{
"cells": [
{
"attachments": {},
"cell_type": "markdown",
"id": "190e8e4c-461f-4521-ae7f-3491fa827ab7",
"metadata": {
"tags": []
},
"source": [
"# Automatic Device Selection with OpenVINO™\n",
"\n",
"The [Auto device](https://docs.openvino.ai/2024/openvino-workflow/running-inference/inference-devices-and-modes/auto-device-selection.html) (or AUTO in short) selects the most suitable device for inference by considering the model precision, power efficiency and processing capability of the available [compute devices](https://docs.openvino.ai/2024/about-openvino/compatibility-and-support/supported-devices.html). The model precision (such as `FP32`, `FP16`, `INT8`, etc.) is the first consideration to filter out the devices that cannot run the network efficiently.\n",
"\n",
"Next, if dedicated accelerators are available, these devices are preferred (for example, integrated and discrete [GPU](https://docs.openvino.ai/2024/openvino-workflow/running-inference/inference-devices-and-modes/gpu-device.html)). [CPU](https://docs.openvino.ai/2024/openvino-workflow/running-inference/inference-devices-and-modes/cpu-device.html) is used as the default \"fallback device\". Keep in mind that AUTO makes this selection only once, during the loading of a model. \n",
"\n",
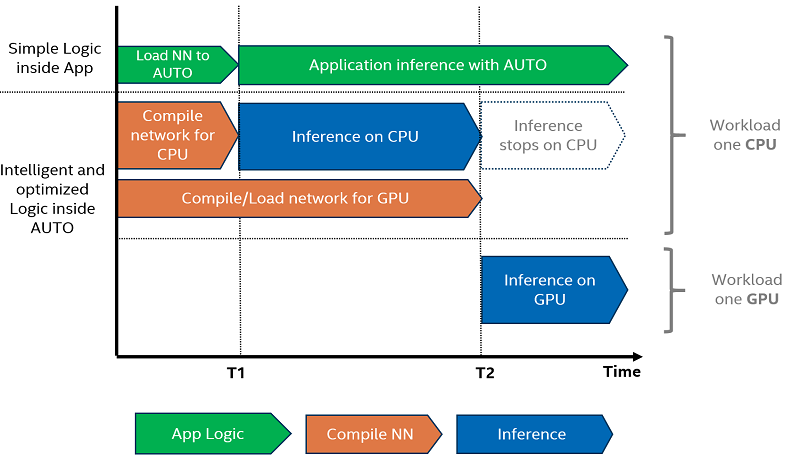
"When using accelerator devices such as GPUs, loading models to these devices may take a long time. To address this challenge for applications that require fast first inference response, AUTO starts inference immediately on the CPU and then transparently shifts inference to the GPU, once it is ready. This dramatically reduces the time to execute first inference.\n",
"\n",
"\n",
"\n",
"\n",
"\n",
"#### Table of contents:\n",
"\n",
"- [Import modules and create Core](#Import-modules-and-create-Core)\n",
"- [Convert the model to OpenVINO IR format](#Convert-the-model-to-OpenVINO-IR-format)\n",
"- [(1) Simplify selection logic](#(1)-Simplify-selection-logic)\n",
" - [Default behavior of Core::compile_model API without device_name](#Default-behavior-of-Core::compile_model-API-without-device_name)\n",
" - [Explicitly pass AUTO as device_name to Core::compile_model API](#Explicitly-pass-AUTO-as-device_name-to-Core::compile_model-API)\n",
"- [(2) Improve the first inference latency](#(2)-Improve-the-first-inference-latency)\n",
" - [Load an Image](#Load-an-Image)\n",
" - [Load the model to GPU device and perform inference](#Load-the-model-to-GPU-device-and-perform-inference)\n",
" - [Load the model using AUTO device and do inference](#Load-the-model-using-AUTO-device-and-do-inference)\n",
"- [(3) Achieve different performance for different targets](#(3)-Achieve-different-performance-for-different-targets)\n",
" - [Class and callback definition](#Class-and-callback-definition)\n",
" - [Inference with THROUGHPUT hint](#Inference-with-THROUGHPUT-hint)\n",
" - [Inference with LATENCY hint](#Inference-with-LATENCY-hint)\n",
" - [Difference in FPS and latency](#Difference-in-FPS-and-latency)\n",
"\n"
]
},
{
"attachments": {},
"cell_type": "markdown",
"id": "fcfc461c",
"metadata": {},
"source": [
"## Import modules and create Core\n",
"[back to top ⬆️](#Table-of-contents:)\n"
]
},
{
"cell_type": "code",
"execution_count": 1,
"id": "967c128a",
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"import platform\n",
"\n",
"# Install required packages\n",
"%pip install -q \"openvino>=2023.1.0\" Pillow torch torchvision tqdm --extra-index-url https://download.pytorch.org/whl/cpu\n",
"\n",
"if platform.system() != \"Windows\":\n",
" %pip install -q \"matplotlib>=3.4\"\n",
"else:\n",
" %pip install -q \"matplotlib>=3.4,<3.7\""
]
},
{
"cell_type": "code",
"execution_count": 2,
"id": "6c7f9f06",
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"import time\n",
"import sys\n",
"\n",
"import openvino as ov\n",
"\n",
"from IPython.display import Markdown, display\n",
"\n",
"core = ov.Core()\n",
"\n",
"if not any(\"GPU\" in device for device in core.available_devices):\n",
" display(\n",
" Markdown(\n",
" '
Warning: A GPU device is not available. This notebook requires GPU device to have meaningful results.
'\n",
" )\n",
" )"
]
},
{
"attachments": {},
"cell_type": "markdown",
"id": "ee513ee2",
"metadata": {},
"source": [
"## Convert the model to OpenVINO IR format\n",
"[back to top ⬆️](#Table-of-contents:)\n",
"\n",
"This tutorial uses [resnet50](https://pytorch.org/vision/main/models/generated/torchvision.models.resnet50.html#resnet50) model from [torchvision](https://pytorch.org/vision/main/index.html?highlight=torchvision#module-torchvision) library.\n",
"ResNet 50 is image classification model pre-trained on ImageNet dataset described in paper [\"Deep Residual Learning for Image Recognition\"](https://arxiv.org/abs/1512.03385).\n",
"From OpenVINO 2023.0, we can directly convert a model from the PyTorch format to the OpenVINO IR format using model conversion API. To convert model, we should provide model object instance into `ov.convert_model` function, optionally, we can specify input shape for conversion (by default models from PyTorch converted with dynamic input shapes). `ov.convert_model` returns openvino.runtime.Model object ready to be loaded on a device with `ov.compile_model` or serialized for next usage with `ov.save_model`. \n",
"\n",
"For more information about model conversion API, see this [page](https://docs.openvino.ai/2024/openvino-workflow/model-preparation.html)."
]
},
{
"cell_type": "code",
"execution_count": 3,
"id": "e58e0582-a77f-4621-ba92-429a9c5f5e56",
"metadata": {
"tags": []
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Read IR model from model/resnet50.xml\n"
]
}
],
"source": [
"import torchvision\n",
"from pathlib import Path\n",
"\n",
"base_model_dir = Path(\"./model\")\n",
"base_model_dir.mkdir(exist_ok=True)\n",
"model_path = base_model_dir / \"resnet50.xml\"\n",
"\n",
"if not model_path.exists():\n",
" pt_model = torchvision.models.resnet50(weights=\"DEFAULT\")\n",
" ov_model = ov.convert_model(pt_model, input=[[1, 3, 224, 224]])\n",
" ov.save_model(ov_model, str(model_path))\n",
" print(\"IR model saved to {}\".format(model_path))\n",
"else:\n",
" print(\"Read IR model from {}\".format(model_path))\n",
" ov_model = core.read_model(model_path)"
]
},
{
"attachments": {},
"cell_type": "markdown",
"id": "740bfdd8",
"metadata": {},
"source": [
"## (1) Simplify selection logic\n",
"[back to top ⬆️](#Table-of-contents:)\n",
"\n",
"### Default behavior of Core::compile_model API without device_name\n",
"[back to top ⬆️](#Table-of-contents:)\n",
"\n",
"\n",
"By default, `compile_model` API will select **AUTO** as `device_name` if no device is specified."
]
},
{
"cell_type": "code",
"execution_count": 4,
"id": "73d7aedb",
"metadata": {
"tags": []
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Successfully compiled model without a device_name.\n"
]
}
],
"source": [
"# Set LOG_LEVEL to LOG_INFO.\n",
"core.set_property(\"AUTO\", {\"LOG_LEVEL\": \"LOG_INFO\"})\n",
"\n",
"# Load the model onto the target device.\n",
"compiled_model = core.compile_model(ov_model)\n",
"\n",
"if isinstance(compiled_model, ov.CompiledModel):\n",
" print(\"Successfully compiled model without a device_name.\")"
]
},
{
"cell_type": "code",
"execution_count": 5,
"id": "66bfa571-8241-4623-9e9e-01bf2d0f89d4",
"metadata": {
"tags": []
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Deleted compiled_model\n"
]
}
],
"source": [
"# Deleted model will wait until compiling on the selected device is complete.\n",
"del compiled_model\n",
"print(\"Deleted compiled_model\")"
]
},
{
"attachments": {},
"cell_type": "markdown",
"id": "85b48949",
"metadata": {},
"source": [
"### Explicitly pass AUTO as device_name to Core::compile_model API\n",
"[back to top ⬆️](#Table-of-contents:)\n",
"\n",
"It is optional, but passing AUTO explicitly as `device_name` may improve readability of your code."
]
},
{
"cell_type": "code",
"execution_count": 6,
"id": "0814073d",
"metadata": {
"tags": []
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Successfully compiled model using AUTO.\n"
]
}
],
"source": [
"# Set LOG_LEVEL to LOG_NONE.\n",
"core.set_property(\"AUTO\", {\"LOG_LEVEL\": \"LOG_NONE\"})\n",
"\n",
"compiled_model = core.compile_model(model=ov_model, device_name=\"AUTO\")\n",
"\n",
"if isinstance(compiled_model, ov.CompiledModel):\n",
" print(\"Successfully compiled model using AUTO.\")"
]
},
{
"cell_type": "code",
"execution_count": 7,
"id": "58e765f5-8e31-4eb4-bed8-9fba30bb29e8",
"metadata": {
"tags": []
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Deleted compiled_model\n"
]
}
],
"source": [
"# Deleted model will wait until compiling on the selected device is complete.\n",
"del compiled_model\n",
"print(\"Deleted compiled_model\")"
]
},
{
"attachments": {},
"cell_type": "markdown",
"id": "705ce668",
"metadata": {},
"source": [
"## (2) Improve the first inference latency\n",
"[back to top ⬆️](#Table-of-contents:)\n",
"\n",
"One of the benefits of using AUTO device selection is reducing FIL (first inference latency). FIL is the model compilation time combined with the first inference execution time. Using the CPU device explicitly will produce the shortest first inference latency, as the OpenVINO graph representation loads quickly on CPU, using just-in-time (JIT) compilation. The challenge is with GPU devices since OpenCL graph complication to GPU-optimized kernels takes a few seconds to complete. This initialization time may be intolerable for some applications. To avoid this delay, the AUTO uses CPU transparently as the first inference device until GPU is ready.\n",
"\n",
"### Load an Image\n",
"[back to top ⬆️](#Table-of-contents:)\n",
"\n",
"torchvision library provides model specific input transformation function, we will reuse it for preparing input data."
]
},
{
"cell_type": "code",
"execution_count": null,
"id": "384cb81a",
"metadata": {},
"outputs": [],
"source": [
"# Fetch `notebook_utils` module\n",
"import requests\n",
"\n",
"r = requests.get(url=\"https://raw.githubusercontent.com/openvinotoolkit/openvino_notebooks/latest/utils/notebook_utils.py\")\n",
"open(\"notebook_utils.py\", \"w\").write(r.text)\n",
"\n",
"from notebook_utils import download_file"
]
},
{
"cell_type": "code",
"execution_count": 8,
"id": "dc1cfeaf",
"metadata": {
"tags": []
},
"outputs": [
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAAyAAAAJBCAIAAAAxzUZ0AAABVmlDQ1BJQ0MgUHJvZmlsZQAAeJxjYGBSSSwoyGFhYGDIzSspCnJ3UoiIjFJgf8jADoS8DGIMConJxQWOAQE+QCUMMBoVfLvGwAiiL+uCzDolNbVJtV7A12Km8NWLr0SbMNWjAK6U1OJkIP0HiFOTC4pKGBgYU4Bs5fKSAhC7A8gWKQI6CsieA2KnQ9gbQOwkCPsIWE1IkDOQfQPIVkjOSASawfgDyNZJQhJPR2JD7QUBbpfM4oKcxEqFAGMCriUDlKRWlIBo5/yCyqLM9IwSBUdgKKUqeOYl6+koGBkYmjMwgMIcovpzIDgsGcXOIMSa7zMw2O7/////boSY134Gho1AnVw7EWIaFgwMgtwMDCd2FiQWJYKFmIGYKS2NgeHTcgYG3kgGBuELQD3RxWnGRmB5Rh4nBgbWe///f1ZjYGCfzMDwd8L//78X/f//dzFQ8x0GhgN5ABUhZe5sUv9jAAEAAElEQVR4nMy9d5Qcx3kvWlWdpyfnmZ3Z2ZwTdpEzA0gwiQpUtiUr2cpWliXf5/uug3T9nOQrB2VbkZTEnEmQBEDktAGbc5icc+fuen8MCUEkQcu+953z6szB6e2p/uqrqh58v/59oeHb3/sJUa6YeKJvsK0uFqxOm66RogKFGrLZAmbGHm5qSmysZFJr4aDL5eJK1YymixNXxq02PpuMsRzJcyaapsLNTYuLizTFRaNxbMDW1vZKVQAEolhaVORQIBiPx1sikY2NjUQszvO8y+7gOM4wjHw+H4o0j4+Pq6qKEEFRFo7jRbFuGLrNZrNY+VqtwrIsArBSqZjNdoqiGJqVJMlicVAU5DlaAwqCtKio3mDo9PlL0a1YpLVNFEWWpmxWK0uiernEELBSKucLaZfbOjI6vLW1lU6nFUVrbm6+ePGizWbjeU7XVUmSOjpby+WyP+C2WCzLy8vDQ2OSJFcr9XK5XCyWWZYt5PIMS5EkGhoaVCSBZdlKpUJRlCyruWxxYmo+1BS57bZba/XqhYsXCRIqiuRwOGiO3dzcxBjfeeedFM2ePXuW4/hIJFLIFxFCuVyBoiiWZXVdNwzDYrEkEgmWZc1mE0mSLMeQJGk2m2KxWCYRp1iGptiNrc2BoX4AQDaX9ng8JECaphGIWV5edbq8dofH0KGEkdfXKqpg/PK4zeqgININxWSiEWXU6iVMoHxBCEd6GCYwNHKwuWng/l89aCC8/9CImRfDTc6f/vCBYDDc1t55/MzZw7fdni7UALaRNOv3mqevXmjyWsv5BKtps1PjdVEYHh7O5EqqguMbSY7jhvp6XW7z2vJMIOi0u63HTx5vibRfvHBurLfXypP53IaB1K6ujhOnz0sCJBCLRc3EUk0ee29/f65Uf/DJF0MdY7tuuhsyjlihwtk8FMNXc6VcoWwLBCNtgUiQPf30Ly48+tOgmZMlTSdhGUjVWrE3EJCVmkzrNM81B7sq+VouVjQAFBTRILjRbbc8+cylW+/4/eF9R2bTqXBHi1EvMiRbrOhOO0/B3De/9ocHb9mxfcfotpEDf/mX3zh8eOfI4DaxROZLFWQmaqKRTuJ9O7avz74QWxrnNGixeVhv+KeP/OToW3p1Panm4mJNN/TAVqq6c/9YKhV3mLlcsr66qn7zG9968LFflIpRv4fUpHx8ebk56OpqC5048Vy4ufnp5x6/+2130xRcnV++4447aCu/EksubRbd/i6/u29qcikSCJh52NvvqSmFbKkqQW5moez39AXMLd/7X/+851C/rBdqUnFwZPvmujY6unsruXjixKMUWTu0Z2d3S8+Lz/+6Xp+6467DhmJPZzO50no6ne7t2NMcHMAyb7bosdTzBiryJjsi28JN93zjb77vjVhcNsOuFrBUiaezzW39BOVeXE309g0ISvXi+In73nmP3WF12D3jE0uxaOqpp5787g/+fWJq5Zmnn9i/rUuuZgIe65ULZ5tbIjzPlOoZh5Pt6vIBEq+txeZXYu1du2RJe/nYs9/+h7+//4EHT5068/GP/+ETTz6s6pUdO3aoKuPxuovlWCK5TlAony9ThNlichXT1bfcc8+58y9vbKzdeuT2bSO7JyeXmsOtL595+X2/945f/OqHqVSC4+29XTuTcbmro3f88olbbtq7trrU09+qGZUT50/ec++7SgJbqYVkjRfUuqLJdpsNgrrJUqlXyoLAQmAtVlSbs8lsCyXSZYfTd/7SZQpTt9yy49TxB+bnn7rv7YOxzcuFdFKuqkFnh90WibSNhVpHn3ph/NjxS4duvivS0latlf1+z+ra/NPPPfPhD3+Et9rOnDlXrov7Dtyk6VjTNIwxQghCCADAGIPr2m//icAbNQjxtW4QwoacxrXXX359n9eM8kYy4WsufP0ZYLyxkOt7/uYS+Jt/rzUEIADAMIw3vBDrxvUnr63PGy7UjcZ9rRrXXXWj/tf0eU2314zb2DIIoa7rEMLXTA0gCAAwAEDXbQQCEEKoqxpFUbqq6rrOsiyEUNM0kiQVTYMQ0jSt63qtViNJsmEWEULgul27Jg1CAgAAISYIAr5yE+iNbwmCUGQNY9yQoCgaQRCGInMcR5IkTdMIoVQqtbm5Wa/XXR630+m02+0EQej6KxJ0DZMkBTCCwAAAIwAAMHSAMQQGQJAkdENFFMKaTlJAEgSGRjQwIECShiDiKEDqqkqTBCIAxliFsCppGoAMx0OsG2Kd4RgdAh0bQFE6W9vy8dTffuKTH//mX5ktFklXCYbmOC6dzcTj8X379sk14aWXXurv6R0ZGUimc9/4xje+8tWvKromqwrP84qukSSZy+ftdjsAgCRJURCKxWIoFJIVBUOAECAMDWMAgAXqatDJ/vV/+0SHXXr/fTdvRVdT6dj24ZGt6MbY0Mj8ylIqW7n1yGFKlxwO+9xSbPst7zm/iRZSMsubAEC0CiEGgAGKgQlk0iHASDaQQmKIACA0iDGBDUjQFESqXEkGLbqWX1Izczwho5GR0aZgsyCIFy5cTqcKSwtrVqsdYpTNZtZWl2LxtfW1OYuNttlNa+vzk1OXCoX8zMzMvn17GIYxAEKQNpnMhoHn55asFoffH/T7/TxvKZVKsiyxLIMQmp+fj0Qi7R2tsiwHAj5ZlgWhVi6XV9eW8/k8b+YSiYTTaW/cRpIkqqrauP+i0ej6+nqpVMrn8+VymSAIVZUZhslk07Is8zzH8/zyyuL8/HxNqCIEWJb+8B98cMfO7fv37tmza+fu3btJCC0WXpbFSqUiSvVqtby4vPTwww8Xi8VIJOJ0Or1e7/79+ymKUBQFY2xgTRAEjPW2trbu7k6Hw5FKJZLJhNfnlmXZMDSXy9Xd3W2xWAqFQr1eN5nMc3MLNpsDQkLXDKvVqut6NLp58eLFXC5H0cTm5jpFUTMzM+VyedeuXXfeeWculzt79mwgELBYLIqiyLLM87zJZKJpularcRzX1NQEAJAkyTCMYrFYrVZzuVypVFJVlWEYSVI4lvf5fB6Pp1Aoqara1zsQiUQEQeA4biu6YbfbSZLUNI0giHqlurW1dfL4S3fcdtudR4/U6uVEbLOnu6O9rWVoaCDg87e1RMw8d+jAboYwZmcuHr1tv1RPTFw6Ltez0bU5VcwFPKaN1bn41sra8oLP5WgO+2vlwpff9e50Mh2Nxh579PHNWLyzd6CnbyBbLPEWs4G12+642e3lT556+tKlk3UxZ7FyQrX2pc9/BWBKEvD80kpVlCVNj7S0bUZjTU1NrW0dxWK5Xq/XarWBgf6Otsh73vX2P/2TL+bSW1evnFNlAWv65OTVuflliNiOzl5N0uauTq2vLl2+dJbjKAy1UCQ4MNC7fWSwPRLeikWr1WoyFbfb7bVKKZlMmi08QUBFUSiCjMfjNENabDaXx+3xujc3NxVFkWTBH3BlsrF8Pvuxz3zuzMtnHrz/16Vc8V1vf8e5U6f/8e/+furqlcWVRcUANqdPUpSrM9OLqysb8djaVtTqcDu9TYA0rWxkm1sGPYEugnROL0T3Hby9rWv41qNv+YMPf7x/eGxhdnYzkRgcGq5LojcQNAA+eMsBq8uSzCd6+vu+9md/9pFP/HGhomHSCSjHc8fPn704RTJm3uQo5MR6HbvdoUQybbGYLl85tzh3hYDV1fkL/T3u3i57NjP3v779F5pafdtb737Xu+/jrRYFq7ly3h8MfOwTn2wKR+KpNEKkLGkryxsP/OxX84sLsoJLZSNXwMlMvSppTr/NFbAFW0I1UdhKZC5fvpLPZwf6u0eGhrCOFR3cevRODRMVQbQ47B/9ww8LSnX3nlGSVC5ffrm7o+n4C090tXo6W9xf/OxHv/KFPzpz6une7qabbtmdK8SzuXhTsy+W3LK6rJzJFI3Hnn3+pcX5tY2NmMvhPnPq5ejWZlNTU6FYfu9739/e1jEzM7d9+44jR45ACHmOu3LlSmxza3FxmSJYl8OVTecKhcL+A3tVVVxenvd4HQ/88mff+/4/uT3ml04809vX8dOf/nsymezp6bHZbF6fc2npqtPNvee9b0uk1lPprYX5mebmliM3H3E6rMnkam+P3eUWm5tpbGQdVtLMgZXFyb/+H196/NEfNwXMhiqsLMwm40sOG6xVont3Dezc2be+tnDvW9/yvvd+KLZZizSPvvXe3+/sHO7sHiqUxROnzn39z/7H2XMXP/npz+zYuRsQJMfzgix5A0EAoIFhqVTau//gbUeONp6grjfhr4FEvyNoeE3Dr7bXnIevthuJhdc1fF270UDwBu1G/Q3DeI3Y6+X/hzN9Dc5787F+F53fvM+NtGp82wA9b6I/xK/tfw2fMQzTMDEMwxiGoaoqQgghRJIkRVG6rmuaxrIsRVHX0NX100cIEQRBkiRBEBRFEQShaZqiKLqu67quqirGWNM0iqIaAzWMhclkCoaaMMbpdHpiYuKFF17Y2Nhobm7es29vb2+v1+tFCMmyrKoqAKAhGQAA4CtY04CGAX8zFwIhCAiEUWOmCCECQoqiDKyzNE0CbGgaSZIAQQyArGuFUonjOI5haQStJo7jOF1VINY5irRZzUKt+ref/Pjtf/Sx3r4+QCCGZWVVkRR5dWN9586dWDfOnDkz0N/f3tlRLNf+5m/+5jOf/SxvtUAITSaToiiNxWmscGOVNE3jOO41iw8B0dgvh8NarVZ1XRcEgWVZi8VSrVZjsVhPT8/W1pYgCDzPC4JQLpcdDgdr4gRBgBBi9Oq+IwgAIAkIDB0ZOjIwYZAII4hf2SlIkrqBDUyZLW5AstlCNdDc5vQFEYBIVoxaTeM5N9ZZQ2Nim5lQILx7+1go4LTZiKqQPHfxuaoQl42ioleyuThBwNnZ2VBTuKkpfOimI01NbQ6nPxxqh4C5eGHcYff0Dw443S6f30NRhKbKHEOdO3uaochCLmvoaktzCAFDlOpms0nTFQAMw9AIEtIshUhE0zTDMAghq9UaDAYb6DsUCtrsFgx0kkTHjx+LRMKIgCdOvuhwWoPh4MrK8sbGmtvjrFbKzz79eDKxJUv1memrm2vLqiLMzVwdHd125123hUL+tvbWwcH+1tYIRRGCUHO7ndVqWZZFq9Wq66rX53a7XSYTG2zy5/PZeDzu83kYllJVeXZ2xuG0ORyOarUsq1JPb+8tt9xitzt0DDw+v93pEiQ1my3Kkj4yMhJsCkiyWC4XOY47evRoKBRqbg4BYEiSUK2Wl5aWZFlOJBL1enVjY0PTtKtXr8bj0UIh5/V6KYqam5vzer0HDuwDwFhZWTEMQ9d1giByuVxra6thGAzDra9vEgQl1KW1tY1yubyyvNbe3l4oFDiOMwyNooitrY3LVy5Wq5WWSHPA55mbnapVcjYrs2f3CMCC12kt5jKJ6EY6vqUKpYtnjyly+srlZ2evPm/n8zY6ld24dOX0Ezau2t/hKCTnWwNWpFQvnzm+uTxlM6EPfPWrH3jv768tro8M7yQZ8/krU1vJfE3Uu/r6SRYYRPW2O3a2d9u7+928VQdILBaLL75wusnX/cd//H/tOnjbA489dXlmvlQTJq7OtrZ1tbd3Ouwus9nqdjjXVpcLuVR0Y9Hv5m4/NJrcmGFJvbOjvbmlw+kJqQZDIt7v8XU1R1jCCPrsQ9t6GCvMFOKaUU/Elpw2NhD0GADfcftRnqFLpUIkHJSUuqKKDpu1Vilns5ltY6OyKp29cLa5OWy32tLpdCodj6UWWjs8E5OXfR7/J//wM/WCkFzZcrHWgfau7dsGV9fmODNjdTali3Jdleu60DU8pCGmY3DbWjK3lSp96WvfPHTr+67OlfMV66Wp7MDobZy9FdD+8xPrDzx2LC+o7/zwxxdWNzREbiXSW/FEa2eHoAkkT/SOdKmU8eNfPZSrwVvu/ojFNxbovXl8tVzV6ESmnsuqj/z6JYoMulztbV29nqBdV7OnTj7UHmbclnJs9en25trIAD0397TZLJ16+XlRFiItLa3d7Xmh4gj6BE17+fTZq7Pzjzz6xIc/9PHRoV2j23Ypqh7PlPfsfdfg4L3PvjRXN6gaqtz/5L9Fi/Hmzi4dMAcOHPnh97+zuji7b2ynhbVemZ6nrO7BXXvyNaEs1dZiSw88+KOrs6dvvnmUZ8Vqac3MVZAS7Wpmjhzo+tY3vzg98eTi4vFodJwgKs0tThXXJL2iIUkn9eEdOyQJuD0hrFLIIAIe99bG+tDI8A/+7d9n55d4i2MrlhzeNhYKhWZnZ+v1WlukhefMNx28uZAp93YODvUPBn3+p5957OUzL916++Ghkb4jtx1sCjs6e3w6LprMOBpb3dzcLBYq8a3o7NykzQkzmbkf//gfnE7q0OHthUKKRGR7cxuF9OYg/fCjf35l8rup1NO9PYgwkudPPeEwi1/9bx++52ivLq6TasVlppLRcUNZb2+jJXEZwrTDDpbm52pluH3kHfmU88yZ9YWV3MpGYStV3kqX3/X+D33tv/+FhuiljQ0FA4wIQBAkxdz37vewJp6guEy2UChXNB03DMP1tuHNMcGNAM1rYBPGuIFm3gRYvBYQvO7b6zu8vvObKPYm+r+hwBvBncb53xHk3ajDf7m9fjWuhzjXvjUM4/VLeu2gYXIRQgjABl3XYOAMw4AEQVCUjrEBAEEQxqtNFEVVVWmapiiqwUVdG6uxrY2dbYzbgFaNbg1qimXZa0rquo4QcrvdZrO5UCg8+eSTZ86dTWczHp93157de/btbQqHNE0TRbEmCJKiQIKgWRaRpGYYsiZDCCAEAAFAYAwBhgADZAAEIAIAIAghBghAiAFLUgREgAAQYgZCQtehodM0qQKtjmWVMBieoUmCwhiqarVU1DSVYSmOgHq91tns+4s/+WrPnUffdt+dS+vLGjIkoLr87tnFheZIhOMtP/3pzzs7u7s6ewiC+OY3v/nOd75z27aWfD6vaVqD7bu2qo1lQhAqimIymX4bkV//DAM8Ho+mabFYDCHEsuzm5mYoFOJ5fn5+ftu2bQ0jS5Kk2WaFEAqCRCAKQdIAALz6U4UQU1ilDZXUEamTUCfgNYwFCUywskqqgM8VdZW0PH3i9IkL4/APPvV/KapcqxS2bRuanZsKBHzLy8sYY5PFbDbzFIERoWNdiDT7MuktTZE41haLJvxef3Nzs1iXMMYkQhDCcrEEABDFerFUaG1vEcV6JpPJl4oUTXd1dRUKBYokOY7L5XJOm31+ft7hcNRqNYIgKpWK2+dVFCWVTrOs2cQ6LBarLMv1eo0zMWazqVDIURSFIMznc16vNxqNWcy21tZWVdUFobZj58j09HSlVh8b3e5y+2PJ1MmXT5lMJo/Lm0jEzCZTsZD1ez3dPZ1nT5265y13YKwnU/FCviQIgslkrtVqDMMYhuYPeE0mrljMl8oFUazv3LmjXC5TFBWNRu12RyFfsdkcmUw2mUhXKpWdO3cSCNlsNovFgjEuFSuxWMzKWzGGlyfG3/GOtyWTyY2NNYfLabHwLMvKsry8tsrzfC6XEwSBYc0EQTidTopiCIKolKuqqlYqlUik1e12p9PparXqcNga60OSJEGijo6OtbUVj8fDIPpXDz24f/+BA4cOnHz5lM/njbSEH3nkoZ7Orr17d1er9Y31reWVdUFUXS6vhilZRQCjSrVEIRgIelpbwsVcFiEUTcTT6XRdUMtV8fY772FNlsXF9Y6OZhOrxjaWCYw5hi2VC21tPbFkxR/qoc0+kyPAWd2Xr8zs23Pz4uJiIrGBgNLZ1ezzu0+fPl2vVYR66dD+7YpYTCeXC+nNXbu2Xb0yYbd5wqH+ro7RhYXElcmpo/cenrx6+sVnH+zrbkGG6nJ5mkPdE1empKrIIIOBcmd7s8fnboq0ePyR5Xj51KWN7be8a72ABI2BClZFIRJ2+byMLG39w19/cd9QczmzOT01s2fPLkPVAACqqhcrxUDYOzgy/M//9IO25vZysQ4NUtOhDhibs90Z7Nt18zumluO029s30F/JJq1m5oWXn5blYndzkxloHp5LJ5JYZxFJYFgp1avxZNkR7PC2jEmYokiyt71pafrUz77/Tx951+8HQp2Ms70O9JqUXJy/7Oep55859vFP/wnB8KJS1vR6dHMBYdJp7YSAKtcSlVJUrqfK+fWWoNVuI7q7QkuLa4vLme6+ffkS9vgj4daWq1cvRtcvux3OJx87tWvn0Xe/79OSolQqS08//t2924PDA00EwhaHJdAaWVzafOrRl+dnY3fc/f6yYKzEksGWgZaOXVvxnIal3t7IxKXjLNQOju7LJZfGLz6MoZAsSIdufhtFBGoCok1mmjWSqalsfr5e2yhkkpRubQ70G5KVY+1LS3OHD+8+c+a5nbvGYsl0qSIMDW8bv3pZEso+Hz9++Xhnu2/f7rGlublQoHlzPep3B9PF6i33vOWBX/0qurrS09EOsC6p2i23H33w0UcQSRAQeWyO1nDz3MxssVzK5gqd3X1mi2NuYZmhrdCADMPs2zv21FM/7+nt6u0abom0VWrZ8+dPO53ul156KRyOdHd3QmRMTl6+9dZbIcInTx73+jzbd+zwegNLKxuPP/bM4MC2QDDscDhmZmYCAZ+mi2dPvfSlL/7xwtxidCsZ8LX39vauxxZ0QtzMLOcrOacruDCfHBu6x+PyLiwdn5k7PzI8rEjm1tAdfQM7f/HIj3WoOjz+nbsOra6mrGZPpVJRZdAa7nA4mAcf/sd6PZNOFA8dvv3I0XdenlwFlKNWxxaHp1ytUwTQdElVBKfToWgawEjWdIKkG/bv9VzIjfHEG7sIATBe8/c1A3wjOPWmo7y2/w2R3w0EvN6lCG7gImxIuCFpZ/yG6Loe0v2OU/j/or1egWum/bVTg9AA+NoljZk2sJGuagRB0DQNAGi4FyCEiqJc46JIkjSZTAAAVVVJkgTXzfT6KZMkrWkaAEaD61IUBUCDYRgAAEVRvMnSwBCJREKSFABAV0ebx+Np0Fq6rtdFUVMUkqYblzcwGcZYM3QEIEIIQANhAABqODoNAABAGAIIEEQA6wZCABgKgQBNEAaWFK3KMSagkLpCYIKmWKYoVRWsUgzNUCxUEDIQNgxdV1iekmVRrtf27xn63Of+VNeNb33rm+MTC06vbz225Q3486VisVjes3PXj773o1sOHQ4FghRBfvvb3x4aHnjLvUcuXZr1+H2KooiyZLfbJVXRdb0uCFar1dB1hmGi0WggEIAQqpoGEEQIIF0DGBmYA5rSHfH8yafe02KuHb1pOJ7Y8HgdJAahpsDundvvufdt//df/bXZYrLSkCAIFZm6d9z5k+fXVD4EGcrQdA7QwDBUqCAEaB1AjAxIGgBiiAE0ADB0DDGiEWWq1QSeBgG7IRUWcGnBZQXo4OGD/qCPZk12u6sp0GzhbIO9g0DXpXqpVkkVi/FUcpkilWRy1WphNF3O5pKRljBAIF8skTTDsOZMrrSyGi1XRFkxSpUqRTPVarVcLktyrTXSZLOaV1eWzDxHIShUKyaGJgjocNgQAm1tLQ63o6u3y+12IgT6B3pDoaAg1jRN8/l8uq4Xi8XBwcG9e/dSNMmyjNls0jSlp6czFA6k0vFMNk5S+KFHHpQ1geOo6ZnJZGLLwjP3vfUtPMPUKsXBvu4D+/eEQ367w6Ioos1lyWbTm1vrmUymVC7k8pmNjTVZFhmGMrC2sbHx7LPPIoQ+9alP7dmzp+GnczhtgaBvevpqa1tEFOvVapWm6ZaWlsuXx5dX1o698NLU5HQsmnC7vR0dPc0t7alMVpblyclJu90+MDDQ2tp64cKFer2uarKmKZVKiSAIhmEwxqIoVio1nucpinJ7XIFAwOPxAGAgBAxD03U1Go1Go9FKpZLL5RrAlCRJs9m6uLi0bdsox/K/fOBXqVRmc3Pr2LFjmUxmfn6+XhcvXLgwNzfn83tJCsmyFAx42iKhfDbp89ho2lDE0uz0+ObmcnRrPZ9OIkN3280Bry26PmMoubYWzswJlFGzMrTTZHeZ3QGnv1wo+xyBteUtQ6VXF7d+ff/Diwtrs3MbnZ07Dh1426Fb3j63Fn3u5MsEbw63deSLNc7s7B/YZjE7AaZOnzpHEBTLsi8dfyGW3Orp7+js7Th2/KVSTeRMvKIora2trZFmCAyMdZfLQVKUy+vZiscy2YTPY7NZSY6ShvvDx489ZuUtLGN2OC1tbf5UcunSmRdffOaYXNXn5pfL9dqROw/OL0zazCwFUbVaPXLkiK6oa0vLX/nCH/MmBkEDIowNg6WYZDJVqVbNVovT47ZbbTNXp6282WbmeztaLj98/9zkCQqVsVqqlbKra8uZXHrH3p1PPffs2kZ6sG/vyMCYjXP5vIG1tbXl1c2uniEVI5bjZ+bm1jdiCwsxwzCvRfMf+8QfT88vbEbXc8UsopCsGKHmVkTDzt5Wf8BFEDjU3Hzopps9gabZ+eWXTp4hOT7U2slaHDPza+mSdG5qNdg+GmoZ2zZ6+Pbb7zx/6dRa9KqK8p4mx5Gjd106v3z1UmZluhxdqD310PEmX1NbhyPUyum4tnv37psO3WYxu3PpitMRAAY3M7PRN7irKdJz9tLEWjRRklSdtCLKo2GHCm3RtEyb2tIFK8ENH7jpMxiOhsL3WGxjYp3nWPPq8szIQCfUJE1Si9nK+krc5wr6fP6t9Q1EGLNz05IkFYvl733v+4gAPr/L5bK3tbVtHx2tFIr1QrmrpaMj0jk2uidfrF6Zmra7/VVBlzVq+66bQk3drS09NMH29nQxFFEo1W+99a2VsrFjxxGLqSmfVf/+b38Qj5Y4xn3yxMVf/vzxYk5WRNTdMehyOCvlwvrGfKDJbWAtk8n0DfRncumnn3n02eceaY34j9x2WJKkB37xS5vFLtZrq6uzsdjSO9999+LyZKDJGmpy9nZ1L86uuK2R5x4/JRalL3zqs3YTlYlv+F02n93eEmwb7BrKpqNBP9/b6VtbuHLp5OMhF9KK0UpyZeLsS6QutIRCvT19ANm+/Z0HZldy6Qps6ds5uP3msxMLCuQEBZK8pSoqJMPqEHIWq8XhrMuqpBiShkmKk2W1EUMDftupd40d+Q+Zoett+euPr3EerzfMr7/qNRe+5vg1CtxIvTfRtnHmt6aGAcTXhxO90hqMyCuf35Z2I7H/4fr8Z9vrBb75vF6vXuOgMRdg4GvBag08rRk6SVMYAs3QCYqEBNIMveH4wxg3WKgGU0UQhKqq18jIxhpeaw3yBkLYOGAYphFhQhBEtVq9dOnSsWPH4vF4MBjcvn37/v37zVarZhi5QiFXKEiKQrMMazLRLENQJCIJgKABsI4NHRsAQZImADAMaBjQAAhjCAGCAEEIUANOIGAQ2CCwAXWVRAbUtGIuyzOkrikQYoKAoiJrhg5IChKUqhmKpkBgIGyYWQbqmirWd40Ofe9f/r28tflXf/7nMzMrFEMVayWP30dz7PTMXE9v/zPPPHfo0E1ej99sYn/+8593dnbecuuR5eWk1WpXVZ1hOIbhZFmFgNA1jACBAIEgaejA0AEEBMCo8RO79ssiCIIgCJIkqtVqw43Y8BIGAgGWZUVR3LFjh9frpWm6UCgghPx+P0IkxpgkSdXQDYANCCCBQANPIwzQbzmIMcYGwJphyLLE8xwEaia9pSl1QakkMzHywpVzDMOEQsFYbCuXSS/n01arxe3gOZ5RtTpJkSbeQiCjLqhOpx1CuLy0MT09bbc5x8ZakvFUJp3zur3d3d1nT5+u12sdHW2aLiWTyf7+bmGpEo/HI82tmqysLi3bbLZGcNXGxgbHcRjjer0OIezu7q7VapIkxWKxSHO7x+OJbsXq9ZrVZq5W9XPnzgCIHQ5bMp7QDdXldrg9ToIg2jsizz77rD/g7u7pvHLlit8XpGn2wYd+vW/vfkGQENZcTtfi/JyuSWYzryhSrV4xm02nzp4J+r35fF7XdZ83wLKsJEmlUsnhtOXzeb/fv7CwcPnyZZIkFxcXMcbZbLYl0pbLFlZWVrwef0eHBQIiFksEg0GMscPhQIhcX9/EmIjH4wSiOzo6ZEW6evUqQRB9fT2BpuCBAwfGx8dHtg2ZTKZqtV6v10mS9njduVzBYrFIklSv1wEAsqRwHBcKhfr7+/P5fL1eD4fDJpNpaWnJYrE0GGCM8dLCot8fVDStXq87ne5Ia8vzzz9vMjGhUDMJwaVLl8rlcqFQ6OzuCQR8S4trABEMa420BNfXViwWzsRZVBW7Hd5yuer1eGKxmJk3hfzugeFek8VUEypWCw0Vym4yT11Z1m1kpKVFxTBX0iMtbW6Pt3Mokqk+oWIaE/CF4ydGRsZojti55yjDomefebKYL3R0j/zDP3yvsLXyuS9+sq937/zs+PDQaGtbZGk19cN///7IyN6tVOYd734HQsrl089OT24YQqWvp1c3KI/LaeiQYUmCAW6TfyMWrdRrDq/7nrtu+8WDzzt5aDNToqYlYstCJW1j9YvnT7/tnrca9dLs5LMD+7oxkv0BdyFX1DXoCwaK5ZLdYpu8MsFz/N49u5aXNpaXtgxF4RhTYSuD44lgc/ix4+eOvuW+dDL6D3/3jfe/6+47bts9d/mAnZE2V8a39+92OBxVVY7lCvc/9uS+m28f6rvZ5w3NTs3SJh7qis/rTlltfa377v/hD/7iL4Z7e1umltYJCOwOZ7A9+NzTT33gYx979PGHVtcWJLm2Z8dOp9U6vbmiytXLl0+96513/er+n4wO9/lcQZKyQ5J84smXdu094nTaHS5221jPwmbKYrM7HS2Tk5s7d91Csq6nn3tcUOsDvR133Xb4c1/479HlhYvnTwVCHbhS+/nPHwVIu+nWe3/+05c240A2yOa2/nCLJ1cUfF53vpCen1ux8UywpUsoJ9MT6KY77k2n9XwJurxM9+CgCine4RNEZiOuDY++zcaTfqv5pz/4p+j6JNCqLx9f7exo271j55kLlzFg87nqc8+8IIna9NX5/v7W733nn3/2k++vLq9OTs23RLq6e3sXZlYRwVVlCRhGMVdYwSsur8fn8ymqemV8nLc4VQWsrcaWZmfvuPVwZ2frd7/3T/6m5lzVuDo9+/a3vZuhLeWiMj4+fuuRfRRpWlxa3bN7fyQSTibjq2vLgaB7eeVqqZL+/Bc+nU6nN9ailUoNQ9ASab/t9kO5fDae2KxXi319PaoCvvOd7+zevZ2h9XhyZXVlobUlvLg09y//+OyffNHW0tLtDQRHhrZvJad/+ZNfmx38u9/xtuYm5+LC4uHDh/r6P/zQo/c/+vBz8ZXHd+86+LUvffbhRx5Qde3g3rEjB4eefvL++97zsemFzZ99+xf73vH2D33m9+dXpmjAJgqyRlho2oIwq+kAEwgQSNUAh0hRFiBAuqHzvMnAyMSTqiKDV0Oqfwf66k2ilDD8bQ/j63vC11FZ12iha+1auM81Nf43A8J+C6NggAEG8FWZ1833+nHfZKBrOOY1Sv6X242mc81Yvh5OXT/ob7AixhC+ls67fkd+w3JhDABocFcNC9iAUA1jr0iyrusMwzROwkZU03VRetdvCsYYIZIgiEaQe8MuZLKpWCxWr9d5nrfbnD09PXa7vVKplMtVRZEa3BXLshzHSYqMMKZZRlGUhpMRIURRFEGRDW+loqkIQdjYM4Aa/kEAAIAYQUwAA0CDhAYEmq4pNCZlRdQFkWk4NBHUsCEpCiBJE8MoukYAgqZpTdEZkhCFmoGV4b7eF545du6BX/7Vj39cLpd5i7kqivV6Pezxnrlwcdu2bRfOnQ8Gg4FAgGfYhx9+QlX1d73n7qWlOISQt1oURdE0zTAMkiQxhA0yuDGLRsbAb1AvQgC8ys8BBBAhCGIgEGjyYY/Hc+jQIRNPVwtFCKEsy7IsaprGcqwAcKlUwnTBsBUhhBhBXdMJgsAGNtArMg1EAgNjCA0IANQAMAyAoQGArtEUpJEEQNXpILb39V88PpdLZMlkOsHzJk0SCawxNCJJpVpO7t69vVItQkSWqkVsGBRJWXlbPJY2mXiP21cubkCIUqlUPp+3WCx1sR4MBXmrmeWZrt6uXD7NVdmaKBy++eZCLjc3u2DiuFKhnE5mTCaTKIoulyuXy7EmTtOMsxfOT0xMhcJhj8dj5q2rq+ssY/F4PA14bjKZRFFQVNlkYg8ePJhMxa1WsyDUdB2zrOPOO2/LZDIUw0ZaWyhEu91eu9Vh4jiH3e6w2hKJVC6T8rgcGBvhlvDK6hKEOBAIAAP7fUGWZUVRrtfF5uZQPB4/ceLEyMjIwMC2tbWVqamp/v5+QRAtFosg1M+cOSuKoiiougbb27omJqYCgSYI4dramqIoJjMPEJybn3c6nSYTv7EVTaUzVpsjnclZ7cmtWLS3t3ttba1cqprNVpvNMTMzx9BUvSq0t7bbbLZKpdLa15LL5dbW1ghkunTx4tTkpMPhYBkGG0akuXlpcZEkCEWSOY6z8NZ6NQUAUBTN6XRXatVSsULTNEGQ3V29Yq1qd1hNJtOhgzeNT06pmm6z2UrloprPMQzjclsrlQrP89WqceXKxGDfYLVaDfr8NpulJtY2N1YhqZlMTLVEWS0ulrLLBoims2Wx7msKQcYUbAk//sxjLT2DOqk1R1pae5qsPqc76EmnClKV5Tjm0IF3nnjxaVfQd2CfSd9Wd1r6eBZIVWZhKZYrStt37nH6oxNTV/oHtp0+fXpkqLezpWN1oWSiaY/Tls5VLRZudT3a1tYGDQUBVYPUpanpl86c6+rpD4e6UmUtGb1q87X6B30XTk/X6nJfb7vV4tJUNhDoLOTEQBPT1z944fj45kasc6h/YXGxpcnvtNpPnTh54NAtNE1Xq1VkcCTBURTf0d1fFaXm1paJiYmhoZ75K08ee+YnmeiZT3/4XS8+8YtMMnP+zGnO3rZ9/1sZp/sf/uUbH/rgh3joSSaTQQ8DCa2ulABALeGgmdJlIUvCSnxjdbi3RzN8Z08dNxv2lYVLy7P9JqpG4oLTRAjFzNmXnvf5W06+8NStt+2rVYssa46Ee4RKuVxhNQV3tI1urm4hSB7Y17E4+1xRxAv17J7h281k6PhLF7bv2r7zwMGltfnEZvTsmamZS2dX5qcO7h+VIGrqGFJodzjSnUhWm0L7GNptYowrl45rRr2puTOZKdstJp735jNZmsSI8PqaD+SrHofHX43GAE1cmj4dixXuuuetmijbzU6hXPzJTx48vGuEoEiSNXo7O6RKqTXS+tLxky53mONcuWI11Bq+7UjrqXMvtbcP//KXz/3sp08c3Herx2M5fWaio60jEStsbiU++KEPVMo1jiEX5q7my2neatkxvENSFZLiC9nSc889xUL4/IvPMDSUNXF4rH9pLXt1ZpGhrZNX5m696WgoFHrkkUfuestd5VLd4bacv7TZ3tHC2Zinn3nkXe+7c9u23skr40899ZyZ8w0NjhUKha2N9PPPnQRQrdVqR2+/54FfPMFQ1lAgmIgm6vX8fe+8Z2Nr/szpc6FQ+MjRvpOnj3V3JXfuPhAIBM5dPElQXDtnn1maam3p8wbYXD72N3/7hKLx4fC+9YXEI488+p533UEDoCrlJx78fixV8TUNfP+735KB61N//jV3U+tGKklxTSSkJAwBCeoKIEhEskypWLHazARFVuo1hqIAADazRRRkTTEAAAT5Wnv8hojhOkh0Q6Dwio1/I9/cjZDE6zHZtSAhAAC8/viN4sNgw/jeQJ83PI/xK+a60ek1nRsI5Q0xzZsjoWvC/w+SWOC3Z/0aNus1ut0I2kIMIHhlaxCA2HglhIqkyGsuuUbWHiIJTdMaDsHGyQYgewVAvHpjXM/2NSZtsfAAgFQqNTs7K8uy1Wp1u7yDA4FG8mC1Wo3H4xBCmiYJgsAQaIYK9AYKUQxDw9DQDM1kNjUC5HWsQR1CCDHCCEPw6v5iCCAgXg1lMgDWITRIoJPQAFADQCYRhXTZZ7M3CB0NgbqmAJqkEUKAQKpKMwSJSFXHJE0rYs3ndBfS2V/93d+9/0//m9nuWNvcpFgGQdLl8iSTaQqi+dmFjra2ULDJYWNPvHR6bW3ly1/+/OpqClGkruv5fN5sNguSaLVaFUUBEF4LVsMYK4rSCN1uIIdXHeuNY2AYBsMwqqrKsp5Op0WpEgh6AAAMw0Sjm+VyWZZlsV61Wq1er68s4Xg8ThCcgRBAEJGEIWNgYIMEGCAISIwAABgiHUD9lXWCyESzulwTa9mwDxHSxv/65l+2eJi7bjtEWm2Olkgon4kJlYIiFC1mwm5z53JbwaZAOp10Wi2xRDwty2aziSChJOqlYo3nzbquq6pst1shhLWa+NjjDzUFgogAiWTUZrNUqyCZTOfz+ZHBoZ6u3sXFRUEQBEEgSdpkMmWzed5isVqtc3MLvMni9/l7e/sbsduqklpeXvN6vaqq8jzXcMhTFLW1teVy2v1+bzabZRg6kYyzHMOyLCBApVKJNLdm05larRaPJhRFcVjt45cuW80Wt9OlyFJff39dqNZqtUKh0NnZjjWMMajVhEql4vcHe3v7vV4/y7I8z8/NzbvdLlWVE/HUwMDQ3NzcxsaW3++nKMZiJup1YXFxeWNjy8zbTSaTmbfuu30PRVETExOSJK1vbdI0wzCMKMqBQJPDYSuXqogACwtLJpOZohiaM2GMD+w/VCiUSqVyrSpUyoLJxC4uLtXrtcYTjNfrjUajhmHY7fYGVOd5PpvNejyeRpqDKErZbFYzQLlcBRASFLrppptqtdrCwsLBfXv7+nt+8pOfyLLscDgy2RzNkFaHPdQcXltbE0XRYrEsr6zpqu50eKLxFMdxglADwGjpaM4Xs4amBAPeQrEUrSZ1vWDzeBBkfH737OICyZo1hg+1BM5eONE1MHB+/LSgy/v23To+fqVc1Ps6domCQCFw5513ZlLrWr0cbu/OZovz6VhPTyvNEUtr061drSPbd6nIJNTVzs7Ocklob+tJbCy0NLd4vd6Z2YV8SbA6vFuJGEdTQb/bH4qcOHF2+67tExNTmxvJaFaS2KJfzitiQZWyNGW6dGV6dSn7jnvvfuj+q/W6fHVqg8AKzZq9wTAgqcHh4Wo67bS7Wts7CQBzhbyBIUlyigoJxiwqmqCogXD4/Lnx4Z7mD3/gXZn49LmXn/nRv4yboFLI5Cg6KIKijAFEzMD2Q9mazthoilEdNnZldTEQaTl37tz+XSPHnvr1yFDnmVNPOps6zIzw3PMnetpbf/Dtv73vvrvTsbXhvo6WoO3UiZczW1ujo3sJoL//fe8R5NLV6fl9+27ZjBUVUTaZmklCHR7qkeTS8y88HGm9CeJMbCUZjV4e6bzFbPO39wxsJdOu5k6xVh8Z3jF58VLvwNhtt98yu3DuW9//1527Dxy5/Z3VKkXRrqN37N2KrvJWff+hnY8+9uTkxNTQyCEL780lE3ZHk8PtJUkyevJMN7aoZaAhFlFUpK3JYjeVa3F/0FdIpzRJvfPOo6mN5d17954/HTfb2L7ebf/87X85cstbhoZ2ffbTX73tLe/8vT/46DPPPdXU1Lm6ngsH/F/+yjcsPEjFV1xO389/8tMjN9/1F3/4mWdfOLaVSJNYdnmdrW3hK+PjF8+eqYu6IBQlQdm3ew+BjdmZqTvvui1dzKdzFZYzDQ0NTF2ZuP32u00MT5EujODo6HCxWPrX73wvmYoTPO3xeO64962eJl+4vf3YsRc72ruc9lAikfL5/KIoTk3O7t6zvTncdvnyeLFY3LtniCLohx9+uKMzoihawBcslwq8yeZ2ATOv6EjQQX3v/p2lWvnKxPj4+NqHP/qRtY0VXzCwc9+eeFq8eDG2ffTgnh382tLCj/7tl0dvv9Vq15965vHbjx5++ti4L7Djk1/8xspWYTOxpQBEkJyBENANgGiCgoigBEFwe5z1epUgICCIhiunUq4xFEOSiKIoTZcbkS3X+IlrMT1vaLDfBAqA36Zz3hyX3MhdeH289vWG/Hr09rtr9ebaXn9wozINrz/55vTe7x5V9ubSbsRgXY9f33yFr1fpetdhIzYOYQwAuBY4xTAMQLBarTIkxfN8I6+w4S5UVbUR6t64/FqyYSOFMJvNrq2tlUoli8USDAbtdjvDMCRJ1uv1hoer4Vu8lk5oGBpN04qiQAjNZrOmabKiMAxTr9cJgmjwiK/cA42sO+OVGH0ICABewVsQGECXITQIqFNQh1CHQKEJjcCK3+/DGjYMQ0NY1Qyzmce6aigqSzOqogISIgRrtRpDUU677TMf/IM7P/WZAzftn19YRxQtq1jVtbbm8OTEi9Vqdffu3RzHWTjTlUtTzz///N/+9Z9Ho1mMoCzLZrOZJElZVcxmsyAIFEUZGAMACOIVh3sjRaDBAmKAGxi38cMyMGggWkVREKI4jiuVs2azWaxUAQCCIHR1dJAIcDYbUGuSJMky5J08QUAMIUKIJGjDkA2IAcY6RAZs1M/QIQSNQEqAEULA0NRIyENoWK2uRFcvB+y4yU3XsptkKpnfPjrGUnhDKhqqThMY4ypElCyVSAoYhuFyuGu12tbWlsXCa5pBkAwEJAAwl8spiqyqaltrxGKldV0iCIqkUCy+RUJkM1tKpdLs7HxzKFLMFVubWwmCMFmssiy63N7FxUW7zdne2b24uCiK8urqOsdxDMNEIpHBwW0vvviiz+fr6Gh76aUX7HY7w9JerzcWi2Gsa5qm66phGJlMxut1S5IEIeH1+u1WRyjYdOLFE5qqOWx2hqKz6bTFZhNFsVKpMCxl5c3t7e0Mw6wtrzUix202h83qePnl0+FwuLOzG2MsCEIhX0YEmJw8kUqlent7QQRBCDs7el968WQ4HEkmspHmNklVi6nUkSO3rqys1GoVm812+JbDSyvLg4PDG2sbcl0VBVVVCusbqyMjQ6Vi6vbbb9/cWidpemFhae/e7mAwfOz54zoNDQNACGVFVFVV141AwMZxnNfrVWQtl8tJkphMpDvau4698FylUhEEgWUrJEkePnw4lkhtbkbb2ttJmojGNsvlcmdnp6Io0a14U1PT8vKyKGlt7R0WCxtNJjgr62/yvvjiSZfNbTU7VEWmaFaoVDRdEiVR09WgGu5o7y5VSjRtNbCUyqYsNreJA+HmZoqk3f5gNBWvrs3aXM1t7U2BgOeut94tq/r84qVzFyYP7bmDIFQzZxi4WK4USao8PNp65exEf1dvc7Pn5ZPPRlpdkqY/8fTz7V39oUjflYkzN91y35WzLwFB6ugYGJ+YZk0sw3FCOmMlXEAHoVCrmWNLml6tirKsj43tUERlef1iJpcjqQrPMruGh7biwl133We2ODWopVKJWw+PzM5kp+fmerr7IENtReNel7urs9di5jejG6Ioez3BQl4DqrUm0YV8tqm5E5K0JGljYzuuTk2FXWIutcnQasBn85mt0zX59rvurgPXpcW5VsbcNzS6urTcGerOlvPjUwvxxJak6XabqVItcCyajc77A4xF4n/0vWPpTG3qAty5bdDKcqcvnmcI2NnZfO8d92xtZNeX1zu6B7CBHn7k6Tvfci9psq9Nbm4b2sGbm9tbmuanz8uibrVYJsdPWiw8h1All3v59MttncP2kN2kAZZHe/fu3lrM9XYOd3QFF9cv3XrvEVuzLZuRTl+8YrN0ed2tqWyOoFCllivOpAf6R5dW0hTyaLLF4+42oCwp6plTL47u2eZwO8p5XZS0VDrPcGB2ZuKWWy0EBKdOPbx3+2FdpzVdjicTLp93NbZ+9sIph99l9dh/fP/Pe0Z3MGbbH37yC0duv/UrX//Lb/+vbyHSvLyc5lkdQaM5FDx69A6Lyf7SSydEFbZ1D0bXJqv1yvzs1K6d2zejGajB/u4BEtILM9OKInm8TSRj5/jQxmYlFtvavWufieXGtg97nMFLF1/uHeicnpu0WGydvZ233nH7D3/0kz/4yCc7wzv+7Wf/9NNf/Hq0t2NlZf3uO7eZzda1lfVatVzMl/KZEsRofmahKeBPJqIup2dsbKSvt3txfimd3Xjb2+7N5+vLyydpDjW1eB95+hdvf8f72nt6As095Yrwj//rF4Jc+Pqffa0mIae35cChkamJpZ7Olh37brrr3ncoSuG7P/zLukGsxJKs1fHu3/vo5cszgk5QJgtClAYIXQcUxRoG0DSNAhpDkfVaiaIow9ARMCAkAQAmjtMUlSRIXVNAI1DnVWrqmvm+MWFzI1P+W8TGjZiwN0QAb/Lnm/gH3ziM/T9TW+v6/gRs+J5+V4XfHPrcqN0IgL7+/JvHq70eYL3i4oS/pQmEkCQIRZIghBRNq7ouCAIAwGQyQQJpmtagqRBJYAh0TdN1nTNbG0UWKIpqwPFGdmGj5oLZbGYYRhTFVCqVzWYFQaBpOhAI9Pf3cxzXSAasVCoAgEakUQPMNaBYI5wLwFfOQAivDQQAoGn6NdwYbrggG5WvoAEgJAhS0zSWRroscTSAmoIMiSShJFUtZrZeyUhSpVSkZJ1UEa0BymQyY00HGEMMgKaSAPI0q6qqgfG2bZE//IPPdm0fu++9d03OJgyCggQpiWJvb9tzz5y4fP7SZz7zGWAYEONCOvvYww99/et/EkvmVKBBRDAcq2hqg69qpAVgjCmSBIZB07Qoij6fr1wuN6qLQUhAgBsOdARJwzAMbJAkyTCEKIomky2XyzWyzZq8vnwuk4xt9vZ2l0olk8lUFwSKojFmSJKEECiyRjK0YRgUSWJgGFBHCGED6BgSAAKIMAAYYF1TgI7lirhUippA2gSSrQFzqG9s8tyJ43OXkN/XXCzUKJIhEdEcbmprDStqnWOgqkksTeVymXg8brFYfD6fIEiGYXAsT9Osob9SdoJmkCBWNF0ysFKrlywWDmO9EcrN8xYCkl6Xd8eOXbKsAoKMx+Oajut1oam5uVKvS5LcEml32N2aii9fmijky0tLK8vLy5FIpFDIOZ3OnTt3yrIsCpLd7jRx5lyuoChKrVYzdIwQqtdFp81p4swnj59IxJIYw507d/I8T9P0wMCA3+932Gwsy2YzmVwu5/cH21o7TJy5r3cAG1CoS/WaKEkSQ3Nrqxv1ukhRTCDQ1N3du3vX3ptuutlqtV+6dKVWEzY2to4fP2E2W4vFciAQZBjO7fI6HW7DwIlEol6vLy4vzc7PeTyeQiFXqVbrklyvC1arPRgIbW5Go9HYU0897fMGajWho6MjkUheOH9JFOVaTRAFSRRlCAiTycRxnMvlavDDjYpw9Xo9kUgghO668x6G5np6erLZXCqVOn78eCKRsFj4Yil/5coVSZLMZtO5c+cWF5ePHTvGcdzI8GhbW5thGFtbWxjoM7PTM3OzLpdLw0BRjVyh7PaGevqHqzXRZnfbHO6NzdjaekIzqKXleDJV3NhMJFK51dXV+cXFUkVQNRAMNDEkRRO4s7XNwnDPPfnszOSEzczv2bG9r6fT5YAGyJJUGaBiND77xNP3E4yWKyVNFsrmtkVTMZJh733ne/tHdhdL4ODhe7//g18cueOtq1sZDXJju28aGN7u8HgNBArlIoDG/PxstVJpbY4M9g8kookLZ88l47Ghge5SZo02SkiupbZiQl31h1pcwaDDayco4+zpE7t37t65Y6+KAWcxI4qcmJhwerwEIoPBkKZoS0vLgaYWFTBLm+lAW8/ozn3ReFqSZZ43j27bXsxW8rlKcyQyNTtTrgvtHT2Dw9v2Hzxw8MCuYiHFczRFkTMzM81t7azF+dZ3vr9YqgYDzbFo6q1vf4c/6KtVCsGAk4AiSyh//zd/2dHeYjKZPv+5Ly0urR8/dia6mfneD35stXla2wdOn53o6dtRruPxqyvRXJUwu5o6BmMZoVCDYzsPcZxtY2NjbX05tRn9yhe/RDJMvJC9NDv54FOPloWyJFdLpYzP7/7Lv/6rl06duTA1t33PkUOH75Mli6LQlbKgYa1vsGfi6pUf/Pj7ki4fvvmI1ebBmDEwaWDKgOCWIze73W5RkVkT19rW0RSM6Aro6+wtpPNQ0faMjZEQFLK5pcXVSk1SDQqSvMXupjhTsVxo6YikconPfeHzg8PDv3jgkVodZvOqzdG8a/dRQaJ6enc+/ezpcKTf5gy4Ay1tXduS6ZqGma7ugYH+EZYyhfwtya1UKVsupPMdbZ0W3prKFO7/1WPvef/HR0YPNYe6OdZmNptZmp4cv1iuZGkGxhNb3//R98vVcq0uf+BDn6wJVKGAOjsPOJw96+uF5nDbxuaaKFXsDs7lNg8NDWxubiYT2aamsNPpdDqtg0PdY9sH/+Vf/8njdTAMFYsllpZWRsd2La6u942M7j10y8zC+onTVzI5efuOo+0du8ORodm5+AO/PIahLZ+vnr9wqSaJpy6cu+/9H3nXBz6N+Oae0duef+nq+z70RUk1SSpJURzHsFjFNCQZhtN1qKo6SzMENAxNNtEk0BQCG41ydAhAQ9N1XYeGgTXtRll4/39rbwg43sQRCW/Q/s+qdH37XS75P6vJNZ/da9yI18tvuPwa8EXTNABAwwOoKEqj3lUjevpaQaZG3FXDJ9goSYUQ4jiukfqXTCbPnz9/7ty5XC7n9/tHR0d37drV3NyMMc7lcoVCQZblRm3ShoQGqGokIV4L5LoWIP8aXu0N14qmWEPTGIqlKUpTFY6msC4TQEG6bKJ0t5Vt8tqXFiYYUjebCTPPAoQZzmQx23iWBwbUVNUwDIKEJElSBKqXK7ooj41Evvrlv5IL+a98/Yvnr6yoGBAUYwDU0tK6vpq8OjH1uU9/lqMYqGMCwO/+63c+/elPa5pG0oSoiAYARgMu/fYONvIAGmqrqirLMgBA07TGfCEgXkM3yrLe1NS0srKCMZ6bm1tdXW3UHmvwf42qVwAAQRACgUBjGRtkZGOUVz3pOgAGiQABSQKSEEMECJIkGYryebxCpWo3822h4PLsdDK6iVW5rTWI/J7mbLq0sRarVkUICIIgbDabqEiiWBfEOkSYooilpQVVlQkCq6qczWQ4hm3Uwxgc6Bsa7K/VKvHElj/gqVSLi0sLhqHlchmEUHMo3NnZfeHCxWQytbK2Pn11plyqLC+vLC2tbKxviYJM0exWLC4pajAY6urqIUlaltVEIpHNpq1W67Fjx4rFcnt7J8awWqlBSKoKTiayAJAul0cUJFlScrmC1Wrv6uqp14Xx8QmSpPbt2+/z+cxms6rrmmGYTCZBEMy8lWVM45fGL5y9MDMzW6lUKYomCDKXy7tcrga1mM/nX3755fX19c3NTYBRU1PopptubmoKNTdH7DanYYBMOlevi6qiT05epSgql8+vbazTLGMYxlvecnc6m5pfXGhrawMYVsqC1eJQFL1WFUZGRvfv328y8bpupNOZWlUwDMPn8zkdLpY1RaPRZDyOMPQ4XbIgarLm9/hr5drG6ka5UA76grIgv/D88xRBuB3uo0eODg8MXrx4cWpqYn19dXl5sX+g1+Px8Dw/OjpaKBQIglhf21xcXGz8gDHGVou9OdKiY0M3AE2x+WK5VpeXV9YHh0ZHRneWKxIiuWJFVg2K45ytHQM7dx32uJrHRnbecfudfT09M1Ozya0kUCHQEFRgyNWkVnQ7aZ84M3nxxKXMRvqZRx9eX70IYTIUoiMRS1PI1tUd7u1vC4Q8KpAltZbIJiZnp2dmF622wKGb7xndeZMC2JJktPduw7Q12NLz8oUpm9vf0tHpcNgmx8cJrHsctujGhtXEOax8pVxcW1859fKJrpZwfHXdRnO1YjUWzaxsbJ05f07UJI/X7nLyqdiGz+/SILa73WNjY6IoX7p4JZsvYQPoGsxlS/l8tVTTApGuj//xV0nWpunA7fZWq9V8obxj58005UK084Mf+4xGm5ajiS995U//4n/8ZWprM+y12Xn94J6BU6dO5os1X2v/0maRszadvTDd1Nw1MbXo9oTT2WI+m9VV5S1vuRtj49kXjhWq9Y14dmpuM19WJ6Y3vvy1v6TN/lMX52654925CsSUizB7SiJ+8qUTKkmVVcPmaZIMbnYx0dwyePTofdvGdl+8Mm6y2/u2jUW6+1u6e5554VkdC80t9o4ur9XBd/UNFwpsPMpOXa7v2PZ2n6vtpz/92VZ0fWL6Uld/+3s/+G7KTMTzWxWljEkd0qhYKdbr9UKuWM7XNlfjm5vRra2t5aU1C+fsahvrDI+JJT4SHK0WDCvv3j62LxTsikerNmvzzt2Hpq/ObhsaILHa393+zFOPfPD3/0CWtKeeOr597FChpNMmb11m81Xi9z/8xedPTGqkrVDDyZweadsRDA6IIuNyRK6OLzstfjPjUupaX8+A0+7w+4OR5ra9e292ekLZnLAVLfzRRz/DkKZ4IipKlbbW5mefeaJUKnR3d9aq9UQqPzu7mc8ayQS45+5PdbUfjG4WOdqCdS2d3pxfvGyxkR1dkdGxEUXRrk7NRre2FFm6cuXcxsbcZz/34VOnX9i5fVQQBB0b3f2D73rPR7NZHGndL8juQoE+9sLkv37nV6OjRz75iT8NNQ1Xy9zacmF0dHRktPvJ5x9e3lq+851v+/a//3LvkQ+WlPAt7/iygEPrCYHjPSbOZsjYTNBI0YGKEUImmgK6gnWZJg2oKwTWsKFAbGDdgBBirCMEIMIE+QYA5T90Of0uwOU/BBD/OwDo+s6v1Ea67tNINLvR5/XtWnWo/1p7c5j1mnndaKb/4Qq8RsLrRwc3WPNGsSuAkGYYGGOapmmahhA2KKVXqrQDKAlio9wlRVGqqgqCgDG22+1utxshlMvlJiYmpqamstlsKBTav3//2NiY0+lUVbVaK9fqFUmSIIQsyzIMAyGhqjoAyDBAo0jpK+He0ADQaJQ6feXTUNjAWDd+k7b5ahgcwgABiHWVY2hFEoChI6gDLDHQYAnsd/EcqQqVdDkfO7B7G00bidi6IFVViGWMdUWHCqYxZBBJkggSQNMUrKssQu1NTb/8yZOpS5e/+d3vzK9uWuw2iqYlWXG7PbVa7Xvf+96HPvQRiqJK2byF57/9rX/8/d/7PbvdXq5Wkpm0y+O+dptdQ1rX1hkhRBEEQ1GapjXqY10rUwIhbBTturZrAABN04vFoiRJt99+u6ZpCKFGXJeqqhAChGAjWJ5hOKEuNQDWtWzQV29dgzQUEuukgQiNJDQK6YgAsNHZ5/bazK7ZqaXduw6IgvLQY88nszlUq9TLperS4trqyvriwsraehQSpNvlkySpWq+4XK6WluampoAkCQ2vLQCgYctVVR0fn4zHkmaz2WQyFwoljuOLxaLVanW5XJqmVSqVjY2NWq1G0nSjOqrV7qAYrlqvC4JQLFcqldrGxsbMzMyLLxzXVMPt8vb09FgsvCRJtVqNoihZlht1ycvlKoEoTdMZhstlC4qiuVweQZBSqczG2iZDMRzHiaJ46tSpeDxO0lSpUm5kUlSrVZ/PNzQ0JElSOBwOhUIWi6Wjo6tBdJEkefbs2XQ6feHChampqc7OznA4LAjCwsLClcsTLS0tjecMv98fjUYbldYrlYrdbo/FEqdOnSEQ6XZ7JUXWDLxr157NjWgqk+U4niCo9fVNlmUDgab5+flYLPbiiy/m83mbzVar1axWa+Mhxut1220Om82GMS4UCo2Ax4mJCZIk9+zZMzw87Ha7Z2Zm3C6v1WK/cOGCqqo333zr3/3d3/j8bo/X5XI5rl69GottNQqTms2mSCRis9lcLo/Nas/ni/Wa2NPTd8fRe7yeIEkwFpud5y0ExdRE4cz58xVBkjS8tBati3p7Z38o0h0ItFGU2e30xDejuWzSZuZ6u9p8Xk8hl3HyFrlavXrlsp3jE+sxG2sb7hmWyrX+3q5MeiuX3vrEH33s4Yce7+0ZvnRxcnJq7qc/fyCWSJ4+d9HA6K+++f+cPXfx/gceuHDpvNPtyJfzzz73fP+27T2DYwsb8R/++P7v/ttPa4Ici6esVmsqkcjEk8DQIMSVSgkS2BfySUrd0HWWpDbXN7ra2vfs37e4srq4ulqpVXO5jKbKNIVsVr6jo6NWq6UTSV3XJ6auXpmYUFU9VyharE5Zh4JBbt93kzvYsh6NI0TWqzWWZSmGjSbyXX27FGDNVWB7z86zVxbCbdtW1tII01DRLp09efrESwij+3/xa85sITlucGDE520av3L1Fz//tSKDUCB8+eJlv8+nqeJffuMvKIZ57sUTnmDL57/yZ75wT+fA9l8+dszf2jO844CgEp5Aq4Kp9q7h937wD8p14cS509lysSSIlMkxuuuWK5MbK2t5iz1QLNaXVjclzWhqbnN7QxBR69HY2Uvn5paWPvihT4abR1radtsdPXWB/bd/fzAQbPrqn3zdarNfujzudPtZzpzJZ21ui8NtUnF5Y3OeYoGuq1BHdovXUEmGNrnd3r7eXgiJxFbKZnFDg5+ZWLNaXKGmSG9vL8fxLG3vbB9KxLP7du/Np1PHjz0dCbofe+iXilT/1Mc/RZGsze6dmVvaiKZs7pAG+BNnpzv7dqYKkqBTokLQnH18YpGlXZubBYa2plNFbACPy/3UE48/99wzHEc5XI6nnnnqwqWL4eYWk8k8P7/gDzir5YxhCOVKJpOKLi/NfuwjH6AonEpE21qamwIhM+848cK5alnbObpnY2PrM5/9FEkCs4VZWZ1Pp+NbW1ulUomimAMHDlitZozVZCqWLyTDzYFz586NjY2trq4+d+z4RjS/lZCTSWzm2w8duufgwdv27jloGPqvfvUAhYibD92eSub/7d9+eubcxeGxbX/1N389vHPnuSvTm2nF7h/ed/Cd2TIkWJuKoaZDRTaAgRiS03Ud6xpNIV2TCKjTCIjVMkOTFCL0V//TfzUbX29EvLzewL+Jpcc3aK838L87YPpPtetl/meR2f9HalyvzI20eg2quybhDTX/L0zqegR2/UGDSVJVVdd1kiQbxdkb7i1ZlhsYS5ZliqJomq5Xa6qqWiwWj8eDEIrFYjMzM8vLy+l02uFwDA4OjoyMNOqFFovFhntRUZSGy69hv+Cr/spGcPe12vHXpnN9Jf1XbibDeO17gfAr/0IAVFmiCEgRyFBEM0uRwNCVOk1otXzSTAEzg50WhqUxgVWANRPP0iYekbQBEcaYABhBjA1NUyWSAAyJ/E775vLy8z/87le/9fcMz9TkuiDUgK7xJgZC8M2vf+2ee+42m03xeDwU8X3rW986ePBwZ2d7JpNjGMZssZUrtd9oiX5ru/GrEe4NNqFROxQABAAEGF7/G2lcRdNEsVg8cuQISZIzMzPBYBAhVK1W/X6/KIocx0mS1JBZqVTQdbkX1yQ0ACgEBjJ0pEPCQIRBNKqMYowlSQkEmkr5CjBgdCMqyvp73nsfy9tQdHO5r6fjS1/43M2Hb706tZDP1oL+doa1bEYTm5tRSRJyxazP7wmHw4MDA26ny2GzKrKoKTLHmCRRLpVqoqBqKs6lC71d/b2dfaV8iSJJikQ0icqFPG81NwrL1uv1RplNkiQtNitN083NzUeOHGlubg6FQmazuVIup5Mpq9Xq93vdbrfNZnM4XNPTsxaLzel0b23FVEWHgCyXa/Wa7HR421q7wqGI0+kslUoNDIsRSGZS+VIhnkqwJtZkNrk9HpKiHn/ssZZIhCJJXdM0TctkUo0YwHw+x3Fc4yWAbrc7l8vlcjmXy+X1eu0O68svv3zy5MnJ8YkTx1/cvn1U1eSpqYnGswhCaHl5VVX1uiCTBPPLBx5MprMt7e25bGFoaMRstfJWS7UubsVj4UiEoCmL3drf01PM5RAwCrlcvVKulIqGpnV1tAeDQYZh2to6ajVBVXRDB5pmkCTd0tIWiyUYhoMQ0jQtSypFMrOzs//8z/80Nratp6e7XCmFw00Qwmq1ura2NjQ0tLi42GChL126tHfv3g9/+MOFQmn8yrQkYpvN5fP6fQHv733wvV/5k69kctmz5y60tHb4fBGPr3l5NTY3v7S0vFarCUDXYpsr2fTW+XMvLixcqpbiLoe5Vsm1RYI0UMRK7p6jt+we2wE0VVEqlVLm6JE7ejq2W7lIwD24ulDTNS+JPHMnr8ZilXfc9wecyfv8syc/9rGPOZ3muflzU9MnBgZavX5bW3uLpOnJTPEPP/25nv7Rs+cnOM5CkyxDMseOHdu7d293Xy8moNlhWVidPXL0Vt5sQYh4/vkXxqfGLTZ2554dvQODuULN4w6qkr6xtlLIpFOxaCy65XLat20bdvm8BEVjBE0mE8bA5faLGBEWe7Eu8zYnAIDneUkSDQAQy337ez8p1uh//eGTixvVr/33f3nymStNoVGK8VotvnQ0c/KF4x/5wIc9Tsevf/XvTgd5deqSw2J2uxxvvfceVZAr+ZrNZHVabPVaNRIJx9OpXfsPVmT855//ysDOvZ7mDpWyWLzNRUGrSirDW8cnZ3L5siyp73jH2yA0eAurQ7C2mbQ4mkXVNrecX98oOF1hjuZITCh1vZCp3nTw7qamfquzRdDMi2s1VXfb7T2qznlCXtZGXZmZzJQLHT39vmBrOi088IsnHn/sqQfu//GDD/3giad/uvfAgNdrQRiwjEXX6J7ubV5PWJH1crlIIG1ja2FjY0VVMYCsxebKFbL5QuLS5dPZbLaUqxzae/jw/sNnXz5p5Zh333fPhz7wzqefeLi9Lfz8c88cPTo8ff5MJpfp6x+cnlsmGLvF1cRa3blKbf/BfRDiaDS+uZnctfsAQZsT6cyOXTvSuXhzq793oB2SerDJve/A9vPnTxTLCUToyyszLi+naEVRziXii1/60qdvObz7mad+nYwtdXV6OEYytEJTwJzPr5tNRF9fH00yP/3xz5pD4e1jY1aLhSap/t6+e+66m+dMDodjfX09mUoAYFTrVavV8v73v39mepbjLWfPXZREkuMCV6fTLBtEyBSJhBeWL9VqW5nM7N/93dePv/jI5saK19/xic98fXTX4fGZOUkzNEQawOT2tsSSJYrlEUMRLCWqKsFwOqY1TFIUo6uyLNV4jmIIqMsCTRFA0ygSYU3nGJNhAITIxsPxawqB3ggo/KfM/P8m1rnRoK8BJW+OYH7XsfAb1ylF133+Qz1f397kkhsdX4+K3nBSrx/0d5oghNcCoeCrNTwbJaYQQmazufESm3w+T1EUQ9Eul4skyUKhsLi4uLS0VKlU3G730NDQnj17gsFgIyUQAHDt7ToNb2CDEtN1vSGtAQsawVsNMNdwXzRQCMIAGhgauFG/CQJAgFfones/DXQFDZ0moShVbBaWIgAFdcKQaKgCtW7IVauJCPlcQBcrpdzq2rKJZwNNQR0bgCRohqEZEiFAYI2C2ERATayYaciQ+O+/+rn3f/lLbZ2tUzNTtInkEMRyrT3sfuTXv9h+84F9B8eiya3WzpZv/+v3d+3be+vR/fFEChBIkKVXpgMBBo3SVghCAkICYAQw0jXcKIUFAaEoGkUxEBLX0CR4hbVqXNIAmqABEiwWy/z8fMN7WywWPR4PQhBjLAgCNgyKIKW6YLVaDQNADMnGTxdChCGEkACQgABCTEDcIK4IgoAQ6RgTBFUslE+dOpVOp4PBoNVmHh4dg4gi7U768uXTS/MXA35nf/+QxczUquryypIkqpAAmVxWUTShVudYnqFYwwCiKJrNpnq9Xi6XIYEavk+rzSJLeH5u2eNyhELNxUKuVCrxLON0WWUV1kUBkURdEgVJcbicFEMjhFpbW61WK0VR6+vrFEVRFFUulSiKaCBxj8djt9szmdzY2JimGufPnzd03WQyybJqtdhrtfqVKxM2m61cLjc3hSlEWG3mVDat63oulxNFsS4KXq93aNtQNBq/ePGi2+VaWFhIpVJ2u91sNg8PD585c0aWJZfLVSjmnC47RREsy6qqCCEulQsECTVNX1hY6OzsSCdTO3bsYDmzqurFQkWU6oVyyecL7N27d3V19fSps909ndNzs9lCMRyKJOIJm9nX4L2sVitJwYY3PZ1OZTIZs9lsGIYgCCaT1cSZ3W7vhQsXANRKpcLi4vL73ve+l0+ettls9Xq9Xq87nc6enh5FUVwuV6lUiUajZ8+ezeUzbe3hVDqxvLwcbm6pVisYG+FwKJPJ1Molr9c7OTm5a9ee2267bSsWM3R04fzlqqDu3LXPYbeurCxtRTdjsS2bzdXUFKQpFhFMoZga3rZN05WFpTWWI2uVIlLrPV1tNoe1WMrzPCIprCk13VCjWyssZ7t48WXeZg+Huh5/5rmuntbHHv9VMrlWrVbf+54PvOPtb3v88We/9MWv84ypVhULxSpFUR5X8+VLV9rLtR1jg02R5mPHjpWLmVU582g5nUvF29qaa0J5dMfelpaWqxfOu+2eiM9XD1R+8rP73U0eu9+/srXE0sBkNY3sGE3F8laLU4eabijhcLOGiGaX5YwIRgZ2rC1NpBNpnjcXsSZUKzabrVSqqNhYWFzs6hkQdW51c2v/TXdv27l3I1mgTWasGUKtwput9WrZZ3d97BNf5ixkMNT97BOP3XT4/R/62Bd4m9sdiOTKmQuXZz/7qc/YzPYPvOfdf/63X12YdI0MbEvH46lE7GMfePtXnvq3Ww7tDEeaf/3Iw6KuG5D+xCc+sfvgnf/wvV8Bm39+OeYPhr/wtf+RTOcAQzq8zqePPWUymbvb29bXVyFL7BobefihB99x71tdZnvAb4/FrmazmztH+92+tuml/PlTx2+7866wNzR+aWF4sHdw5Kb5+fXWrm2FUl3BVC6dc/hcB47s/cH3//WTn/x4tlSzO1siIe8H3t80OXXOF/D2DQ7EUtlnn36ws7Pf5w/rBiPUpLogGzqQRaVSSQ8ORNram3QgIsyYrZa19a1KJeOyU0Mjg7pYlcX64szc2HCHvmfv0GD/3//D/3zn+z/W1RMhaX196sLjT778zg+/Z2FpYniktSbkrVayvb3DF7D/7Gc/y+ZjXd3t7R1ddVE9f36yUlEirc2QQN6gTxBrklD1+5ry5dqO0V1Ti2vPPv1MX1enATWC1D0+RyYuX74w+ezT1MTkBVmWb731SLFSsdvQ1lb07OlVj9dJE1omHTNx/Mryxo/+7V9W15YunBtfnDs3OrpTVZDdYV1ZWfZ4XfFEtfEU1NPXe+LES55A88DQ0OzSse7ekd6B7aq6CQA5MXmhs7Np+9jAzMxpmwWuTU0seLs+8ek/X01opbo0vngVIGPb9oM2i0kzTPWaQlCkIqmapvE8TzA0IEhRUqChkxBSFKmqdYvJJAkCwDjg925uJSxWB2g4jADC+NVSoiTR4A5eY7BfH1r+O8YYvR493KjdSCB8XQj59fTYjYDX6xX+XXS7USd4g+M3FAV/uzLF76jJ6zm//3DRXo+D37APfqNSEdfeg6SqKiQQRVG1Wq1R0VDTtL6+vnq9Ho/Hi8UiRZAcx9lstlAo1HiVniRJxWLRMAyTyURRVOO9e40ypKIoEiSEEGIDNkpYGYahaca18loIgQbAQgjBVzW8ph5CiMIQQ0wAgAA04G9W71VEaUCoE8ioVYskhURBrBST2we7M7HVgNeRS8UIrFE0ymXSLGcyWyyVSkXHVh1gjHUAISQgwgDoCjZkt5lvCzX93i23bzt65x13H7o4Pedw2crlspuz9nR1PfL4Y5JY/uCHPrKxEQ21hn/xq1+5/O7tu3etrKVImgZYZUkThkCUJIpkfoPyr7tRG2FSjX9lWW6sz2u2+9r0DQw1DSuKsr6+rgtUuVyuVCr5fF4U6w3qS5Zlp9NJGkYDM1EUBbF+bdORgSAwDAwAgo1CFjrGBGyUaTB0jHUDcCRdrxduveXQQAsVXX12dnaqlPfk83lkd6D2Tv/G5tLi4oLL6YvGM0tLWy5XYGhoR9/AiNlq7+3v9weacrnC9PQcQZA2C491VZZlhJChYafdEwq2SnWjVpWTiVypWJckJRZNaLJE0aQo1mmadLmcJhM3MjLMcnRHR5umKeVq6fL4pZOnTiiKMjAwUK2Vi6U8xjpJkqlUqhF0trCwIEnS+tpmPJ6wWm1m3iKKMsua7HYnTbEMwxaLJcPAjbcgy7LUYFl1rFVqZR1r0fjW/OJcNpt2uuwWC2+3W00MXatVMpm0osgsy9Tqlbfce3dXV4dhaGazyWLh2ztaC8Xc4uLC0tKi1Wo5cGC/oki8mQk2+Z97/pm5uRkIAc/zTqezs7OzXhMBRoODw9WKOLptZ6iphaa4cKilEQJltVpVVd61a4fdYa1UyiSJrDaz2WKKJ6KGocdiW9HY5rFjzxEEHB4c6uroNjR8dXLa7w10tneVCsVquTI1MXXuzLlMKjN++crC3HzAF0wl0iNDw0NDA+l00u120zQNoGFgDQPdH/DSNJ3P52+++daRkZFarTYzM1OtVo8cud3vDSuSEQyGHA5HT0+H3cHLSk2UqoVS0W53tbd1nz9/uben//Nf/AJF0x6Pq6OjnSRJVVVHRobcPiuAcqmc7+hoqQuVuYUpi50Spcr5i+fsTnsw7Pz05z984NDo+uacx2t96tmn0rloKrvxgx//U7jFZbUxPM9tbiRuv+3e+972rlq1Mj97Mbo12d5s1cVca7OnXi9OXLlMEBRFcsND27u7Bmdml6KxpM8fUjAqCmJRlixuN6ToC+MXN+KrroCto6+FM1PJTGxhce7KpYvpdDaZKM1ObUDdEt/IlHIZr8sqS/XFhTlBFrx+j81mi0ajtVpNx3Bs125BNUiWU1TVZDKRJFmtlVmTNVtUnJ4ODVtHt9/S23voM3/8f990xxF7wFvVlbOTkx09O32+nmQsZwjS1z79R88++O8+u94apoXqyvTkixaTnoqt1EuZliaf3+XIpFOlUikaT6ka9fuf/VpH9wjHO2OpvKhqBE2srS8qSuXmQ7vnJscjgYCN43LJpMPMTV25WBdq5VJlbPv+QDD8k/t/+Ozzvw54mLCPf/yXP1mbXejvGs3n8Mx8yh3svTIzrxIA00CnVMwAhdDe/4e/X1GEmow97g65Zgu7h+++5X0j3dsr6cLth/YfuenAysrc7ML0VmwLMwiwyOLgu7s7+vtGNjdjFA9JTjU5CN7BcmZXpGWAM9ktFsvAYOfc3OWt9UWahL969GFM0/7W4M8f/mlRyL146pm7P/SOH/34W4iuTE2/dOz5B/KZxaO3jl0+9/S/f+ev1xbOX5047ffbXU67IMgYMibeubYRz5fqTZH2fL5eKmkPPfx8vUKcOjmxMhsb7B1FiNzc3AwGg+fPXww1hf/4s18GGtXZ2u9x+iaujLeEfT/6wbf+5Z+/MTjoGxrwBX30QH8nxzAUZB984ImHfv3s3t1Hbr3l7vPnLi8uLrpcrkKhcPLkyVC4heHML714amZmtqu7PRj01mvie973gbn55a2tLR0LTWHr9p09ul4Ra0WX1WKmme/88J9vO3xzNplP5CsmV8gf7i0UQbVI1YrQELGNZk0QWBiK5/hqpaYjXYY1gShhXpA1gaYIjqF0RQaGDrGmSKKZ5zDGHMcLgsgwjKppBoCIpG9k1N+QH3rNV78jbXOj9uZyrv/zDb99Q2m/u/z/s+2a5DdBV/A6vIh/O2fwDTV//RBvMvS1hXp9BwPga2FDkEAERTaC3O12eyPvb2FhYX52bnZ6Rle11kjL6Ohoe3u7zWYzDKNWq9VqtUbktcVi0XVdluWGyZdluQHuWZZtBA1fq9QKG9UEXg1sh/CVkCAAQOOgUVy+EfpGQESiV/INr9FajQ8BIALQ0BUTR6pqHWAFQQXoCo0Az6B8OiZUiqoizs1Oh4KBQCCAIAkBYTHxFEXpACtYVbBqYBWrMpaEgY62z3z8Y6ZI6HNf/tzU3ALNUoaudrVH/A77ueMviKXi295yV7VWdPtdjz/5SE2qfPTjb0sXMrKuERSpaIasaroBKJIxIDDgb2qvXb/yDQ9pI4GgUebqlfkiBCECjZdSQ/hq0i622WwURR09enTPnj0Nb5XP52sEYwEATCZTA5hqmlar1RrCMcbAwPA6v6QGCBUQBlQ1qChYVLGiQQwRrei6z+dzOE253PrwQGtTwOZ32zraW0mXnWFZtq+3I5tKF4t5WZbr9brLbSvXaqurS1abmaZNQDdUzQg3twh1CWOMqFdqctTrtUKhYDabI6GmcqVYrZbr9Zrf5963f8/m2qrL5aIYdmU1yrAmp8fN8qZisUjRJEEiURQ5jikUSrVaxe32ulwuVVVVVTWZ+e7u7pmZqy6XBwCQSq1ZLXZZlkVRYmnGZDKl02mLxcIwlMfjCocsm+vrhmG0t7ZNXp1UFMXqsEp1UVVVmmWCQX+lUhlfuLJnzx6vy1sulTmOk6sVXdfn5ubMFpPf73/88UcHBvpaWyPJVNzldphMXK1WZVlGEITh4eGFhQVZlm1WazQaffe733XhwkVVwV5PsFqt8TyzMD8bCoVq1bLDZve5PSzLPfTQQy3NrdjQKtUSQ0FVUxxWW6lWkAVRqNVEsX7mzBlZVg8fPtze3j45Od3Z2Wm320ulysjISEdHl9/v/8dvffuuu+7ieX59fR0hgmVZj8eTyWTq9ZrFZt21a1ehnM1kUnaHJZ3KESTNcTxJMARNEIhyOPmFxXnN0FPZrMXqtNm9yUyZ44mbb777yvj4P337u0ODXW6PLZVMCnVpsH+wu2sgkynnS/me3t6z588JUn3nzp2ZTCy2OssQWC6LyVTU7rT3Dw2OX55f31jNppJOd8DqdApS3eHwaABePHN827Z+Qde6Iq65idOLy2smM28oRZ7DtWru+ImX2ls63/POd6maNHXlksvCJdKbnRGvIeTdFkquZm8+sCOVypRK+XQivmW3bduxq1wuL89NF4VaR1cbbzdnK3kTay5USyQiJsevnBcvdrX3WZ0t518+fsdb3+/ds93BsTxnyhSyPgdHszxJkqVSwWQym8y8ruuiWEcY2O3+wupGa9dIPJtXSeBwNyED1OtVmiYpSCiKRDDmimToOrm+mdt38Pa+/rGZlbiK1WqtPLZjJzE6Vi4USSxfOHUu1ET2tHiOP38/QRqD3S6fE/z9//PfTh57/sr4hXBbd18gbPO1/OT+B9/LNd9y250OdzgVjVIMb0DaxLGpxCLCUrPfh2URaOra0gLHA44FH/i9d589c2p29kKllKNI3NczZrNarl69Ojd1yemMYFEwO/zrmwnEcKzJ6fB6c5OTwRZQqFQtNnu+mmdZUocQQsRxVkWnLpw409URGexvTic3VjZWCZraf9O+yxNzgqQ43Nz41SsAU1K9Vi3muzvC24YjPq+zWs3PT10aHT1o4Vld12XZNj830dPsk+tytJbeiG7k8/maKPBWS7876PW655fWyxXpjjsOyfXigZ39teJmJbeWTSxdOve8xcqODfcEPdz9//4vAb91pZQ5c+HCrbfeSnH0j370A/uFix3tbb5gk8UihUMdvQOuk6fPMSwJDbJWKnAsv7S4gmV85x1HBUmXJaNUrOlQnp4Zv/OOg1/4wvZ0Lj89NYt1kNtKMZylNdgpyTCdLJ94+bEvffHz+w/UEvGtppA3nUnv27fPzFsXFhYOHDj01nveevrUi6fPPNozsL8t1JxNLX/tS5/9n3/9NyQsba5NXJ264ncFDh/c190dAgbhdnmvzC5C32ChpkzPrVUq6mOPHbv5ptsJEhlAV7GMVaTqpNcfSBfSGKkut7VUKLLQrMiiiQGGpvAmslTIbmS3du3eHU9nOTMXTVQ4a0ASBUODiMC6bgBAQoBesRjoVfYI/OaB+3emZN7w9H9A4bxJ/2scz2tS5N6k/S6d/1NU3O/SrkGr/6Jk2OA5cMMAXzsJYePVNA3DjACA173t8ZWy4L8lBCMAjd/2aqIG2gHAaATeXXt5s6YpsVhCVdVCoeDxeLxuz9DQSLVaNQyjQVaBV0s6GVhDkGy4/K7P+2tAIk1XdF0lCAIRBAQIY6xpGsaYIigIsa6rABgEQUD0Cq9GkoSuGsDAAGOEDALor6weADr+rZdZQggBJggIsaEibISDrmKxaDHR1qB3Y3k+6DYrNFOtFSGJOlrbKALxPLsVXW/vCycKGoA0QSJoGFhXGVK3WSkz4/rK5z9VXJ6//8TZuZU1mmEK1QLDATuHZqcuFzKxwf5uTRKCAf+Jc5fyhdIf/uFHz19cp0nKbLWIikzSFEEQiqoihBpuzcYqYICvuZivr9/WSL1UVbXhS22wcxBdq4lrAACArpk5E0mL6XR6+/btyyt8LpN1uNwUzRgQkBQCWC2XiybeLIkaZBREUBBArKsAQgwRRAhihAEgGvQkQhgbGCIDGCQkCRJBWamUi0J90UpGay6KZuDFixe3j+5A2URs4uJZr9Pa2hrIZrZMLFzfWI7HtzDGfn+AoU3JRCZfrJhttlKlTNAMQdEEYljWRJIkz1FivVQsJEQxX6/lAZByuXilmpuZuVqqVk6dOTs+MWWz2SRZuHDuzNTUBMcxmiJTBIJA11Ql4PM2qvgHgkHOZJYVrVAsF0rFrp7eVCZdrlasViuABmdirFaLINZVTWlvabWYeIvJkklm6pX6ju27zGbr0sry7t17GIbJZrP1as1mse7asdPQ9YDf7/X4O9q7wqFIvlAiaMYwAElSxWIxHo9rmpJMxpdXFnkzGw4HBaGq62pfX4/b7Xa73fF4wmTix8Z2NsL/52fndm7fzjJoc3OhrS2YTGzs27Pd47JVCnmgqamtLSxLfqcjl4qRSL/9yGGOpQxVOXvmVD6TtdtsTrtjY23dZrH6vZ5KqVwpl91OV093d093t6woC4vL4xNTc/OLu3fvuXDhoiCIkUjLnj375uYWNEOv1KqIJBVNL1UqVofVbOdFsWo2m8wmXhE1CpmgwQh1XVFhV99Avlw6df5srl7vGtweS8oAeTIFadvovv37bi5kKi89/UI1W2prakKGRjO4KeINhFw6lN0+N8Mwsa0kz/IYYYfX6XZ5bXZ3viCuribNZqtcE5xWWyVX8HubNA1wHGOoQpA3Tb304ubUBVYp1pLzdxwcCFqB2ww50kjHY+97z7vtDtvpM8cjIdfO7T3x9Wm5EPeZSAdDVzPJ2OpsfG2OgpLLykmiACBaXNvacfBgz/YR3usoVIvpeIzTiMTiVnuwxcpZrAwf9ocoxLz47HNOwpg++Uy/l/eyOsPoFaEgIZmwMJKhYYIUNG1obMTrsSOgF/LleLomGLzL3+XyBnxBHwaqItcJmkIIEdDASFGhKgKZ4ti6KNRVCZooZOFVgtINoMqSUEgHHAShJ1fnjk+ce96EhJmJk0BOMqCwMHlya22SIhRDrTWHm7zeUF0jP/rZPzFM1qdeeH4ztsnSHIOYal40RE0spHtbgj6brZDKtTU3v3T82UJtyyDKl66c2LGjJxwhm0KmcDBSLmAIrB/64Mdbg6FnH31k4tJUV1ePxWndTMXMTlOxWrLaeIIgKMpSlzBvMqu6pkEGsnZB0w0K7jy0M56LXbp6BTFMR89APFGamolznIskzeHmyJ79ew4f2T+2f9uBI7sRpalSNba8sHH1ytE9fVJ2mkBbnKWylVqBLHvlwmIhIyua/p3v/evR224e6e332D26hCcmpjmaa2tuavF7Lp58kTFkM6EOdjS98OyvP/qh9xw/8fytNx94+pc/DjsIq0kJtTja+9pm1lbvevv73vaeP3AHW1ze8Oz8miAbZy9MbKxvHTi0e3Z6wkyzm4vrZ148/d53v9cb8ClYzZaqA9t29A2PWeyOM+fO3Hn3TWNj7Y8/+lNFEN7/7t9XVGS1+3K5msMZ+OSnvnDPW97x5FPPdHR1nL24eHniLMkAr9+TSCQIgshkUuVKcfzS1bGhHXffcgulS+++6/af/OvfyYXl7/3Dn144+YQulTwuJ0Xzq2v5B379woXJuR0HDjod3npN3Hfw4Nvedd/o/u2klZEpvQ4kEekGgxBLZ/NFE2PmabNeN1jAmGnWQpPAEKvVtNdts5uhz66VM+NiYSLslUgjTxh1sV7GWGcIgLCBAIKAAZCCiMaQwJAAiATwFVPaoBkgxBBiREJENsz8G3z+C4zRK0P8dntN1Pz1cl5P/Lwh09NojffovT4Y/7dk3iCvEF/3acTZvBJt81vRWagRUoMxbHxe6XNdxuIrWY0NAPW6l9s0gBHCBsIGARphNAQBCIh1iFWIFQJqJAQkJBGkICAhhBBhDBFBUhgizdAhgWRVohjSADpAWMdaozY6hBAhEkECG0AQJQNDl8tjsVgURUmlEnNzM0vLCwxDWSz8zp07u7u7Gc6UzmQrVUFRtUaQD0EQjaQ/goCIAKomv+oLQ4bxypuFGjcDQUAEDE1TMNAbtbIoAkKsIUOBRp1nDAIL9UqaozGEMjI0BAyGphE2kC7ztEGjOlYLHKEiXSaxAQ2VJgxsSBDrQIMkoGnCUMScWMkwWEGKyOiaw8yIpZIuqGbOIdc1qAGHldOkanPAT2rQbLIaMuYIqpxM8IYAqpmOID87cXJt/Mw//+qBaDJTFbSaKNktXGvA8vKxX+dzq36/GQKprSU0PTXz7JPPfeRDH41HczxroWlW0xSEAIS4gVBf2UFgNN5XixDQsUYypGqogAAYYdVQCZpACBAEZBhK0xSAsGFoGBsEARv1PxE2GIYkKWS28AiBZDqVzedCoRBG0GyxFesiRISmCiYTMlloAwICsZKIGwXhCRJDUtMIXcUGNkgCk0jTGAIADRg6QZM2pDO6oPMEtHGG1aqlsksnzxw7c/FMrS4iQGiyhtoiLYN9vefOnMpn0s2RoD/gGRsbFUXR6XA7nW6H3UMQlMPuaWvrCDW3lMtlQweKqmuaJkkShAARBoI6SYGmoHvb8MDv/d57d+zY7nK5ICS6e/osFlujxGpfX19rJCIIgolne/u6b735ls7OdoomZVlcXJyXZbmrq4vjTLIsK7KWTqftdrsoiuVyWRRFgiA6OttGR0cGBvoIAsbjUVUTeTNXKhc2t9ZdLkd3d9fa2uqOHTtUVfV4Xa2trflcxufztbe3t7W1KYoyMzMDAMhkMplMxjAMs9mCIFkqlfx+PwB4ZmZmfn5elOqzc9OiKJ4/f3ZjY+Opp57yuH2qoicSSZfLHYvFHnn0obHt20RR2NxcN3TZ43bu2b2rraUVGxqCMJNO9/f1cSz93vfct762JEpVUajF43GhVr969WqDH3a5XHfffXcqlRAEYXJy/MyZM1ar9fbbb+d53mq18jwPISAIIhwO79u37+zZ0wgBv99fLpdpluU4bmNr68UXjudzBYRoSVI0zdA0IIrK6LadnR29gqQ6nf7Wtt7de28lCIvDGQo0tUJEO93uUqXUHIkEg8G3v/3t973jbeFQcG1t6fKlsxDI4WZ/vpBSVDEQ9Gez2cmJKafLl8mVe3qHIuGey5cXqlXc0tLX3jU0NLjd54tMTi5IMh6/Or28tHLlwhVdEjlC5ymZISSkloNeq1jJWxiqlEsXsslI2MOyxj//y1//+v7vy/WU3QwMpZzaWjHzFNCFmelxXRHnpuddTn++IM0uRKfmNot1PZrK6RCVy+VwINjf0WWoBkOxLc2tne2dDMP4XM756Yszl17+/rf/50vPPNTX0+7wOvzhgCfgzxcrFMkiSBGAyGXyWDMY2pbLSyzrvzC+MDu3mkymVUUnCApoSFEMjAFNs5BGOtAFsW6ymBRdVrFRkzWdoCBBKaq8Y+dwOrP20MPftTpAqZxpCvjdTpuJo2mamJmdfPncy2vx9Tvvvevxp56OpXKf/uxX6xrZM7Djrre8NZFMFyq1tY11s4lKxdf6u0PIqHW2NM1Mjjts9t27dm5uLW/FFpPJ1RdeeKil1WE2g/a2DhPv2b33totX5h967KlPfOqzA4MjkqyHIs2Rtsipc2ebW+wAy5JYYUkC6bBeEXmTE0FOU4GqaaIskCZqdM8oZ7OoiLS5ghZXIJkuV+vK1lZcV4FSl0u5PEtTXp9vbGybUK/88DvfTqzNxTemzZxy6cILm5vzXR0RlqYDwfC9b3nnkSN3HDpwGALw4K9+mctkm8NNHoeZAPLZl5+r5OM379+Rjq7aWGgzkT2dLZJY+853vlur1EJeT2x92ee2EUgjaNjT1/3DH/3b0vJGV9dgsVL//Je/ni3WMrnc/Px8IZsaHuxpbgodueW2Qql+dXpRULQTp84PjGz/xa8edvtDf/FXf/2lL30ZY/jwI79eX11t8rn/9m++GWkLBcP+k6dOUDQ9PjGdTGR8/iaCIP/sv//RtrHRcKj5woULtZoQCoVsdj4a3eJoDmEwMzlx5uUX52aujF849civfyyLWY4zhga7t6JrrIl3upvvvPfdU3MLp8+dzeaSNt6UTWWXFldsVkddrKmGihiComkMkVCX7Ha7LNYRAJokWximVoiaGTnkM7WGHIZSpoHk5IHHBjmqnM/MuZ1koRQPt4RFUTQwpCgKIQQRvkZOYNigT36DXV45QBCA3+IY/jfb9djoNdmIrzl/vTI36nmj9p/q/J9t8D9KBvxdLgfgGol1PfbCFA0h0g2sadi4PjgaQUIUxYbHBgDDZDLV63VsQE3TCILgTAxFE7quN4LNGYbzuNwA44WFhenp6VhsyzCM1rZId3e3y2nnzZwii+VyWZUVkiRpkkKAwBhg/JqK+fg1gLWBsQAAGOsIYIQwQxGGqiBgAMMgEURAJwiNJjGBVQLpCOiGrmiSoKkiTWAKqRYTQSEV6CIJNQvHYF2lSYqEiCKQqokAK6pSh0BHQAO6EvZ7KayyhG5hCUMVbGYmmdhyuuwURS8srCi6LqlKqVSqVSXDAJosmU1UIR3vbgs5zXTIY3numUf/9Vt/84W/+DMda+lszmq1UYgYG+47f+o4YShtrU0GVvv7emOx2MMPPfSFz32xUqqLgvTKRkADQANe9wiB4GuD5xpr8vq3XzceHkDj5TXolQL0EGIADQQMQRBUVXa73Q6Hg6bp8Ykps9lssds1A5YqVUUSOYbkeQ4hWK3Wm4JhXdcNrAOoIwJDsnE7QMIAFtZULVcAQDTN1uuimbf4fa58NptOxhPRGMfbrXbf00+/rBvswODYubOXyGg82RQKmMzW9a0o0DVNVw4cOFAsFhFGDMFYTZyJYavVuiqqNrPN7/fnswWWo1mWNfG0KkmiVLXZbH6/XxDqlVptZWUVQkiQdK1eB5AwmczxeNxuc9rt9paWFrPVWq/XHXZXrVZLpVJWq705HInHk7VabXV1ORJpxhhns2mGsZIEYWg4uhVvbW2VRUkWpf+Xtf8Ol+Soz8XxquocJudwco579uzZHLUraSWBEiKIJHAAbLCNA47XGPteh3ttYxuwMSaDjDFIQjmuNud8zu7JOUzOqXs61++PWS2yJDD+Pd965plntru6unq6zvY7n8/7eV+apufmZhiKAFAvV3LRaBRCbJgSRTtD4UA8sZHNJb0+t8fjkuu1xcX5u+66y7KMmlSBCC8sztXr9Xe/+92vvnJEkiSfz+dyuQSRMU1dlmWbzdbZ2ZlMxVVVvXrtcjgcLpergsA/9/wzPM+HwtFkOuULBHwBfzqTszsdqUxaVfRUOs8Lto14zDQwQVAsS3Mcpxn6wNDgRny9WC4QFGIpRtW12dnZdDbl93tFka/J1baO9o315Gd+8zeuXLk2NTOZTCYrlYrfF6zVKk6X/QMfeH8ikfjGN77+iU98Ynx8fHLyZktLs6Jrcl0iCKKpqWVjI8/xrqamnuWlFafDb7M5M5lMOpsLhSIsY1+az3b2DI9u6plbWDh0557zF89JdSoc9aQTa6xIpnLJulqs16X2jpZEJnf50tlcviTYPCwJjh97TVOkYDBst9sW5tanbqz39w/9+q/90bPPv2h3yB63H9GMSZZMiDt7RjhXoZzPigyjVjey5SQiVcuEuVLW42nCyKzKEk2hvp7WpeVFyyhEIvZ0fCocEn1+VzqRrBslkUXZQtHA+s2pBQvwaxuVuw4/kCuUFpfn2to2a6ohKVVR4Cme6I10TU1NJRJph92l6XmCZHr72lVDNw2wuHjDNCW32+122UiSNC2qo7WrXC5uHt6cXs9KRbUl6C2UYC6rigH7yPBuh7tJ4HwsyWGLaBiF6oaKMaxrmmjjLWwwFKGrwOZwSpoBEKEYms/r+bXf+pScX+hrdxXrektX1469+67eOLscX00mloMB70qupNeVoW3cL/36p7/6nWeiQwfcrtDaasrhjfRv2pJJJAmBAnR1bePKzevT27eMRLxdmwa7L124xIpcb3vfrr2DtWL68e/965HXMjTpNBV//+DQxOxEW/eWrdvvUiXjA7+0J57K5kvlgcHh2fm1q9dnnG4GWBXS4ikT2O3BUqGGScgwpEUDhiGK1RzHUJ6mqKLI8YJEMqJhWdGmluGhLUdfPbJtdCdv82iGkoklmsIebKH3PPzA+x/Y//wLz/YFRlua2luau1Ox3L5t23/yg//s3j1azRe72npz+dVytRyJ+iMhd76St8wSTdarlXWIZZGzMslVhuMEp/3E6Qu/8buf0+pa78CmtuZIsVrKZ7I0Z+aI+Mp61u5w9/UNVCKRr3/zO06Xu1aputyOuZkbAFgnzp5gGMbu8gcj0ctXrgBoiWKsroETx88uLsxm0isvPP8yAdHWrZuXV+bWVqcnxs/u2bN3/x1bf/Af3x0e2jo6uu3s2dNP/OiF1vbAex55MODzLy1uVCoVRa189GOPWKYaCLpVTfH63ILdd/HShV279/7xn/3RP3zpbzEybW5hNNpD8Gwpll6dW77v4fs9wfaFZSm5Oh9tbmWBYdUBQ1CAtCxDRwjVZdUheuVqjaEhATXNVAIe++T5M4wRVKpCIZvriLYW0xtbN3c5vGyxzBFIR7QZbYkkM6VAU3MunWZoGiEModF4nGLQwFcYAwAhRuCWax+ExK0HLgS3/dR+QQDx34Kb2x0aH9D/kFD/88/+/8U4P8VnjSHfNL3bp3hTRvVtc3jLPN4Sh7Max8I3DQchBlDRVQJRJM1CwFgmYVgmxgaAFkuRlmk0ooaGaZCARiTFC4JaV1RFUYDCsqzDKUBAVStyPp9dW191Ox0cx0VCHbzAmqYJgFWpVChEECSBMNBNnYQkBCYCGCKArQZxG0AIoYUhQAgjACyAEASEBeEbUAMDgBEgELBIABACOjYQRAQ2KJKwTCxXSjSDLEiRkGBIiiJIgyAZBkJcg9iCAJCkoakaw/EkwRmGBSBpAQuRBNYxorCBVUTWEYK6psolTCGcScVJt5/jYGxjWZJLiILjN8bHdu0S7FxNqfojHXMLaVipqrgOCJqh6sX8enPIa+jWN/71a5/53B+0dfYk0lmadFqa4nM5/+0rXwv6yMG+4dnZxUN3v2sjVfrKV776wcc+RVFUJlu0iaJlmQBbCFgWvHWn4K3789Oahtsr/M3p7EaZ3e1d8FY6ETS+UtAAacBCCG1sbLgR7bWZbe3RbDbrsIsUIrBh6qrBkIypm73dPcvLKQSxZeoQW40XwABaJgQQAQwArtdVl9OnqJamKYLA5PLJTDZBAtDf3sECT0doJOYO7hzewoDytfMnGcFBxuOJBjts0/BmU1cnJq7nsoWent5SqbRly6hl4dnZmXA4Uq1W0umUqirFUt5mCls2j9akSjK+3u5uLxQKmqb09vY0ZKIIghJEsbOze2MjXiyUAUYrKysMw1SrVX8omM/nY7HY8vIyzTINgE8gslDMra/FOjq6TNO020Vd1xGE3d3dSl3TNK0u1zweD8am02UPeL00AwNBT3d31/nzZ8PhKMPCjY2VcNivKEpbW0s6nQ6FQk1NTWtra5lMxjCMYrFos9kaQmQDAwOLiyscJywuzjEspWmyz+9pbW0NBHwsy27atOnUqVPFYlHTlHQ6y/PC4cOHKZIplUrnz13o7ul0uz1utycaaX711SMkQV+9es3r8c/NzXk8Pobhksn09m07n376qWKxmM1m29vbm5qaarXqzp07Q2Fff3//qVMnXnjhBVG0h0KRUqkYDgcFwWYYRjQaDQbCly5dCgYCx08cnZ2Z37p1azab3bRp0+vHjqqqanM6VFVlGIrlRZ/LDxEqFSvlisxzGiewFI36Bnu8nuDpM5flOqSQoNVNnqWzmdWdO4fOX7gWjy0mE+sOGzvY352IrWnYLFcrAscipJmmw+V0KrIs1ZXt23YHg8EzZ09Jsi7w7oXFWP/gFgvyE9PLTnfJ43AyNp+bp/PF2n3vevD4sddXpWJ7b//N8SNuFwUQWVdMVdU627rmFpZbmjxSLS0KZmIjJoqI51GllF9W8na73et3Ugzv9rvsVT2fMxguMDh8sLV9xOashZp6SUpOpuI8I68uXK3Wy4tLU9WKUqlJBMkipKqa4fF4I1Fvva6oWi2VXjNMiWaIRCIGEeYZVuBsuqxurKxSiKrWNMMS86XS5/7375qMK1Gs6hDpmmlZJkkwJEFZCCqm7nY56lIRWUq9VhUYEWKNJkBd1ziGvnz58uiWsWyM8zmtjaW5Q3cOzi1vTE2t+IMuRHlzZbOluVOpSa+fvux2R2wO9/paPBAeSBR0pa5Xa5rD40aYdwnEgw/c/b2vX71542LctvbYR39jfqlgETCeyYxfuRpfX9g8PHLp4hkCilZ3hOLdmgkp0V1SrUpFKtaXQ9Foppzd2NgYHdu2OD8dDYkMMjqb3bMzK0pFtYkO1dBZkqypck3HHC+Uq2WLIDGiSY42dN3ClippUiXe29m1vDjX19dXKuY8dl6RytjS7zq0/+r1K4CE5y5d3rrtHkU2kqurtKEnUgur6+wrT/9HJCTqZml48wAizL//h786dNfh5cVxmwCCHsFt8wC1tDA/29PTffzU6WBzZygYff75F8+eOWc7fCeA5vsefujE6StTE9cGhncODI9+8YtfPHTnXV29fRzNrC4sLCzMPPzgwZdefsHm8JRlKextfvDhD9nd0ZdffOHC5RvBQMjl4l0OryorHq9dqpUtSyMJ3NkdDYVHJ29OF/LV3bsORkLBY0dP9/b2N0mRUiV1/NgZuSY9/NB7v/TlfwqFXYlkLJ9LpXNZQ8mUq7IkmQcP3a/opX/7+pP5Ur6ppZmgBcHuO3nqSqFsHLzzLh0o5y8cizZ1NoVFubJkswUAoFXT0tQaghYgSIYgzXqdoyhF02xO0dRr5XL6oXfdkVyb8XpZvy1oY2nLa8+lN15+5dx7P/To9EqK4biV1QSgvcVi0eFw1BUJYBPjhpcHgABYEEAIMG7gqzeq0jAAEGAACADBL8BtejO4+VlA5+egKPg2KtWt6NrbYlHvkCP8n5/3vwVib0GKb7k6/IYAwVvO+JYQ4DuTwyC8PZ2fPsIhBBjRFIsxNk3TMjULkxBiRCACAcvQaBIpqkRQiKEZWVJIiivkyx6XWxRFDPRKpbS8nK5VZQgpiqRHRzZxPIMtaFp6Q5mdJhBDUg0zWQgxQxIEgSzL0LFJWAQBKAtCAt7ieb1pbg2xUGhZoAEoG84sJITAsixLZxv7AYSWhaCJLc3GNWRLLRIRCACIsaVrNGEgoCuKzNK0bugICKqqAsRZuokBbgiJQwSwCSxL1k3DJYiF5JrLLUQDnkqlWJcrAgv7B3umZ2929HaaAJZlw+EJrcQzNR1GfQE3AWRZruWr0aY2lka/9MGPbDl0wOHxJjNZRNoomnC7HefOnKCgtXvbrosXznR0D2Rzlb/6m7/78Ed/tbm1LZbMsqyIsQUhxsACDStEjCyAIbAwRO+4rm7HWRFCiqI0KP9vW8O3AFZjq80msixrmnoqlWqU6BmqZhiGqVsMxSKAqtXqxsZquaz39u2zLJOkCIKEJrQsCwBsQAsgSEAEAIKGqQGCJBFhYI1iUXNzk91mw3VLValkSp2azu0dayHMdHN7Xy61hmiaVVXN6XTNz8+vrG2IDufGRlypa709/a+9duTKpavJeHJuZt7QjL2795WLJa/boyrywuJca2tLX1+fzWaLNjW5vZ54POFwOG12Z02SECL9/iDAKBQKezxejuNpmhkfH19bW7PZHIIg7NmzpyFIn8/nXS5Xd2fX0GB/vS6pah1BqGsaTbGWCVwuF0VRHo/H7XZ6fW6WZQrFzHvf91BHRyvHE2NbN2WyG+l0giAhBiZEeH19NRZbJwjocNgymZTP52ttbc1msy6X695776Uptl6vUxQ1NTUlCCLPie3tna0t7cePHz9//nw0GnU63Lt27RJFMZ1O2+1iKBScnZ29cOFSNptvbW3fOrY9HIrqmnn8+PGenr729g673UkQREtLG0XRBEE0SjwcDsfAQH8D0um6nsvlRkdHbTbbtWvXMMYMw3Ac5/V6L1y4YJpmLpcRRZ7jmPWNVY5nrl27FovFNo0M2ezC5OSkrus7dmwLBv2aphAErNSqDMOQNFGryzVJU3WrUiurZk3Hcqmcj8WSB+84LPD248ePHj/5ws2piwuLkwRp2ezM2vqCBUzNNMo1qSqrkGJU3cyks7l0zlS0SqlaKVV27dxXLFXX1uOSrHgDfgsCp9N5beJGW0c3YAXE2TNS/frcQq5Se/XYsRdffXVo84jN47l8Y8Yf6Pc4+wzNjk1equk3b4wbejkUYI8d/dGpk08aerpWSRYyqXQirymUoVEIkWsbq6l0muPF1Vjc6QkpOjp9dnx6Ph5LSPPzGR3bbkwtsrzDImCxWnZ53D6fr1Qq1VV5eubGRmwZkapuVptavA4Xnc3FWY4kESIhKQi2gf6hSrnQ3hr1BrxlqZapVGxeH6bptXRaMVXNVAHSEWGZlqZhA5OAYshauRT2eThCC/t5lpK+9A+fF9h6wEPztLlr+9jnPvuJVLzW37Pr3vsenZ5eTKZz6VSNpQMHD31ANTz9g4fsnt4H3vOY3RVEkJ6dnmFJClkmBBbL0TVVkpR6JpnSFPP+dz2YTMRYwXjuhW/VtbXeHk807HHYHB0tg+1Nm/u6d28a2tXX30kwhg4MXyiSKpY6Nw0VpNL1m9fCYb8gcgCgUCgil6uxlbnjL//YIch+r+mwqy4nkc5ssAzPMoKqIdHusxAja6aJKZpzcoyX470O0dPa2tzf13Tz5kmXw+IYmaPqAg8saGUKRUnHLS1dqXiKI9D+XaOV4voDD+0h6KrXS+7cNcQJYGl5+sTxlxkaU6Rx3+EDUjUnV/M0ApnERrmQ5xg2Go2OjIxcvnyZYZhSuTo5PdPa2nr1ypUbVy9/8L3vUatlvS4PDQ1PTk7bbI6p6Wmf393b13Hj+iWPW7jr3kP9mwZWN1Lf/8FPOrs2/fn/+ftItK2Qr1omsWP73mi468yJazevzy8trMpSJZvd2DzSd+jQzuHh7mtXL/zkqR953HYCos0jIx6Xp62lPZ3JSbJ2192Hi+XKkddfz+WL9z/wcKSpBWOTs5EzC1eOnX5pYvLy4XvuO3jw3WfPTF6/vt7bd6C1efvXvvbjv/rrv8/klxGc7++VRjehYvYcBVMcqoRcjIODNtrgCJ1BlsgymlxXa/JAbztPk5lE2uf09ve0iwLkeTA83G23sTu3bttYTStVSpN4Cjhddi9NQlnOEVABUAdQB9AA0ADAQtiCECP0RkE4BrcSIwBB+HNkod6EEn6x0NE7oyX4U+rSm5XZf44++89qv8gc/kft7SP/nBThm3Hhf7m6tw2IIcAQ4YY2VONiAWpcmomBbhoYgoazMsCmoamGLiGocwyJLbPhAufz+ZubW/P54uLi8s2JG4lYXBC4nt6u3v6etvZWgoT1WlWRa7VyRasrFCI0zbAs4LDZKYI0NB1bBoIYAgtBA0GTQICEiIDoDWWHWxJWjRQhMK1bM22Us2EMMcS6ocpVliEJCCgSGppCAsCQWBQYliEMTUMAYBMTBAGBRQDIkhQJTalWpEgEsWmapmFqEOmIMAxDpSkCYkARtKEpuiQzEPS0tPrsAjBllgIuhyjJlWwxI7gET8inI1I1yevTq/mqRXCuXKmKsVXMpcI+l8fG/u5v/ea7P/jBv//iP9rdPsFuw0CPBF3nT76qVLMfet/DUxPjPm8oHGn7p698/YEH3ju8eSwRT/I8T5AQYxNiE2ELYtAQT0cYIAAgfockeWMlN0AVSZKWZbEs2yiibKQI37IMMIImwJIkNxz86vV6Pp+32+1dXV0UQTMUy5B0uVB2O9yvvvyy2+Vw2EXL0CDEAFjw1jQABAA2UCA262qNpCBFI8PQGJ7lRS6bTSuKVijUpqbWPO7W+cXsj598dfvug82dvejAgQOhUERVVYfDWSqVTAMjhBKJ1LVr1+qyallWX99Ac3Ozw+Hief7w4XtEkacoMpVKnjp14uLF8/l8VtM0WZar1erMzFwmk1lfj128eDkeS/K8kM1mWZZvbW33+/0+n19V1UaVYqNQruEbML8wpygyQRBen9vrc5fLZQAAQcJ6vY4xttvthUJhenpalmW7XRwaGlhbW7U7+OvjV5ZX5gkSA2jV63KhkA8E/MFQgOWYhYWFpaUlh8MhiuLc3JwgCIuLi3Nzc+vr64VCMRJu4jkRY4gQIcvKzMwcywj5fOmZZ55bXV3NZQtDg5sOHz7c29vv9/vvvPNOXddrNZlhuIsXL09M3CyXqwzDKYoyNzeXyxYURcvn8wzDpFLpbdu2GYbR8DqIx+OyLN+8eTMcjqyurno8PpIku7q6BEFoeEUxDFMoFCiK6uzsbFSKnjhxIhKJfOELX0in07IsNzU1La+unDhxqiLVGjqzqqrGE4lCqcIwnImhzxfgRJvd5t5YT1++NG6YUNfMgwcPtHc0OZ28rskcy146fymZiDntDoSQzx/KlySSFSsVVZJNm+iJhFs42ibVVJq2LSxucGLg6KlLJqA6uvtT6dzqWoIkedHue9eDjyqYcYfaPvVbvx+MtCKCu3JlnCBomrPTnLOuoGJRv35tulyQdm7fEY+tStWcrlebIo7tY0NbRocANhmaHx7a6nJELSz0DYx0dHRhiLKFwtj2bW6vBxAom8/pBt40uv2Bhx/dd+De4eFtkmKtx1K8aNcMHSGkaHUArFDIL9qYnt725pYgy0NEmNGm0Pr6KkURxWK+p6enoSPn9Ljtbs/w2Na1THFk11570FWsK4hlEQlJEpEUtJBhYsOEACBULRUvnj5uZxEyS68+9z0WFl78ydfVylo5M1vJrH7/mz8JeyKlnLq0kLrnvgcGh4d27dx54/okS9nlijkzta4pxNNPPdve2jEy3B/wOvKZmMdhoxFQpBpNIVHkDR0Cg+ho79u7d/9rR148e/51pZ5/8aVnRI4P+ZrOnrz4zE9effC+D2XTtW9+89sszwwO9ueLBYfLNz27uG/vPqlWP3/+sq4aHM1oitrX0w9NK59OTF47f/L4sz/8wb9qatnv8wAALRNhTEBEq6rK87xlWVKtbuiYQCwk6GQ6gSm9pdPv8TKWVtblwshQz1M/eebZl17fvusOj8dXLqSvXj5paLlYbPra1dN+n0BS1paxYalWtLBqmarX47w5cePKlWsPvvvBUDCSTGYgwQwODheLRbfTNTM1kYitTU9eD4a8gYCnVCosLSx0d3aEfF6Py76xsrh182a/z7OxsTY41L9v/x5RYJaWFkLhwPMvPHNt4prH4+vo7D169PTCwtLq6npbW5umGrlcadPwtve/76PdXYPRSMvw8LDI82fPnfYHvA8+eP/0zDzLEdVqyWZnDbOeySanpm56fe4zZ0/pujm6eWxpKX3vPff39gxevz6uaGqpnK+rBYEHv/7pTyiqbLe5RLuPQGJbyyBDue+564GPffQjH/rAAyJbz8SvO/lad7uIlQ0HX4NGwsaVgBXnmRLHVOPrN0MBO8ug9dU1qabUama1rn/zO9+/fmOC5blcIb0RWw6FvXMz0/lMXuDsTtFRzsaRVQ37bXaBJIFJAIwgQAAQCCACIIQazse3MdatZwP+KSz4xWHNL9Lz7dv/225v7/mW9nZ6+/9XZKxf5GLBf5ejvN0HAeKdvhakaQaEkKZYkiSxaZmGhrFJkYClLEutiixl4zmOYSEkxsfHT548WSqVnE7npk2bN2/eEvAFdV2vVEqSVDYMTdd1hADDUA1R0Ibn3W3nFgihrmuaXqcIyJAkAU0IDAQMBDAEBoDWLVSBTQAtiDECAEFMQPBGVQKwDFNT6iQCEJskwJahExAzNKJIiC1TqlUQIIBp0SRFEzTWLGhYDCLkWoWlSIwxTdPYMCCyCGhASyOBSQMg0pRAEjyJXIKAsF4upC1NYhmiWMitrq7miwV/IFCs1jCkNZOmGbfgDOkWVaxKMzMzHEP5XM4//J3foSD42EcfO3P6QiFfAgC0tkRfe/VpbFV2jA2cO30sk8ls2rz5y//y9YN3vXvfwbsXljZsDqesqLBRPtlIB8M37il+o6wV/5ebCN8IT94OWZmm2VBeva2D9ZbV0liHTiePMaYoKhwOl0olqVrz+Xz5fN5ms6mK7vf7i4Vyb0+/y+VSVaVWrzXKFwBAqKE2CknQ4MBRgBM5qV4rlkoETUGAVFV1uVw+nwtAMxZbb2lr7ejs3jw6durMmb7+fnTuwlle5HieP3z4cGdnZ7FY9Hq9sizH43HDMCRJQghVyxW1rsTWN5YWFyxseL1ul8tBUsjhcDRqI70efzAU8QcCLMuTJG0aWFFUjHE2my8UCrVarVwuR6PRSCQSCAQ8Hk8mk2lva4lGQgLH1irVYqmgqnWOoSkChYMBp91WzBcQxBzLWqZpWYDnRZETWYq9ePHi0aNHn376aY7jtmzZ3NHR4bQ7lLpEEMS1a9dqtZrL5QoGg6aJvV7/3NyCw+Ho7Oienl1NprP5fCGRSCwsLFQqFY4VKIohEB3wR7q6+jLpQrFQSSTSly9fy+UKd95598jI5v37DywuLANEEhRTLJcxgmuxjXKtane6EUlXarLD7WpqbSlXa2sbG6qur6ytUyw3NTWztrZ+773v4jjBbncihF555ZXHH3+cIIgzZ85pmpFOp2u1WsOec35+MZFIBQIhgJHL6enu6j1/7mJba4csKQChcrl83333OZ3uUqniD4QikYiiaAvzq5lsSbCJFoAeV+S5p08IXNPmkQN1ydIN1ecV/UGHaZrdnX084wQm3dXa3d/T3xzpUOoYEbZcQTMwFw515QvK7NxGPl/3eJpVg2b4wJUby/kydvqaIMHHkgUDM9lCvVzFFONtbh+WDOrClelNm3e9/30f5QjbkZdOTE0ubt2yVxBs99133wMP3D81NXHk1ecVuVwtF65ePFfOFeSanIhlbII32tSjqsTCUiqXkzfWMnabp6210+/3Hz58V3NL8Nr189V6IZGJ/8mf/vE3vv0d0e4a27ovHO24cGGcpgSW4VmeYRgyk01CZMbiq5VSjiKAqSmhgKero2VkeGB9Y6W9vbVcLGi6UpbkfEX2N7Vfn10hRM/o3rsW4xIlOg2EVNPSddWyNAAwIAAgEYago7NtZKj/+NEXvvblv24OwOFOwS9Ian7mm1/6/He/+pe7N/fs2z52YNehTKI4MzWVzcTTiUVgVC+fO/mXf/ZnY4ObZ8dvTF27/q9f/rvL549RUJZKab1ekEpZXa4YtUomlliYXS+WjKtXp3p6hj7/+c+//9EPjG3bmctWv/ov31Ekw2FzXHju+Ykbs5tGtqfT5X/44pc8bjcDkd/ulXL1MyevP3T//ZFQu1SWGZKSK1Ws4X07DuZShdGR0Y625qaQj+dZCAlZVhCisGEZmioKjKZWGQrzDElRlKrqgKQUbOblougRpmdvbKwv5xMb3//Gt8MtXR39oydOnX/2uZ8k1m/G1i7fuHkyGnX+2Z/8YTqenp2df+rJn/zu7/12bGPNaRNNzahW5FpFl2XiyOsXllayDO82AVOuSMGQl2XQxtpsc9TT2hq0OzjD1Hp6u5we28XL531ep2mozz/3E7lSEjlmsLfzpReeXl5Zam5rJgiis7NdFAXL0lLJjYN37Lt27Up/bw/HsaKNz2Zyzzz93K/+yidZVlBVc3FpleNtO7buee3lY+l09s4794RCPn/QcfL0K+MT5y0sdXSFy6VsNp1aXVnP58q7d+6Kx3J/9Td/GwhGd2zfJVdrqlL1em1Xr1x44kf/OTc787GPfLS1uSWxvpaKxe0C29kSKCTXLp44L+eklem5qM/B09XudiqfP3/ixL+Vy1eczszQJnb7jmClvIiAXCtWC/l6qHUgU7E6h8aGx3bRdtc3v/99i9Sqcpqk1bGt3SIHLK3QFOZslHz+2IuVTJyEACHyjQAVghjBN/QC0E9Rwi2XuJ8PGt4RbfycvW+x+739+Hk7EPlZ7WehqJ+ff3zH9gtf1ltHe/v7Ow74dtR1u+etUk0MIP6pJR9D0SQiAMa6qutK3dJ1miQEjnSJJM9Y1XIum0xM3ZhKpVI8z+3YsbV/oMfhsFXKtWQyXanUAAAURRAkbsSfFN1QDVOqq+WqBAmKE2yKplsAUhRFkiQ2TGBaCAHTUjE2INYhMCE2oGUBy4LYhMAgkUVAQCJAQPP2CwFMIqJRdWiZOsAmxpgmSRJBlmUgNk1dVVWVYRhdNw3D0DSNQrSumpZh2QUHQiS0ELAgSRAkwNDSSGBBQ+MgYi3LTkI7A+VyXq6U6kqZIEEul0mlUptGttidnlJNhoi5Pj6PkdDWPphIlAKhkM3mYGixt2voS//4ZUVWH//296+cv0wRtMNudznE1488LzDWfYf3ZZLLsY2lu+45/PVvfc9C7Oj2vTPza6xgMyzEc6Kq6oZlYgAa5PY3x0pvS1i9PSF+G9M3qg0sy2pYCb25z5vXrWGBhmRBd2dXIZdvHGWz2RqCrpYFGp5FJrZiibjDZb8V6QTIxAgDEkMEEIEhMLAhaxJJE3aXE0G6Xtd13dI0pVhOyUp6dGu73WVJSprhLFHk/vNH/4GuXbt24cJ5t9v9xBM/jkajhqkVi0XT1GmaJilUKBSmpqY4jovFYplMxuVyNYQ3+vp7WJb1et1OpzOZTJqmabfbdd00DKu/b1AUbZlMhmX5bdu2mabZwBOFQmF5eVmSqiRJKqrc2dlJEER3T+cDD7ybZWlB5GfnZgxTv3L1UqGYU9U6QRCRSEjXda/XizF+9dVXJyYm5uYWisVSZ2e3phoAoGAwnM/no5Fmj8eztrYe8gfrskKSdF/fQKVS6+rsYRk+m81/7nO/deeddx4/flyWFV03ZVlZXV2vlGsMw9ntDo/bNza2jefF2ZlFhuZsovNH//nk1SvXn3ziJ4uLywiRyWSqVKqUS1VDt5aXVgmCunlzslqt+ny+UrFcqVQaemXLy8tLS0upVEqSpHPnzjXMENfXY729fQiS6XQ2nc7qutnc3FoqVhAiFheXGYZ58cUXdc2cnJz0+XwkSV6+fHlpaUlVtXQ6/Z73PBJpau7o6KgrSiqVqssqhJDn2URivVItbto0EApF7n/3e0yDyKQLGOip9NrU7MVaNSlVc6LIanWlNdoklWqxtdjW0bGRTWPbtu6ORDow4O3OQDDc3t29yeNvujYxv5EsXbg6qwF+cHS3CTgTcL5wK2vzbN1xR6VmQigcuvv+e+572ITk+PhEvS59+APvX5yddTkdm0eHLKy+8spPNK0UDNjL5WRPTxOCusftqFQqNtHlsPkdjpDX21yumR2dg5FoZ7lSNw149fI1r8dfqZROnT66Hlvo6gx/5LFHdu3eOj09efrEaV23DB0G/FFJVnWsUxQiSOhyOdo7WtvaWuR6zTC0QCDQ09NTrVYCQU9LS4RhSYgMkiSy+TzJCMlcIZEt9o9u9YWbVuMpiuMty6IILAiUXaBZEiOsWaZqmEo2my2UKhzDNEUDwCxtHoyyuLIyc/Fzv/FRqbB86cJz9929NbGxuH3r2NPPPnv8xBGKVluaxXol8a//9Jd9naE/+O1P7t890tsRqZXThlq5efPyxvpi0O9x220MAaOB0I7tuwOBpkS69NwLRxaXkuPj80888fLHPv7poeEd//74E+l0+n/90z/4/X6H3flnf/HnABt/8ae/K9KqXsnt3jwye+Pm6nJ2sK+zpTnqtKOuNv/K/KSuKSwnplPFUq7a2z1oqViulO0CZ+iywBMEMmqVPM9SAJsQYkNXBJGt1IpuvxcQpGYBnhe9LrffFRgaGG1rH25pH/T6IwihZHJlZKQ7lV7XdfXx7/17Jpm98867RbujmC2H/NFSsZaI51pbeh/72Cf7BraEm3tp3nPg4H3eQHR+eWVuYb65JSRVstiQvG4hkVh97rmnE6l4qVw2gZnJpSS57HEI7zp88Mlv/+uVi2cy6Y1iMWsBrGoGiYhKMTsy1G+Z0jNP/7Cns+mOAzsO333wsQ9/+KWXX9yxc9vly5c7u7pS6Vw6VSzkq1//xvfCodZdO/fOzMy4PS5Nk6u13OLyTYoxLFzftXtMEFmKJmw2O8eJiURKkqShoaF4PEkQJEsx6WSqnM/fc9dBqZYvF9eBmZOrqxEf0RSk15cvG3Jm68jg3MR0rVA58drr+dTq8SNPY6O4Y6yvmFqLBJyT42euXXtNFGsAZ202RlXMRKpokTYD2CzK9aMnX33X/R/cvusQxTp6+zaV89WN1RVDr7e3BDtaA2G/rbMt0mD9IIyA9QaPFmOMf5oOfOPZYAGEb9e7/YLI4xeBJrd7vvm59XaY8nbY9HPQFf6vcgy/CIr6b4HX27e/HTP9/At/h8ctRgSABIC3FasAsAC0MMa6rmt1zdRMgWb9Pp/H5QaGmsvEVhdvxJYnZyauOEShv7dvaGAwHArompzPp3VNYWmaZ3gCEJaBCYQ5joUQkwwNAGBZlmVZAABFMRjDxi9qAFBDwImmG0KSVWBpEGvY0hDQIDCQpUOgI2BCaCFgAGhgoAPLNE3DMjXDVAkSNYwIDd1q3BSaJgkSqnK9Uik1dEobQsoNfxS7XSQANkw9Eg4CCyOMNEllEEUAjLDJEhahy4xVB/UCaZSBVpSkrKJWRZHTDXWgf1NnZ382VyVJoVJVHS5/a1t3raLHY9louKlSqaiqOrp56w//48nl+dVvf+PbF89fCPt9PpeTAuj0ieMcAfftHluYvVkqF++5795Xjhxb3ch8/BO/nkgXbA5PVVIhIjXTsABmGO6W1x8iMCQwIt4QJPup7sZbbmVDNqzxDTT0RRthrQaAbuxqFDTcXskMz1EURRBEMpl02R35bE6SJF4QipWybul1TXV5PaVKxeGyq7pKkiSCpAUIy0K6CSwTYgtCCDEEFEURBFTVuq7rAmOziw6eZmwiFY3YBUGpVlfGr58YG+sVBGLP7u2oraUlm0ldv37NH/C++NLzwaDfMDREAENXOYbxeFzZbNqyjEDAt7S0UKlURI6nCCIZi0MLJ9KZfKmsW+aV69duTs8QNFWqVBZXlkmGZgXe7nQODg83Nzf7/f6mpqZ9+/ZtH9uKTVNRlEKhEI/HIcSvv/7a5NQNh13UVeXR979vZHjo3nvvCYWCiiovLMwtLCzIck1X1FK+1NPd53K5Q6FIwB/yuAOi6FhZjq2ubLicvlKpDDHcvm1nPJa8Y9+hfL54/doEy/CRSJNp4kwmGwyGrl27DhBpAaBbJsUyJEMb2JpfXJ6amXv1yLFcoUwxgmGhZDov1XWK5Vo7Ols7Ot/3gQ8GgyGn07l58+ZwOAwAiMeLsViMIAin07m2tjY7O9vW1jY0NNTb2wsgbjhHJhKpfXsPYAtSJFMqVgjEHD58X093/5bRrf19g81NrT09vT5fwOv1Tozf3LF9Vz5fzOUKAwND6+sboVC4oclfyJfOnb2gqjqCRE9P7+7de4Y2bQqHg5VaxuvjaNqoVvPZQpJioWHKDhe9ZVvP7MKlVHrOMPPpzPzk5Dmvl7908fT4tas0QS4tLJ84dmphfmX79t3xWPrcuWseb7S9a1jWic1b93T2jXYOjO4+eN/ozjs0i0nmqi0dg6mcNDmzePLV46lM8czpi1NTM62tzYVisi7lgn7x4x95GJi1J3/8bZZRl9fGE+lZlxdxnLq6MtnS7Kdpcmxsh8sZXFhKraxkVjdy80sxi2Qjza2DAyMjm7aEQ01zMzNrK4sMjYcHWicnL9Zr6cc+8tCj73tAU6Wl+YVMMuN2+TXNYFna7hYDYV9bZ5vdLobD0b7eAZKkw+HIxsbG+vq6qirBkN/CmmbWU5m41+/NFfKLK6ut7e00TZdKJadLhFjHuhzwiMn1+aWZ6yJlOljAAIXAuqoZ5ary6Id+1TSATeRWFqcmrpxLrMw999QP333Prv17O59+7l/Czeyd9+zZc2C/6HT1DUT+8I9/6cGHttmd0j9/6Y+mbhyJrV3LZRaCQfuFS2d4kZPqMk3TPMvZOUGtS7qlluXa2I49NO87fubGlfG1VFpdWc03RXv7+jaVy6XnnvuJ1+MiSFCuZO44ODo2El6fP70xd85OyR979KGnf/T49evXn3ziu5nkjR1bIpEwW6qkuvsHpmc3duy4L+ju0qp60O1BRo2hZN3IISQzLDRMDQCs6TJFWxjIBGnVqjLL+XSFFXjnl7/81aXFWF/vmKqwiXjtwrnrBKLHNo8Bi9g0uPXmjflqRQOY5ARHOlWAgLU06sD+e7dvPdDfvyWVqc2vpAzINXUNEoLT4Q198tO/Icvy1csXW5qCq0vTG2vzycTaex55aMvYWKaYlzQ52hId3bLpr//P50u5+Ec+/kGRwRwNW5rCkqKuxxPZdK63vR3o1ZaIa2N1IrY+9eSPv//Csz/++7/7G0Or3bxx9Sv//I/xxIbb43O7g11dm7o7h9rbe4+8dpxjbZlMJptLhSNen985Mze1ZetgJhvvH+gc6OslIFpdXrHZbAxLrq+v1qqK39Nk6eTBPXe1hJvOnz6m19OWEd+9O9TTDUlioZQ+L5IZv8NIx2a1eoUjhJAryhNcNV+hLYYFrvw6SCzKV8+NR/3Ozk5+775On4fye+2qaSWyNYen8+rVDZ9/kBfaJ28Url5O1SoCxi6POxQOhyfGx9fXVreM9hcLacuysEVASCFII0Q21J4whg2HtVtl6hA3KCA/R6jhLYgEv6k28B3jSW9HPG8HWz8nIoXf8Hf7aRzojfaGI9s7IKS3xMzePP5bRLN+ehTCjRcG5u0XgBYibu0C0IIIIwI0vqu3jPz2hzF8Q9ncMAxT1wmIGoLmCANsGqauY8MkAORozmGz2wTR0o1kLD5+7Uo6lZi5ed3OWXcd2Nbb0eJ1OikIcplUtZa3sEpRmCIwAMDQLWxBkiQRAVRNalCnSILWdFM3LYphIYEggTTDgCShm4aJLYplLAgIgshlMxRhKbWSy8aZmoSwxvOkaagQGASyDF3Blk6RkCJhg8ZOkYikiUKpaAFIMTRJUfiNejqWZW02BwREMBis1SqWZZimBQBQVClXSptWvSaVCISwZbEUI5erpqy4BYGFlkgYDK5yqIKldY+o+bys4KAQATTVWF1LtLT1qhq0LBYCWpYMCGipWicRApZBIcvvc509f/nHX//m3/zN/11ZWq5Vyw5RKKbTR1950SNwu7ZumboxoSry4MDQ4kr8ycef+MM/+6tCRTUhqWgWw/KGYSJEEIjUdd3EViNihAFpYYghAQjUIFq94ZX+UwGRRrCqwXBviIsahtFwfYb41sK7JXaPIIAQEoimga7rDX8/URRN09zY2BAErq5IBAVNbDndrlwhL9VlRdca8ABDBBFtYYJADEWzjaVEIQ5YJLAggQFH0bG19eW5BYZApew6Q9Xb22wAZ+w2NbY+pUi5Qj5FcjxTr9dVVeV4iudZw9BokpRliWe5Wq1G07Tb7ZqZmQkGg06nc319Neh3q5IsSVKxmHd5PeVyGSGEEMzlcqViBSEkSXW73eFyucbHxxuhL0WRm5oi165dFW08xqai6sGg3+l0lstlu93u93stCyS0RKVaWphf2rZtG8NQPp/v7NlzmqZomu5xulZXly3LGBzqpyhy08gQhKZl4WQysXXr1skbk8vLq6IoupyeQCDEsuzGepym6evXJ6anZ7du3RaJRI4fP57P5+84uH91ZT0eTwuCUKlUNE3ZsmWLYRjVatk0cDqdk+QqQuj114+1t7czdJHnxVQqk81maZouFIqGoTudzh07hufm5sPhCMa4VCpFotFgIHT16tVKtdze3k4QUFVVURQdDkc8Hpdlxe12p9PpU6dOOZ1Ov9+7sbFRr9e7uno7OzuDgbDd5sxkcqlUanBwcH5+ftPQJpqmaZq9efMmLwhTU1Pr8ZjX72MYBiBYLpQluerzu0rlDAD+UrESCbeLNrap2V8q58cnLkebgtFoQBA4r9cr1bTV1UWaIYJ+t2XoNpEnoLW8ON/a2v7Rjz724x//2LTQkeOnNm/efur85a6hsfd/+KOL66mVleVMviaVyoZGrsRSzW0jvaPbVpdWKZHtG2zz+oRVN1erJk+deM5pF7xOwjQgT5OiyBuGRhI4kynpuqaqenNLZzjStbSU9HijpgV9Ph8r2qR67fK1Kx9+9MFkctUwDI/bff3ypXBzO8vR+WLm5Rd/NDKyk2fo8asXHnr3HTu2bb92+fWRTW2ynBdtlMvtgBCaml6vywvzZ2tVmWPtsY2EpmnLy8terzscbl5dW1bUOoF4kiFMXZmfnfrM7z+GDYlBQlkqhPy28cunHTScvznBQNzZP1gpVTjOJnhcyG174YVjpsnZHfb//OE3du86KMnWw488kkwnLGCmsonnX3n24J0PUqxTN8m5pWXHeehzR3p6WzdWVm7cvKjpVRNQABEmRtdvzLT2ONPZgmFCl41DCBI0zGWy0bCL4byyGv/UZ/7I7WrRNez1+zCo3XX3Hd/65r/+yR/93u/94R/09UVXVs499sE7E6vr4ZGeF176/vDWu/bt3zQ7d53n0fPP/ns2NlTMFPfuuUsQerZs2w8gncusCyKdiy94Qz4d4rIkmxaDCNrEiCAIAEyCxOVyyem012TJ1ABHcXql+PnPf57QiHK1fuPmVHOo6d5D26Tiuo0yZiauR4LB4f4xu0NcrhU9Hgc23FOTixzjIaAYigiagRZXlts7ulq77D6PY25xXq6VNL3mcHlCAXc8tm4T7J/81C//3d/+o2Fi1mZTdE202yysE1A/dfL1Myde7+3pqpX05og3U8gPDQ3dvHlz5ubkYF/v5QsnNUNtb/ExVD0ccGia9NCD926srbe1tUEIn33+uWq1nM3zJMOqmplIZF577ZVAIGCz2WS5xvFiNh/btm0TxnqlWszny9hMrKysNDUHzpw5ZRm6okrrq0lLN5qaQ+sra163x8ZxPAMX5q5evnyKJez799x148ZlTUvt3XYPjfsZxre2LJmaOjK6uXQqDQ0dKNb+nXdpVbh76x6BNU8dfYnhL3ZE72VIAZGwtak9n65JNSvkETc21nwOSDFsOp1xeGiLpFcWZkNRL0mxK6tJ3SRZWwgAyjIBBg11hgb7CmAMEAYAQguABsa6BR0AfkcTZHi7Lv0Xjui8uQ9+xyK7/26c2we+eYTbW8DbEo4/fw5vQWO3P4F3uq43n+vNhximeRvqNWaFTauRMGoQnzHGDakkkiRZmi4XCxzNQBICjEmS4mkWIGyaermUr1SqhUyNQKTL4W5va+nqCl42cwEXd/H0qxbhYwkjWyzb7a6qpAGsk8jAFsAmJCABEcTIwgAgkoAWxBhbuKELjwGAlgUBsEiSNAwDIfDGrCDDMC1NzcjSnTY6m1o3LDMUCsmK4nSwddW0TI2mCIoiarWa3S6Wc2UIocNBF4t5RCGX022YulLXfF63qWn5fMJpIzc24qpieP1hREDDQCa2bHbb5OUzXZ0hiFSEgMslVsu6rhokMh02GusVDik0qVOWVpdzLFkr5Yu8M0AyAk0xUMEUI66tZQBgRcE1fnPcNAVTs5m61hQNrqwtOH0MT6Ov/K8//r2//CveJp69dKazrVlTpPNnTvR1te/asWNtYy0aCs8trFio+A9f/Oof/e2/lGWsGLeXyxvxRQAgQhAgiDAEBAAANnwKGpAe/BcJ3Ab1qnGjG3r3twF0I6b1BnZvaIbdapZlVSqGoiiGAefm5jo6OiLBQKVYqJTKAOG6JlvQVapUBLvN5rDrplar1WgmUDGgaVgQkAiRloENQ2ERZRnY0k1BJDVNQwbuagkCbDDIIkV6Y2XChuxzUxc8NnJjY87ntG+sriBNU7xedyQY0NV6czRsF4V8Pud0OhVFoRkyk01Va2W7w1aulNKZVDgc5nmeIIhDhw6Jor1cqjY1NZEkyXECgISqa42IJQCYYeiRzcOpdMLrdWcymUuXLnq8rlKpJAhCyO+zCVw46O9oa9m5c3upVPD5PCMjw8ePHy2VC9/+5te/+s/fFHn23rvv3jQ04HU7W9uad+3eoRtqPB5PJJKZdG56en51JQYwsbiwAiFhqIbX46cohiTpxx//QU9Pn9Pp5gXxxs3JUrl85uzZUqlot9ui0cjBQwcefvj+jo42l8vhdruHhoZomrbZHARBVKtVhuYE3tbR0VmrSZlM7ubNyddfP8qwPMtxJEXVVaVcrQxtGn7fB96/tLzsDwbGtm31+nyXrlxKZ9PpTGZyaiqWiAs2mwXA9NxsXVM5UVB0TbfM9Vjs8tWrkCRa2ttUQ48nk4vLy9NzsxjBS5cupFKJYDDIMMz4+PiNGzeyuVwoHA6Hww1sjjGemZk5cuQIRVGDm4b9Hm9PRx9h8bWKWa3IJEI0bViWnNhIYINcXU7PzqwVMuV0Ip1KxCkEDUOWaoW1lVmHjQ767ATQKqVsc3PT9RvXFVWfW1kZHB1tamt95chrq+urNMsMD23hedeeA3fqGIaaWn7v935f5IXP/fb9lqWsr82Uy/FkajYeuzE5eYplpFRqZWlx3Wlv0lW6LsGW9qGm1v6r1xfGJxYmJhbqGqQZsVSpRVuaHG6+q6+Z4fHpc8f8Qa/b5UwmEtFIZGRwkCVwS9h79eJxuZL84b9/Y++erR977APxjWUANYqEvMCuri1vrK6lE8mVlTW/L+h1+yKhSC5baG/vHB4ebmlpcvlc6XxSViVEWKahlLJJr53v72x288TNq2cnL5+ypHwxsbw2N15Kr3U1B7711S9+7R//GqklJ0uYWHZ5XKNb9z/83l+5dHV+cGR3U+cgLfrDraM7dr/31WNTPUN7B0d2HTlxQaqTdndHW/f2f/63J85dnbYItiRLd957b3v3AM07F9eyO/fe964HPliVca4oOd1ezTQQjSyoiy4bxdjGdtzxocc+4/a3ZEo5SS+nixvHTjwPCeV3f+fXHXb2r//P//r37331vnt2mkZqbeXCD3/w1yePfefxf/9rVY/fffcemkEf+dCjF86dWV1eeu21V5575Zm1+MrEzRtt7VG5tCoVFiqFVVXJO102TuBNQENSqEi6aHNJkmQTOENRGARIw7KUulIv22xcupgtVcq7to62hnypxHK1VioVq//xg6fXFpIf//DHXzv6QrWeDkcdQ8M92XTl0B0PbBrafvPGrCjY9t+xr3egSzfqcwszbp+zVC5jREDEJOJ5VQE0ZUsmcjVJwZCsyeq+/Yc2j47OL82cOXty8sb17VtHJq5dXF9bsIlMpZybmpmMRCIOUchn0uVCsr+nmYBysZjo7AjnM7HXXn0RAmN25qZpqZs3DwWD/pGR0aHBkampqevXr46MjFAUU6tKDMNJUr21pdPt9PzmZ/7vpz7xSZ5lrlw+39oSCgadtVquf6CnUi3sP7Czt6+zrTly/PXXc6nU+9/3yL7d+5pCEb/bWSrG//3xL2tSuqcjfPbE69hSC6VEsbwmOox/+sfP57PLXW0Rr9vGQMRAgkWknbEPdg86aRePbJZkcYBamVtYnFrYPDCA9Yxpbmzf1dbb76X4Ku/UOJca7XBjiq/IREUm/aEODIjbLmkIEgAiCFAjEXKLg/IOQAS/4wsA6502/g/wzc9pP7/nmxHP7dDRf4uu3jzC7eDWOw3+DteFsYmx+TZFe9DQbm08RE3TNE2z8X/m7e3gDTioaZokSY3Sb5oknXY7TdPZbHp6enpiYiKVShMEMTAwcPDgnZ1d7cDCdamazyWOvPyToJvlkAaNmp1Fqlyy21ls1EkCAFODpkEjSFIIYYAxbhCiAQAAm40cfeM2YWwiAhiG1mALqapqqJoi10kEpGqJhgYJDY9TxIaiylUSWCwJWZqE2DI1VeSZYj7HMZTf6/S4HBWpQjOMCaBuApqmJUkqV4put1PXzVq1bpqNb8kEUCNJlMmkCJoAEFIU5XTZMqnVSjlRKKx63IACNUPJYSPPEDVTTZlaXmQMhtQZFjs9IkAkRYuqijyeSDKRcbh8BKAYkqJJuH3bSDa1wnNme7Pv0596bOyeQ+0dLSuri6NbRziRevGlZ4IB954d204fPy7yYrFQczgCP3rixT/+i79vaumv1SzTQhYECEGEIAAY3dYAg7Ch+/Um58HbS8sCwGoovEOILWw0wpkkhQxTQwQgKdSQEYAI3wb6jdXYWGYAAKeTJEkynU4vzM2LHI8xbthvu1xOQRA0TaMoShRFhJDNZiMo0jAaRQ8MSZIIAwgMigAcDZFmujgeahJHaDSo2Tmz2WeXi0mBwlPXL/3+Zz/jFNjdO8ZeeOYnpl4Phz2kqel2QVxbX4lGo3v37p2enlpZWZEkiaIJTdMCgUB3dzdDsclksq2trVQqvPj80x//+MdqVRljzHFcsVBmGV5R5UZxHHyDx1culyGEfr8/n8l1dnbohmoYWmtrc6VSEkQml8tOT08Fg8Hhkc0Oh4OmGYfD4fV6W1pamsKRQqF05coVgbfl83mKopPJuCAIgYAPY0uSpOnpable0zStpaVpZGS0ViobqtHU1LKxsTE9PW0YRjwer1aroUi4qTkqybW6Inu93vX11RdffP6RR95nmKpu1ENhn2VZk5M3vF6vYRirq6v79++PRCJzc3OSJEUiEVmWbTZ7MpnMZDI9PV0UTVIUYbe7FxYW+vr6aIbyet0ej0uWld/67G984+vfCoUDuq4nEjGGou12O4SYYRiapjVNq9elaDRqWvrs7Ew4HHa5XPPzs8eOne/vbztw4MD27dsRQmfPnnY4XDzHpdMZwzLdbrcN2WiO7h8cUhQ50hQtl0smxgCATCYzODhsGTXLJJx24aWXn7E5WJtNiCfX5XoVIeRyuarlYqFQaG1tTSQSPGeH2ELIyMQTycT1melJkhQIRnA6vQaucYLN7nJXqtLF6xMOp/+ee+7bNTIY8UdnFqfvf8/7vv7N7+7bdcfU1NwT/+EneOXatasiC9dWV7b09WEdV8vlgb6Bvq7hp554cm4h/q77Dre3Nj373NMH7niwUKwtLcc8XpLh0djYWKGUdbn5jdi8YVVZznX69EnDMPx+/7WrV0Tepsh1hJj+nubpyQvvvm8/x9Lf+fZXl5ZnIkHh4qXzm0b6m5taa5VKJpPJZvJbxzhBEOpQoRmh4eQoCBxv52OxdZ7nK8WyWlNNE5qqkiuuPfWf/9E9tHdk02aHyzs/fyOfTonQDPkDH3jkvTQv6pKkSSVgURfPT+/ZvN3t9n/ow5/61ne/RAuBHfvG/vjzX3r/o4/FUzCWWti1y4cR097R/fJLU5/65V+9dGFiej7Pj0V6h/f+yzd+ODwwfOju9z738vlgsH3vPQeT+eOGhVVdI0kSQCCpimXgfKVMMLzAcols0YJQ4EkHEDu6I2sb08hUf+lj7331yGuvPf2EriQ5smZnSYeT//gvfeDafMqwqrqh9nQPcIzz9z7359VseWFpbWZxWXQKF65M7No17PeLXZ2eE+evbN61P1Wu1XWa4Tyahh02p1StCRxtKBIJMcczhm6JHEfoXKGYFx18c3NYqxYZWC/X888++8OO5s47Dh2QquX1teW9e7e+/OqTPZ2e8Us3H3rXL5fL+srKRqFQSKZiGtZMy9Xb22rowcH+7iOvPBuNBF1On8gLuUzmzkP77XYOIf7KlUmXN6CZxunTp/t7e9x2R2xlo1Iqt7c3G6aaLyTf+74HfvTU85kkMHS1f3Q4k49du34REdYDD9y/OL/c0hq1i46rVy9zPAuRtX3HDp/fc+LUOdPUW1paKuVcIhFrPFEAABSNpqZmbDZi377uCxcuAGD19fVs3zH2/kcf/Od//qcTJ0589StfW1nciK0uOpzB93/gobm5hWwqm0gUGE44d/7i2NiIxyFmsxu10oaBLYa1bd91oFq5fu7cK+GweP7CqxaQ7rjjQVEgB4c6zl06ffrY+LY9I9DJF9MJtxg1SU2rZPffcU8ysej1QRvLfvUr/5dmiL0HDtM2cXIxZkAXSQoUZYtGXcVSHUPWBLrV+NV+S0izkTW8hQYapBP8Rl0VhOAXRk3//7SfFcF6x3TbL37427v9LPj1X0ZoxO/eqfPPONF/yQw2whgIQAhhwyb59vYGJ4kmSZqkIE3lC9nJmclaVXG4nOFw2OGw0QwJTKgqOBaLKXVJ4AmaoxkCtrRE7AwmCJolVcswESahSTIUAYAFiYZ2lQYwgbEFMAIWBBAQAEIALYQbHssIWBAijHUCYpaj1LoJEaAZ1jJNra54HGI2uaEZutslVqslu020TN3ULQuQloUJgrLb7aVSgWU40zA2NtYwMOwO0TSBqugcQxmGQSALW6bL6SvmCwBYdpGvylKxWPH4mxBClgV4XjBNiQCQolE2E/f7Q1ItWZeK4ZCLAAY2FQjrPp9AWFa5WhVtbDqTVBQSkV6b6K3XtZ7+gUuXLwgCJ9oEhnIU8hseF81y9P/58z8UaPTeh+5Hlul2202gHj1xxBf0HbrzwLWrVz0eb7VST6aLL7128mOf+M22rv65pQSgGJKCAFkIQIwxCbAFAcDYwgQGGIMGkeqW3NqtnxsNUbg3bjaEsBGbbCQBTdNkGAa+SbOtQcH6qVhpQ7uBIFQVEARRLpebfT6O4yAAFEWRFKFqdZ5nG0oIGBg0S8iybACpXicR50QQKooGoMVSFrQ0U6u7eFGp52iy3tXV/O/f+77IC8MDg3baquTjXS3B0U/9ConNF5578WMf/ZjHya2t5EmlXo/H4+FwuFqufPfb32lra2tvbatWq/W6ijEe27KtVqvlskmWZTXdME3c2tp+9MhRj88bjTRXpFqlUkIkASBhWRZN05VKxW63q2rdMLRqtUySyOv1qFodAJDLZQIBn2lxGONAIKAoysbGWr1ed7vdslwHAMi1yvUrV8tlqVaVI5FINpPfuXOnx+NZWlpaXFxkGMY0TZfLmS9kXS4Xy7IzM3OTk9PvPnwvy/Bf/OIXe3t7m1vanA63pNT9fn9Nljo72x0OWyQSoCnKtFSGpY4ee/XjH/84RGY+V1QUBSILQHNhce6Dj3744sWLr7zySlNTkyRJcr2GEKpUKn6/38J4amqK41lB4BiGaWlpcrkcHo+rXC5rmnH27FlR5O+86+C3vvWN1tZWkkQ2u2Bhw7R0mmaXlpbC4XBHR9upU6d8fo/dbjt69Gg4HB4eHtq6la1Wq5qu1KQKy7JDwwMAo0ql8p73vmd9fb1UKlVqEkkRc3MzLpfT7/ctLs4FI+FNw72VQmZ2emrHjl3LK2vXxk8zNGHpaiFXiUYcpqkylGNhbqa/d2D71m1zC+O8CC1D0U1YXF8aHtjkc2U7uwbqOq5KRiJb2zI6linJ6VR+aPOWoeHRoydOXDl7Vk6VZmbmwh3R7bv3t0QGn/rh0/ceuv/Iiy//6V/97sL8ZCI+U6/j1dWUz+3at+/OQqE0txgfGtnZ3NIztm0sEYvHEsbcXHHv/gPRFqWpOfL4D74XinpMs9zTF1XqsfhG0ukZmp6elqrKru17RgZHn3rqKZqjASIc7kA2k15bpTpaW9LpNVGkI5HA1q0Di3MzJEQ20cWxgqGai/NzTqfb43UvLS5XKyW7w1Uul9P5dE2WRFEMR1sXp1cJxEBM2lgW6mZmPWYTo5l0kSaYuw/d9/KzzwCDGugfkTU9ly3bXd7VpfGnv/3NI+7A3/3NX62sJK+euHF9JhNt7t+0857x6cx7P/T73/3m1/7ly9/pGuhqamm9++67FxbLH/7Ynz37wlOxNPzIhx+pa67YyvLCcuV97/uVS+OLdl/y9MljH3jslxYW5kY3D+XzebvDV6tVTGAZFi5k8i63W7eUUq3itbO794wdfembQKmOXzv2J7//W+995F3f+vbXbF5vTdLriLbV0L477ol2bplbkXiOAYT7yuWb8zfnfvMzvxaK3JCrtZaOUKoQ+/Y3/9Xjdth9TYYObYKf0AiScihSEZFYqRZcnAOAOjTUge7NJ06cYPw+m+jgGCqZSZ45d2T/6NAT3/+mNwhbIuLy8tWHH3g/kCEA1bnpqy4b9/qrr+3ZeRBRdEUuVVUJAKOUT7Q0e5/7yQ9279ym6/pT//Ht9taWjbVYPJ746Ic+2ny4dXl5mRH4T37mj55/7hWnM1gsZeZnZu0cnVhfgwZQlLqs1u84uPe1oy/JSu2eO/e9fuTU6OhIsVwgCGh3iOvrK5VKxe1267q5Y9vOifEb0XDo8OG7zl04T1KMYSix+AbLmPv271pZWRHttnCkOZvNb9s6Ojc/0dzs3zI28m//8nVVMVVVf+apnzC0tnXLSDIVe+XVZ++7677f/t1PPP/c04Zherx2h8uLgTsYaVVVurOzeW7mgsfrX55diDa3anX2xsScTWBkKbdv391btvRMTs9trF0xDXFt9XJrZ1ckyK0vTDnsUWgQPk/wyvULrVEG6mmPDTlZZmzLHU0+euLG9fnZuWgrlUlkh7YM54uWYRi1OiApzsAWhDoECAMTNHgnEIOGZ87/pL0lQ3cbgvyCiOd2+5no7bZaxFtO+l9kO/9LKOs2MLq9Hb4pb/jTjW+7kLfM+RfPM4I32fs0/mmapmlhjPFtSaSGJo5pmoqiqPX6ytKyYWiiyLd1tLtdft0yFUWpa6qsyrqi84yD4ziGoVS1WCoVQuEAU8itL8zag+2W4aFJiqYdkl6HiDZNk0SIQNg0VN1EEBEEpABA2LCAZSIIG64tFrAIiAgCKopimSZPkwS2IIIIIRIigiIpaChSGUNIQcvOMwRJVqS6oposJ3IMhzGslMpetwdYhlJX0qlEe3eXZemKbPG8CLEOsCHahER83evw2jiH3cGSwEonVz2+kK5KuWy2ual1eSnW1OSzTGgaitPB+Dx0uVho7o5SJC7ksrJc8DqEulQ3VYNlhUqlUimrXm+nognAolLJxMjWAZoxgaXrWsUm8BZWvF73P/7T306efv0Lf/+VYia1trDo9vILczdauzs7O9qWVlfsLrfPG55f2jh68sIjj36kpaNncXnFbg/UdQMg0wQGsHRoYQQhAgQAyMQWRETD8xxigN6IYr5lveA3dBkoigINS23LaqRc37RsMIAQIdQIZII3MoyGBUiSZFlWluVcLtfSHA0EAqqmIABlWe7r7gIAXLlyZWTz1khTlPV4+TqSCQgsg4QWTRgMgTGuU0ATSNPvARW5dOPCjc39vs6ONrtgW16cNpXM/t2jTQHXi88/6XEEvvudH3rczGc/+2skAMDj8Zim6fMFGKaSTCYZhnE6HZqmGYbR2EtRdK1WO3/+PEUSjzzyyCsvvTg1NeVyuZrbWlmWJ2mKYZhUKoUQ8vl8siwjAE3T9Hq9lmX5/J5jx16XJKmrq2N6ZtLr9ZgmzTCU02kPBv0zM3OSJDEMWygUOjs7eU7ct+/gEz9+qiHLefnKxW3btkFkBkPeRtR3aWkpGAxWKhWSJEOhkGmaDcmrv/iLv/jhD3+4sbHh9XpJkmQYyrBoUeSdTjtEWKnLBIGj0eDq6urNm9dbW1vsdjEWizEskU4nHQ77V//1n5PJZCgUSiaToo0vFAosy6qqWigU7Ha7otbD4bDX6xYEjiRJRVFcLtfa+urmkVGHwzE9Pe1wONraWjo62ldWlyuVMgAgFAoqisqwFC+w6+vrbe0tfr+vo6Ptjjv2nz17FgArl8sKgjAw0H/+zNlYLHbw4MGdO3cfPXr07NnTkUikVqvUpFp7e3s2nyuW8rIiNTVHeJ49f/78/Nw0Q6MTx4/YnY7envZytbKystLe0erzubPZbDaTdTjEVCqRSsVYHvI8rxtkOZPzeNzx2Fo6nZGqNU70rScKnN3v9fq37R5ZS2ZyuWpdNkIeXzFX9Lud/37tgoyGvSH/QPumhx5+8PzxSy7R+ZGD9/i3tP3F//79C6eP3zh/kWXdPO+/fn3h0rXrv/zLvyzms9/5/g97urt/+3N/9Pj3f8Bdv/bhj36oXC5kc/FiyXvu3NFUqoskzEpZfvHFl3jOztD8t771nf279uzZvXNm9oZqGuVijOO4+PpsfH1ux7YtW0d71ldmVUXv7x+CEGYySYjgzp07Z2dnY7H1np4+uS4pikKzjGZpNUniWAFgJMtKW0cntAhd1+eXEnff84FAy/DEbMIXbm5qa86m460dHfF46syF7957/wNbtu9IZlfefdfWgztafvvTv/H8M98aGNz2y5/9wmI8kykp3ZvGWpqbVufin/29zxUL834fa2EFYLqUNWyO5kjzsGbW11Larjve+8fP/04qduWz/t7pG5MdvSO//onHbszM+sPRfL7scgYqVZmkOIwlkqKcHntFkiysIGDU64ZoFw7fee/MtfNKSfrPx7+1tL7KUXR722ZVA63tPUvriR8+daR/uNbSuY0XHTaH97s/eNrPezAGqXiqUMu09nUzInff/e//7re/I42vKdh5+P4PAMWsFMohry+fWunviJYKq0Efo6vmMz/59/aOXo7jCAQXFmf8AcfY3ftryY2l2ektQ4ce/civHzt9MhHPtEQ6a1J+ZLD/6rUSR3iCoUiwKXD+6vW5+ekPPPqIx+vc2FgJe4STr7+UiMXvf/BBQwe1imS3uWPxrN0Z/uGPn480hbu7u6tV8+qlCcuUPvKBD56/cCro99vcTkWu79i1Xa4XvV7n3NzNxaX5kU1b7zp855/+6Z+2dUV1E991zz2pbFauyhRBb6zHhoaGlhcXXn7hRU4Ujhw50tzeZrMz0aZAtVqWZZmm2GAwiBAKBAK79/zya68995WvfKU53OJy+qamZt1ux/Fjx3bv2z62ZQAA8ORPHs+k0i6bHRLU4cMPnj0/5XDau7qHBIcrEZ/ff2gvNNXkRookBFkBqdnV1nbfRz76aCjol6Tq+tp8a7OTYRyXr0wefe2aze7y+AP7dg/HNhSn23DZdQMYdltVoeRqOX/m5AIEpYXZqZ173u3k/a1hp1rFpVwmEIwQlJUv5liHEwOIsYUxNoEJMQEhgUiETes21wpDYEGEQcNM7WeGbn5xFPJz2v8UkL2FcfWWw98CrW5/fns87OfM/+dHsN68qwGkbmlyAgAAuGWcDABFUQ2KRaVSyWaztVoNAMBx3KbNIyxLY2xWpEqumCNImiRJRBIYI1ZgCEiVKhWOY3hRAEjC2DRVpas1mKqWitlV0hEpSwbJeiwMTN2iKIwIHZMWskiACAtQAKCGcTKCCEKEgQksAyCEIEEgy9I0Q68DbJm6oekWS9MUgTS5FgkEarJMI8RxzEYsRbI8z3Esx1kYKnXDgsDUTZZlEUIQYpKCEEGpYkIL0DRhaBYEwCZwtXJldXkl0uRtbYvQNGhtCS2v5iOhoN9pZym4vrzkHe0vF8oAKLVK2e20xzdiEGgsa9E07fZ41ivLmmoKosPtcte1aiqZZ1gGgLooiuurK7pWm525ec8998xNTzhd9u99/4fLKzeeOvL89MRSxBsa6Og9ef719q5uhiPOXrw01Dfc3BQtlZQnnnl6bOf+bXv2Tc8tc6K9VstRNIuBBbEFLAthQAASQmg1KIgQmBBZAAOEIcYQ4Fsa9ojAb7rdEELDMBrlmZqmNQB0ozCzcfdNw0LopwWGGFsWsBDGGIN6vd4VCftslmma+XyeZxmX3aFpmsDxtXLt4sVzDic3NjY2Mb7sF9spwg6wSRAEzxHA0BWlShOyz8MgKVVIJ8qVFENjgRNeevqb/f0DLE0sL1xLr5OLLic2rMm5hQcfeF9bm/v6+CRJEjRDQ4qi8vk8hFAQhHw+T5Lk3Xcfnp+fT6XSDz/8cLFYjsVifX0DE9evXTh/aXR0zO31pdNJAG6J3jIM0zfgTiaTJIny+eyWLVtIkizk8xDhlZUlmiZVFVnYaFR1CYJQLCo8z3f3dDay5qJoT6dTgUBAVfRKuXb48D3VapWmableO3fujNfrJkkyk8ncf//98fhGKBSwLAMAUKtVeJ6PxdejTTtKpVIul+vo6tyIrQVCIUEIGpapadryymJ/fy9Jwea25tj62n3vOjw+Pg6RNTw8kkzFZmcnK5VaV1fPzp3bGmRzjE2CQASBDEMPhYKSJBVL5ba2NozxyspKc3OUZkibzeZ2uycnZ9rb2yORkMfj6uzsbG9vPXr0qCiKFAlKpdLs7PTAwJDP5y0U8oLI9fb2IATkem19Y3X7jq2VSsW09CtXLo2OjgSDAYytixcvrK6uPvDAA5OT0zcnJ7xer2nqMzNTfQP9+Xx+I7YWioaSqXgqHnOINlVVujq7qlJlZXWJJMmmpiapppKE3Nbaa+PTC4tzBGlBSECLz6Zkzi5yvGhaOsOwLZFIqVIv5bKH9h+qaczFC1efefFUMNz2wEMP5/NFBqPYwtL6+uxnf+eXxxemz18+IhVK77v/jtii/6UnHn/oE7/iDvNnz12AkNy559CVCxc7NooGZgWH44tf/oc9O3fQArO0Nq9ale7BcLhVjKenI9Hgnn0jLqf465/8lGWYHEVKJWt6Ycpu9w/2DOUyxWq1mkoYpi6nMzGaY0f7dxCkKEtqMOQ9cexoyO9iXTxFctVyWVOMulKDGLhcrmIpPzc/FYkEVFUvl4uC3UFRFMYQI1ipVGnCtEyQziRd3sCla6cc68n+0TtWkxunLh1/9NFH991zKBJsOn/hal03Xj5x5OCBLd/857+K+sgPvXeT3Q5ohO1icGzrlvbB9mtTc8uJFZubXEtd99jlldXVaNj7+mvnr1zOPPbx3zx64syjH/0wyXmW4/nYxGKwp8Pjcg4PdLoE3NHbtLa25Hc7r16d27FnH8A0QsA0oWEYiDYphvQHmpCpWFLl8rmTpfi4g2F0qV418wQoWCT9yitnPvjY782vliTdd8+7fylbLOYKRbsDxTLar3zyV6OucDYnHX31laKUQZdOfu4P/ld7z97P//meF159tq2rS5LqFKR5kqym0z6RKeeWZqZOFAuxTK7w4IMf5DghlS4yNDh9+oTIW/8yOfFbv/Trn/yV3zrx6tMfe9Q+1LPp7Jmv33HwLlOtX/jmKalWEt3ur37jXz/yMbhpa5/dQ0zPXu3v7ZJLGaNePrBza7Xa73c65LqFA6TY5a1JajpT1AE9vGVfvSaXStod+3ePXz4ZW13xu135bEaWdN00XeXK6TPHe3uiPb3tp0+e6etuP3/5XCAa0gwzFIkur2ywLE0iSpIVlhcuXLj08Y8+duXqxfnLl/bs2726vux02fbu3X3k9VcTqdTO3XuL2eLS0qJlagBtLpWKbW1tpmrt2LHD0Kzp6alos2d5eXF2fnxwsFevawSJ/+RP/vDb330cEsDpdly9Pu6NNK/Gll5++YcPP7Jz/PIF3WKGNm1ZWUuEQ02DfT3XJy5Yqnn6zNGz5655XLZrV6e6e4f37R5rbe9IZpIUURFYOZ8pdHb6S7UyQSebQo4bV2MlqRj00nt2jmqykVwth/1jqVK1NeKLJW42hcKBAFuQyhbiIEINclGD4/tGOuONbAgk4K36OAL83MzazyKD/7ftp0f9DJzzjlElCCH6xXKF74iHwO20zc89EON3gH1vvt43U74a0Op2uRlCDVV8WCwWq9VqpVJBCHk8ntbWVoqiIISKpkmKBIBBUCTF0JpuGppJ0yQGwDAMSFqCKFIkkqSsCRSMzYDXp1SqLofd2eTRaB7WSIx4XacM1cKWAUiLJgloYd3EJkYAIwoRGBsQWiQEAGIDYABMbJoCR+sIUAQBEcIYqKZGQGTU1YDLQRHC9NxsXZKhpiOIBY4nSFY1DNMCECKX3V4oFCz6lvlxMr7W1TOAbUw2U3C7eRtPY0Ny2m2OgEeRZJFnpVqZIrAsFRkC0BRVrZZdLlfAM/baqy+87733nT17LJetEIAxNEoUeLeTSWeWJyaneJrCiMjmixZNV4oqhcLNkdZSySpJeb/fvR6/0dIanJy6CjGZTGRe/NF3v/Pj/+AY5PM62/2dP3n6xfVY/IFHHjp99lhnd1+0pbVSrf/+H/+vOw8/8N4PPTq3skpyBCJ0htYAMCxIEQATCCEMELAwMBCEJoCWZUKEMcDQgrdKaKF1K+8HiTcWxq0UIQAAIaRpGkEQFEU1lLpvuz7fXhsNehfGwDAtUQQsy+q67HR6KIqqVqsMgbxer6kbQX/gheeee+Thh0gKLy0s2m0OgWf1tGoAmWAYAiFDrytS3iLKhkgYlSW5tLa8MHnX3XdbltbRbFtfuiiKPE1Vh4ZGZm8uaJI+unn7li0Dx449ux5bIjEwVa2uG6qu6xzHuVwelmVjsdiLL74YjUYlSXr22Wc7OjoMQ08k8t09HePXLt24eX1ufr6np8dmE3mek+WaLNfC4fb+3p5CoeDxunLZvNvjDEdDhVw+l8tYpokIkM/nfT6vpmGMTYRQsVicnp4Oh6Lr6+udnZ2ZTGZ8fNzvCz7x5I/aWjuamiMtLU26rtfrUj6f5wU2Eg1JkrR79+719fWWlrbJyUm/3+/1eoXePrlev3Llktvram1tdjrFbKEo1yu6Uff7veVyuVwp2WwCy5KiyFer5aamCIRwbm7G5/MtL60EAgGXy5VOp71eb+MPMpfLVatVkiTtdgeEiKYoWZanJ29iaDU1hzKZwtramt3mZFmqXq97PB5Zltc31gRBICnY0dGyvLQwONjrdLrvvvvu+fnFkydP1ut1SS4PDvYnk8mJiTWXQ6jVak3h0OZfHpqfnZZqFYokHQ5He3vbxMSELxgABDBNU1aUfD6/srLidDptNlspXxoZGWFIKhWPiaKIEMnSXCGfd7mFbLrAC4IsqbKkAgTr9brgFXLZEu93Bv2OfKUEAKhLMmZ0ra5oqtXeNpBMLlfqBMc4okHP4XsOIcvq7ew4ffq0y+WyOcTpmalwSyhfKuVymdU16d+++uVv/fgHziD7hb/5Am8nIqGgL+Q8cNe9L71ypL29tbuvP5GOtbS3dHU1Pf/cj12uZpbhqpXkE0+eaWtrs4uOZCrBkqTX7X7mmecBwA6bM53MVHJnw+GgqWir6+sYqDwvii5bLpdze5hgMLyxnuzsGliYny2WlLamqCJrguhyuJyx2FpHezPL0dFIM4TEzZtTq6uLbq8fkRTP87ppina7ZRiWiV0uB4BWJh1bjefW0rlCzVg4d8EfCUKA6gboGRqanV/u6HbWZQNYxI4dO3kRTE5vKAakBbfdG7oxGbN73KauyJrGU+TEjet37B64evHkmRMvejxDP/j+V0bHtmGtZpquYqnasmuPWskUKimOlScuvTh147jdHom6oNHr16V02BOsG0qhJuuGhlTJYbMde+knLod9dGjz5cuTS9cudLT7HQJoa3FqhkrQtKqbpaqyedu+7/zgR8G27rHtB6am5hiGMQ0zEA5hk4QM1btp01psYXDrqGmQ66mK3ea54573SPUatpCsqhTkEUn4fI7//PfvpeMXeMGMryebw5+uGwyCVDa76nWQ3c3eB/dtrZXlbZu2+DyOxZWEZOQdNmFtZfXShXM0JTz26cdeOfrq/nA4EHbNL052trW8fuRGNrX6wL3vWpqdmZ+ekaT61I0pm8vjDzVZhjw1NaUoisvJF/Ppzs7OmdkJh4PoG+hPJNcZllQt0lTUvr6uVDY2snkgvrHc1bk1nchcvHhRsLsDQQ8GhqrWt2zZEo9v5LOFoD/4+OPfc3tdtXptPR7bvHnT+saKVKtU5dKzTz81NLJJ1+CR147b7S6GYXmRO/L6UZvI7NlzkCaZZ555zul02R1ioVAIRdr//M+/UFcqLz/3imrqx8+cAoh4/vnn/+kr3/zff/W1lZVpt882vKnv+eefd9tt6+tJkiHf896HJyZvzs0vUYS4uLyxf99du3Zvh8CiCHp6aqEpHKnXigG3e/rmpFQFuknmSqXmjuZKIc5R3qaILZ9Vu3u7IOZfe216aDBUqOQJrKrVjFxenS+tb9qyJ5GvAhqRlEAgBmFo3kpkmBCgNyJYbwhSN97/i5vxT0nwCBDWO6Or/76a761HQeuWQsSb3iEgbn/GDRKRBQG0CEhi2Ai2WfhNec13POObk4Y/n1Z16/ObspxvLxh8c3tjL4IYEBRJESRA0ND0arVSqVTq9TrDMDabLRgM0gwJAaHpiqZpiAAAYoJCABCWZWJA0DQJoGVZBgIEy1DY0EzTghgQpOV1e9Ss4Ga9ekkhaKCrtVRWzlcp0cEgILCAwKaOLJNkCQigoWpYlQlI0iSwDAsAq6EPgCGwsIEtoGsmghBiE5sWzZAMTUMIs4VqmUIcjXVdtTvEdK7odnktTMiSamBEMwxBgmo153KJiiK7XK7+3p71jeViKsVSTpeAbLRJWEatUna7XKZZJ5Fut9lEG8GL7rnJawFfO8dSJjAB1pKZYnN7Z61uNbf21yolxaDtnqZyJUdJls0WmFld6mxtxphgOMsC0AIwHG5SFFWSZQrhQi6p1WscwxMI9PZ2/fZnP/0PX/uyqtWuXrnQ37Xl5ddeICnwgQ8+lE7F8vliV2cQAeHTj/3SoQcf/PRnfm1qcZ4AWFYVtyOYqdYcDoeqK4hAiCCgCSwLYAwtaEGEVANhE6BbHlEIwsY9voWkb9crAABuA6xGfpAkSU3TGnEshBBBkBgCDDCEEEEEIWGZ0MKwXgder7eQGqd7Q06nE2A9n8keOXLkwKEDDMOYBm5ra7t46VwzxTm9nNvrEtKKqlMAawhbdlbjoVmv5MqJspuRFFzePNh+5sTLxVLtk7/26Y2NjYuXzre1hHxe+3i9vGV0O0cLp06dImlqx85dpAU0r99Zq0gsS2marmmKaWJRtNfrdUmSJEk6ffrU5NREvS65XI7RzSNNzcFMOhkKe0jKglh1OG2qViVMa/LmxME7D7125BW7Xdy8ecvy8qIgcKlM0uVwy4Yh2GypVKqzpwtCWC2VHQ7R6XAoinLi2Ml8Pl/Ml/r7+4P+4PLycrGU9tRsg4ODc3MzW7duhcCbTqctE9RkhWZVj9sHUMqwgM3hMjFhYjh+42ZTUyQQ8vsjvqW1eV1XHQ6XaSksgwA2mpvCJElWSmWOY3RDXVldagpHKJKplGssyw/2DVYqtXq9PjU15XQ6GYaJJTYgJAYGBsKhyPHjJ4GFvT530B+wuuvlWnlxfq5QKITD4fvuPTw/u7AwNz80vEk3tGqtVCoVWtuaMdSCEa8o8tFw4PKVc4ZhOF2cy8HPTk+Yeu3AgQMH9u2WqrUjR47QFIptrJaK+aZwUy5btKCVyWR379uzsraazmQIgrAAtjtdhmZVSpIg2BFClVJ109BIXZKlWiUWixeLRafDTQCuUkzRFKdT+vr6umWZPn/Y0HSn081ypKaqRl2DEBi6SnIk4jGGSu9A8PzFcctinU7KxGTAQ//DP/1zMNwyNLzFQtAZCJk0k4ynbYQnlyr+ykd/eWTX1rNXztcN6d577l9en1dV+frkrGloMjRn1xZFgTp48MDG6sLa8tTOLX1jg+3j1y+vLy4iTIgEW8oWoqHw4uLi5VIWo3pfb8/KimUTbKaBDVULtjRfuJCryLphmYJDrNWAppYD/s68nMcWHN16tyJL5UIykykzFFa1CkHgQrEaCvqXltZiG0lF0XQNlIpSTZYEQQiEAySFCJpAkGQoFmOmtpG9Y//e5UTB6w86fe9aW10Xnb7ZV48N9G8eHNisKxDq0rbdH1jYyEBSh3xvx9COogyTxQTnsFkmaRi8kwtApdDavEVXgVMM3HNov1a3rl6dcpIdl44/GWoZ7ukb/t0/+N211Zt//4VfH97U2hpwIhNIpPNSZtIT7VydrRx+14cSiysFvRoI+HrC4eWZGVbOSPXCPEk+9L4P5XfvO3TH2HPPff3J//y3kFv0+0hesJ8+9/LYgTvuefdds4urnM0V8ARrtRqEhG5Z6VJKRa6xQ3cf5B8y61q5pACeLJoSoVMICaqhQ4YyIWMYVrJY2n1g3/e/+twDdx++//+998yFSd5DYVOv5uY5XGA1Atb5bWO7bs7NBaP+UzOX3FzdLfKFeM7niLTsa4909fAXT4WiYdNSWBo89+yTv/6pT5w7eXp6emZwYHRudj6TSY9uHe0d6FxeXUomJrvaXHYbGO1vWl+7ho04zZd7RprGtu8/cfKCqhj3HnxPIbf83W/9056dw12Dm/Kp2PpKon9ga7FQzmRyFIM8Hs/s1GTQ62prbV5fW1taqx44uE/X9XKtGAz72jpbjAWFpkmCxDRDzE3PqRLR2T6Yy+XS+aRFWJFoaHpq9sz5f92zc5c/HN2+ZdPK8vzk1MTM9Pxnf+c3QiF/fK04Mz37+vEzwUD0yLEL+/bvPnzPQ63N/nMXz7kctkO778vlcg8e3gpJ6wdPfM/hckZDTYV4ZWhoO01BTeVS6fVIJLKxsYGB6nTaZ2cT164t33/fh0ulSj5VclGUz+GzsFFT5FdfPbK+nkOUfd8d9yVTKcAY7a2BckVnqJCpIifPB31MVaFliaAom2lhikGqUSVJaBiGZZkIQIKECGJgmhAjCAnc0HmHFsYmwNZttAFxA40geLt0EFoYYwgaP/Tfmf/0Ruznp+MACNAtb5b/8g4hbHzGlgkBAtgCEFkQN6hjb7Dwf/rYQ+hNqAgjbDUK7fEboThwewoN5IgQtCzzdqnX7d0QQoxRI3TxpsnDhtBRQyvdNE0IQYO3bhpYVdVaqVyp1UxdZVnW63bZ7c2Ncn3DMLS6bFkAQkwgEkAAoGFiA0KISBIAaFkGMDQKIWAgAhkk0jVTgiYIer0ba4nhns18eWpy6Xqzt52ASORd5bJOqMAhclK51CDa6qpWhzWS5Y1aiWFsFGAohjQsq1QtQoR4m2hZ0DQxgQECiISEpMiYIBECLrfDwEq1DtyegD8SYEUuPTVLkLwg2EhkqbKMWGhacrmc7e/fFk/UisWEwPLNgWi1WCBsmkhoPOQszXBztNfOJ5NxipaHhkcunj8V8LsFpAftZr0e3zS8JZ0rT04naoquTy01dN5dNJ/KSgzF1ZL5zhYPzwTia4WWaIs36J5eX84VNJu9pikqhIhlQDyxllhZat29s6ur6yMf+dDvfe6zW0e3nDx7IhwIX795lffwO3fsjqdWZqdnDVl+8J577r/vV7bsetcffu5PJ8YvV5Sc6LLZKTKfWDFVXNHrwYBb12QICYqlazU5X6h09w/GEymP01uoVDGmAUYUweqWSTGUpmOACMsCFEk2qkQxxqIoUhQFAYEgCYGpKjpJ0IZucDRnmuYt9ROEIQTIAgREGFEA6JYFNNXweb2iXWQFliLYa1ev1OtSIOC7du0KQsg0saEabrenoFTpYs7ErCJXMFQcbtYqrYdt1vj41YHNPYVMfnV+0R3wiLwtHi/+xw+eGhoaCgVar1y80NfVc+b08d7ODt6DalLeAtLE5GUyEg3U63XLpGs1uRFhdTgckiRZllWv1y3LCoUDlUrJwrrNzvsD7lwmASG+6+5DpmnmcrlCIdfa2pxIJEqlQjGf27ZtLJlMmqbu9XoRiYY2DSXWky0tLTzP3nfffS+/8lJzc7Pb7dZ1nSIRwzChUCgQCEiSdPPmzc62juHBga1bx6ZnZy5cOB+NRuPx+NLSkqFboijOzs73dBNul98wrPHxG4IgVKuyZWGHyyM67C2trcnkRjQaJQgYCARSqdTGxkY+n6/V5MHBwaWlpVAo4PH4ItFQNpECFj579qzN5tyxfVd7e2e+WN60ibDZbIuLizzPG4aRyWSKhZIoina7vV6t1MqVYDC4dnGlvau9ta2FQOTKysrY2Nhrr73OcVxuIxeJBiOREMdTgsjH4zWGpTKZVLGU11SD5/m5mZmW1ojX5x6fuEaTjM/n87gcpq467aLP7SWAEApGLWhduXZ1Y2OD47hyteJwOHK5gt1uLxZLBCI77E5FradTWYZhAoHAUq3CsYLK6W6HV9f0hpcOQgizmGIZRdYq5WpLS0tbS5tUkWRJBQAILFlXKgxD8KJYqRa2bRsevzmfTC64ve2vv/5MsRh3+7ymqZE0Y5jI5QrlMrWdW8deeeU1oMp//Xefe/rZE0DGwWiUEfjFlcXunsGnnnpCqtX3792VzSTyFYVFKBRqcjrdJCLkas3r9AYCkQP7Dvzb17/V2dbOUMTIcL/f5zx+4mhzuIUiGZfL/dxzzzk8Do/f1+HuzmazholrNWVk08Ds7LymmpDgCsW5R9//Xozrly+eWl6c4QWH18V7vHa3yz0zPc9xAsvYAGBlVbGLJGIIjLGqanKt6LS7q1WjVMg5Xf7JyRuR9n6LYu7deXgjXXnxlWORaMuVq+MAMy57wG23RZo3G1aV4bEJwY25eYc3xIscRoQkmQwllkty0O0qZ+lvfeuHPKHu2jokivT8zKyhpkv55bsO39XS4Vd0XJFqO+86tGNTS35tCis10yiMX7jsjrR7Am3x2RNHXzr6nk/8yksvPxf3+jIbG7lcpq17aHjzcLUGeDEwu1Z58EO/ARi7nM5dOHdex9VdfZHpuWlK8AkOeyyRCrndHE2rqkbQTEtne6GUL5YqpqbjWo1mGZVAqqYRhB0iUtVUQbSXKxKBVVJEQYevu6t9dXlhZX7GqFer+ZUdu/acefkbUKvGVgo+l+M73/uaZMGD9x6maNrlEgTALMxmZ+aXuja1nzp7JZ7MTs/NBps6Hn300T3bt7c2N5GW9d1vP97Z0dfR3ZMt1nQD3Lh50+ERu/pay+XqpUsnOzo6a5UEwyvNbW5vyLaaXJ+Ynt00tGMllpmbuvLI+x/Wpfjc3ATHEBMTE03RbrfHZ2iFmlSs1QpBnyedigOAFakmq4piyIViYduWMdHO/ud//kdzc7OuaoZp+L0e00JYEEY3jZ27eE63VIZhAKKHh7dt2bLlB9/77ujm/rXYmtfvZRa5bDb7+HefiDZHXn75RCgUCoaaVVXtH2z1eQMXzh8lCXV0uNfpdI6PT2RTuc73dHr8gSs3xodHRuVyXdPQ+lq6Xq8tLUxEom5JJLu7u4Mh3/WrVx32toP7DlUrCk3Q+/dsf+mVH/UPdQMK8jbn1rGd/kA3w3tWV9ZEpyC6cC53U1MNG+sEtDA1cYPyNCPEioxNVS2bKJTlMkFbmqpynGgauKEyAIEJgUUiSCCkA4hxA0xBACCAGOFbmUSEAUZvS8y9LZD09hjSmwNCt9AV+Jnvb8pdYgJA8x36IPBOqcD/liV2m4cOfipfdIufflvXCrwh7oAQMgyjYTwnCALGWJKkUqlUKVYaW8LBIE2TEEJd12u12hslhBaEDbM7iLFpmeANrg6haQpNsSyF6prGMzZIsFKtQjBSW4s3m80AIDtFYWFhKTt5Ystgu2mCcrlWrhORSJehkk4bnVpN+IOBdCaNeTLS01IoFlkaI6xAC+imRlCkKPIYIAihaULLwggSiCCr1SrPMbVaxeG0GZZOc7TbY1uPreXzWafHbXcIBAF1XdN10+N2KprEcyTpsV+/dkFVVQhI0hM0ZN3vEkii6rDRUiVPE7TD5i/lEwBXQwF+duoSRRjIMvxOOw0Um0tcW5zOlGWfzz3W0bO6uFav1wVBsDkcOsY+r6uc0hx2D8eJkCJdXl+pWqMZR6TJRrEUSRCp5Ia7NTg9dT0UDG7qH/3whz/6kQ/+6kDv5ldfOd4/0PnUT57kWPvhex95+bXnWI6YnJz+xC/99v/7v/8iSeo/fukLU1M360pVrZcJpOkGIkjBLthVVQW6YilVRTMEQXA6RNOiN1ZnRKdHkXI0QVgQkKygGzo2sA4QQqT1hpLZW7PDEOi63kgNNzhYt9LlEDbCV2/oaN165zhgWCaiEM/ziUSivbWpq6czk0rXarVsNrtt2zZd1yFEum5aANTqMsPYBIHQTbNUzgpadW1htSXgmZ+8Ybfxba29Xr8v2NIk1V7ZuXfvtWvj4aBvemopGct+5tO/+erLz+/ft5ekdZvDlcpS6OSJ40uLC5Zl+P1eh8MxOXnLBGbLli12u52maV3XXS6HKIo3b97MZrMIkjTDNTe16pq5ML+0e9dehmEEQVBV9ZVXXjEMIxwO5/LZQNCPMSYIYuvWrYZhFItFTdO2bNni8XgAsOx2kSCIWq1mswvBkH/Tpk39/f3xRCybzWYymf7efrvdUalUL5y/FNtIEARVKJRcTo/b7S6XyxRFBQJBvz8AEQkg0dralkxkpybn3G5/T3c/tlA+VzINADBFU4LAO/O5ksfth4BMJDLVSp1huEKh8Mgjj4RCoUwmc/nyxXQmKddrLEd/9LEPb9++NZ1O1+t1RVHcbndD1iybzYYiTdt27mhraxvoH8zlCouLy/F4PBKJ8DzPsiyERKlUqVRqtaqkqnqxUGZZ3uP2eTw+r9cfCkYARoZusQzvcDhWV1efef65XLEwv7Q4PTd74dKFq1evXrlyRTX0VCYdi8cpimo4VVuWFY1GXW7nyupyqVQgSHjmzKmbUzfcbnepVKJpWlXVSqXCsnwkEgkEQiRJLy4uK4palxVDNxcXlkmajUQiNM0igsOA1w26XDQWFzYQwYYiUafLVpOKc/M3QhH3nv3bPX6n0+m8euXGxLUplhFN0yyX88DJ/OX/+9IzLz2Zr+S/8d1vzSwsDAyPmoD71Kd//3N/8Jdd3dvcwY5tew63dY+tZ6TphWQqr7Z3b+4fHtu0Zev1iYmV1aV4bI3nqHQiodflvs7uYrF45eqlheXFTaMjqVQy2hTO5TKlUqG7p33Xrm3jE5cr5ZyqVsvFNM8Rc/OTJ0+eKFdKQ0MDW8Y2IwKcPHlyeXlZtAmqWq9UygiB24Fi0zQL+VK1VAcWRRKcIDr7B4d37Npns3tbWvquXJq2caHP/fYXPvmJTz3wwENNLWGKNc9fOasaRF0lCqXa4tLCs8/9GGJVKpdMxXLZnJamNkWdcr30re/+4IMf+cx6Ai5vkFdvFON5wyJROGr/f3/7O9/8t7+SqrmludVcygLAH2jqUwGqKaXd+0buPDjWHhHKsau8kbx28uW7926bvHGhWIj5AkJJzsqGVtFBWSMquvPGjBWIvmvP4d//wz//USiw7f77P8ZxnrpuAAR0U9X1qiIVRBq47PyJYycRpEVeyOc3ohHTxmcZoySQJsZ1E2qCU6xUSwwJXSJNguoPfvBvAOF4MpNM5S6ePTE/cVxOT63N3qQhoSJ47PwpHUqxjdljzz/VEQxePnUtnVJD4f5f/eTviTbvkddPPPLeDysKIgD3pS/+2+Ls+urSWjqdfP8HHlpZnV9ZW0IEjUl23133CC5XvlqCDOJcTCwdEx325cUlp0OQqsVEbCUYcLMMNTTYPzIyMj5xdc/enQcO7tSNWk3OJ1PrC4szHE/Lco0kkWnpc3Nzrx99jee5rvb2F597rloq/e3/+7vOjo4d27YLPBsO+qPRaCAQ6ezsPXTokMfj4jhGVXUEqRvXpmZnFrKZwmOPPZbP5zHG5XKFQPTmkR3/P8reOkyy6z4TPucyFjN1NXP3TA+TZkZkoVEyxI5jxxBeJw5sHFh742QTZ5M4uIkdOzHLJMtilkbD2NMzzVxdzHgZvz9KGsu02e88/fQzc+tW9bndp+q8933f3/t74dkLj377xXbdwgA3MjjZ29M30Nd/7z133Xnn0Wx2gyStd7/7bYrcrtfKZ06/cu70mdGR6e2tvNgxQsH4xPiu6ekZvy8kCDJNcYODw81Gi6LIYMhj2pLbS96YP39j/uzBw9MYbpu6sb2e7o+PaKJNIYwmqbqkZLY3zrz6cjTkDwd9i/M3WIoOuoKmpFG4DSxJlaoYlCgMUCSuSLKuGrYJEAARBEDENC1Z08VutM+PBng97ceCr+c4gDdsXD9z/Mxiw9df6cf/+38ZP4Gcfmr8VP5WN4/+jVyinzl0Xe9uEACALqzsBhGRJNmtC+u20tM0Tdf1buc4hmFomlZVNZfLbW9v1+t127bD4XAkEvH7vTRNWpalaRoAgKKoLlyDbwr1RhAEAtw2GWiztmbTGIGYmq0obtZhaLah2RiGMSy5vrVwdfY1RatzLGw1qyhKaDrQNIxhPLJqrm+tGnYnX13DKdnpRoeGewf7h5ZvrEKLHBucxGyMoihNU2RFsW2omZaiWraN4zhvWFBRNQxHDEunaELTNFlUvC5vu9nI7KT8Pg8CzFDYx3IEipkkBUSpWauWZKkjCu12s+3z+JKJfhfLuxwYT1uG1jC1hsuBOTl0Z3sRWpJtdCyt0xMJNSplS9N1WdUVXe4IkiS5HDyB2tVCJhHxuFjod2G2XA17KVMq22ZnfWOe42i3z10X2gTn2FzNsqTDNKRyZWPPgd7t9PW+gfCHPvzhT3zij+++83333vWBF5+9PpCcPv3qRZ7l3vWut9EUhaFUsyG/9z2/dPXajW898o1/+8Ln88UNUa5bltbT0x8OJTzuYH/vgINjKYJYWlyTFMuyEIbhOp0OjqMuNy8rbQQ1SRI1NBnaJrQBhhGIhQALIK/TmfYtgHULl6uqeivtDEGQ1yHYm1bsm716CAIURbFtu9thWdM0giB4nq/Vam63m6TwfD7v9/s5jgOW7eIdkqSYps3ybgxjRiZ2Hb/zPg3SkHBRXGho5ABJhV5+4fL6+haOoh4X/+9f+KLfE3326deWl7buvucBzZB3suuCUGFoDP7ZX/x6vlAqFcqRaIxhHNdnbwwMDFardU3T2u0miiIYjoyODgaC3kIhZ5qm1+na2dlOpVKHDh0yTXNxcTHWkwgG/TRNr6+vMxzr9XopmqzVagzLSqLI0Zyq6pcuXVAU5aGH3xWNRi+dPxcIBAxdxzCs2WxSFFWrNhAE8brdnU7HhsjAwIANwdWrV9fXNnft2lWp1BiGSaWzAIBoNG7btihKoii22gJFUZoq33333efOnY3FIh6vwzAMjuPS6TSOk6IocqzD6XTSDFkqlZrNutvjsHVFVVWX21solFiWMw272qjzPO92ezmOkxXl7NmzbrfX5wuIgkRRjKGr1VKJdbB3v+XObDYtSZIgCKIoDw+N67ohiLIoihDaFE06HMzi0rzTyY+MDpu6YRiGy+XKZHYQG7EsA8OwQqEwPDTEsmwqlRoYGDAMQ1WMWqlz5dosgqE2AlEcDYXDrVabophWoy1JUsDnRxBEVVVVlQmKFGWBpmmWZcPByNbGtiIqNE17A36H01mtVm1oSarSEVpuh5PAcFmUOM4hCgoACMuyiqKgKIoRqNfraQsdC0Fk0y7XBFknGC4sKdjhY3ePjs5sp4rj45M8Q2eLuT/90z8+dORgcqDf6fZAjMRJamFpzTCscCgyPDDM0kyjWbu5fNPjYngS3rx2PuQhCUsmcWv31Ojy4vzVKxdYlglH/MeOHsxnd4r5TD6fJ2kGQhQjKLfbbVnW6upqOBpCEETX9f0HD1y+dHV5dcPj9JUq9US8LxqNWobWaTeCQYemi5GgS5I689dnWZYXBaXZbEMEBwhG03SlVjZs0+VyuTgemoiqIwClNdP2hnvmFrZn9t157/0fypdlhKB0y3R6aFHu6KqWy5bDgR6OpwGszi9cTqVSLO9LJKbCkSFRNMMx/3MvPBuP+vKZrfe/5z0vP3s2EggkEr4L55947tl/37Ur2RNPXLmymEgemJw+trG2ReE6Dgt9Ca7T2FlZnuMcHrEl7Rrf/eLpa3Xovu2OBzZu3lDEOsXYe47eQfkmMDomdmxTJ1CEIXBCFkW/i+0NgvXNYkXusD43ThLzc9eDPDfYE6dp+tHHn7i+tPnXn/8fnabcqW2qjaXDB2bSOSVf103cq1qUBggEwXDLEpvZ8QHX17/0v/PpxdsOH+yPDVy9fM626pauOdiI1xf2x+P/58v/RmLYO9/21r5IJB4MXrx44eaN5Q9/5LeHR4efe+lb6exqJBJgWf74bXf90R/9MUviolCfnhrstOvpTMHnj2ezLc7hOnry0NVrZ/YcnLh5c25rM4PZaNDtVTWp0iy/9V3vPn7HOx751lOtuvqud771pee+dfHcExyteDxMPl3SdNTQcUGUA17OtNRYIqFphmHaTqdb0VS3ywsAWFtbsy2r02qeOHlbPpPt7++/fv36ieN3Li6vDQ+PHz5y9OVXXw5FI7lczuH0BPyR1ZUlSawMDSY0rbm6vNzXM5hJF1XVHBgYKBQy1+cut9qVD/zie4Ih742bs9PTk+12e2VlDdiILGvxWE9f39DGRrZ/eE++0Ng9sevmzZuba0vHbjvYbhQz2bVIxONyczYAs9cWbj95v9MZXVlJZ7I7g0OBcNA1e2POH4iGw0OLy+menmmn07+8thxNBDFKzWS3A+GQJJizs2sYHty9/76tTIsg3SZALdRGCLwtdFCcJkiHaQDTNGyg26iGoBa0oGWCbm1alyuy7Vs2XuRHJqQ3thMLmAAACNA3Jxfcwhm32KCfgF/Yz3G5/8QudWtYPwfKvdmP9RM/5WeOrje5G+fYhVmGYei6DgDoRip247lvzaHdbkuSJEkShmEOh8PhcJAkCQAgUEJVVUWRbNvuxiOZpqnrevfR7m/sR5MHmGkQGIZAq0OgBrANaJsYhmiqDW0OYBbFivV6qlYtxiNxFx9oZVJWddXvwAfGxqqy2daZtmZJYt3Qpb5IGMeobFE2EE6ybIbhaqVixB/EcLTealIsS3MuVbd1AxomgBDlGLpZKxqGgCGW2+m0bVvXLTfLFHYWxHblxIlj6VwaIKhuobJkWTYKENQwDIbFI9FQtVJHUbxVEzia5CmTZ8xKdX0gGeu02p1mh6HdDofDglapWhAEIeANaLJBk4yDY5ptgXL4yi1BMVBBkIb7k7nsjsfBS4ro9HlIkmjWCoitAE1WVMmGuMcXnZtdjsUSPp/HsMTtnaViMfvpT3/2rtvfZmuu//jSd+bmbgaCzrXNy4KcGxmNoxixtlKWZHjg0OGF+ZXP/dXf/MM//wtFUds7Wzvpreldu0zT8nr9po122iKKQQhho94aHx/f3Fo3TNMwNZbnLWCXqzWPP0RQXLMjU7QTw3ndghDipmWbENMts9sqB0VRWZYhhDRNAxvJ5XKhUAjH8a7bvZuPZdt2txQRAAu1TARihk0ZijQz5v6DX/tYCCsf2z/YblXcTs7ndd+4Pjc0NNBsNndNTbE0lc9mwvG4CPHe6TuWSlxVISygh/3s9dee4lEp4mZqxfRgX4xlSMPQFhavV6tZRW2zLLu+tt1paz5v8IH77qpUMq+deXpjff2etxzyeJ3we9/7/PlLF+uV5uDwqNCRr16d83n9CILpphEI+ObmrjucDIYhiioeOXIIQrizueXz+RRFOX/+/N4D+0dGhkqlkqIobrezVCoZthEOhwVBoChKURQcx90Od1dtLBQKuqFFIhFomZ1OZ3RkBMOwbDbb6XRURUdRFNp2p9PBSYqiGJfLVa1WM9n84OCgJCk8zyuacePGDZfLbVkWgLBWq5mmPTo6fH322v79e3VDTaW2HnjgvlQqZdu2YVgoim9tbUUjcZ7nFVVKp9PHjh1JpbZ0pROLxdKZ3Obmtmlahw8fHpuYOHv2bH//YC6X002jWqlvb+/4/cEfdfRGoM/nCYUDxWJxaGgoHA7/x5e/4nJ5ksleGyCFQgFBAE5ggiBYlsaw1NjYyLlz5yiKCvj8EAEIRBeXFvp6kqFQaGtry7Ztp4PbvXs3iqJPPvFMX+/I9es3TMuyEWjZwO31kCRtGEa72bFNi6MZw9ScbrduqNVazeFy2rbt8fh41pFOp03dokjaMIxGqxmJRAqlIk6SNrC8LicEAEcxDMNUzVQUhWG47ueOqqqDg4OaZa5tbWum7fbFBAWghLtcV0nGe+TwCQzBUQSr1irnz5/3BPyf/fNPX55dNgFerrVl3ZwY39XlI11OHkdgrdmwEJjJpuRWdSAeglr75tWzcrvo5IlwwOXg8NT2hig0R4cHZKkNbTOfzzcFMRJLQIiapkkQWLvddrr4YCh06fIFgiAeuP+txXIltZkuFKuhUOQjH/nYmddOF4t5BNEhomlyu9Wqp7c2BUFKxHvcbm+rLWVyeQzDNFNTNC3o97IEZZoAQVkTxbOlKsk4CdaNYO79B+6f2Xei2ZRsFKt3ajRLtToSz7lrFQFFDUUtXb706omTxwb7J4QOpSi4beOSrohyNRwLEihRKjahyZIYQdNAlTL/+cVPjw14GNx+xzvfTXHJGzcyqsmNDA02G+s/+O6/AD2nSoXx8X6e5+9+yzuaCrletr/3vad39fe8+vyjkTBm49hqWvn0n/8jSTgECXYkWjUQX9Tz6He/Yzal3/nEr2xkixpiGablZLnl6zc8DrZ/MCar0t/+wz/29MYiIe8dR3dfPvO4x0l5XL54cle+hSvQpdi0Zdk8hUG9w9Pmdx/5qm2Cj/7yr2wtrTkdqNhcqZYyG6vVB97+fj7UA3A0s7k6PdSTWrqSz6wdPnHwtfOnvZ6wbUobGxdz+VQglNy150g81nf61JnD+/ddvXJBV9uJnuj169cLparbHX37Ox4mSfJ7j31n3/6pUjmH2IDn6M//9d985n/+QTqfe+a5lz/7V/9SLotXL91gSYwixXYj1WmleJ6cu3rj6G232xbhcnt/+OgjDz74QL5U7LSFZF9/IV/CMCyVSkcikXq9nk7t7N03MzO9a2tzfXJy8u/+9u+Pn3jLnXff9+Uvf3lyaurw0SNz8zeFjiyJ2vz80v79e0yjPTaWlOVGNps9eezuf/nnL9x+4s5jx44oqri8Mp/Lb0HEKJUz5Urh3rvvqlarJEkLgoRAdHBweHR0XNXJl0/dePQHz37zq1975JFvAFONxgIri7Nj4/04btZqpcHBwY4oIZBEULbTViGECNB4B+Nyc/liNRBI2CZz8eJKJJoMhaPleqEjVQBmoRg2Nb3n+txaODrSbGI46as2JJJ14CzX7MiiYqsqimIsBBjATBSzcMrGMEQzbFXVbwUQ/AjKQAAB2j3+Rk3fj86x38Be3dv9nwmw4Juklp8HsH7esH5G/+mf0cnnJx59M+S6lWb05v42t/RBiqLgG/3mVFXtigldwMQwDMdxBEGYptlNEbJt21A1giC6wUhdJqyLzyzLsN80uq9pIyiwcQSBFFQNtU1hEEMtWemQFK9pLMEwHbnocGAsjdVKxUQksXXjipZf7Ev4W4pFuSMtk3YGAygqanLTSSHlQpNm+ySVRFlHq9WCqrRrenI7kxYkkeYdBMMpOmJamGFglgUoErWNTr2eDvidtUrZybscvB+oyvXLL/l97K7dk5VajaQpE6KKBAwTEDRDEIRp6pqm8QxvGBYKyFa95OEtrwPk8iteF40AaOkWxzgEUSRoQhA7KIr29w2lt3IEQVmGubmTRSgXSvM055JFycmRsYA3dADIKwABAABJREFUvb0qyIIvGLKghUILQYxcKhVNxHVAEDi9OLfAsfQDb7vnP7/ybx2x+rGPf/w//+Nbr7x65etfemJxYRND4ez1czSjReK8qQvFcpMiQ25vb60m/8s//+vf/v3nvQFHvpSyLMPn88mq3agLBM7YhoUTGEmisiw32h2X00MxZLd7CsRQUZYIkpZUleVcNiAsiGMEI8smjpMWgquGbQF4y8Pe6XRwiuw6efL5fCzeAwDoVhF2//TA+jGAhSJ4F2ANJVyf/uRHomRtcsjf3xcb6OuBwEptbZu2USzmd0/PtJt13Aa9g4M71SYdnujgo9tVg3Pz0JK1eprHdF2oBjxkNMwVCpsvP//s8aN7Ou28JLQQAKs1IeAdgAgDALKxuTg0EAC2qKodCEzk+tw1j9M1ONhfK1dUWd6/f68kSdls1rbtnZ0dh8PBMIwkSZqmnTt3LhqN+gIhDCPOnDnXarVWVlZmZ+dM0/b7/fV63bKsZDKpqmr3glmW1XX9u9/97tbWVrPZ5Hk+EAhsb2/H43GKol577bWnnnqq3W7jON5utw3D6OvrO3ToUFcgw3Hc6/VGo9Fms9ls1svlsm2bNE3LskSShCiKTqdzZmZXqVy8/4G3AGiYpiorwrPPPUXRuCC2MBx6PI5wOGiYiih1ZFlkGGpnZ9vJc6Iodu+ZpqYmOI7d3Nw8f/58p9PZ2FgrlQoQ2iSFB4P+vXtndEMTRZGiKMMwotF4OBQ9dPBIpVz78pf+0+XydDrC1atXr1y5srOz024LsqSYhiWKarXSbDVFjnV5vX6n002RrKYZ4VCkWq2FQiFFUarVKgCAIIh6vc4wdCaz43K7cYqkWcYX8KMo6vP5nE4ngeEkiXM8AyEsFHM2ALyTV3StI8mzcze3trcD/tCu6d3JZFLXzbc+8LZOR/T7ggzJuF0eTTNYjlN1TdU1jMAYjkEQu91uIAhwuPhcPr+zk3nwwbe/5e4H/cEYy3s3ttIQwsnJyXw+fe3SWaFZPHpgemw44XFSL730EkEiTz/zZDgcDgUj1WqNpmiXw1UoFM68dto2dIaldF0PBsOZbHErla83xD37Do9PTAMIvV5vvpCt1srzCzd2dnYcvEdTrWZDyGbzlUrV5XL5fIF6vZ5Op+dvzjkcvGHor51+ZXnpJk3hyWSkmEv/yz//faNRs4G5vb3VaDSuXLmiqurY2Njk5Lg/4CNJnGVpAkNb7abL5RgZGlBVtdNu4zgOEQzFqHA0pgPLglaxvPPyiz9Ib13bWDv/zFNfKWQWCEy/dvXc8y88Loh5l4eQFSEej4uCnE6nK6WSJHRESYDA8Ie81XolU6gAnDUgbhJ4XZLdofg9976/3aIw1P/9bz//oQ989Kknn0v2Dq9t5xEqNLn3no7GRZK7tjZrm5uF//5Hf/SVr3+lVaueOHb08OGjXq+7Wsvumkg+/Najn/3UR7/z1b/2cmoi4qAoS9HqD7z9roVXn/3zz/3txHhIbnRIgHeawt4Dh3KVynMvvhqJR04cPzjUFzm6f5cii7wrjJGep558ZmtztTceIVHAkJChUIJABFlpi9aHPvp773jvryu2kw8NEo5wqG9qYOrYVlHyJqbTdXt+vd47fGBxvfDKhblw36hKMKwvLBtG/9BgJBD0u/wLi9vf/f6zooo6vdHz1+aLtQ7O+Co1TVSQe+97x8TU5IWL55aXl+88cXcxXUdNent95/mnn/nc//qffYmBUrEZ8Pe88NQrLzz9/FBfzwP334Gh1uBg/8mTd+ma1d/fT5N4sjds2+KBA3vr9SrLsooqS5KAYtDrc1MUUamUnA7OtPTDB/aXivkDB/bFI+FIKLQ4v2Bq+n1vuefihQsOng36Ao//4PFWqz05Mb28vOz1ep965uknnnqaIKhisfw7v/NJVZU/+clPfvGLX5oYnzp65MToyFQ8Njg5vhfFHFupQqMuyZKhKvYTjz/32A+ePHv2nNftpXDi1VdfcfDswECvpkoulyOZTGbSOYKgvva1r8miRJLY2TMvVmopl5tmOabRaFiWxbOELNRmr57yulEHY9t6e3Xh2uToEGqbtqXjGOjrjaytzHqctial/W6lkLu6tXHOtqooFL0uGuoqtDXEMoClmYZmGIbd9WP9VNfnbr828HOIojcf+nli3y1SCoHQ/jkda34mVnqTCPP/dP6tOYA3dS/pHunKdrZta5qmKIplWSzLBgIBXdc7nU7XRFsulw3DcLvdPT09sVjM5XIBALqlV13PO0VRHo+n62PpHqFpuusW6ALQN0uEEEIALIwAwFIkqe1kGVuT5HYtEnSZugCAoes6hjGtli60TZJwYBDrCA2aQRHUQhCEdzhxgsZQvFpvmLahKBKGYSROYCgqdwQ3ywb97s21RQK1aBpFUUNXJUNTbdtGURzHCFVWCALzeji3iyYIyzLloNdTKRfj8XhvsqfTFnmeV3Wz0xY1Q9ct0+FwqKoqCAJJkhhGKLLavRCx3UEhEg3HbBPgCIpjiNBp0iRG4RYK9VDAk9paJwnU7/MEQ/5YLOL3B3jeVSlVCYKwNaPdavREI8ePHPJ6nLqqkARWr9acTjcEmCipkqLu3jXp4omzr72gacIv/MIvvPLKqW8/8v1P/48/e+rpxzWjdfrsU74gMbkr2ajlXU5+dGj4LXffe+Twbd/9zmMPv+eD/kB4aWVZVATOw2xn00vLK/5AFENpUZQRBKnXKqah9CVjjWalUi6iGEQQxFANjnbYJnTzXgzBSRy3dB2aBo6YEOjAkOEbHGR38XQ5zi6YfrMB6+e9HW6tN5YFBEFQFOVyuRiGyWazoijiOFoqleLxuCRJ3R1Z01WP22XphmVZHMdDBFd04PbHOW+cdEa5wMBOVQzE+++4956N7S2eZyEwGrWSy8n6A65mq3JjfnZ0fOzK1TnDAJFI5OLFi4jQ7lQrlXRqJ7Wz1em0/B6vx+Pp6YlbhqmrWr1eBwBgBBbvSfT0Jq9evYogmCiryb4Bl8dXrzUzmUyxWNzY2Gh12j29ye2tlK4ZJEl2NU6n0/me97xH07RuLoMoiqFQqNttcWxsrNVqWZYlCEIikZienu6+jiJKjWoFwxBNUxw8Gwr6K5VSsZgvFHMQ2vlirt6sUTRZKher9er4+PDQcO/wUCIc8gT9zqDfRWD2vj1TFAE8btbn4YV2g8BsXZUG+5PnzpxCEDAxMVEsFgEA9Xp9cHCQZRmIABRDJFnUDU1R5WQyYZrms88+W61WUQxptZqKoqysrJw5c+5b3/r20tJKJBJzuz3tdntocKS/d2BqYjoSilZK1Xazw9JsJpObm1ugKCaXLW1tpjnO0d8/CCHKO92VWj0QCHg8np5kciedPn/hgmlbhqXrlu72ejqCoOt6Mtln6JYia7IsWpZVrVYBsLqkkW2DQCCEExTncFoQWdvYSKV35ucXe3p6Ox1x394DLMuXy9Vqqep0ugRBarVazWaz02mZUIeY4fQwuiWKUlPT5T1796+v7aS2CxjiaNbV247e1dM7oOu6qsgEap15+blrF16bn7vgc1PQ6ly/evbE8f0MDVkKHRoMLS4sbK6tLVy//uRjP0inNr08OdwbQQw1n9lemLt+5NDBQqGQ2t5s1Gsut3NgICmKwr333H/vPQ+aNkLSDofLy7AOl9PTagrNRqfTkbY2U7puSoJUq1Tz2VylVCJx2KiXY5EgsPXVtWXLMu65556lpaW9e/d2g2T7+vp8Pt/W1latXkkmE4lETFVVmqZdTp6kCUmSqo221xdj+ZCu46lUGoFWu5n67J9+/PLFR1VxLbN9qZJfOrBnbN/u4UgEkaWUbUo35ubLpRpJcCzvYHkGJSCC241WE6IY6/BYABiYKptNDbTKjUqyf+ZjH/+zUp584uuv3HHHO47ednI7m+ob7WvISmJo+jd/7y8Wluu79r6N4/o+8N4PvvO+u1qF9dTiJdsQP/XHf7jn4L621GhWdx64+2BfjPv83/zpjWtneQptVfIMaY/ef2z73POnX7k2MzZMWihPc9Vm68DJkyMzM8sb27unJ5fmZp/8wfeL2cq+Qw/OHHz729/zG9959IWllVWWxTWlYhjNVqfFOL2KxWWrqmLZNamuoh2DMeu67YwPB4bHSopEebysz2/i2HefeWb04JHttvK1J1765uOvpHMSYnvWFoq6SI8MHj5+2zu30m0VYXGOz5YbvtDg6MSxi5fWn33mDMcxqtZ89pnvX71wmgAIC2kOJT72wY/0xHtnr6+YMjs1ctznTB45ePLL//6F5559YnFhdmNt+dzpC5pktZpiNpv+6tf/vVJL5fI7JIXn81kEQTiW6bSaly9eYmgSQyGFY7Fw6PrsrN/vf/6ZZ9utVn9/bywWeemlF0qlwuTk+JnT52zbnpmZee/D73a62GO3HUFR1Ov1337yDsO0aI6ut2rrW6uaqbz17Q/mi6XzF64+99zpvt5JAverCnXsyFsliTBN3rK5UHigI9j5XBVA8467js7sGWdYtFBKMSw2OJS8cvl8LBbbv3//2972tlRqa2NzZXAoQdFwatcwQVGtVueFF54XheZAfzAecxJom8TFzPYNjjTXlq7vnhwBprp4Y65aKV65+Fp662rYr6nq8ugwOjKCmcYGTdYbjZVEnAkHKZ7VTaMhtktSp24YOo5CDIEYYmMIRKH9hjgIuzgHAGBDC7zhc0JfB1ddd5aFQLv7vfuFIqD7D/jGCfAN3GbBn/Flv/HMnzj4s7Yw66e7B94ChbfQ1Zu3SQihpmndSG632x0IBCiKKpfLN2/ezOUygtDmOCaRiPX394ZCAZLEdV1tt5uC0NY0BUKbIDCCwACwDEPrSB0TmARNYCSmW7qsyZqpAfT1+QMUefMXhBBAw4QasE0Chxhqo0DHoIZCg+WoVruNkw4E4RQVRSCZzxdcPF9rFd1+DsGtRrPOcQ6I0hjOsoy7URdEQa3XmwxFQ1PzOBmOsHBEtXSBwCyaREgCUCREITA11dJ1lsZ1XSQJu93MxyNev5tv18ui0I5HwxiK0zTTasulckMQdRtiBMmmM3kEJVTNQlByZX2NpAgAjWDQL3SU1HZhcz2LIayuAaEjO3hnrVbJpFOmoa6tLjp4dntna2Fp4fqN64qmOhwON+/u6x3AcbLV6iwtrYiyeu3a3PLSGgLReq2NoWRvcqBQqOAogZh2NOSDtqYp8jsefEe5UP/iv339zz7zN73J4f6h3ktXXhmZCNx2Ypym1RMnDjo5HtqoZSHvfc8HDh44+tGPfbxYrvhC4Y4iFUoV1uHrHRyr1oRWRwiEA5omESRKkGgun/J5WRSamiJjKKppum1AjnbSOAc0BDEhalm2LnMMigDJNEUUsVEIoG1B27pltwIAGIaB4ziCANPUX+8AjSJvvgH4iTUqCEBRlEqlguN4oVD413/9VxzH19fXL126NDIyUi6XSZL0eF1dkYemSduGKIJLsk5SvGJisomZlGenIlt4pFRDIj1jqglv3lgZH5u2bdjfm7h2/VQ6txCJc8Xy5mtnXpm9ccXrpffvG0W8Xn/3Dmx0eARBEEEQhoYHk8mkpml+v7+b8+T1evv7+2dmZianp7xebzqdcbncDoeLptmAP1QqlWq1BoTo3NycKIqKokiS1Gq1dnZ2ms2mqqqjo6P9/f1Op9PpdDocDgjRS5cu2bbNsmy9XjcMQ5blcrns8Xiy2Wyz2XQ6nd1HVVXGcXTv3r2C0IbQ7utPHjp0IJ/PWpbW0xNttuoMS2matLGxahhqLp9+7/seCkf8AFo9yZgsC4LYjMUimcxOs1n3+Tz33Hu3qskul6ubTsbzfDabFQTB6XTiONpN88pkdtKZHRuYXSe+ruuSJEEIs9nszZs3JUmSJLlYLC0uLvYm++PxuNvtjkQiFEV5vX4MIwzdggBLbe+sLK/X603DsFLb6Z1UZnx8MhyOOp1uHCcYhtne3lldXU2lUtVGHaCIBUzOwU5OTtI0u7W1lU6nK+VyJBKJRqMkiRM0ZZi2aQOcotsdEcUZzuGuN9rNtgAh2mq1uhi3Vms4OGdvb6/fH0xtp2u1OkUyKIappmrbZr1es2xdVgQcRy0IarUaihDra6mB/pGBgWHTtEaHRsfHR10OhiWApbaef/r7PIU0K7m15ZurS7PXLp7JpTa+/c2vfOtr337ka1/WpMaHPvDwBz/wTkRvCdUds1NauH728N6J3/nNj0udRqtWsQ1DlcXnnn0yGom43c5LV69+7evfeubZl3ULMy0kFIzFYslGo1Ovt/v7Bh9++L2GbvG8c3h4mCZJr9ttGEZ6O9Vo1vqTvaGAX9O0xcV5v98fDkUty05ncisrK7VaDUEhjqMMS/X1JA1NbzXrLMs6HA7TRg0DC4X6HVx4evLQ1Oi+RqX+jrfe+8sfee/+Xb1H9w8mwoSL0RyURuGSKmVsveHmub7kYCzar+ogWygWaxUEt1XTIGnKhrii6JqhUzQEqErzmGYYHcnMFdsf//Xf/9T//qee5OD5K1f+9n999kv/+bVys1ntyCQfHN19IpLcv//w23sGZoLBSMTjWJmf/dQf/o8nn35N0giS8m6vZ5bmFoRW08lws7Oz+XwRMdBivvS+X3zvb/79X3/hc3/9L//wb8mYT1NUhERrnRbr9loIYRqYk/NrCvLt7z1TrOvbRZnx9ntjY8+8fA4lKYoiGJogKVSWRYjgOE4ZFtAtTTWFerNsIkhbUT2B8Hd/8FggxFAMfv3mDc7jG9p9EHEGqzLy4MMfslHXb3/y04Fg7+y1+fc+9N49M/urVTkQGjAAmegbsiH1hS9988473vmOd37wq19/JJ6IzuyZqNeK6e2t9PbWPXfe5Xd7VpbX3v3u9/bEh4K++OlXz2e20h/6xV8UmrWD+w+gAG+31EZNNXQ84I/5fF6CIKamJgOBAEEQfr93z549e/ftOXBgn9/vpwlyaWnJ7XLde+9bvC7n+Ph4Or0T8Pl1Vbl29TKB41JHgACosnLH7SeWludvXL/6pS99cWVlxeP21Wvt+fnFL37xi7PXL0PMtBF9cWX+meefefGVl2uN1hNPPHPi9nvmri+ltvM07XrhhddMEzt+4s6dVG5jY8Prc2ha6/TZZ5dWrq1vLOzZO3H40N5wJGCY2ubmZiKRXF1dnZubnZgYGxntv3rtPIJafr8bgSYCze3NtWQiMD938X/9+R8QuDg12aOr1Z3tRRK16/XiyEDvsUP7esLOqfGYi1cJojo65Bwf9UhS6uihoWZ9TZPzBCpwpEETNo6YqG0A20ARC0UsBNoQAuRnJXC+eaA/bna/dWf/0wzWLT7pvxz/f5mqHx8/4t5+4ie6XC6WZU3TzOVy8/PzGxsbhmGEQqGBgYFIJMIwjGmakiTJstwVE7utXW8Zs25Jil1H/C1x8Bar0d2Gu+Jjd9i2bUOgGxYAiNvrqVRKbicXjQSXFua9HhfDMBznUBQFIBiOE8BGNE1ze5yDQ32GKSd7Y8Ggt1armKZVKjZ2UkWnI+jzBDxOh22qPg8PodpuVmgS8AzGUBBHdGjJ0FKhJePQYikEWioGDIYEnWbJUJsoVG9evzyQ7Gk2mzuZbDTeq2iApt2hSC/DelQdQJRWNCsYTtg2GB8ft6Cl6aIotWiaJQne6QjYgIQow7DuVkdgeS4UCbfbbZ83IMlqKJLgHG6C5iyAtNvtYimv6tpOOhtLJscnd7VEhWKdBMM73D4boC6nT9e0nkjMQbMkhm9vbJ565bVYJHLx4qWPf/hXH37oA73JkaXF9ZWVtdGJ4eMnDs8vXEUQYBtmpVQdHhr/zKf/jHPwf/I/fvvixcuSomTzeYrmVAN4fdFKpdMRRYbjDEM3TMXrdbfaNZJANE2iKVwWO+VCkWc5lma8Lk+lWOm02tAGHENBYFEEAk0VhRaKwluu9u4ft7sGbjXJuSV2Qwht+DPWYXedkCQgCEKSpNdeey2RSESjUZqmXS5Xlxbtqswsy6Io6nbyDEUzJKUoGoZSBkAVC+toCOUI6dBJMPFcxZq9kT5y24OR6MgLz59ZmF8tl8v9gzFPgBDlMsPBcMz90MNvdzq5tfUl+Lm//G+vvvrq/oOHREHudCQUwR1uz/rahgXsUqnk9/s0XfIFvG6PA0FAIpFs1ztz128ahuHzeyqVMk2Tqq6IotiTjMuyHImEMAzb2NhoNpu7d++2LEuVNcMwGIbqurMNU4eWXa/XFUm2bXt4eHhgYOArX/lKs9mcHJvQNA0lsPHx8c3NTRRFq/VaKpUKhyMejydXKPh8AZIkFUVZ21jv6enRNTMc8Uti09SV/fv3r62vNBq1u+66o9lsdzpiOBS9eXMeRUgMw1ZWVnien5waLxQKiqQODQ2trK7TNM0wTK1WIxlS0xSHw7G4uFiuVgYGhnTNOv3aeYpiPB6fx+VpNBpdyyRJksBGVFVtNpscx/X29mIYViwWfb4AiqK5XK5UKsUScRSFlmXJskjT9Mye3RzHaZqyvbVx8OD+a9euGKbOMEy73QbAKperjXrz0OHbkn39r506k0j0NhoNr9uHoqimyFvbG06nkyKZRqvd7ogWgoiKmsmVx0ZGeY6FpuHhnaomExhu23BzKwUhRDA0Ho8KQhtBQblYtKFFcZQFTJokTdOsFEscxwdCiVpN9Ad6C6U2Srkhyswvr3FOz7vf/z7EMnClefbV57dS2/5QGKBEU1JGx/cNT8zsZGtHjt3+8sun+nt7S8W8gyNrtXwhsx2JuC5dONcTTxqq5nRwQ4N9Xifz0otPTk4OXLp4enxiJBgMKrKuG2D+5kq5WiNxrPubJEjM43ILQoeiMZrBKQKNxSKlUskwDL/XBwDy/HMvOlyuUqXm8jh7EnEbqNDU44lwMZcLh8MXzp+fnp62TLvRarrd3manLcsyAjFRlB18OFswjt/xTocr3OqIkajv0sVTxcL6r//aB1966Yfp3Nbd99xHc57F1eLG5vb+w1MsF7h6NV+vW2+57x0mQjQFFaMoiCKmbQNoAxuFNgOgZQMJgSqwbAygUIN+p1NtVdM7m26vh/P4cM6jmpZqKboh4YguNlqvPPXqX3zmd+dmX4ZGc3P5xuHDd7Lu0Ws3Fy5ef356rO/o5Mzv/+7v3HXvPY+/dN4Z2vfrv/0nqiq3xbpFmT6X+4lvPJ3dyo5PjZ14y507jSLG0ZpqumiWVC2p0bQthXJwKkF0FI2jOafTLUmSpkuq0sJQBEMATbCKBHXdxHAbxTVNKbdapVDAyzFenon+9d/807seeigQCj75xGMTU+PRZKJYKX77u998/7seOja995nvfHVz4cUjB8b3Hz76r1/+fu/wcYgRoQjW1xOen1uZvTT72c/8Vam4/cJL3xodDX/z61/yOF1jgxO5nVyzXkz0RPcc3tPsaJm0mE03Hnrovf/0z397150HRsfily++JnRaDs7dn+xfXLzBcOjMntELF08PDPb94z/+y+23Hx8eGp2fXzx27Njy8oogCAN9g9/97nfHhocefPDBfC63e/euzc3Nf/qnf773vrf29g9//u/+cXhk7LaTtyuqxvNcNp87evTw3/3d391+8uTIyNCp115eXV0eG+1fXVua2buboonz5y7yvDMQCL31wbd94rd+e2p6t9PhMHRrenp6eWUxFAqxLE0TZCafSfbGSRK/NntlcmwM2HqhmDMVzefz9fb2UhSTz+efe+6ZB956fyDof/nlF2dm9i4sre7ZtbvVrOcyWY/TNTI0amqmIAiGoWWK+VhvfGsnh5GOiakDG5ul9eWtu24/mctvyaDR0YWZI0fTufbN+VJvcveFswuRcG88Hq+12g53QJYhgrtMgNpAMyzTMiHESMtGTBu1bAghfMPSboE3wkgRG9i2/fNM6D+tD/70PvQzn/VTUMy6ZZy6VTz/OoXwBvTpqjbdnCpdN7vop9vwA0VRRVFkWW40Gt1CQoZhuqoNAKB75GfO6v+iWv70Nf705bxOpAFEsxAc2hyqUYhkdKpuJ7W9szE2uT9TMFHKrSGqonYIYLA4zKU2Du3qWbvyfYbQDcThDAxBdqBYE0gKITF76dr52w4f1XVSt1CIgnqjFPM6mo0KRpMYSVSbjVyp1jewy0ZYQ6Usy3I5SVEqetxmtZruT/Y2quLNa9snT9x54+ZVmmMBSuTy1WCkh6I5A6AI0m3/YuME1DURgbrTQZMoqJWKLsppybKiNrxettWsEhh0u9i11Zscj/f29i4sbTidwXCkH0C8XC2pholAAmJ0sdaJROMMiVZLBQyxeJ4tVKooBm1dHunvEapFHENFSV9aXG3W6nfddbsv6PjgRz787vd98D3v+xAGPY9859Gd9Oav/caHS8WlUmnT6+b9Ll9/cvRTn/rs869d+8a3Hhcl5NSZsweO7mcc5PL6oscfkARbaMqT4xNbWyvhAI9AtVIqdoTW+Ph4p9NpN0TdtMKhBMe7z529SFBcIBBkOYdhWyiOaLpOMCSEUDGhbHEWpAAAKIqqumYYBsmwEEJFUQAADMvquo5hmGEYEEUAAIiF3PJgIaYBAWoC2lTl4R7X5//s91bPfe+d9x8+cnjv+upSMODrS/bkCnkMQ3TVcDt5zDZ5twdleNQzmOpE66YH5VndtIEho4iNAKRaLpUzhb1TAxde+S6DNN95zwGplVlfub64fBmgav9oX1/vQLst4ghx7rVTjUr2U//99+Bdd0w4XZ5EIlEuV5oNwRcMNZtN07DGJsZXVpZFqYOi0LQNl8vJcnQmnTM0KxyM4DhKkJhhGNVqiaQpw9BohvR4PLFYhGGYnZ0dFEV3dnYAAG6nJx6Pd7WqiYkJDMOuXLrY09PjcblFUewWhhAEEY/H65Vau93eTG2Fw2Gv11sul4dHRzqdTrPZBAC4PN5ms9kNR7h+Yw5ClOd5miQ8Lp7lSJIke3oSV69dPnnyZLVaLRbK0WhieWnVsgDDMJZlZTIZCCHDUD2JBIqi+UKJZVkIIUUR9VaTpsnXU5IhSlFMeifXqHfGxiauX7/RaXW6PRZcTk+n08FxvEuAdf0Bk5OTCII88sijR44csG146tTFyekBjuM8Hs/S0oKmaQcP7jctY8+e3d955Nsjo0MMQ3EcEwj619fXCQJLJJI35xfmby4n+/p5zsUwnN/vVyQVwxBJ7MzOzvp8PkGUbzt+x9XZG6lsYWR0gmQdV65cOXH4sNfNl/NZFAHNemNzc1M3rEQiyTn4TqcVDPo7Qotn2WK50BI6bq+r2WgwDINYiG1DQVJ379qfztUwgocY6w3Ep2b2nrt01eX1Ldy46iG0VrXo9folVa83RH8o6Q0l/vQzn3zhpZXrN+dDodDKytLVy+dMUyisLvI+p6F1kolINNLjcjqHh4erpeLS4g2Xk+mIVX/AzTC0qqqKam1spH2BGElSRw4exDHk1KlToVAol8lGooFWu+7zufLZtG4o4XBYUZR8NkdTbKlUSiSTiWRfJpeWRCEQ9KwtLYTCPhJDIQTtVgtFUY/bi+O4y+O1LEtV1VqjdfPGYig6VKvBsekjBw/ePndjfs/MxNbWyssvPXHfW45JctGwJafHXW0IjaalaGYg6Ka5oGVHj9/+ULkuCgYoVGqBcEhQ5e5HM2LjtkUgwAKIAIGBIaQuKQxFECj4x8//ldhpAhs9fsc99z3wzlS+JOmSy8sbquh3+770z1956z0ne/oorZPyk1ql3K5J/vG9xz7z2T9cPfXSc8+/+PX//I+BqeGqZGlkT2JgqlapYhiAtGUZZoByexz8+tY24aAhS3V0xTJQzMYx1Ya6SZAIwRAS1FuyQlIOFCGETgeHNksBAuq23jY1zdBhMJCotyQEQzBcSm3N33PXUSfHt2vGM0+/cP3mtV/68IdaokLx7nJDTCT75m5czWxsvvfBdzSLG3/xPz5y4tiEIrRGxvcfu/0Xv/uDJzLphTvvPJpL5zjG6ff6f/j490hSnpzsz+ysOXi2ki/HQsHhod5XXn2pIXYczqAiEsdvu7s30Ts5MXzh0ksL81dS2xsEhls6PHToEAAGhsOz516e3j2yvnGTIJG9e/erqup2+fP5/NLScjgc5hh+enr6/JnTPp+PJIhksuc//uM/jh49Nnv9RjgcDYRiP3j08WAo9rFf/ZWFhZsYgU5MjoqSNDd7c2ho6Nvf/rbHy2tae2Fh4T3vfzgajT755JN79ux7/tnnKIo6ePDgmTNnAoHQ+9///lwm22g0isWioig+n29mZuob3/rP3/qNj1Wr1b5kstVqtRq182cvtFqtPXv29vcNbm/vIAjYNbO7UMiVK6VUaiuaiPMM22m1J8enauWqpugP3nf/a6dewQis1qpUGvXpmX1t0ZAVpN2xxkenbl6dPXX6JdFsvvfDH+joIFPo8GxfpwNjoWQi0XP+/BnTRgZHpm7MbzvdSYCSnJPULVPXEctGLEBYNmJBBEAUQtuGrwMsYNkAANjN9vwpFe//Ajv+y/FmfPOGuvdGWBeEGIZ1uYRbjBF4E5XVbYMGIdpNhpQkqVardTqdLu3E83zXtN6tIFZV9c0v8tNz+C8B1v8LXrQBYkEKWioFZdIWoN6qV7I4AW2EJelelHRqUDVM2e2kLUXYWl89uiu5ce0Hiaij0tQYT29y9MT8crZerw71Jc68+ORb77u3Ixg2ggqq6Pd69E67Vi2KSqenr2c7vdM/PNoWLMuicNTVbDYZBqFp0zSqW5vz42OTnZaM2C6XM5ArZ0mKq9Q70Vi/BYlcoebx+1EU13XVNI12q8bzeCTo2ty4OTzco4kyoiKWpqOYYWhivVZhaCyZiFy+fDoS9Q4ODr/wwunBoV2hUH+x2khndyiW8rh4RTOKddHh8pm66vd5WIra2t5w+fwAGOVsKuik9HYNg2YiOfCdb/9gcmLmoYfe9Ru//dGxybF3PPS+TKZx/tz8zN7D4xPD2cyqJBdYFhqKMj4y9s//8IUXXjj9uX/8gmZijZbi9Yc028BILJ3PVkrNgD/O885atZjsCWXSKwyDORgaw7BqucaybG+yP58vJXp6q5WmYdks75IlVZQVUZZdHg/DsuVatdPpBGN9TQWzIAEAQBBEVhXLskiGBQCIokgQBEXT3TQsy7IgigDLhjZiARui4CcA1uSg8+8/+yfNjdMf++CDlilHw4EL589OjI02Ws3+/t5KqUriKGabTq+H9gQNOpbXekoyb5KMblsYNFEAcYrURFVudQbivrWbZx24wCEd1K5J7ZyiVVW9TjJ4sVhcXFy66/g9zz3z7FvuuLNRr2LNlsQ5faVKXVHNruExnU6LkpTOplmO7kkm6/W62+XsdFoAwESiR5WNbDbb29vT29c3NzdHUGQul4vHo4ZhdHMyFxaWAAAOh4NleU3TXC5P17der9e7ySUTE5Ner1eRJJ/P98orr77x7rJb9dbVq5d3752pNeoWsBmONU1zdHR0e3u7UCgEgn6cwAYG+0+dOhXw+67PzvX391ME7nb7WJbZ3t6UJIWh+WtX57LZvNfjr5QXaJpJ9iTPnj1fqVQGBvpkWaYolsApp9NZb7QpirYss1qtsg6+Vqv4A15d1y3bajQKw8PDKEKurW0Ui0WKpFmSbDRaBKnSLGdZlqqoCIKMj49XqqWO0IrFYr/5mx9fXV3v6xvI5XI+b6DRaKyU1pLJPq/XLUmCKAkXLlxgOLbVbuumhhEo5+Cz+dzhw4cvXr4kS8rQ0FCuUBQFBUIUgdi5s6dN04xFwz09PYV8qdkSL1+9PjwyGYgMen3BWksYGpra3ErD/vhOJjfU32NZhsfj4nlnsVRJJOPtdnN7e3tgsE/XNRzHLcsyDOD3RhqNjm3Ybpcb2sqNG/MMyx8+emRsatcTT79QyG+4nZRhKNGIb+Pm+Voxe8cdd1y6dAOxMZrgclv5e09+gHN5l9eWGZbcs3dyciQcj/k8777zysUzTpbSVHl0pLdYrlSK2+Vy2bblVlPQddnr6qVp+vylSwcO3MYwrlpLkkT5sccei8difX0DkiTccdedc3OzO6kMTZP9fYNXr10SOEmW5XAoOj8/39OTZGhO07RsJtPX1wsB6nZ5LBOxUShJIv9GswGWZYV2B8MwUZC8LveBwwdSO6Vw1D846PcHkOnpcKuTcruwgf4khNjGesbpZhvNwuGjxza3irJsypLq8PpKFf3lF1+ZXdgY270vXS71G5bb50UQgAIUAASxEWDbwCYgxHUJ0LQHIwxZb5caFYLEE6H4sdvuzBeaOMZxFKPKKkRIRUfue+Dt//mN//Pp//URQarbYq7YrH7nhwsf8XL3P/gABuBHPv6JD37g/f/z9//w9//53waGprdzTYLlaJKSJQlaeksWZUNiPLyoampTghiOABRFIcoQwAKqaUqKZmMWQxGy3CIJliZwxIKYAaGpOWhA0KDVarfq26YV5jm/JIkOpiebypaB6KGcdx3o2zvG33Y0eW0+vbiewjF/NV3ZNbBr7cpyqdzx+WKUN+jwhzZXlxhq8Y+e/VAolrzztmMEtGnMCgWI73z/Cwhq7dpzyOfzoQTfm4g/++zj0YH+2ZW53rHBOwfGquWOkwv2JgduXL/2w8e/rkiN47cddjmcP3zssXe/693Ly4vBgDcSCW2uZQ7s33/ffQ8me8Nf+MK/AwAcvKdSqexs73hc3tTWwsbGxtjwiN/vN02TopmH3/2eWq1Wq5c9HldfXyLZG3c4fJ1OiyCwq9cvF0s7siyHArFapfruhx7eSW9l0kt33HF8aXF9YXEbQ9lMOk8x9K5dU7olR+I+J89kc+sojuKUTZD2+samqopHju79lY998MrlM4lEIp/beu3UGduyCJzatWsXiqKnz5xyOtw7OzvVek1V1XgyrhnWO97xtqeffJwgsfMXzjYqzXqtpohSX19fNpfOl0qHjhze2NqmWFe53o7F+zc25gYGowODH17aWt1YKwdCE8M9e1SFDbvZei23vbbkc6MdQWhXdxIhB8TQliDLgoTiOIUzuoEYtm1bAMVQiGCWZQC7m4puAWAjNgJsYEOkm694C238TFzy0+Djp0/rIqc3Y6Y3MBZEUaSb4gnfSO3sxtFZlmVZBoQQx3Ecx2mahhCKolytVlutlmEYDMMEg0GaphEE6XY4EQShW37fhVZd5/J/ObcfH9YbJ9y6qB+rW/yxi4WWrgksg3EkIzQaQNMJirRtebA/ISqMqNq6ovu9fk1upXeyMzMz2ex8s9nGgOgNJYIR/9rKPEW4fR4HTSAzU+Nrqwss53Z4fbLSzubFgMMrdJRg2C8Lnf5kXO60CJQybSALeQpFSBQBumyonaDPKwsdHCUIDL185WwwGgGGnkj0CrLRkbRgKAogquiaZUOO4xS543E6gWlwLNlslN08h+Po2vJmMOSxgFGql0eG+gmaarZbDItXKrW+3uFspkJRUUGwdu05en3ucrFSPHH78ZXtAsO6DN2q1+sEQ4cSybYksAyzZ9/M/OUz473hzdWFRjWDY5o/4PrUn/zetdnzd7zl6PrG0uzs2sjoAa+bz2d3Op02SWGtZjvo9X3zG9974vFn/+eff44icVmQeAfZahVsFGuXxHqtAywMAdDpYDDMYwNNklsOh29gYOD8uctupyccigiCHI/HV1aWaJq2AKy3qrph8U7PwFC/rOjNtoThrNPjUBQIIAqQ7iq3X6+cRYBlWbqudwtOf1Q8YQPLtt+ILXnDjAW6TQ2goryeg9VqtTxutlgsRiKRdrvdvUkoVcrhUIClqe4iNk0TARABlmkZEEFRFNU0zdJQiMNo0pfJZbyhWMJP3bz0AtDaKDAWF1aTyUg2W9ra3nS7IqvLaZcjsbXWkUSAcLzXMKFlIR1B0jSjWqsxLOvxupwuniAIQRAwDCvkSzTNyrJarzcL+RJN0ysra+VyORaL0TQ9NTXVfZM4nc719fVYLNbX1+f1erstfnAcx3FSVfXBwcGhoZFQKLS8vLy9vb24uPTUU09vbGxQFNVut/P5vGEYTo+33mzyPK9pOkVRsqw8/vjjJElNTU1lM7lmsymJssfjiYSjH/3oRxEE2bVrV3onu7a6GQxGtjbTly/NGjpQZKPVEuKxZKlY63Tk3bv39Pb2a5q1b98BSVQymazT6RocHOzeszIMA4Dl83s0TR0cHPD5PQ6Hg6bp8+fPnzt3zu12u91uABCaZhv1liJr7ZagaUat1lhZWel+Ijz22GPlStHlcghCOxaLAQCCweDx48fj8Xir1YEQZRkum81DCEmSNAxD04yF+UWfz0fTNIbiHOcoFAoUyaiqqmlas1U/evToQH+vk+NSqVQkEnG4XAASBOXYSZcMC3/LPW/3+yIPPfwLqVQ2m82+9NIL6xtrgtgpl4uWbTTqVZfL0eXYRFEkaCocjZEEhWEUBBiB0whCOJ1uDCIkgdEUsrm+VCqmDEO4evXcwtysqRvhSNzlDT7yyGPlSrO/b2Tu2s2D+w5OjI8N9Eb+4e/+4vc/+Svve/cDD7/z3p54QGzXbF1ZW1rMplK5zM7mxsoPH/9+s1XleJqm8XAkWKtUFUXZN7NndW15anoSRe29+3aPjY+oqrywcDOVSp0/f9627ePHj6+srF2/fl1RFNM0uyW4hw4d0nW9VCpJktTXO9DpCLqikyRt6KahW5YFOh0xFouFQiGHw6FpGgBIs9ksFsvlcjmWCMcS3vNnn06lLtt26fLF57ZTN3meTmfzmVyDpHwPPvgeoa17HF6a5KSOwZKuG3NzsXDI4/HMzc0lEsmNjQ3LsqAFoY0gNgS2ads2sBBoYhhGWJZdb7Q5zvPwL3z43gce/sQn/5iiOV3XEQSa3SAj1VQlxevxdBr1bHp77+4plsQiQdfePcM+Pz85vTsQ6S821dVM7WN//r/LHVU2TIzAVQCagophHEXwOrDqYlMFBkFTLO2icY4lGQCAqkuaJVuICRBoWUBXDSfL4ECHhoKYKolAoClqp14tp1xOFEF1SRJSmZKimhTjaDQaPMu8/NwzO+uLIwORqxdOnXrlh343NdKbxE3TEpVkNLm4sO7yOQ6duLsuqffe99Y/+qM/DIbYB+87eXjfQQfl+tpXvjk7OwugbkP7/MXZbK7DsX0YGStVzZdOz7567lqu1F5czt68ufncc6/867/+a6mU/8Rv/eqxowcZlvK43Xv3zni8LEbos3PnMrm1icnhdrupqsrv/d7vQQhZhu+GKScSyZ2dHZIkBwcHn3vuudOnzxqG9corrzz77LPFYvHo0aPJ3p50ZuvIkQM76c1KqZDsTfT3Jp96+om9+2acTsfy8rLT6Zybm2s2mw6Hy9QJGvP4vQnLIHoSA5KorSyvLy2sKoqytb3RbDSuXL7Y9X0263VNkXoSkYDPu7y4UCqVIuEwBCjDcEePHp2cnEwkEsPDw5yD72YHqIr58MPvvXD+CsO50pnC1PTuSCQyPDwc60lk8rlMOkdTXKFU9fsiqqoroohjFkmBYnlHt6RWq0NgzsHBfcWs1qnbQlPFEdgT8bRqO0O9XietDyV9iNHEbJElAAJMQ1csQyEwlCZxDCKaonbhQtfhhLwORNCu1f3N1qv/KzT50fiZglpX+3uzS/3NuO3W8W4iKISQYRiPx+NyubolTdvb2ysrK6lUyjTNnp6esbGxeDxO03Q3ZEEURV3Xb8mL3QZz3d3u/9fM/8szf/wEy+EkDVPOFnMMy/FOJ0ZiFINZQJTEGg41B8OobQHottAS3E7etk0EweKROEWRzVY9GPC0mhUIdNvSeI50cATvoHL5bc7J4AQmq1q93jJULRGPmrpuqBJDIPmddZ+T5GjLxaGdermUy40Nj1AE0Wg0VlaX9uybcbh4FIUMw3R/gbquG6amqjJFE4oqSWJnZXmx3WqEg0GeJurVYqtdpWhYbxSdbi4Wi3g8HtPUOY4ZGhqo1+sswwwPDwOAsbzzytVZh9M5MjJy9epVVdURFK83W21BbDTbCE6Eoz2WCVbX1iC0Lcu4484Tly6cOXHyyPLq/NLKzX/993958O33ZXM74xPDfb1xSW5lsptOB4UhcHRoeGF+6fEfPvXFL34pkUh0Oo1QyJPaXiRJm8KBz+UcGxr2uZw4Yhby2z43026VfF43jqIvvfhKPN7jdPkzmbJhwvmFpVKphGBIpV4GiEkyZFvqNIR2pdlsSwqCcxTj1izEelOwSJc3vbVguuFYP7Ha3/z9x1c48Hg8Xc/35uYmAEDXdU3TWq0GSZJOp9OyrEa7ZdmQpHDT1AGwuko4Cu2uq88wDMuy6q0mSVE073nx1YvlpkI7AluZCsX6rs+uFQutE8fubtYFDCMlURUEbXJyPzx67ADNUg6e3UmnEWgblsGyLEFgiqJQNGGZwLZtjuNIknY6ncViUZUVyzYoiuJ5Gsdxh5Ot1+uFQs7n96Ao6uBdpmlub29/8IMfrFar589fjITCR48dnp2d5Tjuxo0bFEX43B5JkjRVVRSFYZhuiJzb7Y5H4tvp7Vq9HolHdN0EwMJxkiAwUZTHx0db9VazVUcRHMORUrFy+PBhnudffvnl4eHhlZUVSRZ4nltaWrBt2+XyuN2eVrND0yzDcP39/fl83jTNeDxKkmRqezMYDGq6vrW9YZpGT0+cd/GarjQadZ7nGY7jWAeG0q+8fDqbzfO8k8BJTTPi8Z58rqhpummaLENLkuB2OztCa3R05MqVK7YNIuGY1JEolnE43ZVKxeFweH3uxcVFFIU8zyIorNerg4P9O9nUG1n2jomJcQRBVVlbW90oleuKohqaOTIyYupGLB5BAfjhk0+6Xf4jx273BZNXr6+QjPvc+Su/+uu/ubm5bpudaMj19A+/k0uvOx0sgSGGBSRZdbs9fQP9LM/7fL5ypbSxseH2eG0bKpKKY5QmawSGIyggabJYLh87flujI7ZFHSMd+UK1UGiUSjUHxx/Yd0ARNVGQEYiPjY1NzUyNjo68fOo5kka3U+sXzp8hUaxSKjtYbv/efaViNpfPsjyXSMZN267WyroqGbosNpu7dk+psjI4PCRIysLSMut01WtNaAEMRS0ToBjc2dnZtWu62ahtbKxFY0Gv11MqlUKhQKVU2r/vYDaby2QyR44dV1V14cZNnEB5jq7VKjgKHA5OVSSe5wGweJ5vtTqiKIuCbNoW7/MABLqdLoalEMTa3tnmWHdv73iuoLg90UKxevDgQZJCXnjhuampXdVS3TRQiLKHbrt3K1unXFGEdmIMoVmgXK7hCI5CFELUNi0bmMBGIGKTGNYRWpzL3Ww2g/4ADoDUljRNRQkLpbCmJCQSUV02bEUlTXD6pR+2W8ujSbadm5+Ymvjcv33n4Q//7oHj7/zhE685WJ834O+b6Pvc3/7tXXc+EI316QamqSZQTRTVKUbDCFMSVcvEEcBCgKOoYUHFBLJtmyhCIxC3LdwyTQKxga1hwERti0ZJS287eM1CZclQFINqS862aLE0US9v7p2Jm0LjzFOv9SfCySEPyVOs2/fNbz+T7DnAM+FYOMFw9Of/+at/8Ie/9Ozz337msS+f2Ds5PTrQFqTnnz/DkfFgIPaOd70NpYwvfeUfcYLY2q785m986srV1aOHDn/nO//x+7//8S99+W9Zhly8sQYhumt8sicRKuTWN1ZvKEp9bHTwvrfcc/XaJX+QGxzqmb12vl6vv+XOe69cuw5Q0zT1s2fPHzl8zNQtTdNzuQKGYdNTu59//nkURfft39NNFOze0uA42mg0enuTAMBmS67XWjN79zeatUIx1dvbq8iGrpvjIxOGoYpytS3IPfGZjfUMgIami1eunj927JDHy9+8cW3uxvUDB/axNNl1FHzmM5+RBJnjicce+3ohn2JZnmMdOEoGAqH7H3ggk8lcm73icrk0XW80Wtvb26vrm3fccVetVovHe6ampqBlKrK4MH9jbHjINM2FhaWjh4+9euqs1x/ACNIT8O87sPfm4vz5C2ddLEvzrp7+yZtLlUjsUCAwVqsout4h8ZrPa21tXpqYnqAo3/pm1e0ZUE1KNGzVRgGgOpJpQUbTEIhTBoAQfR1g2baF2hACFNqIDQGEP7Jh/bQ/6f/ibf+JPenNDNCbIw9M0+6iLtM0u3E83YB1SRK6sQKCIOi6ThCEw+FgWZbjuG6iVTeLoRtS1Q1PvpVf1Q21Aq+TYT9bJfz5EuGPRYm+ado/63xomkDGUJu0MRyYBFTXVi8RWOfYkdvmrqXjsYliqeV0eRxO7uKlM/v2D18582SfU/W58GK9ObX/pE1EbixtTY6NV/JpL4cosiAZdktSveG4IptyQwGa5vNRDI2mMimv34dhGETxeqWOYZhtGboiq5oUikbmFxbjPYOGgTCssyl2qrVOMNiPoizr9AqKblh6t3CSY2mh2eQoFIGKk4M4KhcLWV1WotGookiWZfEMy7H0+dOv+P08idsul4cmA23BjsQnbq6uq6Y6tXv8yoVTNMPQrrCiAxRgtm2TBIaTxPLqCgTa/ukhtVUIObDN1YX0Tmp1c3ttI/P1R74pytXT587iqOPOOx9Mp2o0xRuWUG8UenoC2XTqj//w05/8b7+/a2rP4tJKQxIICocotv/goa3tgiTbFO0IBMOKKlQqRUGsF4r58dExluVSm5lET1+10jYse2xsJJPP+PyuTDarmYbL4wYQb7RljOBk2Xa4QyhGd0QNYrgJgQVfb+3clQV5nhdFsdVqhUIh24bdrNruME0TRXDTtt4sERo2ZWnK5KDjz37/E3Lm0u6xMIoYx48dTm1vTk2Mr6wt7969u1pvmLohthqxnoQnHKlpvMpM11ReRVHNsjEMMQwDI0gEQGBoNIau3Fjw8Bhpt6VWJrd9/Xc/8dGdjSUSM59/5rEbN68G/N7V1fX3vvuXLAtiJMXmc3nJ7fR4fILQRgHmdPKmpesGVBSFZXie59fXN10uN4Kg/f0D5WKxI7RuRdR3Gwv29ByUFbFYLObzeY/H09fX98Mf/rC/fxAAMDc3VygUwuFwJpNJJpOLi4sBr8/pdJZLpW4sL8uyOI4rimIYRiyaEES52WwTBBWNhm/eXHC5HBTFvPbamWgoahhavV7y+70EQVy+fHnv3r2BQIBmyGO3Hcnnc0tLC1PTEydPnnzxhZfL5arL7ejvG2w0Wo1GLRDwoSg8f/7s3r17BUFgWbavv390bPj06dNDQ0MmMEWpI0miJEm807m2tlYs1Hy+EMvyN27Mu5xummY7bbHVauM46Xa7JEF0Op09PT0bm6u5XObgwf1ut/fq1WutdmNwZBjDCBzHX3zxxeldkwRBtNtNn8+j6WokEtN1PeAP4QQKgCXL8qlTp1RVM3VremoPRfOdjmAZNgBAENulEjJ75WokEuntG9pOZzJFkeO9R267e2bviWK57PEEAt7khbMvlsvlvXv3ikKjmM9SDCfKkigKuq5ns9lqreL1uv1+f7FUdjhcGIYIYoMlGAQ1dUPFdLh3ZtelC5duLq329o8026ogmz5/xOV0887AuUtLQlM8sO9gTzzxvUefeOS737nnvpPJ/kh2M02QcHxsUGwLB/fvu/v2e7c3U6db0v0PHFpYWWR4783FObfH4fa6hGa9J56gSMbQ9HKxxPJcIh4ORsJraxvNektTFUlSdF3nOJok8cXFeZfLceTIYYahnnnmmVq90tMT39re8PuCOzvWhQsX3G43TdPpdDoWDfl8AQQYgtDBMVyWZQzDDMMKBsOLC8sAQJpmNFknaKJSKo0M9zIsmYG6LLVbrZYvkLRs9tCxveFw8PSZF51eP05iTaHhc0dYzsE5iauPn1/erv33P/7TjUzBtAGBkQiwEYAiFrDQ7rZkQwg1U0NxXDc1jnfUqm0CxSgEwTAMQfV2u0XS1PXZ2W984Qvvffid73/7WxZ5++juE//wuT/tDVKyYPhd3NM//PbQ6OHbT9wh6ni93WnLxvj4JGlb+Y3VYM8ABBZG4wRGKloHtUwEQzEUU2WdonBJlknKpnDMNC3TVGwbQARHIK4YKmIbCDRYEscRWzPsSkeotovrO5kDh253eN04oSKI1kCMRkOkEGZ83+08g29klrx+K0LZx4/fPnst1W6pvoDTFDWfl65XO4Vcvqd32ONNvvTarMfLve1dD/ldQy5nEKLWo489EYoMfOffv/inf/dvsWT/xcvLuWLB4/PWm21FtiA0+geHT5w42Z9IZnfWTL2eiB1NpRb9fu57j37D7/fgLcnnnzh/8VVVVYV2I5HonRib2slkM+ncmm+t0xJZlkUQTNf1XC7XLfhVFX1sdOLc+TM+n69arYaCMZ/P12zVBgcHozEq4I+dPX9FFDsUyQ0MDOi6qcjaiRO3pVLbz7+4eGNu8Qazk82V3/3QQ6MTe0eGB3p6oo1m9cTRY8+/8LTP5+1NJlZWloLB4OLC3PLiIoLYHo/T8EWj4Wi5VKdI7vhtdz36/SfzhazTyXo8ngMHDqRSKdXQDxw6tr6+6fMGhbZeyNXj0bCmybt3Hzx/7rVGrXLixIl8sTC1e8owwWunz//i3oPrKykad0yN7kExu1JreXz+ufkXBdUdT0yQtDU83Ncoixtr56GlFtMpXS+4vEmfk7i+sEm5QgCSOEVTBG5BXNMNBEFwDDFN3QY/kvCADSCEEIE/AThuAZT/F1D188abWYFuZLZt2yRJdsFTq9XKZrOdTqvbMy0QCHTDqLpSS6PR6CqA3TqhW1QEx3FdiRAAgGEYQRD2612cfyzW4b+ap/VfnvPm4xBBcIzUFAkl8U5bcNBgcmI6k57d2lwd7h+1DDPgoU1L7jTFwb5wpZofHes3Soui0KZJyungzl5dYGiPLHUa9QqiIeNjQ089/6onHCdpan5hri86iDOUZWnVSp2iGBzF2q1mR2jTFMPRhGWgzkC0WqvrmjU5sQfipChp5Wq1t7eXwBsICggKMwyFpnBVt3DcZBiyXq1I7ZbfFauVChzOSXLdwdAtVSrktr1er2FouWwtGg4FAx4M1RuNEgKtpiEBxHH16tnV7Z3EQGJh/hrHOr2+0EamZtu4y+ViaDrk912ZvULhzO5d+1hCl+slt8cvyEpLlDPZ4q/++n9bXU+9+tpTBw8eTPQMnT9/URJsDMNwwhocjOcyO5/97Gff9a53xZOJ1fUly9agpSzML3SEtm1pIyMzUb+zI2o3rp4PRj3BgANWmnRPhMBwiqDDgfD1a3P7D92GEeSN+cXxybHUzlYqk+0fGGp2VIwAFOfkeT+uGKaFmjYCcMKCCATWm8Rf0F1L3dZJGIapqv5mMvVnKt1diRBFAUEQjmBwcnISQ80uROuG+wiC0LUVEgTxRstLwzR12zZRBMOAjQAbQyACbE1TFUEkXO6Z/XtVoXnz6qmF2WvJMH/qzNXizvKe6UEbmIrcKVekO+46eP7SMzzvwKZ27TWvXzNMzesPtkUBAMtGIIAIQRCtVisY4NrtdjKZrFSq8zcXZUnFcCRfKITDYVWXgGWjGBgfHxeEtmVZsWiiG23F806SpKPReLlc5XnF5/PVajWaZjOZTDgcLhbL3byGbvMWAACOkVNTUziKWgBgJJHJZhmGGx0bMw3b6XTLkoogGIJgxWK2v3/Qtk0MMUzTvHZl1uf3LC8u7to9FQx4KmXX4tLCyPCA0Gns37c7FIoUC2W3iyuXy4rcNgxjYnwkvbPFsrxlgk6nU64U/X4/iqIvvfSSDUyCwFVVrdbryZ4+VbHK5bLD4fH7AhhGsCzbbrdVVUUQrPvBgWFYJrvj9/sLhVw6nYYWnBqf+O7i93O53K5dMzYAAwMDXT8+irolRWYYGsUwh4svlUqhcGBnZzsSiQSDgUajSWIMAODihQvRSAxBsK4bdGcn1d/fL6nq5cuXw9FBl9dz6cp1SHgFQeN5J4DG1ctnX37+sdtv262qij/g1RRRM42envj8/KKr6AYo0mw1LMtgGAbHcdPUvR53oZRifT4bIqahkRT/L//0r4Fg9OjBk08/93I4kvR5/T6P933v/2VIuN3uMAIwQ7X+4fN/r5t4PD4givq3H/luJObWtDaENmIjly9d+up/fH1618F4or/YUDfT1adePmXZKoBGIhLAoCk26kN9vbZlRKMhkiSgbeyk1l1OliLwZ555bt++A7Ozs6FQyAb6oSP7l1eW5udvOF28y811Oh3VUHEK30xtyprid7gsCxQKpaGhIdPQOm3RwVEul7tYyDIMJQjCxsaG3xuwTAtDcctEbJuwTQa10dR64e67T6hJcHl2AUPF4Yngk8+e3iuRmWKVcjguzZ2hHNDGlGxxY/dM4My5l6I9AcYdXV/bJDnKMG0CmsBGoIUAABCgW4huQ2ADxNBQnGIUo0PiCMlYFGorLYmmaV03XC43ShKLCzdHxwemJ6KnXvzqi8//B7Dv+9O/+Mz3v/qle9761qOG+PLZ2Zce/86B297lDI00TKNTLd1+aC/SFoWOZEoVgqAMiMmGjaMkCm1ZEUkSoXlSUzsUg1umrksaCmwaxwGKKbol6TrGUBhKQE2QFLXWbmAkoHwuj8c7HZ8SNNTuqAyKoqYxNTyZzxdrlu3x9SIszUOiUEpfuXEtEo7xLl+z03r8+e+4nWyjle90Rlq1PGLhB4++Ldm7J5WZm963L7WZL7cz33/0sXc99I7RidFL127opra2cY3im7X2dZKp/NVf/46pye973/smpiYvnL+USS/ffcdxl0vZ2b45OBTEUXDlcoogzUbLeOF5sGt6/8GD+2evXH/0+4+l0tl9+/b1JBIXL1x673vet7a2Vi4X+3oHKpVardYIRcJrG+vReKwn2be2thYIBPbs2/+97z0iSLWdzFYo2ON1VzbXNsfGxpaW51aXVhOJGLTtl19+aXFp3ulg7r77zlOnzg4O+YMh/OzZZ0eGBnZSK1evXr7hcUaioUMHZ3a2t9ZWb5w88bFz53fm5s799m//9lf+4ysPveu9hWwptV2gKObalYVdU3uz6SzDcK1W61Of+tT999/PMIzX6921e2+nLYsdlaG5555+zutz9/XGXa4ITbOiIrc7DRZoBM4cOXpgeztFkY7hkckXnr34rnc9TFHVldXM0PAA70Ffu/jYcP/EufMX++LOnkikUrJyqarP22NLtiqqOAI5hqi1ZU0HFmSc7iBEdNVCOoqC4yh4UyD76y6k13HJLeB1S9oDt3apW3sQhBAA24Y/Yox+jPFC4I/a+aHoLbMLhqAYShiG0Wy0W+2GYRivN+8Kh7s/urvJdeOmTdMkSbKLtG55rboAS1GUrmvi1gbZrcA3Tf3WJH9eheCbN1AL2F349zNsZT/9FBuFJmrrpmTogUBIahZpmp2Y2HXm5ReVFp6I9GG2TpKoZqi6KahSPRRk1hYLHAVjyeHU1rbYkTk+YJsmgSE4hnQ6nTvuuGN+batarU5OTxEImdtKuTmqLcgcTzebTYahOq263+fAEJQgmFazo2mGm/faKC4qOs3yaKuN4yhF4uVqvSfpk3W9Vq/EeiKS1K7VWu1mszeWNA3FxXOqrBAYTiAWReCDg2Pnz5/3er08y1RKeY4hW616OODM59KxyFC5VmwJoL8/qFjt1bW1t5x8Z60me50hh9PfabXUjrle2YQqMrFnd71SzraLTgpeunyjUKjPzi3dc99Dx44/8Fef+9yR24709Q+ffu1ib89Qf0/s4sWLPclQOp39p3/42w9/6KMz0weKxWJHqCcSiX4uOTDYy7K0JOsrize9niiK4QEv4+Rhq5GplHJeb1CVZZZynD19Jjkw5HI5SrW6Da1KvdaRtJ7eYYLhFVGlWVdH1rSOjFO8qKoAAhSnEASzLANaP+KourSOpmk4jmMYJsvqrZpWxAYQIuabih4QBIEAIhABCCIIoGulUhQF2KrQbvA8j2GYIstOp5Og6EIujyMoSVIMz7VaKIIA09IBwDEMAtu0gWkDaGgaRXKaaojQkOSWjZP3v/3dazfOP/fi6YQP3dhc6etNLNxEf+3Xf7klVkrVxd6BIHzfL/1SNpstFAqxWATHEI4nLVvVDRmYhiAI8XhPuyWoqi5JMo6RgtimKApBbAzDHE5GU1RFFXt7e0kSJwiimz6gKAqOk9vb29FovL+/f272eq1WGxsbS6W2VFV1uR1Cqw0hDAX9DodjaWmJIAiaYjmOG+jrqzVaL516dXh0RNf1dDp18MCBSCSSyWSq1WoynlhdXdU07Z577rl69Wqj0eBZjnewlqU7Xfzu3dOvvPKSIAi7dk9vb6WOHDnSbLZfeOElluETicTi4qLb7WZZtlarYyjl8XkDgUCr1fB4PJIq4QSytbWBoihEEb/f39vbX683W01BFFRBkDY3UhzniMeSCIKtr20iCGKZer1RcXtYBLEDQR9J4g7W8a53Pfz97z2WzeZX1jaiscSdd9759W981enk2+2m0+mc3j194+Z1lqV5B6soSq1W2bVrV6VS8Xq9PfHk8tKqbaMet7dSqWmaEQz6c7mc08EFguFiobq+neGcoZmZo6zDz3GeJ554iiLRWNTrcZGpzYXhgXi5lNV0WRBETdddLp8ky6qquryefD5vGJbXF2w2m3fccXJleeHMa6+Oj48jAM1mSjjGsKzHtIlqo33yzrckB4auzV3/td/43fXN8o2Fda/b98TjT7kdrre9/a2q0p6cGvmDP/ytZr0QiwWiEZ+Ld3As26g2eIcvnBj8+iPfkRQRYmD/gRlN6QBdtlSp06gM9/c1m3WOp2mGlDXZAma91iRwdmho7Pz58yzLVqtVHEeHhgYQFJYK+Ux2x+HgHA4esWEkElFVHcGoYCDSanXK5bLY7iDQhtC2Tc00dRQDuVwGQRCO4wzNdLnchmGZBqQ4B03Tlq45nGwg6GF556Wry4n+3SQd5z2xGwuL99x3R76wePrMU2PDcRRCU8cQ1BGIDDvcyZ2CTLGeQMQvKappQtskEIu0EQhQzUJ0GwAboBjKG4Zho5INNGhaqA0YjBMEiSAISVNpjl1bvTGQ8D3x3S+5qTYwBVW3Z6amB+ORF59/YngysbFVzGZMxfJ8/Lf/BFDc5vaK28H2eP3ARhQMz1SbgOE0HaI2QkAUQYGqKwDYGEHahg1sG7NMBFi2bZs2tFHSxijFthFoEWqLJ6GtChiJSrZcaQkMG2q3VCfFu2iCp3Xb0tdXs6FYwheNPvnM07md7ZPHjgZ8fs7Bl6t1BLcbrXx6a62ay2lCM59d/+1P/L6quEKh4MraGd6B3H785Cd/5/eOHjl5/PjJr3/96z3JWKIn9A9//7mpyUFNawqtst/nYQmuJzmwvLXBOxw0TkRDHhozZKG6tTnfaTY0zbj99jumJnd97OMfufvOO/P5fCgQoGn64pWLGIbpuv5rv/obmqZ/7WtfIwmWJEmG4d797ndDFOkm+CuKND4+Pj8/324Lb3vngxBIjz/1ZMgXxwlndrt68s67hHZ9YfG6posUhU1N7SoW8z6vt6+v57nnnzp+/JggCGMTk8tLq5ubmw6HY3tra3x8tFIpSXIHQ6z3f+C9C/PXt7Y2Tp68Y3MtE4/1V8rVdDorSUq9Xq9Wy9Va6Zc+/IFOp9Vo1ra2d/bvP1iq1By827KQfK5yz533VatVVZMbtaooNXHcPn7y8GunX+10OjTjqNc6sfhgONTj4N1Ly5vBQExQ5NhAtC1JNxY3QpEkBkip3RroCYcD7lMvnertHSAIF4T02YtXHIHgyMyeWkc3LLojQYCxtbZEMDyKU4YJbRvatgmBBW0TQghsBELUgj8W+/6zwdObGKlbAOsnSKPurXxX1OvqFd2qQLEjybKsKjpOoN2e9F1ppuuP6dYY3jJUoSjaLfICb8Q3dF+5uyO+WbV8k5nmv4xpeBMihNaPXdebnoogmA1/igmzgWnaFI5h0BDapUTY0Wxkwz7S43QiBrmztQOAyXK0qHTcHgdOImsLV8z6xuhAcnOnQnBRnOvBSQeKmLVarj/mkRXBRsiWpFG8V5R1sSl6eKehKAyNA2jiOGpaKsvSlWqZY3mXy1MolNI7+XC8B0DcHw43W61iqTDU17OznQqGeiyAdWTFAibvZOqNKsewHpdbbkumrqLA4ljcwaCrq/O6qsSjkcXFxf7+fhQBLEvWaxkEMYChuN3eSlXeTpXHdh1ULINzMyzn3Fyt+n29pgVN015bW/N5vDzPMxwLCWRrc8XW24mAs1JI/fVf/9WJk3cdue2u7z36/OFjh3p7/aVydmJ0AgJsdXGzt7fH6+M+8z//6I6Tt/UP9IqCyjCMrquBQEBoi4ZlAhRAiAZ88dlr88FgOBT25fIbDE+hGCHKBs+HVcUq5EvegN/hdiE43m4JSyurfYOjDqdHMWyMoAVZ512+jqxZCAYw0rKBomjdhWcZJoqipml3S5ooiioUcjTNhkKBRqP1RvKZAS0IUGDbtgVsBGIQQhQYACFsm7Q0ZbSH/ue/+rTDymFaOV9I3XbssCoK+/bMZLI7w8PDxVKp2WiE/H6nx8O4vfkOxkRvSzeARVAAopZlAWhRNKvKKoPTqqyoukCTSG/Cd/PKxQCHnH350UMzPQ5KkToZhrRlqe0PuYMxXzqXxoq1XCgehiiRzuQPHTjQaJY7nU4k6qVJxLZ0sdNGIFRlBUPQvt4EiqKZTIZ3sK1WS5Fk0zQDgYDb7cYwpFytyKpSLBYNw4jFEs12q1AsW5alqhqEiG0DRdFYloEAJWhKkqRqrbGTzuq6TlJMsVyZCASTfQOVa1clSWIYpt1uerwuX8Cdze84XVw0NlatVlECTo6Nl6oljCRkTeU4B05Qe/ce/vzf/y3NcJVq89ixYxDCja3tianp+YWlk7fffvny1bWNjbe/46FMJmNZlssdKBVrG1vpTK7k9boBQsiKuLW15fV7+vr7N7c2Njd3+vqHOZ7PFwrRROzC+Sv5fN7p0BBAMwwPbDyfKz5w/z0XLr7GMwyKWX3JWCaTzma2vvbVL95//1uffe6lzWcrkUhkJ7UFLNPv87AMKYodhsb7e5PBkN+27VOnTu3fv19RFJfDXcwXqpXi/fc/uLaybRpIrd6maUYUTZJ0bu/kFpe3br/9dhQjMYzYWLm0b++hF5/84dWz526//cSBqQO7dk+89CLMF9KyYiiqTpD0dirt9wfzW1mapimRIjG8XCpqJub3hTQdHx0/mM+3VtZSiqRGQ+GZmb1nz56VVfO+t751Y2f11Quvsjz/v//mz65eWgyHk/sO7nv7Ow7THN+Q0qViNTEY/4d/+crvffJ3s/nMzO5xWaxLsgoR7crsy8Na40O//JBq2rKibW5sDPYPqe2qmyNRW19cnDehaSFIKJ7I5/O1eqlcacSiPobxTEzMFIr5yYmoaemC0NINbXBwcHNrXeoITo7HMazVaLIsi6GwLXQK5YptWK1WS1NUr9upyKLDxRumEk30yLJsGIYBTN0G1WqdYRijpSgi4vV6cAIsr6+5/REd4ls7Wd1ue32du+44US9mbUkOcJxSr3m8LskEpg2vXVqcm382ObTr/re9zTJ0TVcxhAUoAqD9+se2jdo2BAAxLQNAC1o4BNCGpgWAaBiQolQTMLxjfXUx6A/09ffG+wcwRCRRaWwo/vRj37lySU/Ggy+++LxlIoOD+0RF//oX//DDH//NkMu8OnvudKPB8u7+kSl/JNmWNAylTBNRAMABCRHMNA3bQgEwIAAWgtqWaQPbQiwADcuWMUjphgYpaOGyppUIBEMF9cjIRKVitnWs1akrEJU6rXgkbCi17YV8p+44vjfB333QglS12l7cyviDERMigWhsoO/A3Omn1VY27qUq2UwwGb08O4ejOktj21urXhe9ND831Ns72h+fvXruzAs7ST/eKix5nHgszupy2+zIR3a/vdNpFJulC+deQ2zl6P79k+PjJ47ftTC/JCviK6dOez3B//Zbn3zx+VdIwmEZ1Nzs8lDfaLVW8ng8wLRTm1vHjx7b3slVKhVFUSwL/NM//uOxY8cKhYIkCQRBhEKBsxdOu4Ps7SePdQTpnW+/bWkpZYHmmTNXKBIHkPX5XQBRz5x9haKIlZWbj/4gt3fPKI7LbjeeTq/s7KxxPLuyuoSiqCSriqaHwjHb0leW1w0T0hSPQMIEcG5+DoHQsKVowk/QRiDMebwzhXy63RFPnrxjcGB0Y2Nre2PT7faGQuHd0xPPPvtDr9cTjQUFqUIQeKIn3mh0eNY/MDA5d30+mymOjkxm0iuWZWVyRZ/f4XLxuG1fPXNucnqmJ9lz/uzFRr21vbLo8Xh6k0MtEQiFyuEjtxnW1WAwuLJ6kw/EACRXt1P7jhyREFXWBBrHgUHbJgYBQIBmQwnHERNAXdMwlDBNu0sXQfgjFsqyzFsOpzecWBAAYNnGG3TPj8Edw7BomiZJUtf1VqslCIJhGAiCMRTtdjtpmu0aUwxD70KrWz4tAMCbEVU3MAsAACFAMGjbtg0sACGAwAY2AMAGNnwTx2baP5oMAiAANtJ9/1k2AF07DmoD8HqFI8Rer6O0bWgDBFi3qA5dM3CKNi3LMAwUgwAAy9ABiiAopgODZbF6TbQBhePoytoWTeIhfwyQKAowiKIMSTVKJRy1JgcHTZF1OrjF1dqR48eWNorNRp13UCzPtBWBwpGrVy4NjUyy0G41GjzOba+ux8IRzuNtduoIBqotiXR4KD4qaEZ2vUIRVP/ojA1hs93a3EqzvPPA/sONUioScDppW7e0Ymq9f7CPYwGpAZYFPKnXkDakbILEL116LZ4IR+PheqWa3tkWhbamihSBciyjq3RqZ0tVdIB5BAUdGN4lyapmq3Gn/9K1q15PX62ViYd8rWY16JP9QUOQa9lSBsMwQcjvGu3fNT76Kx/9P0eP3v3e9//W17/zmD8xeOzu+zPpdYcXBbjDxTsGh7DpqfFf/fiHJscmHW6HjdiKKbt5/1Dv7svnr/TEk9V6BeI2hiFVoeUJuFwOJrO9hUIrt5X1hsNDo1M3F7cQlNx7cCafz7aa+VgstpBaOnbooI2SsgZ1VZMVheE9jbqEMYwNEMMwEQzVbYMiWUs1AUQBRC3bJEgaw0lNNSBEec7Z6Yhv1J9aENoAhQBYALMwgCImRGyoAxRYACKWZRuWDrxOh1JNEwQhSUosFnvt5RfuvuvkdsqgCVJoNmevXnrf+96nqiouaZntUtyv2ygNAQEAjkAbQYAuGzhExGbd7XY7MCZfKL526hrQOvsnJ3cSoUx+CzWrpfT8B9/3rnOnVr79jUd+7bf+wOubgB/5xMdWVzaOHb1zfSVVyOZ+8QPvvnz1lNAp7do10mzWM5kCsFGK5NLptGUboVDI5/EXCgXd1DRNUVUZJ7BQKOB08sVyaX19fXh4mOf5RCJ57dq1Rr2FIKgsKh6XG0VRFIMsy2ia4na7FVVq1urtdntsbKzZbN+4cSMRT+6anr42OxuORav1SrvdjMUjXq/b43UL7Q6CgHZbaLVaiXiP1+s/ffpspy36fL6hoaFGrUJRhCRJ+UI2HA4dPXr0+vVr6XQ6EonUarW+vsHe3t6V5bVarTE9vXtxcTFXKImi6PP5ug2tZmZ2IRhqGNrG5prP57l+Yy4SCb/zXW+/cuWKpmmmAUwNy2Wqm5upaKSn3RJ1XWcZMhL1pbZXx8b7R0YHvvvdR/bMzExPT7db4sVL18bHdlVqDZ/PV64UZVlqtVoYhgBonTh5cmV1qVAoDAwM1Go1wzBGRkYikdDS8nyz2W7WRU21CZIf6B999vkX/X6/rIjRaDgRi1y5ctnjcg8MDDAMm8vl9s7sW1hYuHlzYWpq6gO/+Ivnzp959NHvuVzOgcE+UewYhraxsYFguNvlVRRNN0G11h4ZmyAIplAoFAqFoDfocjpJEt9YWymWyx/+yC/XW21J1WZv3iBZ1rZwaJHHj56wUTC1a/rK9VlRNYKhnkq5eejA7Y1a85FvfmN6YpDEFUWqQqvDOhkEp4r1to3QgWDk+rU5qGlH9k7Hwr5yPt0Umi+9+srBI4cBhJquKHKnVetgKGtb6L79e5aXF70+VzgYmLtx1bIMyzQsy2g36zzLdfs/ogDGenudnuCrp86ODA0nY9H11bWNtRUcg/F4VNFkG7E7UqfTFhiG0zSDpThomzxHOV3czs7O6OSUw+nJlZvFmrJv/8n9B+745jcfJUny3nvuqpQ2Z2dPj/RHBUmyMTaVEcbH76y1TMrp9wT9FmJiBKlq0AIYsBEAAIAGAMAGGAAIsLtdY81uSrVt2wAgACAIQG3TsE2VZVEKN1qtQijizm4tXjzz3ObiHDQ1yxD7E34cQyuldiSalC1res/Rsamj6VLr+sJSvaPc++A7EIQRRBtBKRtgtgVtBLEsy7J0FNoY+nopMoQQQhQAywKWZSMk7Wo2aw6H5XZYtfzizPiwKejryxmXs0c2EBMzbcw0TZHFscUrC512/eCRCYjhOurIlUWPN4GSXL0tQIwyDYyGVpSzr597Ipu+RpDU4bt+AcFI2hI4xqhUdqq1Ck/7v/3NRzxuh8/LmnpzbCwmC5ViYbPdKvg94b7Yri9/7VHC4x2eGtC1woH9Y3Jb4Eju5vXVubm5244fXlpa+PhHPrqysuHkvAAgu6emO0Lje9//ltfrzGQyCILMzMzkcrmZvQeff/75QqFiWRbL8QxDG4ZhA7NUKszM7Ko2K7IqzczMhMPRG9dXctnqwf23ez3hv/zLvzxwcNehQ5Mra9fbrdLIyCCOYbatG1ozkYi+dvqcacI77ronEund3slWq3WXyyPLMkuRKGKltjYnp0YL+bTL6cFwWlRUnqEXl24IndbRo0eDwcCrr75KYBRFMtO7ZzbWt6LRqG3b2zupoaHhzE42mUx2Oq1CMZvLZU6ePLmzsxMMhgvFCorg6XR2cHBwcXH+8JGDgtBaX9+MxgaKxQpF8wF/qNpoJOJJh8sNIKaoACK0IJqZTCUcjmE42Wq18pW8J+TMlZpju25XbbrY7JgIgZGsLENgsBTpsEwT2grNgk6nZQEUw4hbrM+biSL4pgjQW4TQ62AIf52a6j6EYVjXhN41SHU6HdM0aZrmOI6iKBRFuxavrl+q+5TuJtdlrX562Lb5own8nMbSP2KekG661+ts1Y8CVIEJAfo6HYVioPvGs22A3OoOBKBtoTa4dfk2QABADNtCEIBhmG2blqFDCA0LWobqcRKtap5AVBIzSQJDbFAsFrukUbmQUYX6zPSIoQibq7OF7GIymWy2wJ4Dd6WydZp3BUMehkOq5Uww4BVagiQoqgwcTu/S0mpPor9WbRcr5Zl9U22xregazTsApFstUZRUp9PZqFfCYX+jWRNFkWV4DJo+Ft1aXSBJcmhoUFdllIAMRdWa9ZDfV65VcZxkeU7V9Ew+BwFqm3oxlwt5/T3JOAIMTRXSma10emffvn3tlkwzznCkr9WWOlInGPGjmHHx6uw9971n9tocCeWeRCifz7UEhXPFEZwpFcuVUv4jv/ieT37iv60srvz+H35akFCcdQ9OThdKeUVq+dxsp1HjCGy4v/8v/9efdVq1X/v1j65vrPAufnhsfGNrx+H0YQjZrrVcHmdyMPHyqZc31tYS4aiLYnuiEZahOqJgEdTG1k7v4ISi6bIsszRl6OLC0vz42O5oon9lPd0SdH8wQbGejmxAggIYKemqASBBkjYEum5AC4MQoih+q2GlZZjtdtvlctnAtG0bQcAbn8MAIMBGDASgmIEjNqYhpo2gEGC2Jg34uK/+n89K5ZtH9w/dmLvy4H13zc1e3LtnplasjYwMVcoFw9BQnPAFwk5n8LUb6d7D7yvJtA0pG2CWDVAE2paGARMBJoqTP3zyhfe95wGpIXKYVElf+943/sHntUcHPQEHlNvVzMbWKy9vcB76o7/yW/BP//JPFEXvS471RPs+/elPMzT+4Q8//NST3ydpwDF0Op2lKS4cjgqCVCoVSqWSomhDQ0MYgRqGJoodURIcDs7r9bZaDY7jOqLU39+PYdiFCxdcTk+73SEwstlshsNhSRJkSRocHBgZGXI6nalUamlpKRIKGbrVbDZPn754++3HqtVqNBF3eVymaQYCPoiY9XqVZzkbWCRBdRvX5HIFhuHaLSEajSMIoinC8PDgtWvXzp47/fa3vw3DsN7envX19fX1dYZhAoHw5OTk/M1FVVXdbi+Ok1dnZ7vRo5ZlOVzO6elJ0zTnF26kUqnR0eFavTo42M9xnM/nqdfrsVhSla2V5c3nn3+ZJJiAP4IgWHpnkyBREreDIc+Bg3uWl5dYmolGY62m6AsE0zs5XyC0vr5eq/9/lP1nlGPJeSWKRsSxwDnw3iSQ3mdlZXnfZdp7Qza9NyIpaUZ3pJnRnUe9O28kivJ3NCNDSrQSTZNNdrN9dVV1l/cuvXfIBBLeH+/i/kB3s0mZ916ss7AOgANk1VpxEDv2t7+9iw4HzzBMo1FzODlJljVNc7kdgiBACAuFwt49+wkS+nyeu3cndu86iCBVrYk+byCTyy8sLIhik2VpYOmiKA4NDrpcrkq5tmPHjtRaqlAouL2+ra2tarXKcbZkMlkqFU1LDwb9nMOuquq1azc8bp/L5V1f28gWigAS1UojHo8nkx29vf2hQPDWrVvXr1/t6ekJhIKtiDELgs30lqiou7bvVhSjt38omyssrC7yDpeqA0EwDu6//9g99yqiMDd9+8xbvwgHnKPbBmfnJjLZzbook4zzyJF7Nzfybp6bG7/TlWzDltHemdzM5tbSGxxny2TSCOt93T3Ts4uBQCAcDlZr5XA46OS5zc21qemJoYH+aCS8trY2PTne29tL0zQBUS5f7OwdlBUtl8188Mmnr129nMukKZJwuRzprU1EoWwhG/AHDcOiaTbkD4ui6HBymqZYluV2uxHBiKpudwQF2XriyY8Wy41CsYqxOTjUl1pfXpibjCeTDVEPRHpGt9+v6Kys45okIBLImgoRAwEFAALAgu/AKQQwwpgAAGBovK8QgwBAECPLMCkCQqApcoXnCJ4n69USMExoKB6eOvnSjwrZ2QN7Rrs7+v7xH77TMzCw5+B9SxvC3sMPLKcz3/nn537nd38fQLrZ0BAkEYUAACY2EQkRAUxTBxaGAEMLQ4gQIgEmsYUwJnQD0Qxh6NVEm0MXczbKLG5ksEVFIl3lprhVznEOG8sQYr3uYZycjfb6mYnpqUCw3YJcKNxbqUtb1RLBchjxlmqGOaqUnnr7zLd5JzEyduDhh5547bkXQn4377LKlfzmWq5SbiTbEtXKlt1ubaZnw2Fbb09icvw2S7k9fH8s1htub3/l1M/bkxxL6ZcvvA0s3NXei03TtGRd1xBCw0Oj9YqczeZXl5Y/9vGPrK4tbG6uzczMxONxt8+rKArL8Bjjel10uVzYAvlCzuf3pzMbDzxw361bt8Kx6Pr6KsvSjz/+5OTUws3rk0cO39fbM8DZ7T9+7nsOHlbr6bZk0LK01ZWVbduGd40NxuOxb337exPjs4n2Xo53DQyN6ZpB06yiKNDCbhdfLRcvXzn/+GMPq6pq55xTU1P33XdvqVTwed3f/vY/RsLhvXv3pjdzTqe7LZ7QNK3WqK+urvb19S0vLxMEsW/f3tTGGscxtXql2WxCQGAMd+85cOvmXUGQtm/fUa9X5+dni6Xck08+ni9kJiamRFmvVBtf/NJXUpsb8bbk0srGaqpw6OAD6XSDYd2mBWOJtrfOvploiw52ts/MLjoC7awnli7qkmGjOT+iOJa1i2KTZQhVkxC2eN6la1jVTUSAdxkj+P4GwJaN53sk1ntRM4om0zTNMExLXdrylmvZZHMc53A4GIbBGOu63tJRUQT9nqbqPbrofXDq1yGU9a6A5t8CWBD+siqIIYCQwO9FVltma/UEAEOI3mHjEAkhNFvsFwQYYwQgwgDBltuqhTGwIEAE1TKPoCgKQBNbBgkBhJAmbWJTYCkMTAkZKoI6Ni23222aJstQslgHhlIppBrlzAMnDozfuWiouba2tmxeQrTHF2pXTdxo1HwBn2kodpYNeINXr17fyuZ27dpl47mtbFlqomg0oZoiY6MUQ+cd7oZg2OwOmuFUVa7XigSJ05ur0bA/4AvmMqk2v1+slR1Oey6XTiTCjI00DVXVFUPTNzNbXk8AIDqXLTucXgSpZrPZ3Z1Q5WYms1GvFzuSMYYia9Wqw+4AmDJ0i3N4OIc9ndkYGuljWKJcFwol2ePxSI2CnSMlUTEgA0iviW0Q0DRCJ199fvzW9XAsPLp9x/Z9hwHpsJBjY3PL7+W62mNzk7c648EXf/7jfHbrqScez2az+/btMyxsYiyrqiCKCEKOtHEct5bJSIrocttpErMQJ+OxW9fveP1BfzQ2u7DicHuxRUTDcY7jbDx17tJFvz8MSaYpqE5voC7oTk+QZB1NRZN1i7FzGCJJUQEiTROTBIMQgpAQRRFCyHGcruuyLDudztZ8+P8KsAAmCEvr9LJ/8gdfsZmZT3zooanJ2zu3D517++S9J44XMoXBwf7NjTWHg6s3BZfHz/P+nGKzdR7LyzYLMBYmWn8FWwZClmoq5y9e2bP7iCZI9c21g2PdP/zWX2Q27j79zBFZzgC9PDt+bWxo6OTJMxwfllQL7r1nu83mGOrbuXvXvnAg/Mdf/0NNqx08uPPV1144fvzY3Nw8wGj//oPz8/NtbbG1tbVUKuNwOMLREMNQoiiyLD03P9vf3xuPx0kSLa2splIpj8dTr9dZxq4oqtiUAEA+n4+myYX52ba2to6O9p6eLlEUZ2ZmqqVqW1ubqmrlcjmZ7FB1vdao79mzy+/3X75yyW6nPV6Xz+M1TT0QCFy8eDGXK0BItCc7TRNDiGiaMnU1Gg2zLP3aa689/MiDJEksLS0ZhoYQCgbDPO+w2WwQEKlUyul00zQ9M7egKMqtW7cef/zxHbvGxifuuN1uXVczmUytXh0c7LfZbC0rqfX19bm5BZJgnnj8mddfO3358vVEW4dhGB6Xm2HJWMQviLViKXvs2DGGoptNsS3e8cbJUyxr8wVCpXJBkiSOsyOEBKEhCEL/YJ+maQxLAQAikcj6+vrmRoaiqIGBAY/Ht7qSmp9f5ngXRTLtXZ0kSZ4+/WayPU6TiKIIBIhsNutwODCGuqqtrKxtHxurVmsejwcArGna9rFtqipvbm4WSvnu7t5KuaZphqHjTCZD07QJcCQSQwTt9fh9vsDExNTdu3dDoZDdzhYKhXgyvnf/vvHJuxgSJElSFKMqJoBsrSG6PA5BlQGG+/efWJjbYhlHOOT7yY+/9/QzD1QrBbEhUhS1a/fo8uraciobjXa4XF5dlqv5LEOAsR3bDcPYc/jQGydPTUzc7e/r3VxfvHPndrK9I51Obx8bTcRjxVI+HA6Yurq2tsLQ5OBg/8L8fKVSDvr8dru9UirnCoX55bVYtC0cCuwY3Xbt0sX2jiQCuN6oOly83+9fTa0RJEVRTKFQcvEegiJTqXXaxg729c/OzvX09HAOj2kRc4vriY7e/qFR3hVYWlsrlSo872w2mxubmZ6BgX0H71U1Z61hsQ4PpEnDUgGClokAQBAQEBgAGgC0fvYRwGTrtx8j491lAQFAIkAQiNQ1lYAmgUwIFE1tOhwObNE0Am7Omh8/tzz79raBhFCpvfHGm/5wNJOThrbfH+0cdYVj3kiyVJUQydhIGlgGIKAJNFXXSZoiCELTDIQABBZsrTGYgICCgIaAkhXd43VKStmyGmqjEPTxlXx24u7E/kNHTYBol7MpCDRF8DSLVMNpp7OljZs3rz7+yNMEaS+UJdkArNshaABg3tBMJDWH+0JXL/343PmX9u3fT0PaZ/dHQ743Tz/fFKpHjzwEMPWtb31v766dH//k01evnb5w4TWSNo/fc4Qm3TPjleHB/YtrS04v2d3tvnn9zPbhfgdvz6azCwtzito0LdXj8ezZfYBC3J3bE4lY4uKlc7F46PjxI+l0Op/Pa6axY8eOa1dvWZaVy5Xi8fjszNzIyIhu6pcuX/jiF79YKBTOnH6bczri8ej6+vrHP/6pK1du9/YMhcNRUWi8/MrzDh74AvYj9+xdXJpLxNtGtg1lM6lGo7GynDp24kGEbBcvXLMAhSDd1dWzvrI6MT4uy82erg6aIeq10o4dO7ayeUVR9u7bWSjkq5XSwsJCNByRZdnpdF+7ev3IkaM0zRaKxVAolM/nNV158MH7Xn/jZbudHRzqn56eCofDloUbdclmd5IEE4m0NRoNp9N55cqlwcH+7WND//zP33S5HXa7t6dvxOcPcC735atXom2dU7Mp3bSHAv0s55+ZXQ5Ggi6vTRGqlCK3tSWzlSbpjCg40JAZzbQznLPazENCYyiLYRihqTO0A1ukYViAAO+lLL8f/bznk97SnkMIaZqmaRqRUJblRqMhiqJpmjRNtyqDraBAwzAMw2hhqVbN0dR/adnw/lJgS73+S9H9L+0SzF+ew3+j1et9uAtD1LrTILZaSBCAd2p/pmliCwICIYQs8J7fREv6hd/LYWxVPzEkDMskSEhAaGgSgpihCYSBrhpunmvUy27eLjQqYlNwOBw0zUIITUOzDJkA8nBv/PWXnxvojihCnuf0YrEQifWvpArRtj6PPzw+OWEYxo4dO2qVajZbYFmWdzgYjt3KpTiHz+vqJEimKVRqjSrvctrt7lpT9/kjlVqTc/C57Aa2lGjIIzWrqigkY7FqNscQgONpDDSaAU2hEgq6NVPLpjPhaFuzofoD0fNnr8XaOvt6R9fWVrK5FGsjatWs3UaPDPWdP3tu1469uXS+s7N3eWnF6/PQNtrhZE1sKIpE0SzPeURF1lVBM7VgNOH1ty2vV72+CMTw+R//cH1p6lOf/PB3v//9//7Hf7pVEmqiUatpPV29tWr2zvULn/nUsxfffv3ixdNf/o3PLS+uDA6MbGXKzYYoSHJXb1e9XuFszM2r1/K5UjjZS7Is56CTbeH02oLH7VyeX/MHY3VRsvEOhJAkKqaO4/GE1+8u1ip9A4PlSq1aE1QTd3T1mQAVKwLB2CgbL2umpmNIkHYbpxrYtABCBMa43mwyJGPjOVEUdd1sOVe9O7t+BWBBjCiTBiYySIwRYZmQJbDTEv78D36zKwrvPzp28o1XHnv4vtnpO3v37M5sZLs72yWxYVkGQASGZDTamRYotuOegsJZgMGAfA9gQcKySIghSVPkqVfeGkxE7t07+Nrz36uWVixcBVa1mJ031aqXo0RRqjb13sFh1BaJxILBcjH74x/+07mzZz736U+Vi6XN9Y3DBw5PT0z5PV4C4unpyXK5yLKsw+Fwu92KooiiSBCEJEmthtt0Oi1Jkq6b0XCkPZEs5EuhYARjLAgCQVAtP9Ll5eUdO3fu2LnTF/BvpDONhmCzcW6f78ixYxRjm1tYyuaLLGsfHBxOpTZv3rzt8/oDgZDX48/ni7dv3717dyIQCLW1JWVZ3traIkny8OHDgiC0/iXVar1SqZw9e5bn+VgsRpJ0qVTxer2KoiiK0mw2s9nstWvXJicnEUKQQMfvPVGpVW/evEmSZCqVKhQKoigyDKPKyp1bN8+cOk0iwu1yNGpViCzWRnp9jp7edstUsKV7fS5BaNRqNY7jIuFYb0//+N3pUrF288YdQRB5np+anmAYxufzIYQymUzLcHZxcbGnp2d025ihW0uLK6FgJBAIVCq1W7fGG3XRMIDfF1RVlaKJ3FbazlJ+r6uQ22prizmdDkWRotFwJBKhadLGsZFYcGV1yefzEgTq6upqNptXrlwxTdPhcEQiMVVVRVFcXl7e2tpyOp19vV3RoF9XxWgk6A94x8fHl1fXvf6gjXNgSHn8AZq1baTWdE0lgO7iGVWqBnwuEkMaEouzc8lYOOR3jd++Uilnr187H/DxH/nY07VGMdYW9fgjgojv3lor5S07ExGb2OeNyKphc/KAIqYXZiLt8TsT45zLKWn6hYuXAsHokcPHksnksXtPcA6Hx+c1LWt1ddXr9TqdznK53BJU2Wx2SJK6ZYmy7HJ6BgYGWhXDXC7ncrnsrM0ydY/HJUmSIAgkQUVC4WK+gE2rFUoVjifiia5gNBGJJXnOTRO0oWm7x7bt2jmykVpeTy3GE20mJD2B+K4D93f07fSFOm+NLygmdHj9JGtTdWxC0rAQhgSGBIDWe346+B01iQWABaD1q2JcS3/HbhFBQJkWoRskbfMKElmsw0INyCaVKZaml2bfOn9yaX3a46MBVqJRn9/v7+zo9bjiDOkl6QBNewEgMbYwMFvEOIIMxE5g8sB0AuyGyAEJO0Q0QAghEhLI5XPmyllBkRnOxXmjBuEIJfsTfcMNw9BISrQIT6TH5kpWRKquUg2dIhn/6Ng9NOPQDdXG6/Ekj4FiYxAJZL+DcDmNUmFlz66dA919eqMS99sK2YlvffNrgwOhj374saXFcQIZn//MZz/9qc+vrW4lkwNPf+CTXd2jokq5/R1d/dsl1Tp44OjBPUe8fOjCW1e//Y/fLeVLr732iiTWwxF/o1Hd3EzNzc2spVZ/+rMXG2Kjs6dbEITl5dVfvPLyrbt3MpnM4uJiNBqdmZlxuVyiKFIUlclknv3gB48fPbaysnL50tV6XSAhNT0xw7F8vVK/c/v2yvLiiy/89Ic/+l6huGXnmN27d01Njg/09wJobW6mTp069Zd/8Q2nw/Pmybfu3p2UJWNtNaNr4Bt/821VAY8+8tQnPv5ZiuS2j+4Oh9oIxAQDEbudf/ml1xGkwqHY8WP3trd3xqKJRFvH8eP3r6ysNeoCQ7F+b2B9faO/v18Sm8ePHd65Y3R1ZfGeIwcYGvX29jz++KNra2v1ep2gKM7hvHbjZkdXb7na/MUvXm7vSPT39wf9kfXlzMpSbmO9/NLLZzLZajzencvVw209yY6RQLSbYgMmcJ25cEsxieW1lAHw8uoKxnj8zm2AdV2pMoTgc5mylJbFnM9nE6WKbkgEDRH6FcurlhGoqqotFkrXdYqinE6n3W5XVTWfzy8sLORyOQhhIBBIJBKRSMTpdFIU1XKuan2QoqiWjYKmaS3pegtOtbAaxrj19F+yUwAAAhAEICD89453iuwYvWPCDgDEvyxlEhAjgAkISARJAlMEJpFFQYtGmCQwQ0AaAQoCBDEEFoKYQAghiIFJIEBACLGOoMWSgAS6qdZYSlDEdMRPm0ZNFMvJ9ijH2xpCUzUNjCAggCQLqc1lr8fGsqBQ2jQtxemy2zla1ySXk1PEem9XZ9DnZymaRNSuHbuTiQ6bzRaNhh1OnqSAatRVvWZYTZLUfB6+KdQQQqVqjWGdJqZsdo/XFynkqxRkOuLtq3OLs9PjNoZ0O+26Kjbrle7OhK4qHqcjGgk167Xt24Y31lNOhwPrhtwQWIpu1urxSLSzvWNwsH9ycrJSblgW7XCGs7l6PNk7MDyqGmY2X7JzznS2AiFJIkxiMxyO6ZbNRN7Jhfzs8lauWPnFCz9ZXrjzH3/706+//rNkR8LtCy+sFQWFjEXDi/N3iltr9xze9d1v/fU3vvln//W/fnFlZRxAeXllbm1t1W7n22JRWWxUK1uGIQQjvseefuLAkaM79x31xwbqCpsc2J/s39+7/djQrhN92+8JJ4ZDid4Dx+7tHRzwB31NUVEVY2lxTZIUiiZ0QxGl+ubGCkkaglAyVUGV6tiQSGhpiqiKDRKYEJgAGxAbFAkJiE1dJSFoHe9uIlqz6J0J8/7HFo1LUQQiQFsi3qp9d3R0tDjLUqkEAOA4juM4WZZpkrLRDENTLEUD08KWgbCFAH6P+UUAIgMrgiwp4MEnToQ7O9I1YdfR4w8/9SGXM6orzFOPfIy0uGZD273nwCc+9xkdmYiEQFNEEmKaBNevXbpw7swnP/7RCxcuSJLkcrlUVS0UCtVqtaMz+fbZM/l83rKs3p4+l9PD806fzyeK4kD/oNPp3tzMbG1tFYtFgiBisVihUGht8lrf0N3d3dHRUa/XTcvo6OhYWVlpmU+0t7ffvXu3UqnEYjGCIGw2W6VSkWV1a2tLEISpqZlLl67kcjlF0RqNRjAYbKlfdV1fWVm5detWf3+/y+VqNpv5fD4SiT36yOMEQbrdHkEQ9u3bDwBsNBrxePz1119veZlaENSbjUaj0UrSTqfTuq7zPJ9KpTiO27dvn9/vHxwcfPjhh/P5PEUyTz311FNPPMnaGNZGx+PRtkQMY3NjY93OsYVCYWZmLhSK6Lq5vLw6NrYzmUwKglSpVFpJhVtbGZvNNjg4GAwGR0dHfT5fsVicmJjgeT4YDDabzWaz6XA4ODufTud0zeR5nuc5p9OxsZF68cWfJ5LRnTvHGo06AMDr8xiG4Xa7Y7EYy7IHDhx47LHHSqXS3Nz8K6+8wjAMwzCTk9Ozs7OSJLmcnuHhbX5/QNd1nuNYhmo2av29vZ2dnTdv3L49PoEhdLj9w6M7nR4fQJTL7U0kO4L+gIO3d7THDcPAlhUMhkL+yP69+0lMSIJYr5VZGh7cvzsc8cmaZCHsCfiTXb0NQU+0D+zYccjjiRSrwvlLV02IZN2QTT2abL81OXXt7gSk7CPbdm1mSzOzyx/7+KdjsdjY2HaHk7tx+4YkCwihWq3mdDrdbvetW7eCweD6+vrc3JxpmivLa4Ks2FhudHTUxTvKpQJEoFjMVyolWZYRgIVCwel0GoblcnmEpgQALuRLkqwaGEzPzHG8U5ENWVLXlldXV1dnpqZZlkYILS0t9fUPhCJtmo5phts2suP++x+0LPOnzz9XrhQBtFpxk62b89doAAwBbC0A774MIYAIQ4htdoagSIIkEUVBgrIwSdGcAUjW7jYR6fR4VjayFqRpzjMxNR8IJwnSvrFROH3mvD8QNUxYLDd1AwNIyIaiWpph6diCJKSwQRoqACaNDQqbNMAMAjZIsADRJgQYmIrU8HocPM83GzJCfK1hCiIMRboImgMEy7LerWxjKyP4vUme83g9wUAobLPZqrWynaN8QZtoVE69/YZpyISliNXN9PoksBohf6iva2h+au7lF573uYhv/sPXfW7mpz/5pyOHdstS3ed16obMc44LF69rOnF3fNEwqaaoRNuiwYg3Eg7UKuWL587fd+L+D33gQx3J9o98+NlyuVSrVQYHB5944nHdUM+de3vnruFiqWCz2XRdn5ycdLlcf/iHf8gwTCaT0Q31nnvuEYSGw+HQNA0h9Nd//deTk9PVavXgwYMel9vJu1RZczgc9Xp93+5dTt72gQ8+9ZWvfFHXFYIgisViuVz9xYsvd3f15nKFZEfP6NiwYSHLhDPTC9lscWz7LobhHn7osZXl9WAgcv36bYyBqug93QN3bk8sLi5KknTu3IXLly/Xao25uXnLxDRN5/N5kiRv3byzsrISj8cnJyf/83/+z/F4fHl5sVQqen1ur9dZq1UmJycvXDh39uzZSCQSicRkWbl+7baD95RL9VKx7nT4NNUqZMtb6aqDCzm4SCmvffJjv1XKK4ZJHTpyol4T5xeWCYJzOsO37ywdOPBo98ihqm5byQg2R1Q3ybGxnTYakkD2OklNKg90J7CpQFN3uxwU3SqjWe9aM7wzWotDi5RiGEYQhLW1tZWVlXq9TtN0Z2dnNBptNQO2QJWu65ZltbAUx3E2m60FziCErfP3vha+6xPx64zU+8y133/+3lvvP3n/OcIAvfs5AsJ3mGEICAQANhG0CIRJiAlgIWhBYJLAIoCJsEFgA1k6snRsGcAyATYRxgS0INYB1mw0sDMAYUVXqvEw63ToJq4sr9wtlTYkua6bsi/sMbAu6RLLs4FoYC21HIoGHE7bwEBvXahLqnTr1k2aomRBrJSqJEROjr97967f75ckAUDL5XKl0+m+3n6KIhqNQjDMI6SEQq5CflOTG8GAz+V0A0RUa00MCb8/jBDp9/nSa6nNjfUTx++hGdAUav6AN+D3lwplTTNmpxeuXb1FE+zPf/ZipVjq6+5iKUqWqn6fy+V0ZLfSTicvNprlcrm9sxNA5A2EDEg6vYGzl25MzK6IBnn+6qQ/2p0piPPz62trmdmltEU6ZJNNF5sHjxynbPybZ07/5//yu+nMxtraSntnx+Vr13l3oKOrM7U+36hsxkKO7Mbi1MS1b37jr06fes3ltoXCPhMbjz/5xODwUKVWvXHjBraMc+fOtHcmJUNb38qVBS1f1bcqZkmkp5bLnmjfQroqWZwz2Enag6vpgsPnk0wd0bZkR69uWoigQpFYd1ePLMttbW00TYqNuqqIDAFcnI0lIUMAN28H2MCGCkwNAoukEMTY1HWSQhD9q74cv5xdGJsQYogBxpgmCakpLC4uio0mtiwnb7fZbDaGRZBgGIamaVVVWZYFAFiWWa/XXS5HK5v4fTfRu5PZgg67w9QNSQIYwaauIZvDIu12X9zhaauLmGI999//uKFbmXQ6vbGBLEMjIRCaJVVuAEtbWV6oV2tjo9tvXr+1Y/tOwzBcLpff62YpmiRJTVc4nq/UqrVabWNjQ5bler2+tLTkdDqDwWAkEguHw8lk0ungopGQg+fvPX4iEPD5/d6rVy/zvL1YLN68efPUqVOSJCwuLzA2uik2G0KDoFA8EeMcdgtgTdNqtZosyxsbGy0ze1EUY7FIsVgsl8sjI0OWZUUikZ6erlu3bt69ezeTyUxOTquq7vV6ed65ML905/b4tm2jNMUW8iWnww0B4XS6MYY0Tbcs4FTNWFlZI0kSIdIygSRJNputt7sntbaOEKkoGjawi3dlNjJLSyuvv/76n339z2amppv1hmkaHG+jCMJQtUQi4XQ6g8Hwt7/93XA0Uq3VJicng8EghDAYDACATdNkWba7u9Nut5dKpXg8wbL2FhKNRGKqqvO8k2FsAKBMOpvP5zc2NlZXltZWFzs72hw8u7K0bBo6grCQz+uaYbNxBEFwnKNWFeo1EUGKJKmurp7e3oFisQIByfHOtkR7syEuLi6yLLtr1y6O4/L5rKqqiUTCZrOn1jer1fqJex/45Gd+Y2B4zBdOHjh6P213YUjrhuV0OilENGvNPXv2cbx7ZTnVbEjBQLxUrHd39dM0U64UC8XMzMJUvVnTDWNicnZpNTU0tnNs717A0oSdeeKDzwxsH9nIbUGGKTaEl954a6vY6O4fQ7TTRLYTJx5jbe5UKr19+/ZSYUtsVhEwNVVSNbFcyfMcQxLQwXOyLI2MDJMkubGx4Q34KYpiWfbOnTvlctnpdPb391I0YZpmvV7TdT0SiaiqDgDwer0ul6tZr/MOeytZvUV2VhuNpqhs37V3YHB0dm65WhMZmuvt7ts2PJLeWF1fXnBwzPidGzeuXLh760os7PF57E6ORpYOTAMBCwELgHeYKggRhAgC4ldu43daDDGAlqYpuqGouqrqKkAEhoSkGDTDWEi2kFSq1w8fO5HOieubUnf/sWyRXN1UO/sO1AW0li7YnLxFGjY7krQ6YUckRyOagiSFIAl0DHSTJSmGpAhImCZpYMLEhAGRjkwNq8jSgaoRJkYYAZPkGLeddrGkg4acnXSqdcvPR0KumFxTWAAtuUFakp21VLFqYfnF156/efvKb3z5S2KzzpFGT5vn8O7+pdm7f/e3/3jmzI1kcttXvvw7f/g/vppOzW9trn79j/57LBSgkcWyuK0tMD837XW7y4Xqw/c/9uRjT5MIjo9fMHEJgkatnA6HfBcvnJuenNraTFu6sXvPTppmWdaWzmYBIh0Ox0MPPdRsNhuNhp3nFV07fvz43bt3e3t74/G4x+NpNBp37tzJ5XKBQCCdTsdiMUmSTN3o6+3duX0stbrC29ncVtbtdIQjQZpBG+vLhiZ3tidKpbIkqflctaO9V1Px3duzbfH2D334Y7zDs5nOffc7pw8eOHLPPScG+ocBQBsb6WKx7HS4Y9G2l19+9eWXX2VZdnR09Lmf/rS9vX3nzp3BYLCrq0tR5Xw+n0gkCAIePnLwvvtPMCw1sm0ok9549eWXQgFfwOcp5XN+r/e1117btWvHnj17wuFwIBDc2sq98frpSKTNZneJkp5s72kI6kMPPO3gQvFoL0H4VhaqJAzSRDjg7TFV2s37gIUr5XJHsn1jfctSmVB4+OXz8yrXGx+4z+4dFhSGojls6QSWsNgopTY7ox1dkU65ITMkAwGhG0bLEr2lVScIomWy0AKIqVRqc3NTlmWfz9fCVQ6Hw9QNbFoIQBIRNElRBEkiAgHo4HgSEaZuaIpqGSbEAFjY1I33tO2tEmGrSvhecfD9kA6+SyD8cgnEv6wG4nfz4969v345EPilNxfGGEALAAyxhYBFohbkwgCbEFgkwAhrBNARMt6BXwhDZEKIETQJZAGsIayTwACWCkyFIfXZ2esOp6VqhUiU6+yNLK1NCFqtJpUQY3lCzonZuwur8ybCi8tLK6urBgYdnZ0+f9AfDDEs39XZa5kolys1m81wwE8zSNUkWZZMy3C5PON3Z/NbRZow02tznXF/LOxp1oqaKqpys1mvtXbyvNORzeUs3WhPJHVNGejrEsSyhdS+/i6e5wmSUTUAIdfW1rd399HFhZTXHfT7fJl0yu/nSVJlaX2gt91Ok4loLJvNvvSLV7x+f7wjqQLLIsm7C4vQ7jrx6AcGdhzqGNrbMDh/2zZvbEgFXov2sa5QrlbrGezPlgpf/9M/eeLJD2xkinv2HY+29QZC8UQiwdKAACpWq888eizkY1958Qf/8SufE2qVWDhCEEyl2mRsjl+8+urffvMbt+7eoRimWCrdc+y4oKos76wKQkMxYh0jPcOHBd2hEp7b8xsVBeiUs6FRTd2+mqkLhsU4HBTLWoBMdPQyNieAdKUmKapZKtcpim1r60gk2jmOUxVFbDYQsDRVRBAjCAgEKQQphC2sGabG0rRlmRiYGLeO1twjYGuz+36IjzAGJkECTVOCQX9bIl6r1Wq1WqPRME3sdDhIkiwWixibHpcDQqwoSovlQgiRELwH4/C7sxRhADEgIcKmyTIUQuj1U2d++OIr//Tia3Nb5faR3Z/+0u8g0hYPt+0Z3BZzuOBvfflZRVGKxSoERK3WbBFCFEUgAtvtLMvStUZdVVWXy+n0uNfW1hnGCSEiSYJmSEVRWkUTn8+nqLJlWYGAz+VyZbNZjPHW1paiaF2d3bVaLRAIOF0ORVFa/weSRIqiVatVCCFJ0gRByJLS3t7u9wcXFpYcDsfS0gJBQJKCJIncLocsy7FYrBXxaFnWzMzcrp17BEEoFEoOzma329PptGVZ27ZtK5UKLRFVpVLz+70IkQzDlEqlSqVSrVZZO18oVrx+38zU9P4D+xqNBsfZqtWyP+Bti8URArOzs6ZlRENhhJDT6Tx16lQ03sYwtq6unmKhms3mECSFRoMg4NLS0qOPPtLRmXz++ef37zvY1dV17u1zW7lsNBqxoGW386VSIRgMyrLscrmq1arL4+7t7W00GteuXWNZdnBwUBAEu53fSGVr1YaqyV6vt16vRqPhHTt2lCsll8t18uRJl9PtcDhIkt7czISCEZZla7UmSZKTE9OBQICmWYZhTFOXFfHI0cPVamVpaUGWZYfDNTg4WCqVc7kcQ6JSqVIs1ziH98Dh+zy+6CtvvpXs7HZ5AkNDA1cvXwCWUitnAl57IhYcHBw8/fblfEncNrDX4fKvr6/rpnLr7s2hkWF/IPrGm29+9OMfKdcr2Wy2XG7yfJhlHIFAINoWz1fqkiLX61XexnYmYhsbGyRJ5wuVUCTO83zA5/U77TcuvkVgadv27rn58YWFOZfTWa2WFUng7bZtI8Nra2skSXq93qmpqVYkEUPbCILq7hlwOBwvvvDT4f4eJ2+zTNXUDc3QWLudpmkTw0AgNDU1VciXkm1tiKYASfNuTzgQZll7yB+5cfOuZuBINDm7uGIC0sIonmx/8KFHZFn+2U+f/+znP/+zn7/UkNSB4Z079xx88+1LvYMjCLHeQFASZQwRfL+AFyAAALIQAABDqxVUAiF41+SRMAyLZe2GYeiqxrIsNi3d1AAFaRKaSrMt5JybuPTyz57/xLMfLxbLFsCdPcO+UPfsyqbT79WAhWhW1RUMNJKAJCZoSDEEiU2LJim321ataZJmSpppYguQBELAgjowdMbAJEGYEBgmIEkWGhYwNYK0ADQomhckCAFDQYT1mscukkSdJkUINLEhE3a2d+fw9fFZSWb7Ogd5YF2/ePrUmy9iC+7d/+DB/YfcTvT7v/upRBCPjrQf2H+wXK1dvHDtc5//TZqxP/vsR8PRti9+8YuBUIAg8ezsZKGYtduY9vZ2parcvHFjeKg36HdpckPVRF2Xf/TTHx49eoRi6Os3bwOAejp65+eXo+EYz/PBoHd1bdnlcpTL5Y2NDYqiRkfHarWaxx0gSXork+V4ez6fL5eLHo/n0Ucfnbgz4Xa729vb/+Zv/uYTn/4Uxnh6Zqarq6uvvyefz87Pz37u85/Zymz8wR/8QUdHB0mCZz/ygfX19fvve2Rqcv7a1TuHDx2/dWdyx9huAhDFYtFuY8rlwtUrZ6PRkMvJ2zj2jVNvjIwMP/PUE8vLi4161WZj9+/b98ILL7QnO2KxthYoTKVSXq83n88mkrGOZOy1119Op9cHh/qffPrp8+fPUzSPLbS1VWuLd1brcrUiBEMRQZDcbufAQNfLL/7gwIFDQpPI59VwuDuW6FpcXgIk3HNoz407t2mbE0A24O8oV5QLF27uOHSPSJCMy6uKJjYgS1KGKtgohSIUlx2M370VjSUCkWSurJkEYyJax4gkmFYvYUvI0UrIME3T6/XSNM2y7HuOVq1lybKMX+OT3tNRgXeza96rOVqWhRD5XvHx/fzB+9sVf+XbDBNC+CvpPeh93NW739FaukCrIRAAiE1gWQhYEFsIYgRMiAEi3gkrtCzLME0AAIEANkyIMIQQQRIAhCHRujN1XScpZBgKMBUKmchSETZo2pCbGY6nXC5PpdzwhSKCZOgmaoiajeMty3JxTGZtIe6zm1KFAUqtkgnHXdF47Pvf+fkTT37y/PkbJMF29XbNzExtHxth7TZJ1lRVD4fidaGp6XokHDRUoVzMlcr5UCi8uLixVRCjiWF/tAeTPCQJisaWLjRLm/0d8cnrl2Nhj2GKff2dNhu3ML84M7Owe9dej9O9uLgoiiKCgGGY+++/d35hOpfLBoK+ubk5qal1dXW53c6Tp0729HXv3n9gdn6l2pB27Ny/sVUkSXulIdbqjWRHD4SUIkohr2tqamJobMSAuFxvdHX1fPkLv9nf07t/x/b7jh1QhMoff/1/fOijH4kmOs6cu5rPZo7v2ybWc9/82//1hc9/xutzViolC8NKQ17fKDZFA5H2xx57IhQK2GkilVpqb08sLC5HO/uu3l0Oto24fB0Gphu1cldXslrN5gp5hzNIIYpjWIgFqbnOUphArCiqqqo6nC6ESN2wFN1gGEY3zHyxzHGcnXewLCtKisfjkRSVZjgTQAgIQRI53mEYRrZQbGtL6oZlmqb5y67qll87MKAGTGADNkPTAENgCGTFiAecqfHrP/rmnyUDxrFD23W12dORXF1ZYGjSxnI9XR3NRnl1ebF/cLhab0SincjVXmV787LdQqyJCQtDgiCwpSEEKESJsk6xtIUxwlq9mCkXt869ferzX/jMlfNvsrjxpY8/+t3/+78Tem1kuG9uZopMb6RcLhdvp9ObWzTNqrIQDQfq9bqmKYIgmCYzMjK8sLDwyusXT5zYvXPH7tdPvtnR3iXLMmtzEQRhGCZBEI1Gg0BQ0zRZlLBpMRQdDAab9YYk5AWxSTNUsVSQ5CZBvGOX0tffQyBqamoqEAisraVqtZrH48PAmpmZymbzDoeDZWlBbCqqqWnKvr27GYZiGOb8+fPlcnl0dIzn7TdvXQ+HoooisRQtmBJJ0CbUNzc3WzXEY8fucTrdkqS0WKJSqbJv376LFy9aANlsnCobyWQXwMSe3Xuv37jm9wa8bvfp0285HFw4EKw3qpub6XA4XKvVFVkPBdtIkq4U6vmtXKlQamtrC3Z2YmySJBkMBjc2Nk6cOFEoFDiO+8xnP/3yK684XTzLsZzdkc16rl+/3tHRoWkaz/MtZr7RaBw4cCCfz09OTmKMe3r6bDamUFAURSJJ7/0PnGg26wuLs62o8Eg4evXq9bGxnbt3ba9WmoqiVip1zu5CkB4a3D47O4tQk2GYYyeOXr5yaWpyhnfYW13Y+XyWpmm7gwcAl8rVldW1SLT9vvsfXlnPzi5nOKdXkLEnyI9PLXoDcY6F0Vho8tYlU5NlSQ+F4zVhs1KvQYpZWV3nXU7LpFZXMn19o8lkx6m3zt173wMA8mO72ldWsgtLy2VBIBx2FcNYR09tZs4AdKWOdu95eH09vWNPd65QMi1NlBp+N/QGXchCV6+dr9eKCJrpjVWfx20igCC4fPH8wMBANps1Nd3v8daazWKh7HR4fb7A+trm0aNH77v3oanxGwzl1zWp5Q2taVq1WrXzzqWlpVAo5Ha7EQYmwA2x4XY7h4f6Tp0+O7Zj34Ohtms3Jwtl8Td+879wDve5c+feOvXmuTOnP/rhZ9qCzFuv/pA0zIePHTUAqhWWgVZ68+XnPvrxL6qNCkHQGGPLxJCgKJrVNA2/E6OL3lkFMHjXydACGEHCIimg6zLGmKQJw9IhAIgAEBCmhhnKm82IvX3HPvTRjmCkwxfTHS776bNvtxvuRG9XoVzQsQo0zcbZVVWnKFKoNn728ss7BrsfOHFwYuLSmzMTgKCP3/co6/A1JCxpls3hKtcqTp6DAAuCZPd4EAE0A1uWZaNJ09IxBrosc1xAkhREYADEurzc3WYPu5Am6XxbSNIoO2YGkoOrqcILz/1gfWE25HN/4cu/xzsCiknNr6/2dATGdh/JLtyaurPpd2319Hd+5tOfuHXr7ObmZkenWxJL43feunnzZqGYHdsx8uGPPNVslCx94+KVi48/8lQ+m11eTsUiIQJZFGeLx+Mbqa1oPHbs6L2iKN+5eSccDjcajY2NjWYz4g/4wuGgaZput2tycrKrq2NjI63IRk9Pz8LCgiA2Y7HYhQs3P/ax7cVifmCwq5DL79w1+sFnn2o26xzHYctgaHJ8fNyyLI5z3bg+7na6nHxosH9nX39XJp0bvzuztJAeHBj53Ge/8OEPf+zJJz4wPzv9xutvju0YHRsdvXDx7ZGhfpICKysL4UgIIZjsaP/hcz8cGRlCJJqamWRYqr2joy0ef+XlV0iS3Ldv39Bw/+3bt0VZcLsHfvSjH42NjTocnN/nEwRpZmZu/4F72uIdirIEISGJanaruGv3Ac7uuHnz5tTk/NDwGEnR166fpyhvsr07EvFcv5E/dv/xwlZKbGbdbry6PpNaG19Zyt577zOBuHO51Gg2ygRgaJLG2CAJQ9ebgz2J1Mrknl2D5VLtlRd+NLr7WCTR2VRNgKhyTazKVVVVIYQ0TTudPMMwFEW1mC3D0N7PNoF3Pav+ZaXvPVD1XnxNa7QAGXifTXxrIAQxtjD+le3+e4/vgSf4bsvg+9XuCP+KoyjGGL4bcoJQq4sQIAIgbEHLFGSJYRgIAMdxgiDIUiMajlQqFdaOSqVipdYIR2KIIiGEsqxSBHDyrNisJOLhTGq1Xqp0tycq5YJckzVRaRZrgKQUSfe5PU1ZdPD8xK2rIa9zayM10tueSy1PTs4Wm96mblgUVW5WAQX2H95bqhQxqVmU2ZDrhWI1Fk2sbq7V6/X29vZ6tdzVFvdzvC5IJKY42v7M4w9IOqNDW13SVEs2DR2bzWDQXq1ueIM2xg5pzM7OLVAUrWuYpFhZMSWxsrSSTiaTEBuNZv0Pv/Y/IhFfZ1d8M11maOyJBIu5PAHxPYfv0Sy9VMxzdlRrSrnCqoVJSTZ53snxHstCFEmYGAgmkAAsVhuNZmXnjt1//zd/T5j48fsfJhA6e+4aS1mIoqcmbuUyy/uGuy+W5mxQfunVlz741BM9He23bo67PX6K4muVLbs9cfz+e1w+3+kzp2KR8EBfj8ebXFzMYIsO+sJ+d8PjclEkaag6xzGLSzOI1ENhryDq1YbUxIKTI5s1nY94G4Kg6Cbn8Gxs5S0TBkMxh8tPUYxhmQ5PtF6vm6apqAaiSM00CIqACDs4XhAkACzWxhQLTYqi3sX6CEL0y80AwBYGGEAMsWGaGEKAMSIIyzBpEmDLRATgOA4Ay263t3K1EcS6XiMIRBAETdOS0NAU1WHnipJkUqaFTWBh8I5tyDup6qZu0CQyDFNVZRfPRKPRRq348Y9/0ueP9vWP1LNLf/f339q7fVezuHr2zFmf14l6e3u9Xm9XV7vLbff6HBxPjY4OHTp0QBSbsixubKYWl+ZHd4yOjXVdu3ZTVdXDhw8jhGw2W6PRIAiIMSZJssVCW5YhCEIrVabRrEWioXAkaLMx8Xi0vT1hGFo2lymW8hub63fv3r10+cJTTz8xPDyMEKAoyufz5PP5SrUMITZNnWFpu53leXt3T2ejUfP7/SRFhCOhgYGBXG4rmUy2tyc8Ho8kSfPz88ViURCE9OYWtiDP81uZ3M9+9oLdxns9wXyuuLqyXipWzpx+m6bY1aWVeDRp6FZ7slNRtHPnLrQnO1RVv3N7PBKO1evNYrHs9fhlSV1cWLaxjr17D9psvCSqq6vr6fSW3cbLslwoFMrl8gMP3E8QxMLCgt1uTyaTFy+dv3Xrxuj2EdpG22y2tfWVxaX5cDjcUri3BkVR8Xh8ZmaGIAhZllvtpsFg0GZjtm/fFo1FNE0hCMIwtHA4nMvl/H7/Rz7ysXNnL3zta39qWdhm4/y+YL3ekCV11649w8Pbvv71Py0USvPziwzN8ryTYZj+/n6SJJeXV1ZWliCEmVzWHwweO37/vgMHc7lCoVjlHJ5AKNbZPXD1xh1Rse458YCsm8VSNdHe7fL4KvXa/NIiTZPZfHpheYGx2zJbeYZ1bNu267mfvuB0+eoNqVCsTU4tXbl0u9lQvL6Q3eXZvf9wsrOf41179hw6duyh3t7thYLQP7CT48J7D+zUNPTjn/6svatbVpSGUG/UK7LYFBo1v9cjCk1JkkgEYrFYPle0sVytVuddLmwRgVA4EomVK3VBVDfTOQAg73AFAiG329vKCJdlmaFtEBIIIV3X3W53o1GjEGRJyFLg5o1rhmGMT07cvDvJOQPdgzuu35yZmlnu6Rl+4omners7xm9e3krNbS5Pqc3iS8//863Lp+YmLm+uTHG0pUnVRCTEIswxpKYoNoZq1OuWBRAkISD+lQxZjMA79tkYQBMiC0DjnQMAU1MRIDTZstl8TZGYXy5tFMSmwSyl8wfuvffyndurGxssz9I07XW7TVXBllUplkYGOlkEXn3hx6q49eN/+vNTP/6Luek3X37hmwSum2rNZWNloR7ye3RNwsjwBD2yLgu6BBmC5lnFVCGNEEUDimwITUSChli2OWD3QDzRFVCkqlDNT9y8hkx1/OqNr3zqc9/7xt/3diS//Bufe+qZp53+aLpYyZWrLO8wLD0cjf/e7/6fCNg8Hj+J4OTUzatX3/J62fuO7x8Z6sxmFoFVDwaoZMxx+8bpSxdf9nrBsx+6r1hcSiS8nV1tpqHmctlGoxYIBLa2ss2GdPr02fm5ZZuNazabLper1SBZqzYkSQmFQl1dXUNDQ62Ie4KAN2/eTCbbms36s89+4NlnHzp+/GgiHi0Vcz297Vcun8/ltmgSRGNBm506c+ZUIOA7ceLE/NwSgdhQMNHVOViripWyYOiQs7ssCzcawrlz5w4fPnzp0oV0enPX7jFVlf7nX//F7Ts38qXspauXMLCu3rja09dLUZRpmoODg11dXclksqury7T027dvkxQxtmP76TMn7969PTY24nDYSpXinn0HBgeHISBXVlJ/+Idfq9eb6XT6hRd+oaqqrpuBQOiJJ568e2fC7fZSFFMqVpMdPcVK9aOf+MiBQ2MEJT3/029Vq5mZyZvrK9PJqJelpPuODnckqKOHu2IhY3nmbNSLHVQt6NYCHpOCNd6mR4KuXHZDlCqpjfl6M/u5z34oGuI1pbqxPJPeWGrUqxBCn88XjUYDgYDdbocQttDV+8HT/y+KqF+78tfG+1/8tYvBuxDq31K+/9qffv9o7VggBgBaEFsYt5zoLAAs0zRFqcnb2dbXFovFSqXU1dVVqZZsdsbUDZuN7enqIBDwup31ahmbutfjKpWKLEtvplOFYo7nuHy6YIomUIAu6gxAbT6/n7eVtzZDTpshFoHa7IwFVKFWLxaEWnX78FCj3KwV60N9/etL808/9oDcKFTymwf377p17arcbPZ29HCULRmO7R7Z5mJo2rIunDkzNz3l5HhggmKxvLSwXK9U5WaDocDK/CRLGMAS/T5uY3NFFOuck9Mti3O4BcloS3aGo4l8rqQb1o6duyVJsvO8P+B7+JEHt2/fZln6yLaBcMTf29f50MMPpNY3FxaWHBx//frVSjV38OAOr4cpF1KRoNNpI30Ozs3SltwUG2UITIeDy2Q2n3zi6W/94z9eeOPkf/qt/9AZbzu4e1d/Z6JSTCNDHenvPLR7dGX69hc/+eyV86cPHtjz5KMPvfD8z0zN6OkeXlrKO91tDz3+Mbc/4Q7E733oMUzROkaM3e33R2maNXSTptmlxZXp6elsdrNUzgtijeNsBEVBhFxut8vnlXWzWBEVAzm9AZcvaHO4uvuG4x09LOc1MavqpChD3aARxdN2F8XyiCBlXWtKUrFYLObyuVxOEARD0yGEDMOAd4ObwK8Srr+mPgQAYGwhAlAUqFQqQqPOc7bVpeV6teb3+/P5vMPhCAQCpmlKktQSKRqGpmqy3W5r0aLgfTYi7z3F2LQsw+3lBaGRy+UO7N2bbEsgjA7uP9jd2dfT1T8zu3jl6o2KKPz0latkrdGMxaMQ6+GIPxwOl0qVjc21/v6Bx596vFKpECT44Y9/JCnKgw8+CNFbl69ee+Thx0rFimnpuqRrGuJ5HkFcq9VkWQoG/Xa7XdVkw8RrayuWZQ0MDFWr1a3MpqIooVAAQWwYWl9Pd7Va3bZtWBAa0zOTDifHMEw+n22lfdltnK7rmkaQJGkYWiKREBr1peVFhmESiUQ0Ejt79izG2Ov1pjdz0Wj04QcevnTpMkVRAEBRlHp6ulXFQAguLS3rut7b2zszMxMMhvr7++/evQshkd3KCQ0hm8kCiKvlSj6X29raQghqmhaPxwmCyJfKHOeYmZnZuROGgpFqtbG8sNze3j43u5DL5dxu9yOPPNLX13Pt2lWe5x988MFsNpNOpzc3UydPvnnvvffkS8WhoaFqtVws5vv7BznextC2RqMBCVKWVYpibDZueXm1hYdURZNlORqNJpNJREBVll579eVyubxjbFehUIaA2LZtx1NPPHX95o1isbx7997z5y6KgoYt4oc/eo6m6b/527/ftXvvI48+dOfOrVq9LDSlYrlsAji6Y3sLBVIkzdg4t9dfLldlDTAMW6lUw3H/ZnprcHh7tVb73Ac/3D7aH/HSQa8NGFo0Gu3gneMTc9FEdGU5zVDOL3/5Sz9+7vnO7v727p7b43ePHLrvwQce1bQ3p6fmvvTlTzRlWbWMrWx9oH/7D37wA7/XrwRVS9OLhWo2V7589eZX/sN/HB3bNTV1/dTbZwvlSjm7GPTyWJc4G0tRFLZMiqKcDjdFUapikAQTirgZmnW6fKzdFo7Eaw1V0aTbdyd/57e/lMmk5xYW/V4XSVMNQSAJulXssNlszVpVajYIBDo7EuOTdxv1iqqVewa2NxpCXcR6DXIO5A+2mRa9nkpvptbtLLNnx7aNtcnZqWmWsvM0YWn11fl80NeGSWJxZpxj7ZYJVVUNeFx1QXQ7nJJmMgwryxKBEAQQQAgAAQEEwMIQt7bzELwTCP2OGSnAEFi8zW5omGCYfKns93uO3HtIVkBVrBEslEx5YPvg0vqKaoRpkpm6M99o1j/80ceFmquSa/zOl39zbe5aLrX0Z3/81SvX3vrBj59/5pkPDg90TkxmKvWqg3Oo9YrPZV9eXeFc7nBbslCpy2bTMAwaWTzLik2BtTlJ2m5aBudzZErzHT1tr5x8RcnnHj1+Ir01/8rLr164MvHofcf27D+qGPr4+Pjc6uqHPv5p2mknVKA0m1iBQBW+9c2/k4R6OOJ75bXnOroCPI9Eof7yS6+Joux1Of/4T/6gXMouzk8Pb+upVO3XLpw6dPREtbFhY+mZ6cWuZLvbw5erpXR6w+/3h0IhzuGZnZ3lbDaGYWRZBgAomppob/P7/c1m/a/+6u/27Nl28+bNL3/5K+fOXUitbx48eNAwtMnJcaeLX1qYq9ZKolBjt9D43emnnv7g6dOnNzbWP/bJT8zMzFy8dC2fL/b1Ddy5PRkKxmnGbucc+UJxYXFS1eRDB49IkrK0tBSNhh966KGB/qFKtTQ+fqevvzMQ9LEsabtBO3n++u2bTz7Vv7aR2j62s1Kri83GnYlJjnO0t7effOPUyMjI4vLCQ488PDIy9M1v/n1vXzdnd/B2V1NUFc1yebxf+PxviKJYKFY++YnHSmWhUVMrNTEWi924fmdhbnF4cGR1bVGRzSuXb9hsTKI9EQ7FmmJ+eGhnJluoVkWnHc4sTCTjHGHlWZbLblzR6hKncgkbkctPVxVYrhrbRveITZ2iTFFtEEiZX54lbAAid6EgtSW6ZJ2iHTED063OQV3XAQCtyqCmab8ih/rlavHLLJr3n/87kAj8uhEDft96huGv6a7eJ0aG73t876VWp8h7qyP49R0MbuUbappqs9lIhm4IQltbMpPJGCb2+4OFUnkrm4/FYiRJNptNmqYDAV+xXPL7vSRJGIbmcjohNBRFae/syK6thTmHqcjzC/N79uwiKXDt7bcC0XAjtyXzoLcz0RncOzN5Jx7gTLV29NDO5YWFharQWMt0d/UFPS6rWpi+el5WFScBDm/bmc3XBKsWiyUcdrssNdKLCxSFTLHB+FzxePSv/+bvvYGEjbO73e6GpFq6lIh6hWre77MJ9YplmA6fv1IW3K7g4vJKOBQlSLYt0Z7ZzEiqdObs6c9++pP+gPvmjcuXLl3cNtK3d+/ec2dPx+PtrJ0/eerMrbvjn/r0p90+x1NPPDG/PHXj2sX9+w92t4cMqao0TQJxBCKxLA8nQwRjbRniE08/9Zd/8RdvvfT67/23/2vvnl2l9Prbr/9kdvqaZQn5jcnexCfz6U3SQH/95/8LEUY07J+fmz58+KAkmv/47e+7fZ0H7z1YLAsVUSjevVMsb20f6V/dSJEWHOztFDVhdmEu0T7WaQuU6kq5USOQwXFeUZZUxSIoGmPLQkY4HuV4WpEFjuUto1GqCx63HyPWAjTGpGlYGNksREICQGQCosVDmSRFsAxvZ+yKZpE0hRBhWRZBkK2JbUEA31HyYfiOXO+diYoQsqyWUI9ACFEUUBSptTO3k6C1J29FJAcCgdbs1TRN09SWshASBAkRAtj6F/eBaekUxWACKbpp4zlTE7/xjW9e+elPyEj8mcce8NvB8z/4diJE9PS2ByPbw71r8Le/8qGu7s58YXN2euKhhx5Kb2bm55fbkl1ut9vr86Uz67Vm4/XXTnKcw845XU4fRVE2O6NpWi63ZZomQmD3rl1zc7OKIgUCgVg8IopNVVWTyeTCwoIgCCRJh0KhSqWiKFIymQTAcjgcYzu2z80vXLhwwe32SpIUjyWcTufaWmpgYCiXzTscjmqtIggNCPE9Rw83atXFpYVYLOb3BUiSHBoaWVpaSqU2ObsjldpUJSWVSvl8vl27dl27ds0wjEAgwPNOVVUzmUxXVxfL2Gu12ptvnu7q6hgb21mp1avVOkmicCRUKOR0Q3a7XYGAr1qtrq6uHj5y8MyZM8MDwwihQqEQDITT6SzPOfft25faWIvFIsFg8MqVy+vr67qh9vX1dXd3Xr58MRgM9vX3zMzMsCwrq6ppYpIkXS6XqurVatXpcJumuZHOyLLs9/sJgggGg5qm1ev1Rr3J825VVTc21sORQCwS7uvr29zctNv5cqlWqzUMHdM0HYlFWwnTs7Pztao4MjyKIaIoiqFtmUymt6+7WMy7PY58PjMzPwMgtttZr9dbqzU4O+/3B+02pyipxXIzHO2MtnV39G8XVFypy6F4tFErfO/bf8ciuSfpD7hZWWpaJEXR9oXF9c6OAQDYQ4dPrKylZ2bnIUEhhPYdOLCyuh4Ox+/emXj2wx9zeby5cuXcxYsWxnabjUJo28jI7Ws3l5fWLUDt2nNI1PE9x46cfvPnqljcXLrDwEbET+e31liWZVmWJGC5XEYI9XT3RUPRS1ev2VguEIxohpnazPC8o6Ozu1ionTt39qMfekpV65fOneI4ymZjdFW2sRxFUaphIoRkoUlSaHhwkCCh02mnaHsqk29KuG9wL+eNSxo9MbP62BPPNptNp529feN8Jbfc0+GfvHVx29BwPlfPF8uRRLAiSDUBF6t6e/fY5asTPb0Dn/rcFwmKLVUEC9GAZHTDoCiqpa5993azQEuPBTAG5vtCdol3NlgWJiEyNNMyCRvHIwQq9RpB2BxuTtKqEJkUyWXTGZ5jAh6vKpmn3njj8IlDjVpVrjST4cCpV3/cFreF4+Rmdjm1mU9t1u697+Mj247yvF/TNEkph8LehZX5YqW89/CxuiCpik5SCGi6pekUYjCgFRVBCJwOQpLSe3bGxXLqb//0z9ujMdO0XE7P6LZdI2N7JiaWEMM0VOlHL/zi45/5vGHBeqlhifXdg/Hs6oRU2Xzr1IuH79mTLa5/8EOPTE1PUMAe8EenpqZCQd/gYNsPf/Sdrs72/fv3LC/PzMxNxZLto9v3Ls1uKTJ2cvzy8rKqSR6/r1QS1jcyTqf79q279x4/evPmza6ObppmQ5FgKrXmdrpkpWlZpiRJrYbfra1spVLDGPM8f//9929tpbvaO6ZnJqJhX1tb28DAKMPY/+vv//4HPvSs0+kQJDGZbD/5xtu9PUO6hmdmZh944IGf/vTHh4/sL1dyqdQaz/N2Ox8Mhk0Dd3V1T05Ojo/fPXLkSDgSDAb9hqHl8lvnz58LR2P33nv/rVu3Go1aLBK22ZhGvWrqKgCgUirv2rXrpZd+0T/QG4tF4vGoKDUZ2pZa22rUm4lkLJVaC4V9fr8fQKJcaq6tZ33e8Guvv71tZIfNxo/fnXz66ac9Xtfc3LSmC2O7B+JtoZdeesnnDSNgr9Wa24ZHVlbnz114bfuOvoGBvuXlZYDZPXuO5AtCXZASnT065JZW625/O4bcxSsXVL3cP5h0OOyCIC8vFw8fftDjjy2s5FTMmYB5Z52AsOVlZZpmq7Dy7wCs94Onf4muwL9AXf/WZb/2Onrf+a9FJP6yRPj+BQxDACwEMAQWwhYEJoKYABhgU9M0hmFME8uyTFIMx3EIgVq94vO4dV3XVbXlHGTneUmSvF6vosoIAYaCYrPC0gSydJedlnPFSn7L63Gqkri+ttTX302z1FY+U6zkBgf7iqVswONMry2FA17C1MvFUk9XV2ozs7WVu+fI0fHJCUnROnp6IvGu6dn1kZG9qfWCIqvY0i1doGktmQh7ve65pWULEe1dg5lCTZBBINyuapaiCBSFoxGXZSrFfGZ9dW14aLvQEOcXF9raEhRFGoaxtLTk9Xppijh06MDF8283GjWvx5FMhH0e98rqYiwa1lSjXBI0HfCcm2aZ8fFbDEc++dTDmqmoir62klIk2NM9nEuXFVlzOjiPz1soVVyBwKkLl//p29/7b1/7k85Espbfaha3rl88DUyhKZbuu++EomiFfMVG8Y1G48SDhy5fOT+2bZthwX/+/s+Gxw7+p//6J6lC4+r4zNTCQndfezjig7rcrJTaQiGOJYqlTcWAOgxURdjeM0AytCzWKYoyMVRUXbEsA1sAWJZucQxHk6gplDAwSYKx25yyrAPIEASNAYKQgAgZpoaxQZDYQiaEmIQIG6aN5SqVio3jSIrKl8o2O0+xjGm+s5WFEKJ3Z50FsUUCAABrMdi0MDIBgWRFHe70vPjdf56+8UZXAACzpgrCI48+2KiWDFPTNG3f7t1Cs7qytOD1egwLjgzvkOlQzdaflVgL2g2AMIaIIAA2IcQMQ2smlnUDW5bHRupS4y+/9oeFWzef/Q//hyJWLp7+RTU797EP3Zfdmnf7HbFEBDUEsVKtNoR6uVa+dvOKYsixRMTt5lVVvnjpfKlUcDi4hx5+YPuOMYKgTNOUZblUKjUaDYSQg+N7e3pu3bpVKpVa2vtWfDqFCJYmvW4nRUCvy00TpN/jHeofAKaVz2bdbvf6WsrB8Qf27XdwvJ3lqtX6xkZaVfVyuTw6OgohDIVCg4ODsizfuHEjHA4//NAjNtZumiYA6Ec/eu6HP/jJ3TtTZ8+e39xMC4LAcdzW1taFCxdqtUalUhMESRIVXTObDfHkG6cEQfrEJz41NjYmScqlS5fLhbJQb9Sr1emJyVxmC5jvNDZrmjY41A8h3Lt3bygaSnYmd+7eXS6Xh4YGDh3cu7mxarfRpqH+6If/5HJzg0O9fX09+XxWkoRDhw75A17D0O+//76dO3eQJNnX19PV1RUOhwmCqFQqc3NzfX190WgUIeTgnQgSdhtnY+0URXEc53J6aIqlKMbnDdI0m05vjQyOeJxuhJGlW60Ox0ajsbKybGF9eHhg/8HdNp4pFLZqtVI2t8nayM3NlMfjKhbzZ86cIUnSNE1JUppN0TIxQRClSjlfygliIxQODA0O8JydADDo9y8tLwDTaNlY8DyfzWYlWXS6eKFRXV9fFUVRVVXD1L/7vX+8c+dmJBJ6+OGHk8n2F174uaYJp069YFrVnzz3jfE754BZrRRWp+6c42mxt527celnK3NnE1Hy6ccPtyd9Tz91TJHl7q7htZWc29W2nipXq7LXFzItpBtga6tMEHbTJHP56vjEQiLRG4l1xpO9ooJ5V9CC7EamZAK6u3dobmFFUU1/KByOxAzDIGlaVOS6IOqaiTFmGEYUxUazVijkhGbTMvWOZKehW9ev35ycnK7X6/6Aj2II3VT//lt/F4qHd+7dOzO/pmPb7fF5C9OFfKW3f3B4eFhRpFqtSiDqq1/9and3t6rKb7/91uzcdCDgNAwNImxh41eXCQQAgLgVQo1aBwLEO4+AAAibSOJckOFM1awpRt3r42x2WpIkYAKsQ4akaZJOr69Vi/mA2z42OrC2uNiZbPd6/azNuXPv8UINdPYeVqzw0x/+nS/+9v/YzKmpdNk0oWnoDpbMrEz3h5lOl4mLS6i6TjY3g4TQ6wdxTtkWd0npeZtSGo65Yw6CM7WTP3n5b/7sG+WSimj3vmP3P/OJj7f3JTfTy3YGrC7NT45PfODpp2gKNmvF9oivNxFploo01E2rNLqzLZtf/sAzj0xP3kmnNjTN0HU90da2tDz31ltvut1OBMlXXj7pdgV7e0Zu3bp76eLlRkNiGZ4gmNHR0QMH9rW3x7eyG6Pbh/fs2eXzuxRF6unpIghibm4uGAwGAoHNTPr6zRvRaNQf8B49dqRarcbjsc9//rMsSx86dGCwr5eAIBwJ8bx9enraMIxLly597Wtf03Uzn8/bbLbnn/9JoZAfHOnfyKRmF6aHR4eqjdLs4sRbb5/MZjOKLCfa2u6/74ST5069+drZc2cQgQ8e2t/RmZRU6fK1q7fHJ/LFstPtw5jY3Mh39wydO3/V648YBh6fmKEY7tyFK4Ko5guVekMslWuIoDLZ3Ftvn7t4+Uosnuzs6puemW/v7FpYXM4V8n/3d383PTNJkghj08ZQpq7aGXpsdGRuZurka6/LsqYoxvrK5tkzFwb6Bvfv3Xf71q14NDbQ27exthEORA/tO1LM5SOh4M6xofFbF1msJHye3Hpqc2kJ69pmKp3ayCXaB0e2HWW5Ds3y8p5emzNRrOOp2ayJOYhoAICu66qqmqZJEATDMCzL/jvVun8JpP5VBuv/r/H+WiIC4F1Dk185AMTvnEPwvsve80bBrXOEECCQBTAiCQvDpiComtHqv26KKiSYSkOWFaPelAlE2VhObIher1+SFIChaeJ8vlhvSIhkJM2sN6VMIR1LhIvl3MbmitfLR8I+XRUsXXTzLAG0Y0f2h0Ier8/VaFRS6VS5UZGwVpLrBk3w4eBqqWQ5nbZI4sbShuWJXllKVwg+j2nJ7iDDkayqrVRKb144W2mWKTurQWvv4SMqtirVKoRYqFdCbkcxs3Hu1EmeZvfs2r84t3712l2WcRw+dM/a2vrW1tb+/Xs9Xsf+A7sWl2ZoBo3tGDl4aJ/b7b59+3alVEnG2jFG8wtLG1uZ6fm5bLHgDUYOHL738rWJ73zn+fmFTbvdu210p6qqAJg+vwtjs5wvGk3l1vmrz33/e1/+D1/aOdaNQW129soTT54IR3ypVOro0QcTHYOdvWOKQa9uFU888jjB8g1RBSR98eqN3/39//LYU4//5d/8+Z/85R9uFTLtPR3x9g5VNyRFBtDQ1LoklAr5TZYl25MhijKnJ29P3L7RrNVq5bJQq3N2O4KmrDR9QTdiCElVNQsjkhFlDSBS0TWSpmmWwhADhA1L1y0dEAAQCCAaAFo3oG4CTbckSdZ1AwJC100AWva2CEECvNuEBCFACKJ3Z917hcJ3WlkxwADU69VisUhR1NjYqM3OlMvlSqXC0LbWigkRpihS1/X3As5Bi2qFv/y1xxhjCGqKZBAQUZSbY7SGTKrWZz72id/+2h8fOnaYdNj333/8j/73/53s7c0VKrl08e71Kfi5zz6ZTMYRqQlidW11ibPzANNeb4B3uDRNK1VLW1tbpXI1HuuoVaVUaiPZHvf5fOvrq5IksQy1a9cujK2VlRVVlRVVoiiir68vEgqIolgul9bW1lmGtyzAMIzH4+ru7m4264giEQIIoVqtUa83K+WabhoOh8vn83F2XhAkgiDK5WIun3U4OJuNoSnC43Gtrq47nc6+voFyqTo/v2hZ2LIsr8dvGVokEqnX65Ikra6uDw4OLi+tDg4O5vPFS5fuhkJ8IpGMxWLxeFyRtdTGWmdHt2nppVKx0ajVG1WHg9Mtze1x6rr+2GOPVCq1arXq9XprtRrLsmurqaX5pbZ4XBAaPG/XdV0QG9V6hWEYp8PtcDg6OzvrjSpFkdFotFQqbG1tmQB6PT5NM6rVaqFQikajxULZ4/HMLSxqmhYORQAAoVAoGo3evnMrHIrxnCefLxqGytrofC5tWRZDUm1tyUZdwhjYed5ms5UqpUazxrI0xhgRzO7de2am52q1hiQpfr8/Fot5vd7Ll89Xa+VYW9tWNtPZ2Vkqln0+X7PZpFmbIAgEYsKhtlpdxdB+6MQjm7mKpGMdWAgBbAgTt84O98SlRhZBU9GtSlWOx3srNbGnd5DjHb94+XVNx0ePPfT008+8eerVu+M37n/wnlqlsLS4Yrc5SJoPRaJnzpyMhP1+jz29vu51e2QFU2zAJD39Iwci8Y7uri5ZKL/50k83Vu76nDpD6uPj436/PxgISKKi67qJgd3mUBSNZnmX2+P1h9s7uq5ev0FQtJ2xf+yjH/r2P/wvux0GffapqZsENE3d0DRD0zSSoF1uBwFwuVJw8Ozw8CCCQFb0G7dnk13bPIGOM+du7jp4/MSDj/3Pv/nbUCS8vroiNkqH9u0Z6e9ZnJ2+c+2G3+FV1IbNQ3/iM5+emF31BDqe+8npoW27nV5fsVQhGXZkdEd792C1IVmWRTE0tN7LXPu1zbkFIH6ndNIqEUKEsWFiybIMG8urioKx5eDdtZrGcQ7TkimKbNQkt4O/c/PSi9/6ByBKn/+Drx4+tn95JcOSPDCtUNAjK00LSTRHleoCQfE2xptJ5UJep6nVEW6wsNruR81aMV+RnZ5AW3vb22+fdtnp4cHB/FaV5/12VyBXKN25e+PVl1+kKfyZT3/y8IGDFgGml6Z5F1/I5NvC8fxmuVITKafXF21TTEiTjFarUZbcEXdP3T51z+Hk9Sun11Yzx+89dvHS29u2bZMlIxKJrK+tfOe7f3/wwPbhkcGl+VSirf3wkQOaLtWE+re/84NayXz2gx+rlUvVWuFzX/r4K6+9fPKNt7t7hvYdOPzzn72QWlnp7u7JpksPP/xovpgLhUKqKp9889Xuzs5A0NcKjNdUA2McCARnZ2fKxdLv/d7/kUqlXC7H7PSErhmdXQM7d+0VRfnnv/j5xz/54f/+//l/kzT9mc98QVWs9bX00NCQoki1Rr5SKZ07fe6LX/yS3W4/f/58d3c3y7KhcHh+fjEajWKMx6cmc7ncsaMnSqWSoiiRWHx2ZuGhhx4RxebK6qKhqYXc1r69uwcH++emZ27dvun1ekMhX2pj7dCh/fG26K2b4wRgRFFuNCuhsPeZZ554/mc/0TWTZe2SZJWK9RPHH/n+934wNDQ6OjrabDYXF5Y2t7JdXe3LqzP9/d0Q4Vi0Lb9VGhkePXfugsttb28PSXJ1PbV06PC+q1evxiMdTrtPN9j59fzuAw/cmFmriqBnaF9d0GnGTjHs2sYagESyo7dcFRmbW1ENE7/ji9gSArceW2vGv8pg/VsI6b3Uwl/7yPvHvw/aWtcjq8XyAvBuh+C/ck1L4/JO1wjACLQoK2i1vK8QQiC9sZ5IJEiCXlxc7unpMywsCALNMhzHFYtFl8Ohq7Khq7zN3qqrmCYmaMI09XwhFw56EbQ0RV6eu7NjsM1SGoasxkLBQmajkMupmuxyOXwBT1NsWFjLpFP1WunJxx99+YUXHnroAUSB0+feHhna1dM/cu7ijc6+EYuwN1VIMD53MFGryIZh9HRF5mdu6WrJUipeGhq62tbZX6xJJuR1g9Q1Kx4OOW2Ez0U//9z3ervbAUAU7dQtRpSU4ZH+1bXF2dmZo0ePrKdWp6cnI+HA9m2D6XTa6bCXC0WAzfZkmyJKJElev3l7z/7DTre/Uq2yHL+ZzmAMm4LU19cniqLH42k0BBIRiqQoihYNRbEJVueW/+wv//QTX/jMo08+XBdrd25dsxFk0Ov7/vd+sH3HroeffEpWjNXV1UIuf+/Re65fu1wsZVRNigQDgiBoBvAEIqJFdfZvZ5whuzNAULTYqNtJs15MEXqdY4jU+nKys492BA1g413hTDorS5JpmiTFECxdEZusyxmMxDdSGQJwXrfHtJRcbsvj8UFIMKwdY6DpJk2zJsAYIIIgTNOEEJnA0jSNISmeplVVFgTJ6/ephi5KCmO3WZaFCBLjljoDEu8kUmITWSYBLctiLQZiAAjLgpaiaENd3m/9+V+V1u5E3er+3f0v/fxnn/7MJ2qlCoQYQKu3q0tR6ulUiqIoluW2je6WyWCJ6sopdhOxJqBaDBa2DEgADViIpAkATdlkTY20tGTcRVJgIZXt7YsUs6k/+urvdIVsjfzmUF9vqVyAn/3cM6yN8Ac5isa6Kq2trRkaYVlw5469m5upza1NCGEkmlhfy/AOf7PZzGXTiUScpumJiYlQ0F8sFlmW2bdvn9vtTG2sVYqFUChkszMej9vn8127dl1saJZlkTSlaQqEkKbJbdu2raysVOo1hrF5PJ5CvoQQSdMMRVHBQBggWKlU8vlso1nXNMXh4LBlQYgJgnK5XOnNLY5zIESYBtZ1E0KoSALH2fr6BhqNBsCoWCxCSNA0HYlEfT5fpVLxuH2hUGhqamp2dn5kZOjunVsEgfzBwI4d2zNbqUajbmGjWi1jhIeHB2VZrVQqo2Pbq9Wqpmlup+fS+QskImLxyNLSAsMwH/3oR4LB4Ne//vViUTxwYGxoZDgUCpVKxVqthhDAGOsWrlarpmE1m6IoyoFAoFKuGYZF0Uw+n2+ZkgeDwWg0WiwWRVFdXkr19Q7QDFpdXfG4eYZhKILAGNdrIkXRiCQhhIouxWIRiCzDMDY205FIrFKuMYyNZW2iINts3NzcjKQq7e2Jer3e39/f1dV15844xpggCEFq0jTt5D0Uadd1Qrco3heLtfebJDM4PHz5yqVY2HXr2mkWKtCol/I5RHMs60XILYiKNxh45LFHrt28wbCOV187+6FnPzK8ratSSU1OXQxHfCxpq1UlaDEO3l0q55cWpyWx6nM5CUhiZKvUrY6Bvdv3ndAxUSrlu9pj2c35iRvnHnvg2N2bV2dmZgqFgiqp0Wh0YGBwfHIaYyKzld2992Ai2cXxruXVdVU3Lly4cOyeo0MDXVcuvdXdFdGU6trKDG9nIMSSIFMUpWsmRNjlsPG8DWC9LR4rlktra5m9+47/4pW3nvzAZ3oHd/7ijbdOPPTw5PzswtJiZ2f7Cz/9ycjQth3bd146e9FStAM7ts/PjWdKq4FYxIC2weG9Xd17/vfffuv+hx5sCM2jx+/VTIAo3oQEz9vL1YqdYQAAyCLeBVitR6slfmzZ9uB3bIURBggSiGKYerXKcwyCmqYoFMFrmkGR2DBMErA8Z2Mp67d/6ze+8sXfOHrv3juzaw6X19BhK91W0WWLxJhEkGarddHBOnmW0YQST+lAKUac2j3bfOmV2VxVcfmCTbkuiZWAh81vZUORpKrhb33/hwRtH9k21NvTf+jAYVWUfvHiT2pC7VO/9aXnfv6qKtKlrUpPW6y3f7hpEA0J1epEtVSul1Ptba54xFUtzAx2k1upBZr0NZtitZalaKAZys1bl/PF9OEje+KxCE3ZN1fLLqc/Fot2diXOXTp/+tT540ceS7R1zc2On3zzxY9+6qmf/+J5CEjDIg0DfeITnxKq9ZdeemXX2L5AIFIoFqOx8OXLF1MbK4899mg8Hv3RD//5s5/97MrK2vDw8J2bd6ampmw2W19fjyg2t7LptaWVvr6BaLSzf2BE1/X5pXlRqWKgM3bb5kZm5679r776eiKR8Ac8piV53Z5ipspSTH9/fywWUw29ZdpXLJbHJyaGh7f5goFMOtsUpVAwvLGRttv5zo4eE1s2hmFtNE0StXp5x/Ztt2/f7mxP/vi5H44Oj+zbv/utt9789Gc+eeX61cW5BWjRpmkm22Nnz54ZGOxibbSu65zdNTA4qsiWg/f+9Ccv0JTtwx/+6NzcHMuyHOeAEMuyKMlCtVIXBAFjODo6ZmeZRrOsqA0Lq4lkdG19mSTJrs5eSQJL6+W25I5UoWn3+HWCMREdivQUipYoQpK2qYYOKCTqmoVZkiShpVAEghC+l2DzXvjgr0Gif5+m+nccRP+dC/7li61gqX8JsN7fyfirAAtjBH8NYBEEXFteCQaDLMeLoogt6PF4m02Rotlao+5yuRRJpEhkp2kCYgIiDC1JUkxTd7hdjUaFt9vqtVKtVvF5aCenNKtbWNUJw3LbeIfNjhBSFEkUxeHRkbsTdyys0RSpiIKDt/d0xk6e/NmJe483G1Zqs57JN+PtQ8Fkr2RSMqYIilcNBLBJQXMzNdeecPvsKL82m89ujezaH4h3rWdKANOGrObTa3E/57TjUm51eLBbkIzZ+bW2zmGKZhW5ubK6GAj4uru7y+ViOBLKpjcdTtvGesrOUpqqet2uoN9768bNplAfHhlDDIcomz8UvHHrdj5f7R/e7nKHNR2bpqmbmq6rzUa9o6OD5x0ba1ldUf/o//pvR+858Adf/S+57GZ6ffn6tWuj28b+5//65ld+978lh0azDQkS1M9//IP7D+8bbIu+feoNSNHbt2+/cuncttGRhtjIFUuf+fJvnTx/rSoSqY0Sa/c8dN+9zcKmWE2p9XTAxcgNgeMcBMfRvKPRMBTNCvsCFjZMoJJ2drNYgjRfqukAciFvApJksZzHCAeDQYIgmoKkaRoiCZa1GxY2MUCQ1EwLAgQQoeu6jWFZCJqNmmFYPr9fkCUTY5Kmf6nTs/D7AZYBTZNClmXZLRZYGCPdgkDTjNE+z9f/y1edsBFySLGQvT0eQwRuVGqGoSECdLW3G4a4ub6OIPT5QyPbdhUVe93en1NYE9ktSGMMEYGwZUKISZJsCgrLs5YOPDxYml9R5VpXVxJSUFFqPKF/86+/tmcwMXHtYrVcsiwLORyczWaTRFkSlVKxYmO5eDwei8UcDq5UKum6rmnG4sICTdNupzMRbwuFQqnUJkFQ/f39qfXN48ePj43taDQarXhdkiQ1TWv5dG1tbVmWZZq63+8Ph8MAINPEm5uZlZW1trY2CCFJolqt0tvXaRja5uZ6NruVzmyUS4WFhTmCRIcOHbAsy9D1eDyOEBkOh+v1OgCAJEkCQMMwvC53WzTW0dFRLpdTqVSz2ZQV0eN1OZy29vbE1tbmpUsX8/ncSy+/ODk1vri4uLKyvJVN9w30dXS1m5Z6Z+JOKyFHkiSPxxOLxarVeotXPPn6G5ubm41a/cKFc21tbR1dnaFw+Pi9Jyxgff+f/4nn+S9+6Teefvoh3um4e/fu9PT0xMTk0tKyIEiWBWiaTq1v1Go1mqadTqemGm631+l0CoLQ19dHURRJkg6Ha21trVSqtIKfNzY2isVid3c3TbOFQiGTzXf19PX29oajUbvdrqgyQiiZbFMU5fLlax3Jdo/HtXPXWDDoX1tbCwQCqiq3Mg0ZxjY0NGIY1uZmplZrOBwugGC5UkIEBMhkbBQicFsi6vc5Lpx/4/a18yvzkzyD3z79aim3xXMMAJamaSxljwRjNEH6/UFRFGdnZ9c3UnYH/8wzT5mWmohHy8WC2KhXi4WtzZSlStXS1u0bF/Nb6w470x4N8zbGUEQKmgEv53JgSy91tnv6uyMv/uyfz555Y6Cv/82Tb0HIJRID0Whf7/BObzh5Z2Ypkuh2eMK9AzuGhna//vrZ9Y0sBgSByN/9T7+3sLgUSyQPHj4yNTXldDo9bl+t2mjUmq3KoMPJOZ28oigbG+lKWZiZWQEWwzKuUrnx6c98YWlpSZbFhx489uMffUtq5Hs7w+Xi5tMfeHJra8s04Oc+95u/91+/StLs/OLC0PCoLGnbhrbHY+2iKPr9/pmZuc7u3o3NjMPlBsCiSaJarfB2+7tLjfVurfDXK4bgncSPFn2NVA2oCqAZh24AXccExZimSVEEAICiKIKAqqqKgnzs6L2vv3FyM13nHG7FMA1Ls6ChWprN6dIhAyhONwmOcyCEGvUySyOANX/IXSimf/aTH9y9cen6+TPIECyt1tMVuXX9XLm0cvnCi//5P33i8Qd2jA0F4hEW4PKrr/3T6vpNl0teW7n27X/4y9GhTsrS2iLB/Qf2rK4uX710dWVhBRt4oG9wcKhnfXPxq//j9zt6O27euH310nWOc/Ccoz3ZXSpVjh8/7g94K3U12ZkMRyI/fu55hzPIO0L/9//85ve//8LS8taXvvIfPd4ghvjcpfNf/M3fWFpZCoeDgXCwu7t9547t9xw+NLswz7JsZ3dH/2APgcDi/NyHnv3AkSNHZmen3zj5mtPprNUqTp5dmp8rlXK7du3wet1XrlwhaGpwYPiLX/qyaYGJybsAWj6/h+NtDE1v376dQqgp1EWh/uWvfFHTxVgspKpyX3/P0HBfuVKyc7ZLVy+/8MLPEYJdXV3Z/FahUGBZ1u8LkiRz/30PEQSzurIxum3M5XKtr66dOHZicz0zcWeKIexvvH7KwTl/8YtfZLNZTVO+8Y1vOByuP//Lv/7RD5+fW1hpSyY+8YlPtMWTBw8e6usbUhVTEhWM8crKcqlUuHz58r333mtZ1uTk5PLy4u3bN5eW5gxDi8fj2CLsdt7p9CYS7bVahaAQ73QMDA0KgjA9PdsWT0bCsbfPnr81NVUol+uyTNIUzdGQ1HoG4uub82vry4ikIeQUlUKUk6TtgIIkDUmShJDAGAKACIJqoauW1cK/Ov4tgPVr77739NdO3rvm36LEMPw36KvWG++8DQGAGEIAoAUIgFuqZQABBthEwEDAikQiLetUTTVaib8AWBAYLp4zVEmTBTtNEgBahmlaKrYMCAye5y3d8rq8Vy5eKOS3ervaWRKqimK3250uVyqTzpXKVVGpSdrcyqaggaXVTEdPX//gNguD106+mcsVNtJbBITn3np7bWU9ny+0xXvHdh3RTZ5mAwjxuoVUQ8XQ0gw1FInICjYBAymnYjK8M766mqdIG0LAZmdoljEt+KMf/WxgaFu+XJMVRdfVi+fOQmDV67VGo9be3p7P5zHGU+MTlmnKTaGYzU7eHU9EI2srS9mt9OLS/OjoqKqqzYaczxf/+Yc/Sme2HnniqYXlzdt3FqtNnKto2ZJMcZ6O3kFIs2cvXjKA9u1/+tanvvjZL33lN5aWFhgCYVVNhEKp5bVQJI4ZPldXbZ7oX/39tzsHRvceOHb9xl2POzw4sNPpDHd0j4bjvd39YyM79z//wsumaXZ1xMdG+50MvnH+FNTqUR/flQh7HLbOtggDFLWRdhCCmxHtoFzPTW+uXLaU5WL62uLkWwyuxX3OiMelNGtKoxnweINenyLUxWZFk2scRzg4SleamiQYioQtjQAYERAhYGFoYWgCYGFI0TQkCc3QTdMwTRMh+K+ieQAQsDACECIMETYBxBgiBCgSKLIAgVEulwFAiq4hSNbr1WDIT9O0BUFLrkOSCJuGZVmtVHIIIQQEhASCCEFAAEhAqKsqTRGmBiwLWBBwToeNdzA2Nhb32Rj2p889/8RjT1Ok/cChI7/127+JgIma9QqwDEu3HHY3BGwhX8/nS4VCYTOd0jTN0q2gL0gAQhKF06ded7v4cChq6Nbqyno+X+QcznKl5vF6S5Xy1tbWjh077A4+W8gnO7o6u3sYmz3W1sbYaM7BUhTV1tbW1dXV3z8oiuLW1tahA3uFRrla2aqUMy4nzdkJGwNlpaFqgtfLOx02oVl1uzgXzyVi0WgoKDUbUlPwuBwIWDxn70i2EchiaFJoNJ28q7e7K+DzImi5XbxparohHTq894EHj+qG+ORTj9hs9NT0Ynt3QlQku4PtHey28TaSJjinw+5wYEiUq81CvqLIBkFQHOcIBEIEJElItrUlC6WKqMgDwyOqbiY7uvsHh/7sL/6iWK4MDA4PDY7YWG56al6WdATpZkNp1MVCvuwPhhibXTcs3TAIiswXC5FozG7nGw0hGAzbbFyjIVgWEASJJMlQyG9hNZ3eFMQGa+O6enrbO7pq9SbJ0NOz0xRD2TmuFbsRjcTCoeClS9cgJqFFkoh+/NHHdE2bnZ0PBEJOpxsA5HS6e3v7XR7vvfff53A5d+/e+cjjj2DSqokNSRc9Qaes1e12cO/RPTuH2hYmLwApP9aX2DM6wBCorS05OLydYbi9e/ceOryvvSPGsDRjt3/y05+TZFWQmnPz0//7r/+X1NCSkcEAn+wI9ztZbzAQFWTFxtjFurS6vCnWFdOAHreb44j15cm7199cnLoolFJhj6NZqq3Mp2pFBZsOt6cvGNsuGs6yjJyhRKpQHRw74A10UaTX54lfvXjT7/NBYK6sLrrd3kK+MjIyEg6HU2vrxWKRgEioN4BpWbomivVKpcTaeZLmdJ20LE5V7DQdvHR5YmJ6QVDkU2+9trBw58iBbR7OLKXn12futPvdH/vAMwM93du2bVdVNVtItXfE8tmCm/NRgFlbXI2HQ7/1m1+ORCKXLl+fmp576+w5l9dHkIgiSUPXESQgQBZAFgQmMC1otY7WeUuI1aoYYmxirNMUtrAKoA4hxpC0MAIEsiDAEFIMreiKhTBpt8W7enYevIeyu1QDWhhCygJIhoQmSTUaQdKyoNL00YAzmwEakGqTIbGg1Qv1imGQe/bcs/fAQV8w4HB5JyYXvvuDn9ydnBGl2tf/6KvtUT/S5UpmK72xkt6aq4jLdpf8xJNHNhenxi+c9dlNXcyTwNANNeAPul2utjaPBSveAPH0h+6//5H9V6691ZbocbmjuUx6eWnG63YePnTP+PhUvlgNhV087/8//+CvmyI8/fZlA9NHjz4ai/VGwz3FYlMx5Ym5O5LROHXu5EZ2U8cWhLi9vT2VSv3mb/62x+PbuWd3VazWhPL+Azv7ejqataqhaYosHz96bGSo3+t2LC3OKUojFPJsbqzIsji0beTV186cv3wtEIn6gwGSJq/fuFQoZiIhb71SXpxfoEjywN69Qb87n9toT7Q98vCDHpd3K5PLZDa38huVemlq+u7q2nKpUlZ1zen2Dm0bvTM+/f3v/2D/vsP5XPnFF14eGdlOkpRpqCeO3/P1r/3Rd771vUcffnx5cTUR73jz9TeWFmY+/cmPDAx2Dw31ERTz2c984U+//j/37Dpcrddfff21n7/wUjZbTaXyhWKtt3eQ47jU+urmxvqOHTsKhWJP/0B6K2cC+OxHnh0c6uMdtlKtaGBtYHgglU4pupLOpr//g+/XherFKxdJmgiFAhY2zrx1MtGRGN42FO+Ih6MOpw/RjFKqrF+/dTaVnvYGQCzBE6Rhs9lkQcWawdIyBDUALGwRAKBWxh/GsJUV+GtQ6f3A6N+CWe9fwPCvjn8Jxd7fgfj+Yb574Hds298BVRASCJGWBUwTA0QCRFqAxIBBhA0iFliAwBaBDZaEdprUFJnnbLVawzQwQZG6rlMUydsZRaxhpdYR9rhsuFnNAUsjkAWBKisV1kZQJJAaQrNcP7RnR9hF1/PLHhZ6KKeL9HIkn4h3FGs1FYO1rYIv3rlt7+GyKC6sLs+vzKha4/CBsW1D3RyFPC53si0JoJFoTwQi0VyxKatkqSRBRHp9DpZWWVokCcnjooI+x+rqqonoe0483qiSNuSTKhWs1N4+/TLNEIJOPfqhL6RKiohtN6fmCYYd2z4aCfgzmQzD8rJiyJK+uZn1uv3JeHLi9l0SWwd37bh26TxDwIvnzvE8VyyUr924UyzXDIt44slnHK7AzVuzPm9yca1QqWkmYiOJbpcnki/W3jpzpr0t+PKL3ztxdPTeew+kM6kzb5x+7eWTpXzlwvkrU/PzO/bsdbrcG6sbP3/uuQ88+tgD99zz53/yV8WCvH//fdWy9NaZCyTtLgvG1buLlCO4uLb18kuvlrNrPVHbgwc6B+M4u3SeNNLVwqIsZHibhmADqMV6YcFlE+IB087moyGJRCmeLTxy3xBPNMvpJVNqIkvnWQYoulavOe0EspoMKfG0qjaKLpYMOfmo2wMUlQImxLphaQSLTGRhCAiCbBW4VVUlSUQRCGATAowgQK1ApVaAGUIkJCiIkIUJAqm6RjN2DAgKEboMGtVcpZwBlkmS5KXLV1s0EAkha2cJCmGCZOw2RRUQgUVVMzGCBAIAqWbLBwtgA7fMGjCySBqRCEBD0wUQ8Qf7ursMRf7ff/k33/3GP7CEvV4WGNqhqnpXR8znZ5DX57bb7ZpmZdJ5hrbHognLslRVrVarBw4ccDrdEMKRkRGaID0ux40b1wqFgs1m53m+XmtalpVOp0VR7ununZtbuHL5GsPYgsHg3Nzc1avXTRPXao3h4WG/37++vr6xsbG4sJzNZpvNJkUTiiLt3beT52333ntsYLCrvSPWloiSyJLlJkkijPWJibuKJHz6M59kbXRff097e7vDwSmSzNlYj8eVz2VdbufmZqpSKfl8Ho/H09HZrqry9PR4sZStVAv/9M/fEaV6JpOGEDeatVjM1aripTbXs/lMJBYqlgpNsanpOsfxHo/XNDEAaGpyLp8rcizXrNULhZKN5QKhIETkW2+/Xa7UTBMXi+Xhbdtv3777+psnNzLpAwcOPfDAAx6Pj6IYCAmA6ImJKcuybCynKIogSIFAyG7jTp8+vXPnToZhZFltybMMw/J4PJqm2exMb1+3P+BtNRAoshYOh2maphmm5QlEEIQoiqur6+3tnQ8//LiNsc9NL0iSnEx2rK9vnH37/ODgsNvlk0Q1HkvqmlUsVQlEI0gRiHr99ZOFbC7sC5i6USmXy6UiTcHLF05X8pvz07eWpu/s3NZfLxamxicUSXc5gqZBVkrNn//sZVXHA/1Dx4+daNSFcqEY9Lp6OtsO79/10AP3caxNbCjp9ezi7DKJKL/ff8+hw4cOHfrwsx/p6e4HmLLznky2JEpaKBTCurY8O3PxrVPl7ObIQJ+uahgRbl+wo3vogYefSnQNOH2h3/v9/xfLu27dngqG2/oGtt9z7EFMUNG2DsbhnJ5fpG3sd7733eXl5UwmIwgNioC83R4MhhmG4Xk+FAi0ImwdvFtSLAAZSdRrVSHZ3oUQGY2G2+KR9ZW54tbGxtJ8emUx5ne3hQKdibavf+2PZ2dnNzPppthgOfvGZtbC5JXLN2an53O5QjQa/cIXv3Dw0OHtu/Z29w7WajVd10mCctj51tL1q/t169/iAyDCAFgENNG7RBcGqLVptwAQZZl12CwCl4XG0I6xo/cfLQtNQJC6aQIECYrCFkSQJEkS6Cbz/3D2l+GRpde5MLyZahczV0mlEkNLrUY183T3gIeMY0gMcWLHcU7yJid0HHCO48SO7cQwtmOm8Yw9DD3TPU1qBjFLxcywmd4fmhmPIe8537evunQ9tbVLpR9r73U/a93rvkGNr1VhQaAgCJIBhRNpUh8Oh0EYlWUZw6APfvB9jz323jNnzpw6+QACk7u2765VatlUdsvA6M7x3ZFgBATUcrk0NTu3tLze3zXkMju3bRnriYZv37kai6+Mbemx2XCeSQNK2UCD60t3wz67zDPVcoVhGAAUnS7L9MwdEASTscy9px7+u7/97K1bC16376//+nM7dx4pFtiO0KCOdLhdoVyuNDQ0NDs/PbRlYPfEBEHSLCNZzO5auSHxQj6TH+jtuf/+e69cubywMBfwua0WY5tp+TyuUCggCNz73ve+tfUVv99r0JN7J3YzbGtwqJ/n+W3bxgYHB2MbCYPZNLFvItobZdlmOp0cGOzr7uq6cO68jqIQCJ6bnikVct/+9rdHh8ee+MnP1zfWPvihD7z66iujoyOhjmB/f+9rr73qdDr37tn/6KOPjm7Z6vV6s5kMz/OAqvV298iC+Od/+j9ADfizP/3Ud7/9rZmpu5MXL4yPj33sDz6KINCNm9dWV1c5jisUSleu3uRFCcfxlfUVp9OtKOB3v/Pk1rFdQ4NbZAnYOratp7svFouVihUUwa1WG8cKCwsrsqRl0vn1taTd7p6amunsDIc7/RP7duycGC9XK13RntGtOxLJNMfz73z3wz6/M7mxnk3GapWkkQJxWKvmiwoj7Z/Ya7fR8fXZfH7DaqZxGNJRBKjyqsKBwBt54DdDEQQB8FfaCr8Rq787ev/val2/8+L/9o54E5upqgwAKoZAIKiBqiZJEqDIm4VhVZVhGNI0FUUgUNPq9QYMwIoKWe1OlhNlWTGbzSLfLhZSGCybDXg6uSyzdRLTFKGFo4AiszzfJHCoWEiXChmLmUZhGYUkTW4k48vFVEaHkvlMFtKAkZERXhRCkS6707m2sW6yWUVZlCQhX8jcuXtjfW1paWmBZxSL2VWu1DQIFGWB4ZqKykeifgBos+08287fvX0Fg5Vascg2WjiOzy+v5EvVRr3dqDSNtG526q7dZjabzcGOKKm3cwparLdhDKtWq8VsqphNmwz0pQsXIQAyGIz9Pb1GI33n9tVWowoo4vTUnVajoaepjo6O3p6BZksYGtne0z/q8ndWaoIv1IeTJoTQfezjH+/qjprNZhSF/+Vz//z5z31W5ttf/dK/lfPp/ft21uqFi1cv9W0ZOXT81NnJGzyIiQASHRjKZHLPPfOLia0jD96z739/5q89DsPhIwc3EhuKxgoy4/Q78uWKzmip1pgtI+N/8OGPUJBSjM2ef+l7AYe2eyxQyy+m1u8uzd6cvn2tUcrRqGoiocWpyWYpDmvt5blbMttk6pVGIY8qUthrtxswp5VUxQoKNfSEWM2tee1UwGkEJMZCoWKzAgpNia2aaYSAFQxSUQiEgLeJXUGbz9vNAFahzZFB8NcrWNobI0cQAAKaAkGgqgAgAIMAAGoACqnx2CrHMxzH2WwO2mhQJInjOBRFJUmp1WoURYUCQYIg0tkM8YYO1qYPGgABAKAqoKYBqoqThKxKsiwa9ZgsizzLwQBYr9Z2bt81PDiiowyRzv670wuXLk9iOHjs6D7wYx9/SKcjAQCwWE3NZn3TFG/Lli2JRAKGYbfb6/P5VlfWCYJaX9+olGswQiAIynEsQRCpdMJiMQmCYDIZqpUyTVNerxdBoc2hPBAEy+Wyz+3J54s2m63ZaDNsy+/3rq2tbNu+xeW2bcRW19ZWent7adoQDIQVBVheWkUQPJVKxWIxv9+fTqe3bt26bdu2s2fPRqPR3t7e2Zn5Gzdubdu2bW1tIxGLd3REWIYTRdFms1ltlmK5kE4njx8/3mo1JievAgBgMtqGhoZTqczqynqjzSiK1NUTtlqNJ0+e/M53vpdMJl0uDwLBmzhmU3KdIAiGYXAcZVm+0ahBCGy1WhuNxokTx1aWlyuVitFodDqd5XKZYRi73V4oFARWIAhC4CUQAU1mAwCCpVKlWq0yDKfT6Xxef7PZdLu9oijmcjm73Q5BUDwe1+v1mqZt6nA0Gi2e5/1+fyqVUmQtEAiUy+Xu7u5UOlEsFt1ut9FozGbTJpOlVWfabZYT+Eq5lk7nH330YZfbc/nyFYvdVq1WRUmyWq3j4+PVRt1sNs9M3SlmEhgCU7QOgpBgKKLIKiuI+UJJlgCdjrZYbOl0WhKVjo4OgiAqtWal2lxYWdM0GEYwh9vR1R0plnJutzMajbRbLSOtz2bTjXqtVMjlcymv3xsMd6ysrPT39Pb19dE6Xb5Q2Yinzp2bhHFSbzCZbfZisXjkwP7Xz50hMezA4UOsIE3NrwGq7qFH380KbDYX7wh7E7FkMds8evDErZvTrCCKoPTMi0/v2rPr9KkTP/rm4zgsP/Lg8dfPPl9Ir1mMZCmXIzDcbDZyAtto1lqtFgijOspEIDTDcP5gqFpvTOw9GAiH/+Gf/nlwcJDWU4oomsyGjfU4QemrTdbm6kznqp5A96MPP/jNr32+WsxVaq2e3qFsvkob7IykHT5xX6irB8bJ67ento5vE0WR53kEQkVRRFEU+D+JKP7aXf92jZ+3HQSBtVqtTYVenuc31XpbTBslKU3TAFnSFBUCCQhGFUBRZZ6mYJVlzbixXiwrkux00xJcldk4XF1+4anv6kw6l8/l8vhPnrq/Uqo+/tX/vP/00bu37xgo67ve/aHZxdXl9aWGWDh+8vDtOzONKr9tdP+3v/nDU6dOyapSb1XT+VygI2K2OOq1Rlckoop8pZjBAPUXP//+1pGoJreHhnpQFJYVsNlm0+ncwMjwjdvXzr1+fvfOQ1aL12XrMBqs6XhybX1x+46h+cU7t6auRntDOhrf2Fj3uP06km7WmqAGqJpIUUQk2jUzP3fr5p3BvkETrQ/4vT/56RMEgQ2PbikW87IoCCJj1Bv0et1jj33gypVrP/3Zk5Va6z3vfezatWswCIk8WygUrFZrRzio0+kSiUQ4HCYIAoC07mjvT3/+hKZpBpMx4AsuLS0MDPSNjm35X3/3mYcffnjfvgOXJ6/evTvdaDRRhKQo+sTxUy6X59zZ8zPzCzu3bV9aWo7FNj7ykY/IovTkk086XfYXXzx7+uS+hx6+P59PV2slvclIEES7xV26NOlye5PJeKmcv//++yd27f2nf/znvp6e3bt3Xrl6CUVhs9l87tz5gweOmYz2Yqm5trZusznK5fLo0NZ8vjA8PNxoN50uc7mW3Ygtlsr5/sGhUqmWThW8LlerXQkG7TglGXQGqyG0tBjbSKZoi8cb3mKydoggna803H5fJl8nKbcG0pWmiBIoopM4joNBA6BtUgDfbF6/mYc0TXlj7vVtEla/pTv1K8D0VtD+3zC3/q9UG0DtbapYKgiCCAwLEo+jhCCKMAQBIKjBiCKLOAwoAqfDMUWWq5W63e7iJa3RahsMhnQ6rijcYH8ERdV6uYioKokjsY21weEhVQF5ScznMw6Xs5AvIwhmt7kpDC4W1tlWSa8Duzs72lW23WzxAlOulnbs2HHm7DkMo7du37aysmSz6jfWF3q6AjLXTMVXl+ZmOwMdmgzlC+VwNLL3yEkF1s8sxWuMhOsNnMhiGEYQVK1U15NmmqSqxVy1VhjdMSzwCq4ZZUGZvnupKxoy2iyJVM7n70ZxZGn1JqC0YKl19oXnP/mRj5VL1dvziw+842GmLbJM22jGzrz8DNuueFw2n8sbDIQzmQxFUSoI4ripUOKj/VsYFWzxigYibk9gfmkRJ4l8oWSxWJx2xwvPPknhwP/8iz/5ww+/32E1vfORRyiDPl0ptDkhEh74ype//v73feDxxx93OByf/OM/OXf2giiKh48c+OIXPufzWu6/97756WWb3cSLNU4SHe4OhgfbLOBy+erVIqQwNjPSKsf9LopvFXUolE4l8pms3eoBZLxUKglS0x90a6Bar9ftdrfT7ZuZnSd0JpK2l2pioGtIhYlCpcbLgsNp0DTV7fZl82VR0HCMJEldtVqrVOsIofMEQowACDIqqrgKEjCKAZoksCyCYyRJlqslnU63SStU3ujiwQAAQG88ZCEAVFVQAwAVAUBVA1UQ0wAFUoRun+GT7zuFCKWQxzA20ttut0e3DBQSMQyDcYry+/2SxMOA1KoWXnjxTP/Y3m2HHuZ0kRxLsqoOQQlIVTVVggFQgzVOkXBChwCgyCm0DgY1NZFYtttMLruDbTaFFoOqwsc/cO/Eri6RiTmcOvDe+3cpirJt21YAAFLpRDIZ1+l0KIpuciQVRWs1mUAgtL6+brc7JFHBcB3H8TzPGY3GufkZHMcFgUNRGEWQZrPR19e3desogiCNZo3AqWw2W69WWYav1+s0TauafP/9p4qlXK1e2rNn17nXz6ytrRgMBqPRbNBbSqUyRRp4XgJB0GQy4TiuadrGxgZBENlsNhQK+Xy+TeUnGEYJgpiZmfO6PZuNtp6ennh8o6evWxA4RVHy+fy5c+e7u7u3jIy320yrxbz04it2pycY8klqC4LVvXv3Yyhx9uxZBMEKubzN5pBlud1uG40mDMMkSXyj3y+K84tzExMTm6iL5xgcxwEAMBgMIAheunSJIAiT0bI4Px8OdYbDYVlT/UFfLpfLZDIWi6VQKAmCkM8Vdu7cSRDU6upqs9kMBAIgCCqKsil5393dbTAY0ulsLpcLBoPJZLKzowvH8Wq1imFYs1VnWRbDsN7e3nh8Y3V1fah/hKIM6xsb169PPfbYuyKRrn//0ld0eqPL5dp34KAsy5PXrgIA0Gq19Ho9Cqo6GGrWa5SOYDmOpPUwgsAoNjA0fPfO7NLyul5vwkm90WAZGRmdvHxt58SeQEfX/OIKCGE2m21lZenV11588MGTmWzi9s1rfX19zUar3W7fc+IECIPnz7/m83s0RTHq9ZsJLxjuSKYKN2/N7Nh1wGr31RstVQVIAsmlYqfvOfzqq89txGK//8k//uo3vruxUeqK9MfjG1KltPvEoUwy2xMZHBvdVSzXfvyzJ4a3j04c3OfwupfnZ2rp1eGejq988R97oj5AYiqFbDgYWFla9ng8oshDqGa1WrP5Is/JNrOzUq6FI502h31uYdlktnOsGI32eDyeZDxBU0ShVOIlNZkt6m2+WktUICoajahiIxQIyLIWT2Ru3pz9xbM/vnorLsgQhOsABK232VQ6OzQ0xDCMjqIUSf5t4eDNxdu7MP9dvtkc9N1MUbIsEhS5KVMEw7AgSaosYwQlAyAMgAgAQgCsqZCkqCqoUAQkcVVIEhEJoGBcT1KDI4bHv/fTJ3787w8e7hkf9Hf3daysxnSkbXBg65XJm/lc+k8/9dHXzp5BIbLR5G12f7FazJdjo9vH48nCg+94zxf+5T9lWR0fH6vVyyrIr8WXNBhUFGXX9t2aAiAqBAiC02b9wuf/Mdrl6u0PgYA0OTnp9QZ6e4ev35zOZPMQCnl9wbGtu5PxAgrpMYxIJxMILA0NdSKY8trrL8iaFAx5JVFZXl4/dfz0xlrs+Wefdjit3d2dmXymXC2DILRly1ghnT1w4MDs7Ozy2urw8KCsSM89/czRo4dbzTrPszt37p6Zna/UmiRlSKQzJIYjMOiyOxKJhMfjkUTe4/GMjIzcvHlzYmKi0WiIonh5ctLl8viCgeefeRYjCUFgCBInCWrPnj3Vaj2TyagaODQ0Mj+3lEplrGbbxJ59mVRuamba5XCfv3DJZDIfOnTolZde6h/o1TQJw+FjRw5ls+mLF8+TJLlt545qtUpR1MzMjNPtQlH09OlT09MzHCsszC0TBGUxmmq1ytVrlz796U8Xi8VYLLGxnuzuHWo12UadwTCyIxCdmJhYX1+vt8sOpwHXaQDEcCLX2zP8+tlryXi5v3+QpCBFqzfaKZvJ2Onqo3VmQRVuTS8ObDnUFnTpnLSRLm/fu7NQqasQ1WRUnHLVmRaMqxACAgrxBmb6tf29+utS1/CvolT73dWp3wmw3q4vCvxWD/F34avfELvSNmEfCKggCKqqDMGgIko6nW5zBEpSNQglRFFEQBWQJBJFAE1j2oLRZJU0SFE1ANAoHVbMJ8qllMNiMNCogUARUG00qzqdrt5oFYulUEe42WYhEKMommdYQJMCXls+H8dgGYPAXDJr1BtJkiiXiyaTaT224Q0EMQyTJIHSYRCgNGslswEjEKiYSzntrmKmdntq9v6HHmgJ0u2Zpb7hMb3FlszmVFDt7OzWE5b5uTWJ0Xbv2nnt2ustptY73J1J52CFyKYLNpMeIzC9yShrYDyVC4b8CCbcuXGuK2D78be//mef+FQ+nyeNZm+g81vf/MFAbx+Ky0NDERAQZFHAYLrZYGq1mtlsjqXSjYbkdEQRnZUDQVYCBAlIZ3JdPR1en6NaKQgcV8rlcRj480//4f/41B9NT19fX5l6/tkL127djoz0cYr20gvnP/bRTyiK9o5Tp3/285+defkVSZDHx7YsLc5USql7Th2ZmpoSeY026TSw1WKaRosPBPRz84ltY+OFfCYSdBNQO7l+pytka1SSMtey2yz1St2kt+YyDY/PWypnK/VST18vxwnNumA0OZxuH4LTrCBjlAHA9YtrCZPNJYOS02OqVsvxWAFD9F5PiKIMzXaD1OmK5QqlN+mMthanKYBOUlFVxWAEEyWW41icIlEMrjcaNE1vPmzVt4UVDEAAAGgquAmwYEADNA2CUVGBIFCDFaHDRX/qg6eFanykLzAyGE2nk4f27dlYnot2RSrVhtPjNOqp5375pJ5AvP7gniP3ZxmMp7tKPMmqNIjisKZoqgxBgAYCEEqwnARqCEmArUbz0sWzXREfAmlMi+XbzNH9B5954vs9QePG8sVQACUwAWq0mhACz87PtZh2q93GcLJQLLfaLILiCIpjOOnxeREM3blrd6PZlBTZ4bTBMMRxHMdxOp1u09ZH08BwqPPEiXt4Xnj99QuTk1fTqWwqlblx45YiayRJ4jgOIyCKwi+9/IKqyl6v+8LF1zmOOX78+OHDh++77z4URVut1mbpC8dIWVKnp2bjsaTN6sAwTK/X12q1n/zkJ0899VS73eZ5FsOQnp7oemzNZrMIArOwNNtmG/V6VZIFSRbcbvdjjz126NAhSZJYll1ZW+sbHMAwrFQqEDh6/NhRh80qCsz2bVt5jkFRNJtN12o1g8FQbzTKlQrL8flCkSCpNssEAoHp6WmSJFdXV4ulCsPyt27euTJ5LZPObaxXdZT+Yx/7uNFsrTWbJE0rimKx2HCctNudNpvD5/UTOHn8+D3NZntjY0On08EwrKpqs9mUZdnjcQ0NDeTz+VKplM2mW61GtVqFIMhoNG7ZsgWG4Uwms2lxnUgkNgGf3W4vl6uTl682Gq3u7s5qtTY7M49hBIJgmUyu2WiPbtm6d89+ktAhKG6zO0EAbbc4k96EwBiO4yzblBU+lV5fXVvavXfH6LYRs91WrlSTmfzFyzcBlOZVLFlo9I3tsrnCZnvggYfe81d//RkIxkLBjvvve8Buc2zdusMf7NIZHd5gtG90e7nGQBAKg5DH4zFZLBAC9/T3nL7/gVKt7vIGd+zaJytwf/+We+994HOf+5zI8Yoqv/LKKzt37t67e9+9J+/7p3/47Ef/9M+tFofT6Vlfj5G07tiJ432DfWNjo5OTV86+dr5UrGTT6dfPvdQZ9oOabDTqIQhsNlomk7leb4iijGOkqqoEilnN5larBcFALL7caFQ0QN5YW03E4vOzC4AEzk0vXL5wNZ3ItxqMJGoETn3gQ7/X4tvleiPY0TMwPG61e3fsPmiw2Pbte5DQGSmDCYARSQFsdmewo3MtFnc4jEyb4wRe07RNg/O3Xr/xdvP1poqPBoMaDGrQmyehN3KMCoCwKMiaCmogLCkaTlIUbZAVjcIpVdZgEAI0pd1qojCkp8hKuaxqkt6AbRkN2h2QrJU+8pFPX5m8+Ll/+ee//+zfuYKuUqU8OLBlbiZ+98ZGNDyuKbqzr1/s6on0DHXG08sLS7O0zhAJ9b9+5lpv19iXvvj1UrG2e+fExlqsUCiMjAyRJCawzSMHJzpD7nwqxtZKt69O1nO5vkikWMg5bHZap+sIh2EQSiXSoihjGImhepcz6HGHNA1eWVmuN0r+oM1oRmGYnbz8stdpPbRvb7VUbdaaB/buUxXp7u2boAYMDQyFQhGzwTo8OPyhD31QpyPyhcz5C+e2jo+eOHFMkqQ2w7i8nnw+f+TIEavVfvHiZUXRQqEQiqJWq9VitymKQlFEKpXo6+txuVzz8/OXLlxsNZrPPv2MIsmx9bjISz6PX5VUA20EFMDvD0IgHIlESJK8du2K0WgkcBQE1O5o556JHe999yMgIC/Oz9A6YnV5niQwAqdefunMxN49G/HV6zeu5AtpQeZCnaFUNvPRj//h9es3FxeXMZzctmP7/v377r33NIoTKE7OzC+srceqtabJ4myz0siWnRvrSRTFt28f/8hHPxSNdnR3R48ePUoSuvW12NSdaVkWU+mNbD5ms+sgTHO7XbMzCxBEbdmyx2wJ0npfq40oGmV3hQvF5osvvihI9RP37smVF+OZmRZXcHusxWIZQvA2K4IopkAqjGOiBgIItqlsDYDabwfk28Pyzbf/LboC/hti+5tMKk0DVOBXxCrtV6JWb1e62hz30CAIeIuBBWwqiEKAgkAaDCowpGoqD2iCpvIwqICaBgOwJqkQBCmqpIGq3kgJMi+rggopoirmchkcx/3eQLVcjW9swLC0sT5DYJok1pv1tMCWC9k0ooEWg1HkWa/HAUNqtVwxUEYUIkEA8fl8pA7fBC7xeHx0y/COrcP1SlaR2Hq5eOPa1fX1dQylbt26k0illpcXXzv/qtFE+gPelaU5A006LIaB7rAO1Yw49vrLLy9OzzOVZjgQSMdXLUbc5zGoIkNiQCy2sH3nkMvv1WBUAzFZBcZGR1AEWF9cGh0afOC+UwcPTLzy6tMgzOfzK9/8xr89eP8Jn9fR0x1hWZYkdTrKVKtxmWyl2RLX4zlZg8Z27nIFOlQIE0SAJOnevqGR0bGurgjLtikSqZWz/dHwg/fe8z8++ck7N65feO3c00+/evXaja3jOwRWi69kjx08sba0/KH3vnvLSN/d21eef+bJTCr2yiuvZHP5rdsmXjlznuWUcq1Zr7UqlSqKIJokAHLLSMpsIxNy69lahm9VFI6ZPH/ObbWRBDY3daevt8PmIG0uWAEqHp95eGQAwzCrxY5hmCjy2VyqXEomU/OLyzcr5ZTRQHNNFUccuVzzyvVZnLSZzT4MM9VqDIxQMK4DUBLE6GS2XqoKrACoGixJgiSymqYCoArBgKIoEARBMACA6lvyVJCmwoAGABoAbKoRvs3+EgCBNw3LVVVtNZoUTpA4US6WivnCZuugXq+jKBoOhDfWYhwnbN++vaenr9lsthpNCNQgCIRgFXrDS+ANHelWi6FplKJAXlBxkvz9jz0wt7R46dq1SLQ7FO6qVGoul6tYLK6sLnf3RPOFLLh1R7irq6tYLNrtVpqmZVncbA4Gg0EIgprNtiyrsqRsVlxAEFYUzaA3iaKIYVi9Ua3X67IsWywmUAOGhobq9TrDtkAQlCSxXm8MDw8TKNZsNtvt1tz8jN/vBiGVF9oEgbrctlKpgON4T08f0xYAACwWqjwv2qxOFMUbjUYqlTKbzToduUlCisViNputp6cHgiCKonCK5HnxiSeecNkdB/bvXVhcTCRjEAQ1Go3t27c7nc7env52mz1z5jUYwiRF83r9Fy9MBkMet9e0bftYtVqNxxKCIFEUDYFIsVhcWVmzWq0sz/n9/s6OyNT0XRAEXS5Xo1FrNBoURdXrdYZhwuFwo1bflOoHQdhgMKiq5vP53G73jRs3tm7devHSJRiBQBCkSJ2qqslkMhAIYRjWaDRkWWZZFoZhgiAwDMvlMv39/QaDSRCERqPRarVaLcblcpmMFrfbXalUVFWt1SvVatVgMMAwzDCtzs6umbtL5VI13NnJsqymgm2WoQ0mh8NFUnS73QZguKOjI5lObT5Byrm8zDAQIMMYLMq8pmkQDtMG/dzCEqUzffgjH791e57WWwCVTGdLigzX2ixuNATDXRwrIwimI9ADB3bSNPCzH39nfXVJp6MNesuuXXsnr1/nBKG7rwsFZbFeTMdWKJpaXF2x2m0tTtiz50j/0PgX//3x/r6RUrHmdtoP7d95+eLZXzz5o46uCK+AQ1t2veddHzl//kq9Xm8z9Uw26XK5yoUqAKJd3dFasxHs7Pjql77cMzru91hnrp9xWRBQ5Ux6rFHOIRAEqUC73TaZTBAEcgJLEFij0XA4PAiMlyo1p8eaL5V83g4Y1lVKbVUF900c1DRt6s4dgqJm5pciA4OvX73xyHs+0JaARDyFwpoiSj19Q7lsEcN1tRZzz+kHDWZrtcmgJMkLCknrYrEYgWJBv49hGUB9cxf+pjfIG7c6BP3OTfxbdS3lrTIACIAgiGJEs9kEEZgkSVEUJUWGIAjUIEiDaIKS+KaqqhRpYHlBBjS/X4chgNgqvv7iU8nYqirKuyf27j10qFFLYnJsbfnaN77xpS/8y1cSS00UNksikM3FDh0b2YjPMjx3/vUr28cPUKQhEu6YW1ww2Rw4RkY7ezKZzPLyosvnsDqMhVJ2IxF78MEHf/nkU1y71eULJtdX7EaTgcZK9fTgSLckMgsLC5HO3t6+LSBITc0uiYq6srrRPzBCkfpapVqu5Lq6vKsrUz6PMR5b9QdCLZZbW10f3TrucblXV1fPvXre4/Jk0jm3x+lwObKFtKyKqXTCarb98R//cSqZzuSyP/nJTw4ePDjQ3/fUU0+dPH4slUzOzS70DQzkCqV8ueLzhy6ev7B7x/jgYG8unSNIrFKuyZI0MDBw9tXXjh07Fg6H/+u/vnv02LFQqOOv/uqvTp48FQgFXn71xXA4aLVaDQbD5cuXT58+LQjC+sq6KMqrq+u1at3hcB06dOTLX/5yd7TX6fSYzF67w6Go4n/85xf+x59+6vkXnn7ve9/daDSWlpY6O7vu3J7K5/PRnq7llcWxsdF2u12tt3btmrh0cfKee07LvKrTGRRJzuWyECja7Ear1Xj+/Hmc1O/edVCV8XKpcfPKnUDAd/PO5LETewW1envq6vbd23p7h1949pLL2V0tK7lCmdbj4YgzX15UebY/PLK0ONvRa68yFZ3V1Tuw59btAoQ6IcyqQDoZxHkFlEFUVEGMIkVRRrRNxPT24dY3+X+/4qG/VcECwbdk236Luv7bJwEA0H5dj/033HV+u74FaZt0ZPWNT4MqpL0hGodhCKApmqaoiqSqiqZpCEpIEqqCECALCKwCqoggCIzizTaDYhQIIyzL4iiiiBwGyG6nuZDdkPmS2YDTJAUj4OXLF3r7hzyeSDZTQXG9JAmC2DLqKQJB69UKAqpDg923bl9FIMBssAEAUCzkMAyq1asoCuI4DiGw1Wy7eP6cqohWs06VGVnkbBZHMBQCEVRHG0UFvXln1h8M9fQOlCqVa9fvqDLZGx3EcfLz//rZv/3MpziuZaTNr1+46PJ7I5H+akPy+Trj8bimyvlssr83Mnv7an9vaKDH/d3vfhVUhD/+1CfW19cBEO8IDV+8dKVYykGQeurk8b/928888tD7CVwvKbKiKaVaNdo7cnc6vh4vhDojdre73myHO0MoAWYz8dmpG/ccPhT0uP/3Z/5xbWnxheeeWVie/9ETP+4fGMJ0ulKpsWffoXy6Mjs7O3nhnM1ulhV+69atzz7zosFs+uAH33936rbFYhod3VqvcnarqVqLqwpfrzdjsdi999774nPPl0u5Rx+6r5SNFzMxr8vcrBWymQ1NEfv6oziOKoB2Z+puZ0evyeTIZcuSCEoixAmq0+XxBX2FSk4GwGKN0RlDPu9YIl+2+oy1dt1IminSVK82CAoXFVEBtRrDW5z+clXAcANO0IAGqZqIYQjHCYIg6Qx6URQFiadpWpIkGIZVAAIAANI2Q26TfQWqgLpJ0gIBAIZQUYVUVaYQwGWAPvboYTPG9nd5A15bNpue2D1ezWftNqska4cOHXrhheca1cKh/RPJdGbH3uNLGQ71jJREkldpDcY0RdA0BQRBFUBACAcBQJY1XmBtNt36xvrK8sL73nW6UZZQECrG18+88PN3nNz+P//sg4f2RqPdHsRitq6vr9fr9Wg0wjDMplJLu91OJFI4jtO0gaYpTQVWV1ftdmepVGIYbvPOKZUL4VCnwEubiEFT1NXVdYPBgKFEq9WyO6woQhAEwTRbVqu13W719/dmsgmPx01SaG9vVAMUjhMQBOFYKR5PrSyvHTx4RFUApsVrCqTXGQb6Blmem5+fd7lcEAQwvOBAsS1bx6vV6i9/+ctgMBiJRPr7+5lmI5GKD48Mjm8ba7VaLMuIopjJZFhe1OuN2Xze7fa53Z5UKmUwGDCMiK/H11aWJEkK+EPbd+3M54upZGaTSsVxjNPlhCBgcWkBx1FRFOv16lsUGVVV3W4vhhGcIOI4zrYZq9XYbjPZTB6BMUCDHHbX49/4ltFsIEnSbrdznKBpWjZb8HgCNpspkUhsMumsVitBYBiG7dq1i6ZpDMMuXbqkaWAkEonFEpVKxel0rm+sVso1m822+e1ms9lgMMAwuLCwAIKwTqcTBN5isczMzo+MjOCkLpXKEGS7Wq0WymWz2by4sByNRkEIWU+k+qJdbJsBcRRAUFEQUARtClp0cNRsdX79Oz/CcPr0fQ+98tJFr6/DarTu6un/2bO/JBt1Pe0YGN0aW1u/Mr148OAOsy+CFRt2l5umrC+fu9UV7TfbrGuJZa5eVOo5I6mDIAhHUYFnJVG8cuWcw2ELBe0MV+nqDqkKcPP2tD/c9/kvfjMWS+RzlZXVVCnLbN2y5+dP/dzh8iogcunShd2796iqevbsq/0DvfnkxqEj+13OwO9/4N1f/LfCnRtnuzq8q0uzTqsRhuF2q6mnjaIgEyQGAJDH42u1mHw+7/MG9QYdBEEYhnGiVKsX+vq2lkvN518973S6K3XeDNHv+uBHGF4iLH6zzTuxZfS/vvM9p9Wya8fOZ5998Q8+/kevvHpuce36wtLS3oMH1RajKAqCIDzPhwPBhYUFA603GuhNB7237+x/o134mwkJenr8nqgAAQAASURBVKsvs+mWBYIACAAAy7UpHQFokCyIEAAQGA6CIKhqqAbK7TpJQKqkylwr6DOxInDl8o1XX3miklt75P4D73nffbIg9vWNLG/EJZHbWIitLq29//c+3mTb2XLy4N7hp3/xCm0kNQjPlbl0NieqRKXODg2Nz87eMJro6bsX9+/Zy7Qy5fy6z2OiaYKptwnUGFspfe0/fgRqysSuca9DF/AZG9V8JByMp8C19WVZand0+suV3M+fXAyF+sqVlsPpLRZz7qqH9KKNVj4YtmULSxY71NvnDYaMv/jlC3MLyyeOn96ILS8tTsEwHOnyAxqsanIqmWE57sDhg9//0bcRBBkZGZmbm8uks15/wG53Ihixth7fu+dANlvQAPiek/e+8PIrbYajDcZatXXg0OHZqesTe3dYLBajyTA3O5/PZgFIO3biqMfjvXr9Wv/AQKlUSiRS23fuyOXzoY6QwWBYWFrcvXNXPB532m1P/PQngiB0hDq6uro4tu1xObdu3ZZIJAkM/cQffXxmdvG1s1eaLSadSXzmM/8wsXsHxzGzs7P9/f2bbuIjW4bu3JHdbrff73/9/NlCviSrEIbr9UbT977/w76eQZfNjSF4ZySSyW4gGDY3P03r8Ug0ksnGNYUMBbsNBrpQzJgspCS3HW5rNBoVeZBjIAQxudydmtoEYMpgpkIdAYfH2qiUWQZ/6JGPP//aTxw+P2nUTc3eqLdhDAcHOwfnl7MQCqIYbjBStSYHyCAggyAEAuB/2617A1H9Cva/qUD1Vnz+KpLBt378GoQCfvdGAnhboes34Reo/lq3EgQAAIBBEAAAURQxBAYUFUdRURQ3q1wwCIIIrMgCAgEQrAkiiyAATsCirBAYKosCTRGgzLOtNihresKgSZKKQitLywiE6HAivppwOkK1RrPZrnt8ZpZppDdKfT29ksDMzy/CMJxMxLAwCcOIwEvtBhPu8BUrxWw2u2/fAZYRdLTFbKRNJsLvs01ePNtsV/N5KF8oWWzurVv3dndGMIxOrqfnFuajkS4U0c8tzAqC9Eef+DCGA7PTi8f232OhDX6vS2+hmwpfajf0NjPfrA50h6evXT60Z5cqM3ybPbj/gKhyr154nWk29LR1bTWjo8zVavXhhx/+xS9fdDgCtN6iqFA8nor09DKF6jMvvtZmwf6B0Wa9US8B2WKuUo6fu/C6zWII+7w3rlz9m6d+Dival77wlVfPXNDbLA8/+thKakmUOR0BplYXb11fcLt8FERiKnL88ImFpdm+npDRbPr61/5tbGwslaiCChzpGJm5s96uFSS+0WLKo1v6vvIv/4RAotVivDX5Sm9P18SubbVquVau2BzBQNCjKGKhlN9IrBOE3mhxZvMllNAFIxFQ01+7Mo3hnkoFonRu2kK3pUS9WcOIUmeke2Z9Nl3I7d0ZEBRZgWQJgHPVEqk3YHqTBCB6u1EDEUmWFVEEAEGRYQ1GVVAFQU1RpM0AU3/DzhIA3rAs08A3fwFtmkFDECTLKgzDqiKxHIPLnElvgDRAlmWj0ZhLxCwWy8rq2o0bN+r1uiSrCIbjBNlotXlRhlX1VzOzGgQAmgpBgAajCNBqiSSFOoy6NsP7fL7xrZ3JeIOA0ZW1xVef/XkkYMpmVu89fdxEibNTCwjLsgRO2u1oJpMzm80cxyEIRpKkqgKbzjM4RmiaRhBEpVIpFAoIgmEYls/ndTpdJpOBIKher3McbjIazWZDJpMhSVLTtFaTwTBs6u6M22nHMNRkNuA4KogMCGp+v59lOVEU87nS8PCWTLro9YQUCUklCyShE3heEuVNI0ZZVboiPRzHYhgWCkYK+fxPfvyzw4cPm01WTQVT6eyevXsJBF5ZXWq323a7rdVqejyey5cvJxKJA4cOS5KgaVoiEV9ZXnO5PBiOJhKJ7mggl0uhCEmSuhvX70AQNDo6ev36dRAELRYLAKgM0yoUCm6322CkcByPdvWJokhRlCiKAACk0+lcLmexWPQ6PcMwPCcODQ05HI6ZmZn19ZjVajeY9IoiEQS1srJSLFY7OgK1Wm3Tf7Cjo8NqtcZiMUWR2+02y7I8z/M8r2ma1WpLJpM+n69UKq2vr2+6UdbrdY/X5XK5CoXC0tLSzp07LWbHyy+eGRocVTQVRZHe3u5UKkXSOoIgiqU80+ZcLmcmk7FYTYlEoiPSGe3p3khkfT4fw7K8BEoKRCm41WpvNNsED7q8HZl08fnnX7VZvT19/bTO1Gy3Ojo6/MFIrSmIKuDwhQrF7IVrU6yMezv6solUNBL44O//4fnzF0vlRqSzn2vaXnvmNuq1kSBu0BtbXBPSVAqDXn7xlzCmUzW8AAJzC6t7Jg7itKnUUDHaNbp10GLNLS2nHnjH3lOnHjJadRgJCYqGktS2sbH77j/5+Ne+huFgKZu7NXmLghSX3RbuCBhNZCgUaFRKLN+iKRoEYQxDGZaFINBgMHg8nkQiFYvFhkZGSRor1Vo3b80Mj+7Ol1u8DGer/K6D4wFJun379s+efhmA0AcefueW7TtyxerY+K7p27fT+cr7Hvtgo8VmcyWDyVKvNRuNNoqiGgAoigRBkE4H4xjSajbNJsPbDAd/bcv+3wKsN5LYG595a0nihCAIIAjDEKQoCqRqIATKooAAIIpqepIwuvBiiXv5hQtzK0uKxt537z3DPX6XFZXYxtXLkwiMWSzBXE68emP1oQcfNZuaVpvungf6ZA4IRQOyohaqbauz0+UfPnna89X/+M986WmrmdAgBYXVtdWF2ZlfuN2+cDhss1nsdudn/vFzx+95cGhoZHFpCgDUdGZdFKoK17h2a314eHh1fWZoMJrJZARR3r5tLBEv//BHP+iMdL/rPe9XVO38hXNOh7mnb+vKalUUaotLS4sLC16vV6c3IBjoctlu3rwpiaLXEwQU1e60KoomKeqPfvJjAqej3ZFUOrOyumYwmIIYsXXbrmeeeUZgeYYBHn7weLgjKIqq0WDGKWMqnfUHjWPjW1PJ1e/98AeHDxwMo+G5hTmX00nRtF6nE0TR7fFAEBIKhe7encZ1FI5guUKhWq+12+1yuSyK4t6J3Yqi1CrVzeLTBz/4fqPRvDC/tLS09Gd//qcLizO1WjOXT0uy9s53vlMQhEsXL7/wwkv7D0y02+1CIZ9MJkOh0K1bNxwOm6ICJKE/eHiss7PL4XStra3t23sQg6l0OouB+Pr6OsfX705f+eAHHlFVyWCy/uD7T+hIR2dHd2fEf+nSxXCXRwOUZqMNaFix0BjsN3V29GXSJYvV0zs4ZHUYbt+9YrYQxUrbY7YtLCd1lIfhxNRSSgEBlzuqKFqtkjRQIEYBosrJHOe22UvlNowQiqqpAAAA0NuKWJtr6M0AfIPnrr1p0vzf0QrfHt5vX7ydnvV2LPX2j/xq/uutr3zjgDcdcRRN0US51WT0NAWqEEoRIi8qkgRDCAApEKiJnIDiCAzCIs/qjZZNf3dZlBBYw2Gt1W4ZLDSOwRSqQ0BgZXE5GonUGjQEwHaztVwsebw+q5kWlarIt0JBryyyzUY9EHTV6lDLYskXijSlJ0lKryNJkvR5PCzLp9PZ2Zmlzs5OvZ60WmiGqVaqTbOBFEXR43byvFzMF0w6U6Xawkmdw2JMJ2MoTm3fOXJl8kZPX3e5nrvn1H3ZpTTf4lAYSmcSLYlCCaiUSwN8Ky80CVjmG/U7t66ilPx7f/D+f/3yv96dunP80NF6jenu6kxnCh/9yB9Mz86WivVdu/el0ulitWa2Oo0WW+bqHZ3Rtfvgrnq9hUCwy2l1eWyZfCbk8x47cshjtz750x84beaH73/H3Tu3tu/ae/X2nQvXLkYG/KoqmhBiKpbaMb5/bSM1s7DkdTsI6sbK6vzu3ds7OoMhvyOZSdmsJr/P9cqZF0eHtyGULdTdF0/MlTO5HVsGnS6a5xqixN29NRk3W6vlaq1WGx4enp5bo2mqs7MLI02VSqVUawVCEQTDOUbEUeDUvfeBmm7y6iSTq0wcGI90BUpV1mQiRbEe6ejqHx4tF4uqrCgaUCiVBUFz+p04bc1XWhgFCqIAagCCIhgEy7L8ZpD+ygBnM25VVfuNIisIgKAGgBCoqioIgcDmZlZRIQDRNI3AcAyViqW839MLwQDDMDzPIQhiMpnaXFuQxVAoKMkyipM4Sbi8hqosK4qiapuseRAE0U1TJ1EAEBgUBbZUrlqtVlUBMmnRoDc6LUAhAezZM8zXUwJX/uWTP/70Jz7MNHjwyD1bZVkOhUK5XA5FUYoieV4AAE2SZARBGIYhSV2r1UIQRBRkiqI6wkFRFHO5wmaLShAEQRCNRqPA8XaHrVgsNhq1+++//9q1axAEURQhiCyKwoLIPfLIQzqa+O53/wsENZ7nOzu7CoUCgevK5arb5Q+HI7Mz8+1mU6+jU6mUBgLDw8NLS0s0Tbfb7UajYXPaIAgiCEKno1RA27QvbTbrY8MD5UpRliWCIObn5xVFomnabLaeuve+mzdv+33hqamZRDzN86LBYEokYgN90VAoODk56XQ69SYjy7IAADBMC4ZhBIUEiQcAIBwORiKRTDYdjyV83pCiaIVCQRAECEIkSVJkNZFI+P1BVVX37z+YTqdXV1dZliUIQq/X6/W6ZrPJ8zwIgpsEfJ/PBwBAu91GUZQk8WKxSBBYrVYjSXKzqJZMJs1mMwAAKytrfr/fYXctLi6azeZNoE2SZCQSee3sGb1e77C7bt+8a7XaJVnu6OhwOt1tlimUyqoKdEWjy8urpWrNaDCLskQQpM1mC4W7jBYnbbBcv359eXVFlsXBwWGTyXTp8mRP9wDDC6Nbxmdm5wEA2b/vgNls/a/v/+DAoYNmp2dqZi2Trzi9Aa/fwwutqbs3Bnu67ty4jmjwH3/iU36/dWZm5fFvf93vMnW4de1q/s6d2+lM3GY3kyTebNbNZnOt1Tbb3ZIEY7TtnpPvTGVqCG5wu/3JtaTFZL92/Y7RYH7/773LYASuXJuGYGBpaens2Vf8fqfLYQ353MuLK52h3vPnXgr4MFWuKGLL7bQmN9bYVptAaVUFSIpmuTYEAToDpapqvd4wG6xtljfZrQRlNNr8L5+d9Ib7/u4zn//pE0+Pjm1zu90fOnUKtDv27NuravDufQdEGVheXv7ohx987LE/InHq43/4ifPnLwqKMrFnn9FqExVV1QAV0EAQpAhdtVwyG8ySLIAw/Pak8tZCkiQMwzbNSTaZdoqiwCgCwqAsy2+pacMwDGrg5mUIBIuijCDI5iND4gUUAe022kijUzeWbt+ertbqnd3RoycOGExAuZQ1kZoJV19+7hmf0+3xhngJ0Zuc8XjWH9b7/XwycbdRbo4Ojl+dnHY5A0ar/YUXznpcXePj27/5+FetFqK3N5BKzN9zbOKbj3/D4wiKnKyjybGtW+cWVkQVOnXy3c1mc21jenb+4vgWfz63XM1nNUXet2/ftetX+vu6MAyDQDy2np+Z2XC7w7FEun94tFZvxWKxPXt30Xq4Wks4bIZ0snDmzBmzWe/yOGmjwev1Ly4um2jTpQuXPvzhDxdLhXgsodcbmy1OBWAQBFFYvfe+Uy++cKbRalssttX1Nb83AAPa8PBwNpttNZsXL13aum2XKEvrG3Gb3RSPLxw9dghQtZ6enrW1tWwq3d3dLQoCgZMkSZbL1UKh4HJ5pqan7VYHbdBDsCqKYqQjzPO8w2Z94oknJnbvxBCUJMlQqINj+WQybTAYms02z4lz80vpXPVjf/CJ2ZmZubm5rVtGJFno6Aiurs3TejKXy7TbbUJHOeyezs6oJEHbdu68eOHylWtXx8fHMpmcx+XHUBLRYA2QrDZakOrVSnrr+NDM3JLJaF9fzVOkucMXvXPnjjfgzOUTwY5QuVIldWafr0tVCQAkiqVquVbujAZRQmsx5Wa9FfUPGHQWWVXnV2dwSivXisFgEEaJWk0Y3bpjdSO2kUwLMoCR1u6eXRvJmgQbFADVNE37tZ2A+qbyLfCbDUFQezseejtC+p0AS9Pesor6TYD1G2c2S2WaCmggAKi/+joQBCFNlSWJwjFNlSVBUCQJRWGKxHmepQ26ZrOBoXC5mKcoymyyJtIZry/I8jKKEYAmGfVEvZzhmarPbUJUQGbVxEaiIxhYmJ9CMGnPnn31qpjJlDEK8/htidQcrcPsFhfPcgLLSLKoM5C5XM5l87YabRiCEEhbW18AACWZydptLoPRNjY2xrLMxvpiMrHcqOYefeCBa5MX+/u7NRB1OgJXr91WNcwXCMTS67v3T4iKeuXabZcnoqNNFK2HFY0t1DKpOO2laIez3AZbbUGHo0M9oalLrwQd1nq2KvBsT38Ho7CvXHj10UffiSgYgZFLS0tOl6vN8F/9xtc//cefFhW5zTYaLQZB6Wu3FvuHd+7YfbhQbvIcA8msnsZIHfXss88MDAwIXEts1X/8w29/4D0P9fX09vVuuXD55n/94Ccf+5M/2rFvfOru1ce/+EWT3jI4tOdfPvtvof6hj370o+fOvJjcWP3yv31elVrZ7IbP76w0qplC1eIIZBJlr9HrttpkuZ7PrwBaTQEaK0vTff3RWqXK82K9wdE6PUXRBEW3220EwQb7hu7cuaVBaq1RDIY9XV29Gyu5ndsPV0tiuVpGCLHSyuUqqWqT8fsGNNSK6ALZYtPrccEwajSZOV7GaEuhVFcREiZpVQM1CARVDdRADEZkWWpxLZLEEQwtlUp2ux0AAA2EZVneDEh40zDwbSEKQoiiKDAEKLIGwYQo8jYTrrRy/89HHrLigtdO7Z/YtpHc2D4+ujw7tW18jOPFaqO+EY91Rzv8bicvyO5QT7B/90YNTzdBTtEJKoQhqCCJEIbDAABpgCqLispqkGYymSvlBqwirVpVYMr14trWQdfPfvTlXGz2wVMncolUpVyGJEnieb7VatlsNlmWBUFEEESS5Ha7LQgCTRt4nt8sqFAUpdfrY7FYPp/fLFOJoihJEoqigiDYbLZ6raGqqtFonp+fZxgGAID19XWHw8ELbFdXJ8O0aJoOh8Nms5Wi6MuXr0giIAgKBBIWs3NtNV4u1xUNFiUt0tVNErpioQyBiCjIfl+Q1hnyuTLL8DwnkiQFaKBBb9RUIJfJLi4uFotFv9+/c+fO06dPut1umqb37Nl989YNmqYy2VQiEUtnkm63EwS1/fv3b1J0R0bGbt68Gw539PT0CoIIQYjdbicILBAIdHaG7Q7bwGBvV1cngsK5fAbDsJ6eHpqmN02Re3t7d+/enUgkUqlUpVJZXl6+cWM+Go16PB6WZUVRVFUVQRAQBDfPrKysiKK46b0qSYper+c4wWazbY5JptNpEASr1erS0pLP58tkMqlUyu12i6Ko0+nsdrtery8UCpHOaH/fYCqVMhjoZrNuMhswDNvYWLtz6yYKQ+Vy8fnnnimXi/VKWVbEvt5um80qCcKNG9dm5md4kWsx7R07dvyvv/uHQwcPWy2O0yfvVyS1XqqNDAyEfV4KA6fvXEdAcXykL7W2kovFdo9vvfee4+FgwO125/PFkydOYygxNDCIQcDX//ML60srUzcn//Wf/s7nsj/33LM6g56kaZPRhsFUMV+2W+xGWtfTGRLadUlk2s1KrVlFKdwVCNg9PthAW/2+9/z+B8ps7eOf/MSrZ69evXqVJMmV5bXHHvtQR2f3xcuT5XrD7Q/0DA35gqGNjTVFFmma3thYB0EQwzAIgjQAajbbsgrwkthqtRVFJUkdCMBGg6VeZ4uVtt0ZOHbqHcvx/JlLN8J9I5kq880f/nzPe3/vsY/+kT/St+/IyTYjYzjFcuKZ1+588hOfonT6b377O9t27Nw2vsPtdm+CJEkSEQRGEFiVpXw20241KIL8bbnFzQWCIG9PNpudyk0nUUJHyZoqqcpmo3kTaUEAqEiSntIBkgKrACApfrfF7Tanc9l//8rj3/nRjzqi0T//nx89cuxApV5fWFjj2ozA8cvzCwPRyHBfdzWXnrl5jW+2LTZvLFG7dXfjuZeu8CLOSWiTkXKlyq1bMwcOHjda3LUaByHkzolD/YO7Orq2qpAx0jNaa0jRvuGDh44pigKAcndXaGHhFobz3T2e3TsHMJyf2Dny7nc9+J53vzOZTNM6w8Se/a0m6/OG6vXm3Ny8TqePRqNzc3OAqnV0dKiqCgCQLCvXb07HYyUUsfX1bQdAnaoS0zOL03cX4sncex97//PPP3/u3Dmf33vrzu1qo57NFDsjPWab/cv/8dU7U9NLK6uCKPd0D0AgVmtw09PzlUqjzQgDQ6O9/QN2hwsjyVBnZPeevU6nM9TRMTs/5/P5G+1Ws9ns7ulBMHRweCiWiHMCvxGLtVgGwdD9+/fSOsPU1NTMzNza2tr6+rrL4dy1Y2ckEqFp+sUXn791+2Y6nbx06RJJ4jt2blNUyWwxzMzelmXx2LEjZrPZbDbfunVrfX29Ui10RgIHDk5QBJpNJ+PxuM1qffqpp2maPnDggCAI4XBQlsVkfL1cyXf3RDZiqyiKBIP+GzduXL06GQ4HOzoDTpclk1sBII6mqd6ewXZTspl9y/Mb589dKJVKN25eE0QOw1FVVVmWRRAkEg2LAP/MK0/PLCyoKtGoqY2afGXyZjGXGxkKX7zw1JVLv3jfO480a/GBHk+tsJpYm4MA5Q1sBEDgW6Bqc8zqbaIMv94o/A1U9Mbit9HV/8cB/tYBAAAAqBACQRAEwhAA/QreqSC02SRRFYCidCRJyqLUbLRZlm3UazoKMxt1ZpNe5FgcBQd7e0SWwWFIk3gKgxMbKwYK7Y74EFCWpfbqyoLP7fB6HE67lcCQc6+eYVr1zk6fyUCsL89JHENgSD6XTsVjOIaSONZqN1iWRVC4Xq/DMEiSpMvpsVjs3dE+s9nqcfump2avX7/BMMKxoycJ3HDutUsQgJdKtYDPx7aaZqMx0hHSNPn0yaNzMzfvTl9RAM7uMCEY3mxJBpMbw/WirO7bdwDUFKHVCns9QZ9T5luSyBAk7PHarFbj6nqsXKpHwj0zUyuyiC7MrRMklc1mf/rTJ/74k39qd3okUUFRZHR8hBc5GIZ37zqQL1YTyVSpWnH7fX1DWx7/1vftNl/Q3ymwwve//82//stPDw50ra3NfePxLydTa1/+0hdMesMf/P7H/+F/fW7/vkPbd+z6l3/4+20HDv78mScUCH71+Rfe9YHf42To7Pnr/8///Mzlq3fy5VqLZWrtxsBI78r68vd+9O2fPfmj2bnb5UqukEvv37d76u6tQjEfj8eNegMMw81mEwKAbaNj+3fvrZYaAieTKCbxXCq+mtiYZ5n8zNSF+bkLjdpqITtfK6/bTMhwjw9S6zvG+p1WM03RMIyCEJTNFThJKZTqOoNdb7BrKqQoCgyAIAhKkiRICo5Tb4Xfptbo23H/28PyrbWqqqAGQCoEgiAEQRAAIhAMqCrbalEUBYIApSNsZgsAABzHibIEI2C1XtHrdSAMkTpKBQEcxycnJ1mmBaiaLIskjomiqNPhiqJJKgCoiqpIBIl53ebZ6SkIAAJe3WCvX2Ca3/nWf/7L//7rcMC6b+/4yspcNNqjpy3gnv2DgiCoqupyuVAUVRTFYDCgKFoqlRiGMRrNjUaj3W5DEGQ2mwmCSKUSm2YvHMcROMWyrCTJKIoSGC6KIoajsiy3202/31+vV3P5DIbBlI7Yv3+it68nnU6iKLq6uhoMhl89c65UrEUi3a0mU6+3R0dHE/FkvVHr7+ltNBrlclnWVI/Hs7CwsElp2tjYQFHY4XD09/cCANBsNqvVqj/gqZQylWpJp6PsdjtKoJIknT9/YXh4qLOzM5PJOexunheffeaFzs5IX/9AoVCiKX2pVDKbzQ6H48aNa3v3TRQKhRs3rosiH+7wYwQeDPkajdquXTt4npckJb6epGlTKp0WRRkE4bt379ptDp1Ox7J8f/9gKpW6fPnu0HDUYDAYjUaHw5bPZYrFok6n3xwLkCRJllRFUSwWCy+wfr+fZduVSkWSpM2PaCDQbrdr1YYkSTRtQBAEAECn0xmLxXAcP3LkyNLSEgiCOI4vLCwU8wWTwYjjeDAc2nTFTiUzOElQtEGWZYKiRFF0Otx6vXF1I9bTFa212qIKFIplvd6opw2SII+Pby+VKl6Xe2F+8cUXX7TZbJIsBsKhzaKaKGgnTzwkyHBLVE888JDRZnrp7KTDYctmkgNdwb/5iz/p6wo77abBgb7JycmNjY3+/t611QWGbWAw5rQ74hsbGAw67Wadjmi2qhoCIaS+3JIAwqa3BGKZmt3pe+d736eCgCrIQ31d3/761+en7zIt9uQ9927duiPS5f+jT3xSkLl/+se/m5tf2LXz0N0bF5fvvmwzghdef9luNYg8K/EyqCKSqEiSokGaJAkUTZrNZkXRNAUKh7s30jkQ09+YWvqbz37R2zn03R/9/J77HwYh1EBTBAZUy+1f/PzJ3t7erq7ubDYfiUQ+99l/CIWCgiB0d/fgON5otnv6eimjXtFAFdBgBJFlGQGRUj7nsDkxDOMk6Y1U8VsJRnvTZ3ezQAUAgKwqMIZwPK/T6VRFUSUZQRBFkgmC4FleUxQEgk16A00DAADMTK2fn7wEYPD2nTsGerowGCiXeY5nSBIDQY5GJRJk12cu9HS4ZZ4pF2sWc9Dp719MtHGaUIAMiSmyABh1BhwFGvUyhIAb60k97VhcWBFE9v3vf39sI63TEXOLVw/tn7h59UYmsbF/z7aLF85094ZcLgfLsuFOD4FLHFsA1RYGajILwAh5cfJmi2n7/C671QIB+H98+Ztbxydm5xatdnsslQ6Hu65cvfqudz8a7Q5Xq8n19dit62uRjv6JPdsuTp4/d+7Mex57V293dGlxdmzLyL9/6V8NtO6+++478+rroqwdOXIilU4HA55CMR+PpdKZnF5v7u7pxVFifX292agZjcbx8a03b94cHBpeWlluc/y27VsErn712oV7jp/keIbAqUq1hKOYqqrXrl3T6XRMmwMAAMMIhmPtVlsmk2Fb7fFtY91dUZPJkIzH7Fab3WZ5+umnDTq6o6Pj7swsrdM3m229Xu/1BWRZvTs7bzJa0onsqVOnJ3btTqdT6xuLrXa1UEo6nVaDkTaZrflczWzxsIwcT6RBBO7o6Lh9+9aRI0c0WVlZWeVZzuG0O2ymQjH94EOnf/zjH+CUbs/E/kad3djYcNuttVojlaroKAsvaBsbcUESA6FwudJ4+JH3PPX0S22Wj3R3+IOuaj3NcvVIJJrOFv3ebqvFw3MqCCpXr5+Lx+b/4n9+6sr1yxcvXzp09GSpKiTTDZJyjO04makgEkBvVq3epEC9rbb0a6IMEACo2huTsP9/ehT+n7EXCG+mPU3TgDfqDRoIgoAsQRqgKTKKQBCgQYCGwjDPt+uNCtOu53Pp7q7OdDIRjUbT6ezQ8BaEoGq1Gk1TqsqzrXKrXoBU3mkzBTyB2zduBgOBRrXS2eGfnLzqsHuNBmuLaZtsBparabIi8DJF6GAYhmDNaKEKhXylVKtV6rt37C4UcggCiaKIkVSt3rJa7IVC4e6dW488+iCOAq++9DxXr9dKBZfb7Pa5vO6QTm8VRKVSr+QrKaffDuKoqCA2exepc9dqosfuvnHhHNuujO0empqb7e3dYjJZM+lYvZLW4xKJAul41mqyGwxGg8nCiizPyaVCpb+3t1hJz83NHTt+GgJxGCVfOfPC4EiEE4VMrrb/4P25oiSpcJNnw12hdrv9X9/8NttUTx47btYj3/v2lz7wvuPHjuz4yr9/PpPJHDl8ShQRGDXMLq5JKvyBD3xAEtqf/dz/1pvcn/jUpxlOeP8HP7B3796PfeSj3/3WD/bumQA0ASeBZqskykImW2zWG1u6e0Je+8LcNUmowmDLqMeGBrorpfLl81cpytAd7TOZLHNzM9GuCMc2AQ0aG92xtLRUqWUDYVc2l3A4LDaLvdViuDYbj8doEwZAQLFWHd26l2mjCuwlbaNNEW3xLZPdnK/WBBnCCKsGEpICwygKQRovtEEQxClSkUFZEHmO0ev1IAw1m009bdQ0DYARTXu7oNobqh+QBqggoGogqAEoBKuqBkCYIHAeB1XPrv35hx/s9RuteujA/u08z0c6Q+fOvLh7YieCIKuxDb1ebzTpbVaTLGlufzTXAk2h7YmyJGgGANXBMKwCoASCIAhAoqSjUAiVb926USxWTx45ub6cMBAw20idffmHOJjxeTBE5taX1ysFNhKOIputDU3TGIZxOp0sy25KKW4y3DVN0+v1IAjabLZms8kwjNvtxnEcACBZljdHCA0Go6ZpHMdt3mw8z0uStHPn9lQq1dffMzl50W63vvLKK81Wo6+vp9VqHT9+T7VSGx4au3nztqaCjUZLVTUEQbZtH79587rJauIlHiMxocUwDGM0GlOplMlkwjBM0xQYhkul0maVyGg0NhoNVQXuueeeVqsFgoAgC7OzsydOHOU4TpIknY4sFvPHj99jNpu//KUfirKko2iRlwAAQlF8x44dJInPzc1hOHLffffRNDU3P1MsFyAQdjgc6+vrJpPp+vWbdouzWFyz2Z2yLAuCdPr06UK+WK/XOzqi1Wo1n8/ff/+Raq0hSZKqqsvLyyzDmEwGRdFkWdY0rVqtEjiFYRhN0yAI1ut1QRBMJktXV2elUkmlUoIkMgxjtdglSdqkeQWDoampKRRF8/n8ZuaYmJjYvNjj8aiy0t3dLUiiKPIsyzuctkAwnEwmNQXMptOKogqCQFN6t8OBwshgbw8niQikvfzssy5/kMDIcy8+Q+lNAX/QbDRGO7x+v69YKVfycQxDPB6PqsDnX36pxSrucMdXv7Ae6O4OdfWYaYLyudaXpo8fmnDZdFcvnyNgxm7GtIDTajFad+567rnnQIqIJ7IgROj1dK5QoimMYxsyqDl9hA5H8/XiB3//D/Jl7sK1m1294ZW1Fa/DMjV91WEnSjYiw9bv3Lw8d3f2Q7//4ePH73n13EuxeELW1Ewuh5HE8ur67XJMT+OyrAi8JPKC2WDTQEkBJEmWVUCTJIVleU2FBU6SFEDR4Eq54fKFllfj+Sa0a88hSYFAFczkaziK6nDssQ9+oNXiZFleXF7zB8Nf+OJnpqbiZ1555dbtux/96EdBGBJkSVYVUZZpvV4QBBiGFUX2BQOwBrAMv6kM/NupBYbhzdnSTYD1FuRSVZUkCI5ldTodAEKSIKIoWioWbWZrIGxoNIDERvr2zVuxWMxoNB46dqRjwN9qA5W6IIk8isKUgZYVEZBBGUYwmuro6shnlyW+IYua1dbPci2jnkJIemG5vmW4fyOXFtpCNOrm2PbFS2dDgRCOACMjPdOzdwvlbCyRGh3d6vb2xtP1cKT31vVr169fH+jrE8V6OrFC63FJQHKZZDjghFT8B//1QxozudxhmnaabQEIVqanVxEIf99jvzc0OEaQz5ptFoPV9NKLZ4a3jBw+fLhWK62u1J9/7pWjhx5JJ0tPP31mx85tDz74ntW1hUhnb6VS+f73v6+p4Ec/+oeqqg72DymaxvMshsJPP/PLvv6BHbt23rw1lUykWZbPVgtGo/nwwSMcx2SyqYk9e3me37J17O7UDC9I1UrV6w68+OLL0Wh0eXl5+/i2RCa1vr7udrvD4XAul8vlCm6vB0EQo9G4tLJ89NChtbW1Zr0VDPoljtUUdW11uVqt7ty2neO4PXv2qIqGINjk1SsLCwtmq41jmuFwkGOMTz/zc1Xh8/ksigFbRgfsRcof8ExM7MrlCgvz6z09I3/+Z38V7RmY2LVnaXXJYjE9+/STHMeMDA87XEaCAMrlfL1e/4e//+eDBw/6goG11XgwGIJgzWjFc4VaKh3bsS3UZpR2u/3Qw/dXqvWhoaHnnv3lQN+oyeyYnptOJbJmK4WZkDbXjvZ0SQLSardxzITjqN/f5fa69QbH5JWbDnfHpSvTOr1ncMuuxZUUjJMqqLzF9d1UVdC0t/X7NpUS3oBZ2hsmgNqvVK/+u2HA/x8Q1a8fqia/IbH9Vj0MACFNBWEQ2ZwtVCVVU2AIRGAAgyGf20PTEbEn2m5UyZCPQjWLHtXh6np8oVKrMgxD6/BqMTvQ20mitMAzjVZ++86BtZV1BFHzuZTLabZa9QSOSIrablYgQMNQXNAknuMQGDOZ6XqlAqpSOZ/etm0HxzcwHLJZHc1mGyd1BEnbrI5KuTixZ+fi/LTb6WQZpt1qnTp1CsVUu8u2sZbCSEHTYIIgOjvDUwtTfUPDDqc3X6y125DV5n/9/FkjAfeEoqtLyz6Xm4IATJVUtl1IpXxbIgisRHo6quWGzmgyW2y5hYX+/v56uT555UIytbr/4IFWowlCpMVMRrt60sn42sbaOx55r6aKLNNECUOtlpt97o6ogO94+D0mykmC0D/9/Z8enNhx/Ni+97zr1J49u0/fd6pSYlPpar3BDwyOT0wcbjHtx//rm4oKfvhDv9+ut599/jkzbbj33ntnFpaPnL4PI3CH3Xz2tZdy2Q2P2+lyhO852vfCL783N1PcvrW/lC82alWTwXH96g2rxTYwMLK4sDI/tzw41D8yPHT35rVkcuXgwYPF/EY8Nt/R6QdkXuDb8bVK01wWWM5goJv1tN/XTVAUx7LpjbVGVbH6cKsHb3AqQVGFSk2GEEynV0FMliEQhgVBwFAIwzAIAhVFFiQJRlGV0yAIUlR1k0qhaZqmqr8RhCAAv8E41CBQexsLUFUBVUYhgGc5TVE1TbFYbOViKVfIRTpDBEFQBFlv1ph20+fzYRjSrNUhBOV4xuPqUFEQhQCMJDhBAlVVUlSEIGEYkGRAUmSebYXDnbt27CrlahtrS8cO7P7+M9965MFThcztMy/80OMwm81mBNCVqxVEEARJkoxGM8uya2sbIAhiGCHLcj6fD4c66/VaqVQCAMBktLSaDACqGGZIpVI4TtI0TeBUPB6HYZhlWRzF4vE4SRGhUIhl27FYrFgscnzb7XZ3dnYODPTF4hvf+MY3du2aqFWbpVLF4w6RJAXDsM1ms1hMssxnc/FavVSrl1qths1mabValUoJwzC/37u+vqrX6xVFzeVym/stSRYgGKjXa8n4WqVSOnriKK3XGQy01Wqlaardbl+6dMloNLeZ1tLSQjAc/su/+tjrr78OQZDL4xQESZSFl8+8gmFIrVGXJcFqtVitXV1dXWazsVGri5JA05TT7tIUdWFhobOzM1/I2qwOjuNwHHc4HJs1v2KxuGPnTo7jrFZrqVSq1WqqKsdisZGRod27d7/44osgCA4MDMRjyc7OznA4vLq6WiqVMtnUzp07SVJHEJwoyn5/sFwut1pMIBCoVmvJZDLa1bt/38GVlRWX01MuVTs7uqqVuqqqLCPHNpL9fb2lShVBEJLU8bwIgmA2kyqVCjqd/sSxI1euXKMoHQJCC/OzPMN39/YurSz6/f5PfOIPzp07b7PYuzsCEi/t3btXVdXvf//7Xq/FZqYQUO/1+6rV6vGjp69dnl9Y3vA4DaVW86knvss32kPbdmwbG+2L+BoZCZabRp02efGV8W07QVDT6w2dXYOhYH86nS4W8utrKygCGjTN47GFAq7ltZVSpSJqkNPsWrh7syM6uGO0jwDFdjl36c7lYiaBAuLu8b603XzPiQdfPXvj8//82dPvOJVPZ1968bnj95y8fu3i6sLMR37vI5//7F9wnEBisN/vz2VyEIIoLL9JyCNArMUyQr2hp02KClVrLQAmCuXi0ZMP3nf/Q6kSi1ImUYGaLYbEKQQC2+22plIcx9F6/dHjxziOW13jKFr/J5/+6Fe//sNUJts/1FVLtUlaB2mCpCoqCOkIkmc5SVJEWYFRRNPUN+arfj3RwDAky4CmqYoiq6oCQRCCwDAMCZKEIgiuw+rVGoqiGIJKgrRlyFevA889d2VjY4PjuEi440O//6GeHmOhAmQzEghBOI4CoKSogqjIsgphCMFwbRySzrz6Squ8ajVgjz70zvVYrLvH2+SkVGzNZnDEVnMEYnLYzbduXEUR9pH7712aXzJQeKVeu3TxeRSXPZ4eo5lKZbTJO1cHenxut1EU2iLX5pj2/fcfrTSSs/O3QEjSfG6eRc3mcG9nf6sttmVN4iGmXbXYvEFvuF5vvnr2teHhYdpI6kyEogpjW3fcunHd7XE+9NA7RQHYOrbnRz94cnBo2+l737G2tub3RVCUxDDiypXVRx450BXp+drXvoHjOACCqdS0pEqZTCqTy6ZSmVK5ThK0CgJGk6nZaNy+ffvWrRt79u5Op9Mzs9ODW0YAUD137tyRA3vNevPLL1zeu/vgpfOTt67fHhkZzuEFFEIrxUoo1IEgRKlUKRQK/f39ZrNVFGWO43LZrMNhsxqNjz76SDIR23ReT6fTP/rpzzrCnZKiNuotj8fXZpmjR4+63e4Xss8PDnRFIr5SKRYMBnQ6ZG1tQaeD/+Vz/3z4yLH5+WkYwXbtHjdbHfHEis/jgEEl4LVROuL5Z56ORqNut7vVYsLhsJ62kLhlYy13586dbKZ03wPHG/VkuNNnt/s5Bly6NX3q9NGN2PKNm7f/6JN/Ist8Opncu+dQo9GyOS2cUFUAwe6yyopayJe9ng5BFoqVIk7ql2ZWnnr6QrT7gM0ZeOm1SzpLyOkfl9FIKs9rGgWAwK/LNACbQ1W/IqtA8K9GLzT1LeLw2yHUW1nqN6jEb//L/x847K0zmqpuWku91TQENU0DFBSCFEmEAZUgYEWQeK4FqSiCYChI1so1WBMtRkNL46rlTIffyzSyfVEvL9pQBF9bX3GZOoN+v8i1CvlUvV5RZQZG1Pn5mYA3lM9mSRxbXJrp6e7lRdVqcmoaQOK6SqXSbjaLuZTdSVI6dMtQNwLykqzCEDg/N1ep1nlRLpcrBoPeZjft2rZ1ha3TJOrzuA0dwWDIe+3mZQ1Sq9WqIIHBUCcv8flsyWX3cW1JTytBT6DNqRdff6mjI+SwGlVF3LdvTyIWF9i2KnAyyzxy//28WJmbvzs/P59O5d756PtbDBuJdpXKBb/PVqnE3/2uBzlBRiCQIIjlpcViuXD12oX3PPYer8OVLdQrxdTU3KLVZRkZHvVHBuMbBUkQf/LD7x3dP/HJP3zkP/7jbyNdoYHhoVSqlMm29+07DoFYo86cv3DuyV/8fGCkd3TrIUUQFAm8+tpFrtW+fvHqyM4dOou+0qhPXZ0Z2DpiTZuNOOWzhWCJO3Xy8OLsxVRqUZVYn8ct8RzPSbl0qaOz1+UJwTAMAvDCwpzBSB05cqAzEs5mCgYDJqsMy4EwAOpNNovJ0dBqxVylVhKMOm8qnc7GywjRpkjD6HBPstpSRFLRYJ5HUINRhUlVw0VVpnEcUEBQUUENUOBNfUAEQuBN10qJlSAQUQAQhCBNBcC39RDe2CloEKC9cf5tuwUNAAAUBTiOURUJ1ACB5WSZXltb07QjFEVxHFcpVUv5Uk83gKMYBEMcL5hputFuAXCbxAgY1QiUKFaqtMHISLyiISCoSYqKkzTI8bUqo6d1e/aMh4L6zpCbJrEzt+847G6H3bK8tESTJgUQwAceOlCv1xVFQxCEZVlBEGia9vl8qWQGRVEIghiGaTQam3x7CAaMRmO9XoUghCTJvt6Ba9euaRrAsiwEgKIotplWKBRoNGrBYNDldmSzGZ2OFCUWwxCL1Tw/P68oyv59B15//dLaavzYseO5bGF5ebm7J+LxuABQrVarEIyXiuWDBw7Ua825uTmSJHGcfPnlc06nGcOQZrOpqFJfX5/X6717967f74NBLZmMU3oKRWGH0x4M+r1ed6FQUBSlWq1u6ni9693vuX37bjabzefKigwEAiFVBWRZbLVaRqOxUa9KkmSxmOPxDRSD9+/fazTq641asVh0OBzJRIphGJfHS5Lk1Ss3R0ZGVlc20un01q07isWi0+WiKOrWrTsgCBqNRo5j9DSNonBnZxcIgtevX7fZbJKoNBqNUCjEMMzS0hIMw4oqmc3marVqt9spna5UKvG8CMPwtm3bdTodoEGFQqFer7Msu2mwA0HAZreRpulMOi3Lcl9fX6FQkGV580H20EMPvfzKqyzLEgQVjyVsNofL5Wq32Uajodfry9XqqVOnVldXAVVVFeDunTsHDx6UZTmdyaAoni3kLRZLuVJhGGZ864SBcl6YvHbonkOf/PM/lTX4Hz/7uVdfPivzQoffrsNlRaoybF2FINroJPVehz28bfsBvz9I01S5mKs3ihfPv7pz2/DkpXMWI03rydXVtXKtidPWlVhqeGwHhOv6Bkc9Xld8bWl9dZptlLZtGZubXbXZQtWq+srLZwFVevyn3332uZ9rIDA/s6II7V1jXd2drpWl6em7N1wOi1Fv2FhPahqoAbAKajiOS7IAAjCtM2Iw6Q50JvL16PDW9WTxxOlHk7lm98Bopc6QpA5H4GajRulwCAIkWRUEQW8yN5tNHUaqqkKTukQ6Wa1Wt4yNVBt1EIY0GFIUBUVxVVUREBI4HkNRGIZlRfmN7PLW1n9TCg+GYUVRFEXZTCoQAEmSpCgKQRA4ilqtqCAA585NXrtyZXh4eNu2bX6/CcOAYlFp1RsaAmsIqWgaAkqKKsKwhhG4qCCqrMCS6LKi09efGu53AVJDFBRZMZv0PoGTM5lcoVju7IgGwz2x9YVU6nYkZO2NdPzvf/jsiWPvOHriyMOPnXrfBz9ksnY4HaHrkzd9PgvfXqcJafHuDApCAbd/euZGOGo7dnL/888/j8BkT3R8bWkdAsGTp07NrqxMXr1sMlL3nT554fWLN69dFwRp58ROkoYZniFwnd3hQyEdhhG1WqlWr5RLVVUF3J4gBOMCL27bPvbcs095PBav25pJJwVWQBDE6/WWa+XZ2RkUR/KlIoLhsgKgCIkRumazXS83KYoy6HXFfO7Y8SPXb16n9XqG5wwmY7FYdJgszXqjWa/29fWFw8HFxcWpu7fHxkfr9fqdO3dGR0d5Sdg2vv3s+bMogmEoIrCc3W632yxWq1kVhUDAX8hnh4aG4usb80uLZrM12t2D4+SPfvzTsbHx69evj41tGRzsT8Q3SqViR9jPCyyOIzgBT0/f3bdvXzQalWX1y1/5migo73//70EwNnnldrizU+C4GzevaIrkdNoCQV88lty9a//lS9eDgR6PO5DJFQgS6+2L3Lx1iWXz27dvFzhoZTnh9YTMJmsqm0qlMrygGE2uXK7Z1TXIS3K+mNu2fcvFK693dgUMBlM2XcsXqsPDW8w2c71ZzxdLM7PLp069o8mrjAQXqm1vZ08q0yB0JgT5DSX3zQn2TZMc9dcLVBAA/I6xwd+uUb0dPG0KAv06evu1scHfBFiaBoIgDIIaCEIAoKqypmmApkKqBAEaDCgIpKqSAKgyTZEgCAsc0Gq1mrXi+EjfwtyNYMCl01HFcmFxeWVsfFsmm/f5PQ67pVLK5TPpjo5gMrVhNZlBALh++dojD757ZWlRb8BEiS2XyzBKQiDebDDNZmPfnj2aop6/8BpNapLSctrtEAJrKoSgOrPJNTu3YnM4y9WqxWrQFFFPYky70R2NXrt8CYXA/oHub337G+989N0thkcQItwReenMKxSNB0JBFURzhbrR6Eok06Ii7tq9PZ5Yi0ajs1OzK4urj7zjgdjGBgrBA/0958+/2GaqNru5WmvQtLMr0htPJQ00MXP7qtVipCgilcmaja53PPSuy5euoRh8730n1jZWJydvAjClIbTN6RvbMQ7h+ut3V13O4Le+9J+Q1PrXf/qz+dmLUzPnHE6TBGBub3epqhlNHrfDraOIZ375U4atcbLQ19d/YNeJT/zhnwgc//f/9FkNQ6osc3byaqFWed9j79IkzohBYr1ZSVeS61Op7LVDh7d+5+uPbxkaPrhn352bd1iWO3Hi5PWbt0OhDhAG0qkYzzb0NIEjGtNq4gTt9bk5sb1j57aF+aVyueq0OEEQxGEonU4TBDE4PPS5z//b2PhWX9BbZ1BH4BBi7Cy0edTkFBCq1uZRXCcLIiBLNElosqKosgpBIIqpCMKyrCTwFpOpUW9hGAahGAzDiqyCIAi9vSaqaW+1CDUNgCAIVFVNA0AYFTimt0t/9cy5f/3Ljwx1uymEf+x9jz733LNHjx1empsaHOgTWE7WVJvDroIqCYGlajXaO5KpiYHB/cvJBqKzYzqzJEkQhrV4SYMxGMIUDdAUFcOwVqNGY/CJI4affueKHhUjAeMH3n0fiUuRDr8osJqmFcsl8JFHjzUajXq9bjQaKYrK5/Msy7vdbhAEK5WKyWQiSbJer6fT6VAoBIJam2V8Pg9BUPPz806HW1VVHCd4nlckmWGYbC4zONjv93tXVlaCIb/JZIzHN7qincvLi7NzU319fc1mM5POmkw2m9UVDIZMJtOFC+dL5ZymSaFw0OPxNJu8JGlms9lqsb366qsDAwPhYMfS0tK1a9d8Pt873/nOW7dv3Lh67dFHH2m1Wrl8xmKxZLPpVDbFMC1/wAfD4IED+9LpNE6g1UodQmCr1Q6C8OzMHARBDrun1eIoUieKsqJIoVCoVqvhGFapVLq7o88++7TJZNqzd3dvtDubTSeTSR1NthhGFEW90bSwsFApN8xmM4HryuWyyWwPBoPXrl3r6OhgGI5l2Xa7XamUtoyMDA72r6+vq6oqijKKovNzi5IkIQjicrkEQdhsHSqKIko8iqKSrG5OmSEIomlANBpdmF8SBMnj8XAcF4lEVFVNpVIQBJXL5c7OznazJYqixWJpt9ubVHqj0WgymRYXF3O5XCjUQRDk+Nbt1Wq1UCihGOHzBddWNxYWFiiKQhCEILFN6yGX0yMqcrlSM1ltJEENbxldX19fXtnoCEY1EMhUUkaHOdwV9XoCl85eM9F6hWkUCxuaUmsLTbvLh9HORhtfWMiaaCfTYmwOU7Wew3AlEHCoUrtRLZRy6eGBfpbhAQgOBCPFSoMRBJvdC2rUrp07WbZMYsrM9FWjUR9PlKoN+QMf+DRG6L/6+NdICjEakO07xmdvLwh822wmExvzRgPGtMpetx0AgNhaEkVxUVJlTSFJEsFQmqJVBTJQ5q6+obl4dn4t8Rd/81mPr+unT7x44tRJjgfqdQZFYQgERJHFSUxUVFFVSB3NsQIOozzP4wihgookSToDXW80DCYjL4mKqiIIyrIsRZCgpmEQIoqiBmq/kWDenkgg6A1a8WYXG0NRGIBoitTrAU0DCgVucnJyeXnZ5/M9/PB9BAGUqyLLsoLAmUwmURDUNy13YAhCEEQGJV6SFQCFIRwFEUhuO4wS00gtL94e37ajxSDVfMFCCPVK3heMGIzOy5fveD02l0ttVNIb80sD3cMyDy+vLVI2DdYROOV99ulXhnr6du/qk/iVoNd09oWzkEK6rGGn037l1pnhscHVWFJVqUjHlq997Ruf/pMP11pFhq+948F7/+5v/9JhtbkcbllWdu/e89prr2zfNYoSeLPBqyoWXytkM2UUhh1OUzyzQJBwMNRZr7VpvYlhuNGRsZ5o11f+/d9mp28/cP+pVCo+MDDg8fl/+IMf3Z66+9C7HplbmA8EQ/19w0srMZ4XC5kSRVF+nyeXy9x776m//4fPOF0uQREQFJVFxWGy3rx28/TJe3AcFyWB4zi3w372/Nnh4WEA0paXlxmeefDBh0kSTybTzz77tM/jaTYbBI7KstgT6dy5c8c3H//6jh07FEUhSfKee079+Cc/nZjYG4snFxaWYBiWJMFk1H3kwx+6eu2SBoi9vV0//9lPT58+ybJsPl/sGxhMpTIsy7OcUKlUsrnixJ4jsVhKFngEhcqV3MBAH8e2EBjPZatmoy8Rr/p9nYFw2O/3zC3cjsWXeqIhnMCMBhNJ6lothmlz8/OLgVAYRclKpdXZNaBqsNlie/7Fl8a2jiII8Nd/+T96u3vf+c7fX1ld9wZd/YPRWGrD7Q01W0ChwqfztejQFhHB620lV1FNJpemqACo/XrBSQVAVVNBEPq1wcA3DaF/U9fq/8TBUn7nlb8TXQFvEulBbXP+SgNATdMUCFBhUCVQSBFYUWBBRSQJlMRRhuFQzESgGAopFAIk46sUgSAQWG82EumM2WKpNeoer9NmN8zP3T18aO+t6zcJ0m6kzRfPX7jnyPFmjVNkBgBaGsxVqyWdjgY1KhgMslxjeWUR1IB7jh+ZmbpWq+S7e7oajUY+Vw6Go/MLyY5I7+DQ6NraSi6fdDnNPNOcunP71PETqXhiaWkh0hNJJOJutzscinAcV63XLk5efvRdj6TSeavZ5/VFzrx6kRXYo8f2gYjUatfbDBvbyI6PbVtZXdRhhM/p0WR56vYVgWsMDHXV24ze6C3VWhoMlIs5I4msLy9areZ2uw2CyJ69+wEAaLebq2sr3/3+948eOzU6vnfy6jSE6BKZAojRO/fd89qZsw4D9td/+rErrz/z3DM/9Ifsj33og6WmHM+0KjUi2jva293zja//K4yUu6O+2fnF++57RyZWeO7Zlz7/+c+vx+JNltWbHOM7tj311IuAxlkMMK61hXohvriEwJzLT0oih4M6lQcABYtG+2q12uz8TKDTt7K2yAjtwaFeu8Vaq9RL2WJnZyeCILV6idIjGAYjCJJMpgBFxTC0v6fj4sXz28Z32R2ejURCp9cpALuynhndehKm/G3N0tZMFQ4BcEO73bTZ9BJTw2BQEWSzySZrRLHKgIROUFRJZo0mfalYoWkaRFAURWVJAQAA2oxeUP3vABYAgCCM8my7J6J/9RfPfOPvPzkyGCIg9pOf+OiVK5MmsyGxvnz04IF0MuMPBhRAy+ZTXoet1W77Q92Azq7qfDMbZau7E0RIFEUFTVNgVAUxWcM0AEVhQJI0UJEe/9q/GzBxx2jvxNaeX/zkO2YdInL1m9cvYDhoc+itDiu4e2JAURRN02RZNpvNIAiazdZms0mSJAAAxWJRlmWbzVYqldxut9VqLVcLiqL4/cF0Or0wv+T3+w0GQ7PZtFnNrVZrZWWJ45ndu/aUygWr1QoAwOBgH4JCGxtr8fgGCIIHDhxIpTKvvnrWaLCOjW1VFEWno+YX7raZhtttLxaLQ8PbCJzO5XJdXV3pdPa1117bt2fv2tra3bvJY8e27tmzp9lsojCoadry8jJBEKlUSlVVhmeMRn21Wk4mK339gd7ebpZlQVCrNZomk8nnC+Tz+Ua9WSyWEZjyenylUmWz/ON2uzmGbbVaG7E1s9lEEASOo3q9HgBVVZLDkTDHcaLIgzCCIngmk6tW6zqKrtebTqfb6/Ml4vGp6enOcMRoNrWbrWarXqtVjAba7XbDCMKybL3etNlsG7EEDCIGg4Hneb3eQBAEx3GyLImiCEEQjCIMwyiK0mq1JUlyu7wgCGMYhmFYd3d3PB6fnp4eGxtrt9uyLOt19Ka2O0mSgiDwPK+jKBhBWq2WzxfAMLzNcIlEamhoSAWgSrnudgUTiTTPtH0+X7gjdOnSJV4UEQQ5de+9t6am19YTKgC22vzRE/d0RXvWVpdff/nFnt5O2k4lMjENRLeNbucZ4PyZ1wa7owJfjSfnQRQAMQrCzH/511+IxaoEbGo22Z89+eMjx/f98MffbDfyDqepI+i5deWKWW84duTo4sLq3NLavv2HDSaLJKldHV1Tt653dror5YwkNouVMoToGi2N5VGL3d9o1dOZjcHBLgNFFLOFT/zRx378k++VKxkdAbFMs6sjWCqVIACuVuuCKJMkCSCAIMpmk0MQFZqyhrr7ZZQq1BiG17y+zo14UYPI97z7AwAAKYqkqDJBYCqgsJJAUFSj1dTrjUydMRnNAidIqkhRVIttEyQpyhIAQ4AGgjCkaZoqKwgEqbIMv2E4qL4tkbyxfd8Eu5tUPBiGIQ3AMMxgQGEQWFlMzc3NVSpVHMe7eroHBgbMVjCbZXmexTBMg0AEhDatETRA0TQFhRFFVFQVUEBARRANxUVRpSBcExpWUgTVmsgXMYLgZRJSJZ1S8jlMZ85fsjo8GkDIQrszROfTqzoY1+H6q1du9Q72LCbuegPhW7eSFpu3Kxy8fvXl4SGbgQS5Cq+nrKBMHT6y//rU+bmleY+/Z8/ek6U898TPf/bgQwfnlq65vabRscH4RuylF17u7+lnWc5kMM/Mzsbia/1Dg6FgV7nY8ri6rly67nE5B4Y6CpXFM2ef3b59+4FDx7721W/5vGG/L/yD7/6AwNFoJHTo8N61tZVaraECEALrBoeHVuNLL7z0whe/+OWf/fQpHKNPn3rgkUceOXbsmM1muX379pYtY9PTdwkaIwg8m806rHYUxGEA7oqG52dnzGZz0O8PhzpxAn3t9VfT6WSxlO3qjhpMFoIgdHra5/HevHl9bWUlFAjwAosjcC6b7ugIK7JYqzV6envr9caevftjsYQGwhAEnzt3dnRokNbhAKhEukLZXALDoGq5FI1G3G5vNptrtJjr12++733vS6VS2Wx26/iO558/azSaivnSe9/77pdfeYFhGl3Rzka9ZbN6k4lCKNCfzVY7O7v0Jj0EadMzt80Ww927t0+duOe5555rNptHjhzJ54sUpavUWgcPHak1WFUDI13Rnz/1jMfnt9tM81M3eroHXI6OeoPBKRijIEqPbMST1Qrn8oQdvtD8aqKjf6TKorkqJCkEuOnsoWoAqIKaCrxpiaNqIACAGvSmLe6vwM/v8HIGf5fS1dsu/jUpuP/mmjfwFaRBmqZs/jMQoECgAoEqBMiqyGuqCCgiiUIIrEEAAAEywwiijLndHlXks6kYDGhsuzE8PDw/P1+p1U7de3p2drrFNmIbSyxT37FtNBZLmAzuoL9D5FibzdmscRgK4wTw0stP+4Jui8UCKHAhl9q5e2R1ZV4WRRhSEU1QJD4cDkIQBEPERjxbb8ksq0qyZjIZbDZDKr1msxrWlhZPnjghCeLM7Lw/4L148WIkEvEHw8lkKpFKhDo6vH5/LJ7GURPDqqoCDw4P2J36Z559wmKlx3ds5xggmUwvL84/9t73pWOphZnphx964Jmnf5JIrh0+ejxbqK9uJAIdYVHg2Gr5nQ+9I1/K1+qVzo6uXK7w5JNPWmxmlmuMjo4NjmyXFLxY5GOpMoTggc7uV85eu35tMuw1nDy4c2nmpqqwn/jUJ5scN7W42jO8o1qDjXrXV774hXCHbXiL7elnf/Rnn/rzRp398z/7m0cefrdRT7M8F+qMTE0tKRIWDocTG/MWI6jw+VxyafuWYZFrkgYgFY+jEF3MNWxGj05nXF5bDneGQFwRJE5nxF98+aXt4ztkXg74wi67M5crIAhIUMDS6qLH4zIbjQgC5bKprkgARqB6rVGvN0lCX66WBkaiKgApChoIj9Y5mgXtFcHYFGBFEwG5adNLFj3ebHAgbGxLhhoDYjpLrdnSYE1vpPP5rMlgRBAExShJhBRA0zQJAJVNqjsEIAAAKJCy+UBGQPgNWRAEZZv1/g7zcz/50Q++/JmhiEtiS0eP7MdwyGTWry7Ojm8ZgSEIx/FgZ+Ty5fNdneFCuegNhgmDYznVxPWuUGSwLaqpbM7o9oiwTgJwDDPUazyBoxgCmfVgYi32/NM/5RuZtYXbfoehPxJqVHPVSs7tsSyvTsEYhEAw2mY4iqJAFWBYHkGQSrVqNBoJgsxms5SO5nl+cWnZYrFUqjVeEIwGKplMlgplEAS7IhGLxTQzM8PxrUqFjEYjp+89/q1v/ezO3ZsdHZ3NBiuK/J2p6WIxOzo2YnPYR0ZGEARZWFyWZLXVZu7cnQ4EfIqmdHVH640KQUI4Sayvrx89cnxgoO/8+fMoij7wwGmGbR0+tu/IUWBxcTGd2cjlcjqdvlgschxHEjpZVUVRlCX18OGjy8vLNL1ut1mLhQqEwIVCAQAABMYFXpREmSRJkiRTybwoKKIo26wOVVXzuYper+cFhRcUDKeCoaCqKaVSCUVhDEHLpbrdYfb5fPV6k2VZUAMMtN5qtbkcbklSbt28uXV03OX03Lh+HUVRo8HQbjXcdlsul61Virv37KnVyxgO5gqZHRPbBEZaXFy2OxwCL7XbbFdXF9tmSpViq9XEIABQNRRGXA6nKIqaqmI4imOIokiNehXHEJLANFUGNMXpsHEcp6NJlmnlsmm73c60WySKiKK4Sf83mW2KBvpC4Zml1W07dsCEAcf1XdG+VqO+vLIIQQgIYxzP6Y2G85dvY3rjjv0nIIyUNMDicLxw8bomtg8cmSjnY/N3phRN9gc7V2duE6hBTyCJ2CrHNw0ms9FmSqZyJgP5/C9/duTYg2fOXH740XcPb//7JtMy2unVtSW2Wbl47rXP/NO/37p+4/mXL5w+dX84OoESeoI0rq4tyivzpB6anrutIzBF4jQV1lT48OH9dUZpsYIKefce3nXl4usYAhvM9F/85Z/YbRRFIpqGgiDYaDBsW1AlGQZASJM0FaYwvQZiIEYkkql//Oe/6R3c8s3v/vjw0X1PP/cShCC0iapWGYyEBF4FIBiGYF7SNAgEYVSQRJzEJInT6SiB52RRJChCFAWSJCVJgiEIAmBRVhRRwnFcVCUIgiAYlEVOR1I4QjSZNgzDIAzJkropU6LJIIwgkKJpimo1GGxWIJUSLrx6+ebtW4oi+f3BgwcPdPV4JAWoVNhKjKcoDKdwDVA0TZMBAEIhBVAAAABAWFY1CARhGFJBVAMhWQUhBJRERo+oelgU2fLe7ZFMMX1nYdludbcy9bwsdIS9uVLe6/WbDZbU6hSJyNu3D127Nikhib6tuyJb9miqfmOxeurQUVQHzi1cm5vPxZYW3vXAuxxOt9NlLbMFe9DiV/1zC2s9g9Uvf+2/aB02vmM42EU9+/wTLF99x/3vnrqzmslWFUWjCLvd0WF3dAAAxLYQFDZJrCZzQrTTF1udsjiAD77vHaIoxlbudnc55+emJb6xZSz6vve+d3llZTW+Um03IRy3W1yqjJK0eWFxfefOiVdeeYUidLlMtVlvT0xMtFhGq8GlBrdr30m7s+Pq1ddpgsKBKgZRzRYbDgdREtt3+AAGYq+9di7g65ZFOBzoyGRSw8NDmVya1OmS6cTY+DZBkVZW1qLRaK1S4VnW6Hftmth9/fr1E8eOSZKs1+uDQRCGYQiCEAy3WKwej2fHzm25TNrn9165cpkgsJEtQ0aDnaB0lyavSZJ08uTpzs4uBMaq/y9l/x3lxn2f++Of6YOZQe99d7G9L7nksndSjVS1JFvFlruTa8ctTnHiFCeOYzt24pbEXbJkyVZvFEVKFHvncnsvAHbROzAYTJ/5/bFykntv7r3f3/y1Z4GDPWcBnHk+z/t5v55ita93UGwoI8NbUumMr993/I23w+GW9vbWa9euDG/Z/tZbbx09djffkFfjqYmpzN69+10ePzKDUZSlubkLRumBoW3R5SVJ1Ldv25VOp3lRXlycNxhNEIIkconmjqaOzu6rVy93b+rzev1T40sWqzebZpuaAiwrOqwOp6k+NBhYXFoYjNhq9RQQTUCnAYRoKsBRWFclDAGKwJMECiCoIYowSugQBumIDmE6tJFOgWGgqUCB/ify+4Yd+39yp2AIgQGAf8+1+i9JL0j7T18BvL9RrwFYg3Ed6BimaxIHAYXEdAJWIE0EmmikCL4hNGplHdY5rq6qqtsbBBgjS3y1VGZMNkFoDGzumZ2d5RWwbefuqelZkiQNFGE00O0drWKDwxGmPRJYWp4vVkoNMStKaCTS8+qrb3d27965bfu7p0+0tfgIgigXS2aaKgncgb27FmdG12K56OIsSRlDwdb16KrN6gaC4LTb7TamXMpt6uvi2CLZ05zPr6bTaZLAKsX0YF+X3eEEQKlUijAM+3x+oMPR1bjfB9FGK4Lg165dsFrNHpfH52OcZkOsmKjl148ePnDt3HvJ9dSWrZtn58ZPnHr7kccellXppZd/+5GPPBEKNf3jN/7RQptfRd5ASMVkMsIIUS7VrDb35i1DLJeTNOHkOydUnWlr3S7K2sF921964435+YnnfvfzRj31zK9+5gu2trZ0/PzXp1AC1Sktnj/e3tzzk+99Xeb42x7/7MVbbx3cu3VLb+RP//hrvU1hqVIcmxpdWp1PptMH9t8eaR7w0AjqtRRLMUkoBoLOap29duUSAniziWoOt1aqmaFNPdlsnjGBialLu/bszq8lAGTcOrSZrVQrlYokigSBwbBOEKTb5QA6XCzlqzpXqRba2yMQilZrFafbmc2luEat0WjkUhkNqKNjN/cfZG3WZgTxGfQgRlhL1VIkbGzzqZqYux6fYRUb49kOSZgGVXRQJ0iLqkpcvdwe8fF1bnVloa29O1uGYIOiQw0KxWVe1XUDSho4qWwwGeSGCiAYA6ikKiiiA0ynCEAjkJOxkoCEMYum45qq8VzDaKKL1bwBNzhczeVCnmXZSkNkHDYVVwlGve/OrW+8fqq+JniaIppdsXjJS9OJMg93tw8YDJDWKAwMuf/h6z/DIPDML//8b//mZyQqrUenk7mEhSJQFIVh1O3yr0YXoa3bummartfrPM9vhK5CoRBFUaqqAQDm5+fNZrOmaRs0rHK55HE7EQTSdWiDfbVjx7aFxdl8Ic1x1e7u7ra2ttHRsYnxGQjgblegzrEwpjAMSZLk3fccnZ2drVQqifXUffc9cPLtd2/evLl58+ZSudjaFtKBQjOY1WKfGJ81GOiurq4bN24QBNHS0lStVt1uN22gcBxPp9MEQSwvL3McTxDEykrU6fCGw2GapkulQiQSqVar0WgUJ9BKtVoqF+w2p6yIuq4PDvaXShVZUsfHp42MJRRqyqRzCILqOoSi6MBA39pavForLi0twDDc19+by+U0TfP5PKoioSgMwyiGYThGhUKhaDSWWE+hKF6pVBYXlzZv3hSJtD377O86OloVRdi3e0cqtVZlawiODG3etJ5MZNK57t7Bep2fm10oFypmkxVFEIfDIQlipVKSVTncFMQx8syZM01NzbIsq6pOEISiKBv4eBRF19bWuru7eZ5nGCaVSsEwbCDIYDCYWIvV63Vdgygj4/OH2TqXTmdxymi1Ozme7x8YIgymC+eu33HHsYXZmXKpwNa4TCYjqxrFmAJNLYVyra2r22i2vHP63U984hNNLc2/efKnhdik3UQAVIMQWJKkaqk+OLAl0tT65ptvhkL+ZHbd4XJkc/mGpNY5XdXxnv4RSUd27Npjd7o0AK7fuNrb1T0xen1y7NZrLz33oYc+XKs2jt3zgcNHjp44+W5zi+/ce7+bm7ke8nmFOtsUDgEInZ5bZixOXgF/+dd/99obb1SrFanBanKjlE3huOLz0IV8us4KsqziME5gBNBUSeQRBMIIvFTlYJyirG7K7LTYA75wm6gg6Wxpy8h2u9szN7+EGZjuroFSmUVRAuiwrkO6rqpABYgGQSqkwxjAYRhRJQkgsCDxMPb+R0JWVABgs5ksFmsoikIQALrscZlPnzhtNjG7d4/UOTWVzlgsFoCgjYaAYZgiazYzY7GA+bn8m2++ybH1oaGBzu4uj89pNIIKC4olVlVVCIV0SENReINjqus6ADAEIeD3pjekA0wDugapECbBsIxqACg0CgE274D5rmbj3PQZxoiYXG6LxVFYzV69fBEiYYOJlCSprSlw6b23vvZnX/qHb/yNILPb9+1qSHx7VzdbUo1osyAiiUJ6NbpktxgjgYAqqjzHMkasUMkSZlTVtHxJiDR3f/TDn/n63/3VA/cenpy5evbcSbvD6XG2HH/txKGDewHQGNoGdAyByUAg9J3vfIskiJHNm3S14XYTg5taFpZujY1f37fvQLXGmUyu9WQ2n6sIooog2Mj2HT/9+S+2DG+3mJ25fHl8bGZ9Pf7hj39oYXF6emyss6MPg41d3f20kTzx7qmunoG9+2+/emk8Ho/6vbTUqJUL+YWFBZSgqrXiY489IIuCiTYff/0UChHBoL+13e/02CSFffGllyAEN1ttq7FouVxuCoU5tj7Q21fnasVCdmCgj6uxNbbisDnLlQpJkgMDQ6VKDUHQi5cvbR/Z1hFpjkVXNkb5GIagGBKLLTc1BxijobOzfWFhgef5QCDU3dX70ksv87y4a+e+RkMoF0q1an1ubmFkZGRqasJAEW6fa8eObYVSeWU5uhpNlEv19s5+XQO8KOA4Dumwrsq6riuKrMgigCCKouwuZ0t7RyZf1AFudXrOnb8EIVBzs3s9njCg1va2PqPZub4ex1CBIBUzqQhCha+LNydXI/2HEHMkxdMAtxtwppTNe5x2tpZnSBwCSjabNdtdKkBUhAAQqkOIDuCNahxYBypQ/5dE/H/rTv2nxoIRoMPg/UHh/yqwEIAAAIAO67qu65AGIEWFMAJv1ItWE0HASiW/xhAQhYFaMWszMWytQpGoriomhlZlhaCNGspIKlyvcZUa67DZBVEu5LMMQyEoVC4U3C4bTqAMRZdKRV3RvF6rKheWl2c9fp+kQOWy2NIyMDu7vm1kd6FQgDWhmF9tjTghpX7i+EsjW4Y7IqG12EKtUszlCiajWZYgi81JEDQEY+VStbu7e2p6olormC2UrNRFiaNIQz5T7Onq0QH8xvETe/btJw1UlRPGJqYtVueR2+5YXo7KkkoQtMPlMtHGWj3P1hNmM6PwSiqVaw21Xr589dChQxW2Eo2tTM1MPPL4Y+fPn5UF2eFwnDxx6v77HnTa3DMzEw6vkaTIgD9y+cqYzxdweew3x96DENDdPVIsSoUi1NO/5dL1i6fefedH//azldX5malLb7918q/+9Fs2qzcaW/MEnLemzrS1+U8fP4Vr0OMfeuSdU2+urE/t3rOtXir1d22CYfPPf/YrAIt79u5AcVSRIUQzdXR0cfXc+NTFam0tHPbv3LH/mSefqhVTLqdt165dCwsLRqOxWmVL5bKm6Vu3jSAIMjs/b7c733jjjUOHDgEYUmXNzJhJnJiYmmQYKpFY27N3F2OmV6OLuipt2tSfy6YQFKqUyiaTqVqq9vT3JLLxer1O4yazo1UzdCio2eF2ZhNj1bVzlUIi3L7V1bK7CDoXk6LD4+Z4gaHNHMdKUt1pNV4482441On2DssAqCSvQw1dlAwwiehGXpJlSlMgDdFRSIENGCFJuoqomsQOhKy/+cG/HP/1Tzf1RFi+1N4RdjoYr9e8MDuxb+/OUq5SLJbb2iIogYq6rqPAYqc8HpfUEH/+77/8yIc/li3V7C1t15dzqrHTHeqrFHmVr4e9plwy+qt//+ljjzz2vX/+4b69uxuN3DvPP7l7//DmgfaTx191uSwA1nO5LIyiWKPBK4pqMFAAQKqqCYI4MzNbqZQNBrJeZwWBJ0miUimLohAOhwGAVRXK54sOh0NV5VPvnEhn4kvLs9HYciodX1ya27x5CAC4VKrAMGpkLFaLo7e332AwnDx5Mp1OAwCeeOIJs9ns83vtDlsqnQwEfL29vZIkiYJcLpc7OjrOnTv/3nvveTwuXVfzhZzDaY+vxYqlQrlSMpmNBor0B3xOp91opCORCEEQRqNxcXGxXm+cO3chHl8nCEOpWNF1COgwx/FAhykD09TUUi5Vs9ksDMOKIgWDQU3T4vG40UiTJB6Px2jGoGna0NDQ5uFNjUbD6/VuzB9pmt6o3RZFEYKgWCw2NjamqBLLVmEYtLdH5uZmbt68/sgjD+TzWcZIKYoUCAR2797Z3BxeXV3u7u4eHBwkSAxBIEkWZFmCEaAokiA0CAKDYCBJ0vVrN+Px+H333adpWrFY3NjKZGhTIV8qFsp1tkHghump2cnJyeXlZUEQEAQhKQMvCjhJWWwORdd4nl9ZWdno8IlEIul0urm5eXp6GicMHUPDY8uxloEt3vbeD//B5wMdfVv3Htp54DCKM16PP7UWv33f7j2Dfc/8+J9PPfdkOb5sMZlNNlex3OA4lSDMnT0Dk9MzC0tLW7Zt9QUDXq+3Wq0NDW1ub+8MBHwWK6MCMdjsu3rj0rtnz8wurMzMxp5/8WQyJ0RnEv/j83/70GMfX19cPH3+TIUrhFvdY9NXewf7DJSRos3NbZ29/Zt1BL/v/ofcPn9f/+Dk9LTNYS8UCutrsUq5qKlSJBxOJdYJFFUl0WoywxC00QtJkqQiqZqi0wYaADi5llxeWG6PtI+PTS+vpLN53uFuqrCiwWz3BMKFahnBER3euAdouq7DOgxpCKTjsI42BEGUJQ0COgSQ31+armMYpqpyqVBjKFpTFQJHOZbl6kJ/T1s2FTVg4Fv/8DfzsxMQ0Ev5nMnEmM2U28MsrsT++us//vXTz+zes/ev/uZzu/fucTid5RI3v1gsFmoYhhAEBsMAwxAdaPoGdhFGAITrOqbrBgDh+sbgRscggG94DAAoGizzekM1QFPRZZi2zK+kf/3rp3GktrZ8UZFiDz90kMD5of62kNcp1KsffPC+GzcuKGJt+5bNXqfbbraNXrt6+fIpm0MxkFW+mp24cW3/zi2VSsrhJiv1fKkqBIMDl87FLl2KhkPNmEH5/B9/+Ng9h65enSWxpkce/UIup2mK+YEHn3juhRcvXr4oSCKKkSyrfv/7P+vq7r/3gTuL1ZigJ1lxcSl+BafUg4cPzMwu5fPc4sK6wxYuFTkMNbEs9Jtn3nri0T/1ujY36kxspRpp7t+x62ClxDns3v37D99559EPPfJYrcb+yw/+bWFxLZOp/dVff+vSpdFgKBKNpyUFtLV3y6pmttBWG7O8vKjpyujo6KEjBwGiGRgSI/HrN66uryV1HaJpM9BREjM8+sHHCIys1WrL0dVyuaxrUCy2xgnilpHta+vJ1dWYw+FqjrRBEAwAfPexewGAz529DEMEZTCbTXa+zuuKSmAYz9VxBJ6eHKuWc067aXLqxpVrZx1OI4Dkt0++GY0uWexmo5VZXJo99c5bt99xZPPmTRRFnTr17vj4OEVRw8ObUAzKZpM6kCYmrjQ3u4eGIoGAtbPLa7boDidmtoDBoWaPm06sL167ekFosGaa8jpd/T29NInSJIRC9Qa7tjxzxu/WjEbeaJRrfN5gomQI6e7btLqy9usnn25vaiYgUMkX3U4XpOsojBAYXipVFEUzm80AABgoOqzpsAxgEcACgHgNFgGk/Ldjvv9db70/PdQB9L8IMkiDYB0CCAQQbSPzBQEdhnQYgmCAoQBHdauREupVoElWs6nOVk0MEwgELly4IAgCQRAAAJTAVV27efP6wvyUJNUQWKIppFLKoajqcdlcDittwEkD6nI7crns+voaW69CMIjHozMzcx2dPflcha0Jm4ZGUqm0wLOSWHNYCYpW7Q5MEArriaVAwG+12M68d+n6tXHCYKJoa12QFQB4UajWanMLs7IqReOrRjOzEl1tcLyi6BDAjEar0OApiiJwtLuzPZ/N0QYqurLaFAred+zoyuICV6tZLSZRqGuKBHTNYbM1OEFRVFlWKQO9srLy4IMPLi4uvvrqq7VarbOzc/T6DRLDSRKv1+tf/OIX/QEvisJHjx6FIMhoNE3PLvT2DaAo9Y1/+LaqYharVxSVSrl+x+1HJ25NvPXGWz/6wQ8zqYTf6yZJav+B21yB9iKne5sj5Wrh/mO3VdIxINW/8+2/+8nPfxhdWzl6+K5iMj8zNvHTf/vRqy/+jsS0Jz7ysMWML8yONgVtbjddZ7MIIjvtFr/XQ+Do87993mFzPPTQB9vaOianZgRRrlRZq83e2trW0tI6P7eIY2TQFyRQYvv2nQYDbWLMHR0dkiQQBNbb222zWYaHh41GI1fjwoFwX+8AhhF2u0sUFLPJYSBNI1t3Xbp8I19stHf12+zGXHpWFRYdTMGKp2qpUY8Z2r99mCvVKwUBQ0w2R0hUsGQ6Nz56zUJBBphnCF7l11v8pAWvw1IN03Sx2qARVKpVQb1iQSCDoBpEoIsq0ABQAY5AG7AkhgEwClnsJhjXdVhmG1Ve5hRFYVk2mcrpEJkv1gCAS6USWy5ZjUy1XEMRBMcgr88Si01OTJx79+SLzR5rm9dvBITHbB/qbjr99us8mww1GZuanP/yve/bLEFFNP3w569Ua/Lla1dZrtDR2bRv376mcBvUPxghSXJj78lms21U45nNZpatWa3WfD7PsqzJZNog+ui6jsKopmlOpxNAqqLyLrelp7d9dm7S7/dRFFUsVF5/7YSuER53uFTgvD53vpTs7IocPLi/UinNz89LsjA1OROJRLZv3zk3N7e0tMLz3L79u3ACuXTpXGdnN4FTlUptZmaqp6fHYjWXSiWPx7O2tsZWaz6fjyCIcrlsNptTqZTNap+fX+TqckdHZ6PBEQShaRrLsvV63eFwcHzDaKQlSUmlEoFAgKYNLMtZLBaWZUVR1lSIoph4bL29vb1QKLa3t61GlxcWZg4dOlQqF+PxeGdn58bfhYDS19c3Pz8PdLhYLCeTSZPJbDKZNBUwDIOiKFuvqoreEmkKBZtOnjqBwvrw8KCsyT6fjzYyy8vL8fUERhjW4imCIF02T61WZ6s1giDcLlc4HF5YXMxmszzPu1yuzs6uEydOOBwup9OJY+TFixcRBGlubl5ZWXE6naom9/b2Li0t0TTNcZzL5VIkWRAEkiTT6bTd4SmXK3WOf/Txj5w5d94fDKcyGYcnbA109A5s/pfv/fPu3bsJDLfZHKIg799/YHpiul6vvfDcc22RcNjjNlKEkcKv3biWr5ZDkXAmk0FR9Natm4899hikKufOnW2NNGMIjOP4/OICYaBgjNy9e3+mWHr7zFl3oNlq9bIN9cMf+RSBmS5duup1+wZ7u3/w/e82hbx79o0888yTff3dEKpXywWX3UZjsMg3Usnk6PUb/mBzS6RDUDTcYGqIUmdXuwHDf/DdfzAZ0P7u9lolnU4tW6xGoSEROK0oGo5gkiDgGKYoSjqTKZVr7b2DhSqvw1Qo0qUijDPQa/c3oRjWPzSowkBR1Y1VA11DgAYg7T/DJRD8n3F1XdcA8v4xXVF1TdMgCCYIAoHgOseSJG5iDInE+m+f/tVHHr4/lYiVK7XrN0bvPHrP/Q/syZVAvsDfHBtfWYmKgrxtx/YdO9pFEaQSNQiCEAADBIYgSAOarus6rOuQAqD/bCqBAKYBRNcwABAAdADzsK6hKgbpAECagqgSoumQCiMaJDZQnmtx2arpFUTL9g3Znv7Vj5qdoX37DqysxydmZjzOgCw1cI1XxHqkpSmZSCMkY3XZVuKzi/NzAb9f4qBKBQAI93ltE9OjH/3Y46IIVJlujgyWy0q5Vjhz8eWevrDBgCwvrpNwqFhiDUawZcsWqYHcuH7JapNffOm5v/jq389Mxl547u2jR4/u3NN34sSzfh8diVh9PlyW+anJxYOHjh5/7V2vrzW2mvYHmqan53bvPZhOF0tFtrW1/9nfvLB58xbcQJrNTEMor60vjE1c9bsdoVCT39tiNFkvXrk8s7C4a8/h+Frhjz73pxgGPfnLH545c3zb8CBDo/PzM5uH+ycmrg8NDeXSlUP7D/m8octXzqfSUQhWh4aGoqvxyelFCII6OtrKlWKpVCJJkmVZksRLhRwKw0ajcdu2bRt9CThOLC4u9vb2u11eu9Oxurxy9fLlUCC4uDD3yCMfrJTy6cwajCht7U2ywjcabKmcs1gsA0Obz1+8MNC/OZVKS7wei61jGBYKNsVX4zMzMw8++GAymXS4XQ6H68zZs01NTR5vwGKxcRw/MT0BQZDTZjWQeH9/3+rKEi+wuq7Ozc21t7d39/RNzi5xnMxyigaIluaOTD67Fp+jDEh7c0e9UvX7vYVywWJn1tJrHMfZ7C4T4420bl1eY1dTAmlvzuQFlzsoyzKsyT6va252EsOwlpaWeCKJMUYdxhQY+T3LXYOABkGIrqG/j2T9f7z+I7mlgvfZWu8jiP6358DvB7Y0CdYlEoNkoUrjEI1BslC3miiZ5ySRl4S6zWLOFzKKKK3GY81t7U3NLevraQw1KIrq8wbi8XWLzdqos7l8BoYhykBUq+Vt27ZN3BrTVLG9tXlldcFit2E4WchXVQWyWd3Ly8t9vV26Vi8WYk1Bx+z0RHMoiCPk7PSM225zuRwLS4s4jvsCoWg0uraW2Lx58/z8gtVkIggiX8h6XM4bN6/6/V6f181VK+FAwO32nDl3Ye/+A4vLq3/7jX/+9ne+oSi6rGh/9tWvKYr+4gsvzS8uNOp8uVrk+Nyhw/sMKLUWT5ZzJbPZqiiKqsoarMmq2NLS8vzzvz169KjP57t+9QZJ0u0tnbVG5eQ7xz/80ScaDTiXq/3iV7/+xCc/CmBOA+qtm7P79h8VOPL4W6f+9C//JJNP1bgKgiCjYzd7+kdMlvZSuaYqZaG2ptSjE9cvfPTDn6iy9bGJWwjQaQRkk2uBgKM10l4s8iiKWhy0onEEiVAGi5nxL8wvr8WXlpanAwFbU1OIb4BYdI3ENFHiBgaGEARKpTKKomzduvX111/XdN1oNHq9/mAwmC3k5+fnOzo62EqVJDCKIlEcSyUzHMdRNJnP5zYPDwgCp6gSgaEEQbidnkwm09bSVqxVnCGvqvHR2fGL587/wR/9cUNSFhfn3Va62WXyeSJnrydUY28R76hoFkHTIF1mc/GFmWsjWzqDActbrzz3yIc+AkG+ZE7gIMJkNuOwaDUQxWSa5yWEZGDaXFdRRceFuoyRhIKCBpfb3e/61p9/deLM8UjQWqhm29pDLUG/22ldXVpwWO2Rlq752bldOzfPzk12dnfXG6zD56CNpIEgCRxdXV2p1usSSuw+8qHZKECIAE5R7757lq+tPPzQHd/9zj+Eg+3bth31uVt++5uXGvXs+Ojr7a3Gy+dea2tt6undPD42DXX3hjfWyyEIstvtG/aAxWLJZNKxWMzn83Ecp+kKTdMYhvEN0Wn3ZrNZgwGrVPMECff0te7Zu00QuVKpYDAYQsHI66+efOv4ufbWHlmCV1ZWPvHpx2PxRYLEBwb65udnE4mEokrx2LrP5wuFQoqi0bSBMVIICnAcNRgMC/PLlUrFaDQyDEOQuNvtXlqYh2GYIIiVlRVBEMxms9vtzmazFMW4XT4DaZ6ZmUVRNJ/PwzBMUZSqqqIoAgjyB3zjYxMQDBiGsVhMoiibzUZZlmEYJnAqHl+naSOKok6Hmxe4Wq0CQTpN0zACbRhdAX8w3BSSRWF8fHyjR0hRNKfTmUwmy+Wypuk0TVssFrPZhKLY8PDmeHyNpqlapUDThlK1ZDKZfEEfBOBT776TzebtTm82UzAzZllSC/m8w+GgDZQgCCazNRaLud0ep9OZyeTS6bTJaPF6vRcvXmYYxuFwSJLU1BQiCCKTyfh8vunZKZfLFfD7s9msxWIpFouaolYqFRQzWCzWqenZ/QcPu72+2flFp9NltDmrgrpl28533nmnWmWP3H40kcxsGd6ZzRW3b99pMZnuO3ZPo1ZuCfqtNDk/MxFpa9MJ3OJymUymv//7v/7uP3331Km39u/ZvrqyWK+VKqVya2urLKuhcMtyLF4qlVQIkGamUK4jCOPxR1ye1nvu+dDqyvqmwd4GJ926eeVHP/qnH3z/mwQJPv/Fz9x516FAwH/qrdMhr1/gGqViUZLVjq7edKZAUsamSKuuQ6ury2Kj3hbyuG30qeOv2S2EpLCyLLIVlsBpFMUNhIHEiXKxMDE1YTRa9uw9+MaJk7qKfPxzXxnZte+Z5986cOzxmqiHIs21OotTBkmRERgDANYUFdIhWIch6D8zJzoEMBwRZXmDZw1BkKorCIQiCKIomiRJjIHSdZUgsWI+l8unT7z+UikZDfocDqeX46W77/1AOlu4enPCQBlbIm3NrW2tbW5eBGtrBQCAxWqGNF0SJBzHAQCCJMIwjBsIDag8z6E49n4Frw7rOgx0GABU1XUNUWGgorqG6AqAZAA0FcJ1AEmSZDZQRhyvpNIRv4dCa++d+2U+OeOkyLbmUKqYdLpd68m0zWRcXphqCYY1BYlHM05vsHeo9zvf/ctP/+Hj27YORFfib7x6dnBw88j2LRMzoziF6AhhNTUZyACkO2Zn51985eePP3FvOherVgSjoWlpOdE32HHmzIU7Dz+MIarDraVSq5KAFXP8wT33/vrXT9rdWl9/MJ9d3bmrz2U3XLp8wWYJJhKFTLIAwYSRsc8tLO/csXdwcOjm6NjaWuKVV19/5JHH2zt7f/PMcy6Xu7u3c2l57I03Xxzq62UY5vq1W7ffeUcindBgRNIJmzW4MJfauXPnWmz6+MvP3P/QMaMRXVqYslpoo4kGAJw/e23/3gMQBOlA6e1rTyTWWJYb6N9cyJbj8XgmkzQwBgRBcJJIJZLNLeFyuQxpKkEQgtjYMHVaI+0cx8uyXCyWRVH0ebyarBSKuYW52a/++Z/mswkI1rZuGaixxbn5SQyHVF2p1+u+QMgX8L/7ztlgOGw1OVAUf+eddzZv3oyj+Ntvn6pWqzt37Ha7/dHVWCaXDQaDXV1d07MzgsC3t7fTlCmfy6XTyb7eHk2WSANqMBClcnF1dXlw07DX73/mN79zuHwGxoqhpA7BqfQ6QxB9HV0UTrBsNZ1L7zm8/1dP/zqdy1ntvtbIoMkUqrBoKDKULAi02VNmWcJASjwPA41ja0ajuS5IKE6pKKZDhIIgAIIBADrQYEj9L5+9/8ay+r2Q+u/T7u/rqv+4/suL6NCGCwtDQNNVUVMlRJdsZgrSRBxSpUYV0RRNEvlGjcARm4VJp9ZZturzuxwO+/jkBMuybm/AYffUWVHTQLFQBjDcFArpQG1uDl+5dOHy5YsPPvggCiOKonF1kSAxSWnk8im320kSBFvjcQQt5PJ+vzO1vtyoF4JBN0OTmWRKUzSrxT16c3zrti0bPO1iqXDt2jWj0eh0OiVBrNVq5XKxWi4PD2/q6mjPZtKRoCcej9ntDhQnp2Zmr9+8tXl4S2d3D9DRnXv2wBDq9vocdpcOI2vR+OLKQjoXX40u6hKIx9Z6O3p8voCqqg6HrVApZDLJfLGQz2d7e3qamprePfnuQP/Q0uIqTuGd3a2lGgfDxsmZZVlB/vJrX/3Rv35L09T77n1odjr6rW/++LHHP4oSut3BEAaQTOfZBjGy+454to4T0FC/+2c/+FufUW/xeCbG53v7BoJNwfXYQikd3TWyuVjMOhyucpnPZrP+oGVyarSjp20tnlIkMtLSMTc3Mz0z0dcbIQgCaAaGMdnsxlqtxLKcKPJOpxsAEIvFbDZbKBSKRqNGo3FmZsbpdEIQ5PP5zGZjg2PD4dDVq1cNBspqt4miiGFosZTlec7tdiEwbLPZEBjN5/P5bMEf9ncP9zzz9C99jKmzNcLydZIiJybHDu/dj0t4Ni+8dX7e2bFz8PbHsg1UhUlVFFwm7Jc/+dYXPv+hZHTild899YlPfMrlam8oTEO3zcyvxJYnOiLuwTa/gcTZGmhodEGhVcQCa6SkQTIOJKnSG7T8/Vc+szJ6ZrA7lCunu7pbrbTB63GtrUTDoZDZZEcA1BT0PPfsM9u3j/gCXhVTQ03hRDI3NTmHoui2nTuqfHV6ef3Oez/5m+dPvfLGOafT+a2//+pzv/mJIjeGt46kM8IPf/Tkpz72uanxa0ZDbWr8PatRCgY8BsqKwBi0abgjm80iCLIhTUwmU3Nzc7FYJElieXmZYRgEhXAcLxaLHo+nt6e/UqoX8iVeqNrsRozQVE0gDZCqiZs2bVpbS7xz8uyO7XuvX51BYAoCZDK5bncZaQafno4eODjMMBQE6XWuxvO8qujt7e0AAE1XhoYGSqUSjEAYhl26eFlV1Xq9vm3bNkmSkqkEiRMul6NerxcKhUwmYzab/X7/wsJCoyHs3rWvwUmpVGZxccnhsNM0Y7fbRVFcWVkJBIMb7KhqtRpuCpXLZaPRKIoiz7N2u91icWQzOVlWEQRTFEUQBKvVTNOGTDbd09NTqVRomk4mUg6HA4ZAOp10OByiKOo65HK5WJadmZlpaWmx2WynTp2yWCw0TVMUNTg46HDYnHbr0tICbTKSJK5oqqIoKI4tLCylMgWuLtSrdYvFwnOC0WhEIAAAjOEkSZKCIObzeYIwGAwGCCAYhl26dCUYDG5Ur0CQHolEOI7L5/Nmq0lRFL/PV6lUSqWSKIoEhtM0Xa3VW1vbSQO1tLQSbo7womS3OVmBF1VFVjSAoKoG6QB1uAMms1uQwc0bY52dvTCAvG5XKrYScDsJGJ5dmG3u6i7V2GtXr99zzz3NTcFvf+tv+/vbF+Yntmzqr5VLa7FkKNy8aXikXK0Vi/nl+IrX742tJSsV6eFHPs5y+tat+26MTqZSmUc/+LDXS7176t1Ll94hDJrJhJ85e3Jk6/agt+XyxWu7d+zs6el77nfP04zltruOPfvcCwhGlMvlxfFbvqD39oO7/XbjzMT12ambTc1ei9koiVo8vk4SVDFfTCUSPp/3a1/72gMPfICgsFPvXLnz7gc6ewatLt9KojSy755Dxz4AUIRXlAYvUCazIEgogiuKCunwRtEVDCAAabqu6xBQFEWDdAxDNgA/kiQhCIZC8IaniyKIJAn1akXVFJfT2tvpfubnvyIQKJPPj08t4AY6GGrdufdQe0cXQIGigkpNkhSZpmld1ziOA5BmNJCCIOgahJEGXdcFQdABoChKURQdvL/xrmsbdHhY03UN0QGkIroCARWCRFiHdGCAdQjHMa5aoVFUqtd0QTLgDYu1lk9MsqkkCkmZYgImAAQQRVG2Dm7iWAHVqbFbMyzPH7p97+ziJRQXcQSmDIbWpk7GZI3F189fuWRzW4e3bU8nK22RwdaWTWytMTZxmWuUhrduev2tU7cfeVTV0YsXz8myhqkWl8fc32+7ePl0vQK8ro6u9pFf/vLnOFn+7Ocef/63T6XT0Y5WP4YRsdVspKVTkpQrl6/vP3SYpowQhObzWbfX7XDYfvqzfx/eMmK1uE6fuWSkHWPjo5FWXyG/ThmIjo42TdMA0NPFRK3Bmy3BSNvmu+56dHlh9Utf+sw9R/d/4pMP37x2dnL8Rq1apCjK6/XXWb67u/fChXMzs5NbhvsPHNz/s58+6XEHB3uH8/n8anTe63NNz84yJiPQdJvNBiCNoiiv15tci+s6hCBIIBBoNBp33HHXL37xi+bmZp/Ps7q8kk0nR0a2vPzSi8ObB24/sn95eQaGda/P8e7ptzm+sXf/fovNfubsheHNWyuVmsFAm40mFIUvXrz40IMPjo9NCoLc0tx66eL1cLh5cWnl6LE7L1264PY44usxo9G4Fk11dnbXa2w6nW5vbbHZrC6nvVjOXbhwbmTHtpu3RjEMa26JaBDscnt93pDRaPnZT37+xCOPXXjv/NDQUEMS51aWaKsl0tHp8oVjq7lGAyCwpdqARJVEDUYVgiEEwJqu67quAlnRZB2x2D01XlVhQoHR3xc9aRDY2Lr6fwis/0ZmQdr//kxd+y+h+P8isDBEE4W6iSI0uQFUwW01pxNRBkftZvPiwozFSEGwrKmSzWbihTrHselkvLu7O76eJgkjBGH5Qnn3rv0bUMBqrWgwELVaFYL1rq6uqYlJs8lms/vNJsvs/JjLbTYyhnRy3ecNyJLkdXsUqVErZ2SJ4+ql0RtXBwcGZEVnq0qV5fsG+i9cOGc2mzs726vVaiad7O/vL+ZzU1NThw7sN9J0NpvFUUQSeaFe0RSJ5/n+wU3P/e755dWYy+355Cc/vXf/gUsXr0iKrmlaV09vR1c3ABskV0mQ+NGro3NzC1O3Jnmer9frXq+boAmz2VRlKwMDfWyttr6+7rI7/P7g3//dNz//pS863fapuYVCSbk+On333R9YjS7DqLR1eDNJ0D/8wU+2Du/DMMJkpTxeK4HKz/7u1SN3f5o0+fL1qtPNxJYuvfzMT+87tEfjBJvF0dHRoUj81NS1axeO33XHARzHFVmFIQpCgKrXIVgxmSgDZarXtAanMAxz6fK5ZCJ24MABRcI4ju/p79A0ZYObreu6KIoURTU1NTUajWw2q+t6Op0ul8u7d+9eWlriee6O2w9Xa+WF+SVd132BAEHggtAAkOb1ujOZtNlkwnH81Ml3jhy5fXlxxeayDO3oe+v1V9emV3dt3dqQuEDIU6mV6zVBraLzK/nD934YcYY5yl6R0KnpWH9PvxGVb914e9/etvPvvVrPZz77B3/42lunMDroad6jwcZnn/7plqGmiA8xkihj8LASI5vCNcmAwxZe0nkEQhC5w8/81Rc+tXzzdNhvllR2+47hbCo9snlTZj3Z0daJoqgiCU6rla2UdV0FsB5qCxut9vnlZFfPpsnJhbmF2Tvu3vfaieP5Ek8y7jvvfqRaaVAY9G8//GfaiHp8vpnFWC5X2zS0/Qff+8Z7J9/41j/8KaxWQkFPNJY0kDTUP9hGkqSiKBzHEQQmiiJNU16vd0NypTPJarXqcrkajTqGYU3hVk2By+Wy0WjIF1IYDjZv6S0UMqn0OgzDkUjrubNXspmSJEAOu7810mUwGFZic8GQx2ikuUZd0xQEgaq18gb23mazEQSRSCR8Po/X68VwNJPJ1FkukUhNTCxs3drrsNlz+azNZqvVajiOu91uhmGef/4FM8Ps3bs3k8k6HW6LzbW6uhqLrSEIZLHYTCYTSZLVahXFsVQqBQAol8t2mwNFUYZhUAwBQMlmswMDQyzL3bh+y2q1Op3uRCJB0wZFkUgDgaKoJEmKotAUU6/XgwE/z28UnOEYhtXr9UajAcNwS0vL4GD/wsLCCy+80N3d3dramkqlGnw90tIGIA2GYYoio/FVq9WqQ/Dw5q3Hj59Yiydp2kgSVC6bRRDEajaJoswYzQiCbtCPeF5kWRaGUF3Xi8UyQRAwDKuq6nK5CIIwGAyapqA4kkindEW9//77X3n55UqlEgqFKpUKDKFOp3v7jp1ra4lzFy65PN5Dhw5Foytjt64ZKCIYasYIut6Qccpc5RSAUHcce6BWExaWogaC6O3uee/dd3o62s9dON8zMHjk9jtOvHWKY9no6iJXz3W0ed1u06Vz78GQThPm1dX4vfc/dGtszGI1jezYEl1Zvnb1+o5dB1Uda4p0B8OtkgSdPvPePcfunp4Z/80zv9oy3BsOeSrlLE5Ab584+cRHPp1JFwKBUHw9SdGmt0+9t3nrDlVHMJxwe1xP/eLnIY8j5LO5zYZqIWMx4gN97Rcunmtpbj179vzc3MKePXt279j5sY99LBDwAwgAGMgyyJUa1bqwsrp+4cZ4qiTsPnQH2xAxg8nmdrN1pVoXUZRQlf8CAYK0/yBZbxQIIggkiA0MwzRNAQDmuYbRaKRpgyIqqVSqpTnk9YI6C6LLK8VsrJBLF0rVPXsPdvd1KirIFpRSuaYjuCArKIIhGCrLkg4BDEMAkCAgKKqsKgBGDDhmgCFcUfSN3UOgqwBokL6RWgEAaACGdF3VIF2HNAA0AOuQDkMageiaJjcYQnfYSLaUcVhMDKXZbdpLz/2yur7e2hToH+5eiS0aaGNf75DAiX//t//YFGynabq1LegPW3KlxUqltB6vGHD6D//gIzdvjb/62pn+wZFkNruysnLg4E6zkWIrhZNvv/PXf/23SytrY1PL5ZrcN7TtzNlLRoo+dvQ+h8lz/uIJgszMzo/t3HpnpQg2DxyKx+PLK9c6O0PP/PqX20aGVZUNBsO1ilQqVfr6eggCz2azHZ1tN2/eVDXBaqNVXfyHb37D6/c2hzsJzNbS1J/PFe86duCzn/v0Ex/+yOzMREskPHrr8lp6ZefevbxMTk2n/uQr3zl7+uLOHcO3H9n+yye/MzLc8+qLz188f0HR9JbmyH33P/Tmm28SJJJIRkdGhhwOBwbR42NzE6PT7W2R9o4wW68cvO3I8y++wPN8tVrdOEB6vV6+UZ+ZnqMZw5e+9KWZmZlwIGi3269du9ba2vLm8ddgSL/t0OHT757aMjwki5zbZetsj7z55qtGi4kwkAtLy+GmVrbOSwoYGxtzOSz79u9dnJ8LBH1bt2598YVXe7r79+w58M1/+CdZ0u12RyTSwtbLOAEVi1mj0djR3lercbPTcwxtyuXyHR0dTaFgJpNCUD2TT9fqZQCpJotxZMeIruu1asNIuxOxbD6Rz2VK+w8cWViOOoK+RC7X2deTTmVhGMMxplIRTCaPoKEagsE4xvGNTCrbHmmv1fkay7e09RaqvKQRKoyrKK4DWIc06PcCCwDo//uIUNf1//rd2Yhm/f4xGACgvf/Qf3TjaBgKN+pVAgEUgcRWFrwOi52hs6l1E4mhCBC5WjDk4fnq7PR4e3uEa1RVRaRpGscMsVhCVZGmcIRhTIVyCYbhYjHf1t4KgCKIjXK5rMkyxZhRwpRMZnmuGg4H6mwVgfSujvZcNkUgQOCrbK3IN2osWw34vNVyxeH0yBqhA9RoNJrN5tnZ2ZWVFYZh+vt7SQLTVBmFAAyBRr0mSVKjznH1CgbpBgPx0ksvRdraW1paKrX6xz/xyZ5Nw688/wJDm4rlmqZpNG2854EHxIYAYzCC6jCCAFWTRBkn6MmbN0ulQq1WS+VSyWSiUMo7HI6A32u328dHb1UqFQw1tPd0dXR13bg1PreQ3nvgzlpNnJqe6O2PuF32P/z0H37mM58NeJopirI5zQyNnj193N/UzTg2X5uY3XtkeHV1/De/+vFHP/TBxYnF3rYOE01K9crsxKjVDPnDOGWA2WqjVuIYxkwYDOlsrFYrh5uC6UxBU0iSYEKhUKGQczgtAAC2JnP1RiafKlaKh/YfcDgczz33HAAgmUxu377dZKRtNhsEQRzHra6uUhQ1MjKSSiUcDrusiMlEOhAITE9P4zgeCPkxHJmaGN+9ZxdJktlsNp1OYyi+adPwlavnDUaVJg3x6fTeHXvnV+Y9AVe4tYmt8dWclMxU9x29dyVXgC3Whoq98rt39u4+sGmg61vf/JMPPLR1/Pp7ty5c/bM/+dPoepy2tdb1CGYISGIjsz6+uddYSC6RmM0d6BaNgdUkl1lng5Geug5ls8nDuzo/86GH66kFCwMAKhw8uHdxera7vYOrsg6bLdwSKhVyve2dSwvzOIKLitjW14kyFhW2jE6uBsOd7517T1TyQ8M92Wy2tb07EunyuAJf/9rfdXe0Z3OJd86eoqz08MhWFCG2DW95/pmnEU3UhHpfb+dbJ04uLqxB23cOoihqs9lYlqVpQzKZnJ9faG9v7e7uNplMqXSiWCxuzM5QFCVJyusKjo6OkgZM0yRRqofCPofTurg4r6rqvn0HzCZbg1OuXb05M73Y3d1vMBhaWkPnL7wXCgUkSbJYzfF4FIJ0gsTMZvNG9R4Mw6lUoq+vD0D6/NyCqur5fN7v9weDQaDpHMcaDAZREkRRxDDM5/OVSqXo8uq+ffsQBJmfW2xpa79x40adbQSCPpvVsfGyZ8+eja0lm5vDZrO5UqmgKOpyuRRZJUjc43GUy+VQqIlluZNvv2s0Gq1WO8/zAGgEgeXzeavN4na7x8bGIi2tPM877Ha/37dB9azVarVajSAIjuNWV5e7uroajUY8Hr///vtRFL10+cJaPNHT01cqlbxe98i2LaNjNxVFCYaaqlVWFOSJicm21q5EIgFDkKIoGIIKgqAD2Gg0RSIRQRByuYLdbl+YXyoWi263dyNfZTAYNvyzWq3W0dWeyWTqfN3rcmezWaDrPM+TJClJEk0Zk8mkzeGMtLTmS+XEesrlcvn8nqaga25uBgBYVgCMkSabGyGZTL7WPbClUhVnZhdbIu2KoszNzNrt9g9/+IlXXzve2dOTy5b8fr+m8MffeN7vpQf7W29dvzw0OFjKVVUFWl6NO1yO5ZXFj3zkcUUW2Uo1k6uMjk8ZTbbb7jomyXoqk6tVKjabZXlpjq0WPv6xDx9/87VQ2Edi5Otvvv3wQ49Uauz4xExrRzdjcVRrQjKdLRRLDMOQGHzstoOFTOzmxfca1eKBvTsUiX35xedj8bUdO3d94hOfuvPOOx0OqyopCIqqsozgmKYBGAELKxmf3wMTIF8FFQ5cvDoaTeSyBRbCmDvvvjO+VkJQUttAV0MAAO0/ztsIgHRNk2WR41ibzWa1GlEU1MoSDMMcW4/FYh63c319LZdJZbPpYjFtZpCBgb5AsLm1vWstlYMRAsNojKJ4UYVgWNeBrms6BHRd1YGKwKqqNVAMhiFCVRBNRYCOQACDIWgDtwh0BQYyBBQANBjSIEiHVE2HgAIhKoRqEK4DFNJhRNcwqIGCBo7UmvwmFBEvvPdme6vbTJCL4wuyJJjszPjUaCaXU1RoPZb9H3/4Ja6iVcp5Wc4fu3f3pRvH8/myxFnTqZLJgvX1D05Oxny+1s6Ovpm5W436uteDFwsrXrcTaPTSanH/4Q+++uZpVzBEUczYzdG9u/ZuHhoevfne5esv3HXnod6uXdHlklQ3uFyuS1ePR2OLgz0Da+urg/0dQ0ND42Nzv/vtCxgOHT58SJS4XD7t9lj7+jtPv/f2xz724ddef2V2bsXtbGpw0OWLEzCMHji44+0Tb2IoShuwhz9470sv/1bQ6uFIq9nWfPudj46NxvO5an932/Ubp+OxmwcObD/+2uuqrGIogWD4pqEtmVyWZvBIa+jcuZMWiwWHTbdGp/zO8OBQf6m4XuOqFoc9lUm3t7dfuXJFUZRwOFyr1Tb2c1uamnft3pFKpSrF0uzstK7r991/j9nMjI+NLi/Ot0VaA37f9SuXaQpHYf2++++p1qs/+/kvO7p6mppbayyvaFBLpFmR6rxQTycTFE3Ozsy3tLSajNalxXjA3wxB6Mpy/MiRQ/lCKpNdv3Hz0sc//nGbzTU7s3BrdHJkZMfi3Eq1yobDYZ/PE19baW4NlsrZw7fti8aWl6PLFE0QOLM0k3Y6QlxFMpsczZHuQoUtNQTMQCZSydZIcz6d7+7sjseTKEFpKMlLqg4jjNkyNT7V29OXTOfZutzVN8yrGCvqGmJQEEQHsA4rkP4fAgv5/yODBW10Nv83AgsCyH8rsFRVhiGA6Iom8RJfM6BwMZ1sawrBsmi10reuXxkc6K6Ws4lUtLevo1jIsLUyBiN2m4vjVa8nIMm6KEoIigIAVEip1yoNsbEei7VEmsxmc6VWlzUMgmDGwHBsTREln9cDQ/ri/NSRw3unp0btFkaUuFK+YDTR1XJFAQhOGhmTLZlM53OFkZGdNE1PTU299967uipZzMaO9pbujnZVEWVRXF1eYhjK53IBSHO4PCdPnrTbHV/68pddbu/orbHXXn3D7nJ94IGHnn/+eY/H9+DDD6E4ASAAIE0URYIgFEFEIQygMFBVgCAA1gAAHFt96qlfJdbjq0vLA329vkCQohiCZtLZ7KWrN+3u1oHBEVVFLQ7LjWvnb968vG3riMlo9rkD2WyWIOGtW4ae+fWvdu25g9OcNp83k5/+xt99tSnQ3NnSrSmGllDAaYQCTubsidfa2zzDOyMXL79TylWbAhFNhafnZgcGezAMLZeLmUze427VdQSGYY/H1eArS0tLGEpTDA0QoOsqX+e7uzsbDaFSKSWTyQ1m8gYPGUEQTdNIksRxfGFhHsMwf8DrcnomJyclSXK5XCaL0etzT0+NBwK+jdxFS0vr2tpaMpkGkMQ1CkBRe5qHXDZvKp8t1Mp2j8vucHB1ZWllde9tR77/k59s2rnr0JFjL//mrUK+4g8FL158Y//h1usXTpIK1d7a0TPYa/f2l8VmQXOUSyykFVF5yURKF89c+sCjH12t1Ks8vDibu+/Bj82t5U6cfPvvv/qJTz/y4fnrZ7rafDKo33bkYL1ShTUdBbCJoSKRpko573W6SBSLrsaNFrO3OSQhpDcyfPnWwguvnCIM+Pe+/zcn3n5tenLqwJ49BhJ//tnfTN2a3rFtezabrPHVZDFx211HVlZW2WqtqymyHovNjk185PHHUBz71j/+MzSyvV/XdRSFAQCiKNrt9oGB/kuXLmE4YrPZGIZBECSbTW/QxmVZtVsdtVqtUMg5nfY6V6Npiuc5SZI4jkMQxOFwwTDCN2RBkDbQi5uGh4JB/yuvvOT1elmWJUi8Xq9hGNI/0Ds5Oel2OyEI2iBnxmIxRVEiza3r68mZmdXbb99NEES1WpZl2WazmUymRqNhIAin01mr1jcw/BRFGRhjoZDbcLCamyMIgjAMs7y8TJDUzMyM3W6HYXgjSUaSFE0b6vWa2+12OFzFYjmdyl2+fNXpdJpMJoLAdF1FUTSRSFAUZbPZZFlVVbm5qUnX9eXl5fb29kIh73K5YBgul8stLU0sy24UMO/Zs+fs2bOFQoEkqUQypaq60Uj7/F6bzZJIJEqVMo6RACB1tuHz+EulEkVRhWJuLRbftWsX1xASiWQgEMAwrFSqyLJcKlZqtZrPF9hoXxEEgWGYDZI7gHWapjESM9FMvV7XNE0UxQ0PBoZRgiAqlRqG4jiO4wZK1/VarbJ586ZqrczV+Q3MqaQoOGnSITSZKQea2nL5kqojhw7fxvMCDMMWq8dkdY9PzTsd3h/8y/ecDnNTkwtolVo51RTyumz21cU4ipAIRgqSiKIIjICgP6CIUrnGajpAMOLAocOZQvHCxctmo2lgYGBhYSHSHJydmSJw1GYy+f3ecrl86p3TR+++T1YAQMk/+OynfvnUa8VytVAsTU9N7tu1nSaRhelbDjMZ9Djefet1t8NqNTOf+cwf7t27F8IAAEBqiCgGwxAQBYGgaU1RAYwmkmkNAF/AV6mKZZajTTZJBf/68xfePXfloQ89YTBaAILDuAHDSVYQYATFCEOtziEQrAuSw2Y1msGvfvXCAw88MDZ+C4YQoOulYiUYCExMTJz+zTNAFnc8cH8g6GuOhHih1tHdVSnXCsVKU0sbx8sYbhBlHYLhjawvABtrVhoAGgQDDahAhyEIBToKNBjoMAQArGuqyhsIWNcaqsrjqEoSKInDQFWsBrJaafA6JcOmbElCSCNGIqrCIxDvtMLZtXGPQ28Pkk/97HuPPXhPk6/16pXowvJaJr9OGXFJkwmCPn9h9Kmfv7AwnUmuR10uaGzqFE6WGoIyNVr+o8997fmXX1M16A8+88Uz751t1Pljd+1NJW789tl/fvSD+3t7Ol55+UyuBCz23oGte2KZ5Jkzpw/u2bMeXfW6PW+8+Ztt25tbIuHocjHga4c1BidRt4965jdPdbZ09/b2ToxdxXHc4w3Mzs573Z7BoT6gCVevXXB5jJlMcnFxcefOXelUKZevbxrc8f0f/MRqcTY1NaUz63W2Uq/WfvTD79FGdM+euw7cNsxy0rYdtxfLiqpQH/3ox8fHrl+8dMLnJYw0On5zgqKY9fWkze4AOroaXZaVxvCWPklhcRzPp1mBV3vaBrq6OxgaGp8ae/X1V7r7ereObE+lUhMTE5FIZGU1ZrfbzRZjo87VapWA31/MZXmBq9frH/3oEzar2WRiFufm//3ffvonf/wFGOg0Rf7wh//c19/D8/z8wtIDDz7sD4YmJmdm5ha2bdtmZFC+UYMQqF6vGY3mzo4uXcMuXri2b88hi9kxN7vEC1wo7JmcGm3wVQCU/sEBTQOLC9FyiUUhcnBwOBaLVWs1h9OWSMQ8XnuZLTicFl7k7A7ryJZdmUSdrSmSAJUrfIWVRAUKtrYHwuFcOoNCEBBFq9ly/vz59u4exmFL5Yoed7BYZkmMpI0WVYPTuaov1FZqyDJEAMygIIiqaxCsoSjQVFERFQQ2gA22wn8rqP5LEeHG0BGGYV1/f0So/c+sLBRF/8Mn3qiK0iGg6RCCQgjQNIknEZ2ANBqFKoUsqqsum/Ha5XM2K2NicKORyOWTBA7TBGGxWLKZAoKSHrc/mc4HAoF6g7NYTMlMolwsNEVCmVQylUr19fUtr0ZpkxXBDGJD9Lq9VpPVQOLlYlFo1GBYAZqUTsRwAjWbmUIx19/TPb+0PL+0fMfRezQNvnjhWijYYiAZXddpihyfGE0lYt0dbQyFtrU2l4v56Mqyy+VyOp08z8/Oztrt9j//87/4wY9+/MlPfhLA6Ne//nc3ro/+5Cc/ee/sOZoyPvaRxwEEZEnBCFSWRQzDgA6AIAEEETmO4+ucwBsMBofH/Vdf/bNTb7911113kTgWagpXq6zN5b589XqtLhvtfpcr1Nu3qVwufvvbX3/s8Yf37t41fuuWw+Y0m411rjo1NeX1hGjaajDZGhL7x3/6iWKu+Dd/+ePOzm35Eo8jio2pTlw/VVpbffihO6uN9I2bl6wmq8vpq5RZl8vz9ttvZfO54eGtugYbSGud5atsJRJpicYWWiJNJEEVK1UYBuFwcHZ2fnz81t5dexVV6u7uRlH0lZdeZhg6HA4riiLwfE9PlyiKsVjM7nDpuu71+jYK11VVkRWRYchypQBBeo2tmM3GWq1ms9nYeiMY8s/PTfZ29+A6cvPGWGtnnwzg8bmZQjk3vKUvnU0okI5gVHvnoCxAty6POZ3eTdu2/vAn3z10uPf7333mc0/cd2jvkeMn3w237bSFbk8XCJwwLcyOVrOTfifhd5t8YVe8lpicW0F05113f+THT73U0tL28LGDj91zH5tasRph2krcftvB1NpaR0srTZDTUxNDQ30wUHVVtJrM1SrLCYov0sy4writKVkWF9czCIHLav29d09/+Q///O3XX7126c2e9kAyujw5MdbV1QUIuFhjLU7z6K0bVosxEgjFFpddVqfD5qhUq0tLK9Dw1p6NqjsIgpxOJ0VRLpeTYRiny55MJhcXFxmGUVV5Y0QlSVK1XKNpmmWrlUoFx3Gj0bjR1sKyXKVS2UiurK5GW1ubvV5vtVZ+7PHHXS7Xk08+uVEkUq1WERT2et1Op71aK7e1RfL5fDKZjEajbrdbkiSn3WU2W41GYzK5XiqVdF03m41WqzUYDKZSKRRCNwQ1RTGqqra2thoYQyqVoihqZWWFZVlVVT0e3/Xr1weHhjKZTCqVoShqQyZaLBan014sFn0+n83mmpudr9Ua0WiUpumNmiCKIufm5rxe98bgHEEwo9E42D8QX4tGo9E9e/ZIkpjJZGAYzuVyTU1Nu3btIAjDzMxMOByOxWJzc3OVSlVRIVmWXS6H1Wre8AVRHINhGOhoMpnGECyTydjt9kaDk0RR0zQERW02u8ViAQAUi+X5+XnKwGiaBsMoTdMAgHq9jiAITdO6rjcadZwkrA5rrVzBcbxWq6EoqqoqQRAcx8MwvNFpaDabdV0XJNnhcgIYVVXVbKQZilJlURRFFCcz2QJBW3KlCo4zkbaunr7+m6O3BEFaXFlneaSrdygUaAZAu3b1PEGo7RHP7NT1UMBLESQMUIfdd/HCJY/P+8THPzY9PZVcS6iq6nQ6AQIvLix39XR39PTn8/nVlZgsy4qiLMzN7Nm98/LFC93tbW6nQ1Z4SVTW09muvkENwvfsvw3GDNl88amnnh6/dXPzYJ+JwsMeW62UFflaS8D3yScebW1v2aipVVVNFHmKpnVFgoAGNF0DOozjAIBCoVit1SKRtpWlZZPJJqswQVkQGuTLIJGt50rVRKYgKkBHSYSgGLO9XOMpk9VAwCYM/OqXv7333nufffY3LpdreOsWm80my8ry4sprr73WaDQ+9fFPiCI/vKXn5s3xTDY1tGUTZTZqGsgXSozJJokqjGIbYKHfH+7fn/dBQAMQpOmYBjbC9chGuB7WVAiSEUjJZmJNzW4C0RBY4hvs8tJcJBxaGJ/s7e43O8PZoqTClmy1YbJbFE22242Tty5Xc4sP37e9sHZJrK25KIPdHoylte9+/+ePPvro7XfeGV2Pmyz2GzdmLl+c4CrwFz73BxYT9+SvvylIMUnS6mXnI49+gW2oZy5c/uCDD9XZ8vLCtMxnDVhufvq9j330WHR1GQbO9ZSIks0YbVtORSkaG+xpM1L43//1XwdCzo9+5N6vfvWr9xx75PHHPtEQ5LW1qAqx/oB3YnTO6/JaLNTZs+9tGd4+MzPDGCkIKNncWrmY2bV7ZD0RF3g1sZa/NTr34cc+XW/I585e8PjcydS60WjctnXrpQvnqpX8luE+q91+5eqtYFOnKBtWYumBwc0PPfRgrZrP56PVcqxSzrptvuvXb2AYRhvNN2+M+4O+ZDKqw+Ke3VuyuUxzuFvklGym1OC4yakbg0M9La2RE6dOrK6sh5uDPp+P43jGaDSZTJVKxWI1KZI4MTnGkERTUxhFUSNDbdq0iWXZWrmyHl+DABjs65VkwWq1vPvOiYGhwdnZWbfXS9Fmk8VSKlaWVxaP3nU7jsPpbOqll17asWMHQdCUwcQ3FF3BGNqiKKrVaoERJRZfeeADxy5fuTA3P88wpmQi09LaydUaTrd3cXGxu7vbZjeVKiUM1X77wrP33nvUajOXSqX1tazL3rJj+0GBV8o1HiaMK2up/k0jvCiJdSmfTDe5PUCRSQNRE+ozq0ubh7dWK0IhX2ZZrqOrT5LB/NJa58AIJ0MyapAB2lBVUZYApOIYhMIqABCk/98EFvgvVPf/wnDX/1uBBUEQ0OGNnjgVqAhAVF0XZMVgMChSg0B0AtYJSJXYGqJLNI7OT4/x9fL2LUMGA7waXaApLOBzVQqFer0e8IenZxdp2hRuaqnX6yiBA6DNL84xRoOiSBRFAUgzm835QskXaJIV1WAwUgRz68at7du2Ak3LpBLlUm7z0OCVSxcL+XSktclkJgWR8/o9qXQ6up4qFVkj42Boq9nixhCkWi13dbYX86lTJ980m8lHP/SBN15/OdLU7HK5lpZWRFk9derU5z73uX37Dvzd3/3dl770pVAo/E/f+Z4GdKPRDAB45LEP2+12BIE3CKy6pmqqrMmKLikICjXqHI7jCIbOLS5omqqq6lO/+kVnZ7vQ4GAYhhCYZIzzS8skZW2O9AWaWpOJ7I9//MMdO4Y/8ODdN65eVRXJYrFZLKa19dXRW5N33fWw0cSUiutP//pnLZHAvn1Hm5r3FUuA5XgYsPnUNV1IKWzJZafypaQk860tbQiMvv76W+VSdXh4uKurq1AoGxlrJl3kGkKNrTgc1rX11XQuWavVjhw5MjMzUywVto1s9wd8hWxuIxUzNDRA4gZJFubm5jweVyaVVVW5paUlGo3ana6e7r58vlCv161W68TEuNVmLhQyOlBsdlNrazPXYMvlsqqqqq61t7ffuD66th4z0eRtR+5YS+QJ2sLJ0uTM2L4DWwql5Goseujg7d2dw+feu3z57HkDZXzwkccvXL+QSE2l16NSWfiDj3/OZPa88taNXbf9D06x5SvC6LUr60tjT/382yffemp08qxmEBGc6uve19a16zevnRnZtm8gEvn4ww+q5QyNqTiDjuzYUsikSRTZOji0urzY2dXKcTUYyIlEIhxoIhgzYbZYfBFjoGt2LY8Z3TWRT6aiLqu7J9I7dWPspWd/ZEBYWKsDhc8Wiql01h9pj66v9fR2DvR13bp61W13TI9N0QaqWC4xDIUqioQgiMvlqtfZSqVstVokSUqlUnaHtVarlctlm82maTDLspqm4ThOMYSsCADWzVYLy7L5Ysnr8SsqzDVkAOEECWua2hwJu7wOi51JpFd/+aufHThwoLW1FUXRZDJdrVZ1DaiqXqlUAKQXCoVCobCxG2i1WoeGhi6cu+hwODwe1/z8tM1m6e7uvnnzZiKRoAgKgzFBkHK5AoZhkqQBALLZbHmpvBEdQ1HU6XQuLCyYTCaPxzU3N+fxeNrbW2VZdrvda2trLFtlGArDMF2HJicn+YaAYQaH3WW32wmCqNbKjYaGomg+X7RarXa7oVpljUZjsVisVeuDg4O5XM7j8UiSnM1m29raaJo5ffoMDCNNTU2vvfa62Wzu7Ow68dZJm91dZ3muLjKMnkplisUiQRAUxbicHrvVLopiZ2dnrVItC0VFUTRN4xqNDYJotVqdmZlTVZWmoEajAUFIvV4nSZJhGE1TGo33mwd1XYc0SNNApVIDAGwgLjGMiER8uVxuo2yYl3iGYUIeD8txXl+wWq3yokjiCo7CXZ194+PjNjMlSHzQY9u77/CLr7wxPzcxtHmYFxC/x3b14gS1ZWTH9iGKIs1GqMGVXA4qtjSzFk888sGHSoXK5MRsMBhUdfDrp55xez0wQfX29fM8Nz8z6w81X781YXcF+wc2+XxNZrO1Xq9duHRpbmm5f2jTwtwUBGuKwLEsZ3W4ea5Rb1R/8bOf3PeBD515972OSMjrMG4ZGoA06dMfOabJILm21tsZggBQBBU1IEADuq5TDA10AEFQsVAUBB7W37875Ar5gaGhejWXWl2OivK27btVjTMitMEJjBTT1syU655soXr5xsTVS/Pb9xzxByIaBFKJ6s356YWZqW/NTIWbm9bjUZfbcfH8hUaD9wdCf/7Vr3q9cKkIIAisJ4tdvX29g4Nj01Piera5uZmkLTqMIjiqqrqq6zAMwRvvzu9rdhEI0nQU0ggY/Je8MKRAsAJBkiBWAyEHL1SrjZoq87Mzk6oibduydUIZp80MV082KsW+gW0BF5Uq5SWA1QpQ2NfTvGXHwsyV6OwyqhZa9u4tl+VcpfpX//ANA+Gamavwki2TBbv23X9ronb7HQePnzw7O/POH37mvm9/5ys+b9jr76430GJVNNt96Xwh6DcPbmpJr9dK2do9997xwvOvDvZtddgD2fSkN4Ssr62ZTPTgUNv89NVyIX3owLaDBw9US3mJQ/bsPFQuVAul/IWLZ9479/Z999/T2tRdLBZnZqd27zlYyFcOHDxy7vy7Ho8lX9TvuvsuFIavXZ3QFOKRh/9wsDeKwORicjoSidS4EgxDfb0DuXwJhtH5+YX21paDh+5+5aUrQ/1dA0M7ZF23uYzXrl7GUEnXuSsXL9125NDS3OrS4sqXv/zly5cve1yOHdtHjr+RtjqdDbbhcbpTibVXXzm+fWTfF77whf/xuZujt8ZRHDOQdCgUhHRY04AsKYlE0uWSK5WyKPEOm7W9vb27vbW/v/f4m68vLyy2R9ptFrtQk1qaO0rFYjZfqbHlZDq7/8CROl+/5777ZFleia5u2Tq4uhKr1go0bfD5fIuLiyNbdlitzsGB4eWlaKmQxjDE6/flcvnVWFQSeaPRcPLtM9u2bRUEuLW9IxaLyYoWDDY1eH77rq3r67FcKVasFj72kQ9fuXUumU1mi9loNIoiVEvL4LlL5wnC4As1x6Ixs8Nz+ebZB+7/4OkT52xGsyiqpWzRZjeV6+XtI1sLpaLIy52RYLnGokCeW17uaO81EEiBZVHGoOs6DKM4DsNAhxEdBSoEQYr6f2seBP+XLUIA4P+5w1BTNRgGEIB0VYNhAEO6DjQDSeqaAmkaAkN8va7Bqio1zBRZr1YMJNHkb8cJlOfrxWLR7WqVZTmbzVpMlqnJSdJgFEW+VCoEg8EKW4ER2GY1Wa3Wcrlot9o4jltZXK3VOQNpbIiikZHqCOv3uXO5bDy2amaMbldwYmy+Xte3bj0Qjc2vxqK8UEpn7a3tbSajgcAMkUiPLKKqClXZemdn98T4mNlE3n777adPv7VxK1ldXdU07fS587t37/3Kn/6Z0Wg8f+EiTpCtbe2vvvp6bC1usdgURfvjP/kTo8nENwTCQDbqDQiGcQxrcIIs8hSOkSQjl8uTkxO3xseXlpb+7C++Ggj4J8ZG5+Zm2lsjbo8rlUnWuTKCQE1NAa/PwdXLTz/9swcfvMfvtd+4cglFYUjTOLZYKWXiifixY8fsbncmFf2nb35l6+b+zX1DFGFbWEzYXUFVrUBQBUOluiJ09HSW8kmr3WmkDblcIRRsGhzaHA43AR2+cuWK1erMZMoQwHVdxzAsnct29/USURwnsAOHDwSC/nK5OD8zPzF2c9OmTTiOplIJf8D96suvHT16Z3t76+zstKJo/f29tVqNMRk1Tbt69WpnZ5eqqhiGWa1WGOgMTQfD3mwumS9kC4WcgabYOqsoynoyqaJIa3ePxUykypn1fGZ3V+eNmxMOqyMRT9jsxnKxEo+uTY0tGSkTQSKSzK+uxjraei9cPM/X9Y5wJJFO9VlDWzcPL8yPOoLdAFI6e12f+MhfvH36+D//+9c/+OhtdVGBINhuI5568seelk0DfZG5a7eiywsuAiZowoQzEi9JvGRg6DfffHP7yOZKpUgZMB0ggWBIEBUGw2AYCDxHy4quAh3CYQTq6OyXGjwMA4/HdduRY+vLtwQuSVFQOp01GW333PWBN99+Z/vwnnwuvbZaWF/KdERa42srpAFTIQllWVaSxFAoZLVaAQAwDPM8L8vy9PR0tVrdsHYURarVahszKb/fW6mWSZKsVCper3d9PSkIotcbUGSAomg0thIOB44ee7TBVyFYbW7xv/LKa08++cuWlvbenr7V1VWDwWAyWTRVBwDl6lUURTeMK4PBIAhCoVDYvHkonU6Pjd9EMaRQzE/PTNnsVppiYARQFKNpNbPZTNM0hhG6rtfr9e7u7uXl5RMnTrhcri1bthw5cmRubu7RRx8/f+HC/Pw8giAQBPE873a7eZ5fWloJBoMzM3OjN6c6OloJXCoWS8ViyWw22+22ZDLR3z9YqZTW15M4jtvt9v7+wbPvnQ4Gg7Isl8tlRVEikUhPT4/D4ZidnSVwSpbl0ZtjigKWl2KJ9YyqQvU6Z7HYCILg6nydq6EoIghStZoWBZmmmWqVFUVZaDSMjKlcKaEoKsmyruscx3k8nqWlFU3TNE0zGAy6DsEwjOO4LMsoCptMpo3oPYIgG8oMhmG/35/JZARBSCaTG+EwURQlSUIJHIZhg4HTNLVcLBCEAUIkRRIEWUysxf1e39z8IkEzuq6urCy7HJa5hRWhwXlcnoMHbztw+OjvXnx9aTEcCgdIAjz8gce+/71/nBof7+7q/PWvn+nq6GppacnmijhJbd6y9elnnl3L5FhZG968aWjLtthq9NboeDqVO3r07rvvuefNN9+s1+vd3V1TU2N7d49QJHTtyiVF4I8cuX01npQLBcZsO3/+/I3Rsb6+fpfDfuehfYN9PV1tNKqDSl3s7QxJoo5BACURAICsKhiBAgAEgSMNBkEUl5aWmkNhVZPHJyenpieMDEWSJI6hbrtDlhorqzFR1UZ27kqtzIqaMjTUH/bYvK49B/fu5mX0qd8erzcgvz/Y0931iY/u/Nd/PXF99OZ6IpHPZz/2yU/19oVFAZQq8vxiXVVVGAY2my1byKME7g2GS+UqbqA1FUiSogJdB/rvFZQOvy+uNmYrEKwDDWgQ2GiA1iBYhYCqwwoEVBSFPR7PG6+/nE6u7dm1++67H4EgaHl5CTLYTU4vV1kX6utLUzUAYc5gq4pYi+UGRhoz6/nmQLtW79P4JK+SJqetGr+VLZcZgpJEQ7Egt3b2/uKpt1hB8YSDHp9lbu7cO+9ceOyxz0xMzBQKpZXosjvcZLHS12+cd7v21Sqpi5ff+duvfXZ1YQIlLMfu+WChoD3xya/+8EeH77znWHQ9ajShn/r2t7/21c8zFPPzn/xrS7jl8IGD+XQq6A/WuRoCk/v23NUe2Xzjxk2apqvlaqksrqzmBBn2+pva2/w0g9nt7qeefDadLH32M185e+5mMVvxh8Jmk0WDpER6dduOERQhxi9fz6bX//br//j2iTf+8Zvf1RQil6nyDWVqbhpgotvFxFajifWFLZs3O6yOqpP9iz//y3dPn5ibmxsYGBzq6/3Zv/1409CRhlCWRWn37p3zc0uPf/jR8YlbDU5oiTRJopJaT/X29rm8HlUDJFHWAWw00fF43O12b9o07HRYLl8899vnnrvztiN2u/3ixavXrlzraO8aHx+PNLc6HC5BECRFQjDyynun7Xb79PSkosnXr14pFEptrS2vvvrqwYMHk8nsF7/4xYX55W/8/T9u2bJdVTSg49PT0xaLBcMwFEYAgLKZUnwtWyrwE9yix+M5efLV3Xt2Kop06vSpLVs3hf1NeAbRYOWBB+7/3ve+d/vttz/66CPXr09WauW+wc1mk3U1HjdQKIICCNI3LIGV1ZjGiYiqs/VyU1tTtVy0WU06o7BstpjLO5w+sVHihWo1IyO4RRJ5GSIgBEdRHIZ0oCm6qukbQPf/h8T6vYCCoN/btP+d2IJhTVFhGNJ1DdI1CEIgXYOArss8AsMYrOuyYCQREkNKdT6VSGFAG97ULwpcLrMmS7wkSThpyOezLofTarEIgtDZ2ZXNFZLp9PpatL2zrVKpwDAwm43xeLRaZQEA6+vpO++802y1jI9NSBxv81hzuTwEwUaj0WKzYTiuwsDh8pw9dwEnQL1eqzfK3T2dhVze53GVi8L05JSu4f5AC1/n0ul0W0fr2tqy32Q7ePjAc8/9zmQ0dHX1LK4sb9267bN/9HkAwL/+67/azDa32/vrXz9z9epVRdEMBsOdd94pCAKGYQbKUGc5DegETqIoDEGQw+0EsvzS888vLSyqquryeFwu19LSUqCpCYZQSZBvXLvpC3oi7aFMMd3a1tzgahxXeurJ5x64585QOFjIZsJBryjyCIK0t7c//fTTw8PDu3btevHVk9/9p6//5Zc/vnfnjpMnJzSFoChqPb5opHmU4N9++9Wu9qB7zzYdiLoknD9/FsfJUpkjSSqbL0Ia5HS63W7vWjxx7dpVk8mydfvW4eGhbCFlslJWq3lpaSEej+q6bjTSgcAwjACzxdje0dpoNA4fPhiPx0kSb2pq0nW9Wq1Wq9V4fH3LlpFyqcpx3EZjGEmSQFcZo6tUqqiqyjfEnTt3JlJJi8WEINjE1MzQyLaFxcV0gQuG/HsP7j975oLbFQgGg9dvXIjF1uxGJ45gFhP24osvHj50pM5Kv33uhWP3fWDn9sPT09cVTd66bfjsySsdvdu3BIMKgSIGBkBOWcxduPyG0a7lytFEOhcKdBaLebOZHtrUu7o8d+qd4zimW01GTeEz6dwHP/jwywuLKARa29tqbMVic0uyiKAYjGKIpoqiSJlpigCqwNoYZnxuLtjajkHAYmPeOfEyV67iALS0d41dTwrFupGxHji4A9LhbCr/+qvHUQjQhKWQTUmSmsvlEFwONgege+8/FIuvbugqVVU31pg3bvMbBbSKouA4jiCIIAi5XCYY9NsdNqvVWsgX19bWdB0qFWtDQ5uMRnM8HrdYTFevXfIHXPfedydBwhiGVSq1VDKbSuYaDUEUNJqmFUXBcZRlq2YL02jUTWbKZDKVykWT0RwI+jm2nkis+Xw+XddrtVo2mzVS9G233VEqlYrFEsdxiwvLMIz6/X6KYgwGg6zJmqaVSqW1tbVisXjPPfd4vd7lpdVanV1ZWUFRNBqN+nw+u91utVo5jmNZTlU0npfrbENVNa/Xn0wmJUlyuRzlcknTNASFJFHZkDLtHa2z01NGo3FgYEAQBF7gisViT3ffhrfEcXwqlcrn8xaLDcMwFMFSqRTHCyazmSAxXdeMDGUwGBAE0XUdx0iWZW0WG0VRuq5ns9lsLmOz2QAEzc7ODgwM9PT0vPTSyxaLpVarUxTlsLvq9frGCZKiKAiC6lzNZrPJkloul8PhcD6ft9isDMNcvXo1EAik0+lIJIIb8A251mg07HY7w5jW4gmXw0FgKEWTJI4lk+lKla03eKcnCOMGnCBZTrznvvtnpmfz+TyKU5/94p+/+tobLpfj4KH9J0+8Zbeal5cWLSajy2H7t3/9UaPR2DQ0XGP5ekMc2bYn1NIST2d/9sMfIrShvaX58P79M1OT5XLV7XaHm5tyhQJpwG0206m3j995x+G56bFrV66SJH3s6H3ZYlmUNANlghB8emZOVSQCgffv3tnb0dLf3dnWEsRgnaEIXdXe705GIRiDIQTWgSaJIo5h5UIxk04uLywSBOF0Oqr1aqlcGBoaWplbNZnMbrc3XyiQNNXSGhkdH4NRaGDzsA6Tq7G0gjBVDl5azds8Lfl8dWZmZn5xzmKxCLK0ddsIipOVKusPhkoVlmFMEIzquq5BG98FFMMwVQc8z6Moqqjvc0pRAocgXVf+YzgIIB3AOoAA0CFtYyvwP0DYAGgA0mBdkxURhWEEggichHQYaJCmwtlcuq2rOZOcPfXyv+/e3OYwwV6vmzB5Yut1k629xupWk9VmIVYXr8zOXScItH/zQJFlJ2eWg56OuenU4cMPJHL5i9cu3n3vXRLHWmjCAPhLZ97cs6vn9OnTO/fcsX33oU9+9rMj27ZU8vlcKmo1ww/df1tz2Pahhx/o7xno6uz3eFpWoqmF+ehttx3L5yqLy1OXL7z+wgtPnTpxYi0ebWtru379utlid7pCJlMAxS2KiiZSqUIx5fM7+3u7Ll+9EQp2DAz0Xbz4ltdvSqVWPU4XpGGXLt6gCNvtdxzl2FoilVhPRI/cfvBb3/5HjCAdTn93Vx8KoN8+98zWTX2FQoUm3cfu/VCouSMaX/35Uz++/cj+Pbt3PvWrfz+wf8vSwmwqkSmXi9HY4uc/94edHT0XLly6efPm0Ka+UNj9b//249Hx7L/881+xrPwXf/HNUJPz81/4o+jKws2b1yuVWktre//AUDqdVnXt7XdO3XP0LrOFXlyYb2kOet32TDphoimSwJaWVnbv2js+PmkymcOh5jfffBOCIBRHwiE/BOsWi7FQzLW3t6ZSiUwmQxKEzWbr7xtcX0/rAMpmioIgkQZq1649uULpzJlz+/fv93q9Vy5esVisiqJUyrVqpeH0eAEAKytLOIlGWsOZQrKjOwIgqVor1GqlgcH+69evKopitVpvXB+v1tXt2/bsGN4ZiycdrmC5Lrl8zZWa+OLzbzT5mwbau4AsGygExYHRyggSy9XKDEUDHUEIJpWpshIUjAwKgGYVTNQJRcc1AMEAaJqK6BoMA+3/ILD+D33PG9shOqz/Zzbr/cE3DGuygmKIpmmQDhAM1hQVgnVI14w02WDLJAHjkJZPryeiSyGf22xiFEEwMWQqtUbRBIJCuVy6rSVsNmBT42MOlzsUbIqtrbm93kQiASFwIpGIxWLDw1sZ2qSqOkObS6WKokip3HogEDLSjmQqHw5FYATAsIYTUIOr1jl2fnohEAhYLSa/13X23Lua2tizb0s8HjeQlkikt86pxVKVJKlSqYDhgDJgolCTRA5SVSPNkBje1tlptFrePH7CYjYjCBLyB6anpz0u98YqVVNLc7lcrtfrx+69l+cbOEZKigwjGIGjQAe6IsxPT7/y6ktBX0gQBEXT0qmsw+H4oz/+43fefO3Z55657fChRDpWrKQj7W1Gk11WoSeffHbnrr1Hj9598uRJGNK3bdtWq1VXVlaj0ej+A4eC4ch3v/cv0/OLH/vYIwakylBGFAk3tw2vxpOiVOvrtp577810IoZAoMZWj9555NqFcxfOnT946E6aNooiT9MGGIIWFuZOvnXy0KFDHo9nYGCgIQrz87MYhozeulllSxRFBf2Bzvb26enp/v5+q9UqSZLdbocgaGMUk01nKpVKT09POp32+Twsy2kasFkdAECJRMLv9SVTCYOBKBbzJjMtyXWjmYFgbT2ZaG9vjcbXY2vxvoFNhXKJlwSPx2M0mn773Itf/vyf8ZxQKBTWE1Fd5y02pt5g86Wy2eycnYt77K2+QMtifN5mxXs6HHbaEHa1zy3GQ53dp69cFoC+Z9+hidFJVamUKtO3Jq/39e31envYCqQA44GjD7326lt2gnrl6ae1YtmAIwYL/djjH5qdmrSYaRyDhUa1JeyRZZmkjBzHIwDxB9x1rrz78O2FGvGpL/3tp7749WQ+b7JCZ0+/4bUxtIEmCcfxN946sndk/MaVZCL2yCOPLEXXnn3qKU9TSy6VC3p8lWL29tsOePyWnz/94wOHd8OqJm/Q230+X0tLCwBgQ2lt4Do3SBiVSqVarYqiaDSaIQhiWbZard5x5+3DWzbzPJfNJa9dvzw+PmqzmSuVst1unZ5euHXr5vLyos1u8vk8BgqnKBKCIBzH1+IJWVL5hqzrUKVSoyhqA4uw8UM8HheEuj/gttqMFiuDoHp3T3u4KXj58sVMJpVMJrLZjMNp83rdJpNJ19V4PMrWOEEQ8rmi3W5vCrfcvHFLFOSN/cR9+/ZtjDU37m2rq6s4TkqiLAgSTRlxnIBhdC2eUGTN5w2gKE6SBpIkCdywce602Wx8Q2QYU39/fy6XE0UxEokgCHLr1q1CoaAomq5Da2sJI2MplyrFQgWCsLb27lCwaeOfxvM8RVEbuTSz2cxxXDKZXFhYmJmZicViTpejqalp43Ry6NAhmqafffbZjbz/hz70oUceeSQejyMIQpLkhlrCMAxBkA3wFUVRxWIRwzBVVTdGohzHdXZ2Wq3WlpYWk8mEYVgwGGRZtlQq7NmxvVFnJUkSRTGbK5ltdsxA9w9tBSihANhodRRK5d8++xwGQb0dHR2tTb/+5U/ERuXyhXeX5icIHLC1cnI9YWbMUxPT+/cdhCBoLRFfXl6+8+hdmWzut7976fEPP/GBxz/SHG4JBYLLS3Oq1MBgJb46+/ZbL5eL67n0amxl1mGj/V5zT2fzH33u093d3flyRQfw57/wpd7+/rW1WFPYjwJd5rkL750s51Kwyl85f/rW1YtrK/N8vUQypAZURZUUTW4InA50giAgGLa5nBRtFmWdpow8L/jcvnCoOZlIx1PJE++empydqdZZmqbzuYzf7XRZrAwKZWOLqCa4jHjIaRKr6b//iy/96F++Wa+XnvjI448+9uCxY3fhOE7ThuaWsA5DNoe9LvAkg6sQUAFksZs1CBYVVZE1E2PGENxAkAxFYxgCaaokNP7nxlywQRCFAQRDGgLJCKTC7yffAdBRDaAGyspLEIAZRSdKrFzhVEFFra5AmRV4UT935uodR47ROHXz6pV333rVxKgYUrKbhHJu8dqF9/ze9mBosHNwdzxbJxnX3Xc/BGBU0ZVXXnt18/DAvfff4/TaIFSUlKrX7RzetOX8metzM8sv/O75d945Hg643nz1RY/T1BRyI0B/6cXX3jl19cDBB+649/Gtew5PLy+wYvnsxbcuXT65a/smkWUHe/oW5+bdLgeKwsV80u2xbNnaKUillZUFh8NNUa6+vm2BYATByLdOnR0c2nb33Q9JCpJM1+bmUj5PlyjiOG7iGnK5Vi6UMvlSFiPhUFPQwNAtrR11TnziY58IhpsPHLwLw8wfevSjn/v850+9d9xAq1OzF//xO3/xsY8/arUZR2+O9fcOrqxEV1dXE4m1fD73uf/xqc2bevP55IVz737j639LovjS/MIff/nLTz/5TVkW/+qvvvmt7/zNyPYdzzz9HIqQfT2Df/zlP0FRHGjg7LmLJ946ZbPa0+ksiuKf/uSnEQTJZbL1et1kNMqytGf3tmDQOTzcq2oCYzQ0BK63v2/vgf3zi0ulcnV5JUYZGFGUZVE5uP+QxWxrbW31eDwrKyvFfGn37r333/cgz4sXL15878y7RpMhlV4bHb2xtrY2dmvCbLLv3nWAIOjtW7f73cGW5vZQMKJrGKST2XRlcnzB4wqbjK5XXznudvlUBfzyF6+MbN82MjJss5kXF+YqhSoJaAtpBxJeK/EOh3v7zl25ciEYCcqqCCO6LPNWiwmD9WqlIPB1TRECPrfbZeca1Uq1COkyDHQY0SAYQBBAYQRDUAT5f6Sv/rffIP/LE/7jgnWwgfDVFBmGAYpAmq4QCAAiW87GVb5sIvT02qImsq3NPiOF5dJrDIVyXHVDoNlsNoqi5xbmBbHR0RlhGBJGFK/PUS7mAkGvz+vyeJ1Hj96lKJKu6x63Px5P2m0uQVAozFDMFXLp/MiWHTabHYKgbC4dW1+5fO3iWiLe1tMmyMLaehLA2ODAJpPZPnrjlsvhBJqeXE/IIs/VqwisGii0wddEqS5JDRzHUBxfjcb+7hvfbgq3siyXz+dpmvZ6vY1Go7+/nyRJo9Go6/q5M2ffPfXO7OwsV6sZSAKBgcFAEDharzdURYFQVJblQqGQzWaTyWQul6NpetOmYSBJO3fuam1tnZubkyRp776dDqcJx8DX/+YvPW57V0fL2OhVAwH73W6Z5y+fv4BAcFdnz43rY3/z19+YHJ/+86/8scfp+sfv/jBVaMgI/utnfz07e9Nk1Dg25bDhkCpiCBgeGqyUqgP9m/cfuL2ppcNqdzWFI8VimWGogwf3//BH/3zg4G6H03j12rlf/PJfL146E42tbt8+snP7jtuOHKJIslKpwDA8MzNTLpcbjcbo6GgmkykWi7FYDIbh3t5ej8ej6/qGh2e1Wmu1WiwWlSSpUqmgCGYyWbxeryiKHnfA4XDVWT4UbLpxfaypqaWjrRMBEFDBof0HKYZ56eVXH3jwoYWFhVyu4HZ7oyurFotpNbpst5ldLpsMtN7+vnQ6ffr0O8nUWnR9qc6VYUQuFBIULp8+9VsKrdcK8dTazMzkhXwuylDMBx/6aHfPyOJiYt++2yGATk9Pt7Y2Dw8P8lyNF1inyybL0srqao2r1Rt1s9VEm2hekiAUhRDUZLY2RIHEMRSWKVhWGmmltr42f63VRwvF6FCntz1gJgC/nlgd2rqpZ2Dz8krS5fTruk6Q0MjeEQLXt+/YhCJqlS01+GqpnG9paVldiaH5fL67u1tRlEql4nQ6CYIolUoAAHljiU6WLRZLIV9qcAKGYQ6nTZIEHMcXFxfX1mI9PT1mC7N3366lxeWFxVkUAzabDYK1e++9zem2hMP+aDT6/PPP+33h9raeXK4kCjIEwRiGO53OfCHTaNQEQdB0GIZhm90aj8VRDLFEgooioygyPDyCIEi5XD596l2aIQgSMxgIQRDsdjtJkpSBaXAcgiCLi4uBQABBMElUyuVqc3NzNpsvFsursWihUDIYaKfTDcNwoyHgOBmLxUxGazDoSSbSoiiqCqQo2kYEXpJlTdOMRuPG2bHRaOg68Hq9ksjLsjw0NDQ+Pr66ErNZHankdCaTaTQEAGCH3cnzosvlq1QquWzB4YIMBoOk0LIi8nyjUCioqsxxbL1ekwRZ1xSuIfn8bRtDPU1TcByvsRWPx2OzOmw229TUNEVR0WgUgiCaMWi6UmM5iiZRDK7WyhvQUZIgBEHYeF8wDFNlBUaRUqkUbgkPjwyfOXMGgiCHw8ayLIYhxWIxGo1aLBaDwSDKisXhAhAytLW9JdJ+/daEzeGWBfGB+x5Ir6+vr6wUSNzhdEMIMXbrGmlAbly/oOt6vdbYuXP7xK0JgedVmScIIhQOptO3qtWqoihGo/n73/uhwUCFfQEKR/0upywYG3X2+o0ohaHF1HK1WrZYzXa7+c1XfmeiSH+wBYLhCsvVG9KLL796/wc+8N57ZybHxg8f3CdUy+uri4uzk1/98h8cf2V14tbY+A0FRdGmto57Hn4YAE1WRQNJCIpIoqQoCDBAJiemi8UyiuINthZdjYcjYUFUCJoCGP76WydIkrJbrDRFmhn6Aw/cB0H44tR0/6bhWiG1lq4du213a6RFVPHXTp0nCHx+fomkKa/XXazWdAhwjQZjspI0U2YFCIIwgsgUKpSRUQQRUXVNVlRJ1CCgaygEaQiCQDCm69rGGHBDXWkAQmAI6BACNAAQoEEahMIA1iAAdEiH9EqVs9vdHN+QBR6jcKDpOqIpmgjrUntz81O/eGXseryrdVethgoQz0sNSU/kUsXOpoEL79xicCeK+4wWnyPQUa1VFhZTPC/39PS9/dbVn/70N1/4yqPnrlyBQTUcCVVrhVq5ks9Uv/LFv3rw/gcOHbq3O7Lptv1Hs+mF8++8sX1kEwyjimoNhEbOnl+47U5f3/Cml1945rY7di4uXofA47DGOdzWudmZQjYnSlx7a5Oo1iWl+O6Zl3fveqh/qDORFPOF0tkL77jc9v37jly5Pnbxyq1EIuWy27bv2FNny7TRuLw62z/Uk86sp/JLly9cPXj4NhQnFxZjs7OrH3j4EbPd6guGp0ZX/vJr/4Dh6LkLb/UMhi7deK25re22Y1t37t70zJPPFXMcQ2Gjo+e+/jd//uQvnyqW0rfGrk5MXNk6vO3PvvKl2alJiRcO7ttvsppyxYLF5gqGLLquf+CBD/7ud78rFUrBYCAeT2zdsp1hTIcOHVleXl6NxxjG2OCE1ZVYf99gbGUOQKokSW6Xg6GhUjFus1sr1WyNLdxx55HV2Hoz09LV01so5P3+IN+oZzOFW6NTDqubq/ESL7z84ot2u71UZG/dGksmstl8LpPPYBiydevWbDbtcQc6urs62ruX56O8Q+xoa/nFL34CQcjA0OZUJm00GpuburPZZDjY7bCFf/fbVzs6W1HYHA513nc3Ndi3GTfip0+d7wj0wYK0vpgz0O7kWh43mW47fM/C8iyOw5VGaT0Tv/POgxMTY6lkw8YwGEwgCMrWOFERSIu7VCpQ9kCDr+s4pMMGHcA6ABAMdE3TFA3A6H+03/zfr/e7CCEIAOj3Ti0MAIDB++wGBIaBpquKgmMY0HRJEGmEgBTBYkDmpqamruc62po9LqvFxEhig6+jAJIBpFqtZozEytVquVY10TTPc8V8imsILrdd06SFxamQ3MIwjKJIs3PTXk8gm803hTs2DW2+evmG0Wj0h70EQSyvrl2/cnnr9q00g9EiipLmHrI7ny8WC5XmUFtsdfm53/12oL9r+46RxfmJWrkmysBkRkulgiDWK1XY43VmMqurq4nhTQMDff3XrtwYHBz+0ENPrMVT77x3Op1KHbvj9vHx8empKZqm+7p7KqWCIAg8x5I4mkknc9l0yBBCMEKWJABhDENpigqA3r9p4FjpLkmQm5si/mCQNtsAhABNoRhGkTVZVrUGX6uWOYn73nd/+Pjjj/f3D518+7TFYr3j9rtWl6NvvPY6DMP5TL5Sa1hs7kqZ+8Lnv0JjhuOnjvdv2d8ysDWTLnvDzp7WsJnSX3nhtw02197W2tPVbbe73nj9OAzjuoasr2UYhlEIGAAwOTnp9jiERi0Y9Asiu3P3cGtb+NKly3arkWGoBl+LRqOHDx1enF9yOz2tra1vnzwpSdKuXbs4jmtwAkVROGHAcPLS5ascx5nM1vVEvC3SThrwfD7vdrunpqa2bNnS2dm5sDCnFrLJZDoQ8hsZq9fjOX7i1OAmXRW1H//7k4dv266pytLCwgMfuK9aqTtcXqDpDjfjDVpGxy709nex9TKK4bCseX0ueBBn69WxpZuUmapxuVxegBtJXYUxvS5zEKbo0dmlmbGx3bt3I6qTQppXksV0tnH12pQkQ8VyeWRkJLO4VK5krQhqoLBspYGgEGEgVaBrQJVVzWh0FPNFHVY4rkoSWI0tW40UW05RMPz5zzwQzSxP31ySZLa/u3t5cmk9UcTdYYOR+cWvnj546LZ7jh1cWZ7Jz6wlEguqqiUSNTNtvO3I9oZQnDh/BcLQ7t4e2GRiANAQBFIUKRqNbtDPN0wsBEFKxYrASxtgDxiG2RrH86KuI50dXU6nm2XZrVu3Hjy4/7HHP9Tb19kSCZcrBYoirTYzZaBnZubeeP14W2uXwUDTlFEQhEajYbPZ8vn8RmBIkqRarY7jJAyjDY63WCwEQcRj6yiKpVLpV1559fTp927eHEVRNJ3O3rp1K1cstLQ0of8/vv47SpLjuhKHX0SkL+/be29musd7DICBBwnQgQ4UrUgZrsxypZVWWtmV9FvtSruiKJIiRe8EGjiChMdgvLc93T3tfXlflT4z4vujBiCl1fny1KmTXd2nOisrM+LGfffdK/Jzc3NTt25cuXpVlsW2lhbXZW1tbV6v3+/33759O58v6LqRy+RmZ25LghTwBzHgUDAcCUUIFkzTFgW5VqunUplqtdrZ2WkYRi6Xa9SPOY5XFGV1dVUUxUDAXyjmGsXKxcVFn88HAPF4PBwONzc3NwIBASCRSDTK8MPDw6VSqViulEqVcrkcCARs25YkhVJgDAmSmEg0i6JICOno6Gg0PBqGUa3Uf/bCi6+88ipj0NzcahjW9Ws3l5dWh4aGGg6rtVqtWCwWCgVFUURRNAyDUqrIciwWK5fL0Wi0tbnl2LF7ZFne3NwMBoOAUbFcAUzWNpKyx5srlVO5QqGsR+Lt+bKdzKm5oh5r7T555uLI6HaXka7u3oGBgXgiaur1cjmbSa/xHCPMuXT+tFopnz55/Aff/WapmGWuGYwEW1oS4+Ojjzzy0LPP/KS5qSkWiebzRULI0XvuFgThi1/6x3NnT9lWPRb2EWYbWiUaC2BMqWsP9/cKGN26dsNUDVM39Lr69NPPfOEfv3j07vuCkejGZhJjqNUqu/fsBAIcDxhcjiCMYX5+fmZqqjGaU5dJnGSZpiRJGONMNiUryszMrZvTN1fW106cOLGysuIL+D/05Aff9Z53d/d2DY+N3v/gA81trWtrq+VsyuPx5DLZ5cVFjsNNTSBJwhsn3vjpz59/+dWXGm0Ea2urCKhjmZFwsFavSCIhCDieIAaKomAGoig2EjYEQRA5nlIHMXBdFyhDDP49h3XHc4sDxiMQEXAIOGA8QxgACaKiGxZ1gSCOwzxBnGPZmGHbMMGF+bmVjWSpWEFYTIxsP1qo0Od/9pri87Z3tz78yAOlciEUCfvDkaef/9lLL78yODTc2tKlCJ6//qs/vn713PHXT/a0BjmnUMnN7Zzo1rVKpayXi+b//j//NHX1elsk7ueFzZWlvbt3vO9978+mS50dY7v3PtDRvX1+MX385IV9hw4rPq9j2d/++tcvX7gYDUUxIvv27fvMZz7j9XrHxsYAkZa21offef/c/M1vfutLFy6eGBruT6c3M5lkW2vkz//sD8ZGu1taYzzB2Uw+Go1v3759eKR/fNuQoVc+9OH3MddcmL+VzWx1dLRfuHD+4P59/+fv/v5HP/phc3OT47qSJJZr2WR6YSs57/eRN157MZtJB33ero7OXDpz7erVRx59aHNt8/lnX5m/vZhPF1dX10+fOnXsvntPnzp78uTpQqFSqaif/MRnXnrptStXru7bs69QLNfrajFfWppf4Hm+o6390F1HDh4+NDI28di7ntBMN5OtdPeNPfroexdWNzEvenxBSunli+c3N9ZqtdqVaze6ewZWV5Ky4m3v7FhaW93K5uKtHfuOHL05Ne8PRq5cm/rAkx8eHBxUvKJpatsnRh5/1yMfev8TDz/88P333z8wMCTLHkYhmUxzolCsFN44/UZbV2u8OR4MBkvFqij7L126EY23ZzK1z//DN1xLEbnIyz87derExYXFtdvzc0tLC4Ggr1zV4k3tLuVsF/f3D7Q1t2UymYDP39La3tTW4SCYmp0xHRUTp1wrS5IgCIKiKMGQ39I1jyxx4MoS55GITBAHlDCXQ8Dx+C0Gi/7S8/+/jSKKUANescblzdCdaGeARietTR0DqEEd3TZq1NFCfnFlftorc7smx8dGhxYXF1dWVq5dn/IHI4FIQlD8xboBRAGiyN5Id98ow7IoBwPBiGE6qVSmt3ewv2+wp7uvkM/ee/fR7q7OsbGRdDr57HPPcDzs37szFo1Uinlqa4Xsxrkzry7N35QEMNVKLpsaHx3xe32Z1NahQ4cOHTioadqtW7duTc34/WGfL3DixPGFlfkDB/dSWytltzqa4xOjw5vrG6+++qrX633ig+8PRIP/+OUvdHZ39fT2vvL6azMzM7wgBIPBQDi0sLBgGEYjwIPn+fn5eSIIlq7zgsDxxLQczBHHcR2X3v3AQw+847GB8TFPwA+M2oYOgIAXd+7cFQpHB4fGLJu98vLrhw/dPbF9O2J0dGQAU2d54XY+m6yWi7FYrFgpHz5y9Mat6Q88+ZHJ3Xt++JPneCnwvic+vbJWEoRgorkVE7h86Xy9Vp7Yvs2vyEGv7wff/m42lfX6fGPbt5XypfRWGvNcuVaNxiOyLCqKdPHCWYGj1UquuTn867/xqSN3H8YYF7PlMycuPP2T5ze3UidOnv7Zz186dOgIL8mrG5tTM9OpbKaua41wbr/fPz4+7rpuW2vH8vLy1atXQ6GQ3+8fHBq4NT01NzeXTKeu37gRjkYKhQJgVK7Vq3X11Kkz8eaWQEi0KVtYWCAc8ngUQcSLS7Op7FpVz3X1tnT0tAGBXLmIORII+65cP4+I3tkdwUQTBWRZVk01dcfpHx56xzsfl2W5u6vrpZ+/6PXI4+PbTZXdvL5wYN+xQr7G83xba2J5fkriXMusua7T1NpSV9VqvaaqtVgs4vHIjQKdZbkA2O8LCoQIAidJUjZXCIQiUzNTf/u//ubGzUvZ3Fa1XLo9PZNc33jfu9/zX3//97/xja/Nzs6Go5EbU9M//dkLxVy+pSkaCnjXltaCYfngoV2Y2M0t0XA4KEkSrlULmfSWWq8QDNFwiDouQbhWqYdDUV0z/f5ArVbDGFNKHccpFouW6eqaVcjXRMGLQCiXalevXp+amkokYhyHt20bUxTpxvWplZU1UfB6PRFTc6sl7fVX36xX66ZuAKNej7Kxvlar1Af6hpviLYhyTbFWnkhN8ebkRjIcjkuif/v4nv7esXJRFzgfL/hHxib2H7xr34H9hXJpeXVJ9io1rR6MBLfSKVVVs+nkjavXlhcWTc1ojjfNz84jikK+iFcJFLNVy2D7dh0a7B8jTKyW1Wwm/9prr2cyGa/Xq2kapY4o8pqmAUC5XG5AJUHkmltiCLuGoaUyScOy/cFQXdPrmhqORjBHOIFXdS0YClGgql5vbo1bjvnKay/ruppOp3meN3THtigDUq1pLgXTckrlaigc8QeCxVJ5eWW1qblFN2xNt3K5PELc4sLqa6++uTC/oql2W1uHadqrK+u5XO7BBx9sb2/t6uoYGOgLhQKUOrquZlNJrywRDMmtDcPUFI+kG6rjWI5j8SLHS6IDyLChrbu/pb2H93h7h8YTbX1Xb6z6Ah2x5iHREzl99vLYxM6nn/9pU2v7N771vdtzi6qu22CF4v6OzuZY1Dc8NLBncufY0PDRAweGB3uoq/KCUyylYvHQhQvnyuXiQG9fcn11duomIciwzKd/+tzEnl2/+du/k8xkLl++zBibmJjo6+/HvNDa2VWra5Wytm1k8uCO/Ua5xjSzu6PzYx/5WHNze0/f4Ec/8emqZnjC0Z6hIdHjBQSqrm1l05vp1PXpqWKlHA5FgSFwgWCeua4oioxSy9AqlZLPL1qOLiq8IHO8yFeq5XI+f/rECcvWjhw93DfUY1CjtadNCCrzq4slrX7pxo1Mpbqayn7tBydfOH7m1JVrxx64/+bM9dW15eefffpLX/xCKZfJJjfVUiEe9JpaReCogBm1DY4CWA5HASHmMMdh1AWGMQeAEcMNERVQ9BbMoggDbQAuxgMVgfEIOIYRYIYQY8jlCABzkWMrnCQ6HG+RAPLxJk9cL2BxdmlOCEiL6a2FZNFCic6euzu672K4fX4lK3il5dTNn73+Xdstt7SFHnn3PR4/P3Nraf72cqmY//pX/uabX/5LpzoX4fNr02+kNy9fv3Fi5+59bd2DXq/31Zefa40rteLa8syN1nj89Jun73/g0W9//0eq4d519IG6DqWSLXDRRx58fzzaXS7pD9z/jolt+4K+6Nmzp7/+9X+JNzdlspVLlxZkKf7t736nrGZCMXT3sZ0+n/zkhz9QqW4oivH9b3++t8N/9PBIJAzxqPj1r/3TzPR1kScTY6MyL144eyYW8Xd1RBIx6eiRibsP7vr1T37yx9///vsef8jnxRg7165dO3Lo8DsffWzq6s31xeWhnj7sWLZZXV64pava5urWt7727d/6T5/rah/ct/vB/t7Jmanl/QcOvfnmm7eXlqLxli//87eef/7V0ZEdE2M7qY1qNXXnzr2pdD6RSKytLi/MTa9vLLe1tezZt++V4yeeeeGVpZXM9//1pyfP3rw2s/rhT3z2ez96aXmj7Au27pjc+/GPfLKQr21uFgkXlJVoJpVfWVlp723r3z584urleHdv78j46QvX6qb94quvERGNjfcPDrchXLt27QylRiwcmZmeT24WZCXQ0dnrUmraOuXs8d3jLu9mS/l0NjM5ubNaUwfHxzv6B5Vg/GMf/83+3kmtiiwN+33xZDaTyqczmUw+VxwaHZeDYTHs7xvrV4IcIlo0JJeLebVqX7l0+8qVWc10iMK5vK1blZbW2PTtG8nseqlacqmpiJwicApG2LZ41yGWrQgKBs4yEGUcIQQhAKCskSiAGEXUBZdh9osHQgzdycexHJ0hhyMIGHWYwxBiPI9Io2XQcmzd6xEQMj0SigUlZlaX56c9sjA0NCBLno31dEtLj9ffMjS2N1m0SxqnhLqburavZ/WNtFbVhY2kzkut8eZxr7/95VfPLS5lKBPXlpJzMwv9Pb2z01OXL541jTqj9uFDew7dtbtc3Uwnbwd88M6HD336k+9uiQqF1FIlvWGVK2FJXr19O7Ox0t4Sy6U3mpoSsVgiFm1pbuqYnVtcXFrazGytp1ZOnX5957bhsCStTd1SGDm8d3+xUOjp6b524/K3v//1bCXLOAjGIsFItG9ouKe/LxaPnz17NhyLNsJFREWWFeXW7VkGwEkyA2AMiMBRBkA4IILtgENdh7rA8Q5QXpYAI0C4s3dgdTNtM/HsxdlKjdz34GMbGxlTM4NeX0dr0/rKolqvIOS6jH7s4x///o9/mGhvDcQiL594c6NYXdwsEBxWuOaQt6eSd9PpquT19/R0Xbl8cXF6fn5qztLYoYN3zS7OnLlwMhT0HTmw3+fztHa2msytm2pbc0tve2duc3Ogu9M0Krdu31hZXzx58uSrr5z81U/8ZiqTr2t6OBrDHH/uwkVMONtxB4dHRFmpqZoLLN7cVFXrm6mkz+9RVRUjThaVRCxRLBQc1x0eHcrk0rqpPfDQg0QUbKAOYh6fV/EpaxuribamXQf3NnW0Xbh4aaC37+SJV+u1PEP1QnkjFPYSSahaDhMU0eOt1uuA7I7OWFuPP1de2z053tvRl4h167a4kq4lq/Z3f/xiuqj9/JVXFlcr733/B3THmNizDfNQq1Yfvu+B82feCHrhvQ8dfvnp75554yV/wJuvVKko6Zrp8Xg0tUoQ4zCxTRsDE0TCHBOYi4EizHFyoKQy4muJd4039066XDRZoDdnt27Mzn37u9+5ee3mRz74oc9+9tdypew//OPnXUZCwcTY8I5f/cRnHn30/tbW5h/++Ic3b93QDHWgvzOTWUMPv2OHZVk8JyqKt1gsiYIsivLi4nJrW/vS0pKiKIIgYIy8Xq9lWeFwxDRthJDr2hgjUeIxpoIg8AI3P3/b61VaW1vz+bzX6w0EAjt27KpWq+ViJZvNVirVrc1UMBiuVusYY1VVdV3fvXu3ogiYgK5r9XrVMDXT1E1Tr9fru3btGxkZ8Xq9hmGsrq7W61Ve5HiBCwQCyeRmqVQxDct13XA4urWetgzDdVgymXzwwYd27dozfWv2/Pnzum4KgmBZdj6f37VrV6PvRjdNr9/n9Xq3tlK2bcuSx+PxbGxsSJLE8/zI6NDW1gbGKJ6IYgyrq8uFQiEcjqqq3tvbixBaWlpQFGX//v3Ly8uOQwEgEW8OBAKpVDoWix0/fqJer1dr6vj49mw2rapqKBRgjFm2EY/HS6VSe3t7pVRudDXKsmyatq7rjLmmaSuyVxAkXTcEQWjED/r9XtPS29raAKjrMkEQZmZmotGooemCIITDYUJIIBDaSm1mMplYIhqJRFKZTGt7myj75uaXMBZ8/uDQ0Mjs7HRyK/fwI+9/9tlXfuXjv9Y/MPjiaz8rlfMPPXzfxYvnXdOqlIpXL56SRWhu8mdyKUDC7r0HHdMxdSMUCNXrdYxRNp9Rdc1hVFa883NLBEsYSZ/+1G/kyvWay/ljkdnpm2G/GPYJPh6feeNV19SS6eTEzh0lrWJaloBJvVjeNTLa0txR1d2zl6/bSDz20DsSnX0vvvRKoVDq7+kwqoVjR/bctW/HSH+LqWm2Xt/a2txMpQLB6K6de4AgcBlwiNo25gkAVEulL33pnzo7Oy9fuRQOh30+D0LEsqyOtvZsPlfT9e7+AcaY1+8J+/3pdJJDOF8onTp7ZXRi39iuu6aXUvNr2en5lWK51NXVZZt2a2vr2TPnW1tbt23bsWPP7nyp4lAQJFk3beoiRfG6Lms09fy7oskdsoqxf/dKQ5hCKbpj04ARRYyCC0AZcxlQgjABTCh2LAYURCIjDkxL9/uQVdt67eVnP/TB9yVTuaLqDg6NK4pULqYiPra2dLNaSR88uF9z3UK5vLi6Qh1Ps3+sXrPbusJ1PTl3+1wueXOoXXr5Z08/+eFPvPzyNdvtUnzx3/+vn/n9z/1Gc8Dv88pDw30M8GYq7wnGp2bXW9r7eocGFEW8NXVhc31hpLcjv7GFbKqWK7t2b8OcmS0sO64eSyROnDzDS6H27j6OF3btO5hKlQr56qkTp3/1Vz/646e/NdDTkQjHDxzcd+7C2Wi85fVXT3d39wR8ypvHX+3uau9obRvsH3rm2R9t2z7c09f7tW98e8eOA1/4/Nd+67f+8wfe/6Fz58+8/vrL9x47evzNl3p6uya2bf+T//7nTbG2D3/oV3jC/e3/+v9CAaVUKvQPDb73vU/89q//zje+8c0Tbx5vbokEQ57b8zOH7zrynR/84OKlqY/+yq/GYk3Tt2Z1Q33iifeeOv3miy/8dKCn23XdHbt3ZgoF1XYNx21u6Qz4Q/lUXlGU6elby+vL73v/e//5y/8QlNl7H7+/XthKJBJzixtryWK5Yh85csQnsqnpyzq1JnfvPH7yTHtrx2c/8cn15eXnfv60qPCH9u1V1QrByHXdjfVkZ9dgOllSvFGgouU4sVjMsszzF0739nYREd24euPogWP5XGVkbPLC1WuuQPoHB+p1bbhv6OrZS8/+5MeTkyOil1y9feHQ0b2T2wY3NzKdbZOWKecLuih5Xn/91fbOdkGQHYoNDQmCsG37kMsqLhQwM3Jrmxwjo9snU9lSLNaxlS1bLpdo6zNtLl2ox5u7yjWLk7yGzUTJoxk65jEFCoxRxholQIB/I72iCDDDFAAxRhGVBcEwDOQwQRCAcLpt2S4lCDB1g15FrRa1arG5OUTAnr1xLRr0JeKxeqXq9Sn5fD4UCLe0tt2YmpYUj0NxOBZDCC0sLABAT0+3Wq2EfEo84EmtL8oSMvVapVwMhUK2aeh6zbZrCLsI+GyuNDK8fW1zY319ORTwSgR6ujt5nsMYTNP0eDzpbM7vC2xspGRPQJTktvZO27ZX1tdc19XVGofYrl07ktnkwMhwuVa9fvmSRJFWKIUCwbnlRU841NzR5vF4crkcAhIMBlXLcF2XQ5ggbOi6bZseSfZ6PKqqJhKJbC6HMa7rxu//1//q8XgAEcbg7ZQIxCgAYLjTDeM4DkcE6rqYYdM0P/axj1FEM7nsjl3bY5FgMZ/u7Wzfu2fX/NzM1atXZcXX3TPgjzb9+OmfcYr/wYcfl5TA6fMXl1a27rr7/lCgKZ3OC4SLRhXiFp750Zfnbp74yPse8wrSxsZWNNG+uL5qIaOrs319av5Tn/rU3OayauqZXNbWtSAv10v55Mby/kN76m6NKEo43MIcMbNSWVlZJwLWzXo8Ho/H41euXIlEIkePHv3qv/xza2vr2NgIpZQgrOt6cnNjeHj49sxsNp09evQeSilCLFfIeTyeZHorGPLHmmLVapUXeV1X+wYHbty49v3vP/2e9z3a2zewurE+NXUjHAvE4sFcMVsqF5qa4oM9AxQYIvzU9K2WWJMkKVVNjcXDqeTq7Ozsnj0HNjdSjz74+Csvv76RzHzm07/+3HPPraytqpr+u7/7u2fOn3vxxZc/9vGP5/LaI4981DSd42/+vFjK2JaxtLCaiLS9/LPjvV39Ii9uba594mNPErDr9XJTLK5WayPDQ4tz8+FYWNPqzYkYxghxpG94/Mb82l/+/Rf+9G/+r8uIqat/8Ud/MNbVRinVsfKRj38qEgo88/QPF+fmjh4+8PKLL/T1dgoczMxOeRQhEPRWamUAatsuQgy/4x3vuOeee4LBoGEY4XB4cnKSEKLrerVabW9vLxaLDbvL2dnZhmSPUlqv1xvmltFotGGnnkgk9u/fPzo6znHcyMhIPN5Uq6nT07OE8LKsNCVaHZuOjIxls/l6TdU1QxJlvy+wsLCgqnpzU2t3d080Gm9r7QiFIpbluK67uLj4wgsvfOfb33v++ec3NjYQQhzHOY6TSCS6u3sL+WIsFqvV1GKh3NbWhjnB4/eHotGFpZXrN2/Ozs/duDVf09S6rgHG3b2965ub7Z2dwXDYtu1isayquqYaxUJZECRJUnheFEWxra2tVqsFg8GpqanW1lafz9fV1RMOR71eP8dxV65cKRQKHMfJsjw/Pz84ONje3u73+1taWpqbmx3H2djY2LVrF8Y4FAplMqk7jWaO47ouxpjjuO3bt1uWtb6+Xi6XRVHUdd0wDI7DsiwhRC1b042a45iGoeu6ZhhaJpPRdf38+fOFQmltdWN1ZTMeawkFY81t7YKsJDPZhisxL0jbtk/alus6jENcraItzMwnwnHsos3VrddfeuPS+Ru3Z1dSqcr9D77r6WdfOXX+RqXOovHutfW8JAaOv3Fqa3OzraMtEFR0qxJPhCKRkKVrHEaWqc/Nz5QrhfWN1VqtxvO8bbnZTKGlpW3nzp2hcOCrX/1SrpB77IknRF9gcX1jZPvkZqrw42d/OrFz9933Pdjc3Hbp/MVipkBctrW+4Vgmw2xuaTpb3OjojpuuhkXu5Nkz+XJNUHzbJ3Yf2H/0S1/8WjzWAgwQCN5wfHB8x733P7Jrz17gEGMABAEAQwgAA4JCucQw4SUZEc5lUCxXVd2QFA/CBDAv8FLAH9JUQ9fMWrV+6dKVXLYAjBw+dLRW1W7Pzm8b23bfPff+yq/8Smt7RyqXiyTiwyMjT3zg/Rvp5Fe/8fWp6VuSR6HA6obOEGCOGJZuOabsURBCBLHGAwP9dw/EXMTct/ddZDOiu0SjnE6xhpHOIYuAySGHA5uBiQWmUY34OSEi52lNI0wOyqWyZVr43nvvQ9jRjIKksJdff+HG9C1V19LpZGpzsadZ2pw97iav+NT1e7ePeGwnJMvNTXEH0eNnT7928s1gNLqZSr/jHY8eObCrKS7394eOPTBx6dbx8T29mpXr6U5cu3xpaGDYMowDe/a87z0Pzdw6x5xaMZ8ul/RtYwcsU1pcSZVq9Zsz12VFqFaKqlrR9dr8wm3EkVi0+dCBe0PhrtMnbnW2be/p2n7l8q2F+eXxoSGeME0rnj3zRmpr+dqls3cfOdDZ2prP5vbu3udT/KdPnvX7Q6FgbHl5ORIJbB8fuXL53L59OyJh/5/9xR9cvnLG65OfeuqpRLxz7657//Pv/MmRww84tvvhJz+yubWya/d4Z1fbH/zRH/YPDnz7+9859tB9s0vTNtOxwFo6EvMrCy6C93/4yd//w/+2lkremJ0qaaWVjflSNaPWimOjQ3v37H74wYemb84oolfEolfwM4vKWOpq7kqv5caH9+3d+UC1KsWaRj/0kV/zeEMXLl/K5bd8AdzW7otFBbOWu3bhgkj5Rw49lF1M7R4e35i5+Td/9NvV7OJdB/ZhF62tbqysbBSrdc1yugaG7n3gQdW0bk3fphQZqnvijdOuzY4eubuaL/ZHEh984CEtmdq8PWeUSu0tCa1WDPhl26qtr80PD3b//u99ztbdB+59/E//2z+EA/21Mtm1465rV2+trq5WSjnLrL/3iUd37RqbnBgeGeo5emTfsbvviQbjIV9TekOLhfq628damnoWbq/UyqppGB5FsO16KrUkiLasuC6tSLJj6AUChqWXMdgYGEaIAMIIYQbAWKPix1zaeCDKgLpAHeY6yMFuDUu2TwQvM5CjWgIjiuQRFZ/NS3VGsOKPN7Uaperi9avIqEQC0sbGpqD444l2xRPyB8LFchUAM0TSmWxHe5emGv5geN/eAw3NRj6fdywbA0ultzCBTCa3vLBIEOls71IkTyQYDwXC+/fuv3n9BnPYfffct2vXrh17dzrIWU9tUMIK1WK2lEvnkheuXsIi0qz6ytpSRS23drWuri+3d7aGwwG/IjPbcoFl8rkbV68R4Fc3UqB4HdGz/9iDOw4ckXzh+eVkItYZl6P1zbJCpHAgXCpVVFXN5XLVaj0SiZUrNVUzHJcJgiTLnkKhcPXqVddthGcDZoAZEACMGu54dzouOY4DxiilwCFBljhRQIh89jd/1++LGxpLxNsDoch3v/e9jc3Nw0eO3H//sbbOtq997Wujo6P7dh1wLbS+vAUOt2P7HoLF1eRmrCveOpSo2fnzF0+cPXHqviMP79h+oLm9o2+03+U1yY+Hh4drleLIWPT8pZ+EIi4jqu5ociB08uI1zhN58ld/o2K7BuA3z57+2//796+/edxibjKdrZTrBIk8kXXVvuvwve2t3euryXik1dKZa+FcuqzVrIHekaAvWimqoyMTe/YcWFhYmp657fOHA4Gw68Lw8Fg00pRO5R0bdM0aHBwBRhgjk5Pjat0sl2sXLl4bmdg5dXvp5ZMXOgdGe4fHTYcZhqFWyq6qtocT5XTp3JvnZ68tOhqau73ywAMPJeLNCJFyrdrZ093a2nz23OlbM1OLi6uPPf7OQNB/9uyZv/iLPwuFA5pevXbtzNzctWo1296eGBrs+eQnP9rX14Vwo23PkSQJAEzTBMAcERqNYq7rNlTX9XpdURRBEOv1ek9P77333H/q5Lmz5y4zEBDnWdrI6BYrV4p//Td/pumFvfu2T+wY/NZ3vjI80l8s5ZOprXA4eOTIYY/H4/P4mYvVuuk6hHvjjTfa29sVRanVapS6+Xy+kR/c3dMbCATC4XAmk2lE6NRqNU3TQqGwKIqua5fLpbpa9Xoly7J0QwsG/Qih9fX1ra2toaERSunMzMy5s+cRw11dPQC4XK7GYwme51OpjOsyj8dHCCoUSisra5FIiOP4YDCQz+c7Ojp6e7urVa1Wq1mmY5qmYRiSpGiaWi4Xb1y/eejQoUgkcvXq9aN33TM3txCPN/G8uLq61uCiTNMslSrj4wMNjsrrQfV6vVar3bhxQ5blSCRS1/RG62k6nV5dXe3p6fF4PI2on2q12t3TGQyGKuWaYeqnT591HCuRaO7p6RFFsVAoeDyyx+OpVqtnz55tamrxer2XLl2q1Wr9/QNnzpwRBMnv92u62TBYJ4RUq9VG+HQjUtS27VAoRClVVZVSihDhOE7XNZ/f4zqsWq3xvKjrZkOh5fHKuq6Hw+FIOLa2mtS1/PDwqOPiXC7nC3irqsVxcjZfijc1Ly+tZbKZhu/o7OyCLCnlQs3nDcWCUQA8PjLOi17Hdnp6+praBr/9/af+5n/+dWeX9E+f/9bm+vo7H3m3ZZWf+sG/tLUGBNHy+by6bl2+fLW7s0vxSLZtFotmJByTFGV2YbGnt1+UvalUplRRCS8KHnnb5Laf/OQngXBMrdRKhfLo0PDyzM3NZBozRxCE9vZ2w9Ar5WI0GgyG/GWjajGDp0z2R+994K4XX3upc2D77/z+70cCkfmpqUuXLvT09Pn9QCkQnnMcxgAcx5El3nUoxpgxAEZJY5ByWSqZIYQYukUpYMzxvIgxQYiYpqtrpuL1SbxUrdYbkL1UrM4aC4Ig8VJA9ERTW+lC5c2BbbvzmeKTH/zQ+UuXz585O9g3WK1W//xP/vzihcsry6sDgyPxaES3aaVWZ8wVBMlxqFZXJYH7d0v8X2aw4P/pvWLkjv81YpgCNJqtGGOEENd1DMPgJLFUrzguxJqi1aIOOo855Pf5osHI9Stn9hzYjwSfIAerNXVhebkpQANeolbSufW5DHW7+0avL6digYFo2FNSbTko7d25PRFij963++Vnv33z2kx3S0dLLLxr774fPv/zYKuHF5xieSsSvuehhx9cWVoo5HL5zEa+Vm5v9cXjnn996tnt4/vGRieuXjz/P//2H25efbNcTtqOqSjK3EIBCF1d32hq7d25c8+Z0xdrmju+bXc81qyrZjWbCwcCPIdsuxL2e25OXR8b3Xb+4vXrV28ktzIer7R75/ZaOdfb1/H9735j+8Roe8fOhbnFQr4c8kf37L3r9u3be/fu+tnPnysUCt1d/dWK9sbrZ3ZOHmhr7XrhuWf/8i//23e/9w2e54O+wFe+8lVBkavV6p/88R//9KfPV9SiNzgwNTN17333XLl+rVhW9+67Z/vkxOzs7I7d2/CekZOnX9HKxc721vau2OvHT+4+sHttdZPZtshDLZ8Gw6zV9FgioZvaxOSufFUr5jXLFC5fvTUwMFEo6X0DvR09PmMAejv6v3Tthix633j9lKCIQ0NDne9+146xjh//5KnDdz/y6MOPrK6vjW4bz+Vycwvz1fnV3r4RXTdlWW5pbvvOy99997vfHQz5Xnn1p3cfPQjMuXz5aizatv/w4UK5Mr244BCWTab0clnLF5bK1z/5sU+3JD61kc2vLq1fujrb1RGeujY3sW0vQ2IslrAdp1IvVSqVttYuQ697pKBtGeVS1aX27omjjlNH2HCAmibOlfLA+0PRmCh5feEYAxyJRGqagwjHcQgLzDFMry9UV03ABAHCAIwyAIYAAUYCJgwAIUQRYNbIewLGCKUYYw6BAwjzBBAB3VbVuiF4ZNM0ooq8OjMLWml8cMR2NMTjlvboyuq6xxfAHL+6udWIiwmGIxThE2dOBAPh7p7OpbUlj0eJJxJDvR2LU5d1Nbdn94RWr0QioXA4HI/G0pmtuqrnCtmurp5cLjc8PNzd23P8zVe9PjERD4mysHP3xOLiAuGR5Rh9fT0ra6sI0Xwhs2vn3uW1+XI1t2fvBAPTcdSYz3f98sVQV+vS8sLIwGC1XAt4AoQQw3QWl1ZzhcKeg/t7BoY2VjfKy5ttLU31cm1j7nYgEDB1S+AlTCCVyYmS6LpuuVxu1FhCodDC/PyRI0ccx8JY+MW937C8Z3cYLEopRhzH87blYIwfe+yxn/38JVn2TG7fKQrk1vRVhHlfMCTK8vTsrK6Z5bre0d410D+Eie/ytZl//so3Pvjkx/lmaWVjo3ewr14r1Mr1mWvn1m7d/PQnfrW7tekb3/j+rv2jgyPdU/PXJ3fuAofHjrZjW0utni9X87l0MrWRRQluoH+ko2fwy1/9Znd/GyV6b8/gvr13UQOvzi3fe+yueqUaCAfr9XpbW8ubb540DK2np2fnzslCoVCuFG3bjkRCjmPVarXW1taZmRlFUcKRyN79+2ZnZ/OFQiKR4Hm+rquK4vUFvKlUKpnO6roejTU90NF17cb1hfmljo4Ojgij4xOyRwZG2lu7HM3gEJdMFTyS1tbWrlatpkRLoaZm88XHHnt8evqWIIi9vb35fP76javRSHx9fdXn90Sj0a6ujr/5m78qlUrlcimXz/MEZmauIsx5vQQjS9XMcklYWlzQarrAE+q6lm4AZY5NQ4EgIUTTNE3TGtU5Qghzqes4kqwYhtXaGtc0Y3R0MJ2r/vTnr6fTlXuP7DP1ej45J3slyhzKnK995Z8QRsnk5sb6erVcGB0dPnHixNr6SiwWI5g3DadUzHGRSCidToqiHAgEdN3M5XKN4L9UOnXu3FlBEC3LCoVCruuur6818EHDBKGBBD0e0bIswmHDMOr1uijK27ZtC4ejmUwuEAh0d/WIouf5514QBMFx3L6+PkS4UrnagDg+vwcRrBvWqTOnFUVqaWkxLHNwoGdra2tzM+3z+dS6btt2c3NzpVJBBBzH8fv9xWLRdZnPGyiXq16vX5Qlj+0TJYUXJMdFHV3dY+PBXC4nK75wOHz79m2Pz0t4bmNjo729XZSlZDoTCkYikajPFyiVSqlUquH2MT+/2NfXUywWH3744eXl5fn5ucHBwc3NTUEQ1tbWWlpa/H6/qtZSqVQ8HlcU5b777nv11VdrtVogEHj11VcTiQTHCa7rdnV1NYwtbNum1CkWi23tLWNjY9lsdmlpKR6NNWKFLMthzC6XNX/Qy/G841qcwMcTMY/ii0Qia2trgigur6zs3Llb1UwGXCDoS2eKYlXHIl/VGCNyoVL1e73pdGV2Zq6ltSm5ldmzd3ci1ryxsSFwvG0ZsigXi0WO2bbDfMH221PXxiYOvuexx//8v//5H//xH0+O70EuzE7PtraEPvTBj77wwvfvvXfv8uqSZjiYEzOFormp3nP0bsDk2tXrOwdHLST/7Oev3HPv/Q8++p4zZ84AL29mM/MLC9QVz1278dH3vS+XXE9trhy7955yITU3e8vrlUxXUzxC3TCaO+KheHAtubF9x/aA5L11a3llc237rgmHhEq12uVL1w7t3pXqbJ8rJREAxgAEAKG6ocuKzBgQggEBdRnGCAAoMMyRQqkYDEU0w6QMWbYb9Pgcx7EdECSv62Y9it+yXGAkHm/KJLcw5lpa2uqqiTkxm826nF/whHPpjEf2ry2t7pncHfWG/vkLX56cmPjJvz69Z8+eal397te/uW3HzvaOLp7jEWBkuzxgSZIpdf5DXEXQ2wG3vygRuhjZCDFEEcMYEGKYMgYAGChGGJglCpxuWpFg2GG0Vq4TwgBsxccK+dT6ehmhUDFPHORGw52AFpsSTaBvBaIhNbmBHbE1EUM2qRRz+fKs4m9JZkuQNKhbe/Kd77h07o2hztFD23Y9+5N/5ZC4ufrDu+46cn3+2sBo/7E/+L2ZG7dmZuYoI9GQp1pN+7zi/n3jajW3d8/Ezsl9P/rhs66p/+zFn9tGhvDohReev+/Y3Y8/9sT5ixc6O8drmh0Ot5w995N3vvu9sabQ6dOv3XX0SM9g58LCrZlb5yTeUUR8+PBhn8efiLScOH5l1649hWLS71NyhVWRx9FYKNHsu3LlAgXp9MkbI0M7V5ayTYmO23Mz7R0te/ftwEhcnE+lksVfefIjpXL2kUcfnNwx9qMffSccCWKi+Hx+XiF79+790pe+OHXz+sH9u3K5VCq9cfDQkVdeO7Gyljp23+P1ur5nz+7X3vjZ7OyV97zz/rn0ba8nXFQ3ajQPHpMJRkckfOPy1Uw6/enPfvbi1LSvmS+WrbyaXFtKHtl34Ov//O3tIz0Tew+trN1+/tlTj7338WpNf+3k2ebuPkVUaqqRKeci7R23Zi6kTi9MHNx97ea15FZ+x849F85f7uzs7O8bLBQKb7z2WiwS9UoRn+Q9dvcDczOLqlGJRqMnzp2558H7ew7um7oyk1lcP3jg6N4D9/CiIImEM5lr1kMtTc888z2T4emFFV+i7cixe6MeYaiv9/y5i4SnjqUtLi1pej0Wj1fLRZ7wlqnrqtne1lvIl12LP378PM8bHd2tk/uP8JKysprkZB8z6sUq1NK5SLyVYrGuGbLi0yxblMVMISOLXkwBYUwQAkwoMMTuuGABahBaAAwwAmDMxcz1EMNRecYEAtTRTUPDHIqGJIIMht3S1mZr2Nc63J/LZZbWCi6mPX3dwXjs9MWL+/fuxhJXV6vUpnbZ7R/pe/311/fu3722thaOBtV61SWODbbkF7yByPT8zaDf19zR7JE8+VIhnUvHo4EwF+AFoVYvtzTH0rm05ZqBcBQTWquWA36Z5wAjIskCATcSDoTD0WgkoKtFRcAE7GxqfWV9BSzLDIQjkYjPK3A8cIitzM0NDwxznHBrdbazryebzhUzBSKLDKPJPTvAdhe3lsO+UCQUKVUrhPCp1JbPG2KAbZcVy9VQJFaq1EL+wMbqGjDgCKF3XIcZAvR2KDZj7E7cEDCEEOExpfS+B+73eP17dh/w+xRegFRq43//77//3Od+++SJN1xGEcLH7n84Hm87f+4qJoprGv/1c//Z4aTe8bE9iQTnWmY5V8muFniCE4lquXKzUt5/zz2Sh6ULuR07dhQymZXbm4Gg95s/OD840t0Ub12cXtg+vNPvi2Wh+vRTP8oV0m2d7fsOHPzWt7420OPIvCJjoHa9XE2V9UwqlaqorXsPbuc4vLW1VdWyidbw9etXRVHWrNLG7CIvuxat7twzXq6qqqqfvXC6Vqt5PJ6KXmE8czE1qcVZ+tLqkuHqtVptfXNj985dhOe6WtuXVlds3RgbGGSITt28Wq+Wuzs7M8mC1xMoZHP5YkW1bZcgJNGyWvjpCzPA3LGxbYQQjuMYY51d7YVCwTC0e+6559q1K6urW/sO7v6///D3I6Pj7e0dsoTizWFdrawsz4TDERQMywqveASMsWU6hPCCIFgGNgzLI7scx5mmSalDCLFtm+M4jvCGYQmcc/PmrVMnz1Rs5cF3PrGylr330ffcvHju1z798Qv/3/+IxGP/9IV/Xl293T88HPT6q9U6AhLwh9fWNoIBuampibrg8XgNHZAk4kbUcS6XEwRBEIRCMef1Kul0uhHA7DiOoig+n0+W5cnJyWAwGAwGOY5wHJFkwXVtw7BqtVq9XjdN2+v1NjU18Tx/+fLlhkW74zjnz58fGBjo6uqOxWKVSi2dTns8ntHR0TtBMaq6uLhoGNba2sYbb7xh224+n4/FEh6Pp+E71WCMVlfWBV6SJMW2XUL4UDDS1NSysrIGDN2enTtz5lypVEIIBYPBcDj8yCOPjI6O3n333W1tbc3NzYVCwefzBYPBbDY7OzuLEJIkqV6vYgyBQMC2TUJIKBTwer2ZTKZQKJw7d65SqfA8r6pqKBSSZblcLieTScuy8vl8U1NTe3t7Z2fn2tra7t27t23bpihKZ2fn+vp6oya4urpqWZZt26ZptrW1TU5OxuPxfD6vqmpnZyfGeGFhoVarSZLkui7HcTwvmqbZSCuyLKthZ9+QfPX1DRiGdePGlCJ7l5fXmpvaR0YnPb7oVrKsW8jjiSwtbxXL6rH7HnYd1NbZRV2mG0Zvb68gcKFQoK5WFI+4sbGyc+dENBYiyJ2bn7525bKqqk899dTla9cHBofjzS2irCiKcujgYU0z/N4Qj6TmeKvICdFwbGFhaerGlCR4lpc2goHYE+/9iFZ3f/LjF2wL8bx499F787nMaG/HzqEet15qjweH+7pSG6sIUdMxa7WqIAhAmU9SFucXfD5forXl1Llzi0sbmXQpuZXb3Mz6A7HB4a5Spfb0s88c3L93987tpDE4Mcd2dEniHWbDW5oQTO70LzWoeFXVCeGTySTBouuges1Q66bAS2pd0w1bVrz1mgaABV7c2NiiLpimjRDmiBAKRaLhsKUbPMYtiaalxZU3Xj9x+uylSlmrVvSO9u5nnnomkWidnNjd1tqFEU8YpygejhOQi4BhQDzFBBChmDDAb++//YqLcON1BpgBh4DDTADGAxMY8IAEhHgKnG07BBBPCGGOQjAxTVBrAeKGFKslwSmKZmjpXTvGXNspZ/ObK/O97YH2OEdY8fL5NzgOM4RWN7dscIFYw2MdxfKSY2/cuvqSyPL/8Df//dKpk+Fgc13DkVi3xx+nlA32D8TCkRdffLEp0Yx5zhfw7N032TfQUixuLNy+dvPGBZ6zXKuWSi7u3TP2/icerdTSN6cvve+Jx5qa4vO3529cnwEm/uiHz1++dDOTyTU3Nze3xA2ztm1i4OSJV979rodrleL40FhHW7coSDsmd+ZyOV2rDwz2RiIBx9YLxfTddx36nd/5bH9//+lT58bHdloGHuibSCerOyb3H3/j5Pj4+MTEtn379vh83qmpKcMwOE44c+ZMS0vTa6+/Mje3IYnK4MAYdbmQNyjz/K6JyZHBAYJwNBjyKb43XjvumNbYyNj68komuXX81VckQn73t/4TYna5klW16pkLZ4qV4tPP/DgY9CqywKjd1d26lVzlRNrSGkpml9vbYoX8xsnjr+yc3PHBDz557ux1xBSfN/75//vVV195o6uzp1KtbybTe/fu7+nszWWLpmn3DAyXavVnnvtpW1vH5mYyk8zcuDElCdJA30DQ43MMU8BcJpXJZwvFYrGnpycUi4pepaprr584KQf8j73n3bemZ10X8pkyxwRwkKk758+fHx4ZDAR8H/zgBwVerFfqt67f/sqXvhaNRIJ+Xz6bcSxr7669/b1DHa1dmGG9Vi3msoVMUhb5M2+e1moGFsQb09N1067rjqAEkulKrmh2dAz39G4vV+xiQfUoYdtiuVzBdmk8HgeGATAgghDBHMdxPOF5QjjAGCEMCCO484wwAYJdYjPeZdim1AIAQRBkWfSIfLWUm71xKewVm6KhfD4ref3je/cPju+0XdTW1pFINDWapYJ+v1qrgWPl0puhoHdtdVGReVMrO4Yq87iQSy0tz83fnikXC6pWS6fT6XS6Uqm2tLRFo3G/L2jbbqVSffPNk+DSrq6u1ObW+uoas5yrFy8ZdZXZztr84vLcAnGc3GaSGka9XJI5MjEyIhEY6OrqaGnx+iSKLVOreCSysbY0PjaQSW69+fprHIHJifGJifFkelOtV3r6OxIdTSZYXq/X6/EYuo4Z1Ov1RKJZ1QyeFx3KHOo2eu0dhxaLxeWFBWgsBBl929LiFz5hGGOM3w7hwBgrivLQQ/dFwgohwBgcOnTkvU988LU3Tl25PssL/sGhiZMnzz/zzE8DgSBiwFz70YeOjY8OVsrFz//9//7rP/mjl5/90cXjx2OKr14sv/LiSwCwc8duDnNqxdCqpk/09XT2RMLx97z3EyvL5WsXb7/nHU9QiyqCFAmEWxLNn/n0Z48cuFcRAh/70Ke2D29va2ob7O1DruP1ei5fvDA8OHDP0btv3bzh2s7OnZPDw4OL83NDA4Miz/E8Hw2HBwYG1FpdV43WplbGUD5fDoVinZ29kWAsGIgszC57RK8k+g4euGt0aMKnhGtlY2l+vVrSN9bTasW4cfXWC8/8vCWUQDrKrZW0stvdva25ZbhQcnfuOnr3/Q/KPm9zeywWCw0PD4dCEVVVOY4rl4v1ei2TSRMed3R0FMuFdDoty9x/+S//5Yn3fWByctLj8UTC3o2VhXotX6vmE/GIRxZuXL0iCTx1GGIMMSgUSrqqVSolQRAaHpyUUsaYJCkcJ6ysrDQwTyAQwJhsJTP/9KWvxFs6B4Z3YDH84SefHBnZtbaYziQLsWhLtaSPjU1MTuzOZAqxaHMsGm/g6Ww2u7q6rsheSfJyTU1NjXJVJp2zLKetrW1xcdHnCyiKoqqqIAiMsXQ63aivhcORra1NQgghpFItAdBIJOLzeVzq8DxfqdRc102lMq5De3p6OI47dfl0Nlvked7nDbS0tNTr2u3btwcHB0WJlxVR13VJElRV9fk9bW3DiiKFwsF6rRSJREKhQrlc9ng8Ho/PNM1UaiUSC/f09AwPjaZSKdO08/liW2t7tVrf2Np0bGpaWiAYRhhfvzGVzuSLxWJnZ2c8Hj9z7mJvb6du6tV6NZFIUMo4TASRkySppbUpHmuq1SurK+scj0VBdlyrqanJ45Hz+XxzczMDt+HF0KghMsYaict+v//atWutre2hUOjy5cuEEL8/0NXVJUlSJpORZE+9XhdF3nXtZDKpaRomQCltlAh7uronJiZu3ZrJ5XKBQMAwDEXxlKtV27T8wYhpu+VaXcuNZew7AAEAAElEQVRkG56WgGAzmarWNcspDAyNfOwTn/qXr33zxPkrn/zUp9/17seuXLp47crll1786aFDhx56+B1z87e6ezq2tjZzmQzDrm7WHWqaliEFfQWtdvnm7WS6/sAj70u0RF545oeb6fWm5vjPX30mEfOnNhfamgLH7t47fWsrncwEvS1WzfSIHgyuXq77/UGERb1iBNrCj33w/bNzCy6j3/vet+pqxTF0Rp1Xnn+qJRG3itjX3R7ycjUvZ4MdDgctTR/q7Xvlpz+Lx6MCE8++cWHv0UPNYXtuejOf19r6Oudvp5o6rCuX1nyKfyuT+tlPn3/0nn3UBiw4iFocRyygCGEGjXw/ijFuSBw4jnddZuiWbbkbm0mv16d4vYwxwJhwomaYHBE8Hl+pVOA4juM4TdNaW9tNyyFYoJSKoqg7DjAciwR0rX7o6LGLV6Y+8xsPTe46IHCcbdsj47sY4WYWVpq6+gMRT7nm1jQHIcLzPMXgAqII00YCTqN3kAJFgBijABiAIYQBGvtAAWOGWKNNq1E1AACKEKIulUXOrJSjPiW1ML25uvLwgw9pai6fXphZ3AwGcSJiYcjIHMrU0ju39Tz91P8ZGAgM9zbbnfGP/MqTf/Fnfw7EKNj5kpW9eP31js4hymohf0Gr3Az51O3bD6mWcfLijXyhXi6W/vav/uczLzzb0d+6/mLur/7X/4n4fGq93Nwa1IxcOOz1+Hzv2PfI7NJGPruiSESSpGw+u32yrSlhO049l8mWCuXzF7T7H3zAtOi9992XLWQfe88j5WqmWC6KoruyNpve2Hr3O9+5NDt7c3llfNvo7OxcKpMOhRV/kJ+evzIy1nv+/Gm/V1pfS129PC2JvrnZlN/b+u7HHrk1s3Dzxsza2oZlOsdPvLZt29jpUxcbq7hnn3uuXK0Mjd5z4crpzu742LZtBPwb65fGR7rNmnr/0XsunTkzPzW3b9fuaDB+4vhpw6CpZJGZxAXW198t8jTk8b25sFw36YEj99VfPy0L7vCR7cdfe9Mnecu6NTw5Obe8kikVKRaaQoHZ6xccszo40PbQI0cvXz9XU6sT8fHm1pZ0Nnv0yBFT113TQC5JLa/lVje9PFY8wmsvvKYb9UcefOT6tRuBYDQQiNxzzz0nT77Z19u5NL/U1dofCgSuXJwrV7UPPfnhqbkbIDBFUbaWVncMjm6ubaZXl3vb2ixNrRQqb84v9vS2d/UMFsuFclX3+6JnTl3sSvQEPcF0dXnb2Aii7ur6mm27Xl+oWjYZcwr5suRRYuFQOMz0WrVaLe/aORpvjV28cWpoW5+q1fyiRzdsnzcYjoaYw1uq1RRtV3x+w7aoWxnpH7GpXS6rhMgUYcoAAUIYvc24cILwNu9C32JkMaIi2C6zMQMOibIkAUCpUthYX4/FAmMTu0XXdZjjD/mrhsVjajGbx8Sumx2JFp5AqZSWZak9FstkMhrGEqV+jpMwtoAEAyHXcUy1fHj3Po+Mr1+7cOX85V2Te13DnRzbkU4ni9k8Y7alWwOdAxOjgVqtCibjKLd/146l+dmwJ9TZ1Onz+SqpUnt7u+u6y1trarHe3dUbDoeNsurWneHh4YXl2cGhrutTV/qaemdn52ZuL1l9gz7Zf/ddB8r12snTr6/l0xQjl9Wrdbq6dMsjeoJBv1rTFhZXJnftRChHEdQq1WpN5XjRNGm+WJJFATEWicSWFhZ7urqBIPQfSQgAMKWU43kAMG1L4AWCoFKteWSF4wkA9A/0eT3BSsVqbx8cHt5ZLleAiV5PyHXZrt0THo/n+rXzTz39fN4An8/XFQsVkxuz164MD/RHI4lDBw4P9fUklxfPvny8s70tmdqKxMKhWNRh9NLpuY3FGmF2Iri6uZFmTC4VtcGB0euXpoqVYjDk8SqCrtU9siJzksfnb461TY7tnJ9eLGUr0UB8cyVZL+sA0NUysLy4nMsVpq7MJeLxcDiMGVg17tTxq6qqd3Z2Xj59Y2wbbWlpmbuxmtuqnHj1O/fdd1/DTbNUKkU9bXFf+/ee+teBkdGuns6rl6Y1tfr3/+PzzHGT6frwgD9fEl97/Q29Zn3hy0+19Ea2TfZVcpucxK9tpi3L6e7uXFiYYwyFwr5CKd/b13PzxtTiwvLGxlYs0Xzu7AVdN7ZSqeHBIVPXujpaavVSKOBra26qV5yD+w987daPB3plC0xd1zVNUwQMCDNwy+WSJHKN2p2iKKVSaW5urrd/QFGUG9cWDh88suvoO7/11E/37juytLQaCDX93f/9rs/T8ujDgxjrL73y3Lsfe1xXVa2mt7f1lErVaMxXruTqaqm7q6uttfP0ySvhcJx77rnn9u7dW6lUOjs7l5dX5+fnOCIahlbX9FpVlWXFsqxcLheLxRrddi0tzfPz8/6At62tjVKnVqupKvh8vq3NJCZIEISWlpaN9c2NjY16ve7z+eLxpny+WKvVopF4f/9AMOgvlUq1WsW2bUkSCME9vV2ZTMYwDFHka7VaqVgsFEqaprW3dXq9foxTHMc1NbWkUhmE0I4duyRJqVa1aCTm9fovXbrS09tvWdbNmze9Xm8DIBqG4fP5yuWyZVn79++OxaKN2MTOzs4333yzq6Mznd6KRmMbG2uiyPv9flWrdHR0xONx27ar1XIo5BcEHhAVeEHXdcdxWlpagsFgoVAIhUKSJC0sLHi93tXV1aWlpXA4fPPmzWg0hjFOpVKSJIVCoXq9TgihlDZE8S61fT5fOByu1+tTU1O9vb2BQKBerzPGJFlOp/LNba0IiM8bYJTk6jnLdK5fu9na2uq6rsfjefTRvevrSY/i/9a3vpXO5T/ykY8ahnP2zMUD+3cnNzY//ZlfX1mZy+Ysy6WlWr1YLjnAltZW29raB4eHl9dWI9HQ1WvnXYc/cGDi0YfvmZpe/PoPvvl3//D5lY31/Qd2f+oTH3nqB9+8cOr1l146EfJKWhWceoUgjnmortZjsYgieoslvViqe+VgvWK8+uKbH/6VD8ejLa7jpJM55BpNQV9fR8vm+trq4kJTZ6vH77t49YrXF6gX6i+/cmpocCIUCIYioenlhZGhfe1t+k8Wnr7/7ofevHD9Qx/82K4Dh7dShXvvvveEWbfLa5GQj+MBTBMkDoC5wDjggCHcsDMEsCyH57lGFa5BEG5sbdmWa1suAG7IpAzdaiReN4KebNvOZrOyLBPCAWYCIYahuSBIoo9H1LB0rMh9/V3Xr86KPNqzu9+yQNNcw3F9fikUUCzLpY4mSQpzHddlBBGEKGUACAgAA4bf2r9j1ogAAO5MVKjhDASIMoowY4wBBqAIHAwuJwCPTFFwrWqyO+EL0Fhtaz4e8/AeaA0GM4XlI/v3zt6asQz+yfc9eOHcabeS3N4z+pUv/sO+fft+57f+Uzga80fDW5mMIvt1ky6vLHgVMjLYUcqkPv6RD9+ezyyspEdG9ra3t7/84s+feuqFdC4XaWr767/8p29//ZvRWNOuXbHVlempG5cPHz4oCr7Z6TlRCYg8d/v29faOZsuSIyHf3OzNgCfY29ub2Ndy+eqVqanpu+++2zD0WCg4M3vL6/MhxD3z9POPvePx//57/22sf1u1aJQKuiQE5+Y3AdkoKNTqmqrWkpn00MhoqVCemV27+553Pv/ci+FI6/aJ3S+9fCoSjeRymSNHD6fT2XK5un//YY74vvbVf33ogXdvbianbiV5QSkWqx5foLWl/fzZqT/64z98+ec/2j42aKj63UfuvX79esif+OI//fOxBx7kROWNN089+NADt2fnipkcA6teyeqa84EPf8oC6dD+e7KpgsB7d47vnb49u3PP4bmVZUQgncx1deidbd2vvfbmlQtX/+iP/giYMbl9RCHYMAwwnY7W9qWFRcbYgw8+PDt1e25qIRqJe7DvysVz/WN973nisSsXrgp8oGGNfuHchaA/1NbWsbmWcRzn1KlTo6N7JTkwt7igmVrIJ4uiGPHHQr5gLVcTERnbPjo9tfTOhx569qfPm6aVLZUm9uxZXl4mWEIOmrl2e2BgYNfEZF0trK+vd7a1M0za23rrdXdtLR0JN4VCweWV27Zj1Wo1j+KNR0O3pq46ln7i9dcS8fahIUaQtJVKBgKmpeoUi5phYze+tLwajIV0x7Sp6xNlB9sOpZQCAAUHA2ZAGQNmG4zeKW01onAQBgTIJcTmqUuwgMGsVvP1msYwi3g9AkK1Qq6u6x6B9ymyaRo6qNV6HauWAdirSC6yy9mMJXFzqWRfX09dq3pE0aoVVueSzKV9fX2GquVzKaPMRaL+9dUVv9djm6Zrsdszc7du3dy1c5RS2MokDc2enpnN5jIPPnRPuVh55aXXwiF/IBA4d+piqVwYGhqanr4NlNm2G481zU7fDoRCuq6LonDrxi0H2WcvXk6lN42yWamoftm3sbrVloBcsRSMRJK5DCMII/Tmy6/2dHVGYtF6Vb2+dN3QTI4TTp8+bbtuS0c7Q2CaVrlcJgSLvOH1ek1d43k+k0wBx2Hq/pvoobc0BAgBpZRgDAACL+iGLktyIOBj1FHVaiFfKhbLtbrGEBJF78rq1pEjR4ZsO5fJKh5J4MjC/Oza2sq73nF/tKnb5wt4JKSWCuTDH/z+d7+Xzebf9953EWwszd966IGHmUvjiY5oUzxdTFk2cwuV0aG93oAkBpRufyIWS3hCektze9/gpOXagoRMS5NFKRQK5VJZTdWbW5sP3vuIruuVSoUQEg6HS5UypSBw/Dvf14oQmpmZcS1HURSfxwuAJzMFnucjkYhhGIlEwgVm6YblWrlcYceOHa7r3rm2GAuHQr/7h39JRJEXOEUmpq7ptRpCRJK9vOKvMe43PvcXvONKCptP3vyDP/z1XWNdHDg8JqFECGMsy1KtVh8aGcxlC88+91w0mujrHSiW6yMjo+vrW+VytVqpl8vlWzdvcIQNDPSMDA3fnp3F4Mlm80ABXOpRfIFAYKC3r1hMZjJb+XwOELVtm+f54bGx73//u5tr6/ffdy/G2FC1WCT0yY/fM5eqf+hDT9ZqKkcE06abW/nJiV0vvvCTxx+/v7mpzauENje2lhYW9+/dtzA/U6lkI5FIrV70evyZTMbn8wUCPk5V9Vu3ZnzeQLFYDIVChUIBGKnVarwoIcxM02h0C9ZqtUas3vLysuM49XrdcRzXtXmeFwTJMAxZll3X5TlhdWWtUqlEo9GGmFcU+ZGRIcZYLpezbN3v9y0uLvT09PA8n8mkOc67vLy8e/fuYjF/+fLlicnt4VD05s2bzU2tkqRks1mEMELYcZxMNrdjxw4AbJp247ZPJpOdnd2aZpTL5dbWdsehbW3tpmn6fD6McSMyKRaLrq6uyrL8+OPvfOaZZ/x+r+NaGxsb5XLZNA1VrXMcaWlpbmtrNU2zq6tzfX19cWm+ublZVWscJ25uJoPB8MbGxvz8/OHDhzc21hrRN42mA4RQJCwNDQ3VanXbthsVT0mWI5GQpmnlcjkQ9CkeqVjUeJ4PBoO9vb2mblWrVZ/PFwgENjeSmqGbhkNdoqrq8vJauVweHBz0+fyqqpqm5ff7u7t76/W6KIqZTEoUPRic1Oaa4gv+9R994ch9x2zH4gWk1kubW6s7d06Eo5FUJl3M5RLtHZvpnCeYxxwxtFIowCGXNyvJp7/7xYGhHUGRfvZTH/29P/4jryK9/vrxrs5BtaBihzLdePej76xWK8fffDUsBRPx9mw2XSim2tv7FW9zOlO+dGlq565Df/u3n3/i/e9C2P78F/7XUG+nUy0WMnlBkFc21pVwpKm7Y/fB4Mr6Rm+4u167winNLkirG+pDD3x4Ytux//W3f9eaGDm051h71+7Z5Y1j90NVlCUCrqHuGB/vbm8DAEAEGEEIIwfhRv8gAkoBYxAEjlKglGma5lD3wqWLfr+/Uq6Vy9WmppZarebzBXhR0Ay9WMxvbGxEo9FSoZDJZERRFASRIUKw6CKim7S5vUerlzjRUytvekV5Jb9w+/bt9NoNx3EOHDhAAfd3+M36OgUkUKBaCShCDFGgHAaO3Rk2fzH9ADDGMMaNa76xNUoDlDaUw5gCBsAIMcAuQtR1TdtWZQ6YWrt6eUbAKDo6ouUx1XLRJt/ZG1Myoy4Trly6odDqytLstv6u4y+81BptyW/mdVVVRXlpZd4fjCmiv71r4NS5U8fuPzgwkHj25lO3ZtaTSb23a7fsaSqnC6Odu3//v3zu/vvub7t/ePZqLhbcdu99D7/0wg94EjEM5crFpV0793d29Cs+/22y0TfRt7Q8m15fqycijuE2d7WWWGXXnt2nz545de7Uu979bkDOCy/8dMeeA4W85tj47kOPP3Tve7/W9oNnfvjyr3/q0yP9ky4yLlyeur04vf/gvj27Dzz99CuUCcODO3/wgy+0N3edOXN9bGzXl776ld17rzsODdTCtu1yHHr22WfL1cKf/Mn/GBme/OhHP1Op6jenZpaWN7/znR+dPXv1He984OSZ06ZBgVhLqwsCj6nDz88vNTV1XLs229c/7vNFlldXWltbr1y5Uq2rqa3NY/fedenC6e6+wX/+l+8FAgEv9nAuyacKvKgcP3vm4cfeuZZc7+rqVEvm8Z+9IfPi/O2Znp6+ai6dLKR/9uLP15eSOye3E4LKlUJrV5tL6fzi2rVrc8nlTNAT0Mxqc09iYaXwud/7H31t7emtZKlUOfbAsZs3pyq18vDw8J59+xjlXbh97ca1QDBS02uEZzdvbHZ2dvta4i+++Ho0HMzn5jLpouOyZ5/7UVWtI85f0vI2jqm2PTowLAlVD1G9nLS5tmW7VX/Ia1rGzO2FE8fP79hxKOiPmqZ9+tSp5ZXZ93/gXbO3CwB6obimqyWjVg7LsodQRyv6vKEdg82a4a5vzFWqaqK5nRh2awgsPc+BJBLeKBc5kecwA4YBUQSEYYoBAUYEY8B3alsIoYZNA2KOQpht66I/WKvXCGjBiOT1BSilpm0IISXaFBGAIXCaMF+gWsQvhfhmhZP0WhWDvWOkk1GrVGijlPpDPYVCoVZVd40PKJIkCIJj+Yb7Eh6PZDtqwHtMEITkZnZ4aBwxMjjUHY8GGLg7J3dQCg8++KAgcC41LHtfrVZTFCkajQJ16vWaaemO43hln8fjoZTZtmuYJmOM47EgCJgnDrBqsRQTfYrkKVZrnCwqsjdXLHnCoURrMxGFtaUl4QO/1pKIm65tWVZqK0kI4TjBRXDuwoWltdVYvKmq1iMxkTFX1zXTNP1+v2NZyWSyXi57Q364w2W/xfsBbgwIHMe9bUUsiqJLXaAsk94UCOcPeOPx+Nj4dsIDMKAI7tiOMWAMELADB3YBYsAIMAD0i7c/dO9BaIhCkQPIAAzQyETlBWAuIA5cDhi4PNgALgAFkAGwAxgBIHAxMKC0IcG48w+BArA7XDsggO5frBwBAA73jr+9lmQAY78MJuHO0VGA0X9L31EABOALRxvv4wBwYjAQbJwobAMQAIuCJAMG6G7fJsnxxYVsf1dTV1dPJp+2LLO5JRF1YplMxjQdRVH27dv3+vFTA/3DsVji5y++LElSc3Pz7OycV/EGA96WplYAcO3Kh5/8UDHzHQBoaMcRQoy59Xo1EPTX1TLHYVnkNU3L5/OpVOrQoUOd3V26rkseSin9y7/88/3H3r3v7kdT2cpddw3mUslDe3cT2/zON77IcTgQCFQqlVOnTv31//irG9cuZzIpzNkPHHywta0pHI6sr212dPkdh6K77h5uaWlpaWmhlBqGVSgUGUWzs7O2SwVBEAXZMAxdN2zbDofDAKAocrVapcxpmJILAhcKhXw+n2Fouq4zxrxer6qqpmm6rtvW1lYo5iVJsm07Eo5qmlGv19vbO69cuUIIEQShUCjE43GfzzM8PMxxeH5+fnRksKen58yZc7puzM/PB4PB4aHRYik/Mzv7sY9/NJ/PX7x4UZYU23YrlRpjLBAM27a9tLTEGOvo6OQ4rlAoBAKBlZWVvr5eRVEuXDj34IMPrq+vLyws9PR2CRxv23ZnZ+fq6mq5XO3oaKtW6/v377127QZjriQpGEOtVjMMo1Kp+P3+aDRummY4HPZ4PDMztxqFQoxxMBg2TZMjwurqaqFQ9Hq99brGcVwsHm9ublZVtVwub2yuNWwsqtWqLMujo6OHDhx+8cUXVVWdnJw8eeK0JCnpTF6QlFKp9MgjjwwMDJw4cWJzc1NWxHK5GAqFVFVvb293bBAEydDN97z3A9dvzfCipEjy4uJ8e3v7/MIsY25Xd3sw6K/UygihrXTKsUH2eKgLtWqJIJUDVy1rsWhLNl2b2LE/3tKLRc/3f/zjBx55dHFxvlYqT45uT68lf/LUU7/9a5+NtoXOXz59+eK53bt3njl1WtdNw7A9vpiqueDA8K69wyOD2yaGCUf/5V++mFpdPrpnT7Wcr9Zq23dNvHriuC8e6R4aSWayrZHmYqpoVrR6qYox5iSxvbd7ayvVneiq1ExPOMZE+f0fedIwVImn48MdI12+gAxg20BtEAQA4iCEEGAAy7RFkW8wWILAAcDi4vKZs+enp6eTWxm/PxgIhDweD8EcY0yUhHq9+pGPfFiSBY7jZFnK5/Ou6xLCUQCEBYa4uu5gTvR4/RXVYDwne7ha2aqUy+GAv4HSLNdBPMcQpndWowgxAIaBuRwgAIYZ/KK7igFFQAAxjBr74NLGbykCTuJYQzzG7ixkAQAjcC2LuRZBtsRhW9cIgqDX6xi6rVUJ51pYFyTedoiuWxIvEWBtzcFSOWtZFmPItomk+AjhDY01NXWsrhaZCL394fXV24ZaikdaVR1hIVGtWrlktjkSczQjEAgRkasZsLyei8SD1eI6h+seGYk8EUXZFwjW1Don4GBUVrWyY9c9smJpOma8qVmlYsXv91uuoxn66PZt88triUQnIsrGRmZ6aj61uZVPJsN+34E9ewlBnf2tG6lV3aqIsqDIfsMwtpJrg/0DxWLZtRDPKcFgYD05jwiVJCUea+KJWKlVtpIrlmVks3nbYiPDO3XTyWfylUpBM0oerzAy2n/z+rVIJNbW2pzaWq2Wqx1NPbdnlx966JFcLmPammapvMhppsGA1Gsaz/Md7a31askb8FbMuixKar62bWB09uYsZcgG0j8+UlXr6+urHkkM+33VQq6Yy+/ds0tWlIX1JV6U1YrBXBB4vqkl5o8FZufnJNEX9IT0gmZrBhAIN4eWCusd3e2c7rimUatVRseGPD7l4qVzTa1NvX0Dy6tbPm/Y64lQF1JbGwKP69W8PxRWlGi+WFUkjlJLFATbcgOBCCGEYlbTa5JHLJXKEX/UrLlG2fUoCie7wNm2a/ACR4HUaxbBfr8vQghZWr49uXNI1crlSj7gD+mqFQ5HDa0KAB6fD2OuUqlRBoIo2y5iDHhBIDwAgGWD4wLGwHGA8C/5NqF//wwYGtbtjXUEYkAYcAQsFzAByoBSaOQTMgACwDFALjAKjAMT36mSCwhcBzAFkQcE4NiAEDSOxLaB599CEhQQBoYBAFxqcphX67ZHEQHAdYBwb03d7lsIAwFQBwjHHAcRDOACMECNY+LuYACGgVJgDPi3EQIGywHEAcWNEj78Ml6AO28DGAADcwBxb/0I8JOfPLewtOjzB4Fgx3E4jtPqVZ4QRh3L0BzLfM973jM0NuxSl3ACMOY4DiEEYY5S2lhuvQ2wGDDGGFBG8J3VGmWIMgSAKQBjIHDA7vQfA2EMEAVggAi4qPGxXGAUEKFAGhmnHDCzDBxlHMacDMA7FiOEgAs2dV2eEkJs6vLAYZNxFAGHAFHADmDXBQSMIMYzBoRzGXPeOh0NZxxACP3iKnkr3hsoAuYCpv/xpUN/KRjgjr6/8QMHCAGmgFxo1J9dAggBx7k2JZYNxFnMzP/hn/5eLbM1MNAmKGBTQzdUy7Is225r61hd2+xo71lYWvcowbHRiVQqs2ff3rNnT5ummUknezu6fF6lVM7WarW9ew4Clf7pH7+9tpKbGNsLLkptrX/ow++Nx/2lcpa6dsjvszST5/mFpbW6qt599Igs8q7r9g6MLG3l/ttf/p9//PqPeV/8C1/8hmE5D93/AKHO0ux1wuyz54/X6kXE7IH+Hq1e29hcQczJZZP9A10tifg73vGOL3/5K329g4FACO070KcoimmamqZFozEAYBRtbW1xgoiANIiZSCTq8XgQQplMhjHaoLIocxogCWMAgFAo0DA7KJfLgFgkEolEIqVSCYDath2JRHTd7O3tFQWptbX9q1/9aj6fb0Rm+v1+WZYppfv27avVKk2JeC6XMwyzVKzkcjnXdfv7B4NBf02ttrS0nD5zCgA6O7pyuUK9rpWKFU4QwuGw4ziNwyuVSqFQ6ODBg1evXtnY2HjggQcuXjzf1NRkO6bruqLIG5oei8Wampp8Pt/S0kqlUuJ5MRDwFYtlnifBYJhSR1VVRVG8Xu/Vq9cRIjt37jRNc3Z2NhaLCIKQTqcTiUQ4HM1ms5Ko5PP5jY3NcDhsGJaiKB2dnZFIpOFtwcBtRA8lEglVVQ3D4Imwurp637EHVlZWNjY2RFGWZEVV9aamlg996EPf/tZ3r12/MjIywvNEELhgMFitVlOpjGVZ73zn47Mzc4+88zGP15srFjo7O//u7/6uUQzleOzxets7Wiljg4Oj5y9e2rlr35lzF/ftPXTm7CmCjWDAu7605vf6g97o5kaK8Eqpqt73wEOf+73fyucKplqPeEPMYFuLm4Bp21CLw1ulfK6Qz1aKpXAsahpupaqLSoABx0uy1+9xqTkyMlgqpTObyeGuQb2mXrpycXxitGqq2WLWcOxStZYIhr2StyvRUszmGmHhFLO+/iFRCObyNSIrdctq6Wh3mcVcY+e2ZgEAORamFuJ5AAyMYxg5DvDkzsjbGARd10WI3Lx588TJ07qu2xb1eHyOQ03DCkailmVUq5XhkcHH3/EoJkCpa5q63++1LIdh0miQwjy4FFwKjEJdBY4HDgPPA0EgcMBc0HXgBLBZoxHozsCC2R21PXlrpmEIEAPAd/Yx3HluFFsoAGLgYrAAXAQIAWZ3RnLM7oznHA+WBYQDngADoAyoA14OLIsREemmy4CIApgaEAymo3m9kuW44PICAr0CCoZyGVIZzetXbGCCDJJsNzULhZJuUaYEFMZA5IGZIALoVeA5yBXgc3/0RcO2Dx/caZulIwd37NzRqqvgD4FmgDcANQ0wcSSBMOrwHG9rOs/JgIHawACIALYD6Yx+9eb03Pz6xYuXy4VycyIejwazqbSA+A996AOjE6NNrWA6wDDwPKgqeLyAGdgWCDw4NhgmeH3AEACDcs1WRN5xmKw0hGpgWUwQkEuBvNXc4FIgdyZBqul1ReYdSpEjASOEgOMA4igF27ANXhR4LDuU8hhXy1XXsShhnpDfAeoBESjjXAwYNb5I9y1a1LVBIEBthjkElgM8AUDgvj0xAPBgulQQMHMYbrSG2QbIgoawA6AAIAcIAct2BAEAXBfABewCQXdoAqAmlXgMtguEAGmkEjAAIICAAXIabbPgUhcIa0y+BIQ7M33jLTAF5gImwLBpgCCA4wAhgDlwqUkaNXTGU5dhgoA6gBsAgQFCgBosCFAA+pY+yHYbkc9A/t+AnP9QQdQ4HwhsAMSAbwAdApSBg8EFoI4LAJxwx5WEAPAOYACbAccBAgAHADOgLjAXCGGWiUQBGAaEwHUBE0C08WEd1+bu0CkcUNLITQRwALNGrCdQAhgA2QAuIO4O+rtD0CBwXSAEGAL4pWjqBg5w6Z1P17jZMAGgwChgDigCRsBkwElAwLIs5BEwBuIA2BYQzrScL3/lq5ZjS7InVyzJssxx2DZ1nhBJ5AlilqF3dna+64n3bG1tBAJBr88HgKnrIsw1iG30bwPhGTDE4M4XwoACZQjwnZHuLTxCGQBgin/xvSDGELylNwCAt04bBsBgg0rBxsABCK4hcAJYACKmxFWB2WCagDE4jVZtAKCAHEAMoGHTIQBQYBYwGxoj2VsH0ziDbx/PnfuCAbDGjfrWNcTYnQfAL1A5Y8AQAAWGgAE4CKBxwTOgAMwBhwFyARxAGCwGPuX4z3/85R99v7Ozs1QrqlaxuS3W3df94osvmpYzMTFpOyCJnstXZmKxpruOHvvud787NjZmmjoghyeCgPjJ7RPJ1Jrruozi3p6Rr335Xy+cu3nXoftKpbJWr7zr3Y+0t8UKhVQ2lezt6amVa36//+at2/lC4ZFHH4pHI2qt1tbVXTfZb/3+n4EnoTNp557D4UjiM5/8hFYrfvfbX1panCkXC16ffO3KhQ9/+IPXrl5Kbm2Ew0HqWD6ft1Qo3nPPvd/5znc++MEPzs/Pc4ZhmqbV8Bb3er3lUjWfz+u6KQHH81iSJFEUG+4Muq5TSi3LbFiPWqYjCJjxjFKEENM0IxQKqKpaqZY7Ozur1SoAcBxmjBGC1tfXA4HA9PS0pmnRSOzw4YOXLl2pVCocxwFApVLx+Xwej+/KlSvJra1kMhnwh3TdrNfr4XB4ZWXF4/HwIue6bjgUKRaLqqoripLLlkZGRijA7Ozsvn375ufnfT7fk08+WalULl26GIvFJie3T09Pb9s+duvWLds2KaWhUMjQdELI5uZmS0tLQ7TOcTibzbquK8tBVa05jpPP5+v1+qFDR8bHx23b5TguHo+Lojgzc8vn8/X19UmSlE5nBUHo6OjgeX51dU1V1UAgBADnzp07duxYo0lQEKVCoRCLxUzTbHhb1Ov1RCJhWdbq6qrP50MI+fxeRVFUtTI7O71z1yQD17btUqkUj0cJIV6vl+fzkUhifv52R2f72sqcx+9xXefl6SuRoJTN1lNbK4cPH84VC5cunO8fHNrc3EylMsvLqz2dfefPX/LJga2tQjFTkCUhmU6VhMr4+OTGejrKeR5/9N6WMDQHIzyKOBZwAIODAXDBFcDFjO9tBnanYdu2GSc0FlDQWF05LvAcdMY7YKCDMGBuaHRbWyOVjN4Z0gE1WrsdgPGeOzcgBqBgO8AJYLqAeGAAJvXwGAgAdXSeAOIIAAWbAgKEeYLANCxRElyHEoId10EIYQyGYWCMq9WqJHrK5YZhrKSqqq6riqIcOnSI46BUrhCCCUHVap0xZlMGDLkMGOLRnTBmXiAgYGYbdcfCFJBhO4IguLbNg+RaNm0ErCGEGGYIASDMgDYo+F8E3741K/07+yv2VlgbcTBGmBHMMAbc8CEEALcxwNqubroGwQ51XYZEjlfLhiQItu4AJ1AHKkXgMTg2cBJfsB3bAY8M6TSszZXTK1vTN6aA0N7+Ho/fF4n6wxFlda4eSQTD8UC9YpqOLkkCdRjPREXkbi8UvvCFbyLMSaIwN3Nb5NhMYCUeTTTFueSWDbxjUgmQQzggAKZhMVuTJKla14Hxpo4Dfrx2W7189cq5C+d108aE84jeUHfA6xFzuazH4zHqTjpT6rfcxSVdUJDHK+qGw/PEcVCpXPAIHlnyIgBdp9WKpZsaz0mKV6loVDNVWRGr1ZKs8LzI1Wo1r9frONRxHJ7nHct2HKvRdWXZeqFqYcRRW/X5QsVCGWEmShgRShEFw3LsumXZBDhZFAnmXNsUgYjAXK0mChIABpuC6wJChGCCMdiMIAKqjTmB6i4WuAZuAAZOHTACLIBpgslcYK6IXXBNaPh0MJdDsu1gBEAcAAABMbBNYBaxXSLJgAmzXdSYZhAGE8B0gCfAMQQuxwuAOctiPCcAAdcBxoBhoIhyGNu2A9gijKOWgzmhQSFQx3GYQzBPOA4hYACYgKbVFUVkzEEIu45DCOc6DsYYKKA7dyA0RDBOo7WNUYoZB5gnd1iIO9MeazBAjfsUAbC3YA28BV8aUzziOdG1XWAEEOg1XfDwAnMAucBMcAxgANQBRIDxoDbuYRcIBQTg2uCYAAg4DA0WxMFAKbgOUAaEAHXBpSCIHLMBXKAUEA+GC4QHDoOpAocBMLgM3AaxZkHDN53ht6Z5CtQBtzG7N3A0hYb1CwGgDFybqjrmsUkdx7VEhKjjuK4rcgJ2ia07vBSu1LUkdZrHRr2+prqlB3gBKACPq6VqrpDjRdHrC8iy3CAFXGQ3TplDbdN2rly7HIyFBIGfmJikruu6DiGkga7g/9nuEEMuYAQNaPUWpHIbvwWAhv70F+wa3Fmfvd2PQAEobkiMgABgEBDcgWOYBwQgMJ1QDYrpK9//ZoDZMnId6hqWQzEBAJ5SjBAg5CLsEgIAyNEJc+8Yd93p6UYAgDFmjN1ZHLJfCCHYW1I9+tb2i3roWzoKRO84gQFDhGEK2OSAAWDKOOpIrkuY5RCXYIxqltjasllIhRW2Y2I8Wy5upldyhXRdm8nniiNjY47L9uzev7qeopQJvJRKpWRZPnPmVE9vx/btYxtrm+fPn7v/2AOzt6feeOP1++97CGPsunZffw/Hcapa5zmuVqle3Fru7etACPE8bxm6Sohtm36/3zRNVdc8fo8o8gvLi5ZRjSXahrv7u9uih++666Mffnc8Frx44XWzlHnHEx987bXXWpqbv/u973R2tDjUVrXa3Xff/eZrb5ZKFceG5qb2u+++23FsbmR4rJF62AgcZOxOKohlOw2xMADYts0Y8/l8jfIfz/ONrroGNmKMBYN+0zRVVSWE9Pf3B4PBZHJT0+qO43R0tafSW4THnEDK5aooyZeuXJ5bmI9EYlglmmYSThBF2XYoJjzG3ML80t69e5eWlkzTjMebGt8rpdS27XK57DhONBp1HIcxNjAw0Nramkymgv5AcnPLMkzm0tdeeRUhMA0jGo6kU6mO9nbG3B0Tk45j6bpeqZbr1Vo6nd61a1elUrl582YikdB1HSHk8fhM08YYx2KxWCxBKS0Wy729vVeuXJmZmWlqahoaGkokEtVqVVXVQqEQCkVmZmZmpm9HIpHOzk5d1xVFoZR2dXW5rhuNhXmBNGDW1tZW41P09vamttKFQqFhFUEpzebSzS2xcHNscWH16pWLw8MjksAX8zmEkMDzruMsLS40LF4d29rcWNuzZ3epnL52/coD9z8ki1wmlUTUziQ3FK83GgxYqnrrxnVF4DdXV7o6+7va2lLr68WNZH9fezKzJQgEsL24NB0MRLqjLZn1We7AqGmUHI5xokgBAATbdgljAuLNuirKCjNMhBDPi65uE0lW6/WGl4dIwDJ1juMdlzGOpxy4LtiWIfCI57BT14isgGUDJwDBQJltubwoOIbFiRwnUEAIgY2BQ4A5DA6zCoVsyO8TOKlxn2KuoWR3EAJREhqDS6lULpUKPT09lNJcLufajm1aXk8AgDLGbNtmDIXDYU1TAcAw7kAlQRIs22aMCYIADFFALkMIEdehlFqYE1yXMSw11mqI4y2bYizVdYcTJNwoBuK3OKcG8/3Li7r/aPtloMUACHMRZQQogjsL2DviBsZ03UUEE8IzQDzHgQuODR5FNgzLxZTZtmsLtg2OA7IIRs0xbTsQ9aeT8NxP3rx1edovCTwCoOziucuJeLw5Hu8f6o81xaIeBVkQlHkqspqpUyA6dizgfn72+Fphbfv4RLVcZ5bpunRjY8E2R0035A1ywGOH6RyHdV13HEHgsKHZouzDBDs2+H3w/HPTN2/ezGazLmWSItvM5jlkWdWSYzOwLQdhXqrU6oQjHkHkFbday3n9Pkqtak3r6mpSS5DcrOVS9dW1Ld2oRWOxSCTR3KyE45gnPsQgEk0AsrHATNdwkSUooqs5hm14ZI+MvNVq3XE5jL2Us2zHwYSrG7o/GKDIQZgatko4kVIAhGPRWLVUM3QLI1cRKGfXwVA5JIDlgGYCdUDmwDbA1oEh4ERgGFQb4i2YI8y2NrPZufn19HpdLZu2bnsVMdLsaWoLtrUFm2NecKpQr4BhghIgSlQEqZDJxxTJqSaJXcLEBaBAMRgmIA4JGEQMtgUuAhfAYOA4wDMQBI14KiA2T+xnDFwKDAMhcKfgw0DguUYhDIsCACAM1HFcQILIMQqO6wIiggCUgaIoABQhznYcxATAgDH3lnoHGAVKASFMCADDCAEAYWBTYAwcAHAZxcTz1vTN/b8X87+jtwhQRB0OAwC1TZMPigA22CoYtZVvftWnVzls29QwEeKQIKoMY66OTBMcDhgGyqjDYYwxcRyHFySHui7cUSsy5jZWJRTzhOMoNRgCBBx1wXEoIchxDYQBUcQYAcYBACAHUdcxbNd1XdsCRAkhhGCCCKWUEJ4yxFzKEHAchznEXOpQl+dFG4PFuxQosm3iMsIAu1jkvKpOwRNZU42Ow4eDkUnTyvsFHwB1kMsh6g/6jh49OjU9Xa/XA16faZoIQBJFxlzHcRCiXr+fYff06dORWCQSi/b19XM83wActm0LggD/ETl4B0Hd6Yp5a9xgFCH8b/78F7v4LeQDLoANrtug1zEQAA4IMB6QC9SyAWHL4IgKRv7G5/8yXE2F7ZqMHZfDLsE2EjBggQJhCAOjmFk8YggQw+jOcIcaVNlbwxpijSU3AHmLzaJ38ljfPuxf4EhsoV9+5e0VKcacjZhJCQPADATmiq6NwTZcU5Jlit2axvpafHMqf+7Kqfb+oalbsxyPhseG773nwXA0ki+UfvSjp3v7hzHmmlpaqcsOHjzoUn3q1lWepx4vv3fv7lQmDRhZjs0J/K2ZqXMXZ8eH+3x+jz/gZY7NcSSTyfR2dwBFm5ubsVB4dXXdF/ArXn86m21paarXa45jGaZaLmZauvqvXTiZyyRPH3/JqKQzZuab3/zyf/4vn/vpc88DI+96zwempq6/efzFyR3jq8tLt6Znf/dzf/iNr3/75y++4brWb/6nz376M5/kLl26Eo/HeZ5v5Bw3ziPHcT5/0DAMVVVrtZphmDzPy7Ks63q9Xvf7/Qghy7IAmGNTBq6mGYoilctlTdN4gdva2ti1a1d3d/fi4nypWozH450d3fPz88PDw6FgxLJsQZA0TWMUxePxUqlSLlf9fn+lUp2Y3Lm+ujY3NydJiqJwmqobhoEwtLW19PT1rqwsCQLWdb1SqQ0PDzsOvXnzZn//wPLycjKZbGtrSyaTy8vLACwWi+XyGUKI3+8VRXlgYMB2LL/ff/r06eGhkY6OjjNnzjQgmtfrFQRBEKTp6WlBEBKJBKVgWVZbW1upVFpcXBwaGpIkqVar5XK5YDDI8zzP8wCg6/rY2FguWzBNMxyOlEolXdcLhYLP7yeEFAoFSmkymazVag2Prp6enrW1tbGR8WQy2XDAchynra3NH/B0dbfOzs6UUrnl5UVKobu7x7bt1dVVSRIBqKrWenq6Hn/88UwmMzs7297Rdnt2+umf/KS9vV0g2KvIy4sLY9vGBQ5R1yrlM15v0MJmMZcKBCP93V33Hdr/2us/jyXixUo+GPaptTrHPEs3Ln3wngNglUVsgKMBY9i1gZNFwoOLoe6KRADTQgDguMA0Ai4YVQ9PgQHULLBcweMBE3OuAxUbiwIwmxd40C0wbY4BmCIgDIB03ZKbW3iZ03RDkSVGKcIA4Ig8sh2DAXAcxyHkFT2OxVwOUUZ4Ir41yLio8demzUl8Pp/P57MIoc3kVq1WKVeKoihatiHwiiBI1GWUQqVSQ4hRhniJY4aLeb5ROyaEtyyHAgLMATCBcIQjpulQxzYdkxCCAFMAgeNs5koK72iMUpchRIGCi2mDvnprtqF3TBj+/TNjbkPGjhC+U91hLo8whjsW7m8NNkABMMHMdgSeowhsi2GMOAauC9QG3iGIIM2y1aru6kwmsoBEZnCRgJzcNL/3nX9dWUvzkij4eEtTBYEPePlaNVPIbuSyye3jIyJtD/pYsM0PCvHJIeABEGzlrVuXz0dCUjG/LHCirptAUaXklMul1q5QXatzCjjIpYiTPT5EiWO7khw0TewPwrWr1Z/8689z6ZJtWx6vSDhimDXbMYC4DlXlRugH4Frd2EqlHeaCZRIJezw+6nKEkFjU/+Zrl3/67MuL81syH7Es17YtwKittXNs2+jhu/d198mlikVc4AQXubYkKpRS07ARwl6vbOgWok40Gi3ky5woMAdLosexGl5oNUHhDL1GeA4AexRvuaBVywa4WORFj8zJTDv9g6dYJe+VPJV8XuY45BoeATgwnXoFmG2Z1MKi3NxVoNz1jcxyvpKqVCyL88kJmfhc3eQJY8RyXNXnxc0hocUDAR55RClV1p749d/DApQ3l2Qf5BauLF082apwtFoNKSHdsA0ELufaYNqOITFQsCS7kuWyErgsEp+v0A/89h+CYyORA/K2mggIgGs7mOfoWxXSBi/DMOM5AQAc1yZEtB2X5wlGv1AlEowwIbbFCI8ogGMzhBDP35m/WYOWapSlAFNwGUMYgEcC/JKu+d9N5eyXhDMA0CiJI8sFQlxq8R7OBZVYKpjV2a9+ARanJaPK8Q6PXEwIBzzSGELI4yE8tTlABDEMwBMOAFmWwwALCAgvAmYYY9sxOQ5zHGe7hOeJ4xoYI8owz4u25WICHM8Yc4ERhHgCPGCCmM2YS0QChIDNgLmuazFGOb4hN1ABMGDAGGOOa8jBXGAEM5s6FHOYYwwsDgNmHDCHcbbTFLqeyx+6/wH/0WNgWaIUAMCO6yAeW7YhiMq99x2t1GrTt2Z9vkCDeiCYUIpMQ6fUQQhxnIAIymQyt27d6uzs5CQOAN5GV//h9laPzC8WZggIQm8VN9m/Xc/d8S7FjdEFA3DAANxfkpJhAAlMHajNizZgEzYXb3z57xJ2ucmLQLOA2SAKYNt39A0NGM4ogCs0CoOMvP3+//ZA33ZNhTu118YrbsNZ9d/q+OCtYuIvjrwBISkwxiEghFCEEAOBMuTaAK4kIXAodiGgNE1dvbpZrKJQ29ZmhuOkSDgAjK/VtcGhpldfO5EvVmUlHAiGR0dHp2/NXDh9tq+/3bZ1TGyvT/TJnr/6q78aGu5+17sekyTR74uOjbfkc3lFERhjhq4mEgmBjEqSJMseAigWi124cOnIsWNLK2uaZgXCoUIxWywVwiEfAjubWqnX7ZbY5MjI2JkTb24kNyRJamnuaG8Z+dM//QsOk6d/8nws2hIMREOh6vVrtzD98QP3P2rq2ukzb9y8dWF+/jYnSYrPF1BVtVKpeb1ejuNs2w2Ho7phAICieAghoihSSh3HUVVVECS/P4gQKxQKtu2IoojuNEmwSCQsCIJLHcbcWq2WSm2FQiGG6ebmJkZcU1NTuVyenZkrlcper7+zo5vg9NbWFkJYkmSE8Pe/96+/+dlfVxRF101CxEwm8/+j7b+jJLvO+1D02+nkyqGr80zP9OSEnAECzCRAghGSLNOSLFOSLflashyebdnX4cqWZckSdWlSFCXREiVSEimKmSBACiARB8AkTO6cQ3XlOnGn98fpnhkE+t313vNZWFg1XVWnq+vss/e3v18CjfL5/NWpq7VadW1tjRDCeWwYhm3bV65cWV1dLxbKWusTJ05861vfKpVKjLFMJjM8PDQ4OHjx0vlMJhMEAUL2/Pz84tLC4cOH+/3+6spavx8gRBzHwxgjRGZm5hAiIyNjSZJ0Or3Aj1qtVn2zMTY2Nj+3uLa2NjExkclkwjDc3FxP22mVSsUwrBTfFELU6/VWqwWAUynl008/7bjW2NjYxsZG6hSAMb5w4cLevXuXl5fL5bLfDx3HsW3XtBDC4ukfPJnNWVJxrXW5VEuSGADy+ZyUUkpYXVuOk/BTn165fPnyO97+rqAf3nbz3U899VSz3um0Wrv27LIsKw58znnUabkWwToSPF5fmdU8Gihme2GQLVUnx8vLG0uNrc1DByb7SxvZOGi8/CLsG229/H3HksTQ681Nq1DsdX1TIB3LrJvlcRL5UcZzer0OYViDkCDDMNQAru1hzIJeYFBiEIWJiuMYlDYpi0PhuoWeRB1k9Cz3wH0P2TkX3KzpWBxAAaYaCMKCc0YdAAh7fdvJZj1z+87FIAEwAE8Sg2EAAgooZaBhaX6h0++srKykaeJRFJWKlSiKeZwIoRg1GDMTKRBCjuMoBX4/9FybcwEYUYpM0+RSIcKEUEopSgklCCHpWFSC0iKRUiJNpBBxojBJN3CpOTtgjSElTKQBztsb+9f8X2utQQJohHTaX9ca6bQDBjR9QqWMUQwaAJASRGHQIuZaaKwYkeAAdgAgQ7hPNhYbly9f7tQbecN2idFv9YIkmVlZnF2eK48PhKqzvNXxHKcbxCYiREM+V1hYPrs8d+pMxiqoeNiUHsaV6iB4hSif31Lc3Niwq0WtdNAPLOa0m13XNIr5ooxBcASCUMvkUlKDxjEQoPkcbKzDX/zB3547e7nbihzLMIjs9JdMQ4dJ33Y8zrlUMo6TyA+qlbEwbDqOwxjBxPR7oWHYlsVMCn/4ma9++a/+cqBS9Ry3lM8opZkBMZed7sbj352rt5c+/Nj7B4dyEklCME8xD42UwpggP4gtyxCJ7PpdalLTZHGsRKKRQlJy08BaJBnbkkpNXZ2pDYyFPaEVHh2sFgtw8eI06db9ubXW4uzs8rKXcyyKod8etGFPNWfyLrVILpPtEHH23DMn5zbb2jHLI4VsgStCAGMVA4sQ0swkRJrtbh8nMuC9g7uGH/3Yx7sbm1ZplPudXeMVY8jJsPXuy53BRDs6MVoRohYHpZBOWEhcLeNE876tXXDzruWd3Vr/yX/yf8LYmNSQAJD0P8oBBGhsMAIIFAGuAGkwqBI8Tv2TkiRhzEQIECYpS50ZhgZI4tg0TSEEM6iSQDFQY3vR01pqrRFKkwNStjYBIHDj8ofUDWSla8voG8lZGoAIZBIKHFEJXcNvgY6u/tf/y20vj9VsSCItpYwFERoRCpgAoyBiICkvR29vRTRYGLa58RSD4KAlTyKqMOLEIiaoBFQMGGmpEE/M9E/hCWgJQAEogAkYAUhAGjgH2wYtQEkShzxJwDAAYLtETX8LT3sumggNvYhpDT0AgrZpQAKBwr6JrjZ7+973wexbHgTqSWVzn1kW1iARAGUsTkLTsNOdM8ZYCS0lF1gTgjAhhOFEJEophJHnOUEQdDodwzAB8I+urlJ6OOxcqZRIvsOs2mZcXf+/1hr0DRWMBqSBIkyR1BDHoBSwGAwDAGkbCIG4A9PnZv/ok3vijle0wK8DpqCJ3wzdbEElGAAQCJRW3SqNpMfb/FGlt/FBBBjSztZ2RwprQEiB3hFRU7wzNq5N4QAA27z+62V72v+X2wUaVZJgDSA0YgoBYZHEcShVBwr7Bi9d+W5Dk4ly6fzJi1bGuHx5ut0LxnaNdjo9glmz0T7xkZvf8uDbf/d3PvGDHz79lgfvPnho8pXTP5iZdR776E8++e0XTdu474F719ZWykXk1uyZmdWD+/cP1CoXLlza+SwojmMhRD6bb7fbabSd1KpYLDQaDds2EdK1wYF/9k//j7/+1hPZgtGsL//td+evXDg3NjH5cz/7C5uN4MXnXiXY/vVf//VsdmhhoUENd329+WM//rEXnz37x5/7c60EoHBs9/jTzzxNBwYGtNYp0SoIgpQ3XavVojheXV0NgjCFDuM4IoQmSZIkSa9nW5aRgqxa6zRrKZfLtdvdOA4JxZ6XXVxcDIJgZGQoiQXBbG1t7Qc/eOaDH/iwY2eeeOJ7BnNM056cnMznC8vLy4EftZod3/fPnz8/Nj5x+tQrrpN1HU8I0ev1HnrwoVfPn9tqNCjDt956M4CQUpbL5ampqUIht7yysG/yQLFY6HTatm0PDu5ptrZeePG5TqczPj7KGGKMzM3N7T+w78qVK81mM4m57/ta683Nrfn5+Ww2u2vXrnq9vra2NjQ01Ol0qtWaZVn9fn96eqbVahOCS8UKxtiy7M1gK5/PLy4uYmQUCnh6+mKn0xkaGqKUlEqlfr/f7XYHh4f2Tk4sLy+vra0SQlzXSTteqcVlq9XY2toyDKNWq5VKpdNnXjp4+I5bbrnpm9/89tjYyOZGM+ERRtT3w0qlwnncavX37t1r2/bzz7+0f/+ehYWFKEocy3n/+x/91re+ectttxWKucXFxXa7ldqm+2E34+UwwknUXVzwQfGjx2/WRG5tbe4e33Xu7GnKZQmQi/XW5Vdb3zOCpfMSAm2CSXAwmzimSSW1CEtWYwOwhRDa0jXT5DyWSADWVZMmSUIiyhNVNj0cSRA+xlqAoJTqrgTMeNLDdsEHb8++w4UDh8GylVKSCKWAEiqVxoApNUUcE0JsN6sUIA1Sbc/ohILUwAwDAASPKTGBgt/pT89Np2bQQ0NDYRgjIFIqrRFjDBFKCU2SyLXMTD5nGCxJpOU6hBGpJcZYalCcSw0WNZUWCecIDK01QiClUFoghBgjBBDGNEkiahpSAWilEdM6ZQanWh20zUtBabygIoAQSKRBadAIC9CgASOFNSClkEKAiUQgtrMzALBWSiOstdJEaioSiwvbcbdpFhhgI9g4v/nSleknnnp6s7ExUCwaXJBEqgQkaGGiWi3bDtexQQq2UkmbIkQIYYy1/DXqOo5Eca9umYbeaokork+vbyW8nfUWZZTPMq14y4+AmbEOM1nTkIlobBZH88WaBwBAodX2kyQixHJcmL4Kf/Cpz124fLlSHsAaoigSssdMlMggm/WkREroSqGmEThGvt+JGvXmsSNHlYzDuFcolAAhy4RPf+p7n//cF2666aBSgcWoH25RYgilpdaGCRU3uzA7/73v/vC9j7zbzWDFEtMxBZcJTwzDiOOYUoPHCiGMlKYEJ1GIQDFshGHseV4Y9QA0pVRLDALPT6+UcsN79pTDPvzZ57/7G7/+a++6+5YxxF96+tkDt9661G0ZDBeZzYKO02gf2T3o5d0fXrh0ZnltTZiZkf1Smb7AKlIIsyDqYdAGRlwKzZlC2HBzmuAgSE6fn39oerV2153hwpy9uwoaX/y93zDbq6NIOVFgYgpaAA8ZwSCEwbvIwiAQIFOAbMXBbJi865f/JYzvgUSSjJ2ubjrtIsURMJaakiBMEd4W3RNGeJJsNVqZTMYwrHanl8tlyE5NJKU2TRMA0p4KxjvFDAKlBcI6pVRpJRHGANsjdXuFlwBMAiisdoCe6/uH68e17oQGDCb0ExC4W6AhqM7VT/w3d2OmRnmyXhc6JIxhpZFEwGPJJYoQBgCCQCMQfLvzoQAQBs1BKwhxwrlhMaoE0hQkB5BaC0QREEBCSx6kKT6AhE4LRE1Ah5AyIjEARiA4j0KENEWYaQ2gdBwjwkBrBSC0RAgRggAAKYRkDJhBwAEUmCYIgAQS073Uqh/60I+59z+oqNuPlGUYhoGUAI2VHwWW5ZiGlSQijiPbtn3fZ5QiRAEphDRCiNLtzX/CozCM1tbWoygmmGiNpJSA0evY60gDAAIkFCgEGjRD1643el3Fkn73CpBSABpIqo24/gIECGMTKAciAYQGhhMQPTj/3Ok//f1dYc+zSby0QCysCCjQrleI/FRYkTbTZQoK7hAhEGicEqlUSv5D22ywaxwsnfrUaK201lLDdQQQIFV5pvrvG8vBlIwFGDQCpLDSFCRCCAMBTDSAFCrrFvwohkgSIyMj2WyHA9VRDuHc7OVieWBmemGgOpj6bh47fvxvvvLVubmFxz76Y2fPndoYbPzWf/vE2bMvffYP/uT2W9/yz/7lP1uYm756dXriXfsajQZjIKVcX1+v1zeq5WK3156em73nzjs7pIcI63R6zDSq1erV6ekkDg2Dtrf8odrg+sryf/j3vzs0XhoYGquvLW9sbIwMD44ODyxubO3ft7/dbn/6U7/9lT/7892HJm+/7b5dY7uCE/H5V6eWl9eiMCnkM6Zt1DfrfhBTahDOOSCgBlG+zmSzSuml5ZUoijY3N13XQQiiKGQG0UI7jh2GUafTYqxsWZaUIgzDQjHHOe/3+0qpWq3WbDU458VieWJib7/fNQzrrrvuCfyIUeeJJ568774H3vfIo9/61ndmZ2cRwggh0zRbrZZh0mzOe+qpp/bt3V+pDG81W71eb3R0dGBgoFAqv+e97/urv/orw6BxJOMkpBSvr6+WK7luryEXuRDJHXfe8swzz5TKuYQHR44ceuklf8+e3YuL8xgDY2xjY8N13eGhkYsXLimhe8VuGCemYd9/31t++MMfem72vvvu+9rXv75RX/cDvyCLQsme3+92e4TRVqP97LMvHDt6Yot3wkBEYcOxcwZzZ6YXDcOu1bz19fWRkeFCMccMvLK6uMeaKObzM1NTlXJRcNVo1rOZ/NbWFsYYA+zevTtJ+MLCwvzC7PrG6k033RRHimDrXe985Mknn/T9AGMMwKXkm1sbY2Njj7z/fSnp7cGH3kYp/frXv65AlyrllbUV07aYaSyvrMzOzVmWRZlJmZmlRr/fz+eLGHAYhidfeq4XdjqdDgHdWB0QofR7Ya+5ZTc3RBmjaK1C24aONPUSKSpE834HmTYocLfF1gAAEFITAWgFWIIEBhI0tjRAFG8TLLlPMkzLCMkQiKcwbiXO8B1vzdz3biBFwFQgDiAZBgySYJxujolJ0x0O2uZkXtf8ILQNvBFmaq0R0huNtVanWSgUOJeGZc/OLVFqCg4IGMaMEprSLKUSGoRWMo5Dx3HCOEHbxqCAECKgeRKB1oxipQSAThkSQmpKGVAslEQEUWomScKoFYWKUWIYREkAAIy4ApBAmGlqgDiOPWZyPyISZRwzUdBJOPOY0CA5MA2WhiQSkoEvlGDYssDU4Bio1fcJIQbQnGGDAgATNlswv7D6yoWrV6cWOt3lIFiTCTeNfNmWiAtQhGFia2oagQp7qg02pkJ4/cTSOCE6xCLgXFMqIcZaew7mSWQxo4ANIrXpWSxjhogt66gvE0WoxgoboMJItVqPf+qTq8ODg0OVoROTpZuPFbw8INAMnnh69rOf+BPN6VB5F+dc8sQwkSBGmEhA5uZcXYWCx+JCbzqbL952+52by9M/8cEfP7ZvHw+7TtaIon6pnPneE0t/9If/8y3339nrrzpWGEe+ZWUDP7RsN4h827XiKOnW4envvFz2dr/tvYe5Ugj7CjQzSD9oZr2cFFgqhZQGLVUSYyQkCCESx/XCMDKMTBhFSYKV0kePnPAc6LbgG187/Sd//Ller16p7bFLw5cWL/I9k1eUEVhFxnBdRUUtiJtXwjv19IW5bii9CV0sb4bYjxOLGqbQSCeGgTSSEQ97SWRZ1TDhMo4GMjlDGjKh/+q//t7f++hsNm7AF64Uks346gVP4VKtxBGOBTeJCwkHjCAWihAIMcREmU7f9k43++/41/8WhvcBzWhEkQILg5JAMAJtgIFSeVtabRNNAUBjpBRKuORSXJ2eUkrVakO5XGZntZaYwDXLJNCAUKoIU5AWU3qnPEqp1hptK+/SN1MlIEGALYXS1rHWSGGhEChNADBBSGvAihPMNIdQCm1SwGGBxsC3Tv/ev+fnX95Xq8qtTcP2CNhcUKVASJ1GGWqsNJBt0jZQpBAACK20ltf6MBhTyRUARkoD4G1COFcKKYIoRgYoUFrfQBFLhaCgtUZCgeIaASCiNOaaUImRBqRNoAgwKJAIYdBacomVlkgTAzgPTduFUEA/AjOrDOvUWv3Y3/0Z550f4Npt+ShnZWUYMoYSHiKDUkziMDI8q9Nu1jc2i+UyJSSKQsaY1iCVxAilVATOJSYmJjrh+vSZ82PjewABYJ3CvEorhBBOtaVoG2LTICUIogjBJInAMLcdNBAA7EgeU08KmZafUrnE2MZ0MYDSgBko0BIIAwEgZZehLpz/4ZXPfmKCBxlmQCRNkykALJVGSIYx0xih7auiNbpWcOPt8m67tbadQ7kNBSp0g5QHoRSj3G7X71zMHemP3q6nXkvuTzthVGsJKqZKIUQBJCAMIF2iVbvumbmE9zmoysjo7oNHDMfr+w1MabFcvnjl3OXLl3ftHnv4/Q+vrS9funSpVBlcW201G/4zT7/CsLu6vBz22cZ66+kfPHfP3be/+73vqxQHnnz8qVw2E4bx7Mx8EASMVVO6OTGYQggQvXT56k033dTvdrKu2e12HINSStvtdqVcO3p4ZGLywPLaJgZZLhURgSvTVw4d3LvVCn76Zz74Cz//j3OZv/O5P/ij8dGhnFN99umzv/RL/+jBe9Rf/OUXtIxAKpN4zDOp7/cwxoQwKWVqWMWY4ft+p9NJkgRjpLVWWlBtWTZrtVr5fCnN6cMYF4vFzc3N5eXlarUqpcxms2NjYymxf25uzvf9SqWScG5bddt27rnnnu9857t/+Rd//eCDD1qWNTU1XavVMMadTgcAtra2hoeH+n1/c2NLKaCUFfIlznm9Xp+ZmRkdHc14OYwxxiyfsxeX5sOw57jm4OCgUhAE/TNnTt19951LS0ulUuHcuTOVSmlpaWHfvn1JkrTb7Ww2v76+ubi4DIBzOW9lZQUwcZ3MsWPHf+zHfvzq1Svzc4vlcrnTbVmWtVlfz2aKhBDbtpNYOI7DqCmljqKEc8UY0xpvbNQRIt1Of9fusYmJXULwOAml5G9720Ocy/MXzmWybi6XcxzHMHEQRJVqKY7j3bt3R1GUJMlNN53AmPT7/Xq9HgT+0tLS7l17yqUqArqxsZHNZlEOdbr93bt333///ZcvX37iiScOHDiAEDp06NDq6vqVq1dfPPnCu971rkTEfhgMDNbCMExlB6nUIJvNY4wopTedONZsN5EWRGsi1a6x3SJOJg4d5vO432vLpGdADLyvNMhEAkEMkI4DhQBSIU8qL1JsW9SCAQgHpLaVO0qBxpBwyNqIB3HcNz0vjOI1xYrH92VuvRu8otJU4ZR/KTEIrRTG9k5bHOltSjB+IxoB18hNShBC1jZWhUxSdqAQgnNhMEsIxZgBGvf7fdd1Pc/1w369vrG2tjI5Oba52UmFIYQgkUqrts967abX6c3GwAAggmshJUIaGwgITpLEsjzQJAwVBk2Z1qCFlBJjrSDyQ8swRaIty4JY9wOODKq1lhJiAQYCwaHvg2PSVgsihJUBEAOWoTLUgInAMkFiWN7aeuXs9Mun1qcuxY2Gl2BtmG6pnKHId80eQxHIMIkpIItSrRItQTAgSiqfOwIPC2oq1OEcM92nOkEABATSMdEx1jHWYcxtjQBQrOJAJzHWEhFCqOBaydBSUCLg+t3OuXr7leiV7xPu2iMHD+2/58EfLCz/xTe/N5bdpQXr9zqO4xBKIj8I41692zBsemDy8M1Hjg1Wqu1ed3pm5vc+/T9+/ud//tGPvD0IApMSJREznF4Xfv3Xf33/gb2t9pZlAUKIc0GUzuUKfT/M5XKr9eVCtlwq50Ro/uBvXxjbNXbk1gxXfYS00iKXzUYhT0LBGDMZ83t+uZjdamwatsm56HW3CoVSFIcIUUY8YoAW8J1vTH/xC3995pXTtcHK0SPHL14+3Y3kplBtwC6xIsGoRJHUYURxF56bvZJgS+SHAsREbBKDWZQZghthhGJfiNhyGejEAoT6lGHGDLvdbpeYEWNiZsy/+ebX7iqSSdItmMFI0aZgg8ZaEoWJwhoxhHQsRUwMW0uINZVG/pm55Uf+w2/A0KTyKqCZRITANswF27q6nTYLoGs9CqU1wcxxmeNmarVaHMcYYyGTG8ZzejPt6LS0uq4H3C68rvN4dsRn2/IuQCkohfTOkpkqxlLpISNICM0wIpqIMCKWZRtU6YTwDiS9l3/3N/jFV2+ulXmrznJZCCXRRGqqAGkNAIJur83XzOTIdXU/6GvQGEAKgSCtAaUaZI13sPXt2Bm0DW5eW9vTt2EAAEKR1gwMBRgpggCBVoBS802JEAJE0M7vJkgBAKUobDXt0gCEuhWKBeHf9hM/Rd76HrBynBPTMCmhknIEEmlJkQEYg5IA0G63NUittVR8x9dKaqVh214Yaa20BEqMMAzrm42tzXqpUtZaY0w0AEEEAKSWWipGCAEMGmNAFDHBEzCYYULgC8Om6BrzXd8wXQHBgAnBfqw9hkCDjmNkMgClBSiMsQbZazi2hFPPvPCHnziiQs+mIBLAeGcbew0aTt3CUvAVXf9K8Q010Y6K/DWT8rZC5/rP0c6Lr18dvTMirz997e1YU4wU2nZLAwIYa6Q0ICQkNm2ItGE4jUajuO/w2tayVywvzM60trYwNR566B2U8an5q5ubm1uNztWZ6b/3sX/wpb/40mBtlBLtOsUjhwaffeF5BDSTyayubRCML5+fDsJ4a6s3PlbWWg8PDzcajc2tjUKhMDg4+Oq5iwyTPfsmC/nsyFDt8sVXCdJZz6MYe56HEOKcry4vFUpl2zHb3T4XwrIsyyTdzoaW6j3vuX9u3+7TZ07uGh/80l/9BefhT/6dxz77h7+/vHT5wMGJzY1Gr9PAGGitVjMMIwiCKGIrK2ue5yGAQiEfBEGpVNraqiulHMeJwiQNQUxXcUopQsj3/dSHKZvNJkmklJqZmatUKlEUObZb39yihCGC19c3ut1uHHPB1d69EydPnnzHO97x/PMvbG5uVioV13UNw0ijD1NfU9t2EYKlpaXJfXuy2ez01KzfDzGmCMlup690Ekd8cnJ/r98eGRnb3KgTQrTWjz322De/+c1Tp04NDQ1ls9lSueg4zsLCAqGYUaNUGvr+979fq9UGatVez+90eswgV69esW2bc76xsSGlNA1baZEaUgghOOdK6XSR3txcT8vQOI60NtLvpNVqXLlyZf/+Sdu2jh49eurUy51Ox7KsWq26srKCkO73u0Ike/bsbrfbk5OT3W7fMGmr1Wq1GwazAGB9fW10dHRqaur5504eOnSw1+sPDQ0FQVStVu+6+97z589/+tOfHh0drVQqly9fPnz48OrqarfbJ4Tce++9+Xx+eXnx8uXLw8OD3W43l83yMAaNy+Vyu90eGhqan58H0K6X0UxG/R5j7OajN71y8qWzFy79nQfugisvC80SLiDwwbUpIaAUiEQxpgEkaAI7oJ2SABgw0tv9aKS1RgohhQA0UAVBB0DRRCcUNbGrBw/k3/o+KFUAlKYaAHHJDYIQmNdJTfp6K3w7iuP16rztlSNdSBbmlwhmWmvTNDqdTqfT8dy8ZTlKaan4tupCcNu2t1pbSimlgFLs+72UPpjSJnZmgNfIW7aTHBRBCFumB6CEjJSShBBCddALbMthDHr90GSUGQYATUJesGweaq20YEhjRXNMSp5xWaPVpsyh1FAaZue35qdXu524WK4Uavndg7nKmA0AsDG/dvrl08+c9JfX5HojQ1jVtc1MTkWyJ0AIiaiUGhKCJcaCEC5VgiSiWCahq1heAenzAWXsUgxzmTWYrdWm1j2thRBSQ1/JJugsAq2VAiIx6SjRUZwTgoBQiXEiDZCekhmAsmkMg0GxFSgIhNmfa/zW9/7LasYZHBpXfivqxU4x63e3PLA3F9cM03n0HQ8fufX43oPjSirPwZ4Lrnd3acg5eOyI8IDYBgamJVSK5D/9+l91e1t7Jmtx0FfK8H1TxOWVZhBFi4kMx/eOlgvlJElAtZlTWF6bf+6553fvf4fh2oBCrVQUINCmbTNMZBg2EFHr9QgjQyQGIYaXScKoCYAJ8iwDlubFF//863/75FMakiOHDygdct43KInjRGiQGlNMqFS2wKY0lbDqfaJyo90wdo0CE7rb7+S1nZM8WJ/VvDGUNfMmyZmFtoCYWivNjbmtdmXvQUWNhPvIVoJEXb8jZLFQLPP2RWoKUImII4lMhEmsQ6RDC2lCsWr72Mtz1znXbDzyy/8S9h0HoyClqVOCynYbALataLc3MRgANKRm3hgDljuhwmm2ZrooKn3N+wRuoLq8zi4EXxvq6Npqem1ZREA1YWk3iGhBt+EpoglRhBIkJVgE6YQDJhSjACnFfU/1QIVXf/u39NmLd+3aq1vrUjIIOCgKWlMiOSDOgGkAiXdaGq/5DASwBo3edOXevvF32iJo5wn02pdefy8CjEBhEAhrAhoD1oJyAImx0NuMSIYUAURAAWgJIGTC7VJFd8PYzs1zsesDHyIPvx/MvI4lldJhLFahBG4g02AEMCI7NgsbGxtpTvO1eSm1t9imygAgRDjnlmXFUdTtdOobm9VqVUiBMXDBMaUIkIEIomS7cpIYKQoYUQY67EcxdzJZKUSvH7b77VwxZ1kGIKCYYqAgMQUADIiiFoBDwLQw8AgIAYOEwC0QGVPAs0+f+p+fPWjYXjajWuvYINtOoa89dsyq3kBOfx1r6vrAuvHx68/2Jj/Hb/YaJBGIbR0kNjRQwJojCQgMw4YYAFy/0SdCnz978uB995y9/PzJH07dfdsBADU1dSWbs8fHxxcXF/ftPyx5Evq9iYldXsZ59oc/2LNnd3OzixAKw7BarYHmpmnmh4vt1tVarYIxPnz48HPPPZfuTzzXOXfuXByGmcxoPudtrC2dfuVUMV/0g36z2RwYGKCUtrvNK1c3/umvvvfZF08SagwMVF565VR1YHBu5qrrGO2o84v/6Gc31jb7QZDL0IXFM+979B2f/7Pf/eJffGZkzMxmIsZoXHYfeutbKEKoVqu1Wq1MJoMx3dzclCLZ3NwUQjLGUkY559zzPIS1bbmUsmupfN1up1wuW5YVJ2EYxkEQPPzww48//riUcmhoqFwunz59es/kXq1Rq9UJ/CiNjr7pppvOnj17xx13PPHEE81mc8+ePbt3767X6+fPn9+1a9fC3GKv15mcnDx4aP9HP/rR3/iN3/B9f9euXZ1OL5vNZrO5bM5ZXl4cHh6tVm+iFC8uLKUJM3/8x398yy23PPPMM6Ojo4SQzfpGFEVHjx5tNpuzs7NbjfqRI0c2NzeDIMjlMqVSyfdDrXWq8isUComIHcfp+xGjZhCEnAvQWMqEA3DOCQZCSBzzOI5zudzg4GAchwmPhoeH4zjCGK2vr999991PPPGEEKJUKu3bt2/37t1B0J+fR0NDtVwu47p2qVT6yle+YtvuwsJC6iVWKlbSCKc0T9p13W63G4YxISSKeb1e39jY6PV6q6uraRTlxsZGu92tVCq+71+5colSOjAwAACjo6OUEADIZQue550+fbbdbt97772nT5+uVAdcx95ScqO+ftSxbM+llYFvPv7k28bKXBPD9mTUSaRUShkKgJlIbxOMQOOd6Z5qwEoDaIlSb7zUVVgjACWxJFpBLIhTWEsoH9675/0/CYMToLACiQkVoLaNE1XKJEjJlWQbB7lBoJzO76kXur7BXzqJ49XVVdu2AcA0zaWlFd/3K+VBzgXGxDCMKIqE4IB1qtYcGBjodn3XdZvNpmEY6Nru/k3nBAygkeBCCjAMhLBOtY1KqV6vk3VLQRAnCfVcu9vuMWXGSiihZQIWRpqiWAtpANcJ50HW8DzLxsiIEtjajL/7vR+89NwZ18w6tn3owO7srYfsmd6Fp77ZWrio/HaWWaVEubZtahBRGCddilzHzbW1TKToSxFKJjFWBAPGChRjBElEksjjqKLZkKSVRMo4calJNRKgtFR9BAmoADQG2cYEUUSxwQlqa+FjkJQoQCARwcxEiCoeJ0GYqDgkEGua8eKA13lnaNcuZJMYEi2DkVqp0VwfMGzdbf/8Bx+55y1vU5YtCyhAkMniMOJhJwqV9fGf/1A3gq12ixCGBauWzEsX4ctf/urxE4cI4ZRhKUh9LaiVhx75Ow8Vyt7pcy//2Rf/55Fjh23HSlSQqE6+UDh79uyt548cvmlIU01NppSltNIQCRVGom8zu7XZA82QppVKySA0jtTw0Fi7FX/1r0/+2ef+en2tNT424riI4DgMupJrEcU8ig3Dwti3MdUgTERM0+AEAgIhCGkgKXWGokzGiOqLbhTePpYfLBaGMqyEEAPW1w6n9nq3O9XMPLe4YA6MhBozxwx5P5fLbDX7DUTLlqFFoEBo06DI0FpjRCg1QcRADK1IC9h0oO75+78IdzwAygJtK4UxRhgDwqkJFegd6o3eAcLQDu6XrndpXk3acwVIc5dv3JGoa3K/1yYN70A2bzry0/VQEwAFOAWMKNp+DyAAShTEAhEKXIDBEPc9yiFqL3zyd8ILrx6vVNVmGwOmThH8HhAMCGEAjBRghBQAEEBop2C6Bi295gG6ftdvw37pc9c9Kt9YAbzuECmLDW07/yIBWGkiNUikMdIYFIDG23ZfACpJDGZDKPvMOlNv3/GTP2M8/AEgjtRYImS4NiAAnlCclms45a4RgkGhzc0tg1np5KDkTu8QCEIaaQJab1tZATBCkyheWlqanJw0TFNKaVAmtUpLNa0QSIUJAYwQMNnz/agzMzvNeWzZLmFsdbM+NDaaKXqAkYYdW9rUX0wDRmBgABCKc0wZYJQkgUEjBknv8a+d/4sv3lIsGIkf1OuOa2mQqQTnNZf+jVPiNc8qeD2wB3Adub0+qt70eE0f6w0nAQDQoAWA0ogqjbTWEkAiDAggjpEgzKCxFNTED7//XbFnfeVbT3z8H7zfIOYPn33xyJFDlmW2tlrj4+PDw8P/5t/8q7NnzufydpLEt91+c7PZXFhYeeaZcz/1s+/78Y8+9u1vfW10dDQJBADu9/sEW5lMZv/+/Qtz00rIubm5O++8Y+/eiX6vW8q7URT2EB4bG+t0OiKRAik3k1GSHz5SvHT53MSe0bX1et/v3HTT8TNnXy2UK0TrfNabnbpgmU45n1mYv7hvcnh54dLXv/pnj330vbt2Dz/+na/dftuRbq+pVI82GvU4Dvfu3bu5uWkY1DColXX27d/bbLQvXLhQLBZvv/32U6dOJUlCEXVdt9FoJolIGVdK6Var1e/3M1m3XC4Xi8WpqZnUAfLKldbVq9Oe512+fDWXLWQzec8F3/fX19cPHz529erU9PT0yMhIr9d74IEHnn/+ecdxSqXSmbOnBiq1OEEzs1Pvfs8vXr58+dVXr1QrxWazWSpV0jFR32y0290zp8+1O809e3Y7jlMulx3HmZqaSvP+0pzEsbGxv/zLv7z77rtTly/LMkqlimWbAAAaRVGEEGo2m6Zpjo6Otlot13WCIAj8KAxbjuMZhqFkolQa5wtKCx7HGFHbNpMkCkMfY2ya5t69e8+ceWVwcNAwjIWFhdQmqt1uHzy43/d7ly5dKhaLTzz53ZGRkStXLze2mmNjY3HMHccqFHLlctnzsmdOnysWiwMDtYWFhYGBoV6vZ5huFMdR3EitMWzbxhjbtj0zM3PvvfdSSr/3ve+lkXmNRqPdbnLOFxYWarVav99fXV2tVquOY1Wr5WZz6/jx45wLk5mEID9IvvzlLxuGdXBsAjSKpd8NJRgMU2YYhpQAMYDAmGKEFAIEWIHGWgMgqnbmPYTSuVcDIgAUkCRpV9kt+DHRQ/t3v+OjMHFCKkosEyEkQUotbWqBSj2uNeCd3rfemUB3usrprJwuLTuNZlBKb25sdTud4eFhITVjrNvtEkISHpmGK4SUUipQjucqJRhjd955p+vaKWbqeV66oUy5Vm+42zGAlFIyahkGkRhhTJVKlAZNNKHIwmYUB4Zhak54BNlMpttNGGa2AcGWbxTchMrIENihvW53wMz1tvqenY9iSBQ8/r0nn376b0cHRxHSDHqzF19qvvL93SIsBK0hhxBhUqBSCkgSjYAZlFKWcNJL/IAYiYmlSTlFUgqlgCBMKVaSWxhZIc/GMIysUiKMvo+VtjBwE3yFYqo5wZxiQUlISAcBA2pgFmLVAUgoVYQmoAkCDFoQrkA6DiKWyTBRWEaO1cVoursFBTMScaJFIW/2mgvjZpb4YYayot8oswT2OXEMSkOMQTLpem4igqWVFibIpUAJk9IwDfifn/u869oIcam4aWQ2VrpZd+jHHvupYycGEhE/9M6D9z9058c+9vGDRw6OjGTbrZ5h5TfWmmfPXN6zf8h0KdaAAEmtMZKYaAC9sr5R3wx5glzbZIxkMvmh6q7py/7n/ugvvvGVJ8bH9xw5fFDwfr+/aTCheWhns4VswbHcmLdwkhgJ55JLhkKKJDNClWjLBB7oqM0b9bLs31PJHC3XhrMGJlyFHYcHWoJnZINQVYie2FXyk+hy1M8URiMCBgPu99rdUFeqJssCj8GyCTXiMEJcGswEZUCsIeNEOetSRxx97O/D3e8FSYC5Egih24CNBJ4qShXs2Bi9ZnAKAECACL4u8tPbYovXrVro2qqHfvTyt3Pa1x0pe5oDUKoANAgCAIBVH2MAQiCMIZMBULaIIehs/uZ/khfOHB4b492O4ToQADQDsJz0PBo4AaACIw2ACOyIzW783Ujr67WU3p4MEEp1t7Dtbpr+XfpNKrPX/eUgAUAJrDRKEAAChRRHWqYEIKIw2qYCacBKIYUJVYh2NLvY5Tf93Z8z3vs+qUkIzGCOJoorKRJuYEIMQ3OFCI45xxhjTDnnW1tbKXSjJABgrXfKDoy03i6CTQaSCwIoiZO5mZmtI0eGRkcJwqABA5JCUEoBI8CEd4Nuu9PY2FpfX7109Vwv6D722EdOnz59xx137d+/r97v2I4jdq4pTnnxChABAxQBLmKODE8g6AZx0TYh2Qq+86W5v/nyrSWPyQBEQBwCLpM9jt+sffWmxsiwrat84xjRANeYWq8t4a8jitsXK1XzaPX6+VYhAFAapX41fPsNimEgGJRBCNcypnFsu4/+3Q+d7nfOPH9qZMCenb747nc/8v2nnnrppRdP3HKs3W0wi22srz791HNXLs/UarU4CcuF4uTegy9tbJTLxpEjR06fPv3csy+4TiYJuWEYpmkO1oYvXbpUKpVs2zYMAyFotVpIgda602mOjgwJodrtdpIIz831/I5hGK1W/eDBfTFPLp4/lS/Wzp47+4EPfHh2dp5HXCsspdy3d7Lb7c7NzVWr1X6/6TnG+GjluWd/8OLz6uixA/sn98zPw8zsFDVNMw1BpJSWSiXLshqNVirTO3DggOd5QRD0er1cLkcI6XZ7pmlrjYRI2u22ZVmMGa7rmoa9vra5sbExMjIyMjJm2y4haH5+3jTtXj/Y2mpallWr1YIgSPGafr+f5h+7rhvH8bve9a4f/OAHk5OT+/bt+8svfuOee04sLi5+8pO/9/DDD584cWBzc6tcLlPKgiBYWlqq1aqO44Rh5LnZpaWVbNajlI6NjRFCUvrXzMxMtVpdXV0VQly5cmXfvr2WZVy+fHnfPrVr166pqRkhRBJz1804ruX3w9nZWdd1HddK02x8P0wSmc/nu90mAJiGlTrFEUIsy0pjpLvdbmrjvrm5PjIymiRxq9VyXXdsbOzFF1+0LGt1dXXfvr39fh9jfO89903PTNm2PThUcxyHMX7ixInl5eXl5WVC2MDAQLPZXFtbdxwnzXVutbta606nI6Ws1Wrr6+uc84sXL5bL5bQl43lePp83TbNcLjabW+VyeWhoqN1ul0qlA/v3CyHCIF5YWMhkMkmShGEEStu2HfFk994DFy9NPff8ycOVSm58OOQ4QQBSMQBCGUgEXGxnHSBIq6vtggjh1L4c7eDroHYKLkK0wkGCupmB0QcegaN3aeREjFloe/LDQNJ9C0IAFIEGQNd27HibDXBt9n3D7Y0JmZ2dJThNLAMhRK/rU0qz2Wyz0abUYIx2Wp23v/2tt99+tNuNqUnT6jlJEsuyKKVhGBqGodRrzpxyPlLSQRjGcawxpmlhLaQUIuJRnPFyURBLjJHUCBFCUKfVv3jhqkONd7/lZj+RCLSUnAtNLbsf81IxH/ch6seWa85dvZLJWtmi0fcbAJxpaYnEVqLAaEYA5oTHmmEGiHIeJjyShCiEuEED0AHIBKhGQDGBtHmYCK0SC5GCJiUpc1pZcQJJaBqGiMKMpgWgoYK+qQCIQBgI9ikyKQXAfR77CElGJMZKatMyhOCJ4CLyDZ4UkdkitmZ4New2XNsaH17sNUybuUipdr1KSNbv1FjWisXM33774nPfP/zQPXd89NHh/bWwrxpRnISR5ZiKmKZJQXDJZT6Hpqfgh888tWvvCOcdABBStxrBh3/mkSNHBjq9nptHF6+s3nPf5P/49Gd/8Rf/oWmMe54n4sh22NTV+fpauPeAHcd9JQPCsFZCY+Q4RYOV4rBx4viBV148n88NgjK++OfP/f6n/oRR6+abb9VKdNobtoU9x0HAC5mclmp58eqRQ3vjHkJ+gPMBViLBKAYuAXOV4CApGmDHWwO4+859IyeqLmmu6FafmVkexx4TUsSYYYOHJhFZoMfHqudOzglW7CDMDEUV9DkHYkhlYG1IQZWQnEsXE5AYwgAcb6Udzprk6Ec+lnnrIzymzPU0R3onvE9IAUimQNOOidGN5gkp/zGFEEEqmQ7gNMlAg05l8DeO5+37R73+Dnrty274BVojUKC1BimRQqDSsJmUE4YxEUGLEgc8M+aByQPQwdRv/2d6/qWJWjFsrkiFJBdJp29XByHqg44VKKUFUoA1BoU13qHr34DIXwPo0Rv2O2lkS8pLQDuh6dfe8qYF1vZijUAjKVInfFBIKbzTnENp7wo0ECGxllgB4I7Ecxxu+rG/57z3UalYHygAC5IYpJJSEgWGQRXnkeAGNtK9GcY0SuJOu4cxEVxxzglhqaoRIYUgBQoBY6QBOOcME0ppc6uxsrQ8VBuE1MuMMcpYEoZ+L+i22suLSytLy51Wq91rI6KkVs8888wLL7xQzBUHRsYKuTwFLEELkBQo0jt8LCQISNULqJPRCKSAos2gv9n86y8sf+9vDmUZDRoqUZoRiXG371s7M93rxsO14fS6QfLmjaed6up/BQX8r0vh9CRpMAZWCBIAoRQF0FQRjEBF/UQkLGNHKPr2D164nAihaS6bb3YbG5tL1YGS7wedTmdtbXVy3+6Fhbn61voj73vX4OBgp9Npbm2NjA79zM/81NT07D/6+C/990/95oc+9KF+v5/L5VrNS61m+9iRjE60ECKJYsdx9u7dm816IGFxYa5YGMQYLMviiVIKut2+5ViVUiFfyC3OT3/wIx/8+rfqyyuz99135+VLF8bHx+tb7ZHh0SAITp8+bXtuuVzqddqDgwOgucEYj2UY9Fv1rucWNtfazXqf+kHfcZxvf+dbAwMDxUIpiiIAdfbs6dHRcUxwu91eWFjAmERRnKrB0/ZAFEVpk8B1Xc/LbGysCyFs297c2HJdN4piLuJCoeQ4Tibi9fqWbdrNreZAdUAkopArGtRMIh4FsWmaz/7wOSn5xsbGiRMn7r777tnpadd1OE8KhcLVq1f6/d7Q0ICUotXq5XI5IRIhRD6fN03W7Xa8jDMyMjQ2NrK4uBjH8cWLF7PZbErqKpfLExMT9frG2bNnjx8/XizmU9BHa9lut5XU5XIVIVLfbBSLRc55r+tTYigReI4bJUmSJIwxjLEQIpfLhGGMEBIyiYMYYe1lnDiOu91uq9XIZrNHjx5ZWV1ijB08eBAhkmrIz5599e1vf/vMzNSZM2ds23Zs88rsFYClVqv11re+HWO8trZRqVR40jJNq1QqA0Amm9vY2OCcl8tlwzBWVlaUUrZt+1FITSNMwpn5GYzp7r17Mhm33qwvzs1PTEw4rhVFUSbrVqtVhPGr588jgMHBQcEVISSTySRRnJ5zamqqWCy+6/53wlaDqjABRUwbfBYEAQFmYRcMEyRHoBXa2bJs7/8k0RpAApLb8RoAaetaJpoUyqtdMvnQ++H2hxQ4ihkMgMuIEIyAEk0AQEpFbRT0OpJLxphlmGCw7TIrPZl6rWHdtbUG4StXrmQyGZ5I27ajIPR933W9NIo75gIRnMlkqtUqAERR5DAn9WxLoUPLstICa+e0+AYOltJaU2r1up1uJ9RaR16UzTmmhUES2877fuS5uW4nKheo34ff+s3/+2+f+sHw0K6g17/1yG+XipYALTjuI0EsS1DcikB2k+FBc30ubCzMOLbZ52sJbvWCji1IznYVQxqzbqfvSawlAUIYIAwgAAuNYkaVYfhYBQiEUlgSK1V7SamEJAhsJYqaljA2wwREghhorAiXnkIlhUOJthQCLZXCElAfASW4r1WkdEIMBVopRTDt93uEIkoINSyCUEyMlqQh1euAVlTABcauSUTM+v4YprkwqdGMrK8ViVW1UML44pNfffnpr+y7+653f+THR/btBwpz65vStYAwApjH2rTg8e9+J4ybuezubg9MIzN3devYsZsfeMuhUIDpSWroUjl37tzK296+5yMfeezr3/jyLbfcDEjYjt1utk69dH5o+DbDMQ1TAOGJACVMnuizZ6/Mza4+98NXH7rvoYtnlv/881+em1vMeVnPs4VsCRkwkySJwrFhEK/di1vNLR7BLYeOvvzD+Y0opEkAWHOsfa0IZlhHFSyC6am9BfbW/QMHmW+tzhuiC6Yt+9hgDigkRKijLqMKxX0aOx4uYS4xMEwMXwc5xxFa1VuNsIQNZJNYgda24RCCIIwAIbC8y61492Mfy7/zw4m0qWuDEghjLTXSSEkFWlAGAEoCIttZlxrrndUQbTsGKSUBNEaI0u09hpRSSEnIdRQG3YDIvAbKeQ3d8Ea/ou1XbkfHIa2BaACJgCAgadQvxtjKxlhx2XO1AMRP/Yd/S2dfPVLJQH/Dpi5YnujGdq2WbNWRicAAhTQGAK1SARmk+n6CUn+4lHa5zWS/9glfu5xvP4WvV1Q31lg/4sAAimihkZAYAIBqihTFkmyz4LEGLBWRgJQGyql3YaNzx8d/1n7bw+2uIF6WakoEFkgSkyGEkMZKai5ijTSXHO9YrQsh4jh2M5m0rpIaIaSR1inDTGutQIPexmoR1phArx8sLCxMTOzKZrOdXh8AfN9fWVlZnF9qbNbjMAEQiKr8QC6M4l5XSKDvfs/7JaBeq+UW8kqBgQ0GwNLrRgAgAeUDZtgugAa/F3s2grC18uef6T795EHToCIBC2MSgmVLoTBmSGr0Zk2p12O11/+JtdYavf7F25P0G8qsN3awtl+RJljfSMoC0AAKE4wkBgFIK6S1ApzuIWzG/J5RcmdnpgIpj9x6x4Uri0PDQ+O17CunTpYrQ61WKwz9W2+9OQwDpHUS9aOg+8LzV/bu3atV8t9/+3f7HfhX//pf/Obv/ObFy68eO3ro5Zdf/umP/WxzK3j8Gyc3N+vFTKnX85vN5vj4+IXzZzEGx3QwhmzWazWaw8PjTjm3tLgW+BHnIUJo//49s3Nbb3nwvv/jn/3zRx/9QKvbHBvb/bdPPZvNFa5OXWm3217G9Twv1VddvTrNCKUU33vPXa++enZjzT966N4v/OnXT7/coNlslhAyMTGxtrYWhbFhGBjTsbGxubn5bDZLMIvjuFAopBZEzWYzihJCyODgYBrt3Ov1MpnM8PBIksTNZjMdQ0KITqdDCOm0e7btVKvVNBZ6fX3d932E0PDwcL1eTxPllFLz87MTExNCiFdffXXX7rG5uZmBWqnX64VRb2S0NjU1U63UhIyYUYyTsOqUKaVpFnKv31lfX+9227feeuvy8nKhUEg5Yc8++2ylUnFce2OjPj4+ijHs2bMnjYKOoqjdbp44fsvCwpLrZgqFAue8UCh0Oh3bttOPXavV6vX65OSeVqslRVIul+fnF1O7hEwmYxiGlDKlBAEUfN/f2NhsNtpJkrSanRPHb7ly5cq+yX1LS0srK2sPPPDgzMxMPp9FCKXRQ0NDQ/1+MDw8jBAhmAVBeNNNNzHGTp48mcnmKaVxzH3fT5Ikk8nU63Xf96lpGIYRx1E2m7Vtt9frXbp0oVKpaK2bzWavT1ImVrfbXV/bJITUBgbq9bpp2HHMe72+yRgjutPvGbY7NztLBP25D31048Vn20HbZ8ICZFBKEAOuRBBTi6TcUI3R9gyFNEn5oUoA4pBWXYAVaAWU08xmH/a+41G4713A8gJvz+EmYQB6m7wFQA0MIK7OXE380HOcbCbveZ5t24wZOA2txXhHfnLNklgB4DhKFhaWhoeH4zi0bdv3w3TvxTk3TbPnBxhj2zZt20wSIBQFQeA4TuqVL6WMosh1XSlfo6u6cXaOQs6YVa1mEEJcRUpxpQgA+H5kGm6nHWYzztUrm5/5zGeuXrkwsWeX7RQ31ta/8+QTf/djj3QbXe2wrOtFsdSJsDDJ1YzOYvjpT/y2iv18LdtNWpgJ0yGGoGGcNIKoRGymFMaUAgEFUgkARQkRSsdS+VL1sZLUspgRA4gwUUJijA1MLK2MMHIEdTVGXGIlCUFchERjqmlWGFkMtpSmohxhiXCkZVNLpYSkGlEKkhOuDANjpLTSEqRQWgJLiNVEpCnCOkEok+EysRS4STJmOpV+nE80DdplixqBb2BNpRi3cM2zp5/620899+ItD7399ocf2X1kEhAstQJNGTOZFPDNb3x7oFIM+j2QTMYkDJL3PfxewGAaCjOsQWJC8vncZh1+4R/+zFe+8pUkRlIIpDkAvPzSmZtv3XfgcE6iOEliSlyNbYngwquLP/vxD3/itz7/J3/8FzxUTz/9zC233IIxQpgLHhGMQWLT8GSI2p2o027efPPRu+788Ucfftvs89+2eSJVIghoTUEmJkau4k6zMelad45W9nrE6WwaOgIDgUgIcUAJQNp0s0rGGARwoMTu93gQcc8weMwDnXR4NGCZQFC3389ZmmCNOQcteD9kiYBC9dml+m0f+7nswz/exY5JTSUkCIUZZUgBJlqlmY9UgpCJIIaBNIKdtg4CpZXeVuPtrG5SyrTawBgzxq71et8M+/6RFckbXowBX2NIKYQFAE7v+kQwwsxevFY2NcjOq5/4LTn96pFyRsTrhmVCLEEE1LRE0NYO0wQ0TiMa8TZTXyOkU4GaVjtUMHQDYf016/ENnxuDvsaP3jarfANh6Ho/DABAg9ZYC4olINCIgSKAGah0/8YBKUUkR1IjHGLj3HrvLf/wn8H990tFnPKA0IwmYDAc85gABq0U0hwEtQyGSJLEBBGtESFMa6QRMMYQMKVAbncYU19krRVSSgEgSoikJBGcx7Hv+6urq61WK5PLNhqNixcvzs3NEUKyXs7zPJMJjYTASdvvWKbruLmN9cY9d983Pjbyyiuv3Hz7HUghzACl4d0ACHMgWiMiBDAMYTf0PAzh+uwf/W547qVJSzPLgKADmEOGRVHfpDmNMAH1poPhR9as29/2G2QT6Frp+9qf6+2u140vA9hWLb2R6Y4AYYQACIAiSGvEyfZF5Ea55IfxUtu/7x3vvhrDubNPdNudgxMPPPDAPbZbfP7554HIsbF7Nuoblm3UatXVtcUHHrh/fX29Wi1OTNSyXu1jf+8nvvqNr3uet7i4ePLkqTtvuzQzNYMxOI4jdo5Ubt/v9wvZglKq0+kUirmzZ87dfPPtxWIpn88jLE+devnq7IV2B37rt37zne95by6X+do3X33XO4oDA5UgjAuFXKmU29jYiGNfiMQ02e233z46PNLv969culzIDzBC/ugP/2xsZLKxt0+L+UK9XgeA4cGhJOGmac7Pz+/Zs+e2W26enp62LSObcTc26qC1ErKQy0uttFZSyjQpudlsnjx58tChQ6VSqdPppsakSZLUaoOu6y4vLxNCpNQAkMY/dzqd+flZAOW6dq/Xsywrm81WqzVKjbm5hSiKiqVcPp81DGN1VY3vGhFCYKz2Tu7qdHrVSm1wcGB1dYVzJCRJkmR9fbVSKTFG6vX64uJiHHPGzMOHj1JKX3311WwuUygUtNb1ej2TyVydujxQHbz51lsOHDrIExVNTRuGlfFyq6tru3bt3traSoFR3/d7na5tWqsrK2mEcLVaPXz4YL/fZ8wsFouTk5Nf+9rXSqVSvV5nzKxUHEKIZdnZbI5S2uv5R4/cFIT9gYGa1urll08NDQ1ZloMQuuOOuwqFwsmTJ69cmbIsy3OznU7H8dyXT71CMHPcTBBEQRBlMpl+v99otEzTxIz6UUh4YllWkkSO4wCgRqOxZ8+eIAgUgkQKolCr1apWqwsLC0uLK6Ojo1EcI4zb3Y4QKuNmoijiSCqC4l6/Wi13Op2vf+Mbv/C+9x53otYzfzqAsWFavB9hRClj22a7JNWgKa0Q1QQQApUA0ZCEQDCYnpA6EQpcdzlI9r3zfXD3O8EqcA1ag4kAAKQQhFLQiKZ+DiCxkgyjWPKNteULr57zPK9arRmmnc3mXCfjeZ7Q4GUyWilECUilNGCGNlY3GCZSyjjmSsH8/Py1LZeUMvVfSFMygzhEhBgYp3juNeB7p7rCaTWfztrpHM2oOTczNzMzVy6X9x/YUyxlkyTgKqbEoJjEgfRc58L5lf/4f/67MOofO7bP932/13Y9Z32rIRGEwDKWk3TCDGOebUIIp7/xgy/+1V/OrK/uPnxgq90mBKuYYU04lwlXiFpBHGewEsInwAjGCKQQAkADZZKQGAG2rETIJEwUpaCRIkQg0ErYUpkKeYiRJEJSGYhIETOMNAKhYuDIIWYWkbaCWCggGCjzldSUACFYCSKVo7AldJaQdhwEpgaD8UC1Yw0UegYNLKKxsIXKhnyIo2GlyxGmAdckUQoUQRGAAoU4GL3ggJeJErn8ncfPf/O7N7/jXTf95E+O7io3Oxq7cPqV5urKyk03HxCxINjbWG3ef9/dY7tKzBRcBQ51Yp4QQqiJwnhrZLj86Ps/9N3vfv/woTEpIImTJElaW6HkOYGUZdudNspkoFiFV89O/8zP/IuRgcGZK3Nh17/1liOAon6/53lZhl2eYJtl15bqFjH37T94662H3vLQLWHUTAL/loP7Vbg1o2MpEqbUoOEgmbhBuIfrO0eGd5nY6DYRYLA8rTgCDUiCCrlhIUxlFJmGC8wBb2J+qWlVBiMRF/KOqbSXSNMiURJ6OYZ1H2SIUAK2w3gYZd3pMDrydz+efc+PdUOFXGRAgigWMcUMAxFah5TihHNglACzmAGp2ON69zbFDFPq1Y8KvyQ769yPeP7/wbENOqXOTCAwjgADJBhMRxDsCyibLgQLM7/7H+HV07eO7E66HWJYWktEESgKRGkGEimkgSpENEYIa7QN+ZPUsAFhfCMsuLMMo5Qk/iMAqe3lnLzRYX773Tt0eAyUQhIBoZgQAyRgCthKYiBaEscEEYGOgRIJBFjm8ob/wD//v2DiCBh5QgypNdWaUqIVmMQE0IC4Rgqx1PkYGdQAwNdqQdu24zg2bUOCJmTbxk8phbWmlGICQnClNUI6SRKE8Yc/+pHLly+vb27sPbB//6FDE3v3PvPMc08//bRlOrlsNub9mEvqUKWxTDTSIKX80pe+9Iu/9A9vvf22TruTL9dAQBJrw0UKgGtBEIsT2zBYV6lsRkK4Wv/8J5OXvr0/41ANIDSYBmgCsbSQuxNio/8XQ+RNGoQYbTeertfiKZrxWjwaoe1W5Y2o9o3l13Xh0rWSC4EGjJBOODJtAKk5JxSBDEEKyGTmu745tC+73/r01x4fvfn2o5N7bYusr62UyvlvfOtJKeG+++65cPF8oZA7/cq50bExKeXM9OVDhw4tL6/eetuJvRPH/82v/asXX3rpnnvvunR1qljMpzEqlIKUWvLYdV2E0OLiotayWKoImWSybgoBu667trZWKBTa7XZ1sLSy3nQc53Of+9czc3Of/vSnX3qlNTAAxWKRGQ41SKPdWl1dNV2KEFJYaiJMhwCWA4Plq1PKcsysl/vhs8+ajFHDpM1mM7V88H1/bGzcNE3DMBhjR48cP3XqVBQlqQ4rpa6PjY0JJaMoarfbvu87jpOCcRsbG5RSx3Hq9Xrq8N7pdPr9PiGEc6mUQoikXGPTNEul0qVLl0ZHR2u12vz8YmqMm+I4Q0NDV66ebzQ3T5w4ccutJ/bu3buyssJFsrGxViiUgrBfKhcpQ2fPnt3YWLv//vvj2M/n857nTU9Pb2xs+H4Yx/HW1lYmk9m7d1+lUgr8EBM0PT3LGDt+7CbOebPZtC230aiPjo6ur9SV7AwMDKysrBBC0no2hQVTunqSJLlcbm5ubnJyEiFULpcLhUKj0XjooYeef/55KSVCKI75+HhpZWUlDMPx8d0YGVGULC+tNxr16kCREGwYxsbGRhQFBw8efPnllxcWFhqN1t69ewVPDcRZWpLm8/lsNt9sNrvdrmma2Ww2iiLBxbUSIeWrCaGklKurq4wxz/Oy2axrm41Go9FoHDt2TCuUNhqDIBgb29VoNBACajAptN8PDM/DWimMZhdmL01dufeXf6bzwhcNavqdjpsr8GbEMnngIWBASBGskQYggFP1n1KAAEwTMCScc+wgL7MpSOXm++HEvZAdCDgYFhgAIDQQTYglEo4pJDzGFFGCF+YWGvWmgTWhGGPodttRlCAgpm0bzKLUyGaz2UIx5ZBmMhnTtkzTPH/+fDabz+UKCKE4jpNESKkWFhZy2f5AdTCXy0VR4DgV06KxH2GC30iu3JlB0LUGAEJICAEAhkFM037ssbefO7f8xBOP33f/7ZVqkSCklFKSuo7VbsFv/9YnwpAfPnJ4fX0BADJulSBCLXO9KSzHVkFcNWxg0Hv21S9+/k8Xtza0xUYnhpZX5ku5UpzIWGONDSSVVrFUIg0rxCA0KIWwxlpToRFJCA4J7mPkI8xBIY2pxoIghLAmmkhEubQkMqU2uCZaIYSIBgIoAqk0wkqaUrkSOwT7CnGsFQKNSYIVQtrQmipwhXZBUYo5Ah8gwTjGBAMTBPe0TAhQxbNcDghdTVQullYkqQJNQGghEcGIaIWUVAgQQdpm1LXMAUVnvvv9l5549r6f+LGDH/0QGHDx1CmGSTFXXl5eydgOlv0DeyerFTuSPiZaAULERARpSADJXk9//Od+6ruPPxUEUT5X9DtRHMlnnzl5623v09TQAo8NGkvLMDMNu8f3/OZv/BoAfueD76ruGtnc3ATA5dIATyAKMQJzdaMzPr7n3ntvPXRw/NCR/OrqlmmBYRuO4wRRrDxmWJahCBOSRnFFiJvK+XGi3dinkCCCEiAaYcYAKwlIJSIhWFnMBGSGmG20xEI3YYUSMmkkQodKB2sTQd61PFsn7a5hY3Co6tRRoXqpJUbf+kjubR8Aq+BqhIHEoY+VYRhUx4AsDToBYhjMAsBaglCasRvXMgCkXlN5/P9QQv1/PGTaMBKKUA1aglLgeEqD1pADAL916VO/Sy68fDTrQNAyDUNLinagN4GkQBoQIA1UA1LbxMo09AWhFClScCOl+po88NqfpuE1PyGvbYRcO153BgBIXTYRAGOAEtA6pWABRpQSjCWIQCd9ZBrYdTs9fnGx/tZf+Xdw6HbIlEBzEQtqoNQYTMZASUrPxghkehai0Y0YpmEYlmUJISFVGUuttX49xpmS5CgxLPPEseOFQiGKolOnTh09ejRXKAFGD771LcOjI09+94mrU1ODg8OlbKXe3vLcIlUQ9/u2ZbiuvbC8uHv3RH6gGnX6rXq7XBmQnIKFFJiBSDKGFXXjbFZBvLXwJ5/g516YsDE1BCQJEKo1VUCQJhg0KA2Iv8b/5kZxH0JwrYl4/dtW10fbjxKfvhnz73/5jp0jRaQlR7alIoEZIzbTnS3EDChXFrvJAs0/8NP/KPyDP9p78GguX/Am9o6N1X740nf7/crBgwe1wpZlNJvNw4f3X7x4/uTJk29729tAyX6//41vfH1+Dv7dr+3zPGdhbvPETT5C6OqlNtJwxx13fP1vnon8IOjHtUo1SRKMcalU4pxn3ezo6Ojq8lylVB4YGEgS1W63BwdrQdD3cvlwqzu3sPTYj//EO9798G//zicXV7YuX70yv7BUqlbCyLdte/+BydOnzkop2+1+PD7e67f/9PN/BQoGB7cwkLW1FlJw++1H6fr6uuu61Wq13++fPn3q6NGjnPNut/u1r/8NoahUKjiOozVaXl5++JH3rq6uXr5yJUkS27Ydx7Yss9VqeV4mpZ9ns9mjR4/Ozs4GQcAYa7VaAwMDjDEpZbVaXV9f39zcTOuG1JhUa10oFIQQKYhjGna3273tttumpi8Xi8X9+yd7vV6n07nttluSRDQa9Ww232ppxli1Wr7jjlu4SMbGR8ulyle/+tUwFKOjtSiKPM9DiKQ+qJub6xsbGx/+yIeazS3PcwzD2LZFrdQ8z1tf3/TDYHV9/fjRYwgh0zTjOE5zAwnBUgrPy0SRllJns/n5+UWl1Orqei6XW11dHRsbS4ubXC53+vTper1x9933njp1aqveHB72Tp58qd1uW5bperZlGUuLK1Lx1CdsZWXFMIzHHntsZWVlcWF5bGys1emUipVmszk9PU2pIaUkhAVBlGbaJXECAGkIt23bCCHTZAAQBAEAppS02+0gMGzb3dzYwojath1FEecSAM/MzDDGCIkGKtVeR+Uy+Y1WM5NB1VK1PFB59eKrs1/9ykCpXJ+arw4NiG6fZXIgk9fdEzgVP2sNFIMSwHAihXIyMXI6HLt7Dhfe8SjU9gC1DYrpNntjm8OugWIEpkkSiBXguakZSDh2zSgIUwZ6NpvVCikApZTGaG2zfnV63nXdgcHB4dFR2zN5JGdn5xzHQUpXS9XBkeGDBw8jTGZmZs6cPu/7PmBEKfVyWcBAKZWSw43ydX0dXEAIpZuVNFEkJa5SCp7tPv6tl+vN9bm52SPH9u7dO95sNQ1qxAJvbUXnXrl68dyl2++4pdlsai1z2awF1szmQmVw0MtSv92q1Aowu/78F7/03LefLA/VPIvFVEUyQVqxIDaxURdKM4oAQCslJFJAMAbQEqRASuPUkBF8Cm0KHYpDAyeKYY00whqQRKAwKK4MCa5GplSEK6xAI000QRo0kgoprBSRyhHgEt0hKpRa4W25JigJWjKtsxJyWmOsQq3WCcQYGMEKsESIIwyK21yUuB4SupqAEwpQWhOSSsMlRhpjrInWOgKICQkYpgjRlj+aLY1J+tzvffrF737z/b/8K1sLU4V8dmuzmXHKqwt11/Xe9uB9kgNhqd5UE0IRFkorSkzfj3aP2SeOHZqavlQtD7subNV7L7300vLSw0dushpN+P3PP/PdJ55dWJq/455bP/ThH5+ZvnjnXTfNTc3nswWkbRG7YV+3mgFC8SOPvOfee44PjpgI9yWN3byglHIkl1udxVY3dgc0s4hEOOjkgU8W7EMFLy86CfSBCEyx1lopBBgD5pLHrmPJMABGw37X3nvXsy/P1AWmmaxUnPAww4iTiBzBFddGyRaSEZhOIjh3vOUIWXe+p/zhfwDOgFaUdGMwiGW4QIH7wGwAYAhbOpGIEQCMEJAbA1J2brsbHB2v+139//tQABgQJAl3CIFYA7OAQASk4zcH3AxEW3P/47/xl549WPCAx0oIbGYRp4BAU8GxUiAxKKYAKwC53W9LS38AKTAAUkRhdK3Aeo2PJbz2Qdrw0AAKMHqT1tZ1fk+qgkuNUrFQkhACQLTUGBhIDEpiAgAciEImBUb7CZ3xk7f+038Ld74NWEFQRjmjkKSiOQ0aMwQaA9KAsAZKUmBTKwCMcMoV0qZpFovFxcUlm5iwA1++8XNiRpHUvShK8ahCIbewsNBut3OFEgAIofbu3Ts6Mv74d77zwgsv1CoDpeJgfWMzm3eIEXd7DZq3DIMSSlcXF1987kWs4S0PPpjNlttRQCyXUQtF4BIJ/vrsH//35PKpyayFegmEMTANmEsNShtIMdAK4wS0Aq3Vtlnaa6wTbvzoCN746IYj7XIBAq2vc7B2bB1e+8obHl5na12/4tu6Js4xdXQUocBHmQwAmV/vLBb2PPCLvwreyNm1jmGZgxnH84qzs9MjA8P5wWoUasDkmWee2z0x9uqFi3sm9+ULlempufvuu/fylYtRBJ/61L/23MqZsxceffTt3W7/3OkLBw8Wb7n5tk/87qcIgXK53GNBr9dLHS4LtYEo6M/PzhWLeSl1GCcIUaW1UCIRcRz4dsaIY/nCSy/VBkcqg0NT03O9PsfEsiwnCCIFuDowHIR8o97cs2d3sVzp+f1er3f0xARF2DSM0A8sm3S73Xa/QR3HqVarqQBw//79cRy3251Go5ESs5qNtm3bWkNKkeacj4yMAIBt24uLi2EYUkoNw2i1Wqm9+9raWmrs1Gg0TNNMmfwpFF2tVk3TTINrLMvqdrv1er1YLKcxpVtbW8eP3XTl6iXboXfffTfnXAjR7/cXF+cHBgYnJva2mm0AaLe7vV4nl8tsNeq7d4/v2jV29er0vffeOzo6+uSTT6Zk5+Xl1UKhcOzYsa2tzW63//RTP3jgLff3ep3V1XUpZalUIoS4rjc+5jYbXc/LpDhgp9OhlKT0HdM0rzmB+X6fMcYYi6IoCAIAOHTo0KVLl9IW1+rqaq1WO3b0RKlcWJhfWlxcjKKZxlarVC4wRsMgTpJo9+5dm/VVrfX8/Lznefv373cc5/jx4wvzS1NTU34YgsbX/OvSPk0cx7lCYWhoaKuxGUWRbdtCiCRRlmWZprm+vl4oFBzH6fV6QoggCHzfz2eycRz3+/1er5ckwvO8VPMYx3Gj1ew0OpOT+0zbVlp7nuXZZlJvfePb3/jZmweqIyNJp2k4DiSxFJoQvD1/bbeCYVswSA3gigsJTjY0va0YZ3ftr77lnTA0mSAznaMAJEgJhALGQgBOA1lBYlAYQHFRyOZNC0dxYFlx2jcFRAg2GDOTRCRJUqvVDh89UiwWldJaQDoMXNcNw8h13dS3YmOzvry8vGvXrk6no0AzRsrlstLbupgfJe2+riLWOu3IYoyVgnI5/yd/8twrZ14+dvzg8WMnthpNy7KikEthDNasr80tCqGSJNGgs9lsr9djTt51HIa1C5ArFBrfe/Ybn/6smah9e3Y1gC+srdByQQTBRLZQAbMXJW2pYiYlxYkAH8mAIEmQ3BZJpftIkBgnCPmU9CkKEXCkiQa8zevQWmokE1OCA8gQkiiZzv/pMowpU1qB1lhJQylTACEACGFMNMJYK9AKS20pnZM4L5UCaWNpSogRkYTEgCUGrMCMZIXLWqyLMXixJEogRPS2gJISBSgBpogmqE9Ii6B1IglBBc+RYb8q2M1jIytB79P/9l/OOJVdY+NxlCBQDJHbbr4pl4VmP3ZMBpQmUhICCmKtlWlkolC22vDRxz74K7/8q51OjxlWvuC6Vm5q6sr3nr70+OPfTWKrWBi4+cRNjfXNXRNj+/fump1aDH1pm4VWM4iCwPUKt9564MG33n3oSD6ThTDpAe33I+kVvchPqGudm5vrAzOIgxUWIpa9VtmFfaVsFodMdSWJMNUYEZxaFCmQAMR0IBHEsqNuk9Z2n+10L/YDnBviWikuLcqoji0d10xSJCDCvlPM+5HPndxSD1sH79z/s78KRilKsKEBmSYIOP9Kd3mzG/aDA5PDw+MsWzFT6EYpwAQw2n7wpgvV/+ZDYVC2ARBywExECXIsqcMBj0Jr9tLv/05y+tnju4ZgYwUQwpls3OiYZh601goQaAySAmCZ9n7Scm37jsOABFEA6DVZKjf6WsG2TcPrHCzVmwkM4Ud38ThIwAQ0RkCBMACtpMAUAARoAGZ1BZypN+//pX8BdzwIdr4eKgtDhgAgAzQoGWmkKaGgpYY03ZDilF+VplmAAUhrjRkju3fvvnz5iuNl0zoyRcq2JxakUv98LSRl1LKspaWl0eHBSqWysrLyyiuvjE/sRQgRisMwNg3z0Q88MjEx8f3vPb22slXK5ZPE1yCZxZaWFs6cO/s7//cnW1vt97zr3XvGx7yMibDKWqYPgmmNIQbRvvA7/14vX96bt6TfNTI51WthrBRIjUAjCZqobQvaHzmU9DXjq+v6QQ3w5oz47Wt3w3uvsSzelAKYXso3OQdoRLSOOTIQsl2VCCGgR81wYNf9v/jvoTAMhF2eWSt40dn11dZGB5vs9gfv3Oq1K+WhE8fJZn21Uq6uba7kc8VWsx9H4eZm49DBowf3H1paWqKk1WjWTSs7PDz8sY/9BABkMpm5uQXHpL4fEkBJkjBmrK+uIRVnsx4hBCFUyJcREISQYVKtdRj5rmszSoul8sjwxH/5z//tn/6Lf1mtDL348ssnTuzN52nPDzFGVy7PNpvNwcGBkeHxpaWl5aXZMAgxhlql/MEPfOD+e+/5zGc+o0F+8IMfpKurawcOHMxmc4VCYXZ2hhDS7/dLpeLg4ODW1lbKTz996qzneUHQd10XEQQA2ZxXKhdaTZyuVYVC3jAM13UpZWkrqNfrFYvFJEmazUaSJLlctt/vAehdu8aff/75MAyHhoZSiky9Xs94OdOwX331QrGUbTV7V6/MHD58sN3uvvTSS3fddc9tt93xhS98YWZ69uDBg65rb21tep63sbnOeVyr1YaGhtbW1i5fvpzP58vlahBEoyPjs7OzLzx/8j3vfdeRI0dKpcLs7GytNjQzM1eplDq97tBgOQhC13XvuuuuZrPV6/qYknw+H8dRGIZKC8s2AKmZmTXPw0Ioz/NSnb9SqlAoBH7k2F6v1+t2+oSQfZMHjh49/tRT3798+Wq327VtZ3h4uN1pNhrdtzx4f72+Pjo2fPTYwUql8kd/9FnDoEHQ/8M//IOJiYl2pxX4kVCKEkNKHQRRPl/EGEdJF1MaBEGKDKakPM65bZtCiDjm2UyeEiP1gDAMKw0panU6UkrHdBzHi+NOGMYAgDGYjun7Pc/LlPKlkfGRi5fPGwaEQceQATVMjaDfbFsEST8guRzhEoQCpIEASgFCtBOkIBUwW0ihrPxKIEh1tPbuD8PowUQRZTKiQUYhZRQI2rarY4ABWq12p7Nhu5aWqpgvEITjOBZSG4aFgBBqUmJIKcMk1hodPXp0z/7J7RtRIUThwumLnHMAYIxZlp3ezCsrK5ubm7pMHMcRSoahnzLt4ji2LOOaSh2h18wuae9KKSWlpNSg1NBax7HK5fHP/oOfdv/S+uhHP2QYyLa8tIlIkBkEUB0omyZLxU2dTsfzvFDEQob7hqp0bfPk5/70la9+7eDoeGSxadm/GvfJYNXALOfDUE8NuHiq0zYzRkhUQgyNVFOpglIVRUhiMAlUIyzSvAysGYowxIyEWiVKUpXeZ0AIpkiboA0hbM2oFEhpRYCDBowxBoQ0VpgooBKwkhgURhQjrJRERBGtQUlL6YzGGQmeVgmILBZ5grQWCBscSaFFhsvhAMYFHeTSiyLEJUEYIS2USohiiFoSaKyZBGKbDUK2qN4oZtpJXCIwalukn1hhw7bUwVqprY2F3lYxX+00Wjzu7d410G1DJmsKBQQrpEOEkdZCa0QwIZj0fXX3XXtHR0bazU65TIQMJWJ/9D8/o3SUzxddu6wV6bZbtmNeOnfRMmwDF6hiG2tNPwpHR0ff+tYH7rz3MODYcMNO1LQdTBmYzI6ixHS96YXl8wvLRiZHtCGTBEAYVI4X3PEC1a1VTfrUUBgDFpykTSOJtWEnEoxEaSlxtbbu2n/+g1O97IjlWDyICLEpYlF/awjzPRk3w33HsaSIWGbo7GpQvON9kz/7K2BkOgnPGVh19OZ89Puf/uLLlxZihe6682bFea+f2X9wzMsBIbBtMIoAiH6dhvb/++P/eXGGAIFCwBFgIARCDllLAbhRBLKz/Mn/yK6c2lO2ZWudODmQCnq+mctAwgEQlgrzndQpjAAhhTFgtOObgBAAk6DSPlOaibhzV75GHvjGT4WvWcHcuPDfiFztbJ92QH+NgQicWsYAUUoIjCUQQ3Pd58Z0pO7/lX8Ox+8CK9tRkLFtrCGWwBBgncbXcAAhEAIAmobJIAYgAUSqJFBKEYwAYHJy8vHHv4sxBsCYqGvlYQropn9akiSUmNmMG/S7oR9Yhuk57sLCQhxFhFEAsCxTCI0ROnL08O5d+5749vcX5mYdSzfbzfGJoYGxWqvVOHHixNzc4lvf/rbzr56JReQoipV0EKYqgtbs1U/9lrE4N1nKBZ0GZljHCTY9LTgA10SClggFGmEOCCGEAe+4n75mZOywr7YNLXaMMd5s/KDt7x22+6jXYwcAroUv3XDmNygNr/16BKCkwqYBUgMzoFC90mjoytixn/4nkB/vCjNLWEaak7WB6YUL040VJ5+/3XR6q/Wt+gwAjI7tWlpZsG3L94OpqwujI2O9TvLC89/aPTHKGDt08ITnec+/8LJhGFHQ/8AHPvDpT3/GNE3TNIMgcA2HENLr9VKUMAx9z3Mdx8EYR5w7pqMUrzfrmYJre1Ycx3fcfs+X/uarppU5fOSmf/SP/8NNJyYazTZoEidKSuU4mYP7BuM4vnDucq/XI5TYzDIM4xf/4T9+4YXn/8e5T+/bO/Hii89/+pOfpDfffHOj0TAM4/vf//7Q0ODExESSJISQlZWV1OVSSjk2NtZqtQqFfL1eN22r2+32+/0wDIMgpJRijFOXy7W1tYGB2u7duy9evJhyuRqNxujoCOc8juNyuewHvZdfOZnNZj3P63a7AHptbaVcrgZ+mM1m45j3uj6luErK/X4QR0mr1fnqV79++fLVRqOhlDpz5sy+ffscxzl67Ig8I7rdjmVZUZRsbGzsGt8dBMHy8jrGmBKjUqk4jrO4sNzttcvl4ujo6DM/fPa55165595bXM9bWlryvFy7teF5OaUU5zzwI9va9qy3bAdjXCgUNtY7uVy2XB5I9YmtVqtYLHY6Hc/NJkkyNDTUbDYZM9fWNr797W9PT08LIXK5vBQ6CPtDQ4NxnO92u+9973sLxdyZMy8XCrmf+/mPv/LyqTvuuKPf71+5MjUyMlIqleJEjo6M+3745JNPIkRyuRzs5DBsbGwoLQghqWixUim1292V5bWBgYGNjQ3TNIulPMZ4YmKiVqudP3++3W5HUZSGwwghstlsqVpaWVs0LJb3ikkiNtfW65vrWOertWq1VDw2VnJzSX9BU9MAjGTQR4BxupXWO+aFeueO0QgwRZa72PJxbffBt78PRiaBeYrZCsBCAAYFDYCRRkQCxImyDBwn4dTlKcc2CZCBci1JuI40TzSjViaT0YB9P5QAuVzuxImbKWOgIU4SwzCUSggYrVaDUooRNUyaWvyl0opisbg9G2NsmqZtm1JKSq8n8LyudwU3bMBSTXX6rUrFuz1arWZ+9Vc/DgCdtpBKAoBWKIkTkxnlcqnX76ysLo3vqsU+JHFoEzKUNbYunf/Tzz6PL1y9c3hPyHnXUJsi6RqYIi27vV3UdXuh6vTGcm4TiZ7kEmONdYJloCHGiCPEEAGlt62TAWmFBCABgAERhCjCGJDUCmuJtERSIM0NTEErrSVgJEFjnboYIay0IUESlWo/EdIMAVcKEJJIMwm2BldrT2lLKALSNSAndIRVRKTQEpSwlB5QuCZQlgvCJUgBDAMQpTmkQSSaSkCK0J7BGiatM1UnJMm4loBGNyw6xCaWIeOk26a5MmNIidA0dK1mHTu2y3PBjwJiM60xgEYYEBDQoLQgGDCipgn33HPPF7/wpYFaybSQaYty1bWtKgBK4qgfROXicOD748O7kli1NuN2q5fJZN729rfcff9tQ8O2RAnQUJEgnzUwgTiOI64AU2raf/alL/mc56tVJTWVyiRywDVHPebJAENEMKeIggYpFQEArEFpBFopLajJbTfOF79z+tKSMLxMOdFKKWVYLog+8fsDJTLiIjv0lVIhsa6u+bvufO/Q3/snYGR6CWDKlIJvffvJ//j/+u/F4q6h3Ye6fnzlyoyQnNLDhtmuDeaLA8BsAAQKpARJgabspTft3/zvOwhgLRRCBDImCGAqAhld+O3/hM6/eGjAgyTUQgFDXGlm2aClYgjrlAKOQLNtzSDCqbELhnRjpgEQ3g5teE0wzpt2l2HnR/AauOpaIbVz977hLRghAzTSKu0HKyUQ1pgowKA07ZnuTEhu/uVfgSM3g5kNsEHBoKAIwhxrhNBOHh/SgAFwOix3vGMQIHLDZKK0xuVyvlwuB0FgmnZaTqVuL9vvQYAx8EQShJGWPE5WFpf27ds3Mjg0PTd75dKlg4cPI5rWJ0hKoBgyOfbIo+/8889/YWl5+n0feLRYyqxtrlUqg51uf3LfwbmlxYHaoOM4IDgimIoYosb8n/2e118cquWg23MKOYiDKOxbtosIQQgxkBoJQBJprRBBGmHAr6+ZXlfaXttC/6j6/oYC63WvT6/Bm13GH3kaTAggLCKuDO98vZ05dPvk3/8lYBXOPIMBcGhsdZ9pzx27ff8+1z555uzqeqPfi7/85R8ePlzxg1HDxP2+/+q5yx949MNxJJVSoyP9r/7ND0ZGnEJ+YP/+yedfOHXLLbcE/W6tVuMRfOWvv+VYeYyxZVlCJELpTrfleftMk9Q3toQQBw8eXltbU0w5jiNkkstlkyTK5nP1Zmt1dZNQ6w8/+ycTu4fy+WLfj7fqrUplMOYiTecrFov9fp8xo1TIB0F/z8Sur33ta8/88OWRwezo8MC73/3ulZVlajBrZXMlCPujo6Oe5/q+TyltNpvr6+umaRaLpVKptLa2BgBRtC6lDFohAKQcdtM0CUV+P5idna1WqwihIPAPHTq4srIyPz+/a9cuAAjD0Ms4mUyGi9g0zUKhkJJgoihKXZrS9c+yrJWVNcOgmCgpRr71re9Uq+UPfuBDc3NzU1NTY2NjegitrKzMzS3UatUnnniiVqvt379/c3NTiD6lNAiClITIOUcIhWHY7/dt296zd/dzzz1z8uTJtbWNkZFKGIau50kp19bWQON+PywWykGwLqVMkiST8WzbjpMw1fY/cP/thw4dkQrNzsxvbm6WijQtgdfX1x3HKRbLQqgwDBuNxoULF5MkGRkZ4ZwLnqysbCglB4cqzeaWBsl5fPz48e88/u1arbq6tvJffuM/79279447bms2m5SyOJFbW81KpbJnzx7GzDAMMcZaa8ZYr9cjFKX/jKKo0+s2261sPre6vg5K5XK5brdLKeVcvvLKaSFEpTIwOzVt23ZKnC+XKlEcKi2FQFtbW0mYEKIjP1iJ22XX6AC9fHnj3tv2IIQAYyBYSb7N27ne+9UAkArIgRmR0jE2zWJx4p6H4OBNIE0NJgWIEwVMAVISgKcTV7oJBKhWahOjE821LS/jFMp507anL89JgQEjqbDW2nUzA0ODe/ZPKi4xI4DAtAwAYCZNkmhubgZjLKVEiJmmSQiJoqjVagFALpcLgoDLJJfLua4rhEjZfgjtEA4AYGcDrbVGO9wstOOzp7XGGGvFlUahj3kiEKEGo+n3oZX2AzE8MvBPf/WffPYzv9/ubJy4+aBO+ihuDDB9+q+/fMDK5exCvx3GBXcLFLcshiXi3EUafL9iZqzAb3WiTM6wpOBKGgBUaiw0VgghJJBSoDHWgJEC0ForpZBUFqGp8hkprbHSWmsltUy0loiCRkpiBYQoqQVGqZk01dgErBDRBEu6nWBElE7jZREoR6KsxqbWRCSIgK3BBEVT0w1AVAsP0RzClhBICq0lxlprqbACJE0sQahYGdKye4a55tBpG29YyEeaAQKtAx53JKZSF7XJTAOD9hymRcyobAcb7e7UwTurck0KhBAYgKhUhDGmdSRkmzLmd7BJM2976K1/+cW/QkgjLDr9jUzWFdxPYm4w6nksjiIk6crCWrPZHKgM3377ocd+4sOVKmy1fWLGlMZABKEGEOIHsesWeaINZnf70ekzrxbLJde2OBcIMA7DIZvm4jjpbxUcgiRGCQVCEywTBIZCIGMIe1ahupHQuFB7aXbrStvJ1/ZI5nHe0yZWhJEYj5vuPg9s6FAWxYrUY5I5evvQT/8CUEeGktkEEXjh5cV/8e//y3133eZYmTDuFAwbYXf66rJjFYJIA6aK2pUBQk2lQCoQCjCkzYY3ocb8bzs0BoEQIwGAksKL+6D9V//rr4nZM4eGKhD5EGnk5FQYsYybiFhKZdIU2sSQgoSwHThItqNj1M4Cq7aLFYwQuZZdnP7SN4UA3+xZtEPMet2ifQ3e0qmLsQRmAoCWMSiBkIyBdk1jKtR3/5N/DgduA2wl2rQAAwgpOCLUSMtYDABIaoyBYUgTWwBSr1MkOcIKsAEIY6y0llIwyg4ePPjUD54xTROldrGgtNYpnR8QwggRhCnGoLRnO/XNzcOHDuWyWZnwqampYydOAIDg8po1fxxLREGy6OGPPJor5i5PXSkV8ssraynfSwhFmAFAQWuII+D+yd/7rwPtqSEXJXHHKLrR5qZlGVbBhTAEYgAAUgTp1OBGEZky1tV1WuoNCoPXWl1sP7ttYPb6QQI739XOSbZVhKkl9Y0k+uuvvxE63JExaAQSKwEY00Lx5cXN/F0P7f2pXwCUA51hQjOCut12PY6PHL+5hRVixkCpMFAd3r3rQC5fm5q+jKkxOj769b/56iOPfEArcvbMq/V6/cRNR37vE//p3/67X2t1uh/60Dtb7SiXy4V+r9vt1yrD5XLZM4pSyn6/b1nGYKXSarVWV1ePHDkQelGaBce57PkhMQjGSEqeCA4AluVUqoMnXz63sv7tRx79wKXLlxHChWKu223Gcex5nt9r9zpGxnXKxQLSsLq89PxGvVLKnji6t1QqzE7P7BobP3b0KN23b9/xE0effvrpCxcujIwMp/LATCYzOjo6ODi4sbG5uLBsGEYQRJ1Oh5lGt9u1bTtFYQ3DSGJRLper1aplWWNjY2traydPnozjuFKprK6uhmEQJ+HI6M2maaamDIyxer3OqOk4ThTFpmkCoHwh6/eDQ4cO5HK5oeHa888/G0Vxu9198snvj4+Pj4yMhWHc6XS63W4+n1cKGDVs204SAYBTKebTTz9tGNbg4HC9XndsL+Wqnz59Wko5Pr77iSf+9vDhSUppvxdubF4sFsumYZdK5TBIms3msWPHLly40Ot2+33fMBhCTm1gCJAaGBhYXVubmJicn59P860xxpxzSmm5XF5dXV1fXz9+/PjMzEy5XEYIBUEQhiEAlEq5RqORzXq7J8aef+7F6kB5fHz4zjvv7HbbQ0NDBw8ePH/+/ObmZr3eGB0dl0KfPHlycnIyVQimNqqp6xgh6Y4KW6bZ7/e3tpqc81438DwPlNrc3CwUCrZtpwEOUspms2lZlmEY2WxeCDE/P18eqBRzxSCIPCfrWu7wYK2+ubywcnVpcT7BrMgU3D7pZgvAAxGHzLO2TdUVBq3RTu4sEK00xqbjC7UpzINvfxjueAiUrU1XMcq5cgwMWmkulUERGOkdRRHmMjYAj47sXptfc1106cqVam3g4JHDjJntdhtRMvT/puy/4y3LrvpAfK0dTrz55VRVr1LnnNVSq1sJCQlJBoEAgbEHjG2wPWPPYA/GCZPGxuA0BocxxogkBJLAMooooI7qXKkrx5ffu/nek/bea/3+OO9VV0vN7zNzPvdz69ZN74R79ln7u75hZnbpwH5QCpiEBECwxiitia01djgcDkbDZmVCa62UCsOAmbvdbpqmtVptnAyjKDLDAgDq9bp1Jk2zUqn6LYzg61LkErsqVYRl+9XzlBDaZLkSvu8rh5BlLgrlsJf7ng+eojj88Ic/+IH3vfsn/saP9ba3pycqgsyw07mrthAnVjmAIOgpXLP5Tka5khXLdfQaGlSSeIWp+bphaJvMEBC0ZlAGXIYylwzWanAgwEo0QuUKLLBlstY6dgIkIGHpfMwoQTogEtIh6L0ptWAQDNIJCYKkLrRKPZlLJmBmAVxShZ0iiAgiAp+ddMTEAiSX3HkEYPBBhlJ7QOAK63ItGEsPf0CF6DOnxmQg81BtR/6Kwg0PRp4SCot0bECCBLQolWahB0WeaUzSYTWus02Wm+Fv/crPm7WPPfaxHxr3+kZgwUzAQggplLUsNYahTwSHj0w3JiZ7g36lquMwGg7avleLK/FwkGjhD/vjQXc0MRG++91vf/d73jM71yycG6Tp1HwImOc2V0oQiCKzYdAocpcXpJQoDEuptZTj4Uh7MlLAlE9WonpkgiELwZBbAAFCo9QEAEyA2kgBfs215r9y8trZrvFmbqJ4amgy7WvmQuXdatG/teUvR8aNexxHFzpZePO9R/7WT4OogC1kJbYFoIV//2/+y/KRW9izqduy0rPW2NRKGT391PNE9x8+fCBLOM9A+QJBvf57xW8NJOG9H/MbSoy/uAhj3A2b2jWxe/2bb+TW7FnN7XYnoXBJQzK44Wv/8mf58qv37JtK+22TW+1VIbFCSZOlMvBAMJlsNz8RBZVVFKHk6xkPctegC2WZrwLMUIZWl1diKj/yRqLPjVToXaAD3/jqjZ6V5QlNwMzkECVICUEAEjGzYB2gNxLeyYF5/O/+n3DbgxaijKUntSAHzonSQswaYAYlGRWyBBBAJYe7TCJiBiybho5YomDnyjW7+eabvvrVr0ZRVMqM+DqVEsuGnJLSpmkqAIVWvU633++XLOf11ZV0PPbDUGsJDNaCECAkSA0f/EsfvHD+yomTZ5rN5sZ2N9SiGI4G3azT6SzOz8LRfZAPYePKKx//b1Hn2nQoIB0rHWajfhCFYC2MEwAAtMACnNztOfBesYhqFxRlht21faOxPu7+nna3BXFX/fDG+xvUh68rh5gRiAhB3BBwtPvXgOn6WrBAIMnMCIXSxotPr+0svvU9s9//o+BNQaFA+lBYQNke7FzdWn94+m2jZPPKxStnT3a/Xv2zRmvmpedfOnj48GRz5vzpKwjemdPnH33LopQyCKK3P/bOT336DwK/ykaeOH7m6SefnJ+fr9erjVrTmw8DLxwNx56uRDWV5ykIOLh8uBLXer1BpVIpiqLT6dTrdQByzvlKJ0kyMTElhFpbXd/c2L777jsB8ezZ06tr1zY2d/IcnIXl5YlKHPthcPXyVa3EhatX7rrrrl/6pV/6F//yl1qN+vLy8h//8Zf+8g9/19NPfuOWW24Sly+eX7lyJfS8h+6/XwI2qrWpqan5+Xnt+Tvtzsrqem6KUZIKqWv1pjXke2GRWyU9gSoKK5OTUzs77U6nu7PTvnLlalEUSZL4vmdM4XnaDzQi9/vder0qxK5FXhRW0jQTQiJK57jdbh85ciQv0l6/89rpk889+3yt1jh8+CZnIQyqmxvtIIiEUM5xqzWZZZkxZn5+MfDjZJyvr205S51298iRm6ampkrfhH6/7xyladZqTZw4cRJB3nfvPVcur2oV5rnZXOtI8O647a6tjZ1TJ0/GYaXb7nnKB5QMYnun2xsMhuNxu9N79rnnwzg6d/78ytq1ze2NcTrqdrtE5HnB2trG5vqGp/S+ffsBMPCjZmPC98IyaMU4E8bRytrq0888X1hbGLeyujkcjHZ2OtbSzMxMt9NbWFhSyjtx/LU0Te+4446iKLa3t4sis7bI01QiGmPTNIuiWCktpWo0mlr44ESWZUQEQqCUaZqNhslwMO52+lOTMwgSQFQqtZJpFEYBWeur2FchoAsr/uzUvK/iSlgjQ2xzXzCMUwhCIyVFQWLSQhgnDCt2zGAB0AMHoIXRbihgW4W3fOAH4aH3gTcDlRkrQgDQGhkcI6PnKVAKQAH4ABpAsQQWXq0yvX9xo98Jwkq3Pzp7/lylXrn7vrsfeusjS0f2Oy6cSUAQoGMulBaARJY95W9vt0tXW2OMH4aFs9VqdWdni5kQUfsqL4oy30kpUcoSrbWMwFiiAq6EqfbAfMfsrsNXJcndWrKWpNQCmRw7BPTEcGQDz6cUIgUCYWd7Y2Em/Nj3fff5469WozDTUlRjwQDWCF+OPFrX+U7IqVYEMnK6amRcgDZGs/Fc1szzSpZpD4ZYGC/ogV4jSIKIQQgmIluA7SvuKy4EWuBUWOOB0WyYAABZIAkAZaSXgADhA0m0pICFyWMhPYPksOfJ7UDtAG/neZpbBM1SEqIEGQgRAQbWamfLLm4Grs88EoJ1iMJjJ9CSc8aBQXSAhoQDwUisCuePbOwUh0E/0JvCbmIxRCaJwloP0EmHSsQofIIxupFmJ0h7mGQ7VW0WnLvPq77833/nd3/yJ2IfGhNeknaUD6NkDKBCbwooRsTMgF+Bm++6a6MzFF5obdk6tEAoROPylR4K/4d/+GP/4H//X//aj310/kDE4cirFHFTsBgTZsoHoRWCp2WNnFQy8pQvAIrCaBVm44KsJTCd4bq1g7gqnOdAW0gGIBi0AxqzTZxzLANbmzGLt78yij7+9TPHNimPFrq5aPfao0E3TQwn/bh/9rZw5/4ZGWWdeq1xujNM7rx/+e/9QwgnDARQja1znoCzr6y8+tTLE1FjvXOla3Y6WTungYGO9MYC7Mljrz31589eOLva2+FRDyQJyiSCRCgYMoKUICewDsroGjAOCreLBzkCZ/fqFgJyYA0wQF5Y3uUNFQYyBgNoACzYHMACWAbKXG6BHFDBpnyzAc6Fc5A07ADGm1f+5T+NLhy7peHl3S1iIC8GIwAkECOQKTKyBp0AK8EiGhYGhCXpylUhIALn2AEQQhkeDQiW2TI4AMu7N0OvPy430vDurXBQEBgLpiCTc5GDKcA4KBhyAotAEkgUlnLryBpkHqcJaA3E0G7DcAy56xb86ub48X/6b2DprpT8RGpE5jyB1IKVLjemsIbQsDCGrXWOjDW5tZlxhXGFcdY4Z5wVxgjjnLF5nhORRMizbH5uqlGvDHptCWiyVAhVer4IIXYJZ1KgVhbYi+KwWjl/+VKlWW1MNkbjwenTp4QQZB0wKAVFQVrLzk73ledeGW/161692xn1x9nlldVOu7ez1rl08vzNB/eD68Hpr5//Nz9du3zsiCA5yk3KbpDKgm2au8KBAbDIGVNmoTBcGDaWCwcFQAFQOMgd5A4KAgvoEB0KEkiI5WHa/Z0h3nhjcf3GpV/93n+BkB3s3giZFDrJDtA5tISGwBAYEiAUgzNWCi1JyIzQsFBRB+IXum7uXR+Z/djfhMq8cREEUVmQAVKSjTwfXJ7cevjw9/6l7/7Rv/IdDz545/RU5V3vfPzeu+6lwttaG2RjICNOHj9x5fLFB+67/+tfffK5p15937s+oqD62rEL99/zgKckWXfslePt7UE6tJVKQ0pJYFrTTdCY5kVcbcRB/fKFy2StlFgUGdkCHJRTWWaQQsVxXKlU+v3uhYtnTp85jpA/+OBtP/Ij3/XIW46ORr1ef2s86rWatUajWhgHaF9+9aU0yxjh+GunPvjBdzzzzDNRFLx2+qSanp7qdDql/dKdd97p+3530E+SpNFofPOb36zXm71eTwpfKUsAyvMipXq9njGGmbe3d+I4npiYKGngUsqNjfUyZKbZqo/HYyFgeXl/FAXnz59vNBqTk5Pb29tpmuZ5TgRSyvF4nCTJ1NTUvffe+9xzzx0+fPjs2bOd7s79999/4MCBM2fOtFrNEj2KouiWW2559tmn2+322tpanucTE1NE0On0SpXf0tJSlhWeDgBwMBiUpVi9Xt/ZaXueNzk59cQT7zhx4nijPjEajT//+S9KKZX0jh07NhgMjh49GsfxxsaG1hJBZFmmlHrooYekVBcuX3LA5JwxRitPCDEej8fjMTtSSrVarSRJKnEtjuMkSfIiJaIgiKWUWtebzfr01OzFi+cPH14Ow7jIzdmzZ4eD0ZEjNyVJhiCr1WoQREmSKKWazeZ4PJZSSqlL6UBJVtvZ2UmSLAxDIZRS3sTEBBHleR4EAQDkeSEEVqvV0rUcAJRSJcyGiFmWaamdpWHSHY7GLsfhoE+oQIl6Pd5YudDZ3mlxURD7SrtkGHlhnhulJAsFSsF4DHHk0jHVm+dGyW3v+yDc9TCouhUhAUgFyIC7M2NZYu5ibwrqHCulnLFMtHBg8eylczVAZkjTPEmycZrMzc3VGjXpebvAtRS7lAgWiASIV65cI8uIKBRWq1UhBLNrt9thGJZTLqnQWq5UKuX0UQiF+Bc5tv+F9i2ucEJrFIAKCusAMIqUSUBH0OkmvucvTTQCA5MCl+cW+t02BegksmUCMIJSwSOJiWILHBDEFiuWfWcVW0CrUNRIT0hvxxrwvZRAatVzbojY0FI4IGIQwiqZaWmEcBIsskHwGQCBCMDZcnfkKFNmByhQaSxhgcK6gmWYa68biHXNbUUZegSCgBnRMQMxOhKWhGVhCciBJ3MEI4FKWypGRFkQkUSUQhJIkE6AZVYsicGoYKxER+stAR2FmRKopUShHCABKXDo2DERZBJzhtQ5oQVokWeJzmCWFRdSXWv/xo//rY/81N8+8uD9Vzc2K41pNugLKLJyvuyklEcPHXzuma8H/r7RIPF8qRU6azvt5H3v/9BbHnz0wD4lBQzTftCQgAaAQCGJ8uIApS8YitIxjqTkKIZjXzlx6eLVWw4sDIZbPoICpyNZSOgzCJCRrqJJwVEhFUU1Cqs9GQ9F/KUXz5/YSEx9sQhrSW4wkIUp4lBF6KjfOxikD89N68GKBr7ctrB0x/1/52fAaxWFloFK8lSiUEqeOnHSZnkchoWMLKSFFdIrCjtKRuNabTkZJ1/76tNRFLZaLedCLZXUkl3py7HLHKc9bMpa8MrAJAAyrDUi7uEfAqwjpYVz7HmqKJjIgWYhhWEQ5KCwgoRASYAZWeX5jh0iInFBhdKeddbxyIcM7PjFn/un3smX71iYgnyQmLHw4zIWa5fIbgCVBQB2eN3XCm8wsdwFRcrgvxvgJ0dul+0Epd8LXweSvwXz2EVcSoGiLG1KSDADG+SSCuhACBAoS7IhEwGg8KBwSftqFAUQxde6w6syeMfP/iuozZuwaaTPjCXZ0aJDIEPuDfDYrgvxt40bu6tEnvKL3FqyiCglGpNXq9WtzZ14poI5EpEQSghyzhExSgEOjCUhMDeFRe4PByWI5XnelcsX77n3XiEVEyCCEGJtZfPsa6e00NbhlatrVkBu0+7Olq03Nq90PvRd39WcnUxPPXnm4/95NtmZnZjl0YCxhAnL7CHBCMQSAZEYywOyp87cgzD3DF3x9fYrA+D1/b+nZb6BH3ejw21pIiJehxhvGEURdpOBQKhdE3+mvUakc4UJotBYK1iIIASh04zOJubBH/yx8JF3QTAJMjYAReriSKKHIKk/7C0uLh575fixF59bmmsN+ls333Yoz7IXnz+1MHcQQN16652VSgUA5uZnv/SlL509e3Z6au6BBx5RMvra175w8eLqnXcvhpFXr9QR0WRFMk4rEWqtpEQCp7VudzvG8NTUzNXLFwaD3uzsLAApoX3teZ4npUJi57gockTZ6XSWlw/dcfft733ve1bXrt19990vvXz8+PHjX/rCF8+cXv9Xv/yPP/7xjzPD1NTkl7/85TRNLbm5ubnJmenxi8nc4sLTT/65Onbs2OLi4szMzNzc3JUrV1qtlgPe2dmZX1i855574rh64cKFjfUdpZT2Pc/z0nFSr9dHo1HJEyoBFc/z0jQp7Zq01lmelDSmOK5KKUfjYeCHxuSnTp1oNFpaawD2PDUajebnZ5ldFAWXLl04ePDAd37ne/v97rFjJ4bD/u2339bv99Y3Vjc217rdbhj6STJaW9toNBqtVjWKIlM4P9Db25vW2qNHFy5cuBAGca/Xi+NKq9VqNFpPP/20MSaOq2EYT09Pv/zyy61WKwwrn/nMZ5aXlwEgz8adTuf973//008/neZZtVoVAokoSZJms1mt1kr+frfb9ZUmoizJrxc3RZbPzs4eO3YsiqKS8kVEaZoGQZBlmed5Ozs7d955+7Vr17TWV69erVaiqakpIcTp06fX19cXF/dNTU0NBsPyl1pSx0q+Ua/Xq1Qqvf6gVBhIKQFsaRvmnCvyPMuyarU6GAya9Ua/369Wq1tb25ubWxMTE1qKPM/LT1lrpZRJMkYppO9J7Se2QN8XMnBYhBMTB5rRCLnimIjtMKt6Ndga+lHsHDtlrUkDzTToyMnFle3hzNvf7b/lcYhbwJ4SYA1IDQwOGPboCN+yEICUWllr40ptcWn/tWvXWo2mYCGlHo/y1ZXNNM0nJppKa2es0MpZVFowgXMsFVy+eKVWrSNIKTEKAiEwz/Nut1utNdI0JQCllLW2Xq8T7XKY3jhYv7mg6sbqSgJGgSKEbpKClsLzijRPHTjixPPC6ShZ2TqwOL3+ueef/J0/3D8zNXBGgqdQGiAnMSfKwBkW7MhjGTuuEMeOfOckOxLEIHzCiSBUeSp9zAUrBWPhUkaWClgoZs2SURrEQjAJBUyScVcH7ojIgRCgRG7yHLUrX+GyOSMKIXJPDbTe8GhNFNsCEk+XKd1YyqzKkZYQnJOGBCMJmbNxDJJBGEYCFpiRzQkMgyQlnCkkEwskZaQaVvyOxjUFW5K7ggspBQg07FlEh+iACS1DIdggGwSW0gltBKeYJcweiJbRciMLOvkf/Z2f/dA/+al973l8tb3DwvPI84V2ArMskVA9emBeFkNKuwotAI+SUeCHcT06dOTA8hGVF6AQ6jP1zCYCJaJEASgU7VYi6JzzPAVoGXJLplL1V66uAnoqnhh220JI58TQwtowr1eCavNAkoxi34IUXhCMpH9+mL64vnF2a9C3friwv09eykbHYVGkztmKwf7a5buq8uGJeLboe+C2DK5E+976U78MomasUkoJBK04z1Nf+73x0IDJTJonVkjpQYiEUoJfkUnSIY6SsTl14vLc3DwSN1s14cgXiIwoPUYuO2TMBCA8BSY3xDYIAqWZwTKz0miKogyScVYWORnLgR+SUZBLy5aRhAAlfSWEKYRlYM8fJ1YJCLVUqFiAcaCZQ0WQJKd/4efDC+cOTDSBnQX0vABtLkkAaWABLEVJBUIShAjyddZ5GVG6dx0HuKFndsPpxo7K8/F6c2rX9XdPMbj7JAIhAwjplERpBTh2yllgArTAxE4hakUCGB1KAox0SINRVIkBcXWQX/En3/pTvwBH7gIrSAjfGiZ0gAbRSgtIEuSbygj+IruB0k8bUJXT4DAMb7311qtXvliK/ImopI44Z5lZKwVSGmO0p8qXRqNRGbPRaDSuXr3a3tmZmJx2jgWLfn9w5coVDWqr01kbDA1BPk4DLeab0+12e+HQwVsevA2ALl/bSFNsNWbJ5NYZpfZklgy77FJw100TcK8vjHhdLoHX714fA9/wz7c1mpkJr1P739CNvtGrncEhA6IDQOCQQQBaEAbBABBYllEECBrAaWm8YDAyVxJ87CN/De5/NwSTZmgpZuWhiCUzj8e9Sr3abrdPnDh9//33nrtw8dmvnX74kf1rq+3DRw+DeA0VFHm2sbXaG7Zbrebxk8fCOAqiMK5Wnn/xpddOn37k0Yebk8eHg528GBVZvm9peTweMZDWmpnLi4UjE0VR6W9gjGlNTACAc86hMCYvBfslbXA8Gn/f933/l7/y1Z3OzosvHPu1//AJFPDJT/7nT3/qM+12+3u+5yMvvvjiz//8z7/zne985C2P1Wq1V149cf/991eq0aDX+8pXvnLkyJGXX351aXG/stYS0dmzZ0vSVa1WAykmJiaOHz++sbExNTVT7soyhq/b7ZJz5e9MKVWr1ZMkGY1Go9Go0ajPzMxEUdTrd4SEWq0yNzf3yisvHT5yiNmbaE2ur69funTp9ttjIaHdbjvn6vX6+vp6p9N+7LHHzp8/9/nPf2FxcWFpaTGOo2otOnHyWK1eAZwZDEZSojFma2ur1FWWLg9ZWpRhNUtL+7vdbslDKlX9Jc40Nzc3Go2stWVqcq/XO3fu3M0333r48GFjTBxVB/3R4cOH+/2+UqqiK1mWaa17vc7MzAwRfe5zn5ubmzOOb7vttvFguLq62mq1Njc3O51BFHlTE5PD4bA1OfnQQw8de/XEaDRqtVrbO5u+73d7HSL6mZ/5mT/5k8+k6djYPAh0t9uN49Bae8cdd3zuc18Kw/ZwOB6NRoC62+0i4vz8fKVSWV9fT5Ks1WpJ7Q2HwzLAxxhXQoYAcPTo0aIo+v1+HMednXYURWVtR0RxHLNWUsqSZlQWHFoqR9aB8WQ4ylMppVNKePK1S1d2ehtvbzywrxWPt7oeAIACGQJGxainJzyHVIxzr9La6afVm+6eff/3Qn2OEhSBAgZnM6UVAsObV1dQGuKXQBozLy8fOnfuwtr6Njqu15pxJSwKay0hyNZEQ3l+GVAPACjA8/V4lO1st1utFjMrpZ2znhf2+31rbemvBntUqnq9bq0r98Cbrsnrwwri62PLLn8W8tyyFEEcOgSyrIVUiM6jQTYMUR5Ymj7xG5/63H/5+G2HDjyfb2mtARFBFsRGCWM5Q7IgFCNaqLKoO66Q88lKJofEzMLaCHzfsMgt+n7mXKFEYrlADEFqACRlGDKigoGFFIQl6X03uK3sb0rMgDLJhUYnRe4ME7EUFPg9qdoerCvaljBU4ARLBiQSUArjkAGMhEIIQMHILCRBUYq8pCVE4RAyoDFCipiB1AgZghOChVdoveOLTQ82FHeQcwkgpHAMRAqlZQQGC8JKYck5YOdcFNXalox0qHwSeZ4XCkTsqCKCQEW/9Y9/4R3r63f+yA/0ul3gQgUeG6sjtb1l77rtZk8Im+YqVBaNF2hDmbHZn33pM5H/3QcPLrFHjgUIFChKIzNAK4QCgl2yCBoQObBzVCCClDIMw3E6GBejhmwxee2hfeXS+pbEi4Fe8r0YmYk2h9sXhsm6g1FUt9UFS76T1RHl4Ctjc2TbjCPubB2u6pubalqPIymvdot8+tBbf/pXIZrPssyvVJDA5Vb7gpUiAlQ6qGqhmR0QoxICCA0ZJxJnWQlVrdZeO3WhUqk8Iu5YPFCLqsJZkEqjQGQAJEICZCTnHGlPCgjIQW4dOyrZmVrFWWa0UGnu8lQMBuNaJSQDChBRkwbLbFwOaDzlV6qSDNgMQWLBjpnI5QJIhQyj9tf+2f85efHy7YtzMOwU6diLvTwxvkRAAkngAEiAYAlIgEKIvQD4N9ClEeUeIemGYkXsanRQ4JtXMN8mOSMhAYRwCksf3V1IjEEhOGLcxWnAMQhQAk1/pD0NRKtpcjWcfOs/+hewdLuhwApGBuEIUJCQJBmlE0zICv+/yAeiKDLGAGIJHzjnynaBc04I4fbmddc3vETmiEBKVEqNmdrt9vLychzH29vbly9fnpieVihWVtZePXbi4oULkfZJCCsUSBlFkSfBkGUhH3n0UWOBpLjlnoee+vKnj10+cbgeNUIPyL5RBoBlmfUX7tsbt5X3hOF76p+9b+CyVn79e3YrthuI6m8m5NwNJ0dRCh8YgYUAFMigAsnG2DQXQeh8fzUx2xA++Ff/Ktz3LoAIMNQ1mdHuClrK41oMQIPBIBnkvop+9Ed+/NN/9PtnTl9ZOjA3OTFVqzZeeOGbt956u5DeCy9e+pmfecdoNPqO97zvwP4j//Cn/8nq6kalUtncXBsO+7V69Ud/9Ed+5+O/fffdd++bu+njv/X7eZGGYUjspPQAYDDonThxYt/8zNzcXKUaOGcASWsJAGWCrVY+gpyamv7Ff/HLqxvr9UYjqlb+0offc/c9d/3273xiMBjVGvXPfvaz+/fvn5qaIqIvfvGL3W53emZ+MBhcvXb56NEjvTM9T8HM9FS321VxHGdZxsxxHAPAxsbG6sb61NRUEAT79++P4+oLL7wwNTUTRn5J4mbHo1G70Wh4np/nuda6VM4753Z2dgqTWWvn5+enpiYAoMwKmJ+f9X2vVq9OTU30er1mc2L54P7xeKw9aa15+JEH+/3eSy+/cPjwoSQd9QdtqaBerzpnLl48v7Awt7y8f2VlRQhRZiZKKZ3ljfUtIWTZeWTCdrvdbDZBopRqPE53djpZWhw6dGg0TJJxVq3FANDv9+fm5kzh+r3h5uamEOr973//1tbWn/7pn33nd757nCarq9fSNJ2ent6/f//58+dr1UaWFoacc66sgYqi2NnpN5vV0t6zNLB45ZVXpJSVSqWMsu4PRnfeddvc3Nwf/MEfjEYDIWBre+PAgf2raxtxJex3O3NzcwcPHhwMBs1mM45jYyEMw2q1Wq/Xy5QhY9yVK1emZmZGo+FoNFJK7bkGgxCis9NO07T0rC/NTkurDyLa3t6u1+uLi4vtre3SbV95ipxlcI6cMSYryA8CkDZ1MNma3DdV9+MKgKtVq5AkMEwgqkJahEFUUCaUp7XuJJwuH1n6vh+G5tKYg1j7wADo/ECWs1W8UUXyBpO6610AgYhxVJ1oTb/00ivTzak861SSqFqNs8INRuOp4eTs7HSlUhESi9wxs++rK5evAgjfD5l3Uy9939++tK21ZnBCCESBDFLKer1eDnblbwPc6+vw7f3CPdLl3hsQrHBFUVTiiAvgpKhX/MzZ0aA7V6uEoC79l9/581//rfsWDuQCIy26ZDWHACojMp4qgBMAh0KjCEnULdUtVArjOyPAFsCWSTH5xtVQ9ApjoyhHUygcFWbMIpLCY8kgUnZj5hwIESXtTUZLCAqRS89EJYdAQ8TQk77zidEIypTcUWJd8LpwPcUWJRNJIgWqnN4CgBMwVjzSnGgRlB0YIRiZgCU7BGRBueCBELHWPkqPIZFgQKYkUu1dBLslseNxIkmi9JG1Kx3Z0ZIg5BAVKcmEpU2nJq0Kx1ppFCjdmE0SAgpBLgtkdE9r7vO/+utpf/jQ3/qxcTq8lmyoKGZQRWGbjeC+ex8+e+7UXQ/fut1bs5wHgZyaDFcuH/tP//6cktH+Awd/7Cd+JJ5EUCxREiCAAqSSX60D4SgnzoUA7YGx0JpoJGl/YqLR7WXOjoFlUFtESSujztX2wFfGWjIETkayMi380ALmhgO/2en0vaoGBoGokV1nfZ9P9zWDWRo1JlqnV1bN7K33/B8/C419/ZQq9bpjUAwCpM3GiAIFOOYkH6GkMAzzNAUmKQGlGo3GFa2ly/M0QZTnz109eGh/rwNBCKRACCwVbICE6FAAI3sKickWgKB8qUFAkcB2h4AYhb54bjUvnJKxksG5/o5WqhVGQeBhACPnVOxHNcxzV+TWA/ACRQp6ybgaczVESMcw6Jz6tX9ZW79wS70CW+tQ84rhwNMVLfeusrLklpeOUPK6ERLc4GW1dyHnki3Nu+Ky3VeYHeGe6eV1B/br48X1a/ze6VkWAEVJAbQgAXfjugRZEEgCmIEYHEkmAKk9D5R/MUlWKvOP/eNfhP23WAoThx5KAHJCkESWKARJEKKct7C48Y9eHxu+bbQAACiDTbXnAUAZ9TE3N1de16TUzFB2pa/PaQXvumFFUcDEUspOp5Om6cLCwsbGxunTp+978MEsy3q9zmg8UFp303Ga5HFc9YLIC4LBeDhMOkcOHDy0f660PYWwsfzoY/Mfejd8/YuDV16szUygACDCPXL6nhqiPDQ3lkEMAK6kcu65WJXHghC+Db7aPTSvN393jwzuoVZ0/Tt3mawoBO+CkAwFgEUhEQSADyULVpDwpaxWt3JxzYjH/u5PwcE7wPigK6AkIGhdsgZzJbGwuRBidXV1olW/+ejhl1583hjz+OOPxbF+8smnjxw5srW1ffTo4cGw+/3f/9jq2uUgiM5fOP2P/tEvLi7M/eiP/tVKpTIc9e6577aJVnzu/Jn9B5Yajdpdd99Rr9fzPGfmaq3V6XRKH4PBYNCPg9npZgnEOCBVrVpry+uItTYdDm+57c4wjMcjOzdf21jfWlzcV69NPvXksxOTtYOHl7/+lVd935+bm/vc574Shh4KYa29du1ao9FIklQpb2trZ25mtjMaqzAMkyQpo4u73e7hw4fLJlelUi37VrfccstgMLp69WqjOVGv17c3t8v9XeJpZXsrDMM0TYmoWosBqCiy4bCfJMmH/9KHBoPe+vr6aDQqA3OMMUWRAUClUul2u8sH9zcajc/88afq9fpjj73t61//6tGjh//8G19H5Ln52YsXLx88eMCYfH5+dmFh6Wtf+1rZDEqS5PTpS7fccuh7v/f7XnrppdFoODc3b4zp9/vj8VgIxcxlQmIJeIzH49nZ2dIB4dSpU/V6vZxvHT9+XEp54MBCp9Ox5KamZlZWrirlraysbWxs3Hfffcx88vRrRDTqD/I8D/0ojr1eb1irxd1ub3p66sSJEwsLCyvX1nZ2dqSUcRy/9zvfe9ddd/3yL/9ypz249bbDvV7vtlvvGI56q6urU9MTrUbrhRde6vUGkxPTUkrPC9qdrVKVuba21mq1oihClOWGXNdrlObyZVbxcDjM87xWqyXJbq+2BLFqtVr5PaVFWZqmzBxGQZYWQeRXUIFUIIWS0hKkSZZ7vg7Dre32VMw1zRIBKiEYA85BUC2KsZR+ocOuVz303R+DhZsSF4CMQAJYA5J2FeVCvulksPxhOGeF8KTEIifPE3lurCGpg3Q07vcGSkvpySDwysJ9cnJyampKa4kCgOHUqVPl9mopylISgNrtttbaGKM9aQpyzmmty6T03dHtxuCtN1ur65Y816WFwtOB5+cj54ythT4VVIz7c2GgCI79P7/x4n/8/XcdvHU4Sjd6hR87aQlIOBZjlxdhmBHmDhmFAhEz1ogqrgid9cgyEgMQsMeorWv5escUhhwhGRRjpiFARaoAZCEpAZsBMGJpanVd8OiAQEoAyh1JLYaFawNqT8fSA/BTytvkuhK3BHcEFwI1gybUxFqAYXbAxGwBM4ljBalEyaAch0JJNkSWUTGSBRZSdtBqjUJ6HuBYQe6ILY6F21aqq0TPI5IQGxLG+BYFCyucRXaIhcAC0UhlhXWIRW6070khtMs8VgIsaJFmmVTSJMMqVN+ytPzV3/jvO52t9//zfzCh3dZoFAWt/mi0bzq46dZ7Xnj5xGDkHHlRVWejAeSDO28/nA/l6mr/3Okrq1d3DjcmyyiW18FIURb6yOCUEuXVbjQyhw4dCgJvdWPV81QQBEVO3WEyEhiHU0FrfrPXVmEo/JhAsEV21iOSCnMDzdakdakrxrEnVTZqueHtleoCjidr/togSyaXH/x7PweT+xJjg3qYWqbc1DwPFSqrUmOUB5PTU47yJB0SWyUkEFtrPT+EyDdD62mQirQOrS3Onb14xz1H44pX18Cq3KrdKhhJMkFurO97QsCgAytXk43Vdq87Lgr7b3/1377nve/TKhwMxpWoNRylSZIdWFyiLK1UI+H5vXzQmGscvGmhGctGrINquNPtFAEtLE/mo9UqErjBqV/9uez8y3dOtmRJMM+GlVYdikJoRUQMghAUEFJp0KZ2L7xIyMAIWAJKXM5bkIGRkYElAyEJBt7lVSKXIjvYK7+grJy+dSlFbQQoCHB36oYgGITnwAqJYrc6YBAIqAEEKL9tYGdy32P/8Gdh7sDIyTAMVW41SgYggSxACRYgFGtEAUp/q75yb3B400FD+T4wlxke5VAzOztdrVZ7g0G91hQMzrk9DqiwziEKKbXJLTMCC8/zknG2sbExPz/v+/7Kysp4MIhrjVtvvfW2O+4ghtS49dWNL3/+C71uR/phSsUDjzz8+FvfphjAAjBAtTn/vg/By1/l4bg2PwvsABiEeN0uAUqFoHhTYE7c2GHg13lVb8Ci9r4Ev+X53fMLbzzdrr//hqdZ7KovS6RRApQXCJRR1GFvXfiP/dTfgwM3OatktcYgi9w5piDQEgFAAjgWqIRKkmQ86t9y8+GXX37G0Lg5WfFCeMtb3/f0U89vbHQ3Nzc9X1Zr4SuvvPToo4/2et3pmag1Ubl46dzG+pYjE4Tq8bc/fOnSxdOnTi8uHDx//vylS2s333Rzo9FoNSe0lmRdt9tvLLWmp6fb7Y2Z2aOj0cjZorTDLIqi7IQUZtf0Z35+plat58aur23+wSf+EEDMzMw9/fTTd961tLS09NZHH3vggYe63b5U+j/9p9++6eb9w+Hw9OnTtUplUGTnLpzfv29JFYXZv//Abbfd9vzzz1trjx8/3pycWFhYOHf+wvT0dLvdnZiYCIIIEYmxdLys1+vMLKUsWeoljjU7O+Oca7fbGxtri4uL9Xp1e3v75MmThw4tJ0kihCq9pkqsa2KitbW1xezG42GtdugLX/jCzs7O5GQrDP3haPDYY289ceLU/MLM/Q/c5cg2m80wiHzfn52dHQ7HRW7f+973TU9Pr66uP//88wAQx5XhcCyE6Hb7zJyl4zAMt7KtmZmZVqv12muvVSqVhfml++978NVXXz106MiFCxdmZmaGw+F4PJ6YmOj1ev1+/7Y7bh+NRoj7z549vbMzWFiYeu21M61Wq9VqWWur1XqlwmdPX7jlliO+H+Z5Xq/WyozqMAyJLQp2zv3ET/wEAf327/32x374h1999dXnn3uuVqtkWTY9PXPhwvDChQu0vJwkiS3cgf0H0zSrVKq1WraxsVGWp8w8Ho+Hw/HS0tLWzk7pQGGMSUapc9b3y7Rsr1KJ8zxDhF6vp7UuLd2tpVZrst1ul4GJUbU2HA5Hw7EnFRCyc5Tn4FThWHoUB5HL7Beffv6x993VPHwwXT0X+hqcM1joOHDZWKkwF9VO1Dz0gY/C/rsMVLUMsETBwZS4dEFSSiluHJd2227uuis1ASOgJdIgrl5bbTYnkiRRnq7FESJYV4xGo3Z7+/jx441m/ejRowcOHJifn3OW19bWoihAZN8PtNae5w0GgzRNg8Aj6wQgM1trS/wut7lUwlpLBGIXBRcAIHb13AA3sAeYmV/Pd2PK8kYtynKMA18oSEbJpBcCi1O/9l9e+d0/enzfcrq6yiCiyfq0H29mQ8PCokqgSJTKnMyZgYUHGJOIrQst+84pItJY+ochkLKu5qmmUKOsCDxtnc2EHCLXtPRZJsiJkE4joARH6JyvPUAorCmVOiiAiFHoMdptJQhQSwTEwomupb6CnsZcSGQbG6iA9IVyjCmxQbQAjJAJHiseKwhI6AIqQniETMSajSAiR54cWRJCpIASMBWQSzSKC4Tc93PJTjoE51kTJ65BSvqybS1IskJnAkaICpikchosshBCEunMVQyGximUDlyhmBxQPsaM33Hkluf/7OufFeYD/+QfkqRRaiM/6vXhgbc8/l9/+w/6CUgdpEnP95SzyWCwkY30ZGuWyY16OTlR9iVKEgoiETKDo7J2FsqRAYY8N/sXF5rNCeEZ5cVpzr4Xtlo1UFAUxfY49evzBM5aA85qRl8qDzQhjoFYsDY0KXU4Gswp98iBuUq2s79R20mLTjjz0P/xz2ByKUcZxNa6QahCUF4+Bl8DeLGEHBmWFhZnp6akZHZCR9qVRHdXwV2vN8/zIBl3hAzPnT997erd9ca+ah1AgxAWwDELYF3Ku3zpbV2Fbz597uknX1q52vVEqLXvnIvU4srFEbnR5uZ2szkcJYlSqrszLLK0pFRv97bA56X907ccXnzovttnotATweR0VAx6kxMB9K+e/ne/JC4fv3eyCvnQWlCVAKSGNAHP46Jw2rcSkAGE1aIkQZdWnBZA7po+CLzhIuvKEw9vuC81FAA33DPsdejevE8nStcsKYAJFAIKEooB0JVu6szCOgUKFOQMBDvM53T0yD/4OZg7PAatw4BsEvsaCBjQihLnJARE1oD6jZlE/y8WZgDwAy2FTNLRf/uN//4jP/JX77///s994QtYGl/J0pliFzgnQBaIUlhrPSW11jbN19c2Z2dnp6ene/3h6dOn773/wXL7kUGiOHhwIYj8pmi84x3vqU80GhMRAGRjGwRqnHLsCRgVn/ndP3xcpo0ig8AD3qOWlyYLZcXJb0KlKnfotw7QN74K14l0eyz4co66+8wNCFn5j3hjCwCxRDgFu9JwC5mABLAE5QHShvNXZXzfT/5vcOBmdghxPQM2kPqBDkGSLRARJVqA8SjXNb/f62gFvd76I4/c9vHfP7bZvhgE0b/7d//urjvvf+ihe30/3GmvD4ZkXXH12oXHHnv7bbfd9onf/9Szzz35l3/4f/nGN75x8eLF/+Wv/uDc/OR4OJqcnPzEJz4xOVnN83zl2trkZMtaSpKsWasfOXIEUb7yyrGDh/a1Wq2dbqesj8vcP601S4WCsyxbWd0UUk3NTl+7dq1EMVZXV2+55bb29s6hw0cff/zxv/N3/rdut3//Aw/ec8/NZ89dQMR6vdrvD2ZnZu6/925mp7a3t1944YVLly49/PDDg8HgzJkzQquVlZV6vX727FnnuNvtel6Q5zmD8DwvDMM8z6211Wo1z/OiKMpQvCxL6/U6IJT+7yUmkef5aJRMTk6urW1IKWu12pUrV4xxjUaj1WqlaYqIw+HwiSee+MpXvvLii89/9Pu/b319NYqiJ554+8bGRp6n29ubWVbcd999zGit7Xb6MzMz6+vrTz31lOcFpQfVYDBYWFjo9/tPPPFEHMff+POnarVarVZbW1vbv39/URQnTpwVQpROWs5xvV7vdrvW2n379q2urh49enRiYqJSq/b7/dJFKQwlEdVqNWOMH4XG5Nvt7Q9+8IN5muV5fujQEQCwhQnDUGp9+fLlkhWxuLDwhS9+8fiJY0sHlk6fPl3uojTNBoPRrbfdPBoNt7eh9GGvRsHFixedg2q1evsdd2VZVu7DshG5vb0thBiMRiXWUqlUyhahMcaYIgyDUhVcq9UQxWAwKA9BURRlu7AkV5a2q1JqZrd37DSizvJcIVbqdZFn+/ZNemEAaP1A2WwsvFBXInDEQqci2MLo8Du/C+55G8imRe0xkAXQDj0ERyCUksoCqDec0gJ2qyuwzirlFdYCqzBUF86vJEk2MTGRp3mZV4AIQkIch0eOHFnatzg5ORnHoVIeIoyT0Wg0KoPAPc9jJkTudrvMzvO8PDflDin7hlprQ6Z0Zi/9GP6CcfINqVu7mDlD6AXZ0JrcRkHQ6SVNT4PQK7/7ied/79N3tCaLXlsD1fwgLQo5thUpeoQWMBEiUzI1KgdiRsUQOPYda0dIDhERBKIQxIJYsasQ14Vcy4sgCl1uCi0SogR06EQKnEskJVjIsvHhIyohwJq0nFQKJBYkZKFwwFAw5pQzkZIik2ogwWgJ4FRKtRwmlFJapm5PIIgMoPZcrxwASEMVrSLDAVjUoUOyyEoKE3gD58bEzGQQC4UslEPJRM6RMCZk18xcs7CTQoRS59kw0+ACVSD2kUmC0rKQSMJ3Atjk6EgiOmOdJFRoTN6o1oreGA2ZzZ3bmpMvfu7LRVZ898/+kuzlQxDsYP9yZWJ2NsmL6Xp1nPQhz5v1CudOBYFUotPfvra2ejst4i7BjKEU+jMws1KetWytcY485QGD1jpJklYljuI4yxPP8621QijfC33RYHYoHIITZBSxZlRWMNmKALSjWOU1k9w8oQ6EcavoTNbjjW5/S9Ue+cm/D9MHhpZ0pPN8GPoqt4lWNe0hCHCOnEPQUI8rvucFvm8FI6IKlOcCZytrW/255mKeFlKZmdnJNHVE4szpC8sHF4lKWKEkyGgkIAtQwCf/8PjLL5167eRVZ1QtmiqEysdWSJib3TfqZ0r7+/cdbLe7lbDiR/44GcX1WpYnCNRohUTF1tXV4fq6HeWdWw8dPDLdWd1cPlSB/uaJ//rr2elT989NQtoDsKoa59Z5rDCogHXoKRAoBCETgCCJyAKphKvVrqb+hot02fsr8ScEAKTdRwjsgLAM1txVGl+HkG9gBN3QsNst5ixASRRkYgUAomxuobXOOKFAKelwx8qrcf2R//2fwOIhp2NAQQC+kmAzkDEilqPTnre8BoA30hj+XyyIAGCNlZ4cDodPPvnkxz72w/sPLJVGeqW0EEBa6xgIdxPlARELYzylESRK0ev10jSdmpq6dPnqyZMn73vgobLWFAihxjRzH/no94ahV+4fC8AEfqzSxAax4gKxOXPnQ2/d+fqnGpVgFzCkvUbtLojFQLtt2RJTJGDkby1hd+uybxkgmd+88CofX2doveHV643I65WWAC4lhOX/PTC4YVQ+vXzfD/4oLB4iVhwEBYgCCAFLUazczaMXCkSjNmEpH41GDHD82HMHjy5Ozau4rsb90fFjg7/+4w+Phtlzzz2XJsXi0lJrorK4NPPsc984uHzT/gOL21vdbrf9/DdPfe/3vTdJR3/4h5/8gY/+oLPq5Zdfnptb6Hezer0xHqfAqJQOgnA8SlQce563tbVTrzfzPC+0jyhKxrAjY6zb2tr61V/9V9946pnPfeGLxubNVr3T2WnE9azIjx07tr057nQ6/+7f/Mb8fH1xcd8nP/npg8sHjxw5cvHixWZzIgr9ffuXk6wweap8P5yamrl6dWVn57OVSuU97/mOJM82NjaCUEVRZWFh6erVq+NR6pxjhGvXrtUqNd8PwzDMsoKIo6jinCkBLQAoo3mLopic3H/u3LksT4lISlmJq9PT00899dR4PJ6YmBoMBrVarVqtSinPnz+/vLz/O77j3VEUaU8dOrTsnJucnKxUop2dLWPCer2ZZVmXumWZWRTF2tqa5wVFbm+/7c4rV65UK/VknO1sd86cPjc7O5skyWAwuP322z3PO3PmzJEjR7a323lunBv7fkjERDw1NZ1l2fr6Rr3eOHfuHDNfuXa1VqsFQVCv10vjUOecc2Y4HFar1ccff/z8+fNHjhxZXFw8der0bbfddvzVYw899JBj/vrXv37XXXdNTk4+99xz995338zMTJZlX/r8nwkNU1NT07Ozhw8ecJalVB/4wAe2trY2NzdXV9cBYG11Sym5ubVT9vXKomFhYeHOO29PkiTNc611URRZlgVBULb8pqenR6ORVOjrsNQktlpNRPHKK68opZgdgAjDMPAja63vhZ4SApmsTbJMoA6V8FH6iJjbqYmp/sbFscsglI5yLQik5sxiJRpa6tYay29/v3zs3eDqZHTI4BCEBCZCwSB3e/hvqK72xqNyjL2eXU3EALizs9Pv951zSsiZmZmJiYnZ2emDy/srVW/3/EUAAFNYFHDq1AlH1vM1AIRhgAxKqc3NTV9rtye3FIKdc1NTU1ICWQsClVLOGSABcF2edONYUXLCkIiuU7CYGK3AwkVxOEpsGAdKiWu/9akv/8ffvHNyVufjTFr0Qdks0FElpwAdacdaOc/vWybpJVSgYx9lVcoArQBiAMfkCJFQgZREwroKR7Elj2mUJgyYSx4i9sjF2kuZMnA5oyNiRnTWZxewdABDphwBQTEI59ggdiUyQiE1AGjLAGA8aZ312E2gngOcAFUQW2elklCiOuyAjGDwCKVxHrHOzYyvMgedLIEoFFokeS5AkVRGkC17nkoWwM7YEMErCj/JWwBLBU9YqDrLZrQUSlcYkxtSqo0208JXMiFIgCy6QAEQpkVRD1WWZ54zvpDFcOwjSiWtLYLCf6C5ePYbx/7wp3/5I7/wU40qnD47+hf/4T+Nsu5sdV+SJZEfJUkyzi2wcJxZHOuWSNzQOvQhEOysGwvPhWGQJoUQnilA69Aaq7UHDL7vb24NGo1akXZ9XwexV3BOgoBIktOkmKwQgMIJYBRlQo7RZhzmnQbnU4pvna8u8iAohhOTjYvt3kY4/+jP/CLMHBkVNqiG1hSBjoGdr4CZHEoUkOU2DDxg+KPf/1QgNbIQInBMCLIwTjLec/uDz3391JFDhxK7kSQjR7JambhyZWVjY2th/2wsAQitISUBLPzxJy99+pNfSMYZODnVWC4KAkIiC1A4lwslBBut1WCwE1fCosgEAos8A8uRKUSqINcMvlbOBM8+++qpy5f/9t/8fjVch8B/5b//Ml09ddfCAox7kBMotJyzUs4IYSWABiZJRjIJIBKyEAoAfWZ0zEylxhHfELGCfGOP7Ua0WAippEAhgNmVShQuTTUIdhWTyHtzHpQAgtkiOJBghWWQggVaRklABUinPSlYjZ3cdGI7bLzlp/85NGdAALPRqAUIBo1KAjlgd11VB6h2Kfl/Adfq9dFrb813hy/nhJRKqTRLtdY///M/X6lUAJKycWEdlBc42Ju2SbUr3y6VrUJAGc7b7/cXFxdnZ6auXL26vnptdnYWpQZENqQVCqkJSqYZSAQCKsh5kWYAFgItLt9y14t/9ikIQzvqK6VA7uX8lL1CABAS9jzUAWGvJbtXEl3f6D0a3PXER7hOZue9im2vjVs6DpZvYyIUosydfP2rdn00AKRX+msAOihSCJqXhzafv/mm7/8JWDySG6eiqgRALmDXYqYMCNHlH2VAEMAM4+FAIly+cu6J997/Az/0kZdffvmd3/HEq6+e/exnP7t/35Htre7G1sbBQwsLCwtJ0qvWom8+/9REa340Tj/9mT964omHz58/f/zEM0ePHhoOh//jT77Y7/e9iaZznOcFgrSuABbO8vZ2+85bb1tb3SdQpUku0LOWfF+XdKnp6QobW69Xnv7mM2fOnjx9+tSd99xeFG5yqrnT2bbOCSGmp+Nqtbq8LBvVmpTyyJFlazjLstbktCE3TrI8L4o8v3Llkmo2Ju67774sy65du3bgwIG5uZmssAvzS8dPngCAkr1U6vVW1lar1RqwKCne5U72PK90ECViY4yUKklHg8FoPB53Op1Wq5EmWRRFcSNO07RarbZakyWAVObljUajycnJkydP3nLLLbfffvtwNACwaTa+fPkyEd1///1PPfWM5/lFUcRR7eDBg8CqrEWU8gSq06dPl0jYeDyenp7e3Ny8fPlys9kEgCeffObQoQPMvLOzc8cdd2xvb990000XL14EwFI9WxpHaa0OHDhw7dq15kSrWq2mabq1tXX06NHxeGyMGY/HUTUajUbnz59vt9uVKN7a2lpb2zhz5kyr0VxdXb1y7dr8/Hy73V5dXZ2bmzt/4Vyj0djubNealdJJodvtbq6v33TToWarsbm53W53Tpw4MTk5XRRmbm7WWru1tVWv18uUwzAM19bWGo1GyWFHxDRNrbWVSkUpValUjhw91Ov1rLVpmvb7/ampKWYej5Obb745y7LRaAQglFJlfYOIO51O5Ol6s1aLQpvbrCiQLKW8NRjESgnfH7IjV4BCQA1WoF9Lc9f1w6mHHvUefdwYT4WRyPbORABECQwWAcvcMYY3QNM3uEWXZ6aSKjM2TanZbN533z21Wu2mI0cnJupa3zB7LSftRCiEUgIANjY2pERrbRRFntJa6zzPx8mwZGUJqYmoVL1EUSTEnrkOgMJyovsmQuxv4bTucjkRHFNUDcdp7gkMhbr0+a89+TufPBBVVWHYkUEGgSBAIldRViWWk9lcqjFKFGBR+iykcZqdtg7IMaNDRYCKJQAoIA+YjI09EaNIHVslDUIiKUVMJOakcnQOsCCW7CJgnylyZBxLwUjMyFwa6yMaTxZAiSAAqgoZSCnyospURTlLMG24amxfIYIFhde9lJBREiIDkiUiz+GEVYVUhS2KNIEwUEpwgY7BKGGBkRmtZQE+clgUkbUx4CS5Gcd1a/0CrXETOhiwS6wYa8gD6QBDgU56hoiZHTuHZCUZSQ6BBTrnPKHIgVRSemG318+A988vvvDy8d/5uf8ULiz+6m/8hovjW267NS8SU6RoisiPjE1QaeEJA5ny6fipVx5/56N5Lien/SDwHY/GSV9iBCwRNIIUqBBLaZf1/XBuZn51ZYssGUOWSQhPMKMx4ArKjQykUGxd6rKRs3kNsAHp0ZZerlXmfdmkpEo5o+2kST+uP/rTPw8zh1NCrxYqBr3rvi6BwTlHQiKC8hUKOPHCxmf/5H8ePLTocs6ZDVGj3jh96tRjDx/9Zz/zfX/5+//L+XNXFg9W8yJXOuy0h/VmAOTnGXR2ipk5Tyn16jd7//U//tHT3zi1b/5Q4DeSohj0c2ZkZx0VUuZhpMbJoFKpFXkhhZ8kSRCqwbALmgsixlxgn6DQLAVGFj0Asbm5PTNZTS+mX/i3//dk59y98xOmuw3CAiOQIMsAxIYdI4GUCJJK+AqEAFBMpS0bu70wlW89w65fiQEAQACWXmy4K+2VApVCIjSGHSEiMTOxK9+6y6nmUhEnpAQJoEgpAcKDAgAYyp+zFlmS+vVWewTp4vJbfvLvQX3KhDUNQgIiEyM6EOhYCtgtHRCgRLJwzxHqzZbrQiJ4o5eEEIKck1KWKkLEciLnnLPXt5r5dTnN3meRGZ1zzMBEALC+vr60tNRoNC5cuHDt2rW5xUVTGKUUSpCwx2RCBFHGIgoQwjFZK7Rg0AHuO1hb2LfdvdYKPFfkQghUuyUjKAlE14npr/dfX6+E3tg9vAHL/1bG1bcRsK4/eYNv1l5BhgggOc8wrti0kFIiFQAAQeX0Vie+84mb/vrfh3AqLaQXVwpDoRI+ehbs9eMBUDY99oYp4uWDB777u7/j8NG5p59+dnuwAVJcvHjxh37oo//y//rEB95fnZ6eZjBraxs7ndWZ2drlK5fe8sjbmNQDD2SN+hw7vbA4U2/IJO2HYej7fqPe6nZ61cp0lhZZVhQm39raWd63PDExVWYWG+OU8piRCIIg8rwhABRFkeUZsf3Up/7wxZfPHTg48+qxE61WJY7Do0cPX7m6Um3UO1vbly5dnm5OAsDqyppQejRMao36aDTyvFYcV4+fOFWJw+2tHbW2tnH58uUyj/nsmfPzC7OT07OLi4vz84vnz19s7/TjOJ6YmIzjytzcfJZlttiVxO/aDiEqpQCEtRRFcRgG42QopfQ8L45ja6nd7l6+fPX+++9vNBrXrq2+7W1vl1K22912uyuELAn1tVrNWnv16tUkHWdZEgReEESXL1/+5jdfqNVqMzMzpQvU9va2tdZaWxSmUqlp5adp2u0PAKBSiYbjESA0J1r9ft/zvOnZyU6v22g0Nre3HMP07MzTzz4zMztz5NCRF198sQxFrtWqvV7POddo1Ioic85YWwSBVwoKELFWqzlw1tqVlZVGo6GUd+nSldIBZXt7+/Tp0wcPHxoM+sxQkq+FEJ1ORylFDsbjcaPRtNZ0Op1ra+tpmt5x560HDx7c2toajxMhRJEXQqhqtToej2+//fa1tbXBYDAcDgHA9/0kHWVZZq0FgCxPWq1WpRKtra1NNlsFZuB0HFebrfrZs2e3NncWFha01mmaBkFUrVbDMNzc3ESQQRAMRiMnUfkeIgpgT4JWyrG6tr5Rt/lONsolELHOGQxBFPYlT979YPWJ7wC/qrkJZlc5RBIYQZIEsevm6QPtMiu/9azc7eITkxBCK+EsHzq4f9/SUhgKY0BrAABjWCpkcs45LSQjM5NAaYpiZWWlVA6WITlBEAyH/SxJ682GtUVZUUkpiaheq0mxN6g5QllC77sL3bBmArDUuSGCBCF2hTBcaLYmkcihCO2rZ/70V37tVh01tHCUOCRCIGAnyIIDEoFAsLnzZSHlGEGwcFICO2WND9IjJwAcChRckpUls+csIhZFFvphXaiusbkncuYcOQFMhEiZHaITYImBWaILyEXsnGOfKZPMAgUgW8eoEBgl7k75ycnCxqmpo2gJnHI8lRklRIZSSnYCLApmELTLOmFmQmKFkrlVEKLMlLCCetaREiWBWRB6gNI6cFaiCwgaBE3HE5bqlivW+M4hA1uu5WJS0CC3hcJEqpSZHWtEjQLBCoEgmURpRI8kJQqZGucLhUIl1haBnwdqx2VRq/rM83++8WTRmqrMHr1ps71TZOlEI2ableZm1hglC0QdB6K3s/nHn/yff/0nfyhLRkIxgdVCChk4o4HVrgEmElFhrQmCyvL+g1fPPUe+xyJwIIiERyQLp5yVZKUVqEXkq4kwnlPRfonTIm75pgZp06VZdwMmGtuOr/qV+//h/wWzRxLpWYI8Mw1FwAAogSUAKg0F5xagzBP8zKc/WySuGtZzW4ySLHdU5KPxKHvXu98eRPADH/3wP/0nvzi7VClyZKeLVOxkoxeeOdVs3H3k5hgMfPw3nvyv//mP6uH88tJRT0fD4djToRI+ERVkPc+zlGd54XuV8aiQsjoYJFEU9Htj4RGZhJEJEscjRiNBS1RO5M7xuLv11Oe/8M1P/srb5sWBiWi8cTUuE64kMAptBJNkAgZiuWduxrKEJXxmCxaoxEYIaE/b/+3X5jdcuffqFQcgBaAqfTHLvhpbi4iC99SHJWSCIIQAJYGdcySFBEQQDD5AFFB3W+QczC1dWh3l87fd+WN/F6YPFqgIUAMhE3LpjwVaSiBTAiUlms2CAQoAAlBvSnKHN9ZVexuBgGxM7ssAEUszbWYuZ7mlDuC6ucGezgaFECilc7yns0Yp5erq6mg0qtfrWutz5849+MgjDA6lKj+s+DqAtLfbmIS1vvBQIgNiszV39O71b6y1Yk2U7umfygpS7NKnvv2gvF7H8A335UFxeGMFdr0PWJLiueS871U/iFAWkY5f3z9SIAIK3w5TFXhkchQyQ71WqMqD71z8kb8NccuS58VaEoRCAAOTUNIDYMEEZS5R2VtEQODtna1nn336ez/yna+dO3bl8npn1HvHu99x8dzFm49OfPQH3vXqqycvXli/865D+5YPrm9cdIAPPfKW4ThdPnD07vtqO9v9s2cuk80mJ0Nj02Hvz+++++4nHl36hZ/7182Gqlb98XislCgJRWTsWx9+wNEu1SSO41GvW63GzWZzfn4uy7LSEf3atStHjs51+50Pf/i93V776tWrDz54v+eHW+2de+65BwCe+tqft1otKeXs3NyW2CHGVmuiKMpATByNRsQgELHVmvS8oLT/vnpl5ctf/vILL7wQhuE999xz7733luCWEGJmZqasIUrKUVlnOOfKoqcsm65cuTocjMvMFt8Pm82mlDpJkhdffDnPzfT0bIkG+b4PAI1Gw1pKkqTb7T/33HMvv/zys888l2XZ6ur6K6+8EgRBaZhpjNne2kmShIi2dzbPnDkTBIGU+NLLL8Rx3O/3G41GaVhAREEQLC0tEdHW1o4xJsuyiYmJnZ2ddrvteR4ivvzyy1tbW6PRqHTKqVar8/Oz18uaRqPx4IMPljK9cikdU5l5dnY2iqKS4TQ9PV0Uxdvf/vbxeCyECMOwrBSNMdbafr+PiFEUOefG4+To0aNbW+2tra3hcNRoNEtvJyllvz9M07QoCqXUxYsXS9/5RqMRRVGj0SgDm8s9XBRF6bzS7/eTZNRuty9cuDAeD/v9fmnHsLW1NRgMSlpSqTkoNRHVei2uVgzxOE2MMZatQ2CA3NHYWCPUuHDoh9ILIapB2EjYb9z+UO29fwnC6TF5u8lWBFCGwO+erQJLVOd1BvmbLIh43YBUKlQKwrB0UgBmMIYBSQiQUnqe2tXgWAsA29vtXq9XrdaVUmVT3PNVv98FgPL919F7Zq5Wq6VMCfd8v/7/LG8YNwGIyLI1glBBtRLDlZU/+sVf2W+hZq0kS2SZWbAAxlywQZLIvgDFjp01yGOGESApJQE8dAFbj40ABIEOhQUEJnQW2ElwYPKAuALCs4TEBmDMNAQ3AE4lOBQIEhElsg8QOFe1rkIUMnqOpGMBqFFI52ReeGleMa5mXCXLKuN0H6gDBhcNTGa2ktugsJqtRgAAJ8AKsAKdlA7BCTDIrBHYBKmpZ3aGxBwEVUbIDFoCR8Kxx1ghnHQwXdBcYecdL1iey6g5zvw0l+QQnUTSed4knnAU5wWSI4HGgSVWALJUFRErx8qi54QkQUJmWo98ryNwR4q82RjVqheTYReT6mx9YrYxPz/d2dqoBcF0o2GTLFSBSWygK5IkWERLGmU9rj7/3Etf+eLzgap0tkcSfGDtcgIQwFBKjMsDbV2hFCwuLo6GmSucZJCOyaQ2T8nmKByjs7YwWco204w+Sp+VYg3sjcduOLYynNnue6s8d/8//jWoLg8SZARfQiw1oA8oQDAgGeOIQCJIICn1eASf/ezn9i8fZvQ21nc67X6R2ae+8eyHP/zh2+443OnAe98/NbfQ6PeHAqI0oThqMenTr13YWBsFCv7GX/n1f/+vf6cWzDF5QDjsD8qxtLSbyfO0KLJ+v7uxsbG93e60h6NhFgYVYxxIYMwYMsBcgpOIAJADFVgUIiOR1gL72gtfr2Ix04jYpr4GjDSZzAIzSbRKWCkJBDvNRoAFkMAILIEALWt6HRr5lttuR6m8Ee09FuVNCSkYwLoyvAocITEAlkmauxA4AxADMRI6JmJiRmEFWAHGgDMAznQ7IohhYv78pfVsaunmH//bMH+ob6VDRcDgdi2YyhYYlchVSVdiZAAHzoKz4Ki0dX+zpfzl3PiAmUv8iXgXU2BmItra2rLW3vjOXcUjIjMjynJEKsFnRFnaPm9tbYVhODMzs7q6ur2xobWG6+Ibh0AM7LgsYQCACKVEQQA2sxaEV73l7sKrFo6VUgIRnNstjAoDu9lgDvY8l3ePBRFYB86Boxvfw+51lISIyDkqqTPXP3i9UNvbCTdWn3vPERHkhCqumXEitMdR/VzCcOj+xb/yv0J1pptZ8LRz4AoGBspZICgADQhl/uN11w8AAex74ujRw5/73Od2djqXLq5cuzr4rd/8TL+XXLp0ZWVl5eSx9TvuPPiOdz52++23vv/97+/3hr3uyBTwmU//6QvPv3Tq1KmZmYl7H7jnwoVzWst2Z7sESvqDMSLOzMwwcxQH1lpml+fp1tZmpRIj8ng8HgwGU1NTtVptZWWlTKnp9bsTExO+71tbHDly5OTJkysrK0EQ/N7v/d7Zs2cbjVa1Wj1//nxpb0ZEq6urly9fds61Wq0oiqXU29vDPDcAoOK4kue5MTYM4zw3Qqg777y72+1+6Yt/NjU1ValUJyYmO51eu91Ns6xaqSfjMQAgSCkkkyVXnmYySwvtSSKOolhKZQq3s90ZDoe1amPfvgMb61uXLl7p94ZXLj/barWWlioCVVkcDAa90WhUqdTW1jYOHjyQ56bXG/T7wziuLi8fOnfu3LmzF/ft23fixIlGo3HPPfccPnT03LnziBiGYZYWlUoliqLRaCClVEq12+1Go3bfffc8++yzRHZ+fnY8Hler8dbWxsGDh0ej0blz5xuNunN2e3t7ZmaG2b3yyivW2sV9C1JimhZra2unXzt/YHne98Pt7e3+aLCwMK+Ut73dtoWZmJjwPG99ff27vuu7er3eN77xjZtvvrko8uFwKKX0Q384HNbr9Twzg8Gg1ZpYWlq66aabzpx9rdqov3bmzHPPPVer1QaDwbve9a6v955qtVqlTvDWW28dDocnTuy2Zcvzs9FojMdjIqpUKnme53k+Pz/ryLQmGv1B9+q1yzsvnopiMbuwqEkWuY3jiIi3tzfLED7fV1mW+L4vmVyRky1ACPQ8J2WSOAKF2t/Z7ne64xp7GYtcB6PG3MJ7PwSNJWdkrGuQAzBACHZvquMQBIDHN4y1b1henxpe7+IBUNm1LIrShFqjAOUhgASAso4pC6xyiFpdXWVGKZQU4Gm/rLG63a7WunQuLSxpra0lJWSlUnFutx9ajm6Ee1TPN1Z7u2XZbsADMTETMHJaJDPNFqx2P/svfqW2un243hok3QIMCEbHAQuH0iogiVpwqCBybszGCS8BFohCCmFdgM4n4zsrWQJAuQ7CWQQL6AAlkPMI6iSqJEeOjUCj5MhCX5XXLwAACSgJPOKAbGAVM1QRU0ZkJiZfaY9ZG4vOisIppApjHcSCwdi4AJy2ReSsEVI6ZCQkTUJYIQGcZDASckVGskWnJUhrg4ImpSc8WTg0eU5oLSCD0CBbgA2QNcehtaErKo6qGYMxJcWMFQCjJFsFNcU4yilRDoUnpSRHCIzsAEhYCgqspljNBAOkHuSVYMwwFkhB2HNF2xo7Wc0CN8h3vLhlTM5pwZxJpWLhC8PCepojgRGDLFKnUUrU1UD94e9/SqF76+P3ckFJPq7U/CLPpfSRiXd5x9pZFhImplqp4bwAbXIJOdmcADIpjZTkSDBLS1y4a9Z2GVeFX5Nc0eOWrycgioNa11Wf+MmfAnXYFBB6AENQABgAF2CJdEzAToeVJDN+SACIBM9/8+TK6vZNR+4dDEerqxsf/dj3/+APfezy5ZX5uUlHSWWi6mn4wIce+93f/tT+A5N5bvM8VwqccyePX/5v//V3L56/dPDgTaEXm7xgMlHsIUZZZnqDoe/rIBDVWnj4pjv37VscJwbI39wYrK+vgzJZkUgcCd8QS2ShnOcQLbCVhCr1hK1LUwyu3Xl08dzll+M5H7CoDMZgjRIegAC320QTbMERIABr4JLW48AZYAChABFcycR/IxUaAFB+K4i1+yqW5BywDMxsmZkFculBwHtv3w0LRs7JicIFKEAEYAlckSlCVFJGoOvnrvT6tf33/+2/D9NLaU5RVGHOgIitRKEA0DlrrCsUCAbJQjsSTIDE0ubKAoByTvKbzMRubBHCDRwsAaiUKoqinAFaaytxWLYphBB7kzu4vkMscRkczczknBC7FllRFG1tbc3NzS0sLFy5evXcuTNTs7POWpAALErkioXbVfExgFQARK5gBE8FUFg4fDvVZ/ud02EkwbLNCuV5DEzGSt8D66jU7dzAQxd7yTm7XUJi3vMhQxDXDVd38x5KANgBwBu9r3bxOQG73K5dU1JkcsCkdZKnUb2W5XRivbfw9g/M/eDfhLCVGahVQgkEgp1kAil8hBKr2x2U4brku1Scj8eD8xfONGrB9NRMoz51+dLm/Y8cueuOe3d2thcWokcfc0v75nfa65vblwaDzuTkjDXy7JmL1crEn/3ZC088cd+B5YVLl88eObrcbm8fWj6KyC+99EKl4g8Gfc/zlEJrrTG50qLVaGhPNhq1JB0FgTdKJQC8/PLLw2G/2+3WajWSWBRFHMcL+/bfetttf/qFzw+Hg7e//e1Cnp2bXzx28tSg3Y3CSjLop2l65513vnLs+PLy8iOPvvX3PvEHH/3oR1966UUvFEJKMla12+25ubkTJ07s37+//IH2er1S9dDv9611eZ6X8jQG6Ha7ntbOOXq9Wsfr3HMlw8xkuTNCqDCMGo0mIjQaDQCYnJw0xlSr1enp6a2trbW1tdIFNc9MEERzcwuj0YCZR6MkCIKiKKanp8fjsed5k5OTWnmlR4MxZnV1tSiK7e2tsi5Js/Hc/OKdd975wgvfXFtbC4KgxG9LQrpS6rlnX52da/h+KIR43/ve9+u//uuPPfa2Y8eOSSmLotje3my1WuPxuFar3XzzzcaYdrtNRDfdvLy9vR0EdmZmpjHR2NjYiPzI87woCIfDYWkQeu7cuaWlpQMHDiiltre3iajRaGpfdwfd2I/TJAeAPM83NjY2Nzf2LR0ApDxPwzAcDofW2pMnXiOiUvq3f/9+rXUYhrfccktRFEVRbG5uFs4iYhAEZdKitTbP816vNx72H3zwgdtvv73f77/80qs7Ozvr6+vNZjPLCkSMolgp1ev1SnQnz3NCYuuoyJWUINCxgzhuVefToYmVo2zgQ+SFsLrZ9vZPL7zvwzC3PM4wrjQ5d7sOKEgOyjB5IXfbf+UZIngX530TyL00qeI99QMAaC0R0ZIrSyvY4y5cf4NSHgBcu7bqe4G1FARBEES+72dZ1uv1SiyzrNU8T+V56ge7beiSUrpbRb0Z1wq+TUVYykU1YhRGkBZf/dV/W5y7fEulyqNe1Zc5OWZiFshCgJCWHVoAUGgrAfbBZQgWmRA8ZgYTCFIuV9YJ8hglggSkspQDZEbyhHLW1ZTXALlNIJRwilOEoQJmshaBEIkVQQCorQuMA8CKxBGBJXIILs8Coad9PzZSFLksXCC4DjIajwNLSjpFhOwQQLJUxKWAEQQwghPgGKxCkkjGCGSlBRBFqSElJ1EnIHsIVisWIIgCC03LE4ULigJt4RNLCwwIsnRAYsksrfMK1UToEZrFfAABAABJREFUC+7m1ilyCAVxgCyYJUApRGCJRgsrYBSJjqKhkoX2E8AuQ6F8CMIhJqIWj4ZpzQ/mG81xP1UGkiyVvueFzXHXglBBENhiHMZBWhRRGIpc/tEn/ufkxNzBo7ONyQkk1p4DMCgcECEoKaRjQIR6o8IAzrHJC4cZoxVCFMRUkBIKiJVBZkmsHGHq1I4rZGbkTj6pWxJkc/+tX3hyZ/hSMre8UAnN0txUJZJr54eFEpntzs/pQdKemj4YVgKiIktNNQg+/9mvxZUGau/SufWlfYe/9yPfU43Uow8fWFtPWlNRf5hNNYPv/p4nfus3/6DfGzYak9s7O0JaAv/rX/+qNXD0yB15khaUMzMwGzPe2L40Ozt3y+3zd911+223HZqaUWEEvg9hCO1t+P3ffembL15e3DdRpGPNCVhjSQohGCyzsZKZrFAGITNuSGB3uoMIXdRqDjb6EkWzOlkkRgIDEzCBMMAOwAEKRgCQCLj7UglXI7CzbyZDu5GIeUOZgsAIRISSkAGYqTBExMYiYmkzWpJ7SvEvMUvF1loHWiKDzQidClUBbGX82uqo7U0//jP/CiZn2700qsTjQdfTgh0RKCEIWRgyFohsOd8CIkAmQLKOjStXwdK3rP/emHB9uHgD1E3seV7ZoimZKgDQ7XbLLBPjWAghBDiyN241oASwfB3fQpBSttvtwWBQr9ejKLp69epbrv+JXVqDgFIKyAC8N0NEEmXaKysIG9OHbh2vnQAPgMAZK1EAAFknhWOi19lX11uu8G10VGIsjR2+bdt3N3nvg288krCr0ZYCXsf5iJGkZNJyezheydShd3+k+d1/GfzphLXnATs2RaJDX2q01glUpiCtb7hYCAAAV3LdwG2sr2ZJ79ogO/Xa8R/7Gz8xu/D0F7/41Mq1Kw89dN/c3NyDD903Nd38D7/261kGH/jAI888/eLddz0wPbl07NgpYHjnO99RrXm1hszGgzRdeviBt1w4v3Ly5HHPU41GLY6josiSZCQkeJ4OQl8IUhp8UoPBII7DJBldvXr5/R/4zlq9PhwO89z5vv9d3/WhT/zhJze3dmq1Rqs1ubW1s7CwtNPuFkVx3333Pfnkk0VRlNep0WBYna9vb28fOXLkmWeeuXLl8vzcopa4unpNVSv1+bnFhfklIiq7j73BgAkWFhZ3dnaE0GWfLsuyer3peUEyHlpriVzZIhRClJ2gOK46Z6SUQRhGUdRudzudjuephYXFXq+XZfloNA7D0Dna3Nx661vfWq1WX3jh+ampqcGwNxqNkiRTSpT1U54XztLi4mK73R6Pkrm5uZLrTUQ7OztlTo7v+91ud25ubn5+/qtf/Wqep7VajchOTrZKw/fLVy4++uijb3vsgTNnzly5vH7HnTf95m/+5uLiYqvVuummm9rtneFwSGSFEPv2Lw4Gg5MnT950002IXBRZs9lExMFgtL29jVJW4pqn1ObmZugHQogkSaSUTzzxxAc+8IEf+/G/ppRaWFi4dOlSlqVZkTFzp9cVIEtTUN/3pVRE1O216/UqIE9PTwMLIcT09PTOzk6j0djY2Cgt7MrWZBmGaJnK9CsiGgwGWutarTYeD621Fy9eLOvrxaX50XiQ5FlJoQMArb04jgvjjDGl8b9lYrTo2AN2kpM8Y+NVas1iYE1qMQFIILNsq/XGA/fC3XfkzpOVCjOgkjB2EErOjfJFDg6APSBksds4BwAQfIMHzK6DHQAAlAB4OUlisuWviAGlkMRUWg/CntiwLHeEEKPBeG1tLY6rAEIprywuu712kiS1WoX3gCgAKF0wyqZtSX7fXYFSnlxWhjcMLt9SXTGzlBAJ6Ut5/L//3sY3vnlXdYqSQeFSkYEnFbKwjFYAI0YWAoLCmUiIihCaXS7AIDCCdWStEey0s4oJmBgl7LZViYCsIAcsUClrKwZb2vNMnvpopSB0Q0nAUFhAZk2giXwGj1g7B6gigoAwISBJzuRScB3FlIM4Z1EYQKeg8CxIBmBH4IxwDoUA9lh4hhVwWQUiA6AkIADSiIKckcyAQUEwtk2hhp431MCBJnQ2ybGgyGKtcH5uQTAxWQZWggUCoHCkmLQla8cViiZDb7vgVNo00KliLREtCkBAmWrqRjwIIBPQC+WGdTaQRqt+YaBaldobFGmidMSeJ5nGGWXZXKVVWCDkJNWAlXFiGQBEbMj1slQpyWSq1dqg537343/6nu987B3vuW086k1MhYay8niTE8gCgFBwXBVSOgFkSeQkGKWUkoidJeFpa2xhWAvpSVEACyrA5hZttdLc7kcSJgfHR5tPf4ljsbDQnK5hJfCShFba7be+590PvvXOQeIuXTrPqr2/MocsQxWDheefPd5qTY+TtNMfvu3xtxy9qdLeyocDOb8QFQRK+0UKC/vhnnvuef6Fk63JWPpDhiR3Qnk1zwv7g45g8P3AZIYKtGDe/o673/r4g3fdcaBWB+1Dbkgqi6DIis5g9I1nP2dcMhhCFPujNCVXkAyRCGwm2AiNwpeG0FCx2l2bCCuyIvORuXDp6oFmozCiP+QIhAQLmAPY3VqqxDowZxQASqBAUgAM5BBu0OXtnU7IgnlXGnb9PHv9mo3MwMQgaBfUYWbnSEqJ9DolqGReCyAfBJNzUjlbuDQJfU8UIh+5CzbtTe17/J/9a6hO9Hu5HzYVG0Djcg0gCmmAjQABKCQo4cq5ljWYg7AAAkhLFwCAEI7Rwpst14cIvGGcAQBjTDlslMNaURSl43E5cDEzAJYAWIk2IO6p+Pa+sHw1TdOtrc2bbrppbm5ue3t7Z3N9cnbGAMm9sZP2bNEBwDIIBLnnYuVASBHO3vPA5Wf+xGUDqbSnlCtd5pUC53Bv1rq7CXBDnNENhVK5SmUKR7nPmXdhrde3+no6R0mPuxHN2j1k5XNCgwVte6P8AtVv+54fqb7nB0HWigyiCJwBqRCCyJpMaS0VFmy0L3fdHHbn6cLtfa8D2x+0X37l8oc+/MBgMHrumaenJ1of+uB7RuPeV7/6zKAL73rvLY+/45F//3//4pe//KVXXzmhpP+1rzxz6y333HnHffXaxfX19a2dLIrlzs4WEX3xS5+fntw3Pz+3sXZaaVGrVXbaiVJic3PjLQ8/4Elx5uzp6clqFNeddVLKQT8p7ayTJAmCMBn0fS9M09z3orW19ahSWV5efu3UmWq9trG1ObewcPHixWvXVvIxTE/Hn//TP21OTPV6vWBrq9lsbm1tLS0tnT9z0fMhCAKxMD974vgrhw7uZ+e67XaaJhPNhufrTqcTBEGSJHlRDIfDLM9LfyZPB1Lo3Twsra+7M5RlRxzHZSWEyM1mvV6vl9ztkqUkpez1evv27VtZWXnuueeYuSiK0srI87zp6em3vOUtURSURg+9Xm9paSkIgvX1dc8LENFampyY9nQwNTU9P7/gHOd5niRZEATjcUpEeW7SNJ2ZmdNaB370uT/9cqPReOc73720bybP87W1tTAMjSmef/6bRHTkyJGSe2gNHT1yc6fTAxBFYUtXiDAMicjzvNFoFMdxbkwQBM2JFiKurl6rVuOoEn7uC3+KyP1+N8uyar3Ge4a/WmvtSWOM1ipJxmmalPTGVqs1Ozu7vLx8zz33IOLy8nKr1drZ2VldXf3GN75x7ty5lZWVlZWVTqdzPfu5PDOFEGVKQxRF9Xp9a2v7xRdfOnfufJ7n1tDs7GxJwCwhq+Fw6PmqWouLosiLNBkNPCU9z7NMjCC1yo3t7rSFdeyAdG0j01dtOH3f4813vA9kRF4MZcgMAkTSpRlqXaLDCMxAsOsp9xfqca4v1hLv8aKU1lhuTok1lcMBIu1mL+yODv3+sNvpxUHoSaWF1EKi4OGwb0yOshRICgBwjonI94LA07BnP1OOHeL1uqrEb66vpQAQBMjMyCyZA0CfYPDnz77we5/aJ0MYDoVg4QkiglKR7oBAkfTAi2RY1VHDC2saA0kKGRSwZC5tohwxSkDhUFpAC+iQqVSlW0BHIBDRGOGszyAsIEsrMAdMBRQMFndHLA3CB6Ed+M6FzoaOg1KRSKg83wCNknE6GKlxVim4koOfuWq17tdqOq6C75NEi+7GKwQCCQDBCkkDBiS8MmsodwWB00Chs9XMNSxoYwQ6CeyYCkIDCpUnPE8HoRACAaRj6RidJbaIrKSQxsSGWiyrJJVlAVIKbVkYxIIhRehoXPfEiidXtbhKdlSJd5TXFuhqUaExKbJQ66mg4o2yCYdLWs+Cq4x7RyYaE34onEpGQstJ5qY0NcXV7fUUOJBSZUni+djp7nzqD/701Rc3bBEN+gW7MpqWnXMGLIETyJHWzEYIFgKA2GauSAzm1nfA40Rb9lUoRVA4GJu8AEI/tKqxk4YDMbeahNcGOQVBYdzW5s6p1849+dTTTz73zPrG1u98/A9PvHwh6YkH7nt0bnYhz4uy07d2Da5eWWu2JpKsYJJ33XkPOPB9GUSYpEVhCj/EvABQ8D0f+aCxaae/RZyCGGs/K2wnydqR783MzA5648GgZ2n4vd//7h/9a9/1trcfaEyChUL6TgcDP0qFHnkBrK5dHvS3KlWfwPV6Hen5Aj0tlQRkJkaSgqVgBRagmJ2bHCbD7W5vkOSWVZI54YcFMe9ewl1pTbR7ou9B1yVhilGw2D1VX/deuuFWdjFQSpQCBILYjYtEgUJILYVgcs4QWUT2pPKkgjfgKGVJwghIxgqQnqe9QGutIQhBBqsJZ9MHHvvnvwLVyU4hw9qkh74g9FB6yldeoLRGKYUSUgslpJLS01prqTypPK201lp7yvelr/6CRX7bUj6pfY+AtfYQhUQVeGGem0F/BIDGsTHGMREBOS6HIEkgCZAdMxNbx2TIOOf8IACAMvd2enq63+9fuHABmJGYeTebfQ83g9Iiq3yWiIFBah9QwKGbqdYaOQGgUIfsiJlBaSB+4xFhECX+fsOTQtx4QyGwfCx3SdXl/R6ctidTKMtERNSekBpFKXBkIUFoZt/bHtgN2Xr4+368+p7vAQ4KUl6oyYJUuzonpT0oU+dLVSoSIO1y7vZak8wsQbTbO/fcs/De9717YrIWV7zPfPp/rK9e/pG/8kM/8APf+/CjR9/1zvf99m998tOf+p9ve9tj1VqUFyOp6NVXXzlw4MCBA8vnzl78sy9//c+++LVBf2wK+MafP7e12fU8v2Rm9/v90nQzDEPn3GDY832NiErIJEkC7a2srvthpD0fURhTKCmJbZIkl6+uVOtNS3z2/AVmLrJ8cX6hSJIXX/jmww/fHUbQ7Y0R6ZZbbiqNhLa3t06fPPPDf/ljH/rwdxQ5IJD68Aff98d/8ul+t3d4eeHokX1ra2sf/tD7X3r51aef+2aes9KeZUiG4xCEEDDo9bX2lfKzLCuVg0QUBJ5zJggCIWGc9AEYMWo2G3mel7xApTznWAiVpqnWul6vBUEgpXBkGJxSqtPpBIFXFEUQeDfdfPSVV15Z2rd49uzZ7e3thx56aHZ2/otf/HKamDiuaO297W2Pnz93cW11SwpNTqyurva6/cmJqbzInGMA0WxOnDp1otlsTk+L//EnXzp8ZN99993X7XZ7vd5oNNjaWEeE9fXVbrc9OTkdx1Wt9cbGVp4bawlRai03NjaEELOz02matqZaxlk7NFOzS1mWZUW6sDQ/HA+++udfjuO42ogG/ZEWHgjhB15SFFmWaSettdpTWZ4EoefIMGghwBgTRfWTr52ZmZmZmJ66unp1u7M9GCczM1N5nrd73SAIVtbXoijK87xkc5fBoiVeVRRFmqZHjx6Oh8OiKNrd/k6nlxamKnWrWS3zs6vVSp7nw35fKVUUptlsSKW1VBSrPJdWgiClc46FCMlRYbaj+uV48c777qo/8QRgA1gFiFQa9iIAgKwG5Snv7RUpIOB6LAPuPfemi1LXo913DbOkLL/gOjGACYCZAIRz7CGcPn2anWOybLgSNARZJDceD33fV0o5x4UlKRWAcIURQkgJxbhgBKVk4axCIQgEgJHsxHURkUBGV84wpSRnAqVkXoTWwHD8P3/hV44UUDHWuQJQotJCi5xIAaLy0YmVnd7FUZ+CAKU/8sR21XcTFe0JawoflS44jBqhr/LNVYPk7Eh7IZNjZh2oPDWuEEEQpePEr0a9PM2Fb9mpepCByyn1HVhTSE9neaERUQrMRcAi4GI0TuvBzAhVpzDoC/axV4wqUVTVkA/zMDeSnAU8u7ZlhUiSwXQ9nI18Zs6sc55fKOG0MGBCGXhG5sNilIvA6JXBxvJs3WVZlozr9WY2TmsUjHLTkIXLXa61EDqRwQ7qzs6KHrYj6RaqtX1BnbKscEXPJEVVK08nvTQQUhmHgzxo1VtBDdkz+ZhjrxCU2xykcgQNP+DcpKbIZABBNTH2/8fbe4dZll7lvWt9YaeTz6mcO0+H6Z7umZ6k0YzCKCMkYRmQjG2MkCWwuUST4eJrbGyDA75cCTAY2QghQALlMJLQaDQ598x07q6urq58qk7e8Qvr/rGre3qCsOG519+zn/3s2nXqnLP3qfPttdd61+8lB5EST6IOe2Xwnb4pWazoxNWRIENcJkvzZVbuuZUwZCBk2Fdz9caRw6999uSzz77w5I69EyxIoqzZGCm3m/b3PvJn733fu/cfGh+fZJb3DGjmMnBZnEZlU6oUyoViQNwIxLLDiQubmqGCj8Ymg0Q6oq+1lkL6yLlje72qPyJTV1N1MPBdx5uqs3bYHKmXLWUSfUusMVSKYnX27PrnP/1n041/UnRnqqMA0gJk4MPZC2dTlQReAVBWyuUdO3ZkBjSSYCAlI4tA5HiYhnDTsbFK1cuybHRsuBsnjKuiAyo1kEKW8GhAu/fO/fhPvndyNuBexHnmuMWgIIllTEgyVqAX9sHhRbTC4dL3HeaWgSdguUOIArnDudDANWCGZBjZAmMqUsMTU1an6AhweZh2qgVB2lgGgCKXZl8FV0J+M8Rz2z4CYAzz0tT1t1UvpnmuwynhNfk7A7LbMZukq2kUBhYAkQtHK0UWQAggBGsAFXBk3EelQCuVRLJcMsTOdJNwds+tv/ZvoVjNpOu5QmSWMQnoAOb3K8BAiryqSQw5v3qPIQH5VQzM9lxkLUCeZLqaznml9Or6H4ms67pE5AgXLSKILNaGyPGCRBvLOIA1ZFlugq0tGZOLb6TgwHmmdRAEYdTHhCrV6vr6RrvdKRbL1Wr95POnbrv9TqOM68k0Sx3XBSAEtFelGAgI4DAGBIwQULrgFWo33bp2/0ZFFiCLZLGgs4Sxa3oqBmSBDCBZ3BbOci7yA8ltLZBeBtS4WmTYrixeqw7y/G4aEEEwFFyDNcbI3OyVMgADknd56Uyw79bv+QAcuwPABcdxGAIaJjkBWCQAYa5KreTVU5onyLbDNwK0wIUAMK7rVRv1hx595OyF07fcets//MG3/tVnvvLHf/KRQzfePDu997//t88uLyUqPcM5f9e733H/t752aX7p9mNvTuPeQw88NDc3Mzu5b2Zm8uKFc8vLF44dubvgjywvnfX9krU2jmPXLwwGAymdqampJx97+J7X3LG4cKFSLg/VgyTJXL+474a9ly4v75idZGgZB0fgwqXzjifjTAHnkiEKZGA4USlwmgaOH7th4eLzk5NTp05d/tYD3yoUqo7nXpw/Dwhfv++L586c3bt7Qgghnn3mSat1rVZdXVsGAK3V179+X6aNlNISKGUSldWHh7I40Sp1pNfpdPPEVa/XK5VKSZIkSVQoFJROtcmEYLkJdO79wrkQwtFa571yhUIh71PNsnR0dHQQ9vr9fhzHQrBCoSCESJIkjAaNRiNJkj179qytrj/77HO7dydZlsVx4jiu1nZlZWVkZGR6evaWW25dWlp69LHHh4eH2+12sVgsFoujo6PNZrNQKEVREkXRzOzElSvLly4tzs5ONRqNfr8fh9HQUCPvy1tfXx8fH5fSaTSGriwtL1y63Biq93r9er1ujFlaWgqTeHZ2utvrTk1NCUfqwUCTjuO4XCm6rtNqbSmVeb4kRtLhve4gCILGUJUxyA0BkyTJI2XOMWfNxXH8xje+8aGHHup2uwCQpmmtlsMzHNd1O51OEAQ5ZyWO41qtlhPni8ViGIbVarXX6w0GkecFrVanWq3X6/VOpxNHablc7vf7m5ubAJBrlVzXDQKRJYknHCklc/2taL1SHdJpVpIeTxMV9jPCdS35zJ7pN78HPBcs5NZVL/oLvhg7sZcloP+/GMyCge3mdgBgxsDSlWVEdIV0HIcz9D0nTePm5rrrusYYbRkiMZbLsNxapYK4rabXObac5a2/14qEL+rDOGOAPM3SUsFP2+2i1VCqffsj/7nUTyrM9QUzKFMy2mgC4kLEGVljYm3v+O53vP3mm1aSKEs0BqVHzp//9P1fc4WWrsMsL3pBFkXLnfaoX3WZkw46WRo7vmsJe4Ow6AeQYaqBVyqXu92OE3gjc2ZtPQkhE4LLEhApo8AiE5KDoChFDZBpRrrkOYk2Hoii42ZoI50B5wO0oZAxgyLjNjPa4ZNHDw8ETPl+c+HChYsXd8zOuRYd4RID4TqQmihKhSl4pWEInF5nvTo1ffrS6cnG0PBIY9DrabJSZQ2/XLPU7Sssl6IMU1m71Brcfdvr5ob8zubiqW9/e3WtO+J406O1iu+0RdoJ+2UhXL/cb6da8o1294XVZnlut1+qRUkHBeOyEBky3DXgo82E72kio6U1GSaph1SCtMplKdNOqsuWl5QWxjBQiutQoJa+CXuV8vRKp1erNVaWVsYbw+/9e9/f6feff+7J/TfOFkvu5ta6H0xz9P/kv//59/6DdxXcOUNqfLaqeBqaWHqOVZnLHJezouf5ATdKo3EEt6NFv8CMKLB+v7+Vpb3QFIqNQZKNTs712uDyibCHjl9k0iR2qVzNuDCcsTiOq3V/eePU8ND4zFS1ubLWXNmcm5l0RjmTQW8wIIIXTp6qVqvFYrHb7SMSYyzvnANjPEeggDgacMNLxWDEgde98a6v3Xd/teY7jiMdAQaLQS3c8hYWFt/79971zncdKteSYiWzzDBHICMSgEIwFESGtCxaGGpUhqqVTBvJ5CClYqFqbEJZxIhtp0OYEZx5xDzOi8xmyKpBEcpVB2JPMAeNJxlam/fhwjZcBLdpF9uk4Jd+Za8Kp1788dUnBbqqXr7aDsMEw22GNyAAIahMcAZSgCGwJi8bkbXWaskFgJGlSpSqS4myuw7e+tO/An5FycCCRMyB7QwIgSHnuW8Pv+5d5HmRXKC9rRkCIAAFsH2ULwutrrXIXPsRrgVbeQONRYYMLAMCrbXKDMC20BK2mVPICJGAgDzPY4z1Bj3pcCTo9/vS4QSIiErr9fX1ifGpgh8MBoP1ldXRqUmjdS6UuHZS6drZJHatG1IzEELWDh9ffPpha1JmLHDLBAetrwNPMAAiNDlCia5L4FsERtt22q/47K77iV/rOwCAq/6GSGQt55D0e14QAJfAZQfgYipe84M/yW64DaQAq8ESMG2MRWEJXuoYenXD4nU76arJEAGBLQSlK1eWn33u+enZahA4StHhIztT1f/TT/7JrTe9KRxku3cdLFdFq9Xq9zuHj+xrt5tTM7UnHjtz/PgxY6zgkoi95s7XxVF64pmTnhMzFECotZbC1dqmynAmd+/ae3n+/Pz8fMF3l5aWDh449PiTT222eneN3HXq5PPNpjPUKAMpq1UYhu2u4p7mUvajMAv7UxMjra3myupgbpYdPLBz5Ed/cH1z65Zbj//xxz8dRp1UO8js2FTlwQefrlZ4qTSlUy06vR4wRM66vUEuCVpYWCiV62EYIuOeXxqv1aIoQoJ+L2zU3enpqdXVVSndQsFP0zgIPK311tZWoVBgjJErAPTVpjDMsrRWLSLwQdjrdDq9npPTBJTKxsfHu92uJV2pVKy1vd7AGLNr1y5r9X333beysnXs2MEwjLMse/LJJxljjuMsLi76fiEIAinc8fFxIrpw4QIyqFTLK6vLjiulI9bW1oLA8zxna6tfrZY3N5s7d87ldsJ5N6bv+9Vq9bnnTjqOrFarKysrpVL5u77ru1bX1prNZhgNcknjzp07jTFrzY1ck57HbUEQANh4EHqep7VGJABLBHF/gMgBSMptMyOlTJoqgJxrqLNM59wmIZxeb/DOd77roYceklIaQ4i4uLhIRK7rDg0N5SL9IAiCIMgrpznGHRG3trZyS/brkXe+7/teodVqVSqVvCsznxjz5juVpsBwY6NZHRoeqjc2W+1iUHBdd2tzUypVrFTdSvnYnXeA50KWKcalI+F/42BXv2UAwAUCQA4XzWPKvPA3iAZbm+3JyUltDdG2A43WGjjWhuqWwFojhMgBuzbHDedPaOG6CJEholba9VyjMkdy1y8N/vqRJ75w39FiFSxZq8la5jLL0VijyYAULCgsrq7fuGOUvfPuKaMBBHhQWLrzYw8+4PplZFxHNlbch6IFe+HiZb9eCLDsMK0U1wTCKaYGXC4TBic7WzQ+8Q9+/GeD1xw+/c///Yknnt5146FMx2nWZ+hZjWkSSik97jmgmTXaZFJKnqUu8iJze1qBMEwyk1mFFDGbuRwzMr5447/7FQgEeD5E2R+8890Lm1vDIzO2GwdD1VakBJdOoZC0zXKW7Xv9a//+m+/xa+yzP/7h3tKyl6Q9FVVLtbifmkFar1ZDlKt9DqK40YNSYRKmDtz2fW+GIXjLoNv69lOf/g+/PX/6/K2HD5o4qwZ1TrYZJ7HDo3Lh3/zhH/76R3//L7/5yIHhUSeNuEoNuHECmSqHmUOD1HV8p+D3Wl1ANhz4Zd0fZ3ZIa9vulvzAJQgUcGMsZpnQhshFWffrTdsrllyLoRXJyUsnKxdHfvxnP/jb/wlOnn1638GpSqUW9duAqReI3//o7/Y23vWWt901aFNoEl7lpBI3QK5Sx2pJxLiMlWZgGCnMdMXRMw0sjIqltWbGvdOrFx1v/MqlVqRGtAZt+PCYaA0Wq6OJ5SFQZiwbHq902puVmpfp0HEbxZL/1NOPHT56Q5oGjgCBRSS4dHGpXKy4Dk+TwVC9MTlelxwcIYVDWiWWkkLRtxkPIyi4sLKyhMzUh6utbi9LjYPlLHPa7f673/OO7/uBQ64PfplrFnGvYLmjgFkGiJyLnEBgCdmhw7Xv/Xvf9bH/9hcDlLWhsYEepJaKTiDRgMg4yxizAqzPybc6AO1wW2bWCxw/7vsAPmo3/0Ihu45fBdd9KV858uuzBXj5FfolBKbrt3NRMwlEZAgEllAhadAKmLPNLGUcuANEaBR3JCQxCAHcu2wwm9t79Kd+CYqjwDxpuGBgCbUQjIBBBkCIgl39mr9ErP0d8lJXrYtf8hiE6y/7L4USb1sAESIZphkIbVKVxQwsJ2tzFiu9KJJn0mmHIWNQrlYY2U6aBK4rhIjSBICk56+sru+e2ztUG2o1W88/f3J0atJaKx2Hrr0NAEuWI7v+PVzdELB7v2iMda6crjMFGpmURhOXEozeVn4iAwJO9npXQX71APNLFsB1HoXXclcAgNayvP2QbXvuIABZ0ITWcEfyWg0GEZSGmmE273m3ffgnYNcR4A4ggUWQAhA4YwTXxYjXXuSlu3Lt/7XMmbXw3HPP7dy587aRmzbb654XdNqbjcbw8TuOfvWr9zOhDt6464nHn1SLg3e++9bPfPZT3/t97zp+67FOt1kqOwy906fOPX3i0t13v/br93114VLLc/Cu17yec56k8cjIRBJnnX5veLgRkr58+fLBgwdPnnjm2E2Hbj1+bGFhvtvbSLOs091wXJQOE5J5fjGKIs7kjrmp3fsOFcuVL3/5iwcPHulurff7g3vuueGXfuUn5hdO33L7kU996tNPPXXK8ai5BcNFe/DI4Xvvvffyxcu9Tn9tZfPK4jwDgEqleuDAwTe++U0jI6PIhesHrW6nWCxyzhFsNAiRIEvTozfdNBgMVleXHZdpneUqP9/3EbFWq+VSKswhOCRURllqEWSSJAAgeE6qcoRwfL8wNDRMBL7vS+HmuPNOp7OxsXnx4kUp3dHR0UOH9pw4cXJzczN3P3QdnzF2++23VyoVpdTCwsLp06fDMMxF7rmuK8uydrudJFGr1YqiqFarEdHevXvz6tLm5lan00uSJEmS06dPO470fX99vRkEwU033fTAAw9MTU29+93vLhaLeZptcXExSZJarcaYQMRCoZAr4IQQlUolDAfdblsIEcdx3vmpVOoHLgAMBoMwDHMmVg7iiuM4TVMiYoxdunTpgQce+OIXvyiE0FqPj49LKSuViu/7RFQul3MRSd48mCex+v2+53l5hi8v4eff/7xVMEmS9fX1ra0tzvno6Gi5XOacB0HAGMvzWNYSEGtubMWDGDSQgTRNR8YmasMjfqVspITAByArBXPcVxd//u8aV66sqjQtlUpCiEIh8H03CLxWqyOQSSktMGB4TRSvta5UKsbY/MTm1jjaGA1kMG/SBk7Abe4NTFprz3d0lugkKXkebHU+/7t/MOMWPSYAIP+wridpaa256yQctkAD15fD5tJgc3lt0NO6UKq3tvpGM2NZt58mxvupX/7XN9795kfOLIhS3ZIUwNGQEK6xKH3/9MqVwg27f/hPPxYcPmAiOHjoVkg4ZAK0ozPOrCQrSQmVcrDSQelKR1ulTeZYUwQqWBJGcTBCcAU2AdNHih1MBKaehGwQpb3La4tQcN77Uz9xqd/TjqMZszx3Z0djSHDPMGc9MafWW2BYW0NmUXCHSxGa1DArHDfs6E5TD7pOFAXkVTtGfP7bT33hsZMrA7ukTf09b/jg1z97/Pvf99Dps75XTruJSQmFVNLpC4SGOHLL7d1OvLKw7oJkCm2KnAKrA6V8WZhIIZhf2EhDfWzuhjceuGmol84qMW35DjcoqjRQma8yV6WuVlJHjoodGwUsCUTmsmQw2Ah8HB6pDga9dhf+yQ9/oFqpP/fcGSkKQjCCtFh0xkZGP/dXX/niZ791Zb5HqiSx7DulqD+QaBq+65MVjDMuGeeA2qb9AoXD0Bmj5h1T8uiYeN2NuyZrtaH6ZCc0mvjQ2OhGa7VUE07BGAiVDTmnza11x3ONlUYJ0Jwzp+D7CFopSGLw3AAIojC92gynq7VytQZag+8DonFc4BwEd4yVhQJ85jOnvvGNb87t2tHttY1RjuMVgka3k46PTd5255FYQwqZ9I1XDqTvCY9xH4QD6AAJIIfAJSroTjS4503HfvwnfxhtvLF8uddarThU0P2S7dUhGmJJA+MGxXU7qNuoQfFMwXHTbpFURYCjM2kNGI2AwNiLSp1XHdeTrl6JvnvZH76cdWkAGSAHcpActByJbYuMjAWlyVjidtt9yyCkCTAOjn+uk9gdh47+9C9DbRJkCdADK9AiIzAIGbOaGcu0BXMNy0TXjZe+wRfH9b99EelEluBV9l/dNERkaBvkBWAZEmkNRueTDL7o9EyJNtx1UmM1WbSU9gYqjFFbADDWBoVCp9PJkrRRrfmuN3/+AmktHSeXnH8H/un1R8LALTd272+pFCQHJkgzYhyEc/WRuO1hREwYxi3jlglCJMiLcS+CMa5//uteYrtlFC2AIbbNzrImk9yCim2nA351uWNW3ZHb/vmvwp7jwCSRArDgyatVAzL2RbQ9uz6sIrjaHvUSKAYAcCEefPDhqcnpm2++5cFvn3zowccmJ2d27tzdbrenpifuu+/+02eeD+PBHXfcsnfv3rvuurvd7s7MzFSqxb37ZtfWL5947tLOXVPlcvDau+/6yEd+661vfau1WptsaGgoy7LcJaVSqWxubt533307d+6cmJpcW1urVqu9fqdWqxw9eiRJ42q1SkSDwWDQj4rFsut7Gxsb9aHGNx/41r33vvm9f+974yzdvWf3bbfd9qd/+mfffuCRZrOVpGZyem56ZnbHzurszl2jo6OPPfbY2XOnP/O5+5ZXLx84uFs8/OijaZqePnu2UCq2u30LVCqVisWiUsa1MDszG4YhAOzduaNUKnW2Nhsjw5lOr1xZVjpVOiUwuYMPYk6AtMViuVqt5WETACJud7c60nOkk9u8IBLkYnApEXgh8BzpGWOiKHnooYdmZmbGx8fvvPPupaWly5cvt7Y61WqVyFy5ciVN41ZrM1PJyOiQsarT6SATiCQEcxzhuq7neXl7oBBMSm9qamJlZSWKBkLg2972tg984AO//7v/dW1tI6eYSil8P2i322fPnr37nntOnTq1a+futbW19Y01KSVjAhBc1x0ZGx30+kZpKWUUDTigdFi5XLSkkzQii7VaQylVLBZLpdLa6oZWVitLFq0BawwRSscFYv3+QAjR7fQDvzgyPGZMfkRpEARhGOZk0Tw2yrJsYmIiLzLu2bMnSRLHcVqtVpIkxphCoQAAvV7v0vzlvXv3SuEmSdLtdoMgyPsGOBecM86FFA4DTh4GQmpjq8VSFEWxIXJ14EjFOQpx+tLCyK49kPdUv+LO43/nePDBB9fW1iYmJjjfRs5Yazc3mqVSyRgiImSY6+JzEF6xVDLXEfDyCdQwYoCcYLvdiTDnOyNHCwaRhM7ABt/6nd9jq1s7y7Wk19Gcu4KDAa21sZoh96Qbqyzt9Dkyv1QAX2SRLPGCTOXkqDgwtetLX//8zunZzXQgC+VTl1bObfVv/79+ptlpPvHMozdNTGCcyswyF1LkG9HADtW+/9d/WUF2en1zdnLm5puOTVSHB51uoV5grmt1zAwGfgUVj+MUDEpkzBVGGxehoG2gs4rgESlDJgMzsCCZrggpeS7S4FYyzQtbWdx4x5vdj33suc012Rhq25Q86XCpQ+VkouxUaoVhR5RBuk6hlkaXdUELISwi8+ViuzV10xvCPjt9bnl0bPL8hTONRiVOUsIg3srcSvH0Rr/C7O3//hc3Bq3zDz58dGoS4igWdqHfkpPj0DY3zO06vmN/r9fjFW5QooaAe52+KpYqhw4fBm5Gx6qTZe+1u3fAyvxH//z3ilNDkCVEWkrgAAjEmUW0AsAB46MuSN22Axe9WiDjztZqrMZGZrmGygj7o//xrz/4oZ9/5pmTNx+5ZXN9UzDLGY0ONb7x1b8eDMK3vuvelDIukmo5EIxP1kutbkurAkeJErgBnqkKY4VBr+okkiFhIWyrH/qhX63c8MaFTfj610589Pd/b+8NU24xDqOEmJBOoDOsVIeRmFUYFKpnzq/Ozuz43u/7nlLFcRxAAQhABq5LVItSqRQEEKXglSAe9EqFAMDp97JywTt3Gn7yp3755uO3p1FoIaw1vF437oZ9o1mhVOz0OxO8OD7txNkACQUHuGo9R2gINIDWnFiBjewuthb0PW/ZtW//L33iTz7++FP3N3SvovtFUI4mBw1nRjLlo3W5LglsFAtB3A1sNFKSPEs9JnJuAbwaF+o7JajIXkcAv37jlQxxRECw2xUgzoCDMkgIjAgJpQMWc2oAWAM23hYNeR443onNAb/h2KF//tNQHSMWWHC4uSqmEkSgDRgEawlAaySG3yk0fKWsCl689l//V4yxa7HXtRJhXmdEJAt5kx0ywYSLrivRGgbILRJCTqEgtIBIjGVWF0pFUmm/3akXy57gZEFKaYAsobawcOnS/r37GvXq6vrahXMX9xzYn2WpEAJ5DmUHhtfRcK5/74yDCMaO3f78A5/RkAnhYKqY4KDUNrIKmQXghAAEliHkonK8ruqXf5T4YovBSzJYKIAbZhUjELB9QABoDGgNzGHMu9xKelMHDn/4p2B4zKKP0jGWONtunSYgBE7satfS9suw75gSvfoe0iTVWj/48CNx1v9n/+wf7du3z3GLn/70X9x0y8Fbj+86deJKsVA/duymsfHGFz5/n1+wt91x0/lz8ytXNvbtPVCp+kPDMDExMjI6fMvR28+fW1AqTZJka2trempHrxu7nsyLTrlyqdvrBUHwlS98Y2NjHcEOwnj/wWOMyzgaGMadooeIqcqSJDFGLS9fYcw2N5fv/3a7Vi8vLy8/e+LkxfnTQrJezzzy8FOHbrw5jfy1lZVKxQ282slTZ2ZnJu66+8DM1OTy8rJgjJVKJel69frQd7/7ULvbP3XqVBRFUjJraPnKZWttNAjDbmfp8uLoxHiWJYMorFRKURT1+/1Op7Nr555+v7+11S6Xy4hsMAi73Z4xRgo3z7vkM07eCGo0WAME1lqbxxZSSsa4MUmWZf1eKKSQ0tXaBoFcWloKgsBo6nQ6vh/Mzc0tLy+3222lKM8k9ft9pc3c3Nzq6ioRVSqVpaXFUqnkum7OT/r8575WLIk77rhjbW0tSaM9e/b87M/+7Pp688yZM3miKAiCZrNZLBb7/T4RbWxsGGPyFkIhRKpUY6geJfHi4mIuzBJCjA43Op22lNIS7ty5s9PpuI7rui4TjuM411gpeXOK1tpoyrnqlUoFAJRSzWbzoYceKhQKORm/WCo2m03f93MaRU4L279//9NPP10sFvOnWl5e7vf7jLFisdhsNg8dOnTbbbdFYbK1tZVj6LXW+QYAEGlElFJaBMG5x33H8RB4FIYl30PgYRhqLYkzWfB7Waq2xavIv/NX4P/fQQwQOu12vV4vBgVHCNd1i8Wi1rrT6VTrlSzLCIhdvQFljOXl0TznZK3NnXA45wrJ0tUokZAR27aRZawX9uqFoBDUkm8++sKXv3Hn8JTdagEabS23gECcc0Qgbcmq4aDczrRjIO5HYEgbIwUbrG32nklvGpu8MDXV77aICcsAfa8rOJTgnb/567/3vvcudJv7inUbRUCgGVzY2nrHT/0ojA5fam+NzE5iCvvHy0PCRD4gTxlYMIY0WSbjVIx5BYrSKEoaBam04kZzSgLulgXrIEZgFcfQWimh7wjXcwwQKBsM1bNee3XQaYz4//TXfvUnf/BHJup17vlJNhAs851ikZVUikYBkISIELnDeNnxW2mUaZ3YpJXSD/+z/+NPv/TQ+pPn3G5/anokS/qlWuGbX//qzXt+cLzinIrNatovtXvf/e/+zR+8/Z1X1lenigWf+ES1srrVBofv2V157Q2H7vv2A2maWkkWODDmcHtg1+y733r3zDQIAZ4A4ABLA5l2q2LIkNDaWtBXY2fOmEUkjiTA6nTABNUqldaAuOdI7mysbnRaLeYXyg33N37zX//cT//Ss8+cPnbkln7URVLGZuNjY088fIJJ/y1//27h2s5GVB/2xquFQXNJR0VDXHMLqc7SyKROqVqwSWh8Z7ndet13/0jt2C3ggujBb/6Hf7lr7y5lenG7ZyArVYtggyTOFhcuBV5BpdamG43K3G233eZ4slTxuAA3gEwBEaRp6jq+UiZJMiISDug4JeClsqN1ZrRXLjmDLvzAP/iR8dEdzEptdalU7XVWVYa+dMrFwsrKytLS4s2vPbzV7VdrvheIKAaGgAIYU0SarCWWG/NRPxuUJoqqBROT/Jd//H0r5/bd/1d/4vRjDyLBDGeWMyOYdTl3GXmA9aKTdGNKBsVK3QDLfWtg23GFXRUsXl0TXr8n70R5+TYhIuXaarr6+O09YIHQ5laEaC1pTpZbACAgBuAoYwVD5ByQDCkwliMHxwXuPLPc9G++54Yf/jGojacsyBRRlpSYR8YaZq4i4a2yxADRbqObXn1eeZWw72/ye7gWYNFVSnueDsoP1QAxybjknu8wtm19TIiG5YEnI06ecNrdjucKAVQpl+uef+7UyZHpyVBrIzBNs2KxuLi4uHfnjkqxtLaxfvHixT0H9gvGOecviwRf8q7zc4oMmYPTe9yxiY3lMxOuCwAMWZbGDhAAs5C3JuRUfdruCd3OXL38UF/+AgCQK2ItIBiLNi8RalASDBCzKbRZoKZ23PiTPw/1SaWJyUCDJWZou6C43f0k4KX6vZdUjwkQr3G+4GqU7npeozF86uzTAKzb7f3BH37s1uOvGUTZ57/w1STO3vSGdyI4zzxz4szpC9XKaJJ2v/C5b8zMTuya2/H88ydfc+fdlXLDcZwsy/7jf/yPg37aanZ37twzNjbWbDYRHN8v5GkLYOh53srKChEdOny4UatEg9D1CloBB+q0B6XJ0TRVORVheHg4zWhp+bLny+WVxQv99u5dO4xpaIWeWxkZGZm/sBoN4InHX4ji7NCNRxcWLzueK6V76dKl224/dvutxx57VAvOJeei0+6FcRqnChgSQpIkm5ubgettNtv1SvHO219z+vTpRr1Wr1Q3NzfDOMkJ+6Mj43Ecr66uZlm2tdUqFArT0xNhGJ4/f6HX6xWLxUwlw8NDiCiEk2VZFCVE5hoWElHEcbq8vJxX5TjfJmQuXVmZnp6+ePFikiQ7d+4cGRkxxnQ63dHRUSnl5cuXp6ZGGINvfON+xqBSKRudHT58OI/YOINOp5OlcRwNlFLf8z1vOXfunMqSt77lTVEU/eqv/Eq71Y2iqF6vI6K1lPvnpGn69NNPT05Oaq2llHnjXpIk9aGhKIqU0b1ej3Ner5QLnlutVovFQr/XkUIMjw6NjIy0tjpEmCZ6dWk556Pm9SZEJqWjdZJl2vPcMIyEEK7rKqU2NprDwxCGg15vcOONB3ft3MMYy5kU5VJ1ZHjszOlzg340GAzy/oCJ8am219Zat9tt3yt0O/2FS4vVanVxcZFznoduxpg4ThhjUoo4jhljlUpFWVOpVFrNliOkYDg01EiSbHpmfL25IX2vG8dr7a2rXTCgNOVaqP+dI9dhzl+83O30KqWSUiqflqWUGxtrWmtjiBggQ8ZyCaXlHCFnaNF21LUtwBLcomEAFjlSroZlzBIgKKs4Z0ylkJkvffS/7fPKTj/MtGYuKLCorWAouCMQlVaojI7DwPWLIHiUAWCF+w3h9pab//dP/tr4xMRsPViDCLmTZqZULy91Ni+sjO3e6b3/V3/q//7Qh3eVir4nejpJXOHvnpm88zblMu67BVLuIPydX/2NETnoFvgmxQJIOGiVzDLbjckdHh4ui97z81VfgiUwSgAUXVnIbMAxNJakiCw56PQlN56XWAvM63UGxWIhydKljbWpozccffPbvvXNB8arc0UpuKA07A1SQbZMRFZp8LHoOANrmbZuxhw/aA/Cw3feBXMwc/Oh9H98QsOgiHEhSDkm0frWb/3iL3zXe9+x762viZiz0RuUdpbf+WM//Cf/8tdmJ+rZVncoKEqbnf+N/9wr1DdOnRwuO9aTqcNTpTLVz9KEBmsXHvxKNlIwqjXksWHBNs+fGm7I2PTJcoMWAInAEGfILOWZSgIyxcBpW+ipSHqFuKfiKB51C4NYTRadzVavWAl+8z/9xq//4u889O2nb77lMJcMWBIOuoKJJx99ZrO/+Za33FGdboCGRsAv675Jh5hhGSpGNkxtq5eGfqlRnXuheXn/W9/beMt7watACG9783dVa56UMVipMu0HtYtnlsAG1rDRsUnPc8ia6fGZQ/tvvf34zUOjjpBAaIBxAsWEzLIkjuM4yqIw3Wy2jAbkaaYz1xHGoCucLIRf/rn/sbbUu/nIDc31raGhcnNl1UBcLFb7nZ5AWS4NG2OyTPsloQ3GIbmAzIK1ZJgVhEiSa2aIQpO5ftDPYhGoErcgZPJn35jrXJioGGl7gAZQI1m2zURh3DInSgtoNqOBiQtkKSOGRNuXdbKA9LI1gQUiyI0vr26zF9XrdFWlDNuM8Kvbed4YAAjBAiO0gH1DQCTROmAcAEs2MdIQN5qQkDtcgMmUyk51Y3bw5hv+0QdhbLqdYZaqAqGLQqnEWpsxgwRoDBLpPNlDgNd5Lf8N4/rs1Cv3wyuiMSICtEjAGFowwFDTdoYSEPNWG0CBDA1Zi2SAAMHobKRa6bSbFUfU3NLaxfOPfO3rb/2e98iqnxgFaKUr0m6/vblVKPqFgr9yZTHsdAvVykte+jox+tVTmn9ILCMeeIWJG49dunR6gmkwGhTlgFIgsKgtgLWa0XbD5HZp8JWtCXjtta57XWSaMdQgFQGgkUZLDZglhJ5Xu7QepjumD/z8r0JQ6aMteX6chNxzCbgGyidtQgCjtLFCXH8hMddeixAYMiAisrneIz/rG82Np55++t57771w4cyly/Mz03Nf/tLXMqORg1LmTz7+KWvYxPj0qVMv7Nw9XSwV56YPB75MY0bGOfnC+U6nB8QPH54EYPV6/fDBozfffOt//q3/p9eN6kOjTAittRAMEd3A9/3C5lq3Xh+Sgk1NNcrVSr8fFopFz/MqlVoc9YUQSRTfe+8bNnr9s5cuC1c4gkMgNzc3OPgPP/rM6HAtTTby4AERp2dmmq31NIsvXbp07OZDWkdPPXniq1/66qFDB4TJVBiGaaaHRkc2mlujo6Ozs7Pnz54bGxkq+4WbDx9cW1k9dMOeQzfsuXjx0sEjNz38xFPPvnAyM5kjnRxwJYSQUgZBcXFxsdVqjY2NlUpFIXhesVpZWdkGwRNprV3XZYwlSZbXFhuNRrFYHAwGnU7H933fD6IoGh0d7ff7Qoipqak83q9Wq1NTU4888sjIyMjNN998/Pjxs2fPHj9OhUJhz559Fy5cGBkZmZiY+MQnPuG6brlcXF1dbTQaACCl/N7v/d5SqdRsNr/61a8S0e233TU6Ov7Nb36zVqvV642LFy/WajXf9z3fB4Byucw4xkmktd6/f78y5tLCRS5FtVq11nY6nVK5EAQBoq3XKsvLV5aWlsbGxpIkIcJisbS2tpGbBuamhNZSrjrPI7ZSqZRnXHI/x/X1ddd1JybGEHFoaOjy5cuu605OTh49enRjY2Nra2tmZmZtbS1JEsZYu90eGhrq9/s58mowGARBsLW1lVdFe71etVotFApxnOQK8a2trTRNh4eHtaG19XXXcTzPIQNJNJCu3+l0pJSj42NLqytnz57NXSAkF574zqn2/7/Gdo0+HERgrVFaFEUhCKTDtc62trZynwo38CHv5rGWEeTeXkbrPLTK/8utMWAR2HZWOk+TA4BBRmC5QK7J596ZP/nz3tmLs0FVUub4TqoSLjiTQATaZBaAM+a6LtPWdT2ZRjpTYCELY/DKBW0mBd9VLbbVKnMMFwyBd5ubbtELxr351e7O1985efTgxRfmD43OIGBfqcL0NOzdudHfcjkrlb0/+MVfiy+f3r9z5lvhUuaA5xdQc0aScc8OWMbciR17micetJZx4BxQIBQZd7LUk4CkjS81YMJZyISRJoyp2zdepbHR2xK+I4tuf2Bvf9M7v/bgU4iSqwGiZpyhx3XKiXFCAAXSQUQyaSYywMDtRq13v+0tlMLk/squPRNpvMWKSgilE1svloox/+8f/X/eFG++4Xve3syyjctro6+7q/w/ZlZam/vqw612z2f24T//ZLtQCSZ310rBSjZIhQAXhcSgFkgTPvLZTz+Ttkoy1mHLNVnN42NFj2zGmG8tbuc88qIuSgBNREiQRn0e1DgzWifFoq/dQhhFYZIsXVnZe3Bc6cj3i//nv/yx3/4Pf/TIw0/s27ObW+s7HmmuGTvx5LlsEBXffvekKPKsj3Fb4BhqT4PSAgaK1iNaTZyn5ufvfN97Rv7+B8nWQMDb3v6haBDv3jXV2myWivUoyU49f2b//v0f/NCP3nTTkaAIyysbcdQvFArMynrDAQHSBwMqzVJEBiCzLFtfb46MTAAIY7DVgvpYWdutdqfn8CHXgT/+2Ik//qNPHbvptuUrG7VqfX2p63m+dOqdjRitx1hkda+12V5ZXA9KdWPA6IyBRG0UTwkUI2DAtZbagiy4na3NQgnKXgIsO/Fb/6n5zW/ftWc2jhYRY46QS4WAwJq8UIMmpnKpupllSRQ7rrAWrSVr7MtzV3muBPl1YRMjMtv7ty+U9mVrRAZAROb62MsSARcAhmFKABosErLcOQeZtlqZNDVWSg+l11ewkCTJjv13/PQvgt9Ya0VYqCRJ4gCCTYAzQ9ZoZJYJxsiSRUuIeX3zWsLpVaeYV4rfXxlLXb3YvySDlXOqgKNGS2iVNUKoTBtr83Q6A+Q2jyMtWrTMkjAaTVpy2NzI0OkHHll4/lSJgeq1KuO7BlFPCJYkiRRiY2PthhsPVKuVCxcuLS8v762UyVKe3ciTTt9xumQARhYPHR986TPaWmE0kGaIxjLK7VhRW7JggVl2TdZ+/aEBkUXAV0swERBHYsTBMiDDuUHDMiFi7j232Jq9+227fuBDUKolzFHaxEnoSi/V1jJCmxtfoLWEBFIIY14S9V57CeSMrur5tkuyiEAQx/HZs1fe9Ja7ojiZGJ+6557XLS5tfPpTX7j9zuMnnn2+XKgXS2WjsVoZmT+/futtNx06cPD8hRe+/rWH9u7d+fa33f3ss89dvLBw8cJCmug777hlfWVzbXVjz549J184CwBhGJbL1ZyJVSqVcgo3QyqVSlZrxxH9tbX6UI2sE8chkXEcp1qt/cHv/+EL85drw8NoKUnjgu9blVlIZ+cmkjDqdjv33HNPfbjx3POnBmE3TlWxWCjXqput3plTz0mBO+d2vuXN38WAzPjI6PT0dLlcPn78eLlcfvzRx5Iofvd3v/P4LUezaDA2XN0xM26zpNfdeu7ZZ7797W8TYZZppUyxWPa8AAA8z7vhhr3f931/f3Z2+uTJc2HYn56eHBqqt1qbudq60+kMBoM8OMiDJ4ZibXUjHMSe51lrfb8AwPJKmVKac8G5sJY8zxdChmFUqVTyfrooii5duuT7fhAEhw8fXllZ2rlzbm1t5Vvf+qbWWRj2G41GmqZ5QuiFF57/q7/6y69+9StPPvnExMT43r17d+/ezTk6joiiwdbW5oED+2u1WpqmeVNenES53WO9Xo2iwdLyYh4X5qbR1torV6401zcmxsdLpdL+/fsP7j9glB4dHS0UCrljYBiGw8Mjvh/Eg9QY02l3w17EOc+xYYjcWmBMeF5QqzXGxsbGxsYGg8HZs2dXV1c7nc6OHTtc111aWpqcnFxZWYmiCBFzbf7y8nIURTnBYWhoyHEcACiVSrlvQ5apNM3ymcIYc/To0b179yZZGqu4Nlwrl4vaZJlKpOQM7NTkuDFq/uL59ubWhbPn0jgSQJSmSGC+w9Ba5xvXTE9fKSb9XxkEkClzlZPDVZrlGJf5Cxestbl3pud5rutaa1dWVpjgvl/IMg3AlFKCc2uM4LzbaZFWAoFzzDXv+QlhBA4Xxtr83YLkkU2NIErShuvBSvP+P/6z2WKlxBkS9budXMdJ5qqTK1AGNqYsQRsZpZESrQABJIIGAcDTXklkDCKASPBUYFYP3JWLFwVAaiyAvfd9711Nwx4ot1Je3traefgwIKhETVbqrYceXXjk24dGyzLeLDvKczJFfY0Z4zZJEmCi3Yv333SLkV4S62JQNMZwQIiSMrCCoQIKQtSMDbRpKxVKGUlvfqnX7ULZralIJYoNEqZFjTuNJLQCHGOMJp0QDZCMK2MEcCDSSWJS7khPuEkYy1KhePRgM4wKRbjz+D7INoD3EuhhQM3eBrrm6JH9X/zUJy++cLpYb7SVgaB85LV3b/XCQZIah7lFsWfH2P7Z4bKvGHUdaYipzCRJEnJGg83NvcMjt07sOFwcuXNs9vjk3K5qo4DMMVYoK3KbDITcOM8CAUMGiGRczlFFiMqR4AhMk7C1tWGyzGqWpeR5jusq7vZ/9f/6J3e89uazZ+Y5lrNESilJm2p5aH2p8+ef+KsnHn5svOw1XJI68QBsplrtXjfDDeM8vh42bnvL7Pf+aNqTKij8p4987RuPPXn88Gu21toO+v0tu3hu661veNd//cjvvfmNRwqFTLpmasafmPG8YlQe1jLogewmumNZCqDzVp6hoZE4ytqtjlY0f/HyM08vcAYqdXQaFPzg3Cn4rd/46L7dB/rdQdEvdDcjyIKk74ctz+djYdeAkTqzrWZ3fbnf3oiiQRzHYWgiBUqHoUeMZYZSoy1YwDTOKgjl3jpkG8/9p5/bfPJzt04HtnNFABEIZUArUhmpjKwmMMSBM2I61ZVKTSljCZNUGQvabpsCv+pClDsWY94QnQMAjCVLuO3O/Iq1sWRsDpFkwFmukkSNlBljlMWMMNM2U2QtkDVZwWE+kQbxbF/F+47e8a9+S1tvqzNgllisfBSKTMJ0YgfGRmgzUjZLKc1A60zpOBdrXpuaXtStXzeu32kMGUOvPExjSOvt32pt8/1AjAxkiRFMGGUZY1GYMCa4cCyBQQZCJEpR3jWP1uUoVSLjaKZafv6hB08//vCQL4cCd/3yQsETSTjI6Y+a9FpzPUzCoeG6EOzsqZNgNPJtqQMAGPMq8yrmlCwLgAKm9vgTu7f6IaAFqxiSQTSIgBmCAjDXQDXXT9QWtxfI+4TyFiGA/BqntQZrIE2Qme2qcWRYiq6sn2vr4Xe+f/SDPwlD4+2UuDYlZXw3b6VHRowBlygEcQGCowADHDBvXbwaRCHPqfOMc8wzDNvKuTyt9cILL7gu3Pe1b6SpKpdrSysbX/j8l3fM7QgHqlioGYNpooyBYqE2Mjz57DOn/+LPPvfM02eSiC7Nr3z+c18Bkgy9cKCUtp/80z9fWlp56KGH+mHY6vTK5SoAtNvt/DBzjoG1dmtrq9/vTU6N9PrNOOkh09qkN+zfUyoV+v2+UmpsbMwoiMLEaIwH6eX5jdXVTrvbzMzGRntzbSv69Ge/XCo77/metxdL7iAMW+3NpaWlpx55+s47Xjc2Ortwafm/f+xPWalQbG01p6cmJOMLly7t3rVj797dE2NDzbXlkUYpHrSefPSp82ee39xY2jkz4Uqcmpzs9frlcqVcroRhOBgMACDLsitXrviBe/DQ/nrDb7X7C5cvbDTXavUK51goFPLrZX5OC4VCbgVYq9U2Nze3Ntu5D4zneaVSJQzDPPsyMjJy8eLS8vLyrl27ZmZmFhcX8+68Z5555sEHH2w2m2mafuYzn3nhhRd6vZ5SKgzDgwcP5oHX7t27rbWcc9d1NzY2Hn/88bW1tTiOB4PBwuX5ixcv5ibKRHTmzJkoinJURJxEiFitlj3PySlZSRhVKpU8allcXGw0Grt27rHWLi+t9vv95557bn19nTExMTGxubn5zNMn8g64fr8/NjY2Mj48OTl55KbDY5OjUsrx8fEcPZBXD3NaRLlc3dhotlqtOI7DMErTNMuy559/Xil14sSJHDd66dKlOI6JqFQqHT169NixY29605sOHDiQmwUNBoNcihTH8dLSUp5NVEpdvHhxYmIiCIJer5cnqDKlcunfzMzU0FB9bm5u7969vuu50kmiSDJ0pACVvdy76trX+xVQvr/zECK3ebZE5LouAISDZGlpKSdcSCkYY8YopdM0i4VwNNl8FmCAgvG80zgehFmaCs7RUm6zqKyx1pKxRlkikMLlXMZJoiRlpFyjIaNzn/5CoRNWPSdNY2TEOUeAl2ofwCAYBMNRMaOBLBlggJwBA9eTRoVkIoFGIDC0DDMEs7p4maVQ9AuZ0pM3HhJDjW6mwzgrBeXxiRlgwIEj4Ma5CxVjfJU4aVxAkASIZJg1ZBANF6iMdip1vzbU6YUmMwDAGEgiV9uSxYIFAQjILYqYoG10X+Plhfb8yebWYm84qOtIFIpw7sJaagsAgTbMGAQSAIIxgUICQ+AAktkclcNEN0lqO2ehVsAACeDo3kkKN/2AWWlTMhi4zajdSXplz3/u8Wfivgm1AL9Q37kvZDwTQjNMVaLTnk073MbCJowyTtpl4HASzBqbZkmYhj2IQh4mIk55qpnerlkwACSLZGGbZW+RLAPLjXbASrIOKIEZ55nraM7Tfn+zs9XJYmMyY2zsFTID4a/+2gfufv2d5y/Oa8ukdBljWllXBi88e/L8ybOTjfpkvVBwyHOoUS2NjE349Yker7eDmePv+qdXLiVdVT99Jvn5f/ErN+8/3h300QrU8ty5S+95x/v+w7/96SRKjSYhU4QBl8r3Zank+wFjriaRgMgYhzRVSZKRgT279zMmlFJCsCzTX/3y/WEXOlusXBhqN+HD//RXwr6WzHGYJAOlQsnlwWtufT2nMqfKxPgMWJvGiclARXzQgX4rQSZim4Q6dF03jRMyRkgZ6wQFcpX4yQA8fP63/3XvuW8fHnaE2mKUaDLagiWugVsSQByAW8zDI8qjEENWmzwMykWNr7K2Ng8yXr4GgKv0k5evt+0Iru7Jn0c4nEshuMeZi8iNUamOM5tkOs2yzJciTZKM8ZMbW4Ujr7nzF/5topwWSE2CaWKpBq0MkQZLeWRADIiZ3A4LLKCxpL9TXPXK+8D/qRaeXjHy/yirrNUWLTpC+L4vPT/RxiBr93vckVprxsHjIuq2yhx3jw498ddfe/7RB2eGqtKmJZcvXDxr4qgc+IIxx3E83x1E/ebWBhO8VqstLy+nSQLGcsattVpbwV/lfSIAAysAgEtw6hOHbg0tgmCAwBgSF8QZ4ySYZRyQI3EAjsABOEPGUHB+NbZBxhjneUO63fYN45xzhoSkQCfgEAgD9caAnIcubd72/h/Z8d5/TMXRNnjSr0rhc0Aw4AjPQekw7jAu8uVqg1W+XAPic86RM/YS9sSLYjhEOH36dJrCjh07JsanGsPDKytrhw4dDoJiDtn2PEdrHYbh/Px8s7lVKTdKxcb01I79N9wouHfi2ZMnXzi9vLQa+MUdO3YtLoWPP/HUO9/5rk6nVygUWq1WrqjOPY7PnTv30EMPTU5O5m65C5fnjVUTk2P9ftf3/W9+85sAUCwGADQ7O2stTI6Pb21uTIyOvf51t3/Pu9+wZ9+w45m3vu2WP/rYv/qx/+P9Tz755B//8ae73e7+/bsdx1FKe6ViFKavf90be92k0+kKyZnvet/8+jeOHLt5enp6YWHh+M1H337v6x5/6IGOQ+98+5vHfnDowQceeuSRR3bu2jc+s/vOO+9c/dyX8pyBlNJ1XQAbxzEyeuGFF17/+te/5z3vmp+fVypbXLyilOLM7Xa7eUiRu/YGgVcqlQqFQh5R5gTOQiHcvWdnp9NpNrvlcjmHUR04sGt8fDwIgs9+9vNEsGvXXJZljUaj0+n0er3Nzc08BDl37lyWZf1+31o7Ojra6/WyLKtUyo1GY35+3vO8mZmZMAyzLCsWS3v37r148aLryUq1pDLjOGJ5eSkIAuQMDAFsM0KjaOD7frEYbGxslMtlpZTneZ1Or1Ip7dm9Z3Z2pttrLy9fSVNVLvsvPP98pVRGEFGU3Hrrra1Wy1rjOLJWq+WGQtfM8nJmhFY2jtI4StfW1tI0dl1XSqdWq9Vq9StXljY3N4MgYIx7no+IjcaQ7/u9Xk8p3Wq1V1aW9+7dm3tC55+C7wdpmvq+n4MzGGN79uxRSp08edIC7dq5Z2lpqRh4YK21hjtCuHJ1dbVcqXlBoV6pqzhprq7X/EBIDoIxBPrOcPb/TwZeZ32FiNbQ5ubm5ubmyPAYXO0tdRyn22nFSRKUa9oQAOQRs0BmTMbJxv1eGoVcSGsMFzLvmwAABpwBWmMsGCBmwDBPYpaVHBfOLjzyiU/v9CtZlpCDFCdCCEWUi0wQc7oQEpBmxARYstu6pas2D9KTBqwymWQSQRGRBRAOLl25FK+n9XG3H0WN3fuGdu5qn18ed1iRF0YbYxCCYzkQLJw8W3VcB5gkXrTc07YvuAHMSKEEz7AkiWWtOrlz9/z8C4icMQNkGSmhWYGcogFXQyYZcJZYUoasZeeeWyjyEQHQNOHQeCFpw+piu9kcjI2OaxMTJRJ9pqSDboCOQAEIljGLzDK0AjeycO7QLiiJpNepcH+uVpBpn7Hp1HILEqUY6NihtF6qXjxx9ubXpV6lFAKMH725J/1YOAQIaYykUaWCEUPixroGGVkGHLjREgakfFJcGGmMtBYhN/HghAjEGGgk4KQBAMEw0IJAEHCdIHJmHM4YIgS+pyHqtZbKJRZ2e9VGzeoMeUbcaOX9i196/3/5996XP/u1G2+8kQgdTxCogl9MB4lDVCt6JYCuzlzuE0ng5dCiN33sbKvUGB2ZHnb+/b/5yFS5PDlZXzh/cbhYGXSz19365h/6x+8PezDUcB3XqixhTDhcCq9ABMCspRQQOedaWQ7CYQ4SlAuVqD+wOiWigucuXFheWYA9ewr9HnzgH/3LxfmVfXv3MUPc4dYCs+yGQwcOHjx47vzpUtkfhG3X5YZEvx+uLfdGRmvFAguDzGnwhKKSkDqzvu8lJiFPdAfNIWaxJE/+1r+59I0vvmH/bNJcB28048wiA2RkCZDnrStX++QRORJD5AyvZRQ4Z2T/Zt33i19bQCLiVzthXjVYuT6lfS11AYBWSCFdRkqTzqRliGjJ4dJBm0r2Qqtdu/XN+/7Fv4siyBzucPQYMECLTHHQHC2T3AK3DCzPofIWNTAJwJkRQOIVM8zLqaHf6Q1/p/e/fT9JwIhJVwBY4QrOGSEic4wxUnqpUo2hkX6vo9JQoFQ6HAq8CtDjf/31Kyef2zsx7kQpKe26jkmjzbXVytjYRi/KMiWkSww7ve745ESlUr5w4eLC/IV9h26Eq82M3/kjAAEAwIAVRm6+q/O1TwOPgHMgYpwTgti2D+QEHC0HYGjzUOYlqK/8Xjk/TWy7z4/lZTsUDBwHkgj8oKPUgizd9S9+AY7dCX5dK+aQcRxMgDGv6FgXaBu2dd3zXhsMtl8e4CVKL/aqlDUhxMGDO7XWE5Mju/ft7fUG3/72E5evLArBoigSTLpOUCqVb9i/d32tOQh7680OLKjdO6fe8IZ7n376yXK5vLHe+uY3v3llMbzp6Ey1XD/x3AtpmgZBQWstOLNArVarXq8n8WBrq91oDPV6A0R24fz8XXe/VltmCdbW1suFQtiPAK0rZJbGHGGrtZrFdmNj8eabdr3vfe9auHKj4zvT4zvbWxEn5x1v/54oTpqbnVNnzkf9bHh86siRI1//4hekwOO3Hnn88RPisQdfmNs1NDE6trm+gYwNjzQQKoLj1OSIjgfrK5c/+IPve+Pdd/7Yj/34rl3Tjz37zOzB2z3PzbIUAKzVWZbkFsU5G/0Tn/j4zp07d+3a9fTTT0VRlKZpsSCCIMiV3Z1OJ+eMJ0lSrVZzfz0hRLlcHhsby3+s1+v5/3cO3lxdXWWM3XvvG06fPp3Hod/93d8dhmEezG5tdcbGhjc2NnIy5/r6eqlU4pyPjIwA0GAwqNfrly9f7vV65XK53W5fubJYLAY/9EM/9Ad/8AdnzpwZHRkvlUqu6/u+v7q+1mjUhocbS0uLnufcdNOdi4uL7XZ7cnIy1627rouWarXa+npzYeFSvVGtVqtDQ0OO41nDNjaanhdEUbK8vDw1NbWxsTEYDDzPz/2eiUhrk1chczF+ns9TOpXSyUXx5XKZMfbUU081Go0oiqamprTWJ0+elFLmmR4iunDhQhgO8kSX7/s5Ip9zkW8LIfJeiVOnTuXKsInJ6UF3EMdp3B+4go+NjlxZXsq08v1gaXnd87xyuZpEKRkjPA+yBATPsXr/05kIXqFj+NuOfAqL49hz/OXlZZWZQqGACPnxcs5z70tAVMZwjkTECBBAIOMWov5ApxkgkDbg5nOF5UJYayVwA2SMQYbSdUKVFgEA3Wc++emgF5VloB3W7XYawtdKX50hgIi4Rdw2ZyOLYMlwIkpTsMANgTJCMOkKrTVzuLCQGjJkCyWnt9lbvnBxcurAZmwaXM4eOHTy5KKDrjApFCsQZ5ILMLC5tFz1fGZJWBZo12HaGlSCWTSuBGlM2O0oayd27z53n83N1I3KGBOSU9FSYCDQlHK0UlhlgSNz3dNnzyMF+/WcTs3Fs6s337z71HNnquWGJkdZycmTMoCMcSk8LhlHsGCJMwIhZGj1AHVxahI4dJPB9MTQueZKVXJUxmjgQmQETLKBTqvEu+3+5bNX9t5y08L64ODkpA6CvjEFYAKZZCwlK4FcFC6RNgDWaoAMs5DjwFVFNGULRgMzyJApjojILCCBJMytIQkMoQayaEEQMWsE5wjGUmrJogQg3OpcGZ8cGnS6lFUIueMVlI4N9gnLH/6x7xkfbXzsj/700OGb0JUmjLM4SaM0bHVMmhlQxEFbEyvOQKY2uP/JRVu8eOux4pnTq1//7FfvOHYkot7krhHqQrox2L1nxhBEMWhGVqbIBUMXSSJIxoCYtkYDCGQSFbmun/fX57S/kdF6u92q1YaXV678xr/+nfe85z2f/OSfnz556ZbjN7eaPcl8jpIjbaxvCicdGi+PTY1cubJoKfJLXpaa1lbz9Em3Vi+OT04LazmAX6iEUVptDA+iPrqOx8RIaQzS+OSf/MHlk+fuue2edO3i0NhcHJFRKPk172BOREjAAREs59wYxjkndAjBcQQXuG3w8moarFddExkO/G9Wa117JBHmVoaACByQM0EOkkAGKJApxRAzQ0tWz779beM/8GOguFcb4lY7nCExsBrQeIJpBEOAJLZR6QiGGUCOIBgBWvk3uHW9cpr6TmHWd9pvNQnJgQwwC0RaGwPcdbx2PywVy1E80FqVi76Ke1IlMyNjj3/py+efe3p6tIHJQACmKmIcXI8vL14+Mrez3U8cP3CEzLJsbW1tenq6VCwWCoUTJ07sO3wjgAHgnKO1L2vDe3EwBDBgDWOTu6p7DzbPPTFc8CCOuACTT92EYBkSB86u/sF13eEva95DBiiBKC+UAiIApzTBaqmrzDy6xz74E3D4HoCiToFzXpASwGbAWe5+Zl/GufqfjRf7u1nuSAiQvyjb2tqsVCrT09O9fuv++++vVYeXlpbWV7uTM6XZucmtjY7g/OL8uZ07dheK7pUr6zffcuToscNf++oXGYp9+/bPz89XKpUXnl9pDLH9+w9Mjs9cml9sNreqlUa5VMvb89lVtmqr1YrSxHXdOE4nxme7nUi6BSa45xZHRsaSZBAUPGOV50tHws4dUzcfqywtzZ858/R//6ONX/iVX/r8F7/y3373U8tLGypjd7/uDWtrG71wsLy4MjU3MzQ09vQTTwbF0v3feGB8ojY3Ny6+//ve8oUvfjVe2pzbM9PcWEuzcOHCmWM3HZioV+KBPbh3V3tzbahW/+cf/sDpsxfnl1ZVGo6ND62trRERWiRNQjI/cEul0tDQkLU2CIqPPPLYyZPze/dO9/v9XL/GOQaBr5SPiGEY5qmd3AeGMZapZP+BfWfOnNnc3CwWA8dxhBBKqdXV1Rxe0Gg09uzZc/LkyXq9nnO5FhYWpqenrbUArF6vMQZ5XLW4uFir1aSUrVYrR0lVq7U8EMmDj2eeeWZsbKxYDBiDcqVorUVF3W57dna6WCyurKxUq1VjjDZZsRQ4rihX68vLqVU2HoRa62azefDAgeXl5OzZs1rrSmVdSjnox1mmHdcXwlHGTE9P56iILMvCcDA8PCyEWF9v5hnsnGkJAPkdpOM4aZpeE/sDgBAiiqInn3xy165dtVrtmi4+13mMjY2FYZi7QSMy3w/yc8g59zyvVCpFUdRqddbXmzt37q5VG43G8K4wvHDhXL1RrZaKyyur9cYQA56lXZVqMsAItNaAYIC4tdtfy/+F8XcuFxIBy28QcyQ1wuX5S46QSMAIXCHzLoHV1VXHcZQ1xhLnkuWRj7ECGRrb22qbJAMCJOBA9poTvCFGllkEyWO0yFCHUbVUhSdOnvz6/TdU6w7aSCnLESTP0hQ4IyBA4Ba4IY7WsBwwrBGEaxHjDDR4gGA1k8JxHKtJSCGBgwUDFjymuZ6/eO72NxxIgIDM1J7dTypDxnpeAAVPMxKCg9IqHFSQZUlMXHpGupaRtZoxlEBgKEkGYXu9vdUYn0qN1cqiNWgN4+gAekqViZW4TZmOHa45AJBgvDvoP3nq2cSkr7nr9m986eu9tX64uVYvelpbbTgXBUE+ZdaTwAURGeDAgKMBAZhZYx3HqdQzAkIEAc2VyzXX8TQvkqOADGjm8DRWKUNDOH9qft/hm+PEQiBKjXq/3SlwR1hwBGfayswWHOFxTAkUGo0mFam1xtVZgaU1aTJjDLfESHNCsq7RjhWuAU6Y44mI5aIX5BYE41JKEDwDlRqFgjIyJku32iu7dk1niQlcP+yHTIrqUGFzc7NaH3njO245ff7kxQvLtZGhku/U6hWrjcO9JNax1ilHw3zGClb5mXG9wuRf/uW3wqatBLooXNT9wrBjrVhY2nr7d7/zu971pmb/onEKVbdgB9wr1AyBRbAMuADGkaED4CJJ1zGMMQUGgO8/sG9ux/TwSLVY5lIUCkW5tHz5N3/zN4vF6q23HWcMggJnmSQF3bAVVKA2iiDbDz/21+VyFdEKF6QnaoWqlH5rMwz7NiixQuYhs4VasR0nbrnmAWBqQbOv/7c/P/vtx47NHbvQX55o7F/pt4dKpWIWMdVnqAFY/pXYxjchMgaCI3JgnAMg52iZQJaL09lVDsBL18hhu2cw15Ln+9l129fW+V3ZdXsIiYARI8sJLfDEMMbIIXKBcwQjXEkACwPlH79r/J/+LDh1MB4jcJFBXkjiIscECAAObJuqhQAAHCwCMJCI/H99vvq7DXQAwG63OlviCEI4c3Nziw8/MTE+2Vxf9wUIpbnOZsdH7v/cZ7cW5mdHR60KESlVyvGd2GSFYrC2tHQwSW2quCvSRGlre1vtwSAabQxXK+WlxcWo1wtKFWsME9wYwzh/dSYhgkVICXzhjhy77cTZZ4aFAyJFNDxHXlkBTALxbRICXu3ufGX3pLWIDBiCtWQVIoIMgIRxvLZO1t3SsX/8o7D/9kwXARxHQs4QBUAXBABoC0IAbDvKvuRToKv2Pnht/3YFFhjD6zNYiNuQjZWVlWeeeWZ8qi6EeO65597+jncdOnR4aeH+4eGh97//+373I7+vlb7rrjuzTJ87d8YPpOfL5eUrQog//dNPdjpmerp67733Tk5Ofe1r3+h1I092er2B4M7Y2ES309fa+oXAWp2mKeciQ8jV3sDE1MR0u931fC9JUkf6UrhegIjGqGz+/Jkds/Xbbj369nfcu7w0f2X+zJNPPn3/Xz/++x/91PLl7rFjN77hDW/43Be+cOHiRZRw+OY9jhtcWbxcKhUdIT3PIwsOL7Bf+YVf/PV/9X+Oj9U2NjaeePQMR3bzsZv63c7wUO2mQ/sLgRybHd9srt5+7+uP3XRQpYON5qrWqbVqaKi2Z8/Om246vH//vpznHoah67q5KmjvnlmGYmR4LAzj4eFhRNzc3Gw0Gvv379+5c+f4+Pjk5OTu3bvzklmlUimVSj/6oz9622235dWiVqs1GAzyXyVJ0mw2c+15kiQPP/zwU089tbS0tGfPnje96U1aawCQUmZZNjQ0NDk5mXM7GWPVavXixYszMzOzs7M5tsBxnF27dj3xxBPW2snJyZwsleMMhoeHh4bqriuvXLmidNrtdvPuvGazubW1VS6XETGO483NzQceeMDz/GNHb9m/f78x5sL5+dXVdZWZ+fmFZrOplHrqqafOnj3barXy6m8URXmBMsuyPHeVmzlqrZVSvu8DwOjoqDHm9MkzruuGYeh5Xq1WW1lZySm0/X7fGJPDnwaDgbU2t3T0fX9kZEQIEYZh/sxKqSiKgiAYDAaXLl1qtVocuFU0OTY5N7uzNjR89Jab53bt1pYmJ6d3795b9IPh4dEs1USWOAP2d4yZ/lYjD8zyNhM/CKyiK1eu1Ov1vPUSEQtFX2s9GAyIoTIaWG45TwBgtXG40Ena73bBWjDAcbvkAQDWWsE4KY3GckANNiNTd30g8eSnPuNHmceAAUX9XtEPMmss5y/2L5MRFrgmbq51uBjOwGYpgOWcEwPwHMYYGMuACyaYJQY2pRilXVtZJANWMHJ4fWxEI4Vp7JZ88Hgq0XIElTKVSKvJZhLBtRigAACDoLnRmAEmmpLLayuV4WEQUiklgFwBjFuymVQqMFBUxtUGydi80ZlbURUhS87MLzz37Nk0MV/84ueKNSfW/dioyKCynEBqrYVEIUmbBAS4rovGgjJIxLksF6pgwHUDsKCigWNVCaCIwG0EGCtBqcOMz63DV5eW9SCpBEVwYXxyPMsSLnITNQNA0hgPuDZWESNE5MxKriVLOaSCGWREiBa5RXb1lhrJEjILwoIgZHmHmQUGxK1hiMwQGCJihphirmZSx2HY7/Q3VpqdrYHvFSuV2lZno1zzBllzaML5mZ//kWrdXV9f11qTVYJToz4uRUk4dWCVTJWULmZakJVpqoaHxvfuOZikenh0pFgrMBf7KnrdvW/8uV9+X1Bju28YHZuuMQGDSBFBloLWeRna5vdFgjsMUAiBjITELIEjR+o7dk5vtdZr9SKwsFKTUzO1HbvGRseqlmILYbkqy+WAObjVXvn773vHz/zC22+5o77/0K5CpTw1NxcUSkwgoDZGMcYLflCvBh4waYVKoBx4InfJMObf//Kv/tEff6IL7leevvB8C79+eu3kRtTKbD8KOTOIBpll3HCOnBFjyDgBGuQWUHNBnFtAy7hBtAAG4NXW2wkGA0jb63wPs8AI8g8KzfZ2vuYAnIBDvgeZZQwZt1xAToFhgIKjREYgtAyeXu8Xjt4z9+GfB6ceggPMgkny6IoYGDB0lZ6J5kVRUp6Q4cAQ5FWl16uMv20jzsseuf0kQJqsASBrgMy23R7B3MwMY6zf79cqFYdh0u/sHBu9/wufWzl/ZqxaccAUHIEmKxe9KAnRQT8IsjihTJeDolUWkTfqw54brCwtC2R5ev7cubOASGC0tlLya+8D8tMBkAcxloA4cMmBSdh3KKsO9zSA4wIaBAPEAAXQVXNrtJCr3RFoO7e1vQHiamxKuZ4fgDFgfKBt1ymuOPVD/+DDcOD20HjgOFICIIC1oLXRVhDwvE2bAWBuNY3AEBgSQ2I5Sf4lfP/c15m9SsC4XUPs9XqpgvHx8dWN9bGJ8aeeemr//v0/+MPfPzMzNTzSmJiYsFYzxhYXFzY3m2NjI+vr6ydPnmxtdcql+hte/5o3v+nti4tL3W7/tlvv2NxsnT17Pks156LXHSRJljujaG2JMAiCWq0WhqElYowNBgPH9wihUCgMBoPBYCClDMMwHAykEOsbrTOnnmtvbd77htc//thDzz07/7M/85tXrnR3756+5ZZbvnbf18+duTg7Nzo6UooGnReeP8E5Uyp1XXd4eFilenl5hX3lS19klu649bY//K+///73vf2rX37sxIkTrhSXLp4/c/oFh8Gl559dvHw+a65stdY9l09Nj03PjJfKhXZnq9Xe7Pd7jGEQeJVKpdFoJHHWbnU5k1rbVqvjON7tt9++vr4aRVGj0djc3Lxy5crevXvzdMuOHTu+/33fi4yazebFixdPnDhx4MCB48ePv+Y1r/E8r9PppGkaRVGu4B4dHd2xY4cxJITDmJiZmdvY2Dx58jQRxXHMucwyffLk6TRVGxsbea1wcXERADY2Ns6dO28tpWm6vr5+6dL8sWNH8wxZkkSdTktIRmAWFuYvXrx47Nixaq0cBEGWZZcvL+SfRK/X01rfcsstrnS0UlNTU71e77kTJ86ePjc8NDo1NbV79+44jsulSppkRBRG/TyoIqLcuHplZSXLEmMUADiOUyoXKtVSrVYbHx/Pwyki8jyPCcyyLIqiJEmGh4c9zwOAIAjCMFpbWzNX7fau6TEhTygj5iFXr9fL7YP27dt3zz331Gq11eXlfrdfKVSKxfKZM+cWr1wpFMtXllYKpVI4iIHQ94NyucIdiUxw6dLfNSn1dxjXprNLly4NBoO8meCa/9LW1lZeKLQGOBc5vpURkLGSiySKQVtXOmDstXOSCy8kMm7BAWYMpYwMUaNQhXOXzj70+HChwCTrDLoVL7BJBozra0wHIgBgloQFZggJDBjLERlL0hRAK0GRMOCiRkNgGBNAxDW5SDYLGVe9QbMXxTwQGWheLgiPJ1z1REau6Xk2BgVouEqkTaTQnBlulccY42CZNUxrTNGxMhAnz5zmruu4LhFxApFzoqxGrQpEJcIgL1agBastpqHsJ0HWyeKnTp2KQcmaMxAdbNiBSCJuY84V50ZYGaDjkoEYOOS+TFYpD1Ckps7LTgJcc9BgdeKQLhvjJQPJupp1BhANpGkJlfq4sbrWvLAg4hgSGKoEmQqFy4ywMWYgSRrgBBHHvgCDjKMQIBk6JALDfGZ9R/vFxK+kfjmTRcMkIXKWMhELEUseSxlznnKhmTAorOFkpckILXeQCwAHyBdieWH5zMkLknuccy7sZnvN9QuDKOIugYgLVfrpn/9nnuelifJ8xgVw4Vool4s7HT6TRjVr60ieL1nBNZWCXdu8stFpDs9NZEI6QW2zFb7m9W9ED8ZnKo3xokblFr3GcIU4gCDmGuEoJhRDLQW4DggJXFhkOihwbaFch9tvP76xsRonPcJBZprEtoC3DWxJN0EeCUenpstl8uv/5hfe9T23oQOjczC7ezaMsqDQsOD6xQIwKyQMDVeQmUxBpqFUBo+0SKNARcImv/BzP/HtJx8aP7y/HZSikZ3LYmiD13F4ejXpuDXH4NX2+GvaI0aASGgBLZAGMAAGTAqggTSQIjCvXODVFnrpNoGha0+4Hatd3UYLjIhllicoNAOPKSd32mE2UUY/utwdf+v7Jj/0S6AKYLyCAcLMuJgKyBjYPP7bTmwK4NuRBgfLyaLlYOW2T/B3KFD9bfPrOerllT8atAY0MgAk4Ln9rM07yrXWcRLGYXhwz94v/uVfrF08t3NsRMURQyKtgEx30CtWi51BHwV2u72lxWXP8Y2yBnAQJ9EgOnPqbLfbLReKxULh1PMvWKWu9dZdnSVfchQEbNvthgMgg6Gx4QNHOmleMLUImpDZ7WmDXXuClyxX9wACCg6cEVlgiK4DjGU6Cxm7rOHIB38WDr3eqIrLi06WYY5BcwU4PhdOrkkVwurtzx0ALYE1202ZcG15BcwUvxPSfXbH3G233ZRfu4eGhlZWVn7nIx+97+tfj6Lo4x//+OLiEmPi4YcftRY+9KEP33HHHUmShGEsRVApD4WDLI704uWVpSsrm5utZrN55swZzqXjeKVSKdNqc6udxFneaZd34ueYcaVS6WCa9dNsgEzX6uXN5mqaxbnV3t5du0lDuVj7nf/ykd/+j7/9wx/4cBCAIXjrWw/e+Zob19cur60tcAGMwb333ttqtRqNeruzxTl3XBYnIeOGIBMnT5596sSzoxMT8SD+6Ec/+oY3/NmHP/SzpUCOj+yvVAvNzuD506c9zxtkem73nl4cBgwa9er46Mjq+trIyAgCz7Isl1jl6KZut7u2tpar1AHg+PHjAPb8+fNxHLuuu7i4ODMz53nepUuXHMfpdrulUml1daPf7z/22GOtVksIduzYsVyitLCwkOd+tNadTq/T6cVxnF99jxw5Uq/XkyQRQhhjut1uXpLrdDoAGATF+fmFkZGRRmM4TVUQFLXWUjqlUvnBBx9673vfW6s1zp27MDw8GkWRlHJra8v1vCzL7v/WX+dNhRMTE6VS0VpqbzWHavVLly4aY+655x4C47rupUsXbzp67MCBA5ubmydPnnYdf6PZ1sqUqpV2u10qlbTWvu9zznu9nut6Bw8efP7558vlchAUc5pAFEU5WWDnzrlcp1+tVkdHR7Msu/POOyuVyuXLl48ePXrmzBnHcdbW1trtdl45JXLDMFRqkD9PLsm/ZlOY96BGUeI4zvT0dL/TX1q6sm/Pvrxpiwgdx+t0Bkmkyn6x3w+DIFheXQ8HCVGOYRa07Tx/NcFMcK2vkPC6WRuuZ5v8bSYyAGNMXh4lC8jgwoULHBkZJRhUyiXOwKjs8sI8ABT9oJemDK3WlhgQcgIlEUwyqHCsuRJAA1qtrBUMJGMEKlOSC+Y4xmSco1QKMn3i81+2m1tj0zP9sCsDT2fKkSIZRMJ1ckggAjDKZx9GaAktB05AAJBqA5qMBUMW0CIZQcitBWMYoce9REeOYHEW98OeGKqEceI6gXA87vFOuGWFJUYEBI6fWVJkJYIymQHF0OHWCgvCELNWCBYU/VOnTkd33s6EaxEsKbRkJQdgpKxLVDG2r9JQy4yhAodQpDrmrmsjE9soNX2CSPM4s4hYBGJkBaCD3PE833EFkAEDjuMAkCHtSWmTLOAcMjCZAgE21kXu+sZgPPAbxU6WEgIJ1jdJqdxoLfZWV5enulVIAxeZiiMmuEK0hpBzsMqalHmSMcYNgGUGCAASoAQw4VwDMIPCAjEOjCxYAmYRCEHnXpIEnBi3HBhHJoAJTdYAIYI1hiDhJCql2uVLFy6cGz/aONwPo3K93g67pXKR2yzu9V0pJ2dqP/UzP/Jf/t1vba5eMvtu3Erdrbio/RFLAaH2/bJVHbLWY27UG1y88FylJlq9iAkEI5JQtTtrfmUSYhiEWXWomCYkJSSZkS45LiJDMhoAGc+bsQC5BWVB5sp89sa3vPazX/j4YDAoV7wsS3OIuTVIBCozSLC+sfpdb3/HseM7qg3IAIBBY7SSI516/XDI9awBIpKChWGvrAqe51kLkgyAhSx76M8/efKpR3feeLRn7SBOK05BZfFYbeTc5uI909Uwbbv2WmGIQY47wm2/YkCw9mqS+iXf5etJ7i9ezK9uXFfQIQDKvycvsrjzuzLkV3+1PXKqOyJcy6kQWA2cUksrho3f/eaJH/iQtg6vVTAlEIzAGmDX3sS2nMjQds4qn3FyOnluvZJHCfi3mIC2e1le/VdXT9vVRxIRoRWYO7jmfskM0BJApV6tD1WsiQuOmJub+PInP7a1cGHn2FAW9oquGw66rkC/4PejfpIltUopMqbAZXNlaXR2jktGaJvNZrFcGh8Z6Xa7M7NTrW5nZWUlHPRK5SrnqDOTt1pfd2TsWqWPAKwGAA5OcWzfwQuPfctsy8nzeBMR9PZZJHNVUMvwJfRSazLFHQcAwFgQEhxPZWYlVnFj+NiHfgKmDiTGE05BAABmAAqFVABA4CAAGSADnFmiv8H+g7brgi8T2FuCHI4PuH2VsQR2bGxkbm6GuB4ZGdm9e/eunXs+/7n7Br3WyirOTs8MBr29ew6Fg/l2ewuZ/cpXv7i63CtWAEEYoJXF03Gc/sxP/9Lv/u5Hnnj8hOMCWDQafK+UJNr3Clr1GWNgKYzjXTtmfcnTLLOkHVeUKwXglKRJq5WUCsX6UINL2QsHSlttWa8HX7vv2/0BvHBi4eypkz/wj97PHG4s0yk7l13ef2BnqVJdXF50HPH93/f+z37hi1ms0ixWWSYl9wuBMhm7cHlZGfbQI0/92Sc/7crC00+cuPHQTLuTvHBmsZvK00tbxm/UZ/Y++sK5p8+eH5meJaLpiQmVxirNGGC309naaknpJmna64crKyvGmCxNiwXfdcTpUy/8xV/8Rblc9YKCBXQ8f+8N+x9/4slUael68wuXHnjgAWtgZKSRlz3r9err73ndow8/cvnSwuT4RMEvZom657Wv63X68xcXPM8bHx+/4YYbXFeeOPHMxuZ6nCRTU1O97iAcxNbAvr37fa+wdGUlChPBnX4vDAfx8NBotVI3mgT3yPJqZWh9bWv+4kK1Uo+jFIjFUYrAHSmzNAWL5WLl/NlzK0vLOtOryyulQlFwLJcK58+deeiRB59+5plypfK617+pP0hOn7lw4rkzi1dWXzh1OlVaEyhlisWSBSiUSoYIOa/W62sr68OjIzcfv8UCtTpbSytXoiTs9jvtbmt2x8zs7Oz4+PiNN97oOE4ekM3MzLz3ve/1PI9zXq1Wfd+v1Wq7d++u1WpJkqRR6gpXMpnFGSMW9sLcFyjHieU5zxyfsdFs1oZqW52NxeV5JummGw9Xy7XHH32KkdgxvTNTVKnWGZe5xAsJKGNor2LurtqD5k1A12QWFkABmO3p1267mF0jC4L9DsuLc5ZSKedojEHEXGtx6dKloVqdM5IM0GQFhxddJwvjsNPbWF9tbiyG3c20N7AKLRPCkYhqsLY44VINUsDMkBZCEjFC0EjARArQQhUK7QGNIoOVtWe+8MXd9UbcbmU2SUlJjkLZgEluyBBpNGAVkck4SwXL+DaPWJJliCrWYBxBjrQIFiRynaaoE0mAVpqMSwys4a1+EmvSiXHBg0RmobYmFZTysO/EGSgC4Zhitc/8UCFwD6WT6dSzVCHmx0YmBoAx4W01O631tvAKmjEFGQmTWSLGgQuTZYWkP5xFjTguZtYwJzSsiD70ekKmGMQR70bQFRIDIURiiuTy1E17SJkXOLVKUAukCxEUvEIKKUg0RvmStTrLEABKAwQFVpKx9Ij5jhuHwLEMsQ1QGJUBM+jxtc4WBi5obVLloWetkxmJ4CExQEUQuTbxdOYochQ4Cpm2iuwATZtlA4eUJGAIIBAEcUaMXGOlsRazjKUIRlhwLLqEXKCiVHGrBWUSjYtWWBDK8j7hYPHy2fn5+UFsYyWkX8i0UpmpVqvGKOTZ3v3DP/lzP2Qd6pG7YkaSwsGMjbc6xIWXaJUxkVo0lnmOizrqb60IZqQFCHXD9zhrAYcsBd93hABkmklwC1Z6BrhCxqTrcMmBGWQJYaRNKqRI0zQosjCBGw75//AHf+CJp55NM+E4Q1nsu6LBoJyE0pVDq8utGw8feO/3vmlkDJBDUALgoChREMWq4xWFVSixxLTM4sxzmBOwmBslACSDzMDnv7T8pa8cnBrt9DthaoRXNMwmlKyl3T7jUeJ4fAjIByvAMKCrxTRgQLmgSiBzgCSRAHRyggOAvPqw6xZi3yGHBaRZ3uuJWqJxkTwgl0BazUgzsDmjkgMxsAhGMiiAkYAKZAaOzXz5fKT54eO7PvAhcD1VDFIA4AjEGHkSpAfgEnBgQBKYC9IBsd0Dh7ksLPfru05b/eL0A1fdqO12DPDyhTAv/G1THDRdW/I5DixZbbTOjFG5rzMHQtIKICPUUQrcBc7ABXCJqL9nKHjwU/9j68yzR2ZGuhsrnhAmjT3JSFKoY+5KAOBKFyyMloOt5ctcGCuylNLaaG1scrzTa29sbWy12+VyWXLx3DPPAnLQSuRSt3xBsNv3uAzBAqQMrNR5GdXz9h0pTExuZFGKZMEanSGlQBGYAUACRoEBUAgZgQJUiApRI1rGmaP6MRAgsdRiJ6WLAzMY2bX/X/w6jOwD8hzhbjsICgGMI1gJVjILYIEjcIEgHJTXwil88b/H5kte0ca8uIwWUANqC0aDJsgNpYkQDWUWzDfu/9rS2tJTTz316KOntpqb1qgsHTiOrZQLNx4+8HM//zOzc+OVeuGOu45/+jOfPHJs/4f/j7+3/9DMgcNzP/EzH95/466nn33+gx/8ySceP+MV/OGhsXptvLnRy1JMYkOGyqUSAhBRsViO47TVajMmCuVCu9tWhtqb7Wq5pjPT6w2K5Sq6bqxNlCnp+1JAmsDOHUNDI+Xq8ORWp7+4uPjlL33u/PzJ0YmKgXjv/l1vetO9n/nM5z7zmc8J7lYqFTLW8zytbZzqcnWYtfphZmF0bPyhRx/9wA994FN/+VfaYLvTX15rPfDYk5HCgcIXLly2TvDoMyf6cXzgwA3zF88fOLjv7W99U7u9NRj0rDWdTqvb7YZhuLq6+sQTT1QqpSDwPM9hDObnL33qU5+VXMzOzvZ6vY2NDQBYXFwkIqVMsVh87WtfG0XRCy+80Gg08sJ2pVK566677r///nK5vLKy8s1vfqtWa0xNTQExz/MGg8H+/fsPHz7suq7rydfc+drx8fF+v58XBCcmJpIk9TxvbGyCCF3XzxXfYRh3u31rYWurfeTI0Xa72+32cxBIFEWe5+WGykEQIOLMzMzy8rJSqlAotNvtHKblulJrvbW19fzzJx9++OEbbjjwla/c99ijj7dbnfmFy7lSqtvtxmmilMotbpaWllzXnds9d+XKlRx0xjknoo2NjSiKduzYEUXRiRMnnn/++aWlJd/3cwSrUuq5555rNptXrlzxfT/Pz+U8i7GxMXl15PaOSqVRFOVkCmttEASFQiH3+UmS5OLFi4gmjAf9fl863OGOVbrbbodhGARBb9DnnAsp19ebkLeamBfvXF+KOn7JXLYdNNHLHvS/NPIiIOecCIyBdqsXhiEXSFY3aqXA4WjN1sb63Oz0W97ylqM3Hbn52E0zs9Ojo6OIPEzSzGjMEht2qtywtA+UGWbz1LdBIATGpUXQDAgtxhF3vI2//hZtdXwCgcAYQ0YWgMgwmxN1CC0xS5BLLrYXA2CJDCJqstuaWgAQaK1FJNfj0mMgUREog9oIZfnaRjcOMxcE9CIdp41KKR300o3NoUI552BXJ6YjS5WgrAYhJ8OJmLUSMRCOJyUiGdJIrNPp5oQfywgYWQRDiMgdooJRVZXVtSpbkJZzK3gGjmHWZsqGlmcoNWLGybqADnHUiNYl6/V7iU41RwYCFFLGIQFFXBiyWiWA5AUeaBgbnuhvtotSSGuAM2TCZZ6JjMudwSASbqHZDbVB8CQZIyQYMJwLgR4HAWAdDgKIEwEwQs4ArLWKrOIQSQgFpcIq9qI6BslyC5wsoKXcVpaAGczBGYaBZVYhGSBNORkx9QJUqltw0OeYhHEUpXmNWEo5GAwcTwQlxwn04aN73/9P3ofFMq/PscrOi1e6UWSNMWkaK5OhwzIVZbqfZa1Mda2OrUlNmqg4KZd8yKBSA87BcaFck14RggKXvhCulFJwITjnOVgSkQQXqVLS9Tq9qFAEJuDeN7/xJ37yp599+vTaSt+VjbWVkGMRyD19av4Nb3jjP/3wP2yMAfNBVsAKDQijo6MchWCMGdLKxnGaWXt5eclKxj0e+OhCClmn+Zd/8tDH//Bwo9xdXJCEKlG97qDfHRiyqSdbRm2FShlXaQaawAJoAmPAGNpGfyIZAIsvwYdaBGNAE+hrawOawFxHpbx+AYbboYoFyGVJOSOLGDIkgMyA0qA0aDKGlDFgWRIOgIxmELn+Y4vrk697y84P/RQ4xYQ5+X1ajhzPXXm2wzgDZF+yGG2Nttq8fFHaaqP11bUx2ph8/apDXQOTXsOTbv8i0yrLlFLaZNuLzrRRSZagRRc4ZFZ4ZZOprV7PZc6hHdNVq+7/i0+svvD0zuFa1GlVSkWtM2YNs2QNGUJrACxwDUJTgCztD9Io8n2XSa6s3mq3+v1+u93lnJdKJSnY4sJl0Ckgg6uSs3ymzXHsQEBgAawBxbbBFBIKteEd+7oJuE6RFAgmQee8fQ7EABgoAmPBwFULRwvWgjaUpNKRkGTaEHqFpVCpyZ2HfuKXwB/RTtVyF5FvS6a22yByef21G+Zr6nX2N623D+LaGjCP+EEQ8NzpUUoBYD3fdV2322sfPbqLyPT6rcnphtKwf98uo9JP/OnHHn3sobtfezsX9oYb9rz27juUjjxf7t4ze/7Cqc32BufcagDkQoiV9bW1tbULF+Zz1XKaplprAEtEWtvNZqvT7/X7fSn56OiwUmm/3y94frlQzO1VpOsExZJh4BeK1ao/PFxtt7pLy71SuX74yM2Li0tHjhypVqvNzfWxyTFLem19wxhaWe62N9sAgIidTqfZbOYCQeH6Bcu41ro+zB946MFaoz40MhyG/UEUze6e63T7Fmy1Wh4bGh0dHXWDxQcf/fbc7K7Li0vlcnVouLZn765HHn28VCpVKyVrIfGc8YlRlWaO49x1110LCwtSyvPnz184f3bX7t2B5166tDI6Wh/0ulkSS87a7fbevXvf/va3f/zjn758+fLc3NyTTz55yy23NJvNhYXlOE737t175sy56enpG264YXV1dWl50fO86enJMAyN0tVy5amnnrLWFotFpdS3vvWtgwcP7t27h3Oehzt5HmhjY6PfT4SAkZHhwWDwpS99aXZ2ttVqbW1teZ5XLpettX5Qyh/JGFOK55guxtjMzAwA7Nmzr1gsCilzM+bTp0+HYVytVrXaurK4In0RhiEA8zyvXKyMjY09//zzWmud6oX5y6Ojo7ffesfm5ubF8/M5fkKDPrh/b7VaPXfuXLVaNsbkGNVGozE3N5enoHbs2JFlWS6nnZycrFara2tredkx95AGsFmW5FkrIThjaAzlRAlEjoi+52mtmXSSJLl8+XIcx75X2rNnjxByMBi4rpvDPIOCo3WSf3/xOsAdwks7QwAALb7YSvRqiXm67i/+Z2l7a4kh5kL+oWrF973BYPD/cvbf0ZZd13knOlfc8eRwz811K0cUChkgAOZMSqKoQEqyla2WRdluS93vue0nP8vtZ7vt7te2JJuW9BQoiRQlkiIFMYIEAZLIQEVUDjfne/LZea01+499qwCS0ujXfcYZexwc3Ko6Yd+155rz+34f2Nbc3j1PPf30iy++ODE1ZfsusYky1OYlTSkVtuNwm8RxZ7vscIxHBI2hRBMwjCBBIGiUImA4EjRgawLKvPC1b/pUACWGADO7e3tNgWpEBK6QE8o05koVoGAYAgChCokyjKeoAFTKDGfEsShKGhsV6mikdYgypbZFpbTcVFntdlTWnEtYuHbJklRHkQuku7TSOnX3aDSCRqUx3rz2/EjYVsuSSRoxQZQ2kTIUDCEMheY2M7Fa21ynFBRqoMwQArk2HElOFbIAPCQlg0OD1KAxAilPDVOpYkwLqqnRlDBu+UmkLeGlGbYqNQPUkpLzDCQEXKeSBhRcwTVjnZ3ONJAoCGGs6pcLlm+him2bJGoQM9c2LqZgCTtQAMbdWut3dyI4XBmGPeAZmpBgBgZMhjQH7lCuKNGAQMEYlaqMgtYEMqApYwkDyxggGUBeX9I7ECaSV1d58AigAtSIuXcPkBDUaJBqpUjoCNZfX59rNPoqE2hQIyEoLU4QM5UFUc/inuWQt7z7rcO1TtWpR9nlYZgBlwDG6MgwpbWhhjHIEsjQjASmXLNU2WESE3R1BpQAZQAEGAMkqLURggNCPsnMR2IEJCBoQxgRFEjBc9FAFMLUFPt7P/lDUR//9BOfXYTuzPTcretr/X73rpPH3/HOtx475USZ0TLVJEu0dni54DbCrtaBjoajcrmUqijUydi+2ZBhqGI7NaBHyRN/fv6Tv//Ann19kk25pfOL6850JQwDRKJdMsySOMl6DnSTxNlN+b3zQvNmNAHUZBebnz+5q4bRxnzf1EzDd2uYXld/oyGQATE6xzvkrCNDd6//BkEbIAwoAZZLqAyooc0RMxMQ+drOYO87Pjz+E78EsgRoW4oASTU1GWUGGDMW04B5VfJ9N41/O6zL7O74KIAhSAEMBQbEvHEtel3ItGtfuZPisvszb+RmIe7qikhObGO2imNJMx7FIBgwkSahRNgnrKe/8mWyuX5qZrYbR7FB4bIkjCRYQAxBwwwSMAwpNRSBlLwitvvdrZ3q3r2pihhlJosLbqnb2+n3+/V607btxcXF9bW18ckZRCRM/G2WI6qBazCMA2hIKXNo0T9wv37qW0RJngZgC1SKoARCAcEQVBQIRZ6nNhONAJpSikAFB611FlG/fH2r4x4+tfeXfh38MeAuo2L3+3/Dvpq8zgilrz8L+TlG/87jrgeV4q4fleZosXxyvBsMBHwYDlcWl7a2V9700IP33HvXlasXq9XyseM/sL296ViyUi4c2LdH2t6t+StjY2MPPfTw7/3uf+WcZln2wH0PXrs6v702BAOO4wKY0WB46v7DP/CeH/7cZ5/Y2eq6rmQcEDXn1PeLS0srvmNn2eipp556z3veMjneTJIEiNncWhdCENRCsjSNsyyJosDznH375my/UCoXZvZMDMLOH/7hHx45fPClF185dvyurc3u9ZuLt26ur6xuZgpbrWqaqn5/4Pu+53lhOKIUkiSmbtG3XUcRTLXhlp0aMwgj4CLR6tLlq+3+YLvd6/aH3f5wGEXStu+77543PfrAzOwkF3Dq5BHOCQEzGHaGw0Gv1zFG9fv9Y8eOTU1NBUGwZ8+evXv3/ORPfvTDH/7BJB796sf+4a/+o1/Y2e4gaKVUuVx+z3ve8wd/8AcbGxtHjuxpt9vVanV9ff3WrVuFQuHEicNxHA8Gg1qtNj8///Wvf93zvBwltbGxcfToUULIwsJCDkHI2fZKqZWVlVynFYZhs9nMuzutVuvee++qVit5bykMw/379zuOc/LkyWazmde5WuvhcCilrNVqURQVi8UgCLTWrVbr7rvvLhaLW1tbORwhSRLO+enTp7XWY2Nj0mKWZWWxysX47XZ7c3MziiLGmO06+Uv65Cc/mcMpXNfNLYSIuLi4GIYhInLO8xBopdTm5ubZs2efffZZY4zWejAYIGIQBNvb23n9lyRRkkRpGmdZluM9AHaFBbZt57qu8fHxPK8wBzdXKpU9e/a0d7qXL1/udDqDwSDN4iAcup69ubm+vr6mdIY5Mu7vqooI3Fn1vrvqov9Xm1h5XIUxgIiEwuLiIqe7JaPr2dwSwyDY2tpqtsZ83x8MBkEQBUEQRgOtM20MALicZkG/WbCzeAiogDBEpEAIGIpgjOKUMQOWMkXbVWcvrl+53vBLymQZGtSGaGMAVU7fI4QZQhAQqCYUCWhqDDGGGgVag2aASqWAylBUqEBwz/UFYxblnBFhc8LBKJ0mEAWmux0VRQES6GxvmCyUlDjA+itrkKBlWcBh7+HD3eFAAkl7fYdR1xbcFoZxBSRRmVYxh4xQtbm9lvf5gBCDQAxSBGpQaGBaC4VeZioKKtp4GoQRjHkGRKYQtAHUCKkhGbDMgNaAVAi7VJzYO0csZgRBCkZQwmgeZGFLZ+naTSBQKnj9jd6+u4/1R12LAI8jmkYFR1CjKZAsSR3hacWi0OysdKEL7XabCQBMATPUmhjGNCMpEUhRQ6IwzVMgKUFC8oSfmLCMQcqNIQohyzniu+eXQWZ2yxcA0AQMoCaoKRhEA6iRoCGoTRwH1ZKzuXBTD7pjBd8koclSRslwOOScUk4IR2GzYTjkDjt66qhVrC1v92yvSDnTKkYTU5Jl6UBDoFmkaahIlGIS6yTLMkC+vLTDbOj1gUkAog1EjGnGv4ellE+sOAFOKeOcJknCOGQqkxYEAQgJ/+SffOh/+9/+4wMP3BeGo+ZY5Wd/7qf+2f/0q3v3FUchUJFSmWoaMQEAEA8Tqlk6iiuF4qDfJZwSTqI4iOPQ0YkvsrXP/fHpz/zeqZYtdacgkn0F6QXdqLtsSaCUhmFMAR2HgtBEEpMH696O0rvz4I1kczCI2mCOPgLQiBrxzjg//8/X76DvHDFvWWnQxigwGo0x+SmnM50Z1MByvQ01CBqIMiYOe8Ag4YUrnaz1yPsnf/qfgNsahIDAiEFiNBitQGkwBlJD1K4YH+B7joQQQvD7j3caJHeefP0Pktvxw991y3/y9VuuK99Nb6FA79yAUEJMmkjGMVHU9Q1oRtIJm0DYvvCFP++ceelIqxkPBpRSJjhoRTFXQTEGDIASYBSBIlBAgoYRunTrJgdUaQKIlHLH8VzX3draQsR6vSmlvHXrFjBGcpgZ4vdscQkAA8KBUDCaaGQUqIDpQ35zLhjGICwwhlAKIIBaGYBmJA+xJwKBI1ICdHfIinGMiFCqXugMK/c/tvcX/jF4dZA+ME7IbbPTHXnI66ne8Lrqg/yf7KJvl/n09nH33eRlV361QQNZlm2ub125dOXAgUMXX7v6uc99/s/+9OmtzU6jPj4cBp/61F996s8/efDg/qOHD3zr6Ssvvfz8H//xH9Vqtfe+973ve98HPv7xTz7xhedPndp/7Pi+KBpE8YgweN973mowqtV9IREhRdTDYT9JEsex8hcwVm/4vp/DDTbXV13XRdSWZUkpiTEqzVqt5s7OlpTiwz/yIduRExOtwWCwtbXRHG8tr2zUqq1zZy9NT+37kQ9/VFqe0jA9NWtZjjFGK1Or1Q4fPlwo+MPhYGt9hyfa1MZa/SDsjXZs29ZK9Ycj13OSTEfpABaXsyS6/4FTlmNvbKzVaxVj1Jmzr1iSymppMOxNTo3NzEyGYby6suE4nusUwSYXzp3p9/uzs7Olgjc53tra2vjA+94bh8Gl187ffc89P/rh933u81+amZkgYBbmbx48sI8J3u/3t7Y2Xn311QcffHAwGFy/fv3AgQOW5ViWNRyFpXI5TdNr1665njsYDGq1ymuvvbaysoKIOeD06NGjZ8+ezbIs7wfu7OwwxqTklNIoivKUZUQcHx9fXV2dnJyMoujkyZNJkjz77LONRq3RaMRx3Otu+wXXGOP7xcFgRAjhXGqNjIk4jt/85jcPBoMzZ86YJriuOzk5mSRJvdao1Wrr61uMgWRcSomE9XvDgl/KoQmCW7ZtdzudZ57+9tGjR7e2tnq9nud5iwvLxpjmWD3PySmVSoSQnMi6vb2dU8uNMYQQ27Zz48PExESOTjWokyQRkgNADvfKw6Tz2JmciYWIKjOUYJzEAHTf3kO+VwzDOO+W5ZPEarVi21Z/0O33u7uTdZ0BZfA97as3bGUo0O/aSP5fc+oYACA5CAUhh0gvLS1ZtkjTuFgp59FGYTRKs9h17SxLi4WCtCwkoJQWgipCVBKDjlRva2yumQYdaQxQBgYZNULl2TKSUIA0s4EAEy/+zVecOPNtZlSqwTBEMFTRnA4EBHImHzWU5aMKRUExg5QIAhSREsAsBaW4DcYYYJxpYhJFfQOYEYcRBG6EK7xba0F/cyhCDWBWbl1zHW5JzgHXr986pFSx6Hfao5mTJ8C28knuZpKkEmJDUyCSMWIIzzKiU0J4d7DTEowiVbB7veRIqEaKiBSZUh5hmuiQKEXNagIp5RkCkjSnJGuqKEmVSqnt6sQwxwkJNvfNjjAjoICBxYSVoq0o1bpi+xs3FiAFozKQFkyPVRqVZKczVS1symSp17N4KUETp8qXFSY4McKMcLTU7fV6057DciE1cgaWJMwyzFVMAgkMM4RxRiiTnCYUUAFTVCeM2mgIKIaa7HY+AIihiDkCFczudGh3TIRoCM2zQCgaQoBSY0v0Tfr8l7/8E7/2DxdGfVJwAXi+8xGOZwjNVCgsCoRlDNpREiM1nBudaZMBVZIhWAgmoRyQojaGMGIMZUz6XuXFF8/95E+8i1JIUi2sGDEBoJRS/X1QIoRcUWwANGMZopEW0zrlUkQBZCk5dV/r+F3/3eZG3Ou2m816axy0AcZA2LaCmAJHQkHB9tqGJ4TkTKuYUi4oN1Ey3NhxI79RrI7+8j8vfOH3j1Zdn6bDIMh09Pi+icWt+RdG806jgKEwgZ50RSFUmGyj5xuqze0aIq8tDPnePdDrthVAvG2dv9Oxyont5I67drdqyd8wJ5lkt71sFICCAQBNMWaEMOBAqCZM52p3ggTsSiHU7Hw7OPzBnyh/5OdBFhWyYsmHLANAYBIo8FzuTAwhhjFGkL5+FSY5lBKIzntKu/LQ14Wh+Hoz/Q5+HQDM9/jvblt2AHjekbvz+ZBdmbYhhJAceYsaEVmeQuxQFaem4DNGNE1p3AWanPtP/7G2ef2esWI86sUG4iy1HGmCXtX2MoWGUHNbk24IGGIQTJKGlZK3s70uOOGUaDCGmFRlQtora+vT03OWZbmue+HChTc9/laDmjCRfyXfDZgCvqsbj4QxlHqgCZTrkyfvWfrK2b0tx4QDKqXJFHASYSoko1neCEsQjQbOQeZjRiKkkvLcMJl49w+3fuyXQBQhyf81/QZ+6J0On/nuGuu24n6Xi/b9Vex3L/pv+GO7Z9qdM1AbQGy3O5MTs29/y7v/9JN/eum1xf17G7dubJQKNwQUp6dalOGFSxemp6f/5b/+uU996lNRGJ44ceLGjXnPLTSrXuvI1K//0//xpRdPX3ztdxiH93zgVJR0/vSPP7O9oY8enEvjURwOmvWGVyjEcVwplpRKPbcgWmQ4HDoWFUK4ru26TpJEUgrKgAs63O5LVz740P3/7t/+h95w9Nxzy1vtjT/79B996UtfOvvKhShSWUo31tunz1xV2hQL1bW1La9QUAa5YFrr7e0trfWhAwek5Hxje8tyHWDUtl1tjLQdjTAKQmnZjmMNBl3fdxeW1pgQjcbYYNCzbfnqq68W/OLevQePHDmcxOpHP/zhnU7vO995dnurrVSKSNI0PXLkyGAw0FoNR91ef2d56db4ROOTf/qpubmZ973vvd/85lNGJaV6dX5+fnt7+x/9o3/k+/7Oztbm5uZEa5wQMhgM1tfXh8NhrVY7fuLkJz7xCSFEoVDQJvM8L2/85GCI9Y3VPEm6UCgkSQIAefBfs9n89re/XSpVyuVyPoj1fR8RlVJRFK2urm5vbzebzUajkZe3xWIxV0ElSeJ5Xq/X830/p2elaer7/q1btwaDQY50X1lZMQaSJOn1epOTk+trW/keqN8bAGO2befBz8VicWdnBwAOHT4cRVGulNJaFwqFwWBgjFGZGY3CarU8NTW1uLjY6XR839+7d+/29vbGxkahUMgjERExy7KFhQVCSLVavt24AgDIE8KzLDNK5QVZFEUbGxuEkJyVVfA8Y0yh6LVaLUpprdZgjN1zzz2f+9znLl++jNqkabqzs0MoBWOA5ZP77+M4E/O6c+f1dfr/jgYLEAFY3jDb2m4Pe/1yqQAAYRja5UK5Utzc3EzSVDh2nKRlrxwGkWVLYowlKeVMGp31OjyJJnwPgwC0pmAjIgPKNAJFwojS2ujMsSzY6tx86XTLLbLMAKUGONUaCGpCzG6k/K55UBMAAE4JzR3aYHabRkhoYkAZQWimNRApvSInmWeXnERSJCpV0iCTTEWqvbo1bjNYX7t05pWHWo1ep11wvGvnzr/FqDiKpGPD9LQ3Nbmw1ZltjhMmgAuTGUUoI4wTyF2SlOs4DhgnVFGTuwiQEESikBKkiMxoGzXSrETTiBuuiEKmCQrhCggkMsZAGyU4oDGudFHpYqWoGaIgimhCwKdMJOhqGmeq7Nqr211YXWtM15c31kqVqdlTJ8Lr10vK81TqEZoQZRi3uY2KEMqTIPGobK9sxZGyKw7onPBqCEVOQBriK1JEERgZgzBoGKOCGAIKEA1lmmSagKYGtM7DGJEYAKAI+vb0KieLIzFISO5EAwSKlAKhYJROsmQ0Wa9cP/Nyf3Vlcm5sS48Ict/3gyAwKs20BoWO5RIAYsHS1k6hMd5faUvpUqIjoxmJXIcpg4wRyoBpm3EwmtjSqdWcxYXV02e2Hnm8OUxSKg2nVGMGwAnhu0UIue2VQwIASRpZUnIuAAANIoK0iDGoGKiRBgbFiilWS1KiwqxUFZTmO3sOoNMULArDQS/PCEpNZtm2itNG0cWttYeOvmXzs79386/+4NSY7ThW3BsWCoUw0xJHjx4Ya28H64MNgPGSLd3RdiWLJqqcJgMuGBhG6Bv2R+T1Edid0mr3o0bMZ7IEAeguJ/2NRwoGgRGA/EgMB8oBGKOABJkBIAqIMVRRzoEBMYYaZMiAcUfwlMqA60vdweEf/HvlD/80OA3NqVLIAW9zxhkDSgAoGEKy260RsjuVylccggB5TyevhNguseH14xvscXfe9Ruu+W+8/N+2q75+phFgcHumlad4AeYut13NPLelRqJVKiAAFpz7t/9TcO3i247fvXzhdECAem7R8Tqdjapjo0kRmQZE0ACAoBEBAZFQhKxU9pbWN6Jhz5YsTI3kVGtlWVYQDvMkj1KpNL+4MOh0is260d/1pm4/oqAJUARiCEMGFIgA6fF77k+e/YzBGMAAAQCNhBFUDA0liu4u4MAJBcpyMUiIMB+QuXf/WPWHfhJkI9LcsZkOA+YKJPi3fqRvqKv+/739LT9NdnNIAVhetAkp4zg6duzYTqd96tSp++67b3l5kXB2/tyV5kT13nseYpKmWey6/vT09KGDR1599cwX/+b5e+45cM/dj/zMT/3i009/6zd/838+f36eUfiZn/0h280+/vFPJwHs2VNmjLjlojGm3+9Oz87lIx3f84wxg153e2OTYdZq1ofDYbGAExMTa2traRaV0oLr2hNjrevXrz711IupgXrTevu73va5z33u3Llzve2oXh9z7GwUplGcaYVCWFEU2a6Xs5ZyOTgqUJMqCIYUgQ6GwfTMHiElY6zX6zHOuRS7hC7Hd/3C+trmtWu3XrtwudcbDodBFKYHDhyhhF84d8F13StXrrz60svXr1wNhkOVpGkUep67sbHOOev1OoLRqcmJLz7xhfGx5lsee/S5Z7/d73V+7Ec/XPDdJAqLvre93f7iF58Ya9QffPDBarXKOZ+amqrX60mSEEZffvWVtbW1PFyvWq3mqTK5rHViYiJXUJXKhULRm5wab7dHnU7n+PHjjz32WKFQOHDgQN7PzDHu1Wq13W4TQk6fPh3H8cbGxubmppQSEfft2zcYDIQQju1JYbfb7ZxHNRqNNjY2nnjiifW1zUsXr6wsrzUbrYnWJCPc87zJyclr166tra1VayVETNO4XCm5rhtHURiGeahzpVIhhFy/fv3YsWN5wrTv+91uNyeC5s2qLNOdTq9YLHMugyB6/PG3jEbhaBTmxK/hMMgyvbPTuXHjVl4MDQaDJImUSsNwFATDKAqSJMrVi/n8MZ85ZlmGiNPTkzMzU/1+dzDsdTqdvB++ubl14sRdea62Mabf7wPA61Lu20dzZxP5hn0Uvf2b83+juAIANMRonePp5+fntdacc9sS1Wo5b0Ksra0RQvI8QqWNIx1OmKAEjMIkcwjPut2WbTdti0UhaKTAbm+jNCJmaFKdMYIg7f7zL2cbW1XbYW8QcBCkZBckpsEgQWCIFPKMYc2NEQotBRKJUGgpwhMETSRKmhEgYr7du7k92OljlNiUlCj1DTKttWA07feIBd/53F97WjOjVJpZQnS3NwZnTk9O1HqDEfjyJ3791565eWsDubaLllXzacXFEjVOqlikdQoKmNEmAWMQURPE/LJnDEGkQBilDIlU2kmzQpYV0qzllFyUlrYtY9la+sbyUXralMEUTFYnuibI3okxVInjWpIL0OBrKsKsABLS1CLESpKl51/gUnBHQpnve+zh0/OLXnHMiayqKZgMkHDK3TSP+01TF+nK1ZvMMCGcLIyp0YRmBiONoYVZKcWqlr4p8LSAsUuVI4yUhjEEAgYoIjG5wBoJICWGgNllpO9e/Mwuqud2p8LoXfE7UopUoYrioS+pz+D0s89UKyXQGgCSJCGUGkDGaaHoZSaOVGQEKMqkV+JWiRDPtaqeKDHDOWOWZFwwxgSXFhc2IYQydD3hF+xvfOMbmxvGthwCFmceJZISSsFQ0EA0gCEkh3kCISClg8DSlABYhFicWwiQKRVnI+kZu6CKdSg3eLkhSzWRaG0oEAAOPgHHYQUwMOhv+0WuWcZtkaZpybHCtVtv3l/vfeXT17/wJ4+0ao5mMKSc1yn4VPPR5tpdrcqjjepsFNTSUZOYRqL3ced4udqSXAABRvM7cor89mNKgFHCKMl5woTgbheK3bkTQiiQ7zrmz98+5sUa0F2oJMBut5GBZqC50VZmeGrAEEAGGiLDrgxw7v0fLf/Ez4FfySiNY7ApgSwBqoACYC7KAYJvFBvQv+u+O3B7/b77O/3da8zr/yun1+bPmN3nb6u/3/CXIIC+LS69TcCigBQoNYiZziCLGWbQ3Xj1//Mv/LVLd9V50FkmDhmgikDEgWpWxxOlFWPIkFC4M7sk+R6OKETFQSdhb235lkUBkwBQUYBUZUDYxuYWEJoLA86dO7f74u8M0L/rzRGgAok0RBIEYAyFA3v22/sPbUSKMgcUUI1MY0FRmWbcxIAJICdgA3IwCEYNkb4WWVPv/fvVH/wl4OORsjkTcZAw2wOQBG2CEpCDobt35IACUABagBagAOSAuU3wjsfzu+5/6xdJAABzdK2BXOtGFIBOkuj5F769vLywtb3WGWzN7J3ae2B278EZy7GVlleuLH3ta985c+byE088efLu+w8evOtd73788OF7vvD5r/z2b/3ef/rff+/ia/OFAvw//tk/HA672zubv/qrP/rP/tnPtcabV67cgvwcJZCPsIIgcBzHskWtVhsbGyOEpGnqOF6aZt1udzgcHjt6YmJiIgxDzvnLL7+aJDAzUy0USs888+2//IvPjIZBu91J4swtFIuF0jvf+U7O+Y0bNwSXQRAB0CzTeRyLV3SyLAvDmKI2WZYRBMfxlFLlUjX3qJZKZZUZIaw0UoPBqFSstVpTo2F84fwVxy70usOdne7pV88//dS3BbeKxdJjj715bm4ux6QCQM4cX1ya32lvcwJ33XXi+We/02jWtjbW/uqvPmvbcnZ2dmd7M47j/XunL168ePXqVSHE2NhYjnQqFAqj0ejkyZNTU1Ptdnt2djaP6mOM5UExlNKbN29eunRpY2Oj2Ww++uijWmvbJoyxjY2NlZWVbrf7rne9K4qivP8Ux3EQBI1GIz+JwzA8cOCA67rD4XBiYmLPnj179+7NBU9KqdxRmAM8sywrFAr9fp9SOj4+bllW3kkKgmBnZ6der+djSgCQUkZRlGVZvn3MC5coigDAsqydnZ1isdjv93MBvtY6b4blM8FisYiIlmXFcXzu3LmJiYnZ2VnXdcvl8szMTD46HB8fz5tkjLF6vT4xMVEqlWzbllLm6EhEjOM4F7flvkjHtQaDnhCs3+87jlUoepVKKYriF1988dKlS6VS+fjxE/fec7/r+ipDAPL9Ow5zexRyB2VC3rCAIfm+xe3/7EZez/6DtbU1QjDni+ZBQEKIMIoyozUaJngQhcCFRsItSSlhBB1G497AJdznFknz1gkgoiGAAAowJSrFTHIGqC8//yKPUpKmxihAc9ucbXL1DyJiLnlHIGjyhZ4Zyg0wpCyfPiA1BgEJIUwBAcb2Pvqwd/hw5o8NUmuQWpG2U0KQoYK4VS/AhbXzTz01WSqROPEdV8fp/ub4k5/6NAzNWKmyMr9cfftbf/13/+uXb9149sbirbVuOiA8siB1VEZTA4YSQg2g0iZDREBKKCeEgNnFTBNGOAWJaGntZImlsolyuSQdSYQ0QmTCUsxF7mhip3GFqGxnda7hVTzmewIYCslAA0MDWlFBNQGDyjHm5ulXAXUWhWtbO4/89EdOffADf/7kN22rIUxJiKrGQn9Is0QCEN8WPIsWL1+2mUOJlWUaiCHCIE0MiTlJXW1KRnpYoKpgUg9Tm2pBkVLMLed3zhtqCMXXZVfAbp97uW+MgmEEhUFugGmkBolBQLRtO00TnUYVz7p0+lUYDiQSVBqBEi4YY1prY7TWynXtJMPaWDPOjOdVwpFOIgAtGUhqOEGitU6VUZobTZVSSgWAkefLb33rW8+/eIYRSEKRRByV1Jredt7dtnMBAKi8v6s1ETI3xEGaACXgF0Sj6QNLvRJzCkhYjCxKTei4dLeDAABGckIGbVhcWihXiwaAMBCS9bZXHzw+Cd3r5578s3unfAj6gAjagFEminzBq66D3a0H68UP7G0dd+JWsnmq4h70bTHq2pgSkxqjvv+eu2J3VVWoDSo0Kp/Eklx/hQYQXrftGf233LUCSAEThBgwBUgBMgBFjGGohUJIDWQENAENvTS9HqWz7/5Q/SO/ANQLQCAFywLMNDAByHKcVp52BQiADAz/uxaU21D277l/l5bhznf0ukv1+267orTXMe9o0CDmv2B5d4u+cckzFDhJGYlh6fpr//k/0KsX9gA4wYhBRiU1FDmnnNJhf8AsqQgaygylQBghjBIOlOZYcyklZSAZi/r9sutKyvIqNtfg5l5113XLxdL169fhtl7p+/pyYHY/XTBATQKAMAQAxy7s2b8ZKrAKgAyN2f08VT7CpRmK1FgAzCDrI1sGefLDP116708YKA2NYJyksbZ9J0vT79Ww33n8/ftphL8tzOe2JA7M7eP3VF0UCAXCgDBAqg0AkChJPb+skQrLe+e73keZ85nP/s1fP/HVV169+IUvfP3a9bV77n7Tymp3FOinn3lR2qXJ8X3tnVGp1NraHh4+ePStb3vsl/7BL1+9etl1Xd8r2pZ79933rCxv1OvlXrff6fQKhVKpVEqSrFQqTU5OCiEylXQ6O6VywXX9KIqyTGuNjuPduHFj4eaCLR2jYWZqFgB8r+y5hXq98eMf+anH3/z2URQ+/e2zc3NzE1OTnU5ncXGRUmpZlta6Wq0KIbJMS2lnmVpaXI6jhGZJksZJGseCcdf2ojC0pDRKg8H2zs7UxDQDRgx900OPHDt8ot8dqYzvbA9/73c/f/G162PNqdEw6uz0wJDVlfVqpR6G4aFDh6amJoRg3OJCiJwvWqmUXNeOovDuu086lrh149rs1OSePTO1WsXznKPHjoyCYa/XK5VKmVZREnf7vWZr7NVXX+12uzs7O6PR6ODBg2EYDodDAEiieHN9QzDuu1673c6V6ePj40IypbOzZy+3Wq3HHnvM87zHH3+82+32+13GSBAM9+/f+453vMP3/XwYly+XSqnvfOc7QgjbtnNdeb3W9NxCHKWeWwCkgls5N9UYk1dCaZp6jmuUFkLcyeqB2/GChDAAyrlEJFpjFCWEsMXF5Y2NrWKxrJRhTORIeqWUIy3fcUGbVqPZ73SnJybPnT4zNzN77PCRrfWNguslYWQy1ajWSn6h4HqHDh68/977xhotx3IfeOCB++67z/MKjIm8zLK42Fzb5EzWa81jx47Nzs5ubm4uLi3cvHn9/PnzcRx//OMf/y//5b88+eSTzz/3YrfTV8poDUaTMIhu0/wAAIz+rt+YTJnd3ZQBMJBFhuBtyJUxAGC01koBQJYqAHij4+eOA+l1OLLWjFCd6U6nY9s2ISTn0QshtDFbW1tS2oCUEMotGYFOOGhG4iwVjEsuRqNRqVIR0hkMI6DSEJqCJhbTksWoNKeEgc0pDIY3Xj3bsF3LFpnOjNIEDRCGQAlShoyTfLeKmMekAmRGG2MAqdEIVICUCYGYEpOkilMlWZ/pH/2N/+d/92f/8aEf/ui28TdjrqziCLGXjWpNt7ez+Lk//F0vCgtImSa2tCE1dUV7Zy6Pnj9TlJI47tZoMPWTH/p3T37pg//9P60fOhmOKAaWgz6m3LELSikpOQHF8iw3RKM0RaCUck41qlQpwhklRqWhL2jY3pioV+86elhQwghjhGNGSIxl4bhK28moxNPexvVqgbgOKIwSHQMFygnx7Z00iBwMMakX3SvPPmfOnt9TqfazeHE0+Nn/8O9+4J/+2o1Bst7DtTVi1LiAmXBomxTqBb+9dGtn+WbVK8ZBZgkbc1k9iwyJEWJIgqK0XO7HQ5CsmmYSjMWQEq1IlhmVASIAJcDRUGVQodGIFCkFRpAigjHGKM2BWEgsBEsby4AEaiFlBrTOhC3SLKoUvY2F+ZWr11qVik5SSplBoITlM/08nFRr3RgT5Wq50+nZVoGim8XMYoU4VOEwdC2XE4sYzogUnGMWIAZ+wRKSPfHXXzl/psMMAU0YAcw4MZQC1VmORuK355lgDBC2C3lMUhBWrhMHAyBsKiSlHB2fu74QFhCeCUtRkjEAlQEgdDp6fWMTuKBCxmlCmR5r2WBWl259a98kV9E6+ALSQJs+t2Ku+5D0KSE8iuvDrb3R6jubydvH1IzuTArtYkIx5YxwSigaSoADmDjmjDGtGSJViqiMqIwYQxEpIjW3ffvGgNagcmvH7XuWgdZAKWQJUACVAtVgacA+IRGaEdAIpAZMgKNAShMDmQC7BE45JPxcEk994AP1j/5CikVgvkcFakMIEMlQUa04gFAEspytZwAzAiiMIoDUKASkSpk3dkAIYUYhBYZ4Bzaxq0jKMg1AtUZCGGrQmdEatUZGKCOUEhpHKTHEKMyyDAgJw5AQYpTmhDJCjFKoNdzO78qSDAiDTAMFAEVoCP35jU/8p+r1107Vqkz4jHh+pX7k0MGgt1EtCqNDyQkaJSyLcotwy/JKhDsahOWWE01tpxAnCg07MHdwY3nTJJojo5oYZYzBVmv8xRdfXFpaKhRKlUqt3+8v3boFjGRZkq+uAKA1Go15wafBACgOOoc1MAZAsX7PAwMiB4lSRqcWVdQAs8FYMfiJrA5QqkKpJ70VZl3S4uhP/qL1jg8BdTVlzIA04FksSULhSCAmTaM7xZ1Wt2spAoDftbwbgzlc4/Y6j8bsEj4AjFYpgDY6I7uPDYAxSqMhWZbr9yBODGW20rw/UBubwyhiWtnPPfdaklj33fv2Rx/9QLEwI2VzcaG/sjK6+tpyuTx14MCpYrH18f/6x0/8zVNnXr28sdEnzGHC9QoFy3EzbSYn9hT8OhrebIxnGqTtW9IJgzhK0mK5RAXf3N4wRlcq5XqjFgRBGIalYkUKu+CXCMJoFDAmfL9IKe92egCQprrfHxEQn/nM5y9durJ///7jx6fuvvv41WuXnn/+WcuRpVJJWqJaLa+sLCVJknfF8lM3yzSnQLbXNyqFomNZWZJsbkYAUKlU+v2u7xVMpn2/6HvF3/+9P3Idp1IpMSoArQP7pxfmV/u9cGxsrN8LWq3W4uIrhULhV37lV8+fP3vjxg3LdQqFQprGCwsLJ48fQyTNZmt+fn7//v2lUikvSvbO7rl+a34UBNyyx8fH+4NhlmXb29u1Wi3PeM5bPsaY8+fPM8Zc1xVSBEHApOCcM8YqlYrrF7a3t8+cOZP3nAoFP45GTz755JEjRw4ePHjo0KHFxcUbN27kTZ3nn39+ZmbP1taW7/ubm5uDwaBQKMRx7DjO+vp6kiQ5d8pxnA9/+MNf/epXr127lku+OOe1Wu3WrVuEkMnJ6aWlpTiOtdYbm1taQa1eNsYkSUIp59Ku1+t5CmG5XEbEvFmVpmkO2YqiSEqZ6+4phUKhIKW8efMm5zyKorW1tXq9funSpdFotLW1lSRJFEXlcrnf74+NjQkhCME0TWdmZtbX10+duve3f/u3u91uq9XSWhOgBd8ulSqtVitXpGmTlUqlq9euUMJ2dnaWlpby6apSqlKpVKtVMCTLMsuyAKhJwaDRYDjnlOYbWs0oi9LEkRYg6jRjQIEwaVGjQSNmJvMsjkYBQcaEVooQopVhb0hg/R4PeJamnHNCodfu9Xq9guvkA00CaNv21tbOIAgr1aoyBnahVlSj1oTZjj0KQlOwr2+uN5R+bWOTjTuNKLSatTjMBtGQcmY5nuEcMiIoxRvzSbtTcQpRNGKS3VGtAbzeNsnVVxq0AQOEIoC+7UbODCJqzUiYhJilObh8qLLOdrvIxzYGo0GkM2FTTV1bEoyFNqP2UjeLGoR4hOok6uuhwyXG6kCx/Cf/+t/+8l/8+WS9dnVtdTgKC8XSfR9493okn3nuSl0Us9hUitXeaKvseSxWdNdpn2/3AFEDUJ1DAvJ4aEIkoxozmkatuje77/hKvxOl/ai74ThWySbdrZW6V87SYdWTy1s3BAzKtfqApL5ngUnB4gnVWhJKZRCPKl6hxtnn/+vv//Bv/3/Lse5F8Sqa9//iT73pPT/20itXP/u1Z1+7tlQp1l1acJmpOtBZu65HHeYbChSQIVAk+o5FSKdREg5m991/q7/a7wXlmi95LLkQCQhiOCBBAKAakSFFRJJ70XP/fA5DYpRSypWxOHEZaEINQUDkwJASpFQwwjmgVgXOznz7Ox88dZxpzG35WmtOGSWAqJVSHNT4JJ+Zq22udfvtUKfG87wg2OaSA5XDfsiESwjvtbvVimNUEo2GWbxdqZQ21nf+6A8//Su/8suVKlgOVBqgDRACUnAAQCSALFWRtCxKIc4MpZQz4BakGgTNQ3CBUppmqW25eaAiEgMk02nCpAcGjAZF4NzFq4k2ymQGDeGQxD1WYJqPatNeTDYdx00AoGwZiybRqCAlE5ZiDjI/TtOyLzHu14plZnugjbJ4L+hLyoQQlNLdWsHmRDhhFgomkOYyLMybuEgQCEhuaTSoDVDCdqN/UaOyhExVRjA3DDKXW3FmJJNZFkuvGGSJcByOZDQaFcrVTCllKJekIP1he6g9Zx7Z8Y/8ZO2HfjQlnnGKOjPMGIvRNE0NlVxSCpCmhktKuQFiwJA0M5ZglDC8XVUQQnLjNgBwzvN1OAxDLoXgQhutlNY6llJyLpXSnPM0TVEby7aBQJJkAKzXG/i+77q2UoYxQgkD1J7npWkspRwMerZt01x7pZXRmhFKKQWtgfM0GjFHdedvfen//Rv0xtUHJsau3FxhjA2MGXZvRl7l5koaymUOTpLEhiYg4iDo+oXKMBy6ro2I2Wan5BXa6RAo6a5txlR046TTGyIRwCyLUlvS1y5fcn2v3+/Pzs45jhPH8cLCwsy+vQSAUqrREKSMkV0yOgEAQ97QtwMAAxZt7ikfe+DcpZdnqrV+ECZRWgRqy2KGpt8JHbc42hmFRkO59uaf+Sjc+ygYNJxRDsJAmmppEcsWABkAcLkruo2TVHAJu0o1JBSFRQGUASRIKKf5Z55TQXIv5p2XxDgHAIMIYBinYNAoRZkARgEhipRB4rpsEGjfZ75ffd/7fnhu/5wxUC6Xr9+8deLYwUZ97Pr163v37lU6bY5VHn7kzbYtWuPNV18587/8r799+uVzly5deuyRN3W6W5/60z/82pNf/YmPfOjll19+9eVX0lQd2nfXcJDEkdre7lLKi+VKXjBsbW29+bGHk6AvmErTvvScWq0WBonv+6NRyJjwHZdSurPTaY1NDYcBBRDcAsK6vaGQziiICsWi4zgf/93/Zgysb254nue6dr8/lDZWKpUoSrIsA4V+udyo1ZRSvF6ptg0Ouj2/VCwVivvm5sJwZDJV8guI+O1vPfuhH/7BKIjOnz937Ngxxy6MwrBabQXBcrFYD0YRNIWUFufi8OEj167dqNdfefLJr6VazZaKYRj6vr+5unLm/IU3PfJoY8xIaa2vr4+Ptbrdruu6hw8fXtvcOnXPPV/66td6vd7E5ORwOCCE5KkvlmXV6/XhcMjZbm/JGCO5PdJGKVWv17XW09PTzz77vOu6SwuLhw8ffttb3vrMM8/4Hu12duZv3Tp1992j0ahULB48cCDPccwF73n2cx6QnDd+KOVpGvt+MYoiKe2FhaVbtxaEsHy/GI4Cz/OSJBn0hvff/+DOzs6NGzeEEIhQrzcASLFYbHc6zWZTKbWz04nDsFapoM4c26ZgJqcm19fXCUGNmoIhQHSWpGlar5a1Bgp8MBjEcWzbdp6+1+/3+/3+29/+9nK5fPbs2dwbmH8U3W632+16rl0ul4vF0iOPvOnq1aue4wGSaqXWaDQuXLiQJEPG2K0bNyqVShjEU9MTzWbzpZdfPLD/4F133b28vNpqtfr9UT763NzcHGs2jSGbm5tZltCSTYHyXeeORqW4ZADK6EhrwwhlnAAgoIYooUJKyQTwNIulkGAwTSNpWYA0CmPHteFvu+3OuSgFgNXV1WgU1MqlfAFljDmOc+7cuSiKxqQVJxkAkYLb0grjCIFTZgVZr6Nj7/Dch9/zjtreQ9CPA9sJdYocOHIAqmOjrIynChz3wref41HilqphNOS2DUrR21Allm98cygDoCEGc0hL7o4mjBDCOTWEc2HZScqC0KEwadm240SJxpRW3EKrXBtwEqdDKrRORxXhllFbUVAUlMWJJZ3UGAYgEKP2YML2Pv3Lv/rD//zXD929r90ZbXb6/fa2EWJ8eiKKYkvYSgWgjIkVB5qDNwGAmV2rUw5gyJ2PymhKKGPcGE11JFjYqolTx6a7I/+101dNFqU6rhVKDmeWVkG44Xv8mSc/80sP/HPQUW97Fbwp4bAYMyIpKEWNtik0HOvKmXNP/+a/f8u//A2vM9gZjc5t9GxZK8xM3H/yocGaMoZaRDsQuJDG3eVmkXOdEGAIUgOhJtdVcGAWlSKMB0fnWlc6w2QrKbhWmiRxFJSp4WB4HjmCND8ZKOauJdhVYBs0hBJCBCFCa0dhgQkkJiXaAOMk/+oMMxqJMZi2SsXzzz7/wZ//6aLlhkqhoMQgZxQIUEqNBsrMKIKpPeLsmc76les6Ay70MFzef3gi1pioLBzEpVKlUqjrNOTcGRurJ6lMU7a/tre92f3iF776zve+vVBifoEwAUkI0gJKIYmNJaiUThKHQJhtWQAmVRGlIBhDIFoTQG5JS2tIEp2PJCilnDFgCDpT2pICkMBXvv7N1tR0pV7Z3lkTTBXq1jBZv7S8lFbVyI7dVE2WKp3eDhQt1NJXihmtKUuRIyVqOCrZIlhY56bM7GJXo/RqHmoVhMYoQojjOAqFNHw4JL6/u4RSQjjnnDIAMMYkkSKMUiCIAAaBIqOUMhb0R7bjGZ0xwUF4RFNDpVHIhQ9INTOS23EYiWIliFJmlTJUruPKiDiT44v9/v0/8tHSe98MvALg3N4kMNAguVQEMoA00Y5gBNM0i5m0UtCu5+YzSp0l3LYAjNGZkBIAtFIAxpKccS4lR0StUsYYlwJh13uftxSFELkIPoliy7aH/UG5VASAHEIquAXEYJYQKqQUAFgs+oCY7wLRGEYJEGSSmyyjXEjmQDLQQ/PIBz7S8qwkHpUbtTjOpOVRYhkQ56OPKxCeX+KSpTrpBX2v4BtAQojtugDQbW8zQl3XRQINpdFygkwtbnXvuu+B7iBaWVlZW51HrU7dfe/FS1dOnDiZe7muXr366OOP3a6e8PXBgkFghAJneYFFAUhu/LOpbJ38yMfA9ME2EI7A8iChkBiIQ5AcHAHGQKyh0oRmS40iJrM03hZu2SDPCDAgLImSeGAsSYWgRFLKmUDKjEaTqYwxonRmS5nphBCmtZZUpipT2jbAJKeAkGVGm0wwzhjJ0tSyLJMZlcSUUpVqx3FUli0urFie22qMG4DeMJHSAoTnn3/p+edf+vGP/v04Tn/jX/6rf/kbv/kXf/G5r37pedu2zp29AkQNh71jxw9lKn7twlUhrMuXbs7M7n3kTY9TIEkaHjly+PyFV1Klmo1p15GPP/aWleXtCxfmHbdkWdbyylJmcHbPnl6vJwS7ePFiEg9tYR558K7RsK8yY1lOGASCW8aYTqdXrVcHg4HreuOtSULgAx/4gRsL83/+F58dnyrNzu6dHG/9/u///vj4pDFw+PCh1dW1nW4HDQl7Pd/3KaW1akNrrNVqtpCbm5ucETo5PoGIjFDXtQkhvuukKrMscfPmzXq9Hkfp5ORkt9tVSmdaA3JCWBBElmWhIZcvXe31Ox/+8IdPHD95+vTpbz3zHaDM5iLNjGXJJMssxz175sLkxMxddx3vOP7S0lJOJZifn3ccp1wuz9+69fM/87O/8a/+g+/7jHNjjOd5W1tbxWJxe7tdqVSCUeQ4Tk54Msbs2bNne3tzaWlpbGzszJkz3W6XEDI7O7uxsZEkSb+fzMw0Fxe3qtXk0qVLH/vYx8Iw/OQnPzkzM9NoNBYWFq5eWzhx4kjuQFRK5V2iarVKKQ2CIG/8OI6zsbERRREiGmM6nU7ei0LEkydPnj59OgiCUqlcr9f37t37wgsvVCqV6enpxcVFz3MsC4wxjzzyyNWrVwGg3W7nHsZcX5VXS0mSGGOklFLK0WhQrVaHw+Hc3NxoNMqyrFKp5J2zXJi/ubl5+PDhwWBw69atiYmJLEmffvrp73z7uXvuvfvq1as5zyOfovq+H8dprk6LoiiNM7/oVavlqcnp5eXVNDVpolqt1t69c71ef31j9cSJE4wRIfjS8vzv/Jf//MH3vd+yWbHgEQKS0yiKMpMFSeh4riWFABr2Br6wJJe26yggA5XYBW/QG2aptiyLMT4+Ps64dFxbZZrL782oyqsrIaXRmjK2uLgopSQAnFACTAgJQNbW1gWXAFQhMCTGQDSKioVCkmW97qjWqI4w7UixREnJkG3CXcuKspRiRjVK4jDGVJZKRFB46bnnq56HSlFBE5XsLki3Ja8ARpPcR21gV0Oda34pMUAo01mWpKkhWLS9dGFJjlXsuAfYc0gx6oRW1Jsqyo0kGxnjCm5zRwyjsmcXGKFxEkVRwfONgUQlSJlvS8bIxtran/zmv777A++5521vrU20RpZ2RrRz7OA3v/1t4qYa00a1yLMRTzSheMdVzvIZCBikYN4wbQUw1GifEx/D2cMlh++zC+5fhdee++b5qakJi1Adxlwr3wJkcPXi6fWzLx59/7shKEDJbpSLYHQ0ClKlPctKgkCr9GCldvaJL3NjP/qxXynWG9Nj/OZKp+iwu2em7PvvO3/lslGDEiOu6bCs4wjFlKZANGEUAYwkBAlQ0EJy6hI4Oltf7fTTaMfEPRUPa82iGEYMdtVkhhAGSJGS3cYV5sOGXJWVv3GZaYcRj6EBjCgoUDRXXQOlKlM61UCbvr82f3P+3IW5x990ddBmwr59mhlKKSIQqptj4DtTY60PXr24dP7cVZUmUTa+unbLdrhL7L4Jh/12tVIgQLqd3s2b1yem5obDbG1tzWj+iT85e3P+tR/78R8E2to759vuLmfcdigAoEoty9YGCRgEZXGKoAggAmVMAtA0QUAiGGMEkArOdzsEYAjnkGk4d2brmae+UbSn0mgIGJbKMkyyRx8+fnTPI0dna5PjdYAMwiH4HhQdiAOIAwABVhWQQDKCmgc7S+A4MKTgVMBwIAbMEDAFzwPGQCkIAiiVwPOg1wPGgDGgFHatjAjGAOO7ojBKwOSpJhQYhTCCcgGGQ5ASECGNoFiBNAVKIMmAc0gSyAzYNmQJ+B5kCVAJGQVFDiQKZiYTknRGsU2H2ShtlCqgdTAMiZQxJUCIbbE4CRgxlJP2qO3Y3sbmmu8WKBhKYdgJ4jj0vEIUBUoZz3OGw6Fty263a7tWEmcGlWN7YRimKuNc2radpilBYIxwKgbDnpRSd7XJVBiNdJrZnhuGIaIGbSiBLMvyrF8pZa/Xuy3tIEoZyhmjPEe9c0YJxLXa2Ny7DkEcOlr3k4AKEaSqwAsmgnd+9BcAaGZ0plNmMwOaMQyTGBHb3Z7v+77va62NyoTkQRg5heJGu3fx+q2nn31hs90HMPtnJ31X5oak9fX1Wq3mum6v19va2GxOjoNBxli+A8nf3e0eFtwRS4lcyUhcLLSWVwYOSqswJZg0qIzKCmPjEIegE3Cdvkocq7K20rYcbukEjM6CIM4gM8LmzCcZoaY3GIGw00QHQeQ4nlaIiIwx25GDQY8xIi1OKVVKCW5pTYwSiEQIRiimcQJgcv0rAKBWlHJBGefcdZz19YVKtWoA0zS9dvM6Y2J7a6darZ89d+E//i//tlAq/YNf+vn2TgcM/tzP/n2lAQyp15u+705MtqrT5eXFNWPSOIsdy361fTYcBbmuemZqvFT29u6bdmw53pouFLzLl240G9Mf+qEfm52de+zxx7/59DdefvmFJElczytXVX84fNubH+nurFqWs721MRgMOBfBMD506BAhpRs3rimlSn5pOByurq7X6+UkSX2/UKkVG43mxctXKRDGRLPZWl9fz7IsyzIpJQEWhlEQRFmqpbAZ41EUJWFkjOGcsSiKhBCjMNi7d2+UJmmaMUJvZySnzz///MmTJx3Xb3c65UotDMP1ze3WxNRoNKrVasPhUFjyG089ffDgwdbYBOFi3He3trbCMHZdP44T1y+niTp/4eLs7Gyaqump2Vs3b87NzU1MTOzs7DSb9WefvcoYuffeg5cuXbr33nsJIZ1OJ69CGGOj0ShNlG3bBKBWrSLq69evT09Ppmlar9dLpZJOtW3bjWrtpRs3T506VStXrl69+vib7n311VenJ8b/53/1m4QQTigDsrW+8Uu/9Es3bs5/+tOfzjKYm5uanJwcHx8PwzAP75NSxnGcqw7Pnj176tSpmZkZo/TVq1cdxzl//vyb3vSmol+I49jzPNd1lVK9Xm98fDxN00G/D4jHjx2zbL/f79dqtWKxmLfNfN/PvYp507tcLvu+zxhL07RUKgGYnNSltR4fH69UKjdu3AjD8J577nn66acPHDjwkY985OLFi1euXMkXhWF/UK81m81WMIqOHT3RbreTOLGlA0AqlcrCwsK99967d+/+c+fOIaKUUggxM7P3yJET167eKBaLeWIPgK5WS5Riu7NRq1WOHd93a/7yf/u9m5Iz1+a2JVvNRrPZLNdKW53terO+urIESjcL5fFKfXVp1XKdSKleFgnPs50SY2I0Cg8eODw1PZ33Ihj7XukjAADQnK9jjAGgKysrnucppUp+IWe9BqNoGESVWl1pJJQTZmmNFtB4GArLQU677Y5fkt7szCe+8XSy85VWa8/P/w93Mckk5SQxNEMKVHJad32Y3xzdWplxi1kaU4uGYehQa3fLl4tcd+WXhhl6u46hhhBGICdepkpVHQ9BUpV97bf+S/r7zJBYU0iMrUgx0HYBrIzbkmTZcAAm8oGTIDJZbIjhjkxRIUFqiZhQrRNpTBWxEI7O/8Efnf2zz0wfu2vyyKmt7oh2Vg6MFzosTSUk6SBLwhqz8ga9AaAIDAApIgKlVClNEAjhSKlSyKiq2WLhxW95Usyvblq+DSvXJkhWS+NRd1D0CmjQoUan8WHHOvOpT8udLnOEY8Hg1s2JcsUhXFJGkSitXCHiYPSmPfsvfv7LW+ev3PWD79j/pkcOVxtoS8LFrIpV59JOe8CSjjA9B0PIMkIMANOEInCGlBli0CCDKBr4ZbtM+o8cLI/7B1c2F+cXl8hoJDXwXVQlUkQKQAkyyFtzCIQSktvEUBtDQAmgbkYVy3U1JCHcEE2R8vzLMsZoJamsc/n8k1+fe/vjRCtEFIwanSlASqkQgoF59fSLw16/4E2M77NkcU+aKGnxnZ290qKDbm9ifIZRyjm3BPn2d566fv2y43vVOgmDjDFr/4FGFK+dPfetRO+7cG44OTNuWwLACMEYJ4gmCCNChLAsIBlCluMKAajRTAp/OIh9r5ym6WDYcT3LdeVo2LZtTqnU6BgtX37hxbnZ5tzkviyJNJqJqdqjjz4KmEyNl5SAlZ5qNsspEbLgbQcZEVVi+yZNSKKQ0IQ5dsI0KepBVCzUozh1rXIYhtIuh+GQG4oEGZOpBtozptPPMiUEIWjyHC1AFEJwITRinKZGKcKYYEyDQZVvoylZ66skzYzmhGYmE7QTZ6mhRErb4gKULvmFbne1XCsP11cV0XEYVexCGmcMWLK8hkUvztKClKPB8HJiNABwYbkOMTpOIsQsSiPhWIQQCizfcGqFnIpBr1fwi8VSIYnTIBwlcSokBySZUZyLHJWhVGbbDlAShDHnfH19XSnFCLUk9x0fwFiWFQRBuVTqDwZZmiZp6nqO77tG6TgJ42CklMqyjDHWqNWTJMnbTnGcAqN54kq72y+PVZcHm7bthjuJyFiRM61i4THXdbvtkKFVsHxbCunQQdCzjD0KBiqNKpUKEzarVALAhZVlAAhHQ4OKMdbrDhKN07MHRhpGBo4fPeJQkwSjsD8sl6tra2tjY2O1anV9ff3q1autmSm8DWvYdQPkEIacEwcaKAFDuaGAAGlGvNpT33p1eXOp2mxsbm4WnRJBDaCSKHaFl2SGSYtIGupEYUwZcS0bM0AkNneMMVmaKAAUBe76UjhS2mliOBOcc2mJKArCaJRlWR4ZxxijlDPGOLGGw2GSRAYVBeI5koDp97uotCV5lmkKpNfuhGHYaDRWN1ab4/XWxNi3n31+cXFxZWUlSZJBr1eoFF0Xle5aVlSslIPBwLOd/lan0xmkSWXhxsVCuUQpFEu+XyrsbG55xUKlUGi3ty1BN9ZXF2+Ozp87DUYxRvyCQ4AGw3SsORWEMfv3/37f/j29Ye/mzesH9u2rVRvTE+O9Xs/3Cr3BkBJOCNFaCyGuXbs2MTFRKhUG/X673c63arVq4799/Pda05NHjxzb2l7tDft/+Pxfzc012p1+nKjRcBCFGeWk2axyLobDoFj0AACMGvZDwS3f93neYhFCMEK3trZsz223t23Xyf8BxlgQR1tbW83xFmPs8rWr1Wp9ds/0sWPHnn766cFgwBjbv3//6urquXPnZmdnVZZtrO9QLrRSUawIlQZNfazV7fYvvHZp/759s7NzN67djOOYMtbpdPbs23vy5MmrV69+4L3vW1hY2tzcTDMFALOzsysrK5blKKXylLE0ScbHx6Mofeihh27evH7//fe3Wq1XXnnl137t1373d393MBi4rru2tuZ53uHDhz3Pu/vuu5eXlx944KFnnnmmVqt1Op1KpfLXf/X5f/7/+pfj4+OnT5++dOnSpUuXcvxVfoHf2dmpVqtKqUajkXv9KpWKWyiWSqXl5WVK6cTExLFjx77z3LMAUKvVTp8+LaX0PO/AgQO5V3E0Gt28tSSEWFtba7VaURTlW6s4jimltm0jIqW00WhsbW3lzsThsL+9vXPs2NHhcHjx4sVyuZy/pOeeey4IAkLIlStXGo0GIl6+fHk4HEppJ0lWLBY9z2u3277vp2nabrdLlXIURVrrW7duTU/PPvzww3ndXPBL165dQ0Ny9RUhZHt7W+kUAEZB74H779nZ2Zpf6NVqFaPilbUNgRqMXna9Awf27T+4b3tnIwp3Xn7lpclanY1PPv+1Lw863f2HDxdqlfM3rrrV2pHj965vdJQyb3vb29DoXXP333FDRGM0FyIYhd1ut16pa4VCCK0yyfjOzo4QolSsREkqhGBcGmMIo460w0AXa0VuMI6DfpqVJ+esuqtTUvLLg6CfmthhghLOgJFME9sbPP+qGKXM0sYoZhi7naeRd6oMeZ29SPMUXAQEkhLQhOZUPSpooiI0uuSWktHQSoHLLIzjolUJIUUqabGSmBgpTQn3qF82IJIIADTNc/0MNwoJJFkqGKeYFjjt9zb3WA4myfLXv3HlW88GwlVWoVAqjHSIoIU0riNpmif2ECRACaFIEMHQXVg/o3mRShAN1ViWcmP5+pf+8IqhPEjCct26a7xugti3XYI0RVCDvm/zMqHDpcUv/9ZvoWCGpBUhG5zHcWxxJ+gNQRpJJTXYW1o6Wm5sra5/8bd+a/j7/7U6u6dWnIhXwm4nGHH0SxbJRgWpbWGoykgeEkOZQQpaUKMYUQCkVSxsDNtf/pPfWe4GzCkx1y7rlKOSGpkBRDSgDUEgxEagQBTuEl9zG9edYHCh0dLGyowDxqDRDJEYgoRlyqGUUyBKQRhOFApXz56HQeBYVmgUYdwYBZRojbbtYBZ98YnPj7fqpepOGOpyeRy5GESZ5RPOsDVdmp8/Uyr4oI3jOA89cuLt73loOBz6xQLnvN1uSy6yLFtaWtzYvD4x0VpYuBQEwySNCMFc0let1tGwKIosmxFiCCFBOJTCRqRpYlynQAjjnOdJPjs7m4ZklmvHUVIsNAadeGps9p987KcZlfVGqT9ajFUQjDbiKO1eW0mTqFEpXXnqNbfg7oz6KD2nWIiiqOT7zXK10+lEoJMsLnn2aNhzfScZpQVRcW1vdWvNdu1CodAfDozSXIoctmxZ1p0+TX72p2maJAnn4g7HPOe957WpbcuNjY1yuTwcDqXFK5XKYDDgQjApoijpbO8YpTFTFEgYB0EccFvMzM0sLCzYwrap6HcHaIgtZXdn4+4TdxlCtAFFYae9ZVFe8D0DOkoTpXW/Pxwfaw0Gg/WdrT1ze4NeuLGxAQBKqU6nMz09PTk5mTf1syw7fOxono3muu7GxkaaqFqzef/9909MTL3jHW+zhXziiSe+8Y0nR8HQd72dna1ut/umN73p4Ycf3tnZuXzxtemZycXF+UuXLv7iz//sgX37b926NTs988UvfvHcuXP33HNPt98LgqhSq47iOMkyJmRtqrmz2fuzv/gDjo4vnJl67cThvUtr8+1eezBKGAiJ0nXtct1fXLk5t292Zmp66dZ8s94sV2peoQKUbu/sZFmWZkmeCTFWHyv7xUG/fWD/3NTMnmvXrxSl8CxZq9Xa7XYOSvR933Xda9euPfrWNzOW78wJpbdJn68z1lWOZAdDgBDknDBIM/qbv/m/Hjt5sjscuFIMg4FXLNi2vbPdyzJ98OD+MBwpTNrtnSzLLMY9YdWKZaXU+tZWZqhbqU/PHW9OzKSJYUy0d3qc89EorFRKcRxKS0RRlGVJjopEREp5uVja2toYjvpZHBmd+a7LBYwGPYLgWPLMmdOe402OTwx6Pa0Mt8TG9jITTKEZGxvTGm3b5vU649jvdQwYycX22rpf8Po7m1xanmeFQd/37GFvBwj0OxvA2O2gSuCWpdIYALxSIQkjZZAw1u8GQMCRhY2NDYOEUnjx5ZeAaL/gDoLB3r17y9XK9UsXplr1Vqvc7Q+atSYhYFmi1+soVddaJ0nS7/cdx8my7NLV68eOHw+S9KWXXqmNlRGzicmq1rC8tC6l9P2y6xY3traVMkJYlqV8z0+SRHKeZ8MgaA4AlmX1er2ceDY1OxXH4cXLlxqNhiGQpsrzi73haBQnP/ezP/u5z392Y2PjzLnTrVaz2azfun4jzzOpVqtpqnZ2OoVSiXOBBIxBRvkoiCxJx8cb/d5gY2OrUqredfJ4vdnoD0b79+9dX1+/efPmiRMnvvXtZxuNxvvf/97PfvavxicmldHtdrvRaCwuLgshorCX0x/W19dPnDjmum4uEr98+fIrr5x+4L7TxYJ35fJlxlgSx9tbW8VicXlpqVgshkGwtbH50R//yBNPPDHRGg+CIEzTj33sY7/+P/4PH/3oR3/nd35ncXHRGDMcDh3HSZKkUChEURTHcT4ldBzn+vXrYDBnbuVvs1qtci6uXLkSBKHjOL7vLywsAMADDzxw9uxZRGw2m4yxvBPW7XZt256bm9ve3o6iKC+WR6MRY0wpVSqVgiCwbffee++bnJy8evWqlKNSqdJoNCilcZxGUYJIhsNge7s9NzdXLJbjOAVDPK8wGoVhGAohLMsqFovVavXKtatRFDWbTUJIvsMYDAaTE9M7O52jR49vbGyUSpXNzc0wHNm2TSgxJpWWd+99JwsF9+tPfvXSlTNHDx2amWp4QliMhsGQYhwOdwTNmvXCW9/80Mb8QtTfnp2oHH3Lw2fOX1hf2nnkwbsn9h48c+FmFEeWtItFn1CKBrM0kdL5W6urO4+XlpZ2t0FAcqcMpTSvF4UQGsFQxoTUaGzbShJdrtZr5VK3HSZRunhroV6dZMNs1A2inVGl4oVpQinLUkgzhahAm2svvFImnBoDlBqtpRBoAHY7VbsdrDfgBykAIKEZo5oQTimBTFFjQNvUSjGgVFMAh2SuQ7NoRJnMXKaIptwmIDkxaAjVVDKOjCbGEJ04jIPWJNFl4SVpJBySqKFkBtKkyPzGRKVDRNeQzJHr2cgqyLbJCCNGaUF4Xl3lICIOROep86A5BU5opjIERghhCDYx4yW7xYUh1ICjaDzaWbFp2RgrMZpQXfRdloRl5C3Pn3VLBlChNioWwqhEWZxZnq8gypTSFPyCy5O4aLIHZyc3hm21vJTFi2WrzAFrJZ85mGYjmmhQKYICooAqTRhDAKMYyYAGDEUaqhqVOtiaAm0yhbEbUmqUsRA4UoqABDQgyzlYBimlhgDcTgjITxJmDDAitbG0ySimFC2ADJAaIzK0BKFoOAGWJWXbx3Zv/uyZxuMPDAdd4ATAMM7jJGOEZhq+8bVnHnr4Xk0WBkEgncq+A0ePHDh+6+b1erVw/cqlM6e/8+yz37zv1N2PPvr4V755XSmcnpo7evTwhddOLy5dz7e2rUbrxo1bjzzy6Ic+9IOf+eyfK5Vdvnb59OmzH/uVf7y2Pr+6tNzp7jiOMzU1NRgM+v2+UrlrBCzLSpIobySvrq5WKpWT95zstMMgCOa/9bWK13h+O755c/Guu+569uVvzB6qSluMRiKNCWbqF37up1679ty1q6+99/0f2txZwrT92qU1gvbU2NRWFL744vMTs+OVVv1Cr/PYmx9duHkhCQIWa98pLq9vSNfzfb836Lu2U2vUc5FDTvfJI8U8xy2VSpZlIWKSKEq5EAwYy+O5GKfcskY9vbOwAPVqvouGYZ0QlL4/2BrEcUy18RwnU1mlVL5+dR3StOBUl69d2O61naJvFK4urh6c2RuMyHAUrG5tRPFwc3PN9xxCUGkyOTm5s9MeazQhTlavXV6+eundH/jA2fPn/EJxZ327XquNRqNRFLiOZVtiMOjNzc1GUfCtb32r3d5GRNd1o9Hwwtkz03tmi6psubbnOQb1aDTUWs3t3bOystSo1RlHRvClF54rF/2PfvTHb16//Fu/9b+/811vr1QLTz751XqtIjiEox6YtL293utsbbd3+sMR5RgrTTgbq48NNrt6Piq1xZ6jU91Re2aqGoSdcsUbhm3PxVazlgbpjfmbympN75+wHb2xeYOY9N67j+3bfziMsxs35xPPQwJJHA4620XLnm01FxeWLdvfWZ53C7UD01M6UwxIMBx4njcaDYIgoJROT09fv3VzeXl5z559OSkwX6c0AqVgKKVgAKjJu/DCGKABVTYVP/PTv/gHv/cJ7haQWgyySqVikDm+F6aJW7C9mkyBQmxPtvZZ1AKVFRzLc/nGxoZfKE3vPzq594j0mt1uUK4VVKajteF4rXXg0OTW9oZbMJ7nhFEwHA6FELloR2s9PTnFLT8cDdI0DkZ9wYjriFKxtr25SSh933t/6OzpM//8X/yr9vbOYDB697vf+Y53v+XYiaNZlqWpopRmWRKGYZYl441Kp991pOXa9WgUFQsli1s7O1uMgu3ZWpMchBkl8XDQd4sFlcSMGYWKMhb0B7t8NkMAQEqBBIAiJ0ybDIySroiTJNna2t7e3jMze/jIkWDQpYQ3G2MIOopi1/L37JmRkicpApjWeHMwGDAgFqfXrl0r1eq5DtsYVfTKzXozTpJCobC+takUSml32j3HcdCQXq+HiGDbudFEqZRmSgspHcdFApTL1dX1ianp0WikAaWUnPNCoRDFcRAEK6urx46eUEpNTLQ2Nzc9z5uYmIjjOE1TYwyAyWlGw+Egb4mlaUoJyxkHxWJxc3NzbW0tSZK9e/d2OjthGE5MTHQ6ne3t9jve8Y4zZ84dOHBoenq61+tRIK7rDgYDQoiUMo9bppSGYdjp9Obm5vr9/lij0eu098xMvvryK/lW7LHHHgOAQqFAKdXGvPzKmVEQvfDSiy+98vLk5OSP//iPjwaDSqnsu/Yn/vgPR4Ph8eNHhRBewXc8FwnkR6XUnUxAznm9Xr9y5era2trs7OyDDz4IADs7O51Op9Fo5MiGXncghX3j+q0vf/nLruvalisEi+M4z70xxjz++OMPPvhgo9HIVVwAkCRJu922LOvw4cOO4xSLRc5pLiObmZnZt29fXp/Nzs4ePXrUdV3XdW3b7nQ6+UBNWla32wWARmOMIPQ63YLvAwBBqFQqlFJgFChVxtSbzXzuub6+nrsEkiTJhfx5b3xjY+2P//gPPvPZTx4+MveLv/ATJ07un51rlipybLzs+TLOhivrK8tryxevXu73+zvtbq83uPTa5dMvnz54YJ822dr68ue+8JejcJQD9x3HNVojorSsv6uDlVczaODmzZucUCGY41oEjSVlroFzXV9rtKTDucjZEwhQrZb3H9y3sbF+89Z1W8iiLFBNXNdVKk2DwJFCpSpJMsOI7VoWo6Chu77lCUdQwYFBhhQZEqopaHKbdYNAIO+kEACDt8VYAEaD1hSA0QwBJA3TyLWFI3gWZVmUUYMctCsozSIXM8dEPoCVppZRDJBQZjkuUKbQAIDrupIyYpAxpoxxHMe1pU7TLBhBMhQqsrKgCFkRUzeOSH9Q0MbT2tKaErNbAlIChOXT1bzNoNAY0IwxQ8AYZeIQkxFNhjQJRZYUBHMYStCSmZJrYZIwQJ3EJg5IHLA4tsLIQ2IyJW0RxFE+f5RSUkqzJEnSoOjJ0dpqg9AJxmYcUWXpdNmSQRs7awXIbJXZlHIg+SCVgCKggWRAMgqKgeKgpcmsNKpbWCKRq4a+jj2dSdQMczsgUgQ0gKhxN+wEDTFIjSEaiKEAjBCS0yrRcNQWGttoG41E4yBaqFErSpCgIVnmG7z0/Au+J4nRxBAASpnQWufOsFKxlqXwjaeeaXeHgyB47oXnby4tjOKoO+iWa/4995546OFTDz58l+/DoYNTcdRu1P3Dh2anZ+vSxoceOVlveoeO7Hnb2x/7+pNffM+73/67H/+459q2kJ7nIYGzZ89evnK+4Fu+ZyOqdnvn2LHD01MTwah3//3HazWnWrUpjcfGCnv3TuzdP/nlr/z1Ky+/IDlTWby6Ot/rre3d2+z0Fj/0oXf/g1/4e2Ot6v33nmA0m5isf/Ppr/2n3/7P41OtCxfOjYb9VrXcrPiHZqfDfhdV8o9++Rcnm9Wwv+NZnIPeMz3RqPq2ZYSMp6aqM1PVmclaveoKobKkDyZ0bWAkq1WcA/smDx+cmZ2q1ytOyedlj7fqBV8CVbGEtOzKSkFaVKdBJ+htFmwoe2L/TKtZdrOgKzALutsSUkcYCenO5lIS95aXrs5Mj+2dHcckTINBvVIsl7x9+2YfePCeRrO8tb3ammwG0ahY9IAoTtXEZDNJg+GoPz091dnZvn710p6ZyVq18uSTTzabzSgIfc+L43jPnj3vfve7JyfHAUwQDhcWb1ZrpSNHDzaa1bFWw5L8+LEjB/bvnZ6YnJ5qjXr9T/7pp37ogz/8Iz/y409/45ue5125cgUhW1i4dfDgwWKx/PRTzzz19W++/70fePfb3xEHo1azfvbMq5/+1CcpQq/fXVyYv+vkiSgOLVtSCnESlor+XXfddeTwwVdeeFEN47JwsyAsOvLyxQura8sLCwu9Xk/peHVt3vXZnrlJ22VpFq2uLPmufPCBe2YmWku3bnmObI010ji0LZHFiZR2PpQsFotSsLJXCAddanS+2jMpfN9XWq+urpZKJQJGKbWyuATE3GYJ5cKKXQhWBjS7jV3VAAqAM6EQpC+OHj2+MD+fK5/SNN3a2Nre2KyWi8N+b37+pl8stCanet3hoB92tvtrK6vzt5a3u4N6a646cWh5M1xe6fil5ihS5y5eO3T0Ltsrr25uGSRK43AYDAaDMBxZljBGpWkcx2GUhN1+r9PvBXESJ6o/jLq9Ua8/SpOMENbrDpQyf/j/+6NKpVYslj76kz9Fpd0Pot4oBMp6gyAKU0blxsZOvxcVnLIUXqVYq1abjUrTtpxWc7xSKXHO6rXq2FgzyzLfdef27rWFLJfLjLFqrSaE8Hzf8TwhLMo55xYaFscJE1aaJlopJmUapypJszg9ffr02uryjWs3QZM4SDbXt4Tl2K5PJL9w8dJffeGvpWWnqUpiVfBLxWJJKdNsNcI4YJJlWgnLZoy1O50wDM+cORPHab/fT+Is1zXl1jHHcXLZHGOEMUbrjbFMa8al5bqIoJSeGJ/8wAd+wOIWo4ISnkSpY9tpkmxubKAxM1OzOjPdbj93+yOi1plSaalUKBb9za31IBx2Om1jNKDRKsvSeHZ6plapGGPWN1bb7W3GyPjE2ObW+tjYWBAE165dq1brhULx/Jlzd504ZUuHEd5qjjdqzSSKdaZ63W6jXr95Y35yYrrX7vU7/fe8611PfOELnfZ2qegbowGg1WgmYfSed79vbXUjilPHLxRKZccruH5xYWlla2vr1o0bc7N7tlbW6sUy13px/mazUVMmC5MwA8UdYTmORvQLRUKZ0mbvvv1Xrl67Nb8wPjFlOc7ps2fm9u31i54B3W7vMMZs21aZiZK02Rqv1hvagOcXM63AIKeEAva7nUqlNBoNhC0GwSAzWWayHKSuMxWHEWozOT7h2hYBs7292W5vh+EoDEdxHOdewmKxmJdK0rYJY4YYJCQzOklTIUSWpEYpx7LSKC6XSpOTk+Vy2SuUKBNIwACmShPOUp0SThKVCduyHJcwbjl+kmkAyhhrdzYB0vFW0S/S8QnHL2hpJV4B7CKvTTYCUO0o/psnn9nupY7f9IvjE1OHMiPOnL964Ojx89evpQi25yHigQMHACCfLwBSrfKgiTdkTiHuTiIYIRRuXrtZq1eIVgVHMmoci8VxrJTx3ILRxHF8Szqu6wsmGcJdx4+cf+3lMxdfrk40MgqCcU5NpLox9kdpL8lSzj3CHCBEm6TkWLC1tb6+adsOUZQZZhNbp1pRFlNMiFZEcUCLkl0OllaI2oBG1MJklsksBGGApcwjrk7Q5pbJADSXssJ4STslxTzUtq3sUsYainnDoA7ExcznzJISkAsuBWXSsTNUSgCxbUWksMqJslCWM68Q2paWNrUlkQQgYUlSpnzcLZWRleOwYlKXUy6ZFiJlHCingjMpqMU0NdKRTFAiCAqgFuecU8Ip4Yzmb8vWWgPJJE+IDrgxoA24ViRJyFQqtOJaoxKUoTZcgEFFKdUaBXDCKFo00LFlOSbRxhiNRhGdREERadlQK1GuRpEpqUGAoIZbWgjCAcBQhtTRRgJAjlpEpQlogYmlR7YJLZMI1JxSDlwoxvOB7W7ws1FEa9AEDUXDAHMQtoEMQTFUls6sNLHT2FWp1IlEAzpN05hJgiqe8QqLL74Kg7Rie1mi0LAgiBhjSseFotNqjfd74X//j//F+NiBXlc99uh73vbO9xnCn33xlRN3P/hXX/jKieP3UbSDXjjdaD1w96kzr7z44gvPTbYmz5++dPnS/GiovvqVp25cuyWofXDPkQ+864dmJg51t+OC1/jq177z9W9+p1JrjrUmCKWrG+v3P3T/8tpqfzAIw/DC+cs7W51Kqea6frvd3dzeane7R48e83mhvz4cq7fGW5NjU+MgYBQFV6/f+Myff2WsPLu9tvWut73lsTc99O53vevkiVObm0PLKp0/f+2pb74cBLrd6yYmRotvDHpaWrHCydbkxQuXKFLG5ezBA8S1+uEg1enC8iISWNtYX1ldn5qedVw/COOddjcM4+Xl1ZwXo7I0CoI8ryLNMsrEcBSGUbKxuU0otxy7Wq8pow2iNqY/GJ4999rS8lp3FHqVCnDeHGv1gmBxY6MzGrWHQ6tYzJQZdgcYZB61ov5w2O9PTk9Uyp5js+2dzUOHjjiFKuNurd7c3Np65fSrRNKDJ49XJyb2Hz0yNT29d8+cTtLlpfUzL5/71jPPfeYvP/fMt76zsbUpBLdtiajf8553MQqubX/gfe+tlSucUKKVRYhOYt8qTY/tm2rNHTxwvNcN9u8/ePLu49VaaXlpfWutt7a89cTnv7p8a/UD7/qBcBCmYSyYFFTs2bP33Nnzqcocx7Ft2ensZFmqMxUH4fL8wrAzPHXq1GvLl9zJgkaVxZljecEoy1IIRmkUGtcpI2GNRmN9YXn15iI3Vsmv37h28xvfeNLzndXlJVtwQkgUJoSJVBO7WOtFWcZ4oHQKQLmYX1ysNep+paQJDKKg2Wx2OjvGKClFs1o5f/pVMCAES9OUcWrYbqAPA2BAGTAGIrctSAAbQGoDBH7mF//+9uZKueioNKEGa2WvUfbKtgeRivtJf7vv+z5hOIo6jVZJWHR9Z6c5dVBWpm9tpeWpY3sPndJE3lhYnprbm6DuhUPCIExGlCqKcTxsVwpc0mA0WAbSF3aUZL1MjVzfjpIwUVmYpqkCAMo554TubG9Wy6X/+O//3Qff9/4f/5EfLRQK1YkGeNIp+UaQZqsxMzNz6tSpf/pP/undd909PTlj226SJISgNqkUlHFMkswAFIqlVCkuLAMghCwWS7btlUpVYbmVWrNQKhdKlXqj0RgbL1VafrHh+TXHLfrlernesmzPL9YmpvccPHBEpdlYvSEIxUz5bsl1St1hMEzi1GC9NZ5k2itURiPVHybLSxtJphUA4bRULSDVVIooi0dJMIqHQRzWxxpZliDi7QhgDkB9v2gMKGOAUsolEkbXNjcGo3C70+60e0mczS8sfepTn7p08bLneXEY3sEmGWPW19dv3LgxNjbW7w8ppZ1Or1Ao5Nv0fr+vlCIEm80655QQTJIoCALLEnEcX7t2bf/+fZZltdvtixcvOo7TbDbzfvXx43fdvHnzxo0bR44cmb+1KCi75577hsNgeXn51KlTzWYzB3tOTU0dPHhoa2sbEV955RUw6PkOqsy1JGOs0+l0u92nnnqq1WqdOnVKKePYXmti3HYdv1jI+z1f+8pXfdc7sHdft71z6MDBUtGfnZ11XXs0Ghw7dmxyerpYLnHO8/SYU6dOVavVHO0qhJBSrqysLi0tzc7OpmnqeZ7WqtcddLvd/fsO1mvNLMuyTF+4cEFrnWWZ67oAsLGxMTc3l+v09+zZk7MYbNsejUYTExO5qp0xEgSB1tqyhO+7jLHNzc1ut7u2tpY7CvN5X06up5QG4TDvGBNCOOdgUKWZ1tp13Vq16rpuqVQql8vCtpgUhBBltG1LyxK3sRfNqamZWq1mDMRx6nne8vKm7/vb29svvPACY2z/wQODMFzZakuvdPXWSmTYZjchdvXZV67cWhk8//LVDP3UuBevr95cbi9vDBLDC8VqpVydnJzOFeRaIwAw/sbgizs3AwA6g5WljdFoRIFIyQEMoeC6bqfToVwqZYrlUu4MSMKgVCrce+qez3/+82fOvlSpl4RjK2P6/UGlXI6TgaEpUgRKEAmhDIgJRyMGJFhciMNRLjfRCrXWVHAFhlpMehaTwqBK40RrTSmhnBFGFUdNDRBFASk1nDLJOaeMU5r/CmRZpjQB7hhCqeQWcwRQF2iJ0SIFyyS+xRhRhIDl2K7vyqIjCzYrWMxnomzJkitLPnUtlFK7FrgWdwRlJAyGVc93gVS4TYex7g7KXLhgGGouGXMssAVKRoUknBlKDKfUEsyWzJbUEkRyJjihOXubUGQMhBBCWpRhSlXMjSEa4jiOslSDphTy6FeAXadiDrwGswtKUAQ1BYK7FPucDUtRSdS20bbRErUEyoESDaARNYI2u9nMyAAoggHMAaIpNRnolKtEmJiblBnFtM5zPKhBY5RGrUFrVHiHpo2oUSFqQjEvwGxjHK1do1ytHJ0JjZgkEqggJE5TCuAToru9nUtXXMKNQSktISxGaJrGURh4nnffvQ/cuDF/5PDJH/jghwuFyl/+5WepkG9+y9vjRIVBohXNYlMt1xvVxpseeOiX/8EvCkb/4s//4uGHH1EZcmYdP3Z3a2xiemK6Xq3//Z/6masXr3/nOy8cPHB8NAynpmb27dsnpUy1SpKk0+v2h70Lr52jnMVxfJtHZYQQR44dQ9C9Xs+VjmBie3NnFAy22usn7zk+OdPat2+f1vDCc69UyuUXnn/2ya995amnnup0+mGQFfzy8WMnhfDiyHz2c59/7dLFYq1y9uKFV8+erdXHFheXUevW2HijMX5rcUnY9vTszKOPPXbsxPG77777oz/xU4eOHF5ZWzdAKKVZpqWwtdY3btyI49gYU61WEdHz/UKhJCzb8VwmRaFcmpyZlo61vrXe7rUznSqjx8ZbDz744F0nT95198mFpSWv6O90O8LiR44dXlpbdYuFtfX1RmPswN4DnuUu3LiZBGGpVJqcGmcc253NarUax3Ga6U63X6s1PvrRn7znnrsPHjrUD0aFankUR0iJkGw4HGZxcvTosWPHjo1PjB06fGA06s/MTP3NF/+6199ZWLy1ubm+tbH2yksv/+mffEKl2hLywpkzrrT2z8550vWkW/BKp07e9eCD93e73ZmZmV6vNzk13poYX1lZ+ou/+NSTX/9SrVLqd7oP3Hvfm9/85tFoNBwOC4XCKAoHwcjx3GazefT4sdXV1fW1zYWFpctXr7zz/e+8fONyb9hLU4WGTE/M+nbhfe/+4Fsff8fx4yfPnj0fDkeH9h186N4H90zNLFyf55w/+uijR48enpiYmJqacl2XAkhpcSk1ogJQAAphFIWNRsOyrCeffLJarRYKBaVSBSqIwn6v26jXfd8bDQbri/OAIKVM0gRyjMbr6FVKbkcWEQSqDWgFFB5/26N75qYW529aQuSTpW63u3hrniMtup5vO93tDWJiRlVv1GkPBodOnNLC92rTdz/wuF9qdvuDs2fOFUtlKeUg6FNmlI5dW0iqB50tFQ8rnm2SocXSks90OrSFyeJRZ2tTEMJg108WhqGUMgiHBd9tNetf/NITzzzzzX/zb/7NTrtdKhRd27KktIQkCMPh8NaN+ZdefGU4GmmDtuuVKrVyrVoolyzfFo5dKBb9YllpUihVHMezHE9lEKeKUYtyKaUrhMWYBQCpNnGSITANzCkUCGduwWdSVOvNZnOsVqlXKpV77j71yksvJ0lkOW6hWI5itdMdJKl56dWz127NX705/+xzL5+/eG1zp2+odeyuU+97/7t7g76UcnJyMo5jIazBoAdgKAODKgcaC8lc181lP3mmy+6lR2tjDKecGcAkS1OVMcFd111fXz164jjnfGFp2bYtKaUxwKgYDAb5rOr48eNbW1vGGEeK2dnZ9fX1nB3qOE65Vl1ZWSGUG2PSNHUci3N++fLlt73lzevr6xfOn43jeKfbAcpr1cbCwsKeffuLxeIrL718/PjxeqM6GPamJmeatWoSRt/65tMPP/zwc889p5TyPO/Q/gOf/vRnHnjwHq11mqp7Tt33Gjvb7w9m5/Ztbm7V63Wl1Cf+6I8OHDo0MTHRHw4nJiaCIBgNhq5tM8YmJydv3Ljx8MMPX791vVgsHti7DzjbOzd3/tLFjY2NsbGx9fbK6tqy7/h7ZmeOHzv25S9/udPe9j2nVm20O8H4+LhSan193RjT7XbHxsYsyxoMBoPBIDf3aa0dx7pw/rV6rXr06NG8bOr3+6PRKM7SI0eOPPvss67rOgXHsqycCpFH8VBK/XzGR4jrugsLC4VC6ejRo+p2eDPnXCmVK5ZyJL8xZjDolQo+YwwR4zjOzaJhEttc5v5Ezjka1Dpnf5L8appPJOM4Hg2D6uzkwvzVD/3QD7397W9tt1c9p379+urc3L7pufuWVrY2V4fPv3yLCMsQSaW3vrqzhL3ZeuvyQru7sz02OfnN71xeH2VOJX36qeePHD68Z3Y/ADNGScuCPDuP0e8rsCgAYQIWFhby1KO8UkQDmdaj0cigqpQqQZx4np1mkbTI/gNzz3zjqWvXrh05cmQUjeI4TdOUAlOpJoShIXnsNyGEC5FnpABnG7fmQaeUojIamTGoDSUaMIszrdAG5jDGhUgxS5XiQmgAAJL/PQCYq5UBwCBSwoXkknJE1AY1JNJxCKNKgGWoIYYw4lIhGLEF9yT1me1QZFlCjeCMxHEoXElVyhiAIVQJzoVtKBpGqGBRSrkglAG3h3E2W2lyiqPuOhfUYdKiRCBKxBx3kX+HhBADqNIsSTJEQxnlhBLUBCgS0Frvpn8Yw9AYpS1CKaFgKCJywqgmiOJOYM2dIwIQJIgaEQgh+LpNwRCl6G292hv+nIFc9UAJxdvBIjkQEtAgIUBUnjlCDAJFzLuFhgMSgv8HYf8dbVl6lvei7xdmniuHnXOqnKu7OndLLamRkFqJIBElnK9tDGfYx8cY23AAA+YCtu/BYCQENgYThCSQuqXuVudQqau6cu2qnfNae+WZ5/zC/WPuKgmw712jxh679qi1dq01w/d+z/u8vwcRwEIikEgiQALjPUAhuhemzEEiISmXOhZCIpKma2AAhAhgEXNMiUZABCFWdR0pzGkt3bz9wMkjuz3n3lQiJQAEk8uXL+maWR4c9jxn/9EjccLzpfzO1qoEUa/XKpVKp9Np7Ww6nXI+k5FSBnFMADWb7ZHRccBB6nVdXV6ZGp3sdLo///P/7sK7l37g+7/fDf2n3/fkf/rPv74yM1wtFzKZTKvViqJgZGRII7hSKeVzuSAIbt++lcll0/uvoVuCI6/nmRk1X7QLhUK7bTRadT/01jeDan+lXKmYplmtVlkiLDMzPDRaLBbr9fr6+vqP/MiPfPH3vvD444+fPHW80+n0em4+V0w3vQ8++LHLl69YlrF//0HHcTCgv/zLr1cqlUajOTI6bpq2qaN0Tqjb7XY6ncHBQV2hAGAauuv7XAjOEx6FURLmcjnOcBj6td0dLlkmZwshgjigGhVIbu1s+mFY6hQq1dJOfRtTXCmWe71euVJstRuqRqXkrttLzQxJEqU7arfn9fcP1muNVqv1yCOPKopyZ+HO888/3+22JycnN9fWe+3e5ORUpVj68z/5007b2bfv0ImTRw3buHLF+8AHn3zllRcXF25/8hMfa7fbt2/fFix5+MmnVpfXDhw4cOzwiaWlpZ3t7dXlpVy2qiiyUu4/tH//neUri0u3O71uoVA8cGR2YWFJ0DhbNa/ePW8U2Ic/8BHf9RRF/epXvkwVZd++fRMzk1LKd9+9EIZhLl9Udd3O5d+9fGlxafXk6YeiMCwV8iqlcRg9+uCDgyPDv/Eff32rtj0yOnT79s2JiTHDsMbHRpIwqNe2BeeH9h/Y3W16wVU7U2AcCCFRlCAEcRwbhhHHcafTGR+d6HQ6jtPNZrOO57/xxhtPPPZor9PCGOdyuZWVlUKhkM1kNgGuX78+MD6RXqno/2f8a+oXTAk43/d93/fFL35xbm7uzsJCJpdnIHQ7I3iyvb5qUHjs1AeKKl5cXl9e26wOTXlCmz1yIt83ttPpWLrlu04Sen2lcYFEFEUKwXEUxIgjkIHrDPdV4sBhia8rqLO7Y6iGJiFLqeO1FF1gznGSMOCIMycIKqVcr9tKePTbX/wdlgjTzpTKBYUL7HHGBEVYVSkgHLCw02NU0wlFBKuIYEBSMEakqiKqqGY2a0sOEonQjyQStpmpUOS7gUQCIZKGiSRJxJjgICPGDEIMw2AsIRizOMpYhqZQp9vxe92Zqclz77y1ppDTD59ZXF8NJbOV7I3rd6anZ3/8x3+8kC8RQjAmxUpZSlmoVD75mR/cd2A/Anzy2GmNGkHg1wSoKg2CKA0gSZdgQNw0dSEE7KnvkOogmqZhRVHCJDYMg2pqGIa6ZVrZjOu6w8PDqQs7NX+kU3UAUK/XNU1Ln7yzs5MmzNwv3yillmWlpQDG2HV9VdVtO/v662889NBDhm7t7NTv3l1ECPX19dm2vb29PTc3V6/XFxYWyuUyxnhjYyOtOW7evNVfqT7zzDO7u7sptH14eA+psLS0JCVMTU2FYdjr9YaGhvr7+w3DcBwn8DxNUdPucDabLZfLc3Mzd+7cfeyJxx9/8okbN64dPHgwDMONjY1UcCKASoViFIRCiP5K1dD0qampWzduBIFfrVYxxlEcMMYQgvS33LhxI5vNapq+f//+z33uJ4Ig2NnZMU2zWCx2Op3+gb5Ummq32ymGfn19/dKlS2+++ebg4GCat5NOO6YHhnOu6zpjzPM8Qki1Wh0eHs5ms6VSKZfLpapV6nDknKcVSZoh3ev1ACDdIodhmNLh0zoMANI6mlKaksMwxopCCCEYQ5pII4QIggiwamdKrhO124HrSQn27m78jW+9/WdfefGvnn/DD0mnJxxf9npMM0uCWJ1QBEKNsFHvJljLY5p3PfT6G2ctM4uJyhKOELnfEPzf3wqgtr1lGlp6y0gBu2EYxzGTUiY8zmQNLiLO/IHByp/+zz/8nd/5L0KypaWllLDPuUzzi5xeIAQgRHRdFUL4npsksaGrwOXu8rKJEZZJwkKiYKJgIYSCwFSVnGGZqiYliuOYCcBESYQUcu9i2at6QTKRCCyJSqhBFF1RLcXMWdlyNlvKqgbVDZrJ6gN95XLB1lSEUcKSkCpCtxU9oxGTYEsxS1m7L6eXLLVg4ZzJTQKWQnOGmjP1vK1mVKIT01SL+YylU1slFoWRYn6kr6KrxMrZmZKtWBrWqZI11UKGZHWrWqQZk+uUZsxcf191bLg40G8VC2rW1LOmWciYOVsxNWqomqmrhm5oukIpQVgllGKiEqoCFgmTUt6Lndur29JC6l427XdNgKK9n2AJSKYh2XsQMQGYS8QBuJCJBCYhufdHSLQX+MiF4BwxQAxASEg4Yul0uYS9nJP0X2LBkOQgGRJcCi4TLriQAIhIrDGsMdAYaEwoAogUqpSKlJqUVKbzcFwBaWK8fmseMFCEOZOcCSyxQqmuqkIIhKXvu6pGb9266Tjdof6+qampcrG0cPfuz//8z8dxrKp6EvN8vnDx4rt/9j//5OrV60MDg7duzTdbnUazvVNvhHFy++6doaFBLvmDD542TC30PafXGRkatgxjenp6fHy8v78qBHvv8rvZrN1qN13XqVYrtm3n8/koihzHmb97x85mBoYHwtAtV/KWrT308Olurzk42Hfy5AkAqRvqwsLCwMDAhz70IcuyFEXZ3W22Wp2Jialz585dvXo1DGPOZKfd293d3bdvH0g8Ojr2zjvnyqX+er3R63pSolqtoWl6EovRkfFabXe33tzY2KjX65xzStUwDNvtNgDmnGuaVt+thUkoECiKwqQIkzhmEWDZdXvdblc11GpfWdGpF7he4MY88SO/43SEYK12Y2Cw0u01HaebJKFpGsVioX+gOj4+XiqV0kHpc+fO3b59e3d3Nx2prlarjuO899571WqVUrq6urqzs/Pss8/atrmxsbG8vDw9OYUJyuft/v7yzeuX67tbly6dBySHRwY8r7u+vjow0BeG4SuvvKLrZsbOvvTSS6qqHjh4sFKpjI0NHzt2CGO4cP6s5JHnO6VCxXODOwt3SpXCzNz0qdMnrKyx29g+eHD/7Ozs66+/3tfX95GPfMR13S996UtBEMzumzt2/LhhGBcuXNANK1cotrq95eVlkTBNUVicpF2IrGX/1E/+9PuffF+5UJ6b2x/5kaEZvuOzmK8urxUy+Xy+WKvV6vVGrVY7d+6cQrFlGRhjEDKNdOt2u57npX5lyzZct7e0tDB/68bo6KjXc9Ik3HR6KZ/PLy8vJ6EvRKIp6nfU57/+2NvYKEqSJAAghfj4xz+eUqlLpUqn63Q9P+FCCCF5ktU1DYvBvur3fM+HP/DhjxnFgakjD5RHJ1uOg0Xs9XbXV+ZHBsoUJSLxNSKxjC2DqFgEXttQUV856/daiMcKiMTrYskizyEEmZoaJyGSQgjm+Q4mUjeVrt+jukZ0OjI1PjQ5Uugv50t5iomCqIrT4oQomqobhmrogBBgKhEWAgRHIAlFKiVazHjX9SLB3CBUTJ1qOhO813MxpZSqlCqKoquqZhi2ZdmWaacDHLquFQsFVaWZjAUAgCSlNJu1a7Xa5My07/vNVgsrlCja2XcuFvLVX/rl/3Dm8afmjhwrDw0PT85Qww6YdNyg2/MNMzsyNP7yt769urBiakYhm0uVEYSQbVuc83QqLl15U/dVKo5gjFVVxYgSLgSiBBAK4sgPAkVTF5eXfN9PSU5po8owjDhiruNrqrG6sj4xMSGE0DSjVttN6QPpOF6r1cpms+mqaVlW6rC2bdsLoma7Mz07IwGiKNrZqZsZu39osNPplMtl27YbjUYcR6ZpFPJZVSHZjDU9M/HnX/7T/bNzTz3+xNf+4iuLi4unTp1KomRzfYtFrNtqV6v9U1MzKSLIcbqe55RKhV6vE4Z+LpfpdFvTUxPtThMAjhw5fO7cO7Ztmqa5vLyMMTDGbt68mbbtOp1Wt9vOWjZPmOt0l5cW2s1dSpBKabfdnhgbP33y1NbG5sba+u3bt7e3tymlQoharfbyyy+HQWCZZr1e9zzPtu2RkaF03jCVlEZGRvL5/OzMPoVqumaC3LuvpaVqmmWBEHIch1KVUtVxvKGhkb6+vl6vxxKBEU2zDjnney1Cz0ulrPT4pTpk+uGn2NK0stlb4f7WRciliJIQEYypEkeJplkXLl71PD4wMNPfP1UpT/73P/zKlesLTKqFYr+q2KpqWHpGIarregzETrPVCjxOlZWtnUbbMax8u+kWC/1Hj5yWHDiTiqKDQJzHmKJ7qZ9/7X8BAE7P3draSEVUSikhiqYZjAkvDFJGhu+7CQv2H5jNZFXTUj73+R85ceLY2PiI7/u6rjeb7TCMMaYEiEY13w+TWDIWp7KtjjFErLO4ZklEhcCCg0yQFIqUOIppxEnMMRMgpMQEIYKBUEkUSRRBqCQKUIowxQQRIpGkukJMNSEilDFXgGZ0q5Cx83omq+s6Vgg3VVzKmpW8rVFp6UQhUiIOClJsDVsKNjW1kOOqia0CsgrYLoKZ4YaBLANMLSFCzWhSSfIl086SsbESJSGL2/2jlWwlq2R0JafTvA4ZCjbFWd1DSaQB02lIwQXmyCRUEdcJzRk4o5GsTrI6tlTF0syCbeUzesY0LEPVNURJeoYAAMZYoIRDlP4RKBYoljgRKEaYIcxSu7rEicSJRFyAQEjBSEegIdAkqCBVIVUJKsI6QrrEuiQaxyrHKkOKQKrAqiQaQhpgDSMdI5UglSIVg4IkRZJKpABSACuSKAhrCtJV0DWpa2AoyCDYwMRAxMBSU6SuSlXlVBMKFRRLUCQijOmAMGOYiTRtEJKkZNmbN29BKzAURWKECAVAgskkiqvVatfpOm53fHy0kM92ex2EIWFRo1H3fb+vb+Du3buZTObIkSNRFJ06deqJJ56Kgtgws30DQ34YBVHMAFTdkAhWN9aLxWIul83lshjDO2++kbHMTCbT6XS+/e1vx3E8Njrq+36xVDBNff/+uY2NNVWj3W4bIXTnzp2DBw/5vr9d237v+uXNnY1ExH/y53/cP1TN5a1Gc6dUKg0ODk5OTrque+rUqatXr9+9u5jL5lud9jeef+4P/vt/y+SyhmWGcXRr/na50re0sFwqlAmolmEhifurQ+urW1cuXYsjFkes2Wyvr2+vr25gICBxFCa9Xs/3/fRm6/v+1tbW3bt303hawBIrGFMUxgHVaKla0U0NUYQp8YIgiCI7Z8c8bnWaRCWTk+NrG6sjI0MrK0ue53CRGKZmGFrMkp36zo0b1xyn29/fzxg7ffr0iRMnjh49Ojgw3G53ANCdOwtSyuXFpWK+8KEPfrBaqdy9c0dT1TMPPDg7M9NqNGemJimB19/4NlVgfHTo+NFDod/rtnfj0H/koQcHqn1DA4Ojw2OX3r28srK2uLh68tSZH/3xH9uqbVy7+V4Ue4Vi/sUXXywWq5/9zI80djs8gTMPPsIYX11eW5xfqpYGkhjt7NRVVX3ggQcajQZImWbdfutb33rhhRfu3l1cWVkdGBgqFIqZTM4yM74f1LZ3es3myWNHK8VCo9Ha2Nj60pf+4MUXv33lveubq1uMCdf1m83m6vIKAbKzVavXdsMgSjfGqqp2u90gCCzbEILrqnr37t3XX399bW2FEBTzmFI6NDT0+c9/fnJyMp/Pj4yMAEAYhltbW7quZ7PZdru1sryMMUFIMh4juJdI/b+qsaSUmBCE8czc3NHjx9N0tY994uNzc3Ou6wau98hDD3/swx+BhOfsXM9LVrZbI3NHrerwRr0dxbGtIRJ3/V6tr2KzuIeFJxOXBV0FJwpOBPMyNm01dyydYBknQa9UMHnicSx2Wg2pYg5cYMYpTzCLZMKpDHgcQNwJvV23KzS6223Xe+00uFe1LNW2pEI4QZJiSXCaA0sEqEgxkWoiVeUUxUJRNE03cvmCqulxwhAmAhCmShAlYZzETCRccokkIimmR0GYcIkSjrlUEVEpBSHTiMAwDFutlkaVXDb71ptvDlT7JROCE0XLeB67e2el1XI1IxdJpNt2tlzW7czIxESn3fv2t1/BQIb7h9qNpu/7qScnLRDjOKIUa5oShEpWNd4AAQAASURBVB7jsQQuJAMkMAFAgvGYEkoNw0gYE0IYpimlTDGYN27cyOVyxWIxnYZLRayUX9Dr9arVqhBieWExPa5p6yrtiKUXre/7hmEZhhFHwe3bdyYnJ69du/HwmQfa7Xa34yCEPC/I5XKp6+jYsWMvvviilbH7q31AoL+/v9FoZO3M1tbWH/3xH/b3DY6Njd26fVNwqSqKbdsLCwuDg/1JzFLPU5IkjVpdSqnrZhAEa2trz37yE9947pvVanloaKhe3xkcGFhaWorDaHZ2dnhkcGNjI4hi27Yzod/udNxur1wu80TYlqUgvLW+MTExoVElgWhqeiKTsUul8sDAQLfbPXv2bLVaTRIGAJub29vb2319A6mVwXG6KZC9mFfjOE7HsiilGGPDMKSUi4uLjDFT19OMQoz35sLSZS+VANNwobSclQKlU9MpjSxdIBWqIYSAkyiKoihKXyElxaek+yBKMCWpbYhLLoRAEjEmhEgYY5wzxlj6q5MkKeSLKysbf/hHfz48PJzLWPX6TqPllYoDXhA5PU9TNAQyiB0uwdRVJHGMWCKZ57lWLitAijjRFDVfLRw8cAQhrCh7w4Ppm7qni/y1RiGS0G40XdctFfOWbmiaJoQAgn3fSWmrCEuE4ZFHz6xuLBMFfe7zPxx6rFbb9QJ/Y2u71dw1TT0OoyThnuelo8IYI0MzQUFMcAwMQtar17MKVRQqAccsBikopVnd5IlACZeYKoZFKE5AJEwYiprWghIDxlhSwBRJggFLrClACSaIqJqiaZiSSCRYqqqmCwGMJVjRClk7SrgTuAwLpKuaqWVMVQje63VQzHTDEhIpqq4SQAjFSYQkaJquSakFMQKiRBFLRC6T00yDMxFLFem45zhRGBkZRVMNjDHFSFGUIIqplEnC4yAMEg4CgIPgQiGYYWFqQDGVEgsmYyTiOFYURIihCiS5ZDRmUSwlUIwhlik+HQDSZqiUQgJQkBKkBJmmCaXHSwpAIAEkkRLS/GkABFIgIITIPfVLypQznRLm9xDhQO6dABIJkGl+XwpK3XsRAAAJGIBAyqUVaREuEWApkUAgBUiMpJQixoBoIgEjyrFCEGNcEowx5jGXkudMfaHeDFZWzKmJbhxgSiRngFCqEPf3949NzXR7rUr/UGdtfWHx9uT42O2rlwcHB7/whS8MDY5gTACTRqsz0NfnOj5VNAk4YezosVPbtR1TN3RN0Qhu7+5W+iue56mq2ut21lfXjp44Ojw0urm1Nj0xmS/lV1dXs9lsSuW+cvXylStXHn34MUDkhZdeBEzW1zbzpWKxWGQsLpeKtm3v2ze3s7NTzBWLxbJp2KVS5cK58+Pjk9eu3di3b9+1q9ffeedco9V+9NFHe73O8eNHLdvc2amHYXj69OnXX32jVtvt6xtgLN7a2qaUBEH01FMfuHnzJkJJtVqQAtlWttvtpsPglUqlUPB9P3ScbsYyRkZGUvsmUahIEiY4xjhMQsopQuD7fiaXXVy8W61Wh4aGoiBU1XBodISJZGVtNZfLdjptKQVCqFDISYniJEwV9916Iy3gpJTr6+uqolOsMMZSms/m5ubDDz9cKhVWV1fsjKkoSqFQyFj22XfefujMw0ePHX7v8tVu1ymVSo8/9jhV8Orqku/7hw8fXltbSzf8o6MjlUr/e+9dvXr16qc+8f2YwHPf+mauUHRd/6133pqZmqMKbKxusognYby2vbq8vDw7PfnA8dNJFJ+/0Aq7/rvnL3/vRz+cz+ePHj1qmubu7q7T7um6nsvlVKqEWHnn7QuOGxSL1TjmxVxxZ3NrdGRESlmv1/v6BlRVXVpaGhkZUWy622h870MfyeWst19/bai/v1ruK+Vzum5OTJeqlf4oiYMoXl5bHRubaDZb6eoQx/GRI0dSn4ZlWevrq48+9oTjeAMDA4ZhECk2NjZ4HG9sbAwMDOiaRjGZv3lzZv9+KQCEBJLih/foo9/9kEKomgZShmGYy+c/+clP/qff/E0pORJ8YeFOHEaj4yOZTO76jduzs7NtJz576XpueGZs39F621VUVchYhp2VO+/NTvQRCEB4FAMToUZxEnZ9r8d5oGqK47TsjJ6EAeORDHixbyibz7W6nXwmD0hGcQgY6YoasYiHXLfMTrNl2Jaqqp7nlUqlOAzjhGNMkUIQkhFjjHMge42atKsjuRBAQCLOeMxEsVqsDFTSbcztm7eklIQoqm4YBk57DgAgJeKc8ziRkilE5UmCKfF93zAMzhNMSRhGBKMoZplctue55UrfysoKE9Bz/ZDxWEg/ivOFAtE0oFQK3vNDIYSuqmGYjI6Orq+tpXbzrJUNu4GmakKA7/uCg6ZpxWIJY0yIkrrVUzUk/b8JIagfBoqiSM6IQlNfEROcc9nqtEuV8vDoKEKo2+6EYSSljOPEdV3G2NLiyqlTp25cvZbJZHRdTyFPqqoyKVJ5RkoZx6EQVKFaPp9fWFjwfVfTNM0wKaWO666srj7xxBP5fP7q1asf//jBSrW0tbFZzBfKhRKWQBBsbG3lclkQcm11lSfM1I0kSYSQlBKsaa7rzs93BvoH9V735s2bpWLR7TkqJZRSALG7W3vqqSfefP3VbCZP8pnt7c0nnnhsZ2v7xq3rqqratr20tKBnrJgJliSWYXuOnyRJqVRa7S6buiEFe99TT1y+fPnO3cUf/7HPSwnXr1/zfb9YKNy8cUPXddM02y2nXC67rmuaZhLFhqZXy5WERSkszjTNvr4+wKS/fzCKorTXZxgakuC5nqaoYRjCvVba/RzTVDz33ACpxDB0z/M4l4TQe2At0HU9SRJAgnMexzGRAiFJCPE8L5fLWZblh22EkK6bGGOKsJSSxQnGKfdMEiEoJZRSQhBVFaJQTGi35yUr67ZptTstIZDjOARhxJmiqYLxrGW6XuB2W7phVIrWxubS6PBYGIYqoZaVWVtbmx0/UyzmAADjvV0UIlgK8V25n3sGm3RJ3dzcRCAs3VBVlWBFSgkSt5qdfK4YhiET0b6DsxsbK//u5352dHzo5MmTxXxldmZfsZQz7PFrV2+9d/ndmem51E2iqpoUQAhwzludrgBeLBSgvtPzegVDiYlgAExKIjFIJEJGgGBJwkR0E9cHKSnGiKqxwBIEEogAoQirBCMKGCzTTKQAAoquclUNkRQikQAMRC6j29lC3jQF0fWMBQhrpVyxkOurFChBUiRRFCS1mu+7iarm8lmiYMY5QojwGCFkZ3JIyDhMBOcW4I31rUzG4opKsFIwNUmFGlpJkhiqZpq6qtFU7TNMMwwCp+dxLjNWxjJM3w97raYIoyQIDVWjlAaeL5lAQrpdN+y6IBCKhUgYoViEiMWcglQ4R3xvH4zSjBSB0x1U6t+SCBCQ+5IjEqk3F+T9qgsBSBAsBpwiT7/Ly4VlirlKDfLpa2Bxz0q/V0L9tS14+s9TF5jEICQAgpS1IKUUEgmCOJIAQpOAOCGCIolVCQjS9yERAlVKGkSbdxamD+5joatiyhnChEjBExbt7GytbGxkiyVJrheKpY2NNdNQJfCZybmMgo4fnFtbWbx+/Xq5WLAsK5MvxEtrjLFDR094YfiBD33vu+9e2FxfO3Jwn+/7se97nnf27NuFQuEnfuInNrc2PMcfGhzVDWVzc93IGGfOnLk7f5sQlB3oe+KJJxYXloMgGh4aK5aru83W2trG2NjQ8Nj4xupat+fpqtZqdUaHRlMGje+v9/X1FYvFmzdvDgwMfPazn/33v/Kffvqn//Hi4mKj0XAcBxO0sLDwYz/2udu3b/teEAbRyvIqwlCplPr6qpQqb7z+lm1ZlVJ1dGzs/PkLly9fPnz4cDabk1I0m01NV3Rdz2QsECxFH1NCCcKKbghAiqJEUeS6LucMkAz9oJDL67reaDRc13d6nm3bpVJpcWle0RQhJFWUTM50XVfXTMu2wzAihIyNjbXb3StXrhUKhVMnH7h48SIIpKpauWwnCccYFwqFXCZbyOdNU9/Y2Oi02rZh2ob51utvlMvV0dHxVss/fvSRu7fXo8h7+503FJUu3V0vFPPddkdKubvb3NjYmJwafvoDT144/27nuaaiW/sPHVx961yhmMvYmk6xqZgz4zOv4JcL2ew//Sc/lc1mv/oXf3727bObKzuT0xPNZrfTdQ4dPvrVr3611e5OTU2trKyoWGnVm6cefGBz7XLQ82wz47S6owMjMhYsitvNxv4DB/qHBlutzhDIA3P7DNsKQz+Xy3V6vVa3JRA2LBNipiiKENDYbWUz+Vwhv7q+VqvtHDx4UFHV23cXBvqHjgwN02PHDcM4f/58uhLXarUDBw70Wu1ms8nCYHh4eHlhodlspulquVxubW3NabczhUKKlZH/qy4hAKSeV8542hg5evSoABgeHh7or+YsPaao2+2+u1MrVfpmj5x57ZVXjPLwwVOP7HaDIAh0InIa1BYXDBL0Fc12ry4ElwhpFCsKdrpOnLgIi0TERCNB5Mc8CaOQ82TUztbrDQUrSCLEgUeMUoIBUMIt0yCSVHLFIAgki3mYAKi2YgABBFgIACE5lwJQKgGoikIpjUXMBQgpOEhJQVAwbUNVlXRXk9qRNUXtddpxzBRFSe97iqJRSqmiUkq90OOAEMECCUmxACQYMCniMLGytu/5hKCMZXpJcuXWra1GQypKEMdYUTKFQhRF7XY7V8xrqu45fqvTKeXzhqlJye2MWd/eoRo1TZtJ5nk9KSVjLJ/P27bFGCsUckEQBEGA0J5ukvpO6H0bNQCkGXlp/QWS93q99LabWn/SdpXjONls9uLFi8eOHTtx4sTNmzeFgBTRaVlWIrjjONlcIYVwxHGMMdb1TLFQbneaN27cGhjos00dADwvCMNwaGjo9u3bly9ffvjhh7/1zRdbjQZiUtf18fFx3/fn5+fTUGeq4Gw26/tht9srFIo8js+fv/jMMx8sl8v7Dh7oNFv7ZucWFhaWFhdHR0eq5cqNa1dPP3im2+2YphlFoWVZiBJEcKfTOXz48NrGOlEVz/OIoqXhg4qi2JZFEc5nc0kUJGHkO+6p4yfu3LmTtW3TzsRx7Pv+7Ozse5evCiE4k4ZhtFqtNC5ASmkYel9f38rqEgAkSZJSOhqtdjabVRDKZDJ37ixomqZgkopVaYXreZ6UghKsaSoApHVqNpMPgsB1XYwxoTQdNkxlKtd1U9iBYRiUUhYG6Sec9oDSAwQYUUI55xgDSBzHTFG0FEuWtg4JIVKK9IlpL1FKtLVTs22bxyGLOcLCNkwWxiBl0O2alskZljwKQ1SqlhutXdu0NE0LHS90glPHTyEESQyKCgAQx7FmqOiv6VZ/TcdaWVlJ3/5eereqpqEWAEAoymazAOJ3v/BfhYhX15ae/fiHd2uNhaUbna4rOFT6Bj/wgfft7rY8N9q/f3+z2bpx48bg4KDrux3PMS0Ll6tyYzt2XWIUwjhCWGBVURGRMcdUE4kIQfi64mUykammM3CYI4wkwpgqoCgKUTHWCCIAtgUYEY1KSvwoDqPIzmZK1UqukKWqLhD142R1c7uzskQ11fMc2+0NJCHjsaKQ0dHhkaFhABAyAR5wFnV7PQZSAsUKRRkrSRKnE1OscC5Rn+0CGJay3WgUrIIQTM/qBGleEvnYN1U9PTEI6yiKIixIojgQPQskNkAWdZNkuu1WKBDBOKKKShUVq3pWRyUrdIJWrRnEgaIRgVGMpSIQYYDRXi2FEEYAAgkBe1Y/KRFgdK88wgiEAoBThU/K9DjueT7o3ozhvUMMCCGBpZCSQvo3hAEBABJ7RVg6IwiQoqcRICkFEIFBSiyFQBIj4FgA4HR4VgjJMeYIJOJYIJUJDEJKzqWgGGNMEsGBYAVjkSQo9Nvrm6AiDBJTlXPOpRBxPDQ09JnPftbIZGMhRiYmv/7c80NDQ4P9A73Gzp/+6Z9+9vs+vr68uLKycvTIQd/t6aZRAEVI8tiTTxjZAgO0VW+8efbC6NDgtZvz5UK2Ojhg2+aFCxc++MyHfC+q7dRTz2Wt7mKMMKKUqqVS6ebN6x//2LP5fH5tdUuC4rp+zDgCms+VVcWuVvpXFzd8zxucGxkZniAIra9t9vf3Y4xKpdL8/LzT8yYmpqqVvuHBUhiG6+vrw8OjAwNDZ8++rWlamug1NDQ0OTl59+7dbDabzeZ9L1xeXjUMjRIlnyv84R/+D875s88+2+l0VFX1fT8MQ9eV+/fN1ut1AjKTteI4llJmc1nfDxv1ejaf01QDYek4XaxQANTXN4AxXllbxYiWShVFUXs9d3xiaqe2VSwUarVaY3cjn89PT093u069vpHErNPpOY43NTU1OjK+vr4+Ojpu6uba2lqv13v++eff//73Z7PZN9980zD1mZmZ8fFxp9O9c+dONpvXdX1lZWV69gBGzd/4jf949OjhU6ePDw+N7dQ2OQeMaDZTvHDhws7Ozuzs7NGjJxzHuXTpveMnTk7N9vEo7u8rNGpbt29t2Ba2dXn7xnsnjx44cuSYYPHuTq1UKA5U++avLHZazo3rt/PlwjPPPFMsloeGRs6ePdtotOZmZ8fHxnrN7sL8wvr6xvTUgXJ1YHNp3XXdOHSn56YVRXGjIAz91dXllZUl13ULhUK2lLMsa3V9BRDSdAMT1mp1SqWSFcf5YgEh5Pv+QF8FQDqOU8jmdF1PyfgpYVHX9b6+Pgl4eXkZGKeUUoB8Pp8vFLqdTrvdtizLtu2VtdX1ldUDhQISUgqGMJXob88P7XFwCCGWbbMk+eAHP/jMM88cP3nC87xu1/E9Z3pishnxZi/4wy9/Y3Bi7tRjH1yvtR0/zNlW5OzW69vMd/pKuTh2CWKKgnupUuv3HMdJoY9BwghCIAkn1Avi2dlZL0jOn7tmaHmVaiJKNEKJRK7rAMFxmOgIEaxmbVUyWcrqnuMyGWOqCpBICKIqmrJnRI6iKEUzKpgIAhIwBhAgFUmtjI0xDgMnNR1hjB956OE4jh3HASGiMPE8z/f9MAjCIA7jgAGiGkm4MHWDJVxVNC+KCZA4DnZrDcMwwjDUjcz49Myl69dnZmaWFlc0y4h4IpHMZI0MGI7jgqpyFkrGPLfbauzqBl1bW+l2u9X+quAy5nEURdlsNon3LNSMsTCM4jhGCOm6jhBJ1SxCCBUI/Cg0TCMIAp6wNCchCAJd1Xpdl1BUrVa73a5m6KEfpBDOVEq5cePGA6dOLSwspH3DvQBITWdMpMVWEARCCIRJs90qFYrVarVer+/u7m7G8fDwIDC+tbUDAoaHRrvd7uLCcl+l0mq1DNVgjBk9fWRkZHNz89aNG/sOHOS8NzI2urKyNtPXPzY29t7lSzNzc+ffvfjoow9LKbu9TrFUqDqVzY31MPTzuexOfbvTap48cez6tZvDI4OUqFtbmw8+cDph8f6DB4Io3NypEaKk0XOcx5wxDihfrmoE37pxM2tn7t6df+CBB2ZmZq5cuVIolcIwNE3z4oVLnuepVHEdJ47jNPGaUlos5qMoOH/+fMIi27Y1XUlVh3K53Ov1MFXDME5hFsVc/v4MZ1qzJongTBqmmlZmmqalFnVFUdKfpItV+o/TwAqV0tAPwjDUU4d44FNNZYy5rmtZFlGoG4SKoiAgEmQUxoV80fcCkEihFKQUnOuaAgiCwC8U8oxx33cJQa7vE4RUDFKiMIwl40iCYWrAJAbCOOdcYkQAUylIGDAZctvIPPLwowCgqCA4YAqqqgKAFEIiwGgvnCddhRGCwA831tfLhSJPWMayTcNI8xxT/T9hUT6fc133xRff/Jl/+0+sjLq4NL+6vFyt9s3fWfK9eGhk/OSJMwcP7ms02hkj1+n0MEA2mzUsc2BkRIAEqvOup7osmzETv0t0yiXzk5gimgghdHXLcSr75z76//6/QUOgaRCEoBiAJcQJQAKaDrEPSAKLQVUhCsAwIIqAcSgUQAjods+98srzz3/j2q07juvnixXP8zBVKEb5fJ7FgW6opVIBn8WaaYyNjVWL+XJGGRvqH3rwJNgW2CbEAcQxBEE+9Fmc9LrdvsMT6QRQvjdACCnm8q7rapqWiBQlCL1ep6iWAaDZbE5NTnqO32g0sv3lOIycBkOamh0YlRx831ek1FUNBKKBpQisBRHqVHvtnu8GSRglQRQECQQZiHkcx+m0BBKSMZYkPAojDlLuzfZhIQTjUiQxSUIskrQgA8Ag7ulcUiKUThymB3hPpKJp9jEAkhJJBAAkHQHEGCGECMYYS5zOKqbj5ZACRVHqo0CSIEoASYk4xa7g1NIBhCFhRLFQwhnmiFIhgHNOKBGMuaGjm3bJMBavXTudjlIikAhxEIBQvlB44MxpwLjR6nqe01ctPvX4g1Eifv8LVx584BSlNAxD27affPLJ2zevnz17PlfsGxwb1cyswMrc/v2//X/89MDgaCL4w488dO7t1wo5e3N764EHHqhWq3fmFw3LnBifLFdKVEV3F+ZzuVyjUVcVY2Z6n2HYi4sra6ubH/zQR9577+rG+rau2QcOHXR9p1AYeODMYzeuXtvZabjuSmu34Xle1s7Ytn3w4KFDhw79p//8/xw4dLhQLlT7K6+99toHPvCBzc3N1P588uQjW5vbClVd19/ZqRcKpVKpkMvlLr574eTJU4BEFISLi8uCyScef9JxPCHA8zxKqefFANDtdgGAg2x1O1nLllJ2Oj0ssaVbURBnM/kw8n03QgTy+azT8YQQBFRN1XXVtMzMtru1tLSWzdpBEGmakcnkhoaGbty4RanKmVAUzTRNzwvCID5//uLu7u6TTz61sbGhadrIyMjTTz+dz+Y8x02SZGZ4+vbt29Vq+eihw91ulxDl+LETccy++cLLn/7UD2TzmfPnz25uLf3dv/t3r167Mj9/68KFC/l8XlX0p9//kW984xtzM8cJMvsqozzGGlZ1jHq1la9/+bV/86+f3VrfiMPVQmFgeGTw2y99PYop4zKMXKLhwZHKwtL8+/Y9eWv+DiJ0bmZ2a3Pn/PmLScR2d3a9nmdZ1umjx7/3gx+5euXWt1781g99+sc48PMX36EqFVhgBVf7K1EY/ty/+zfXrlzd3N5a2VzruV1MkWbrhm35zfb03Kxp2ALcXq+Xy2ccp5vLZVZXV/sHB7tdJ4kiz/NSVNLk5HQqAHtuoGka2Wt1SVVVc7lcq9VaXV09ffq047oIoevXrx04fpRQ/Ldtrd9RsNLBZ5AYISa4SkmpUv75n//5gZFxxlGx1KcZGURDxczrucqxBx/b2W33uu1SNpt4DQMFSeyFkZ/LlZIwSBJGKTVUret4ccwI1VkSBzFHCDmOa+paFIjK0BQH4/atlYnx2VazlyavypgJjDO2rem6FwaBH2kGYVFsGTZn0rIyXAhQSMSZJBgI7nWdUqnUau4qhOqKGvqBqhCEEeOMaEqv1xsc6kcgtzbX3Z4DAHHM2u32uXfeNgyj2+0W84VsNtffV4njWFdUjGki+Nr2TqvT5gkL/QgEk4QoXJq6qUkchn4cJwSR0A+5AKfnj45Prmysb9a3EhkFoXPlvXnB2L7Zma3tjZ2dreHh4VJ+WNPpTs01qhWiYT1jhGGYhEk6UZexcwDQ6XRM0wzDIJvNIoRTh0AUJXEsNE2j6bHhnOdyObfbS3tPqcbleZ4Ennqw4jhO/UCmaXqep2n6zs5OHMflcnVrayNtFK6trU3P7fN9P316ynNPEoEx4ZzHEbOtbByHjInz5y+eOn5ia2v7oQfPbG5uttttSmk+n/d9v91ul0qljY2N8fHxBx544L/9t7946JFCrbb7yiuv7Nt3wPf9tbW1UqlkmrrrurVaLfBcSumFCxcUgjuthm3q9c6WpisKwYapG6a2vb1pmna329UU8pGPfOTqlWuLK8uZbD5MYq/jEUJS9CpCaGlpaaBS3bdv3+Li3UycuTt/58iRI9/+9ou6adfr9cHBwatXr8ZxnMvlW60OYyybzaqqmn4snucRitL0wL6+vpGRkVqtRlXNNE2JSCrIa5qmKEqn0xFcUxRFURTP8+I43IuZI2nzjmCM09f8G7uT9FNNkgTdQzMYCk2tlERRhBDpUBYS4t5ymM4Maum4FiEkCVOeFgBAnIQqpxjrCAHGGCEMUmCJpUASIwFSSKA4BawIxhjCVFP1bL6QMAgTjiSP/XhwYHhgYOBvbqQA3YvO+s5UmhCSYLS+vtnr9Ur5XPqZ+75vmmbTbd/T0kQ+nz//7jsA8Oqrr376+581TWN1bVHIeGR0IInlTr2RsBBhbhiqpiuWZdi2lc1moyTmCJIkAQ5BzwcGOP24EBISMKaYqEJioSg+JaivDLbi8FAilKgQx46uKVpGE0yAiI2MRhCAVAFjoWCsKJDNAODa0tJf/MVfvPLKK9vb24QoViZrlKug6pXRsRQ0l8/aUgrOE822DVNLkmSh7czv1EwkJD+vmUaxXChUi6apD40MjY+NKJmcaWjG6AjYNggGAIbvgq6DQFkhQNM0kUAcgKXaIIElAKJMFXDd3Phgju6DKNJVIysAIHW+4iIBSFt7EiAd95MYRKoXEQACUkICIA0QKLVJQcpakAiY2PuTcOAcOAYuQQgQDOIQJEvnJkCgtMBCQsZxnKZICRanqDbGmBSMh7EUQnAAISQXkgskpJQyCAIpJZMi3fAlPGZCCiEQl4gzwWKeJIzHgnGccBBIwdRlLBYR0kmv0cQxW91q9RuWphApAQMIgSSXCCEgIATLqkptawO6QcYw3ShKBMsZuut0t7a2AKDT7jYa9a899/UHHjojAK5fuSI5O3ny5Osvvzg5Ouz0Gtvb23/8x3/88U9++u7SBlX0ruPmK9bv/Nff2210hkfGhof6n3zq/bu1rd/8jf/wg5/+1Ojo6MbGRsfpJEnium631ymU8stLq1pNzeUyLA737z8oBXr9tbdnZvYvL68msYhCfuzEIcvKLK+sN3YvGLo2Njp19p23Tp06YR83d3frLE7Onz9/+vQDpqkTQn7zN3/9Z37mZ8vl8vLy+tbmzvz8PICYmpryPG91dXXfvn1I4qWlpcOHD4dhHMe7qfq4trr+3uV3BwcHP/WpT21tbUVJzDn3PKe/v7/T6QwNDQkhpJRJEuu6nt72VaJEcUSI4nQ6qqIjREzDtmwjigJMcRLH+Uwu5sJzg3bLkwhsKxf4QalU4gwQkKtXr2fsLEi0ubk9OTm5b98B33sPY5rJZDAm+Xw+9APf91dXVznnfX19b7755uzs9PjYxJEjR65fv3r37t0DBw71uk4UJZaVmZub+7Mv/+ng4ODP/uzPvHvp4qXL7x49etSyrGw222y0hBDffP7FjF0sFfuazSZCGCNUzVqUtRpbl37uXz/6T/6vz6xeu3H1vXVFMTPm4EsvvTA5c2R1fVMz1Du354f6h6b2Tb31ztsPPXJmZHiUC+m7XqlYmRgePXb8SDFfwIA++tFPbK1tH5i+/qmPffLJJz744qsvvfXO677vM8EqlXKr1Zoenvp7f/fzX/7TP3vjjTeef/GlGIVWxjYMo+f2Fu7emZ2ZEUK0Wp1+Q1lfX81krVdffVUzMiMjo+mnbVmZtB0spQQs00GzFFhIuJRIMsZUVUuT7FKdor/at7W1xcKQEIJV9X83n53e89Obu67rQoiPfvSjv/uF3xtWjbnDR5fnbwNR9h06enN+6amHHnMdjycsZ6oyaOqIBb2W027a2axpZQVLPK/lOgFCJAqTKGFE0xTVNq1svlgYlGCaJo+Txm6tVu+pNMNDphEaOD0shYhjRFAYMJ7EQgqqUF1VBCUISUwAAdc1KinWsS4QeIFXqZYIIaZpYkDABSWEIiwRSkQkE9BViqXc3txwXTcVF+7evRtFwbvvvsujCACIovIkTt++qmq6ZmTyuVy+nMnnNDuTsy3G42677TldhFDMEtPOgO/GLHF7PcOyWMxXl1Zm56Z3m3WE5G5ju92sGaq2vrKoKWopY6kYfLcX+D2JBIeEGoofeoLJtH2U3tPSeimFMkgpOWfpUGC69kkpKRKSsQRL0DJZbuzpWKqmpV0nKSHwI4IVAJAKEhJFQZQWAe125/Lly5OTk7u7NU3TCCnoeqPZbBqG4biuEOKe871t27bjeaquWRmbdZND+/c3W/2vv/Xm6dMnDcMYGBpyHBcApWwtJFC71VI05fbt28dPnigWVd/3JyYmavXGzs5OtdIXx3HP6Q6ofRNTk57bOXzwwO5uTTCOMJqbmymXy0KIjtPZ2t44fPTQ1NTEwsKdKArGx0cvXbqIMXa8cHe3adl53w97PTeTyWiKzhJhZ+3tzS1gfGZmamhwsFKt3l24wwS3bTvh0s6Yk1PjKysr+Xy+0Wioqu45TV03U05d6rIqFgulUnFrazs9IVLjHmcyiAPDMFK0Y2pjd3qdVOFL+7j4Xgxz+s0exygFbOxVJ5ByBFLDO8ZYCJawCMD4a2ODnKdf70+NIYSoqjDBJQJE8D33PaGUcp5QjChBAiEuBWM8YglwSa2sBIlASoIkQRQDCOACALgX+AWMVMto1JuaqcaSHzxysG8gCwikgHsyFUoNWAiQBIn2ulF7ldadO3dUQhWipo6e9CRptVppVxphNZPJvvLKK9ksqdfr/+pf/sLnPv+pz3z/Dzz/wvO7jc7RIycwVQ8c2Lexug2Spvnt6ceVfkScSxC82e0xSjilXKEISQEII4IxFYkUAmIGxf4+MMxuz6OcAlWIYnACPcYyppXEMTbNTrela5qqqli3AODGe1e+/vXnzp0712g0MSGD+w4qqk6IYttZzw3ScRLdUImi5HKZJIqjOPAkTgBTQ83k+/1eV0rpiqTXRSu9RhAHwWvvAoh8xshmzFI2e2D/zPDI0PDwINVtUDXgHAgBFgEAwzhxXUUlIATVVeZ1MQGMGSQRgADOgCgykTFjCGEFUYQw5xwJiYkiBSBEUyYoANlr9FHEJMNExYBkSmxBJOVVAVYERwnjQhKQFAhJI3oIwmlFBQBIYkiNWRK0vbvIPe7hfWsIvfcNvxdPm57Fyt/YcX/X1/vE/9QbxtDeTzgAEmBhcEPg6PzP/9q7X/vLA9kyRCFIhDFwIbEERICLKGfoS41mvFPLjg55UZg6HzBBnPPazk7f4OD27nbguWdOn4rD8NbtG9ms/fJLL+qU3L59e2V56dr194bHhjmwRqtlZoueHxLHu379ZjZfiqJkZmb2vcuXf+Jznz/3+isbG2vTUxNbW1v9AyM7Oztvvf3mmTNn9qLKkEAIRb7XbHTj8M7a2kalnOSLxUKhNDm7v9Lfd/PW7cCLn3rqqfmbNzTN/Pizny7ms3/w+1/I5XKHDh389Kc/3el0u93uCy+88Oyzz/7Zl7986NDhC+9e+9ZLL37mMz8QJ6FKSRSH+/bPJUlcKOQmJ8eLxeLW1laz0VQIrW3vDA8OvXfpcrXSv7297XmeYZm6rjMWSylHR0c1TUMEB1GoUqIoShQmUsogDjRNkxJZlmXpVs/p6Kra6/WEEJmMxbl0ekEiJACWQEzTbHeDVtc17IzEpNXtaYbJmOh0epqmIUTCIHYcZ3Z23/r6ehiG9Xo9pQwmEeurVMfGxlqt1o0b1xYXFyUIhNCBAwcQJURVgjh64aWXR0bGJLC7S/PuV7pRlGxvb/e6zpEjRxzH+cxnfuhLX/oDLwg/8MEPr29ubG9vJzyxTdrYvoP55j/6O+97+ukDW9e/jDiMjSp+4N29ffXSe8uZ4lBlaODGrZtWKb/drX3oQx+aCKbOv3M2DpPjx4/mLLvb7cokvnbt2oF9+8vFUm1r8+t/9Vcb6zs/9+9+odsJGvXd6akp3TY8z4tYpKp0e3P19ZdfPHJw9s3XXvrAU6dxxnADX0pZ7quSRNy8efPAwUOZTKbX63GeUEqazUYmJ+I4KhRyjhMIIZKYRzHTNEUC31NhBaS3SIIVDtK0LdO2e467vVMbGOi3LGt1fe3WrVuHjx8XcYJSK8bfetx3Q6ZAH875I4880jc41Op6A3bRjWXMwPPDTCYzPDSwWWuIsFctZkSEeMzc2FNUIrG6UWuLMEQSLCtbLJZVzUi45ABYUeOEtzodyeTmZjPyfJ2quUxVkZ6CSV9B7apK5Dl5BUVxaBi5ZqetqjSRidtrCSEwQVk7QwlWMCIIJJJUUfrLw1u7tRjQ+OjY9vY2wkKjCiVIURSVkpgxnsjWzk7a3JBSxkGoYCKoUp0cb7fb91s9lFLfcdP6sttu1bfrGFOqqjGLStXS3IE5EXtNt1fqr3S6LcUyZIhNwy7k89V8uV2r29LO5+wk8oero8UTR23NaDXqIKSUikZwEodCMEoxpdRQKROgKhqLE5YIVdFDHvq+n1Ib0tU5FTcURSNESateShAOGVOpksI5OOeqqqaGR13XASClWymKkhIspZS6biVJJIS4ePFipVKxLCs1AJmm6bhupVJJG6uZTMa27e3tenr4wzDinKc2jtOnHpQc3nrr7Tdfe/fwkcm+SnV8fHx6YvK5556jWDEypmkYPacLAH0DA5ubmxOT0xMTE7Xaruu6cRLZtq1pGmNxEIWvv/X65YtXvueDTzmdrmWY3U6r0+komqJo6m6t9uSTTzRb9bnZfUEQECQ7Ti+O+MzsLAeUMJaKc1EUZW1bME6AIIRu3Ljx4OkHHLc7NjZWKJYmZir9g8PvXbl09+5dTdMQQqVSJQgCQpSUxWDbdhyHYeTncuOMJSkOfnd31zAMTDTXdR3Xq1arpmnWajWpG7Ztpo43XddT7ELKfUiPB2NMoSKtmQAA3SOfpI0YIQSlVKE09V3dx8UCh7SBdx+YKfewmYAxSMnTBk1azKVAh9RBf78Ow0QqgohU8UBYUiQlMCljmVAgqYPSdR3HcUw7IxEAwQKJ4ydPAIEkBkohZWAhjDkTqeItOCcEADBCe/Nla2trxWIRISQFIoSoqpqS93K5XBiGxVL+7t27t27c/uxnfzhbMH/vS7/ref7hw0ffePudocFCvV5nAm9ubtp2ljMURxwhyVjMBZNSIgGEEFBUt+dQTPY6UJACnAC4wAKIwJzzQqUfCGYYE6JSTDElYRhoKu04biGbqTVb1VIRAXDJm43Wl770peef+1a5XLXyZUGMvv5+iZFhmXHEqKplFLNUKgVB0Go1MMWNbq9e226322kv1TRNjWpJwrOFPCZEN1TN1MqFEdUOkji0MlYSR3fX2kvrZzHIYilfqVZHhgfmZqftjK5bumoYVDEpJAAcQIRhR1U1AAEYgFDJE0QwSI40NTXwpUUK2dtICaIoKZpTSJCCSykAY0kxRwCII0RkejFKiSTmEjhjTKJYSsYRl0QwLBHmEnEhBcJYpuHTBEu4PzsIkEalSSn3anoJnO2dqijNeUwxWgCQxmp9ZzHAaX8REoQABJUcg0RIUkAqB0UoMuGaZXsKuNtu3O0cGZ00xkZaggHB6etgIIJxTBBgxBmnCGgctze3imNjmkI5EykSpdvtUkqlEM8//42Z2alGo762tnbsyOHbV69mzOrBgwef/8Zfnj59entn4xMf/96r128sryw++PBokkQIIQQ4a1lDA8NZO4MS78p7l5YW7pRLufHx0VarsXBn/vDBA9euXNU0hSDc6/WePP3kyspKNpuXEnluMD42ubq6duDgkZ3dxu7u7suvvVqu9D9w8qHtje1Op3f3zp3Wbv39Tz+5b9+B1BhbLpevXr12587C+97/oZ/5mZ/95V/91WKx7HneI488MjIy0mjubK6t1+o7R44cWVhYwBLv7Ozs7jYHB/vz+bzj9DzPKRbzTz/9tOd5t2/fOn36dMyS9O69uro6OTkhpex0OqVSKfS9MAyxBFVVHccRCIb6B9rtruM4LBE9p0MUxbT0OOFSoDBhhXyZCRlHrL7bDpMwm803djujo8NxxKp95Yxpzc/P53IFXdfvLsy///3vT5KkXC6Pj49vbW17nrewsDA6POb7/nPPPWdZFgDk8/lcPjs/P3/hwoWNjY1Ssdxud51eEEQxUeiP/ejnC7n84uLySy+9dPPmncHB0d3d2he/+MVarTY1NXbl2vlPfOLZTJFevMKJEugqPXPi0JmHclcuv6CSUDcLGi7l+yYRqvzID35CGtbFq1dPP/gwpnhx4eZ7V68cOnA4jmNFUfL5fDlfyOUzGcuUkl+5eumZD35ocWn+wKF973vf+27cvLq+ttNu72IMQRAYeUsIpqu643R+/4u/PdRXNXV8+MBspKBu4AVBxHniOF2VqF4YxHE8MFxtNuuMxUePHr41v7DbqA0MjNXrrTiOMaIYY0XRkiRKFX8hBUYICEYEs0ToimZZlu96rVZrdHSUEFIsFi9ffPfw8eOcc/o3Nip/65EuvumW9fu/7wf+63//80of6IatG/bubuOp93+g09r949//oqrQhx86OT5Y3dxYubu4WBkatnJ5U6K+XF5BmCUiCIIwjLkEIFQgISUaHRrVNK3VaOqYAktYFA9k8zwMdrc3C0jGBKSQWtYGEBMTI7qdSaSIGWOMBZ6nUBx5LvYTAihiSdv3b9RqJx95lBjGtcuX5vYd8D0viiLH9RWFcJAIgWma7V47SZI4jgcGBlKWm23bo2NjU9PT7VbLMM0kju/7apxO1zAshaqMiZAliUg6bvfa/I1yX5nY2q7bzuUzgeNmivnI9RPG6ts7qkYGx/sS5jvtFu/vb+/Wy5NTuYxNMPZ9X9MUzTbzmbzrB7quBwlLPaVRFLuuq6rK/eHHXq+XWnoIoXtiAUKcc8YYRQAKoSBl6AdSE5ILgSGtAL7Tk/quHpauaZ7nUYpTGNrCwsLw8GC3201fLpfLua6bOrK73W6hUCiVSjs7O2k2TpLgYrF49+4iIeT9739/u90MXG+33lxZWn3j1bP79k14njc8OBKzhERYoWoQBJOTk9vbO41GwzAMK2uFSVSr1QpxrOiKrqucc6fXefSxU3NzMyuLS2+8/vqRI4dPnDj+/Leem56bbbZ2X3315aH+vuMnjm1ubp6/cC5j5zXVNq1Mz/X7+gZWVlYBoH+83+329Jxu23atVtNV5e7du4zHiKC+/gHB+MrSUhyEvXYnVVzq9ebY2BjB2vb2tqYZbs/J5jO60TcyMnL58qW0rOz1eqVSKcWHYozjOB4fm1hYWMAYt1qtNN5nbm7G85x7nzNO0eRJwkwDEUKkRBhjec8+nC5gCCEuEoRIuqzdp0lJjIQQknNEFIQIwfi7OFhSCE4IFoKnEwwa1VSiEiAESPpSGEDeW/VAJAgRwJQJzgUHwRFSCUFSSss0o9DPZDIZy2SCMcEOHTsIAEIyRCikU/0YUBrUi1H6e6UUaauw0ei02+2+XDEN8yZYUVXaarXSoUvXd4qlkoRESqlQVSTi3//7XyFE/vZ/+eL8naW52f35YqneaK+urh8+cMTpuaZuYdjzSEoJQvL03cZd1wREEqEwSShwiYiUmDEFaRJhimgmkwGEERBFYMS5DJOiZSEsLYMEPbeSK2BALEneeuut//HHf7S5sT0xNe25getFhXIfEwgBSIYMRVOIFsTBxuqa53mNZj3me3ZLhBBFhFLKIhaGcbZY8Bu7URKnJkVVVQnCtqlTiXJ2JmvZhXwWABqNeG1j8/r1rddffzeK3Uw+43hdjpKHHjp96uThfM62NBMrCOJIxhwpCGG6p/8wASJVe+5X4kAkAsYAScCAUxICwkAIAFZYDDIBASAxIAKYgkQgEagaMBkDiqRIWPqqiCEpKJX3QO0o3WrvebUAIYQoIIQRIgjt2aqihO1V9t+1qwYAmxj3RPF7M4UAHAFVFYkElRwkZ8CFlAlDUmAdGW6UBFyCRqmtAeFjByY5EUwKLAVGGCSQvbl1kMAVJBQh2uubfQSJIJGYy3s4zWw2u7a2hhB65plnrl+/mslkjh4+/DXDGB0e7nQ6Tz311MED0//5//ObX/urrz36+OODg/2rq0vHTjx069YN1+kZunb62LGRgYE7Ny598Q+/eOL44ePHDntuNwq9bMZYXVmamBwrlvIJiwYG+xqNRrFY3NrY6HZ7D595qNdz0u1lHMe6YfzSL/3C8sr6uXcuHj5wuNdpR17vg0//wJHD+3/3d35b1ZRet6NQurGxMTw8/Ou//uuWlSmVyr1ez7Ks0dHRSqVy4+aVM2fO/PH//CNdV4VgcczLlVJtp761tXX40KEoCgcH+2u12sjQQOA5H/7whzudjkTCcYIgCKanp23biqJodW15cnJS8r0ACSR4NmdjjNe3Nk3TNGwjq2SLleJ2bccwTSaFncsnnIVB0u31VNXUDEtiGfhBLp9rtTqdTqdWqwnJfN+XjKeuvpTXIziMjIxsbe1QTKanppYWlzjnhUIpSZJPf/rTr7/+eqVajZOkr6+v3W5vbW0//cEPJbE8d/Zi1q688M036vX62bNn87nc/v37/+cf/2mlWlpZWTh85EC2YOYLZgyNO0tnO+7C4sbG9zzxQ089/fCdu39pWlTBmu96pjGkEpsg88d/7O83fD9T7H/k8Udu3r7x8kvfHh0eXF1dffDBBx88/QBCqNtrbW9v8kqpXMxJxEqV/M2bt4v5ElGJ64agosPHDtY6u8RQndhDmDd2dxSWDPeVVOA7tVpCUUBxADKKk6BQKhQKk2OTfX19XuBtbq4vLS1iRfqBG0bBnTu3B4dGU/kqm81wCWmjXFGU9PLAmIJEnMskiSmlhpWR0Oi5TswSVdez2ez6+nq32cwVS+lOKm0X/I1uIZcCASaUcsExxjFLfviHf/i/fOEPgYsnH39ifv5Wf39/1jb/n9/6z5ZlfOLZ79lYX71+/Xr/QPWhxx43MtmYY4RIr9XUKREcmEglaMRZLJKo4/RWV1wWxaHnjVT7CSCn0VCl3F1apjwJe92CpQfdVqWYz2czIWO3NzYzuXwul8tYtoVkIZvRVT1vWa1ao+fHP/dPf/Jrr7z8A3//HwzMzf6rX/jFzWar3N8XhHGn05HAQfA4DoGgiHHVsrKF4ltnz2UymVwuv7q6ulWrDw4O9lfKXdexdANh7Hg9TdMK5UIUM6mS3W6jUq1SqeSHi1ESRkmUzeWCIIiC0CxkQjdMEHdbdTtnJXHQqdctQ41dXyc4a9luzxFCRlGkagZVNdWwVFUXHBSstHo9oigc8XtVrCCE6rqmKDQ1TaXK1N6mUkqQmCWCRlGU1kPpcIqmaSmVKx1Juz/vlpZclmXFURTHcZJIXddtK9Nut4eHB9OnGIbRcXq6rqfW0WazKYTIZjP1en1vRkChqbK1srLGkuSZZz68vrLKWGwo6sbGxmuvnzcNdOzISd/34zgM4+jm7duqqo6Mjc7Pz+cKlRS2XSqVtnc2m63d48ePJkliGNrMzMydO3eq5dL3fM8zcehHUfDIw2eCMHQDv1gouJ73/PPfSGWSy5eWq33ZA4eObW5vWZZVrlR83/cC37btVEmqlKqZjNFqtRCWCU/q9frkdDFK/Hq9DgDFYrHRaHzkI9+7tblz9crN+84hAJidnU0LqVwuXygUnJ5HCBEiShFW29vbjzz8aDaTS90PUohWq5W22NNVJ93f3wdfIYQ4/06X8D72PYWwp1JWuk1JyyyRXm8SYUTSRfZ+7ywtpRVFSQ9BOsSbZtQAABLABJcCuGBJzEBwiZBEEjgWUjDGMCiSSoJx4IXlSpUBSvw4Z+fqO7VivjgzOQUAhMi0jhNCEEwxuTfkfw9/J6UkBC0sLDDGCMYIkfTsMkwtNXSnJ2Ecx0vLC8VC+e23z7Y7jf135oRMfMf90Ps/srG9lbHzm1uNfL6Y0nJTNZTxWAiGMd0znQke9noqYCwk4hIRRBCmCAl+b2OnUNXQQQiJMJGABRBN9dweQjKbs03DiONwe3X7t3/7t8+fP3/o0KG5ubl227HtbC6XV3UzjmPP6XZarSRiQohWq7WysqJpmqLRIA6ZSBSqqaoa+H7ieZbOGBO9TUcihBCxMramqKEfsIh5HdfS9MZOiyeJpmm6aamqqmiqZWqFrGIZpqbkQyruzl978YVXDuyb/Jl/+X8c2DcDTIDgUnAkBShIIokkACGQJAAcFAUQgiQBhEBV7hVeaRMQhGDAMcYYBAchQKQYIwpEAAAIDDKRAgNHwAWSlCICRFUpDlnEMSAJCAAjdA+HJdOjIKWUUvA9z5/gIAlR0jt/yoK4X2CxKLm/EiCECGCEECAcMYZQ2oIUmAIHAIIQIoxDIoESleo44nG318kNDXCVxCzS01NLYkUAgOBSAJYqxqqUrc0doBB4vjSpQmiYsFwut7W583/+q//zX/yrf1HMZjVNq1QqS4t36vWdWiEPkg/29X3hC1+Iomh0dPTLX/7zgwePMKCAxOryim3oU+MToyNDLz7/3Mvf+qvhgbypYY1gS1OxFEeOHHr+hW8FgZcrZOr13VKpdP78+cOHD6fJFrZtDw0NhWE8MzPTaLdUU19cXLxy5drwQP/E2OiXfve3q32lXqc9Pz/f11+NoujIkSPnz58/fvTYsRMnr12/+fW/ev7G7bvtllMoFBqNxptvvqkoytLyomFoL7300vDwcOg7k5OTcZSsb6wtLi40m7uDg/1RFL388sv5fD5iyeLiomHpaa7XxYsXZ2amt7e3GY9fffVVFidpMQQgqALABcZUoZrneak8H7GEUhzGURQlhmlHUUxVkyWi1WplspamKZubm4pKEZKO053bNzM4OGiommFoQRABQLlc7O8fdBzn4MGDK4tLW1tbqY/q0KEjpVJpa2vjB3/wB7/yta/0ej3XdT/84Y/cujUfBnFtp8GlyGSt9bXNal/5V371l7Y2tt55552HHnoIYf7Y42d+5dd+6/CR6hPvf/jI0blEtn/kc5+6+d57f/UXf2Xb8ZnT47XtntNpFeyBrfVgc+eKF4/ZZVxzOkkUXzx3fmVl6bGHHtE0dXN9tVTI67qazdgKkQjJOA7aPZHPZ7/96gsf/d5nr169zuvy1q0742PT9UZ7d7eeLRUkFtRQdKJyFk4MDRw/eODazetffv4bkLNH5mYZRyOjQzuL62+/86aia1Mz0zdvvddzOoVSHkBMTIztbNfScel2u63rppSSc0iHQPbmRAiWQjIh0tZSuVxeX1l1HX93dzelQmqa9u67777vgx/6/6Nf7ZVrOEkSVVHnZsYPz81urC4fP7ifECWXy33lK18JfecD7398ZWWpXC4XSyUzYwsBvh9qqu44HUC82ek6jsOiOEkYY0wARgRTlcSBb+iaKsDv1bK6njcxDiO7WlRZElAZ9dpZipVeu2LpUooYOHUcLYw432KMdRBGMu6Ccuzwkfz4xHtf+zpzez//0z/VAPjcT/3U7/yPP97tdoEqUiKMAWEqAGMAXTdYnOxs1/7Nz/7bf/qTfwcjePGlt//iL/5ifn7e932MEaJEsMS0bSFEz/MIIWGQDA4PSC6SIFYS2qu3MJKh60sh8qZZ39iOokRKaZp2z3PK+ZzbbBvF/P6JaUvVYxJwztNZnAQEC2OixZ2ey2LBExl7MaY82bvbIV3XMcZRFGGMyuVyHCf0XmfpvrohpaSScYRJumBTSikhnJDUD5Su02lzECHE5d7TLMtK534l5YpK79y5Mzg42Ol0LMta39osFosJY2np4Pu+omiVSrnT6WQyGYlgt9mYGBsnhHTaPV3Xbdu+evXq6ePHPve5z+2bnXv99dcvXLgwOTnp+s7c3AyTfHV1dWJqKs3Sooriun4ml1V1ZWdnZ3l1BYNUiajVapVq+aUXXizk8rPTk+12OxGJkDKbs3/8x3/01vztX/21X2u1vH/+z/9Zq/mldjtqNtrpbjz1DYBEmXxhd3sLY7xTr3Oe45zPTk9v7WxtbGwkQh46fPR+6t8HPvCB4eHhr//Vc0EQlMvVKIrC0M/k7CAIarXawMBAOkeQ1l6GYbiuK6UM/NBxnEqlsr66Uizmu52OEKLZbKaz8UKIe/c7+G5PFUJI8HsAbiEQIqk1Na2Z0g60lBL28nb3WidSSoC9AgshBBTiJDawhrBMZ0rTQNzACyhVpMAISwSEYAoKwYJThhACTu4pE5IQoFRgHMUiEHY2FwdM11UZy4cee9i0qGRA6J6n77sQo+k6SlJ+OAAIAXcX5tMa//675pw7jqMbapyEKbn4xs2bBw4dqtW3VJU2m+1qtTzQn9/eanheLDjdN3c4Y2fjiKUFIsJYMo4QohRzIAIBIBS6nooIhhTEJQAJjpDgiAkeJjHVqWaZQFOCE8ZYYgUrVMEYmk6rr1TZrm3/i3/5LzzHnZmZ7na7nHcydoEQxe+5SZBESew4XYSg2+40m81utxsEHqao1WghAkyyOOlQStMxAcaEEELFCCFgUuw6LduwUiU5SJgwTIUQhJAXhl2/xQTXTbOUy4eu6fV6U3NTE1PDjz1UeeLRp3yn+bu//Qc/8MmPnXnopIw4YICszX0HqwoQ4EnEJAMAKhBCkiEupSQcECYCACGJESCEhZAAGDDGQoLEUgDnHDhgKQBJgSTVdMmxBBAIcYa4xIAUQCAxQTIBuE92QED2DHYAIDCSEtKRQgCCAVI9TMKeKS+NGUQIib1KTt679ewJXFmpEilUIQRCISQJBiExcEAcGURLBIiAqViRCYOBASuXi+PYRIQAEhIoICkgFoISLBi3dL2xsQECFEw4ISCYqlJClG9+85sjIyNf+9rX3nnnrVt3bg/29x88cOhjH/sY4iJjm2++9trt27c/9MzT3W73qaee+vpz3zr9wCOu1w28nu95jz7y0LXLl9567dX27k7s1H78xz771JMPXbhwoZCxFxfvTo2P3b674PnO/v37SpVyz3OuXH3v9IlT09PT3/jGN2q12rPPPttqNzqdFo20r3/9Ly0rUymWa/XNhx5+QEqesGh1ZZGA/Mf/8B986UtfSm+t165dGx2b+o3f+I2f+4VfvHb1xtDQyJkzZ3RdFTL+lX//S5VKaWJiIp/PDvT1r6+vx0n05JNPeo5bqZQwxrl8plKpBEEwMTE2MND3zrmzU1NTUgrGcisrK4qinDx5cmVlxTYt3/ejKMrns9mcSQiOorhYLAd+lDY40tDVXCGvaoZhZ8Ig4gI7jtfpdJIkMkwtl7F1Q+M8wRj8wEVIRlFgWpqUvFKpqKra67n9/dVutz00NGTbWdvKbG1tXbt27ZFHHrl46d3X3nhdCK7rumFZt+Zvd7q9W7fmtzZrM7PTqh5P7isDh6s33lpcWF3dXD12fL9pGS+9/O2J8QJLBAK6tVm7fOnGww89utvyMqXxO0tOs7X1yY8+bmvIa4lmPbJ1s39ottYJV+6uvPzGS6Pjlb6+SuiJlaXVcl9pcGAgl83ouhoFDlVI/2AfwhyQMHPm//iz/2GZdtcJisXqpZuXzzz42MLi6vZ2bfbITBwHwLnX6y7fvZNVcMZQC5bZPzdd63VjBsVcbitZzmdzw8PDqfd5aGgoZkEQBCDp5OR4kiR7s2/FKqGpmZsCYARkT3QGgZBQFSVJWDabr1QqOzs7u/Xm6OioYVt2nFtcXHwf50Ao/G8e5P7OFpCUkgtOMfmR7//4r/36fwzcrud0FW0yk8vt3z8HABIjUBRq2JFAACL0eu3adqNZExhFSYIBKZgA4oqKFIUIJLvdRtY2I6/JgyCXzVoKCoOeRZVe1Nndrh2Zm9Z4rj+bjXud1fn5hx84c2pkBAPJWbZBlIKuKQCx6yZhFHOxurrUFUJSpCPotVv/9mf/dYuJfN+gxIQzkYSRQkkSh7qiSsmJqmzX6sura9947tVGo8VYfPTY8YOHD33961/f2tpSdY0oNIxjQoidzSRJkkRht9nMm0aGS7XZ22/kRBhaWAcQSSAOTxzoBF47Dj3GcKlIEBSK+aDbM4lGkRKHSa5gBVGIFCXmjGAUM+l5vqYZPBGmaiSct7tdRFEa70YIui88pRv4dLGTAtLkFcYEJaqSZlHFcZxyLFPhIRWl0lUw9XBFYdzr9VKkKcY4CAI7lwUA1/UeevSRF57/phcGAwMDSZIkjMVxnLYUHcdJEWGKonApFEXZ2Ng4efLkjWvXV5bXnn7fk1tbW9du3piYGCuXi2fOPFCtVi9evHjx0h3Pc8bGR6WUm+sbx46eePvcWcO0EUJRFBGiWFam1eyUilmM6fraZl+lamWyURKvrm+Wy8X1xU0/DAQSv/hLv9w/NPjoo4+/8cYb586dC+MIkHDcbn9/NYjiXreb9uM1bdg0zb5yOWObt2/fHhsbWV1bsyyr0WqW+/qXl5fX19czmdz+gwf37z9w8+ZthFCK/krBfT/0Qz+0tLRw7do1Xdenpqa6HUdRFNf1DdNOMz65yufv3LYzVkrP4ixWVZrqfGkhK7kAALpHvSJ8D9v4HSFqr7unGQhIWpAxxsQetwhJIeEe51NIieR3WoQppDStfu5RNqSqqkSh6UMCR4AlcJ4+Pe30ACAJBGGM01sAVnTNcbxKdUD4AYtiFZOHHzwDEhhjlAIgAQiQxIAAhJRpaPKeCQyl7PD6Ts1QldR6pSgKoSiVOW3bVlVKFOoH7vDQwNraKgZ5+PDhhMU9r7e+vn3+4qUPfeiDUuD1lfXR0UlCFCljQFgCcJ4wFmMMgicSMEgeJDEiGAggJDkWnHMFsBCSYMoRYNMEUweJERcMcURwu92yMjoIUSlVF1eX/v0v/mLMkoGhwShJTNPmTGKMEWAheK/Xa7Vau80656zT6SKEkijmnEdRGMcxl0w1dMaiOGYqVUXCoihRCA3i0LYs3TAYY6Hv9+JY03RVVdqdVjoBquqKqutIJAiLKInWG51Kqbxwd/nye1ezOX1qenxifPDAvpPffP6N3Xrnox/93iR0d+/WBocHoiAKkgghIKqBMY5jQQhRVQqA4yRBKKX57/mhpADAiGJMIMUfSy4llxIJghEBRJBEAmGgRMEEKCISi9RxgImUcN+uJ+U9rfB+k+JeFLRECEuccty/U+sjhBESKSUe9rqaSIJAgKXAgAVn6WQHwgIjRACBBIyQRIAJAR6D5BJQkCT5glno64tWVxElGIMUHCPEuZRcUkqDILB0rV2rQwS2pvoYeUGQNc2dna18wZ6ZnXjrnbfWVhfsjDk9NqjIKOh0hRCxp2CUHDl8wHM7vU6z1dwdHx22LDObN8dGB+Mwefv1VzSCTh4/9luvv/yRZx7PWNZXvvzViYmx973/yee++dLW5uZgX7VV2/UcP5cvGKo+MzEbRyxJkv7BAaKQq9evnjhxolAobGxtvvvu5c9+9odByF/7lV89dvzo/rnZt996zQ+8X/zF/3t4dqbebGxsbIVRfPLUmZjxqzfn5/YdunDxPS/w19ZW8oVsFAV/7+/9vQsXzl26dKlarfZV9K2tnZ3t2tjYWF9fXzZrv/ray3EcF4qFHOTm5+dPP3j60KFDAHJra2v//v3dbnd0dNRxnMHBwWw2y1gsGKcaMgzVD1zd1ChFiooIoZRSO2t1u90wjiTB3EVcyMWFVc8LCKGCsU6bNxSSyViKirlknMVh6Gez2SIUdV33fd9xHNO009BiLplh6csrS/lc4dChqbNnz46PT164cOHw0UMnT5587psv+GFcq+0+/fTTKtUuX7lECBkaGsCYFgrFu/MLI0ODI6PDf/mXf0kIEQJyhSqlma0tN5sdXlnpaEr/iRNjzZ3FG/Pz587/8s/+i3/2lT97QZX7vvcjf395vffiN/9qcm7q73/+c3cWr3z1q1+dmz5SLVea7V3dVLmIpBC6pgoRt502ppDPZ89dvpDL5JGiRFG0tb2tKGqxWOirljc2NhEQxmQhU1q+vWCDUSwPvf32m1PTcxuNzub21sOPPaVS1Q/jat+ARLC0vHj1+rVyudA/XB2bnLCt7Pnzl2q1LawYKJG6qaRXKMYUAcIYEy4RQgJAAuIIHNe3s5lipbq7u9tsNn0vzJjWzs627/vLK0sTU7P/y+oqLacAgHOOCdFUzfXcjGU/+eTjX/nKV4Vg09PTrtvL5XKzJ44KwVwv8H1fYmV7e1vyRCSR8J1iKX9l/k4mm6+Uygoh6VA8AA49VyXUcRwsuJ3NOJ4LjPVXyiPlvlWBH3zw9O76SrHY7/a6drUiajtJxoqDEBIpBWt6XtsjEMc8COI4Bl3bldJVyXqr0dJUYmg5w0YCJZIJLjBgBFJXNSKF5EIimclkjG5nc3Pzj/7oj958883TJ0+dPXvWcXsPPvhgp9MKAo+xmDGWRhEohIauhyR0NEWVgu22n3308QOjM7W7dynHtU6bB76tKxwSQ6VJEhiqovtR3tA/96lP/+Of/ulnfvD7ajs7oCoIiKbqqqbphkWontGpFMjKZIIgUBQlV8ylfXDDMEqlAgD2PJ9Seh8TiDDGGKcoGUqomqIvDaomjKWenrSRlCIMOOd7gS0Ic85931dVFWEspASMGGMxY+9eeu/Mw49+5WtftSyr1WrZtpk2GRFCCRftTteyrYSzOA41TfO8oNFqHjpy+O233z56+ODY2Mj1a63l9aW56anL186NTQ18+GNPKyq+cOFCEkcCpOO4G5vbAGBaepIkCeeM8b7q4OT49LX3LuO83kha77x94eFHnrgzf2t8fHxlZaVQ6Ts8PEwUurSyXNtp1HdrP/nPfvpnf/bny+XikcMH7i6uRKFfyBd70PUcp79aXV9fy1jW5s52HIfDoyOdnlOplO7evauZRsIEk4KqetdxANDt23cSxlRd6/ScUqm0ubn54Q9/+MCBA+fOnXN6nq6ZScxVVU/v+FTRUixCFMVScoRkX3+p0Wj0Om7aUe31esVCodtxhBBJFKu6Fka+H/mqrkmJuWSYKEKIKEoUReNxIqWkiEZRQqkaxSyII4mRQAJASMkJJkhyjAhRlLjTYZksSIE5aEQTHKIwSaVjRDFWCJM8TCKiKIpKkZAEE4REyHhMkK4pAgkspURS8phTKjGSKmIRwwQhwRVCDU195OHTgICoRIJEKUoUgQRAGCEAkYq8EqIw1nR1eXm122pPTkwIwSzLYIyputJsNgFLomDH601PTfpeb2V5wTC0UjE/PDRYq23v7LhEUT7xqU9MTc4sLi5qmpGzcz3Xl4A4SEAoETxOQjtjRnFAVQIijhHjVEgkJZEhDxGSRBCCMJICYRoiAZoGQWQTlaqa4/Ysy1IIsUzj2y+9+Gu/9uuNRmNycrLnhFIgKRJK1E6jXalUDMsslkuI4LbTdjtuGEdJkoCQMUt6rhMzhhAKg4RSFUnp+6EUAiEUE6IS3HVdLwwxpUjKhLEo9qiCVVXlADHnOAo1g6uakiSR7wQUK81eD2PQDLvnBGfPXblxc+Hg/rmZmX3vXt/a7T336U9+fGh2moWhbis6As7Y3s4VY54kSEpMFKIDAsQ4o0RJkdBxHKuq4fse1XUpOaGUYMYSoagqIAIIBAeQSFEUDeOEQRKLjY1NoiqVvnIci1QoFUIQQhHBafw5AKCUQXofD5Fi2NGeSUSmoR4ypcN/VwR4OrmBkQDAWHKZUv5JqmlRiSWCCHMpmabQJJGgUN/jIKAyMl6/dnNqMNd2PFXXUrugihTgSADDGMdOF1zX1IjL45DHJiGzs2PN2ua+/WOWjnu99szB8Y27N9aXlxSCEUI91/nwR79X08f/9E/+pLaxlS+WBqenvvXS85Ih08gc3Dcehe7s7IHL776LAdrt7qV33wsj99Tp0xfOv7u7s727s725slEsVRqtbqvTJYr+iU9+cru+XSpWEsHcNffUgyc2ttdUTRkaGHzyp5/+2Pd+/I2X3/zRH/7c4uLd5cWV7//+Hxwc7K/XG7//X78wPDJWHRha29g5duqBr3/jpbuLi33VoZ4XzuQziIqtnc0kiR956OH9/uHbt/5ibXWzUetMTc5KgRfuLjd2m/Xd2r59s1EcxHEIgBOevPr6K8VimTEWs2RrZ7uvr39tY9113Vwu09taV1VMCUaxWNpoDAwMJGEcRr6m6AlLdpsOQsi0DTNjJrGMkpAlMpPJaIoRhjFRJFVIxKJCoRTGfjab851eJpvtq1Z3Nrcymdxgf58fBghJ1dA5yLuLt0+ePN1s6lzEN65eO3PmoZXV9Uq1/4d++CcMy/yzr339z7/8lX1zc4pCbFPrL/cv3F3lofnRj33k1q0bLIJiqbS6uvqJT3zipW+/rKmmYWXmZk73Dw5tb/PFOxGFoST0PDee2jfZ6cQXbp0bPzBY0Kc3dpZBFP7t//UzfuLmqsZX/rL7+MOPDAxOvXPubGmk2Oju7psZjkI/CkLD1OxcVsuaYeL2jY/gBLdbDnB67b3LTz31VK/TKhfyvV53d7elWbYTIKxXry5s3foP/zUKHN0y+iaHZaLtbLYCd/72rcUf+ZGHJQI/8o2MNb+0MHN41g2Drtcbmx7NlWyWyEajwUVIqIYVShXddz0DCMFYcsCYCgSxEEYm23W8YqGEEJGCb21uDo8OVSqV1fW1m7dvj0/OICwBJGOMUBUAOGOUUoIwSAAkCEnvvtIwtISzyX3TlcGhXLFw7MSpm7dv7dbqKysrG6srmqkNDg6GvRaKIs6Yrqokk0FIizyhKZhH1Mxk8tmsG/hBEDBuWJYBoQ+CxwKwboQUH3z06amxsUB5OaSEIbEaR4udbl+5RI8eHfn0JyzDfPG5b7bqu44fbiysfPJjz06Pji2urLSC0CqVbt66cWl7g6iqFyWu38CazhAKo5ggjDEFxJIoFkIwFscyoRRfu3bl8ccefd9TT77vicePHz2kqOSrX/3q7vZGsVhMBC+VStu1baLQbs/PCh2p1FW4kBFVk1feesXomxriUMDqvkLxT66+ugSQAIQAGMAAsAAmR4ZUIf7+T3z+hdGJuUce7nY8ohuO4yCEETCECGPMsHQhmOSyOlDWddPzvEKhoCiKZWU8N0hijiVWdVUhSlrjpjQaJDmlqgIAiKexwfw+hCkFDaQb1u/uXqX4ovsYJ9u2NUO/evVq6sRUVbVYLK6traSJVJRSkCgt1BBCuq72ej2E0Orq6uT4hJWxL1y4cPLk8d369p07tzOWNjc3u7q6NDu77+ChuUuXLz744Olez71+4yYA9j1PCAGIEEUlhGysr/+jf/iPnU73vfeu9FWMgeoQQmR0bGpza7PnBJZlrK1vZ/M53cyGYbiyunHx4uVTD5xaXl6Nomh0eLBYrjabTUVR5vbNSIE2Nzer5bLv+0KI4eFhvrZWrzfy+XyK7XEchzE2OjqqKEqv19vc2tre3rYsa3e3VigUHnzw9G/91m/dunWjUCg5juf7YcqnSOtUXde367VcLqdpShzHGIOiENu2O50OFwkXSdbI+UqY5m8jhDCle8KhFHtT8QilBwIIlVJomiHEXt5zOswu7nEZMMYgJSBBME5bUQBISnGf78CSRFEUKWXK7ldV1bQMKSWPE8Z4kiQRS7BCOdoTKpDk6UopkEQYM5Gouq5FUafVHh8Z7R+o/I1ELPldX+8/MMYgoL69kxbcBDAIwZHAWHN9hyqKqtIkQfl8/saNKywOianu7uzYptV/9GiuUJyenfsH/+gfHjxwuFLpazRaTzzOEcKqqqVnKWeSMZaKNBgQSC6RkJIjCQQkIQQRIIIgSkAooKq+YKCqIHDs+vZgzs6UPc8XLPm9L/7el7/85Uq578jhY+kUAqWqYRiKomZyAUa01Wotr6ysra/s7GwHQRBFMbqH1RBCICkRpoLJmCXptB1gsvffwyC4iFlMyN5hIoRgoF4Q3MfFMSGDAEsQBFMiYwSEUqpoqqobMeNr6zvbO83bd1cfeuihS1fubNX+2w/90GcmJiYYY4zHiqJzARhjyWW3FxaLRUAIhOBCINAAqEI1kJhgFYCappbEsaKaURiqqoEId70wFZgxUQCJ9CxSKCgEV8p5PwyQTAdL0X1HHXynE33vaKffp8XUXz8F0pHDva/f5XlH9xDwHBG099S96gwD4giIgrkUae9RYoQ1BTTIl8rbQgJgggWSQmKJgCCBhBCapscEB54Dbg8rGSkSXdOAwPr62vjwAEuijfWVH/nM9/cV8gVDW6kUw8A/cuzwucuX+0o5JsT2+lroBB//+CerkxNvnj33ztsXHj7z6LFDJ3zf7y/3dVut4aGhKGTT03OO07l8+VqjXtvZ3p4an/B6XqnYNzMx+8prr4cxW1tdHRoZarVar736eqGcW9tYr9fr3/fpz7z0wsvbmztu183n84t3F8rFkuN25ufnd3a2JqcnPc+zMhnph/N3Fl546WXA+IMf+ojrhJyjqcmZK9euTYyNPfbY49987vm5ubnHH3/S87xWo9vruSdPnrx06WKnIyzLYozl89mYGZ1Ou9VpC8H6+vry+ezi4mKhUGi1WqlZZH7+VjZnWrZuGNpAf6Xe2o7jsFKueJ6fojsyGavnOggRx3GCMDbNbBQxKRgGqVECQmqKqihkdXX51IMndlu7fhSWC0XBQTdtlSpbW1udXrdYLGqaFoZhrljo9TpjYyOb6zuE4quXL/3D/9dP/sIv/9Iv/+qvPPX0+zXNGBkfO3HiWDaT8bvdnJ0ZGZ5sNXsiodsbu04vUBXv5IlTd+7cOXfuwhNPvX9oaLTZ6G3v9Ha2u4JZp48f8dq11cWLppX/sR//52fPvmzRkteEyYmxJChIDqW8Hcfuxz78oR/90R/+L//lDwqFvOSsXCzs1ncKuQzGOGZCYIWoRrtVj4NQ5aqtZf1OGEey7bhdx9vcqWWzuSjkhq0HCSqPTPcNTQdOr5TPUgVypVwi+Mz+A47jnH48Z5cGS9XymWJ5bHtzY3vtnXNXNzbWBgb6VUVZWV0bGBjJFbLb25ul8oCq22EYZrNZFgQgJKD7kjCWSKZ+j8HBwc31DafbkXzA1HTD0JaXl6Mo0DQD7l2P9y+l9PIB+V3AFBACoUTAJz79qT/7sy+nk4mMxyyKR0dHM1krCHwW+bZhOE4EknW6Xqu9cfTwMd3I6JohhOh5LmdYoaah0263jTGVkmBKVFXp9trffvNs0/EKI2Pbm+s9TIanZx85dMhxnFar1bbsSNP3fejpzm5zZ3vzyZHPDA8OfekLX3z19Td9IRnCVjaTG+h3giDkAquKH/kIkYxtJQn3fd/3XVVVbdMSgnm+q+t6q9n477//B8ePH11fXvqpn/rJV1555fL5c6VqFUkQSbK1vm5mbC9wLcPUmdLzA0f61CSlfEZjaKWxrmKLCxizhz77/u9Z7tQuL9zSTZP3gsT3K5WKbVorna4O8M5rb8w9/mTH2TEQZZgmYYSTkCqKHwScJ47vFgqFbrfnur09r2Gp6rlBEASGYSCB0qN2316ValWUJ3G6PhGCAOj9gbUUSXDffI3uPe7bugkhnu8oimIYZqPRuHTpUqlUWlxcPH369PLyYuqOl1KqqiaE8Dyvv7+/1WpwzlMf35UrVw4ePLi1trq+vj44OKgbdGtra3h4KJPJ1Ot1JNHp06dXl1cmpqYnJiYK5ZKQaHFleWu7pmlGxsoQQm7fvDk3M7u8NF+qVCenZ27cvAUA7U6rXtt97PFH33333YWl5eMnT/peWCkPPPzQ4y+/9nKr1VtbWx8YGNg/O1ev1zd3anEcl4qVKIrWNzeHhoZ8111YWt7Z2jx48CBB6M7CAudJs+kcOLhvfGxybW2t3e4UC3lNpXEUSME+8pHvEYKtr68SijAGw9DS2ZAkSWzbFhLFcVypVFzXTfu1cRgTohCShGGYFj1SyjSpMMXK38MKYdjrs6D7s1eccynFvTqMCJCEEEVRwiD+zkqPBEJ7BIT0UKavn1bMcRSlPvfUBaWq6v3cHriHM4W98F553yOf/pAL4ft+isiL4/gDz3wI6QAcEP3bwaN/s8CSXCwtLRm6jiXohn7/13U6nRRRkXZLDU3rq1SZSADg1VdfzeYzgIkfRraVrdcbtdpuf/9gLpfb3W1GSaQoCkjgXEZhghHd+9AEwkwgJhUmgSGCgXMIJE+EBEo9JIxSEXQV4mjhzt3WxctA4erVy+9dudRstNMdSbPZBADTNJOECyFc12m32xsbm6urq2mWOYDknEMaXI++c0Wl70gIjvZw5RgApfwCKZEQ30F23bPQMQBASN4nnyGENE1DHFLKf88xc7mcaeq2bYdh2Gg03njjjf6+iqIov/Eb//Hv/J3PHzl6NAxDgCSl3WKMi6USSLm2ulosFu1MBgCiIEYIqZrCGZOCt9ttwzAUVaWUBkFkWhaKUn8VchxH0zQA3Ol0NM3gnBcKdh7Zrp9812kg/9cFFqTEB0gbw9+prtD/+sz462UWQntLA4fvWh3uNxlRiutCCACKxeLe9UIJpgQzQTAVEoSQQgisUN93IAjUvpLwXfL/pew/4yM77jNRuMLJoXNAaGTMYDA5khxmUkySLImUqGQ5r717N9i+K9vrdfpd793gtGuvZck5yEE5UqQoUQxinuEEkjODGUxADg10DqdPrvB+KACkZMnv3vMB08Cg0d3nnKp66v9/ApZJGE6MjRzcP93utPZMTvgd55lXXp0sDdbL65qifO7CxWQuh/ft7/b8j3/84688/3K323vly99QDCtpZdN2lhJw6ODxl55/4fLM1cnJKcBJtdIaHR3aKK/cefs9NGZXZi4O5HLLc9c4QCdPHJ29MVfIJJxO+9LFxj333PP6m6+3ms7g0Njf/N0/QAafe+6FO+6488777rZM5VOf+pMf/dhH3njj/L79ex23e/XqVd00DSvR19efTKZnr8ydvKX/cvXqgw+8M45JNpVv1jqry2v7p/c///zze/dMjwwNb25WZ2ZmTp48KUlSoa/Yczt20jItvbux4fv+0aNHl5cXdV13PadYzMdxmE5nwzB0HGdiYsK01F6vCyFQZK2/f7BWqzhtJ46JgpQoihiHumkQEoUxkRUNY6gqMoliQEmn00knM2HoG5aezqTm52/4vptOpxknV69dieN499gE5zyVSrmua8t2p9NJWvbi4nKz3jpy6OjQwNBT3/7O7//B/+gr5lGz9eef+uStt976/ve++6tf/NLeyd1Vx8ll+2UlvVlprJfLEEt79x1IZ5J/9Vd/d+bM6cndU3FMa7UalrSIgKmpXbt2TWHONlZXLC2RMQuXXl9hfrpv7MBnvvHdp59YGuybjmO6WZ8jwAFSHNPoxlw5X+iLeAxDmuxLxlHs+GRxpQzM5PWXT4+MlAxVw0jVkFVutQmXB8Z3XZpf/M63ntq391AykbWt1PjU3s1ma21zY/rY0VqtJstyo+domjG7UCeMasnB2dXWUrlr6kqn449MHJucumlu7rrTbZU31hBKxCHyPWobal+hWK02MZZ9x5Ew/L5hIr73PK9QKJTX1tvtdhiGhmEk7cTqerm2WSmNjIrpAgDAONuhXonpVtSxtv8OxBDs3btXV57ghEaBt7lenpqa4py22y1JwpIstzrNdrNTKBRGRkbGJ1RVT/hB5AYeiRljFELuBV7kRBjjdreTsGxJkpAs6ab5yiuvfOOrX4aA9eVyiiIzxooD/cI32w1cQ9M0Rd49MXn0llteffmV3/wv/2+jXs9kMtlEWjWtnudFZEuO13McSVMVRcnlcu12N5FIqJK6sbEh6jihF6h2gqlUy+dfP3MGAPDqSy9yzvr7BjVD7fV6hmZAE8aM0pghEzNJlgA1FYwAD8J4k8QEsSN339pe2rhy4/IBvMeU5PccuVPDsu/0VFnBGl7YLKt9iYYbNTarwHEYgkrSUCTU83uIkWQxs3ZhKZNNWppqKHI9DIR/uOM4nU5HYKE4jiUoxXFMGRCEdTFNifijLWsysF0s2bG+/GecZQghjKJIVGgElcfzPIxxOp2uVCrdbld4LKXTaeGqhRAKwjgIAgC3QgCE85Npmpubm4cOHSqVStevX+8r5sbHx2cuvnn16tW9e/cAAHpdN5NJrS6vXL1y2UokEQeJpJ1LZwhhuq73HG94cODZp79jWvro6KjrORcvz9iG6XkeRpJlJU69euamm26avX7NcbyhoVEO8F/8+V8jGd24PjfY399oNM6fP29Zlq6ojLFcLpdOp1944QXHcUT0iozRysrK3Xffvb6x4ThOzGir1Yrja1FIwjDwPA9j6HnezTefvO++e1986fkw8gcGBmq1WiqZGBjoW1hYEhU7RVba7Xahv69arWIMoygSOk2nE9m2TQhRFd3tuTv1QnEtKKWyqmyf/+2E3e01KYoCwWES2EUAFLTty7C9/rEdby0Eobi+gr4qTLfFdQ/DUPxZTVZ2iitbQvqtlRJuU9QZ59wwzSAIJEnqee6xY0cA/Wfukd97MAYgBwghv+eur68bhgEhFMhPxmoUhp7r6oYRhmEum+EkLpfLpqkvL1f7+vqsZAJC7kXR6dOn77//wbNnzyqKFkckCKJkMt1ut4Fw/YIwighCEuAIcAQAhIRBxhFAGEoI8hiDGKEYYSqbsWVoxdyLL724QcILN65fnp11fX9tYwVJEHBULpcF+ozjOJFIYCyL29t13fX1ciS8gyUMtu1LEEJb5Rq+BTvEGQYACAo5hAhjzNlW6ifclnZuWZdtV3SEbmWH28QJFxCWMQYhl+WsiGMiJC6XyyvLi8eOHZucnPyrv/qbBx544D3v/RFKCMIojmNKKSRkZmZGzLzCRUVVVQBhGATihpmdnT148GAUxJzzl1566cGHHtrhACiK0u12fT/UdZ0xX9jTO44PkPA3eyvy6K1OH3h7dAcDWxFp/0Kexw86IOcQcLplM8G3n08Y3YJfGG0ZkTJgJRNhGIrIeg5iSjmUMAdc1ACE5xn1fRlLCEAMIMZ4cXGRxcH09B5bM2rlzYnSCAi8uOdLGscEDA8MWqqp6uaFizNYVuu1hoSU9ZUNVTFSyezg4FC93my2OqdOvVYs5mUM5heXs9nM2NhEsVjcWF8Pe56vdvftmb4+N3/98oV6q1XbHDh+8uTU/v2f/dznau1mNj9weeZ6vd6cmZl510PvTiQS/+t3/1syYY2Nj2QyqXQm0Wo1/vhPPrG0uPLzv/iLpmFn0sX+QjF0ycLc/OryytXZ2f5ietfk2GZ389VXTr/vPe/5pV/6pT/71J86joOxvGfPnrW1NdO2VldXGY+LxbyqyZzBMIyq1drg4JDjdKIoSqfTQRB0Oh1VVRkjQcA3NtcVRUql7dXVdT/yMdICP3I6jipr/f39rU4n8GNKOeHMsvUwjCUkG4ahJTVKSLtVy2bTPaddGh7sul2MYRj5MUHpdDoOwqWV5Vwu1+k4ViLhuUE2k4+CoK9vQAKKoOcOlgZITFVZ+siH3j82PDQzM3P04KHf+tVfGyz03XXb7bVGR9O0m266ZXV1vb9v8MKFC4qihkF8z70PAADm5+fzheLLr5wKYzo9vW9zc+PksRPJZPL1M6u1xsJddx3t7xtqd9Rjx+9ZXui89MK5RrPSN2BBJVJ01Gy3s9msaZr9SQszFAWxblhhUB8fnc7nRmo1N/agbiS8TnD1wuthBAPONxvOlSuzd9533+U3r8QcG4lMFLPHvvlkJwi+fepVWca6pCR1M3ADVVYrtfrknunQD6AXDfX3rZVX3bCXSJmqJg3053P5MafdmJwYYLRWXq+Oj+1mhMpYwrLMGGGAb/MV3yoUe56XSyUTiUSrWe12u319RUPTNEW9dvXq0Og4pzHetnjYHkc/eDMThGR0eMA09WvXrnU6nSgKarWKbqiGoXe7bc/viRIAY6zT6WTz+SB0Y0IZo5TFURz5vh8EgdBUYSwRQnzf1zSl63TiON61Z7fb6nTbTcPQOYLr6+tYkpLJ5FNPP8MYCwIvaSdEooOla7sPHAAA+CGlnAVRFLo9wqikKHYyQRgr9ve12+0wjIvFIo0oQmh0dNRxHIjA0UOHs9lsdbNSyD3U7XYtw1wvr7700kuyK6uq7HQ6MSOyoqiS3O12FUlNp9M4DjzfSWWTxHcXnfq5VtW24PCdtwwMjZWS6ajnRZ6/2u2U+rNhHM5urh24406pUXNZDBS543Rh2whIhCAfKvUfO3TwwpnXosDXNUUI/10/iCJi23bgBztCfgAApZS/Tewlpn1JyON3JnoABNNiS8//fWWMnblVAAVdM0WCNMYYYxwEYbvdKpVKKytLrVZLEOlVRem025qhbWxsDA+XqtUqpwQBaNv2iy+++Av/7t9+61vfXF8vF/vyDz34rie/9fjaRnnPrt2+G8RxXCwWNzeqhEStdjMk8cDAQK3WQBxk0+lOq10aGgAAOE47lcnOzc1hiBRFmdqzK5Up9Hq9bs8DHK2vbZhWolQaXlhYaDtdRTFIzDCUNjc2dMNoNtu6rqeSmYmJicOHD1+8eFGoPxYWFgYGBnTTMCxzbWN9eHh4ZGSIMVap1ILQgxBSSgYHB370Rz+yurL0zHeeTiWSMsZxGHoQ9ff3r62VRQ8uk83Lsjy/tGgYhqJojuMKn09VVTHGovIUxzGEeHuJhaKcIOCC0GuJ0wi3DBsxg4ACLmGFMSpijyjlkoR29vqilLUDkUVLV8juRLVT2bLMkIV1mSzLUMKMUYCRrqpBEADOEYQICncuCBkHlGmavri4+H/97L/rdDrXr145dGQ/kLeL0jtj/G0Dm28rHBGG9Xrddd1MOo0QwgBTSlVFabbqjDFZkgIvLBQK12evFItFRuJKpWJYhhd6tm2rpmkYViqRrG7WFEW9//77e10HIKzIGmNAkiQZyTSKJYgABUBGAGJFUSiSAUCMo5DjAMFQVUNNJZrGs5nA0p546blGGAYQQAiiwLcsq73t4iYUHpzDMGxUKhVVVYWXbBxHkrwl3hGddACACFfdxggC1yIIMAAAoi0tp3gKQmj7N7eKVZQyCLkkSZwjQpgQNDJGfT+UEAgiRgihnMRxSAhRFFlRFBEu5Pv48pWrlUptdHT4ueeeq1Q27r333o2NjaNHj+qGsb62durV1z7ykY9kMhnHcV568RXbtqenp0+fPj08PNxoNBYWFm6//c7V1dVKpWJbycALO53O/Pz84OCgoqmVSqXd7k5MTMzNXS6VSuNjE7IsxzsmDECw5XdqVHD7A+6EecMfPs//4EMg051vGWTbWzpx1yNAOISQQQ4QBJSlsymAkRBGcgQhE1MTAgBjDBFCsiw7jmNuT1O2aT379DM/+1M/njCti6+/cd+dd4auN3v+9eG+PurFCpRNxfB6/srm5quvnkEQr5eripHIpfOUsvW1tfe975F6vem4vUw+V63XJARlCa33F1NJs16pDvYPLF6bXeu03nnvO5YXFxCL7779ZIxQo14LPNewE8995bG773nnjetLa+ub2VzxjYsX9kzvfua5p99x712Hjx7s9Fqr62vn3zh38uTJTtsZHh5+842ZmSs3jh29eag0/sabM3/xF3+5a9eu4dLI9Ss3sARlWXr26Wcefvjhe++978knnwzCOJPJrK6v/czP/NSlSxd6vut4fjKT5hyaRrLV7CwtLQ0NDUxN7bl+/fqVK1fGxiYMw0BI6nTaqyvrt99xa71ejaJIMyzOpWy6kLKJ73oYGYYOsSQtLCyphk5iiBCKI8FMALKkZrNpw9QjGjSaNaxgjFAYxIZhKLIiQRQE0erqejKRjmOqKNDzIl3Ro5Cbpn3lytViLl8sFjc3N6M4fOKxx5KpdHWjPDc7e/PR47EfhK5vG1a55n36Hz4rSdI9995FKE8ks7/0y7/addq//Mu/PDox3tfXFwTBr/3mb2GMFVmbGBldvV4wNHliV4FQd2V5+Ysvf93tgPJaa3ho9CMPf/T4TfteePEZw9Irm40b11ajiG2U60ODpYSZUQ2zXpufvbLgBUo+VTp+9OC12av9xYFum3kB6cumas0ehRJDWLPM3bt3j05MzC/O+z333nc+CFX5xvycBJGB5IRpeY5bHCxFlBm6RZXQj2C+b7RkSM1O07T1tc3mylq1Ul7tdvybjh/bWK82m+1cOtPr9TiPOfwBY2Znwe3r66vVN6qblYGBfhlLCdOanZ2978EtswYmJEkAcMbQD0iARhAgGXEJgVtP3vzrv/6bk5OTA/39diIRxcHKygrntOd24zjGSB4YGAAABXEIEfOjIAgIiWkYk4jEjAmvYUx5HJEYy0jTtCAIGASu62qaZg8OIkmSJAli5Pou5SyZzSmKIkkIIeS0O5qmYQSIJEVRRCEPPI8BqKi6jrEXBqqiG4rcbnc1TZdltdvthl6oquqD99+fSqXiOJq7fqPdbIW+v7S0oilybbNi27apG4qmEhIxxjhhQixPKMGKvFndKBbyipx0Ha+Qy+YK+cdPnU3pCEfsF/71z07ddeypL3/l9NnX3vfow4ff9c5nn3rSaw71RvP7+9/xn/7bfwemNjo6UqlUNVnxek49DKEfQAKiMFRUiXGOJEmWZdf1McaJREJV1W63KyJSOOcIA2E9KqYwjLEURZHQD4pNNsY4DEPRtUHbxw7wAtseGwKj7ThmiROtqqrrujdu3LjjjjvOnDlTLBYxxoqi2bYVkbjVauXz2Vwu16y3xNN932+2u0NDQ9euXpmdnbUNvVQa6vS6UMK6rqdSyfXVtUw2ValULEI0TWs2agN9/aurq5aFIt9ncVwqlZAEBK4cHh7u9XrXr80xxorFIgBIkhRJ4YuLy51O58477+wfLPlub3V56fzrZzVNc3u9ZrOZyWQURTl37tzIyAghZH19/erV6wnLqNVqX/rSl47ffBNHsFQqFYvFa9dujI+Pq6oa+JHv++9+97sTCfsrX/lKrVabnt5jmqYsy9VqdWZmplQqzc3NdTqdbK4wNjb25qWL+XxeOLwnLANCmEgkxElGCMmSSjgTC7wGobg24r92TDW2qkrbZQ9RPgzD2PdDXVfFVdsqGkNIKI3jGEBGCNU0HbwNcu04zIoeovgq/Dx22r5vH+Q7X0V9ZXRk5IknHw98/+abb0YyABAEQaxo8g9cUiEEO5WOlZUV4c4gDgSRhFC73ZYllTGiKArG8NKlS7qhppOJkZGRVCZl2Mbi8lK9Xk/ZiVardezYsZmZy3FEU6lUGJMoJGA7PziOqTCahxAChKAkE8gDzn2EIkUJTdVL6KGuEVXtYb7a2KwGfo/RTreHIGy0W17gQoRESoE4V67rh2G4dd63/TK2qG6M7HwwzjnY7rVDCBGSGGMcUFFWBED0ragki3YhYNtpSNv9XLLT2BUnX9wDSMZBEAgDbk4ZY8wwdMuyxJ2g63qj0eCMtdvtW2+99c03LwKAxsdHG43WoKYNDg4+8sgjzz777C233HL58uVjx47Nzs4KK/M909PdTgdC2Ov1FhYWjh079vLLL7uuf+HChePHj7/44ouHjx7Z3NwsFPqee+65++677+zZsxPjExhjwgUoFDx1ICZ0sO2TDwB7G9L6/wOw+PdmDGxdMnGDoS0GyjZYYwhJYicDMeScQgQBo8lsRpJlLKYmsQkUpTUMCCFQljGAkR8lIWKEM8I4BcVC/8LcomUaR48cbzbbfYnEj7z7vd1mS1WkXuAX+4d6bhhT8I77HvzOU8+srJeLRXxjfrnV7iSS6V/5lV+p1Gu7pnZzCW3Wa6W+YrlaGR4b0TSt1e0cOLBvvDSwfO3a5cuXx0ZGH7np+Ge//KVMf/93v/vs6O6pgweO/D//ZY9pJNdWK41mJ5/P1mo1VVWzhTxAKFfIb25uLiwsrJfLfYX+2+64w3MDxkCv1zt9+rXE/dnLl2b27J6SJKnT7JRKpSiKwsgP/Oib3/wmQujmm29eWV2Pomh1tf70s98t9uU3q1VNU9/9I+8tr5X/7m/+WlVlTVOOH795Y6OsKBrGIocjbrXasiwfPHg4ncpXNmtuL5QUK45JLq1GQRyGset7pmE3261UNmPbtqwohmF02m0MaaNWpyQ2VG1tbSWfz3IM65V6rlDgDDbrrWKuKEkK4EjXTAqgrllBGGuawYBMoxgwKSZhz/M7nU6n2943sK9erw/0DwLKHvvaN0aHRmevXPmHf/jsRz/6k4yCK9euAcre/d73jI3uqjVb58+/Mbe4UGu07rhrJJfLDQ8P7949+alPfWpiYmJtZQkT+O5HPmDlk0G3ceRmuPvAXSk798rLr128eLEbe0889+zMzKWEnQFMQmrG1nVZDiVV9yPaC7t+wCYmD3zgIz9mJZLVavmOe0dLAyOPGrZlJWMWz6/PW7Z+Y/Zqq+kkMtlmq8UY279veu7KlasLc8dOHPddb61erlWqo0OjdirZbLZsM+E1XcCgrEpd33EDF0sAIYAhzWQLbkgsM6lqeq/npRNJRqmsKBxw9ratKdweKZIkRZQk0ylZluv1ehSGhqYburq5uFIpl4t9AwJhwW1rlO+ffjkAECIOgihSJP1d73rnb//2b+fz+UajtrG5jjFSFKnY1y+22YEfHT58uF5vLiwvIYy7rut7IQASB5gxFkVRHFGBBwxTY4yXy+V2q5NOp0PPDUiIdQ0BQBj1fRfLMgMwjEJJVrwoDr1AVZWIcddxs5lMx/VkJFHOEMYAI0lRZMCsZMKyrCCK2+22iJBZWVk5duzYv/k3/yabtSEHrhtdv3p1eHhYU1RCSLvVCMMwjkOI0Sc/+YlP//2nE8mkZVkMgG63ixC2UkkAAI1iDLDr+v2J4uDoUBj4bq/7iS9+3hgb2v+eB6ff9Q4/jl5YunYj6mWO7HUsbbG+/uVvP7m4sFrM92uKqmLJ0GRFwpfevCBjYNt2TCkFLPCjRCLJOWy324V8n3jDotLx9hq/mOgIIRKjMaMxgiqEoqeBt/5bqK8RhBi9HR0jhIQFg2hkyLKMkSxLKgCAEGIYxpUrV4aGhu688+5nnvnOLbfc0u32LMtqtVq2aTidbi6Xazc7lFLTtBqNxtNPP/2vfvana7Wa63XXNjZ37Rp/8aUXNjYqtmYEQZDOpCSA15ZX5JTkOj3DtKIgzGUyrVbLTpiHDx7arFZYj42Mj9XPn1cN/cjxYws35prN9sbGRr3ZsizLthKu6/b3DdRrjU67p2mKpmk0ohDgdCpdrTV839+1a9fy8nK1XssV8o1Wc2hkeLO8UWs0+vv7bdu2bbvnujMzV65cvhpH1Pd9XTfGxydGR8fW1tYvX75cKBTimCiK6rS7hUJhcXFxYmJXJpNpNpvC2n7v3r2VSkUYmW6VSQBSFM2yrC2YhberVgLKMCDk7YKizjlnQmfABL9KFv0j8adM09zRIuxUsOI4BggyxhGCjGz5kQpoJeKPxBZJ9IYEzU6w7H3fxwAi4SopAgS3QVKn3TYMQ0DSe++/L4qAJAFNl3f4Mf98hAtTd8DA0uKiZZqIAxlLiqIItCESG6MoKuTyopnt9dwo8G/cuDE+OZ7MpBcXFw3LTpXSzz77/Ec/9rG77777jTfejKIojghnQETziPEPEAAYQcgBBBQCH4KuBAhWI0sNklrHUHoKrrneRrNTcz01nQo5JZBCxiVVkokaBAGlURBsjRNCQglDRgHgFHAaRwFjjFEmGn1sO8SaM7h9IrdgEwAAcLRTH0YIbA2e7QsEttuLAAAAJFEgRAhyDglhlPJt9MwQgrIsRTwKooBSEkVRKpUSreF0Ot3r9bqO88qrr548efL06TMzMzO/8RtHIEKNetMwrIMHDy8sLOm6efXq9YMHD9u2/eqrpzkDvZ7n+yGEuNvtEcIQQmEYBkFk28nh4VFCWKk0PDY21mw2Bwb6EUKdbieVTsYMbU8Zoqf51gzyQ5HUDnj6Zz95W3tx+xe2Ig3FyUSccwgg234q5xxBBBDkEHJKkKEL3QmlFGAm7lsEIMJMbBviOI7jGCqIEMK5HATB7l27jh8/qmlacmiourZGAVgqb+RSmY7nSZqZ6x8yAVUyheWV1bGJ3Ru1FpKUq9duTE9PdbqtL339qxzh/UcPSppcLA3MLS7fcnz/x37yJ27Mzsxfv7y6XJ4cHs7Z6epm5fSZUwHkESWNVnNsYpIy8PgTT37ik38R+ORPPvkXTtc7evToBsYQY8NMLq2Ub0fy1evzrhvv3X+k1+kCLnleFAaR53j/6j/862889uQ9d941M3P51KlXB/sLEIDBgYF6vdpqNU3DzmQy7Vb3+PETvu+vrK/v238om8s4fvDMM9/52I/T06fOvXb63AMP3NfpNP/xHz7z3vf9iK57rut1u44saXYyGwSBbiau3VhAkiqpmu+7vu+u89g09XwxFYSe67UgitMZU5Zxp9varC4xQi1D9wLH1E3TVC3fCoJI1lQSM103IcScIghw4JP+/hKE0A9j34/CiCDIV5dXOGOJhHX1yuWRodKDD92/uDhfrdQK+eL8/HwmkxsaGrntltt+7l/9m6efeiaKWSqTndqz9+TNt9jJ5Kc+9afT+/ZublRN2/r4L/1qq9345Cf/NJfLnDl/9vEnvi3uEEWW3v3ud2MMddPotJ35+cVcrvDLv/Sf+gPn/KVLlmXsOnCy0+lxIoftsOZ0Dh0cTfVlUoU+RTWdM5cn9uzv+vTi/MWvPf6VQrHIKE1aSd/xMeC6DiUJZYt9xZHRWrdbKg3Pv/6mnUhVl5b/8n/+4dT0nka7YVlWebP8yx//pTh29u6esu3EZrmSzxVX1lZTxfyHPvrziiZTSqubm1/53Gcdt+dHIeXM9wKApTAiqmkREoo5RDAYhTsvBABgFMexgqVMJlNeW69UKkNDg7qqqao6MzNTHBzkjECIIGBcePZ+n7Zoa4hx09R9N1AV9cEH7v/6Y9+46aabUqmUZZl+6F27Ptvr9YaGhtLZfK3ZWFxerlarpmUxwDVNo5S7Xuy6PmVQ0fQgCBDiQaOtqJJpqFFEothP2Vav3ZJl7AU+kjDEMmc8jMNcMd/t9GRNSmfztXpF07REOt1otlRVZZQRBizLkmXZ6fWsRCqVSrVaLVnVGGPtZkvXdVVTZEW6ePFiFEXDpRIAYKNSabRahw4cwBhnslnGmKzgbNbiHGKslEql9Y0NWZYzqRRgDCIeRaGiKHEURU4QaX5asmEySdOF9Wr5T//uH/fsngSc8ohEcRCwUE8kHHfh1/7zb3EmHUwVSgPDo6UhGaNE0gCU//4f/09Z1yjgrV5X1XXBG5EkKZVKUUqFz6Vt24Er2oVgy3JhK5qQSZZlua4LAIiiCCImKDKKohBGd+bBnYrlzrQo4IKu65xzEQ8CASaEcA663e7p06dvueWWp576Vq/XsyzLcRzBQGq32wKbS5LU6/UymWy9Xn/qqacOHTr01HeeLJfLlmWUBoc4oRhjCABkPJ1LJZO26zjJdDbwwjgmwpEccjB3/YaVMBljiiJlMpn5+fk4joeHh3O5AkKo1+tls9mrs9cSiUSv521uVjHGhqFVy+VcPhNF0cTERHlzg1KaSqVKpVKz3UII6bqOEBofH5+dnR0cHFRkzfW9ZDL9nW8/JUmSoqi+H1y7du3Hf/zH9+/f/9nPfrbVaiUSiWaz7Xne4OBQ1+0hgOfn5/v7+xuNRq1W29zcTCaToqyVTqe77SZjLPSDXC4n+NpB6Km6KUlbBuiUUuEgJcRxAmCJ4hNCWHQYoygSLSe+ne7p+76sbIeAMkYphQAByhFCEY1E0PcOwIqiSHzSHXo1QkjTtK1G+1ZV5vvWUZjNZiuVyq7JqTvvvPPIkUOKChgDlDAkQfBDWO4QicheXqvVhBWbKO1wzoMoDsPQtCw/CDLZdL1enZ+7vmfPnm63PThUkjWVcvb+Rz/42GOPra6u2ra5tLzw5S89/q53PWQYBgBeEEQQIlGbIyQSU4l4x6ptclP3NcVl1MG84rurbrNCghhLIedMVZqddrmyadqW13M7nQ5mSND8xTlnjMUkFiNEQE+MMcYwjtmWk9xWRgwEkHEmyIxQuAVKkoSRzLZ9+UUfltAtP9gd3pW4ZOhtnr8CE3POFUViNBahRlEUhUEANE3GEoRwm0PDMMbiASH09dffmN4zpSja7/3e7/3SL/1SoZA7c+YMQuj2229njJ09e3Z1dXV8fHz37t2O46RSqUKhoOt6qVRaWlrK5Qp9fX0jIyNPPfXUvn37kunUlStXXNellPZ6rqIoqVQyjkWK5U4v761y5tYJ/xePt08ab4dW3/O/bwNYHELAgTAthRAgALkgimLIpSimVJEwliUkYSRLiqIwKHxsuSzJHGOo61EQxlEEEOCEqqoKAWnWGivLZUnBN918/OjNJ7/1+OMGlC5dO7OwsNBod9in/15L2ATgZCJ97OjRYv9Qp9P52Mc+GlPa8709+/Yrqrq8umYkkjmITMsyk5m/+fSnT734fLdTj/3eY91e2Apy2Wy+v/jVrz9ZHBmgjn/optshljOZQqVS8wMy0D+8tLTk+8Hi4mKt1njgoXdfuzILoZ5I5gZHJtrtNomBCaV0tjA8ClZXqreevL1WbS0vr3qem0qlapVqaahvZWVFlvGBAwcwxpVKZdfU7osXL54+c+7o8WMdx292lh5//Kn3PfyeC29eqVYbP/Luh/dM73700Yf/23//r1cuX3//+9/v9vxXXjnl+cw0rampqeef/24qlVpZWZnaM0FZtGvXVGVjvVqtGiNqPp9fL5cJicIQcU45oNXNzZGhwYStZ5KGKqm6lsr39TMOJUWmHLVbTj6fb9TbjuMBjmSJ5vPFG3MX7ESq58d2Qv+F//tXbty4sbq89P4PfPj0qZcK/UMcoOe/++z09PToyORQP+0r9l+fW04mCsX+4TDmMZLvu++Bgwf3/9t/+2/7+/tNwx4dHX38icc455//0mdvuum4YWh+7H3ko4+6ruOH0cZm/Y0LF2kAzUxhdNewnurrdrt/8CefzOVy2Wz22tL67PXK4OAIZNQP4tHRsfOXLp55ozc8XIpjullxBofGCYOyauSKg/1DA2EYBl5oJROARizoOa4/smsKyVrSTui6kc/k5+fn7zh+c18yU10thyTEAIwOjxw6dGBlaclznb58ZmpyyEokLlw6feudd+2bnlxeW5UNdXrPHbau/cp//Ph9d99V7B/cWF/bu3+fbplBGEIMIAAMgu8DSRjLJAojSnL54vr6+tra2tjwiKJoSTuxNL8Atpk8nHOhvf0+tsbWEOMgjiJJQpIM77///q989WvpdPratautdqPY11cul1VVBgAUCoXNzc1OpzMwOEgp9cIg3NK1s50OhiJrURQpiibLMArJ+PgkhLTX7VASeb4ryzLl3Os52WxW1fV2q6soGmTAdX1ZUgEFkR8J/XsckVQq1Wy2IUKJdErX9Xq9jhBqNBpiZdc0TRhMKopMKVF17crMZYTQysoKY+zmEyfWN9Yty1q4NHfHHXfMXr1KOXNc17ZtSmkQhzyORN4l5xxwZNgJziAHGEAcsjjdPxgD8uKZ8167zYJYQgBryHXZA++87767719dqciyZhm2rqhR6G9u1mzb9IJIM3Qrkeq4HoQYI8l1u4qiqaq6vr6ez+cty2o0GmKNFp7bO/ttzrk0Pjpy+fJlzpmua61OR9VkwzLDMORcbKxjQghWVAghBxRCSMgWpSuKItEflCRFqKUghMlksl6vt1qt8fHxW2+99dq1a7fccuvm5mYURTtFHUmSoyhKJBK1Wk2R5LNnzu+d2lMoFDut1vLycl9fQbCUwtCXJOQ6vUw6ff3GvKIZigpd1x0fm9worwEA1tZWBkr9YehTGoehzzltNGph6CeTaTNhblQq+w8enJqe/tu//dvDBw5RGiOEVFUdHx9fWlpyA//QoSODg0Pr6+uU0kQicfX6tUQiYRjmxsbmxMREMp3eNTVVLBbfeOMNzoGm6aZpyrLabnczmdzAQOnZZ787M3MFcZROpJWctr6+irGMoMRY6DhONptNJBIIoRs3bgwOD/X39/d6PdM0fS80dAshFAQB5zCTybRq9SDwFEUL/UgzdNM0e44rMK4oZmztb7goTgFFUcIwVCUZISTWaeG8IIAXQFtAIWmnPDeItll4YlEXyzkhJJFIAAijeAtJCNcu8WAr1hdBwclTFEVwh6MoSiUzIq15et/emABJBgiif75wbg9uQAnDGN24cSMIAtu2FUUxDIMCbhnG8tqyKD/oug4AaLfb+Xx+dXU1X8xVKpWIkuM3nfDDAMvywuI8glhG8Gd+6qMdx2ecMMABgowThGUoQT/yAQCSjILQS2omNrUOjRIJPZakVhxcb1Su9ZpaIRcTwhijUeB6HqCs13UE4OMR45z3ej1R6WWCmQ+24jgB2AFw2271EiRkKzybEsg5j+PY0FWI0LbwlsuKCiGM4zgmoSit7zAaRT9XzIziJcRjQYIkhEARYSNJjDEsSZTSIAoJo5qiYozjmGAscQ4IoZR6GOPZ2dlkMskY+/3f//1f+7Vfu+WWW7agLcC33XYr5wAicPjwYc45wvDAwf0AgGPHD+9cpUOHDh46dBBAEITRLbfcIknowQfvBwA8+OADEAJZxjRm4kRRwhmjCCHG/49o7DtFu51v//kvvPVY+GlBBgAQrXAGOIdMlaUwDJmGZEVmEQfbp04UgyUkYYwhZwgBRdEjhFKplKZpAAGhGkFAajWds2dfl031ie98Z3FpYWJsZKjYLyPsYYnZJtb1CEsQoJbrlcv1hYXV4ZFSf39peHwsjKN9zdal2auWnczk+4Mg8D2v3axemVt5x0M/Yqg4cNsJ3SIeGBocvnTlQpvEVto+fe5sSPihw8dW1hv/4ed/caNcK5VKx4+e8Hr+8OCwplo9J+551A9B16GXZubm5+c5ocePHz937qIsy8+/+PKpM2dX1ssj42M936u1an353MrqaqVSeeDB+0bGRs+dP5NIpnbt2XPu9Qscojtuv6fTcywr8cgjH5yamtq7d08h2zc0OLC2vjJ14MjD7//gM89859Llq6+cOnfg0PHpvXvX1srVWuvY8ZNDQ4Of//znIVJdx708c90y1EJ+YGrP/q985StBEExPTzMK6rV2Jpuant6bsgzb0ny31+l02y3ftLOEMoRlw0gwClZXKo26M3Z0F4TQ6fbaLYfE4NaTd33n2efGxqcXlyupzMCefQcty1jbrFydW4gCr29wFCJlsL/0J3/8yYtvXAIApZIZ00xCLHsxLQwOfvvp76SyuWQm63juzOyVjuO895GHT5167ZVTr73v4Xd/6D0fRAh2uy07kVhYXQ4iamjJX/yPv3r+zVnOkKwqAwOlmMoRUUmsljeqXWep224iBFbXjJh2TUu59PSz2XTu6OGTJOIpy3755Ze9VmfXHScnJidffP4lr+sAAhTNTmdHstlsrdqEMbOweuzAIRjTjfXN//E/fpchWBwcCFkky3I6nTuw9wBnTJNgKmkwQD/2sQ8SDi5eOJ9IJevNhtNuBaE3MNDXbLeHBwYjRludNkRQiEeAkP1BgLf3IxzyKI4RghwC3TKTyWSz2fQ8z9INUzeqzfrKwsLQ2Kjv+7phMLDVvn8bxkJb7joQyAoGAFPCbr75xPBQ6dzZM2EU2QnTdd0gCA4cOJDNZpvNZqvVEg7+AwMDQSdQZJ1SIkuSLAMIQBQSCLYibilBgLNer4cQiCjRDF2SEEISknBMQK3ayGazEEDP8QxDAwzISA583zA0yiiGEpBxFNMojrPZrOAjiakPQ4AVWYjDeOCX+vtuvvmEYUDOwZ49Q45DgiDQNK1WrRLOMvlcp9dBMqq3mlDCDHDGWURiSZKQjAESW2EgK2pISE9liqkHcQQVlQBGGcj1l+yxifLSEiIkpWjrztpdh25VQxl6lCuk6TSQBCmJcrkMlhTdNAjlkR8qkiIjuVKpYIwRkjqdTq/n6roupn2IxBoNxcwjllpZlqVcLpPJpObmFrL5vG3bsiy32l1VVQnZmka/r3aFtnkn38t/xxDyOGYQcdu2AeDXrl0rlQYWFhYajYau65KEfN+3bRtC2O12E4nElmU5pQCAS5cuHT58+PnnnqtW64yxocH+MAwnJyfPvnq6UDBXV1dUVZURdl1XgnK73e7r61teXiwNDRSKxSFLD6Lo8OGDL7zwwsjISLVaXVsrDw0NJZPJl19++cSJE4ODg5qmJZPJy5cvK4rCKB0cHNw9vUeSpLm5Oc55p9NJJBKJRELULavVJgBAkqSvf/3r99/3YBjEqqInE9mV1aWRkbHh4WHOeblcfuKJJ4IgKBT6ms32bbfdtrm52W63dV3XdT0Igmq1KvSYvV4v4aRuu+22r3zlK4qiJBIJQkgYhr1eL45jwzA8z5NVVVEkJOEw9CmAiqKIKsjO6d3pLiGEojAmMVUlOY6p74eMMUo4BzQIgmQyyQBECIUxdZ0ewm85mQmamugKAQB2SlkCnAnK3RYZiIM4jgVlePtG2aLiMQ6CINB0RdcVjAUZ6S0t/T9fYhljGKP5+XkAgDBbiqJIVyXCiTAhwxJkjBJCGo3GiZtvev755+fm5nTLlBVFVtRP/9M/cc6GR0d/5qd+6p/+8TP1ev3Bd77Hcbqu51tWgjEQRBFCojpCRNsUQKBn0l3ISNJ2GW3TAGVS+VyyB3nU68VRzL2QhzFnTKQZaLISxGEcx57nxSTGCEuSRNlWbNEPPCilwr8ecCRJiizLnCGEEIBQ4F2xlRF1R0FxAACIatYOnQ5u6wp3TqBQIXBOOWXbvLut9yA6YpADCKEkhQL1Ct8jMYjOnDlz+PBhQsjv/u7v/vqv/3oqlQIUYAwhBBCBbsdJJG0IICUES5IwdwdvJ0tBALbjKcVrvp1PsN1EFn1PCSEkIDjfTtf+F2DT/6dDcBK+py7GOIRcyD8oowxigKDn+1EUEUY45xxQQiAGEGDguHFMYuEkAiLAGI8iIisSpXxgcMjKJOxs+tZ77uaUXJm57Habhw8f3nf4IIVwctdUodC3vrxeXa8sLa0psrWyUjn3xmUC+dUb13XbphxaVkKWVUKIDNng0K6Q4CtXZ5OWahnR5kr9mZfPrq4vj+/aXalvWOnCRq3x5FPfabVaR48endVuiIyUUmlgdW1xeXntzJkLu/fsefnlc2fPvt7fP14sjjYaDSDpK2tVWcaHjt30hS9++dlnn/3d3/mdYrH49a9/XexjJ3bvcjw3ZtRKpI4cO3b5ypWp6b3veeTRKCKUAEXVjh45UalVn3v2xW6z8Q+f/vtMJnX//fd/6Ytfu/3221995TVVsxjHGKsL88u1ZuPE0WPLqxu1Wqvd7qZSqXw+S6isyPZmueX2ov7+wWQid3FmZnhkaObStcnx4devvoEhTafsw4ePVBs9z/e6jnf6zOueG+zff8A0zcnJXflcYW1tLZ3OVuvNW2+/Y2h07H0PP+r5keMGmmHfmFsBkHIsb1SalMT1zfquyek//fO/Km/Uj99yW7PRLZWGG/VmGBMVS4cOHXr11VcFa9P3wygKjhw5EgZRHMcf/ehHo9g7deoUIVE6ncSy9PgTT8YUvnnhahwQDOR2zzk8ubvdcQwNY6CuLG+2Gi2YA5qmyBLXTCl2cKPZOXj0WDaT9yOKOOGcd5tNv9vq1Oqfe/XVer1uaHpfPjcw2m+YWm19df/0fo3BzZW1RN/gT33oQ/Pra/We48Rxq9dlrssJra1VGuXK5uZmp1X/0Afea9na33/mswygoZGRmDBZUxVFAZQ99NBDhqa1Om1JktzAS6VSnucJDuHORhoAADiCCECECCFeEKWTtm0nXadXq9XHxkZN06S1yvXr14fHx0UHCUDIOMM/gOQuRjfkcYQlJZNN792799vf/vbwyAih0dDwcKvdEFv9juNCiMMgsk17fn7BsK16p5lMpjGSKQW+19N1o91up9NpzmkUBbKEEMKUxRKWOeCKInEOPc8bHx9njC0uLgvWIKcMYxAFQT6TdRxHkTChNCSEAzAwMCBmbMMwOp2OZVkAALEsGoaRKRROnz79q7/6q9lsNpnJUhoXsrk9e/bYtp1Op03LUlT18JG9r546X282TNMUDFooYQr4liAGI44gxlhSJIilnus7gZfO52gUYyyTiDbd9sDgiAKAQujSyno+2wcQyGcL7a4DKUFINsxE4PmKImMsh2HMGFAlNfADSZJEeG4cx+l0Wtd1Xzga8rf4yjtsdUmSJBKHIyNDWwA5kRANIwghE3Gt38ulENJxBJFY+hkDjAEIt9pYYjFQFAVCsLa2NjxcKpVKiwtzk5OTlWqVMSaWcxHIQ0iQsFNur8s5m5mZGR4uvffhh//kE39EKbV0Q0Kor5gvFosi18mybUqZpmlxxFutVkxCzdDX1tcOHDloWPbf/f2nBwYGOKWdTiebzSIktdvtgYGBSnXjySefLJVK6+W1TqejKlqj0Qhdr1gsXrhw4ad+6qfqzcY3v/md2dnZgYEBwzDq9fqJEyfefHMm8CNNQ6qiv/LKK6XScCKBHNezEykJK91OzzCMK5evthvtTCYj3ERnL189duT4Cy+8wDmXZZlD1mg0OOe5fDGRSKysrExPT4+MjDWbzTiOwzA0dD0MY0JYOp02TZ1B0HXahmmLMgPHMAwDQeJGCEMIOaMAAIjQVi4kRkiWRO1ki/EDtmQLcUy2AnC2d/lIlqIohhIGGEkQxXEs7myR8C3LMt2mtwupv6IohDMAJIQlKDyfIBJQmFJKSdRXKEoSoIzjLY7zDkfnB3BuAADra2u6okLGJYRlWQaAEULa7bZmqISQZNL2fX91dXV8dLjT6SAEgyAw7USt2crli6l04gOPPHL23GsRjfsGB0RzM5lMBkGAZEXYekUkJpRKsswYAwiY+RywzcjWNqrVcs8JTJ1JoNtp8YjEXgi8AFCGAWecC8gokK54w5TFlH0PqP1BBwKAiVbgFk7CkizLWFH5VhNxy90KIagoW9xEwWEShSqEkCxLGMuMsZ2YBPGilHIA8E4ujfihwGQeYxwCxhghcSKRFNumOI7rjYZt229euLB79+7BUul3fvd3/9cf/l6v5yGEDENjjCVStjBzx7JECJF+SJaZJG1N0N836LeBIEAI7dAE/9m13hES/n8+EAdgK3hHFLG2CfNbFmFMuG8RSgGCYFvhsf0LW61LtK2O3m47ArFhkGXZ7fmO447tndZTKSuViOPwyE220+v0en4vjE+cvPXrX//Gc88+Xy1vJhVrcnw8jmGxf/j0uTe9KNx/8EjEuB9GlCEAkKLgerX2zSdfSCcN12nWKqvHjx7rdFzO4OiefWZCz2B04crVI8du/od/+AcIpJGRMcrik7fe3Gw27WTKbKcuX55jXHrzwrVW/VXGqSRJjUbNsizOaTJh7d+//6F33vTsM89M79+XTKUWl5YQxrV6s91u7923O1/ouzRzuVAoTO2ZfvyJb1pWqlJrvPjCK+lsLpfLdTqdTrdbq26eOH7sx378Jz/4oQ/EcVgaGjVM60Mf/rHPfuHzQcj9gPkhHZ+YYhC9+z3vWl9fX1tbN43k1dmF/fv3jIzusRPmL/zir/7TP/3T8ko1Yeddh/Tlhjwn+k8f/7VKZTXynJiS6/Nr9z/0bkU2du/ZG0cAYfnLX/7y7bfffvXG9TNnzpw8edutt97WajunT51ZXikfOXqi0FfKF/o5p57flbtaYcB/+jvf/tbjj1+7OrdR3jQSadeLekH06mvnpqb3KjL0Qm9ubs40TU3TpvfuPX/+fNfpvPfh97z+5hvrm6u/+Zu/DgBzem3bMs+ePVNdqfznX/ntX/+N/6fXDKKQtuutgYEBTGk+ZQ8Uh+KYDff3UT+srK/ExFN1UKttICTtPbSv3u54jPX3DUtIbjrNH/3Yh7JJs97Y3DM+dP6NC7KiXZmdsW08YZcmBrNJHmxcmy/PXh+/8+533HbibutOakoxAgwAGQBEAYyBLAOKQBQBFQPXi9710CMR461up+f5cRzX69XLl2bWl1f9wN2ze0pS5JXVVTtpUU4QkAAHkEO4fedzBAHjGAMGOOA8pjSVTm9srK+trZVKpUTStgzj+uzV+x58ECDEKEViL/WDZyrAGYEIiWbCBz/4wS984Qu+7/uBG0fR4YOHao26aZqGqglZnOcFhUIfAAAQJEsKxrIsqY16C2NYKOR835exZBpGHPicMxnjkAhvIAghFB2bOKYJK6EpmmVYTrsjKxKL4m67Y1mW2+siCcuyLMlyt9vFGGsY9zpdU9Mh47apj40MIYR83y/kMr1e74UXv9vtdhlArutijBkjYRgODQ1pmib4EtVqtduqj01NEUIcz5VlGSAAZIgpppzCKIYM2qalYkSCmDluyw/S6bSiYE6BqSfiXgg1OUIIpTL5iZG26zuuxyjXFT1hmUHg+YFPFIVEMWAcIQkAIuRoYRhKkmJZFqNATK07AAvCrSVgR1ImOY5j2/bu3btnZq+QKAYA7CQS8m0TxbdmtJ2kaC5KI2/hNUKIWDN839c0FWMs+B8b5XKn0xHlHLGZs6zExsaGrlmtVsvQVVmWvZ7z8ssv/9Iv/8ejx06sLi65rqvJkqWpIyMjL730kmVZwgt+s97K5oooipyum0galLNLly5lcvnBwUHOoNsLZi5cH99VSiRSruvWarWjR4+ePXO+VqthCAXakGUZK/Ly2moymfjjP/lEOp02LPXKlSvT09Oe59m2PTs7u2vXGKOg2WwihFqtTrE4aJq253m6rvZ6vV6vRym9MXdtYGAAANDpdPbv3x944d69e69du3b1+myhvyDLimUlms2m7/vZbLZSr62vr4+Pj7uu67RbYhkghHQ6nWRy//Bwqev2rl+/LiuKqmuE8TgOFVXn/Hug7VabD0AhV0QQQwlTxiDEOwseIQRyQCkFUOTNbVGqe72eAIKGqiGEXNcVDkmCe4QQwgiJ8pKiKDsc7W3aDdpZaAVm37NnNwBbPk8IQcZ+cPlKlIhoGDuOk0gkxE0iSRLkIIh8wmIAZd93p6Ymlxbna7WajGGhr29jcz2XzVy5csWPo8mp3eVy+Y0Lb7qu++KL5//9v//po0eP1hpN20oQDjClCMsYUNd1OYeyqoRhCBgFhgZSiQ6GHQSYaWJd7dRqTqcnQxCHESYUcQAxBJyTKA6i0HNdgaQwwnTbS+yHTFhbB0RIiHIZA5wDWZYMw+Boq+snINSW2A5yRdEQQqL5KHp/4hB1Qfg2BywAAKVCyPn9dUHGGCUkDEMaE0IIxpLAXpIkISQSAtDVq1cHBga63e4XvvClD3/4g3FMCWFRtLXlEqRJSZKEf8bORxFtBc4BxG/9eIuvzzkDfJuUzyDEwpBi5/heyysKAN/uTfyfHogLuRNDgNHv/TkXhHrOEUai3wgRAICLlqvEEAUcIQTFsNjC+luKWcABZzCOKeBQt0wSs5WVleWNdS9wZVk+evjQ4MDQ5mb1yLETL7748jeeeHKkNDw8UFpfWA2DeGOjMjoxOTQ0glUpm827fsBh4Hqh50ayDAZLY1dnL916662NWjmRTJrprKQnz549u16rHDg4vWtyald5M5lMZjKZO26/q1zeaLXbrus0Gg1NN1XN2txsr67XM9k8Vg0ZAYRQadS2LGtpaZEA3HGD1bUNPwh37d7TdroDQ6Vbbrs9itn+/fs7nabjBwApZiIJsPTu977vm09861tfeSyVzmzOzoZRqMiKpuu6plSrmwcP7f+5n/s5jPH//t9/+MUvf/Xe+x7467/9B0OHzz3/wp7pvbZtr6+vfvJTn7JM49CRQ5SAdCb5gQ88fOGNs/5CL46jkZHhpaUlXdf/7//4C7/9W7/5wUcfaTYqV2bezKasSq1arW3MzM60mk6+0L+ytjYzc/nQ4QPV2mbCsh555OFdu3b/2q//pmEk9h86ury08f4PfaSQH7wxP0c4hZAPDBYfe+Lx226/+9477/vHT//drbfec+b0WYiIopqKQcd2TXW73Vp1I5VKXb9+/e677+50On39BcriIAgymTSJWaPR2twsj40PxYT92n/+jddeO/e//ten1par515703XdiYmJof4+CNmu8bEgiBZvzL3jrjtu+/VfPXRoOpkCAIGvfe0JxvHUvr0//x//3fTErsHCIAqZzqS8akIvPHHw+NieXZ0wdAn95tNPPfvS04ZhUKd74eLFxo3l6dGJa2dOnXn6W3vfcXelFTsAEgqYE2YNO59Ml1sNgkB/qbC21kilUrqW4GFw2y2HAQBxDGQZAP4oY0BG4BN/8mcXZi6OjI5u1UICInZkEG5ROcUIoJRxAGVJbnedZDar62a306vX6/l8LpfLXZ+bW19dLfQPYOmHZj/D7ckKcEBjCiG87/57hoaGPM9LJJLtdrvRiDO5rCJr3Y5HKXNcv91udzodSVbHxiYg5ywmrU7X0BUsCZkvwxKXZYlTLArYQr3OONM0TcKK5wWmbhQKhTiOTU03ikXLNNpWmzFCaKRrimlb7Z5bbzREi0awUBzHsWwDYyxwgizLiqJYlpXP503T9H0/IiSTSoVxLPjclNKBgYE4jkdGhwSaCYKgv7+fE0o49eOQkCjwfN/p+WEoYwkCQMJQQ1IUxX7HsQsFwpiC5Jj4Xo+UO41UfyEzMEARjhjRDBVSRjiLWayYOlIxh8ywTFXXXd8X6XaURiJF1u35olohyzIG+O1NCQGwJBE3K/yd8/l8p91jjCHIOecIYQAAh5hDygHgkO04dkMocBfa+gcJt9JYzPiu52CMTNMsl8tjY2MnT5588sknx8dHMQKME+ESkUql6rWWLMu+HxqGpuv6ysrK+fPnH3roob/9y79qNtuQUVVGpYFBU9cDI6IMyrKcTCZ9348ZRbJUb7bTuawfRn7Pb9SaDz34Lk0zRMek2e4Kylur2SmVhrrd7vr6OiEuiVg+l4YAmKYJAOw5vVQqJTZ/qq719fXNzc0hhCuVyv59B4MgCLxwsH/AMIxyuRxFQT6fTaVSjWat0ax5Xo+EJJvNJiyzVtkslYZnZi6WSgMLS/OEEEKpadqmaYYRcV03lcosLCxNTEwMDAwsLyzuoI0oiur1eiqVSucylcomgIxzGsckiqJUOhsEIQAAgLfqCYwxToimaRBC4SlAKY3iWFgysohKUmhZlhf4hMWKonAQWZbFEVRVVfRnOYIcbW01RP8bgK29PmWMcS5hTOmWQ4dYqDDe4uvpqtbrunv37pmcHAdc0AWYQOA/dPnE8OqVG77vF7I5BKComVmWUdtoy7IMIGSAJ9Op1ZfXIAZIknRdTybSlVrdTqYvX54dmZis1ZvltRWn0yn02V//xmO6kZie3uf2PFnVKOFYkhkDfhABiOOYxjEFEPTvmggt7WptoxH6XS9GMWk1m5xRLwp4TGXGOKcRBABBSojvegihiIRioIo2mSg4/TDDTL5NS5ckCWMkSZIsy7qu9/xAlmVJ2rIfYwxHURSTSEwiGAswhDDGjAmCF0UIYQw5f2sDwxhhjACEIYCcMcDZziZHvDphFJDY81wAuGmalmX1er1EIiFw/wsvfvfYsWNvvvlmoVC4887bHaebSqXiOI7jUJZl8VUkBG7fVMJE9Hs8NXYQkuhYxHHEmAhr5mC70ga3TGhFuYiJytb3u6L9Hx5wm4rAdx4L9TIEEHLGJYgAoAAAhDFgbLuVyRjgCAqECoTGVgDct6k4kSRJhw4dKmRz52cvzN+YS6TsOIwuw5nBwUFVVTu1xuOPfWO0NFTZrEyOjpUGBq9duXbvvZPr66uqKockXF5cUAxzdbXMoaKoZqvV2bt3/+ryyo2FlX17J5bXFl945dVUOjO+e1cUh5uV2uTk5N69+5547IkDe/dxGi4tz6fSNmXh2Pi4YSU7vdBMZvl6s1JrSJKUSid83y+vbSKEMpmUH/iLSyuFQkE1rYWlJc/zarWaYZiOE3/l699M2sYjj7zvK1/+wjee+ObjTzw5NjY2PDr26Ic+cOzoiRMnbrJtO5lMFvqKtqmGQVCtbf70z/70c88997XHHv/rv/0bwrjT89bWL+mm8fXHHgeApTPJxZX5/mJudHSYcYIhvDx7JuJOpbGUzaZvOnkYYGf3rj3nzz1/6PCEpkenXvmuaWKEmKZHx28+2O51OGTrm2vX56/ee/89qVQmaZnVygaEcH7h6oc+/MhGuX7kxIlMZvHGjWtO14+iaH2znEhY7W7r2LHjp195dWF+7uStdwLOJ3btWlleM6zE0NgElqRXT5360KOP5NKpxcX5Tqd14uab6vVqJpceGhn+7nefGxwcbHc6Pc+t1du2bX75K1/v9YKH3/vhZCL38Y//8mc+85ko9hv1ysBA4dKl86+++qptpb773DMHDx25/fbbBwb7Uim70JdvtJz/9Cu/0pfOjqWyvfnVa6++DhpOfWl1eCD/uXa97Lnv++mfvOldD64trExO7I6Jh6K4kEr/6n/5mb501kimwWgp4jSfslUA0wmbR0DlQCYgdCXZNmQMBgezGAM7kYki4LsgiginJAgCTZHrtcrk5PhAoe8yv4QYL6+ty4omSSrgW2ZY26YlACJOKEMYhpSSiChZI1/oW19ZbjabxWJBU1VVVi68+eaDgyWw7Yb1PXkabwvM4ducBEopwtI999zzxS99aWRkpFrblGVZkdSe40iStL5e7jkekhWM5SiIO622JEmZTNYkuizjXq+HkDQwkI+DsFqt6prCOavVaqoqUxYREjHCHaeSsFOlvv75uQVZli8uLsmyXG/UTNMsFvOe1/M9L4pjw04kEgldV0UouKqqqiLRmERB6Hk9AIBt21XPFWtcMpkMwzCVSjmtZrVey+fzAADRKBA/D4IgikKx7nPGTNPUZcMnUFYRZiiSfEnChMWUxpquhp2gVBqMKel5PdfrVdY2ZF3jhtxXKGCMOeKyrjAIKOQUBlxHkoSRrRMZeTSOeBwygjjTdR0AJhpruVxOqJEsy3LaDkJIrIZw22J0q0vo+z4HKJvNtluOqihBGGOMOURsKyEHccpEx2p7Xv4eA1K4bQxPKcVYcK6B7/sYw4WFhQfuv//UqVPLy8tjY2M9z6UsplQeHR0VYA5C6Pu+riq6br780qvT09N79+698Mbr6YTZbLbz2dzw8LAXzK2uVXpOLKkmB5hQtm//9NzctVa7ZllWf//g/Pzi8sLy7sldzz33/PGbTgRBtLa2lslkKGXZbFbX9Waz2el0ErYBIUynUtdvLEAI9u/fe9e9d//t3/5ttxc89dRTN910040bN/r7+y9dunThwgXTNJutpmEYxWK+0+kAANrtZhB6CIFHH32/aZp/9slPNRq18bExp+uGob+62hU5jGsba8MjI47jcM5T6Wyv15M1vVqt6ro+NjYGhHkYkCVJSqfTcRxzwPL5XCabajTbhEQQQYH3xZq3dZ7FUOGcUVEdwWHgc84JYaLWKM5kHEaxGgdBgJHMJMbiOAiCkMQCSw0MDLRaLdd1c+mMYAuJbYSiKNuKRWHW8JbEdMf6CEIYhrHjONPT0wgDSgGWJA4o40TE1Pzzkg8hRJallZUVAACNiWoYO+7ztUYVywhhkEjYURxsbpbT6XS73bZtWzP0BGCyogyPjd64Md/f348B2btnemVttVFvzcxcmd53kCMcR5RDJDzRxfQRhQRiGSDME2Yl7C13OkRSWrUOwnLP8bCMgiAAjBHOCGcUQARkxlhMKed05x4WYGj7Dv/BeABhzKiAo1DkFmCExbq+vdgTziGAHGHIOQJbzOytHi5CSFCs0LZ3huibC0gny7LvR2/ViLbTdbYkKhhvX4uQcy5cGzKZjJDhmKYZx7Hod3/pS1965ZWXPv7xj4uetQCL2/GUDEIgClbbzmoIALCDkxnb4aczDrcmCwGndsym30Kf8IeS1f7PDyQo7m+/g7bkgRBuQzogSulRCCGGAlFxDhAHQs0JmIIQlCQAuKZpQAYMAkmWGeAXZy6dOHJYwRJgJPaDA/v255LpN994w/P9M6+cyhSLjuvdffsdgPG52RsPPHjf9PTU2bNn5+dmZVWRNLVoG6mk1Wq7EoZBEDz11FOUhgiNf+HLX1yZv6JY5kduv51SqiC0d2p3tbLx55/686PHDjWb1VtP3gx5XF5fppSurNcQ1irV7o25BUmS4jjmHLa7nUKhsHtqmpBI7NQZjVc3NiGS2t2e4E06vTBbGMpj7dq1y8889+Lv/+H//vxn//Fzn/tMp9MZHR3/7d/+7SAInnnmGdHj3qxU3F73ppuOj4+NTE9PYYxX19aOHTv20ksv9Q30v3r69OTkpG3bQRx0ep277rpzfGKUg8gylDD0HK8BYTy9d5zx6Oy5l1PpZHlz/tqV2cOH9j/z9GN9+cSBA2Mba4sblUXS7ORLu5qddr4w+MA771tZXm0264yTvlwOQtjptt9x3/1vvH75wsXzmUxf12mFIVU1c2Bg4OrVK+sbaxMTE2tra6XBobW19cX5hepGNWZc1Zw9+/a1e+6jH/7Q3LXZM7Xq4SOHOadf/eqXG43G7XfeUS6v9/f3f/SjH81ms8lkEmNcb1THRyf+6q//qNCfzaTzL7783R957zsrm5tR5A8MDPgL3tGjhwlhIyMje/cdlDX8j5/5+8OHD2qmcWX2xk0njrHQufLm66Dp+Y1ahir7R4Ya9cr7f+RdDQje8e53dWRl7vr84O5hTVEVM7F0df6//8EfqoSdPHkbM/W9d9+ulUqNmFAoYQISqr48N7eyspQuZEzLAgB1u71ut1saHrZt+9iRQ7qqGqqkSlLSGJYQ2L937zcef6xZb4wlxy3TdlwP8Lf56QkmAQMcAc6h5/mGIgdBlEhn1ldWW80OpYxznkqlbty48SAACCH2A0Xc2xgLIgRF7AQDgIOf/Mmf/PwXviD2kKIP63thrVZvNBoD/cPlchkwEAQBQqjTahNC8vn89fny0NAQozyKvE6n1XWalBgIwSDw4hgByAiJQi9UFCUKguXlZdd1x8fH9+3b12g0fvu//D9zi3P/9b/+V47gw48+cvny5QsXLm2srQHA8n19+Xze932Rk8YYyWazArgoipJKpRzHwRgbmu50ur2uo+u60+lyCEI/0E2DRHGj0Qh8zzAMSikEII7jyPUtRYuiCKuybVkwaSEAA9eDnGEsFwq5VrsRRoQx1mo0T95xu6TIl65dsXUzDLwoCCiLGQCqqlJAMJa6npPACVmVvF43DkIVSZ7fGxoabLfbnEO0ZRIOBY17S3ADt3p6AgJyziXEmaZpYRhKqmJZFpalIIw5gmg7Zw1sZ4HB7Z3uVmuQbydYMLFgAIQQIbHonlBKVVVbWV1qt9t33nnnpz/9t6VSSRDAAZcSicStt976+c9/fmJ8nJCIQ6hb5o0bN65cuXLTiZuvzV7VdTMOvaWlpVwmY9t2o3FlYjx/+ercYGmk1e00Wy0kYTuZcJ3eyspKJp1bXy/nioXdu6dmLl2emJjASOII6rqpKBqldNeuqStXrnS7vVQqc/LW28fGJ59//jlCCKVs9+6perNeLpcFuqrVaoODg/VqgxJSGiwNDg52Op319VXPcwuFnCCt33TTTWNjo5oif+ELX9jYKOdy+Wptc3BgqNPpjIwMLa2uYIxt23IcR5Zlz/OI71uWVa1Wx8bGhoeHNzY2opC4PR8AsHv35IXXX6M0VlV1i2yuqBBCz/MkrIDv88jgHELIGJdlOfBcAAAhRPQ9gyAQ3BqhDdFURHwfAOQ4Tr6vWK1WK5WKbdsrKyuEkDgINU0TfHyBssUyLzzTOIKEM8ShUBTuUOAF3+vmm29mFADAAASAUQR2ihlvG9o7LB4GarWaEIYIZw3N0EX4jLAILxYLlVotjKNsOuNhN5PJ5ArFgMSr6+V8f9/M5Stj46Mbaxue51U2a61WZ2hkzDTNTtvVTT0MQxIzxgHnMGYcYElRlLWNzSef+fZqrx0ZGoOSZBg0ZrIsxzRiABDAEOIMgxgCRmNOojCOIxqLIE7hCyowBMZ4S0T4FrVo20uTQ0mSZFkVn1FVVQgwpVz4e9EtBAwZ3ypQISQhhCDYMmUQ6meMIUJ4h3oFtkSL3xNOxd9eaXqrZoaFpwOlVNVk19N3TU45juN5HiEEYVAulxuNxsjIyKVLFyRJ+umf/knOeSKRMAxDLMMShhBBcQVFq1S8HGNbnUGxjRKbagBhGIcYYwiRkG1v40i2dd3fcnX/Poj0zyb8H4JY0Q8TobLvUSAihDiCYRwB9v3EULEJZIyCbQ4o4CCKIsZUz/NM01xYWBgcGX7PQ++qVCr5ZHJsYECOiev6qml0wgBIeH1tNYqi0tCA5zmnXn3JtNS77jyxa8/Ut596WkLxUClvWZbTi/O5RDqd7evL31i4WuzP3X7XT9x+28m+voHXTp81FDmRSHAS/8Zv/EY2Yy8tz9WrGxPjI9cXFpvN+qUri/2lidLwFIdKOpNgnCiyJsZUuVz2/RDLUsfpJhOWH4S33HzTyMjIFz7/2aNHj66tbi6trA/0D5+87W5Tly5empVV7b77HoiioFLZ+NznPvPVr3610WhMTU2tr68Xi/npvVNz89fKG6u/8qu/EgTh5z77BQjxp//+HwuFvpMnTxLGIAJJOTlYKg6PDdRqFVkBHEg9p97fl7dMq9fpJFNmNleKoqjbDo4c3S9LoDSUHxsqFPOpob4Di2sLaiZpJbVsfqped86/cWagb7BRa8zOXi5mM6l0wrbtrz/2FYw0y9IbzWoyk5UktLG+XioNHj9+3LpuXrlyZffuPZyylcZiLlco5vovzFzav38/VuRe3TMsc35hobZRnto71el0VldXoyjM5bJXrsx88CMfPnjkYKfTsWyLxWRyYvL11y/+0Sf+6IF3vqNcWYGK2uzVFUNLZVLXri/5fnjzLXcMDA6+/vrrbbeVL+U/8Wd/PDm169vf/BYhLPJcRoNkLrW0uXm9vvyf//0vHtm3//mXnvvAf/9/gaoCBh/+wI+OTOzSoII59EhsD09dev5l5EUXP/MlqKiHVjY/+DM/48s4ALGhaj3MksXCu08c03Sp3W6apilJ0ne/+91dU8MrKytvXjg7PFgKPZ9HJI7jvmIxbdn7p/aub5RpTCM/4gxuDTcImTAq4YxDDhBEgpMDeKfbNVVF0/VWt9PpdBRFsW27sry4vLw8PjHxL2fBCpIWo5xSirF05Mjh6em9S0tLqXQilUpRwiuViut6hqbXKlUAgKIotN0Wy0qv1xsY6GtUK4izYrF449pVSqksy0HoapqWsExKY4whpRKNWX9ff6vVCbygWCwqimIm7Mmp3dl8/jvPPf2bv/VbsoKPHD8yMTb8youvLS4u0ij+i7/4i9XV1VQqReJQlXFMASEkikNZljGCntuL40jIi2WRYBaGhMTJTBoxBXBmaGpEianpCMAwjBAHhqpxiXGAZF3HMvZJREhMadxzHASYRInYBseEIVlRbdODVAYwlbTDbre+XrYPHg7dnqIoUeARTu2kReIQcKqpsqGpuoQpZxqSKuWNRrsly6qggok2guu6kIuZ/K3gYDHbS4quKYHfardNKTk4ONBoNQFgiGOMRPYH5CKFdWunCwXY/t7ZkgkHAVWVgyCWFUwpFXmFUUhWltduuummQqHvxo35o8eOOV2XxL0gCHft2lUqlRzHSSQszhmhJJPPvfLKK5PjE6LiYunmlStXbr/99sHBUj47Xy6vZdJJp9dJpROXLl7IFbIIwUw2X9mshWGk6/r5M+fMhF0aHFxeXu7r61vfrGiaITQ4wh9reLDkOI4wGshkMuvr6616wzAMpasghMvljaGhIQm7YRC7rjswMMAZ3KxW9uSm7WRq//4Dioy7rWY2mYQ0rm6s7pocffDB+7/5+JMI43a7SxhNZdLNZnOkNLi4MDc9vQ8h5PQ6qqr6UagomiRJm5ubiURidXU1kbJ7vV6tVstms4QGgedIElIUBTDIYgahjJEsqkpvt1ZHSEIQBSxWJBkAADgUbWyEZUpdocgQpOme77muq2lGGEXvfeThJ554wvO8er3ueV5fX58Iot4Ru4k/IgLvXNeVVEVE9sqyDBkgUcwAQADLmpzLZU6cOME5wDISfkUI47dBkO0wRIAAAJKMnVavVm0oiia0rIQQjICo7UEZRn5oWdbmZhkrMpalmJKZmZl9Bw7SOFYkeWVpmRDyxhtvJG3LMIyh0THdbE5PT8dxDBF3na6mGfG25jEMQyxJHICLV69+99VTQNMTqfTS8iqPCI8540R8HBYzhAGWJcZpHIVRFIZxBBGglG5R17EsHNsJIT+Mtc0oFTF/Aq8Io13BYWcQKJKMZQND0PM9EgY7/VPBdSOEiJBvSZIQknbo7TubHs75Fq1BFI+38BaHEFJCwHaAN2GUU+K6rqwolUpl//79p06dajabkiRhCVLGVlZXVU3+whc+9+abr3/g0UeKxWIYhmEYinRtjLEiqRBCwAW2VjGWk6mULMuapiuKjBCGcEsvrNl6TBhCmBDGKMD4e/uAHO0UsRBgDGz5Sv8QkyzBhX/b1632IgPgbZAKigmHIowhBRRwQYKXAAwiymOypV+EHHDKAWCAywAwQgUxS1YlIAGOKJIlxmipVNJlKZ8vtLstGeGNtY3KSlmR5EwqnUlldRp3XOfEkcNuz69ubOq6jFCAcNzt1J9/bqmQz+ULRT+EmmoQUjXsDGeA8aiQz+TyCcs0v/vMs+9//6MKljY2Kpokr62uKxKYn5vNZ5O+79bWV9xub73SOHr0sGpk19fLnh/13I4fuNlsttForK+vP/jgg3v37v3EJz5x+PDh++67b6Cv+KlP/sn997/j4fc/kstkDx7imp51nJ5pGpSFvV6vUOg7efNN3W7b7fVMU7/nnns2NjYajdqePbtVTTYMo39gcH5+fv++Q2EYnj/7uqKpjLF6vf7yqVfe9yPvoTR+4cVnd01+oNNqWrZumurqymKzvplK2Iwxw7AZhSvL657ndVpd2zY1SdI0+Pqb1994/UIxl1TVrNOJZJ24nY7vhUcOHbUMu7/oHz10uFbdFCowzkEqk5pbWPmnzzyGEOBMyuWK/+O/VWVD+9M//dPx4dJT33qq1WgkTVtV9Tvvvt1OJXP5YrlabbfbrVbr6PETp195GUD5xvyCZSejOFhYXkom7X/4p3989fSpOI77i32mpttm4qmnnnrkfe87d+HM9fnrtxy/I5NJRgG7PDNrmqaRSJ6/cPHeB+5//4c/+IlPfOLoiaNmKrFZrbzw8os3Ll2b3r0rk7UvXnrjwx/4wJ//5V9Ejgc5+/HbDnVam8iyvvvKmW7kQsx73W5Eo5Dx4aGxP/ybnz0ytQcQenn2WisMllbW8yOjEoYIQM/vIcBlVSpvbjhOJw9yESXDE6N7pqd83/Wc3vr6qtt1TMXI53Jf+8pX//zP/+K973tfOpFpVhpDY0kxvLczDbZ95gAgMVUUrOpGHAaM06RpZHLZlcVOvV4bGxvzPA9xcPXyzPjEBKERxvIPg1kIywAAhAHCUhTGiio//PD7/uAP/mDX7olUKnXt6g1N0wih7XZXVXSx3ctm0zSOc/nM2tra3NxcNpfuOu2YhFEcCPjICCUk8qNARpDEHAAmK3KjWaOE79o11W63Z2ZmhAX3X//1Xzm9jmFosro1GBVJ8Xv+wYMHK5WaLKueF2AMAQYISUEQYCQJsi8hxND1KIo4YSKHRyjf/Z4bBIFlWX4Uh2Eodu87QRcAgkDQIaKoUqt2Oi1CCGBU1zVFkhVF4Rwmkmk3CrCmLJXXAKN3nLhp9tLM1Suz73vf+4IgSGia0+4m0qkwCBihoR+wiNmGzShotVqKokQk0nVd5EwYhiF4L3xb+I2RmLaRLMti8ywNDpUarWZIQuj1OOejI0OCjU4IVeWtmEJGKJRkRoGq6Fu1KwQgAFEci1xhUb6K4kBWMIRQkmXGAYDQMKwrV2aHhobvv++hz3/+87VKQ5E0Qkiz3oCTu3ZNjp89f258ctR13V6Pt9tNXddnZmbuve8dzz3ztNJflBX13Lnzd9x+VyqVcF2/mE93XE+RYDabjuM4CAJF0SjgfhRACXWczmatcuzYsaGhoZmZmcHBQUAJJ5BxbhgaQmBlfa3TbCWT9qWLbxYL/UNDI0EQcQK7rV5W0hvVtiabff0Db7xxQdUMiKRavbpn77QXRGFMx8cnvW6nU6tk0smBfPLK7ExIaD6Xane6pp02rFSr41qW4bru4EBfJp3odDshie1EyrR0t+7rugoZJGFEY2Kblh+4lMV+EDi9jmnIm+uLPKaYAwhlXbOj2AUAYwUTEmMJQMijMIQQq5ohSRKECDAiYxxz7vu+aBgxDhkjEYnjiDqub1mWYZmKomTzmc997nPNZtO2bc/z0uk0QgipqhsEOAgnJiZF5QNjCSEchpGoWmGMMUIkpnEQI4BtS0Mc+j33wIF9Q8NFFm9VnxnH6HvQleg3AcYoY0DC0sbGZs/xR8fyUUQUhRi6KknI6XY5YzSKMcbJdOq7Lzxn2fbAUKnTaqdSKRlLXOYH9+2fvXGDMtjtdov9A6+88lIUkYmx8Xa7LSEY+Z4kSVHQiyk3LLvdcxjnBAJd167OLRhWJp2S16ubMKAYQgIZpbFoeGGEIICAABDT2PUD3+OAQYixhERMJweCDgURQkLLsaPsEaCCcQABlpCsKaquaowxU9cJoalU2nVdRVMRANV6zdSNyA9kLEGAIEBREAGZK4oChB0/AJzSKBIDFcVxHEZhFASMMSRJlHKAEOWMAajIUuC6qqbumGuIoHTDMNzA5wC1uk7ScQ7lcsVi3xtvvJ7N5xSoxHFAOIuaQT6bPnvudCpl/PRP//Se6b1ra2t9A4XlpTXGgGklGOG1WsPUdEripaX5TrdnJWzOhVUEsG3TtqzV9ZW9B/fd/+D93W4XIQAhB5BBxiBHgPMtGMW3IRcHEFIKEQcAArZTZBINxy2KFedbPu2QIQ4EtxdAEfXBKeAcAighCDCU5CAITV0Jo4hjLgOEJLm5tiFRZKpG4AaSJlPfxxhCBDlDKlCigFiWlUjbcRxChWEMeQyrlZqpqs1Gu29w4PCh49Vq9eUXXty9e/fUgUPn3zh3fWHesqxz585tbKwP9g+Ylrr/4CTjURSH6WQCQVBeWS2NTHW67suvvGAkkraVWF1XS6UBVcozLyY+7TY6/+W3fv2P/+hTX/jc5286flzCytjYZKO5mcrmuISaXefw4YOUqplMcnO94nSaqVzKTvXFod/fX/jt3/6te+69q1wuf/e5p0uDfV/76pd6XaevrxCG/v0P3T9//XqpNPTjP/aRF188//Wvf/3118/ZlrF3755vfetb+Xw2DAJhFlipVH7rN399fn7+j//4jxvN7pPPvrxv3/6BbP7iG2/OXLii6FocxwCjXRMjYdC1DfXwvqmV+auHjh0hMG6326XBsdtuvpNRGkVBFEXpdKqvb2+32wWUZVJpDpjXa+cyaQiYpsjZTI5CBcnC4UXdSpWgwPd96aCUTCYvXrzoef7Q0MihA8Hk6FS13hwaGW61Wo7jMMa/+dgXcpm8IcNIlsprq3FMzp07BwC65977VNNoN+uvvnJ67/R0rn+o44ayZsfMi4JYNWzdTgxNjE1MjrWbraRlSwxceONir9memhjv1pyJwYlsIkOCcGlpud2pMp6yEraqK19/4vHnXn7xgz/6IUKp5/tra2u1RuO220+ur6x0OiCV7Y+gbJRKBueAc8biS6+dvu2Ou55/9UUCwsHh/KULF7Es+4TV3e7rizf6JsZKpdzBoZsBA31zaxdmLuu2tblekWXJsgxG44mxUUmS3DDqea6kKF5M3DCmDNIwVhS92WzVNqutevP4keOqrMUBgRixiFIGKUSMMwQZhwBjzAFgnEuS4rmhZRmSopHAdQIvP1BYW12obZTHSyVLUwf7+q7OXnngnQ/Jskw55VvsH6FP+b5tDUcQUkoVTWYM/OhHP/ybv/FrlmE6nW4um/Vcv9lcF/ImWZZN0+w6bQwBJ7GCkdvrcghUVaU0zmbTAIA4jhmgnDNFkxmJSRBIGBNGTdOsNKory/N9fQOR76fTmc31MoTAVnVOqG2rGMOVGzcoA61Wd/by1UKhL5FKRVGEFdl1e5xRhCQMOYsp4kBCEogpopwIj03GOOchiSGEkqpElIg+Ztftcs5FN2bLk0hiDNOQRMdvOiZhGMcxJKBZb8zPz3MKGAALCwsA8WRfMfTp0GDpwsWZfDrzha9++SM/8WOZQn6zVkWyHAQh5yzySOQTRdJrjZaVSMmGKSk4ny7GcRzHVLSPOGcYSup2aYPECEIEOOAUQAQhR1K72x0ZG6s1GrVaBSGpWCwmE1alUul1XV03MJYhhGKnLRhbUejvcFbe7vRKaCS6JGEYMs7FBYvjOIzIs89+9x3veMf4+GSz2U6n09VqNZlMbm5uZjKZTCbNGEun0/Pz86qqUsqvXr165+23nTx58vTp0/39Q0tLC/V6fXh4uK9voNXudnpOHPscyqZpBhHxgkgExU9PT2ua9u1vP3Px4sUf+/GfWFhYEB06SZIMw2g1G8JiFIyDp775BGNgdGR8Y70sUHMuW2g326lspt3u3nzy1kwmt7y8KKhpmUym43rpTE5T9Aj1MEQH9k1nk4let9XueWOTewAAsqwCiNsdJwzDRqOhIHDnXbdfuHR5aW1NVVXX9wUTWcFKLpcTOk1R0qjX65wzRUK5XHrp7GUvBHYiEUeUEMaDGEoiOIRTuOVRKTKhMtlUGIaKoogPGIYxVuTI7XFOYRQRwoQ1ZRRFogZGOeSct9ttwzCiKDJN03U93/cH+/qFskw0iEUd6C2vDUlhDCiSipAUB7Gkq47j7Ns/DfhbMcYIou9hU24nYgnHeUbA0tIShJATjhUsy7LQWDiOo6saVmRJw2HoVyobqWTS7XZIFOuq2qxX293ewQOH55eWFFmWZbXZdiZ371tbW7t2fb5YGECSCrAkqRqjAHHiOA6n1Pc8wzTdriNxGMfUbfdYSNOm7XhuEPY4Z5IkBRHB265KkDIJQEmSCACCXyjePudcmGhy9gPEcBBABKGdSARBIHwrhBmsYegQAssyRSfL1I0wDFV5q9rEOBMVWdM0xSXbgVaiyis2QMKcPaZU0zQv8CVJiuMw8Dwzabudrm4YjLEwCHYEJhDCiBLEURSFhJD+/v4330QIoWqjbietdr1mm0atVstY1uuvnd+/a+rEkcOFgznK2fEjN20X51AcU1nCAICeS95440Kj0RD+ZL2e12jWm812t+fkcgXGuNCKilRywEXYItqRAmy3/yjY2ooDADEHAIkYbMAFox+IbdnWq2MIAUQSYxwAxCEDAAoyFmIQQk6iWMZKEESyjCnjsR8CC7iNLuaAE8o5Z4KDBThAEmAAQkxjJsky1LWIhJIihXGUkLVmu5WfnJyamorjuLyxeePGDVnXddt+7Y3zMzOXW60GlqUH778vV3jXKy+/mM2mvJ5LWeg7IZFZNmM1er1aparI6uTkpKTpwoQ5nU5fvTLbny8cOnTwr//yr0+/epoQ8gu/8Auf//znF+ev/9y//snl1fnZa5f2H9p/5513Wnbq5ZfPfeWrX+wrjgAWvfud73rq6W+vr67phvL5z33m0sXXV5aWaRwsLcyTKOx12tbYaHVz82tf/spP/MSPf/WrX/3Qox++885jt9927BOf+NPz588PDQ4+9MADL7304uOPfeOOO2/TdfPixYv/63/+0Xp59fq1uc1KrdV27rzzziAIrl69OtjXH8fh2upqKpP8lV/6eK26CRgl0XQY+UbC5Bgomo4BrtecOIwURYljHgZtBKBlWTSK55vrCEDD0EPf4Zx7nue616MwVhTFdX0kS7qidt0eZFzVTYRQGJPSwKBm6BcvXFE0ta8wcPDgYTf0BgYLuUz+7Nmzn/7rv2EUZFJpx3FVzZAkhdJYVjWEgO86NI4zmfTXv/G1kZGR/v6i43R1RcMQLc8vzV0PvNDvdFujo8MkjCzVzGWzxf4+jGXAsNPxymsboR/ls5nFxUXbNqM4jqLohRdekBT5tbOnBweHstn0qVOn0olksVh87ZVTHIKbb755o9a4Pr+USiUp4LIsHzx+0o/iy5dnJybGzIS5Wd1odLr7jhxve7126J27dnm9UczlcgqWxiZLuWLBj0KMsW7q5fIa5azd7lJKkYRbrQ7GsF5puF0XQwQB4hDqpj11eNcHf/wjgIEbV278zu/9bv/gkB+GRFI4BxwwzDmCgAPGIQIIspggAKOIcBZjgHzf1zU7m806tVq71bCSKVnGcRDOz8/t3rOHc/Y2n4fvOTgAoqAMMeKcIwQty7jjjtuWl5ePHDm2vLTS81wx8xu6UiwWm42aMGIUFXEKOAMcY6yqhuM4CCFN0zzPE/QjSgiSJEmROWVtp1voK1y7cf3h9z/y0R/90S9+8YuJRKrbbeuGGgTe4uLC4o0blmVJWMvns2EY1+v1Vrvj+z5HUFGUZMpyXUdXZdM0GWFhTCRJ3mGbCPopwnDH10Ys7hAqQRDU6/VeryeEelbC9Lxeo9G4+eYThq7rur66tHro0KFHH33Udd1ez9t3YP+zLzz/2X/6x7HpvdW1cuT53U6nUi5X6jWOkGbovusRQlRJhhBxCjTNAAAhSQYoDCnZ3KxKElIUTczDdDvYV6yhgANJkgDncRxvxXs4jpPJZPr7+x3HCcPYdV3DMHRdbzU7nDMAGWUsigLOqSQpGGPGuchXE3Mq3BG4QS6oWvxtXltitY7ieG5+fu++fWfPvRaRMJFIdLvda9euTkxMDPT1h2HYV8znsukgCFr1Wuz35ufnjx4+kkpdBQAoinb9+lwQBCdvvf369euDklRvNSFWRTMYACg+3lp5HQCg6Uoqnbl8+XIqlZqcnNzY2NioVuqtZjab7XQ6KysrBw8evOeee8rlcnlzY+/evR2Bitpty7JyuVy9Xg+C4NZbb11YmEskEuKsGYaBMXYcR9TM0ul0TIlhW5VGS7hMaYZOCY+iKAxD27bXNjYiwiYmd71xecZOpQ0r4XkB51C8YXGjCPRZr9eFcl7XLU3TOj1nm8QMBf8GbYNXUVChlEK45QgqbEgppXEcy5rMGMNYYmzrcog3I56rGVav1ws8z7ZtjHGj0fA8TwQqiaqmMM0SnWNJkgiJGWMYY0oJENGTgW8YGkLovvvuAxzgbcMkiAD4nnQH+HayMoRgaWlJN1TOqSSpGAEMYOB5ntMzE2a32x3NDcd+0KzWUoYBGSvkMhvr5SCIsrnC09/5zrW5uYNHj1WqTR5Ld93xjm9961s0VgaGJhudIAZy6IS6rhMKaUxoGOEoTiQkQDwTwV6r0+l0ZFVRVbXtdIUVBYdbPHEGQRAEYRhuGZMCACFHQoLMOAAMQGFasM17A9vque0s6SAIVF3jEMSUZPM5hBBAMJ3NCKNhAABAUNSu2+2253mqJAtATCkV7qAiXVs47/u+L5I9hY1IRAjGUjqddp0uwBLAFHFg6Ibvu8lk0rYMVVXbnU6r6ZmWlUgkAQCWYa4sLh47fOT18+fanU4mk+m4Pd20YxpHYRzxKGw4L33rhXff+86xqd0Y4dhpcwgCEkcAcIxjDhgDsqyeOHmYEw4hVFXs+mSzuhnEccfp5jOFMN6q03MOAUAxjbEsCR3rW9ceQgQw25KF853JfVtaCNm2kwKEWyk7DADAAQIYAMAAg4BhzmXKMUMAIFlQ2RhSuEw5hwQAAtrVpiKpfNvAAgK8xU6EAGEcMYZUGaQSfhjKshLHsWwnKeDXblwvVzZ9308kknNzc2NjY6fPvOZ5br1eL/blSyPDi8tLISN2IgEAxFz5+mNPvf897xkeHoNADkL8uS9+8aMf+5lctjA8Pt7z3Kef+Q6nJPRdBUtvXHjzox/76M/93L9aWVl78fkXsIwVXWl1O1Yy4Vx309mM6/agJHddp7K5jrCGJO1v//qvkIQfuO/+XbvHC4XC7/3e76wsLe3evds07KnJKRlIlBDbtH7+5//97qld42NjVy9f2azVa5uV0aHheqVa2dj0XU+RlPc//H7G6alTpzgFp1857biddDJ76PChVrf+7JNf67TarZZz9twrg4OD991919WrV2M/IiHL5fJC+lSpV2JCitni+saaJCmGZjLGksl0MpncWC9vbFQAZZKEPM9LJBIJ20YIUA4Gh0bb7XYqlXJ7PoegmC8wwBu1erfnAgBC6nadnhdFm5XqwFDJ1ozTZ85m81mIUaPe1Q3747/8y91ub+7a9W63N3djIZlM7j2wP4zi86+/tlnZlDUjinuTuwdMXZ69clZXtGZ1dWR4rC+Vfv3Cm5QT3/dmWpcVVZUkqdd789Zbb911YH8UE4zgYP9gKpNeWVnJpXMsZj3H7e/v3zU5Jcsy4SSRSCmaPDm+i8ekttnUdXt0dLTnBH3F0gvPv5JM2qZpBkEwMFSqlDfqm61bjt+2srDeajhjuyYjQtwwWt3YSCRTzUZLW1T6Cv03FmE2mwUYGIbhkzCizNZNWZZtU5c5CB03m80mU6nszYlEQicxo5QiURcHgEMgZ0xqSD0Yca+dTOU5iwFnAEHGGSecQ4xlmVKCFZlEMWBEVqXAdQMlyGZz7c3NSq1qZ7OmaUIIr83OTk7uwhIW1i7/Ah0Lgi3qpGlbH/jghz71yT/rdLt+GEiSoqmGbhqpVKbnuaquiey7RCLR6XRiSihnouEltmSUckJYEEQQQl3XIcAeiTVFkWRsZdIHTxz99nPfEeTj7EAWUixZmp3S/69Hf+QX/t1/+LO//NNGudbrdMvlTc4Q57DTcTzPU1V5Y2M9aevVarVcXk8mUxDCdqcnSVLP7+1YDmFpiy5sGAaEMAgCSmPxLSHE87yNtfXBgT7DMIz+0mf+8bOAMSBhEBPdsjDAJI4hB++4+55ut2crluzFUkSthF1rNRVdF/LkSrWaSmY4ZVvlCUpF8I6AU4QSp9PRNIXzrbCNneagpmnCtk/A0ziOIYAYY6nb7QrKUa/X29ioOI6TyeSSyWS309N1nUPIGJOkWCADxohY78Xxdgq2yG7bIrtsvzDGuNVuDw4Ozs7Onjhx4oEHHvjGN75RzBdarZaiyEJilkzZmqaVSqXLly+bmmpZ1vXr10eGhvv6Bq5fnbUsq1Gr1xr1Xq+n6Joty0FMel4QE4qxpOt6t91qd73hUS2OY8+PIIQrKyvCNXRxZblQKGxsbIjgmiiKrl+/XsxlBwcHOUC2bXc6Tq1WU3XTcRzGWKFQePPNN0+ePHny5MmNjY2NjY10NjM6uavTaksM6YomSVIqlSqXy6dPvbZZrXV6QS6Xi+N4c6M6MDBA4tD1At/3z59//e773mGZiTCMjQSOCVNUtdNuR1EkujyargAAPNddWFjQDCsK/Ylduxrti5RSVcEYY4gQh1zQciRJkKUIZxwhFEVROp1eWlrSNFW8bQEUgiAQAI4xFseRsByTJKnb7SqKYlhWFEWGYTDGMpkMxliYYwmsFkWRsBvYwnYAIiTJCJKIYsw1TeOcDw72Hz58+O3EJAgBY4ADABGHAG2vpZwxBjkI3KjVaOTSWUWWFAlzzhVVqlQqjDHEEeRgeLB05txrgdtLGEbsB+vLy5VKpVjsQxASQu65+x0M40atPlSyNpZX15dXqtVq5EeIIxJz206Fns8oUxXDaTsIYEihhlW/63W7XUKIpMiikY8wRtKWyg8hRBkVsEbUjYRk4/uAws76/fa5STxggHNGTUkSBWpxhwtcPjY2JjhwAi2JPdbw8HCj0RT6ANGz3xGeCHwsvHB25JyGYXR7Xhj6URRhCVmW2e22c9lsMmULt73R0VGE0NLiSs9zKaWGrnbaTcxZs9k8edPNz77wvLiUvu/buhFzqihGq+WWN+tjk/uAIvdadUVGAHEKEQUMSIgSShiTAChvbuiSBhiHEFLOEonEYDpBGXC7HiFE2jZE2Cldv50duHW6IMfCvgu8FfMgYBYHAOwE7Ih24fcQ1RmGXKB1BIBMAQCMYykisaIohBGMIZIQoKBRqyqaTAEHeMetjQEOCINAkmNGkKaChB2HbagqiENJgkiRr16+PDhU2r179+joGIF8ZHSUQB6Uo5tvvxUhQAhRdaV/cODo8SPnz56buXgpn+tb3ajlisOGYSCsSEgrFouvnT976dKlMI4wxjNvvDk2MpxNpefnrj/4wD2zVy9/6k/+dH19fWRo2PMy7Waj3WjGcVxeW19ZW81l+wxNKfQVdE1GGHtuVC6vb5ZXM2nzi5//JwzZ6PBQLpN+5ZVTtmVNT+2q16tnXzv15NjwV77krqysMcY3Njb6+wYHBvtGR4YvXLiwsrLcarUqlUoYhs1GbXh4WFEkVVULhUI+m2a8P4oiKEt79kzvnd4fBkHKTq2vbUgY9xUH/JhcnV/Sdd3p9FRF0RRzcnwqiHxGaBAEQRB0Ot1EIjk4WJIQZIyJfnSjUYvjWFc1zdDtRCaMYw4k07b7+/ooB8l0DmPsum6z1Wk2GnYikUxk88VcLpNPZNIcAtd1AYO9Xi9hpoeHh+1HTdd1VUXnnOeKhV6vN7cwTxlbWlr5vf/5O+V1T9Gl0dJwo1EO/WhtaeHa5Zn9+w/WGo3Yi9zIA7JKCFUU5cDhQ+1uh1OWTKQbtVoxn89nC7XKlUwqm0vKlbXy2vKK53mypvb39wdh6LnO6OioYWpIgmEUSTJyXddOWq1Wq9Fucc6RLJ17/Xy2kKeA27aNJSkIgmw2iyQZMra6vJJNphRFWV5cURSFUEoIKQ4UOeeNZn1sbEzTlMjzTUlfmJvbd+CAZugQQixLlMaKtBWY4YeBG/hOr5fM5rw41BFAEmAR44BxDhjkjDPAOaCQciRGE97yocSNeqeYsU3TbjQapSAwDMOyrLWVVc/z7ETiX/BHEZI09JYtALzvvvu+8dgTiqKqqt7pdmNKNM5brZbQWtXq9cHBwaMnjj/zzDNBEGBZUhRF+JWL9UWWVGQiUcluNtuyrFAZB0G4sr7meW4cx/8/1v47SLbsvA8Ev2OvT1++6nnb3a8NGt2NRgMkCJAESIpckZSo5Qw5sytpQ6txK81IGxOj2Z1dxew/kkIzEkVJDA2llVtRS0ochSgCoAOaIHyjDbqfd/XKV/q8ee2x+8fJKnSDoGJiQzc6suvVy3qV15xzvvP7fkZkGfK82+99u9HrKaWKefr53/7cL//yL99759tgTXdpuddbbiWtqpStVqvTaQghnn3uGWvN4eGhMebKlathEB8eHud5Tr2FWaBSqqrLNE1dA6EoCoxxXRsHJbioDKvN40ePAGBpeTkOw7wsnQi/EtKKgnNPK/XZz38WAX768vXj42PKmXMKBZDGmOl0ihAqyxIAiHMxXqAbRgmJMUbSmRx9Z5lAJ0ahi2nffOeP2CFY4/GYENJoNJrN5nSaCiGKoiCE+L5PKdXWbWo9Vz8Joa21FjRghCkCaS0yBjRgixC1Cwxr4TPu+i2Us+NBH2H07ffe/fmf+488zzse9J0s+fDwsN1pep6X53mr1Wg3EodMKqXce5rNdl3XBmye57u7u2ESu7KgrmvKPa20M/KiHM3mmbU2iLy8KsMwTPNs/+hwNpu1Wi2plVQGABwEtbe3d/369aPjwRe+8IVLV661u10hVF3XOzs7Fy5cmEwmt27d+sQnPrG9vS2E2N7eLmu5tbXFKZuMR0EUdnrLnhfcuHFj+zc/+wdf+Uqnd2ZldTMvqjSbh4EXhUmVFI8eP7l+PHj6xrM7e3vO+18pbbTV2rjbEASB7/tCVt/61re+/7UP9Q+PCAsp92bztEV8cJahFGkjLWBKF3JCtwyXZbm8vLy9/ZhSCgTXqg4hdM/fqZLfsWXAIKPBgmacIOydeARY5+QmyuoEarTWGseztNYihK01SilGmRIaYxJ6XppOP/Sh1/yQgzntCdoTLOL9tQgG6yzp0Pb2I6lqxiilmHHCMAr9IJ3OGKFaqiQIEz/8xh/8Qci8C2fOirpE58+tLi1n83wyHARJ69bNmx/+yKsffv65+zdvo7Xll5+59mQ3DAnGWmJlynmGMAXEEOa1QoUwGrFROr73+AnlnPseALhSgxCitEYIGQTWGmdkL6W0xmBACGGtlSUuC8+c1lqnRuqLU3UwCQCyhDPmLFgQQmmarq6uPv300wCwsrKyu7vrVMdra2vO8cGR5OI4di1C9zCclrMu4NkJOd140VoDGCVkp9Uqy6LVaJ7Z2qCYcE77/b4QAozlPo/iwIJ2hAlCCI+8STrZPLt55cqVew/uM0Ip82UltILxLMNhFPVWbm0/vvz0lYm2PsVGaU2oRthoBIhRjrRCzUYPCWu05oRqsKKSk+NUahH6nlAVQRissdpgwinRYGuEF7ndAGCsq4ksssAQnEpgvtOzOPm/+cPsd23dY4QtAGgCQAi2gARUhtnSaoUVCT1ZCfDMYHzoc+pIdcYs6jkw2NVotdYsboLHVKmNMZR6BqCW4szF8x/72Meazea/+Tf/xvO8VrcdNeJnV55/9tln5/PZF77whZevffjs+fONZgyUtdY3mqubjNJxVY2LwouCuJ28/c6b169eYQTfuX3z+lNPf//Hv+8PvviFP/0n/9Qv/N2//c4bX/87v/A/xUFsDAz290ejwYUzm2VRLLV6Tx5u3394r/dq1yqJtLSy8Dib6xyh+nOf+18/9+8kAHRXer12L/Dxf/S//+nPf/63RVVfu3YNI/MPf/mXer2OEKKsRbvd/trXH927d/vCxYvPPvusCy351A9/Yjweh74XBMHVq1fX1tY6nc7jR4+oRWfOnZ/XZV5XdS1nRT2Z7imhA+5hzjDBrXDp4qXz1KJ8lhKEi6qcTdI8z5MkCYIoTVPLSS1UoZQQQhk7z4s8L+q6LpkojvpOY6GEPB6NhsPR0vKq1nowGIRhOM8LP4i0hbKqRvfuz2dvra6tWWsvXrkcev7+3l6Wzu/cuUcRXllZUXokhHi885hS6odBEIXdXvsv/eW/0B8cfvWrX35871GVqVdffDkOky986fcf3Ls7LeY/9iM//kM/+sP/4l/+yh985Q+iRrS3/ehwb38yGG4urQSeHwVhNstnw7EsxGQ2dSgyY2wyHN186y3C6NPXnzre3+t1mkIVg/HhRz/+0aKojieHCKFeryeFKaosSoJ5PhtPh5PxOGqGq6vLVV0RRNqN5OK5i0kQutTnPM8xIZTSSoqj/nGv3dFC9keTVtLcO+4fDdLWwWieZYsIZzD8RP8bxyGiJJ2XW5sXjvrHopLWKAvKGmUwRgAIYefrhjCRUmILiCIljceDo9Gw12omzebx4f5sNuutrjTiZPfo4PjgMGk0TjYv77eEP3FqAOQS1NEiFgKdO3d2fXPDWlhbX9/d28MYA6ZJ0vjpn/6px9sP/92/+7dZWbhgt3a302y0kySp69qVCsaY/tEArMWYjoajcxvnVlbWLl6+IFXlR5wQFHjclSBRGL715juu+inrejKZrH7/p2pZHBwcPNp+yAgvsxJjQjFRahFJEkWR7we3b90jhEVJ0/MZQtrzeXByOJZ9EAR1Xbs9njHmxNUZeZSpolJK5VWprJmks0arKbQyGlzXj2DMAMuyun712u33br7x1psrZ9bmk3Gr1V5aWgJAt+/ewYheu3ZtNhprrRBCrlkkhKCcYIwZpadztbvaEjQipK5rrbU1yOkHEUKAwWhDsyyL4/jOnTvnz59fWVk5Pj6ezWZhGLq5uxLi1IR6UTNZZQwmsHD3cd905YuDQIQQQBZW165rJoTwff/4+Pitt976+Mc//hu/8RutVrMoijDypZRaS0qx7/vr6+t3796NQt9a+/DBo82tjazIrTZxo0XYYX80XKbUDyNVFp1ObzZPXRnLOXeBwUtLS9vbe4yVzWYTAJaXl1ut1vGg7/u+53lpmtZ1HcfxcDK+d+/e8vJyFEW7+4dJkgihHL3s8PCw1Wnv7u6urCwxxq5evXruwvnJbH7//v313urKysroeK+qKkrbGNNnnnn2jbe/HYZhq9Xq9ZbG41Gv15nNJoiSyXjy9W+8ceXa1ThuOOKiqOtOpzNNUy2Fi7ImhBBKp9NZnpXzohyN+saYLCu8MGHMU0ICOHcrQgBZBI7JmKZFmqZO8aeU8n1eVZVboTnnrgg+7Qo71KQZJ0CwlLLZbEqhEUJumT9VqznnUjgBVBhjSmhVK+K5JrSRUs5ms1dffdVqQBjAasDEGnvikgVO0OWY4I6jAwge3L/vM46RJRgYRoQia02apohgbU3o+Wk2RwSfObuVptMkjouiMKCb3da0Kr0oJEJSP2CBf+bC5vbeo/FsunVu6+yFzbwqjVE+D6RSCOGyrhDBaZ6dDeHm/dv7/YN2r6OFLMsSM+oHQV4U7r5joFJKB2vZkwRAcOQdQhBCyhh4nx3Ggpr9vkYhQsha7eAoN8J7vV6n07lw4YK1dm9vzz11jmVFKe12uzs7Oy7lerF/LUv34242caA0AGCMHbg4mUwYY41mwjDZ2FjtdbtxHO/v7hwdHQ0GA2cYE0VRHEZuZpnP561Os9luZUWeFfnzzz//+PFjQqjWWlgcN0JRqzAIbj9+9Kd+/j/9xb/3d17+yIujWSqNRYDBghKaEs4IVVoLbaw2eAFBYYMJJiT2QyELAEBkgdJbhCjnxhhrDOD35doghBEgC1ppdDInnBapbktnF6YQ9rRv6IpXhMAipJFFBjvLUoNsZbTfiOezqRf4CGNGEGhIh+O2zwGAIgzYEgCwQAizBhtMCiFbKyuAkdIWjEGEKGUwJZjio+Pj/YODs+fOXb9+/UMf+tBnP/vZX/21X/3aN766vr6+eWYrzea/9q//VTafDYbjtfUz7966+fyNZ1nAnzx+YozhPusPD1bI6s2bb/3ID3/6v/mL//UXfud3Hz18EAR+kiRGw0c/+rEyK7/1xlvZfP6xj33891//8v0H9//kz/xEoxETzKfTORgyGU3YUvBksK2N+cwP/WCWp5cvX7x8+bKU9dHh4fLS6re+9dZo2OeUfe2rX47j8Md/4seklK+//vrS8vLtm++dP3/xwy9+qNdbfuGFF9rNVhhHrUYzzeYrK0tOfzqZTY/6x/NZSgyd5dWszIXVWut2o0kQCkM/jmNESacRAEaj0SCbTqgBimgllB+EnPvuNjHmNRqJtTZuJNZaKWWWzZOk4fkKrMXcc+2PzkYnjuPF2qN0d2lZKdVivK6kMYYy6ERRGMQAQD3/vfdu+YxvbGycOXOmyPLd7Se3b98mFC0tLWGGrdLcsMP9PYTQ2c2tF5575mOvfnQ6niVRsvNwdzqarqyuHx4eDSdj5tN33/v25sbqz/7Mnzw83P/c//qvG42Gzwkg/ZWvfumLr//u9WtPez69e++m28wc9isMCGPSaCQY4+l48NLLH9pYX33993/36uUr/aODsizPXbgwn88fTsZZVly8ePHhg3u+xxCYy5cvDo/783QWxUkY+vfefXd8cNBqNOuiXF1dB4LruvaDYGllGWEUeXy52/HW18CgJGpsbGxcvHgxK3LmedbafD6fTsdWG8aYsUpKWVNUziYga0fAMGDBhT4RgjFYi40F4hZ1hBEmSkg/DjCmpaiTZrM/OJrOZu2lXhRFFOFHDx9eunIFTubi7zoWI+1knrHWKqUpxR/+8Ev/4B/8g1c/8prQBlNuwL78kVea7dZaveYYNZPJ5My5s0qpeZrv7OxkWeb7vuvoccrc1vHKuQtXz1wIGH/3q18rZDlNJ8TDjLGtrY0XXnjhwd79w929OI7jOGk3msudZUssDeinf3QJNEgpicFKqSLLq6qq6mIymYyGkzRNa6GVBVGr+WCuTQnIuqnbnKS6eZ7n+74rccIw9H3uuFkMk0YUM8YMWECo0+0Mx6MgSprNhjPQoQgDQFGV33r3nTzPS1PXdS3K6sOf+jAAPH78+Pj4eHPjzK1bt85sbgEAwRRO4TEwjDFRL5A8WMSZIEQRIcQodcLFt266c9ecIoTqup5MJp1OJwzjVquVplld15z5vu8zz3OEFQCLLaaUlrW2J5HPbpl3n0BZbRAAWGUNKHNqilhUIkkSURXtdvutt9/+Y3/sj62traZpGsexkHI4HK6uLvfandF4QCja2FybTlLm4YPjowsXLkRhXIsKUyKULspqNBqtrm8EEHCGaimE0nVdI0JqKSlnW2fPfOONt7pLPaEkYwxhyj3CaBkGsRDC9cUODg7CwNs/OqyVrqrK4WGYUsBonme9Xq+u66Iojo6Otra2gigcDAYXL1/u9/tK60zUdV0fHh7WIsOUnL908d72Xpqmzrl/f39vMBiEoV8URbfTzbJid/9weWWtPxoWec459yifTqcYrDK6rCpCqXsmtnd2wiAe2vT9UcGEEESQtYYTqrW1VkXNJvhoNJ2UoirqknrcLdUn4XfoNJa8rmvfD51dOKFUitoLA855VVVa69XV1XSWzWYzn/FTvpd7IIjTmJ5E9Jw2s6qqajTiVz7y0sJzADspvlnst054zggt7EatMWDM/v5uEHgIWbeb4ZQVWTbP5yxsKAJnttYPp6Pe+mqv27r7+BEGwzmnvj9IZ14rgcDr782mVb507swc6kkxQ+3GncO9reOjlz+8NZhNUJ0vPCZAWiIyMRZYfeWd1yWuGmG3kMogoJSiE6IVIYRS4rArd8VOyyZHgzvttALAooNlXC2w0MedlgsO0HXEqQsXLgDAzs7OeDzudDorKytFUVRVZYxptVoA0Gg0oihygOVkMjFGO2RbCFGWBee83W7ZhRoUOGdxHLGa1nWpldpYX0cW7ty6ORoMqqpSQoiqyuezra0Na9t5njsyMkIozbIrV65lVXluY/kT3//9v/+F12M/MD6Z5xmNvHmd9zrdT33/97FK97ePbORJMEQC0pZog0EqpLSF0mjue5biqq60ti4bhymMtEbWoIWfLYA0p6AgnKiW7HeMZq1HvZNJxpoPTvh24Zj2frMGsAi5mGdrNWBAxnoIAUCFKULMEN8AlfNq3W/B3rDszyI/pFZQhCwAwRgZSxA2hGBKMiGeOnfOWaZiQFprowFRfPfubSnlz//8z4/Hw5/6qZ/a3Ny89+BuGAWNZvPWrVv7+7ta642NjTAMMcZ5Ous1Gh4lD+7e2d190mw2e0vNl1567td+7V9/5KMvejH95I98MvD8OAr/7e/+u6Dd2D0cfv63f5tgBgDPPHXj+jMvfuGLX15e3lpfv6RB/+iPf2Q4Gq2urv/GZ7+4d9AHgKtXrjxz/Snf5/cf3P3SF1+P4/hwb//ChWJw0P+xH/7Rc+fOzWazCxcuJElU5PNPfd8ntTWVEEtLK1pLhEjcSMBYRDAYy6k3OB678PgkSapCJkmbYjLPs1artbS+KoSIAx+UlnXFOR9PR7PjEfeoqGqCwGPYahVFQS0MAKKUej4DgDwvhRBjM62qwgEG+wdHlDOP8Wk6E6Lq9XqAye7+wfHxsVtm3N6Mc15X0u0xnGtMlmXT0UgIMRNyZ2enyOerq6uXL1564cMvPnpwb2dn52jgjOw7k+kUIdRqtaxFABCG8cH+iHPeXl+58fKLWZY5Ruz2o4eXL56tijJA+nhpqairo9noW9+eCKHjOAAiD/s7YcI9n2yevUQ5D31+5fq1NE3ffPNNrcvXv/D5q1evX9g498Xf+r0ojj3PW1q92e12J5PJaDT5vc/9znw+39rawgqKaRbzgGiLtdx+eAcUHO0+LouCUloWNQAsr64YBFKpStQE4cWeGWNGeaPRaLe7Bmwcx0mjsdTrhb4X+j7SLC/m1lofQzOwSNu0yJTwEfMxIcZaoYybhbUFBFZbgxAixlhrhRBhEs/SrLXaC8J4Ok3rovY9r91sPX7woMozL4rczvZ7Hiej1R3GGPjMZz7z1/7aX9s/OmSMzfJ53Ggw6v3Kr/zLj7764WYzmaazx0+2HaclnWXubk4mE98PKaWD40GSJJcvXGwytkTQ1774e5YRTND55V5/Os7maRBc2t5+9OTJkyhKNNhpmj7Z30OIsMCf5tMw8kGBtdanXAjRTJJet5um0ygKqjjwff/yletJqz0Zz6RWvocYp65147jFzozUFfpFUTg2ratDPM+bTKeMsTydM98riiori3LnkHJmMSilmMctgiSJAKDG8sLT1xjgw6N9zmmn03nzzbe01o6kyxiDk8xmtwEeT0eMEZc8uDA71AAAzkJSAtiFJBSBxQYBQoAZpW5bHIbh9vb2yspar9eL48bDhw+nk7TX64VxjDHOsqyqKiXN6Z7e/Q5XVLqvuYvWsdYRUFzHyvf9ucirqvIYK8tSKfHuu++eOXPm7t27xpggCMqicJfJ/TvXrl17/Ytf8jxvks6Gk3Gz3dp9ssMYS5JESjmajKU2axtbg2F/ZWXlye4eIQQwqirpHgUAyPO81WpZax3onSRJmqaOleJIeRhDEATD4fCUohTGiYN/8jyfTqfNZvPx48cOmfgX//Jf+mG4trZSzevR8dH58+effvrGvfs3d/a3G+2lXq/n+4oxtry81GzE43E/8Fe11p/4xCeOB8OD/vGNZ1e+ffO9IAgbjYYoKt/3A49nWSaEWFpams7GZVkeHfZfevlFxILB5O0wDCkjWkuMYYGsABGiMsZwzhlZKGkdrQpjXBSZgwy11lmWtdttzrlD7Bz/HRDyfb8oyyAInGYwyzLHQKIIR1HkHtNTZywplZIGAFPKpZQ+9QjBgOD8+YsbGxuAwBqFFoazYK0FZAxge5Js4uoSJYSsRTqZthpNsJoAogRxzmeTsVIqDoPRbLq8uvL6F3/3yZMn589t9Xq9+w/udjqdyTxbXdvsjyf90RAQyasSUdJaXh7m6f0799PprFayliIOQlkLQFZr4ftsbGohi3k5u3P3JguolHUlhTHGWHtqVeXoVq4/6LYdmBBkvhP8cgq0nL5+z0kKnTiyUkqbzabW2ilCHHa7urr6+PFjZz2HEJrP52fPnh0Oh47V3m63nWZiNpu5G1pVFQAkSdJoNACgKIrpdOr7vNVqrSwvHxwcHOzt9vv90PdXV1f7/b5DvERVuX/NLTllXTHM+sOBlFKUYqW3tNzu1nVtCGq1GqNiXtclkvIv/9n/88a582ABKAAFUCdVowFQAB7Awq0dAIWLE5aLKB0AAH0i/lMA7CT9z+2ODYB1/u8AAGKhqjYWFgXWAlE/caV/H3xlLQIDyCLQoN27iAVmEQBQQtR03qbU5HU6HkXnr1S337OjubcZgbaA3D9vnRurBksDVmrZWVsBDAgRTjiSBp/QVIM4+vVf//VXX31lOBy+/fbbUsoXXnihf3z8/PPPPvfcc3Vd53keBIHPvd3t3dDn9+/erutyNJ08+9xzrWb8aPvh2fObBvT+4d5zLzxbFEWvt/ynfv7n//pf/+sPHz36K//dX/nyl7/6ta9+o9frnT17vtloP3ry4M7tB7u7T77RfKOqqjBOPvShD3k8XF9fm4yHB4c7cRx3u+3r1692Op3QCwkhn/70p30vTNPMGMM51UaWoU85CcM4jGM3L1kEVVWmaQYAThEchKE2ptPtYowRxs1mE6w+e/5MLUWaZdbaXKm6zK21dVU0GkmgmZXaQ4RTirRCnEsDGOMkSaq6wBg7SyH3pHHOpayttUVVOo/lOI43N69gjDn14jh+6tp1L/Dns7SWwuceYGSUns7m8zQllM6mU8ZYp8n8KLRKt1otzthsNptOp1rrV1991ff93f39O3dvBX507hxIZRAiRqOlpZWDvd3VlbgW5TSdHA2P+/1+lqcIoa3VdUpI5PFm6H/swy/WSt7f33vn9s2qqtI0vf3gDuf8+HB46dIFzAlhWIJ679a7xpiNrfXD/f33bt9+9ODxxYuXGWPWmP29vXv377mR0G5067q+ePFiI4r3Hu/4YRB4/tvferOz0rVW5/NsNBhoqcIwpIgaBD3Tfbj9GBN25swZjHFVVXEUGWPKPBVVvv3kIeM+5SzPc4QQI5RgIMi2Gk3GUVlVZ85uLS11la6MMQxTB1VobSy2BCNjHbsVACOLECKoqKsgCo/2hhe9derx6WicZdlSsNRqNm/fuZPNUj+MnBT3fYMWwHXQ8MLl2JUFzmhqc3PlhRdeuHPvXpIkSttXXnlFGm0xtNvtVqu1vbPrfnx5eTnwIzc7ra2tVZUoy/LChQutVivygwDswcM7TGbt7oog2IDN0vnHf/AHVjY27969zbkfx426ro22Wxtn0jQjnDXbrVrVHvWQBdCmqgtG2Pb2NoA5PCwHozEgktc1pXwyzbSWHsdhFDjEyK1u7ixcG8ctXkEQOP5rVVWe71dVVVcVIaTMckqpUlooRRgRWimjp+lsMDh2/lPXr10pp3NMyNLSkpBVo9G4dec2RvTy5cvWWm2te5tjQpdlaS1vNhqnTUDnhmWMqeuaniAmrv75jtSx3W7v7u72esuHh4cHBwfdbndlZWU+n9+bPGCMEYKzbL6ysjIcDt365BzDKaVuE+9WHa01nDhT4xMLedcHMVYBokUtGWd1Xe7s7Fy5fLnVao1GI86pMca5iQ7H08gP0ln23HMvfO1rX0uS5PDw+OrVq5QzY20tJPdCAJBSO4oYRoRzvyxLa8za2nKWZW+99Van05hOp91ud3V1VSurlHr8+LFbzBqNRhAERVGUVU4ICcJwOBxWlTh79mxdSyllq9U6d+7c7/7e7yGMl5a7b3/7ne/7vu/jnD948OD69euZypVSJ7urkBDyG7/xG7W2L3zoFSHE2TNnzp07k84Gg+OjRhR/8Ytf7C2vFEVx+/bt1dXV3d29lZWVSmullBL1dDrd2Fibz+dKymargxm9f+9hb3ldSeP72BhjDRhrGCGiFrWxlDKj5dFh//KlSwihoigYY5PJpNfrzWYTIQRjbOE4irETqVVVjU7khJRh9yByzglm2byQUvq+7yqqsiw55xgTa0EpfVIu09MNAeds98mTn/mZn2o0Y7CACHGIlYsPP8UmtLKUIiEUxYR5/re++aYb0kEQBKHnfvtwOPQ8H2kVeVwU+bh/HDEvpDzy/MSPN5bXx+ksS+dGWY8yW0uo5Pq5tbdvvjPcO+4lnQaPuCGmVMxiUUth6igJi7wCaat5/rUvfTmfZsvLK/NhLoTwPE8q1Wg0ZvPU54Hv+0VdOfaerGvAmHMuq9pFYjknUjjJGYSTPByEsTXGxW1qpVybrMjzpaWlTqfz1FNPSSkJIa1WqyzLhw8fuskriqL9/X23rrudw/Hx8dmzZ8fjcRzHnU6n0WgMh0PG2OPHj5Mk8X2/LEt3ExljDgx69OB+nufNZjNN06LIpaw5p6PxxO0ZJuNZHIReGMynM46xrTVBFPlMASSN5k//9E/9/uuv33lwP2gmy722jkI8nn79V399PccynVZEhXFgpWYIe4RijFngV0YphjVBlmLKGGcsoJxjghFFzMOUEMwwxkCwQ8sxJW7LjikHSoFSvDBKtIHvA3HbNwwIASFAKRACQAA5XzC8+O/9EQCnKgKwYPCi2eGeNS9aj5tQSfVwu1HXngUpJWADyGqtGKHEoEoqzYUiZOPiBZvOrQWrtM98qzQn9Ozm1tnNjf29vffeffetN99M06kQYjabWW0mo+Gt924WRaG0AgACqN1uv/rKR27evrV/sL+8uhzFQRiGb3zrWwAYUYIQKou6KKoHj3bmVZ1V9TydfvpTP/DMtStfev1377z39uf/XfL005ebzWBrc/WTP/AaIOOmx0uXrxpjDAJEwBgthCiKLM/zeTGZpmNrEcbE44HvhwAwLyVjxI98wIA49MdHQghhKs45Qqi1lDh/xaIoirK01NSmYoSRiJaq0ErND1ItFXL2tietikbSUkIyQ0EhiglDTCNrLBiCk2bkeZ7nk6qqrDWEYIRsURXTdOJgct/3e73etWvXWq1WHAaUUinEaDyeTadZltZVVVZV7Xl+ELRbrfX1dZ97BqyWSltz1D/O8zxN03k2M0oDgOexui4fPNp288OZrXN5XkZRwLk/Gk20pKqGS+evUA8bpJRZRxQ989w1jEmj0TjcP7JCJV5gRB1SXoh6+dLlH/jRH8cYF0UhSuHams67ZzQaYQLD4dAtTGVRX76CfM9779vv+p5f1VUYhOcunHvlpZeePHny7rdv5nU2z9PhnVGe5n4UPn/j2eFkXAgxn8/zeUYQCoKAa+wFfhj4+4fDqjZVNcuL+54XYEBg+4Qggkwcx1EjEUrldV1UJed+XksAE4aBzIsGCRWhM63XO21biGlaLHvNshDWWu4FGqxWhhCijPECvy4LSrjFlmBsETCP33v44PyZs2majkajKIo8ysIgeHj/QW9jwxptjKaUaG0JcTtGwBjbE6eDE9Y24pwBwM/93M/9+f/8v+x2sZSSUlJVxdWrV4MgKKsiCnxOyXSahaFfi3Ixy1vLKG6vrXSanfF4XJQ5w5CNDp575mI/zbvLyzvD4drGetzsHB4dC2nipDUbTxmhola6Ur4fGku0NFLayPOzdO4xEgaN+XTS7fTKKpNS9no97gVuyu31OlVVKVm6e2qtnc/nDiaQUlJK5/O5A02c8zNCKC8KwhnnnBNqtMYWYUDGGKGkRWg8nVy5fvWlFz8c+lzWosznUspb791cX1+/cOHC4eHhxsbG1atXhdRBEO3vH66uLjvHA2NMnuecMs6YgyeSuOnGtdMMWmsdWynPc4wxpTjLMs5jhBDd2NgoisJx6YUQo9Go11tut9tLS0vHx8dnz59rNBqz2Ul88mTimMDOIR0h1O12d3d3kyTJF+HEC0HjCZ9uAWi5td/xfsbjcRhG0+k0ipIyryhj83nOGEvTrNfz19fX3IpVlPXuzn672xse9wFAKdVZ6h0fDTBnlHh5nrtGe6OVOBlXVVXuupdl6YpHZ7Q6Hk+bzaaUMk1Tl74khIiiuCzL+TxP0zSOG+5HPvaxj+3u7b333nuAzNLS0oMHD9rttoO7MBDnv+oISa999OPv3bn76PFOs9lEwLIsPXd2681v/oFSCixTyjx69Gh1bS3Pc0TJysrKdDRe7i0dHR1hWPDjut3uYDwYjUbx5vpgPKmEbbVatVSEIKEVADJGk5N0bge5u0aG01k4VAYh5KpeY8ypt7irnRdgjDFaWQ0LVzRGtT3JtnNluMNjiqJ0z+h8PkcWCVE146bPPSmklIJzev36dQCXEIdOFsKTHZI1GLlYB8BAMCCwsPN4myDscUoR1lozQuu6Hg5GnDItVbfZMkIND4/Prm+Oj4c+8a6cv1xUZcCD3Z3HcavFKes2W1VezI6HXT9+6syF7e3tSX+83GqBUFk6b8aJ0EoJzTBf7q09fri3/eQJtlwLzKiHcaVdWrs1nucFQUAIsVUphBBVRRgDAFHXge9XVQnWar1IBjyFqtyrtdYFF2i1cKwwxkRxTAi5evVqmqYIoaqq9vf3GWOrq6uuzC3L0hmmu0LWaVK+/vWvO6msw2tXVlam0+nFixfruq6qqt/vl2XpeIq+xyilcRi4TYgQotvtuCRyANjY2DDGrK6ucs5v37vb6XT6e0dgcQl64/xZo8w777xzYXX9qWvXsUcGs5HCEAaenBYP33yrmtl6Z6/Z9gdlZoVKotgYk5cF9phEutRSIWsACELUIgKIG2IQSMAKkLVWg7IGWdBgsUHGoZaIYIyxc3wBAI1BEmwJQkAMMgSIxRZjijEw5rn3uw74qRK5rCVCFmNMKKKUMMYYpkAwCUMNllggBOWiXGbc35ue6zRAVMgaaw0CRBAGg6w1BLNKG+x5jdUVRZDv+7UCQMAp7bY7r//+Fwb9/mw2cw1ipUSSJI04mWZpo9FwsVF5nmOAuq4p4V4Ur66vH/SPD4/78yJvtVqj0UQrE4Th+XMXWdd75+13EKX//X/3fxdVPptN/pv/+r9aX1//s//Hn2eMcUKjaOtn/sRPGKPn87nbT7d6vffeeWOaZsPxqNXpCFVTQpJmHAUhYdT3KGVet92jnGMgaZqOx2mWySDwGSfHx8etTjvwvVoKqnGr07bWTkZDjHElhJQKIaQVqcVivrUYEQAOhGJiLbgQR4txLSprDBHWo4wTWpQl474Ga62WsrZWu6fXYR5uIx7HcbPZbDQabvUyxkhZv/vt+3meTyaTsiyjKFpeXnZFf1VV8zQ92N+v6xoB8X2/0WhEcdBstcLQX17uWYuUkEVR5POsqipjoKqqE4RAV5WwFhFM19Y2hBD5fFZPcu6BH3nW2CwXlPB+v+8xv9ftzSZThmllUVpVYMwsy93GxiHBzmZlc2PD5b1mWeo6PsWP/gjjHGMqpaxrmWXZ6vKKkwNjjMfj8XPPPfdX/+r/+Prrryet5tLSUtRIlpaXhZCbm5sE4SxNy7wwSpdlWVRlJcTmmbNKqclkIuoy8EKjtDGQF9m9B/cMoCBMkk7LIuKotJxTPy+zND1zZoP53ix72Op0gyCq5lYLbYwNo8gAyuZpGIbaGi0EGMU49QKuRE0ZjYOwyENuRF4WVV0rpSgmjLGAe2+++eYLL7/EwxADUkpQypUylODv1iC977AWPvWpT0ZREEXBpUuXms3m4eHh2bNbcRy6VbKu69APPM/zPM8YcMaKYKi1dj6f1XV59erV3Vs3NzY3jkdjCOOD4WhvOH3pYx83iPcnWVkZMKrMa050VZR5XgLChDPsM0Tw/vYeaOsHHrLAGJnNZpjYWtZCSqlUmDSUEpXIpZQuQdjJwB185UJBrLWNRqMsy9M4XSEE97xaSa21sICMRQgThJXRQoiqqrwgyEaT3/z2vz7e3V9qtWI/YD574dWXJ7NxVRXdVvu9O3evX7/+xrfeeffmex9/9TUp6/F42mq1HG8nCAJjlbOncfvnRYgIIcZ8cAUBcJ9ZSklbrVaSJHt7By5S5+joaGlphXO+vNI7Oj4Yj8ftdlspGUUhY5Rz5pZzqYTneaCBc+4kgYwwNzjBAkYUALQyCIH79ZzQWtSEMK3tcDRaXl52NmKNVjPLsv29w5XVpUF/kmY7caN1+er1L3/pS57ncc4pJ4SzvKotJisnNgSIouFkHAQRY+zo6KgoS/cZEBBK+HSSjpOpo9RQSn2fB77vcW6U1Vr7nFsAbY0fBtz3tDXGWsb5/QcP/tJf+kvNVqvdbrt24WAwAACnRuHUI4Q8c+MG8zildGdn55UPv1SUAowpyvnx0cFyr33u7IZS5v697ThpzgdDzog1Steac89lCa2trfWPDsMwTNN0Y2MjjmMAAIz7x6NBf5w0WmUtAFOMqdLKmEUW5CL+qarG42Gz2Tw+xs7/o65LF9/rqlgAcFOe1hoZq4U02iirpZQGgVZWK+WEtRgThLAQ0jUcAZBDmBzbnRKahBEGLISgmAghgyB45sZTHxye+PQVWY0RAAJjgGAECHRtjg77Lq3JfTDX1hxNJ0tLS/OyOttqzieTm+98O3rpxXajWea5RTAcjjD3BoPRm2+9+/SNG3HUKKfT1YuXxk+edDCbWIziBpEm9oMUE2VASEu4V5Y1ANp9Mhr1i4tnbszSaS5yYy2n1BjjJAWIkrKupZSDwQCsdYYlpVNvOD7WqW3bCVPBkdK0UoTShaKQUgOgrUWUJK1mXpXDydjzvMFgkCSJH4UHBwedTmd1dTXLsiCOHOkqzTMCyO1vKKW7u7sODEAIuat9eHiY57lSKgiCzc3NbrdrtHz33XfzefrCCy+4QgqDKcuy210qispau7S09PoXv7SxsXH27Pk8nUdxcjjs22LOorDVaHLOb968eeXS5StXrhx//cuW4yAKLt64NpgObixdCgGCPGVeCCGinBWiljSgvidUzfyGtZYYIBaIBaIsNgjAKIL0QqRYMFesAAEAAElEQVRjMaYWWwQEkNHKWnTaTsUIIQNgERJGA0YLu1CDzAnDShX5CTVroVw92U9Tay3SyhhljNFWAyAFtiK4kgIAiM8nIhtas279Hg+NqZwlKULGGZlqY0nAClEHnSYs93IpCWbW1FoqsEAJObt15tHjR1EYibo8f+78T/zET/zar/3a4cF+I2lMx2MhBQKy1Fv6+Mc//uDxo739w3feu1nU1frZCy5XeHlp6TOfXhFVDdYuL61ooZ++9Ewp6qIoOmfP/ic/+yfCyJvNZk4Dce7MWSllXqeUUktkmucrKyuE0A+99CFjDGe+EEophYzFDDNCpNZGKWUAGcjmlRbSo/TC+hb3aFWVo+mEGuQjFvtRCcRqowvBOW/6sZSSeRT5JxINpaSUtdWKWEwRRx5zubNIW6ItwbWqA86NloYADhmlJO7GWVEys6AMu4aD67NUVRUEgZRyOOwfHOydAuQY4+Vur9lMms3k9DtFkRVFwTBhGC11um5HLYSoqmKezfb29y1ox4dzE7LnBZxzgjBjDLsYFMqVUi7QU+n6maevt5vh/Qc37z+4k0/mXhhQgLpSzWanrPXxcIoQDlrN4WjEg0iURV1kxhhTVTX3lVJGaUyJi3PZR0hrjQkQQkRZSQulVNwLtLYY4+kkHQwGo9HI87xWqzUcTd586+3heDwcj7O82N3bP+4fITAfffkjP/cf/+zFixc//5uf/eVf/uWiLl58/sUne7tvf+trFiyn/Nlnn719846qRa/XSyeT//6//Ssra2t/6xf/7t17970okVKZhWmcpZgOD4600X/mT/8fPv3xH/rc5z4PmomiTJrtulaU8zCIwjAoy5xTmmVpXRUYaVcFep53vL//V/6vf3Ey6D+4d78sq9FgsLW1tb66tnO4/+j+/WvPPQcIaa0phYXX3Peurhas9zDkz9248Wv/6tevXL26t7+/v7//6kdf2d2+//a33hgMRq50sBhZa0UtrVJ+FNW1bDQa2ILned/38ddUuikGxzK0uUJhb/mZCzdYY/n3vvy14Wi0urKcBH53ab3TbgZ+NM+zSiilhajyPJ8/c+26EnI4HA0G/X5/2GjEZTWf5/O6LoMg8LO5s0rnnKcz4jZgvu9Tyt2e1rVxGGOnhFoH6xCMfcZhwSpG2NGWDPYIieN4NpkyDTfOXW6UmklVHYwGel5dv+oxXpelY/HXQjjD0vl8DmA8Qv/CX/gLn/3sZ4+Ojrrdbj6fB37k2nfGmKqqlFKdTsfJ1aWUymjn5GIRWGSUVtT1OI6PB6cz/v7+frfbdSvBZDIBAN/3q6ryPC+KIkc080ngZsmyLK9cufLuu+/ik2w7xxZ2Z04pVScsbPe3dV1LCU7UNp3Out1umqbHx/1er4cx6feP79+/f+PGjWazOR5Pe73ewcHRynLPATZ1XXd63bqWypROQuWIAm73HEURJdLxWuI4XlpaunXrlnMQ7bTb8/k8CILD44OzjbOYyKoSYRi6eGOwc865a4w6iCgIAs55mqZ+GBJGsywj4YJYFsfxc889/81vfd1aK+uaIJuEgVG11WpzfY1SuvNoT0sVBz6llBJkAEtR+0E4Go2uX79e5tn+/j5CNs2zMAy5H1LCEaZCiFoKSqm12vfDeVY4zM+hJq5ynU6nrtfpnD/cqHOVuzkhuDiuVanKuq6NsQbA2BIzerJrca5o1gkuTh3L4AT34txHymitAaEkSQLPT+fTKxcvXL12+aQyN/DBg2BiwSJAGIFVABj6h31R1404Yoy5KZgxdnTUR4gQyi0qllaW/sk//sfL62tnL1463NufTqcbZ7auPPOc1CrpLH3l61/f3T/c2MCXlleVUoEXckrX1zYfb3+F+940m0swFqQAhRVgSjqdznQy23myJ8WEcYwx9X3fufDVUnDOCWMuYbouCj+KFi4kUSTKChNmrbYnJPZTKuj79nnWWosoZYyJuqbMc73/mzdvxnHsmAFCiPv371NKB4OBA6jckHOSiLXlFTeD+75/eHiYpunLL79sjEmS5Pj4uCgKZz/jRKzNZjNJkqtXr05GwwcPHpw5c+YjH/nIbDL61V/91cFw9PRTT29vb3/mM5955ZVXfud3fudMLTZW18IkjspcUHR4eJj44WQ4rrNse3v72nNPfez7Pn575wFWqig1NJN9OW/LopvPexhbbWVVEYwoRVYJKwVIQRAiBiggYomrtKzVBrnrY2BBZl/w1bizGjbIJQ/aExItW6Q7YIsAjHUKKVdknxblJ0nSYBForR1thCIG3Nm5Ek2QRMjR4C3HJWspXfu58gwStUKUOU8NhLAxFgEQyufzbOPGFQj8+WxOfIoQwpgIIayBF1980fO8LMuuXbvy0ksvXbhw4bnnnnv+2WcZY81mc2trS0mzt7fXbDbjZuPDL73S6nQA47quMSVgrNXaOYwM+/3JYFjk1dra2nA8WllZqqri8ZPd9Y3VZrPl0hufHOwZo5Y6XUBo68y51dVVIcTu7v6jx08QQggR0NhBqlVduH6HtVbUTsPqAitL0R8RgjyPYYyjMMnzUtYqiMIoSQBgPs9dP8JixDAxCJAxUmkptTa6RkAIASux0UZrqYVE1iCLMc5NoWuBAYVhmZcFy9I0z9tBAy3iGcCJqeEklMkhjujE+cxaC8am01kU+pz7Wkv3HkfYqpSDyRe8YAdSAkBdVYRhghlG1lGVs6yw1lLMHJHFCRgdOZISNh4OH9y/tbG29OyNa6+8/KF79+4cHw+8IGTUGx4NS6HDODFghairumg1kjAOmknkPrMxC8KltbbZaxij9CK6CZRSuqGVthrhWptW0mq1Wmmabm1tuZ+9c/v2rVu3PvXJHwiiH1HSBKFnNCBsw9A3So+no+DA+8xnfvjHfuxHxuPxcDKezdOyLP0oRMb+4Cd/6NGjR7vbTx492j48PHzllVe473/iE5+4cvV6Wcu6Fr4fBtyry6rTbo4GfQDzoadfSIcTUwlKsCqKilAWhNPxuNFqDo/73V4zCvzNjeVuM240ErfBpp6n67rRbHpkoRmvqoogzAjBFt556+1rN542sDC6JIR8hzd5cqATBz4AawwyBv7O3/mFT33qU2fOnGFesL+/v7q6mgTeZz79Q4QQbUwQRK6M1mAXy1+UALKirH3fp5jAa68tR81mkmgakCAsLaK+/2cnY48TYlUj9MPAAzBxo1kIWQiZ5zmR5e/+9u+8++7NS5ee6/aW2+32ZDIBbAeD41u33+OcbWys5VWZpmmel8fHx5zTsizn87kQDkRTbu2z1o5GIwcduVad53mudYAxZtg5FmFjjEUIU4IQEqI2Siy3VnbKysdkbWlFHhWHu3vPPvfM5uama7mGYfjpT3+6rmufe3dv37l7cO/KpYvr6+sPH951avS6kr7vn3YGHXnO8cCqqjo1jj7F6Wme591ud2lpmue5m3GKIrNWt1qd1dVVykaTybjd7jomUxRFeZ7P53OjdK0rQqio6ySOtzY3n+zsOZE/pVQIpYSglHJKtaydNtLzPNe/DIJgPJ52Op28qGbTeRCEs+n84OiIcb/d7Y6n08FodPnq1S9/+cvzIscYz7Oi21uu61oqE4bhfJ4bQEEQSKnruiYMJ3Fc5JU7YUJIkiSOm1UWxXQ6vXbtmscD6Wnf9ytREkIMaMcgWVpamk6njLFWq+XYBmmaurKg0+nMZrNTy42yLJ2/7dbW1uc/9xuc86TZOO10UIw4hYCTZ288986bNx/vHAIGKSrGGGWUcyqEyItsOBqcO3fujTfeSFpJv98PgsAR6MIwtjbn3GeMGMBSSgTGTTpwEv+JEKpEPZqMKaUGNKZESukTz9VeQRAcHh5ijKu8AgA3GZ5McDU58YbV2unrjbUWeEAp19oiBJz7WtuyrN1CeHx8DAbNZsHh0QEAfPoHPwX4fV3B7zbhNEa7vgQoZZmHHj58WJX1UrfjVmJKKSAyGI7jpC2MjTutVBUP97cHo/43vv3W1ubZS2e20jz75s2b7V738ePHAqE72w8LJdbPbg3n035RjkfTvJgPqurewd4K6LzM5FQCwXk6J5gdDX1sUbvrp2kWhYnSfl2DUDIrcsdtcqTALMuo5zHGqjynlC13e1mWZVkmpQZ7Yj6OMV7kK4MBQJRbhKwxlDGtLRhoNBquf40Qqut6MBi44Ag3OpzUQAgxHo/39vasta1WK8syZzxmrd3c3HSRpcaYhw8fzmYz1z136NpsOu32er7H4jjuLa84be8//af/tCqK2Sx99sazL7zwwrWrTxVFce7ipZ9dXdt+/EQphSm2GAjBZV3fuXM7pHxyeMw979Hjx+sXz1y9elWI6ubXv9Vttsi5s8P37jVMImrpZqgojJRReZYTThBCFlmLQSOEATsKqgaMGHHOZtZaY9TpZtEYYxG4RAdksUOtkDUYEwwu/QYQBldmWWuzBangJKzAFWoIKYKQBSuNsRqk1VYbMAasAeQxRpQVptIBsSC1stIii10/GllrLcJgDSAMGE2L4oWnnwICmhCwBmHMOFdaLy8vp9PR09evLi0tuTX1977wO2fPbbVarfF4fPbM+aOjoywrmp32F7/4xSSMOPV6vZ7U6uH2YwuwvLxMCWGYxGHkB/zalYvM9yxAcykhDHe6S8wLhRBRHAKYZis651/e3NxIomg6ne7u7O33x6PRKAxjGiTddkdri4kXRTFCkOdzBxIghKTUhFBRK2stoYgx5vsL68EF6Q2QUNIxAVpL/sI7DSOKMBCMjJVGG6PAErCcAEYAxFqrlbZKWWPAUorruuacMY8z38uLQmHEKOEA2CziR9zvckPmg+vxd+w2OOeMEUq5u68AgABOSQuuZqJooWO31hLOkLNugcUIc21lt2/UWlu72Hu7yccoba0mSHOGCSVXb9wAba22QiHGfQNEG1XWhe9Tz6ez2QwQ9f0QI+oUV85sWWutpHSVH2POe7nmnDsapbWWnKSwm5P9v1U/ijkDC8ZITJg1yoXZS20ooW5Ctu75xx8sWwAA8LMvPgfaUO5Nh8N33n3v87/9O+1248MvvVRJ5fmRlgoZpIWMA18riYyepZO3vvHGxTPnfO5Zi6SFaVas9FqMc86aSohCioAjUH47iW88dwMAlAHqcg+suXTp0oM7d5mFPM8pRu1WY2dnZ3Dc762vASCtNMYYLFgDiACcCFrQ+3aPBIGo65Xlzp/7c3/aWkAIlAJC3Abo5ZPgaVDa8aoX5ymEYQyjE54IAgAFoAA4aAMKgDK4sBETAlAV4CEADVKAX/kRxMApBCDllf/sz/zWb37uP/vP/y9ZUQImve5yLUVdl93lbtKI+6Nhr93K89wY8+zTT8XNhrtBrqbRWgNgB2LN53O3E0hn87qulVJ5kWWz1FqNLAYLWqlK1EIpbU273QKMxrMpPnO21WolgFfi1sG4PxgMfuj6H59MJg8ePKB+YCzM518WQhzuH7SbrSQK/ubf/BvvvPPOxsaKECKMfKNBSukcWZ1yVikVhmElaqmVq38wxq4jZIyhu7u7m5ubzWbTefB0Oh0p5WQyQYiEYXjhwoVvf/vbjp/rlvlGo+FOTGtNqXFc3fX19YPDY8f5ZYxZu9jcOFaQGz/ucXfjyglJ1tbW9nZ2W3GrKsVkPGu1Wh4PyqLe3t4+u3VmdXW1rmSjGbuCwDXLqqrq9XpSm+l06upzB0i4oauUcsX7bDYb9PsXL1588OCBG7pJkkwmk067jShJwmQymR0fHz/11DOPHj1KZ5nv+w4P831/Nps99fS111577Wtf+9pwPHYmXj7yizDs9XrW2sePH61vrjnt/aB/dGbrnM+pNdqjpNWIu+1WOs8Hk3Q+nzVbrXk+94LIeVPt7u4++/Qz6+vrR4Mjz/MqUSdJooxGCJV1lUCjFDWltCgK31+ER7qUKGMc9dk6O117El3nZjSXbddut0971XACGWqlKGOOSAQneIy7RI6v5nYATtHm/AXSvOx0OlEQX758eWV5eXV1+Wd++k8sqiuETh0L3i+0WwxaAwQhsHC4f+R+O8YUADCiVSWyrGg1O7WqRVFsrK79f/7ZP3/3nXfe/OZbeV5obazBrVan3e5ai65fDz726kexBZ8wzrynrl07e/7chz70/MrqktBiZWWprCvf9+q6DoMIAP/9v//3P/e531pZWfM4kUoQggGgLEuHZXqeV0nh2nBuMKxtbnaarbqufd/PssyeNAdPWUHudJRd1ExCa621NYb5vgtQklJGUTSbzZw5fhiGSZLMZjNXE7sl0xVhQoilTteJOhuNhnNuu3XrVpqmzpL0/ZhZGEUOp3SBgN1u9+L5c3Vdh76/sbHhyv2dnZ3j4+NSSEqpNbC/uxsFwdb6xt3HDzu97ng8Hs2z3vrKvCryo/rB/k53fenKpYuf/NQP3fzGm199dPvGcudoMqUeAxLoskRKEWuQRR713NjRmFgnE0ZgEbbWSqkRAYwpgLVAELYEM0SREhoAEEYnoJR7LBBZGI06k0UCABZZCzYI4xNm4MlzaK0BK8EiCxgBQgQYAuQyHwEDRho8C6CtNqjSCAFChII9VS6CcV5cgCohKy3PX70G1lpGpDEWsAZrjP6n/+wfWWUQw2CtrGvGuVNZ5VkWxfF8li1MGhGAAa0NIYuETWMspggArDCIYpAKKAatAAxgCwRrWREegmEnw8BYXSOCAEyezc5urD175aoxhngBaAMIgbFACAA9WZ2c8NKFxSFQJ8oA97cuaVFr0AYIAachOD2UAkoXFx0hsHZhlI8JaPpdWb+Ls3OvGLQGoRXxqAYgCJAyBAN+X9Hg7o6DLgj5bkkaPjHFPRFSAULEBQoDet+rs+FwS/cHDxf2cDrQ3Ndwso1URlLMAawQpZaScw8YB2u9kFkJFAHl1KM+yDkY0ooQAAErASRn7gxrMIiBBk4ACVAKFMIIUWrAaNAarAYEYBHIGpiP0QK/RkqBpWAtRhbUSYGhEMPYmRCD0cjdIHsC5CMAIQFjMEApAwCoi1aDfv9rH+ro8uGTXc8zE1E2eDivq9APWOiDtdRnBNHVsP3M1lKYxNN5zoKwUjavJHD/aDhcX10qy9z3mJb19uOH2Xx24fz5OInLvEIYjKrazcaFSxff+uYbieeXebG80qtETQl58uTJ0vq6topStrjCf+hBeP/heWw+z8MwlEIjQrTWBFElJCBjrXXzAGBkrUttI0JWURhVdYWAYALIYrCYUGQJGAMIwMMARQnMwHQMowNwMLiSwKiRCvGQrp8BQ4FAkU2e7Dx46vqNnYOjg6N9LwyMMdvb2xhjbZQoC845Y8yRmN1zGIahI9S224s2tGMHhmG4vr7uHsswCuI4Vkpo4QBWXdd1WuRlXR0dHYoomBwPJDa9zZX+9o4YVUm3LRm88cYbm1tnn37u+Xdv3+GeH8etGzdupBcvUUp/+JOvFUX2+hd+zzlFj0YjrazWutVqBUHgeZ4ze2o0Gq5l59pibuw4XIZmWTYej7W2bsPEOe92u/P5vCgKAFhdW1tdXd3e3imKwi3qURAmUVxVFQYkpASAg4ODVqu1trJ6eHiopULcgxNNu5QSw8J+0BDNKVMnoQGDwWBtba3d7WmtvSCsqqqsBcbgqPh7B/ur62tZOi+LOuy1KynKsuSBL8qy3e3GjM/neV1JhFGr1er3+8710cUtG60bSbI7nfb7/ZXltW6nd/vmza2trZWlpd2D3bXNDcLJdJ4VdVXWNSIkTVOnpZ9MJnEcO8LQYDBw/bhK1GmaJr2k2+2+/fbbjNmlpaW19ZXJdJrl6ZMnwvd9rDWjqNtpN5KIe3Rrc70sy7ookYO+LQqCABnuAi42Nzf393cwxrPZbH11jWCmDTgYQ4M+ndG01p7nSbnADLTWyFqMoa4lALimr9FGKTWZjOo6PHPmDGNseDw0xmi9MCK31nq+p8EaDQDIGmdeiglmyFlpYGYNsgZRwl1X9Bd/8Rd/6qd+4iRvELQCQkBLcxpBCADvh5611gQz0AAAmEGVyuFw2Gi0MKYneZwoTeeLKtnarc6yGE9/+w++Ph1PLq5sWIQwYVLbpNPa2d194dLTxhifksjz6yKfDEevfOyVi889A4SAVkBCMHUECgwKEYCSAFil8wgTrC0ipCprA8bROjzPsxjxwM+r0kEFSqlGo/Hcc89pIR8+fOi8dwEwRpgwetrUOF0IMKZaW0yYtdYPgk6ngxBxeginqHC6VGttv993NA438p22xfM8xlgSJ86dYWtrazAYHBwcuPrpBLqQ7kcAIIqiuq4de8LJ3B4+fKi1DjyvKIpG0nr44LHneY1GI01HGGOCqRAi5l6VpufW13cO97WxB/1jxCglZCVZskI8/Pado/s7L9x49sqlq0bIWSVUzE0lmz5HVtpaJoSGLGAGG4MAY+XimhGyCGFtAQHB1LUALSDncIaQtcqw72yNnRnDguNpkXbcLASArcspX7ipva+aRO/vwxqw7j9trEJWIaSt5YRjqbllDBNgzCBLwWpjNMIWDHK5uNoSQsCioipbva5/dktpKYxhmCFAtRTEaq0WgYVKKRZwcKVVFDHOASBpNgBASk0ZkUpxTrWWmAAAElYigwggYxVHHGwNloCVYDVgBFoTCqDnID1AFFQFxCJiQGvQKvIxyAwhRBCGWiwUlNaCsoAwGAVaAQF4f/liyWJkWQ1SAMbA8OIKq+8MNpDSyTZBuFjykwrGfYHMiYErBgRgMdiTV0QAY6gV4ZwDEORbaYRWzAustY7+71TSJ6g8s9bKWp067QGAc2ZCi8ILa22MUmA1RtaVWdYirSUAJggcu444KA3eZ+27AESFw4sRQsaAMcYYo61hvpeLyll7c8qFxUghhCk2UJVl6PugJcyHkDCYHI3u3OogQFVttMZOqWqVa+25V4SQC1dFyCJECLKYYCsqhBloaZTVWhKE6roOms3hwT7nPIijyWTi3CyFEGEQuYnCYxRZkKoGbRBFdV1bBIHnW2u10HVZMUIRZqVGftL81md/69HO7ub5y5M8t4hawFlZBUEwn8+NUc1mQihSWktETNw7nGTYCz79Yz8hpd5Y7ZaVaIQBJYgGLKSEEKSERBYCz8MYGY4B4Omnn/7CCRSyvNLDGDcajfv371979kYYRQv06Y9kuBsAAIMwwkkcVbWgjBKMpMUYA2YMTvlbCBlrAEApwTmnxKtFTQjilFmrESJ5XVHsGzAIpE8AqhSIgv7+zV/5f5cHT0JdElkhhJDnS8ItjzpPPbf2mZ+GxtIv/dLfYhikKhvNSGmQWgshMMWe74M1DBPH0lPKIHpiR2CMW6mPjvqO/+S4UFprzjz33EZJVJYl48TnQcT9OIyjKKKcaQSEkSiJ0zQtib384eeu3Lg+Ox5Wun5xY317cOT7/srKSm91LQij0WRuraWU93qdw8PRZDIBY1ZXVwEAkKlOlKpOCOJKJs55JWqHAZ8CPbWSaTanvV5PCKG1dTSFLMs2Nzc7nc5kMtNaz+fz1dX16TQdDIa+X1kLURD5fuBSyXSeuTpgMBhsbGz0B0d5XnDOrdWEIMcoshY7ZM+p0B0qwDk3Su8+2blw4dLR0ZHHOAZU17UXeH7kj0aj4XB4ZnMrCMLJaIgtTsJkNp4xzIqqOD7ur6ysLS8vHx4cZ3mqjXHVep7nANDtdj3POzo6whgfHR1VpaCUKiEmkxFjXtSIzrMzeVEstVuc4L2d7ShKNjY2EEJZVgRBlKbZSy+9Mp2O93YP4qiRZgXFTGMzngwjjz94eG82G6Sz4cc//tpTz9wQeb26tZ5P0zDwWkmDEOv7njG6KDLKsDAmz3Ofey5UxD0N7733nhd6PAic9U5W5C4X06k2eMBPELiJRTgKEyFqhJDWNC/mxqgkSebz3Fqb57nW2mMLHFIIMRwOm81mmk4JYVVVGqM9L2Q+L6tKGe2EcsZQ5wJFCInDUClFKHJ1WBgESZLIsuq0upRAlklOiePXKwXUw6C/a4ieYP7AAEC7zbmBnd3t4Wi0sbnmMtI5RRSZusoIsUIID8NWIz54+639WzdXlpb33twNw0Ze17UQiAFgm3MGGtJJttRs+WDqYna3OtjUg3I29T0iVU0pJZaVtWr0ehNhBhU8vPleHAUWtNamlrUQgnPuZnOtjdtGOGCJc+6e7f2dXYf2GWMIJpRSytmpZtMdgMBxe10B1Gw2O53OZDJx8lV0Yn+itXY4lgtvNsbEcdxoNKSUZVm6bsXm5iZj7PDwcG9v7/Dw0OGFhBC3K3I96Pc3TZRSzrXr8LgfhwFCZDSZVUJlWba1vvHg8SNKeRzHk/G0KPKXn39hMhkNZ5Nuu7N/dNxqtYaT8ZkzZ6bzlBhYXV5DymSz9EH9qNlsrp4/FzTjnfduNUW90U5QrpFUoGpZVowzjaxZOEtZMGABsLbYGmutwWABKHKZhE7UoNxbzKLgttjt7h1gZU/ZVmQRA08W5gvGcbbAUkAIwIU0EVehIUDIImSxBQQICFiASmotrLaaEKqMdN1Ltzm3oBFiytpc1r2rF2G5KxRIqb2IUiB1ViAEFoGwmgMFZLTSCKEojrU0jPiiktzHymgFGgMhDCulKCXGKo2MJQiAWLAUDIgStJh9/avVrE9AA1JSS0KIMdaHxFoERlpsKTZClEop7lGjgRBa1xJjjCx2cKbHuJHCpRpIKRFe4PpKKQREqcXYBGMsAmuU42WKWmmtCUWcMmxBi9pN69qAPQljsaABNMIWY2wRsQgbcNwpwNpqRCtDUyApCV/+4c+01jaN1mCNx726qtGJ+4ar05wCwWHhhBBKKTrdbhlLCFJ6AV8RQgiQRfllLcYUITCGASwQIOseEQR4YZmmATBgAggMAtcOJgiDUQQRxhggZACA+5gzAmTxDBmELGALYSOAqgaRQUhgtPuVf/R35k8erjHGlbIalNFWu4wCZBEwQpXRBIPSmmDMPCoqaYzCFggGo4FgQIhoLa3STvPf6XTmWWqMiRuN2WzmiP+L5HdrtNbIwon9gWWcIIyP5kUURUapJEmm8wxhlgqTLK1G/cf+4LAEURfCcE4YDxAqB2U7CrXW9dEAEaylYs3lx0ejkoZ/8md/NPC5KGqrVRS6mQRRz8Nx5Fi2CIPHkNSAMa6rqtVbOXPu3O6DR5WoLeAgCLy8ONjdm/SH8fnYpapo8z4D4D98nIijfY9rY4213MNaGuI2mcTdYiy09ijj3Hd8QZ9TWICOpCiyMAwFAANMCUA5BlTCeHf7n/8ybD+4EvkJNQhrAAMUFBKH/cMCSXjmhQfFg937t5sxq6siL6Tnh1ILbY1Rdl7kFCGMUFG43oLRtUs5s85oyhjDuaUUJ0lSVYVTAWutHUclLwvqcc/3KcLzPBuNRgRjQikiuBC1H/CiKOq6vBOFTd9HxvR6vSYlw8F4aak82D8aTadhlKysrVtt2s0WA9pIWhgIWBQESZrNpIIgiNrtrhCV86JyXTsphaOnB0FACKOUOxyLIrqYAih1Rl7UEePX19erSozHY6NhbW1tY2MTAa2qCizOiwphGidNqWoxGQdBUBQ5xqgsizNntrIs6/cHYRAIgrTSGCGtdF1KJ6A1yjLCKbZFVYZBgAAG/aPA54QQBKYspKgBIRTH8WQsptO0lTRajZaWutfpPXn8pCoqJdQ4H6+urjcajbKqMEV1Vfk8IIiWZUkwswj6x0MH4k3nKUEWEeTYjq+++ipl6GjncbvdzMrq+uXrDJOqljWWxgBhXBtjDLpy7en79+9qa7OsaMatuq7TUSqREcV8faVb5tmDBw/LrGhGvYglslDL7diomhFaFLP9wwPus3meLq0u3bu/V1UVZV7/qH/hwqVCFmfOn8myrJhkvs+VkYyR+XxWFflwOEySZHl5WUppEZpOp0IIRPB0OnUCaWut1tJZY5RlMZ/PQz8gCACM73MAyPN8PBxORqFLUWWMIWSVEsoag1UcBbPZnABmFAujMEbNJGK+V9e1QcajTEtVZipknijEo3sP4VOvecQSro0Q1CPWYteROHGxMwCAFi0AWATMELAYkDY7uw8N1eAxxKnSmjHiYzMa7lFqCAbf6MvN6Gu/8vlpf79i1Ac2qxXzG7UqEcqIZ8q6IiSirD15rBOR6WLM8ov94rGZDyosDVVSaGpixOMdoYLzV762l+kqi3sr46oSygCzHHt1Xbs6lROilMrTObagtVJ1tbm2Ojw+2t19UhRFlqUIWUDYMXnRSWaOW10AwakEN45j5+5RliXDRAtpEHieJ6RknFuApNFAJ9pDyliWZVpr0KZWZWZhNBptbGw8efLk6OjINewdX8QtkwBACGk2m64WxBgDVK5T7HleWQuE6zhpjsZTz/PGs5Rxz1o7nkykkkEcff53f2dpaSluNykghJDRuttsjfqDXrdbS+Ec8ES/34jivaPjosqffupK57WX8P7oeOcICFCFPWsiyrQSnGGrjSVWKIUJ8SgDKQNlgcJUKR6FQggGpCqLMAwQMUYpjUEbYIwjIKqqA+xRpeui7C6vDNMp9pjQRmHgnMtaOGDFIgCjiQWQFgNQ4oxGXd1uCTiAAyOkCUWV0ZYjDRpjrKxBhIE2XuAXVe77XEpRVWWnt3Fnd/f8pfPQTKajQRCExoBQVcAoAqUw4IV1HwYrACGwGGOGLHDCrAaEEWZIgaRgKSDQ2EiNfWbBGGDISiYAkIQvfvYb/+gXLi35VOezedput8q6RkALTQFhgrBFrq40AFCfRJi5Jqk7rLUlAHK9vD8kFsEYnxKVCLIGAbZgEVSAtEUWgTXaWMOM4cZyAIsYIKwxNQQBkoAktgWAqS1hNLI18rivrShVpSmyflSY4EmGfuA//S9aa5vAIgUglQox8YIPfEJYJDWgU3Tt/Uu0Ky8oQfDB1iEsesR2gaPZU9YP0gi0MzVDkmKNAKwFhUgNoBFBgAkYHzMCDmwDjEBbjRGrrECGeoQirCgACAUWjBU4IHC4/fVf+KvN8cNnAuYJRIxDNQHhxXUzziYEATZgMGALprYY0HeQd4oRGLAGMQsMAxjoJWAFJD4AAChoRbAA7dypEACyYEKc3C+LALUiAABGQZUQEAtQUuRzXa13Rv3DXjPxPV0SAEY4xjThtqyYx1CQTGbZUnft3vG00Vz+uf/kTxPulVJFgTfP80anYyglhAjtuLRoOBmvrC0jhDDShNC8qDwPPf3cjbt37+p0ejQcdLvdOIwGg8E73/zW1rlzjrFHKJMA7HvAWM6f0mBKrLUWLCFIa62UpZQ6D2EJSmEwYDHFCoBYoISaWgPBmCKwWCkThiFY7IlFex2sgb07j/7FL+knd55qtZGqQBulSxowK2aE004T1YEu9x7Mp7pF6EwWspTWoFoqYwyAkcYEQai1tkorIwOKhBAI++7RqqrK1X6T2ZhSKmtJOaWc5WVmjDEaGo0GpdRaJCsVNRLO+bA6ArBh6AulwoDFcdKIE1nV/cHoUTon1hRVHXz5GyurGy+93GzErXRWtuMWErbVbGFA3XZbFHUYxstrG81WVxgTJS2Ry0bYnorx5pmtyWzmB94sTfNiLoRoNFqyFp7vg6kJomVZN+M2dS7ejgDPOVVKDQbHW1tng8ADgDgJF814iubz+WnzpSgKIRSlNM9zxihCaHt7e2tr65VXXvnKV746Go183xcitwYRRI1Z9NdPeege40WZUUojPwBijLFnNjbvF3mazwmlLk6kqqoMYauNEebixYv3gnuiVkEQldXk3r17V69dW19fH4/HAOA4LkIIaxbWAxsbG1EUWWuPjw4ppb1exxgzGBx/9NWXt+/f1KpUGhiFpW7n2zfvFIWQynSXlg8Pj8+ePYsxNgbCMEDOClyT5eXVKCT37723sn61LiOPo6evPf2Nr381DILRsD+bDuMkyItpLYrrTz914eKZb7z1jgYbRfTwcH95ZYMSsre3s7qxfni432q1jEVJMx6Px7Is+/3++bPnnJ+HK8/duYzHY8DIEaLhRJXjPJYcYq+MBgCGUCVqZ9/XbLfdGk85B2M0aKVFWdfYI57H2o1kNpvLTPq+zzwuhFhaXXZOS0aqsB1SRJFB66urWipQwDymVO4HntI1IQFl8J2Y5wUF4QTBIqA0GKIxILBqd/eJFwTaGtfEtEZVtarrinMftIg9j1d5UM46WCYcMyMVACKqNpJQSYhSvjJIAJIY6w7TFtWXQ7SmZwTPEZQgJVAPFLHKRGGUySqfzRwnVylViZpzX2oBAK5wcSkiDlgaj8fdbtdae+qMQAhxyJa7vOgkIB0WPVnVarXyPCeE9Hq92Wx2cHDQ6/XqonTtA8/z0ElUkTGm3W6732uMmYzHVVWFnu953nA4vHTpUpqms9kMY7y6uupkg0784oAuB185oNdhBs6X3y1ZcSMZTyehH2CMLSxwNfe0GGOavQ72mJCyqqo8z4t55rQmeZ77vo+M9QIfA8rrSgpxd+fJrf2d9V7nWmflwtZqNs30NGsFOJulviUUGaNMwD1G3FbPxMwDEB4PmCiqquJeYDR4fggAtVAIWYYpttYoja1FFlwLO2m3huMR8zwhVRgG86qoqxwTZkEjQK57iCxghLAF14OwaEEcxM6aHYxjYymCT5lbizcQsnB6M4YgzDxvMk8FI+eefxYoRoRSRBHCBmOkDUIAyCzWVUsBWTixnDiVMVqEEWgMhgB2ewbKPAFYQo2h9hAAltVv/dvb//qffGQpSFgJOt/qBqArQBZ8BkJ+hyB1SopCaEG1+iDwCwAnHKA/VLwgu3jzB+iNAEC/M+4W7DMEFoFRQBggBRgAFFgJrsKjTJU59SOoM8AafGw5n2B0OC3+1H/538Izr4LFymjAxPeoMUD+MGP7P/SBACxoA9qCQQsCPtCTU8eLUCrrmqRaC0KpAssQxwRbAKRBasUogXKOqYVHt17/n/9fy/VgE1QiFdTgClNsLZy4mJ90W09eEfrOWX7vmIY/8qMTRN4XPfCBV/S9vhMYiys/wAYroSqBtAsVs8IIjMHnWFs1Gk+bneU7D/Y756/84J/4U9Lzh5MpoTyMIz8MpJQWHJqLLQKlTVVVLvkVIWQ1BEEEgC5fvd7otGRZ94eDtbU1inEUhEd7+1AJ4gUYI/XvPbPv0jGc6gwAO0ASI1jIVDAARqCEppws0qMJEMBa27qsQ98DBVAXMHzy7v/yt1tVfy3xEKpBAPCAImplXanCkrDAobRMjKftxkY2mRuDfObJKscuD5szmefz+dxaSzFWVQUMIYS0lIgyt+n1POb7vgErhOA+d70y3/fLsk4akbJmPp/7PCrLsipyQnFRlQhZZZVrxUip11fWW0kLA4INk0TxUf94ZWVFKiO1TrOZ5zPnegVgwigQokhaQZZPhpOjvJ5Sz5RlWVV1//6+MWp7777SgjBsrT137my707p79y4j7PBI5GkeRRFjnrWWirKyfsAYYYy4Ft50OvV9f2Nr/ah/vL3zeHlpdWlpaXl5aTgcFmWmjWw2m1EcQG5cY0tK5SjCjx9vdzrdZ288//u///tSaLCYEKy1qWWlbcQos1obYyhzpoLUGJOVhTQaIaTBJq32LMtns1mUxGDseDTSQrZaLUKZsiZuNkajkZP1FVWVpgtDNiEl59w4pixa+KE5TvF8PscUb5zZWl3qlWV53D+6d+/e1evX7t25zTx/Pp+98spLX/jSl6Swl69cG4wnlOLpdLyzs11VRVHOV3pLnHMT4HQ2eeqpG0U+Kqvsf/cTP7K7vd1utw+PnuhRGTXY008/ffnyxX/1r371+lNXhpOhF3jf//2v5ll9eDTYO+iPxsdFLpZXV2azSafbevT4cbOVCCH8gGOM8yzbOrOxs7MzGB6PJ57rqSshgeBW0nJm63VdY0allKpUhBMguBOFCCEXnEwIc0Q/9wgihLzAN0pbgikmGkFZzIfDYRzEnHMNFmOM7CKZu9PpiLIaj8dpmnrUQwb5jFulgYAoSx57SkrKmDOh/feMVWstwcSCnozHuweHa+tbFGxAmU8JRjCbzUqp25GvMtEKGzKbinnKMBCEMViGsbQaIyBAkNaMcqWcBM1QjAyCiDBTVQAGGQsCiEdAV7VWprV0mIn98bz0m6iuKEGcegTRWorTssk1X5xSzxrjetkPHz506IIrp5wSxBmpLyyvTnTpzp6q0Wi4pvsp5lTXtXtokyQxxrhKx9mKFnnuNCYO2G82m87+AyG0vLw8Go2cvOPUm861WpwtiEMoHXHtVJPYarUc8qyVdgXZaSHoikKP81NKsgtQWoi0ATDGoq445wgTN4eOxlNF0P7R4Xv49pX19atr61ubyQpg0seNSpNp1iQ+ABdlFdJWo93KslQinlU19iJkVCUsYNSIG5PRqN1sUUAh5UYqqS3GWFONfAZJJD0GWJVV3Q5DKesQtMEgQRgAbAFbTCzGBgPCBp3m9ZysaO9TrgEAtmDtB4oUhJBUCgg2GpglGNO5BRvw8y+9YEWtwBqwxNGlwRKwFDRxi7dFFjhCALYGqAH7GoEEAAAPDAIFJgCDVZnTRjSrhe95CdQwPYC3vvr2r/7StQglIa/HY8owIdQowCSC2gAoQHqx+Titlyx8Rw5iFxYWJ6f0wXeeHubkLM13Tt/RFgGMQQDI4EVcNraANANDJIAhBoi2YAnoGBDoSmBKABlAAgCBxkfHxT4n3/fn/zI8/4oBJpnxkNG1JNRffNQ/mgv972kx/fveefIlssAMAAKFwQLWAAAEG4IN+G7DRg0gC8g5+ANgQ6kVUGHNKSG1NVbakFGEaZ5PI6rh/lvv/M//47lydLaV2MwHAwDS4u+GA+FkdJ/+6fTr9wdkvv9J+54nu4CsTgG5979+z6tmAQOAFH4QWEKFUgz51mgjLXCalXPl+8A8HQa3jybnnnv5Yz/y44daTqYT7nEgdC4EwdRYgwkDixEGhrGWoshKZBEgwBhbDZggI2Wj01lbW3t8/+F0OpVSJknSrutH29u7OztbV64BgLGW/NG37/T6nE4XjulLMAEEBCgBQItELQkAhJNSVYxSBFYpAZZxyr3Yq3Tpwwze/cqDf/WPutlBw9cQePNaMcO8WiCmEceGBhlPgs3nl268Bi+8Wm4f78513GqV0lDOOWd1XaoyI6CRZRqAMY6MBVCO7VfXEmNgjFWVKLMCsF1eW3M0jKKoCGG+jzqdjjWoystWo6GUyOepW2AoxdZaQhhCzBgYDkdCiOXeUhgGvu+fObN5ODxABCtcaSIRt5opIMQSZJkuRLUedfwGGF1t77/jh97q6mrSYEu6wxjrrfQQshsba57Pp9Px2traT/zk93HqpWlKAHe73SRqeJ5H8zwXslpZW4vjeDQaKS0RQuPJqLfcu3bt8p07d7mHj/uHnue5AOm6riYTvbGxwRhz63RZlmEQK6W0snduP/jBH/zk6urqzs6OwzDKMq3r2rUqtTVSSUzAWMsYq4UoisJYixF68PDh+tqaHwST2ZT7Xjqdaa0tRg4MYx4PgoByVlSlBquNefj40WgydjyYuq6FUMYYignGWGm1t7fnArqjKAIwYRgCstba3/viH/z0H//BvMzSYX9lY0No9dRT13d2DybTke/7Son9g72Hj+5x7iNkhaiqSnTaK/P5LIjC85fOv/HNL7U7/u13v725sfbCSy+2es1zW+cePdmOk+D6jacmk9GD139PGyiEPD4eUh42mmFRSspYmk+b1Jq56HRb83mqlMYYJ0kSRdHdu3dPKdLLy8v37t2zAEmSjMdjQkij0cAYO5q2ywQghPWWl4zSj7YfY0AMY2stoqSuKoQRIhhREoch8TkBFLViTJaGg7GTuSrQYIEQwj026g8AgBPaSJLpaFKrAlk66g/KsgQNnHGrpBuBnHNrv8d04vjNCIA46oXV9x8+UtKEYailYsRSgijx0lxIg5UFbETTxzKbmCLjkW+lEkoCZspZACgLxhAPWakRV2CVBU2sjQiiRlgGRiOGPFAAsjYe135879FoWFQljmCeSQvKggbtzL3c/izP89Fo5KwTGOd5nj98+LDIc8c4dikizrDETS7OqsN9TRk1xrgA4H6/TwjpdDrGGI97Tnyutc7zvCxL7nmODzufzxGAY8X5vk8Rdlx15zDnYDOMF7mwDoZxzUR7kr7uIqLruu50OlmWWWtdsKarw05th8hJRJWDwbTWhFKMsaNzLSQRCLmIaGstxYRSyhmz2pjacu5lovrmowdPpoPNTu9yp/fc+TOsNGQ87z8+yo/6HBGttR4e1XUZMrLR6Z4JE5jNKEKYssPRWCB868kTJWRoGdLGYosZFVZWyJTI+L4fYnxpdd2UMsYIa8QwMaZGCMBibA0zBAAZwNZq+0EE5XTNOxUcftdTp6wxxlCPWgVgwCJcYtQ6swlnNkfpRKOFWyZBYBEoqxCcIFiudWUAEAZsNCgJRAMiAMgSMBgMAjA09AGBT6knc7CFfPP33/7Hf+96Ypo+kaM9oJjEzTzNMQRcAyBAGE5IZx84zGl2uPMyOFnqToUUi8Lr5ECnTTfswCo3vNynAoysa24CwgDEYJCgDVIYFIBFQLDGYDywlgS+UXNQNVAEzJ/lcITjD/+ZvwAvflwBywnxEQcAQsmCPv++rdN3Vbf/YQ4DAJYioxAoIAAUwwkUhwC0AWIsMo585WosBhhhqiUwhDEHUQOIPPIw3PzW1/7Gf3eFiA5HUNUIMauNIdbC9yqwToLaF1f+JMPe4g+U6x849z9UY1ljsX3fGz/wir7H9y2ABVPLIEkYpZWoiO8RwBhAChkGiaF0IvXBvNi8+vzzP/jjA2CpVQpjz/MqoaRUScIJoicPP0ZArIWyrJwbCSzkIwghBEY/8/Szjx48BIB+v39mczMIgiAIbt++vXX5ipSKcP7vuy3GnIbnuGJrsRF1UJk5GSmggRgAMIAYpQDagCEEUUStBlOVfjQWt778xj/+Wx9uh7wVgS1TCzX1uZ9YY+p8gD0+xQS1txrf/5MQbYxvPum88NKf+/P/xf/09/+X5lKDE1YWsyjkaTpP4thillfKIqCeZxVRWhrjWgSAMSwtLTUaDQOLICA3zSqlHJFmeWWFMVYVVRyHStfWameOU9dSa9FIeBgmcRASQtqthtZqPp8D1kpJRqlUlecxFNBWq4EQYYwgMD6hx/295aXkJ3/2k+fOrx8c7Z27cH59fZMzr9FM8jxPkujx44dJI+rmDFlLkJJ1fv2Zc+PxWNUzZVU2rWi31+73+0qIRhz1B8dFUQRB0O22v/XmN1dWVvyQE4aqtPBDvrzWCcPo8cPt6XQeBN7S0oqLrQWLpdQAiFI+GIzefPPt8+cvTqfp9vajVqtVibqWVVkXFpmTNQwwJVIpR0uUWikhRTpzngXGQCWUUNIoLaSUQtRK8sA/Hhwhio01VV0RQuZpWpZ5kjSNMUIsAImyrhhjYFAtxTybWWuzrLBWb2xsNFqtF196aWnpQZ7nP/7jP3773v2trc00ndZ16fu80+mlWQFgzpzZ9H0+Go3C0J9ns8CPGu3G8TG59+BukrAbN57a2FzrdaO333zrb//i3/zJn/zJh0/uUub9g3/4S4TxosgePxmfv9R1wmqta8aZzmvKvCBuSCmOB/0wDJJGZDTMZjOlJCHUAvODgFL6ZGcnL4qiLF3biFI6Go0wo61Wq5pWWmvn7zWbp9SnGJDUIvB8hKAqq1pW1lrf95VVSNVRFDBEtVRRFBmrIj9AFjPmqVpZazGjGIMFfbi/63kesthqwymLglgW1Xg4Ag3gUWSkqKsgjhEgrQz5I3oJ1jjasSEI33vwKIxjWamAE2YUBY4JTStBvEhJ3eW4xawajrgSPgowWOFMlyxCCFOgykikELEWgSbEWmU8Tn1iMShlkQbECAepADRtNPYL/db20RyFFiErrdQO37YWjMOBnKnHfD53OVZa69lsZo0hlJ7OKQ6UctCREwY66MsY47krX1WHh4dSSifEdXlExhhsrWOjl2UJCDlEqt1uO95oo9HI87zKi0aj0Ww2l5aWjo6O3A1ttVoOVHOcTYelueav53lJkgCA7/vOkc4VTOfOnZNSjgbDUzDf/brTU9Baq5OOIedcGu0ALSmlw7eEEFJKJSXHFEnFEYvDIK0yaemwrAcPH+5N0xtnL6ystT/9J3/66Y98FCgt9nfB41QrTsk//x/+n/fv7l1vLquy0BJqgy598rVPfeJjo7IMBNK1rHVdU5NCVRvR4Ek+mt556+23HzwMpvm1Xq9FucgzwgjCBpBBiGCXggfWnPZuXJvoj9hvu0XuO9ADRthiMBobAMKejI4+8R//JDDItcBejDDRSiKKLcagMTEYTthNyAFWmAEBBbWFygNKLANNFw8PMhpTrVUCFlQBX/ncN//R37oR64QpmFeEERrERhGMvICHKlPU5yeF2/sW3cVtwie8JPc37tOTU/7/dzWrlHRC3+9eBwEwgCFgT//OYNAaKCcncgJrgVlLEXAArGUJsDA1OpgUj2382l/8v8Fzr0gFJo4iIADWGIQJBmOBnX6Y0zM4QXr+g1Ra1p2CAYsQQgaoAcAEyGmBRcBiK8Gx8ayr+RAmoDUhhADkWW2YSQIN7/zB1//m/+MSLTscQ6lBaeA+ogQsQvZ7TU2nde3p9T/p3wKYPwxW2RNPL3hfoWkBAH032+z9//73PF+lRQAoZmS3SlngYUtBg4eoliSTcP9odPW1T772oz99MFPjedbsxWBUKgRFhAV+pTTFmHMOxhpjCMYEYaWUlNrziDFgnN0vpWD1s88++3u/+9u6rgeDwdrKCsa41Wo9efLECME8ZpzRL/re8/Zpoe+sZd3sQSg1AMQ1q12BRQwA1mCUrSmiGEBrIISCkkgbxjL79d986//7Dy43ANVDwFoqrXkILNieTOM4Xrtw6eHhQff89ZQsffZXfvvpV3+YrfZA4DtPDoJWd2l187i/73meVaIRhpyzrBRVXemaLRzRwHqYMo85Y9VWq+1W58lkUszngHGnt8wYq5WcmrTd6vV6PYJx0ojRrnEBes4tiFFKKc+yAlucJNHe3h4heHNjrSpLKxX1PFlIn3gWMauRsRppC0ZpU9KQGF1X2UyU8cZquyj6Dw9mw+l4bWU5TdP+4DiJQmStlHXghesrq3VRwn4x7A+yLG9EcRAE9MKFC2VZjsejlZWVVqs1n8/6/aO1taXl5d54PMQEI2zXN5a11mUlAPxWK0HIHh7td7tdSonzFC7LMgzjsiyNMbdu3QrD8PLli7u7TwCZui61lmWZu+6GW108z7MIjDGAYD6fZ1mWJMnu/l4lhYuwDpN4cHRsETTipK5ryli7183Loq5rTAhlLIgjjHGt6lNTL9c1MyepfPN57vu83U7Onj07GPQfP84uXDy3cWbr8oUtKetr168bhMfTyfr6ulT71lq3mA2HgygKut02IcRanZUFAKxtbgz6O3mBLl5Y3X7yZDoZLq0vv+R9+ODo0BpYX988f/limqYWmRc+3G62G7fv3qU+Oe6nYKHV6XpBPJ1OqYeff+HpJ092jTF+4CPcELWSskzTlFEPAJRSw+EwDEO3TLrOUZqmrqPkshQxxvP5vKhKJxB1ZuKuXHCkIkSw1loZbYypRI0IVlUJyBBC1tdXtdDz+VwaHQTBaDSyCAghyEISJkqoKs+cRAUogLGz2SwviyCOAYBQ/J3l4INTEyJgtUVgpVKTyayRtJQQYdzwMfEILpVWFvtxk8piKY4SpgeHu0gJZq0xGiGjrTCAjNEMIYroAjYzEgEIUbU8jJkFlyaiAZAGLW0U1zx652E/RTzodlJlrSah5xmjZ9mMUA544QfmGsqu13Y6aVJK66py3mALPjuAu/7vn31cUFpZls71ymULnvII3f7PgUn4pN+XpmkUhpzzLMsAII5jpxXlnFNK19fXAcBBVqfyE0fGcgIuN+lXVeWId1LKbrd7fHxcluWzzz77za9/w20xT92zAIAQok7Yxe6xYYyVokYIuVFgjdVac8Yc0GUtMsrmddEJu80gkVIahbTBO+PpKH9vc2Xt7uf+zdZ7b//xP/FTz3zkBSAw2T/i7SRcW05vPq6rimnLAprPxMUXPxT82KdjMAsARBvwLHgKEECmgfBXlYHHT776K7/6+j/7Fy+vbraiJogKGaWRo3lbg4yxVjvN4fvaVN/dtXnfd9CJMQ8BoqWiGhFEBcJHdfHMD34C6koRxAnGCOuTnzLWakuIxQYAvT+c3N1lAAoa7IlxFEUarNR1YATUObzz1a//w194tsVimcE8g7iFiV8V2oLwiAfGUk7AVICMg0qcku70LE5/1wfW8u9UV98NF1HndG8/SMwCx7gCAAvYAgJAGGPEAUBpADDgeMrYYEKsBdAEE6AhEDau5EHYeO2/+h/gysvCejj2CSCjaoIwJtRYQFidjObvvQb/b+8P/tGHs4x19xe7skoDEAxA3PdAAigAApg6uM4SsFTXJQkDK2WEJdBavvH6O3/vb2zptNcKoSqBMUAAjGolyQcyw9//6T/4xwUQ5T4J+sPXGTl+/qIJaE8wqf8/rgAi1lJik4ZfHg+tTRgEViEEdF7qW6PRi5/50ec/9SMPBxMSdnmDDtNZEHKjDfEZJlxUFaaEALIIrEYAQCm31mZZ7nmN7/iQaYMJoVG4ur728O59zqVQyvd93/f7e3t37tx56vlnMYD+nq0H9ylPnBHdFy5mlxDiB8F3LiAGQNQ602WEtZaEcIoJ1AKIATG2t7/yzX/yd8+QohdF1kgwwFq99lPPwd7x0jPrgAGeuVb8yq8SlFz42f/TuSyG7gZoIY3+9d/8bHdlfTCZEMoJUR4lFC+2uKEfaMwJ40ZpRmjkcc9jQegLIbIsOz7OyzL3PC+IYyfEJoRMJhOl1HA48n2vriqETtgynse5jwADYGPAvZ9SXFUlJsA9XNVG1gKHsamlxzj3IqM0Y8yCskYsL3WKclJW2ZXLZy0RRZGymCspNjc7q6u99HZ/a3MJYZuEEcawt7OvoJQm//adJ5vrG5vLK3makcDQLJ0ThAeTCQAQgiI/ODg4uHXr1nMvPJ9lqR8GjBHCSZ7mFptKFUHMud8d3Lpz7+HtqlR5WXQ7USXknbt3W62W48J//rd/65VXXoobUX/Yl1Jqo2tR1XVNOBNCFHXh+z5jCzDAebZWUhSVQAgxTvrD4zAMCWca7Hg60Vpy/8LG5pV79+8XVVErUSsBGIVeqKW21mJC7P+Ptv8Otyw97wLR9/3CyjvvE+rUqdxdnVuh1Qoty5LHyLItG5kMFwPGgIdgMMxDZgaGez3m8R3MBWOSbS4Yj22SAWMYE2zLlmUlSy11rO7qruoKp07cea/4pff+8e1zqqrV7QEus57q/azeZ4eV9vre7/f+AgJyxgT3vGPGWJJEdV0Dw1Ont4zRo5fHn/v856NQGvXuXq/z7//9zwVRXDWq3equb2wtihyBJ0mSL/LJZHbhwoXpdCpEJKXc2dmRYSCC4Ohof2/vZq8bF+W8rLM0Tlqt1muvXXvj5p33vOc9f+AP/aF/9s9/6tr16w88cOnshXOz6fL2zn4StybT5Xg2X1sbcCm2tjbPX7r4qU99ihgxyVxtsqxlrfN0NCFbTdMoXTtGLGAr74ayBHStVotxIHJBGAwGg6IoBBeSCwYoGOdx7DW0vhQDWMnfAGA+n/fbrTRNjw5GVVWZxnhEB8CFofTfq7QpioIBc455O1kgAKNf+Mpz73zq3U1ZhnHn7k3qrYkHFgHu3N6p6qbbziLGIy7jAAXD6XihHEgRhVYNI4xttRztS2eArHMAzGmywLhzYByXyK2pZCi1M0TUqCJutSEKIS8kSh4GoEsIGHY2d0r2ytEy2jhdhxxzRVZYLbStTaPCKPEolLXWauP/FXkeBIIzZq1VTQMAPn2QHZuSA8AJbcvvlGpqb1gVx7F3R/MjYsBFGIbAGRF5ZxAgEj64kLHFYgEArVYrDENwtIqz4Hw2m926dcs7XVlrkyTx1gzeS9aH0foSzf+v35h+v885H4/Hi8XC87Q8LuXds1b2jL4f6lETKTxh/8SBzNO/vAOL4LxuVNBKm6I+Go+iIAw5E6TbSWYZEPCbB6M3jsafv/r6515/7fLDj3ziE5/48ONPgKr1dE5aZVmki8I43ahqlOebpr5S5bGNYy5dXTlsGtkAQBta9XIUROHphx78wP/8Fx/5wAd/6Lu+56nB+ibGwjYOlWVk0QAwh4yco5POCgDcWwOtwKD7+VgMAR045AQCOONybz6/+J53wQPnR4uZkKG11rt1W2sZAwtg0KvHNAIBk7AaV4CjRO+E6fEPBjUAgIihAJfD5/7Dr/2Tv/9oQhkS8AhiqZR10AiRCBmBJigLiCSQAs6RTrxGVxuN8BYGm6tB68Q/7NjK8XiH6c0rfvGeqsAAiAQZbhFJeIDBCUYMAEEAcQesBkBwYInfKPR+3Png9/wVuPSUpswFAo3jaASTAMxZsAwIwJEOMfwvLyLuJza91QvetLue0A6+pLmbkWAYCARApwAMMADGgd1VGiDwJCZTOTRclPDZ//D5H/zeiyGe6saguLMRQu0EaU1hkIDW93/fm7f4rbaP3bN+svC3MmjFlYPrVy9veRy84BDBCtsaxDTRjOvARQpEbsWhpvd8y299/zd9/MrNHWJBXRaOYZZlKNCQUkoBxzAMJQ+UUmEgHFuRRB3Y2WLWH7Z9b3DFuQQAck888cRrV15ljC8Wy42NDU8/ePmFFx965GEWSAYO4W0QuOPlhFChlDJKx2HsjRVWbmoA6M8OOM4lAKy8dptZ84X/8zP/9B98YBBE2gACJmk9LeS84K/dGu/tD7I2dNtw5drlR98TP/gumFVw5tJkkffb2ed+4ZOhDKUU88WincVaW6dUHIXGOMaECONaA7gVMFkUBYNYN814PDZGe18bAIiiSGtd5DlDDEQADuq8qCvvOr66nwMw55wUgnPJiEVRpJqqLBZJLAn0xlrXqKVN4zAMCCyga3eSvMrjrFfkuVKVOVwIaS9c2o5TsyynO3tlK01kKIo8v/7iy8NWWjU1A1Bl4ZwhsNffeH1tbW1z+xRxrGwjWnHabYsrV66kaSqlnM1miNgddIfD4XQ+efbZZ8+ePwMAy+UiPyyFEHES7u7eqfN6e/tMqx0fHe0LEQZB2DTVdDqWAWccxqPRxua6c+7KlZe6vU6+rAGBsVVCOzFsmsZp7zrIfTFujOn1eovFIkvb2qqmqD08s3JiJBenybIsJlcn08XceCgTiAFzzjVaITGw2mcVrd6iFOe8qioAmEwWL7/88qVLF621Zdk89vgjcZqNZ/P3vv8Di7w42D+6s7cfpp0oTKSUBwdHSZYBgJSeNo7W2tliSkSCgzI0nxYA0G53b9zcDcPQqltEVDflzds7f/Pv/O1HLj/0P3z04v7BnV6v1+0N3/+BDx0cjv/5P/tXy2WeJEkishdffLE3HFy8eH5//9AbSTS1RkTfweGc+7ztNEk8Y7qqqlar5blxQoi1tbXJZKIa45wLhFRGV0VpwkByUVZlGid5lQvGmeBGaZGIQMjFbD64cH5jYwMchpGUnEu5tsznqq5rXTPGGIogCJzVUdyytSnLcrFY2NJMZgej0SjLMpBvZQx9fHfy+RFExACvX79RVU0rtWmrjeAECxjA0XTWaBuB5c4kRFAsnKrCQAhklhFwIOu4ZAjMNi7iwlouhLBAiM6RjdMI0IFSICXIAKwxMlZh79Xd+etHs7RzarKcJGlfRsliliPptbWN3YP9bq/nSVHz+Xw2W8V++0ah33hPIT+xBPNKQHYcpulJUUwIgNW9TEoZRZFn+qMj59yyLAAAET3iCAA+BscvQohOp5PFifej82EADz300P7+vieteyeOk5rJb5jPJRwMBh7l7fV6e3t7URSdPn366Ogoy7Isy/DYxcO7QXqdqdba+OxqIF9Yx3HMGNvY2MjzvGkaq81isZBRZB3Vtmn327PxKBAsCeP5dKpqHaaxQiLJNYFjUNT6y195fnQ0/ezm+p//3b9LpqnI4tw0jAxjIhSScSG7LUJAF/djkbgUGIB0AASawxqM58X+bEHOnPr6D//h7/ve/++f/otr2xe4cUDWgXbMmxAQMs/jPr6o7h0O32Yg9xOAADjnnHh4c//O//BNvx8kL7UJ47QoGskF59w5y5E5FAYAPZPFD+WwIqawlQnn6iIGAAYoXAVmBl/4xef/5T96KOMtY6DSIDjJiHPLnBMM7XLOgxgCBrYCgWAJAFcO5sC9SQCRRb9ObPUIFoidfJ/fkzev3L+fq58ZrshhAGgILBAnAgbgCIwGG3hgCJkFbAA58XhPmYN47YP/4/fAg+8udCBiYR2EgqEhAAbkvI+YAstRvOVBhv8+8NVJy428sT4c96usL13A0TGNjZPwdg6GQaGgEwFCwylvPv1zV/7R33x3W3DbIOd1oaQMiSyQjcJI17Vkv24BcQ+seOybf8/RftP1dgwGr/bdP/N/YYf+pq9zYAwIzkF3kiBAkJwDl8qFByX7wG/5tq2nnv7KzZ2QR7EMLRAxqrWymrI0RQJda6uNIOSMeaNYRGQMnKVlWTgAYujAMUQZBM5axtljT7zjZ3/m3xrn7uzt+gThVqs1Ho/LskxlGxy9DTq52s17cX0AqOvaq1wdggOvzVydQ6+7N8taSAdqufiP/+LFT/7TJ4ZxVGuwaFSjQcVZRrVtdm61ZVi89molRbK2mbz/I9AdvPTsl860NjqDU2DNow9dlMwtF7M4zfKqFM5ITg+fv0BEtWWNpcPRjHPJGAhk5IyqS+9uQ+SUUsty6Zmsq1YYkY9p4VL6nTJKw3FbgBysilRtqqpIk9ARRSHngp07v3Xt5isvvXrl/KWz58VZZReH8+ZLX/7SxsZani/Kanl4cBuZUbp448arp7bXDueHrX58dGefEXQHfVU3kvE0S7wDZRbrXrtDRIPBwE+S83yhVC0IYZEvq6quqjKII310NB6PkyyezWbpOOl2u8uy6Pd7p0+f/pmf/Tdntre1aZ57/itSBEkazWdFtxMTOJ9cPRmPZcAALaATgnGODzx49satHQAwzilttS05585a5CvnLUQmAl6UpZDSkhFhoKxB5oCcqutWq4UW8rK48uorURCsDPHCwCfw5FXptG2l7bIsG11zKYIgWvV9tPbXRZpFo/F472BPCBFF8vnnXvziF79iLXQ76ebmFgDvdgaddm82W2htwzAWomgaHQSRcwvOhTHGGC2lrFXd1PZovJjN8ixLyqKUspFc9PrdTpy9cXMHGEwmE98MFUIM104J8fxLL7+6XBTb584j4mwx10bfuXWbMaaUabVa3W738GCUZa3FYqGUStPUGONBDs6Y0wYdVXlhGiWQgXWHe/vW2rKoZRQyAgZolXbOaQIuhapqcBSFgXZWNw3nXCBbHwzv3LnjIyDzPAcLa2trjky32wXua3ww2gVMIojBdr+p1J07d+bz+dqZMx8fftxb4hy7JL81fOU7MkD0xuvXkjSNosgalWTtQDCUcr5chGEaAPCmGkSx2RtV5YIJbsFxLhtSQRRWSkseeV6RTzTzioQglAAASoMQnEtolEUQa6demsNnXt/n/bVpVc1mCykyKVxeFHFAPhzQGx8UReHJj2VZetdDX7ifEMNP5m2+RjnR6FljkLF2r+uca7Vag8HAdxhPcmRDKYloPp8ncdxUddM0p0+fHnR7vlfe7XavXr26e3snaWUbGxvxsQHpyUzRx721Wq2yLD0Ni4g8Qtbtdj2V3hhz584dj3V564duu6O17vV6eZ7Xdd1qtfx0om6aVrtNi4UQwv80PGyWJAkAXLx48eDgoJVm3orl8PAwldIY02qlxlnDHUsDForGKQPIEXw2QD6aRkEwo70bZfEH/6fvuSSDRx+4sHf99ukoFULaxrpagQWqm/Od1o1ffPHw05/fTELRhgp0kHbmRO/8+DdSJztw1Y3DO+d/y7dc+Nc/e+XTz77/wllTGAAyHBQZR0Yyfuxg7kc0vMsBuktnum9UcORiEZmiJMFqSdjvPPC+p6u6FEGgax0KScYSR6+WlZwzDoDgnEHboABAJJL+S6xjhMAlgFJgbQAAegFf+sVP/uD/671nt1IDRpGIsmWhYhGArjgYcA3nAK5cMYEJAEOgVTcFnE+tQfR+Xx4Mdsfcn1UstnvTjq3YP6se1vHQvurdIXiyPHGwKIDAkmOuARd6cCUMoW7AKuAOhLJheEj2dZIf+WN/ER56j4WExwE4iBgggXf4BGAMDADIlZPn23Arv2oLT87RW7/+rZ9kyEEpBUEAAAIACTiCVpXjyDgna0KUDARYAAMgoAZgERyVkzVZwM//y2f/wV9/emNdaGUgbiqN0jkCdAEngLqR4JzvYB0z2d9iI/HeFbyf5oYne+d8Eg749Ke7+8Tve/k9H3sMG/sDtHLSZwQxANn84GgzbnUdC2R6UNDNvPjW7/oTRZS+Mp1QkjANnBwHp4wNQ06cobEMMQkkOAJrnEMDJCQnspxL41DrxgEQOgaMnFv5/ToroujJJ5/8yrNf5lm2LPJut9tut2/cuvna1Vfe8dR7TlIifp0Td+IZG4ZhJYtpPm13+gpQAEoCrRQLhEWmBUNLIkDIx82//T9ufOrfXu5S1mjbIHcRciWRbFkwYqFgQArrOuWt+e7t6S/9fO+dH9zuDNttDjYHazPu0gAashyIc07EjCNNbLlcEg+COBsOh8aYJJBxHG+sDY6OjpxzeZ4bo+M4ns+nZVn2ej0p5Suvve5BfdU0YRQ1TeOImPCzVoTjDImyLPvdblkWStuqXgLIRy9eanfC7XPro3zvnc88eupC93Mv/uL+4X6p8nG9vn9wp6qWaRze3rmRdZIzD59O21G0ds4aEEkUybC/tra3t9vrD5q67vXWhsN+VdSttFXX9exw0u/3CewH3vme3d07wtvndDqdLMuUMct8cf7CpcVydjSaXL16/eKDF7Vu3vWud9V19Z73vPfTv/LZtbXO+973tNFuOl08cKnT6fSBxGQy29/fH4/Hk8k8zxcA4I0uoyha3xiWRQ0AnDfes5FL6UdT3+kAAG8/TwzrpgwjqZTKssyTlP1bqqpSRgsQJxxka60IgzCJtFWMsSAMnXP+9eibhrQaQY0x3iJZchYEQZZlRNg0za3bO4i8qhomoizLfPJxEAQ+/CQMY611EATGWk+jKesmDFpCCIYiScLlcp7rajrLHSkZsK2t9U53CODCQHDOZ/PCGtXUutPpIbCN9Y3Hn3hyMpn4wMem0deuvXH7+kvrW2tN03S73SRJ5vN5nudJkvhQF68R84qwk98AALTb7bqu66riQiRxDIhaKXTEOe93ur6iP6F4t1qtxXJmrfXJibrWe3t7iDhYH3hsYz6fq8ac3jyt6lKCiII4iRMhBGhtrUWjBQ8Z587S2wVbERBjTNd1URScSSIrUERRwCXM8sISSrK2Krd7LV6OhauVUpqAARlnLGkkxhgyxsDjOATOj0RAYE0YSmDMkUNVO8maIJsr8ckrN3eVyAWQswLC6WgOzFqiWlNV5d1+92Q25pnjRDSbz9jxXO1E3rVaR/S+HgBAzgVh6GsdDxedO3eu1Wr5Nl9ZllLKW7duBUEQCpllmVeEnD9/3tc6k8nE66WTJEnTdFHkUkokCMNwMBjcuHHD9xw91Kq1Xi6XHtL3gJMxxkdH+2DQIAg2Nja8Tvbo6Kgqys3NTXcc4e73wu+pd0c7edKjYoyx2WzW6/U2NzfzxbLb7QZBEMbRsiyQw3Kec8CmaUQWoxCpvzcBk41CYMvJeFzVh8B22+k73/XI1Jo8a3XO0ehg0gaUYYgWgCAiEBpe+tVf/dRf/9vvOb09KXZ5LJdNI9aG//GnfuKP/MD3Ro9eXEYAIfy27/6uH/r0HyyUDoOgVspPwEgiGSI6gXbedF29aXgEIiIAznlRFIOs40T48mx64X3vih584PrsKJYJRwGwioEGIrCEAOA83QeBIaAF4B4Xcg6QAwE01nFnhavBGvjSL33qB/+3pze7ocqLokmTdlXpJEtVUwV3GeirOBqLDkAw49ADVH6rV+ZIvvmIAHRcV92zDvchK/gmiwe4H9xCB8jAEZBDC9JxEmgZUoCWrFDLVYctDCAMbi6rK7r8+F/5W7D1JJjQhgF62R65u30x9HviOEj3dvjG/ePxf4m6kN7GYEorw4NIEXAEqx3pWkYiCgSBy8u8lXTAMbdUjEsIkBhIBk09WYvs/Bd/7uV/+LceTwNRN6CsCBNgAGgBkYFAWh1MBkQMgPDeJETyeOG92YjHj3j/FXXyiHdznP7LFmvvvtH/I990rbU12fCiLV3A2suK7Sn42Hf8wTLNpkSKbBgGDMg0yiHIMNDkyBFDb6lASICIDAjQw1fIBIIDrfXJVbKiT+Eqdvr8hUvPPfectnY6nfb7fc/Eun3j5jvf9ZTRmotfT0t4chwQMYqiTq8vk8gCEwBoCdDJkBkAA5qsFWChme3/+N+ZfOHnn9xq18VRlKREBMC4Y8SsA+bQcUQgy5oapAws5eP9+vZr0XoN4xsQdyDI5oc7plrGnWFdV0EYOebarV5R1jxMirIq6nmSJGRs0ZTMmdfn0/F47MF+KYUQYnVPy/NOp9Pr9W7fuAGEgaeOOceEOL5VgJ8PM8aE5EWRO1Kz2ZIxc3b7rHP64PDO1374/e/9yNNxK47S6JXXXh5Nbp7aGk6nb0SBO7UxWN8Y/vbf8U3PPfdlZfSyKsoylzI8c+FCsShqY7NuV4Rh2TSS8b39wzBOgiBqp+3FYiGZ0LXauXWbcy6MAy7DomqGw+FyNGLI4zgZjcatVrdp6snhzDlz440dxuFd73zqgYsPOGc7nU5V1c8994LR7o2bN6uq2dra3j633V/rN00TBKKqKim51np3d99astYlSeIVlXEcE0JVVVJKAFo5M0lkyBDRkQiCAICWZe6c85kk1jkUjBESIgoeSMmDlWuRMUYyIUMRoHTOGWU9D8mDDT7rSiklA+EBQw9vCC6DMFLWIXBuoCzLJMmMtkZbIDTaamUYctWUQjofmMA5T+LWclb0exu3b99GxDBsxVHL2Dov5koZ68RwuHXh/PYLzz/30otXCHi73b1w4YGiKJyD/f3DF156udPptFqtfr+zvdV96MGHf+VTv3rz+u0gifyQyTlPkxYROQvkVkEufk4vhIij2Hs1GWOiMIxk4D2LgWEopAiDKi9ypYaDwXA4LMvyRNi/tj7odDpIbDKetbNMSlnrej6fb25uioAncZYlrTiIm0ovJ4tbN24/8/QH2v0OMCOj8CRF3d+c3vLH6ZwTjO3tH+V52emvS46B9O0bHM8X2qqYh0wVp9tDPl26MtfWQBCQFJqMtZY5R+RzRv0o5A3iUaBwVsdJCIjaURjJQtvszAO//NrBq/NmyiMFAEpLnpRFrXERpwlY7gAXi2W73fJYlKc6+dRn/2O7d8t9lS+E8Kc4TVP/Sh8j2On3NjY2fGbzYDBQSvX7/Z2dHU94D4X01/NwONxYW9/f3+fIzm6fufr6a7PZzPPlt7a2lFIBF61Wa7FYCCF8nsH29vZ0Oh2NRg899JBSyseFTqdTz4Lf3Nz0wkOt9eHhoWdf+Uakd6CI4/j06dMA4An43kDrxMrLOuMJ757dXyxz2e0WRdFqtaIoirPUSACJNTpGYGpcRc4h8VA6bZBRGEnXaMFQMoacf+7FVzba6Y3p61936cGLl87NRgsj4/l0se0AmgqG0B1GZza7735ge3Fk44AFjE+UunJr55/9lf/nH/pXP1YlosyPknND1ovmqhoEyAiEBcfACqFRczguP+5f7gUaTlYZgbMuDAILVIC7o4rf9U3fAFFgANDHLN//XgQQDhgHREncIZBXkFkAy8CQseTQ6FBI0ARf+MVnf/yHnuzFGXfFokEmgQnGG9BL6RtcwMAxwBUByng80pdMXz0wv91Qff9FSG8qs970VwSDBGAFA3QMDAcAdIwLl+uy1U4gz8EhWAAMXl80N4Pux//nvwoXnoAigDAWxhJDQueQMbrnkKIDcAiOA7wdgvVVe/O2NdYxL/zuX09mMAxAMKkqg4FQxmShABEBaKcqEjJLMmcIHbAoIISaW2PLlnWhW85/+ie/+JM/+niStrptfTSVrQ40SjhmMSAEJANgAKxvuXqRKTkL4AHCX+cRmFdD0zHp/fiucFwtrXb25Jl7r8z7a+D7j8bJW9AFQQzLRkTro1Lsc/zEd39P3R1OlksUPAQk3WgCFnBA0TjiDJlDQCJ0x7UaHLPznNficM6Vqv0GOHL8rjCQA7jLly+32926LMbj8dmzZ711387OTl0VSdqCt/px3bucEE8553GSNgBFUXYZE+ggkhbcUTVLA95GguXo2g/+NX3lK49uZLCcRDKC0iACoAafbMXBIQcgDsR4BKZx2jJHi9deXL74peHzn26Svnj8g9//D/+ZMdQNeFO7oijCSDqC23f2u/0esJXEWwqGKDgDJAqETOM4juO6ro8ODmtVtVota20QBFZpAGy1W0qpplZxHCtjAJAzLrj0+bmcM865qspONz3Ynw8H7Q9/5EOM23Yrbupqf7p/53BXhvLGzdef+cB7iuXk1Fq/yGeznVuLnduXN051efDcy1dBcsHEYjIFEzz3wvMXL17s9/s3r75W5ItBt5ckSa/bvbm7u9bvHxwdDJ3hkbwz2vfptMI5d/v2bUS+sXEqy7LJdDqb5tqqsqxns+r06bW9vYM0Tf/Tf/x5rfUHnnnfyy9fef75F2fTRRQl5GB9fb0olnt7e4PBQGs9n9fdbjuO436/f+rU6aOjVQB1WZZVVRljjFu1RQDAc35PrLSDQGqtEMnP1D1Dy48WXpOltW6aBgC8btNaq6ra/yTCMExjeXLdexAIwEVRlMVJGAUeMNPKFHWVJJlEaYxPQUmklAjMI169Xs9rxBhj5MAPjdY6pZRzLAgirW3TNGWJUvJAYBSmxjbXXr9x/fob7XZruZhLztud/osvXH38sSdU47TWlijg8XQ6v3VrJ4reiILwocuPPPHEk0KE1q00w4vFwqNW3jWUIXooxSMxvsdERHEQZlkWx3Ge575OZSETQrzvPU8DgAXSWhtjFotFVVWMc+uc4EG/OxgOh2kcz+fzfFkuFovReBzFAWfSanfrjZ04jDkG9bL47v/xjwGHoizSdujvSYggBPtqrxn/BDkExl577ZozNk2SMAh8bS2DcLJYOOcCRimnNmpZLap8WTXWiYhx5gcGtLSS84EFJOtIEAKicw6sy6LQ6CZMo6qsg/6p1+buytSMeahlrE1lGyMMYygB60qVnAJnwTHnXQ+8sHR/f38+nwsujFX33jpPVMpRFF24cGE+n/syFxG3trZarZY/kl46sFwub968CQDeFisMQ6eN1tpnp08mE48yjkYjj69orYuisEBra2tFUcxmM9/m8xZZ+/v7Hlw8PDyMosh/iPfs3dra8ibsW1tb/vL2V+NgMKjLKssyrwuBFYmbeW2j3+yTJuaJR0Oapsvl0leNQoj5fF6WJZNMCtHvtLVSWZxUVeWUq+saiOq6NpWSUuqqTqJIBpwEWC6uHY4Kxj8/2oezF7Yvnj4aTZeCgaWYcQCQpJmqJju3Iqiw0lqpTpK9c3PzP7/2+vzVV9PzW6quktPr3VPDcn+SaSEIQi5qo4khECJyxLvlyFfbBPgR8JgW49A6GYbKwEhX8uzG1jPvyWeLKEyMBQ6rIES+wgEcEgARXwmiguNr1gEwBk4iCgTJLDQFvPCFL//kj5xjqpsEZj5Jsw1wWMynaTt29RLAEgstCI6+p6YJVrMB6dVwDk6wEyRG6BD4mzAV/7zfMQ9znawDrBztuTeeJyDmJxyOiAhBoRHAOAI4Bo6hpTSOmqoOhTC1cTIaUXCTya//s38VLj1ZNiKOQgTDJAN0tbWSCzwpENAPzMeDtKNffwB+0/LVZRbdU5TAyTccrzDCQAri4CwC+Tm1YUEAwLS1AFxKUI0mMIxDQjmo4uhf/sSL//wfvW9rPSOCshZx6JqKOQRiwJCQHDaAihPA3fLBAtExjujTqU/O9f2P9k0izeO9P9EPHoOL6K+9t68/7+7yPUZo6IQirtLW65VVg9O//bu+50CGB5PCMc4ZQ3DOGg2MywCIO+2Y95L1AZyEwAgRCcARGWfBeZ9Mfg+CtYLhEZGcI6Ko0z5/4cKVF1+o63qxWHS73SxJx+PxjWvXH33XO+/Njf3qU3nSlPd3FWLMWRAkwGlIBIAh0P1YhKRh98ZX/sHfSHauPHymBcUSSIOR4BwEGsABCWAMQAKBQ8fAOZXzMEllzDWYpuhJBkev7+YG4uHLL7zIADiyKBCLcnFme+viAxcO9vbLuiqqerHI6zJPorDfSouccxHUdcXY6v7W7mSRDv2E09twMsZ86uvm5uZ4PGZMIKIQTEoJSL7ZhUhJkswmU924n/3Znz27vbG7d7Pfa/3aV75w+OwESfyHn/nk44+dL48WgZBH13dNXe/duvk1H3j/L/yzf19rtXnq9Gg606YedFuDuH/u6775Vz/zK4fXdx555JFaJnVdgnCzoymzVBRlp9MNo3g+nylnn3vpRbHMS0RMs/b+wREycXA4EkJsb599+ZUrqoFWO8yXdZHvtdvtIA7Ksryzc2AtnN46N528eHQ4e/zxh+M4NsZcuHDu8PDQOWCMVVWzWOSdTme5XEomgyBaFMVyuQQAay0hxHFcVVWaprostPYkGNU0TZJE/X5/Mh0FgfA6c8YwCAJj1GQy8TAPAGhtjLEA0DR1wMUxu4VYwBhnzsIJ5cXnvssoDKKICSmllJWCRjXKAAASC4LAF21ZlqGCuq43NzfLsvRu2v5DtNZhGJVlmbVaeVF0e73pbMw5aq3KZRVGPEmSMG4r1WjF1ofbrSxrt7qd9vpiUcRJK5COGM7n00vnH+z1eohQlmXTqM21zXe966kv/Nqv3bhxo8jzbqfTbre9vaSPJGq323EQzufzg4MDrTUwLhlnTBjjqqppGu0cWEtlXVtrf/4Xf8n3E+G4+mSCMwZa66vXXufAGWNIrCiWQRC0OxkgLopcVSqJ4rNnzwYiqAq11l+7/PBDwIExBpwDOUsOwTFkbxaPH99RiCEAvPHGzShKOEfBKYwkcuaQH85mURqRrnohJLZyxUI4s8xrE7clIZHlKDhwBEGA4CwheQ0/OGGNjjmLJeekAAHjbEbhJ1/ZeWGsZiJemqYbpyTQVhgEASOqbeMpVsNhvywLRPRkz9FoRPf4OJ9MxMnnIAEMh8Pt7W2v8Lh8+XKn02m32+PxuCzyMAx97RKG4fb2to/H8a6w7TTrdrudTocx9uqVV3z6oTFmNBn7u6F3q0rTVFX1vd6SHtzyyaDejLjT6QghkiTxf/Kgmu9Knz59OggCT6K02gBAlmVpmk6nUx8SJYQghCiOrTaeTBZFkW9oLucLyYUxpq7rfr9vra2amoyVyJNAMi4xjMGhsoFGU7NwWeSOOHCGCCAYTyRKodC2en1Nzkh+ZTmZ3DHvfvjR/tc8UT+4BRGapoZF2SI2CNOICYfCCGCMsySaFwUn1tk4NSnriAmoKxJguNPMMXIBISdUDu96FngU4S2Fd8cnjwCQIORymefJYH1/Onr8Y98Ap9eq2dzrQS2uYjIFAPmChRExA8DBMSRGHBw4BooDWccEk9ViEUQE1z/7M3/9z33N+nAgZD4fJUlHKyUZD9BCs2RMGQDLAIgRcU4+k24lXrPedAKYI4vEnC+kwDEgAufXwSHhah2P23QEd20BVkMngCNPHUHP/EcCQUAIDQcjnWCOkxMWgIhpEspAENQsmYjWTRZ//Z/8U3DxnYsZJr0hgKmbIpSRNi4S8bFJwepbjoNqDIBPEv2viMv5dc4UwJtnYd4VgSEYDcxZAA6I4BCAKaKGKBRsaXQodchNUR+EXE9/4odf+zc//aEzF4TVSpWOdCDRWct4BCQ4IGPackPMOhJIKBweN13fXDm99SaePI8rTtZxOYVfDToiQ2B3vd/vbYP6SRoi3jPWMKQQWKp4+NnpfP1rPvYtv/HbX7gz50lqCxNnUpW1Y1YE0qKotUEQoQid1QiWEME5xNWF4YMSyQKBFcJxzsE6VZsoWqn7HBBH5o694Z588skrL74ERPP5vN/vB0EQBMFzX/7yo+94Et5GBOC3/N7jRkRoIAJI4oAxBljXpokECqNh5/XXfuRvbi13ex0GeuoEAxagchgy4MqhBhcCRcxx9PoL1DxrqaJAa6KoBdaCKq1ddNrtrScfi9MWwCFj4mD3YPPs+Y9//OObm+utNKlUYyzUdX1wcHCwt3u4t3N0cPjGG2/47TRWnRzzIBD9fj+O4zSNAZwQwlqzWMyllGZFcSRrLSD56gqAp1FMhA8//MCXv/zcT/+LVwLJ+t1sc3vr6575RhGI7/gt35lFYRrw61dfme3vDjsteEwJwsutBz/5yU/OxkdpmuweHJqk0jfzVrf1VP9CoxWb2V6Q7s6XxWjUW+8HMj29efbm7q2iqEQYLsfjtNMRfpiJosS58tat2366fPr06Xe+4ylj1GKxmC9mQoidnd0oTfK83N39hSeeeEwplaUdhmVZlgDgC2fnXFFUjDHfUlFKKWUcgueee/vExWJRNTXnvNVq9Xq9OEvrus6yTCmV54skSbq9NheY57k3MfJ6QGNMEIR+tFBKEYEnr6wClRgBgFe8AwAC990xj4o1jWmakaf7hWFoHbRaLR9x3c46jLHZbHEyBPqjcVJgeWWf1poIut2uUsY5E4QsTaM4CYNAWG2s01JKziQAREFA1oSBmE7ydrvT7awLIeaLxeap9XJtk3FQyty4cT2KIufgs5/9fJIku/v7cRq1Wq2maZbLpf/Suq6bpiEiFYRKqTAMoyjyaApjwpOm/XhvnOPeXlJr7/busRARyCiKDsejfr8bucRpBwCCycFg4JxptAIOAfBO1qlrBZwVZS0wCIJgbXMDAOIsBbDkYV9gSplQ3hUcuXsMGxBxsSwmk0mr1QJnOIhIiiRJlk0zy6vt4VCP73QSFtrGVHnIWa0dJALAEhEjAE0EjggcGoYERM4xItCNWYviSDLkrlgU6dkn3ri5eG53vsuSXJIGW1cmYqEx2jirUTl0gOTQhXE4nU6yLEuSZDweK63CIGxU89XQCADEcXzmzJk0TZMkabfbXgk4mUyOjo72Dg8efvjhuq79lbC5uZmm6dWrV71Zy9bGZrvdns/nxpj9/f2qqh588EGl1EtXXvancnNz0zur+YmEf6UvnYfDoT+/vV7vjTfe8AX9rVu3Ll686Leq1+v5FqdSyrt1TKdTz73zHg2z2axpmjRN19bWHFAQBFYbH5voXbUYY942xs8wlstlVVWWHBIwYtTYyXQ27PURaH24vlwuY2uqvCBtmlo5cAS2bgQiGcbq0VHWyhbjcZoEB8z8wqsvPP3wO9jhnSfny0F3AEmiEF6+c7N/6YGKKibAGWOm6urh+Gt//7eDiFIZmvkclBmNjnqh5Jy7WnupAUdhnDnu0Rz/d88A8NVgCSIGjDPGCjAjV//u3/iNxioHTKJwDAk8yQaYcYDQMCI6Hn4BgLzlJRI5DsgsQVPGHOHKlz73oz/w3tNpVs9MY7PemjG2WM67aSqTgHRhrJVJ4ryUgxM5QEDHhG+xIRJ5M3eEFXBG6C2xHSIjtACMrdYdcl9kvekR3lQfnJheOkIQwEAwMNxZQUBOGAIHYIjLqMRwn8tRNvjQd343XH5HUbh2d40ANFkZBhqsECEQrMLajyNEjw+J8ASv/wa54Nv1P7+qQoG/9n3f5wz9pf/1LwkZAIFzFhg46zgPQ8HyumlHoXAVUJEKd+3Hf3j07/7FMw9fgmmhmiZox+QYgmWCg/E2CquQKIe0Yugb9mZTq3vsXt9icfcqCd5+91b+sABI7L6i+PjROh8nw5xlxIF7k31BPPv8azcv/87fc+53/4EvfO6Va8/fuNjajGLhtOYgwCEpZ4VDCNAxIvRGJUgADBEIiBGhW32zswaE1gDAAJfzRRz2791s3/EAqy9cutTqtGeTaVWUztg0jnud7t7eXj6dZYPBr3MefWm4+hy/rC4uEshlo6FpYDZ6+R/87d5sZz0lEESN1lyGSQaaQVOCDBA4AEPHwCF6VzmGTi+DVgIshNqCNtBqcSlsiXD6AgsigQDIN7dOl2X5d3/oBwMhhmv9Trcbp+2NU1sPPvjgBz/4wc21/vb2drvV1VqPxoe+F3F0dHTjxvX9/f2dnZ2Dg4N2p+esrauq0+3OZ4soTpzzmT8AYBj3QR0okKmm6feHQgT/+B/9+Km1wXhy0O92RCjGi9w5N+h0B632Rrsz3t2xRXn57BlhTCrl5qmNb3jqG4qqTFst9jifLaaz+ZgxWIzyiOGyXIzyZRpHqQzWdMKEPHrh2vVXr2yc3hxsrp9Ph8ONdbFcFlrrqqp7vV6atZMkmc1mL7505ezZ81tb23E83d4+S0RZ2tJarw9YrfT+3hgRWq3O448/2e93j46OsqwthGDM+6XmV6682m63h8Oh4EGxXBptPUEYJHDOkygOA+8FutROO+e0bjhnaZpyzvM8Hwx6nizlnGMMOeedTgeA5XnOuWi3Y28CZIwh8n7WXDCGCG7FB7eMMeucI/IjjbdsQCTOeRCFiFiVzQlPSylV12UQiCAQnW6bwIVR4Jyr6jJN06qohBBKK875dLrfH3SN1TIgxg0gALeIwJkUInAOVOMG3Z5RdRTJqtLVNJdSZu3sYH9MZJf5PAylVbZxDSL3bdNOp+Oca2pFhI7AWTBNY7QxxiyaReFTogiEEFa7WikA5T3lAkQ4tseUYRDGUU/2F4uFMjqMo1orXRatVosInQMpQwAAR03TyFAkSeLQaa198Ei+LNIolSgZcimlrhyG1jkFDH0YbBCIu5Pg+xeGsLu7X5XNYDBARBlwD/lc3dnjIjDOApl+ltnlXsRxMS8BJXHpjqeF1hgHkoikACTnyJFhiGgb2+20ZCCgKcKAaSNmJtytkW+v1fU0SVJWcEY8iKDWtRRxGHIAl2aRP9erDu+x9TkczzhPaOD+Etrc3Gy32865ra0t59yNGzcmk0nTNIPBYDgcTiaTs2fPhmE4n8/H47FPa97Y2JBShmF4cHDw/Fee8/z09fV1IcQLL7xA1pF1ng519erVCxcu+PTufr8/m8082308HnsZB2Ps4sWL3jrrzJkznmKllCqKwneKvWFEp9PxcJdHKKMo6vf7XpuSZZm3lo3a7SiJi2UOAD4J0dd5xhitda2aVT6PNgHjtWmmyyWLQkLQQbBsKnKOJwmWOQNwxgKj5WKhdMCl7GQiMbrVzkQobCiWy+UvfO4zb9zZe/H6jW/62Dd+4lu/qffYI62nnsyHvUUznxeLJGopy77ut/6uD/6ZPzlrlrP58vxww375uSovwo2NWteCWQ4CAJBIoEBnT4AP7wV6go4gomfJHK8DElltsix7aXL08AeeSh99YGcx504GoSyd9Wk33H+II+LgcPVGB+AIOAEiaBcROEkOmIPd65/90b91SuWnegLQApdVVRpg3fUOOK0rLVtt1I4YC3xV4hwgAEiGEAADcMgNIMFx6cR9e48ReN6TBc4YOOTevgsBiHEEILj38b7xnmjFlXfe34EDYMBAcGuZZmiAW7AAEELY3mv4YW/zmT/6Z2HzIkCWJsI2BiUFnFtnBUhkvNRWBtwCwIp0Bb7MIgT4rzMh+K9bCMABXH7soReffwkQ6rKRoW9BMGstB6a0a0ehKpYiNLCcH/yrH9Nf/LX3Pfoo3L4GgwFGDAJAy2xe8yCA0B1fJwwp5CABLQADxt7SiuCEP/rmrSLzlkz2ey8z/wG0MhB5G3hPiNUpcwiIPrtjSXhlnn/tH/5u+dFvAQgeevydP//5KwtjyUHgIBYhJ9M0mizwkHMUrtHAwTLwDQKGjAAZICNgyBg4IDTGIiFHtpzO19f6gOBgxXA4JjwgCvnYY4/98id/qa7r2Ww2XB8macwm7OrVq+/+wAfe5jjQyR2Sjp0pCKBBo51jKIqjWSdNYO/Oa3/3+wfV3sZmB5aHYAn76zIvq3IRd3rAQ4AYkQAaQAeOwPnQ7oAFGdgKWAPtEFRQagLZW4oAos40VyXBcmfPoETOtK4dx1tvTIUMGu0AkIWRMxqsydLs8uXLjz/22OWHH9zc3Dx9+tTDD1/+Tb/pE4PBIAiCO3fuZO3Wz/3cz/2lv/i/FEXR6XYXiyWX4XGSmLdlZhzQWmu1W1tbe+jyQ5yjrvPt0xdbabw/OorjXq3VeFLqpRvdGt9+5fUOl9VOuX/jjRAx5NAfdLTTQRrGaRSGQSsMh/3uA+unKlW1T5+Lkmi5XKbttNFqND4KS8yLsDOmAbPTxczu1AKRPfTQw0EQjEdTB1QURZq2hBBlWY5GI6WMb1FFURQEoq7qMIytIHR2PJ7MJhPOsd1ua934SqUoina7HQcyDsJisayrijFQunFkZRAjWWOV0a6u696g7wlYjoxVNs3iUEbGKnC6KQruQDIsy7o9GCZhNJstgiAA65zWlsgq7ZwVQmZxslwuAZEAGefe5Na3XeM4dhaiKAqCwPd6AMA5IwLp2TPtVrcoCkQeysD7nXoTES/myvN8Opl53owQQgbixo0b89mk3YoDyZva6sYaXXMmORfGqqpqwALn/M5eoRtlnG1lHePsslgW1VJZE0qunZ4tZ0kSoeDGmCCMqqra27/jBWuMMWtdgMKQUVbppmFScI7W6qbRiBQEEWPMITCBgE6ZBhGRITlXNqVkfFkuASBJk6qqGt1kSaqMKuuCMcaTltaaAwdwTEaOrLEqzZL5fN7q9gTJWCaT0eLMw2fXtzrOAJPMATkiZy0iA8bpPlfjlUUKACDCwd5+YwmZkBzjMPSg+cHhUdJul3mxxmEYQbWzF4fBZDYnIvJ9QAbSk/gBSTDFHEdGZJhzAgzYupW0QQDkDYooB7O7XHTW1ncbl8mYOSaYMNphgP6wc2TzcpEkiTEqyzIvKQ3DEMCVVckY3KMdBN9K840/Y8xyuUzT1CNAFy9eXC6XrVYrbbcODg7m8/n6+rrHjba3t9fW1jw4ur+/v7+/P5lMtra2PHy4t7fnbfdni7mPkmz3uk3TdAYtX6L5U1zXtWdr+qzJjY2Nuq47nc5JReizdHz95Hn0dV2fPXvWF0/+huiLs4ODA0QMorAoCu8xOJ/OAIBzrpQioizLlsulMUZKmaZpnud1VUUiYEKkrazRqqiavaORrwiZo2VROWM4F0zy+XJmnYsiULxOuGScceCLour313kLFnkxu/LKr33+i1/84hf/wnf/iT//n38WlAIJwBBqgiAADtVo7DKZgQDDfuJ//6EOiYQFZb0UTHAhjXHKOB4GQM63xFbD2l2kEQjBE7RhlRIN3DGrrU34rWL5Pb/n/wGhLB1kUiptiAGRRSIgR+i85QMHhiDB5ww7iyu0gLhVABauPvfc//GDD6Z2OOjA/AACAGPjdg9AgM2BkWxlYEEEAoQA03iLIAAGyFcpgeSAHZdI9/kt4bFHo/+5EHgs2Ls2Aqw413eHO4QTso8vCJFWLSnLABggME7IBDIC5j0ggtuNnayffeaP/hlYu9hoGaIAAh4IAgMEnAXOARGEAT+W58KbGDluZS/x1gPwm555U11yAmKfNHABgPu1lVYRLMA3feJbP/x1HwELURQCgjaVAZIimDd1K4xsWSQBQTHZ/8l/dPjZX3hy2ILDA+h1ja5YKMko5AEPAhACGK04bUDgOHiHVX86fL34Ztb5W+0VOnQr+IrwPp4fslWL8GS/vMkGI4+cuXt2lQECMAZowFlABxgAipzJO0a883f8Nvnhj0HUAQpEwDv9ngXLOedCaq3JghCREKCVJaelQEMWyauI2AkljwiJCBlHAGsIyQDjPh/ieOfuKkMQERCeeOKJX/rFTzZaTWbTjVObABBIeeXKlV+nwDohYJ2UWZaMZaquihsvv/H0E4/Bzdev/PD/5yyWaVdCNYbAWSI9m0cijdPE1AUTktkInCWuCcFyjRyZY0hgtasM5LpuOJlowHvD7trZZmmgferP/qW//Eu/9qXB6XO3d/YWi4UzTVMt0zQ+OjoaTWZl3TTKKGvKxXw8Hn/5y1984fmvGKsI4N4Z8unTpx9//PFHHnt0c3Nz+8zWtdffqOuy1cqsdVwKwdBaC+TI2lrpqqoEk/Np+Nlf/ZWqKjrtrN/pnDt/pjcYTMqiE7ZE0jJlzQx1Wp3Q0mS6jKP2xrBX5su9g9HGqfVrr98M4gDIJiKYjCadTmqtBWeTJOl22mmaBoGQUvb73a974muAoXPu6cee3N3fExcvPZjn+dFo4jXtvpHhnPHYWrfbrmuxvj68c+eO55jneRmGYSB5GsVGq6auVNAMBgNntY1sJ0ullIkU+3sH3W6Xg43iyAEJbpXO4yg9t30auFgsFtPJHBGDIGAgrTIShKu15BjH8XI+z/NyMByGWUZNgwARY1YptGbQaQdBYBwoXcdRqrVeG6z5bqBHpJRSnK9SbxeLpTEKEX3jzJN/yzqXUrTbbUTI0tgbypNDzqUxRlVNHCfzySxN036nf3Cw126np7dPTcYzVZW9TuuNa9eiKBgO+4xjURRCGIMcgWlt67IJ40hK3oAO4/DO0Y1+v29RzYs5E7xRZJyVUuZlHoZaKSVlDQBJEjHmp0CYJDHnLI6zKFlTTUUIB3v7KKHTbmndeCokWgiiAKxDwTzjSsaybhqLUKsqSRJtlQh4JEIm0Gnd62dVVYkQuAzrWgkhGlsZo3v9Tl0WaSuMY2FqsEAW4aMf+wZgYJ1lxJEEWCsDTkQnbozGGsEFWceY8Dg6Ely/9lrW6RKXUmLAMBKSrFuUlUiijIu+yyM3UmYEQevW0Yy4taa2ATECQcQYGnQNohYhAAQkMgFCVU4tL198NzQVMGSSuQRsoLcGgwQ7+6N5Y8iSc4yiIEBNRld+7OECi8Wy3x1kWTadTqezMYDvnzbI0TkDDKWUXIgkTdfX1/uDgdY2z4vZbJ5lWafTjeMYkUkprTKbaxvT6bRcFue2z45GoziIQhEsiqUx5rkXX+j3+/3hIIhCpZSU8ujoyDOiVtOMXnc6nSZJMp1OvVVpp9PpdrvT6TQ6XrrdrtbaJx6eOXOGMdY0jW7UbDJN0zTJWtbaM6e3lVKT0biu6+vXr/d6vdu3b+/s7GxsbARB0DSNcxSG4QiPfLvTWru7u5umqZ9mpFkMAEqpuipUU3V77TTJirIMw2A+n3POs8g7sk45MmWauqystUEURmFCREisLmoTZ8RZvztcyzKOKAmXs7wsy2xr8z/90i99+gtf+NN/4k98/OMfPTycOAeZSBdHRyILIXCpbtLe8OYP/ejis19+9/ZZmas2JGCcJXSco4QGtOQknacdASED8oW7E5zndcFasUNUygTIUsNQU6c9/MLh7vmveSb90Aev7R2IVqdpkDknkHHrsw7JMfJ+COgY89RnDUxyMk1DVRQJcDm89JWX/uk/3DZHvaCuinncCvNlk6VdaDSABkIADtaPYg6MWvlXOTqufk5I4vZuy4lW2YBEdDe8+Z7FIWhOiCSdRWeAzGq4dBwwBBKAAGCBOYeKgQYC0ByiFJxzCAhoa+RBC8L42qJcbp17+o//BeierU3MQwnkwGjAEHGFN7P7HMvvQWLQc9V8dfVfk5NzXGoQsLvF2Wqi5SnkDE6QJg5MQK7qtN8CB1ArECildAhLUCKMFOWxbKAYH/zID1Qv/tqTvQzKHIIQHAgeO00AnAyhkACOaIW5ERHzx+2YDoae1X5cN6y2/y1pYuQPigNCtCvLBgJgyJx1Jyw5Bg4RvaLZ3+L8xWSQgIRwCMgNWgs6ENo2Soio1PAaxQ98428Kvv7bACNgibMkQrm9tf7cC6+ePXu2KWsCazljjABQMADQFhCZQ+aljQ4BwRECMYYcODjggnFAQGRCjuezxbJsdxLfkWYnnVDGgKi3Nlw/tamaZrbIF3k56A8X8+V8OpvP5+1uVzWN90k+WXyArC/rvSsOAnIGEbB8MXlyPYO9qy///f/tNOZpoIByjSUhOc45C6ERYEBwbq0DZuuylBGvrHZhIGNZFg2XoWrC9NT5U5cfuXa0aJ1/bONDHwOKe/Mawu7HPvFtDzzz/heuXn36mfeDtrapHZnGNFVVkVacc4tQqwa0RUQi9D2o0XRycHAwnY7zvCzLcr5YfOlLv/ZzP/fvjXHAAJE1Tdk0JRATATdKw8o7Go223/iN3/Bdf+A7NzY2mroaHe6PRodfefZLV197tazm127e0FrHMhi2uq0wkRGBcVESZUHnYDROsjhNN/eKvHvufF4s4ihlnK8PTxf5Ik1TwdEqParKua7Ho6MqL0IZxGHYVPW5c+eefPLJqqrE4eEozxeMCa3VcrnMsiyKosVi0e/3wzAOw9Azq+bzJSKmaWt7q3vu3LnR+JAxdubMdpIku3duz+dzgVFZltpQO8tOXXpga3O0u7tbzQsIZF7knXZ3tpiPjo6EEFKGgYyQZrrRkQwDGcgkkyg0aduoStthr7fWHd7auZ2mGQCEQZwlqda6vdXxXC5lLICraxUFASGzlqzVnmLVbrd8n6Xf7589ezYIQqUUAGuapizqXr9TNaUxmnNellWja2/wzRj3sk/JZBhGDEVZ1N6vcjIeA1lrSQpRzgvJA7KwnOe9Xo8Bi4LYGJMvqyiKsqydl8vGuCiJDo72Hn3s4Rs3bsRxGIfBaHS4vr65vr4epcne7sF8PjfOhDJE5GhcFIVKKUQwxlR1kaQtYXkQhbdu3Wp3W0SUV6UQIgwCpRQALJezLGs7qziXxumqMUEgGOOdbmYtiUDEcewhnFYn07pK0iCQQmkXxj60kcqmODo6GA771pj5fJpFvVYns4bd3tmpKxfF3GlCBCElEBAZhujA4l18wSv/AJyr8uVsPInSDnHGOEkh4jiezpel0u0kUlXZ60ihlg4VEC5qnSRJHTDn1V0+0wBJCKGZQOQIzjlFoNttHicctIMkbsomlCIL5fUvvvTIB7+pqJxelkHAUaAySmvtnEGJcRwTkQcsW63WjRs35vMpAHiFMzhinDtrPc1OCKGUGo1Gk8nMWnfCYPPxjr6HuLOz0263iejOnTsA4H8XDunatWvdbrcsSw7IGNPOXb58OUmSZ599dn1zw1obZ2m73X7ttdfKslxMZ95ZbX193XOqGGOdTmdra6uu66OjI+8s6pl2YRiWedFut090hS+99FK/379+/bpSqmmaGzdueOctT66aTqdBEJ4AYEVR+Ctfa+27isau6F+tVstHTGhjhsPhaDQSQviQAASIgqA49tlaLpf9fn84HFZVVde1qZta6a31dRmGAkUry7bWNubT2Veef246WXb6gwbsX/x/f//nrr7y5/70H0eCg1uL7um1ghpRmjRtP/e3/v5/+v6//TVnHghqzZxzznf9wDkHDo5xGwfA3qSHN0YFUaiAFGngXDIJtY3CZGrshODb/8B3guSEQisXMYkcgIh7G08kzYAQmF1pMZAAOIAllBgxBmYO11947Z//8HCxO+gIIMU5dyIK4thoFOSO01FONujEe/34SW9PBceMHG8ySceI7psH9fuRFS/m8HkjqxcgMC+vO3nGMY/NMIQsKSbztN1hQjSzZRilgPGVg6W6cPmd/9NfgnAw1xBL6YgA1Yq8Tsdbeyw8OxlV71fVvW119X+xINyPv/lvu6fbeJeiCe0kU7YCQggFNAaEqGwTiKgy85ZwoMbXf/ivw5UvXxy0oViCM0DCkWDGozSOGAI4QobkCBG95hHJegYn4d0MQearE99afZuoIgCw5tiiDAA5MEQi30r2nqLH0T737C1aAOvFE8dopVVNk3TiapHHrTaI5PW8ufSt39b62G8BnpKICBgLGLewPlwT8LKuKwAAhhZOFDeECIAWGHkO8aoJ7u+tAEDkiJx2nkZEAMbZoirb7eS+I48IzgERC4KLDz7w5S9+SSs1nU63t7e77fbO7p0XXnjhgx/6kHcpWmWp/ToHh9h8Md/Y2KKXXv78T/7ww7LpUAncODBgwcehkzcq9BJLcko1YZRgv53pumqWRlVCsk63e+ON/fWH3wEPv+NSdxPaA+ABlQYHfVDu3/z0P7/TFDLNpoejmMs0jouikJFEJC44GattY61hwBjjRukgEO322tmz2yIMPFYCAFwERVF4yXaj1WKxmE7nZVnmi3ld1zdu3Njb2xuPRqPRKBL84rmznXbLWRUI9sADF59+6p0f+fDX3L59czqfjKazvb07O2/cHh8cLkaT+WhSzBe2sZvDQSSjqSp9yeHiMI6G1riqUlKSDWKKY+DCYuUcGsY6m6e71qEjBlyU1aJ0n//SSwcHB+L27ZuMgZShdwNaLpdeUlfX9YsvvjyZTKIo2tjYSJIMgQvJRCAns/HZs2ettV/4whcGg0EUSmvtssybpulkrTRptTrt3qB/5txZxpg1ZIxzzi2KfNBf6/S64/EYkHU7natXrx4dHS1m80BIDpi0MkTqtLMsjs6cOff00++/c+fO3v7+dDqPo3htbcNZ4FJEUVQUpRC8rOrpdMo4B7CMScYYkfOKzTCS3hXCD2lSBqvcR8QkzoxViOgskvXKIGJMGGOUUnWtlDVV09R17fnCgLys9GAwbHf68/mrxlYcGBcRF1GcoLGagPcHG0IIrV2n29VUTRfjhx+5/MEPfqCqisPD/Y2NjYuXnhZBOJlMJpNRnIRhNDw8PJzOxkBsc7DBuZAh+oEfkE+ns+l0Fd5siRtjyHEEmS9rxlgSBUkUBEGUV7mzliElaSIkOzocn94+VRa1NkorZIw1ddluZ06jM7ZSpZARR1bXtRAslHLj7Lm9/TtxmAyHw9H+nAzPot6nfvmXf+VD7//oN3wYOFrnPK3dA7MrGzLGTxr21jrB2f7+/nwxPTvcFMgAHeMySbNXru8gYiA5r5pBO63HBSO2KJvJfBmstR1yYwEo5MAQLCOUhNI6B0ygZGSNxVavD3EIyoBquAhDzd597vK//cy1N25e71x8sJ7MpCM0TtcFA6wBVNO0WITOBjL0HKnpdOpD/byDlLarLOcoigaDQZIk3v9CiCCOozRNvO1709REpLVqtVrD4WA4HF67dq1pmgsXLhhjnLPLsmi326+//rq1NpLBaDTa2jz1xhtv3Lhxg4jm8/na2trp06f39/e9xcbB7h5jrCxL34JcW1sLw9BnKcxms6qqXn75ZQ+yeov2Xqfb7/fDMKyqyqsOy7Lc2Ni4evXqcDhst9thGLbbbW/D0el0oihqmtpa46VDTdN45D9JEiFEEApP5/I5AVpro52/K506deqYm4hhGJZl2e12iCDPcx+a7vvjPAx67Xa334vjOJTBM8+8XzdmNJ20Bz1eho1p4jjeuHDh53/mZ1/90pf/3J/+c+9+10PXdudHevb0hXP/+i983y//wN/7fe9+hs0WDWnDiDNgAOSIgZMWhPPt/ROLMgICIEcAllwUJ4tiwQPJkdlaMSYpCl+fHp153ztaz7x3Pp1yxsiSEEjHJk+0wjpOpgFgCKQETcAYcgeoK3j+M8//1I+erSbdWEBVEYAVcTU1MQQCgKxBRnfpzAxX6z410a2wsfueZ7h6PH4GPQn6hBB9/C4GFFoFiIDCgUTkhODQEToCg9wIB+gAjAAmCEMCYYxNu5u2yJ3KwzACZC+PxvKRpx759j8C0ak8V51ODFCtCj6HwN9Wln/P8t9UV4E/JgxWTGiP/6xi4H3njbPjlh0Di86CA2hCBoSoGs2RCUR0kaqrYcihHr/x93+gfvUrD3bbYJRVBY8jIGArASgAADpa1SL+ruMcIpAj/wjekxh9nbGCD8G5k3vUcd1wfDYBAAmcA+eNZ1c7gc59Vf/zGKpEILDEiBGBd5oAB4RJFEJlY2hNS/ka6Hf+ru8IPvQJcCGgQMascYwxzuHUqVNSSmct4/JYtQfeV5/Qeo4HIrJjays89js9qbI8tcDzB4qiABjedzqOr3mOePHixa986dkwDBeLWZ632+32YDB47ZVXn37ve6UQcMxGdc6xN8GrJ/Q/YGk2BGfdsmnG085ZCfMir6us1WLagWWWCYtcScN8jDcwIeOyqFI2B0GyXFqjO5un4bFHzp+5DPsHu5/7J9mlB9tPvRfOnUULMDmEcC1i0EnCVq/bLMumrAqjpZRaa86RAaDgUZhlXpShjQmMjyE5Ojoq6sb7U1hr19bX/QAdhmEcp51O7/x5DgChFFwgZ7JpmsV8vr6+Pp2Ob968OZlNOUfB+P5RresqSeNer9ce9C7JMAylAK6rhrTRZT3aP9jf3fvCZz67u7N7/fr1VqtFzr7w7FfCQKwNh6qoJOOcMetUt9t16DAWRhvOpWHWNCoIeJT0lDK1MXLYE5xjEARFUdR1mSSZn5pPJhOfPt3rDjqdjndm4lxmWTKeHLz66pXD/SMZcGNsFEVVUbbb7SAIZrMZY+LwcPTss89WVRXHsbXU7fbf8eQ7pZRZ1AJLV1+5WlVNmmXzyXw+XThDWZaFQjZNU5albtTBnV2t9QsvXOn1eka7dq/bSqlumn5vSESLPJ9Mpt5L09tpVnnlVe5JEgOAdTpN016vF8ex0Y4xNp1Ob9++XdcN5/ro6MA68GIua61RKxDSOR3HsR/wnDPe6l1KiTUyxpbjMsta7W6/2+0qa4yqHTJfdDMmgijaGG5UqlnOch5IrSvOkTH4zGc+PZ2O19aHaZbcvHmzaprNzc1+v2eta7fb7373O+ta7ezsmMZUed3OWgDgjSH29/d9lN5gMDwcj4IgGAyGnr4DQEg2SaK9vb04jrlgxkAUB0VRJGk0GAxaLTWdToUMvRoxSRLOYDhcPzwYVVXTyjrAUOsmibMnn3yy3+/fvnWryqskigGgrIrx0fjg4MBpYgEicqO1kBIAPK69+hESId4lPdy+fdujKYwD5xIYJx4cTaZxFEhwqaBWAPVi0ZHy4HCZ17oF1lpA4JxLxrmzioFh1nJkyhkWSECujUnT7gp/CGLJssnh7NTZ82u9fi4wV2Xczcx8WSxzrTVjjCw1tZYOWnE6HK4nSeLz/mA1zSKlFBO+1wne89ZjPN5pzP9ivQTVO1oBQNM0URRtb2+/4x3vuHnzpq+KxuNxnKX+T2EYkrFCCO+U5hnrVVOfOXOmPxweHR2laXp4eOgpVsPh0Mun5/N5URRJkjz//PO9Xs+rFOM49iYReZ4Xy9y7t29sbPzCL/xClmU7OzthGD7zzDNlWfb7fUTc3d1ttVqe6ZVlmTc19omW1trpdNrr9RBRay0DHoZhEAT+mFRVlSYrCryUMs/zS5cujUaj2WwWRdHh4aFSumkaIcRkMnHO9Xq9drfjgGazmRDiqXe9+9u//Xf843/8Uw7hN3z0o3lVfvbzn5NSxlxu9gbl0fRPf/f3fNcf+iO/7Ts/QbWsmuZD733/teFPU9lEnBfWEkdExtyKXST8WHdcGK2urmMkSATBYrGI00gbZ61J4kQvmhrdHTR/9A/+XlDNJM/Ddl8QoDaMABk5cuRbLPcMlpyDRSicFapsCQ2vfeWVf/njG/moKx1oDbXBOIt44pqSOQvceQbhcasIya3YLujIHT9yQOfg7k/CR+vZu78Q+KoF/Q+HCKy35UJg3AH3m+qYs+gYOOaAW18roGXcIXIhbVFyQxwlJO2Xb+6Idz3z4O/8/bD5QFOzrDUEo4AbQGYMCRH+txdP/4XLsbXEMVXurgmxXdU7wDg4cAYsgAuAGPKyKcOwrQwAQspBMID5wZf/5vdGt648utaFWhfTSbo1rI8Oorh1nDJ0wmxzdzFCPPZMcCeMN3cfHkOr5e4L3rT5/G41cfz5gIDO3O0zeoTvWH9KgA6ZAwAwDMABQ2BolxWPWgtKXpmZx37v7wk+8nHg7UZRwAWedCoddNvtNIqFEAjMnxnPOvV+Z56AelJOwXFpdbfMglWeByI6Zz0N66QX/SYcanPrVLfbnc/neVlorR+8dKnd7+0cHvr+oNEaEbl42/RJAEBCyQRo5KfOXLh4MZ9+MYtY7IK6KCKIgQR3HJAssxadPyRkTcAAygqsEqHIkqg+PNL/7t+14gGwuO3Y0fOfP7j+4vqlc7OyeG1vsXb5a+aHuWvHKgydMt0sC8NwWRbWaM4DYGiMaXQDgBwZIjKCMAw961Qfn1OtdV4UHm4/OjoyjjjnQghEypIU0PGVXt7t7e0xBhcvXswXc60tcPIia2A4m87zqnQMkyRJw0gyHskgzdIzly5ubm9/7OMfX87m49EoCIJGqWeffXaxWKim2dvZee3q1dlkGoDlqrhx44bWOgpCq2wcx1EQJUgJ5zySIU/bYSgeuvzgfD4/vXVqfX19NBovl8ssSWWnay0557zMpKkUABhTF8s8SoOLFx8QIpjPp2nWnkxne7u7nU7HT4KLvO71esP1LSHE+vp6VRR11RzuH81mM22NNwdLkuzocHzj+nUhWJqmm5ubnXb79OnTp05tdjqdrY1TZV4sl0tLNoriV167OplMlNaj0Xg2myFnjLHReIqISZIppYQQQnClmqrOAYBzPp/Pb9y47r9oZaUqWQSh57gwHjgHShnGGPN5iACq1oejRdM0Xl4NCJ1eFkXRbDYrq4ocFnWpJpZJxiVq47Sts1bbobbOFIt8Mh1FcZxEraJaOGhkwO7s77RaLYc0no2X5TKO43YktWkm0xE5nMwmB0cH7XZnMOhZZe80d5b5NI5j15iiKJhkSSsJTDCajtM00VpXVVmW5YMPPtg0zZ3bNxkDRPRG4UdHR01ZpVFclvXkaOIA6kq1RIgEaZw5a5IwKxZFt9UdDsOd27uNVkKIqqr+/c/+n+94xzu2NraODidKkUTWVE0URe9///sZQ6NJSPSWh0ZrKSWAN8KD44qEvKHwjRs32lnLWR3EWRRIEYTzqlqUZRBJqPN+REGTN8U86GSz+ZhHqSUisOgYIVecEThutQQTOHSGUIaAoKxrBTE0DRinG2MTUTmhS/31H/vG7//Jf3mh3RFtpsEsmpwxIENoXCLDUIadTs+73foERu/N4adHq0RFxjzO5BuC7Xa7LGsi8sBPGIZSSh83MR6PwzB8/vnnsyzb29vzRPh2u30wOloul4NuryzLtN2+ePHi3p3dqqre/e53W2uzdmuxWHzx81/wpMBer4eOhBB1Xd+5c8fT0tM0HQwGjLG9vb3hcOinp8vlkoguXLhw6Mhj4Ldv397a2jo4OPB2Wbdu3UrT9NatW76Yi6LIu0v4kByt9e7uruf1I6KUcpnPAQBQeiMVf9a89TwR+RjEtbU1r9P2zhHj8Zhz1mplntTvCfsWgTH2/ve+d3249o53vGM6L4y1H/3mb9zd3d0anL48fnA2nizH00zKnKoHTm//zE/90/d84D3Bw5tHk6OLX/fB3vb67sFoM4kaQSQIySGBQPID44nwgDsfkeQIwXBAArJWcqGqJolTw6BRqtvtfnH39oVv/HD4oQ9M5ocySSXn0BhGxBgzvji7hzyEBOjQARhrBS5bQQlXvvz5H/lbj9siDTjkOQQCwsRZwEWVcgHMga6BrSAaP4dABK/po2NECj05+hj8uM8U4KuiV07+93hQZ2CFH7odOADHyAE6NBY5AwiIwDlkjgEgOgKmHbPU1FwRrJ1++eYd98jTl//on4fOKdcEYZyAc6AMJJFxILh8O6nvPcv/3+UXebPxN3+Qx3x8kckBvFO8l3VqreIwNkC1wKrRfdbA4evX/+7/3rr28gPdtto9ZCGTqaiXsyBLQDtw+t5D+tV0+/t2kohOWqv3/A3fpsACR3dPmVkVxYTHldYx6x3g+Mx6IwtfsVkAxogRMYAQ7xTL29T5wB/9C/D015VWhkIGEUNiZJ1g0lpiiIyxOI4JaUX9IvJu7X4S4HkWbz7AtJJqCSE8yLYKTkVXVZX1vVg/D/FEdb4STLZ7vQsXz/3qr/6qVrKsq6Px+ObtW40zr7z04tPvf0Yw7o7dbck5QL4C/+5fTA0B4zAcJqfW996YPjgUHPx5ZX6bOVpkyjKfI01Wz4MgBBSQa1sYDpFM4oCx2WQigGVxEjOLJq+ev9HW9WOt7aKcf/zrf8PNevn67p4it7+3Y7RLW1nQSq01DLgMw0CkRKQbo5XijCMyxrxGTSOip3CspyljzFry1HDnnCVnjCqLknGoqmlZ5YL5KR3jnPf7/QCBIzpnrIOqroEoCGNiWJZ1WdZxECKAVVownkTxzuEhIqZxYhHa/f43fMu3ZFlW1EW7254vpkZpDliV5QvPPX/t6mu3btycjWeqqp22+aLYuXO90pUAKbkUk8lIa11V1WKxMMZwLqy13lVcyrDVagEA50wcV75lXYRhWNd5HKeIZK29cP7ScrmMwmx9bdNqt74xFEIsl3OtrXEkhFCmieMYmtq3QowxaRx/8zd/M4ArikIIUdflZDrN8yUAPPTA5W63G8dxu9sOwzDOEmttXha3dnaiJK7r2pIr8nK6mB/u7UdpYnJrnfbjhBCCsZUpbZqmnU57uZwbYzqdHkBTFIUfYxDRA3KI4CN+i3JurY3iAACULhBZO4zbnZgLRwSIaI06Gh11Op2t00NtWlqrRT6J45AJFgooy3o8nefBXAacc1K6skDGqq3Tm865W7duSSm9e6TPNiFgZVnu7u4657IkRaI8zxkfSBEQaRnwl15+7vTpM4xjq5V2Op1XX3314Ycvh2EYx2EUXOp0Op1O59SpU77NdHh4mKZpU+vlcukQ4jhVSo1GE86Fc66TZVIGt2/tWsDNza12u31wtN/vdxnSZDKPZLC+tpVPy0F/o1g0WSt54MGzx0Rj8I724p5JD9Fdei/jWCwWe3t7/f4QyIWBjKIkDMPR4Uxp3U5j3iy2egEs93lTg8tmi0JGETBgBORAO2sYWnQRRwbOkUVwSFow5hx14ggaBZbJbGOu5Z527/m6j5x/6Kkf/YVPqaoM0yRJorqThTyYT2fWQbfTiePQe9uOx+MXX3xxPp+vCLknvNfjeaE3R2aMzefzulZeAOGf9408rXVd19vb27du3fKduCzLPLvrcDzy4NBwOOz1eoeHh0EQxHG8trY2Ho+93ehwOFxbW3vxysuj0UhV9cp2mShNU68j2d3dTZIky7I7d+74RC3fyJtOpycuox5mu3DhQl3X0+nUQ8LeL34wGIRhWBTFqVOnjo6OfJj8+vq6r7cYY3me+xLKw1S+ovKW8fv7+/6Vo9HIH5yHHnro9u3bnU7Hh1VPJhMvYMyy2DgbBEGn07n8wIPf8R3fsb+//6lPfUqEwY1bt6qqOnfu3G/+xLe9+vKVf/fT/7qpysV8yRy1gtbf+Rt/46/8yA8spACnPvxbv/U/f/8PrQ/OoTUExgIiWARGgJoRIePks/zuH2MQnHVhGLqq4pYcsNK6I13PAv77vvsPG9uoMEREozSzEIZhZepVytJJdeUYOgCyEoA1yziq3JUv/NLf+euPSxDTQ5ABJG3QCphUdeOUTuIYyIDRIPkJh+lNQ/vK0PLk8U2D093Qm/sWvK8CY4AcgCEZRoDg0PkQHuKOWQYWGSEDBIbIiTiQtdqQhqR18/YuPfiOx//UX4ZsS0NLSoTGAmoIIwCBDMiBMSDlm4fM/54LrWoPhuy+AC3fprsrHwQGwIEBgHGGmDTWEbfCUAtLmN360t/8q+ErX358+zQs5gFnxmjHnAFCi0I75t6iCnxz1++uScGxkdpxXctWlqFvXWARrUobgLvV210MiVa7d7yzDIABef/3lWJUEyhijYyu2/pDf/LPwxMftJhgGFgAclZ4mIqB111zZN75KEkkHd9/jrfF3cUB79EznrgneAQLEX2GB+dMKWWME2LlWnX3mDA0RgkhLzxw6cUXX5RcePsYKeW1azesc0+/7wOe6gEAXAijNRdvbUAaBAAKQLLBO5+8+av/VGuSHlsy3oJBA1qGChkoFiBiEEZ2seCKQZTyMLV1UyjFAy4DSAMBtoAqZxWmBGm7MytK4DibTja2T1189BHJ4uWyqMpm9+jgpVdfUUYbpRExiOMoigIRxlFqdeMpqtZaZY2vrgDAc4EYE96nUAgBDIksgvNCPSJazhf+flgUxWQyYYxx9IVBR0YxOgriKJCRcdZq498lY2ktzatKSlnmueUc6vJwNgsED8MYGMnJQRAIY1xdFqGM3vWB9374ox9dTGedVrudtSXj1167fuuNW+Tc6PDo6tWr4vJDDzjnqnLFOirLWgjR7faklPPZ0lp7dHTkp5qcc3KYtjIm+Xy8DK0NhLDWOlchF4C8Vnoymu7u7xljnDOcyzSJynIZRZFgjBhGcUJEzLK0nRoyAI5JJgKRyMxXoGVZvvDyi9evX58cjfpr/bIsZRgIwUQYWHJhFLXbXREGo6OJCCQy0FqLkDtlGUMpuR/5kLOsnWqtW53MgS3LktDVqlKmSZLEWWAMATAIBZEDbQmJcQLOZMyKonDOBEG0e3jrcLLbbrfa7Xa73SaCrXODs2fPCsFv79x8441rvTjigjVNEwRBmCY4U0kiNje3iEjrxkO1PvkkSaIwDMfjcZrG3kFeKSWEJLJN0yhdSsllhPN8LERw4cKFjY1TSRouF0WeL+eS79y5sb19drGcVYfVaDTaPn1+d/9wNpstFoter9/pdLwnxXCwXtZaShkGSVM7KZKVnzuyixcefPp9Hzo8GB0eHp3a2grCuCxLKUVZzKplsTZshUF6dDh58fkrv//3/z5rgHGfynH3nnX8C/ceQwDHlJed27tNo4UQYRhKxgUyKcLReAIAgrmU9HooYHQYOQdVs1wukQnnPKTvLJmSiAQhADlCsk4QQ42OImf7YQzKOYujhTmSybu/9TfDw49AlHSHG4dH48FgTbZaxJAxIcNQL5okisM4YEJM5zPvWcU5Z4x7x05/P/aTwk6nkyatuq6JaDabhWHsf42+5MrzfD6fL5fLbrd769atMAzjOO50OgCQ5/ne3t7R/kEQBHHWms1mXiEohNjc3JzMplyKyWRSVZVv3lV5EclAIMvz3MsGfW5gGIYe8T3JePY4rudpTccT37I/PDy8ePGiN4t/9NFHj46OXn/99bW1Nc75aDQ6d+6c55l599E8z6WUe3t7YRgO1/oyyHyp56fCiOi9RpMkCcPwzp07w+FwMBgsl8v5fC4DnmaxVtZaWxSFr+TW1taSJAEALkUogx/7sR/78R/7J7/n9/3el668fPnRRyzQb/vNv2V9uDY7HH3p858ry/zUqc3Xb76RZrE21f7tW7ODQ+ROC3jgN370Z/7ejyzIRsDQoQWyQIIIkBnGCIE5hwT2xKPgWKcWRGE+X5wabo7HUy1E1Ot94ea1j/6RPwQPP7g7GbEo0FrHIIEcMLLkABkxh9YX0J5FBdwaUBVnDTz3+c/8g++/4PKhkGzQg8qAEUY7i4qFTCQSnIZKAxxzp/zG3D+ev+WAdL87w9ssd93D3Yox7ecwd/9xAOIEhluD5ARKC8wSWMedhSS7slTm0See+LPfB9itmlgKBGtBEnCujUUQyKBp4Fgo9iZE579r0/CYA07I7rVuORmumT+J3nASgSG3TGgAqhYtoWG589n/+bu36tm5C5swn4KUAE6kbV3OKUCjLScgsidU75MFkd//vyd/tW96pWdg+yIJv/qcME73foK3H3zTclLheZySEJzwUdPEbENmbNme6Hzof/leeOBJspyYjQG0tkJycLSy4EJwDqIoaGXZ/v5+kmSMwDl7byVHDLxZIx1jS34mdjerzVh/d/JG8Z4ozFjAvO/jqsglAPKCpFOnTrXb7clodPPmDYawsbFeNVVRV5Ojg/76urOWEYHgQkq6vzV/3xKCReCPPsbWzzV6LAMGywWJNgEwsGCVD0kUnDvGTa1E0AXBwBAoy7lsS2GcArRNtRDIeJqCFWA56AiCXlnSVz73hTwOGsk3hqfbre6pU6cuXXrg8Xe/yzq3mE5v3rx58/bt2Xxu9RwBBt3eCQrFQfrBSGsdRRERGe2dnmj1As6buvSQv1Zqc3NTCJHnea/X8zkfTdMopZZFWataN8o5xxj3k2fnXBAESZYgQWMNMpZ0e8h5UxWNNiB4XVUciTfkrEFgWSstymq+XATykDN2tJgvFotuq93tdi+86xEGeJmxj/723yjyPI/j+KGHHlpbW1tfX2+1WkKIw8PReDyezWZCsP39fWOVN9RRWjtkUoTDYb+u6/HhUafTXi6LVqs1nY49LTeKIkDT6bXJOQC3ttkPAhEEQa83mEwms+miN+hNp/O9gz1/MVlrrbVKqbW1NcGRjE7bQXdwbjQaJa3QkJ0uZmauB8Nh0Zh6Uo3GE6VUECdra2sWrNEGALRuFotqBaWC86nSh4eHTdMQOK44MghCXpZ5GKbWgVJK6cIbUkgpuXCtLIuTMM2Czc3N4XB45cpLo9Fo81T/8OggjCFfFjShGzdfDaMgjuPBMJNSllWepCyKoqbR3f6pjfXTRFgWVa+35Ue+Gzdu9Pv9zc2txWKWZe12u90otVwulTJSSo/vAmml1Pnz55fL5WKR+2H4scceA2KHh4evvPKq73kdHBwsFossbU8m0zCIh4ONdqvX6w2m02kYJgjizp2Dk5ycqmyiKFKN07rpZK1P/uKnH3/Hk3GUPvf8y7t7R4zBbDYbrvU7nU5pqulkGYdpFGXO4jPPfA0XAADOEuM+pMgIcZwWeFxs+XkVOdjb2+OcE2EchODIGcsQizLnDFEp6XQLeFMuIkbUGKMtIldaoxDMu66QBWAWqCGLAJwBcxq0FURxEANVcxfcMeJdH/8EfPAjwLP//J/+0+mLl4IoLefLQRZLxoHz4fqGjmtdN1JKZc1rr722t7c3Ho+Pb2KwQqcAyDlf3CDw5XLp60Lvm+899L0cL01TjzgmSbKxsXH79u0zZ84Q0c2bN3d2djY3N7XW4/HYE5s2NzcXi4V3dfdlqA/3nEwmQRB4F9OjoyMfj5imqW/tWWs9pd17o8zn893d3fl8DgBZkj711FNN0/T7/Y2NjbIs4zjWWrdarbNnzxZFEcex7zl6+7Sqqqy1WZZ5n9JLly5p0/iP8s69nk0IAMvlcjQanT592sfynERHX79+3VqrlTXGhGHY7/c94uUNVwMuttY3mqr5lU//ymc+85ms3frlT/7S448//hM/9k/iMHr9lVdvXL9urd2fHca91ng5G/bjo/2DduOSYXY4OTp9buvUE4/c/sorTw7WmKaKGUKOyFYCLiAkn60BzgczH/s1VU2dtjrTo2kSpUIGt/PcbvYe+2PfuZhNeRxra4QIYh4uljMwDDk3YNixLRKs1GYucApgAa9/5fl/+HcfAlxLEr2YslZHWROAEEniXGWsIqTG6BQZiBCcJbwLxtytqzxh4tg76j4m+ZsdmPDNTx6vOyCHBhG5O7YURw7gVmR5/xrURMAdMK/KCNsvH874O9/3xHf+cQiHGttcgeAAjANz2jZMxgzAWQijk5rg/87FV4S+CwgAcOyVSu6E3QR0bNbAQDMGSNw1odCwf/VX/sqfehCKDemgWkIWQlkB8no2jlvtQtVShgw1Y3eP7l34mbG3JrchJ3QrJ3S6C2it8C0/t/IsOv+IaL3sjjEfpUzgwB5Tu1bI13H14VUIRMwBIgfBGhRjCm5B/LV/+W9AZ4NYqKQQ4JQuAplaDT462d8/jXFBwNI0ddYec8PuIlXH3wdEdBLCcy8g55yzxnhAyz9tjDHGWMuFeHPRrJWSgWj1esON9el4PJ1Ou51OlmVxGO3s7Fy7+lqv12MyhJW1ob/w3uLskiUKcAnYlfH2k+/f+cV/83CfQxSg8W4OK69XAM6RMeIYpqANKAtCAGPgNFnrOAMRQZLVDqfzKohbIs729qYX3vXo5vnL7dsHg+3NpTMSw+l8/tqNNwgAQ3nq1KkLZ88+9NBD7//AMwBw+9atm9dv7u7u+nuRcw4F9xEdPvKVHS9A5EU5xiop5cHBQZqmQRD4Rpw/mH6mHcdxq9VysCJh53muG9M0zWKRG2MapRyZKI5brVZelO1OC42WYZSFseRcKRXHsa7KIIhU3SzzqizLtN0SQVipCrWN2llh9RuvvMQYW1tbA5971ig1mU7zoshuZ0opRCyKYqXibiVBII1RXKCU0hjlCISMpsvZerwet/jpeL3T6Whti6IoGkzabedcnufWNkXjtre2+v3efDFGpJu3ro1nB1narnW+f1SWZZkmrSAI8rxkApFz43BZLBApiQOtdaUozHi329k/3N/cHihr9g7203brzObZbJD52fbe3r6UARKLZMA5P3/+fByHrVbLdzqKMs/znAtmjKrqEpGE4IxJrSsAQEaMiziOhWDWWiGp02k/ePnSIs9b7WwwGGye6h2PN93pdLq/f+jpw2trg8lk0ummiOhcuz/oVlW1mOeIOJkcLua5ZNHN67c9VrEo8rpW16/darVTILZcFF631ep0pBR5Pjp16vQH3v/ePF9cu3aNcxnHrVu3dspCJUkiZdDrDU9v1XVdb25spkkrCCIAPDiY1bW6fPlBL0ewjgHgZDLxijMOAgm0ckZXSZKoxtbckuP7e6MHH+ydPXt+Pp8naZqkHXJyNi0ZsbwoTMKCADq9/oc+9GFygMyDfAAAvj+IK0dsBgCMsaZSYRQAwM7OThynoZAcmWQ8DpNisRyPx/1uO7TNIAmEzovlJGQcgZV5YUMuJbfGkVUMKRKSvG+QBYOWMyHAolOdNNGOoD+8fnv3Xb/1d8JHvhlkOp0V2eb2b/iNn/j7P/iDaE0+mfWHazKKl1VNkiPxvf07t2/ffvmlK5ZWLbmTGSER+UmQ76yRQ6+QSNNUa8MY8/HsPn+Gcx5FkVLq8uXLo9Foc3PT4zqc8wceeCCKIo8GCSFOSiVPiiqKYjgcvv7668aY7e1tb4IwGAzu3Lmzs7PTarU8e11r7cW5aZp6rL/dbvf7fV+ugaMwDC9dulSWJR5HWBRFAQDdbtfzCL3CdDAY5Hm+tbXloS8AGK71j0YHHiTzJltENBgMptPxbDYxxviiNgxlFAVNUyFSVRU++DKKMM1iIhqNRnmeE9g4zsqigEodmN0Hzp/Pi+X+4cFTZ7Zff/11VVaHt3asNoeHB8sij9vJdLpwjF/aOGWbsg2w98UXHv/mr+eIINg3/o7f+sO/9GdEe7MvWnvVpHaGhbFDhtpwzhkgMdTMERFzyAAlMcewITLOZmm2mJedM4M3rt/6PX/n+yCRVdNY7TgXgkgpFUaRYmDQ5zcjt8gAiRw4yxj2Eg7Xn33lx35omOdrnQx0aVhCgLwdQWnBFpI54qgZMCmAvKkVeNNJP9Y6IHC08oFEcATA8FineIzyrhDSY0rW/XXAyQsAAMExRnfbi14ssqLQOAykUYXkIkxTWObACdLB1QWVZ9/3vj/yVyEbKsWDAPxmWYkWGGOxR4w4N8eD9Ffzo/5vWe5zaiAHZID5PeXWwsqwHoAYM2rRYhp2rjz7vX/mcSx7UQB1YZm0ZFjCmDMRl2B0ylKvLFjlPHo2wsl33OfMfrLuVtYxjhBopd88LrDudniPDf1XUgPOVqXYsfswcgZCWKW48MAb2qbhSQrG498WBUIUAQ9uHIwXZy997V/+axCfAhkhsxKMAoNSEADnAAjWOC4YORCckYNz5848++wXVVOFYei/kBha6xCRrAXmtxPvXfxWNU0TB9LroJ1zkknn7Gg0euCB89YS58iQOXKOfBIiWGM4F0888fjLzz3f7/dns8mpUxtcoJBsZ+f208+8H8gCcsY4Wc/iuo8nj+AAwTGqVM2DmMAO3/211z/9C8qOAqfARcAlkIZWi4qcyCN6xhGvnQtaIYAzRssk0I4WjbI82p9WjYiz0xcaHtaGP/ybPpZ8+JuB9Q5+8O/yOIQklpxHSfrAcC2vSgXucDzauXkzCIIkS4fD4cMPPPg1H/4QAMvnc2/sfOfOnaOjoz29J6VcX1/3aI61Fp1z1oah9NEXYRhYa4g8OVt5FbkPMkbOlNGqMb6bEYfJWjfztayyShtjjGm00lpXqqqORmAdOSeESKI4iiKjbZrEXAhonCM3WNvQ1izyMowDpZQjIyM53Nwoy7LUdRAExEgIIVqtltZ6NBoRURzHW1tba+uDyWRsjAojzjQaq4xV3V53PJtundle0x1EXC4LZZqDo3m32w0iKwKbZSERW988tba2dv36taPpnb2jm7UuHnvssQsPneFMMuC3927OZotW1pkXM8pJioBLUeaVMpoECA5ZpzWZLoIgOH36lNb6zIVTzrkwjs49uG0sESEy0el0gdj65tpsli8m8zRKvWLOWu3n7oyxqqqWy2XTVGEYWqurqgiCQErJuddlMADinGSAaCAIkyiWOzu3DZkbN69xjkmSjA4Pq6Y5f/58rze4ffu2EGJtbcODT9PpvNttl2Xl+V6ci7quq7IJw9g20O8P8zwnwn5vraoqa12R1747s7a2WVXVaDxOkiSO0qY2v/rpL5w9u52lg8Vi0e10L114NIqig4MDhkG+bBCFNWx0NI+i6Ghv0l9bB8fm88VLL76SpFEcpUTAGBrtQhk4osFwbTqdci6llHlexnFcFNX6+ubOrR2lTK/XM2la5KXW+o1rbwx6/a2t7eFwfTnPyVQf+chHer2Tac2bOSberMGP95xzIFgslru7u2mSeGxWCBEIkecLRCLSqizWtnuumZJ1mHZHexPHZKOplURgGkCWBKK0rqorwXiaZcaosiyTJC3zYmttMzt15tlbV5/6tt8OH/4NEGYAUdJNt1j6kz/xU6UxpwaDo507y8nCcLksq0VZ1FVRzedlviCydMyeoWO34ntXGGNCBkmSVFXVNA3nEgA8+BQEgS+wvHm6L2Wcc97xwfOTmqbxxdNisfCUKSnldDr16Q0vvPCCUsqzuPr9frfb3dvbK4piuVz6b/TI09mzZz1k22q1PB3eOykkSVLmxcHBgT/gHt/1PKrNzc3RaORjBrzhwtWrV71d1pkzZ7xUFhmdPXvWhxX6GOnlcomIvhu4WCzOnj3rUavpdOqjF5qmkTL0Msaqqg4ODnysZBiGRBRyYRs9b6aj6eRbPvGtf++Hf9jfa579wq8NO73xeJSm/z/a/jRasiy9CgS/70x3vjY9e7PP7uEeERlzRM6DUspMQEJCFEohaIHQgqIaIehaUE2XKFbTlFgFvYCimi66qUJUFyBUElCrkBpUkKkhB+WckYo5ffbnz5/7G22+85n6xzF7/jwikqmVN2K9ZWZuw7Vr956zz/723l9kjPrGy18ngdftLw32984G/Sf6q1/8pf/1Pe99MQ2j6XDQ/V3f522u5FLa0VRELErjSZZbBI9w0M4pal0SECEELVhESzD0wiqvKquWTp/6zTdff+oHPr78qY8PZ2NLAg4U7NzNZhAUagWWWnAdlq2xwAARKSKgeuOf/c/+8N561INGgrFBGBlm6yb3mUGLSAgFNEgQKBBzfKrDAjARWIiJHt0emr5OFphOtrs5rkA98jIEop3EHSwBt2hxNR5Kqc8i8AERlKkteP3uW1tH/Pnf9b6f+hkQcdmwQAgwAKgtBQXMEUloHM6QANIAIeB9dzmsE+8+J5rsgvUxRsqK+SFwZp3iHUHl48RXsPXmV//Wzz4Z0KQGaBoIQmu0YQhowVhiDWgAwwAQUAHRiwN4spPPyZvHPwiZOyWI49UQrJ1HjC64i7fv/kKmh4++p1WKMgZC6KKgjFHBrayNMRYNiyKojDb2xmTKHn/hvX/hr4DXBgiMddQhGiAIdBFJenz+zPc0DEMXQfeQxEJyPCKZxSJwvnuLwepYuOmaocG82W41m83cW2kNSCxBorVyKzE3qV04e255eXkwGEShn+d5r9er6/rq1atHBwdLyysAWiukjNnvUB4khHjEq4EAeNDf7Fx4fLLz+T5ngB5oClyYsgY/QmtACKgqEvhh1AJBR6MxCfzaIqHB8uVzECVrFy/DxSuAFJACEUA4ENHc2k57y1PCRuOpR4TVRgjBPRGkYbvd5q0ORVDGjIejz3/+8031mXPnL5w7d+HMmTMXL10CQkDr7fs7N2/evHv3bl3Xw+GQcxqGcRyHrkNO09RRFFlrj+tprtOGs41bhMVkxQBAKZXnudXGyf+RoVv3WoS1tTWtddNUTV27lEQn/4jjmAI6U1TaaXueAEBirDTWoAZJEK3ni8VsY9h4NuWcu8Z/lOKD/Qd7h3tFmYeRUKpZ5SuMQ5JEwmOEwOapfpSQ06cvff3rX79z91ar1Tpz+uyNG1cBYHV1vaqK5X7fD7zxePep5y4dHh4i4umzZwHg5s2bZTkbD6Yf+sgHDg6OvvGNb3bavf39w7Nnz2VlwTzCgmA0Gj373HuW+wnxpJSyvZwmSUIFvXr1KhE2SSMp1eHBQBlLCJnMMin17u6uz4LhZFxVlTvtGGMAptPprK+vCd/P8iljLMumlSxEIFz8ARK01lZVRRlS5huj4zhy/VWCwDuzeWpnZ2drayuOIp/jt9+4HoUJpVRrrWtSlnld10kazUal1tJ1ElTKcM59lgCQrf1t3wvqWhZFkSRWKRVFiRDCagTFKPGefurx/f39oiiWlpYGg+F0kg2PynbSXu609vb2fvPlLzdN0+v1fC/s9XpNDlWmqkxDi6Pho8Op0ZCEKSFMN6a2jed5FFkcJk1ZBSLYu//Aif6KWUYpRWM5ZdZaxkjTVDs723meF0UVRdGP/cEffenF9+7c3fnqV77SSqLD/aPnn3t6IWe39kRr+eN18THAIoQAwtH+QZZl/aWuA1hulTAajRgjlCEQ63leOS4t5RC27x5sZQbS5X5TFloRoxQ22hfCZ7Eyup7WPBDtpMsRCxC8t3qnVBc/8QPwqd8LfvvOzuGv/9pv3dq6/7Xf/u0H+3vEKC2bzeWV7Vt3DkdTHgSlljv37+WTI8G5tuZtk9p8MtDaaD0ej5VSngjcohARCWKe58aYOI4pgWw2KQsqhLh541qr1cqyzJny8mw6mUyaul7q9o8ODsfjsVOUX716td3rnjlzZjKZTCaTmzdvRlH09NNPA8DwaHBwcPDgwQMhBCO0Kkqj9drKKiLWZZUkyWQ0no4nQghHdLsZYXNzs65r16UnTVPX6TxJksPDQ0JIt9tN0/SYM9vc3CzK7O72nbIsO91WWZaTySRJkn6/PxqNlFJh6FtrreUvvfSS67rjWke7dj0uOaLT6Tx48CBN09ls0m63kyRx2izGmJVNxwuNMRbg4PDw8Sef/O2XX37vs8+PZ/l+WWmtK9mMs6mUMo58bJoQxLnEfzxIXnn5Vfnt6+HHn7+3u5UG7P1/8Pfd+h/+6UudNaWrclZYgYQw3oA1umYa0HJLXa9mQNAUgSAqa7WF0N9V1TDx/tO/9H8BozONAWHH/I/ruWTnsysAEGuMoywBrati+apZSULgHMYFEAMaEGufG6O061BLgRJF0AKABLJYVxyf/e+88baNnqCsThYH8V1f5YTLBtC1u5mnYwGA1ooaBpaCgqpW/vL6tw/3gg9+4NyP/UmIurqQQSBASQsKBdeOSwaYlxoJWZA6b/fT/Q5vCEANWGJPhjUsPAHQ1DwUFajSqgAjJECbOhESrr/85f/2Z88RmaRtMFLKmgMhVnNtLVIXAgvoBEXurfBROOV+yRNfzZ4s3S6cgG9zJCwefds/WZyjZ0Q8kexqkVIlJZtnSlGlpEXg3ZadHKnJgMUrN/dG0/e8971/8a8CW2pqLYQhqGpECx4DRgAsgqWuSm2dEMtoSxHjOIqisCwra+dJMYszxHnYNZzYTtYQKaXHGkoHuRwgAADGiFLGKk05WUjd0Ugpm9oLo0uPXZh9a+IGilYnRbRh5L/22mvf+6nfVeW5H7Vk0zDBAeDt57QlYIBRKsEaAzSMly9deXDjM0sBwboCGoMX59lEgkRTR9UUQfN+BM9ehju3d3ZG5y89EbVW8qMMXngvjMagNdz8NvSWoaoOrt1afvElyOGNN3Y0pV6S9DsdVco6LzgXUjbD7XtB4MXCJxQNGkppHMc0SXd3d/f29lx7+I2NjStXrmyurZ5aX0P2cVlV2/d3RqPhzs790WjoxE5Oeez7/lyJJaUTDs2tpgaUltY2hBDGBKXUGCWbxhhDOfOYB9Y2dd1I6czajHI/9jmnjl9QRo8nM9dqdjabjSezRlaIyAhpt9tglDGKUPCFYIxRtJRSVlWF1IwS4odBp9VudEMQoySsqwKp7S11wtiryrzX78m6qppy/+A+ofrM2Y0wEtNJ9sEPvdTttW7dutXpxrOZPTzam0xG7U66t6+jKPKCoNGllHJltT8cjJ955pk8L/0ZW13tb2/vtTvxC+997itf+cqNN3effO7MuYvP3Lu3pW0LQHkBv3r1jaKukiSqmrosS2sxjtqNVEXR7O8NDgfDJGmVRd0QBQYJIZ7nEUKklMPhyFobhkEURVG84nk8y0LP485C2Gq1uGAEaVEUURC49tKE0KaRw+Gw3+8/2Nk9PDzyeMCox1nIuvFkOqM+z7NaNgPGCKVsMi7D0Eopy2IEAIyJwKe+H7bb7V53fTqdhkHs7PFRFJVlNRgMPD9QSuVZ9Y2vf8t576tSlmU9Gedbs11Vu+ZxaStdquvaaIrImkZz7lNagcHB4TgIAtCGUZZEkbvYVFMRMFZSjqDQUgK+xxljWqskDieTCSVAAZtCr60uj0aD6XTye3/v733ppZcuXbr8xS9+8TP/+l/t3nsgG9VutaaTww+89PzxyITvmE4c9zMf04whlG5tbQW+H3o+pUgYJZxZa6fTqRcI5vGk17OAeWMtDYG3ZjTcnVRjMoo8LwlixoRqpJSKAGGcUjTSqnFWemmHtpb3JXvhhQ8Fn/g48Ki2NFxaHhf1629++83X39rcXD882tu3enY4qGZlPi2yw8Nc1mVTGbCVbN42Or9t2DVaTycTgMwpqHzfV1Jaaznn7rJxwVRpmjo5pAt6cNmbDkc6H6gB65RVAACUjEYjFyvsbBbutXVZVVX1wgsv3Lp1y32ca3BujGm1WsPh0FX6fN9HRNdIIEmSr371q25l4sQErs/g+vo6pXQwGNy8edN10nTSq+3t7TgJXS5ov98vy/JYrxAEgdaaEHClzP39/f39/TAMr1y54tRgTdPcu3cvTdOjoyMn50qSJE3bjhtzOwBSF0WxtrYm2q3tnXurq6v9fv/1V18LuRcGvh8G1+7eysqZ4Ixp3bb0qeW1TUW7s+IUD7/6r/73j7zvyUj4kMbv/f5P/qu/+t9danVTzkyes1Zc5YWvGV0AAmaAWtAIioAGixZkU3tR3ITer73+2p/7H/8OnFrZHR6gHyIg2uMVv8FFBiUDShfkk0VlXU8bo0I/UCMFpgSmQVCQhapyFlADFqwllqAG4mIq5/5AYsG+C/Pxbq1vjk+yR24satPv9lRjQFk0YBk6lbhxQ78RYTi8v9tdXgcgFcG7EynPPP74T/wpaJ8eN7YdBWAMMEDCNRALyFzm+EOimS/Q1XeXwLLgiknzSuQJbo+C50uwAMBQKzvxLQOo4OXP/8u//V+/fyVtG2xGQ8oYS5IyzwVa1I5tImAZWAJQA7ik+0Xlbn4M3w6S5g7PxTnwdmiFc3n7OwRPAADWmLlay0WJLv7V6coNWCBorEHOtFKzg/0k8VncevXaTvf933f5L/xVYGmmwY99UBWgtcAMMG6BWDDEvZ2hSLQ2C+0UBoEIwzDPC6cAc/lXQB4y6wBvz0s43uGT6IoS5JwfGwmNMYyS42fqRlLOhdYA4FgrY0xVFbPZLE3TWqqdnW2w1g8CAOCcf0dHhjFAiLAIBsHS1vlL9712afKQczBalsYLgigSJPXt7rbWmO3tDn/5bhUETz7zHEmX4fzj0Y3bt37+5zUHZHSY50mrVTcYxa20kZCu5Vklwk6uasqZ4/MopVpjr9Ot6mI6myAiMuRCsJCFcRhGcdM0Tny2s7Nz48aNIAja7TYiXrx0YWVt7cKF8y++9JJsmrt37x4cHBwcHAwGg729PcdFuUHb2YYcZnJLaymlUsaFbDmBvAtPcKYl5gnTSOCMGFtJmefSHTTGWCtJrbXoYxLFdsVSSrWR2XRmjNGyKYrGNEorq/RMNZIxyvzIL+taqmYwHWmjgig6vbm5cXpjPDg6e+Hswd7une1bvmCjyWR1eakl2r1eZ2dnp2rU8ur6lSeWXnn9ja072y+99NK3vvWty1cupWk6Gg0mkxHnfDQeVgcHh4NhmrSF8Eej0crK6uuvvzEbTy5cvLC+sXr79u1XX/vWRz76wfd/SN28ef3U6dXJdE9r9bHv+ehoNHjttVf6q/12p+X5vtamKCpPREbj9vaD2bQIRCSo77VCtMQa4/Ih3dFZWlra3Nw8e/ZM0zSj8WA2myklCSFVXWazfHNzMwgCxoQQvs9F0zSy0ZPxDAzmeSFoNhsVpiFSq72de9nMEg4IqJVttdMyy4u8PHf+bOB7K0t9500AgP7SSqvVLsu6ruszZ04dHh6Ox9Otra2dew9arQaRGkkPRuMoiibjUafTScLWzWu3ilnVSjvEUo5elCaOxmhqWeZVmqbj4aQumwsXLjSVLLM88oNslgFA0k5kXUspGWMB5wShrnIXMhkFHepTKRulGm2bJOSTyXB5qV8UGaLsd5Onn7p8ZnPltz7/a7/48/+oKCqtTZUVAOT0Wv/9733u4oXNuaoEDcI7pxMkBMGCVvMR7ebNm0HgEQKUImOEe6JqmqIu0COGQZ5LSWNNhMHgQQFi9eK552LDxP797YPBuGlU5EdJlHDCgGigaC2ubK6N9scHE/XxP/oHgk/9fgiFtUhp1AnFT//0T33Px77vn/7iL/6zf/ZLoJpJU+1nBbGkquQ0KzQYQAMMQbtuvo8qME58AUKI1hqMdfEciOh73vLyshBCa+3wt1sDuUvOhe46jOVKeMPhEACiJPZ9P6/KyXhc1JVsGiSEMeaFAQC89dZbq6urq8srp06d2tnZcZVEp/pyOHVvb895+pyLEGAuXyWEuG6PnPOiKM6ePXvx4sUgCMqyTNP07NmzR0dHd+7ccQbV9fX1PM/H4/H6+vp0Op1Opy6pZDweIyJjJAz9TqcznU4dQGy1WufPn5eyrqqCMZJl01dfffXUqVNLS0sujSVN06oqDg4OpJQOcgGQTisZTMaqzEUUZAfV93zP93zxVz97/8G2BQDKMGBJu72SpF6jTovkkkjOGgJ7e5tR9Nu/+fmPTH6qG/hH93aWLl/6xH/yg1uf++rjSyvcEzNZaWI8n9ZFAwgu15xY0NQJfsEioYzTKPzavTvP/YHf0/q9n5xOh8i9UAS60egSr9CABbSGub54BghQFxtsGQGlUGkAO6mMaWzHN2Al1BkQQwRIbYj10FKq2VwD7RoJWz3vsvxuM8/JOfyR249M/Ys88XfgHGutJRqMsk7WbhkxlLhG1GBA591+F4zKWbCVWTx/6Zn//L+AsFfWNvY4QK2h0cSXRoeEEdd1GgwQMk+WtwQhIO8SbPQ7uVkAMyfP3tZsh4AlQFmjcsYIs0UAGqRWn//MG//0515KRQxYKxUwZq3J81wIbpTi2oWTMgAPiAFaAmiw5ERsxwmFEFmMSIsM0ock2gkLzuLZJwIRHIh5yHjhPHMf5posBGOtpQwdGciTROZl3dRxHPPQn+WzW3uD1R/8Q6s/8WeAphWKyOcAShJpCQXgHICYBRGJrom3i+Ynbr8IQpqmewcHsOD+CWHWGESqQdF3A1iwqBUei7OklBaIEEI1cjQcLi8vEUSXzO4sLE6dh5yDMadPn24lKUWLhDZN0+l04rq5ev367s7O6tqaMYpy9ug5bua/LgBQAtYl8guABk5dXD791PTmb/sBtVIqzQRyAhaUBksoC2wle60u7/aI6Njt/eyVqxHChdCU1ZQCXkp8rXKa9I8G44Phq/XSsPFX/N7ybLBvq+LUyobX6aCT84NuGl9VVV3Xs7qcDcdHRyNGaOh7js1K0zSMgrqutdaAtqzKN9547c03XyeErKys9Hq91dXVi5cuaGWUUkcHB9euXdve3nKLXkRst9uqUQCEUuoLTinVytR1Xdelq8xwzn2PG0Pd2VzXFdUMqDBgHQ1W0YYTtFK54FNrbV7WlDMhRBBEnudZNFJKi5YQUhRZVhaIyAbjASCGQQAE87Jkgm/d27pzb0tJef3OrSefuGyRVLLJBvnt27d93w8jfzKZlEXd6/WiKD44OCiK6l/9q3+9vr4eBq0vfuFL58+fu3PnXprGSZJs372fpO2qaqTUhNAvf/nLlFLP87a3t1ZXV3/8x/8wIcSPQmt1nIjNzc205dVVkSTJYHD4/PPPR1EUhL7wvNFo3G4tTSbZcDBF2KfEayUdray1qFTjzjO26AaglJnNZtvb21xQt6KVUjrb1Jmzp+tK1bWeTEZa69ALrbWeFzHG8mneSpdAkc2NC3EcC8ZXVlYQ6XgyFUGY53m71XVd3qSUZZV/+ctf3r57nxCGiAhXz527sLFxajabvfbqv1la6mZZQanXbi9VVQXW1JXi3K9rxbn/4MGu7/trq5vj0YQgp5S7IpELLnKFZFf9ZYxMJqNWK6mLHNEGgWesEgQoYz4n1loCxiiVRr7XdZVKtT8YWmuTJBmPxxcuXAg4ASM315fCMKSCHe7t/Py3vl7Xdbvd+ehHv2e5v9ptt3udpdl40u/3Op0QLMzzW96xnVhMAhcsm+VHR0fdTgtQC48xjwnBJuOhMpoQIsFQztGPpAhFd73ExFtJ33Pmico0F555sizLo8PZ3u7h3u7eeP+gUhmg7MaxF3ePSts79+SFH/1jwDhQYZCoqmqaSiFbXVv+yIc++L/843/YTsK6KUkYjqezvJHcD5i1jSysskgezoP4jhQ/a4yeT37EGFOWZZ7nvW4XAFyMu114AAkh0+k0CILhcDidTp263KUt1HXt8kgd3QXGaK25EC4rCwCKosgm09FotL66NhwOHZOklHIyeXfBO27M9Sh0C6O53kKrwA+cqTYMw0uXLnW7XYeNtNauDw/n3IG/3d1d3/cnk4m7/p350ZmN0zR1CWq7u7vf/OY3L126dPbs2TzP79y5026nzrdY1/WZM2fCMHR0XZIkjgA7jn2v69pKVdYVUoKUTIs8n2Y+YY9fudJrtW/f2xoUk+WV5VDwNT+OK70m6Yphfp3ZOg9aSTgsvv0P/+njf/zHl5Jl0PjBD374Fz/3ZRRUV7qWdRSEulIIhpt5mrkGa63rsQxggPnBjaN92Fj64b/xs9Px4chCu9Wpa2kAgBhijcsspQDGIrUENSBai2AIagRC0JkUoyAgxNUQFagaGFAuwBCwlBgG9tHMpHlc+AnF+ne8Eh69MS/6PPSivS1e3J2QaAlYjwAqwiySecnI9XjRAJ5XWn59VLSe+fD5n/wp8NcriZ7nK1UCs5SyGox5mHBqAF1W6yKr6aHy/ru+nehGaMD1lrYuhSuykAWgoc7gS5//9q/84gVhEkZVVfqeD1aDUj5BLRtCqAt7mCMeQEusBUMMfbQ+iO88ku+2P+8Giu2JlkfHz0B8iGfs/H9EBC5MU9dNHXiCMUY5A0oaZFen+vz3/XDvJ/80iJa0PmccrZR1RnxhgArrlnMwT65B13IHj6UU1hpA0ul05oYbOtdnEUIsQdAuTMIskk0XtonFbbMojFprjUXOmQWYzWbLy0ucU2fAZxSbprFKaqV00zBCoyCM47jMZ5Rza9RkMnr88St379372te++sOf/jQ1tK5rITx4l80ABWMIccsE5ITFS2eeeeuVV9qhIqQORCjLijZ1vZcB9bnnR16cV83enV11a2ejv1If7ke+AKoCVCAlECSZGuzNpNc+/b73VVGv3T/fefLp5z1yOJk1k4JpjL2IEFLp2vO82Pep4BJtWVfj0SSbzWRdj4fDwWCwvb3tYJAjopIkcup1p5G9ffu2I91X1zfX1tY21ta+95OfBDC6aba2tu7cuTMYDNyI7cbeKIrCIHKdl7MsK8tSSqkRnUyeECKEcAI4t2qllGqwYE0Q+E1djgY1Uur+SSlVlIWUklAKBCmlBgj34oQKIMhanVQbY41hgkrdUKRKkwd796025y+e++JvfSlpJWD19s799dUeoeb+tW0hRFU11sxu3ri/sbFxevPU3bt311bOZlNJSXRv+6DbXR+Ph4jqIx/9Phcy8fqrr+3tHXz/9/+e3d3dN19/wwvCqsxff/1VQjEvy6ouNjc3v3zv1tbW1ksvvHdra+sb3/jG5uY653w8HmutPS9g1J9O89FwdrA/4CyKotRoYoyhlAvBHKPjyABj4PDwUCnZyIpzHgTe5ub66uoqEojjuKwkQXF0cFgURVPW0+lUUFqVVb+70uv1z5w6E0dpmqa9bvfBgwcPdnevXHliMBjcun7rNz/7+StXrnzoQx8yYLbvbK8srQwODgkxS0tL00m2fWebo5+24pWllaLIDnYPPM8zxlZ56QURIcwYGA4GQRD4IorDOLezMNSMCU7nAR6eiOfd4rQhVJ/eXJNSUlRPv+fpvaXWzZs3kzQ2es5Gcs7zPAejOOfrq6dd76DhcPj4lUta61OnNtI0dflMZZ632yljTBpJCHJPrK2tB35kLWbTPJ9mlOJBMT5z6kkgGpQEwmGBU+y72ZEoJWDh/vY9a63vCyRWeNSdf4Ph0KIBBkCJpeRgmglNdK0ZJYeFmWWjcTFlQgZhHJw5f/mx93wwbS+tdoIE0ZT//P/z87/5ha+/8PRHP/XpPwo20CgAoSxVTJipilmdUd//5svfqKsiWe7ubd8pqoaHLRFGWV1DI4FQBswapedZyW9nsNDF9z0qJgVrR6ORG8XmV5HWiOhiUQ4PD137Z9c9RghxeHjo9FvuaYwxCMO6qhzEdxEn1loKmGWZu/IdDeZAWxAEeZ7nRS64CIJgMp0AAKW0KAsAEFy4/AXG2OnTpwFga2vL9clpt9vuIyilzurrgHir1bp1+8ZkMmm1Wmmauu8lhBiNRmWZj0YjIcT6+vpkMplOp+Px+Pr166dObbzwwguvvPJKXderq8tBEAyHo7W1NadK9DxveXmZkN3BYGCt1qClVq1ed3cyLmRNKbl3b3s5bHHOn3v++Z3R/t5sYAupNE2tfyHoroAoJ6NT/d7dvb3Huv1r/+IzW1997QjqpsgueHHkB0AJ5Uyglk1d1yakjBjQCJKCtkAsCIvUUMWwoPbaeO8v/+IvAzNTq+Nef3gwTuK0IRoAiLGOekILTFtLAC0CoAar0VoEi8YFRNrZxGSzOg48ghAkYLSuDQAhli4mbrMoGFmYg7R3AykPT6djLPXOOX2hsHkngzWvHnJQHIBQrhSVmiiLmoBCTYAFRW5uVc3Ki9+z/pN/Bvy2sRHliLIRjIGlTS09LgjFWmnOKHECcGuc+cviCYz1H7K9k+h123cocQLMy4IWQC3uMZfy7fAMNwS0zn/jX7/xC//o8Zj5ugKLrLGgLFQFxAGTFRPCaLCauV8NTAlojQGFlJt5L8Lj/Zj/NY/Iy95+dTsI9S6JVvYRgIUn7li7WI1pC2BN5dqEjAaDVtoh3e7g7t3thp7/kT/e++H/AxC/ttRjHJoGqOHCB0so0DnOdLVSdAl/1rjTCDQgcan97W4HFvq7eUUSCb5DKnryS7kRw9WzHHegtWmahhF6PM299cabiBj6QmstOI2iyEipKWazxtUWHRGetlqU0hdffPHq1evuYLJ3Nsxxpz8xCqwhRhhmFWjBCQng7DMk7Gt6REwJknNrgRiPe+B1oQEpTeRFycaZ4mDX09KLAhAEqhp8H5QAyTQP65Ct/8z/FTjLrt7+xhuv5Nev9S9faK+sRjxopYmp1e7ug73BQVEUdVESzpJet73Ui+M0SdM4CB67eNEZj8bj4Wg0mk6nVVXt7OyEYUgIVFUVhuHy8jJjbDAYbW1t3b59WzAWRVG7nS4vL6+trVx47CIA6KYZDcb37t27f393NBrtT3YbJYEQ1901iSItVZ7nxILHeFPV87ZplBDKEdESJARKVSEDxjgASKlVlRMuGGNgiZaACNqqeew5FUZbJpWy1jaNcqtza7HVbuVl0e/3V1b6YRgKIb599c3+Ur+RFsEkcbfT6RRFNZ1O11Y3W2mvaXSSdK5du8U511rv7T1od1pL/b7V5mB39O3BzU6nI3i83CW/+RtfnE6njNK61tPd6eHR2FrdbrcPBgdFXh8Nj9ZW1u7vHCilpsNyEle6mTmebTw+OH3qLIJHiQz8llK2LKSSVkqpdN1up8YYSnVVVc4IxplXVTJNO91uezabDo5mWqPLOqpq1W51jbJBEALnSuZVUR4cDI/I7P7O0euvXDt79mzoR65L3f7h3m9+/gtLS0tSyk6ns7W1nWXFRz7yoQvnL129evXZZ5+/f//+aDRK4hYA3Nm6mSRJu5UcHR2dPrURRdHB/tFsMmmqwlpblw0F++xT78mybDA8jAIPrU6jYDodS9Cq0UAsZx6C5hQIqCKfDAaHhwf09de+VZZlu5OeO3dOSbmxuqS17nQ6lNKlTkcI0e12tZFlUV/+PZ+KokhK2TSV53n37t3zBYv9rrXWWj0eDEXgZXvZ66++TpnQ0rRaHU5onueqkUHkA3UJeydB1Tsax7oxQcOdO3dwkf9GGAM0UtaT2RgRGKGCi6YojQhXHnvyjW++rBtD29048Nd7Sbcfx2nSam0maYdRakBZVjFi/vwHvvdn/+SfPXP+Od3pQiwaA2AgCBhIGyYRiSMvDKqqOHv2dBrHUZgok9dNI6nxPB99YWVjam2MdkMYnghtn68LHxHJWqM1IOLcFIkA87HMLT2rqnL6KufydfoM5+mrqgoRCaOc8ySMOku96WisrPG54JzPxhNVN1JKl5KAiIeHh57nuRwsF0kVk/ixxx7zPG9ra8sltjs9e7fbPTg4ePqpp4IgcOSZlHJra+vO7dv95eULFy44H0YY+WVRF2VmDebFbGNjoyzLsix3d3dbrRaAyfOyqorJyJ46dSrw/IvnLyBiEIUPHjzo9XpRkr519VpR1ffv3zs6OlpeXk7j1v7uHgAkrbSqZXVwJKXmnIPSgrGoHc+KmVQ1WG00UMSqruuqPMjHNObWqCcuXtowfCOHF5fO8P2DIPT2hwedViurykiR8dE1HnAP7bDZW+/1jo4O0lYYcJFNZ36YVGVFkGhETYw1SA0QS4CSmotfu/bWT/zV/wrOb46yLO10h+NZf6k/ns3AQ4sGYJ6ADgAABI2lSCyiAmMWbi03l1gpk9ATgpVlzjVFpGAoZR4otQA97rxGDQBgyElo9J01VYtpEgxFNJYah0jM4lUWkDieB2DeQA8tAWNBARAD2hg0GjVA4wx0loU3xkX64kfW/9B/CiKxLECCDADRggagRHgeWLAaKJ3bEOcYax45ddJb9x+0oXV1M7Bo57tsAeZRVw+l7AAW0KVezR9axIHhQ7Tl6Rp0vv8rv/TtX/5fnvZJahoL1tSKiBCyAoQHSuuqtEoD8axRxDBqNaACV521qLU6vlCPj/k70d6x0MptBixYWNQWcd6+EBaQy0ndEQAIWg32oRHBddp2XSZVY/y4JZhX1ma4vb9Twkuf/qP0h39cYYR+Yo0Bo4AASAnCkaDzhjVgwaJBM/ctGLQUUGtN6fwXiaLghMHUsVHO1oIwJ27fhbtCRAtEa0kpp9Q5CnVjGq21MZDPsm984xuMkE4r9TwPie2129lsEgRBU5VoNee8LvO8MCurq6+88sqFCxeeeuqpt157/Ymnn1lwusf7RBZUKJS2FCgAncmVgCVw9onW+cf373xmw0cjG8J9yMZAeQ1yWJBhUUvI3tNbRT/ee7C13IpsWWeVbBpaWszKTPKgEMntv/f3W+95dvXxZx97aumVqzduXb9Vv3UtYlErTJMo7vf7jz12mXMmKM/K4ta9uzeuXgvDeGN99dZgGIeBG36XlpaeeeaZIIiybGoMzGaT4XA4m83u379/dDR0wvZAWyeAQ8TBYLS980AwEsRRK05cJuXTzz733HvfZ5UaDkbjyWg4Hjsd/fDoCBEJIGPcgVpXK7AElbZKKQuIiHldEgIeWM8LBOXGGGO0MWiNsdZy7jlrKGGEEKKahhHghBJN66ZRXhBpY/cODv0wKuvm+s3baRxPp0UcdNx7NZVExOFwGoahEP5kMhsNZ05B5tReaCzntM6bq4fXVd0sLy/PZvkgzYQQ+7t7TdN0u90abNM0hARg/LqqDlVVlTQXQG26v5sZmVlrCcR3rh8xQmtZWWuVgq9vv9FutzkPAj9pUCNQRjFNBRBrjJqTQH4EAEg4F56UsihMng+krJumYfeOjDFlWWutq+rNppJJ0lrur1JKZWXjeFnWjQURR1GWNZ4IPco454L7aZpubW2laYrEBoFXVcXnP//FD3zgfWurq9vbW4LxwBNG1xZ0EARSTvZ2h604IaYeH003VvvrK60333wziqKBzC9cOTM63L5+/brrgnduc+3mzZtRFARhUOYl9/jNG7csmDiOnfHh4sXznPMrV650Wm2p6nPnzmmtH794xeOiLMumafwwePDggda63U6/+c1vjYej6XhSVVXVzG1oURQ5x74ngqIoltdWl1dXHnvsaaAsjeKmaaIoyrKMEfrM+z6gi5KGwUk70mL4hrkd24lHCACB27dvB77wfZ8JjxAWCF5XxXQ26vbaSjZFltVldcTs+QtPvff3nZtlTX9llQk+mU0syJ0HD27vX9XGlmU9GAyiNAqE90N/4Ec++cf+1De+/koZexqAcdDaZU5qGniexddef+3qW290el1PeFaIaTXwfD/yhDGKM68xKlOGILdWHeteH6KrtxFXDzUHaOb/pHHhrHULXERnllbuVY46BgBjFSW0LDKv3RaMMyS9TtcitJKUMDrcP5R1Q9AStDv3t8uiFr6Xl6UxWnii119qmqbX6SKi53mnTp0ajQd5MQM009m4bkq0sHN3azadLi8vHx4ednu9S+fPXTp/ziAEQTAaDafZ7PLlS0VRCME49+7cuVNk+Yc+8uH79+/lZZGXmWs07ns89Pz79+7eM3D58uWqbJpG9fsrlImiruqyzOtmffP0dDzcuXfvzLrNpzkLvCCKG22msxlHUpdNzMOyzCtZTYsZIPE5y7KZ1IZwW9RlZate2v3Uhz/sV7W3c3QxXTYHe7yuldXgidxIwkXCSCsMGCC1RoNnq5IGXMoGFUm8sNbaeLzQTZQkMiu4xISF06IKT6998861Z3780+d+8o8cDQ4hjHShW35rmueWEmZcx1/nN3S/qqbWWGtgvkSw1gI1TtpEkBIppeHIKbFI5y10qgaItggaCQBhmgIAIdYcuwAf5UcW/7uQ8YchIJJCg5QQjLQB7fRbBtCANUCotbYhCJYwYNRJoLUClGBMQ3ildEC5AF5PZl6v98r9SfrSx879mZ+BMK0sIiI3GSEUKAfHTjkqhwBbrHnQXZju8f/o7CsEC6ABNKAH2hnrEOEhwLKLb784LEbXRjBtiTWGEKAI0hhDLK0GQIvD/+0X3vonP/fhM2uYz4y1FogmhDQ1MMLAgAEqIoNEa0C0gMpdgFYbtJQhEHKisfzxZk+UXOf42SyuZ4dpiOuAs8jHx4evtDB397kjpCUgAanBCwAtYVg0GVJkBH3KIS8QvNry7Ya/78/+DP3g9wEGhHrWAkfikrmQB2CdVukYzzksAohAwCVMWUTq8J9SOk2cxBbruhbCNxat1kCpPa5Ho1OVgbV20aZwngWAhDbOMEipQaCUTKYZAAghOJKtO1vDMJBS+oEQjCVplEQhAVMUs7IolFLSmulssry8dPPmzXv3d59+9rknnnoKkYBBAGse6tMcUCYCfQSrsaacNgatpchZ5/n379/4wqbxCFLISxOETRB+e1BuPvOBJ5/9GHg+nF9lr3xl75//owJ5aTE5dyk5denm0WB1fbV7/vx4f3h/UD3+7CfJqUs7v/VbhKfrrWSWZ5zyLM+Hk8mte9tNozinSdJqtVrIaBq3EHE2mT524WIUhy7y2hiT52VTayTQSttp0jp95oKWEgC+8pWv7O7uVqWspHKh74QQ4UdB3EIAY+3B0ejB3uHrb151WdPtdrvT6UVJur65+dwzz1gDTdNUVTWdTnd3dw8PDtxaepaXymiHLhBRGsUFMdoYaRQoYxrGGGVMKc04bRotVck4t9TUUnLwuMcYIpnNMs/zGOfT0QQZTcKkqqqmbJRq8mmBaCkyShkBZrSq69raqqk1IQQsRbTGWMa4lFIIPwp8pZTWuttaAgCtTBp1m7JRtfFEyKhXFqqWDSFEqXo6KZumyWcVENjfG0dRRIFS4HVdp2lKaWCM7abdzdOnKKVK6TzPwZKyLKnw0jQ9ODgyxnS77UbJMi9meaalYoJrqcuqEsyrZY0WkFLdMNlYTkXgB2htO2FSSqNBK6CWEhRoSZqGoA1jLAw8ADsaDYPQi2Jvltl+r6uUahpn3eRK1m+8/vrGxkan0ymK7LHLF3d3HxwdHWhTccqaslnutn2PMQpa1VVVhYGgxF44f+bUqVPj8biVRk7vQin9vu/9mM/FmbOnBPeDOAjDuNttIyL3BEWS5VOjQXjMYxwAqqrKsuyN116dzWbj8TRNY+EHLuZ7a2srTpPDwdG8CZ3FKIpOnTlHKX3syhNlWXHOPRF0et2dB3vbOwdN0+zu7roS/uHh/ie/7/uM1DSIQOuFup08XBkDATDWLrxWAIODozzPkziUUsYsQUI9IXYf3Hf0j0/5qM6UrLfu36u0jONYSVO+/npRFHGaSFnXTQUWESkTHoqAsGhc1Vs7R35vZahUa2MNKRAABUpKGwj+jZe//uqrr7tcfq310WC0tLJaSTWZTIyS1tqyaZRScZz4vlcWWVUVroTn0JWz87g64He2d8Hxku7Y23JsL1q0L5vbedzjTlnVVLV7ced0Z3d31zkTizK7d++e53kAoIwOghDAdrvdJElcQodSysUojCfD4XDYarXG47Hv+x4Xg/2Di+fOXzh7rttqb9/fuXH9eqvd3tjYUHUTx3EUBc4M6GTpzz//7OH+0dWrVzdOrQdR6OzEd+9s9Xq9YjpbXV0tiurWrVuT8azbXxJeQBilRHBPPH75CaWaOAz73c7+zoOllWVL2e7e3sFwlKatbppGUaJM5ofBrCg1AqdMKcUZy6vSQg0Cn7jwRMAw396JkZ8TQauWkWwCaxuNmlhLrNESjUYnHwdD6VxQQhf9khUhGqFGq7OZp9DnkTZEdHufv3k1eurS7/9rP1s3FcaJRSYr2dQFj0IAjUa60rUBMAiAhphF8rez+qNdzNAEHoqj0Kl5CCFoCaAFUPMCjkVAChYQDSLiiQXGo0BkMY+eKMNZCpoCsYCGAs7tFeACIhAQQRBiAIlGBAJIgBjgANYaWbWSlizKWVEnZ6688u2t/oc/tfmn/jzwaKxQMJ+BImDBOs3Vw5Z/Jz99ced3IFYU50hkfseexHB48iMNaEOoV8uGckEpL+sabS2o8m0JrLj9j//e/hc++4HNVT6bAFqwxFAEIJYCUHCcjNOc0TmwWMAJIHSOl7TBeaD/I39xka9PEM0iOw3RJY25t3KVuYVLYS5aBwuO7EOCABa4BakhCiEvIQykbMK0ZaxSVdEYJfykxPDaoPrgX/5rcPlZBZwyH4A434xLRZvHbL1TmH4syXP/zfcJjoPupJQuF8ACM8ZYrY1RllCAY0ckWGuPaTlrLYIrZGt3H9HWdVlVTrtJCaPGKKfQHwyOCCHb94pTpzbGowEiWKV938+nEzfadLvdySx/7ZXf/uQnPgUUACi4Q/LoaoIBtaCt1RaBEYGeB4L4Fy/x7lpZHApjIIosVPcHo2c+9AnyA38QZDD8jd/sju/BaJd6NuxE8bnHoLMKjz37WLsHAQWr22d0G2LAHsyqWVn7YUIM9VgAAO1Oj3DmfIIO09zf2wUAxx5Nxube1l3hLdJWteWcOxPSvP8gkKqqHI+glAGqhRdorcuydgUE93xCSBgl85IfwHSWD4ZjKW9orQnaJAqTOE3TtNVqJUly+fLly5cvu1ZFAKRpmtls5nrT1XU5Hg2LIpsUFWLmYgiRUq217weMEYvQyMpaK4QAYosqZ6rRBKhqNBLLCDfGZtO8UXUraVurpdTWarSkqSRDK2vp+UFd101toiggaI0xSiqwjFKoaxl6YVPr7a3dRyzDZn4Fi4As91c7adcdozRNT58+k7TSXq/najF5nndbfQBCKTot+f379y2AUxQNh8OyrLOs0GUzM7Mqq5qmIYYQzkwDsjJGWoKEAhoFxlo0lADIWlMQlBLUNsvL0POpINRyo2Vd1IpIQoigrJiV3U5KiDo8uB/FQRyHgvOmaTY3lu/e3b5x/WoUJadPn/aDsNvudDqdF154Icun58+dStPkehiur61Yqzc21kZHo1arNZnMtDUGrB8GV554HACaptl5cO9jH/u4y+JyOrtWq9VUtTGGc2GMrqr6xq3bR0dHVdPsbG+Px0PfDwkBTlkcx03TWK2ttVEQen6oAPLxtKolMlopTbVdWl69/ORSHMdgsa5rl2aUF+V0mjVNU9eylrooiqWl5aquH7v8uDGmrqowDD/2sY8RzkGbR+OSH9mMsZTOZeO3bt0qy9J9Zc650x4eHBw4KMO5qOva8wJAejQYDYZjN7hIKVfjtelUBaETpRkhfEYF87xZkR8dHaVp6gwjxEUv1joIvC9/5ct/4S/8Bc/zPvKRjzg/XRxzY8xjjz32xhtvjMdTxwZrpbRWiJCmKYBxonVHO7li30lcdUxrPeLftg+HmuN/ss5GfmIIcq91gTRKGmfa4Jx//etfT9PUvdBd/Eqp9fX10XhqrSnLcnV11Qned/f3JpNJt90hhIzHYyc0BACPC0EZ9dnwaPDmm28+/vjjL66tHh0dXbt27bXXXnvpvS+sbWy0Wq0bN27ker6WmEwmgMT3/c9+9rOf+MQn2r3O4eFhGEeTyYQQ0mglfH8pDPsra1Kr8WhaFEW/t9KUhalrA3qp19s7PDCcYeR7wt9opyvrG9PRuMwLsLauikpLL4lAkaZURZYzxrQ1jay5oLduXt/wow2kj69uXmZhNM4hK4wxIaPakgrB9SdSaCsOBi1DoBpChUyjIkQyVIAaTBwnzSRLRSIrWQi7K7PZcuv//Pf+H8DZwe4g7a80Wgdh2CittbJawwn1CLHO1PZv0x3NKzEutdKhK0ucgnchZl/IqOdPO1kVe/irH986eZeBQWMIGCAuNZQCEEBi0cWauDsa0Fqq5xyB1mBtwBlkMy58noZfvXnziR/5Q+kf+EkI2rOsTtKYggQwAD5oC+9oivI7u+FCQWTBGARAF7e6SPhcfDgBM690WgZS+ZxVUiFnDIXvWZQZyNGbf+9vmrfe2DDSoxH4MVQ1UCSAFIG4Q+0uMTyR+XLCimLnz3kEX8AxG4VO8D7fG1z8EMYqtIS6IHd8GC42x27opFHWgkWkFq1CMByZ1jQOQSpOmSqVNCrwQ2Vhq6juC+9Df/1vwZkrQJHNdxj/LYq073BUHz7fRaWkafrgwYMoSZ0JzhiDxtiTbJwT1MGiaDh3EaqHb2WJ1hj63mg8aJoqCLxa1YZavx0Nh8MgjRGxqCtgXBFCKQKipoRQNhyM1jY2fd93S769vb3VjQ0XtXO8k8YaVyCjFowxOC9uGgOEIMLyauvMhaPXdlucgZHUE6lvyelTYCr4wq+PvvVl5inUs5Zf1tU+v1mNy1f466/G6xt3hoelJWurZ3qr56eYJBuPZbOh9ZNaScZYXdcGLFpT1zUSQhkLwlB4HiWEUuqMQXErdecCGGNRK2uMbKihtZKcc6WMlLLRinuCCg4Ariur7/uulapbBkspAYJjAbsLdfJ9nxBCCSBireTuwf7WvW03WTh0xTlPkla32+31epdWL3ue5/jaLMuOjo4mk0lRFLPZbDieNE2ltXF9kB22UUpRAEqRqVoxJpqqkrrxfV9baHQT+kmel77vS9kQQCCglOE+9b24ltIaqgEI4U5F74C5EHx3d9caemrz3MULV5aWls6ePbeysmyl6na7lPPBYDAcjvI8393dffBgz32B2bTUCifDzGUkFkWllFlbW4vj2AmJxqNsNBoBsW5GQUsIYQRwNpvFUZRZOx6NkiThTMRe2GBjpFYWPSKssaqqKeWCccZYIyUBGno+WFsWBczjyK2RinLKPYYAxjadpP34lfOnz2xQsEHoCSEo8eAjH7px7eaDvd3B0XD/6EDXRVVnv/wr2+vrq+1264037xweHiZJxDkdDAZxGEdR0uv1+/2+c58holMZO4WyQ4pRFD148KAsqsPDw8FgYJQFYinljW5832eMLS8vn+l067pmSJRSdaNaacfhD8/zLAAhZPNM31rbaDObzfb394fT7Etf/+bdu3ezLJvNZlrbXq/XTlubm5uEccbYUm+Zi2yW5YeHhzdv3mGM+MJrd1rvefJpAKKlpP67WkvmIyEs+lXcvn3bLcsA5vmiUsosyzkh7qJ0MkznqmuahnNOOfO0J3wPc9LUNaKhlGplZVMyY5Q0UkrXZjjwfGvBWOCcf+1r3/gbf+Nv9Pv9J5544tq1a+Px+PTp02VRL3pdd8IwRsTxeFzXtZKyqgqjXWqadaL140Dkh4P2YqxcKB5OkBwnHndXGiHzzvXzgXAh0rLW1nWtpHG5Dw5RHdtPbty85jx9LtXdrczG43Ge5/fv33eeYbfActS3c6xMZ9Nzp870Wm1GaFbkb775ZlEUyprV1dVTp061Wsnq8vIrr7wSxrG1dmVlpaqq8XTiEtsff/zxz33uc6fPnb58+XLkB7u7u+PxeH9/f21tY21tbXd3v6rr7lJvw9vIRhlY+OoXvxyn4eqpDWAYpPG9g93JaNprd0IelHnRbrVqWWVNRX0xy0ulNJHaWjAAhPGmqWglhbGBYk+un12XRD3Y54CcQBrHZVkCEM+ggz4KwTBrEKSxBE/CWbQIxqIsmihIy2lNw2jA8PXx0V/61f8V1nq79+6l3Z41oKWxQgMF5hxblpg5CnLszsNf9qSqxE0PjrIihCBSQGPtsRjbOsLpIcBCM59HH/UDvvt2QvBOrQEAS2CeL2Cpdg1wwOKcjSCAWiMAMYhopOKMgbbAGRDxxjC/9EN/MP3BPwhhe1qpJE0BZFPXwvNAc3hUKvPd2CwYBBd4YRUhGoj78mS+KHZEoUsfAAqIoMFaJEQgsRY8UKhKkJO9n/97k69+7rmV5cBr17OCEUI9H4wGtAThbYbeY3Q1/3usPUJEnPccdCEHx+DqkcNwfK0SREsQALQFSxDRotXWEjQU0PF/BkETA5Ywoy1Ag6ARtdVhEFjZIDLQmnGvNLCv4Ki78qE/9zNw6grQ0NYVCrogx/79j+dCULXgBJ3Us9Pp3L592wEsQplz2CDOq4Rv244lpG//xtocHe5HgT+djv1ghXKiwVZNra0xChCRMj7Li97S8mBwSBkvpaKcTafT9U2sqooQcuHCpe3t7dX1dUBrDTogZcEe821ggRgC9FiKB41sBOWbTz378mtfgzCAbASGeNYOfuPXq3/zWaHUugcBUWU2CXqhrKqmaDwS2MnB7bu3w26nl3Y61IDN3/jMr/af+gA17UJJTpkX+NwTGiwiRlFUVtWxSMNo7TpYuC4sDhi5Ada1/3I2LymlteiUqQDzSafX67mmZ85a5OYpznnT1Iu2K4/EtyowuBglPM9z2YTO1l1V1e7u7s7OjpMaA4Axpp3EURw68/XGxkYQBECo8xUdHBwcDo7yPHd1JGcmYJEfIyWRCBslpZRSSTBQlzXnnCKlSB33DdY66tv3fBpSY4wnQkT0fd8w5dbx3mboLzZGg4P98WSco1a+f99FgE4ms6Ojo9FoNJ1mLr2Ds2kcx74fGmN0Y62yYPHu1nar1Wq1WtYQRNpud6Ws0bPKGqu053kUUEoZesIqLxScMQYWuO8bIYqiKKrKjamhLyjhWZYpQpBR3/cqqSgC8rl+raqqMi+rUuYz63l8NjvKJ0MCkoCcTcecszRNm0ZqbQ/3DrOiiOP0ycev+MIjjDLK66a6f+/e5ub6hz/wQUIgbcWzac48P89KKeXhYPT6m98+OjqazWZN05w/f77X6/m+f+fu3aWl/iwv7u/u+b4/nEw7S/0qrxrd9JdWsmLm9PVHg1G73T44OBCch0FcVRUit4iHw2l/ZbnVatVS3bizvbW1NRpPXbM8R5D4fnzu0pVOp9PpdE6fPk3BNRCQ0+n09q2t3d39paWl3tLyxVaXC5pNZ51OK0laoIEy8W8ZzQlxyxmoSrm3t+dyzKMoYIQySsfjsTEGKUXEqqktEoskK0ohBBOeMrasa4/zWslayUYrShGRWoLGzpMwlVJ7e3tBELTbrUYqztlwNPoHP/dzTz7xVJ7nb7159atf/eqnPvUpwb0bO7d6vd6DBw/iOO50OCLu7+9yzrWWsmlkY2DR2MchnpMKquO64QlV1kOC6nhcc/96HLB+TGghojGAgASZscZYleXTqi7cGJHl0ziO250NTwT9pRVEzLKs1QqLuko7bT8KKaDrP3jx4sWjw/29vb1Wkj733HNnzpz5+3//7zPK7t67mwRh1GoTQoqq5Jz32+3HL1/xwsDzeJTEOzs7WZa5zAXXZkcIVlXFuXPnhBD7+/u//plfv/z448vLyxZpu929cf3WW9++1m63wzC8efPm0tLSUtKLo+CjH/pwravRbFrW9Xg/swCPXb788le+JoA99/Qzt27diNopCbnwg4PtB2jQ40Ibm49HURjEnHcoTQv5eNp7LGr36ga1CQXTSo/LqWKMGhvVyABKZp2kGxGoBmJAUzQEjAW9gOu6arSwUa+/lU1/ezL4mf/5/wWb/QeDvbDfI0RURS28oGhqREz9sFKlnRfFDJkXTo7FNY6x0Cd/R9eq7liRc5KwdKMannDYz02J33F7t5B0p+8hoIFYQpgmuMiIQrBzIT4aRakixCmWOedAKKgSUPz2pDj7Az/a+ZGfBL9TlTINQgBZNhX1EgWMwYL7/64BLAvGgKEORwEAGLuQCDg6zoIGUE7spYBqAEYtAHFZZEZapjLQB7v/498evPz59y61mW502XhMgEHQ2mqFnM5h8KOyyPmGJ6qeizIuLCq7x567R558ckO0lIAFBAKu/QTBBYQ2CHa+nwTQWrQEkDAhwOhQQJ2NhR8qqVgQWEvePBiZC0+++F/919BZAeTTqoz8xDpm8t+mK/iOGy64KHcmuh7qcOIkPKapTijG4G1c2eLJBgCtBQOmFabGNp/9zGfCKNLGtHvdPC/8IMhmMwLUGNjfO+o9ccUYAoRqMMZYDjiZzAhhcZwCwP7e3mQ0avWWHoa1Htc7nRzPEABirHLLD0MoIIdn34+f/Zez7EECGiSmfjRrKsGpTyyoujbAeQuymlvkgQeUa20vdTpQKdAT2Pm1ktALLAjUZOD3ZmAFJePZlBCChEgpgyBwsx4AaK3NgkbinNfNvGDtnuAtOnAYq6SUYK3weVVVQCxSoIQ7IsM1ujg+hi4g09mVTtY0CCGUodIKNMyzchCkVgZsUytKqctldbVFB/KyrCiKwjmWkFHnLo/j+MqVK/1+/7ErlwUXADCdTR88ePDgwQN29a3rSMEqAIC4nToLXhAEiBQAQsFcFdOJ6qWxWlkH9Jx8viqVbiSimk1LSmme1dPpvbpu3NyWJvHG6gqhQCmNoggRlTKeF7RaVElTlaXUaliNOh00xjBCGWFlno3H4yLLVNP0+0sUkFES+2lZ5tlgQCkFWVtrPQpaNVEo8ixTVS2l9H0/TducAViplBoOx1VTUyRVU8dRCgRlmU+ziSeYg7ROZ7O60p/XboxkjMi6ms0m23fvGmN8XxwdDd7z+BOU0s21dSGEF0SEkCwriqoEgDiOsywzRl27dq2oi+loPBiPxqOsKMput3tMYCBikiT7+wd13ezu7qZp+sYbbxpjgiDyfR8sKfIqz3PCaF4WSplut4OE9Pue53lp2qWUttttMJjnuQXIy+LwaHz12i1lzWw88aOw3W63u/04jt1BDqLQGFMUxYPdgztb97S2jDHXjjr0Iz9MhR9v9HrT8cQTgfL1s88+z30GGv6dA7nWmjC6u7ubZdnS0pJbZDgW0/VqJIQQZGVVAkAQBEVRSCkJY8bFlKcpF77W1lXQrUGlFAAaDXVdU0qPjo56vR4gUCSI8NnPfpYx1mq1vvKVr9y9e9dhdGfn9H1/Y2Pj5s2bnPOVlRVCiEtSMMY4mgQR56foowwWWXSkgYU26+3D4sJ46K5nuwgNP0ZmRgMiUkqNmi+bHPyqqsplOhRF4WqdQRAgJXlV1nXtmCoXlujiWJ5++ukkSVzd7e7duz/6oz/6i7/0iwzIzZs3N9bWNzc3KaUHR4cPHjzodruXL18ui9zzvCuPXf7Nz39ua2srCILz589bxDRNx7Oxi8haXuofHB3meX79+vVz586FYRhH6dHR0YMHDwAgz4udnZ3Tm2dNU6+vrgWhSNOU1jk1CghWZbmy1I94MNg7aLdau0f70VIrbcWmltaix0XTVGBNRGgLaVvqTR6+2N8Uw6nJi9haKxsuSG2sZAgGiUSqgRqgxBIDAFYYQw0AAY2gkBgCCIQhsiC2jN8tszcmB3/6b/81+uLTB7MxRLEmbDSehF5orfHCQMtaNhVoBcQjFtAuZDaP4p45RkI798fPyy7EGhe/QI5/ZjcJW9BgXZXKgNULRPPvqso9TMBioAxYsEiOi5VztgYtWANWA0FDCQJhGomxIDxTZsD814ezC7//J9If+nHLOhICP/BMnTdQCS9WwOYek+8yfYVzjZLTsFE47sDjmvDMU53mzuJ5H2ZbM+ZNyyakxCM1mMn1//tfJltvvmepDcXMAKFBAI0FwaDRBgw9EVn88HJ7JEvsWMCPjzz+tuzQk6863six0NLBMgLoRF8IgK6LNgIwQGoACEEgzCCn3DQVUEAOhIosL+5L4j/x0pX/8v9mbdhgTMAQig1QAgzA0kf9ff+uQ/ouRBsALC0tuSn/GP0bVyd9dAR654hkjMEF7jfazvIs9LyiKsqq0tZorcum9rwg8EJOOEhrlLUaojAu6ooTrqkty9rZouM43dnZqar68OCg1V0CBygW2jaAYx+D4wQNc9AVGRADPFp9/Nnsa/eTJIZSg1KcAUjCPQba5kC8MIW6BKbB1FU+Rhah9YgkIFWWlyOk/qm1WaXHKpMe932/rCrf9+MwdN96Npv5vj9HUZ7nBnNX8HEHYY6rFnVVJOh5nkvMcSGXiKiN1HounJ2fIIS4GSpNYxfm7JTH7gmEEErRPeLwgBvbCSGUzptFnqSvAKCuKoo0ipIkSZBR9+lFUfzGb/wGIsZpsrS0tLy8vLy8fObMmQsXLrCf/jP/pzDylTSNrLSBg4OD7e3toij8KC7L0nG5WmtrbFWUstHWglQWwUgpBWWNqt0397go85JSnsZt1hYujd7z+NHRyPMEgMmz0rFznDECNM+mRmnGDGPMGs0ZY0g0oxRxbWWlrPLdB/e0KlutlrV6Oi4JAdkUmqDneUpJxglo3TSS2CbtpIwlnuetrqy7qhxhVGt7f3c3DsOl5eVer3dwdIgWkeLe7n3P41GUcM4ZFZ207Vx7rq6EAForpZTLxa6qQqmmadTewfDo6EhK3e/3W+1O0zTW2t39AymlyyYmDMejUae7tLFxYTKZ+L7vJGVSyqIosrwMguBoMIqTVhBGL7x41hgDQIIgoJROpxljLElThwna7W7Z1IKypmmCMK6qajLNwMBoNHJV3kZpwnjse4EfMsGttbVUxdGAUkqGo0YpB9hdCFur1UnT9PLjT6VpOm9BYWxRFKsra9PZZDweP/nkkwBvExp9h7EDEQDu3LkDAEII1zzbnb6DwQAAXBNNY4w1WNYSCKNcIGUAmnJuAAfjkWvzZMHpUwhYdEDHQZDl5RSsJYQMDodf+MLnHn/88X/xy//foihWVlbc8Wy1Wt1ud39/vygzqeog7Hk+73Rb+/v7nNIkTWaTbNEeFd0A7LhlFxlHKXNXqTEa5pIPfXL0PDHAkbeVDhdX7ENCy23u8nNXWhRFe3t7w8FYCHHlypXheLSz+yBttTjnUqlZOZvNpkkSK9UkSfJDP/RDN6/f+NznPtfv9j7ywQ+1/8SfbOr6F//JLzgmb2VlpdfpZln25uuvHR3sX7hwwff9Xrvzniee/MbL3zh35tz+7gOk5P69e0hpURQPdu5fvny5nOWM0cY2h3uHq6urcSu11hLCVCOTKG21Wrv7R/1+762b16PQ293dPXPutBf42to3rt6+eOFCPpy1k/TwaH9laWn3aL8pSkHB94J2vzU6Ur241yYkymRaq6d7S6dRqFLGQAJOG1kqpYlDpYiKISJQBGodWABmgIE1BgwBScESFAYRaKNRh96X7978M3/7r7V/4FOzbAR+aAwqAC+KkYk8n8U8ttZK2fjCb8zJBb8rzsG7+M4ePWkR0c75BETjCoLHzzDHSY8Ai6n6ke2dgvfjT3cgjhBD3BvTuUfVgDGAFpjVBAEMM0A1A81AQ+1335iOn/yxnwg/+WkbLAEGUAPYhgjik7ACoi1whEJDKL67AAvAIDQABKjnYtUJgDCu8Z+GOVLx3AGgBCwahUyCYZ7yUMFs/42//pf6e7dXQgb5DOKYGADf13Kq60oEIZUGtDqmqRCOi7M4v3F8GMkcXVnzbkzh4lpdPH1BOVucX6boqrF6YcuxirqaMVCXlT93FwItNAhaNjJII6ibUttdPxTvee7cn/qL4PeQRp4FaZTPA31S+P/vh67edbfdzqZp6lRBbsqnlLrC1DEgezik2IcsrH0I+l0R3KZhWzaVNcQi5kVGkSZhIuumKWqF2iorkE+Gk8D3q7IEBEHFYDyTja4rGQY2CePBYHjnzp2Lly5b1x7a7SeAAYtAFkI3JIRZqwkgALHAkIbrz7335tf+dygrqDQw5hMiTVWOymCpH5GgrgxqQcBK1F471UoSn5WHZdA/7T/7gbK0m+/7uExWJl/8JhdCKsUYa5qmqErXPSxJEqmVqwDOjw+A1joIY0r5Yoie6zQW2IsSAsea1zkIW6S8Ojh1DMjyfOb0G654BQAOV5G5mB2OmS2CDNH6vu/6QwPAMccEAHGYuL4pxiojNWMsDH0A6K8su/Rmlzh49epVzpkQgj3xxBOuu9lgMPjmt17e3d21FouiksaWRZ0kiTGmLCvGmDHWgCUorEVGPUMgCMK53oU4KGeItbWRs2npvljBUFZlGPmEEN9X7jtEoU8pFYwSwcuy9DyeTca9Xk/KmlNopeH2vS2lFGOknI09Zjc3N4XoeZ43nYy2t7fjiAPwKIp6vd5sMt7c3FxZ6VdVs729XVfTPDNBFIdeGEf+6tqT3c5SlmWEs/W1vud5s9lsqXdlMDyaTmaTSVXl1R2LAERKudxfKcvSyeuqqtrb23M6J8iwIAABAABJREFUcWtVVVWeF6xvbniM7+0fTGeZBtRaC8/L83x1dXV9s6O0Xt84LYQva6UUFEXh8mF93+/31+I47na77XY7TVMhRFVVrqjqrqKmafKiGI/HUmpjzM07t6uqymZ5WZZpHLu02Y2Njcceu2KsJZzFcTzLs9ls1mq1JpNJWZaI6LL167ou6qrX67nKNOecCe/o6Gh3Z/fWzdtlWSul8slUKRV6wg88Ari6vvZwGPnOY4jW8/XW3t6eI6uCIJizVoRkWeaAPyEUAI8XEFIrVMRa2yjlIwZeNKVTaTTTmnOPEnYsPFRKeZ7nZkAl1a1bt5xi6Zvf/OYLL7wQhqEjfty14SirbrdbVdXLL788nU6dqHw6nfpecLwccTeklDBfrNCTa5GHFP2JAe54GHXso/t27hH3Ku2WPs5QROnxZQzzvpPlYDDwRFDX9b1796RWrozu6G7f86bTqed5e3t7g8EgSZKzZ89++tOf/sV/8gs///M/f/ny5Xvb2+12+2h4eO3mtYODgzRNL1y4sLf3QEp5/dq10WjEOUdj21G6u3P/8uVLTz/77CuvvNY0DWrDGX/lmy9zT1DOO73u9t27Tu+ZZVmvs+R7XjtOgJJT585Za3c5QzCCkYCLIisaJdfX1nzhZXY6Gg9aSYpSbrR6aRxlZpLGSafdemvn/qlWN9VmM+lstFZPU0/tHYqm9j1hjCScVFpS16PG8ppoDUANUAvczNOGlCsBoINEhABawmpOv3jjrZ/+7/7a8n/yA+PR4dTagAceoUoawnhZV8L3tJZWK8apsgqAL07JeRzucVkPYVHyA1hENOFcRYcUrDMVWrQA1swD4x/yKxbw0an9bcL2xVkCCxBgrSWu8mUtQWuRuLcgFueTORqgiGiJ0tQYUAg0aJj/2tHo/A/9SPjJ3w/xcgOBABAMXD8+A8iAOzOi8KBS2mP0uwuxgME8pgEoAHP40C4y4u0JMs8CIGmqyhcqoTWMdr751//KymhvCRUAggaTVyQIbF0iR4pQlTNOBTq73zvcM3ae8wTgZOzGHktwwNF/CC4+1t222hzfBmPdbZdfZRCcAovqhTjPGgAwxCIYUAgaFyVlDZZB2QSBbzQWgG+OJysf+cjZP/Hnwes2SggK0ADnTBvXMwbpv0uP987NNUokj8aSCSE8z2uUPhYeaEBKKej5uXSigHhSgIWP6LEsmZWl53mUgEaNlBktpZRgkAnfNkZwX4HMZ4XvcYZEa6WsdQohZ13v9/tHo+HNmzc/9tGackY4w7lw1jzUuwHMuUwEa4wgzAIHEsHKWSWSompCxoATowsukAOHpsytLhrDwUcLyoCsTRoHWVbqVp+sXfB+5I8/xjtgPCvtTH8j1Xo2mwVBoIx2CCYIAsfIUCRuFijLEqz1PG84HDpRFOecc+pWyy7GSGuttHa6WEd5HM8O7iXHjm9jjNNyNU3jPhEWydKOJHMq2ONSIAC4WfV4cS6ldG9bFTUA+L7PWKD0PPNZa+16HTrh/OJDdVVV7Jd+6Z95nhcEQRiGxsDKytrhwYDgRDY6SVIgWFUVEGIAtAFKGSHEVeoZE0VeOWeOkaoqS7doq6vKGKCU1k0DhjWNsrZ0JxABUEoJSojHQ1/UdW1UNZuUYRDU9RQAVlbWp9n0Qx94cTqdFkVhlC6rvCym62vnut0u2tWL58/4vpjNZmHoE0KSxy8SQvb29upKdtstA5ZS2jRqNBoCgKMTqqpy4ZBJq+X7fjadKKWsBUbI5uZmq9WRUvu+XxZVVVVa26qquPCFF3DOKcUwDIPQz2b5NM+MMZPJbDKZcOFZUJSLpeX4cDCczLJayt3d3eXl1TIrnep5aWnpwsXHfN9vmqYoit29g929A9cJmFLq+76rK6Vp6mLNwjDkvuc4TABwz6maxua5NfjKb7/m+9eVUkAdKyPKsqyq6rgLUF3XYRQ5c8Rd4U8mk/F4TDgrq5oJHnh+HMdp3Op2u+HmKUopBXv7zq0nHn9iaallXCyfMcfJeO/c3NhX1erWrVutOArD0D0ShuHu7m5d161Wy3EWs7zMyhIZC4JAKlWVddJulWUphJjlmTGGEKoMWKUCwYQQ2hruCc/zsix75plnwFou2De/+fUoCLMsW1lZOX369O7u7mw2OxocPPPMM5zzuinLslRKuYjz44tBNk3WaMcwO+hzvPPGGOfvcPs8nU5dDffkwnQxzBFEpJS4S+6YOjYatNGUsOO1jlJOpmAcz8w5dSuwTqczGo08z0/bLcYYzDkz01/qxnE4HgxHo9G3vvWtg4ODy5cee/HFF//cn//P/+7f/btf+/pX/uiP/5FXv/XqYxcv3b598zO/8ZmmLu/u3H7isSfSJOl3e7fvbinV3L1794Xnnz999kyr1Vrq9wcHh1/4whfOnT0LACRKDFip7eRobIy5dfNmHKWMsViE+/fux35w7tJF6gd5WbZaLcGpv7oyGY05ZZzzuN2ZznLiC1VpUDofDjyLXlvHdTO+8xYs9b+nveqXdjVO+tyPpfaL0rPK51wZqalVFBshADS3hFqrGEipQ0CPMEFIQyFD21jlEW6V4VZw5ISKvap8bTr4c3/nb6U/8LG8mDQ+96lHDbGNJRaN0oy5priGMTZv8GveHn7rfjQGxC6mIiQLKcu8q6tyMYD2ZDVqXiK01hpqNFiwbq5zMUrzs8LAu1MXx2FRFpyeAyghzBBm5v47BKpQiCKfMIuCeVAr4LTS8pWRfO7H/zPvE59SQUsZ5hGJxgAwoFwjAACdGweVBYsM/r1Klv/xG3OYCgA4AOpjDyWbl1MXlsqqAe6B1pB4IchDOLz28t/5q8G9a6f6fcgBLJFUaGNoWQAYZSQhhDFurCYWXcSLbBrOmOsGppWaqyTdXhB0VyicgMtwoue2nUvR5occ50EN1hqL1KEuq42hju4BA8RYY7VRoefPdeeAUDcgBFgF1oCEQpnfzuvz3//pjR/7zyDoAQhB+LxYOkdX7qv/B2/4diUVWAucI2NsOJ70+/28aI61oWjsSRsNIQTxYeixK1Edi4cQEbjHgmQ6OeAcgQjZNJRyg8ZIRMaKoqBIZrPJ6bMbo9GRMUb4HgBqbaqqVmrQarXaSXr77ta1a9eeevYZC6CkZJwbYygTx2kg+nj1As4CAQo5D9prl9+z96XPnm+1bJ1bruuq8vxA6doSyOri3EffC9pOX3813ViDpmlU/caRlrz83hHF1Z4mPC9nXITGmFanjYguYmp5edmRWNZaoKiMzmdZlmWB77uiodRK1lXV1A64CMF83xee4ACI/jGn5eARnmh3c4x1EJFzevw09wQ3QUjdOHDGOQ+CecD4sSAE5iVa4mJ+jNRowc3RQRC481Dp5niV3mgFAIDGIbwkSVm73Y6iyPUGIYRYhFarVVXVdDorisJBQmuQMk48qOvaR+aQIFpNkRippJR0kVhvQTd1GYWJRaAUjVFpmlqr3T4xzuMk9AQnFHxPLPU7QXAOwGTTvK7Lp556ptVKVteWO51OXdc7Ozuz2STP82w6mYyGN69/W2tNkWyeWj99+jRjREpJCEzGs3anzynzw2B7exsIzYdTDZYxcXA4nEwmvV6v2+1RysMkbpqmv7QaxzEAccRDUTVW66woQ88XgR96oSXoMV6rmiFR1ozH0+Fkcng4mEwmTdMAQUo9bcBY3NreaRp1/vz5zc1Nytizz70khAi8QEsppXQ05mw2m06nDl602+1Op+Mqd07lwxgry6Ioislkcnh4eDgcONIrSZIwDNGAL/wwDKMwYJxEUeR5Xp6VIvDruq6qglKXQ2YIAd/3wyBommZ/f58gUsaiIPTD4PzFJXeqGWmaphkeHeyWjVJNU1b7B3s/+APf79TrlINp7HcaUY4XWLu7u45qcsSMEAIRDw8PAUBKyZG7YmscpZwJV5UjhLjkJ8o5IcRoYIy45ZRL3tfadjodz/OKophX3LXe3t7+3b/7d1dN/au/+q+NMWEYZlkWBMGtW7cuXbrUarVWV1cPDg4mk8lgMHD6RNk0lDGjrBDCda1x0Hb+6ZQ6jIWIVVW9K3H1tlXj8Rc/JuROqm4RHkpG3IOdTmc8HjdNc3BwsLKycuHChdfffKPd60wmE6VUkiSTycRd3u4AvvXWW01VP3jw4OMf+8hP//RP/9qv/Vp3qddut9/znvdcuHDu9OnTN65f/9a3vjUdjau8ONzbP3v2bLuVdNLWcm+pzIs4jEZHg3Onz7yWpFVRdtJWEPt5VVJtHxzut3pdIQQC5Fm2LzVHMsnK283VUZWHrcRjlHGyd+++YDxJknFTHwwnVHBEbLQqK/Xep5/tGo7jcT8lPOmncbLS7ZBaysmUzwoqZUQ5tcZRUxpBI1ggrjkgWq0BCAOgTFtjlCwbaSNOGJduFAVkXnj78PBWMfnz/8P/k37geaB20ljq+2CIaTSxhCABtMQigEFrAK0BY5E4foggMaDRCUUXrq131aGfIAaO7z5yiuOiYrX41fHECXDyrHjkRSfkRMcp6oYseCsgFhidTidpkkAlwXiAWjF+rajf/xM/Dc9/DKL10hJhNYIFlIBGI9cuJAwArAKUCEDngqjv4mYXRw2P7xAAClKDBS0IQlOBF3o+NBqItCDHUB1+6a/8pQ05PNNrm3zcGI/7AjSlRnFrwFqKnBCqwEopA+bLukGtCSFACCwoh5NH9fhSQgsLEdCcizz51+0uEgRjCaK77fT5xDqya/7rAVBOkXu+nM3QIhMhGAAvAACwDXi01OSNo8lzf+SPxz/0o8A7JQYeUOIMfYtWSfg7LYBL0/RoOJpLiBbI6W0nl110+jq+O8ediNZabZH6/v5okMSR0iVDiMNwMhkRwrQ1WhvkwlpjCI5nUy/wp7OxT0LHA3U6nTRNpZRpmlLA0dEAkLilCyx8nQveziFah7DnmixlCEev9cKHd77+FQmCkopGPtVoGi0tzOq802pDNlV7+1LWk50HLIy6H/rERy+8CEvngbU1ZbUy17duc08kSVzXdSUbhzoc0e7IgqIoAIAAhmHoe56x1vM8j/ju6y8QknSra0R0ERiuPoCIAMRqONZaHR86dzI5CsrJr483YbkQwlFiAOD6ui6QLi7+MjfFoAXHhrgSiqsJco/5vu9GdTewU4aOYGuahhEwnKLVklGqam0Q6qpgnPi+V2eNUhYRy6qom5JQnue59qTv+04WioiAGqwiyAQnZTEjhKVJqJU0xgS+UEpVZU4IQbTT8Ywz0u22ReJFUdjv9YxRm5ubh4f73Xbn+Reevbt1j1C49tab7ui4Ykq/3++f6y4tLQkhHMs3m03A2ps3b2RZ5nnB0VG2u3/o8HYYhtpC4PncE57w+/1+stHtLfe11oeHg6LSVVVNJ1kURcfquayYIUBV1512u5FSq2aazdCCMsrjwiIiEVXZCCE49wBpEEdp2tZax3H8VPA8AMZxXJbl4XCgrNXjyd6D/aZpnMvAUVlpmiZJ4geeMmaaZZ7nOdhaNQ1FrOvKaNlqJefOnen1elEUASXWWlej1I125x8hpC6rWTbjXOxsb80VRYBCMI9xY1UcpUopaXQSh2kUAyVGGsLZwd4uOJGgNFJKLZXWhoAFYwNPPPvMU2BBG0OAGKdneMd0YueWOkSEW7duueIgAJz0sgZ+5AnfRXwND4dpmroIqiiJhfA1WN/3KZLD/QPOuWx0UZQA4HsBpVRr6fthnufGmHa36y6IWZ59/ZtfO336NKV4d+u2UmoymQDArRs3jdJXrlxJ40TWTVmWHhcNqauqcmMiY2w2m81ms3a7vbS0lKbpaDQaDodaa8ffFkXhPCYOKUrp2jzPv/WjSAvAEqMXgcdzc+Lb9T7u+DhX7NHRESKWVbl1d2s8nownY6AoZU0IQTDFLHPxDVVV9ZaW0jQ9OjqgFP/lr/7q+973vj/84z9+8/r1o9HRz/1Pf7+pas65J0TTNFmWRUE4Hg0QTNHtBVF4sL9f1/XO1t2lfp8Q8p7Hn/jiF7/ATuFyf/XSpUvXbtxqlUUSJt3uUiB8tLC/88A0MuLecO8gSmKc5qU1UtYeUqtknRcSTFZUltPe0hIAMMD9rXvve9/H2vFSMhrFQuVZxqsjohTLsk4Q+V4om0qB1cQYBE0ALHCN1Fo0FgAooiVYGoXGcgoeF1pqYgGp1xBNgvhONtmP2Z//xz8PT1wCj+xNx5oSj3AjlTGGMwoA1KJdsA8G5p9CKBBLEAyZB2YDoEV0sqF3zId44medD7QnZNTzmhTMMdpDgGWPX3fyTQDguAfLCTBGAcACcQ+hE2BZo+smCQJoDNQAXig5eb3OLvz+T8NHPwnhGhjua2CcAkiLcxU5XYjJnZULDAFL/l05X///bQuWxgIAKLBO00Y0QsMIAOGgUBCAuqmkRY9TBVvf/tp/+7Pny2pFeIiAYQgAWVUkxCcuy8G4RseIWjdVHT73lNjdrQ6PHMCinmelfPhzPBxw3IX3EEi9fSCyJ/fV6bEeKuTJIv0T5ogboVFQNjxMwYIuKuoHgMLUBYm9gTG3pH7/n/4v4H2/B+hSRb1KSs41QQ1AgdHFAZm/5e/IZgz0+/2t7XsOXR0fAUJcD3o7Z+dcIZaQhYzBWRjnp5xFM2tykfjSSq1rTm02m7biaDLNmOfJSmpELVVl1O7gcGO1T6vcdZRXSmVZ5nExm0w7nU632711+8b7y/dz4QMSREoIcT++frjL5HjFggiMAjQMzr6HLp/O81E7SQGnVlsSdWCcrz3xJKxvZF/8QpaPV196FkZDOHUR6qr86le8UyPy1PM0QKXlrDosy1ngiaZpjNZECKWU8wC5Lzhff3IhhEBCqqpSqnD6J1eMY4SiNY3SVhtjrbJWEU1P6KiE8GFhZjq5rDJGH4/txzestQQERXYsF5mnlFnDKbPWWoMWQGulF2DXFQ1d8FCUxH4YuE83xlBK63o+Ezk2xFpgw6PBaDB0EMz3/b39w6qqpNGDwUhpzbngvme1qaUUHBmh2kijiBDCGijzqZKSEQSjsuk4SZLh8AigzbmnlSqLWZK2fT8yxsRJCNBuJWkQ8qLIR+MBWs0Y29raOn36dDadfe2r3wCA3d3dssoJAU64smZteSVM0sDzj4YTrfVoNHDtcss80xpXVjenkzxt+1QkiBiGYV3X0ui6kmEUKWVmucyy0fXb96qilFq1krZUihE2GM6qomSCBUHAOPE8j3JbNwoI4X6QUuZ5nDHmB541JE67lPKlXj+MgulklmVZXhaj0Whv/6DX6yml7t27J/zQWru/d6iaRjAehv6CtzNKNZRya3VZlsLjAGDBEKSAliBlBBlFL4wYE+PJ8OrVq/sHu1XZAIWiKOI4bqfpdDrVWodhaJQ2BoQXtFotQoLZbCY84UqQjHlHR/tFUWRZ7qC9w3ZJq5W2W3EcB4HrZFlapaMoSqK42+0GoffYYxcBgVJ0RLFWipJ39AFdXGPGwJ07d4IgcLU2d8Y77XmatKuqIhaklI7LZJ5gTFgNs9mMEJK0W0qpum44F+5EjKLIkUyOzHOkaxzH1hhXm/+FX/iFD3/4w+12uyiKhafPJkly586dNE17vZ4LJnCR6ADgMJMT+BNCXPyu53krKysvvPDCdDq9ceOGUspJTZ2G0eXpz+tOJ7ZjWgsXJPPDYfFkpsOj/sTjNy+LmnM+nowpIXs796nHoigqikJQ5ur0blfdhToYDDjnX/rSl+7du/fBD37wv/yLP3O4f/Avf/lXvvC5z/++H/qhl55/4Zf/t38xGB6Gnj84ONzfeRAl8fJSP223yrKcTibtTmc2m330gx8+Ojo6c+rU4088OZvl93cf5LMsRqwtPnbx0pm1jYN790HpTpQcHexJWZd1acBsrG/4YVA0cmN5aVLLu7v3j/b2e0kriUJmyO2bt17or2R7ByFjvtWMIrdAPc/TSk4yFngutlGDJRoooNCWAWoEhdpaYgkqhlZbIMiBtLifVVJaq7n/6v79ptf+qf/p5+DselbnBVLrCY9w0NYYg8RqsMytWZ3u+Rgdzac+12PAIlnY/o9nIddK70S0kGt5hGiBWFxkM5yYQh6e4M6D9na+6t2iAU7kYCEgswiWULAErQXr9k1TznVVU+KD3zY0emM4u/Rjfyj5PT8MJtHAcdExQQE1ICiQh+kIx02ULQNLv5v1QbCL05kCgGXgclspWABlLUOU1jIwBK3nGaincPW1L/3tnz1nqrW0BfmkGc8aoRVHShF1BZaBIWCcaYCisWgsJAlMJu6oWqWQ87cfVWsfHtL5bSe6do/A/O9cs/72FeC8pOiePG9OQ9AaYB5YBXkFwqNBUErJKKVpezsfHVDx3p/8KXjfJ4CvluhJZUIeIKiFB1VZACdN+x10cR4nNbgiqasuHeOsxXPwYSlw8QgiHieRAiVJ6OfFjBgZckh9f7p7r66L2I+GeWGQaastIzz0y7qaM2UAWutOp1MURRons9ksjuNuu3Pz9q2rV68+/dyLSksG1BI0BvBEYZQAzLWmZo5lpbScxWee/eDeb/xKu+XJSWmVErphNCy37sHWPdHY1bRbXrthBE7ufx5Eb5gLs3b/6SefAjCCUTc8umKxEMIa6/RPTdO4rqxRFGmt3ToZAJRygT7zw+IKEa5dlROBGGPc32OKixCGJ7YTv8Bc62YeHesX9AE5XkK7pbKZb/NfARbdIbV2BSp5XMBxTJXjTZwm2f2CTdNorVmRz4IgmIyLNE2nk5HHaFZXXPCVXtdYOytKa4ygFMB6giVxWJaF57PHLz92+dIFiqCkFJRQgnt7e57HlTLamjwr3IE7HI6MRc75xvqqEKzVagnBuaBB4AnKpNR1Xd+/v7u8uvbmm29ms5wx5vmx1toPwpW1VS3117/+imwaY22WZa1Wazqd5kW2trYGAFv39pKkJbxkaXk9jlNrbdM0jPOyrOYOPqWQeIRgp5sGYWi0ruq6LhutVRgnUqmqViHzLdA4TRgSwolzfnoed7O+UmaWlXl+dPXazboujXl4rGez2XSauZWB+2FcT29OiZaNlMpoRQB8wTkXnDMAQLRVkY8GuVJuFCbGKM6IUo3jexAp59T3U0rxqScfp5SuLq8sLy/3+/1utwvWCs/Ly2rrzrZrm3P//n2tdZqmQRC0Wi+1Wq04Th28cL+6lHI0nTRNU5W1ahoE6nteFEW+4EEQbJ7aCCJuDQCx1hpAQ/k7tKiLMcZaGAwGTnltrXUYy/f93d3d41OWc89a7PV6YRjmeRkmodZaacMYqLpRtVpZ6leyUUoDkOk0U55xCfVOQ3YsNuScZtmUe2LvYL/VSqIoopRWVdE0TbfbPjg4+MpXvvL0008/+eSTu7u7nHMhfKUUIlWqOb4S3DVT1/X29vbe3p4DYVLK8Xi8vr6+tra2v7+f5zkh1FrjvIQnr8nju29bCdl54vTDEdCpQTjnziCilLIAQggAVEoCopEqn86KWRYEwWAwiKKo3W4rWU+n0zAMp7NZv98vqvILX/jCzs7O/Xv3vu/j3/s3/+bf/I1f+/W/+9//9+dOn/nBH/xBo9StG9e/9PUvBcS32ty4fl2BXu4t17JZ3VgFgsYEvu8f7h84reXq6vrhZEy52N/fv39v5xMf/Z4nnnji8N6DpTPnVz/0oTjwV1ZW9vYf/JvPfCbLaqI1afRK2mnFycFgwJ3xwuiCmMO6uLC+XB0NKKOuzJ9wjtpwzi24bCGgAEwTX2OggABKz2bWKLSWI2ECmK2qpq5qlSvh+UiDm+Mj77kn/8Q/+LsQ+keDQ2y1DBhu0SgjVUMIQc6MU1ohkPkaEiwAMS5EwDieY17BcfMUwNsl6m5YtI/Kh0+Ot3MNFsw72zw64J6gMI9ndDO/e/LJSPRcq0RwHsZpXMkPypL6MdBot8JDQ576w3+cffKTIFpaudEUAGwFaIBwENTp7lFbVAAEgYLhCyvFd3fTaCgQVAAWgBJNQIFBMC0AMMQAR4IaZlRN4Ztf/uo//H8/HxlvVjQTLdI2V0zEZDK5FycBZgosAeRA0BAgxBLgPvfh2jWQDWEUKZGNZNZaYyhjYMzDg+lEwY6OPN4zhIeo65GD7pQMTvS9CMUwFggYSzQxxAIBa2cz0mqDEUDJrK4VY1ES3zgalq3eiz/6E/DCxzXrWu4RAykQMGAJU2AAJAIQoLgoVf5ObYgQx7HDCowJrbWLabDWFZUtIlrXq2lRvSIPQ/hcaQEZsUUxSgNPz2ZLYTDb3/3W53/94qXLTz73/GyWAWN5XVsAaolRtsxLZnGaZ0op1wPD9pcnk8ny8rIrZjmARdCJREFrSwm6BlQPzzzHyrrjIHwACJ7/wOzXfqXJC6OszzlYZpTizEBtMGvA72JVoqrWI9oMd9bbj+nIB4UmI16c+rTtC0ft2EZKtximlFAkTdO4Ep6bvKqmRguEEM8TCycgGGOkrBGRMVZVjaO7EJExZIwSgoTAeDwmi+YNjDHP89xUJeUjUoHj7XjyOsZT7rVC+Mead1wYzB1NdWxCdPsshAiCwOm8KaWce7CwKFqLbHx0GK6v+5SH3GvyMoyCyYhk01lVNUjJdJZ7YZCmKTOMItFNEwXedDzaun1TEOsJhtZ0WmmSRmvr/VYr4dzL83xtdaOsK4cxa6lHkwkYU1VVWWU79w+zLKuqanh4pJQZj6fTyazd7mqtk6R1eHh45swZwuloPJtkddM0jlkVwl/bCPwgaLUTl4LNGOOccs6nk2KWZ1VV3759WwiRZZmS5ljNE8epUirLChiOm6YJwzAIAmJNFMcarFXaCwNES5DO8lxqpbWezWbW2ko2nFBjwOXUH3MkDsYRQtrtNiIGQXDu3DlHYLZarSKbybqqibtAlEOQWZY50O353BNBkkattNPupO4863c7jDEuhKslU4aEckrRGBOEfuiH1prJZLp/8KCpGiZ4lpeAIDwSo//Ms09GUVRVTdNU7XYXEQk1gEob28imqppGVnWRT6fTIs+FEEu95f7SkivwSSmXlrrWgNYSiOWcVnXhe/67rpittYTA1taWy75yeMKdizdv3nR160W2OywvLxNClpdXKaW1qgkhjJGyrvI897xgeXlZGp0krb29vdl41m63m6ZJ0/Tu3bthHFPGtNHO0uL7fhzH4+GormtHvbo8unPnzt29ezcMw8uXL7/66qt1Xft+6H4gZ8FdLD7M8eUkpRRC1HXd6XTa7fb9+/ddTunS0tJwOHxkDl5Qx/CoHuIR6dW7jJ4ohHC2Xs45AmR5RgkjhBitKKMAoKQ0ngcLk0sctV1caq/X63a7k8nk9OnTt2/fbiXJ3bt3r1+//n3f8/Gf+GN/7J//4i/duXW712p/+IMfWukv37179+U3vsWBPP/Uc994/WWfeK99+y0K0O8tB8K7Xz0oyrq3srpzsNfuLy0tLY2HwzIvPve5z210+3/up//s97z0fqiKXpKQ5T6U5U/9+E/+xhc//09/5V++eu1q1JOdtWW/t3L//v1oqe0THKM+hPpiu12OjgJCfM6ZRWttIWtGENAoV84ApA6CE6rBSGuJYIKRxhpdNxyITz0a+p24vZfNPvPay5/6qT/xgf/mLzVVURaapG2NoBvt4jNcXyJDgAExylgAnAcaAVlkMbg/CGDRvA0zoeu4a8Ha40wqNz/NB0pjFQKdLxfe5Wd8WBM5ySIsZvT5Zzx8ZD4wWwAgViMsUtGdDIj4Fr2BhK3GvPCHP80++v3gtyeNaQkX56sAgQBD9730HCwuGCV2LDf+bsc0GDAIhiJzH2fnB4I0Zc2BkMCzxYyyrPnGb331H/ydpyPmFWMSeALEbDLwfKZHZStK5CzjloNVQChQUhMgxHoWhRDVcEg4o8QZRyhxPYVOHMCTh9pai2SxE29DV4++6gTMQgAAgpbMhYAGDbGEtDswnYEXSCXDdtuE/p2dB0MWfuDH/o/w4kfB72r0DFhOUOY1Dzy0APMwMwDXGPE/WuX+HTbHeWitGUdjjAW0VltjHETXWjvPJs77n9qTaGB+iIxlRqq8vLi6dOO3X/76b/66V1RmNGRVHVOaA4RcGEQGII2qpzkY3U5bwveco5wQsr+/v7m56Vr37OzszEaTpNN2H0GIK9I6qwEBAIvg4sMsgAJgnIKNoLvZWTs12X2jHwVgGqDoebRsssDzwedQNb4XK2A2n4n+2uBwdmN0/Zm9w+DJ86BhcO8BKO0xXhSFbJogCLQxZVkyxsIgPI6DnpsBASmlTpXFGHMTunvOwwrDgu849jM59S2cSAd1XfgIAXzY1+Hhj+qe7Oixk4fa1Rzftrp2fJVZpJUqpdyOOd6rrmuHDRbwTggh2Mbq6vrq6ksvvVcpdf78+aIoAj+6u3NvNssPB0fXbtzKilxp22jlLN9BwKNwuRVHhNq0FQWCh4GXxpHW+nB/j1JaVNXBwd5kMqllU9e11NaBu6ZpfN8vy7zX6wVBsLK+tra2oWtz6tQZpUxdSSH8dru9d3iwc//+wf6+BUxSbi1y7vP/H3F/Hm9Zll6Fgd+3pzPf8Y0xR+RcVVlzlVSlGhBCKgkhBompjEyDxGQDMgZj3KIxGNqtNrRbNtA/jBjE1K02aMBILWGDWkNJJamqsoasrMyMysiMjOmN993xjHv6+o99343IrJIsdwv6/PHivhv33ffuPufsvfb61rdWFBHypnXN0fzkZNm2rfe+6xrt9Gw2E5IHX0fjbW/Y1525cPlCUOgHj3itdVikEbE1dds1Zt5FSayENE4DsGo6c5YseSmjOBkKIZSxgnEAX2RxlsabMnDXdXVdElHTNM45RD47m65Wq6ZpjDEHB/e97eJE9YrBaDzo94aD4TjPekkaxXE8HPa3t3ezLAncFV+DYQodB4wxYLhR5XZdpwSfzaZ1XZbLCtDXVbtYLXuDflk3Ozs723vbpu0AfL9fAGRE6JxDZIxB07RN08RxurU92NnajqJICQkAXWdM2wXUz6XY29lCBoJzAgdAXPKvyoifow24efNmMO7amIKERIIQcVVVlWQyjHkURWsKTXdJnuV5bzAYRZFMsnRrayvP88FgcHZ29ulPPzebzUIHZd22gaWrqsp7m6bpycnJu971rjxLptOp8yzLEyBGROPx0Jhue3u7ruu7d+97vzblqqvWGB1MGTa3yvkWcH3/zGazJEmuXbumlFosFicnJxsH4c1Whs7NjQAwMCCPYqzzm/PNc990Os3zvOuMMUaKKMDENVNxfotWZcmFcNZOz86EYKPRaGtr6+zs7OjoKJCyNx5/7PkXXugXRbUqP/3Lv/Led7/nL/yFv3Bxd+f/8L1/Mc/zj33jNzZN8+4vvfPxG4/94e/+rr/6V//qD/7Tf/If/u7veOKpp/7Lv/yXe0neNV0HbnqnckDuDGerpQk266m6f//+9/0f/+uzP/iHfvs3fv3B3al8/c64NxAq+qav+dA3fOgbPvn5z/0/fvRHvvjlm2959m0Xn93+5Kd/+am3PT13eiphxnze62PZonGSGCPySviIt1aHVnlGYBh4jg0AADjwSiiBnDqNhmKGCXLD8FdefvGucH/2x/5h8U2/ab6YUZz7hoQDLjmSiFRiwDprPJAzFjFoadAHbggYhqQZIs/WPX4Upr81NmHnJcI3Hw9pyDc+e14txLVyZx2Vw9/MYD18/RsX+/AvkPAWINBgzDPmOHeMM2IyK87m9evOfuC7/jh83TcsWpuD7AsAAwAdSCAACQzhXFQMDLwExgDBAngEjv9u9VcAAMBYSHTkBsADgSApgDkEnyYGwM9O4tjpf/mjz/3Y//2tWyohjVna1Y0UWIwkWa8gBm2lzwEIyADXNhKWED0Ge4w4ibwLm1knI7W+b5yDR3oLAACI2OYcPYplH9XMvbFfAdasJQMA4OjY+mc4cQAHDCGSEAlwzHm4ff9eLcQH/ux/AY99gzMxj4TyLXGGwHgahVMgECzIcz8wv6ZEGfsNOQdEEEVRnufL5XINEULjpPecYZigiEgIgcBDH4D3nnxQqXGG4dsuY3Rle/yFT/zsi7/8Sztx3B8OJ6cnuFop61e63b9wVcWxQOyWS7daNk1VlRUhhDm/rivnbF3X+/v7ZV2dTs+++MUvfvCjH3HWA2ecB6sOwnOg7TE4W4R2QuYADEEC6vI73314/4vABOhG65XKE+NbyUjEAjoH0O8ob6LhF149ia6/7UN/8j+FvRufeu6T77/+9Ne95Yn/5ZNHoagXlBLBNGFjhbPZ2RKRAwIHUnEGyLkMYMozZq3VXVfk/U3n4MYOmoiOjo7CO7/JZOdR/LRBWowxCE3iAJwx9gjQt9psLsZNPQQYSsk7o0MXOfg1wguN/JzzTavM+iM4Jw5PjlHwV199NchEEJGQT6dTxoQxZmdn52qWOg+dNYyx+/fvO2cuXbogObZtXa7qimgxm2rTNmVFjAIbqaJkd3e3aro4jvt5j3OepmmapuPxuGma0MuwXJZVVSvJz2aL4+NT76FtOmPMbDEXSuZpZh0hE1Ko1aqyi2WIFAruA0qpNE0ZY8goThMheJIky+Wq1+vVVYPIl8vSey8ElOUkkC4h/bGuy8tXLjRN1bY6SVMGjBAiGa+qMlKJtZ5z4b0HJpqmC9p8jna1WjnnvLddZ+q6XK1Wq3IZspDiKAnO3devX98ajX73t/+O4ahI03jQGyZZzIB7cJILoaTkotWNNYYAyHttDJDnnJPzzrm2bdaXCHpyYJ3mnDMk78xwMOj3ekmSZHHiEYy1ddtE68zwhoiMthvgDODJUxzJPM0Cg4hgrfHOtkTovXdAgN4BK/JkMBp555hAY4yUUjIRbAgA4CsasljT1Hfu3Onl/cDbhYhya32a5n3Z7/UGi8UiluqcA2f9fpEkSZYlWZZxJaMoEpIRkScC8EdHR5cuXbp+/ernPvcFpdRssZjP56PRyDgbRZGKenmeE2HXdbPZbDlfDIdDwdXJycl4PFYqvnj5ymNPPF43XdO2XIj5YhHHqVASGAbkCkSh+XZT6Qt0tLfu5Ojw0LtrV69du3J5NOjfvf8gDN3Gk/2cnyciT54hIyAO6IGCyfv55P5GDVZRFKvVijGhlGpbDQBCcOecUiIkT0dx3LUteR+sHLrOFkVRVdXb3/5OzvnLL7/cdd073/WurjN1Xc9W5XJVta2+devWt//23/Hdf/SPPfPU0//6J/9fn/jELyaRnJzN/oe/8wNPPfnMf/Knv+eFl764lfd++zd802PXHgNiL7z0YqNNpdva6qrpjo6OxoNBsyyHvUIb81/9d3/l6N5rf+nP/2dHt15H5xYPDrIiX+qzZ69f+2t/4X//y5/9zA/8o3+UDHrvfvadh8tpstWvOLvblm/d6oMh2ywZY0TeIzRdixyBAAE9AgkMmIARIDBrLVnLiMVxKpmYrpq7q5l6+rH//O9+Pzy2NzO1zlOnaZz3bN16RwzAmK7SLSElScK8A08eHAIScjiHcQHuruU5CAjIwK21zgQeH0aOcPJ47hHJODGOyIgBAmNIeB5kzIA8BIF5MBqlc2C10U5T8AKCzSn/imXTP9QMoWeMeYYepWbRtKIjyN77B/8wvPMDxAvMEtsBF2s0GLABkkWHwGRIpQkSmHWR5t/XgQAEzIFhYBEZkAPPOIIGkK7F1Jl/+xM3f+Kfv70vMwbWeg/MMhYpAK87ZyKM0SHIFMCBIy8ZCC6IkSUPDJG8teQ9P88VdtZwLuBRHgs9UIB5COiDjyx6CN0D8NCJcxMi+YibA8e1WIo5xlgIS2bEADhYB0ppb7E3ePHoTF648a4/9ifg0luA5VAw2xoRrQ3GjDWSS4C1vuuRsfdvsAH7/+3wHoRgaZrO53PnXDjF3offKcgbay14JxgCC/k5zBM57wBAMoaM0Hegqys7/c/+23/9pV/6hcujYQLerOa6aleLZbG9f7I6K+KICxkLLsZDNRpo3bXgyrYxxmrdMcaGw+F0Ot3a2oqiqEiKV1995YMf/Yj3nq/NOR0XDweAEzBcB4+v+0sZgMrg2fcs/vUPb5lOSsm9BwFJnCJjkGbAEyr94fFs923v+obv+V5ItyApjqvFwfTYXLougPpF72Q+t97lMm/KyngXx3HbdQAglAxq9039gYi8dci59966dQhmSBYuyxLPteqBlmJMINJgMAhrU8BeAVd575USgXMKApJN42GQpmxorVCi9URZloWaoDs/AIAQziVWYSdGD39qTYYxt87hIedA61a8933vj+O46tp5uQp64X5/2FlTlU2cJjs7ewRgjDk+PqnrumpqAGpfvSM4B2eHw2GWpjv71/Ii3d3d3d3d9d5qa4IQzBM1TaetXy7LruvKs/rV1w+7rvPWBk5Limg2nRpjIpUEabYHCl1mi8WcibVNkbU+juM8SRezSspob2dLaw3glRAOSCheNnVrTKQSoWIA5ix12iyXSwBYKwoZVQfVzs4WeHrppZck4yFx2XamahpnjAeGiN4DEa1LXcSMMdq0p6fHiGSt5YIVeU9FUnExHvR3dnZ2d3f39/eHw2FepL1eb9Drp2lalkvGQTDurHYerTet8x48Od8ZLRgXSgqOnsg7x1B1ulkbyIZ6PFEkVS/vdV3X1VU/70VR1LZtvSpX0zmXQjvLGJi2q+u6KArrHQJlaRK65xgKCJECzkwXsyiKEIGQK6lCflGSZeBxOp9d3bqMiIxzb50SqbcOGeOMwt1knRZceA/OeSkia8zB/Qd1udrqD2MphFDW+iiJX3/9deeZAFXVbZxk/V6+vb3dzzNEFDIkDJBzzoFzXoNdm3ySd/1eMZtOxuNhHCsZS2SkTTsY9QHg7t27k8mkrbsrl64WRb+qGkeL49NJ2Jo4gvli5RFeuvnK8fEpcIGMAJmIY2utTGKjW2SMrFvvjxkLlDtH8NaEfi1EuHvn9Xt3XkcEENKdKxk3dBesZY9EhN47DL3hSJYcIoN1ww+dvxgRsWk14zJoCxhH771xmjMWQp2BqGtbjsGZMvwUOzk9m5zNjIU8z5GJnd3x4fHk+pNP3759++hs2jVNf7x1MJn+9e//m70i+9aPffNv/Z2/8/0f+FCeJUrFV596+id/+IfTJFHa3P/8i++5/mRdNyqJv/2bvvFLN18+Ppv0t0bLqv60bYkII340ub832P1D/+EfWZSLX/jcr7znxtNtWfWHBXiXC6yqRevpw+955wfe97f/2Q//6M9/5lOKK+6iCvwsFceS7fVTu1xkHBEIBUQoUDshhCXSAI4xAOCOOBEYXfR6K1N5KWyW3J7Obq2m3/xdf/Ctf/5PA5plo1vBGYmYM61b4M6zMKW5REoAD8YgIMOHsTaegIVAZQTia3Ptc5YRg9N0KGwgA/RrdAXOEyCAY9widEAKETkgMH5eHlQA5woeButYm/AusCFRHpVaB/N3fAP8AgSlfFWxSIFgQJYZn+Sjo07cYdnXfNcfh3d/CGRsvEoZCuHXDksoaNMwKM6X8Icw7qGV6m8g0HpUubQ5ENbrpgEeGDWBAMyD7hJmoJm4n//x5/7FDz5TqCxVrtIIjJyPpDDWIwDj0oFnkjG04AlUTADgUNLaAJwIOXDrfRAVeG9R4JoXPi/uEXkCAvA+3KkIEhgSraNPyWuGiCitBwBIBFmPzgEyMBqYAC7BOWc6HqW2s8hiiFLw1tmSJJPDwadeP8zf9oG3/sd/Hnr7miIuGRCISG7Oo5TnFWM8TwUKD7/CHPVN4/mVeHs9pA93p2tWLdzynLPt7e2XXnopywcOqG21kApZ1OpOMIzj2HUN+LVfgCcGKNuuihPBJS6mx6NRcnE8+oV//kOru68+vdWTaLyDKM8fVPrO0cn1/et5MaTWlN1CJBGXjEeKC0qZzLLEARZFcffevdlsZq2bzWaDwagoirPTycmDg52LF5q2i+JICh4IYc48OADLEIFL5gE8aA6COQZMwOCKeur9k5d+bj9XnnW2Md6iAVLbquy6/iB//Ld/J/AIDu+a7kBceXp46drHvvHbpBM//S//1cHkJO0V/bQPDBlj4NaRgggAnoxrrV1b/wcNEwBYTxwZcuGMNdoIxuM0k1wE/0/vvbWGyDEmhGBFkcdxvFqtiFySpAGrCSGCU2iappzz8FOhrwQ5s54EQ85C8DZyxoCTtgbO7eCDnGtTHwy+MaHzILx5yNIFAEQMHE3Y2AsRiyTPFotFcKFAxGLQ51JGnAFyRFyuVmVZ123XdZ2M4pwLY7pHWJOybY3urJqtnn/+JuNAAEkaSRE1bdV0nbWecdW2baAHvHecc85YsDDgnKOnXq8X3FqjSAKAdlopxZVMkiRJY8650VZKyRGLXlZXbVWtiqII5q1McGNclhYA0Lb6zp173nuBQkqp9do4XikK5ee21U1VSs7qrgSAYESexpEsiiBLCtssa62zxAUqGXOB2fvetb2zNRqNBoPezs5Or9eTjCOjPM8RiTHhvbXatF2tO1vVCyWFc1brdnMCnHOebJIkuYqcI+c6S0xKyRnXuuUc2aaFyDNrbdc1bVsbrY0x1aquqqrruhAtHsfxaGtcVStEsSn6ciEQeVVVzjnw5L0XjCnJExVxKYQQhB4AnLNaG+ecs9g0TW/QZ4I/Mgvwcw8YT+A2lrgAQN4LKV955ZVgMRD6VIPU6Ww2DcoRzmWSxGmaKiUAwHnjNQSKMZBIzq2hW5JkgayO0ySTWaObKE2qqqqbpuu66XQ6n88/8YlffP75F0aj0fHhCWPi2tUbd+/elSJyluazZbCx+IVf+KQxxrRtnGWMi6ZpnLVRHIV6pUVE79CtRaOwXh5DZupauoOhQCIE+oeiBzp3qHPOsIczrAdguA4328ywFABxeOzgPOXjvAYP55wI0htWtgAOojjmnNdVc3h4OB5vDYdDGUVt29586eU0Td/3nvd0Xffyiy/1e8XOcEwIf/cf/P2f/8Wfv3LxyoW9XbIk/82/uXHjxqd/6ZPKW621krJX5KeTyS+99lrZNXm/tzg5XVbl0zduLJdLvisnk17XGR6Jq3vXP/vC85fHOxfTHmjtjVFKtp0TxpazmUiy/93HP/7kU0//7X/4g41fjK/tH3fLfqy2Bz2xqLqyShCdsei9QAbWMSmYs51u4zjOubJVI3lUL0pSUTQe/8/PPTd45sk/90//OVy/BNAuASrGEAQSwjmz79cY52HcDb6RRuDwJqDhAGBDVp2LlsCvuwODRJcAMMRCIzEOAkACOEAeBM0IwByFFg5C8Og5nBNHb1pVNycunPtwOZ1XEgCYaVuZZa6r0TsmBElxb1GeyvHX/NE/BU++B1S/BogYcA/gOwAAHrlHlu5H2LGHnPEbF+7fMBLlqwKCIOdGFA5EbepMKg4t2AVQN/mxf/alH/+hD17f583CzWY8Hei65hwBfdDocAAAIgj5byxEa2Ow+gyfjoi8Q09r91WPDhwLoumNwB0hVAoZgEcGhJ6AAQJDQAIeAjwJJAeiuiy54pzAd63q9ZrFAiVFUnHiUDeiGLplBVJY3bBI1JzfenCy+76vu/YH/iPo7Wo1MABAINaNKm8anc2XNzzzaxy/Gsb6VQYfiaDf78fpOmpCRgoInbcQXMWRutbazsaQSZVqy4AoiaJMClNP93uZIv3//pF/wU+O+uRia8h11pPnPFbs6OjoScZM1zIyipG3nSOwHMg5xz0iIGNat4Nzh8uyLIfDcZokJ8699tqtnYsXpOSIYD2xNb/rAQmIAQEnsAgcEMAyUMAYpMPRM+86femT5CyoWLdNkfWSb/omuHgh/rlPvPbil2/cfPnunQcv3T956gPfdO1dX6MAa2O8Yzeeehupl4/PjidnJ1mWpVnGADjDJMmNMc5aYzrrnZSSrRW9LCiogIFiIsozOF9StTVB+RqcsbxH770xrq7rIArafGWMbfzfu86FB1JKgYKIlIoXq5Vv2yiKAnWWJEkwcgq7gqA53mCmrgsmuoIx5b211oZmstCedf6ygK4QkYsHB0dN0yRJ4gmddVC31tZCiOl0zjlnXNZ1bZznnCMPFqNWSpnmqTTGWtMsl1prxLW1vFKqrmsUMkmiKEriGKezZRynSRI554Inh2BcyUgI0bYtMsj7vTzPQ30aEaM0iZMEAQKECl6dgRK7du1aGiVlWYYi62w2O5lMjbPlqq7ruij6iUqcc13TKaWUUELwAHKNMYLJfjEY9geCUTB1DX4VvV5vNNpK05SI+v1+v99XSgkhsyzN8yKKlBBr26e2qwMc1qZ1zjijrdPWeAJnjHHOCiHjONK6s057B4yDlFIqaS0Gv4Yoks4Z7y0REjmllNZtEMpBAOzOMcYEV6H9IUmSXq8XznFwqEfEyWRSVZUj5Ex676WKQ4rROpBbqbquTWeN86brwGoAaLraWk9ESkWc87ruuq7b3t4O93wg4dfuemurvXX3CiIwxnRrpJQ3b95cn6AoCn3ydVOW5TKKknDlhSyIUGtz3gjBAdbVGHaOaxhjbdtKKbU10inrXUD288WCCAHY88+/cHJy8uKLL04mEyVjhsKRmUym1noAtr09ruv6zp07g8HAG51GESNvdBcmeMm518bzwNlyKSMShIjgPIFhjIWQLyAgb0OYhgN0xhHAxvb3oQTgkfKiJzrvZoNzvPRwjd0YIz10TzoHWGEaRr7pBnJABECE0HU14xwQrNWTyWnXtVmWbg+HUPTqsvKrum1WF3e2FotZtWKnx3We55/7wmcPDg7A2X4xIOdC3lSnG912w7y3NRo1Xe0V3x7u3r9/v24aJrhtuhvXrk2n8yeffJIIb9++vT18V9Pq09PTnUspOquiGIiYI4FMIDZleXx8+rEPfzSW6q9//9+sYjm8vnOqu3ttfSFO0sZE3gvnhEKP0HmtreZS9IDbqtaOMpXEIq8FvLY4++K9z/22P/cfv+M//VOAtiZbaecZlyDXBoZAiMCQWbJ0PmiPft3UXn+V46E75vnjR4EICwof8BJsDqaAKAXSAM6hs0wDUKgPEaBHRsAsMQUcCfzaZ+ERGRaeW1qH37gRAwE4JBcpAzbKY2M65nmjsteq9qN//I/A02+DuNd1XjDGGYAzgBwYwmYJe/PBHvksv/HHV4cCwbq9dVxyLgFkaslw0MC747/3N2e/8gsf3NuXyw60gGzLlgtkxH1QpJ3rFB9K0R0gfhU4yBU6TQ6QATIumADn6TwCAQLAOq/uIjBA7ixwImDQoAUg5RizFjoLUqR5b7WYFVkPeLpa1cVwCzIOs6lurEoKKGc8IrM6lINRaeSdCsbv+U1XvvtPQTZ2yJ3rJI/4eRbir/P41S7DN7VAvPH5r8TEGPyct7a2kiSx1hJDwYW1NubU2toZYFIIJR2y4M4sBCPtJQNaLrYEXsyzH/t//tPy4PXdmBVpFDNvgXHmtTOjLL09nVK3Als500ohOtM4h8i8A5Qscc5xxKZpiqJf1PVyuVqtVt7bKJJRFN28efNrP/yRcLUzWruHhHr1JqBWAQCA9W5dy+Zs8MxbpvmwNlPbuf5b3gb1En7m36ycnCz1SsPnf+VL0nbP7u2//tJnz37QvOcPfE8ajYGJ8e7ulcf3T0+Pbt++c+/evflsKpQMub2c82APHpzUnffWOSLbK4pQ6XPWdNZA2M06xzlnnIf9K2MiuDkgYtPVzHJHHhAC+glr1iOidQ/gvPdda7TWMopVkKMrtW4k9FQuV2s/0vOk57B4SSmrqgmX7uYINcrz3MN1MWpTExdXr14PTl+co3MU0gqdc/v7+4DIubTkyQNyFlRZAf31+33nXFtXVVUJxowxQsg0TXZ2dp2znbFZngaZ83hr1z+yp/He67YLkvCdnZ08zzvd9vNiOp0aY5I808ZoY5q6DgAoNKaF9e9LX/qS7XTbtrPZDBGLopBSARNxmsRxrHVrjeGcG6Pn81non1SRKHrFeDAcbo33trcIXFkuCFysEhVL09mmq/M0G29vjYejrMizJA8aqbVSSrfGUlnN6VyMaa1GxEgpbVoA4gIBOAAxFpzKnJQCGTdgiCjkqTDGg+981/nFYhFMUABgNBrled7r9fI87/f7WZYVWSZUBMACPV4t10dZlpPJ5ORkgohSRpzzSMq2bUOrZhifIPwPcn7wb1Bk93q9JMk4596TEKLfw5CK+KaZInwHsN6Ebj4y5/zk5GQ2m+3v74dulCC0WiwWSkohhGAoBOMCA7oCFqrYjCgM5Fo/zoQQQnAugyTQObeqaimlkHI+nwfnC++hLMubN28GTFkUBTD03odeP6XU4eFh6BO5fPmyd+7s7KyuqvWljEzbznuLgguhNu5zjixjfpP8SM4H1O3IggMINBeuI0IZY/RIs+5mpfd+LfLx5B9d/vGR2fpNUs1NlzUicrYeDeccPZya10Ih58xisbh79+48nyWC66a9+dKXkjwbjQYqjjynC1cv3r17Nxv2J8upZLw2nRCiqeo8zzujy+Xi9YMDicCMHxbF2599dnd39+WXX87yfDTok/NJkpyenuZ578knn3zx5Zun9+4vHhw/9Sf/tOQCGKO25cgkgraOIQ6L9OUvfv6D73rPH/r2b/+//bMf7D+2XzJ2Rna7n+qqXi3LiIA5arxmSkrv0PhURpAI42zD5O3F7Pbk7Jnf9OG/+Bf/LLz1Mdut5oJqQKUUJ84BmT/PgmQYnKe+2vr1v/lYjzkG1fq5XJqhA3LrpYI8cwCW0AFaAERiHgQEngQ4gUD0HjpgoYK38cRCZGStR0ZADBkBhK+BZiFjTBSlHcklibtz99Hv+V54y3sBE4tMxWzNZAoJ5MF7+Oo2c/9/ONZMnCWIOHUWhUAC1pXAVnd+6O9Pf+mn37U71tMZJCmghEqLLAWvwZn1qhs+GFtbJMBDkdwbj/PSCbg12wXBUIEzAE4IjBwAQx+SplFyQUCIREiWMURCD8wTZClYA8YUaQ+INU2b5r3lctnjSds08XjPlZVHLQWTvaTm9NKsvvrhb9v5Q38aogGwBJiMgf1qpNOvgbf+V6HYV/aVfuU4h5cFpwYlZKcdY8J7D84KjgKs8+QJuIwk94648x6JJPO+rnZStRWJH/3BHzCLswt5oljnndHkiRF5aLuKJVKCXp0d9uNcN2U8HGlNjrw2DpgQFId6bKh2ZVmWpqkxpqoqpdRwMDg8PTk7OekPh4Qogo87rmO/MZxWWtOrArgHcAjkSIy3x9eeXL306ULy+sWXDdUWBU+3eZxfunatlxdwdix7hWnbrWeeBKXAkfFuXq8WVZVn8r3ve+e73v3s4eHha6++fjI5DUknCExKiUKC80Seo2Cczedzfo6eQqN9qNOt1xTGGGMh4S0QS8jXveSICB4DAELEwGZtYg03sImcZ4KT81VVOWM3rWx0Hk0I5zKvQGGE2ETvbZhw1r3/nAe4Ao9M+4HNEnv7F5ummc/nxllyQIRbWztCiKbVZVm2beeIrPXAEMF6BERazecBhDHA0LRVVdV4MGzbrqzbOFZ53uv3i4AKy7rZxJUYY5bL5WqxDDgggBWt9dWrVxGxbjuYL8q6AoCuaeu6BqQNBQfg67oeDAYXL168dOkCY6woiiRJJrN5SBouimKwMzLGsO1h+Njj8TjIpHp5LpTsmnY6myi1LwRzxpf1igEv+nmeZciYdw7Jt83KWEveI2Oh82U46neddc6H4G7OkDGG4ARHInDOAoCSnMfB1qsBxzjnkqMxtq2b8zxKt729XRTF7vbW9vZ2nudCiOF4C84nKm9N27bLsq6q08n5EVhKREyShDGmkjjPel2nnXPT6cwYE6eJEHI2m7dtOx6PicB7UioSjAfgJQTXWku5Nhcpy8oYozsfMp7ePDucqyLCDiy0sTDGuGCvvfYaAHDOpeShhgjol8t5kkQAGCkVR1EkFXpy2hAHxrBpGsbhHJXagMxkFA0GiXG2rbs8z+fzeQD3h4eHhPDlW698/nPPv/jii6fHkxs3bgghl8tVb9Dr9/uBHz07mxnjRoMh5xzQr1Zl19RK8CiKyqp0tkMI/TIAYIUQQIiIhBwYMaHCpe+9ByGJG2MMOSME936dq7DGQ2t0xTcFqI3YiiEjcmvBxhthFp0DrHBfMcYYZ4JLay0xjghrgTZhkKAIyRHReOucRsY44tnk5OjwgeTq0qVLV5563BPduXubCbG1s12dTfZuXLXWfvmzdwVjURQtZnMkCBuVWHCwfn8wet873mXr+hd+7hOTk9OdnR1wxLlYLpciTop+v6pWL700u3716o/9+I88D/zp64//wd/57dPDo1G/n8Sx0Hp6cpT0+8a5Qa+499or3/bN3/Tq0b3Pzg7yfrJSYPKkKyNTL/qInhxPYlO3fRlHIKtlZZWccv+lyT1x7bE/+rf+evSRrwHm57MzOehJZIlfm3yiI/ROEhAng2ABNz3Tj1JWvwZ9FbYxiGs3v4cbCQpfgyg6zKoM0Lu4tUkFMYKzDLxHLwkYCLQePA8CegeckWCEQIiSeX5uZ40Pf6vzDhGCiG79FZGB59r2hYIG6k6+zvMP/Zn/Aq69DVwKcSzAElgHDFAyACRmPQr6tWtP/+6drx4eoVJuALCTjLxWvuKsuvcD//3pL/+bZy8NqvmRjCNHmkmOyKhrMFp37yORB8IgZGcADMGF592GkUICAOY9MKlAyhB+S0BCcK7kGniFc7eu7zIiQlh3NCCDiDNE5ORBRsZZmaTQarAesgxd3VVlkeft2TQebLVWtxEUUdGSb1n2wqS++ts+vvPtfxjiHYIcHXA6H136dzLGvx5KDBGEwCRJmnYVMa6dZxy0bqVgErkldIREHIARQ9tUAuHiXuHmp//ih/55e3Z4bWvAbEvCrUwdC+m9JYZeAECXJnh6cPvxd77/ZNUyBkIyJCIyjJDIMSallA6hqqokTfv93unp6WI2397dSZIEPX32M5/+xm/9lmCSsPkcHoCHwO81TewReVDsWeKCRf23vvPw+U/t5Tl0rY2iBaFR6sqHPwbPvAtkDKsF3Hz5ar8P7/waIIJENpWudF0kRGAXi2nXdcNh/zd/w0fquj06PHnw4MF0Oi/LChCViOI04Vwa0ynJQ0tgqEQBOaVUmkSz+TIoVZRSHrDrOmOs9U4I5pyz1jMWkh9QcMU5lxLbtnXGcmREzHnPOAjOI5U0XeuMRYYBz2xQVEBm51ZbAnH9vwB+05+49n/xPkkSIgrAKxxr+de9ewdRpIxxUipHdrlcOkvW2mBc1GoTRZEjYIx5CGgRm6ZhAEQUq4hobcYavE2dc2VZaz1/8OCB1tpa64G6rmuaBmDdTj8ejnZ2doJbUlFkjLHpdLrR3yTkvfeSizRLQnzSYDBIkmhvby/PU+99Va9M283n87OzM+fcM09dD3nASqlebxAaDMN6yZEFVFdVK8GZ6kVZvm+09t5KGV3NLgJAcFuQUnAehdWXsYCvWEDBi/kZAXDOiRhnLE0kY0GI5qXkSkWByzRGt62u67KBdeFWCDEaDYfDYTDeTNM0zYvzq5eaqlrOZ4vF8vj4mDNpra3rumoba60xzpjOGJemaRynWrfGuJDTtFyUiCLLsjhO0zRs2LHf7z/22GMBwoalHQk2PRQErml0VbdKKSllmqbWwNWrVzcE1Ztmh8269Wid6/bt21EUSSmzLNtcVaE5DgA4R6VEiJ60zqIFxhigJ/MwcmvtccJY0zTIWdM0/eFwPp+fnk0uXrrinBuNRkqpQE/u7++3bZtlYjQanc3OpJTBTPX+/fvD4VBwkabp9Ow08HkBvcF5OTLU2C2h954H0kzIgCYDRmJMIBOMSy6ssZ1t61A6pEeMdhDx3OH9EWXMmugKBgKhoEqPMoUb0gsAwm8VQtgGGKIHD4gsOLp6DwDWuM2bkvfWdwicC2G8u3339ZVuoywa7e+naay1/fwXn79eXr9///4TNx67cunyzRdvMi6ttdr5JMuvX7uyN9ryVZv1e1/3W76RWfvpX/mVn/mZnxnv7hT9XlnXD46PjyanURTt7+9f2L/0sY9888/+/P/yN//BD7z/ve99y/XHyqPjPEl102ZJyqV03C5WcwC2XM5/52/7FvH8p47nx2eT1w8FFKPcV0tTaU7U1jqNs84xJ+QySr94cFc+ceFj//mfeeo7vxPSpK5LiKXLMyGitqqVUi7E8+JazEScCMmRRSZDug7+utao8+IdrUUtj1zD56j3nC/xQSkrrFfGS43kEDYSLARP4JFhEB4aRj50sXGy4AnAISLQw7PPKYiFwh8QKF5LAEIqMGyqaa7GH/qe74XLT0E01p4UgOtKUMwh98AFMI4g5G8MXff/xfHohRoORAT0XlDb1kIpxTzo6uX/4W+wFz/1jlGK7dKjV/28mS6SNNd1peLI1SseCwiODnBuBI+IgEFmRWuNN2FwNSPPlCTn0Wqg0M4pgSFY673d/D3njZoeEZytORfggRworhyRBkDJOyHvPji8no9ZkoPWca9ndeuNjrNhu1xRqphic+s7Fr1y0rz1Wz6+9Xu/C9R42fE0BoFQzXQ2VM4B/w1iEL9yPP/XXr+2ZxuPx0cnp8HTHBGJceLcWOcdIpcCwDknnEkALo3y2f3XfuKH/vGI+7dd3Z3duzvsZ63VgqGUUncAQEUSa089JWcnR8JbsLbrOqYi8sY547zhQJEQjHPFsK5bIgpC77IsL1y4QOSKonj++ee/8WPfxLn0jxB8axS62XXj+u5hCFJI0AJuPG16o66ZRRyElOOtsWU57BTw4mcOvvSKmi1ny1rvXbio1eBrPgbeqUT1BplrZmXZci6jODJGHxw8EELu7G5dunSpLMv5fHl4eHTv3r3ZtIqjlDE22upXTVMuS+sprEHGmLIspYw2gg44t1HgnHvvvPdtqze7L8Gkcy5oc5H8Zj0KPJjuLCKuM545cOAeqG3bUBDcCI4DwLLWVlUF50XARyefczXYQ/+t8CcJD+xsNj87OzPGKCG6rg08xxrBcSllhI4YY9pZ7z1HzJJECOG9lyLSWkshkiTrus4jOzubNU0ToFXAK0WRcWT9ojcej/f396MoCmr6e/fu1XXNOWZZFrwbrLVxHEdRJIRQkUTELMuInJScMZidnTaViqKo3y+Gly4GG/HtnS1EqlZlMCwg36yWi/nMAQDn3GittQ4rZVEUzpH3nhxFSjGEarUMnCESNdUqDFAYOwZAzmnTOCAhGCIGI3xvLHhrjW3bijHWNa5tu7ZtiCBNk9FofOnC7nA4LIqi3x8kSbIJwLC6a9v29Pg4gMjValWWZUg7BhLB/pSIWqOJiDMZRQmgtc7VTVfXlTEuSZJefyiEiKOMzt3Ygglq27Z11RprACB0oq7LUpwBgGBCKRVkVXXdOGOlSvf29jYAKzTrIG4ePKRnwuPZdPrgwYNgp75hX8uyDL9dMpSMS8bRkyUbLLUQUSoeroHNjyBw56iqKhkpJqQxtqoqzvnh4eGqqr/4wssHBweHh8dKxatVOZ1O9/b2qqrK87yX90ILYb/oz+fzi1cudl13cGCSNPFAVVO3TQ0AHn3oBwxJHx4AuGcQ2kJVUKFZFySlSgjFghGo7jaTCZFjjAWFX7n25sDzd3x4bEqHX7m6h+PRgWIh5Ov8dRCgp6dIqa7V4AkZMYbOBbEwAucg+GQxG6stXzWDwcB1zQff94G2qreeetvsbPri519YzVdZlnnuOfDH3/LkE088Yet6NZkeTE7+xx/7kbc+9fR3/8k/+b1/9a/8q3/1r6Ik7Yyx3n3yl39JKfXEY09ee+zxD37wQ7PV8jOf++R/+wN/57/9K3+t8y7yDgUfFsNJuaitzYaZsf54eXJ4evKx97zn5muvfH45O51NLxTjfp7oWRmT2NvaP10t7zXdg+aM725/w1/5z5/8/d8O271V2y6bBQLEToJH5lEi5yjIO+DMMm+Cto8jeuJO4FdkO27A61ddqPC8BkhrYTScN+QhInogHhSFQEQEzDvmHfNr2sgRAIIP3utBTmIBaW1FJTwQgld8c9IfWT5ZePKhMAvXFvDGLjF9IIpn/9T3wtaToLYbTSrlAJZLCWtlC1gAb0CJh2Kuf8/HG4ramycBiDMVgaAGZienf+e/H91+YcBqmRZ+6ZNs0JxMokRpu1KJgK7jcQpeI1uL3MPbratIsBFjwSMJg4xIG+/J2XBrCBTe+a7rkij6yr8HEKzRPGLWerIokXMPS7Q6jff+s/8k/8VPzv+nnx40NTAA1CLm3mq3auI00nUlerlX+a3D8mu/409EH/t20BGoJOFEFjxAOlYtnHtm/caN55v2V/AVyvfNVcwAtCMp8cKFC5/6zHNpmnIU1gNTSeu9ccC8SHnMnWPWJwxGkZp86YWf/OF/+sTOoEBnDg8eGw7m81ksuGICa2ReOeckMLI2Z2xVN9VspmSvakwvK5xnHq3ptCRaexYAheJgpFQSx6tl2XUd57xXZIeHh6+99tqNJ59YV743Q0QA6GnNZiEQ8CCc4wCoYLy79ba3H336p67GYD2Iriub6eDnfqw8mxe1K6Cwq27r2tOitwNldefw9vbjT83mZ7uDjIMy2lVls8El0+mEAyfCYb+4uLf/zmefrev64ODw1Vdvffnlm0kW52mWRMpaU3WtUCrPM+c8AHjCrusYY1KIICZBZIgoJQ+iXzzPYWuqmjHGuAinLLTNBXujsLhrrT1AlmWMsaZpqqpCAiZ40FdtbLTCorYhqALBJKVsmupRSoJt7EZffvnlACyaplFcBLOiwWAAAJxzD4xzbqpmvVSQA8AQ0Ni2reCqrmt/Hq4UmKq9vb3t7W1rrVIqSaKg6auqSmt9cnJirZ7PlyF2puua8D5ZluVFlmfF5SuXLl28HCdRURQAnnO+WMwAgAt86vEnjOk451ww772QXJvuxRdfEJxCiG8URdY6FUljHHhSiiVxynnBGCvLUgggAiEUet62bWc6IViSxKGmy5h3zoaSXJIkURQROK0dWVfkxWyx6JqKiAKMS9NUKZVlqRCiKIpAsyVJEscxro1uQLfN2dlZVTZ1U66WVVktgdjZ9LRrzXkgDAiuxqOCiDvn2sZ4csiF4AwArfFKRWW5kpJnWYHIpBSMrSt9WtswOMaYfr+PiCcnJ6PxIKD7tm2JKI7jLEsRsa5Wga8Mq76UUqo4TdMNN0Nrb6E3PAhoPVyak8lksVhcu3Yt/FcA9cvlMvCl4VhruMFtJpqNB0mA/0TknXfGeKBFVfV6vYOjw2W56hWDF1++uVgsLl+6ev/+/cVikee5lHJ3dzeA49BhmsbJ3fv3oihK0zTLckRsmlZKKWQ0Go+bpqnqlXMO0J932zIf2ksAGOMGkXPpnPPOeaIQboqInLH+cOitCWVoIsrzfGdnZzwef/H55zd19M1Aee/Xsqk3MgFhv7Ip2IftjvfeOLfxroSN+J0AALpWC8kF422rAUgpQYTGOGActAHG5seTfpZOrPfGKjOIhEyjWOTFfL7cvXLFeue9n8xns8nZy6YzTVckacRZlsavH9z/a3/j//z4Y9evXrv205/4udbod73rXcAZ5/zV26/91L/+t0mSEIOtncuf/OIX/smP/fD3fPefOH7x5VGazidnSZ5GRXa8nK2aVsXRYFgs7h5c643kW97+6U/87KyuR/2Cli2h/NTrt8+sTm9c/60f/yM3vuN3wSgv23K2XFgp0mGBtfXGRVHUdR1yBowYMc+IEKz3Hkg6poBxDKJyeHQwAX51YuDNww6wqeNufooAEd0axwhgiYecWOHRMiQEBB4cfYIRgAfwwNzao8ELgAhIvGFtXP8+u9bRbFR3iMD4vdli1Sue/eN/AS4+CdEYGMoUW0cRR8YkAyLnGXcIDMWvXRz893S8YWMAYG0bMYDp8Zf/3t+SL37m+jABrmC+ZCzyBpLByJMFshSsSogDU555BnztEIbrjJt1WdCTAwqeVhzQI1jyPIm4kuCcaVtDJOMoTaOH88/mryIgBC4iKFJoPRoE2UPrWrA6TeGlVx68/KoUCnpDV854prxpmIwhYyCkyrLjqj0C/uH/4E/gR34XYAFJag1JuTbdCEHWHuy5Yvt/w3B91ec3N/t6JB8KBn7Vc+ytAym2x+OmqtuiTeKsM5oLTsiZENJz5oBaGzPYLbLl4e2f+B9/6G3XLw0iqCenSsjlqorjzDHuGa86o+IEjNHGe0IVp6rDclmlF3aXzvEo8RaRWTAu1LOtMZb8YFg0s1mkVJqmpyeTxWKxtbUVQgC/9KUvXb1xnYvN4LA1fYvg4dwkzjkARg4YA884U9nO29750ud/FooEtKnmrUj49PheShirFADGO9viqbfCrPyxn/p77/zWbwN0P/3T//btTz1x48ql/f0Lzrn5fN51OixMkYiC2eRieWaM6fV6b3/2LU8+cePLt145mUym06lzTZKlUdTz3mtrnfMhCqXt1kqpUAXasE2MMedoIwsJ0zIA1HVtrc6yTChFRCG+NuyHg5Q5vD7LMu99YGSNMdbatar7PHMl9MkFLslaC+A3lauNnJcxJjiXXVcrpfI8l4wDwPb2dtjER1HUGfP6669neRLHcfjjtNbGdIyJa9euheiY4XAopSyXqyRJiqIwxjCCxWKxWq1ms9nRgwOpeCBpwFsGNBr0EHuj0bjf721vb4f1rCiyKEpCR4DWbfB4VUqlWTyZTOq6JHLWdc4aJSOlpDUaEXd3tsA7Au+9B/JScIagpADnndEiinTbOOeSOCYiYw0wZrRB8EmkuMC2qUIwThwrxljXNkTEkIxum6buug4Ydt06HDugqMFgMBwOlVJplm2segCga5rj45P5fH42mQWU470HYFq31nrOsdcbpEmexBjOKCJzzs5mqyROjTGIPI4jEcXhziVyWrutrW3dWeeNd9B1WorIOSOltFaHfCXvnO46JbkUjJx3YBlAkWVN12rdCcG7rjO6RUQgliRJmqb37t1773u+Fh6prXD+8AGtW2wQzhVFnPPPfOYzeZ6z8xTMYKzatm04+wAQGi4Q0Xuy1haDnvf+zp07p6eniJim6TNPPpUkSddp4Ex3hjHRdQYQF/PVK6/eWi7L+/fvV03XHw0vXLgwHo9PTk4CDD06OiqXqzROdNvOp7Pv+I7f88orr6xW1e7udpxkvcFAW9tMOxTc2vV87ZzD9cfhSGCd0S3EcQTkOJJQsjVacJSCdV2HSJxzxlEIUde11tQ03euvv37//v3QorEJmQ4bhq7ruOTe+4fp0G9UYoXbeBMH6ZyTUrV1naSR995bh4iMgDNuwEopwZMQzDtvtOWMx4J74xKhOlNHxkPbonZFEtnJ2bKuVawuX71y6akb9w4Pdve2m651YHqDYVEUDSs5x7ZpkOCsqQDg1oO7vc9/LpioLX/xk+C86bSUUdTL016xrKvjanVpe/u/+YG/dWV793d++OtXh8cR8Igx5wmNiZWw6J3RoyTvqmY37v/eb/2OX/ypnzooy9fv3uacv+1DH/im3/7bdj72WyBPdd3WTe24RO8zoaDrBDDk6LwBwYihIUdEQc3MGRMEzAdX0jWe2ixmYSr81Rc28gAMKLQiBqPgDYuweeC9BfCIDCzO52x5DCZ1sZCrxTKKpJCsq1e5Up1uWcQbZ5iS1ltmPUeUZIVgwfouVAc2EzSRR0ZhQ9i2bRRFR12z2r/6df/Rn4Wdp0ENgInGauDEuWyBC+DCgWAApAGNcxwEOzd/onWgwrnYFh8ZhM3jTYvxVxVna22VEuvaUwhZxkBF+0c303C+2wl3dHjD89G0ERdwcO+Tf/u/sa98/l1Xt2erKWkUmICB1hufUNO14zhf1I2MBAFYjUJEzlpkyBnrtJZChHwCT8QZN9YiAOOcvAVGIHF6evrke94LVXXv5s2iKGzdkvdSysABBG2y994byznvmq7H4mWlI1DJZN5xfltXX/fH/mj9/Bee+9zNd/a3F/OGHHarWVwkzlmyHJU6mjd+9/Lbf9vvxvd+FKKeBQUEyJBc8OQAQIjA4Dom/M0iLH/unL6Z9950hGvAe/9ICDF/9JQ98sr1LHR+Zn1gRBB5nCgCiKLo0qVLSZIQAvecM+GRCY4CmTdmUCTKtp9/7pd/6Wd+8srFnWWz6mprrU+EAGBd2QkpiYNnyrUOgCGBkHFTm3mj8WR6/fITi2W5jYwA47ggz/I87xU9Y0zdtXVdp2nqiVQUbW2Pz6aT7e1t59yVq5deeulLv+VjvyX8lvWFxxkggPfAWSCNgQvwgAIsAHDJvORPv7NJdl89Ok2ICRGfLRdZP11ZPV9Nn3rnU59/4d5jN2+12c57Pvh1V9721oOzs2LQv/Xq7YN7B+Px+OLFi7s7W8NhEaouumsBwDmQUkYyMV171tRSyieeeOztb39bo7vXX3/91VdfPTk5EkLEcSyFstZ475012ppOc8aYs5qhJA9AjICCf2yQsmwkH+fTMyPEJMus1g830ozRubY92C5wIcLE8jBtBcBa2zRNeM1gMPDeaq2tpaqqyrJkjI3H4ziOrdNRFAljzGAwWC6XQUdljOl0c/fuXcbYpUuX7ty799RTT2VJLJT0Hp588vGLFy8GapFzXpb1bHZWliWA7+V9pUSSJOPxcGe8k+VJvzcUkkkprTW67eq2CUtanudFUTRN0+/3g+HnZDI5nRyGCzRYZGmtq6q6detWVa2uXLmilLh0+eJoMOz3i9BOnySJigRjTLcNAOPs3JzeevCeiDgXANi2XVmWWZYlSUIEWmvwYVLzxnjGWL/ft1af6+gh3DZKydHoYsitS/MspDkiF2vJs3Nd101OJ2dnk7OzaSiJNk3TtYaIoijx3lvrGQPOgy8DAPCjoxMAr1SMiM45xlgUJUmcd53JsmJtPgtB/kVEqBTXnd0kMXkHhkzIliZwADnjIIRgDDgXwXZW625tzepdgNhEFNKvEPh0Ol0uV0KI8Xj81ZauNx9hnK21IZM4LAbh60MbM8SAugJ5JhVnUjRNc3p6GpinwHVNp9NLly4TUVPXjMu6rRljt27deu5zn12tKq31tWvXnvvcF9797nc/9dRTzz333LVr1xaLhW51VVVvefrpIstePTpK4zgsG3EcP3bjqZ/61//WWeJcXrp85YUXvgiEPIqdMegdRxYG2QOGlVi3HRMixONsjXfm87m1WnEVzO5CMT6EuiOi7rT33lnLhUjTNJCsGx5O2w4A8Nz5dy3DWge5r70ewmNEVEKsyjLNstAhEcexMQY8C6qy5XK5DjRVSik1ny8lsgzB2/qJwXZPxauTszGJD731vZKzW7duCcUvjfYWuinrLi4rq9u337i2MKZzpu7q4agf8yzvZZFJX331VZWkJ6v5iA0sUTuf9fI+l8p5OJ5NMEusYCLPa6S8v/Vffd//6d1PvuXKzi6U1XQ6xZgPonTaVZzzYmtreTBXMkkwUhJ/z+/9zuc++6knP/iBD3zH74KrF0EK5/S0nlvPpEoUcgbSWeuRvLeBX0Lga/kzQwxtXB45ItJad+yBAb5Rrn6+pH21q5IDOB8yZAJ9Res1jQM6IABw4BAAGBIikLr0zo/o8YVBHDdVNUiiVbXEWLquqZFFkap0q5J4Ua4Gg4Fd1YJxq7323lodxzEi1lqHxTVscI3RjLESAAAcomX8A7/vO+HKM6ZTWhsRIXDHQXTQdZonQqEjAQDGguCeHGLEAMPuK03Tuq7DPE5EWuuwI0fEIKII91fTdHDecRLgctidb2bgjclLkiRN0272SxuBYDiC16KUMshSA7xLpNBl9Qs/+W9mk/mTT7zlpWoSZdu69v283zRVPiwoUdOzs9ILzIlFsjOtQ58kCTnvgSQXlIO3rm6bNE0IgSOz3iEBMATvCH2rG+rlr5wZraEdXq2UMsZEUgXAtxbLBhQrQuA6Pahdb/vyQgND0xvvlKvj7rB8Ze7Sa28rVVYuypgDIiyYIc4UV7Om5dfe+vbf/FvxPR8AjCZ12xskvnGCcY9gHTjmGXeA1juDDMiv40o3g0znwtOvPOI4Dg1iURR570NBSggRloy1o1Jg6L1HRGt9gPgb/6RQB5BSNE3nCY3R4O1sNouiSCq5WiyEkAQCGefoyrqeHLz+2ec/vffYZe9b57EyOhvtdI44j8haTabVHVOJs2tBY+sMchlng5JQEwJK8hglhamXRBglWZQm3dIIJZ2luq437ElIeBNCBGX27VuvvuXt79jsTgk9kCegcw+fhwa8hEAADiTn+WMf/dazL30+EqJZLftFbNFJpVJjjovh6P3XT9voLR/9erhweTVfDYfDrm4u7OzbppueLU5Pz2IVjcfDS5cube+MhciDb5fz1qNHgYI4CjSmW61WxPDq1as3btw4PT29/frdyWQSzJsIUSmVxrGMInJrP1spJXkMZwcAEDnnnAFuiINw9tcqpvMARMYYntdbwi2jtSZrAzERvq3r+hGxlw8lL85xQ5tdvHgxiqLQ1ccFdl2Hz77j66Io4gKNMZHgo9HIOt3v9x9//LFerxdFUd7vWWtHo5HRtqxWd+7cOT4+ns/ny+UyidPdvZ1+b3Dh4v7O9i4XLI0S52zbdqenJ3VZa90dHR90XeetS7J4NBoFbwIppdZ6sVjUda2UCOv3BuXUdb1YLJw3V69e3d3djaJof3/POQfkaK0RDs6ZzhgTiSiIaQBg0w4W3iRJktCxFcwt27YNur8AiTYqtsD77e3t9Hq90WjU6/WYlA83jM4B57Ztg3ZquVyezaar1cpZKqul7mzw/2SMBV04Y8I5pztD4BlyQGLIo1h1rWYc4ygJWCRgLMZYHKfB7ss55+AN0vKAjZxzTVMtl8uAZqy1iBBFcRxHUirOGTvf9TpnTHBpO9fxLRYLDtg0TZzmRVH0ev0LFy48++y7nbVMPLIDO5+F6VxLsSnzHR4e/pN/9I+3t7eVUkVRCMaUUlVVHR4eRlIhYpFmeZ5HkdRaW7ChN/D+gwdh8x3aRfd2d59+6i1a66Zr4zRflqvnnnvu1duvLRYLwZUD6rruxRdfFEIkSTYYDHpZPplMTKf39vaKJMvz/Auf/+J4PDaeyrL8yEc/+uyz7/gv/8pffuyxx6z3yOj4+PDOvbtRJCUXTVVZbZx3nDEhpDE6ICDO+O7urjHGWgcASZb28r71pu6atm3TNL127dp4PP7xH//xd7/jnQcHB/P5FADyPN/d3QWA2Wx2NpkYY0LGcKAZ4RwLhDkXzt1RwpkKJ2Iw2pnNZmW5RESnWwAQUnrvGVCe54LJ4B9xcnKys7N3enAvAhgivu3yjaf3Ll7PR2MQe1HRzudgPVOiIi3HvRNdvT47efnB68fORI/f2Hn8sQcPHgRH2yhSeZ4DY1laLBeLWzdv7e3sTg5PmYU8SsqmHu7vvnLndm80dNYsTk97xPZQFYb+wV///guDEXBWrxbRKD+cnS27yvNIkxSgoraLOQx2xjhMeh94FzBz2tYNOSQW80iBkAaFB+DQCGOQHAMkkB6YZzzYWzAkYIyAEeMheoMzj+SJNh6jv1o55tHDoyei4HWNwbANGCEgoiW/7h/0BOSQICKbFgzIQdNBpIAjGANJBN6DJ2ByfYMLDp0BJsFYkAIQwBgIzvJBmQjnJNL6W7/+FjlEmQUhwowEzJATGIfPxBmANYAAxgFjhjPPMEJudCuVctYyxrTWURwDQFjAwr5l8xXPj7DV2VxjYZMTtsQhXST8b/iRTX/TBraGZ7qu22C49e9iHAyB08Ba8DVwAPLgGBgDCkAw8ACdBS6D7gY2LZDGAOdr3iyMjzPA2bpgGwAWhUEjAIBgz805hBC38IBzIAbWAueP9DPzh37qtQHBIBHAERyAJ/AA1q81QmhBAUAHyIBn4IWTqQ3OqdpHXoQ/2XuwHBgHBI/gGPA3MVhhbDd9YfTG/p5fzxGg2KM/dT7I3loruAIAT379/gD/8l/+xP2Dw9B1ZLUGgKCR1V3D0I8GeaIoiXnXlkqg1Y5xVVfakRCCAevqthJC6c5yZOh8W9VKRJ6JuwfHUdI7PJ1euHBhPB4K0kqKXi/Pssw4a707OZ4kSbDFYm3T3LlzZ3tn58qVK8uyPDw92d7e/v1/4DuRGBAj4T2A9VYxsVaW0TpcwQanBgDhjfAtcAerKUQMHIGRIHOgCJBAtYAE2oHjwGJIsrJZ/MiP/EieFpGMVSQAwLRd29aeHCJdv359Z3vc7xcbpgC8ZUwgsI0uygFmWRYqJw8OjsJRVRUiJlmRJQkh+nXAs/HeKxUDQNcaY8y5vYIHgLBZ2mCszVZkLV3n681z+N+NoxWsW9RDqdEHnfoGWjVNY63t9fMkScqy1FoH1ZD4zu/8zvl83ukmiqKurvIivX79ujF6sVjs7e31er3bt19lTNy8efO11167c+dOL8uTJBoPhvv7uyHBt23b+Xz64MG9xWKxmi/C5iyOY86Y9/6Jx26kWdzr9bIs4xxb3dVl1XS1kCIv4ijmzrlO10Q0GAy2trYAQEq5t7cXvO3jWE0mU6PbjS9+mHAAQAiRprntrNHWOQdr+1QRRZEQLHQZOGO9d7PZrCwrAMjzLE3jOI57vd7Ozk6/3w8O6UmaAucQCGVyuunm8+lstqiqVdcZY7rZbDGfTxkTQgguRBQlaRopFXddZ60l4kQsOEqw0BcQRVLKzfZUCJEmWdu2XdeFT+GcU0qFU1jXtXOklIhU5Jyx1hMFZGUCF5KmaZaljHEheJqmnuzGwUFrrVuDeM6aeAqW7nEcj0aj/f39ve2dJEl6g1Ge58i4NebX8mw5nywCE8MYu337dhCzh8JzwPjBLXdzsUop27aN0sQ2Hhlruy7spwOKTZJkuSjLslRKxXE6mUye+9xnHxwcWeOLvN80zQsvvMA5v3jx4v3796W0WmtKaWtra3d7BxFPj0/PZjPOednUbauVjH/v7/59r96+fePq49PT2XDUv7h/mbS/89q94Xh04cKFpmlCfLLzRiD3oZGEC+/9yclJoCUuX74ipazrendvt+vaF2++HCrudV1//OMf/+Lnv1AURV2X4WNeuHChKIr79+83dW2Msd748wMe0Qxtaj1wXpHx3iPwUb+ntTZtE/bBKorOs04jKeVqURLRarX6lm/51u/7vu+78+otbuq+4C//0nOvffrzB/fvlZ1bGHaxP4xRXBjsPzg9dn6+m8it7Utv2dp7cXL0YlXf/fTn5qvl/v6+J6pnqxrPatN5wChO27q5f//g2pXrs5PJ9v5+e+/+q3de39m7sKqWeZpVOONCjHcvTl+78+f+0l/8x3/n7yohHVE5W6VCSSlPV2VLbG/c080kz/rI5GRVVvfuFDcudqkUPBWegSawxAVxD5YsJyBca2V5IJIAzkNmPCAnCt1U6+UU2cPLEd/YOvBVDzxfiQkeGnaeI4lwRohxCO08Duj0cGa6hoxFxA6RxaoympArxgXj3kOYeZlxiWdIsOxKlcRxHDvXOmcCnxSIikBzAkCWpcvlMoqiTjtUttZ1KqyxDcPYGop5wRFUBM425IxEyUmhVLUETc43TYjqqqpqZ2en6zo3nVZVlWaFcy6UIUL9MVDvoSJZVVUQ22ZZtoFWeK4RDuiqaZo0TYNycVN9C7dzAGRwXpqMoijEsYN1MfBO64Z5jDgZ7Y3JkqizhqXSey86J5ERt8541F7KqDMtE4wBCiW9dZ3RkgsPBOSCnxAhkPOOvGDcu/W5N8bFsQqSCaVi5xy5dZXQGMO55By9B++tNk4o7jnOlrOtrbEjOyuXRRJLDc5YrzhHIQwZRz5VmjRSpbUWaqjyXudOrNURg5QpXyEn5QA1WMcNco/g0ZO3a13Oo3frIxW99TP+vBEskFgAEGKJA4oNRaLQjhf2xmGvHlbc8OOcc0QyxjDgUkrjwjnqEPHBgwer5TJOM902RRTV1Up7yopcKD6vVyezBwBeSfTecQZcKGswSQttmVLCuDJNleIcIzEejJ2xUFjvSaG42ttC5MlgoLiIlOjqzvsuh6zVnYojKeJLV9MHDx5kcdJ1nVQqz/Ozs7Prj91AxNFodO/evenpyXhr33uDIAk8MrYGswQBlRKe67GIwKOFxCH3uUqgA8mBBPAULAAHIoXCQOIBBFAEBKY1ly9cburOOarKJiDaJMmcM57ciy++fJNjHKu9vb0nn3js4uXLum2Xy6XWJvRCKaUkF23blmUJAHt7e7u7u88888zJycm9e/em0+lZXXoP29vb/nxPElauIDILNTrOeVCEE9HmLvAhAZi8c86RD8aIATaF2z/YYsVxHFQi3ntcN9mEa9uE6yesKYGWhiBqV0r8y//pR3u9XiyV977Xyx8c6NnZ1BidJMlsOjk+Pu4Pe9b4xWKBiI9du6q7bnd/B4HPF9MXv/j8YjmTUZSm6fWrV598/Mb+/m6/35dcBLkXY8wb7b03VmutrTGCsdGgj3xkjMmyTEUi8Hjh6gy1GCnl5PT4XCKNSsVdU3PO00itSz9+Pc/qpk2STGvtvHUuZOg2gWfWrQmdhnmej8fDOE63trb29vY4Ry7ZQ81C2FUYo9v24ODg3t0H88U0KJ+AmJAMgTMO3sFgMBIy6rqu67q21dPpPNyojDEZSRnFSRaI4jUJSUSdXS/Gwjutu3BnpmmqoggAovO1NslTAPTekbXgHXpP5OLz5EutNZBnCFZb07nF8gwAmrIK1lBExFHkReq918Z47/M8v3rp4oULF6I0YYzFMuacd00zn06N81tbW3mmOOe/JlfgEdE5y5i4ffvVYGS/djRFQR51ZxmKIOMLJ66zLmEsz/OuM8Y4S6Cd185LqYioXJSOABhfLMs79+7P5ktr/XQ6X1ZlkiScy9AeEdLKGIPHH79xfHw8X87OJpOuNU3TNlW7s7Pjvb9+/fpgMH7m8ejy3qXZyXR6NLu0c/n6hWu9qDg6Omrm7WhvN04L5OrBvTvaAoAA8DKKghqxrMpe0Wua+tKlJ2azWRxHy+WiXq2effZZpdSdO3fqun73u9+9Wq36/f50Oj05Ofr0pz8dLraqrjnn3gEil0JutkHrYoG1jDFELoXYbICs7T732c+Ot7YE50A0Ho2jKDo4OMjzfDwc9fv96eSl5bIUQn7843/gyceefOaZpwAdePf+b/xmmC3K1+4c33z1iz//yZuf+0J9PO0tDjMZRUJwxkajURFF4/H1y04vyZ/NZ0enp2VT7xbF0fzs4OR+HRLX0oz1el/+8peruvnCSy8OBoNr164lSSyJGMD2YOS79tMvfOGJi5e+fHj0Z/7aX/qT3/VHr1+8iM601QoY5nHKmairVS9PtNfGECrcTnvlrBYMWSSQkffeCIactd661imQkQVGQACE3nDwLPgcEQBYWPdlMgJxHgH5KHH162AOGACts1UomASEOiHhOrQ5vA+F7cCirH/pFz9549KVyWQS5anMksl8lqa5bbpg6hx6NWzbJcCtNtmoqLtaCDGbzbz3vV7POZemKedBtIcB5czncyGErvQgGTsyTVzWXbmTX0hZrhswpvF85WwTISIoQ7HmQkvStutJFUoheZ7//M//LCJyLre3tzutwwYgoKWdnZ2zs1m/3w9dPqE+GGitYIijz48wf6ZpWlVVyBCDRzgVOteXGGNGo1GAAs65siyFEGCNrhZCqPGl66++dreIZdZL5napna5WbZ4WERPoPDoLHskLxhihT/IEnF/Vle10kmexkmezWZ6mXEpnzNonxftIcuuBi8RaH+ZShsI67SxtqpzWO+ccY5zIW+sAKI7k2dnp9taICay8Rg6DNG0WC976JElMJJdlJT1zgNFw0HQlBycccMe01p3vZCxJQNfogRo64x1Zz8lyR0TScg6cK+nPQ3wD0/yoYhJCa9c5t7FpLd9Qg6EVJrS6P1pnDPA3TDIAEATRcRSFXxS6PYioaXVIXbtwYS/Ji8XZhDuTX90HIcu20eSGbCAYj+OorWvJkCx57432aZqfnszuHx6kmXAAn/30Z1544QWhorOzWZoP6k5zQCllniVJpJ5+8vHf/PUfnZjaOuJSMMG7ruun6fvf//5/+I9+kHOupHTGZnk+Xyzm87lSCiTz5G7dujXevsAYs955AGR8bWhy3vvqwQOQgHX2BxFnBu6+fnbr5meKKMrFsFwZrjIQVHeHLPatN+PRDtfRcrYkZ+fLhUxSQ845D85yzgVHAvQE/eHIOVvX9cuv3Hr99bv90fDi3u7Ozs5wOGyapus627WhYShcObPpJAzyhf3dK5cvOudms9nR8emtW7cYY96DECKOYs553emm1f1B4b031nsgJpAxziVDDt5RcDtigOAfVtU3vCbnPFTYAtreZEg8OlOFC4kx5vy6NsU5D1v9tVvP3t7ebHYmJJuczU+OjoKqva5Lay3Rpcn0LCjLCGTTVMeHR9qawWDwvve/5+LF/b2LFwCArGMMuq6zzrSdJlBVabqu7eV5qNwhUhyrsFMxphOSW9faGry3nMtgsIbovCdjrDGdtbbf73vvu7rK8zzsvc7Dsde+tERUlsuQdSgky/O8P+j1er00TfpFL03TouhFSQLsnHS2FoQgY8rlsizLsiwXi8VkMlkul22jA+OSZVkURcwzImLIjDG2tYGFYoaMMUTBoCz23ksZxXFMDLtON7UJCcfhXvXeBzGdUkpKIaUI92cwVmjaqqpE01beQZrFQKxpK8lkv1/Ecdx1HSKEYnFZzkO8TLD4KgbDnZ2d8XAYhGWMMSQWxD2cc8b5RkxmySulqmXVNM1yubp9+/Z0vvjwhz/c641/9QAIYrheAxljy+VyMpmEWTtICrjggbQLeCuUt8KMU1VNmifL5bJqm+CItsEfoYViuSg///nPv/jSzel81nVdnudt2x4eHgaLr9Fo8M3f/M2BCj44OJhOp2dnZ9ba0AnSHw3ni1WSZAcHh5/4mU/8we/8D5556i2KyelkujpbXLl02SVOJ21UZOlouJ1E2/uXVk1rukbK3nIxa+oWOJdKEVHTNPfv39/Z2bl+/Xqru/l8PhiPA8e7tbU1m82ef/750Wi0vb39xBNPELl79+69+OKLs9ks4PXg6Ba2X5vajXcOgnUSYphwH1qnGNM2DQBcunRpa2sUCvlXr14dD0cvv/xyIDvbNrgMs9OjiSXtvCniNMvS/N3vyN/x7GO/7zug6eD+wexLN1974UvLk7OTO3dfPThynW6MbuNI9fO9LNu6cMUildZu93pf/6GPfPaVm8+99NJkOa1q3dveSrNCJmk4I7/8i79YRGnTVRxgb7z3bb/nd496xUe+9mufunylx6NPf/q5p65eY1HknIskd46cN5IrJErSeFUvdd0M9q5VVW2JeQ+e0FhjjBNKxllGrUMEJEBGljNg3gN5XJcBPYZNsCdgiA/zB990/Dp4LP6m1zDGPHkg5wEJPEPkggsOCppx6lI/f/v1Ud02ZX08HCqlbAONd5APRncPDvPeqFOYyaQqaxlJ42WWZaEwIYRYrVZRFCVJHNqU0jRljAWunTLXTprR7hh6vVVT9mRPkkQyjAsLMpJskPeBqcZj50kk0pjOd+14OApJX6vVam9vb3d333tf1bWUcn9/P+C5JEmqqnHOBd1JaLbIsuz09LQoinV7JuLx8XG/3w+Nz2GxX61WQYLNz+NE8dwgMcuy2WyWJAkieu/7/b6SXPKLZVmOd3baxu6M+/cO7gyHw2LQbxctEnpC8j7ijJxnqIQQhN6Tras2ZeDTpN/vF0WRFHkoT29scYgoTVPnPIFgKIwxrdG9LDfeLaazOEsZW8uH6Xx3HbCLVPzq9SuzwyPkrBiMz2ZnAsXu1r7wgJwtui5K/PZoS2sLnOVJ7KwWHqQlyYWMpGO+ccb2HUdpjLbeMAZMMoFKOA7AjHdwjjvhvFoUcHNYvIOgKkz4ITY4CFrCGIZLLshCgtI5zIFhDQqimrBOee+TOA53XJZli8XCWptmMBgMrCMiYpynaSrJMQ4OkXMeC8mFICIpVUtdpFKViKaq8yRijA2G+Z27zfTYXr9+lVlWTsv+VnxyOks6PJ3NjTF6NUN0jPzRg2c+8uGv9eAJQVtb9PuBs0El3/GOd/z8z37ixo0bobislLp///7jTz3pGt0bDF5+5ctf87UfBC7QOxb6QOm8BLxWknix3joBIPMAgkNR9E9OF1Nv+qoy2oNSret4pF1pLeCDe2fKyPFwhEj9fmEYi2UWai9NUzWtZhh0h10cq35/oG3WNe3pZLaYr+7cf5An8aWL+/v7+0IIrdfBd03ThICdsDMP9NJgMOj3+08/+dTZbHr37v2jo6PAWsk4ybJsU/5KkkSILIBm6x1ytqkOh1U71LQ3NYoN3xmwcoDjeN70EK6TAMrPE3F46IgKWhrx0Q99+Mtf/vKrr76ita7Kpff+ve99z2I5y5L0wt5uVuRE7umnn9zd3UXOhsMhR5bnefh4VVM3TbWcTZfLpZQyihUSSMnJEZBTgscqa5tSKZXEIRnROOuQCS6QIWvaCgCSJEaOTVsbbZGB7czR0eHe3n4URV1T9ft9b/ViOeMotNbOrjcfAJBlWX/Y27uwIyUvimI46kdxCus+ETi3SGPgtWl115nVarWYr05OTheLVaAZgdYRQpzzXm9g1odr29UGKed5LoRjgkspyUOkgn6Za2ettUCMkAMBAuecCc7bLshOvRAsjHXT1OvRj0ToDwAAznEwGqSZKop+nqdKxUQujdJeLw+088GDB9Zq51yWxv1+f29vryiKYti3zgouAUi3LXgK7RDeaKkUcAYAaLyxfjqd3jt40DSNbvR0Og3Ga6Ot7e3tbQBYLpdFv3d+z3zF8gYuKAZu377ddV2/GKw9M63lnM/n87bVURR55wO5hYiC86qqiOLRaPTg6FApFSgLY5wnTJPsZDJ96YUvffaznz0+mdRtm/d6B0fHR0fHaZo67sdbW71B//W7d0ynj4+Pu2adfmO066yL4/h0esaBW+uVUD/90z/99JPPfMNHv35+cqZXXVUuFbHJg6NBXvTGOz6LnOSjra1e/0unJ0fD8Y5K4snBAy6FaRvGOQAoJW/feR0Rh+PR8fHJzt5er9ebzWYAcOHChdPT0zv375m2I6Iokoyx3d3dCxcuBPAXANa6COjWZqHsvKVoM3HjuRtWv9dbzhfGmiceexw8NlW7NdrO02I2W0wmU2Odc9TPez//Mz/38Y//XhVniuWAqJ2utJa2bdoqT+JIMXZla/jsE+8x3wwAYAlmC1gs7r18s17OT46PbafLsj49OxsQWc4rYz784Q9/8Ot/8ye/8LnX7h+++NotTWsH65P799/22FNXd/ff8ezbf9Nv+ugTb3n68lsfBwZdV0dKgYF3j4qf/YmffPrqtasXLx0e3FcMkXvXLqMoYt4gUts2adsyxrz1SCxRUS5i40yrTUtGcakFegDPAXCdrs2D+hxAhtisIJJlwXqRB6EkPGIw9mtAq+C0D49sITd9/vCIhxYRAPMK9Wuf/Z/l9P7Z/WZwZX9xdH82P97Z25mUtWARV5lebO3G/enkrD/cm59N4mygu06gaMomLLS1q4Vg6KkpawDwxnFgnDGppJTSOtPYhmWMa650fFadgfDIQCSinhnvBCnJOPPcAbcJkwqZ6vfPTk/iNM3z/AMf+MDx8fFqtRBCpFmcpFGv15tMJvP5fDabRZEMextx3spU13W4E7uum0wmURRVVRVkVYFZD7gq7H+Cqp0xFhSiR0dHYeEPAC50b8yXrYrT49Pp0dnq2rVry6qUkRqxYnl/fuXK5eWqLLWttVNZanTDUBunBefGGMlVb7sIeznwGMlosph667TWG8U3A+acZQBKqYhzJI+2kQyHeSQiXteVlJIAPZFCYJJ13ndGI0bVaplz1dS19bCTbS3m06Sfes7X0hapnLUMiZpGMc6Vkomq67rqTI8lQAgdcSm1MiYCZwgs5TZOotQhdl1nvQvGRRvxzYavCpvG0METSiVhLQ8vDqqMwGkFC8OwuAZkFv4rSZLQwWCdrqqqa+vz/bYRghMhF7yuy1Yb732e9bIs03VV1Q0IzoQkzoz3Xd3p1sWyEFw2TaW19uCY5NlQ9kf52fEyzwaj0RYiDgYDmaQYRXHR16vF+NLlUS6Y686mh2enh0kxKMuyruvd3V0hRJwmpm3f+zVf80u/+MtN00jOhZJpns1ms/ARer3e4fHx/cODS5eucGRACB7AAcnwL7C1EM8HiAWIxKABGO31rl69Oj044NzFmarBgvc8ziIek8a9PKHOeOpqqLXTtkWlQo7IukgX8MpqtSIQziOgzPI45ww8IXOrVfX88y/cuvXapUuXdna2oiiKZaIGfa1127YAFEeKiKzRle6Md1JGO9vjC3v7ZVkeHp/cu3fv+HTStm1IG4niGABbbcKtIaUk8v6NRoYUlNCAHAVHBkHtHhgWxoJH6aOqu3UJTjLnYYO9AEBKGcexePFLX+j3+9tbTyDC5cuXx1vDLImFZIvFIo4V53y8Pa7LSluTZVnXtZ7xw6NFEOI4Z3uDvhR8NB7GKpJSIpKUsq4qInLWcB7qXD5k3QghGRPWO60NgAnmE977tiuDpEByKQR/+umnGeOh9jmbzaSIBFfOOWTC+w45u3rp0uNPPrE12ia0QpLzJnykqlwa0wXNQdM0AUg1dVcuq6qpddtpa70DpWLOJREhgYojb50x5vT0NMQVh5jqsLISkXPknEPOvPdt153XZVsmVdgLkg82SCLcjc5rrRvTdca5WCmhlORcKLW3s9MbDGKlhlvDXpZHaRRFsbVGCAlAXd1Mp9Ojo6ODw7uIGEUqT/M8H+3s7CRpxDh31tZ1rZvKOmcZCy4BSRSjlGBMuVr5arWYL48np4eHh5221trpdAoAcZxGUbK1tXX50pWdnR0uVLUqe/1+ELTjV8NYgSxUUt2/fz84NiohBGOOKDA9YZ8KnqSUHAERjbVxrPpF7/pjN1544YUQdBV2DEFq9txzn/vMZz4zn8+dp8Viceu118bjsZSyaZo0z5SSs+ni1q1b4LGuy8FgwDnv6oZJAQBVWRMRBx7lsXPu+Ojg+//G/+VbfsvHiiRdcsVFOlS9Hqbl4dIb/rn7t1kRfc0HvhZQdZpknG1nhXc0O5sAU+R9HMnhaFgUxXOf++zla1eTPI1iFWQWr7zyymOPPRZHifd+UPSqqiJyYfMnZRRFUVnWRVEAZ4ygs8a0nfGOAwJn3lgmhWTcAZElB+E2tAutR+NRuVxxyZyxzpkkyb33R0dH1nrOOGcCEb/whS80ZSc5lo1RWeIdyiTpjI6Gow5956wj7+enEWfUmTxO0mEG/fjy09dBd08hAxd66gR4D0IAMlguYTj8c4hnR6errv3UZz93cnp68cKFvdHo2oWL+xcvAxEIBKT7Dx4k/azsmixSsGy23vLkNybx3/+bf+sjH/y63UGP6e704EGRFDJLGnCNt6Pd3dZ0lkdCSeYZWTKdA6BYSpDMGOMZeg4EgboCfh5EzwiQGBIw9ATeMaCvaJhfoyv0b7IlCL31fm3PwwIlRrjxUnLOeWIb2xskD8aCNfqZqxdWbFGovi7Prm2JJ/cvJrmaTBoEaGw73o55b9BreOdwTjrNEtO48Wi8Wq2cM3VdhVh059dsepolZVlywVblUim1rJa9Ya/qarOwSZKkWZb0I2Jal2aYba+WBmSknfZOozedo2q58gi9QX+xWlVVdfHipTiOJ5PJaDRScRSUPWGpCwKA09NTOneei6JoPp/v7e1prSeTyd7eHgCsDYrbFgAWi8V4PN7o/5xzIaYibNhCkv1isTg8PJRSBhosTfNV06bFQIC7efMlEamYR2flJFbR66+8prKERFQuSu+Bc4wklqsFeBRcxTFvG70qF0SU57kxpiiKOI6bpgoIb5Pm5qzx1vT7fZlEp8cnhDDoDavV3DniCESktXZWBg3ZqqriPCuijIjG4/FK6ziKWW84ny/SXgFC7gwGjLH7xw/Gw1HRS9u2raqacW7JE4JQkbeeg1RpjKqNBLVtq1ctehRMeu9a3SESvvE47w81oSF6UwQMErGAroLlYaCyAj+xAVtlWSJiYBxms1nXdXEcSyWCZAcAbFUbZ+M4Rs44k227DpC1TpdllyW5B0AuWt14D2mWKpTee9tZy3G1Wo1GA2LEJdZNOV/OLJEjz6SoOw1MeEdGOyEEQ573e6Yr+2l29/adewcP3vu+K6enp2mchEEejUacSwD21re+9ctf/vLOzo5CVEoRw7ZtpYoEkdXmzp07+/v7HMWj9+N5dFSoEzKgtSMIsmC2i4PB4NUXX8z3ds8WM96LmeCdcV3bSBcvzNLrLutFZVPyWEQsapqqqtZV1LBrDaJDIjLWhwp4JIQD1zVdLCKMsGn1yzdfufXq7TSN8yxTSu3t7YWhVkmKAN5ZZCxLYmNMsF5SSt24dvXKlUuz2Wy5LG/fvr0sq+nZqZQyzYpYRc453RrrHRMCPTL+MEM2HETEcS2DceQZrPd+wRaLn7tJByBuDAjJ2kZzgcFNvW3bPM/Fx3//d+RFGsdxsH7pupacE4L1i13vrbW2qedKchVJa2vvNHmepXEURaNhz3vfae2sdd53bb1a6rCahrEz3pFDBiFZmnlvATnjjANDcFprx8h7zThEUSSZMMYwQpGknbHGdAAgZeS9b40FABXFpN3+xW0uJUe8f3B08+Vbk/lpUSR1s+q6Lk1zznldNWGXBsCs9ZxJzrk3DjiTLAc0THgPzFmPiJGUwJiUmBWCyAV/s65rvLd104V7r266MOUROakEEWVZ2rYtEHZtE3jEuq6NcVEUxbHKs3Q8Hg4HA6nU3s5+kuVt3WR5AZyfdx6R79q6bZbT2aos62rVGc0Ae73e5UsXnnryMaWUiAQ4AMFs15blMs9zrmTkpFJCeIHAUXKnu8OjB0HQPZ1OvffOUpBe9nr9PEsuX7rQ7w8vXbwWRXFSFEDMaw0eszy3xggp32SZGSrtBATIlVTW2gf3DhRXSRRxZKbTkVRGt3W1SmLFGchIMcYED3VPnC+Xb33rW4VgTVP1R8OmaYxxSZx1nVksVz//iV+4e/d+mqarsvTej/ojgQIF55w7Y7WnylQMuPFOyKiqW845AprOAKEPjKuIyOuuKYXzmsnP/PInf8e3fFvU0Gsv37q+dbnZWXx5+kof85148LlbL3MQw8HO/bsPXr93cuni7vbOpSxKD+/dQfRWm+3x1pXHrss8feHzn9/e2b1+48Z8sdi/cLHIe8fHx0mSOetb0EwK50hEqlpWed5njDnnuYqqumaInqA1FhCjJPZEQiguBBA5a7lkkRLe+rZr8iQdjkbeWxXL3vZgujjd2hlrbReLFQCSB865bjuOaHQjhEhTpnXNvCEHijPpCRhYDwI4caYiwVRijJ2ZjryPKvLOCGQcWaDNich3IJWygpnFVMgoH/UyNvyOa1fWNiNErqlX1SlwZmpvgeJear0b9vq2bVieLOeT3o0r3/Envvtv/V//u/e95Zn33XhMJOnhYnHqadI0/UsXYDhwbd3oRsQJAgghkNBqHwGz1iEj7zrOmBDBWIiQofckkK87vgEEMgDPnTXeccGtBwCMItm1rXMmKPkYnsfeIXqEkB/uyTmPSnFjDDJurIkkN8YIwRgn5xyS5yiAmLFOiCiOB5zSLBkz1LIAoqY/yqputX/jCUSuSUa9vUXN8qJ/58v3k3zUGANcrOoVcBgMhihYjhlyKBeliBgAnJ6e7u3tdbpjknn0nHNrjOls1s+6rilnJUGvLJdF0W+gbW0jsOvl+eSsjiLlgeIiQ2BV01ZVPRgMzs7OqqqK4/jBgwfD4XB/f386ncaR6tq6rsrlchkyoxDJeTc5PR6Px/PZ2XQ6HY/Hy9UcEQ8ODqy1Fy9erOpVFMvjk8Pg2LdaLQFgNpuFpSh0vRjbTWeTy1cutm17enq6vb0NxPI4stYqlQhCGalYRfPJmVecrGyMHRY9JXE+Pbl8+TI5y1CoRAEAcjibTkLpfzqdJkmS5om2XZTEZVlKKfvDQV3XRdFbrZYqijpj61WLXDDOl6tyWa3G461lWaVp6gE5oPeUJGmv1zfOIkGDpmkWyIQgKyKxtbsV9sxlU6Zpuj3eMsaUvltVpVJqMpsGdqGDZjgeNb72TFdn8yRPt/ujSXWaZEnV1YA4Hg9PT0+zLJNSzufzoK0ZDAaTyQTO6eeQJb9cLlerlRCCvAciawwRNcZ470PTfmi6EkrKSGmt67YRQuS9QukocAGA1lifJEmWCy7FclUJJeNYykgx56qqWjfWtFWaxk3TgXdRJG3bFEWxWq2SPGrbtj/qL6syzbJhb/gv/sWPIuL+hUsPJg9Geztnq4V1JKVkDG1nMqW4B+3ZdFEzFb3y2v13vgeyLAtGP5xzJSImFBA8/sSTz3/xBcbFYlWKKJJSnZ5OLu9fdo7Gva1bL9/8wNd+LSABIlkrpHDOyYeddALIA3BAAGSMQJDjjL/lLW957tOfnjWNygtjXR5nrTYE3lMHjETGDdgkyoyxoFiaJgGjbHr5AeAcy1olYwAwug3PW88YjxOVhTHvjFudzOq6PjlbCCH6g2IyX8RxXBSZUjJkNKH3Sqm2bbqmjJIkz9RouH/92gUANpsuXnv9zsGDw7JukiSJVQyMd1ojMRY+EmeeqG3aOI6d8wbMmqYiQiJEFAyl4nGinHO600opIZS1LSIG2yAg3zVaCAGIZ6dTwdGZtjFdDRCU39454xzztPbZU0oionOaAWVJDIx7D1q3oYImOHpH3q3JqsBgw3ltm3PutAntIW5tQb6Wuwb4H2BBS2tzFyFE2+pN88u5YtIBwGpZ+U2kHSAAtG0bROqcyzgSQKg75xwKEQvOiqJomjaoW5gIuSVcAkMOnHOEh9auRB4Ys11nra3rkjGG6BGQc2SMFUUR1PdxHB8eHjIG0+lJ6DxKkmQ0HoXG0eFwvL29rZIIQowWcq+1s4QEQkhn7XwyWSwWVVWV5er09LhuytFodOHCXpom2/koTXJkpLVelYtA/AS/g36/z5h46aWbALC/vx8peu2115xzbdseHR3N5/MgwCdwFy9cHo1Gg8FgOBwFmUiUZIACHAAK1+qqqnq9ges0V1JI+Qhp8CbzYYbonXOL+bwuyziOQyGSA3LAru1M24koDluEcKaUUt7bQdEDgPlsBgCr+SJKE0TunJvP56/cem06nWqtvQNPDyPNPYL3LPiQrdV15xSGtS5UNJSQoaVS+9YzyQi4h5qJ5z7zKenhGz70m0/vHkpgg6yfRxknduPy9QfLabWqe6Px1cefnpXz1199PYrkU9eufu173/PFz33ulddeunv33uPPPHXl2rXXXr+d9tL+oGgb88ILLzx+4wkAFkotWZbeuXNnNjvb3d0NPqtN3SmlrPcA0IWMhTheW/gYE6dpuDLlOgHTxnE8GPYjIb33xlmt9cHhMk6S+/fvHx+fNm0bydgb35o258nk7OTWzZff/YH3nxwdciU5cqm4NR6d9gaUZJzLqim72jHJOHKQSI636FWWlm2rdVsMimlVFUWxmK8iz5QSdd0K431XITEpubUekcAaYCSEIEYoRBpH3kHV1F3TpnFCzidpcXZ8vP/MM//193//9/2lv/T5T33m6evX500z2N298ba3fs1v/aaqqgxS0stXdZWlhe5aITBNo6as0iR2XKBl3lvbkXOeAQjBOUhnnZIRcmaM1tYzxiSPgFHVNMPRVui+Cc22dRu6N87TSBAAGDAgYkg+klx3rXMURcJ6TyQYY+e2c7xrtUzjrjVZVujOWQevH5X1pDK6UdIZ3eCDVa+fIW9WVa1J9LfEybQh3ksHOzwfT+YrKUAJsVotj44O+4MiTdO6LqXkYcZTSpydnQqhRqNRHMdJEi2XJWPs8ORwPB5vbW0tFos0Lo4PT7bGO0mirLWCw3Qyefrpp+fzea/Xi6J4dXDw1FNPHR0dBeJnMBiEm71t27Ozs9BDvVqtLl++HJoH67rOsmx3dzco9gKlGp4Mmi3nXOCogkaec761teWcC6QL57yqqvl8PhwO4zgORFcwiyFw09Npv9+3moQQHJlzLu0VRNTv94JdTr9f7O3tEFFrTSDMQiN6URRhDg9mlZPJJMj/N3KCcNkzxq2narWM41hGsTEm7/fiLAWALMuCbinINMMF0NbNarXK8xwRy9UcOGz05gGMBslzkiSt0cWg3zRNlmWBK+pMd3R2OFvMMpsVeU5E88lUcG69i9Oo67pQhCWi1Wq1tbUVhLzHx8fhbw5S1409d+i4ipQKa39gtgKbGPRYbdt6WEfxtm07mUyCQm48HoeOhHWJNo+ttVmRa63LsuScZ1kWlm2t9Xw6i+MLcay0br01nHOru7aunNSMMQLeHwzato1U8s0f+60/+ZM/qZRwYLgUUZymeUbOmaYt0rRheHx4lGbxoJelxfDo9GyxWAIwY9rp5GRn71Jxvsfe2dlTKm7b/w9hfxZj2ZqdB2L/uOfhzEOcmDIj82beeaqJZHEWKcJwqyUBgmG9GHYPbgvqfmjADUOALb0IBlowZAF+ENpCy4b7wWqxBQGmSIqiOFaxijXfuvfmnDHHiTNPe977H/yw4py6JCV1FKqQlRlx4py997/Wt771rW/lQRgu5vMwDGej2dHgSFYqcL3r2+v5ZNxodyhjUmsGO/W+mCx2658BcGGKNGKM3X/w4OzsrNJovV4vF+vBYIAZVlwB36EUooQz08jLgpAKYwxJCkAtPL1qu24EEu7dQkDTUkoRSgghCFMpJTeIS1gpRJrnGiO7FEmax0li27bvOTXPx0qCfk5pSTAuikxWBcaUUV5vhD/V/Uqa5sPh7eXF9WK1LIXipsVthjFBSIF02LINoHjuqHfYe4OQUqqCdWyawCZg6BPCe4Z7KoRUUiolMKYYawasDAAXw2CUUlhIV5bK82zDMMoSRM0G6PUqKYW4G0MFCGUYFjTIQKsIPcjdohWFkdZaY6QJrioBlLVhGBophIlp2GS760coXeUlhE5g3tAXdvq0W431eg2Kws1mo7X2PFdrXVUFQlQIoRRSSimJpNBFUcCjTCkzTRN6eUIIpXhRFAQT2FiEwNmsqgD2AbvoOI5hMM55JXSeR0CrJknU6XRc1+50W5SSVqsVBJ5pmrZjgsaNUBMpuVlNXjw9HQ5H0MgXQjiOC6r2JInLMi+KQsjScayDg/1Wq04ZsmyCcBUnC7hirusTwsqyrEopBXr54nS5XMdRWpblk8/OMNZxsoFFS+CofnJyf29vUK/XGOOG4yCEZFEppbhlIUSj5TLLyjwrb25uKKVf+ZmvU84QQrIsqfHnV0bgLSdMEJVS3FzfJkkShuEdX6owxjRNcyEUtzDGGNZngolUXgkpq+fPn8dxTAjzPK+UgmCa5cVisbq8vLpztFNip7OpqkqiP6O8UUrBVBHa2pxqraVWCCGptVJCgRWFJlGWlrr61//2dwxqfOVnvqpypU2c65wgR0r98Qcff/fHP5xO5m9/9P47H7z77W9948XTT7/05a80Qsd3vQePHjx78fR3/82//fCrX33jjUevXrz49NNPjw7v12q14XDoui7ndDwe50XW7Xb7/a5SSlXKcVzTsJM0WkeRY9vasu58Q6TknHuuCyeIEMIZZZQopTDSVVW1G83FfNpqNE1unN4pHQtKuWVaeVGYxHRtN07WkH0RQqZpai2zLJEV4dzkjCNEHM8usrIW+ga3hKqKrOQmM7iltEiLvFWva6RFWXqt5maz6XfbGOPNat2ohcBp5WmBiYZBCj8IkzRlzMCcVVJFm4QQZhk2wyTPSlFVOS4Yd3WBSkX/zv/t//7kj76Zx9Gjdx+67RC5dpmuklKYnq8wMiyelgtmqAqjXJTY1GlBGPG14JzbJuWwEhlrrLW2Oc7LUmpBDU44qYQqBMJYMwvH8QZRQjhDhFRSI2JohAgxMEJaY4yQVhgphTUhuMQit5DShDJMNLGQQEgbjFGENFKgDmGgQMVEK25mdjt8fKBlFW3WDcfmjJgmv7m5RTWKlF5qE9dIUO9UCp8vlgeHD9LFuKpK0zQNw2h3mlVVTadjMIFbr9fQUHJdX0q9XkcYY1BNYYzb7fZsNiOElGXZarV63V6SJFVV3dzchGE4n88bjcYuNw+Hw1qtBsJbCFa1Wg3SDKg6HMeBQT/P85RSw+GwqioARhDNfd+HWGrbNrym4ziLxYJzXqvVptMp6IHgRBdF0el01us1DBvCADnAhZlcQKELi+pWq1W73W40GhBjN5tNEARKKYg2QCNRSkHKnec5cGMwSA+lJvw92lqbkq27BBBCvu/D54JGGyEEZGTQG43j+ODgYDqdFkXhui5MuvR6vel0GoYhADJosYEQCjyrwfsGcKRhGGDahykBWxxoPlZVBYZJRVEWReH7vuM4FxcXoA3I89y27cViAQDRNM1Wq7XZbPI8L4vCMIwgCDDGUinbcWCeAAQYWqo4jUpxZ5kB04VJkkwmk90QjO/78L8gngOhNGyJcBzHMkzwMt3Jc6WUQG6BMqlWqxFCbm9vQTYHlxR+V1VVnucV1d06jSAILNtI0wR8PYbD4dHBfpbEgFzdMNRlRTi3TKPf7y/mU891LcuEOLZer2tBU5VSCPH8+fOv9/eQ1kDD/M/O9WqlMMYPHz68vLys1+vNZhNuK92auOrtPAqcF6016EyggtrZH0DYBytX8OsCFbmUEhbR7NgWxpiQJSEky/L1es0Ya7fbWuMsyZNNxgh1XZtzThlmGBFmAD7OqyLOUkq553lvvHFy795xnCbXw+FyuRqPx0mSACxjzCCUUoxgDkMphRABlIUo0JxCa7DhlFpLSjVjd4AMYw2zhAphRqlhGQx0kXAVgMG6yxOcc2YSgsHz4q4TKRUimPOtbfrdauG7XWyEEECd8Pfw5kCvQ7dG9fC/VVUZBoP4AicQ383EIs8zoR0LviNou/VpNBoRQqIogsENcLNwHCeO052ZuGU6OxEodEwIIRpJIQvgJNmdjxWF2hhmByjGGGPGSL1eT9MUYxxFa4QQqBZarU673a7XQ8t1QT6vZYWQwpQhJfM836zv1jbPZrPb28liGolK+77PDZYkaZpmhmEoJTmnnl/r9XqHh/uNRt1xHGYZCCktCrwjYDHTQs7n8+lkPp8viqICYw6lEOcmYzyOozCo9/e6e/19z3dqtRoxmCqFUoIxA4Q4lFsyyybD6Wg0Ojs7Qwh7bpCmab/fR1LCPmf6RQbr3/VFKb24uIAmKVSHcBcAtsLVhhsNEQom7BDCVSU9L6CU6korrbOsgLqQUqo1FkIAnrpTimBoeKOd2hTKca1/4lUDJYXGSEqFCNJYSS1yWTS7rdSy/vDbf0Q5/2v/i78aNMLv/vC7xKaWZcZZ8rWv/vTv/PEfPH3yPGiE8/ninXffn6/W0WaZbBahH77/wUefPvkUnEfu9L8C3b9/f7OKEELT6dTzvCxPpbzbvBn6oZRSaWBhS4TvlOy7iaFdtpBSQhy3LIsxhrFeLmar1SIMw6dPny5XkcEZ57yqZC5zk1tEE4QVQtrzvL29vTKLGcWG6YZhiBlDCM3G44vrK3hNMHTRGKVxojEKPB9TLKCzIIRt2ya3EMFZmmitCaGT6QiG89M4K8tyf39fa71ar23b1gRXRUGZ0ajVDG6UVYkRVUo1GzXYPZZFmWlbSKi3fu5nEFEIS6TKLE247bR9q5BVWVWBbVVIc0QrVGZKB26AEDKQpUqppVIqK2WplCIUI6yk0BhVnGCCDK0o0ZgzwzAMQliSRoxQpRSjLI5jP3CFEEpl+IsrhZVGmmAkKMooI1IIWQiKuUZMKU0QVUoVVcmYUZYlZXq9mdu2rSlx2+3Ti4t6WHt1s9zfs13bGV+NHz58pyqlyrJSVK7rCKSZa6ANms6nLc+KVrlhGJThi4sLSI3NZlNrDTa/gFnBJNlxHMZYv98XQoDJAkIIkvRsNkuSBMgMeJiXy2Wz2dxsIs/zQK9dr9efPn0KLTyQoSiloD8FaTjLMmCeBoPBYDA4PT0FG+7r62vYkmbbNoiEoIxsNptSyvl8DhJgaBfCHD50ZKBegoc2jmMpZavVAsu61WpFCGk2m4wxcMoG+LJjqTnngA/Oz89rtRoolAGdtFqt5WoOQVtrvVOolGVJMAHwB/p3QGNVVQE+gD8YhjEej6Hh+PLly06nM51OpZTHx8cwnddsNmHLQlEUoB0GwAfSfoCGkJUBnmZZRjmjlAZBsMtE0NqDWewoij755JO9vT3HceD6UEoPDg7q9XqSJLPZLMsyQkgYhpQQwJE7MTsoxyFFgobYtC2Yc4fvUUp5ngcmi3EcF0UBhho7r0t4Bcuy6vX6Dknv7+8XRfH5559rrd977z0wrnQcB9BhEAS1Ws11XRDdCyEajcZsNqvVavPluigraHq4nj3NE4wp5/z6evjw5D64/wsh7ibHMUZK3bt3dHlx1mq1GGOcM8/zZrNZu9lL86Tb7T558uTrv/CLeZ5blou2e4T+/fBKY0IQQq1WCzqStVoN0ijgp908NYR3IGUhwsMDAFcS0j08FYBxgTKELpbWaDfTB8CjUW9Bl9z37yjJNM08x43XCSPUD9x6veZ5jtZYKQ2KQMdxMCZ5nsfxBuCsVuKNB8eY0WgVXVxf3V7fjKYTWUrTdjqdTlkKISWjBmNMIa2ElkoZJtMaxtSIaVK8NRwpyzscSSgiCsy/ldaaIaSAjddaK4WllEKUQCrM53OgyyilRVFWlbBtW8k7VfRuGBVjuiMhdtdUKYURVfKuEwfsFyQhdDcDiUCpTSmFgTvGmBQaEyakrqqqLCu0FVxrrbMiF0IYBjNMo6hyznnNC8tStNsdKGgQQlVVJUlKCNZaI6ww0ZiAZQ4iBBGiKMUGZYwxhIjWUmtdCrHbXAEJrNFonLzxcG9vLwxrVZVzzpBWUoj1cgYlBXyNbidVBeo2qRUADiYEsq0A2xhjrKT2fd913b29fqfTCmu+1tK2LWZZSAslBJICESIFlYVM03SxWEyns+VyCdJUxgwYC7csC4xGj46OBnsHcKoRplKUhHKEkFaYcVOUcjweL5fLLCuGw+F8vqjX651O53Y4zmluu87JwweIUlVVYFi7zVz/7lMjhBoOR54baIXBGJAwKrSK0oRwJoXmrkkwU0oJrYQomWkhhIqiSBJYGVRSw8yyLMsLTGiv1xuPx1kRK6VMw97mTKzvIMvdg6S1RlpTTDQcRqWU1oxxRAmiREmhEOVaYSyIIpnMvKbv9Zzf+r3fevn6xd/+W//V/hv7qygrCsQwazfbjx6+8dmLZ/EmCcL61dXVx++/41tGGm/iPMVY/9zP/+Lpxfl8OaOUEorH4/FsNuv3B0EQQM+Ccx6GPpTaq9VmsVjkWeF5HrSVK1XBe4YHmFJaVYVlWZwbCKmiKMDQy7Zti/Hr6wQguGGwshQYY9O0ZKWKKreYORgcv3weHx8fOrUAEWUghLAWRXHx8nUcx9fX14QQz/PSJJ2laVVVXhAwQvKyzKIIEeL51unr21qtJqVUQpdVlcQxxrhRb0H/5fbm5sc//lRr/fDhQ8YYw8yyrKwsoAhO0tR13eFweO/ePc756emp67pJlPb7fd/3P3/y6f5emzFWlch2/VqtVsm5VOXrsxcPH9zXGjNqVaXizHVt/ypbqioNWU5QZlqUW5jgimCBqUJaYUooIUpSXFkG94nlIcGLWMyzvN0blKXgzDANzqnmVElUZMWK4ZJSzZDGhCBNYE2vrBJKTIIJRsy06oiZUmGFidLaNJlhUyFyRonBlWmajMrx9Iyb0gvom28f+149Wm1Mm00mw7IsvcBHKEeyjOO1XRp1R3geT6KV0qKsVM2tcc593wU8NBqNDg8PoZiUQu8PDmGdV7fXHo1GYK0cx/GjR4+ePn1KCPG90HVdECRprU3TLMtSKVWr1QCrnZ+fG4bx6NEjqOahu2ea5suXL8Mw7Pf7jUZjOp2CNa7W+vXr17tkuWs5wc514PUhEwPmA1TXbrdvbm5830+SZL1et9ttYAgg2WOMfd/XCm82m1arBYIkzvl8PgeKBdoISZLs7e0hhGDoHTCB53nT6RQh1G63YaQxCL31eg3UGgCLKIqqqqqHNcMwbm9v4e9nsxm4p8Kl2Gw2tm1nWbZDQq7rAm2WJMlisWg0GvP5HKZe4G3DkSyKAkRsm82m0WjAYQSkBfwc+D3CNOXO30cIYVsulEO2bYdhWN21LzCUjvP5HBI85JQoiqaTida60+1algU9GUCZQCXuPB2UkLB/nSCMNcIID69voOzhnPuuJ4RQQhZZ7jhOrVYrPT+O49ViGTO22/PbbDa/+tWvQkWqlAK8kuc5QMnpdDoYDCazcavVyvN8b2/v+npYrzfSm9ugFkopV5uNH7iDwWC1WAZBADY3tm3PlzOMsRYCc0tXFSa63+uVZSmlgPuVeOnugwdm8OzF05uLy729vTup7n/QNkUIwTjXSpmmeXJy8uTJE2gcw06nHcza1c/Q7PsiKoAeIiBvUCUppdbrNRyKu0lVRPVWgS6lLstsOBxalgW+u0II17MJZnGc2oa9ibJNnGhEavVGWAuEyONko6UEORrn3LUtUUlZCkTQYj4xbcMyrffeefTx++9M57PTV2eT6Xw+nSCNbds1TIKQyrJMC40ZFeUdooJHS2sttYCKuixLjRWlIHZV4MzHdiU4oPstKv2Joa2oGKVYSlkWoiwENfhdQ08pgG/Qor1jGrbD0jvQs4P58gvLTeXWjGvHo5ZlmcRZVVV6uywTbWkSQLuWZYWhD0EE5lagdhElzMtLw2CEEEoJpRQTrTVF6I6Ngx16CFMpq0pp2N8CYgLP83q9nuu6rVar0WgYto0QUkoKIVar5XK5XExn0+kY9hYjhBi781D2vEBKTYnBbSalFkLkmSirPPDcRrPm+36/3+v1OpxzTDQiBGSDd5dXIFHh2Wx6e3u7XkVA/EIBBFEYE8057nQ67Xb74GAAcJ4xFsfrMGhWlaQUCaHSdB1FETDqsFo7jlPXdU3TqtfrBLPxaAqFDiLY8zyEEOFcSQkrD/+9RQlC8/l8vV43whoACGhfQiawbVtJdWe0gxVjFPhbIUSWFUVeEcIsy86KQlRSaw2bkYDL3FmG3DXmt1Ng+M96HCh9tx+Kbl0TFQB2hBBo3IjSRNm+U5Wy3mtEZfT3/q9/t9Nqt9p7sqR5UT1//uytx4/Pbq4+//zzv/SXf/Hi3MyrUlR5b7BnWVyqKgjD2XLBOW0E3udPPhUiZ4xdXl6WZdlpNfMiOz4+1lqfnZ0JIeI4bbfbZVEBtrZtGwJ9WRVya/dVq9UgPwE+y/MUIUWQKoqi2WxGUYQQqioBz3xZloxwRlkpiuVyoZH86Z/+aVRVyKTr5Xw4vL6+Hs7n03a767o2pbyqijAMw9BfrTaEIMdxarWAczOON7Ksjg72oyiazWe93t5ms+p2uxChNpsNXPyTk/udTkcIGccx2I8ppSzLYowk8cb37KPj/bxIRuPVdDYa7H+gdJWVUTReeoG1Stb93mCTbGY313Ga2bZ5efXa4PjzT37sux7DBsMGqnCeZmkWbxbXh13s2qLe8sOazbhUpEK4kloIiaTAmHim2VDCXa2raF3mJc4R5rYXrSLP8zbruWMz19amUfZ6AcMFpYIgqSVCklDEJaaE23FeNpsDiczr68tSMm77t5OFYdm2bStUKSWQVpZlVGUZp2vPtaMoev78Wa/Xz2flZh13u900jrM4sSSrisQ0bNvQq/ktpeSw3ynTQlE6m83KsjQMhjFO0zSKosPDQ4xxFMXdbldJlGVZmqae5yVJstlsCCGdTscwjKdPnwIESeIMITQYDIbDYaPRgKy8XC7DsHZ5eVmr1fr9/mq1ms/n0+n00aNHkJO63W632wV3mNvb2yiKjo6OTk9P7927N51OwY2Jc97pdJIsBRNUst2LhTEGM94sy0AsBdrt6XTabDZt24YqrlarNRoN+L+z2YxgBkz/zc0N+HJBlN7f3x8Oh5xzSOfQJIWTmyQJ8FtKqcvLS5B8xckGgB0wfIZhwOtweidBAcYCvgewC3gFAekFPBZQETDhyDmHU7bLR+BMBpgMVukFQQAaNSBCNpuN67qNRiNNU4CYZVkCVoOrxBgDtR9E++VyKaWEBiXQTrtO3y4SQisWui4QnIFxwVvrrLIswbqFGTwIAi0VwC/QYEGihJ4M1NsQKoEKBUUdlKag+IY3SQhxXXc0GnHOT05O4MD2+/2qqp78T58fHh5qrYPQU5fKce6A8nw+V0qtViuD0qIotES3t7fD4XB/r1/kVRRFGFY/IYQoDcPQskyo3oUQnu+cn59H0doPg7zKbdv+8Y9/PDg8lHlJKSX0P5QpAIEBfuj3+3/6p386HA7h7rMvbA8DbGSaJiIY+ry7mL+jZnbpHh5mtJ3XA6iwgxaEEBB8R1F0N7PJuagUxtI0zTjNCaOirM7Ozs7OzoLQvX//uN/v2pZRlgWk2lJKQohhckqpbdJKySJL0iy2uGUZxrtvvYkoO399PhxNZrP5apmbhm0Y3LBMbhpVKRElkPHh05XiztAHuBbOKcYaE8wYJwQxpcRd2kIIJDJ3mhutHcdRCkkppRSEEK1Vmqa+Eeo784KdJf3dMySlpIRLoTFGGBOpJCHE9129XaQFR04rjDhRSiGt0iQHiAr3gDFGKINmJWPMNO8AH+cc2pcIIdPiQlRCltC4xZoiKURVMWIyxkzOwS3CMIw8T/M8LyS4OFJKCVL68PjA931o/5muixC6WwIgxGQyGT1/eXNzA+Q5nBysiMkt2/bq9fpiscBaG4xalhlH8RalOWEY9noH3W7XcWzXM03HRFIiihAmSFWIUIT0er4Adqcoqtl0OZ3Oy1IQgqSs8iLFGNdqtU6nBeO+UlYayYcPH0pZrVYr0zTBTEtr9OTzF2UpIIyWZY63qzxM0/R933V9eCi11oQijHGUxFKrRqMBE08AmPC/88xohBDSEhGKYUMOhBKplEaIYBZtEowoRpQxDDelEoXQQiJdpSml1HHdTZQIpeIoRZQgREzTtizn5va6FBXGyDQNyrAohJCl1hrhO4EdPHVCiLvum77zkaKUIkyUUhRhggnGSGqJEVJISawFln7N6fSaZVqKQvzoRz9qLqZvPv6IVqrTrkfr1Zc//vBHzz49PT01DcY5L/PoejglCP38L/xskkQUa9c2kaoODw+nkwXG+ObmVko5Xy4cx769vdVabjYr1/WVUvP5fL3aMMZA4RutVgghavJ2u12v1wkhtm0WRSElFMQcYxs00fEmmU9npagQQpwbQigpNSVcSMEoswxrMhkRjHu93nw2e3n2YrleIIqwwo1GjRDEGJFSKCWyLKnVAsNgeZ5WVYGx1FqXZT6e3L755pvRev32m2+apmlymib5+PbWsJ3NZnN6egrJdb1el2Xl+z6oQ0yT31xeYIK0llWRCEnTNA4Dx7L382Ld32++ePHCcZz5ctEMup9/+rTTaU8nN0oXlmXt7+2rSmCEao49vbkgcpXFM5WtP3584rzTc7wC6ZhRQfFSFKkSFWg6NaLcC7HpFhUartfLZVEJk5n+Sa93dv7apSUts3J5VqNWzXcCRxvpjOEc40opgaXSGivEFLUz6jm13vXts8k8dbzu5fV8PIvqjX5ZKcK4ElIIQRBmjJV5Hseb7l4HU6vbCaVQSqmThw/G43FeZof3DqPV0vMdQgiStNvYw1hfnA4Ny3IcazDog8YgSRLGjDCsx3FqGEaWFp99+sRx3MFgYBimECLZRLByBEb2MMafffbZYDCwTGe1WrVaLVjb2u/30zTt9Xrr9abZbIIsGmRYhmFMJpN2u+153tnZWRAE0+kU9FKEkOvra9jU2Wg0oKt4dnbW7/cdx1FbR0CIAFD/gFPDzc1Nu90GZRIIw0HoAwAI4OP+/n6325VCCyGA36rVauBfulgsYJ8YGL81m00wZN7b21utVsDMQTcfmCRImdAEWCwWQJxAiJBEgB4f+mLAWsE7GY/HUAA4jgO0me/73W63LMsoiur1OpimwtuoqgokHEB1AzIAug5MDTnnIDZSSi2XS8MyIaSA4kdKuZP1wEgBACDI3LCYqCxL4MD0Vsyutb53//5qtZrNZnEcw9UD8g+IE7j+QRAYhpFl2Wa17na7YJFVr9fh1sAX9GFBcAbgA5RPkP4Af8MdB8ldGIaQUmezGXzk2WwGbylN08AzHctGSmOMwzAsy9I0zYNarczT5XJhmXdd49VyfTDYdxzn9evXP/9Lv4S0xgwjhCzHaTabUbT2XTtPSqgYp/OZF/ha61qt9vr16yrPOTellOyLyeKL1nOAG6RUSnHDQAj1+v1+vw+3Es7CTukBIAljXIoK0DPburvBpU6SBCD7ri0AVwyyA92uzYDvd+6+PKWgXYBs25ZSp2kOlKEyOWVYKZVl8Wefffbtb//JvXv39g/29np90BEWRVHkpVSCEEUoMg1TIyTKUguCKMNKvfXm47feeUeU5Xy2vLy8ur4dLlZLqXGt0eSYa6GqqhL8buIBAEyapgpppWCiTiuEGaMMHk2A1Tvt1A6hw1IajLEQCiEEe2mAx6PbNpPeStWEEJyZOwYVXhlIbLXV2CullES7TiJCCLr78FKmaRqWBQCfEIIxgueYECSERlhF8cZxHN/3AQKb3MjijJkGZUgpEccpnDrDYLPZhDFWb4SNxiAIgmaz2Ww2MWVIagQsWlHMRqPr6+vLq5vVapUkSZ7nYb0JdB/G2LZtz/Md7sL9GI1G6/XadkzD4Gka3bt3r9Gs7e3t1et1SundvlKtkYKFaxIJnWXxYjlbr9ej0Wi9irRGVSWTOJMSNeqtw8NBGIZ+4HLOHMdxXfdOGgVO2AhpUcAjdXp6ulgsDIPd3NymSU4IrMfWoCdACEH1o7XOshye5jwvpZQGt0By++DBA8K5FopSigjemb78O1CW1gjhm5sbqCR2yyLgDMAhgQqPUlqUSsrK9eyyEAjhOwUSYoQQqTFjhokRpXS9XsP9YttF5XfPz3a/BChOoFsHp24ndSeYVlpjje7+o5TQkhO8iVZlle/1BnEaO9ystWr79wbf+cEPo6T82k/9/HS1XhVZ7/jg6GDv6ZNPf+ZnfipNVibHju/ePzo8Obm3Xi9LUU0mI9d1pJRSICjTpZRCKMb4ZrPBWNs2zDkTQsiv/MqvfPDBB+12e7PZxHE8m81uhtebzQaEMkLYtm07jvWT+gyrXdOcMaA5lVKIEiqk4JQ5jiPLIgzDr//MT11dXfz2b/+2X/e4yaAT4bhulRem42VxIpEWRbZe6/V6aZomxnfkBGOsUav/we/9fqfTWa1WV1dXnJm1Wm0wGGDGj46Orq+G0JqXUvp+kOc557QoikYzRFj7vguTB5UoQFuKCZJSPvn8U8M0DYMdHx/fnE88LyjL0nGtOFpzRubTCUEai2K8mRK5Oeh779yvB04N41xVkUKpQgVWGmlEZIUVZtRE1MhLhrAzm6xfXS1zbTW7x4x5y/ns+bOzIl598M5bqti8c3gSOEQUC4JzrBKEK1jprCnDmGFqKupFuPbDHz5fRhlCFjUEZu79Bw/KSrfdII5TRmiapqZhrBdrx7Jt04qW+eDw4OzitN1uK6WfPn0Wp/H+/n6cJBITg1uz2YwjpiRSleKWF20ibt0JXCCbMmbsDGbb7TbGmFK22WzW67XrOkKIssp7vR4hZDKZcM7v379vmqYUOgzDb33rW2EYghFAr9cbDoecG9C5A4l6EARpmvq+D9ABVNKtVguE2BCWPc+DqAuDzECRVlkKuivG2HQ6BdkT0B5FURweHoIaHVgoyJqwOw8UwWDsghDKspxSent7C3aUUsp+vz8ej6HvBiQQaOf7/X5RFPV6vdFoLBYLAAQQCoA6An4LOgMgLdJaX11dwU+BuhlobCC0Go0GtCxns1mz2czzPEmSfr+/XC5Bkw6pdz6fA0uRJEkcx/1+//b2llJar9dfv37d7/dBkA4jmQDO2u12VuSgrFosFvBq0MPlzIQIBuzRer12XRduBOiudvI4UH/f3t5C7oBDBC1a+APAu81mgxCCpRoQCmAUEaTokExXqxXcUPggURTh7aAPaGZAnUIpBfwKbVOItwBEDMMAJrLb7U4mE8uwgyCgDCdJ4trmZLHknGuMOaWEEFlW8/m81+lCG9eyrKurq/PXr48fPCzT1LBtRHCtFsASFMs28qzaP9gb3kyOjw8BDETR9Pb29vDeCXQP/gMaLEIp/GueZZxz2AYbhiGwbnCjIbZLKYHjAT4PVBPQ4AalL+QCoBg2m80OgQHqAgYUzgjnfDKZMMbCMDQMI8uKNM3hthZFUVVFURSGwSyT27ZDbJsQcns7Hg6HYRAcHh7u7++HYb3Ki6LIKNFllUuhtxmJEULKoorkSmuMCK7Vve7elz6qqqurq8vLy5evz4OwzjknFFsGrPtSSt0tvsNYm7aFMZayIohgzBikcECIu84dxpgQJqXGWENNAEIozjnCBCFNyE+ILgCqaZJTSpUs4AgtFgsgijWCQb2KUurYHmOG0AJ+keM4IJwEVCeEmM/n9XojyzLGqGEYJTCEFEkhKKWe69XDWlUVVVURpJWUhZJC5lLkRVFhjBuNBvDz0Odutds/WduOkCyKMk2Ws/lweH0zGu+KIUKIZfJe7yTLMljMkub5ZrOBNso4usEYB0HQaocnDw73Br29vZ5pW4gQJEtEGUIIKVEVqRCiyFVVsFcvz4Usl8t5XsRFkWIiHccmFDWbdc/zbNtutVqgKtBaE26KvGKmhTBWZUoMazmdKomm02ma5mVZxnECVLbBLUyw43gYayFKyN9pFnPO8yIDZ0JGDcMwer0O7F5stdqGaRPYe4+QUopydsfKfqEg2ZphI6U0paRMi8uz83oQQoSCG1qKKs0zy7YADEEsI4Sg7boYx/GWq02e59x0EMFVUQBUhVLbNM0gaBFCVptIY0w5J4SUeV5VFaNUSynKYhf4dvI+pRSjBBOGpOKGUaSZRHcPJMFYKbFczqu8cBxnFa8wxfeOjs4uXm7+TfTgzbcevPXm7Xx6fDRgXKXxyrY4EoXWsqxyrWWv35VSalWtN5uTkxNCqJT6ww++/PTZ5z/8wQ+mt7eIEj/05vN5v9//b/6b/xOlNE2yNE1BgNxsNuv1+le+8hWl1N/9e/+XPM8JaQJlHcfx3l4P0luWJEkUY4xFJRljQijLtKuqQghLpdbRhhEc1Gs/9ws/f3b2+vLm+i+9/cuLzbySIo7jUlSM0GK54JQZlpnGCTONoF4jhBBKNcEPHjyYjsaUkHfffd80zSRKLcNWElHKi6JcTxadTgchbNsOIXS5XEmpqqoMa57rtinlo9GQMWJZ1ng8dhwr2SSMGbZtm9y0uOM4rpaozKtWp+25gVSV63paK6ylKrP16pbIlZbzjz442O/aKh9pmRZJYppGkSWUmxqTokKmERQ5497+zeUqyuh4kUelrrXfwEjOkpLZcdBi01fnX/vwQWBtlJkZOKZZRblCuNB5gh1TlTgXGFPfsOqTebzJ0evJXLFB4FvrOEXYIczMCySVzrKsErnCSIikzITn2Z1OK4lLMwpvrhZYO0WuDMtyPWz7QSk0piwty+Vqudc/SjdZs9l++tnTTjcQKso2KyEEEAObzQZj6vt+LWxEUcRoeXR0fHt7C2q8sixs2zYtDjtVGGPQDVRKXVxc9nq9k5MTUPxgjIE7PDw8/Oyzz0BlNRqNQIq+Wq0gLIB0qdVqQf0DRSmwI1CTuK6LEMqyzA+DxWLh+z64jyKEQE/d6XQ2m814PLYsa29vD1pv8N523QmQZ0VRFMexwa0syx48eAApnBBycXHRarUgN8PC6d3kPEg1fvSjH7mu2+l0RqNRWZbdbtd1XY3ker0GAHG3JISxMAyh/HMcZ7lc3jHiWnnBnU4LhjZM2+KmUUlRiurzzz8PwxDE5sBhANAEOAIqLhB+AQxKkmS5XNZqNdhpwxgDkgwS+Xq9Bi4N4q1SCmp+6NvCkCb8FOAz0IpJKUE8B/OSMHcZx3EQBDCGCRIu13XH4zFEucVisVwuYU8G9BBAUwGJdW9vbzabAXEI7g+1Wi0IApgAhcY9JEEgYOr1+o73gmYuwG7DMPb398/Pz3d6G9/3l8tVVRWe5xHGZpOR1irPUqUanufd3Nyuo41hmUEQ/M7v/Jv//MFDwzRlWVDTbNbrr18+x0EA9xQ0DLPZLGzUW83mzc3tp59+enh8nxCC75Q/d+TVnxNjwc4PIQRhlHLW2+vf3A5LURVVCcVDJQUiOCtysjVlAOAOHUOgcnYcAaAo+Ce4ILsuIfwZECdCSErNGFksVnCboLcghKCcCFEyRhBWlRRaaKw1MyzCDCnlepM+f3F6fnYdhuHJyUmjFlKCLVGmaVrkJeeckrsVcEAJCSFkVW6ylDF2/ODo+N7Bm2+//erVq9evzyopfC9gjEmEOTOVqDinSqGqEBhjwojWWFWK7VxHAWoghABXgp89fOAdDiWEIHp3mbTWO/EQxhhpAlAJiCuA+Rhj0+JAikL6h6gB7XaAODupIGMsCAKlJKUEXlwpRehdf1AIkecpnHOYOPADr1mr1cMaLCG6u1uMb6VORJXlYjqNomg+W4KCIUmSMk8ZI9yyAetQStM0haHWLMuAbCSMgQSy02qEgRcEQbNZt20bEVgOrVRVqkppLZPVYjqdLhYrmFvcrLMiI3kma7WwrFLb4QcHD/YGnVaraTucMIIw2SIahRDGiCCkGSdlHg9vRtfX11EUz+dLwzCk0L4fZlmeJEkY1GuhJ6VWSmR5rHQJMyYAAWF8+uDgoN1uNxvtMAxNx0Fal3mJECIUp0li2zaihDC6I5D+fRWJFgq6EjAHBzfdNM3NJkZb8RxEf0KIVlgjlGUpZUxraRhGrVbbxIlSCmMdRZuPvvTl+Xx6dnZWlkW3ez+O4yhJIVYqpWRV7ZgqcJ/D280DkE7gKWcKKYI4oYpTeHKqqpKiREhxyjTWhCLKCTaw49u9ZidJsz/+7h+8vj79+Ke/hlXVqAeWBQuctFaq1+t845t/bFlGo9E6OTkZTyar1ToIanBJ+70B/4o5m0+Wy/lyNqWc27Y9HA6Hw6HvBRD4YAC+LMt2u311dRXH8de//nXHcYbD688++8yyrCwrGGPr9TparwnCsG+BEm7YTAiFEGnUQ0opIfj46KDf7yZJ9Lu/+7uH+wcPHz3w657WGpaaXVxcAHOwWq2iKDIsM/B8aDyBFMawLV0Jk3Gt8Hy2fO+996bTKch7j4+PV6tVrVZbr9fgWoQxns3WgW+MJyspZbvdZMzwfd+ynPF4XK+32632ZrN58fRVEHh1r3F7e5NX6263P5sNTUb3+t3Pf/x9VcaBg+/3/U6j7Vg13xHT4bPQ41qkpsUwrizHLytsuXVcklxaxK+fjsqrKVLIMYL+vWarkvl6fO7XeRxd2bL6tV96Cxcrkc44VowzlOfVOuOuhakhM03NuuMGq5iMpvpiWGaSGt7+eBGHzLJcx7CsNM+qUkTRmjLiONZ6s+p12qIsq6JcTGeVJI7dWK1EPXBszyqKLPDd4ehGaKW1tm0XOguVFKPRpN5sp3limqbtUAjcQDK1Wh3TNJM4g9wAM3oQFYHVyLJssVhAozCKojRNO53OBx98sFwufd+H9X+bzebo6AikjY8fP2aMXV9fAw1zdXUFwrjZbJam6eHhIaiLwDouTVOY9UvTNMuyk5MT0E7lRQGJ7eDgYDKZ7O3tgX8BNKH29/fH4zHQWvP5HCwkQCCY53kcx7ZtgyHC1eUN2B9Mp1PHcfTWoByOHmjPQWQNiGGxWARBAPAIQCFCaDQaMU5c1/V9H/RMjuNIKcHMkxCyXq/DMISQDhgFIRQEAWjSIbtD4QSsIXBO5nanMnRhYDwcYzyfz0EuDGkVOpWgxwIGK8/zUlQgD4c8DbJdILE8z+t2u9Dch/FJxlie58CahGEIY30Y481mAzgbJv5A5gWgE1iDRqOxWq3gctVqNbWdtYKsD1kP5hsgcg4GA/gtQMgBDQbNUEjnwPZBa8zzPACOruuCVRjkuCiKUB9BlT6fziileZqVbrlZLFaLRavZiPLy+Pj+ZrOxLAs+gmGY8/n82WefPX7nHVnkqMhc1wbEI4TQCruuy/litVq1up04juv1+unp6R2ygcr8LmX8ean7TjcGYbnX68F3QtcVkgWQKXfTAFuDJ/i6SzpbIfwOOMIlhcbuYrEAH0pIRnEcr1arWq0B6Qku+FYRjqSqGCMEw7ieIOTO58kwDCmVQbnWeLXe3AzHV5dDz3f6nc5gv99udxDBVZaCwwjnYLjFGKeUEqVxWWV4oyopPMf62k996e133jx9fX5zO0zTXAqV6cx1Xct0KKV5WeV5rkpFKSWUsqKoYNgVfWEjDyEMjElg7g/+Xmw7HHCl4AmD20MI2U1kgAIRDg9jDCkF90ApRYBNUwJhTDB2LANeVpQ5XAI4Qr5rY4zzPE/TPEsywHDtdltL6dj24f6g2+36vm/bNjNMLQrMOEIIaQXwJVmvLi+vrq+HURRlaUEpLYoKzjPn3LJrjBEp9WKxgOY9iA339wa2bTdazXa7DaQxpZRyivB2uaGScRSBZR9Mr2iFi6LI8wJGSQlmnPNur+Z53oOH913XtSyDGBwJobQghMDuEK0RxkRrstlsptNpFEVZlmZZNpvNEUKcm67rhmGoJEqSBGMUhoHWcjob53leloVSor/XfeONN2q1AKBPq9UCCEtNU5VCa11mmeE4hskRIqvlklKOOUMIUUS01gpprTXFfwFjaUQQRhSdn70GvAuVNwDozWYFzBkoLXbNL855khTcMIuqRFi7rj1fzatK2o7zwUcf1GrBt7/9TaXkL/zCL1xdXcC+vx09DnOkSt0lKrKdfAaYDuEJKa01QloqWTFKGaVaSyGEwhhkp5TSoqoQzEwwvMmXmyw2mTsaX37jj9JH77xFCLG7bcL4dDZ9eHLvp7725dV8sVjOLNN5efratNxao/Xq9NwP6/E6rtfrtVrt5MG9KFr/+MefXJ6enp5d/IP/9r9FSpm2G4Z1k9P79+8jhAaDgayqH//4xwzTl8+e1+v15XIpS4kNjZVeL9bRZmPZTp4lCiFKeFlWGimEsGVZmygzLWpZ5vnlRW+vG2fp6/OzqqoWi4XpGrVGuFqtyrI8OjrCGK9WKzB15JwjghHBz148bzab+XJhmxaqoNtOjo/vj8dTjPHh4fFqtapK0W51Xrx4YVmWGwQAju+fHC/nIykr23ajeO064fn5pWk4nlv3HPf5k+e+43brXYyUzlW/0b+4Pj/oNjc2PnvxJOXRXpgdD2qNADOSqWrFNZJr2Ql7VZESYgtdRVHuhy07bIxnUSLwzThORYlY3W3fE6VMZVUsryY3L5oh7RrBV09aSKzE+oyoxDS4LApdYWzYWCGEaKFZhRylG+dnm9PhutG9L4L7RSbyqvSbrmnzi8trx3EoJ61Wq90JhBCg/sGYi0poba835Wq+sKyR5zkcF4HNCo6yfNFpuHlZVpU0TZxlcS3oFnHBTU4IU4qVqkKIHh0dKaWyrMCYpkluGrbregjdrUyB2JAkiW1bg8Egy4MoiiaTCUjRoeX3g+//6OjoaLFYwB3s9Xo3NzebzabRaIKBMAzTwcgOWCR0Oh3oMS2XS/CggaJ3uVzyO2kpHg6Hm83m4OBgsVrC6huEEKh2BoPBrnSJ43jnAsU5XywWYL4AcigYFYTeXK/X63a7z549gwHqKIqAtwPwB1kAJFAwVA6mEgBo0NYGj3NumIxurTVBngXpYDweI4QAQQIcEUI0Gg2QHwH9QwhJkgQKxXa7Db8IdCBAMkElzxgDi07QsENOEUIA/gCsBlJU3/dd3wMEA/QG+PAlScKoYZpmp9ORUk4mE4A1t7e3+/v7y+USLh18M/BMi9WSEOI5LjQcQIBvGAZ8UhjbvFOVIASIFv4VTDoAMViWBXccQDmQMfv7+5vN5vb2ljFmWdZ0Oq2qqt/vA7IEqhKQlu/70+l0uVx6nvflL33phz/4QRRFQUDr9TrS66BWu7i6EqK0jDsBBjiuGYa1XM4X8yWYjIAzxcOHDw3bQVjd9R+QUgoriWzbtlxnHUV5niOsmvXGsxfPX7169cYbbyClKfmzyeLPKrF2HC10KjqdznA4rNfr8/kcRg3gsuyMr9T2a4euoIcGYR/GIOh2u6thGJ1OBzjUzWYDQLPZbCKEiiITQgHuBLhWFFkpMsbv3q3J75xEiqIQQmJMOTdEpfyw3ur0RFnGcfzy9fnrs0vHMtq97sHenu/7jBPDYJSzLMuKMncchxk0L6XMM8uyhCyidUkYf+/9tz746P31cjOZzNIsv7i4WC/nhDA/DO0wgINjuw7boSKoFUC4TQgBhLSbAQZnVSkl4WwnQAYGiFEDLiIQuXS7bRSeeFj2SbeupAAz4Xvk3SS+pJRhrLMsAU5VKYEQEaK0LKPbbXe73W6v7Xke54xSighF0JQrCikrzpiucnB/ub0dR1GUZ2UURUmSKoVc18WIbh96WVXVcrUhBAVB7fj4uNfrgfs5t21VCAIJDG489NSqKk2iyWQ0mUziOM7zbHd9iqIghCKELMvpdALfCxuNRqfb8usBUhUiRFWVlGWV5tDdq8qKUqaUnkwmZ6cX6/VaKVRVhUZ3Dit5XtTrdZAxAZsClJ5t24ZhQL1SVdVgMLgrJgjSUiKEMOfgmYEQIpRqpSpVLafTm5ub6XS+Wm++8pWvuYEvhOCGpTEiX7Di1X9u/hYjhBDoNnbbuCBWgiAAwhzfer4pLcmdh5rWWnLOG82glB0pZVCrY6LPL14Tiu7fvz8ajfr9vtb4eniLQGiPMbhFKCV3I7tkO8ELRxFKEGhPQyWKMWYMVgtIUELAs5TnOeNEVGpw0G9kxdXNkDK+mN5+6w9HQaNlfeVLrUbwxoP7g73+cDhsNWrf/tMXQoje3v7R8cnteDoeT998s5VGaRQl7Xb77Oz1N775R81mvd5uSynLohjs7U8ms8ntrWkZV5eXuwtGGZNCXKfp9dWVaVkY4zhO4zhVsvKDWrRZcc4RIlJojbDrBoPBwODmar1sNsOyys5OX7mue319XVUyybOnL54/fueRKCvLMIuqnE2mhmXmaQYBBY4hWDVCei6KyrM9rFGr1RqNRnA3b25uoJtzcRk7tpsXWcvuXF9fMcalKjnnrmsjRJTElPI8Kxw7zLNyOp4dHxwuFzPLoFqoF5//8J13347mV//H//If/J2/81+/feI7RnHw1n6VjFG1orgUeUGYgQRFrree5n5YM+1moxaMRlk0y29GsR10JutqE5emmyX5uNn0b26ePTxqdB95b93vqXwpVhcGrRApizJDVFOLIymkrrDtILNZZjyX3sVNcjvTXudRyZ3z4ai31zcJmU3HiKmgbmNEDJMJmd8MR5wy3w8OBvtxHBvclqJcraOD4wNVbUqRaEyfPvus1e1ohUshTNM0KIN5t2fPn4Sen2Z5nueWZdieyxiBpw4Sc+A7ZVmmaQZ4Zb1eg0Q9DMM0TU7PXu36GsCFlGV5dnb28uVLeIYfP36c5/nLly/b7fZ77703Go0BwYCB5/Pnz4FYyrLsBz/4AbQUXdetqgrm3ZrN5ltvvVVVFRQnRVF4nrder4UQQLSMRiNYUAjCc9/34Vx7ngdnZAfgdggMHl2gOaeT+Wg0AnOEP/qjPxoMBmEYglhqMplApgfNe61WY4wBQqrVaiDqByruvffemy+mMFkJV3U3e99oNMCzHryRoE25Wq0gkjSbzZubm16vB0Dt9vbWc9xdDw7GA0GyY5omvAJ4woGOHhoaoHPHX9gquF6v4zTZZWgoCMGSlBIOe7KBVtxsNuA6AX1M4M9g/8/t7e3e3h6gE4IwSLI45yASgiA2m81gNrAoCkqI4ziE0jzP2+02pRRwKjQQIX6CvBjkR6C4gpUAMFMJbx74QnAXg8+yWq2Av0FbWylCCMYahlgpo4wxWQkYZpqMp4N+D2MMox6vX79+5923YZLg4uLiT/7km1/78le4Z9/c3ABVSQgB5SsMIszn88F+X1SqUat/7zvfefzmm1VZ8r/gSv3FL8hHcI+01g/A0h3olS1+AnN8oK92xTk8D0Br4S/YPJHtnCb0zWB2G/ICoJGdcgu8QCEZ7XRHmCBgEYAJq0qZZQWj1DAoo0aWRkIozk2pMaa8225jjMu8GN6Ob65vDZOFYVCrBb1Oq9FrI42i5bwsBWjs4PZRSqUUYDuMMR4M+rbtnty/lxflZDK7urqaT8cKI4sbcVQx6HPD+9PbmUmE0Hq93nkZgP4OGCBq8N35ARyaV/nuuiil4NVs21ZKl2XlWjYlDCENM65aa84pY8zznCzLEKKW7WJEK1F4vmPbfcswG41Gvd4MQ58YBtIaSYnYdpGfUqrKCaWEUZs5CKE8iT///PPT09M0TUFfD/sHTdMqyzzP8Wq14ZzXarU4Smv14Fe//pfhaTMMQwpRFMV6vTaybNcYxhjDGPZms0nTfLmIAfEoJRBWSmHGqGGZjx+/3em0giBgjBJ4/qRUUmbxUm9tV8FcXiuMMeGcPnny7Pr6GqjLPM+VRBjjqpKcc9uybMvvtDuGwbhBXddtNGqNZhNRosqScI6wUlVFCM+zEqoibhgYUyGEKOI4jpVCcRzHcbzZbKTQVVVpfdfA7vf7hFKDUoQwvBuhFQFvb3DLBmCFEUJoPV9Mp1ODU0YxQFnMcF7laZHD+AznnDIYUUYIKSEkY0zICmMMfc96w5dSaqTyPPNDbxOv/+RPvlGv1/1amBZ35igcTAjvOvp3gyF5nstKSKkIRRwsRoTSGGusyLZdKJXi3GSMKFUKITKZM8ZQWQBdjDFWskKI7B30KDGExGmRi0p96xt/vNfv/vW//lcHvX6Z5Xmef/nLX55MJkGt4br+t771G73eXp6XQmnPd2Fyp8yyZvOBbVvf/da3OnuDoio//PijB/dPFrPJaDTaaf9h+gHkt0VeIISarVav14uijW07G8/b3987OjqaThcY8Qcnjxrt1tOnzxeLWafb/MY3/kAjZLvOt775DYTRfLH6jd/4zf/9f/afbjarJEn8Rjgtx5bphE6wnK8opVoi2P7baDbnsyVoDpbLZafTOT0/AzF7lqU7UUWtFmiNozhHSrq26ThekkSI6dls7jq+adqn5xePHr3JCU+SZDiceyd7BFur2bjd8OnAwdV4r6n+yq+81eS3/U4di1RHE5VtTN9Tm0SVgoQ1lOWnLz6rtQZmrbNYZKfXN5G0byZxp3WkC48T8903OoTk8eYmH7/81a8dujyxXapWz1BRmH4TFQgpYgUhUlle5Zpw229mlfn89XQ0w1npWn7fbu1tsjyNZ5IWiBWG5fmhL4RwHLvMy8loxBh7+MbJaHhbFqliIknWOU21xtzGksgSySgrLcuuMBfacBzPZVxqhRGdzxetVst2wvl8XhR5p9MRooReKrixpEneatpVJTg37t/v39zc3NzcvP3226PR7WazSRLmuq6QGtr0UACAhJwx9lf+yl+xLGu1Wp2fn7/55pv9fv/i4mIymYBFE1QIUOBBw6ter4O8Bmacl8slpbTZbPq+D4pyIHKGw+H+/j4kacjrYKy1I1RAmw+ScwjUgMMGg0Ecx7DSHgpjmHvaGYj3er2jo6OLiwulFCgst09UBoMdCCHAWEAFgSAJ3vmLFy9cz3ZdFxqC0GcpyxKGK99++23QJwG7BlpyEP/tAB8MDRBCoigCswkYV9Jag816FEVZloEDO7w4CNuBkKvVatDShYZar9fLihxEWqA/a7VasAMYfjWkOXA4gwUh8G1SSnAGxxiDlhcTAqwepVRLsMiGURgRRRGldDqdiqoCbA0XllK6Wa9N08yBNhMCI8QZW69Wvu9LIcqiaDWby8UCSlZwpuh2u0KI1WoFcMG27eVyqbWu1+sAKaDWLYri4OBgtdwEQRCGIcxV2I4lhQJDuzzPsyzLsxKJCoY64zguyhJhrJT67LPPVCUIRZPJxHGsosg4N2Fa0HEcAJ191c3zvNlsvj47V1XFOZdCYMrQds3dXU2OfwKwdr0/cKWxbXs0GgGiBeAL8qmd8GPb0YPV7HdsFtl6NEA/DV4QPF3heYYWs+u69XodTNcQErv6/u6NKUQIJpQppYq8rKoKIUIpZ5zHSVoJhTAiDJei0Ej7vqsQsS2bYJaLihrYMFicpNP57Pz8stVp7vX67U7Td10kyvV6LYSyTRsSEyfUNG2lVFHkS7CrtK233nzjrXffUmV+Ox7NJtOsyBn0+PUXvmCiAUxH9Naddicug2kaOL3ozvLqDpNCvxmijG3bjuMWRYGVRggpLXfOv1JWWmtwFZOqiuI1nJPj4+PDw0OsUVVVUbSOojXGWIjqi0yykHfN7KqqYP55tVphjF3Hb7Vad209ZhJCODfKsoTBY5h2mc1mnU4H4bsqpyxLpHWapre3t6PRCMaYofONEYXzjDFdr1IYgXEcq94IO512s1nnjolEiRhFUlZVXqXF7ppgjOAEYkxNk2FmIqURIqvFAgx1tNaWZdTroed5rusO9o4AwhJCMOcIKyQloljkeZ6loAKh6s7ynjDT8jwkUZYk8/ntZDLZbDYQrEFJhjHO0kJrXZbC933OjV5vj1CapalpWYCAESWArrasFf7J2K1G5+fnQObTrfUIlGK7hiCoH+BgEIKllJyzSgpCSCXKLC8x5aB59AP34vKSUtzrd959531E2e3tLUyL7PgzeKgwxrPZjDFmmxZCqBLF3QenVGx3I+z0DYxSgGhaaykV2rqwwKH1fOv09LTT3mu0W4vlptNslWUphIek+u6f/qnF2L2T4/FoirBKkmS5jkbjheM4UZS0Wi2tkBCCuXw8nnLTCcO61jJoNH7qp37qj//4m8+fvTw5OamFjV6vB61MUNr+3M/9nGma//Sf/tPb29t33333008/JYQcHx8Ph0OE0MnJydHR0fHxCdLs9dnlH37jmzc3N2+++ej169fT0eiDD99DCJ2enhKCwbPnT77xzY8++uBsNPY8r8yLNE0Dz18tFp1OxzTNMAxBtAsCYSml7/rX19dKqWazOZlMms1mkiRh6Od52mo1rq6uwtC/vr7knLbb7SyLpND3772RJFkURb4fFkVxPbo0TPrmo+Pp/NK1dFncXl0+bzd8xwp/5quHfushSmao3GT5TFDEKFrcXDT29i1NkSTEbg5OuknBn7xeXQ8jgYMPv/aL5uVIC4SkqPlydPV5YFcP7tX2ug8RWpbRBCGFZaGlLMYJN2zE3SoRpWKm34sLdXlVFRLNi5DXG0S7haBFITAl3bC7Thaz0Vh4MF/GKeZa4/29Qy2raBGZzFxFG9tGx/eOLq+uDcs+eePhZrPhNjVdDyPa6R/N53OFkOsFk8lEKXRwcJQkkef5nPP1eiWE8H0fNtt897vf/9KXvgTcvO/7FxcXoLaG7K6UgjZxURRCGkDHzufzTqeTpimckTRNz8/PYYTw008/BUMsz/Peeeddxtjl5SUh5NmzZ0qpr3/961dXV+fn53t7e57n1et1ICBrtRrML0P0gzYZ9GJ838+KPE3TwWCwXq+fP38Oku3BYBBF0Xw+Rwg1Go3hcAjE1cXFxeeffw6GL81mczwe79ROzWZTCAGad5i/A5UhHHN4A+BWNZvNoGDr9XoQrwghw+EQWCvYsQE0j9Y6DMP9/X3GGEjQwHABkAQIoYIgaLfbMAEDbA0QV3maUUqdu82ed9pn4I0opSDYBaSVZVmj0YDoB6gCRGDQMKqkEEKkaQoQLUkS+CB6OwIPwefx48fAFAAHBn1JKWWj0Wi323meZ9mdOyXnnBEKvD58M7hvUEqllA8ePFgul/BmLMs6OztDCB0cHFBKx+NxvV6HwTrQEgF0BlxblGWe5/V6HS4vYLtarXZ9fV2v1+v1+vX19WQyyfP84cOHoMp67733/sd/9usAsIBiNE1znW18xjabjWmag8FACoGVwkhzzm9vb+u1RlVVruNorZ8/f16UCeecc3+9XmuNCWEYYcMwXNedTCZRFNnWnUjm008/ff+jj3a0y18UuaOtgopsvcQRQvv7+5988gl0sXasDd6ansNPka0F5u5F6NYjU2/l4JAaduwU3L6dAhIIIEAd25yLldKq1AiBdQL8njvlCTCIwIoBNZDnuSglnF9KKee0SLKyyolW9Vojy4onz54Xn2TNZvPevXvNRs1wHJHESimtShBfwlPkeV6apoygaD3PysK1zMFBf9DvrNYrFsepaZqWddciBHmy1hpUjeTO6VEKIYUolVKIMgBbUkopNCaEUAIKKogFcFmKooQXNChTUiohMcYCV0qpPE+FEIP9fhiGvu9yzuDxhWvHKTUY9V3njhTFWElZFBkc0TSKQfKGEDJNsxHWHt5/2Ov1DNdHWCMp7xADQoiQu/lBfefwOdjrI/AmkAhsgtfrNZjH/MRivhJllhNCCFKeY5mm+cGH7/T73Vq9ju7sQFSVZ2kUO46VJ5HWmnNOKfh5GJRShDUiFJcV0mSzTubz66urq2iTMMY833n8+HGzWW806pbjIIIQQlpUSqk8izDGOtNbvZr2PI9xDvOPVVYwStI0ffHs6W5UDbSf8AYAL0JkrNUapmkGQdjr9XzfNy0HEWLbNtoK7JRWBBNgrf7MWdEIaXRxccEJdhwLNh4ihBilURTBhIPBGDcoHAApJcZECo2xhBXOGGtKMeGEULaJIimrXq/3x3/8TYC5WRmHYZhnBQgLCCFY3023aq0Xi0W9Xq8FIWMsze4qckyIxEorTTjBGsMmZqU1BS/dOwcErjVmjEObMknTt955a3gzHo5uZKUpIY7tCUIRVvEm+uzTT5er+Ycffsg5N7hFDdM0/Vqj8z/9+r9QUsMY3c3NzXg4tD0HIfThhx++99573/rWny7m80eP3srznEidF2m9Xi+KAgYRppN5kiQfvP/RavkH//l/9l80m82/+Tf/16JSzWYzzWLfD5VCq018dnp1dTWshY3Do3u2bb589QRh5PjeDz/5pKiEZdlZkq+WmzhOGGZEE1UphpnlOKEX5nnJqVGkBUWUYTYej23XRQob3IrjTVFkCKEoWh8fH65WqzD0iyKzbTPP0263XZTZ3l5vNp+8evWi0+lsVonnBE8+fxlF0YNHb8xmE69mmxyl+YLSbDQ+PzqqDzot3yW2hTbz6/JWiixxPNN2HYQF4oyKElEsiCWVM5wUy0jNlpnj7RmhGS/Szz659j17Nb+sysnhnnfcY82QmmQTLxeeZyKl8rgyTCMSm1qrhjQVSplGU1XW7USNVrpCHjJDxSW3rdVyRhluNOrRIiaV3PcPptV8uVi22u2yFLPxshE2fLuxWiyTNArDoFWzV9FmE6W9/iDJs/FidnV19eF7H80mE9M00zwTQtRqYRJvbMuI45hg6djG9dV5p9OhBFVVcXY6rtdD8KTmnE8nM4SQYZhgJAZm369evWo2G/P5PAg92zGT5G7dwv3794EyAU5is9l0Oh0wSTEM4+bmZn9/v9FovHjxYjQaHR0dEUK63a5hGD/60Y/AIOr29vb4+Hg+nwNK+Pzzz4+OjqAnuEsnoFKHChZtO4b7+/vAJzHGhsPhwcHBaDSCjU/r9RpOlta62+0GQTAej2E+A7a7JHGGMb64uAC2DOAOiJlgF5DneSCib7VaYFexXC6FEHt7e7ABBj7gar2AZANVNCAbjDEkITAlB/uJoiharRbU5FmWAZYC6BaGoSir9XrdaDSA5AZnY2hxkq03Nch8YdRJKeV5HuzpA4UT2IqOpxMw6AIe8erqijHW7XabjfZoNKKUuq4LOjBIc9CWhdQGighCyHq9/uIanBKcJKsqSZJ2u22aJiUk8H2QuCVJopSC4RLYqw19Ltd1Z7MZeGQURdHv95VSi8UCJgbCWm0wGMB8GMBTQKugys+yDMi5q6sroCQuLoowDF3HUdvJM6hFN5tNlMS1Wm21WN67d8933Muz03arsVjNx6PJ4cHRZrMpioIQrBB2XbcqyixJgRVL89y2PYywZVlEozSKA78mpQyC4Ac/+MGjN9+0bFttF+38+76gbwuqkuPj49evX8MbA8wEBTkkDoAZeqvHgvgPfU+4zmirIdlV8qCjB5ISELBhMMexwOq9LEuIgbbtAquk7hyzEEKoEqKsZJHAenIGiheNses7eZ63WkEcp3meE0YJo0JJygzHNtdxgrF2HEdjMhxNr25uDcZ83/3Sxx/W6g3DxdlmA2Baa52mKUibCNWubShRrqYjSpDJOev1etDxhVlQzrnWCnqccKRBQQW4kjGWV2Kn/98Rg/AFzzf8GTAQIVhUpRAijjeg3dvb23v7nQ+Pj48x50iUWiuE72yWCGMII4QIUkqV5Xw+B+SulErTOAzrhsEcx3v77TdrtQZiBGGKMIbvF1mCCGGUFmWJlDJdFymFKEVKyarK01RooSo1HI2KolytI2iAAii2LQu2UxGCMGMIqSAI+v1+v9+3Qx9hgZCWZSaKEp4eISrGKNgibJEZwYwjRPJkAyr4s9OLLMvLsnQcr9/vf/zxx55fQ0SDwB8hXRYpnCWtJaaEG9SwHSQFogwppJRK4iTNiulksliuZSXSPMuSO48rWN4Hj6BUlUYEE71/sGfbdrvdPtg/IoQgxnQl8zy3HadIU9N1tFIIY5ArCq0Y3pYI8F9gtLSYTsdg9kC3UzAA4KAIgL/XWmKMtZYIIW5QKQXCSAiId7IQGbrzhmV/8Pu//3u/93tf+9pPE0KKNGP8TmsFDwlBBIhDKWWtVgOCnXPu0TvHubKqLMvRWzM6aInCU1ptd1zQrVUgaF7TPEri9N69k4vzK+igWYbJKJESYY3Ozs7G4zE0Hfp7eycnD+8/uHc7nlsGByWvadYbjcbg8Ojm4vze8YljB1fDq+uroel4vh826q3p7fDe8XFZlpUQo/nk1atTSikh6Ojo3q/8yq/8w3/4D//BP/gH77/3vmEYFxcXh/sHD45PZrNZtNhooTrNjkLEsqzeoH9xc4oMjik5Pz/XSimJTMs5Pb/45je+9fjhG/V6g2KcJIks8ukk6bRas9kszTPLcpbzWbNetz3r9euXVVU9fPjQc22E0GKxODt9pZTyfN8N3L3G3mw2E1XVaDSkrBih3U4HZATf/OY3P/zwQ0LwcjV9+Pa94c25FJHBciTWX36/32s76/k1Fmg6nDdrvooyp+aqIq9KgTkry8IIOym2R9OccG8aG2luDo4fzhaZYwWUFTZDl6ef7nVZe993jHWvbSAZF9nGYkTlkips2B5irNYL42hFuIlpsElIVhnLFCtWs51OlFdC5TXHJxQtFxOipO85VYZkidr1PjcM07QCz7CZTQhZzldao35vgDFmBg1qjddnr7ygKqUI641ut3t2dtZpthFCjGhwcsIYeZ4beO56tTQMNuh3Xdd1bfP6dvj48eP5fJ4kCayOeeONZlEUWZZDJAR6A7pgVVVeXl4+ePAAqERgZRqNRpIkoJFoNBpKqTAMYcPM/fv3Ybrt/v37IA8HHTqkdvBkr9VqEIdh2Uuv1wOgs8Mx4FyQZdlwOOz0upzz9XrteR68yHg8hrE+6O9Ay3IwGAAxX20XS6/Xaxj9A4sB23LzPIccD95CzWYTdjSBq/vZ2RksoobpVJCfNhoNaE6dnJzAWBy4G8Bn320E2ZXcoKZHCAHjDjaqoJ0CvLjTpWB959gOfBv8uvl8fv/+ffALnc/nsBIb3zk1KvDN2s2pAWcG5p+UUrhBX/rSl+bzeb1eXy7W4MgFUQVgHLTGAPDBcA/YTNTr9ThNYMQe6JM4jgPPbzaby+Wy0Whs1muEEHBdnU4HHFPBQpYxBhQa6GjBHoJtfbOUUrZtHx8fl1W1bX1guCZpmoLSHz4aTDsGQQAKkNF4+ODBg0ajkWYFN6pGs52maeCHSZLUmw0ppZaScy7B/1kKzvl8voyiBICOlApRIoQqRVVu7jiUIs8d00FIm5y6ni1Elacx5abn2KPJdLNaWbZNENJ42xz8YlWuNZBMELohUwA/t/MYA+CFvrCxA221WQArd+lsB6ogqsutwdMXIceW36lAJYm3vozAlWw2sW3bBrcQlkoiQmG7jgTuGTY5gphVCJVlmSil6/pAi5alhLtclMI0OHBgcZxKqWu1elXJ6Xz127/1O3t7eycnJ4P9fUSpSGOQZhJClNJKKthrYhCttZaywv/jP/sfdtop6EPBdyOs7rpyQuyuCEJodxh+oljatlShDQdzs1prjOhqvTApCUN/f3+/0+n0+31iGHkcE4KrqrJsgxomQgpJEceb5XK52WySJAMCEJg34Ngdx+KWi7RAmCKkESJaFErddW0RpoSxn9AxCuV5tpwvKykmo/HteKSEnC1mBjOCIMjzEgaP4eZ5noeVBHH94dHB8dG9sBZgzhHGSIiyyDSqDIPneQGayizLXC9ECCFmIKWQxkWazmeL6XQ6Ho+XmzUhpNaodbs9OBiWbSOEpBCiUnCzt3h/+2aVKkRFNJqvltFqc3F11aw1hVbnr0+5ZbuW7XhBvNlIrSki3GCirJQSeZ47rmXbtuvag8GgVqu5toUMA0lZbMWkRV5yyzatQCOGMUZfaJzD7VTb4VtALUKI1WL53/3j/0e73YaCGGOKEJrNFt///ve/8pWv5Hkehr5hGFJWhBClJSFEiBLmt6F5EccxM6B9QM8vrv7JP/nvf+ZnfhZGTbXW4+l0PJus1+tmswkN0729veFwOJvNGCZHR0cAYUFdFMcxFBwQpuGcABWslErTO7m33u6rh4EJtj3P7Vb39vY2TTO43UEQdDptmNnBGN+7dw8hdHM7fPzWu+9/8NHV5eXwduy63mazadRbGOPf+K3fjKL10dHRi1cviyRFjP71v/rX2s2mSDOTG8PhcDqflaLqdDphvc44IZr4vvu973zXcZzB3l6/0/3jP/wj33F/+qtf+cf/+L87OL7/9nsfJWU5WSxc31W0+uGPvpNm0YOTox9+7/sUEyQJIwZjZH/Q+bt/7/9cc/14s3JMsx66o/GV69qe50mpGTWystRCKF3mRWQYhu3WVssNDGYojfyaL5BeJWtmmZUoGDVkWbWCRrSIqKaWZUmKbdfyHfPq8vRwr1Xz6MXZj31bHR3UagFhpCizlRIFI7BqW3HLQBIlWe4220rTpERRRjYpnizKvDTC2kBrq9nYW8zXhLC9vdrTT/8osKv9lrnXoAhtVDpTOmemiYRGxECSIGqmaU5dv0C4Qq6S9ZevJ4U0LK87X1dpqQM/5AbLs/V8Oun3Wp127/XpBTHcssLM4K7Dtayk1OC3+erVq8ePH8NA7sHRUVFmURTdu39/Pp+Pp5NWq2UwE9yh8jRbLpfz+TwIAigbiqKAXC6lRAiVZWk7Jniag7ocaAbPDfI8N00rTVOoYQAD2bY9n8/DMJjNJ67raq0BaS2XS+gHUUqLvFqtVqPR6N13302SZDweDw4OoOMGRgagmJ5MJiBYhjYlWCFAWMb6rogH/HF8fAxaJUQwvH9Y1BOG4XyxqKrKNAyQacP6LOgqAt4CbxEY1oODA0kxz/MoigB9Au+lt7tuwjCcTqcQ0kHhBItogNKDcxfHcafTAdUHiPdBAg9mPSDJ6na7YOA5m82klJxz6EKCKSXMcYPzFkQA8M0CTACL/CilkKHg0gHSlVIalokxBlkbVFkQVyFKwKshhGCjM9hN2bZdFncboHeaKnSnQ0C7LhLGmBCUpqlp8Z2uERjEqqpAuwYtTtAGwUwSIWSHRKMoAv9teIcIoZ0wH3q+3W43ibM0TQGaz2Yz0LyDLxrefu0YoKOjo+lkZNv2t//0u69fn+3vHxLKnzx5+u3vfG88HtdqtSSJ4s3m//C3/9Z8Mo6TjZbKYGaZ5Q/fOHn48GS5XHJOXc9RotJIerYDdBGnjFIOVy/P8zTPfC/klmnbzs1w9O677//CL/9yWRSGaVZCQj25Y6f+HNja/fnZs2d/8id/cv/+/fV6DVhWbh15dhTs7haA6AquJ6Af+ODwpO0g111ZTghAJeD5YCwMeoidTidJkiRJbNslBGmNbduEjSxATAKkFkIIURZFBXcKtDrQtQN4DaQU3CxoDTFGWq2O61hlmY+GN0BMdjqdk3vHYRgiTkSSlmUuK2GY3GC8KDIppe2YbNcoBTgFF86yrDSL4e8ppYAQdyp10DnqrWkYcHRaaxD6UUqTJOGcC1Hev3/81hsPg8C3fR8JgRhDSFuOjQgxtJ6Oh5PJJE3jLMuKIjNNs1ar9Xod1/WDIOAWbAXWSGuktapKhBCMC8ABoJwgrTGhSOkiy5IkWa+j9Xo9ny/m8/lysQbptNa60WgM9g7zPCeUmiaGYwbCr6qqkBT3799/9OiR5dqIMaS1yDIpK7ipQlaYUNtxkNaEmW7NQVpXaX5zerlcLhfzJUxKN5vNe/dOPmiEfhhYlgWSwN0Xxth0TISwrEpwUoF+fJZl8+USql6EkON4VVUhxIQQ9Va73+9PxrPRaAReZev1ptfrttut0Pf8wG02m3cEGOdIVHma6izZIn2ttTJMzo0/8zbusNVddxB/EV1BfHn1+gWoLuDOYqwxxhjrRqMmhCAEmaZpGKwoJUIISVVVFSEoz1PGaJrGGFPfDxerdb1eX602//0/+afvv//h4eHhv/qN3zo5OZFSVVVVq9V2dQ+sRYvjeLFY3Du+V6/XoUsCyzQg3iGEYD07ZCyoJi3Lgkp9p6/c7h5p5GkWbZL6XjOO44ODA3A4Wy4Xtm0BnjYMY7lc/vCHP9zf39/fG7x8/nS9Xt/c3A4Gg/39fRiEqUrxq7/6q9/85jcnk9nJycNGo+E4ju16RVUVWV5VAlG6f3DoeZ7ju1mWxZuNazvzyfSdx29+84+/IeMsm60Oun2G8Px6/N7Dx58+ffnk82fvvv+lvaMDp+bOluPxaPjo8YObmxutBGUmJpRixqlxeTX6jf/fb/8X/9v/zXJ02Wy2F+OnJJv3u3s//N7vm6ZtMg9jooVotXyfS5mrKuVNK0jSYjxfNLuDZtB8cX4xOD4ppdKYKIXi9UZjFjYboettVkukMo716YvPui0XFzeK6C+92QpqBqqWIl9jKi0kEcVKorIUjBublQgabdcy1ps8KXWcojjHheCHB2/929/75sXp+td+7deePf+R79lFll6d5f1Ovt+xQ4uq9UQkC8NhxHZRVSBqINPOl7nlW06zkaw2xDBvzm5MU6mstE1DFev15LrbH+gqGV+N7x0fViTF+TqaKYtTSfVkPL334KTI0sVsYhhGWeaDweDDD9+/Gd0qpYJ6kOWJ1rrdbi8XC8s0bdPyHHc2mU8mkyLL4da/9957kJsvLy8hT4NkCuCC5/q1Wi1JkjAMX79+7fv+O++88/rV2RtvvHF6elYUxQcffPDZZ5+t1xGlFKGlZRlAVoGBJGwntCxrOBxCSwhpwjn/2te+NhqNlFJvvfVWKcTt7S2YYUJigB9XSoGLQVVV4E8N/M16uYJpbkhFoOxer9f3Tu6DOh4UnLDIBfh4KeVisTg+PoZzsb+//+LFC2BZlFKgPoaWlm3bk8mk1+sppWCiDSEE6R+o5el0CloTz/OgnTefz1utFvwrwFAw1oLiB5xFCSHgywBF7K4oAnGnZVmwfzpJkvv37282G+iwwPgkYDsAXoBa0jixLAshBPJNx3HgO8HdABFcbpdAQxPNcRwg0rYNB1Gv16EhAy+YJInBLcjTu/YfTKUhRNjWWFspBXs/CUWLxQJYzMvLy51PB1giA90Fq4e01uDpBWZggAWB14G4By6yt7e3IAy6urq6d3yCEFoul3crLJMEOqoQ2eA9Q8AUQlxcXBic3t6Oe729168vpEKGyfNSXJ6d+bUaYD5mctu2Hd+7Gl71Oh2LOVmcvXp52uv17t9/sNmsOKdxEiGls7LA6q6rK8pKlIXjOEKUBGkhS5/7UkopytevX/78z//8jluCNLLjk/4ipwVfsPMAdPqmaQJ1BOAVxKO7BZGgsYb2iNpu1QSIbHxhObLYWk/DxYcfgYc2CAKgcpVSYFq0E0iZJgcYUBTFrnkNFbveTjwAhEJb/yCgjQAZQ5cJJPZSyjTLlotFrdHknKdpenFx8fz5c9d2jo4O3n/3XWaaSMhos0qTrBYG2DCqNL4bfAApD6igoM2542Bh+BaSMcYYfL13WrMddwesA1wRMHR599137907urPLEGI+X6zXa9hpVVUlIYQyHARBp9Oq1WqmyQ3DYIaBNIzuqyLLIetTSrVGUiFumghhiu5cZbUUm010enoaRQlEK6W0aZqMGgSzdrtLCNkarkjDMBgz4KBqrTGp8qJSSj18+PD4+Nj2XVkUWZZXVYUxMhjj3CSMIYIosWSZK6XW6/VstpjNZtPptCrvJpBP3njQ6/UszwMctXWNJ1oIAM4Q1DDGMEUPgRj0qsCO+rWw3e4CSCWEWdYdR4gR/f73fogQghlsy7Lu3z85ONj3HIdzqpRCSKVZJmSJNSqKPAzDolBS6m1ZgU3GtcZb/90/3z6HswHPza6R//lnT1utTujXXNtTShGMGWWB57/5+A1RKU0pwVorWRU7EZVkjOV5zrlp2y4YYRBC5vP5b//275im+Uu/9Evf//73r66u2u32wdHRYrVcLGY7VASj4FrrVqsFE+CwkgI8/WCiRykB0+AwP4G2VeDOphmuMAhpKaX7+/swlw4lESHk4cOHeZ6fn59XVfXWW2+FYfjxxx8/e/bs6uqqqio/DJEStm3+y3/xLwYHB/Va86133m40mo7j/Nqv/SpcHJjDyoo8LVKvGXDOkc0xxmUlZBIzQtvNRhbFnaB+sL//5Hvff/K977/x4OHHH32UbKJ4NnvrwYOTw5PJYvnq8vqHNzfvfPj2ZHKjs4IKMR8OsdBaS4opIYoiKjP8/JPn6Xr5zoPu6OL79zoUiUV89embtQpX2sSuxS2FBFrklolyWT27GHYOTvrNbqFXLcudX3/u8aBcp3nJg0arqKp6WBMyHS1H2iZno5ePDzoqmb91Lzw+bHgOktmMyhglha5ypEqMLV2qUmjOTcNwEHW468/XeLZYI2bmOUoL0u3e++EnT3Sx+qt/+a+tN9NoerqZfNJt9L268j3SrrliPUMxJdww7BqSFRIEmVau1HoRd/v3r16e2yhq7R+++N63y1VkePGDeqtURaG12606nbwsyzYqPGNc3yd5lQwno3mqWvtv/PzP/czr0wtOaavVggy9Xq8vLy87/V673Z5MJlChwuT8kydPHj1+DE0KcF0Hq6coioBaoJTCtBoADgiDo9HIdkyQ+kIV+/Tp0+lkrrUmhAJ5Y1mWEHebdynFlJKz89fgbnB2dgaACWwkDw8PN+u41+vN53OYXJ5Op5hSsEQCfAOLwKG+evXqVb/fhwBrGMbt7W1Zlq1GE0INvCXLskCdA+4MlFJggiF7dTud9XoN6ef09NSyLNisCscByKq7unHrUAqyLc6553kwoggDjHEcQ9ECTbputwsh68033xyPx2DXCe8cJFCw2gXcQ8AHAbiKe/furdfryWRi23a9Xm+326vVarFYAOsGHBvM7fZ6vaurKyDYKKWAsWBwR2+XQF9dXX3wwQebzWbXdZovF0CGie1aZRjsBw90IQS4Ye1IBMj0cHPBawpMECC2UIoJoVWFtupsMBAvwQgehgdbrRbs/gJMBgJ8ICBg5yOAA/AdhUAHLAalFLYMwZzp5eUl8J3Q5IWADPrUWq0GC4JgmxAAaxBp5Hm5v7+/XG1AaF8UxW//9m+H2+3daZo0W03w7LizB8sVePT8q9/614NBf7Df7/U6rVZTlLmsBGW6hB3IRWGblmEYddPSmJSFkFISzuv1+mg8nUxG3f5AKwVO2eo/uDwHvlqt1t7e3mQyAaBMCIFbI6WEGdXd4kiMMdwpjDHgS2iwQkdYbb17dqhrW/xjYGRAwAcOR9DkBctAcCPb9ZEBdkPXHg4CdDPh6O1k8pAHgYbcye3BZKQsS9e1gXIGfisMw8ViniXJ6fnZkydP7p8cf/T+B367g6pKFDnKi6wo2W5yAfI99NGLopCqAsJz96nArNwwDJjOpVtrK7RVscETD8Mg8FRFUVKkyXQyms/n8Hls2z45OWm1WkGjsWWnBCJkt65FSUSYQQgymfmTVS6iIoTnabFcLsGSCpSkwJZrrTkzTcMxDNjESYuiUFIXRZFnlVZEKaU5VgpFUcL5HVJ8/Pjxe++8iw2ax3EW3W3ZsyzLME1EKEKqiOPojv9YRlEEgLper3/5S1/b2+t/0ZpBFgXwn0rpy6ub29tbIPPgRt55jtk2HFqYQ+Gcw/THbLnQWleVhOcPKki4sO+///7e3h5YqmBCfuLvpqUSAiFkGBgTFxHiI4Wk5Ja9c7FHUiJMkMawyvovfgF0AC4Q2uEwxW1yDncToHNRZovl4s6BTINnFYWDQQjRmiFEHMcpilJrnab5arUybecP/uCPvv+9H/6Nv/E3arXa+fk5jEODBAF2coHID4atEEK7sfB+vw/Ktvl8Do+7aRqwOg2WzoIND0gZ4O89z6OUQtiazWaOZR8fH3/22WdAtcLA0XvvvddoNGC9PNSylmUdHh6maQoO/o/efPNv/K/+xr/8l/9yOp1+9tkn3LRPTk729/ePjo4c37MdC5w/MSWm6yCEZI45oYwQhhFRWknZqTdVVb568qQd1Ac//fXVYqnzEpUlwzhaLoTEe522aZq3swnX+ub01KH8+vQcSQX+hJhQSpCUVVCvff782Q9+8L2vfnBIsGjVw3Q57h92PG5QRXSOijizLLNMNoaLojjyayd7b39UluTo0SOvc//sNv7s+Xh2O3b89ve/8ce/9Jd+2TBxlCdFVv7o+7/70bv3e0HlUd5/dJzfvErGS9cmSiSEEoxKRiiSGDOfU064ozFbJ2i8wGfXs/3BQZmJm5vbe8cPQr/eCcN8NZ1cCs7y0JP/y1/+gPAY46goljpeo7JC2kSCIYWQYSNuxqX0moMMp5fD4vNn42w2/cq72WY0djh2ynl6O1+uV16tVvPcp9/4E8uyGu3Wj77/rLt/7+jk3cwWewfHL6+GP5itDDc0XO/o+PiTTz7xfR9WpmR5DuDj8PBwPB53u93FYtFqtUBhyQhrNpsY4w8//BCCJnQigLUCU9+d5BSgPIhvHj58KIT4zd/8zZP7D/f39589ew6ORI7jHBwcwJoahBRjDPo7APcJIc+ePTMMA+ioT3/8+cHBwWw2A1jQarVc3x+Px4vFotvtEkIg07TbbYgMUNyD5PluWzMm0+nUsizwQgM4hRDClIBbHsRhqCRrtdrp6SlAoiAIwOQpiqIwDC8vL3u9nud5o9EI0B6wwo7jQNuxLEuYOIERtn6/DxuX4XjCFVZKff/73wfiGThmmIWCPLozggdHJRjEgeE44LFAnwT0M2hVpZQAjyCH7dxPJpMJRMJ6vV7mBRCNRVF8+ctfns/nAI8QQo7jgKkmCHzB7Bf2FgRBMBqNoBUFPw5RCNIQ0gQhBFPAQB/sFO4QjXe6zzRNKcO2bcPLIoTACA0qf7r1EQCfDsuygGLIt4tNwbEMsBEkVvgnALhZlq1XEYCq+Xzuui6QkfCIxnEMSAIQA7y9zXo9m8063X6tVvN9/5//818vswxc8sFsAmk8Go2Gw6Hv+xhRjEmaZI7j+H4YRcmffPPbcbJ5++03f/5nv54Xue96pomZwbXWGqN1tLEcF5L+ZrPxwjAIgsl0/sknn/zq3j5GCFbmKHkHsP4cfYW/MBWIEHr48CGQrCCDg/QHj7fa7iaGpxcuCFxVwKmATXfDZ5ChdhIuANyQkeGwAEe1Q376C76JQHpBOz7Lst2p32XbHYaDP8BthVIBhLnQRqSUSnk3CwkLADDGjUbjaP9wOpsYzHz29MXrV2cPHz589PBh0GggggLLxv/v/9f/Ez4GAD28XS3nBy7ars2Bk6+/YNkAfwaG7SfiG8bgOQNZwHg8ZowhKYIguHfv3qNHj8JaTQoBn5wQIiSovuA3ltsSxKGEV1UFU37A9BJCoEIFIAnoBNK8JiBQIEoppIlhGJzD2kgBDy4wtNDtyvOcUgIZ+uBw8MbJA79WQwjdebUjVOX5YjlbzOZAXOd5jjGt1euuZ/d6PShK8qycTEfwcGw2a7jB4P+bppllOmmaw2GDMg5sLwAIQxW4q2y01pjRoihEpSAlwE0Fy4nHjx+DrA1sP6tKVFWl1N0GAG5Qhu9MkzHWAJTh9S3DjuO43W73B/uEmRr9pALYfemdcQh4HzD26sXLX//1Xz/c3ze5YZpmVRUAsNbrlefdCUjBoE8pVFUVxkRrNVtMDcMYjSaLxYIwZlnWcrn6/d//w/fe//Cnf/qnhVD/6B/9o9F4+vHHHwNLen07hGoYfjVYXTPGPNuB5/vg4KBWq/3oRz8CvafnOY1GY7lcgsgAbM2hkoNnEiIL1KNRFHVabegXgPQVHOparVaj0QAy/0c/+tGjR48opZPJ5P79+8zgl5eXq9WqVqt/8MEHv/07v3t9ccEtpyoKbllBENTrddjxzDmP8rRUEjYDYq2RUK5p2cwwKcnW0WIynQ5HnWZjdH2TbKKf/dmfLYu8KsqiKqXC3LRLpYNGTVP0//n//g+mQ1fJijFaKakUMg2bM0sRRE0jL5Kvf/ze3/5P/mbdqgy1DoyMipiqimOcxUXou61mLYkXmJTcts1GX1I/U+Zwnl1OkkJak8mm1epwSiwTcyoIzhwHMa6b7aDXclE64UTl8cYyLVmklCEkS0SR1IharhSUOp08IVc3USWtKEGFdruDY1kWtkm1zD//8fdXi5uvffXdvXYo5ZrgzLaxquKyStzAUlUhsspwbWRyVBaqFJgHufama307FYbd2KwTmygUj0OaWeXcY8LQUklBGC2F4I6lkPQ8Ly+K2WJ9/PDtDNlPz2b33vmZ0UZ+/npUYEsr5gc1zvl0Oh0MBkopzGie57ASZG9v7+LiArgKbhhZlilxF5dhBUq5XYsOmQxIoE8//RQMhzHG3KCTyUQpBd6Ph4eHolLATnHO9/YGp6ennudBrhVCPH/+bLDf33FLq9Uqz0rDMECHpLejUoPB4OXLl2EY+mEIA0DL5RLQSavVAn06iBlub29B7IwQsm27yHJYKA6098OHD03b2kkyoEjYbDbQ9XMcZzKZUEo3mw0YN0CvJE3Tbrd7fX19dHRkmubl5eVms3nw4IEQAobv4BvA7enm5sZ1Xch2EKsh1cEHAVwFYCgIgpubG0opLLwHL01CCDjRg18XpDelFBBvkK4ARYHuG2RMQD5FUbRYLMD7gDEGVuCcMoQQqPjBcAdeEFYQCiVrtRqsAoSQC/GNUgrDyxDc1us1CMggc0EndzKegUAThOfQpQJGhFJqGJaUVRAEN8MrcEcDkx1g0+HjQNkMvCbkI9ggBDgS0iVgI3gSvij5gm8o8gr8SKHnCBwMcK6wQhsuNd265Ae+r7UWUp+dXfzGv/qt3/nXv9Pq9suyFELVasFisWi1Gv/Jf/q/m8+nl5eXq/nK5DYI9QyDUUqELIUopaz++l/7j2eTMefctS3LsjilwL0Bu6kxzbLMdXADBnoAAQAASURBVD3HceaLVZ7nf/tv/1eYMSkEZUwqCZ/o39cfRFu3hd/93d/FGMM7B4MnoFrR1vUKIQR1PhBau6E8hBDgCkhq8MADZ0G267EB/YBPGMAPvR1chVeDMwUPG1DXcO+gh15VVRAEO+S3IyPhUkMlBuIwyL/wEeJovSNHLi8v5/P54eFhv9/VQhomT9M0jmOkNBTwjx8/ZsB3oT87D2kYxs76CCDUrqsNHxXeCujvwMAe3g20gcvt8ibXdTnBVVVdXV1dXV1tz5VZlvnuEksF9rh3Dq0Ec8YMSJw/meffri+klHve3fhrVclSCnjDnHGCiZCyKMqiEFVVSQEtMIkRBbGO67qex4qioFRzzm+H49OXr1qtVr/fB85Zawn+oqKqGCOcm5gQxvBisXr58qVpPofQAMNEZVl6vgOyOMuytEaGYSKEMeL9fh06u/l2wyM8UsBRQXgFzB7HceDXaO2OC4Tpth2J+I1vfANcleFg+35QliVC+q7XzhinFCElpYRRI63v6FCK6Xq9/uADc//Y/EJF8We+4GrDEwzw6/z83DCMqhCMcMBSmOgoLpIkKqsUZg62YYgnSbJcrrIsO788NwwGjrphGFLKfvM3/7Vt2++//74QgtI7ySrA7vF47Aa+2logwikF7lBv1X4gXYTOd7PZXC7ngOPZ1m4EbqWUGh5LCHZALNu2PZtMwZEZ+P/j42O9VQeCIeHXv/71y8vLvb090Nlw0wBqYT6fv3r18uTe0XR8W+Qx4WaVJfMsmc8nr54/4bb57rvvf/mrX23WG4gwkzKGiMm4zVm+iZP1ZnI7klXR7bUdy351fra/1xdYKYbyrGx1W5XQqyg2LLMQxfD6xrKMNItN08iLUmKEMNJUS6w0xoZJLGxc304EtolZc+3O5cXnWBn3Dg6Tqrqa3NjafBnFjBtFWbbaQZFWo8mZX+sS7lXaMg37vXf3iiyyTURVFEejQdc7eThAqEBVks0vOcuR71IdIS0pZ3lWWk6oMUGYlcg8H8426XUl3aKywnrLqLnJMvP95tXVayHkYnKG0fIv/fK73aYtqzGmGcGCKEmpyuMkX5WmaRm1jog2WbSxgoAG7emiOrtcjmZycPju1XCeZQVH5cdvPe77uJhdleuJ32tHt9eYUlSVqZIY49NnV4Zlt9p7cWVKaj96+6Pz2XK8loVEo/nUdYIgrIOgFVLX6cV5o9HY29sD86FOpwPZlDK2v78/GU0JIeDBCEQysPVQht7e3j548OD4+BgO1M3Njec7O4k6RPNXr15AhwgQxvHxMYTvy8tLSsk777wTxWs4F7CmkGAGUip4TVCH3NzcQBnw+dOnBwcH3W736OgIVjtDHQybM16/fg0iEkD/6/U62mzg+MD2niRJ0jzbbDa9Xi9NU2hzQ8Kez+dxHN+7d68sy16vt1gswKcA1GBwml6/ft1sNu/fv399fb3ZbKDN12w2HcdZrVb9fn86nb799tvX19c3NzeQUR49egQGBDD6Z5omkCvQ1wOK68WLF2+99RYAHULI/v4+nFMQme2CIeRjiJ8QxHaD98BpIYT29vZ2OBiU4F7dBXwJmjnoAJydndXr9TRNhbobXQTyryxLEHKVZTkcDoEKqqoKPF0BfYLeH3wZ7wTHaQrgBpI6vRtbo1JWSRrBWAMASiin4UZAQQguDOv1ejAYzOdzsOaCUL8zXzAMI4oiWDsIRGlRFDAMAWGTEAK3AFhDKAXBcnbn3QWoBViPsNZqt9v/5t/8bhCGYDdqWRa447bb3ffefX86m3S7/X/+z/95zaOYMFEpxnGZ5UBCFUUlpCaMR0kqhFgu14SgbrsNfl2TyUQoBRcKpiLm8/nFxcXxyQnkjv9ZARba2rvX6/XLy0sQ2oKHGRQ20CTZIS24kkBcwX2Bbwa91A6mA2sIjVrgLAAeAa7Y4RPQL0IvD4b94boBVwrftre3B28eqqBdpw6aeCDSAvE7nC9IkVrrfr+PEBqPx2mahmE4GAwQQptNHHq+wc2KKdNWjunEWfzjT588ffmSwXOptpOiZLvQBhrDaOvFAJgAJP2gnvni1QQ4ybc7gIMggF1aZVnm1Z3XKsj9GGOMGZvNKssyyL5VVSFGwIgrz3PCrKqUlagIM1zzznFYCKExRhgprZXUQlX4zlkfUcoJZZhSJaVUSGsFHC+cK4S01IoyZprmerPJ8qRer9uWA8p01/XH0/nl9dAw2W6OlJuW5wUY66qSVVVQSktZOX4ARUyWZZrQoN4Yj8fMsKTGGGOhUF4KSimmpm2YCJGyFJRy3zcBj0dREgSBlFprBP76WmMptVJoNpsDooWgDxhlNpu32+2yBJ1bBSZPcPu5aXDTtAwT7o5SsiqFzMssy7RGrmWbliWEMi0nCOsIka1i7d+NsQjCWipGaJ5ml5eX0P81TVMpiRCqigIYcsaI1rKqipubm2iTcG6WZSmEJIT4vp8VhZTKcZwsy1+/fl2U5S/+4i9CFX59c5vlea1Wu7y8hOISepGUUtu2oT6TW+dYz/M6nc50OoW2HWhmF4sZxFkpZbvdhl4MDJtIKWFdmmmarVYLdB5ZlnU6nZubG8dxgJ+Aew0q3aLMnjx58tFHHy0WC631yYN7EOxubm72B/3b25tavfkrv/KXvvOd70zGEwRdb0IqUVVZ+oPv/OkPvvPth2++PRgMPMe1DTOOomi5mE2m6TqyTDPPM0jJe/cP4yL9Z7/5LxFCSbKWSPpWaNpuHCeVEIjgTOYaCY4NCS1cjQolkMKOZ+uy9Azj9YvTP/i9b/3X/+XfGt1emvWTTrf+8vzUrzXsB8dCqkqgRqNRZZurJDFNc/B24/b62qeGYyikU1SU7ZBWxWr/IGgO3kHZXEavsEqQzG3biBZz32jxuh9NYz/sWVY3StSTF1d+raeoMVvX16lo9w76rV6SlVlW1NvB93/wB64t3QZ7+IAPDt5HOs6mL22TySonliXznFLm1xuIkDRO1Grt1NqmYS1TNLtF0ykt80a701DSOr7XWifj0ej8fL68uE7bTpik6E+/O0qyQmOKMfb8hmkYC8GN0nh5oVaf33hhE1tljq3m4LjM4ve/9iFTukhSpZQQMooSKWWn3cuyLFbpwf5RkiSL+Qr0OlKr29uxwWmeZ1G8rjdqcRxzg47HY9M0K1F0uq2qql6fvoQSpVarNZq1LMtAyAzhaDKZfPnLX/7kk0+Am7++vgLIEkWbVqsVRZuzs7Nmqw5LtTkzPTdYLBa2badpBpiv3W4fHh7ADkHHcR4/fgz7a5fLJTz8y+Wy2+3ChtMwDFut1nK5dF0XBvUBIqRpOhqNDMuEfgKQbTD31+12d8TJ4eEhVDJBEHQ6nc8++2x/fx8k5y9evKjX6w8ePDg/P4f+I5DH0BYE5mCxWIB1c7fbBY28lHI4HIJ/xN7eHkxr7u3tAYCAYTc4ekAhQ7d0Pp9DqxFm423bBikVgIOdSMswjNVqdf/+/fF4PBwO2+02ZBZAYBAAQUoPOQ9C02KxQAi9++67MHUOr6+3evBdX+9uEIpS4OdA8LBTocESHkKI0mq5mhOKobSDBL9VXpdCCJGVfLs3LM9zqOXgBu2UOoCigNCCvgdwacBLIYSg3wTfDLqFLMvefvvt4XCIEd29Z5BUg+ABlHyACOEtgXQMWhzH9+p//+//fSiSX79+bRiGZTlCCFmWwAuORqO3337btpxKaaqkaVtCS0wYoSiO8+Vqc355dbg/EEIgQqSu4jgrimIdRf3+4OziSim1v79/h4oQdSz7xz/+0fH9Y4yxVgr8Gv7DMiyI6o1G4+XLl3AfYeoTEA9Cdyo3tF3gCNwSzCUAtwIwF9AP3XrMou1OaJg57Xa7wO8AWwnX1tquFYIeOrCMjUYDxhQA1ILxLHxMgFBVVeXb9Z3w42maQlIGYqUsyyRJ4k3kuq5je5yZYAFfVZVp2FlRFaLK0kJjZRrYMG0/ZNxkDCEEmQ/4DKCCy7IEHhUhBKWGaZoQbnYEL9s6g8GHh4cAqBRocgFtgMlPPLSKotpsYsdxtMaeF0hZcc5hA4/WsiolwYwxptVP+llAqqEvCOvEdiUkMFtFVWJRUVoppUSltiwil1ISggzDzvO0KAqAho7jLJeLbre7U2USQsCFD3YCQvmCMcaYWBb3PC+vcoNggNsQ7IQQUJ8xamWygmEZkBZZlkUIg7sClw7YQagUgW8ETxQgAm3bzooSHgKIPhD1arUaCCngIuxGVYFuJISY3Ni9W/hdruulaYoQyfOyqqTvh73eHkJk1/38iweAMYY0UlLCOojlcuk4jpLALGLGUFFmRZFJJctSQR96vY4iHEGoQghrhNartRcGSinXdZfL5Q9+8IO333nv4ODg6urq/fffv/7T78ZxTAiDdAWxwzCMo6MjMGB7/vy5lHJvb893XCHE9773vcFgIKWE+AVmM0+fPm232zA2b5rmo0ePhsNhWVbQSoACHfahzmazr33ta6enp0dHR7e3txcXF1Cmw4T83t5ePN4cHh7+4R/+4ccffwypJYrWnueBTdGjR49Go9FiMbt//9iyrOvr66osKGPEYEoIZnBRFC+ffH7+8nVVlRQRhAQAJIYoRkgiqZBuNtrpYtRoNjeyKIoMI2VyPsvXKI8MYpa6QhLZjl1UeV6UjGNFsaoUkgJhZJo1nFeoRIHpf+ub33n9H/0VpSvTDmeJaB4/fnV2HoY1qXAp0NXLSRB4vtfmFl0ulwZTq+nVvb1G4NqhS21bW25b5Iv4+tpzGcUpQhmymU7WfqORplLrwj96XKzQcFTEGTfrb28qQqnnNnmsp3FeZeOb2WzUqgdK5IGz+fiDNwiOdLWQ8ZXMV7ZLkJLU0lW2IdSsFOHYWK3iWuegqOjZaPP04jIRZrvz2HQPKeMmd0bjm4FjG3bQ6h0xhhIVbYhfOu7RvXdvxyOkSVBvIY1vb28ffPlno/VmvV4fHTmO55dKE9NepbkQcrOOTYQsgwP7m6bp/v6+YZrQLAB/TpAceZ739PmzIAg67f3FYgH2MdBSBP043u4MRggdHh7e3t6en58fHx/7vt9oNKbTKYwO+f9/vv6kSZYsvQ4E76Czqs2zmY/PhzfF+DIzMjMSgQRIsDlA0CWgFIstQhY2wIJc9q77L3SvSnrRO1R3kygBuwToZBFVRJFggmAikUNkTG/293x2M7d5VtNZ7+3FcTMGCIAuKSkez93N1FTvvd/5zne+82UyJycnx8fHp6enOA8bjcZ0OgXvWyqVLNsIguD09NSyLIVrwBxCiGq1miRJq9VSFOX58+cohFmWlcnlUPlaLBaFQqFcLqPVA5pZx3Gm0ymMqU5PTxVFqZYrnudBtlipVcfjca/Xa7VamBit6zouBoZJG53GmzdvHj9+jDQdpRC4WzHG4JAyGo0QgSzL+vGPf1ypVO7du5ckCbQpAC6ZTIYxBtyD3BL1QUIIbvLR0dGbN29gngnrCjBShUIB6nJEBCTYpmkiTULxbjQaOY7z7rvvzufz29tbWLQAQKA2cnNzc+dY4WTAwAkhDMPA4CDQ7bZtJyJFuRAaLHQ7IZpugjeKKnhreNaD+UAWt6kcQROGCIhfVhRF1WCzrEDvi5YXDIEBsEvTdHt7GzAOrc2Q2KK5EpcNmhAyEoS8vb09wKxsJo8uSEhfkAciBCM5BNBEeVTTtFAIIcRkMqrX6w8fPnj06PGb03PP88bjKf4wTVPLsjhTEOCCYH5w72i+mILa8f2VbZvj8XTQH92/f384HOKGOw5fzhe+32u3b2ezWT6fPz4+9rwxYkS5XD4/P5dpypiSpCm989z+r5FYuIE7OzsXFxdYBhvIAp8UZDWI7EAXiBFgmDYRCvp3QIiNOBiLCq18gKRA8OPxGLk3MhMUNzRNG41GyXrGAJ7yRnwMchRxxLZt/NpGB4lrS9eWH6VSSSR3WB+QC5AJ1KmmaaquRVHkeitFUQSRq5XPcBxsdGdkPeYJ5kZAXWCD8T2uEtEdQijP8+Dbi8+JfGg0GgFSGJYTJYIwZbnyEyENy3Y9nymqZpiqboZxKhklnAVxkhIqKHNdN4z8VMRCJoQKrlBFZYrKMlmbcRLFgaIyxgllMhUx40TTFMZIksRCpPhRKuJUxGHoJ2kUhr4kqarx225bkpQQqaoqZJLZbLZcrTjZjGboXFXSRBLJREpURU8ljVO5WLmL1UJVuZQp59SyDM6p57l4lpRw110lSRrHiaLomUw+my0kifTDKIjiRMgwTrwgxDejyZQwThiPknTlB8uVN50vVN2IU+G6nmFYQhDO1VyuoGkGwNxwOKSUVioVbOZKpYK7rSo6o4rnh0EYrw81TdcNKallOZSrmmGZdiZfLOuGJcCw/RUBFiGEMy5TAd8LQkin04GYCZEDgBugHqQj9ARgcTGckVK6XK7SVAZBxLk6ny//9D/+J0L54eGx5wVOJhfF6fX1dRAEiRSxSAlniq5hyeIAiqKoVqvdu3cPtT+YEOJkATd+eXmZ3rleeRD5Ak0iMzYM9DRQNP3CD8wwjEqlomlapVJpNBqbtlbLNvqDruM4zWbzN3/zN5Mk6XQ6UsqDg4PpdDqfTzVNoVQ+fvywXqvkss7u7vb9+0e2Y3FORRQySkiaMMZNw8znMhnLyuUyhBBOuCBSUCIYZVyt1evvf/MD1bEmvuuJkBhqwslKxoIzwUlIYkFlSoTrLeM4powksRShIOTO3C3yIhpzERBOeRB4N+3zaj2nGOL08kQ3eLFY9FeepRuLwUB6C+7NbLly6FhPO1v54Mmx8959e2+LF3Irg42Id03DkWNzQhIpmCCmDBVqNgSrxayuFe4//XJwekuv+uoyrXmiMlxokcyM526pnJ+Nr0111ijFrfJquz79+FsZnV7zZKjKFY1jmhJCdSJSQplUVGpaXso8YVrlg/NO+JMvBjcDI+W71eY3E5qfreKYiJvuNVeU/mD29myYkkJ/Km+G/vVsnhhmb+KlSrY/i24H7mAWSbVw3pn1JqFqV6Ti+IHwlsFyPGae+2irkeFCxiGU0Ts7O++88w6gM5rOMFIXXprIdiCwDYJgZ2fHMIyXL192Oh30Uuzu7mLMNlYCzCEBxTDbOJfLYfhgpVp6e3qCITY42QaDQaVSESLFeBbPc4F1ABEMw9R1AwpUZFZw64EU5vT07Wg0TJJY17Xd3Z2zs9N//a9/8OjRQ8exKSXz+UyINJvNTKeTWq3aajXH08nCXQoiLcfu9XrL5RIo0LZtgB5d10uFYiGXz9gOlQRVHkxuyeVymHkF+3jIEAEC8GGhPfjOd75zeHiIBB2VU4xkabfbUspSqbRRq+BkgBU76mUobwG4IHYEQYAGSRhZgV2DwFxVVegvUZiDvGQwGGCoTqfTGQ6HMHoFIwUQgwlFeOgwH9rZ2UF2hFQW9RbINHF0IAxBR482F/S1ABPg/IcfKcJcu90mhCBPA/OEewvjrp2dHciq4jjedOyD+d7Il5W1rSjORkin4bYAPIoZSqgSwjHfdd2tra18IcsV6gcr3VCFTNzVwrINw9QMUyNUFEt5SVJCRb6QtWyDUAGlXZqm/+yf/bPvf//7isK/+91vf/LJ9z7++Dvf/OYT03EgQcGd/+3f/u2bdvu2110sV6kQjHOuKqkU944OB+MRIURSZph2HMdeECiaajkZVdNz+cJi6QpJ7sQVKlNUFofRZ599Rhj5y26Of2OJEESMpmmZTGaDe0zTBHeAX0CrOChAKGGAYsEgAqwDhqIFavObWD+gpgCPYB2Cbgko0KFsi+N4M8IIYAtgCI2ZIDixpDf9idjIhUKh2Wzu7e2hpX0jQAfrBheuOBVMUSlX/DCSlPlhFARRFCWMq04mJwkbDMfKRga4sdVCVRhHA7acZVmZTAZ9HBtmD0Bv454FGgYGd6BtcOiAlCN3sxsVTKFCqDYMA1y3SAlWP/R9IEvpui0THB0SNbC+YFDQ1SgJYYwpigaNYRTF+JMkjQlV0jQC4Mvlsrquo50BCqe1vb0AP4SB6tAkIR2J45gQHgRBksbrK4HTPU1iEceJYVBKeblcDYPYMAx3ufI8z3ZM5GGz2WyjAMhkMsi3MKISfCbM8ba2tizLAu8NrW4262zqAkhr9K/l6EJSCBTCMIzilK7tQKSkhmE4djaXy3leUKlUCCWUUEn/ehGWgN0IpYqiECkhVuWUUg79u2CMrVYrzlUpKFWoquqEsOVymcTgFGkYeJPJxHTsgmX5vj8ajVzXfe+997CQshn7Bz/4wcXFRavVWgUhKGI4DAHsIxXGsPrpdJrGsaIouVwuTdONCyJuFCxkIFAj67bqb3/7wfqDSwTUNE2Xy+WLFy8gSF+tVvl8HnqacrkcRj7wIs7lZrMJ2y1FYVtbW7i90Mzd3NwYhqHqmqrxw8PDt2/fYs9HYWjZtrfy/cD/3sff+53f+Z1//f/7wZ/96Z8u3DlXlSAKypVqY2drOBmHSTydz4gUaZQQQoggkggi7/6fEMIIlWT9ZCjhjCdpSuI0pJ6p5RJJM4Xi7bD/i6++2D1qzRejRqt+dXWpKPruVv3V0xe79QoTymTUprZZLlv5umOpRDNYOr3iPBGBy0yVMMnzDvHjwWBWre5QxZKC+jFbunLpE28YDWaW4ZirJF0uIt1QKBfLZZfTFRfk/YelasFUFU2lnq7yeNVOo1RRNEXRQs9LU8H8REg9lowoRpLYPOMk0jy7GvUGScY5NDL1ZrF4dt2hlJfLOX8+1201iWJdd/bv3Y9EKqj3wZPvdm5OBVUni3kSCytbTBKycsNWaxsm2lSS6WxUKRRG3R6jabVUSgPP0c3lYkUY55zjQDBN05tOMfY4jmOcJzs7OycnJyilDfrdSqWCEsDe3h6mraOIYBhGrVaD3BAh8/Xr1xgVHMcxfBZwcFmWVavVCCG3t7dhGB4dHUVRFEWRkIkaUZx7cRwzqjx8+HA8noDUIYSse+giSHFVVZ1cT+/du/fq1auN3vmXfumXXr16hSZZfKidnZ0XL17A5FPTdByqQAygNIBRINUKgqBSKpfL5eFwmM/nNwbxURRdXV01Gg2AJOBISIyPjo4uLy+LxSK8TiD9JoQUi8V+v5/L5bAdHj16dHNzMx6PW60WLBtKpRISJFRboMdHBR+FC0TQMAwvLy+3trbABKB3LwgCbEY4qty/f7/T6WCMD1wVUCCjlKJeifo+BMs45XzfhwtXFEUQVDmOM1vMAZUODg5ms1lwN0GE4Qgtl8sbFRSi0mKxgPoNnQrY2vADK5fLKN0ilOBISe/MYgRwHpzZ4SAAjAu4A2NVBPhNfATlBoqFMTabzeCFAaEVWDFAZAitgCDRJYqOAURJONSAwfJXAaV0NBrV68pHH33zBz/4X1TdWywWhmFYlvWrv/qrw+HwzZs3+/v7N+3r169OqtWqsp5fFEWRZTq2Y87n0+VyNZ0vOVP9MFC5oigk8gMik41OfDAYWKaJoUDo4ZiMxiRNGeciFVTh4r9q1gCwgjaRTqcDtJCufdHgo4b+ShBUSE7IeqQsYCuQ64b6IWvdNhA89iCqilhpAEz4AmLDbcGqC8NwtVrBCQi8HQxIN3BCrkfAIWNHlQnXgDUJ7gO/ZllWnN6NsCSEKGsnVQi/4jjmXD04OLoT4uFvfN+HAE1RFAQkbCd8gwlQm5WKmiBUxrj6jaYbHiQoUYv07r64rsu5AlIaUElKKYRcrZbg3BgnYRiufNcwDFW/a2BxbBtwRze1JEmSNFEoj5M4iPx4PUaKMSJlGoYQezL0z0ZRKKXQdc00DUKI57mcU8exfD9Ey+VwOJRSQgo9nU5zmSw+C6gR/Mgwtel0rCoa2Mso8jnnhDBGpW3buFGLuQvRFYAdWZvVwm8D4jPQ0UBvqBPjCIjjeD6fRlGwWMwAsev1KjxyYGoAFBLH8QaZrdzVYrEo5POGrqt3bdK6bWeAUEkqAs/zXd8xrc1al+s04+vpBkRslBAUpK+urmzTxFUlaco4kUTO5nOusERILimjXBK2dD1F0TzPI5JGURLHsXD9pXtVKpV+8dkXtVrj3r1Dw7R933/+/PkvfvELLwxwoxhjYRRRxoC04Km9v7+Pdop6vT4ZjmCKQwjBlkAUwSYhhCTrQVeYobFYLBDY0KAEbjlN02w2O55OarXa7v7e9fV1t98zTZ0wmc1mm61Wr3+78t2V7+bz+YePHjKFWoYdx7FlOZ1OJ0kiSun777//7NmzyWSiqmoYBQ/uH5mmHUVR5/ZWVVVSU6+uLj/94vPh//3/9tE3v/F3f+MfXF9eua57cLivqmqv1/vxj3/MFIoPQrki04QQQr6GcteyK0IFlQQJakolYYxojK6kJyTRFDMk9GdfvPj+3/m1fL48mfY4FTlHO335Ey6CVqmQtZXMw51CjkkyS+IZlWLWn+QL2TQKeMUhK5ckIhonWqFVPTxwR7G3NM6uR7qVNZ38fOHHKS3VjiThTAvCZBUGfSqnjiF367mcTbI2J/6EpKmMlkRdMeGrtkXSmJBEkMSwM4Rbqppj0gpT/fJmMpwuV8HCD9JcfmfumXM/zKehTrSrq3NL3e20r+7duzeaTGar6SIKpvO5pWmT4UAVLG9ll3PfMg3DcobjkWkb+UpuNB9amuW67sJfVhu1fLWsMeo49mw0Dqar1u5utz8Yj8eVSuXm5gYuA2hK13UdtuOvX7/WdV3V7+zTMNym3W5D/RqG4cbzyXGcy8tLRVEwwBuVMngynZycAH5BH5OKeD6fHx7dI4S8fv1aVdVisWio1nK1NG2r3enEcVwuVwejEaNKLl9M0/Tq+tp2zIOjw9PTt4JIIqWu8AcPHkwmE5Skl8vlxn+yWq2mabqzszMajeB0s8GLiqIMh4NSqSREWqtVhUilFLe3HcMwNEWp1WpnZ6f4aIrCJ70JXm17ezuKovF4vL29/eMf//jhw4eoqiA8ZzKZJEmKxWKapv1+H3yDZVn7+/uLxQIuEpgJjbHKABC4JAA4VGGg4hoOhxt7IYSoXq+HRCufz8M4o1KpoIUIMeXm5oasPe0ajQbsV5BfOY4Dq2HUzsQ6KrP1AOw4juH7E8exqmsQG0wmkyRJYC6PMIRIjFwden8hhO97hqFPp1PIXhFBbduOooXnu4QKxgkYgfl8rus6gPUmVYbUDBXGjaKIrg0qQfXhyjfgA9w8GgN9jAzZ2YHfB3TJAF6EEEwlAukF/1joYRDX0fimMLVSqei6ioKvqvKluygU85Sw2WxWKOTiOPy93/u9SqVyfnFmGtbu3raq6IhreDqU0mw2u1q6nhfkcrn+wGOqJimNhR8mESGEMA44/uEHH0wmE5IKKmQma7c71/P5PFcs4kBja++uvxZgsbuZygTmIEDPuF3QC4HCxELaMJGIvEi/8eDAewFOocQB7kqux8ng2AfFtdE4AbBCqy6EmEwmaBfb2I2i/gaFu+d5yBMQphGhSqXS1dUVVhTQDmJNqVJGLkcIYZJA9ofKXi6XQ86fpqmqKHEcucuY/k+/9//CL+FaNx1emq4AQtq2vTGZSNM0k8mgJo37BRYXin0wYWCtkvXAgeViRQiBnx4hFFTqWv6yxNmXpommaamI0zRVNc0PVsAuoIJwLqA4iue06SlA5soYi6MUuYtt27puApSAkTJNExMPJEk55yJlOEpwXyAMEkJkbAdwGFsFy5crdD6fIrEA0KaUg8JRVS2OY9vOzKZ3TCPnXNO0VIS9Xm9/f98wjPl8jhIq9ht+DWw5bhQSKdM0s9kstAXZbBZjrYHB8dlxJzHUTNNN13VNw8D6Q+0Mkys0TUujlBCSzeS/+93vck2RkhAmJSV/7WhnKYQQgivK9dXVv/gX/6JRq6HVPIoiw9BWq9WrVy9wYKmagnX2J3/yJ7lsfrVaQWomGVVUHafYl19++d3vfnd7e1sSdnNz8/z58+l0KijxfZ9Sruu65/u6rsdRpKrq0dFRPp+v1+uwAQyCII1iuTZixVGFtElV+aYTSl2bbtu2ncnkkOU4jqOq6vn5eRzH4AJhWnNwcIBqkWFoV1dXe3t7lFJJUqiDIRBRVTUKYuSR8/m8UikhnQCPfXJyMhgMbNsulSqPHz9O0rQ7GDqZ7FfPn7159pxQWqpWLNN85513VotlmsbPnz1bGzPeTVmPk/hu3LiURMgNuiJrEuvrD4RzpppGTGUYhPl8VeHc0tT/6//l//zBe/cuL14U8qqIl61K8eHB7qh3VcyoNHWTeK5pCVdEkqZBHBmWmaYpI3w6WVSLTWoU0lDvjaI3F9Ny84GfGtPZKmdlFZUNBgOuMdPiYTzT1Khc4tWK7uixyWMignQxk2GkSEZMlRCXcEmYFocp53ZKTEEtP1S9SLm4Hl/fzovlXd0qcNXJF6unZ9dbjXtxlLZvL4p5y3Y03VBM0xxOJ+fXV9l83nKyvu8XszlT0ZbjMecq161UCkFIlMTD8cDOZkzbur29JZLpuq4pqr90SZK2GnVT1weDgWE5umkAH8DoyLAsy7Kgku52u0+ePDk7O1MUxXLs0WhkGlq73c7lcqCvcF4BwUMvZRjG7u7uV199BbIhk8kAdeGI6HQ6pVKpWq2enZ2BwNjd3QXHxjk/OzsrVYrlcvny4tqyrDBMfN/XVANGIdDrqBq3LJMQcnV1hUGEg8EA3AlOBjA0OHAuLi4ODw9xvoOWwDaHchm94qgugb27vrx68uQJY+zs7Mz3/Z2dneVqhU7k2WzW7/er1erGjBHiITD6KKKBvWs0GqjrgTLBi0MqNJlM7uz6RiPsVrkeGgjuGaAKpxzYgk3lDm1x6M91XbdUKoH7UVXVdV0c0avVCuc5HDhR38hkMpCKI7zFYYQQyNZzggE6oUb1Ah8cUpIk5XIZMQL/CT4PHVf4qzAMHcf2fT+TyYIsiNZ22SgpoLwYRynIy+FwmC9kYWePLA7gD4VFpOIIQJzzfr+/Wq2Oj49x5eAjcCUoqg4GA7ijcc7RQwa52MZsCWEC/49XAKTQdR1PxzRNx8osFoskTZMkIYy/fvVmNJ15nud7dwQhHErH43EqkmKhRLkS+BFoGJQmV94ym80O+72Dg4OH9487nRuFc8ZI6AepiMFrzMYjRVH+j7/xGycnJ/d29zRNU3Tt/Pz8H/z6bzx+7z0iaZqmXFX+KwCLrNXSlNLPP/8c3h8ol0NNBb4HaAHTskHioI0DJAVZ8zgbMABF3derzEAI+PPN9SRrLyQM+gSBCic2dKvgvUajEcAcpG+IINB8YxIXwjr2DtAFYjountI7bT5eH/kYprEBZ/u+f1cZBF4h66pqkiRLd57NZnFMIOzh0+JRge5C5xeUyxsPAsQYuGtms1mmcCmlHwaSkiRJDMtc+Z4gkjEWJbGaJhrXJCWpFJIwRWWwvEvXhqqEEM4VSjiRIp8rivXoIkO30jSdz5a2ZSlc0W1mmaYUFB+EMWZoOs9yQgXot2KhIESSpimhKnYmX8/rZoQqyh1DCCyMH+Gh5nKFMAwXCxeJl65pIo1wxgERc656/p3sUWd8OV86jh1FoWkaQqRBEFcqZRQcbdvudDpRpOZyWWBZReGz2XQ4HJTLZVVVVVUJwyAMA6wwKeVaZCeDIKKU53KFi/MrcPthGBaLRdu2FYUJkczGo0KhICX1fX93d5frCknTJE0VTf2bNgBljAhBCOl2OhgRqqqqZDIlKeFk7s5TQqNUMMZEnBR1o9vtTucL3XS4pitckzRSFMW0HcOw/viP//j99z/M5YuSsPPz86dPn8YiFfRujxFKkzQFzEcODZ0HhKV4ZAplmIzLOYc/EBomkA5iLwHBw9SqWCy7rntxcQHNRLVaReczRKxwVsxms++9916329ne3g6C4Ojo6M3b15TSbrdbqVQ8zw2C1F167sp3HKvZanU6na+ePt/d2/YC3/O8vXv7lLObm5tma/v07Gx//6BYLA5H4ydPnjQajT/79/9+PBqOKQujaDqZCJE4poV+bEKEbVq+71NCqKB3A7UpkTLdgCpJmCSSEcooEVJIImUq4iiwC9koDphIORHhfHHz5tnDLeVeXatX9VzWMhUio7NKIQ3cARUxZ4KljGqGQmNN1SMpFCsriGGp27PQ8MfKxdU0Sszc1pP+Mmzt7VolIZar6agb+WOeBDpPmxX1YL+kcE8mI5YEwXJlaConCcmYJJFEZXEoVc0JAxYTU6VFSXMXN+Ob21Fz94iaZutgfzLxbKNkmNmT0+69/QdBEFFF7m410nS1XEzbnVkmV9Rtp1SuhZHPqagUM52b68PdgyBKdU3b2dp+9vK5YZmj0cC2jVq51BsObNvc3t6dL1fL2eLwwaNBt9fuj03DcJzsYjFvZjNhGMLqCabVKNykadpqtfr9/mKxaDabvV6PELJchkdHR69fv65UKuhxA2dgGEaj0Xjz5g0MooC2VVV9+vTpvXv3kMil6xnkONaq1Woul7u9vTXWdqC7u7t+6MFi1Lbt4fCmUqlEYWIYRrFYvr1t27Y9Gg9Go+HR0dHx8eHr16/jON3e3n79+jUhZHt7G1AMiWsYhr/2a78mhLi6uoJMCgnYarWChMDzPEyzqVarp2/eFovFUqk0n8+vrq5wMZPJxLTtN2/eaJr24MED6KI6nQ6gT6VSgQ8nXEkfPXp0dnZmmub5+Xmj0WCMQe+BkLZYLKbTKTyiIPMAHkVr2/7+fi6XOz8/n81msCfQdb3b7R4cHJRKpdvbW0SEjR4XTpgnJyfoDEDIBMjYqJ1QOUKFcaMadl2XEQrNJZAcMBxCbKlUevbieRRFgF+bYiI889CqBdcGeInFcby9vbVcLl13ORj001SAzonXLcwAtY6jdG5vdM3cGO4TQkDggbXCsQwciQRY13V07KMJNAgCvCzawqrVKuJjr9er1WpJkgwGA1xhp9OBZhQUBoQNSPWh2QKXCQVbNptNkqher3qBPxnP7h0enZycYCTd6el5FIdJGleqZd/3nYytqupsOs8Virt726ZpttvtpbeEVQEoBsz/wf2nVMpURFEsSSqltCxnOp2iCWA+n9frdZVx4PjH771H/jpR73/xBSiM94ItCKwxAKlhE4pDHqwkX8+QBReFY3+DgBVFgduqXPtH4vUhH0K83vBBG1KDEBKG4Ww2wx9CpQMkA1ifzWbRlwpYmSQJCkf5fB5IHSo0IcTR0ZFlWScnJ/HaFQJ52p1WJwoIEb6/0jQtn88SIaPAD33fMgyF3vkd3Nk1ofmCMQbkBLc9SD5ReAaB+TX0w8HcbCxGEfgxy2K5XDaaW5RSFFy+bpuLWyOldF03DAPcazCxUAygKAbAi7gLhIcNhmWXJAk8NOF7EYUJWmFhbcIYY5SnaYCxD4QIw7CETCG4gxsqtgcOMkDMDRAGdamqWhwJvFeaECkYlPKmaSVJQikc7TKqqgaBmqZpo1FHCbnX60E1ORqNNvZlmqZpa3dabB4nY4E5B2ySUtZqtdVqxbmCSrAQwjQtYGd8QVhaLBZbrdZisRiNBmmaQjYnBJFS4hQmjKmc/xc0yeYLlnFcUaQQV1dXWIKqygkRisKEEBuXfEqpEJIS1ffDbKZoWxm6vueqqsapePPmjeM4jx8/zuXz7Xb74uJisVgo+l07KiGEM4Ztg/2G1icIp7CQHMdx5wus6Xw+Dw4PXNp8PsUkE5gPgcazLOvm5gZSDMuycEMwSWN7ext21YSQxWLx+vXrQiGHISfX19dHR0coJ81mM89zbTtj23alUru6uoqi/kcffTSbzfDB4XN7fHwshLi4uGCMRVHSbDZN3ZgORh++9/7TL76cDge6bXLO641Gv3c7n88URVVVlTHi+R4hhDM1vSOuKKF330CHxSgVUgoiOeVSpoQQripUZZ4f6ZopReIYhpAyXQ0/+egBoxOZDGaTKy3nBOGSMepkFMIV4oVxKmQiuJHVdZOmPKVWf+QHodK5nSs8ly0cRIvV0vNVjQ37p8vp2JsOG9Xc0aGZscxWy07jsfQ7QqyojBknhqYQmRBKZRCmqYx9qjlVP1KJkrGz9fPL6duzy4WbFGo7xKgZmlwuVtsHrfl8tZwM6/Xq0psHka+pNA3DwF8ahubkym/OL97/4IlhkMl4TNLUrlWnw9G55Fw1J7Oxd/Jye3en3+9mM3a5XBz0urZh1Hd3+oNJHCWB53c6N77rZ3LZJIkSkZar1V6vF8cxukqXy+XWzg6sBzCCBht/e3sbw55FGqPyJYQ4PT0dDodPnjzZ3t7udruEkPv372uadnFxAR3edDpFCa9QKKD7fWtrC5NzPvjgA9gvgW1aR7sErAAlnBDy4MED13XRh7tarcbjaalUAAvV7/er1XK1WuVchYTWdV3wQChMoEYGfqteryNRfvbsGbwPisUiauWr1QoeV2gtglR/d3d3OBxCFR6n6cHBAbosbdtG+alYLLbb7a2tLSCY1WrVbDaxtdM0rVQqt7e3pVIpiqLr62vYYu3u7sI1Edpt/CE4OdwQFA2BwHCCgTm7vr7GTscDQukQkQX+pe12G9wMhMlCCKRD6KM8Pz9HNAECXq1WoR9QSqfTKZSsIHUKhUIQBDc3N++88w5qQJgwi1ANMzC4G8KtGkUYjKAB2iuXy0JIHMhQieEtYKCVzWbhnZakERAhcsXxeAz6AMgYrwk8CnUvABMSYM759vY25xy21ZZloSdOVVXcXlgGbLTOG6zWbrch3AblkclkwKghPLXbbcMydUMdDHqFQmEwmsRxfHt7W6/X4enoum4ul5tOp5KIMPSfP39eLpfz+bxumpzzKAgg/I/u5tVoURhKSRG2GGdCCMPUXNfFGJ/V0kXwKhQKnZu277qG5TDOvy6N+qtfDNodQgghkD3BexbbE3cPJWxMpUR9DVWyjfIJIsWNTgZPAdwtyiYggKCpwgOC6e7mLYAH8LIIK3Jtlx2GITpqi8Ui+qhQE+Oco0cBaAdo5M2bN0IIdJCQNfEGjooxVqvVrq6uUNkvlUqcMsgBhUzoH/7B7ydJgvoLoBmyCsokdO74R+A7EHEbpT0qkSYeWxThKtHuscH7cZIwxjwv0HU9SVKwFwCnuAWEkDRNyHqOOuccRnOApch1kMEAsWJl4EvXdSJTKSWjd5YncRwzxqFIiKIwTVNKaSpiYGdKqSRkwzSahrGJ+nhaUIxRKXExIpXdwVBVdCRbjGNQIGjDSFEUyzYIIZmMvVgsoigYj6eaZsALJ45jTMPAMwBaQq8ASGAkRmiEdF1PW7u5Vso1z/M8z8fZLYSI4xR5RhzHpmGbpgkTfMc0NqMhALcZY7Ztf/tb33EyGZGmTFUk45sSIb7wnUhSxjkhZDwa/b//x/8RplP5fDYWsaJw3w+eP3/OmKJpGmeqlLLZ3Do7e7ta+Zp2R5Cqqso5Pz2/ePr06d/+tV9rNpvL5fJHP/oR1mIQR7que4Efx7FlOng0uVwuTZIwDFut1v7+PkqimUxmsVigRMgYq1Qql5eX+CCMsdevX1qWBakK3mLtA8SHwyFuJvYJcBh0yq7rjsdj0A9CJIyxKA5A1hYKheGwX6vVOp2O63qWmUXa/aMf/Wg47N+/f78/6A6HQ8dx5vM5o8q9e/fQAi2E0BT1+PA4jmNFU/vDwZ/9x/9IGKs2apZlhZG/mM193xdRbJhm4PuECMuwgyAmhEgiCRWEiP+sh+OqTAQhhCpMJhHj1DRNpmhxQg3NJLFfsni6Gn3z3cb//Af/T290QuXczGn+dGjWimTlzmfDXDkX+qFe3E8jZTEXiTRfnwwMp3lzuyzUthXd8n0/X3DcxbBzfXJvt0qTII6mzd1cPqdXyiUSeP58KqLANhViqMSdEU4IZX4Up0Qlim5YOcKdy8vFymNeSBeuiFKtuXukmbnr21tFU5nCl8vF0dHRcr4IA08I0ht07bwThDFPVV21iOSaYbZ2WqenbxzDIElMokhKOZ4vjKyTb9UGoyGN06LjBJ6fdSx/4aZJnHGygsgwTOM0jZI0lVLVuKqqs9mEEPLg6MEvfvG5lBKTDzKZjGFZcEVHUp7L5TAdXNU1QsjV5Tn6tpBQIVUFv44DhDH25MmT6+vrs7Ozb33rW5j6Ai2XWM+2BwiDMBn1ayigHzx48PT5V5TS2XRBCKnXW+Px2LYymUzu008/dRynUik1mrUkSa6vr5bLeaPRUBQNQRp9fKqqosxUKpVA5Lx69Wp7e/vx48c//OEPa7Vao9XsdrtxGB0dHVFKYWGapqmmqEhQAaHiOAbTppum67qwnjk/P0dorFQqhmHA6xwJKg4WQggwBzgq1EOhUUvTtN1uP3jwAAnG/fv3DcN4+/btarVqNBrQwt/c3Ozu7kLLBcUSIA6YRdxbbKV8Pn91dbW/vx8EwaZ9DyPI6vU6MjEAHfyIcz4ajVqtlud5nrtSMKFZ01RV3d7ehpwuCILt7e3L66tWq9XpdKAWB02ObBw5PJw7UCTN5XJB4AMJIQnXNC2K7giSdru9mYJn27aq6IZheL5LCAGiQguhsjaLhjQWdR6AY9d1oWlGl4PjOPCexe0FD4rJxGJt5DEcDqEV0XUdFCNWJiFkQ2pApYP0Mo1jzrmA0jeMVVX93/7437Varaurm7dv37Za25lMplAo3NzcoAsvFRIjI6fTaRjGu7u7GKOZRHGaxvlsRtM0RiXnXKYJpTRKYsaYqrDlbN6oV3d3d28ur+7fv88YY6rSaXd/9W//rfc//AahVEhBGGV/k8vi2hYVaOHTTz89OTk5PDwcjUaI8vBi2JRH/fUYR4QzYPpNhg9cAfkU+lGAtxDHYbq0UWUBtZO1hSdUWXguKExtHuKmok3WbmrBekJ5NpsFgkySBOVFlALRD4ES5xrDuZVKZT6boU0B6A1pWBQFyuZVwC05GYsz7vkuKDVAKBQaQTYAgydJAu6Oc476FzRPuq5DNr7xcOKce14AkRqlDMK9XC6HRh7P8xi7E2bRtXfZxpSCEAKtACrZbD0wiK7nHnLOpZCEkDhK0BGAevxq5c7n80zGQZkpXXudh2HIFWWjSlMVBSVY1HGTJEkTqWmaWOvmiKSVSoUxpnAtigNCCOdUCCalSNPUsg3P8wxDG41GIHUymYxj59M0rdcbhEhFUX3fi+Mkm81EUcw5V1XN81aWZadp0u32CoW8qnFgZ8YYJVwKAVN/iPKwOoW4o4IMw5AkTUUcBIHrLiap4Jxns1k0evR6Pdxbx3EI54xzQhn5GxgsxnmaJIyx0Wg0m8329vYgK/EjH4dXEES6TolkQgiYoyaJsG07jkOcgECEb9++vXfvHpieP/qjP3r9+o1hGCmRKqHL5YpQypkq1i55SZIQKUEWwomnVCqpqlqv17vtDkhjSAh3d3fRPl2r1ZBPQPYXRRFoXsOwHjx4AKer2Wx2//79L774AnK0Tqezv79PKe10OoVCwXEsUAXA2YvFIp8vapqWzebTVJ6cnKSpaDbdYrGYpvHNzc3e3p5t27PpQlMNjJ/b1J2X84WUUldVQtmjBw9d13369Ong9rZcq5XLxcDzS6WSqemdTodQqnAljCNFUaQggghJ5NcdyaQQhAquGqquJBGVUqZEJlHCmBMGwtGtOPJztj4Z9Qbnr6q7DgldEsxMxySrUEgzVzkmVOq27q+c8+upynNXN1MhiguP6GbdcapB5C/d6evXf/H4qPWdD3dU4e7tbBFWIHoUezNvPCVJalkOKeTJZEzckFAmpJpKZubqUrVjoZ/e9G9urrL2zngalqtNR+Nnl532Zy+LlcZ0OX/06JFmalGYLJdup9NROM061u5Oc+67ppVzJ4HnB5Tokqf/6c/+/MHDY282ZSIVUawoSr3eVBzzqnt7eP/Q7Y8F5HdBOJ1OG7W67/tBEKmqXq1WmKKsfE9V1cVqkctl4jh9/fp1tVpF70i/35dSZvN5JLJBEDQajclk8vLlS5x0YRgWCoU4jtvtNorLWGM4AWBIq+v6X/zFX1iW1Wq1zs/PkbaC4cY56zjOZDIBDoBHqK7rnU5HUZQXL57NZ0tKaavVymRyT58+vXfvYDZddDo3OztbtVrt9vb24uIiSZJ8PocdxJjAKYqKieM4w+EQQnLMNzw4OIBRZK1W45y/fP6iWq0ePjwYjUaXl5dY4ZqmaYqKOAqPH8Tj8XhcrdcXiwV0iohnlUrl9PS0VCphQh/YWd/38/k8FFRhGMI/PZ/PHx4eYuQGpRTxHm2VmC147949iFFg44QBi4SQ8/PznZ0dmDRCVKSqKm4UQIxt2/l8/u3bt+jbR2MNaBVUHgeDQa1WA0TDmQ8PmsVi4bmrcrlcLpdhi3B5eYkoCycI13Wvrq6EEBgw5/v+ZoY04rS4m5oqIRqDk1a9Xt/QHmjMpJQ2m81NyjcYDDQ1xemKSKxpGgzT0e+JaYmgr6DQQtm6XC5TSsfjMapgCD1pmqLHU1GUjWsAOHhQ9TC2xbRsFI7o2swJTUKwZqWUBkG4u7vbvu0YhgG+M43j+XTaqNaSJPmf/j+/t7W3W6/X8TqWZYVRDL+MSqUSx+nl5WW3293b2T06OuJULhZzhVNN0zkloZ8oqpqmqa6rUkpohQFu5vN5oVBQVZWrysuT1+8/+WacxIqqCinI30Bi4eJBFxFCjo6Orq6uUPrEbr29vcWWhCpc13W0OOBRbuR9mPkGyI7chqydO0GSQdujaRpi+qY0CfSG34HAEdjLMAxUvb/OEOE6N7AMEyQ3LwgqJFqbuObz+UajMZ/PcURgUVmNBhSKII/XhEiocIVSyjjXdONuZh/jRFEYalt07esFwRPM2TfSS8hlcNFCSi6Eouruyked1bZtxlno+4qiCiF13SBEEiIdx47jGM5VUgpKFc65EEmaxpTSKEnsjCWl9IIV59zOWEKIMAwNS0cWEkQ+5zwRCVdZGAUiSe/Kq4aFGQ6MsUIpP58uhEyE5JKkkFUiNouUxGFSq9cBK9M0HfSHmUxG4RpjzLH1NE0jQiSlmmHg7gehp3BpZ5zb29uVJ1DjA2JTVdU0bd+fmKbp+76mWlEUe57nOFnfX3GuhqGfzeY9z6WUF4slsIHdbt809ShKbNtJkmQxn5qmqWumrhtSkqur63q9niTpZpkSIqIoYIxJmYZxZGes2I1KlbK7WGqaqutat3ebcbK5XG44HHOuEgZoRaQQlLOv7wApJZF3giDGGGXs5cuXluMIQijnhCmcq5yro9EkChNDt5L1VOk4DhkjjAhTV1FjzeVy/+Z//bc3Nze/9Vu/VS5W/vAP//Dzz79sNlvL1Qo6OUmoTATjVKRpSoiyhnQQchJCMHaQr62KIZFJkgSgKggCz/NM0yyVKvP5fDqdc46eXrRQKCjEoAQwHo8RzzCpHjbZAKmLhZvLZUzT9H1i6JaRM0zTvLw6n4ymUsr9/f3Ly4vJZFwul8vl6s3NzXA49jyXEFap1B4/fpdSOhxi3mJvPJ189sXnjx49klJyXW21mmEYvH79Olh5Ipc3VEMm6d/7jb/b7/d///d/X9PufAibrQbn/Pa2HUUCZ2uxXNI0bTKbUUE0hdt6ZrVamZoZpzTwUoUbvp9STS3q+dmyPxyOq7sGiVyic0I1YlXmY2opjbM3PXdFImLGIisJz5UPBJFB4JmOwRWPRaOMNv34w+ZW1S7nFEXLE3+Yhqs4DhSVWU42TZbE90TgCS48P2SaRbmpmmVXGOdvF69Pr3K51tzTF4FkPBNKc+66pUqdTucq54d79149e/Hee+8FbvT86vXezk4YhpFH69XmfH6VhLRSqi8Wy9l0sdWqcdlkIs1ms6vlUnNU4GOVJFuF0sVXL+MoOtg/VImSpnFrZxcTi7mZuK57O+gzpsQ4cx2TECWOIymppmmj0ejw8PDg4ODTTz/94rPPNh6buqpWSiXHslAEmc7naE8BQEcSCIn6fD7HWBjMh4ZSwrbtOEqXixVqatD8WpbV6/Ucx+Kcdzo3kEvatpmmqeu6xUKBM1UkcjlfGJo+GY3K5QpnxHXdk9cvv/3tb19eXkZRNJ/Ot7a2oigaTyecK3gv113MZhPbNieTUa1Wy+UykIFDj1Kv1weDgW07MpVvT94ahpF1ssP+cHt7u9vrViqVdrvzve99zzQtoKVO51ZV1evLKwCmIAiSKCZCjoejerWGDDnwfIzQ2T7c6vf7k/lYN42dnR1YB1UqldevX6drm99arYYQgHY8TdNOTk5KpZJt25eXl4VCAcprwzAKhUIaJwllcRjZpuXGS8swDU03DdNubQVBMB1PoiAkQsKsq9/t5YsF27bfvHmDysODBw/G4zHCjbI2cIF+3M44URJbjm0qPEmSMI6Qz+9kM+5qhTEspmlWq1VwBOAboiiCvgXi19VqtTalVBwnk8lkR6NRNptjjJVKZcj4giA4ODgYjUZhGB4cHFBKR6OR68ZCiOVyCbE8JKRQ6kDCD6A8m81QBQN9BR/2TqezWq3u2mukHI1Gm44xdBvc3t5WSmWUUDx3BW7GcZyMfadPLeYLq9VKJGkxX0DVOFfIjyczkZI0kUSV9/b239RPptOpypVf/qWPM6b1+//qX7UvrwzTDKJY0zTTdkDEpmlaLpZs207j6MWLZwojv/xLvySSxPfcKIlNU89lHEKIxmicRrquz7wVpVShjCnaeDrPFUpRmJRKpU6ns1zOLNsmhDCK9PuvkWRt/gWl0nw+b9s21H6orAFUoKEVlzcejxuNRpIkuJnqegIgetHw+9jFKMgiPoL9AhdlrCfngDFB/xMaP1HWh3gaLw62FYAvSZLpdIrODM45VDqoKkKuDXEtY8z3V9PpGG1zURjW6/ViIUek9LzQMh085USkuVxO080gDBW2nkYspYyiIEmSMPTjOB4Oh4DtgHWoDwZBYFp30mO0dCEXTNdDfNC1h4wfCEbXDZBPnHMhUjB++AU0voZhiPZ47LR6vQ57WXxUCBuLxWKSJJiAAZgFNs+yrDiMcCrB2QI6Qc55Lp9Bq79YtxOvWSKqadrt7S2GAYu15SsuCakDLhh+XbqhWnY+CII4DvP5rGEYUZRAGwjXlk6n0+8Nd3d3dd1YLpdxnNh2Bi4anKdSEtgK6LqeJIJSWqs1FEVTVTWTEZ4XxHFYLlcIIYPBMAiCQqGwt7c3GAxQRNDWQ6zQ1EAYVTR1Mp1ixbRazdVqJdMUqqZCoQB3TcI5SVNBGOP/pU/Jf94JlEoh0jiGRAx0YJqmaSIDP0riu7QPglOQ4fV6PfBcJBC2bfd6vWfPv/qd3/mdJ0+e/K9/9G9/9unPG42m7/tCEEXRwjgRSZomiUIUqv7nuQpgQEejUbPZxFODpANHFWhe5ARSSlQGUeKBTKTRaIA8MAzj+fPnhUIBCb2UEisH0I1Suru7C+ee2Wx2cnICIyL0/gyHw/ls6bruYDB4/M57R0dHmJV5eHj44YcfLpfLt2/fet7y6dOnjx49Ojg4qFarEF1SSn0/WLhLTdM+++yz4+MjXdcVxj13FYeRqRvlSpEQcn19jcxva2srCDwp08PDo8ePH3711VdQnqmqalgmMrw4jre2tpDyklTIJCVUIQrjuhHKUCHkpjt7XPxevJirmcJkuJoMoiAuhkEShXVJDc+PLSfLuIjiyAumQricC285Pzqo2fcqBUcl6Spc9qSXqArnquSGSaKIRCE3DMJYuHSJYhnZimaXL66Gl89vrm4mzZ1347Q0XijZTNULfM/3dS9OBTFNo1YzNE1bLNzDe/d0VX14/GC5XPqexwjzVkGvO9S4Fcdx77ZXKBQq5aKuKTvbrcFg4Eehbprj8bg76CuKkg2dIAiqpXLkRwplUlWjKNINa9npSq6YpumFQa1W872QEwIBO1VIvmCynMTRCXdQwHHwTIimOJoqlcpwODy8d6/dbadrj0p4PmENYB5Lt9sF4HNdF7WnUrGCYlmr1ZIk1TTt008/LRaLoJ1QeoPILwx9tJ7YViYMw1evXuXzeV3Xg8B3HHu5XO7u7j59+hSBYblcQpmAznxVVWDpdHb2Nk3TnZ2d29vb99577+rqCr3JyF1t287YGQSSbDYLOooQ0mw2hRB7e3vX19d87ZaE2tPu7q6U8osvvnj//fcXiwUYYqTslFK8exAEMOgql8thHEEQubu7C6OgMAwxXePi4uL4+Hg8HsOXB8AULlbVahV1tM3pMZ/O5HqE9uY4hSF+HMdY3ijdaprWbDb9MAA/DWey2Wz2+PHjwWBwc3NTKpWQGiHuQIF+c3ODnZ7NZpHNIrenlKJy1263MUSrVqv5vr+1tYURgfV6PYoiVHwAuzGjekNgzGYzVGaFEDs7O69fvz48POz1epqmofyKVjVwhGCwsIQajcZoNLIsC6Zcvu/fu3ePUgoRZ7lc3tvbWywWo9FIUZRKpQL1GF9PP4RCS1PUjdYHimyoHYCz4VB6e3tr2/bR0ZGUMk6EF7pogez1etlstlGv93s9w7DO3p5+73vf+3t/7++dvDkdDAbLlffy5cvpfIF17i+X3RAkUCjTtHfbsU3zm9/4kFK5Wi6jwF9MZ5JRrlB00hWLRREnvV4PI8yR62LQ+OnZ2QcffBAnMaDwX/sFMHSn62KMELK1tQU2d9NPhrRHVVXcItCTCEMbb1gkSDjSkXiAhA7uHLCVNE0hX6Nrd3g81mBtuIpHjJIXIQSIagObUEjFGCuwyBA3397eUkrRfLApChNCoGxB1ZWsmdTRaGToFrr6NE1LRAqNl2mad7JulDCTJEIUgVMRRGdSSkoJNDG4NXw9eRsUKO4gVO24EeiAwDdxnKypE7B3YiOQj+PY91e4KRuBOT4YJPaoDUHkjiQAwR4lbTwqxhiEz9VqFYTqbDYbjUblUgmXisoXEGuSJGkqNE3Dctk47EE0F0VRoVAQd4OoaL/fT5KkXCmiRo70wnU9JHNRmKxc3zAMy3R2dy2UwPL5fJLc1bl0XcVnDMNQUdhqtYSmO0kiRWGKwhYLN1qbJk+nU5yYmP/aaDTg8vB1rV8cx5qhU0oHg0G9VtN1HdMDjfUASyGEaerwUyCMUflfa/SQQkAhAXCzeRdKOcJGNpsHO50kd1Zn8/k8k7UhZTUd+4d/9sN6vf4rv/Irn3/25b/6n/+/k8kkny8sVytVvZs5mCSJTBLJOf4TawM8PyAvAuSd+k0IaLB0XcfuCoJga2sLBBXo8dvbW4j/EO2wMEDXb21tJUkCNSXgPp67oii7u7uapoWhj4ZzjPfyPC9JU8rYZ599dnBw8OjRo3a7DRfvg4ODg4MDz/Py+fxnn32GwRHgmYUQYPi/8Y1vhGF4dnYmhEilIIxO5zO8O0wXEb89z3v//XeXy+XV1dXu7u7x8bGU0vM8x3Ew4gOaIWhECCHucp4zC2kaUsoYp27gxT7500/f/r1/XOgv69PbVUxL/Wmw8uNcVl8tfCqDUt6iZLBaTcN46jhkf7e41cpTojHii9jzl0uSxAqjqqkSTmN3qao6ySkkiL0g5tzWnTpz6uGC9Ls0ikwiFx988HFKlJRMXM/TLaW5vef7fiFfevX6Ra83f/jwoeu6uVym3W4Xi/nTs7f1el3VVdM2F8ulbduEs36/v7FMfPv2LZ5CpVKJ44gxtrW1dX19fXl5ee/ePc45AjZOVfgBQhS8tbX18uXL99/7EM0icRw3Ws0XL16olGEIKxw0UPNqtVo//OEP8/k8ZKPwU9A07eXLl/lSHnnLcDjcNEngaSItRv36+Pj45cuXSZJwhY7Gg1TEJ29e7e3tFYvFcrlcKpVGo1GvN6jVKihhw9WpXq8PBiMsiY8//tiyrG63++zZs29961vongMi8Tzv4cOHYFtrjfpXX31l2zbnLJvNbm3tSJli8N+LFy8cxymXy+iDc5xsJpPp3HRQ5by8vEQHTL/fxwdPkmQymYAeAInFOUcZa29vD/LZwWAA5RbsYHBa7u3t4XCjlMZpoqoqjlPMikbsB2GDm7y1tfX27VvovnHqIptHiXM6nV5cXHz/k1/GHUYUnM/nUkrIItGXgyHWmEM6n89ni3mhUBiNRrVaDQ1019fXhmHcu3cPqvlgbU18eHh4fX3NGINLQrweLoJZQxC2wiv8+Ph4MBiI9WAfzjka9BARITBATRM690qlgpvJOf/444/R5f3hhx9SSl+/fo2i2Gq1chwH857x0RCYcN7iDkDeV61Wu90u+A/XdWez2dXVFTp4gvWQO845cOqmWBanCedc1bXRZJzJZLL5Oy+lIAhyuZyTcQijO3u7juOsfG8ymTh2Fm0Kq9UK4hDbsn7yk58UimXEkZubG8O0Hz9+7GRzn3zySZwKeMBOJpPLy8uf//znuYzzt/7W3/rV7/+ylJISMZuM69WqlOmg38Vcv+ls5ti2pmlEVWKRqqqGfjVIjkzTfPbs2QcffECEZOuWnb/6hUweIRjax729vZ///OeQMYXr+XsYnoP4CyUxTk4kGOioQGkP/Zs4JVAOns/naLMAqEUq7vs+zC/wJ71ez7Is1PdxMsfr4c24ADALSM+g07q+vobXz6YLZJMwUEpfvXqVyWQODw+3t7fHoxFGV1UqFSnk2dlZJpPJ5/OSEjRYFItFBRQFXU+125QwS6US7ouUMk2TKIqIxAS6O08HyMzRE6EoCmUMaHTTSwm9GCE0TVNANLH2fgXMwrIDGMf7ghYCmtl4yeC94FGBQiwQITSttmnpuj6fz8fjMW4Wqtqj0QjdN0jXCCEQzSVJmslkMD0KJCEQm67ryHIgcgTTAKkZsB0AL2CWpmmOnR2PxzCnqVarm0HorrvCgYJhHSilAQq4rgsmE/23OEGAr5GZ4aTD2YS6BsA7ZAqc8/l0lslla7UacrLQ9y3LYtBmibuk4S6r+CusrfzLniVpmiqqenl5iZ2PB4d1DwoQrICUkhBhWdZ8Pt/e3rZsYz6fHxwc/OQnP+l0Ov/D//D/8DzvD/7gD4bDYaPRmM4XOHYxOgmXAY5XSgn8BFwFnhwuw2CG0ygG6mKMzWYzfIJer1coFBCG0Xdze3uLYYWEkI1wIZPJ9Ho93/ePj483FcPpdIqRZ2DsDUN78eIF8gHf95vN5ps3b8rlspT01atXIA6//PJLXdc/++wzPAvMKARW++KLL+r1erFYrNVqm7mNV1eXh4eHm0ZURVEYlRBAAB+gjvz+++8bhvGf/tN/qtfrhmFUKhW0tTuOgym5kL/s7+9zeuPNvTAOLc3xY1+KRDe0r950X74a+p45XwiiWJdXw5tO75d+qZgvmoWsnkRjd36bz5KDg1Yxr0bBJJidMhmINDJUzWScOBZJoyQKFKKqpuH6AY0EZbrulNwVHQ5k1J6+edvPV/Yvr4f3H3wQxvL08ty0bdPKMMZgPI3Wy62trelsrKrqcjk/ONiPoqDRqHHOwjCZTGbVWoVQCfEluuTQhQD6B9O1y+Xy9fV1o9Eold750Y/+rFQqHd07StejW0Hpjcfjer0uhHjw4MHFxUW9Xu92u6hNSCmbrSbUD9VqFX1qnPNf/OIXW1tbjUZjMBiAdwcpgj4pZOSIo2EYDofDQqFACEHZAiUztLZBbiWEAGSB7Bp6L3yDVQFfBs/zkkT0e0M4T97c3OAt9vf3b29vZ7O5aZqHh4cI+cPhEBN4ILQCy4KGDCnTZ8+eIV9HPx3a0Aghvu8XCgWAANS5zs/PNwcguuo22/np06fHx8fwQEJRAifzcrn85JNPvvzyS6hUq9Xq7e1trVYzDGM2mw1Gw+3tbWieptPpq1evPvnkE8Mwvvjii+FwCJVVt9vFBEZCCLrANtX8OI7ha39ycoLjDsh1e3sb1ZnpdHp8fIzGT3BjQMCmbcm1h/6GCUMVDGw9sg5FUf74j/+4WCxWKpWdnR0YJhUKhU6nA2cW9I3iZAMt0e12UfFAQxWsj5DaoRkLjyCKotPTUwiTC4XCpmkaUPLb3/42ThJ4GdyBobUNMjCToii5XA6IAR8QRwEmSyKioQsBTQA4w+M4Rg65OWkhJIKYGp+dc95sNnEy45aiNFQoFBhV+v0+OqiEEKPRqFS8cy/CSoBgejKZ9AZDQoikLJfLgbl88ODB3//7fz+NI5yQpmlKkZi2lUTxarkqlkrbOztnZ2e246xcF3Rvmqa+t4TNDSJms1a/uL4ajUblchXVrb/2C+wMBEWEEPTb7u/vA9kjHKxWq2q1Wq/XQcVhDUB7jUYQ5D8IhTDjgNAQkBHapPl8Dqk7IQQtArgbuFqgCyB+FKY2xiiAPfgICMdon0IGfhdCKTUMAwUoQItyuQwB5fn5OZGyXC5DbGfoFjzn4jieLxfQNRFCFF0zCSFCJoQQxhTOVUJiQggOlHWIJYqipInM5/NLd47KGqCGsZ48EydJGIZJIsBP4C4DFQJdIcBDH72xANU0RVEU9E0gANuWrbA7h6ooigiTMhVpnDBC0zhJohh7Yz6dMUKzTub2todWMsjcCLnjHvP5PEq8lFJNuxOzh+Hdn28012jpRGrb6/XAG6NXBXsPKZfCtTAMKeG2ZXGmTiaT2XRhmmY2mxuPx3F8q+t6sVhSVTWX47qubcYeSSnCECY6lfF47HmrYrEYx3GaJvl8znVdzPYB4oRoIE1TzLSC+xmUmyj/Y6RxPp9v7OxEUSQlGY3GlWKJMyWMQ0ppoVDQLYtISSiVAkKsO3QFdHuHseRd2nF+fm5ZFiLHGviqvh8m6yEGiqJomq7reqNZAzMPt5jf/d3fff/996Mw+Zf/8vdevXqF7UEYF0IkIg4iXwhBqWSayhRO1gMQ8OV5Hg7WKIouLi4URanX66CmhsMhTlJ4Qubz+VKphO50TdPQ+hfH8aYvBuNdnzx5MhgMBoPBeDz+zne+gxEWGJuNraXrers9KJfLv/jFL3Z2dlqt1s9//nOgwEq9UVyWv3j61SeffFKp15bLpaFat/3e/v4+4Yxwdn52WWs27h0dXlxcpEQWi0Wm8tt+V9M0O5uRjOZLxV6vR6VcLBYHBwf9wej8/Oy73/3u5dVVt9v95jefwMb68ePH+FBIpNIwuLi4UFW11Wo1Gg3QJzu7u912dzyZSJWvktjUDN3RuzP/J1++eXR0n2kKZ/rf+uVfXrrT+aQ76txqqWU6weGhUcjbaTSY9paWxmxGk0hIwZhghFOZJLFI/Tjkaco1U8+0KMmEMeuPktev23FqZnO5saupWSVfbc48N5PLZ/P53f17K9d7+uyreqO4s7WlKEqj0eh2u1RKz1uVK+WtreaPf/zjcrUOTqhULnlesApWg/6oXm8Mh8M4jo+PH8CSm6+NagBuEKTfeec9wClVVRuNRhRF6NJQdM3zvHa73Ww2ISZFRgGecjFfLubLXC4XhfFtpzufz4ulwt7eXpqm7XabEAGqJgzD2WxSLOaX3gqJIrb8XSuxlMhoz87O6vU6pO5IKW3bnEwmi8XMNPVeryeEuHfvXr/f13Udzdi5XM7zPFVdQWmAgwLCZ/ge4XUwpwU2B8gMP/nkk8vLy/FkVqs2KKFRFHW73SRJMhl7e3s7SaNSuTAc9imTURxMp1PO1FKpIlMJk3rTNCuVCtzdUNro9XqAdDB5abVay+Wy3W43Gg3AL5wkgF9w1ULIB9ZB5IDrEsiD4+NjvALI40ajgUMeTZqmaQLpxmtD6ZubG9Q3W61W6Ae+7zuOs7e3N5lMJpMJSJ0oiv78z/8cFZK/+3f/7snJCQZYnV9eoIpnGMZgMMBtRAEI+QbiAiHkV37lV5Ako0wDIUE2m4VZPOhMlBF7vV4QBLgPyt3sjQg4tVQqjcdjrI1erzccDlGIBGREygcUWygUoECHuzq4PYh1oODxPK/Vavm+73ler9d7+/btxx9/DI9TVBIQpDVNa7Va3W5XSom5kJD1QFqzEb9vQBWU9WCncPG6rl9dXWWz2f39/U6nAyMMhWsbxQsIuWaj8c4773Rue67r6vqd/UGaCmALQpi7WCIE3IV8hUVRtLe7Y9jWYjrRdVNzNE1XFotZLNLH7707nU77t93sOtVHewGod6bwQqHAJHnx/Pmv/MrfFl8b/PxXvzbaLNAThJDDw8PlcrnhBVEhOT093fBDlmVBAYK5meh7BeLckGH4+NF6OmG4nroNXIUyNHhK9I3iGzj14OzF334d2qbrvnj4dYOpRXsvcDDgOyqncRzPZrPt7W3OGAYSOI4DORrAFig30BYKkI2Qd04NiqKoKgeBgfdwXVcIoqpqGHjz+Zyyu6mHQF2KoiBmZHM5VVXR7ybXQ4VA9gDPruM3B1sm7uzj70IvjCXQiIFG62RthQVKBgUXfAbUKCFaf/fdd9H5CRNYRVEIEXfzmClFGTVJKHpB8/lsHElMAMX9wnLE70PpBvYC7r0YAQFFKp4xWCJcraIomECMRjMQlYrCcawge8Yz29SqxuMxlGFQMMxms1KpjH+BNw9M+VA6zGaz0+kUKAcd3cD7GMx+fX19fHjk+/71xSW6YGC1cEdW/eVJnFh/X38QjDFvtep0OmjqAZwihKSp3HSAJkmCJ6iqarGUh3ZK1/U//MM/VBTlt3/7t1+8fP0nf/IntpNFtqqvJwyqqgo1G7ubhCA3/AQSPnCWWJ3vv/9+v99XGS+VSqhxpGlarVaPj48xWAO5eK/Xu729xRJFUxJskMrl8nw+NwyjXC57ngf5raZpoItR126327lcZjqdHhwctNtteHN3u93z83Ou6U+ePPn5z3+O6Wlobup0Os+ePcOZaFnW06dPDw4O8I5yPVcAJ8L19TUSdOj3EVc+/vhjIYS3WnFFGQxGW1vN2Wx2e3sLdX8cx4ZhqKoGYMEYw6eglKaJfPKNb3z+5RfD6ZSpClX0pRenUTgaT7PfcEb9WRxNb87OK+XMw33bfnDPtFPNCeazXricKURmVK4wRsKAJYIZJhFUpMQPUm46Tq4axQlhzm03eXVymibKvaN3CtV3PE8oVmb3qNwdDBVdy2Xsn/7iZ7u7+9fX134YNZvNNPGev3hqW5nPP//86urqyZMnp+dno9HoH/yDX89ms4NBb7lcMqZIKbvd7jvvvGcadrvdwYK/vb1FEhnH8dOnT3d3dw3D+OEPf/hP/+k/7fY6iP0KZYhAURTBjGoyn2FDeZ6XJhILAIaWSKORpMHwRlEUwCAQS4ahgd1BR6GmaWESg41GHcp1XTCgGLL27rvvgkQEFjFNM5/PYi+7rpvN5mzbvr6+zufzEIyi46nVak0mEyhtUytFU8VmvlOSJI1GI03FxcUFRnCgXgDQCSFBGIZ2nHn06HEcRzgDpZTQf+A6t7e3M07O9/3xcELpnUx2Mpkg3Pb7/TRNy+UygvHh4SHG2lxfX5fLZYgRX716BSJQSvnnf/7nT548QRxarVYHBwfn5+fT6RTCcNAAkNq8ffsWlqRgXOR6xi04hmq1CiEs9N3f/va3p9Pp06dP9/f37WJxMBgkSQLADW4AlcTt7W2oJC8uLiaTCbaA4ziGYQAFolYAnAqWEdROFEXlcrndbmNGOyh2qD8ppZjsfnNzA8iLF4FeJQgCQEY4aywWC0AuaEgcx8GjQaEDI2vAtsL9eDwe27aNhBYEGNhTUEHdbhea9/F4XCgUnjx5gmrMbDaDWLDdboMxArxjjFUqFfhVbuyNIG7BfwJYIIfEv4OwSZIEZcqNIhnKY6S4WNWFQgEyxJ/89Odov4jChDNq2/bK96MoUhQNCEAIESWxlJJzFQQKTrCV79mmUalW4/iuiJnJZOx7d5ZmhBDP9YGzPc8zbQtKjDevXn//l77PGPvrC4SEQFi2MVaA1Am5x3g8LhaL1Wq13+9DJaIoCmAupOhIkCaTSalU2pTXADrhWAaCEA8O9S4gCkIIoi3c4xaLBZhsUNGIQWAZAao27hsweTFNE8V00GMAgvg4YIjSr5lphWFoWxa8OTzP297axbBq0zQ1Q/d9H6VPBQ0RpmmqiqYoGOdyJxTFboyiSNMMTdNMK03TmMq7uUtQBdF1NynIW8OAhFNljG20NUBa2DDgrjjn0FMBjUGDla5tM9rtdrfbhfMYaFIQacp6OiZ+FEXRfD6fz5eGYRJC5/OFpt1NMLBtG8Davxu7yCil0EAsFz7wHMo3WGfgSFRV3d/fx1/hI+zv70tJkO3hFk8mU3yDQ7bf7xNCMDIsWs+KBmRGyxIWMTa54zioCqmqigoxhI2oOmE6Vbye/1goFFBPBJVYqVSy2azneZZtLZfL5XyRsR0sJtO04zhljOk6tyyHpJJQSujXra+IWBu4McaoJFJKrigXFxcbHxc0LTPGfD8Mw5AxRVE0SqVpmo5jq6ra7/cty3r06NHr169//Bd/8Y//8T+O4vhf/st/yajCuRKGkeVk0MIZxpHneURKyhilJE0TkRLOuUIZIYIoXNd1ZLSU0kqlYllWu91ezuaPHj1CeoeHC8vsUqkE2z0kE6CsVqtVrVZDgvXw4UP8DlIcXdWW88VdwPN8Thm6zaHMjeP47Ozs9PR0e3sbXP2L1691XccEupcvX6Jtfnt7+4svvkB2C4jw4sUL2HElabpYLjVNG49GG8iIbSak7PS6hULBcbKdTqfZ2r69bQ+Hw48//vjVq1eKolUqFYx9VBSNcWoatm1lms1mp9OB6Q5sJHd39wbjhYypCLlMAqEnsTfrtZ+RcPLuwx2Fqqbmm2achi4JosVqLmWStXJcKCIUJKWEGMxWZORPZvOUqCkz8nYllvmLm7HrEtezFOUR47I3IEvXTajkXqgZBtWYampvzs/SNEU3COdqNuecn/aymbzv+/1+/x/9o/9uPB43Gk3HyaDtVNOMfF5VdU1ScnB0GIThcu6iZLZYLDgnUIVTSg8Pj6VMKaW/+qu/2u/3LdMRQmQymcV0BnwMEfpkMsnkc/V6HRwkcnSkrTgrstms5wWT+YKrWpjEgpK9e/fG43GUJA8fP766vhCUpCRlKusNezjfIYsGH4CGwTiOF3O32dgaDsa+F0pBTcNeLpezcOa6i2Kx+Pbt2/fee28+n9/cXKkqfNdou93OODkpJGeqZTpxlO7t3oPwApa/EM/CbFnKO4nq5eVlJpO5f//++fk5LELO3p7HSZjP5x3disPQyTiMMW+1XMzmhVzeXSwVRaGSLGZz3w8zTi6KYqhPEKvwgpsBdrquYzpHEASbqXyaptXr9XQ9eguXB17fcZx2u418ErpsSDXAB/+Tf/JPPM/D2K7JZNJqtVBcg1vNmzdvvvvd715eXsIDczQaAWR0u91Wo4m7NJ/Psfuy2Syou7vovm4/j6KoWCyOJuPT01MIPzYGUZhzjH0aBEGtVptOp3CmQDDKZDLwmgIA0jQNKBNZFuRo/X4fhpBoRUIsC4IA5Rs0b9Xr9UqlApSM9BJ2DPF62iDOQ9d1YU+PodF4wVKphLHQ+HTg1UDsQaqF8ijqJ3BPvby8hFMrqktIXAELbMdpt9sQHlWr1fl8ThnT7+SwVNf1fr+fyWSardbt7a0QYnurjjkEMNaCFwkU0ovFwrYzxUJ5uVolScK5yjnZkMdxHFMO/Ml0XXdXK8u2uapEUbBwl5QzzPwABXBwcMA5H8+muq4zNpvNZlEScynSOPFXXi6Tvb6+vr682j08IEL8tU5Y/6VChRBCCCA1gu/JyQlEdcArYm2OvwEJG8oNJTLAUFSfOOcbkzBQU6COyuUyRDtJkvR6Pax/oLFNto/CBXALSC/0nIL0NU0TlW7w7r7v432B3uI4TlOCuuFgMFAVBY4SQoiTk5NcLgcNNwqgQNJKsVika/ctKPg0zYB8Ek7wmzIwEByYUlzZho7inBt3o4LVjeYftxh3as0k3UmaDMPQNB0PGzoycEjo3QOFAyoY6leQ22CtsHmwyIQQaUo2WxfFeCBQTeWwAo+iyDR1HEaLhVsoGGjsxI+wacEK0rXJFvI2FGuTJNXXtq3IfsA/nZ6e7uzsMMZAKuLuNRqNKApHoxG2B5YI+lAMwzg9PUUTEBRmy+WyUqksl2632wUbCQwEbvz29hZCE9TU4B/j+/5oNHJdVyQpZGS+7+/s7GA+q23bpuMQWIlKSf4yg7X5IvJOct5ut5FSgxbC3fa8+aY9hxC5gfwQG/b7/T/4gz84Pj7+zne+87u/+7uj0ahYLs1mc6Yogeui7M04I1IqqqooCiES62GjxAp8VA/pHYOqKECWCmWYSgHCA5KCXC7X7XZ7vR4ePRyuZ7NZrVbrdrv7+/u4G0hfsOsQSFASYoy9evXq0TuPdV0fjQbdbhcYF3xnvV7P5XL90fjt27cPHjxAp/rJycmjR49Go1EUBMt1KgkVDiqbyIcA2rDyP/vss62trQ8++OD58+cgGn/605+uNZKcEIJhultbW6qqQnbjOM6Lly+xsVGnnk6nGJySJtHjh4963Um/N0i82DEN4U8u3rz4P/36N3YbpTjoqtRXVUlSwWlKGMvqlrtwSZQQhTOVkiSN0liTPGWGlbfNQqM/WD1/MxuM+tN5enT0YWOryZl+3b64HfR1S6vUKl6wopwHS9fkysHB0bK6ZFKYprl055fn5w8ePMSxkM8XMPvv4N5RFAemnYHKzbKs217XMAxvFXQ6nVKh3GptvXz5klK6t1eB1JpSinPm1asX77zzThxH0+m03qheXl767qrZbCLYQ6ktGe31emBA67XmwcFBt9tVVdW2bd/3T0/PhRD379+fTCaWZWaz2dPTU4CJTqeDh7i93crn8+syQWpZViaTAQnB1w7UMEHAsY7DGkNOYG5Xr9fPzs7u379PKU0SYVkWJNX7ewer1Qriy8Vi8fTpU9gjHR4elkolVIKwXLG84zj+xje+gXVl23ar1VK44Xne0o1x1idJspi7isqQtt3c3MC0HYpPKel4PPY8f3t7GxIunBtIRPHLJycniqLAbwKtIXcNX7oOPmBDD0AciQ0Cawaoi9a5sQE3XeSc5M7C0INuF6qjQqHw9u3bjdIcHF6r1RoOh6jZjcfjUqlUKBQgMkMI6Pf7GxKi1WrhfdM03dvb63Q6juPAkHk6nTabzcFggLwU6vg0TTED8erq6vDwEGKJDz/88M2bNyhENptNcFeopXS7XThyDQaDTWcDIQRCCGC7i4sLx3Hevn2LrLVSqUBAhmZhtDnP53McQYeHh+12O4qiarWK0g8UTkhKwVAig4WIChQATl1MQsSqhmAIBl1ojsZbLF0XtSqEAJSVcalgYgDm2u02Ytz19TXoMTjRmKbpxjEUKYwxbxVknFjcDV6MQdxu9DloswVNaFmmojJIbpIomM0mjXodSYJt2ycnJ+Vy+d69e4wxXdEnkwnCHxYMHuXFxcXuwb2/gcC6G8PM13NfNgLc7e3tzz//HNH2buIIIRDe4STn67402LRuTnKkK1gbYHlBkWJTFwqYaLcghARBgPgCXgN3CYFsQ3TxdVcNMAnMPkCywOsfbbnIsTdbSVVVRWFQ3GqapnDu+z6k25p6tzBUVbUcGx11vu8zSlmSpGiREClZz3I3ms0mHhLn6nQ6xS0GL4XNDyi6KeFhCwEKhGE4Ho/RBYB1gLiIWxmG/mq17PV6YPBQKVcURZI0iu8Gz8FpaaOhAyBAKzV0qYjWwAf4JCjt4eDDZ4mjFOeF63rD4Xg6nePiwYWYpmmaZq1WQ/vhnandejoEDiN4o+m6iawXNCM8CavVKoqSUsrhcAiTMQzaxFoHcAR1BEuI3d1d6NxLpRLW69XVled5kBmhpRFt0gi9IEgNw0BPJfqlsS4xvWE6miZh0ul0ptNpq7V9dHRfCpFA7Uhpmv5n+harDQBLrEccnJ+fY4mDHgDyQ0sUznFd18vlIlrQ54sFofTLr559+dWz/+a/+c3nz1/+9Kc/51z1PJ8pGnAhU7ggMo5j3TAIkYzdadv52qiTrf3rgb+llLPZ7PLyEk3jqJ2h+okiZrfbhWoH1UNMF9ne3p5Op7PZTEpZKBSQ5G0Yb8aJqnFFZXES2o5ZrhS/+uqL0WigKNrZ2cXNTcd1vcXCHQ7Hk/nip5/+YmdnxzTN58+fh2GIebRXV1ez2SybzwerVRSGtm1DchsGAdp90TuN0Z6EEE3TELQ8zxNrMxHwu1IIaPvAGVBKR6MRSttYQpidh2R9Pp8buh6Hvgyj3/z1Xz9o7bAwyaumJkhO1w6fvCuDqcFcJiZEDYh0JY2FpKtxlHg09ELCYkGWqe6HPIpV7vHMPCm8OFk9P/G5udvc/3D3+L2YK/3x4KZ33dprMZU2thqKod90uoPhtFHf1jW73xuevj33/XA6mRAhm83WfL50Xe/mppPLFTw/nM4WlPKMk9N107YzjKvuyh8NJ8vFqlgsG4aVy+XOz8/y+XytVlsu52kaQ2I8mYxubq7giAGFSq/Xi6IIzbyIJeAIDcPgnO/t7X3rW98CoYja9/X19aYyi6JbGIa+72+aHpDhbG1tIXptageMsc8++0zTtPfee8/3/dev3mA2fLlcPj4+BlxwHMc0LUidkMuVy2W006IKM58tVUX/9NNPcV7btq0oqm07xWJxe3t7uVy+efMmWnt2o76PKgYQg+M4eB2MyatUKqBbkBCmaVooFAqFAqo8SKPRObu3t4cSGwhOQgiaAdGD4jjO8fFxo9FAO0g+n282m5D5J0myWq3gvY4DhHM+n88HgwHmdXY6Hcuyzs/PLy8vXdc9PT2NoggTi9H7hnk13W4XRM5oNELPJuogoPk1TYOy8O3bt/Dghqrh2bNncRxPJpNutwvyG+8+Ho993z8/P0fOjAjX7XY///zzZO3Q6K7HvIKUgseEaZoY4FipVH7xi18QQprNJiqPxWIRdw/UEfg8TdMwUAg5DJCZZVmj0QgpFsyZXdfFpSLk4/4ka+PWWq2GDlNMForjGPotaA/wmlgPyLHRlIDTVdO07e1taFFQrQYagNoVjxI1TdRScDHdbvfi4qLdbkOn6Hke9H/j8Rh2P6alx0koSRpGvm6omawthNjf37937x4gePy1YXmoRVDKYY5E1jUy8AsQ84G/UFV1MBgIkaJkaRh3JMtiscjkc7VmYwNH0PzhOM7r16/JOsZ9PUwDbpK1HOXrbMsG2c9ms0ajgbZuMAiQrkPsBaIRAwkcyyZCpnESh1EUhKEfqFwJPD+J4jROCrm8pqgqVzhllVK5XLzrIsfSArhsNBqYObgJf9iYuCp8XtQKwbvruo5P2u/3McCq0+mAdECXJV+3u+EBYYoAXmQjQAdo0zSNAe5JSQAsHDuLVAaCJ/hO6bpeLpfh34PUHOVqwJcNxgST1u12EYfwTtpalwNMh7MS3gRhGOIzAJzB0FZKOZ/PoV7Chydr031d13u93s3NDe4LYKxlmXCAhQphb29vZ2cH7XhIR3K5HJ43UlWcaJDsYX9CwokQnqYpzgLU7Le2thwnC94OdwCEOQyOkyTBebFprsbOjOMYnaKlUgkvu7+/D1IRmWK328XrgDKFTwyO5lar9eDBAygM0LmQpilkDVDzMcYga3NdF4UVVIs3Mv+7Vf61nkG5/p6ue/oope2bG6TayLbxGXHxIO0Vhe3v74L2bDabSBH+w3/4D9///vfr9fof/uEPhCBCUsIUKWUcp1CfgMRCINzAbr52akAiAqS14dXQwRTHMWMMXbXoisfpA5XS6ekppBX5fB6cfLVaXa1Wvu/DzBpuRuBHN2pTaJsgWZBSQryC7OrFixfL5bJUKmH2GRip8/Nz3L3A8xbTKSFEUVUUuB3H0XRdgDJNEuDjOAzR83J0dIQnSNY2b4j9hNLZbFYqle7fv58kye3tLSJ6v9+HZRfYu2632+129/b2OKeqoY4XI1Xl73/wnqnrSRKLJP3ZT37qXZxp5byIAq4phKZEYdTUJKOmY+crNStXCkMRSI1opUBmV6LQGcpF6BC9GbNiprx3O1wSzXRDPxSeF89PL06COLjt9qMoKZYq+XxxOp2iD3erWWeEmoa909oxDGs+Wy7mLqPKcDDO5QqlUkVKOZstUEVaLFzGlL29e5blXFxcoNwM1w/40pmmiU6FDXrY2mrBmhldUbVaDTr3nZ2dnZ0dOE2Dz3jx4gWmEZO1tCKO43ffffzRRx9hcCekAsDlhmEcHR2hrIPCAdhiBOyDgwNN00B7Hx8fg9h/8+bNs2fP1PWMVAj5dV3HRBfP8+C1PZ/PP//8c4i00Fc1HA5B1VQqFQizKKUIxlLKb3zjG6jIqKoK93C078Frp1DMvXjxAjz9aDTyfZ9xgkxDSrm7uwsxGXS4IEVAAEgpoREENHn9+vVqtULbFESBs9kMTTCAI5lM5uHDh5gRtHGyRiLUbrfhZj6bzaDEQn0KJRhIPxFLgJnQjTsejy8uLlarla7rp6enINQRwxRFwVNGza5YLMLabTqdYnNB6Y9GvFwu12w2TdOE0hxNvu+++260HiAGppysJ95eX1/DWA4iSJwtIDhxLl1dXSGHGQwGrVYLDwWzYoCYMVMvCILr62von0B67e7ulkqlg4MDjILpdrubYzwMQzx9rEMEbPDZhBCcmcViEbp48AiwyUCsNU0TVUKwDKDi8Ilw2kMLj9MGFUnOeavVYox98MEHjx8/RuqLIgbnfHt7+/b2djQagTPe/PLGaQycFtYD7qFYz7jbRIGNmjtJEsBHKSWhIpfLaZpmWWYQBPCz2NraQokTwXF7exu/jPMKdyAMw7evXyuqilqT+FpHIWN/o/JdVdXHjx9zzkG4gKBBxoLMCsseSRQISFAtEKpXq1VCCGJxJpNBGoD60s3NDZQ82WwWZS5Ij7C7o7VBA8INiCTATcuyYCRJCCkUCrCsw37Bo8FHhiIQOiUpJRA5xF4owQGcgVhB9cy2bZamMr6bh6NuSkVSSs7VJBEg6xDpoTB1XRfCps26wUqSUqKJA90BMFFN0xTFcsaIEEkUBVKmADeAPoVirljKm5YO02QYvJJ13wEU1ojKgHE4phG8vwZLhaap2ezdSGB4Srmu2+l0hoNxHKWFfKlea8ZR2usO+v1+r9cDfMSegWKacw7yadOWCVnfukLkWJYD4hGPFmwWNgPOVmwJSKzQio9yL44/8EbwvwBjuak2JkmytbUFel/TtH6/f3t7C7sdeOghoQSZqavaeDiCLDcIgsVikaYyDGMpaMbJEUop5UISwij7WgvhBusAXTHOB4MBGjpwk3F5s9ksCSOZpJZl4ENFUSRkcu9g78GDBz/4wQ9Wq9U//If/7R/84Q++evq8Uq3HcQLmNhFpnN41xxJOuaZgY2yo2k0qgx3O1m4dYH3B2w2Hw9vb29vbW5TkgNgWiwWGl2HPgDJEvQl8HnIdoE+EIl3VhBBQ8IRhuLuzs3Ldt2/fmqZ5//792WyWLxW9MBgOh5xzd76I/EDjisp44K5Cz/eWLqNMUVRKWRKE/tKN/MBbunEQMsbSNM6XCtPJyFstc4UCwl6r1dppbR3u3yuXK7Px5NmzZ5Bs49w8OTkBB/b27VuYNyKWQIs2mUyAla+urpa+x0x999Hhs7PnelYtNvOdcbtYKXf64Q/+l39LmEWJRphGYkmETIVwEy+QqzBeelGq2i3derD0W/1J5enLeBXV20MaMSdRjFdnp7lqmWm65MQu6IohNVP91kcf5UvFxdxlhIskzecyqkLqtTyhiee7QojxdHl12aGUE8Yzubyi6YwpUZQMx1PNsKaTeRjEnCuapodh1Gy2crn8naRUV6IoLJdLSRJPJuNut3N9fQmgMJmMwacOhr3z83NUoCBM/NnPfnZycoKAzRgrl8vAxEEQXF1dLZdL7IXhcPjZZ58OBr0g8ODNgYSw3++/ffv29PSUEDKZzKbTeZIIzlXwi1DhgFYHUwJHSs/zh8NRqVTOZnPofdF1fTSaaJqRzxdzuVyj0dA188mH3zQMo9lsNpvNs7MzEEu2bbnuEi8Ikh79raenp4PB4Pb2djgcoggITynwmovF4p13H4FWwfk5HA5hxBCG4eXlZbvdrlQq9Xo9CCKcpQBSiqKg5wZlqWazubOzs0GNOGbDMMxmM7lcdrlcGIY+Gg0rlbJtW/l8zvNWX3zxOSFS17VsNvP48aMwDEajYbPZxPEuhIAEUEqJMIZogXwJabZhGEkSg1+bz2ft9o2mqYxRReGEyPF4FEXhcDhYLOaqqrRazVwui3bpJIlns6lh6KZpDAZ9ztloNHz27OloNHQc2/e909O3vu+laYImMjQ5oURA1uNucTNhzeW6LtYP7KCg8WDrwSmwx0NnPrwAoMhBYMKg6CRJLi4u0B6xSfLRXoBgD14Q0eHp06dxHKNbE3Ck1+uB3gDzij/fCNvBZoGmQqABIwW1uJRyMBhAvG9b1nQySeI4ieP2zQ2j9OWLF198/rnCeblUqlYqvudNxmMi5eHBwcMHD9rt9u3tba/Xe/bsGSZmAkDcv39/M10tTdMkFoSwjSXh13mKu+IdY5VSuX11Pez1RZKqisIIVbmy1WimUTwYDDKZzOPHjwFflstlJp/jmuqHgeutUDXTFfXnP/0ZUCNdf4Ef+pvQFRL4ZrNJNiOPKbUsC1p+nIoIRmAlVVVN0iiM/Hwha9mGH6wok3ESrrylu1pMZ+PxZOgHq1TETsayHfP07E0ch/P5dDDoRVHAGDEMjXOqqtwwNMPQVJVzTm0b9gWMEGEYmqYpQeBpmrJYzHx/de/enq6rhqFRKhkjQeDZtpnNOkkSYdgMiIzVagWPAni8oSUCmnUU0HHmKIwxSpmiMEVRhEiTJJGEoikMFgawk6nX6zgRUJjE00KGCp1dKoRt24YhkdND6lgqlWA9APdLTMAGF4dqGlYDyCTsIiIpXGrgs0LW4xsByYFXkEVBaLlcrkDzQE6BKpsQgggJlI1DE5sHpikg0kDY4HCk67ZP5CjIltBKkyRpGMZg1FDqEkIA/XQ6Heg0QXXmcrmjo6PLywtUfEDbQFkCtFEul4fD4enpKdoM0QYVxwmSYFCAEFLgjADOYIxBiQWYguMPpzkmNM3ny0Kh4DiObt0Zsv8XnR2AaBvSCJvt+voatwU0oVi785mmXijk5u5yf3+Xcz4ajVIRR1H0s5///NWrk1/7tf+D67qfffbF9vbOcDhiVPGCaEO9QnmGRwk4Qtb8MKWUpHd7D7+PnybrAQDYXZhvjaiJywZcBguVzWaLxSLyV0w2QOXRNM3JZLK/vz+fz7vtG+Qu8Jra1OMuLn8CjTMhZDwe7+3tvX79+uzsrJjLY8Egx12tVlIITddR4COEKKoK5k/TNCpkEsdOpQKdH6UUrlfZbDbRIySyhBDEb/ArvuejMohUBOTN9vZ2JpsNggB1lmazWSqVXr58+c6H7wqVTdzFKvFVR/vgow/DaNGbDXI2+aN/+8N/9Jt/R63tk8llFPmJypilanbWzBeTWZhE2mUnPL86C2PDcGpWpuzFjGuca7nz66/ee//9cqX2p3/6Zx9+8E6ceJlC8fLscjyfFwol1FIVrg2HfdPUkQHv7u3FcVrMl4IoFEKUy2VtPbIzn8+3b2/H47FpWkLIMA7hFYnpWEKktWrZNM0wiEHPQLsGu5NSqYgyDcZ6Yosh1EH+f3x87LpumMSdTgcibsQt2DstV26pVBKJQKHKNM12u43YCRyGVlycEpibVKvVILQaj8dIjaSUk/EMc3bhxAZVOIjV5XK5v783nU7h+7Czs3N9fY1SO3JLuFm6rvvixYtHjx4VCgXsXKRAaJpTFOXBgwfz+QLqCN/3Z7MZKBnP8whhqIAkSZTNZmaz2d7+DnJ3nMtYor1ebzyebG/tuu7KNE2MbAN3Dk5ud3cX7WzVahXt7kg50I8WxzGUf/A6QT59cHCwSZVfvXplmmar1UqlhK0rKB8k4tlsdjgc4siFizfYmmw2e319tQEW7777Ls5z5Ego5yGXgC88ZFVbW1uvX7/GmYl6JXo5MTVlo/SAGRV2LvQSYJ62trbgMlir1VD/opS+++67sB32/TuBGo4LOGllMhk47cHHYblcPnjwgHP+6aefosHo9evXDx8+VBQlSZLRaASlIBRg6JIrl8toshmNRoPBoNlsouSCh4jYKYSAcghVILB0nHP8P1h5sjajL5VKOLg2TfGEkA0KRP4cx/HR0RFKMbqu45TDOQ8cieF3UAQCfb558ybr5ObzOVq5Qf8oqsGYFISAChJrS4JUCkopuggdx7krzZvWYrEoFnJJEhuahoW6tbV1cX2FOkwUJWmaQt66IsvlcpmxHZA9veFgMZ9n8zmypsr+cwnlb/gCdadpGnrOgB9gg4dSjBAC1CNIBCFYGIaQ7gAz4KcQqyFScM6Hw2GtVkuSRBKCTAyPAKsCLWV0PRwPzBaID1SHcDOhPAZruFqt0POIQhlUQwg6+/v7EHBnHAcjJdI0LRbKmJuOZc8YA0BkAA1g0pA+Ahlg8UG0hdwIsAPoHpcL9QCK7rZtT6fTfr/f7/fH4zHM9DzPcxwrDH1IuIy1jRi6wHK53ObFIWHxPG8+m0GjHUdREsdhEIRBoGtaFIYK57qmmYaha5q7XHZvbyfjsaYphIjN/3RdzefzENbUarVcLu84mThOPM83TatYLH300UdHR0eEEAi5cAdN06Rfs6qDDU+73V47l3DOKecUekYoxgiRq5W7XC4oJePxSNc1z1s9f/5sb2+fUjYYDAmhrrtCXc62HSHk7W03imLXXc1m8zhOxuNJmorlcoky69XVFfQZEFI8fPiwXC6DhEchDC3icRwpCseqQsBzHCeOUhhGpAloYSIEEUTCZleux4wjdyGUhkGAOsUmYwD0gbKPUgo1N1w5JCFBGP7RH/1ve3t7v/TJJ//u3/97+PdoqrFa+VLKdO0FRzhj6p10nVDBFcoVKmQCVEfXM4hAeuFfNt+jd2k0GkGrns/nW60W5xxElKIoqFFGUXRzcwNYDDwNNh4nNfIJVVULuXw+m4OkYzgcGobx/vvvh2HohcHh/WOcfY1G4w76SbKcL6IgZIRSSQghURjeoSuuiCSNo0hh3DJM3/NqtVq9UmWS6Ipayue++9G37u3uLaYzdE5xypI41hRNpnLQG4gkZYyVSqX9/X0o3nZ2dvr9/vPnz3EEQIAMfWWxWHzz5vSm2zs5O8+Vigt/qTj642++bxTy85j8+WeDP/7TnxCaCQNNy+1YpYM4todj8tUvun/6k5uLW3LejgrV+0++/XfCRJvMQtspq5r9+s3F7s7hcr760Z/9+PDeobeKNaXY7S64ajWbTSdjOhk16+gZW1MYYZI5dp5RbT6fz935+dVJoZxTdGW2WFy320xREiHCOK5Wq++//z7nTNe1+XSaxrHCmMp5HIajwdB13el03OvflivFD5+8zzjJZJxms7G11cpkMru7u5RJIIkHD46DwAN7VywW8/n8mzdvrq+vIScHOJvP561Wy3EcgO/z83PTNLAFGo3648ePDEO3LAuK6Xq9buhWIV9iVDl5/Tbwo6++fJbNZnd3d6EWhfMQJFbVai1N7yaIM6ZompHLFY6Pj1VVbdRbCtfGo+lf/PinjXoLHDMkO1LKi4uLIPS+90vfZZxcXJ45joPh06VS6ejoqFQqRVF0enra6XRs265UKru7u4VC4Tvf+Q4SPNs2g8Arl4voWd7f3weo9bwgm82HYbxcrqIoCYLItjKoPsRxjOHNyPEwoaXT6cA9Dl0ggDjlchnrja6nQoFc0XUdLgDj8XjTWoUS1WKxaLVal5eXIIFM02w2m2/fvt3f398AWezTfr+PyTxBEOzs7ED1iIwUV1itVre2tqrV6jvvvIMsFCn0D3/4wyiK0EMH6RImJUMogn+EF9TOzk6pVEJXNVmLo9H3B11HFEW6rqN5ZdMShH4gHI+olCHI4dqggjo9PW2320dHRzBJ39raQqNimqaVSqVWqylr8x3IYyDyq9VqpVJJ13XI3YAF8Zq4XZusW9f1jW7Y87zZbIaRQTs7O1Druq5bLBaPj49RNd7e3q7X65eXlzDJA3oTQrx586bRaLRarevra7xLvV5njCEhR6cnLH+Pj49brVa9Xj84OEAqgqwP+fmmMiikFJsSBuH4JyKkpRskFbs7O41GQ1UUTqjCmMqVSrlMKZ1Op9VS2TTNTqdDKcWCQewGExGGoaCEKfyrr75C+rGpSP5X6oP4UhRld3cX+LJSqQD9o5oM9Ok4DuAHOotxSCIfQIELcihk4+gIwdQBFME3hS9AMXAuZD1VZQN5+XpuFa4fDxdsMfonlstlt9sVQpimaVkW5lPBbCVdDwLCFiiXy0D/UO9AT3xn4r2m5hRd1yk1OGdJGuFGbCRHuClsPZV64+uFeiKOSwgIptM56pdITHO5HCESWxTiKii4ob8Dntv4MOEEVJiKWhiKqeBXUcmK1jbuAPIIpYRSJEB0Pfua0rvaIoJuoVCI7ubTcWSBy+UCTxFtPsCRIMkgtsVugYr/7OwcEkWUsQCHTdPMZJz9/X1VVSEbAm+h6zq4CpQD8IIQAUBYKoRoNBo4C7ArALen0ylIr/l83mw2YfeHfQWGaTN6RVH41dWVbTumaU6Gk2KxnMsWhsMhWH2gK0LvnERh1fD1FS+EIJxcX18vl8vt7W1cIZbLarUKgkDj2tKdlyoVXddX3hJGCX/xF39xdnb2z//5P/d9//nzl8ViKY5SRVG4phJK4yC4qzJrCtYrntSGdJTrCYNCCMbvXHTxyORatASojdMEbQo4cT788MPZ7M4YaaPqwxhafT3+E7jtTgZB5Hg8xqh2bNStrS30D6IXAcfE1dWVpmn5fF7EKWMsSRKU3oUUmqpFcaQq6oZd0zUdQgE4jxwdHaGJBt3yum6q62EjMBP3gyBZuxULQeA+vLOzU6/XC4XC5eXl0dFRoVh89uwZIQQAEQZsoUgW43kmn/MWy9lgZFmWqelPvvXR62efrkb9T798/Rv/8NdTlo9DPfDFybXfGS01q1auH3cnq1ViF9T8xXWfK4ZpOadnb3LZwnazxTlljJFUDHv9/cOj0XhqWxnLLidpMBkOS6WC7/tpKqSg2Wx+sXAtJxsnoaZprhe+OnmpML1YKG/Es+PxmHOOVOr+/fuNRsPzPCigNU2rVEtJEpXL9VotyGazZ2dnUspsNjsYDBDI54sp5xwqny+//NJ13b3tPWT2kHrEcXx6cY5GcegqLi8vd3Z2OOfNrZZt27B3StP0/Pzctm08X8gVRqPR8fHxbDaDNwQ8P+GThEQZ9pUK18bjcZKkURRBYjiZ3E3tvbi4Yoz4vhdF0fb2tqIob968we+oqgoyA0r8+Xze6XQajQYkz1LK169fIwZDBlAsluI47na70HB0Op1Op/PgwYMkSa6vrwuFwmrlvn37Fj6f2A4g8lHxLJfLjp398ssv9/b2Qdvj8IQr2/7+vmVZFxcXeHEY0EspX716dXBwb7VaFQoFwKPRaIReIrCMDx486Ha7q9VqZ2cHeTbaLcH0gPpK0/Q73/kOOgrR97dYLPr9vuM4jUZjtXKx7KEAGY/HR0dH8IWKoujs7Aw+nyjx4wiFhwLynEaj8eGHH7bbbddbgSBH7zCcipBsYFwgBGEQxcLuSF27//R6PdhtIGm/ubnZ2tqColzTtIODg9vbW3yP6YSc83q9DpXh1tYWHHOA4F3X7ff7Ozs7kEYVCoVqtYp1rqoqOMv3339/tVrd3Nwg0heLRcSOdru9XC5h1xcEQbPZvLq6wvsWCgUsTkopBg8YhvHs2TOkYUhrAe+gGgRWQO2p1WqdnZ2hrIHEAE0SOJ+RSAshrq6uUOIArDQtp9VqvX51unExxL+LtScl0I9YK4IKhaKmKZVKZdDv7G3vJEm0mM/gniCEePzOO4qipN5KVdXz8/MgCPb29rLZ7GQ4gt4on8+nqeScv3nz5rvf+xhQeBNl5F+eGrL52vBbmHYAbR/yZ8AX3IHpdIosfeNHCkcGsDzY3WCd8UZJkmA9r1YrQikkjMjScbYDCcFoFM8XeiS6noAM901QSMViEZZms9ns3Xffvby89Dwvl8tdXFxUKhXcfxzv89mMEKLrOsp6iCCVSqXRagKoVSqVu9FRG+IqSRIhBfr4QO0AV25acmazGUAJZAQbNR+kl2EYo+sKkimUnPh6piF81ZA1er4LEIrLStZD9yQjgDJYE6hY426CDwT0gVJquVzmizndUNNEgtLI5XLL5er29jZjZ4SQkFWuVig5xZRSNMpWKhV8KNT7wRIhWcRmQHVJCAE1wJ1m+U6XQDxvparq27dvYW5p2cZ0OtV1PWNm0lQoiqaq+mq1UlUdrsTZrOJ5QblcffXqFczu10MSlGq1AEc1tp7tNR6P0SmqrIf2bFRivu+Xy6V6vS7iO8ntYrEY9EeZTMbJZIggnDO4kjBG5NqfZKMxR3ohhYD3OqRm+B1VVdF0o2Y4GpWbrTrOu17/9o/+6I9+67d+68mTJz/7+S/m83kcJ1GYBHEiBaVcivUYQbr27RVCMIWLuyu5M2jAA91U6AFA6XpG06ZeCc1KPp8Hr4YmfCklZh/BM6ndbmPVYfPACiUIAvQYwxZFCOFkHCxaPFnDMK6vr5FqOI5zdXVlWRYTdxkCWsdx/QpX4iQmhHDGQTshbaKUJiIWQhwfH7958+ZunQThcr5o1hsYsvHgwYMvv/xqUy0ql8uDwcBxnP39fc45hBdYlkg2UEOvVCppmupMsYnO3VBTVJVoPOGRSOM42do7fLsc/eTzVxdv+5Zq99qTmGixul+o2XMvHrpGo7Un+l03TPzV6vr66ujoyNZp//biYO/j0WQaJolp6OVSUZKIML83GLS0bSIkEXroM5FosaClQtVxsqZp90f92WxWKpd1wymWammcQNhBCak3qjBbV1V1d2/b893lcjkYDB49enRzc0OZbLbql5fn0+m42dwaj4eYijMY9izL2t5pXVxclMvl0WhUrZYXi9kv//Iv9/v98WB8eXmZpilGcE4mE/3OgZr4vv/JJ5+AaTg5OcnmcyA8FE21NPve4cHPfvYzXdeXKxcx+PjBfc/zfvrzn73zzjv5fL5UKe/t7XXa18ndvK8UBpWqqmM9PHjwYD6f93q9JBEoe+m6HgReoYBBKywMo0KhaFkmYwwNxflCVvEZLACQ0yex6HQ6R0dHkJ9jbsxGP4v4/fDhQ0rpzs4OVqNpmpyzbDazv79/dv5W0zRUHyAbd103CpPZdGEYBkTHnHO4kNfr9evrazhXobZQKBQwEBNelCiHVSqVKIpGo9HJyclHH33EGDs7OwNERocgIQQd01EUUc4xjWo4HIIwKxaLvV6v0WigmZcQgtgDQLOJlFgGH3zwAXp9sAdRGQRU2traQrIkpURBStf1wWDw5ZdfAlaenJxUq9Xd3V148IJeqlQqcOEJgqBYLKJlajweHx8fY8SN67porwaPEobh4eEhhggVCoWLiwtIx3BmQtFfLBYBFiFFgFTD9/39/f1CoXB9fd1utyFBy+Vyrntn5HZns+l5wNNgp77xjW989dVXoAOq1eqzZ88YY5jhc3Z2Zts23KTRiYW6KigJzvnu7u5qtYJmFIUqwzBu2x3f82zTyuVysCm+PL/glO1sbY9GI01Rs5ksHIgwucTzVuVyud8fIJK22+29nf1cLtfudKHch65GUZQwCeM4VtYKEEKIqigoNaCKSglRuXJzc2NqurucrxaLOAhbrRZKkEII07Gr1er29i56ck3TzJeK4/E4jCPCqG1YqRS9waDT6ezu7m7kH38ttPo6xhJCZDIZzGAlhNi2jXmy0NrCSwKUMITwG20WyqnoDcJMuY3cCIe/YRjh2ihLSomqNGReIPYQwXE4Q0eO1Av4FWDm7du3aGKA/SE06DBj8jwPs3Egrm00GiCPRqORbWXQ42KaZiLS4XCITcpQVqNUjkYjAH8QaziDkAYhEcHOxN4ATYWoid8HbAcCBd2FcI4q2yaK49JBIEFbwBjL2I5t27ZpESFB3GFI53g8hlUxyK3d3V0MmQKuv2sxIHzl+qiCg0cFZYcuaKA909RLpQKKMjgvIDLbEIOQUBSLRcybg4gH+ROmuqZpWq/X8dkJoSDhd3Z2QJ7PZjPIqgAWN4gb8qzN2kIFENcAOh36xM26gfy23W63Wi1CCMw2bNuG72Icx0KkL1++REfrxtG+Vq8cHR0RRqIkJpSIFHTR3Ztu1j1gEFYepkQjO2TriZPgQvFG8OtbrVaVSunf/+//bmu7+e1vfwvCUtxY1dANw0hFHISeJKmiKJxTKqQQghOqaZrKOP5zQ2Xhe7GemQPNFn4qpUSGulwuMV4X7w6yHdPQcrnczs6OEGI+n19dXcFLBrgKFuGKoizni8FoCOE5bFpLpdLl5WW1WgU8wn2L43g6nWLoAfoMGGNRHEkpGWU4uymhxUJR07Q4CR3HabbqOzs7R8cHmCfYarW++93vogb0+PHj+Xz+6tUrVGriOJZEbtYVqK9yqep5XhQm9Xrd98LRaKSqeqlU0nUzm80Oh2NCSBynYRDMhoPU9QtOXqHKoNf3/XAwGl9fD7L57ecvxn/2558ull4UeDIK5MobX1/G44FcDG/ffEmWg3B4sey8bmXF1fM/N5LBTol+9dN/O7h+Nhmcu7NO//bMd8dBsMrlM7ZtD4djx8kIQQ3DqjdaaSp6vd7l9bXv+4dHR0KI5XLV7w8Hg1GaplLS2Ww2my6QaSiKUiqVoOv88MMPpZQffvhhpVKZTseMsWZzC2jmgw8+ADcMUTBspXZ3d6MounfvHib4knV770cffQQ31w2nm8/n0RNHKc0XsqPR6M2b16A6wjD80Y9+hG41gOPJZPL555+jGRMJZbFYPDl55XnearUUQlQqJcT+8WRo27bj2KPRcDqFmZYzHg91XVUURlLBKVEYTZJY4wpmXcB8SFEUFNY//PBDiDBAQpTL5TCMDMPI5/OKpo7H4yAKx+PxZ599hrOIEDKbTc/Ozs7Pz3E64/h+8/Y1dj3UCKenpy9evMAhLoSAbzuyBdDqaF6GOhbGOhh7hxgP6KBp2mQ2TdO0070tFouD0dCyrOZWizHGFD4ajTRDLxQKC3cphChVynEct9ttIJs0Tff3929ubvC+QoiDgwNsT/Bqo9EQnkAo/2E+wdnZmakbi8UCI1+FEI8ePTo+PtZ1/ebmBskDmtvRqgKaRFXVjz76KIqif/Nv/g2m57quC9vh8XgMJTsUe2gExtE6Go02sRaCE4xbqFQqpmmCqEMrKBqGarXagwcP4EIM4IW/LZVK7777ru/7w+Hw4cOHm/iCWgd6Fe/fv69pWrFYxFQP5OFIEqAPG4/Hu7u7uVwO1QZ4IGOsSKVSQeC4uLjA+G34jMBzAVITx3Esy9rd3d3d3Z1MJsPhsNVqmaaJKT1AumDQQckgnG0Im3K5jEDpui66Q2q1mqrxle8t3TmKp5tW7q/nwJRSQ9McxyaEbG01W63WZDKKoqi5vW3YtpQyjKLJZDJbLnzfn06nvV4P5SNU64QQsUhHo5EgEquxfX1DJNlkp+Qvty5+HVoha0JRtVqtjkYjdNm/efMGuBYV2O3tbcMwID3CUkfXF+aFQxGepim8uGHNFUWRZVl48Wq1CnUN9gghpNvtgp3BDUSsga2JWJsWITlBPYrdDSBJQJvhlznnsJPFeTWZTMbjMQw1gIA3nGgYhnA2SJJEEUmsMJokSca2stksYwTDRorFItUNESeff/oL1NQNVYuiSMrUtk3HsaBVjONQCO44TpII3/MYlYG/Qq4QhxEAE7SWhBAphG4Yrut6q9VduYEqy+WyVW9QhXNCI5KALkJ8QtlluVxiwUEMgaZKsGtRFN1cX0dhgmOacy4SqapqSgiefTabnc3QVLiMohhrNAxDxnxgIHVtC6vpymq1UlR1PB6nMtF1nTAZJTFjrFgsw13i9PQUZ8TV1TVSRt/3dF0Pg/jmusM5lzIxDDNN4+VybpqmEInjZLvdLpbOauVuHIEzmepyubQsAwQpOgY2ji/L5RIuwJSSXC4bx9F0OoFjEKXUD1au6+bzhSiJltNV4EeP332XEKJpKiGEKRAb3i3rOEk0TaGUpGksU66o6uuTt/P5slQqoYMwTVPCZCqTyWxs23YYMydbjKKIMpnPOP/qX/3+9fXVf//f/5bveYTyFy9ezGazTF76/ipNU8JSJqQkMoojrjAnk2Gcp0ki4oQzlsZCpl9zQ1G4JETjGugEnGUbvWE2m9UtU9O07qDfHfQty1p6q8VikS3kNdOgLrezmav2zWLlklQ0m000mQOwAkSiedA07MVikcmaXPGTMFQVfTi6LldqtVrt1atXe9s7OAFRxWaMERHrhhpGPmNESqHpOtJ0zvnjdx5alnV9fck4KZeLluUQIhjLj0YjTVWPj47Oz8/7vZ6mqvVGVdM0VeOqovd6vW+sx5Kcn5+3Wq0P3n8yGAyvr9r37h2sXH84HFUq5eV8GQUx50oQi1wm5y5WjHGRyNhb0Wzm9dnbYqVc321etm+y2QIV3BB0qQ7enFz8g1/9gEcLW3FltKpYkeAUMaaQLQSen2uU7IwznZvdUc+P4oU/doxKQsyb7jSfr3YWPW6WFN1JojSfzSVJzLmimtrZ5Vk+m1E0rZ7LhXF0e9vDgQ4KQWFqt98zTSOOkzCIc7m8wjXIdeELUCzmw9APQx9M0nK5Gg6HmDR37949hISvH7KZTM4wjNvb2/l8+ej+seu6s9ns9raNxNTzAl3RfT8cRmPPdz//YvDee+9ZluF5QT6XsW2TEDGZjCzLQJNXNpuD0eXR0bGmqavVSogkCKI4DsuVoq5q4/EwSeLJZOQ4d26Tmq50OjeMsTAKnYxVqzcMy7i8vGzUq5rKtpqNn//857VGXdfUJIrOzs5UVTU0zXNdHD5/+qf/oVwub2+3Op2uYToiSfqDUWurEcfxTbvjZLOZbHblLvcP7sZCTKeT+w+Onn7xtLW9M53PVyt3d3cX/YNoLWrUW/P5/Pu//DhJksvLy+l0CpGQqqoCPROOjal2lNJSqdTa3hqOR042E0WRo6oorb58/apar3mB74cBzdFSpbxaunGaLNyl662iKPru9z7+6V/8ZDqfyVTYGcfOWvPlolypLBYuJgd7nnt1fY2EOY7jvb293u2tqqrDfl9KmclkJCWr1TJfzIkkdV13d3tnPB5XSpVKsdTpdEr5YugFKle++vzLfD7PVF6r1SqwXImim6srO5OZz+embe3s7dZqtTAMa7XKe++943vui+dPLcvqdb2l6+3u7ubzucFgkMlk5/O5bVqmYUZRZGg6tCW6qj5++BADHqAlcNePBpsarRVRFPV6PXQFAYiYppnGSalQHAwGnDJV1yqVyng8siwToXG5XBQKBYQMRgjnSq/Xy2byINoPDg4AoTRNY4Talo0ZIbqq+r4/m0yyTiaVIk0kkUwIaRp2o96azSc40oMgaDQaiqIwRqMoms9no9Go1Wih3RjFE1T9oigCSwqVPZRh5+fnjuMYhjEZTQIvyOVy/srTFJUoLJvNSsIcx6lUq73eIAgCwkkchJqmSXhOE6JyLY5SxlkSRvl83nGsRKT5Ys6yDEVhhqp5vr+1tXNz23F9n6laJptdLJcoL7w+OTEMa2dnx/O8Xn/oB5GumV4QOI7TqNVevXjxnY8+0jSNSJLGCdPvTOr/KtJCdANqBAZF97QQIpt1pJRh6KdpPBoNdF0PgoRSAm0fwPFkMkE6Acwax7FlOqViBf6iYRA36q3xdBKGcRRFjpMlhAhBMpmcqupUkiiK0lRMx7Osk+NUGQ8nMElAeylMa6FKBFiEWS647Q1SBE+GTrhcPo/Syl2JcLUK4wCPslAovPvu436/r5imHoahorA4jj3PVRQFfAm4gdPT00aj8f8n7L9jbE3T/DDsDV8OJ+fK4Ya+qXu6J/Rsz85sGO+KAEmtaFJL2SQoS5T/swUZBGwLMGDDgBMsw5AhUxIpiOJSlMUlzeVyNnETZ2emZ6fndrh9u2+onE7VqZPDl8P7+o9f1dle7tAqDAa369atOvWdNzzPLz2A42APDuIAvxsgWU3TkNqQpjmKQYBGQggpqGEYqq7Ytg3dhqaq6CyXPjJT06trZd/3Hc1hjAVBEKUJ8DNVVRuNxmg0AnAKxxy79W+Djo3jmFGlULDwMgB3LRFCKeXFxQXGiAohwjDUNBWWac9bAIWCeWexWKgxLxaLfhAAeUrTtNFoRFESBAGl/Pr6GmZv9BP4Q5IkCNwjhKB8hs0NagNgfoAx4ZQsl8v9fr/RaIAY6vf7xWJxmWCLF48qezgcPn78eDqdhmEAVgU/aDKZlMoFRTVsywXuUqmUONOXkbh/dmqBpmlZlmRZZhiGyGSWpoeHh2hloATE5ReGIWWSUpomOWPM84I7d7cO917/we/93l//G39jZ2d7MBiPJ5P5fK6qPEkSxilhPE7jMAo0TTMt46a5SVOIarFGl6Th8n7F0vzi3sMXoDXBP0ffcGsLzwghURTt7e3doEHlCmK4t7e3sywbDAYQtAKLQujUy5cvUdNzzl3XPT8/h3oXchk8Ft/3FcriNF06BkA4vvvuu1BHbWxsrKy0w9B/4417OL5BWEMV0Wg0jo+Pq9Vqp9N58eJFGIadTkfkhFLabDZhFaxWq5SyJEnTNK1Wa6urq3t7e0ie1HU9z0UU+VmWm6ZJCPU8jxKp6IYXpZJwP05jmiVxOI1zGkuuGI1CdXh6vLg8nl1+JFW6uA5q5YbqGDIUDuU8NdUk63e9T198rjvW6vbmg4cPW62m0AtqoWFZ5sTLFMPyUzLsj0I/wpUJQNc0jSCKZrPZzp1dxlin0xkOh1AKV8vVwWBw586dfr/veZ6iqFhLmq6Mx+PLy0sMb0bH3O/3GVOgVFuqDgzDgIjh7Oys1WqZpgmiCv3o8+fPEfl2fX399a9/nVL6/Pnnq6urVUV5/vz5xuba3bt3R6NRFAWc89XV1TgJT8+OO+1VxphpRr7vCyGhfex0OpeXAzQ2Ukq3YL969aperUFXzpjiOCYiIebzabNZ7/V66ErPzk4452+8ca97caFyfnFx4RYLUsrZYqrr5sbGBgzU1Wp1s7j9+vXrer3ZbNZfvXqlKFqz0bHadhQmC29WLBaT4bA/GIwnkwcP3zg6Oio4rmVZWRqfnJzs7m7DLdVsNk9OTlCC4wJD+kClUsH6tCwL0B1j7Ozi4u2334ZWCci6bdtPnz4dDoerq6uYGIsR1KAgvcAnhAgiLcsyTTOKosPjozfffHOxWPzKr/wK5/xnf/Zn0cT7vk8kJYRtb28PBoPhcOg4lqqq5DZGfBkpbts2lG3T+WwymWQi9eY3knlFUfz5IvKDq6trQojr2jDYSynBKgCZcBwnybI4jlfWViEDePHiBWPMsgxEVdVqtc8++6xSqRiG8fLly06nA9NVuVzO0wx+eEVRINlB9Ea1WkXUHCT88GmBzcHUUfgoUSxC7aQoSrvZ8n2/2+2+fPnyzr27pVLp7Ox0fX0dJgBEQCNZfjGbJ0mcZhJ6A8/z3IJdq9VwG+ZpxjmfzaaAo2Bu8LxFEN6wKJubm9Pp9Pj42DA1vBHQvfT7/Sz7EwpsMBigycR4RLSakCQSQhDPYZqmaZogUsGQcM7Pz89ns1m73RYiv7y85IqG7Nnx+EWj1c6ybFniUEx9p5QxxjlNQnE7WzNUuRJE4cnRcafTMVTj6PQkzbLRaIToskqlcn19XalUdnZ2MEIN2E8URVESZ+JmLPfp8cn19XVnZUUSomraT2QJl3Jb8EhgCXFiIEf66qqL8BEc5jidOOeDfl8IgYrZtu1er4eY9dXV1cvLS2Svx3EMMgd+EQxUQMAkvbXiccqW0T+An0GFKRpfRpLik4D9Wq2W53nIDAJ4jGFKSZJcXl5CpATOB54MVVWhPoS4nlIKXaMC1era2lqv14PrChptCM9rtVqhUIA8Bay/oAJhD2AcEVvSbrfz/IY0BLYEzXiapkJKDBUxTZMScnJysqSioBqGPDOKIqQUlmwLhTycxpD1IQAJ1pjT01NsBiDPmmqoqgpdy5KvhNqUEILElKUUDhYPjBxCLk61WtUNNRdp7IVZliVpCuYeBjpNU2RObNv2/UWSRJzzOE4AmENAt1gs0jRjjILYHg6Hvd51o9EoFAog2iaTyWw2m81mOzs7qD5hTMCyALQIXH1p4YQ6++zsDEtwOBxeX1+vra0BLQACGUdpu93Osnw6nTbqHd0wyL/GG4sFfRuOklNKMU2ZUgrWDA/H931GFcYUSjPT1DudRpIk//if/n/f++mffvfddyeTCeP8k08+ubq6ajRaSZZHYRzFEe4AzjlmNcC6jLYSPwIMIF4J/gyJ5bLqQjnLGMNoJl3XUVEt4yVhrUCxhQo7z/PDw8Nyufz555+naYo0RUopIxQoJt5rYI1hGNbr9V6vh4kiUkrbtheLhW6ahqrBiwvcfrkgbdv+uZ/7ucvLS7wA7Cis2HK5jFgdQlgYhnfv3kUVAr6y3+/HUZokCTgXfPMgCObzWZLEqqqcnp4cHh4wRjlnaZpEUYgE4SDwCZGWZaZplmd0NI9000nnoRZLEqdRsChw3cjSaHjhbpR3ilqcOLqIiFEnSUbMWIiEqWocT2QcrDVcXS1b5WJprTZbnPqeNLUNmZfefvvtj5+fZtyVi1w1Chh6A4Ht22+/jX5gZWXl2fNPHz58CGefoii9Xi/wAsy11TTN9z3P89bWHliW1bu+hMO50+lEUXB6etpqtdbW1mzbPTg4gDoQOSmU0uVwYmRV4yL8yle+gpyFfr/fanVct/j06UdPnjyBrMdyHJD4GLRSqdSazfrz5881TWs3W7PptFKpcMrm05llWZqilIvF8XCIS7dULI5GI3/hFRzYdNIsE0IkjAVRlLRandFodHnZC4IgCpNG3Td1azgcHu4fPX78WNHUi4uLjY2N2WwmaVxvtnCqekGoGeZiOs/irLHaILncXNvMpMiy9O//vb/3y7/8V5MkvrzsXl9fFwqFk/OzMPAJIdPxaGNjYzScVavVWrMx8xauZlqWXSgUZ7OZbTvYjxCjeJ5PCGm3O4vFQtNuhUSVCtS4YAmllB9//PHKygq059CFYJgxsgBMw8rzXOSSc0YJpYR12itJnC7mXqPeXFtb01T96Ogoy7KNjY1er3dycnJwcLC9valpiqaqyM3HcaRpWrVegxQBkbyKppqmybmqacbq6up4OFYUNRIhtIac80qldHBwsLqxRghJZrNOpxOGkR9GURQZlolRwefn58VyySm4hULh6OCwUCgwSqWUnU7n7bffPjg8jpJ4NpttbGw8e/bp+vq6adjZZKaqilsoEboolIq2bZ+cnORSgroCYWIYBohFqC1RhE0mk7feegt5+rcTBcageKrVKqZG3r179/j4GGcFpgLA/Ite3WKq7/uWbTBOkFqHq5QRupzDUa/XDw8PcVVVq1X0LVmWYU5iq9VCgBa8co7jZFkKTf3KykrvsndxcVGr1Wq12s7ODkxquJuXrwEdOxCB2WxWr9fn8/njx48hUS0Wy5ZlQQO0s7MDh7Lv++Vy1fM8RVOFEIzxXKSM3iRE1Ot1hdM8o0KIVqslc6Hr+sXFZZIklWq13W6XSqXj42NFUdbX18EXnZ1dQELdaDT29/fDMCwWi6ZbcCyLMfb69evO2prMc0oIxHn/Clf4xT/jalBVtd1u/9Ef/RHUxtPpdOlspbfWOqj7Ud9DnrW5uXl1dUUIwWdETlDA5HmOFMw8Exg66Xler9dbXV1F0noSxQhAwW3FGMOPmC3mlFJKuWFYUZRA+afr5PDwmHOu62an0/F9P03zSqUmpRyPh5C7wJEGNhD4CGy8y2iM58+fm6apwBBxfHycZRmERBBWo4QqFAqQd4Hm8zxP0RUQn1AaaZqGr5GSIpQsTVOYMjA/PElTiKmjKIqjCBcnPF+u63LKUC0BRJFS0iwFwQ8ZP8pJDCeBrhmvDSWUEAIp3ojHQGEubiYx3eR2ol6GnqlarXqeNx6Pgb0tGVmsofx2Zjgo2MFg4HthFCTIOkqS5Pr6GrntkF/UajXUEKqqAGxEl4m9ndyO3EqSBOw+zASg+ZDJBB8AfjqkJzjNodKYTqeMUV3XMYwddSRltm3bvas+AjI8z3vyuCXynDH+EwssxkiW5WCU4zjZ399HUwIEC+ueUfbFwGjHcfxg8eu//muLxfzf+Xf+lu/7s9k8y+XZ2ZnjFBhj0+kIqCmKEvD6/DYk7FYu9ic5wkthO71N87vROVHKbqeGL6XBuNrhAIUUFIfjF+V9wCNLpRLuFRxnWZKihLq4uLhx1pjmeDy2DR2aSiweYAaAhTnnQRDAG/LixYtSqdRqtX784x//4i/+4p07d/b39+v1apZlH3/8MYQg19fXd+7cGQ6HxWLZNM1WqwXt87vvvtvtdjFNHbFq5Dan8dGjRwcHB5A2drtd8Bf4TzwxSJtvU3x9xlU/TC0pKSW6KfI8JURQKqXI4lhKwpNUTL2UBvNGsxlHs+lkVqgXvfnCtA3dLPYXM6LrpWbLD6Lizv0iL0ShFpPKH//ok+GEcIN0++NUEkVR6vV6HMdf+9rX9vf30aUhQhPzv7C1V1dXiSCnp6fg6w3DaDablmWdnJyUygXYac/PzzEkHglzcOThm8BIdXR0VK/XV1ZWLi4u2u02optM0/z444/TNK2Wip1OR9MMvBHdbrdcLqdpGpyfm6Z5eHh4//59rtA8zy8uLjGHpN1uK8oAYggYQYBA/O7v/u43vvENIAp4PcVikVI+n8/hLIMLbzwel4qVyXhmWy5i0zudDqTTlVo1yVKqKh8++2Sl3XZLpcFoiENmpd3pdru7W9uapumaYVrGwcGBZRmt9uq3fvq9PE2SKIbyDwQ07u96vXp6elpw3SRJPvzww2Kh3O8PPv/8BWLTsyzDiK0vf/nLYIVM03z//fe/+c1vHh4eoi9yiwXHcYbDIcoIpNsgfUfXdRhT7t+/jxyc+XzOFQWea3gzQTPt7e0VCgWEaSFDEnJPPBDsesi6oewBHtzv9w1Dj6IoT7MnT55wztM8q1RKx6cnmqJfXFwoTDk+Pt7Z3HJd9/p6AIpjc3Nz5s0B2He7Xc/zkyxVFEUNg3K55BTcUqXc6XSAweAuDwMPiNoHH3zgB4FmmP7CC4Lg7t27hBC8SKCqCF2bTCZ37twBXIHcaUTZgUBEGFiapm+++abruoeHh81mE4WLYRiEScDPlNIaZ/P5vNvtggzCkGwhhGPZKBHCMKQ8i+PYtHRFUQARQakyGY1N06zXa5xz6JMQNtG9vEaUNGzOX/3qV09Oj2Ccx8TYjY0NKcXa2hp00G+//TZsCnmeIyYXcjdkXwF9gLQOaOLjx48RlH11dQWBtnI7FyhJklKlSgjx5nNN0xqNlq7rmbhhEvI8p0zmuciypNFo5LnEUNeNjY2nH/wYF265XMZsxNevXyPlH4FwqEdxzhcKBSSHxXHsM9/QtEaj8eLFi5/9uZ9jjIk8X3bUfxbHwpGOAzyKot3dXfCDo9FoGVSx9F8DlJFCIMpuZWXl1atX9+7dQ9c6Ho9rtVqWprqul8tlCM4wjwFa9dFo9ODBg16vNxwO19bWYi1C5hmWuhA3Tj4kAADmwImdJAkStnZ3dweDARp+EF+FQgHZHLAoSSlnsxkhBJJKuD3IbbxIqVQql8sKmC9MhcRlv3SbI3IjDMPFYoGJH47jTBfTpTacc7VUcnVdJ4S12+1ut1upVFRV/fDDD/M8X11dzbIsiWPOWCQENq11OwMI63Li+/Cor62tQZSDyQyIhmKM2baNmAYhBDo2TMhSFAXAGAhazvnSjRjH8WKx6HQ6lUoFdQyy7VH+N5q16WycpFEuUq7Q+WIa3gwlFYwRjelZnpD8pgznnNfrtSSJg8C/lbo3K5UqylVovBA6oKrQXZqwK6Ow8zxvKXaDNxgdDDAqz/PSNMXexu8ILAeMVRAErVZL09TDw0PkRKBsb7UbgIjwfIQQhUKBcX4ra/8Jaxplx3Q69RfBRx99lKexqauMMZXfuEuWiqgsSzRNK5UK//w7f/j+++//x//x/5YQ0u1eOo7DFfb69evhcEgpA/638D1VVbnCwOihysE3/KLmZqmvB8BJbgPc8cLIbYYKjg+UaPga/EMY14UQ19fXyKUEpAENbLPZRNt3cXFhm5bjOJISwmicJggddosFrDrUZ/3edZZljVodLnTbtCiTjLEXL148fPgQ6aBSyt/93d9dX1/Pssw09cvLS+TlInbk2bNnd+7cCcOwXC5jABwGuYdh+NZbb33n/DfhwQGPBnIkyzLY6QF0YfGAIwCGBHQ6jmNFZWE4o1ImSS4R7CYz0zBCQSIv0ur1y0QfKq3Wl35RJgEhjr5BmmWWZj6dzOxyeTabKdWksb5Bchn2R1HfODrrhqnuJeN6a2c2nzFul0qk2mw+efJkNBqdnJz0etdpmrVarSAIFEV98Ojh+fl5oVDc2Njs9XqLhZclabvdRqylEHkYhoeHh/D2wwt9G67oTCYjXEutVmt/fx+pueHt5DKcktfX161Wi3N+dnaGCGzfD23bns1GnPNyuTCfz+ezha7rrVYbV0uapo5TVlR2dXUFU/rx8Wmn0xkMBr1e7/79+5VK5Vd+5VcopY8fPzZN8+joyA8WMKAkSZYmcalY6V31fS/EYODpdOr7gabpyOdkjF9d9cbjSb1el5J0r6500yiWy3PPV3UjCEPXLcZRyrnaanVOT89VlWdpimMz9AMqSZpEo0H/7OQ4jcPNne3hcMgZGQyuMcil2+1iTrDIyfn5uR+G9Xp9tpirutbrXyuKkom8PxxAzE45e/LWmwvf29rZxvAcED04DeI4xmhO1I6vX7++e/eupmndbhdnwlIHnSTJaDj0fb9aqUwnk1q1qqrqyfFxvV6vr64GQTDwvGspr66uCsViq9UaDga2beNCWramm5ub0+mEUmpWzMFoyCmjlF5dXVPKS6UypdSbLzRNi7M0X8wrlZLv+2fdORT6CFIhhHzpnS/tHezDiw2CRtf168HA1HVKaRQGQaBUK5Xz83OVcdu2wygKfa9YdKMoEIKoqjqbzxVFiZKYMLq1sz2ZTFZWVl6+fAl1zmg0wrDw4XCINOx2u3337t2PPvpoeXF8+umngBwuLy831tb39/eRtBIl8fr6+mg0mk5n7Xar1WotFovr6+skiuEdK5VKSZahhcNlhA6EEJIlaavVWpqZ7t+/j69BX3dyckIpZZycnZ/caIXPz3HiHRwcbG9v9/sDznm9XpnOZ26xIIRwCi6oKM/z2u12EIWUM8uxhRBJlvrhDb6wd7CPrJksyzByjXN1Op1qqlEsFnd2dsrlcpKkVMrJZMS5SjljVCGUEkoZJ1mWG4ZRrVZw1ZLb6YQbGxuaZozH43a7jdNpa2uLUgqRe6lUQlh5kuQoZKMoiqLIsewwDF3XPbs4Pz052djezrJM1X8CS/hFDRPeC1Q2i8VisVg8ePDg9PQYYSv4ApQs1Wr1sttVVRU0XLvdhnEEddhgMPAWgeu63/3ud9XbbNLO6ornebu7u2AMFUXZ3t5Gf5jneaPRQDXW7XZRy46nE0VRltEBqJ6llBi0BZEPXCZQzeMtZkwxDG4Yxmw2S5IszyXCzx3nxvKp67qiaNPpXMFth7ls4P5wjUEMjucCUBR30ubm5rK7evDgLvJV6/W6qqqVSmU0Gtm3HxCLmaaJLPhisQjpz3w+R9ALillFUYDlxHEMmhM9qJQyCAJcroCvkiRZWiFwo1er1cn4Zno5uCEYByBNUBSlXC7jkgY+nKQRTDpg3/BAERURx6GUcjAa4kcEQYD0OSoJIRzgFkKTPc8fDAYoSaMoMk1zadYAdoX3YDKZGLcTWxF0BpYEE1rw/o1Go6XxUN6OYYZ5Ci7WcrlUKpXwC4KGw81UKpWQEVIsll3XTeIYFdif/fgiZ0cIwVKbz+cIkhFSUkpRmAJbaq+2j44P/sW/+O2/+Bf/4te//vU/+IM/2Nzcmi/873znN2dzr1qtJUniBQHAJGChN56GW9QK76n4wsAEevtBbolC1Pj45wBvOOe2bQPzx9MGiotjBeo0fAd0WrAO5Xm+t7dHCGk2m5qimqZ5cnaKswAsIZY3VlSe5wCHEY2Gxnc46mNo/HvvvXd4eIi6wbKsyWQSRRGlN5MDIOPAkwyCQEqKuxwRfMAeNjc3MbwZnY2U8u7du4PBAFfO1dWV67qj0Qhx1ThKlu5XSqllWVyhaRIoCpNEZlRmmUhFbuhanIksZyoxXl/7f/j84mtf3llMIpLmhmufHu1rtpr4qdlbuHaRU6X7eTAeT59/+nmzvSqotra5qav61Mt3HzwejWea68w977vf/S6M9L7vb25uhmF4cHCwvr4+m82Wciucoffu3E3T9JNPPlFV1fc9yMtgyZFSVioV+Kpms9nm5iaYR0jTQM4yxjCMfDQaPXz4EEOXd3d3scvW19c/+fAjz/MKhVK9Xj87O9vY2Aj8sN/vM1XxPA/hcGmaHh9frK518BNVVcW8wlKphPFc7Xb74cOH1WoVxDq+EvFOpaKDcmQ8HsNsKMRNC4t3DVfpxsbGYrH48MOngtFGq7mxtmbbzvHx8TvvvPPixSvopRACoqpc4TwIAsdxVFUZDQaPHz90HCcX6d27d59/9gK9E5R/n3322ePHj9ESZKkghGxubkKEAGBG13Uk0KqqCnQNKqsbz3kco4968uQJPPlZlmG0OaLXIFW5urpCX9fr9XZ2drC5kiRpNps4TtFbwwMFjTa8uoqiTKbTdrsdhSFillRVPTw8rNVqkMppt2M6syyjXMmlqFQqgkhv7kVRFAUhsh+n06nKeL1e//jTZ1mW1WrVOI4dx+GqQhglt9GLnPMwDOeel6Zp0XVVlYOMHo/H19fX5UIxjcL1tRWuKvP5PAwgXXd0XatUqv7CU1QFQCPkBLZtu66bxCFeJ9AINNh/8Ad/sLm5SSk9OTlxHAdg7WKxaLVaq6ur2MKVSiXoX+/t7SEJtt+/hs69Vqtpys3wN9/3KefkltUCxIKnpzBOKZVSQPsFvVetVq/Wyt1uF6OXLdsAFiKlRNTF9vY2gF5oiYIgOD8/h0r4+voad2KapsuxeoSQcrl8dXUFVBJBG8VicT6dMcZWVlaiKFJVnVIqBUWqTrPRePlqj5AWjk0pKL11ERJCkiQqlQsA0aMoyPKkXqs/evSo1+ul6aRWq71+/frhw4dPnjx59eoVyqC33noL2UyFQqFQ0KMogl42iqKiWzB1HU3+s2fPNra3NV2XRIpbw/5PRLAQUoO64lvf+tb7778PcAidOXhwyIEQZK9pGnIQMe91sVjgjpjNZnGUZlm2urqKjQznzZ07d0BZgPq4uroaj8drK6vLuBYo5W8031EE5TRuDTA5OOI8zysUClBxAN8ihAyHQ5Q6uC5hUAMcA+4VkVUANTVNU+CN55yfnp7GcYwkAqj9IRUCQoOi1TRNKen29m6xWLy+vgaRDLji2bNn+LfQE6CiZLfDTJbysWKxaNv2YDAYj8cYY5nnealawamRihz8MQo4vFDM9wV1hfWNxg42e0lyRWUgdEGL4rLXNE3IbHWts1S0If4uz3NKpRAZY0qep5439/0F8GFAu1Dh4HFfXFy4dsFxTc5dsFHADG3bAggP+Q5sC1EUJ0li2yZklbZtA95QVRX5FCgywMMeHByA+DMMA+NR8TrDMJzP57h9OeeYVP/2228vAdtutws3hGGYum6iD9B0nfxrBhTAZSPyvNloXF5e5iIlhED7SSnFcOLQj4igiq5pmkao+Nt/+2+vr6//4i/+wosXLzY2NihnjLGPP34Wxyljqaqbei4BMaIMwlmQ3aapydsE0eWmon96igK7HUSI5Y6OBKcbmFycyKZpLse3wT6D0tzUdAC8UspCocA5x7uQRDGIkt6gr5sGvnkEoVMYombCG4FNXiqVKKUrq23f97/61a9+4xvfmM/nn332mZRS0zTgl8j6Q/UJKhkaCCHI69ev19bWfN+HePHBgweLxWJ3d/fX//mvb6xvQKQ/m81W1zqtduPk5GQ0HnQ6Ha7QMPIJFblIw8jXDVXTlSSNJCFZnkymC9s00lwwzqSQaZ7HqQwVwXJFME6kUmx1tPL2gjYOR3OV267iWI03596UGqpSqCaC+7Mwy0RGar/07/ybpm2cX3ZzSkquOxyPX58emI5rmFbLdUCyI1jo8vKyUCh87WtfI4QEUbi3twf5SKlUCoLg4uK8Vqu5rqNpGiESw2EajcZw1Ecthb5f1/Xz826apldXV/fu3Xv16tXW1haiW3Acg0+H9f3q6gqH0Xw+d5wCMP+Dg4NioTSfLTzPw3GG/Gvbti8uLgghjCrzxRyvGT80iqI0TV+9frGxuSZk9tHHT4ENw2TT6XQopZTw09NT9DAg+kulElQvGKt3eHj45uPH4+EgDMOvfvkrC987OTseXfcsy1EU5fPPnpum1Wk3NU2ZzSYaV6SUlm23V9pJFJdKha2NlX/6T/7x0dHR/+Sv/U8vLy82N9cXi8X29maa5sHl5e7OjqooRLJSqYyE+rOzMwxIub6+xppcWVkZDocoy9rtNpYrxvoCpMdMBRT6MLFDyrmzs0MIwQ0BjOTnf/7nj4+PUQ1ggw+Hw93dXWDk1WoV5ydymMDLl0uli/PzVqsFszPqvO3tbQiQR6Nxt3uJvIPZbFapVEajMaCdly9fKozv7e3dv3//ZoqLyB8/fkwp9UNfEGmYhpRyb+8VRDaeN7csy7JMSmWpVPIXXhzHlXLZ9+alVntzbfX87KxWq0ynY5yKWSYUTpM4vLN7b39/3/eDd77y5cFgMBkPGWOWqeMEQNgYbvSrqyvwPrithsMhQuoh08E4nfFwUq/XJSWXvSsku06mU4RP4pozTXM6Gfm+75hWmkvTtkGYBEGAqCQsS01RgXag7NY0HSoalUhV4+PJUFEVpJfhfFtdXY2iCAJc1NaYeoRpToVCAarqPM+XQalbW1torfHW53nebrfPTi9sy13bWPd93zCMxWLx6tWeYRj37z24uroaDAZbW1sfffwsjiO3WCS305QhDMLNWK1WNU1J4pQxpqsaIRKVB3QsnZVW9/KcENJqNxy7gNoa0WjD4RAXKEaVw/hVKhSAdJyfn/ueZzvOT7yG6BcypfGfKE0sywK1vbm5jq4gyzJQsejBLs7PweeenZ2hkPra176GhHchRO+qj7ExwOE6nU6pUh6Px4jS1DQNUEij0TB1A5UuCAewOvP53DCtPJdSyjhO0zSXkoZh3O8PCSGmaU6nc3B3s9lsNJqgYlnWf+h/oCdbtuVop5d9NSOEYAI5qgrAMJA0EUJOTk4AyWCu5PL7Hh8f48Fhdubr168B5ECQfu/evUKhAIERDgW8JZTSXq8HXqzT6aDcQ3OvKMrq6ioETJCFCSHW1tYQLQjoW1GU5V5Ch9fr9eAfQamHSeBQxAshKpUKNOZnZ2eoTMMwTNMY/N3Lly9/+MMfYsoVpbRerwshIIfCEU8I2d3d1XUdYkmoBOCdBkEZRRFIH/gHNU1rtVrNZnNtba3dbjcaDWTJ4KDXdR3PRNd1zDpAsl+tVtve3oYCCaVPmqYbGxsrKyuapj1+/PjevXuQoOFiwIw2JL/1ej3HcRRVFbdJYz+xadA0zbQsytjp6Sl+NbDUS2AJ1CTA7X/yT/6J69p/8S/+BTxGt1hsNtq/8Vu/3R+M6vWGqptwJOCkXr4XaJLQFkgpwRXizIK+Hn/Gf4rbeHegXIAQoIYGnEMIQUAftjeq3iUgCtkBJGuz2QxO2tlsNh6P3WKh0+lAnbO0nMRx3O12sd/wLiBuB8sS7eP9+/fPz89HoxHC1gEGIFUFpx72JFS03W4XvwXEiNALYwqhYRh3du9giC+wYniaTk9Pye1Ae4CvS9/KeDzGM4QsLM2FtwiiJE2SJAqTNEoiP8rzXAgy8/zD466fsEXICrV1blbN0mqYWLX6PaZUxxMxnrHRglK1Vl95Y+jJ874fZMqzV4e98fToomuXi4Szhe9hQ6GIBJ6BfX14eAhHsGVZaBMx1gOXfXgbjQ17DoSShmF0u10ckZjDtb6+Pp1Ov/GNb6yvrz9//nw0GoFouInQTJLxeEwIgcQE2oskSRBKDmkq4E+o2eI4RojlnTt3kBXEGENRiyEehJB2u80Yg8AL0gU8fFwJAJPQOz179izLk4ODA01XRqORJPl4PF7fWL24uKBUxnH87OMPD1+/oiJ3db3o2NPRMA6j8+NjhVGZZ4zI0Wh0dn4aJ1GtViGM2rbdu+y+9dZb77zzzqsXL3/mp79ZKrqu66ZRnOc5NEAYLYd+slAoNJvNFy9eoAOEwgG9ZRRFwAkQnom7AQnpS0EutGthGMKPOZ1OweghpGB3d/ezzz7DMjMMA7mdk8nkj/7ojzATEJd0mqbon5F/yznHkwdLsLOz02g0MLQKbC9WCwBjIAdxHENk/ejRo7t376J9Bx7z6aefTqfTi4uLJEkwjNIwDM/z+v0+kHK0qbgRsyyr1SoY0qcoyubmputYIstMy+h0Oo1GjTFWKDiD4TWujO75xcXZue/7uqotFouLs/OjoyN4iQCi4P6DyQs+L4xw+Oyzz1AlbG5uYkBWFEXwxaO6PTs7Qy0LXBNKI03TDFNLohhir9XVVbT60HeiqiiVShiUBOPkfD7Xdb3dbgOkgBrEdV0UtZ999hmy+3HB4acsH2yv10P+Vn47y2gwGCxl1BiPOJ/Pv/KVr0gpYbsBLrCzs7O+vo6kQCFEqVSC5APe3mVDu+x+i8WiovAkSQgVURRKITDt8fXr1/v7+yB2Ia7f29uLoghgLbIkUCcBPkRxj6eB4rLf72dpKm8TGeSf7vmX1w3snPgk+CvMKTFv5xr7vg9irt/v428Nw7h79y6uBviKsAiTJHnzzTdxqo9Go8lk0u/3kfCJHhJgB66qpWQcoKMQAqU/VLnj8XgZxE8phaeqVqs9fPgQ9125XAbgCt/VcDjEygcOhQNcSgmnIBhJIQT9lV/5O0uGcm1t7eLiAr8/RmGgurIsC7ElcRwbugVfVbVajeIAWwip8EutOlATpFZALgN8CNAonI0A3LDb8f9guDF2AK5X2C7gjAWIha0INBsAJob1AlcEx6+q6nw+h3gL9o3FYgEWY7FYWK4FRhJNIdgcvAGU0jhN0EqC4AjD0NAQ8xpCAUYIubq8Xl1d5VzBYVGpVBRF833/Vm+UgfqEBwp6argOMbH48vISykGUF3BHgt/EiBj0i0mSTKdT3/fwBeic8jwHvHd0dOw4zoMHj+7fv+86xT+JvfoJIbqCEJJnGVeU7/zaP/vss88KhUK1Wq1W63hiYRh2r67CMKw3W59//vz73/vuL//yX7lzZ7der/thMJ8vFnP/P/vb//l04sVpxrmaZWI8HTHGkiSybZtIod6Oc6JfmNmODZbfTjOglOa3wev0VvmOv8XOx18B8kSXAy4YLTWldLFYFIvFra2touMyxjRNc10XmASMe41a3XLsp0+f1poNUIGWbixbArRxaZxgROb5+Tm6McYJsrZLpdL5+fnl5eXl5SVg3jiOS6UCkhXL5TKOLcdxXNe1bfedd95ptVpRFB0fH6N2393dnU0X4/H4d37nd+ALKZfL9+7fQaN2dnaWZRl07jiYltAddjUWtiQszQWlnDBJiKSEUEFEQspOydAYkdEv//Jf+Ot/7d/+9NNPVc2pVuujST+KIscpMKZQybIs83y/Wq2+ePVya3drMptqtu64xWqjfn5xqTCuEDYdT1zXRf2k6zqgoHK5PBwOy9XKdDqFOAnJ1CvtNkb/mqbZ6/WAoQohkBNYqZYg2K9Wq71eL8/zer2OQcL1eh0PH6SGlHJtbW1/fx8YNswctm0bqgGfSpqmhm5mWea67mw2A0WIjvPu3Tv7+/twCVm2sVRwLxYLBKG12+29vb2VlRUg6LgIm83m+++/X69UNzc3mapgpw+HfcbVUrkQh0mpVFhMF4QIRrhhaqZhn58ec047nY5lmMPxZLFYOE4hybJGo3F1dRWnSalUIUSMZ1NdV03TXu+0g9ksz1Iv8Nvt9n/99/6bo9OTnd27m5ubVOGbm5uMKZTS+cKXUoZ+IKVcWVubTqeI03RdFycnNJowDeBXwHlVKBSePn2qadrDhw9RLT148AAEGc6WNE2fP3/+5ptv4rjAkjMMA4HmSA3M83xlZUUIgU4SxGu/38dGQ1WRZdnKygoaaSQIIhcAWZc4xHBhNxvt+Xz+8uVLxtjqShu6BQTNHB0dFcslGKmyLKOM6YZGpQAOfXR0tLm5iZkcnU4nS2NVVUPP9zzP0PXhcFgplvzIH4yGnU67WCwlSZJnyJ124jjGAIz5fG7adqlQ6PX7zXrdLRY/e/ECqj5sUpA+6BBw4GAsBOCryWSyu3P36uoqz/NqtRpG/mAwKBSLiqIQKbIss0wdJ1WhUBj1B34UNhudOE1gR4CCB72cqRsAolAxWJZ1cXFx9+7dMI5evny5vb0NvxQGWs/nc8/zkOSOACBEuKFNhWjk6uoK9g7GGNAKvEhU5xBdUUrnM69cLq+trb1+/do0DGyixWKxmPuu65q2Uy6X/4v/8u8ahrG9vSMI0XRbUKIynqapbRnds/Nf/rf/8ptvPZxNR5zTNE2KxWIcJ7/zO7+jagYhxHZM/LJLvkwKiiNd0zSUUwhV+eSTT6qVSrvR1lVNN43z8/PN7e0//+f/PFeV/DYHa9nkky9E9ojbpAZ0DrPZ7Dvf+U6r1cDdnSQJKtRer6eqqq5pgEvAp6PrLhaL0FcNB2PQCODsrq6uKGdZlnU6nYODg8PDw7W1NbxH1XJlMBjU63WwfmjeqtWqIBQGBfC/gL5s226326gQkC+DqisIAkLEssPETGgsSzScAKRBskG2y2zbXjr7Li8vUavC3NHv96GEx9QFZGr3+30kiY/HY7wCx3GwOTEhwTAMJL/DWg+Iu1QqYaQ87DOe5x0eHna7XWRc4RH4vo+7DVABiomNjQ3tNiOf3Q7OcxynVqvhegCdge4BbwOqFrwZMDYiCB/NRBRFJycncDgCjQf6FYYh+AUIJoDfMMaGwyEyadCySCkxVA6kWJ7n19fXkD/jOxSLRczgtCyr3W6//fbbd+/exal3eXmJWKzs9gP9AarSNE1hSRVCPHv27Pj4GCEcYLtt276+vobvo91uv/nmm3iMiqIQSvNbUflPKK+AEikKuUVHAVbhb2GKAXmxWCz+0T/6R7/4i7+4urqKQBpoMn7046enJ+d+GFHKoyhZWg1arRbYT0BKqJzQ+iz17MC08Fconuifjp6jt1EOoOToF4bqLHsvwFTQU4/HYwSmo9ZBHYMp677vH+ztI5wWrispJZIGoS+EaBrDyJERf3h4+Pz58ziOP/roo16vB/ILFRigrCzLUIhg/SxbsSAInj59CqVdv98HVfH06VPTNL/61a8+evQIDQZj7I033sBxAJsxtjGWJaRmqJgJIf1+HxW/onIpcyFyzggnUua5osowmoXBolC0XNedzr1SpUIYnSxmUZIngjqlslVwM5IFSZCKKOfZ7v1tSYVhG6VixXWLi7kfBUkaZYCoV1ZWIIvBdG34/HFeNJtNXOE7OzuY+Ht6eooMMIwXBHz4ySefoOnc39//wQ9+gHmRYE9WVlYeP34MrQlEpoqi3Lt3r9vtQo88n89v9Uzq2dkZWhpwGYPB4Orq6vLyst/vgwXY2NjApDDYViBWg6ILkxBt28ZcM4jbMB8Qm/rtt9+uVqtwzs5ms36/V6lUCkUnCAIhspOTkzgOXdeNk3A6nS5mk5/55k8XbHvQvexdXGic5Uls6lr/suvNp6auX3UvkyQKQ9+2cQktzi5OZ/Mpkns+/vjjb33rW3/1r/7Ver3ebreRSnV9fT0ej1++fKmq6urqKuJXoObBUZ7n+enp6Xg8xpQ6fDDGIGwtFouNRuOrX/0qHEJJklxdXQFtiuP42bNnP/rRj548eWJZVq/Xe/jw4erqKpBgTHEFUoJi9OTkBGagcrmMCBKEi+JMgAH21atXURRdXl5CUYThg1CvAomvVCoA8t9444319fV6vY5xFBBQYswG7F04yrI0L5erFxeXYRhvbm5blqMoWrlcNQzD8wJKuecFGxtb3/rmz/6P/9Jf+fJX3zVNe2dnhzBu6NZ0Mrdtl1IuhFgsfORlr66uNmq1xWLRrNdBodqmhdE02Iwovkej0c7ODhY5IQTJPrgsu92ulBLWIs55p9NBqBAQCxzm+MyDBw/effddTVPRAOMKQ6YGxF4ItEMxcXl5CXl4r9f72te+1mw2US7AcFcoFFBMD4dDxJRgzSdJ0u12AXjv7u622+1KpYJrC/v01atX3W4X/QlEJris//iP/xhVAgQnaGxgXVxdXd3c3Dw5OQFuIuSNKY9Smiep41qFgpumGd41HGiWbWNNQsb07Nmz6XQKBxVqTfh1tre3cdDN53OYUieTyXJKLMBaMCT0z/gHv4hjffH8hwdwa2sL8yUNw7i+vgZ7gKjYPM8BUMGdjeU6nU7B2C5dwMg8AnZgGEa5XC4Wi3/pL/2lra0tsI39fh+m1P39fUop1idEnFgbAAg6nQ4YJ2CHwPWhBAXwgekdm5ubyyoFPxcjt1E64/yBqVYBIYj6BlwA9ifOWaQt4GKYz+eWZcVxout6s9nM8zyKVNcpiJwEQQQO0g8WBwcHtm3fuXOn0Wh0u93hdb/VanFC0yjGDQrqENPpofwHPDObzVZWVvCug4uFgAN4GHAgoNkoIUE6qMUSBpqCvEMNh5MXG8P3/VKpBCgPP6tYLBJC0JABBuScM6ZcXV2pmlYuVYUQIieM0SwVwIH7/SHEaqjeptNpv39t23a1ujKdTheLWRQFhBDLsjxvvr+/v7Gx0Wq1MH1I13VxO4pR0zQ0IoQQ3KwARbFGgWdyzqEAI4RUKpV6vX58fAz3gK7rSZKORmNAYo8fPzYtK40T9Scr3AX5AqQFDgILRdM0IeDTNiilnKuKov3jX/nvvvz2V37x2z/vBx7UCZqmf/755x9++CGAQyFEmmWmZRWKzmw2I4QJkee36njcpvxWE4py5It0obz9ILf41hflWex2nM6ywGK3QwxRxsGArShKu9F0HOeNN94IguDFixcINc2ybDGbK4rihwGGTiyms+vra845gi4hwouCEIU1ZKRpmmq6RghB94P67969e7PZ7OLiAnkqQPtBWWKHdzqdNM0x6ULX9b29PUop7BRRFB0dHQGRQiDhs2fPUEsBz+ecL78hAtKWBTfo5lzEjClCpnmWM6ZIKYUUjKq6YUdR4MVaznmYi0AIaejletMWxA+CvudRSmqNejzotzp1lbM0TWmaG4Z1fT10zLBUra3UVmazSavRDhwPGilw7jC0f/7551jq5+fnW1tbiD2cTCYFxyGEjMdjjGmjlK6vr5+dnd25cwfWwu2t3dWfXsXEN2hx8jwHyoWOCH3X8fGxEALlBWiv2Wx2fn6+s7mVJBHO9x9+/v4bb7whcmlZVrlW7Xa7nrc4PDyAqnQ6G8dxvLW+ESy8Wrny8dMPXddeaTUvLs41TeOWNR4MOJGLxcK2XddxZ7NZsPDW1laiKPC8OedFBBAkWZokSafVJoSstJu/+qu/urG2XnILLz/99Df/+a9/8xtf/4Vv/4+klHt7Bw/u3StWKrZlZHleKJUfvfno5PT0Rz/60c7dO5STOImyLJFx3G62ZtN5pVwtVcrHZ6c/9VM/dXJywlQF+1fXdd8LQz/glOV5XiwWNE0dDoe2bXHOoiiMosgw9PX1tYuLc2S2maZp2zbi0548eTwcDn3f03Vta2sTY1twn331q1+J4/js7GxlZUXXtadPf/ylL70dBEGa5HGclIoVTP8QeSZyYplOnsnJZFYqlQpu6eDggDO10azFYcQYdV0ny7JisXB2dra+voESNs/z8/NzWB+Gw6HtOFEcZ1mqqCwIPdxJaBohbXzw4MHZebdYLJ6cnoOJc91i76qX5+Lqque6riTULRT7/X5/OJiMxnGSffb884vL3v7+4YsXL9rt9osXL/6tv/xvqaYVpdm3fu7nn33yfOEFBaa4xRK6qX7vCskFQRBcXJxphpXnQtVUGLSBiJfL5YuLi+fPnwPHAkr06NEjKeVoNIqjFFXOvXv3Li7PSZ4bhnF+fu46drVajSPTMIzv/cvvXl9f7+xsbe7s3rv7BuXMMIzpdFoouHmer66unp+fJ3G8sbEB+BZQU5ZlYRginuP6+hoKBPN2lDtCIpDvdXZ6gdPe98JlmOd0OgWcA7TCMAzohzCqHG2267qShMVyCTkOnHPP98vlMiFEklxVDExj3FzfePrBj6fTCVdVzTDTXEjKOOdRFAIxiaIb9xhjLAg903LqzYbCtSRJ+gMPRyv6vUaj4Rbs2XzCMmV/fz/P816vB/thuVxezOdojXBZ7x8edrvdYrm0VFwti6ov0oVom1G1A51yHMdxnM8//xzNMBheYByX3S7AVBRhYDNxOdbr9fnM6/V6YOEhv7YcG/EuQoj9/X3Qr6VSqegWJpMJnB+KovR6PULIcphKnqelUsHzvOGwn2XZnTt3rq+vp9MxZD+eN7dtcyleBIPZarUwrwlJ7r1eD9f31taW7/uYs8wYU4BSgKm5c+cOcFScpJCYRFEEgR7YQE01fN+HC30pKgd0MZ1OFZXduXMHQDTW+lpnBd1tpVIplEt4OoggIoQAjoPT23Ec/BRcigia6vf74IPy22wIsJYQGCKsBRdkpVIZDofwMaGOQboB7kiYDjRNcwo3qkPo0CHpUBTFNO21tbXrfh/IEHTNpVJp0O9vb29fXFyiwtA0bTqZg4sEAADKQ9M023YPDw/r9Wqn0yGEAJ8XtxNJUXoDHel2u5g2Dd0oADCA8+VyGYNIwZUAQYEcPgzDu3fvjscTMP1QcGdpqmr6v65dIIRQxqQQhBC8rcsMWEKIYRiEMKhDfuu3fqvf7/+tv/W/iqLI9/1MCLBsv/f7f3h6ci4ZVynPspQQAvg6DP0kicHs0C9kMSzBOeyBL9ZVy8rpi5XWF7sZvC8otpZfABye3Q61BHKJPDPk7xFC+v3+2dlZo1YHE7/kmtEYnJyc4NSzbfvs7AzyTLy/i8UiyxlkjEgHFkLgBPnyl788Go3yPAVaZlkWKJskSebzOaW80Wg8ffp0a2urWCw+f/78/v37SCmklLZarcPDQ6itEUXYarX++I//eDwer6+v9/t9vDYEcyDvDe2B7/uM8zzJJaGEsCTOKKUKY0KIJI1qtcp0Nk7TnBJuW8XpYt69umSqVayUTdN8+epz27bdYiFNY99PsiRVKKtW67WKNDRDpkkUxHkc7b18YbnOMu1iyf6USqXnz59X67V6vQ79U61Wy/MMg9IAdyGP5/Xr14yxYrGIyhJUICEEIC6EbpAHgDkFSOa67v7+PkZw/vEf//Ha2tqjR4+q1ep8Mi0UCqqqn5ycfOtb39I07V/+4XehjLEsq1IpgxxhnFQqlX6/j74W/aVp6lAjAT5fWVmBW1BRlE8//ZRSWq1WhSB5npfLVds2p9PpvXv3Do+PIOhUVXXQH7377rvtWmM+n4d+UHCdLElfvXpxdHSiqurh0cnF1WWpVFZU9eq6X6yUn7z55r17947PTr/0zlvT6bRRq7uacXx4lCQJYXQR+JVa9fz8PAiCYqXs+/5kcr29vV0qlcBShWE4vpq0222o+s7Pzxljjx49whF69+7d733ve1//+tcRm66q6unpKZpptGeDwWB7exu9KMAn5E4tpTy+75mGjV0JjAQiaxxTgCVwNb7zzjtJkrx48SLw/Hq9trK2ikmpqAhx7W1vbx8fH7948aJer19fXzdbrUqlcnHLrZumObjuV6vV9fX1V69eYQFA2jifz3/jN35rf3//3r17v/RLv/TeN37m4uJiPB7nOb17/75mOJLk62tbhJC//FcefvLJJ5Sr3/yZn5/NZnfuP3Rcp1Qun5+fe0FaLFVVzYRI4OLiQtOVQrE0mkwVlZer1eurq42NjSTLMPxK07R2u310dKRpGoLgVVV9/PjxfD6nlPb7/YuLC9M0S8XKdDq9e/cucMf5fL61tfXkyZOPP/qQMeY6lu/7b7311vn5eZYl/5//9h/87M//4s/+/M9hs0BmxBgvFArHg6M4jiGfnc/nd+7cgTwxiEKUVoh1AE2B7KE4jiEHDPwDy7LALqmqWigUIPwC1gI4FvgTDI/9fh/W+NlsNpneDBSByD2O44vzcwTUEUIm/RGcaoB2SpWqoihpnuKK9ON4ZbVt2/bCmyic5nnOb4gHWq1WDvaPF4vFZDpCeYdx5oSQXq9nGEbgR6AF4CEAj08pReNqCgsrZ29v7/6DN8ifAbG+CFyh9sJSRE++trZ2dHSwvr4O+z9ueZzeUMcCHkvTtNvt4nAAh2iZzuPHj09PT5feQELIaDSC5KlWqwVBsLGxcXR0NB6OUARTShEB/7Wvfe3169fVapUxBtaYEIIo+YuLi+Fw+LM/+7Oz2ezw8BBsGKheSFMwXno6nYJPQ9OOCgG5Ibu7u69evdJ1XcGBiGsViVBhGKJiwD/At4MrajweR2FSq9WFEOPxhBDZaDSAu+LaNi0dqkZIJnFnTKfTdruN+kmkWSxlkiQIXltfXw/D8LrfLxQKwMkr5TKizIByw2CMeTIg2qB2AmOY53nz9lpFr/DkyRNd11FOTiYTIDFLLfb6+nqURq9fv65W65TyILgZzMy5Sim9vr6+vLpeX9cURZOSJkkSx3GlUul2r6DHx07e3b1zeHhYr9fRNmVZmmU5IWR1tViplDzPgyVwaWHDPoH1Bur4JY+5tra2WCxQeQCTgzUGoCiqDQRPgFQej8cXF108nzzPK5WKoqoyF5RS8qcWtJBfmE6DP/T7/TgOHcfSVK5wSoS0TWswGjPGzs7Ovve97/3Nv/k/bzabg+tuuVSRjGqa/v4PPzg4OLAsK0zSKIooU6SUk8lkvqCGYUiRqwpj1FgWRqiHUGR8Udi+BKi+uOuW2NVSkrUkDZcfaHeAP4GMxopCvuL29vZisXj69CkKIHgzDcMoFYqXF10gnaVSaXd3F8OqFEUJolAQORyPDMMQRIZxpAkOHdLLly8bjcb29jbW/OHhIbh5vCTI4xAbMZvNCoUSOIXj42NVVeGYg9YQphVU9uhuIYQnhCDIFFUXqEzQPTDDd7tdkRNTM6MkVlWNKzQIAo0rqqFlaZKJPJgvdtY3uSAVt/z+j36wutpRdfPo7NKkSpJGb91/XKtVhv1rzXTTNE7TNI2T2WS6WCx8lcVxKNKsUK6oxJjNZ1tbm2maQuebJNnp6YnjOK1WUzeNOI4ePXoUxxGlxDCMk5OT8WT4xv2HaJOgbwDsijbj5OSk3+/v7OzMpos8z0vlAvZdmqaPHz+GTx7EN0JKVVV97733sFSEEFEUvHx5GUUJXFTj8bhULlq26QWBaRr1ep1zvvBmhJC9vb1Go4akX1hYdF0VQswX01KpJGRmmBqQA8uyfuqnfgrPfG9vT9f1olPcO9zb2tq66vUN3To7OxsNxpZlmJpeKlb6/WGtVqtW65ap97rdZ88/yzNZrlU7a2vVZlPTDElJZ3Vt/+hwNltIKTc3N4f9UZZl5yfn3YsLjStIK7i6vu6srOi6HibxZDKTUq5vbIRRlOf52dlZvV5P03R9bYVSWiq6vu+bhlar1WrV8ng8vji/0DTtG+99HdfY0eH++vq6bRkAgHENzGazTz755K233gKcD5cMcls2NjYw96LolqWURErf8/rX141GQ9e0JI4NXa+Uy57nqYqyv7eH26harqyvrnne4uTouNVqBVF49+7d733v+41G48GDB0+fPkU8oVso/Bt/7s89e/a8VKqg1el02sViUWFMVdWDg33HsZ2Ce9m7YlRJ03RzczsKs1zSg6Ozk7PLs/NrlGu968nnr35jOBw2mw14ERbz+Ze+9KWVVhtif8noq/29P/zuf3N0dGQa9vbW1ptvvlkrlzq6rRnmbDZr1Dtf/srXzi9O5563vrk1nc9x3kIfAusW+r1KpQKJBXzchBCIYYIg2NjYGk3G/X7/vffey/O82z13HGdra2s6nZ6dnW1vb2tc2d3d5Yx8+9vfDqJsf38fOmAEH56enu3s7Ozu7iqKUq/Xx+Px9vb2D37wgzt37mVZUigVr6972OBhyHC8w8M4nU6jMPns+YvV1dXwdiZSFMeKqhJKpZSarm9Uq2jIUYhoui4JYZxrmoYBA5VKJc8lSmewNA8ePEB9cHBw8JWvvjsYDHZ3766udYajSZIk5LZZhaalXC5zhVIisizXNDXPU845Z7xUKh0eHrZare3tbWhSz8/Pv//977daLYxxbDQatXrlujdAY1Aul2u12rheH/QGnucZlgmgCFkE2i2j8me5wuXB/sUyC+aw6XRKCEHCDiRNSZIgFxcz5UCm4TIFFYCqC90LUkBni7mUMoqiYrE4HA4h2CoUCoxQ9GyoxRlji8UCKl5sHKjlRqMRWpdKpfLixYvZbNZsNqGygp+vUimNx+PRaGAYxspKu9fr1euYuUc9z7tzZ+fy8vLk5Gg0GpimnmWZAumulBLK0JWVFd/3Yb0BT4dAJlx1i8WCMw15pJVKJc8z8FxLYmi5nlzXxZMyVG2p3MTnFV0DmgJbBKUU0gq4bBilSP7A+buUTgO6wI0FYQEEcXgboCEA5IMCHJUKtGmYhut53t7enmEbsNkjhWgwGIB7QsPx1ltv9ft9qOFc1x2Px8WCg8ogyzIAITAPopZHVpCiqGmaItT7jTfe6Pf70O3ie8JOqOv6+fk5uDPgT3meI5sHlArwOQTcowcdDAaMUcwSKZfLwBHfeecdqIg2NjYs2xZ5zpj6ryziL4JDRErKGBoRKeXSNJHEGQro6XT667/+6+++++43v/lN0KZ5nnOu9vrXv/qrvzqfe7ppM8oFp5TcRNrkglQqpSxNBIYw3FZR+AO5lUOicAQQvUSwQLSRW6B4uQmXtCBeHvYhXjA8EPgyFCVQY3z22Wd4bviheN91Xb+4uJC3M1NRn7148WJrawtiKUCkEItwziFQxWB2JK/gQJlMJrZtDwbXhBAYPBFbACUH+PTd3V1Eib569erJkyfoK66urmq12urqKqxhp6en4P7X19cRf6zrOuxFeAJwe1iWVa1W+9fDPJNCECkpIVRKmkkiJZWCWK6l60qeS0Loixcvd7bvUFUuFovN1RUiiR9EJwf7nz/zd3a2IVCA+StOs0zkhqpbjpHGiaKxYrlRb3I44bGVgJFMJpP19fW5t3Bd9+nTp5AtE0IIFY8ePRoOxtPpdHt7G1E0r1+/XllZQZTovXv3tre3ccRjzCh8mkgbgZQbUelvv/321dUVTklCCDoHlEpRlDx58uTo6ASAJed8dXX14OAgSZJiyY3jOEmSjY21JElUQ/U8D+62bvc8TdNC0el2u+ArGVVWV1eDIBiNRvP5fGVlxbKcJ0+efPTRR1LQxdy/HvTq9Wa9Xk/iuN/vr6+szmazJEqEEOvrm69fv2yvrtRqlV5/EEVRu9lMkqTdXrm87hWLxbv3H1z2rlRV/eSTT7Ms+epX36UiL5fLzVpd1/Xr4SAXYjKZMFXZ3d2dTudL9x9jDE2s67rT2dj3fXj6kH63v78PXzr0OmgUq9Uqpoo5bhHo9Z07d6CzgRMNAuokSRqNBlL94A2ybRt9IMLtoNpEtzYYDA4ODu7du/fw4UPMeKVUohbZ3t7udrsw23/5y1+eTqeADSCrP7+4wKY+Pj4OAw8He6/Xi8PIcZwldlUoFKaTueMUoji1bfvysjcajv/z/+LvRmEipaQKZ7fJdn4YuK7NGFvM5p1Op+i6CFufzWbD8bhcreR5Xi6z3/yd3/tn3/mtgmP9jb/xN772ta9yVe+PJ4PRcDabLhYzBDSg5cYFgRs0SRJQ+aZpWpbVaDROTk7Ah4zHY8cuQaH86NEjuA0IId1ut9Vs1Ov1eq2CBzWbzaTIFFX1wxRBoIeHh7jUWq3WeDyulMqDwQA2rDt37ty/f3+x8Nvt5sHRYaNRx+EfxwmEv6PRKE3TcrlcKddAxANTNE2z15/hwDk9PYUZ2TTN1dVV4OjD4bDdbk+nU0rp1tZWt9t1nBKlSaFQwO0jpSwWi6enp91uFx61yWRSLlcppePxeH1zK89zRJGBWa7X6yLLOee4IlB1xUlcrdYgP1VUhkrANM2f//mfR3qfEKLf77daLfSHEB/neW7b9lV2FYYhOCVoAXu93vr6Ovkf+sCNgIuDUuq6LtpgKMTBxEkpT09PK5UKOjTAe/iVQfb5XhiGISijNE0RWVAul5cBGYQQdONJFEM+BWmsqqpA5hCbAlfT2tra8fExKkWUiZgNg82SJInrunhVsExlWba9vQ0tb6fTsW0bAbPr6+tLiZuCKoRzjnsLcwCBE9CbOTDq6uqqlBKZQL4X4fPz+TzLUlQenudB4mrZBhzySwu6yjjeMERaHx8fU4UjIx6VZpqm7U6Hcz4ajXRdp7cOdoTrEEJWV1eXfgrwRChTIOcCLYqYMsbY0dER7kvf91GpIE8BhogkSabTOSacIC4B+rM8z8MgNm8/1tbWVFVNkrRUKqkKw4u0LAsqeBRSeZ6322105KBC+v1rQsjLly/x20F+q6oqZIygnFH2ZVl2fX2NjbRYLKB0xudREUK1Xa/X5/OZoijwGaAsgEXLNO1Go4W6JE0i3TD+/6xj1FhXV1dwHiy1jXi8v/d7v6coyp/7c3/utoBmQRAoufb8+XPIQeI0pVRRFTWObgzeXKFxHEmZx3FKCFvuE/y4pSuY3LJ+XyQKlzvqi82NvI3O+uJfLflEcL6AgjRNM00T8zEbjcZisRiNRnCVZsmNHReQ57Lvf/HiBXpcTOKczWZRmmialhOZZxnCZi3Leu+99/b29jBL7v79+5ubm6PR6Oqqi8mVUkqokqEqVRQNoGaSJHD0YIT2SmcNoDH4X8MwTMOuVuqVck1V9KOjoywVlPByqTqbzYrF4urKOs7f6WReLJT718M48hXOZB5lkiDoPkwjTeWCyUCkNV0td9rUMkeBJ0jGqJxdX5cLRcqE61q6qV5dX0pGpZQZkVzXgiTWLFu37SSNFMuGQJVItpT07e3tVSqVTqfT7/efP38ep8lXvvIVQghk+EEQMCpPT09BW6dZjD4e2GG9XodpAP3D6urqxcWFYWrogtAONptNKSUkWajqELqBCrVYLFq6piiK66rvv/99zlU02YVC4fjkZDAYECqyPIFkECXv8uSC9woF+srKytHRkZRyd+euruvj8RQbtlgsR0Hy+fPPbcspVarT6bRcri4WHqWkUio/fPD45eefc66sdBpXva4/D8LI94LFYDZpNJpTz/vjHz/95je/+eLV3txbPC5V+sNrIYgQ5N7uPcexAi+cTsetZv3i6pIztVgsMha/fPl65+4dzwsuul2sW0VRVjodJKQoilIoOhDG4n5SVRW8Z6vVgqRp6dlcLBZQ125ubgohjo6OVlZWdnZ29vf30XxzzpGPD/oPwVevX7+G6QQTYzDkDsu+WCx+5StfWYKmnU7n6qo7nU4pJXi2F2fn8/ncth0oR588efL5ixcffvRRu72CWKb5fG4aK0dHhxg51e/3T05OkKpfx65X+HA8KrilR4+e/Lt/w/jnv/Gbp+dXW9t1zrkX+JZl5VKg3zZNYzweO7Y9Ho+nnt8f73HKCqVi2yqggXHcwvau6/u+zLP/6r/+lZOzi0cP7j9+/Kh31W2vrL2z8pWj/YO19c04Cm7DCG/yd/I8n8/nkMicnp7CY4HLAgjWaDTSTe3i4gLqzMlksrq6mmdpnufz2cS27TgOKZUiz+uNRrPtzL0FufUDCSHSNFs2+aiHjo5O2u02pfz8/LzT6SjKjSUQFU8QBA8ePECAIixpP/zhD8vl8vX19erq6srKCvL/7t+/TylN0xQ3AmPs1atXS+k9HGMoGaWUnNOzi3Nd1e7du/ejH/0IkPloNFrf2IKnodVqnV9cLhaLQqWqKAoVN7NJGo1GlmVSSiZJnqaGbWRZNpvNGvVmrVHvXl0qnCoKz7J8c3MTs4lgfgQxnSY5brdGo4Ek/cvzyy8Gbruu+/z5842NDflnwtzxAVyffCE8Al33/fv3MdPC87zXr1+/9dZbrVbrs88+e+ONN6AbXqp60MdihgoEWx999BFjzHEcSinlDDLrZZIONoJj2Y8fP/7www8ppRsbG91uF9Y63dRGo4GqqpTKyWRUrZZVVR0MBqap53mK4GhdVwsFR9PULEukzFEZ67qOEeymab711luQ8EKHJ4RoNBooiug/+kd/H1+NBiu6nd0BXArv1vLOcF13PEKoa3EyGSMoASQ04KU0i5dlE2KfoigihBQd14/CxXQG/QcuPCx6TdP6g0GWZZhuEYUhkDAo4i3LQiQrwr7kbSQuxLmqqtbKlTRNgSrheIJTF4p4RVFQX8OsRynNifQ8r1QqYRsrijIcDoExTCYTTTcZI+Px1HEc4FWayiH7IIQgZGs4GGuahm+Lihs1hKIo2HtZlum6OZmMKOU7O1tCkLOzE8OwZrMJ56oQmWnaeZ5WKrUkiRBngtUAjBQmL8TQmaaBIerIGAvDKE/SIIhc1/36N94rVyqEECJu+cHb9Szln8RiwbpPmfxP/9P/Jye0025bpgMPcKFU/Ht//x9897vf/ff+vX+v1WoVnWKh6EiZR2kUhuF/8V/+3f39fcqVNJGUK1kmckFA26sq933PNLQwDPP8ZhTPsrTCH/Dn/Db4alk2weW0xKj+lQILC++LxRZe6tKZSCmtFEubm5uPHz8eDofHx8eLxSIOI4SdgBdH6BrujGarPhpPoyjgXA0CL4qSLMu8MEAXkaapqSq40TEJCklLjx8/Bj7a7Z5/8MEHhBB8MaqxQqEQx+nu7u4777wDtOCjjz7yff/Ro0ft1srx8fHm5uaPf/zjg4MDDNNYWVlZXV1dcjrHx8eKyu7evQvAEoVCFEVpksOmZLtOmsZZlmmmhQdYsK08SxqNRrPZ/pv/wX/w8OHjk/MTp2DrmhLPQ8vQKKXXw+t79+6dnJ3ounH33r2Li8tisbhY+HEcM0Zms1m5XCSEJFHKGFtfX4daBZPdEJADXP2yd2XqRi6FrmqO4xweHlZr5YJbEjK77g0gDdze3v7oo48wCxL2ESklQjKLxeJF98zQrULR6V31m636fOZNpqMnj98KQm8ynjFObMs9PNp/+0tf7l6ezyZTyzLjOBmPx/fv38+ybDqdLxYLx3VVVZ1MR4hoKZWKi4XnOE7oB6urq6en5+PxuNmsb25u+r53dHQUxQEOk2q1SiTDqltZWR31R77vI6bBD4KHjx8dHRxGcQCP8PrqWhiGo/5ga3Pz8vzCcu1cJpV67fLy0rZtKalt27PpAj2C4zjISiiXy51OBzd0q1HnnE/G0yRJqo16GIa260AYKglRb2NlQOolSWIa9nDUl4K2O00p6Hgy1FSj0az1rvqFouM6xcHwulSsTGdj07Cvr69tt4CQCGRbIBqm3W7v7u7+4Ac/QHoIQqFXOyuIrnAcJ40zRbuxngDR6XQ65+enl5c9zunm5rZpmnt7e+VysV6vh5EPU/qv//qv379/f31jK0kS+O84VxGz2e120yQnVLTbTU1T8iwbDoebm5uTyaRSqQwGg8Ojk3q9ubq+3u8Pa7VGGIZJmv3Gb/zWb/z27xuG5Xuh41qSMCGzNJeUSiGEqqry9rFQSsEBJUliWFaeyzgOVc5VlTNC54tZEsVpGhuasru73WzUq9VqrVZptVp3drZAFICY3tzcRGyh67r4hjhqoCeZzWaaahBCNFMLwxCgkaKyUX8ghIjjMM8y0zTXV9fCMDBUXdG1NBNJlnKqPP3ox1/98tcMyww8H6KFRqOhKMp8Ps9zmec5pu6oKl8sZoSQKIo0TXOLBWSyQIsS+sFkMrFsA2EWOFgkIZPxeDqfFt2i5ViaosVpHPqhHwQrnY7juoPbYaxRmIRxxBjDjKAkivM8p4QgX5QQEkYQjDppmv6dv/t31za31rd2dV2nUsZhxAn99//mv6twmqWhrvBcZAJGb4U7tvsHf/AvDw4OvvHTP3V6etrr9TD8EWppJHdIKaMwAVA9Go3W19dn0+nB64Or7mWz3Wq326Zte5532bv6j/6j/5AQtmQAf2LbD1MUABpFUQgR//1//99HUfT1r38dVAN0nAqCsoVAN/v1r3+dEHJ8fHx8fHzv3j1KOHTYa2trWOpusYDR8gCwga0wxoiQsEEAiwGvpet6EPmIKD87OxsMBpTSJEnu3r2rKMre3l673VZV9eLiAo6llZUVjNGEXxImoTt37oxGo8PDwzt37kBXxxjrdrtgw5ROp3N9fY3qAQlYeC74T9RYUF8hAiQXqWUbjFFV45jqGoZhuVIUMvODSOQ3SF21WmVU4UwN/KmiqcPxtFAqrqyVLMe+vLx8vXfgOFahUNB0HSbJVqu1trYGGEC7nbiMRg2+2SRJwAS7rntwcIDkQwC8+FUvLy/B3aJkAawKtBABdOQ2e2lpJzZNE+IthIZpmiJFNpvPO+22oijj0YBSGgsiZe66NjyZo9HItlzwSpZlHR+fVKtV07TymynUWbvR9DxvMfNUpgpBpqOp7RbjOHUdfWfnzquXe6trHSIZoWI6W9i2CdoID219fX2pN0IYWhCEpVJ5MpmkaXR93Tc1XeUaI1xharlQzuOMaxqhhFDQgss0rBuMShIpcqpo6t7rz7MktBxXZnnBLiyCsFCsPv/8+Q9+9IN/48//G07BNkwtS+O7u29eDXtiLt//4Y/29/cty4nilDGR5TlqR13XNU1J80zTtDTPcinyXOiasVTl53meJimIgzzPGeWayvObuFFBGaGM5SIVgqqqyhUOYE8IySkF8CxlDvqMc8Y5VxQNyxIlTrFYhP+r37smhBia7hNPCpEmSZ5ljLFiyc2y9HrQY4xFSXh2ceo6xTgJBYmjOIjiJEkScZNAJjjnCtfiKNWqxurKuufPpZQIN4e+8vHjx3Ecf/e7363VaoZhjEajcrFEhBRZenZyfHd3p91sfPbZC5kL3/eDIEjSqFwpRlHUarV6/WtJbwbCw8yys7vV7/cr1dLGxlq9Xn/x4gXnVFEY56xQcEqlysHBwdX19Ww2V1WlWCwM+n3NUFVVJRK5MizNxMXlIM5ezDzfLcbz6aReLav8xgEw/vFnh0cHIpcfPH2xurra7X7gOM7GxgYRIghSbzHEQR8EwecvDnEbqZp7ft4/Pj6GucYaeZTzQb8/HI/jMEyyrFwuJ7ny4w9fe9787t37hJDjs6NubzabzYMYM7N1QlgYhn7Ug0irWi33+kNx2js5OavVKqqqS5kf/7Pf3b2z7S0C09K78eyqN06T55TJLMvK1RXCkvXNpiCGqvNCySyUmsPhUBKW53qp1Dk8PBwOL23bGY0GlxfdP/qjp1LSUqn0/e9/dPfu3WLRvbzsbu9uVWqNJIkueyPGWL1edy3no2efoaZHWMNgMPj97/7R9uYmY2Q4HD58+PDF6z20oWGaOY4juHp23t0/ufB937Ks4XDsOM75eXc+nwMLgZN8/+iYfvRxsViMoiTwI8gxF4uFsn8CAiVJktXV1ThLB71rAPCgXPv94ZMnbz5/vq+pxmjsX/cGzVZ9Mb988au/nia5W7Cbjfbh0X67tbK1vXF2ejHzFm6hYln2eDxuNpuWYSC07JNPDvP8u+R2+lbv+tKyrDgIKaW2bQah59oFL1isrHQsyzo9Pc6yjKnKZDKK43RjY+318elsNuv1epVSmXOuK2ocxzs7O4Lqpxf9H3/0AgLWYrGoKhoE9eVy+fp6kGUJ49J1XUPVVEP/3vtPGWMwPlu2++nn+26p6LpuHH8SBMFgMLjoXheL5YUXMEWVhElJozCRjNu2iT1IOAvjVEoipRhNZpywgltaLBaUco1riqLEUaxyxTJdXTGLRVdk2enJ1fFRF/ymYRiuY62traVp+u1vf/vk5AzKv36/j1C02WyC6UZodRaLhR8G1WoVegDdcA6PzrIsUzg3DMPz0ixOhNBf759fXV3t7t7xfb97cbW1u9Npdu6/8U4Y0uFk0qo3NK3keV4c835/WigULMuI4/jqauI4hevepWEY1XoFWsAojVM/VlVTUq4auud55WrJtswoChVOVVUtFQpnF+fDfl/VlcVsNpkMy8WKIHmtUu902lfdS9/3LMPKktS1C/PpQmS5W3Rmk+loMASo5jiOZdvJbYcJJ3un07FMPYujKPAMTZFSBuFid2ubcyplLgnLCSWMyzxnjOdpLvL88aMHr1+/Pj/rVit1bxH0rvrwjUEzXqlUHMeB5m88GVJGgtBDKOBxEoNDkEyals6o/Oz5szff/BIh8iaFMZdLZcjNBUUprHVoqtGhvfnmlw4PD+M4DcM4yzJNM6IoiaPA87z19XV06Xt7e3CooHiaTCb3798PI38yHbXbbc8T3e55EIWqqo6no+3tTcexXr9+7TiOJLLRqt8IxH2/Uql4/nw6y7JcTiazLEssy6pUbghijDAejUZCZisrK5RJx7W4Qs/OT87PzwuFApqcpX3NNE3MrmWMwX0JejfLspuph7DaAYGH0h7ZAchn4pwjPgsSKynlbD4BL8s5R+MIVotzBegF0G9CiO06cRy7xUKe52EcqbomhFhZWZnNJtDF48SfzWYfffQRIaTZaEgpcZ9BUAw4Std1wBIwhS2V/IiqQyQr6mUMD8KsQOAKCFJCq63oGvw4yDI1TRMjuhQFiCWB4KzdbkdRgHxUZHIYhkEptyxL0zRsHsYYxgBD8lIuVy8uLvb2DmA6RY7w+XnXsCaU8CRJxqNpuVwGBGgYhh8GnFNKBJjHarUKZXSe50ggg4ADwRnwH+iaTgTvNFu6ZRLKuMbTJOGqQiShf6ZXkEQSSaUkRBLcIu1mCwQN0mL/y7/7d+7cv/fg8YNg4em6WrKLp6enqqVNJpM/+IM/CIJACOwKbmgqIQx21ijKkiyRUnKFcs7T+AagAisE8Ang4pI0XG4qxqhCKSc3rt0vcoKgAv8sggVsHDIsSD3SNEUOtaqqjFLHtuMoKpfLjmkdn50u/LnrumiMGCcQupmmiaGtQmScU0W5AR2zLNNsDWlqWHWz2cz3fSDVg8GgWi0/fPiQEPK9730PAw/8hQcXPQJjvv3tbz948KBarX7w9MdQKS0Wi9pmA9zNcDislivj8fjo6KhWqxmmpmlaqVSo1WpXV91+vwdBQBBElFJN077x0z9tWq5p2/PpVNP4/Xv3FIWdnBwFQWCadpwkluP+4b/8o/39oyjLF/OwWC6IPCYy87xA0xSNa6lIvZlXKDiqqg+HfUXRigUnS0WWJ4ZuMU5ETgiTaZpLmRPCsiyhlDNGdN2M41BKyjmVkkqZM3aT+2UX3MXcS7OkXmsImc9nC93QOFOSNA6DSNUUzhQhc4WrlBEpSJanVJCcCNuwFF21dHM6nSRJquvadDpTVcUyrFzmjuVIKjnnWXZTljQarSSJ5nMvyxLTtBWFpWnOOZ1O5/V6NQzj6+urYqGgqYYQEr31997/sectFJXlMrMsYzQaKioD0K5pmpRE100wYnmew+eYpjG5DTzM85wxBhceaHqoo+AJct0i4Px2a8X3/U8/+z1FURSVgWeHgBLt1he/DwBX3/chL4PqSNO0brfb6awGf+fvz+cLy7IQuYd0D+SPiC8MNkCsq67rXDUhZ4bMhXPqmI4QGXYZnLDtdnsyHTHCMawd1jPOues6QeQLIQgVeZ5X6hUp6PQ3fzsM4kKpiLbeXywMQxNC2LY9n88VXZOC2rYdxylEDoZhTIYT8Cnz+bxUKkiSx2GSyyyJM0VlaZLnRK6srAzHI0KYEFkYxqrKVVUXUrZb64qimKaZZQljClMVSnkQBJpmECIIgWOfUyoo5YTSOMsJV1SuCIFBqZxyJnMSJ9nOzr3RaHBx2atXqopmGpqSS0ml/OT5K5XzHz39TxzL0k3zH/yDf7S5s+nPfa5xmedUYZPhSDVUJplqqIAM8HykzIUQcRw7jpMlSZqmumbinJ/NZq7tBFFoaAZXFUZ4nEaWYc+9maGZcRoZmslVFocJU6iuGnEambrlOFaw8MIooJTqll4qlRSNF4vuT//MN7c21lzXpgrPszTNsyzLkjjVVGM4OKjWa4W77mXvyl94u3e24c0PI78/6KmKrinqZDJhjM3nHprG4ahvmQ7ABQh8IcYaDoeGYUEcjKZiOlt4i7njOIxizJ+q63oU+lg8y3RubARVVSkR19cDztW1tbVlYh/yJhHOnIsUsGWj0UjTdO7NMIzkxs5VKVJKTVN/+fLlm2+9lWcZVzRyG7jzE6Gs5QfnvNlsPnv2DI46KSUmaJmGJoRYhqudn58LIdrttuu64AohSfzggw+iKDJME79RoVB49913/YUH2Tf+CUSNoNRd10Wqoqubk8kE7sXhcIgRYRD+PnjwYOHN+v0+iAu416eTOQob0BFw1EGqhVjNUqkEbAj/UGGMIfn+7OwMmBD2Em472OAhMoVqcpnVhHgFMFkI+xqNRgtv0W63USfiu7Uazaurqzi8CWGajMbYt7VqdTGfQ41o23a71ZpMJvv7+4auQ+ReKpXAA0JAAKskfn98Hrm3+LlJkgCdW+aLokbEUCd+Oz+IUpqnWZhmJbcgszwJI4SIQJ6VZVm3e7WxsVEoOEiTi+M4TfP19c1+vz+dzpDdBQPweDzGfxJCNE07OzvrdDqGoaVRrCgsTeM8T3Vd1XVVMorHOF9MNU1TVGbZruu6+kLN83zhLaD9BNovpVyO0wLtCLVWuVwulUq97mUS5UmStFY6WJdLMu5fmUQoCSoYlDbk4ODIcQp5LgvlUppI2zb+X//v/4xS+gu/8AuGYYVeyLiaS6ESMhqNPvzww/Pz89XV1SjKkiQJozRJEkm5RLF2q08UQsKRIYmgjCgqz0WGQkoSQahknEpJ8lxIgv9JKUHzcUKkyIUUQlEYpYwSKqVgjDPGCaEwFFJKCWFwUTimxTmPg1ChzChXbNsuOO7BwQF6CBRzpxfnnPN2uz2eTAghlmVBvgOIGAo2eBuh7V36FovFomUb48lQ9VQUixh6eHR0JOVGHMdPnjzRNO373/8+goC73W6r1bJt++DgIAxDw7Kr1erbb7/9ne98h1L6xhtvTGfji+4ZWMtqtco59/y5piuFotNsNj1v/i/+xb9YLGaLxUJRNKwfoOJJmrfb7WK5PLbt8XgQx7GuOwgrH09nlllgjDWbTc8LU0l8L6acFAtWFIdZmjNONa7ZBXsxXVi2KQVZ29xglCuMJkkqpdA0nSosTTLKSJpklm1SwrI8dWw3F1kcJWEU5JlQVM6Zoqhc4aogEk6ldkflnFLKhcgaTZGmMedqkkSaZiw/HwQRY0RRNCnzolvCJTSaDItuySkUDMOK47CzStI0VpnKVCZSQTiJ41gSUXCLnr8gkjIpKrV6tVYZ9IeFoqtrRi4y251ZtlllyurGOjoERvl0ejNZQbcdzqlh6p43rzVUiDO44rTbK1EYJ6n0/bBarVJKZ7OJU9DQtiEHCCqCYslFtUQJl0K0WmUpZRzHURQ3GraiKFGUaLq5sblqmuZsNiGEuK5bLm8oipIkN+Ua8F3wPux2LAmmz+J4WVu/H8UBMFqg1OVqHT2tqqpBEJTLZRDocD3Xm21CCOUMDTC/mdcuGOG6fjOaI8syBDQ0kwaTNM8kYxqjqhBZTiRjVJI8yzK3UAiCIBcpZ2qtuSbFTbwcpVSKhFFCKU3zrI3GhjDwd8Vi8fKyl2XZ+toOFLpvt1qz2UIIkcUZ4YRIphtqnslciiRJCoWW47iU0yiMkzSOwjgjuR94rmtnMstklieprqucK2ku4jSiVFLK8TMZI0RKSiinqiQkJzKXQmWUa1xSGkdJqVo8Ojn86KOP1tbWNra3JCXnp2e+79WrtU3bMTQ9yVKFccLo5ubuwp93OutxGiVRbLvWSmdVt/QszgijeKc8f7EcuhVFka7raYwCy0Bb2+qsiFQQzkguBCVMslSkruW6QUnjWpRGTLKc5AWX5SR3LTdMQl3RsywplCsdZ3U8Ho+nY+L5tm0ef/ri4OT0rTcf7+7ufPNb3zBUZX/vlcaVer2eJalpuaqm+553eHTsOk6cZFHkUUq9ube1tX12ds5VdXvnzosXLwyDQu6mqQZEBVBhZ5nodFbh3JKSqqo+my0sy9nY2Dr/wQ+wGhXOQBNpmup7OedU5Dci1yV/6hYL9WYjicUybgD3KQYlgaF2XAvz3zAG0bbtub8olUonZ2cL36/nOZqKq6sr3/MgFyOEUPqTiUL6hXwsiC9brRZuPYQPSClVhd29e3dvbw+0NSJkgZtqmmZZ1vb29rNnz957771qtfp7v//7yEYWWR4FIYpOiNbDMHRd1zLNly9fAlI5PT198OBBkuZQHNm2fffu3eUMGOSIbmyuZdmN+vPFixcPHz5sNpvD4XBtbQ2EBnSWIO6RyANKCmm3pmkqlNIf/ehHrVbr3r17sGNMJhPMAMGIK0BHqLHwZJEMhBoZjwYAeLvdDvyIUopSDGxjt9v1PA8CQySqo2lDhwfLGJwgiqI8fvwYBi48eqRxHB8fQ1a2bDrhkUFdiMQXNJHlchnSMaAdECyDWySEGIaBVwWX04sXLyClGveuEDCtKAoKONe1R6PR6enp7u5diAOQpIe1Va814XEwTdN1M0JIq9UCakIpVSjzfb9WawSBd3FxUa9XV9Y3Li7ObNstl4uLhV+tlqfT+dnZCWMKY6RSqSC1C/JGtJIYSrVUDiKiZjwe50laKdWvrq6+3PgqYRSkGMqdn4BgSUmoVFQ2Gk2uLq8rpUrBLQd+VK3W3//hj/YPD/7Cv/kXmWRHR0frK6uFQiGPE7dYyGj+9CmQ/xxSVtctEEIGowlKEwjChBBC3mgI4ELFb7HkN7/4MpY6d0JIesO4E3Gb2oBfQUhJCFl6D5d2QkVRqJDQYAVBAGBpNpspjCP+1DCMJI4RwJgLESYhnluapkHoQ8Onadp0Psd3zrJMyhuhPWMMCeCS5Egmg7ELU640TYNq9dWrV81mc3Nzc7FYxFG0TIjGGvvmz/zs3bt3oeZ++vQp2k3EwxQKBRiJm626bduDweDw8ND3F1LKxWJGKVUUDZF0WZYNBoPr60G7s9br9+vVSrHoHuzvFwpOrVYJw7hcqtZqDSml53mXvZ6krFJt5nkaRUkUxZpmxFGYKyToh5yrXhgmUco5ZUyRMheCZFlCwphzmqY5YZJzNacSU/uCOM3zNM9lnqecq2mSZ1kkZU4pxzUcJYmum6rKgXsxpqRpyphUVZUoahCHWRYrCpNcyWSeJ5mQWTQccYX6QRIlaT6bC5n5QSJJblsuU9QoyZnM0yTnCjVMK8nime9TSnMhC+VyHKd+FFmFAlX4ZLGwbdN03fFkZNsuIWIwHjPGHKcw94OypiuKQiXRLb0/uHYcR1fUTDKmqE7Rms5DKSklTLftMErn/lxlnAiShglRVc+PFENN/CgjuReEXFMlUXIhOFMn83mWCVVVgzjLZAgPisK1TLDhZKooap7npxdXEB0jhFDlWhjHnh9xlSlMlVSkcRYloWsXwiQRmRQkz6eLIPIIEMT2AAEAAElEQVRNQ9cMXaQyiDOR5UnuZ0lqu858ESY54ZRRzgxNH89mhqYTIoLQEyLDUek4Tp7nOO4twxQyBw5xfHKEvjnPiMKJkBklIpcizzNV17z5LEziNE0FJaamG7aV5kmSJHGWCyFURuMkpJJkInccJ81zmclF4CuU+XGWpHkcJ6PpgnOaJfn5RS8OY85VdhsCHEVpLoSUknOe52Qy9bLbYaNhknBO0e7HcWiapu/7UipxGkGTzhiTEl7mnBAuREYppzTDaSCpyCWVuWCMCUrG02kUBFxVmMI/ePrj+w/e2NrZPj8/P+9elEvVLBVCiDyXisIYU7JUzOYehIy5FFmWJdmNwTlOE9u2S8XqYrHI0gjbPM9IlmWUsyynuWBSSlVT58Fc07QsSQ1T44qap4kfxlLSHLgaU5ikqqJrTErKNc0QgvpR3Oterq52dF0vVaqmbWmGVhVS05XDk9P3f/ijH3/44V/6pV/68pe+JmR2fdXLqWIZ2mAwoZS+995PO44jRPb555+bhg4+zvcDjFyD9xBhBEjqBgJ6eXl5ednb2dk5Pj6mlKqqjps6SZLt7e3f/b3fg2yGmwYhpNlsxkkURQEMW2maSnkjbw3D0DDN1ZX1OE6r1epiMcvzHCYJRK7M5/NarbbwZohFQA7FycmJbRRw9yGKXNf1UqlweXl5dHT0+MkTIeRSO/uvk70vyywp5dra2ieffAKF1tXVVbVaHfRH19fXIENd133y5Aml1Pf9s7MzKGpevXoFTKff7zfqdUVRwjgy7ZtsKtwFkGRZljWdTp88eZKmqed5d+/exY1g23YY+oQQz/Mwgh2Cos3NzYPDPfBsIOs8zysVNUIIYpPhWAT7h0kYCJUYDAa6rkNmx5ATs7OzgxAmYEIocSqVimmaV1dXGEQA39/x8TEeWZIkyGVGHEgcx7ATc85RD6G7QoOOkAUkUtQb1WqtjMkhhULhwYMH6JKRbFatVuFGxoxJTEYDB9xqtaSUYC0JIUEQILQzz3ME1MJ7CVPG559/nqYp0kfQtWBqrGVZR0dHP/jBD/BNVFX90pM34yBEkcsYG41Gr1/v1+vNL33pHezJ4+PjDz74QEqZZ9J1isPh8OTkZDab/dqv/doPfvD90Wh4dHSY59loNJxMxqqm2I5FiKCM7O5ul8pFkSackuGwn6aJ7y9834vjMEli2zahC+73+5ZlAQ+bTCYgxSilWMSwIuNdhIgb/seb1fk/hL4mWep5XpYJKTilaqlUOTo5/mff+We/8AvfxoSBTrNjaGYQREmeTeazT59//urlHudqmqaqppFblyhjhFKJpll+IY0dYUi3KqscFf2yqFoWxPI2SnTZMy117vgFlgJ5eTt0HQWWxhXLMEM/CP2gXCxpinpxdn64fzAajQaDAZCk6WyWC+EHAaKQMdkX84VQbc/nc28+j8OQCMEpRfUGQ2KaxUkawf0RhiEhxLbtZrP5zjvvYBHmeX7v3j3kYiAEH/3TeDymnJm25TgOpFrvvffeL/3SL5mmiQEprmtb1o2H3PO8Tz/99NWrF2kaI3MOXeNwOIyi6Pz8PE3TNM3RkJSLRUTqNRqNnZ0dw7BgpABXjsmbGxsbjDGosihXJGGaYVKmBFFMKE9zybgqKUvSPM0FoZwpKuMq03TNstNcclVniiYpT3O58EPCFKZoimZwVSdMkZQTpnBV57qRU8YUNRcE34cwLiRlikoo56oWJ1mS5VkuMyE13VQ0nWu6ohlhksZpHme5Zlhc01XdlJRJwvwwStJcEJoLomi6JGzq+YIwSbmiGUkmJrOFICyXNIxTL4gWfjide4QpllNQdTOX1C2X5oFPFF7vtPw4mQdhkovx1FM0K8lIJmicirkX5ZLPvZApKtdZmCz8eC5ZarpaTuJURkzJVZNxVXCdKJrMSBQli4xERMlyFoWpR5Q0p9HWnVXJkzgPDEclahpm83kwyUhsuopT0hVDJsLvrLeZxqMkZBpnCg3TyA+9OE8kFUShhqUHSaibWqFSnHszy3UUVROESkKZoiqqxhRV0400F6ZlC0Ip42kuhCSaYUpC01woqm7aTr3Z0k0rzYVmmLVaw7ZtpnDKuGnZhDJNN4QkiqpxlUXpQrBgNL0iPOFaHiQzy9UES1MZSZYuwmmSB2GyoEouSBynQU6kpCqhqqRqnMo0I0zViqWKYTvzhe+Wym6pHCUp13TLdoIw0gxd0xRF45KKXGZJFkuSUybTPCFMMkY4p5qpmY5p26bjWIZhSUk5Vwlhqm6EcRIE0WLhM6ZwrlLKOVcFYYQpgjBJaZJlqUgFFZLSNM+jJMxlpuqKqmuqrperVT8MC6XiJ59++i//6Ltzb+G4RS8IMyEFoaqmS8om0xlhnDKum5btFhhXhaS5IIyrXNFMw6VETVKZZmL5SSGpkJQwJYwTwjihSi4ooYxxxXIcypQ0z7NcCkIYVwUhlCmUc92wDMtSNcMLgiyXlHO3UNrc3hWMp5IQrgnJp3OfMJUwNZe83VnvXvb/r/+3/+T/8n//f+ztn7qFaqFYiVOpm/Z4Oh9P50cnZ6VqbWv3jpDELRSfffo8jKLJdLrw59V65ccfPj06OlI1/vzTTxbzKWfk8aNH49HIdazRsN9qNDfW1jfXN7Ik1VXt8qLbajTLpZI3m6dJTIVUKCuXSlmSKpwTKYXIULjjiI7jWErquu7e3t7FxQVsbZeXl4PB4OzsLEkSjD9JkgSE4BLsqFarbrG4DEvCeauq6ueff07+dASPlPJfd0mRWxqxVCoNBgMhBPSO0IwiWtx1XQydRHH5xhtv2La9u7ubpmm9Xoe348mTJ4yxUqGI0xWCbMyVWl9f127nkvm+j3sW1rcsy6CthFh+mQwKmUe32wWCgFyM8/PzXq8HQzpaLF3XLctaW1ubzWZg26AYq9frhBD6W7/1T2u12osXL6AqaDQayJxAF25ZFuKg0jSdTqfIDMTTBFZh2zYYOojzFX6jT0fhBR3V+fl5s9mcz+dZlnHO2Z9MgSTw1kZR1Gg04jjGw43jeGtrC4Ie6AmAVQAUrVar19fX4PXTNG1Uawi6IITU63VUmlDHO46zDHZHdBh4VnCIq6urwAaRm1yslAkh5+fnyLsqFAq+F15eXlaqJVz5WZZVyjU4ZlE0lEql6+vrZT+BFWZoWpZljuNAmI/RPZzzOE1RMwkhYMnMbmbLKOg5CCGtVgv+I8uyELICA7aU8u7du71eL4uT6dT7qXe//uStN4UQTFWlECAR/jUUoSSE/OB77//w+z8qFQpbGxumbfwf/8//h4ePHv3sz3/7s88+M3SrWHCq1WqzWQ+D4Pzi4h/+w3/48ccfM6ZomiYkRSSBlCRKkiXsxFWeZVkUB1JKIijqfUj80GCBRMfXo/Bavhgh5dJwQAhBGSW+kI+FzQYYjBOqqze0Lz6JF2AYxpKJxjwipCvleW7aBrA0IYRl38TSYrwGThNCiCAMkKqlG+ltkhCqPc65YRiO4yDbNkki1EPQ1eV5PuwPUNMnSTKdz+r1+pe+9E6pVMJQrVKptLe39+zZs16vN18sNE0jgmqaRpn0fZ8QYVkWJvFlWZIkiZQUNSXnnHM1SRK3UA7DkFLiuq6hq5qmcM4lJaqim467s3tvPJ2fX1xxps89v1arZVmiKApCooEcM/VGzYPfF6KTG1xQ4Ug2gcIU/hX0FfJP5+wjfCTP81xSpFXh4aC5hOQOmwI8C7Z2mqZZnCCdNb8dvaBr2tKSDQrshlBT1FTkguQIPcHBAqwe6we6EGwZQgji9wzbUBRFCpqmua4blNIkjMrlUpIkoOCFEKPhpFarC0FUleuGMp9PS6XSsg0wDC1JEuV2MAMo5jiODVPHr7+MiTENS0qJgc1Q4+JQFiID+K0qimU6s9lCpJldcJkkklEmCVMVKiThLPKDnEhdUZM8MzU9yTOFKkmW50mq6BonlHDGCfWjUKFM0TWV8ShN4iC0C24WJ4xTTVMW3qxSriVptJj7pqU7ppukkRBCVXkcp0kSmaYtRAb8Js2SKI7zLLNsm1CR5rmhaZbjYHj5bDZrr3TyNJOU5LmkhHGqCUGYoKnMiKS5vAkgoJRC7LiYz3H8JmFkWVYep3grM5FjXeEyo5RSzhhjURRJQbiuMEFVU0ujOM5iQzUWwcI07YU/h2JJVw2uMpFJzVCjMFF0JYszqlBVVYPQY1RhnKiqKtKbSVxYS+ViCfI4aH9N09YV3fO8MIhAY4HiwfITQgiZYz3rus4YSdPUMKwwDKMgNG2LMaZpSprm0FlThfu+ryoapZRz9YbzjaM4jjljiqoaup6kaZamhmnGUcQ4VxVFEjKfzRzXZZQyxrIsJQwitjjO4jiOLcfknIssp0wWHTcMg8tuV1XVn3r369/61k+bOl9d6fT7/SDwOKdSSsPUisViGoW6ridJgsRUbPCVTsdfeNAwFIvF+XweRQkKHV3XFa7d8jxkNputra39t//dP+xdDx69+aRaKmdZ8jf//f+ZlFKKDCg+VEBLeKlYqnS73e997wemaaoqZ4zh6gG1BesGV2iSJIPBoNPpjMdjx3Ecs4iAydFoZDvm5uamZRme5/X7/b/+1/96vdEihGTZDe24/HF/ck/dVl2IX+Gcv//++6PRiBCC/LyXLz5DqoCqqisrK6gl1tfXGWOHh4dhGKLgQ2xyqVQilN6OZjGR1gmFN27VwPdHoxGGgoM6NC0njmPHsfr9Pkor8F1YYIwTaEswm6jX6ylcY4wtIwjiOMY33NzcPD4+RgcOARm0PTdEPob7omSB2h21HojCIAhWVlZQLSVJEoYhbL3QwdVqNSzo6+vrcqkKJTJScPAF3W4XfH8uUlW7mZCD0gFD9yaTkefNCSGua3Ou4nEDFfQ8r1qtxnEMgAE5n1A6z+fzSqUCZzK05ziCCSEQviDRERkzsO7neS5z0W63zy7OoShHkhvn/PknzzVNq9brhJAoTIaDEwiQy8UiIcQP/FKpdLC3V6vVojhAokmchI5rFQqFvb09P1jcv38/TsJyqQjPJyo8w9B8f4FaMwxD2zFBrmm6MRoPCCHVSp0xWq/Xrq+vDw72m81mtVq9urqC5JZJUrAdSmn37BwYaalU2tjaXMZ0JkmiGXqWZYr6J3GjlBAKITmllMinH/1Y41rJrRqG+U/+yT8WUv6VX/7LH330CaXUsc3FbF4uOXEUWLbth8GPfvwUUCXlLI8zQkicpZRSKEUYv8GW8izDVlFuR+LgdwTAgyhC+QV5+/JapZQJcSMNY4QSQYSUlDIil2AWUdAhkpscTl3TbMcBO6br+srKSq1WC6KwXq9HSXzevYCLIgxDriqQT0GH3u/3kQgMPHwJpxHJmCQ5V1LGYbUlhJRKJbggIcKA+C+KEk0zCoXSq1ev+v0+Jm1bjjufz7d2dnu9HhJ+0zT97d/+7cVi8Qu/8AvVavXZs2fQLsznc9M0c5GmcaooihAQ2gs0D0IQReFpmqqqLm9DLhbzOVcUZBpJQpI0VyTVdZ0xRVXV6+vrKBGFQmE+C3CZMXZTyqC6UlU1ztIlx4pYNUmJFIJSJoQIg9iwHNQrSZakucxzseRMOeeSSEmkIEwKkqT5rYqC3srXbt5HuFyxAiHZyW4Ja3wGGS7o07I4lkKYpvknP0XKTApN0zRd96MQa4kpmqqbaS4FYY7r+L7PVdUt6jjvFouFYWjefM50pihKJmQWJ7qum6bheZ4UWaNWBWq+0mllmYijIEtYFBLLcvxFhBEihsZns4miKIqmR0kUJHGe54yommLmiQxD37S00PdKpUq72ZrN5sjd4Zxrij6bzfIs4ZxTwuIoEnmuWVYaB0XXoIRIIsMg0HQ9TZP5eMEZ44riOo5rmrPpVEhJdcapiKNINyzKNcJoEsVxmNimZeoKIzROQsK4Y1tMZGkcECEdt+h5Xhbns8mcUmloZholfhYQKhRFIYLmqVC5RgTlVEnSWGHcNtwszZvNxnQ+E4LYlhP6gabm3syvVqsK1fOEZolkimLqOhFCCiqoUFQljxNNMzJJGaNJHN7scaHahn5TGUuRpaGUghDBqEJAROYZnOOGYXCmqKoqBckywWgqpEyiRKG6QhWZS044yaShmYaiq6qaxxkjXOYZlYxKygkXRHDKVU51hRNCpcyZFJQRRmiW5aqqGraOkCF02qen57Ph0HKKhUJB4epkMtnc3DRNczKZua6r6xr6FiFEnEQ4eXRdF1mqq4pRdFVNWywWQRpSwnXTECJTBDFNHVM9iKRpGodhdrNQFY1rqpAyztI4DInCKaVJnjHGciIN06QKz5JUZplpGXBQ6pYJgUcuhJQijVPLMq4HI0Vlm1vbQRB8+NHHr169ajer/5v/9d/6yle+8t3v/iFERY5l9Hq9yWT05ptv2pb56uULxpjjOM8++fhgf++Ne/ebzeZoNDw8PLAsq9FoohKyLKvfHwah12w2x6NppVISIrt3796r1/uRH3gKR7ij7/uUCDRXIAe/2Dsh0tP3fUL0TqezsbGBNM5Xr14lSbKysjKdThDZikiqIAiyWHLOEeAJJbSuq6VSqd/vv3jx4luNlhSCU0aEZIQCBviJXOEyiAfqLoyLAP0HBfZ8Po/juN1uTyaTy8tLAPx37txJkuSTTz65jY2c1+p1RHYpioJ848lk4vt+pVymhOB2wGmGVATOVMs0p5NJ4PvlUgnJFMBiVldXB4Pr2WzGKVMYVxivlMpc0ebzOTJRoZjCDOxut4u8TwzCAVASx7ESRdEHH3yAaVPFYhG3I7QpMBEgvRp9XrVajaIImBtmJCFi6/PPP3/48CEq4tPTU0RoYpIMZlZjOPF0Ns7zvNFowLODaXfYBs1m8/Xr14QQy3Lgs/3ss89AuIKRQXpYHMfgodFwm6Y5vO6j6wWRjBHfUkrHcebzuWEYGMIDwSmmYSP/8OzsDOvs8vISlUGj0WCKgrJU1/V33313NpvBXQJ4b3NzE5zRchRlHMfPnz8HrghPEJEEvzIG38JfcH5+Dn6TKUqz2ez1erh7UEAkSXJ1dRVFEV7e0dERQpkLhUISRsC9VFVFEdls1imlRErCuRRC13VCqaqqgkhK/tSqpZQSmV8P+pxzwlitVvvh+z/64Q9/+L//P/3vptNpmMSGYaRJ1KiVGpXSeDpKsvQ3f/M38zwHN4fwCMdxojQDd0YpRfuDpvDGUkA4+pulMB/X/BIxorcf+FeMUbEMbWd8SReiwqBf8A/i895iISxrNp8TQjB0CG+3JPL169efffYZJrIhEH84GNiOhZFei8VC1Xi9XkfE301pBSya3MQ+pWmqKgr2G1zcOzs7mOF6cnJycXGh6/ra2lqhUPiZn/mZq6ur169ff/jhh9vb2zs7O7//+7+PPunjjz9++PDhnTt39vf35/P57u7uxsYGRuggrgLfuVAoIMyCfCG2Pk1TwD9AhnRd54qGVxuGoZQa2gAvDEqlylajqWjWq1d7hCog4g3DmM+nQgjLMKfzGSoYlfGMUkopUKg0TZM4oZypXMmJEDLNc5ZGqWaoKlPn/lyhClMoySVTqcp4kicyExkRKlPxZAC1Lt9Z/BnnFChsyDVQNTabTSEEmpM0vQkiZpTK22HeQgiAXvgOURwruqIyJUzC8cC3XCsOItVQ55MpU1noJZqp5UkumdQVNYkiKFiloArnCleTOHIcR1WYrppCZIzkjqVrmr5YLO7tbAZ+FMZJnuemabTqDVzPTDKSi2ARKApTFb3SKI1GIyIFkbJZr0eR79q2Y1rj8bjguJqmpVGMTCyr2YzjmzEAUlEty/J9j4hc4zoWMNE1YGlE5DA+B0HAiaxVynh/TV2TpgkwnlJiGVaSKHieOIsIIXE4LxRs7MHhYCQEWV1ZwXzZTqcKIMG2C3kSB0HgWiaWU5pm5YKbZZk/XxQs11ANnYVMV2zLLtrF6XRaL9dN3UwjQXJSLlRAcERxEAWhqlBdV5M41zWiSW45dhSFaZrprpMlWSwiS3dkLhXdUDUlixNKKWgHzjkjUtM0QU0qZCaFFDmRgjNp6gbRichlmgqdq0mS1CrVIAhM1Y6iyDKMlDBFUVJJTd0guTB1I2WcqSyMFqZhQLCF/WIbtqIoKudJmlIphRCGpuVSbm9sToslztXJZJJEcb1eX8znhWKxXquEUZTEIopjhXNVVzllqUiIoITKUtFNo5gQEiZxueSgzvDDQNeUJEsZoV4w54Srhk6lIJwpXGGcEsayPJVMMS1DSskVlmeCSqIaehJ4kpAsCoikisphtPQjLmUOwUwaJ6qq6roOE7rC2HQ6l1KWy9UkCo+Pj/+X/4v/8OGjB3/tr/01x7F6vcv9/XP0LdPpVNdUaDTTNN3d3R2Pxy9fvoTIGgjF/v7ezs7O6uqKpume5zWbTdM0J5MJZTJOwkLBSeIwigJV5e1OEwFGjFLXdeG0yG8DotM0TTOB1jqOY8PQDg4Ojo6OAAqur6+vra3Zti1JjrsSH9PpNPJTXO44sTEWDDbY4+Pjb/0MEUJwrkgh/qxK+IsfkNhalvX2229jTOTx8fF0Og38BZLnNjc3+W1cn5RyZ2cHIbFhGD569CgMwwcPHgyHw/liAchqbW3t5cuXmqZBb4MyoFQqbWxs4Eagt8MfoR4DRVguly8vL0ejUavV+uCDDxqNGjYmopI1TRuNpzs7O4gTLxQKURShh0cRXCgUTk5OarXa0dERrmz6a7/2D23bvry8HI/HyGJA3e04ThzH19fXhmFcXFygpIjjuFC4GVoJqTxEUYg2MAxDCopIYmjHOOeT6QgeOmS+CSH+f5T9Z9BtWXoehq2488n5y+mmvt23uydHYAhgaJECRQRGo1hFySJFiXSBP1wuFmWVbLFMyy4VBUokTdowWQAhkEgESIFgGAwwg0HP9PT09HS6+cvp5LzzXsE/3nNOfz0YgND50X3rhu+cs/faa73v8z4BxjEQeJymMSjwof4AeTDgJeAJyzkHjzXAn2AkB816q9WCYccSD1Bw+kItCCg3QgjqgLOzM7D/zuIEmFjwdjAAWs2YISF1VdMIIcIwfvnll6+uLoD7Va1Wbds+PT0tVspQBwC7DSHU7/cZYxZnejmKmvt+vV43TbPX66VpCsYQQoipPwfUkBAynweO4xjcAvc2eCZzuRwjRGvd7fTABL9QKHDOr6+vi+X6Zz7zGdOylJSEUiHFwtcAoTRLTW6sAAaRZsygb7717V//9d/46P1PHD89+tl/+o//xn/zNzb3154ePb++aFfLFZ3G9XLB9SxNyWga/zf/1/8ujlOMscaLKZ4QIk0F8NVWkPKCn040xlhmCua8MDllN1zXoVoSS6PRJSdLr4qnm2NBKaVhGMbShg2WlhCiVi7rZeSRkNJ1F1m2iGCl1JMnT/L5/Gg6gdxA0zSD2RQqOYSQRnLBalfqZlYj1h8aR4LBPXwGiHXb2tqqVqtnZ2fvvvvubDbb29s7ODiAgqbb633ta1/b3t6+d+/e8+fPJ5PJ1dXVRz/60X6v5zjOK6+8srGx8Uu/9EvvvPMOTBsBxF2SzzRch++iI1C68OokBIwscD6fR1hxwxBCrG1uZFmmFLpz997Mjw8PjzHhnpuXGlmWlSUxoYggLPWiaNNaS63gWUNLcoPUmhGCYZirJMWMm0wJ7YdzLZFhcS0RIhopLLXAmmCKCKJSKyi4YTEAbA73hdzIOFvx55RSjVp9MpmsNgSY6iKpYLuAv7kquDMlMcZSC6QwYZhTAxEtM5XJlGKGKWKEw6cSKlNiMcS0DTNNBXgfCCG0FLP5JEnDfr9tW0Yul5tPpqZpjsdTz81Xys3r606t1oAKHz42UKEJQYPBqFIpQTBckiSZSJycm897aSq01uAu2Ov2QWwIHA5CCNisKy1LpRJDGvKUVlGycHNBswL7ZJZlzWYTBi5CpHCqwZWBZY9uaD4wxkABYYwJoTAxXHcRwam18n0f/DNt0wKvkCzLTIubphkEQc7JYUQYY0mSaa25ZULAxmp5a63BSAI2mTgONQIuDsrlXI3RZDIpV6tRHJiGrZEMZgEhiFODEMS5GUURQgRpAiW1kCnsTkBHwMtu2TRNpVSWZVpj23bgxAVd/XQ+h44C6LYPHz7M5/OmaSqkgY/MDRZGUZIkGxsb0PYzwhTSIpWgEySMupY38+cEYWMZmKuVUhrUyxoprZAmCCOCOWV+ONdKOZ49n876/X4p500mY9ezIe0FLBtsz202m91+r1Kp2Y5DCen1+47laExM202yFEa/WmHGCSU8SSMlEWWYEq6RVBJpJDGijOIsTkDMYZgM9MumYYP6B1JSZLYIc+OM5fOObZFBr5uJdGdn50/+8H98+87B8fHh2toaJcg0zclo1Gw2337nrfX1ddj3IHINYr9BRQiGNVphMMc5PDzc2trO5XKTySSXL/73//3/a2d3v9lo/Pk//2fv3bkbJyF09WHow22C4UOapgjTYrH45Mmzt99+O0kioBPBMdpoNMDTYTobg570/v37MI2dT0IwjXv8+PFkOvI8r1QqQKLO4eHhX/pL/0W5XBaZYsBmIQT9/oThbGny/m//7b/t9XoPHjwYDAZIy42NDfCUD4Jgf3/ftu3Dw0N4TLTW19fXYPh8dXW1v78/HI3CMNzc3Dw7O2u1Wpubm6PhEJyVgiDodDpghzSbzSxubG5uTmb+dDqd+9NqtQqB8fP5HIxqwzAkBBUKBaVUuVw+PT3d3NxMM5kkyWAwWFtb01q/88475XIZ8i3AvQUMHdrt9nQ6bTab+Ctf+Q2oOgHS7/f7ABeBZgE2jizLGo0GxrjX652fX0LINkB5qwjMRX0QJqZpAtQJ1i+5vAszGq31ymQIBknVatX3ZzAEdF338vKy2WxOp3Pwr9rc3ASnK+BPwM4CJz1wekAL0Gg01tbWOp0O3PjVWBBAIAiBAmI/PMkMExhtQFsAdhJwX8F0HtQZnHPIqLZtl1K6vb15eXkJUBZ4YsVZmmVZvV4fDAalUgnOs9lsprMUiiEpZalcBv0CQmg0GkHcRK/XS6Uol8tQ9c/nwfn5ealY2dnZOTo6Aj67bdtaymKxOBlPMcalUglyvMfj8a0792/fuYMQUlISRlfnH5zYSRxby9gcLRWm6Nf+1b+8vmz7g+hXfumX/tJf+s9e/uhLvWm3Px61Lzs5x2Yi2d9puZ6FOf+1f/PbP/NPf5FzEyEk9aIeAvI1LH3oqlflCyIaIQTHHl2GUXLOoTBFS3nITZI7QkhkcnWQrGAtrTXYuiCltNaw/ED9ZxvGfD5fNM1JAvPrXC6XiqzdboOlyDvvvweLSggRBz5aEok0kmhJtLxZ02D9oV4KMDPYrAEtB3j5Ix/5SD6f/9rXvgaJxbdu3XIcx3Yc4LLAfgfAez6f/6n/8X/8gR/4gY9+9KNXV1df+cpXLi4uoCRFSy4UFFirz4ZuyGcoXXjuMcayTOZz+TgJCSG5fN5xHNtzLcth3NjY2ul2++1On1Ju2S7SVMgMKUnwUoCJ0U0UcFVyrS444NNxmsLzvlg5S7YcXjJS8dKlRWvtON5kNhVpZtoWQTiIQoKwm/MoJkJJJaRCGrRvFC9c6G6+HUJICwkFGVB5VlcATh1MNKYU3u7mOlkoVdUHVSM03CYzTdNUYpErJbIkjkPHNff2dop5x3aM6XgE6LhMJTVMfxIoTLI4CeLIoIRwRhHuDvpJGM3D4BMf/Vh30C/kXKl1pVQajEaghsmyLI5T2LJffvnlKErAbbzX68GO53kOY2w+n7q2TSkN5j4zOCMUkMJUZNVyBVPiWLYfBhSTyWxqMI4pDvyZYfHZZCqU3NrYDOMo9AM356VxIrVq1OrVeq3X6c78efvq+nOf//7pPCyVKhC9ksvlhsN+o9GALJT5fD7o9fb39y8vL4XIPM+7uLjMuZ5p2hC/EwSB47oGM4vlwqA3nPlTz3WlUpwx07JcxzEsPp/O8sU8pEY2m3VNsO/7URKncWJZFqXUMS0YOEB+K9JUSg16N4QQ53w+n8dZ6phWvdUc9Qfj2dQxrVngU4Ql0pDekUbxYDyq1+tCyWa9cXRyrKVCBB/s7RNGJ5MJIkQJkWQZjMKn0+nFxVU+n9/Y2gznYSaFlgh6KtM0lVxIwpVSSsoVBC6FhpUD+ChlsA41OCE1Gg2TU9viSIpO93p9c/P6+rpQKBQKhaOT48lk0h8N+72hULJSKjfXWo7lDseTKJWGZa/iCuDkAu0hGAesxm2UUoy1SRmwOzBeVDycmdBdlMtl27SGwyF4t4ZBMJ9PRRowqj3PS7OkXCj+hb/wEy+/8hKlOJj7Gkms0fb2VrfbHQx7lXItl3fhvTjng8EA3KGgLWy32wghx/aAAzQcDjHGd1944Wd/5ucPj05eefmln/zJnzQNBtUVUAuAsKhXea+I5HK5brf/T/7JP9na2gCA6sUXX1xfX//mN78JzGzbMRFCnU4HrqdS6ttvvA1mb2tra48ev08p3d/fhQHc06dPP/Wpz3z++74PaSKFoCAt/30KLDjIQJs/mUx+7dd+jVK6t7cnsgVcMhqNxuMxFBJwxID5JdwasFlhjEVx/IUvfOHRo0eQp/zuu+9urK9XKpXRaAQeEIAzTafT7nW72WxGSSalLJULCCEITbEsq9FoXF9fc84rlRIhBKy2oCwzLQfsM8GdwLZtSunFxcXt27dN03z06JHruqVSCZBm27bZcDiUUgI5znGcVqsFsQxA7IKwPNu2r6+vq9VqLpc7ODiAQIONjY3r62swP4WyKcsyyOIGTAhchhlBURQFWea6LsOkXqkCDQVjPer3EEIm493rdr1eb9UbTx8/Wd/aLhaL3/nOd8AhIl3macOCpsskba01DN3Pz8/h7YAqDpnY0P9lWba+vg54IPgpI6DVW6bv+8l4hOSCF2LbdhjM9/d2sizr9/vbWxtpmhKsX7x/bzScxHHc63QZoWubLcjQ2N/fPzs7Q8soJbg4kCXpGBygJsMwppMJsNYKhcLa2tr5+TlI21yE0igOyNxxHMjNlVKcnB5lInGZ7dqL2PDz83MllOd508lkPB4Xi8XxeAyMN6WV1AqQGDiRlJQAMCCElJAIIUJpFPrwMHz5t770Yz/yJ195+X4QzQghoe97jmsQlPM400k4G6/vHFxdnAkhTNMWCoFQekEUXXKf4RfwIoRoDQQdZRgMLbk4WhMpkVKSEKI1HN4KIaW1ghMXE4QQDAERAqsejbRGSRTy5cuyTEJwksRpmsSYSCkRxiA+hrM/l8sdn54EQWBZ1nQ6LReKw+FwOvcRQoR+MJEEHzCt9GKo+kGFhW58ESSlQggrtdqxFwjEcDiEHFCwvLu+vs7lcrbjeJ53+/btJEneeuutdrt99+5dxtjBrVtxknznO9/+zne+AzbTsC8AloAQlA4flHq/l4VAMCOYmQacDcQwDNgjCoWS7/vN1tqq9ZdSK6UwInEc2xbTSt6YxiJKKKKEEELVsn6FLEiEFMHA4GaEKCnFMhdSa71gfWktpZRSijSFTzVLU6WUwQjWCiPEKVFCBPOZY1lg7SCUYoQgsrjwSqQwAQS4khCCOCGUMQL+sXLF5SIYASNTay2zTC8hzcV3oRTrZSGsFEaIEUIxNhgP5qGWijFGLZSkmUjj5s76X/nL//nB/k6SBEqkEJay1mxFSXh9dWXa5u2DW2Ec9Trtze0tfzaP00RLVSyX5tMZ5axYyA2GQ9MwKtX6u+++XylXoygSQsF2jzFOkmyZAUcrlUoQBJ3OdavVUkKORpNqtVqv1jq9biGXRwTv7ey+9/B9JWS92RgPR9w0ZCZGk3Ehl6ec2ZYRJ8l4NDJME3ha08lEKlUuleIkQVpzwwiDwMvlRJbFSWI5LiX8nXfeoQx//vOfPzk5AXYBbIx/7k//SL/ff/nBPds2kyQxLd5tt+H8AOBhMpsywm7fvX30/Gg0Gdmm5XguULw3N9YOj044NTvd/vr6OrA+SpUyISSMY9e2F9hnJgCPRIhAcBBMRubz+fr6umGy8/NzTEi5VGp3OvVaDROipEzSVCtFGJaZIIyWCkWhZJqm0/lcpGm92UzjeDydlgoFTCkhxPHc0WBoWHaayPk8sCzr229+5/nz5//uN78U+VFrY71UKM583zQtYFlpwzC5NZ2BWzXCGCulEcMIIUIRJrpcKQJ1gTE2m83C0H/ppfv/+X/2n0b+aD6duq57en52586tfr+fJMlf/E//wrNnhxubm0dHR+8+fP9br7/x9PC5Fnr/zt1CxZ3NgygKYMwnRLoo8pSgFBPCpZRCZOBeizFOCJUy49wkS6MZblBCTaR0lsaM0Lt37965c2d3d7dSLkuZDfudaq3Y63SbzXqn0+n1u0mctdYanet2tVYejUan5+dpnDQba8ViSYis1+9DzC5jLBPq+OQsn88/fvKMELKzszOdT0qlUqFQMCyulMrnc5/85Me/+c1vBkHQbDbns4kQAklhUKK1xuqDLR1jrDUSQtTr9b29PVhOGxsb5+fnk8kEJPZJkjx99rjVakFOa6/Xu3v37n/0x/8YQghAa8qY7/vX19e3bt2CJ+XRo0ef+9znMCaL3fj3F7yv2myMsWVZt27dAsAYaX10dGQYxt7eHuQyAecM1DnA7QZbis3NTehDLi4uppOJlLK2u/uZT3+aEDIcDkEy79kOwyTyg87VNaW01+vVGq0kSR49egReOfV6XSn19a9/HaxHJ5MRTPrAYr3ZbM7mAWjmzs7O7t69Ox6Pt7a2wKwATNEB7Ts/PwcZFv6N3/jlarXa6XTG4zFCCNLEisUiRCeCMxM8z/1+f3193fPywHOH+RqcrDA94ZyHQay19jyv3W4nSdJoNJIoAIQM0Gm4QFJK2zZBZg/lJxxplmXlS2WQE96/f//58+cQdwrGElDkAqgrpYzjeGNjA2R6EO4IjTK4NxFCwEoVvvBkMoF/AsVysVjMsmy92bq6uoLOQ2QZOF1hrAuF0tGzp83mGgTZMsOCLwtIXpTEUO15nkcNDnQ/0zRBuhn7c5iOSSlbrRa4n21vb0PpjRACAGxFnjUdF+a+0+l0d3c3CII0Sufz+fb29mw2s00bDjxwoy4Wiy++/FHLsoSSZGlmiDBWWlEoRBAihMhMMMYQxp12+5d/7Ze/8lu/XbEr/8e/9l91exepTollvPv+w1KuTEScZ/HLL+3eemGv159+8U/+xU4/NhxXqQXoIqXMskwItaoJYM+Fy4uQgqEDyM2AFc6XBu43q7EFVoExY0ypD7wYPjQiTDNoPeF7AZiktc57OUYp49yyLJimw1pKRdZoNE5OTp4/f661TpMEYWzbdprGK8hKaaGV+m6BJULgH718LTCS1Wc2DAuqDdjFoH+AQXur1SpXKjs7O5BICAxKvUx3f+ONN+IomEwmoHIihMRxDG5Sq3TIFWqFfg+ChTSBctx1XdPicRwXS6V8Pl+sVJXWXr6UZbLbH1DColgwZiBCCdJIZ1pLpBbzr9Vba4zUMmN79QuEEOUGdNuL4enyzsLtW42A9cqYV0pIKIe+HBx0oNK9+UXQDYuN1Y6Jly+ttckNeSOYcvFeGEEjlC2S7xYQKRRhUG3D+oFdiFFDCGEwU0oZh5HtmJRS358YDP/Ij/4nG+tNggRCqlQowrdrNGu9XlujbDQawXCzWq0IIUulIqUsTRMY6w+Hw2arjjTRWk8n4cbWdue6nWRppVShjI2Gw1u373au25gSLVWcJoVcfjge1KrVLMtGwwmM+YCrAM7vIJ25c+dOp9MB5bIQolqtApsCCBhA24eOEUylHceB/FOYucABY1hmsViMogQhBfvP+fn5aDTa3t4eDvuVUtVxLYxoJpLLy8udne0wmqVprCW6al9vbWy21teG/dHzo2eWYZarld3tHT+cy0zEcTybTzmz4khubO4+ffrUsMxWo5lJUavVRpPJ5fl5kiT1er1cLnNqQBgGWNVrraMoUkoA87JWq4HhEExC4zh0HI8QBNpqKeXDR+/tbO9pJBGmYegXCqVut12t1rMsQYhMp+Nbd+8dHj5z3VzOKwyH0+FgUq/Xi8Wi6+XfeOONTqf3K7/yK4PB0DCMSq3hOI5lOWEYmoZtmqZUmVCZElJjRBBFGC+6Q6U0QpZpIqKTKM4VvGK+8BN//s/VK7nrq/P9/f3JZNLuXudyOZDTC4XG47HG6O7du2EQX15e/rt/9+9//p//YqW1Uas3gXyCEIJ5Luy0sF8ppcDuWEqJlMZEM0zAUR04iLDzY4201oEfwTQGEIpGvdps1n/8R3/Etk3OuevZxWI+iSPbNge9Dsa407mOghB0WpZpCilr9QqkQY9GI6C1gIq/UqnU67V+v4+QGo1G0+nU87zd3f2nTw7/2T/7hfv37//tv/23A3/GGPNsCx4xQojQC7haSqk05py7bu6NN944PT2G47XT6aClnfXFxcXO7haYMSGEqtWqUmpjfQdWuFJqNpucnZ3lc+7u7i4s7Pfff/QX/+JfrNeagEQQSv+AEeFqL0qS5OnTp8PhMAxDjBQEI0JxAlaXADeAzM5xnFKp9OTJk3K53Gq1gjCcTCaObYPD1N7eHoBbURTt7++rTPT7fXA7un37dq1WOz49v7y8fPDyi0ABgkj17e1tYPWArhP8DgGHCqMEuE9RFG1ubg4Gg36/D482QggiEa+vryEbDSGEf/Zn/yHGeG1tDegCsFwIIVEUpWkK4vOLi4tCoQDy1yhKIBlGSgmp77Vazfd9qBBHwwkoSwkh7Xa7XC5TrKHS1FpnWeY4jhAp0OQBWgQ2AEzfOOduvkAIOTo6ApZ6pVKBgSh8mJWh6P7+/nQ6feeddzzPa7Vab731FiSKQzI0HNKWZW1ubh4eHgI5F0SLhmkTQpQS5XK5026vra3500m32/VclzFiMn51fZnEabGQl0INRkMhRKVSE1pRSpMkcV13Np/fv3//5ORMCOEV8uPxuNlYGw6HuVzOsg1/MqaUrhIMoOiO41hICajm6empYRi3b98ej8eO41TqtePjY9BvFotlQsh8MrUsy3G8NE3TOJ1MJjs7O4yx77z57U999jP7t18AP2JCiEZII40RlkpSkOBppKQkCAkhmGl+5623/tb/429pqf76f/HXXMtMszli6Oj66vGTw/2t2+Hweq9lvvLiVmuj8i//zW//n/4v/zPPNWdBJpc1EJgRSJGi5aSJLA04CCFag7JsQdBGS5IWnJRANFkNd+AsJ4QQshj9rGosoj8E6kABBwM7QojB+MrkLIoi8OsvlUqtVivLst/8rS+D/gB00XEcZ1myKiYQVggBePShIgvfKLA0+qCHW5YFi5RxKItBo5pl2XwWIITyxYIm+IUX7p6fn2+tb1xcXORyOdM02+32O++8Y1qcUhoFi+QT2Ig/9NYYL93wocDCcBGUUkgTxphpMCklNw3GWC6fZ4w5ubzjupVa8+qqHSUpZ0acSEp5KqTj2lkcwShhtQ9CmZIuIaibFxYhxI3FdHv191cX/4PCdOWgQSlFC1GCWmowYQHAePGDOeDK+QwjKKYXtLklkZZhsirH2VJYAA8moovqdrVI6NKoGvB/wLxXE8Y4CDGmjVodYzwaDTKRKJn+uT/9p37kR384SyNCkOc4g8Fg0B8VS/lms3p5deF53traGiFkOh1PJrP5fLq3d9DpXLuuO51OOedJEj148MrJyUkSK0x5uVhkhjHoDhRGk+EoXyqPB0OJNNGImYZtmKZjYqUNkyVJBB4xaZp+4hOfAIlTlmWwEYHKB9irQJpJE/X8+fOdnR1oI6E17/f7V1dXL7/8MrjMWJYFwbRxHFuuk897pmkPBj1ggczn842NDax1kkSTyaxaLQ+HY8syoGJrNGrcYN/+1rf39vddxxkMh41akzA8Gg4dz6GY2K4js/Ty8jJf8Dw3P5tGtpMXQlTqNaz0ZD4jhFx32qVCGb6F7/sWXzS3lBLPc6TKYPgVRVEQzME11PM8IcR0OnVdGyHSbl81Gg3PywOz6ujoZDwelkqV0Wjw2c9+fjwehmGcZUmUZF7OcWxv7k/zuWIYhkkiW8216+vrer3u5vL93rBQKHmed3h88vjx4//1f/3Xz5492907EEKBRaKUmVASBo6McEwJ1khqxQiNkpBTZtg8jROFdBT4/9H/7o/+tb/yfzg5OoyiYG1t7eHDh2tra1GawG7jui7j5mAw6PcH9+/fz+VyX/ryb//dv/cPi+UqYA0r3s9N3xmyTPeCpwOSTpRCq0aRaKSUglwTmMdpjYGpHQV+t9c2GA+C+c7OTpxErVbjB77wfeVycX2tZdv23bu3w7kPHYhWajafgzkO/DTDYEop8CkoFApPnjzCGDeadeBOua7baXfXmus//dP/OPBnP/3TP72+sTEZj1WWAhCOEJIg3iYMISSVIoR4Xv6dd975xjdegzga0IY/fPiwXq8LIVprDcdxnj17BmRlhNBwMAXH71ar9fTp46OjI4PT9fV1EKU9efLslVde+SNf+EFMCJIS/YEFFlp6/RBCDg8PAUYyOIW2ZH19fTabNZtNwzCOjo5Ao91qtaD6AfcDYPFDTsODBw9ms9n5+TmEOs/nc9/3/ekMABel1CIJyvE8z3v67PH29jaEHp6cnNi2DQPHIJhPJpNCoTCfz8HLt1ypQVMNYrhFwBRjnHMoPKDYGo/HoHBk+XyeUjoYDCaTycHBAWPs+fPnUNfDShqPx7u7u7Bf+74/Hk9hLoMQgpoRdlLQ93W7/VdeeSVN05OTk0ql4nmeEikQtx3HgdZ5MhnZtn1wcPD8+XP4ZOB0FYZhrVYbj8fgwV8oFMALddX1QuUHkTIPHz4Epo7W+vT0dH19HY6Kw8PDRqOxOmD6/T7cOdM0d3Z2CCEakfF4PBoNrq+vt7e2Li4uVJY2Gg2RJUJkrbXmdftqNp3Ua9UgC/b3dk3LjuPYj2IABi3LyuXzQGwHkWAul5NCg24iE4nBLW7Q0WgUBAGYQoH5eGttDSEExpigjqlWq71eT5PFQ5vL5a6urlzXDef+bDZbXzefP39+sHdQr9ch1rterxNCMCEfeFzBiYg0JVQsGYKEUpVljHMtxL/6V//KMIz/+I/98ZznjHodQjPqcABCKcalQsG2MsNQJG92rs9klqZzH1NrZap1E8yAY3uFSaAlYgGiqtWf6qUhO5zQGGO1tAyAH6WWL4RWXhMfKq1gV4IjHGMMs//hcAhjrFKpBA0EHGPr6+vwduDn6XleECzrOaUQVvCjb8It36vi+aC8QJDYgRDQOFqt1vr6OuRYxVFaLJeklLbnlkqFtbW1JIx2dnaEEJ1O52tf+xpaBntBTam1BqTz5ttprW/C5L93UBiEgeu4ELoyGo0+/bnPFovlXn+AMY7jGGECpjIYE6UyKSVmFCrUBVZ0w9ZvhR6tgCWFdJqmSqvlOA6jG2WZXLrFLhljmBCilpl3wCIAMA98d+Cf3ywiJdIYLUpGuONQXYHuQakPit0PkDMlCVqMB6GcgkoLqIRiaQsOC0kIkYoMUUwxCbMkyzJMWTHn+fPpuw8f9Uf9Qs4dj0fj0ahea0yn01KpdHVxPgv8F+7cTkS2t70zGI/mk2mpWvlH/++f3drd4RQzw9hYW3vtG99o1n9r5oftdldpXatWGTfGwxHlxng4QgRbhhmnydbGppvz/Nk8k8I2rXK1ZNtWtVYej6aPnzz8B//onxRLeSjsPDf/+MnD+SwolQuem6cMu06OUqqUBsNY2A8ty+r3+2EYtlqtb377O2mafutb37JtG8K+Wq3WbDZrt9u72x/gBI1GI8uyNEvm8/nt/QMw//sgGIOzLMu2trYeP/vt1157bTab7e3uf+rTnxwMBicnR3t7e9VqWUvpurZlWZPJZDoJNKHj0WRtYx1Mj2u1GjV4lkpCiMn5aDTKeQXbtjljvu8Xi14U+J1Ol1Ly4osv+v7s9dffUEpsbGy1Wg1CyHgyPD46NUx27+59xlitVmPM4JyPR0EhX2s1t3/ll//l7du3Ly8vJdLb29tHhxdAbAWrRozxZDJJ4rTb7V53ur7vY0TDJN3Z3jUM4/Of//zG5vbh4TFIkTAlSmpKKV5w+xaxO5xwhFChUArDcD4LKpUKJppz/pXf+WoSzH70T/5wEERXV1fFYrk76GuNOaeMGd1u37LtYrH04osvAs/k4x//5P7+l/rD8WzmGwazLEeIVEptGDxJMoTAIw12DE0pp1TFcSq10lKtsCtKKSMEnpcsy6IowpjyZdzF7Tv3bdtkjI3GA8ypH0b/8Kf/fwbjpVKh3+3euXNrvbUGRoDb29sv3b+/vr4Jp950Os2yZDKZdNqD+y/em8/nCJFcLs+ZYZm2RopgCpx3x3GODp89ffoU6NSlfB4mOattYfUw6mV0mFIKVIrgzgBn0+7u7je/+c2zs7MHDx54ngedD9Qls9kMdA+FQiHwZ9PpFAjTtVrt+Pj485/7/pXmDOnvTcNaQNSMaa0B3gM1t2VyCAiaTqfb29sXFxcwIuOcl8vl0Wj03nvv1ev1er3ebrcBBAGzibOzM4xxtVotlUrAXn/69Onm5iYgcJDbIYTodrtA0Yam/eHDh6BVBx+oRqMWhmEul9ve3j49Pc2yLJcvgt4FuNphGFarVegHdnd35/N5FEWDwaBer7/11lv37t3D3/rWVx3HgRkk0LH39vZA3AFTEjhB4zgGI/xcrgBzQ8CEgF0ELKgsy6TQEDYCVLuTk5OdrQ2w9TMMA+Zcvj/L5/OAT4RhCGuFc57Lu6Vi5fTistPpQHY3FKSu6wK7DUhtgMUBwQusWk9PT13X3draev/992GIC0IbQghUbGdnZ3fu3AFaGGXG5fWVbZuGYQRz3zSMaqk4m80Kec9x7PFwmCXx5vrGe++9p7WuNeqI0KvLa4RQo9GwXA8GmoVCwbLdMAwzqSuVCnBlZrNZu3NFpG6tNa6urmAD1VoXi8XhcGiYpm3bMDYC0/zbt2+/+eabrY31YrH45ptv3rp1C+jk/nRGCCkXK/P5HCFsmibRC3DoIx//WL5U03jZPIG8SyuCCYZJXJpZtg3RaG+88cb//Pf//qc//9mNtVbZcolKualSnT09vwojWbCK0ejqMw8aL33qVvv5u3/9//zffut9Xxs1Ra1Uabl0iUzTVGnxwewJfVCOKAXMxEVOM1TAcGADhgHjwlV9DGNEdNNiFEaNUq0WzHJkRjnnBueUUsoMWAlZllFMQMXp+/5oNIJj++zsDNia4EenkIRCQQihtUAIfZd7hdb69yJYNyswzs3VsNLzvHq9zpkJy6nRahJCQED64MGD6+vLcrn8xR/4wX/wD/7Br/7qryopEVZkeZWg7lyNSm9WeEAJwxjDsJLgxfjYMAyCNcY4FZnneYTSQrlECNvd2x+MJr3ewLQdIZFtuRpMIgmidCFLJEv9AUUL4BC+lFIKqUVNI7WKosSwrVUps6osyZJjvqqh4QaBfg00+bDRr8aON6vSD2qsJW63GvYRQgzDgD1LLXFN+LfAFri5HvQyGwAKrJvzTUIIwpiZLAxDrbFpWioTWZaahmEyGsXzQb8n0sR1XX86K5UqpmkOBsO1ZssPA5FmURIzQlORlYtFqVXoB6VK2WDcD4P5dFauVkI/sF1Hyoxb5nQ0zpQu5QuUG0oIy3GSKEqFcG17PJ0qITTGhVxOIhVHSRgFxUIpzRIIvZZCpVkihWq2GpwZcRJNJ7NaverPg9l8Ctuj1ppzPhwOAf7P5XLgiAv6xFwuNx6PQTc9ncxcN5clEdSgEAw3HA4BNkiiyHGc4XAIEmnGGOVsOp0B97zRaDDGslQyTtI0JYQgpJUSjFKElOd50/ksDENEiBAKGBqVWtX3Q8aYaZrT6TTyI8/zCGFhGEJiVZqmpsEMw4LEJ4yRELJarYzHE85ZHMdSZZ6bz+XdQX9Ub1TBhaherwOVByHEOR+PxytZlVzqWqIoipPQNo04iUzLyjLBmJGmqVCIMSNLRZKlnpfP54rzeVCt12DLZYxpsmgklPxgZk0pRRgWjwQXJdd1kUrH3U4UzlzXNS1j0B/WGrUgCE3TUEpPJpNKpWIY1mrJYWpSZmLCIHIKAskIYRAtxRiB5E2InCKEYYaF1CCkWOG+CCHOGJQjsOMRvFjnhBDHcTqdjuu6+UIuyxKClOvaWZKalhGHwWQyyeJkFe9RyOd3tzZbrVYu725ubu7s7ORyOcsy+/1us9kcjQe+7yOkOOez2cQ07VKpZHLrO99+6+/9/f/pb/7Nv/mX//Jf6l5fr9pXrbXCQF9D8HAppVw35/v+r/7qr5TL5clkghDa2dm5urqC3WnuT8EqGeaDaZrWa2vgTcA5z+XcN998M00iwGUNwyCEnZ6e/vAf++G9/f3FxofxHwBirbgBUsp33nmn3W47thkEAcBU4HMOBCzgrQOXHIJkINllc3Pz6dOnsJjH4zF4N+zu7l5fXIKdJyhgYNJdq9WYYaVpyg0K4NOXv/zljY2NYrH4+uuvE0J+6Id+4L333nv27NnLL78MR3kuXwRre2CfV6vVy8tLmF3OZrPt7W1IlwHwz/d9/Au/8DP1ehVs1k3TBHwFEgMfP34MdlZwpGVZVi6XhVCdTgc8fnzf73Q68HegaDW4BWSpwWDgOI7v+6VCDkx9GGNxHK+trU0mk1zOhVE0QsiyrNFoZJpmGPkGt5hpeF4eXMs2NzfB7xQMl6FFA9HE9fU1Z6bjWqBDNihzcp7jOIPBAFJ6APOQUm5sbIxGo3K5PJ1OW62WVIgwCg7dw/4giWOKtOu6lKAkCiml/mwOP8EyeBDFXi6fL5UvTs/WNjcuLi6Go9HG+np/MKhUKvV6U2GkFQb4ZDQYDIf9crm8t7eXpunp6TEMByG9Ti5J1KVSaYWpnJ6ebu1slkvVr3/99XK1nsu7tm3HcVjKl3q9nufkJpNpoVCwmNVut7d3Nj/6mU8jhNHSQwGcRYQUjDIJGX8Lxrt65+23f+7nfu7+/fvE4CY36nnPNrBAwTSY9yeJVBTHaY4nn/toq7Vb+dV/9s//2//7z8Qkh+16mKlMLIZBsHw1Wnj+EkLY0oYfxlswHwR4A+obwCFAnwyIGuQMrMgK+APi0VKTKBZOS2QpNFvhYQihnJtHBOdyOdu2kdJgLwSF9Ww2u7q6gjQoaL4zkSRLxEgpJVUGCbJk6Vmw+PB6gQIipPANXeTy7KcIIWA3U0pfeeUV8Ffz56Fh8Y9//JPtXts07dlscnp6enV1de/2nel0+uabbyKEhEy11tC/goXVzcLuu1A0GLOuahGCmWEypVSaxuVyGRMWRZGTyzeazcbaWr83zqSybCcIIs7MOE5tzwWWgFICK0woQpooLYDmriTCRGNFlBZaYYSVVlgpRTkj3NBCxlnKCTVsi2gUpYnJuESaIgyQWKakFlIibRgGkCEgSxQqZrSEJ+G/H/p2GEY0GBNNMENYSbHwDVmdfPiGE5hamvjrJfUK7gIY265cIZQSlHLKycz3LctizJjPfcMwCl4uDPwsSyiltsk5p1mWaYmklBhRz3XnswBqd4BJms1mp3sN0DIYGGqtw7lv2BYnNBEJpZQQlGUS+vgwDAuF0oos1e224SLAYq5UKpkUUbQQ7XNmSpWB1zNobuDDg8m+UsrLOUoJsFmeTqdAjQBCG+yuw+EQtHtJGoMUhBETKFbwFdI0FUlaqlbSKBZaWZzBvp1lGTRFmPF8odDrDQD6BUky/FGSJLZlCJHC/SIEJUnCTGaappLasMw4jChnSiGAXcvlcugHjBqTyQToj1opJVGtUgmCIMsy01xo60BUZBhGliWgb8cYg8YKHgpg8pGFYSnipkExS0VCCRdaxPFiaGUYDBNFKYY8KM5NpdR0Oi+WS1qhMIyl0EIIy3JgxKa15qYhtEJSIUo4oZpgKZRUwjQsP5gvChqCoEOTWWJxipUEqAMzipCKoqjRaIAozDAsCDaglPp+mM8VKLPiNIFlm2WLGbdeEk+hl8BLTqHCKM0yibRMM72UHMJSNw0DKmB4fDjnWSpgi6Cc5VxvNB5aloExlmnGDTqbzcrFAnSqhVx+MplwzqMgkFmmtNBCRukiLeP+/Xv7+7tbW1vbO1tpmookbrVarVYLYzwYDKqVSrfb/ct/+S//+I//6N/9qb8TBEEch45pLVoXAiC0BhBbSqk1LpVKP//zPwfxMsPhEB5PGB8hrICiwzm/uroq5Eu+7zuOB1YFg0FvMpl8643XC4VCrVar1+ucm6enp3vbe3/8T/wJtNwfvmeB9QHKrhQIhC8uLn7jN35DZMnt27cJIcCjHw6HP/iDP/juu+8CnRwspQ4PD/P5/NbWFow1QMwOsA6wmKrVqmc7YN4G/jue5wHxo7m2cXZ2JlV279698/NzuDsXFxcvvfTSfD6fTEars48QsrGx0e8PwyiCnUFrDeHTADYhhHzfZ4y9+uqrZ2dnIPzHv/gLP0fZIpITKv3xeLy5uQnF0/p6CxxWOOcwIxBCCSEgLvD58+cwuprP54ByAaYNM1HYJRldBFMAVSVf8C4vL/P5PCcLmm2pVPL9GVzc+XxODa6UopQbhgGUQCj4CsWcEKJUKkCIQRQmjPFczouCOUIqDhNEcCoFY8wPIlgNhmHkcjlCSKNWD8Mw9H2FkOXY0/mMEZzL5QjGtm2rTJwen5QKObiU9+7d+epXv2pZlszE/q3bUZIxg3fbHcKwlJJwVsi5mNL5fJ6mAisthMrn8ycnJ816o9FqKkTG04nMxHgyLBQKzWZz2OsHQZDznEqlEgbxYDBwbRsQ1F6vw6iqVBuuVx+MxtRAbt46PT1uNZoUcS2RUrpz2bl9+4Xr6+v17caDj74qJSKUK4VgvKY1IhgJoRghSmktJDXYW29+6/333w/9OWDROzs7SCS2Q2IxHk5n7XZcypfCSXutgr//M5sqTX/u57/89/6/v0JLG5NIwv6yApzkUmgGjwFUP3Dj6NIoHNjuQI8DJBzc9lfDoJscrJuE61WlsfrhxjJWBWNsmqZtmJZhZ5mQUkDs1Hw+r1ar5XKZMHp5eZnLuVrrwWBwfn4+m82yLBNZBmXfEmZT6Pe8PgQm3fh96K+Uxggh13XheNjb2wNmZb8/fPr8ycc/9snNnc1Go5Uk0cP33vv3//7f7+zs7OzsvPbaa1maIk0oYxjgosXs7Ls/AF692eL/GFOCMcaIIqwQWvhwMsPCmFaq9Y2N7SSTvh8qjaRWYRgb3BJCYEaVUiYllGIptdbSMCytpRCKUqwUiuMw7xWm0zFjhmUZQqhMCqSJaVtKSKEkuAoRhDMpTG4EUWgZJlC5DcvEGoVxFGcpGClJKVdqFfjYQPjVS4fMlWrdNLlp2lEUYEwZI2kqALZZ8bFWRTYhhGGyPO8XToPQGZuODaZxS6KYVAgjhBihSySAwS+g7ID/grmxZTtQ01BM0izhnLuuHYZhEkZZlpnciOM4l8vlcjk/mI3H43q1lmSpSDPLdgkhkGkNezRCyLKcKApAmK2WjiRQFxomy5IUYmoQUpRyjLWUGrhl8AQBFAdVFEIoCObATY6iiBtspf+HS6qUglIAijxKqVQ4iTPwvgHSNME4CENGKSYEI7SABpUyTVMqxUxKKZVi8YgBU8o0TbW0p+GcMsaApkMpVZlYkLUxglkzQJsAVGCMbdtFSyhRpBlGagVAwl8A60SpFNwFxlgqMjhNGMW+7zuWDQUTIWQ+n7uWjRnVQhu2oTWOklCrRaWukJYqA1BWCAGBXVLKJIotyzK5BXUVUIzLhWKcpVKBnhrBSpZawapTmEiZwV5E+SIWCSmtU4HRQmljWKbWMkzile0zEPOHvaHrura5MLHDGGPCMNEYUfQBqnpTirwUZyhBCJFaaLnoH1aNol66IYRhSCn1PA9jCmZUQgiLG4Qz4D1TShEiGGPbMAHi1VIAEmwaDCmhteaUEbbIRJlMJoPBgHMehkGz2TQNVqvVHjx4sVwoOo5z9/6Lm1tb//Xf/BtBMP+Ff/Zzm5vrg37X4DRNU86ZaVpJkhDCpJScmUopQpGXyz1/9uxrX/vaxsZGFEWwj21sbBwdHa2vrzPGOp1OPp8Hw/RavX5+fu7YdqfTaTQaCKHHjx+DVK5cLruWDcL8/+qv/lWEEKIEHMq+50stA/pgP0EIff3rX0/jpNvt7u7uOo7za//yX5RKpVdffRmITPfu3YvjuNvtTqdzz/PApgdjvfJyAvOI27dvv/7664PB6BOf+MRgMFgRxCGBw+CW53mT6QghlMvlQMYBqYCUUssyhBBAp4aQ2UePnnzxi1+klE6nU8b5kydPGq0mIFiFQqHX6d65c+f46Ai8VIbDIcvn82dnZ8VSHjhi5XIZxnDVavXBgwft9lW5XB4MBsViMU3TwWBQqVR7vV6/3wfXVwg4BLh7bW3tyZMn0DO1Wi0hxGw2C/wIYwy2JQih6ysfejuytMScTCamyUHI0Gw2z68u8/l8lsnJeGaalufZMO+0bMM0eRzHtm0GQSSEKJXK/X4Pa1kulrSJ4nSRcALWIOPxmHMOgBwcvaZpQjBVFEWubVFKA9/3fd+1oNwRGFPHsY6PT23bNQzjanA1nIwpM4TShFFKqenYQRB0+/1SqTQejy3LsrhFiFprtnKuN5/Pu93uZDLZ2N6KtYRso7Ozs167A10d0iRN0ziO0zSd+T7GuF6vIpT2utfbThW08X53rLUaDPs6Q/58vtHaKJbyvu9Xq9Xt7W2ZpsSwFQKBGCjZUZZpSonWKEkS27be+ta3h6Phn/pTf+qn/z//yDAM285TpDFjWktCURLHJrO1RLZJt7Ybfui3NrfffOvpeC7X1wsonjJmgHMT9GdqGaQAO+BN1hQcmYwtW7QFu1OtsCv8PehNHwBFKzIWxovTGn4gUJuBo0ApdV1XS40I6vf7kIcA8ws/DMDIYzAYQCgTWcQ+fMCX1x+m+3zvx/pGaQV/DcIyIWkbY5ymKVgKUUo/8YlPRFF4cnICO5rrul/4wheeP38OQ+3xeJwmQi49wOC6AWDwh3lJJJFGhOIwiVWkDJ6alqeUVghRSoVUGGM4dGHAJLTihMLHphhJhGWWSq2Q0hIRsEWI45CbhmWYmRRArQPMRi1drxBAiYyKNCOEWJaFCI7DKE1TpLRSCmLFodZZlRf6xmsBnCzNt+Anx3GIEMJ4tUJElsnVKBMQAnj3LM1WsxJoyeAEhThCtvDHElJKjRGnzLIMRpBWGDJbll4cijITxo2WbTs5z49COBhsw0iSJIwiblDDtmzPFUlKJcOUDEZDionruqALNgxDCp1li/nmjVUqEEK+70v1IakjVlhpAeISzgnGC/UGIdhxrCCIXNeFqghGYADh5/NFrVGapoQwzgytNLCIFmuGEIzgSMZaCykUpgzsagG1xRinWQbAHpy+8FgySgmlmBCtkGYYUZwmiVKKmQY1uERaCMENQ0rpBxHGWGmMCYuT1DK51Fpk6WpQC2UWNOgY4ygK4OEyTRNTnCUCXD8M0+SGAc0A5QxJSbVSSiVKgHA3U1Jhyg0LU2JYZiaESYxqtaoUiqJIIx3FKcYYYYop0hhphBXGhp3TSKo00xhrTDDlJjUYNbRUehljajKOpJJSZnFCOANYXUklgACKpBBIIg0GwpRSoRYR9QRjaphZkjKDI4QyKbTGhJqZUMVi3vd9jQgmhuV4UqMkVZQZFC8mfUIIIWKMMWcmY2w2mxmGBex4RInWWmSLhopiopYchBVASwiBgx96fq21UplpmlkSaa0zhE1CgKMMhVmWiiQTSEIdbxCmsyQNwlgrQRFOiZBQIxpWoVRzciXOGCEoTVOZJUfHZ+++875t25xzw7JaG2uOaWRSnV5c1hvVLMsMk9m2daOFpsuqUSulozC8dft2kiRvvvnmzs4O0C47nQ4AWnB+gRRDa93pdPr9frlUsm0bqF1goACg5vIbocePHt178UUpBCV81d1+155885iABt6yrOl4cuvWLaXU8fHxn/kzf6bdbp+fn5+fn2OMwXh9fX29WCyDJ2KhUAB1BfRySZL4vn96erqzs8OYMZ1Ox+MxmCHA6Var1UbDyXA4ZJxMp1OAu3Z3d0ulEpRujmPt7OzUarXXXnutVqt98pOfrBQrjmkdn526rtvpdG7dumW7zuXlpRBiPp+DrA0m4AZl2xubzLKsF154YTDsAYMYyNe+719eXlJKgcwkpXz8+HEcx5ubm0Aisyzr8PAQIdRsNsHiDApbKSVIZo6OjiD4ZT4Lcrkc5xzyERdQmWEziqGWxxgbhtXr9cDEol6vM8aOnj3a3dnLsiznuIW11mw2MQzW7lyFYSjSWCmVc02ls0Ix1+90h+NJlmWVSsW07bOzM9uRtm3v7pYcxwnDUCk9Go1d1x0Nx4Szar26tbUVzGeDwcBciqs1RpbjxHE8nk3BBqxQLm1sb11dXW3v7J2eHkM+gE41MKuOj08ZY8VieT6ZCiGePHlSrVbv3bv/rW99s5yzLw8fV6v1T7z8UpIk/dF4a2Oz0Vqbz+eZlHbOYo4zHo+dfE4pMcvinI23DjY67bPZPOoNr72c22g0gtl8Mhq7tv3s+XsFr5Rm17cO7hgGp5zHaUKYwRlFCGWZZIxyjhFCURjbjnXy/Ljf73/xj/5gr9ebz+ebm5u2a2mqOaZICyVw7GcGK4oMEcJnUXL/we6zZ8dvvvN+td4cDycg6lRKr6or2HMXSuMlp0cvg/OEEBhTsUxQARwLJn0rjs4KLlqVOze7Oq01FFgrutKK5gzTQyhlwIYDHO0BY8vn80+ePAlDH/xjAdzinOsPE6q+ayr3PV+r6mr1ArILXA3DMLa2tqDR7PZ79+7dk1p3Op3z8/NBrwffFBBcKSXCCoK2MSbAUfv93nQFiX9wZRBCCEmpYBO3bdd23KWf4cKdVUrJqAGSLpUqTDHCKEkE1ghTQhAijGGCQFfleDmkdCaF1AgRalmmiiOpVSoEw4RwhjUSWiEpFEYIaYm01AohopCWShGNMKNCAGUeQZmtF0ZZUGkRxighK049QkiCPSwkoS7wA8qFgI6faK2k1ForQhY3mnOKFNEYa4KZaQB0qhHC+gMAQGsKXkeE4CiKhEwxAtctTQgCO6JUJIQiIVNuUM8xZRYTw9Bah3FCGUVSIk2iOOWcCyGZaWlCqcENyhZ1IiJBGBuGIdEiSQKli9unicJM27ahFFu2HIhgQHFQHC94h6uegTGGCE0zyVJBCMGEaaXiJGNSC6kBCYMvpxFTWiGCMGVSSqSR1iiTSiqMMVYaYYwNwhEihgGVK/Q5dAXwZJlEiGiNKWWgbUizDGcYMwrll5RQACtYwBjjfD6PMZlOpxgTx3GEjDWSSiuEESFEYy20ElIwxrjNOOdZlmGlEVaaSqxJPp9PkixNU0o5QgQRGiVp5geWZWlCESYEY86pVCoTQgjBMJn7CedcI5KkQmmsFMKEwdI3DIMwmqZpKgWj3OA0CMMPICKN00wiraGcMjm2LCdN01SoVCipM0RYmknOAePUCGFKKSVYKcUJQQr5fgi31zAMjAnBmGqSqMUty2JJCKKEaKl9P0ySDCk8HS9gOZUppRSlWCIJmwIFl0GsMpURTjDD8Gu94H4RIKSi319Vs9roVmgo7JNCKywFXdo1w38xxkpmSCKEVw4sJiVoIUZJU6CLYMIUklGcGgYLoySfc/eqdZGkhJAgnCNCjo+PN9da09n413/91z//mU9algX9s9basmwAgyFSnVJq2UYURaaUL770kuu6X/nKV+Bwdxzn9PRUSrm+vn55eQlJz4PBoN5oNBoNmAWBrCRN0+FwCNWGQRcBte++++69F19cPms3Jdu/xw7wBkGz2Wx22535fP7aa68VCgWNZLvdbjRqe3t7gNcEQdDr9arV+vb2dj6ff/z4sVIKAosBl+Wcd7tdaMXBeCIMw+PjY2io0jSt1+ubm5tvfOt1eF+I7ANK0p07d6Io+NKXvlQul5vNJgwWNcHvPXoIVEjIOB6MhuDTCTYFMJcHRVoYxwyo64Bjw+kImr6DgwPDME5PTyC1BiGUz+crlYrjeL1er9frgYn5kydPICMCqkXwzIVkH0IIoNOO44B4st/vw04khLAMBtYvUHIlSQJ6RsZIt9ve2dlSWtqOdd2+Oj078TwnDH3LNuAsr1Qqo+EEWG/N5pphGP48MG07ny9sbGwqpCFuExQQQP8CVlp/NEySxLTBU8lyHWc+n8/mfj6fxxqNx+Pdve1Wq/X8+XNYJY1mE2MMwZO+78fZgp8OBMAwDGEue356cXV15ThetVyOo9na2lqWydFwkKRZwctz05pOp4ZhlCqVdreTZdndF+6ZJn///fdrm41J/yqKkziRm5vrjWbp/PzcNewUheV87tbt/bPTo3qjyWkxly/ZuTzCyDSYQgQUhJxThBDSKEmk7Vj93uDtt9/+4T/xxwnnR0dHuVzOckxucUSQVhojEgciiwR3aCpFrpirb2zSYvPdZ19GhoUx54QXDdOPfLSsclZ4A1nmyq0gihUCAaNYaGSh81htIqsCSy1VaautZ/XCS/oC/PzVFrPg6HBiG4ZpmqPRqFareZ4HhNDLy0vKWaVSyeXc4XDY6XRAqZokCaMf0s39YV5Q4cGjr5TGRGGMQdDkeV6/39daQ0LAdDbt9/toOej0PO/q6gpywd5+++0FdkUIXhDY9X+wvPsQ0oYQQggScxkztMZKaYQIXAk4crTCmtyctBIltdTaYAwRAsWLybmS2ORcap1mSSqE5zgWJPtijDDWCmFGNUaZlGCXhSnhnEmR+lFIGEVIE0axRpSQMFx0onDrYV9GSw4W3L7VTcfYTJcvtBwor24xWo5X8FJmKKVkjLIlBZgsfdQgrhtWwsr0AS3zlJgmwDZLExHFgVZYa80MbhhGlqVZpudzojV059q1HGaaCQlhfm0YRoqx1hrytQzbgCEI9Ltaa9sx8VJyvwKKoFi5ibyurgZBixWrP+xAAemoq0cAmknGWBjGhBBKDSGyKALKFxWZIoRrLZHGUmiEGMbI4A5CKE0hfNAF41mwuwSLXb4M2F49ZUAUi6KI0gUiCA8C/BPTNDEhcRwzxk3ThKGSYRK01PMuPu2NhCuA31blYyZkFs9g6k4IwZQsxtmMSaTJ0pWDGwZeBF4ZHCOEEGDSSQQW0MZi8qW1QpoIEmepUkpgiZOF/mTJnVq4skmtCMYKacKozpBGGlOCKTE4x2n6YbhRwTO3ukewcizLipMkEwIT/sE2hTAmFOOFFJoQwrnh+77reKZhSpQhhATKpFgsBkgcAtOEZfpQJoSAYQJjxqquWpVZ8ILfgXEw5DIBNAvcREqpUIuKSgiRZRIKGoSQEh8ElS5GaxrBl8QYa42lViJNwHFAKG05bhSns3lAF9uyFUZz0+RCpns7u08ePhJSEELSLLYMQ4hF9jylatU/g40fobTf681ms52dHdd1YQ+ESBXO+YMHD8D6v9FoHJ+cfOQjH0FaA84K2XyVSqXX60VRZBum53kg80rC0HQdJTRaot3fc0tcLUWEUL1eB4xtbW3t5ZdfbneuDg4OPM+BkQVbpledn5/XarXz8/PhcGgYDChMCKE4jmu1GiTUcW622+2LiwvDMO7fvw9pMf1+H6PRYDCYzWaQ1SGlBB+H6+treJY/97nPAZvq5Zdfvrq62tzc5pw/fPjw9u3bGOMnT54wgwNQNxgMGrU6+I2DUdlsNmMIoXK5fHV9AWRMjPFgMIAKDp5q8Lq1LCtN07OzszQVkEUDGyJ4vsdxXCqVwJcMfr/ZbA4GA8bYcDj0/YBSAl4dgMvN53POzXy+CMGF4/EQIXT37t04Di/OT8rlMues3x82Dw4cxxoOh6VSqVjMDwaD27fuzmazZ4en+VzRsXNaYT+MeCbCOAniaDSaUsZguzQNu9VcR1oTRDVBGOPZzG80GoPRYH55mc97tm378zljDAQsWKNCoTCbz99/+DCXyyVpevvOnUePHu3v37I91zAYt/h4PJ5Op6BwLJfL8/kcM8y5eevWnW63++6777muEye+aVmGYbi5wlq57PvhZDKhlGotz9875ZzX69X+1YVpmkyp+XhGiXVxfm1bhX5vNJtPK8V60amwEtMqnPS6OZdyLA0TKyWRJnGUmLZFMIrixDRNSlCSZJRS06Ltq863vvWtH/nR/wRTirQeDvsgN6UcI6qUIpywcJ5QbWlJkCa5UnkwDg5//d//uy9/PZaYUpRlWSIkZXQFMuEbrEN0A8JdVULw5K+MK1dn502YSt6IylmVaKu/vHoB7EyWRqYAHcERorW+d+9eEASQuAnqB8ZJlsbzeWKaZj6fX4Fn4DK4eoDx8mG+WevcfLbxDR9SBW5SeKEBBCp0lmVRnI4ns2KSbWxsUErjOG53rk5OTwEVYIxtbm6+/fbbCGOKyaqgXL77H1xiLV4aVIUYHM4YYRRpDAluhmHEcZokCUKEEaalMm0LdHaEkExlJuWWYSqkQz9QUjGGKTekRn4YcsoMi0uNkzDKkrTWqKeJIFJQhP0oVJnglkkwppw7tiMxgchepFWWSZGkCCEXNvob32jhBrI6I5fyKGBnwxHCGFcKCaEo5bAhhKG/KgUwInCLCSVQFsBwEMopuFMwI0CISCkIWVj1CCGCKKYUM0YZNw3T1VoyZhiG0W13tASrSZQlKYRPM9OQUuo4hq8APety9aooijgvrkSL1Wp1NpuJDFFCsTYMRgnFQggpdCIyjLFlmQbnprGQbQohMpRoJKGI1FpjQihjSBMhBGELImMURpRShTTlTErNDdBwgBJt6RUH+XkaYY0VUpRQtGBYastaXG1yw0UWCF6r5U1uCDUWRUkmZJqJJAXQETNqGIxSLKUSWQYiG0YJX9j5EghxR0gzxhgxTGPhKQD3zjSNlaZBJRLelFIaJTF4diilQMoHn5BxvgKh/SAA/fhqtO049mQycRwPQHJgF3HOgcXlWq6+oVGFPQj+nwnhR2GaphY3uGnopYGIzAQ41sKaJAgDD4xSajJOEI6zGHpGQojSkjGqldYEQRETpQml3Fi0Z9wybcd0kiTJMuF5DkFYaqGUzKRAAhNCNEaUM60WDzahCCNCGUZaSakIWWCiN/DXD0lu4WOsKP9aZrA8VvsG3GipBF5m6RqMSymTJAIXZUopYwZCJE4TlGWMcsOypUa+H3DOLYMjqTTCUiE/DBgltmHOpzODEyTF0dHRwd7u3JdQ5FHKoihS6oMyGswpLy8ujo6Onj9/fuvWreFwCIaUJycnUCEA+iCEKJfLDx48ePLkSRSGIBsEevvv/u7vwhTVtWwwsMQYP378+JWPffQP2ANXuzQUmnAd1tbWer3ezs7O4eFhoZhrtVpXVxelUunk5ASsGarV6nweXF5ebm9vN5vN0WgAvUS0pKJnWTaZTBAit2/f7vV6cRz3er1KpQLy23qtCWIXiA6cTCblchkapH/9r//1iy++AM0MSAIZY71ebzgcbm9vt1qtOEny+Xy32wWRY7Vc8X0fdHXAJSWEMIyx7/tCCBjt5XK5j370o5A/M5lMXnzxBbBwBD+nZrN5ddUG/B88i4vF4uHhYbPZBJ0RELBgq0IIga7QdT1KCVhEwOIDuSKkC4FrhZQyTdNOp1NvNjzPefutdza2toIgmM186GijKKrUa71eT2hVqzYGgwHnVpLEoGq2LItSYzgawR0CQ4QwDKUQz58/393dnU6nIJ3IuTnP81zXns1mQGtgmCRJ4tpOu93OJKrVaqenp/l8vtfrFYtFhVEUBL4vQbwGJwHoMCmlpmEGQWAws1arlUplbhjz0B9PJ8VqLQzDdn9AMC5VK7PxiFJcq1VMw3AcJwkjkWZYKhFnc9/33GLeK9br9WGfcUom/R7F0jTFRfvYy/HYUFEqX7y/g5SybDsTGWHUskyMkZTwkODr687h8+ff933fhxlDSkmRdjodz3E1UoxiQhDCSmsW+CkzHKSJYRiGYQ2G14hYx2e90TTMFwpxmrlePkxCqH5W9dCHioAlCAH7u1IqSeLVcQtSKfh94IuoG1wfdGM+uPrJN9s7vVT1k6VuJU1TIrHjOG+++SZIczc2Nu7evTufz6+uL6DXgVwBvaRaSyFXn/P3a5K+d31zg3kDOz7wgUDeUa1WOefQaczncwBHT09Pwcn62bNnUkqkNVQMv3fL+A++++pqYEyllFgwzmkuV/A8L05FEARIaWYwg1tLvf0CQ+KUCyWTLMUYM4NjYAovmUyWY0PVghDKpFjVvgRhADaYYWRxQhHqdDqIEse0CCWMMkSJYpxSSjCGEoQsLUzlMkBJLc3W9Y2RMTC4gXsEdx8WDATXL15qcXEIIVIuiE1wAEPIuuu6YFsANOfVxeTcFFJrheMohX+llCIktSzLdXNZljFGKMVZliVJlsUZ4RpjnMQZY4xgpJUIg7lhGJ7tIEw8x5r70zAMDcYx0UpmCCGssZRSS6SwwohohTDCMERNSYoUklpqqTXWFFNKuRSSEMQIk1oooVKVEoQV0kjqVGQUE0KRabB5EEuRKo0ZNVcaW4yxkBmSCLZEpKAm03TJaxQitRzXtk1wxnFdV2vl+zM4P4SgCCkps2XhiDDWaZxwg1JKNZIIK8Z5kiRBOGeMzaNAawAadRSFWktCiMzAK45QzBAIbDVGCKtMaoQpohphLTRAkoZhyCxdAkskS2JkGhQTZsDwVFCEESMYKSUzraSS2jAMblApUsvksEWIjFKG0zQ2DANJlEpBEFFYI61ty8iWSQzqw7Iy0zRBfkopRhRJKRkhmZQmY0pqrTWlwBAFVgP2DFtqlaYyyxKsJUKLtCYtNOEUnkqTM6EkVhIhJZKMUoaw1lpnWQKPTJIkAkmlFCEMCIWwS3DOwZldaUE0w8vWCOnFdkc+zIKAB2TFYlyBvounQQGVcKGiJYQihGDIRRHWWqdKg3CHLeEDjDGl2OSGxkgjpZESQuXyXhTGUZrINCOEGJY56k8skzkWw1j3+32G0cXF2e2D/fF4nHNdpRTnhmmauXxRKzUaTtrt9m9++d9fX1+/8sorhUJhc3Oz0+kQQgAfgrwWEDPl83nIlul0OqVSaXtrSynVarXAqm1jY+PZs2e+74deDsZzIIl78OorGFP94Rb3u7bBVT0K1+rg4ODk5ATAAtu2Ly8vT06OKaXVanU+n9+6davdbhuG0Ww2l9abDpCwsyzb2dkZjUbtdnt7e/trX3sNXH83NzfDMIS4YTjQi8ViFAfgZgABi51OB34mVAha66urK8bY9vZ2t9sHud7R0dHde/cgjabT6QDmcnV1NZvNBv0+xnhjYyOOYyalBLMs3/e11kEQ+L4PRIp+v//Vr361Wq2maeo4DrwTKJbhIs5ms0Kh8NJLLwGpDazbYeYI5tqnp6eVcu38/Kzf79frdYzx2toaHKKDwUAv1fsYA7EAbW/vXlyepEK+9ODVi+v2ZNpzXdd1vYvLM875eD4zOI3TZK3lWY4dhalGqFZvQuhPEASEUoC+2+22Y9thEORyuRdeeCGO4729Pdsw+6M+Qsh2bMe2RZYhrcfjcRyEkEKKCK7Vqru7u5brZFmWJLFS6vHjh5ubm1mW+b4PHCCp1frmBtZkPB6LJKxUKlma+b5fK1fmYVis1CRlxLCYUkkU2o4tZZYveEmSlEvFOIino7FjuZwwk9ocmUynG9tbWKnnj99rVErTwaBVaaTJLBPT7ZbtlsxqoyZkpdgsJ0FgugXOeZpJzheiV0px57p7cnT88Y9/3HasyPcZY8+ePLZNK83iYqlGsSJKYcLiKA0T7di2Rtq0DM+xCSuNJ9l8LvPFGkLcdHlv3De5AaK/FRx1c7NYPQkw0VuVNSvQaIFMLOX3N/8VuuESvurtllUFXsmpAKNaHcCu4YBWESirQohnz59AVILWOgyC2XQ6m83SNNWLn/yhJ/YmYv+9X5ioDyJfPvQ5OeeW7WpEIKsBYF0AzN5++23HcTgzlUQXFxdpmoo0A/R+VQ3chLL+gJfWGi359TCkSFMhRYL1QkuVxQmQrhzLZIahkczSWEmZSYUIxowqKQHvWZCg01RLBXgS7IaWZXmeRxCejieQ0a0JYZjkPA9hHM19SqnnupQxzliSpkpKpFSWpgL4NFJgjCjFS88tqRREjCvGQNCwiLJWSsSBr0WWSgFVOEWmYxpSSoMbaZoKKSkhGussy4RSlFJqUNBsKCU455xTKJJsw5RSapWZhkE+cFYzDNMRmYqTUCkF540SmUgFRRhLZHIDE2RYhpSy0iiHceC4VhiGUCAahuE5ltZapEnOs8AhkLqOazuIYJFmxUJOC5KKTHGFKdZSGQY3uZFkKVKackIQFSoTqUREW4bNTZbEVGFFEcWMa6EzKbBGlDOCcJKlJjcIo7ZpEYIsw0QEa0U5W4RbZ1lmIgqjUlj/CKEsywyDAzAmBM25LsaYYK2UghBAgnWhkKOLsF4mhCgWcuDro5QwODcsEx49aVswQ0EICSGKxSo0q4QQ1+aWZUVRIoXGjDL8IcRaKSURgnhvoSRBi5mpwbmgi0XLOeeMmLaFlJZaMcaCKJSZoIRorQxGuG0ajFJKsyyjWjuOnWVZ6M+D+dSwLEKIwWmGFMLUtm2hpJQSIoMIKAq1wghTShVCGmuspQl2G5hgpNIsMR1HI2IYDFTMBGuMFEYqy7I0ix3HUkpRgqhBDMNTSEspkyS2TUekGSVEIR0nvtYaI4WUEFnqmqbWmmIkZEYpYZQlaZrIFBHNmcE4AbBWSo2x4pxihLFiSkqYvSOk0dJXmSyjt27CiqvtTmu98h/GGIksw/gDaSr0MICaIKmSJEmzSAhBMDZNLkWWZRljzLzhZoekMLhpcqY401ra5aIQwvdnSZIMr8+ZQRqNBuO03em89tprX/zBH9rd3V1udfji/Py3fusrX/rSl9745ptHR0dJGmGMf+ZnfgbS4SBrDmNcKpUgX65ara68kzDG1+02YywMw9FoBFXRZDLxfR8szoFqxjnP5/OAp1TKtZWK8LvKLKio8I3Brta6WCqVSiXgUUG43M7OzuXlZaFQADSnVCqBwaxlWYVCYTodg5tBpVK5vr6G3Eal1Pd93/eBcva9997b3NyEUOBarTaZTCaTyfbOZrPZvL6+Hg6H4LtZKpUePHgwm01s23733Xc55x//+McrlcrJydnGxsZ0NnM97/T09PT0dGtri1J6dXUF063t7e1+v399fb3In4Z7iTF2HIdSenR0VCgUSqUStJIvvPBCp9MBaApjfHFx4XnevXv3jo6OBoMBSNlns9nGxsbZ2dlgMLh16xZCCIhKlNJaraYVzuVy1Wq1VqtNp1Nga3HOq9Uq9Ky9Xg+qt+Pj4yAI8qX8LBjFkWLcMjiVShNCm611358xKSvV0sXFRZrGnuflcjhNM61wr9fzfZ9zCvS9fD4/GvaVUmAFBhPPKIrCua+0Mm1rPB532lej0ci27WazyTDp9/tQTwRB8Prrr2dKgl8XEKhBxogQWpmvuK47m8yFEI7p+L5vsEXct9CqVK/GQTgdDWv16mg+K3h2tzso5r1GrT4ajWQqEUKDwcA07GazmaYpwap/fVouutUia9aYRbCI2zYX9bpZaZZMBwdJZFkYpb7pwFw5NUwDIRRFsetYg8Ho0aNHr776qm1baZLYnoeQmkwmfjCrVquMEYYwUoIQI0yzRGqLUISlweRwcK1RcnF0NZ+mjDoZIolKTMfWQn5w8N8gzayks99VGKHloHDVjaFltt1NxdnqKVpJ6+FB0ksaFpQIN2mehmFYlpXFGTDYoOwjhDBO7ty5A/ma4DW8AMRAioXUHxI3uvl1Vl+WLH1roOYDmX25XF553gJD8WMf+9jFxUW32/3Upz5Vb1SfPXsGvR1CfxCx/T/4STDGkPzouk65XK5VypCPyTDKtDJMjrRmjIRhTAjLREwp1RKZpmlyU2uNlBBSYq1d28yy1HPySqSIESnS2WSEtXIdN47SLMsy6OAZRQgRrSwGhCqksjSLQpj3MYNDEUAIYoQggpASSilOsWGYjJAwjpESWaZklmBKTW4iTjWSjJMsFpoomYkYyaJRyrJMiSxNYyWkYZkGYxhrJSSmRCuhMEJChXFU4gXbMbHCSRSB2aYQghuUUp6JRApkMUPJRUQmrEmCcJylWkhmWdxgSKl+dwDa9bVW4/T02HEsx7URQkmSQN4FqPmQFI1G4/r6GjI3gG9hGIbvh0LIFYSJELIsK4oiw+DANYQ1DCWRYRhKCXBRh5RGEPbDyQedBjScwLiI43QehEAAjeMYpg+2bWci5czIRKrBrcq2YYqkluZ5CCHOuTyXMG1woeoiRCkFiYGTyQR+DYWFEAIRTBCmnIk0c3MeuJMppVKRKSGTwDcc1zCMhYJMaoQ1RZQygjRWWiqpXc9RUqdZwpnBOGWYUkpkJrTWGi+M4kRqQ9DbLPDBnKVYLK7gZyFS2zDhMpqmWcjnHZOFYSgS5Xr5OJyPx2NmGvmcQzSZhnMlU04QwTrLUkAXbEjpIzyIQikScNiCVodRFEVRGgV6aUhhGAY3CKEsy7LpZIgI5pQlWcopk1rBoIpRFcuIYUMpEYYhYdRgJtKYESyyKMsk4wxJHceB4qZeml8QDC0GEkvn5CTRYIR8o0ogCOklvERvbinA8YI1tqQ9LcbKMCkmBK+Gv5QuFp4QQgtJCDJhTC8zhJDnOUmSwLw2yzIpMkKY61hSyjgKTIOHYZzE2rStj3301b/wF35i0L38xV/4+X6/r7XsXKc/93M/932f/yxCKAj8N95447e//NtvvfVWHAuMUblU8TyvmavfuXPn9PR0d3cX8BjQ1u3v789mM9/38/n85eUl9LcYY8jh1UrVajWlVKVSARnckydPfN9fBT9AZX9xcVGp1P+Dc4XVpcuyzODG3t7eo0ePTNPMRKKUiuP44OAAWPbX19etVisIFs6d8AlN03znnXeUUvv7++vr6++//3673X7hhRcJIZVKJZ/Pv/XWWwcHBxA31Gg0SqVSnITvvvsujCY9zwM+2XA4ZIykaXr79m3Am+bz+Ysvvvjo0SON0K1btzqdziuvvBIEgeu6Gxsb0Gk/ffrUsqz19fX5bMY5x//yX/yC53mNRg0sBrTWYHsDNxhIfPV6PY5jYNJN/QCqwjiOwRkvn89rrVfm2q7rAr8SEhPBpdrzPELIkydPwD8jjmPbNOFrEELAvV5rbVi2VMjLF7RUpuUUC4X+YGBwGqfB3J+9+urLQqTPD5/u792SUg6HwyiIlcJKaNiP0jRNkujy8vLll160TPvq6kprXalUUinK5XIUJc+ePak3G0JktmUghApebrVoIG+IECSEiLMUZuRxHFuWAa56GxsbQHjyPG8+n2dxBp46YRjePjgIw/Dk5EQIYTomOA7ALm9Z1traGowA5vM5WJ4OBgMQFtzZ33766Ns5h3IutZg3a3nHYgXH4y7VSVeiIBKpwkXTuW+VX0CkqAUVCGu0oLf3uv3nz5/f2j9oNOtaLM2fGPmFn/tfojgoFArlYo5heESL7z8+nPvKMAyTyUbVTqJBoVB46ztP/85P/cNCbWMaR6GMEFI4k1myMDQC+ir+XjSmVWcGm8UqPgWeCjhgYPIbLxkwUB7ppVOf1it1OoXqbeWVBW9BKeWcI4mq1SrY8tZrFTAHgZ4JEtwIIWkaA3IOzR/6gyGr7+JgfVjKtyp0pFpoZyAbACFUKBRgcq+1Pjs7a7fbhJCPfvSjpycnvV4vSaLvgqx+v88A7/chtSMBbgemlBrUgi9Yazb29/fjKLm6ujIsezKZpImglG/t7gyHwzTJqtUqXjonAbQWBIFt20qpYrEIk0HXdaH5QwgdHBy4rvvrv/FvIDkVQF+lVKPRgGYLCMvQPkKTqpTIsgyQmFwhPx1PuGk4lp1kKcXEy+dGgyEzeBonhmW2r6739/fBnMW1PY1VlghuMqQwmEeA85aXz3HKBqOhSLNiuZCksUZICsENw5/PCaUGM2DVYYxBfJNl0vdnjBnFcunyuqekLpWLWZZNp1OiUaVSSuNEyLTRaHTbnf393Vu3bk0mE6y157n93nWhkINuqtVqnZ2dCSHW1taA4eBY5nA4XF9fB8rdycnJ+tY6GF222+319XVoz4BuEgTB06dP9/f3bdt+9uzZzs5Ou909PT3/5Cc+pZR6+vSpbdu5XO76+ppz7jgOiKqKxSKlFLJECCH7+7d833/+/Pne3h5CiHMehuHp6bFlOZ/4xMem0ylQOsIwbLfbnHPDMmez2cHBwWw2g0ej1WpprR3HOTo6mk6nYLZ3cnLy6U9/ejgcXl1dSSkfPHhw2b5mmIymE4sbcZbahhFnKSHk+PSkUauvb25oqbIsG3R7lm0QzC6vzj03L1V2dnpRKhco4bP5JPSjarVMCAtDP58vTiYThil4U8VxPJ3PwbnRMIxGo/HpT3/6V3/1V8HXFDZ2OCbGkxE4y3NCkyRhjBuGcXl5mSTJpz7zmdls9vDhw0wKuHoyE0KIYrkEfPlisXh9fW1ZFmwm4HRADYDfIi0kIcy27clkgjHmnE4mk9lkUm82C4UComQ6Ghm2JdNME0wp9X0/DMOCl+PcyLK0WCwKrcaD0XQ0pIaNKS+Xq/liwTEdmKsIJTViichsw5RIiyRlJiArEiG0GpvCbg+/hnV7k30FbSQQFkHvDGAz/BMpM7I0N1bgLYsoQogzFscxRZC0Q7u9tmPZaRrnXEdr7TrWbD5f6QHhpwmtlFoY+IVx1Ot0P/KRV37qf/h/joe9x48fY6Ibjcbbb78VBnMp5Xw+q9fro8Hos5/9rOvmptNprVyZz+emY9++fTsMw6OjI2CJ/e7v/i48IK1WC6ZYIOtut9umaTqum8vlgKkJW2K9Xj85OQmC4PDwMOe46+vrjuOAQR0zjT/9p/8cRHXBBVwRAH7/3RLPZ7MvfelLxWJxNB54nre7uz0ajY6Pj4vFImxfFxdXWutWq3VxcQFWt2Ars7m5eX5+Xi6XsyyD5Nx33nnn+7//+/f39/v9/mw2C8MwTYTv+2DPeevWrY2NDfAVq9VqT548uXfvzmg0gp0WTjHXy+dyOWCJgH1Pr9stlUrAJmec93q9brf7wgsv9Hq92WyGf+1X/rnjOHEcgr8FWGaDv3Capjs7W3CYZVkGDdxv/87XyuXywcEBNGdgTXtxcXH//n2lFLhh9Xo9cCaUUhYL5SAICCGgk9zd3X3//fellGvNplIKSHOnp6cQD6QxLpRKpuXM5/MoSkqlEiSHz+fjYqkwHPYphQAWGgRB6AeO4+W9/MppOo3iza0NhNDTp49brRZjhpTSc3Odfq/RaERRMp2OCSPggDefz7WQ0EFKKUulklKq07kGxCJMYiFEEAT1ejWKojAMLcsyTduyrOvra4RQs9Ysl8tnJ6f5fN6fzQqFXJJknmOPJwMIJK6UqxhTYMykaZqmMTeYH0w4p2kWlcv5OAlVGtpcrNVyroNtSykRGFTLRFoGwjxMRUgtL4hz+eLHUe4uSm3ETE2RkEopNZvN3v7Od1555ZVatRJHicEIYQwhNRmNfuWXf9F13VzOy3uOgWSmJLNzb7//RCOPYGkb0dZaPg16RPOvv/b4f/nFX2e58sCfpyzDWIswRtlizA+DDLzEvVeA0+p5WDZhUt9gESGEFiMtx4EBNPxldUM+dnPQrhRaac1WHeFqbyrlS7BTa60pQRhj27br9fp0Oj07O+t2u9AFwsdYlSx/+ALru+qh1f6I8Id8vxhjruu6rpvP52/duvXuu+8+e/p0Y3Pzj/7RP/rWt7/99ttvgx/Ydw0C/pAFFmHgsogIIRa3LMtCiHiec//+S5rg8/Pz8XjMKP+BH/rB508Pnx8d1qqNqT/vd7pQ7VmWlaVpJoRj20maxlFkmGbg+5ZtM0oZ59PJxHHdWrV6eHSUzxdXlmPFYtH3/WG3W6xWoQFgjBUKhX6/n8/nHcdp97quaxeLRc458AHa7XYQBJVKBZA8iCuB2loI0Wg0wjCOosigLExiLWShXCIazQKfaGQ6Nic0ztIkjAzboghHaSRECmh/EAS5XAEaU3A5j9OEYuYHvm3ZXj6nhFQaUc5A/cQ5y7m5i6PnppdzXTtN05xr+77/wz/8wz/5kz+ZxpFhWEkSFfO566uLSqVSrVahl5tMJvV6HZRHhUIuiqI4jIIodG2n1qg+efpwe3dr0Bted64evPjydD77yCuvPjt8/vzpM9t1GKFgSdpcazFChVTXl91CsUwwns3nrWaTUDqfzfqDQalYdFzXc90ojnvdbr3RyHne8cmJY7nD8SgKfcM011otPwhcxxmORo5tI4wZxcVyadgfJFlaKZW5aQzH01RktmllUpQKRUTwoNdnBmeEMoNXSuWLq8u8l0tFRm4kFjQaDYig9sNAZoJyNh4ODMucTqcvvPDC4eGhYVtpFHPO0yRqNptayMZa66u/9dv7t29ttNaGwyHGuFAogMAq53oKaZFmjDFCWK83yLJsf3+/0+nESeK5br5QoIS4nhdH0eHREcEY1t5gOGQUb+1sc8og0j4Igp2tXdt1Hj98RBi9f//+4dHRcDhsrq8NBoNms+lPZ7B1QH8LiShg6w++plu7OzBJvL6+LpfLpVIFIUQpHY3HWRrnCvn5dObmvIuzc2bw/d2d6XwWBeH+rYPZbAZZ2o7jKCGjJMYa+WHQrLcms2m33fOD4N133/t3/+5LaSJK1Uq93lRSE8YJZgAcwppMU4EZXjWKAL0DExF6yxXWvlL/yKWhIPB+oL0BHNSyoMIgCCHwLgULEpFl+Xw+nM+UUtPJaG9vbzwciTTmDI9GkEwaGoxFSbK7vd0bDAzD6Ha7npe3XafT6QDnZz4d37l168/82R/74he/WC4XYRRAsM7lckkSCyHKxfJgMLi6aruu2+90Dw4OrjrtSqWitb68vMQY53K5YrE4n8/B+RJQgyAIisWiaZqtVuu9998/Pz//1Cc/CaAyeJPm8/nhcPj+++/PxpNms1mr1YrFYhiGveHgz/6ZPw+JrjAZX4gwfv/dUmaCcf7N119/9uxZmsXr6+vb25vtdhuGj1DKFwolrfX7779fKpUajVqpVALZI6RFbW5unpyc9HqDra0t3/fL5bJpmk+fPnUcZ319vdcd2LadpFGSJKenp0Ct/shHPqK1vrq6un37AHA4jDGsxihOz8/PwzDc3t72PO/NN9/c2tysVqtPnz71ff+F+/eh/eh0OjCIxP/m1381SRKlBDSycOPB6VhrHcfhaDRaW1ujlAZB8MILLzx88hQSYGD6CNa01WoV3E4hpjFJEhg4gg3pwcEBvP36+nq/38+yLJ/Pp1Gcz+eDILIsK5/Pp2k6n88N2yjXi0+fP3dMp1AoHR+f1msNxlgmUqwR6BHy+UKn3TMMi2KSpmm5kr88P9vZ2eGc9jpdyjCYrhaLxcvLy063z7npeF4URaZpbW5uBoE/HA5Ni9dqNQgqz7keuGKcnZ3FSbi2thaGYbFUAt8LxglCqFKpuK57dnoBqdjVarWQz8O32N/fHw2G4/EQIWJwall8PB5jTBnjWSoxxibnnBOkM0xEGAyTbJIJv1r1XI+7Jt9oVDnJkmTMqUAoNU1DxwqpVJKQWc50Jr38PVr8tE4q2CkgguZB7OasQX/wrW996wtf+ILr2kmUmpahhcCUIqSfvP/+b/32bzYajbzr5nMuUVkqRazxO4+e5dymUmHRmd3dK280Cs+fnP3UT/3iV7/+fnFtK9AipmI6G5NUEqn1DUIVXr5WhdTNsRqsPFAPgRKQUhpFkWEYoKQANceylvogA3U1j4OgBvh9eBe8zDFUSnFCwd4dLEwYY7cODsbjcRzHDx8+nM0mwM65+fH+gwUW+l7A1Qd/RBhZSoXB3wsqLaBqMma8+uqr5+enjx49qlYq9+7de++9966urm66T9ws337v57hZYMG7UM4QQgJSsTG2Tcu23ZdfffDjP/anIX8dLo7tuZEfIUpEJi+vr3a2tufzOSBPWkqhVOf6Osmy+XQap+l8Oi2Wy912u9FqiTSlnI8Gg6t2O5/Pg2o6CIKdnR04b6Abgy7C9/2NjY3xeGwYxtXVVbvdRQRvbGxAG5PL5Q4ODizLGgwGgE/EcXx5eQlI7XA4bLfblUqlmC8YlmkwPhyP5tNJpVb1Z3PTtpIozhcLru0IJYO5X65WgsCfTCatVotzXiqVgyDodDp7e3sHB7cfP32qhKg1GlcXFxpjTngQB7V6ZTQZrTVblWqpWqlLlfU73SgKLMt6/vRZpVKZzSef/exnj549nc38zfUNJeVaa2M46gMzAUb/pVIJ3Bk6nWspZSlfMGzLZHwe+tPZOErCjbVNRPTVxfXm1lbg+6ZlmYbx/PDwM5/+dJwk08mEUDro9/OFkkgVoRxrtH/r4Oj5oe06Wxubj548LuTyiGCtRCaEbVmT6dQ0jEwIJSWh9Ojw0DBNgnVrfW3Q6+cKedd23n/0sFlv9IcDLeXdF+416412t3t0fFqslGvlyjvvv4ek2j3YNxkPk/j+3XtHpyeRH9RbzZPDo63dnXDuz+fz27fvvvPOO5DaViwWh+PxoNfZv31LCzmZz5RSADP3B4NmoxGGIUXaMIzJeIwJKRWL48lkY319NBrV6/Xj42M4LF3bMW1LS8U5Pz+/3NraKhaL5+fnp6enD15+eWd7++GjR0hrPwhsyzIta2N9fTAc1qpVy7YfP3p/Z2839AOQDV1eXhrUsD3Xs51EZMfHx621tY2NDcLodDq/uLg42NufzWalUgl6M5jHAcf3wYMHp6enk9nUtm3XdcENElCTIAiaa2v9bndze7uY9x49fYKk+ugnPv78yWOvkDcZF1p1u91yuQx0Edsw/SjMu16cpcPesFgpU0RrjYbvh0EQvPXW21//xjdef/2bluV4uUqt1vA8bzgcMsaiJBaZMiwT5jAQUkINUy8p6owRUF/CKBMgYagkoIEEJRDAokop27VWe8ZiL9IEY5ylMeccSeU4zmQ83Fzf+Dt/538wGD09eV4u5pMkGY9HrUbzqn1tGmw8mVQqFeAfH52eHB8fN5tNQlg+n885NiWo0Wj0eh3Lsrq9dqPR0FoLkRUKhUFvMJ1OESJbW1sqE0mSGLYF1tx37969vr4GTC6OY2h7Njc32+32YDDY2NiwLOvNN9/c299//PixFOKP/JE/8vTp0ziOQWXseV6v1+t3uoVCARwxTdM8vTj/zKc/9/Krr0BVuoKFyE3m7He9NJJCPHv27OHDh6bFkyRx3YVnLzzRpVJpNJpEUQTA29PnT4CA/+TJkzt37kC5k6ZpEmeQQsiXCbkf+chHOp2Oa3uEkG+8/hrnvNVqnZ6elkolqIXq9frl5XmlUoGyeHt7+/Lycu6HMKbjnIssgyW6vb2NMT48PAT3r3qjkWVZs9ns9/v4td/58mQy0VoCKgDUNohUPD4+zuc9ssycAWegYqXa7/cBSIDBJ0wVMcZQ6OGlaY1t2xBwjTEuFovwrIIbpO/7xVwe0AvoUaDw96NZruREcVCt1AeDUZpmnpOrVRvz+Xw6mRQL5aurK62RFrhRb1HKLy/PmSFLRa9cLl9eXvrTSXN9zTaNN958czab/cAP/KDjeBeX13fvvzAZz7rdrmGY1Wrl+fPnjJO9vb3ID3zf11KBb1iSJAgrIBBcXFy8+uqrQsrReJBlWaFQ2NjYyFIJWYe2bYdBkKapyXgY+kjpTKQmN3q9DmW4XC5Wq/XpaBwEQbGQowhlmR/ORpzLcom31oulkoFxIqRPtcZSa5UxLtNkSojSEnHTQ0IiminFJCoS4xYtfAbRihZIYsQs9OTZ86dPnnzhC18oFHJSapkBewnLLKOc/c5v/+bTp0/L5VLByxULOZmlhNHTbueqPci5dZWO16vR/dvl7Vubh289+8m//j89P59blfrVeCgMzTkNJzMosBBCsCNA8bRyW1ih3yuhOGi5V+M5hBDsO0AlAfk9QggQ/hUDVC/l5UotnNxXoDp0hIsqR2kpJQg3DMPY398nGGutO53OO++8I0QKGOHNd//DFFirGmtVJt74A4oxVsADM81FnpoQYIVl265Sqt2+CsNwb3e3XC5/5zvfwRhLma04rX/4AgsuAvhKg51VMV/gnHqe98UvfvH7v//7y9UKDOCiKOp2u5TyW7dunRyfEc4KXg44YXEcT8bjZqtVLpWms9mg36/V6wf7+1//xjeajcZwNKpVq621tdFwqLReW1ubzWbPnj27f/8+nBCO45ycnGxtbRUKhcPDQ700vBkOh/V6XQg19eetemN9a/Ps+GQW+CJJwyTeWt8o16qDbi+V4u6t2+8+fL+Yy0PXDnkjWmuIZVVKXFxcwIkICmpYUcAJrTeq0+nUcZzz8/NBf3RwcJDP56+7nZOTszt37ti2fXh0tL6+Hsfx1tb2yclxJiKlhOtY7Xb77OzswYMHo9Ho2ZPHjUZjsWC0Mk2zP+h+4ft/YDgYjPsTkCVOJpNcLtfv90ulUrVWefs77xzc2r++vk6SpFarbW1tPXv2jDFmOmapVPJ9HwLmKaXt624URXt7exSsbhqNcrl8cnJSLBYxJm+88UahUHIcp1qtQilcKBRAhRTHYZqms9msWCwSQubz+dHREUwY19fXXdedz2cAqsFIvVarwTjMca3Dw8PPfe5zGOPf+dprjVbz8Nnhwe2DyWiikHJtd21j7fHDx0mW3Ll1pz/sT8fTXCFXLpYhIno29SvlcpKmrVYrSuLRsB9GkWkYpmXVa7Vur7e2tnZ8fNzv92u1mus43W53fW1z7k+LhXK31+51B7ZjpnG2s7NVqdSUElGUpGk8nwe2bZqmeX19VS5XgsDHmEgpCoXiw4fv7+3tM0YLheJg0JdSxXGUptmrr76SJEm73S4UCuPx2DKMRqMxnU4Hg0GruQZpBJ7n9YeD8Xjs5XK5XO7tb7/9sY995OnT55Riz8ufn59ubGx5nkMIu7q6MEy7XCmenpxXa+XJeIYQcl03yVLPcQ3LHA9H9WatkM+PJ5NKufz0+dNmvfHaN363Wq5xk5UK5UqtOp1OIeuXMVYqFBljl5eXk8lkfX0DYZzGWZTE9XpTKHV4ePz++4++9cZbT58cVatV07aazVYm5WQywZRgTAmjlHCEkJRaLN1hgLyx6rXQTVB8mYa0IhIQQoQCf8FlMKvWBDNCCKOYUppGsWObSsjj4+PPfvbTf/W//CuBP7q6OL93524UB8PhsNGoQcmYZZllGdedbq/X+YEf+CHTNAul0tnJCUG4UMh95StfabVajBNgDhBCer3u3t6eyU1ocQuFwnQ09n1/HgZra2tAbwerhdFoBCgU4MpAzgH7UMuyur0e59yfzyETtt1ut1ot+LJBEBw/