new file mode 100644 index 0000000000000000000000000000000000000000..0148515f670101945d574f1b14d916721e67b89a --- /dev/null +++ b/tests/test_actions/test_builtin_actions.py @@ -0,0 +1,44 @@ +from unittest import TestCase + +from lagent.actions.builtin_actions import FinishAction, InvalidAction, NoAction +from lagent.schema import ActionStatusCode + + +class TestFinishAction(TestCase): + + def test_call(self): + action = FinishAction() + response = 'finish' + action_return = action(response) + self.assertEqual(action_return.state, ActionStatusCode.SUCCESS) + self.assertDictEqual(action_return.result, dict(text='finish')) + + +class TestInvalidAction(TestCase): + + def test_call(self): + action = InvalidAction() + response = 'invalid' + action_return = action(response) + self.assertEqual(action_return.state, ActionStatusCode.API_ERROR) + self.assertEqual(action_return.errmsg, response) + + action = InvalidAction(err_msg='error') + action_return = action() + self.assertEqual(action_return.state, ActionStatusCode.API_ERROR) + self.assertEqual(action_return.errmsg, 'error') + + +class TestNoAction(TestCase): + + def test_call(self): + action = NoAction() + response = 'no' + action_return = action(response) + self.assertEqual(action_return.state, ActionStatusCode.API_ERROR) + self.assertEqual(action_return.errmsg, response) + + action = NoAction(err_msg='error') + action_return = action() + self.assertEqual(action_return.state, ActionStatusCode.API_ERROR) + self.assertEqual(action_return.errmsg, 'error') diff --git a/tests/test_actions/test_google_search.py b/tests/test_actions/test_google_search.py new file mode 100644 index 0000000000000000000000000000000000000000..2688409b62d08e9c0fe40edcfa25f772d2642161 --- /dev/null +++ b/tests/test_actions/test_google_search.py @@ -0,0 +1,35 @@ +import json +from unittest import TestCase, mock + +from lagent.actions import GoogleSearch +from lagent.schema import ActionStatusCode + + +class TestGoogleSearch(TestCase): + + @mock.patch.object(GoogleSearch, '_search') + def test_search_tool(self, mock_search_func): + mock_response = (200, json.load('tests/data/search.json')) + mock_search_func.return_value = mock_response + search_tool = GoogleSearch(api_key='abc') + tool_return = search_tool.run("What's the capital of China?") + self.assertEqual(tool_return.state, ActionStatusCode.SUCCESS) + self.assertDictEqual(tool_return.result, dict(text="['Beijing']")) + + @mock.patch.object(GoogleSearch, '_search') + def test_api_error(self, mock_search_func): + mock_response = (403, {'message': 'bad requests'}) + mock_search_func.return_value = mock_response + search_tool = GoogleSearch(api_key='abc') + tool_return = search_tool.run("What's the capital of China?") + self.assertEqual(tool_return.state, ActionStatusCode.API_ERROR) + self.assertEqual(tool_return.errmsg, str(403)) + + @mock.patch.object(GoogleSearch, '_search') + def test_http_error(self, mock_search_func): + mock_response = (-1, 'HTTPSConnectionPool') + mock_search_func.return_value = mock_response + search_tool = GoogleSearch(api_key='abc') + tool_return = search_tool.run("What's the capital of China?") + self.assertEqual(tool_return.state, ActionStatusCode.HTTP_ERROR) + self.assertEqual(tool_return.errmsg, 'HTTPSConnectionPool') diff --git a/tests/test_actions/test_python_interpreter.py b/tests/test_actions/test_python_interpreter.py new file mode 100644 index 0000000000000000000000000000000000000000..f698c777c6523f140dd86f74730eb3a717225ba0 --- /dev/null +++ b/tests/test_actions/test_python_interpreter.py @@ -0,0 +1,21 @@ +from unittest import TestCase + +from lagent.actions.python_interpreter import PythonInterpreter +from lagent.schema import ActionStatusCode + + +class TestPythonInterpreter(TestCase): + + def test_python_executor(self): + python_executor = PythonInterpreter() + tool_return = python_executor( + '```python\ndef solution():\n return 1\n```') + self.assertEqual(tool_return.state, ActionStatusCode.SUCCESS) + self.assertDictEqual(tool_return.result, dict(text='1')) + + def test_timeout(self): + python_executor = PythonInterpreter(timeout=2) + tool_return = python_executor( + '```python\ndef solution():\n while True:\n pass\n```') + self.assertEqual(tool_return.state, ActionStatusCode.API_ERROR) + self.assertIn('FunctionTimedOut', tool_return.errmsg) diff --git a/tests/test_agents/test_rewoo.py b/tests/test_agents/test_rewoo.py new file mode 100644 index 0000000000000000000000000000000000000000..52fa1ed729d4a9e3544a691876286596bd873354 --- /dev/null +++ b/tests/test_agents/test_rewoo.py @@ -0,0 +1,87 @@ +from unittest import TestCase, mock + +from lagent.actions import ActionExecutor +from lagent.actions.llm_qa import LLMQA +from lagent.actions.serper_search import SerperSearch +from lagent.agents.rewoo import ReWOO, ReWOOProtocol +from lagent.schema import ActionReturn, ActionStatusCode + + +class TestReWOO(TestCase): + + @mock.patch.object(SerperSearch, 'run') + @mock.patch.object(LLMQA, 'run') + @mock.patch.object(ReWOOProtocol, 'parse_worker') + def test_normal_chat(self, mock_parse_worker_func, mock_qa_func, + mock_search_func): + mock_model = mock.Mock() + mock_model.generate_from_template.return_value = 'LLM response' + + mock_parse_worker_func.return_value = (['Thought1', 'Thought2' + ], ['LLMQA', 'SerperSearch'], + ['abc', 'abc']) + + search_return = ActionReturn(args=None) + search_return.state = ActionStatusCode.SUCCESS + search_return.result = dict(text='search_return') + mock_search_func.return_value = search_return + + qa_return = ActionReturn(args=None) + qa_return.state = ActionStatusCode.SUCCESS + qa_return.result = dict(text='qa_return') + mock_qa_func.return_value = qa_return + + chatbot = ReWOO( + llm=mock_model, + action_executor=ActionExecutor(actions=[ + LLMQA(mock_model), + SerperSearch(api_key=''), + ])) + agent_return = chatbot.chat('abc') + self.assertEqual(agent_return.response, 'LLM response') + + def test_parse_worker(self): + prompt = ReWOOProtocol() + message = """ + Plan: a. + #E1 = tool1["a"] + #E2 = tool2["b"] + """ + try: + thoughts, actions, actions_input = prompt.parse_worker(message) + except Exception as e: + self.assertEqual( + 'Each Plan should only correspond to only ONE action', str(e)) + else: + self.assertFalse( + True, 'it should raise exception when the format is incorrect') + + message = """ + Plan: a. + #E1 = tool1("a") + Plan: b. + #E2 = tool2["b"] + """ + try: + thoughts, actions, actions_input = prompt.parse_worker(message) + except Exception as e: + self.assertIsInstance(e, BaseException) + else: + self.assertFalse( + True, 'it should raise exception when the format is incorrect') + + message = """ + Plan: a. + #E1 = tool1["a"] + Plan: b. + #E2 = tool2["b"] + """ + try: + thoughts, actions, actions_input = prompt.parse_worker(message) + except Exception: + self.assertFalse( + True, + 'it should not raise exception when the format is correct') + self.assertEqual(thoughts, ['a.', 'b.']) + self.assertEqual(actions, ['tool1', 'tool2']) + self.assertEqual(actions_input, ['"a"', '"b"'])