P0zTdHd3t1gsep7X7nUd2/uxP/XjN/f/m7SQ71lgIYTms9lbb71FGc6yLI5DpRQ4FUA8V6fTq9frxWJxMBgYFo+iaHNzExjukEDjeR5nJsAor7/++t7e3vb2dhzHT548Odi7xTm/ur5IkuTu3btra2tvvfUWhFvncrlut10sFl966SWAUTHGfhDB0JAQsrmxAS7r3W73h37oh4CVPp1O0yyr1WpZlr3++uv4t3/z35imeXJyhBCCIetsNoO049Fo5Lq24zhw7U5PT5vNpuV6/X6fMQZzSqhYhRCGYYBSYEWCARjMtk2wsYd1UCgU0jQdjUatemMymbhuzrKsTqcDvLBZMPGjEbjCGIYlhBr2R5sbW1Iu4jNnkzmlPO/mkCZJIjHWhZKFsRyNh77vb6y1QLPjeK7v+9wykSbzIJjOA8YMhGkURZZhaq0d1xJCBLO54zj+bM4IYYwVi0WEFPinXVxc7O7ujmfTJIlgf4QqEHgVlUrFn85ms5ltWoViHmuUJBHFeDodC5QEwbxRrZUr+TQM+71LJOOt9aptorxL8jmqpS+yqRC+ZVDMmEy01prZFMkQUaoySainhcIGDUKJ+YZTeICsjyLCEEWaoHfefXx0/OSLX/xiPu9FQWw7FkQ0ME5VlmGtfuVf/FIQBJ7n1soVyzayLLNd91vvfEdrwnGOiNG9XXF7zyUyyOc3/tJ/+Xe/8e1z7eQTgmMdj8dDA3O8LArwDVUgsLLQUgC4qreg/wD0yDAM0ADCnrKyd4c/1UvfmptoExRYQKFDCK08LQFm11onYQRoaD6fbzQanHMwuR0N+0+ePAH612rn+sNXVx+qeJbbn9IfINUrFqpSSmNCKOWcM0yq1Wqz3phOp9fX13/2z/3pz3/+8z/7sz/7O7/zO0Kkepnb8nv2hw+/3fJd0VKZDPYKiBDLMBjBxUJua2vrx37sx3Z3d23XGQ+Hbs4DLYzn5R4+fKgVPrh96+LsvFwuB+E8CIJSoRglcalQnPnzarkiteq2O5iSzfWNKImvL68Io0rIcrWCNHEcZzweZ1m2vb39+PHj4+PjBw8eNBqN8XgMbNxKpfL222+7rlutVoMgsl0HKY0Ifvut75SrlWq54ocBQbjebDiW7YdB57oNA5eXX3653+8C4RouXbPZ9Dzv8vKytdZY0VAuLy8ZY2BB3Go0oXN79uxZoVgGko0fBtPp/NatW4VC4fT8HCECMmStJSOqVC6ChEVKOZ9Pc7mcSDPY/U3TxEh5nndxcdZudw3KPv7xTz9//rxYLFYqFSllEAQXFxc7O1uO4z1+/BD4GWDjNxqNbNul3ID0vcPDQ845FASFQqHb6Tebzel0urW1BdaAGGNM9ObmZrfbnk6nsPx2d3e73a5SKgxD13WiKDo/PyeEgHles9mEnYQQMp1Od3d3e71eEM7L5TLgvoVCAXwdJ5PJxsaaUshxnPFkUsyX2t3rrY3td957e2drdzQZtq8627tbOTefiiQK4jAO7t154fLy8uzsfHt72zbMeRiAUqFUKJ5dnGsp293O5vrGZDYtlUo7OzudTmc2myuJLMsSQm1url9fd66uLtbXN6MoMJhZrhSnk3maxa6Ta7bqaSIm01Eu54wnQ4yoafHAj0yLZ6kcjvrTyXw0HuztHng5hzPzy7/1pdnUf/mVlw4ODs7Ozj72sY89evRIKfXyyy+fHh0nSZIvlgGXjaJIaoUQYgZPkiRne74/7/X6Ozvbtu3EcTQYDMvl0s7O7vPnzwqFYhD4jUZzMOhrjRYO3WlCMTk+PSkXS0mWFPMFRDBSOslifz6vNarBPExF0u8ONre24jieTqfFYrFcLs+m01XRkM8V290OxbS51oqjlDBqWQ7nPInl06fPnj9//tWvfnU4GHPLrtfrpuVkUkmtpNQKaYIZpVThD+TV+IYrL2yhcunxBsNEAPsNw5j5U8YY5wuj5lV7KdIsDMOca3PKsiRFSD167707d+/8d/+3/7q11hz1e4Zh9LrdQiFHKe1226VSKc1i23IRVs8Pj9fW1mCAYJuWyJI4juv1eqfXPTo6+tSnPjkajcByYq25hjEejSac8/lk+uKLL55enE8mE8dxwJ5pMBgA02M+n4MLw0c+8hFwdgzDMJ/Pa4S63a5pGPP5HJwOgGwDX+Ti9Kzdbu/u7tZqNdM0FUanJ+d//if+99VqdbX/f0/CxuqlhCSUZmn6jW98o9tr12o1IVKonE5OTuCU2djYYoxdXV2Vy+VUJNDzTyaTq6urer3earWklJ127+WXX4bfX19fPz4+BmJlMV8ajUamxafTaZZls9ksiiKIM0rT9N69O0opQJTgrnHDKpSKjNDT09NioTAej8MwvHPnTqfTeeGFFyiljx8/funBgydPnoynk4ODA/zz//QfV6tVzilYZkVRdO/ePa318fGx67pCpCAZuHPnDswIMqUxxsABh/tUKpUgmw8cHMD82nGcXC6HkLJt2/dnpmn3ej1CCADF6+vrcRBSSn0/HA6Hu7u7oLWxbTPTMSJYCm1wfn52sbu9HcdxEsUYIy2z9dZGHMdIaSHkfBaUSqXRdDCbTVqtFsJKCBFFgRCww15UqlXDdtJMWpYdxikmzPPy4+GoWCw6rjUej5Mwyns5k3NAsNI0nU8n+Xze8zwwDRqPx4QT3/drtdpoNAI3DrDx9aezaq1CECYEJVEsVZZ3vcuL4ygcFUtOpVygTBtU5B3DsbDnIEQFSmYimcssNDlCDCElkciQlUdKiMRnJkWIIMNBEdGaZkgYucZkYhXLH0X5l5FCoUBvv//w2dN3fuRP/nCxmE+SzDQ4QkgrhAmkmehRt/fLv/KLruvk8/lWo5ZkmVCam+brb3yjUCijmDl0+so9vb2OOE0VLv/4n/lbR5fCKFZHc38ez6SUBC08lMkNH+oPhl/L35FLR28g54E0ZpXUu/JcWMnRV1NC+CGrrQchBN488Dgxxhb+mRlo3bRr2YVCwff9e/fuQX+Qy+Wurq6Gg1673V6VYujDtLD/TdUVvBBCGi1drLSmjFkWaHMialrFYhEhNJ1ObWbM/Xmr2cqyrForr62tPX369OrqClIy9O/xZfgDCqzV5wS9HmHMsQzL5JzSV1555Sd+4ic8zyMU+b6/vb05Gk8hgWEwGAihYEIxHo85ZYViDmnSH3QP9m8TipI4m0xHlPBavdLvDdc3WlkqJ9NRFCa1Wm00GTPGWq3W06dP0bKGhuRQpdR0OoWpX7FYtG07imJonIb9USqSYr7ETZbGGSLaYCZh2GDmYNT3nFyUhBSzjY21hw8flsslJQTUi34YUoxLlYptmpftS5GkzfW12XhycX2lMrG7uwtM4SwR1532nTt3ECGdTqdQKq2vrw+HwzCIa4360dHR7sH+1WU7Dn2M1MHBvj+bb+1sv/a1393Z20VaKqVKpdLDhw9fffXV2XiSy7lXV1dZlimFwNASbNBBsjCdjgHYB84Z5xzGnWtra0kmy+XK4eExFJqFQgFMBcfjcc4rOI7z7rvvAk0NjsN6vT4c9S3LmM/n+/v7v/mbv7m+vg4T7VKp+Pjx47W1NdipoesFVuzOzg5cebD76vV6tXoF+KbHx8cwjDg8PKzVakAthXY3jmMYwsZxvL29zTk/PDwE0SLoMDDGrpMLZr5hGHD7fN9PRNbr9XK5XLFYgBFJu93e2tqCb23a1mQybTbWhBDn5+eGYbRarXK5/Pz5c0ZpoVCAWlAIATTcRqOGkM5EAlm2ILSE9juO40ajcXp6WqlUgiAAxXs+n18xF5vNZrfbBetpIFTt7e1dXlwTRh3HGU8nt27d6vV6WKM4jAA+gbg3jPHBwcHjx48tyzo+/v9z9t9hlmb3eRh4zvlyvPd+N4fKVV1V3dV5IjDEDIYUiESIlGUwKNGUdyWLlBzWaz2yZK4lytZa0io8a1MmZcmiIZMiERiQCRAEMIOZ6enp3NVdOd2c05fT2T9+VTUNkOKu9v7R011Pza1b937fOe95f284mJ2dhR+dMQxRFB3Pj8/i0SmNQUN8cnIiiFwqlfJ9l+O40Wi0uLg4mUziOJ5OLdtx0obRaDQgbppQdHh4qOvJ51968emTbUJIHNOkkbrz3r1SqVQuz6RTxnA4rjcbtWrjG3/wzcODk3qraaSzRjYnS4rrB17g85yImFMr9PmR8vx0CuskrFTAiIOsgud513cYhuE4Af7Hc3usNTV1XfdtyzTNfDYjiqLI8ycnxywX//Vf+Pnl5WXHnI7Gg0Iu//jxQz2hlkoluGKr1erS8nIqldrf36/VaulkCjTazWYzlTZc19V1rVqtXrly5eTkZDwcQ8wBwzCuZeu6riUTCKFWq8UwDGyLLMsClDEM4+jo6Id+6Ids265Wq7lcjlLK8bxpmo5t5/P5QqGwvb0NRi5gfzvN1t7eHmjAJUkyspkH9x/90KsfunHjBjpT5f7JAAsWUBrH+/v7t9592zCMM9UaAgSyuLgYBFG32wXX3WgyhN3n+Pj4E5/4hGVZ0+l0PB47tgcbB2SNMgyzsbGRTCYHvWGlUqnVT6CuBuSnmqaBj7JWO4H7FH6jar02GZt6MpFKJO/cubO8tHTjxo2dnR2Iv0cIbWxsNJvN/YODKIqu3bj+3nvv4T/4/S9LkjSdjmEo0+v1MMbZbBbEUuBEpZSKogiB8YKsgBB1YWGB47j9/X1Kqed5CwsLmqaB+6ZUKsFKrWnK8fGxLIuQXg/Vyxgzk8lkMhwpikIptW27WCyfPrkgWY7veyGl1HMsTdMEnu33O2lDdeyJJLMCx55UDxiMNE3zXS8IaTY/Y6TSnU4HY1ypVCiK44j2h4MgCCZTixMllhOy2Vyj1XFcP4oiKGHVNcUwDBzTbrsj8jzP80k9sbW1tbQw3+/34zhmeY5l2VTaqDaqjUZ9aWkZ6rUlSXItOwxDQeR5nmcwcSzTtc3j40NJFCN/nE7i+ZlMMqWwbMgQl2E8Ql3PHWPkYxqzCLOCiGKEQowihHgmcieMKiAcIRYjL0SYjz2WKHoYuqyYDqJczCwIxk3fR9977+2t3Sc/++f+gsDzruvKskgjFMcxw5I4ooQghOmju/e++8a3C9lsMpk00knTdmOWsR1n88ljQ08xDsnr/saaW8g4rIymFv+JT/3d4zbDKsmxZVMaYYb44WkWC8w70FkuDnqGGYLDGcbvi2rhz3PLIXwbaOYEQTjvTqFn2nagOYGsgpzqc07rPK4avp9BOAgCICcopaVSKZVKPX78eDTsw6IP5xWMMXqmcOb/98ezd3j8rHqKUkEUMca+77OCmEgkKKWTyWRlftHzPNARXr9xdW9v76233pIkyfddSimiMbQYnT/iP/KCzkeE5y8ARO4sz6uyqMliFHif/OQnf+qnforjONs2J5Y5O1sJwxjOMMvLy61WJ45j0BN0ut2YhhgxiaQWhTSmYeBHosTLkrq7t72+dmkw7OWyhf2DXXNqA1GPEILtcDgczs7OwjvQbDZBAL64uAixlpTSfD7f7w4URUknjaPqMaE4YSQFlvdC3xxPO/0uz3Araxcc0+4N+xxhEQZGE7GEYTjWtR3MkISm265VPTnREwnf80BuPxyNxqPR7OzsZDJhGCbyo/nFxXa77XhuJpPZPzyGezAIwsxZ68V4PM1ms5PhCGM86g8s13n+xk1Rkfd3tmFaAdKTO++9Bx1h6XS6PxhoulqZnYW+AaDSZUUE2w0odl9//fWdnR0IRwBXUaFUHA6Hvu8jhCEdEFopJUlaXFiGKaooiqBjm52dTaVSB4d7mqapqjqZTHK5XKPRGI2GgDY2NjYg27pcLs/Pz28+2oStVNd1CP6AoVuj0XjllVfgGL2wsHB0dJTP5zvdFkcYQAzPP//8w4cP4f/CGE+n0/X19fF4XCwW4fOq1+uZTG46nkYhBZDH87ykyPv7uxcuXNB1HdJ6DcMQRN627dFolM5mKY5HkzHoC0HMBMkglVIZogo1TTNNEzzw3W43nU6bpul53szMTLvdzuVyrVYLbmo4aVerVUgDP6exFUXZ29vL5/PgGkskEjs7OwAfLcuhGIFWCc5p4+FIFMWbN2/evXsXhvKmaXa7XXMynT37HOGbjw4OeJ5nGc73fcgi2tvfvXnzJvSoyLJo2zbLkvF4DL+UIAiEY+MYzc3NTYYDKGc7Pj7OpNOWZfleKKsKz4uYYTqdrmlb+Xz+2rVrD+/ci6Ko1xuoCf3a1RuiLB2fNDafbv36v/vNp9u7juMtLa/kCnnTtEFJYtouYCn43Znv7/46jzUHOTxCiGLQXUCpeQyCCkKIyAsYYxQGoijSKLQsSxIEWZZ6/Van07x69ep/9V/+55qm1KvV8XioKJIsSZPJGKKRbNep1WqFQoFSKvMSSHfG43G+mJckaTgeWZa1cfFSu93udnsiL1CKi7l8EASO44iKDKgdLonhcFgsFk3TxBhnMpnd3V2MMVhbQK/Z7nQQQutra6AnmU6noAPZ2Njo9XpH+wdHR0cIodnZWcMwtGSielJXde2Tn/ykIAjxM3Vq/z6YFXg+x/MIoeFg8Pvf+JokSYLA+b4P3v9UKrW3t7e+funw8DCfz5umadpTQkipVNrc3IQSZEmSQFYxmUwKhQJktSiK8u6776bTaSOZNk1zNB6wLHvx4sWTkxM45E8mk0wm0+22wWoNSmJV1yzTeekDLzdq9clkgihdXl52LVtRlCAI7t+/P7e4MDs7++DhQ9d1K7MzvV4P/+Hvf6nebCwvLjEc22m1U2nDc1zCMnDQEQSh3+92Oj2OYwRBmp2tTCZmEEfNZrNSqQRB0O/30+n0xYsX33jjDcMwNE2rntShx1uSJMueqqpKaQTxWrquZ3LZ7ac7uq57ngcRKYIghGF8em2FSOA1TdM7rVYuY9AoRDisFDOt5onnjtZWF7rd6mjQ5ngchZ4iCkGECaeGEXEcR5KUlJFpNBrdbq9SqYi80OsPMcalmVknCCdTCyGczuQSqazjea1GWxRkhuFGo1EhlxkMBv1up1Qq0ejULmfbtqwqtm3KqoIYTAgDHmOOZwPPR3Gk6VLoOyyKBv0OQp4iioSJixl9biaBiOdPBxT5mPHDyBJ5jLFPaUgwpQHCDI9ighgRhRhhiqiNmBjFyPMDIZFBAYNYBQkS8tz2wJuY2srzn0Kh8S//zW8QCf/0n/9JNsI8ezr4Zwim8SnGQpQiFH/ja185PDwoF4qqqiqq5HgeEflmu1Or1hOSIvjMXAZdWjGTSQvppHlifuLP/gMzynFqbjiahIEVhB5huBid9tWcWwjPKSt4RKeJwwRAOSRTw0kXkh0AToG+R1VVz/Ns24b/69kR4VlIKT7/cfD8pwENCIFfbGF2TlVV6KeD1P6jo6PdnS2EEBRNwsGRRvEfM6I7AzH/PloLf5/anSAoE8QYfjXg/KMoBj0aIYRQJIuSYRizs7P5Qvbu3btwxiAEUUpRTBH+vh/0JwCs85WFsAxCiOdERZVSukJp/FM/9VMfevUVhmF837UsS5IESmm3271x48Z4PNa0xHA45nl+OBzqSQ3UTrCLnO+sMHXyfb/b7VZKM0cnhyzhsvlMu9XleMZ1fD9wC/nS1BxzrMDxTKfdsx2zWChb9pQhXK1+cnnjaiqV+tpXvl7M569evToYDOAm7fcGKxeWO+1uGAXJRMr1HIB6QRBMp1Nd1xuNmue4mVwWU+T6XkLTGY4d9LtLy8uI0k63SzCemqZj2xBhgBCSREVRpWaj3e335ubmTNO0HE/X9cFouLa2pmn67ffeQ5SyLLuydKHXHZiTSSKVsqZThmEcx2IYBjTIiURClmVraqbSxuH+QRD5K2uriiI3Go1er3fp0qVOp9No1ubn5wVBgND5W7duwT8B99QbjWw2Ozc3d//+/aWlFcg/g6LVKIocxx0Oh6qqwh7z8OHDudmFTCYjyUK1WtV13bZt0IKEYfDiiy8eHBxwHNfv9xFCQK64tivL8u7u7traGlSaVqtVx3EqlbIkSYeHh5lMBiyZBwcHr776qijx9+/fv3ntuhv4d2/fLc/MTMdjlucZjCnGuqo22g3PdiJEX7j53HRqVU9qpVKlUasLkpjP5urNmud5+XxeVdWnT59euXJlak4gBToMw+FkmEzqtuukUql6vT4/P99utzmeZxhmOBiAaBp2wVKpBNMijJgoioDMOD4+5nkeWDrIpwiC4OrVqyC54zgOymdZlvW8IJtNP3jw4LXXXhsMBvV6PQzD8Xj8+us/EkThztZ20kj1+/1EIuFYdrlcBq97JpNZWlqCnC3HsmEFgMzn6XSaMYxyudxpdwnHspj0hgNM43Q26zmOpCie40iqFAchJdh33Havi6JYVOSFhYUoiur1eiaT4QgzHg8JYROJBI1iVddGo0m73dYSCUVRvCCIgoBjmMFgkMvmgyAwHVsQJD+ICsVyENNOu/udN9784pe/2q3XU8VSpVJhGS6IYhrjc8c0OjuOUkoZnjsvBEMIQZpXROMw9BEiZxaf0wIlgePjMOQYFlYViFjDGEsyz/Pk6dOnH//ER3/+r/7Vau243Wx4vlPK58IwFAVhMOgXi8X5+fmtrS2O4wIvgI9gPJ0gROfm5lzfi6LoYG+/VCoRwszMzPS7PRpGmqZ1Op3uYDgzM4Mx1nV9b28P4gaguY8QAiKib37zm7AUgEsG7v10Ot3tdiHQgTBMHEWu6zqO45gWfJSQ1xDEUaPZ/Jmf/mlN10/X2z95UEgRBe0vw3z7238AlCrGVJblTqcD47l+fwiBBpIkERYDn22aJqTMw1YyHk0NwwBCp1AoMAxTq9UymYxtOizLRnGwurq6u7sLK1i3242iKJvNZrPpbrcriiJI+1OpVBSjVNqYrcxYlqXIcq1WS2o6/Lj37t0VRTGZSsmyLMoSQDT8u7/1f7ACr0ryYDziGZYSnNITveEgjhAELjQaDdf1i8W8quqXL1/qdFutdjuZTA6HQzi1VKv1+fl5y/GOjo7m5+cFQQT4DFUzuUJ+MpnAFjgej13PS+g6y7KD/mg8Gum6funSpfpJvdvtaorquq5ne7quJhPaXLk0GvYaJ4eha29t3r+wXLm0vphLqywb4tjh+NhxxlEcNzo9QVRVPcWwYrs7ymSL5sRs1ppREOYyhiRJO3t7ejpVKJaHU5OTtOHYjbFkO4gQCWE+iKOXXr5p2ePq8QGmyJpaBLMQ+pUyEqIsYsLAlh8FoSJLu9tPs5lkPmt0WscsdgU2SGg4l5aTSRHhMHKnJHJxHIeUIswQlqGEIhwgHEVRwLMMwjgOAkI4FMeI40NzEiEqpLK+HbJCAnNJisTh0OkNhqZp2i77Qx/9y94o/se//MvXX3j5tT/1UZYjLKKYxggRdNb9iTBCiGJMY9/7zP/xaxzHJHU9mUwKrOjGjqAK9x889F1GYgQlilZL3OqsIypjlJO37h/8xF/8nz2u6Mcpy3FxNGCZOIoZiplzJfu5DAtub3rWkxN/f+DT+fTw/J8wSwUvIaTmnEI0dArUEEIEv0+Snf8lmUxizGCMYTIIOx/DMIZhaLLCMEwYBI1G4+BgL4qiOATH4/uhyf9fH/iPsxnC6hbHMcuyDMsDaUcIEQQpiiLIJYfeD4LQwsJCtXqiKMrNmze/9MUvIhQLohj4PqXRH30NGCFYRxBCGP2gSouQ0zpklmVFQZZkQRC4SqX0t//O3xIEIQh8hsFB6CUSiUGvC2VB3/3ud3U9WanMjkdT27aH44HtmJ/8xKd6vV715CSZTI5GI57nc7kcKCPH43GlWDk4PlhZXBmb4/FoShjke+F4MizkS1Ec2JZbKhd63UFMQ88PMxnDNG1B4HQ9eXJyEvqBIIggr8QYFwqFOEae5zAMZ9umqur5fBZ8BqPRqNvt8jyv65rnONV6vVIqzc7PnxwdibIsi+Kjzc0Ly8thHGfT6dFkEgWB7/u6rtfr1XQ6WyjkxuOprKrT6XRra4tlOQjzfP75513X3T88WJxf6A36+7sHlZmZOIoSyeT21hZCSJKkubm5ZDJ569at1dVVlmWPDw4VXeu22i9+4EXbtm3bAuYD0pharValUgFfWDKZ3N/fB5MUd1Z8yXFcNpvd39+H8ZZt29BfW61WIdsCBPu2bY/HE01Pgg4Vjg2maU7NcSaTSafToLIAKMNxnOe5ELUliuLi4qJlWb1er9PpPP/888fHx5VKBQTXAMVEUYR7rdfrJRIJqNsL/RAzpFlvlCpl27QQwTSKeZG3TasyO9Ns1MIgvnBh1TRtz7Y6/Z4mK5hlfN93HDufz4P6hKKo0+kUi8XDw8M48FOplO95DMuyLFtt1NPpNCfwHMfNzszfu3cvkUgYhtHv9YCWmJmZOT6qchwHyYjggIHk7kwmA7QN6AFg+Luzs6Npmq7rvh+4ruP7PkhNwP13/fr1t99+++bzzx3sHbA8p2ka5IjCrTc3N3dycrK5uQki4PnZuffee299fb1SqTx9+rRQKPT7fcjTurC2ur+7t7SyrMpKvdmIwyhppNrNFiJIlRWGY+MwimjMYMIJ/Gg0yufzoAof9Pocz8zOzJ+cnERBIKsqxtiyLF3XKYo2Hz9NpVIrKyvwuxuG0et0ojBGDGm328srqwzDGelss9O9f//+b/7WZ6uNuuuExcKsrifhzIkJgcsJ+B5BEoH8FgSJgrKbQV4AfVxMEAQ0ihn2tB7Dd1xNS/iuB+l3GGNKURRFgsBSFKVSiVa7+YGXXvy5n/tZFIeDQb/f62SzaducWOakVqtd2bgcBD6lNJUyBqMh2Bgnk0kYRbzAQcswz/OhH1QqFWtquq4rcNxkMgmiGMRnkGbu+361Wt3Y2Gg0Gr7vr6ysMAyzu7s7MzPT7/clSUqoSqvVUhRlbnGhVmvs7u1JkpI0UrWTajKZXFiYe+/27clwwHFcqVhMZzKqpuwfHq4sLn/o9Q+fLYzv136cgyqEEMIxojSm708YptPp17/+VZhmIIQWFxfr9Trg1Gq1CrlcvMBqmga/oK7rW1tbYNkBO2GhUAAhBAA1hmEkQQZPHlzMMPWGMD8Yf8NpBy7aSqWSSOlHR0coptPpFLCaY1qapk1t68KFC2EYPn6yubS0lMlm9/f3gzjCv/FvfjlhpPKZbKPd4gg3uzA/HY2PqieSqEiSdHxcLZSKxXxha2c7n81xAm9Z0+Pjw9LMLHS8R1EkiUq/35dV9eLFi5bpYIwJYTudDkIIovkESUzqKVEWptMpAGHHcTRF9zyvkMtblpXUdFVVJUmyranEc5oqPbr/3r27tzuNauSaOSMhc3h5oRK4IxRY8zPZSjEpy8T3ppzALly+hhCzv3OYyVf0RLY3GJtjM/D8YbeTSmrHx4fNdmNrZ3thZfnHfvwnaq1hfxyxYlaU8/X2hBVV0/WMtJY0NERDx7JEThyNJixhjHTSdS1B5BAljjXleda2zFwmaU4HljVgsTtXyeYykpYUEHKQ3Y+CKaIhwRFmEEIEBRQxPBIU5IeuZ7MCYXnW9xwcRxzPI1ZAEQ0cl5M0GmPESP2JH1HZDYXxOBDEZLvT39nZe+7Gq9ZU+p2vfONH//Trr/zIhzGjhmEs8RijEFH2bMs+BViIRo1G9Yu//TuJhJZKJNLpdBxQxERuZD/a3JKEjMLyUmRdX9Zn8xaKWiivf+Mrb/3Xf/+zHrvYHbG8KMRug1KPUg4zAmCgc3feef/dOYCgz/T9xc+035yrrE6Ha2dewvDsEcXB+ZNA4gs6C+1VFOXsqdhkMplIJCaTydQyGYZBMVVVNWukk8mk73kHBwdgsKdRjBCi+D9Y2H7+EATO84Lz188wDC9IMKYEf43rujFGhBDfC1iW5RhmeXkZIfrhD39Y1/XPfOYzvu82G42z9+cHMRZGzxpk4vdXj/NeZ0IQJYQQSZIUVQrj4KWXXvhLf+kvEUKm44miSpqmJpO661i2bXa73cXFRVXVDw6OLNPhOI4XuSD0SsXKeDxWFaVUKkFUFc/zDMMwiAmCAPhzz/MSiQQnCLB8GIYBKWIgmoFxTKfXVRSFYZjhcChJkiiK3XYXY5xMJrvdbiKRAgwKHxMkIfm+r2nK1tbWCy+8AAbvVCrVbDaz2ex5+LAsy5CJD1QQKGym0+loNIqisFQqgVDGcRzo2pJl+dq163fv3gXdt2EYcDEMh8N0Jlev1yFmD2M8OzvLc9yjR49kWb548WKj0djd3dU0DbK1BIFLJBJhGHQ6HUigtiyL47j19XXolIRZW6fTkSQJNADJZFLTtH6/D6+nWCzCUeHg4ABQxfXr1xuNRq1Wg72T5UT4xIfDITBAMQ3X1tagIs0wjGazCaklvV4X8OLW1tZ5pPPc3BwoqA4PD2FuXq/XVVVdWlrK5/O7u7umac7PzzcaTUAGoihKovLgwYP19fXDw8OFxTnDMOr1WjabNc3J8XE1qSdZlicEQd4jeBXffvvtGzduLC8vN1t1SqmiKKZpplIJWRAd2waleS6f39vbm1tcODo64gQ+lUwPh0OQIcqSNBwOVUnWdb3R6sBnIYoiTOtmZ2dv3boFk2XP80CYCzv62traYDAEVdnjx49XVpZhOySEVKtVQRBAVZZMpuAwtru7m8llwXwKIUZgpfI8z5xMZ2ZmIMkJziTb29uJRGJuYR6a4DiOi6IILh7HcWC2Wy6XQYUDQeTNZhMyeKFrRBB4wzBGgyFAQ5B8bWxsNFt1cC4bhtHt9OGKdV2XY5g4joEROa7WPM+7fOWa74fpTG5sTl3X/7f/569vPT04OjoWeKlcLifTBqSf5PP5bm8AB8UgCn0/hJoX8FGGccAwTByHKKaY0NNA5jAihA3cUBAEnhc9z8eI4Xkes1QQuF6/k82mayfV2bnyX//5v5ZM6Uf7+6trS81qrdmsh56bTCYkQSiXy2FMgygEt+zi4iJFaDQe6ro+HA41Teu2OzzPy6IURr6u6IZhdPsD1/VhUraysgLSTFmWoTBgPB4/efIkm80mEgnwC+MojOOYYdmxOdW0RBhFoqzEcSyK4vHxMYPR7Ozsre+96XnelcuXFUWRFKnbbauq/vGPf5ywXBwjhuXhavljABZCCJ2Wn8Lp6Itf/CIgsclkUiwWM5nM17/+9VdffRXS+yzLYlgMBxVJkvL5fBiGmUwGUg52dnZALA6LD1wG+WyhUCiAynA8HnueB3JwwzCAggWsWSwWL1++/NZbb3mBW6lUbNMqFArwMrqttqIoiyvLk8nE8dw4jkfjsSRJkqo0Gg1863vfnJpmu9VKplKBF2KGKJLMcCwhp4F+iqYZidTW7o6uqJwocAIP6trl5eXhYJxMJh3PPzw8VBUdOto6nQ5mucPDQ9u24zhOG5nNzU17ai8sL4ii2Ol0KIpFUTTHk0QiwWAyGAxmZ2YQQqVSicHRfKXQ69Vuv/3meNSdK2dUkQnsCRM5usSlVCEhs7rMuJOB74wZHOl6MpWZEZXk0XFdNzK6kW00257n8Bxz4+pFI6V4vlkoZav16sHJwQsvvhxQyQ6Mo6qp6OWRS1kx0R4OAxSWZkqEINdyc5k8jaKkrqWNxMnRjudaHCYkDhg2nk67hVIin5M5LhCE2LMHLBMg6sdRQCiFrhEURyj2kSCgMIhDTHgJhXEUhIwkRJ7F8AwiNArjwCMsqw+Gnqpm5HSu3x8fHTe6A0tPlH2flcUUwyq2GX3u818dDPz/9hf/u/XnF2IcRkiIKeJwjFGMKKid3r8kMaa333373bfeLhRy6VTKMAxrYgsy3x20t7b3ZTHNUj8tuq89P6dnTWTVEcv/xhe+80//9zdGfnpocaZpJiSfZWI/xAwn0TM7DAzgbNuGdEp61myDzgRV5/IpuENAbw6nAfD3wW4KGMvzvCD0KKUAKX6A9OJ5nmV54JyhiiuKIsdzS6USpkiSpJlS2bKsJ5ubR0dHcRyeC+3PJ4B/wijwT3hgjKBgFXQ2McWmaYKE07ZdczrFp9gx4iXp6sZl0Ouoqgrygl6v47pueOqyfD9rFJ4Z0T8eYJ09CMdxkHwjy7KmK75vf/RjH/nZv/RzYRh3Wt2FhTmOZ0xzEtPAtk3fd9Pp9HA4tG336tXrh4eH5UplOp3C4V6WJIyxJCq1Wg3OcAShOI6DIAALMQAs8AQBPALHxsHBwQsvvNBoNARJtCzLcZx0Oh2G4fHxsWu7giAUCoVyuQypK8Bduq7L8zzPswghXdcty4KcGN/3IVAeWJm5uTnwK0BrLOzuANlBcx2GAcdxg8HAsqzJZLK0tJTL5SzLUhQV4vRgNndeMEIRAU40DMNut7uxsWFOp61WC2T7LMuaprm8vLy2tvb06dNiMe/7/sHBPkKo2WxeuXKl0+nwPA9TSNM0QWzR6/VWV1dN05ybm/v6178uimIul5ufn0+n02+//TYkpzuOA7XiwOamUilZlm3bPjquxXE8OzsbxzEoTfcPdpeXlwFgiaJYr9fX1tba7TbG6PDwEOwaUIMoCALU6II7xDRNUK8CLIDxXBB4jUZjbm7h6OioXm+sr6+DvwGkjXApMgyRJEkUeY4TCCKNRsvzHPAb6br++PGjxcVFaAqK4kDXdTgIua57cXUtjgKA4/cfPCiVSqlMemdnT5ZlPwhgC+n3+6IghGFojk1N00zbLhQKcNsyDNPpdCDuAW4HqGPf2tqanZ2F7UpVNVVVj4+Pc7mcLEsQlgGOzmq1CiA1nc7Ax8EwTCKV3NnZgRVAkqSjo6Of/MmfvHPnzqDXhxYQx3EsywLILggCJ/DdbrdYLEKvy4ULF4D4BInLYDCYTCYA0cCPBb4BYJUojR3HSSWScAUmEglgzSmKtre3X3nllXq9Xq81gb8xTZMgBEhrfX19e3dvOp3Ozi0MBoMgimVVZRhuZmZOEtVf/dVfvfXue0+ePBEEKZPJzC0sOo7j+6Hl2J4bMAwjinIYhhgTSZa9MAijgBAC6fAYn7agAuYI3ADWQ2D/gX1JpRJB6Pm+axjG3v52KqF/5E/98I99/OODYWd5foHn2XajrihyNp3GGL/51tvQUzKajDOZDEJoMp1ijD3Xhfz3SqVCEPZ9b9DtY4yzhSI441zXBbEdiA3gPADgEpaUQqEQBEHOSImi+HRrK8ZoPJ4mksmkkW61Wul0OgiCKPAdxxl02uPxWFPVZDKZzWejKOp2u3/6T//pRMrAmCEMdz7BOF02T8tZY4QQpCSis8nD/fv3J5MRnLW63W6lUimVStVqlWEYURQfPXrkOM78/DwsBaAmhzLm1dVVVVWfPHmSz+fz+Xy/3+/1ekEQrK2ugr4KFoFqtQqTTUmSrl27dvv2bQiv7/f70IQxMceQRQCkZqPREDm+VCpZrnP//v35xQXDMFKGAd5hQRDwd//wa14Y2FNTkKXxaAoKG0mSGIYNgsDzvHqzoSjKxqUrIILLFYqKpt26davXG0DGSbc3kGXZcdzNzc04jhOJxGA0SSQShJDQC1VVh/7gqWXapiVIfELXoyiYTqfZdGo8HrOEkWV5PB6lDSOdkrA3CNyhpgnZlEaoEzpTkaGGJnjjfjGdKBmJQlpPCGwmqUaBY9lu3/IZTuYk9dHTrf3jk8ULKysrK1HstZvVdqexsXFRUaSZmRnLdTDLuZFsBenb945z5SVBze6fNBhJqizNOp4nCXzg+bEfsASjyHWsIaUWIWFWV2crRY6POTZkOBdjRxSiwJ9GkYMxZTClMSaIIYSnMYppZDsjVZcZlqdhjCOMEIdiGqOYEBLSMIwoK6qskEZcsnE0PDppM4reH4yTCWN2ZvnrX33j4vpNVUkdn7S/9vVvez75+//DP8xXkh51iUAR4RAlzGmnKXcKrM4YJYzpV774O816LZvNFnI5URStia0oytbO9mg0TiZyoT8uJoMP3MwLfCcyexFW3rnf+Bv/3b9qm2KIJNu2DZVxPZNikeVPxd1wk+Oz8M9ncMP7LRCAwGC1hRsPIQRHWxBLAkoDc7LnecBgYXQ6hTxFGYTA7iuKMhRTwhbOMAxYuCVB1DSNZ9g4jqeTSafTGQ774VkjNfoPSRb9I1+HZC8GptiqqmLCgsuMZdkwjKMwxIQghFiBL5fLIscPBoPXXnvt4sWLv/zLv9zr9SiNKOz9lMIqeYb2Tp/+9BNC9I9lsABgIYQkSdJ0ZTDofPrTn/4bv/Cfd7vdSmXWNCcHh3uKIpXLpUazFkWnFQs3btwYDAaeF9iOAzLnIAgIxo7j8JyYyWT6/b7jOLqqQiJAqVRSVXVvbw8qzIBchBJShFAikXjjjTfK5fJgNIR2l4ODg5mZmUKhYE5MaOTY3d2FCrxCoeT7PnhBZmcr7XYbngS8L51OB5q5wLzmeV4mkzEMA6IH8vl8rVaDtE+IoTeM1HQ6TaVSx8fHo9FoZWVlMplMJpO5uXlCyJtvvnnjxg1CSDab7ff7k8lkMBxPJpP19fVisQiW0r3d3UKhIAgCyFphb1heXj48PBQEThRFz3OhgwymnJBPcXJyYlnW0dHRtWvXDg8PXdcF/knTNDj1QgsTEEXQM3HhwgXQicPFb5pmOp3O5oqmaW5tbUGKcjKZ7HRbqVQKcnFBijsajWq12qVLF4HE5Xme47itrS2ob4MICWB0FhcXd3d3z7N2GYYZjQYIIZ4Xfd9fXFyilG5ubi4tLcGWgBCam5t1Xffw8FBVZY4TDvYOstl8GPqAwxiGieOoXC47jjMYDHiBJYRA+L6iKCwmsix6rquDPzqOTNM0jIzneYlkUlXV+/fvX7161bHtyWRSO67Nzs4iQgaDAVjfAZJ6ngd0CEhtIMGHUgoxHP3+QBAECAMbDgfQ+lqpVGZmZt55550wDCuVSjqdAdua53k7e7upVGpmZgZmWOl0utPp+L7vux68IeDRm06nCwsLkiQ5nntwcPDaa68Nh8P9/X1JkgzDMAyj1WqZpgl8ajqdnk6nuVyuXq9jjIG+siwrCPwwDJcXlyil1WoVYMHMzAzHM9lsdnNzMwgCnhOBwiGE0CiC4CVZlk3biaLo+vWbvX6/3e6yPOd7YYToYDCYn1/MZrONZvNXfuVX79170OsOjGyukC/m88VWq4UJ6zpOoViu1eocx8mK4kchy51aCIPAgyvE8zyYajEMI7AcJRjsPqqq2rYdRr6mKQghXmA6raaqyT/16U8rkmAkE4VcxrHN6XicTadHoxHLC5qmVatVWZZTaWN/f//y5cthFE0nE1irx+Pxwtxip9NiEEMIEWQpnU6DpRTi12ELAMoWzskcx0GWGCGEQac9dalMmmH54+Pj4XgCHQDj8biYz9m2nUrqJ4dHHMsuLy8rmqIoyu7u7gc+8IH1SxsMy4IOJT5rgEUIYYoQxucMFqyf8Gprtdr9+3fB4QGFyLlcLpvNwrB4NBrt7e212+1isbi2tjYYDLrdLtynDMNA9no2m6WUHh8fQ4FYFIaghYeRKCB+2JKGwyEIVMCA3Ov1isVirpDtdrtREMKZMJ1OR35gGMb+0aHjOM+98HwikUgkk9vb20CIstu7+6m0QaNY5UUjI5imCULCSnkWcghfePkDtm13u/0nW9uHx9X9g6PtvT2WZR3bS2czcRxLkjKdViVJyZXmLMtieb5QTFJKwzAUVRKFZOw4QRBwopBMSUEcuF7o+76qpfwQibKO48gPIi2RmJqWyPkZfsyibpLVWW9qm0OBQbLAxqMoxWLW7AWxSYgtarIghoglsk6y+ZQTelOntzzPvfr6D+vZ3KDfSxk5hh1MHHLltVeQG7ljJ5UuxTHbqw0f79eLC2u8lBiOLYZjU6kEDYJyNhVHgYe8wbivG4om49gguVyB50ORQ5xoBc6UZaIodMLAiiilkc9QynMC4iQUMyjEkY8oJRRHiXR2PO5xJJSVJA0iz/N5XiS8hChhBZklguuRvf1xvdmUlNwo0KQ4FfKih0SKk7ncRccUxuPRv/0/f6vbH37m1/9dfjbphZQTRExQGIUYRwTj70+yRJhShGNnOh0MBjBugEEywzBRFPtuKLCy7zpxaOmGxsrIm068wNcXrob3hs22qeczbkQo4m1nLHKsT/G5QxCdDQFBnnI+BDx/nGOXcy4K/gJoCZ8FOgASAh4LIY4+k6eFzmKo4J/nfNj5YmraFtjULcuigug4Tq/btW0bY4YQRGlwflv+/zclZFne932WJSB5jqIIU6xpGmwSCCFMECEkCkNCkSJKL7744t7eXiaTGQwGqVSi3+/GUSxKku9552PT91cKjJ8lrJ51DsKgDWOCMY4RiuPYD0PX8Y1k/urlG9Z0alnWrXe/d+HCsuOYosixHIHwOkJIMplstZqKovh+mM/lNh89KZfL7WanUCjIkooQgvNTqVSqVmuZTGYynhopz/eC/b2DbCGXTqdhR5dleXl5uVqtbm5ubmxs+L5vOTaUYMiyDB2jtm3DLgVlnUEQlEolWRZnZq40Gg2Y1qmq6rou+PheeOEFSNm4fPny7u7u4eFhr9djWVZV1Vwu12w2ISanUqk0m80oihxHBDEExHN4nre6umbb9sOHDw3D+OhHPwqn0nQ6fXR0JMtyOp1eWlqCLkggRwPfh75LSEje2Ng4Pj7u9/srKyvtdnM6nV6+vNHv90F5TSnVdX1/f//w8FCSJOj4y+fzpVLp5OSE4zgICWs0GuDXA8829LLfu3dvdXWV47inT59alnXp0qVqtbqzsyNJ0vr6ehAEkKW3vLIIG/n+/j603oJ/8N133/34xz/e7XZPTk4ymUwul2MYxrIsy7KgL9KyrN3d3dOk9W53OBw+99xzjmONRqMoio6Pj7vdLrykR48eQqsu5GsfHx/Pz896njeZmJlcdmZmttNtrays3L9/3w8DRZIdx4WhHjQkvvjc84eHh7lcDpwBhLBhGPO86AahLKsQx58vFFZXVwMvFHlpOjbjCGVyucFopKrq5ubml7/85eeff/5jH/vYW2+9BUC52+1CkxJsw47jAGNUKBQheLZer1MaJ5NJmDc9ffp0YWGhWCzu7e21Wi0IG3McZ2lpaTgcXrt2rVargfwfNHDW1GQYZnV11XEcQRBSqVSj0SgUCo7nIoTu3buXTqfhQjo4OADEvLCwADQnRJDX6/XBYJDNZtvttqIoxWIRY5ROp1uNpqqqly9fXllZOT4+xhjDYYBSOh6PL1zIu66bzWaOj48RQrOzs/bUbDabo9EkkUrduvX21atXW3E4GkzS6SwvCovzlVqtFofK0uLsP/un/7Dd7t6+fee3PvuFWrXRbbdmZ+eG42k6mT4+OkjoKUmR/TAgiOIIsYjB3GnUO0JE15Nh6HMcp+oaprHtOgxheIkfjsaCICT0lO2YsiCCg2E46n/mM5/5L/7GLxSLxX63PR4NEKJRJ7Jtm8XMdDSuVCqWZTXrDYZhGMKNhhNRkDHyBEEQeOnunfuzc5W5uUXbMWu12nQ6lSSp1+sBNVitVsvl8s2bNyEZbjqdgmoeUg85hriuO5mYhONtx6GULi8v7+3twcXGMSSTyXAsK8iKa5nhmVMK3H8bV64ihMIw5Lg/7vQLR1N82mMLSql0Ou37PhDP+XxeEARI6AD3LsdxFy9uHBwcPHz4cHt7V9d1nhc3NhZh6ocx0+8PFUXjOI7jhEQi1Ww211ZXYLeyLOvu3bvD4RB4dzicjEYjXddFUYQFyvf94XAIcXrAOkdRNBiPgjgCyj8Mw06nU61WYf6YTqfxd974NkJofn6+0+lgzDAcBy2PqqqHYXh0dASVCMPxKPDCw6NjI5d3/UDXkqdRkARbEzOdy8ZBGFEscJztuphSLwgyqYxlWRzmKEVB4LMsy7A4imOGkCgKEIppFLIsSzBlWZaGgaZpmhgqYV0mFs8xKPZZBqkCy9GYizyBhjwKFRzNFYyZjFbKJlgeI5mlLHYwpQyr5HJIlB3LCSKsZ/O+EzWa/fLMIiGybUW2HfshOW6MtMKF3eP2xLSTyWRltpzNGU+f3HesUcbQUeizOChmE4WiJssxYp3AHwW+aVpjgWcFluE5QlgSWDbHCwgzKIqpjyLKEMIRhkOIjUkUMR4n8AhzoRVFIRH0NIpJp96ZTB1KJNOjbsjZAePG7MLSxcHYGplmEEQKJ41a45WZ9UcP7v/6b/2rqT39O//9//Sxn/iPvSDgBQ4h5DgeRPoSFj+L6yk9BVj7O9vf+sM/yBgpSZLKxaLruhzhPc+/fetuKpkmHGXJdONSYr7MYb8l6gnElX7p//Ev/vfPfkdMlr0IdTsNJvY1TQsiEkSnAAiuPBiBn+sQ4SvnsemAJM79MvBt56U3cAkCaS8IAjnLxDr/X2A5Pr9dWZaHWFFgWcIwJCzjeV42nVEUBcdUURTLNPf29mByFMfhfxC6epbHehYJQbUIcLRRfMrGgeQZeKYwCAjDzM3Nvfjii5/61Ke2trb+3t/9uxzPwuv3PQ8YLBgRPvuzMCWnwAtRit6HpGcYlIGxF0KIZTmB40Ve+tt/62/mcmlJZi5eWW80ar1eZ2VlZTgc+37IMvx0ag6Hg2QySRhkGAZGzPHxMWhlZmdnQWyOEOI47u7du/l8YWVl5Tvf+kOMMbTcMDwLpVWSJD1+/BiCeQCOi6LIiwLENEMfWRzHw/5QkqRMJjMcDgkhOzs76XR6fn5+b28P1rs4jg3DuH///iuvvPLo0SNA0jMzM2EYHh4ezs/PJxIJUGTu7OxA/k2j0YCcHlEUZ2YqDx8+TKVScD2IojidmhDycvHiRWjiiuN4bW0Noo+Xli+0Wq1GowGqmuFwmEmn2+12v9+fn5/XdR0ShiDPRtfV4XAA52mwPKdSKYxxs9kE/DSdTldXV19++eXxeNxqtSAJPQzDfD6/t7cXx/HS0tJ4PLZte3FxEbZt6CaDYROllOXEZrO5srIC8T9RFB2fHCYSCVVVQZ8O9Fuz2ZyZqYiieOvWLUEQALwOh8NyuQwsxczMzObm5mg0Wlpa6vf7p/JWSZpOxxDw0+12r127wTDMgwcPQNcIrbSf/OQnoyiANtyrV6/fvv3eczdfePf2O8ViEbTARjI1nU6hey6VStVqtQvLi9BEC+lu3Nmj3euGYfihD33o4cOHMaVhGIZ+lM1moakG7ugoiubm5g4ODsCsihAyTRM4VOAI4aXKstzv94fD4ezsnOd5hUJhMBi4rjMzMzMajWDwBLfbzMyMbTsw1GZZ1sikAeDatv3JT37y/v37ECnZ63RzuRwIv+BzhOuzMjsDGrKnT59CIlcymQT2azqdUkp9319bW3v8+DG4E6DMBEIyDSPFMEyjVs9ms51Op9frwUczGPZkWc5ms7lcrt1uI4QgvUgURdd1aRhhjFOp9HQ67Q9HsiynUmmO4yrl2Vu33+kPOtdv3uh2u71uP5FIMLxw/drzvd6g0+7+r7/6Lx/cfSwpcjKZymbyGDOO72FCHM+NIhrHMcfyDM8BVRPHMcKUIsQLbBAEvu+CZEISZDh/+r47HQ9zuWwYeBzHDPpdjmP/3n//i8VC5v6du0uL857jBoEfekGlUokQ3d7ehko6TFgI09Y0DSFSrVarxyeFQmF5eXk6nYaRn8lkIJugXC6Lonj//n1wXQCmn06nw+EQPDRQRx3H8dR2OI4zLWt1dXViWtCOMBqN5mdnMMbbW1uNRmPU7xUKhWKpANjr6dOnP/Pn/4KqqhRBO+0fGRGe/ePZtT0Igq9//auNRqNYLEJ4SjqdFkURytN8379y5Rq4KwaDwXkVGFTXQ2UC4LNSqQQuFsucAEgFpgqy5SaTSalUunTpEkTZZbNZOEmmUqnheNDpdMrFEsgGZFmeTCaKoiwvL3ue92TrKRxQt7e384WCYRj4S1/7BkyvwUt/cHho2042m33y5Al4OkajEccJScPQFCWIKCWMGwSEEAjsRhizhFN1zXe98dRUZWVqmbqqub4XBTHDMAJhWZYFQQ/DMGEcYYriOEQIEUx931UkUZKk4aA3Pz8vkDga1ZIqRyilKGIwQqHHxKHEIo2jSRmpjF8wpFJGyKclljoMj8aBX7l8BWEeiSr1MRY0JCYtM2h2RulcudUeVOsdUVBHY8v3ot7YsUO1PL+UyWgM9lFsdtuHPOtfWV+q5AyOZxCHUGShcBJTK6BmhFxwSymSiuKQQwQjTKMIcyKKIkQIwgRRjMIwjiOMMWLYkGGDgBAsibKBIrHXmg4GNsIyw+uYFVsD04sx5Xg3DinGzW47nTNkXnO70fLs8ld/57O/87v/+vpLlb//D/7HRPE5z+F4WYsQ9XxH5kVMWXviyLqEcPxHAdYb3/7Dnd3tfDaT0JRUIhkEAcNwnXb/6KDK87wXWJUZ/eWXFzTZG7UPwpBubff/p//Xr9k0fVDrOaEfRUFC5iejsahoEcXn+ipYVWEIiM7EUvFZqzH8/Vk4hRACLSc5666BuSGIuGGeCM92DowYhuF5nuMEyH2ARIbxeAwLShiCm08QRbGQzQiCcHx01Gw2gyA4/4kQhno6uEd//CjwWTj17FcYjoXlGMISEULALYVBfD5/hYAGWZahMmJubu7HfuzHtra2PvOZz5ycnEBnFEPef3++H+2R86+foSsgus4CR09T4jmW5RjMLs4v/a3/5v9OGV8QycxczrYnE3McxyjwkcArNGZ9P1xcmEMo3t7eIgxK6KkoiqA8C2oG9vcPJpPJ7Ozs4uIix3G6rr/xxhuKonheIMvipUsX7969G4ZhLpcDkRAh5OjoCAoxJuZUURRZlsMwBJVPHMapVIrneRALJxIJ27YQQrqul8vl4+MTWO5lWQZ+BXx2oKIFukWW5cePH0uSdOHChWazeW6DiOO4VCq9++4toAMvXLggywpQCIByBEEA+14co7t371YqFdd1g8i3LOvll1/udrsgEi3k8q7rnpycrKysjEYjkK5HUaSqahRFYRi0Wi1BECA/OQzDnZ2d1dXVOI7r9TpQU5RS13XhYobAs8FgsLCwAAENkiRNp1NFUZ4+fQqTRJ7nfd9fXl5uNBqtds+27YWFBeAeoijieAbgiCRJ1Wo1m80Oh8M4jhcW5n3fBzg7mUx0XZ9MJjA6FwQBMuIRQpqmPX782DRNVVUzmcxkMjqpHimyJoqiKIqQ8Om6rmU5HMcBDN3b25udnX36dPPatRu9/gAQ9nkgNcHYMIx+t1soFEaDQRAEgCM5jkulUqzAQi0jzM4YhokjpChKuVze2dmBtwLwHxgUEMK+7wMiAZTTbrchDRXSkobDIaiDQae/v7+fTqdBMmVDbGY+DxdJrVZrtVqFQsGybEmSPvCBDxBCfvOzvwXRYoqiDAaD4XCYTqdbrZYqK5CkD/qkMAxN0wyCIFfIA3MviiJU3zqOA3ldi4uLR0dHEMQVRRHs65C5BWK4paVF0NOoqrq/vw8oE2OsqBJcDBCOnUgk5ufna7XaZDJpNBrP37jZ6/WGw+H6+jrHCc1GKwgi4FQQg8bT4YULFxBCtVpDluU33vzeBz7wShRRglnC8Qkl+e6d937jN37z5OREUxPFcgmxLBy0HNeH2nto5ogx4jgOERzHUUhDXmAFQbAmU5ZwCJEwDDGmmqZFUSBwzHQ6kUQ+Ct1mrfYX/vzPfPQjP9JuNzFFHEtEnrNte25hAe4C0zS73V65XJ6aNujJWJZtNk8/wWazmUxo4/E4nT6t0NY0DbRuEOw+mUzK5fL29nY6nQap+Eyp3G63RUVOpVLNVqvdbqfSBuCHYrG4unLh6dOnLMNEUbS3vaMoUqlcVFU1l80/ePDgxvPP3bhxA6rJzhZnWEafWbfR6bp9fiw/OTn60pe+VCgUWJYdDocQend4eAiS/MPD43w+Dy9+MBjA6Jnn+Xw+jzG+cuXK/v5+u90OggAiJ3zPkSRpPB6D7H1lZSWKona7Dc7Bq1evuq57//79bDYLFGlEQ9/3Z2ZmJpPJydHxjRs3qtUqqDPH47GsKtPpFMa4UBeGZxbXjEzGcxzCshzD2K4rSQrcb0EUJvWEqms0QkEUhn5AGHZq2XoyORyPQGcTBAHGDAQaRVEUhRRONiC4IRiLHMuznOu6MYJVFUHCEEHU8zwah77vJjSNZRmCMINpZE+TqsIwmBCCKGUQZWhsm0ND5RlqS9i+cnHm5Zsry/M5gl0kMkg3EC+iiYtEtVXrjK3QDvBw6oSUC2JGVhLtdkdRNMJwhJDt3aNe1/34j31S4LzR8KRckBTBn1kqIquHPAfR0DVHhKGYiygTshLjhz7LcizhUBQjhFBMQ9djVQ25PnCXCFGEMSIYYYwojTCHiM4ouUFzfHzY8TzGD4QwZBU96/mUFbSx5QmKTHjWdC0vctPpRCaf7DQH8Zj73d/8ze1H3/2rP//jf+Y//fC4N2bFa0pyPcScF4QiR2gcI4+wAocw+mMB1hd/57eHg24uYxiGIXAgSMeHB8fNejeVSjB8lM5KRppMx00cuLpufOObt37lX31OzSx4MdcZ9HmWoNAJA5/jJZYXQQMbRdF5ESE9C2g4H4SdwyyoEYR4PWDp4RvAm4MQglgsKBPEGAMzdA6wgL6KImoYBsz4h8MhQggK4REijuMQQhRFKRfyHMfVqtXJZGJZFkwe0Zky9E8GWD+Ars4xFkWUYVmgzWBDPR13UmCV2CAIaBzzgqBpWiaTmZmZyWQy3W53bm7u29/+9gGkHbJsFPoIoWeh59kPZf7IV2DJYBBCMaUIIZbleZ5nWQ7FdH314v/4D37JccetTk1L8Pl8utvt2rZbLMzqWoZlBMfxJqNxLm90ux1VkwM/ymQycLJUFOX4+DidzoCUmOd5cOZDtQUI6h8+vF8qFbPZ7OPHj1VV5Xk+k8nAlCeO49FkDFt4p9M51SIgAhzMgwcPYKhUKOQrlUqj0TAMQxSlx48fgwwCbHfj8Xh1ddW2bXCeYoxBFMUwDBygQTkLTb2pVCqVSgqCcO/evaWlpTimcJ0cHR3BrwO7aafTYxhmcXExlUqNpyNgPmzbPjw8VFX12pWrBwcHmqbNz8/btj0cDsFYzrKsYRgPHty3bRuqP8CrAeX05zIO13Wh5HVubg4hdP/+/evXrwOHdHx8DEGsm5ubi4uLQC2AziyTyVQqlV6vbzseaPP7/X6325UkqVQugL4brnNIykilUpZlQlx7t9tVVXV+fv7o6Ghvb++DH/xgq9Wq1+tLS0uQgogQCsMQTt48z+oJlWD2yZMnqqrCTMS2bU1LwM0YhuGFCxc6nQ7LEtt2JVmBISNCCMIIh4PBaDTSVVUUxf3d3fX1ddBNQx761u5WLpeDtAVFUS5evFg9qcMLmE6nkLder9dhKQjDkON4UJRrmra/v18sFoHMMwwDHH/1er1SqQA9Bg1ucL4Kw1BVFeCEIGdV0zSoak4kkr7v7+/vf+QjH3m0+dh13UKhAHei4zgQk33z+o3JZPLmm29WKhWIjIcXVpmdaTQaAPEJIQsLCycnJ7Va7bnnntM07d69e2+++eZHPvIRiC85tzNDmKeqKpZl9bs9Xdd7vd7a2hqY+1zPhvn12toaeBvz+fw777xTKBReeumlOAjBzCFJEscJkAzHcQJCKAx9ysSO60Lr5aVLl1ut1mAwvHjp8nRqObYnCIKiaAihB48ef+Fznzs4OvKi2Mhkc5lsRJFj+2FEgyDCiOi67gZ+FEUMx4ZhEOOY5/nA8+KQguwaCH5ZFlmCfN/lWEaSBM+xn24++rn/5Gf/2l/5v967f6fXac/OlKI4EAV5Op2CsbfT6RJCVC0BNyPLssvLF7a3t0GJ8WTzkaIo6+vrUBrRbDYvXboEUwtw14LBAq7qIAgSqjY2pxCy6riuIAhHJ8e6rgMihwQvWZKq1Wq70XQcZ2FhLpvLJBOper0eY/TTP/MzoDQ5i2n4QYCFMIKhMHxPFEUMg3/lV35lZmYGwB8ICkFSefPmzeXlC2+++SaM4MEtcXx8PDMzoyiKqqqQaAXaFehti0IfzBMwpOZ5Hg5m+Xz+jTfegAK3IAhgvQqCIJvPwBDG8zxFkmF+LQgCeBVjRB88eKAoCryZr776Kr7y3Gssz6GYYoaIvIAIBreO74cUI4JwROM4jGJEGUwYjrVdH7SxIM0BITyspHCwI+R8kIw4jsM0ojTy/RDmRJg5VZBxhAnDkGVwGIYsYXieRTBOCgKGYShFPM/zgsSzAkKIJYhDMU/ChZlMpaBpUpwzRCMh4jiaTlxR1jlOGEzGiGUkTR+MreF0yvJCIpVOZzO6muj3+zimyWSy12rzhHftkST4vGgZSTq/kA7MDsfS2HMJxyKeR56PCEY86/qeqMihEzCIIERpHBIaIxajKEYYI4wQJTFFRJDiKCK8iDAXBWy7E9sWS6no+axto4kZ6MlMjEkYRJbliJIiCAIrsDENbXMsKnzCUN7+3jtf/I0vqlzwf/lPP/qhH7seOnsTjzfyn4jxXMypgAQwjZg4RhgjwkQ0ZjALF2IcUcLgYa/1hc9/TtOUdCqRTqcwhdIG7rvfeTOpGyxLiBheWJ3r91qiwARukMsWfvV/+7WvfvO7crJkOoHl+I5r0tDmGSIqahRSQEsw/wI66jwHi54ZCYE/AAgCkikoige0DbTW6Rz57AFanHN8BgjpPAsKygrAzC8IgmFkqtVqHMeapl29elVVVce0Tk5OWs36ZDKBKxueCkGmfBQhjNGpGef0AT/omRv4fTLpVC7GMudg8dmpKM/zvuexrBAGAYLpgOO89PLLa2trL7744pe+9KVvfOMbEGPN8UwURaEfnAvRng3lYhiOxvjZ9K/3Z5oYI4oJwyCEYS8cj0c/+pHX//bf+ZtB4Lu+pSfUer2GMW63O9euPue6vmu7+Xx+0OsbRqrf7fI8jwiBoyd79nBdD+rre70eyJ9Zls1ms47jUUoFgYNU7lKpRCm9d+/e+vo6QqjX64mimEobpmnCYYkQUiwWq8e1paWle/fusCwryxL0HM/Pz5+cnMzNzfV6wN8schxHKW42m5IkwJ0OpW+VSmU4HIKBgGEYRVE0TQONFGREUUplWU4kEo8ePUokEvDWgT6J5/m7d+8///zzh4eHMGayLCuR0l3XhTRwsJquLC1D7NDu7m69Xs/n8x/5yEe+/e1vQzlaEAQvvfSS53m1Wg24unK5PBwOs9ksDKwlSYrjGN4lhBCY7GRZPj4+LhaLQRCsra09fPhQFEUoULt3797Kyoqu6xCMGVPc7XZhA6jVamtra/1B1/M8kMxDZubZxYY6nY4sy2tra/V6HXIOWZaFGC2wndu2Da4ojuNg/4ii4Pj4eDqd3rx5E4S38/PzvV7PcZxGo/Hyyx/s9/u1Wg2Ytkwm4wchK/ACyyWTyePj42Qymc/lTk5OjGQKvL2NRsN3HVVVwXPA8nyn1wW0V8jlh8MhTDaBhcpksqDpBmIPYzwYDQVBgFAVQgiU3YJwzfd9uPBAsA8mUF3X6/X64uKiaZq+743HY0jTjuOY53lYQyRJXl9fPzg4gI+s1WqdfwqwfWqa5trO7Ozs8fExRElVKhW4SoMo1DTt8PAQRAWZTAbiXsEoA7gwl8v5vl+r1a5du/atb30rn8/Lsry3t+c49vXr14v5wtHREeDCKIr6/X42l4ZLJZFIMITzfT9fyILKENw/6XS63W6LosixguM4KT3Zbrd1PWnbZnfQMwxjfn4eanm1hG7bTrfb5TmREGKapm3bV69ezeTyB3v7E3P6O1/68u27d1q1Fi9JpeKsrOi6nux0+8PhWFY1QRAoRhhj3/cgsgQjFAYRrGaEkJhGtm1TGmmKJAk8RpQjeHvn6as/9MrP/8Jfa9aPJZGlNOR5EXDGYDCoVCocx41G43K5/PDhQ8uykgmD53mgvSFo/uHDh6VSCcRGgHchDgpYTDgJdDqdUqnkua7ruplMBmE8HA49z/N9H6YWcEMBf9lut9utVqfTmS2XoE5KUZSHm4//4l/8i1pCxxhjxJwfO58FWFEcgWLkPKaOZcndu3d3dnag5jKRSORyuWq1+ru/+7u5XO4Tn/ixvb29wWDwyiuvQHefIAjHx8c7Ozs//uM/DtQjSGBhBQhDf39/P5/Pt9tteFWj0QgcTvBDYWOCJNV6vZ7LZwzDADuFLMvVahXibFZXV+HJFxcXB70+mDPCMMTXX/ooL7AYMVEchEEcRj6ihOU5sDDANAc2HiAwEEPgF4ZrF7YKmOzEcQz8PM/zYegziGFYHIYeoEVKESvwLMOD7iTyA4oiljBRFHEMyzA49H1KKcvwQRAIskIYxrIcSVZEUYyjiGdZgUXXLl/QZCat85VKJpdWnz59mk7kgiDSNE3X1e6gz3KcG/iIINM0JUU0UpqqSI1addjv5IwUjgNz2FEEnMlKuh6Lkp9K8fZkSFCoyAoKQoQQ4jmEuRhTRFhKMYkQZhgaRRTFBBPEM7EXIEz8MOZ4xfNjN0Djqef4ISK865LhAMli1nbCdKaUzlQOj+qJVFoQhMl0wLPUsaeeNRF4Np1M5VJZXub/13/9q1/8vd/+4M3rf/0/+3P5yynU37G8gaDPsfpriMxHjAj6HUwRg31EESIkRgxBOI4RwSiOIkLQ9tPN7735RjKlFrIZTdPikFJKgyB6/PhxNlMYTwZyks/ns5///G+/8vIrhfxMs9H+R//kH7X7A1FL+QFyvMg0JzwX8RwTR6fo55yvAtwAMh10ppoC8ARTcDgKwHaFz/pzYDEC0QY9a8iBYRx5PyEd1PSncaOQ6w0/jmEYzwvAsQJjRFEUZUGsVquuY0GJG9hYKKVhFGGM4yhCCLHsKZA6J5POsdSzxNU5pwXrFzpr+3lWGRaFoSDI0VkAPaX0lVdeuXr1KtxOv/iLvzgej03T5HgmCAIGkz8yHIQDGEfpabzq+Q+FNYQQEkcUABbMQC1rcvnGhX/yT/5hsVgeDqaO5w36I0EQaBz2+33fdWzbnimXEKW9Xu/S2qVerxdFkeN52WwWsg8UReE4fjqd9vv9crmcTqd3dnZgNyWEDYKgVCqAEgXwTafTAToKWPROr9vtdkG4APGbAieWSqUvf/mLzz33XBD4/X7/4sWL4LrvdDqQbgVjo9FoUqlUxuMhDNqq1SrYD8ENTimFrbfb7X7qU5+C7R9jvLe3B4k74/H43G4GjH0mkyGEZVm21WoZhgHLiyDx0Be0ubnJcdzKysrD+w/K5TJoksrlsmmaiURif39/aWnpwYMHiUQim80yDAMUxeHhoWEYtVoNxlvwibAsC9cSZC+1Wi1N02A0pqpqu91eXl5utVqQmwCEJfAlvu+njEwYhk+fPoVTL8dxnW4L9P7Ly8uw2XAcVywW2+1WEARAA0BK0+7u7srKyvXr1/f393VdD8MQlEnQItJutzmOG4+HH/7wh2u1GkBAXddhksXz/OHh4Xg8NQwDoqF0XXcclyIkKnLkBzCM29/fZwgRBKHf7cHLnpubG/S6sFBTjNPZDIQaOI7zwZc/8K1vfev69evj8Rhu/MlkKstyLpdDCMEIuDI7A8lq0EDy9OlTmMFB6gR8J2BHSPqGcpWFhYXj42PHsSFljRACLjOYt06nJs/zMzMzjUYDtnNKKSiiAN7lcrlWowlTkWw2CyGQkK1QmZ05OTkBTRvDMKDL1nW9Wq3ChQTNRZANC88A3bIsy2KMPM9LpwxgZzmOOzk5MQxDVkRRFCElrlKexRhDzTDHcePx2Pf9x48fFwoFRVGAGSoUir7j8rxoWVYqkyoUCo8fP06lkjwvbG5uCpIIBAnLMmEYLi8vQ3z/6urq8vLy3tFRFNF7dx987fe/8fDBpu148wsrpXKF44TBcEwpDuIoCAKO5z3XNQwjDE6FrXDihXVJlASB5YLAQzTiGMKwpFmrvv7Dr/3cf/IXh/2mqkmdVgchJEmS57mmaUFNkCRJBwcHjuPMzsxzHDc3N3fv3j1QJQJbeXh4eO3aNYjPsCzr4OBgdXW13W4DFWQYhmVZ5nSKMcaEtNvt9fX1b37zm5AnZxjG8vIyyOlAeMdz3N7ensAyMAJOJpN7hwcrKysvfeBlhNC/D2DBQAKwTnTa/0EajcbXvvY1YNFefvllSPmCsd10akEmliRJiqIAmv/Od77z/PPPV6vV/f19yEoVBKHX6y0tLQ0GvUwmc3BwMB6P2+12pVJZXV0djUaqqkJ3BWgQWZY9OjpaXl72fAeYArhPu90uaFthouL7frPZvLC8QggB5wobI+y4/qknCxOWEwhhYXvGLMPA6TyOcUwRwpRgFmGCYpYgljAsy8DORDC1zQkhhMGU5zmeZ30URkEUBBHLYYQwJiyNMUMYGodRHKKYQRgJvEAQjuPQ913CYBxTTVFRGJMA8XHQbB6XZir1xgHHcYVizjSdl3/kwwKDsgUjk1IEWZx4YbYyO566Siox8jxzNE6nc4RBZqPJsiSd0P3AHPWqgYlJMEwrZikjJFQum19HfISwj2KbelNMkJpMY4pQFAexG/iuzDOIxjj0scwgz0cxRqyIUYwpiiklEedFRNIMUTSmfbPZm0ZUshzU7ZkxYjARrYlDeJlVyUmnY1PCKcLUdizHDr2xHQ5lwU4no6SszsxVprXWv/mXv3nr9jsf+/Bz/81//ZeR4gfVBxzHMigT+xmEZYQJQShC6Mw3SBCJzoeDcRwThhCGQTRqt5oMpiwmcJKOooBl+el0pCiKG9iaoSsqP5k6nsc4Hi+rxZ39+1u7J/liLooiSuEwxDI8C7zSDzBA57jh/E+gN87hyLnCHW54fNYkDyfI04NIFJ3DMp7nMWYoDeMYMcxpZLwkSZPJRFE0QGayrJpmB4aMrut6tqPrOtJ0VVbSKQMCIM51MzSOGY6D393zndP3B1GEKMKnknL6bBsDPftdEEUxRee11nEcn9VjxXGMCYmjgGUYwnEcx2UymbnZiuc7xyeHf/jtPxAlfjyJKYp8L+QFAcWnqJR+f1TY2btHEKIIxRiDBxmj72O5mFOZP5bKs/mxM0R9sV7rtRrDhYUVjpf7/fba+tXxqJNKyGHgHuzvl0o5QtCFCxegxLPX603HY1GWoa1icXEhmUwMh0NVnZufn9/Z2SmVSqVS6fj4GIIDYB4KhPnBwYEsy4uLi6qq9gZ9wzAg4Qb6PSGwIJ/Pf/nLX15aWmRZttNtsRxxXCuR1O7feygIwoULq0BVnqemgdURuswajcbCwgIghlwuB/LSRCLRbrcvX7782muv3bp16+7du8VisVAo7O/vQ7xTEERRRIG/qVQqiUQCBlWQp6yqKijDOI6DNRQU8XCZDYdDUEYXCoVEIgEn8pdffnlvbw+k+qPRKI5jCO7CGAOk6Pf7QNzCnBFQDiy1/X4fnjkIgpWVlcePH0P7e7/f9/xTf5PneUdHR9lsFoT2gCAXFxeBoOr1egzDgOgKWt5gSggCfFmW4euPHj1qNps//MM/DJHuyWTScazd3V1QwwAFGIbh5uYmQBNKqSiKi4tL3W6X54VHjx7PLyzk0pk7d+7AHlAqldBZvXqpVAo8/969e5PJ5Cd/8ifb7bZpmrZjjyZjURSTyeTh8dHM3GwcU9t2QAEmSfKZcKcrKTIiWNO0R48eQW7t3t4etAw9evTI87ylpSXbtk9OTq5du7a/vw87k2EYOzs7xWKR53mOY2F0Ai8eRrTJZNJ1PcuydnZ2DMM416jlcjmYjbiue3R0ZJtWpVLJZDJAWmSz2VarBfJkSOtgGObtt98WRXFlZSWTyUBl5NzcHGjXTNOEuCMIrQXEIIqCLMvb29txHIPwCPwZtfoJzGrBNQZlKbbl2u4wnU5zvL+8ssJxQjab9TyfEwRE8GA8MoyMH4WTiWmaB/3+sNfrRRGdmSlblpXUE7IoTs2xlNQ1Vbat6dLifKtZzeWNYbc9HE8+9qM//NLLL7z91i2EuX/1r/7Nwwd30+msrKiyrIa2Xy7kR9OJLqcGg76q6izBNEQ0jDDHgjbDc3HExgxGgiCGgcdgdn5x5XNf+L07d+78jb/+V3lJBGF7jhNkRRUFBSGkadru7m65NNPv9zGhvMA2242V1eXQj9LpNOBmMFMTQjRNwxgDYw3ZGb7vj0YjSZI4XoyiiOOYVCrV6/V+9md/ljDo1q1bURSNJ8PBYJBKpUB6oao6CAYcxwGwaxjG9vb2Cy+9SAiBUAZKn1FiPfM432hgzczlcisrKzBVv3//vm3bMDBZW1t77727w+GQ5/nBYCCK4u///u9zHPfiiy8Ctobg34sXL1JKzwuygNNKJpMXL16EOnYAo1euXHn69Ckkv0B6VqPRyGQzjUaDYRgY5W9sbLRarTfffBMazYHHrVarqqqa44ksiPjF134CRi1APMAG6fs+YgiQDeeqZEIIQjFLTn/b830IiDt0loTEcRwC0M1xDEtcz+N4hmV4GMiAXYJlWdu2JUkgCCNMGYwopY41VQUpDkJZ5GVZooSqujIzUxZlCWSz+XxWUxXfc0SO9T07kdRa7bbjB9lcLptKtppVlkahb4s8FwXuZNJTZFZT2VxaTmmsICDExsgdxdGEcNTzLURwTHGMWIFRo4AKDBcFfuhNBR4jEqM4QhyPKEZYRJREfswIEuLkOGJO6gNRMQ5Ouo5PeD6ZMMoTK7aswPXjmXK53+1wLE6mteGwN7UmqiZGQajJTEJlSGzOFHVZ4pGebr595//59/5pq9P5K//FL7z+534MjY8m3X1N4WIs+2FWSqwj4yIiCUpIhBCmCFNEMEIojClChCEIh2HMMgQhFNjW733xt33XTiS0SqWEEIqCkGGYvb0jRDDDYD/ytYSWzRQwI7caQ1nW/5f/5f/9re/8fqGUtV0fE973aBiGiI2iOCBnhFP8/eUz8VmpM1wM590ywEKdYyk4noIYCyaA51cUoCiEEMdxDMMB3kdnonggjRAicBZXVRXYV4BfiigpiiJwPOyXW1tbCMfT6RREXX4QwHdalhVGPswd4meaRH+Ax/oBqomc9QLRZ/IjACxCgnwqldI0bWZm5vLly9u7O9Vq9d69e57rIoQSyaRpmnEccwz7A5zf6c+KTxOKKaUInwIsdEaSATvMshxsAxEJPvyjHyyUiqZFFdlIpyqqqr93611N5T/xidcX5vO16t7CXKXf6RZzRccMarXGeDq5evUqQqjdbmdyuclkAryIbdtzc3N37tyFIykMViDkGkKwztvNoiiq1+vr6+tRFGXzOYZh2u12t9tdWFhACD3d3FpfX79//+5kMlEUeXFpHmMMI61EIkEwG8dxuVwJw7Db7ff7fV1XgZ5JpVJgVgKxJri7AdtNp1PTNAkh3W4XJi8bGxu1Wg22w7t37x4fHwdBpKrq4uIiBG6B+y+KovnFOQh6eO+99yBHqtfpvvLKKw8ePOh2u+12+8qVKxhjmBpMp1MQayeTSRAGgXwnjmMQKsEIj2XZBw8eVCqVSqUynU7H4/FoNHrllVfa7fZkMlleXgYt8NbWFs/z1Wp1dnaW4zjILDUtByFULBZLpdLOzg7P85hQEEsNBoMgCHK5HBgPOY4FNyJohnRd39zcTKVSS0tLe3t7YGIFFxtc/K+++qpt27dv34JwgfO4qUajAXt/LpczjIxt24eHRysrK6Igj8fjQim/v78Pqf1wC8dRVC6XYUMtFc7Cw/b2BoNB0kh1+92ZmZl8Nnd8fFyv1xVF0VVdFMVyuQwMEIRODQaDuYV5SinoI+HruVwOLFSEEPhKFEUzMzNHR0fQ+wYTFvD8x3FcLBZgmAt3PYTpj8fj1dW1arVaqVTG4zFkPMKGt7W1JUkS+AFzmSwwLr7vLyws9Hq903cgkwbFHsMwqVQKgm1brRZYVR48eBAEAfjjCoWCJEngcAQZcrfbyWQyo8GQEFIqlcIwdBynVqtdWF0Ow7Ber5fLZdfxk8kkiAsZjhUEwfOcVCoVx+jg6FCRFND39Pv9wI+Gg8HF9Y1Wq9XpthYXF4G/7Pe7uVxuOBzML8w6jnN4uJ9IJARBeOmllzY3Nx3HG08myaQxGI7W1y8pWmJ7e3fzydZnP/uFrZ09huEKxRLLsuXyDAQvBWGsqirkoiHCIIRs2yWEKIrEcRxB1HEs17NFXtA05WB/z7VH6Uzyl37pl1aWlieTSb167Pv+TLkCKzkhpFY7SaVSgsiNJ5NisYgpAREkx3GLi4vf/e53Lct66aWXzhVstVoNWsYhCYXnxcFgwDA4k8lMJpPRaNQfdJeWlliW3d7eXphf2traglTeMIx93z3ePygW88ViUVEUhue2t7d/4j/6MxBpixCCyOXvC2fGiH5/U2Ech4SQt99+O45j3/fPjQhPnz5dWloKw3hra+u1114D3x7UWy0sLDx+/FjTtFKpBJfHlStXWq3WyspKHIePHj2Co0sul9vb24OqcoRQt9t95ZVXYOWE65zn+Va7IYriuS/EsixN04BPtW07m826rospCsMw8gNKKX7h1U/BsA8oAdj/4jgm3On4D9xkoHQOggA0FqcUxVk4GGg7MMYEnWZ/wyIO5B6UhmLMRDT2vRAhxAts6AeyLMZR6Puua5sMgxmCZ0rFhCbMz87Mzc0YRpKX+EQiYVkWxky/37dtd3V5pd1scRyX0DRJEmq1E0oYTEOWBL49LOV0iY/LJUORuSC0ZYlBcRDHLok9jENEw9gbYzHAPPUCn7AixkLgE57RfTsQOR7FQRyYoT8VJA5xLPICxGmISmHMxZQNQ3ZiRc3O5KjaS6ZLHJ+0vJginjB8REmhVGm12umUHjmWqoie5ykqOzZreiIw0lRWQpFDJGRYmkAk8cVf+3ef+de/8eqHXvi5v/wz0sa8f7IVBracVOPQRjgVxHNCYgOpc4iwlKAIxQhhQvH7hXYIYYTCMGYwwoQ0T46/8tUv5rNpVZXz2UwUh4jiKIo2N7clRY6igBOFXD4fBFTTM74fH5+c/M2/+TcxCViW9QJfFFTH8SlmwjgIacTQOIqCcyYGkNM5/wTDdWDjARV5nsedFTPD1/GZJQRQDuzl8Hco9iZnLdEg4IOlFjxrun6aqpxKpcCdN+z1U6kUhEeHfgAhbSB7Hw6HFEVBEIRRlEqlWIG3bTsOffC7gcsVdmUKQspnANb7lYAMA44+/P0POMQQhDOZzPLyciaTyWQyqqo2261f//Vf5zgO0InrujSORUkKPP8cSMED3rGzUiOEEKL4/QJHGLsDJY4Z9tRHKTDXX3x+49r1pcW1927ftyx3Y2MjCtyZSv7e3bd+6tOfeunGVQZR17UlUXnnzbfMqc0JfBRFkEpgGIbv+xHFULWmadri4uLBwQEn8Pfu3dM0LZlMhn5YLBYBA4GoaDQaQTq853lJI2VZFnzEoHka9kfD4VDX1aWlJV3XHjy8x7JsqVSYTCaU0jCM87mi47j7+/u5XGE4HFIagTSNYZhcLmfbNqxoi4uLnU4nl8vB5QQLSKlUymQywH+A3J4QMpmYMEr2PA+E847jLC8vQ194qVLc2dkBZmh/f39+fl7g+Eql8s4770AMFcStYYy73S7Lwo7obWxsfPe7383n8/Pz82+88QaEUAAEnJubA0FYEATlcvnOnTsMw1y5cgXM/CCwNU1zNBp1Op3l5WU4HD733HMPHz50HCemGCEEYWAw9hIl/oUXXrh16xZEGiaTyd3d3cXFRdd1oija39/PZDKapkHL3uLiItC0cRzDhxJFEWSoQozheDyem5vb39+FEqHZ2dlHjx5hjLPZ/M2bNxuNZr1eL+RLvV6P44Qg8PSECgs49HwXi8VEIgGaJIg8gF4gz/MgZT6VTjEcZ0+tXC436PevX7++v7sHQ96VlZXRaDKZTCjktPk+Qmh1bWU4HO7t7UFGKLQmJ5NJSK63LItSCplnjUYDglsTiQSo+xGihmEghBqNhiRJ29vbQRCsrq5euLD65MkTjDHYHqMoggkOyAN4nm80GoVcHmNsGIbjOODKdBynUCj0Bv04jsHhBQFOsJGBo7Df7xuGAZcE4APYyzudTjabzedzHMepsrK3twdvEdRyT80xfJqzs7OO6RDMpHPZra0tTuAuX748Maf9fp8Qcuny5dpxtd1ul0oV+BATmj7oDafTaTqTgj7sarWq6+rBwUEmk56bn4EP5fXXXx8O+7VardFo5HIFjhX6/X42n+M4/uDgoFSsTC372tUbfhR//nNf+O6b33uyuYVZplSqFAqF0XjCcQLCjO/7HCcIguD6AcY4RnQ6naqKzDD4TNAccByLUWxNJ5PJ5MOv/tDHPvaxlaVlazq5c+eOpspRFF27ds22zcPjI0Hg1tfXNzc3p+PJhQsXoLLz+vXr77zzzqVLlyDSpVgsgrO7VqvBiaXZbPK8OBqNbNvUdV2UeDAagzAglUptbm4qilIpzzabTUXRjo8Px/2BLIuFQiGZTCq6dnJyMrcw/9qrr8U0PodWMC48hVM0Pp+QwF+CwGNZ9unTp//23/7bQqHwyiuvyLI8GAyg+5nn+VQqVS6XAXZfuHDh6OgoiiIwYYRhmEgkPM9LJpOmaW5ubl66dAnOnHClEULgSkgkEnNzc7Zt7+/vx3EM6IphmNGwn0qlRpNxuVz2PC+KIoTxyckJx7IQfquqqjmZBkHQbbUrlQq+9vJHYxpixGBCaYwxoQzhKIoiCodtAn9SGsGfcAOcnvijCDZLSimMliCWHTT28CfLiPDKEEIRRUEQYEwlSQp8l+VwHAYsS1hCy5ViuVi4tL5qJJViLiuIXKNRh7Z5kRdkWWZZTuKFWq02GgwTiYRpTX3flUS2kE0yyOu1T1I6t7KQVSTquWNJJTQOEKEIIRqHcRSSOCAUIyYOqYN5HNEQYwZhyQ+QIqZQRCIviEMXYy/0HVGUkKwjK0KMjBhtaEZhgLt9c2pTy46DiJ9fWB+ZLmE4QZBc1x0O+6oqHx4d5IwEj4OEKrieWS4njCyrprE12nPsUVIzWGO2effkn/3DX+51ep/+yZ94/cPPc+XE9GhLM1TECr5tcSJnuYokX2fSlxFJI4IigiiKMYoJIhgRRBE99cqhOEYEUYTp43v37967XSkVFEXQNTWKIoawk8lke3tf1RWEkKypspIY9MdxHFfmZj/3hc9+/vOf53nedV2CGFFSTNOmiLhhiDFCNIJCPXwWExoEAaisADGfKdNPR2BBEMCo4nwaCPzW+SYKMe6A2HieD8MYZkkwgnEcB2MMwnZFUSDSF2Msy3IymfQ8z3fcXC43Go0wxpcvbViW9fDhw6WlpSAIms3mZDqyLIsiVCwWjWyG53lrOoYuT9u20RmrHMdnmQvvTwnp6d8JQXGMKD1NOz17QLOywPHpdPratWtAWrTb7fsPH3z1K1/BhEiSBFgBYxz4PqLvM2Fn3kaMMSaY/6MA63yMyLI8pZTheI7jCGFFJfkzf/kXCCsdHh2sr69cvXbpO9/+g4X58qWLS64zsSb9TFKbKRZWl9Yi3//W7/+BpChzc3MPHz+CzHRI2pQUDQIk5+bmjo6OVldXh+NREASn+uLxFHgIGAHAwTSVSg0Gg3q9ni8WIPEBLH5xHAucKEmSaU4SCX0wGPiBy7IEeIgwDGdn51ut1lvfu1WpVAqFEsb45OQom80uLy+D5x9EsuC8A8sSNE4WCoVer2eaJjSzApmBEJJlud3uyrLMsmylUgG50vXr12/fvp3NZm3b5kWOUjoej0FkSikdDYbVapXn+UqlUiwW79y589xzz02n07t3737605/+1re+dfnyZc/ztre3T7O+zrw4juMAEFxYWLhx4wYs0IlEYjAYbG9vr62tgZUyk8m02+1bt25duXJlYWEBIkBVVW02m6urq5Ks7u/vY4yBtarX66omQ1xhu90eDAYQseP7viSJcNgYj8cQq/PBD37w6OioVqvNz88DY9rpdK5duwYC9nK5vLu7C+yp69r37t27cePGdDpdWVnpdrvdbp8Qoihqq9VyHX9+fr7d7lJKw9AXRA4ypXRdz+fz9+7d4zhuZmaGUgq9QKPR6MMf/rDruo8eP9ZTycGgH3qBLMvZTGZvb++F554HbOp5XhjG+Xx+PJl4nmdZ1sbGxkn1CAYrHMeNRiPIa4Dj9MLCAlxmnU6nXC4vLCw0m004+kPBdq/XLZfLECe2trYGdgrHccrlyve+971er7e+vg76HjjqdzodaOcNwzAKQlhGwN0pyzLUE42nEwjCBWZOUZTvfOc7iqKsra31+33gKaFqM4qiQqEA8yD47BiGtNttljCKoriu67ou+OwqMyUYU2Yz+WatMRgMEkZKlmVeFLr97mAwCONYVdVEIqHrCUJIt9Wt1WqJROKll16yTWt/bw867+bn5/f396MoQAjNzc0ihE5OTpZXFkVBHk+Gjx49UhTFSBie6zuuvX7p0u7uLnCog9FodXWVYXlK8eFxlWG4r37t62+++ZZlWbyoagk9bWTCmFqmE0U0pDHLcLbrFAr5yXiMUExpxHGc41pgDEqnjCgOD/b2Q8/9s3/2z7726g9dvrTebXcEgX/rrbeMdFKS5cl0dPXq1cPD/VwmW6vVwEdyeHgIUS9ra2vb29tQkn379u2LFy/Clez7fr8/LJVKvV6n3++LEg+yS13XYZ4YhuHKysoffPMPFxYWkknj6dOnjXo18r18Pj8zMyOpymQyGYyGP/3TPw2n9FMl1jMAi6LTcz4YZTDGcXx6kv/n//yfgwW4Vqv96I/+qOu6lmVVq1WM8cLCwnn2la7rcDwwDAMYU7C2mKZZqVSSyWS9XqeU+r4PKySILkBvsLi4CJ7fg4MDcBQmdJXn+ePqCVS2R1FEGKZYLO7t7iYSCWDHr16+EoZhu9EMwxA//+onoijw/RChmOdFjGkYxlEUMAxHCMIMRxgE4neGcLArU4oh2xQ4RpYlcRxjSn3fj+MQEiMppYIgxCH13IglLMOx54Z/jJEgcJ5r+4HDknhxcb5UzM3Nl+M4lAVRVeSEptu2zWDaaDSy6Uw6lXJti1Lq2GYUuEZKW1ycO6nuURS6Vi+t4WJWLmR1JiujzjFCDmKj2LOIqvieQxHDEA5jhsEEYYwQgwKMWIx4hGiICAlslyV8EAQ8y/meywpsTIlpxlEsY5R0A/bJ7qEboGJhLsZ8yih6Ae52x4gyPC86juO5Fop9WWIVmXEdM51QkgpSpVhPYcSY1qTFYCLwOs4to47/m5/5wle/+rViKfNXfv7Pz7+8Hnf3g2AsEDYKQ0bSrYkpp1REcl5wQcxeQ1ShmInOwmwJigEaxIjBCNMYEVD1oPiNb/3hsN9JJVVNU3iBA4BVq9VarZ6WUD3PW1y+4LlxfzjSNCmZ0f7OL/63Dx8+VCQNUZZQzLK87blhRL0Qx4hiFGFMz4ECqFIAPAHhD//EzwjDYTQMF310VswJgvfzbwDUBQwWSJ5hmYbvJ4QAxwQzRNAnptPpwWDAMxylNJHQNU3rd3vgUgFBd7fbdX0Hnl9RFD2VNAzDtU2o7QQmBp2Lys9IrPNb93TGjRACeybGzCnoYTmOgx0ilUhKkrSxcbFYLPZ6vbfffvutd94+2D9UNcWcWrwgRFF02qUTP1MM+Yye/RxgYYyfZbAA0cGewfICACw1Wfnx//i/qrWHlZnECy+tlyp6p7Mvifjll55naLy/u9uttRsnVUWQE5rK0JjleUkWEMbD4Rh8drIsN9qtt99+e2NjAyGkyJqu67woWJZVr9dt2zaShizLgiB0Op3RaDQYDG7evAl6LFVVwzgCQQMUFjUaDUmQ5+bmOp2WZZnj8TiXz0ynY9hfGYYZDsc8z8uShhAaDseU0pmZcr/fB204uAE6nY5hGKZpgk+iWq0uLS2BDBzkBzDOgwtsMpkIggTLdyaTqVarFy5cAD85wexoPMjmM5TGII2/fv36YDDYfrql63oymZxOp8DhIYRAVLC7u5tIJKFtejweQ2fi0tLS1tbW0dHR0tLShQsXQDaRTqc/97nPbWxswBFc07Q4jvf29lRVrVQqhBDLskCPBadz8LGm02lNT969e3dxcRHSDre3txcW50zTNAzj5s2b9+7dAyw4GAzm5+eCIAAFNDy/YRgAPqB6qFKpAGq3bXs6nQqCsLS0dPfuXajQaTQaq6srrus+evSoWCwuLa1861vfMox0MpmURGUwGBHC8jyrqrLtmICQSqUSJKxKkrS3t8fzvKLqII2CdyMM/WqjXiqVQs8vlUqDfj+fz/e7vVdeeeXb3/4unPtd1+0PBqAvsW1b0xUwo+RyOfjFeZ6XJGlrawuyhcCQBQmQ4ICp1WovvfRSs9msVk90XQedu6IoDx484Hk+kUjMzMx2Op3BYJDJZB4+fDgzM5PL5WAw9zCaEgABAABJREFUCkXL+/v76ZQRhiHUXILwDq4KYHCB/IMj2dzc3LvvvsuyLMi5ILvu4OCg2WxOp9MwDKE3KZlMPnmyefXqVZYw3W4X0sVSqZQoin7gwpTZsT2e4YIgUnSt0ahNzOnS8nIymZxYZhRFWzvboC0TODGTyVRP6hsX1773xpvDQQ/kX5cvXwbNH6Q0IYS2t7fDMCgWS7quhWEYRbEqqUEQOI6FEGo06812O5HUZEXxfZ9iwnNCpTJr267r+67rbz7Z+sLvfLE/HBHCqqqq6QlNS1iONxyORUmC40G700wkNFmWfd/FCMURQVEsiTzHcZjGO1tbgectryxeuXTxYx//0Vwup6rKeDxsd5rgDpFFARBSvV6H9hjoespms8AK5/P56Kwy6Pj4WJDkZDKZ0NTxeJwvZKfTKVTKgOLt8uXL1Wq12WhXKhXH8+Mw2t/bsadmIqHNz8/Lmsqy7O7+7uuvv76wsPjHAixQH9Nn/NcIxVEUMQzz5MkTWAcgOQJj7DhOLp+B13D58mXYYqrVKhQ6NZvNer0ONfAIIShQsi0X2rF4ni8UCp1Oh2EYEJ4Wi8U4jm/fvg3d8DB3Tuhqo9HQErppmhuXL7/99tugK713716pVHr65Mnq6irPcpPhaDweX79+HV956XVY5WGaA9MNIKWCIIjQKW8G4hKGcEEQwawH5IcYY56H0g+MEOIYzIkCTChEUaQhjXxEEMEYMwzBhLqu7XkOJogjWJTYcil/8+b1UiFTLuVtxySYzeUKg8Gw1Wpe2bhsjUeH+/tR4FcKOdcdtxuHszMFVeaC0FpdnZuag3JRQ/FQ5P3AtTkmRtRFgYt4jDBCDInCiLA8QiQII5blMUU0xITVke8jlkaRy4g8CkOEuCiOGUENXZ+VFMSoT580Oj1f1eem04CyhGJSLs11en2WE+OIBEHEMAyOqCQwvjNy7X4hp0p8lNAlkYs57LK8H0UDjALCCEhMI6bw7lfe/LVf+03btj/8pz70M3/hx9k0NocnMTZZHMocgyjre4hP5SbDCSWZRPFVxJQRUSni4vO2PhSi09kgixCKI8oQjCilgf+VL/0eIVhTxVQqcc4v7u7uW5ajJxNu4JYrs6GHCMsIIvvtN771P/+Lf8ZxnO9iTUm4rg9HZy8Mwph4fohRTAiCyRqgeKBbgHai3+f+e79LBxhyAP4wFD6fO58L+GCf8/0Q4ig5jhNFkRAUB6djR8BVtucWc/kIYVkQKaVQJQt9tKAF7rTax9WTdMro9ntxHMKtRSlVdK1cLru2CVoKEL5EZxGp56jq/K/vE07nbBNCGGNBEGBvu3z5cqVSQTGdmSlLknT37t3Pf/7z1XrtfcBE8TmIBJH7s+jtbFE49UWCtj3GiFBECWYxSwnmGdaPQo7l4b3VU8uXb/zMwAw5cfLpn3w9V8A8bw8GjdlS0beCnSc7K/Mrw04PhYHnOvOzFYbBiGXUhN6oNgRZmimV/Sjc39+HfPAoihzbG4/HRiZ9euCJ41ajBZpxKLR+6623FhcXLcuC84+RSYOepl6vX7lyZTweT8emKIqapgwGA13Xev0Oy7LpdBo6dDudzv7eIcfxmqYlk0an05qfn797966u61BHiDGG+WMURZBTBe8M/MRMJgOqJtM0M5kMDHrCMD4+PgYaElbDXC537dq1d999dzgcLl9YMs0pGPKPjo4qlQpLGF3XAZGcC9jByb+/v48xsW27UCjU6/VUKhVFEbj9ZVkGgmE6nW5tbT3//PMgS2dZ9sqVKxBvBvmBhUKBYRgYHkHqxPb2Nuw3URQtLC5D1yykJbEsy3Ikl8v93u/9niAIH/rQh/r9fjqdVlW1Wj2B6jTI7RyPx41GA0bJmUymUCgcHh6eK2OAgjJNE4Ya9LQKnfU8Zzq1ALt0Op04phjjwI+SSePatWvNZvPgYC+Z0qMoymQyd+7cgfc/m836vn/37t0bN264njfoDVmecW2PF7kIUYZhjETy4OBAVZRcLodimsvl+v0h8IsHBwe6rmNCNFXVEwlNV46Pj8EQSgiZnZ2FVAVKaT6fhykkpBgA9xZFEWh+K5XKm2++sbCwABY2juOg+yiTyViWDR9cIpGAlO07d+6Ar3AwGIDpb9DrS5Jk2zYU5I1GI9iYTNsCBxlEea2trTUaDWibNgwDOEhQvAG7APlMrusaRmp/f59SOjcza6STnXZPVVU41B0c7gGGZhle1xMf+tBrt27dGo3HFEXJVGptbe3ewweZTEYUxb29vVQqBWc0geX29/c5lqxdWIWuGFCRbmxsgEcYynZ4noe66ziO+/2+a7ntdpvjGEqwwLF+GF6+cunw8HA4GuVyOUGSaYyGw+FkYqbT6Zm5BYYR3rn17u3bd+7cu3d8XNUSyWKhpOoJy3HCMGYYDLR0EIUYU88LVFnDGIeeTxBmWIwpyhjJbrfT73V4nk+nU+vrqx969Yd0Xed5ttPppBJasVh0bQeaGVVVHo1GEFIALpC19QvvvPMOpNQGfgTHKkKQrutwLsIYt1qtS5cu1RvV4+PjdDq9tnrRsiwjk56Mxg/u33dMi2GYUqmQTCaNbGZ3d2d2dvbVV1+j+Pu9hM88zmcmkIMFbNZwOLx9+/bi4uJkMtne3oYVb3Z2tlY/SSXTQeghSniBBckjcJ9wTLp48SIkJIxGI8f2UqlUsVhsNpuLi4sIITAaw8z66tWrHMf1+/3BYIAQ8jxvfm4mnU7vHez3er1cPg/F80CeybK8vrZ2eHjoOW4qlWpUa6zA4xsf+FGETgdPgK4ww4BEJoqi+CwM6Xw3DWMEOTeUUvhVeVFwXZdhsO/7iixLsjwaTYAGYAkjsEKv3aE0cu0pQ2IjnVheXsxkjOtXL4sSl0ro+VxmZ2uzmM1EoX9SrStGqdnt6qogcuxMsTTodMp5QxKiB3e+szifyRhyOilHge1542RKIpzvxSNKIpZilhNiL0QRIjyPghASYGGmiZhTNRkmXOwEhBAky7E1IbyEeAHFPCJSr2NpiVKv771z5ynLpQvlCyyfmFoupdF4PCxXCoSgIAgEkRt2+ygOVJFL6tJkVEuqaHnOQMRCxI7dURx6rCz7psmwCSZ/dbzV+je/9vl33nlrdjH1N/7Lny2vF1E4NScThBAvsHFgishFUYwYDfHpqU0wX1RLN1CcQIyGkBBj9geSMymiwLfROCQE1/b3b9++rWuKllBhUYY8mM3Np7IoIYIlTeZEQZX0wWjEsuz33n7rV37lV1RVjSOMCGYYDmMaRZEXBgCgfd8HIwI6MwzC8BdEVxDNcA7BwebzLNJ6dnQIrC+or0DETQixLCeKojj0Ya0RBA7FGI4UcAPoyURSTzAsL0vSYDhkGMZyHdClwpbTqNbG4xHH8TFGgA5BugF5zSgOYV+E5oQ/SlyhH1C7x6f5bSzLxjhmGAbhOJPJ3Lx5s1KpzM7OspiUSpV6vf7Zz3726OhoNBiel7BijOEkByNR+v0ZDae4CsO4kKGn/yQophQRhpAoioBRh5vftexM8erzH/zPDhv9P/vpV178wNxg8FiRQokjJKa1wzYK6MnBYVJVfuon/0zt5GA4GkwmE1lLKomk57q245jTqZ5IuK4PSBSkNrZtJxJJiBQihJgTixAiSRLDMIPB4MmTJ5cvX8YYcxyjKMpx9YTjOHg3dF2r1+s0osvLy+AUy2azy8tLrVYLZnOWZU0mk2KxBJY3GOH1Bv2FhXlwdPa7vegszb9UKg2HQ45hoD4PCAZBELwg2NraAv4smUz2ej2O47vd7mAwKJfLQG595CMf2draguwAjmOhaYfjOAinwJi02+10Oq1p2s7OzsbGBs/z/X4f8mBHown0/GiaVqudQB9iJpNxHKfT6QwGfWi50TTt5ZdfHgwGhDA7OzsHBwc/8iM/AuXQtVoNxn+A9T3PgyKX+fn5w8NDSCKFxHaM8eXLl7/zne9IknTtxvW7d+8mk0lovltdXYUqN45hQUULOe9ra2vNZhOSIyBAP5FIEIJt255fmO33hizLjscTCDSfTqeiKAwGQ0gyGw6Hs7OzcFaRZRWd5VGBUjuKonw+C31ttVoNehsVRdnZ20loiUKpwBKWE/hev88K/HQ0Bnl4t9v1XJdlWYHjCSEcYeI4zuVyg/FoPBhKqmLalu/7xWLx0aNH8/PzCCFd17e3t+fn5yHs3jCMZDLZaDTg2j48PLx48WIYhrARQkTwxYsXd3d3JUmChrt6vb6wsJDJZJ48eRL4EYxpTNPkBbZYLIK+EIaqo9Fwfn6+2+1yHJfL5Q4ODhbmFnieb7Va29vbFy5cgAUQFGYQWK8oymQyOWdlKI1FUZQkaX5hdjgcQv675zm5XCGdTt+9exd6JBcWFjYuXQmC4PHjzTCiQHgkk8kHDx5ksgbc26lUql6vw1Sn3W5fvXIFQpKhsgJMduC2W1lZgYURzLOWZa2urp7SlqUydIErmirygmlbURQCbzcajV555YeePHkCU6qLFy8+fvSkUCiJspRMGFoy9S/+xb94vPnk1q3bmOHS2dzCwkIYxePxmOMELwiAZoZARBxTy7JEUZQEcWqOBUEQBC4IAse1R6NBHIef/OQnP/z6q7IoFbNZhNDmw0eGYdi2KcmCpmksy7q2FQSBOR0bRgqeand398KFVYbhdC2JENrd3T3tJJVPmw+CwCMso6qqYST7/f7R0VE2kwm8sN1uO6Y1MzOTTOrpdLo/6Lmu+xM/8RO8JHm+L/BSRGOECMIEIfSDUOvsEXg+IeTdd99FCB0fH4PFYWdvl2EYI5OSBJnn2W63H4Y+sFOKLOu6btsmwzCXL19+8uRJr9fd2Njo9fqNRmNxcbHZbMKkBa4fI52tVCpHR0ezs7MHBweGYbS7nfn5+clobFlWLpdzXZfn+U6nA0wEy7KapkEE64MHDzY2NhClKcPAz73ysSiKInoqPWYYJqIU6AdQWcXneUIxpZTGiMqqyrJ84DmQH4MxCNt9sBBPJpNEIgURQQRhXVUyyeTy4mypnC+XcotLs6qqRFEgy7LnOyimg16HRWi2UpY4/tHmUyTIybSBYl/gmWG7SUMr9EYMtl98biWhYkwtxMUociJ3wogMihwndKRcOh7ZjuMrshaHNPIjThSRwCHPQ5giQlEQIIQQw9EwxpinYYxlCQUIiQqKyKTvDEah43FhrExszPAJwmmimEiksycnJ612PaEJs7OF8ag7GXXShsbimKGhIrDZtCoJceQPR4OjdFpEaEo4jDjJGTvSzEU0pF/53B9+4be/Ecfo0z/9qR/9xE2cjGKz4QcWz0s0ZqIQ8SKHvB6iyHE5StJEKCImJ6YWkJRHVERIoIj5gWTyGKE4CjmGxFFACLN59+7B/q4sy4mUrqoqsGuDwWB3dzelG0Hsy7qyenF9OrXeu333uRde+Mf/6J989atfz+Vyru8hhGDXj+M4jHxASFFI4/j7Eskpjc4ZSjglAOamZ/mc+OxJ0DORDed4C4aApy65KAIGNA79OI4ZjOBcjhAiGHMcF1PKMIwsqzzPU4qjOKaUZgt5yILLZrN3796FDhCw/kZRpKoqZAjBBIFnTxNQwzA8112d80nPoisAWCzhMMY+RHlxJAxDVZMFQXj99deuXLkiCJJt20kt+fTp07feeqvVallTE2agMJUAEAmC+j8OYJ024lBy+h+EEUIEUUIYJg4ChufhdQiCwBGczl9K5l7zKPeP/8n/TZQniHZE3kdhMOqNVubWl+bm93Z2Hz24x7FU4DDDEkQY2w8SSQPCslut1sbGxsHBERzuj4+PU6nU4uIix/Ggyjo5OdEUfW5ubjQanbc4Q6NWNpt+++235xcXLMsCF/1wOLAsi0Z0MpmAux5jPD8/D1MP13WXl5fb7Xav17MsS9d1YKEkRSqVSrdv3/Y87+LaOiSSn5ycADXY73bn5+cBj/b7/WKxOByPWZYtFAqNRgPk8OVyBSrnQO03Go0g3QDYjv39PZjZwVbNsizLco7j1Ov1jY0NIDbCMIQmsoWFhd3dfbhiNzY23nnnLdu219bWoCDWdV1JEkGanUqlnj59Wi6XKUWgar98+fKbb76ZzWYheAngy/HxcTabBfOjruudTgf4m5mZGRigcByXSCQqlUoYR6DtyOfzUP4KW+bqyoXxeHzv3r2LFy9C2Znvh7quB4G3sLAAlWrFYqHT6fiBm0qlhoMJEDCtVgsMlYIg9Pv9XC6naZppmhDONJlMIPeh2WwDfMxkMhzH7O3tAd8sSVI+n9/d3VlfX4dAoEql0u52BFESFVmTFQhkxxhz4Erx/Gq1+qEPvvLee++Vy2WQ9NaajXa7bWTSQMBADTBMVUA/AAridrsNrcy6rkMGFfwJFwMEjEH4NXwPkARQo7Rx6Qqk1zabzZnZcrFYhDgG0IBGUVir1W78fyj78+jIsvs8ELzL21+82PdAYAcSyD2zqrKKVWQtJItbiaJIiRSthdKMbMuW7LFM222f6TM9PWN5kXvmtFpmu90ay5IsS7I5bpGSSJFikSxVkbVmVuWGxL4GEIh9j7e/d+/88QNQSYq0NTg8dcAEEAi8eHHvd7/ft1y/HovFvvnNb0aj0XQy7XneaDS6cOHCcDiEhDMI0AK3F+SmgtRGEARd1yRJSqUT8Xj8zp07sVgslUpAbshgMCgWJ0zT7HQ6nPNUMlOtVoulyc3NzfPnz8/NzdVqtf39fSrgiYkJ3/e3trag7nBxcQEazefm5nZ394CbB/8jaKthuYDD2OLi4oMHD6CoCsQV4/EYWDpw5wBkFwQBbIPdblcQBMiBK5VKnuNvb2+rmjYxMZlIJT032Nje+cqffvW1N94cmaamRWRVS8STDHFRFPujIUVUlmXPDSDLPggC6CKjAhYEQVVlSollWe1OMwgCRRJf+PBHnnvm2dFopOtqPBFjvvfgwYOJclFXta2tjVQ6QTGGHsC9vT3DMOLxVCKearVanHMo3sgXC6Zp3rnzzuLiYiqTvHnz5rlz5yIRDSG0t7srUmk4GI+HfcMwZmem4vG46zr7+/svfPxHsvm8IEoIIY6Iz0OCRc6ZgMkP6T5DvuetrKy88cYbMAHEGEejUS/wj46rw/4ALBGapg0GvWg0GgZBNpstlQo3b96EHqpMJi2K4mg0vnDhwoMHD+Cy1Go10LekMzlN03Z3d4fDoWEYFy9eTGXSu7u7jmVDTcXU1FSxWNzY2IDjAaX06OgoGo2+5z3v+epXv6pp2mOPPfbmm2/iq088LwgCBLjDrsAQOnPX44e2WVCZYEow5qIou7ZFCFFlRRCEYb+PEDJHY8fxFFGamZnp9/sLc/OFYrZUTMcMbXqqPDs36bpWr99ptlqSJIUIq6oaNeLf+sY3NVUVMEklktlMWsRIUwTGws3Ne4mEKIrWpQuTiuLrCkbEca02FQNKAsZCKsmhE1JRRyEKxmOMMY1GUOij0EcoQDxAgoC8gBOKFQMFPPQCKkcR0TgTsKIPO6NGY9Rom5yrghgzjFwQEkwURGiz2fTDMJGMqarkuFboWxEVIWZTbKbiaiwiygLnYSBQ7tpjz7ccu5/JJRxvFIZINwooO7v64tu/+b//dq1W/cAHnvprP/1xY3ECtY6tUUfROCEh4j5iBDEVYYyQhRQV+XrI4yHJSsY00kqI64jokBd/2lnHMGIcIZC2U4y473HGXnnpJdsaq6ocTybOKpC2tnZqtVrMiJq2NTFdjqeSnW4/Fktsbm792r/8nyzHZYxBoGiI+IldgfmAD3wvBKX52XCQcx4EgSie6KXOoAl8FfTCD//L2ecsDOlphxKUhbmuC/QvD33f91nggzBLkqQAbIaKgjFOJtOqqrZaHUEUdV3vDvrZbHZycnJnZ2d/f19VVdu2z9oDzyKGT/wWoX/y5M8Gdj+EvoLnSbHAOYf5HRZw4LqZQjYSiTz55JOXL18OwzAajR4fHt2/fx9EpiwIYeoPg5vhcHiqLPzBAIud/n6Oz/rh4b8CYkwQRc65SCgwOogYSnTxx3/yp/7xP/lsrXacSAq6gkUqyESSBWVzfevu7TtzM1OdTsu2TN93OeeMYphWQB/tzMwM4qTT6RwfH2ezWbARjEZj2MYopScxv2E4Ho8nJydTqdTR0dFgMIhENEmSKkeHkOUI4d3vvPNOPpsTBKFQKACXE4bhYDDI5XL5fL5eryOEINYPxOOu64qyuLGxASoukQqwoU5PT4ORPpNKbW5uQuaCaZq6rsuquru7m8lkCoVCr9czTTMIIDc4enBwADKOwWCwvr6OEMpkMrOzswcHBxD6v7q6GoYhNIckk0lFUWKx2MbGBtiWz58/PxqNdnf3m81mOp2E+3lpacnzPEDko9Ho4GBf1/VcLgdFMfV6PZlMpVKpSqUiy3Kj0QAkB7IhcP8Nh0MIkT9//jz4j0qlEqBMWZZN0ywUCpVKpdPrQsDHaDQCAAquNB4yQgh05cJKPRqZxWKx1WqALSMIgnw+hxCKJ6K7u7uZdD4WiwGaNAyjUCiAnxFCpEDvMhqNYGjLOc/ni4PBoNM5SdkAkQps3r7vMxYuLS3dvXv3ZNbPmSBKq6urL7zwwmg06rTbENClqmqjVvd9/7HHHjNNE6ZF7UYTCzSRSJi2BT5fQBVwAW/evAlmBehvHo/Hg8EAY5zP58HI0uv1OOcTExOQSQGACWIpYFoNrghN0Q8PDzudFsjaIK4W2OhYLAZlH0EQKIpyfHyMMd7b2wf8B2e5TqcDbDfYOwRB2N7efvTRRx3HqdVqxWJxMOgDpef7/szs1NbWVjQawRifKtyt+fn542odpA65XK7bG8IRDmN8VK1A1vnKykosFksmk5XKAed8eXm53W7v7+8rinL+/IWDgwPA34PBoFwuA2UFZVyEEMj4Pj4+7na7hUIBHPcXL16ERDQICKCUVioVQsji4mIYhqurq5D9m8lkFEmu1+vNdgtxUm82DCP22OOPT05OO67/1a9//e6d+6+88gqlYiaXlWVZlBTEkOu6iqJZlgVm7bFpw7HQdkxd1z3PYYypqqKqau34eDwcebZ19erVZ597mlL6xI3HgiBYXXvwwkc+/PIrLwmCoKsKY6w/6M7MzIhU6PV6nGOw1KytrxMigIgTMvYMw0CILSwsQNvmYDAgiPb7/crhvm3bF5eXUqlUPpc9ODiIRI2nn31WEESOEUI04AifMlg/EGAN+4NoLNao11988UWE0OTkJITEeoFvWVa5XIaURFVV19dXJyYmxqNRr9dbXj4HusD9/f1K5aBYLFqWnUgk4JAPth7OeaVSmZ1bAKkJuNrB01CtVs8UWrAUwMgb8tLAWbm6ugrrm+/7mUwGX3n8g7IsE4GexfRxjNlp4Ql5WLHLEULMDzyEmKZFUIiCIEAhlOPxeDyqa9q1K1cNXVtcnC8V8p7veI4pitiyR65jIYQ4DymlXuCrEX04MmcX5kf9Ubvd9BxXUyTXtnLJuNk9FlHAeaho/PKVKU0PkOojpx96LhWQ640wCThyOAoFqoQukgMl9BmVKBIpCt3Qs6iuoNBFBCNRRoIcjn3XJ1oyjyTdbIzafb/Ttz0fmU5IaYTQiKwnMVfarV6hUN7d3WaBx0LHcUfpZDSVNBJJfThsSjQoFxPxCOHhiHALh67nO5IkI0SQrIy7/cHQKs3Po1Shv3n07/4/v//ad+5curD8uZ/7xNzjC8g+9kcdkWrcD7AsItdCEqSHSsjnSBSRoCI5jXCqceymsueExCxiCiICx+9mjCLEMAoRQn7ICREwZwTxfqf9yl98W5UlTdOS6RQYf1RVvX37ru/7qqz4YTCzMI8oGY5M1/WOq/V/9a/+VX84UlUVEozCk9BcxjlnPOAMe14A5yoY7UEWg+/7kJB+ArUfwlgPAyx06toDcgsYGoxx4Pt6JAJWHUGQMMaYh77vB56LEIK4SBiZiZKEMU6ns6Io1utNVdPG47EXBjdu3GCMfec73wEEyRiDtQlWDdd1QVfBGCOIAcCCt8q7cQynoOr7ABYPEUJIAJ8j4TwIssXc0tLSwsICxEcRQg73D/7Tf/pPruv7vo85AvvM3/t7f++73/0uyGnxacHiXwZY/HuWB/C1YoQRwgImhGAchqEqyVCn2u4OPvXpz/327/z6cBxS4msKGfQ72WSy3e2ur651213PC/Z3dguFXLlctiwrX8hZjuMHLnSRwl7e6w4gOghmuN1u1zCi8/PzR0dHqqpqWuT27dutVuvRRx8FudX58+f39/cTiVij0ZiYLEcikZWVFbBoNRqNYr4AS8HR0RFoR/r9PnSswowjm81CbjshhDEmyiJAT8dxBELBrA71XmEYhr4PQo1utwv5nN1+H558Npu9e/euqqqGEb1z506pVFpeXh4Oh6lU6t69exD0d3h4CNmVGxsba2trkKABqeLLy8uVSiUej8OAKZlMWpa1vr6OEDl//jznISAAeP5Xr16FysJisQAyL9ChI4QcxwUzF8jwr1271mg04Ii8vr6eTqfBhZRKpaDfFzIYoSIQInMIIXNzc//xD34/Ho8DG+H7PuzHvV4vm84AvXR0dAS/MRqNdzqddru5tLTkuq5t25QSQRAy2ZTneaoSwaeCyOPj44mJCejcBUkyvBcopcVi8f79+6Zp5vPFTCazvr46OTkJdWyVSmV+fj4aja6urs7NzcJ8JxaL9fv98XjMEBJEEZ4/JQQaPwghB3v7mUym0+lkMhlZluv1OsbYMIyROSaETExMQCYF6MqhzDEWi6XT6c3NzVQq5bru22+/HY/HS6USIHs4jcBZKBaLTU5Obm9vI4RUVQU4AmFjmVQ2CAKw4u/v70P2I3Q7ZjKZaNQA1jCVSgEpSKmAMYbaH0h4L5VK0CENzBbnHAKKYEouiidFXpzz6vHhe97zntXVlXg8DhwMY0jX9VazE41G0+n0zs5OPJlMxFPgYj48Omi328ViESGUSqUuXbq0uvoALmypVIpGo7ZtS5IMx61sNnv//n1ZlovFIpCOtVptcnKyVquBCg3wKGOs1Wql02mEEOSttNttYCgikQiBtoBEAtZ2QghiXJJELwgcxwnCECGi63rA0GhkGrHoZHnaDfwv/C//+u07t2u1GkZ0cnK6OFEeDkYAQH0/lGXZDxhYhTjnhCKAxYIgGIZOMWFB2Om2TdOsbG/mSxM//3/63Pmlc4lkPJlMHh1V7LEZhJ6u6zwMCCFB6LEgRIik02nP94vF4t7eAUJI0zTDMAAHb26uT09PQ4WRQMTBsFetVh3HmixNJBKJfC5rmma1dvzzv/ALgR9wjARB5YjzE7b/h5TLMo4wti3rj/7ojwC8whh6c3sLGuLhZjMMo1jMHx0duY6jqqrnOf1+H/L2tre3Ll26hBCGgSaMdw3DgJQ4UVKgC6FSqaTT6VgshhBKp9N3794FgzmcBsHHc+vWLUmSYG6eSCQikUgymTQMYzAY4Gvv+dDZpggNOQghz/POqnI455if1FlzFGDiG7rue4z5SJF1z/EzyczHf+RjiiJduXwBMa/Xa7Q7x7oqYMLC0I9EogIVJUEcjUaIYS8IPTdgiNueq0VUSsJLl8/1uvUHK7eXFqY0kScVllAF1xupCRnhIQqHtj1QFZ2FIhEUxDkiIWNWEDqEEORz5ISCICKCEPORLHDfxRINAl+QVdsOgkAwEiUUyXQOWvv79ZBrt+/vz567lMrkavXW2HRlPRaPpR3HVVU1GomEntVv17MJXdPo5tqdTCqSy2uKghSJGKqIkRW4fYG4PHRwREauH3qICnHEYyhaRmP2n7/4R1/6ky8pivS5z33u/Z/8MPJr/uhIFFzPcSViICmG7DAMPJrUkNljoYVFDcv5ZsPq9oNobNJ0lYXlx5GWR1yEvKuH7i+GEUMIuX4giQoLfUrw3vr63TvvxIxINB5LphOO4zCMPM+7fet2IpHAHGkRY2JuptFsB0FAqbCxvvXf//f/t2Kp7LouCK0CDrnt7/Y3BwGjVDwN2ghgZQTnIEwBznKwOA/PunHQQwzW2egwDAJRkhBCvucZ0Wg0GnVdVxAkQohAEGMs8KDxMCSE+J4nyzJHhJzGUWJMk6kUxliQJajysCwrCAI4OsfjcViyQQyEzgqdAg9UTT9QffXDABYRMOfwy0nE0J577jkQSczPzNZqtX/37/5ds9mURcgsFiF573d/93d/9Vd/9fd+7/fOLJM/EGBhjDnip/kahCN4URGGgqCQIYRUWRFFMZVKjcaDiXL2C1/415Zl65pBKRUoVhTZtEbr6+vZbPro6HiiNOl5PvSmxWLRarUaMj+dTjPGNjc3Mcac4XPnzoFHHdIa5+bmOOf9fj8ajW1sbEWjUUAhCLHbt28LggBXlTGGCFYUZX5+HjKEyuXy5vqGqqqwg4JrASREMCaG2uZOp9Nut8vlciwWgwAIfhKjisbjMURYdbtdKAwpFAoCJvF4fG1tzXGceCoBlBgkCHDOC4UisGWEkJWVlXK5DJEHw+FwYmKiWq3lcjlFUUzTzGQyk5OTh4cHcHwUBAEaYOBLo9HI9/10Og1zFkmSnnzyyUaj8eDBg0ql8rGPfSwej3POXnvttX6/Xy6XW60WIUSWlXg83uv1IHkVPH2MMcMwOOdvvvlmNpvVdX1+fr5arYqi6DjO6upqLpfDGC8vL/u+Dz2D1x995PDw0Pd9qKzudDqLi4vvvPNOMp5IJpOg2QI9OOd4MBgMh30Y9hmGsbOzXS6XR+NBu92G3G2Y6haLRVCKSJIE6zshxDAM4Mkcx4F9ZXt7+33ve58oiu+8886NGzeazaau6/F43DTNUqm4urq6ubm5uLjoOM6NGzfevHlT1/VCoXB8fAwPCE8VXA6vv/56Op3GGOdyOfDtgt6Rcw5tQpA1Cn6rBw8eCIIATDMwCgsLCwAsQITeaDQwxmBZhRdLFEVoaur3++AAFQgdDAaTk5MIIZhig+0xHo8rihKLRW/dulUoFABg9fv9qalpAPq9Xm80GjUaDQjpiMVizWYTgiqazSbkPlQqlfn5uSAIQCWWTMXhTut2u1BYKcvy3t5eIp7yfR8KEwVJAgoTlGfApRmGMTs7A0FfsiwDmOv3+wihdrszNzcHVseDgwNCCPRmQjkxvHDVanVpaSmbzVYqFVEU4arCFNh13ZmZmf39/UuXLq2trd2/fx8ymVKplCiK1Wo1n89hzIvFCRi/1uoNCOWanJy2Pbd23MjksteuXN/a2R4Oh9/482++9dbbpu1iTC9cuGBZVtSIjUamaVsRPUopBdAW8pO08FQqNR6Ph4Pe3Nxcs9mkFGOOdna3YxFd05VPfepT73//s5qiOq6tKMrbb92Mx6O5fIoSVKlUfN9XZK3RaHQ6PYjan5qaeueddzKZzLPPvG99fR0MrRwh3/fbrVYY+oamz8xO66qm6/rO3u7zzz+fLRQ54giJHHGGMPrhDBbiqNftJpLJN994AzL8YMkNOQPF+srKim3bH/nIR6rVQ+gkDcOwPFFstVr1en1paUmSxDfffDOXy8PqxzlXFCWbzZq21ev1REGGN8V4PAY4BcQ/OJExxiAGgEQSAPRw+125cuX+/fugryWE4CuPf5Cc9uAS4UTeDpob0LJwzikm+MSWH3Dm67rKfBYETFM0UZTjRvSZZ96XTEQpYc1WbXa6OBg0MGGyTAWRjk1H14xsOjceDh3T8Rxf1w3diPT77Vg8wpA9GNSmp1KEOPlMVBUCyR8JyObc98OxklBDs0dFygMc+BQTEXrrOGEnT5kxJClsMMQYc4yIKLueK8fjiBGEKMIKIpFez93bb5sml+QYQ7KgJXsDqzvoc0QSiZTPQkmUCcWaJFIcBHafcjsdk1NxVcCermPO+4KIeOAEoYtCSyABljDCzB0NZT2GQhUZeTQU797Z/U9/8CeHR8fvfebRv/m3fpZExWBwJMie7/Yo4YSIyBcYl4kQRVQKHccNXE0XR6ZnxBdHI7R70HR9MVdamjp/HXGVhwQJ0AX80IZ98hczQgjiIeLs5quvNhs1Q9fSmaQeiViOLalKo9FYW1nLZDKu7cTTmYnpmXqz2el0UsnMV77yZ3/4h3+oR6L9fl/XDc55eNqRd9oTAw9PThms4PR1Z+ANxKeZ7IIgIMRADX32PYCrTh+H8TAkp0q+SDQajUbDMKRUJIRIAsEYB57vui6MujBCmqa5XqAoCgCsaDQejUYRxlQS4d3CGAMmfzQaNWo13TBAeg+jlpOrxEMg0B5GOv8VgEUQJLQFGGMK4glNfuaZZ2ZnZ2VZ1hX1937v9yqViud5ru1FIhGQQP6zf/bPfuzHfuxrX/vaP/pH/widCvx/GMBCmHOGEEIQFosRZRghRDDGIqGaphGEfd+Px+OyjGJR/E/+8T+6dPHR1QdbRiRBBDoa9SbKhUIxs76+RgRxYmJyOLK3traKxWIY+r7nVSqVarV648YNyCn2vdC2bVj6s9ksxO7dunXLdd2JiQnTtHw/BLrl8PDgve99L3ipZFlOJBKyqkD2MWSQHhwcxIxoKpWSZRk6DeFLkAM5Ho9nZmaKxeJ3v/vdVCpVLpdt24ZI7sXFxUqlAsr0ubk5iCM6ODh473vfu7u7m4onYEOilHqhTymF8PRHH33Usqz19Y2ZmRlN0zzPg0EDLPfQdDEeW5qm1Wq1Rx99dGtrazgcch7CxBZuBtizK5UKFCc3m8319fVyudzr9UBElc1mM5kMjAVFUYCMb1DeLCws2LYDOxZMr954441SqTQxMXHv3j3DMNLpdKVSyWazrVZrOBxCvxDkCECL+XA4BMUrFYVoNFosFgeDAcRMm6ZZLBZr1eNkMgkMVrFY7Pf7luWoqirLInSfIYQEgaZSqWarrqqq77GLFy/eunULWhrhB6G1AwKKMMau63Y6HdgsQWwLbUWe583OzkJAa6/X03U9DIP9/f2pqSl4tNFoNDk97XnegwcPQKMDSVQ7OzuU0na7rev6hQsXdnZ2HMep1+uyLEPIWaPRANWL7/tzc3Ptdnttbe3atWvHx8eFQkHTtK2tLXjRgRuDIoTj42OICF5fX4/H4xAjBLPCSCQCVbv141q3243H44wx0zQ3NjZKpRLGGGwQjIUwWQbarFqtYkyCIGg2m4ZhHB0dgRl2YmICZlLlcnlzcxNSIcBUaFnm7OwsIeT27duXLl+AaPJMJpNIJIIggLEmC5Gqqo1GI5fLReNxOEW89dZbkiTBqN3zvEajXigUYCQUBAEYdIbD4dWr14DrbTabMBoGUhOG7Kurqx/60IdAr8M5397eXlhYgBkouF8553DPAGgDjlOWZaDqh8OBYRjj8XBmZiaVSt25c8+yLNO2giCYmpyWZXk0GnFCD/cPoon47NS0KKujkX1QObx79/5X/uzPWvVWeXpqojQFg2nb8QghsVjCdV1FUwE3U0p936WUjsdjXdc5CyIRLQx80zS3trYmJyeWF889+9zT58+fVyQZITY2e5X93enp6cDzq9VavV5XFAXg2mg0euaZZyYmirs7OzA4y+fzoiRRSisHe/V6PfDcCxcuaIoai8VG5tj3/U986scRQggJ7ITn/yHoCqHA8wVRRJzv7u6+9dZbxWIRAj5iifjOzk4+nx+Px5BKLQgEbE++7+dzGYQQHBIURd7d3c3nC5IkgRZwMBhsbm6ms5lSqeS5AXSlK4oCdwiUl4MQfmVlZX5+HhJb6vX6eDyGngBIOi0Wi6PRqFKpFAoFgT/UcgODZ+Dwz/bLE+xFCMaYEpGgyGhgU4w5Z8NgWJ4sJLKq6bUSFPfN0YWr85qm6Ak1Ho9WKhVRFKKyjxAbWMPRqO+Yji6rIXOGvWEum9zbXU0mpZQRbq28/Mwzj2i0S5EdsIGkiYiHlBM2tjFSEKdY4CJ1EQ4QIijEmEmIiwhxhER37FAlIiQyGIsIS6RruY5Ub/YkOeb4pD+wRibHuBQI1LIwwlSjQnlqPuu6nU6HUopdR0IMBaFAAnPYKOWiiiRGFC8RQUEwRL4jiCi0rZB5VGJUFRAirhNwRuzAkJVJpGb3b638m9/437ud4fXrN37u5z6x9L5ryKwhu0vRGIWCKMqu5YmiQCRkO2Nd1oOQ1AcE4/ROfbS93X7yiSshlyLRiNMfG/E8YhiREAkMYcrPplropP8SSBbGGCHYNU+8yqf5UgEVCCHYcWxZFjHmAJcVRdV0I5XOvv76m2+89aYRjbuuH48nHd/DBGNOOQ9OJHaMMcYQIvAJxhghwjlCiMHCDbiEnPb6ESLKMuX8RH70MGo5uXOggJlBZtdZ1PtJgw0QThhjjCnIv33vhBIDiZVljX3fFSXF933mB+ZwlEqlJCrsbm0bhpFOpS3LGg6GCGNVVWVBBEIFGggRegjufE+GysnQ9eQ5IwyyesxgXocFQZgsTyuyBvTyf/gP/2FrawsAUDIZd1038N1HH7l25cqlo6PKo49ef+yxR27duiXLknua5H72ASsEEMCn4O8EMVOEGQtlWRaIKAkiBGYFXiALZDgYihSPB+PAYUpcH4yHmXQaI3Z0dLC8fG73oLK+vprKZCenirFE9M47tzVFf+KJJ6rVarFYPDw8BBF0GIbZXNpxHM93BsPe1tbW2WQtm83pum6ao4WFOVWVQdIOQ6jhcNhoNSG4CDRYzWZTkWTIQIJVIp1Oj8fjTqcDpW/9fv873/kOY0zTNGi/URSt0WgBaJienoXp7csvfyeXy01OTlarNUlSvvaNFycnJ+PxuBe6siyBJf7y5cumaUIdvWma8ISBlwqCAPYYy7KyqfTu7u5EofjFP/xPAG7y+XxEjQDuDwKPIlyvHmPGm7V6r90x4rFUKgWx4xCwBJKmfr/vOI7v07m5+fF4jDGxbWcwGIKq2jTNWCwGqU6GYYC+ajweHx4eXrhwYTQaDYdDaI1dWVlZXl7OZrOvvvrqpUuXgNoxDKPT64LUAwbZ0KfBOZ+enu52u91uFyKmxuOxJClQVghjGs55uTxLKV1cXNR1fXtrb2try/d9GJZtbW2dO3cOHJfASo7HY1j3AUBDDRE4LiORyPHxMVzAVqvFGIvH48lkShSlSMTw/aBUmui02oqizM3Mcs7z2Vyz3vATHsUEKpaj0Wg2m11fX5+fn7cdp1gsTpRKkM46Ho/n5uZarRYwN0AbUEr39/dnZ2chiuLtt9+GOCuM8cHBAVj/YAR2/fr14+PjXq8H95IkSZCrkstkC4XC3bt3n3zySWgthNcL7FqaphFCR6MxIWR9fQOyWGOxWKlU0nUdwr0uXbq0ubnZarUAf09PT1erVRhEQjYY2AUmJydHQ7PRaBSLRUVRascN4BSArZQkKZvNHh0dZT0vn8+zIJgoFl3XVWQ5Ho/v7+/PTE0nk8kH91cEQdCN6Ozs7NHR0dLiOYRwKpEkhEiCKEZj0MBzcHBgjsaxWGxuZnY8HEHkRyKRSMYThJBarQaOWuiuAFi2uroKIfgwR4LDLaW0VCp997s7zWYThs6cy6VSCZblfr8vUKLpOpmc8INge2sjlU4LgpJJxz7/9//O5csXtja2Xn39tbu3b8mams8XF+anHcdrNNuEEMyZ5/gBCw3DsD1f08RoImmapkiwqkVta0yo/9iNx4MguPXO3dv37hNCPv6xF27ceDQe10rlGUUz7q7fTqfTl7J56A9QFSmVSt29e7vX64iCQAhyHMtxrHank8/nFU1FCAmCYNt2LBZDBGuatr293Wm3U+k0pHeeRUH/wA9BFD3XFUVxdm5uc3MTAs9isZjneZlMZmlpaXNz07btSCSCMYdiK03TNre32u12KpFkjFFKZFnudLqpVAowVq1RXzi3OB6Ph8NhMpF2HAegEggGotFoq9XyPM+yLJjqwI4WjUbhBAt1I1DcCfJWx3FOXIQnxIVAz0Q2MBs6Edag05hrLLGQurYnK1QWkWUPZAXn8snnnn0qnYlPFPO97mA8GiUSCd8NZEkNQkfVSK1eETFJJWLDdns8HGDOMuloNKoM+w3DEEvFeCopUWSLxPfcMRF8ScSIMyTJyCcIUUQI8sdI8hDmiAjIJdyXMdEQEhAVkSghQb751p3X33j74qXHJycXHRfv7B4repwQTZB0TBTGBUREgqUw9EUhCJljm5YekWNR4+hgVxZ4qZiORWRVChNxCSOL+73A7YsRAXkmCkNEEJIQD32GEcLEc4kgGOLEOf+g8W//1996/dW3L12Y/ciHP3DtyUdRRA7rB5jamFpYl9nYC0JRSk2FwxFNRJEfNprj/crAD5KilKo1e9nMhGezd96+LylqOpv/xKd+XI1GESV+4AuCeNp5SU4AFvyPItexZFnpNmvf/YuXIhEtoqv5fM4LfExJEATrm5vjwcgwYpqm5Qql3MT0q6+/8cUvftEc2+CJEEU5DEPIOEAIQRADB6Ip5FD1/a6OijGM4Vjjo1N7IOAVOHq6rv3Q4zB+kuzAzmaFiDEqirBmwWmMECIJAsY49APXdSEoiwUhIZCYhkEjAsNsy3YHgwFCqNfrwfEUBIZQRNrv94GMBTUiYyzw3bM34Zni/nsA1ukH/HsYclGSGA8IIQwhwzDe//735/N5xoNKpfLi1//c94JEPAbZXZIk2Zbzt//2L/7Ixz+ezWYVRfnDP/zDf/kv/yVj/BTIPfRBMMaYcMb5idINn8jbT9qEdF0PfWAsxFgsxkMmCkHg9X7t137tvU9+8KjSbjZbiq6qOg64lS+kEEL9odVudYgAyfiBYRgECY7jJZPJ3d1dkCdjjGGKB7J3y7LSqSyM7Uaj0XA4AuACPqCZmRmM8Wg0ajabMzMzw/EILJ9w4FtYWBgNhjCCKRQKq6uroGA9d+4cZECcGZtN01xaWup2u6ZpQ0r77u7us88+u7GxEQQBTAAjkUgkEoFYnbt3705PTyuKRCklBCOETNPM5/OO43Q63ampKfCmweY6Go0g4ebevXvpRBpcDpDm32g0yuWyaZrHx8eu62qaMhqNFEUBEVi5XFZ0DWN8584dmBapqgp1K41GAwa+/X4fNDEwUYK4hwcPHhiGIYrixYsX79+/D/bAZrN54cIFwBZASNy6dSsMw2KxuLe3J0nS1NQUmPY1TQtYCKyYJElQQQiCdFVWarUaZK0BZRKJRH3fF0WqadpoNEqn041GPQzDQjFXrVbn586Zpnnr1q2rV69C1tfjjz9++/Zty7J0Xb9//365XAYBH3BOkB1fKpW63S4hBJizS5cugSKk0WjMzc1BphEomSBeH8rUIHdgZmbm3r17pm3lcjkwjoACyfP9a9euNRsN2FcikRNQ22w2oYcuFos5jrOxsSFJ0vXr1xFCa2trnPNHHnlkf3+/1WpNTU2pqlqr1ZaWlr797W8vLi5C+EWhUNjb25uenk6n051Wm1IKGRYQ/JHL5SRJeueddwghpVIJwqWgqBvicA8ODiDCChL2oTYAIXThwoXBYAD3NqSEDAYDhHgatnBCMpkMVEhduHBhfX0dCLzhcAhkhud5kUhE1/VKpbK7u3vlyhVI6o/H45lMBsZSuVyu1WrBvBiw0XhsTk9PVyqVxx57bGdn55VXXvnUpz4F6nVojwErw+TkJNRf2q5zZs0G8WIkEtnb24OLCc1Cv//7vz85OQka+XQ6lU4n2+0uQkwQJPB2AE0Ik2iEkGs7yXSqkMuvbazbtpNKpznHxfKELOmu6/a6wy/+l//va6++Va3XEvH07Oysrhu1Rj3wGaWiFtEd34PUG4SQ67quZcZiMYFiMCtIkoQYN83RcDh2PWtupnzx/PIHP/jBubm5RCKxs7W1u7uTTMYxQoQg0xwFQXDh/BKlZH19vTw1+WBlHWLWH6zeD/2AYnT+/HlIQOz3+wvnls6dO+f5oSQpQcgJ+WEewhMNVhgEVBC+88or8HaoVquqrtm2Db5gwzBUVbVts1qtQhRcrV6F5k3P89rt1vLycr3eABdnIpEgAq3VatFoFLq9YeECVUOj0WCMwRwQpu3QPQqFpxAIfOXKFWCRR6NRv99/+umnEUL42uPPM8YwJeQ0TZQIFCEENmmCMBSh+L5PEOZIoESTJRWTcNBviRJ/zxNXp2dKpWJWFelw0OMc+46bSWVFIgQ+OzraPne+YNudwLF0lRazsUw6oSkEo1BRiO+YooAQRdweYxQixJlnEk0MQlsQCSIkcAOBiEiiKLSCcCxIFHEpDCSqFBBXR63BwPYFNVZrD1579Wal0nzvk8/ni1OEaMOxk0hmGq22rOqO43HOQ84Mw+i064ZGu82jZMLIJI1GYy+ikvPnZkXi6wpmoeV5A8wdQWAceQR5VJJ4EIQhF1Tdd0OGqKxGUbKMmPhnv/uf//APvpjLpn7mZz999cZFFOGoV7XNkRrPeeZYUpBlmlokgaL57Xc2qJgwHYyIGhK103OInDRtlMqWYkZq2B5jTuqN1vziwvnrV8MgCJgvySJsyqc0qYAQQgwhjAI/5MgXRWlnY/Xu27cyqWQyFdd1zXadSNQIguCll19JJtO+7/OAP/PcB3711/7f9+4/6HQ6hUIJwhsDzsByH4bhSU4YQiAMB1yAThOwEGJnXwJEciq3CulpqTNgqYf5zhPpHmOEUsYYCkMqSXCvAywTRVESBEIIDxE0zTHGeMgEQcCUyLIMWb1AnjdbHeCcLcvSNM00TVA2yLIMbXFnqadhGLLT5/yXPx4GWN9zEpJEz3UlWZYkaTwaXb5y5cn3vrfdbrebza2trfpxNQy5qsqcc8/1RFEoFHK//uu/Pjs7u729LSuaLMsvvPCC6/oYI4wR55iDOvPEOsgpIu8iPIDKJ2VHVFXViK6Lohh4J+XomiIEvvXP//k/v3b1ibt3VmRZJiIzohIjfhi6Fy5cWH2ws79fOb98sd1p9nqt6elpy3IIEUqlErSnQQYjJKeDEplSCuIAx3EeeeQRggVI0hMEgXOUyWSOj4+hsG88HutGxHGcXC7Xbrehqebrf/a1xcXF+fl5UK2CKMo0TVhxFhYW4KAGMrjxeKyq+tHREQQTQIIfMEAwOfrmN7+Zy+Xm5uZgynZ0VBmPx+XyRL1et217YWGBcy7LCrBooCIHeQS8+ul0ullrRqNRyI6CDT6ZTAZBIEnC8fExLIgw38nn89ls9i++8wohJJ1Og3hidnZ2ZWUFDqCQWwO3fSaTAY52Y2NDURRI2ILCMgBG3/72t69fvw5++52dnccff/z4+BgsYKVSqVKpwH91XU+n09ls9rB6VC6Xb926BedjkA8GQZBNZ6CUw/M8CNRxXV/XdUpxPB6HW9o0x67r+oHr+342U/A8b3FxcWtra39//4knniCEgAkuk8lQSuG1huKgra2tdDptWVY2m4XjDVxYAB+WZaXTaWilrdfrrVYrFovlM1nAvoVCYWxbkBeQSCTevv3O3NwcBBZMTU+HYbi1tXXp0iXPdV/5i5cXFhaKxSJMIRuNBqwDkKEKNhSwAmCMq9Xqo48+CiK5drsNaWoTExOAyWDnA08iYGJJkuBgAM5HYAsKhQKwgJZlQadWpVK5evUqhI/Ytg23cTKZhA0SpPQzMzNbW1uapkHAGAiW+/1eNpvVNB0814PB4Pr1647jQDYp7HSVSoVSGonocMVgA7506RIgjN3d3Xa7DbefpumwUYLnACEEWr2jo6OZmRlYLVdWVhzHeeGFF6rVarVaBUS7vLzcbDYhhQRGRkDWttttCAQejUZnWmlFUe7evRuPxw8PD6PxmKoqPOTNZmNnZ/dDH/oQ3Lfr6+uZTAYU3BIVxrZVO6oiivvDwfHx8eOPP84xcmzfiMemp+aLxeLG+vbrb77xlT/9+t7eXhjy4kRZVXUv8EOGiCi4lg3hIBAhBmGtvu9bliXLMgtCTVcoEVno9/rtZq1uGMbTTz+tacp7n3rq3LmFra2NVCLOWIAR6w/aqVSyXj8OguDChUvDgdnt9wRCu7129fBIEISZqclUKpVMJuv1uiTKH/7YR6kAQYPi2RQC/yUuiwUhoZSFIaH0uFp9++23BUGACR0hpNvtLi0t9YeD9fX1mZkpiJ06Pj4em0Ow+0xNTQWBb9s2xgS8O5lMplKpMMY8z1NV9eZbb2uadu3atXq9LktStVpdWFg4ODjI5nKU0kgksr297XkeZL6AKgvCQTqdzqVLl+7fv18qlVZWVvC1x5/HGGNKAEeLokhFAcJJRVHUVQ3afEVRNEdjWdE8H3YRX6BIoPzxG1c/8sFnx6NeuZgbdJos9DzHjukR37Uppa4zSGVILCqk45FIRBBpwJnFAitkHmIhZwGllCLMQ0ZEAYki8n2EQi90RQljVUVB4JkOx0iSJCwSJCiIy7aJLQt3Oma3M6aSwQVtaHoTpRnLYYiL5tgbjR3fY6IsqRHddR3HsYLQy+ez/eGgsru5NFe+dH6u267Wqlszk6mpyRTiFnKGiAYI+ch3Q+ZhARN6WuKNKaKiNfZkKUILM2js/8Wf/vmff/1F1/V/8tOffPxHPoSIh4Z1hC0UjJCoIK5wRlmIqRLxTP+g0u4Nwni8FLBIgOX+yJH1aIiIG6BoPMOZUD9sCFgQJOXSlcvZQpZjhAlinGHMEWKnAIsgRNDZyCvwMEHffemlZu04X0gnEgld1/zQE2WlUW/eX13LZDLm2H7fk+975bXXfun/8veffOp9hAjAVIMpD97DjLGzAR97t935XbwFEaPwVWA08Ulwx0n38/fV5sD7gT2U3g5Sd0wILHPgJ1IURRKEIAhYwGGNNk0TMY4x9gJfVVXgzJ588slWq3VQOYLWl3a7DbWv62trCCFV086A4JmDD2PMWYB+0McPA1iMM4SQrCggMvvoRz8qSNLq6mq/2200GoiFIGQmhGTS6Xq9+eu//v/68Ic/3Gq1TNMURJlS+jf+xt/Y2dnFGL2r+zoDWAiJmJ5dW44R5xwRTClVFV2SJE1VKaW+GwQn/Yyi79qf//znH33kiUQ65ZjjVq8mK6jdacRisVQqc+/ORiqVvXr16s7O1nHtEGPuOJ4kSYqigOxXURRoF4bYHsYYNL7BYnF8fJyIp27dugXAqNVqw4AJGBpJkmRV0TTt1q1bExMTyWRyc3PT0COgLaCUQhQZ5CKqqgp5VCAtaDQazWYzkUgkEqlWqwWUJyyaxWIR5jiJRGJ7e3tubg7WI8/zUqlEpXIAsfKAnuPxeCwWh8D0o6MjSA8qlUqNRuPpp58ej8d33r5z/fr1SqUyHA5BYVar1RBiqVQKxlWXL18Gw+m1a9c45ytrq0CtYYwhBNz3fQiwEUURdn3o84HOnHg8nkgkHMehlIKceTQatVot13XT6XS5XN7Y2EgkEp7nQemq53lQn9xsNm/cuAEZpIVCoVo77vV6MzMzEApQKpVmZ2c3Nzf73V4ul4vFYnCuWF1dnZ2dz+fzb731xvLysuu6h4eHk5NlhND+we6lS5eqR3WI4fjOd74DbgDf9x999NGzxrSzcATo1VBVtVKpuK4LDGutVgNP3+zsbKfTAZ5jY2MDIUQpXVhYIBxBuRmlNOAMtPPT09NUFO7fvw9R+6qmdTqdmZmZ0WgUev7Ozg4Y34BGgrrJUql048aN1dVVuHTVahU0T/F43DAMuFatVkvTtOPjY0mSoOZI1/V2uw3sQrVavX79+srKCgDH3d1dCEdVVRVcqwgh0MEQQoBJnZ2dHQwGh4eHmqZZltXr9WRZnpqaQghBJzSAxePjY8dxTqP4AkrpaDQGBrFYLILZsFarwdQVIWRZ1sTERCSib2xsnDt3bjAYwDPf2Ni4cuXK5OQkuFybzebU1HSj0YCS8l6vVygUQA2m6/r+/j5CCEafIOUBdFKtVhljkiRtbm4ahnH9+nXXdUG6xDmHcvHJyUnbtoE2rlQqIIEfjUazs7Pbuzuzs7OjwfCll16anJy8dOnSq6++WiwWTwgRjoDSy+Vy6XSa8TBEoR8EjUZDkqTh2BQFyXE8UVYLhZIkSaoS2d7d+d3f+f2joyPbdm3PLU/PQjQrIcQam7oRcV2XYAFu+BPrm+fDmmYYBuIhyPOPjyqKonDObjz2yPve99Rjjz2iq0oQOpY1rh0f5nIZ0zRN20kls54X2Ka1vr4qS1K3256bmc7lcqlUyrbt42rtYx/7WCKdQRhzjtlpgPsPBFhnnxNCbt68ORgMzghpKCDvDwfD4ZAQBOhQVdVurw0Wh2g0urOznUqlotFYrVaLxWKgYIPjgaIoG+tbGGNA9r1ud2lp6eLFi9/5znfiiQTnvFqtQuwcdFAeHx/Pzc1Bouy9e/eE01ZAURSFky3zIbkV/D2Qk8YZBx0ijHIUwiWNuK4bi0REKjxy5dLi7Eyj2uSBjVMJlXDEfZlaGnZCcRyL6oYulCZSCDkoNLlr+v4YEVcUCZUoCjxECEIEMYQxR0RE3Ec4RKIkaQnkula3K0lUyqZRIAzbY4NO7Ww0m+3R0PQYp5FYTI6kfU6G3TEn2mDI2q2uqkZESRFFkVJm22NBCgSKIjpuNXuYRXJJXROmHLPbaBxkU9rC7DUiWu7giLkDVeKeaQoCIYpKRQ0FyHUDjKkoS37oSaKhFRIIqXe+8sqffPlPXdt85n1PfuTTH0MKRt1Nc9RTNJ3KCkdpLBrj8VhWk8MxaeybnbY7Gsm57IQbxgg1up2haqRlSer0W5ZrNZttUVCMSJJSOZlIJdKps5soDLAgQJQth2xRhMBUQbgPwnMOhiNVkgVMKKUMiZD9L4oiwYJlOaKi3Lu3MjMzh6jQHw4Nw9CjxsgyCSe+70M0wxkkYgwacsip0Apxjk4zBuBL/LRUBkEKKXooteFh5TjQVPw0gJRTCvsQ9EWAPzH0Qt/3A9+HSElFUVzbEQQh5MzzvGvXroHNByGUSsbjMWM4HPqeQzBXZDGRiFmW5XsOgDzEGeLhqdCKfN+Y7r/5gU8bGFgYzs/PZ7PZb33rW+Px+MRyj7AsC5IoaprWbjSfe/qpD3zgA61W68GDB+fPn4fs+FKptLOzC7ZKfvqYD80lCT/VrCEOfVNUFEVBJJhwWEEwRZgjQhCldOyHI9PM5FPrm2vZTDKW1BOJqBqRHdvb2z9cXFz2Pf7i116KRqP5dHk06hFuq6q8trY2yGQmJibGrhe4XjqRNIejqB7BGCeiMUkSut3uvdvvCIK0vbUL9nvYayVJHAz6jUZ9ZmYmn8+NLSsSiVy9elXX9V//9V//5V/+ZRaEYGOGOQ7AKYiSAnrDMIytrS0I7Dk8PISMZsdxNC3FCcaY12rVQiEHBNLCwhwM8iil9foJgeG67uLiIsQjxePxfn9g2zZCaDAYgJYCBD337t07Ux21Wq1UKmWao729nVKppCiaruuDYX+iXDquVRFCH3z+A2+99Zau64yFnLNa7TgajR4fVwVBuH79EWARwHIfi8Xu3LkzPz8P+zfk/4FIHCFUqVSAh4Nzre/7IKZmjIGzzLKshYUF4HFhwPfgwYOrV6/argMVh4eHh1AgDeSK7/u2bZ87d25nZwckQYZhQGbjxsaGruszMzOdThvUNrVaTVW1wWDgOE4+n19cXJycnFxZWQHovLW1hTEuFovQ3FevAxSTMUbRqOE4dqvVTCaTQDzv7OyAnXA0Gp0/fx4cc5VKZWZmptFuQVI8/CMg4P3Ng1gsJori7OzsvXv38vk8FATJogjUURiGYIRstVphGN69exfi9cFJIElSIpFIp9MQlAAmuEgkYhjG7OxspVJpNBrgz5qZmVlbW9M0rVQqOY6TiEWH/Z6iKFcuXYS+5I31zamJMiDjMAwrjSbgxfFwZA5Hx8dVQaCe54ZhMDlZJoR0Ou1yuex5bqlUVFV1e3tL1/XHHnsUfKnb2zuMsatXr77xxhuU0osXLzabbUpFxpCiaLlcBlLZYGSJEDZN65FHHt3e3n799dfz+UI2m9vY2PQ8/+ioGo1GHzxYQwjVag0YrL/22huFQg4kZRCyAHs5gCSE0Pb29vnz58GB8bnPfe673/0utG0C1EYIAYCGIjxZlsHOD0Mk13WPjo56nf53j14VRXFp6bxlWd/61ksTExO+H87PzPd6vW63TQhZWFgYj8f9fl8QKRYwpdiI6pbp8DBgmDz/wef6g+HKyiohZGF+uZDP/Oo//b93u90vfemPDw4r9x9sDMej+fl5QZTjUSOZTtXrdVlWVEXyfZ+HjIeMigLh3HV903YEQocjW9ONyel52CwerG58+6WXJ6eKE8XCZ37yx5eWFmfnFmu1aq1ey2Xzw+FYUpRCqRgE3oOVFWjKymQyjmXrmuZ6zuFRJZFOnfS44h+6nBN6kvHOGUMYK4oCffCQPwKz43a73ajViYDf8573gOeAc67reiwWu3nzZhgGgJIhrRdOSpBxWCwWS6VSIpEY9PsEYxA6w/sX8sng+8fjMbgLIdJdkqR79+7BPY8xBj8KfuQ9H/Z9H07VsBFQUTgTIAeeD8MghJBAqOXYIQ9kTY1pEYLR3NTkjetXFmbLyLMPdlZ0hRsqEqmdT0d1naZTOo3I4bCLmI+4T0G7jVyEGGIeJxgLlCOCEMGUIgbJFwQhkQWcUBEJEmK+47F2zzmuWbI0sbnTSmYmcqXy2B4igQqiMh6aJMS+G0iiKsqSKMoAtC1r3Go1VE3yA9f3XV1TT9SLmjw3V0pExSAYe3aX8rEkuKrEWWhTgaKQc4a8AAUcU1EVJQVRSrN51G1/96XXv/5n3+g2Oi98+EMv/MjzaCKNGruIu4hwJKtW3z487PhMViOJaqt1eNzTlVJEzyUThYCh8dgKQmTZnAqKKMrRuO4F5tgezs5NNeotWTEokVQ9tri4pKgyQigIEBXRQxI/CGjgJ46KECGCBs3WN/78z3KZdCJmGEZEMyK+7/uMvfXWLY6pIEjRaOzRR2588sd/wkc0moiPRiOEEPT7gq7l4WgGmJJQiimljJ0YGh6a+p35AtkZWQX70NmI8JTZevfjdOCI4PsxxnAOAyGnKqnJZFLXNOCHOp2ObVoQeAvVb6IoOo7l+ycWM4gipJRubW1BEjRIdyGs6+En8F/DUhijv3wYIlgQBM91SxMTzz333MrKSrvdbrfb4OciJwwicxxPk4Xf+73fyxULnHNVVSHv8fLly//0V//5F7/4RVgNQ8bx6dVDYA3hhIUhOgWdjAWSIsMpHCEkCTKoo8IwFAiF0o+/8Yt//ed+/qePjg4935qYKPT6nXgsubm5k8uWSvkpxlDtqMY5n5ub8QP3weqdaDSCEAJLfK/X6/V6586dOzw8TCaTcGXG4yFCCGJdfMY5w57nLSwsNJvNg4MDRVEgNC8ej48tC2KTYPSzsLCAGD8+PoY5F+iRDcOglL744ovQ0xKLxUBcYpqm67o8CAExb21tlaenYCAFlQ9QILixsVEoFKanpwkhBwcH7XZrYmICwE0ymYxGo8PhCOpoMMalUglGJJ1OBzztzGdhGN64cWN/f19VZXClKYoST8QgvLvRaNTr9YWFOVhn88WJF198Ecxx0P3XarWhFRGMiiCjASs+BCTatp3NZiFUDGMMXTecc/jmTqdz7dq13d3dVqtVKpWgP6BarS4vLzuOAwgGCkPa7TaMxUEls7a2duXKlWa9AdgUVPYXL17s9Qaqqg6H/UcffdS27bW1Nc5ZJBJJZ5L1ep0SCRIm+/0+CNgnJiYODw8B3oHyCVwIgNt6vS68LyCZ2rZtzpFwWh8JaaUQbg41avB2AD/j7u6uruuJRKLf7zPEE4lEo9EAKyJjbPHcuZX79wPPh10fmCdKaSaTiUQio9HorbfeWl5eBpqZcz4/P394eIgxBuFdPp+XZRmMhJFIJJ1Ob29vQ8a6LMv37t2Drh4IHz4jDqPR6Gg4hoknvMdhF8zn81NTU5zzav3YNM3HHnvs1q1bYL7rdrvD4RBch6PRSNM06EYcDAZXrlwJQ9bv90FRDtCzXm/CFUskErFY7ObNNx977DFd119//XXocjZNM5fLQdJSv98/cUdhLIpiNBoH6gHOY7FYjLEAho+rq6sQ/oQQEgTh8PAQnIBzc3PXr1//1re+pWna4uKiaZo3b940TbNUKl25cuXg4KBer8/Oztbr9fX1dSD+8/l8Pp+3LGs8HheLE6+99tqlS5cgeh5j3O12bduemigfHx/Pzk4D2wquz8mp8sz8TL/fJ5RCVFiv19vY2IpEIovnlhzHcRzP98NOu5ctFC8un1c0/aWX/+LrX//G2trawcFBLJqIxKL5fLHf73OEYWuQJdULfALkCEKIcRh2SZLkew6U8GiKVK/XDo/2yuVSIhH/8U/92NLSYjwR3d7e7rQHjLGJQpGjcGNt1RwPmR9cunwxGjHS6fRh9UiW5Y/+yMdBXMX5yUTlLzNYcCDnnAPTXK/X/+AP/qBQKKiqms/n4RgGxUSiLFy/ft227W63y1EIzLGqqrXacSQSiUZjZ/YIoNUdxxmNRjcee+Lg4KBRr0OCGgTNaJqGMJ6ZmXnw4IEsy6urq7Isw2oJntlkMgnAbmJiYn19vdfr4WuPP396wCYcozMLIUxeAF0RdELW6boehLzZbAo4LORTVy4tXb+6TLgj02BmMhOL0FhEVESmaDS0R7YzCnxHlmWKMKGMIIS4z1hABYwlAVGCeBAyBvM45vsh8ykRiaB4ZiiJcd8jlaP6aOy7AW223YhepJIRTaZG9mhoD7KFvCCqhwdHyAny2ULgI+gSDzkzTXM46huGLklCKpmwLIsgrOv60sI5pIuIDwO7i1FIVQkFLvIdRAVkjREREehoCEaqiihF41FlZ+/Pvvbnr7/+OiXsYx/64AsfeU5NRZA7tAYNhBgRqBcgzxNsVzBNbrnCyApdFx/V2pOTs9F4SlFV27O73a4oSK7PdS1Oidpptoajbr6QWjg32Wq1RFnzfJ7K5OdmF/CJ2w4JAiCCE3xy+l+COMAsdu/mre2t9YliIaIpuq4RUWCMUUn6+te/kckVHMfPZQvF4sSnP/NZPZEQZcV1XcMwmq1Gq9XCmJ8lcTAWwOICqwAQmwCvTyTqp+NCjsKHARZ8TxAELERn+OYMq53hM3RqUEUI6bpuGAZjTBCEdCKtaZrrOAghWVIZY/1eLwiCbD6TTCYbjQZCKBLRoHkJKBMw1FSr1dFoBDDa8zwIZIK7l30vC/tXBFgMMUKwrhvPP/885B1YpjPo94mABUHAHEEohuN4/90/+JVPf/rTvX6Xc2677szMzGAwtCzrq1/7s9/4jX8jS6Lv+4wjBG8lzjlCBFHMTy41oSczXlkRNU0TBDBFiyAahaGqJIhhGP7kZ3/8//wLP9duNzvdZjqd9oOw1epMlCaj0USj1uz1eqV8IQiYoii+7zaax8lkHJQfx8fHUD+iKEokorXb7dFoBCWsICX2PK80ObW7uwtDVdfxgRyCPUOW5WqtJooiOMIWFxf39/cr+wfLy8tLS0v37t0DjGiaJozwhsPhpUuXvvKVr8zMzEBqvOu6jdoxpHCpqgqtvaquw8p1lu8gyhIc0B88eCAJoqIosGe7rhuJRKBrD8pGLMsCqRPQIVtbWwuzc0EQ7OzsAKURiUQQ5gsLC2+88UYmk5mdnYYAMIAOsVis2e4CGoDcpmQy6ThuJpNBCLXb7cPDw/Pnz0PdTSQSffXVV5944kapVLp582apVBoMBoAGwHV/9erVSqUShiEwl4BXIKF+enqaUtpqtcrlMuAqjlEYhp7nHR4eTk9PQ0sgpRQxbts2pH4TQi5fvmwYsd3dXUrx8vLy9va2ZVmWZZbL5aNq5dy5c+lULhaLvfHGG4CiDMPIZrNra2v5fB4aDEHyD0azTqczNzcLwRBQsC3LMgQZQPYVJPiDtr3ZbIdhODVVBo12p9NJJpOdTiedzcBsMZ1OdzqdeDwO47bl5eXxeLy1sQkJApAWC5ozkOlAgyTMbeEQD6NnGBa3Wi04ksXj8WKxCKpkhNC9e/eSySSI3izL8hw7Fou99dZbTz311GAwoJR22l2Q321vb3/84x8/OjoCDK2q+vz87Mb2JvQJIoSgx2l2dnY8HjuOk06nd3d3Xdft9XqVSiWVSrXb7UKhePnyZXCEDQaj0WiUzeRhYusHLsa4UqlIknDu3Ll6vb6/vw8cHigOz51bhkDds0CQ8ciCP7ZYLDLG+oOuKFLQOCeTyVQqBZPoycnJ0WgEbyjoDIB4NkIIWA0KhQLwkYwxqAeAXsV+vw/yskwmA/o8sPJAS5gsy7FYDDjCXrsDkcsQpTExMQE1QflSoVqtWo6NMYaKQyCDNU1LJJLVatX3wieffG+n2z/Y34/GYrquq6qqqvqbb775W7/9O/1+nzGkRfTixCTG1LRsXTegvoIKEkTqm6apygogVIiyEwUShv70zFSv19nb27HGY1kWP/OZzzz11JOu6z7z9NPrD1b39nZ63XanXY9FjFg8Ojs9lUql/DA4Ojr6yMd+BPJ7EcIIU7ALff9qztEZCcEZwxh/+ctfBjQPLtrJyUlFUdbX11PphKqqpmU5jjMaD6B3fDAYKIqMMSaEwkQVzgBQ2NXtdmen57a3t6enpxcXF0HyCFyAoqqFQuHBgwfgn5iamioUCu12G/CZLMuHh4eO40QiEc65pmn40iPPCYJACAEeS9M0kA3CqwuHAIrJxMREq9WqVqsCFgjmP/ajLzz15CNzcxNXryw4ZjeaMhCzmN3zrCHiviTgkLkEcyoqiBFEKaIYYY58h9tWyBkhiCiS53mMBxxSTkMvDH0eMsxwvdZR5ISipo4qrWZzjIgacilipGyfeYFLFSGZjjOMTMvRNS2bSG+sbmQyuWQizRjTjAiopDPZFBYpYpz7LhYVhBDyQiTw0O9SVUKIId9HooQcH4UUqTriFPk+ogLC3G0379x556WXvvXGW29OFMs/8ROfevajH0ASQ8zkw4YfmH5gKYpCReXtm/f29ptTk+fHY7a1fRxP5JeXLo8ty7JN0x4rhprJZgkhtWajUqmMR87SwjJBlBBy+eLS+sYD2zZjidRobF++dr1QmEAcMcaJgE+TDb73juIIc4SYj3j47RdfDHw3HtENQ08k4oIspScmbr722ttv380XJzw3vHTpyurq+q/8/X9w9cZjnV4PdHn3V+5JkuT7LjmdYYWh73neaYACPc1N+B5CCIRWVMAPewPJafICACx4QJDxIvQuBwafwyfQwgFVcRRRSZIS8XipVDIiMdd1KwcHYRiKsgAnY8dx6vVj2NtgM4PA92q1CsyE53lnvBp6qG/gv/7xfaNMhBARsO8F7//AB2q12tHREaV0NDQZY7IiBkGAGI9EIsNB/8aNx/71r//PlmVFDL1er8eTSUopxsR13a/9+df/xb/4nwhGZ27BdyOwMCUhhEJghDjHiBAkK6Isy4JAGGOCIMmyDDEQGGNJEIf97sd/9GO/+Iu/EI3plmWFHDlOIIiy47jD4VBTJUEQmO85jpfNFGKx2NgcmeZIEARRFGVZhrM7Y2w0GriuWy6Xt7e3IZ6g1WoNBoO9yqEsy3AiF6gEnjg4WzuOk0ilYM4FPvD19fXlc0swImSMASEBs8Lnn3+eMfbSSy8tLS3JskwphSDQ0Pc2NzeB3OKc379/f3p2VpblbrcL+Gl/fz+VSS8uLnLOW63WUeVwdnYWws0PDg5SqVQikQSMcnx8nM/nYXVyXbfZbE5NTR3uH0A1TbfbPXfunGVZmCDHccIwjEYjnU4nCAKIpJJlsdlsHlYbAP5AypPNZrPZHOS5I4TW1tZADuF5Xq3WeOyxx1qtBkIIpD9g+BoOh2A/BGrw6OhoNBpNT08PBgPGWCQSgRgeEBfCfY4QUjR1e3ubMQbNvtvb26BB7Hd7iURC07R6vQ4ZpBMTkwghQSDr6+vJZHJpackwInfu3IEJMkbCaDQC1dHjjz9erVYHg0Emk7l58yalFCK/gWIBDD0ej/L5PLgF19bWwjC8cuVqu91eWVmZnZ2FV/b4+PjcuXOyrK6trTmOlcvloEAQdOumbfX7fdBcwzlKFMVSqQRKJk1RE4lEr9cDeVY0Gj06OoLnAEd5wCggPAeGWxAEyEiD7hGAIzCNJYRAg5Cqqvfu3XMcp5DLgkod+iIppUvnluv1Oszs4vH4vXv34A7PZHKDQW8wHkWjhmma/X6/UChA2N7BwUGr1ZqdnZ2Zmbl///7S0lI0Gn3nnXempqYwJu12e3FxcXd3V5IU27YVWfN9H1LZMtnU0dGR69rgNATPP+R/ZrPZ8diCMH2YzJqmKUsnpekIIQhsKxRzb731BlD1kEIJSnwAZBAtBlxXOp1uNBqQbZHNZmELh7hzkDzCMgsJFG+++aZhGFNTUxCHixACORT0KzuOo8kKZN/DoDaXy9VqtbFtwZiSIV4sFsfj8RtvvA7rcKfTmZubcxw3nU5TIq6urkODezwelSTpYK/SbLcmJ6enpmcbjcb/+P/8p7v7B7Pzi4whVdNjsYTneb3+0DAMjkLXdSkmsBHAvGw0GumaZlnjVColCGQwGFCBjMfj4+Oj61cvP/HEjYlS8drlS/Va9datt3zbSqWTi/Nz0WhU1bXDw8PFxaXrjz0W+L4giCczrh8EsMCc5HueKEmcsZs3bz548ODatWsPHjwYjUau60JnzhPvuVGr1dqdjud5mPBWq5VIJFzXjUR0Sun29k4kEimVSpTS27dvP/XUU5Ala5vOmdUUkmCz2WwkEvnuq69C98P09HQmk4Guz8FgoOs6dMYjhJaWltbW1kRRFAQBP/6+F9hZPiTicCtAbHypVIJYrEQsvrOz47ruRz70wY9/+ENPv+8pVaNB4AsSQshDyEMoQChAzEOYIYwR4ghBG4yIkIwQQixAhCHEEAsQYohQ5LucMUwgT5MjQlHo26Oh54wRQr4fDvqW59BYNCsrcctyGAqpRKkgSIocSyY456Y9isYihIquZcpaDCHMA4YFwfc9UZQQCoPQx5hTIniOTQihINmhyA89ggVKpIBxSmSMBB4KzOeVg6O9nd0777zzxuvfdW3rsRvXHn/0sec/+H6kawj5KHCQjBD2EHIB6aAwQFSzxvbe1nEYCIGHR4NxVJcJ4b1hL2C+6XkcESSIo9FINxRFlVRZ0VWtWWuGPgqcMJFIEZFYjv3EE08m0+mQ+RhjQvFDA8J35e0n0bYEjfvtb33jGxFd1SSxUMglEnFEyerq2pu3bmazRSOWbLX7n/n0Z3/7t37nt377txcvnr//4MHU1FQYhvdX7kH5VBAEokgRQmEYuq578nsBXSGKEOIoPNW8ozMuk3N+KthjpyJ3FgYcPgeABWQYLJ1noAdoLegIO6FzOKGUxow4iDM8zxv0+xjjwXCoqqoo0dFoZBg6UGKiKIJTA4ScEEZy9pb7b04GfyDAOvvxkIfl8kQ0Goe2O4wxZxg02hjjiK4ShM3R4H/4H/6HD3/4edM0G82653mpTIYxNjFRDsNwd3/vJ3/ypxBHlBKOURgyxBGhlGPMOcYBppQighkLMcaiSAVZoJQSihhjsiDCFCkIAooFRRZdc/yzP/3Zn/3Zv7a6saYoarPVyxUmBEE6d+5cp9O8ffeNK1cuCCJZW93QZCMMOCFCLleIxYyDgwOQAUE0dhB4IJsFlRsEO/V6PU4oRH7LstxunSRx9/v9VColCEKr00kkEuFpPzfGmCDsOM729jaEf45GI2DmOeewvkxOTgI/ASxUKhEHWQMAF865adv1eh0s6FNTU5VKJZ5MAKYhhLAgtG37+PgYcgR+6qd+qt3udDqdw8PDpaUlMHARQhKJRLPZVBQlFjE81+31eoqi5PM5MMBzztPppGVZtm0XijnwliqKUj0+Ho6d4XD40Y9+FPrjLMuybQcUFTB6i0Qi5fLUgwcPgKchBEGaDgwu6/X6Bz7wgS9/+cswRS2Xy2Chh2cLrDlY/EDDVK1WIfEhkUpOTExAMMrCwgJCaGVlJZvNqrICCagQvCmKYrfb1zTN913oKxwOh6VScTAY5PKZo6Mj1wkQQs8999yDBw+2t7fz+TycsMGeubu7e0axQHLV3bt3nnjiic3NzVwut7m5mU6nDSMK81bIKR0MBsfH9UwmMx6P9/b2dENjjGmaBmNlSKWXJKnVao3H44WFhVKp1KjVx+MxVMSAS5EQUq1Ws9nszs5OMplMJBIwSoPAKiAPCCHHx8czMzM7Ozu9Xu/ZZ5/d3NyEWxGqRaGzb3p6+u23385ms1B1VchlwzCEEHmgS5OJ1Hg8hqPU8vJyEAR7ewdhGM7Pzx8eHgzGo3Q6xTkHOAirVrPZLJfLh4eH8I/pdBosMqZpFoulvb29MAwLhUKpVJYkqV5rHhwcAEFuWqNSqWRZY0CW4/E4FksAI1gul1dXV6Fv+/z584HPVFVljN2/f//JJ5+sVqsHB4cXLizv7m0jxCYnJ6PRqOd5Ozs7ECMOmAwiPCCyNRaL7e7uAt8GVS0ArRRFSafT0CcNGfeWZc3MzNy5c2dyctKyTE3TfN+H+aDv+5DSBAfOZrNZKBR8P4BmiH6/zzn2fH9vb29+fr5Rr2cyqVQq5fv+wcEB1FhhjGVZ1XV9e2v32vUrw2GfENxtdS5eudxudyfKUweVo6Fp1Y7r33n1tU5vtLu72x8MZ2ZmCqWJwWCAMYfjUyKR8jwvDMCfGxOp0O/3DcMYDHqxWExRlF6vF9HlZr3qeqbr2OlE/NM/8alcLrO+cl+PaPOzM9Bz1Wy3HMf5zGc+wzAiROT8hwIs2CU5YzD5abda3/rWtyAJFqRdkLpi2eOtra33Pf10EAT3V+4ahnF8fMwY0w39+Pj4yuWrlmVRQiCUGJYdxtir33ntc5/73P7+PlS2g1djNBqFjKmqCqev3d1dyEC2LCufzwOnVS6XL1++vLKyAsdd/P/4F/8rkMlnZnhCCMg5QVehiFKz2czm0n/rb/5iqWBghlDIGArD0CWUh8yVFIn5DuO+IBBEiO/almPDsu76SBBjnGOCuUAQ4iELPIQQoRhxjDBFRESch55PBdG37dpxNZONqVEDEYI4QlxBXEIBR4KAsI+YjyhFCHE/xKKIsM8ClwgYIeI5LhZESoQgYAifCHQEkRBEToZrJ5sxC0MuCDJHOGS82x/v7x1WKsfNRmd9bbuyv9/rdBPx6KPXr3zkQx+4dv0KlQhCiDsOxhiplPkuEjHGIcccI+76riyqQchFqiJEAzsUZBHxAAWuY42IQC3PR0TgGAuiyLhPKBsNBp7nESRgRiWqiaI8tkZ+GM7Nz4ehRwUBIYY445xjAi05fwlgsfBwf+utN96cnpmMR41SodDvdyvVo//8xf+yuLjk+WE6lysWJsvlqQ9+4EOmbWFR+MjHPvrzP//zv/mbv/ntb39b0RVKKfSqYszDkPu+C4AJMo1gc2X8XU4LABY6C5FHjDFEKcaYBkHAGT5jsGCWB+eYM0ADpkIgb2FEGIYhZljX9UwqaxgGYHoWhoPBQJSkmZmZre0N3/dHowGQrtVqFd5gMBwEwx08Vf69Pt7/JtL6ywALUwI1w+PRSNN1y7YRO4kmCZkf1SKmaZ5bmPvt3/r3mPCjoyOEsR41wjCE8UHI2fPPP//5z3/+T/74K6IoIoI9z2MMUQBYAecMESpgfCJEUxSJSpQQIkqUMSYSCjgm8HxCBE0Se63mP/z852+855GZ+bmNzc1qtbF0/pI5tm3HfOSRq4fVbUkinu9E9Kg9duu1Vhjyxx9/j+u6W1sb589f3Nxcb7e7hUKu2+0GQQAMEIz8Dg8PjXgsmUiPx+NSqdRqtSqViiAIkYjheS4hNAxDjtHU1BQkBkEmJEEYZAMY42QyGYvF7t69C1Ik0GNBlCgc78BDJ4pCPBrtD4cRTXv5O9+B75menp6YmDBNM5lM1puNe/fugflRkeQgCBYWFjRNgyjIavUY9Haqquzu7k1MlCRJHg4HhhElhGytb2SzWcQ54zzwvcFoGPpBLBHvddoL5xbN8bDVbj/5nvfcvbfSbXe0iJ4rlGAtevHFFy9cuDAzM/ONb7x46dIlqGiNx+OapoHcezAY6boaj8cBFzabzUwmA8BF13UozZAkCSLEWq3WxYsXU6nUzZs3Pc+9cuXqm2++US5Puq4jywrGiCEUBL6uRyzLLJcnfd/b29sPw0Aggu97QRAmEnFCKMjvQLQB1q0wDD3PTaVSgkju3rmfTKaAAIvFYsBTwgw0EokcHh5C8hkY1EHzVKsdX79+HayOwBfKsgLStGKxGI/Hd3Z2IpEoJFCMRiMjFsnn851OBw7fCAEdGGSzOUoJQsiyrD//2tevXr1KCOl0OhgT+EVQXyNJ0vT09NraGgib+v3+7Oxsv98vlUowunIcR1VVGCRBrEY0GgXcD0eyw8NDaPsRBAH6SYENBfKAc373zr3r168D1wXPeXZ23rKsTqejKJKsqQhxkBKWy2WEEJBAjLGjo6N0Og3sZr1eP3/+PITwxeNx23ZA9eV5wcHBwezs7HG1bloj4DYSiRjAekEQxmNrdna22+3CBgyexFgsFo8lXdeFWS2cP0VR1HXddkzGTkIihsPh4eEhxD4pigIwsd/vX7t2bX193XGciYkJMPlCsAjUJ1BKIXgMgMJoNIK7ThCEZDIZi0UrlQoo9JeXl1dX18CyMBqNLly4EIlEvvvd70IxEYgrEKaMoXw+v7W1lUzE5ubmXnnlL2BztyxraWnp4OBgfn7RcRzOcDaXvn37bVVVIqo+MTUZBEGt3hwOh5bjplPZeCpdLE188Yv/5fbd+ysrq71eb3J6KgzDWCzm2O7pciqoktbr9VzXL5fLtVqdUhqPx+BghjGPGqpAuGmNhv1e/bj6y7/8tznzet32heWldDq5uLjY6XS2trZ++qd/WjMMxDFHP3hECDEN/F2hMCKEvPzyy5VKBWO8vLxsmuZ4PKaUaroyGo3GpmlZFsIMBKMHBwfzCwvtdlvTtE67DePjRCIxHA4BClNMksnkq6++XizmDSNWqeyXy1OtVkOUlHrjuJAvpdKJ42qdo/Da1Ue2tjd8LyxPluq1JhWw5waaruSyBT9w8c/94uclSYrHkywIBUESMAFFCOac81AUxTDwpqenf/Znf0qkSJAAp4QIM4RR4FiCKiDEEQ8R5ogHiHPXHGLMpUgEMYaIjJCMEAUlDyHkjGdCiDAWEiIizhHHCGNrNGKMRWIxhFDguoIgICqikCNKIe3zZNcXBFDAIcQ5DxAKMAYsgsOQIU6oIAZ+KAgyZywMOSEEhWh3d5cQWm82W61Ou9NrNtumaY7G5tHRMczXo9FoIZ996qknPvj8s9PTJYRZ4LuCQL9nzyYgecYIIcYZRgxxwjn/nmkepqefIAShR5wghDgKETqLO8eYI4Qp4oTzgJ1U+50yRsynhCJEgiAQBAmdzppZiAhGiHu3Xn3t1VdfnZiYiMeMer2+uLg4GAzeePNmLBZDCAcsvHD+0s7+3iuvfPdjH/vYlSuXZufnFC3yMz/zM1/5s69OTs24gc85D1iIEPK90PVszrkoigKhnJ9E3kFmBzod9j08FuQo5AxzFGJEMcYsCABOnUU2hKdZoyDfZqfpBbKqJBIJiCVLJ1ORSMQe25zzfDYHUUZhGEL0uRZR9/b26vV6Npsdjgcgyz08PDwRujImKwos1pj/VYeDD2Ms+LsAPmoR3fECYEEQQgxxxEKMMUGIECJTMWbon/uZn/2bv/DXm41GfzAQNcUNAyiuDsPQ9b2pqfLv/u7vfuEL/wbkJowxMFDCcCTwQgqpqohDEAOQ/7IoSpIkUgGAlwgx/Jx7pvlzP/+zH/v4jwzHw9n5eUTInTt3xiPr4qXz3XZ7a3sjnYgDQtKMqOu6ApUkSW40Go899uj+/oEgUNO08vkcUAXtdjubzebz+VarNRqNVFWt1eqRqAH8OdTpzM0udHttTY1ks1lQ0vT7/SAIQGWsyHKpVIIMCIinArqi0+kUi0UYK2SzWTAnRyJaOp0+Oq6eX1oemWPEuB8GcIIHyYGqqp1OR9d1QgjkmAsC1TQNPIZQfhKLxUBl4rp2MplmLBiNzFwus79f4SHTNP3wsDo1URYVURLo6vp6JpWgkljZ21+6cD4Zi9dbzVF/8MZbt8ql0sTkZBAEuUIeancxxoIgzM3NVSoVCENPpVJQ4JhMJk3Tchzbdz04sOq6Di4hMBv6fjAcDtPptGEYQNNCMoLj2IViLgy4rIieG6iavLW54/lOIp4am8OIHrUdM5PO7e3vzM7Mh8z3vTCRjBEsbGyuuY6v6/rk5KRpmsBJQCBZNpsFalCSpFarDZcL7thCofDqq69+8pOfvHXrJsY4Go1ubGzE4/FIJNLr9RhjQAXF43FQPu3s7AiCOBwOoUjUMGL1eh0iVcMwLJfLsixijEDdtby8XKvVdnd35+Zn7t65Pzk1Ua/Xr127BooRy7ISiUSr2dF1fW1t7X3ve59lWaZp1mp1GOpBQ1GpVNrfr6TT6UgkwljQarXCMBgMhufOnYN52crKCpT6CYLQ7w+BDzjRIEpCp9UEoV6lUkkmk5AnUqvVqkfHhUIB1OJBEICWGYgAWKmgUBKY0W9+85ugigvDEMK0QE2PMF9eXt7YWJMkRdd1y7LqtcbKysoLL7yQyxX29vbOhETggmy32/Pn5m3brlQq0Wi03e7Ozc1tbe44jsM5T6fTokQBx+i6LkmSpmmJRGw4HA4GgzAMs9lssVhcWVlRVdX3Q8hxgDcmIWQ0GmWz2WatDhPSzc1N8CtA685xo845hxrH9fX15eVlWZbX11chYSeXy0FpWC5XAF1XMpkEKYXnOZBURwixbdsPGHClkUgE2mCh5rnf7w8Gg2QyKYri1NTUYDCAQTzG1DCMQb/b6/cRZoJAr1y54vv+2tp6o9mkVHzm6Q80Gi1KhT//+ot//s0XN7d2EulUPl+EpMPhaBx4viDJvhcihKLR+Gg0smwH6t5lSbRtk7OAEJRMJfZ3N6enJz/7kz9x/+7tiC7PzEzPzkwlorG1tQdzs7NPPv004hhh6Ywf+csfD49TYD35+te+Ojk5CR6d4XB47dq1IAiq1Srw64IoApCVJElV1fJkqdPpmKOR4ziFQqHf7wNxCxG7w+FQEETOWTQai8WiBwcVw4hwjDVNNU3L971UKt1qNQuFomFEBEGsVA4IoRijSMTQNNV1vcGgLxzXG77vi7SiaZrZHyeTSVmUIpoW+kEmkwo9l3PGPO/3fvt3Ll68SAhSNSGZiiPGdV0lFImugDH3XdtxLEowxlgQCBWw6wwxRyEf+0jgWISxI0CNIAglSfJ92MRDggVy2lJCqThudAUqEUIEAbveGCbNZyHgjmMh5IuiaNk2sKlB6EConWN7rWbT98JareE4HuJ4MBi5rs8577V7o+E4Eom0e11KKUPcsb3BYAAFINPTs0tLi5/81CeWlhaMqIAwsuyhJIlU5JYzkhWFIUQQwWe9k5wghAi86jzECJ9MDBHiGHHG+MmXzm4DkCLRh//xNPk75AgBQAFrHjw++DUIOeFpMMYYE444whh5/tr6A8ZYLBZrtVq1WiMImOd509MzMPLPFfKRSOTqo5/827/0S4jS01EmTWeS8WgsZL6AienajJ/I1TGiGCNKREox5+RMRPUwHEFn3TIYY0QxOUtwQGCogS/B5ywMAbE9LOdCCAHtBKgL3ueEEziZwXpECBkNh47jaBEVIQRTDIhkOxOzC4JwBv7+/8VVZ1DsYZukZTpeGIDRDwA0IhgjzKDegLP5+Svz8/MQLF4ul50wdMOg1+sYhuE4TjKdsm376tWrgR8SQiBrLgw5PE/OOaaI8QBhEMa+q0uD1/rkKTEe8EAghCA8HA4Dn8WiiaFlE0HY2t42otGJclkQhFqjYWhGPj8xOTm5u7uryJokKu12ZzQap1Kpo6Mq1LmIoug4bq/X9zzP8/zx2Gy12oPB0HEcQijj2LZcxpgoyE88/iSl9PDwMB5LQoQMPDeYkcXj8cXFRUWWwXMA4Q5AAMA9aVkWsBG7u7v9fn9iYoJzvLq+lslkqrXjtbW12dlZmIOcP38etoFCoYAQAlEXNORgLMITdhzHcdx+v++6XjqdchyHUlKpVOLxKOfItm0wBxEszM3NDQaDYDziPARrj4rRo4/feOONN6C9R5bUz372s74f2LadTCePjo7g5Y5EIhAiADUv3W53e3sbsjpbrRYU7xCEm606YAgQop2xs3BLg88IfKzws6ZphmGYSE6Mx01mBp7vhGGYyaYKQg7omdm56XQmaVmWosQgBkk35IWFBYyx67qNZk2W5fMXzt+9e1eRNUJIr9e7cOECjNtkWYH4cnhzNZtN6MMhhCSTydu3b0P86c7ODmyEoJyDGKpoNDozM+M4LggfO50OY2hubm5ubu70/gyz2QyEoBJCbt68OTU1lUzFK5XKs889bdu2KNKjo4ooiqPRKJVKIcSCIIAG6NXVVYiPz2Qy+Xz+zTffhDrInZ2dRx55zLKsarU6HPYlSbJti3N+eHi4srJy4cIFXde//OUvX7p0aXZ2FopywX2ZTqd3d7fN4SidkZLJ5Llz5zY2NsbjMfjez58/D7FkhBBAP1BYpKoqFF9GIhHI91paWnr00UcxxnNzc5ubm7quX7t2bW1tLQiC2bkZSnE2m+31eoNBjxAhnUn99E//9Ntvv721teW6bi5XkCQJY2zbdiKRAiLz4GA/FotrmhaLhZB0CmBuOBxSAedyOWhSsm2TcxnMGYZh2LYdhiE0GA4Gg1gsAQkCsAKA3nxvb29+ZhZiOJaXlyEANpVKHRwclCbLnU4HotFAROj7PnDthmGAA+PwsHp8XNfUyLWrjyCEIEP/6tWr3W4b+tOOjo7gjQZOW0EQdnZ2crmcLMuXL18GFdDu7u69e/egUNJ13UQiJUmSZbtBEEiycO7cOd93QRQ/WZ4Yj81moxo1YpoW+cD7n3nu/c/0h+MXv/ntb774YrtRX1hYUGRJj8WGY5ORMBI1bMvCmEeNiKTI4+EoCHAslkCIuZ5t2Y4o67brN1tdTgXHDTU9MhiO4/F4oVBafbD+5HufCb2AyiJ/l5j4HmgFmwss5rC/aJo2Pz8P0SrgyYAK+StXrty9e5cxBpWUoCl88cUXI5FIKpGs7O8rigLytUQisb+/b9v2tWvXbt68OR6Pn3jiCdu2EOKiKIzHY5A3wGRcFAVFUWq1405H2t/fB47ZdV2YsE9PT+dyOfyP/8f/udVqUUyazWbg2KZp2pZ1dFAJPF/TldD3c/kMtFKEYRiGvqJokUikXj2ORiOZTMZxLcexEQ8lSRAJDoIgYmiEYNsxZVEKQs6IwBABhgadWNI4+B1AUgMaFNd1QbpIBCpKkgzJ2mMLjragdAYBfhAECOFut+s4jizLnuPC2Mh1/XazZRiG74eRSMRzgzAMVVVTFGU8GAYBY4yZjtloHo/MISXi5OTktWvXnnjiievXH83njeAkSoljEmLMMWEYn4QswaaMTrkrBFNhjhBmpxY/jjA7mehxxH8Q4n54g3/4A6Z1oihC3hg5qRokwPucAR1AA4JAjvZ2/7cvfCEej09PT/e7Pd/3ZVkBcHP+/PlsPpdOp/VEAmHk2zbnXCSUYUSJ+Nc+9zP37z2gsui5genYIWdnTBX8OMUEIXRWfcNPk5zgV5/iPExOk9/hG+gphDr7Bj8MwWR0RnpB3amu65qmBYzD73Ich3BSLpdnpqY1TYOUl0ajEY/HNV0Bz9TR0REQgqATAr1tcNpBjqDd76/GYJGHsqnO/gTGGMIUQfY6IQi/m+nFfD+ZSv2tv/43P/Hxj1+7cllUVGbbRFUR5zCnZvykcdz3/Var9ez7n9ve3iYnsXgULhkVBHhBwaOHKQW+ShAEyLIXCCWEQNqLJAgiFdqN+he+8IUf/8ynh7YZi8cdzxVFCo0Rnu+FjocxVnR91O9rhu667mAwhHDR3d3dMAzT6TRwgWfXn55m7sN0RlY0CJ4JwxCCGT3Pg6EMpVTXdWjaBuUs5/xgf39/f//pp5+GRCVJkuAEDBpeGI7Ar8tkMs1mM2A+pGZDsMLc3BxM3OBq67reaDQwxicSAtcF7xgLEaEoasSHo74kKggzzrkgUN8PNE31/cAwIuCGC7yQYEGUaBAEg0FPFAXw70B/pSiK+/v72WyOELK3t5fL5YxYtNvtAlsDo6LxeAyp9/Pz847jnFiiKFVVdW9vF3MEqYPj8Rhiq+D6BEHY7/fBvzYcDlOp1NTUFCEkFosyxqBJulqtghMeXnTgwGD0BjwKQqhQzIEGCL7hkUceGQ6HlmVpagSuPwiSJEna398HGbIgCGtra8lkcmJiAgqwRVEUBFqr1QghMJyt1WpBEMAoU1VVSMpACMG5hTEWhiyRSEBtOejhwjBMpVII8W63m06nNzc3gbqbmi5vbW0Bqb+3tzc1NeW6Njymbdu25YN2DezorusSQuEOxBiD+SAej9+/f//ChUvXr199/fXX4/FYuTx579490Al8+9vfvnz5MswNgoD94i/+4v3792GcRyn2bCcaM1qtVj6fr1arcF/Ztg1xXOl0ularQXRnOp3e39+HbiIo14I/7ejoyLKsZDJZLBaBxrhw4QKE1hYKBYgUP3/+fLVa9bwgm83W63XLssyxVS6XJUkyDCMIGIRBpFKJSvWwPFkqT0z90R/90ezsXDqdplSE5uMLFy5AHKiuqzBArFarkiRCXQ+lNJFIAs356quv/uiP/qgkSXfu3JmZmTk6Oo7H4+AqjUV0URRv374tiuLMzAz4o4fD4ebOtuM4V65cMU0zCALAoKlUanJyslY73t7eEQShVCofHh4CLJ6YmIBOhenpafCJ1+u11dXVD37weYjRbzQaILWEPdf3/atXr6qq+vLLLyeTye3tbdd1H3/8PQ9WVznnc3Nz7U4TIR6GoWmOEEKlUjkIgqOj6nAwLhRKrut7npdOZWOJBKaioen//nd/56tf/WrEiPW63WyuoKoqQ9jzAl3X6/U6piSiGaqqjsdjWRYZYxhzgrjjWI8/8VgiEe02G4Vi7sLy0vzczKg/uHvvzmd+4tOFyTJnmCNyJu34PoB19n/P5iRf+qP/Aoo0yMRPpVIYYyhBeuedd6ggXLx4sV6vQ7zwaDS6d/d2Pp9fXl4GlgukbL7vS5IEbDE0T0CYyN27dy3H7vf7k5OTuq5jjEEpATq/arUKdyOc5TKZzO7uLv6lf/CrsiyLFAgTTintddue53UajX6/Pxz07t69HQRMVeVEIjExMckZOYtK6ve70Wg0l0l3Oi3DMDDmIfNlWYbhfURXqSAFQRjyk6guSZJAJQ0hbIRi13U5D0EzqygKQ9yyLHJqgnVdH5QZsqyAvQuACOcYtM+DwYgFDAb8giAEng/7KByROecQFYNCBo1msVS0PFVYPn/uueeeu3r1qhGJwGsErj3GEeecUowQO00lgP44hhCBQSagK9jaEXoIY737WuP/CqWJvlcnBCoEmCWdUUHQF4FPG+tgy4ddU5aE7/7FS6+89FK5fJK8F9H0WCw+MzOTTCbjyYRhGFiREWOcwRz25MPsjz7y8RfarW6AGAuRG/gcn8W1M8AckPnkec736Zn46cjvbLfmpzFXGGP0UCYW3PQh5/CYZ2IpyJiGjic/ZFDBJAiCSMRYLJZNZzRNgy0ZSmod1yoUCru7uwcHB9G4ASQWKJdhvuY6DpgA/jLA+gFyyO/997NPTjAipieICiPEQ/gOQogiSbqu/9iPfuLv/NIvX758MXBcQVbgBx3XPTk2YSZKEhxZ/uE//If/y7/+DQjXplT0PA8hdNbEAhY/dJqOQQiRgM+jAoRBcM5lUVQkuVk7/tKXvnTjqScDHmJCCKVjc9zptKKGkUwkmecTUWS+TwQBPVTTxRnb2toajUbXr1/nnIM6IQxDqESFpjlCiChJEHyKT+M2zijGs8sCglx44Rhj49EIIRSNxTzXFQThJN8PrvmZUSAIgiCQFbg+DCHkeq4syYPhIBKJUEI932OMSZJEMGl32tLpB8ECnNwURUOIhSG8+wiUY55CYRYETBBIEDBBEBAnruPIqoQQcmwbouM81xFFERNyqnh994lxjAQqMM6AfJIl+Qe8JRH3PA9WVUkUEToxKMEjULgUISOUIs6DIID4hiAIjo+PY7Ho/Pw8vCls245Go1C5DXFEqVQK1E6cc8MwGo3G1HSZMeY4DrQYTU1NbW1tDQYDc2wDHQjfDGOyycnJ3d29dDo9PT19cHAA7XgQHB+NGgghEAtCDhAMPsADBUbxMy+eKIoYEwjKAnFSuVweDAabm5u5XBb2FcifG4/HY3O4tLRUrVbB8H90dEQphjaebrefSedmZ2dv3brlOA5sURgTWZZhHAlvc1h+XddPJGIPHqwsLy+HIYPGIUBOmqa12+179+4FAZuZmUkkEpRSqGyK6lq70wqCALIGOp1Ou92em5uDwnKAZalUKp1OwxMGlAkzVpCcgwhsdnb2/PnzYFxoNBqqqi4sLLTb7amp8t7e3mAwSKVSruvDSb5arfpeAHYN3/c3NrbgwgaBl85lmq26ImudTocQKghCIpGam5s7OjqamJio1+uDwaBQyFWr1Xw+3+m0GWPj8Xh+fr7Vag0Gw1wu12g0oJSp2+2appnJZDjHICnL5XIUcVmWQR+2trZ2fHwM9VCpbAYQuSzLoIv3PC8IfMdxDMOwbQdQ7NNPPwspX1A35DgOY0G73W61mmC6HI3Gc3NzBwcHpmlqmjY5OQnvepgUa5p29erV119/HfK64vE4FYX19XWYHsbjMYRQPB5Np9PVag1jLEmyaZqSqLiujxAajUxRkF3fm56cunLtar3euH379hf/83+5u3LfNG1JlnO5wkN3bAwGEYqmsSDwPNf3/dFotLg4f/HCsjUehqHne961a1c+8P5nb735xuzMzONPPMEwOVuif+DCfrZDIYQIIa+8/NLx8fHFixfX1tYMw4BctCAIoF+SI9Rut5eWloC1dV3XHA8VRYHizqmpqWq1ChN20zShuqDZbIKHN5FIBEFgu85wOHz/+9+/vr6+srISjUYnJiYODg4uXLgABOTVq1eDIFhbW5ucnKzX6/iXPv/POOcsDCjFIkaSLHiOIyvi3/3bf2tiIhOGyLbd/+P/+NLt22+/9tpra6tbjh3KsgqyDMiD8T0HTBAIMVmWwzDAGEMlkCzLqqoFAYOUalEUEeIh8yEHCCFECHJcG060YRgyzqmABVGEkzFjiDEmCCJnWBAEx/EkSbEsyzJtAGS93gAxHIYczljxeNQ0Tc91m826bduWZcLVv3L10tzc3KVLl5566vHCROqsrs6yLYyxImsPowHOIRuWn7JHMI0CzHHm7Dv7YAgz9DC++m8BLHSKXU4IFfgZjEGngglBD2m6At8H8QWCfr4w/Ooff7lWr0IVqCzLM5NTiURicXGRqirCCIVh4Psnj3gqNndsu9Pp/Pxf/4V+f9gbDhRFG5mm6wfv0lf4BDETQgAZPKydOmF6EIKxCMb47AcFQfAcB1z6Zwp3AItAeILjzLIsWHlVVXV9DxxzgiCgkAmCkEllU6kUKG/8wIXSNMaY77uWZZm2BU8A0vNOrpXn/UCA9V95E6Lv1ZOdMcwnncyYM8RPXhFKMcah5yVTqdFgGNH02enpJ248/vGPv/Dkk08aiSQPOCYcURp6TsAZAJd//1u/9Qt//W+m08nhcBgwDrvaKe8onFh2KcUYE4TORL4CoaIogupRFkVVVtqN5h/8wR888/wHPd+TFDlgPiXUcR0eMlVVURBiQUAYBb4fBMHZr4DRJMZYEMUwCAghmBAAB67jQNEs3A+e70M1LBiqYY55Fkp0tpCd3QDhKXIKfB8enJ9WUhJKH8IfIcA4x3WhF4VSenR0FATB9PQ0PCCw1Jzzs+ou13XDkOu6jhDhPESIUIo9LxCEkxGqbduyLMJXwVSBGIcNVVZERVXDAKwhKPD9M1DoeQEcBsA1Ylom51zTNIIJQmhsjmF1CoJAkRU/8CmlBJNev4cxNnQdAksRxq7jAHcF2y0VBOg+g4sgiKJlmu12C/K94IXGhNiWBT1O8M0nmI9zhLHveRyFkiQjhM40qYyFhFCEyGg4JIRAcZ4oSYhzy7L29vZhondm3iSUmuOxHtED32eMSbLsOo6sKKegEIdB4Pse1FJ5ngdIEb6n2Wgkk8lerwcRPKurq81m0/O8GzduQAgWiKgymYxpjeLxeLPZDMMQIGMikRiPx73uABgamIJZloUQhtbIaDQKYUK1Ws0wjE6nMxqN0ulUuVy2bWd7exukx61Wa2dnJwzDp556amZm7qWXXoJAh2azmc/ne+2W7/tzc3O9Xi8aMxBCu7u7tm0nErH5+flutwu5CaBhgr8FypQg8g1yp6B0cmdnB24DSAF1XXdiYgJ4dDAAdjody7LOn7+YyWRu3brlum4+VzAM480334xGo4yxZDJpew4VMOIEyM5EIiHLCmxPrVYL2oFAxa+qCmQmzy/MYozj8Xij3oKqQWB5Dw8PwcEXjydA61MsFvudbi6X29vbW15eZozt7+93e518Pq9FIuPx+OjoKBqNQmELQsg0TV3XqYDLE1OQuPHmm2898sgjAKz7/b5t29lsxjAM6OHRdGU8skB9CCEphUIBvJzAsUFp+s7OzuHh4dWrV4fDIayxuq7fuXMHppPpdFrX9UQiCepJznmn08GYgqF1PLIQwf3ugGMEZ5hzi8v7lQPTNP/kT/5kZeUBQ2hmZkaSJNf1NS3i+77teLZpAeUJ9Y75QpYirqiSJIgf/OAHMGK+7w773b/7K7/CwjMC6wdPCeHzM6Zg0O/+8R//MeiSU6kUNHAzxlRVbbVakiw/88wzILsE90AyETNNs9vtHh8fl0qlxx9//MGDB4eHh/Pz82+88Uav1/voRz8KI2ZJknK53O079xBCtVrt6tWrOzs7AEwPDg7AI7+3tycIAvy9+Xz+8PAQ/51/+Gucc02Vfc+WBdpoHl+/duWnfuqz8ajKAs45lySCEHKcUFHo5ubBm2+889K3X753797a2prlWhjhaCQ6OzcdjyUx4aBlwxhDKpdAJUVSGUOCQDDGokQJQWEYqBpEMCNdV33fJxRDwHcQhqomy4oCXAXn2HU9XTMYY6ORKQhCGPLRcAzLtyQphJDRYAyz+WazPhwOa/WqKitTU5PFUj6RiL3//e+/ePH89MzEGQJiyAtDD52OimDN9QNfFGSOUBiGApUQOkmtpJQi9HC3HYyZvg8/AYMFMAufiZO+7+Ph++P7MIHnujs7O2+++Wa3252cnFw6d35qagp6uAgh0BkOf7Jr27/5m/9WlRVRFBPJmGEYzz77LJVlxDkCkkmSQs8LgkDWVFiO11cexGKx+ysrv/IPPm8Yse6gT6k4Mk2OCbBihBCBvMvunE1yz4aADyOSM4AFog1RFH3XhZkFxH7CSy8IgndKaMF5HSEE1fSO51JKCaJBEISeryjK5MQUzD4cx7HsMdD7lUolEtEGg0G720GnHB6E8OLTSAiEEGJ/VXSFEMjaYFxyQr9RSoOAnZI4nGME0yIIjUYIyaKkqirFRKTUts1yeepnf+bnPvOZzxQnS77jiJKEMGdBQEThzTfffOqpp0RRZJwzhOH1OrtKsKMjQjDGFGOYtSGEJEEUBAExDrJ3RZI7zda//bf/9mOf/DHHsRVNHY5HRkSHmwb+QN92RFX5vj8tBKsBxoHvU0rBtwxbOwznzmAQgU1XkhBCEJQAOzd6aCiMHpI4IIQ81wX9/ilkeejWD0N8GugP+PuM1gJULYoi/N8zSu9MfIZPiy99H0i+E3fIWQgcYygM/VMeC0FZZOD5tm3ruk4oRZid4CrM0SkiJJTCw3quSwihgmDZ40ajARVjmqYJVEAw4cVg2jiZbjPGREEMfF8QBQYHYkoRQpZpgQUMKlDg/QhXIwxDzhlsXWdcINxjQRAAfg1P09IxxqIkIcQcx4YjKHxVlhXbtlQ1Aq/XaDg0olH+7n1+clARRJGFIbxnVU0LfE84vbZwEeC9DAQsQvwsHwhjPBgMIpEIFQTf806OUqdFuXBrwZQT5vgAyBBinucihCRJ9jxXkuTTMglysoRxDt26pmnFEwnXcRhjJw2hjD0ENE+o/jNSMPB9SF3JFwrm2NIjEfgr4Pv77dZoNMrn86IohiwAYEQIMeLRUb8vCIKq64NeL5ZIIIyZ7xNRBCqeEIIofTd8MggQQqZpAgMBPb7xeBzYCIwxxHxXq1Vo81xcXIxEIgf7FahYtm377t27P/bJT/SHw5UH9ygRoV3eNM2lpWVJkmq1GtSiW5YFrSmapnY6HUEk8XgcIZTJZOZmF6DpHOQNoG3QNG0wGIIgPZFICJisr6+DQOLnfu7nCCGdbns8HtuuC9Htw+EQxjhwP9Qbx7quj4ZmLpczDAMyeJvNJueo1+smk8nZ2VmYvEdjkVarJVBpPB6Xy+Vms7mxscE5hxANeNpw2oF3N5QucBRCLpTr+Iwx8FpSSmVZGY1GYRiCExPqF9vtdhAEkqToihpw9uDe/fL0FGc4lUljjqgoECJ86Utfevnll4+qVU3RE6lkNBqLJ9M8CN3A73b7qqID5ypSfO3aNcc2L148f7C/p+tqrXr4hf/tC6lkBqDbD1zezzDWqQghEEXx5b/4i7MQMigR39ragsvY6/dhNA/2YYQQZwFQFf1+X5KkJ5988v79+6DiIoTk8/k7d+7cv3//6aefxhjXajU/YDCXV1UV+hNjsRgUkN+7dw/yAi9fvgwhDoqi4L/z+X8VBJ6uKX7gDPvtz3zmxz/0/HsRQgQh1/UVWUQIua4PzDnGyHOQJCPG0a1bd/f3Km+//fbLL79cOdxvtbtwLo/FYqlUCkzCmqJrSoRgAbRTjAech0HgSzLkxQeEIM45oRjAhCCKrusKkogQEgQhCEKEEAsRQigMwzDk8HLCHK3d6vQHPR6ybrcty3Isbly/fn1paXFxcfHcucVyuQBvac4DWN9FkSLEMSUYcYaCs60aY0wxdT1flmSECOOchYhS8fQVZQ+9ng9BK4xO96STbwBkRf4KDBZ6CGOx0KdUQGG4srKysbEFHRqQY1YoFObn5yenp8+WjMPDwz/90z9dXl6Ox+Mwyb5w4QIRRd9xoIBZkGXO2elSywkh5mCkx2J/+B//49/9lb83P7/YHw19PwwYc30PlEyCIFBMwjDEMCAjZzTeuwALHjAMQ3qayHDGYAF9AmDi4ZRR+MHgdAoJkALwt+/7jCFJkiKqJoqiKmtwpqSUchQeHx+DJafTa6+trUEDKzwf3/eD015ncHL91QEW/j7pFULwVDljGJ3UMGOMiUDPdG8IId/14KgHTQ6jwQBxks1kPvGJT/x3/9d/ghAKfc/zHDUS8R3nyvVr6+ubEUMPOQJohU45oRMGC5+EtQLIEAQBABaMm2VRlEWpcVz7jd/4jU9+9icRZxwhTAmHRmrGCSGIcaBDOOeO56qqGni+IAiAmYIgONl0H844/r7IWsxgMUWnI0JYu+GY+30Xzfd9gYiYEMe2FVUFDlWUJMs0NV0/o6/gI/D98XgsKTLoASCbgz7UEQ5/PuAkxhjIiThHtuVpuoQQGo8tWZYFgUJzdhiGonjy42EYQqj6UeWw3+8vLS3B9FNSRH7aNwD+YoQQpZLrOKIoEgEjhPr9/s7OzszMDMh0wGgWBAHE1cI9DCjT8x1ZkhHnQPycHWyOjo5ANQwBzSfvGkoJpQjxh7k9YNGAjQbxFnyJCgJnzPd9TLgoSpxDO6cShgHBwsmVxxhxHoah67qarnN28u4DGsy2bU3XEUK+5/m+r6oKjM6hIfuMZSTkROcHPmtzPFZVFYAUZyxk/gn7SKjj2IwxTTMc2+acq5p2RrOdwOLTkCHOGHCcAPjgq7Ztq5oGa+x4NJIkSZLlwPddGCUTIkqS6ziUwmqAAd6BnODkhgkCQZAwIb1uF4YhnHNJEs52U0LwyUFXEDgPfN+XJNl1HUkSoBQZYxy4gaSqgesKgAvD8Axn+54nKopn25KqIs5D36eShBBCjPV7PV3XRUka9Pv7+5ULFy68qxml1LddUVEQY5Y1JoIgShRyFiRJRafjY4Cn7DQjEDArQogx33VdyPuNxeK2bQGVeLIkMgzXE15WeFb/P97+NEayLEsPxM65y1tsN/Pdw2OPyMjMilwqq2q6eqnp7uLSbLLFTdQMyQE1BKQR9KtBaSAJBEcYCNQIGIAUe8gZagAKTQxEaEARVA9nRIndrK4u9lLN6szKpbIql4jIjM13d3Pbzd5y7z36cd679twjMquqSelVIsrd3OzZe/fde8853/nOdwCguDAAAEhms6heL39zpawjX7jlQIWdEu4S3Wq1er0ekFBaSClZa5A3Sa2DPEmEEFJrZ4yQ8uT4mIFG7oPEU2V/f5/Ft+7fv8+pmyiKiHA+TxqNRp4Znu3vvvvu6enp3bt3V9dWWMml1+sBwEcffry9tYVC1OL43v374/E4ybOt9Y1Gu8XNA0ajyaPHj3//29/+xm/+1urq6t7+4WKW3HnppXqtOZ8ns9lCKXV8fBzH4S/9qV/M8zQMtNby9PT4L/yFv/Dn/vyfKZbGhaOyxUEJDTD0++EH3//93/99KaW1lOf5V77ylTzPf//3f//y5cuPnzxhYaBXXnnl6Ojoe9/73ubGxrVr1/r9/snJCdc7c2afO6xzeHx2dsYNIjudTnelM5vNjo6Obty4kWUZN3QfDAZBEHC3sZ2dHSHE22+/jYh/5I/8Efxf/vL/qdNpTcYDId2//z/5H//ET3zBGjA2q4VBbvJAcbZOIUKekdJIlubzab1eRymAIDdWKTmdLPb39z999PCtt7776NGjx48fP378OE3TPDVKRs16kwn2URTGtVApUa/XtZbMp2m2GgwVxnEslUIpOCDm2qIoio6Pj9nRPj09dRa01qVI4EYY6n/nK1+6e/cL169fv3b9SrvdLGkcMJ9NarUoz3PnbFjwPTMplbFMITeIKAUSUJYnUkolAgJyTiAKgYqdJGY/MzoF8BwHC5aukisdLAk/1kGOSqdB6BAAZuNxlmWPHz8+Ozvj6lkm3K2urh4eHqKUL7zwQrPVAudAlHoWTNC2dpGlURShENZZAJIogBCI/u5/8V/8rb/zf7558/bhyXGWmUWapnnGThKLBVhrwRlEzC2VeA5V0SxOQpG1RalgWQ3niVke5eLwvWgOn6YlGEnM4c3zPEkSImw2m616g4hCHXF9TRRFV69dPjk5efTo0Ysvvvi977/HvAoGzPh6vJZp4SQ942B9lpvFdoUqB7+uhEREB+TToMxO46Vbi2vcnqJWq2mparVaPaozXPTVr371P/1P//dXb97MkpnWGpX6c3/6T//3//yfNxr16WwhtWK+IP/L5hkAOIvKP2utA6XZbQKAQKlA6f7xyX/2N/+P/9P/xX9EzqBSjhyXWSghnXMCxRJ44Bsl8Pa7Clzx3RXGEpGdAH57gYTlOduGoNzcqSTPVceKscbCQlScNn8ZnHsCgPlslqZps91SSjHv2MPA/AP76PzsuCLPlWUQUHpXWsskyYQAIZRSgrvRcXzJAsomyzmGLpw2IQAdXxKPg7Ol+AsAAFgqZESgFHI7Pj7m3sZeg43jB+ZgAVnuNcRceEZimEvHeFieZUTEEtKI6JwNwpAHi4edkRjOmTLzoSh0KJxR6+OQMkoJufBWKsX5faV1nmU6KE6b5znbsytXrvCVWGvzPGMmPhvUIAjYA7PG8nmICID4wTGt01qb5QWdAxGV0gCQJhmWpVic92Q8zFTkV/h+AcDkOQAWrm0Ysm3jVDXL7ntWHyLmeR6EIWNpzhEHGIiFh8Ht25IkY8d9NpsxLS/P0zzP641GmiRKlUUhWlubScn6w83h8AwAOp2uMTkZ4jcwR5AF4rkUg/3yKI6tMf5ZFEh8GM4nk1q9Ts6hCsaDQZIk61tbeZIopYCQGwM3W40ky1BQGEaDwdlinkZRxJ0lqRQIYAead7k8z3UgpVRMD6eyttoYo5SeTif1WpNjIT/lwG+tRJzcZL9/kaZxHCvNWlxTnvO8LzEx4OnTpxsbG1EUG1OgvETEterG5Epp5+x8Pm/U6rPpNC0H5+nTp9YWtbdcBMr68teuXbty9SojAyZbKBUCYp5aREQQhf9nbZZlQRwCIlg7m02klFpyQ0BtTMYrd7ZITk6Orly51uy0TJpnWVar10EIa8xisYii+NNHD3/j17/5e7/3+08e7yodXb58lasu0jR1NhcC2q06gJvNZkGo/t5/+V9+ht0sHKwqacEY45zhKodut7tYpFxhc+Xq1d/9nd8hola7XavVeOfhp7O/tzefz0ejEdO4EfHGjRucO+aeRcxEbLfbBwcH1tpGq87dSL/3ve8x55KLfrhxQqfTuXXr1ltvvcUlyQCAv/wf/+dxHE5GZz/38z/z5//sH0szB87Gscayxa9ShbfBgSK5TAoEosxYQSA0x+UgC+3Hpa7348dPH376+PS0/+jRk48++uj4+NAYw099Np/wAlZKBTrivAyPW1SruTIk5UsPgiCOI5ambTbrKysrd+7cuXnz5qVLlzc2VpikvrSauJQdAyABCEsgioCEAwASKHj/JQQ6h1GBWsp7FrvyOT7v8qi8QM9/eQlTeatffaXIyLhStP3CV1jL1Wp5kgyHZ2yxGo1GXG/ChRoKskBkgThJBES5zZhWYp1F44QQf//v/9d/+1f+zvbWzmAyGo1GxrlFyoqgKKUUgEQkwAkhcrtErc55UYh+y4BKFaGWAdcrLRaLIAy5gt1zg2azmZQybtRZSVxrvVjMWAInjmNu3NtutbgtMRevTafTerPmW+0yL5KTg+xpcU6qsKB0cXh9mobtukfa4Dws5z/F984fRCl4U3aORV0Bi3sXfFNaqlpYi+N6FOrJZLKzs/2rv/qr165dEUKIQP+v/9pf+3t//79SSgHKNE1BoNZaooiiSOqivydfGCIy+yrUgRCCrAWAIAiiIDx4svu3/tbf+ot/9T+EMmvJZru8w8rcenZKPo+mcPFNwD0oi3ZmnL6sIkymAIFkuWWrZ85QHIyE8agyP5qIuE2NvxIPFl7w2kXZlMmVDS496gkARFYINZmM3nzzzZdffrnX6yUl1U/wpRbVqyU9n7tBQLmIym9BRBBFi0xv7TxA4l1MjzUKIbi6hf1Cv0gBgFcTAEjBrQ6IiPeRZXa1+gOPiX9DKZ5nyRkppTXkKzbYfWFUwz8u76YwFDqfz1nlkgHdk5OTtbVVPgPjWGEYFrCKkIWrR8TqjvfufbxYLL76kz9p8hzQqbLVLN+d1hF/qkhrhiEALOZzIUQYRc5a9js9jYzKzlS8yrAkDPAS82PLzgcKYXJGrQQ/GlY/UYUQtDa5ZRpZlqb8dIREcs45CxWVI84CG5Pz8ucgTSnVaDR+4zd+49133/3KV77SbDavXbvW6/U8jeFCxMWDmyY5fxFHfRzMAwBvYuXSyDh7HgRaa802ZYk9l91F/ZkRfeBNuUkBilatiNzf3bEV8+EEd7/wsCKWldpYyQ8oAd4O6iAAxDxNeV8FgNFo1O/3d3a2o1otmc85ZmMheESs1RpxHIMQZK1zjsuDarVaEEVQfhFWqlWK7JoxzhkppZAghUYhgCQRkStGT2ptTeacOzo6QqT19XUA4KYpZIHAAjt4qEBCOl0ICdPJPLcZc/yJSAa6rI4PiPD09Oxbv/W7/+p3fuft774bx3G701zp9qQUyWK2ubmuA3lwcPDLv/zLr772GpRbdIGwBgFAwUON4hgAJuNxqXi8WqxoxPJT8hnzfY5F7ay9d+/e5cuX640GOccwWLJYHBwcDAaD/f19FiD9+OOPlVI6VC+99CLXF7NCMitrbG5uPnnypN/vcxXh9vb2pUuXnHNKCZqOB+vrq1/50pdyA0oJLQtnkLN2UKTnrJRaSgAhgSyQCxRCSXdwJsvmCRFZBzxZtdbXrl25evXyhU0/SZLh8GwymXBCN8tMlpksy1hVwTmXlxSuMAzDMIzjqN1uN5v1ZrPZajcQkcgyecI6C+AclRypwpU6P+8LHjktOyUTT2tAJMDCe+JPExBwqSBAUTnIVuyHkXt+3OPCmn/+2UuPU0fR2vp6QTJQkhEpPOeTIQBIKU+Oj621a+vrWmkCykweKG3JgpTcgVIoSUTGuUajkeZDfzFYOhnW2iCIXKm9jqX+grUWpPSVGuwlFA5Wyc6p1+tpViTUuNUrlwLleZ7kGUsk89rm5HeWZRJkt9vttNscurlC6zzy7RH5h3I8CqF5dpiK159xIKoWDs7nK6tW8IJPVsByUPHASrTGe1tKKUIxS9IsM2qlu7Kycnx8+su//Mu/9mu/pkINRF/+8pfBUlALcuMAgDtaeMfC4wTF1wE6zwYD4Etl5uJ4PGZlXRQCCw0HP1XKySKKG3ieC/WcmeYP58gbbx/YeC/nuR/5rMN/NZ8ES4qeH+rzRgir/sqFr6v+SsS23zabzddee63T6ciyowAwL4oISpwYvatZvezz9+D9cmbCUdlygDeZZahTXK5AWWwIUDpS/iK9v1iMAJy7neq8Yu8KylCkBOpQygDASSlEWVZCRJyUFEJIWdZpQjFlGXdsNJucg+NbXltbs9b4byxcCmPSNFVKs7vmY/RLly6FYTibThk4VMp7twIAOJdatMIMwzzLHFOpyjHx5ZncR4FpTFgWi/A1+FVWfcrOOQGgtOb8JhHx+PM7ldbJYhGGMf/gNcbYAVZqaRTZ9bS24DNAuVKk0ErJn/u5n9vZ2eHUTJIkXC/Jevo8gq5MIfFX1+pBkVRil7GE6IrrF0IKEQvJE0MIkSQLHRStQQquodAeDigfN5aBAZ/HL/llIHF+UQARsa/p186F9zhniUiFoQTgLKeOIs4eHh8cDIfDmzdvykDlSRLV6zbLAJGBdp7nbD5QKWktVxAjIhROPAvcVHx5XmBCOKecM1gop3P5fLGEhdZkjFRKClGrRUSko8ikKQgB5ABZ9sfYnBAN5ODIaBnWGzFAGNRqAGCy1OZOqMA5l+cLBLm2tvJn/9wv/Y/+9J8ajibf+MY3/tk/+2fvvPN2t9d++cU7BFYpvbLS/e3f/u1XX3vNOcfrwuS5DgKPIiutR8Mhi7Q1W63FfP6jb198MBbLCvKnp6dXr11DLEQQr9+4sTaZvP7660R07969l156Kc/TqBavrq5wf0lmFfd6vTRNWUyKK3nZIBLReDxWzUaQpZOdS5uNWqAljMfTZqOmlFCSdTUdm3OmoJJj+XIEqYGIjGUsWgihdaiU4o2PnLM5GyoHghgu4rkuFWxsrm5urrFZ4TpBAIEohbg4NkRgi7gB8zyV6KxjjSUphEBwuESfBCJiZc445wCQQAB5/Sq64CsRn4A3UsRnXB0Hyw8W533uQypzNT/8qD7+IgpE8fy3cswkCIUAKYSsvE3gedBMAhAQahUKye6IICBE6RzIMHJZfnh43Gp2JpMZkFhZWev3+4XJB4kkpABEdCS8O+WpTgAgyj2UiMg6pEKiAku3gzmeKysrURhaazNr2+02AAwGAz6PSbPGymogFSImeZLnuQBQQiihEKAUcQ64s0EQBJPhmDFz5rJQ2WgMyi1MFNtByX47r4lStXaeUu0qkXf1nURWctQGwN4Uv6FAtoonS8ZZYRyisbmTtdpoOpvNZqurq3/w1pt/42/8jb/1K78C4N544w0CZl8V4hQAoESRgfKmBVhoFAv7qpTiQXfGoiMUtEhmDMpiGWk5coJ3uoIxXM6Rz5haz45J5W0SAIkcO5/MNSwL2XizZY4OgzrPnmB5qAoByznH20o5qhc9j+deJACUi/ZiqtfYTAjR7bWJHAAqJQCdkoIDKizeJtgcLY2xB67KLAAZ67GH6sUwddpz8D0/Twhxfhx50oATrpTpJ6UUlptK0bvzeZESUSH7R0QkSAhRkg0KyI35NHwNQRBiCcVZa1k2gsvLEVEq5WUjAEAqRbRE/go2kjHL0TNGSslddLTWUqksTS0jVdb7fAAAYRTPptOTkxOtNUv5+zQu35eUkot+nAMi9NCUKHtVVec2D7AfNWsdWGDXhL15Ti57h945ByXAwzhcnqdSCucu7pPGOCYzcbyjtQRAa/JarfmFl1+x1gKJWq2ZZ5lSQgoNhERA5HkdWPy33OcREJXSiHx37HYs64t5SiMikAASCBKBxZ6R74J9qSKsByBCTpKw283wk39G/KyxhIaXe1Sx7njDWWYMgJCcS2Yza229XrdZwfVM5/PpdLq+vi6DIJlNolotWyyUUuSrTABQKJ9BAylVGKC1IIQFQoGAwhH5hVhcPiIKIYFcDiAKEUjghVzEL0QCHj9+zBWFbLVVGIJzTDxmhxWhuGuFTmghUZRIO2seAZKVQiG6PM+FFYAURWGban/5L/37/8Ff/vc+/PDDb3zjN/67X/s1Y7Lt7W1WOiDnREkA4HFjet9333rrW9/61re//e3T09Ovfe1rf+Wv/JU7d+4Yky2X33M2nIvWNghDTtp2ut1PPv1UB8H29jbXkTjnojhmx/zW7dtaawKbZVkQaIaQarUal48kSXJ8fByGYbfbZaVZBDTW1Ot1de/+hzduXPtzf+ZPtTs156DbaUBldyYHRE5I3obQGKuUBHLgAFBw1zwptQwCa401JIRDIZAV4wEBJWEOPhyUwjnDsYiUzAiBomydrLUCSkq7EEIqXqbWObLWSYUAIAQqJaWUiFzN5wTKyqixJ4dEbEjOb3rlSigHny2BAAJA580ugcPSbUcsplf1mf1bB7Sef05mTaLzvKEC9vyMLyfnOp0OCCKi3BoppZLK5DlZECh39/ejWhzHcZbnLKDF+YXys8vo01uRpSuz3GeLfKm3WJyhYC4LlxB2u12l9cnJCTCfiYj7eHAozDlfY4wSIgxDASJJEk6CcI+IZrOptR5Nhj6BxVfImJl3+/h7EdFDCH5b9LbcXz9UuhbS81dd8f6q+1V4b7j8K8evcVgbj8f1ep3rtm7dfOEf/aN/9PWvf/1P/ulfun3z1vbW5tHRUe5SpbVSylO7ik2zHDrnnPdjtNZUMticc6zoCFJi4WP5jfji1kAARPBMVPK8uVHeNZ3PA3r+k6eie3vwQ89Z/TgA8JMVlQ7f/4aHkirLM9aVBQDWrel0OmyouG5GnB8TKvM41V+ds4VpL0EXnorMYPVMfP5Idf5ABYGrAiFQeFzc1eCHDxRWDyGssQAklTLGcD8Trs28ECFwVQSV6VSvalYQuajgAyzp0lAWwBJ4ShCT/4Djfq3LXBsKyWkhsta6LAOAS5cucckhILI3xt9eWoGCVdlsNjn/BQAF+OZXWZGlvehJc5FaGIaMhEGZUEYhojgGEOQcB2laa6kEByN4HlZkr04IAejnO3uiLs+TINBBGA0HZ9x9yjlmkhlE3kRFmcRgd6HY3ASDWCV8g6WbXiVNE6szOmvLJH5RYrJkGizNAz9gAEkV99RPxWrAU9wat3MoPSFEdGVZAwphshwRme1OxsggwDw92t+fz5MrV65IKfMksdaaLGMA0pecA4dh7F0KAVBEp1Ukj4hKuRi+sOUK8pDb8jkiAUCeZUqpx48fX7lyZW19nZxz1gnJiWNCoRAcLPMqTjjJbpu11uYZ/0UoBQSAKFCy/ApYC+C0ltamRPTyyy+++OIL/8Ff/ou/+7u/+81vfvPNN9+Motp3v/vdV199lfs1WWvffffdDz744A/+4A8ODg5WVlZ+/ud/fnV1lRPfULnyH/FwzjFjT0p59epVbiC2sbFBRCw17GuA5vN5rVYLgzDL09WVNUdWoOQynVar1e30oPAkLEOuAFiv19Wf+sU/+pf/8r/HYaQjmy5sGAVY5MoIhWAWAwAQOCGlc5QkqXMuDEMdBIEOOESQMoAKYYkAiQCBECSAs85yyCWE4uicC7ARpRASC8BfAACw/+aczbmW3kkpEFWep6hACKGVPj9ES74U8W3Q+TCf7/v8sC9XKX8lYNWrQHRLvKEy+8qznU/W+HP+WA/WX9v5L6kcJTa3JPN+3jcwyZccyCKVy1udEEKdHh0fH5+2Om1nIc+tMQ5RAlkEKUTBxwQAKRAECg9WnUfXi1BVLXFsLVUQBCgVOxzMwtFaX758+fjoqN5osAFj2QUqsTFnTKCElNo5R+S8hhazdweDPieDhBBJngQqIFNsOlUH6PNX0QVH4YLn5N9T/sSkmwyKoPP8qQpXWwAViXLn5gJEbkwQhmej4Vpv5fLly3/7b//tn/3Zr9Xb7evXrx8cHGqlXWnLLxhsAABHZJ0FW+50yFut54VEUanCUFZX8K4OlVlHRFSE4j9k3l0YMSJiH5rxgKXvft4eXBylZ46qg84fYSVhfnbem7lw5uoJywt7FsHluxZSaAQZaAkAi3kahMpaW8xrdICOuO71OUW7rvzXee/qwjtYrIsq6a3SBAoicu5iPaySgSpCjMp0wuckqat36p9p+YqTUjpnoRz2pZt4fnp7CQYvo8ULsvCzn8nnMpUHhcizfDQacQE/Q8JSaiF4DSOAAMA8y+bz6XQ6n07HvHgvXbrU1rogv2sdhCG7Pux2mDxjJnulaLQIG84tKyxYL1BZg6XcTJHZ4BiJHYskSaKo5pybTCaj0ejGjRvz2WzJ5RJFk3vnHBFoHSAiEKInBSJoHSJinqcA1On2Pv3k4cbGWhwHACiEQmT+DZXZrsI5q05B8E+Riqnot32pCioPoqCyp72/Tf9YiVk+AACycF6XADBCARlQGCgoE9y+fBsRiYAv1TlnLU9IJ6VUYWzSlDVLUIh0Pj856Z+dne3sXFFhDDY3xtRbLXakWD2kclMMFpUsqwKcskQEVHVSAZ/F9IuGs/xLGZSiI3SETii5dWkbAHNrAx3lea6kKIELRi95bjM7HoUKlK+YQUcEiL4NcaEgg9IpJRw5gdLZ3BizsrL6Z/7Mn/2Tv/AnTk5O/uU3f+vo6Ojtt9/m2gLeUr72ta/9pb/0lzhuF5VdKC9SzOfx+881Fhzw88a1urpqrX348KFzbmtrizts+o4IJWAv8twEOs7zFIGiMDbGScHq68gVSQiSgJwFIUD9xb/0Fxw5bpOipQQll9dEQI5QFFEvO2bGOGNJgOBexcDd9xCcsSCQ6w1hCdujMVYIIYtY03HUDWBLP0k4YvCZlwEoJVCCFATALkUxfIU6C5Gzrho2IQCBK5cQ+WvnUa6MpF9m/liuASJ2KXi6nmPdLlN4y03tc57Xj3F8PlpQnfjeSllruf3zEgGGiud34YYJECUKODw8ZGLpwfGRVLJer49Go4rhQTZUzhEAepIOVarrsczKcU9ipmQKQCFEo9lkGiy3DmBNsi9/+ctvvvVWvV7f2NhgPhbjT0Go1EJZmzNqxWmyMAy5AjxN07OzvnNOBToIgtSkfhvyWAX6zMJnD2b1/VW/+bM+QmVEiuWNw3JiVFw6Tr7kptlqGZOPx+N2q3E6ONvaWHv8+PGv/Mqv/I3/5D/5mZ/5md/79u83m83RaJSalHEID1/xoxQosBI3W2uhQr3nXhnMHkFV8KmZsMU7B1/JjxWoVb0rxuEKMKOC+px3Ms6R0597zgtPRAjBVTPVM3ga0HPP86yzVb4uWFUXK2WG3AaAwArBc5IV7C7yvaqZTf6ZDSGfzTtM/rQ+g8zAmFKKZQW87/vslZdkTf/zjzT+PBooiJ8+uzK1Wo1rPLlmsATXiRNn/r6kEK5snc4JRHZ0vFO1/CYipRQntqSUHAMXNFlrPYlNB0E76DUarSzrGVP0BhmPxyz+7jU4OOfLjjhnIavSWdVnRyWKduHh8raDJeVcVsuNCwQLpZTtdns2m6EQURSx8oU/D89DLhyB6kImUU4VUKqooOx2u+PxVKkglBE7OkAEhOWWfp7pcX7mcAIFK/VlQghECbTUVSEvULz0nyrVFVQOx/L6i6xLQSEqHTKPbyEKH2DwNy5pDyy5IsDlOTcNC4LgtTfeABDpfB7WIq01gAB0JstUEPipAwDLKVExE8sFvrzgSuiF58pEqIC1ymAGQCoEdEGguOhYCs3EHk6sIiO6BAiMhRfhBAAIocrGDAIAXG6FQGtBBIBCyNKBS9MkjmL2dZLZjH2p7UuX/8O/+lf9fCvKmUUxn4WUJs850VFoxEcBVWDUH+Vg+m8QBGyhoii6evXq06dPtdbcdsyVfVYYEpZSxlHdWpJCW0vOgVJBmQsuUG1E6YxzzmWpUUA5IgKo+WxWqzXBOfAuhSv6qYEEa22epw4o0FEQxUpIji4sOcYUVcCvgHF5qYSuBAqW9eMhco4ACAUIVI58lLmMFAHA2Vws0ZpCP9A5J4TimE/IZQ22MVYpQcBxrYd8ijMhQmWuUyXSvbDX85Za2BufOC8iSixa7FX22aU5hGrbnPJkP+KjPX/OH/7X8hVXfi1VZSPIOR/15rmVRWtBcJYGg0GWmdl0oZQSSvYHw0CHhEX/6YpFJJMbFOQqRmX5aBxprVgHWaLg9hrGmF6vd/Xq1clkwjJFXMa8trZGAMPhsN/vMwbb6XQWi8X+wa5SypiMyPmUGe8p/X4/juP1zQ0mIHsXECx4RM1bUJ/yuzA+/oJF2c7Z10JeeNty3M6bimf+tBxh3qF1FE3G4zAKyTrGkI+PjxvNxt/7e//VT//01774xS8CwHA41FpLVFgmUtErYAnhXUZZVuoxK4WZN/V6fXNzHcBamytV8PqVVMioMj4rAvIM7FZefjnPix+cc1mWEaHnakAFnoTSmPmJ90PnJ18b/8pOJC8fviR2o9lCCyE+4zo/c0nKstSGK9TCMGboJQgU4fJURMXd+UigvGXvZztAAnRQuRcC68hVqGwOBTnnssxJySkVyWvC3x27RIDucwan+ootxWyLR8xoGQIAoRBQaD4FpWFGV7byvJAL9hmrZ71qr7PlyuoT55yQihuRSSkbjRYX97CBF0KQQ7JFhaOUQVxTQCF7eMWgOyelBmAuR1FpiCCVVIDIXwTFWkS/EyKb59Ku+hGw5U3xgAGrcxkDLCASBKwNFoRhrVZbzOdKidwaIiel1EoDlv3XPRKMks41b3DgSEilVWhz1+2uDs7OstSEYQEKli74uepbIZALA5ejTeTBuQvNoBi64i3eWa79ZLzg/NN3BbjsnCNwQJxzrAR+BaArAZDRuBIAFn7qCFE6wUICgstzAXI6nSdJcvv27VqzCdYCQlirkTEqDF2eZ1kW1eNssWD/m5vwME4JzgGRL5Zi5i7nDYQQRXFg+WD4J+CcEwD3LynrPIARqel0xpKntbjuE9DWWiJWfywqZXkb5nIaHmfrCICkEIgStQZCxWNljZ8vcRg5a7meNKo3XZ6HcYOsIaCCwKeUF+Mo4qWCmi8Ascjegit9Aypcuh8WiFpr6/V4OhuHYRiG2rq8Vosu7Ww9efJEB7LdagPAIlnEUWydJcIsM6WujUSkNE2iSDlHUgoi4CwlAEipGb5QUghHLsuTWj0GKEWUyxksgwDAuSxPZlMiCuJIB9Jx6x9BAqRAzl4QOc4nOimkEsWm7pxDFOxTouB4URJZ60oZRs83PBcJUTlEVIwjlyt6qMYhSgASSiFPbQRyAJ77XfrLzFIviaVl6qE0OW6ZW+RVV7xtqZrDET8iSakRzyXRBT4neKVnE4cX3vAjZLj8g/fhNZVJHCmfta9F8FHyLiWPMxGBQyGEcPC9731vPBheuXIlTdPZfF602XbWI16F1+KcszbUkQXLLnL1fpkQEwRB0VIwz2eT6TxZXLlyxRjDfSrG47FzbjgcplnGncnDMGRdu9FoVK/XlQxmZhZFEThMksQhcqam3+9zuJBlGXd549vPssykhhuVlI9J+CDY77NVa+e94aphu/CeZx9BGdNefFLVN/M35ukCENIkUVobZ6fTKTQaMVGz3frf/O/+t1//o3+0t7J62j/NrWHdHf9xV+pssfNX8GfPX78hs7ra297eBil8BwGyDqR/z48Lnwoiw/tdntskKVoFY9k7kgE2IuLWztUrrIY9zx6+GII9SF8/6D/imV5VLvyFgeWYz/9cOrFLAEwV4i+FGxcEkXUpFcykc5FqdTJUfwZABCeFBnBECOgQpK8YccwiFTLQgXV2MU+NMYi1ambTTyc+I5Q2iYAcOYGfKWPhD/9xIYSzuZBCKZ1lKYOmAKSDwPmY4Xloq1elEuysWwsAaZoiiojIWi5LlESQpSmroXLkMp9MwjAMo8gag4hCaCjLVrDQXCByjn0dljRTWlhjdBCokhmW5akQQmkN6Hh7ZG/Ji6T4irzq4+AJUKvVALEgPjGMV27p3HUgCDUQBYHKsmwyWRwcHWqtut3eyspKoAMO5BAxDGKlVIlfYrlgEQUSGR0EANZZ213pHOwdArpGvYWCACQKQpKAjqUEpBTlg3WIiq2Ac0YIZW2OKIVEXi/F9/CtXdhDKp3E+AlCweUmISRR2ai2hL29Sw4AKIRaIkznH3RljyrECIgmTNQLNFgLDFsyRkWIKKN6HawN4rpJ02LNsiYiAhCndCRjGQKF3zwQsAQ4yt+XuKxHbZc5H7bDRR/JuJZmKYsr8bQkdEDF/wCQwBZfB06AAgSU0pEBQGuts6CDgBwhoLVWBwEPX0GocK5QG9EaLF8AISLr/AEA/5Vx3wKDRHTWEoAEMLlVSvig60c5pJQEtlFv8UxgZmyj3rh29cZg2E+TfH19VcnAkUOQUgkAzgZCnlutpdYhLIFwJvIge1q8PSkCRJRKczNj5x0eay2AlUCA9PjJp+Ph6Pbt2xEnyIF4q2eOJRaFFez4C+CB5rmEAORpI8XKQxASFZzfZgEAUaAoYC1+osiSj5yzEo7TkQis4bEEwPj8okwDAwAiZGnqnJVSaa2ojK78BCpcqxIBwqVvtjwE1+wKZsDAbD5N5gvOZxVtX3NjDUkphdKsbkocJxPABUeqFLsq6xkrX/MZM0EWhQWVC68O44XP8smLdDgIojRLwygiByDg7bff7Xa7s9ksSZI0TYNQE1FZiQnGGGsJABBkoCPnwBobRbUsSwChVqtleeKci2rxZDZttlsq0PVGS0oZhnEzzxm7Xl1be/ToUb/f7/V6+wcH9VZzsVg0m01uJcGWMgrDMAhCHRhjwLluu+OcI+tEAEKAlOgc5NYS0Wg00lorVIZMHEY+KUmWBc3ROUICj09WfVBukk2ExjjnGPJZejnLUSz9s8+g0EA1g7wcb56Vhb9ls9wSEc2mSZYSUVhv/N7v/2sQSACWnHE5Co5mCre4cGTJSSGZRJxkKeMNlkgF2lpj0WVkgJwKlLW5UJIVdFCo5zj0/NzAPYts8dpBBIZmjSFEWavVqoLyqmze5ypVC1W/6lmYcDk6nDLWS0Jk6fco9hucgzy3cVyXUnudJAB4xnkAa3P2HIhgNptYS0Ur6AoH379ZipDpfCYvbmEJEpSP9Xk4n88oYTWsAhIIhXFEkNyxMUkSoqL/IJXlHWXJhcjzXGsFAGmSeB8aKl4Un3lZQXLRv+fMJkipsBDBMVLJi3lIf1IEANA65IuxxjGEo7VutTvkwDmDqKbTcb0udaAkIAgk6xDRgXVgjbXaORRM9mLAmIQQBSmndA1QCB0GjhyAQ+kzCZBnmXNW6xDAGZMFMuZyPz/sHLCxCSzRkYJ+xy0dAZbYVuHbUlFzyhaCyBE5pWS73W40GkqpyWTmDFl0NndREI9GIwFSKwXgoMj3cRG5dcDWLpUKhVKLZNZb7T55+uj2rRYAEVnnDIJEJGDYpsiFUYFQEllrnLNCSqkkEJCzjBYDkLNWSA2IWZoRURiFQiCrqMe1GktcFhwYqZ11OgjISgDJmLtzFoABMwRwBJYcCU7pENOkCjE563JZsLeQSSkoC4c+t8YZq4MIUBTON/sVgKg0AIFAsIw7FiwCIAAseH4IQrAqhLMAoKQgh46j9xLcQ6jYJm7vWtDv2KIJJVSaJlEQr62sk3MSEZGAcnJ5bknp0HP/scwFAVkBbOVJgCzwC8ni3k5IwXGFhyPRrxcglABkQQoEBCe0UuCgIGo7QKEcV98jSCUJQMhC1lIqZZ1DgayTV137n32I0mae2+20Di9tXz49Pbt378Hq6nqn03KuBIm5FyprpiClaeLrxH2+Qsoi16ygtFPlyR0BErEeuppOJvu7T/d399bWVmqtBgBAQZgiQQIQKkqefm/wJczn9gq/ZfBQnLNs/gwkAN0FCUXem8hZH0+QMwCA7INX9Qsq5xwMBohYWBRRglKeQ/DjHsjdD7VSEsnZzGRpjogkJKJi7yo3oH00e8GM/AiQ1R/6qCIt/oewbCg2HcwffvJpu93m5hLG2cl8xsVEvBqLUS2FCSw59lHW1jZGo8FsNuutdObzOcuSsaLa6clZFEXtTmexWJwcHw8GgweffJLneZ7n+/v7Ogrh6JCD14Mw4vogbu0khECCelybTqfz+ZztE7fTmkwmzFjiPsRsorTWNjeezVPGwK5yx0uWmEcaPHDlV8znOAo/4lEFZirGEqxz1gFaEgJm87mQ0joQqhCQVEoxLM8ZQE6WFSCcdew5pWkqYKluupjPZ7MZOOfIISE4AsGcoefAo1gstefPLiFEGXsDh83sABQ1DVI656bTKT8phrX8Z8+DQBePzxlPDyBx654lh+YzDtY25Ks6PT2dTCaNRqPRqHmH6cIjKDEzQWQ80inK0qfqp57ZYYt/OcCtArTVN3OvDFPgPUvOFusX8O6ZpmkYhixVj4jPHY0LL54fRuGc8bvccy/juTvGuRss8m6EKKWSjUZLKZUs5qHSWAJUSqkoipQMhBB+0XgvEACEkOQoN3leEEUgCAIGMwoDD6S14gQXAiol02QupWJlLE53FiBopbOWP6rfdeFQSnFdDoMuSZJ0OpFSSkotpazVKAgCIWUURVKpVqvlyTcFLEQESIjC2kyAUlogIIHlirDV1VXGUQBJYJFlBCTJijasd1iEwoXzl3OPVNZE5fkjEAHJGedAKdYno/l8zgqOcRzzVIziqH/an8/nGxtbaZKEYa14WMIhCOKGvs4Zm2mtUUhy1jkUQiAJV/Zo8gNljAl04MghorEGAAaDwQsvvCBQJGkShRebkJZpG8EpHQDwOXogS4RoHVVYK7yvWGuVn1HVdCc73GxYq0YZsH86WOmtJUkSxbESIkuTIAx1oKeTKSKKIEJcipcSy08QAXB5fsEjBaCCel9hMT539yKEZyGPZw9Xui6cxCUUiFTqeP1IR8mLIEQOcnh/kEpBmmbcMGd3dzdJku3tbWZZMOEYAPhnKeXJyQmLO3ob5LcjVdbEVQuC2IahIzObzYxz9WYjiGKb5oQgteZ4zwFU5eyUDAAAS3oEEfG1fuYSOw8oXPwjnt99EKvVRuhRnfNJHajsa6ur64WFO7d/fc41fMZBRdigtRaAUkpykGcGAMIwNATW5WhFAbgVQcCPcNp/w+OZr6AyP1nkFhFNlkspv/3tb+/v71++emV0NMmN8Wqffrfy3gJvNiY13L3y7OwMwHEH0PF4/OUvf3mxWOR5vru7u7d7YK3tdrvD4TCOovF4PJlO2QKlaaryTAixWCwmk4lCwa7S3t5es9FwzrWbDVl0ySWhZJpnean1wq9nSerLvqpcK3G+eLvqAVTntGAig80vWNkf18d6vtmrDngxw7EkmqjJZMZ+Eov6OAdCFI2cbakk7g2kv2YppUTBZKM4Ds8Wi9FoBEJS7qSSUKaWwJEXHQUAogtkv4vVG896SAxcO2d83o339wvZZ++Yfs4m9fn7lysleVieseRgPf/w8CQA9Ho9dsSllK7Uj/ZfdwEK8iWQUCakqtWC/s0XiGVwfvI8eztczUplMwB+kR8xgy6+OAAryJn/Uv+i/97njM95BuGz53mOd/Xc6Vg5Cet5DgaDjdU1L5kvhAyCQCCb8ELBlT/onEPGAaTgTG69VgcAY4v2i1JIcq7w4srboULyUAI4a/MlKikEixX5/a+SUS0QF34bVK+cIM9NFMdn/X4UxQCcCQJEjOOY38aPIPR1tRXWdml3lO/b7ZyTQk6n02azyVkwRERA66zvT6CqU9EnfJfORNnhjop931UapSNCHMdJkrBs2Nr6+mI+V0qtrK6642MAF0YxWVaotkWmjOWCAQIZAxQKGkEQAyIQdw5g3RZkrz/QEUBhxaUQ9x/cX1tb50dTXiQuI61iWL2HwQR2RgTZ43UAArkmpCgtRACHVXkXKnNMROAKUWX0tqxg78D6+gY3n+71MIrjIIzms1kQBFEU+QoAPz291a6QfcrtSDIbnnxkWHz5Z/hT59YXnnuRluFjubThIoXxhx7Vp+8DeN4YOUSs1Wo3b948Ojp68uTJzs4OFxWyLga/ARFXVlYuBN7+ftXzwmIUQkgUgsTKytrG5iZYl6YLoUrNWeCsNFVJxFKcSxb4A+CZSfxvcPimXf6LqietbltSqRIjLYuG0I/+Z/GCn3P4y5ZSIoEQAuySIKkLCr+PP5xSP94D/rd+8LAjIgvn/OZvfVOHQZJnjmg6nxERg1uFyk4xYssBYfE0bhWulOj3+8bkP/mTP1mr1dI0HY1GT548UTIYDofT6TTLMq1UkiRhFM3n8zRNgyBgaAqLHhqZEIJRASXllStXuu1Wv99nnmBuTb1ej+PYWsutoFhBgN0OnuW5zXw04BGFz/F+bNlb+t8ifFX9LnFuJqNfBXybhaUXGiCpWnT2BkSZOQAAcMQkZSmlEtIYY/O8VotMmg37Z8VdiYLMWBJXq1fif/whk5kKqu/yFvhFTttx4OVBwc8Hrn6UN0C5TwkhmI5a8nafvy6o5NVVXzTG+BT5hTd7YiKyYnWlXNHP/OokuVA/WLn4pad+YYbwPPQUb4ZmGV6FsjLOld30PmcQLvhe/K8tW7iIZ3hL1Q8vf/5sTIup64hLcQQeCqaFEVGpeFmgp94N5RfBFkyMMAy5FIl5OYEOoAyefWqPl3OWZXFcK7NsbEELNlJpYIqbpSWuvKyMw4r7QkTz+bzeaJg839/ff+mll5xz5Byi5DLJYquXstpTvPB7hABuRE0EyOMgAEAK6cgV+GIY+afgnPPKCCqMLsTz6KlLpb1gc8Uj4GemtRYRlNbtdpv1LwDg3r17xpg33vjS6upqlmVA5FzZBqcYC2vKuaSUkkpJpdjpLFpnVp5IEfk4G4WRIzeZTqbT6e1bt7M8k/JcOv7C4X0vQChYOmD9fBNCoM9UIEKx3EqyNf9XcYmw8iD9VyittdZxHI9Go/F4vL6xUavXT09OVtfW+J2uKnryzMerUU3pbpd/+jcGJIgzpn+o81xYpN6lYQPEj0Zrvb29PZvNDg4Ooijq9XqsPcZ7gvMibf5iKodCqJDCsPAoEaHQZUZJhChVGNeAJ1l5VaKo3H9+PTMRsdh/WaMnLvz1M3fwqqNaeb0g5RWwrfPDwW5fOVgVSQzuUi51UUpQhDimnFs/rhsk0Ac8CmWgnXOD0TCO61EcW5MJIVCoKnH+h96pv98f66ie7DwdC/kVoSS3vpFaAcD9Tz9ptFus08ibLEoJpcl3zglEYJkrAix1Frj7mzHmxRdfjGuhc+709HRvb4/r+6Kwxu5UFEUJc9LLxpFCiMzkLDqqtSZjhRBhGDKivlgsmvWavzYHxLsGFd0CtBCi0WgMh0M2YFEUmSyvWl9e/J74AuWEdktt6NxvEN524vPzOIzhfdbrFzVLy0leknzLCIpl5Vi4zyfFuIzIOaeE9BtoaeGUUsoZyyrbvIjCMKRSHPLk5BQ8N4EIgLc/V/66nOdUEQmsjEaVcyaq5WwAYC14HSyPHnlNSz/IF0ak+lc/pM+MWzl8Jdboye/VrO6zZy4fnCsTc6rqXT0bFHrUvHoNVcfLf8pbenhmJT57R3x4rNG7RFgKk/o3eL4F763PThV4JqS84GBprZnH6eftZ45PpXU3lLcEfvcrtdHzPA+jiJV7lFPszJDzLk3xfiztqFIK0JBAFIKM9a0V2VPJ0rRsa7MszmBNu7Ozs42NjSAIsNhvSEpJpbw7fxMUaTheHfbiwyJiS8xn5n7eQgjuUa2UPOfEF2Lixc3yJGFPhc9gyXjTLoXknq1SymqPIz8PS8jNX4y3Zhc8Ws5+cmKHxSmEDnSeZWmSBKG6cnXHGAPgbty4MZvNJpNxHMdhFAEgE7nKQQAAYCiXI40SBBUAgIKIDJfyeMYh93KVQsyms729gxvXb/FJhJBFYRlKLPGe6kpcprzJIQgAgc6hc2CX4YeoVC6XwyuBCCoii+iBxvOBx3QyaTSb3AxxMBg8uH//2rVrjUYjzzIppRCqSpS8QMUpBcYIypRhUfpWaDs8swNXquPZiX+2GKD6qwAEKlQw/R9+6DZVfdvyVL6Vk1LsqQPAbDZjEewsywaD/nw+5SXAkHBBAXxGpqQ4Txn4le4LIptqtny8OQooOGhS8jgtE6hSyBLuE8/9Ar8d/FBX49xtlwmvCztXqUpFS8G65x28hfGIQSV6Zp7aj4tgXbQ9WKTkp9Mp56Q5LaW47ckzir3/fzuss7JUXuAa2qOjo5OTEyaxL9IkCIJZsgBrut0uW9kikVHemrclg8FAa93ptNgMHx4ecmtPhkzP+kPeF6BU+B2PRrV6HQBm02lYr6VJAlyA6YiJVlmWza3tdDoMX6EU3K41z/PRaBSG4dbWlrWWf8YSwfLBgSt6kRYW4rkyDdWZdgERwfMpRf8yf+65g/nc81ftLpQRmiu12n3dNWLRt9VaG+rA+7L+2oIgMJAzldtaawniOCZrBUiB6vT0FAAKmQ22kN5V/BGwJT7ceaknHkBr7WKxYLF4rLSTqw7UhbM9J/T83MPTkqqB3ed80L+BWLYAwKc4LzwyPN/VESoaHz7Sg/MeG5U9m5/r7jz3QETflxdL+TchxGQyefLkSbPZvHTpEr+TE6D+5NWJAZ/9mPAZzOyHurNVL8lVEjGiNIRFal6pIIhMmtD5Lpz+KTwLIjrnRoOBULJer3NfdgBoNpqyVPavZiMYB/r0009rtdrKygoRcc28lJL7DknplTmLrZ8Zlj59D7BMJAFis9mcTacAsLOzw0lG3j8vmMYLD84n+/iLTG58kAYAeZ43Gg2eSJWgqCiGkEKW4fsyXOHvsCb3OFaWp4xPBEFYaBtVkke8tSqlF4t5s9lstlrFYFqbJLM4ajoH1uaOeG4Q3z3rUxCRc2RMpnQoGJwTgnUEAYDXJgCMRiPuwdJut9n9AgAllbFGPM/iYYnIQoGVEILk7jVF397y8LO0kM6XmlcOsrtvLcqLdEkeQ60150ODMNzY2Njb27t///5LL7/MLLoLkBV6jBME4vkd5vzJf3Sv4LkO07loCoiIGIj50T2N6jsvfCoMQ/bm6/U6Q9orKytxHJ6dnR0fHzebTe7nUa3gefbWFFKhswAASB6nASjcEd/NrWggVXIG/Xscpz6r44gIKEgUBQ0CEQm4hSEAYy2IrkrOPj/svmTUATkgLmsAhMViYa0tui5IgQBCFDWoVQ4ZFA+DobViT2YeulJcivVjwFe4lHUALNR0igfB8WKeJToIlJDkjGXaTTmCjpaI4I/ra/0oM+SCg2CtVUKyXgZPx48++qh/dsYGg+MnroxlpMRV9C2JyDAR0RjewhqNRqPRWCwW1qler8cY+3g81lpzyTdxbX95Et5M+QdAlEpZY6jiGHW73Tt37kynY96Rp9MpAARBwC0zhRDj8ZgJpPyUoyC0uWGdQ99jp2pKq8ez7sVn/FUQfc7yuzgxyg+KYp/lGhss34nL8TfOgRDkWMdcgBQgFJkCPcKyF57fEYQQ3ISBvwcRnTGs3TDoD4EECA1UlIhz4oMDd0Qs67/YWj9/EJglUI0qjckuYFdUds+lz0Z3oIIG4fOBwIuHf5v/4OdwsDxznHlXzjkuhvIUK7rYS5gvwKe22ZeFUtUdAFhvj68Enq0ofNYHqr7i/UIqs0sMWR0dHR0eHlprNzc3ZSk5WEX+sEJUAnhG5bycBtwWxjkn/TVgKSIFHqF8XjxQ+ujepcNSE45/K1oRS/YhLiJ8/pKcc9yFiazNrHnrrbeu37wBAPfv359Npt1u96WXXuJieJ8i5LpHJUQchsw3d2XHJ2OM1sJ/dSmrq9gbS9M0CNQFB5dvjc+/WCy63S6jHSyIRY588pSdywuj4TsQMNaipVKyqOG3xgRKhzooIBNgq+vAgxzO19tWZTgI/BSteJOFNAYJLpDkhD4LXsxnSRRFgY6W8CCRtaZWr+epkVIGYQiogShJ5pPJLEkSpWSSJJ1Ot93pAJHJU6UK1CoKQwAwec5y3GmSjIbDOI7X1tYAoIw6AABkqQny7EokQqKiTWzhxCOCKzqXq3JKU+kpYhEF8b4lJEkAMMYhFfUHy+mHCERhGGZZpoOAuyO/+OKLe3t7o+GQ2SBVOLao4CMqG1F4RAMZy3oWskLAiyBV5W8XzOdzPW8A4CYL3sGqJM2exVN+uAPgFzgvf601pwVrtVqtFp32T3f3nqysrGxubKIgAnuhp3DhwBAV1WQCllvS8k1l6rBAZeW5KK2y5fFMfg4shIgSJZWi6p/lrn5W8xl/Gbx9DAYDJjD2er2CflGqrj8LQ1SNmbe21pKQP6pv+5zbqeiDI1EQhpw463Q629vb3PWFYLlbfs4t///ikNJnr4po9dGjR2ma1uv107O+lNIC1ev1eqPB8RkPEZUIPD+jbrd7dna2vr7ebDattY1GQyp0zj148IDTdlmWRXGcLBaFzhuTpbTO85xlaa213DZZBQFKcs6xpst8Pj88PLxz5/ZkMgmCYLFYjMdj7qTBJYSu7MQXBAGvkPl83mq1OEpYJgKe1/nEH6KihgzPAwzgR0aPnz2IQ5Hn5YCg0BisQlnlRyo4ikcC6nFtNBoRUbPZRAIvZuGcm0wmUOYHnbFCgTOGs67LDip8C0sejyCypX4PAZeDlf4BlV1ZpJT1uhZl4yN/2c8SCJ4dHKyI+3/OEHmwRFT26M8Z6ipXXYiL7QX9o6zM7aLnkiiLoonI36N/3FRSu/zFUiV5B1DdsZe3Vt00LtzmzZs3r169Wso5ks8PXphLz06tC2eWSkGWOVf0GMUSwMMyecef8b6pP0sVruO0oJCSwxuldQzAcYiSAqWEUsLRg75UaYGFCEIIEiQt/uRP/uR0PguC4PXXX1dCnpycGGOCUpS/mvjTWjebzbt37/JSZV5UlmVScoV1IAvBQuDEdJqm8/lc6yZ4O12OO8/M4+PjjY0NUdYSKqVMnkup+SRY4lXLKcHLv+zGyCZQlqadn0jMnEJrq8go+oYqz8sLU8lPIuf4nGEY8T0i9wcsFxQPuLWWUXmtNZU9znl+mjzXQVDERVB8SkpZr9f7/dPvf//7iOLVV1/d2Ngo6ri93hWAEEJpPRmP9/f319fXu72eyXOuXQAAFIJVyqpz8llD7DM/RewnhHMkBEA5AlQS5rjxho+6i4+zWH/ZeWX51AAAMQhDr1NVq9dv3LjBtVC1Wq1Wa+ggKAbZFT0GWBMAzl9xkQOquFn/5hys6uFKsvmPaHndeXK6P5ZUxXKErbVKiTzPAd3qyioAjEaj0/5pq9UKdJDlGZaAN1cTsLi9IkYygaepxeIxAAqQAtkS+22O53GeZbwCfarVWSskMl2AJYmdtUrrwgFiIEuILMtYQyUMQ4SiKkeU2hLFhgXOkXPOKVb1EpjZPFCBlPHOpStpmi4WC5s7ktw/obBYLDvhSp4gHz4GRUQAzHOrlLRmWUUFz1A3qp+Fys5bvshTmZguIKRQSh0cHKx2e/V6A8gmaSoVIhYFTVJAuT6X/Z+8PbMlYZ9l1uR58NcyFlKZfCyKqERhUS5gD/yn5cdLnVJLDmXJiVEqCAIgisLQFsEuEdF4PI6iiPnOeZ5fvny50WhYawFQKUVgd3d3x+PxeDzmuWitRSHKTY1xb4uIUnOVLIBEMsbaHNm3EJLAZlkyHg/H43Gv1xsMBmEYXrt2bTwe53kuhBgOh91u11o7HA6xlMGs1Wp85VmWCSGYXcEo1+csmGefIwBUo5aqofW6ss/iDURU8LFguQIRsSgNpqWnBVCQgqUUhBYQ4iDM0iyOY6757/V6xhhmrTmgJElsmdowxrSbLSnlaDDI8zyKon6/D9aClOCcCAJw1jlXixtBGFpnpeSu9ewZF4rMomBcEEs0lZReRoaKQs7pdJqmKQBw/UsYhpzE9BOm6gdcOJ51UqtuWfXXz3K/LvgclUHG0pguP+h3vTLR76phKM95XmLPaply+WoQBM1mk5/gc+8LK+sRS/DJ11SyA+ddKH930+nUWhsEQRzH3pXkteYb7jLUwePJyXFE5OjLWiuFiItWSMTTxl+b7/0HrJ1Y9W/KB8QetncgeEbNptP5fB7HcaPZBGuA30bk6Xf+ZsvIqtjcpJQaYWtzi/0GhpDr9fpsOiWmhAsNznkxBURUQWDy3D8Ctg7szTM8wruBUqrT7XY6HcZ8nXOuzBVSod6MLEEcx3GtXudOPjoITG4lG7Oy+JRNTMbuRTlJmAjPPHGmAQHKs7OTbrcrpRRCQsH7KaXcC8jKmdxqrY3NkNN2PCyMzWS5czaKorIzoDXGcG5Eae2MgRJCqz5inqK8GRInW4gAC2V3IYq2Ddvbly7tXB4OBkTEqRhmnrHGLAerAPD06dONjY1ms5mlBa3HT4AwDIEIUJYPEazNhRCLNEFE5sUjCiqntEAJsHRPi3aKSilJQjljLSIIqYMK3zFQ6NXPOcXEdaG+bpFYsEMKFvIIonCrvv0b//I3pNA/9VM/Fcdxnudah9ZYKSQiWlsQ+AAgzRa8rIIgEFhEJh74uRCiXHilCpHC8+w1LAFa9CGuL3B55iOu+in47KP6VyllUYeLaKxZXVldXVkdDAeDwaDRaNRqNa5XRcDc5PwRrXQBBi7m0ziqCykZACQqhlQrzYlh55y1OU8mv535sEBIafJUlblwISVYy8xHu+yWABz/+Z3LGxjvIRIRcLsuiQBgnXXOcVULADC0Xq/XdbnLMLUTK1QDH+RBCbz5MdJaVi/ewwxERGRZ1TfLjId2PutB8gxQWltj1jc2fuEXfiEMo2yxCGpRFMWAgqjYr2W5bBhwrmIbPu6xVOrHnNeBZ3LbOb3d8oO+eMEDUUmSKCGlLtB4tjr85tFowJZGSunKiJB3OmMMELFrdXp6aq3d2NgYnQ263S5X9jln8jzP8uTo6IjNcwkCL+P7gixV0dDn6BzKAWTkSWvdqNW73a5Sajwec8g7HA65q0yz2czznMXEecSCIOCNDABqtZoxZjweV/e1z8dRPufwD9c/4ue+rfCw4Zl3PgNO+NNaY4Igds7leSF/wPsvIy4sXGmttbT8K08MbjrETsz6+vpkMpmOx41eL10kKIXWWkchYhEVCCGyNA2jyGQZohRSOAdAIKWUArLMBIHSWhOBMSbPbRyHxrjZbPbee+93Oq2trS0eW1dWa14YFqqAzd7Tfc7IlNk0P5g/+hOprqnqQvPj6ffEknCDuAylZBWpVdX6MgBEZLFQUfZ5ZC+zulnzz94z4z1KlXiMh/r4bOwe8XCxbaCy0S8/OPZT+VR85mJdl933qn0IsAIJ4HnIig2qz46JktfC/Y+11rrsN8dLmJ9LFMfkXK1WY70ok+dKsEg0z1Xpn4t/WHmeO5tnWRYqHdZqYA05x4RI3lpr9TqUSX+mP8vyqxELjUo/nkrrkqoArqzwQJRLZM73ki+RJyqxxlqtxoOTLBaz2YwFS7vdFRQiWyy4KOfw8DBN062trTiO93Z36/U6K5AREXuZJs8LWNE551ySJK1Wi4hsSY+7sEh1hZ5l8jzP8yBQSqlksUjTVAg0puA58VPWOvJPxOQ5k9CLvpCVOVxYGRRQ9vq7MOERkZxrNBpKaz4PAJebLAlYUsput9tutxm4wjI15nE4ACBynKtiD9hamyQJx8bFd5XcZQfOWkKw8kKRmW+OUu1D6uONz8zVPS+1h0hAP//zP//pJ4/ef//9K1eurKys5OUTgbI2gkpVNl9C628KRLGT4HmP6oLZrULs/rH6t1XfzEuVZ7tHT1xZD3judood4zPu9nlv5jtCFLnJF8lCa91qtfjkLOLdarUAQCvN1nyRLJTJU+dcqORsMoqiKAgDMplQAbHDrlQch+TYKmsgAmeFEEDOpKnSGoRweS6EUCpkvXJBAhwqyW22iO/LOsPJ9TDUAGCsMbkLdEBA3EkbwBmbxToGwDRLeYfSWnNPaJPnRCgQgygioixNhRBK6TCSDCsxmgo+CgQAcFIAa/KavKhEQ5BUqYspI7nSZQenNb9IPkqoZh85tU/EMa4BRCBMkuxgd+/azZuUZSgVF01eABi98+dzGSUpNUCAC9gVlYcQQqCwXghDSikkCLQms9YGYciDCeCiKAACIpumWRhFSgkglsgrcu286RfGI9D8c5am1rm1tTUu5Il0oIW8du1arVbb2tr6+OOP03Shtf7kk0/Yu2JLg4jklq0/sJAPXkKpDoowTpTkVr4Flnqazmfz+Xy1t8L+UxiGnU5nZWVlNptx8SDD73meSxTgiKXMPQ0LKlmPP8RxzrsiQSVr4TnwlXtOpp+XDRFBIVS4dA6KYDrPpZRRFCulZvNJkiZREPpdvrC7gFiJq9izdEsKvHrydO/Bg09f/3IvjGrcfJ2cIwIHFASBMS6MIyIgFJnJj3ZPkiRJ0yxJFqPR+PDwoN1u12q1ZrMZhCoM4v2D3aPDk9ykk/HsZ3/ua91udz6fs8vrR9LXy1Snn/+1OnTeV6iiI377ppLU9dzD+0D+Vw9d4zOBZumaFxpjUCIu3hVbkp1L/MCDl9UY6bMOvk7vZjE7zfer5j8VVbclvsVbtr8AnqVc/+UBY7fsr7WM+qBiGPz4Vn8tTl62cKYydcjxj7V2Op3GcUxETKCkEpIUQhwfHxf023LknXO2aNCx1N3lr2PbzLEZWRPWIr48JjahEGz+AUAJ6XIDDqXW/DD4ESyShEcpyzIiiqJISMW+Dj+gkjHjgCjPM63DskEbB705AEopF4uF1prZWkJgo9FqNlFrzcwBbvq7WCzm83mSJNPpVCn19OlTtmEvv/wyR5hKa9a14rwEk5ag9AKpoqJMS/qa5ZLqKIqMMXmeay0RkVtISVn4tQWpy9o0SbTWQioU0mZ5o9EExDRJ2Cui5dMEROAmbozOXHDs+CmwkRJCNJpNcm5vb291dVWIAMApJYSQjMBdKB2tTmVneQFaJvMBQL0WSYl5nhCRVIqhI3aaSBAwgb0QaC9FHcslbK25MEulVEUj7fLLeR4Wj7XYDcoXidI0jcLo1u0bRKRkkCTJ8fGR1rrdbsdxjChYYp6IgEQYxI7Mckwcb8IAJC54b1Rizw6KnVNU9ArgPC5b7FGOiAjVcrX6dz7jXfFkXv78zFcvR/7CK0SsKqYEgkAlhJAsBI2qUQ8X85RjlUajIaWIo7pSWk0nk72jo3arU281oNhzHUoBzs4no1qziY4cWcEQGT8JYxQjlnzw5mKM0BqlzJJEa41KudyIQOYm98m74WjISrtKKip2F7LWCiV4yqZZylTfMAgBIDe5VhoRFff+LMdLCAHOZWka1GJEBGt5EvhnsEzD83AXHaaAm1BXRrbMfpIhIikkADlynsd6fnCd95n8M2M47a3vfOeLr7/GdCVX8j9EWQbvHXm2aqPR6PT0tNPpsBj08rFXCBNQycv4Dd0YEwReTAWsMYIAleKMUjKbP378ODV5p9NZXV2t1WphGEZhyFacg3WtNUrpnOP3MKcty7JOpyMBjTGdTqfVak0mk/F4PJtNRqPRdDaez+cc5Rd3ZCsXDKxnR97WntvTK3xD71/yg+aiNh69s7MzH3AwJ8A555zN8zwOtDGG21N4kODf/KClzfixP+h/8J4TEYVRBEBpkpg8rddjfl61Wi1LCt/FB52ibLzlx5AlRbBIrwLzV8hZlMJmGSEqrQlAIlpLSoknj/dPTo8+/uj+cDhEFJPJhAi1logyz9PDwxMhYDQaIUKj0ZzPZ9a6drs1ny8ePXzyyitfYBni6l18jp5TtTDWT07v30DFT/qhPg1WUC4+A2N7AMDEOyhhbC9vzW03XEke93+ispYQS9Coev5iBzgv7lW9BX4cfpFCWWblkSp/qjAMq1Bx9Tz8SpZleZ4vFotarcZ5Q4+jVx1HP9Rwfl37P6lSt4/K1CGUjiMALBYLzk5ubm6yY8cby2w2A4D5fN7pdMpMGQghBMGFx+ELHqVCreta6zxNwLnpbC6lrNVqvEXwIg2jCIyVUgpZcJwRERCprJAwZSlM4R1KWey3lVwEVrZrKF0cKDlkDLpQQSFYOhO1et0/zSAMu93udDplqsBXf/InmfPERIJ6vc48dI4bAUBpvZjPC1e1rLjkn3n7FaUUAgdyvKFV5feEQCzHSpYdAo6PjwFwc2tLlIUpYRQBCCjrKmj54J615ctpyf4NY6JCSu67CgBFryEpEQVrV+ogKHtHVtoVVwjQHnklsJGOZCndzPaUQQMeagHcVk4QmeoMFCi4wynHiuUsxQvlYhdu5Nlfy9QkIiKjBjs7OyxJzUZfa+3Z21LK0sHgibEMzKrOUzmcrtgScZlJoPNw7IXrQUTnbPURVJ0tv7i4Zfvnc7+qdv/Z1xmwoEqc6dUlnXPf+ta3tre3r1y5opRS3/veO5ubmzs720IoAAKBlBuUODg6mi7m3CPl2q1bkOfz2VRINFn+8OFDIeTt27eDOAamYRkDqIRUYCwIEUQxAEDu0jSlnGr1+mw6vffRx71e79KlS8YYAUjOjcfjdqfD3L08y9I0ffr06WQyieP45bL+Uytt00wGAQCCsYAIQkgUNjdSqSCO2d1WKgQAIKeUBgDuWAfOknMopVISyIFzmcmTJAt0JJUHFTgazomId0kuYZNKmNw4cFQQcJjPZKyzAEJKSYastWGgavX6tZs3V1ZWpFRHBwf7R8fz+Vxrvbm5ub6+HoahEMgBCgd2aTLXSuxc2gqjyNkcys20fKKIQnDNI5SqOVJJIOJ4jveFUAcgBBk7nkz5SfPFC8D5ZFqPYkGAQnjBz+rS4tTjYjpbu7IC1p0cHl26dClNU6lkFEUcWR4dHU0mk8lkdHh4COh8Vo639aJXPBsAsZzcxbRDhFKHzBYlzSoMw1oUcwV1FEVJkmQmZ1pSkiRMcl9ZWQGA6XQKjuKyDwn7plWkAc6b6j/EwegULQubL/xZACC3lV2uSX42gOciHg7NiRAxTRZKqka9YWx21u+/8cbrH3wwnE9nvBX6BLFzDmXhg8JyU1gadR3o6XR6ctZHUXRHBymtozTJ9/b29g72Hz16NByODg72tza2tNaNRlNKjSCty/PMtlqtLDVCwsrK2snJUZJk6+sbzkGtFqXp0YMHn3z66aNr164IIbj8m4iq8JU/nt2/oALDYCnyyb770nD+yO6qH1sPsnq/rdzCkEE9PI+Qed+ObSp/u3eVLrgUUHFrLhxaa9ZMms1m9+/fr9Vq3W73008/XVtbW1tb44flBYpU2cq6+tQ8KszOWVqSZhj3kpVCXX/x1XspbGeJsjhrmQLBBAA/pAAgpFxZWTHGcOEtz5Y4jjnKarXbK2nKjxKF4DRCtX8YXzALghBYY5xEkabJ8Oys3+9vbG3neQ6InB4FgFBpttFCSpBlHlMIl+fT6bTRalvrrHWsuesXR0kXKYBqUWZaiyL2MtvlqzR8pYLPPPixDaNoPptNJhNW7zw8PGw0Gr1eLwhDFCIIQ5PnK6urADCdTAAgTdNGs5ksFlEcc4tAZ22apkX9V4mS8smlUvV6nYiCMCRnACQg+qSStQUAKYQgAufcN7/5zSzL1tfXW61WGMZCKGutswUbl90MIcgP9PNUX7jHB0oQAEV4mWfZbDZbWVmp1Wu8HgCAyPlciixQgHOEBCIiZwEEOWedq9ei+Xw+GAxWVnpBwIC0QABH5MAxz8kVwBMBoBCSydfWWW5cKy9MlErWxU/aCxPpwq/GFrSNPM+1CpVSACKKIvaD5/O5EIJTz8yTFgWxWGDl5vxpyx8EVDgnRGSpIIRhoV9d8PmKf/lE4hxf1pYIiyvkWpDp3X5llVfy/MPf+IVAxUv0EREXNfHO0O8P2NrGcf3ll+9eunRJa52mqXrnnXfu3r17b/rR+vp6q9FOkqTTbD969Ojw8LDZbCLi0enJ+++/v7NziYg6ve6gf/bw4cNarT6ZTNbW1pxzjUbj6dOnQOLWrVtExEjDbDYbDEbdbnttY/03v/ENJoG+/fbbly5d2tzcPDs7a7fbSZIsFovbt28/ePCg1Wo9fPgQAF5//XUp5f3797kdQRRFZOxisVhb2yiQrTBk8aRGo3Ht2rUkyYiI6/wBXBBFxORELKpmpJZAbjwcSinrrVaa5kIW+UEUAoCYy8URLeetWFisYDtp7dlRJaAlhBAShVKKnEmTJAp0s9P53W99q9frbayuTeYzRGSRDI9gsRlIk6Tf7ydJsrm5GUZRARoTUVnjUyw2ruaQskpc0FrzTBVCAAqTpg/u3d/f3798+fLtF14AgEaz+cLLL1OeY6BNmgJAqIMkSeoNx26NLTVqtdaNRoOHt16vt1qtwWDANubRo0cnJyej0WgymXCZG7ed8kEYIgohfRSC3G4dlqbXA42Cd1mlmLTBRoi/NM/zOI6jKOJeeJye5y0+CALuzQcA7XY7twZKShaUftuPbsg/Y+U8T93us95/nht33t9a4lgAYKyZzsb1eh3A/eqv/urf/bt/9x/+w3/ImZ0sy2q1Gqfq0Qnux1JF5qFkNdWajdTke3t7nBxMsmyepA8fPnzrzbeHw+FssVhdXZVSXrt2HQny3J71h4gYhrExzjlnDbFP8N6770dxsL29za8fHZ2srKwAuN/6rd9qtRp37ty5desWW2VddtkrbuoZWgM8s89W38CYB5xvyfzZI18couxhF4YhVQoAhU89I6RpmqYpXyH7MXmez+dzAIiiqNlssmILn5CvgR0+9ntEISX/mQ+aVyUjN81mc21trdlssp/E1JY0TdvtdtXYXBgHvjYpJbNUmaTIuUUf41Z9surHiciTYESZAfG5vOJTZYUdEYVR0fWcRaeIiFPnzEPlxsNgrRLSp5Rc5dt5iIJAkSRwrtFsxmEopQRZoMJMJkMhgIBKeBLLp8UXnKZprRReWRYEMNZSVszwjTMolWdZlnGIqKpzhvPpnmPODWT4kXmOabvdlkrFSm1tbXHcyz4of+9Zv//o0aM3vvQlZ+1wODw5OXny5Mnm5ub169fZR1flN/JpZSkFAgXYvJwzSggp5bluPBVa1de//nWtNRYCClkYRVIGJs+VQgAJ3rU6X4SxvFlcSgygKEEvRGQd5lLPnTd8RMG9HRkOXJ6Hl6RgESWkQppfAmIYhpPZJM/zMAif3RWxqKDnOaXY++OdljTv5OeCVSxp6Xg+rYbPFOX5X7kHgBAijmIAkWWZc8CqvL4maTQa1Wq1KGJZiotNIy4cvD9X3JrlohOFT38R62JZluIjgnhRQMEC8uCcEyi4r+szX/d8g/LcF/23u1LmhvUNuGUkACRJcvPmTefcdDpttVrqa1/76ePj43o9Pj4+vP/xvclkMhlONjc34zBSSk4mk2uXL49GIynlw4cPv/Od39/e3mFV09ls2u+fAkC32zs9PZVCLxaLwWBERN1uFxH39/edM+1uB8Ax0n7l0g4i7j15urKyQsaeHh1rrb/7B2+22+37H32stQ7D8P1333vppZe+9+676+vra72VJElWV1e/973v9fsD5xxZxyTWw8PD+Xz+4doHizRbLBaXL1+OogjA1ev1xWJmrV1bW6vValleUEfn82mz2ZRSNpstzj8DOAAkZ2bT6Xg8HI1GW1tbebpIF7PRaDLUutfrBYF2xPiNVVIhCK00ASIgO9F5lgVB4Kz75//dP2vW45dfeWU8HLZajTAMNa9Y56RA1oGfjkaj0SjQWtfiRi0GcmANSOFYNJVzEFzVJSVYw14+lR1t2VcxaY6BBOeUUi+88MKLL78MKCDPm52umc9VLUatwbnpdNoJw8lkwpEcj22WpFLIelyLoqjT6URBmOuM/d1QB0rI+XS2WCyCIDg4OGBsKc9zXbJ0qzkXH46zng0z2wrbwAtPKaUUEvm8wyI30+mUdRna7XYURZPJxJJzxnoLigRxGDEtqYiAnWUzhiWXq3olP+5RLCeo1gb/EE+r8k4kcHjuT0sNNgTXbrWTJFnM5jev33jt1df+yNd/7h/+6q/yO6tIBo+SfSY1zPaV+xR98MEH33/vvb3dg+lifnR8OhgMxtMpANx54SU2/JPxKIqiMIyjMDTGWOsARBgGu7v7Usp+v//kyZNr165oFS4WiyiKkkWGIBdJQpBNJqPV1dVr1655X4Sji+duoP6Cq0iM/5fTfFXn+7OG8cIj85bvwoveLiKSvzauuuIoaHt7GwBEWSJzwb3LsozxY98iben3n49KoUzu1+v1W7du8b0wgRpKCVMhBHdwYuej6iphCXswEsOXLUpFXKUUxxIXHGjvVPkxWfrZiN7tro6JbxoDAJ6gDQDD4ZAJ3ZPJhLsvFLkkuywxKR8Hx/EFwWA2m82n02azGSgFQuRZ5pwj55TWZ/1+rVaLdLDM2Qkgaw0T8AEbjYaUkvO25aQohpSLx/mDzloq/V1RaQ9VXA8z6Mttja0gl6UDURCGxb8AriBFBAyr+8Q6izwfHx+zb7e6usodbKSUQRAUnp/3bDiJXD74ohiLlgdPHnLgYWalAnZrhARrMmOMUgEKEQZxnuZKKY/DgQMCL3pcEPyrE5r/n0dAlDRBnueNRv3s7OzRo+Ner8fbexRFZJ2Q0uaGAwksgVIpZdFDQojJeBxFARYNth04Akdcii6EBABuNVjscgLP72BEhJyEKbaj845EKaF1LiUH5x2R6nr3PQCAlcyCoKzXFgDA5QiLxWI2m1lrm816oUH/GZ06y5riyvUA2xQqr38ZyCGiACQiS7b6PHmq+8SOtbbZbPqIWpQKFL4a4ILThh5grvxauULyz8V5ol6aXr161VWklRGR+e/q6GDv+Pj4jS9+mStIX3zxxXsffbS+sbqYJkqpo6OjS5cuxXH87rvvLrJFvV7nJPTp6en6+joRxXGsteJOPVJir9fJsuzgYC8Mw2azjojdXmc8HltroyhaXV0looODg/l8LqVst9ucqtja2mq32/1+/+TkxDm3f7DX7XbPBn2Gqfb29ur1+mQyWVnpCpC5Sa2hWj2SUjYaDakTa/NOp9VqtYzJ2M2yzkgpUcDJyclsNmu3m16RXIrT2WyWJIkOFD/+2Wwym836/T6vrjzPp9N5EASrq6vgXJbneZ4DYBhHRT0jC00KQHBhFMxG473d3Y21lZdeeunBBx/GjXoUx0opZQzL4zJLYzqdjkajIAguXbkCzgGiy3MVhslsluWpQBkDyEq3KaE1WDufzzlPUVAWjFGhBkBwzhiTzBfOuWatjlK6dP7k6aMgjtI01UHEisD379+PoigMw1AH9bgWKB0EwcrKCnMauHZvPB4TkbV2NpsNBoMkS8/OzpjekSwW3V5vMDgNo4j9pGLCkfD5O4GaHSyspAjZGfIZd36zDnQcx5wHabfbbBfr9XoyX+R5bi1xtwfGNbm7zmKxEKqQdPfECB+g/OEPLGRaUJCzAtABCQKL5z2MC6vr2YrOCrjlEHA0Hq30VvpnJ3/9r/91IvP6668jQp7nDNKw3VVK8R35zb3YfIXgp5Bkabvb+e47b1/9xjcXi8X6xtZ4PF5ZW3MA49GUXcwwDDc2Nk5Pz/I8n88TrTU4MM5gmj568vjLb3ypt7ry2muvgcDjwwMdBsPhsNPrjsfjeiP+43/8F69d3+F158t4tZY+CoTKDROW/AfWryFgFWBLTqLw5UayVJisDs0F9L3iZFhW7RIFISYrKJXgELnERDhnOFnmE5F+7hERCgKH1uUCpJAohCawNreCUwXoBCKKQkVRa11ejQNYfjuVsBn7RjwUk8mkXqsRWa0DrSU5OD4+1DqMI174FggBHAoNwMkOh6gcmVCFIAhB5iYdDibj8TgKw7hWi6PIcos91haighvlx4S8E1CB8arl5VBWYLmyAovdrLX19TzLjDG7u7vHx8evvPpqu9Xy1WTkSfQAPEnZoQWAPM/n80UYhkFBVLJhGDpHzpgHDx50Op213kq32y2uCmCRppNSsK0W18E6FvvmKmOoGCT+IU2S2WyGZZFgEDKyBYgEWNRIssIC3yPfb5bnk/H44ODg2rVrrXY7S1MACMIwKBVx2cHiXcjk+ZWrl69cvUrOoGCOETSbzfl8zlXJXkSDSl52Mc4lFZjHRwfB0tJjQeTi++EvtdZKiUopFCLPMq0jrTWUbQoJLDnkfUMI3yGqdLNwOeuKOczt1bVmPkyj2QjDMI5rShU5ZSHkYjGPazVRKtWVcTXnWJF5qexEMsqVJMnp6Wm320U4VyroQ2JRprR862uttFKqzBye6+LnqBhhPD9LlwN4fi0DFJ/mftu66HdZBDzMwY/jOI7jfr/PHgLbXIDnFAACAMCSLVCEMbCM64o8CaAfH96XVLmy/G1yiDQajY6Ojqy1W1tbcS30QV1xwmJhOCouA0tNVPG8CyvphkKy94ZlqY2UstfrhSXXmVl0PlBUq721+x8/+N577zXiWhSoQImf+qmvfvzxx7u7+91Zd3Nr/aP7H4VhOJlPXn/9DaXUwd5TKWW92Wm3m86ZxWL2ZPfx2tpGrVbrdDqT0SSMtA7keDy+ef2qCoO9/X2e+qPR6P79+zs7Ozdv3jw9PWW9Jd4RfvCDH8zncybEbayvSYmD/tlKr2MtJcni4aef9vv99fV1KXA+XwjB5AzX7bUJzMb6Shzpo8O9MJBCiECrbqdtTDabTU+OD7TWcRgM+merq6vJfPHo04ej0SRN02azubLSrdVqWuter6elytNs0D/jffbS1hYR9U+OOXFmrU1z0263r16/7rc/REQpJ2eDxXSGzm2srTVbrUCpxOaj0Whv9ymvjcVisb+/3+l01tbWBOJwcHZ6WCt2ojS11h4eHj558ujFF192zmVZtrm5iYhZls1mc0Tk1jG1Wm1nZ4eDaQYwpJTj8TgM4sVikS5m3W733if3W60Wp3s2t7bn8/nDx0//5b/8zXrcCHWAAM7aWhxnWSYQW80mATAw6UN/lCK3xuRpmsytyRBct9sNtG422l7Fhy9bacXq8M45ECQEMHGNt29EcM5GgWJVBUSI4xARtdZpngigQf80T7Msy8bDydbWVhzW7t27J1DFtRDAGuukVlIrS4bx3na7zTWMpug1sSw9q079H3ZUMXwo8nsOECWRAEAEX9BQpIGLPWd5cs+TQFHu+8Ca9RYIoNNpn56d/Pk//+f/Z//R/9w5MxqP/9gf/2O//uv/slarZVlSr8d5nmqtrcnLCFKSBa0DQ1me5yiIBCVZFoTxPMmazfb6+qaxTusAQV6/djM1djqdNhrNfr//3Xf/1e0bN6MoiuMwiKNkloAFZ+xXf/qrjbg2XcxniykJjGoxKtloNIRWjVYTwL333ntJOr9z504QBECQJonSgqt0dRDkWaqDAFk0yBosMtSFwRFCZGkWhJqsIcAkz4QQgZZEJJAAnDch5YAJYIlqKaVEZy05kkoYY5QSjowxRiACWQRwzhA4xX/VUkqZJgtO3Jg8E0JIpZLFIgxDk+cutzoKbJaKOJyPR7VmXQnM0iQIoiDsgCVjjc0zGWgA1rmN8iyRUjtnlA5tqWnEX0HOAAljTLNZB2P7Z/3RcDybT1+889Jqryt1CM6As+liHkc1kILyDIt2cghESgh01jonBWilWvVardkwaabCABGkAGddmqa1KAbnAEgIQcagUkIoMrnWITgLiGQMSokCwToQwmapDAIgRPL7PQIic1JNmuow1EHw2muvvfvee4s0WY/W2YtheA2kpDxDrfzM10oBiE6r3e10TZ6zkeTCnydPHt+7d+/mzZs3b91KFguQ6Kl1tXo9iuJ+v390crq9HURR7PJcKKUQHAqhNQDYLJNSmCxTQcBdNRFRS0nWgnMAkFuntfLtZtI0lVqx4+KcWySJcfat73738uXLtbjhMhsEIVgLxoKULjeB5kq0IkUoJVqTW+u0VsZmSso0W2itUcLgbLC1teXACpRE5IgTRpZz9ACOkBDAkgMCJVVm8jAIHRC5otLckcmyLAojY20Q6jy3UiiORqzLEdFZh4goUQoJIAAEM3tya/I8E4BxHHP163w2EQK1DtgSc0rXWcsZZJObRrNVb7RLfj04B1Lr3BgpZbPVyvJMq9A5ZywpJQGF5SIDKbMybEuybGNrazydroZRluVRGBGQI6OlNjaXUgI4TsJopR1ZlhjQShfxFPnuc0BESMKzlErqkhRCVCt2fSm3KMqSBBA5awlJCKY1AwA4Z7jlIgcz7Xaz9JtEbvIsy+I4RgByTknB/pl1lktlCAiFYLoYla2+CQhRcjAPJVpcJKltAcBbaxEAhWQ7LoWIrlyBAi+XRGSNAwkAZEyulNJaAhTwW5mdIAL7XG6W50QgknNcXQHWOiFErRZZmyOic+bwkMkYooioXW5Wu70sSVNRaLecnZ3t7+9fvXo5TdMwjmvOTafT1dXV73//+1evXg2CoNvtLtL04ODg7Oys2Wzevn37nXfeefHFF4mslCJJkjiOzs76w+HgdHB2eHjU7nS2t7dv3LiRZdn3vve9jz/+eG1tbXNz89GjR5wYunz5MhEdHh6urPaUkFmWdDqtjY2Ne/fuHR0dvfLKKwwCAUC73WJjzwSL6XRqbe6cWV3tLRazNE2Pjg7m83m322V+yXw+397efvLkyXg8rtVq29vbly9LROz1elyYM5vNePHcvXt3MpmwHBS7EWdnZ7PZbDGbWWtRyvl0YkzG4zMcDnu93pUrV5BgvpgeHe5nWZYsZpbceDIL4ujo6CiO42azuVgsLl26xDCG1no8Hj9+/JiLrnnW1mpRo9EwJhuPx0Ko09PT6XTa6XS63d79+/e5c/vZ2dnh4WGtVlssFmdn/Z2dHWudtbZRh0ePP13rrTx4cH9ltdtqtdI0XaR2b2+v2WyHYTgajdI0lUL4tEW9XmfXflrmPgCAyXbG2VqtNp9NnHNehoojiUKuphTLAQD2dRqNRmZS3k0YXPFVFcYY5rElScLCjJxL4raD+/uHjE8cHh7mmY2jonSIx4QTQ2lqnHP1eoHE0vncSjnpz/lYeJ7m8tyjEpo43hyh6N5V/kFU00nnozd03PLKr21ccp/dYDC4cuXKP/gH/2A4HP7jf/zfbm1t/ezP/uw3v/kt3pustTqQtVqUZzbPCx9LykK1BUUpigswm82SJHv77beVDh48eBCEca1Wa3a6jUaDiIIg+O3f/u04jl+7+0qSJO99//1er3fz5k2XuZwoy7Kng4ExplarjUajVqvlknw6nY7HY6VUv3/SadR3d3dPT85WVruXtrZbrYaQAGULDo+agHNcnZqmqTFZvdVBk+VpHkTBZDh0zrV7vZDIkFOqaHOepWkQKCE0kHO5FVqDzUFJpfVsNhZCxHEIKLii3joDjgKtnbVCKiAqcitsaawVUoZlK3GuaSfnojgGa3QQQAA2y3QcAkAUh4A4nY6IKAhDk6ZKKQGgahEAzGezWr1uTamXLfViPmW9b6bjmDwPwjDPMq11miRK4MraeqgDpTZ1oEEILoeYT8e1RiNdLMJ6HbnBvDXJYqHDQCoFQkhLWbpg4vxiNq3FdQbOyFgpZS0ITJoqznzludCajDHGcAdAxmZQqelo1Gi3QcpkNovqdbDWuQLM5mkmlJJBkCeJjqJsseCu8xsbG41WEwRmWaZlAM6BlCZdqCDg/iHkHGoliqQSgXMs4weIWksgWl3rzRfbN2/dms9mLDvHEzsIw0WyIIJGq/nJw083tjYL21Ym+BbTadxoyCBwJuMzg5QcfSVJMh6PNzY2UMpAKWctCy44RycnJ5bc3bt3eYchonfeeeeP/LE/GigNJEyaUma9+BYTp4wxSmuWFVVKSqWkApPnhJBmJgzCLM+Y+UBESipfmsc5XEScTCb1epzneRhpJVVuct+9rgiYAVne2S9tR46pyrwlQkmOZnEHYw2U2eQojKQQzlmbG0DMszTLMqbez2ZTBvP4S7iyJwzD8hFIAEHkjCEAkEKjIADITX5wcLCYp0zwJyLnuDte5lPnSqnVlfU0W4xGo+OT4/W19TRLwyDUSltnlZTGGkAHUIBz7ElIKR05X69S3Rh95C9LSU8Okr2mCZbcLP6XZcNN2Re4shlCNV9WTavlWa51yDBBvVY3NkuzXEpZJgHPHVRw6VyWGUTUWlZhcn/xxc4piMBJGbAfzw+L3VDHELKULEHsnbPpbBrHkXEZIp+5CKGNtVoV6pvV5oZEJEoNJih59Axc8QnZpFKpjAoA+Cv/+f9Ba721tdXr9Tj9t1gsGo1Gb3X95OTE15HevHnz8PB4Pp/fuHZlNps92d1944039vb2nHNbl7bv3bu3vb2ttf74w3u+b2iv3Wm0W7PZ/OT0tN1u37lz51//6389n89XV1edc+xzXL9+fTQaXbly5YMPPgiCYL6Y1eNaFAVnZ0PWPtnZ2bl8+fJ0Ol1bW1NKffTRR+vr67VabTweP336lDtaN5vNyWTCGIkqD8Z7fMGRMabVau3v7/OVSCnff//9yWQihKjX651Oh0dkb2/vpZdemk6n/X6fu27FcayUKmhJecZELhZtunTpUrpIxuNxs14PgiBL0slkkhsndFE+w94Md3FiwkQRuxgzn895C2CWOtNshRAPHz5k2cCTkxMe9slkcnx8cu3aNZa9mSdz50y93gyCYDwc8/q31qytrYRhGNdreZ7PZ+mjp7snx/2/+Tf/szCMt7a2ELHVas3n82azyagAF0bx3dXr9b29PZRCKbW3++Tw8JB3AV42XFfMDBWuvTLGMKsXEefJzJUsfigzBfy2IAi47LHVaiHiYDDY2Fj70hffaDQaBwdHeZ5PJrPT09PxaMqwqnNOKoyiSClWGHdKKSl1o9E4Pj7e29vj9GI1YeTnfXVNPrtQ4XmQL3sU5zq389sKB2tZg13587JHrJCyUNICYB9UKfVzP/dzP/XTX/3Od77T7/e5V+uv/dP/ZxAEYaiJSGlRq9WKGkaSQRCEOrDWGpMpLRi5JIeIstFora+vN5qt8Xjc6a4sFovTwbDX6/E839zcDMPwcG9fKfXp40crKyvcPIqTBYPBgGE/NoHj8Zi9+SAI5vPpSrtF5IwxBwcHt2/f/lO/9Iuvvvrq5ub6Sm8lTedKqfv37zebzdFolCRJLYxqtVqjHqeZOT4+7HR6QaBOTk729/evXLmysbHR6XSe7j5xlpSWcVSL4jCZJ2tbmy7LWXB/PJmQhfF0xGRKrXWaJY1G43Rw+soX7k7nM61CY0y/3x+Pxy+++CKvlN7KCpOXwzCcTCaLxaLT6bASYxQEk8kkDEMW9OL5NhgMDg8PhRDz+fz69eusWnnlypXZbEYo2LbFccz2oNFsmjwvNGzr9f7pKeuxscc/GQ3jOK63WnmS6CA46/d9dUWj0XDOHRwcNJvNvb29Vqu1s7Ojo4h46gYBWDsejyyp4/YAAQAASURBVHd3d5vN5uXLV0GIYb/POwZIyXqBbBettVVnCwAY08oWi6LVtNaFmn+BD0mQsnC/iADRpKkQAqQQUqZZulgs2u1OnmdKaCGkzTIA50tkeGaDEM5ZfvrMi5dK2SxhVyZNE4GKBQLYj+ElWW80rHNc51uv1U2SSimLS2WaKeJiOgUknmZEpMOQrJ3P54vFwgHEcXx8fDybzdbW1nhmOufOzgY8H4SUk/HYkuO8nkQlAE2eK6WSZM4ZpTRNo0ads4qclLHWFrQtIJPnHuyPokgIiUKQKznsWtvcHR8f53m+fWlTaZ1nCa9m9rmrggiczGVeGjsWeW69xGtJVSyWv+9yA2VfB1aLZeeSLQ73ZgBEAOTe2Bz2R1GkgyDPMq1DThBzYRZ/nNEE3qiTxULrkMUmoLKJMeWff2R5MwCI4tjkOS92IkcI1pGXc7O580UhVGVMOvRpwdwWDpxHsKDUyfOZLy6zKDRNsChI4snGGDaXFXi6oajw5bn1IWckgkBxpaGxWRzHQRBwGoFjrdKgAIF1ZW0Ab9reb/NMAyJyZEpM8RwjkC9DSMl34Ymn4/G41Wo4skQkhbTOsugJ20RO5lfzlfwtApaKXLPZjMk2zFTm7/Idu3kc8Df+h39ycHDw2muvJUnS7/d5p06SJK43j46Ojo6Oer0el8fv7Fzp9/vHh/uIOE+S27dv37p161/8i3/RbLcuX77c6XROT09Hg/GlS5dardZ4PO4fn8hAr61vOOeGw2G/32ffQggxGAx4d2bNw7W1taOjIwAwNt9c35hMRvv7h5ubm1mWMSrAz57Tw0mSNJvNJ0+e1Gq1+XzunLlx40an0xkMBkEQjMdjV8o9s1Y4AGRZFkURc3rOzs7q9fr29jY7lM6509PTyWTSbrfH43Gz2UyS5Pbt28fHx4PBgH0say0zSdM8E0Jcvnx5MBgQkdY6T7Narba5vn50dLS/v7+yshLVGsfHx1EUMSgdhuHZ2dl8PmfhtTAMuTo3z/MsyyaTSZIkd+7cOT097ff7a2trn3zyyWAwuHXrFnt1JycnN2/enEymvIP0+6dvfPmLp6eni0X60ksvPfr0Ub1eV0qORqPFYsaanPv7+92VtVu3bv/zf/7/+V/9tf/4tde+qHXI4g58v612m4sArLUs2t5ut9l9zPP8yeOH/X6/Xq9nWTadTnlPYdqTz4vzHC0ojYKYLmNLDVXm/LJVm81m7Xabie3T6fTKlSutRn06nbbb3dPT0ywz/X5/NJywKyCECCPNTnOe55ywR5Ra6+Pj45OTkzzPq+o78AyC9TnHZzhYgCjZx1piYCUUXH1bcX50QIQCAFhMsIgIwzCcz+c7Ozs/8zP/7tOnjyeTyZWrO4t5Op1Onzx+PJ1Om816nqdKiyAIgITWOk2t1jpQmoiMyZRSUqExJo7qg8Go1eqsb2w0my2UwuSOiIQOJpPJ1tZW0S3KWrAuiiIVBmmaxnHMeBVPy/F4zDsFnC8IiuM4nc9m0zH3fFwsFoPBWb1ef/kLL37xtdeNyYbD4Z0Xb1+6dGl3d3c2mxDR1tr60dHhzpXLQRCMRiMWH1pfXz8+Pj49Pa3VakRWqcDavN3u9k+OraW7d+9++umnzDe/evUqEYxGQylVrVFzzo1Gg5s3b7777tsbGxsrKysWMFlk7Bsx43BjYyOO4729PW7ZNpvNer3eBx98wAHo3ZdfZiubJMm9e/du3LghhNjd3d3Y2OAt4t69e1/60pcY9/3qV786T9Kjo6MkSTjTMZ1Ou93u/v4++/1Kqa2traOjo93d3VqtppSqReFgMGAvjUPNBw8eXLt27fj4eDqdNhoNFryt1WpcLsShC28InU5nb2/vp7/2tSxJTF6QGrnih4hYEkJK2Wq1wij69JNPhBDtdtsYs7a5yXk3Z8y9e/cuX77MkkJc6x7HcbPdHg+Hxhgu/uX1gkpZazhpYoyJ4xobgWyRBHHMHhtYu7u7W2/Uuitr0/Gw0WoBwO7ubq/Xq9Xr49Go1ag55w5Pjre2tvLM8ma4srKyuroKiAf7+6enp3deekmUzawkSrb0Ls9PT0/TNN3Z2UGlAJzJMq6+tNb21tYA4OMPPjDO3b59+1vf+taTJ0/+xJ/4EzuXLzNnP8typZQOgmQxD8MIBQKgNQYdCa2B0JnMGBPEcZ4kOgyzPAuCABCnkwlj5yjEYj4XAhmGZJOmtUYh0yQhQvY2AIDzv2EYWpcbk+kSCXOlPm0QhuxWsmFeLBZsMljXl//qnGMj6mzOHoMttbWIlrWfRMSUfEYyrLWszhXX6t4h4wx1WURZOAHLNix5nqZplXqLKAExzzIA0EGQllqvUJDe5kopqdTe7q7Wen1jAwCmk0mj2eAdjgAWySKO4izNOdoHr1PARCgSHnkSCr1mmI9guTDWUwO9N8Ypfu9RubIxVBAE3nAsG/hyyUIYl/B/0cA+y5PDw8PNzU2uQzTGSFmUNLHTa6xBKERPtNbsfl1IDjrnjM0CHZBbNhfypQyIyMqKSp2H6sERkHOWHSxexRwRFcnzZxjuAoouDkIIVpFkt4S/qDCLYQhETH7H7/z2bwwGAzb/OztXEPGTTz7Z3d1N8xwRv/jFL/6rf/WviIjTPbdv387znDHkfr//4ssv/fZv/zYnI05OTnZ2dl5++W4cx8l8wUax0+mEcfT48WMAYMxmPB7v7OzwdV+9ejVJkkePHimlLl++3O/3uSiaiYqTyWRnZ4drIJvN5uXLl9miv/XWW6XoQD6fzxezeavV+pN/8k++++677XZ7OBzev3+fW79tbm6urKw453iHjaJoZWWFQzHGCXnLGwwG7PJHUdTtdofD4dnZ2cbGBm+jcb12//7969evf/DBB0mSXL9+/fj4mLtotdttrfVsNpMoGNGRUp6dDevNRqvVstYeHR3xt7AxY/KBn6y1Wq1er0uU3W43y9KDgwMoA2Wu7MvznPdu36NmPp9fv3ktybM8yaWU0+mUC6Ymk4kQMByera2tNdqdk+P+5ctX/u//7T/++3//v37lC6+mac4DnqQpQ2Ws9drr9S5fvjwcDrmLdhhH8/l8PBpwVYGv2+IIsiQwFixINjBCiNxmUOJhfjXyO3u9XrPZbLVa3F9iMBhEUXTtyuXHjx+vrq5PJpMkyY6OjtIkl1Jy8ZcOOD6wRMT00jCMsyxj8+YFsURF2AbO5ek+8/g8B6viQiGW9SoF6cVdOC05J5UiImetlBy/Cq63uHbtWrvdieMoCAJESpKsXq9/+OGHH330QRQHQkCzURNCmJzB84ChPimlMzki6kAi4mKeSqnDqLa6utpud2qNOjkcTsZeRzAIgizL0jTd2Ng4Ojra2dlhyGo+nwdBsLm5OZlMnHOtVmt3d5d96JL64pIkqYUBlxpIKcMybZGmi+PjY6XkF9947erVy3e/8NL6+moYBj/44P1mVHPOPX78+PXXX+dU8v7+PivTcjnCpZ2t/b3DKA42N7aFhNl4Nh6P5/P5xsYGAFhre93Vs8HpfJZsX96eTCaOjFKKVWAODg+bnS4RscHQWr/wwgunp6dHR0dEtL+/3+12W63WRx99BACvvPIKEa2vrLMT4JxbW1tj15Zj4n6//9M//dPf//735/P55ubmcDhcWVlhGIwn8Hg8fvLkCRMiWex3sVgsFovr16+/+OKL8/n8Bz/4wc7Ozmg0Go1G165d63a7LCwOAHEcf/TRRxsbGzs7O6enp5ubm8fHxwzLjcfjN998Uym1srLS6XReffXV09PT05O+EOLOnTt7e3uz2SyKorW1ta2trQ8//JCJRFwk+53vfIdLfK5cuSKEqNVqvKM2m01jzOuvv/69999rNpvM/t57uru+vs4F4Sf9U2stIWqt1zbW19fXh+ORzc34bHD35S9kJn/w4AEHtFrrTz65v7q6HoY6NflwOGSJYygc7sU777zz5S9/eXV19Z333mcvk6fNwcGBlHJtbW0ymUopm+1WmqahUK1WK8uy4XD4O7/zO1mWffWrX11bW9vc2mg0Gpz6ZMfu3r17jx49unbjBjMENjY3bZYZY8JazYMxi+k0rseAkkyGopTLQgRLBeSW5/v7+9vb2yLQaYmde7kZpTWQ41ORMUmSzOfzZqMVxDEAgLWsnVT0+UAcD4f7R/tra2uNRqPf71tr19fXVUUwwrsCrBbBjtRiPo/jGBCTxcJay6Ejuw7W5B5LM3lurTVcV+5cGMdQUuwBIM+M1hqkLF7k16UEFM5aIlteQ8GFZ1vAj4mdUSGUh2T4phBRKkXOIGKappwUklIuFgsiCgItpcytISJjbKPRQEAvAMFtSRGlUqpoJeKcoRJ8ArDG8ORhrM5ay32ZGEHkWDeO46IbSinYwXObvUAuLHNlAbUo+mEXflIpg9Lklb6+vu79Eik1lEJF3NtdqmDZrTKzaZrWGw0g8j0lszTN8zQMQ072ecDJgwLLaQDARVRCCGMzJWSeZ1y7kCYJESGKJEkajQaUorg85gWkpwLfFJwr7rGs6m00GmEUVTsyp2mKv/p/+TvNZhMAarXa06d7+/v7QRD0er1Wp6O1vnnzJoMiw+Hw9ddf5xGfzWa8N/VWV46Ojrrd7pMnT+7cuXN4eKhUsLq6Op/OmGJ1+fLlerNxeHj48OHDs7OzOI6vXr0ax/FkMjk7OzPG/MIv/EKv1/ud3/md2WzmRWjY8Mxms5/5mZ/58MMPj4+PuZ7x6tWrH374IeezG41GEKgkSXqdbpqmDx8+vHbtmtb6ww8/3Nzc5Ex8lmXtdnswGGit5/P5ysoK502EEFycyN7P1atXd3d3z87OLl26xOJbKysrnI0aDodSq8PDQ46PeV7mec6SOYPBgCeQzc3KyorW+vj0pN8f8C30+/3hcHj9+vVWq8Vxv9b69PS0Xq8fHR1JKVnXavfJbq/XC8MAANhluXbt2mg0Ojs7Y5Dp/fff39jYCIKg1WpNZuO9w72f+qmfmk/mZ2dD38zLmKzTae3t7aUmF0IEupZl2X//P/y//5v/5v/2lS/9O3luWTB2kSTb29tSyiRJ1tbWeBrxbhVFESGcnZ1NxsPpdMod8ZiFxmgHe70+slldXZ3P53meM6TMmVC+GCJiT5S3IQbzlFLsQq32utPpdDKZGWNms8XJyclkPBNli1wUJITQWoZhKAQ45zqd3mw24xQDB3beo8Lz9bTOXXSGPuuoOlu+9Zb31ao4/MVu8ADsYjJcF+jIWmuNk0q9/voXV1dXVal8BkBpmoVhMJlM3n77baVEXAujQDsy5LhBITkHhaoka32FSkqZpS7Lsty4O3fu9FZX79+/31tdl1I2Gi0iYhEHfnAcDHBswBKUvV6PLfGTJ0/YdUZEblXG028ymUiglZWVNE3juG5zk6ZpEAS5SZvN5mQyQoQbN6+8+soX6vXohTu3jo4Odra2T46PJ5MJqwQfHBycnJzcuHFjMBiMRqONjQ0Oe/b3919++eXTo+PJZGJzo4KQw8qHDx++8MILOzs777333muvvfb9Dz4YT4aI+MILL1ibB2G8trbx0f17R0dHnU7nJ37iJ+7fv//RRx/FcfxLv/RLb731FuNDi8ViZWXl6dOnvV5vcDq4f/++c84Y84u/+IucyH7y5IkxhnGXg4MDIrp+/fq3v/3tN954gxNV7DNxnrHX6/EmcHJywtqAUsqtrS2Wf2s2mysrK81m89d//dcRcXt7m5kcw+Fwc3OTW3FzR96rV6+GYcjR49ra2sOHD3nMDw4OdnZ2FvMkTdO7d++enp4KIfgp3L9//+rVq/1+f3d39+rVq/ztt27dYrbD0dHRxsZGt9tlnsD29vbBwUEYBbVabX19/c0336zHte3t7U8//bRer7c67Xq9/nRvj3NDxlkOqXc2tzbW1r/z5h+cnZ01Go27d1+u1WofffRRs9lcXV19ur/39OlTJj+dnJxsbm6io06nI4Q4Pj7WYbxYLFqtVq1We+edd5RS169fv3v37oMHn5ydnT3ZfSoAXW5u3759enr62muvffrpp48fP37jjTdGo9FHH3/41a9+9datWycnJwx17O7uSinH02m73eYyK5vnvV5vdXWVd1GGqLXWxphHjx5JFNs7l3wKaTqdxlHt5OTkwYMHtVrtja98udFoVDNlLPQwm4x5HgZBIINgdHYGVMyZTz/9dGNja21j49yKBscM5mSxIKK4VvOFhAyosKgNwzNYaQh91u8z0BBxAqgw/845t1gs9vb2WO3p9s2bLIWqwjBbLHx1bbJII2avpqnPoAEiSFU4WFICLHNqWZqyk+ecs9ax6+C3KSGlNabs3S68h8cliuzffPDBD7hASijZaDSzLNNScXKfuSvsfkgptSjY68YYh6CUGgwGn3zyyWQy2djYWFtbI6Kzs7MrV65wiAUAp6enXAG2trbi0SxOjHLuiKvWOJVRJEmJ0jQVokhDD4dDIaDb7VKpnSlKJRTWAeEd/t133242m9eu3fC9vU1mGY8kIuuKfgzWWmtzKaXShd5HNQfqnPvkk08+/PDD6zduFPU9AKxfg+CsNT6/yQ4Wcwa84wj8YIqGddqH4oVnXxaccqKW+ftQcEgIf+cb/68oinZ3dyeTCbf+ns6TWq22trb24osvfvDBB41GY3W1d3p62ltd2d/f39m+xCzv6XR664XbT548IaIXX3yRiA4ODoRQk8lkpdvb3t7e399//Phxb3WFTSOr9h0fHzO2sbq66mmDTI1CxEaj8WR3FwB+9md/lhGv09NTAOBdcjKZvPyFF621Z2dnQRDMZjNBYLL8+vXri8VibW3NOyWz2SzP8+FwyLk/ftI8peJ6jXeT0Wh06dIlay0TyVdXV4fD4enpKWf9L1++zDs1Q1nj8fjhw4fNZnN9fZ2RpNXVVWZUlLK/NBwOj4+P6/VmGMdMhVksFqurqwDAAEMcx0+fPu10Ooh45coVKeWDBw967S6jg8fHx51uWwjBridLgBJZJtbwyn/ttdfefu/tra2tNM3ffPPNZq159erVJ08evfDCC0GghsNhkmfz+fzFl145Ojr6f/zjf/pP/sk/3dm5Qq5gUCVJsr6+zhOu1+tx/o4beCVJwgBpu9NkGVhuzcHZKKbicSi/tbXFyNZ0Ou31eu1uSwgxGo1KRN1IKYfD4Z07dxhP5j00TVPGEpr12tnZ2cHBkTFGCDWfz/f29pgcwyucsSutNYCz1m5tXWJwYjgccgrpAnwlyuJ2qrDg/3BHEeucI7lfPHg9MwolpebUzPb29rWrN3iU2KcJI33nhZcODvdGo9E777yNSI1mzdrcWhsorbXm1AAr7vDWEAQKESejuRCCQKysrNy+c2cymdSb7SzL5vPER2acPuCSBSHEbDbrdrvW2izLut3u48ePOY27sbHRbrdPT08Z7OQHBNYQ0WQy63R6PvMrpXTOBIFazCdf+vIXX3/97h/7419/7713yJlAKoG0sbExGo1Y4Hdzbf34+Hg+n1+7do05YXfu3HnzzTd/8IMfvPHGG1FUu3Tp0gcffMQQchAEP/jw41LeyXU6Ha11/+zkxo0bT54+fe211x48+HR3d/frX//67/3e7zHkyaHUyckJNxiw1u7s7Dx69Iifzm/+5m8xNHX37t0bN2588sknQRA8fvz47t27PFdZAcsYc+nSJe5GsFgshBBPnjxhjVYuyN3d3b106dJwOOSFzzkdRrC4sJx9VgA4OTm5du0a0w+ePn36yiuvTCYTnpC3bt0aDEb1er3f76dpevv27RdeeOG9995bXV09OT7d2Ng4Pj4+Pj7+0pe+9PHHH3OXm5OTE16GeZ7fu3evXq8j4u3bt0ejETtbDx8+ZFvVbre3t7e/+/ZbSTJ/4403Hj9+3Go0u93uvXv3rl69enRy3O12R6PRaDrJ8zzL8+vXrzcbjbXeyuH+Adutk5OTTqfz1tvfvXr1Moe1zHMqUmxKjkajbJF98sknr776aqPRaDRaH3/8cbvdfvz4cWbMq6+++vHHH3c6nSAIvYO+vbH5/vvvO+dWVlaYl3N2dvbaa68dnxy9+eabm5ubnOHtdDpZlrVarfd/8IMoii5fujSZTHhPZpWD7c0t9oxf/sKLi8UiSRIJaIHSzHS7XRY/6/VWeT9J01SHURRFHBAyOssoJji7mM2llJ1Oh5eDUrper3/yySfOOeZBclI+DMPpfBbHoWeIcojLK5qtY1SvFwgcAKt/ffLpA572Z2dnOzs7nLYOw7DRbnv+3GQ45M2t0+kopYTmpr0OShvsjBFlDUfh7XluA7etLGASNvAEUqbz+fHx8WQyazabl69c45ys4H2DhT+WqJtjJwKEmE8mtWbz0/v3v/nNb778hZd+6mtfm4zHcRwrrWfTaZYk7GA1m01AWVQ/eC/EWmPtcDJmmgGztZRSURRhqYPAzDzu8MaRledXWWN8WwVeqrPZjKmccRx3u916vS6kBEdcF8BkHk7Tg5RkDGcVGWssRSTom9/8Zq1We+mllzqdjrXEnTFBCCAWs2QfqEQxreV0ajnIS70zqdQHP/gBs6FW19Y8U4qc4Wzg8oSeucgeMJ+q7IZiqODUz+fzdqezHEDEPMtOTk7YZ6CyqRfufvKDt99+u1arZVnWanXiOH66d5DnOc9y5hWtrHTjOG53O7u7u81646OPPiKiOI4J4bXXXvvwww+vXLny4MGDyWTS661evXp1NBiyAQ6CoNPr1ut13sKY93dwcMCIxXA4fOmll+7fv09ETB+JoogQrbX1en2xWPT7/c3NzW63+/TpUybBpdmCA4JWq7DroVBxHDOWMxqNGKphrPjatWtKqSdPngBAu93e2Nh48OCBJXfz5s39/X1PY+Sk5CeffLKyssLCfd1ut9frjcdjtmScXmw0GkyTHwwGnU6HP3t8fLy2tnbz5s1Hjx4Nh8O7d+8enfTjOD45ORFC8Gd3dnbG4/FoNBoMBpPJ5KWXXqrX66PRqN1uHx0d5UnGmtREtH+wZ629c+fO/v7+2tradDp9+vQx06f4qur1+mQ+AQAh1GAwuHX91tnZWZouoih64YVbh4eHs2Qxn8+tE61W6//6D/7hN77xze3tHZM75uIxt4CziuwrdDqdS5cusXNzcnLSaDQuX7nEOVmuEpjP59PpdDAYbG1tsQPBadYkSUajUbfbXV1bExKOjo7q9TqzXGu1GnOWd3Z2mCfHif/JZFKv1zut9re+9c35PAGAjY0tY8zDhw+Z1MWwhLWWqYtSohCiVmsgIm9wTEL0tQve4+Ep/qMjWNUDzwsZQ1FP+Px8Ih9SSnJY6CwQXbt2/ctf/vKTx7vsXyJiFEUM73U6Hefcd99+M0kWnW6DmfuB0uxcMoXfGGNMFoYhUz5DXRuNRkqHUsrXvvjFTqezd3BkrQUQnNrj6IrnZJqm7CUwTCulXF9f569eW1vjYgV23z137cql7TTNWRCYHLCjJoQwNhfC1eKw0Yy/9KXX/t2f/ZnT0yMCG0m9sb46HA7ZG3jhhRcW01m73T45ORmPx5cuXfrwww/v3r378ccfK6V6vR4RWqA8yZMs+4mvfOV73/+g3+93u929vb27r74y6J91VzqL2fz49OjSpcuNRuPjjz++8/+l7L+fJOnz80AsfWZlZXnvq73vHv/OvPO+87qFWwC7S4Ig73ABkdLxjtA/IHeMUIRCijuFFNRJDEoRx4MYBzJuDwEEFljs7rsG++7rxvtp76qry3uflT5TPzw9jQVA8kITCMS7Mz09XVWZ3/x8Hru0hLok6I1wRCiKsr6+Xq1Wg8FgrVYLh8M8z+/v78/PLwYCgZcvX87NzUGWJ0kSAI9ms4mxHtC9x+M5OzubTieRSASsDYSApmlC/y7Lst/vh/oqEolMp9ODgwOA07hD/X5/sVikaTqXy62srLx8+dK2bYg10TocjUZPT89w1Gia9ubNG8jXlpaWkonU2dmZz+dzHGcymRwfH7///vuoRsDHB7Ts+PgYuc0YDd1uN/D4q1evViqVWDwaCAQajRpm6G670+/3JUm6efPm0+fPJpPJxsZGsVikOZZhmFq9nkwkMslUt93x+/3gFhzHsRwT0K+maX6/3+VydTodjuNUQx0MBh7RF4lEDg8P0+k0QVCFQoEgiGQyqZsm89ctT/RoNJIkye12m5qOtwVHAfTafr+fIB1sU0dHR+BASqVSIpEYyzLHcZFQqNFozM7OVqvVXq/DsuzczOx0OjVMjSAImiDr9brX6y2cF1PJjMfnlWXZNE1RlFRVXV1d1TRN1Q3HcabT6c7ODnZpzEYulk0kEsViERe81+vlecGyrG63G4vFer1eMpm0TKfRaORyueFwOJoM3W53q9UiCCISieTzeV3Xz8/PIQzKZDK9Xg+qbazEtmN1u10sBpgqIpFIOp0GDgdop9VqgZur1+sulysajZ6fn7fb7Y2NDehus9ksSVDtdpvneX8oBDYTqlPcyBfFvo5FUBTSCfBcL56eVSqVTDobj8chziFJmmSYUb/f7XbBCQQCPhx9sViMZBjbMH7wgx8cHR19+NEH+XzeFwiwHKdrGlCui/HRcS61Xzj4/uYJ9zdOUTi6EonEJVeAAQjvmPk20hOw5UVEy1tdOeE4k8kEGw6e4JRD4LOzLGswGEBDAsUVXOo85h7rwplOc1y/0/F4PAzPEzYB1piiacxY+HFs86LlSdO08VjGPEAyDGKAAVHrus4LAshfxGERBGFbFsdcFGWSJEm8TZi4eP8v3xySRNoIQVEOQeI9gW4Mpz1GLoAULpcrHIlcNKazLPnTv/wTQRAC4ZCqqpVyjWGYTqe3trZGUTRFUcl08vXr1+vr66PR6PT0eGtrK+Dz9/v9R08eB4NB4DSBcMhxHCzKpE36fL5isaiqqsctURQliC6MfsViEW+xJEmCIIxGI5IkL+F6giACgcCrV68EUcxms4ZhdLtdCCwymYxt2xN5BCMerIX41Nvt9rg34Hl+a2urVqs5jjMajQzDABsI9TF2d57nz87OBoNBIpX0+/3dbrfZbOKgRC8jhrNAIDAej+fm5uCgxufX6XQgXbIsq1qtzs3NybKMBVEQBPAviUTitHhmmmY0EoflMB6PI8mz3W6TJAk+kef5hYWFcrkMxW4kEpkMx8FgcCKPNzc3h8PhkydPbt68ORgMdF1tt9vj8djj8cTj8VevXs3NzTAM4/H7Go3G4eFxNBoVeTGdTtu2qSgKRRG6roseieO4wVBOp9P//L/6P3755dfZ3IyumyDgLkU8tm3zLAfpGxTQPp8PZkxAepIkSZI0Go263S4GGrx8KMmQUatpWrfXTmcyOPhAeoqiiOQLYAa5XK5er4OCrNVq4UgwnUzt7Oxsb2+HQiGedymKUq/XkRCjKAqmfgSooO4eo7yiKPABORckPX2ZB3FxJPzN0eqSg/+7U9T//C/y4u+AEjUvQ01JkmVZimQ0VaUZjqIo07SuX7+eTmVbrRbDXIjNsWGrquo4zmg0EASh1+9UqxWCNAVBME0dGzPH8I7jeDy+SqXi9/s9HvdkMkqlUvJYbTQaXl+AIIiZuTnLskaTaTAYtOwLMlRVVeptEdN0OmVYFpwOgCtQPCRJYtgdjUYgLhFTYtu2qigEQQi8OB6PQ6Fwvz9UVdXrlXweaTDo2baZSEavXd+cnc3ajkU6di6VbDabw+FQUZRIOOzz+d68eXPr1q2zs1NVVe/evnNycpJOp+v1Oi6h3YPDQDDMMbxNOCdHx/MLi+12W9f1TqezcWVr0O3plsFQlKzK8VgyHAm26g2aJjVNCwaDg8FAEAQI3gFnRqPR4XA4mUwgZu92+wRBWZZ16Y8ZDocEQQBcWVlZKZfLL1++DAQCMzMzhmEEg0FZHtM0Db2U1+vN5XLgE69du1ar1fCcA2yGmezFixehUCgej4NMLJfLSEIeDoe5XI4kycPDw9FotLW1BWDD7fERBIE+EEmSKIp66x0WwN5Cn4CP4/z8POD1wYJj2/bGxka73S4Wi2jnPDs7Q/+EYRjhcLjZbAZDgWg0yvNsv98nSbJarkCgyTDMX/zFX3zyyScOSZycnNx5726v1wMe+fzJU9u08jNZ0JrQcvX7/WQqNR6P05nk8fExkt/T6fTZ2RnLuGKxmNfr7XQ6luWA4pyZmWE4Dh+Hz+fjOB6DOMuyvXZnMpk4joOBCdaKaDRaq1dlWbZtG7hjo9F4//33z8/PgUEyDNPr9ZLJuMfj6Xd7qVTKdkxsbqqqxiNRAGw2SVAkg6xjgiA++uijX/ziF/F4fDgcGpazsbEBanVvbx9+nWAw2KhUoBYF7WCa5nSqpNNpx3FgOb/QS5Fkr9dbX1/XDQPzeiAQYFn2pz/9KcMwy8vLo9GoXq9jjcSu6DiOx+OxbHMwGIiieHh4iLVzcXFxNBqB0k0kEo7jjMfjSqUiy/Ls7CzP88lk8tmzZwRBhMNh0zQHg0E6nQ4Fw/1+PxwOt9ttwJYcx2GVhTR5cXFRUadzc3OGoZVKJUEQer0ew3C6rhfPzhOJRCwW6/f7rVYHsdtoi7Isy+NxJxKJfr+P4S+RSDx79mw6nQ5HA13X33nnpm3boijxPA+CD9feeDhyu92tVhtJjSzLZjKZTCZjWhZBENAoj0ajyWRSLBa73e7W1hb1di7BE/ytlu5i3oKYBI9UzOIAdZDmiqpcgiAIx3ZM62KaQQCVYZAs6xgGQoViiQRBOBeQnm0T5EUo/2Q0krz+i0GHJC+8nyxK4WxMqHs7O41GKxKJzMzM8Dx/4dN0CeibAg7nOA5JUVNZFgQBJO/FREVR08nk8ePH0+l0c3MTg4rb6704/NGwQlEEdTFcFgoFlmVjsRikZiBJGZa9OGBdLoIgTMMg/90f/qsPPvhANfSjoyMEV47H8sbGRrF4bppmOpvudDpg0IfDfjweD/j89Xr9xauXXq8XilqX5J5MJtPp9J133qmcV4rFYj6fp2n68cNHc3NzvEsYj8cYfbxebygUwnaIpxFBEO12u9Vqra+vb25ufv755+FotF6vm6Y5Ho9FUZQkKZVKMQxjWjoe7aZpNptNlmV7vZ6lG6LgwnANJThwaZjkcQVjLzw+PpYkKZlMTlUFK/7GxgbDMK9evfJ6vb1eD5JzXFII9hyPx6VSKRgMwp6NvqFIJHL5/QOBQCQSef36Ne7AdC6rqqoy1XiexyASCoWq1aqmaeihA5sTjUZN0xwOh6D8hr3BZDIZDPsLCwulUqlUKm1ubpqmGQz6wYrCOjQYDFKpxGAwYAV+PB7bNnH9+nVVVo+PjweDXjqdPjk5WllZmWqqx+OxHToYDP5v/zf/hx/96MfXrt+cTKaDwQBMEMMwODsUebq4uOhyubDpXsp0fD4fJMzQFuApjl8Ae/1+P7gJsNSWY2ItVlUV1TpgBnEkgQnlOK5YLDabTZ/PFw4Fms1moVAAfkOSJKY6RVGgYbdt2+uVkPKPsQAQY71ex2gFo8pfE+H/genq7/7+/8xYdfm3SIJ4W1QH2AOPLhv3mEP5/P7hYATdVTQa7feGBEHwb90xeOQwDAOjQyQSarbqf/VXP2NZmiBtjmMIghBF0bGIQCAwGk2ct2UdKHrSFH06nZqWIwjCxtaWy+VySFpVVUXVCeTBkiT59qd1uVzNVisWi+m6DssbQRAgm/CwB3AFa4XH45EkiWPZWq3Gcy6Komzb0TTN6/ULAmdoquNYXq9kWloqHfu1X/uVaDTc63c7zQblELIsX716tdPpKPJUURSCtAVBUNVpJpNzTGNubu7ly5eGYUwUNRSOTqfTfn/IcVw6lYEwJRgMUiyDoG2GYWKxKBAL0zQHvc54PEyn00hhgA4SDzBce4PBIBqNQpU8GIzu3LnT6w3Ozs78fn8sFnvx4sWdO3eGw2EymfR6vV988QVWl8lkout6KBTa3Fw/Pz/vdDqpVCqfzz9//nw6nUajUZCnHo/n9PT0zp07R0dHr169+vt//+/jQs1ms+l0Wtf1arWKx1KhUIBVMxaLvfPOO+VyGYj7SaGYSCSwCE0mE9u2o9Ho2dnZzMwsQli8Xq/f73/9+jX4I5ogEZuMEWFlZaXdbj98+PD27dv1eh2fXSQSgQbjxs3rZ2enIGU0TVtbWe10Or1e79q1aycnJ5PJxLQtwKWCWxRF8ezsLOjxRSKRiTyCjBX6+k6nw/H80tJSf9D1+/3A1x3H0TUzEAiNRiNE4TSbbfBHJycnh8fH+Xye53m3210uVzBFffnll3dv37kIEeD5tbW1H/7whzCeczy7u7ubz+ddLlepVNra2qpWq+Vy+fr168+fP8/n8/l8vlarSJKkyFNVVX1+j9/vr9Vqsiy7OH4wGFiWxbmEUDi6srKyv7/f6/USiQRQ2PF4PDu/WC6XcUnk8zM4Z+r1+nw+L0nSs2fPBEEA2D8/vwDmGhhJvV5fXFxsNBrLy8vj8Xh3bw+HUrfbBS0IBJHneZIkj46OFhYWMLgcHR3F4tF+v59KparVKhAsIPTJZLJYLHo8Hug3isViLBYbj8eFQmFxcREkMvzvfr//s88+W11dTacyT58+dS50SBQ+fVVV5+fnO51Ou91eXl5eXVv57LPPgkE/3sN8Pm+atqIoAu8qlUqwrLZaHby0SzNpMOhH7s/BwQHObawWBOkwDCMIHIQrs7OzvV4PtFK5XKYIkuf5Xq8PVS4YIUmSur2eYRjIXrcsC17+yWQCfTCiAOLx+LVr1wiCGAwGhm2lUqlyuQz4GQ4YMB7z8/Nw2HQ6HVzPW+sbFEnAseT3+03TikajCHknSXIymdTr9Ww2u7AwD4Oeoij9wdDtdtfrdYZhVFWfnZ0djUa5XE70eAjbfqt1k1++fIlTbmVlDf79SDRaOj9vNpvbe7tYQd999134iDEFhkIhgiB0ZRoIBEKhEMPzZycnr1+/xviLgJtMJhMMBtPpNMPzjmn2+31W4MGfgutHqTMYz7Ozs1gsVigUTNNst9tbW1uLS0vkZz/93mQyMQxrfn6+3eoyDEfTzOnpaSgcZll2b2/v+vXruqEZhrG5uf4v/sW/mE5kv99/6/Y7HMfBteRQ5Pn5OfzD6US62Wzu7u5mMhmGohVFUXUtmUwyDJPL5YrF4sHBAfTRuVzu/Pxc13VEYfV6Pb/fHwwGi2fnLMtCo+Dze/1+v2VZ5XJZFAV0MGMhXlxcZBjKMAxdNXCrgHYE14knDY5ayI8Igrh69ep4PO72e0AsSZL0eDy9Xg/yoPn5eZZlG40GXtfFDRaLISsB1i2v5HG73fhTBDq82dlOp9N4ZEo+797e3uLcom3bjUaj0+msrKwoigJ0BzdwNBqlabpYLHIcF41GC4VCJpPheb5SqRiGQZKOLMuYnT0ez9zcXL/f39/fR5tNKBTiOE639HA43G60BUEMBoOdTqder6fTSYy/FuE0m81Mesbn8/03/9f/+49//NNsbkZV9fF4jDcEPwkYYlVV0U8ej8fRMkbTNAYjpPU4b32nIBPxhIatHfqGSCTy/OWLXC4HKUYmk4F41jRNfAqgeLBd8Tw/Hg8lt0vTtH6/T7xl9zTNGI/HkN4riowZDpu3bV+k4wyHw1KphNUZL8R+mz76HxuV/v8fsEjyosjrcnSjKAr/HIYtTdNJhiEccn5+/p137kwmk2q1juAozDTNZhMWlYv4Vk1nGOrR4wccR7McTVGEcVFnywUCgV6nD0DRcRyPx83zvKJo0+lU10yO4zK5HMMwBMU4yLQhCDC8tm0HAgHLNFVVdUsSTr1YLLa7u7u1tdVoNGZmZhqNBo6JX1Ym4aMfDoc877rcc4L+IEWRlmXFE9Hz8zPbNgUXG49Hb968Oex3N1ZXUqkUEvJ0XTM0bWVl5dGjB5PJJBIJGYbFc0y3200mk+fn56IoLq+snRbPaIrFg3kwGGxsbPh8PppmYYkA3tBqta5du9ZuNouFk/n5+fPz82g0GolEnj175vf7l5eXC4UCrM3Pnz+PRqNXrlzZ3t7GEoxFCH8L2gOoNL744ov5+Xk8tmE9Q5gL8VY4eHR0FI1GcekmEol6vT4ajTCYQuwfDAbTuezJyclgMCiXywCPgWrjCbG5uYlnNix+hmHs7uwDIMfsm06n3waJjer1eigUsiwLOLHL5VpZWXn98gXP861WKx6PIxknFAph4yJJMp/PN5tNVJudnJwsLCycnZ0WCoU7d+4oiiIKLui9fD5fqVSamZkZDAaRWBRGxUA4xDCM3+158eLFxsYGAP5gMFgoFGKxmEvkp9PpRJahThuNRnj4CZzr/PxcEF3BYFCWL5zOc3NzoihCOqJpmmHZoihCf6ZMZOCRiUQCZyBCHxzCnpmZicfjL1++xFu3sLDQaDREUUCVxXg8np2dLZVKi4uL4/F4MhonEgn89aWlpclk0mzVGYaJxZNAzur1OhSrUMom0ik0T7AsW681M5kMSZI+n69UOCMIIp1OUxS1vb2NuwNRW0+ePNnY2PB6vaVSKZ1OG4bx6tWrmblZ6BncbnehUIhGo+l0mud51Li5XK7T09OdnZ1wOLy1tTUajb766qv33nsXw2s0Gq1Wq5PJ5Pbt27qul0qlxcVl7IGhUAh2eMdxTk9PCYLY2NgAbT07O9tut0fDMQ5wAGmmab5+/VoQBJblm81mKpUgSZIXuGAwGAwGIenz+Xy7u7uyLIeCYV3XSZJeXl5+8uQJz/P4MqjyZ2fzpVJpe3s7n8+bpvnq1at8Pi9JkmHqQDFJklxdXWUY5tNPP3Uc59d+7dcMw1BkpVqtoqdkPB6vra3Ztl2r1fIzM36/H5ranZ0daGbG4zFkiOFwuFarHR8fR6NR4Be3bt1iGObp06eBQACZHa1Wi6KoWCw2nU5xBQ6HQwwlo9Eo4PcZhuH3ByCTpyjq1q1b1WoVbz4sI/BneDzSZDLx+n2qqvq8fvg3vV7v8fEpQRD5fD4UCrXbTUEQBoPB+fm5P+DjWL5SqZEkeevWLai9x+MxdHvjqYynWK1WUxRldnZ2PB63Wi3KIVKp1OrqqmVZhUIBuGyz2ZQkETcpmo49Hk+5XEYmn23bwDgVRSmVSisrK5Ik1Wq1t3w6Jcvy4eHh1tbWtWvXyD/57n8/Ho+j0fi1qzcMw/rss8/i8YTP59vc2hIE4Y/+6I+2trZ293bS6fTq6vLPfvazQa8/OzsbjccwBuq6Ho5F8d+iKHL0hY+MJEnbtGzbnkzlXC5XLpc7nQ6eu5g87ty5g1Ppq6++kiQJsIeqqlNZCQQCeHh7vFKxWIShbzjsh0IhSZKm06nX65Ukqdtt0zRdKVVbrRbwJNxyBEHgZDw7O1MUBds85F80Tb968zqZTEqShFBXGN8GgwH8bv1+H1AqgpdSqRSwZZZl0+l0v9uD4tLr9WYyGVVVq9Uqw7HIK19cWW6324loAlcJzlaE2UD7tra2Vq1We71ePB4HQQm1x9bWlqIozWYTZgKIQnDHWpYVCoWQP4RN1O31eL1enuGn02mn07lQcRKEqk49HjdFUXuHRzTFGob5i8+//MUvvqAZjmV5QOiXUwJJkgzDDAaDRCyOZHav14tDDYoZ5m0iLVal6XQKxUMwGIQjcjKZwJfgkAS4A6isTNOECzoQCDx//hwRGIBV4P12CZyuq1ikwDuYpo0nvW3bmqYAeoSoX5IkGBRwKQOHIwgCf/q3Rqi/K5z6j6Bc//EBi3gbH4V3DOgjrmrdslOpVC6bd7lcHCfIsuw4JAZWWBmg3cFgqigK5RB+v7d4Xjg/L4QjQShSTdPkeRdBEALnAi5I0zTPs5IkjcfyaDRyCW7dNAKBoOT1Korm8/kCwXC9XidJEjIR27ZhC4foQdd15JggsA3SK/zAmI/BtyIcBOyD4zi2TZimTjoURRMAWcfjIccxlm1Op9NAwCe5xIDf+41vfGN1eUXRVJoiut3uYNDLZrOGprZarVwuV69XJUlSphPHcUS3ezSarG6sd1vtUqW2sLCQy+VfvXpVrVahTrt9+/arN68B81Sr1UQsFg0HgdTSNI10Bkyco9EomUwiyQVMExx5YNDw6cPC0mg0EOdWrVaBgYmi+NOf/nRjYwNy5kgk0u/3t7e3b926Bfmgbdscx1WrVbzzALSm0ylJkrFkolQqnZ2dybIM/B/fZDweZzKZVqu1uLiIzaFSqdy8eZMimf39/W63++6774JShwA0FovPzs4+evRIluVf//Vfd7lcZ2dn9XodOXAsy6ZSqS+//PLatWutViubzULAAcoMNzU8OoGAD7BNMpnstNqSJKH34vDwUNO0d955p9Fo6KYhy3IoGqlXqhRBrqysrG1u/uF/9985joPgNKTxebxu39u8Vqy4kiQd7h9FIpFQJHxycuL1+i3LSqVSR0dH8Mle5OUGgru7u/fu3atWqzRB4tZGaihwi0ajEQj6t7a2sJcibQgmmPF4aFlWNpuFVRDyD1mWWZppNBpAyNLpdKVSQaFtfnamWCy+evXq3r17BEHAwJ7P5ymWgW61VCoxDNPtdmmKZRjG5/G4eKFWq8ViMUjrjo6OZFmOx+Omaebz+WKxCCUokjVYnvP7/RgOqtVqsVhcXFwE4r6yskIQRL/ff/HiBeI2nj9/nstlcPA2Gg1BEBAjMhqNQDtOp2osFgPMlsvlECgoiiJKdSVJQly2qqqj4fjevXvD4RC7N0EQi4uLw+FQEETHcXierdVq4/H4N3/rm6VSqV6vB4PBZrOZz+eTyeRPfvxTv9/vdnvcbjfiG8fjMcMwfr//4ODg137tV5BM1Ov1ULb285///Pz8/B/87u/gQEAhL45ut9v98uXLYDCYSWWOj48R6AALi+M4+XyeIEkwS/V6HRRNtVpFCLAkSbu7u16vF8Q3bqKlpaU3b97APYc3p9/vw7+P7Q7KSFhkTNOUJ2gK4d1uNzz+fr/f5/Odnp6i++T169cg5efmZjVDB8HlkbzhcFgUxZ2dndXVdcuyXr169Z3vfOfhw/uwXmWz2WQqcXx8bFtkKpWCCL3b7a6urgYCgR/+8IcLy0sITkcggGEYuFoa1drCwgIw5lgs9vr1a8uyNjc3u932eDze2NhoNBr1ev327dtv3rwJh8NA8kCjq6qKWHUwLTjilpaWSqUSgns0TSO//vyHqqqWShWP5NN1k2GYYDAUjcRN2yqVSiTp3Lhx4/DoQNd1iiIgc8bNEIvFeNEFEWgmkwmFQr1er15rDgaDgM8HrLJUKs3NzThvk+MxyrAsi0+rVqu9ePECVpRoNGpZVjabJ2yi1+shzsDr9TQaDYAfqjqVJCkWiyUSiRcvnyEWodvtii7J7/cnk8lyuYz4dQxqfr9/NBrh9U+nU3jler1eLBGHnwhIZjgcxrSO8fNS5oWEm+FwKI8nNE1jCum22xDgV6vVhYUF07YBJnf7PZ7nKZYhSZJyqIDPj7Q9y7Kg3jg/P4flsNFopFIpsJOlUmlvb0/yupGnhbkHXmuodFVVDQQCsVhsNBr5fD7DsCqV0t27d1+9emUYViKRGA1GsixblmlZlqYpV65dhSxM0YzpVDk+Pv1v/5//0nZIXnTD90faDmY+jIm2bcdiMbfbzTEs1NPwN3m9XsxDyItD7zK+nqKo+fn5ZrOJ6YFlWa/fh7sLA58gCMFgEDL/6XQKETHGFGgPaYqwLKvf78K5A8AcSiy8mRhlBEEgCEoQBJ5ncbc0Gg1ggb+scP/lEeqXB6l/7+//B2asv92aji+6tAqDVwV9SVFUNJ5Ip9M+XwCfkaZptk2Am4ZyczweMwzlOA7SjGA773Rar1488Xo9HM/YtmlZFsvyjuMEA2FVVd2iyDCMrqtut9swLFVVGZZXFCUUCs/Oz4/HsuXYSDyHkBwp/0DyAetepCpTFPacVqvl8/kwqQAxAv9LEIRFOJIk1StVhqU8ko/l6KmsOoTl8XhGoxHHsIIgKIoMLZFhGO1mY3V1VVNUr9+3vrZy8+bNq1e3dnd3t9+8YllaEIRIJOw4zrDfzeVyzWaT4xiKopTpVJ6qV69erVbr5XIZz9HZ2dlOp1NrNPL5fLlcHgwGiWTM0g3YU2ZnZ0HWI46uXq/HYrHnz58vLi4eHR0FAgGapp89e7a8vBwIBABCTKdTsOeSJC0vLzMMc3BwACeK1+udTCaTySSVzRQKhWQyCR3JX/zFX2D0ZFl2OBz+1m/9VqvVYlkWSsH5+Xk8q8BrIEjv66+//uY3v1kqlSAztSxrcXGx1WqBy+NYAXCO4zhff/01DOcEQfh8fl3Xc7mcLMuInsf7b2gqbB8Mw2xsbPz4xz/GkJdOp4ECQv5IkuT29jYisnCCBwIByzCn06ksyxsbG6VSCe9AtVqlWQYXm+M4J0fH9+6+V281sSEEg8H9/f3JZPLuu++yLP346ZNgMHipd9R1/eToGISj4zgen388Hi8tLVlvQx2h05+MZUEQeNE1Go1EXvB4PH6/Hwd4LBY7PT2lKMqyTVijer0eTlRsZUG/b3V1tVwuTyYTludSqVSpVALb4PV6FxaWkP+HOYBlaU3TZFnGQw7njGEYyWSyXKsCBSyXy3Nzc6IodDq9cDhsamalUmEYhmVZOBUwt2Fcvnr1KtZgJJ/Nz8/jCYoo12fPnm1tbWE0TyQSuOABkTIMUy6XVVXN5TJutwvWBEmS/uqv/iqVyiBvqFgsQj86Hl+ML91ul2KYcrm8uLgIVKxYLOLjy+Xy2Wy21+t9//vfB/cKXLNaqkLFtba2Iori0dGRaZqBQMDv98O6QdO01+sfjUbIGf7wk0+++vzzs7OzVCqFQ6lYLFy/fh2uLFzGpmn6fL5Hjx/CRwxLkyRJiqLIsjyTn93b2+N5PpfLTcbjVqsFh6zk9rIsWyoXYcjt9/u3b98eDAa6rsPigFWNZVmv1wthViKRWFldPz4+Pjs7W1paikQipVKpWq1ijIb5ZmFh4fz8HFNUuXy+urZSr9d9Xj9JkpVKDWC/z+cTRbFSqdy9e7fZbLbbTcMwcvlssViUJMkmCJdLxGxtGIZtE7jyE4kExzG4CGdmZl6+fOF2u1mKazQabrc7kUgUCoVUKvXmzRuMPisrK9mZ/OnpKYpharUawzAvX7xeXFy88+47z58/L5VKXq83m80iKtztdmuaYhjGnTt3MF0MBoNGtba+vk6S5HQ67fV6kFGOx2OgwtDJNZvNcDgsy3IymSR//IM/tm170J/0+/1kMk3TNM+JsVjs8y+/mJub83jc4/GY5RiWZV0uHiMzqKvBYEBz7HQ6xcCI56Kq6I1GI+DzXbt2TVXV/f39WCzS6/WADOEzhqlbFEU4IxiGQVwynhORUAxBOKIoKsoUk280Gk0m441Go9vtzs/PT5ULStjtdoeCERgxcI5cgh/AnHCbhcNhXFvRaDQSi6qqWi6XQ6EQ0hxomoaevd1uY9bBN8SDPOgPXAZvRkIhQH+tVgs4k8fn83g8Lreo6zpBU+122+vygHfw+/0EQdi2DZUxSZK4+JLJJBRLkBEwHI0bwHEccPmYIaA9h2hUEITT09PxWF5ZWUkkYp1Op9FoOY6jKZqqqrIsx2JRSRKHw+FJ4XRmZiYeSx0XzoaD8b/7H797Viy5JDdQQJ656EwgCAL6g0gk4vf7BY4foGDO55tOp0BBIP6F+mpmZgYbrSiKeIrjtrRt2+2RotFos9mEKBgBs4BPSZKEzAUQlCAIzWaTY+lgMNjttlFDhoEPKR7wYrBv+45omr2szZlOp/V6HdVGeAl/C7u6JPXe5rs4l7//y6PYv2/G+tvlVpcDFqYraB10TXOJYiwWC0djqqpaliOKIpy2un7R3YHzjmEoyMxNUydJejyWHcdxHGtn9zVNOC6Rn04noigSBOX1ejXV4HmeuahvMxEcY1nWcDRhWVYQ3clk0nKI6XSqKno2m9U0bTqdEgSBYkpMfkC8oZKenZ3F70NzeumggUMHA5Zt26auCoKAix/7D5qaxsMRnlUEQYiiNAUuJYqOaTVb9XA4HA6HVpaWQ+FAOBxMp5N+n6/f72qaFg6HAoHA86ePJbfLMLREIoVPrVZvXr96rdXper1edGXqujo7O7+zv6MrKsQKIAfr9TrqttrtNp797Xb7xo0bx8fHu7u7N2/ejMfjR0dHnU5ncXER1mME9szNzeGRFgwGkb2EofP4+Jim6VQ2g1Wn3+8vLS2dnJyUy+WbN2+aplkoFNBgcX5+HgqFtra2Hj58WCgUkFDVbrdpmv7d3/3d7373uyzLJhKJ3d1d2MWRdwC1smOTEHoyDFOr1VAzKggCQZDFYnFzcxMSH6RhURTl4rlisRiPx09PT69fv86yLNwJw+EwEokkk0mPx/PgwQN8HLIs5/P5y/04EYtD8g/3DMuyz549CwaDN27dzGazf/iHf5hIJIIenyiKZ6VzNCjU63W32438+mg0qmjTy7wiaJhokmJZFqkKqUy22WxizQPtCFdmJBwNBoOtbqdQKIwHw7m5uWAwSFFUv9+XZRnYm1sSeZ6PxWLHx8d37tx58eKFLMvXr19vNxuNRgNoDc0ynU4HKAsyciXJCycBUFjTNFdWVkjSefz4Mc5ky7LW1tb6/X61Ub9z506hUBiNRpFIqNVqpVIpgiAkl2SadrfbBdjW7XZnZmYoilpbW/vpT39q23Y+nwcVCFAZ4SYIaDg9Pb127Vq73Y7FYpAaf/XVV9FoNBwOLy0tvXjx4vBw3+fzpVKJZDIJCemXX365tXUVQo7j4+Pf/M3fbLVaR0cnCwsLsDpJXm+z2bx///5kMvnoo48ajQZChU5PC++88w7uNYS6PXnyJBaLxSPxRqMRDod7vZ4kiYFAAC98dXUV7geapn2+ABZvbOmbm5uqqm5vb4OW0XUVBymIlGAwSBDE2trazu425FaO48TjcZqm5+bmOp0OTTH4/VgshmhQ/Ej1WtPtdotuYX9/PxKJwPs/Ho8XFhZmZ2ch70FhHc4c7N7tTi8cDsNek8vlwJySJIkZF1IfYASj0Sifz9I07fV5hoORaZq1WgP2JhjgEokEhl2Goer1eiqdXF1dJWmaJElFUXd2dnw+33A4jEbjiqLcunXr5z//ebfbBhlNEIQsTwaDQTQUAwZ048aNdrvdbDbH43E8Hrdtu16vn5XOoVggCGI4HHIcNx7Jbrc7GgvjRIXw69GjR/Pz88vLy2dnp91u1+Px5PP5/f19kiRp4sIkzvM8LHSIXwGRury8zHHc0dER2Dm3201+9Ysf1Ot1hhbS6fT5ebnT6eiGvbm5CRiDJB3DMOTpRBCEYrEQj8cpilpeXjYMYzQaST5vtVptNpvxeBwNOYcHx5PJhLDtZDIJ4NTv9yLvCi8Vi0ssFkPpBBwH2WwW4jhd12uVRigUQjdFq9UKhUIMQ9M07XLxyWQS0QbF8wKcRIqieD3+s7MzsP5gSRATipMOAUs4DRGFwgk8TEPT6RQ6HmSihEIh2EbAagUCAWiJ1lfXSqVSp9WKx+Oj0ej58+eRUDgWiy0sLXq93mcvXgQCgU6vG4/Hh5Nxt9slTQI8JqwWSPMD9bu8vAz6AD85sG5ZmbjdLjwDkslkKBQ6ODhCWw7xtrlpMpmcnJzAsxDw+RmGsW1HUZRupz87l6ccYjIZT5QJALnRZBwJx2VZSaQy/8O//Xf/43f/2BcM4PtjJCJthyAI/BhLS0umafa7Paw4qAGB2bPT6Vw+lcF5OY6D0ROTCh7bbo+ESw0PCTx7ENsINAIFI5eB2oauQpRgGIZlGfhWkPF2Oh1YkV0uN0AsQRBs24QuBAEZFzMRRV0y0cRFWfqFcApo2S//6d/69XdmrL+BYF1ShJhByYuELQId1ZlMZjSZ2LYtCCI+F0EQBEGExpyiKJal4T00DM00TZKkWZYnCIIknZPTw3ajLnlE2zZFUXQcMhwOt5odjuPcooiYBpIkURYxnkxdLpdpO6FQiGJYlmVZhgfu6FwUoF6kYWGzxK0E/z8IQey+sBDj0Y6/azrmdDr1eDwsyw5HfZ/P5/d4LcsaDocURUEpFfCHDMOoVGqoDbUsQ9e0ZDKJZ8B0MnK7RZom1zdW283WwsJcPBEVRfHOnTsvXzw92Nn+9V/9xOvxQQRab7UDXt9YVpDUkEwmTUsPh6I0S42Gw36/TzgUVMO/+MUv0BYVi8VmZ2fdbjd0xNiD4avo9XqRWNTtdq+srBweHu7s7MzOzqJTAWoPEBbIA+t2u+l0em1j6+zsrN/vY8bCxoLbExfM+fl5uVx+//33/X7/o0ePHMLa2tra2dnx+/2GYUCDQlEUivNgxQAVzjBMIBDgWAGUJVz6uFlOTk6CwRAyS4vFIuLXKYoKBALdduvWrVuIsS4UCuARIFF98eIFHuTQ2BEEwXHcaDIhSdLjdhcKhWQ8AUgeSSjj8djr9c7Pzw9GQ7ASoig6umUYxsrKCsdxvOhqt9svXrxIJBIul3B0dCSK4szMjMstgkCxLCsWCW9vb//BH/xBqVR6+PBxMBgMhkMw/XAcB01qwB8cDAYORYqi+Or5C8wNNE3jy5C/k86kWq3W9vY2YvEfPXqEnyeViLvd7tevX0+nU5plbt++TdMsTdPn5+czMzOD0cg0zfPzEsascrn00QcfaJpWLpdnZ2cFgcN1rut6vVUPhUKXKbu6rluW4XK5lYkiSRcXMJDaa9euffbZZ36/H5IMrMrD4XA0GsXj8W6/n0qlcJwiNgKNCJlMJhqNNhoNSPUTicRgMKjWyiRJrqwsXVbESpJUKBTi8ThNs6PRCLH4CA6cymqhUEBDhiAImUwGFtRCoTA3NzccjkKhUCAQ8Hg8f/EXf/F7v/d7P/vZz9rtdiKRWlpc6Q+6SHZUFIVlaWQ79/t9xyGxJnm93oP9I5Ik3ZILYcuXag1FkZFAASU4rsxUKnV+XpRl2eUSA4EAFI3JWFySpKOjo3g8LstyuVx2uz2pVOr8rLiysgK80LKN5eUlhmEajQZuK8Dk6D999OgRZDNvJbBEvdFC5woMsLZtY7qiKArWWjwdyuWy1+uFjY/j2Ua9ubq6CjXVzMzceDzO5XK9Xs9xrLOzs7W1lfF4LLpd0+mUpGnEOpAkqevGeDyeTKZQoQ0GA55nTdPkODYcDqdSqUKhUK80bl6/YTn28+fP8XC/ceNGtVqFE2s4GUMyj3OgWq22mp1cLgelEMvRiqKAAkb8DUHYH3300cuXLzOZjKIog8Eg6PP7/f79/X1o71KpVDQaffPmTSAQgGZuYWHB5XKhN1bTNPIHf/5dRVHyuVlRFHd3971eH8e7sE5NJqN0Ov3y1Yt4PF6rVViWDgaDy8ur9+/fR7yTaZq+YCAYDFarVZIkBUGoVRt3797defNmMpnwPB+JRNxuV6vV6vV6mNiuX7/e7/crlYqqqo8fP15ZWcnn8yRJQhshCIJjkUDFEaCQSCSGw0GlUkmlEhCbBwKBVrvhDwTwUJfH036/j7ebZVmaZfrdnsfnZSjatC1RcAEkg2ZQ0zTLsfHwRigO2HQkv5MkiRocIC5AF9PJlMvlqler0HghzcG27ZmZmXK5TDFMOBzmBJ4kyXK5nM1mOYaH7Rb+CxyCxWIR7jyA2NVqNZVKpdPpTqe1f7gXDofT6XSz2Zyfn69UKru7+9DQIUSHJMlgMFyplFRV1zQtm86oqqrrRigUYhgmHo/XajVZnuTz+TdvXkUiEUEQO72uPJn+/d/9Rz/76V/903/2B4FwCDuH4ziGYTEkxb1tFMdoP53IwBFx1sMnfynZQSQpBnxsfnCLAOFjeQ4QHXQ2UMpfJjVomiYIApBCZIcSjoO3jiAICJIAFGGkg6kbpmIcHwxDaZqmqmqr1ULNEWgv8m+GuePX5YBlvc2FI/4mXfgfH7Dw61LkDmeDaRiSx4vZl+d5Q7dkVeFoxuP3TSZT/CvU2wxigrDh6CFJh+d5QRBFUbJtU9fV45OjVr3m9UmXmja/3z+VVUVREvE4RRGYzPAZESSpKJqi6cvLy1NVEwSBIhkAM7C3CIKAZz/7tiOM47hutysIAkUx2IvgP5VlmaIoZFtzHMcKvK6rAJNkWZY8oipPYd5BSjDP8yRBD4dDjhNAnQNIcBxnKo9zuZxhaIahddttjmMJgnC5eLcoJJPxubm5xYW5fDotj4ckSY5GA1QIwNzu8fksy/IHvHiZmqaVS1WKoqA2ha97f39/d3dXEESvV/J6/bOz+UKhAJsL/bZ+wOUW8VQbjUaqqrbb7c3NTbBUeCuwbbtcrkgkoihKq9Pb29uLx+MIsAYKuL29PRwONzY2qtXq4eFhJBJBIHAikdAN9fT0tNVqLS0teTweoOkbGxvYN2zbFkURucSNRmM8Hgf8oYsqT03zeDxQJo3HY22q1lvNSCQCn9pgMFAUZX5+Drd5t92uNRoBn4+iKNgksa7oun7v3r0HDx5gMj49PRVEMRgMTkajxcXFTqttmubi4qJt271eDzrO1dXV/nBQLpfBk1qGVavVaIL0BvxIk4KitFqthqNhjuEGo8HG+qbtWAF/cKrIgiAcHOxdvXr16dOnt268c3RyTBAEiP5ms4kbX55MOY5TdI2iKEs35ubmUqnUF198AWPTaDRaWVl59Phht9v95JNPIpHIF198AQdAp9OKRCLlcnluZpbh2EePHqGQ7cGDBwsLC4IgdPv9UCh0cnIaDAaRa+2TPJZtjkYjHFAcx2QymfNKWZIkJL+7XC7DMJAVwnGcrujNZpNhLtjwSqWC2Wh9fR30JcAVy7IajUY+n09lMrVaDSnWwJYWFxfPzs4SiUS1Wh2Px7CjQhteqVQSyVgkEhoOx5PJaGlp5eTkSBQlSZIuh2noQE5PT1VFB/6xv79/7969dDo9GAwQYMZxXKVSxW3Y7XaBTXa73Xx+VhRFjhUePX6AYgCKovr9LtIxer2eadrr6+voBohG4scnh71ez7IMimI0TdF1M5NJYXkwTRPXKkEQW1tboVBIEHhZlv3+wNnZGXyCzVp9MBhgVnjy5Mnt27cty4EtQ9O0eDQWjYXL5bJlmZOJnM1mms1Wp9N2HAciKkTA7O7uJhKJTqcDsXImm+v1BsPh8IMPPvj5z3++uLgITh+FAXt7ez6fD09SnMDpdHI8HsPo5vX6T09PJckbj8en0+nR0dHVq1uGYZTL58jxPi8Vs/mZ4+MjhmFdLhdkzevrm8+fP/d4PLFY7OzsFJuhyyUwDOs4jm1cPJohO7l79240Gn306BGsbL/xW785mUwQFAxJwO7Ofr1en5+fl2XZsg3cLziieZ5vt5sff/zxw4cPFxcXYc25cePG/S+/gtYTp+XbB6uRy+W+/vprj8eDl4w7lOIZPpvKNmq1bqvLMGytVkslkl7JoyhyNBo1LSMaDc8vzX74yb10PkVSTqlUXJib39rYnMnlvZInEgxpUyUSDIUDQV1RvZLoWMbq6rIkiYGAr9frQOYJbntmZubZs2eO40DJ/81vfnNubg4RNdCcut3uhcVFweVKJJPxRCISCbdaTXC9jVaTYmhB5Ld33/T6fVlVJsrUdOxYIm6aZrlaCUXCJE05FCl5PQRN2YSjW6ZuGvFkwiEJiqEBaBOEzTDUdDo5OztV1SlB2MFgEBkNyIXieZ7jhEwmFwyGed4FZEszDEXTNMMgadrr9wdCof3DQ04QGIYJhULxaExT1HQy1et0T06OGrWKKHBPHj148+YVQdi6rgYCPsexGIYiSaff73ICO5mOu/1OoXiGzRhPi729PY7jlpcXQ6HAxsaaIHDyZNTttNrNBstQoYA/Gg4lUkmv3+fxeUzbJGmyVCm1Oi2Kok5OTgKBEJQ9HMNGwqFnjx7I4348Fup3mzTpELZpGRpHU6apQwaEEsler2faluXYqjYV3YKmK4Nhj+Voh7A4ntF0xSEsf8BrWno4EqRoYiKP2p2mpiuWbdAMKQou0iGmE5mlGcJ21KmiThWapFy8QDoEzzGGrpKELbldoosnHMfjlhzL1HXVtk3ybT6baZqD0VA3DYZjBdGl6orlmCRNkDRhmibIVijNoW4m/mYbPEVRwCk5jiMphiBph6AIgnIc0nFI4pf+G/+TfPt/BEFRJEO+lVsRJGk7jm2bjmNRFDGVxwRBRKLRubk5j8dDEjThUIIgCqxAOtSoP/KIHr/H65M8HM1QDiGwnKVbtmHm8/lkMi1JXoIghuPeaDIkSMfn8xA0ZdrEVNVplmV5nmIY2zFFt2BYOkE5Dmk7pG3bJk2TE3nEcQzNUAzD3Lp1i6E5WdX8obBqmLplgyEajvrydGwamqGrjm1bppnPzzoOadsOSdLxVFL0SIZtBcIh0ePVLTsQjgQjUV1RHdMZ9oa2YfMML49khuEWF5d13VQV3dAtxyYNw/D5fDzPDodDwnZEwcXSjG1a0Vii2xsMRxNNt8PRJCe4w9EEQbHd3rhwVv3+X/7kz/7s06+/flEsdieyc1Zs0Yz48Td+bXv3oD8cIxtMdElPHj/74//pTyzTCQRClmVJXg/Lc41Wu9nuSF5fMBzZunKVpJnNrSskzfgCwWg8EYlFO72uIPKqrlQqFcQfQNfPMAxKA0VRTCQSxWLp9ettkqSHw7EsKxTFTKdKMBja29vv9weGYXzxxRdff/11o9EgCGI8Hl+IVbWp1yf5/J7dvW2RF0P+UDqRVCaybege0TU/k9/f2a6Wzn2SW5sqpO2k4qnjg+PtV9seyacoyknhFDl5PMv6vV5Flrc2NuTJeGVpkaHIbDrVbDamUzmejI/lyXm59PT5k0q9kkwnHJL0+HyjyUQQxUAoJIgixTDf/8EPlKk6Go5Zhvv4o0/i0SjHMJANeP0+kqYarWa92ajWa91+b3Z+rlytuN3uTCbj8/n29/c73S5F061uJxQON1utZqtlmKaiqpLHc+fue6OxHEskHYruDYYnZ0VZUfcODgKhSH84Ho7l0WRMEEShUADf8fDhQ1gjLdt0CPvatas3blxf21wfjIff/+Ff5udmGJ5leFa3zCfPn+VmZv/Rf/p7Y1k+ODryBQJffv11pV4R3OJx4dShnPNyae/wwB8KyqpSrdfnFxeH43G1Xtd1I5vN3b59++TkpFZrwMpz7ep13bQqtbqi6Qwn7O4farrp9QVi8SRBUIIgapoRicSePnrKkNRoNOJ5VlFkw9CazXomk+p225FISBA4TVNSqcTOzpvz83Mo7Xq93vHx8fb2NtwS7777rmVZrVYLoRIQY3Q6F0Ff6XR6dXVV4MVisVQuVQOBUOm8cn5eDgUj/d6w3erSFJtMpHXN3N87TCUzS0tLiBu4c+dOt9t9+vTp3t6+punHxydffPHl7u5uIBBwHNLj8eXzszzvyuVmVFVdWlp69frFkydPTk5Onjx89MVnvygXy4RFeN1eZaKwFP34wcNHjx49ePDgxctn0+mUcmyaJFwcq07lkN8X8gdYilblqcvlunr1KjIXtre3z87OhsPRcDh69eoVtGuDwaA/GnoD/la3M5Inv/6b35R8XtVQP/vis4kyoTk6nU3tHxwMR6Nurz9VNJfortYaiWTqndt3zkvls7NiIpFcWlpeWloeDkc+nz+ZTHY6HZIiwuGg3+89Pj50ufjT0+NyrdwddGVVfvnmpenYiq6N5MnM/NxEmY7kCecSu4NhbzgqnJe8AT8r8LVmTdGVN7tvWIF98frVwfGRQ9GKbpRrdVHyaJoRiUQpipEk72QyHQ7Hf/Znf3ZycoI8WIbhlpZWHId0HCIWS3g8vv5oeHR6wrkEzTRojn29s/2zz36ezmXTuez61ubp6emDBw+2t7cRD3t+fq5q00Qytn+w22jWOI4DpgOFj67rPO+aTKa6bpIkLcuKYViFQuHuvfcT6dRx4dTt9VQb9ZE8sQiHoKndg/1vfetbMEx0Oh2kupB/8u/+v9FotFarEQ7193/3H3z++RelUkmSpEg06pbE8/NzhqF8QZ/LxRum3mt3g/6QoVuXqnCWZQ3LRDHOtWvXer3e559/3uv14OqEn3NmZgalDYZhQOxsmibo8GvXrr158waAOQI8vZ5AqVRaXl72er3dTrvRaIATIWlCVdVEItZsNjmXIMsyz/PD4ZByqGQ8oRm6JEmqqmqmAY+A2+0GDVwul0P+gN/vPzk6FkVR8rqBeEWjURDJNM3C/Q6To9vt1jSDZVlgsxThkCQJ/1o0GtU0bX9/H62uSCKAU+NSRxwNh4vFIpDnWCIBjCGRSECdekHxcCyU5gRB2Lbd7bZzuRlVnbZanWDQL4rSaDTIZHJHRwc0yRCkbZlOOBJkaC4ejx+fnmiasbq6iqwz0GGnp6c+j5cgiEt15PLy8snhUSga+T/9N//1/QcP3G4Py7IUxQwGA5KgY7HYcDiWJAms3wXFRtgURUH+AshUFEX8fwwx2LAhgAUKqGlaKBghSRK9QKARL+ceXdct2wA7CbpNVVWv5E6lUmfnRVVVET4OBGuqKqIojsdjmCtBkZimKQoXfOVgMGg2m5cTFfFWtw5GjOd5KM11w7Jt2/mlLp2/C1xd/q5DEARBkRSF7HgszbZlESSJU8nj8Xk8Ho/HS5Ik4VAkSTIUD7Gn1+u1HLvf7/t8HuSLwtzHMIxhG9BRSpI0mgwty2QZxrbN3d1dqGUdx0FvzHQycbvdHo8bVwJN045l27at6oZjk7KqJRMpt+Sv1+vhWPwy8ZWwzHa7bdmGbds+j+R2e0zTFnhxNJlYlpVOp0ejIUFTLEsjxomimF6vl0lnI9Hw0f4B3KaYa3EdAm40DANayYsoZJJkWZYkCMe+4F5103AcBwQNDPyddhPNwaapG6qmqapAs6LguvvenUwm7Q944/Hwzs7O6tqyZZnT6cQwjOPjY1XVAaR3u12Pz+t2u16/3v793//9s0IRP9hoNAIQmEonXS5XqVTMZDKPHj3I5/M0zaJxYXd3V1XV9fX1J0+eBIPBW7duWZb16tUbgiBisVg8Hv/+97//4YcfDkZjCJgePHiQyaRTqVQymTw5OQFWTRCEKIq7e9vvvPMO4nlogmYYZmYmNxgMXC7X6ekxBndFUTRNQx+cJHlVVQXsR9K0ILoMTV9cXHzz6lW5XL5+9RqSnAaDQbvbyefzNMtWq9Wjk+MrV67EYhGUtPb7fY/HF41Gy+cl+Mn9fn8mkzk7O5sMx4jGcByn3qhhP8Y1JklSLpc7OjrSNC2TycCX5/V6of5utVqLC0ugVIB0oi2RpulQNNZsNpeXlxFturCwUK/Xo9FwPJkolc4DPv+1a9dOT08VRfn0hz/Udf2f/tN/2mg0Dg8PFxYWwIaQNC0IgugWptNptVLf3Nx89OiRz+crlcoI7vrmN7/59ddfxeNxr9d7fn7u8aLHaexyuWRZgfJJlmVDt0RRjMViiqKUSmUYYwOBQLPZ5jhOcgnVajWdy9q2jch43dSRoajrumloqDZiGMYjujVN83jcsiwjgYwkaURAwQqdzWYlSXrw4EE2m9/f30deTDAcTqfT4K9JkkwkEicnJyjOw7wOFP/o6AipB7DshUIh27Yh2cZlYxjGZDJ58+bN3Nycpmmbm5v7+/swYi8sLMCntbCwCDErQtfa7bbX68ehOplMyuWyLMterxcCyuFw2Ko3otEoz/OBQGB7ezuTyRAE0e12bZJAPojLxR/s7glv1TIHBweZTGY8mqTTaZpjYbhzu92SJL1580aW5VQqFYlE4PJGvmO73QYOhNWaZdlsNptIJPb29mBLSifSn3zySa/XQ85LLpcbDvuvX79+7+5dv9+P6rxKpeL1egeDfjKZbLZbHo9H1wz42GKx2PNXL8EYTqfTmZm5ZrOJmNyJLF+/fp1j2fv376PE3bIsXMZAlS4jGEulUjweR+xLPp9/8+YNoMHJZHL16lVYXE3T/PjjjxuNxmAwgCcGBAtN02/evFlfX4dd4xe/+EUmkwFjQBDE2toaGCQo64+PjxcWFliWLRQK8/PzL168yGQyBwcH+LLpdHrv3j3HcRAOBW1ZvVmTZTmXyY7H4ytXrlAUdXx8DO/dj370I7fgQpfGZDK5ceNGr9cj/+y7/8ayLJ/P1+sNPvmVXyEIant72+PxtNvtK1eu0CxTqZTa7XajUbtonDAd/OgnJycYR0TJTZKkaZqgxuBs5HkedTSYBxcWFhDmJEkSMuYrlcolcYaUGr/f3+/3HZsC29hut0nCwSlMkmQ0GhZFkWJIkiR9Pl9/NMS/Ph1PU4mkoijD8UhV1WQyGQiHisViq9UKBAJuwVUqlViaAcWwtrZWKJ6GQqFutwvn49HRUb8/hKkH6SnVajWZTKMnRxTFRCyKlGSCIHw+H/JL0LEANff29nYwGJyfnwcyZ5sm6iOSyWQgFAKyisxffEOKokqVMk3TuVwuHo8/f/6cZVmPx9ds1hVFy+UyyWS6Vqv0egPbNh2LCAb97XaXZWmfL7CysnR6VkBG/Pb29vHxcSaTgcg3HAxBSItBFoSx2+N9vbv7//hv/18YcSTJOxgMKJKRJGk6VRHUpCgKuvAwhQg8j+QnDFskSUL1DNcVhiQoEyFuCPhDQFxRLIoGQ0mSxpMLSQTYJXwrXddt28Qpj3YXPLk1TaMYGnMe5iSKoiKRSDwer5YrMD0NBoNqtcrzF5ET1NuedpZlkewAAbhuWJcVB5fSd+ffV1NI/tKAhS+kaRLjI03TpmHk8vloNG5ZFkGQPM/TFGtZ1nSqC4Kg6yqcldDtjcdjziVMp1OaJhHMQRAEjKs8z3Z7HYh+Dg8PoRuYTqeZTMrr9bYaDY7jfD4PJlpBENSpYhiGTZCaahA0E4vGbYemaZpziZCjkiRJOTbLsm7JxfO8rmqqqjoOSTiUYVngwUOh4OHJsdcrkaQznaoweI9HE01XXRzPMBRk7CBKGIbBtISVCR5sJHEgmNQwDOuiZ2bK8zxORsMwBEFotVqRSIgkiMFgwNGMMp2Igivg9TWatclkfO3alYXFmffee6/X67Q7rW984xt7e3sw3nu9XoF3VWsV6JExrBdOzz788EOWZWHgCgaD/oDv9PS0Xq9SFLW0tLCxsXH//sO1tTWXy/X555/7/f4rV67s7e09fPhwYWFBkqTJZBoKhd68eQP7ntfrDUdjo9Go1WptbGycnxfRClWtVmdnZ2mafv36Nc/zuXymXC7DiNdtdX0+30cffVQqFcfjcaPR4Hk2mUySJFkqlRBeCp0cSdK6rscSidevXzMM895778nj8R/+4R9+5zvfwUogSRJUX5wgLC4uJpPJ8Xj84NF93F+SJAmC2Ov1OIYdj8cgH0FDO6Zdr9fn5uaq1eqLl89BweOvIysVf9TpdEKhEEmSCEYOBAKNRmMylsGF+Xy+ly9fejwe9BjSHOs4zuHhcTAYhGgvGo16PO79w4Pf+I1fPz0+gcMmGAzSJMmy7PHxMVTbOH6Xl5d109ze3mY5OhgMaqoxnU5jsVi3211aWt7b20PGxN/7e98B4bKzs/Ps+ZPV1dVf/dVv/OhHP2IYzjRNl8s1OztbPCuBbM1kMuVyBd6Xjz/++OzsvN1uSy7B4/GoBgoPSK/X6/ZISHbIZDIvn79gWbZWr8TjcY5GP4GQzWbBB2maAVuApmkEQaCbnKIoUZRYlj04OFAU5be//e2nT58ipg7yZ6/Xi0kR7dqQ2VEUlclkoNuLxWJYijBYVKvVVqs1OzuLZSkYDD59+jSdTi8sLFSr1VqtBjun2+2eTGSENcDp1ul0PB6fYRhra2v1ev3Jkyf/7J/9sy+++KJer0ej0cXFxUa1lkgkWq0W0uRBk52dnb14/Wo6nabT6atXtzLJ1Jvt12gLQAukpurBYPDzr750HAfOxN3dXb/fn06nkW+ytLRUrVahYLNtu1gshkKhbDbb6XSm0+loNLp16xZAgUAgIPIiZC1I6w0EAs1m3e12+30+giAYhjk8PFxbW/P7/YeHB9/+9re/+8f/k9vtjoSjh4eHt27dqtVq46mcy+UgNYHqAO/J7Tt3arWaZZoPHjxIpVKYgeB1qNVqEBdCdoJUAQwM+FBomj45OYGcHPFvyPaDCgW3W6PRyGQy9+7du3//PtJQeZ7vdDpw5iJoE8rjhYWFzz//HJ1vN2/eBM7S6XSazea1a9dg4BuNRpFIxOfzdbtdJNRj86dZynEcFy+AWonFYhgHT05OIpHI/s5uKBRKJpM7Ozv4OcmHn//o9evX0Wg8GAxONXUynrIsCw6+3x82Ws1Go3H9+nWGYdBgFfT7KIpCjtTu7u7MzEyheIZGAsgI4M4jCGJpaQkG1Evl+MbGRqFQAI+OWBSSJOPxOFJDgAr0ukNs6rIsS24R8oVcLudy8YVCgRdYtySVSqVAIBAIBEajUcAXREIJRVGyMoUsoN3rQqTJkFQsFnMsu1qtYoSaTMenp6ewVQORHgxG+OdAlrdaLdO0IeAwTVMSXYhrg8AIyJau60hUQ2pfrVbrdrvD4TCRSDiWxXHc8vLys2fPeJcrn8+73e6zszPbtlFKJcvySeHUMAxE1DAMB40LhMlIXAQYdvXq1fOzIpJCZmdnK5VKtVqNxMLRaPT09BQdC4i/s217fnYOzwDHcUB+UxRl2s6TFy/+z/+X/xrZOQRB6bpOUyxBECRJI39V0y4OFNj37LfpDECJYFBwu91I6OA4bjAY4IxG3lq/N0TkHSQ+uAw0TSMpx3r761ImBeRmaWmp3W6jn+FyUCNp6pfzFyRJAnXbabW73a5pmqPRCP4yfBk0WICv8KFjwNJ082+5CP/ugHXxpwThEARFs5dyLooicB2ihsLv93u9fkVRWJazbZtjBdu2RVGaTtXJZIRpG3OeLMucS3C73ZZlmG/LuZAukctlYHUW3S6EnJEkaZp6NBr1+TytRsPlcvn9XkEQ8A4TtmMYhkNSylQjGTYUDLO84BY9I3kKB4Bt24aq0DRtWrrjOG6XSFGMZTper9cmiEajwbJsKpUcT8e2bUJDA25UdLmbrYaLYzmOwwMDgjnsatCxiqLYaDQgEsdwbFsGy7KGaft8PschgfJe4o4YyExDM03T0g2e5eKxiG3qPM91Oq0bN699+OG9brc9NzcnuHgMcE+ePEEuncC7LMsyTP369evNZrPdbi8uLLEs+/r1a8x/4/HYsk2CIO7ceWc4HBKEje4/FH55PB7kKQQCgTdv3rTb7WQy2Wp1kA6F6Wo0Gh2fFprNZiqVmpmZ6fd7p6enq6urHMcBAAA17xAWthSCIBiSwfcMh8OWZSAMbzweBgKBs7OzVqs1MzPDsnwymRyNJicnJyzPA1vKZDJBv19V1cFggDiJ8Xi8ubn55s2bbD5fLBZhS4wnY/Pz89vb2++9997u7r5pmi5eIAiiXC5nMhkY9XPpbLvdRsXKeDKCpwFC+MPDQ1TJWpbF8zw+LKQrQ3sbDkUQAlkulz/88EN4TViWlVWlVCq1212v1wtL/9zcXLfbdkiCYWjHspEWQdN0JBR68uSJIAjxeBx2PxxNp2dn165dS6UT3W53NJwkk8nHjx9vbGwEgyEsP6ZpMgy9tLSEJNWJPOJ5vtmsB4NBkqQbjcbW1la9Xg8Gwi9fvtzc3JyZmfn00x9fuXKl3W5Xq1WedzEMw9FUOp0+PDlmWbZSKW9sbGiGXqvVcrnc/v6+ixdcLhcvsBzHteoNkiTj8ShKkyaTSTqdRUcK2hQ0TTs4OCgWi/F4cmVlBdzfebmMHBCO4+ANLxQK6XQaDTPBYHB1dRX6ql6vB1wcmTWoiAW3iDuI47irV6++fv3atu3BYAC/BcMw2D8ty3rzZhsFslhTeZ7v9QaQfBEE8d5777Xb7f39/XQ6vbu7GwqFxoNhLBZrt9uVSgV0EAKic7MzvV4PoVyxcCSRjB8fH/t8Pjg5CIdUFKXV7RAEcevWLThA19bW8LwuFAocx52enq6srESj0clkgtEfrm04t+bn57/88kvs2B7Rk81m9/f3ASEjveejjz4aDgb9fv+9996rVCrwsTYa9Wazubi8NBwO+73B0tISOoLGU9lxnFevXum6nk5nQQS1221FVVdWViLhMMMwWCcoisIqlc/nsY3DtxiLxRAIMDs7K8vywcEBgOdnz565XK7JZHLZhpJKpQAr3LhxAznhXq/3+fPnJElubGzA+tbv90OhUKFQuHv3rmmaX3zxxcLCAsAg7FT4i8hnWVtbQ+2YJEkHBwe48lOpFFKTxuPxytoyx3GtRhMxb2/rIAOHh4csy0ouEeIwBF6ur6+T//2/+r/h5QWDQZ/Pd3x8GgiH9vb2TNPstHvhcHR1dXV5eaXf7z988DiRjEUi4cPDfUEQHMdRFOXb3/52qVJ+8uQJrIWlUikSiQDQghoacJllWZDI4XcEQYD4BiMOwrRUVY3FYoRDN5tNtyT6/X7HspPJpDKR2+32RB5hwxtNJrF4BI2w/X4/Gokrssy7XBhmTdsCCOH3+71eb6/TjUaj7Xa72+1mUqlgOFxrVAG32La9uLiMFFq814jHhLQZDojV1VWapJALh8pP5P8iHA/lMIipbbVa4XDY5XI5loVYtoODA97lwrQBnTiiNXRdJygSRzxFUZ1OzzJtKI6x7kiSBGzP5/NRJHlJypycnCwszLs9YqFQADsJ7KFarsCSfRlGirADgiB009Is6/f/F/8kFIroum6ZDkKA4LVUFAXxDbZtO4SF49XULTx0EXgBnOYSORdFEZAs6oZEUbRMBxmVwGA7nY6qTTGHEb9UwIzxBXmkCwsL3W4XQQ9AKy8gJZIcTcY0TSNVGUbRaDiyv7+P+6HX62G6wpgFZbfL5XK5XMCNNE1TtQtS8pITJN8OVX9H3k4QBEEzHElStm1dDm0Mw7jdbji/eF5AYs14POZYgWEYgqBwVmqaBqWnQzkg3fGeY3mQZZnhWLfbPRoMOY5xu91Irto/2DMMw+uV/B4vTdP9QTedToOzm0wmBEEYmu44Dkkzhm7plu0WJX8wZNs2TbHj8djr9QuCYFmGbdugjZB2wXGCaZqi6DZNUxD4s7OzaDRMUo6q6263W1E0VVWDwbCqqtPxCIPy5RvoOA4oMGDDw+EQwbY4AW3HJElS10y/3w/Rum6ZoigyJK3rOkE4mqYRtuP3+w1N8fs8ldI5TdqxWOzK1c3f/d3fHQ77jUbN5/dyHOf3+03TfPz48ZWtq7Zt9/tDl4tPJONw2qJQCwM6nnyapuFgCQR8s7Ozn376ww8++ODkpHB4eBgIBG7fvt3tdtEMgUhYjuNGownHcel0Gsbb2dnZUCSKUHK/389xbLPZjEajGAjQyxsIBKq18urq6nA4fPDgAWmTkXDUsk2e52dmZjqd1t7e3tLSEsvSlUplMBjcvn17OBxzHNdsNpPJJCeIXq93e3u71WoNer1sNhsMBre2tpDn3u12+/2+LxDodDqrq6ssy3p90ve+9z0AJ+lUdmdnB4Gfw+FQluVSqRQKhbqtTi6Xy+fz1WpVN7R8Pj8YDGBeQxJ6pVJB9UImk2k2my6XS5IkUCq1Wi2dTk/G8nQ6XV5ezuVyv/jFLyiKMmzLcZz33//ge9/73sbGBg6u2dn87Pzco0cPSYdwHAfNsINeD8LTr7766rd/+7fhBdZ1XdX18XisqLLP5/N6/K1WC4GCXq+P53kkxx4dHd69e7fT6Wxvb3/7O7/99OlTQRASicTXX3+NLb1er4dD0aOjI3TvNBrNmZmZYDD4+PHjeDze6/VWFpf29vZojvF6vYi3kJUp0gQ5jpubmR0MBqAsCdvEFYXD5/Hjx9C/Q3o8Ozur6/rLl6/v3bsHxyXwGN4lIjp/Op22Wi0AY5qmAesKBoOXMZWQf6RSyXq9jgaz169fEwRx9+7dzz//3DTNb3/720+ePFEUBQCnYRgnJyc0zfR6vcXFRYS2Q0mSz+dR6QE/R6FQRKjp5To3nU4rlcq9u+8dHx+Dv0ORNkVRV69effT0CYqDIpFQu9EcjYeiKPI8XygUrl69+tWXXy8vL69tbiBHYHZ29vj4uN1ui6KIPaRYLN69e3cwGFQqFUzMSHxAJPLMzAzLsojdLpVKmWQmGAw+evQIOqQrV660Wg1d11E2OhwMwuGw3++vVqsLC/PlctkX8OdyuRfPX87MzLx+/ToQCHQHfcBjbre7XK4iN0vXdY7n4/G4SxD29vaA4GazWbg0QMh0Op3j42O0iG5sbMiyfH5+nkgkgsEgsBg8uQRB2NvbW11dhQthfn6+3++73e5arQZtEkVRvV5vaWlJEITDw0NQtJqmHR8fb2xs4Cl8dnZmmiYoFzhsQKaHQiFgjTg0eJ4fj8fvvPMOwzCnp6dzc3O1RrXVasWjMV3XW63W/Px8KBRChIRlWZJLtG27UqlEIpF2u53NZsk//+P/geO4er0uSZLXK6FthyCIVquTSCQS8dRwOB4ORyzDgzxeXVs6PT1utVrBYBB883m5RBAEfArIT4dqAY4JpIAeHh5OUU5u29ie19bW9vf3WZYVRfHg4CCRSEAxM52qo+HYIexoNOpYtuM4HM14vd7xZAghVzAYJBkSG0Y8HndxLlVVK7UakiMsyxJEF0zRiURCU1RMeDdv3vR5PNu7u+FIMByJYKQbDscwkuC0SiaT6FgFJ6UoSjgcNjTdtm0EG/r9fiSRAlTkOA43gyAImDxqtZrf69U0DUSs5Tj4GsMwJEmC+SscDsvKFK46QRAURRv0h0BxgJqAicB7RTgOrkUgB+l0yh/0wZEbiURgBOUYdjqdQtaALiRoeIfDYSKVnqjqf/Ff/oHb7eF5ftAfwUYbiUSQVynLMsMwFE0gw8myLNtEyCeBRy8kWeTbnH1JkjC9gUfTNM00bABI2EsURdGNvy4lBG4EwIOiCBwl8/Pz3W4XOQKY8C7/IYckoP5BgUk2mxU4vtlswi+GMgAEOCFAC+88/KQQ9k0VDQz9pRyeehua9bcGrAt4i2RIknQcm3wbo8VxnMfjAe/AcTxi2MbjMUUyuq4zDId3A7GTiURsOBlrmhYIBJDUgP4lXdfdHonjOF3V4J/o9Tosy+7v78vTSTgc9knu4XBo2cbNmzcty5hMJsC6x8MRTdMERTs2qegGx3HpTH46nfq8gclkQhAU4i0wm2L8VRRFEMTRaORyiaZpiqKLIGyScgxDU1XVdOyAPySKkmEYLpfbUJXhcHiRiWVZBEGgnhZJYx6PB7W7yC3Dy8Hs5XK50eAheiSaprWpAoyTJB2GphmGqZbKo2E3m0l+51u/FY1G8/nsZDKZTifhSIhhGNAB2AWVqZpMJjud3mQyEkWRoklMGMhd+/CTT548fFgoFCKRCIre37x5RZJkJBKaTqc0za6srDx48ABQAQQlkiShwV3TjGKxmE6nkS79zjvv9IcjtGoMh8PHjx9hFYG0GQqVx48fZ7IpPKfL5fLH9z55+vSp4OIRLn/jxo1ms44YDpomO51ONps1DCubzRYKBcMwHJKu1WokSYZCoUwqBcd+qVRaWlqCiGo6nRaKxc3NzXg8vre398k3Pmq1Wl9++aUgCG7RwzDM6upqs9k8OTn55JNPDg4OSJLc39nz+XzZbPbNmzfRWCQSiVQqFUwb+XwedmzkMgBE+cEPfgDhTjqdRlC4aVgzMzNbW1snJydYPHYP9hcXF1dW1kDHIBPYMDRfwP/8+bNcJoucML/fr6sqtoVwOIw4U5qmq9Uq73LZtk0zJMdx0Ugce6wsyzwvNBoNBPLNzOQxK2xtbVm2USgUsLJiJHIcx+/3a6rRbrdx0rrdEtIrDMPADLG5tv7mzZt2rwOWwDRNwzLxkMYoDy2KrusCxyBP8vHjx9VqVZIklN5AbGSaZiQSsW1iNBpB5gWUlGY5NAnOzMzgUKUoClTanTt3IAZCpkw+n+/3+4NBHzAwbIa4OxCp80d/9EepVGp+fh4dYqVSyeVyVas1OEnn5ubQERSNRu/fv7++vg74s9FoTKcqdMlgUUDXbm9vx8IX+jw8yxmGefPmTTAYFNzi+vo6x3E/+cmny4sLKDnAtKEoitfjOzw89Ph9KMHkeR7kFzRneHycnZ0hZK7b7Z6dnTEMA+lev99H/ly32wU71ml2FEXZ2NigKKper8fj8V6vg3szk8kcHx1FIhFYWXu97vb2NsOxt27d2t3ZwyMykUhU6jWcG5PJZDKZAk/led52HF3X3aIIAhQK4N3d3dXV1UvIAxrcmZkZTFTInf6N3/iN7e1tBPpjMMJ5kkgkEGxhGEYqldre3kbxw9zcnGVZ4XB4b28P8h5weZCgQQkN8sQwDPQFofcJl6iiKKIoIu4fkcX7+/sMwyQSiUqlwvLMdDqdn51rNBqNRgOOWgCK8/PzykTGeIDWAbfbTT65/0WlUgmHgwRBtNoNURTl0RBx3t1un+d5huE01SiXK7nsDEUTmqmPx0M8BaFFDYSCeHdGo1E4HA6FQpVKBcYunJgcx21vb4Mk6na7N27caDQaeKC63W5carquIwiUd7ldLtf+7u54PA76AzRNMxQBVBY8msfjwdyqKDIeeIqiYKWTFQXSacwQOAHD4TDHMMgj6A+HJEkSFIk1CFZMy7ICgYBlWaVSCesvdkGSJKFSwvVXq9VwP6A8Eaom1CcB1EkkEoam+73e/f19URRTqVSr02m1Wn6/XxRFURR3d3c5jovH45OprKoqSj90/cLQB8IFT26M4cFgsFap4qNCQv1kMrEcM5vN4nk8Ho5wq5+fn2ez2fF4PDMzI8sy0gJ5ntcMM5ZI/u/+9//Vzs4e0COCIAzTDofDWK8VVWYYBnCRbZu6btoWgcQXvD/k2xwEx3HwEAKyRRAEvKwA/Ki3wd+yLGOcggzCsg2KopC/hWe5xy2lUqmzszOg35dMHzSSQFZUXQuHw7FYzDAMjmFR2QaR+2UMPVB37O7wtOPYHU+mGLDsv6lzJ/9Orw5+2c4vxzQQBEHg7kIlIsfxsFOwLGtbBBI6KIriXAJEshCERaPhbreLd5Lned008IFOpyrIl+FwaNs2z7PFYlGRJ6Io8jwry3IsHvn444/r9Xqr1dI0xbZtxyIIgrAsxzBNzbQIgkhn8pZlqYqOURKfAqJEFUVxSe7Z2dnt7V3LstyC6HK5QqFgs1mnKUIzVAAn0Wi0VKrYFmHbtm0TIKAREYfEc9BMyNACssWyLAoWIRjiOI6iaEC2LMsAe+Z5VlWUdrtJWPbS8kIuk81mM8lExOuTaJoejQbYziORMPa37e3tubn5k5OTaDS+uLhYLpdJ0qEJUvK4OY6DDokkSUQ/N5v1RCLR6/UMwxgOh+FwmCDsXq93/fpNj8fz5MkTpIx+/PHHrVYLw+76+vrDh49nZmbS6fSf/dmfffzxx4PB4LxcgcgjGAyyLNPv9x3Hyefzp6enOPpPTk6CIT80D5PJxC8Fzs7OEAve7XXC4fDi4uLZ2alt24uLi8+ePVtfX1cUuVKprK2tPXnyLJZIwTtmWVa72RRFMZPJhMPh8Xj88uVL5OmnMplqtQpxG8czWLdevXq1tXkVOyHEVUhy6vf78zNzKysrf/mXfxmJROKJ2PHx8erq6vPnzxFLpqrq+++//9VXXyEofHV1FbEFV65csW0btdYorfd4PLqu65oxOzvb7LRVVW00GuhODQaD6XS2WCxMprKuaxRBCoKA5t3RYIBnUiKROD4+Pjo6gm9mLMuO41y5cgXLDEVRuq5fv369UCjg3kwmk5qmQTURi8VevnwZCATGw74sy4uLi6IoFoslAJP7+/srKytnZ2fLy8vJZLJcqqyurh4dHZ2fnweC/sFgIEpSJBLZ29ubTqfxZAIPC4/Hw9LM0dHR7Owsy7KGpvl8vt6wx/P84uKi2+3+7LPPMpkMeof29w6z2SxBEOCecELOz89/73t//uGHH/v9/k8//RSPHrQwxePxnZ0diH4ODg4IgvB4PIGAr1qtIECVIIgXL17gAIdqJZvNvnz5EtLJ0Wh0fn4ej8fn5uahh4GrPxQKqaqKwxlNOycnJ8lkslqtQlSE3JCf/OQnd+/ebdbqxWIxkUhks9lut+t2u3O5XKvVGk/lfD6PfIdoOITb8/T0lKZpj8ejTNVYLIbQ7/F4vL+/v7S0NDs7++WXX+Ikh3kItgnkY0N0gbnw/Pw8lUr5/f7Hjx/fuXOnVKqsr6/ruj4YDBiSOjk58fk8mUzG7XYjGavT6SjTqWEYPM+lUqli6TwQCIxHE5fLFY/HGYYp16qIYhkOh7KsBAKB5eVly7KOjo9pmrZM85vf/CYywGZnZzHiRCKRra2to6OjdrudyWTS6fTZ2Vmj0QDNF4vFBoNBt9uNx+N4VIFS39jYcEwLoppisbi8vKwoSq3ZEEVxOp1iRY/FYgBTDMOYmZnJZrM/+9nPgATzPL++vr6zs1OpVHK53Orq6mAwQOywy+Wan58HpuU4DiRfH3300f379/MzM8lkcjgY3L9/f2NjA2WRSP3M5/Mz2RwCV1ut1nQ69fl8zOFBQRQFryd0fHJomo5sKxwnIFNKlseTyWR+ft7rpVVV1XQlHA6dH5bi8SiwR/BlmqZBV5hKpRAvAYwKhw7DMHiF+Cs40NFffXp6alkWDmtd12OxmKZpummXSiVZlhOJBBxVuVwWq5Jt2xAAQqXebNYpilIU7Z133kFJp6broP+TySRFUfCRUhSVy+WwV5m2bVlWKBLGXBWJRPS3v9D2hfUIZ1ar1SIIwu/3Q2fj8/lWVlbQvoxzBM/dtbU1RNxigimVSkhPxTMVQA6mPZZlIUrNZDLtdhs0Uygk0DTNcUIw6K/VGoLAxWKxXq/jOKQoCgRByPLY5/OJolAslliWFiU3bEGozgAny3EcAr6hIWs2m7FYTNd1VdPPz8+xcyC2m+M4y75oucHXQ2Nu2zZNkzRNMjQL7wwMhpC645r2er1Q1+G8g20QueEwWiqKAg8aljzbtg1TQyz7ZXiVwRl4ky9itFgWT3SAWJiBwDYChlzY2Gw0GthQu92u87aO/pL1uzC7kaRpmrj98E9D6u78h7sIL42B0EuRJElRJFAxIJqmaSqKiskeEwk09RzPaIZpWUYgENJ1Fc88juMgzLQsC+H14/HYti3HJhDSEwqFNE2BjE/XdYahLrz9PK+qKl61ruuTkUySJEFQhOPwDKtbpqZMOcEFl99ljiherCiKDMui/OHq1au1crXX6w6HPb/Pw/MsQVoz+RxJEicnx4PBUBBEjhV43gXIFvMZPtBIJII6UWj2eZ7HjUxRlGlaPC8MhyOsTyzLkiSBOp3xRA/6faury9eubN26daNWrQ4GPZfI9/vdpaWlcDiIDxrxK71eb2Fhodvtra+vz80tvHjxQtf1fD67/er1engtlUodHBzU63WcucfHx9Bc1uv1jz76KBaLmaYZj0eREIhrstvtfuMb38BjJhKJNBqNP/3TPyUI6uzs7OOPP75y5crJyQl2U9wgJycnPp8XqUVfffVVJBI5OzurVCqbm5vT6RRy5tnZWUu3sFl5vV6f31ssFsFHmKb+8uXL2dnZ7e3tdrtJkuTR0dFkMp1M1c3NTXBMwWDwvffe++yzzxYXFz///PNvfetbEFbDorG+vo6LB9fwlStXDN2cmZk5PT2FAxrp7fPz8w++ug+PDn7yarXq8/lAGhqGcXBw8Od//ucItOz3+7u7u9evX79165aiKL1eDzutZVkrKyv1ej2RSJwXS9h8APmDa6MoCqW8hqFTFOXzeMHIWJZlmaZlWcViEV8/NzeHE2x7d7fX6yHXyjTNmZmZx48fj0ajdDqNpQv7tiiKaAsBoBuLRMLhMCAiny8AI97c3ByOI9TIOo4DPjeVSv3o0x8CvWs0GsvLyzzPszxnWdb+/j4iMe/cuXNwcFAoFBBJGgqFNE1DmenS0lK/3z88PFxeXk4kEjAuVKvV+fn5Dz744NGjR7FYLByOogZbkiQUsNI0/eDBg42NDY7joP+7du3a8+fPbds+PDxeWJgLh0P1en06nb7//vvgNyAA+uKLL5aXlyuVyp07d7744guEQbIsB70OLH4ej2dpaSkWi33ve9+7fv16Npvd2dn5xS9+MTc3BwnN2dlZLBa7du1aqVQK+vz37t3TNC2RSIii2Gq1ICj80U9+XCwWgT+tLi+9fv06lUoFAoFUKqVpWqPerNfrsWQCaaIwvpEkiTKZ1dVVZBbKstxqtVBmvLa2BhYS/ndJkl6/fr20tATIo16v1+t1x3FC/gAMxfv7+xzHwTQQCoVu3bx5//59yzKPj489Pm+3252bnQenhtlRFMVwOOzz+Twe33Q6ffPmTaPRcEvSysqKoevNZjMUCg0Gg62trdevX+N2+9GPfpRIJNbX14vFYqlUgsIplUo9efIEGcJwWUGuE4/Hl5aWut3uqD9ot9uNRsPlcgFdHk/lwWAAigMKCsiw5ubmjo+Pa7Xae++9d3p6euPGDUVRAoHA2toayGjkfhuGcfXq1Ww2e35+/oMf/OBXf/VX+/1+KpWaTCYPHz4URfHk5EQQhHarlc1meZ7/gz/4g88++wx9BgzDoBJ+bW2t0Wh89tlnuVyO/Gf/q//11tbmlSubrXYjFPAr6iSRiHV77XLxDFFpPp9PUTTLsgzDqlar127cgB8EltSlpaVytVKtVrHKKIqCekjHcSKRiNfrhWeQZdn5+fnBYACemKIoQEpgqdG+hweqIErD4TAWiTiO41g2x3EUYRMEgTuh2Wziwnrx4kW/34/H49jGSJLsdDqhSAQN2KCZQ6EQ6Pb93d0L0bGqXr9+nWJoFBSGw+FOp6MoCnadXq+H/4aHERhsPB7P5XI7OzutVgtleThBkOIqSdLp6SnWfZw+yniCzLF+v09QlGmayKjFEu92u58+fZqfnYENBFqiRCJWrzdFUaAoptNpGYbFMNT8/GKn0yJskqKJ46PTufkZnnNpmgai1u12Hx0d2bYNSzB8FvPz85PJpNvtMhw7MzPTarUKhWIilX71evtf/st/GY/HR6OJZVkkxUC6hBgFzF4EQTiUY1kW7bAYKC/VThiUMVtgBgIBR5IktJwYkgiCIEibfNvNAnT3rwEkkiQI27btdru7tLQUCARKpZKpGwDDAGJdTkuXBKXf789kco1Go9lsUhQFAgXyajBcQAopisJU12w2J5PppT/wcpLCN2cYhiapX/7hSZK0HMe2CIK0KYpiWQb5rh6PB3Da27/IEgQBEZXH46EokmFY0zRIkgoEAjZB1Go1sFSdTgeXFsMwLrfodrs55gL6ZlnWxbOFQmE8hmzZ9ng83/72t9+8ecMyFKRUXq/37OyMoigo8lXNMGzL5/X7/X7NMCVJMg0bGADDMIRN8i6h1e0ALeM4bml+4ey0IE+Hfq80Gg1J0hmPx26vxzCMUChCEtR0qvr9QVXR8ekDevH5fOjurNVqLpcLbjVA69OpoutmIBCgaPr8/DwSDTEMY5qGy8WPRwOXixcFPhaL/Jf/xX/e63UYmpydnTk6OlaUKXyduq5Xq9UPP/ywXq/ruh6Px09PC4lEAh/x8fEpSTpryyuKOkUusSgKgUDg/v37gCdt215bW8NUDSLA6/UeHR1tbGzMzc09evRoOBwuLS3BwoPynGAwjJRIZAWbpjk7MzeZTCDdKJXPkTeNiG2Px+PxeE5OTizLQAFOKpWaTlWGYRDIoqrq/Px8rVazLAtXIEk6EMzqur60tLS/v3/t2g2O487Pz69evXpeLs/MzCiKMhqNUJZar9d7vd7G2tpkMgGnsLq67DgO9LPvv/8ByhOh58PwPT8/X6nVkY2paVo2ndrZ2UEOar1eX15enp2dhVXoq6++unXrFsxfWG/gxdnc3AyHw1BqY3Hvdrum7aBEBYggCB1JkgiKGA6HHMMOh0NJkqLRqMBxX375ZT6fn5mZ2dvbCwQCGxsblUolmU7v7u5WKhWIR69fv479Hicttn8oJeDG2t3d3dzc3N1+7fV6r169jqAEWZbBPwLtgE/I5XI9efLk3vsfhMPhw6ODWCxG0jTcds+ePfP4vPl8Xtf1zz//fGlhETLTX/mVX2nW6zs7OyRDejyeo6Ojfr9/9epVkiSPDk8oispms9A4a5q2srJiWRaUyzTNofRmfX394cOHhmHcuHFjd3cX4jmaph89esRx3P7+fi6Xe/fdd0OhwFdffXUZ03Np8TFNE6oAlIKTJNlsNmGAhW3zxo0bHMd9+umnbrcbQv7BYIB2Cjx3gEe2Wi34M+r1ultwRSKR8/Pz2dnZ+/fvp1IpNHiqht7r9aD6WJib/clPfrK6uopcmI8//vj+1w9IkszkcycnJ7Isp9NpBEHfuXPn888/j0QiiBIlSfKDDz54/PgxdmC/3w99WL/fx6UOzHVtbWN+fv709DSTyaiqWiqVPv7g3uvXr0GP8jwPocvNmzfTmdTXX3+N/O3RcAyhXq1WS2bSEBP7/f5KpYae6Zs3b/7o008ty1peWnr58qVpmlevXgXacnJyAu+kKIrz8/OPHj3KZrMURVUqlel0urKyAscVGg7cbrfX602n00f7B0gjKpfLsKrA9qGZRiaTwX5IkqTb7UZvOqbVubk5x3FKpdK1a9cwfAMNwdycTCb39vbAVs/OzvZ6vTt37uzs7DQajXfffde27atXrxbOzn74wx/GolH4gSBzxAWcy+WODw7D4fAlQqYoCvn+O5/EYpHFpfnV1RWfVwwEfP1Bd3Y2N+h1VHUK5SNQEFEU9/YOeJcbrDzC6JCEgSUGEHcoFGo0Gih7xi6ys7MDQTR6VGCCW19f1zQNUQ4oRwQrR1CMx+MZ9Hq6rivyNBAIiAIHlQPy1j0eD0EQOJHBUtm2jbW73myCjoVrF4Ihx3FEQQCepGhaMBjkXQIQBV3Xu91uKpWqVCrIXEBI9MzMTKfTQUUG8logbsDUHw6H9/f3UaKJfJHLejiWZTmKxo0EdAUmSpBZs7Ozu7u7uVxuNBkjVCORSIxGAwx/2K1PTk5IkkSRJ8Mwg34fJgXkNPZ6Pccm2+02FP0sy8IpDVQDpI9pmrxL0HU9mUwOh0OWFyma/Yf/8B8qiiJJXtu2Nd0Mh8OwaiNLCZZAB8OQbcNmCNQKfB/+G/TcLw9Y1NuAgwsUirBAYGF2/GW4yHEclN7ouole1UajQRHkZXQW7gc8WcEFAxO6dev248ePz8/PIb6+QKcIgqZpmB7wOeL06fZ6qmESBOGYFuKsAFZj/qMoinSIy79+wX4yjGOTGA0pioQwDgwp8pYIgjBNC/MiyzKw/gJwAtRn2g5CDZDODOc2RVGcwHMcp6sGy7IcxxGELXBco9GYTMZut9u2zdnZ2W9961t/+qd/Krp4/DxwV+BdIkmSIGnLsjjB5fV6CYq2bZsiGcdxUCAvCm7eJUyn02AkrKqqbZg8yxGkbZsqSRJzczNuydWsN8byRJblqarrummZtscT6Pf7lyFw0IdNJpPhcJjJZPA54mhQVTWZSBuG3ev1QqEQSRO9Xo9h6MlkEgx4TFOXpyOBY77zrd9eW19x8TxJOXBmMTR3cnISjUax2OG8Q98DzwudTieXyy0uLv7sZz9fX181de3f/Jt/8+GHH87MzMjy2O12f/3116DUM5lMq9VC5Fu9XidJEro9TBtv3rxhWRbxBKZpJpPJ7e1tny+wtLR0fHz88uXLUCi0tLRUOi9DJKvrutfnwUpw8+bN7373u3fv3p1MJnt7e8vLi3Nzc/V6vd1uz88vImUKPwMO94WFhWaziYJYRZE5jkMWJcMww+EYoQnBYFAzjFqtNjs7G41Gnz59Oj8/73K59vf33719+/vf//6VK1cGg0G323733XcfPnx47dq1brdP03Q6nQa1hwb6arW6srYOelHTtFQiDlDq+fPnSAxnGGZxcbFUKgFqxTwHrB2WEZ7ncfoRBCHLMgw3DMcTBKGqKo6v5eVlANutTqtSqbxz81alUqnX66lUamVp6eXLl6urq4qi3L9/3+fz1Wq1hYWFuYUFhmFOTk4gaUcHBnoVa7UawCQIpSORCKxe+Xy+fH5Oko5hWLlcDoLio6MjePI3NjbwmZIk2Wq1BN6VyaY7nU6hUFB1HQUmjUZjMBouLCwgm8rtEtHtKMuyPB53Oh3d0t955x2YJ8CCxWPJQCAAAL5cLqMRz+fzvXjxotvteTyetbUNMICoBlleXq7VatFotF6v7+zs4MNFm8jCwgJJOteuXfvyyy+BtNE0jXz2eDwuCEKpVFpdXUWqJBBQzLUIgldVdXV1NR6Po3sXVA+4M6CMsVhsOBxisPZ4PAxJHR8fZ7PZvb09EClIGVjf2sR3G41G4WAgkUjgn4ZWPRqJFYtFimX8fv+1a9eePXt2cnIiSRJUyMVicTKZ/Pqv//qLFy8AsiaTSaCVQOVv3769u7vLMAx6RBRFu6zZxrhmG3ooFNrd3cWDEoUKmqa5ROH09HRzc/PFixf33v9AEAQUwDx+9hTteaFQ6PHjpysrK7Ztz87OshzXarVYhsF6gMb3yWTCsixKABcWFo6OjhByMZ1Ol5aWAKTBp7+6ugrUQ5blo6OjdCKJoQr1iICQDcNI57JHR0fz8/OLi4uFQgFA4MnJyW/91m8pihIMBuF3wQKZTqefPXsGtqff74OmRNQckBq/38+y7KtXr7BoTSaTQDAYCAS6nY4sy7Ozs8+fP69Wq9/4xjcikcj3vve9j+59IMvyw4cP19fXp9Pp9evXyU8++G2Scnq9zt27d65d2QqGvPl89uXL55l0IpNNnR4d6rrOcozf7280GqPheHFltdvpww/YbDYlSSKoCzQSgaW4asGbQKX44sULLFL9ft/r9S4tLcE12mq1hsMhrtpcLgfYSdd1SPddLlc+m7Ms6/zsDENrq9UCQaDqOkEQUEpSBDEajZZWVkzTPD099Xq9sjIFHqDrus/jdRxnPB5vbW2NBgMd5JRtqW+7okHeoXYQTKJhGOl08nIiBsgJbcolpw5BHKAdnC/wmrVaLa/oHg6Hg8EgmUwKokjT9Pn5OY4bqJTi8ThBkeVymaZpWZZZlnYIS9f1d9999+XLl7Ish0KhdDpdKpVKpdJsfuZySdrf3w+Hw3NzC5qmhcNhNGHhxrMsK51Oa5p2dHwMzSxUa/3+sFpvrq2t/6v/z//7Rz/6kdfj13WdZXme5wmSxl8kSVIzDcPQMC3Zv9QzfQks4W3HF+B/Xs5DhmURb7Xh2I8v9IOmdjnKYFy7mNJIBsj8pc2QsJ23rBmDGQ4LkMfjSaVSgssNihDp/yg+AvyL/mBQbObb/tFOf3ApscLPzFI0UH377S/8EWHjhfx1pgNYR4omoC/x+XzwGDv2hUwe4NxoPMDFY1+8MxejJK46kiRJhp6Mxz6/X5IktyAihVVV1Xg8TtMUNOYMQ33nO98Jh0L/9t/+23w+i8/RMAyMgIqmm6aJAUuUPOl0uj8ckSTpkXymaU4nCvR/w/HI5/PIqjIdT7LZ7Gg4pAmn22ltXVn//d//z8aTfiqRrDcb3U7fIanhcOjYZL3eOiucQ3KEtLPj42OsN9PpFH4CiqL8fv9wOFRVPRyK2STh8/lUVQkGgwxL8TxbLZ9HIuGz4vHv/2e/98k3PozHIgxJ9Pqder1uWxT8odevX7csq9vtTiZTv9///PlzTdO8Xq/f7xd4FyjOmZmZH//kU5/Pd/Xq1Xa7LQicruuKIjuOA6/MzZs3p9OpZTkMw6TTaYhtoWXE6IMDd319/dWrV7Ish0IRgLidTuf69eu2bVfKVdR6chxHMxSoh16vB/m2oij37t376qsvsPfjNu90OsFguNfrVavV5eXlYCAEuetwNABPrev6cDhcXJxfWFg4Py9jdt/d3X3v3r3z83NYmME1m6bZaDRSiYRt27FY7PHjx5ub647jINHNtgnsZlCIr62thcNhCLFbrVahULh3796w3wMJtb29DTIUW6XjOPhJULW2trYGkyOS7iORCMIqh8NhLBazbZtiGK/Xu7e3rygKMhIxZBMU4fV6g/7A8+fPwaydn50hBwi7ZS6Xg1Z9//DQ7XbPzMxOJhO/3/f1119Ho9GlpSWaIXd3d4GqRiNx6COTyWQ4HNnZ2X725Mnv/u7vMgxz//79XC6HvY6m6Xq9jv4MWZYjkQicX+ggIknH5fbgI+v1eoZlwplLkmS72ZqZmcGyzZD0eanY7rWRvLi3t5fN5EulEiI5cGRVq1XLsiqVqsvl2traevbsmSAIN27cKJVK3W630WhcvXoVT6snT56srq7CvoqxAzprgiDg7QDgBPwDVwsCTr1eL4RNMM5fuXLthz/84ZUrV/r9/s7OG4jDjo6OFhcX0+n0ZSjDjRs3/H5/s9k8PT0dDodbW1vT6ZSw7FgsVqlUwCog8EjTNAxP8CXQJOFyuXZ2dpLJ5Nzc3N7enmXaXq+X5liIcVG/GI1Gcfr1ej14zqAnNgzj/Pwcoii8omKxiIQddK+dnZ3DQ5dOp0ejUSAQqFbL4/GYpWhRFJGhhSZQtyRiXF5fXxdd7ufPn6fT6fn5+Vfbb7xe78bGxuPHjyOR2PHxMSKXaYYhSdLn9QYCgcePH4uiePv27RcvXjSbzQ8++AAHOCzweFdhoYNuvVKpwNocDAYr5yW823i+AzUMBoMMw/QGfV50aZq2trYG+cqrV69CoVC73UbABM/zsiy3222YK3FDSZK0vr7+4MEDPAX+wT/4Bw8ePECWEzhTxANVKpVsNjscjbxeL89xBEFgKwNki3qJX/n4E0CDDMP86Ec/Mk2T/MaH36IZRCwaPp/vd/7edzLZhKLIHEspimwZGsNQk8mEZqjj4+PZ2dlgOCa6JLjArly5UiwWo/EYUByUGe/u7oJJAVUH7ApKQJZl/X7/zs4O9O8wZhMEgVzas7MzRHdgJSVJ0it5TNNENjpJkgiE9fr9rVaLpulUKgUTXzwa3d3f13V9c3OzPxyQb2O4z8/PvZIHj/ZAIGDqOsNxLM9B4Q4aCPKXy5RFfFtB4CaTyWQyUVXV5brg8pBuUqvV4NL3+/2yLA+HQ9h3bdtOpVLD4dDjEkFlMgyjaBqcqPj+mNi8Xi/Lc8PhsFAopFIpt9vFsBTGNWBdSDepVCoEQSjyFIaOQCDw/PlzhmFEUYKNaDAYAEP2+/0IoR4Oh7l8nqKow8NDmFQpijo4PknEU9/94z/+1//6X2czecMwNM0QBIFmOFmWLcuiaVq3wBLaJEmSb/EkPAL/Ds1HXDryLv4nSeKlYYjBnESSpO2Y+E0IpMBC0jStKxfUDMKXdV0nHQLA29tsOgrcn8vlisViNMPhNoY9ClwPFJperxeooaZp3W632+06ts27JVw8ePmGYZC2Ayr2b8U3wKNKUfTbl0M4juMQf/0FoEoJgmBo7kLjRViXf4S5jOd5mmY1TcOoCrYUoQ8ETRMEAR2DILiGw8GlhNzj8SiK/I//8T9+9vTpzs5OLpcBjug4DkPRBEGouqFpGkHShmHwLnF2dpblhV6vRxK0ZVmORYBYMW1LFAXV0HmGtS2LZ2jbMmiampvN/uf/9H/Z7bZAfK+srJIUUy6XKYY9PS4sLa9qiuoPBtrNFs0yXslzUjiNRaL94UDg+FQmfbC3n5vJN+uNnb294lmpVmuMx2OLsEzT9Hjcpq63Ws1/9J/8zrd/+7eWlhd6nU633bQsQ9WmhmG4Rc90qmI5lmV5ZmZG04x6vb65udlqtSzLmk6nLMNBN33z5s3HTx6Nx+OVlRVEsBaLRVEUoLqtVqsAbAKBkOM4sM0TBFEqlZCUA7tuq9XKZrP9fv/58+eZTM40zW63+/7776dSqdPT0/FoAo08z/OHRweopQc1gH4FURSDQX+73UZpJvbabrcPuafP54vHErVarVKprK6u1hu1aDT64sWLWCyWz+ehMQVt1Ov1eJcLrprBYHB6erqwsBAIBF6+fPnOzZuqqiJEYGfnDXSi8Xic4wSKou7evQtWFPuqJEmnZ8V79+69fPlSkiSeZeCL1HX91q1bl4kDsPoCr3r27FkgEEgmk1CrNJtNv98fCoUgGYEaiROEbrebSqUhN8Gx7PP5mu3m3Nzc08dPYOaybds2TfRAkyT5zW9+89mzZ9FodGNjY3t3d2dnx+USYWfGjuTz+Q6P9nO53PLy8l/91V+FgpFL5IOi6Hw+P+z3JEnieR6GOFBCjuPAWQaSKJ/Px2IxxO4oiixJEsu7sMhNJhN/MEAQBNpaGYoeDodwWB/uHaytremWUa2Vs9msaZokQXe73Xw+D+ktsExd19fW1mFjj0aj4XDY7XbjPcSPCnM0DLmHh4d37949ODjQNC2bzYIbAQUMI+eHH3746tUrn88Hgcr5+TmACqx/0Wj0/Lwcj8ehamIY6ubNm8C3dnZ2SJJMp9MgFobDoWmaMH0HAoEPP/zwT/7kTxiSSqfTlUplfX0d0j0Qvj/77OeAaiKRiDq9kPtUq9V33nnnwYMHpmHNzc25JDdN04AwkMsIeovn+V6vh1D78/Nzj8cTDoeHwyGmscFgoGmay+W6e/fuq1evut1uKBRJJBJHR0c3btzY3t5WVTUUCliWZWr68vLyq1evcGjXarX/9Pf+k8FgUCqV5ufnnz19ju98cHAwv7QYiUTQ4+n1+sfjMQJa/YFAJBIpnp35fL5ms3nnzp1CoZDL5VKp1He/+92VlZXRaATnEyzSSK5aWlr68Y9/DHNlo9EIBoMz2VwkEimVSsFgMBGLb29vY+W+ELZ7PcPJuFwu3759e29vz+12r66uJhKJ169fFwoF4CBQneIZGgwGZ2dnHz9+jIAG6Nvw9Od5/tWrV/l8XpIksC7Hx8cESVqW5RZFWOkvk0hFUez1eo5pGYYRiUQsy4IGlPz4w99kOdo0TdPUg8GgZRrr66vXrl3hWdrjcZOE4/N5zs9OWZZ2SyLhkBZBhoKRo6OjQCAAHYM/GIC7VRTFaDRaKBSgXkTqf7/fB7axvLyMjFSwZrD7XRroqtXq3NwcUFC0UoTDYb/XB9QaNj2gnSRNgTzGK4mEwi9evBgOhysrK0CGNjY2dg/2MWYJLDc3N1cplYfD4fz8/O7urj8YisViSI4QBA7BJGhLpChK0xTsxKjyqNVqoiihexxRpVi8dF1fXV2FjwngcD6f9/v9hUKh3+7g8c9xnE0Qtm0LgmBdZOX38OA3LJOmaSjPCMKGjBqs5Y0bN548eVKtVhcXF30+32Q8Rtpbv99fX19HBt29e/devHgB5M+yLDTl6YaBDBh4PWAA1HVd0Q2fzxfwh/7JP/kn/eEwGomzLO92uwfD8Xg8NmzrkkTDfkaTDoClSzIOaNAvk334hT/STRMr4KXAHKEPoAihDYKajaIIluXHgzHoeezul3iSZZgAVDCQ4arw+/3xRMo0zf39fXDt+AFEUURlPWrnDcOo1WrwJJvOxffEQG/btqFqGPt++Se/gJpIkiYRCmq9FWzZYDN/ecC6LISmKIoiSMs2CJKm3kbJX06f5NuiaNu2RVG0LAv/rsvFEwTlOBY6BEmSVBQlFo3evXv3q6++IgiCZVm4bjVNYyjacRzEudEMp2maZpixWIznXY7j0DRrmibHCvAlGJYpigJBUyxFCzyvTWXT0FaWF775698gCLvdaWQymdWN9Xq9Xjgtrqysvnz15vq1a7phPH70KJ3JUCTZarcpknRLUi6b7fX7yUTivFSKhMPlSiWZSCiq3my2KZr9+c9/XqtVhsOhruu5bDYQ8P3O7/xOKhnXdXVzfe3rr790bJMgiNnZ2SdPn+fzeThXTk5OPB5PLJYAII18DRiCFhcXkQRhGMb+/j5uSdPU+/2+41jLy8u9Xg+PNOAchmFsb+/GYrFAIACEu9VqASnp9/uI0jBNczKZfvLJJz/72c9gWdc07b2777Ms+9Of/jQUCgkufmNjQ9f1SqUCPg7KVly5AFdCoQDHcaYJ3UKUpmmW4fr9Powd3/p7f+9nP/7x9vb27du3z8/PeYFD7fTx8fHKyspYlqEWQuYfXmAymYQvD6tzIhbF6qKqKs+7LMtyuUWCIIBt+P3+drvt8fknk4nf7z85OSFsa3Z2dmdnJxKJrK2t4aEI7Q5N09Fo9DIOzbIsr9frdrtM04zFEp9++in8mIuLi4eHh4lUKpvNWpataRqcWXC0nZfPP/7441/8/DM8UHmet02T53lkuENIh4Tk/cPDXq+naXokEiEIB1LUSCQyGPbw0w6Hw6XFFU3Tvv7665WVlclEXl1dPT8r4EaQZXlra+v58+c3btwoFoumaaLPY3FxEUK0W7duPXz4MJtNN5tNyedtt9vpVHY8Hq9trP/85z/nOG5zczPoDxwcHFiWbdu2i+O9Xu9XD75GhEG9Xne73bdv337y5Emr1WIYZnl5+ejoGPF+sIe32+2zswJwC5TbwDABmR0S9SKRCK69bDbbbDavX7/RbDY7nQ4mhl6vd+XKlXK5vLi4iIyPRCLh8/l2dnYYhtna2tre3s1ms6BNlpaW9vb2DEMDZBAKhSRJKpfLXq+HZdm9vb2trS3bdqrVKgRPnWYL4nSapq9cuQLkJpFIWIQDbncymYwGfbhtIP/NZDLtVicUCvWGg263e/PmzTdv3gB6cblc6CHWdR3fH+Mmgq9ardZ3vvOdg4MDRGSjGHt2dtaynHv37p2enkYikWKxOBwOr1zZfPz48cLCwps3b0xN1zQN4PTR8SHsnPv7+4sLS5IkVatVpHzjw51Op61W59133202m91ud2Z2djQanZ6cLC4ujsdjXdehq8bJfHJyMj8/3+l0lpeXIbeF0M3v93s8nrOzMwjbj4+PbcN0HKfT6ZAkmctkkQYlSdLe9k4yk2Y4dnihwbDRDQXZH9C4O3fu2Lb99OlTRErpuv7y5cvl5eX5+fn9/X0MLZCDMwxz/fp1EKPFYhFRlI7jpNJp0zRfv3qVzWbhTc5kMi9evADpPB4MgSXdvHlzb2+v2+2Si0vrXq/XK3ncbjfHcZqm0RSZy2Xuvfcuz7McS+fzuUatMp1O3G5Xu902HSIeS2JMBvERjkYwSAUCAcwc+Xw+mUxiLUOqaTabhTkIcaaYLSzLunbtGqQPtm0jvrLf76PuezAYhIMhmqZhOQ6FQp1OxyEJYDM7+3vQ/DMktbK0bJpmu9uB8mmqqRBy+v3+cCA4GAw0RV1YWADT7PH58YkyDCPLY2BmGFYEQZAkEYrRy2SBXm+AvNd+vw8PbTAYRNUD8oHgY59MJhhjPS4RuWeVSiWdzRqGEQgEwF3m83kEWFAMfe3atYODAyg2jo4OCIIKBHzTqarrarPZDgR8pmlrmnLnnXf7g27xrOSWXHOzC51uazqdmqa5sbHx+vVryC2hRpKn02QyicImgDqVSiUYDFoE6fF4rmxd++f//J9/94//OBqNBvyhwWBEUowsy6ZjAzcCd2ZZlm3q5NtEqMsZCwKsywEFX/z/o+0/gyzLz/RO7Hh7vfd5TXpfWd51NdqgAQzMgKBiFZxYUprYIYO73xhBacUIKVbUStyIVax2udKKodgYroYDzgwHmAEa3ehutKuqLl+VWZWV3tzM670999zjjT68WQnQrLQMSfmhA53IzrzunP9rnuf3wPclRXkTrnf2RZAYlBHnSzoo4FDUJgjC0hEIt4FVFPgBTdNE7TPaO0jr4Arhed7t8cH67MmTJ4IgEASha1ogGISZ8Hn11mw2DcNwOBy1ZutcYX2mDDNMsDeej99gjgUluGVARWXaiI0gUFCeFWHnXkUUxeE7BEEYuoogCDxY2BEjb5RqCIJYFoLhuGWa8E+SojAMIQgCmA4gL3C5XLqu+32+RCIBqe8g+gYbgSorGIYRFAkrQsMwVN0IhUKgn9N10zAMAqcAw+byuFHU9vh9pdMCx9KKJC7Mzf2NH/5AGPVq9fJ3v/u+aZrj8RjHyb4wZBk+nz+5dOniixcvVlZWPvzwQxB5pNNpmqYhgwhK22g0+tVXX4GNIxqPj4SxKI2TyWQoFDo6OjI03bZtXdNQ1A4HgqZldNsd09QRyxqNRjhJhiJheDtYlkUQhGV5WGeHQiHY9EH4LgA5cRzf3d3N5XLJZHJz8yWO4/n8EcTlnpycJJPJ4+NjiHNYW7sUi8V2dnZKpdL169dVVd3Z2QHdGMCWFEVZXFz+zW9+s7+/D1qZa9euZTO5SqWSz+c5jguFg5BbNTk5qSgKHMM8zyuKBNgbURT7/W4ikdA0o9frnZwUotHo9NQMkHvAEOPz+cLh8NHRUSwWoyiqP+jxPO/1eo+Pj10eDzSKOI6fnp6CMEDXdY5hgsFgq9Xq9XozU5OGYUSj0a+//jqZnAgGg0f5Y5qmMQyDCYHP57NRDGJGfT6fPBYBIr+8vNzr9YbDIQAd4F+//vrrO3fugDYRWv9C4WRubk5VdVAgzczMQHCKy+PBMExVNRzHIcpsaWnp+fPnOIlfuXLl3td3QVllGEY2nd7f3wcimmVZOI7D3V6UJIIg2u1OOp3mOFYQBIBJopgNAQNOp7PXHSSTyWKxyDBMvd4IhUIYYsNtM5PJIAgCNjQURYEmgGFYo9E4OTlZXFz0+Xynp6fpdOrly5e8y8nzPEUyPp9vOBKGwyHHcbIsUwSJIIjP5x+PxziCFotFlMBIkqxUKn6//86dO8+ePYPJE6wpKpUqCN4FQWg0GmtrayiKgNKxUCjAXHM8HgcCASAX3Lp1i2XZL774wu/3l8vlSCSiqhrA2GBMAhNKqD/y+TxFUVNTU5VKBTBsBEEwDPfy5cvbt2+D7andbkciof39/Uwmg+M49Ng4jkFwTb1eb7XaMHr0+/3f//4PPvrlL2GtDMOLWCy2t7en6BoEvxAE4eS581AyEFmXS5VsNjsUR+PxeHd3d25uTpIk0LG4XC7Iw4GtCwBFLcvKZDLPnj2DIgNoLOPxGDzyL15sQOMXjUYDgUAqldrf3wUDBE3TPMOC+dSyrMGw73Q6b968+dVXX/V7A7iEc7nc5vYWoMVt23Y4XCBI3dvbwwlicXFxY319Zmbm8PAQ0HSgap+fn/d4POl0+vPPP4fRoK7r3W53YmICJLY8z+/v7wMHJBIMgfJPFMVKqQztyoULF6SRWKnXMrns7sH+5cuXDcPY3NxcXV2FfszlcgEIbWFhYWNjA/C5sHPb3NxcWVk5Z1W63e7Hjx/Pzc2dS7vu3LkDiXaXLl16vbVVKBQCfv8777zz8ccfT01NASUV3C3iUICBSyqVOtMX/l//b//3jz76qFKpmKYdDoYVRXFwPE5gsXBkfn52aXFeEAYzs5PJZPzZkyc+n0dSNFVV4f4VCoVs2x7LEoxwy+UyCPRcLpdlWSzLKooyMTEBFgBQQULHAFDQ8XgMwAlRFB89ehQIBFAUFQQhm82iKDoej3udLs/zKysrhULhKH+cTCYBjSPKEoZhFMmk0+mDvZ1oONLqtGHwXm81QX4IsQyNRsMwDCfHW5ZFYHin0/EFgmDbEUVRlsfRaHR/f395eXlxcXE4HLbbzXK5DCxgHMcVRel2+zzPz8zMgMAIqH0URcE0HhxYpmlCQZ1KpUxVOzw8BOxnLJE4Pj5mWdbv9x8dHQGmQZZlkqbgbYCpZi6XEwRxMOgxDIeiNkFQo9GQZflwOMhQbCQS+tWvPo7FIrVaw7KMUMDHcRzFMgCyAgH1cDj0+f1Q9mmatru7S5LkzMyMYRgmYk9MTOztHbSanb/4y7988eLFRCoTDIa7vYGmaSZy5rCDA940dU2RzleBvzvEOv8nFF6/ndzgOGy+YL8GgBywFiK//fptTA1mE1BqAL8Ufq1pmizNoG8cgtAEmLrBOfhYPAlxlo8ePSoUCnBtQ6Y1lAWAv+p0OrCRdLg9sD0BhQT4dS3LIlDsfHxlmqZtWZDojCG/fbI2As7HsyLy/DHjb6JvEARBEQTHcNu2LRv+FbURFEEQgiRhgYUgCEUyKIqqmsrQjGHpAEMH2RaCIKD1Cfj8Xq9XEEQQBICRx+VyjUcijuOcg1cURTcsHMcRHAuHIsFguNFoWBYSDodVRYf5TSQWNU1dMzXEsmqV6t//e3/0/nvfalYrJImqytjjdSEI0ht0262ux+Pz+QI0TYuyaNsmmO3hhgWeQY/HAwsviEzZ2toCVaUv4N/Z3kun0wiCvHy5OTk5ORgM4Wqiafr44HBqcvJwb//999/rdbpf3f16aXUJSs92uw2AVpblof+DeMH9/f0rVy5NTk5+/vnnLpeLYlhQwfM8r2mKpimKouA4Pr8w+/r160FfgDKlVCr5fAHAgkOcDtwQYebvcDgeP36saVoslhBF8eDgAFhQqVRqIpXe39+H19xGrHK5DLfRaDQqCEIoFFIUpVotu1yuXC7n8XhYlm53mg7eJcuqqurxePz5sxeaprnd3ng8vrOzs7a29ujRo+XlZYLAut2u3+fVNA3i2/Onp9FolKQpEOBzHDc9OfXy5cvpyclwOFyv1kzTVBSJoijA0DSbbcMwJjJpMNYBCNvv9yuaDrZTjuMs4yxf79mzZ7FYDOijILiEzJxyufyDH/wAdK6yLA+HfQCT3r59m6KYcrlcr9cDgYCsqhDWZhiGrhuWZdVqtWg0ms6mh8NhpVSWJGl6erper0dCIRRFIXMJ/m6z2VxYWOAcjtFoxHF8uVxeW7tg2/bnn3+eyWRcbsdoNEqlUl6v1zTs4XDY7Xar1Womk0VRlCYJnuXa7TacN71ezzTNpaWle/fuYRiWTqcZhgGwLdgaZFVyOBzFStnj8UATHo7E4OXqdDqtRksQhNXV1Z2dnbnpGYfDUayUaJYJBoNHR0dQ6QYCAViVGIZRLlccDsfk5CRBEOVymSCIzMREvV7vdDqRSAQGCkdHRyCoh0TLSCRycnIC9iZRFDmOD4fDHo8HkJhPnz5VVRWCLIG9dHJyAnBLXdfT6fTLl5vgNoB74PT09K9//REwmSCXhuO4YrHg8/lABBKPxy9dujQej9fX11maBvOE3+9vNpszMzOSJBWLxfnFxUgkcvfuXRzH52Zmnj179pOf/AQStbvdbqVcNU3T7fPquv7s2TMURb1eL9Q6AIIZDoepVGpnZwdgBw6HQ5IkgES6XC6w14VCoYWFBcMwdnb3MQy7cf26qqqffvqp0+nkOAaWjyiKRkNhIFRPTk76A76//Mu/dLvd8Xg8GonZtl2v18fjsYUiELbT7XavXr1eq9WuXbv25ZdfSrLs8/lsywLcD1gHQMOOoig0UVALKooC9n/YTsA/MQyD7VYqnrBtu3By+otf/OIP/uAPCoWCg+Xi8TjDMDaGur2e5xvrgUAgFouVy2WAk1+4cIEkyZ/97Gezs7MQDRmNRiE1AfxPMBFUVRV2ZTCABz81CHxBxp1Op7/86q5lWT6P9/T0NJVKSZK0uLgoCMLDhw9dLheJ4zBgAoirqqrol19+aZrmJ5980my293YPAoGAqqq9bpem6YWFuRtXr/EOlqIIB8/qum4Yus/nsywDBEyWZbXbbYzAUdR2Ot0wG4emE6DnwFxJp9PCYNjt93ieB+HkaDQkSRrU0DDrhueQzWZZli8WTz0en2FomqLL8nhmZk7X1U6vb1lngEQTscPhcH8gaIqKWIYojDgHn06nu4O+JEmgX/P5fDzPi6KYSqXEoaCqqpN3dLtdrz8AFjzDMARB8HhcAF+A95Wm6Xq9iiAIJD21Wi2v1w9VbTqd3t7ehtELgiAAph8MBizLQmpeuVwmSbLVaKIoiiHI5PQ0iqJAKA2FQgiCgETJFzgby0FGkiCcYR5BxjEcDr1eLwQDkyQZDUcAd5bL5XK5XKlUqJQKPM/HU8nRaARTXFEUw+HwWJJEUYxGoyzLApEFQp38oaAgiIlE4uXGZrPZ+q//6X/DMjyUOoZpIwhioWflEYIgpqmbmg46JOuNAhxGdEC1gRrofAKEoiiCYaAfIggCQS2YqJ3ty94UJTiOEwRmWYhpmqqk4jgO6fSg9AJhO2qfISGg4OM4DkNQcGh7/b6nT582G+1SsYggCM0wHOcAYSyGYaIogECKpmkLRVAUB5MOTOYAcoaiKIFiv1ssnk+wFEnGcASxMdPS3yz7zhegv42NPhe5W6aJY7hlWTZiYyiGIIhlIziGG9YZFR3qb13XbRuFV8IwNNjDMgyDkwRFkE6n0+/3IwgiihKUgPDZsyzLNi3TtqAiMS2EpmnNNJwOVyKRUBTNMAwSw2FfQFGUKEuqKkOJ/7/42/+h2+WIRcLDfpflqG67RdEEzGV1w1hbu2Tb6PPnz6emctt72xiGRSIRwEfBz7x48WJ6ehKYfkDFvHLlChxFGEaAh46mWVEUwSoRiUQatRrH8qoi53KTvV63dFrs93uJiQRIG88ol5o2MzMXj8fv3btnmmY6nX79+jWGYRMTyWx28vHjx8FwqNfrORwO0zR1XXW7nYuLy5988nG/31cU5erVqwzDVCo18I4Zb2i0ILmAF83hcKBv/Ni//vWnU1NTPp8PfMTZbDYUDO/s7EAJWyoX4QwGtRyGYaIoHh4eOp08xNOKopDNZj/77LN333230WjZNsqy7EgQdV3XdXM8HoM5GibELEu7XC5hNIRMNBzHN7e2vv/973/40a/C4TDE5SbjCcMwaJIEgVGlVE4kEghiud1ey7LG4zHP851e9+LFi9VqdTgc3rp1q16vV8rVUDQii2PgjgYCgfX19dULK06Hy+V2HuwfBkOBwmnR5/diGNbv97vdbjAYBDAEkKUgrAPSYOHm1u52wW585cqVYrEEhsRWqxUOh8CkubS0dHR0VCwWDU0LhUKrq6vg3YnFYgRBPHjwIJFKWZYlimOGYRjmbB4MOgphNHC7vMvLy41G49WrV3Nzc36/HxpIhqK8bg/oWRmG6fV6sCoBw1ClUrEsC6bL4Ct0uPjT09NIPMZx3PPnzwOBQP74dHJ6ajwSTdOcn1+ALtcwjOLJqd/vf/zsidPtcrlc8/Pz/X4f7szwh2ZnZ30+v6IoX3755dWrV9vtdrvd5lkWQRBBEH784x8DriKRSBwfHxcKBRg9VqvVqakpCECr1+uhUHg8Hj99+jSRSMzPz5fLZa/XCzmkm5ubLpcLIAvAEXU4HNFoHJoluKymp6cxDOl0OrZtP3jw4M6dOyiKjsci3FXAmeF0OoPBYCqV2t/dBajEeDyG7OR8Pm9ZVqFUoijqb/yNv6Gq6t72LkmSmUymVCrBH4WGluG5Xq/XaDR+8pOffP3112DHOTg4cLvdsK2bmZmhKOrFixcXL16EDXWxWMykJjAMOzw8JEkyl8uNpHEqlXa6XIos7+3tZTIZr9f75MkjgiBisdj6+nokGJIkaWpq6sqVK3/+F38mCIIkSdlsdm52vlKpwNwkFI04HA4wHoIcBbgYqqZ1u93lpaVutwuKewzDWq2WrutAHgEvF6TWwIppdnb27t27/X7/0oW1cCz61edf6Lq+trb29ddfT2ZzCIIoimLZRqvZcbp4r9cbCoWePH0aTSTn5ubK5XK5XE6n04BiOfdgwQLBtm2Px3NwcABW1tevX8/MzIzHY9u2Z2ZmwPeWSCSA5wwiTlVV2+12NJawbXs8OhNB1ut1l8uFA/FVli3DAGg5LGE2NzfRv/6rn6XTaYIgvnnwKJ/Pb29vD4cjr9cLLglTN3784x9///s/rJaKrVaL4xlFEV1uJ4YhOI6LogBBMQSJ0RQLx3AkEsMw7OSkAJusfrdHUZQoDCq1GhzATqeTZWlRlEiSpBnO4/EEg2GIahoOhzRJoyhyfJyPxaKmaXEcOzM7lz857nZ6FH0WtMzyPIzQ2u12JBQA3wqYmUVRTCaTsPKHnSNccqAY8Pv9Fy9cun//G/AFOByOXq8LCTl7e3terxsAUa1W6+LFi4DVB+QB4DShGgBzB6CDoHXb399fWFjY3d2FDy6CIAzFsjwHaolMJmOaJlwMPM87XC5BEOA2wbKsz+MZDofHx8culysQCEiSVC4XwdIMtJKDg4NYLBaNRnVd39natgzN4/EgOAa39QcPHkAc+kgY+/1+kqagZQFTxrvvvru5uSkIYiaTKVUq9XqjUCj88pe/BAlRfyjgOM7QHBQ6sCFSDR18fKByPScymKYO4yvkPLkZrIHG78QqvxlxweUBaIOz9RlqoQhuGAZL07pqAJnQfJNmQ5KkZRkw3YRyE+656XTa43GBaevFi43hcGQYBss54vEEiqIURaE4rhuaeeZkNHTT0DVTURRgZmJnWS4oiqI0RcF2FehWoOHDEdQ0NNS2bBtFEMtG/k0Y6f/7r3/7p3931AfKLUh5sxGbZVifz8fyXLvZSCQSZ+N6BEUQRBor8MGGIhVFbQwjLNu2bVTXdafTBRxR+BQZmkYQhKJKcLnduXPb6/VevXrV7/e2W62ZmanjwwPD0La3ty9eWIM7HYZhKIo3m01V11xOt6ZpYIAXBOHK1cuj0QjHUU3TnE6+VCrBX/H7/ZZtJBKJYqHscnlgCRUKheAIv3r16vHx8cnJyerqWj5/1O32l5YWNM148OC+YRipVGpxcVFRlMPDY1ipANMEfL7g5CiXy8FAiKQIcPIC3TubzQYCvmq1LsvjQCDw4sWL999/n+f5zz77/K233oK5crFc3traymazMzMzCGqBr5uiKILAFEWxbRQ2yziOQ3byv/qzf5XJZBwOx6NHj1iGSyaTHo8H1IrBYLBWr2azWcPQJElaWlqoVqvdbt8wDIZhWq0ODBI0VQfGCiSd9fv98Xhcr9e73e7Vq1dPTk4GI2FlZaXb7ZbL5cnJSbitj0YCjuOSJEUikW63G41GB8PeWBj3u70PPvjAtpGHDx+AAXZ1dRnSS84T/WRZjScT689frKxegIBt27YzmYl/9a9+trKyFAiESqVCOBylaRKMQdAQoigK9NFf/epXDofD43Xbtr22tlYqFRRFcbvd09PT1Wq92+0O+kNBEBAEm5mZkhXRNM0LFy5sb29vb+++/fbb1UotGAw22i2YGZAkGQicVUupVOrw8PDChQvNZrPVal29eg1KcMsyed6BILZlWel0eiQOASy0tLT0/MlTIGqenJzMzMwB9Nztdmez2UePHkUiEZ/P1+t1YGUDYSYAIIDbwszMTKlUuX3nzuH+PkmSpmGZpgmX8MzMzC9+8Qu3zwuY6JmZGRCoTE5OPn/+3O/3ZzKZo6MjhmFWV1cfP37sdrv9fn84HOoPuhvrr4LBIOz14vEEhmGnp6eJRCIcDsPG8Ouvvy4UTtPpdDyeaLfbwH09oxsiCIBLgCMDlQGwgXAcj0ajCIKcnp6C9uvo6OgP/uAPhsPhgwcPbt68ee/evVgsRtP0YDDgeR7EMO12O5fLwUcU/I8TExNQY0FmSTqd/uyzz6anp5vNpiyrKIqCEMrj8QDNEm4mLMtOTeXgkAJNGHSh1WpVFMXl5eVyuRqNRhHTyufzPp9vMBgQGO5yudqdJoZhq6urd+/eTWUzyWQSYGAgw4hEIvDq3bhxo1QqPXr0aGZmBhKHd3d3MQzLZrNg8QMGuq7r0GAUCgW4RkRRhDFqoVCQJCWbzcKyxe/32rbd7/ehRc/lcuOxXK/XXU4P1GqGYZi6HggEWJqhGFoSR5lcFlTLtVrN7XZvbW29/a07I0EsFE9BlmoYhsvpBnZJLpdLJBLbe7sAlXW5XK9fb4MYrtlsunjH5ORku9f1eDxHR0fJZBLDsFKpBJeb1+sVBAESkxiGOT4+lmU5Go3CB+zg4ABYwa9evaJp+ujo6Pbt23t7e6ZpZjKZZDK5ubn57W9/W5Ik9P/x3/23Pp8PJch2u728vHycz3/xxVedXhdFcF3XKYKOxWLTU1M858hMTORyaYeH+/LL34QCgUDAZ1mWKAo4jsvKmOM4r9dbOC2RJIlhhKqeSS8JG5UkqdVu+Hy+YCQIO/her+NwOObnFwvFIsNwjx8/vn37jm3bW1tbuUy20WjAkTk9Pd1oNHTTsG0bOlS4n3IOB4IgsiyXK8WQP5BKJfb2DpxOfmXlQr1eVVVdlscej8/lcgyHI1EUKIrheVYUJafTOR5JsiybpqUocqvVxjD0e9/7HkVRT58+9XhcsO0SBGFmZqbVajEMMxwJAKSAhX2/34/FYuCIicfj4Lx98OBBJpMB90Gv14vH49VqHUEQENKGw2GYMeA4rmgaePdcLhcwbKYnJ09OTiRJSiQSKIrW6/XRaBiLxTweTz6fh+gh2CKBgYgkMK/LPVZk8MLAOYFhmKYaOI5TDA3gCSASgcwQqDAYivuCgWKx+Md//MetVktWNE3TMII0DMPQLZgb4TguqQqs4eAtgAILwzDAhELxdDYEQkwEQVAEP0Md/Otyb/RNBg7yJtMUOi0CwWHaBP8Kv4ogCNM8C9XRdR3kAhzHzc3NGLpu2+ZYUl6+fNnpDAzDoGguGo0SOEUQBIIjuq5rumpZloWYlmXpmqlbJmrZcIND3uiuLNOEKxCeqa7rpmFgiI3YNmqfadX/f1Vg/e4XjlK2ZbI0Lavy4tLy8vLixx9/DGG6qqraKEIQlGEYDM2B0R3DEdPUCZLGMAzDCE3TcJwYjUahUIimqfFI9HhdlVKRYal4PP7ee+9du3ZNUSRBEHw+L5BEouGgbduQ1sJQdL/fRxCs3W5nMplYLN7p9vv94draarVaBclLKBw8Pj4mCCyRSDQaNYqigB60tLywtLL2619+ZNv2pUuX7t+/PxwOf/CDH4zGIiQ9gD3W5/MdneRVVYWGr1VvUBQFGuoPP/wI7rDtdhtoNw6HYzAYjAQRsh8IgpAV6Vz/DsO8/f19KNEgUOubb75ZW1uzbXs4HF68eLE3GLZaLZ/Pe/utt37xi58jCALu3ULhJBQKZbOTlmV98cUX0JAgCLK6tAqrB03TbAsBvpooip1Ox+Fw9Ppdp9PJ86xpml6vm+d5QZCAlQDjZ1EUXU63JEk8z4MsA3LHYFwtSVIgHIKmS9M0r9cLXp/Dw0NFkQGpQBAEYFMYliJJUuiNSsXi6uoqy7Iul/PBgwfxeLTdbgP4BvL4qtW6ZVkejycYDD1+8kzXzWDQ7/V6EQRxuVy9Xu+cZtLttuGmDw1JpVKZm1tot5s0Tcfj8VK5uLKycnx8CPrcbreLYYTf769Wam63m+Mc1Wo5GgslErHRaKzrOknSrVaLImmfz9cd9CG3anp6+t69u2DpjUQi9XodzvLxeCyKY9C2q6r6+7//+5988kkmk1YUZSj0p6en4/Ho06dP65W6ZVm5XK7T6WiaAUsPGKt0Op1YLKZpmqrKJEm63e7RaAT2lHv37k1NTRUKhVQqdefOt0CVTFGUMBxBaAdAwjwej4nYkFAOgzEMw+ChPnr0CBqJ4XB4+/btzc3N6enp4+OjdruNE6jPG5iengbJQafTvXPnTrFYBKT+xYsXT09Pj46OPB73y5cv/f7A22+/DZFH9+/fV1X1Rz/60ebmJo7jw+FwdnZ2Y2PD6/UCNW1ychKmMicnJxBxncvl2u12NBqdmZnpdDqwu1QUJZvNQr8HWHOv19tut0FqBr/NMIxCocCyLKQJbW5uxmKxk5OTYqH61ltvAY8qGguTJFkoFN59912I9Ha7na1Wa3V11TRN2GCORqN6vQ75jM1mm6IoF+9AECQejYHlkCTJ8ehMw0dzrI0gg5GwubkJfYjL5YJNdCwW8/v9W1tb4/EYVhkrKyuCIHz99dcQ73379u3Xr1+DtAB22YZhHB0dYRi2sLCwtbUF/CaKOmNSBoPBcrlIEARsb1AU1XV9NBq7XC63yzscDuPxpCiKojAYDQVIXgGtpG5qlUoll8v5fL7esF8ul6EWJCmcYZhBu68oCkUzYJjjOE7RtVgs1uv1kskkRTGQFe3xeIT+wLbttcuXXr9+DTgCr9drWZbD4YBwPJgCPHnyBHIkwXfV6Zydp7VaLRwOQ8bzcDicmJi4cOHCq1evtra25ubmANqcyWTQP//p/9BqtTLprKyp4/HY5XGjCP7555+3Wp1+v+9yuFEUFYfC3/t7f/8HP/jBixfPVG3M8TSKojiOQoAa1Hq2bcOHnmXZXm+g6zos0Wmc0DRtZm7ONM1Go+H2OA8ODnw+H0A4ut0urEtfbmxCVKdlWeCNnJ6efv78uaqqvV7P5/O5vR6gv8B5b9s2yNy8XjeGI5pqNFt1DCVC4QBDc6Vywe3ydnttFMFNS08l00OhPxLGbre7Wq0TBLG0tGIYWqVSE4QBuP1FUWQYKp1Ov3jxolar3bhxA3DPgUBI13UIVwdhWavVmpiYsG0bUBmDwUDTNGAeDodDXTdhiwHyYUCVeL3eg4ODdDpdKpXAjA0KxFgshqL23bt3p6enURQtl8uqqk5NTYFep1wuT0xMGIYB1kVoAq5cvlivVwVBAJ/zeDw2DMu2bZKiotFovz88XyrDAL9eb3IsPzU7o6r6H//xH1er1W6vd3p6SpK0pmngViMJGsMwWZYRBNEt83yCdS7DwnHcsgzjTcCf/YaMheM4hhHQN5wPt8AMCAUWaBGguATPo6Xp8MAQBHlTusFIDDkXYMH6huO4mZkpWZIIAlM1Y3d3t1ZrmaZJ0RxgbzEMs2Dxqqu6rtu2iWCoLKlnlc05zcuykDfC9jORvm682XLaAFc9V6H9exVY/1O+UIRAEIQkcN3QY9HIhQsXtna2RVEABbFt2wRBgTZWP4sP1w3DoGjWNE0UxeF3GIaB41gsFvO43LV6ZXlx4cLayvz8vG2b58mpw+FAV1VImLlw4UIymdzZ2YHCol5vLiws8DyvqTpNs7CqLhQKKGrHYjHd0BiGqderoVAIgCZ+v3d/fx9m48JgBO01SJdcLter15uzs7PQ54XD4V6vB2afdq87Pz/PM+y9e/cAovPll1/ncjkQQ8RiMah4IIrYtu1r1651u91evwuaDFCoQIZrp9NZWVl5+fIlqFucTufz588XFhYYhtnfO7h48WKz1eh0OhiG1Ov1ZDIpimImM3FycrK8vFoqlYCGT1GMqqoIgkQikVartbCwcHhwlMlkarVaOp0+I/bRZLlcXliYI0mSZWmCIGKxVKfTgcwAmCkGA6FGo5HP5999910wTwACcTAYDAYD3uUEtst4PC4UCk6nU9NU6KlOTk7m5+dFUZyamnry5Mn8wux4PN59vXft2jWHk//Lv/xLlmXT6XQsFoH0i5cvX4bDUUVRLNOG2BzTNEEHdk7ZlWV5dnaW5/l8Pm8YhiyPgUgJBR+UeqBtSE0kf/Ob34TD4Ww2jeN4t9s9PDyMxc5YYgzDeNzeQvE0EgmhqF2rNSYnJ3Gc7Pf7lXJ1amqq1e1Afi2Koltbrw8PD+Px+MHBwfvvvw+ecUVReN4B9Io7b7/9qw8/3Nvbm5ub1XW91+8Eg8EbN66ZptlutAuFgqqqqqoqigbqyV6vB1a4bDY7Go3y+SOe5wOBgG3bvV4vFouBOQO8KYOBAOzHfD4fCobr9TpMUjVN29jYmF2YX1paev36dS6XOzk5gZw0cIERBOFyuT744IMPP/wQbke7uzuxWIzl6IX5JSADDwYDgiAnJycfPXoEIkjAzV+5cqXdbj1//hxB0O985zs0TT948KBSqcTj8WQyCeAGABOUy2XwciEIwnHc6enpycnJ3NxcqVSamJgAkVMikQDEjyiK1Wr1/fffr1QqsJ2XZTkWi4XD4YmJiY2NjXK5HI/HSZKEY0KSpG63C1GJr1+/tm07GIhallVvVOHmCUU8xDAcHBxcurQGK+NsNtvtdjOZDOQadTodgiAmJ6dHo5EsjiVJunz5crPZHI9EkiTH0ujatWuyOH69s+31+QLh0HA4FEUxEolACjWsdOEEBMQDzBFFURQEYXJyMh6PHx4eapp2eHiYy+WAgAAi+q2tLZfLBXcMXdcNwwLKo8/nIwgMCL31eh06+Xfeea/b7Y5FWRRFXTcdDodt6vl8fmoqNzU1tb6+7nK5NE2B9RSCIEfHh2tra5VaDXmT5Bb0+kql0uzcPMy5bdtmHfzLly8ZhvF4PJ1OLxAIMAxTKBQ4mrlx40a71zVNE1gkIAiDYs7n821ubkKGt6qq165d6/f7gOOH/QOw76PRKBzEwEMpFosQSQQDzlgshv7VX/5LSKTXNI13urrd7s2bN0vlqqoo39x/+OLFi3w+7+JdiqLE4/Ef/40fhUKBRCJGUdT+wV6z2WQYCsMwh4MDZCp8QAVBBASDruutRpPE8VgiYdtndpJerzc9MzkWZXEsQNYhjuO7u9uAjQGqG8vysjxutToej8uykH6/H45Eut1uMpnsdDqGYUHHTNPk/sGuruupVAoMGgsLC5C9I4piuVz2eDyBQOD4+Hh+fr5SqYxGIxTBY7FYq9URhEEsljBNfTyWQXYDivVisQhZQlBz2DbqcDj6/f7s7OzLly9Ho1Eul0ulUuA2h5fYMAwAVRMEYdsoTdOQJgGfbEhUgGrDMIxEIgH0+X6/Xy4X4TwzTbter0Oo4v7+PiROgE48EomgKDoYDKD4wFA7EgmJovjy5Uun0zk9PU0QlKIoumHQNF2rNYDg0ul0qtXq4uKyoZvjsVxt1L/++uuHDx5HoiHLRoH3I8uyaVs0TTM0pygK/EXDtvA3uHbkDc+dIAhdV6HYglsVFEMkSf4Ov/OswALxk/2G/w4FFnzTMAzUtMCqdq4Osc8ScnD4i+gbhBWGYeFwkGUYHEcVVT89PS0UKgiCMCzv9fpcLpdt21A06YamaZpp6iiKjkTpXEB2Jmb/He7oWcllvIEyIBaKILZt/v+pukIQBEMpkiR1TcFJwjYNX8BPUQRYXNE3oblAhUUQjKZpnucxDKNottfrjUZj27ZN0yIIHEEQFLWvXrnyn/wnf5+hSZom8/n8zs7O9773ve3trXg83h90NVl56623UBStVConJyeTk5OhUGhvb29ubmF3dxcywhYXlpxOZ6PRcrkc9+7dCwaDCGpHIpHRaAi1WqPRmJmZGg6HkHxyuH905coV8DRBtt36y407d+6AX/X169fZbBawNOVaNRQKKWMJRlmVSoUkabBBVSoV27YnJyeBkC6OxpcvXy4UCs+fP19cWvB4PGDDhuwEVVVB+gPSh0ajAXEFQPcdDgRd11mOgXirw8P927dv67peKhV6vd7U1Eyj0QDsHMNwgiDAHSMUCkmSZBoW5B0BHUaW5cmpnKZpxeKp2+1mWXo8HguCdHp6OjU15Xa7QW51eHAEEb8g0IY2KZPJwIJvrMjnOAYwpvn9PqCuG4YBUY/Azm626gcHB4lowuVygejk2rVruq4/ffpY07RWq7W4uNhqdZLJ5HAgZDIZ2EqQJA208V6vB2RRiqImJiYODw9t215aWoA4wkQiAQwhoFs5nDyIBCzLarebBEEA9AvDCJAZ6bo+HAg3bl7f29sRReHmzdt37951u73ZbHZvd59lWc00ZmZmXr16lUwmOY4VRTGbzR4dHUHAyBvyggTlr23bJycno9GIZZl4PJ6aSDx9+pQkcafTqckahAtls1kUxWOxmCiKH374IeiWYrHYwsLC0dEBQFX29/ehKKFpGsaoKIo6HC6AznMcpyqaZVmJROLBgwc+ny+dTifTE1tbW91uFwYhNE2LogizH7fbDZIDIIBrmpbLZROJRP7kaH5u0TTN58+fa5rGshy0OmBEtSwL5jrFYuHRo0fLyytQZS4vL6+vr8N4cnZ29urVq59++mm73X7//fcVRanX681mc3p6+tGjR4BpsG271Wp961vfGgwGz58/J0ny+vXrjUYjGo0CyQgkK+CyH4/HUEGCS73dbsOHCgynZ1rnM5KLvv7iZSQagpxKGKOCacMwjHq9ShDE1NRUt9v1eDybm5uGYUxMTACYI53OvnjxIjuRhvcrEAhYhsmybCDooyjK63LnC6djSdItE6DHCwsLJycnoDCGihbocZZlNZtNlmW73S6E/IRCIfhABgIBwEA8f/4c0Bjg6JckCfJItrZ2AGUyOTnZaNRA5ASeg4mJiVevXo9GoztvfUuSpCdPnk1N5RDLisfjtm0+f/4cqG+mqafT6V6v12q1eAc3GAwuXblSLpc7nQ5q27lMVtf1aCz+9OnTtbU1l8v1emcbzlBd1yuVmt/vv3jx4sOHD6WRqCiKw+3y+XyAQQFBodvtBu8/CIc8Hg+4GsG1k8vlXr58SRDE3t4eQILAqgn/A8ACIKf2+Xwejwf95c/+5dTUlKKp7Xb75KSQSqXa7TbvdEkjcXZ2XlGUjY2N4+OTdrt97+u7/8F/8D97//33r9+4aprmL3/5y6WlJQxD+/0+RREA2kIxu9vtCqPRwsIClOGyJFEUxXGc0+HGcbzRaDEMQ9Nkvz8Mh4ONWsUwjFu3bmy+fgWmHpB64CR1fHw0MZGWZQlB0EajASPiXq+nqmo4EsMwDLoonEAB+4kgyGg0AtcAvKD9fh/yEEzTnJubgwMGPr4jYWzZhqFbqYkEy/D7B7sQRttudYESBpowTdN43gmhNBzHgcRVFEUgoTUaDfC/TE9PwwVjGEa3P7Qse3JyMpfL5Q+PCIKwEQvKkdFoZGgqQRAA3wLtIcvRFy6sPH78tFargR6l0WgwDMOxDujDIPIilUp1Or16vYrhiMPBQWhPu9ODrBhZlkVRajQa47GsKIrL45mcnOR5vtFofvXV3c1XWwDCsFGMJHEY1OuGAd5j0KSPx2NJVUCpd74ihErFts1zUOf51g+eEUEQsqz+myXFm69z7TzyBnnwbxRY8ADe/MzZGOm84EBRlGXpcDhs2YY4kprN5uHhCYZhNMM5HA6Hw2lZlm1bCILolqlpmq6rlmWpqn42eDNNxLIQFMVQDJ7ReYGFvNGt27aJ2Gd0hn+PAut8Dfg//l+c7woJnDFtC0NQw9QwDIHdCs+zvIMF3SW8xSiKogiOYZjH43M6nRTNNpvNXm+AIAhctBzH1WqVleXlP/3TP9ne2lQUCcOwXC47lcvt7Gw9fPgQKrO1tVVFUQ4PDzOZDEEQkqQoiqIZFnzkaJqWRLHX66WSE6eFk+XlZXCbg3akUqlkMhNAcwVrod/vtwzT6/VCtoau68lkUhBHEGsPG0mXy7W4uLi/v69pGogYPvjgA+DcaJoB4KtoNOr1eiGknOd5hmYHg0Gj0VhaWjo5zZ9P3ScnJxmGyefzMPZ3uVwgIINLD6JOfV4/IJrE8QgCKH0+DxxFYBMD+aqiKLFYAvZZ8XicZdnhcDjoD4GxAgalTCZTq1dhkocgCMNQTqdTVc3FxcVutzsej4+Pj+PxuM/rh6K/Wq3CeguasUwmc/fu3T/56Z/+8Ic/XF1djcViu7s7U1NT+Xy+2+2C5gNyjtvtNs/zqxeWy+Vyp9nx+XwOh+PVqw2AYm9vb4Mh//Xr1wiCFYvFZCL1gx/8oNFogYT0n/7TfzozM8Pz/A9/+MPBYHBychIMBjmO6ff7Pp9PEIRut3vnzp3j4+NkMtntdcbjsdvtPjg4mJ2dbjabcLwlEolerydJUi6Xq9UacNUHg8F6verxuBAEU1U1Fkt88803kXDU4XDUW02QaSuKMjs7A+0ry7I8z3e7XWCsVKu1wWBgmiZN07du3eI4rtVqqqo6FPrpdBrDkHK5XK3WeZ6/cOHC3bt33S7v1atXBUF48eJFIpHo9/sXL15UFOXV5kYymQQS1bDXB8snLPuGw2G32wfIOM/zpWJ5YmJC07T9/f1EIuFyuUbSGChooK8IhUL37t27ffs2TENBKkRR1Pr6+vLyMkWRJycnE+nk7s6+1+vFMNztdsOte3p6VpIkmiZLpZKmaeVy+eLFi7lc7r/8L//L5eVl0DLW6/Xbt29DZDKwHur1Osuyy8vLoEWLRqPxeLzX68GHVpKk89BxgA2B+QP8ZVAwoSgKalpBEID6puu62+1+9eoVXMIIgszPz4M9kCTJbrd/69atvb09BEGgZHn9+rXT6SRJnCCIUql0+/bt8Xh87969XC5XLBaB/nXhwgWQsSYSiYurFzY2NoCAIAyG7XZbGA1ANWWaJk4QsqbC7evu3buTk5NQQEDIz+npKUwfALLgcrl4ngdPTCaTOTk56Xa7oVBI07SpqalarXZOQhFFEZSRsqw6nU4QDgJSGAoskIqvr7/MZrMc6wAvM8SMVqolp9O5tLTkYLmvv/46GPRPTEwAdxrFEKA+Qaj27u6urmo+n6/T7cGehGGYkTSG0bsgCBcuXBQEAVwvXpd7OByqho4gCEmSpVLpxo0bgiBAusyrV69u3bplWVY2my2VSs+fP3e73VeuXIEbGkmSqVTq8ePHsixfuHDB4/E8f/58bm4OVrFQ7ieTyXq9jr56/rDTbeVPCul0emJiYn19XRAEkqRXV1dtC9nY2EgkEjzvtG3zz3765xBuD44V09KBL+xwOCRpXCgULMtwu91en7vb61lvslPE0RAWSc1Gm+edEAMO5liCICgCYxjK4eCqtYrb7Zyfny+Xq81mk6TpUCgUDoehZup2u6I4hlTFYrFIUKTD4cBQAl6aaq0MJiNAq4F4HEEQHMd1XQc1usvlun//PpSiAIyAUgkopmCEPskXJicnJUlqNBoQR4WiOOzaHQ4HwzCwMEYQBFYPQEMGdRT4fVwuT3ZySpIk6BjajSbYl0zLgBJtIpmo1WqQzBqLxcSx0Gq1VleXYW2KYYQgCJFIxDCMaCT+8uVLBEGAhwYWfYZh3B4eHLDpdBonCL8/CMlc9XrT4/F4vV6W4cq1arfbbbfbf/VXv+h2hkAHQBBEUmTbtuECkBUFRkewuEFR1LAtmHye7/UQBDFN07IMHMdBNn5ePZxL2m37LJEQebOXPP8B8NbCHA56RMuyEMOETSv6BsoAUzHT1M/JDhRFQbNCUVQ4HNR0ZSSMRVHa3t5FEAQnKJZlWZZDEARmVZppGIahaYppmudQUMuy4MHhyL9GSf3d/22ZJora57Xdv0eB9W/9OPo7mPvfeX0wG8Es08QJwjQMBLFYnpHHEkUROI5zPMQeMhDQAV5ajzvgdDotGx0Oh+dIdNM0MQzBMEwaj/7RP/pP1y6sBIOB58+f0ww5Mzn1i1/8Avr+o6ODSCRy7dq1zz///J133rl7924oFNF1nXO4IMeUYRjLMMC/NjMzUygUYM0HN6nT01OHg8MwDEoi2Pz6vT6oKoAkpKoq73RAui2IsvP5fCwW4ziu2Wye39QQBNnf36dp1uv1gtG63+9D2Hm73V5ZXj04OAiHw4ZhnJzmYeMDwQbgbkskEuPxuFargeEUXGPNZjOdTjM0e3p6Cjs4lmNcLlcyGQeXUKPRGAwGS0tLsNxnGK7f78/MzMzPz//6178WRTGbyQUCge3tbbibu1wuw9RN0/T5POvr69PTky6Xq1SqTU1NqapaKpVs285kMp12FzTL59BC4IMIglAqlY5O8tvb23Nzc3/0R390eHhAEAREEL5+/RrmCjCzNwwjk50ol8u2YYdCoZcv123bXl1d/eabb5LJZCaTOTg4EAQhlUqHw+FqpebxeNrtLtSgxWJxd3dXFMWJiYlkMgmnS61W0TTtzp0757skeJ27vQ7Ev6bTadPUgQY3MzNzcHAAqhFVVZ1O9/b29k9+8pNarUJRhCzLxWIZ6FmWZXXaXcuyKJYJBAKVSiWZTJqmUS6XQ6HQ9vZ2MpnMZrOgiwiHI0dHR+D56nQ6f/Nv/s2trdcURYljAUGQaDRcrVY9Hh+CIOvr6/F4HLEx6IRB7XDnzp0HDx7U6/V4IloqlTwez+rq6tH+wd7eHlhBYSJYLJYDgYAsy5OTkx9/9GtYAiQSCVDJuLyeo6OjmzdvnpycNBqNUCiE43i73XY4HAC1v3r1KtzPh8OhbVtOp9Mf8Epjpdls2jYCncC1a9fK5WooFDo9zYfD4VAoVKlUwBEfCAQwDBsOh4DeYBjmnXfe2dvbGw6HPp+v0WjMzc198cUXU1NTDofj/v37KysrpVIJQZClpaVarQbEATB2HB4eQsEEw9FkMikIwsbGxpUrV4bDYaPRiEQi8DS73e65kCYSiXz66adAhLdtG4DDcGvFMGxvb29tbW1ra+vChRW3210sFoGCBE5buEKLxWKxWJyampqYyFAURWL448ePCYKYnp5+/WqTZVndUKGf6Q8Giq5ZlhWJREBvlEgkIArG4XCAf4Vl2YcPH16/fh0OMsuyQFGazWZVVd3c3IRI6atXr3a73RcvXsAjhzxfiqIajRY0QgiCRCKhYrG4tLTEsuyrV68oikokUuVyOeAPgdzI4XAcHu3D+3jt2jVD1fb392dnp8Gnuby8/Hprc39/3+PxwKoOQRBJHK+urv7LP/vzdDo9GAzW1tZIhr5///7Vq1fL5fJwOIKZAsMwFE7gOO4LBnRdr1argiAEg8FkMqnr+ubmJvYmhhge2/Ly8pm1y7Zhc42iaK1WS6VS4NYHpfz+/v7k5GQsFiuVSqDARp8+/EKWx8PhaHZ2VtO0ra0tQRBCwUgmk2EYDkK8cZw4PT0hSWp9ff3J42fJZPL3f//3QXLEcvRgMPB43AzDOJ08bL4GQp/jOEk+w7tTFNXrDgzDEoVxOp1JJpPlcjkZi7daTYLEWq0GQWBT09n5xflSofDVvfuIjcGSyOfzgzAWQRAUxUmShIEqLNdZhu90W/sHB5qmQUQg3Ogh6BSsZxDzDltS2LvFE1GO49qtrizLw+EwGo0SBNHpdFKpFHjmYVpmWZbX69W0M319rVazbRvyW6DcrlQqsAkGpBZ4dEmSpBiW452KLAPgqlA48brcCII4eI4gCMPQWq1WZmKi2+3W63WeZ6/dvEEQ2Pb2tqIovd7g5ORkZmYmFArlslOPHj1yuTxQjRmG4XZ7HA6+1qgCuJZl2UQiwTCcommmaVIUXa/XX716pWlGPp9//fo1SVEUxWAoBQM5IElyHMc5+MFgwDAUiK4sy7IxFC7L8yUgaKpgygNSdGi5zpVVUBgZhkGeybGxc4UT1Bbw/0KpZBgGzN5RFMUsW9d1YPhCLQLfRxALvgMqLrC50jTNsrSmaYqi4Tj+6tVrwzBQBCdJkqQp6MKBTQaP3DJN9HeqvTP0uvXbUdl5XQg/byM2gtpQbf1PK62sf8c3z1AO+O8WW7CRRBHcQhBD13GCIElCkWUUQzwej6JKlmUxDMWzHITbW5blcHKqqvq8IY7jRqIEom8URRVFgzLXMAwCR2OxyD/5P/3nojg6ODigGdJQNZeTB+YCzJAs2z48PARM32Akwu04kUikkulKpdJpNZaWlmCo/Fd/9VfRaDSXy41GI9M0nU4nw3CNRgNu0NgZIM2CfQFERGcyma+++srv96dSKUA3LS4ujkaj8XgMoFeIwIJrVlG0YrEINcHLly+BABkKhQ72DyF4yufznZzmTdOcmJioVCpA22o0GrDUSKVS9Xr9xo0bW1tbKIoKgnB8fBzwB0VRBGYPRZNutxvH0aOjIwRBwuFwMBgcj8d7eweQOWiaJs/zqqomk8lUKvX82QtAgcAcMRqNtjstFEUBvuVwcN1uVxQVUIjrus7zPIi+WZYtFApXr1796KOPfvjDH25tbXm9XqfT+eTJk/e/822HwwHfgdt0qVSC0N9gMNjv9z0eD2y4QINy5/bN7e1tgHdDIiREoxSLZYIgJlLpfr/fbnedTueLFxvvvvvuzs5WJBKBDf7S0tLe3t6lS2uQowIEB5gfwLVTr9cz2bTL5YBpOsQIdjqd5eVljuNgMzUej0Oh0ObmJtSRDgeHoujBwdFoNLp1661AIPDxR7/2+XwOtwvqlX6/73I5b926tbOzMxwOQ6HQ7u4uKGiPjo6z2SwoiME3cOXK5UqlgmJ2rVaLx6OLi4t7ewewqVxYWHj29IXP57tw4cKHH344PT3t9/vBNxeLR4bDIZxYOIICkNPj8UDyXSaTa7Vao9FobW1tJIgffvjh3/pbf4tl2Xa73Wg0xoq8srJimubp6SkEsb/zzjtffvklCKQMwwBwz61bt379618jiO10Oj1eV78HsfF2MBis15uBQMDhcEBqSDgc/uijDz0ej23bLpcL/GXAhXa73cDtBFQ6DKIWFxcty4KMgW+++QZWE61Wq9VqwSgxHA5TFAUrv0KhAFEEtVoNw7BAIHBychIKhWKxmG3bsCKHPD640w4Gg0wmAxIr4Izbtl2v1yFuMhQKxePxbrf78ccff+c738Ew7Pj42DTNSCQCIirwvcZisXw+D5Q4cMTruj4WRh6P5/r16wcHB+Vy0e/3wzR0c3sLwtSBZqJpWrVabbVaoIiHOhIG6qZp+v1+mBQCBXMwGDAMUywWQTPzox/96LPPPoOSN5FIuN3uX/ziF8vLq4Zh4DheqVSgs4IDGkXRaDTKcdyjR49mZ2eB+wMStGvXrh0dHUH/xvP82spytVrtdruyLHMsi+O42+0CzBOO48AB0HTDsqxer5fNZu2zJRsFQUDQKui6vru1ff369cxkLpVK/dmf/RnIx3VdX1xcXF5e/vzzz+EtBm3o0dERSNCA8wJHsMPhuHPnzuvXr4+Pj2E9Df0qNHvFYpGmafR/+O//G/Cv5XK53d19SKW4ePEiSdDFYvH0tMjz/LmoeXJycmN982c/+yunk//Od74Ti8UYhtE0rdtroyiq6xrHcePxCMFQt9tZKpVcbkc4HO52+hMTmdnZ+cP9w42NjXgsqapq0OdHUMuyTE2XlpYWOI+r26j86le/4hwemmbg2WIYIUlSMpkcjUbFYnEilYHbInxKYNI4HAnn2x9Y3sOnGdQecEg3m82Tk5NIJBIKBQBoNhwOPR4fZBdsb29jGNbrDVRVnZ2dhX3E6enpoD/0er02YgGDGN4Y8LDAPbpcLgPCGPySlmVphul0eTiO673JBxUEQVfUiYkkz3H5/DFJkjzPDno9URQNw5iZm5tfmC0UTjY2NlwuD0VRsP6Ix5KyLO/u7vv9/oWFhUKhQFE0giAfffzx9MxUJpPRNQMmcLKmDgZCtVptNtpHR0etVoskSUlSaJomaUqSJBQhYDpimga0ETDHQlEb4pZompY1VVEUOJ7t32Gd4/hZLQL1yjnzHZaDpmmqqoqi+O9Ms852fDAhtywL0mxAD2iaJk2QsiQpikJRFDQc8PtxHD93KcI7iOM4wBoURTJN07ZRl8v18uWmpmmWhRA4gWDoOQxW0xTEtn/LrfrtF4bhOMQnnynY3tSCsL5EUdRCbMQ2kf+vvzCUsBETsTEUs1EEPyuwUEw3LBRFTetsmKeqAMihSJLECZQmKYLAKIrBMAQ42uOx7HK5JFmFhCWQBtu2TdOkbqiojcjK6Ob1G9/97ndYjo5EIieHBzMzM/1+v1qtrqyscBz3/MWLQCAQDoebzaaiGx988MGXX365v78/N7vg9bkb1RpAHQGdEA6HC4UCHB7JZJLnna9fv75y5QpgmcLhsKYpsA1JJpPAbYKPmdPpdDgcmUwGSDawKoJVoCzLc3NzmcnJP//pn2UymYsXLxYKBTCoAzO2WCjhOO71end3d8OR0NLSEjT3mUxGEAS4Qt1ud61WG41GPM9DSiB8RJuN1urq6q1btx48eKBqCoqiweDZXR7QYiiKDgaC2+0GBDzMnmHD6PX4ksnk48ePfT4fuFUs2wyHw8Xiab/fv3jxwvT0tCzrxWJREARQ9fr9fpKgAPogy/LJyYnL5drc3FQU5ebNm8PhsN5qANfx2bNniUQim82CftnlcoH7BzQokFwuimKn1UAQxOfzra6uHh4egttramrq9LTocDhIgrIsKxSK9Pv9eDxJ0/Q339z74IMPvvnmm2AwOD8//+jRo1qtAiqWV69eAZRoYmICMnZYjnE6+cFgAHf/QqEA89GdnZ2ZmRmWZQmCAHUI5Huoqrq4OH9wcOD3B/f395eXVymK2t3Zi8Vi3UEfVD7r6+sulxP0JV6v1+v1fv311/D7IXgnk8lomhaPx30+nyAMX79+nZpIBAKBzc2XLMumUulCoQDxqYqswewBdCCXL18ej8ckSX762a8RBAkGg+Fw2MU7aJre3d2FO/94PJYkBT4t+/v7k7kpYDjDTTsajb7e2eZ5PpPJnJ6ezs3NAVDjm2++abVakBMHCP7FxcVarUZR1NLS4q8/+YjAqVQqVa3W3nvvvXq9ef/+/UAgMD09DZGmwaAfyE+gSykWi+Fw+N69ewiCQITa1tYWCA0lSapUKjdu3IjH43/yJ3/icrlCoRAsiIGLcffuXcgQ3N7ehvVILBb7+c9/vra2hqIoLM6gzgb3OljCoZqB1Xyj0Xj77bdrtVo+n4dbMQCfQJjbbDaz2Ww6nYZgKCjW9/f3p6amoH/u9XqhUAgUw4lEKh6Pg2bLUDWfzydJ0tzc3LNnT5rNJrDEhuJofX39e9/7Xj6fB8Q5RVHQt+zs7IDxAvQ/jx8/Xl5eHo/Hfr//+PgYZqVerxeMuolEYn9/HyBYFEUBMDKbzRaLZbfb7XQ6YWYxMTERiUQePXrE8zxocKPR6NHREbxQw+Ewl8sVCoVer3fp0qWTkxPDMFDLTCaTbrf7+fPnTodDlmWe55xOJyA2UBSNx+MvX23C6eByuZqddi6Xg5igtbVLU1NTT58+LRQK4UCw2Wx2+r1YLBaPx3O5HJghQPL4/PnzdDrd7XYFQbh9+/aLFy9ggEeS5MbGBpDeut0uBM8ANApA4jD0FQShXC5ns1n07he/HI1GQn+QSqWgCZYk5fDwMJVKnZ6ehkIRl8vVaDSy2ayNosPhiOdcBwcHhUJhb29vdnZ+amoKArBW1y7s7+92u12ny0EQmGnqwPAAV6qmGSRJswyHYUSr0YZAb4LAMNx2uRyqPBZGfcPQgsHgwtLq3t4BGCwJnKpWqzCsIwii2WyDZXQ4HOq6/tZbbz158sRGEdDbZjIZcLcCt5DneYgFBeQ6LIxhstrvd10ul66b4FarVCqFQoEkKL/fD7UmQRDdbpdledM0JVVCEATGlZFIBEEQ0JYNBoNYLAY7dRgOAV7M5faenBSuXLmiqqoqK/1Bdzgc2rY5PzPb7/dJgjBNY2dnB+QXuq7u7m1jOM4wDMNwyWSy3W6PRiNZVm3bHvSH54KP4XAEgYmSJImy1Gq1NE3b3ztst9s4jqu6pmkGRVHSWAG/Hqg3MAyXFBmeJhhQXS7XeCxKkoQSuKZpOI6CMQq6TAzDDEODARXUTPAfguUHNJUIggDkHH5GkxXw2MPNAl5hmqYhBwNY6qDQBIVBu9VqtVqwSAKAGfw509ShhoMAHCjmYBKpqirDMC6Xq1gsn56eQm93Ft1zvpf8d42gzio/G3tT7pwVgpZ1xkpFENsG4gRyls2MmCaCokAItUwTOf/NGAbpN4hpoW/wWrZtn4noMcy2bIokNV0ncNy2f7stxXASlLYg/1c1GbFthmUUWXa6HDRNO5ycZSIUTcDQiMQJDMM8Pu9gMBiLMkmSBEHZtm1ZhiSLiVhcGPV6ne7f/Js/+Y/+6A9PTk5w2+J5FjxlgUAomUw+efp0cXFR181ms6kaOoT+wvtIEASBYq1Ww+XyQNNcrVbhYww+ozcyNQSOt0Ag8NVXX3AcF4lEYIrDcdyVK1dev34NfTyoO2HeoKoqhETBbDsUCsViic3NTVCw1uv1CxcuPHnypNVqvfvOe6Zpgk42EAjgON5oNGRZjsfjIKfd3t72eDz7+/uzs7MkSW5tbfn9/hcvXrz33nswz6jXq/F4HEHt4XAI/lNRFGFrybKsomgg0AZUKcRcOBwODMW3tracTue77757cnJSrVYDQX+3252enszn87I8np+fPz0tRyIR6Fw7nQ7HcbVqPZ1Ony9lgB82Go0uXrxYqVT8oQDDUpCnC0m9p6enmqbFognw5Hs8HoZhgL0uCEK9WoaVh6qqa2trcCuzLEsQRNu2GZr1eDyj0djpdCqK1mq1nE6e4zgQuJAkoBm6ExMTxWIRrHYLCwuhcLDZbAKhp9msl8tlaIGgYwHtHbQiLpcL5geQyXPp0qUHD+5zHMfzTpqmu92+bdu9bt/v9wfCoWw2+/DhQ6/Xy/Ncp9MBdxtE9cFO1ufzgxw7kUiA1qJarZimCSsngsB0XQ8Gw7VabWJiolAo2BaqaZrb7X777bchIQemIDu7WxMTE0A+e++9954/f55IJGZnZz/77DPTNMeiDGnEW1tblUo1EAjkcrnNzc1gMCjL8sLCgtPp3NzcBK29IAhzc3MgR0smk//iX/yLDz74ACJcIfTC7/dBEmIgEJBlZTweR6PxRqMB3cLBwYHH48EwBEGQiYkJVVU7nU673YbDG7LIYFx36dKlFy9eLC0t/fKXv4QBGIShKZq6vr6+trZGUdRoNGo2m6FQaGdnh+d5kGcJgoCi6PT0NEEQ+/v7HMNCRXJ6eur3+7PZLEQUw2hgb2/v0qWzMESO4959993PPvsMNozFYhFiSCDeANrUXC5H0zSMr9LpdKvVKhaLPM/DiZZIpDKZDOQPer1eURRNTV9cXKQoYmVl5ZtvvtnY2Hj/Ox8Ak0zTtMXFxe3tbQiERhDEMAwYmkKYbCQS+eqrr/z+oMfj6ff7o9EISF0oigJaSJKkYDAIo9zxeLy6uhoKhX7+85/D89V1fTwe0zQN42pAMYOUnuf5iYmJe/e+xjAsGo0DIo6m6VKpIAiCpRugDMMwbG529tNPPwW+yeLioiRJm5uvVldXdcOs1+s4jmez2ZNiYXp6ulgsxuNxy0IGgwE8i+9++4PHjx+3e10Mw3Z3d6GOBKkixNLDthemxXfu3AFOPbCjQcoJZD6AtsMhCOqrYrGIouh77713fHyMPrr/CUEQw14fqoR6vQ5LH2ignU433AsoimI4TtMMHCemp2aLxeLPf/7zbrcPCOBsNrtyYdXp5EmSnJrK1erVVqsB1LhQKASb15EgkiTd7XZpkrl69appmvl8PhT2BQL+08KRLI8joaCi6a9ebkciMb/fr6oqx/HBYLDb7fZ6vfPVlSAIDt7l83uEoTgYDDRDh5kHwNljsRgMKm/evLm+vp5OpyExClS6BHE2wACrMIhRLAsBDoJt26IoORycKEqQKREIBGiOPj3N1+vNcDjocnlkeUySNIBSgbnF82wwGB4MejTNYhiGE1Q4HIZG3NB0DMPi8Xi70/S63D6fB0VR+iyXlKNpBsXRQMB3enrKcdzi4vKLFy9M03S73YqsgsMOQbDRaARtX6/X6w0EFEX7/SFML4GIWK7UHA7HcDjEcUKSJDjIoSSyUURTDaArweKZIAjD0G3bHiuyaZo4jmIYBhoXKEosy4BCBJYasFqFn3lTlCCAc4SRDI6gcLZBYQQP2+Fw2LYNST7JZNLv97daLbB29rpdTdPApwNCPVgmoqgNZH+4kuHjDioHwzAAN2IY1sbGBuzvz2gU8KD/RxZ8v1tgQY30Zj9ovdkPQtQNCj8KhRr6Bo4KPw+n1FnBZNokSeqahqIETqC2hZqmhiAIThAszYhjkSIpTddw7IxJQZKkqmu2ZWEYCfWobdsoZhuGYZkGgiAYjofDQXicFEVRNEFgOIqiBEViGMbQnGEYmgbJ2RaCILIkWpZhmTrHsX/37/5dj9cliyOKxHVdn5iYMAwrm82+2twcDAaiKLEsu3pxjabpfD4fiURAcUViqCzLa2uXhsMhtDEwlQHUFgyG4/FkqVQKBoOCIAjCADZ3ELgGN/T5+XnYExmGcevWrW63C9uZYrEIjvqXL1+22+1Ll67IsgwQE5fLVS6XEQS5ceNG4bQIV9yFCxfu3bsH08p6vY6iKFx3sEMBXuLExMTi4iIYwkHmOB6PJyaSDodjMOzLspxOp3q9HhwD4F7kOAfDMJAgBhZpFEVDodCTx08hriebzXIcd3R0JMnjtbU1hqEajQaGAfUNhbAvnuc5jhuPx4P+EJqWXq8HAH348KdSqcOjg+FoxLDU1NSU9SZNVRAEh8OBY6RpmiCpPD09BQp8OBzGEAtkoHD5wMNmWdaykFAoxLG8KIrVal2WZctCfD6PKIo4jkOwGJC6/H7/48ePLcv6yU9+QlHUkydP+oPe1NRUs9l8++23Dw72IJgPYHK2bUOyNYqigLKMx+Oqqna7XZ/P9+1vf7vTaVWrVUlSDMPgeWelUmEZzu/3t7odiB9pNpsYhoKYF2Z78LFxu92FQnF6ehooXLZt+/3+vb3diYmJcCT46aefxmKRS5cuPX789JxxRRK0KIoQWQvzibM8jGEvn88vLi6CoBis/g8fPgQ9xtLiCsA/LcsKBkPD4fA8vpNl2VKpBJ0bx3GFQgFFUWiD/X5/MBj82c9+BqxaKF8ODg4SiTiCIK1Wa3Jy8tGjx1NTU16vv9frwTYtk8k8ffr08uWLgCmBUtXr9YbDYcuyDg4OMpmMYRiQfOx0OicnJx88eMAwzO3bt2VZbjQavUGfpmlYB8PDfuuttwaDwRdffAE9SblcBkI6UNYI7ExrAapciGOyLOvixYu6ru/u7kIgW7PZhPb1/OaJYZgsywcHB5OTk/AJB4wWXClgm4C/QhAEWHEF4azddbvdDodjdnZ2e/O1ruuJRGxqagqeMk6R0KXU63VIvIZFp9frffToEXDPIY4wm82Ox2NV1YPBIJCGAoEAJBTDigAEA0dHR7Ozs81mc2JiotPpZDKZjY2N8XgMF7Wqqo1GIx6Pz8/Pv3z5kud5YP37/f69vZ1AIBAOR0EeADKJdrt96cLa0dGRZVmrq6vNRgPUY1988cXs7Gyj0ahUyqPRaPXC2sLCAmTJmIjN8/zh4WE4HB4OR06nE6K3GJIyDINk6EQiAeDQs0GSbcfj8ZOTk2KxCPmM0JbAR5dhKEiUAgvd9PT0w4cPj4+P33rrLdM0JUkCod54PGYYxul0oo/ufwIrgLm5ubEwbjabpmmCh7zX64milMlk1Dds1qdPn/p8gX5/gKIojpGCIP70pz/d2d0PBoMTExNOFz8zN7e0vGCaOooiIL52u92yrPA8b1nI0f5BuVy1TMS2bZqmeQc7Gg0Hg54/4BuPR7Zl+AOhVDLTbLY//fRTy7ICgQBwFiiKsm1bURRJHI9GI9O0p6cnu92+JEmBUDCfz0OLdnx8DAJbkAYDcgLYJLAk0nWdYphOtwWCKnAFul1eVVWHwyGGYSzLm6YuyyqkbbjdThRFEdSSJRUnUE01WI4mCZrlaJbhh0KfpliCxAZ9QdMV07ANw1A0NRSKANmP47herwM6OAxBvT53pVJRJZkgCBxHBwOBILBkMolThCAIpmnZtu1wOAiCGI/l7e1thmEwlABI/5vhsF8QRJKiaJquVCrFYhHDMEEY6bqOYChJ0PB3bds+H5kg6FmoHsiexuOxaRlg8TsfUMHUCsa/OI6e6ZksC+rsc+KGaZpg87YsC3oaiqJIjEQQxOVyaZrW6/WgxrIsC478iYkJsE+enJwMh8PhYICiNoyjoAYCZbdlWTiOwlAKbp0cx8EYHEygsIT1er3r6+tQO74Rs//boijs31lgmbaF4ziGncGxkDerTN00MQKHQupcXob+TkgiPCT0DdSeoVhN0zjOIUmirmg0TSFnpgebIEjT0MDWYBgGy7LiWCRwgmFocTz2eX3D4dC0TJfTBfoeTdMQDPX5vPBichzHMBSKWDRNyqrG87zPG1AURRQlWKeapq7IY9PUOZYtl4t37tz5L/6Lf/L08TeSJMF0IRqN5/N5kiTj8fjOzh5N09FomCRJ3TL7/T5wkhDT8ng8JEmur6/DUi8ajdq2fXJycuXKFafT2Wg0AoHA0dERyB8PDw+DwSBwcZvNZjgcBvEsGMFcDicsiaAONk1T0VTTNNvtNsMwudxUqVS6cuWKLMvQlyuKIssyhuIej4fn+UKhcHh4CHhGmCIAGhus+NlsFtqwubm5ra2tVCp1dHRUqTfG43E4HGy1WqurK5BaU61WFxbnKIqyLfT169coivb7/cuXr8iybOoaALsHgwHLcEtLS41GA0VRl8tVrVbdHtf73/nOyxfP8vk8xzEej6dcrmuahiAIFHnpdHo4EHK5XK1W8/v9MNoHYjiKotMzU6PxeCj03W43hGUZhgHXwo0bN2ia/uTXn8F3wE7vdDozmcxoNOoPum9g1n6oLBmGkSSJZXhVVePxxPr6+uTkdK1W4xl2cXH+6dOnc3NzMK4mCEIQBJBnlMpFDMOAWQ985mq1DE3deDze3d3PZDKhUAioXXNzc6DWRxArEonk83mPx+NwcJIkEQTVarUQBPN4PNJYVlU1nkoCuno4HCqKfOHChS+//JLjuEuXLqVSqfv377969SoWi0cikWKxCIOHZDLZ6bR1XZ+azsmyXK9XW63WxYuXYVBRq9V+9MMfQy5krVaDaDy43CbSySdPnoiiOD8/D7KnRCKhKMrKysrBwQGOkbquw4LS7w+AGoaiqIODg2QySdM0jNDACQQZGK9evVpYWACBJizFQOLz5MkTp9PR6XQYhgW58Ntvv72zswdavUajAcotGHIsLMyB3x7kib1eb2dnZ3FxkWVZAMQzDFOr1UDNzXEc1AG1Rt3r9cK91zRN8FGBkgmO3ps3bz579qxWq8G+laUZTdOazSbYFJLJJGxams2mKIqQ1Q07UKCb3r59C3oh2HWEQqGDg0Oe5+F2DSNkKHafPHny7W9/m2GYV69eQZSTomjVahXKte9+97s7OzvgxPf5PJ1OB1x7INkEx9/m5iZsu/x+P7ywo9Go1Wpls1n4gOXzeZKkv/Wtb33++eelUimZTPp8vsePH8MKG1hF1Wp1cXFR07RgMAgOqqOjo8FgMDs7C08Zx8hEIiGOBagmRVFcWJi7f/8+rGhhLitJUj6fZykaBuSGYayvr8PJCN6Lixcvtlqter3Oc2yz2VRULZ1Og4ysLwxjsRjo9BEEg/zBfr/fqNbm5+c3t7d2dnZ+//d/f3V19f79+6FQ6NWrVzzPRyKRarV68eLFBw8eyLL8rW99i+f5k5OTcrkIjHF4+hx3FoMI0wSQEno8nomJiS+++OK9995Dv/rNX1MU1e/3OY4LeANwdkLbRNN0Njv54MGDYDgci8VevHjB83woFCqXq6Zp0jTj4F2RWPzXH3/613/9106nk6Apy7JGo+GFtZVk8uxez/POZrPZ6w4Mw3BATWMi7XZb13XbtjEckVQJR2yMJFiaklXN4/Tlcrm93QOWo91ud6FQAIYnKKP73R6s8GGyYpqmqhnQeUPv6HQ6EQQBuxMQmcPhMCyb4GK2UAtwpnAuwg5uPB7jOKlpGgSFQrcEJR3P8whi4TiJ46goSpIkDgYCgljZ7KSuqxznQFF7MBCcTr7ZbPd6vXgyIcuy2+0GkSYYDxmGUiQ1EPDJsjwU+n5fUFbGFE453A5IfYeFpsftA7aWoigEQZAk2Wy2GYYiCAqiKGVZ7Q+G4GkXBAHWr4D2QVAcAeiUpSM2BtE0KGbrpgnFE7gNBoOBaRnIG1sfzFQMQ4OCw7ZtgsDMNxnPcJuwLAtSVwmCoCgG6lTYmFAUReFUu93WNA2U6RCbCgxowP+Uy+WTkxP0TfqboasejwfeOyitoNqGIk/XdaAgQlpfv98H4o6mafDNarVaqVQ0Tfv3LbBsFHaaGAgKYeSGYBiKYxiGIQhmmjqCYDiOoihuWQYkCZqmbZo6QVDwfRzHLcOGz48gCAxJIYgF0R+madqIydIMTVNwEUGcGcNSg8GAoWhFU50Odzwer9VqoVC42+3iOE5QpNvt1jQVdqOGoVEk7vG4REmmKIpjHYZhmKYNL7WmaTiGDAY9UzdohhQE4W/9rf/5e+/coSii1+thGOFyuSCCY3p6dn19PZlMViolWZbbvS7DMJlMpt/vm5oO83a32/3kyRO4dsbjMcdxN27c2NnZyeVylmXBR6tUKr377ruNRgNBENjoeb3eVCrVaDRKpRLDMMJgKIri9773PfhhBEFCkTCO44VCwe12G4YF6U9gnYHlgq7rpmFpmubz+a5du3bv3j24QmHrFIvFgBUyHA47nQ6GYdPT0xRFbWxsOJ3OdDota/poNEqnU5999lkgEHA6HdVqNZfLebyu4XCIY+R4PJYkKZ1O67qxvb3t93oQ5MzLvbiw9PDhQ8uygJC0v78/kU6lUqlSqZDNZkejoSRJqVS2UCjs7u6Cjz2fz8/NzkP0FoIgsiwDduvx48fT09PPXzxLppOwbIU9zuLiIsMwoii2Wi0QU0IxtLe3J4riW2+9BbMEVVU5noHNZrVaTafT4/E4lUqpit7pdGwbqVQqhmHxPK8rMhzVFEWBpQbmIrVaTdd1RZXfe++9YDD48ccfw6DC7XZSFAVLHE0zBEEAu0+tVpuenoZ1pKYpOI7D7c7tdo5GIwwjMAzjeefBwUE0EnO5XMenJ4FAYGJiotvtapoK12AwGBRFsdFogMMmGAy9fPlyeXkZhqOCIIRCQYIgTEtPpVLF4qmu6zhOQt1zdHQ0PTXb6XQURfF6vel0emtryzTNQCDQbNVdLteFCxdKpdLu7i5YvKEY/eKLL2LRhN/vB+n0jRs3VVWFRhrHcYiRhQBs0MhPT0+DARYSxmCo8/Dhw2w2GwgEXC7XcDh49eqVrhsURd28efP4+Hh7e/fb3/42giA7OzvLy8vnqWWfffbJnTt3IE5geXkZQp0VRQHX7YMHD1KpVDKZPDk5AU8Z3J2WV1devnx5cHDwD/7BP6jX6y9evGBZFvYwYCsD80GlUgH0ayIWJwgimUxCDEAul1tfX8cw7NKlS1999RXkJF67ds2yrOFwGAwGm80GqJpEUQQn0GgkQkkNVHcoEGmaXl1dLRaL1WpVlmUIAnK5PFNTUxBJB57EaDQaDofH49H29valS5c8Hg+I2y5fvmzb9vHxMYwq9vb2QCED24nxeAzbtGq12mp1QJp87949qBxgv3nt2jX460BYgOoEwEOj0ejy5cuPHj1yOp1ut3tne0+SJH/AG4lEvvOd7/ziF7/w+TwgnhsMBkDogGGNg+W2trYgNhQMENFodGNjw+VyxeNxkPZvb72+fPnyWJJfvnzpdrsvXrx4mD+WZRlEhM1mW1XV5eVlt9vdbbVPT08vXLoIzSRkHIG6GkXRTqdjGEaj0YDBLVT/+Xw+Ho/yPP/8+fPl5WWwZoMGQ1XVYrEIt6/d3d1UKhUKhVqtFvrRL//c4/HQFDUYDGYmZ/L5PMw/IBlKUZRKpWKjqKIo/mCAYZhwONhoNEzT9nh8lXI9Go0jNlapNz766COoFUzbKBaLg0EvGPTzPI/aWCAQgnsEiqJgYYAFKhzSDhdvGaaqa6qsYARu6pamaRMTGdPUIY8PRdHRaMQwFE3Tpq4DX6TT6YRCAV03J3PTiqIAORNGlyAWBpIsoFcNwwANXSqVcvu8cLcClwGCIJIkuVwuFEUVRcEwBEVRGMZyHAcMTwRBMIwQhIFhWAhioSiOYYjT6S6XixhGyPI4EAgxDGUYFkmSvX4/nkx0Oh2Px8OzHEAfWI6mSEZWxoqiWJYB8w8CI3XTcLvdsKUGu5Ou6yDG9Pl8tm0P+gJJ4baFjsdjh8MRDod7vX6z2QSTS6fXhVoHBk5w9VqWieIESRGWaWu6CsIpmEKBA/984QWUSyiY4P/FMORNUjMKvG8Y85imaVlnYcwwqIClCYZhvXYPrjq/3+92u8Focy4X67TbFE3DfEjXNAzHLVMHQc+bR2tBKW/bJtz0YVwETxaiMwBIBqUzHOTD4fDfuRP8N8oseCI2gkFxhGGYDQGKloW+AaJSDIuiqG2hNmJiKEGQGGJjhqkZusWwFI6RhqlpqmHZBknQFEUpsgwK33a7PRxhesFcAAEAAElEQVT2PR6P2+GkGbLZbJIkgaOYJIuwVJ2Zmn733W8RJJZKJWrlWrPTnp6ajcUS//Af/sNut8+wrG3bqq4zDGNZJk3TBE1ZuuZ0MAzDWAhKkiSK4KZpsiwPL5QgCIam8w623Wx5PC5FUfqD7j/5J//55FR2NBoFA2FdVSHIwjRN8MHhOF6v18vl4uzsrN/v3d3dHY3GMzMzgGmG/AdN02ZnZyGEq9frgIW2XC5fvny5VCrVmi2Px0NieKFQ+Hv/8X98/+uvK5VKNBqtVquZTIbEicFggCDI/Px8q9XK5/Msz62urqqq+pvf/IZl+fn5+VKpVK/XMQxrt9vT09PtdjsaiWUyGUmSIFjXsqy1tbUnT57AosfpdH799dc+n8/lcp2cnExPT0uSBIN6j8fT6vZyudzp6akoCpZlSZJkGPrExIQkSaPRyLIsGPILguDxeEulEmpbmqZdvXp1a2urWqlNT0+D+A/HcZZl+4Oeruuj0dDn8+XzRzdu3CBJVhCEc5MX0LOA3WwYBoDgQXjR6XRK5eJQHK6sLJVKJYfD4XC4QPIPJaOqqqD5HQ7OIGT7+/ssyzkcPLxo0GYMhf7c3Nxnn332ve99T1X04XC4vb2jqurKyoqu60Gfv1KpQKpuPB4fjUbvvvvu48ePcQID7S3QrUB1iuP43t5OIpGIxRKlUgnycziWn5ycXF9f39nZeevObchOBX/ueDzmOKbT6czNLYxGo83NLQRBpqdmWJalORbY9KIoiuLorbfeAl4ARVGrq6svX76cnJw8Ojqenp52OBxHR0eiKNq2zbKMw+Ho9Tsej8e2TafTef3KdVjfvHz58lxEGwgEIOLt4OBAluVC4YRlWQCyh2NRwzBgYw6Zj06HOxKJBAKB09PTpaVliF6ORCJwlwbtS61WI0kS3lxZlrPZ7P379/v9/vz8PI7jL168iEaj8JlHEJthGEVRWZYdjcYffvjhxYsXCYLo94YOh+PbH7z36tUrBEFgWRkIBPL5I5/P53Q6ociA2dIPf/hDr9f7q1/9amVlZWJi4quvvgJgmGEYkVgUHgzDMI1GAzyDmqaJovjjH/84EAj88R//sWma2Wy2UCjgOL6ztQ3Sq3K5DJfV5cuXU6nUq1evwBbHMEwqlYIQT5/Px7LM5uYmSC84jgMAgaqqh4dHS0tLAAItFouPHj0CTRJMW4FynkxOXLlyZWtrC9BfkiSpqhqPx4+ODkKhEJy2EBleLpdt2z48PLxz586rV6/C4XAqlYKpLUgAwbgwPz//zTcPY7EYTCUHgwEMNeBGjWHYhQsX2u32rVu3jo6OIpEIaK0ePnwIaYaDviCK4gcffLC1tQXbfAxHkslksXjKsmw6PdHr9Qbd/rmeJBAI1Ot1eIszmczXX38No+6xIhMEcfHixZOjY0PXJicnLRuBfr5Wq4WikXw+n81mWZbd3z+8cePGw4cPbdt2O5yKopSqFdCoQfdSrVYB6AAinEAgAIgAkiShkR4MejA4mJmZgZ5wNBrBKgzDMCjEIbgCx/FarYZ+9uuf12o1kiCi0SiJke12GyxIoijWarVmszk5OWnaNk3TDpezVCrRDE6SpM8bQFGy2Wi12/1Xr7ePjvKGbkqKPBwOQ6Ggz+dzODmKIXu9noNxgZYZ5FMIYgGKnuM4yGnheV7XTAzD4HCFbb3H7R6Px5ZlwPbE6/VC4BqGIF6vdzAY2LbJ8zyKohTFwGoMSiIMwyRJgrRzeC5wOMEQS9d1zTR0XadpGpIpYfYA/62mKbDXkyQJzh6v12sYCOTAA2yzXq/TNA3+Dtizwh4NFKxen88wDJKmoEiVxDGYoqGOARsUxzONegtBLZ5zwkJzNBqxLEcQOEVRYP6CwGaWZWEaRJIkwJd5nh8MhjCO0nW93e0MBgPw95IkiSA2RVGqKiu6QZI4gANgH0TTNMDx4D4I6iIocKH2hWILwxAUtWHiBcqA85+0rLOV2e/+V6qqIiYC5lgoUkFzA0xkmBHalsU7HDClt20bQ+3zqAHrTd6OaZqiKICSA2bvfr8foGWQVAAvFEgQIAsCfUPytP/dAqx/s8CCGgtBUNM0EQyDohNFcRQjzsddUDXab0Dw51M3mLYiCKJpmoPn4UMLACHbNhVJareaGI6vra0itv32229dunQpnU4pssxxTMDnLRROBgNhdeVCqVSRFO3LL7/8r/4v//Xs3ByOkbKqYBgGKe6sg/d63Q6GHEsjmuEYhkMRXFVVjnMAVF2SJGEwpChqJAij0dDtdsvKyOFg//Snf3J0mDdNUx6PU6lUNBIbDAb9QQ9cyiDZB9J9vV5PJFKQpgfvssfjgWEhuKxLpQKEiKmqurS0FI1GByNxa2tLV9RoNArpVf1+f3V1tVqthsPhbruzurq6sbEBHXyr1QqEgoDWBHI3QRDBYNDhcDQajaOjI9u2vV7vW7fvQDjGixcvgsHgxYsXX7161e12gQ88Go1WV1fr9Tr0SyBPgQKFJElRVkiSzOVyv/rVr3AcXVpaisdjf/EXf+F0On/4wx/C9iGdTj979mw0EicmJkgcA/2+w+FgaBaQYz6fr1QqRSIRp8vRbrdpmhwOh7lcRhRFRTEASFGtVkGapqn6/Pz80dFRKBSCz2Gz2Ww2m/v7+29/605mMvPTn/6LxcVFjuOi0ThAI4ENC66rmzdv3v36Psuyi4uLu7u7kiR7PB5FkcH1res6TqCCIMBSDEXwSCSSz5+AInhnZ4fCCbBLg7QFoH04jo8l8Z133gEhHdC0QdLU7badTieK4rIsT0xM7Ozs2BZy8+ZNOD55nrdsczweb29vX7iw0m63Q6FAMBh8/Xo7lUr1egOapocDIRaLFcolmqZ9Pt/9+/dpmnK73ZIkAeQTrn2Xy2WaltPpfP36tWEY4PWmKNLlcoljQdd1jmN4nm/Wmnt7e9euXUMQRNMMwPE7HA5QnUPXxHEMOCTy+fw777/X6XQATXn58uWjo6NWs+P1ehuNhs/nq9cbDMMAzXViYgLMcblcDvbaLpfr8PAwGo2ORiNItIQtEnylUqnJyclSqUhRVLVa29/fj8USlmXNzs7W63XLRILBYKNZA0vHycnJ6upqPp/HcXQ8HkOaJAyfAAoIyXrA2vjkk0+mp6fL5TJN05qhg3OTYZijo6OlpSWIdlZVFSoMoBQlEolGo7G4uPjg/jfQ0p8jWyFWnGVZj8cDcyYYwMCkQNPU5eXlWq12enqayWQARXT9+vVXrzZdLhfQ1IAy/eTJE7fb3Wg0gMxEkqSiaNFodHNzE6YJ4LH45//8n/t8nmw2e/nyZcjYtW273++DMHd+fn5+fv7p06dw1XS73ePj40AgMD8/D1GkHo9vf38fZlETExPffPNNp9O5efMmcOqBcwunA47jGxsbP/rRj3Z3d0ul0szMDIYSzWZzbm4umUweHx/ruo7hiCAIoVAgn88riswwjM/tnZubOzo62tnZgSm7ruuVSsXr9ZIkeXx87Ha7HW4XEBwePHjw9q1bzWaTZli/3w9pLv5QUBAEIFqxLN/tdgGttzS/UC6XNdPodDqAEAuFQiC7hIU+qBcoipqammo0GnAgSpIIfWC/34dJ2P7+PsQ8wBcEBJ8JsFAU/fOf/rGiKJZh5nI5URAcDgec335fMBgMHh0dHRwcpDJpVVVHY5GiiGDIK8uyLKnjsXxarDx9sr69vctxDoKkYKHmD/oVRaEoAkEQh8NhafYZCUmVz8BFpgbLKYIgLBMxLBNFMZZlcYy0bVuRx7Zta5oKECCapr0eF0VRCGJhGDYShyiKkhgOv9Pv98uyChmFcCLC6BimZdZZ1hsBbB54xVneKUkSwzCgzez3+6apwxIBigDT0vU3Ud4ETjkcHl0zIMAH+hKn06lpGhx48GZAIyUIgsvjzmYz3X4PxGeqqsLy3jRNXTfg1/r9vvFYIklC1w1Y/QiC4PMGcAI9L3RYlmVZFopLqNVKpRKGYTMzMzD839p6DbJNSAwFmyhFEQ63S5LE0WhMUQRJ0gRB0AwH9I5CoWBZFlRIJEmaZ6QrFHkjGMcwzLZNHEcR1MJQAn1DqAKWjGGcsTDOF4umYSCWhWGkZZpuj2dxcZGm6Wq1Clt8WHH2er1GowHdP6C25udmQAoG1ZV1FnRoARLivBT2eDxQiFerdRzHnU5+NBrBNT8cDrvd7u/WVb8bsPyvVVsoqKnO8F04jiMYDmUTwzAEQSEIYpi2hZ7Bt86fHcztYFELHkDA04miqKsyjuNif4AgCO9yjcejXCb99ttvTU1NxRNRSRz5/J5IJHLx4sXXrzZJHGs2KpVKKR5PHhwee71+TdWn5+b/9//Z/+Hl5utYLEaQJEFQoiwpioLjuMfjcnF0f9B1ub2maTM0p+s6w3CSdDb3NXWj0ajzHIfjqCRJJImL48Hf/tv/4Xe+812IWcUwrNfuABUwkUi0W00Mw2R5PB6PA0FfIBBAMQI2HcvLy7u7u7AL8/l8kiR2Oh2QXMD1Yprm7Oxsq9sD0nogEDjaPwiHw5evXPn0k09arZbH4/F7fV6vt1KpAHM5kUjkpiZPT0+bzabX69V1s1gsXrt27fnz58FgMJfLPX36dHJyEscIGKIAywO87k6nM5FIwHQdFhDb29sA/jk5OUmlUqBfdrg9pXIZnFwjcRiPx1EUKRaL8/Pz8EH1er21Wg1BEEVRFUleWVq8d+/epUuXut3uSBBB/NFoNCiKCgQCY0lMJpONBvy8pCiKxxPodDrf/e534cWZnZ1laBZGv/V6vVqt0jQ9OTkJbV44EsoX8svLiyzLSpJ0dHSUSqVA3QcJ0/F4fH19fW52AZxKmqbBfeD3fu/3EATZ2FhHEKTVbiQSiUwmw/P8eDwWRVGRNTgXZVmOR2KyLAPMEGic57O32dnZ+/fvw40LnB+9Xo9hKF3XCYLyeDwkQZ2enrrdXhiu8DwLjXgkGq5Wq9PTk4IgjEbDiYmJo6O8z+er15s+n69YKK2srByfnvh8vnA4XCwW/X4fHK5QIs/MzIASmSBIVVWhPkZRdDAY+Hze0Wi0f7BLURRFEQzD0MQZdWVubo4gqEAg8PTp03g8Pjk5+emnn4J0KRwOgh6ZIIijk/yVK1eOj49VVZ2ZmRmNRoO+EAgEoJ3zeLz1ep2iqE6nEwwGs9kszPbG4/H09PQ/+2f/LJfL3bx5E6ZNMGuHmzy4wwKBAM9zjUYjkUgSBBEIhCqVCnz2GJqDyeXMzEy70wSuBMdx8Xi02WxiGDY5Obm3tycIAhTKvV4vHo/fuHHjk08+AZUwqMIvXbkMj2cwGHz7298WBOHhw4fvvPPOycnJy5cvL1y4kM/nc7nc4uLiX//1XyeTyXazBUM4MKbB7vXu3bu3bt2CRDXYorbb7ampqVarpesaSeHFQjkQCMBttl6vu91ugiANw4C8KYZhYN6DYRjAIyD66egon8vlYL0A8+lSqVQsFm/dugHFQSAQAPPH0tISDGxgQgMb2zP3Bo6zLLu3twfGlNnZedh+plIpCM3Udf2LL75wOBwg9gI7YTqdhjhziB9Ip9MOh+PLL772eDwgQ7x8+fL6+nqr3fD5fKPRMJPJtFrNXq+HWkgoGAQ5F8BiFpeWHjx4AJT/dq97cnJy/fp1p9P58OHDdDptKMrs7KzH6/vwww8nJiYWFhY+/vQT2CGm0+mTkwLITiKRyGgwDAQCO/t7sNM8Pj5eWFiAoRfM0eHOj6JoJpOBZvXevXscx8DeU1GUhYWFcrm8sLCwv78PFDG48KFIQBCkXC6j/8///r8D3IhlWdFwuNPpjEYjMCZgKAHe1L3Dg9FoFE8mJEnUNCWRSLx4sSEp2sHB8cH+kWFYiqoTBEmzjG3bTqfDtm232wlDQkXSXA4nnM0EicuyLMkyrL0URXG73ThJWoZtmCbH8LIydrudgA4DdVEwGBz0u4A6xDAECuFuu00QhNfr7vf7KIrTFAsYN13XJVmErBuouuAjCJeu2+2uNRp+fxB9Q8uERRWK2qZpwhvv9jh1XQfbebfbxTHStnEMxYFDfX7FArlgOByCgRH+NEVRLM+5XE7btqFnguEECDh43oHjeKfTQRAbw3BNU1Vdp2na7/frmtnrdjEc97idFmKTOME5eAhfM00TehTAr5Mk2Wo1T05OpqamwKti23a73W61WgzDWJbB8Jyuq4Zh8TwAf02n0y2MRmAWgx0f+ISJN1JuWDLC8EbXVYoiCBIDYSlc4WcLPlU/y2RGEMswENtGcJyiqKlsLpVK+XwBw9BUVec4xuv1b2y8cLk89Xp1d3ffsgwMwQ1Tw1AiHAlev369XC5Xq1UIcpIk6QwNpylvLIq22+0GGxRFUa9fbwPBVRAGMDwDn/z/pxXh7xZYiI3hiG3jBAGSKyiwMIwwbQtDCQTHSAxHCdw2TFhPwHxL1c4+VJ1Oh6IIn89nWRZFEulkamJiIpfLURTBsmwmndI0JZfL2YhZKpWq1Qo8HSfvcjm458+evH37lo3hoih+9/s/+ube3Ugk9uTZ+v/qf/2/iUbjiqprmmZj6FkNiiJ+n0tRJZ830O52fB4/ihEMw0mSBB88AsPhuKVpWhyNSBJHUINl6T/8wz+8fPky9E/zM7MvXrwIBALJVGLQ68Pi+/T0FAjjKIpyDl7TNJZlq9Uq8G/6/T7kD4Ihw+l0AlXo6Oho9+Dw6tWrEF9fKZaazeaVK1fu379vmubU1BSB4bVabWlpaWNjY3Jyslwuozjm8XhGoxHLsqFQ5Pj4GJrLdrudSqVUVc1ms/3eAAxEDodjMBhEIhHAOMHZwzDM/v7+ysrKYDAA/yOs0ZeXl2VNPTkpCKMRRVGRSATF7KdPn4ZCwQsXLjx79iwSiXS7XZZlG43G1NSU0+nkWc627a+//JJhmKtXrz57+lwQhNnZWZjLut1uj9fdbDYNQ4MHEAqFXr/eDkUiqG2ns9lOq8WybK/bB2l5uVxmWfb69es7OzumaUJO9tHJ0dzcDCwoYVaB4yQo2TudzurqarlcFoYi9JYsy56eFtLpNEVRuVxuZ2e71+uFw+HT01PQ5O7u7sL6MhgMIghCUVQsFqdwYnd3lyTJYrF448aNWq02HA6DoQBc+yRJ+ny+o6Oj27dv+3y+J0+ehMNhTdOeP3uBIMj09DRNs9Vq9fT0dG1t9SwuSR7jOE6SOFRss7OzT548uXLlyoMHj1ZXV9dfbDgcDo/fF4/HX758yXEcgpxxEAHekU6nO53O6empz+fP5/MOhyMSCY8FsdFuorYdDofb7SbHcc1mHRDBV65cge1BvV53OFzwspyHvaqqGgz6cRwPBAIQp/jwyeOrV6+KoghnnmnY6+vroCtgWW52dnZjYwMcG1DCgqIonU5DR1cul2Gn0+/30+k0z/Nw0sNqm2XZbDbz6tUmx3GKooFG7fzZzUzPLS7N7+7u1ut1r9fL8yyUFyBjSCaTkiQVCgXAHFy4cGF/fx8szxCwTRAESVMw+2RZFrZIIMFOJBKffPIJSZKLi4tgi4bR7GgocBzX6/Xg3NE0jaZpyMUrFArBYFCSJHB+3Lhxq1ar5HJZ+Ivj8fjg4NDpdIxGIqgdMpnMYDB49erV0tISnHrnbMyTkxOn00mStKIoNE2DXAyKA0EQOI4BsheO4zzPw4eZIIhcLocgyM7ODvRCUMSvra2BzxEIXpKkQOd8fHx8/fr1er0OrhTyTTYDiOKBY7ewsFAsFtPp9OPHj2mahg+qbaGnhXwkHFu9sPz8+fP5+flarTIYDGKxqKIosihhGLa6slKuVH76p3/q9fmSySSwMHmed3k9zWYTgjh7vV40GtUUeWdnh6HZaDQK04HZhflPPvnk4sWLtVrNshCapkGFdvvGzQcPHgTCoX6/ryiKw+F46623Xr58CbkLiUQCVhaQTQy6HZZlVVWenJwkCCKfz0uSJMtyJBKZnJx8/vw5mHt+8IMfQFCNaZrBYBD97MN/RRAEZAusra3BKhSE5IqiSYoyNzen6zoAtWqN5sOHD/3BEIIgd+/eLxbKgjh2OT04SaiqyvAcKF1M0+R5FsdxAsVoksEQDDBLKIqC5oOiSV0zAIZhIaimqLzTQRFgEKV5Bweitk6nAzfiN1tYAyb89pucYFmWIdtIFEXwmnEcA/AkRVHa7TbHMbIs+wPe8XgMTxixMYfLqWlarVaDZSIoXqGPIUkSFFGiKEqS5HS6LRMxDNOyLJ/PNx6L/X4fFN9QpYFgVpJkeOLj8RhDULANG4YxGPbBOhQOh2FSOhgMDEPDMELXVdtGVVUdDgSXx83SDEbgJE6ousbSjKTIsiynUinYT3m9XrBfORy8ZqgwxMYwbG/vYDAYqKoG5QQ42lqtBo6TXq/b5XKZiE3TrGXaheJpt9s9W0ng+LkT0DA0oAnYtg2AVprEYQYOn04YJsMSUBqPUQyzLcvr8wGbJxwO+zyguBf7/W6r1ZmYSIK9fHt7d39/1zAsTVNInDIsnaHYqZlJiAdB37CsAM4kSRI8KWibPB4PQRDQNBdLlU6n43a5LMtSpPF4PFZUqd8f4jhqWbZ1PrBCEcSGtaCN2oiF2AiCoDiGougZqArHLcNwe/wkScqy4nA4SJJWVRVDCZ7ngc5gGgZFUTzPQum8t/2aZGmn08lxzKVLa//RH/2hKsnicOB1u6DYxUlSEIR6ve5wcufhxG63u1KpGIb29tvv7G3veFxugiA0RRoMeq1Wa2p2ZjQaj0TlP/1H/1uCZCma6w+HNE3LiiQOBYahpqcyPMe53e5ava6pKkkxIO+ApSdF0xTFgLPSNi1d12kKGwp927b/8T/+x1NTOV3XUds6OjqazObq9WokEkkmk/1uFyoPSG+1UZQgCFgUKorSbDZTqVRuarJUKpXLRVD4AkdtZmZmMBC63S4gSw4ODmzb9nh84A4BVOnOzs7t27cVRQEqNzQe3W73gw8+ABEPIIvAqr26ukoQxG9+85vV1VU4eDZebaIoOjMzgyDIxsZGOp0Oh6PNZpPnWUg0z2azwWAA0qiARYKiuNPJw+0P1hCiKMZiUeA1a5q2vLKI4/jR0RGGEpZlXbt2DbjPoMB1u93ffPMNrFHgfazX68BhevLkCYqi3X5/ZWl5LEu9TrfX60H/CviJvb09WOKnUqluq62oso3ZBIGl01nY4+A4Dgc8TbFwyEEbeXp6iiCIz+fTFGVpaalSrkI4HWSWn4fFLiwsQJShLMuWbb7z3nvPnz8HT7emabqqptPp8UgEh//MzAzgbKCBrNSqFEVt7exC1go44GBhCouPYDC4t7d38eJav9+3LCsUCo1GI5okoewGLdFwOIRMN8DrgBYCMOJra2uFQgGkEcD5czgc0EX3+12O4U3b6LTagUBgc3PT5XLduHHjL/7iL0KRYDwen56ezmQyH3/8sShK169fhwEVQRBLSyvHx8etVguYIO12++LFC/1+H+wRgiBks9mT/Onx8fHU1BSGYZ3+4Cc/+cnGxsbm5ub169e3t19bluV2u6D8Go3EWCz28OHDcDicTCYrlQrLsoIgVCq1VquVSCRGo2EwGARbn67r+/v7UCjjOJ5IJJ4/f67rZiqVgH4gFoshCFIoFDweN6j6wuEw7DpYlq2USvBx4jjO5XKBsEFSlK2dHZfLBUcAgiD9fh+AvRzHfvTRRwGfHxaIPp8P3oW1tYuwEEyn059//jmGYd1un2VZF+8olUrpdBo4IzMzM81mmyTxZqetaQrP8/V6fX5+EcOQ/f3Dc4IDIKyWlpZGo9HGxsatW7c2NzdHoxHsT+EoAQDpaDSan59XVbVWq8HpmUgkJEkSRdGyLBgsbW1t8TwfjkQikcjLV+uAcwP3TC6XOzg4+P73v/96cxuAR8PhcH9//9vf/jYsW0AEUq1WIS0XNiQOh6PTboIJ9PHjxz/4wQ9QFG0225nMxPr6y1AoAG6JRCLRbDYB4QawvXqlaqHIRCKZyqQBz5tKpUzThM3d/Pw8tOulUmk0GkmSBFbBRqMRDAZhpAcGxolE8uDggGEYt9sNXtHERNrr9RYKhenpaZhT5PN5hmEonIAVGXw2IJ3iyy+/TKUSFy9efPLkCQwyY7EYJExcvXq13+/DPNXtdvd6vbfeekvTNHTj8Zfj8ZhhODjtQP58eHgIjZTT7Q0EAuBU13U9mZygaOYXv/ro5z/761arZVh2KBQSx7JpmjTHgoYG1NPnBRZFkvJYMQzD4/YCYANWWoAeUFWVohgEQRiGsW0bwxDLNjVNg6gNmqaBeA7YFVBxnd/IQJdtGhbY33q9HssxGIbpugqzTcMwCAKDth7DEYAqjUQJjJSxWAzskzAzjEajMIWSJAl+OU3TOE4KQ1FRVCg62+0WCCAA6QFP1uVyybICPbEoiqiN9LtdaIk0TYX5FjRqXq+XpklQyMJ8yOl0MzzXaXdh0wcWMHA0YAQ+Ho8TiQT0iABgHAiDWCyiGyqO44iNdbt9URR9Pj+8erqu8zwHBge32y2KgsPhGEmyrhmvtzZBi6eqKkwXxuMxQRCSJEJuIyj9RVGkyTNEIYyvLMsy3yCyKJoOBAJerxcwQhiGDYfDTqsNTkn4hU6nczAYiKK4t7en6zqB4bZtW/aZ1+/qlauT01NPnjyBChUaTSA1QAIuyDKgdIadnTiWFUUThv1er0eTRLPZbLaa4O/77ULwbEeIIfYZ//O3QywMRVAEQVGMpkiChkqRZzgMw2wbZWkGzDgu3iGKIpjXLNuYmpoKB0PTs9O5bDoQ8F24sJJMxTc21nvdNmZbiG03m02apifS6Xw+DysnyE4HjrNumQCSwTCCwWlRFDmGEEVhe2crl8vNzi/gBPO/+8/+j5989uXU1Kxu2hRFGIbRbbdi0fDvffc7/UFXEATbtuv1uiiKGI4Hg8FWq4OiKIaTtm0HAqFms4lhuGka0ngUCvhLpRLL0RcvXnz//XfDgaA/4Bv0+oGAb2Ji4vPPPx+PRrFoAkVRv9/f6bZIkmy0WizLTk5OQiN4cHDQ7nba7fb8/OyFCxd2dnZAVepyuWwbhTsm0LD29vZ43gnKrWq1OhgMIApD0zSPx4NhWLPZVBSFJMnJyUkY4gaDwcPDQwzDQBMjy3KhUABxxuzsrCCOIWTQ6XRubGz0+/1UKn3r1i0MQ+7evdvtdqemplqtJsdxg2HPMpH5+QVJUsLh4EcffTQzMxMIBPL5fDKZJElid3cXRdHp6WmGpdrtdq1WSyQSTod7cXGx0+mUy2VQRz169AgsFCATBB5KKBTy+Xynp6c/+NGPgDa5t7cHh9Djh48ymcz09PTe3h7DMMAFoChKkxWny+EL+ur1aiqV7nQ6giAAsaLf77MMD3L469ev7+/vkyTZarWi0SiGILZtQ2gxqC1FUYpGo/C/GYYCoUK73dZ0lWVZC0E0Qw8HQziOuxwOHMdJnKjX68CWLJVKPM+DUvP4JB8OhxGMDAaDzWbT7/cfHu7HYrHJyclGowHI752d7VgsBkYw0NcOej0oTFEUDQQCEF8DM6fDw0NwisHObnNzEyStEJBXKBQA9BDweSFtd2Vl5dWrVw6H4+jgIJvNFovFXq/n9rndHg+ISgGaxfNOEFmfnp5OTc2IokgQBAA52+02TRIIgiRSE7Ztb2xsLC8v2xYCt0eKokaSzLIsTdOtVsvn8+m66vV6j4+PQOS3tLTscDgCgcD+/j64NFqtVq/X0zQDDnVRFL1e93A4hCMcLOqXLl3SNK1SqQSDwZOTk9/uc6LRw8PDeDxWq9WAzC4IgmVZyWTy9PS0225fuXLF7Xbfv38fLN4YhvmDQZ53UAwNlhE4HSB40eHgHz58OJWbTCaTMJssFE8mUhlFUQEY5PP5tre3SZIsFsuXLl06PjiEO5Lb7Q4EQk+ePLFt+/Llyy6vC0RIV65cKZVKUNmoqjo9PQ3wUsiVcrlc8M3T09NKpQLg3EKhcOfOnWq12mg0oAgAORCcnr1eD84mGE7XarXDw0O/38/x/OrqarvT3NzcTKfT9Xo9l8sNBgMAXJWKFYiNmpqaOjo6mpmZsW27Wq0qirK9vZ3JZFAUhb0hfM1MT4ZCIZhuXL58+eHDh6B0BNYUCArBr7qxsWFZFk3T0WjU7Xbn8/nf+73fe/DgwTkJqN1ur6ysPHjwYHp6GsfxZrOZy+WOT/LvvPNOqVDc2tpaXFzMZDLPnj3z+/0A9sNsxLIsuDDBwydreiKRSKfTDx48UBQlk8lMTU2Zpvnomwc+nw801t1u91vf+tZgMDg9PSUIjKKobrcLgYMrKyvb29u9Xu/KlSuKohSLRShU1tfXb968WSqV0N/86i8qlYrX689kMrIs8zwPq1bLsvb392mWh1stIN0QBHM4PX/917/c3T+kKEpWNBqGTjQ9lmVgk+qGBuATCicoiuA5zjAMkiQdvAuGTzDKOi+6SZKChR0MMzAMtWzD7XaD8BzwVDRNd7td8ObA8QnecgfvwlF8NBq5PS7YLp0vvFD0LEgYYklAHGoYxlhW4CWAoRS0vFBuwyISqgroM2RZNnQrEAiCkNwwdMuygGU8HA5BEI0gSKfTtSwLWhZTN+BKVlXVH/DBxFWSpEAgABIZsJaEQqFGowG61OFwCK8M7FYQFIXxla7roij6/X6G40A4RdNUu92MxGP9fn88HgcCIbfbPegPwaYLi7OdnZ1oLMLz/Gg0ZFk2EAg9fvwYdgFA38BxfDgcwgTL8+Z1Y1kW8H2qPIY9IORIulyuaDQK7yy8EbC8qNfrsiwriuJ2uoD/ASPuYDB4fHwMj4SiKF3TSIKEGbuma3feukNQZKlUgp0LQRAMw7AsC1c1iNnNswQelGGYeDw+GI5omq7XahBF3O/3i4XCeflkA1H9rNDC3hRc2JuhFY6RBEGSsBu1bUTXdZZlWZoZj8egwmFpqtvtQueNouiPfvSjtbU1gsQwBJ3IpHxeN8cx+Xx+PBZVVR0N+7FoGFxsqqomkslwOLyzs3NycvJ3/s7f+au/+isQK5iIPTU1dXBw4PMFtLHq9brr1XKlUorFozRNC+L46rVb97558n/+r/5pp9NPZydHwz6O4/VqdXllcW11BZqwbDa7s7d9enoaCAS63W4gEKIoyrIQnufbnR7M/zEM67Sbtm1almUYGmLbHo9rfn7+D//wfxn0+xmGKZ4WAJYzGonz8/O1WnV7+zWAlWFrc+vWrYODg+fPn3v9PgRB1tZWZVk+PDyECzAUCimKJopiuVyNRqPxeBzq5suXL29tbVEUBcAYr9dbLpeBWQWTyGKxCNmuoihCjhtcVl6vFy4cXdcVRan/v5j6z2DJ0vy8Dzw2z0nvvc/rvalbvstOtZnuwRgA5IBYIkAuJRIiCTKkwAaDiiV3lxK1itgNURQpUUsRhhBnYMZgMD0zjenu6mpT3l5v8t6bmTe99+aYPOfsh6e7pPk0aExV35t5zvv+zfP8nlLpnXffZRjm8PCo1WrVarXJyUlQxff2dubn54ELajTqPM/rOIahdYPBUNM0s9mMnLJutzs1Nbm9vR0IBDCzmZ+fRy2FUwIekZcvX2IwA8vb22+/HY1Gt7e3nz596vF4IpGI0Wg8ODhwOByBUKharUJSE/QHQG7kOK7X6yUSCUmSjo6OUE/MTE6dpk6MFiNcIyCPQwDb6/XsNifUM+iJYUgMhULp09Pz58//4ucf2Gw2oCtomj06OnK73fF43Om0Y1vU6/UmJhN6vf7Zixfnz5/f39//7LPP3n3nncPDw2K+8N3vfnc0GnW7XfAX5ubm3G63jucymYw01ux2+8OH969cuQIqXiaTCQaDmJOFwyH06w6Hw+/3ZzKZZr2OKxad99ra2tHR0Xg8BrVIFEV0HZgwYUuOZGLISB4+fLi8uABUo8lkajaboVDI43Kl02k8w/lSHtzIo6MjxPZ12j2CIHApoLDDsOHKlSu5XA7LprVz6xaLZXd3/+LFi+l0+unTp1+7fYcgiFqzoShKt9tH0IggDGOx2P7+HkEQsVhMUdTj4+NgMIhNdyQSyefzCwsLR0fHAIm1Wi0YGlRVjUajMOXwPI/cccj+xuPxxMREv99PJpM0Tc/NzUqStL29jeA8fLndbpfUNIfDIb2O9hsMDAaDzeHodnsvN1/Nzc2NRqNLly5JkrSzte3xeM6f34ALpNFo4JCEhz0eT9y9e3dycnJ2dlYQhK2tLavVzvO8Islvv/32y5cvTSbT6emp0+lMpTKTk5Msz56dnbVarY2NDRRYsVjs8PAQins8wxzHiaKI8ACYURKJxMOHDzVNSyQSu7u7Op3O7/cjUASr50uXLk1PTz98+BBpiTRNh8Pher0OLQFBEPPzs6PR6DB5BGMsupparWbUm1ZWVra3t588eXL9+nXMwJCFADLW9PT06ekpTdN37ty5e/fu48cPE4lEp9MJBAIQwHg8HqDdkMu+vb2NOFRAswFtQSLL22+/DaHLYDAA6QkQB1Si8Bh2+z2r1Wrg9efOnUulUljtYVITiURYih4MBqIoQqxpsVgOksfD4fDixYsYEICR5PP5hr0+pFo4qU5OTtC637p1A7EBwWDw+fPnZ2dn8XgcjP5f//Vf/+EPf4idFTx2wWCQ/OP/7V+7XK5OpwcFg81m0+v1h4eHOKcCoQgADxRF+f3+589ffnH/kaaRgjRuNpt6g0lVVWk8ZlmW0emgTKJpmqJJs9msjRVFUUjiS+oMQRBjWX2NPrLZbGCFUxRFUTQmQBRFsiwriEMY6IAGeS3BRtQDQABALzabTWEoGvTGwbBvNBqxg4dF0WIx4YvBT8XzulqtIUkSp+chwUE9BC0qfrxIJIL6A5pQfMeaSgHr0O/3NU2F+xr3E8dxYKaXyxWMHFRVddodWJ1QFMWwtE6ngz4am1273Q5NDwpKAEtQ8QAQR5KkxWrFH5FlORKJSJKUzefxrUejkWqjnkqd0DRtNJqdTqfRaBwNBVT0kH3E43GnywGMRTKZbDbbGK0JglCtViFRRLE1Ho8FYYgaEY5uQRD0HGs0GgOBgM/n8/v9kElBqIjDBQ80BOCiKJqNJmyFKpUKPnDoz3Q6HUVRoiB8ub7UcaIkrq+t2xx2vLeY7cGbyfO83W4HklEQBKDhSZJ0u90aQfX7/VKxWCgUSFJTVbXZqAmChMEVSVKvx2NfEbBokqS+Gm5RNEOxHA+CPz5qWZYZmsK0rJjLypIUCvjn5+e9Xu+tW7fee++9n7//vqIogYBPluVWq3Hp8sX9/X1RHAX9gcGwh/EnhgSHR0cQ1iwuLoKXgwLd7fNWq9VOp+Ow2tSxZjKZ2s36eCyBx9jpD2x2p9Xu+eTT+//6X//bqZk5Qh03m83RYOjxuGPRcCQS+hIANpaRiNBoNARBCofDJpOlUqmoGmk0GhcXFzOZTDp1gruEpsnjo2Q4EpyZmclkUhtr69euv8GxHCBSdrt9Y2NjPB5/9tmnkUgIs0Ps1ovFoqqqvEFPEITf7x2Px6iHZmZmRqORx+MrlUqKoqGDPzo6MhqNFoslHA6LoojHZmVlpVartVotjLjQksmyvLa2RtP0zs4ONqdmsxkQPwy5aZpeWVnZ2dvL5/OKoi4vL1er1dFoRBCU2+02GvV2u31ra6tcLqFMEcTh0tJSs9E2my3lcrlarc7NzV26fPnxo4egZsANhOPF6XQeHBwgyAGdaLvdTiaTV65cGQ6H0C9CU0wQRDgcLhaLNptNEARRlg0GAwDZLofzl7/85crKSq/XA3jQ6XQOBoNWqzU1NUVpRLlSMpgNOp2u0+n0er3FxcUXL14Yjca1tbWtzR1AXB8+fIidC/RShKpWq1WX0z0cDhcWFgKBwNlZbm9vb2NjgyRJVR1brdbj4+NEInGaOiEIwuPzTUxMpFKpo6Mjq9nMsqye46GSwcQdDmKHw9HqtD0eT6VWt9kcvV5HVdWFhQVks3i93p2dnYsXL5bLpXK5DHAXcOq729uwZ2JjCLERwuyq1WoymQSB5dy5c3t7eyizGo0G3t/Z2dlardZq1GdnZ+v1+usILB3DKIoCkHd30AUB9TVwx2Z1NJtNmqZtNlsoFOp2u3t7e+vr661W6/Dw0O/3+3w+iqGnpqZarc7BwUG9Xl9bW3v1cjMQCHAGvdlsHo1EyPLK5SJBfPlkBgKB8VhptVozMzM8z7969crj8XQ6HYfDMT09m0wmMVGLRELYxqCkE0UR7XS73d7Z2Zmbm8MSLZfLHR0d/eZv/ube3i4aiVwuNzk5icmf0+m0mEyoq7DCg8Gz1+vpeH25WkkkEhRFpVIpvV4/NTGZSqUmJhI6ne7g4EBV1cnJyVarhQWWXm9oNBrXr1/f3d11OBynp6dTUzMcx/GsDkv8fr8vSZLP5zs7y+n1es7AZbPZa9eunZycIGBX07TBYLC2tjYcDlOp1DvvvINhcCaTURQFduyXL18ajcbl5eWXL18i56dWqwHsjJRAtEzgTuGqCofD+/v74XB4ZWXlF7/4RSDgm5ube/biOcafmGWaTKbd7b2FhQXAILLZLPZCAECwLBuJRLDOHg6Hly9fTqfTEGDQNA0zDVhcd+/ehe+Boqhnz54h83RycpKm6aOjI71ev7Gx0e/3QflSFMVut8M2i1kvx3HT09Oogb71nW9vbW0p8jgej8N01ev1dDpdJBL58MMP52dmURMDs0JRVLPTxTQL28B2u93tdn/7t3/7s0/uHR0dORyOfD6/vLx8eHh448YNr9fb7bZxfUuSVCqVpqamarVaJpMBdwbCiZOTEzSZgiCQH77/Zz6fr15vgntksViy2aymaVeuXMlmswTFqKpaKBQMBsPU1NQf//F/2treGw4FQZJomqYY1mAwdLp9QRDsdgdUESgdUL6QJMHzOrvD2u8Nca6h3sdkkvgq0E2n41FSqKpKqBoEjBzHgcWH6oGmScz0Xk8vRFE0Gs1Gg7lcLuNhxb8XqBJgpVBIKYpCkGq3049EQwAuo2tBpKskSVB0gUWGWxD7KVmWXU4vGmVZlhmGdjgciioritLtdgVBkMSxIAgkSWESQ9O02+2C5Rgwp16vh35XUVTYGDEwq1Qqg8HA6XQYjcZev/O6VsMQzufzsQxnsVgESTw7O6NpGnPsYrGoEBpOw067i5MFaaYAr12/fj2dTgviCEbxUqnkdDohFsYaDuWRzWazWs12ux1/Q6vVwtacpum5mSm9Xi/LcrVazWaz4Hy+BlLUajWj0YihlyiKMHNp6lclzlerOexYX/939av/PpGYsNpt+ELJr9jxeFF9Ph8EnmimceqZTCaz1ZJMJqvlCkBfvV6v3W4SxJfhzgTxVYFFUSTFEASlqQRw8wRFkgRNMyRD62gGpOy+1WzRCLVaKkqieP7ixsb62uTEhM1sCofDMIfu7e35fb5erzcaDWOxmCiK8/OztVpNlEblQvHO229lMhloO7a3t0FhUTXt5s2bd+/enZubi8fjyWQSLIm1tbVUKlUpVTc2Nga9jtlsLBWKjVaT4XiG1dsc7t/5+/9IUTRprBg4g97ANeuN0WgYDPgcDgen53u9zmvyCIIaZmdnFUU5Pj7meYNer19dW1NVtdVo4ztCmqFezwX9AY1QMpkMy9JL80soZTD1GY1G0UgQjbvNZsM56At4z87OQIZ7PT6cmprq9To7OzuRSGw8Vsfjcb1e/9a3vnVwcCCKYqVSQTaLpmnYj8iyrNMx/X6/1xugZIcMIhqNBoPBX/ziF5cuXcrlcuDreDye4XB469atbrf7R3/8x7FYzO8PYK/R6/XS6XQkErFarYVCwWIxA7sMq93i4mKr2el0Oul0+tatWxzHQQhss9k6nc729nYoFAYoodVq4dI6ONifmZlhWfb09BTCC9ypRqMRuM5Go5FIJAB9LpfLvEE/Ho9Hg2G/39fpdE6n8+23375//z5N0yzLgqU+liRg9trt9tTsVDQaff78OUEQRqOx0Wh0Op2lpaUPf/mx3+8XRfHKlSs8z7tcrlQq9fTp00QsFgwGi4USQRBf2Zk7k5OTBEFUKpVYLIJUYFVVSYogSTKTzdbrdUwahOHQbrePBkOKokKh0MHBQbPZdDqdRrMJiuPt7W2bw+n3+xFuPTc31+v19vf38f7GYjGDQc/zPAhMPM8PBgNCVRHHrmnat7/97d3d3VevXi0sLAwGA5goMYrGYQjkLIh3giCkUimCICRh5PF4lpaWAI7COMFms7169ep1/u709HS5XIYDCTAkbDDa7XYkEsEhhq7+Sw1yt2swGNrtLhagfr//xYtX8/Pz3X5fkiS93oDv0Ww2h8OhRqOB4BrgAy9evPTLX/5ycXGx0+kg7rDdbk9NTYVCIYfDgeMUln4cU8FgEMB6xMtUq9WdnZ1Lly6JoigIgiSJWEGEw+FLly79/Oc/r9Vqg8EgGg5j/4WRD/TOoVDoLJfHbbK6uppKpXZ3dz0et8lk6na7mA4Ui0Wv11ssFhcWFmRZ/vGP/+L27dvQDyGXxmQy7e/vEwrxm7/5m9hoe71eCLZkWbY67BzHwVf4eiWNomFychIJlZig9Ho97DoxksA8hiCITqdz5cqVra2tRCKBTT3OGdyVQBssLi5CQYXEhUQiwTDU48eP7XZ7oVCAgRGol/FYnZiY2N7eZhjm6OjI6XTCNAomOeoVn8+HieDNmzdDoQCguNPT00+ePHE4HBBCLCwsYDFis9muXr2aTCYhcTt37lwul2MYJpVK9ft9LJpjsVgul8MvKAgCxM3Xrl27f/++0WyKRqPCcDQcDqHspGk6nU57PJ5ms1nKF0D3uHjxoizLBwcHlXoDQka9Xo/PGUn2lEbg7FUUBYXU8fExSZI3blxLp9Nms9loND558oQkyYWFBZgtnj9/LggCgjFUVX358qXD4SD3Xt7f2tp6443rmUxGr9dDfoE9N0EQjVbH5/Nhg14oFI6PT4OhaLVaFaRxuVyu1WrSWCFJstsboGLFImk8VsANx0rLZDb0e0OCIMDygoETTAe827KsYGJMEARNUrD0+3w+VVXrjSrDMH6/v9FotFoNLIkh8oCJxuFwWS12VM2lUkkUxXq9jlRzl8uFMSxM1P1+H+p1miFx66Big6yKoigstqDr/DLfUJBNJjPLstAIi6IwHo8Hw14ul3O73aIoqgoxGo30egNEdhRFsSwD5jW+davV6nA46vW6LI+73S7HcVjxFgoF1GQURY4VSa/XYzgEwrXJZCqXqkaj8eg4mUgkYI5Np9N6vZ7WsQsLCyfHp5qmvU6NHQ6HgiAsLi7ifzY9M0WSZKPR0Ol0zWYT2hGMiDiOA1HC7XZijo0TrV6vLy0tNRqNQa+zv78PWEij0SiVSoIgIHcdW0X0ELibv5RnkSShaXqDQRiOOI6D7pUgCGwGaZqWJYkgCD2vd7vdKqHZ7Xbsp2RZhlwaVxGmYtCHYeSu1+ttDns+n8+dZWVZJgii3+83m02KIlSVIGlC00hC0wiKYliWpllVI2VJYRgOqhSYazAc7fbaJpPBoOdbrcbC3MyNG9dWV5eNBr0mjw08B2X6cCg4nfY33ri+s7OVzWSAV242mwxDxePxWq2iKMrzV5uvJ1V37tw5ODjw+nxAYADHH4vFxuNxsVgMBAJer7eQK3IcNxr0RqNRvVoJhMKaRloczn/zP/+vP/rxTy5eeqNYrtjMNpqmm41aq9WymE2KIkdi0UuXLu3v7xOEikMZKgcYEQqFkqIoPr+f53mj3lQoFKAI1Ov1I2EwGgw5juV5Xm/g8mf5QMA3MTF15coVm81mMPBOh83hsD979qzb7cLWeuWNy+h0s9nsq1evJEl69913C4XC06ePLRabzxdoNBqKoly7dg2aG1VV0SdAGb2/v4/OKp/Prq+vNxotNDnT09Obm5tOpzMQCEBG+Wd/9merq6t+vx9+vaOjo1qtZnM4DAYDRdHAECDv2WAwbG5uDofDlZVlh8Pxv/y7f/u3/tbfUlU1m8067K5Op3P+/Pl2u53NZtPpNBxnp6enFoul1WrPzs5iQY+opVevXsIj/I1vfMPn83300Uc0TQcCAdT36BOmpqby+Xy1WsVD2Bv0lxYWV1dXf/jDHyImFgz04+PjW7du7e/vy6KIi99oNDIcMxwO0+m0w+Fot9vYO+/t7bVbXaPReP78eYIgarUaVromk2nY70cikbNMFhs0giDa7S7ewWAwqNMxz58/H4/Her0+Gou02+3RVweaIAgmg8Hr9WZS6cFgAJs9fllZGRsMht3dXbPZ7HR7UqkUqEv1eh1eUaTdA3wP+gCmjMVi0Wm3oz6Ynp7e3d2FHhkOfGiWK5VKKpWanJyEUvjs7EyW5XA4PDk5eXJyksvlgn4faA5YOHS73eXl5eFw+Omnn4ZCIayGkZBx583bkL9Axc9xHDwEeHrn5ub29vY8Ho8oiu1Oh2VZTSNBvSdJUlWJfD7vDwaNRqMoStCJHh0dcZwOClfdV0GoVqsNaRB4Sl0u12AwODk5mZmZabfbDMO89957f/InfwK9hMfjkWX53Llzqqq+ePEClX21WkWKXzqdnp2d6Xa76XQaMNtarXb58uVarVYuFgHIwAkPKWe9Xtfx+mw2u7u7qyjK6upqOp2emZnGVuv8+fMQnyFw5vz584IgwImJkCWDwYBpa7fb1ev00WhUUZSTk5PFxcXT01NRFBcWFkrVis1mA8sU5onXaAC/34+rU9M07DQByuJ5Hqc3toFer9dms2E/w7Ls3NwcvKu5XE6n001OTuL1wYIlHA53Op319fXT02NILaHF3NvbI0lydnY2k8kiWgrBFWhjZFnG5a4oCiont9tdLBZLpVKlUlpZWYErGVUpJp1w6WKr/vz581gshjBv4N8ODw8nJibwu9y4caNSqRwfHyN6C4od/I52u52kKavVKo4EXO6Q+t24ceP58+dvv/12u9FEPNfNmzdHo5HD4ej0B7IsNxoNRCmASd5sNoe9fjAYDIVC1Wr15cuXgKlWq1WCUP1+/9TU1J/8yZ+8ZsrPzc3Nz8/b7fZ79+5hCoiBVrlcJp8/+Mhut6fTZ/jEIRWC6S+dTpM0C6clhhajkahqxHA4zGSyDx4/IklyrGiqqo7HKs/z4FiSJEloFFCTkiTRLIVdEpZT4/EYy2xRlFEyi6IoSRL2dBRFSZIMMqcgCGaz2Wg00DSNFZWmKVBzo2NmdTRBEEa9CZjvRqNRrzWR8m2z2XQ6XblcluUx1mHYtSO1FIQqUBahmkciAR4L7IP1ej22SOVypV6v8zwHI8loNBLEIQakiqIwtA49h9Fo5JGLzutAQK3X61CPchwP2T6WF6PRqNcdoF7m9Tp1PKZoAuQ0q8XucDh6g/7p6Wm1Wh2PxwsLiwg20TQNLTVvMOAtXV9fTyaT29vbHMfNzMxgmOl0ORA91mq1AL5jSEqn08Ehgo+6223DKwvlFsMwYFKUSqVUKqWoMj6u4XCIyZOO4yRRJEgS5DRRFEVBQKYM6mlVUSiaVhWFZhhlPCYJTCV1ePFe/werSYfDAQofzkRJkjBIUxQFvE3YP3Hlw7AzGAzS6XS1WoXZot5sEK9xXCpJkAQNMQfFKIpKkjRJsyjsUOeRqkaQKq9jCVK7fPHczMzUufVVh8MuCMPhoOdze8ayjIi9fK5IMyTP8jodA9UkNoB4bkejwbNnz/yhMDqBc+fOzczM/PjHP+73+6FQaGJy8ujoCP6dn//85zdu3MBYKBwK5XI5SiNGo5GOYSenpzKZLGc0ff29b9KMbnnlnCCI4kiKxWL9bq9Wq/SHfZZlXS7X5StfAoU5ju31euOxFI1Gp6am+v0+wnOMRuPu7n4wFJEkuVAoZDJpSRBJkhwMBrxexzCMxWIaS4qmKRyn93q9HMctLs7zOub69TdwzrY7LavVarFYnj17lkjEKIrCU3f+/PnHjx/H43GKolZW1t5//33A0O/fvx8Oh+fn5xuNxsHBgSAIExNxWZY1TYPewu/3sywHgTko/G+99Va9Xq/X6xBgoeoajUazs7OfffbZrVu37t+/ryhKNBq9fPnyX/7kp9AdBoPBTCbj9/sNRr1Op3O7nYIgYAZQr9dLpRJctH5/EMZGnuedDtfR0dHa2trOzo4oivF4vFgs37x5vdfvvnjxAt0U2hi0W5he4EiFidjr9WIX7/V6IXzp9XrXr1/f3NycmprKpFKA/UABQxDE4uJio9G4e++e0WiECMPlckFdBEzUeDyenZ1Fps2bb7754YcfejwehqIqlYrD7sQQYjAY2GyOUCj08OHD3/iN37h79yOapmOxGE3T6Uzq+PjYYrOpqtptt0EwGo/H66trCP188uQJCk1ZGZ+cnNhstrfeemtrcxvaqampKZZld3d3i8UibFbI5K5Wq6qqRiKRCxcu3L17F0qXdru9sbGBc+Odd945Pj5GSQFLdafT6XQ6+Xx+dnZWHkvQPr+m/9++ffOnP/0pwzDQLLMsOzczazAYqtVqq9UaSxIqS+COeZ5vNuvY2ozHY01TAErw+XwOh+PVq1cur+/WrVv5QgEkgn6/b7HY4P4plUrR+MTTp0/h0YvF4jqdTpalZDIZDAa3trYcDkc0Gg2Hw4IgfPbZ5+FwGOS8YrG4vLwsyzJ2WD6f7969e5cuXQLvFCoUvV4PnCy04Zubm+FwWJKkcrmEgl4URYzlSqXS5cuX7VYrPmee53O5nMlkisVim5ubOpbrdru1ZuPVq1fnz284nU70WgaDASJ0uPBIkqRZRpIki8kiiiL25uVyuVQqQWpczOXRzHAcB3PGyclJIBCgdexwOMQ6G39kYmJidnb22bNnmUwGLFzMXWBOxEL/9PQUWQuNRmNubg7DS4yOcK3AYlytVkVpHAqFMum02+2u1+uyLCuKcuvWrYODPeiebTYbQRDdbrff6TocDoJmgIQsl8tvvPEGMJssyw4Gg3K5DDpJIpFIp9N4Afv9LipmfLx6vd7tdiNXMZvNXrlyZW5u7v79+7VaDRVSuVz+2te+9vTp0+3t7dXV1U6nc+7cuXw+j8F5tVpFgGmtVoOubnd/7+rVq912h6ZpSGIkSZqZmYGudCxKeB+hABuPx1aH8/nz5wgYhTBgaWlpb2/PpDdQFLW5uXnu3LmFhYVkMlkuly9cuLCzswWs/8rKCmJF1tfXf/GLX8zNzXm9XkjEvva1r0EY4HQ6ya2nn/b7/Ww273A4kFyI12w4HM7Pz2sknc/nRVGEZCcej1frjT/4gz9A/lf6LCuKImhD7XbbZDLxvAGCcZqmGYrleV4lNEmWMTHCXMflclUqFY7Tj0YjiqJAqMIxLcsyQZAYY0BmjtwlTVNZloUfod/vYteGmsn0Jc9dx7Ks3eZEsYXEK5qmPR7vYDDAyBpzEaPR0Ov10Ly2Wi2sThiGAXcKtZHdbocLrNvtiqKEhdFrK6XJbEA1QFGUxWzTNM3lcrEsK0nyeDwmabLVauXzeZ7n5+bmzGZzs9mCfB5iI5IkSYJGpcLrdTqG0XGM1WKH4L3b7dabDXj6nE6n3e4Aiw8sbxT10niMpEl0YE6nk2ao4WDk9rhYln3x4sXx8TG63itXrhh5/XA4BN4CDMZWq6HT6arVaq1Ww8MKcd/R0RGhaTaHFXaz1y8qPnbMY2GNwUzotbuQZpgvF4KaRhAETX0JQ8cdRn/FfWVZ1u12w3ICpiLGXW6322w2AzKExIZKpfJ6jIqnAr1Ov99XNLVQKAz6fZKiNJLGvxHp1xpBjccKy+khxgI7lGEohqIoQusPem/dufmP/tE/7HVb1Wo5EvabzebcWabT6ZIaQVHMzMyMJEmbm5s0TZv0BoPBcPXq1Xv37tXr9WAwiPbXaDRu7mzX63XsMgAVu3jxIkEQe/v79Xp9OBxC3I2Zc7vdNptMlUqlVW8wDDOWZLPV5nH7aF5XKJU/+/z+//6f/nRlZc3j8oxG4qDXH41G0lisVMoXL14kSbLZqi8vL8uyqGma0ajHiSMIwmAwwtaPYXQer1+vN+BSP9jb+xLzPRhQFDUc9S0mM8MwWPEYDIZYLCKOBno993f/7t8FA9ZkNmK6SZJkp9Oan58/PDxEfwXI52AwWlpaOjk5AdHtrbfeSqfTn3zyycLCQq1WC4UCiKmHZjwajY5GIsI08vl8JBJBpb6zs+PxeM6dOwdjWqlUikQidrsdJrh6vX7jxo3PP/98Z3v3m9/8ZjKZ7PV6DoeDpmmX27m1tTU7O22321+zDZ1OJ0mShUJBksbXr1/f398vl8uTE1NAmeCrlyQpFIpwHNtutwlSc7lcyEIol8uRSAQz6YWFhWw2W6vVFhcXQfLMZDIsx/X7/bW1tWQyCZ82ZjCxSATAOYfDkclk0MJ99NFH586fn52drVar+/v7sVgMFxuM4ijOADQG8vvevXsBn6/RaDA0i1k1SZK93gD4bHAEQqGQoijJZHJtffXBgwcmi0XTNB3DzM7ONptNQRDEkQAfEijS9XpdJTSI+q1WazQSy2azOzs78/PzTqczk8ngOikUCuvr6wAiAPxjs9m2tracTueFCxcePXrk9/vNZvOTJ08Gg8Ht27chS4dMbXt7u1aroTuanJrQ6/UOhwOeTa/XW6mUwPXe3d0tl8vf/va3aZJ68eIFrEU6hjk6OlpZWalUKhg2WK1mk8n04sULv9/vdjsxLPH5fIgPunr9Rj6f7/X70LgoitLvD7EhLZfLbq9/OByaTKapqanT09SrV68WFxcSiYQoikdHRxcvXtzc3LRYLA6H4/79B3CHFQoFAAIsFsunn346OTkJyhTyyOGnm5qaevDgwc2bN8fj8ePHj6E3h5pwOBw4HI54PL63twfj0atXrxYXF9dXV6Eo39zcZFkWMyGdTjcaChRFkQwtCEK73cKkAIstjH5BlNjf3+f0/MrKCqESiD1ARYL2/ujoKBaO6HQ6RMokk0mSJI+PjzmOs7ucoih2u90333xzf39fUZTXKhQECpVKpXv37q2urtpstrOzM5gSaJq+evUqyuV6vd5oNP7aX/tr3W73o48+wnp6dnb20aNHBoPBanO0Wq252dmTk5NisajX6zGJGAx6vV4vGAxCIMGyrMvukGU5XypfuXIFDF6UED6fD8MqgDbAcWRZFlCPjY31vb29ZDJpsVhQxLMsG41G4XFpNpuAjGCQSdN0KpVCqhJFUTqdrlAooLF/991379+/n0qlYGmE8KDb7eaLhXg8PuwPTk5Orly5Aj8jFmU+n89qMiNlHIb6fr8fjsVlWUaUda1Wg+B7bW3tZ3/5U7fbjScEZBbcaC6Xg6bpRqNx8eLFVCr14MGDK1euQM6FMgO+n1Qq1e12eZ4n9189EEXxxYtXgUBgamrq5cuXMLtZLJZut0sxunq93ul0bDZbNpuNRqNY/didjsXFxe/96Z9Uq9XhQMhms7BldjrdSCSiqsRoNDLpDRTLUDRH0TQKSeBNx2MV40SYFqF0oyjKYrGaTCZxJGmahrFNr9cThCGcJq1WiyA0aO2xdLNarayObjabo9HAZnOgC2m328pYo2l6c3NTr9crCvhVA+g6dTodTVOQ8hgMBlj8sLR+Pb7iOA7RaUCY8Ly+1+tFoxHsX3w+n9vt3t3dRQ4PHItWi73dbvd6faPRWKlVZFmMxRKYioNfp6oqRdH4AtrttkFvQlSzzWZTFXkw6LOsLpPJYD4H9xw4vBRFIY4aX/DE1GS1WkFqgc1mAwlwc3Oz1+uwLGc2G9vtdi6Xm5ubE0VxdnbWaDSOx6rJZELrVijkZFl2u90I2qxWq7jeJFkgCAJtFnwTS0tLNE2j3Yft9rPPPoOBXBJF0LC+FJZ/JbGiIKGDNkrTWIbFiYM51mu5AxbeZrMZEV3QgiAKClN9g8GQz+dxAbhcLofD1m63YaE/SaVVVc3niv3RkNA0ima/3D9SFM/zJEmxLGswWQiKbjcbLMtyLDsY9MwmI8/r/F73P/9n/1TTVIbWpqYmOq16qVRSVVVVyUF/BAthp9PBusGg1yPXrFyqBgKBZDIJuqzdYQVPKJvNsiybSCSwh4VIttFoGIxGVNL4jjRNoyliMBiQKtnr9QiVbLZbkXDME/RrJGWzO+8/fPQ7f+/ve1xeq9Xm9wZmZmaOT5OlUsnn83Ic1+2119bWarWKTqdzuRwnJyfYI4xGInYHdrvTbLGJogTNHPIDxpLM8xyobFAiGgwG8Cl8XvfG+uonn3w8Pz//ne98iyRJFN+COMLJUq9X0WO4XC68DhTF9Pt9tKdPnjwBtJqiqHT6FBHFtVoNkqB+v28ymRwOFz5YWOspivL5fPF4/PT0FApWmFcYhikUCj6fDxLyV69eLS0tVcrVjY0NgOCRnmGxmlmWPTjYW1tbKxRyFEXpdPz6+nq5XE6n0y6XZ2pq6v333+d5XlMJ8JePjo6wkbFa7VarWRRFSRYXFxdLpVI6nb5w4QK+LJfLBRMWDl+9Xn9ycsIwjCBJS0tLWGFjvf7GG2+02+3c2dnKygriE6rVKias+PSwakG35vV6QWjEmAcgyo2NjV6vp2ka/Juj0WgsK/v7+9/97nc/+OADr9ePF2E4HHo8LiwcFxYWvD4P8mR4nt/d3R0MBgGfHzoVlFPtdhueKShHHS5XIBB4+uhJpVJ59913a7UaSZIoxIHnmZiY2NvbQ8Sn2WyORCJ7e3tDUQDUl6IoaLNAaMShsbCwQJLk+++/v76+Ho1Gt7a2ZqYmoRM4OzuTJMnv9+/ubgcCgZ2dHZZll5aW0D/D0BMNR/rdrsvlevHiBeT2drs9Egl1u91kMvnOO+98/PHHbrfbajUDy+J0Os02ey6Xc3s8hUKhVquVSqWZmTlBEL5aALGvr16GYWu1Guy9w+FwZWUFICIM0tD/EARpNBrL5TIQphAFzs3NYZIHshqk+rDddbvdVCo1Ho+xYj5//nylUs7lcriev/jii/n5eZvNViqVGIqCEoggiJmZmQ8++ABYTqQwQYuGSujy1avhcPg//af/hHDJ4XAIbuJpOhUKhdSxIsuyzWaz2WzxeHw8Hp+dnREEYbd8SVHHzc1x3Nzc3O7ubrPTnpychBZ2d3fX7XbLskyS5He/+93Dw8O7d+9COoILzmazIcbgO9/5zqefflqpVJrNJnpXk8lULBZdLle5XPZ4PLFYDP/f+YWls7MzhqaxZUYa9IMHD8rl4sbGxmnyGIkLxWLRZDItLy8/e/kK4UU7OzuAh7Xb7UKhQBDE17/+9b29vX6/n8/n19bWGo1Gq9UKBHzD4RCm/lgstrGx8dFHHy0uLsqyfOHChVevXp2dna2vr+P+fR1rCK+V1WqFeRB6a0zvsB3ieX5ra0sQBJbTkSQpjoTp6Wl0QdDn+Xy+Z8+ezU3PYBDIcVwsFqtWq2f5AqwbYEi1Wq3Z2dm19fXdzS2UhsfHx/l83mAwJBIJaHsikciLFy94np+ZmcGYw2QyQZNz/fp1kiQfPXqE+UihUCBP958nk0mfL5BKpaCRgmb8woULLMt2+0MMKovFIriXFE2cnJzoOA5of7PN2uv1UIMfH58mk8lCobCzvcexrCiKlXJVpVia0XncbrPFMhoOdRxnNBhYnU4Yig6Xk6WZTq8LMqSmqE6nC0Z6UZQZhhJFGckPmJTq9XqC0BBzDXIGRRMmk4ll6V5vgFtcFEWW4Wq1Gqajsjx2OBxut7tUKkEJaDDoYTXCWBK5WgA4YV7Csuz+/j4EWyzLsqxuPB4bDHqO4yiakCQJ5F9QMTHREQVoiWwkSVhsZlVV6/UmTgGj0QiBUSqVxmTV7XZDBTyW1f6gKwkiBgYGgyEUCsE9hyWFKAo6Hddo1CEn1DTtk08+4TguEgvjR33y5AkwhpIsKGMNTnVFUW7fvt1oNL744oupqSmKYjCSNRgMBKFiilYqlfR6PfY4/X5f1cZ+vx8J3J1OBzFbuJJtNlu1Ws3lct1uF2YZQtNQS2EKiH9CfHWUo1bWNE0dK//n/SDcgk6nMxqNYoZst9sxnIOZ1OPxYKcO3WK322UYJhqNkqQGHmOpVCqUyoRGlWvVwWBEkqQ8HsP+idKKJEma5UiakWWZ17GDwYDXMSajwe/3srT2O3/vP19dWbTZLGNJaLXqxydHk5OTVqt189VeKBhBnQQv52AwiMfj5y5c2Hz+3KA3Id8eh4IgCE6X3ev1lstlpIzt7OwA5pvP5zOZzO2vfQ1nrs/nSyaT169ff/b0sdfrDflDJycnOobrDfqERnWGfb/f3xsMOd5Qrtb+zt/+z2xWx+L8YrvdFmVpcXGx0agfHBzY7JYbN250u21FUXheJ4oiIthKpUq5XOZ5XpaVsayOVRWO91qtpmmanuNVVWUYGtUD9CiAsQ1HfYfNurG+itY2EPC988478AAenySj0WgyeQjwTD6fd7lcgUBgNBIrlQomkdjMgsfrcjl+8pOfLC8vr6ys7O/vn52ddTqdiYkJu90ZjUaz2SxYCScnJzdv3mw0GrCgonEcj8f5fB7GNHS3pVJpfX293xtgTpbNZjGui8WjiqIEg/5yuZzPZ81mc63WQBdOEISiaDivPB4PTTGY0WIhzjDM1tZOoZALhYOoA6BcxpPc7XZXVlYg3MzlciRJms3mVqt15cqVTDbrcDgIgnjw4MG1a9cAYMzn8598/PF7771nMBgePHhgtVppmg4GgyRJvnz5EiWmpmlXr17FzbG6uvro0SOaphE6NBwOb9y4AQHQ06dP33rrrYP9w2QyOTExwTDM9PRsqVT66hfPaJr2W7/1W4eHh7l81ul0ptNprNSr1arf6+v3+xRFraysvHz5MhgMkjSF4mM8Hru9XoIg9rZ3/X5/t9tFdmQ2m/38889pmoa0FNMdgiDgJzCZTBa77bPPPgsGg6urq4eHh4IgnD9//vnz57VabXl52eVyHRwcIHBiZmbm+fPn4WAAvj+e5202WywWG40GUCBdvX59d2ur1+vl83ncN6FQqFQoOu12hmGw4iiXy7OzX27Kzp07hzig3d1dOCScTme91a5UKpNTU2dnZ5OTk4lE4sGDR+fOndvZ2RmPx61Or1AooKowmy12u93lcqJRZxjm7OysWq3euXMnm81icS9JssFgyGQy9Xr9V37lV54+fXp0dIRlKxbT0GxAeQP97tTU1HA4rFQqhULh1q1b/X4PxzWQlVhO0TRtNZubzeby8nKlUpEkCdm1GHBeuXLlyZMn2BKMRqNoPG6328E5SyQSJycnz5+/mJ2dZTkdimaEiBwdHcViMSgiCIKolspQJmDO2uv1sOehWAZcqGQyCYJdp9O5ffs2SZI7Ozv4ZsvlcjKZXFpagpdoZmam2+3m8/mpqanvf//7cF1AMSLLMgyJsiwvLCy02+3+YGQ0Gnvd7utSBusUo1F///79Yi7v8XhGo9G5c+empqb29vbu3Hlr7/CgUCjAXQhG9NTU1J//+Z/H43Ge5xOJRKvVAtX97OwMS2FAvHiex6gbl6nFYslkMoIg3Lx5EycAhnlQYpVKpYWFBRwLcGupqrq9ve3z+bxer8FgAJaPN+hjsdju9s709PRgMDCbzdPT06PRaGtra3Fx0WI0wSGLldqTJ08EeRyJRMBKfS0Fs1qtzVp9bm4ulUphSYqc9YmJCbjHMAgPBoMPHz5cW1tLp9OoPYbD4dTU1O7ubiQSabfbExMT5F/++R/VajW32wtXC0EQuOGuXbvWbDaHggQfH4ZGnU7HZDbQNMkwTK1RX1paevXq1be+9S1Jkp48e9brDUx6g9vtVhTts3ufyrK8vbsXCEW3d/ZGg6Ev4HfY7NJYJlQtEAo26612tzPsD+xOB0szsjK2WazyWMXNrSiqLEsGg7HX6yqKgjYRAUBwVGHlYTDyDMMoiowDCEFdvd4Af4QgCLfLOx6PK5UKZFWoITB24jgOv2m/33c4HJhMwoONmwneTgS7ogjTcQygHQRBjEYjSMdGo5GeN0IU32q1aJZSFAVdBUUxTqez1WoVi0Wj0YhxKIZMmUwmGo0xDDPsD7ASdTqdLMuMRiNQshiabjbrBEHRNNlut+EZ6Q970P4jHQ/xCAaDYWIiHo3G0aLB0fbw4UOSpFutlkYQmqZBEYJZIGySaN97/Q5N02gIMpkMCPjQFuCLgFXqK0QZ9WUjKMsEQWCO9eUEC9HL/yfCJ80wJEkS6v+xK8RfgkMNHhPgr/DZAi0LNYymabDghkIhRZEpirJYbM1ms1AsD4fDaqPZ7nSh5bRarSRDDweCqqpQErAcL8tyt91iWMqk14+GfZbW/r//n/+e0zFfu3WN43RPnzySJAkIe0GQTCaH0+MVhOHi4iKMkya9AZdHuVw+OjpOJBIsyw2HQ1IjVHU8NzP1OlW+VK04HI6JiQmdToe1LGRqZosFIrByucywlJ7jN9Y2dnf3aYIhKHI8Hp8V8+Px2Gq3Mzr21q3b//U/+We///t/ODs1azCbFFUVJDGbOWu32/MLs2+99RZFEZ1OZzjsezye4+PjWq0mirLRaOy02oqmqirBcwYYMAFLK5XKZrOZIDSYg5aWlrw+d7vd/vJ7pEiPx7O9s4kHUlXVmzevz8/PW82mRqMRi8XS6XQ8HnW5XOl0GjHA8ViCIIjt7e35hbnDw0PsBEOhQL1ePzs7u379uiiKDx48+Pa3vynLcrPZFkURRCuMaSF5xL7myZMnh4eHt2/f7vV6eKqj0Wi326Vp1u/39/v9x48fGw2mr3/961abJZ1OY+iSTp96PB632+lwOLrdfrFYXllZOT09hYiEYZhEIgEPRPLo+NKlSzzPFwoF6NDrjRpFUV6vt1qtYkhZLBatVutgMDg7O9vY2MCJd/78+W63Wy6Xx6oKt1c2m/W63ejuRFEE7X1qaurTTz8VRXF+fr5Wqfb7fY0gcWiwLBsKhdbW1p49e3bu3DlVU7B8x1B8a2sL9xys+PVaw+l04jNpNFqAxQwGA0kSoHFhWVaUBEEQ5ubmIJMQRVESRLC4RqPR/v7+0tJSuVrpdruKpsGHWyqVKIKgKGp/fx+LLUVRZGl8enrq8XjwDkKNB/sYQRCCLNntdox54vG4JElAE8E1CUYlDpmzs7OJiYmDvd3l5eVAIAAFjKIo/X4XKmxYrUOhUL5UhHA+eXB4YeM8ik5Jkubm5p4+fZrP5+/cuZPL5YBR8Pl8HMc1W18uWUDIs9ntgUCAIKiHDx8eHx+/9dZbgOyQNK1pmtFooigKOD2r1RKJhiqVSqlUmp6aJUny/v37oVAIGeSIqWBZnSAIAE/YbDYUVRBFnZ6ewgv5mjgKjdf6+jpgh7IsnZycrK+vp1Kp2dnZfD6vKIrH4yE1LZlMzszMNBoNDCPr9fqjR4+uXLrc6/WgylpYWtzZ2YEhWtE0juM0jYhGo5VaFSCoTCYzOz2TSqVevHgRCAQikQjKFFEU45Hoo0ePzBbTa2ojvpdSpQpBLZga8FpxHDcxMbG1tQU42ZMnT/CdBgKBUCi0s7OTTqdDoRDYQ7du3Xr58iVBEF6vF0Gi+XwesTkTExNHyRNoxvV6/ViWDQYD7qOnjx5OTEwcHx97vd5et9tqtdxud6lcXl/fwNPodDq9Xi+UiOiQUXD4/X5cshsbG4FA4NMvPo1EIlCDLS0tHR0dzczMVKtVLEAvXLgAtZbP50NgKMuyhUIhkUjAZ2o2m7PZbKPRWFlZAdI9Ho/LsjwxMYGPKJM9i8fj7WZLp9OZzeadnR0M2rEXioUj+HbK5fLFixebzeaLza18Pv/rv/7rIA0hFbHb7aryGDYsTdMQjTUzM4PpO4YCGNNA6IzqjeM4jNwqlcqlS5eq1arFYiF//Ce/bzAY8vni1atXaZrOZDImkwlqULvdfpg8wcGN5zKVSvkDXqvVjHpzKIwkSaJpKhaLHRwlrVYrqWmj0UgcSblczmAwrCyvtdq91FmW0ojD46Q0EvQmoyLJr7a38mdZl9dDE7RGkiaDYSgI/W5X0TS320uzDK4KYA7a7Tb8KZB61Ot1Zax5PJ5KpSKPRVUdY82EO89kMlmtdthS4OZTVZUiGZ/PZzKZUJmxLIv/QnzlQEZwARBwqDLRpGJNGY1GEZrWbNVHo1GtVkM7CGmUyWSyWR0EQXyp7+MYTPU7nY6mkZDk4+6H4RM1CoQg8DtAloR1NUGq8GxKwqher8NGvra+4nQ6KYpaXFz0+TwqoZ0/fx4ozkajgSxeg8GwML+0t7f35MmzR48eWa1WimL29/ctVivGXdB24LXs9/ulUmk4HDqcNlDpSqUSFlt4qoAoZBgGjR22QiDYYvcE1sb/sS4kSZIkUW9BAw4CFgTvUEHiX4QPE18ZfjCAduCPAy6o3+8DBErTtE7H2Gw2o9GM2JxKvdHudPEdURTjcLlQUhOEqtPxLMtqJEGS5FgSzUZ9v9e2W43/1X/5j/0+d8DnWl9f+8M/+A8gmBeLRWkkyIomyWooGlMUGZwCn8/ncbo+/fRTh8PBsqzN5sjlchTFCIIQ8PkZhqJJsljMv/nmm1988UWt2VhaWsIAGdlqXq/XaDQ+f/FiZmbmS5OaNBoOh9cuvbG/f5iITrx8+VLR1InpqWq9Um81R4Lg8wU8Lt9f/Pgv//2/+/dTs3OSLA9Gw7EkN5o1r9cbCoWGw77X6zWbjRBVpNNpgqBYlh30+jzPj1UNWBeW4cCBE0VpOBxynA4TndXV1Vg8cnx83Ol0wuHwWBJpms4Xsq1W6/z5851ORxCGv/Vbv+Vze1RNwaBLkgRMPTmOq9dakPr1ej1ez718+VKv1wcCAZomE4kE3NTT09OdTicQ8H3++efT07Oapp2enq6trRmNxonp6eTBwf7+vs/nw1dMkuSVN95IHh5ubm5eu3YNCutsNg9aislk4nR8o9GIRMPYp/T73dFodOHCBUWRHzx41On0nE4nwNwIP1hdXR2NRqenpxzHGQ0maNjRZV69enUw7OdyuXw+jyEH5nmiKEIZHY1GkY+RyWQikUi9XtcbjYA2ud1udTxG8iuIx9habm5u/uqv/urp6SnH6uLx+Fk212q1nE5nvV6H7N1gMNRqNX/A9+rVqytXrlQqlWq1GgwGwWBrNBrhcNjt8sAlUCqVdDoeC8TvfOc7w2H/5cuXkUiE47hOtw1KJGJeJEmKhMK1Wg2eNVVVT05O7E6HwWCYW1jY2trK5XKj0YhjWZAPB4MBqoFatR4KhSYmJiAIW15eRhgoUj4olsFBl0qlrl+/jlJsYWEBRNlOp/P1r3/95cuXx8fHdrs9GAw67bbt7W2TyfTGG28MBoPd3d1+vwueBY5Nu93+6RefT09PBwKBg4MDVZQ7nQ5oAtieQ8mERheDjdFolEqlLl682GzVE4nE2traD3/0I5Ikz5+/iJjwSqWSTp/p9frF5WVFUYxGE9CMbrfbbDa92nyBhAlRkBFlBliow+GAzs/r9f3kJz9xOBznzp3DzmE4HB4eHnY6nd/7vd/b39+/d++eXq+PRqMejyebzb58+fJXf/VXeZ4/OzvjOF02mwV7E2avqampWCx2kkwOh8NisSgIAtwSFy5cKBaL2cwZcKy1Ws3msL+2abu93uPjY6vVZrPZqvUaiCEkSWZS6UQicfnyZTQAiNO+efNmMZff2dmZm5+tVCpnZ2czMzM0TR8cHExOzyD1pVqtIhHo1atXCFMCXQwVea/XE0XxG9/4xrNnzzBxz2QyHMeB8uX1eo+OjuLxeCgUunfv3szMTCgU2traarVaHq8fha+iKO1WS1GUK1eunJ2dtRt1p9OJnq1cKgmCEAgEisViKBxFc9vr9WKxGOZAJycn6XT661//eq1WM5vN+/v7mOfNzc31hj34vdCngSIE+XwgEIAEvFqtchwHjTzsLJD3WCwWgiA2NzffeOONly9f4rzN5XIURcGC2mq1bt6+JYpipVQulUq/9mu/dnBwcHR0BOhatVqNhsLILSUIAiTL08zZ69sZx/jFixcTicQP/+zP4XFZPXfu3scf7+zsAIF2/vx5rIZhy+t2uzhGJEn64osvnE5np9MplUpXr16NRqNPnz4ld198QVFUPl80m80mkwlx8cg893q9FpsDQUVYh7ndbh3D9HodhdBUVaVZymAwlEpFl8uFRWa9WofmiaKo2anZRrv14vmWyWL2e321Rl0cCYPRkNfxDMuenpwwLMvQdPL4uN/rqZrWbrVC4bBG0VCVHh8fQ1NFUywmCh6PR6/XN5tNTSMrlQpGiEajPhKJQNRVLpddLhccgtgroQ+LRuOlUslisRwdHek4PWLjwCyA9AFon1gsRpKk0Wj0er2NRsNoNEKHhEJKFEWNgFpLxEDIarUSBEVRVLlUBaxoNBpZrCYoKDEPAEoE7CsUDdDr+Xw+WAUB6ZFFKZfLtVqt6elJs9ncaNYcDpvX6yVUBXkgDMOUSoWZ+TlhJCHlA08tJLRut7tarUYi0Xq9/kd/9Mcmk8nhcPR7Q0ESB0MBMbR37twhSRJkW1mWK9UStOdYPmazWfx4WL+SJIlDEFJxaNiRhwPjJ/6/giC0u90vDX2apn6FhFUVBSD1sSyTFMXSDDAcoii63W70x3C5g4iGIG1oUcfjMb4dyNdMBqPdbtdIqlqtForlRrs1HAmKoimaJssKviNF0fR6jiRpSZJ4Tk+QmiKJNKO1W/VvfuOtf/J7v5fNnMQTkeGg12m2zp07d//+/U6nFw5F+qOhRjAcx+l0DI4tvV6fOj3GTjYQCFQqtcFgMDe7MBwOU6mMxWJaXlw8PT2G9RJFVX80fD2lw9x0MBhghxUMBjm9rtVqmXkTSdLCQPR6fY1WY35pvtvv7B7sG0xGs9ms15kWFpb/we/8g5/+5c9mFhZFWWIYqtfr6VhWkgQgD3heNx6PPR5fPp/vtjsGg4FhdKqqtttNXBjhcFSSpHq93my2+/2+1WbT6/WxeCQSiQCT22jU3G53NBptNpscq6tUKtVaeW5urlqtLi7OX716dXJyMneW0ev1sixmMplOp7O6ujoaSqhX2u223WGTJCmRSGxtbTkctrOzs7fffpthmF6vg4JmYmKiUqkpijI5OQkKw2vXMMdx6HqHw2G1Wg2Hw4VCIRgMiqKYSqV6vQHMARCdrKysYG2xsbFer9drtVqpVNDr9RaLrdXq7O7s3blzZzweIwIsl88CEANtKUEQ0C9iQSAIAjhSgUBga2sLxQTWDSzL4g+i90XaT65QFEWRZ3VTU1OJRKJarYIMIkkSvK47OzvvvftuLpcD5EJvMAAdvLW19Su/8isQMguCYDIbj4+PV1ZWQAD2+XwIAy4UCisrK5IoQxxzenrqdLpXVlYQAtts1ovF4pUrV/b29kxmI0EQ6XT6a1/72qDXt9vtyH6QZXlmZubly5cGg6FarxkMBpbjoDEdDofiaAQuGrS6qVSKImmPx7O7u4vJPTIlrVbraCROTU0ZLcadnR273Y5hD2R8wWAQEXVQZANeqGmaJEn1agVI2Hq97vF4otFouVx0OBy5YgHel9PT0xs3bhiNxp2dnUgk0qk3p6amnj9/LsuyzeYAay0SiWxvb2P/hdEdtBlOp31/f39mZsbr952cnJAkjV+20+nksnlJkkaSKEnS+voGymKbzfL8+bNINJTP56enp5vN5tnZ2ezMPEEQHo8Ho6D9/f1isXj9+vW5ubkPPviA5/WIc8H7ixGOxWKpVqvdbndiYgKnHLZ+giA4HHYA5CCrqlQq8Xj88PCwWi5fuHAhlUqdnp5GIpGpqSlBENLp9OWLl3q9XqfTgZLY5XIdn55IkpSYnFIUBSVab9BfW1tDPrEwHOVyOa/XGwwGj4+PFxcXkXqZO8s8evQoEomQJImwapxOM3Pz1Wo1EAhg5/AaeaXT6dBpg90AiBS2afBsITkb6UCiKCYSCYASy+UyfmWM8EeCBCmS0+kkNA3w0kQiocqSyWQyGgw0TZ+dnUFZ2Gw2CZJutVoIkmq1WqFQKJfLORyORCIBb+yDBw/W1tbsdns8Hq9UKh98+IHP57t9+/b29jYWxHBQQdTY7XYHgwF6JJhzJUk6OTnBqYULC1ct1oL447CwoG83mIyj0YilGZqmUdl3Oh1EjFSr1VF/YLfbo9EoloaRSMTjD6D6xN+8srLyySefzM/PXzi38f3vf9/pdEK5XygUWJYNh8MMw+DnQYkvSdLVq1e9Xm+/33/x4gVEGhhpr62tGQwG8uWju6Io4rDGYmt/f1+W5cnJSYvF0mx3UZ+C8Onz+Rq1mtFozObzLreDYVlJFqxWa6VShsDIYrKQJOl2u9vttiqrJpNJJb+U4CiKguE8TbGvWagEQXAcB1UESHG9wbBQKqHVA0xL0whBEFRV1TQynU6bTKZ6rQkykNFohNWT4zho1VVVrVQqPp8P5BjIPxmGwdiz1xtIY9lktED+CbYnLnuTyYTdHwpbGNlEUcRPGAgELBZLr98xGAw6HYONuyiKxWKZ4ziWgf242e12LVYT5CZQ7UC03mw2AVuD0yGbzWqa4vf72+222+22Wq2yKEWiIbfbjWxLr9fNMLTdYdXRzGDQg5Yrnohub2+znN5qtZ6cpBiGmpmZ0+u5g4Mjr9c7Nze3v3f4/Pnzhw8f6fXGUChUrzVzuZyiEdVaDQZmNAput9vlcg2GPRikQXwBjq9cLsPZh64LzRneYZyA+LRhEsTwbySKKLAIglBk+TWsEhUVdBXCcGQymV77AaPRKAgdQPzzPE/TNASwGKHhz0LORZOUwWAYjIRiqdRqdTq9fqfXVxSFZrnxeMyyHJRheLuUsappJEURBp5rNkpWs+E//If/2eu09/qtZr2u45jpiclyuVooFJwO1+7ufiQSa3e7N2/f6vU65XLZaDD0eh2KolRVhdmq0+nNz8+rslqp1TiW1TRN0xRMwnEwCYLQGw6Wl5fhuAHxEom5/X6/Wi3LyliWZR3JttvdgDdEEMRZ7sxkNVlsZrfPXa5WLBZLo9Y26M35dOH/8f/8FxanndXx/X6XIAiaIpDTwnEcTZOapi0sLDWbTVmUzGZzrzfo9XrDYV9V1XPnzjkcjqdPn9tstrOzXDabZVjWaDTOzc/E4/FWq+Vw2BqNBu4Vi8VCagTHcZtbL8PhcDwe//73v/8v/+V/U6/XxdFwYWFBUWSsKmZnZx8+eHL+/HnklxGkJsuyxWKxWCzdbhuY6Xq9brWaFxcXd3d37Xb7eKwiASaXy8GerSgKVN4AS4LXtbCw8OrVKzxmg8FgcnIa56zT6cRpW61WfT7fwsLc1tZWp9Oiafob3/jG4WFya2tn49x5FCvYRUaiYczGcG1rmhaPx/ECYoTj9/v1ej3qP+AYkKfmdDrhXUUIQbvdNpvN585fyOVyRl6/tbWF/TWSNxcXF+/evQsGL01Rfr+/UChEo9FUOp1OpyVJWl5ehogHsv3MWdpisej1eoQ6Y6xis9kwQmg2Wm63G7k909OzwPvF4/GnTx+zLOt0OsvlcjAUgA+ApulysQRZwsTEBPioL1680Ol02XzOZDJJ43EwGIzH4/1+X8cwzWZzNBotLi6m02lN0+KxxN27d2dmZjDOBxiz1WpFo/FGoyGrsizL2NGfnJxEIpGlpaXHjx8LggA2PUb+oVAIny1LU6qq1uv1mZmZer0eDocxwSpWyvCl46ZYXl7e3d3VNG1hdu7Rg4fwhErSGIEQ+BtYlsVii6KoO3fuNJvNnZ2d1dXlJ0+e6I2GYDCIFIrp6WmLxfLhLz9yuVydfk9V1WAwDC58On2qKGOb3TIajTwez9TU1N27dycnpjGG39rawjUsCMKFCxeAEh0MhtVqFT0DnCvATWHF7HA4MAh0uVzIV2k06rC041Py+XwIr1ycn9/c3EQ8hqqqYBA2m80LG+eRRTMcDjVNC4fD/eGAoiiKYff399fX1/P5fG/Qv3bt2o9+9COHw+H3+mDuw4pAVVVsRSRhNDMzAxMoRVEnJydYeXv9AVA3JyYmarWayWRqtVoul6ter49GI+jMgJm9devW8fExBGowMfj9/q2tLSRDgC8FazZiMaGCJSkGfLKNjY1GvZ7JZCiKmpiY0MZyr9crl0owuqVSKTBjF5dWTCbT4eEhWqxAILC+vv7JJ59cu3YtlUrhPcXAFecGZ+C2trba7XY8HseQG6Gfv/ZrvwYbY7PZRLVUr9cnJydTqVStVnvnnXe8Xu/u7m4mk/F6vdhEQyAoy3Iul5uZmVleXv7kk084PW8wGI6Pkjdu3Hj27FksFvN4PD/60Y/cbvfMzAzP6jKZDBjx8Dk22p1cLjc1NYWNjcVikSTpT//0T9+4fAUmaNx3mUwG3hpgt81mM9aOgiDcunXr7t27L168+N3f/d1MJgNhAxqwdrtN/vH/9q/tdjse2WKxCLkZEtbMZnOt0cIGx+/3n56ettttQiEYhml22tFoWNM0SRaksVir1RYWFgRB6LY74/FYGknQx7hcrmq1rNPp4NEFUhIUg9FIxNEPVEa9XjcajWNN7fZ6mqYZjWafz/f8+XOfz9fp9FiW7Xa7hEbCrVMqVSYmJg4PD51OJ6PjoVDDIBHhZfV6vdlsYuVns9nyhSw+kXAoyug4PPe1Wg0dtqIomNIBZwUqCThSdrudpliPx6Oq6mAw6PU7jUaDogiIInu93mgkOp1Os8mKX8Tj8WCk1B90VVVttVpLS0s6nU7TNEiphsOhz+czGo1raysrKys8z7MMAyGt02m/e/dup9OOhEJms7FSKZGUBnFxr9OZnp6OJ6LpTLZab3S7Xbvd6fN5BoMRw1Ao8nq93vz84n/1X/4ex/GxWKLRaNAUm0wmHS43mEmdTuf09BR7yVgsNjmZUFX18PCw2+0i/gxeKpbTSZKErT98AyhDgaj40jlIUdjhsiw7FAT8z2iapkkS+0H4BzHS0+l0vU4Xe2tZls1ms9vtRrsMoRtMTDCDQGkOCyGUcJqisizb6fXTmUy/P+wNhrVGUyNpZIQzrE6SJHWsMMyXm1lSpQlCFUYDg5H9h3//P79160o5n202KoNe1+fz2K2OwWBAkWyj0To5Ts0tzM8uzNYbVeCjXHYbVqjhSEiW5SdPnqyvnZNlWRiKh8mjgM/f6rRVVUVKTKFQgChVkCU8bJOTk6hLsNfmOG5paaHRalar1YDbTxCUOJSHw6HNYeOMbLffqbcavF7PMEy72ZUl7a1bb/3v3/v+/+2f/teXLl8ej8fD4ZBmSFEUKeLLZoBhGB3DxmIxvd4IWWG/31fVcTDkv3XrVjabpSl2MBjs7x++rv+i0ajf76coAtfMeDzWGw2KopGkRlHU/c+/KBaL/8Xf/3vPnj1zOGzf+973mvWaKIqDQa9UKgHUmcsW/X4/zhS9Xj8xMbG9s1WpVPx+r8ViOTk5EUXR7XYuLS2VSqWPP/642+3Pzs5qmgYzMo4hwBWxp8ZyCg+Joihup4vn+XT6DJoE3AQwHHk8Hp7XtdvteCI6MTEhCML9Lx5KkhIORTe3XkYikcnJyeFwCErNs2dPJycnAfh2u50QmKfT6cnJab/f//TpU8xKUVo9f/78woULGPKfnJwAOR2LxexOx1kuT5KkzWwJBAKPHz+GzBSt7f7+PkkQmE9DD1utVk1mq81mC4eDOp3u888/H41GU1NTNE3rDXw2m8XR53A4ut3ulStX8vl8sVh0OBzNRgtPeLVaZRjduXPn8FkRhJpKpTBDOjjcB9Q3m81euXQZ21WIh7AoLBaLFEM7nc7TdFqn07W7ndFgmIjFOFaHTdnCwoLRaOx0uvv7+4uLizab7eOPPz537lw4FN3e3m6324PRcGV9JZ1OBwIBWNK8Xi/LslB9hcPhx48fLy4u+v1+wIdJkgz4vE8fPwmEghMTE7u7uxcuXKhUStVqleF0gILCwglbFkEQg25PFMU7d+4UCoXDw+Ty8jIAgRRJQ1mL2o7jOOADTEZDPp+9cOmy1+v96U9/Gg6HeU4Pw6PJZLI6nI1Gw2q1siwbi8UeP36oaarL7QB3Y3JyUhCEo8Nj0OGdTqfNZnv//fdnZmbAlJckSRSlTqdz7dq1Vqt1enoKfzowmGBoYQGK+Cmv15vLZfv9frfbDYVCyGOBhEPPcdgBrayslMtleIAikUjy8IAgCI/HZzQaocgxWcyDwYBiWAgk7t27t3948I1vfGNxcfHhw4eKPA4EAhinWSyWs7MzsO5Gg/6bb775wQcfWCyW/f395eXllZWl+/fvExSzurr65MmTqakpXDf9fv/58+cTExMmk+nly5dTU1Ozs7MvX77EugCDAwhaFEXJ5/NwOPn9/tu3b29tbZXL5WAwCAGcKEq9/nBiYiKRSDx79mx7awv8epIk3//JXwQCAR3LYtZwcnKSyWTm5+cHQ4FhGBA0zWbz1tZWKBSy2+0nJyeqqgYCAbhigRW12+3tXhu8rpWVlX6/XygUpqenEb2wubm5vr6uadovf/lLvV7PMEw4HIZN59mzZ0AZALYM1PPx8TGYZ4Ig5PN5pHHs7O36fD49x0MBNj093ev1lpeXHz9+fOnSJafN/vTp03Q6fefOHXRxRou1Vqslk8mNjY16vY6YxWg0uvXyld/vd7vdH330kd/vNxqNgGXCCorOx2AwIA1pdnY2nU4LgnB0dARtMQA0Xq+XfPL5h61WiyAo/AJerxuPBSzcDpfn+PjYbDZPz0weHiQVReEYzmw26/S8z+c5ODigaMJsNp87v87SzNOnTxmGqZbKLMs1Gg1UrINBj2aoQX/o83uFkdjrd3UsB1cgJIcEQUD0QBCEzekgCOI0lYHiFV5Zg8F0fHzcanUCgYDZbC6VSoRGGox6o8Gkqmq710cKOogmAOFbLJbhcIhxC03TkiRgvr24uCxJ0qOHT/x+f7PZBCO+0+kcHB0O+wODyTjsD9rdDsSwgJjjyGYo1ut1Y7m2uraMBr3f7+v1+kF/pCgKz/NutzudTrdara9//etgnbtcrnw+r6qqyWSy2S12ux0WHqfT3u124YUWh6NwONztdeCbkCTB4/EIwnB6evooeaCqqtvtUuSxoijlSjEciQxGkt1ut9lsyD9XFGV2drbT6ZXLZZvN8d/+N/9dNptbWFjidHq93nj//n1ZGcP+CZAaEHOhUGh6erLb7R4fH0uShJMOYsyR+KUnFkMp1ElY2L0O/sQGFuJ0gqJQjZEkyXyV9wefMz4fSZJ0DItWAKgOBKe/BvhiH4fpaSwWazab1WoVCV+KotitNrQCR8cn/cFIlMftbo83mAiCGKsaSVCaplEECSuGUa838EZZFmVxeG5j5V/8v/7vFKkc7G3yHGvgOb1ez+l4QRCa9ZbXH+B0+nqj2h/1AwFf+iQdi0VAtPf5vbBl+Xw+WZBFUfR6/e12GwVis93iOJZhdMCLkAyN1hbmHQTaPH782O12oz9mdDTHcVaz7XDvcDgQ3G53OBJ8sfkiPhGTFcVkNva6fYpirCarjtXncrl//i/+ZTafA2t0MBgwDEOoGsAWgiDE4/FwOEwRtN3pKOYL4/F4cWmWYZif/OQndrt9aXFlNBo9efKkUqlQFAPq4GAwmJ6e7PV6FE2oCmFz2EmSpiiiXq8nYvF6vS6IQxy1//Sf/hOaIDvddiKRKJeLtVrNZnP0e4N8Pg/PXTKZxDDYYjW7XC6LxQQrUCKRSCYP+/1+NpudnJyGOvX1DgLESPCR33nnHfBsTSYT+uyAzz8cDk9P0wgrhNoPEQVutzuTydA0ifEPTdMWk8lpc2XzuXA8zhsNz58/n4wnKuUyx3Fra2vVajVbLGiapmnqsN8PB0PaWCFoCsE+4/F4MBjAPGE0m6LhSLFcOj0+0el0c3NzBwcHs7OzDKt7/Pixz+ebnp5Gnjc6CmAws9lsrVpVVYVh2OnpKY/H84d/+IdGk/natWs6nQ4SYwxiJUnSCBVRG8Ph8OnTp6FQiNdxvEF/dHT0d/7O33ny+CkS+gwGw9TUDILVRqOB3W6fmpoqlUo8z7c7LUBDeJ6fTExubW0CZPXpp5+ur68XCoWlpaVILGqxWLZ3dx89evTee++lUqlmvR6LxRR5PDE1yeu4F69euhxfRi9jYTQ9PW00mJGfs7C0WGvWjo6OgsEgQIAej+fTTz/d2Ngwm83NZpPjuOPjY0i8AZGem5nu9/uvVWUAQPC8jiCocDiMPIBgMOh0u3/8wx/CYGu1WjGenJ6eNplML1+8wk2Zz+cxlsMXBKfb+rm1aDT84Ycfg2dbr9c77a7X68X/Wak3cLBrmjYxMcEw1OnpSa1eWV9fx4Hj9XqLhTKo381m89y5czjl7Ha7pmm7u7srK6sYduZyuU6nY7FYQP8C3HUwGHg8nkKh8PrXv3371vb29q1bt/b29hCSjaPP7/VOTU0B4AJZNyhrmjImSdLnCzx9+tTv93N6vlaribI8P7+AKVGlVgXv/vr16zs7O9nMmaZpiCSiKEqv1+dyuWg0eri/Z7PZ1tbWgNSZnZ2F38Jis3322WewnCOTF9v2UChks9kODg46nQ5ERZDQzc/Pb25ugoMAhziYWziQr1y58vLlS6y0oOM2GC2oTT/77DOnwwGNlMlk4lkmGo2+evXKaDQGA4GRIBwdHpotFoPBlMlkUOgAGXXp0qVPP/0U0J/hcNhqtV4zC1iW9Qa8nU4HIm8UlOBT3L9/H08IFqZra2sEQWxtbYHvipwAWPix+4LXVVVVpMJcu3bt008/jcfjmqYh6xayjUQi0e12KYpCcMXK4tInn3xisVgSiQSiVhSCdLlcXyJaBMFgMGxtbc3OzsYj0S+++MJkMl26dCmZTB4fH8OCcHZ2lkjECILiOK5YLM7OzmKQn8/n4/E4QRBA8r711luHh4e5XI58/wd/KkkSpJc2my2byzgcDofDUSoVMIEEqFBVx/V6ExJRk8kiSZKmKXByCYJgMJsK2RwcPYNeH8T9K1eu/PKXv7Q7HZqmDIdCrVaxWGw6HWOx2Fwu1+bmJiZPBoPB4/Gsr69nMhlZVfr9PqvjMXx7vVdSFGV5efnBgwdgcUUisUqlZDZbc7mc2WzGdApVQiQSKZVK0OJhJQyrkdfrhc0eFUC5XPb7/SD5OhwOt9fbabUgtCcoCjs+pEhC6eVze80WE9bDCNyWhJGmaWNJMuhN4/EYrMJmsxkIh1qdNrj2SMICThDyZ2BzZ2ZmVFU9OzvjdVyrUZNlGf9Snue7vTbP84ASAW3Q6bQ0klhdXQXAOn12RtN0JBJJJpNfggrbPZZle70Bzxv+8ic//fDDj7/9rV8fDoc0zWZy2U6vrSgypjvlchn8MBj0nE5noZADgwcxQYPByG63Y/eErHhUUeOvgAhjRcE/hHVZ0zSGpaBiQQWG0RROQMwCMYqH/kOn01EEiZG7qqrIz4KxEZ4GvV6fyWTwrMdiMafTKQlit9vN5XKg+QuSLGuEKMnSmOD0BpKgpLHM0gxNUjRD6Vlm2OvLkmC3W/75P/ungaBHx5CyJDSbda/Xazabi8Wy0+nstTv1VnN9fb3X6xUKOa/Xo0jjmZkZeJ4xyiU1AtmUiOUaDAaNRmN2djZXyJ9lMwtLy+FwGNP4TCarEQTe/+XlVYIg0APVarVer0MzpNPp+OijjxOxCbfbbTJaGo2GxWZlGApzCIqirFY7AmfC4XA6V/g3/+bfCIJweHi4vLw86I9QvwqCxDCMxWKLxmIGvd5qs1nNtkazlsulO92WJElra2ucTg84yHA43N8/zOVyv/7rv465aS6Xg4TfbDavra3du/tJLpf77d/+7TfffHNnZ4fV0VartVIp+dyeQNAPkJUsixsbF6rlqtFgRsBfu93u9TtTU1Plcgnmapqm+/2uIPwfXWy338MhCOsGxDE+n+/jjz+GpRGMhnq9DoOhIo/NRqPH7YO33+12m6yWzz77DJuISqUCyBY6K5/TXcmfqYQmcWwgGtMbjenkiYnlbt+4SZBks9P99PFjo80iDIYnhwdxT8BhtWg0UawUQSXw+n0YDRrMpl67I6uKjtaZzeZqpYYBVSAQctodP/rRj5aXlwVBaLUbJpPJbDbZbDaaZaBk73Ra7Xb30qULSFbheQNygicmJiiKevHixczMjCzLyJtzO104soxG46P7D6fnZuuNhtfrjcfjBwcHGDA0m81MJvPee+/9/Bc/i8ViUO/ZbDYU2UaDqVwuVyo1TVNWV1e3t7fPzs7eeOONbq8zHo9rtQr2OziC0tmzSDCUyWVTxyfxyQkjbzRZLDtbW3CZdTodl9ONYFlQcy0WS65YAqNkY2NjZ2fHaDRC+5JOp/GTwK8DnrjDYdvd3ZmIx01GM8uyR4eHCMYpl0sURZ+ensZisUQi8cUXX8zNzzvs9kq1KstKrdnAfkBVVZ7XnZ3l5udnEQ8H3WcwGMAR1G63HU7bYDAYy+ru7m4ikcCHeXJyMjU1/eLFC543mM3mDz/8MJFIuN3uUqkQCgUZhrl8+fK9e/ecTifDMNiX4ThiWXY8HrdarbfffvvBgweCIPC8HqIR6Hq3trauXLkyGo0KhcLU1BS6O8j1EHIAbjaEgzAeQu9xdnYGCWkmk8Gbe3JyEo/HXA7b2VmaJGm/399qdUKhUK1az+SymkaazGZ848lkkjfoBUEIB0OqIjebTURWANG5s7Njs9nQjlIUBfYyTdMohsBaOzw8hGJV07RAICBJUjqd9vl8X95BgQCyjY1G43e/+9c/+OCDlZUVhA+WSqVSqZRIJDqdzuTkpM1m+/DDD6HKj8fjOzs7sqyCB4tZJkK1gQEbjUaNRmNiYkKVx9lC3moyS8p45qtYtlarFQwG9/b2gNVF8bG9vY09kizLUO7a7U6e5zc2NjY3N2u12uzsbL/fBSq2Wq1iP+jxeL7xjW/s7Gw/ePDgm9/81v7+viRJHo8nEolYLJa/+Iu/yOVy167daDabsCeDlAHu4NramoHjP/vsM57noWPe3tmy2+3JZPKNN95AshAe+Hg8Xq3U9g6PoDCORqO7u7vr6+sbGxuY14IRHwgEwFYtFAqdTsdqNVMUubu7Nz8/v7Oz8+abb3a73fv372Ow/Z3v/Jqqqnt7e9PT09BEkT/50++DPSpJYiwWq9VqrI7O5/PNZh2OD4/Hc3R0IEnShQsXjo6OBoMRuAbNZhOaL1EUt7a2MBB22OyQUS8uLno8np2dHZXQ4GYC7SkYDB4cHADX2ev1AIBxuVzoaHO5HEmzJosZlItOpwMaJ7ZskUjk+PgYPoVerzczMwMWGRRUgDhj8AZZIpBaTqdT07RSqWQymTKZzNLCYjqdXllZabfbSJwYCqNmszkxMYFAeJvN5gsGKpXK+vr6cDgkFBWKxWq1ajIYMcgNhUKNWqXX69ks1lAolEwmm83msD+ITyRiiYmj42NUJIPBAOYalmUBf8LRORgMkGOwurqaz2YsJnOn11VVFSQFjHbzpeJwOPR6vV6v9+WrV5FIBIsGVRu/2tqKxWJGoxF7jW6rWywW4/GpQCDwh3/wxz/84Y9v37ojy4ooiv3RkCBUWZGePHni9/tDoRDCX8PhMGyrmqZA+VQoFERRLJUq4XC41erglUZbBgASiqqx8uV/UGCRX5KwNIZhsAR8LaJCAwFgI/yA0DbxOg76qtdif6PRCOpsJBIhCALvM5T7HMeRGlEsFs/Sp7Isj0S5N+jLY4JkWYrRdXpDvcFI0/SwP3C7nNJI0PMMMZZPT4//13/3b1fXFnudNs8zsiRIkiQIkslk8vuCZrM5GPLfu3eP43lVGzts9nK5ZDYaLRZLrVoHn4JhmHazVa1W8Urncrnp6WlUBha7pVqtmq3WUCiUSqV5nuf1Ro/Hc3BwYDKZPB5fv9+H43U4HDoctkazxnE6ltWRJKmppKZp5XJV0zSs8Ox2O/73HMdNTU3U63WSYXm9MZvN/uAHP3j48JHFYjHoMerTjcfjaq2BwPbRaBQOR/P5rDDqyWPR7fKurq6SJCmK4sTERLlcHgwG9XqzWq0uLS31+/3PPvvM6XRGIhGY+Zv1BmTCZrP5ypUroigqqry8vPx/+Y3v7u/vJ4+PXC6Xx+Maj1VN0VKnmatXr2azWQSKG036QqGgaSpqSpZl9XqOYRiAEPvDwblz55B7j2XEwsJCOp3udDooYgBxdrlca2trDx48ODtN3bhxg6F1IObX6/V8qYjifjAYUBSNJKhut1ssFmvFkjLs+EOBAakSrM5osTZrdRtvthnNmWx27+jw3V/7VZrTbb18tbG8KjQ7L549LdXKsYmYIAgej6dYLoXDYVrHgjIfj8cr5dqVK1ce3X94enrqcnlmZmZ2t3doghRkSVEUmoGiVl5fXy+WS0dHRy6XA59zqVRKp08TiUQqlZmfn280WuFwuNvtNhoNgiAgr6Rp2ufxfv7550Gfv1KpGAxGs816586ddqfzV3/1V1iCYChy586d45MkRNmNRgMhqh6PRxCEdquH8ujo6Ijj2Ne0UofTbjQaOY5NpVJoHg4ODsbjsdVhx0RB0zSP29dutyuVCk3TBp6/ffv2q5ebEAPgRv/8888r9cbU1JTdbp+bm/ve974H8TV4tizLQuCsKAp8J16v2263UxSZTZ8piuKw2/v9vt1ilSQJ8IVed1Cr1SiWATc/Go+VKrXXWJx2p8my7Ozs7OnpqSiO5ubmMOA0m03IWolGo8NRX1EUZazxPI8bBDE7kiQPBgOz2QooEUQjmUxqNBqFQkG73Y5zBkAc1AFQnUciEUmSMEYtlUqqqnk8HtCbV1ZWstks4Ku4Vmw22xdffHHz5k273X54eAiXEoS/GKMyDONwOOCzCwQCEFesr6/v7u4+e/ZsdXXFajZmMimSpAmC0Ol4SZI0klpYWMic5URRBCzt4OgQCnqPx9NtNV8niNA0/ezZs8nJyV6vh7U1qhxRFFEQAx5rMpmQ5312dra3t7e8vAxABpzmWAJAO2WxWLrdjk6n8/v9yWQSq67Dw0NRFCGTx1+LD2R3d9dud5RKlX6//yu/8ivJZBLyL+jPKpXKxMQEioxoNCqKYjabvX79+osXz1iWvXr16t7eXjAY3N/fb7Vaq6urIHi3222KoiYnJ7e2trrd7vz8fCqVAaITLhZFUSiKaDabkCeWSiWHwwHCQjweOzg4CIXCXq/3448/RqwI2rZKpWKzOdA1offDGmEwGBwfHsEA7na7+/2uwWCoN2qj0Whxcf7s7GxnZw9Rkk6n0+VyVcrV/kh4++239Xr9D3/4Q4zJ33vvva2trZOTk3g87nK53n//fWBlBoOB0ag3mUwEoR0dHRkMBlkeY3ZAURT4jgsLS/fu3QM0O5VKnT9/nvzo/Z9ARZtKpUqlks/vwR7a7/fqdDqIeyCXsdutuVzO4/HVarWrV68iSAuZLTB6wIZjNpsVRRmNRpCzGAwGVOIMw0BnMxgMoHFTVRUsE4/HU6/XaZpWVZVmOUVRwF7DWDsQCKB4el1LdrtdTPNsNlun1wVCIpPJ4LVBWQDrRKvVEkURFAaTyWS324f9L4ue/f19SAsrtarBYID2NhAIYFyBzsBisSAFVs/xoBsYDAa3x6lp2t72Dp4JWZbr1ZrH48GpZLJYm+02NID4KMbjMZ4AbBux/oDEezQajSXBYDBA3qQoSr1e1+l5h8OBFWoikYCmFTO5eCLx0Ucf4bkcDoeTk5M4OAaDQbPZdblcFrP9d3/3dz0eXzgUpShmKAokqZ3lMoPBoN/v2+12TPu73S7mWKhrv3rQKXyJ7XYbpzAKJtgrpLGMSRUqKvxzwLEgFBuNRqi9YARTFIXjOKyAQVUGZIulGZiKUTTzPB8Ohy0WC0CyZ2dnUAS73W6j0WgwGEwGY6PRSKVS+MFGotDrC5Kq8gaLrKgUzSiKoo4Vo0E/FiWXzdzrtpcW5/7H//F/ePzkPq+jvV53p900GAwUxdRqtaXFld3dXYqinC57sVRaXJp32OztRvP09BR6/PF43Gg0/H4/x+pGo1E+n6dpOhAIWK1WgiDy+bzd6SAIgtaxuVzO5XJBLzg9PV2pViuVSqvVWVtbQ+i4Xq9nGEoeiy6Xs1aru1yuXLYwGo16vQFQ+2dnZ4IgeL1enY4xGAx+v5/n+eRpSpZlZawZDIbD5NH3vve94+OTer1tNOg9Hk8kEqtWqyyn0zSNoXWCIFjMRkEYRqPxRCIxHA77/f7S0tKTJ0/0ev3v/u4/liTpX/2rfwUteafT8fu97XaboghC02q1mqoQbrdbIxSXywWB+c1rb4RCIY1QVVUVxdHBwZHb5dHrjZAnZjIpvV4fDAZVVW21m4FAoF6vT0xMlMtFqMQgQSUIAsBPQRBSqZTH4wHswO/346Hd3NzMZrNzc3OaplGqNhwO3W43Kj+z2byzd6AoChjTEA4jxO3o6IihCL/dNjM7zZn1+8dH3U6fZVmT3iwJskpoOp432a0I57mwdm5vc/fo6Oj8xQuFckmW5dFoRFCaXq93eT06nQ6a90K+dOHChS8++2wwGOhYrtfrNRuNixcvQvZuNpuDwWA2e2Y0Gt1e18uXL0ejUTwe73RaOp3u4sWLuVyOZTkcvvAYkiRpMFkQEdPv94WhcOPGjWGvjxV88vTEarWurq2BWI0A71qtlslkEhNx7KCxjsxkMqDpmE22n/3sZ7Ozs0+ePJmenoTXtd/vmy2mubm5ZPJwbm7u4cOHaGmi0Wi3PwSoaTAYYBCVzebefPPNzRcvHQ6HxWIBjwYGoKWlpWqjuby8bLfbf/CDH4TDYbfbDeVrKpV66623Go0GTdN7e3sTExOyLNdqlUgkEgj4U6m00WgkVW0wGBCaptPp6pWq2+3WSHp/f9/j8TgcDkESeZ6nWQ5/pyiKLrcDm/darcZxLE3ThUKepun19XWaplHHnGXTBoMhEo4h6BDhFnq9niDIwWBA0yw2VrIsW61Wi8XEcdxg0IfIBEKiYrEYDoc9Hg8OE7jjEbk4Go3sdodOp8tms5qmJRIJyFpCoVA4HH727Jksy5cvX/70009jsRieGYwtAfm02+1ra2vZbBYUkgcPHly6dAlk8GQyabfbb9y4/tOf/BiNtNPpLJUqiUSiVKm2Wq1QOIoVSjAY7PS6KHA5jkufHGOWD3MiQRCJRAKlbaVSmZ+fx8MACNbq6ioODcAwK5XKN77xjZ/97GfLy8uj0ejs7AxuO/jsbt++nUqltra2rl696vP5Njc36/X62tqaoiigvSQSienpaQRAIS+LYRi32/vFF18gvXtpaanb7WqaBoxOpVJBXEEoFHqtawyFAsViERsnCB/r9TpsTEdHRxaLBecqvFPBYNBksmQymcePH1+9enU8HhcKBYfDhvU94PJQb0ej0WTyyGKxUBSN0AXkufE8jxDeqamZra0to9EIoBpEojMzM+mTUyzyGIZpt5sulyueiGFf+ed//ueIVwmHw61Wi6HZXq9nsTvwCRsMhosXL/7iF79AihcWxMPhEK2OLMuff/75W2/dqVarej0P8gVF0d1ud21tDf86nucBLPL5fLA4SJJEfu/3/z3MkDabbTDs1Wo1SZIsFgvL0nj0K5UKAh9IUmMYZmlpBZQpiOZarRb21tjoYevxJX5Tr+c4DtT84XAIdBNEYSDFIzJ2bW2tUqlg1tdsNnW8AQyeiYmJTCaDXhPDunK5rGlao9HgeR6S2EqlMlYViqLq9TrqMIZh3njjjX6/D7Oo1Wrd3NwMBAKDwQBrMkkQBUFAGw0Tpslihq/E4/GAPorsC1TfsC7HozFIkYbDIa/XKYoijQQoyRiGUccKdJG8QU+zHBhrFosFFWqn00HqMyqVLy2WqgoDiKbIBEFYLBZsrEulktVhRywAmshKpbK4uFiv1zOZDJSMJEWNRqOHDx9GIpHhcMjzvN3uFATh5CQ1P7fw4Ycf/+AHP9rY2BAFmdax3X7ndZ4J2l8wjVChms1mHFgul+t1flGz2USdoX31H4qiVELDYht/j6IoNE3qdDpRlOEohI6SIAj8sjAemkwmRBLBvCrLMk1ScADpdDqr1Yp9BAyJiqJgk4VJJzJeWJrBt4kfiWZ1ojQWFUVWSJrVCaIkiqKJN0jCyGoxKZKYy6X/zt/+W3/7//pbpVIhFgnmcmcsQ2UymYmJqcnJyefPXkIZ5vF4Gq2m1+umNRUZL8FgsFAogPh/4cIFUiPK5TJ8l2traxRFbW5uxuNxQRJVVe0O+lCGmc3mRGKSZdn9gwO9Xq+qBPytkiTxPG806lvtRr/fs9sdfr9fGWuHh4dutxccB+wHXS5XLncG4mIkEsnk8uPx2O3ynp6emq2W+fn57e2de/fubW3uNBqNYrE8OTmpNxrwfYVCIVKjCEL1eHzjsSRJY6fTHolEfvjDH+r1xvX19UQisb+/XygU7Ha7xWJR1fHZWbrdblvM5k6n8+DBQ5qmLly4AEv/kyeP/v7f+52Z2elQKNRo1Or1Ok2zhwdHVqvdYDA4HI5+v9vtdvFGkBQBZa6qqqury8VisdlsTk1NYZ0UCAReDwagcGcYBjm7lUoFj5bX66Vp2mWzp9PpWCzW6XT6/b7Vaq032/V6HWo/0OGBn1haWspmUnqW3d/dfvfrb7lcDlEUnzx7Ho4mBFEuFssWi4kgVJ7T9Xo9VSFL5fr1mzfLtQruy1gsVq6WNE2zOuzQYqfT6eFAIAhidXmZpmmD3lgul2VJQo5suVxeXFwcDoeapkaj0Vwhi44unU5rmvLaYZfPFzudDlZ7CNRrdXp6vd5iMtVqNXWser3enc2t2dnZSqXC8tzExMTe/r7f7wdxcGlpKZvNFovFeCJWLBYxEaQoCk/jxsbGi+cvZ2fnnU7n8+fPXS6HyWR6/PhxOByGo5MgVGACIaIiSdJicxweHlqt1ng8DhNPp9PV6/XCYOjz+bBLCgaDeOZFUXR5fTzPb29vB4NBKHwpigLfAeew2WwuFovIYDg9PQ4EAliRaJp259bt58+fr6+tJZNJXMAGvanf71++fHkojEajkcVukyUFmYZer5dmyHq9zjBMLBZLJg9Ho9G1a2/AJ4sJuiiK/UF3cnIydZrJZDK3b9+GwINl2V6vb7FYxmMVGA4IBuLxeLfb7nY7fr//dbIv0C21Wi0SiWByhqcUDa0oSq9D64EvARcNGBHsZJ49e8ay7OLiotFohKPt4sWLh4eHGM/DjpfL5RCJgRKwUCh885vfFEXhi88+m5+fLRaLHMd5PD6LxZIvlqLR6OMnz0aj0bvvvttsNludNtJ7YrFYr93CIbm5uQn0JdhyKysrmqZFo1Fky/7jf/yPT05OQORKp9NTU1P4SYCZwNAdi7ClpSXcX6iNMHeA5gQaR/zYFEWFw2Eso+bm5u7duxeLxbLZrNFobrVawOrC7YQ7DhDHqakpBAWi+e/3+wYDj0vZ6/WiMaYoam9vT9O0WCz24MEDDBQSiQQi0QRBGgwGy8vLh4eH0Fl2u21kjqHjevz4MeKuM5l0PB6X5XEoFHr06NH6+rqqqvl8PhAIZLNZi8Umy3KxWFxfXz8+PoYo2Wq1cgwbjUaBE3O7naVSyevzrK6ufv755wRBQMYeDoeTyaTRYDKbzflSeXV1NZPJXLt27aOPPsKU4fr1641G4/j4eGJiolgsYpZpMBhcLlc2m6nXa7Drqao2HA63t7eRKJVKpW7fvgOoHuI+L1y4wHi8Lh3H0Ax5cpq02+2oQymKGg4Fh8Px5MkT7HqBqbhw4cLDhw9PTk5YlgWEvlQqXblyBQUKknbwvOJAx13r9Xrz+Xy5XAbSA+cRpo6AdjgcjpmZGbg8ytW6yWQymUy46qanp9HcYEaCwRKYY2iI1zfOffDBB6FQyOv1AtuKaBdgGiqVCoZz0WgUMslMJsPo2PhEApE1/X6/UquiVSoWixRBiqJotVppHee0O3Q63UgYeNxOi8V0cPBlY93pdECh5TiOVBUUZL1BV1Zkncr12m2Xx93v9zmep2n6+PSE5/mxqmiyhJCBUqVsMBhkWZKVsdFskiVB0zSL3UaSpDoanrtwHosG3En1SpWiKGEwrJUrBo6nKKpWq2EaFwoGSYLwuN3ZXIEgKJ7nL168eHqSikbDA2GwtbsVCcdIWbPZrDabpdVqAJbYaNQURZ6ammo0WuVyGc7BwWCkaQ2WZcdjlWU5jtMr2gCVK6vTYfEqiiOCUDVNUVVVJQmVVCmKIWgKyiqk3REEAbslptOA3YMpCj27oiiEqqH4QL2Lf4gaDvoJiH9Ry8qyPDUxPRwC0qEJkkyNFXms9gXJ7nS3Ol2CpDiOw9fHcVy+XLp189av/dp3UsdJjte5HE6K1AaD3t/8m3/zcO+wmCuaTBZVJQDkbXXaBEF8BRqwog4IhUKj0Yjn+WQyaTAYXGY31+NhZh4Oh4lE4qO7n5islps3b7948QJ5jJggDvr9O1/7WjqdpimiP/hy3TkeS4oqq6q6sLCQz+edDnckEpmcnIZp5fDw8OjoyOfz+Xw+giCgu2I4XSwWGwxGc/Mz+Xw+HAr4fL7vfvevcxz/2Wef/eVP3v/BD35wcnJis1mcTmc0HGFYXb/fF0aSqo1bzU6j0ahUakajWafT7e3twdSDjTlJktVqudVqyGPxOHnI8/x3vvNNQZCQh/pHf/QHq6urly5dIkitVCoRhIqu/fLly7u7+y6XY2ZmBsM/HN80Q4H+AtUj2gmapi0Wi8fjKZVKkBC1Wi14D2HL5zgOkGgMpHmez6bSYAeYTKbBaESzrCyL586tHRwc+P3+qampSqUyEoVAKFiuVg6Ojs8tr/3lT37Ok9Tf/I2/Zg6FnfvJ+5/df+PmrWgk3mpWWVU+TR6ORuJQlN2hxGdfPOh0W7/zO/9FpVKuVquRSGx/f99ktYBPGI1GkZADzQ36JQSiC8LI5XJmMmmr1eoL+AmKtNlsPM/ncjmn0+n1uiFRGg6HFrPZYbeeplKAoZ+dnfkCIfhqKYoKhIMLCwuVSsXqsFvMNllVbDbb9PT0+vo61moYlmN0+hrioGlaq9WCGFmW5WazXijkAgEfx3H5fJ7Xc8PRl5JTp9Mei8UkSZJludvtms1Wntevra0Ph8NarS4IYrFYBPT83Ooa/PBQsuP7ikajveFoc3MzGAxioYaA3s3NTZj2QaPAfPHnP//5pUsXiuXSeCz7/f5wOPzLX/7S6/Xm8nl/IECSJMOysVhid3f3+3/6J1/72tcwmBEEgTdwHp+7UqnYbTan05nLnblcDlmOHxwcvHz+vFKprKysmAwGTVECPl+r2wK+5+bNmziggsFgs9lcX19/9eqVyWSx2+3j8RiK4Z2dnWw2YzAY/P7A+vq509NTRM2YzWZRlCiKdjpdXq+31+uPx+NyueL3+1lWh0wbXEAQQVut1pOTE3wLzWbz4sWLgUBgc3OzUqnMzs7+9Kc/dTgcqVTK6XQ2m00QSUql0uzs7NLS0tOnT10u1/z8/Oeff16v15YXF4+Pj0mS7nb7xXLN5XJpGjkYjNBkapr2V3/1V/Pz83Mzs/li4eDgYCoRB7vEbrd3Oh3wqB49eoTZGwYQBEFks1kovcrlMgTacIVPTExgbooO1uVyjUaj18HJc3NzRqOx2+2+++67m5ub8B1DIglIJvx3T58+HY/HR0dHWBa3221wsJvNJkDwFy5cwDEOGhz06VAwp1L1er2+sbGBDR1BEHt7e3Nzc7lc7smTJ2azeX5+PhwOn52dQTH8/PlL7ItAWwgEAg6HDQ+wJEnFYrFQKFgslosXL05OTmQyGZPJfHBwwDDMz3/+88XFxVqtZrVaHQ5HoVBaXV3FKBri73Q6bbPZeFZXKBQmJyeBHFtdXTWaDB988AHYAoFA4OzsTFU0q8UGnFM6nd7Y2Lhy5cqf/dmfzc3NgX95//59CKYZhllYWIBYRRAEeHd+4zd+4/PPP8c6C2xVkiTRjA0GvWTyMBSKAECv1+vJx599lMmkEonJ4+Pj15YZAJ0tFks+n4WX3mAwQPENdU4mk0GChNFoxDztNbfTYrF0Oh3EuSCgQNM0PBAISsSdhNcvmUxGo1HI0+r1+oULFw6Ojl+Lo0ejEXIcKYrCUh8TOYyyarUaTdPxiQTyuXw+H34qQMBYll1bW4P6DNc5JE3wDwuCgO0ymDEkScbj8Xa7zdIMeASgtJVKJa/P3el0MJGC6K9er+MYUlVVGPQhmUQ2uy8Y4PXmQqGAiTQy4BYWFsbj8ZMnT1iWpWkajjAsT/P5vCgMYZmEABmj2sPDQzjpxqKE2x1lLgZsFrsNA1VA4YWRxHI6aCEVRet2esVK+fd///f39g43NtYcLifDMJxOj+xqgiBqtZrP55udnUevNh6Pp6ZmoA+AHktRlMFw2GjWUPRAnDgajcZjCQ/Ta7YZy7JG3giVOjQKkGtg0PWarGY2m/1+P5KF9ByP99NgMEA47/f7sWnt9XoA5aN6hsGw2+6VSqVKpaSqam8w9PoCiqLuHBwaTJahIOpYjiRJYTR02R3dZsPvc/1P//p/GCuCUa+zWs2NetXr9TYaNa/X26p3dnZ24hNT9XpdFMX33nuv1qj2Ot2xJJTLRZjLvF4vqj2bzQYLMRD5EOa3Wq34RKJSbwCcc3BwgN0uYGzNZhPCvkqlYjJbrVbr8fGxy+UgCMJiNaG/FwVZr9cbDKZqtYpZOnxDHMeiE2VZltaxiqJI0jgcDsPEXipXr1+/XigUS6XS5cuXM+ns2dnZf/yP//Hjjz9mGGZ9/QJFMq8RnVabGaIuXDbw+g2HQrfbpiim2237A+5EIvHOW28vLi5Go1FZliuVGsexu7u7Pp9PFoV+v2+zWQRBMJkMDodLU6nhUNjd3QZ9AGN8v9+fy2exrG+325OTiZmZmYODg1QqNRwOocBgWbZYLE5PTxuNxqdPn2IKqygKknNQPVutVqvZwrEsrEaNVgv2NE3TYCmq1RpGo1HR1Fwu1+v1lhYWw4HQpx/+8pNf/PjtW9e/+Tf+ejFzlspXeastl8s5LCaf3dhvtRhGZ3C4n+0emx2uqcnJRqORy+VkWRIkUa/Xn6RPsHMELqRSqaRP0qA4RiIRXsfzPK8o40ajwTDM48ePv/ntb126dOnZsyepVEqn0+l0OpvNghAPlmUb9bqqqsnjL8n1Ozs7BMWYTCZhOOz3+3Oz8ycnJ6Ph0Gg02kw2s83a7XfwTkHF6HQ64c2kGerKlStms/njjz/OZDJ/42/8jRcvXkxNTdVrjbOzM5/PB/v9j3/8Y1bHQMVYrVb1eg4ADgg33W5vo9X2+4NPnjx6jYDHPTHs9QVBsFgsoihCWY9R0Ek6gxAVMFcxOwdAB57zXq8Hx5/dbu/1OsmTZDgclgRJkqRYOIKt7mAwsFgssix3u32dTnd0dPTuu+8qhPbixYtGsxkIBN58882PPvoo4Pf3ej1ZFjVNwxhmIh4DPAw1ZSgUcnldjx8/tlkdsVhsc3MTtjKGYcZj5c6dO9Vq/cWLFyaTKRKJYKMajYZbrVa1Wi2VSkh9HQ6H8Nxtb283m00cJlarFbTFubk5cIiQjORyuZLJ5Pr6ut/vx3pI+CoINRgMbm1tLSwsNBoNGDJmZmZggB0MBolEAoOxc+fOPX36FN0XQRBjSXQ67Yqitdvtl5tbo9FoYWGpUChAvRoMBhOJxMHBAcuy2XwuHo1lz9KQ7AC+D7y7x+MBqyyfz/f7/YmJiZOTk3A4rKqqzWZDTuL6+jpsFj6fr1Ao9Pv9Vqt17dq1er2OtQ+s0BDb1Gq1WCwGaxeWJ2dnZ6FQCPoNfPgnJyexWMzr9b969ery5csI1xIE4ezsDOFIh4eHNE0j1rPT6ayvr3e7XUkSHA4HPgqe53U6naIo0WjU7XZ/8MEHINcAM4GUqvPnL25ubmqahunMwcHB9PRks9nUNG15eZkkyZOTk1wuNz8/jzpe04hkMnnp0qXj42NM3bxebzqd3ts7gCIIZLs33njj/fffDwQCsiBmMhkUMNPTk6FQ6DR1wvM8DnbgWCmSjsfj9XpdluVoYkJV1d3dXaz4OY7z+XyPHj3yeDzNZvONN96ATgkKlsPDw+npSYTqIJwKoDJN0y5duvTixQuGYUajUS5X8Pv9CJEkv/cH/4vRqA+FIu12G2JAlmUBaNHpdDodj6hRtPj9fr/ZrPv9/tf76UqlgpYCaglURWNNxdrVYrGo8hjQP+zg0O1brVZUxwDNwa5pMpncbjdJ0phnAluMdAuHwwH1MUx8+JFGo5GO51udNkVRcHYgOA8BL5im4uLHRQgTROosMzc3h4fMbrFiREzTNDwj1XKFpmnk9eJK6HVaRqNxKApAoRQKBVVVHQ4HQagAzWPfhB2cqqqd7hDb/d3dXaPROD09DT8CiNIIyhVFkWXZeDwOZUmr1cLW1mTUA+hSrVadNjsUiAi27Pf7sGeaTBaCIlutFlRBI1F0OBz7+/tmqyUYDJbLZZKkV9fXNzc3Nze3/uqvPkCQkyyPoSU6ODhQVQI2vUuXLjG0rlAoFAolzIpZTjeRmOIN+k6n0+m0wAvtdrvdXhvFkAJtO0lSFEXRBE3THMORGoF98ZfgBoIAWgxSADRMrxfH6LE4joOY0WQywUhYLpdRAgLyCaS+0WjsdvudTkcYjgRBGKvK0vIqSVLvf/BX0li12OzKWNU0jSQ0hiQ6jfo//Ae/861vvpvNpcLBQDabcTpsDENJI8HpdDIM3+v1aIqVZdnmdPh8vufPn1YqFT3HXrp0qdVqYW/b7/cjkVChUGi1WoCFms1mq9WKTAyfz2e22Q8Pkr1OS1VVr9eLbhv1rs1mqzUbLpfrNJVyOp0Wi41hqH6/XyjmGFoHMaLf77fbneVyGcciz/OVSoXndQ6H4yyb9ng8S4sruVzuxear4XDodLoJgjAajaPRyGgwRyIRQRI7nS6SKA8PD//k+3/28sWWjtVhx8pxnKYpiFCFLGNnZ6fZqnM6/fTM5JXLb0RjYX/QxzC0pqi1Ws3hcO7s7MzPz8Ne5Pf7xNHoZz/72blza61WS9OUcDh6fHw6PTVjMBjg5PB4PA6nHb81y7JorINBv6Ioi4uLX3zxBc/zsVjs6Ojoxo0bmUwGOSdmsxmzdzgYoAfHRVgs5Hq93q1btwqFwoP7jy5fvowEFZfLJUlSp9cNBoNerx+iXb2ey56lpX7n6zfOGXVEpVTKFkrLF67W2oPHjx8K/c6bNy62G1WfP2TzBEmT568++jx1chaLxXEOeP3eSqXC8izkB51Ox2Qydbtdm9kChaimaSzLTU5O9vv9Wq1mNBrz+Xw8HsUuCV1QrVaLxSKPHj3y+XwMwwz6fVVVExMTy6urO1s7z58/d3v9YFp2Oh1xKBiNxuFQoCjKZDBaLJbkyVEgEACmhOd5qKcpitJxLEEQvV6v0WgAd0mSZCKRqFZqgUDAarNsbW3Nz8/3+31IXqArqFRKJpOJoihAaoLBsDRWKIpB94WsBcTYV0tFbFLMZrPb40qlUtjdH5+m4LzB9Q9E+9raGsirUEnCiD45OXl4eMjoGKPR2Ov0AHcFTBXF4suXLyORGHqGcrkMRI7Faq3Vant7e3a7nedY4BJtNpsqj2u1miSLLperWW/YbDaXy3WYPLLYLZIkJeKTe3t7sBIj6thoNPE83+n0MH5GcAJg+qBsqKpqt9vhZMK4dGlp6dq1a0+fPj09PfX5fIDgt9tNLMvA4LBYLCsrK+Bg/fKXv3znnXf6/f7Z2ZkkScDrm81m8K4LhQKQm8+fP8cHCzS50+mcnp7e3t6GKj95eCAIwsTU1OnpqcPhJAjCZLIgMEOSJEVVQVWQJGlhca5Wqw37A4/Hs7e3p9Ppbt68+ZOf/MTv95dKJYzzj46OAoEATBXT09OXLl2iafr58+fw7+/u7sZiMXgPgeOqVqsQwgMVhoXp9evXK5XKwcEBShOEAoG6Ap5ntVpFtFEikXj//fdRQeJ8Ozo6CofDKAbw2kITjCXS5uZmKBRCCNvx8TEiq+PxOFZmJycnALJDXQ31WDAYZhhmcXFRr9c/efIkEAi8ePFsZWUFIx+appHG1mq1Jicn5ufnHz167PV6A4HARx99hHINVW+r1QmHwxsbG/fv36/ValjFxGIxn9tTrVY7nRZgIl6vV9UUUPq8Xu9wMMpms2jnWq1Ot9u9/eadWq2WSqW++93vKory4x//2Ol0vv322wcHB48ePcKaRafTRSKRXq+XTqc5jgVoHua5QqFw5coVj8dz9+7d8XiMaVE6nUZ+QyAQIF8+ugsrRCAQaLU6+Xw+Go0KgoDD1GKxoUE/ODjodrvT09NOpx3i062tLbPZvLq6Wq1WIeHCPydJUm8yoiP0+/08q9vZ2UGKgqIoIHyWSiWO46BLaLVa6CewGqMoBrJEpCkNh0OLxeJ2uxFNY7VaC4UCUgscDke5Wm02m3ang6ZpvHWgGgKT73A4oEvo9/vnzp1rNpsHBwehaMRisYAgwrM6p9OJN+3w8HA4HHrdHlmWw+Fwu91GDScM+zqdTiUJvNJ4zk5OTgRhiN8FulR0h71ej2H1JEliugZnJaJCtra2XiuToLlDf4B5KcuyDoej025iE7G5uemyO5BL4/V6MQx32h2CIOj1RkEQzFZLq9XClt1ksUDssrm9heJVJQmr1To/t5hKpXZ2dmRZvnfvXj5foChKFEUEe+Mc+drtN9fX19Pps1wuh5Zlbn7RYrMiCxYcS4zQOI6jaIKgKMjvsAEhCILWCCTq4PtFNhH4ovA64I/jH5IkabFYXn9TMPZfuHABY22QGwFxhS8XWNNSqSSL0mg0ksby0vKqwWD86S8+6HaGepNxMBzpeY5nda1m3Wk1/b//+//WoGcvXDhHqON0+rRYyCUSCWkk7O7uXr58rdVqNRttv9/v9nkfPXqk0zGJRCJ3ln7vO9958sUXOzs7Xq9Xr9ezLM2yLLLnkKsVDocxhvF4PHqTORqJ7+9uMwyTzWaRi4f3UFVVSRnzPC9KUrVaDQbDEAHk8meRcAyrZIfDkcsV3G53MBhEfF4wGKxWy6enp5FoyGazlYqVwWDAGfTxePz0NI0AgF6vZzJaeJ632KzFYlGWx6IoLiwsNJtNaaSkUql0Oo1TYKxIJpMpHA5fvHgxnU7XarUXL55dv369UCgg7FKQhFAo1O/2arVaLBa3Wq2NRoNl2U6nHY1GY5FIJpNxOu2FQkEUR6pKnJykrly+ilgC7LOMJgOubbyDs7OzJydJFM0YG9dqNZy8ENzMzMwA144S9vz584eHh6Ded7vdYiGHkXm/34/HJk5PT7FXwkv05ttv3b179/r1m6enp1i5Nhu1XrO4Ohtenk3woUBl7+B/+v/9x7/1n/1dl91RqxVYQnjx7NHy6sbU/Opf/PLz3lC7duVrrWa33WkyDOPyuCRJqrfqwWDw+fPn+MFKpdKFcxtYAbMsC6zxwcEB5LSKopycJDG6g0dH07ROpwW+DMuypWKRIIibt241Go2trZ1AINDtD0EhUlW1XCgVi0Wr1R6JRHgdFw6HzVZTMpm0Wq1guEBd2u/3WR0jCMLExAQCIXK53Pnz51+8eHH92o2HDx+GwkEwsQDLxhzdarWOx1I8Hn/27BlepWAw/P9n6j+DJMvP814wT560J733tjKzvK9q3z3TYzGDIQABQxAEFVRQ3NCudpe7H7Qu4moVu3E37ip0Jd69exUUjYKkSIoiCBDADMAZTM+0d1Vd3malq/Tee3PcfngGHfsNMeiZ7s7Kc/7v/3mf5/e0u71yuTo3N3d+fo5HDLzfzbVV1P44nU45JUskEhAe1Fodzm/Qeb4Wzhmm3++HQqF0Oo20jUKhMBqNFEVJ5dK9vb3gVNDv99+7dw9BGcyIXq/X6XQ/f/6cpmm8x+RyuVqjEQqF+/v7Wq3WajGhCyUQCAh5gVAovIiErVbrzZu3Hj14IJfLh+ORTqepNuocK+A4rlgsBgIBkGkvL5OtVsvhcIHsUKlUUAkHY5ler1coFJ9//vkbb7yBt2K320XqbXFxsVKpINwTDodv376ZTCYR4sMrC9d1XAWlUulr5JLf70edOUmSm5ub4M6cnJzcuHFjZ2cHehsIyXNzczg+NBoNwXNarbbd7er1eopSZDKZ0WiCyB5BELl83ul0vnr1SiqVvvf+O/v7+y6Hs1gsLi4uTiaTfD4PwovT6YSdHBen0Wg0mUzOz88tFovJZIIJ8nUGE8scHHb9fh9edZqmMV4goQzQPJxe4Jlh24Aw3dnZ2fz8fCKRcDgcWq0WkipCi0Kh0G63o7gWJdMCgUAulxeLxY8//jiVSgH9A6OVwWCgKCqbzbpcrtcfYK/Xg2cXr3SKUlIUdX5+jviazWY7PNxHceTW1pbb7UaDlt/vF4nIFy9e9PsDj8eTz+fn5+cfPXoEkotCoWBZvlKp3Lp1C2GaUqlUrVbtdvuw1xeLxT6fR6FQRCKRfr8/PROKRCJgQgWmgrFYDKi5VCrzne985+j05NWrVzdu3NDr9bVazefzpdPpQqGARa3NZltdXX3y5AnQ/G63WyQS1mo1tVqdSqUAOtHr9bj8uN3uFy9ezM7OGgyGFy9euFwunU5H3PvFj4bD4fr6usPh+PnPf24ymfR6YywWQ59XrdbAPf709BR2qHa7CTM/sio0TafTaYqiWAEvFAoxVUC0wA4RJVw+ny+Xy00mExQ4oNlmPB5DlIZDJZ/Pr66uioXiXC4HKR4F7whlpNNp5AvUanW9Xm+32yRJjiYTt9tNikVYiGq1Wji3FhYW0ul0pVJ5vZVDkI1hGKFYBFZQMBi8jMXBgSUIQiaTKRQKAcfzPH9xcYHiSdyzDQaDkBRAhzObzTMzMwcHB3jCWZaGfS+VShGkkCTJdqtvMBiazSYkU61We3p6CjApNgIIF2i1WgS5X8cJK5WKTCJ1Op2Jy5jRaBx0e4hMTk9PD4d9giC0ag3P8+MxTdO03e6Uy+Vn4XOwCkmxGPs4UixqtVoSiUQkEhbKlVQqNTs7i8QTPWH/w3/4D61WKxKJZrNZoIfHY9ZkMrzz9nter7fT6XQ6PYblpVLZaDSqVivJdAq0zE6nI5fLef5rOgMr4LEf5HlWJCAwIGLxgQ+cJEn8TcF0xoFK07RUKn1NVnM6nVhhzMzMoEsBIi12wTRN6/X6hYWFWCyBFS0CoYtLKxKJ9Ef/8FOZVElzLMolmPGIEHD/m//V78/OBOlxX6dXm0yG0WjQ67ZdLlc2lRYKhVarM5/PKyiVSqWqt5oymYwgeLPZLCaJTCYzGAyUSmUkEgkEAjzPq9VqoVAAw1C9Xre7nOVyGT8vnid6vZ5Wpa5UKuPxcGlpKZNKq9Vqr98Hl+FgPFJrdJFIpN3uUpRMoVB0e+3VlfX9/X273Ym6T5Zl8ZoYDHpI6QaDwUg0LBKJFJSKJEmYhE5PT202G0GQfr9/RE+KxWIwMJ1IJIBWn0wmXq8vlUp1Oj2QdQmCkErFQJGBKyOXy/V6HQyqMLM/ff5kdnaW4IWJRIIkyQ8++CCXy+HKNT09nU4mksnkP/kn/ySVSg2H/VQqo9MZ3nzzTajfqE4if10thX60brer02mg8WDWlEql4/E4m80uLi4uLi4+evQIHjvoXrdv3/7kk0/A3el2u61Gc3Z2liTJWCyG5wjUj5u3b4XD4atXr0ej0Xg8bjQaERbutJoiYlIrRDimFwr4E/HU4Um00x1+/+PfXFya9fjMJwc7uVJZa7An822rzS8kZLVqUyIVSaXSTq+TTCZn5mckEslkMvF6vVjW6NQatJHqdDqZjFpaWhIIBDiGfT7f6emx1+stl8vxePyHP/xhoVAANhqzAsfSJpOJYfnJ5Ott/phm6/U6gsOLi0uFQkEsJGma7veHHMcFg1Oj0Wh7exuGHpIk5+bmGIbheDYYDIpEokQioVAoCoWC2+1+/vz55uYm6hrVajWiIbDCKJWU3+8/Pj5GNuX69esvXrxgGE5IkCqVJhwOb25uxmIxqVTa7bbffvvtJ8+fra6ujsejRCIBLVan0wkEgkgkCqW/0WjMzc2ht5Fl2U6nA2Q29o8w4Gs0GpZljEajXE7hjl4sFn1TfpvN9vLly6mpKZVSAwiQVqstFYu1Wq3f7+K4bbVaa2trQDHrdLpU4tLlckmk4l+3CmoFHC8Ukc1m/TR8fuP6LZFIhFIHrPmUSlWv1xsOx41GY3V1FQHATqeDgA7S7oVCIRgMwgOK4oHLy8vp6WkwgVut1hdffPHmm3fy+Xwul7t69errnNZrr7TH40FIRa1WP336FDN0rVabm5tD/7FYLCYIwuVyYbhBNYXL5UIZSTQaVamUGo2GJEUEQaTTWYFAsLy8XKvVCvmSx+MZ0yP8+Q8ODs7DpxRFBfxTBEF4PB6r1Yq4QzKZ/MEPfvD06dPBYLC4uHh5eUnTtMlkQskvFjjlcvn69euNRmNvb280Gvn9fpRtoIgF5iqz2YwndHFxsVQqicXiZDKJq7jBYIBB1ul0ut3ur776CsE6mqYXFhbgTA8GgyzLQkKDO6rX69E07ff7y+Uy3IE6nQ4Fwdvb2++99x7HcdlsdmNjI5VKzc/PcxyH3BLgWKBjqtXaX/7yl263W6VS4drGMF9TQ6VS6cbGhlQq3d3djUajLMv4/X6BgICdFzZchUIBYury8ipC951OBxYjnucZholGo36/v1wuAnRwfHz8zjtvp9Np/LwoSkHTtMfz9TRiMpmggNTr9VevXs3NzQWDwf39/cFgcPXq1cvLS1jS8dxBLhGJhOgVgN52586deDyOtfjq6urTp08hpBWLRZyAxON7Pwc4ymAwAJLbbnf7/b5er5+amiqVKvF43GKxlMtlrPPr9SrcKpPJpFgsIo9NkuRgPMLdAvhB/OVRORcKhVKp1OsAvMlkisfjcL9iHYlih+9+97utVutg98BkMuFhxumOvAa0H9TAYSNpMBgardaEodE/A2c98K8ulwv3YCQQ4ZHHDcPhdonF4kQi0W63ZWKJXC4H6IgkSYVCwUxoWHBQvQk3pUKhODza7/f76+vr4N3jlikQCEiSgNA1mUx4QiCVyIfDMW512Ww2EAjkcrnhcHj16lU8yd1ud25uDgGWdDqN8vlCoYDbs0qhrFarjWbNarUSHN9oNND2EA6fqVSqbrsjFosDgVA2m2VZXqfTEaQQKzmSJMvVqlarHQwGUrmsXC6CCxKanTEYTOPxGFSweOwSeY39/QPsXg8ODh4/fppOZ+VyqcVsczgcBqOVoqhisTQY9IfjEXAm0Hg5jhOJhJPJhBcSeLmICKFSIccvwFSNkREiisFg2NvbQ9waq2FUkkmlUpVKhdSn1+vd2NgIh8Poxm40GoBEwPbn8/kajVatVoNximEYUiTRaLRbu3tCQkRKpDRNK2RSAc8SPPvb3//+t7/9TbVSls2lxuNxt9u22ywcxw17faPROB6zlUqFoTmn01mqVtRqZbVavX79+mQ0SCQS/X7f4/EAZi2VShUKxf37X8KPqNPpVFoNVs8URY1GE7FYzE5omUxSqVQ0WnWz3igWizdv3+q0u4iC0xzPCwTD4Xg4HFarZbfHqaBUzWZTJqPgYlYoFOfn5wqFYmrK9/Tp09/4jd+wWq3/8NMfz8zMOOyui4sL2BQWFhZEItHs7Hy5XC6USyRJmoyWWCwmFos9Ho/X6z09PT08PLRYLOPxZDwe9Xp9kYhE/RYsREajMXxxVi6XHQ7H/Pz8J598IpPLzWaz1WwTi8VABI1GI+wsOI4TcIzFYrHZbLFYbHo6uLu7L5NR4ATK5XIQ+bCLkclkT548gWpVLObhbb927drTp0/9fr/ZbI5EIgRBGI3GcrkcCoUwjjQaDaTbtra2lpeXZ2dn6fHk7OxsPB63220QknArMFstw+Gw0+mhZg4OUwFP9Nsdm9XUbGWE3LBZr4VC03qN7b/85d/87Gc/Ozref/T0V//17/76f/0v/7f7R+d37/5Gf8Btbe1IJJK1tbV0Ol1v1p1Op9lmhkEHLRwOh6PX7gCu3el0Pvzwo7OzM47jAoFALBa7cuUKz7N4X0GlEwgEAPIZjUafz/fy+QutTm21OWAfpmnaaLZCrlYqlQqFUq/XR87Dq6urkwnz8uVLkiQAcIlGo+Px2OVy0TTtdruHo4FIJJJKpfv7+2AE2u12mKy9Xu/jx4/b7fbq6ircjQcHB6PRwGq1YjhDu8vq6mo4HBHwhE5nKBaLLMvKZLJkMuF0Oqenp49OT/R6fafTRusAFl4SiSQajel0OmicpVIJ9GAknS0WSyaTuXnz5mg0AuWIpmmFgtrb27NabXa7HdmuUqU8mUwA5Wm3ujzP/87v/E48Ht96+XJjY2M47MNLzrLso0ePfvjDHyoUinQ6XSmWzGbzaDxUqVQgWsulMpFETHN0r9ezWR1wdns8nkgkcnFx4XA4UbAGVqdWq93Y2Hj16lWj0cClCG8keLawccO0ZDAYEokEUGF2uz0Wi0A67ff72OmEw+Hr169XKpVyuQyfg1gshgQoEAgwZ8jl8oODA5x6YOdWq1WLxSKRSC4vL5HKFAqF09PTsViUIAihkJTJZKVSRSKRYNccmArt7OzcfuMWeO40TXe6Lb/fv/Xi5WAwGI/HBoNBrVa73e5IJDIYDN59991wOIyQEH4WVqs1Hv/aToS3MSz5qDzX6/WJREIkEkHwQ/k3/HY43dA4jg2DXC5H/8/c3BwqaKEmoDoCnhNws4DjhmDh8XjgKF9aWjo/P6/VaqiZwtCv0+nS6TQKcODHf/bsGbLwr7cB5+fnw+H41q1b/X7/4ODAbrd7vd56vYrmsWAwiNXKgwcP/uAP/sBkMiYSiYuLCJCKOC5XV1cPDw8hMUwmE6vV2mg0UP8K7yZ8VG63s9frMQxjMpk+//yzQCDg8XiKxWK93tDr9RwnkMvloVAIdB6JRFIsFuFRy+Vyt27dury8TKfTt2/fzmQyyWRyaWkJnCOCIEiS2NjYePz4MeQuVBJPTU0RBAG59/z8XCQSlUql3/u933O5XMTjez+XSCTNZhN27MPDQ54nIEuGQiGapg8PDx0OFwYspVLJ0pNKpaJUq87OzjweD/ZEOp2u2qjD53h6enrj5s3BYFCv1xmGcTocKHTEhnFtbe358+fQb9CEgykbjstSqdTvDSUSCR5CiUSi1WoNBkOlUkE+UaPRgMF6cXEhFouXlpZ+8tN/wJfva4FK+DVYHCPF1atX9/f3Qd5DBlChUMTj8V6vZzKZkHwsFAomk4njuFqt5nI4EWeAD73dbktkUnwXYa/rdDo8y5nN5lw+A9wcHGCwi3Ecp9cZsRRHchVGEzgqQPB75513hsPh2dkZHG9o6tZoNLOzs8i2iMTC1wekVqXs9XqRSARm8MlkwrMChDUmk4nZakmlUgaDief54XBosdlG4wFQqxRFqVQKsVRCT1i1Wn1ycmYwGOx2ezwebzQaH3zwTVDmYrGYgCf29vb29/fj8ct2r1sq1yUSiVQiN5r0CKfApwIFYjQek79uJ8R9ghBwMGHgk9doNEBRoF7+9PS0XC6D/QH3FcQbuE8QPFxaWioWi5VKZW5uDiwlm802Go1wAwAPF57c4XDMC4TBYOj59qtBfyRTKDmOYcYTSi4WCniZWPQ//Yf/USBghCQvk8kEAk7As5FIhBlPFhYWeJ68vLw0GS2TyUROSQUCgc3hEImFg+6gXq+jS2RhYa7dbkvkMhTFV6tVguCxu4TeAFpxv9932uzBUKBRqw+HfZqms9lspVK5evW6gBDmcjmGF5jN5kaznU6nJRJRMBiEWNvt9nO53PT09Gg0KhQKSqVSrVb2ej2likKUaW1t7XD/aDKZqDWafr8PG+nlZYrjuGQyaTAYkPMwW78O0lqt1i+++CIQ9DM01+m2lhZXqrUybtX1ev327dutVuv+/S+dTufVq1e3t7d7vZ7V5uh2u4l4XCKRLC4sp9Ppdru9ubkJ00yjVltYWBiPh5iKut1uNH5pMBiwPO12u3K5XKfTHR8f53I5BBG0Wu1lMh4KhUDNJjgCe3MsjpvNJu6IDMNYLJaDgwNs2RiGmZqaIkny+PAAnqRisTgYjPx+v1gqUalUL168ePvttzOZzNTUlFgk+eyzz65evXp6em43uo1GQzR+NL8YYOlJ4iKeTZX/D3/wf/yj//gfO4O2TCV654O3zsIRmVSppowupy9XzGl16pOTk1arub65kUqlnB4nSqABzHvjjTcuzi50Oh1svDqDoV6vA3AAs0Q6nXa5XCaDodlsItwHrl6lUtFq1UIBceXKlQePHrZaLYmMwvnU6/VgsUCgxGazn5+fO6w2NPLieMPBA+SjWq1mWLpSqQBg0e12kZIrFAqBgP/8/Hx2dhZgSaPRmE6nq9XqP//n/7zf7//kJz9xOBwOh6NcLisUipWVtXyusLOzAwYNvJuzs7PZXEZGURgFXq/sBQLBxsZGMpmCNxRWuVarNRwO0a88HA4jkQjekCsrK2AWSsWibrc7Mz2byWQkctnKysqzF89ReCCXy8PnkVu3bpVLpVKpBCt9Mh5zuhzNZvPdd9/FNQkSPowZLpcrl8s5nU6e579e7Q264/FYo9Z9zX2gKEg79XrDYrEYjWaCIFKpVDweV6vVd+/eRUkASZIul+v58+fImItEojt37nQ6nePjY3Q2I1HEcRyaZFEeZ7VaQc9B8S48rwKBAC1ew+EQbhC84ZHXQSc3TdNQH8VicSqVIghCq9WC3gTjEdgi0Wjc4XA4He6LiwvMQ0JSAIOaUCgMBqfgoJBIJNCNFAoFKOqA7oIdiqVtPB6Hbw/eEmBU0VmClVGz2XS73TzPNxoNm80G1YBl2X5/6PF48CK9cuXKy5cvg8FgJBIBqwJgd1Q8oThOp9PAMYbesN3d3ZWVFZCosHdaXl7O5/OYL4EIkUgk9Xqdpmmj0Xh0dDQ1NbW8vFytVhFvNJlMkUikUCjMz88Ph8PBYOT1ere3tyEKdrvdyWSEy0C3232d9xoOh3q9LpfLkaQIlX9ardbtdn/++ecweM3NLaDWSafTYbkEwDLaRH7jN7557969RqMxMzPTaDRwmvd6PdjPUYXEsYJarRYI+geDQT6fxxKv0Wg8f/58bm4OflzcDPHzLRQKYrH45ORkZWUF6QGdTgMI+fHxMVhudrsdaQP4qieTCfHwVz9FCiwcDqNmstvtw/mE2BrP8wRBgpZEkqSAYwUCgdfvwxELByJBENVGXa/XO53O09NTg9Fos9lA/JNJpSANYlM7NzeHK5pAIKBpGj9FvV4vl8tRYtrrDsxmMxq/K5WKzWYTi8WQpvb395GZzGazwOg5HA6W554+fdrr9cxmM8uygETDM9Ttdi8uLjweT7PZ9Hq9JpNpf3+/3W6HQiGJRAI8hFKpBC/eaDSSJKnX6lqtFv47SqWy2++dnp7OzMyIRKJcLkdR1HA4DE4FEomEyWQqlQuj0Qg0NoSeRCLR/t4hlsEIF1itVtx91Wo1QrYoeYUZEAnqfr//usbo6tWr0dgFfPGTycRs0OOwbLfb2NVWSuVKpYY/UrffIwji6Ohkc3MTT6bBbIDrolAomM3GcrksEkspipLLFXhHaDSafr9vt9srlcpwOPR6/dCfQBTUafUn5+Gf/uyTXq93dHQEYwqGYJVK5Xa7+8PBaDQiBCTDTiRi2WDYQ1cgnPgA+kE6xm9UKBQ6nU6z2XztX0H5w+tFoUAgCIVCEJwVCgV2TCKRCPhprVbLMEyr1Wo2m4PBoF5vkiKR1+u/iCbSmZyUkguFQgHH6FTKWrU05fP+P/7NvxaLybX15VarVSoV0qlLuVzOjCdyuYJhuEajYTHbGo2GyWzQ67WtbqdarTZrzcXFRavV+vz58/F46HA4xDIp7ht6vZ5hJgifYiQSiURyuVwqlbgcjlKpoFVrCCGfiCex1Zqenn61u+fz+pudLscKxFKZwaCz2+0vXjxzOBzZbLbZbMNRB8IWQRBut5OiKELIp9Np0FZnp+fK5XIqnV5YWAiHwwaDYTSawOOCZLVCoWB5AgPo4uLiV/fvIfMvEonC4TA8OuPx2GazXVxcmEwmkiQajZbdbj0+Pl1aWrLabOVy+fTkZGpqqtPuIQIGAg3HcUcHB06n02w212oVbKkEQlGxWEQLHr5X09PTCoVia2srEAicnZ3Z7XaaGaPcs1ar2cw2vD3UarVAIEBtMF4RBoMBL6l8Pt/tdt96662TkxOtWoU/7WQyubiIhkIhlUYNtRurRoPBcHx0gqo1q9WZSRYuLi6W12b7g854ONCqtFKBjCRE8XhUKCJuvHW92WuchSNGgzXgCR3tH+mMGlJEjMcjhmHK1Uqv1zNZTXNzc+VyuVAooDNEo9QYDIZkMsnzPCcQCIXCfr+Pxg9saqanp7VqNQRaLJsoioIzmpnQIpEwk8svLCzIKArDikQiefr0aavVAlcJ3Z1uhwtzZ7/fL5VKc3Nz0WjUbDZj+GZYemNjw2q1Pnv2DAAhk8kEIJnL5UqlUlqtFg6h+fl57M6w5cfhhACQSqXqdHrNZvPK5tVYPNpqtu0O29nZmdFotNhsoNJglR8IBHZ2dlZWVmq1OiyhT548WVhYgK0CZkGlUjk1NfWzn/0MUB5Ua3AM/cEHH3zxq3uj0cjhdjWbTbFU0mg03nvvvUajkc3kOY4rl0qj0Wh+fj6fz04Hgq12E8IY4HaHh4fXr1/v9Xr7+/tTU1MGg6HdbqPU8r333nv64unu7u47b78HGwMYjRzHmUzmYDCYyxVKpRIawaVSKeAIlUrFbDajaCQajX7/+9+vVqvlcjmXy83MzGCZ7vf7I5FIq9VyOu2wHyHYcXJyolar8VLKZrMoKk6lUgiVK5XKn/70pxRFobJwZmYGydlcLnfjxg2JRHL//n2CINxuN8rdITrifri1tSUSSVZWVnzeqVevXmWzWblcLpGKsM+CuIgWqZ2dHcxn4/F4d3f3nXfe6fV6IGxJpdLbt2//9Kc/vXv37vn5OUEQNE2Px+PXcss3vvENBMhOTk4cDgeuQDzPg22k1WrX1zfPzs4wC6J0T6FQaLVaiqIymYxQKFxZWQFUM5lM9no9i8UET5tYLNZqtffv37fb7YlEYnZ2VqlUnpycIBqv0Wi8Xi+kTdD5AQSBbRo3KHRvw30FDoDRaBwMRg6HA8KEUCgsl8s+n8ftdoMMIpFITk5OIOblclmJRGKz2UejUbfbxQeLrKtMJhuNJiqVKpvNwklpMpngMcURs7m5vrW1BdWN5/lsNourVD5fTCQSBoNBpVKNhhOhUJjLZ7RarV6vBxUyEonQNP2bv/mbcImZTKaZmZkvv/wSmC6Ii06nEyFEk8mwtbUlFApRbIVTcmtr68aNG6urqw8fPlQoFMTei6/wZkRGHZWZarV6eno2l8vlcjlQE0EQqNfrPMv1ej25gkLIM5fLWey2er1uMBjEYnEylVIqlUhd+Xy+yWRSyOcRcUS2qNFogAUQDAYHgwHCg6CiwV/Vanba7fZgMAgGg0gFon/eYDCgCBNmT6PROD8///TpU7VWMxgMvF6v3W4/Pj7G6AMQQ6VSQWXEycnJ4uIiblQcwwIQgMibXC7v9LpYZV5cXICoC0THxcWFUqnUaHQanY4giEajYTGZkslkKpVSqRQmgxHlzfCvMAwDdrPP58tkMmAWYGZyuVwulwu1OY1GAyoaxpdQKCQkRHK5vN1pAgQvlUp1Rh3O8nA4TBD8zMwM2AdAwgh5AaIZw+Gw3e7OzMwcHBxhWKlUKpub6wqFQiDgYHtq97pqzdfJGiynoCNi31oul6emgiqV6tGjR3Nzc1g15otlm81er9fffvvtr776ant7m2G4ly9fvnj5kqbp8ZhWKimDwTQeD0ejCazuRqNxdnbW6XRiB1QoFNRqNURpPEVwYiGU5PF4sGMCMX9qaspisUSjUYfDoVAo0NUNzxxJkgzDEKSAJMlmvVGr1SqVWrvTY1ne4fIeHZ9iacUL6HG/LxGT/8v/9w+XF+artcr0dHAyGhdLeY6eyOVynieSyeR4OIlGo06XRyKRyCnp5uZ6PBnnOC6Xzt24cQv8FWy+kpkkLLoSiYTjGKlU2hv0m81mKBQcjUbBqcDe/s54MNRoVAa93m63tpsdpVIZDocHw7HZakvEL8cMq1Hr5Aql2WZOxhOFQg73RaFQtLm5CUAoyMtCoYCm6Wwuvb6+XiwWstnc/OxCrdoIhUIoJ5mZmeEE/N7eHkVRbre7UCh4PJ5GowVZqFqtnpyfoDjMZrPh5gTcBscK4vH44uIizYxLxYrL7bDbnAw7EZJkuVzOpnNra2u1Wq3f708mtN/vRz6cGU/qjZpGozEYDGdnJyqVSqFW4ab0dfFltwtH7czMDLYPtVqt2WgjFOJwODiGEQgEGo1Gq9UCp4kyxMFg4HK5PB7Po0ePVCqVyWRCEtZutW1vb8Nrz7DcaDR6++23q9VqIpHAO4eiqEa7g4if2WCsVep2u91g1RdLuX6/36g2RCyhpFQGgyEQmjq6OC6UC16/bzKiCYbA7GI0GiA2d3ptqVQqlknB7ROLxRazjSRJejzudruEQNhoNN55/73d/T1mQuMIl0qlw+FwZWXl/Px8YWFhPBg+efJErVYfHR29//77mUxmaXFRLBY9efosNB08OjlBEKfRaCjVKpPJBOIMx7DFUn48okUikYQUAwuJaXVhYeHy8lIqlfICTqlU4i0HaU0ul3McF4tF8O7+4Q9/2Gw2P/nkkzfffBOlmYuLixcXF/Pz8wcHB4DRIMtps9nOzy8Gg14uVxCJhHfv3o3H43qjGVIry7JTU1MXFxcSiSSXy1GUYnFxEXIIx3E3b94ER9DhcMzNzfX7/R//+McURd29e5cgiFgs1uu069WaVCanadpgNhkMht6gj5Ifr9f7xp27sVhsb3cXWT+aHht1+mdPn2xsbIAiFgwGS5UycKbBYLBar1erVbPZrNVq4Qy5iJyDsA+rDXZkSqVSLJaQJKlQqDAfhMNhcCOtVjOuZJVKxWQykSSJtDvKfxqNBjD0GBALhYLdbq/X668DN9hMQS46OTnByfIamg2vSDwexxFms9k++eQTLEbgSTcajVhTvI6FYdWD1Xan3cMUrtVql5aWVCpVLB6JRqNGo1Gv19frVY/Hc3h4iNsd+nkwRpycnCDGCFcJPGqIBNpsth/96Ecg5w2Hw0AggAUrOo/RnFur1W7fvg2aAPxGNE3jb40Cq/n5+UKhoNPpQGHFuW+z2UiS7HbbBoMBfzvsr2GcWFtbQxQUis7MzEw8Hsfx1+/38clDTkPiGJ0NDofD5/PF43Eo5QsLC2dnYcTzm80mKtgVCvnW1pbRaHzrrbfu379P0zQ4q9Vq5fPPP79581YgEICBB0QPJA/m5hZomiZJEiMKTIR+v7/b7VIU1e1+bZjT6/UWi+Xo6Ag/puFw3O/3jQbz1tbWBx98oFQqB8MePG1qtbpYLDYajQ8//LBYLD569Ah1qDRNCwQC7BDH4/H+/v6dO3empqZgYy+VSgaDDjD31xv2eDym0+kATyY++9l/Bekkk8lQFIWwg8fjicUSEGxAfQwGg+D36zTawWBgtlri8TioXwvLS+BYjMfj8WTS6/WuXLmSyWRqtZrNZiuXStCTsCQymUwAcCkUCtRnUhQFIgXuK73uwGg01ut1tVp95cqVw8NDZJ7NZjPSN/Ck44WrUCgopaJcLgNbAginyWTC9Q746aOjI7vdjmgly7KUTI6KNLSgS6XSRPIS23SgjVFvmc1m33rrrUK5VKs2UK3g8/kmoxH+mmazmR6PMPfYbLa9vT2r1aqkKFgFx+MxGLjobzYYDGhcmUwmbre73++D8pXNZimKmoyZdDptMOpAuvJ4PFrD14xakUjU73cxq3m9XuBMZBJxt9uNReMKhWI8puv1eiAQ+nUf8IiiZCzLDod9kHKUSmWj3Wn+Gl0xGo2MRiNUdJZl+/0+cJqvO4gGg4FSqW73uiRJejyeTCZDEITL6QmHw2KpZG9vf3d39+nT5xwnIEkBywjMZuNgMJLL5T6fD/U+NpsNDw8M73D66/X6WCyWyWRomnY6ncCQghMNXiu4zAKB4MqVK1jJgaE/Go2G44FAIBBwfL1ez2Ry3d6gXK6GZmaL5Qq+APVqxWTQ/3f/t//z7PTUZTJRKBQcDlu33dHpNe1GXaPRTCbMYDCgx4xarZZI5XJKury82O2248lLgiAkpGQ8pqGUsCybTCa9U1448IRCoVhM0jQtV1D1ep1lGa1Wq1Er7XYrO6FPz45XlpZZlrU5XVtPn7bbXZ1Bz7HCpeWVYqU6GtORSKw37IWmAg6HLZVKSaXSTqeHyy5gejRN22yWdrtNKWTD4ZDj2FarbTFZGZpDRg/XNYlMiqPxypUr6XRaLpdPJoxOp8M4OxgPEMnEjww7EbVKi4Xm+vr6zs7OaDTa2Nhotdr1eu3w+GBjY+P61RvhcBj4IqlUBgOpTqeTS6StVisai9y4caPdbhqNxmQmjZihVqvNZDJXrlx5+PChz+ezWq2PHj26c+dONpulJyya9QwGw2e//OXU1BSW+PPz8waDAW6no6Oj9957LxQKvXz5EgGxXq+3urp6fnoGd8hgMEhcJt9+++1isYgsBQwWJElK5BSIoDzPy8QSh8NGiISHx0ehUCiTSvM0K+QFOp1uRE94kmh1mhKJxOV0lvIFiUgKI3Ymk/nud7/bH/bUarVYJo3FYpA0RsOJx+Mp5vPz8/Oj4ThfKrpcLqGIlIjEgN8gCUvTdKvVMhgMvXYH0HNIQUtLS5GLC7lcLpZIFApFu9dByCOfzxOkEEmOfr9fr1UwLPb7fZVcjdOxXq8nEon5+Xno306Xw2azPX/+HHwgZK/G4/Hq6jJ6Uebn59GQfXx8zPP897///WQyCX8qgBHoFQDiVSwWA/K0vLwci8XOzs6WV9dxY1Sr1QBOWq1WiqLi8QTMQxjoW62W2WxOJpOYrrRaLeY/WM6NOj3L0K1WSyaTe32+s7OzWrOh0WhsDvtkMmm32/SEDQaDRoOhVqstLS2lEvF8LjccDnBLr9frHMfpjQa73d5sNg8PDx0uF6TZ6enp7e1tnueVKqpYLHrcPp/PNxwOtVrt8fHxjRs3CEL44MEDlUqDs1Ymk2HV8PHH3/35z38Oywf+Id51e3t7JpNpOBzOzMzA9I2PBWR2fF1FIhH4LKgKmJmZIUkS2V6lUgkL2vT0tNVq5Xk+nU6jJNhms4FRqdVqHz9+DMVocXER4yDO40Qi6XA4WIZ3u93tdlutVsOCQjNjWJkrlQrL0vAANJvNWq0GoSEQCGBwAYEdEahEIoEVFY4thUIxPT19dHTU7XYDgQCmWxQ2A4JNUZTBYMBPWaXS+P3+x48fY36FT2Zvb+/q1auHh4cfffSRWq3e3d3FQtZisSwuzsdiMayqRSIRNl8gYB0fH1+9etVisbTb7Z2dHfwPiqKuX7++u7uLQACsSARB3Lp1K5/Pn5+fz83NvZ4+K5WKQqFyu90QLH0+X7FYrFRKGA8Q+UeEv9PpjEZDl8u1vr6BmMv8/LxKpUqlUvhbMAynVqu//e1v/83f/E2/379161a1WsV/NhAIsCwN7KpCoSgWi5FIZH5+vlKpVCo1qVS6troBUmYmk5FT0pmZma+++goryMFgADQPeFWoLeY4rlqtSqVS0A1BjEJUtt1uSyQiZIqz2ew3vvGNx48fe70efLzZbJb42d/9pUajAYqzWCwSBCESCdE3Cd6/xWKJx+NQ+VwuV6fVvby8XN/cwB9LKBQKSCFeQ0qlkuNR4CCQSCQiqYQZT8Dja7VaYrEYppCHDx9OT09DYsFe7+zsDDJPqVQSiaVIJAmFQgQE4NRBkBvgu1KpNBgMpFIp6BQikQivFdTvRCKRq1evnp+fIw+yvLzMsixKhcPhcDqZ8vl8sVgM9Wp6vT5+mYDKBxd8Op3uj4ZisXhlZYWmaQEvHIxGOo223W63Wk2JRCIViwUCQblYCgQC9Xp9f3/fabcaDAbcdUqFIk3TZrMZuGRIMvv7+yDJwpSKWADsKZMxo1Qqp4KBVqtVrZV1Oh1B8Ol0Wm8yzs7OXl7GGYbRGw3RaJQgBFazpVapTCaTbqfndrvlcoXBYMjni9iI93q9yWgIhZ9lWbGYNJiMQrEEQhrLshqNCumnTqdTLpenp6cBroX4p1Qqh+PReDzu9/satc7tdiPpbbLa8MWQSuT4/M/Ozp49e3b/4cNarWXQ61iWX19fx3vKZDLNz8/DQtdsNsViscPhEAi+VlOePXuGZCiytVqtFmZMpVJ5cHBgMpm8Xu9ryC1+yiaLcTgcGnT6SqUSjcZZTpDN5sVS2ZhmANOKXJy9/eYbf/Qf/z/hs+PRYEiKRRQlk4jEyVRiyutptVp6vbFYLPKsQK/X9wZ9lUolFAqSyUSz2czn80ajdXZmXqmi6vX6xsZGqVTq9DtAUWSzWafTbjabaZZpNBrdbsfhsBECTiwme52OSqWqVapnZ6cet1ulVIvFUqPZ1Gr2jCZzrliqN1pisdRgNtjMluPjQ6/Xr9frDw4OwOARiUTHx8fFYnFlZUmv1yuU8uFw6HDYJxOambDFQhkZvde4o2QyGZqZzWaz9Xo9GAym02ksVa9cuTIcj41GI1yiMGcwDDOZ0NVq9c0336xWq+l0WqFQ+P1+rVa/tfUiX8yvri6zNHd5eTk3N6/T6bLZ7Hg8RtFEs1a/c+dOJHoxHA4RKKvUKyaTCdRKkUgEtzK6zGZmZuB1DUyFhsOh2+3udDq1SgX9enq9PhAIZDIZ5FSMRiPKTzD637t3D4KNUCCMxWLIbQ2GQ1xvWJZVqTR2u12v15+dnUnkMoFAAOyqgGXy+TwpEdM0vbi0otVqs8mvCxBlMtll+rLb7Vqtlna7bTbqJ5PJ0cEhHIGTyaTZbonF4kw+d+3aNdxNxSJpr9dr1homk2k8pgfj0WQyqjXqyPb3Ol2WZRGskUrlIpGIoxnQWOx2+/b29jvvvJNKJqRSKaVQZDIZmmOXl5dfvnxhMpmG49HMzEy1Wh4OhzzHYQLe2Ni4/8UDiqKcTufOzg4eRvwdPV63yWRqt9srKyvozzCbzQcHBxqNSqlU4jmdmZmB8ImdIPZW4FbTNN3v9/P5vFhMwhZzfHxsMBjm5ubC4Uir1Zqemy2VSgpKNRqN8H6+vLxcW1tDlwAavZaXlzFGANSO0QpUZ4Zh9Hq93WotFYpqtVoup7786qv5+XkpJQfNX6PTjsfjTqs7GAzggtrZ2g4Gp6QSyXQgAK7B3OICqNzz8/NPnz8bj8dev380Gknlslar5XA4crlcMODv9/tzswuNRuOLL74IhUJms/n8/Lzd7lit1lBoptvt7uzszM7OsizbaDSMRr1YLEasz2q1XlxcWK1WjuNisRhAeizLzs3NoTewVqvBKaFUKsHeQwb8+fPnLpfrNf8WatzS0tLOzg7763LVXzNmtZlMBh/RtWvXUHdI0/TS0lIkEpHL5ROaFQgEKqVyOBwW8qX19fWZmZknT560Wi2bzTYc9bvdLiq0jUY9FruNRuPk5ISiKHAl/H6/SCSSyWS/+MUv3n///bm5uZcvX05PT+dyOaRKc7kcpArwvbAVgVMWrrV+v2+xWJxOZywWE4kkwBrfunWr0+mEw2Gv1wtpAMhr3N4Jgvjyyy9JkvT5PDQ9wRaC47iTk5NAILC+vl4qlfR6fTQafW2GcblcRqPxpz/9GeZgwLeBGnn58uVbb70FPBV6HWAEWl5ePj09j8Vib7zxBvSFbrfbbjfn5+d5ngfEdWpqCrpdNpt59913//EfP5NIJKCRQQFFiXI0Gq9Wq8FgECyVw8PDZrPp8Xhqtdq777771Vf3cB+DUQFj5cLCwsVF9PLy0mF3abXaZDJtMhkazdrMzMx4PIamKxaLQeW02Wztdlun052enprN5slkcu3aNch1crl8MpmA1MDzvM1mQWElRVGbm5v1en0yGU8mExgAiPuf/bzVasDBo9fr0aWAiAq8YJRKebC7NxUKToYjilJGIhGLxcIwjMfva9bqzU4bHREymUytVrfabdgS8/l8aHbm9OjYarGA14c1JyqujEYjx3HA5sIc3Wg0xuNxt9s1GM0AzyMPCNTy1NQU0GqZTAb/rkwGlEC10WjY7fZYLAafo9lsdjqdpVIJAonf71cqlS9fvtTpdFC2REISG2X8uxqNJjQzjZihQCC4vLyUyWT1VtPhcJhMpp2dHZfT4/P58VQ4HHaJRDIeDhUKBUsz6PVLJGJikkSMH2t7sVjscjgxI2KQwt/RYrHU63X49AmCgLbJ0JxCpQT5aXZuOhwO9/tdjuPsLidShAsLc3v7h83W182Ak9HYbrGikapeb3o8Hp4nYPm6vLwkCQHqPjqdjtGor9SqqWxmdnY2k8kJhQKn0wnU+OrqaqfTAfu4Xq9rNDqhUHB5mdLpNJyA53meoqi1tbVUKhUOh5vtLnQgJAm0Wq1cIq23msnL9KNHjx48eNxqt/3eqdtv3Pnqq6/w0wE4DqFil8sll8sjkcgf/MEf/OM//uNf/MVfbGxsKBQKXLitVitWIfF4HKKF2+1Wq9VQQCmKmkxGIpHIYrEUi+VsNtvu9C7TGbFIgotjr9fT6lT//t/+v11Oq4Bjc5n0yspKr9fL5tI0TdvMpsFgoFCozGbzk0dPu/1eKBRSKpUCAYd832AwsFqdve5ArVFyHIca44vYxfz8fDKZBCh/ZWWp0WwLCM7hcGSzGblM0mzWJRJJv9O9detWOBxut1oatW44HNI0y3I8w3MikYQQihwORzqXlZAivCAAD4TFFbBBkUioVCo5jltbX8nn8w6HfWdnl5IpRsNJKBSCMRa8hn6/b7barFYrkrmIW6PhoNPrIW/l9/sNBoNOp8tmc/1+f2VlBV/FcDgMTWhhYSmRiKk0KqWS+ru//dH3vve9fn8AfTSdTsNj8fLZ86WlJZqZHB4ezszMMAxzeHx86/YNNKtMJpPj42OkTGAu3NnZ8Xg8g/4IwF6pVCoVi/P5PFwUWFoh4wNGCZRLr9fL83wymex0Olr1195tnU53cnqKrRwIxnK53Gg0VyoVhVoFvmIoFKKkkmKxOL+0GIslBASh0Wj6vZ5arUYO9OLigqKoubmZ09MTmUSkVCrtVhtJkuVymWGY+GWi2WyO6EkwGOx0OlNTU5Rc6fF4tl9soaHsJz/5iUavI8UikhB6vd75+fmdnZ1+v+9yuWq1hlqtfvVyC1jFVqsFEPw3v/nBy5cvO53O/NLi7u6u2Wz2+bzlcjkSiy4uLvp8nr3d3UwmszA7h4plsViqUqqfP39+5coVq9WayaZ5TuB0ORD1gugikUh8Pk84HAmHz4AjdrlcXq/35cuXsKt2Oh3UiD1+/FgikaCJOZlMu93OdrudSMScTrdEIgoGp7ETtFqt2ULearV+/tkX+FG63W6kWWUy2cHBQSAQsFgsl5eXq6urr169MhiMg8GgWq3qdLper1ut1tbX13q9HsHzQgHhsNqGk0m73b59587JycnR6cnc3ByeWbFYajQaLy8vLy4ufvCb3280av1er9Goa5Qqs816eno6Ho99Pl+73RYICbfbTYrFoCR4fN4rG5v/6T/9p0DQr1arRaQExjVYamQyGdgxNM3iZ12v1zOZjMvlMJlM+XxuaioARCpK2CCTh8NhqVSKbqInT54AkglYNCIO2GoJBIJAIABePF7RIpHo8PAQ7gWYu41GI03To9Ho5OTE7/cjaHl8fIyCFMQAYdlRKNWDwcBiNudyOZVSA4O8UCiEEKBUUfCqC4VClqUBrDo5Ofn/Hzimp6c5joPejzgFTLp4jhCfTyaTMFSEw+GlpSVk0hUKRb1e93g8CLQiljse0/Bl7+7uLiwsUBS1tbX1L/7Fv9ja2oLxEVoOOLoffviNbreD/7hWq02lUqPRaHZ2lmGY7e1XYrFIrdbwPOdyudPpVCAQ0Ol05XIlnU7DJAMuFFaE4KPC3tPtdpVKpUAgWFxcjMVi8XjcbLYOBj2lUl2rVWw22+bm5vHBYb5URIGYw+HAYQq8IrgksKiq1eq9vT2ZTKbV6ofDIXJjVqsVPkX4tl0uVyDgH41GqVRqPB7funULIUSBQGC3O2GT0qh1MzMzl5eXhJAHKwo8JrSA4wFJJpNQmq5du3Z4eJjL5ebn5wF3xYPz8OHDmZkZipK1Wq1KpaLRaJaWlvL5PMexZ2dner1eq9USv/jx31EKGcuyYJ2vr68+ef5Mq9XCjykSiZZXViIXFwqlcjQcEgKSYRiwXBmO9Xm8l6mkwWBotVrVanVtbS2RSKADEj6MTCYTmPIBw7W9vY0mSMT1FQoFOBMOhwMhIySGOJ6Ix+O3bt2aTCa4K0A1XV1dRXgBGinccyzLDofjyWTS6XSWl5ebzbrZbHY67bu7u2Kx2Ol0isXSQqEgk1EkSYI6rVEpx8Mhz/O1Ws1is7ndbny+nV6X4zixWJzL5axWKzD8DMOUShWKoubm5iqVSj6fF4vFUz4vjJAcx3lcrmq1jOVpq9W6ffs2SZJPnj9bWVyC2CiTyTCUYGuG6QcgLplMdnFxAbDqeDzudDoLCwtggsMtKBKJJgxDKWTbr3btdqtKq6lXqkqlkmPZUqnU7/dZlsXMnkgkKsXSW2+9hU058Mr5fL7TaSnUKpVKqdXqBAJBq9XCTlMul4vEUiwx8/m8SCSRSsW1WkOppMB3iEajQqHQ7/fL5XJcRADjxh9bJpWenJ56PD6TyVSvtf7l//5/l8/kZ+bnZmdnX758iTikze7EpC+Xy4vlEsMw/+pf/as/+qM/Otjbf+ONN7Rabb/f5/mv+SKNRgNfcfhtKUqm0WhEIlG3202nLq1Wq93mrNZr7XbXYrV/9fDBZSJps9k4hk6nk5sba//lL/88nYxn0ym7w2o0GpVy6uzsbDgcgtdH07TH4zk9PdXr9ZPJRCgWQUQEvFuj1lWrVVwZjUZjpVIBBxWc1XK5bDTpNWqdVCbGtXh2foZhmHg8vjC3qFAoms2mzepotVpQ4Hiep9mJ2+3OZFMURUklco4TNBotoVCIFapUKi2VCiKRyOVywO9YqX4thSLoZNSbRCIRHEJQoa/dvHmwt3d8fLq4uAhy4NnZWTAYbLVaPp+vXK1DY9BoNMhD9Ho94E9lMhnScMViUaFQ8LxAoaD0Bi0CB/1+n56wXq8XNy2MgChF4XkBFuuNRh0phFevXs3MzFgsFpQG4oXOcZzdakZBHu4Mvd7A4/HIpHKCIA4ODhiW9nq9HMcAIpDNZg8OjhwOh5Ag8bq8vLzMF3LIHMEjsri4SBAE7iQ0TRMCoU6nQycdy/Krq6uEiHj06JFWq7VYLIBHS6VSv9+fSCRQ44PpTSQStdstqVS6MDcnEAi2trYuLi58Po9erwc5RS6Xz8/Pg1ZQqzXAmxYIBAKBgOG4UqGwsrIil1GI6KdSKaChbDbHG2+88ed//ufwr5AkaTYbd/Z3UakUj8c3r14xGo2DwaDf6+TzeYqirm1e4Rh2b29PIZdepjJzcwvnF+GNjY1gMBiLxS4uznU6Q6/XicViV69eFQqFlUplY2Mjk0mJRBLcyvb29ubm5mQyWbFYxgOIehytVnt2dtbr9b5+Ew5G3/jg/fPz81Tqcn5+sVarWCy24bDPMMzi4mK5XHW5XKenpwzDTMa0VCpttVrvvP9ePp8rlPIGg0kkEjUazWKxuLq8ks8XW62W0+l88OBBIOBfml8ql4toltRpNYlEArs2p8stlUpxMk0mE4fb9fnnX3zve987Pz8vlUpLS0vDXrfdbtvs1tPjk40rmwA24osqFouXl5cjkUg4HF5ZWRnTdCGXKxaL0DVh2AAdY319vVar2W0ONAGEQiGBQJBIJDAl6/RasZjM5QqNRiMUCu3u7pqtNoIgotEo4DhKpTJfLOBsjsfjlExWq9WwWVteXo5Go/hKo4EecxW49uPxWCaTV6vV6elZjuOePHmytLQECh3mHritIXrhlkiSJCEgUenBsmwwNAWSwmQyMer0BwcHHo9HKpUOBj1AJfL5vN8fQPbrxYsXcCtioKQ5lmEYg8EAnKRUKnU6nVAuRCIR8iWAnqTT6UajwbIsWoCApwbPXSgUIiTYbDbr9frdu3eRx7fZbKiMK5fLHMdlMimfzweTiUQivn7jai5baDQarVZbq9UqFIpEIuF2e1OpS7FYqtdrSVLc63Xsdnu1Wq1Uyl6vdzgcmc3mvb29jY2NZDKNSmav15tKXeLs0+v1CgWFq9dwOHTZnZ1um2W4W7dv1mq1J0+eKCmF0+26f/++0+nUqLWdTqfRbo1Go9n5OZqmgUId9gcikSh9mdRqtbD590dDqVSazmY8Hg/ABSaDudvt1mq1UCj0wQcfvHjxotfrzczMbG29eP/995vNZjKZHI/HDocLNyWWpSeTSaVSEf6aoY1HG72QMFK///77W1tb6GLB6kyvN6ISERqQ1WpFknHjyvrnn3/ucrnm5+fj8Vij0SC+/MXPh8PhaDxA8eHc3FyhXFCpVPAnkSLRwcEBoG1arb7VaqnV6kKh4HQ6QcMD3gnaQ61WI0ny9u3b+/v7uORRFNVuNeBuw4wMswuYSWDCItvf6XQYhjGbzXqDCfMgbhivq2mmp6cBpb28vPR6vWj8drvdRqN5a2vL6XSORiORSLi5udnptL766iu0MHKcoFarhUIz4/G4WCw6nc5Oq6nXasEri8bjTqezUCgUi0WXxx0KhTiOQ+uCWq0GqPfk5AxPMiIJarW602oSBAFtlpmMDAYDoigKhdxkMvFCMpVK4f/laMZisSAi22g0lEolbL9gQWGUGY7pcDispCg8891ud3l5GTBDn883HI/r9fpUMJDP57PZ7FQo2KrXdDrdoN/vdDog7eJRFxFCo9Ho9Xrr9Tq8L7lcTiIRSSk5yzIwkWg0WhwYo9FILAFajMBsjbSgwWB49uwJPBl4RLHG7vV64JdKxGJA0TweT7/fH/RHnV6fZbjj4+OvvvrqIhaHO/7GjRvVWqNWq+GTrNZriCn85V/+5ez0zPz8PGzvFKXEUNvtdkHaVavVWq1Wr9darVbIfrlsmiAIESlptlu8QLSyshKORP/zf/7PbqdDKBSISOL/9d//P2dDQa1OFT47V2uUUpEY2cxut4v0ELwvk8lkMpmIZVIgT/GC6/V6Al6I1j+1Wh2NRnmeR4QQrYigbN+6davdbiOrrDNo9Xr9ZMLUajVwbowGE3yEVpvFbDbv7e2MRoNA0N9qNc1my/7e8bVrN0DVUygUn3322draSjKZvHp1s1Ao9Afd0Wik1+sbjUY2m11YWJCIpGKxGD9TaO8qtbperw+H46WlpclkUiqVJBJJv9+HaiWWfi2JITyL/xcTPOKKMpns5OQkFArZbLZkMimTS5RKJTYOjXoLVtbl5eWf/OQnKysrc3Nzh4eHnU4XcKZ+v0+SQpZlv/jii5s3byJp5ff79/f30Z3FTEbIliMbe3BwIJcp0U8qlUp/+Y+/sNlsDDMRiUQ+n6/T6Tgcrm63a7c5SqVSLBYTiUQMS8/OzqJ3QalUNpvN0WjQ7XYBH8lmszMzMwpKSVHUzs6ewWBQqBXD4RAuSaPRuLGxkU6nUYQ6Go0QGpLJZOA2SaVSiYhMp9Nms7nVahmNevS+d7tds9ksk8l4nt/b28N4QZIk+kZwh768vOQ5ASanRCKBwIHT6U4mkwKBYHp6ulKpHBzsCcUig0GvUqk6nc7m1Ss7OzvQZeOxyOzsbLvRJElSyPHtdlunUWdyeaPZygl4VOKEQoHj42O/3w/GMuDso9Go1+sg6TY9PV0olNxu99OnT0OhkNlsTSQSOBRxaoLJJJdRIpHIbrd3u90v7v3KYrGIxWJQUre2tqxWs8ViSaUyGB12d3fffee9SqUyHtOX6Uu9XidXyAKBUDqdttnshULBYrJmMhmlQm2xWAgh/7d/+7e/8eE3O52OWEwuLCzEY9FOp4OkcL3RVCqV4J6Hw2Gfz8cRwvX19XA43Gq1vF5vrVYZ9QcOp300Gr0usIe2gZgRx3FWq/XLL78UiUROpxNIJ5FIFIvF4HwHyKrT6UQuoihmBhfq3XffFQgEg2F/NBoRBJ/L5bxeb73e7Ha7nIA4OjqanZ0FuJim6fOLsM1mm52dvbi4kIhEmODBiHK73TDI41oCZnqv19vc3AQr0Wy2LS8vA3YKSipQVah6w1lOURTLsm63u1wu+7xTsBSr1WqL1YSYLUEQLrsjHA6j4U6rVT969Ojtt9/u9/srK2sHBwfY/v/Wb/3W48ePVSrV0tLSyfmZ3++H62hvb296ehore57nkRMfj8f/7J/9s+3t7UKhMDc31+12oRogwJTNZmdnZ+VyOaiTCB3L5XIMlxiRfT4f6isIgpfL5ThzOY4lRQTL8DzP6/WGcrk8HtO4f/p8vvPzc/QuXF5ezs/P0jSdSiWVSmUgEPz000/ff/99pVLZ6w2sVuv9+/elUmk6nbx165bD4Xj+/LlGo8bFzGAw6LXa0WiEU/j89KTT6bz77vulUkkoIqVSKctwKysrz15uMQzj9rrOzs6uXr0aiUQKubzJZFIrlCCsLi4u6k3GyWQiV1DVahVTymgwVqlUjx8/Rmn6+++/Pzs7OxgMer0O2s/glkmn04gIoBYJpEYc9CRJlkolpA4TiUQ2m/X5fAja22w2cEympoKJRAI7BNABvV7v8fGx1++RSCTPnj2bnp52OOxPnjwh/vB/+O8tFgvL0Qi2LC8vJzPJ0Wgkk8mmpqasNlsmk8nlcqPRyGT6etmnUChg2h+NRktLS6lUCsbt16hPoVAIdEqv1+u0m3a7HbisTCaj1Wq73S4gTE6ns16vF4tFzPU4UTie0Ov16XQats3hcLi2tjYYDEiS7HQ6GLMajYbH40F8TyKRIZaVz+c9Hle5XO5225DEDAZDIpE0GAwkKYblwmw2t5sNkiSNRiO6G2HNA1SQIAiYUSw2K0QplmUX5xeAyoQxPBgMDofDfr8PmqhMJqNpejIawAVcKpUYniuXy/BxX5ydg4CKl90bb7xRrVY//fRTo9GI/h+FQiGVyjudDh4DoKUJXiAQCCQyqVAolMrlLMsqFIpGqymRSPR6fbvdLJVK06EQbByAjyO11+v1xoOhyWRCmGIwGHS7bYbnGIZut9uzs7MGgxG+9WKxKKeUyLVh2fo68iqVihFyRgMDejnK5fJ3vvOdSCQS+3UEBqpvNpNPpjNWq5XnBODQ/Nmf/Vk4mvj2t3/ju9/9rkAgIEWiZDL59Onzzc3Nly9fNhoNl8cN6lK9XheLpGq1Gi9fNB8j90EpZEajUSaTWUzmbCZVLBYnY2YwGrY7g9nZWZvT8ed//ucSUsSytMft/I//y//cbtQH/Y5Bp6vXq2j3Q2tbo9FAQkQkEmn0OpqmGYbBch2rN4lEwjI8oPzpdBpQwVwuB6oZRVHIhF+9ehX768lkIpaKlEplvz88PT1Vq7XBYJAQCHFFs1jNBEFwHFOvV1mOrtdrpVJZJlWurq4XCjm0oWGSGI/HAgE3Nzd3cHBAEAR+o7fefpNl2aePn8FPLZfLxyOaoqhWp61UKu12Oz4i7MTFYvHDh48//vjjZDrdbDYBVBsMBhzHobsTHl7Uhl5cXIhEotPTU4qinC773t4efOh6nbFQKOCuBncdSZJvvvnmy5dbQGP4/X6SFGIffXJycufOHZZly8Uiz/NQUFiWJkly2B8IhUK32x2PxzVaA+qqWJadm5/97LPPeJ5FLd3U1NTm5tUnT56USxWhUAhbcbvTMpvNgNhB/6bpcavV6nR6MpkMEJ0pf+DOnTuXl6lYLKbRaxDHWVxcBA1hc3MTCTjkBmq1mlalRmTVbrdXqmXc4qxW63g8RHAPzrNMJmM2m3meFwpFGo2mWq0CVZPP5xHJ3Ny4cu/ePfSHvP+Nb/zspz+NRCIrKysUpex0Omq1utNpefy+ZPJyeXn53r17NpsNkSCO40gRYTAYcumMRqPpNJpYsDocDo3O0Gg1YU9Uq5U6nY4gCEj1QqEwEAiUSiWZTAJkXSaTMRhM6K4RCoUMw0FFBtUdr1mWZVmGw045n8/7/F6Px1Mul+12u0LxdZZIq9WORpODgwNo6hzLz8/Pt1qdMTN2OOwMxx4cHPh8vmKxJBKJRoOx1+sdDocmk0mn0z158mR1abnX6zUatWq1KpNKJpPJ9evXw+GwSCyRyWQA0GPpdh65mEwmNM0uLy8TBJHJpNgJ3em2fT4fdnB+v5+m6V/96lc/+MEPcrlct9vV6XTwJjcaje985ztnZydGo/HVq1c6nU4oFJlMpmKxaDKZ7HY7FIVCoVApVwF6aHda1Wq1VCpIpdKbN29Wq/VOp7O2sSmTyVAkvLm5mUwmr1y7ynHcH//xf7Lb7ZRMjgk7EAjs7e3Bf4I2BdjJzWYzYGNvvfXWJ598YrM54dbCncRkMkG0gNr6mp+cz+enpqbQB4WECqrfaZqmKCqdTivlMvi3XjdrSaXSWq0mkci63W6/35+fnxcKhfV6HYSw6bnZJ0+ejEajq1evRqNRQBby+TygKlKp1Ofz/fjHP7ZarSzLgvKYTCZR2m2xWPr9frVanZubQ5ju4uLCbDa73W5sXbGMvri4kMlkIpGoWq2iuEUqFedy2eGoLyREq6urpVK52Wyq1Vokxm7evPnZZ5+RJGm3W2u1GmpSFxYW4vE4zr7xmI7H49evX+c4LpVK6fV6hN8NBp1KparXaxA7vV5vs14H/VWhUIwG/ampqU6n9+rVK4PJKJPJFuYXM5nM2UVEqVS+/e5buVxu2B9gb2C1WuUS6cnJCYogR/TEbDaDE6Q3GlKpFM8K4PyJRqMKhaLT6fz+7/9+t9s9OztJJBKLi4ubm5uHh4dLS0uff/75aDQCSRU+wm63i6C91+vVaDQ7Ozt6vd7n8wGvBal4MBjIZDKxWMowDEEQc3Nz+Xw+Ho97PB6bzVYo5UHEUKlU6+trf/VXf0VkouFwOKzTa0QiUTqdVqlUlXpFp9PBLfvlV1+99dZbOHXq9aZWq/X7/cPhEKEzlB7Mzs7CUQ4YAa56+Xze5/NVKhW5TIIAVLfbzWQy4/FYKBTixo9OQJZlZ2ZmMpkMaPISqRzNGLlcbmFhAdHTWCxWLpdXVlbQP+VwOKLRKAamubmFcDgM0gRB8BRFNRo1TNm1Ws3r9Z+cnEgkMjhVJ5OJXCqZn5+PRqNqtRqpGZfLBe4ObF4syzrdrnQ6nUgk5ubmGrU6uqIJgsBgQRAELotgo+XzeYNOg+CJUqlstFsWiwVRuPRlEhBFVAewLKvT6QArB/qs0WhoNDqpVDo9PX16egr9v9VojkYjSqkA6UAkkfT7/Vwu53A5NRqNWq0kCKJcKsGuUa1W5XI5wzCo+mEnNMicsJjwPMsKeIGA/3WKp9Hv95eWlrRabbFUGY/HGo0O3ezI4et0OoNBh1jy7OwsageALWUYZmtrixQKkYuZTCbBYNDlcmVzheFwLBZJSJJcWlr69NNP//qv//pXXz6QSERXrlxZWlrafvUqmUz7fD6pVMowTGhm2ul0ojhIKpEjMR6NRuVyOViyRqNRQHDwgVmt1tRlIpFITCaMRCIZDMcmk+XazRuPHz9u1RvdTsvtdPz7f/c/0JMxTY9ZekzTtM/nw6nMsqzZbIaDoVKp+AJTuKqiUheQ/Waz+eYbb+3v7ysUCnz9Li8v8WHW63W5XI6NhtlszuVyIpHIarVKZOJUKpXJ5G7cuNHp9JaXlw8PjrLZrM1mE4lJhpmMx2O73Xp5eZm4jHm9XiEh2ds7WF1dFggE/X4fgEe1Wt3rdSAIabVanU4nl8sHw55Go+FZAd7jHMflc0WJRKIz6MfjMa4iN27cQOMnIsfLy8tbr1653e7p6WnQ/EwmE5wcLMuCzpJMJuv1Og5+tVptMhvMZvPp6anf779+7WYmk8lkMizLXr9+Hblgh8Ph90/V6/VHjx6ZzeZSqehyuTQazenp6eLiYiQS6bbbqNSQy+XZbLrT6Rj1BgRiKIoymqy4EU5NTcnk0t3d3bm5mWg0OjU1Va/XG41WsVgMTAWBRJfJZGKJ6NmzZ4uLi3fv3v2zP/szl8vV6bQymYxCobLZbEajcXV1tVyq5PP5fn9oNBo5gsvlcgKB4Fvf+tbe3t54PI5Go4FA4PLyEjm7O3fufPaLX77GJuv0Wrj4/X5/OHyGUFgymUTiqVqt3r59u98fHh4egh4CM7Lf73/x4oXZZLHZbGiwBu7u/W98o1IuDwajTCbjcDharUalXq1Wq+vr6xAOYdQ9PDy0WE1zc3MiQpjJZPrd3trKytHRUa3RePfd97P5nEqlUqlU2WwaNJmVlRWSJNGHc3x8PDXlQ3QrGAwKBEKUsTx8+FCt1sKCPTs7i87aubm5QqEQi8YXFxebzaZCobA7bN1uF7WPUql4amoKgZ6ZmTm0/Xg8HrVKk0gkbDZHOp3U6HU0S8PpEovF9Xo9wQtDodDe3h5QIOVy2Woy2+32ly+fOxwOrUZN0zQQ3kqVutfrweYRiUQcDofWoK/X6wqFCozTa9eubL98EQ6HMSe9++67uVyu1+uhTYumaY7jsFgXCoXQODudFoo62u221+t//vw5z/Mulwv4Q9C6eU6AFGez1VCpFDKZ7LPPPltfX2822xRFGc0WvEgZhtnY2Pjxj3/sdLvG43GhkB8MBnKpDLOpVqu1Wq25XI7n+WAw+PDhw7W1NZfL9fLlS7C5UVipUKhnZmaQUIPZV6FQdLtdrVZbrVZnZmb29/cDgQAoPyjegB0HoxsGZZFI1KxVS6VSMBj0+XzHx8eAgPh8vv39Q1xOSJKEfmaxWGq1mkgqgQPJZrOhyhPeRHgnHj58aDabj4+PFQrF1NRUNpuNxWL/4Q//8Pzs7ODgAC4ovLSvXbumUCiSyWQulzMYDNPT09lsdmdnB58AYB9erzeXy3U6nXK56HI5xRKSnrD9fl+hUHo8nm63//Dhw42NDbfbfXp6ajAYCoUc7PmxWGxtbS2TybhcLrVa3e8PG43G1NQUkgFarfbi4oLnealUbDabtVoNKk9OT0/9Xi84mkKhcCYUTCQSFKU0mUz1ZkMgEGg1ulQqNbe4lEqlYono7OxsOpnC2qpcLk8HgrDb63S62YX5+/fvoxtRqVaJxWKJSIqLZb1ef30QyOVyv98LySYajaKiDcsZbGCfP3/+/vvvA3jx6tWru3fvXr169f79+1Cz0EqC4CRJkoVCYW5u4fz83O12OxyOw8NDbIozmcyVa5u4pgYCgefPn6nVamLn6aN0Os1yNJCbb7zxRiafGQ6HKIYkhELA4DUajUgkQXxdq9WCl8/z/MXFBeCiIH9iZsLV8+uZQyFHDBU9xPAhvsZZAWTg8Xh2d3dtNptUKh2NafhyEERaWFi4uLjIZDJQ0TudTjKZ/PDDD2Ecvn//vsFgisVidrtdqVSyLA38LjD5UFP7/b5Wqwez6uXLl51Oa21trVQoQlTTaDToganX66urq9h7ZjKZXq8HyvDaylIwGPzqq684jkOjaqVeq9VqBEF4vV6ZlBoMBqiXNhgMUqlUKOCAewCGCnxFGFaAd5NIJNi6arXa4XDITlg40trttpgUwfglFAqTyaTZaslmsxaLJRAK5XI5fCBavebK9evPHj2SSqXQ6vF7QSQgCKLdbivlFFCi9Xo1MB2i6Umz2ZpMJjKZLB6P37x5czwej8b02dkZjl6/P0BRPJEK2AABAABJREFUVK/X02q1ND0G/xMCPgifN27cgOmSZRiz2QzKbaPRMJlMcpmiUCg4HC6BQFAqlSw269LSUj5X+Lf/9t9++eB+sVgVCAQEIbDbbRar1eFweHz+YrEIIouQEFEUdXp6DtR7s9lUKOR6vV4sIfGjEQqFp8dHLMtSlFIkEYtIiVwun52dz2QyiXiUJEmRkPjbv/lLUkjQ46GSkjcaDZPF3O12Yfk0Go3X7typFQqNRqM/GkYiETTloVt6cXFRp9NlM3lsB3Q63f7+Pmr+XC4XYGzIjwC1ZzAY5ufnZSqKHo16vcGLFy8CgRAA9yRJoo8oGJwKh8M8z04mk/6g6/f7K+WGXC5Hda7o1/3QRqOxXC6izf71fIy6WZlELhQKN69dS8bjJycn7777bqVWLRQKp6fnGo0GdHU8Mu12OxwOszyPaQwR8StXrjx69AjyUrvdViqVLMuCfokxUW/Qwme2tLTUbLRxo0UNC3rHRqNRJpMFwAmvfgDkaJqu1arlcnljbU2tVu9svwKpKBAIvH33jcePH+/t7X3/Bz84PjnvdrulcvG73/1uIpFgWbbf74JtW61WFxaWer3eF1988cYbb8hllEaj0eo0sVgM2zHol51OKxKJyOUKm82GyVXAE91ut93u+nw+juDOwucrS8uj0Whvb+/jjz8+OjoSCoX1StVkMqGrHkp5IBBIJpONZp0giNu3bxcKBZoew9SsUCjm5uaePn2K+2s+X8SN3+fzXV5eolqnUqlAnNDrDGDTA9uGNlye56PRKEmSRosJUOVOp+Pz+RqNRjQavXnzptVmfv78eSIa++qrrxw2+2/91m+plUq90ZhOZ8/C54hYQnTMZFKBQMDpdH7xxRdgNrIsG4lEwLpTq9WwqwYCgZ2dvUAgIBaLsSP2+/3gFUklMoZhwNX0+jzoMBmNRiaTQaVSNRoNOClZlvV6/d1ul6HZUql048atarVMqZSVSpkgCKlUmk5nBAIBRSktFotarbbb7cgC06OhWCyGQnNwuI8zHiBvq9Wq1eiePn06MzMzPz+/tbW1trb2y88/w3dyPB67nQ6n0/n06VOlUnnz5s3/+l//q9frDQaD2Ww2Go2iAdPtdm9vb3/729/+0Y9+tLq67Pf7cds8Pz83Go3vv/9+KpVqt9vJZFKj0c3Pz0skkr29PblcHgwGd3a2VSoVy/LFYnEqGLy4uOA4HpxMiqJ4nsf0oNFozGbTwcEBNiE8z9M0je5FjUaTy+U2NzfRM4NAOs/zcrm83W5rNHoc1aVSCZTg1/5rlUql0WgQkjWbzRqN5q/+6q/ef/9d0BArlQp0XJAC1ArljRs3Hj95NB6P0T2VzWblMmphYel1DzqiprCp8EJCoVCgPSUcDqNh+vr161KpFCXEmMYgVWCx0+/34ZQ3Go0nJydTU1NKpdLptMfjcQjnWGKioiCfLwoEgkaj0e12/b6AWCze3d1dXVu+efN6Lpf9NdFDo1QqR6PJ4eGhz+dTq9UQVvR6Lf6QXq9Xq9U/ePAAl+18rohPZjKZ6A1aSCdosxAKhZeXCb/fj6ePYxhAQUejkVwqGY1GHCfQaDSRWJTjuFBwWi6X64ymfD4/mgwNBgPBC+CHYVl2PBgibunz+WxOx/Pnz9PpdCAQaHXacrlcIpIGg8G///u/pyhqdXW1WCz6fL6lpaVHjx6USiXk6sxmcyAQ+OSTT8bjMT5huBQQGBQIBDs7O6jfbrfbGo1mMBh4PB5kFSmKUigUhUIJ0s/a2ppCoXj48KHX69VqtbFEFCMNSZLtdkuv1xN/8j//oVarNZkNeO2yLMsL+U6ng54yk9ksEonMZvPFxYVYLG21Wv1+32q1xmKxTqczMzMD5yNWKrVarVqtzs7OorT1+vXr+Xy+WilB0Go0Ghi8+v3+/v6+WCw2m81+vx+ETCSfhULheThy/fr1fr+PugBANWB9vX//PprGj4+P3W43LnDFYvn8/Pz69evb29s2mwWnCKD7YrEYlwC1Wouhrd1uHx8fWiwWnuWQTQDDHUv0fr8P2ATcOeDEWM1G1NoolcorV67k8/lsIY/8msfjGY9oi8WC0iigega9nlQq/joMQghQkopLktvtfvLkiclkApIbe0aL0YKF/XA4VCtVGN3gt9Xr9V6/b3t7W6lUlioVp9Op1+szuTRBENFIJBgMYtKFfx/xHKxaNEoVy7KwN1rslmTyMhaLa7VaKMnogpjQbDKZNBqNNpvt7CxMUVShUFhdXcWNsFwuY5uASkswumiaJoVCSKDZbNbtdstkska9ZbFYpFJ5o9HAh6xQKev1usPuPDg4yOQL+FL96Z/+qUqtDgaDlVo9Eomgu1TACyuVSrVap2k6FovxPG806mUyGcNOgNEqFosUJVOr1RSlZBiGYwUsy9psDqWSOj87MxsN165s/F//L/+naqmUyabkUolUKoXfq1Kp4JsJz4fT6ay3mkajEZqlWCwGNM/v9x8fnfZ6vatXr56cnDSbzQ8++AA/MmzZAFgHxEilUiWTSY1OPRgMBAIhTdPhcEQqlb733nvRaBQxZoqSdTodipJRFMUL2Eaj0esOAoEQz/M4ogqFwvPnz61W6/z87Pb2drfbnZ2dhQYQj8fFYrHJYAahO5FIoEF2cXmp1+slk+m33normUw6nU6TyZTJZJ4/f/6d73zHYDLFYjGO44xG4/Pnz6empsChRj7x+fPn+OLV6/XJZCKVSrU6dTabTSQSb7/9diqZwZetXq8DPyuTyV68eKHXG5BsmJ+fR4TKarVubW1VqxW5XL6ytBSPx3mW0+l0zWbzW9/97tP7XyJxo1Hrtnd3FUolw9Kbm5vgyjx48JXVagXHuNXqZDIZfKSlYlmhUDSadaPRiCN2bW2N4zijUZ/P52UyqlarOZ1OjuM+/eQXMzMzJCnmCIHZbKw3GxLR153iU1NT29vb+Xz+ow8+bDabqVQK0IpIJOL1esVicafbhiu80+lMTfmQdJmfn59MJtvb28FgUCaTDQYjo9H48OFDvV4PdIJGo5lMJqlUSiwWS8RSrBKwDyqVSsViEddFp9Op0Wvn5+djsVgsFvv+97+PH5zBYGDYSalUKuUL+Xw+m8589NFHAb8/Eosp1RrYY2Ox2NTUlEAgOD8/lUgkwWDwxYsXoVAIew2U5qIkChY9p9OpUmnq9ToWFqhqRUBSo9a2Wi2/399sNqOxiMFg6Ha7vV7vn/7TH0ajUTRPt1qt+fl5qVS+v79vNlnC4bDPNyUWk4RIiJCpSqUSCAiDwVCp1PR6fTweR+UiTdMapaLT6ayvrzcajaPjw4WFBTRz3Lp1K5lMrq6s4clKJpPPnj379re/ncpmFhcX9/b28vm8XCpBNwvMzp1Ox+PxIBfZarXOz8+9Xi+gJEBfchwDswqgmvjrF4tFGOkMBtOVK1f+6I/+CLwbiqLa7aZEIrFYbPV6XaPTtdvtwWDocDgYhsnn8/D1siwrEolqteq3v/3tSCQSiUQQM8SwBa7B0tLS48ePtVot4ibj8fijjz5KJBI0zSSTaZvNdnp6yrLszZs3+/0+9E6QyoGSxn+HJMlKpdTpdG7fvj0ajRKJRL1ev3PnTjgcFvICi8VymUyAGHJ8fKxWq3/jN34jfH4hk1GPHz9+77330NZ3dHRkNBoJEYn1DvAcuNAiZA34GersSJJEZhyhHPC90ASlVCrL5SJJCq9fvx4OX6jV6s3NTYFAcHFxoVarJxNmNBohWkQKxTabbWFh4Tx8yjCTYrGAEH232wO0FigHhUJxdnZWq9VIkjCbzZiwOU6wtLS0vb3dbrfHIxr3TKPRGAj68/k8XPmdTisYDMrlspOTE3DIrl25AiDIxsZGNp3yer2tVockyXyx4PF4ZmfmisViJl+YTCbLq0vVavXo4FCv10skkkaj0azV5XL5wsLC3bt3X+3tNhoNmPZ8U/5Wq/XWm2+jxmpqaurVq1eI3q+srBSLX29p+v1+sViEn7XZbEJCVqlUaFkFNqjb7bbbbZqmHQ6HwWA4PDx0u93IMUwmk2w2yzCc0+nM5XIIH7TbbbTWprMpAEuVSqXZbHr06BHx13/2xxqNRiIVIRhitVo5guM4DuV3Gq02lUphRysSSS4vL5H+kMlk6XRap9MNBoPT09O1tTWxWDyZTEBb6HQ6oOkLBIJhfwC/7fn5+c2bNxdWVn75859joPm6fH48hjhvMplmZ2f3DvaRzoAPEcVVuMap1epwOKzX64GBGY/HeHEnEgkMDWhjOD8/Hw6HJEnK5XKhUGi324+OjtAS5fV6waPChc/lcH5doEYQQDhKRCL0PbXb7cvLy7fffrvf7WQyGZPJVK1WzVYTz/PFYlGj0XCEUCgUZjP527dvp9NpiqLGNNNttzwu1/T0NOoO9UYjsMgURaGyHjcVnU4HgYFl2WG/DzASSZJqpQpygl6vZxgG1nKCFKLc+/T8vFQqlcoFn8+Ht7BarcZTNx6P4bqAQourP4yfOp1GoVAgbIw7t8FgUiqVhWIRHEun04mvmkQiUygUlUoJ8yVBEAqFAsqWVCpFp4pcJkPIZTAYtNvtqakpESEC4NtqtRZKJZT6KZXKwWj84YcfPn/2wu/3X6Yzf/iHf3jt6o1KrRqOXFSrVUquhA+60+n0egOgLIVCIUHw2NLK5XKT2QAZsj8cwiTBsjxBEBqlymq1np2e1quVN27f/G9/+zdH+/s6rXomFNx6tV2pVZeWlg4ODrRarcfj2drakisVYrEYWAFosaPRSC6Xi8RinucZhkODEMCSVquVpulyuYyv097eHsLPN2/eDAaDDx48QMMU3BKFQmlzc3N/f99gMLzxxhvRaJSmxyKRSCIROZ1OUkTkcrnRcAJfFNI9KBoXiURyuYJhGFhSYGZXKpVPnz5lacZms8GHAQBHtV7DfLa+vt7v93me77S7kUhEJpMplcoxM+F5HltXhmHAPQFYGVwcRBdxsVGpVFqdGi9Wi8Vy/6uHm5ub3W4X45FYLEbQqV5vQFqoVquvdnd8Pl+tUn333XeBNMymU2azudfpOhwOpZyiaXp/f9/pdLabrU6va7Hb3R5PMnUpFouXlhYMBsP29rZEIjk8PAyFQiB8hsMRm832xp037927p9GqIf0+f/7c6XRaLJbBoNdutyUSWaVSAWJbJpVfXFz4fFMjekIQvM6gLxdLPM/7/X6LxZJMJimKYif01NSUWCSKxWKvXr0CxZsgCKPZCFa1x+M5OTnCvQ6NPW+88QacCUdHJ3hL9no98JfhKEJ7BtQ7u80BEnKtVgMtGVaBk/NTq9WKfly3251Op69evdrr9S7jcWgGx8fHjx8++qf/9J9CcpgKBrBz//TTT3FmzM3NNZvNfD6LlXS/39/c3Hzw4MHs7CxYu9FoNBQKDYfDVqujUqlYloV5dGpqCtHFmzduffrppz6fT6vVUgr5YDCAlyOXy6B0hWVZnuf1ev1gMLp69erpyVm73f7N3/zNP/7jP3Z6XAzDXLt2/a//+q/RM9ZsNgmCwOHt8Ximp6c7zRZsUgRBLC4t4CqCeBBAXKFQSKVU+/3+v//7v/d6vXhh9no9m81GM5NGo3Hnzp1isYh01NnZGYw4u7u7HMcBrBOLxZD+WVpaUKuVP/7xj2HMbTabkwkDuDZ2DqDjisVigUCYy+WmQlOtViuXLdjt9kaj2Wg0gBVAwtdgMDx58uR73/suFiZyufzZs2cEQbAs6/f74WoCQAv86tXV1XA4DOdiOp0uFAp+/1S328UBBJzSyckJtB8kt1BGcu3atUePHoEoqVKpMpnM0tISIKJyuWw4HE5GI47j3nzzzc8++0wul0PC7Pf7hXxxPB6Px2OsmNEBms1meSExPT0di8UQk8JHiuzCRx999Ktf/cpqtUJS8ng8crlcrVbr9fpMJvPo0SPgXcCD2N7eUmuULMPPzs7W63Wv16vXG0iSFApFp6enFotlOBy2mh1c8m12i0DAsSwzHI4Gg4Hf74/H44PBCDuZ4XA4OztL03S1WmYYxm63dbu98Zim5EpYOUHP0uv1w+EQVwKH0yaXy1UqRbVaFQqJbrcLCreSopB1KxQKPo+73+/LZBTHcW+98/ZkMnn65JnH4wlHY0Kh0Gw29no9v98fjUZr5Qr+JEajMRwOwxypUql8gSmcd3K5XK83npycaDQah8MBPFCn0/nt3/7t8/NThPBw28Tb0uFwgOYA26JKpcrlcg6HAyQ/NAgtLy/ncjmUJfzwhz88Pz//kz/5k7t3315dXf3iiy/MZjNcQBqN5uLiwu60Wa3W8/NzpVJZLBYUCgXx5N7nHMdJpCKQP+VyuUgq8ng86CrK5fMqlarb7eK1iEKDe/fuvfXWWxsbG6iLEgqF8Czfvn0b638cV+Vy2e12py6TJEniCCFJcn5+vtFoXF5eCoVCg8Egk8kODw9XVlbi8XitVvP7/SzPoUQJGRDsetvtNizhUGu9Xi/ghJPJ5OjoyGazvS7ChJIPeC6quQG0QD0OCj2gCet0uvXVNRgAq9Uqfv3czIxWq/3FL35ht9sFAkGn01FSckAvOY4jxUIkvGia5gih0WicmZ5DJ5RCoTCaLUcHh+++fRf16aenpyqNhuO4Gzdu1Go1gJ0QP1QoFLu7u7hkuH9dbNRsNp12Rzgcxt1UqVSm02n8Gp4QWCwWmmVbrRbHM7iPYomALjMsCqVSKSgPYBBg9ppMRvV63efzoWip0+m4XJ7xeKxSq1EdCKArZPZcLsdxDELyCwsLjUaDYRh4I0C27HY6+JJotVrc3rQqLUrLWZZttFrNZnNmZiYWiynVGr1eXy5VxGLx/tHxT37yk3ffef/0/CwajYqlknarazabR6MRwzAMw0HMI0lyOOzDwMvzPCHkhUKhUCTq9/tw+6F/SkUpNGq1Qi5TqRVqueK3fvBxPBwREJzH5XS6XVqtFuRY0JDH4/HM/BzHcYCnj0YjrM9IkryIREaj0dWr10FFhyoJ7lo2m71x44bL5dra2kIj3u3bt+F3vnPnzk9+8hOPxyOTyRqNFi67SJVns9nJZCQWi1UqhUAg0GhVer2eEJB43ZTLZRio8ZVmWX4ymdhsNqDXBALB+vp6NBrlGBa1DIVCwWKxTU1NHRwdoloHjfHRaJQUipaXl2maTiaT1UZNo9FgSsP9AXGtfD6PTBxAiIDoSqVSqUzscDgSiYRcLvd5p3Q63e7uLur2Dg4OdDpdIpEYjycffvihWq2+d++e3miQy+WjwXBxcfHo6Eir1WpUSpqmpWJJJBKxW6yTyWRmZmZ7e9tkMIok4st02uP1KpTU3Nzcw4f3u90uukcYhsEQ6XK5EomkTCbr9wbtdpvlGIVCkc1m19bWjo+PFxcXi8V8p9Nxu71nZ2cwaiwtLufzeYvFJhQKGZ5ZWFqMXkQYhkEUfGdn5+TkRKtSOxyOcqlksVjS6fQPf/jDr776KhwO37x9EyiHnZ2dZDJhMBhw9UL7J7xEpVLlypUr29vbsDcVCoXxeDwzM/PLX/4SralWq1Uuo3B/k0qlWHghWi+WSZxOZ7lcBuPD7XYrFAqRSDQaDOx2O8AEVrOlWq2ibb1YLuE9vrq6OhqNXrx4geIKmh5vbm6iuhi9Uljo0DSNNuhqtZpOZ/1+PwZflUq1ubn5i1/8giRJjVo7Go3UarVOp6s3apD/FxcXe70OUrG4mu/t7b333jf6/f7x0YlYLAYzqdPvGo1GhmHtdvvu7i4aWtHtHQqFVCpVIpEYdHsw1BuNxuFoAHsDVrGdTufy8lKn062urI1Go4uLiytXrhSLxWg0+vbbb29vb/v8XuD4VSpVoVBYW1vDlxNlrGBt1Ot1LI9UKoXP5/urv/rLUCgET9LNmzdfvdoF3AdkealU6nA4SJL0+wO/+tWvZhdm8/m8glKdn58bjabl5WWv1/uLX/zi7Ozs5s2bRqOx1WoZDPpms4nmmQcPHvh8PqDkc7mcy+VKp9Ogi4EuJBQKNRoNuPadTkcgIAqFAnLuGxsbMBm/9dZbn3/+OZaM6XTa7XaDwv3gwYPXAUkcQw6HY4j+Vp4PhUKpVMrr9TIMc3p6qlAoGo3GdGgGES6CII6Ojm7evGkymb766quF5aXT01OtVovAPvA609PTz58/t1gsxWJxMpnodLp0Ok2SpN1uB/Ty6tWrn332GUhG8/PzPM/F4/Hz8KnX44chVSQS+Xx+uVwej1/Ozc2dnp6qVCqVUmM0Gg8PDwNBf7NZt1otmUwWM3S321WrtbVaDc+mXq9/9uyZ1+vmOI5haIIQOhwuUiiGbVogEKDlc2dnZ319/fz8/M27d16+fGkw6DiOo+kJUBrz8/NPHj3CTSaTydDjUSAQ0Gr10WhURslNJlOj3qxUKldv3Mzlcna79fnz58vLy2az+eTwCI1zgI7Ozs5Cpf7z//KXMpkMyKtUKtNoNK5evXrv3j1A/DmOEwqFAgFnNBqxLlMqlahKRAFiu92GdYQkSZZlS6WS1+tFYxtN0+vr64VCAe9wYKLPz8+/9a3voE70Jz/5idvtttvtjx8/ttlsLM9oNJq33347FosJhQRFUcS9T39GkuSEHuGA0Wg0vWEPXSWDwaBaq6lUKrygbTYHGq/Q82A2m+v1OsMwwA3UajVYEOBm7fV6er3e7/dfnIeREMQySyqVrq2twT6GdwfYzSg88vv9lVoVKSFsoGOxGGReSD6wy8Dug/W5Xq9/XYQOK5Ver0cpEtp1sDVHKAyvrUwm02o0YfVHqXO5XC4Xix9++CHP86VS6eDgwGq1iklRo9Fwu50Wi0WhkANbV6lUTs5Ob9++DbzqtZu3IpFI5CKGNVmr1eKYCb7fHMcxHIcKIDQCSSQSp9sFggAYYFqt1mQwSqVSo15PEARgQlq1BsSvfr8vFJEkSd68ebPT6YwmEwSCFhcXk8nkcDgUCAToRY5Go3qjwefz5fN5HAmTyUQsFjPMZDIeTk9PNxoN/PrBYCCTUaPRyGgyoQLy8vLS7XbDAQ37l8fjyefz4/HY4XC85jOp1eo7d+4kLy9zuRwiFZCy2o22UCjkeRYZ10qlMjM/1+/3S8XKaDQJBEPVavVP/uTPJpPJVHB669V2r9cTikiW4UejkUajw+0NzhiAZJCwE4lE8AX2BgOSJDGOKOUUQRBKhYLjuPnZmf/7v/nves32YNjVqzR7+zskIfAHfOMxLaPkhIjE3wVhbJSkKhQKjucrlQr6VsER9Xr9iMTG43GdTqdSqZRKZaVSQR8l6q6tVqvVat3f30d9B66VkNmr1eqtW7dKpVIul4E4v7CwYLWa8W2BRoiP3e/39/v9Xq/HcZzL5Xr1ardWqxmNxkaj8Xu/93vNZjOdTl+5ciV1mUScOxqNmkwWg8FQa9R/XeN1hmu0RCxFqoiiqFqzDoIlAChWq7VQKOBB8/v9l5eXuCfMz8+j+nM46kNIsFqtLqcH3O1kMomHFFo3TTPNZhNUkXg8DqsltpDj8XgmGGIYxmoxIyQ1HA49Thc0Y5fLJVcqfnXvi/fff//TTz/V67VI4+I+jTIrm81WKlUANIY5LBQKffnll+++++5gMCgWi3B4jEYTnNwEQbAM9/bbb/d6g9PTU4vdAnkbl5BOpzPqD7LZLLpNpBKJy+VKJpNLS0tqtfrRo0fxy7jRaAS1BEZXCFE8z0ciEaVSqdfrz87CaKaD/8Fut8MFjAZS1M5sbGy8995729vbmUymWCx+/PHHDx8+HI1GgVCI53n8Fu1mkyAI3AxPTk5sNlsikRiPx9evXz8+Pg6FQlDrwSOo1WpoDDs+Pl5ZWWFZNpVKEQRP0zQwUa8bOQiCgGFLIBBms1l0kcViMQjALMsKCfKb3/xmIpG4vLxMZ1ISicRqNUskEkg+iOI7nc7z83Oz2dpqtZCti8cSDocDxTIAINM0HQgEEpdxkDM9Ho9YLL5///6dN+/io7i8vPzwG++Px2OkvEOhEBLWbrc7n89PJhOM6RzHLS4upn+db0XA6vHjx7joJxIJdDxrtVoEJFUqVaVS+clPfnL79s1EImG1mhEEwxZPqVQPh8Pl5eVXr16hsuLVq1cGg+Fb3/rOgwcPZBQFRHC5XBYICBAcaZrG1vL4+JgkSbfbxfO8gOCSyaTZZEUgA4yAUChkNBqz2Sxk5tPTU5vN5vF4QI8bjUY0zQwGg1AohGrCSCRy8+bNaDSKe9fx8fHHH3/scrn+9E//9Hvf+161Wo1EIq+vx0icMAwtFApVCgVJkijYhtkLf1SeE8ALIZfLP/zww+PjYygxw8nXWHkE2BFrWFlZ+fLLL8FVefnyJTLseGOjhgjwPLztZ2Zm2u1WKpUKBP3ZbLZcLpuMFo1Gw/PAvQn6/f6bb77V7XZHwwlBEP1+3+G0PXnyyOl0zMzMbm9vi0QSNDEQBIHoYqvVwJLKarUKBPxkQs/MzKGsulqtSsRfW4AUCkWjWdPr9VartV6vM8xEqVSm0yls3nU6XSwSwfP1O7/zOxfnZ6lUajSaXLlyZXd/T6VS+bx+juMmLHd0dCSTSd56663d3V2lUklJZRRFnZ+fI06nVqunp6fD4bBCrcrn8+AMw9tw7do1juMODw+9Xi9ikmq1ttVqzczM7O7uTk1NgfJdq9W63fbS0hLmZiTPgHFHHV+323U6na8BGYj32e12mYxCuZDH47m8vBwMBuvr6/l8vt6sKZVKkUgklUqLxYLZbBaiZAP6BM/zKDACVgtGopmZmdu3b/f7fY7jPB7PyckJFhbI8kgkEsCg8SfQarXJZNJkMqnV6nK5fO/evUqlwvP88vIyijPhC2FZFo4rVBqPRiNI9LBdQ2fCLAn0VK1Wu7i48Hg8SMxinSSTyUCvdrvd4IaLxWIMHJj59Hp9uVyuVCp2uz0UCgF+jSIwaKrBYJDjuL29PZ1O5/P5aJpOJBKpVMrhcOB97XQ6UTZycRHFO1QsFn/00UdAZNXrdQA55+fnwQGCXQwN8CiswHIKlVIbGxuQA5VK5czMDBxsIpHI4/E0222O44bDIfwxkNk8Ho/H45mdnQXDqVAoIH4IsAIqzMLhsMfj2djY2NzcvHbt2srKCv4YJEkyDONyeWZn5wuFArgb+Ofdbhe0N6Qa/X7/u+++u7S0hGdJLBa32+1cLtfv9wEBQuZlMBjs7OxA40EljslkQmZVrVYbDAaTyXT37l0A4mUymUQiWV1dBsg+FosB6MpxHMtzHMcBrILcwGAwQO4M63BEFJEkArAK5R7w9uKHHgxOZbPZ44NDmVyiU2vmF2a/851vuT3OTqcjkUkhdykUCkiYr8cadIXCTieXyw0Gw+zsLBwYEOrQn0pRFFhfoCtNT09PTU3BbtxsNh0OBwwKQqEQ5/rp6SlaNQmCWF5eBs4RmLd8Pg/z0/T0dKFQiMVicGwgmfK7v/u7c3NzUL8fPHhQLpc7nc5wOMTZMz09jbdJq9W6du3a5eUlpBcglCCDgTOOuWp+fp5hmMPDQzxxkIVg1PD5fCDs1ev1drvt9/s/+OADm82Wy+WePn0Kc0m/30cpPd4myMtUKpVOp+Nyud577z0ADm7duoUuS0j9kOuTmXQ8efny5ct2r/v46ROKolKpFA74UqlkNn8NIwX69fHjx9Fo9J133tHr9V6v1+/3w2KPikYAciEkAKUNJePg4CAWi1EUdXR0pFAoEJfJ5/M8z9tstmAwiGtAr9crFAoSieQv/uIvPvnkEzB+QZVDhRwmnmQyeXh4eHFxce/evVevXiENBFAFigsBLUNgVqlUQnX48ssvM5mMx+O5fv06HA6wduFl9ezZs/39/Xa7fXBw8Omnn3a73VQqhe7edDoNDh/0s8ePHyeTSWhaUMWQp8EqSiKRgPyH39Risdy9e9dgMEQikXQ6DQnt5z//OfrIodmzLPvll18eHh4C55PL5XK5HCA9CAiTJIncNEEQKysrhUIhEol8//vfRzjU4/GgOByET5FIFIlEULxxenq6sLCAjkvkTvAQ6fV6j8dzcHAA7RwexPF4fHh4CN99KpXCSwx9f5eXl9euXQNN6tq1a2+++aZCofj000+3t7dpmoYZfGpq6ujoZG5uDiYQn883MzPTarWuXb/OcRzkHJSxfPTRR7du3frss88UCgU+LjgOzWazRCJBCkQkEqHCDzY1+NLm5uYAucDtemZm5ujoCMffkydPCIKA0o+VHP71paUlmqYLhUK/34dzAGwtNOJ5vd5ut7u1tXX16tWzszPce0GHwe+IxdzW1hYSV8vLy6h1arfbPp8PMS8gRQaDwU9/+tMXL17Mzc3hyUJ6tNfrVatVuHcikQiQcvfv39dqtd/4xjcIggA93O/3o7xkY2Pj7t27uOx5PF6UlX344Yej0ajf7wObDl1DoVDs7+83Gg08GoPB4OjoiGGYu3fvTiYT9OcsLi7Ozc1ZrVbQH+BnWl9fB/bI4bDT9PjmzZtqtfq3f/u3Z2ZDGo3G6/XirCwWi7FYrFQqgdCxsLCAGI1IJHrjjTcQankdO4BVHD3IDx482N/fR3spboZAI+FijPt/Nps9Pj7OZrOQlDDuSCSSH/7whx9++KFMJvviiy9g+Uin0zijA4HA6ekpjmaHw7G0tEQQxNraGgBM4M73+/2ZmRmDwVCpVEiSXFhY4Hkes4FMJnM4HACLmM1mYNLOz8/FYjFKyYRC4Y0bN0DfyOVya2truVxORNO0yWSaCvhYlt3b29NoNEaL8c6dOzgkPB4PDO//8l/+ywcPHqECGUt6lmXn5+dhkzKZTFivEgThdrshD4jF4g8++KDVaFar1ZcvX+LOzTBMLBaz2WyFQgF1b2iAQuhDIpGwPBcIBFADRJLkwcHB9evXhUJhPB4/Pz8HfbtYLMLtj8jPxcXFaDQaDodisVStVnc6XZmMKperhUJpPKanpoKTyQhg9E6n8/D+A7lcjjrqV1tbRqPRYjLJpdJapXJ4eIhTeXNzMxqNtjpthUIh7clBaCQIojfoOlxOUiTcP9gTCoUarbpSLLTbXfBabFYHKSBA+QKcUKFSsSwLakO1XotfJiAUIT8vFIuSyaTX5WZZVq6g6s0mwo8mkymWiLvdbpqmDTpjp9NpttuYHefm5oRC4dbWllarhaWg0+kMRsNWp90b9Lvdrkaj0el0vV6v2+0iniaViLpd7A1lNM36/QHcibl2G0EMqVQaDofh24CV7/Hjx0KhECY+IMfUajWaNIwGA5aPkMF5ntdoNV6v12o1p1KpV3u7d+6+mc1mxWIxpVRUatXp0Nzf//3fC8UiGaW8vEwxDCeXKXrDgUAwFgqFPMtwhEBAChmabtfqEpmM4VixRMIK+BE90av0MpmsUqlIJDJ4ivFd3dhYYyb0CccDtTrodivlolqtpBQKUiSq1Wo6o6Hf78PWtri4GA6Hh8PhtevXT05O4BvL5/PIsLAsS5Lidrvb7/cLhcL8/Hy73d7fPwQq5vIyZbVaLRabUCiSyxXT07N2p/Pl86flchklOT6fZzAYMMxkeXkZZpfRaPTs2bNqtWy329F5IpNRHCd4/vwlSZIikYhhuEajpdHoeJ7t97sCAbe2tvLLX/5SLpffvfsGGLCdTmdxcRH4LoqSrW2sN5v14XCITl94SEfjYSqdZDkGPp54PI5C8enpabPZjCYDKFJSqRSz4O7urlwuN1uMWNnX6/XXytZwONRoNGCnHR4eLi0tz8zO/urzz4Et3t3d1Wg03/rWt0wm05MnT+RyucvlarbaIpFIJOEzuaxarRZNxlOhYK1Rz2azKEJwuVwg0vE8u7S0KBBwS0sLiURyeXk5EAghe4UnHdW5BwcHuJngo8tkciDRCwQClVJtNBqz2fzMzIxOpxkPhvVKlRlP6NFYKhKTehL3Q6FQKKeowXDY7/c3r1w5PDzsDwZmi4mmaa/Xq1KpcrmMQqHA1gyzMlgnSOQ9e/ZMp9ORQhGwUs1m8+joCNQP0NQYhnE6nevr6199dc9kMqyuLnMcNxzTp6enc3NzEomEkslAQhcKiKWlZa1Wex4OZzIZiUQiJMjLVJoTEHqNlucEdptjeno6noihS8Rms83NzV1cXAgEQrVaO5mMrFZrIpHA3DkajeDBMBiEmUzm8vJyeXl5dXX1r//6rwOBwI0bN1rNNkriFArF8vJyt9sGCqTVarz55p29vb3XY4HXa1Io5OOxenZ2NplMrq2tzc8vfvLJJxqNiqIoiVQ8occURd26dWt6eho7caFQyDC0RqPu93sul/P5yy2Komh6YjQag8Hg8fGx3W6/fv36zs5OrVaTSqX/5OOP45FwNBqtVjtisTgUmonH45jDNBoNEpeHh4cYtoDj2draWlpaYhgGOIYf/ehHZrO5WCyn0+mbN2/uvHollUrRLWa3O9fXN+v1+t7e/m/91m/t7Oy0u125XF6r1RmGLZVKN2/edDqdlUolnU7TNC2TSe/efTOdTA56PavJrNfp67Wm2+1eX1+vVCp4g8FJNjU1tbW1dfv2bY7jdnd3Z2dnMdBcXiZ1Op3H41EoFEdHR4jm4TnFjhXuAplMhpeVwWB48803I5EILtKRSMRoNM3PLzSqtXK5PDs30+v1hsPhxsbG4eGhWq3G5/a7v/u7AH/AN5xKpYIz08glDAaDQCDQ6/WOjo7QuhiLxTQaDRzMZrM5Ho8fHx8TBIEbQiqVApAIGZR6vR6NxM1m84cffLS4uPh3f/d38XjcbrfPzc2lUqmLiwuPx5XNpdudJiyhoVDg/v0HEP6RRtLpdKh3Ozs7G4+Hg8GA57nhcNDv9589e2az2fR6VLmUVSrVaDTZ3NzkOC4WjxiNRqNRH4/HlUolgC8rKytSqTSfz6eTSaVS6XA4KpVKZtAHWSYUCtWbjWazef369UwmI1eqdnd3R6PBZDIpZHO3bt1iGGY4HO68erW0tPThBx/s7Oy8fPkS4o5YSNIcW6vV7t+/f+XKFYlEsry8rFarodDv7u46HC74huGjqtVqCwsLYNjCZgNSutVqBWHb6XSKxWK01GPDXq/XC4XCRx99VCgU9vf38f1/9OgREJJHR0dXr159+fKlQCBAhhTJGOLh579sNBqtdmNlZYXn+fWNDU7AfvbZZ8DFLq+s9Ho9cHWdTjf0iV6vt7CwsL29PT8/b7Va8aKs1+vhcBgpU7FYTJLk6upqNBoVCUlge6AKgLACTZggiHw+j0kZIdVCobCwtCgWi6E04CuCwhbsU7a3t6VSKRQ8uVzearVgkwfHpdFoASKK85Xn+Xw+/81vfrNWq5TLZajT9HjicrmcTuezZ89WlpY4joOxVCgUAseF3oN2u40OqX635/F4KpWKQMCJJKRer1eplXhn8TyvUqoVCsVkwigUKkJAchzX7jQ1Gg1oualMBhbydrttspglEkmz2USqv1arSSm5Wq122R2YFJvNJkszFouFHo8hOL2uczGazZPJBOc69iZQfcbjsVarzRcLEDmazebp6SmosvAYymSyTrupVCqHwyFBELCdisXi09NTiVRaKpWWl5flcvnh4SG0MURY0dWDdSTifolEAjOHTqsF2QGjWC6XK+VLb775ZqvVKJVKQrEoFAo9f/5cLBZPaHYwGKwsr//rf/1vaJa3WCzJZLpQKkqk0manjb4njhPAxg5rFM/z9GgkIEmKkonFYqVSKZVK0XL1NXeDYR12+/rqilQqjUXCH33zg9/6+ONev1PMFyqVEsNMrHYbw3AyBYWGCjA4UCKrNxhYlj09PYVHDTvcZrOpVuvRJ2M0GpPJ5OLiIoYPoVCI7/Z4PN7c3CyXy2BDh8NnYGJBOt3d3RUIBB6PB9lD7PsXF+chuiiVylBohiCIeDyOJnaklMfjsVarDgQCqIFCsBH+5aODY+iyjUYDcrRASHAcxzCcQCCw2+1wFYBE7PV6HS4Xx3GdTqder1ssFrxQ8PCCDwIm+HA4FIlEGo2mWMrrdLqZmRme5ydjJpFIQI/BkgJVVAaDEevjs7OzxcVF1MvDxAPREfIYRVEuh73b7xfzea1ebzWbIXfVajWsWTUaFUmSLEt7vd5fM8CEUqm0Uqk1m00k+D799NMbN26Uy2WMVqPRaHl58eLiguMEkUgEj6dOq3e5XCKRJJlMOp32fD7fqNc5noeTwWq1Qr3HehcVW/BN8jw/noyQR7NYLBKJKJ/PY6ZJJBLAr8tkMrPZ6nZ/3fqSzeQ0Gg2lkMtkMrFYnE6ntVotTIeRSOTKlSsPHjwgScJms52dnV2/fv3o5Eyr1V65cuXVq1fZdPru3bv9bu/09JSiFAzDXEQinU4nEAgwDGNzOhiG8brcUDjG47HDaUc0dTKZLC8vb21t4edbLhedTieKkkiSBLDN7XaPRpNoNArzis/ngxHHarX2un1cX8MX51qtVqGQ1+t1nU53cXH+gx/84OnTpyKRyIu1y2RyenpKUcpvfetb+3sHHMcRBKnRaCQSUSaTYTkGh1AwGFQqlffu3ZuenvZ4PCKJ5OHDh06n85133nn5cstkMpVKxX6/XymVVCrVxsYGeg7S6bTL5UokEp9//o/f+973nE5nKpWiaRayKxzZQMAbjcZIJPKbv/mbyWRya2trbm4OqTqtVut02g8ODiwWCx4NQHCsVitOFoFAqFar79+/D4aITqeTURTP8zwvwD40FArlcjksMd98802r1bK3tzfs92UymcGgKxQKvqkguqEYhgmHw9euXXvdeQfXlMfj0Wq1+/v7t27dGo/H1WoNErhQKBQKhe+++24qlYKSpFQq4dZqNBpvvfXWw4cPgSi6c+cOFjUob724uPD7/YVszufzsRxjNBrj8fhrgNaVzav5fL5UKgkEArgX0KUmkcvw9Ua/nsFg0Ov1o9Ho/PwcGR1wB6GZdbtd7MSz2Sw6f8bjMdKsBoMeBGB8Yq9LrtRqDVzz4/E4kUhmMplgMGi321+92vJ6vVheP3jwSKfTgQRrs9k4jrt27YrJZHry5DEinBaLpVQqKZVKq9V6eHiEMNyNG7f+23/7b9PT07Ozs5999ktkOAiCUKtV2Irq9fpkIoEpcH19PXx2KpfLS6XKyspKNp8bj8c/+K3f5jjuH3/1hUAgqNUqDoej3WhiRySRSHRardVq1Wq1//AP//DhN795dHSEMlNSIu71erdv367Vaul0GqUmcCbs7u4Oh2OHwxEKhZxO5z/+4z+q1WqXyxWNRtPppMfjabVab7755vzCwqeffHJ6enrlypVOpwMBYjgcYimEfT0kGI/Hh/oWs9mMlXS9Xl9bW+MEbCwWSyQSH3/88YsXzwuFAvGz//Y3PM8Phj2M8wqFQq6UIzg2Go3sDodWq4XV12ZzcBwH0ZvneXh70aBiMplkMhk8GTRNY5szOzubzWYbtTq2aXfv3r24uNBqtdlsFm6q4XAIxZsgCLDOR6PRaDLG9wDGcIS2AoEAfjFob8ArWK3WTCYjEHAkSQaD0xaLpdFobW9vQ3QBWAisqXq9arfby+WiSqXqtntyqRSe39XV1fPzc8Ae4eKaTCbYLbrd7vjlpVwuJwVkoZgDnmcyGdlsNoalobp1Op2b1242m02BQKjRaHq9wWg0KlcrFEUplcrLy0uJTDY9PZ1MJoPBIM0yWNUJBAKJXDYajWA8AhG+WCxqtdrQVIDjuEj4QqfTgV8MYbbVapnN5lqjPhqNJCIxyPWj0ajT6+Lw02q1Dx8+BGGZIAiT1YKCP0oqoycjfFDQ8AeDAerKGZbFqhQftVAoBHit0WiApIJxkOO4breLeypFUcPBwG63m81moVBYLpcPDw/VCrXL5coXizabjRDyKPx2uVzHx6cmk6k/nPy7f/fv3S7v3NzCr351r9fvtzrNCctgfBwOxwKBQEiQsGH1+32aHgs4Tq6k0IGFnWwikWAndLVatVosKpVKIZeFQqF2s65UyP+nf//v9/Z35ubmut327qvt6dkZhuGanfbt27cPDg4WFhZyuRxFUSaTSaFUdrvd8/NzJIzwoh8MBp0Oilm+bslgGCYUChEEgevp0dGRRqNBAJBhmHQ6PTU1tba21m63t7e3zWYj6PMIurIsi950eBbBG+R5wuv1l8vF4+Pj3//936/VajBTDwa9b3zjG5lMBvqN2WzW6TXRaHQ0GN+9e/fevXsXFxc3b9zmeb7d7SwtLT19+hSROvAg9Hp9p9NTq9XgYMFW1Ww2Hz58eO3atf8fT/8VJFl6Z3eC7vde11prLcJD68jIjNSVpatQaKCAbqLR3SSt2cYHvnD3YWdsjDTu7swOySbNOGPLZatpATRZ3Y0GUIVSKSp1RmZGRmRo4R6utdba73X3fTgFvMAAFJAR6X7v9/3FOb+D0MxarQb8G4QFeKh4fA6EkiwWSySUwNx6cnLCZrOnp6fhhwiHIxAG5XK5Xm+ANUc2m7VYTMjPOTo6EolE9JARCYTpbIYZDJZWlg/29u12u8NmCwaDwyGdzWanpqZ0Ol2r1ej3+8fHx3NzcywWgcFhs9k0mSx4wPBzE4kEvA4EwZqbm2s227lcDhzd8YhF07TBYAoGg3weJ5vNapQqqUKuUChQESqVShabXavVUHdyBXyZTOZyuRQKxYvNZwKB4If/5J/k0unDw32Mot944418Pu/3+wGbnpqagXuo2Wwm4sm1tbUxa/TFF1988MEHX331lcfjAeCx0+kMh/TW1tbVq1eBwtJoNHan+/z8PJfJILxhcnKyUiqz2WyaZubm5h4/eVIoFNq9rtVq9Xq97Xa7Vq4sLCwkEglEeVSrVZPZuLOzs7q6igYVBnIgoKrVqkqlqFar6CQnJiaLxeL169fh2uHxeMArZNLZZrNpMpmarUa9Xnc67XD1KhSyzc1NZJepVCqn08kwo83NTZ9vymg0/v/+639zu93MYOhwOOqNKofDCQT8Op0unU1JJBJAbVZWViiK+vRXX0xMTIB1FAyGjo+Pp6enCIKAlnTj4kXsxRQKBU33E4nE8eHR8vKyy+V69uzZ9OwcWu6nT5++9dZb2Wy20WgA1EySJNCOiElNJBLT09OVSgkSY4vF0mp1tra23G43BA8g8o9GoyEzghN2dnZ2xB4fn55cvHjp8PBQIZMDZQ40QyQSefvNW8lk8le/+nRlZeW99947Ojo6CwTBnQHlEkkk4XB4bW3NYDDcvn1bqVTCMwhfebvdabfbFy5cKJVK+Xxep9MB34W9MJ/Pr9fro9FoeXl5MBhsb29brXb8AjBvgmrW7/dDAT8eSA6H8/r1a51Op9frT05OpqamyuXyF198sb6+brfb3W7306dPbTZboVzi8XjIloZEks1mb21tORwOLN9BqpPL5VCvI1XlyZMnYESDJOLz+Y6Pj6xWq8PhODk5yWQyXq83l8stLS3duXOXw+FcunQJceAWi6VarbZarWg0yufzseSJxb4NGMDpxzCMy+WQyWSFQj4ejyPma25uDuNVs8kKmfXEhO/zzz/HhpfFYj1//hzcnzfffJNhmHa7NRqNivn8j370o1AodHBwMKQH4MXLZLJiuURRlIAvrNfrnf5gZmamWMybzWamP2i1Wki80Ot02Kvu7+/fuHmzVqux2WwOh/N866XX64U0nCCIXq+XzWYXFhZw3714scVmsyUSCZfLNRqNaB25XO7+/u6lS5dAzPn444/Pz88rlQrGn7gfl5aWEGuBHgakdKVS/fjxY6hgu92uy+UqlUo6nS6ejEE43uv1KpXyxMQE+5O/+gulUklxCKfTmUqlIpGI1qDNZrNKpdJkMkVjMXCP2Gw2SBUA/8NFcnp6ajKZwMGyWq2AMDUaDbPZ3Ol0xuNxuVy2W22QSIMpMBwOsZjI5/PRaNRisSgUivF4HIvFoADoDfoovzweD4Isstksaji/36/X65Fp6PP5oOrv9TocDicajdtsNqPRHIvFpFIpSkD0haFQ6PT02Gq1RqPhUrEoEUqgjgJqFhUPZryDwUAul4MG5Pf7uXy+UCjstroKhaLZqnO5VKvVEgh4HC6FZJLxeFwr1zgcTi5XuHLlSrlcPT4+FknENpvNaDRmMhmRRNLr9eCBb3XayH3rdruZfA66n36/32q11Go1EItel5vFYomFokajkcvlcrmcyWRqNBrHx8cul4tFsEmS7HW6cA8Ui0UOjwshHpfLhaOEIAiRSNRnaC6XC1tTv92iKEqhUExPT//0pz81m83AG3Z7vVQqpVar0TQjRj6ZTCIl48033/T7/UjBXFhYwFrW6XTWazUulwsLq1QqHY1GXJLbarWcbnej0YgnojKZLJfPkySpUKg8nokXW6/+y3/5Py9vXNXpDH/3d/8wHI0qtTI9GgoEAplMNhqxeDzeeMTCAd3r9QiSPRqNBAIe5F/IVaVp+sG9b1rNJqouHoeyW80Ou9Xv9/8//+2/7Q+6Uql4enr62ZPHEplUplRBoI2OE7rA/f193+TkyckJ5OoIOoWPqVptBgIBi8UClater0fkKnamKEogX4CibmJigiCIzc1NqVRKUQSHwxGJRBMTEwjAqlbLFy9erFarZ2dnbDZbKBSTJMdgMJycHKlUKq/XC/J1p9Nhs8fA/IRCofn5eYZhKtVSpVJ5+813lErl48ePBQKBUCBut9tiqQTYOSxtf/N0lUoVlUpVKJUmJiYQ7MVmsxHA8I//+I/QnVy+fHk8Ho9GI7/fj12hTC4ZDAYsFksul+dzxeXlZbx9d+7cAay83+8bDMZGowE9wcHBEewXlUrFYNAVi8WLFy+enp4GgufQRw+HwwsX1rhc7r1793Q6nVqpGvR6rVaDxWJh3iMU8uECE4lEXC7/8PDwxo0ber0+FIog/uK9997b399vt9u/zrNSczgcxFsBu59Kpm/evNnrDV4+f2G3mrHirFar3/vBx8Avdbtdt8fz6tUriqJ8Pl8mn8PANZvNqpUKHM3Hx8dWq1mtVuOTwcRrdnb29PR0Z2dXoVBARq1RawmCoDgk0kVCodDv/u7vEgSxtbUlEolIkg1BN0VRaAs1OoNSqXz04MHMzAyLxer3+yaDUaPRBALnMzMzsXj85OSkUq9dvHgRE4VKsbS2tvbpp5/Ozc1BaDxmjdDawTw0OzsLnz/+dXJyAmpImqbv339oNBqhvsI3hedz0jcFA0EylVCr1alUAuEhFEXU63X4waFac7u92Wx2MGBqtZpUIrt06dLr7d1CobBx+WIwGGy3WzqdrlDKj0YjfNGgp6o0umw2e//+favVGgqF33nnnfF4VKvVEKUl4PEg1zMYDIeH+zdv3uRzef/jf/wPmUwml8uVag2iIVOp1I0bN/DvYbhRq9USiQRycpCNe72eRCJaXV2lafrJkydWqx12P1BmQC3f3d0dDcdIp/3Vl18YDHo2SRSLpXw+v7q84nQ6kWcALH4xn7t69eqvfvXpzMxMtVp1OBypTA5zVoRfkSSJrPFisdjtdo+Ojq5fvy6VSgOBgFQqlclkp6dnyPCABwLAQoIgEonEYDCwWCxOpzMWi7FYLJyrwOGWSqXT01OAqTY2Nrxeb7mQB/oHai0cJr9ZTiUSCQSigHdVrVaX11ahr4V/BVGDCHFCv4dzoNFo7O/vT05OFgoFSPs1Go3BYNjb28N+Q6lUgPdrsVisVuujR48oilpaWkokkugA4UJ4+vQpPjGv1wsHaL/fv3//4crKCkmSaIqmp6d3dl612+3f//3fe/DgQbVW7na7QiF/YWHB7z/PZDJTkzPBYNBstjSbzVwuhxMJHiCoOaenp0ul4tHR0eVLlwiCePHixcLCglwqqVQqx8enarV6amZaIBAkE6nj42Od0aRWqzudFo/Ha9bqWEecnJwM+v319fWXL1/6fD6D0ahUKvf398fjsUKtgoRapVKBmA+6OlKAAoEgrvgf/ehH9+7dI0myUqlMTU3t7LzSaDQYyuDYj0ajExMT6XR6aWkpGAyC4qFUKj/67nd/+pOf9Hq9qampx4+fQlOIuh8c2uFwWGtU5XI51ClIqGP/5//t/2Wz2bQ6NZvNjkajJEnqjDq9Xg9VilgigemjUqnU603cTDdv3oR8NZ/Pz87ORiKRfD5/4cKFwWBQKpW0Wu2vfvUrNpttsViMRmM0HIOH//z8HKkjmJqoVCrIGpDuhweCxWJJZGLcBLBEAn8Ks0m1WvV6vY1G4+DgAB2A3W7/5S9/vri42Gp1Op3OeMwWCoWYPS4sLEQiEcTsDIe0yWTK57MkQcjEsk6rPTk5ubCwcOfOHZqmjWYTQlTK5fKYzQbpAOpCLpfbbnfNZjOHQw7oHp/DrVbL3V5Hq9UadNpSqdRqddRqdb3WiEQiJoO5XK3RQ0at0q6vr4/H49v37gqFQqzVw9EITdM6g2E8HmNbit0/QbGVSmUN4b6ttkQikUtlOKlHo5Hdbi8Wi1q9rlKpJBKJ999/n0txDg8PgUGTKeTgUKTTaZ1O12w2o4k4Ul9Go1Gv1xuNRu16TSQSzc3NYYeFuZRAIOj1+5iIlEolbNzP/CcWi8WgNyUSCZFIxDAM3kAsKSwWi8FgGI9GmE4Xi0WhUOj1es8DoXy+yOVSoVDIZDawWCyb3d5oNPrMcGZ67ic/+emrVzuTvumDg6NCsZzNZmuNKs3QApHIarWKRBIul1uvNarVKsMw9Xqd7ndJLlelUqB+pShqZnJqfn7+Jz/5STablUokPB7PZjHzOKRIyD87O/tf/9f/t8fjYo+H4XDYbrfm8/lYMjU/P4/567d0AIUCG0YMqCFbXlxcfPjwoUqlYhgWj8fz+Xy5XA7hdMlkEgwwdAv1er1arbrdbryBCNtZXFw8OjpqNGoikQiaJC6XQsgrzAej0Uir1WM1g204gj6Gw2Eul0HKymg06g+6+LKgBNLpdDKJHORuq9VaKpUKhYLZYmEYJhqNq9VqmqZtNhuecNypYzYpEAjOzs6mpqaQXlUqldC3oFvY29vD0A7gsV6/k0qlpqenRSLR6YkffNfZ2VnQ14LBYKfTEQpFULPG43GDwUSSpFar3dra0mhUDMNE4zFIJNvtNofLXV5ebndaGMS2m61Socjncmm6Pz8///XXXy8vL9dqFQSli8XiWCwBTNRoNLp37/7FixfhF37y5MmlS5dqtVomk9Fq1XK5PBZL5PN5rVbbaDSEAhF46xRB5rPpD957v1AqfvHFFz/+8Y8JghgMGQ6HU6lWZ2Zm8qUiKHflcpkvFLBGYx6HIkkyHA6bzWatVj0ej3k8XrPZhPLp179hg8ViraysfP311+MRq16ve7xuCIfB2hWLxfF4FHZUpVL59OlTo9FoNBrX1tZ+/svPtFptIZcTiURut/vFixdqpcrr9WJjsn7xolQqbbRbNE3X6s3333svfB4Qi8XPnj0DgqhYLKrUSg6HUywWrVarXC4/OjqiKAoi3C+++EKn0zAMMzExweVyT0/9ABvChIhdcL1ev7h+CUMOh9PebDZfv94Gs6ZWq6yuriJKksfjRSIRHk9w48aNdrv793//9x9++GGr2a6Wa0KhUCoTV6vVYPDcaDT26R6k99D9zMzMTM/On5+fl0oliqJGo/Hc3Nzh4YHb7S6VStPT08eHhycnJ06nHUBtmqaz6QzDMGtraywWK55MjUYjiF0IgkB0lcfjgWoWXi18X1hLLSwsoEFyuVx//ud/rtPpgP1bWlx+/vw5IIvT09NPnjyxWq0iqeTg4EAql+GsWJibj0QiMpkMEY2VSsXlsNtsNpruh8NhKC56AwYF6+rqKhhjACDNzMycnp72+/3Z2dnPPvsMRpA/+ZM/gSFJIBB0u10kUep0OpgMkByMbePh4aHBYODzBeVylR4MKYo6OjpaXJpfWVl58eKFQqHgUZwXL17cvHmz3W5nMinsYcrl8nDE6HS6dDqNPFzMvweDAcnhOJ3O6enpu3fvOp3OWq0GeCx8DKPRCCxTXARcLheZCsBB8/l8ODz4fL7BYFQqlWdnZ4uLiyh0rl27Fo/HuVxOLpcDGrBQKLz77ruVSqVcLpMkhWEKYMsGgyGbzcIuajKZtre32Gw2izXmcDgqtYIkyYkJTzqdPD8Pvfnmm7dv32UYRiqRO51OkUiMQhAZCaPRyGAwxGIxoVDQarXy2azD4bBYLMlkstdpezyedruby+X0RgOXy/3i8y9nZmYWV1bj8Xin07LZbMMBLRQK+71eJBIBGgOLVxBARGJxNBqleFwIS2q1Wj6fX19fVygU+/v76KgtFhvS8K5fv3779m02m63T6TweT7fbfvTo0fLy8uLi4s9//nOJRNLv95FUC1F4oVCIxWJGo9HhcECaXCwWKYqrVCozmQwaA4iebTZbJpeOx+M//OEPR6PR7u5riqLYoeOD09NTtUaJ2jyVyVitVo1WdXhwzCbG3d5AqZQ7ne5EIoFYK5gO2Gx2t9uF3Y+iKBTLqKIuX77c6/XQRvD5fGZAc7ncarXeajVYLIIZ0cV86TeXymg0AhOsWCzCG8gixsVisVarmUwm/BS3241J8mAw6Ha7qE7gZIGxBZ+jRqMRi6VQGmJ4Q9M06gCh8Fto4aDX55CkxWKpV2uj0QhNs0KlxKgGHfNwPJaIRA6Xq9tuj9mkQiobE2z/6TFJslkslsfjqtfrxVLBZDJ12x1UY/FYQq1WczkcpUrD4QpDoRBs4c1O22QywXwhEAmj0Wi334eSDrZ2lUpltZkxRDXq9DKZrFAotBrNXq+HvI5UKhWNx6xWK9yaSqVSKpbcuXNnNBq5XC7wsQKBALbyfD6/0W4BEqhSqUajEZekxuPhoN93Op3wa/h8PighNFqt2WzOZrP45C0Wy9npKcXhIPoKu/nhcFitVm02G9LF3W53t9OJRqPLy8tCoXBvb6/b6YOSz+GQTqczX8iWKxWn03niP2s2umaz+ac//R8cDicSToSjkfGIqNar3X6P4pA6nW56elogEHW7XSTdDplRr9/tNJsCsVilUnA4HEAZeDweVir379/3uN3VatXjcooEvF6vl04l3nzz1v/yv/zPLBbr2ZNHbreTHg1TqYxGo8FSFcCzXD4vl8u5XC42hjweD8nHarW6UqmB3TIYMNlsWq3Wgj9Sq9UKhQJKSRCAlpaWMHCu1+sgt+VyuWIxbzKZEMJ9cLCHlQF2N2azuVqtCwQCDod3cnJCUdT09HQymVQqle12M5lMzs7OxmKR8XjM43PowXBA9/h8vk6nUys1lUolGo0CzCMWi3nfZraPdTpdsVhMpVIMw8zMzPD5/J///Od6o3lychIMhVgsxuPxsB/HIg8uP5Ikq7Wy1WJvNGvxeByrpeFwyKG+ZZCORiPkCNXr9enpaZlMDlYTIvwSiYTRaK7VKhhFswg25gG1Wu3w8JDL442GzPLqilKuuHv3rl6rm56cjEQily6tHx4eIpOu2ayr1WrEbaXTaTyBgwFz9epVROiAY5dOJxF7BQ4Ll8snSRJ6AC6Ht7S0ZDaZ7t+9GwqF4F195513StWKTCa/c/cuKBUavU6pVGKUDppz4OyUw+EYDAa73Z7JpEQiERhRL1++bDQamPmrVBqCIKDpLBZKlUpl4/Klb7755saNG7BIl0qlS5fW2+327du34cVDmmy3252ZWzAajflsFsJNPp8vl8uPj4+NemOz1Wo0GnyR0OfzJZNJvdFgMBjKucLR8SGPxysWSnCt8/jc5eVlkPYgFQV+AsSNVCoBUA44olNTU7u7+wg/WVxcnJ2dPTk5oQdMqVSC8YVmBuPxeGJiwmIx3b17dzikb968+fr169PT03q9bjZbLRbL/Pzis2fPtre3TSYTwSJ8Pl+9XicINtZVUrmk0+ns7e198MEH9+/fJ7mc6anZk5MTmqb1en0mk1WpVGD622y2VqtVLhZv3br11VdfQMf2+PHj3/7BDxOJBChQfKEgGo0D3Q4prd/vR0ACTH/gLYnF4s8///xf/It/weVyj46OMJKHYCOVSp2fn1vM1kAoePniJdzZUql0PB43O+1mszlg6EGvr9FoTCYTtBbhcFgmk5ULRXy2x8fHIpFgbm6hXC4DxJBOp/s0PTkxkSsUhsMhNkfgM5+eno5Go48//hh+TAg8WCz20dHh4uJSJBJuNltXr15ptdqnpycmk7larWg02kIhLxSKMpnMe+998PjxY4YeTU37Tk5Obt68CUEYhyAhnuHxeP1+l8fj6XS67e3t4XAoV8hMRnM0Fmm324Amdrvd13t7NpsN2RsQd0ajMZ1OC0T2pUuXZDLZ/v4+Lhp4oqvVqlQqhW2z3W5jkKZQKCORCGJXZDJZMpkEKo/NZptMxnA4UqtVtVrd9PRUIHCO6Ml6vS6TKbC7393dBTkTvOL5+Vk2m33nzu1/9s/+GU3T//Czv8tm01euXMFqy2Zz+P1+DsVjsViZTBZVr0wmCwQCOp3OaDRCtFAsFi6srsLlxmaz917v4udeu3aN4nIODw/Tqcz3vve9UDSSy+VUKpVYLCZZbMQ/hEIhqVQaDocBCuh2u+fn51NTUzweLxKPJRIJu90OKFK73W40GnC7e71esVj8zTcP+v1+JBJBvk0+n19ZWXr9+jVFUb1eD4kjOG0MBkOxWPR6vQcHBxcurPG5XL5QKODx+jQ9PzP33/7sT1dW1miafvr06Ztvvrm1tbW8vJzNZhH+e//hA4S+Ly8v1+s19tHuKyQYeL1eoOWVSmWtUVWpNDKZJJlM93odgqBQjS4szPn9/lqtcuvWrfv37wuFYolEwh6zstks6uLt7e3r16+Pxt8GX/f7fZLC/1fM53MHA0Zr0B7uHUI9HQqFNBqNXC4PBs69Xm+33VZrtZVaHWFeNE1vbW0hEz6Xy83Ozn4bHT8cZjIZo9FoMBgwRM3lCiwWC1Mu4Jth9p6YmMACrlwuA9TB4XASsbjBYOAQZLFYRJwi9lOFQuHKlSuYXrQaTY1Om01nhuOR2+kaEyORQBhPxiYmJvr9/otXWxqNyuPxNKo17NfFIiEaSh5XyCa4FI9Xr9eggm80GpAqS+USFosVDod5PB5cssfHxzDpnJ6eKhQKu90+Go1qtRrm52BXwiMql8sj8RiI0tO+SYqitra2kNmuUqlQmKtUqqOjI7VaDV+6TCZDrwMuKBKCKYqwWCz9XqdarcLkMjk5zTBMMpHWaDR8Lrfd7fYG/UajIRAIeDyeQqFgsVgWi4XD4Tx79ozP51ut1lwu1+12UbCWy+V+n5bJZAqFbHp6WiwW+/1+Nnvc6nZGQ2L79Y7/LJjJZM7OgrV6naZHDEP3GZrP5+p0umvXrkGwWS2VGYZptTrdbpuhaS6P5/F4aJrmUNRoNCJJts1mSyaT0Wh0amqGIAiTQc8MB8fHx3wO9T/9z/+PxcX5RqMhFgkKhRyLxSJJTq1eHwwGLper0+kMh0PgZCiKi1UpSgepVAoYN0VRoxHDMCORSFAuV9fX1xHcpNfrAbKCaR9OUjDb1tfXi8ViuVyGZtHpdOZyuU6nY7VaIZ02Go3tdhsz0VqtIRQK19bWzGbzkydPkHbQbjcFAsHq6mo6nZ6fny2VKjqdplQqwdMEuYNYLAYsisUiQCEBsbNer2s0OkgMi8UiRVFII6BpulotY6GfSqWmpqbwTxcXFzOZzGDQ4/OF1WoVvDGGGTWbTYPeaDAYAPtAS4fQCcS1plIpvV6/tLry4sVzDofb7/fK5fLq6qpQKAoGgw6Ho16vx2IxgUhot9oqterzZ5sOh2Nhdo7H42UymckpX7Vaffz4odPpZBim3+8COJfNZuVyJSIsvF7f8dEJRVEzs9OjEUOSbB6Ph3cwn8/r9UaCoACm2tt73Wo0PR5Pv99PpVIgShAEQVCkVqtvtFowyj24dx/SAmRRcLncRrOuVqsFAsFPfvKTK1euQCl14cKFP/3T/2a321ksFvjOCoWCz+f3+7RGpz8/P5+Y8EKqHwwGr169mk6nuTzqxYsXEonkypUrT548IQhifn6+0Wg0a024NbEshl3O6/NJxeKzQACwAD6f75nwFgqFTCYz5fWUy5ClVlUq1dLSUq1al0ql9Xp9d3eXz+dDb/ry5cuFhQW9QYfwpdevXzudTpIkjUb9y5evaJqenJxE+gLDMDKpvFqt8vlCrVY7GjEEQRSLRa1OUyqV2OyxXq8HAu3k5MRgMHC53MGAYbPZU1NToVCo2+5olCq5SrmysnL//v3Z2dmd3dedTsdsNlMUxSIIrVaby+U6va5MJpuamoLVem9vz2q1LszNP3v27O2333706JHL5QqHw+VKcX5+fszQON8oiiJJjslkgrOYxSI2Nzfffee9a9eu/eM//mOxWARFM51JSSQSzFcW5hZ4PF5/MPD7/Rq9DvaRer2+vLz8/OWL6cmpRqMBgEutVlMqlUg0mpmcOjg4mJqaglb9+vXrL1++pEgSTwWbzebxuNFoDPxqjUbDZrOLpVKr2VSp1QBGlGtVs9msUCnFYrHb7QaBhc1ms8esdqMZjca73fb7738YDgcFYglFEXt7B0ajvlgsq9VKgqAmJjz1Ruv07JjH4cvl0lKpsrKyZDAY7t+/jxQQnKKYUcFJ8/XXX4MlazQaFxaWOp0Wi8XKZrMnJ8cajQb6cYFACFL8jRs3Xr/eY5gB8hAB3FpbWyuVSjs7OwibajQaS0tLfr8f1HVAiWdn58Vi8fb2NpvNdjqdVqt1d3cXhpharbK2tt5s1vl8YblcLBRKg0EP5EVIGymKcrvdjUaj0Wh0Oh2TyeTz+QwGAzp8m81WLpdIglUqlW7dunVycnJ2dsYwjNvldbvdW1uvIEvXarX5fFGlUpVKpXq9atB++51iFHLt2jUOh9Ptde7fv39ycvK//8f/+PzpU2xj7t69azSYyuWyxWJB9LVYLCZJ8vXr1263ezweFwoFOFGQInr9ytW9vb0vvv4Se08MjHDO/OhHP7p9+3apVP6jP/ojv99vtVofPnxYLpdhMovGInabA11TNBo9Pz9H6bK6uuqbnKAogqI4LJJgsUaZZLrb7pXKlaOjI4CcQN+tVqtWq10oETcaDeR8IHNWLBayXz59iA5mc3MT+zv/eUCtVlssFqzGs9ms1WrF9H5qyjceD4VCIVCW2WxeKpV6XG6gR9Akeb3eRrOG293n88V/TaKbn5//6s5tQOG5XK5MLNvb28PYrV6ticXi8XA4MzeXTmfPAn6LxQIWvFKpHAx6kLQjuVqv13u93qdPn0LziBQ8MK5wsuNeBKyiVCrBzIV8OpIkhXwB1GparZY9GofD4e3t7enpaUQKTk74wuGwTqdDsKBEKuJyueVyORaLaHTaTCbjdrudHncymWw0alwudzigKYoq5gscLuX1epUqdSZdSmWzxWJhdXUVWCMk9I3ZIxRhCGNBmdzpdM5OTvV6PXrBUqVcLBabzeZwOFSpVMgTlUgklXqNz+eDo+Nxumq1GtxPsARi7YWaslargd2Aci0WiwFDB1pMo1Erl8utZl0ikQgEgunpaQQU9Dv9fD7PYrGy+fxgMBCKRRA2zszMHB4egmqNmB2AZ2Dsh44nm80rlcrxeDgajWDwLFVLLpen3en91V/9VTyWSqVSlWqzWq1mM3kWazyzMK9UysPhsMfjQZ4uezQej8fQ541Go9FoZLVY4B9ks9lisRCdPY/Hc7u9FoulVMjncrlwJHjlysa/+zf/9sXL55OTE4NBTyIWttttHl+IwRtgdJFIBMO8fp/u9XoymUylUlEUZTab/+qv/spoNFosJoxzHA5HJpNpNBqIHaVpGgFHxWIRTQ9JkgcHB3q9/ubNm48fP0YikFarjUQi0Wj0448/VqlUBwcHiURCIBBgsoXEN+wRIDKTy+XNZpOm6VarARcbh8ORSqUCgSCbTQM/Ax4bhmEajYbNJgmCePDgAUmS0NJKJDI+n4+wSMhfZDJZrVYjCBYaUMgQNRoNJEoURchkMrVa7ff7JRKZXq9Pp7NQv129evX169cWiyUSiSUSiVKpwOPx3nvvvXL528hIgkPiN4eLhcfjdbs9hmF8Pp9QKCwUCh6Px263b25uFotFPp9v0hsikYjP52u2GgKBAMLwvb09iUQErxNJkolESqfTsdns01O/b2IaZUE6k7DZLPFElCTJVqs14Z2Uy5WHh8eg0dTr1U6nEw6dw9vfbrdJkuQLROfn5yKpRKfT9Xv0aDSa9PoKhUL71/VWMpmcmZtpNptwDlqt1uPjY6fTqdVqsUdDLDTUhKenp6urq9l8MZVKLy0tptNp8B0IgtjZ2fF4XSh/MUoHW5/P59M92u/3Y5OO9CqxVIovDs7fg4MDnUG/tLT08OFDh81OsscMM+h0et1u12Kx1Wo1h90J9hswS7VaDRaWVCq1tLxotZrPz88fPnyo1+tdLgdck5FIZHl5tV6vHx4ej8fj0XBM07TD4dJoNHDXa7Xqhw8fanUarVbb7bbPzs4mJydNJhPszwRBKZVKn8+XzWblUolaqXzy7BlFUWtr63/91389HI+APwyFQsPxmMfjaXTa8/NzoAoQwwwgVjqZ+u53v9vpdM7OzjB2/c5HH/B4vEwyAXOJx+Mpl6sQQYpEovX1S/l8/uT49KOPPnr48DGXy+10WkqlMhwJoe4ZjUZetzeVSo1ZrEgkIpZJtVotouLK1Uqr1Zqeni4UChaTORaL5XK5CxcudFvtcrm8trZ2dHREkiQwh71er1GvC4XCk5OTubm5k5OTarV689r1ZrMJYHefoTFeVSgUdoeDz+fnS8WDgwOtXgd3tsvlWlhcfPzo0XjIkghFCoUCadMXLlzQGQ3/9b/+VxCzpFJpv9/H9CGZStlsNg5FQOsTCoVWV1cLhcLs7GyxWDw4OJicnBSJRK1Wa3Nz8/3333/9+vXExESz2R4MBnw+P5NJ4aHV6bQul+v8/JyiKJlM3ul0hsMxaNI+n28w6OG8wvjT6/UGAgH4k8BOwogLi9RcLicQiCiKgkM8l8vBUAL5DbCZiDDBQNpqtXL5HCDxbt68iYyEjY0NsL6Pj4/tdjtJkg8ePEAsgVqtIljso+ODxcXF/f39iYmJRCJhNJjFYjHDDEEHDIVCKpUGMoNSqcQeDeVyOdbEkUiEYRi0fDQzgFOnUChwOByNRpPNZldWVuq1xmAw6NEDMLQJghiORyAuNZtNIV8AGWg8HidZ7B/96Ef+YODly5fol2QyWT6fn56e1mg0sCaoVOper5dIJI6OjvR6/dtvv202Gra3t4fMCMBLfEerq6t37979+AffVyoVLIJo1sp7e3tbWy/6fXpudunq1WvZXG57exsonLfeeqtQKPziF5/y+XzvpE+v1xMEgaFdNptln+y/Ah0YE121Wo1kzZW1Vb1ef3BwUK/XYRoXSsQcDofp91DZ9Pt9HFt2qwOc39FoVCzloV7CcqfX6/EFgmAwuL6+PjExEQgFwUrJ5/MzkzPlchmw7NnpmUAgkM9m6eFQpzOwSQKKGalU6nK5isX8ycmJXC4PBoMkSV64cCEajR4dHU1OTqKYqFQq2D1LJBJw9LEQjUajOzs7wKzdvn0bQF6RQIj/Mbzudrs9n8+fnp6aDIZer/eDH/wA6YHQJ0okkkGvn0zG290OknZqzcZ3v/tdqAdQdFoslnajmc2mJSKxUCyRSuWVWgPoASjNYdDI57M0TYskYoircEx3Oh2ZRDocDsvlMkmSzXbLYDAg5rnT6YBrRZJkpV4jCALRub12ByBN0OrAtzw4ONBoNEajESl+cEBUq1Wj0QjULBbtVqu5VCpxKIKmaafT2Ww2h8OxUCjkc/iABTTbbb1ePzk9RZLk5uamxWIBXRPfFHZn2HzjPw4Gg0wmp1arhUI+BuBsNpsr4IvFYovZ9od/+IdSmVKhUHz55Z1UKuWdmKrXax7fRLfbRoHfqjdgHcdas1wuMzTNFwhsv07WpCgKaxcYeWq1msvlikcjJycnJMVmmMG//9/+P5NTvlwuYzTqy6VCu91msUmwBPl8vkqlyuVyjUYLQD8Yd2EJkUgk+Xz+e9/73nA43Nragh8e8JLLly+Hw2EEJuDDfP78uVQq1ev1Fy9eDIVCkUikVCqtra3B9A67OAgXoIDq9XqHw5HP5/P5/OrqhUKhgPjVpaUlKHbVarVKpWAYBn5vkHvlcjlShqAjAY19NBpFo1GXy+V2e+HnbTabQM3h0CwWi0AEc7ncer3K4/GQngu/Yb1e1+l0mGrs7OzMz8+z2aRYLB4MmHA4POH1QTA+HA6bzbZCoSiXi6PRSC6XFwoF5KmdBs6WlpY6nU6pVIpGoyqViqI43W4XJzUMraD5QSt5fHAoEoky2bRQKFxdXR2NmG+++UatVg8GPY1GI5XKX758qVKpbt261Wp1FArFqT/o8/nu3PnaO+FKJGIulwulht3urFar9Vozl8v/8Ic/VKqUhwcHgbMTuUwCdUij0biwfikej+eKhUajIeCLNBpNo1aTSCTJeFKtVjebzUql4nK7nU7nyckJQRDtTmtqagpwc8xoo9EwpCFSqRTkuc0XWwKBAOgHvHGNRoOiKB6fg1HEu++++/Tp083Nzd/7vd+r1+uB0wD0v81mE3/TD77znZOTE8zOQ6HQ2tpav98/OzsTCARut/tg7zWPx+NyuRKJRCgUv3r16uL6JTDJLly44Pf7K5WKUqXA1MFkMq2sLGFEIZVKI5GQRqNJJtPoE3g8nlQqD4VC/d4ALmb4ta9du1Ys5kejkUarPjg46HbbWIFhhM/j8ebmFrAIczgccqnsZz/7GTYJANv6piZFIlE0Gq1UKrfevoUwn2vXrj1+8qTT6QgFAoqiRkPWysrKwcEBi8V6+vTp1NSURCRyOp3lchEXIYdDWiwWv99PUdxQKIT5zcTEZDqdfvrkGTYyVqsVcKxQKLSxsUFSxPHxsVwqj0ajl69cGQ6HIzYLha9er8/mcxRF+U/PJBLJzZs34/E4XOetegMvaT6fr9VqQNSmUqlJn89iseDlKhQKFEUZDAaId3k8HhK7jSYTsiCFQmEsmcDsQS6XU1wOQrJJkjQbLUx/gMy7Vqs1GAzSuezk5GQ+nx+Px6urq//4j/+IZqbVbjcajfGIqdVqly9fBrcTbm5wtgeDQbvdDgQCaE1JkiRJ0my2kiTZ63VACWm1mhRFgVIGmHY4HDYaTRRF7ezsFgoFi8UEZQ4sWRKJxGQyYWXB5/OTyaRarUY61ocffggoCQbtRqPx3r17NpsNidGpVCqfz8P35/P5tre38QfCVvJP/+k/3dnZuX379vvvv7+0vPxXf/mXKysrWq32yy+/NBgMOFXy+TyHQ+VyOZFYANNYt9NnsVgbGxsHBwc2m/3w8BApjfF4Epe+Uqk06rR+vx/CLATdqNRK7KaQg3R2dlavV2/dujUej3d2dqFvdrhdgIFxudypmWm1Wh0MBovFolqpIkkSbxmXpKRS6Wdf/GphYaHVauFE/eabb65fv3FwcABfy/Xr1w8PD2UymVAo9Pv9tVptcsKbyWSUChUu01wu53A4EolEq92kaXppYV6r1YYjwXg87vG4GGZ0dhpcX79YrdXw9UGV3mg0aHo4PT0dCAVlMhl8/fV6/d69e+x/8z/93yYmJjqdjs1mOz8/bzQa3//+97vd7uaL5ywWKxaLzczM+Hy+TqczZI1zuZyIz4NDEE+My+WKhKKw/yQSiQvrqyKRCFoQXA/dbnfMYsGRQY+Gv8ncMOlNjUYDyZoqhbLdbterVZ5AoFJpzkNBDoeDUunw8JDP5w6Hw5mZmW63i4FQv98vl8tGo3F6evrZs2fgiWOMjNimVCql1WqlUilimCORyPXr1xOJRCaTIdkEgr3K5TKfz19cXAQALBIKofVXKpWI+vL7/RcvXoxGw9AIv97f+1ardHY2GAycTqdCoYDc2Otyw7VUqVQEIkmlUhuNRnBvwYbj9/vFYqFKpWJGQ6BETSZTOp0ulUokmwAmYDAYtLsdwHYFAgGECCDv1ZoN6GM4HA4xZgEogPBBpVKJXQZN02DjormHev3SpUuZTCYej3O5XKvV2mo1OBxOt9MCrJLL5VYqNR6PN2bGIpEoHA7LlUqbw350dASct0Qi8Xg8iUQCeiyn04nH2mq19nq92dnZbDYbjyeFQiFN91ut1sTEhFQqVeu0x8fHyUT66OhILJH7/f5stjgYDLg8QaFQmJry1ZoNrCwH3R4ypIbDIbgPeM0UcjkKOKyKQKmZn58nSfLWrVt//qd/Ui6XOVzyd3/3nyzMzVIUQVFEs9kUiwSDwUAmV1IUdXp66nQ6p6ambt++LRZL4bcoFArIIQAVEF8f2CrNZtPlcqEgxqwOdDQs4FKplNVqValU9XodacqopTBH9Hg8L168wFAahItQKGQymSCFvnDh4vb2djAYXFxcRLWK1dXh4T5CHgGMgPGEJElo6i9fvlyv13EWC4VCk8kkFktzudzp6enMzIzJZAqFQjClYuN8dnaWzWZ1Oo1cLge0Bvk8CAa12SzpdBqaRS4XOTOCXq83HrGASWSz2SwW4fV6M5kUmJ/wwtRqNYPZCL1LOBxeXV3lcDhff30bGmpYAXg83vT09H//7/99fn6+1+txScpgMByfHIlEIqVSDoH5eDzm87mXL1/+5psH6XT6xo0bDMMEAkGNWjsmSB6PJxDw0pmEz+fb3t6C6JjD4TkcjuOjM5vNJpFIFApFNBpxuVzdZqPTbWk0msPDwxs3bzEM8/DJY7vdfvnytf/x3/+71WyenZ3debUDO14oFBKJxXDaVioVikPChAX4p91uT6USSJUwm82Tk5M7Ozu1RgvBSoPBAF59u90+NzcXjYXr9TpmAHa7/fj4GI4HlVyFgB1w+/L5fKVWg+zD7/fjRcOGCPq58ZCG7Ugul5MkRyaTnQeCIPC98cYbDx8+LJWLs7OzTqfz9u3bHA4pk8mOjo7MZrNGo0mnk81m87d+6/sPHz6sVCoXL14sFssMw/jPAkql0uOZgCaBxWLRdN/j8VAccnt72+t1A/wWDAZhvnvw4BEklfl8vllvgEoKzoJOp7Pav43rsFqtZ+dnNpsNwGGP16tUKs9OTzkcDpfDR8xGKpWq1WoXL17stFpOp/Phw4f9fjcYDP7whz9cWl5+9vTxwcGRRqOBFI/D4f2TH//4q199EYvFFhYW8vk8h8OZm5v75JNPVCoVj88lSVIikohEIrlCwTBMtVGPxWLA4Hl9E4uLi8HAOd4XNNiFQiGTTKFQg6dvPB5vbm6q1erKr/scNKLgTrXb7ZmZGXi+9vf37Q5HqVQym821Wo0eDVF4CYXCRqsJSZbPO3F2fIbWcWtry263m83mdq87NzcHfodQKITSWSQSjRFclssA9YQF/eXLlw8PDycmJnQ63V//9V+bzWYQjux2O5/PL5VKJMmRy6Wrq6v379+/cGHN7/efnp5+5zvfOT4+RnpVv99vtdoymWx2dv7Ro0eLi/PNZhOFlMvlglmv3+9XKhWJRPLy5UtMpzAiAkrD6/XW63UEREJWmMvlDAYDxFharbbVat29e3dxcZFhmEwm43K5kN5js9mazebly5e3trY+++yzDz74QK/XIw6hVCrNzc3R9IDH42WyqeFweOnSJalEjsFSq9WqVKrwRZ2fn9P0EPIDpVIZDQUxVcHGgCRJg1EPT325XL5w4QJN0+FwEKuSV69eddp9gUBQKJckEgmCAXqDfq1We//9961W69aLlyRJnp6eikQiAZenUqk4fK5MJnv9+vXFixfx3j18+Eij0czNzX3++ecmk2lmZubv//7vHQ5HuVyemZmRS6TVWqXd6oxGI4VCgcSOTqejUMpHo1EsEjYYDDKZbPP5U5PJZDAY9veO33jj1pdffSWTyaBYuH79ut/vPzk5W1hYSGUzR0dHQqHQ5/MVi0W9Xs8+2nkejUaRgwu/iVqrdbvdTzefKRQKr9cbCoUS6W8Bcd1uV6NUYHfT6/UEfD66STxPONyr1eqIZqBRUOu0oVBIp9P5A4HRaDQzMyMWi/3B83q9vrq0Go1GoYM7Oji02+2s0ahcrXq9vkqtiheyWq1ubGzUahU08TChQOdeKBSAD0a+CpYs7XYbgCVUNkKhEHWJXC5HYOrm5iai7LVaLUx8IpFIIhJj5rG/v49wZYC4sIcWiQXYyFqt1kg4NhyPUA1AbAHEg0alhsgA+XT1ZkOv16tUKnhuCdb4/fffz+VyT58+tVgswNHiw6zX65DJY10IOJZKo0aUPWxlmM0ilbnf70OdgzOCxWLx+fxIJGK32zEHkkqlKD29Xm+pVIIjCfYZpVKZSiXm5uaEAgHMbo1GQ6lUJpPJVrMzGAwQqMIi2D6fTyQSPXjwAIIVt9sdCATwWQUCAWy4UV3VajUul481EPiTSqUylkwoFIpGvfXJJ5/oDeZMJjM1NRcIBF7v7HV6XZ/Pq9Vqd3d3cSpBBdVut2l6mEwmhwxjt9mRH4DjI5tLYzyzuro6Hg8vX778F3/25+fn55evXPoP/+F/b9Zr7XaTIFjNZpMkWCRJMsMx2CSYe1Wr1ZWVNWhQQFWFpUCr1QqF4mQyyTADDDOKxaLH46nX6wCrgPjH4/FAAcXOTqVS4QAqFovj8djn8ymVylQqhUGpw+FIJpPn5+cCgQBXJkVRiNaORqNWqxVUJ51OF4vFhEI+5oIwPd26dQvnJp8vbLfbiB5rtVqgsGCu/OLFi5npWbfbfX5+jsGV2WwejYe/oYgJhUKSJG02i1arffTokUgkQqchFAqdTqfT6Xz16hVwvmw2+fjx4/m5Bcgzk8mkVguWI4NoZIVCcXZ2RtO0zqiPxWLpdHpjY2NmZuYXv/hFp9NdXFzEAFgul+Nl3N/fx+E4HjI8Hg8eDoYZYD+u0WhisZhEIolG46jzqtWqUCDq9/vMmGUwGNjscbGUY7FY4XDQ5XLMzS1EIrGpqalUMiuVSu/duzc/Pz8/P59Op8IB/+LSfCadGw6Hw/GoVCr16MHExIRIKAmHwzaLZTQatRoto9H4s5/9TCaTuT0esUyKnPVfrwCEUNQ+efKk3+8jNn5paQmeMqA6APlzu91/+7d/++GHH56cnICG5Q+cImMklUrBbD83u9DpdCORyMLCAkEQh4eHly5dOj8/53O4eH/hw4KRSiIVT035IIjh8/kajQ56MuTSbG5uTk9P8/lcLper0+kODw9v3ryJdPDxeHx+fo5RWblchvK60Wio1dp8Pu90uOLxeLvd5fF4SHIkSZLP5/P43EQi4XTasfDFyKfb7VIUFxLAR48eiYVigiAkEvE333zz4x//uNVqDRiax+OJRIJSqcSMR6FQiMvlgpan0+kkQgFN02q1tlQqdbt9m83G4/FkMtnXX932TU6YjSaIa4PBwM2bN//qr/7qw4++U61Ww+FoNBpdXFx0OBxPnzwDEQr0kCtXruAQ2N17zWazCRYxHo8JkkQDXCqVas0Gm82GYgFZI/Pz84eHhyOaUSqV6+vr0Wg0m80aDAan07m7uxsOh202GwTyqysrtVoNRyIGgYlk0m63g0GP1wotk8vrAY0FuxeHwwE5rFwif/369Xg89nq9z549EwqFLJIAw/n09NTj8ZhMJkSMjMbjhYWF4LkfC4ThcHh6eupyueRy+YMHD6ampoxGIwBASqUyEAhcuXIln88jU06n07HZLPBi5Aopxk4XLlzodQe/rlcqarWm1+sh6LDVasF2xuVyEQUI1Qe661wuB9yo3W7v93snJydowyBj2t3dfeONN8bj8dbW1vz8PJvNhhbl66+/FgqFbrcH9Ad0dwzDzM/PI4/v8ePHHo/n9PQUfXswGJRIxA6Hg02MsWpsNTuLi4vZbLbf79M043K5KIra3d1Fq1Ot1ufm5nRq1ebzZyaTicPhgDbSbreDwWCpVLpw4QIW4jqd7tKlS69evWKz2Vsvd2w2W7PTRppnvV7nCwVY/uh0OiFfMB6PkRWWTiQ3NjaEEvHz588RLCuVSjGJ6HQ6RqNZp9MdHx9fvXoVAXoymYym+6V8wWaz4XkIh8NQQGazWa1Ow2KxeBzuW2+/+fDBA41WFYlE2CxSIpERBFmr1xmGwYoZGHabzdFqtfzB8/n5eVg3isXi/Pw8e+/lk0AggOy2wWDA4/H6iFJhjUGwHQ6HsWTC4XBcvHjxyZMnxHiEHFyCIJKJBEmS4LKIRCJQd6empkr5QqlUQrp7s9M2m829fn9/fx8PAVfAL5VKw8EQfGS9Xp+IxTc2NqRi8d7BQblaQ+6eRqOBktrtdp6dnYlEokajweVys9ns9evXwZ6GvBQAaDT6pVIJrdXJyYlSqUSGNNhfEEUiGZrH4w0GA2i9jXoD2nGsXXAZwyMzGAykMjESQ1dXV2v1ZjqddrlcarWaz+cjYUYmk1EEyePxaHpYKBRqjTq4w3hvx+Nxu9kQCoXXr1+Px+NYzbJYLKAQMLcA0V6pVIKMMmaz4GpGRhXUY6VSaWJiAkRQgiAikcjq6irQBgKBwO/3u1wu1GeYr4DqFAgEcJRj3ySVigeDAT0YYHCCCDA2my0WSc1mM2jaN2+9oVQq9/b2MKckSdJsNh8fH7fbbVCPEazm8XjQWXK5/FarBSkuxlrn4RCHw8mkc3/2Z382Oz9vNJhFIskf//F/HvQZo9Ho9XkGgwGykBGKCTNILJYYDAYjZnjlyhWZTLa3t7ewsMDn80/PjiGmuX79+nBIy+Xy48OjeCL67/7dv3W5nDwOmUqlMpmUxWLRalTFYlGnN0KEgTV8KpWSSGQ6nc7v9wPhuL29bbFY5HJ5qVRhGGY4pBEYUCwWfT4fimahUNjv9ycnJ4+OjvBso8xKJBKFQgEYdCgJMF0DnWR9fT0YDB4cHEDfgHc1mUwD5cDn88Fmg3ltNGIePny4uLjY7Xa1Wu3c3NzDhw8JgpDJFBhWT05OHhwcQM0NsdfZ2dmE14dRhEAgwLH1/MUmUONms1kul4dCIalULBKJut0uUpbj8fj09LRKpfryyy/X1tbgBUulMru7uzeu33Q6nQcHB/l8Xi5XQq8DQsrLly/X1tYEAsHjZ08EAgEU3Ega3di4/Pr166tXr/r9fmDiEWuI94tgjX8zRtVoVKCwZrNZhIjl88X5+fnd3d3d3d2bN96gKG6/31eoVd/c/do94W5UKzqjTiQQUFyuQWvYfLkl4Ao6vT7m6z6fr5jPBQP++YXZfK7I4/Ha3c5gMJApFY1GQ6XU7O7uyqVSDofTrDe5XO7x8bHVZjObzVqDHoIqqPFqtSpN016vt9frITepXC673e79/X2v1xsOh9ls9ltvvfXZZ5+JxeJqtYr8WqiGS+XC5OQkKIX9fj+XywkFEojhjo6Oer3ed77zHalU+uLFi9WlZaFQePv2bRgVjUajRCJhscehUIjP52YyGZ/P1+/TkUhELBb3+32MM3k8zuLi4snJSafTgjQ2EAgqFApk02JeMh6PtVqtRCIJBoMIADEZzYlEYjxmu91ujUYVDocrlYrRaCyViwqFgsulDg8P33333cePHyPKbDBgIO1ns9lGvTGdTne7HeA9jUbjqf9sPB6Px8N2u21zOgqFwsTEBIfDQWqvRqlyu9293iAajXI4vEwmg0lzNpPj8Xj5XNZms9E0jbj0Uqmg1mpEIlGt1hgOh1KptNlscjk8OF5nZmbu3r178+ZNiURydnbW63eHw6FCpiAIwmA0Hh0dbW9vc7ncucWFQqFQKBS+973v4eDSaDTRaDSfyeLib7VaH330UblcBvIe9sNvJcxm8+7uLojNJEnyBYKZmZloNMpisSiKisViarUaW5F0Llur1fDLYx4J1TzJIuEkhTv1008/fe/DD8Bv83q9iHOFzFej1TIMk82klpeX1Wr12dkZoq/RUC0tLb148QIprhhNQb+FY6pYLABO1Ol0xBIhlrkKhWLQZ7Dd9nq95XKl1+th11ksFkulkkwmQ2iPw+EAe5PNZgeDweFwiNhfrVZ7enqCgcji4qLb7b5z585wOMzn8x6Pp9PpWCyWwWCgUqlQx1sslmazBbk3ErUB+KjX61euXIG6C97zXq+HTFUOh1paXggEAsfHx9/7rY8DgUA2m52cnCRJKhKJgL+FT4kgqEIhd3p8NDExAfwNKgcclblc7sWLF++++3Y0GoUpfnFx8eXLlww97vf780uLX331lVarxQSLIAiDwcDn81UKZbFYBLZerVCur6/7g+cKhaLZbG5ubuKzNZlM7Xa72+0jF6vf76+srKBLuXr1qkapgFAbJmKwYUulksNpPzw8rJTKv/M7v7O19SKZTN5843oqmTk/D3k8XolUCoM58sf6/b5OZ1haWvq7n/3D4uIi1gJyuTybzVL1aq1arhh0+n63ZzSbwuGwWCptt9u9QV8kEqHittvtUB44nU4eRUbCYZIkWSwW7BhKpRwhjmw2WyVXMP0BSZKg9Uil0kQ61e12RWKxz+cTi8V7e3tOj1ulUonFUrlc/urFS6vVijEMZoBe3+RXX30FWynek2g0jDUB8lusVivQFCg15FJZp9XudDqtRnNxfmHEDIV8Qa/Xm/JNzs7NZdJpkUj08uXLZr3hsNm1Wm21XtPpdIlEQqPRADc3Ho9rtRrFoSDTuXv37tr6hYODg3yxoNFozvz+MYvVHzBbr3bgtEKAxmjEqtebHA5HKBRHIhGlUmm12ORKRavVOjs7MZvNYrEQiwaE5Hz99ddoj+RyOXpWiUSC1F4+nw+5AJvNDgQCXC6302pn8zngxbEKtFqtr1+/ViqV62sXDg4OhjQTDUegW6pUKh6PJ5VITk5Ogi8wYobdbtdms0nFkt6AHo/ZjUYDECYwoKGjEopEXC630WiYDGan09np9JACC3wUVLrQZmE82e12T05OsAVLJpOFQkEkEkmlUoZh9HqtQqEoFArZbFan1tRqNeQtphLJt269HTwP53OZmek5uVLmdruPjo5w3vV6PaPRiNUql+JIRGKcGjAA8vl8tVotFouxNpVKpQaDrlarNZq1999/3+v1ymTSSqngcDhMJkOn09Hr9QsLC+VKbWdnRy5XlkoVi8ViNltjsZjD4WAY5tNPPx2P2QsLCxaLLZ1OY0ohEomazXan09Nq9RDzNZtNjFju3LkD8UoymZyamkK0rVarnZ+fj8ViEGMi2BEP6vb2diKRuHXrVjabzWQyUJrn88XFxUXIHZDXabFY4vH40dHRhx9+GA6HKYpL08Ovv74zGo1WV1ePj05YLNaE19dqtnvd/vTUjMfjefbsmVajW1xY6nQ6z549G4/H169fr1Qqd+/e1Rt0YBCkUim/3w+75ezsLI/HQS+h1+ubzSbMzJVKBVFIAECQJJlOp0GkQxBEvV6v1+szMzO/qTykUulbb70VDAZNJhNAR9FoFGm+GD1arVZMF8BfUCnklUrFajWvrKyEw+GdnR2n0wlySq/XK5VKz549m59beOvNt6PReCQSKRQKr19vCwU8pt+jSJaQzxvSdK/XPchktSplIpZWqlWT3olSqfTsyWM8e+VStdPpxGIxt9czNTW1d3iAGCi9Xl8plcbjcbvZisViXq93YXF+anL64ZPH6PdOTk7sdjufL2g0mtlsDoMEUPibzSZm4VyKslgsd2/f5nO55WLR4/FcuHDhyZMn1fG41+n0O/1auSYRigKnZ3idKT0PE8SLFy9CZFMrV0x6w3A4PDs7w6NrNplevnx57dq1arWSSCRu3LgmFAr39/f1eiNG126322o1VyqVg4ODbDarUMgYhtnd3R0Oh3y+QCqVy+XgK7fAO1AoFM+fP79w4UKj0QL3KBaLCQQCm82CcfV4PLZYLATJhi+HIKjnz1/m80Wbzdbv08fHx6BjJJNJcoVEbLPL5e4NetFoFHuMH//4R36/v1Au2Wy2brfd67HZ7PFwOLTZbMVSPpvJ/zrFJaeQyY1GY6PWKJfL4XCEIEjkHprNFrvdfnRyiLsf0lJ4Ek9Oj5UK1fn5+TvvvNPpdBCu1el0EKEzOzvL0LT/7Gx2dnZubq5QLnE4nOXlZQSfs1isZq0uFAr1ev3MzAyCaCHrgZxgaWkJjBKxWBxPJKw2G6KgodMSCoXxVBIYiHAs2h301Wq12WadmZl58eLFpHcCfFqJUGS3WDvNFsqvy5cvf/LJJx6P5wc/+H6lXguFQpcvX97e3qYoqlQqqFSKQqHgmXCPx2MOReRyuUajEQqFms3m4uIij8djsVgQJCHBCauDcDh869atzc1nOp0ONfpwRKfSieXl5Xa7jf68XClqtCqlQj0YDMbjEZfLGQ5H1Wr16tWrDx48AKcUeSpyuXxpaYnFYiEkLRaLjUYjgUAA2jimOH//938Pafzs7Cz6Z8Q0QckDDFA8Hqco6vbt22+88QZGJIVCAaTTdDotlUox7AE5vF6vq9Wq+9885HK5F78NNWFBqRKPJ6xWK0mSyFdOJpOLi4s0TUPXqNVqDQbD1taWzWaLxSJCIX84HBqNesDfz8/PzWbz5uZmt9vt9xiBQFCpVCwWC2zI5WrFarW6XK54PB6PxwuFglarvXTpkkapyuVyVqsV8vmlpSWxWIpBqVgsPj4+5nK5IEG+eL4lEAhMRksgEEjyuGdnZyqVanp6ejAYPH36FHY3nV47OTn5YvN5LBaDVTydymKy0O/327mcWq0G4iedTg+Hw0AggERX/PLwXUqlUvY3n/8CoxqCIAqlYrPZ1Oh05XJZIpOORqOdnR2FQsGmyFwuBxEre8gcHx9bLBZsMSORyBtv3KjX698qKCkeqOskSW5vb+t0ula3IxAINFqtUCiEZ75QLrndboFAlEgkTo+ONRqNyWA8OzvTaDTj8djhckOl6Ha70YaqVAoUvMD+AumbSCR0Op1YLM5ncwRBANSG9gXLnUqlcnR0BIYW8hOEQqHRaBSKRaDIQJj/rTiMptPpNHLmm82mwWDAdqzdbqfTyX6/73C4YL7g8XjQFI/HbEjzLly4kM8VgE0ajhiRSOR02kHqslqtIpEIF3YyngCgCD3fYDCQyWSY+igUCjab3Ww2sdhSKpXtdns4HnG5XIzooN/HRU6w2MhXQqYhWluCINCLoFMH7AdA1z7NGI1GFmuUSqWkUnG9XrdYLKlUSiwWT0xMoFQVCcQIRXE4HFK5JJVKyeVyzJnH47HdbrdarScnJ0i4oygK4zRMR91uN6LuEAQE7WqtVhNJZH/8x38cCJz/y3/5L7/88uuf//yXlzeuulyuTq87Go/39vYwEZmbm6MoamdnRyKS6vX6ra2tubm5qakpYD+Hw2GhmIMTx+fzPnz4MBwO6nW6//gf//3c3Ozu7m6zXnU6nVKpuFarDZnBcDjkC0RisZgkOSADdTqdcrlcLpeFQiFBEOMxW6vVzs7OhsPhYrHocrkAe/T5fIVCYW/vNQR5mUwG/gmCIFZXVxOJBGLbYX0QCASgnkCxLpVKAUeAI4/D4ej1+lgsRpKk1WrNZHKQWMG1BIuy2+1Gkd3r9aDGKxaLyHh/9PAxQsEwQwIUg8vlIqIqmUziolpeXk6n0wcHBw6nvd1uWywWGI8JgvB4PFartdNpKRSKdDotEAiUSiU+TEBWK5UKSXJsNhuXw4tEInhxRiMWh8OhKCKZTHK53MXFxd3d3UqlMjM/Wy6XQWhDKmi1WlMqlaFQqNfrOZ3OZDKZSqUmJiYMBkMwGLRZzA6H4+Bg7+rVqzCX5XI5nU43MzNzcHBQKlXkcrlUIuPz+ZFITKfTBc/9165dZga9g8Pd5eXFSqVEkuTJydmVK9dkUnkwGNXoDPl8PhyNgIurkEk5HM6nn3767rvvavU6pVKZymaCweBoyFIoFFazmc1my6Wyly9fplKp9UsX67VGq9vB3xpLrvn5ecwqSqVSNpsBPxMoXbfbvb21ZbfbkZE6NTV1dHSkVCrh98Z5kslkDAYdi8XqdruvXu0IRGKIV8RiMUYCzVp9d3dXLBajg1pfX4/HYnw+3+v1ZjLpWqMukYjAfebxBFDq8Hg8iURUKBQ2NjaQt3h4eNho1tgs0mKx0fTQ4bBZLJavv/4aX82LFy/eeuutUqn0N3/z0zfeeGPIjGiaJknym2+++eCDD46OjqampiQSSaVaJkkSIdAQVrNYLKx+3n///c3NzUajodPoLBYLi8V69OiRQCS4ceMGBl0mkyESieiMBqlUen7un5mZSSaTJEnqNCqxWHywf6RWqx0O19nZ2XjI4nK5Doczk8k4HA6o40UiERpRm8Om1aq5XP7x8THq4y+++OKNN97I5womkwmFssfjAaZBLpcXCwWJRAL3+sVLl/r9figaEYlEGo0mn88jo8nrciO8yO/3487GDAmqQY/HA87Cw4cPcbUxDAMDQTqdvv7GzXA4bLfbY7HY+vp6r9dDPinJYmN6PRwO/X4/xpZ8Pt9ms+3s7ExMTOAb53K5pwE/Xm1kGkLQORwOZQq53W6PhiPHx8dXrlxB0A0UIBjy4RrCOBN7NIqiKIpsNpuDwYDD4ZQrRZgwoL7g8/k0Tc/OztptTogshUKhVqtTKBSRSARw7FarNT8/DzshRL2o3gKBALLM6/Vat9s1m824wTFWaTQaKIOQEA9iANYphUJxYmIClywSGMfj8W9MlBBF/PKXv3zvvfeUSuW9e/e+//3vNRqNv/mbv5menhYKheByVatVnU4/Ho+Pj4/lcjnCm+HV5XM5aNugiDAYDDTdX15e3tra4nA4+ImNRgOC93g82ev2f/jDHwYjYfjSisXiG2/eQrzm8vIye8wqFArQKfXanWg02h304cF3uVztdjedTsOVDKnl8fHxv/pX/+rO7XtAkkZj4ZXFpUwmVSwWCYLAzOXu3bvf+c53njx9PBwOeRyuXq8fj4fBYLDb7V65ci0eT1QqlVq97na70e3E4/F8Pr+0tBIIBDr9XqVScbvdiHlYXV1lf/Xzv+NwOIhkOfWfqVQqDo9XKpU++uijfD5/eHyETHu9Xi+SSgKBwLA3QG4al8u12SyQg9jt9hHNoMjI5/MMMzIYDCwWUavVJHKJTCZD2kaz1YrH4ySXY7PZRCJJKpXKpTMrKyuVSqXdbjfrDYlEkspkL168yGKxnj17ZrFYVCrVcEjDlol9X7/fh9i83++n02mbxUpRFGIWHA5HLBaDOs9sNlcqlWfPnmESg9qWw+GUKmWJRIL94+rqKmxcsAO0Wq3Z2VkkfSqVyiFrDNHM9PT0we4exIMEQdD0ELxsFoulUCgsFotIKI7FYj16EI/Hpny+tbWVly9f9vt9ONtJNoGkTAyr0Mrv7e1NTEw4nc7j42OJRFKv1wmCIEkSyLhsNiuVShuNxpjN4nA4sVjMYDBMTk42Go1quYLfCk7AYrGIzs/lcoVCIaxWfT7fyckJUoD6NCORSPh8LkRpSqUym01brVbQszgcHsJEuVyuQqFSqVQnJ0ckSTIMg+UgeEjwqiCfBKWq2WxmGAZmwOPjYwwAYFqEpG96ejYUCn3y9/8gFApfvnx1dHT8O7/9TyqVCk/AhzA/n89zuVyPxyMQiJ4/f/6DH/wAY/lGo6HTGmZnZ+/fv9/v92mmT5Ikj8cpFAozMzOrq8satVog4LXbLQ6Ho1bK+/3+YNCbm5srl0rVatVgNDscjlQqlUwmEap1fn6uVCoNBlMsFtNoNPV6nSTJ4XCIfOV+vz8xMQEVSL1eR1BSoVBgs8cQvYpEIkwKoWbLZrNI0alWq4VCwev1crlcrC0wCsIxDSIzh8Ph8ATQWFSrVWggSqXS5OQkHLh4mOH6wc+1GM293qBSKQ0GAwgfsZadmJjwer2o/LAAqlQqVquVx+fiwLp9+7ZEIgH7Ta/XczicZrMZCp2bTCakvWKh7PV6k8lkPJ60WCz0gMGmoNFoTE/P7u7udrttnAaoFbrdbjgWAXZuYmKiWCwmEgm73QE1JDDHKpVKq9Wenp5eu3Ytl8sZ9bpSqdRut69cv/7V55/hntBoNBcvbty7d69QKCwtLeWyeaFQqNXqy6UC3etptIp2s1GuFMasYb/frdVqt27dikVTJydndpuLLxQlk8l0Nnvr1i2CIBBrf3h4KJFIiuWSXC43W+0IsTeZTHKpdHp6+vmzTci9pXJZpVJZXl3VaDSfffYZHryZmRlIM9FCfO973zs9PQ2Hw2q1mqKodDKO6AUulxuNxhEKrtfr0+m0Xq+vVCogH05OTg4Gg9evX3f7A4qiNBoNl8vd39/v9Xr/9Pd+//Xr1wzDTE9Px6LRdDpNEITT6Tw8PKQoUm80hMNBu92+s7OTTmextrh48WImkxqPxx999FEikej3u5FIhKTYMqmi1xtwuXz8XEQVQXcMyWYikcJFOx6P37h5azAYjFmjdDoNJzU0YViQJRKJ73znO9iLmc1GGGlDoYhBb2w0Gr1+F48B7sLhcCiVihG2bTab5SolQRCtVisWi4iFfL1eXypWhEJhtVqHi3w0GkOocHhwjBAzgiAMRl2n0xFLxVAawIIKuuYf/MEfvH79Wq/XD5nR0dGRTCZTKpWHh4dyubzTbiukssGQsdls4Ugkm82+/d67ZrMZng9E1oTPgwKBANIrp9MJEdjr16+vXbuWzWbhzwd9ezweB4NBTNkxBrQ67LVGncfjnZycmAxGgiDwAZIsNvaAlUql2+lgEba2tpZKp3O5nNls1ul00Wh0amqKHg2R83bhwgUYJLEsttismUyGYLEB/OTxeIjBwb2Orb3RaEQGGryN77zzzuHhgd1uh4Dh4qX1ra2X1WoVRSEyCUwmU79HA3UkEol+9avPv//972PUFwqFIHSZmprC32J6elogEOzv7yMLxOVysVhjKBMEAgGLxTKbzSimk8nkzMwMKj+pVBqNRicnJ8/OzhKJBJK7otGoRCJZWFjAnIXH48HZvbS0VCgUkCzU7/eRGonQiF6vNzExEYlE4LLqdrtyuQIoci6Xe3JysrKy0mjUX716NTMzo1Qqz8/P2+222+1++PDh5OQkwzBIvIBiGOnU7BHL7/dLFd+G2kmlUq1eh6w2pVK5urxSLBZPT085HI5RpxcKhaVqBQedVCqtVGo+n4+m6YODg+9///uj0ejJkycKhWJ5aRVvq0gsoNiEUMiHct9oNI5Go5PT4+vXr5+cnLBYLILFNhqNarV6Z2cnHo9//PHH3W4vHIqqtRqwoqCdkEqlBMFSKBTzS4sPHjyAoxyeLfaLB3dyuRyXy5XJZGqtJhaLafV6OLT39vZUGjVJknC2AyRdyOXn5ubanSZysqxW66tXr8xmc6fZQiKpxWLhcvndblckkozHY5JL4t6SSqU0w3C5XKlCnkgkBgOGy+WyhiMEKRAEQfcHHA6nUCojF48kSYqistms0ajHjQKHAmBxMMuQJNnrdLVaLbZaYC5gdN/v99lsdiqVoigKMBu32312dtanB8BDIyYzFApBIYhBHyLwsGludtp8Pl+v1x8eHlaKJVyEQqFQIBDhdDOZTJB/RSMxv98vEIsajfq7b78JEPN4PBaLxYeHh3arTaFQBAIBzPBQa47HYwSbYDbL5/MXFha63e7Tp0+Xl5exb00kEvVmw2w2g6jb6XRYLJZEJM7lcjAl0DSN+4bFYkGgPRgMWq2WSCRKp9MSiWQwGPimpg0GQy6XefnyJUEQExMTKpWiVquFQiGKomQyBYhEwWDQ7fbGYrFiMS8QCOAP4PP5qBVyuRxGYpArzc3NJZNJdHgIIcEiH+kfuVwuEokIBCKPx/Pn/9dfvnjxotvt/8Ef/IHD7vrpT39qMBjEUglibsG0VKk00LpubGz863/9rzkczsry2ne/+92/+Iu/yOUzjUZDJpNUq9U33rjxW7/1W6Mxwx6zOBwqlUqNRiOTQTcej5vNOo/H43G5gz5DciiDwcAwjFqtTqVSXC5XIBAwDHN+HtLpdLg4gd3SarUcDofD4QgEgmaz2el0JBIJyMU3b948ONirVCoY/yAFDEdkMpnEi4CnBbisubm5UqkEBwA8aNlsFrVLNl80m83r6+t3797lcrnYrSMqqlarpVIptJ7j8VgqlXa7PabPzM/P5/NZoML4fD605JDbw5k7HA5R+dnt9oXF+fv37+fzeditXS7X4eEhNPtisVgo5FMUJRAIyuUymLQgzUSjcbfbXSlXsekYjUYOh6vf7zcaNXB68YyFw2GZ8lt4xI0bNw4ODjY3N69fvwHJI3p0q9X6/Plzq9UKgusf/vN/9umnn6IbGQx6gJWUSiWNRud0OsVisUwmOzv1n5+fC4VivU7D55JSsYAZ0ql0rFwsLCzOT87Ostjsf/jbv2u3ukqlRqPVZ/OFo6Ojmbk5Ho+Hl3ptbY0kyXgy4fV6uXwhiBhyuTwRi3E4nPFwJJPJhsMhi8VyuJz37t8fDAbr6+vAU6VSKYz6SJJE4m8mk+l0OpOTk+PxmD0e9nq9arXqcrnq9aZYLLZarSAQZjIZiqIYhllcXDw4OCBJ8u333nv65Gk0GsXljbqWYhO/eXcy6TSORDgVqtVKIhWfnp6GwoGmh0gnq9VqIpEAEGqdTuf3n4ILr1KphsPx4uJyLpcLBoMmkwFofmRUiESia9du7O7ufvPNNyqVanFhKZfLsdhjhUJRKpW8Xm+tViuVSj6fLxaLYblmtVozmYzTaVcoFChS7XanWqV5+uwJ4BToVKPRqEaj2tra+vjjj4FLwKFarVZb9ZreoE0msFkuisXSRCzRarXcbne9Xr+8cRVZuQsLC9FYWC6XW2yWRCIRiUQMBgOCBc1m89HRkdFoFIlE0UgMA05IyF0uV6tWj8ViRov56Ojo0saGQCDYPdgXCoXLy8ugCQgEgpebz202WygUunnzZq1WC4fDFy9ehOx6ZWUFjtHxeByPx2UymcViiUajS0tLoVBoxGYlk0kOjwuMs81i7fV6arU6EomI+AIQCqvV6vHR0eXLlyFRV6nVBwcHDodjNBrBzklwqI2NjV/96lelUonP5yOtL5vN9unBYDAwG02IaFSpVI8ePVpdXQXlvFQqJRIJMJxBw56fn2+324NBv1qtop9xe5z7+/sbGxsIJbx8+fLOzk6j0chlC9VqNZvNvv3228PhyG63h0Ih4HOxgdnZ2YnFYqurq8vLy9CrAQkpFoutVsvu7i5N081m0+fzhcNhhmGMRqNOp1tYWPjkk0+WlpaQam+z2R49euR2uyORiMPh0Gg0yWSyXC4bDIZWqwV2DJYJNE1fu3at3W7v7e212+1yuWy1WmH3AY1yd3cXoZDXr99QKBT37t3DJOLZs2dsNsvhcICbA5f6wcFBPB5Pp9O3bt3a2NjY3t4OBAKAqV66dOn8LCAUCtO5LCZbEokE1han09npdDwuN9Ys5+fneo3WZDLtHR4YDAakLW1uvrh27ZrL5drZ2cnn8zabDdF5szPz+KIXFuca1dr+/i6SvlD+UhyyWq1SFKVWq0k2US6Xnz9/fu3aNTabnU5nvB5fLBZbXF4CSh0YaolEAjDKex9+wOPx7t2712634Spg/93f/KnD4cAhe+PGDYTCdjodDp8nFArT6TRibjc2NgBZGfSZ0WgkV0jr9Xo+n7Xb7QIeF+MfgUAglyn8fj/DjDgcjkgk6ff7BoMuHA4bzCaSJGv1Ohh6DMOQXB6Xy5UIRaFQKJfLXb16td1sURRVb7YgUh4MBh6PZzQaHR0dSCSS69evZ7PZk5MTrH5wotXrdY1aabdY2Ww23BOg5YpEIpIkq9VqtVqdnp7GrSaRSM7OA1weDwAhiUSCURDUi9VqFZecWq1+vb8HuZVMJgsEgv1+f8LtwfBgamoql8kyDKNWa09PT1UaNWZmLBZLq9cvLi4Oeh2G7qMYB/QLOkqhSIJ8WYIgkPPT6/W2Xrw0GAxatdpgMNA0rdJocIMiLJPD4bBYrEajIRSLSJKMx+PValWtVEEdz+Px5ufnj4+PT05OxGIxlqcYily8eBHBOFqtlkWQMM2dnJzU69XxeCwSCUCfommazSYNBoPN4Xr48CGA4DaLyW63Hx4ecjicUqmkUCiMRmMymcRGf3p6OhqNIuhUKBTC7I395mAwADaXzxfiTJFKpY8fPdnc3BQIBD/+8Y8fP37a6fd2d3ftdjuU+7V6vdVqCQQi4BI+/vjjX/zi093d3Q8//PC99977L//H//HyxQuv1/0v/+UfoRnt9Xq1eoUiSJ1OazabW+2G2WBEJAJJkolYXKVSiaWSVqul0+kgI221Wv0+XalUsA5ut9t2u91ut0ejUYfDEQ6HGXqIEj+bzTZbDZQ+w+Gw0ahBn3Tx4sXnz5/r9XqjUR+LJRqNhlKphq9Yq9WiY3a73YiIxnYVfgu0d/liEQZy1MfYzSsUiuFwBPUPh8PJ5XJGoxF6OPaILRQKIchTq5WhUGhubk6hUDAMs7OzY7Vah8MhDOeXL1/udrvQFrzzzjvPnz9fXFpIJBJ6vR4PJPAig8FALBbu7e1973vfOz8/Pzs7c7vdOp1BLBb7zwI0TWNo1+sNeDyeWCyUSCTb29sTExMQqs8uzMHt++TJE4PBMD093Wg0R6MRRDzlcvmtt97a39/f399H8nyjWqtUKgLht6B5iUTidjuz2Wyj0UIOYDwez6Sz3/3ud09OzoQC3vLiTL1W7rSacoXY7XRwJKJ6Pv8nf/Jn6VTOandKpYr+gFlaWZ2bm/v0V194vV5kPioUqmQyWWvUtVrtmM1Gu+/xeNZWVjY3N2empvl8/ueffz4ej9VaVb1edzqdPp/vF7/4RbvdxpCv1xsQBBGNRkej0dTUlFgshsJjPB5OTk7iH4Gen05n0XdhwvHJJ5+srKyAwavVaqvVKpp7sViMohYEwna7PT8/Hw1H3nrrLTg6L126lEqlnG4HRVH43xAE1Wq1wECfn58PBAIs1shut1er1bW1la+++qpQKCwsLNH0EGji0YhBhA6+VgC6NBpNuVzl8Xiddvf09NTtcbFYrHQ6ffXq1d3Xe9BTm0wm4NQTyfg777wTCJyJxeJvvvnG6XQqlWqoleEoQsQbHj8slBGchSUpl0tVq+UbN26USpVSqaTXG//iL/5CJBSbzWaVSkNR1OVLG6enp9AdUxxCq9XGEjF4SO12O5fLjUajXq8XG7Farfb8+XOFQvFb3/1epVLZ3n6tVqt5JMHn85udNhpyiqIQumCyWlgs1oN730xPT7NYLPy2CwsLn332mc1mU6vVXq/3q6++QnMeDAadHjdECCRJQlipUqlAIxsMBru7u9evX+/3+yKRaHt7+9133x0OaLj/tre3sS1Cxhy6MuzIwBTt9HtsNntpaenly5e/6Wp2dnY2Xzz3+Xys0RgWdY/HEwqFfmNHgKZbLpc7nU5EjwOmAPiOxWLG22Q0GlnsEVB5w+FQKpFHIpG1tbU7d+5MTk6h2UOGL4hfBEFMTk4+f/7c5/NhAIHCC/klzWaTz+dB3oAzJJfLISkZUYB3796VyWSXLl16/vy5yWSSSCTtZhNY6VQqhXaRx+PdfPPNz37xCzjZUZq/8cYb4XC4Xq+vXrgQCASOjo4WFhYgNML1enJysra2Bl43khwjkaher+/3e+A+tlqt1dXV3yBVY7H47OwsnNcAcLJYLDabrVGqyuWyzmjAb1KtVhutJnLE4/G4Xqvz+Xw7OzsGg4Hu9QmC0JuMX375JVSqVqt1Z2cHWaI0PZyamsJEYDAY+Hy+eDxeKpU+fO/9ra0tgmChVa7X6xKpOJlMdrvdqampCY/3+Pi40WjOz89vbm6aTKaNS1f+8i//0mQxI0bFYrHs7+87nU6RSPD8+XO7y4na1+12Iy2e/fzh18ViEccxkLLYl3UHfY/HAx0rcuDlcnmlUhmP2JlMZu3CSr1e73bbCoX8+tWrFI/XqFa//PJLmVReLBaHw/FgMPjOd75bq9X293ddLlc4FqVpWoIAqWZzPB6LpDKHw5FNpRHBW6vVJjzeXq/35NkmOF3QF9dqtVwug4xnrKUYhoHrAW3BmB5gx1ytVlERAoHN5XL5fD4erGQyubW1pdVqNRrNkDWWyeXIWdNoNGaz+eDgAEZo/NxyucwXCRUKxenpKUmSQqHY4XAw/QEU62KxGD1KPl/M5/ONVnNvb8/tdm9sbJAcDt3v8nkcPMeIaF1cXGSz2c+ePROJpdVqFcTt09NTGCprtZpGpdaq1SRJSiSSMZvd7/eLxWImk/F6vfF4HIjXPj0YjUY45rRqjVqtRhGs0+kwbIAdAdGKuVwOsh4spNgkBXPi6ekpQbBEItFwSJdKpV9/vA2FQuGZmIxGo5hgR8PB0Wjk8XjK5fJwOMRhkUwmVSoVUler1Wq9Xoc86ODgAO88kluwFe10egAWhMNhl9NtMBg8Hs/z5887nR6bzf7HX/5if3/fZrMJBIIBTZdKpXa7iy3n2tpaIpHa3NxcXl6+efPmT//2b7u99h//h3+PGXs6k1QoFGKxaDwcdbtdvoDL5XJtZgv8TVKp/OnjJyRJMiMahOW1tTVIiVE6YPiBbmEwGGi12m8HqxIZqu1+v5/LZ2Hm6vV6BoMOS0CcjNPT0y9fPtdqtVyuMBgM/v7v/75MJnv69ClmQpAOYFRDEITdbne73aFQKJlMDhgG4z2Hw/H69WuDwUBRVCgUYrHYGC3A7KPRaOLxeDabpdiUQqEAcqzbbQP9Dxk1n8/H44qkTplMhkCeS5cuQZxerVVQxGOAOjU1lUwmZTKZx+OC6D4YDAJwFYslaJp2uzwAdOXz+WazLRQKpVKxXq8PBAJYk7HZ7Fwxn06n0bbiktZqdX6/H1j/aDR67dq1TCazs7Pzgx/8gCCIXDoDQ7HeoAMJRa1W83ics7NAMpn0+Xy9Xk/AF9I0zeXyj48OjHqNz+tKJqJT074h3Ts+Pvz8889dLs/qynq92b569ca9bx5odHqBSILdazKZzGRSbrf35OTEaDZJJBIWQcCnYrVau+22SCSCycNisfj9p9l8bmpqan5+/smTJ8DcY2XW6fTgpCEIAiK2TqdjNBpfv952u90CgeDVq1fFYvG3f/u3X7zYMhqNUDd6PB65XJ5Op3O53OrqajabffLkyfr6ei6X29jYePjwodvtnp2djcfjbDY7HA5PTviQR6vX6yUSSSQSOTk7xlcjlUrPzgIKhaLVapnNZoPB8OmnnzocDpJkQz3TbDaPj49HI9ZvFDNyuVQikdy/fx8vJk5OiUSSTmdHo9HS4nK73Waxx+l0msfjraysfHPvvslkApQS/mKFUs5mswOBM4IgfvSjHzUajb29vX6fxpYNh386nQYDzOfzHR0doXdC/0zTtNvtVKkUx8enTqdzd3e/1Wo5Ha7z83Oz2crlcm0Wa6fTuXPnjs/na3eacrm8XC1DqKTT6fDHImPY4/Fsbm4CR2fQG8FmEwqFx/t7Eomk3etSFMUmCIRD5PN5p8c9GAzSiSS0ECwWC07MRqOxuLg4HA5R7oAJQpLkzt6uw+HgcrnYrhYKBQBF79y5Mx6PDQYDUlylUikCRtuNJjYwvV4PIjyYZ4fDIZJt8boRBCFVyCuVCpZ3KPVw+gnFosFg0G624CA7PDwERuejjz46ODgAbU4mk2G9tby8jL2QSCRaXFz85JNPLlxYwxT8Bz/8fiAQIEnSYDC8fPFKKBT+7u/+brFYvHPnLpIKX79+vbq6isAlpVLp9/uRLXj58uWHDx++9dZb4FStrq76/f5erwswCgCwEFxiyQAmHJvNXl9fx2ql2Ww2ajUsr7rdb2ks2OGCAdFqtUCKoijqW/xks5nP57Exx2MGaYFKpfqNlc/r9Wo0GrVa8+mnn05NTU5MTNA0vbOzQ9N0PB6/du1aOp1+++13Hj16VCwWUVlWq1XcxSK+gKZp76SvUChgy6TV66xWazabLZfLWrUGy4dGoyGXSDkcjs5owCEPce3q6ipGqtlsfmNjo1Qqfec739na2kJHFIlETHpDt9sNBM5MJlOtVqMoisfnoqGq1Wpmo+nevXtCoQh7Z4lEkkpmFApFKpMmCALwC0iSEokYSZI6oyGXyy0tLdXr9UqlUiwW2X/zf/1/8eECZIxUc5qm5RIpVloQDIJmKZVK2SQnlUpNz0y+evVKJZcpVYpischijaanp1+8eMHnC9utjlQsGw6HCoWq2+0OmP709HSz0w4EAt1eD6PC4+NjpUYLenIymayVK71eT6lUqtVqUF+LxSJYFwRBCAQ8qJXZbDbIJXa7vdvtgvxEdzsEQfR6vfX19Ww2e3p6is+CJEkMOREwiStKIBDwhALUAXApgypmNBpT6TQwkhi6cjicTCZDEITZZjcazPFolKKoerXSbrcBjAgGg4jL0Ol0Ko26VCpZHfZcOkOxxgwzUKk02Wx2dXXVYDT+/Je/qFQqPD5fIBCIpLJGowGKWqFQoNiERqVuNRoMw8hkMsyQ5Uol9r4YFCO6Ev5krEFZLBaLxcJMHrEk8A2BJkeSJCyK9XqdoiiC4uBZ9Pl8y8uLpVIpmUz6/X61TiuTyeAlYY0JDJwSiQSPQ2LikkgkwIuHQguzdDh+oYvEZ3h6etzr9Wh6yOVyM5nM6uqqWq09PDwEnbzb6QkEAoxePR7P2dlZNBFH+CjDMIBc5PJFDOcVCkUikYJkZ3d3t1gu/Zt/829MBv2du1+vr68jLIjFGo+YYbfXlkqlRqNxzIzBEhMJxazxOJ/PeX0eQJBv3LiRzWZ3d3cFApFcLne5XKPRqFqtqlQqpVKZz+fFIsnU7OzxwUEwGMSzBHJMpVpGNSaXy7vdNur1wWCQyaS4XO7p6blQKLTZbCAxSiSSFy9eoD4+PDycmpoyGAw4OpExPGKx6vU6hCDwQuMj/b3f+/1arXZwcGCxWOr1+o0bN8DpoXt9GG0gWbVYLFhN9vpdpVIJ/KlWq71//77H41EqlYV8EZ5HqAxTqVSr3bRYLKVSaTgccrncmZkZh8MhFotzuVyr1UqnkyqViiQ5/X5/NBwj8uKTTz6ZmZkrlUparRo8CPDcm81mu9fBX1YkEgmFwmw2q1ZruFwuel9UYzdu3MCW4cKFCwKB+OsvfgVkA5/PjydiGNJgGVer1aanp4uF0unpqclk6rTbN65dlkhE//k//QeFQiYW8QRC/q1btzqdzv7ekcloC4aiDpe7XK2fnJ7BkUASbBhNKIoSScQikWh3fx9pwWdnZ2aj8fLly19+/sXFixez2XQmk1leXj46PpBKpXK53OFwPHnyJJlIm0wmVJAKhUIsFp+eng6HQ7lceePGjZOz44ODA7fbjc0dLLfRaLTb7Uej0XK5vLS0BM4wi8Wanp5+8uhhLBZLJpNQqxAEATE+T8DH1AfMjna7LZfL8UvCYCsUCtvt7rXr1//8T/9cq9UC+R0IBNYvXsByAYaYZ8+effjBdwiSHQgEfD4vSZJ37tzRaDQulws8OaBSPvroo0AgUCgUMHCCv5vNIpLJZLPZRLptIpHoD3oMwwwGvU6nI5NJjEYjJJKAn+Vyua2tLY1Gs7Ky0u/TmKQOBoNoJDY1NTU3N7e3v1ttVHGWejyeV1s7PB5PKpU1m02X3TUcDj0ez1dffTUc0jhXZTKZ0Wg8PT1VqZVIAxMKhWazsVwu1+vN4XBYKBQuX77c7fT4fH4uV3j27NmltdVCocATCvA+Wq3Ww6MjfFm4ILAtXVpaYrNYsVhsOBphbSoUCjudDkVRqWyGz+dfvXr1+PgYfBAoX2uNukAgsFmsWO7AZYKOPRwOK2Xy8XiMeFwej5dOp7lcLtCGEokEqSS5XM5isQglYrT3+/v7q6urqF04HI5aq2EYRiwUpVKpXq+HCBfo3z0eDy6UdrudyWTeeeedw8NDCMgajZbZbPR6vScnJw6HfWtry+/3f/TRRxRFffPNN+BFdTpdn8/35Mmz4XB469ZNj8dz9+7dfr+PNaLFYnn16tXz58+By8dqmCRJwEgB60G0Dnrg5eXls7MzVFFsNnt2dvbo6Aii25WVlXazgbu+Wq3ifjQYDA8ePEAU5v7+/h/90R/RNP3NN9/gM5EplM1m0263QfQGb6nT6dza2sJPTCQSN2/ezOfzgUAArLhWq9VqtTudDrjKWq02lUrNz8//7Gc/+9f/+v/O4XB+8YtfEAThcDhUKlUpn+t0OhK5bGdn5+rVq8Ph8OTs1Ol0Yi9ZzBewd+r3+6zhSK1Wp7LpxcXFWq0mkUh2dnYGg0Emk52ZmQEPotPpYFncarUgxS4Xyul02uVyxONxgZCPXgKLIJqmFTKFzWaLxWLVarVcqtrt9maz6fF46s1GNpudmZkBN7HVajkcNrVafXhyjDJaIpE8evTo8uXL7J2XDyuVysuXL5eXl6VSKcKMOp2ORChCxQrJuclk+tnPfiYWi2UKVTqdlsrEYrHQ63LrbZYXjx8Gg8GpqalarTYcjpvNJsXmymSy01P/hQsXxuwRj8crVsqBQMBgNKJfTyaTfJFYLpc3Go1kMvnG9RskSe7u7jIMYzJZgNnEQ+zz+UKhc4Bw0MojCRU1daVSMWjUKBQIgkCYnUgkwgTS4XCQJNnpdJLJJF5RPp9PcCiwdIfDIdBTWJFodbpoNAqDMTz/QNQMxyRJkhKRqNVqjYeMx+MpFosajUYgENy+fdtut4/HY0TcKNSqVr3WrtdsFqvFZmcY5unTp8FgcHX9gsPheLW9LRAIdEYTZhKDweDw8LDdaNL9AWs0GgwG9Xod2vxSpYI0qG63y+Fwer1es9lEmB1aW1S6mKDCVVur1bCho2max+NNTk7CtEKSJEFxEKdIURSfz61UKiwWSyAQSOSy/f19mUwmFov7PRplH0EQFpMhFAohlwbAGMgJsbSFHBU4Az6fn0gkkE2JOE9McSmKC/5kKBQqFkrYfDEM895772UymXav43a7d3f3sEUdDAYKpRrhIX/6p3+6u7v/zjvvfPzxx//pP/0nDo/77/7dvy0V81j8EwS7Vqvt7e2plHIAhdvtdq/do2l6YX4xGo2qlMqpqanXe69LpQJo+OVymcvlisXSbrdL0zS0cV6vt1gscrlciVgaDodfv349GAxu3LiBFU+v11OqFEKhsN1u9/t9iUSEKjOTyZAkW6lU9noMRVGQTfR6veXlZXA0Wq1WMpkUCoUikQgclFQqpdFoovE4Boo4bXGgy+VyPl/Q7Xb1ej02rZD8RyIRmViiUCgajcbExASWVkAw8AW8ZrNJkqRCoeBwOE+fPl1fXz8+Ph4yow8//HB3d/fg4OCNN97Y2tqyWM1Ib4Bjv9vtyuVyNJSdTofDIXU6HaJyTEbz5cuXnz9/7vf7DQaTUCjM5TKj0cjtdkPHMLew4A+c6fX6ZDIZDAbfeuutZ8+eCQTCQqGQz+dnZmYYhgHO3mazMQwTDAZH9AjnSzwenZycrNfrjWa93W5zOByowQqFwqBPAyGt0aq1ao1YyPX7T+02c6fboAd9sUhCEMSQYfMEQg5X5D8PlcoVpUbLYrHEYnExlxUJBSKR6OLFi0+ePZVIJGeBAFA3JEle2dh4+PChRCS2Wq35fJbL5Xon3MfHx2+89Va31UIM2Vdf3p6YmFhdXUW4MuYrDMOcnQXkcnm1XmGz2ThP2u025MOpVKrZbCO7CdQx4F0cDsfx4QHEAKD7gm2h1+tZBBvws06nk81mUcEAV+H1eh88eGAymbD767S7CoUCW49+v5/P56emJ58/f47YQf9ZYGlp6eT0uNlsvvPOW3t7exjCYUb19OlTpBDiAePxeIlEArEWPp/v669uYy957do1o9H4N3/zN4tLC+FwWCQSaDSaer3q9XphZxOJJK1WC+rAX1cVMhhFxWIxwSYjkYjRaKzX6/lSgS/gYijSafesVqtIJE4mkxyCYzKZ5HL50dGRVquGL0QsFne73fn5+cC5H8uUjY0NxH4/f/4SQbSpVEqt0hSLReBPDRp1p9N5uf1qfn7eaDQ+ePCAZhi73b6wsBAMBoPBICoDk8nksNt5PF4wFII+Ev+9RqOxu5zdblcsFnO53HA4nE6nseqy2KyHh4fLi0v5fB7bAwgxgcL56IMPHz16FAgEcDgjoaFYLEIVFw6HcYbQNJ3KZtxud7lcvnTpUiwWy2Qydru9UCgIxSIej0cRJKAGS0tLpVKpUqlQFGU0Go1GI/K2L1y4IJVKHz58CHLh4eGx2+3W67W7u7tyudxsNoVCIfCi3W53v9+/f/9+p9MVCoWTk9Pz8/Pn5/7fmC2AQs3n8yaTye12Qy/4xRdfGAyGy1eu/P3f/Z1YLIZ+d319fWtry2g0HhwccDgcpVK5sbGxt7eHdQdIbJBZ0/0ekC5wgdjt9uXl5d3d3ZOTE6/XW61Wz8/Pv/vd70okktPT00ajwReKBoNBLBaVSCQrKyunp6dIXL148SLgzLVaLZlMGo1Gg8GApDIul5vJZHU6HQ66er0OSa5CoSBJDnaywLQKBILLF9fT6XQ8lVxYWMAUecxmiUSibDa7sLCw82pbKpWmUqmNjY1IMPTuu+8+evoYLTGmQjqdzmazQxC5ubkJsj/qGZg5rCZruVy+cmXjwYMHTpfjwYMHAFVizJTL5BKJxIcffjgYDM4DIfSH8XhcLJVotdpEIoFQEx6PVyzma7WaWCalKAqjkImJiWq1yv75P/zN1NQUh6KOj497vd7bb7/9/PnzQqGgkMqgyXW5XP1uL5/P0zQdDIccLo9QKCwUcxRFdJotoUhgsZgMBsPJyQlJkt1ufzQaDbqMQCBgsQiFQiGRif1+v95kzOVyNMNgr6fVakdsApPGRqNhM1sAedLr9d1uH889wzD4MsrlIlw/iN+y2+37+/tarRayKgGHAtsJfVulUvm1J04BsR60ro1Gw+12czicvb09CJjG4zFfJATSE1igarVqsVpNJlMwGITZUiQS7e8fg7QhlUozqaRMJpOKxbDsnp+fS+QSkUg0HI3UarXNZguen7OGjIDHh5Bw/sL6o7t3+wxNkqRMLi8Wi0KJlKbpfKGAgpoeDFRSuV6rxbh1PB6XSiWSw4F+fGtrCxxOTK2gDIAcLxaLYSZht9t5PB6U1yheof4mCGJtba1cLh8cHJlMJpFEPBgMRiMGAjihUCiSSpCjEggEFHIVJBECgYAZ9KArwugbPAK3251KpSB+Zxim2WxOTEwwDHN2dkbTfR6Px2IRGA6bzeZIJFYqlXq9ntfrzefzCwsLmXSWpmmSIgiCWFxelkgkP/vZz3K53OzsbCAQEIslXq83EouORiMuh8/n8+VyZbfbFUnEGo2Kx6W2tl6aTKZKpaLX6yuVUr/XQziMQCDgc/idTmd+bmEwGATOzpUqOZfPFYuFiEjq92mXyzUcDiORCARPWq02Ho9LxNJisZjNZtlstl5vnJ+f53BI5ERZLBYWe4xlayqVarebPB7vvffeC4fDHA6ZSqWaza7D4RAIBBRFYfuj0+mmZ2Yy6XQmkxkMBt1u12q1HhwcCIXCd955Z/PFi1gsBpci7MSYxdI0g8YAQiWFQtHrDSiKWpidCYfDAG5NT09vbW0Vinkkne/t7WHbaLdbcYi3Wh2RUAzFlcvlkkqlR0dHCqUcFTkooC6X6+XLl7D5EARRr1dZLJbJZCmVSlKJjMPhINS50+lNTU01m99GC0C3pNPpkplUs9mMxWKzs7OtVisYDE5Pz4BaVKvVQDGu1WoQ8+7v74/oEYA6ILnzeDy7w4ZLDmN/bKLD4TDSwXu9Hns8strMFDEej+liIadWazudTqPe0Wh1RrPz2eZzksszGM04SfkUezwawoYZioQHgwE9HF68eBFE1sDZyeHh4dLCokQigQkrkYzxeJzp6enxeGw0mguFwvHxMbKq+v2+2WTd398vl8vf/e53m83mP/zDP8DfBKnWs2fPaJoGoX5ra3ttba1UKgEGJhAIkslUNptpNWofffSR3+9Xq9WhSAQRK71ej8vnQTiMBXSz2VRpNaPRqFoqHhwcUBTXbDaLRBK1Wi0SiqFE6ff7crkcBvtisYjm5+XLlxcuXCApgs/nj0YMcjPBRoEN6P79+x7PxNTUVLFYLBQKCoUiHA63Wq1bt25FwlGgRmiaNhgMbDb7xcvnGxsb8XhUJBKRJBueFdR8+/v78PEMh+N2u83l8vV6fTyWuHLlyosXL8CdTybjbIqghwONRhcOhxfmFkCSa7fb/T69t7dHUcTs7OyIZhiGqdYq165du3vnntPp9E54GIYByKrbbTebzYWFheFwmM3m3W53OpWJxWIkyREIBFajQSQS7eztGo1GhmGcTqdcoQgEAvF4XK1WkySJuQhFUflczuVyRaLRVqulUCgQX8PhcNgUabPZQG82mUwikYjL5wHJtra2xuNwhTy+2+1+8uSJzWZLJBLAIz/feolwMCCsvF4vCmuFTGoymUAN3d7eNpvNLo9HIpGcnJzg7sDEPRaLdfu9Wq3mcXm0Wi2i/QQCgUwmwzSLzWZrtVq/32+z2SwWy+eff67VahuNRrfbB+6fJNnobLe3X+GcHwwGQqEoHo83Gq1arWYwGK5fv87jcVKpFELqKpVKOBy+cuUKwFQMw0gkksnJyVevXm1ubl6/fr3T6QSD4fX1dQC0zWbzgwcPOBzO6elpu91+8803MbyfnJysVCrVapXDIT98/71Xr15ptdpyuQx1lEKhWFpaarVa8AbV63UwOEajkVKpbHd7gCLNz88/ePCAoqiLF9cPDg6QI7S/v69WqwmCiMfjiGPKZnNgMr9+/frg4ODSpUtqtTaXy7HZbGAa33777WQirdfrz8/Pp6Z9Qf9ZvV4XiEVut7tUKhUKBbFUwmazsRIh2QSCJovFYr/TvXTpUqFcRBYk2FRQ4EG5kcvlOByu3W4/Pz8HiLFSqagVakBJWq0Wm2BhroHUWqVSSffpWCw2GrJ4PN73v//9eDx+fHw8NzcXDIc+/PDDL774AuV4OBweDHqDwUCl1UAcRpLkP//n//zTTz8lEonE9vY2AHd6vR6AFrVaTY+GkXjMYDB88skn2693Upl0vdmAwLDb7RoNZmiZ6QEzGDB3737z4sVWMBju9/tnp34Y8YLBYCaX3dnZaXU7wWBQLBazWCx4SbDK/Q3OtVKpALZWKBRoui+TSRqNWr1enZ2dnpjwYA3v9Xqxuw2FQpcuXRoOh+PxmMfhnp+HeDweSXJUKlUuV+j1er3eQKlUMsxIKBRyuXyBQCAWSxuNxv7+YSQSUSgU2AvAq99qtYrFIr4PWKb39vbUajWHw2Gz2RDLK5XK0WgEXs5gMGh3u/RwyOFwfvDbv728vAxtL6Lu4Awql8uNRms0YsXOz2u1WjabxaiWw+FUS+V6vT4aDi0WC9xJy4vz7PHI7XRcvHpFwOMq5QqRQNCo1QiC+P73v+/z+aamfSqVajRmpqZ9coW0VqslEgmkx+DPBPi70WigvSBJcjQadTodQHX5fD5i/kqlUrlczmaz8A/Dylsul7ElxMq12WyyWASiZng8HofDkcvlmUymXC4jvCUSidRqNYCMh8PhrVu3Ll7csNud09PTBoOh2WxGIpFWq1Wr1cRicSaTQTMNw2YymdTr9alE4sHDb2ZmZhxO22g0unnzpkgkZLNZ3XaHJEk2a8Qmxvt7r/3+02w6FQycf/nlF/l83mw0yWSyQi6fy+RLxUqlXJubXVDIVeCtRyKR8XjMF3DbnU44HH758iUSBrlc7sHBwdbWFsMwsCzgQ6tUy4VifnllaWFx3mQyCIX8V9tbNDPgcCmVWvkb1ILD4fhNlhkKSghNEB+UzWaj0WgsFhuPx7lsNh6PR6NRyN1wB8hkMuBqxuMxsjXsdrtMJoO01uVyyWQymUzmdDqB+bbZbGKx2O/3I6Ln+Ph4c3MTjSk2jJBK1Go1MBX1ev2b77wlEPL5Ap7H49nf3w8Gg71eL5vNisVivV6PLqJQKJTLZbxuOp1uNGKxWKxarYaUdHCDQEB98uRJOBxGAJ9QKKxWq7/85S8PDw+bzaZSqTw7OwMhCQy5s7Mzl8v1zjvvjMfj9fX1ZDKZy+Xeeeedubk5IPuKxaJOp8OgXiqVYmWZz+dFIhHWx+gEisXiqT9w5+43n33+xcHRGc0Q9Uan22PKlWooGgsEAmq1WqlUZjOpSqWiVMh4XK5cLo9EIul0mmCxSZKUSSTn5+c8Hu/P//zPwTYLhUIQya6vr8/NzY1Go1QqBQx6LBYTi6S5bGF/7/Dk+IwgCIFAwOHwEonEkydPLl++vLGxQdM0AkxkMtnq6urh4eFwOFxZWdnb2zs/PwebMZvNDgaDN9988+Mf/vD5y5fD4dBiszWbTUSslEqlarW6sLAAwzkiQXq9ntls7vUGH3zwwe/8zu9MTk5CfSyXy+/duwdRXSAQwMVJkuTFixch2mOxWHijz8/Pp6en0R/bbI5IJMJiEa1WB5IJfC/wWePPxHy02+26XK5gMOj3+9FHud1uFotVqdSwl2ez2X6/v9lsRqNRFGdQkWYymWw2+5Of/GQ0Gu3t7fF4vLWLlwqFgkAgWlhYwAnZ6XTu3bsXDoelUun7778vlUqPj4/LtSrF45ZKpVevXs3Ozq5euBAKhX76059ubGxA+/jWW28JhcJwOAw0JU4egmAZ9NqNq1da3c4Pf/hDpJ91u93d3V2FQgFNrUqlOjw8hJiSJMnbd+5MTU0hkXN7e3t6ehqvFT7AK1euRCIRUBLBRlErVScnJ0dHR/fu3QP3cjAYLC8vx2IxlUoF0kG73f7xj3+8uLhYLBaXl5cvb1xRKdU2q50kSeRKIX8T4AkoX1+8eCEUCldWVqxWKxzZcP/84R/+IbpToHlardbCwgJWjTAfGI3Gubk5IGNu3XpraWkpnU5brVatVovWBVFy+IgmJiYeP374y1/+slgsOhyOg4MDiqI2NjYqlQqOFOg6Xr16pdFoflNw2+32ycnJ27dvZzKZSCSCSYHdbk8mk0jyQHjz2tpKKHTebDZfvnwJ00Yqlbp58+Yf/MEfQB1P0/Tp6TFoEbFYTC6XazSaSrkK3RVJkp999lm9Xu92u+FwGEv8w8PDaDS6ubkJYQmSghqNBjaJIpHo2rVrBEGAvgEF6tWrV589e7a9s5VKJ+D4U6lUmIwkk8nZ2VmlUtlqtfr9Pnz0mUwGrm2BQAC023g8djqd8Xj81atXzWYT40O3283nCyYmfEjFcblcFotFJJK43V6SJGdnZwcDhiCIVrO9sbGxvLwMSGw4HM5ksw6nUyaTWWzWbrcrU8gFAoHd6eDxeK9evep0On6/H0jI0Wg0MTERj8eRnz0YDO7cuVOpVNhffPYP1WpVLpfm83mDUYdnTiqVJpPJlZUVjUr94sWLwYARi8VSiVwgEBydnPL5fIVMLpdLc7mc3qDNZrMMw5wdn3i9XovF8vTpU5/Phzwyu93ep4f1ZoOiKMAwsFzA8g5xDRhKo+4hSfb9+/dvvnG9Wqnv7e3JZDKaHkKAbLPZut3uuT8wNTWFhDVsGPPZLEWQzUZbrVHWqg2xRNhudV1uR7PRFkuEYpE0mYonE2mSYjvsrjExarUaiyvL5XIZKUUo7bH/crvd7U4H7gCGYcrlMsMwzXoHWkJsDI1GYzqddLicmVRaJBHXajVIsoRC4erq6s9/9o8jhjEa9ehNtVrtwcHBW++802q1njx5otXrCII4Dfh5PB425XqN2qRWdxoNRBNEY/FLly53er0xm1WuVkqlUjyVtNksRpOl22sPh0OdTpdJZTkEB3IomUwWDoc7vR5JksBYlKsVyGWkUimmIO12Gw5tcEcBr2u327DJwPfUbrfBgG21Og6Xi2EYRNFJZWI2m53PZ7HCaDQaLBbB4/E4FA+QJ61Wi0gvcChIklSr1TqNBhyBZrPZbreVSiVrNEZ3SA+ZUqkwHg/ZbDIUOlepNO+//z5o2p1Or9ZosMdjiUw2Oz29+eKFWCypVissFstmt3Rb3Wa7bbdaORQXjuW1tTWQDymKqtYq2D1BDHHtxg24hUdjBqxLBNliBZNMJmma1ul0k5OTw+Ewm0qj4sRkuNls0v0Bn89HAnooFAJ6B0LOPj1IJFIcHi+ViI3HY8CoErF4v9+/efOmXC5/8mwTZ2i73fb6Jl+9egVg/WAwsNlsIpGoWCyGw2GcFCDQYh1crVZhXBcIRGdnZ5Csnp2dNJvNMTOs1+ser5vP5w8GPYPBIBIIM5mMTCZrNpulSlmpVLZaHYwVw+EwkiJUKhVqNaVSqVZpRCLRo0ePuDzOcDzGtm4wGPT7g6mpqbP/f0//FRxZfl75ornT7Z3ee58JIBMJIOFNGZSvrnZsNsmhRgyNqKHmQfc+DF/OeTwvJ+K+zYQi7tyIeyJ0QiORI1IiKXWzDbu7uquqy6FQcAVvMpFAeu997jR7n4fV6rd+6apKYOd/f//1rfVbR6fgMm9sbNy6dcNgMOzuvTGbzWcnpzaHPV8syuVyvEgwEYrF4uPj41Qq7XQ6JRKJ3W7HvRbhIIZhAoFAo9HY3NwEPq1Wq1EU1Wo1RSLRycnJD37wAxg9X79+bTKZAoHpp0+fNpsNq9ksl0u77Q7DMM1mc3JyEmmbYrGs0+nAwBsdHTs7PkGrXZvu1us1UkSx7LDT6dhdzuPjY7lEKpFIIpGY2WwuFYo8HjHu9zLMIB5Pjo2NCQWURCI5Pj5F8IWm6QEzHBsbKxZKdoeNZdnBYABwMQ6rg4OD5eXldrtdLBYZhnG73dFoFDSHSCSSz+etVqtcLq3Uqs16oz8cYJOOLqOxMR9+9dCby+Xy3NycTCYLhc6uXbsWicQYhpmamnr58iWHw2k2mx/+8EePHz8G/a7f77tcrmazGQwGVWolFn8SiQRgjl6vd3Z2Vq3UzBaT2WSBdv6rX/0KNNfNrQ2wME5OTiqVCvobEO+y2WytVgvrWvALDg/3Jyf9X371p6tXrieTyYuLyN27d41G4/HxsUqlEYskJycnLMv2eoN+v28yWVRaFcsOZQo5bExHR0fgDA2HQzTDgh4JfEmvS1+7du3k5Nhms+HBsJhMiURCrVb3ej0E5QiWE4/HQaJpt9uVSnU4HKrUavzAX79+rdFoKpXKlStXMGqcnp4CkoLtPJ/Pz2azYpmUpulgMOjz+bRa7atXr0DCc7lcYAd4PB78ulUqVTqdZVkWJhA+nxuPx99//33MKMFgUKfTfn8pZVnW758QcAUEQTAMc3kZlsokzWZzenrq7OzMN+Hf398nSfL8/PyDDz6o1+unJ8FarTYyMqpQKOAW6HQ6LpdLLpdnMplI+EKhUBgMhsPDQ/BKPvnkk0AgYLFYxGLx8+fPA4GA3mSEelQoFCwWS6PRKBaLd+7c+ed/+s3i4iJSkC6Xa8gMer3exsbGL37xi3Q6vbm52e12R73ed99997/9t//mdDpRckzTtMlk2trattlssFHu7u6urq5OTEydnp7uv9mRSCQWi2VnZ0cikRiMepqmfT5fJBIJBoM//vGPv/nmG4vZ6hv3drvdYjEvFFGh0JlQSFWr1dERbzqdNpnM9Xod+1b4C8GS1el04BLweLzp6QC6ILF1VavVfL5AoVA8ffoUfEqDwVCv1+PxeL/fX1hYQAsqdlDB4DlFCXk8HiKok5OT0WgUvAmAdbDZdzqdaDysVqvLy8sysQRAfxD4/H4/+g/OzkKNRkMmk01MTHzxxReTk5MGg6nZbJ4Gg7du3zg7O5PJJIVCoVqt9vu9QCDAsixI6Uaj0WI07+ztDnvDAcuMeca4//4cYkVms1sKhUKtVsHSdjAYSKUSpGQUCgXxr7/7tUQikckk0WhUrVFWKhXEvKEeN5tNoVDY7w2NRqPFYmNZ9uwsRBCEmBJRFFUs5mUyWb/fr9frw35frVarVAqCIK5du1YoFA4PDwk+L58rOt0ueFasVismKqxm2+12rVZjGGZpaenZs2cKhaLTaQ2GPYPB0Gq1+Hy+WCQdDofVar3X601PT09MTKyvvQLzHZ4SgiB0al2jVp+eno7H43t7e1ardWpqam9vD8I1BJhUKmUwGHg8Hp/ktbvdMe+IQCC4vLzEGxdibL/fFwqFuXzeZDJhl4yvWbPegTkJpNBcLscSDCZxk8kEihUwWj6fTyAQyETiRqORTqfRphwIBIYsi5Ldubm5QqlIUVS336NpmmGYQbdDsgOjVtNut0vFitFoJkViut+jxFIun1coFVutxvjkRDweZwkOHHLDPqNRakD9qVQqDMPkCgWLxZLP5zkcjtPtgrcAPH273Z7L5bLZLCALfD4fcCyapqempvBjAaMWzr75+fk3e4eDwYAkhblcjscnpFKpVCoeDAbY9LfbXb1eT3B46XQai3BUaCFAh94PIZ+P3jRc0C0WSz6bgx7G53MbrbpEIun3+1tbW+Pj4wzDiEQSlmVbrRbDMFeuXBGLxS9fvnS5XGq19s2bN4NBj6bphYWler1erdRkMtnr15szMzMkSe7t7XU6rZmZGYvV/Pz5c1jTjGYzuJ1arbZcKULcAgBdpVJVKiU8hIgTdzqdYa+PNA0qcj0eT7PRaDQauWwBnfO5XO7q1au4rNP93nDIXkQiGpUCWQqn01kqFNfX199+++1ut/vk6TNY0RmGyRdLvV4PDDY0DQiFQpDB5+bmGIbJZDK4OsO7BrJau92NRqMGg0EoFG5uvn7nnXf0Gu3Dhw9JSri0tHRycqRWq9vNFiRMmqYdLifQJCqVisPhJpNJgiDQ4ZPNZvl8/t27d8ulCpfL3draunnzZiafDYfDGo0mFApNTQVIkuQT/NnZ2XA4zDAMgA4kJez3+xyGNVstqVRKJJFA5P/Zz36WTqexrX71ah1dGZ1Ox+v1ulwulL4xDLO3tzc1NQVl3mq1vnjxwmg0ejzuSCSCe/be3h466pVKZbVai8fjCoXC5XIJefxGo5HOpJrNptloGhsb63Ra5+fn6WRSKpUuLy/36MH25jZB8Kr1itVqVWnV5+fnDGdIEES331OpVHKJdDgcZrN5j8dTzBd6vW6Xbk9NTbRaHR6PVy5VvV5vNJrAp7h69WosHo/H4zKZTKPRVGuVra2tDz/4IbgqYGffuHEDvzL4alE9htczYJKhcJDP5/t8PrlcjpUHMko8nmB/fx+ZHjyQ/d7AYjULBLyjoyOtVq/RaKxW6/r6erPZNJvN/vGJi4uLRqMxGAxMJhNgv6VSqdenLRYLMl/wAg/6w0gkglMauFqr1YqoAcuy+UKu2WyCFYLnHK8lLpfb6/UsFsubN2/sdjtiyCw79Pt9KrXi1dprn8/HsgTEhuGQ7ff7Ar6w0WhUq9XBgFlcXLy4iJTLxSFnuLC0CMIcmDKYGNxu96tXrxKJxAcffOB2u3//+98rlUqVSpVKJAQCAbTMr774wu/3kyQ5MjISj8fL5XK1XIHcksvlWJbd2dlxOF2FQgHvKhTDORyOZ8+eJZNJkiSXl5fz+TxA6lKpdGdnJxKPtdvtXq93584dAAUZhhkbG1tbWwMYRSQS8Xg8v99/cHBQrVbFYilJkj/60Y+ePn2aSiWMRuNgMICUKxaLM5k0IOZisdjv9yeTKXbAYrrlcJjRsZFarVaplEZHRwUUCSlrf38fGN6d7V2RSBSPJ5xOp06nu7y8bDQaZrP54ODg/fffb9bqkMeAANXr9djJjoyMqFQqrOAfP/12dHQU/uuxsTHkBAmCSERjBwcHIGP7J8bRYNbpdLrdrkAg8Pl8MpmsVKmYzeZgMAh5GK0e8/Pz4+P+dDp9dHSEAj65XJ5OZweDQb/bEYlEbrf7888/90+MT0xM1OvVp0+fOhwumqZv3br15MmTdqtjMpkKxbxYTI14R05PTzudjkQi4XHJ/f39Gzdux2Ixmu7Aa3j37t319fWDgwNIg+DItFrNra0ttVqN0Giv15udnQNg7PLyMh6PY45EtkylUuG1gsgz+Iujo6O47U9PT4OwoNFokJoHaRy35cnJyXq9HolESvnC0tIS9r94hEwmC1zXpVIJSZdIJGY0GhH9Pjg6unLlSjIV39raun79qkAgCIWCKysrDx8+RFFbvV7ncnnZbLZYLL/zzjt379z/+uuvUSW3ubnpdDrdHmckEikW871eLxAI1Gq1P/3p8zt37sASTfz+n/9RqVQOBj2BQKDValOpVK/fRQa71WoxQw5c+hRFBYPner0+lUhD1m632yAOo5xcRJKvX7+em5sBkQyIjkQ6RZHiATPEpZlhGJfLValUotGo0WiEBpNOp2dmZgB5ksvlg0EPDy7LsgTBGwwGIyNjsVgMUzAzGC4vL+dymVwuR1FUt9utV+parRYbYtBj4bGVSqWxWAws73Q6fefOnXg8Tvc6PIFASPKhMYB2LRAIAoHAq1evyuXycDhcWlqiKCqVSo2NjWm12v29Y0D6ce3W6/UsO9Rqta1OG10H+BoXi0Wapq1Wq4DgwiFbLpcdDker1WIJolqtGs0mpIV7vV6b7ioUilqtRvI4TLOulImlEpnRbIpEYizBk8oUxUpFpVJNz8x8/eixXKUEK6HdbpMk6bK7stksXGV0v8+yLA4jhmFgV0wmk90ebTAY4DMlCAK8BpqmMe/XarV8/jsbOLpjUfKKEc1otmWz2X6/p1arW+0GJhWappVKOY/HKxbLiURCrdJCmZBKpTw+gUHZ4XAYDIZ0Op2KJ6ampgAvdrvdxWKRGQyBlm42m7PzM/v7+0qlEiGDer0ulcoBLUMli8PheP36tdFoHA5Zo9FYqZS4XK7L5fniiy9u3rjF4XD29w9NJtPr168piiqVCv/lv/yXLt15/fo1LlI8gQDJAIQivV4vl8cplUpIA4hEIuDpUXPUbrcJZuj3+/v9frlcpum+XC6XSqUul+vVq1c8Hm/YHwwGg6mpqUKhcHJyZjAZNRrNyNhYIhbT6XQvXz43GAwuh/Pi4gLql9PtEYlE5VKlUChwBXyLxeJyuc7OznAiqNXq169f93q91dXVjY0NnBqor0JoYDAY+P2TIDD1ej2hkD89PR06PSsUCk6XY2dnh8/njo2NxaMxxOIYhun2aLlcjtdnKpUhCMJkMg2Hw6OjI5VKhY826A/hn7h69Wo0Eev1eiRJNhoNqVRWLpeX5pfQbs7j8ba3N5VKpVwh63a7vS6dSCXFYnGxXF5cXOz3+5BnsHfwen0gi75582ZpaQle6fPz82vXrsGwQpIkYCjYd7TbLTBHkPeGoBiPxwmG43a7q9XqO++/v7O1AVC+SqXqtNput/vly5cjIyMLC3MvX76kKKpQKFECks8T9vpduVx+fHZC0/T0bKBYLEoV8pWVFT7BXV9fl0hk+XyeR3BtNotAyKMoYSQSEwqFnTYdDoeFQhEuHhwOx+v1MgxTLpcVCkWtUZNKpQ/eeXdvexus6oWFhVQqhSYAOP3j8Tj4cHNzc1qt1mKxnF+EINPC8TYcDuGD+eKLrxBon5ycDIfDCMTl83mJRJROpwcDxmg0wmOq1WrPzs6sVitJksdHJ1jhvf/++2tra91ut1Quou8Lp9zExMTe7v5wOMROIBgMYleAk73ZbJrMRthx8B2vVCo4prD4BjkZypZer49ELtLpJDL/Ho+n06HX1tZ8Pn+pVAK4MpvJgde1v79PEITP56MHdDqdnp2dRQkYlEu9Xv+9rVggEMDIy7Jss9kcGfHweDz8tPVaLeq5jo+P33333X/6p3+6e/tOOBweGRk5Pj7Ggkwqk1erVby63nnnnW+++Uaj0fT7/d3dXZfLhUZqbMT29/cvLy8nAlOIEdy8eRPmBKvVina5xcXFP/3pT9h44Een0+lODk/C4fDi4jxi5nw+/49//KPP51tcXHz48KHJbOTxeLD5q1SqYqHEsgTcY1wux+sbk0gkyWRcJBJxeNxsNqvT6YrFokFvgtHT5XKlUul3332XZVm1Wr29vX18fOz3+xUKhUIq297exs4klUqhOjAcDsM5g/edVCFHqQmXy00kEmNjY1arlaZpCSVaW1uDBxH5XNzte70euJJCoVAil+3u7v785z9//Pgxn8+/fv3673//ewApaJqu1WoWi0UoFDabzU6HJknSZjaVSiUUWAmEfJPJVCzm8e6maToWS1it1qtXrgWDQZbDzM3NPPr2EXbNNE1LJcpMJiMUisRi8ebma51OByIjh8MJBAI4xpGsKpWKoAGsrKzkcrlut6tSqT/77LNAIGC32/HB4ZaDGlKv19PptMFgAElfo9EEAoGzszOGYUAl1Ol02Cp2Op2xsTEej7e1tTUzM4NtwOLi4pef/wliCkVRABsVCqV79+599dVXqVRqbm5OLBYHg0GbzcbnC9+8eXP9xg2CIC4jYYqi5HLp3t6ez+cVCAS4VqHCgaJEXq83EomwLKFR6/L5vNFoxJDA5XJFYrJery8uzoNCEAwGx8d93xefEF989q8sy3I43yHw+/2+Sq348ssvNRpNr9djGcLtduNDbm+/kUgkSrmKZVnsjyORi8FggN1BpVQSi8Vut9NisQAfJxKJ+szQ7RppddrdbhfwKrg3UB+L0kBk9wqFwsTExMnJCUkK+Hy+3+8fDBhkZXO5Aia2Wq3GDhmpVFqplDDhCQQCCSWJx+NwhWMkNxqNGNfm5uY2NjYYhkFFZbFYLJQLJCVwuVytVisajc7MzJjN5mQyeXR0hCHD4/Ggk8FisUB4sNvczWaz1WqRJBkKhQiCMJkMEolEqVYh0on0zWDwXcCQ4gvAAMT7UqPRcLjcTqcjlcvsdvvp6elgMBBQpMlkEgqFZ0f7GrFAq5SrVCqKEgdD59VqvdsbyBWqdruzsLwUvoi0Ou3r16+zXIJL8Ov1eq/b3d3dbTQalUpFrdW63W6CIILBYLvdFovFJpNJqVS2Om1Yx9DBhH+PQqGAjsUwDOY8TLdIq2K6LRQK3d4AiAeGYSiRUKlU5vN5m80WDJ46HI7hkDUYDNVKHViHUqnUajcQD8EMrVAo+l3a6/UeHx+DBsThcLyjY16vFw0nhVLebrdDjcvlcnq9XiikELMaDof1eh1OOC6XyzAclmWdTrvZbN7efsMwzLjPv7+/L5MpMDhKJBKxmKrVagqlvNvtjo6O7u7uVut1kUiEQhjcUdqdJoK7JEnWarVoNAomCFhrboczm03DOeHz+U0mE8pNuVyuWCyOXFziTl8oFLRafYfuLiwtpVKpYj5PkmSr1RgMBqVC0ePxwE1ZqdWr1SqHJSYmJlrdDjCAz58/pygKHxbIJTjozWYzguUXFxc8Hg/1avV6E5x0oVCoUinGxsZevXh5cXGh0apVKlW32261Wh6XGyZNu93+Zm83FovpdDqdTseyhMvl+tOf/oQLMSYwq9X64vnLq1evymSyjY0NASWUyWRwHHa7dDKZNBvMoFTIZDKa7iQSiUw2bTabp6cC5xfheDwemJmxWCxbW1vdbhcOjLGxsZOTU3A6JicnuVzukydP5HI5MK0sy3o8nocPH3o8Hg6HAwKQWCxCCtLn82FPms/nDQbDoNcrl8ukkOLxuV6vF8GLer1er9akUmk+n/d6vQqFIptNN5vt3d1dpUwxMz1HiYThyCWPxx0fH09nU6VSye5yViqVTDIll8vVam0ikeBzeSMj7nQmKRDwFApVv9/XavTNZvP8/ILL5XG53EajEQgEOBxOJBLh8/lGs1Emk6HHEMb/xcXF3d3dn/3sZ7FYDK3V6B0DQBzdKcVyARYCLpcbDoeLxeL9+/cFAkGr1UkkEqOjo+l0+uTkBFzH4XDodNq3t7elUjmYwwDiv3r1iiRJjUZTKVfv3r0Lfejs7GxycrJQzEej0Xa7PT8/3+v1+Hy+WCSp1WovX77EWu3q1avPnj2TyWTgbHlG3PV6HajrwWAgEolwQPn9/tPT00ajYTQaz8/P79+/n0gkCIJFJQ5i7Z0OrdfrCYKH2onp6enw+YXb7S6Xq9FolKIouVxeqVdwGoPKiLhrt9vV6XT4Z0ilUrfbDXWt3W7LZFK1Wo3HhhIKq9UqkIoov5ufnfv0008B9f5Okmc5MCTg6ovSUhBP4GR4//33//7v/x4vMA6HwxXwlUolpig0WaEuDH3MOp3u7Owsl8vpdDoYdxrVhtfrffLk0b179waDwdnZGa5Gdrudpul6o4YULdw/zWbTbnPYbLY//vGPd+7eZhim2+0mErG9vb3J6QDO25OTE73OCMSGy+WSyxVo1/B6vTh1G41GqVRKJ5IymQxlAPl8HopsMpnElxfMF6lCfnx8DGC6QqHQarVKpXJ3d9eg1YlEIojo2Cm9efNmfHycoiihUIg039XV606n89NPP8VSDBkXUELwfcfdQK/X83iCdDotoch0Oq1UKldXV//pN/9rYWHh9PS4UCgsLy8jCX5ycnL/3lv1ev0f/vF/CoX8v/j5X0YiF2KxuFwu12ttlUoVCl3cuHGjVqtcXl7Ozs6iCkwgEOTzeYSuPB5PtVoBWsxkMuE3bjKZsdHrdrvvv//+8fHx4uIiXB+ZTObq1aulUqlSqQAaJZfLHz9+jKuFVqvFVg7wsKmpKfT5oIgJK692u62UyeFEXFxcBLUkmUxPTk4eHh5SFDU7O3t5ebmxsfHgwQOSFNE0fRoM2u32Lt3udDrvvvt2o9FIpZIMw/zqV7967733kKttNJpITQqFQi4h9Hq9KCyBHFBvVBmGGR/3hsNhODSazcZwOJRKpaVSifjko39mGIbP50L9k8lkXB4Hn+f169dGgxk5NZIkSVKUzWbpThcJHRgb0Y6Ou1osFluYm5PJZOVyEW+OPjNUKTV0vwfQ3MnJSSAQwIMCWf4Pf/gDcAOdTgc3b4qiMHs2m22U952enHk8HpbDCAQCSki22+1WqyESiYwmfSqVajbaKIOjaVqj0YhEomKx6HK5YJ44Pz/PZDJCoRB+IJZl6V5nYnISrNtqtZpKpcQi0dzc3Pb2diaTsZkteNlggrFYLMVyHQvsWq0GmUomkygUima7BR9xoVCQy+WBQODk5OT169cykVgsFlMUVSgUFCpVu93G6NPt0XhQNBoNXBdqtTqXihtU4na9srKyMhyyuXwxFouLJIpmq2MwGAvlksVqR6dQs90Si6Qcgjk/P0+lUiqNBkaQhYUFGGDxI4UhUafTVavVATME8AnPd6/XA4AbNWSAn4XDYdyBxGIxfOsOlwe5M61OjT4cjUaDFnEwP/h8fqdNOxyOXC6n0WhK5YJare73+8ViUS6Rwv6J0G8ul1tcXFxZWfn2229jsdjExITD4SiXiyhCbrfbjUZjamqq06FDoRB2LlCGsSxQqTQYB0UiUb1eZxhGLlPkcrlQKGSxWO7cubO7+11BJEkJ8S5hGIYe0ARBxKIJVL7A2wSBCtgqHo/34sULj8dDUdTp2bHTZp+bm8vlcmtra/fv34dnSyaTjY9PmEwmOMxQysbn88VisYAkO51OqVCATkkQhJDPk8vlhULJ7XbzhYJsNtvt0BaLhRRLeDyeSqU4OTlBLQ9YG9ARt7a2ksmk3W6HQxnIUJVK1el0cNOIRCKT4/7l5eXDowM0P+j1+nq9enBwMDk5KRKJ9vf3kVGampri8/mNRmM4ZKPRKODXKASEQWdzY0smk8HWE4lHe70eWr2azVar1RpxjQQCgXw+H4vF+n16amqqP+gFg0Gr2VJvNtxut95oRPcAFmc43R4/fpLL5SCGAZSKzSaSEwKBAL0r6XS6XC6Pj4+32y00AlEUNTExUSwWM5lMs9lkh8NquaTV6kmStFqtAoGg26PRGo4vDqZbs9m8tbnN4/FKhbLT6VRrlKlUiqJIi82aTMbRrIykM8uyrVbnxz/+scVu//Tjf+t0Wnw+v16rCQSCcqkqEAi83vFWq9Xt0k6nkyCIR48ejY2NejyeiYmJg4ODWCyCeARKdXQ6ndlsfvXqFcKeXq8Xb5FoNNpoNE5PT+VKhcFg0Gg07XYb8EmJRHZ5eanT6YA9GxsbK5fL8KCUSiWfbywSichkCiShFhcXKYqKRqPQJ/CYMUMWw/HJyYnZYhoMBnNzc5CLBAKBQq4slUpnZ2cGgwG2KrgYwTqam59982bbYDC0223Q5L/55htwsA4PD10u18rKCv4o3FKy2TS+caVSSSKRHR0dzczMYQbKZrPFQkkqlaZSmVKpNDo6KhKJCIKVSMVALm9tbUmlUoZhcG0YDoehUKjf79+7d+/09DSRSDidTrlSWavVsNxsNRrD4RDQkGfPnmUyGZvNNjU1hYU18Et8nuC9994jSfK3v/2tzWYrl8tKpZKiqOPjY4lEgvQMznmCIA4ODm7fuxuJRNrt9vT0dDqdPj4+vnLlChIbN27cQCkNj8drNptAu71ee8XlctExj5316OhoLBY7PDycm5sjuByr1YplCJIfyWSSZdl79+5BnMtkUslkUiKRaA16Ho/XbnUHg8Hk5NTR0dHNmzcvLy/dbvevf/3rv/7rvw6FQqFQ6N1333358mWn0zEbjAaD4fXr1+Pj4wcHB2KxGOvLi4uLa9eu1et1gUCg1KixxTs9PYUM3+l0LBaLhBJtbW0BiffWW289evTI6/VCfEI9qM/nI8UibFGlUmkoFEJl9fT09JUrV87Pz3Fp8Xg8wWCQzxcOh0OCGaI9VqPR5Au5SqUiFPIvLi5MJhMiYmenwW63S1FUpVo2GHTLV68cHOyJRKLJycndN4cURbXbtMlkyuezODAx6xMEAUMbrnD1eg2rOmTPSZKsVKp4ng8ODk5OTiAiqlQqp9O5sbFhtVoRt4xGo9BuQPLrdrtffPGFx+PBgYCMISYHvMcxcAMvBW0PXHhUVhuNxvX1DZVKBZPM6urq8+fPDw8PeTze9NxsIBBYW1s7ODiwWL7jxR8cHPj942ARaLXaZrP15s0bn8+nVCpz2VKv1+t2uwaDoVor+3y+o6MjjUZzcLCH7MX169ctFnO73f4OKw0dolar6HQ6rAXrjSrOzdXV1XQqC8BPrVazWGyHh4dmowlxWblczrLsyMgItktYI8LQx7JDq9W6u7sroMh0Kuse8XC53KOjo3a7vbu7C0gg1nkCgQBVuE6nE1b8WCwmk8nq9SYoPv1+f3FxkabpUrnY6XQI2Xd/vsViQUEel+BjPsN2H1WRrVar2+3+/d//PS4K0J8Gg0EwGHSPuLA4h49qZmZGLpOh+GV0dJRg2GKxiJy5TCYrFssclru3t4ebx8TEBN73QqGwXSzE43HcEsC6ZFl2ZmYmm0yhFpfL5XK4XPAjSJIUUuTx8TFcSlALMpmMVCzu9XqkiNrfPzw8PhLwSa5AMOHXaShxv99Xq7TFYlmpVHY7vWQirVQqkb8YGxsTSSQoP0YmfGVlBWhKzCjwXx8eH+EpR/oaMO6trS2TySSTyTDTAIqIZIfb7RYIBL0Bs7+/L5ZQgBDyeDyYWIEqQQEfl+DrdDq3263RaPKFLHDnOp2OHQyxMEVu4P79+4PB4Pnz5zabDQ16iUSi02kRBKHRaG7evLm7u5tMJufnF6VS6cuXL41GI8JQNptNr9dzuXy8ddAm3u/3F5eXjw4O4vG4Tqf74osvhELh/Pz82dlZs9XAd5KiKIvdAscV/t+JiQm9Xt9oNOCfQ+AFTt5Xr17NzS7sbG2o1epSqbS0tLS3twenebPZFAgEz58/Rz8SDHMIM3Pa7Xa7PRwOEbQ0m80Ey2APazKZRn3eR998I6IG+XxeJJUNh8NkMo74vW98fPfNm16vp9Vq4W4Ui8UsyyLhjzYFNEiiacTn89E0/ebNm1K5CLRxp9PJ5TLYQ2GaQVMY5mOaps/PL0CKNxqNJycnExMTzWbz2bNnc7Pz5+fnBEHgL3W73SBbnp0Fh8NhpVTZ29uDdDQxMV4ulykRCYZ1rVI1m82tTmdtbW15eVkikayurgIetrq6GovFUENeLpcR2yYIAkYTtKE5HA7I8ugyQxxdpVIhAKVQKIR8fr1aEYlE3W67220Xi0WdTocYNuzhNE1PTEx0O/TzZy9mZ2fL5XKr1UEmRq1WZ/NZ8Aar1SpehzhwpdLeN998w+Px9Hrt/Pz8zs4W0moSsQyBI51Ol0gkj4+P+Xw+wry1Wi2dTieTyWfPnt25c2cwGEBDAsMQKEvEFI6Pj1UqFcuyOLJ29/e8Xu/m5ibuTt1ut1SqXFxc4KuXTqfFYvHp6elf/dVf5XI57J0rlQqfL7x169ba2lqj0Xj06NFPfvKTnZ0drFwHg4FWo5ucnNzc3JyYmGg061KpFHgtJIXn5xbQEAqWyvn5ucvlgq+uWqucnwcFAgFe2AB0ffjhhyD4EwRBUdSnn35qsVh4PF4+n0elLih00JZwXsnl8nw+//z589mZOTi6cFaLRGSn2z44OMCZbLFYtFrt5uamx+NpNBoqlerevXuRSOT169d4xvL5fKPRwFHD5/NHR0cfP34MyjmakjOZDEAhQB6Wy2WhgNza2tLr9Tdv3kT3lFarff78+XA4BIcJUarDw0OWZR0ORyKRAMmzUCgUCgWCIC4vLwOBwMrKyqNHj+bm5nARrdVqExMTw+HQZrPpdLpIJDI/P3/r1i3oOp1Ox+fz8Xg8gsvB0Q0CVrVa9Xq9eC2en587nfarV68iAPhmf0+tVtdrzUqlgrEJRi6ctJ9//jnuEs+fP8dwE4vFrly5Eg6HT09P33777Uwms7Ozs7KyAp6tWq2ORqMMwQmFQm63++rVq9lsFjO0z+fjDJlarRYIBC4uLoLBYL/f39/fPz8/bzabTqfzr//6r//2b//WN+EHCuEnP/kJ0KNjY2P5fP63v/0tfE6Xl5fT09Nisbjd7pbLZd/oyPn5uVAo3Nzc9E+MDwYDYDt4PF4wGNSo9WazGUWBBEG0291ut3vr1q1//dd/1Wr1PB4PAY6trS25XKrVatPptMfj0Wq13377LX7U4XCYZdlqtYJXHvrf2u22XK44ODjACntqaspisZRKpXQ6bTQagffc39//wQ9+AP8GSpczmczs7OxPf/rT3d3darW6srKyv7+PkQ4BZ7vdzjBMNpvl8Xj9Lo0ewCdPnnC5XNhy7t+/XyiUTk5OUEm3tbW1t7c3OjparVa73e6zZ8/EYvGtW7d+9at/oCjKbDZPTk4uLMwfHR2JRKLLy0un04UHLxQKBUOnI54x1HubLcZPPvnEYrEYjUaSXNTpdJ9//vlwONzd3UVTi9VqJf7//7//rtVqcTTU61WQGrRarVarzeVyfD6/VqvVag0MT9ls1uNyNxoN7EpBiKZpGphKNOJJJJJquSyVSpVK5WU0KpFI+EIBmstSqVSn00FNo0KhQOGd2WxGCwEG0mg0LpVKq5UaykOg9yAWF4/H262mUqlk2eHU1FSxlM/lciJK4nQ6UcME9pfVao1GowgnlsvlqampcDhcq9Xm5+dzuRxfKJAq5IVsrl6vazQah8NBCUms3kQiEZTqy/AFj8crlUqlSjlyGet0Ou/+4P1qtYpa9eGwD1ZQs9nU6nVY6MIXmc/nB10aGfulpSWLzZZOp0kRRVFUIpHA3AM/ECzSEpKfiobHfaN8gheJx3hcgYCkpBJ5p9fT6XRuz+ju7r5cqWjUWzAVFSvlRqPmcrmw2YQ7GO975GZBvATP6fLykiRJgsdFeFOhUICRo1ar8dwoFIp/l0AbAK5iwKdpGuLBv3uPTnBfBH7TaDSazVaMZZVKhaY7gFkgd40/hGXZQCCAnePR0ZHJZAK8TiAQqFQKCEvJZBLymMViw9cJ66RisYgTx+Xy6HS63d3dcrmMu6xUItNqtZHopcPhwHyMTiHgGaVScT6fv4xFMYNWq1U+T7i4uGiz2Z4/f97t0rlcDlTAt956C+uSarWq06gtJqNMId/f3w8EZmw229OnT2FrAE+kUCi0mm0Oh2O0mHGmF4tFpVx2eHgIlnqvS+/s7OClpdMbKIqKRGIEQYikksFgUK9XQX6nKOro6CiXy9XrdYCnFxcXi8Xi8+fPMU7xeLzz8/PFuXmSJDPZtMViAdvd5/OhYen169ccDgPrDwxzUNGAfg2FQoHADE3TUql0bGzsX//1X0EyJElSJpXD30BR1LOXz0dHR3Ex4HAIm832zVffBAIBiN7T01OtVovlMCMjIw+//Gp0dJQn4INJXa/XLy4uwDFXKBRCAYnCY4iCLMvabLZYLAbGlUAguHnz5ueffw6a0dLS0vHJETolIJSCDmAwGF69fFEpFTyj3nQ6DWF/yHLADdHr9Xwhmc1mcTiMj0+kUql2o9nv9+v16sjIyMqV5VevXrVaDZiN0MTi9XqPj0+5XO7Z2ZnZbLx27VoweHp2FrLb7SqVamdnR0yJrFbr9PRsKBTCRIs237GxsU8//XRiYtw3PgbohslkQnEHZLnvrZbI3qPmqFypMQyDO7TD4dra2pqcnES8QygUIlG/vb394x//GA3TQCEolcp79+49e/bM4XCAEDY9PZ3L5TDrNJtNbI3NZvPjx49/8pOfyOXyg4MDHo8Xj8fFIonX60Xzyebm5tzcHJi6oVBoZNSj12vFYioSieh0uu3tbZIk3W63SCTyeDx7e3urq6tHR0eJRAL/tunpaSBnTSaTQCBYW1u7du3a7u7+6OioRqOJx+M3Vm/ip3T79m046hr1WiKRQPkmMrxAcqvV6kKhEA6HLRZLr9ebnZ2Nx+OtTrvdpdGgcPv27eODwy+//PJv/uZvKpUKNP5kMun3+/G5IEVUq9V+vw8EPGRpg8GAJJpcLj87O5udnbXZbGtra1BJISUuLy/D9I0X5GeffYaaMnQ6lctldM8lk0m1SoVv92AwuHXrFj77b37zG5vNBuQv6hCw8Y/FopVa1eVyCIXCYDCIgiN4gA6PT3/4wx9yOARqSVutFssSZrP57OwELxq0XfV6vUqlMjIyEg6GpqamJBLJv/3bv7lcrpGREZ/PB/TP0dGRVCoVCARn56HFxUXYlOPxeKfTQZCLxyG4XC4ASygsgXE2HA5fuXJlZGRkZ2enzwxhVKrVanfu3CEIAsN6NBp1OBywmQeDwVwu5/dPDodDp82ayWRgV/r0s08+/PDDw8P9YrEIx1i91jKZTAcHR9VquVwu/+CD9588e5JKpaanp2u1msc9arfbI5H45ubmlSvLDMMgMdfv9ycnJ+Vy+dOnTyHL7e3tWq1WuVwuFotDoVCn06nV6n6/H+tXiqLK5TI62VCA6/P5ms0mmtrb7TbYhzhYZmZmvv32WzxmmCwFAkEoFFpeXsYUOD4+DvKAw+GA4wWL0WKxePPmzVAolM/n3W437B9/+fOfP3v69Pz8vNlsAzb74Ycf/uY3/6vZbH7wwQdKpXJjYwMrLNBb1Gr1ixcvpFLpwsJStVrN5/PwmczPz+/tvQHRFD2wcrkcI0GvR+v1euJX//P/unHjRq1W297e9vt9+H0j4YK2kIcPH3o8o2KxGJudXpdGjFkmkw0GAzzTYrEYfTWRSMTj8VxdWfn666+NRuNlNKrSqNF3vbS0NBgMfv/730PNk0qlJEmOjo4Oh8NMJgN2Qzwe5/EEfr9/e2sHTcwqlQo5dpqm8/n8uM/L4/FKpYLL5RKJSYFAwAw5JycnGo0Gbj6hUAjvFNymuMZ1u91oNArqRiKV5Ar4BMNC6ONyucP+QCwWlwoFYJqFQqFCJtdoNMjWdbo9mUzGEwpSqRSc7yiawLB/dHJssVgg7H/XUd3uQDix2WyRWKxSqXjHfTBdwul59epVnEQjIyMatbJWyHdaDZ1Ol8sWOBwOwefb7XaWwyVJslAqVqt17/h4o9qoNRsg3g6HfavVihDKYDBAixmqdpFHRRoZ5ptSqZTN58RiMcZlwFRpmna5XOgWBfkdgj86bcRiMRbkEonE7/dvbW2hmwVGE7CD7XYnRMFiscgwA5joZTJZPp8HYlgqlcITnUwmbTab1+vFfElRVLVa7na7DocD7+lUKiUUUujBxI4P0BeNRsOyBOTM4XDYarXGx8eZIdtsNivV8tWrV58/f14sFnF2bG9vj4yMZDKpfr8vUyrAYm2323KZksvlQp/IZnPQoiGNFItFrVbPssN8Oi0U8ucW5gmCqNUaKIgol8uwlVit1kKhoFZpGIZpdr6Dwe7u7gp4XKlUCplTo1Lv7+/jQNnc2haLxf3+kMvlSuQygUBQrZbfe++9169fx2Ixj8cTjUYlEgnEf6fTGQ6HFQqFXq/vdDqTk5PPnj1bXlikKGr/YA/UUI/Hg+XXcDgUi8VSqbjT6VSr1aWlJXRWQlmBEKJWa2HWqdfr0Wh0dXUVP+Fm47t+Jw6Hw+ERbrf7m2++4fP5DodzcnJyQA9IkkQhsUQi4nA4NrvVYDB8+acvnE6nQqWEhR8oGtQnTExM2G2OSCQyNTX14sWLbDZ769atZrO5tra2uroKPObdu3e/+eYbr9ebyWQUCsXEpH9/fx+z78HBAWzmcrlUyOU9e/at3mjGsoCm6SHLqVarcrl8bGwseB6GjDQyMtLp9lwu1+HBQSaZ0uu1LMuOeUfb7Xa/T9frddx58KjIZIr5+fmDg4Ner3f79s1iMZ9OZ3U6XS6Xs9vtL5+/0Gq1Xu/4o0ePhEKhWCxmGGZhYSGbzZZKhampqa8efgEztUQiOTg4GBkZQX3k/Pw8hEZY4zF59PpDv98/Ozt7dHR0dHRis9lUKhWy1UKhsN1uHx8fj4+PA6w/Pz+PiuVqtepyuWB2rtVq+GZ93y+kUCgymQxq2gqFwvj4OO45QqGwVqtZLTbci968efPuu+8yDFOr1QBIXFicr9erOztbOCIuLy/RmwtHC5CPL1++lEqlCwsLBwcHfD7fYDDBDqjX63O5nFwuN5ut2L5JJJLgWQihP8hI7XZ7dmb6/PycZVm0KELuAjaZz+d/8cUXo6OjY2Nj6+vrH3zwQTabTabSd+7fOz4+NhgMrXojl8uZTCZk/bApUyqVzWbz1q1bz58/7/V6uVxOpVLBNYWfvEAg4HA4FxcX9XodIWhoOdlsVqlUOp1OvIm3trZWVlaAzmJZFpNZOBzm8/mhUGh6enpycvLNmze5bBZqAp/Pxw8W2jbWqchYXLt27bPPPltYWFCrVafBE5PJZDQad3Z2SJLEuZdOp00WG0EQsVh8dXVVLBZvbGzw+UKBQCAQ8KrVKt73mJjb7fbl5WW31bZarUAlRSIRp9Mpk8kikYjZbEZbcCAQiKeSJEnabLYvv/wSKIfLy8vx8fFqqYzdXyAQePr0KRyreN81Gg2xWNxsNqfnZhuNRjKZ5HA4h4eH2IGiRxJCw3/95S/39/b+5V/+ZXIy8ODBg8/++HG5XMbcJpVJjEZju938TkKWSs9DlxwOp9lsT01NRaOXw+FQrdOIxGSj0RgZGTk+Ou12uxaLXalUfvbZJ++9997Ozo5Go0HhOigBYHcnEvFKpQKeC/7fp0+foe1RrVYjpREIBAaDwcbGxtWrV58+fWo0GsEyRUt6r9fDgQPzz8rKCkmSH3/8McMw2I8jKoj0QKlUwlQNBw52gnAYw/aDTWW73f7FL36Bsshw+HJqaiqTyVxcXKjVSvw5CG3AQkcQxNbWFi6r1WrVbLYmEond3V2Kov7Df/gPY2Nj4XDo8PAQvLpIJHL16lWoquVyicPhEP/ym/8JmY6iqBs3riM2rFarcbtSq9XFYnFszAfASbFYLBdLOo1mbm6uVCoJKQqMH2gYaBSZmZmp1+t4CHg8nlKt2t7e5nA44+PjNE0Xi0XEm+VyOSCcvV7P5/MxDAMdQiZTyOXyQX8IhphcLu90OlAUbTabXqftdDpKpfzZs2csZ/juu++aTKZisXh2dlar1SYnJ6VSKViLcGLBGnLr1q0//vGPeLHx+MKpqal6ve52u/HLYwbDfD7fp2m1Wj0TmM5ms4jFIXpDcPlqtToej0ulUpPJlM1mKQmFwxevf5FIND4+XiwWK7Uqn88vZNIqlWp6errRaIQjlxOTk5CajBZzvV6nBEKRSFQpl9FlVq/XeQyHyyFEIpHN4QQRJJlMWmxWiqKGLEuSJEtwmvVGoVTEX6pVf8engIsItc2xWKzf7+MVNRgM0M08NTX15s2bZru1sLDA5/Oj0Wgul8O+EovOWq0G8CN6dUQikUajaTRqdrsdQEuAXkhSpNfrGYax2+0IkCcSCalUShAE/kOhUGA5i5ZlsGHAkzQYDIACn5yc4LixWs3pdNpkMk1PT79586ZSqcjlynQ6DddLLpezWq1ut7ter1cqNaPReHx0Ah+o1Wrl8bmIRDWbTZYdosMHCC6Ux7XbbbvL+f2C6ew0hLNsbGys26UnJyfL5fLa2hoovVKpvNttu+12mu4kUkmCIAiCx7JsKpWanZ0ViUQHBwcKlery8lKt1uj1+uFw6HA4eDxuIpEY9vsCgUAqlV5cXHTbLbPZPDU1nc/nuz26XC6rlOpyuQwPlkDAq1TK/44kqNbrdYvFEovFsODH4gbltbdv3242m0cHB6DgIhSG9oLhcEjTHYFAIJFI8E2Bf5+iKPwWdDpdt9vlcLhutxtQAIRGsT1pNlqI+u/t7f30z/8sHo9DQ6XpHkmSXJYL7o5arXY4bCzLHh4d8Hi80+MTkUg0Oz/38uVLj8cDzxCioyqVqtuhTSaT1+v9+OOPZTLZysrK+vo6lG8cFG+99dZnn33m9/slEkkikRAI+WgKx4w+OzsbiUR++tOfPPzTF61Wo9XtzMzM9OhBKBTiCYSjo6MiiSQcDovFEpPJFI0lKIqKRCLNZlMmlc7Ozqrksu3tbZfbeXl5yeVy1Gr10tLSkydPYLzTaHSXl5c8Hq/T6Wi1akyHuHp1u91KpUKSJMFyLi8vZTIZn88fH5+gaXr15s12s/7kyZNypfjzv/7r4/39R48e3b9/HyG4TqcDUEu73QbPDKdWs9VRKFSvX79+6623SqUSSKHwjKOeQavVbm1tuFyuUqk0PT0diyUwVIXDYb/fj54Wq9VaqZSOjo6uX78ukUguLi5CodDt27clEkk0GkdcA4f+2dmZzzuu1WpR/Qla7NLSEmi0JCU8Ozu5desGriVffPEFZju0yzebTWwJUcJjMpmOjo78/kmlUr22tuZwOBYWFhKJRCQSwT0zn8+vrq4OBgNAHdfX1xOJxP/+v/3vf/r8c7RFWa1WmUz26NEjuVw+MTFBkuSXX345MjKCGqJAILC5uSlXKLFuu3HjxvrmBsuyCHCgGwpyxczMTKVSOT4+1mq1aoUSyg0kQzzA4CS/8847Z2dn8AoDGS0QCNxu98HBwerq6v/4H//j9u3bPp/v8vISaIwXL14gX4Z3k8PhCIVCZ6en2JlAENJoNBsbGyaTaTAYSKVSGOrdbjciKefnIbrfRe7KZrO1212FQhEMnkskEu+4/+DgAMtEj2e0VCrpdLpCoUCSAqVS+daDB6/W1vh8PjSqTCYTu4ywLDs1NWU2m//lX/4Fhg2apu/fvx8KharVqk6nE8ukmIZrtRradfb29uRyuUIqY1k2GAz+7Gc/y+fzmBqBEyuXy3Bb3rp7J5PJwA+NdyJ+tsCsMwxz9erVSqUSiUTy+aLJZFJIJYlEAtEBkhIqlcqzsxOhUKhUKovFIt0dUBTlcLiwCNLpNKlsOhaLGU364XD4u3/5w1/91V+dnZ27XK5SqYCarFKpdHFxgcpRgiB0Ol29XrfZrEjdonNQrVavr79G6wM8ggRB+P3+4XCI6pTv4QhutzuZTBaLRYIgVCoV0nwul+vzzz/HSA2VFLZFGBKEQqHf7weVCQmMZDK5vLzscDi++uor8C9MJhO6R+12ezabnZiYoOl+KBSCqAkehFAoZFnWZDLAvysUCgeDPjSaDz74YaPR2tjY0Ok0ZrO5WCxms1mVSvVdPqzb5XK5gNdoNBqBgP/kyRPi+bdfwbt67949gYAXDocRosZhCteqxWKDZC2RSNr1xvz8/NHR0d7e3sLSEpRwxEdHR0chYAA+9h1qgs8DzVIsFu/s7MBoDDSRzWZbXFw8PDy8uLhAhFuhUAwGjEAgYIZstVrFGwXpYuDLatVKOByOx6MffvihkOTDd3x8fFwoFNrtNgCh6XQaHVhwstdqNaweWJa9uLigRBIMEF6//2h/n2XZZr0xPj6+sb6eTCYNOj2qWGmattlsyWTy9Cy0vLwMrJnT6QwGg3ySv7e3x7Jst9s1Go2gcl9cXBTLJZ1G227WKYpSqVRDDtvpdpVKZbfbtdls9VYzm81SAqFWq82k0/juUQKKFIpYlkN3ujaHnaa7lXpNIZUp1Iput5svFsAFhUfBPTpydHQ04RvnMCw+eK1Ww8Iim80WCgUQuZBtwULBbrcHz0N2ux04nKWlJT6fv7e3B3IVsrtIWYZCIQB+gJz9HhEpFAplMgXIVbVaDbvCdDo9GAxqtRqsFWAEYNaUSqUo6jo4ONBoNHg5kSQJtlmn0yFJQbPZNBgMSDLmcjmpVA7KAyCW/X4fbwIeT1AoFKqVGsMwLMtevXo1Fo/euHEjl8sdHx+nUgnAAEFtSaVS5+fnbrebTwrhdJZIJP7xyePjY3BGKpUqqBwQXOHqNRgM7XrdYjEZzaazszOC4CHzQpIkaE8dmj4+PpZIpFBSE4mERqP++c9/Hg6F0CZWqVREpJCmaalUrlQqAzPTL1680Gn1MplModZUq+VkMsHj8SwWC9oLut0uGs2gJjqdTmQCBAJBqVTSaDQchkHPUjQahVXTZDKdnp62202FQpHL5bCjhEsSiAGAD0QiUavVWVxcfP36dTabFQgETqczk8n84Ac/eLOzm81m79y5s76+LpZJYFYgCMJstmQyGR6HB1hAPp+3WExGo3Fza8PhcChk8mq1urC0+NFHH4HWiJ3yrdu3t7e2Nje2LBbL9xeMbPY7r2uxWDw9Pf3xj3+8ubkJaQ0tme1OCxYCbAfgzWq3m+trr/y+sVQ2U6vVeFwBh8Oh+wOdTleqVCYnJ2m6x+FwRGJpv98HP9pht9M0XS7khULhzOz0xsaGWEzJZN+1ZywvL3/55Zfh8CXM11euXCkUcrAtY+eCuicOh8Pn8liWbTQaOp1OrdYiEZlKpc7OToQkH5h1v98/NTX1+PFjhmGOjo7kcrnD4RgOh1ilZbNZh93VHzLj4+MvXrxAnRRc7aFQSCKRpFKpRqOxsrLS7bZBEG21Ws1mGxDISqXicDjgROl2u61W4/Hjxw8ePDg8PMSCrNfrtVotguBdXFzcuHHjq6++wq+pVq3fuHHj6dOn2EUKhUK1Wo19K8thnjx5ND8/CzyjTqcDeq1UKonF4m63i50AHNyTk5O1WgMUe3D+RkdHwVbAy29+ft5ms4VCIeS2sLXptjuYUN96661kMrm7u3v9+vVYLAa34sjIiEKhiMVi5XLZZDJdXl72B8NKpfLBBx8kk0m1TlssFsEox2OMiytOOQysX3z2+ezs7NTU1Pn5eTwe53A4yNOBLY4InlKpzOVy165di8fj6MiD3wuNEdDzRkZGsNTGRzMajRcXFwRB0N3uwsICrvqAVjx8+FAul+Oe89Of/hRTuFar3djY6PVoLp8wGvXgeJ2fX8RisStXrhWLxW+fPV9eXubxeAsLCx999Een00nTNI/Ha7ebc3NzoVCIoqiDgwOn04nb7Htvv7O/v/+HP/xhbm5uZWXl008/DQQCV1dXdzY3wa7T6/UCigwGgw6HY2dnx2Aw4LYsk8lkYgm4zfgqwfSj0WjC4XAqlcJHHrDMysrKycnJ5eXl6OhopVKBd7ZSqXg8nng8bjabV1ZWCoWCSqUJhUJclrm4uPB6vRRFffXwy16vt7AwVygUjEajw+Go11rRaFShUOXzeTRE9Zn+cDigREIej8cl+AKBIJlM1WoNr3d0d3d3fn7+v//3//7+++8DzQiIbiqVWlpalMvlOzs7KNdiWZYkqWg0Oj8/3+l0isWi0+lMp9PQszUajUajOT8/r1ar4IoHg8Ef/vCHINI5nU4A+nHBK5VKUBMx0gGKBu/BvXv3sJGDmlUulwOBABw+GD9gGYe5/Pr1G0CmCQSChYUFoVAoEok2NjY6nRZqPDqdTiRyabPZ8vn8ysoKQXC3tnZUKgVKz5rNJto/ITE6HI52u72+vu5yuUZHR6LRKPGvv/sntIZxudx0Ov3gwYPd3R2GYXA4NpvtSqXSarXg+A4EJm9cvba29qJcLlutVqGQymazpEg0MTEBDMZwOIzFYna7XavV6nS6ra2tMZ83EokghI8rGvbiZrMZHlikEXu9HlatGAW83vF8Ph8IBNrtdrlUkcvlhWLearUm44krV668evWy2WyOeUdisRhWgTqd7uTkxGw2I0qAwkhk/uFh1Gg0gC9QpBiAKFhYKpXKwtzccDjc29tTKpXwCNcqVbxlS6XSVGAGHBRQKFutVi6fGQ6HKo1GKpVisMDoIBaLs9msWilvt9tWh10oFAZDIZqmR31ek8mEDa5ISPb7fZZhKIoS8viNRkvAE/eGjMVo0Br05+GgSCLyjXmj8Vg2mx4Oh61WY8hhMdrK5fJKpSITyxqNhkGnTyQS6B9ot9t4WwsEApFIFIvF4FA2G40uj+fo5BhJpZ2dHTgNQdkAaROG92w2i34PmUwmEPD4Ai5UXIvZtr+/b7HYxsbGtra2Li8vCYJAkIemaSSQ+XwuEJrZbBadQiaTCX5zdBrIZDKJXIYCAb1er5Ir9vf3e70eMudWq7XRaFWrVbgKQFePx+OLi4unp8FsNqtSqmdn5xlmsLa21h/0RCKRzWZB/Af+POCv+v0+asUYgiMUCnlcAfJfX3/99eTkpMViSafTDMOIxWKgwux2+8jo6P7eXuQ8ZDQaoeCWKuVAIIAauGq92e12C4VCIpHwjvuQyR8MBgIe3+PxtJt1g8GAe3a33YGoRpLk1PR3HLheryeRycPhsEqlxIYrm83mcjl41NCnHolEpFLp3Nxct9sFF4PH492/ezudTq+trSGtfe/ePfD0xGIxTii5XN5ot4AnJQgiHAzZbLajoyOGYbhcPpaY6XR6fHzcbrdDYux2aER4qtVqqVo2GAxogT06OiYIYkAPwPTr9Xpms9Fisezt71qtVqfdEQ6Hc4U8dhCNRgM+IbVavbiysrG2HovF8vn8jRs3xsfHf/3rXzebTbfbPRwOJyYmcO2x2WxffPHFwsKC1WotV0r5fL5arT548ODrr78WCASrq6u1WuXZt08lUpHN6jg6OiJFFAIuNE2LJBKLxZJKpXu9nsVmTSaTFCn2eDwmk+mLL75QKmQ8Hq/ZbFitVkrIR1yRJElIO7Vag2XZdre7sLAQDJ0KBILQKaD2SoSreTye2+Xa2tqyWR3dbpcUCKxWa+QyRvB5fD5XppATBPH48eNf/OIXjx49AhFqOBxCvavVaqlUyul0ohzt6Ojk7bffrtfrp6enoIdjd4PfmslkMJlMJpPp2bNnuPCwLAHwr9VqHRkZ2dzcbDbrWN5hzkaiam9vD8PT4uJyNput1+vgx5pMpnKpgtvR4eEhiCco6VpYWJidm/n228eQiB4/fhwIBOD8m5qaajQaWLV89NFHgUAA1WQul0smU2QyGQSQnz59igoaLpdbKpVsNtvY2BgiKbio1Ov1fDZ37dq1Xq93eHiYSCTu379/dnZmNBoBO7XZbEjj2+12eGXKlepgMMA0FgyfI9Xkcrm8Xu8f//hHmUyG62i1Wp2fny+VSpPjfhiJCIKYmZmpVqt//OMf0fwBEi8cbNjdb25uArN5cnJy9+5dgiBCodDx8fHs7CyPx0OiGe1JqM6s1+t8AW9qagoLimw2Gw6H7997C7XQwWBwbm4Oic52u51Op2VyqdVqfv+HPwidnjYajVyuIBKJCIJnsVjK1fH4raQAACo9SURBVBqY9QqFAstTGP/7/T4mJI/Hk0qlyuXy/Px8s9mslStGo1EqlaIGPpPJgKG6ubmZyWQWFhZqtdqjb5/8xV/8BYJpQEXOzc0NBoPPP/nU7XaTJLmzs6NWa3E9drlcKKA7PDx0Op1ylVIqlWJ1AxtWOBwuFApOpx286+3tbYZhSJK02Ry5XK5RrfD5fLjQsrkMEDAQkxiGCZ9HKpVKuVwdH5+w262vXr3KFXMzM9OtdqPVajUb7V6vp1ZrhsMhLLwikej09BRDhsfj6ff7s7OzsVis16PxqvV6vYBjNxpNBHJxbqfTadRa1Ov1bDZ7fn4ObxLYIijYwLqGy+Wen5+3Wi3sAV+8eMHj8Vwul1KpPDo6SqVSU1NTcOlgdLZard/XSOv1ejj5IpFLtVqNwg/8vw6HMxKJoELt+PjU5XKB6YU/p9VqBAKBfr+3vb2NQ14ikbpcLgBRh8MhMiLIZgUCAQQ4GIbBZb7VahH/n//z//B4PBwOUyqV8D2MRi8xXthstlgsMTk5iQImLpev0agalapEIgqHw7j56fX63mCAciU4+VmWvX///scff+x0OgeDQbFc4nK5iHmDnI4pT61Wn5+f1+v1u3fvRiIRNHx9j6alKCocvnS73Zubm3abg6Ioo8lwenqqVqp4PB6SaKVyATcPPDe4IwLPzbIsh8NB/XCpVMIP2mazNRqNHj1QqVQ0TZMk6XQ6X758yWEYPp8P5ZnP5/N4vNnpmfPz80ajweVyG822TCa7/9ZbTx4/xqeQySWtVovL5xcKBTg/Go2GwWBwuVyXl5dGvVYoFIqkkn6/T4lE4XCYw+OWy2U0XRzs7vH5/EG/zzDMiMvtcnmisYxKpeHzuclkstvrGIx6iUTS63VLpZJWq27TXSza0Lu0sLCQTWWLxaJGpcYOCIEmeBrQNgiK2OHhIYdhxny+ZrNZa9RVKlWtVoN2cnl5yTCMx+PJZDJoRlKr1SguEIspi9UUj8dRnUsKRcPhsFAozc/PQxFtt9uHh4dw0AP00G43LRaL2+1mGCaRSCBT3Ww2kalG11WxUsbhq9FoFFIZbMuYTZ1OZzyebDabWFYmEomJiQk+n1+tVlutjt/vNxosuVxue3tTpVJJZRI+n3/lyjJ6oLDsgNIuFovv3LnDJ8mXL1+wLJvN5JVKJc5QrVbbarUMBkOn01lcXMSdQ6fTmUymV+svSe535efValVIkdBKq9WqTKFqtVqwRyhUSnQl9ft9AY+fSice3LvvcDjOzs52d3ctJjO0AZqmzVbb4eEhtGu6P3C5XLncd9IOAm5wa/b7/dPTU/BvS6VSsVicnp7e29tLpVIjbqfZbEZvtFwuv3nnzvnZ2cbGBt7ucCtzeFzkX0iSPNo/mJmZUSgUkUjE5/PjXgEggkQiqdVqvV5vOjDD4XDW19f5fP6obwxrMpfLdXYW7Pf7aoVaJBJhAZrLZc7OzmRy6cXFhdVsmZyc1BsNUIXx1w0GA6VSqVAodt/s4b+np6c7nU4ymaQoCgV8kUhkc3Pz/fffz2QyIpHIbrd/+eWXSpUimUwqlcr33nvvn/7pn8xmc6PR8Pv9lVJxyPT5PKHNZjs4OlxdXd3a2qlWq0azORqNKhTK8fHxMZ/3o48+iseSPp/vu2o2upPJZHg8br1eV8qlarUafZHAcCuV6o8//nhqerpSqbCcYaFQmJ+Z3d7epigh0EHJZFKn1drtdqvF/vr16267rVAohAKq06O5XI5ULgM1Wy6X/+Y3vzEajVeuXNnc3Ewmk9CWCIIANlmtVhcKJUi5kEUjkQjO9+np6XK5rNWqaZqORqOjo6MMw3Q6nV5vAKwo2gsCgUA0elmtVvF9BEfx9PR0amoKS3ytVn95eVkqffcdfPHihYgSY7IH2xPbLovFcnZ2dvv2bZVaKRTy//CHP4yOjmazWaFQ2Ol0RkZG7Hb7mzdvRkZGXrx4US6Xb9++PRwOm80mTfe5XG6r1arVagA1YSvUarVcLhe4gHgh8fn8y8tLIV8AAhPelw6H46OPPvrlL38JnQwZo5mZmfX1dZZltVotw3K+/vprn8/n9/vpQT+RSASDwbfeeovD4YTDYZIkw+HwD3/4wzdv3gBz5XY4KYrC5gV9UJDWjo6OcBFiWRY9P9Fo1G63F4tFyJDYoq6vr8tksg8++ODjjz+GGgERYnx8HMCFdCZlsVj4fD4u1X/+53/+am291WpdvXp1b28vk8mYTCaxWAyiSr6Qk8ulc3Mz9Xr9T3/6k8ViK5fLIyNjBEF4RseSyeTx8fGNGzcw+nz/DgImFK3hb968Acg+GYujyRh4pEQigQL7sbExTKtGo1EooiAVu1yuR48ePXjw4Pj42OfzlQtFOCDr9brXO476ELS+wvB07dq1py+eI3S/uroaDAZpmu50OlNTUy6XY3NzE/zh7e1tn8+nUKg2NjZ0atXy8vJ3XiW1cnNzM5/POp1OyIpmk42iKKdzZHd3VyjkS6XScq1cKpX8/vFOt8VhucPhUKlURSIR3F2hIWFHBMo0lpL5fA6iFCZvmqY1Gi2k0MnJyVQqhUkFOhmaWOv1OrC9iFvhLZNOpwFyQyQTIuuVK1fgNsHbDSo+FjuAGLRarR/84Adisfjhw4fo6h4f97EsC0sr0MpWq+3x48fLy8ulUqlcrgI/hEg1y7Je72gqlep2O1C8dDqdUqn65JNPYOcXi8XxeBy9L/1+3+12syz76tWr//yf/3O5XIaORTz55guDwfDo0ddoOL+4uFAoZEajEVxmmu4bDAZ4kJeWVrrddjlf8HpHc7kchiSUhhaLRUosRpRMIpG43SNQiWUy2VnoVKfTGY1GiCsArNtsNrxEi8Wi0WiMx+Ozs7O42HG5nOnp6VAoJBRSJpNpbW1NJlMghyyVSgOTU8VisVott1qti4sLg1E35hkplQrlclkul0OMhUVJJBLBGbC5uVmr1SC3WCw2qVQuFotLpdLc3FytVkOPh0QigQaDe1u9XheJRFNTUycnJ6RQBPNTJBIRiUQCgUBI8ofDIU8gwGoGFKiNjY2xsTGBQGAy6E5PT9t01+PxXL91a3N9vdZsAIMWDAYHdM/lcvG4XJvNNjMV2N5+s7Wz63A4JRIJfos8HjEcDjVaFcOy7XZbqVQCYS8Wi5vNNv4lIpFoZmYmnU6/frU+NjYmk8levnxptVoBcRCLxexw2O/38/m8SCKpVCr94YAkSZQgAa8CnYbP5wOy+tZbb7Xb7dPTU6vVbLYYj4+PaLpnMBh0WkO9Xr+4iID7Go1G9Xp9pVKRySTf+9K0GhVIktFoVK3RUBQFTAZGFpFUAhOxSqXSaDR7e3vdVrtWq3G5XIvFUq/X9Xr9cPjdKJBMJsET0mq1fD6/Xm8aDIZ2i87n83K5VCAQzMxOl0ql8/NgrVYrFvOw56tUKolEZrFYgFfoDZjbd+7sbG/DqGQ0Go0m/c7ODvwil5eXYFLgpciy7LDb0+k1wWCw2Wyq1FoMnRKJRK3Tulyu/mCwu7trt9vj8TjLElarlRTy4/H49OTU4eH+cDh0uVyDfr9YLCLKfnEZ1ev1YrFUJBKZLBa8ESGSu1wuaOCwDN6+fRuU8Far9dOf/pRhmN///vdqtZrLYaRiid1u39zcHLLM7OwsSZLRaLTT6Wi12tVbN4PBIFrSVSrV5uamVqWGX4HL5XY6tEQiweuEZVmGYbRabTabrZSrAJGrVKrzyzCCKeVyeXR0rNfrWYwW+PaMRqNGo3I4HCenxy6Xix0y+XxeLJXAquLxeJ48eTI9PT06OvqP//iPXIKHcw0DFsxAWBHCBzkzM/Ps2TO9Xs/hcKRSaSqd1Gq19Xr9L/7Tf/q//+7vYJHk8XhCId/lcgHx8N1pWyz3ej2IpktLywKBIJlOEQRRr9eHw2Gn2yNJslIuEgQhIkkOh2PQadLptNlsbrVacrk8lUoFg+cul0sqlz948AAauVqjXFtb02vUsJgolUqL2VwulxE9HtADmUwmlchPQ0GRSBSJRScmJpRKJaKIKpWq1+sJhUIggqCUMwwD9z2WvwAXeTweGDiazaZGo0IG5fj42OPxHB8fIyp1fn6xs7MzOzu7srKSTMa/b0VE9QfmIbGYcjqd+Xw+kUj5/ZPJZBLWxuPjY4qibt64dXx8fHJysrS0BNQnLGivXr3i8/lGk6FQKGBlBqMeaJPw6YNNKpfLI5GI1WrVaDQatRYhLGwznz17lkjGgUrn8/kajarf73M4HDC30ulsrVYbDpharTYzM1MqlSDpAcZtsVgEAsH09PRgMHjy5InX65XL5V9//bXb7VapVAcHB+VaFaYCmqYRyZyYmoRtSCKRWK3WTqt9sLtns9kQjhaJRBCzwf5AZcjjx49BENja2sKZjB8vQRBOp5OiqMvLy4WFBafTGY/HC4VCJBLpdDqrq6v7+/tarbZYKiAJCAGy2WxyCR6+8q1Wq1KpoN3o9PTU75/M57PFUk6lUszMzH366ac3b97udDr5XKFerxvMpnK5fHh4+Mtf/vLiIlwoFBwORyQSSSSSaHCHAEPTdKFQIEmyXCi2Wq3Z2dnT01N8QOTmMBfiBj63uNBoNE5OTuCNwSNhNpt7ne6jR4+MRuPy8nIoFIYPFVDDZrOJjjKvf/ybb75pNpuBQABW97GxMS6X22jUQJDHyXPz5s1sNh+Px2emJleuXNne2ioWi3SvWy6X1WrlxMQE4IKtZpcgCC5XaLFYaJoeDHqdXodhGJlMiqMjmUxqNFro6JVK5c6dO+l0OhwOv3jxAgtWJKz9/vFEIoFFE9ZW5XIFEPZ4PD4/P39xcQEUxeeff45LAnCgoVAImTAgGJrNJnbEMNEbjcZisYhEHcwtoFfCkOf3+69du/bo0SMEgaenp8/OztrtVqPRQPawXq8nEgks2V6/3qAoymKxnJycOBwuuVwejUbdbnen0+HxeIlEzGQyvXq19pd/+Ze5fCabzYpF0kQigY4WkUgUiUTEYsmVK1fOzs663a5SqcQez2w2r6+vT01NEQ+/+ISmaYYZkCSZz+fHxsaUSrlEIjk5OZmZmUkkUmaz+enTp2Kx2Osdj8Ui4bMgRQkx5gsEgtPT09FRL0VR8WQSwE+NRsPl8tG2yLIs3e9Wq1W32w14BqwSyC9YrVbwZhDFBCSGxyMw8iuVylqtIRQKS6XK+vq60Wjs9XrtZovL5YrFVLvd9nq9ao0yn8nm81mHwwFCN9Z8qVQKDjWcieFwGOQCpVK9tbWDa26xWASBE7ukcrm8v78/MTGh0WiAitFoNKVSScAnk8kkPGQEQYyOjsYTUYqieoNBs9kslUp+vx/IgOFwmEwmSQGPz+e7RjyFQmEwHIpEolGfd29vLxgMSiQSk96gVqsH/b5MLCFYzunpqd3pEpBkJpPR6/VGkz6dTtN0x2AwFItFgsdVKdSRaJTH5dK93tREQKaQdzqdvb09g8HQ6/XOg6GJiQlkbbB+Ah+VHQ6Bd5PK5RRFFUpFh8MB6PxgMHA4HBcXF1arFStkoETUavXFxUWv1+UQjFKp6HZpgUBQqzYYhlGpNP1+v9cboKCDw+GMjnqEQuHx8bFQKNTrNOBjeTyeTreLmxNYMoPBwDXiga6m1WolEkk0GlVIZdghymQycBny+aLf76dp+vDw0Gq1Yt1ZKpW0Wn2r1eq0e2q1WqGQdbvdZqvR7/fFYur8/Fyn0yCRS9O0UEhpNBp4ge/ef5BKpV68eIFGObFY7HTZEY/HjAJyusFgUKvVp6enFJ+HjZ7RaKxU6xj1zs/Pf/JnP7VarZ9+9hkWzbFYTKczyGQSLkH0+/1hj15YWKhUKr/73e8CU1OAkvv9/la72+l0Tk+DVqu1Q9OQvgmCwD0MnUuIRqtUKpwR6IpvtVpzc3NPnz4leVwAe2q1WqvT7vf7sPEBJjQ5HXj16pXD4ajVaiB8coZMOp1GewOHw6UoyufzPX36FPjKt95669WrVz7veD6fr1QqSqXy7DxIURSaoyQSaS6X67a6SNbMzs5KpeJut+t0OUiSTCdTrVaLFFEvX77UarWTk5Pw5ufzeYqiFHIlGq6+d5Xm8/l33nknHA7ncrn/+B//IwCh5XI5l8uNjo42W416vX52dgacG8AH3W7X4bDRNO12u7e2thQKxenpqVqr93g86XS61WqVy5UbN26UqxXMytVqtUv3g8GgRq3sdDouh8NisWTTyUqlolarQa9oNpsGg+np06cCkrx69SoG/SHTl8lkTpsVxKxkMklwOBqNplarXblypVFtPHz4UKvRy1XKcrms1etQpTUxMREMBgGnlkgkMIxLJBLoNJjn2u02dmTvvvvuN99802g0IId/+OEHaFt75513vvrqq2KxODIywrIsh8MFRP727dvVavnx48eI9GL3KhaLh8Oh1zu6sbGhVqu9Xm8ikSmVShMTE6hs53A41UptMBigbnl2dvbZs2d8Pl+r1fZ6vYWFhVa7CY/UyckJ6B6QwGOxGM7G7e1tr9eLXfmVK1cOD47gAkQhRzqdbjTrELd+8pOfbGysC4VCg8FAUdT5+bnf7//64WOtVgsj/+eff76ysoJW+06ns7Gx8dZbb/H5/N/97nerq6sikWhtbQ0ZLnR6wie0v78P1WFzc7M/HKyuruKvfvLkSbVa1SnVkHXhyET+Y3d398aNG/F4HI1bSPzBXiOTyfx+//r6ul6vHx8f73a7BEGsr68DwOt2u+Ec3dra8vl8lUolFo/CNe/xeDCOd9pdQLxAzhsfH0crea836Pdpute2Ws18vlAmkx0cHN2+fVsilp6cnGQLeYlEYjQaVSpVLBY9Pz9HnZRSqULO12w2ZzIZrVbLsuzDhw8nfOPQrgCuW19fDwQCCL7pdLp4PF6r1Rxul9frjUajOANB79NoNGKS4nK5Ozs7fr+fYTjg4MBnlkgkwuHw1NRUsVKen59/9eoV4GfgaOTzea1WTRDE7Ows+oUnJiZ+9av/ZTKZeBxWKpWGw+F+v09SQrx5nU4nUgL1WqtSqUQiiR/96EdSqbTZrH/+5RcqlWJ6OgBP/WAwqNXqEDL0ev1XX301OTlZq9XGx8dBOX7y5MnMzEyjUR8bG7t9+/avfvWrRCLx1ltvXVxclkqla9euffPNN6urqyMjI0ClHB8f9/v9cDiMJkf8rsViscFgWF9fX1xcbDQaQqFwOBxubGz88Ic/dDgcDx8+RP86NCSCIOD6d7lceLkA/4aq+Hw+B3xDNBq1Wq1Xr16Nx+MHBwccDmEymfDq9/snj4+PcQOXyWRPnjxRqRQCgcBsNlEUFb4IURT16Jsn9+/fl0gkyGtHo9G1tVe1Wm10dPTP/uzPPv/8cyTzEEVaWFggfvPrvwesxWKx5HKZYrGo02mA6slms73ewGQycThcKNI+31gyGiuXi6Ojo1AFeDxeo9HicrlcPn98fJzD4cTj8V5vwDAM3e+p1epKpYTEIwRejUZjMBjgsrRYLIeHhwDnpNNpt9vN53ODoVOwZ/R6Pd3t1+t1iUQGf75YLK5VqhRFYdkXCASCodNCNiemSEDhoB7zeDxkHiFNIYXrcrkmJyfD4ctMLp9KZux2+/LycigUgi/VarWen597PB4seqBDkiS5vb3tcDh4PB6gwzMzM8lkkmEHqLQEaJ+maTwTBwcHBoNBRArEYjGfFEaj0V6/r9fru/3eyckJArFMf/CDH/ygXCrlM9l8NicQCAgeh8fj8QU8SKnNZtNut2NZptHpfKPes/Mw3e4YTBanzflmf683oCGcjo6OAkKhUiiFQmEqlXry5InFZMJUQZLk5OQk3e/z+fyjk2P0zwDjjm8IvO1wssP90263O50WKeQpVXIuwZ+cnAqHL/v9/vbWm4WFhXy+iMyqRqPBjhi37VK58P2NEwOWWq3G95/H4wlFVKVSwTYELA8xSaHjGVa8wWBA0/1er6fT6fr9/vn5uVwuxwVCJlOwLFutNLrdLgasSrU8GAzGx73FYj6VSqEkEQFgo9G4s7NrNputdif8yCzLcnkcn8+Xz+cBAhUIBPV6FTg3BLxTqVQ6njCZTGhITaXTqJ8rFAp2l/vw8HDIMNA+AcgZDofdTkcul+bSmfn5+afPntRqtdVr1yUSSblcrtVqJrNVLBazLLG7u6vW6nES4dMBG+bxeEAYyufzWq0WhVzY2TebzUqlopbLEEhZWFgoVcqXl5fvvPPOYDCIx+M2my0cuUT3EQxY3W6XbndQLOj1esViKUVRGxsbBEG4XC6MtgzDSMTSTqdjtVqvX7+eLxVwhw6Hw+VyJRqNalVaiUSCmJVareRyuXKF7OLiollvYAThcrnD4RD+dCRPPR5Pt0sjkoN5Ra/XA/MIO2ahUECfLhJz8Xhcq9VYLJZqtfrq1au/+Zu/OT09hd/iMnqhVCoXFpZEItGTf/cAraysJBIJhmHcbvfo6Ojh4WE0GqUoEcHj+iemXr9+LRaRhULB5XAkEgkxJfR4PHKpLBaLVes1iqLMZms8Hrc7nRCWCIKwO6zD4XDKP/769Wu7w5rNZnOZrE6ns5ltZ2dnGo2OYZherzdk2WazrdXrWq1Wq9V6++23Nzc3Y7GY1+uFBZ7L5SLrurS0dHZ2dnBw8P/6m//3yclJ+OLc5/NBiT88PGy1Wnfv3v766691Oh0OE9x/nE5nt9tDcU04HM5m06lUCsAXjOBTUxORSAT9VwhtEIRgMBhg7QjLS73WgKJ2cXEBnMrY2BjaIxQKxVnwFBLRn//FX/x///ZvLRaLSCQymUzxePzo6Ojdd98FILdYLGImlknlfr8f+TIghYDtDQaDJpOpXC4CSIY1usFgGA44mUxmbm5ub2+Pw+EYjUbYJACs//LLL+fm5jKZjFQq9fl8p6eneMKxdhlyvquLRdj+5cuX7hEPXBxisfgf/uEf/ut//a9um+N3v/sdIEYQMM7Pz30+38XFhUKh6HQ6+Xxeo9FwudyVlZWnT58SHI7D4UAqpdls/tu//dvk5CRJkmiPtlqtXC4X0rjBYNDqdFvbm1K5HO2Z4XB4YWGhWCzhDEwkEmKx2Gw2X1xEbDZbIpHg87lqpSwejxqN5g8//DAYPO/1ev3eIJFI3Lxzu1KpHB4ekiS5unqdJMmz4MlwwFKUqFqtRqNRlUo1Pz//2WefzczM1Gq1Zq2eSqX4fP7c3FwgEFhfXw+Hw4PB4J133gGOlWXZActgakdMFXyKVqvldjjhSWq320ajGT86vV6PqPjXX3+dTqcFFAn27+XlpUgkWlhYePny5eLiosGgy2az2Oafnp7Ozs52u71MJtOq1xQKBTDj1VoFdMnLy0u/36/X660WRyQSOTo6EwgEFEUZDDqFWpVKJYxGQzabDYVC7733XjQaw2OJNVGr1YJcBIrbP//zPz948MDpdMhksqWlpb/7u78TCoUffvjh4eERTdNoKAoEAtlsFuvLeDwObnMwGGy1WktLS0aj8be//S2qG3/0ox9tbGxAZdTr9TAaga5cq9U4HE4ikfB6vQaD4fwinEwmjUYjYjEymUyhUPD5/Gq1MjExEY/H+Xy+x+N58+ZNv0/7fP5YJCaTyUiSpChKICARMAelb3t7e2YmkE6nWZax2+2R6IVcLl97uY4iILPZrFKpGo0GTrxkMjkzM9PvD169evXgwYNKpVIul/V6PfHy2aORkZG1tbVOpyOTSQiCKJeLOL65XK5EIuv1erlcARsQq9WsUsqFQqGYpBANEIvFAgHZ6/XqzWav1+NyuYuLi7lcIZFI+Hy+y+gFgL+RSGRiYoKm6enp6ePjY3xOHC4KhQIsfI1GQ9OdYimPoef27dvxWLLdbhcKBZr+LnXFI7jArmCfyA6HrVbDabfhHaBQKCiKMhrNkchFLlcQCvn9fl8ik2rVmpGx0Wa9sbXzxu0egZ9XKpViROi0aYFAANIm9rLxeNzhcJTL5Uql8v7770P9A8wdHUP5Qtbv97darVyhMDExIRQKNzY27t+/P2T6lWKp1WqVa1UcmiyH02q1FhcXQ6GQ0+k8Pj7udjrjY95EIjE3Mxs8D+XzWaPR2B/0QOmAJIuuaIlMLiapYqVq0BpIkSgSjsiUinK5KCCFkNOwA6KEpMFgANxWwOPpdDoIziKRqNlu94cDKEzddqfT6eDCRIooAKKwLcXPrdVq9XtdgYALCI1IJM5kchwOh+72pVJpNpufW5ivlMqNVrPbbrEEhxkMi8Wi3WFFCUy32y0Ui/gzEfMRiUTZQt5ut1ut1ocPHwIqq5TJkZgDbZ+iqEajJZVKcZukaTqdTo+MjLTbbYbh2Gw2LiEQCATZbDqbzY6Mesrlcq/XFYnIVCplt9uROhwOWSAqstnskCWmpqZKpVKtXoFHAVkEm83W6/WSyaRYTGFdSJJkrVxptVqlYhEeAiFJdjqdjY2t8fHxSr3WarUmp6ZarVahUOj3+wKBQCaTFfJ5DoexmW2JRKzRaPD4BDMYrq6uotedZYlINGo2WngCfr8/bLRaFEUhJ5XL5Xg8XiAQYFl2bW2NJEms+VUqFeQcmqaNej3DDDQqNZSYDt1lWRYOYrFYHIlEGu0WnJWAMb569WrE5UbBTrPZJEkRvhqYm5E5EovFLMNBHefa63Uul0C8t1wu53J5Pp+vkqsGgwGQEMNhfzAYuD0uHo8nEYmRQsIvtFgsoq4YhKH19dcURe3t7YnFYpfLJZNJLRZruVwyGk37+3u1Wn1ycuLsLOif9EtEkidPnzjtDuA8ILIi/Mjj8er1qlavIwgemiJ5AsGk3394cqjV6BHGxhj94sWLsTFvu90WkiKxWFyrV6anAu12i+CyF6Fzi8VSLpZSmbRer1coFGtr6x988EE8mRzzjtRrTbrX+W6HWK81Go379+8/fPiQSxBwU+3tHlxdWRmybD5fFIlEntGRIcuKKerRo0foVWRZ1u/393q9nZ0dnNEAbtGdbrlacTqdk5OTX331FWpAKYp69uzZ8vKyXq/d2dkpl8tw/gGBOBgMnHYHJZaAOmE2Gw8PD8Vi8cjICNBx5+dBm8026Pflcvlw2Ed91ulpcGpqKpFIfLcuabRardZ/+qu/evTwYTweHx0ddblcABGl0+nT09Mx7ygppAbD/vdBSMwfgHMWi0WbzaZVa6rVqlKpZFgOgheffPLJzZs3+/1+qVxsNpsIHsnlUiCsut0ukO63b90DI0oqlWYyOT6fC0/FYDBIpZOwXrRbnUKhALgxQLihUEij0RTKpe9hNx6Pu1arpbOZ0dHRfL5wcXExMzOjlCsYhjnc2weyrtlsimXS2GVEpdXYzJZmswkvI/R7jUaDrhWWZTHdPvrmG4lUyjKMWCIRCgTAE1osllQqBZqMkCRFYioSi42NjTHsIJ3KooSApnuxWEwikTmdTmRLCYJQq9XVapnutG/cuH56GqRpulgojY2NsSx7enqq1mknJyd3dnZKpSKagDUajcViiccTer1eJBIVCgWVSvXRRx/B9o5csN1iBSYQsDQkbYfDoVardblcH3/6CXos2u02GIRqtXpiYuLs+OTw8BCZHplM8X0B9nA4/OUvf4nWKZFUcnl5qdXoE4nEgwcPKtUSwzCFQuHo6MDn87399tuIFg2Hw2635/P5Ls9DqF3pdDpmi0kgEFCU8KuvvhofHzcazZ12t1wuSySyer05MTFxeRnu9nuLi/O///3vR0dHVldX19fX/f6JVqv19OnTP/uzP2u1WqiO4HA429vbJpOJJMmtra2JCf9gMNje3r5379711dWPP/pIrzd0u91yoUiKRcvLy7u7uzDgCgSCxcXF7e1tRGrgaDw+PsYA2u/3YcVBWrPRaFit1k8//VSv10skEqfTicuGQCDQaDSJVHJlafno5FhMiUQS8d7ensvlIkmh3+8HzJKm6UAgQJKCVqtTyBVQde/z+Y6PTxOJBLJW3W5Xo1Ghvq/f78lkMrxQ3K4ROM7BoJ6enn718uVkIAD/olgsMZvN1WoVcftwOEzsbq+NjIz84Q9/EIvFIpEIewe8q9CdLBQKt7a2sM2pVqv1etVkMokoChmlbrcrJimKovL5Yq1Www6bw+E0222lUvnBhz/c3t7OFrJclqNUKjUqLRar8PZbLBalUnlxcSEg+fF4nCcUxC4jH374YavZhFiyvvEKvQHBs3Pcj7ttmqIojVIzGAxAlyC4w9u3b4PjDFMXh8OVSESBwEw0esnhcBRq1cLsTJ8ZPnvyLUmSXC4fhyZuhCqVqlAooXl+bm4O/hiKFEORMplMLpfr9PS02WwCu4KkBofDwf0PhRXNVr1Wq42Pe1utVqPRkMkkgwEjFAoJguAK+NCxkeBTKTUT4+O7u7vtdhtbvFqtQopFxWJRpVKRpAAuFmxaSUrcbrXcHk8uk9/Y2rSaLYjGEATRG/QpiqrUa+Pj4wqp7OXzF612w26x0p2uy+VSqlXHx8etbockyZFRbyqV6tM9Locjlym73a5CoUhm0uVqRa1W15o1qVSqU6tomhYKBBQlLBaLHborFovbra5cLh8MBoPBgCAIp9Ot1Kg//fiPcpWSxyHKtapeoyVJkkdwx8fHa7XaYDCo1msqlarV7aRSKaPROD4+jo5CAZf31VdfGQwGHo+IRaNGo37IoPOLEAqFpUoN9ASBQJDJZDweD7Koy4uLhUKhUKrKZLJCNiMUCnVaDRI01WqZw+E4nc7hcHh6ejoxFQiFQla7HduKnZ0drU59fHzIMIxUKq1XqhMTEzyeAMM6RVEjIyMqleLrr7/mC7ge92g0GpXLlWjtGA6HHA53ZWWlWC6rVKpoNKpQKBh20G63B4Nes9nOpTM2m81isSUSMZPBmM4kTXoDl8tFTLLZbBfLZblEzieFVquVwyUEJJlKpWAoKZcrUGWmp6fXnr8YDAaQiqu1CpZQLMv6/T4kCdANgHU5h8Mx26yZTKaQL8lkMqQOx8bGjo6OZqenG40G9r+Tk5O5XK7WaOLbIRKJ+Hw+tlqoxuPz+W63W6tSHxwcoDgIbzKhUFgul69fv47Rp16vfw/oEwqFkAklEolOr4WNEq0goPyBH+P3+2i6X62W0+mszzdWrzf9fl+t1uj0OlyWmy/lbWZLKpUCc7zTaoPiQ1GUy+VJpVJ8PpfL5YZCIZ9/nBkM+8MeVHORVKJQKPb29nQ6XbVSl0plfILP4/GkUvHs7Gy1VkkkYgCW1mqNfD4/MzNH9/udbgtVWjabRaXS7O7uKGVyrVYbjcbj8biAx8crEPLSi7VXw/7AaDaJKHE4culyuSixqFqu8Pl8h8NRr9dL+UKtVpOIxfV6HalyiqI4HE4qnli5dqVQKgqFfPA2fT7f5uamRq8zGo35TH5sbOy3v/1tsVg0G00ikUihUExPT0UuLo5PT+GLMFtt6XQ6FA5fv349cnExGPQoUiAUCiUU2e12WWY4GDLVRlMskuKyDj7f/PwiwzDJdMpqtXY79NbW1v379z/55BOTydRoNKQSidvtPjk+YzlDtUaztLR0dHRE07RITHE4nG67k8lklpYWeASxtra2tra2tHJVoVJicwcrUrPREolEIjFlNpsfPXqkVCqLxfy9e/fS6WShUJKI5eVyFZnB4ZC12SzB4Om1a9eUKsX29qbdbu90OolESi5TyGSyo6MTr9/LMMydO/d6vd5nn30ml0t5PJ7XOyYSk0dHRyCPMEOOQCAUiSQHBwfLy4vBYBB3j0KhMLcwz+UQ5WrF7fTweLwvv/zSYrEw/QFN0ytLy71Bf31zXalUut1uo9FYKZb2Dg+KuTyfFC4vLCJdAYbq3t6eWq3OZrNSmWQw6LXb7Rs3rtN0v9Fo1OvNbocWisTvv/cB2nvSmSRFUfhcfD4/nU7zeALQ6cRi8e72zt27ty8vL5utBoA+fD5fJBKJRCKW4VQqFZPJYrVaVSpVPJXM5/OpdBpVvpVKpUfTQqFQLpdjG35+HpyenjabTd/5WbXadDpNENzz8/MHDx6cnJwolcq333774cOHaFKpVCpKmbLb7RIEm8vlsEfzTfgHA0av15+eBLnc7/xtPB4x6h1hWdZo0G1vbyPAiMRoqVRCqDmZTM7NzcRisYkJ/6tXr1ARODY29s///M8ymRw97icnZ5lMRqlUjo2NFQq5ZrNpNpu1Wm0mk2m1mi6XKxKJKhSK8/NzrVYbj8fdbvf9+/cRb1xfX7937y5FUb/+9a9lMtn09LRGoznc3zcajQqZXCQRg4+IgM6tO3c5HM6TJ08mJiYarSbGR0pILizMHx8eHp2coBvG7XY3Ws3p6enHjx+Pj4+fnZwC2xuNRm0Wi1qtTqfTiVRqbGSk2W5LKDHB5+l0uuPjY5Ikf/SjH7148WJjY2NsbLTf7x8cHapUqrmZOTCuY7EYYjcajebo6Aip1c3NTYfDDpQjHG98AVen0+nUmsFgEA5fjo6OxiJRDpewO53tbieRSNy9e/fjf/t4cnLS7XAmk8n/B7IYGkt70M1nAAAAAElFTkSuQmCC",
"text/plain": [
""
]
},
"execution_count": 7,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"from PIL import Image\n",
"\n",
"# Download the image from the openvino_notebooks storage\n",
"image_filename = download_file(\n",
" \"https://storage.openvinotoolkit.org/repositories/openvino_notebooks/data/data/image/coco.jpg\",\n",
" directory=\"data\",\n",
")\n",
"\n",
"image = Image.open(str(image_filename))\n",
"input_transform = torchvision.models.ResNet50_Weights.DEFAULT.transforms()\n",
"\n",
"input_tensor = input_transform(image)\n",
"input_tensor = input_tensor.unsqueeze(0).numpy()\n",
"image"
]
},
{
"attachments": {},
"cell_type": "markdown",
"id": "f9fcaba9",
"metadata": {},
"source": [
"### Load the model to GPU device and perform inference\n",
"[back to top ⬆️](#Table-of-contents:)\n"
]
},
{
"cell_type": "code",
"execution_count": 9,
"id": "175b43dd",
"metadata": {
"tags": []
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Time to load model on GPU device and get first inference: 0.54 seconds.\n"
]
}
],
"source": [
"if not any(\"GPU\" in device for device in core.available_devices):\n",
" print(f\"A GPU device is not available. Available devices are: {core.available_devices}\")\n",
"else:\n",
" # Start time.\n",
" gpu_load_start_time = time.perf_counter()\n",
" compiled_model = core.compile_model(model=ov_model, device_name=\"GPU\") # load to GPU\n",
"\n",
" # Execute the first inference.\n",
" results = compiled_model(input_tensor)[0]\n",
"\n",
" # Measure time to the first inference.\n",
" gpu_fil_end_time = time.perf_counter()\n",
" gpu_fil_span = gpu_fil_end_time - gpu_load_start_time\n",
" print(f\"Time to load model on GPU device and get first inference: {gpu_fil_end_time-gpu_load_start_time:.2f} seconds.\")\n",
" del compiled_model"
]
},
{
"attachments": {},
"cell_type": "markdown",
"id": "09dfac5d",
"metadata": {},
"source": [
"### Load the model using AUTO device and do inference\n",
"[back to top ⬆️](#Table-of-contents:)\n",
"\n",
"When GPU is the best available device, the first few inferences will be executed on CPU until GPU is ready."
]
},
{
"cell_type": "code",
"execution_count": 10,
"id": "0c6a52b3",
"metadata": {
"tags": []
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Time to load model using AUTO device and get first inference: 0.16 seconds.\n"
]
}
],
"source": [
"# Start time.\n",
"auto_load_start_time = time.perf_counter()\n",
"compiled_model = core.compile_model(model=ov_model) # The device_name is AUTO by default.\n",
"\n",
"# Execute the first inference.\n",
"results = compiled_model(input_tensor)[0]\n",
"\n",
"\n",
"# Measure time to the first inference.\n",
"auto_fil_end_time = time.perf_counter()\n",
"auto_fil_span = auto_fil_end_time - auto_load_start_time\n",
"print(f\"Time to load model using AUTO device and get first inference: {auto_fil_end_time-auto_load_start_time:.2f} seconds.\")"
]
},
{
"cell_type": "code",
"execution_count": 11,
"id": "06673210-5af9-4209-acc3-7b2fed1eb165",
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"# Deleted model will wait for compiling on the selected device to complete.\n",
"del compiled_model"
]
},
{
"attachments": {},
"cell_type": "markdown",
"id": "0a2de05c-6b75-4bc2-814a-08aa4924c2a7",
"metadata": {
"tags": []
},
"source": [
"## (3) Achieve different performance for different targets\n",
"[back to top ⬆️](#Table-of-contents:)\n",
"\n",
"It is an advantage to define **performance hints** when using Automatic Device Selection. By specifying a **THROUGHPUT** or **LATENCY** hint, AUTO optimizes the performance based on the desired metric. The **THROUGHPUT** hint delivers higher frame per second (FPS) performance than the **LATENCY** hint, which delivers lower latency. The performance hints do not require any device-specific settings and they are completely portable between devices – meaning AUTO can configure the performance hint on whichever device is being used.\n",
"\n",
"For more information, refer to the [Performance Hints](https://docs.openvino.ai/2024/openvino-workflow/running-inference/inference-devices-and-modes/auto-device-selection.html#performance-hints-for-auto) section of [Automatic Device Selection](https://docs.openvino.ai/2024/openvino-workflow/running-inference/inference-devices-and-modes/auto-device-selection.html) article.\n",
"\n",
"### Class and callback definition\n",
"[back to top ⬆️](#Table-of-contents:)\n"
]
},
{
"cell_type": "code",
"execution_count": 12,
"id": "37bc1059-5a3c-4d11-a340-09c224a9d5e5",
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"class PerformanceMetrics:\n",
" \"\"\"\n",
" Record the latest performance metrics (fps and latency), update the metrics in each @interval seconds\n",
" :member: fps: Frames per second, indicates the average number of inferences executed each second during the last @interval seconds.\n",
" :member: latency: Average latency of inferences executed in the last @interval seconds.\n",
" :member: start_time: Record the start timestamp of onging @interval seconds duration.\n",
" :member: latency_list: Record the latency of each inference execution over @interval seconds duration.\n",
" :member: interval: The metrics will be updated every @interval seconds\n",
" \"\"\"\n",
"\n",
" def __init__(self, interval):\n",
" \"\"\"\n",
" Create and initilize one instance of class PerformanceMetrics.\n",
" :param: interval: The metrics will be updated every @interval seconds\n",
" :returns:\n",
" Instance of PerformanceMetrics\n",
" \"\"\"\n",
" self.fps = 0\n",
" self.latency = 0\n",
"\n",
" self.start_time = time.perf_counter()\n",
" self.latency_list = []\n",
" self.interval = interval\n",
"\n",
" def update(self, infer_request: ov.InferRequest) -> bool:\n",
" \"\"\"\n",
" Update the metrics if current ongoing @interval seconds duration is expired. Record the latency only if it is not expired.\n",
" :param: infer_request: InferRequest returned from inference callback, which includes the result of inference request.\n",
" :returns:\n",
" True, if metrics are updated.\n",
" False, if @interval seconds duration is not expired and metrics are not updated.\n",
" \"\"\"\n",
" self.latency_list.append(infer_request.latency)\n",
" exec_time = time.perf_counter() - self.start_time\n",
" if exec_time >= self.interval:\n",
" # Update the performance metrics.\n",
" self.start_time = time.perf_counter()\n",
" self.fps = len(self.latency_list) / exec_time\n",
" self.latency = sum(self.latency_list) / len(self.latency_list)\n",
" print(f\"throughput: {self.fps: .2f}fps, latency: {self.latency: .2f}ms, time interval:{exec_time: .2f}s\")\n",
" sys.stdout.flush()\n",
" self.latency_list = []\n",
" return True\n",
" else:\n",
" return False\n",
"\n",
"\n",
"class InferContext:\n",
" \"\"\"\n",
" Inference context. Record and update peforamnce metrics via @metrics, set @feed_inference to False once @remaining_update_num <=0\n",
" :member: metrics: instance of class PerformanceMetrics\n",
" :member: remaining_update_num: the remaining times for peforamnce metrics updating.\n",
" :member: feed_inference: if feed inference request is required or not.\n",
" \"\"\"\n",
"\n",
" def __init__(self, update_interval, num):\n",
" \"\"\"\n",
" Create and initilize one instance of class InferContext.\n",
" :param: update_interval: The performance metrics will be updated every @update_interval seconds. This parameter will be passed to class PerformanceMetrics directly.\n",
" :param: num: The number of times performance metrics are updated.\n",
" :returns:\n",
" Instance of InferContext.\n",
" \"\"\"\n",
" self.metrics = PerformanceMetrics(update_interval)\n",
" self.remaining_update_num = num\n",
" self.feed_inference = True\n",
"\n",
" def update(self, infer_request: ov.InferRequest):\n",
" \"\"\"\n",
" Update the context. Set @feed_inference to False if the number of remaining performance metric updates (@remaining_update_num) reaches 0\n",
" :param: infer_request: InferRequest returned from inference callback, which includes the result of inference request.\n",
" :returns: None\n",
" \"\"\"\n",
" if self.remaining_update_num <= 0:\n",
" self.feed_inference = False\n",
"\n",
" if self.metrics.update(infer_request):\n",
" self.remaining_update_num = self.remaining_update_num - 1\n",
" if self.remaining_update_num <= 0:\n",
" self.feed_inference = False\n",
"\n",
"\n",
"def completion_callback(infer_request: ov.InferRequest, context) -> None:\n",
" \"\"\"\n",
" callback for the inference request, pass the @infer_request to @context for updating\n",
" :param: infer_request: InferRequest returned for the callback, which includes the result of inference request.\n",
" :param: context: user data which is passed as the second parameter to AsyncInferQueue:start_async()\n",
" :returns: None\n",
" \"\"\"\n",
" context.update(infer_request)\n",
"\n",
"\n",
"# Performance metrics update interval (seconds) and number of times.\n",
"metrics_update_interval = 10\n",
"metrics_update_num = 6"
]
},
{
"attachments": {},
"cell_type": "markdown",
"id": "4fbaebca-d7a3-43bd-a3d3-aeab1e177171",
"metadata": {},
"source": [
"### Inference with THROUGHPUT hint\n",
"[back to top ⬆️](#Table-of-contents:)\n",
"\n",
"Loop for inference and update the FPS/Latency every @metrics_update_interval seconds."
]
},
{
"cell_type": "code",
"execution_count": 13,
"id": "94b8e571",
"metadata": {
"tags": []
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Compiling Model for AUTO device with THROUGHPUT hint\n",
"Start inference, 6 groups of FPS/latency will be measured over 10s intervals\n",
"throughput: 215.00fps, latency: 53.28ms, time interval: 10.00s\n",
"throughput: 227.40fps, latency: 52.03ms, time interval: 10.00s\n",
"throughput: 234.33fps, latency: 50.43ms, time interval: 10.00s\n",
"throughput: 231.23fps, latency: 51.10ms, time interval: 10.02s\n",
"throughput: 225.68fps, latency: 52.40ms, time interval: 10.00s\n",
"throughput: 221.66fps, latency: 53.41ms, time interval: 10.01s\n",
"Done\n"
]
}
],
"source": [
"THROUGHPUT_hint_context = InferContext(metrics_update_interval, metrics_update_num)\n",
"\n",
"print(\"Compiling Model for AUTO device with THROUGHPUT hint\")\n",
"sys.stdout.flush()\n",
"\n",
"compiled_model = core.compile_model(model=ov_model, config={\"PERFORMANCE_HINT\": \"THROUGHPUT\"})\n",
"\n",
"infer_queue = ov.AsyncInferQueue(compiled_model, 0) # Setting to 0 will query optimal number by default.\n",
"infer_queue.set_callback(completion_callback)\n",
"\n",
"print(f\"Start inference, {metrics_update_num: .0f} groups of FPS/latency will be measured over {metrics_update_interval: .0f}s intervals\")\n",
"sys.stdout.flush()\n",
"\n",
"while THROUGHPUT_hint_context.feed_inference:\n",
" infer_queue.start_async(input_tensor, THROUGHPUT_hint_context)\n",
"\n",
"infer_queue.wait_all()\n",
"\n",
"# Take the FPS and latency of the latest period.\n",
"THROUGHPUT_hint_fps = THROUGHPUT_hint_context.metrics.fps\n",
"THROUGHPUT_hint_latency = THROUGHPUT_hint_context.metrics.latency\n",
"\n",
"print(\"Done\")\n",
"\n",
"del compiled_model"
]
},
{
"attachments": {},
"cell_type": "markdown",
"id": "a63d446b-0c7c-4f2d-baac-21d5ea92089d",
"metadata": {},
"source": [
"### Inference with LATENCY hint\n",
"[back to top ⬆️](#Table-of-contents:)\n",
"\n",
"Loop for inference and update the FPS/Latency for each @metrics_update_interval seconds"
]
},
{
"cell_type": "code",
"execution_count": 14,
"id": "42e0396c-d7cb-4176-844c-1d5d94ae788f",
"metadata": {
"tags": []
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Compiling Model for AUTO Device with LATENCY hint\n",
"Start inference, 6 groups fps/latency will be out with 10s interval\n",
"throughput: 130.40fps, latency: 7.03ms, time interval: 10.01s\n",
"throughput: 138.42fps, latency: 6.78ms, time interval: 10.01s\n",
"throughput: 136.80fps, latency: 6.86ms, time interval: 10.00s\n",
"throughput: 136.63fps, latency: 6.87ms, time interval: 10.01s\n",
"throughput: 138.39fps, latency: 6.78ms, time interval: 10.00s\n",
"throughput: 134.95fps, latency: 6.96ms, time interval: 10.00s\n",
"Done\n"
]
}
],
"source": [
"LATENCY_hint_context = InferContext(metrics_update_interval, metrics_update_num)\n",
"\n",
"print(\"Compiling Model for AUTO Device with LATENCY hint\")\n",
"sys.stdout.flush()\n",
"\n",
"compiled_model = core.compile_model(model=ov_model, config={\"PERFORMANCE_HINT\": \"LATENCY\"})\n",
"\n",
"# Setting to 0 will query optimal number by default.\n",
"infer_queue = ov.AsyncInferQueue(compiled_model, 0)\n",
"infer_queue.set_callback(completion_callback)\n",
"\n",
"print(f\"Start inference, {metrics_update_num: .0f} groups fps/latency will be out with {metrics_update_interval: .0f}s interval\")\n",
"sys.stdout.flush()\n",
"\n",
"while LATENCY_hint_context.feed_inference:\n",
" infer_queue.start_async(input_tensor, LATENCY_hint_context)\n",
"\n",
"infer_queue.wait_all()\n",
"\n",
"# Take the FPS and latency of the latest period.\n",
"LATENCY_hint_fps = LATENCY_hint_context.metrics.fps\n",
"LATENCY_hint_latency = LATENCY_hint_context.metrics.latency\n",
"\n",
"print(\"Done\")\n",
"\n",
"del compiled_model"
]
},
{
"attachments": {},
"cell_type": "markdown",
"id": "9f1907e4-e71b-471f-891a-66161c03bc85",
"metadata": {},
"source": [
"### Difference in FPS and latency\n",
"[back to top ⬆️](#Table-of-contents:)\n"
]
},
{
"cell_type": "code",
"execution_count": 15,
"id": "e3eb5f0a-a47a-4cc3-886e-347b187867a1",
"metadata": {
"tags": []
},
"outputs": [
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAA+YAAAHWCAYAAAD6hZOjAAAAOXRFWHRTb2Z0d2FyZQBNYXRwbG90bGliIHZlcnNpb24zLjUuMiwgaHR0cHM6Ly9tYXRwbG90bGliLm9yZy8qNh9FAAAACXBIWXMAAA9hAAAPYQGoP6dpAABnaUlEQVR4nO3deZyN5f/H8ffsG2PJliWksiRlbZGdaLOVRLJVKKmIIj9SSbYooYTsEWXNFkLRQpZICl+7jHXMGDPWc35/XHOWmTln1jNuy+v5eJzHOXPOfd/nus/c5zr3576u63P52e12AQAAAAAAa/hbXQAAAAAAAG5mBOYAAAAAAFiIwBwAAAAAAAsRmAMAAAAAYCECcwAAAAAALERgDgAAAACAhQjMAQAAAACwEIE5AAAAAAAWIjAHAAAAAMBCBOYAAAAAAFiIwBwAAAAAAAsRmAMAAAAAYCECcwAAAAAALERgDgAAAACAhQjMAQAAAACwEIE5AAAAAAAWIjAHAAAAAMBCgVYXAMDNzc/P7zZJ+awuBwBYLFjSRasLAQDIFiftdvvB1BYgMAdgGT8/v9vk7/+vbLZQq8sCAJby95dsNqtLAQDIDv7+5/38/EqnFpwTmAOwUj7ZbKF6Z7pUvKzVZQEAa/y+RPqqn6gLAeAGdGCnNKhNqEwPUQJzANew4mWluypZXQoAsMbBneaeuhAAblokfwMAAAAAwEIE5gAAAAAAWIjAHAAAAAAACxGYAwAAAABgIQJzAAAAAAAsRGAOAAAAAICFCMwBAAAAALAQgTkAAAAAABYiMAcAAAAAwEIE5gAAAAAAWIjAHAAAAAAACxGYAwAAAABgIQJzAAAAAAAsRGAOAAAAAICFCMwBAAAAALAQgTkA3GhiTkpP5pGa5pcS4rLvfSYPkOr4SW/U9v2236httj15gO+3fTXV8TO3rWtuzPe73n092HxeX/WzuiRA1rxWwxzLf/9udUluXFH7XXVs1P4b7/1uBCO6mM9r8USrS5IpgVYXAACuuskDpCnvpW/Z1fakf9fxS7mMn58UnlMqXEqqVF9q9qpU8DbP2ztzQvr+S+n3pdLBf6RzMVJELilPQanw7dI9D0v31JDKP5ShXUpiyntS3Bmp81ApLEfS17aukbrXMY9Hrpbuq536tp4tIR07IDVsJ/WenPky4ca3bLI5ebyvdurHleNiS6P2UqES2VyoNDR7VZr9sTRnhPRkFyl/EWvLcy1wrx+T13/ZZesacytUwhwXyJi130nb10n3PyaVuz/l647frXbvSu0HXNWi4Tr27SfmXOLhptId93leJu6MWU6Snn5DypE7+8uVmufekZZNkib3l+q1kkLDrS1PBhGYA7i55SmYufVCI1xBr+2KaaXevcXcFn4u9f9GeuCxpOtsWiW9/4wUezrpdq5ckg78bW6/fm+ez+wJ8aFd0sIvpNz5paZdM7eN9MqVTypWWirg5SIEzOcjSSHX18lBpiybLP251jxOLTB3BH331bY+MA/LIT3zpjS+j2k1f/sra8tzs9q6xhwX99YiMM+oy5ekL982jwm6s1dAkKtODwiytixXw7efmAvzhUqkHpg76vRG7a0PzAveJjXqIC0aJ30zXGrX39ryZBCBOYCb29yozK3XsmfSk6D4s9LKr6Vxvczj91tK0/dIeRMD/2MHpX5NTdfyQiWktv2lGs1cP2JxMdLO36VfFkqrvs78/swZIV25bFq4s/tKcbNXzQ3eTf3H6hIgLY+/aILyFdOkFz+UbrnV6hIB6ffTd9J//5NKV5HKVLW6NDe2/EWo068HjbuYwHzuKKnV21JwiNUlSjfGmAOAL4TnlBp3ll4Zaf5OiJOWT3a9vmiceS4oWPpkrfRoh6RXlnPkkqo+Ir0+WppzJHNliD8rrZxhHtdvk7ltADebXPmkqg3NBa2ltJjjOrPwC3NPnQ8Yd9wnlbhbij0lrf3W6tJkCIE5APhSg+ck/8Sq9Z+Nruf3bDX3pe7zPv7cISQsc+/94ywT/BcvJ91xb+a2kRHpSf62boHUo670RG7p0RzSC/dKM4ea7pfpTR5nt0vfj5devl96PFJ6LKfU9UFpxfS0y7jvL2l4J6nNnVKj8MQyVJAm9DXDD9KzX2u/k3o9IjUrINX1z1hCutSSsZ2Nlr7qL3WqZParQbDUvJAp34guZuhDVpyOkj59VWpVUnok1Gx74HMmt0Fafl0s9X9KalFEeiTEJBN8vaa04HPp0sWkyy6bbPbR0Y19ynuu/XZPXDS4fdIcDd3rJF3m2RIpy2GzSStmSL0fk5oXNJ9R0/zm/7Fqpjk2PHm2hNnmssnmO/FVf6njPebY8ZRIqV5rc//9+LQ/G3h2NtokXBrwjPmsG+c1x92zxaUPWkt//5ZyHUdyK0dX2D/Xpjx2lk32vN7oN6T2d5vvdKNwqW0Z6bPXTe8kTxzHqeM4+3eTKetTt5pjvPXt0pgeZj9Sk3BOmj1Cer2W1CSfOSZbFDV/z/5YOn3M9Xk0CjfvuXp26tv8qp9ZrvXt3o9pTw7tMp+Zn59U99n0r5cRW9dIA1q46oIm+aQe9aSlk6QrV1IuP6qb2Zd3n0752uVLru9g0/ye97VXw9QTMm5fL33YxhxXj4RKT+SSXq4mzRziPdmpo+4Z3N685+IJUreHpSa3eD/GPEkrGduJw9KY7onHZYT5vJ4uLHWqbJ53PyfIjMO7zT60KGq23fI281tx8r/U18toPer4DTx2wPw9pEPK76VkfiNblXSt16pk0mU8/bZfuijNH2vqf8f3p3khqW8Tk3vHG/ff0ujj5rv6/F2u71hyzjr9y9Q/m2sMXdkBwJeCQ6XIW0ySt/jYlK+f+s/8CPp5+CHJqg3LzH2FGr7fdmZ83tOcqDrkyG3G0X/5tvTbYpPoLi22K1K/ZtL6BVJAoOmeH3/WnOT//Zs5UengJZHfzKHShD7mpEQy6165JO3dbm7LJkkfLZburOj9/ce+aYYH+PmZ8vv56Hr2icNSt+quIMLf3yQBjDkpRR8z5Tv4j1S5Xua2f3Sf9EErE5yHhEmBQWa7q76Wfp4rfTBPqtYo5XoXEqSP2iZtZYiINEkKt/1sbj9MlQYvkXLmMa8Hh5lcDWdPmxNv9/wLDv4BriSH0YmBS848UmCwa5nc+ZOuE3va/O+3/eRWlsTP6I8V5vbjLGnAHNMTxZPYU1LnyiaACQr2Ptb/3prm/tgB6cBOqXhZz8vBu+8+dQXY/gHmuJHMMX7soLR6ltT1E+mp11zr+AeYYyIhTjp/zhynOfMm3W5wsguVK2ZIw16QLl0wfweFmO/PoX/NbdkkacC3pgeSNyu/loa0N8drRC7TW+LoPunbkdIfP0hjf0t5DEvSrs1mSNLxQ4nl9zf1QsxJ6eQRc6z6B5gkWDnzSLWfkZZPMcFBnWc8l+XKFRPkStJjL2bst2HjcnNf9C7XsClfGtPDfCaSKVdELjOmeMuP5rZiujRwvukx5nBfHWneaBNAJf+t27nBFTzHnDT1XKkKrtcvX5L+WmceV6ybtCw2mwlu545yPReWw1wo+WejuS2dJA1dLhUq7nl/7HZzkeGn71x1rr+P6vQ9f0o96rgu7Di+A6ejpFNHpd2bzWuZTaL69+/Sxy+Z37+wHGb7xw+Z3nhr50jDVkh3VUq5Xmbq0bAc5nsZc8J87hGRKb+HkhSZ1/Q4clzkzpXPlMv9dXdRB6Q+j0v7d5i//fyk8Ejzm/DLQnNr3EXq/rn3z+HIHun9Z806waGmzvDEUaf/td58Zu7H6DWMFnMA8KWEc64fKfcTzLLVzP2JwyZgTTjn+/fe/rO5L1PN99vOqB9nuYLyeq2l2YelRdHSkrPSm19K/2wwSfLSMn+MOcF7e7K0OFb6PkaafUh66Enz+vSBJjhPbvFEcwEgJFx64UPpu6PS0nPS0njpiz/MSd+po1Lfxt5bWXZtMkF5q7elucekhafNNhp1yMwnktTkASZYKVRCGr5S+uGi2f4PF6SZ+82JSbkHMr/9Md3NSdawH0yZl5yVxv4u3X6PdPG8yYFw4nDK9T7uZILywrdLfWeYz/v7GGlZvDRwgXn+79+koR1d69RtaXI13J04k0DLnuZv91uBYlK3T5PmdHh/btJlvnBrTbpyRerf3JxM3nGfNGiR2Y/vz0hL4qTeU6Q8BcyJnCPxlSeTB0jnYs2FiCVx5hicfUjKXSDpcvmLSvkKm8eOln9kzC2FTdbvL/4wx8vC09LyBOnrvdJTr5tlxvYwCTIdChQz//uWPc3fdz+U8tip29K1/B8rpMFtzQW7Z9+SZu4z77H0nDTlH6lWC3MS/l4L7y3nMSfM8duwnfTNQXNMLT4rvTbanOTv32Eu6iV3/JD0VkNzX6CY1G+WWW/BKVOGSTtM3pFcbheYGr9s7rf8KP2313N5fl9igvqAQOmxjp6X8cYRbGVHnT9vtCsof6KT9O1/5vvzfYzUdaQp75YfpeEvJV3vvtom4Io9Jf3vz6SvbV1t7h0Xbbb8mPT1nb9L5+PNxZa7H0z62uR3TVCep4D0+hjzuS85az77kavNBdZD/5p6w3ExNrmf55qLvC8PlxZGm2P0+xgzlCWrPn/TBN53VpLG/CqtvJT4HTgvTdtl3rPE3Znf/ojOUqGSph5fctYc80OXmx54sael/s3Mse8us/Woow7PX8z8/eqnKb+XkqnD3evtLzYmXeb9ua7XEs5Jbzcy36/7aksj10jLEkxZFp2RXhlhLggs/EL69lPvn8OY7uZi2MerzL4sjpWm/ptyubsqm2PUdsUE59cJAnMAN7fmhbzf9u3I+PYWfu7qFuYeWDXt6jrxnzPCdCd7+1HTxXbdAtM1Kyv+22ta6SWpVDq7sfdvnvr+Ny8knTiU8bLY7a5uiFUaSH2nu6ahCg6VnnjJBJ5pdRmVzDIfzJMatXN18c9fVHp3jvk8bTZpTbJuovFnpS8ST/QHfCu1eUfKW8j8HRAgla4sDVtufrhPHDbdGj1JiJNa9JA6DXa15gaHeG+NyYgdv5j7FweZVvGAAFf5ChU3rQadBmd++xcTpCHLzOfvaLEqW81cBIjMa4LVGR8lXWfbz6YFLE8Bc9JUv7XrBDo4VKre2ORHCI2Q1s13Dc/IDqu+NgHybWVMWR58wpXMMCxCathW+miJ2bcFY71/fy4kmNb9h5u6WlbyF/WcGPGOxJ4TO3719d7cHJ7sZALT0pVdLW9+ftKtJaVXP5GavGJOkuePydz2bTbp067m/vUxUuch5sKWn5+53VZaGjBbeqixOb7njPC8nfPxptt3z/EmwJbM8dCsq9Ssm/n7x5kp15vwjrnoGnmL9Nl6c8HAcRz5+UklypkLEw2ec61T7n4TENnt0mIvwyQcXW0fauyqp9JrZ+Kc5b4eunQhwQTCklS3lfTmOFfZwiJMj4BXEj/f1d+YYQEOkXldv0GbkwXejkD8qTeS/u3gWP7uB02d4xC139RXIWHS0B+kpq+4WmMDg0yg98la893evdkEmp4kxJlyP/Omq24Ly+GbhI+OOv310ea331HvBgVLRe807/lsr8xvPyBQGr7CdZHfz8/0ChmyzLzHsYOufAMOvqpHfWHOCNML7N5a5oLxfbVcSdly5JJadJf6TDV/Tx9oerF44u8vfbxSqlTX1duh2F0plwsJc2XQv47qdAJzADe36GPeb1cupW8bV66Y7lVT3pMm/p95LjKvaZFxyJVPGrXOBEqS6ba5YZk07QPTNbJ5QalzFTPWzdvV/tScchtjlrxLsDdno1Pf/+hjmSvLnq3m85DMnKKeumY2bJf2WHtJKl9dqlgn5fPBIVKVxFaO/21L+tpP35nulndWlKp5aQkJCDRznEqu7qDJ+fub1vLs4Ej8d+po9my/VgvP3bHzFDDzdUvmhNrdkonmvt5zroAlufxFXf8Pb5+bLzjK0vhlc9LmSenKpgXq0kVpy2rPy1RrlPpQBXe58pl79+8SfOeBx8399nWZW3/bT6Z3TK58JpO+N4+0NfepHZ/P/5/n56s3MfdH9pgA3iHhnOv70rq39++HJ45W82WTTVdtdyeOuMbVPtk5/duUTLDvqD9ypbPOT68/Vrim9fQ2BVuTV1wBbfKZRO5LrCPcA++LF0yAFBphLngGBUt//pR0nLqjRf2+ZHX+ssnmok61Rt4vQoTnNBfgJO//+5x5Mv45p1d21+mNu5j6O7niZaWaieP5f5yV9DVf1aO+4ChLix7eu58/3NRcMIk5mfRij7sGz5vfofS4Dut0xpgDuLlldr7wKe+5xlMmlzu/6cLlGIPrcGtJc6X4wE5zRX/Hr9KeLa4ul7s2mSQrq2ZKHy5I2mKQFkdruZRyXJc3I1enPt+0ZBIlORLApNeuzeY+MMjVvTk5Pz+pQi0zRVVqyt7v/TVHD4Szp5M+7+i2dmCnafX35mKCufe2f0Xu8Hwi5AsPPGH+/+N7m1aEms3NZ+Voxcmq5OMzk782Y5Dpanp0nzkuJdfntnRi6lP2nYsx91EZPC7S68oVV6KwKQNMWb1x/O+9/Q/LV0//+zqGnrh/l5Ax/+01LW9bVpspvBLOpry452kIRXo4js9zMSahljeXE5MTejsmIvOa77Yn+dy2ezba1br47x+uoPrBJ9NfZsn0PPmipxlr/Msi8113WPqVCThvLem6aJtecWdcrYrprfPT698/zH2BYp5bIyXTu6diXTMTiGN5h0p1TTf47T+b73NAgGlRvnjedBvPkcvU7dt+Nr97ZauZ1xwtm8kvxjr+9xt/SL1OdwxL8va/L13Vez6KrHrgCdMrYnA7U96HGpvp63w1bWladfqqr6W928xxGhjk23o0q04ccW172AvSxwHel3X/H5bz8PufkTo98vqr0wnMASAz3BNc+fubx7feLlWqJz3aUcp1i/d1i5dN2pp5Osp0Z//6I/Nj9McPpuX95eHpL8/F867HQRbP2RmT+CMYeUvqJ0GO7u2pSS1hS0DiT1jyVihHhtqL55N+Lt64t4y5Sz4O2Zee7WXGX66ZbU7mFo9P7A57t2kVeuxF0zU3s/Kl8tm6f+7Rx12BuaNV4VysuaXlgpfPLavOnnYl9krPcIfUypKR/6FjqER6jhmk9PM8k3DQ8b+TEpNGhUryMwHz2WjTWygzHN/ry5dcCQRTcyHB8/Nh6ahTpKQ9pk675UbI6FCWsBxmKrOFn5tu647A3GZztSI+/lLGE4JmZ51/JrFLc2r1iORquTyTrAt0hZomCdi5WOnfjaZrt6M11hFgVqxrAvMtP5rA/K9fzLETEpbygqzjf3/+XPqOH291enZdaJWkLkOl//aY/Zwzwtz8A8xQhgceN+P00/Ob50166vQrl01Ph7wFfVuPZpV7i7W32VDSW5aM1OnB11+dTmAOAJnRsqf3Ln4ZlbeQmQP94abSixVMsLT0K6nz0PRnjI10uxBwNjp7T0DSKzsyz6eHLbFrZJ2WUv9ZqS+bGv9UrupnVWCQ9O43pqv/z3NN996dv5vp3fb9Jc0ZacbQPvNm9pUhOUeX0u6fm26TVrG5dW0dstRz9vj0CsjA/9DRahSZykU1eBZzymQ5v3TBBFxt+5tgy33qx02rpJ71M/8ejuOi7P0ma/rVlNW6rMnLJjDftMKMly5UwlyAPXbAXAx4NBMJJZPX+deSiEiTw+OfDWbceLkHXN3aK7kF5lPeM8+37u16vXz1lBd0Hf/7Vm9nLfdGdtbpOXJLI340dfkvi0yr+b9/mB4BuzZJ3wyTek10DaHKbr6sR31Zlik7zZj3zLrB63TGmAPAtSJvQemhxDGOZ6Mz1v3KfVx58q7dV5tjvGPMyZRzXrs7cSR73t+RpCi7uuX50h33muneRqwy2WmHrzStTbYr0he9zBQ8mXEylc/W/XN3v4BzrXxukbe4Wi6zq7u8J44xtenN0QCX35eY1tGceUzm5/tqJQ3KpaStzplh5fHpnpQtM8fk7feYoSrureTfJyaDq94k40nfJBO8Ooa++LrOd7RKpjXswPG6p1ZMR3f0LT8mTmm2wQSvdyZO6VXuAXOM/LU+cXxzYmDuqcv2tVI3pcc9D5uLqp+tM3X6wAXm/38hwcwGcDodvT08SU+dHhDo6r5tVT3qSVa/P5l1HdbpBOYAcC1xnzs3OAPdE4ve6foR9jYtz9XimEv18iVXptrk7Pak86r6kmMM2q5N2ZeIJzsEBJoM7YMXm66pdru0eWXmtrU1lSQ+jtci87q6sUuuz+3X7zP3no7eHfY08jY4Wh+9LRcY5Jr+6ddFmStLZkTtM/fMYZ5xjnm9i5X2PqY2tWPZLx3HjuP4PB2VckxzditdxdWKm9ljskliErilX5lAyrGdJzplvlzFy5l7X9f5pauY+xOHpUO7PC9z5YqrLilTNeXrjgRuO36RNq8yvwf31nLVE0HB5n96Pl7atNLMQy55Tvbp+N9vWnlddUt2zmbhmDbs4vnMJz9MT51+ewVXYjVf1KPpqdP93EJJb8sVKuHqim9FnX7b9VOnE5gDwNWw7Wfv494cEuJMt2bJBEyOLK/pEZbD1RLxz4ZMFdFn7rjPlVzp68Gef6xXTM++1o/aLcxnd/mSmTc5tZMKm80kUbraLl7w/lpQiKu7nl8mf6bXzJEOepjbNeaktGiceVy7ZdLXHAHCvr+kBWnMMZ9wLmVviPDE1ru0Ps/0LOcoy+9LpN+WpL69WB+0Fl684Jpz+d5aWd/ezSYiMePz4V2eA6c9W1NPKBiRjmOiYh1XvTKme+q9cSTfHBcOoeFSnWfN468Huy5EZEStFqYV8+R/0sDWpn7KTNI3dxVqmntf1/lVGri6/04e4HmZReNcY7/reuiefc/DJji8kOBKPJa8NdwRvE9934yPDsvhuijg7tGO5sJlzElp0rupl/3SRVcCsavlyuXUZzAJdus9kt7hackt/MLz+OyD/0prvzWP63ip0zNbj6anrnZPWJpqnZ443/2SidLuLRkvS0Yd3efqdXjf9VOnE5gDwNXw3adSy9ukUd3MVX/35FrnYqXVs6VXH3IFqy0yMbbYkWHdMbetVfz8pPaJGes3Lpc+apc0IdviidKIzimz1vtKjtxS10/M4x9nSX0el/7+3XXiZLOZjO2zP5Y63J35FuKseLa4NL6PyZrrHqQf2SMNfM5cxPH3NxmMMyM4VHq7kTnWHBcm/tkovVnfnNyF5zTjOt3dV0tqlDjW9dOuJvhxb4m7eMGU94u3TPmTJ3wqWd7c/74k9WEKjuVWzvB+sapBG6lyfVP2/s2kaQNdx5BkLgxsWS190lVqfXvqn0V67NliTugDAjOW9fdGF3My9ZvjRLzqI+Z4jT1tjl/H///SRVO39Xok9aRrjmNi/w6TBMyTgECp+xfmfvs66fWaZty6e/LH//aaAKZLVZMd3pde/NBMvxR7SupW3eyXI8Gc3W4uaH3RS/rBy0wTwSFSo/bmsaO3UGaSvrlz1Pn//pF02jFvzsen/T+9dNF0MXfkUPlxpjSii6sL9vl46btR0pg3zN91Wpopt5ILi3C12Dp+kyolC8wdfzter1AjaQI+hyKlpOf7mcezhkqD2prP2+HKZXPxZ8r7Ups7zOOr6cRh6fk7TT21e0vSObj/t00a1MY8Do3I/IW/y5ekng1cPQvsdlO/v9XQ5HYoUCxlbpCs1qOO7+Xab73nMciR29UavnSS9/nHn3nTdOm/eF7qXkeaN9rkpnCIO2OmDhzUVnqtRlqfRtocx1Seglkb036VkfwNAK6GwCBzQjdvtLlJJjiy25Ne3ff3l1r2kpp1zfh71GtlTlr+XGuCfV9NvZUZ9VubbLzffmKmRFs53fyAJ8SZE4yKdU0Sp68/yti0cOnVqJ2ZDm306+bH/velpiU6LIcUH5ssk7sFSeqij5mWt68Hm/95RC5zku9obfTzk17+WCpRLnPb7zpSmvCOOZELDTct747jLChE+r+ZnueR7/GFaa1fPMH87779xHxmgUFmmqokrULJPreG7czFjiN7pGdvM7kGHP/bz9a5Mjg37mLGlf70nZk2MHcBczKev6hZTjJleO876cPnzIWTr/qZW0Sk2ZdzMa4LDp5O5DNq/UJz/+ATqc8EcLNpmsbYzFL3ShO2mqE0LXtJM4eYXj8/z008puNdLcMdB5r/pyf31Tbd4A/9a4LenHlcrXUvD5dqJc7TXLmeNGCO9FFbc+Lds745NsMjzfHtnhHeMae1r+QvKg1dLvVtbFrM329pkonlyG0yhTu+u11Het9G4y4mW7fdnvmkb+4q1TPjZ8+cMGO002p9/2aYuaXmg3nms2v2qrnQ8e1I0zr+/ZdmX+PPuoKvinWknuO9b6tiXddUZ3kKuAI9h9JVzPct/qz5O/n85e7a9jPvO32g+U1ZMc1cQAgJN0Gde4IxK+r0//a66in/ADMlXEKcq2dHULDUe3Lmp7brMU76+CXp5WqmTrbbXBc2c+Q23eWT/+ZntR59opPp6bLjF1MX5CkgBSYO6Zi137Vc4y5mu/M+M8dJngJm++UecCVgDcshDVkmvfuUucA7qpv02WumnrDbkjZWeJvOMCMcdfrVSrbnIwTmAHA1vDPN/Mj9scJ0Ozz0rzmZsl0xJ6FF7pDKP2xaVEpVyNx73HGfaaH4Z4M5MXa0zlil60jT1XLuKGn3ZnPSfFtZ6ZHnpaffkMYm9grISJf9jGjcxWSinT/GfO5R+8wJXESkVLiUVO5BM/4vtflhs8uwH0xLxV/rzDz2jumfitwh3VNDatrVcytUet1aUhq/xbSQ/Pq9dPqoOVmqWM+c4HobRx0UbE60H+1oTrC2/Wymukm4YALo28qY/2mtp1NO/VP0TmnkamnGRyZoij3lOoF3b0VpkNh6tGictHe7KZunbqARkSaR2O9LpeVTpL9/TWy1s5sWmuLlTGBQ+5nMf06SOTF1dLN+snPWtnUz6zTYTPc3b7S0b7uZbqzIHdLDzaRn3zK9ErwJCJQ+XmXmW968yiS6crTQJe+W/HBTafoe0yL++1LpyG7zvQ6LMMdnmapmeqr7H/P9Pt5VyWSVXjBWWjdfOviPmas9T0FTpzzUWKrX2vv6Re4w9fTuLZlP+uYuKNj0cpk11PRAyUq3eE+6jpAeetLUoX+tN9/p8JxmHxo8Lz3SNvUs2RXrSNM+MI89Bd0Bgaa++32Ja3lv/Pykju9LdZ4xQ222rjYXSM7FmN/QoneZ3i41mkl3P5jpXc6UfEWkDxeaOv3vX00L+pnjZv8K32H266nXTR2ZWeXul774Q5r+ofmOxJww73v/Y1K7/q4Ln8llpR69t6b00WJzMWn3FvM75amufu4dc3FsxTTznThx2NSrhUok+5wKS6PWSWvnSKtmSrv+ML00/PzNsrffY36j6mSxTk+Ik35ZYB5fZ3W6nz2tJC0AkE38/PwqSdqkcZtcCcOQNcunSoPbmR/aET9aXZrUvVrdXInv8L4JFgEr/PmT9EYtE1hN323NNH8rZ0gfthF14Q3udJT0TDFzoWrocjMEIKv+2ys9f5fpGfPtUXOBAriZXYvnQbs2S50rS1Jlu92+2dtijDEHgBtJ/efMFfAtq6WdFieBS83Wta6M7VbOrwp8/ZG5f2GgNUE5bh4LvzBBeZE7fNe6Xfh26bEXTHfw+WN8s03gemWzmR4kkvTiIGvLkgkE5gBwIwkIkDon/ihNGWBpUfRJV2nZZNNK5OidFXdGWjhO+r/E+dor1vU81Q5wNfz9u7RhmRkCkjyjMeBL//5hcjBIUosevr0I1OF9M4Z39nCT0Au4Wa2ZY5JI1mphxrhfZxhjDgA3mgcfN+O7z8WYsVbuc6NfTX+td2VGDgoxXS3jzriC9OLlpD5TrSkbIJlxmu3eNeOgaS1Hdni2hMmvcTrK/H1nRenxF337HnkLmjwme7ZKUfulknf7dvvA9eLKJVOnN8piYkWLEJgDwI3o6TesLoFpxVk33yQCiz7mStJT4m6pRnOTDC803OpS4mb24BPmBmQXxxSYeQuZYTsvDTaZ5H3t4aa+z0QPXG8cyUWvUwTmAIDsUb2xuQHAzWo1SZYBpA9jzAEAAAAAsBCBOQAAAAAAFiIwBwAAAADAQgTmAAAAAABYiMAcAAAAAAALEZgDAAAAAGAhAnMAAAAAACxEYA4AAAAAgIUIzAEAAAAAsBCBOQAAAAAAFiIwBwAAAADAQgTmAAAAAABYiMAcAAAAAAALEZgDAAAAAGAhAnMAAAAAACxEYA4AAAAAgIUIzAEAAAAAsFBgehf08/O7TVK+bCwLgJtPGUnS70ukgzstLgoAWGT7enNPXQgAN56j+9K1mJ/dbk97IT+/2+Tv/69sttCslgsA3Pn7+8tms1ldDACwFHUhANy4Euv4B+12+2/elklvi3k+2Wyheme6VLysj4oH4Kb3+xLZvuqn6dOnq2xZ6hYAN6clS5aoXz/qQgC4Ee3cuVNt2rSRpIupLZfuruySTFB+V6UsFAsA3CR22SxbtqwqVaJuAXBz2rmTuhAAbnYkfwMAAAAAwEIE5gAAAAAAWIjAHAAAAAAACxGYAwAAAABgIQJzAAAAAAAsRGAOAAAAAICFCMwBAAAAALAQgTkAAAAAABYiMAcAAAAAwEIE5gAAAAAAWIjAHAAAAAAACxGYAwAAAABgIQJzAAAAAAAsRGAOAAAAAICFCMwBAAAAALAQgTlgpWWTpTp+0rMlrFkfAAAAgOWu3cC8jl/mb8smm21E7U/5XGreqG2WfaN2yte2rvH8XvUCpSa3SK8+JE15X4o5mf59PLJHGt9H6lJVappfahAsNS8kvVpdmvKedPK/1Ncf3D79QVlGPovjh6SpH0g96kotikoNw8ytRRHpzfrSV/2k3Vu8r5/a55icI7Cs42fKmNyzJTx/7o/llDqUlz7pKu3/O2v7K3n+LH1xDF7P1s2XJg8w97ihnDp1SpMmTVKbNm1Urlw5RUREKCQkREWLFlXTpk01b968bF0/Pj5eS5cu1cCBA9W8eXMVL15cfn5+8vPz04ABA3y4p1JUVJT69eunypUrK2/evAoLC1Px4sXVqFEjDR48WJcuXcrW9T1p3769c39Tu5UoUSLJevv37/e4XEBAgPLmzasHH3xQ77//vk6e9P47dODAAfXp00dVq1ZVnjx5FBQUpIIFC6pChQp66qmn9Mknn+jPP//M8D4B8K3Jkyenq55YuXKlx/UXLVqknj17qk6dOipVqpQiIyMVHByswoUL69FHH9WkSZN0+fJln5b50qVLqlChgrNs7du397rs/v37NX36dHXv3l21atVSZGSkc739+/f7tFzA9SLQ6gJ4laeg5+cT4qTz51JfJjgse8rkkDOPFBhsHl+6IMWelnb8am7zR0tDlkl3VfK+/pUr0vje0refSFcSK0X/ACkiUoo5IUUfk3b8Is0aKrV/T2rZM3v3x+HSRenLt6X5Y6TLbieboeFmf08dNRcLNq+Spg2UKtSQ+kyTChXP/rIFh0oRucxju81cANm/w9wWj5fe+Fx6/AXfvue1fAw6ROSSipWW8hXx/bbXzZeWT5EatpMebur77cMyhQoVSnJCFhoaqqCgIB05ckRHjhzRggUL9Oijj+rbb79VeHi4z9ffsGGDHnvssezZOTfffPONOnXqpNjYWGc5g4ODdfDgQR08eFDLly9Xly5dlDt37mxZPy3+/v7Knz+/19dTey0yMlJhYaaeuXjxoqKjo/Xbb7/pt99+05gxY7R48WJVqVIlyTozZsxQp06dFB8fn2Q78fHx2r59u7Zv3665c+eqePHinBgD14i06omQkBCPz/fp00c7duxw/p0zZ04FBATo6NGjOnr0qJYtW6bRo0dryZIlKljQy7lMBn344Yfavn17upYdMGCApkyZ4pP3BW4U125gPjfK8/OTB5jW5NSWyW7vz5Xuq+36Oy5GWvqVCbbPnJDeayFN+UcKDEq5rs0mvfuUtH6B+btaI6l1H6l8dSkgwATHW1ZLU983wfkXvaRjB6XXRmXvPl08L/VqKG37yfxd5RGp2atShZpSjsSA+Mplac9WacMyadE4advP0sGdVycwr9NS6j3Z9feFBOnX76VR3cyFjBGdpTJVpVIVfPee1/Ix6FCjmbkBGXD58mVVq1ZN7du3V8OGDXX77bdLMi0YAwcO1MSJE7V06VJ17txZ06ZN8/n6kpQnTx5VqlTJeevevbuionz3fZozZ45at24tm82mTp066fXXX1e5cuUkSWfPntXWrVs1b948BQV5qKd9sH56FCtWLNMB8KeffpqkNSo6Olpjx47Ve++9p+PHj6t58+batWuXQkNDJUkbN25U27ZtZbPZVKFCBfXv31+NGjVSRESEJOnEiRP65ZdfNH/+fG3YsCHT+wTAtzJbTzz99NN6/fXXVb16dZUsWdJ5Ie+///7ThAkT9N5772nz5s1q166dli1bluVybt++XYMGDdLtt9+uc+fO6dixY6ku7+/vr1KlSqly5cqqVKmS7Ha7+vTpk+VyANezazcwv57kyCW16G5aUif1l/7ba4Lrqo+kXHbaQFdQ3rq39NJHSV8PCpaqNZSqNJCGdJB+mCrN+8wEnY88n3378OmrrqD8tc9MUJ5cQKBUuoq5te4tzf746rUMJxcSJtVuYXov9Gwg2a5ICz+Xun9uTXmA68iPP/6oOnXqpHi+RIkSmjBhggIDAzVu3DhNnz5dgwYNUrFixXy6fo0aNXT69Okkz/Xu3dsHe2YcPXpUnTt3ls1m08cff6wePXokeT1nzpyqUaOGatSokS3rWyFPnjzq27evzp8/r4EDB+rQoUNasGCBWrZsKUn65JNPZLPZVKBAAf3000/KlStXkvXz58+vJk2aqEmTJkpISLBiFwD4kLdhQYULF1b//v11/vx5ffTRR1q+fLkOHz6sokWLZvq9rly5oo4dO+rSpUv64osv9NJLL6W5zvjx4xUQEOD8e82aNZl+f+BGce2OMb8eVWvkerx/R8rXo49LMwebxxXrSC8O8r4tf3/pzS+l4mXN3+P7mNb07LB3u2nxl6TGL3sOypMLCJRavS3dVyt7ypReletLt9xqHv+z0dqy+MK/m6QBz0hP3So9EiK1vl0a00M6G+15+dSSv00ekHSs/6ZVUu/HTT6DR0KldmVNy//F80nXc+RTWJ7YxWz5lJRj6Leu8cXewiKegmp3L7zgGhbyxx9/+Hx995Ox7DBq1ChFR0erYsWK6t69+1Vf30rPP++6gLtxo6tO3Lp1qySpdu3aKYLy5BwtawBuXA888IDz8ZEjR7K0rY8//lh//PGH2rZtqwYNGqRrnez8HVizZo1zvLokbdu2Ta1atVLhwoUVFhamsmXLavjw4UmGZK1fv15NmzbVrbfeqtDQUJUvX15jxoyR3W73+B6XL1/Wl19+qdq1aytfvnwKCgrSLbfcotKlS6tly5aaOHFitu0fblwE5r7k/uW1XUn5+rJJpgu2JLV9V0qsMLwKDpFaJbYinTySfUm4Fow1ZQ8IlNr0zZ73yE75E6/yxsdaW46sWvm19OqD0to55ji5clk6uk/6dqT0Wg3TIyOzZg2TejWQNiw12718UTr4jwneez9m8h44BAabsfPBpgusgkPN3+43R44F3JAc3Z8l0xJytdfPqqlTp0qS2rRp4zwxu5rrW8m91csxNt7d4cOHr2ZxAFyjfv75Z0mSn5+fczhSZuzatUvvvvuu8ufPrxEjRviqeD6zdOlS3X///Zo1a5bi4+N14cIF/fPPP+rVq5fzQuaECRNUq1YtLVy4UAkJCbpw4YJ27NihV1991WP3+itXruixxx5T586dtXbtWp06dUoRERE6d+6cdu3apdmzZ+vFF1+82ruKGwCBuS9tcBujc6uHSm7zj+Y+8pb0tzQ/3NQVwG9dnaXiebV5lbm/s5KUPxuSiGU3Rzb3nHktLUaWxJyQhnY0ida+OSh9f0ZafFZ6bbTJVbB/hzRzaOa2/b8/Tf6DVr2lecelRdHSojNS2/7m9S2rXa3jklT+ITN2vo7pAqs6Lc3f7rfyD2Vlb3GNc+9SeM8991z19bNi3759+u8/M6NF5cqVtX37drVu3Vq33nqrM3N8y5YttX79+mxZ32ruY1Hz5nXVidWqVZMk/fLLL/r444918WI29cAC4FMnTpxQ5cqVlSNHDoWFhen2229XmzZtMtX1Oy4uTn/99Zfeeustffzxx5JML5vUksulxm6364UXXtD58+c1cuRI3XLLLZnaTnZq3bq1mjRpogMHDujMmTOKiYlxBtuzZs3S4MGD9corr+iVV15RVFSUzpw5o9OnTztzeAwbNky7du1Kss2ZM2dqxYoVCg0N1YQJE3T27FmdOXNGCQkJOnbsmObOnaunn376au8qbgA3T2A++nUzFVlqtx2/ZG7bcTEmw/qMD83feQpKD3jIOOzo3n5nxfRvOyLSFeTv+ytz5UvN5UvS4d3m8R33+XbbO35J+zMf/XrW3mPttybhniSVeyD1Za9l5+Olus9KPcdLBRLH44aGS826Ss26mb9/nJm5bcedkZ7vJ700SMqVzzwXESl1eE+q0Txr28YN58yZM/roI5P7okaNGipduvRVXT+r3E+g1q9frypVqmjmzJmKiYlRaGiojhw5otmzZ6tGjRr64IMPfL5+Rhw6dEiFChXyevPU4p2WsWPHOh+7d1Xt3bu3cubMKUnq2bOnChUqpGbNmunDDz/UsmXLdObMmSztC4DsER8fr82bNys4OFg2m0379u3TjBkzVKdOHXXs2DHNKc9+++03Z7funDlz6p577tGwYcPk7++vjh076osvvsh02UaPHq1169apYcOGeu655zK9nexUtWpVzZw5U7fddpskkyNk0KBBzhwhffr0Ubt27TRq1CgVKFBAksnZMWHCBJUsWVI2m02zZ89Oss1ffjHxQtu2bfXCCy8oR44ckkzvgwIFCqhZs2aaM2fO1dpF3EBunsD8XKzJ3p3a7XI656Pt39wVWD6ZR3oytzSmuxkDHp5T6v+Nqxuwu9hT5j4yg1cUHcGUY31finVLwBSZSovziC6eA+v+zb2vc/lS2p/5uUx0P7fbpagD0tzPpGGJY1mDgqWmXTO+rWvJ8//n+fnqTcz9kT0mgM+ooBDvU+45tr13W8a3ixuOzWbT888/r6NHjyo0NFSjR4++quv7QnS0Kx9Dv379VLhwYa1YsUJxcXGKiYnRjh07VLt2bdntdvXv319z58716foZYbPZdOzYMa83m82Wru1cvHhRO3fu1GuvvabPPzcJMO+880498cQTzmVKly6ttWvXqmrVqs79nD9/vv7v//5Pjz76qG655RbVrl1b8+fPz/T+APCdwoUL691339Wff/6p8+fP6/Tp04qPj9f69etVv359SdKkSZPSzIMRHBysggULqmDBggoOdg1D69y5s959991M55TYv3+/+vTpo/DwcGe9cy16++23PQ5JatiwofOxp+7qAQEBqlevniQzRt2dY4pMX84kAkg3U2D+9iRptT31273p7F5+NtoVWMadcT1/x33S1H+tT4iWHeLOeA6sY097X+feWml/5m9PSt/7uycgq+svtSohffaaCezDckj/N1Mqeqcv9tQakXmlInd4fi1fYddjb0ngUlPibvMZpbbt1P6PuGm8/vrr+v777yVJY8aMUYUKGZt+MKvr+4J7MGu32/Xdd9+pfv368vc3P3flypXTokWLVKhQIUnSe++959P1M6J48eKy2+1eb6nNj96hQwdnK1hISIjKlSunzz77TDabTSVLltTChQsVGJh04pWKFStqw4YN2rhxo9577z01atTIuR82m01r165Vs2bN1KFDB68JjwBcHY888ogGDBigChUqOOcqDwgI0EMPPaTly5erSRNzYX3s2LHavXu31+1UqlRJUVFRioqKUkJCgnbv3q2uXbvqiy++0N13362FCxdmqnwvvfSSzp07p/fff18lS5bM1DauBscwnuQcc7fnzZvX6xh7xzLuF2wl6bHHHpOfn58WLlyoRx99VDNnznQOgQKy4uYJzH1p5GpXYLnglDToe6l4OTPH98iXkybScudoKc9oy3fMyaTr+5J7K3lqwVn/WUkD6obtfF+W1LgnIMtbSCpcymS2b/euNGWnVDOVlvvrQVhO768FuJ1cX0lnrw534enY9pXUu8LhxtezZ09nC/fIkSPVsWPHq7q+rzi6a0tSvXr1VKlSpRTL5MiRQ127mh4227ZtSzLfblbXv1oiIyOdrWCFCxdWmTJl1LhxY40dO1bbt29XmTJlvK5bpUoV9e/fX0uXLtXRo0e1b98+DR8+XPnymd5ZkydP1pgxY67WrgDIIH9/fw0fPlySuai2aNGidK93xx13aPTo0Ro2bJji4uL03HPP6ejRoxl6/wkTJmjlypWqVKmS3njjjYwW/6pyr9PdOS5cenvdfZlLl5Keez388MMaMmSIgoODtWzZMrVu3VpFihRRsWLF1KFDB61enU05oXDDIzDPqsi80oOPm2A9T0EzR/k0L+MOS5Qz97u3pH/752Klo3sT17876Wshid2PLqZjzln3LtDuc48HBrlamvdsTX+5rjb3BGTfHZVm7JFG/Ci1H+DKyu7OfR8vZODzCclcly7geuaeCGj48OEZPtHK6vq+VKSIK4Fl2bJlvS5Xrlw55+MDBw74bP2r5dNPP3W2gh05ckQ7d+7UggUL9PLLLysiIiJD2ypRooTefPNNrV271tmtdcKECdlRbAA+cscddzgvpu3duzfD67/yyisKCQlRXFycZs5Mf56ZmJgY9ezZU/7+/vrkk0+UkJCguLi4JDdHj5vLly87n0vv0JzrRa9evbRv3z6NHDlSTZs2VYECBXT48GFNnjxZdevWVYsWLVIE9EBaCMx9JU8B6SWT8EhfD3ZlCndXyYxVUeyp9M8D/fM81zRsFesmfc0x9jzmVMq5qJM76TZHZe5k2Tcd5dq9WTqRtbksrxk585i54KWk++6NY5nknw1wg+vVq5eGDRsmSRo6dKjefPPNq7q+r5UrVy5d8+O6d9V2H3+Y1fWvZ+XKldPDDz8sSfr3338tLg2A7BQaGuqcuWHPnj3pXi86OloxMTGy2WyqWbOmcubMmeJ28OBBSdKMGTOczyUfp30jKFy4sN544w3NmzdPx44d07Zt25zTpH377bfX9Nh7XJsIzH3pkbami/WlC9JX/VO+3rC9Kync1PeTznvuycUL0qwh5nG+wmbqNHd3VTb3tivS37+lvq3t68y9n590V7KumU1eMc9fuSxN/zD17VwvgoKlkonTNDn23ZuEc9L/tprHjs8Ukl9i9cBY0xtWz549nd0hhw4dql69el3V9bNDaGioatasKUnauXOn1+X+/vtvSSaoLlGihM/Wv945sgs7xrQCuDb973//08mTZqhjZsZ4nz17VidOmFltUuvOjfS75557NH78eFWvXl2StGLFCotLhOsNgbkvBQRIrd42j1d9LR38J+nreQtKz75lHm9ZLU3o631bNps0orN0IPHE8IVBJth0V7mBaRmWpJlDvAdQZ6Ol7790rZMjd9LXb79HejRxPOjCz6V5Vz+TcrZwzMO97SdpeypzDs8d5erKXvuZ7C/X9SIi0ty7JzjEDaNnz55Jup9nJijPyvrZqUOHDpKkVatWafPmzSlej4uLc04rdv/996eYwzer61+LfvzxxzS7VR45ckQrV66UJI9j6wFcHWklX7Tb7c4619/fP8kMDJLSnEJNMvNzO5arXbt2ustWokSJVJNW2u12FS9eXJLUrl0753P33Xdfut/jWnfhwoVUX3cMCXIkDQXSiyPG1xq2k/IVMa3YkwekfL3du9KDiRXo1x9JvR+Ttv3sShh3+ZK08Qfp9ZomE7lkWrQbeUi2FhYhdXjfPN6wzExdtmerK0C/dFHasNxs63SUmTbL0d0+uddHSxVMK5FGdZN6NZR+WWTmaHew2aRDu6SZQ6XfFmfkU7FG065S4dvN59H3SWnxxKT7c/yQNP4d6avEacpqPS3d/aA1Zb0WlSxv7rf/nPIiE65r7mPCR4wYkeHu51ldXzLdIU+ePOm8OcYfxsfHJ3k+Li4uxboDBgxwZiTfv39/itefe+45VatWTXa7XU899ZRWrVrl3P7OnTvVuHFjRUVFyd/fXx9+mLKXUFbXvxa99dZbuv3229W7d2+tW7dOCQmu3BunT5/WhAkT9PDDD+vs2bOSZPmQBOBmduDAAVWrVk3jxo3T3r17nYG6zWbTb7/9pkcffVTz5s2TZKY9K126dJL1Z8yYocaNG2vu3Lk6fvy483mbzaZt27apU6dO+uADkw+pevXqatSoUYoy1K5dO1t7BF26dClJXR8T4zo/S/77cK2N1W7atKk6duyopUuX6syZM87nT58+rYEDB2rVqlWSpMcff9yiEuJ6FZj2IsiQoGAzZ/SY7tKa2VKbvqZF2sHfX/pgnvTFW9K8z6Tfl5qbf4CUI5dpnXQkyAgONcnNHK3wnjR7VYo+Lk0fKK2bb27BoVJohHQuxpVtOzyn1Gdaym7sDsGh0vAV0ri3pAVjpT9+MDfJbCskTIqPNcG+Q4Ua0svDM/c5XQ0RkdJHi6X/a2IuKAx/Ufr4JdNj4PIlKcHthP/BJ6S3vrKsqNekmk9JE96RzpyQ2pU1OQ1CE5NK9Z8llXvA2vIhUw4ePOgcE+7v768hQ4ZoyJAhXpfv2bOnevbs6bP1HSpWrOgxadqwYcOc25dMi8vkyZPT3C93/v7+WrBggerVq6e///5b9evXV3h4uIKCgpwnf0FBQRozZozq1q3r8/WvRUFBQTp8+LDz/+Xn56fIyEhdunRJ8fGu5KDBwcEaNmwYJ5SAxTZu3KiNGzdKMkNLcubMqbNnzyZpre3QoYNGjRqVYl273a5FixY5s7VHREQoLCxMsbGxunjRdR5Xt25dzZkzx5I8GevXr1edOnU8vpa8x87q1asz1Kqf3RISEjRp0iRNmmSm/I2MND0MY2Njncs8/fTTzvHmQHoRmGeHJzqZsdoxJ6XJ70rvz036ekCg1HWE1ORlafEEafMqkywuPtZMiVbkDqnKI9LjL0n5i3h8iyQ6vi/VbiEt/MJ02z5+0ATlEZFSsdJmW41fNl3pUxMULL36idSih7RssvTnGunQvya5XEKcKdttZaSyD0h1n5VKXf05ijPstjLShD+l5VOldfNMj4Kzp83/oFAJqez9UoPnpQceM+Ps4ZIzj/TpT9KU90yvjjPHXVP3pZVsENcs98y4Npstzam+krdYZ3X9q6VQoULavHmzRo8erW+++Ua7du1SQkKCSpQoobp166p79+4qX758tq1/rVm9erVWrVqlH3/8URs3btTu3bt1+vRp2e125cuXT3fddZfq1Kmjjh07ep3TF8DVUbBgQX322Wf69ddftXXrVp04cULR0dEKDQ1VyZIl9dBDD6ljx47OsczJPf744xo/frzWrFmjrVu36tixY4qOjlZYWJhuv/12Va1aVc8++6wee+yxq7xnN4bPPvtMS5cu1dq1a7V7925FRUXp/PnzKly4sKpUqaJ27dqpefPrfBpfWMIvrXEskuTn51dJ0iaN2+S9xRUAMmrlDOnDNtq0aRNjWgHctGbMmKE2bagLAeBGtHnzZlWuXFmSKtvt9pTJaxIxxhwAAAAAAAsRmAMAAAAAYCECcwAAAAAALERgDgAAAACAhQjMAQAAAACwEIE5AAAAAAAWIjAHAAAAAMBCBOYAAAAAAFiIwBwAAAAAAAsRmAMAAAAAYCECcwAAAAAALERgDgAAAACAhQjMAQAAAACwEIE5AAAAAAAWIjAHAAAAAMBCBOYAAAAAAFiIwBwAAAAAAAsRmAMAAAAAYCECcwAAAAAALERgDgAAAACAhQjMAQAAAACwEIE5AAAAAAAWCszQ0r8vkQ7uzKaiALjpbF8vSVqyZIl27qRuAXBzWr+euhAAblT79u1L13J+drs97YX8/B6Qv/+vstmyWi4ASMLf31826hYANznqQgC4cSXW8Q/a7fbfvC2T3hbzi7LZpHemS8XL+qh4AG56vy+R7at+mj59usqWpW4BcHNasmSJ+vWjLgSAG9HOnTvVpk0bSbqY2nIZ68pevKx0V6UsFAsA3CQOjSlbtqwqVaJuAXBzcnRfpy4EgJsXyd8AAAAAALAQgTkAAAAAABYiMAcAAAAAwEIE5gAAAAAAWIjAHAAAAAAACxGYAwAAAABgIQJzAAAAAAAsRGAOAAAAAICFCMwBAAAAALAQgTkAAAAAABYiMAcAAAAAwEIE5gAAAAAAWIjAHAAAAAAACxGYAwAAAABgIQJzAAAAAAAsRGAOaz1bQqrjJy2bbM36AAAAAGCxaz8wnzzABF51/LK+rQWfu7b1avWUr29d43o9M7eo/WY7yyZnbj1P+9woXDr5n/d9itrvWnbrmtT3/1ysNPcz6Z0npWeLS49GSA3DpBZFpd6PSbNHSKejzLKHdpn3ruMnfdEr7c/2xBHpyTxm+WEvpr38tS7ujPk/TB5gHgM3kPj4eC1dulQDBw5U8+bNVbx4cfn5+cnPz08DBgxIc/21a9eqb9++atiwoe68807lyZNHQUFBKlCggOrUqaNRo0YpISEhw+V69NFHneWoXbt2xnfMzZUrVzRt2jQ1aNBA+fLlU0hIiIoWLapWrVrp119/TXXd2rVrO8vh7Va0aNFMlWv//v1pbttxmzx5cpJ127dv73G5sLAwlSxZUi1bttTy5cu9vrfdbtecOXPUrFkzFS9eXGFhYcqRI4dKlSqlhx9+WD169NC8efMUGxubqX0DYI3Y2FgNGTJEDz30kPLnz++s7+rUqaMBAwbozJkzmd72zz//rJYtW6po0aIKCQlRgQIF1KBBA82cOTPd24iKilK/fv1UuXJl5c2bV2FhYSpevLgaNWqkwYMH69KlS5kuH3AjCbS6AFfVkomuxzt+kQ7+K91W2vVcYLCUp6Dndc+eli5fkgKDpJx5PS/jH5DyuVz5PD+f1noOFxKkKe9Jb45LfRtpWTxRGtdLOhvtei4kTAoKkU4eMbffl0oT+0rP/5/Upq/UaYj02WvSnBFS9SbSPQ973/6wF0wAW6iE1HVk1sqaEYVLScGhUkQu32437oz53CWpUXspR27fbh+w0IYNG/TYY49lev1hw4Zp8eLFzr8jIiIUEhKiEydOaM2aNVqzZo0++eQTLVu2THfddVe6tjl58mQtW7Ys02VyFxcXp2bNmmnlypWSpICAAEVGRuro0aOaNWuWZs+ercGDB6tXr9QvOkZERChHjhweXytQoECWyxkZGamwsDCvr3t7zd/fX/nz53f+ffr0ae3fv1/79+/X7Nmz9cILL2j8+PHy83Nd0D5z5oyaNm2qtWvXOp8LDAxUeHi4Dh48qL1792r9+vUaOXKkJk2apPbt22d5/wBkv9WrV6tVq1Y6duyYJCk4OFjh4eE6cuSIjhw5ojVr1qhp06a67777Mrzt3r17a8iQIc6/c+fOrTNnzmjlypVauXKl5syZo9mzZysw0Hs48c0336hTp07OC36hoaEKDg7WwYMHdfDgQS1fvlxdunRR7ty5M1w+4EZz7beY+8qeP6Vdm6SceaT6z5nn3AN1SSr/kDQ3yvPt7ofMMnenskyBYinf94uN3pdPbT13S78yLdiZNaGvNPxFE5QXLyv1niLNPSYti5e+P2Puhy6XGrQxFx/WzDHrNXtVqlRPstmkwe2lhHOet79wnLRxueTvL709WQrPmfmyZtSIVdLUf6Qaza7eewI3gDx58qhevXrq1auXZs6cqUKFCqV73fr162vUqFHavHmzYmNjFRcXp7i4OJ08eVKjRo1SWFiY9u3bp2bNmslms6W5vaioKPXo0UO5c+dW2bJls7JbkqSXXnpJK1eulL+/vwYNGqTo6GidPn1aJ0+e1FtvvSWbzaa33npLCxcuTHU7PXv2VFRUlMfb5s2bs1zOTz/91Ov2o6Ki1LJlS4/rFStWLMly8fHx+u2331SlShVJ0sSJEzV27Ngk67Rt21Zr165VQECA3nzzTe3atUsXLlzQqVOnlJCQoD///FNDhgzRvffem+X9AnB1rF+/Xo8//riOHTum5s2ba+PGjTp//ryio6N17tw5bdiwQX379lWuXBlvvBg3bpwzKH/22Wd16NAhRUdH6+zZs5o8ebIiIiI0b948vfXWW163MWfOHLVu3VqxsbHq1KmTduzYoYSEBMXExCg2NlY//fSTunfvrqCgoEx/BsCN5OYJzB1BeJ2W0uMvmcc/TJWuXLauTGkpUEy6vYIp44R3MreNH7+RZgwyj2s/I325RWrYVsrj1toTEiZVfUR6Z5o0YatU4m7zvJ+f9PYk0xr93/+kL3qm3P7Rfa7nn3pDuq9W5soJ4KqpUaOGTp8+rZUrV2ro0KF69tlnFRISku7133jjDXXr1k0VK1ZUzpyuC3G33HKLunXrpk8++USS9Pfff6fZbVySXnnlFUVHR2vYsGFZbonevn27Zs2aJUl67bXX1KdPH2cZ8+TJoyFDhjgD3jfffDNdFw6udYGBgbr//vu1ePFi5c1renSNHj3a+fru3bu1aNEiSdLAgQM1fPhw3XnnnfL393euX6FCBb311lvaunWr1wsCAK4d8fHxatu2rRISEtStWzd99913qlKlirOnTHh4uKpWraqBAweqZMmSGdr25cuX9e6770qSKlWqpBkzZjiH74SEhKhdu3YaPny4JOmzzz7T3r17U2zj6NGj6ty5s2w2mz7++GONGzdO5cqVc76eM2dO1ahRQyNGjFBERESmPgPgRnNzBOYXL0irZpjHDdtJ99Y0Xa6jj0m/Lk51VUv5+UsvfWQe//SdtHNDxta/dNF0X5ek4uWkPlOk4DROvkuWNwG6Q4Fi0qufmscLv5A2uI1ftNulIR2khDjTEv/ihxkrn6fyzhomvXCvGf/+RC6pR11pQyrdW1NL/uY+9j7+rDTx/6S2Zcy4+ia3SH2ekP7+PeV6b9SWWrn9iLUqmTQnwBu1s7SbgNUCAtIYXpNFDzzwgPPx4cOHU1129uzZmjdvnmrVqqUXXnghy++9ZMkS52NvXdUdLTx79uzRunXrsvye14oCBQqoYcOGkqR//vlHcXFxkqStW7c6l2nSpEma20mtez2Aa8O0adO0d+9eFSpUSEOHDvXptjdt2uTsGv/mm286L+K5e+mll5Q7d25dvnxZ06dPT/H6qFGjFB0drYoVK6p79+4+LZ8klShRwpmLIz4+XgMGDFDZsmUVHh6uwoUL6/nnn9e+ffucy588eVJvv/227rrrLoWFhalQoUJ68cUXnfvpye+//67nnntOJUuWVGhoqCIiIlS8eHHVqlVLH3zwQZq/b0BG3RyB+bp5UuxpqdhdUrkHTEvwI23Na0snpr6u1R54TLo3sRV6fO+Mrbt+gXT8kHn8XB8zFjs9klfAjdpJDzc1jx1jySXp20+kP9dKAYFSn2np374nCXHS6zWlcW9JB3eaixLnYqUtq01iuiVfZX7bp45KnSpJ0z+Ujh0w+xd7WvptsfRGTWnjD0mXj8xrcgM45Mpncg84bpFecgwAkGSSBTmUKlXK63KnTp1St27dFBISoi+//DLJmOjMOnDggCQpV65cKly4sMdlypQp43yvH374weMy1yv3pHSekrhxIgncGKZOnSpJatGihUJDs3D+5YGjHpWUpJXbXUBAgDOHiKd61FG+Nm3a+KRu9yYmJkYPPPCA3nvvPe3fv1+Saa2fPn26qlevrv3792vv3r2qVq2ahg4dqiNHjshms+nYsWOaOHGiatSo4bGunDJlih588EF9/fXXzu0GBgbq4MGD+umnn9S/f39nHhPAV26OwNzRjb3B867nHIH570tdmcivVZ0Gm/stq1NvPU5u8ypz7+8vPdQ4a2XoMU7Knd8kifv0VZM4b2Jf89rz/yeVrpy17U/qL504LH0wX1p6TlpyVpryj7mQYrdLo1+X4mIyt+1Pu5rEfiN+TNx2nPT5BqlYadNK/3EnM47e4f25JjeAQ/I8Ae/PzdKuAjeihIQE7d69W4MGDdKbb74pSapZs6Zz3LMnr732mo4fP65+/fqlO0lceqXWRd1ms8lut0syXd+9mTFjhkqUKKGQkBDlzp1bVapUUd++ffXff6nMlGExxwmkn5+fM5lS1apVnSfGjvHlAK5fFy5c0B9//CFJqly5sg4ePKhOnTqpWLFiCg4OVsGCBfXkk08mSdKZWVeuXEnztb/++ivJ8/v27XPWk5UrV9b27dvVunVr3Xrrrc6M8S1bttT69euzXL4BAwbo7Nmz+uGHH3Tu3Dnn4/z58+vo0aN6++231apVK+XKlUu//vqrzp07p7i4OH3zzTcKDw/X7t27U/Q4iI+PV7du3WS329WmTRvt2bNH58+fV0xMjOLi4vTHH3+oV69ePkkCCri78QPzqP0mQPXzSxqYFyklla9uxm8vn5J979+lqtS8kPdb/+Zpb6PcA67kZuP7mEA1PfbvMPeFS0kRkZkrv0OeAiY4l6SVM6Se9U3G+LsqmwzuWXU+Xvp4pfRwE5P5XjIZ8z9caFriE+KkX7/P3LYDAqWRq6WKdcxFCj8/qUxVaUBikrtjB6QdaY+DBZBUVFSUc8qu8PBw3XXXXerbt68uXLigJ598UvPmzfO67qJFi/T111+rfPnyqSYPyqgSJUpIks6ePZuk1ced+0lkakH2nj179N9//ykiIkKxsbHatGmTBg0apLJly6a6b+n1+uuvq1ChQh5v/fv3z/D2Dhw44DwRr1ChgsLDwyWZz+TFF800ltu3b1eZMmVUqVIlde3aVV999ZX++usv54UKANe+/fv36+LFi5KkvXv3qnz58ho/fryOHz+uiIgIHT9+XN9//72eeOIJvfTSSxn+fjvqUSll0O1w8eJF7d69W5JptT53zpUg2P3i3/r161WlShXNnDlTMTExCg0N1ZEjRzR79mzVqFFDH3zwQYbKltyFCxe0YsUKNWjQQP7+/goICFCDBg00eLBp1Jo9e7YOHDiglStXOodZBQUF6ZlnnnFeRHbkJXHf57NnzyoiIkKTJk1K0vMrIiJClStX1tChQ7M0uwngyY0fmC+dZALZe2tJhYonfa1hu8RlstBNOi0xJ81Ydm+32NPp286Lg8y0anu2SqvSOXdk7Clz7216t4yq0cx1cePEYRMwvzPNBL5ZVetp6bYyKZ/PnV+6+0HzeO+2zG37iU5Jk9053H6PdGvJrG0buIkFBASoYMGCKliwYJKulC1atNDQoUOdiciSi4mJUZcuXeTv76/x48f7NCPvo48+6nw8cOBAj8t8+KErH4anLoy1a9fWpEmTdOTIEV24cEGnT59WdHS0Jk2apAIFCig2NlYtW7bUb7/9lqWyxsbG6tixYx5vGZlL/MSJE1qwYIEaNGig+Ph4SVKPHj2SLDN27Fj169dPERERstvt2rJli8aOHasXXnhB99xzjwoVKqQePXqkOt4SwLUhOto19e3AgQMVFBSkOXPmKC4uTtHR0Tpw4IBatGghSZowYYJGjszYNLaVKlVSwYJm+uAhQ4bo8uWUiZI/++yzJPWU+2P38vXr10+FCxfWihUrFBcXp5iYGO3YsUO1a9eW3W5X//79NXdu5nsiPvXUU7rjjjtSPO/ItyFJnTp10i233OJ1mf/9739JLiw4ehtdvHhRp06dynTZgIy6sQNzm01aPtk8dnRdd1f7GRNcHtolbfs55eu+MHOftNru/fbJmvRt57Yy0qMdzONJ/cy0ZlZ47TPX48ZdTNI3Xyh7v/fXbkkcJ3o2nRcxrua2gZtY/vz5k0zZdejQIfXt21eLFi1ShQoV9OWXX3pc780339R///2nV155JUmiOF+45557kpyQ9ujRQ/v379elS5e0a9cudezYUd9//73zYoCnpEYDBgxQ+/btVbhwYWcX8Fy5cql9+/b65ZdflDt3bl26dCnLLf2TJk2S3W73eHNktvfkwIEDzp4Kfn5+KlCggJo2bardu3fLz89Pb7/9ttq2TfqbFxgYqPfff19HjhzRtGnT9OKLL+ree+9VcHCwJOn48eMaOXKkypcvrw0bMphoFMBV5T5Ux2azaeLEiXr66aed9dptt92mWbNmOac/HDRokMfg2pvAwEBnr52dO3fqiSee0ObNm3Xx4kVFRUVp2LBh6tOnT5KLqu51qXv57Ha7vvvuO9WvX9+5TLly5bRo0SLnNJ3vvfdeRj8Cp2rVqnl83nFhQTLDedJa5syZM87HpUqVUpkyZXTp0iXdf//9GjJkiLZu3Zpqt37AF27swHzTSunYQSk03LTIJpcjlyupWXa2mvtKuwFmarP/9poM6WmJTLw66MugM4fbXJgRGZ8X06vU5j53tMhn9mJEdm4bgCQzprlo0aIaOHCgZsyYoUuXLunll1/Wn3/+mWS5lStXauLEiSpatKgGDRqULWWZOHGi6tatK0kaOXKkSpYsqeDgYJUuXVqTJk1SkyZN9Pjjj0syU6hlRKlSpdS1a1dJ0rp16yxpTfH393f2VChYsKCKFy+uatWq6dVXX9XGjRudXTg9yZUrl9q0aaPx48dr69atiomJ0YoVK/Tkk09KMpmLn3rqKZ0/f/5q7Q6ADHKfpvLOO+9U06ZNUyzj7++vnj3NdLanTp3Spk2bMvQer7zyinP95cuXq3LlygoJCdGtt96qt956SyVKlEhycdK9LnUvX7169VSpUqUU28+RI4ezLt22bVume+u4v5e7wMDADC1z6ZLrPDAgIECzZs1SyZIldeDAAfXu3VsVK1ZUZGSkGjRooM8//9zZOwnwpRs7MHckfTsfLz0emXTKK8ftx8RxJWvmmCm1rmX5i0jNupnH0weacdepccxH/t//rv19A3DDaN68uW677TZnS467l156SZI0dOhQ+fn5KS4uLsnN0SJx5cqVFM+lV86cObVixQp9/fXXatKkie68806VKFFC9evX15QpUzRv3jydPm0uWGYm6dyDD5rhNXa7Pcl0PFdLsWLFnD0VoqKitH//fv3+++/67LPPVLlyxhJxhoaGqn79+lq4cKHatTPDuw4fPqxlyzKQaBTAVVWkSBHn4zJlPAwDTOSeUd1bzo3UDBs2TOvWrVP79u119913q1ixYqpWrZoGDhyoLVu2OKfeLF68uLP3TfLylS3rvWdlVsuXne699179888/+u6779SpUyeVL19eCQkJWrlypV555RWVKVMm1eShQGb4YHDwNSrmlLR+fvqXP3/OBOlPvJRtRfKJ1r2lxeOl6OPS7I9d4+Q9qVRPWjTOdOlfv0Bq0ObqlRPATa1IkSI6ePCg9uzZk+R5R9bw1q1bp7r+unXrnK0c8+bN89gilBp/f3+1atVKrVq1SvHa5cuXnS35Dz30UIa2eyPr1KmTpkwxyVD//fdfi0sDwJu8efOqSJEiOnLkSKrLuSd9y+yUZdWrV1f16tU9vubIDJ+8Hi1XrpwCAgLSvKjqi/Jlp+DgYDVv3lzNm5tEzadOndK3336rd955R4cOHVK7du20efNmi0uJG8mN22K+YrqZCitPAen7GDP9lrfbU6+bda6H7uw580itEuczn/2xdOaE92WrN5HyJ85pO+Mj6WI6uyamMs3QTcPP7atBtmIgQ9xbkr11IbTSokWLFBMTo7CwMOd49IxwJH3z8/NLkr34epcjRw7n45CQEAtLAiAtjzzyiCQzBtybv//+2/m4ZMmSPn3/Y8eOOefxTp7TIjQ0VDVr1kx3+a6XuvSWW25R586dNWTIEEnSli1bSA4Hn7pxA/Olid0nazQ3U4WF5fB+q/usWfbv36T9f3vf5rWieTcTcMeflaalMs1EULDUOXFuxgN/Sx+1MxcrUrP/b+kjD4nybjbu08vFnbGsGMC1Jj0JhCZNmqSoqChJJsO5O2/Jzhy3WrVqSZJq1arlfC6jreWpOXHihHPcZNeuXVOMMU9rWqF9+/ZpzJgxkkwrUb58+XxWtuyyb9++dM1d7mgtl+RxTCiAa0eHDiYh8J49ezR//vwUr9tsNg0fPlyS6cHky+/0lStX1KVLF128eFHVqlVLkgE9eflWrVrlsVU5Li5OY8eOlSTdf//9yp8/v8/Kl1UXLlxI9fWwsDDnY08JRIHMur6OppiTqd8cAdQ/G6W9ieM+aj+T9nbL3i8VvM08XjIx9WWvBSFhJhGcJP2yKPVl67WSnk1MzrFmtvRSRemHaUlb2i+elzatkoZ0kF68V9rnec7Km0qO3FK+xDFSSyeZ+e6BG0h0dLROnjzpvDmy6MbHxyd5Pi4uaS6LdevWqWbNmpo2bZoOHz6c5LXdu3erd+/e6ty5sySTKK19+/Y+L3v79u2dGck9Wbx4sT799FP973//c3aljI+P15w5c/Tggw9q7969uvfee/X++++nWHfw4MFq166dli5dmiRLb2xsrKZOnaqHHnpI0dHRCgoKcraaXOt27NihsmXL6vHHH9fUqVOdwwkkk/Boy5Yt6tChg0aMGCHJZDl++OGHLSotgPSoUaOGnn7aJDZ+8cUX9d133zkvnB48eFCtWrXStm1mKtgPP/wwRQA5efJkZz26Zs2aFNvfu3ev+vbtq82bNzuTQdpsNq1fv16PPPKI5s+fr9y5czu3k9xzzz2natWqyW6366mnntKqVaucvzM7d+5U48aNFRUVJX9//yRTWF4LZs2aperVq2vcuHHau3ev8/krV65o+fLl6t3b9Fx98MEHM5xAFEjN9TXGvGkaV9NK3StN2OoKrvMUlCrUTHu7fn5SzaelOSOkldOlToOlQB/Nq9ulqpl/PDWvfirVbZmx7TZqL80eLh38J+1lOw+RCpeSvnw7seU8sUU8NFwKDE7aIhwaLtV/LmNluVE17iJ91U+a95n0/ZdmWISfv1TuAan/LKtLB2RJxYoVPSbbGTZsmIYNG+b8u127dpo8eXKSZX7++Wf9/LOZYjI0NFQ5cuTQuXPnlJCQ4Fzm3nvv1fz585O0LFwtu3fvVvfu3fXGG28oICBAkZGRiomJcZ4U1qxZU/PmzfNYtgsXLmjq1KmaOnWqJNMVPygoSGfOnHGunytXLn311Vdex11ea4KCgmSz2bRkyRItWbJEkhk7mSNHDkVHRyfpJVCpUiXNmzePViDgOjB58mQdP35cP/30k55++mmFhIQoPDw8yTzi7777rjOxY0bExsZq0KBBztkz8uTJo7i4OGf28ttuu03z5s3zmtzN399fCxYsUL169fT333+rfv36Cg8PV1BQkGJiYiSZumnMmDHOWTSuFXa7Xb/88ot++eUXSWZoj6O+dPwOFC5cWF99dR0MgcV15foKzNPjQoL040zzuEZzKSCNoNih9jMmMI8+blqhazb3TXliTqa9zMWEtJdJLiBAenGQ1D+d5Xyyk1SnpbRssvTHD9K+7aZsFxJMy3CpClLVRlL91lKua79r5lXx3DtSeKS0Ypq5AHLisBlvXqiE1SUDLFO5cmVNmzZNa9as0R9//KGoqCidOnVKISEhKlWqlCpVqqSnnnpKTz/9tDNj79XWoEEDdevWTevWrdOhQ4cUGxurggULqmrVqnruuefUokULr63tLVq0kN1u16+//qo9e/bo1KlTio2NVZ48eVS2bFk98sgj6tSpU5L5b691DRs21O7du7VkyRKtW7dOf/31lw4fPqwzZ84oPDxchQsXVsWKFdW8eXO1aNGCoBy4TkRERGj16tX66quvNG3aNP311186e/asihQpoho1aqhbt26ZTnBZokQJ9e/fX2vWrNGePXt08uRJRUZGqkyZMmrevLm6dOmi8PDwVLdRqFAhbd68WaNHj9Y333yjXbt2KSEhQSVKlFDdunXVvXt3lS9fPlPly06NGzfW1KlTtXr1am3evFlHjx7V6dOnlTNnTpUuXVpPPvmkXn31VeXOndvqouIG45fWeDpJ8vPzqyRpk8Ztku5i3BkAH1k5Q/qwjTZt2sSYVgA3rRkzZqhNG+pCALgRbd682TGdaWW73e41lT+XxQEAAAAAsBCBOQAAAAAAFiIwBwAAAADAQgTmAAAAAABYiMAcAAAAAAALEZgDAAAAAGAhAnMAAAAAACxEYA4AAAAAgIUIzAEAAAAAsBCBOQAAAAAAFiIwBwAAAADAQgTmAAAAAABYiMAcAAAAAAALEZgDAAAAAGAhAnMAAAAAACxEYA4AAAAAgIUIzAEAAAAAsBCBOQAAAAAAFiIwBwAAAADAQgTmAAAAAABYiMAcAAAAAAALEZgDAAAAAGChwAwtfWBnNhUDwE3p6D5J0s6d1C0Abl779lEXAsCNKr11u5/dbk97IT+/2+Tv/69sttCsFgwA3Pn7+8tms1ldDACwFHUhANy4/P39z9tsttJ2u/2gt2XSFZhLicG5lM9XhQOARMGSLlpdCACwGHUhANy4TqYWlEsZCMwBAAAAAIDvkfwNAAAAAAALEZgDAAAAAGAhAnMAAAAAACxEYA4AAAAAgIUIzAEAAAAAsBCBOQAAAAAAFiIwBwAAAADAQgTmAAAAAABYiMAcAAAAAAALEZgDAAAAAGAhAnMAAAAAACxEYA4AAAAAgIUIzAEAAAAAsBCBOQAAAAAAFiIwBwAAAADAQgTmAAAAAABYiMAcAAAAAAALEZgDAAAAAGAhAnMAAAAAACxEYA4AAAAAgIUIzAEAAAAAsBCBOQAAAAAAFiIwBwAAAADAQgTmAAAAAABYiMAcAAAAAAALEZgDAAAAAGAhAnMAAAAAACxEYA4AAAAAgIUIzAEAAAAAsBCBOQAAAAAAFiIwBwAAAADAQgTmAAAAAABYiMAcAAAAAAALEZgDAAAAAGAhAnMAAAAAACxEYA4AAAAAgIUIzAEAAAAAsBCBOQAAAAAAFiIwBwAAAADAQgTmAAAAAABYiMAcAAAAAAALEZgDAAAAAGAhAnMAAAAAACxEYA4AAAAAgIUIzAEAAAAAsBCBOQAAAAAAFiIwBwAAAADAQgTmAAAAAABYiMAcAAAAAAALEZgDAAAAAGAhAnMAAAAAACxEYA4AAAAAgIUIzAEAAAAAsBCBOQAAAAAAFiIwBwAAAADAQgTmAAAAAABYiMAcAAAAAAALEZgDAAAAAGAhAnMAAAAAACxEYA4AAAAAgIUIzAEAAAAAsBCBOQAAAAAAFiIwBwAAAADAQgTmAAAAAABYiMAcAAAAAAALEZgDAAAAAGAhAnMAAAAAACxEYA4AAAAAgIUIzAEAAAAAsBCBOQAAAAAAFiIwBwAAAADAQgTmAAAAAABYiMAcAAAAAAALEZgDAAAAAGAhAnMAAAAAACxEYA4AAAAAgIUIzAEAAAAAsBCBOQAAAAAAFiIwBwAAAADAQgTmAAAAAABYiMAcAAAAAAALEZgDAAAAAGAhAnMAAAAAACxEYA4AAAAAgIUIzAEAAAAAsBCBOQAAAAAAFiIwBwAAAADAQgTmAAAAAABYiMAcAAAAAAALEZgDAAAAAGAhAnMAAAAAACxEYA4AAAAAgIUIzAEAAAAAsBCBOQAAAAAAFiIwBwAAAADAQgTmAAAAAABYiMAcAAAAAAALEZgDAAAAAGAhAnMAAAAAACxEYA4AAAAAgIUIzAEAAAAAsBCBOQAAAAAAFiIwBwAAAADAQgTmAAAAAABYiMAcAAAAAAALEZgDAAAAAGAhAnMAAAAAACxEYA4AAAAAgIUIzAEAAAAAsBCBOQAAAAAAFiIwBwAAAADAQgTmAAAAAABYiMAcAAAAAAALEZgDAAAAAGAhAnMAAAAAACxEYA4AAAAAgIUIzAEAAAAAsBCBOQAAAAAAFiIwBwAAAADAQgTmAAAAAABYiMAcAAAAAAALEZgDAAAAAGAhAnMAAAAAACxEYA4AAAAAgIUIzAEAAAAAsBCBOQAAAAAAFiIwBwAAAADAQgTmAAAAAABYiMAcAAAAAAALEZgDAAAAAGAhAnMAAAAAACxEYA4AAAAAgIUIzAEAAAAAsBCBOQAAAAAAFiIwBwAAAADAQgTmAAAAAABYiMAcAAAAAAALEZgDAAAAAGAhAnMAAAAAACxEYA4AAAAAgIUIzAEAAAAAsBCBOQAAAAAAFiIwBwAAAADAQgTmAAAAAABYiMAcAAAAAAALEZgDAAAAAGAhAnMAAAAAACxEYA4AAAAAgIUIzAEAAAAAsBCBOQAAAAAAFiIwBwAAAADAQgTmAAAAAABYiMAcAAAAAAALEZgDAAAAAGAhAnMAAAAAACxEYA4AAAAAgIUIzAEAAAAAsBCBOQAAAAAAFiIwBwAAAADAQgTmAAAAAABYiMAcAAAAAAALEZgDAAAAAGAhAnMAAAAAACxEYA4AAAAAgIUIzAEAAAAAsBCBOQAAAAAAFiIwBwAAAADAQgTmAAAAAABYiMAcAAAAAAALEZgDAAAAAGAhAnMAAAAAACxEYA4AAAAAgIUIzAEAAAAAsBCBOQAAAAAAFiIwBwAAAADAQgTmAAAAAABYiMAcAAAAAAALEZgDAAAAAGAhAnMAAAAAACxEYA4AAAAAgIUIzAEAAAAAsBCBOQAAAAAAFiIwBwAAAADAQgTmAAAAAABYiMAcAAAAAAALEZgDAAAAAGAhAnMAAAAAACxEYA4AAAAAgIUIzAEAAAAAsBCBOQAAAAAAFiIwBwAAAADAQgTmAAAAAABYiMAcAAAAAAALEZgDAAAAAGAhAnMAAAAAACxEYA4AAAAAgIUIzAEAAAAAsBCBOQAAAAAAFiIwBwAAAADAQgTmAAAAAABYiMAcAAAAAAALEZgDAAAAAGAhAnMAAAAAACxEYA4AAAAAgIUIzAEAAAAAsBCBOQAAAAAAFiIwBwAAAADAQgTmAAAAAABYiMAcAAAAAAALEZgDAAAAAGAhAnMAAAAAACxEYA4AAAAAgIUIzAEAAAAAsBCBOQAAAAAAFiIwBwAAAADAQgTmAAAAAABYiMAcAAAAAAALEZgDAAAAAGAhAnMAAAAAACxEYA4AAAAAgIUIzAEAAAAAsBCBOQAAAAAAFiIwBwAAAADAQgTmAAAAAABYiMAcAAAAAAALEZgDAAAAAGAhAnMAAAAAACxEYA4AAAAAgIUIzAEAAAAAsBCBOQAAAAAAFiIwBwAAAADAQgTmAAAAAABYiMAcAAAAAAALEZgDAAAAAGAhAnMAAAAAACxEYA4AAAAAgIUIzAEAAAAAsBCBOQAAAAAAFiIwBwAAAADAQgTmAAAAAABYiMAcAAAAAAALEZgDAAAAAGAhAnMAAAAAACxEYA4AAAAAgIUIzAEAAAAAsBCBOQAAAAAAFiIwBwAAAADAQgTmAAAAAABYiMAcAAAAAAALEZgDAAAAAGAhAnMAAAAAACxEYA4AAAAAgIUIzAEAAAAAsBCBOQAAAAAAFiIwBwAAAADAQgTmAAAAAABYiMAcAAAAAAALEZgDAAAAAGAhAnMAAAAAACxEYA4AAAAAgIUIzAEAAAAAsBCBOQAAAAAAFiIwBwAAAADAQgTmAAAAAABYiMAcAAAAAAAL/T8Vf2hgl9gmaQAAAABJRU5ErkJggg==",
"text/plain": [
""
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"import matplotlib.pyplot as plt\n",
"\n",
"TPUT = 0\n",
"LAT = 1\n",
"labels = [\"THROUGHPUT hint\", \"LATENCY hint\"]\n",
"\n",
"fig1, ax1 = plt.subplots(1, 1)\n",
"fig1.patch.set_visible(False)\n",
"ax1.axis(\"tight\")\n",
"ax1.axis(\"off\")\n",
"\n",
"cell_text = []\n",
"cell_text.append(\n",
" [\n",
" \"%.2f%s\" % (THROUGHPUT_hint_fps, \" FPS\"),\n",
" \"%.2f%s\" % (THROUGHPUT_hint_latency, \" ms\"),\n",
" ]\n",
")\n",
"cell_text.append([\"%.2f%s\" % (LATENCY_hint_fps, \" FPS\"), \"%.2f%s\" % (LATENCY_hint_latency, \" ms\")])\n",
"\n",
"table = ax1.table(\n",
" cellText=cell_text,\n",
" colLabels=[\"FPS (Higher is better)\", \"Latency (Lower is better)\"],\n",
" rowLabels=labels,\n",
" rowColours=[\"deepskyblue\"] * 2,\n",
" colColours=[\"deepskyblue\"] * 2,\n",
" cellLoc=\"center\",\n",
" loc=\"upper left\",\n",
")\n",
"table.auto_set_font_size(False)\n",
"table.set_fontsize(18)\n",
"table.auto_set_column_width(0)\n",
"table.auto_set_column_width(1)\n",
"table.scale(1, 3)\n",
"\n",
"fig1.tight_layout()\n",
"plt.show()"
]
},
{
"cell_type": "code",
"execution_count": 16,
"id": "86f5261e-581e-4b91-a8fb-9715981d450e",
"metadata": {
"tags": []
},
"outputs": [
{
"data": {
"image/png": "iVBORw0KGgoAAAANSUhEUgAAA90AAAMVCAYAAABqdZdfAAAAOXRFWHRTb2Z0d2FyZQBNYXRwbG90bGliIHZlcnNpb24zLjUuMiwgaHR0cHM6Ly9tYXRwbG90bGliLm9yZy8qNh9FAAAACXBIWXMAAA9hAAAPYQGoP6dpAACTx0lEQVR4nOzdeVxU9f7H8feAOiIIariL4ILaIplbiyluYZa3NFPT3DCXvNdcc6FEcMslk0rbMdEyl7K0VSwDVDKvueWtVExR3HMDQUWE+f3hg/k1AS7DHIbl9Xw85pFzznfOfA5oZ97zXY7JYrFYBAAAAAAAHM7F2QUAAAAAAFBcEboBAAAAADAIoRsAAAAAAIMQugEAAAAAMAihGwAAAAAAgxC6AQAAAAAwCKEbAAAAAACDlHJ2AQAAAEBxlZGRoczMTGeXAcCBXF1dVbp06VtuT+gGAAAAHCwlJUVnzpxRenq6s0sBYACz2Sxvb295enretC2hGwAAAHCglJQUHTt2TB4eHvL29lbp0qVlMpmcXRYAB7BYLMrIyFBycrKOHTsmSTcN3iaLxWIpiOIAAACAkuDgwYMqXbq0atWqRdgGiimLxaKjR48qIyNDdevWvWFbFlIDAAAAHCQjI0Pp6eny8vIicAPFmMlkkpeXl9LT05WRkXHDtoRuAAAAwEGyF027nUWWABRN2f/Ob7ZYIqEbAAAAcDB6uYHi71b/nRO6AQAAAAAwCKEbAFBopKenKzQ0VA0aNJDZbJbJZJKfn5+zy0IhMHDgQJlMJoWHhzu7FAAAbguhGwBKoLZt28pkMtk8XF1dValSJT300EOaO3eu0tLSCryuYcOGacaMGUpMTNSdd96pVq1aqUWLFgVeBxwnMTHR+ncsMTHxhm2joqIK9IuWxMREhYeH6/XXXy+Q9wMA3Fz2l6w3u2Zki42NLfRfyhK6AaAE8/HxUatWrdSqVSs1b95crq6u2rJliyZOnKj77rtPx48fL7BaLly4oI8//liStGnTJu3atUubN2/Wp59+WmA1oPCqXr26GjZsKG9vb4cdMzExUVOnTiV0Aw70zy90b/aQ/v/LuUcffTTP42YHq+eff95me3ZA+/ujfPnyatasmebOnav09PQb1hsTE6NevXrJx8dHZrNZlSpV0sMPP6yIiAhduXIl19f4+fnddC7vjdpYLBZ9+eWX6tmzp/z8/FSuXDm5ubmpTp06evrpp/XRRx/p6tWrt3T+f5f9xeXs2bNttv/zi3YXFxdVrFhRrVu3VlRUlP5+B+ns9xk4cGCe7/PPNrn9Dm70iIqKuuHPzlluN+zfjlIOPyIAoMgYNGhQjm+GV69erQEDBighIUHDhw/X2rVrC6SW/fv3KzMzU5UrV9b9999fIO+JomPWrFmaNWuWs8sAHKJneICzS8jTqvBf8/X6sLCwHNtef/11JScn57rPUZ577jnVqlVLFotFx48f1xdffKGJEyfqxx9/1Lp163K0v3btmv7zn//o/fffl7u7uzp37qz69esrOTlZ69ev19ixY/Xuu+/qm2++Uf369R1W57lz59SrVy/98MMP8vT0VIcOHVSvXj25uroqKSlJcXFxWr16tebPn6+dO3c67H0lady4cfLw8FBmZqYOHjyozz//XJs3b9b27du1YMECu4/btWvXHCOUYmNjFRcXpyeffFJNmjSx2ffP5/nVsmVL/fHHHw79UtbRCN0AABvdu3fXgQMHNGnSJH399dc6f/68KlasaPj7Xr58WZJUrlw5w98LAGCM3Ib4RkVFKTk52dDhv4MHD9YDDzxgfT579mwFBAQoOjpaMTExateunU37kJAQvf/++2rRooW++OIL1axZ07ovMzNT06ZN07Rp0/Too49qx44d8vT0zHeN165dU9euXbVp0yb169dPb775pipUqGDTJisrS1999ZUiIiLy/X7/9OKLL6patWrW53v27NH999+vt956S2PHjlWdOnXsOm7Xrl3VtWtXm23h4eGKi4tT165db9hr7gjlypVTo0aNDH2P/GJ4OQAghw4dOki6fvE/cOCAzb6YmBj16NFDNWvWVJkyZXTHHXeoU6dOefaIZw93a9u2rbKysvT222+rZcuW8vLysg4zy94vSYcPH77hMLSff/5ZvXr1Us2aNWU2m+Xt7a1OnTpp9erVub7/3+cUS1J0dLQ6d+6sypUry8XFxXr87OF3UVFROnHihIYOHapatWrJzc1NjRo10muvvWYdgnf16lXNmTNHd999t8qVK6eqVatqyJAhOnv2bK417Ny5U1OmTFGrVq1Uq1Yt68+tffv2Wrp0qc3Qvr/7e03nzp3T6NGj5efnJ7PZrJo1a2rIkCE6efJkrq+Vrg9hXLNmjZ588knVqFFDZrNZVatW1QMPPKDp06frxIkTOV6TmZmpxYsXq0OHDvL29laZMmVUs2ZNPfvss9q9e3ee72W0vBZS++fvd/PmzXr88cd1xx13yM3NTQEBAVq4cGGOn3Hbtm2tH8L/+XfOZDIpNjbW2vbAgQMaOnSo6tevr7Jly6pcuXKqXbu22rVrp5kzZzpl/QMAN3bHHXdYg+D27dtt9u3fv1/z589XpUqV9NVXX9kEbklydXXV1KlT1adPH/3555+aN2+eQ2pasmSJNm3apHbt2mnJkiU5Arckubi46Mknn9QPP/zgkPe8kcaNGyswMFAWi0W//PKL4e93uywWi9588001atRIZrNZvr6+mjp1qrKysmza5TWn28/PT35+fkpNTdWoUaOs18GAgAB99tlnOdouWbJEklSnTh3rtSD7s0l+0dMNAMghtxBosVg0atQo6xC0ihUr6p577tHx48e1fv16rV+/XiNGjMhziJrFYlGPHj30+eefy8fHRw0bNtShQ4d07733qlWrVkpOTtb//vc/mc1mNW/e3Pq6qlWrWv8cERGhcePGyWKxqGLFigoICLB5//79+2vx4sVyccn9O+XXX39dY8aMUcWKFVW/fn15eHjkaHP48GE1bdpU58+f19133y2TyaR9+/bpxRdf1OHDh/Xqq68qKChImzZtUqNGjeTr66v9+/crMjJSv/zyi7Zu3aoyZcrYHHPIkCHavn27vLy8VL16dVWvXl3Hjx9XTEyMYmJitG7dOn3yySd5/j6OHj2qJk2a6MSJE7rzzjtlNpt14MABRUZG6scff9TOnTtz9MJcvnxZvXv3tn4ZcscddyggIEDnz5/Xjh07tHXrVvn4+Nj0QJw/f15PPvmkNm3aJEmqUaOG7rnnHh04cECffPKJPv30Uy1dulTPPPNMnrU6U1RUlJ577jlVqFBBdevW1eHDh7Vnzx698MILSkxMtPng3LhxY509ezbXv3OS5OXlJen6FyaBgYG6ePGiypYtq3r16snNzU3Hjh3Txo0bFRsbq169ejl0+CkAxypVyjbyLFmyRFlZWRo6dKjNNeafQkND9cknn+jDDz/UtGnT8l3Hhx9+KEl6+eWXbzon/J81G60w3ld+/PjxiouLU5cuXdSpUyetWbNG4eHhunr1qmbOnHlLx8jIyFBQUJDOnz+v7t2769KlS1qxYoV69uypdevWKSgoSJI0evRoRUVFaffu3Ro1apT1CxFHLexJ6AYA5PDjjz9Kuv6Ne3aYePXVV7VgwQLVqlVL77zzjrp06WJtHx0drf79+2vhwoVq2bKl+vXrl+OY8fHx8vT0VHR0tPUid+3aNUnXeydjY2PVrl07VatWTZs3b87x+piYGGvgnjJliiZPnqzSpUtLkj755BMFBwdr6dKlaty4sV588cVcz2vChAmaN2+eRo8eLVdXV0n/P6w928yZM/X4449r0aJFqlSpkqTrH5See+45vfXWWzp69KhOnTql3377TXfeeack6ZdfflHHjh21a9cuLV26VIMHD7Y55tixYxUQEKB77rnHZvu2bdv07LPPavny5XriiSfyDLPTpk1Tu3bttHXrVlWvXl3S9TDYuXNnHTx4UK+99pqmTp1q85rs+fgVKlTQBx98oKeeesr6ZcTly5f12Wef5RhK+Oyzz2rTpk16+OGH9c4771jrzcrK0ptvvqlx48YpODhYTZs2VYMGDXKt1Zmef/55vfbaa3rhhResv99Zs2bppZde0vz58zV8+HDVq1dPkrRgwYKb/p2TpKlTp+rixYvq27ev3nrrLZsvN/766y+tWrXKIcNOAVwfVZLXEPTbXdzq7NmzWrNmjSSpVatWNvt++uknSf8/qisvjRo1Uo0aNXTs2DElJSXJx8fntmr4u2vXrmnbtm0qVaqUHn74YbuP88svv+T5M9q1a9dtHeu3335TXFycTCZTji8eC4MdO3bo119/tV73QkND5e/vrwULFigsLCzHF9y5OX78uFq0aKHY2Fhr+z59+qhjx46aP3++TejetWuXdu/ebR1V5kiEbgCAjdWrV2v69OmSpC5duqhixYo6f/68pk+fLldXV33xxRc5Ls6dOnXSO++8o+7du2vWrFm5hu7MzEwtXLjQeoGTbu+b/BkzZshiseixxx7LETD79OmjP/74QzNmzNCcOXP0wgsvyGw25zjGwIEDNW7cOJttbm5uNs8rVaqkjz76yKYXfNCgQXr33Xe1bds2rVmzRj///LM1cEtS8+bNNWTIEM2bN0/ffPNNjtDdp0+fXM+pRYsWevvtt/XII49oyZIleYZuLy8vrVy50mYo4n333acJEyZo3Lhx+uqrr2x+Jr/++qt1mNzq1avVvn37HOf8z9/RDz/8oO+++061a9fWV199ZfNeLi4uGj16tA4ePKgFCxbo9ddf19tvv51rrTdi73zBW9W3b1+NHj3aZltISIiWL1+uPXv26JtvvtHIkSNv65h79+6VdH0u5D/DdeXKlfWf//wnXzUD+H9//vlnjv+/36rIyEitW7fOupDamjVrdObMGY0cOTLHrSezp+XcSoj28fHR8ePHdeLEiXyF7nPnzikjI0NVq1bN9foUFRWV44uFgQMH5gh/27dvzzFc/lbNmzfPupDaoUOH9Pnnn+vy5csaOXJkgd2q8XaEhoZaA7ckeXt768knn9SSJUu0b98+NW7c+JaOExERYRPQO3ToIF9fX23bts3hNeeF0A0AJdiHH35onTeWkZGhgwcP6syZM5Ikf39/vfPOO5Kkb7/9Vqmpqbr//vvz/Db8X//6l0qXLq0//vhDJ06csLlQSlL58uXVs2dPu+pMS0tTXFycpOu9xrkZM2aMZs2apTNnzmjr1q1q06ZNjjb/DMO56d27d67Dzps1a6Zt27bp3nvvVcuWLXPsz/65/HMOfLbDhw9rxYoV2rFjh86cOWO9jU32f2+0Sm2fPn1ynfv34IMP5vqen3/+uXX/PwN3XlauXCnp+vnn9l7S9UX2FixYoA0bNtzSMf+pefPmuX7YzHb69GklJCTYdWxJeQbgBx98UHv27Mnzd3Mjvr6+2rdvn1asWKHGjRvnOXUBQP516tQp15XGJVlHpuRl0aJFObaNGzfOYfOxjRYVFWW9zmVr27ZtjjA8bNgwvfvuu3keIzg4OM/3eO211yRdH0ru6emp5s2b67nnnlP//v3zV7xBmjVrlmNbrVq1JF2/zeitqFChQq5f+NaqVUtbtmzJV323g9ANACVYUlKSkpKSJF3vzfT09NSDDz6orl276j//+Y/c3d0lybqA1qFDh244LC57TlhSUlKO0N2wYUO756gdOHBAmZmZkpRjiHa2SpUqqWbNmjpy5Ij27t2ba+i+++67b/peec3NrVKlyi3tT01NzbHvzTff1Pjx43Pcd/Xv8lqETVKeQ7mz5yJevHjRZvuePXskSQ899FCex/yn7N9x9i1kcpN9z9rsvzO369NPP71hb8rNPjDezO3+nG7F+PHj9cMPP2j27NlaunSpOnXqpAcffFCtW7cu9KvlAiXJli1b9MADD+jq1avavXu3/v3vf+u1117TnXfeqeeee86mbbVq1bR3714lJSWpYcOGNzxu9v/v/n5Ny/7yLSsrK88v4rKysmzmSVeqVEmlS5fW2bNnlZ6enuMLyL8v3vj888/rvffeu/lJ36YTJ07YrF6em7+fW16y9xn9JWRuU3eyP0dkfya4mez1OXI7zo3O0dEI3QBQgoWFhd3SLVzOnz8v6XpP5OnTp2/a/tKlSzm2ZQd4e2SHJRcXF2u4zU316tV15MiRPMPVrdSQV5vsD0832//PRei2bNmiUaNGSbreEztgwAD5+/urfPnycnV11cGDB1WvXj3r/PbbqSmvDzwpKSmSlGePdW6yf8cJCQk37W3+5zz4wuJmP6e8Vom/kY4dO+rHH3/UzJkzFRsbq8WLF2vx4sWSpLvuukvTpk1T9+7d7S8agEOVKVNGLVq00LfffquGDRtq5MiRevTRR21WKH/ooYcUGxurDRs2qGPHjnkea+/evTp+/Lhq1qxpM7Q8O8idPXtWlStXzvE6i8Wic+fO2QS+UqVKqUWLFvrpp5+0efPmm84nd5a/n1teskfE5RVokRNjpAAAN5U93Lp///6yWCw3fTjqFhvZypcvL+n6t+s3Cv3Zt8DKbl8YZM+tfvrpp7Vw4UK1aNFCFSpUsC70daMPNvbK7h241eF30v//jj/88MNb+h2XJIGBgVq/fr0uXLigDRs2aOrUqQoICNDvv/+up59+Wt99952zSwTwD5UrV1ZYWJguXbqUY554//795eLiog8++EB//fVXnsfIXiF70KBBNtuz5xLnNTz5119/VVpamgICAmy2Zx9n1qxZhfb/ow0bNlSZMmW0bdu2PL8Mzj7vf55fUZd9Xb7VXvTbQegGANxU9geMX3/91SnvX79+feuQsv/973+5tjl//ryOHTsmSTaLnDnboUOHJCnX4e7S9fuOO1r2B6HsFXpvhbN/x85wu7fIKVeunNq3b68pU6Zo165devrppyXJrkXlABhv2LBhqlGjhhYvXmz9f7F0PViOGjVKZ8+e1b/+9S/rF7bZsrKyNH36dH388ceqV69ejjtiDBgwQJI0ZcqUHF9upqena8KECZKUY670gAED9PDDD2vDhg0KDg5WcnJyjpotFot1tJIzlC1bVj179tRff/2lGTNm5Ni/Z88eRUZGqnz58urWrZsTKjRO9h1L7J1CdSOEbgDATXXp0kVubm7atWuXvv/++wJ/f3d3dwUGBkqS5s+fn2ub119/XZmZmfL29s51oTNnKVeunCTl+FAnXZ8jndd9zfOje/fuMplM2rJli808wRvJXuRu6dKlOnXqlMNrKoyyfze5TYe4GZPJZL0NUfaXPQAKl7Jly2rSpEm6du1ajvtsz507V4MGDdLWrVvl7++vXr166aWXXtKIESPUqFEjTZkyRf7+/lq3bl2OucUdOnTQqFGjtHv3bjVo0ECDBw/W5MmTNXz4cDVo0EDr169Xt27dcqxRUapUKa1du1YdOnTQkiVLVLt2bT311FMaP368Jk6cqAEDBqhu3bpavny5fH1987Vaen689tpr8vf319SpU9W8eXONGzdOL7/8snr06KHmzZsrPT1dixYtuq0pTEVB9sKjQ4cOVUhIiGbMmKGPPvrIIccmdAMAbqpKlSqaPHmyJKlHjx5aunRpjmFn586d09KlSzV+/HhDanj55ZdlMpn07bffKjw8XBkZGdZ9K1eu1Jw5cyRJkyZNuuEK2QUt+8uCt99+2+b2JKdPn9bTTz9tyDfq99xzjwYOHCjpegD/4osvbIYyXrlyRR9//LHNgmldunRRUFCQzp07p3bt2uW6mNrBgwc1d+5cRUZGOrxmZ6hXr55MJpP++uuvPHv4e/Tooc8//zxHMP/zzz/1/vvvS1KO2xEBKDyGDh2qmjVr6qOPPtL+/fut20uVKqVFixbp+++/12OPPabNmzdr3rx5WrZsmby9vfXaa69p9+7deS6e+frrr2v16tVq2rSp1q5dqzlz5mjFihXy8/NTZGSkPvvss1zX3ahUqZK+//57rVmzRkFBQfrll1+0cOFCvfnmm4qLi9N9992npUuXau/evapXr55hP5cbqVKlirZt26awsDBdu3ZN7733nl599VVt3bpVTz/9tLZu3aoePXo4pTYjde7cWXPnzpV0/YuH0NDQXFfFt4sFAFDiBAYGWiRZwsLCbvk1WVlZlvHjx1skWSRZPDw8LE2bNrW0bNnS4uvrazGZTBZJlsDAQJvXLV68ONft/xQTE2ORZPH19c2zzWuvvWZ9n4oVK1patGhhqVmzprWmfv36WTIzM21ec+jQIev+G8n+mSxevDjX/WFhYRZJlgEDBtxW/ampqZY777zTIsliMpksDRo0sNx3332W0qVLW8xmsyUyMjLP+m5W043O7dKlS5YnnnjCuv+OO+6wtGjRwlK/fn1L6dKlcz3u+fPnLR07drS+pkqVKpYWLVpYmjZtaqlcubJ1++38vfl7jYcOHbph2+y/K7n9HRgwYECu730rv98b/e66dOlikWQpU6aM5b777rMEBgZaAgMDLTt37rRYLBaLl5eXRZKlVKlSloYNG1ruv/9+i7+/v/Xvob+/v+XkyZM3+SmgJLl8+bLl999/t1y+fNnZpQAw2K3+e6enGwBwS0wmk+bOnav//ve/Cg4OVtWqVfX7779r586dysjIUKdOnbRgwQJ9/PHHhtUwduxY/fTTT+rRo4fKli2rXbt26fLly3rkkUf06aefaunSpYXuPsru7u7atGmThg8frurVq+vQoUM6ceKEunXrpv/+97+GrWDr5uamNWvWaNWqVercubNcXV21a9cuXbx4Uc2aNdOMGTP06KOP2rymQoUKio6O1qeffqonn3zS+po//vhDnp6e6t27t5YvX57nvdKLoqVLl2rEiBGqVauWfvvtN8XFxSkuLs46T3Pp0qX6z3/+o8aNG+v8+fPavn27Tp06pebNm2vmzJnavn279ZZkAADkxmSxFNKl8wAAAIAi5sqVKzp06JDq1KmjsmXLOrscAAa61X/vhas7AAAAAACAYoTQDQAAAACAQQjdAAAAAAAYhNANAAAAAIBBCN0AAAAAABiE0A0AAAAAgEEI3QAAAAAAGITQDQAAAACAQQjdAAAAAAAYhNANAAAAAIBBCN0AAAAAABiE0A0AAAAARZyfn5/8/PxuuX14eLhMJpNiY2MNqwnXlXJ2AQAAAEBJ4jfpG2eXkKfE2Y/n/xiJiapTp446deqkdevW3dZrN27cqMDAQEnSqlWr1KNHD+u+tm3bKi4u7paPFRMTo7Zt28rPz0+HDx++YdtDhw5ZA+vAgQO1ZMkSSdJPP/2kBx98MEf7Rx99VNHR0Tav+7vt27fr7bff1saNG3X8+HFlZWWpRo0aeuihh9S/f3898sgjev311zVmzBgNHDhQixcvzrWu2NhYtW/fXs2aNdOWLVtUqlThi2/Z55+YmOjUOgqzwvdbAwAAAFAiLVq0SJJkMpn04Ycf2oTugQMHqm3btjbt16xZo927d2vAgAE5wu/fn7u6umry5Ml5vm+FChVy3T5x4kRt3LjxluvPysrSiy++qIiICJUqVUrt27fXE088odKlS+vgwYP65ptv9PHHH2vatGmaPHmy1q5dq6ioKD311FP617/+ZXOs1NRUBQcHy2w2a+nSpQ4P3CNGjNAzzzyj2rVrO/S4yInQDQAAAMDpUlJS9NlnnykgIEBVq1bV+vXrlZSUJB8fH0nXQ/c/JSYmavfu3bkG8r8rVaqUwsPDb6ueevXqadOmTfrqq69yBOK8TJ48WREREWrSpIk+++wz1atXz2b/5cuXtXDhQp09e1Ymk0lRUVEKCAjQkCFD9Ntvv+mOO+6wth03bpwSExMVERGhO++887ZqvxXe3t7y9vZ2+HGRE3O6AQAAADjd8uXLdenSJfXv31/9+/dXVlaWoqKinFZPWFiYSpUqpZdeeklZWVk3bX/gwAHNnTtXd9xxh9atW5cjcEuSm5ubxo8fr6lTp0qSfH199frrr+vUqVMaPny4tV10dLTef/99tWvXTqNGjbqtulNTUzVq1CjVqFFDZrNZAQEB+uyzz3K0y21Od2JiokwmkwYOHKgDBw6oW7duqlixotzd3dWxY0ft3r07R9vDhw/r8OHDMplM1sftfsFR3BG6AQAAADjdokWL5OrqqmeffVZPPfWUPDw8tHjxYlksFqfU4+/vryFDhuh///ufdY73jURFRSkzM1PDhg1T1apVb9jWbDZb/xwcHKwnnnhCn376qZYvX64LFy5o8ODB8vT01OLFi2UymW655oyMDAUFBWn9+vXq3r27+vbtqz///FM9e/bU+vXrb/k4iYmJeuCBB3Tu3DkNGjRIjzzyiDZs2KB27drp1KlTkq4PyQ8LC5OXl5e8vLwUFhZmfdxo1EFJxPByAAAAAE61Z88ebdu2TZ06dVK1atUkSU899ZSWLl2qH3/8UR06dMjX8a9du5Zn72u1atX0/PPP57ovLCxMH330kaZMmaLevXurbNmyeb5HfHy8JKl9+/a3Xd/777+vn376Sf/5z3/Upk0bHT16VB9++KF8fX1v6zjHjx9XixYtFBsbqzJlykiS+vTpo44dO2r+/PkKCgq6pePExcVp9uzZmjhxonVbaGioZsyYocWLF2vSpEmqUKGCwsPDraMR6N3OG6EbAAAAgFNlL6DWv39/67b+/ftr6dKlWrRoUb5Dd2ZmpnVI9z/de++9eYbuqlWrauzYsZo2bZrefPNNTZgwIc/3OHnypCSpVq1at11f1apV9d5776l79+5au3atnnjiCQUHB9/2cSQpIiLCGrglqUOHDvL19dW2bdtu+Rh16tTR+PHjbbY999xzmjFjxm0dB9cxvBwAAACA06Snp+vjjz9W+fLl1a1bN+v2du3aycfHR1988YXOnz+fr/cwm82yWCy5Pnbt2nXD17744ouqXLmyZs+ene86buSpp55Sy5YtJUmzZ8+26xgVKlRQnTp1cmyvVauWLly4cMvHadKkiVxcbKNi9pcJt3McXEfoBgAAAOA0a9as0dmzZ/X000/Lzc3Nut3FxUXPPvusrly5ok8++cRp9ZUvX16hoaE6f/68Zs2alWe77GHxx44ds/u9ss//7z+H2+Hl5ZXr9lKlSt3SYnDZPD09cz2GdH3UAG4PoRsAAACA02QPLc9eNOzvj+we3+w2zvL888+rXr16WrBggZKSknJt06pVK0nShg0bCrI0FAHM6QYAAADgFIcPH9aGDRtUtWpVdenSJdc2P/74o3bu3KmdO3fqvvvuK+AKrytdurRmzJih3r17a8qUKbm2GThwoGbPnq33339fo0ePVuXKlfM8Xnp6us0K5kWZq6urrl696uwyCjV6ugEAAAA4xeLFi5WVlaVhw4YpMjIy18ekSZMkOb+3u1evXmrWrJmWLl2q/fv359hfv359TZgwQWfOnFHnzp116NChHG2uXLmi+fPnF6uVvitVqqQzZ87oypUrzi6l0KKnGwAAAIDD7dmzRwMHDsx1X6NGjTRhwgTrkPK82knXw+7o0aO1bNkyzZs374a37crLjW4ZJknPPPOMGjVqdMNjZA93f+SRR3IN1JI0Y8YMXblyRREREWrYsKHat2+ve+65R6VLl9ahQ4f0ww8/6OzZs5oxY8Ztn0Nh1b59e/3yyy/q3LmzWrdurTJlyqhNmzZq06aNs0srNAjdAAAAABzu+PHjWrJkSa77AgMD1bRpUx05ckSBgYG5rridzcvLS0899ZSWLVumzz//XH369LntWm50yzDp+mrdNwvdktSxY0cFBQVp/fr1ue53cXHR/Pnz1adPH73zzjvauHGjNm7cqKysLFWvXl2dOnVScHCwOnbseNvnUFhlLzL39ddfa9OmTcrMzFRYWBih+29MFovF4uwiAAAAgOLgypUrOnTokOrUqWNXjyyAouNW/70zpxsAAAAAAIMQugEAAAAAMAhzuvMpKytLx48fV/ny5WUymZxdDgCgiLJYLLp48aJq1KghFxe+E79dXI9RWFy9elVZWVnKzMxUZmams8sBcBssFouysrJUunRph15LCN35dPz4cfn4+Di7DABAMZGUlKRatWo5u4wih+sxCgtfX1+9++67unz5srNLAWCngIAAlSlTxmHHI3TnU/ny5SVd/5Dk6enp5GoAAEVVSkqKfHx8rNcV3B6uxygsrl69qlOnTsnPz4+F1IAiJjMzU7/++qvDR5wRuvMpe9iBp6cnF3kAQL4xNNo+XI9RWFy5ckV//fWXXF1d5erq6uxyANjB0ddiJo0BAAAAAGAQQjcAAADgYBaLxdklADDYrf47J3QDAAAADpI9pDwjI8PJlQAwWva/85tNJSF0AwAAAA5SunRpmc1mJScn09sNFGMWi0XJyckym80qXbr0DduykBoAAADgQN7e3jp27JiOHj0qLy8vh9/zF4AxMjMzJV1fEDGv3muLxaKMjAwlJycrNTVVNWvWvOlxCd0AAACAA2WvoH/mzBkdO3bMydUAuFVZWVk6c+aMEhMTb3rbMLPZrJo1a97SHTMI3QAAAICDZd++LiMjw9p7BqBwS01N1eOPP65ffvlFHh4eebZzdXW96ZDyvyN0AwAAAAYpXbr0bX04B+A8V69e1eHDh1WmTBmVLVvWYcdlITUAAAAAAAxC6AYAAAAAwCCEbgAAAAAADELoBgAAAADAIIRuAAAAAAAMQugGAAAAAMAghG4AAAAAAAxC6AYAAAAAwCCEbgAAAAAADELoBgAAAADAIIRuAAAAAAAMQugGAAAAAMAghG4AAAAAAAxC6AYAAAAAwCCEbgAAAAAADELoBgAAAADAIIRuAAAAAAAMQugGAAAAAMAghG4AAAAAAAxC6AYAAAAAwCClnF0AbPUMD3B2CYAhVoX/6uwSAOCWcC1GccW1GHAOeroBAAAAADAIoRsAAAAAAIMQugEAAAAAMAihGwAAAAAAgxC6AQAAAAAwCKEbAAAAAACDELoBAAAAADAIoRsAAAAAAIMQugEAAAAAMAihGwAAAAAAgxC6AQAAAAAwCKEbAAAAAACDELoBAAAAADAIoRsAAAAAAIMQugEAAAAAMAihGwAAAAAAgxC6AQAAAAAwCKEbAAAAAACDELoBAAAAADAIoRsAAAAAAIMQugEAAAAAMAihGwAAAAAAgxC6AQAAAAAwCKEbAAAAAACDELoBAAAAADAIoRsAAAAAAIMQugEAAAAAMAihGwAAAAAAgxC6AQAAAAAwCKEbAAAAAACDELoBAAAAADAIoRsAAAAAAIMQugEAAAAAMAihGwAAOISfn59MJlOuj7Zt2+Zon56ermnTpsnf319ly5ZVjRo1NHToUJ0+fbrgiwcAwCClnF0AAAAoPry8vDR69Ogc2/38/GyeZ2Vl6cknn1R0dLQeeOABde/eXQkJCYqMjNSGDRv0888/q3LlygVTNAAABiJ0AwAAh6lQoYLCw8Nv2m7JkiWKjo5W7969tWzZMplMJknSu+++q+HDh2vy5Ml67733DK4WAADjMbwcAAAUuA8++ECSNGvWLGvglqRhw4apbt26WrZsmS5fvuys8gAAcBhCNwAAcJj09HRFRUXplVde0cKFC7V169Ycba5cuaKtW7eqYcOG8vX1tdlnMpn0yCOPKC0tTb/88ktBlQ0AgGEYXg4AABzm5MmTCg4OttnWokULLV++XPXq1ZMk/fnnn8rKypK/v3+ux8jenpCQoNatWxtbMAAABqOnGwAAOERwcLA2bNigU6dOKS0tTTt37lS/fv20bds2dejQQRcvXpQkJScnS7q+6FpuPD09bdrlJj09XSkpKTYPAAAKI0I3AABwiLCwMLVv315VqlRRuXLl1KRJEy1dulT9+vXT4cOHrfO4HWHWrFny8vKyPnx8fBx2bAAAHInQDQAADDVs2DBJUnx8vKT/7+HOqyc7u9c6r55wSQoJCVFycrL1kZSU5MiSAQBwGOZ0AwAAQ3l7e0uS0tLSJEl169aVi4uLEhIScm2fvT2vOd+SZDabZTabHVwpAACOR083AAAwVPYK5n5+fpIkNzc3tWzZUvv27dPhw4dt2losFn3//fdyd3dX8+bNC7pUAAAcjtANAADybe/evbp06VKu2ydOnChJ6tOnj3X70KFDJV0fJm6xWKzb33vvPR08eFDPPvus3NzcDK4aAADjMbwcAADk24oVKzR//ny1adNGvr6+cnd31/79+/Xtt98qIyNDISEhatOmjbX9gAEDtHLlSi1fvlyHDh1SYGCgDhw4oM8//1x16tTRjBkznHg2AAA4DqEbAADkW7t27fTHH39o586d2rRpky5duiRvb2899thj+ve//62goCCb9i4uLlq7dq1mz56tjz76SBEREapUqZKee+45zZgxQ5UrV3bSmQAA4FiEbgAAkG+BgYEKDAy8rdeYzWaFhYUpLCzMoKoAAHA+5nQDAAAAAGAQQjcAAAAAAAYhdAMAAAAAYBBCNwAAAAAABiF0AwAAAABgEEI3AAAAAAAGIXQDAAAAAGCQQhe6jx07ptdff11BQUGqXbu2ypQpo2rVqql79+7aunVrrq9JSUnR2LFj5evrK7PZLD8/P40fP16pqam5ts/KytKCBQvUuHFjubm5qXLlyurdu7cOHjxo5KkBAAAAAEqYQhe6FyxYoDFjxujgwYMKCgrSuHHj9PDDD2vt2rV66KGHtHLlSpv2aWlpCgwMVEREhBo1aqQxY8aoYcOGmjdvntq3b68rV67keI9hw4Zp5MiRslgsGjlypB599FF9/vnnatGihRISEgrqVAEAAAAAxVwpZxfwTy1btlRsbKwCAwNttm/atEkdOnTQ8OHD1bVrV5nNZknS3LlztWvXLk2cOFGzZ8+2tp80aZLmzJmjiIgIhYSEWLfHxMQoMjJSbdq00ffff68yZcpIkvr06aPHHntMI0aMUHR0dAGcKQAAAACguCt0Pd1PPfVUjsAtSa1bt1a7du10/vx57dmzR5JksVgUGRkpDw8PhYaG2rQPDQ2Vh4eHIiMjbbZ/8MEHkqTp06dbA7ckde7cWW3bttX69et15MgRR58WAAAAAKAEKnSh+0ZKly4tSSpV6noHfUJCgo4fP65WrVrJ3d3dpq27u7tatWqlgwcPKikpybo9NjbWuu+fOnXqJEmKi4sz6hQAAAAAACVIkQndR44c0Q8//KDq1aurcePGkmSdf+3v75/ra7K3Z7dLS0vTiRMnVKdOHbm6ut60fW7S09OVkpJi8wAAAAAAIDdFInRnZGSoX79+Sk9P15w5c6yBOTk5WZLk5eWV6+s8PT1t2t1u+9zMmjVLXl5e1oePj48dZwQAAAAAKAkKfejOysrSwIEDtXHjRg0ZMkT9+vVzaj0hISFKTk62Pv4+dB0AAAAAgL8rdKuX/11WVpYGDRqkTz75RH379tW7775rsz+7xzqvnunsod/Z7W63fW7MZrN15XQAAAAAAG6k0PZ0Z2VlKTg4WEuWLFHv3r0VFRUlFxfbcm82B/ufc77d3d1VvXp1HTp0SJmZmTdtDwAAAABAfhTK0J0duJcuXapevXrpo48+ynPhsxo1aig+Pl5paWk2+9LS0hQfH686derYzLsODAy07vun7Ptzt2nTxsFnBAAAAAAoiQpd6M4eUr506VL16NFDH3/8ca6BW5JMJpMGDx6s1NRUTZ8+3Wbf9OnTlZqaqiFDhthsHzp0qKTr9/G+evWqdft3332n2NhYBQUFydfX18FnBQAAAAAoiQrdnO5p06ZpyZIl8vDwUIMGDTRjxowcbbp27aomTZpIkiZMmKC1a9dqzpw52rlzp5o2baodO3Zo/fr1atGihUaPHm3z2nbt2mnw4MGKjIxU06ZN9fjjj+vEiRNauXKlKlWqpAULFhTAWQIAAAAASoJCF7oTExMlSampqZo5c2aubfz8/Kyh293dXXFxcQoPD9fq1asVExOj6tWra9y4cQoLC5Obm1uO17/33ntq3Lix3n//fb3xxhvy8PBQt27dNHPmTNWrV8+oUwMAAAAAlDAmi8VicXYRRVlKSoq8vLyUnJxsvc93fvQMD3BAVUDhsyr8V2eXABRqjr6elDSO/PlxLUZxxbUYuDGjrsWFbk43AAAAAADFBaEbAAAAAACDELoBAAAAADAIoRsAAAAAAIMQugEAAAAAMAihGwAAAAAAgxC6AQAAAAAwCKEbAAAAAACDELoBAAAAADAIoRsAAAAAAIMQugEAAAAAMAihGwAAAAAAgxC6AQAAAAAwCKEbAAAAAACDELoBAAAAADAIoRsAAAAAAIMQugEAAAAAMAihGwAAAAAAgxC6AQAAAAAwCKEbAAAAAACDELoBAAAAADAIoRsAAAAAAIMQugEAAAAAMAihGwAAAAAAgxC6AQAAAAAwCKEbAAAAAACDELoBAAAAADAIoRsAAAAAAIMQugEAAAAAMAihGwAAAAAAgxC6AQAAAAAwCKEbAAAAAACDELoBAAAAADAIoRsAAAAAAIMQugEAAAAAMAihGwAAAAAAgxC6AQAAAAAwCKEbAAAAAACDELoBAAAAADAIoRsAAAAAAIMQugEAAAAAMAihGwAAAAAAgxC6AQAAAAAwCKEbAAAAAACDELoBAAAAADAIoRsAAAAAAIMQugEAAAAAMAihGwAAAAAAgxC6AQAAAAAwCKEbAAAAAACDELoBAAAAADAIoRsAAAAAAIMQugEAAAAAMAihGwAAAAAAgxC6AQAAAAAwCKEbAAAAAACDELoBAAAAADAIoRsAAAAAAIMQugEAAAAAMAihGwAAAAAAgxC6AQAAAAAwCKEbAAAAAACDELoBAAAAADAIoRsAAAAAAIMQugEAAAAAMAihGwAAAAAAgxC6AQAAAAAwCKEbAAAAAACDELoBAAAAADAIoRsAAAAAAIMQugEAAAAAMAihGwAAAAAAgxC6AQAAAAAwCKEbAAAAAACDELoBAAAAADAIoRsAAAAAAIMQugEAAAAAMAihGwAAAAAAgxC6AQAAAAAwCKEbAAAAAACDELoBAAAAADAIoRsAABhizpw5MplMMplM+vnnn3PsT0lJ0dixY+Xr6yuz2Sw/Pz+NHz9eqampTqgWAABjELoBAIDD/e9//1NYWJjc3d1z3Z+WlqbAwEBFRESoUaNGGjNmjBo2bKh58+apffv2unLlSgFXDACAMQjdAADAoTIyMjRgwAA1adJE3bp1y7XN3LlztWvXLk2cOFHR0dGaPXu2oqOjNXHiRG3btk0REREFXDUAAMYgdAMAAIeaOXOmfvvtN3344YdydXXNsd9isSgyMlIeHh4KDQ212RcaGioPDw9FRkYWVLkAABiK0A0AABxmx44dmjlzpsLCwnTXXXfl2iYhIUHHjx9Xq1atcgw/d3d3V6tWrXTw4EElJSUVRMkAABiK0A0AABwiPT1d/fv3V5MmTTRhwoQ82yUkJEiS/P39c92fvT27XV7vlZKSYvMAAKAwInQDAACHmDJlihISErR48eJch5VnS05OliR5eXnlut/T09OmXW5mzZolLy8v68PHxycflQMAYBxCNwAAyLctW7Zo3rx5mjx5su655x7D3y8kJETJycnWB0PRAQCFVSlnFwAAAIq2a9euacCAAQoICNCkSZNu2j67hzuvnuzsoeJ59YRLktlsltlstqNaAAAKFqEbAADkS2pqqnX+dZkyZXJt8+CDD0qSvvjiC+sCa3nN2b7ZnG8AAIoSQjcAAMgXs9ms5557Ltd9GzduVEJCgp544glVrlxZfn5+8vf3V40aNRQfH6+0tDSbFczT0tIUHx+vOnXqME8bAFAsELoBAEC+uLm55Xlf7YEDByohIUEhISF64IEHrNsHDx6sadOmafr06Zo9e7Z1+/Tp05WamqqXXnrJ8LoBACgIhG4AAFDgJkyYoLVr12rOnDnauXOnmjZtqh07dmj9+vVq0aKFRo8e7ewSAQBwCFYvBwAABc7d3V1xcXEaPXq0/vjjD7322mvau3evxo0bpw0bNsjNzc3ZJQIA4BD0dAMAAMNERUUpKioq131eXl6KiIhQREREwRYFAEABoqcbAAAAAACDELoBAAAAADAIoRsAAAAAAIMQugEAAAAAMAihGwAAAAAAgxC6AQAAAAAwCKEbAAAAAACDELoBAAAAADAIoRsAAAAAAIMQugEAAAAAMAihGwAAAAAAgxC6AQAAAAAwCKEbAAAAAACDELoBAAAAADAIoRsAAAAAAIMQugEAAAAAMAihGwAAAAAAgxC6AQAAAAAwCKEbAAAAAACDELoBAAAAADAIoRsAAAAAAIMQugEAAAAAMAihGwAAAAAAgxC6AQAAAAAwCKEbAAAAAACDELoBAAAAADAIoRsAAAAAAIMQugEAAAAAMAihGwAAAAAAgxC6AQAAAAAwCKEbAAAAAACDFMrQ/fHHH2vYsGFq3ry5zGazTCaToqKicm0bHh4uk8mU5yMxMTHX10VHRyswMFDly5eXp6en2rVrpw0bNhh3UgAAAACAEqeUswvIzeTJk3X48GF5e3urevXqOnz48E1fM2DAAPn5+eXYXqFChRzbPv74Y/Xr10+VK1fWwIEDJUkrV67UI488olWrVunpp5/O5xkAAAAAAFBIQ3dkZKT8/f3l6+ur2bNnKyQk5KavGThwoNq2bXvTdufPn9cLL7wgb29v7dixQ7Vq1ZIkTZw4Uffdd5+GDx+uTp06qXz58vk9DQAAAABACVcoh5d37NhRvr6+hhz7008/1YULF/TCCy9YA7ck1apVSyNGjNCZM2f0xRdfGPLeAAAAAICSpVCGbnts3LhRc+bM0auvvqo1a9YoNTU113axsbGSpKCgoBz7OnXqJEmKi4szrE4AAAAAQMlRKIeX2yMsLMzmeYUKFfTGG2+of//+NtsTEhIkSf7+/jmOkb0tu01u0tPTlZ6ebn2ekpJid80AAAAAgOKtyPd033vvvfrwww918OBBXb58WYcOHdKCBQtkMpk0cOBAffnllzbtk5OTJUleXl45juXp6WnTJjezZs2Sl5eX9eHj4+PAswEAAAAAFCdFPnR369ZNwcHBqlOnjsqWLSs/Pz+NGDFCn376qaTrK6E7UkhIiJKTk62PpKQkhx4fAAAAAFB8FJvh5f/UoUMH1atXT3v27FFKSoq1Fzu7hzs5OVl33HGHzWuyh4rn1guezWw2y2w2G1Q1AAAAAKA4KfI93Tfi7e0tSbp06ZJ1243mbd9ovjcAAAAAALer2IbutLQ0/fbbb3J3d7eGb0kKDAyUJK1fvz7Ha6Kjo23aAAAAAACQH0U6dF+8eFH79+/Psf3y5csaMmSILl68qJ49e6pUqf8fRd+zZ095eXlpwYIFOnr0qHX70aNHtXDhQnl7e6tbt24FUj8AAAAAoHgrlHO6IyMjtXnzZknSnj17rNuy77H98MMPa/DgwTp79qwaNWqkFi1a6M4771S1atV06tQp/fDDDzp69KgaN26sV1991ebYFStW1MKFC9WvXz81bdpUvXr1kiStXLlSZ8+e1cqVK1W+fPmCO1kAAAAAQLF1S6G7ffv2dh3cZDJpw4YNt/26zZs3a8mSJTbb4uPjFR8fb30+ePBgVapUSf/+97/13//+V99++63Onz8vNzc33XnnnRo5cqRGjBghNze3HMfv27evvL299corr2jx4sUymUxq1qyZJk+erI4dO97+iQIAAAAAkItbCt3ZPcz/ZDKZZLFY8txuMpnsKioqKkpRUVE3befp6amFCxfa9R6PPvqoHn30UbteCwAAAADArbilOd1ZWVk2j8uXL6tLly5q0KCBPvroIyUmJury5ctKTEzU0qVL1aBBA/3rX/+yWTUcAAAAAICSxq6F1MLCwrRnzx5t27ZNzz77rGrXri2z2azatWurb9++2rp1q3bv3q2wsDBH1wsAAAAAQJFhV+j+5JNP1L17d3l4eOS639PTU927d9fy5cvzVRwAAAAAAEWZXaH7r7/+UkZGxg3bXLt2TadPn7arKAAAAAAAigO7Qne9evX06aef6uzZs7nu/+uvv7Rq1SrVr18/X8UBAAAAAFCU2RW6R48erZMnT6pp06Z64403tH37diUlJWn79u16/fXX1axZM50+fVpjxoxxdL0AAAAAABQZt3TLsH8aPHiwTpw4oenTp2vs2LE2+ywWi1xdXRUeHq5BgwY5pEgAAAAAAIoiu0K3JIWGhqpPnz5atmyZfv31VyUnJ8vLy0v33nuv+vTpo3r16jmyTgAAAAAAihy7Q7d0fW73lClTHFULAAAAAADFil1zugEAAAAAwM3lq6f7v//9r7Zt26YLFy4oMzMzx36TyaTQ0ND8vAUAAAAAAEWWXaH73Llz6tq1q+Lj42WxWPJsR+gGAAAAAJRkdoXusWPHavPmzWrbtq0GDBigWrVqqVSpfHWaAwAAAABQ7NiVlL/++mu1bNlSGzZskMlkcnRNAAAAAAAUC3YtpHb58mW1adOGwA0AAAAAwA3YFbqbNGmixMREB5cCAAAAAEDxYlfoDgsL05dffqmff/7Z0fUAAAAAAFBs2DWn++TJk3r88ccVGBioZ599Vk2bNpWnp2eubfv375+vAgEAAAAAKKrsCt0DBw6UyWSSxWJRVFSUoqKicszvtlgsMplMhG4AAAAAQIllV+hevHixo+sAAAAAAKDYsSt0DxgwwNF1AAAAAABQ7Ni1kBoAAAAAALg5u3q6syUmJmrZsmXatWuXUlJS5OnpqSZNmujZZ5+Vn5+fg0oEAAAAAKBosjt0v/HGG5owYYKuXbsmi8Vi3b569WpNmzZNc+fO1ahRoxxSJAAAAAAARZFdw8u//vprjRkzRl5eXpoxY4Z++uknHTp0SFu2bNErr7wiLy8vjR07Vt98842j6wUAAAAAoMiwq6d7/vz5qlSpknbs2KFatWpZt/v6+ur+++/Xs88+q/vuu0/z58/X448/7rBiAQAAAAAoSuzq6d6xY4d69eplE7j/zsfHRz179tT27dvzVRwAAAAAAEWZXaH76tWrcnd3v2EbDw8PXb161a6iAAAAAAAoDuwK3Q0aNNBXX32la9eu5br/2rVr+vrrr9WgQYN8FQcAAAAAQFFmV+ju37+/9u3bp06dOuUYQv7LL7+oc+fO2rdvnwYMGOCQIgEAAAAAKIrsWkht1KhR2rhxo7788ku1bNlS5cqVU5UqVXT69GldunRJFotFTz75JLcMAwCgEMrKypKLi+337lu2bNHXX3+tsmXLKjg4OM91WwAAwO2xq6fb1dVVa9asUVRUlNq2basyZcroyJEjKlOmjNq1a6clS5boiy++yHFBBwAAzjVmzBiVK1dOFy5csG777LPP1Lp1a82aNUthYWFq2rSpjh496rwiAQAoRuzq6c7Wv39/9e/f31G1AAAAg8XExKh9+/aqUKGCdduUKVPk5eWlN954QydPnlRISIjmzZun119/3Wl1AgBQXOQrdAMAgKIlKSlJgYGB1ueHDh3S3r17FRYWpr59+0qSNm3apHXr1jmrRAAAihW7QvfXX3+tDz/8UAsXLlSNGjVy7D9+/LhGjBihIUOGqHPnzvkuEkDR5zfpG2eXABgicfbjzi7htqSlpdnc9jMuLk4mk8nmen3XXXdpw4YNzigPAIBix65J12+99Zb+/PPPXAO3JNWoUUOHDh3SW2+9la/iAACAY9WoUUP79u2zPl+3bp08PDzUrFkz67aUlBSZzWZnlAcAQLFjV0/37t271aVLlxu2uf/++/X111/bVRQAADBGYGCgli9froULF6ps2bL6/PPP1bVrV7m6ulrb/Pnnn6xeDgCAg9jV033u3DlVqVLlhm28vb115swZu4oCAADGePnll+Xm5qZRo0Zp6NChMpvNCg8Pt+6/ePGiNm7cqFatWjmvSAAAihG7erorV65sMzQtN/v27VOlSpXsKgoAABijfv36+v3337V69WpJ0r/+9S/5+vpa9yckJGjYsGHq06ePs0oEAKBYsSt0t2nTRqtXr9avv/6qgICAHPt3796tL7/8Uk899VS+CwQAAI5VvXp1jRgxItd9TZs2VdOmTQu4IgAAii+7hpdPnDhRkvTwww9r2rRp2rJli44cOaItW7Zo6tSpat26tVxcXBQSEuLQYgEAAAAAKErs6ukOCAjQsmXLNGDAAE2dOlVTp0617rNYLPLw8NDy5ctz7QUHAAAFZ9CgQXa9zmQyadGiRQ6uBgCAkseu0C1J3bt3V+vWrRUVFaVt27YpOTlZFSpUUMuWLTVgwABVrlzZkXUCAAA7REVF5brdZDLJYrHkuZ3QDQCAY9gduiWpSpUqmjBhgqNqAQAADnbo0CGb51lZWRo1apR+/vlnjRo1Sq1bt1bVqlV16tQpbdy4UW+++aYefPBBRUREOKliAACKl3yF7mznzp1TWlqafHx8HHE4AADgIH9fmVySZs+era1bt2r37t2qXr26dXvDhg3Vpk0bBQcH67777tNnn33GF+sAADiAXQupSVJycrJGjRqlqlWrqnLlyqpTp45139atW/XYY49p+/btDikSAAA4xqJFi9SzZ0+bwP13NWvWVM+ePfXBBx8UcGUAABRPdoXuc+fO6f7779eCBQvk4+OjO++802ZeWEBAgOLj47Vs2TKHFQoAAPLv6NGjKlu27A3blC1bVkePHi2gigAAKN7sCt3h4eHav3+/VqxYoV9++UU9evSw2e/m5qbAwED9+OOPDikSAAA4Rq1atfTFF1/oypUrue6/dOmSvvjiC9WqVauAKwMAoHiyK3R/+eWX6tKli3r27JlnGz8/P74lBwCgkBk8eLAOHjyoVq1aae3atTp79qwk6ezZs1qzZo0efvhhJSYmasiQIU6uFACA4sGuhdROnDihZ5555oZtzGaz0tLS7CoKAAAYY/z48dq/f78WL16sp556SpLk4uKirKwsSZLFYlFwcLDGjx/vzDIBACg27Ardd9xxh5KSkm7YZu/evXku0gIAAJzDxcVFixYtUv/+/bVkyRL9+uuvSk5OlpeXl+69917169dPbdu2dXaZAAAUG3aF7jZt2mjt2rU6evRornO+fv/9d61bt07BwcH5LhAAADheYGCgAgMDnV0GAADFnl1zul9++WVlZmaqVatWWrZsmc6cOSNJ+uOPP7Ro0SK1b99eZrOZoWkAAAAAgBLNrp7uxo0ba+XKlerXr5/69+8v6focsHvuuUcWi0Xly5fXqlWr5O/v79BiAQCAY5w8eVLbt2/XhQsXlJmZmWub7Gs8AACwn12hW5KeeOIJHTp0SEuWLNHWrVt17tw5eXp66v7771dwcLC8vb0dWScAAHCAK1euaMiQIVqxYoV18bR/slgsMplMhG4AABzA7tAtSZUqVdKYMWMcVQsAADDYpEmTtGzZMjVo0EC9e/dWrVq1VKpUvj4OAACAG3DoVdZisejAgQMqW7asfHx8HHloAADgAKtWrdJdd92l7du3y2w2O7scAACKPbsWUvv888/Vv39/nT9/3rotMTFRAQEBatSokfz8/PTMM8/kOUcMAAA4x4ULF/Too486PHBfuXJFY8eOVZs2bVSjRg2VLVtW1apVU6tWrbR48WJlZGTkeE1KSorGjh0rX19fmc1m+fn5afz48UpNTXVobQAAOJNdofudd97Rrl27VLFiReu2MWPG6LffflO7du0UEBCgTz/9VB9++KHDCgUAAPnXsGFDnTp1yuHHTU1N1TvvvCOTyaTHH39cY8eOVbdu3XTs2DENGjRIXbp0sZlDnpaWpsDAQEVERKhRo0YaM2aMGjZsqHnz5ql9+/a6cuWKw2sEAMAZ7Bpe/vvvv6tz587W5xcvXtQ333yjXr16afny5crIyNB9992nDz/8UEOGDHFYsQAAIH/Gjx+v559/XgcOHFD9+vUddtxKlSopOTlZZcqUsdl+7do1PfLII1q/fr2+++47Pf7445KkuXPnateuXZo4caJmz55tbT9p0iTNmTNHERERCgkJcVh9AAA4i1093efOnVO1atWszzdv3qxr166pd+/ekqTSpUvrkUce0Z9//umYKgEAgEPUqlVLnTp1UsuWLTVt2jR9/fXX2rhxY66P2+Hi4pIjcEtSqVKl1K1bN0nSgQMHJF1fAyYyMlIeHh4KDQ21aR8aGioPDw9FRkbaeYYAABQudvV0e3p66uzZs9bnMTExcnFxUevWra3bSpcurbS0tPxXCAAAHKZt27YymUyyWCwKDw+XyWTKs60j1mbJysrSunXrJEn33HOPJCkhIUHHjx9Xp06d5O7ubtPe3d1drVq1UnR0tJKSkliYFQBQ5NkVuhs1aqSvvvpKM2bMkKurqz755BM1a9bMZo734cOHVbVqVYcVCgAA8m/KlCk3DNr5dfXqVb3yyiuyWCw6e/asNmzYoL179yo4OFgdOnSQdD10S5K/v3+ux/D391d0dLQSEhLyDN3p6elKT0+3Pk9JSXHwmQAA4Bh2he6RI0eqR48eqlWrlrVHe8aMGTZtfv75ZzVt2tQhRQIAAMcIDw839PhXr17V1KlTrc9NJpNefPFFzZo1y7otOTlZkuTl5ZXrMTw9PW3a5WbWrFk27wMAQGFl15zu7t2766233tLdd9+tBg0aaM6cORo4cKB1f1xcnFJSUvToo486qk4AAFAEeHh4yGKxKDMzU0lJSXrrrbcUGRmptm3bOrQ3OiQkRMnJydZHUlKSw44NAIAj2dXTLUnDhw/X8OHDc90XGBhocw9vAABQuKSlpWnNmjXatWuXUlJS5OnpqSZNmqhr16455lnbw8XFRbVq1dLw4cPl7e2tnj17aubMmZozZ461hzuvnuzscJ5XT7gkmc1mh99rHAAAI9gdugEAQNG0evVqDR06VBcuXJDFYrFuN5lMqlChgj744AM99dRTDnu/oKAgSVJsbKyk/5/LnT23+59uNucbAICihNANAEAJ8tNPP+mZZ56Rq6urBg8erHbt2ql69eo6efKkYmJitGTJEj3zzDOKi4vTgw8+6JD3PH78uKTrdzaRrofpGjVqKD4+XmlpaTY962lpaYqPj1edOnVYuRwAUCzYNacbAAAUTa+88orMZrO2bt2q9957T88884wCAwPVq1cvvfvuu9q6davKlCmjV1555baO+/vvv+vSpUs5tl+6dEljx46VJD322GOSrveoDx48WKmpqZo+fbpN++nTpys1NVVDhgyx8wwBAChc6OkGAKAE2bJli3r16qV777031/0BAQHq2bOn1q5de1vHXbVqlebPn6+HH35Yfn5+8vT01LFjx/Tdd9/p7Nmzat26tcaMGWNtP2HCBK1du1Zz5szRzp071bRpU+3YsUPr169XixYtNHr06PycJgAAhQahGwCAEuTSpUuqWrXqDdtUrVo1117rG+nSpYuOHz+un376SVu2bFFqaqq8vLwUEBCgZ555RoMGDVKpUv//scPd3V1xcXEKDw/X6tWrFRMTo+rVq2vcuHEKCwuTm5ubXecHAEBhQ+gGAKAE8fPz0/fff3/D4eMbNmyQn5/fbR23efPmat68+W29xsvLSxEREYqIiLit1wEAUJTYNad70KBBXCABACiCevbsqe3bt2vAgAHWBc6ynThxQgMHDtT27dvVq1cvJ1UIAEDxYlfo/uSTT3T69GlH1wIAAAw2ceJEtWjRQh999JHq1q2re+65Rx06dNA999yjOnXqaOnSpWrRooUmTpzo7FIBACgW7Ard9erV04kTJxxdCwAAMFi5cuW0ceNGhYeHq1atWvr9998VExOj33//XbVq1dLUqVMVFxfHnGoAABzErjndgwYN0uzZs3Xs2DHVrFnT0TUBAAADmc1mTZkyRVOmTNHFixeVkpIiT09PlS9f3tmlAQBQ7NgVurt3766YmBg99NBDmjBhglq0aKGqVavKZDLlaFu7du18FwkAAIxRvnx5wjYAAAayK3TXrVtXJpNJFotFI0eOzLOdyWTStWvX7C4OAAA4Vnx8vFavXq0JEyaoWrVqOfafOHFCr776qnr27KkHHnjACRUCAFC82BW6+/fvn2uvNgAAKNzmz5+vX3/9VfPnz891f/Xq1fX111/r2LFjWrlyZQFXBwBA8WNX6I6KinJwGQAAoCBs27ZNHTp0uGGbNm3a6Pvvvy+gigAAKN7sWr0cAAAUTadPn77pIqjVqlXj1qAAADiIXT3d2U6ePKnPP/9ce/fuVVpamhYtWiRJ+uuvv3To0CE1btyYW44AAFCIVKhQQUeOHLlhm8OHD8vDw6OAKgIAoHizu6f77bffVp06dTRixAgtXLjQZsj56dOn9eCDD+rjjz92RI0AAMBBHnjgAX3xxRdKSkrKdf+RI0e0Zs0aPfTQQwVcGQAAxZNdofurr77SiBEj1LhxY3355ZcaPny4zf67775bAQEBWrNmjSNqBAAADjJ27FhdunRJrVq10tKlS3XixAlJ11ctX7JkiVq1aqXLly9r3LhxTq4UAIDiwa7h5a+++qpq166tmJgYubu7a/v27TnaNG7cWJs2bcp3gQAAwHHatGmj+fPna9y4cQoODpYk621AJcnFxUVvvPGG2rRp48wyAQAoNuwK3bt27VK/fv3k7u6eZ5uaNWvq1KlTdhcGAACMMWrUKLVr107vvvuutm3bpuTkZFWoUEEtW7bU888/r3vuucfZJQIAUGzYFbqzsrJUunTpG7Y5ffq0zGazXUUBAABjBQQE6O2333Z2GQAAFHt2zelu2LDhDYeOX7t2TRs3blTjxo3tLgwAAAAAgKLOrtD97LPPaufOnZo6dWqOfZmZmXrxxRd18OBB9e/fP98FAgAAx7p27ZoiIiLUsmVLeXp6qlSp/x/4tmvXLv373//W/v37nVghAADFh13Dy1944QV99dVXmjZtmpYtW6ayZctKknr27KlffvlFiYmJCgoK0nPPPefQYgEAQP5cvnxZQUFB+umnn+Tt7S1PT0+lpaVZ99epU0eLFy9WpUqVNGPGDCdWCgBA8WBXT3fp0qUVHR2tSZMm6ezZs/rf//4ni8Wizz77TOfOndPEiRP15ZdfymQyObpeAACQD6+88ori4+M1a9YsnTx5UoMHD7bZ7+XlpcDAQEVHRzupQgAAihe7erolqUyZMpo5c6ZmzJihffv26dy5c/L09NSdd94pV1dXR9YIAAAcZOXKlWrXrp0mTJggSbl+QV63bl3t3LmzoEsDAKBYsjt0ZzOZTGrUqJEjagEAAAY7cuSIunXrdsM25cuXV3JycgFVBABA8Zav0J2enq5vv/1WO3fuVHJysry8vHTffffpscce43ZhAAAUQuXLl9fp06dv2ObPP/9U5cqVC6giAACKN7tD95dffqmhQ4fqr7/+ksVisW43mUyqUqWK3n//ff3rX/9ySJEAAMAxHnjgAX311Ve6cOGCKlSokGN/UlKSvv3225v2hgMAgFtj10JqGzZsUPfu3XXhwgUNGjRIUVFR+u677xQVFaXg4GCdP39eTz31lH788UdH1wsAAPJh/PjxOn/+vDp06KD4+Hhdu3ZNknTp0iVt2LBBnTp10rVr1zR27FgnVwoAQPFgV093WFiY3Nzc9NNPP+mee+6x2de/f3+NHDlSrVq1UlhYmNq3b++QQgEAQP61adNGCxcu1KhRo9SmTRvr9vLly0uSXF1d9fbbb6tZs2bOKhEAgGLFrtC9c+dO9enTJ0fgzhYQEKCePXtqxYoV+SoOAAA43vDhw9W2bVu9++672rp1q/UOJPfff7/+/e9/6+6773Z2iQAAFBt2he5y5crddIGVKlWqqFy5cnYVBQAAjHXnnXfqjTfecHYZAAAUe3bN6e7YsaN++OGHG7b54Ycf9Mgjj9hVFAAAKHjp6enKyMhwdhkAABQrdoXuefPm6fTp0+rfv7+SkpJs9iUlJalfv346c+aM5s2b55AiAQCAY2zcuFFTpkzRhQsXrNvOnj2rzp07y8PDQ15eXpo0aZLzCgQAoJixa3h5v379VLFiRS1btkwrVqxQ7dq1VbVqVZ06dUpHjhxRZmamAgIC1LdvX5vXmUwmbdiwwSGFAwCA2zdv3jz9/vvvmjZtmnXbuHHjFB0drfr16ys1NVWvvvqqmjZtqp49ezqxUgAAige7QndsbKz1z9euXdPBgwd18OBBmza7d+/O8TqTyWTP2wEAAAfZuXOnOnToYH1+5coVrVq1SkFBQVq3bp0uXryogIAAvfPOO4RuAAAcwK7h5VlZWXY9MjMzHV0/AAC4DWfPnlXNmjWtz7ds2aIrV64oODhY0vVbh3Xp0kX79u1zVokAABQrdoVuAABQNLm5uenixYvW5zExMTKZTAoMDLRu8/Dw0Pnz551RHgAAxY5dw8sBAEDRVL9+fa1bt07p6ekymUxasWKF7rrrLlWrVs3a5siRI6pSpYoTqwQAoPigpxsAgBJkyJAhOnDggOrXr68777xTf/75p3Voebbt27frrrvuclKFAAAUL4RuAABKkOeee07jx4/X5cuXlZycrOHDh2v06NHW/Vu2bNH+/fttFlsDAAD2Y3g5AAAliMlk0pw5czRnzpxc9zdr1kznz5+Xu7t7AVcGAEDxROgGAABWZcqUUZkyZZxdBgAAxQbDywEAAAAAMIjDQ3d6eroyMjIcfVgAAGAHFxcXlSpVSvv377c+d3V1vemjVCkGwwEA4Ah2XVE3btyoH374QWPHjlWFChUkSWfPnlXfvn31ww8/qHTp0ho5cqRmz57tyFoBAMBtatOmjUwmk8qVK2fzHAAAFAy7Qve8efP0+++/a9q0adZt48aNU3R0tOrXr6/U1FS9+uqratq0qXr27OmwYgEAwO2JjY294XMAAGAsu4aX79y5Uw8//LD1+ZUrV7Rq1SoFBQVp//792rdvn2rXrq133nnHYYUCAAAAAFDU2BW6z549q5o1a1qfb9myRVeuXFFwcLAkqXz58urSpYv27dvnmCoBAAAAACiC7Bpe7ubmposXL1qfx8TEyGQyKTAw0LrNw8ND58+fz3+FAADAbn+fCnY7TCaTQkNDHVwNAAAlj12hu379+lq3bp3S09NlMpm0YsUK3XXXXapWrZq1zZEjR1SlShWHFQoAAG5feHi4Xa8jdAMA4Bh2he4hQ4Zo6NChql+/vsqUKaPExES9+uqrNm22b9+uu+66yyFFAgAA+8TExDi7BAAASjS7Qvdzzz2nhIQELVq0SJcvX9bw4cM1evRo6/4tW7Zo//79Gjx4sKPqBAAAdvj71C8AAFDw7ArdJpNJc+bM0Zw5c3Ld36xZM50/f17u7u75Kg4AAAAAgKLMrtB9M2XKlFGZMmWMODQAAAAAAEWGXbcMy/bFF1+oZ8+eCggIUP369a3b9+7dq7lz5+rYsWP5LhAAANjPxcVFrq6ut/0oVcqQ7+UBAChx7LqiZmVlqXfv3vrss88kXb+F2OXLl637K1asqJdfflmZmZkKCQlxTKUAAOC2tWnTRiaTydllAABQYtkVuiMiIvTpp5/q+eef1+zZszV//nxNnz7dur9q1apq3bq1vvnmG0I3AABOFBsb6+wSAAAo0ewaXh4VFaUWLVro7bfflqenZ67foNevX1+HDh3Kd4EAAAAAABRVdoXuAwcOqHXr1jdsc8cdd+js2bN2FQUAAAAAQHFg1/ByNzc3JScn37DN4cOHVaFCBXsOr48//libNm3S9u3btWfPHl29elWLFy/WwIEDc22fkpKi8PBwrV69WidPnlT16tXVo0cPhYWFycPDI0f7rKwsvfXWW3r//fd14MABeXh4qGPHjpo5c6bq1q1rV80AABRG06ZNk8lk0n/+8x9VqlRJ06ZNu6XXmUwmhYaGGlwdAADFn12h+7777lN0dLSuXLmismXL5th/7tw5rVu3Tm3atLGrqMmTJ+vw4cPy9vZW9erVdfjw4TzbpqWlKTAwULt27VJQUJB69+6tnTt3at68eYqLi9PGjRtz1Dhs2DBFRkbq7rvv1siRI3X8+HGtWrVK69ev188//yx/f3+76gYAoLAJDw+XyWRSr169VKlSJYWHh9/S6wjdAAA4hl2he+TIkerWrZu6d++u9957z2bfn3/+qUGDBik5OVkjR460q6jIyEj5+/vL19dXs2fPvuFibHPnztWuXbs0ceJEzZ4927p90qRJmjNnjiIiImxeHxMTo8jISLVp00bff/+99X7iffr00WOPPaYRI0YoOjrarroBAChsYmJiJEm1a9e2eQ4AAAqGXaH7ySef1MSJEzVnzhz5+vrK3d1dklSlShWdPXtWFotFoaGhat++vV1FdezY8ZbaWSwWRUZGysPDI8e38aGhoXrrrbcUGRlpE7o/+OADSdL06dOtgVuSOnfurLZt22r9+vU6cuSI9cMJAABFWWBg4A2fAwAAY9kVuiVp1qxZat++vRYuXKitW7fqypUrysrK0qOPPqqRI0eqU6dOjqwzVwkJCTp+/Lg6depkDf7Z3N3d1apVK0VHRyspKUk+Pj6Srt86JXvfP3Xq1EmxsbGKi4tTv379DK8fAABnyczM1NGjR3X8+HFlZGTk2sbeaWIAAOD/2R26JemRRx7RI4884qhabltCQoIk5TkH29/fX9HR0UpISJCPj4/S0tJ04sQJ3XPPPXJ1dc21/d+Pm5v09HSlp6dbn6ekpOTnFAAAKFBZWVl65ZVX9MYbb+jcuXM3bJuZmVlAVQEAUHzlK3Q7W/YK6l5eXrnu9/T0tGl3u+1zM2vWLE2dOtW+ggEAcLKQkBC9+uqrqlKlioKDg1W9enWVKlWkPw4AAFCo5esqWxKHpoWEhGjs2LHW5ykpKdah6wAAFHZLlixRw4YNtW3btlxvqwkAABzLrtBdWIamZfdY59UznT30O7vd7bbPjdlsltlstq9gAACcLDU1VX379iVwAwBQQOwK3YVlaNrN5mD/c863u7u7qlevrkOHDikzMzPHvO6bzREHAKCoCwgI0PHjx51dBgAAJYZdSbmwDE3z9/dXjRo1FB8fr7S0NJsVzNPS0hQfH686derYDP8ODAzUihUrFB8fn2Poe/b9uYvbkHgAALK9/PLL6tGjh3bs2KGmTZs6uxwAAIo9u0J3YRmaZjKZNHjwYE2bNk3Tp0/X7NmzrfumT5+u1NRUvfTSSzavGTp0qFasWKHQ0FB9//331nt1f/fdd4qNjVVQUJB8fX0L9DwAACgojz/+uKKiotS5c2c98cQTuvfee60Lif5T//79C7g6AACKH7tCt9FD0yIjI7V582ZJ0p49e6zbYmNjJUkPP/ywBg8eLEmaMGGC1q5dqzlz5mjnzp1q2rSpduzYofXr16tFixYaPXq0zbHbtWunwYMHKzIyUk2bNtXjjz+uEydOaOXKlapUqZIWLFhg2HkBAOBs6enp+uqrr3TmzBktWrRI0vUvsf/OYrHIZDIRugEAcAC7QrfRQ9M2b96sJUuW2GyLj49XfHy89Xl26HZ3d1dcXJzCw8O1evVqxcTEqHr16ho3bpzCwsLk5uaW4/jvvfeeGjdurPfff19vvPGGPDw81K1bN82cOVP16tVz+PkAAFBYjB07VsuWLVNAQICefvppbhkGAIDBTBaLxWLPC1etWqUXXnihxA9NS0lJkZeXl5KTk/P8GdyOnuEBDqgKKHz+e2WWs0sADJE4+3GHHMfR15O8VKlSRb6+vtqyZUuxCtuO/PlxLUZxtSr8V2eXABRqRl2L7braMjQNAICi6cqVK2rXrl2xCtwAABRmdl1xGZoGAEDR1KxZMx04cMDZZQAAUGLYlZQ//fRTNWvWrNgNTQMAoLh75ZVX1KFDB3399dfq0qWLs8sBAKDYsysxMzQNAICi6fvvv1fbtm315JNPqn379nmuy2IymRQaGuqECgEAKF7sSs0MTQMAoGgKDw+3/nnDhg3asGFDru0I3QAAOIZdoZuhaQAAFE0xMTHOLgEAgBLFrtDN0DQAAIqmwMBAZ5cAAECJYlfoZmgaAAAAAAA3Z1foZmgaAAAAAAA3Z1foZmgaAAAAAAA35+LsAgAAAAAAKK7yfaPtpKQkHT9+XOnp6bnub9OmTX7fAgAAAACAIsnu0P3VV19p/PjxSkhIuGG7zMxMe98CAAAAAIAiza7h5bGxserWrZtSU1M1YsQIWSwWtWnTRkOHDtVdd90li8Wixx9/XFOmTHF0vQAAAAAAFBl2he7Zs2fLw8ND27dv1xtvvCFJateund555x3t2bNHM2fO1IYNG/Tkk086tFgAAAAAAIoSu0L3tm3b1LVrV1WtWtW6LSsry/rnkJAQ3XffffR0AwAAAABKNLtC96VLl1SzZk3rc7PZrJSUFJs2DzzwgOLj4/NXHQAAAAAARZhdobtatWr666+/rM9r1qyp3377zabN2bNnWUQNAAAAAFCi2RW67733Xv3vf/+zPm/Xrp1iYmK0fPlypaWlKTo6WqtWrVJAQIDDCgUAAAAAoKixK3Q/8cQT2rVrlw4fPixJeumll+Th4aG+ffvK09NTjz32mK5du6YZM2Y4tFgAAAAAAIoSu+7TPWjQIA0aNMj6vE6dOtq2bZvmz5+vgwcPytfXV88//7yaNGniqDoBAAAAAChy7ArdualXr57eeustRx0OAAAAAIAiz67h5a6urnr22WcdXQsAAAAAAMWKXaHb09NTPj4+jq4FAAAAAIBixa7Q3bJlS+3evdvRtQAAAAAAUKzYFbrDw8P1448/aunSpY6uBwAAAACAYsOuhdS+//57tW3bVsHBwVqwYIFatGihqlWrymQy2bQzmUwKDQ11SKEAAAAAABQ1doXu8PBw65+3b9+u7du359qO0A0AAAAAKMnsCt0xMTGOrgMAAAAAgGLnlkL3l19+qUaNGqlBgwaSpMDAQEOLAgAAAACgOLilhdS6deumFStWWJ/XrVtXb775pmFFAQAAAABQHNxS6C5durQyMjKszxMTE3XhwgWjagIAAAAAoFi4pdBdu3Ztbd68WZmZmdZt/1ypHAAAAAAA2Lql0N2nTx/FxcWpUqVKqlu3riQpIiJCdevWveGjXr16hhYPAAAKh2PHjun1119XUFCQateurTJlyqhatWrq3r27tm7dmutrUlJSNHbsWPn6+spsNsvPz0/jx49XampqAVcPAIBxbmkhtcmTJ6ts2bL65ptvdPz4cZlMJlksFlkslhu+7mb7AQBA8bBgwQLNmTNH9erVU1BQkCpXrqyEhAStWbNGa9as0SeffKJevXpZ26elpSkwMFC7du1SUFCQevfurZ07d2revHmKi4vTxo0bVbZsWSeeEQAAjnFLobtUqVKaNGmSJk2aJElycXHRmDFjNGXKFEOLAwAARUPLli0VGxub4w4nmzZtUocOHTR8+HB17dpVZrNZkjR37lzt2rVLEydO1OzZs63tJ02apDlz5igiIkIhISEFeg4AABjhloaX/1NYWJjatm3r4FIAAEBR9dRTT+V6S9HWrVurXbt2On/+vPbs2SPp+ki4yMhIeXh4KDQ01KZ9aGioPDw8FBkZWSB1AwBgNLtDd5s2bRxdCwAAKIZKly4t6frIOUlKSEjQ8ePH1apVK7m7u9u0dXd3V6tWrXTw4EElJSUVeK0AADiaXaEbAADgVhw5ckQ//PCDqlevrsaNG0u6Hrolyd/fP9fXZG/Pbpeb9PR0paSk2DwAACiMCN0AAMAQGRkZ6tevn9LT0zVnzhy5urpKkpKTkyVJXl5eub7O09PTpl1uZs2aJS8vL+vDx8fHwdUDAOAYhG4AAOBwWVlZGjhwoDZu3KghQ4aoX79+Dj1+SEiIkpOTrQ+GogMACqtbWr0cAADgVmVlZWnQoEH65JNP1LdvX7377rs2+7N7uPPqyc4eKp5XT7gkmc1m60roAAAUZoRuAADgMFlZWQoODtbSpUvVu3dvRUVFycXFdmDdzeZs32zONwAARQnDywEAgEP8PXD36tVLH330kXUe99/5+/urRo0aio+PV1pams2+tLQ0xcfHq06dOszTBgAUC4RuAACQb9lDypcuXaoePXro448/zjVwS5LJZNLgwYOVmpqq6dOn2+ybPn26UlNTNWTIkIIoGwAAwzG8HAAA5Nu0adO0ZMkSeXh4qEGDBpoxY0aONl27dlWTJk0kSRMmTNDatWs1Z84c7dy5U02bNtWOHTu0fv16tWjRQqNHjy7YEwAAwCCEbgAAkG+JiYmSpNTUVM2cOTPXNn5+ftbQ7e7urri4OIWHh2v16tWKiYlR9erVNW7cOIWFhcnNza2AKgcAwFiEbgAAkG9RUVGKioq6rdd4eXkpIiJCERERxhQFAEAhwJxuAAAAAAAMQugGAAAAAMAghG4AAAAAAAxC6AYAAAAAwCCEbgAAAAAADELoBgAAAADAIIRuAAAAAAAMQugGAAAAAMAghG4AAAAAAAxC6AYAAAAAwCCEbgAAAAAADELoBgAAAADAIIRuAAAAAAAMQugGAAAAAMAghG4AAAAAAAxC6AYAAAAAwCCEbgAAAAAADELoBgAAAADAIIRuAAAAAAAMQugGAAAAAMAghG4AAAAAAAxC6AYAAAAAwCCEbgAAAAAADELoBgAAAADAIIRuAAAAAAAMQugGAAAAAMAghG4AAAAAAAxC6AYAAAAAwCCEbgAAAAAADELoBgAAAADAIIRuAAAAAAAMQugGAAAAAMAghG4AAAAAAAxC6AYAAAAAwCCEbgAAAAAADELoBgAAAADAIIRuAAAAAAAMQugGAAAAAMAghG4AAAAAAAxC6AYAAAAAwCCEbgAAAAAADELoBgAAAADAIIRuAAAAAAAMQugGAAAAAMAghG4AAAAAAAxC6AYAAAAAwCCEbgAAAAAADELoBgAAAADAIIRuAAAAAAAMQugGAAAAAMAghG4AAAAAAAxC6AYAAAAAwCCEbgAAAAAADELoBgAAAADAIIRuAAAAAAAMQugGAAAAAMAghG4AAAAAAAxC6AYAAAAAwCCEbgAAAAAADELoBgAAAADAIIRuAAAAAAAMQugGAAAAAMAghG4AAAAAAAxC6AYAAAAAwCCEbgAAAAAADELoBgAAAADAIIRuAAAAAAAMQugGAAAAAMAghG4AAAAAAAxC6AYAAAAAwCCEbgAAAAAADELoBgAAAADAIIRuAAAAAAAMQugGAAAAAMAghG4AAAAAAAxC6AYAAAAAwCCEbgAAAAAADELoBgAAAADAIIRuAAAAAAAMUixCt5+fn0wmU66Ptm3b5mifnp6uadOmyd/fX2XLllWNGjU0dOhQnT59uuCLBwAAAAAUW6WcXYCjeHl5afTo0Tm2+/n52TzPysrSk08+qejoaD3wwAPq3r27EhISFBkZqQ0bNujnn39W5cqVC6ZoAAAAAECxVmxCd4UKFRQeHn7TdkuWLFF0dLR69+6tZcuWyWQySZLeffddDR8+XJMnT9Z7771ncLUAAAAAgJKgWAwvvx0ffPCBJGnWrFnWwC1Jw4YNU926dbVs2TJdvnzZWeUBAAAAAIqRYhO609PTFRUVpVdeeUULFy7U1q1bc7S5cuWKtm7dqoYNG8rX19dmn8lk0iOPPKK0tDT98ssvBVU2AAAAAKAYKzbDy0+ePKng4GCbbS1atNDy5ctVr149SdKff/6prKws+fv753qM7O0JCQlq3bp1rm3S09OVnp5ufZ6SkuKI8gEAAAAAxVCx6OkODg7Whg0bdOrUKaWlpWnnzp3q16+ftm3bpg4dOujixYuSpOTkZEnXF13Ljaenp0273MyaNUteXl7Wh4+Pj4PPBgAAAABQXBSL0B0WFqb27durSpUqKleunJo0aaKlS5eqX79+Onz4sHUetyOEhIQoOTnZ+khKSnLYsQEAAAAAxUuxCN15GTZsmCQpPj5e0v/3cOfVk509VDyvnnBJMpvN8vT0tHkAAAAAAJCbYh26vb29JUlpaWmSpLp168rFxUUJCQm5ts/entecbwAAAAAAbkexDt3ZK5j7+flJktzc3NSyZUvt27dPhw8ftmlrsVj0/fffy93dXc2bNy/oUgEAAAAAxVCRD9179+7VpUuXct0+ceJESVKfPn2s24cOHSrp+txsi8Vi3f7ee+/p4MGDevbZZ+Xm5mZw1QAAAACAkqDI3zJsxYoVmj9/vtq0aSNfX1+5u7tr//79+vbbb5WRkaGQkBC1adPG2n7AgAFauXKlli9frkOHDikwMFAHDhzQ559/rjp16mjGjBlOPBsAAAAAQHFS5EN3u3bt9Mcff2jnzp3atGmTLl26JG9vbz322GP697//raCgIJv2Li4uWrt2rWbPnq2PPvpIERERqlSpkp577jnNmDFDlStXdtKZAAAAAACKmyIfugMDAxUYGHhbrzGbzQoLC1NYWJhBVQEAAAAAUAzmdAMAAAAAUFgRugEAAAAAMAihGwAAAAAAgxC6AQAAAAAwCKEbAAAAAACDELoBAAAAADAIoRsAAAAAAIMQugEAAAAAMAihGwAAAAAAgxC6AQBAvn388ccaNmyYmjdvLrPZLJPJpKioqDzbp6SkaOzYsfL19ZXZbJafn5/Gjx+v1NTUgisaAIACUMrZBQAAgKJv8uTJOnz4sLy9vVW9enUdPnw4z7ZpaWkKDAzUrl27FBQUpN69e2vnzp2aN2+e4uLitHHjRpUtW7YAqwcAwDj0dAMAgHyLjIxUYmKi/vrrLz3//PM3bDt37lzt2rVLEydOVHR0tGbPnq3o6GhNnDhR27ZtU0RERAFVDQCA8QjdAAAg3zp27ChfX9+btrNYLIqMjJSHh4dCQ0Nt9oWGhsrDw0ORkZFGlQkAQIEjdAMAgAKTkJCg48ePq1WrVnJ3d7fZ5+7urlatWungwYNKSkpyUoUAADgWoRsAABSYhIQESZK/v3+u+7O3Z7fLS3p6ulJSUmweAAAURoRuAABQYJKTkyVJXl5eue739PS0aZeXWbNmycvLy/rw8fFxbKEAADgIoRsAABQ5ISEhSk5Otj4Yjg4AKKy4ZRgAACgw2T3cefVkZw8Tz6snPJvZbJbZbHZscQAAGICebgAAUGBuNmf7ZnO+AQAoagjdAACgwPj7+6tGjRqKj49XWlqazb60tDTFx8erTp06zNEGABQbhG4AAFBgTCaTBg8erNTUVE2fPt1m3/Tp05WamqohQ4Y4qToAAByPOd0AACDfIiMjtXnzZknSnj17rNtiY2MlSQ8//LAGDx4sSZowYYLWrl2rOXPmaOfOnWratKl27Nih9evXq0WLFho9erQzTgEAAEMQugEAQL5t3rxZS5YssdkWHx+v+Ph46/Ps0O3u7q64uDiFh4dr9erViomJUfXq1TVu3DiFhYXJzc2tQGsHAMBIhG4AAJBvUVFRioqKuuX2Xl5eioiIUEREhHFFAQBQCDCnGwAAAAAAgxC6AQAAAAAwCKEbAAAAAACDELoBAAAAADAIoRsAAAAAAIMQugEAAAAAMAihGwAAAAAAgxC6AQAAAAAwCKEbAAAAAACDELoBAAAAADAIoRsAAAAAAIMQugEAAAAAMAihGwAAAAAAgxC6AQAAAAAwCKEbAAAAAACDELoBAAAAADAIoRsAAAAAAIMQugEAAAAAMAihGwAAAAAAgxC6AQAAAAAwCKEbAAAAAACDELoBAAAAADAIoRsAAAAAAIMQugEAAAAAMAihGwAAAAAAgxC6AQAAAAAwCKEbAAAAAACDlHJ2AQAAAACM5zfpG2eXABgmcfbjzi4hT/R0AwAAAABgEEI3AAAAAAAGIXQDAAAAAGAQQjcAAAAAAAYhdAMAAAAAYBBCNwAAAAAABiF0AwAAAABgEEI3AAAAAAAGIXQDAAAAAGAQQjcAAAAAAAYhdAMAAAAAYBBCNwAAAAAABiF0AwAAAABgEEI3AAAAAAAGIXQDAAAAAGAQQjcAAAAAAAYhdAMAAAAAYBBCNwAAAAAABiF0AwAAAABgEEI3AAAAAAAGIXQDAAAAAGAQQjcAAAAAAAYhdAMAAAAAYBBCNwAAAAAABiF0AwAAAABgEEI3AAAAAAAGIXQDAAAAAGAQQjcAAAAAAAYhdAMAAAAAYBBCNwAAAAAABiF0AwAAAABgEEI3AAAAAAAGIXQDAAAAAGAQQjcAAAAAAAYhdAMAAAAAYBBCNwAAAAAABiF0AwAAAABgEEI3AAAAAAAGIXQDAAAAAGAQQjcAAAAAAAYhdAMAAAAAYBBCNwAAAAAABiF0AwAAAABgEEI3AAAAAAAGIXQDAAAAAGAQQjcAAAAAAAYhdAMAAAAAYBBCNwAAAAAABiF0AwAAAABgEEI3AAAAAAAGIXQDAAAAAGAQQjcAAAAAAAYhdAMAAAAAYBBCNwAAAAAABiF0AwAAAABgEEI3AAAAAAAGIXQDAAAAAGAQQjcAAAAAAAYhdAMAAAAAYBBCNwAAAAAABiF0AwAAAABgEEI3AAAAAAAGIXQDAAAAAGAQQjcAAAAAAAYhdAMAAAAAYBBCNwAAAAAABiF0AwAAAABgEEI3AAAAAAAGIXQDAAAAAGAQQjcAAAAAAAYhdAMAAAAAYBBCNwAAAAAABiF0AwAAAABgEEI3AAAAAAAGIXQDAAAAAGCQEh26t23bpscee0wVKlSQu7u7HnjgAa1atcrZZQEAUGJwLQYAFHelnF2As8TExKhTp04qW7asnnnmGZUvX16rV69Wr169lJSUpHHjxjm7RAAAijWuxQCAkqBE9nRfu3ZNQ4YMkYuLizZu3Kj3339fr732mnbv3q0GDRropZde0uHDh51dJgAAxRbXYgBASVEiQ/ePP/6oP//8U3369FGTJk2s2728vPTSSy/p6tWrWrJkifMKBACgmONaDAAoKUpk6I6NjZUkBQUF5djXqVMnSVJcXFxBlgQAQInCtRgAUFKUyDndCQkJkiR/f/8c+6pVqyYPDw9rm39KT09Xenq69XlycrIkKSUlxSG1ZaRnOuQ4QGGTlX7J2SUAhnDU//+zj2OxWBxyvMIuP9diydjrMddiFFdci1GcOeL//0Zdi0tk6M6+MHt5eeW639PT09rmn2bNmqWpU6fm2O7j4+O4AoFiqaezCwAM4fW6Y4938eLFPK9PxUl+rsUS12PAPlyLUXw58nrs6GtxiQzd+RESEqKxY8dan2dlZencuXO64447ZDKZnFgZUHilpKTIx8dHSUlJ8vT0dHY5QKFksVh08eJF1ahRw9mlFAlcj4Hbw7UYuDmjrsUlMnRnf2uR1zfoKSkpqlixYq77zGazzGazzbYKFSo4tD6guPL09ORCD9xASejhzpafa7HE9RiwF9di4MaMuBaXyIXUsueP5TZX7OTJk0pNTc11jhkAAHAMrsUAgJKiRIbuwMBASdL69etz7IuOjrZpAwAAHI9rMQCgpDBZSsoyqX9z7do1NWzYUMeOHdPPP/9svT9ocnKyWrZsqcTERO3bt09+fn5OrRMoLtLT0zVr1iyFhITkGA4KoGTiWgwULK7FgPOUyNAtSTExMerUqZPKli2rZ555RuXLl9fq1at1+PBhzZs3T+PGjXN2iQAAFGtciwEAJUGJDd2S9N///ldhYWH66aeflJGRocaNG2vs2LHq1auXs0sDAKBE4FoMACjuSnToBgAAAADASCVyITUAAAAAAAoCoRsAAABAvnXt2lV33nmnMjMznVrH5MmTVb58eZ06dcqpdQDZCN0AbkliYqJMJtMNHxcuXJAk+fn52Wx3dXWVt7e3goKCtHbt2hzHPnv2rCZNmqS7775b5cqVU7ly5eTr66sOHTpo6tSpXDQBAA6VfU179NFHHX7s8PBwmUwmxcbGOvzYhVlcXJzWrl2rsLAwubq6OrWWcePGycXFRWFhYU6tA8hWytkFACha6tWrp759++a6r2zZstY/u7q6avLkyZKkq1evau/evfryyy/1/fff26xKfPToUT300ENKSkpSkyZNFBwcrAoVKujEiRP66aefFB4erlatWqlq1arGnxwAALBLaGiofH191bNnT2eXoooVK2rw4MF64403FBISIl9fX2eXhBKO0A3gttSvX1/h4eE3bVeqVKkc7davX69HH31UU6ZM0fDhw1WuXDmFhYUpKSlJ06ZNU2hoaI7j7NmzRxUqVHBM8QAAwOF+++03bdq0SS+//LJcXArHQNq+fftq/vz5ioyM1PTp051dDkq4wvGvAkCJEBQUpIYNG+rSpUv67bffJElbtmyRJL3wwgu5vqZx48by8fEpsBoB4P/au/ewqKv8D+Dv4TaM3AYQDBWGe6CgaIkXFBwywFUC11KXTQEvqYlLpvmYmShtZa0ZakWWqyRPYqWtQhimLHiLIZVCRUWTizcEVEQucp3P7w93vj/GGWBQEXf7vJ6HZ3fOOd9z+fY8nu9n5nvOYayt6upqfPDBBwgICEDfvn1hZGSEvn37YsaMGbh48aJa2bFjx2L16tUAALlcLiyzcnR0VCtXUVGBRYsWwdXVFWKxGL1798bkyZNx+vRpjfYdHR3h6OiI2tpaxMbGom/fvhCLxRg0aBB27typtc9NTU34+OOPMWzYMJiZmcHU1BQDBgzA66+/jqqqKiiVSshkMlhbW6OxsVFrHf7+/jAwMMCVK1c6vUdbt24FALz00ksaeVFRURCJRCgqKsLatWvh7u4OiUSCAQMGYMeOHUJ/33rrLTg6OsLY2BiDBg3Cjz/+qFFXWVkZYmNj4ebmBolEAqlUCk9PT8ybNw/V1dVqZYcMGQJXV1ckJSV12n/Guhv/0s0Y6xEikQgAYG1tDQA4f/48fH19e7JLjDHGmIazZ89i5cqVkMvlmDRpEkxMTHDu3Dls374d6enpyMvLE15fjoqKAnBvfXNkZKQQbLd9Y+vixYsYO3Ysrly5gqCgIISHh6OiogK7du3Cvn37kJmZieHDh6v1obm5GUFBQaiqqsLkyZNRX1+PHTt2YMqUKcjIyEBQUJBQ9u7du3j++edx9OhRuLm5ITo6GmKxGBcuXMCmTZswY8YM+Pj4YPbs2Vi5ciV27dqFiIgItfYKCwtx+PBhTJgwAf379+/0HmVmZsLExAReXl7tlnn99deRm5uL0NBQ6OvrY8eOHYiIiIClpSU2btyIM2fOYMKECWhoaMD27dsRFhaGs2fPwsXFBQBQX18PPz8/lJSUICgoCJMmTUJTUxOKi4uRnJyMJUuWwMLCQq3NkSNHIjk5GefPn4e7u3un42Cs2xBjjOmguLiYAJCLiwvFxcVp/OXk5AhlZTIZicVijToOHDhAIpGITExMqL6+noiINmzYQADI1taWVq5cSVlZWVRdXf3YxsUYY+yPRzWnBQcHd1r29u3bdPPmTY30f//736Snp0ezZ89WS4+LiyMAlJWVpbW+UaNGkb6+PmVkZKilFxYWkpmZGXl7e6uly2QyAkBhYWHU2NgopB84cEDrGBYvXkwAaPr06dTS0qIxlpqaGiIiunr1KhkYGNDYsWM1+rhkyRICQLt379Y6hrZqampIT0+P/Pz8tOZHRkYSAHJ3d6eKigohPTc3lwCQVCql0aNHU21trZD3zTffEABauHChkJaamkoA6LXXXtPah4aGBo309evXEwDasmVLp+NgrDvxL92MsS65ePGi8OpcW1KpFCNGjBA+t7S0CGu6m5ubUVhYiD179oCI8M4770AikQAAYmJicPnyZaxfvx7x8fGIj4+HSCSCp6cnQkNDERsbCzs7u8cyNsYYY+x+9/96qiKXyzFw4EAcOHBA57p+/fVX/Pzzz5g5cyaCg4PV8tzd3TFnzhysW7cOp0+f1vjV+OOPP4aRkZHw+bnnnoNMJsOxY8eEtJaWFnzxxRewsLDA+vXrNXYRbzuWvn37IjQ0FLt378bvv/8OV1dXAPfm7G3btsHOzg4TJkzodEzXrl2DUqnsdMPTt956CzY2NsJnX19fODs7o6ioCO+++y5MTEyEvMmTJ8PQ0BD5+fka9aieH9oyNTXV2qaqT7q8Is9Yd+KgmzHWJcHBwcjIyOi0XGtrqxCc6+npwdLSEoGBgViwYAFeeOEFoZxIJMKHH36IpUuXYu/evVAoFDh+/DhOnDiBM2fOYNOmTcjIyNB41Y4xxhh7XLKzs5GQkIDc3FzcuHEDLS0tQl7bQLgzCoUCAFBeXq51U9Jz584J/9s26JZKpXByctIo379/f2FvFNV1NTU1GDduHCwtLTvtz9y5c/Gvf/0Lmzdvxpo1awAAqampqKiowPLly2Fg0HmocPPmTaGPHfHx8dFIs7OzQ1FRkUaevr4+bG1tce3aNSHN398fdnZ2WLNmDfLz8zFx4kQEBATA09NTWLJ2PysrKwDAjRs3Oh0HY92Jg27GWLcQi8VoaGjQuXzv3r0xY8YMzJgxAwBw/fp1xMTEYNeuXXjllVe0ftvNGGOMdbfvvvsOU6dOhampKYKDg+Ho6IhevXpBJBIhKSkJpaWlOtd169YtAEB6ejrS09PbLVdXV6f2ub1f2w0MDKBUKoXPqs3E+vXrp1N/goKC4OTkhK+++gp///vfYWBggM2bN0MkEmHWrFk61aH65bmzOd/c3Fxr/zvKa25uFj5bWFhAoVBg5cqVSEtLw969ewEA9vb2WLZsGV599VWNOu7evQsA6NWrl05jYay7cNDNGHsiPfXUU0hOTsYPP/yAkydP4ubNm8Kma4wxxtjjsmrVKhgbG+PEiRNwc3NTy1Ptvq0rVXC5ceNGxMTEPLI+qqh+bb569apO5UUiEV555RW8+eabSEtLw7PPPouffvoJzz33HJydnXWqQ/XKuOoLhe7k4OCApKQkKJVKnDx5Ej/99BM2bNiABQsWwNLSEn/5y1/Uyqv61Pa1dsZ6Ah8Zxhh7YonFYhgaGvZ0NxhjjP2BXbx4EZ6enhoBd1lZGYqKijTKq9ZRt7a2auSplkq1fSX8UXr66adhbm6OY8eOoaqqSqdroqOjYWhoiM2bN2PLli1QKpWYM2eOzm327dsX1tbWKCwsfNBud5menh58fHywdOlSpKSkALj3Wvz9VH3y9vZ+bH1jTBsOuhljPeqjjz4S1rDd75NPPkFtbS08PDz4V27GGGM9QiaT4ffff0d5ebmQ1tDQgPnz56u9/qyiWkd8+fJljTxfX18MHz4cKSkp+OabbzTylUolDh48+MB9NTAwwNy5c1FdXY3Y2FiNwL+6uhq1tbVqaX369EF4eDgyMjKQmJiI3r17Izw8XOc2RSIRxowZg+LiYlRWVj5w3ztTUFCg9t9ARZVmbGyskZebmwsDAwOMGjWq2/rFmC749XLGWI9Sna3p7e2N4cOHw9bWFrdv34ZCoUBeXh4kEgkSExN7upuMMcb+B506dUo4W/t+Hh4eWLZsGRYuXIiFCxdiyJAhePHFF9HS0oL9+/eDiDB48GCNPUfkcjlEIhGWL1+OgoICWFhYQCqVCq+Tp6SkQC6XY9q0aUhISMDQoUMhkUhw6dIl5OTkoLKyskt7otwvPj4eCoUCycnJUCgUGD9+PMRiMYqKipCRkYEjR45obFw2b948fPfddygvL8fixYu7tDkcAEyaNAm7d+/G/v37Nc78flT279+PN954A35+fnB3d4e1tTWKioqQmpoKY2NjLFiwQK18bW0tFAoFnn/+ebWd0RnrET19Zhlj7L9DV840be+cbm3y8vJo9erVFBAQQPb29mRkZEQSiYQ8PDxo/vz5dP78+YftOmOMMaZGNad19BcQEEBEREqlkj7//HMaOHAgGRsb01NPPUWzZs2iiooKCggIIG2P00lJSeTt7U1isZgAkEwmU8u/desWrVixgry8vEgikZCpqSm5ublRREQEff/992plZTKZxvUq7bXf0NBAa9euJR8fH6H+AQMG0OLFi6mqqkqjvFKpJAcHBwJAZ8+e1eketnX37l2ysrKi8ePHa+SpzukuLi7Wuf9EmuM+c+YMxcbG0pAhQ8ja2prEYjE5OztTZGQkFRQUaFyflJSk81njjHU3ERHR4w/1GWOMMcYYY0+CsrIyODg4YOTIkTh06NAD1fH2229jzZo1+P333yGTyR5xD7tuzJgxKC8vx9mzZzXOK2fsceM13YwxxhhjjP2BJSQkoKWlBfPnz3/gOpYuXQorKyu8++67j7BnDyYzMxNHjhzBBx98wAE3eyLwmm7GGGOMMcb+YKqrq5GYmIjS0lJs3rwZAwYMwJQpUx64PjMzMyQnJ+P48eNobW3t0WC3uroaa9euxaRJk3qsD4y1xa+XM8YYY4wx9gdTUlICJycnGBsbY8SIEfj888/x9NNP93S3GPufxEE3Y4wxxhhjjDHWTXhNN2OMMcYYY4wx1k046GaMMcYYY4wxxroJB92MMcYYY4wxxlg34aCbMcYYY4wxxhjrJhx0M9ZDoqKiIBKJUFJS8lD1ODo6wtHR8ZH06VEqKSmBSCRCVFTUI603KSkJIpEISUlJj7Rexhhj7H9BdnY2RCIRVq1a9UjrXbVqFUQiEbKzsx9pvYz9EXDQzdhDUAWWISEh7ZZRTX7z5s17jD1jD0MkEmHs2LFa8zjoZ4yxJ5cu8zJ7MnX2ZT0H/ey/mUFPd4CxP6r3338fy5YtQ79+/Xq6K92iX79+OHv2LCwsLHq6K4wxxtgfhq+vL86ePYvevXv3dFcYY//BQTdjPcTOzg52dnY93Y1uY2hoCA8Pj57uBmOMMfaH0qtXL55/GXvC8OvljPWQ9tZ0t7S04P3334eLiwuMjY3h6uqK999/H0VFRR2+dlVbW4vY2Fj07dsXYrEYgwYNws6dO7WWbWpqwrp16zB06FCYmJjAzMwMY8aMQWpqarv9LCoqwkcffYQBAwZALBZ3ula7vdfEysrKEBsbCzc3N0gkEkilUnh6emLevHmorq7usM777dmzB76+vujVqxdsbGwwc+ZMlJeXay1bXFyM2bNnw8HBAWKxGHZ2doiKikJpaalQRrUUAAAOHjwIkUgk/CUlJSEqKgrR0dEAgOjoaLX8tmpqahAXF4eBAwcKYwwODsaRI0c0+jV27FiIRCI0NDRgxYoVcHFxgaGh4SNfi8cYY0xTaWkpZs2ahX79+sHIyAj9+/fHrFmzcOnSJbVyixYtgkgkwvHjx9XSw8PDIRKJ8PLLL6ulq+aT1atXq6U/jvmhvTXdFy5cQHR0NJycnCAWi2FlZYXBgwfjtddeAxF1cqfU/fOf/4S3tzeMjY3Rr18/LFq0CDU1NVrLnjx5EtOmTYOdnR2MjIwgk8mwcOFC3Lx5UyiTlJQEJycnAMBXX32lNr9mZ2dj7Nixwr2Uy+VC3v172lRUVGDRokVwdXWFWCxG7969MXnyZJw+fVqjX6o9cW7fvo2YmBjY29vDwMCAl4+xbsG/dDP2hJk5cyaSk5Ph7OyMBQsWoLGxER9//DFycnLavaa5uRlBQUGoqqrC5MmTUV9fjx07dmDKlCnIyMhAUFCQULaxsREhISHIzs6Gj48PZs2ahebmZqSnpyMsLAwbN25ETEyMRhsLFy6EQqHAhAkTEBoaCltb2y6Prb6+Hn5+figpKUFQUBAmTZqEpqYmFBcXIzk5GUuWLNH5dfRdu3Zh3759ePHFFzFu3DgoFAps3boVhw8fxi+//AJLS0uhbG5uLoKDg1FXV4eJEyfCzc0NJSUl+Prrr/Hjjz8iJycHzs7OcHR0RFxcHFavXg2ZTKb2hYGPjw+kUilu376NPXv2ICwsDD4+Phr9unXrFvz9/VFQUAA/Pz/MmzcPd+7cwZ49eyCXy/Hdd98hPDxc47rJkycjPz8fISEhkEqlwsMHY4yx7nH+/HmMHj0alZWVCA0NxcCBA3H69Gls2bIFaWlpOHLkCNzd3QHcC/QSEhKQlZWFZ599FgCgVCpx6NAhAEBWVpZa3arPcrlcSOvJ+eHatWvw9fVFXV0dJkyYgKlTp6Kurg4XLlzAZ599hrVr18LAQLewYN26dcjMzMTUqVMxYcIEHDhwAAkJCVAoFDh06BAMDQ2FsqmpqZgyZQr09PQQFhYGe3t7nDlzBp988gn27duH3NxcWFpawsfHB7GxsVi/fj0GDx6sdh8cHR2F+fjgwYOIjIwUgm2pVCqUu3jxIsaOHYsrV64gKCgI4eHhqKioEJ4XMjMzMXz4cLWxNDY2IjAwELW1tXjhhRdgYGCAPn36dPn+MtYpYow9sOLiYgJALi4uFBcXp/UvMjKSANDcuXPVrlWlFxcXC2kHDhwgAOTj40N1dXVC+rVr16hPnz4EgCIjI9XqkclkBIDCwsKosbFRo67g4GC18suXLycA9Pbbb5NSqRTS79y5Q88++ywZGRnR1atXNfrZv39/Ki0t7fK9advf1NRUAkCvvfaaRvmamhpqaGjotN6tW7cSAAJAGRkZannLli0jABQTEyOkNTU1kaOjI5mZmVFeXp5a+cOHD5O+vj5NnDhRLR0ABQQEdNj+1q1bteZHREQQAPryyy/V0svLy8ne3p5sbGzo7t27QnpAQIDw3/zmzZudDZ8xxlgHVHPP/XOfNnK5nADQpk2b1NI//fRTAkCBgYFCWlVVFenp6dH48eOFtBMnThAAeu655wgAFRYWCnljxowhiUSiNi8/rvkhKyuLAFBcXJyQtmHDBgJACQkJGuV1rTsuLo4AkJGREeXn5wvpSqVSGNvatWuF9Bs3bpC5uTn169ePSkpK1OpKSUnRmK+1PTdoaz8rK0tr/qhRo0hfX1/j2aCwsJDMzMzI29tbLV31/BQcHEz19fW63ALGHhgH3Yw9BNUEocufLkF3VFQUAaDvv/9eo6333nuvw6C7qKhI4xqZTEZWVlbC59bWVrK0tCQXFxe1gFtFFRRv3LhRo5/r16/X9bYQUcdB95tvvtmlutpSBb3jxo3TyKupqSGpVErm5ubU2tpKRETff/89AaD4+Hit9f35z38mPT09qq6uFtIeNOiurKwkfX19tQe1tlQPPWlpaUKa6qFqz5497Q2ZMcaYjnQNuktLSwkADRgwQGM+bG1tJQ8PDwJAly5dEtKfeeYZMjU1pebmZiIiWrt2LQGgo0ePEgBKTEwkIqL6+noyMjJSmwse5/zQUdB9/xcMXaEKemfPnq2RV1JSQvr6+uTl5SWkrVu3jgDQtm3btNY3dOhQ6t27t/D5YYLuvLw8AkAzZ87Ueu3rr79OAOjUqVNCmur5qe0XCIx1F369nLFHIDg4GBkZGVrzsrOz1V4v60h+fj4AYPTo0Rp5fn5+7V7X3utm/fv3V3stvbCwEFVVVejbt6/GOjMAqKysBACcO3dOI8/X17fzAXTC398fdnZ2WLNmDfLz8zFx4kQEBATA09NTY110Z8aMGaORZmpqCh8fH2RnZ6OoqAiurq5QKBQA7o1d2zq469evQ6lU4vz588Irgw/q2LFjaG1tRWNjo9a2Lly4AODe/Z04caJa3qO4v4wxxnTz22+/AQACAgI05h89PT34+/vj3Llz+O2332Bvbw/g3qviJ06cwLFjxzBy5EhkZWXB09MTo0aNgkwmQ1ZWFubNm4ejR4+iqalJbe7v6fkhNDQUb775JhYsWIDMzEyEhIQgICAAzs7OXa5L2/wrk8lgb2+PgoICNDU1wcjISJh/c3NzcfHiRY1rGhoacOPGDdy4ceOhd1pXtVVeXq71/qqea86dOwcvLy8h3djYGN7e3g/VNmO64KCbsSfInTt3oKenp3Xy6WiNUXvroA0MDKBUKoXPt27dAgAUFBSgoKCg3frq6uq61L6uLCwsoFAosHLlSqSlpWHv3r0AAHt7eyxbtgyvvvqqznW11x9VumpTNtWYv/766w7r0zbmrlK1dfToURw9erRLbfEaMsYYe3zu3LkDoP1/e1Wni6jKAfeC7rVr1yIrKwu+vr44fPgwpk+fLuSp5rT21nMDPTc/ODo6QqFQYNWqVdi7dy++/fZbAICHhwfi4+Px0ksv6VxXR/NvSUkJampqYG1tLYz5008/7bC+urq6hw66VW2lp6cjPT29w7basrW17fKX/ow9CN69nLEniLm5OZRKJW7cuKGR196u3F2tH7i3KQvdW16i9W/r1q0a1z6qScnBwQFJSUmorKzEr7/+ig8++ABKpRILFixASkqKzvW0dz9U6aovIlRjTktL63DMAQEBDzmy/29r8eLFHbYVFxencS1P+owx9vio/r1uby65fv26Wjng3i+8BgYGyMrKQl5eHu7cuSME1nK5HBUVFSgoKEB2djZMTEzUfqF+EuYHLy8v7Ny5E7du3UJOTg5WrlyJ69evY+rUqR1+EXC/juZfkUgEMzMzAP8/5lOnTnU4ZplM9tBjU7W1cePGDtuKjIxUu47nXva4cNDN2BNk8ODBAKB18vv5558fun5PT0+Ym5vj+PHjaG5ufuj6Hoaenh58fHywdOlSIdjWdmRZew4fPqyRVltbi99++w3m5ubCK3OqnUo72v1dW99aW1u15unr6wOA1vxhw4ZBJBJ1qS3GGGOPn+r0iUOHDmkcl0VEwq7kbU+pMDMzwzPPPIOjR48iIyMDIpFICLoDAwMB3PuC99ixYxg1apTaLt5P0vxgaGiIESNGYPXq1diwYQOICD/88IPO12ubf0tLS3H58mUMHDgQRkZGALo+/3Y0v3aW/yBzPWOPEwfdjD1B/vrXvwIA4uPjcffuXSH9+vXrWL9+/UPXb2BggPnz56O0tBRLlizRGnifPn0aFRUVD92WNgUFBVq/IVelGRsb61zXgQMHsG/fPrW0d999F7dv38aMGTOgp3fvn7ewsDA4ODhg3bp1wkNUW83NzRrno1pZWeHKlSta27WysgIAXL58WSPvqaeewpQpU/Dzzz/jH//4h9ZzT3Nzc1FfX6/bIBljjHULBwcHyOVyFBQUYMuWLWp5X3zxBc6ePYvAwEBhPbeKXC7H3bt3sXHjRgwePFiYE/r37w9XV1esW7cOzc3NGnu59PT8cOLECbVX5VUeZP7dtm0bTp48KXwmIixfvhytra1qR21GR0fDzMwMb731ltYlbfX19cJabACwtLSESCTSOr8CHc+/vr6+GD58OFJSUvDNN99o5CuVShw8eFDnMTL2qPGabsaeIOPGjUNERAS2b98Ob29vhIeHo7GxEd9++y2GDx+OtLQ0IZh8UKtXr0ZeXh42bNiA9PR0+Pv7w9bWFlevXsWpU6eQn5+PnJycBzqHuzP79+/HG2+8AT8/P7i7u8Pa2hpFRUVITU2FsbExFixYoHNdEydORGhoKF588UVhrVpWVhZcXFwQHx8vlBOLxdi5cyfGjx+PgIAABAYGwtvbGyKRCKWlpTh8+DCsra3VNo8LDAzEt99+i/DwcAwZMgT6+vp44YUXMGjQIIwcORISiQQJCQmoqqqCjY0NAGDFihUAgM8++wyFhYVYunQpkpOTMXLkSEilUly+fBnHjx/HhQsXUFZWhl69ej2iu8oYY+x+p06dUgsA2/Lw8MCyZcuQmJiI0aNHY86cOUhLS8OAAQNQUFCA1NRU2NjYIDExUeNauVyONWvWoLKyEi+//LJG3pdffin8//v15PyQnJyMTZs2wd/fHy4uLjA3N8eZM2ewd+9eWFlZITo6Wue6goODMXLkSEybNg02NjbIzMzE8ePHMWLECCxcuFAoZ2Njg5SUFLz00ksYPHgwQkJC4OHhgcbGRpSUlODgwYMYNWqUsBGtqakphg0bhkOHDmH69Olwc3ODnp4epk+fDplMBrlcDpFIhOXLl6OgoAAWFhaQSqWIiYkBAKSkpEAul2PatGlISEjA0KFDIZFIcOnSJeTk5KCyshINDQ2P9sYypqtHvyE6Y38cuhxNojq6Q5cjw4iImpub6Z133iEnJycyMjIiZ2dneu+99yg3N5cAUGxsrFp5mUxGMplMa9uq40bu19LSQps2bSI/Pz8yNzcnsVhMDg4OFBISQomJiVRbW9tpPzuj7eiPM2fOUGxsLA0ZMoSsra1JLBaTs7MzRUZGUkFBgU71tj2ya/fu3TRs2DCSSCRkbW1NUVFRVFZWpvW6K1euUGxsLLm5uZFYLCZzc3Py9PSk2bNnU2ZmplrZsrIymjJlCvXu3Zv09PQ0jghLT08X2sV/joRrq76+nj788EN65plnyMTEhCQSCTk5OVF4eDht27ZNOG6GqP3/RowxxrpOl6M82x4JWVJSQtHR0WRnZ0cGBgZkZ2dH0dHRGudKq9TV1ZGhoaHG8V5ERNu3bycAaseK3e9xzA/ajgxTKBQ0d+5c8vLyIqlUShKJhNzc3CgmJoZKS0t1qrftkV1ffvklDRw4kMRiMdnZ2VFsbCzduXNH63Xnzp2jWbNmkUwmIyMjI7K0tCRvb2/629/+Rr/88ota2cLCQvrTn/5EUqmURCKRxhFhSUlJ5O3tTWKxmABoPP/cunWLVqxYQV5eXiSRSMjU1JTc3NwoIiJC4zjWjp6fGHvURERa3m9hjD1xNm/ejDlz5uCzzz7D/Pnze7o7jDHGGGOMMR1w0M3YE+b69evo06eP2o6aV69ehZ+fH65cuYLi4mKNNWaMMcYYY4yxJxOv6WbsCbNmzRqkp6djzJgxsLW1xaVLl/DDDz+gpqYGq1at4oCbMcYYY4yx/yIcdDP2hAkJCcGZM2eQnp6OqqoqGBsbY9CgQXj11VcRERHR091jjDHGGGOMdQG/Xs4YY4wxxhhjjHUTPqebMcYYY4wxxhjrJhx0M8YYY4wxxhhj3YSDbsYYY4wxxhhjrJtw0M0YY4wxxhhjjHUTDroZY4wxxhhjjLFuwkE3Y4wxxhhjjDHWTTjoZowxxhhjjDHGugkH3YwxxhhjjDHGWDfhoJsxxhhjjDHGGOsm/wdf2B2K7LHtZgAAAABJRU5ErkJggg==",
"text/plain": [
""
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"# Output the difference.\n",
"width = 0.4\n",
"fontsize = 14\n",
"\n",
"plt.rc(\"font\", size=fontsize)\n",
"fig, ax = plt.subplots(1, 2, figsize=(10, 8))\n",
"\n",
"rects1 = ax[0].bar([0], THROUGHPUT_hint_fps, width, label=labels[TPUT], color=\"#557f2d\")\n",
"rects2 = ax[0].bar([width], LATENCY_hint_fps, width, label=labels[LAT])\n",
"ax[0].set_ylabel(\"frames per second\")\n",
"ax[0].set_xticks([width / 2])\n",
"ax[0].set_xticklabels([\"FPS\"])\n",
"ax[0].set_xlabel(\"Higher is better\")\n",
"\n",
"rects1 = ax[1].bar([0], THROUGHPUT_hint_latency, width, label=labels[TPUT], color=\"#557f2d\")\n",
"rects2 = ax[1].bar([width], LATENCY_hint_latency, width, label=labels[LAT])\n",
"ax[1].set_ylabel(\"milliseconds\")\n",
"ax[1].set_xticks([width / 2])\n",
"ax[1].set_xticklabels([\"Latency (ms)\"])\n",
"ax[1].set_xlabel(\"Lower is better\")\n",
"\n",
"fig.suptitle(\"Performance Hints\")\n",
"fig.legend(labels, fontsize=fontsize)\n",
"fig.tight_layout()\n",
"\n",
"plt.show()"
]
}
],
"metadata": {
"interpreter": {
"hash": "ae617ccb002f72b3ab6d0069d721eac67ac2a969e83c083c4321cfcab0437cd1"
},
"kernelspec": {
"display_name": "Python 3 (ipykernel)",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.8.10"
},
"openvino_notebooks": {
"imageUrl": "https://user-images.githubusercontent.com/15709723/161451847-759e2bdb-70bc-463d-9818-400c0ccf3c16.png",
"tags": {
"categories": [
"API Overview"
],
"libraries": [],
"other": [],
"tasks": [
"Image Classification"
]
}
},
"toc-autonumbering": false,
"toc-showmarkdowntxt": false,
"toc-showtags": false,
"widgets": {
"application/vnd.jupyter.widget-state+json": {
"state": {},
"version_major": 2,
"version_minor": 0
}
}
},
"nbformat": 4,
"nbformat_minor": 5
}